Область техники, к которой относится изобретение
Настоящее изобретение обеспечивает мультиспецифические полипептиды, рекрутирующие Т-клетки, которые включают иммуноглобулиновый одиночный вариабельный домен, специфически связывающий константный домен Т-клеточного рецептора (TCR) на Т-клетке, и один или несколько иммуноглобулиновых одиночных вариабельных доменов, связывающих CD123, экспрессируемый на клетке-мишени. Настоящее изобретение также относится к одновалентным полипептидам, связывающим CD123, для применения в этих мультиспецифичных полипептидах. Изобретение также относится к нуклеиновым кислотам, кодирующим указанные полипептиды, а также к векторам, хозяевам и способам получения полипептидов по изобретению. Изобретение также относится к способам лечения с использованием полипептидов по изобретению и наборам, в которых они предоставляются.
Предшествующий уровень техники
CD123 (α-субъединица рецептора интерлейкина 3, IL-3Rα) представляет собой гликопротеин 75 кДа, который превращается в 43 кДа при расщеплении N-гликозидазой (Sato et al. 1993, Blood 82: 752-761). CD123 состоит из трех вHEKлеточных доменов, трансмембранного домена и короткой внутриклеточной области. N-концевой вHEKлеточный домен вносит значительный вклад во взаимодействие CD123 с IL-3, в то время как внутриклеточная область необходима для передачи сигналов (Barry et al. 1997, Blood 89: 842-852). CD123 специфически связывает IL-3 с низким аффинностью. Гетеродимеризация CD123 с общей субъединицей β (βc), которая сама по себе не связывается с IL-3, приводит к образованию IL-3R, высокоаффинного рецептора для IL-3. Субъединица βc играет важную роль в сигнальной трансдукции и как таковая вызывает ряд биологических функций (Hara et al., 1996 Stem cells 14: 605-618).
В то время как субъединица βc экспрессируется на поверхности различных клеток, экспрессия CD123 более ограничена клетками, реагирующими на IL-3, такими как гемопоэтические стволовые клетки/клетки-предшественники, моноциты, мегакариоциты, B-лимфоциты и плазмоцитоидные дендритные клетки. Связывание IL-3 стимулирует пролиферацию и дифференцировку кроветворных клеток. Во время созревания этих клеток экспрессия CD123 постепенно снижается и не может быть обнаружена в зрелых лимфоцитах и гранулоцитах.
Сообщается, что CD123 высоко экспрессируется в стволовых клетках лейкоза (LSC) и связан с инициацией и развитием многих заболеваний, таких как острый миелоидный лейкоз (AML), острый лимфобластный лейкоз (ALL) и волосатоклеточный лейкоз (HCL). Подробная информация о CD123 и связанных с ним клинических применениях при лейкозах упоминается в обзоре Liu et al. (2015 Life Sciences 122: 59-64). Учитывая разницу в экспрессии CD123 на нормальных гемопоэтических стволовых клетках и LSC, CD123 является интересной терапевтической мишенью при гематологических онкологических заболеваниях.
AML является клональным злокачественным расстройством, происходящим из небольшой популяции клеток LSC со сверхэкспрессией CD123. AML характеризуется пролиферацией клеток-предшественников миелоидных клеток в костном мозге и периферической крови и приводит к разрушению нормального кроветворения. Несмотря на то, что терапевтические схемы и поддерживающая терапия для пациентов с AML улучшились за эти годы, никаких серьезных изменений в стандартных вариантах лечения за последние три десятилетия не произошло. Общие сведения о новых подходах и вариантах лечения при AML упоминаются в Medinger et al. (2016 Leukemia Research Reports 6: 39-49). В настоящее время только 35-40% пациентов моложе 60 лет излечиваются от этой болезни. Для пожилых пациентов (>60 лет) общий прогноз остается неблагоприятным. Аллогенная трансплантация гемопоэтических стволовых клеток в настоящее время обеспечивает наилучшие шансы на излечение. Следовательно, остается потребность в новых терапевтических средствах для лечения AML.
Возможной стратегией профилактики AML и лечения рецидивов является использование иммунотерапии, которая является быстро развивающейся областью онкологических исследований. Иммунотерапия направляет иммунную систему организма, и в частности Т-клетки, на злокачественные опухолевые клетки.
Цитотоксические Т-клетки (CTL) - это Т-лимфоциты, которые убивают злокачественные опухолевые клетки, клетки, которые инфицированы (особенно вирусами), или клетки, которые повреждены другими способами. Т-лимфоциты (или Т-клетки) экспрессируют Т-клеточный рецептор или молекулу TCR и рецептор CD3 на поверхности клетки. Комплекс αβ TCR-CD3 (или «комплекс TCR») состоит из шести различных одноцепочечных трансмембранных белков типа I: цепей TCRα и TCRβ, которые образуют гетеродимер TCR, ответственный за распознавание лиганда, и HEKовалентно связанных CD3γ, CD3δ CD3ε и ζ цепей, которые несут мотивы цитоплазматической последовательности, которые фосфорилируются при активации рецептора и рекрутируют большое количество сигнальных компонентов (Call et al., 2004, Molecular Immunology 40: 1295-1305).
Обе цепи α и β Т-клеточного рецептора состоят из константного домена и вариабельного домена. Физиологически αβ- цепи Т-клеточного рецептора распознают нагруженный пептидом комплекс МНС и связываются при взаимодействии с цепями CD3. Эти цепи CD3 впоследствии передают сигнал связывания во внутриклеточную среду.
Принимая во внимание потенциал природных цитотоксических Т-лимфоцитов (CTL), способствующих лизису клеток, были изучены различные стратегии привлечения иммунных клеток для опосредования уничтожения опухолевых клеток. Однако выявление специфических ответов Т-клеток зависит от экспрессии злокачественными опухолевыми клетками молекул МНС и от присутствия, выработки, транспорта и презентации специфических пептидных антигенов. В более поздних разработках была предпринята попытка альтернативного подхода, объединявшего преимущества иммунотерапии с терапией антителами путем вовлечения всех Т-клеток пациента поликлональным способом с помощью технологий, основанных на рекомбинантных антителах: «биспецифичность».
Были разработаны биспецифичные антитела, которые имеют часть распознавания опухоли на одном плече (плечо, связывающееся с мишенью), тогда как другое плечо молекулы обладает специфичностью к Т-клеточному антигену (плечо, связывающее эффектор), главным образом к CD3. Посредством одновременного связывания двух плеч с их соответствующими антигенами Т-лимфоциты направляются и активируются в опухолевой клетке, где они могут осуществлять свою цитолитическую функцию.
Концепция использования биспецифичных антител для активации Т-клеток против опухолевых клеток была описана более 20 лет назад, но производственные проблемы и клинические неудачи привели к стагнации. Дальнейший прогресс был достигнут, когда были разработаны биспецифические препараты меньшего формата, полученные в результате уменьшения антител до их вариабельных фрагментов.
Хотя первый формат вовлечения Т-клеток, Блинатумомаб (молекула BiTE, распознающая CD19 и CD3), был одобрен FDA в декабре 2014 года для терапии второй линии, пришлось преодолеть множество препятствий. Первые клинические испытания Блинатумомаба были преждевременно прекращены из-за неврологических нежелательных явлений, синдрома высвобождения цитокинов и инфекций, с одной стороны, и отсутствия объективных клинических реакций или явных признаков биологической активности, с другой стороны.
В качестве варианта лечения AML MacroGenics недавно разработала MGD006, биспецифичные DART CD3 x CD123 (перенацеливающие молекулы с двойной аффинностью). Как описано в Hussaini et al. (2016 Blood 127: 122-131), MGD006 способны распознавать CD123-положительные лейкозные клетки и индуцировать активацию Т-клеток, что приводит к уничтожению сверхэкспрессирующих CD123 опухолевых клеток in vitro и in vivo. Однако DART также активирует CD25, маркер активации Т-клеток, на Т-клетках при инкубации с CD123-отрицательной клеточной линией K562GFP (фигура 1D, Hussaini et al., 2016). Кроме того, мишень-независимое уничтожение наблюдалось с двумя CD123-отрицательными клеточными линиями (фигура 2B, Hussaini et al., 2016). Следовательно, с этими DART могут возникнуть проблемы безопасности из-за этой мишень-независимой активации T-клеток.
Чтобы свести к минимуму риск неблагоприятных эффектов и системных побочных эффектов, таких как цитокиновые бури, необходимо проявлять максимальную осторожность при отборе, как плеча опухолевого антигена, так и плеча Т-клеточного антигена. Последнее должно связываться с константным доменом комплекса TCR моновалентным образом и может не запускать передачу сигналов Т-клеток в отсутствие целевых злокачественных опухолевых клеток. Только специфическое связывание обоих плечей с их мишенями (опухолью и Т-клеточным антигеном) может вызвать образование цитолитических синапсов и последующее уничтожение опухолевых клеток. Специфичность плеча распознавания опухоли в отношении его антигена является необходимым условием, чтобы избежать связывания вне цели, что неизбежно приведет к мишень-независимой активации Т-клеток.
Помимо эффективности, MGD006, как и блинатумомаб, очень малы по размеру и не имеют Fc-домена. Следовательно, для MGD006 потребуется непрерывная внутривенная инфузия, которая не будет способствовать соблюдению пациентом режима лечения. MacroGenics теперь пытается решить эту проблему путем слияния Fc-домена со своими DART следующего поколения (WO2015026892), что делает молекулу не только больше, но также может привести к производственным проблемам и введению других функций Fc. Ожидается, что больший формат с Fc будет иметь лучший PK, но вновь вводит риск нецелевой активности.
Следовательно, остается потребность в альтернативных биспецифических полипептидах, связывающих CD123 x T-клеточный антиген, с минимальной мишень-независимой активацией T-клеток, у которых может быть адаптирован период полувыведения.
Сущность изобретения
Изобретение решает эту проблему, предоставляя мультиспецифичные полипептиды, содержащие иммуноглобулиновый одиночный вариабельный домен (ISV), который специфически связывается с константным доменом Т-клеточного рецептора (TCR), и один или несколько ISV, которые специфически связывают CD123. В конкретном аспекте полипептид перенаправляет Т-клетки к клеткам, экспрессирующим CD123, и индуцирует опосредованное Т-клетками уничтожение.
Комбинация ISV, связывающего T-клеточный рецептор, и ISV, связывающего CD123, была специально выбрана так, чтобы привести к эффективной активации T-клеток в (расположении) CD123-экспрессирующих клеток, в то время как мишень-независимая активация T-клеток выглядит минимальной.
Таким образом, в первом аспекте настоящее изобретение относится к полипептиду, который перенаправляет T-клетки для уничтожения CD123-экспрессирующих клеток, включающему один иммуноглобулиновый одиночный вариабельный домен (ISV), который специфически связывает T-клеточный рецептор (TCR), и один или несколько ISV, которые специфически связывают CD123, где ISV, который специфически связывает TCR (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181-191; или
b) аминокислотные последовательности, которые имеют 4, 3, 2 или 1 аминокислотных различий с аминокислотной последовательностью одной из SEQ ID NO: 181-191; при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность, измерена с помощью поверхностного плазмонного резонанса;
и/или
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192-217; или
d) аминокислотные последовательности, которые имеют различие в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 192-217; при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218-225; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 218-225; при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и где один или несколько ISV, которые специфически связывают CD123 (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16; при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20; при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25; при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в котором:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181-191; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 181-191; при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192-217; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 192-217; при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218-225; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 218-225; при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и где один или несколько ISV, которые специфически связывают CD123 (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16; при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20; при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25; при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в котором:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181-191; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 181-191, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 2, 4, 5, 6, 8 и/или 10 CDR1 (положения 27, 29, 30, 31, 33 и/или 35 согласно нумерации Kabat); при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192-217; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 192-217, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 1, 3, 5, 7, 8 и/или 9 CDR2 (положения 50, 52, 54, 56, 57 и/или 58 согласно нумерации Kabat); при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218-225; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 218-225, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 1, 4, 5 и/или 8 CDR3 (положения 95, 98, 99 и/или 101 согласно нумерации Kabat); при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и где ISV, который специфически связывает CD123, является таким, как описано далее.
В одном аспекте CDR1, включенный в ISV, который специфически связывает TCR, может быть выбран из группы, состоящей из:
а) SEQ ID NO: 181; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 181, где
- в положении 2 D была изменена на A, S, E или G;
- в положении 4 H была изменена на Y;
- в положении 5 K была изменена на L;
- в положении 6 I была изменена на L;
- в положении 8 F была изменена на I или V; и/или
- в положении 10 G была изменена на S;
при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Помимо этого или в дополнение, CDR2, включенный в ISV, который специфически связывает TCR, может быть выбран из группы, состоящей из:
а) SEQ ID NO: 192; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 192, где
- в положении 1 H была изменена на T или R;
- в положении 3 S была изменена на T или A;
- в положении 5 G была изменена на S или A;
- в положении 7 Q была изменена на D, E, T, A или V;
- в положении 8 Т была изменена на А или V; и/или
- в положении 9 D была изменена на A, Q, N, V или S;
при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Помимо этого или в дополнение, CDR3, включенный в ISV, который специфически связывает TCR, может быть выбран из группы, состоящей из:
а) SEQ ID NO: 218; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 218, где
- в положении 1 F была изменена на Y, L или G;
- в положении 4 I была изменена на L;
- в положении 5 Y была изменена на W; и/или
- в положении 8 D была изменена на N или S;
при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Соответственно, настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 181, где
- в положении 2 D была изменена на A, S, E или G;
- в положении 4 H была изменена на Y;
- в положении 5 K была изменена на L;
- в положении 6 I была изменена на L;
- в положении 8 F была изменена на I или V; и/или
- в положении 10 G была изменена на S;
при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 192, где
- в положении 1 H была изменена на T или R;
- в положении 3 S была изменена на T или A;
- в положении 5 G была изменена на S или A;
- в положении 7 Q была изменена на D, E, T, A или V;
- в положении 8 Т была изменена на А или V; и/или
- в положении 9 D была изменена на A, Q, N, V или S;
при условии, что полипептид, содержащий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 218, где
- в положении 1 F была изменена на Y, L или G;
- в положении 4 I была изменена на L;
- в положении 5 Y была изменена на W; и/или
- в положении 8 D была изменена на N или S;
при условии, что полипептид, содержащий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с тем же, примерно одинаковым или более высоким аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и где ISV, который специфически связывает CD123, является таким, как описано далее.
В предпочтительном аспекте ISV, который специфически связывает TCR (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых CDR1 выбрана из группы, состоящей из SEQ ID NO: 181-191, CDR2 выбрана из группы, состоящей из SEQ ID NO: 192-217, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 218-225.
Соответственно, настоящее изобретение относится к полипептиду, включающему ISV, который специфически связывает TCR (по существу), состоящий из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых CDR1 выбрана из группы, состоящей из SEQ ID NO: 181-191, CDR2 выбирается из группы, состоящей из SEQ ID NO: 192-217, и CDR3 выбирается из группы, состоящей из SEQ ID NO: 218-225 и содержащей ISV, который специфически связывается CD123, как описано далее.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которой CDR1 представляет собой SEQ ID NO: 181, CDR2 представляет собой SEQ ID NO: 192 и CDR3 представляет собой SEQ ID NO: 218, и где ISV, который специфически связывает CD123, является таким, как дополнительно описано в данном документе.
Предпочтительные ISV для применения в полипептиде по изобретению могут быть выбраны из группы, состоящей из SEQ ID NO: 42 и 78-180, или из ISV, которые имеют идентичность последовательностей более 80%, более 85%, более 90% более 95% или даже более 99% с одной из SEQ ID NO: 42 и 78-180. Соответственно, настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR, выбран из группы, состоящей из SEQ ID NO: 42 и 78-180, или из ISV, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 42 и 78-180, и где ISV, который специфически связывает CD123, является таким, как описано далее в данном документе.
ISV, который специфически связывает TCR, может присутствовать в любом положении в полипептиде по изобретению. Предпочтительно, ISV, который специфически связывает TCR, присутствует на N-конце полипептида по изобретению. Соответственно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR, расположен на N-конце полипептида.
Полипептид по изобретению дополнительно охватывает один или несколько ISV. ISV для применения в полипептиде по изобретению были специально отобраны по их высокой специфичности к CD123, присутствующему в клетках-мишенях, экспрессирующих CD123.
Следовательно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123 (по существу), состоит из 4 каркасных областей (FR1) FR4, соответственно) и 3 определяющие комплементарность области (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 3, 6, 7 и/или 8 CDR1 (положения 28, 31, 32 и/или 33 согласно нумерации Kabat); при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20, где различие в 3, 2 или 1 аминокислоту присутствует в положениях 3 6 и/или 10 CDR2 (положения 52, 54 и/или 58 согласно нумерации Kabat); при условии, что ISV, включающий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25, где различие в 3, 2 или 1 аминокислоту присутствует в положениях 3, 4 и/или 5 в CDR3 (положения 97, 98 и/или 99 согласно нумерации Kabat); при условии, что ISV, включающий CDR3 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Настоящее изобретение идентифицировало ISV, которые специфически связывают CD123 с выбранными антигенсвязывающими сайтами или паратопами. В одном аспекте ISV, который специфически связывает CD123, связывается с эпитопом, который связан с ISV 56A10 (т.е. ISV, который принадлежит к тому же семейству, что и 56A10, или ISV, который относится к 56A10).
В одном аспекте CDR1, включенный в ISV, который специфически связывает CD123, может быть выбран из группы, состоящей из:
а) SEQ ID NO: 11; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 11, где
- в положении 3 Т была изменена на S или P;
- в положении 6 I была изменена на S;
- в положении 7 N была изменена на D; и/или
- в положении 8 D была изменена на V или A;
при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Помимо этого или в дополнение, CDR2, включенный в ISV, который специфически связывает TCR, может представлять собой SEQ ID NO: 17.
Помимо этого или в дополнение, CDR3, включенный в ISV, который специфически связывает TCR, может быть выбран из группы, состоящей из:
а) SEQ ID NO: 21; или
b) аминокислотных последовательностей с различием в 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 21, где
- в положении 3 P была изменена на A;
при условии, что ISV, включающий CDR3 с разницей в 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR3 без разницы в 1 аминокислоту, причем указанная аффинность измеряется поверхностным плазмонным резонансом,
Соответственно, настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123 (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 11, где
- в положении 3 Т была изменена на S или P;
- в положении 6 I была изменена на S;
- в положении 7 N была изменена на D; и/или
- в положении 8 D была изменена на V или A;
при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 является SEQ ID NO: 17;
и
iii) CDR3 выбрана из группы, состоящей из:
с) SEQ ID NO: 21; или
d) аминокислотных последовательностей с различием в 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 21, где
- в положении 3 P была изменена на A;
при условии, что полипептид, содержащий CDR3 с различием в 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием с полипептидом, содержащим CDR3 без различия в 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса,
В предпочтительном аспекте ISV, который специфически связывает CD123 (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых CDR1 выбрана из группы, состоящей из SEQ ID NO: 11-15, CDR2 представляет собой SEQ ID NO: 17, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 21-22.
Соответственно, настоящее изобретение предлагает полипептид, включающий ISV, который специфически связывает TCR, как описано в данном документе, и включающий один или несколько ISV, которые специфически связывают CD123 (по существу), состоящие из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), где CDR1 выбрана из группы, состоящей из SEQ ID NO: 11-15, CDR2 представляет собой SEQ ID NO: 17, а CDR3 выбрана из группы, состоящей из SEQ ID NO: 21-22.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123 (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющие комплементарность области (CDR1-CDR3, соответственно), в которых CDR1 представляет собой SEQ ID NO: 11, CDR2 представляет собой SEQ ID NO: 17 и CDR3 представляет собой SEQ ID NO: 21.
Предпочтительные ISV для применения в полипептиде по изобретению могут быть выбраны из группы, состоящей из SEQ ID NO: 1-6 или из ISV, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 1-6. Соответственно, настоящее изобретение также относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123, выбирают из группы, состоящей из SEQ ID NO: 1-6 или из ISV, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 1-6.
В другом аспекте ISV, который специфически связывает CD123, связывается с эпитопом, который связывается нанотелом 55F03 (т.е. ISV, который принадлежит к тому же семейству, что и 55F03, или ISV, который относится к 55F03).
В одном аспекте CDR1, включенный в ISV, который специфически связывает CD123, представляет собой SEQ ID NO: 16.
Помимо этого или в дополнение, CDR2, включенный в ISV, который специфически связывает CD123, может быть выбран из группы, состоящей из:
а) SEQ ID NO: 18; или
b) аминокислотных последовательностей, которые имеют различие в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 18, где
- в положении 3 Y была изменена на W;
- в положении 6 N была изменена на S; и/или
- в положении 10 Q была изменена на E;
при условии, что ISV, включающий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Помимо этого или в дополнение, CDR3, включенный в ISV, который специфически связывает CD123, может быть выбран из группы, состоящей из:
а) SEQ ID NO: 23; или
b) аминокислотных последовательностей с различием в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 23, где
- в положении 4 E была изменена на R; и/или
- в положении 5 Т была изменена на D или Y;
при условии, что ISV, включающий CDR3 с различием в 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Соответственно, настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123 (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющие комплементарность области (CDR1-CDR3, соответственно), в которых:
i) CDR1 является SEQ ID NO: 16;
и
ii) CDR2 выбрана из группы, состоящей из:
а) SEQ ID NO: 18; или
b) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 18, где
- в положении 3 Y была изменена на W;
- в положении 6 N была изменена на S; и/или
- в положении 10 Q была изменена на E;
при условии, что полипептид, содержащий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
с) SEQ ID NO: 23; или
d) аминокислотных последовательностей с различием в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 23, где
- в положении 4 E была изменена на R; и/или
- в положении 5 Т была изменена на D или Y;
при условии, что полипептид, содержащий CDR3 с различием в 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3, без различия в 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В предпочтительном аспекте ISV, который специфически связывает CD123 (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых CDR1 представляет собой SEQ ID NO: 16, CDR2 выбрана из группы, состоящей из SEQ ID NO: 18-20, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 23-25.
Соответственно, настоящее изобретение предлагает полипептид, включающий ISV, который специфически связывает TCR, как описано в данном документе, и включающий один или несколько ISV, которые специфически связывают CD123 (по существу), состоящий из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), где CDR1 представляет собой SEQ ID NO: 16, CDR2 выбрана из группы, состоящей из SEQ ID NO: 18-20, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 23-25.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123 (по существу), состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющие комплементарность области (CDR1-CDR3, соответственно), в которых CDR1 представляет собой SEQ ID NO: 16, CDR2 представляет собой SEQ ID NO: 18 и CDR3 представляет собой SEQ ID NO: 23.
Предпочтительные ISV для применения в полипептиде по изобретению могут быть выбраны из группы, состоящей из SEQ ID NO: 7-10, или из ISV, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 7-10. Соответственно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123, выбирают из группы, состоящей из SEQ ID NO: 7-10 или из ISV, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 7-10.
Полипептид по изобретению может включать один ISV, который специфически связывает CD123, или более одного ISV, который специфически связывает CD123, например, два, три или даже больше. В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, включающему ISV, который специфически связывает TCR, как описано в данном документе, и включающему два или более ISV, которые специфически связывают CD123, предпочтительно два.
Два или более, предпочтительно два ISV, включенные в полипептид по изобретению, могут представлять собой любой ISV, который специфически связывается с CD123, как описано в данном документе. Два или более, предпочтительно два ISV, включенные в полипептид по изобретению, могут быть одинаковыми ISV (т.е. с одной и той же аминокислотной последовательностью) или они могут быть разными ISV (т.е. с другой аминокислотной последовательностью). В одном аспекте настоящее изобретение относится к полипептиду, как описано в котором два или более ISV, которые специфически связывают CD123, являются бипаратопными, содержащими первый ISV и второй ISV, где первый ISV связывается с эпитопом на CD123, который отличается от эпитопа на CD123, связываемого вторым ISV.
Предпочтительно два или более, предпочтительно два ISV, которые специфически связывают CD123, представляют собой ISV, относящийся к 56A10, и ISV, относящийся к 55F03. Соответственно, в одном аспекте в настоящем изобретении предлагается полипептид, описанный в данном документе, где первый ISV выбран из ISV, относящихся к 56A10, и второй ISV выбран из ISV, относящихся к 55F03.
Два или более, предпочтительно два ISV, которые специфически связывают CD123, могут присутствовать в любом положении в полипептиде по изобретению. В одном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где второй ISV расположен на N-конце первого ISV. В другом аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где второй ISV расположен на С-конце первого ISV.
ISV, присутствующие в полипептиде по изобретению, могут быть любыми ISV, известными в данной области и описанными в данном документе далее. В одном аспекте ISV, присутствующие в полипептиде по изобретению, выбраны из однодоменного антитела, dAb, нанотела, VHH, гуманизированного VHH, оверблюженного VH или VHH, который был получен путем созревания аффинности. Соответственно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV, который специфически связывает TCR, и один или несколько ISV, которые специфически связывают CD123 (по существу), состоят из однодоменного антитела, dAb, нанотела, VHH, гуманизированного VHH, верблюжьего VH или VHH, который был получен путем созревания аффинности.
Предпочтительные полипептиды по изобретению выбраны из группы, состоящей из SEQ ID NO: 47, 49, 52, 53, 55, 56 и 58-61, или из полипептидов, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 47, 49, 52, 53, 55, 56 и 58-61.
Более предпочтительно, полипептид выбран из группы, состоящей из SEQ ID NO: 47, 49, 52, 53, 55, 56 и 58-61.
Как обсуждалось выше, полипептид по изобретению перенаправляет Т-клетки для уничтожения клеток, экспрессирующих CD123. В одном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где указанный полипептид индуцирует активацию Т-клеток.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где указанная активация Т-клеток не зависит от распознавания MHC.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где указанная активация Т-клеток зависит от презентации Т-клетке указанного полипептида, связанного с CD123, на клетке-мишени.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где указанная активация Т-клеток вызывает один или несколько клеточных ответов у указанных Т-клеток, причем указанный клеточный ответ выбран из группы, состоящей из пролиферации, дифференцировки, секреции цитокинов, высвобождения цитотоксичных эффекторных молекул, цитотоксичной активности, экспрессии маркеров активации и перенаправленного лизиса клеток-мишеней.
В конкретном аспекте активация Т-клеток, индуцированная полипептидом по изобретению, вызывает гибель экспрессирующих CD123 клеток со средним значением EC50 от 1 нМ до 1 пМ, например, при среднем значении EC50 500 пМ или менее, таким как менее 400, 300, 200 или 100 пМ или даже менее, например, менее 90, 80, 70, 60, 50, 40 или 30 пМ или даже менее, где указанное значение EC50 предпочтительно определяют в анализе на основе проточной цитометрии по данным с TOPRO3 с использованием клеток MOLM-13 в качестве клеток-мишеней и Т-клеток человека в качестве эффекторных клеток при соотношении эффекторных клеток и клеток-мишеней 10:1.
В другом конкретном аспекте активация Т-клеток, индуцированная полипептидом по изобретению, вызывает лизис клеток, экспрессирующих CD123, со средним процентом лизиса более чем около 10%, таким как 15%, 16%, 17%, 18%, 19%. или 20% или даже более, например, более 25% или даже более 30%, указанный процент лизиса предпочтительно определяют в анализе на основе проточной цитометрии по данным с TOPRO3 с использованием клеток MOLM-13 в качестве клеток-мишеней и Т-клеток человека в качестве эффекторных клеток при соотношении эффекторных клеток-мишеней 10:1.
В другом конкретном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где указанная активация Т-клеток, индуцированная полипептидом по изобретению, вызывает секрецию IFN-γ со средним значением EC50 от 100 нМ до 10 пМ, например, среднее значение ЕС50 составляет 50 нМ или менее, например, менее 40, 30, 20, 10 или 9 нМ или даже менее, например, менее 8, 7, 6, 5, 4, 3, 2 или 1 нМ или даже менее, например, менее 500 пМ или даже менее, например, менее 400, 300, 200 или 100 пМ или даже менее, указанное значение EC50 предпочтительно определяют в анализе на основе ELISA.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где указанная активация Т-клеток вызывает пролиферацию указанных Т-клеток.
Как обсуждалось выше, полипептиды по настоящему изобретению выбраны так, что независимая от мишени активация Т-клеток должна быть минимальной. Следовательно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где активация Т-клеток в отсутствие CD123-положительных клеток минимальна.
Более конкретно, лизис CD123-отрицательных клеток, индуцированный активацией Т-клеток посредством полипептидов по настоящему изобретению, составляет не более чем около 10%, например, 9% или менее, например, 8, 7 или 6% или даже менее, причем указанный лизис предпочтительно определяется как средний процент лизиса в анализе на основании проточной цитометрии с TOPRO3 с использованием клеток U-937 в качестве клеток-мишеней и Т-клеток человека в качестве эффекторных клеток при соотношении эффекторных клеток-мишеней 10:1.
Настоящее изобретение также относится к структурным элементам, т.е. ISV, которые составляют полипептиды по изобретению. Соответственно, настоящее изобретение также относится к полипептиду, который представляет собой ISV, который специфически связывает CD123 и который включает или (по существу) состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в котором:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16; при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20; при условии, что полипептид, содержащий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25; при условии, что полипептид, содержащий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Более предпочтительно, полипептид, который представляет собой ISV, который специфически связывает CD123, содержит или (по существу) состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16; при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием с полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20; при условии, что полипептид, содержащий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25; при условии, что полипептид, содержащий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В дополнительном аспекте настоящее изобретение также относится к полипептиду, как описано выше, который включает или (по существу) состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 3, 6, 7 и/или 8 CDR1 (положения 28, 31, 32 и/или 33 согласно нумерации Kabat); при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20, где различие в 3, 2 или 1 аминокислоту присутствует в положениях 3 6 и/или 10 CDR2 (положения 52, 54 и/или 58 согласно нумерации Kabat); при условии, что полипептид, содержащий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25, где различие в 3, 2 или 1 аминокислоту присутствует в положениях 3, 4 и/или 5 CDR3 (положения 97, 98 и/или 99 согласно нумерации Kabat); при условии, что полипептид, содержащий CDR3 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Настоящее изобретение идентифицировало ISV, которые специфически связывают CD123 с помощью выбранных антигенсвязывающих сайтов или паратопов. В одном аспекте ISV, который специфически связывает CD123, связывается с эпитопом, который связывается ISV 56A10 (т.е. ISV, который принадлежит к тому же семейству, что и 56A10, или ISV, который относится к 56A10).
Соответственно, в одном аспекте CDR1, включенный в ISV, который специфически связывает CD123, может быть выбран из группы, состоящей из:
а) SEQ ID NO: 11; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 11, где
- в положении 3 Т была изменена на S или P;
- в положении 6 I была изменена на S;
- в положении 7 N была изменена на D; и/или
- в положении 8 D была изменена на V или A;
при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Помимо этого или в дополнение, CDR2, включенный в ISV, который специфически связывает CD123, представляет собой SEQ ID NO: 17.
Помимо этого или в дополнение, CDR3, включенный в ISV, который специфически связывает CD123, может быть выбран из группы, состоящей из:
а) SEQ ID NO: 21; или
b) аминокислотных последовательностей с различием в 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 21, где
- в положении 3 P была изменена на A;
при условии, что полипептид, содержащий CDR3 с различием в 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса,
Соответственно, настоящее изобретение также относится к полипептиду, как описано выше, который включает или (по существу) состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 11, где
- в положении 3 Т была изменена на S или P;
- в положении 6 I была изменена на S;
- в положении 7 N была изменена на D; и/или
- в положении 8 D была изменена на V или A;
при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 является SEQ ID NO: 17;
и
iii) CDR3 выбрана из группы, состоящей из:
с) SEQ ID NO: 21; или
d) аминокислотных последовательностей с различием в 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 21, где
- в положении 3 P была изменена на A;
при условии, что полипептид, содержащий CDR3 с различием в 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса,
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, в котором CDR1 выбрана из группы, состоящей из SEQ ID NO: 11-15, CDR2 представляет собой SEQ ID NO: 17, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 21-22. Предпочтительно, CDR1 представляет собой SEQ ID NO: 11, CDR2 представляет собой SEQ ID NO: 17 и CDR3 представляет собой SEQ ID NO: 21.
Предпочтительные ISV по изобретению, относящиеся к 56A10, могут быть выбраны из группы, состоящей из SEQ ID NO: 1-6 или из полипептидов, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 1-6. Соответственно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где полипептид выбран из группы, состоящей из SEQ ID NO: 1-6 или из полипептидов, которые имеют идентичность последовательностей более 80%, более чем 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 1-6. Предпочтительно полипептид выбран из группы, состоящей из SEQ ID NO: 1-6.
В одном аспекте полипептид по изобретению связывается с CD123 человека, экспрессируемым на клетках MOLM-13, со средним значением EC50 между 10 нМ и 100 пМ, например, со средним значением EC50 5 нМ или менее, например, менее 4, 3, 2 или 1 нМ или даже менее, предпочтительно по данным проточной цитометрии.
В другом аспекте полипептид по изобретению связывается с CD123 человека со средним значением KD от 10 нМ до 100 пМ, например, со средним значением KD 5 нМ или менее, например, менее 4, 3 или 2 нМ или еще менее, указанное значение KD предпочтительно определяют поверхностным плазмонным резонансом.
В еще одном аспекте ISV, который специфически связывает CD123, связывается с эпитопом, который связан с ISV 55F03 (т.е. ISV, который принадлежит к тому же семейству, что и 55F03, или ISV, который относится к 55F03).
Соответственно, в одном аспекте CDR1, включенный в ISV, который специфически связывает CD123, представляет собой SEQ ID NO: 16.
Помимо этого или в дополнение, CDR2, включенный в ISV, который специфически связывает CD123, может быть выбран из группы, состоящей из:
а) SEQ ID NO: 18; или
b) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 18, где
- в положении 3 Y была изменена на W;
- в положении 6 N была изменена на S; и/или
- в положении 10 Q была изменена на E;
при условии, что полипептид, содержащий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Помимо этого или в дополнение, CDR3, включенный в ISV, который специфически связывает CD123, может быть выбран из группы, состоящей из:
а) SEQ ID NO: 23; или
b) аминокислотных последовательностей с различием в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 23, где
- в положении 4 E была изменена на R; и/или
- в положении 5 Т была изменена на D или Y;
при условии, что полипептид, содержащий CDR3 с различием в 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3, без различия в 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Соответственно, настоящее изобретение также относится к полипептиду, как описано выше, который включает или (по существу) состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 является SEQ ID NO: 16;
и
ii) CDR2 выбрана из группы, состоящей из:
а) SEQ ID NO: 18; или
b) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 18, где
- в положении 3 Y была изменена на W;
- в положении 6 N была изменена на S; и/или
- в положении 10 Q была изменена на E;
при условии, что полипептид, содержащий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
с) SEQ ID NO: 23; или
d) аминокислотных последовательностей с различием в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 23, где
- в положении 4 E была изменена на R; и/или
- в положении 5 Т была изменена на D или Y;
при условии, что полипептид, содержащий CDR3 с различием в 2 или 1 аминокислоту, связывает CD123 с такой же, примерно такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3, без различия в 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, в котором CDR1 представляет собой SEQ ID NO: 16, CDR2 выбрана из группы, состоящей из SEQ ID NO: 18-20, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 23-25. Предпочтительно, CDR1 представляет собой SEQ ID NO: 16, CDR2 представляет собой SEQ ID NO: 18 и CDR3 представляет собой SEQ ID NO: 23.
Предпочтительные ISV по изобретению, относящиеся к 56A10, могут быть выбраны из группы, состоящей из SEQ ID NO: 7-10 или из полипептидов, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 7-10. Соответственно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где полипептид выбран из группы, состоящей из SEQ ID NO: 7-10 или из полипептидов, которые имеют идентичность последовательностей более 80%, более чем 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 7-10. Предпочтительно, полипептид выбран из группы, состоящей из SEQ ID NO: 7-10.
В одном аспекте полипептид по изобретению связывается с CD123 человека, экспрессируемым на клетках MOLM-13, со средним значением EC50 от 10 мкМ до 100 нМ, например, со средним значением EC50 5 мкМ или менее, например, менее 4, 3, 2 или 1 мкМ или даже менее, предпочтительно по данным проточной цитометрии.
В другом аспекте полипептид по изобретению связывается с CD123 человека со средним значением KD от 1 мкМ до 10 нМ, например, со средним значением KD 500 нМ или менее, например, менее 400, 300 или 200 нМ или еще меньше, где указанное значение KD предпочтительно определяют поверхностным плазмонным резонансом.
В дополнительном аспекте настоящее изобретение относится к полипептиду, который перекрестно блокирует связывание с CD123, по меньшей мере, одного из полипептидов, описанных в данном документе, или который перекрестно блокирует связывание с CD123 одного из полипептидов с SEQ ID NO: 1- 10.
В дополнительном аспекте настоящее изобретение относится к полипептиду, который перекрестно блокируется от связывания с CD123, по меньшей мере, одним из полипептидов, описанных в данном документе, или который перекрестно блокируется от связывания с CD123 одним из полипептидов с SEQ ID NO: 1-10.
Полипептид, который специфически связывает CD123, как описано в данном документе, предпочтительно (по существу) состоит из однодоменного антитела, dAb, нанотела, VHH, гуманизированного VHH, оверблюженного VH или VHH, который был получен путем созревания аффинности.
Полипептид по изобретению, который специфически связывает CD123, может содержать один или несколько ISV, которые специфически связывают CD123. Соответственно, в дополнительном аспекте настоящее изобретение относится к полипептиду, включающему два или более ISV, предпочтительно два, которые специфически связывают CD123. В предпочтительном аспекте два или более ISV, предпочтительно два ISV, которые специфически связывают CD123, выбираются из группы ISV, относящейся к 56A10, или из группы ISV, относящейся к 55F03.
В дополнительном аспекте настоящее изобретение относится к полипептиду, который специфически связывает CD123, включающему два ISV, которые специфически связывают CD123, где ISV выбраны из группы ISV, относящихся к 56A10, или из группы ISV, относящихся к 55F03.
Полипептид по изобретению, содержащий два или более ISV, предпочтительно два ISV, которые специфически связывают CD123, предпочтительно является бипаратопическим, включающим первый ISV и второй ISV, где первый ISV связывается с эпитопом на CD123, который отличается от эпитопа на CD123, связанном вторым ISV. В предпочтительном аспекте первый ISV выбирается из группы ISV, относящихся к 56A10, и второй ISV выбирается из группы ISV, относящихся к 55F03.
ISV могут присутствовать в любом положении в бипаратопическом полипептиде по изобретению, который связывает CD123. В одном аспекте второй ISV расположен на N-конце первого ISV. В другом аспекте второй ISV расположен на С-конце первого ISV.
ISV, присутствующие в полипептиде по изобретению, могут быть непосредственно связаны друг с другом, или они могут быть связаны через один или несколько линкеров, предпочтительно пептидных линкеров. Соответственно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где ISV непосредственно связаны друг с другом или связаны друг с другом через линкер. Предпочтительные линкеры для применения в полипептидах по изобретению показаны в таблице B-3 (SEQ ID NO: от 325 до 336). Как таковой, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, в котором линкер выбран из группы, состоящей из SEQ ID NO: от 325 до 336.
Настоящее изобретение дополнительно охватывает конструкции (также называемые в данном документе «конструкция(ии) по изобретению»), которые включают полипептид, описанный в данном документе, и дополнительно включают одну или несколько других групп, остатков, фрагментов или связывающих единиц, необязательно связанных через один или более пептидных линкеров.
В дополнительном аспекте указанные одна или несколько других групп, остатков, фрагментов или связывающих единиц могут обеспечивать конструкцию с увеличенным периодом полувыведения по сравнению с соответствующим полипептидом без одной или нескольких других групп, остатков, фрагментов или связывающих единиц. Упомянутая одна или несколько других групп, остатков, фрагментов или связывающих единиц, которые обеспечивают полипептид с увеличенным периодом полувыведения, может быть любой молекулой, которая обеспечивает удержание полипептида в сыворотке. В одном аспекте одна или несколько других групп, остатков, фрагментов или связывающих единиц, которые обеспечивают полипептиду повышенный период полувыведения, выбираются из группы, состоящей из молекулы полиэтиленгликоля, белков сыворотки или их фрагментов, связывающих единиц, которые могут связываться с белками сыворотки, часть Fc и небольшие белки или пептиды, которые могут связываться с белками сыворотки.
Соответственно, в одном аспекте в настоящем изобретении предлагается конструкцию, как описано в данном документе, в которой указанные одна или несколько других групп, остатков, фрагментов или связывающих единиц, которые обеспечивают конструкцию с увеличенным периодом полувыведения, выбирают из группы, состоящей из сывороточного альбумина (такой как человеческий сывороточный альбумин) или сывороточный иммуноглобулин (такой как IgG).
В другом аспекте в настоящем изобретении предлагается конструкция, описанная в данном документе, в которой указанные одно или несколько других связывающих единиц, которые обеспечивают конструкцию с увеличенным периодом полувыведения, выбирают из группы, состоящей из связывающих единиц, которые могут связываться с сывороточным альбумином (таким как человеческий сывороточный альбумин) или сывороточный иммуноглобулин (такой как IgG). Предпочтительно указанное одно или несколько других связывающих единиц, которые обеспечивают полипептиду увеличенный период полувыведения, представляет собой ISV, который связывает сывороточный альбумин. В дополнительном аспекте указанный ISV, который связывает сывороточный альбумин, может (по существу) состоять из однодоменного антитела, dAb, нанотела, VHH, гуманизированного VHH или оверблюженного VH.
Предпочтительным ISV для применения в конструкциях, описанных в данном документе, является ISV, который связывает сывороточный альбумин и который (по существу) состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в котором CDR1 представляет собой GFTFSSFGMS (SEQ ID NO: 363) или GFTFRSFGMS (SEQ ID NO: 364), CDR2 представляет собой SISGSGSDTL (SEQ ID NO: 365) и CDR3 представляет собой GGSLSR (SEQ ID NO: 366). Предпочтительные ISV, которые связывают сывороточный альбумин, выбраны из группы, состоящей из SEQ ID NO: 43 и 351-362.
Что касается полипептидов по изобретению, другие группы, остатки, фрагменты или связывающие единицы, такие как ISV, могут быть непосредственно связаны друг с другом или связаны друг с другом через линкер. В дополнительном аспекте в настоящем изобретении предлагается конструкция, описанная в данном документе, в которой линкер выбран из группы, состоящей из SEQ ID NO: 325- 336.
Предпочтительные конструкции по изобретению могут быть выбраны из группы, состоящей из SEQ ID NO: 63-67 или конструкций, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 63-67, предпочтительно, SEQ ID NO: 63-67.
Конструкции по изобретению могут быть оптимизированы по последовательности, например, чтобы сделать конструкцию более похожей на человеческие, улучшить экспрессию конструкций, повысить стабильность конструкций при хранении и/или сделать конструкции менее склонными к связыванию антителами, предсуществовавшими в сыворотке. В одном аспекте настоящее изобретение обеспечивает конструкцию, описанную в данном документе, дополнительно содержащую C-концевое удлинение (X)n, в котором n равно от 1 до 5, например, 1, 2, 3, 4 или 5, и в котором X является природной аминокислотой, предпочтительно не цистеин. Предпочтительные конструкции выбраны из группы, состоящей из SEQ ID NO: 338-342.
Настоящее изобретение также относится к нуклеиновым кислотам, кодирующим полипептиды и конструкции (которые таковы, что они могут быть получены путем экспрессии нуклеиновой кислоты, кодирующей их), как определено в данном документе. В одном аспекте нуклеиновая кислота, как описано в данном документе, находится в форме генетической конструкции.
Настоящее изобретение также относится к экспрессирующему вектору, содержащему нуклеиновую кислоту, как определено в данном документе.
Настоящее изобретение также относится к хозяину или клетке-хозяину, содержащим нуклеиновую кислоту, определенную в данном документе, или экспрессирующий вектор, определенный в данном документе.
В дополнительном аспекте в настоящем изобретении предлагается способ получения полипептида или конструкции (т.е. такие, которые могут быть получены путем экспрессии нуклеиновой кислоты, кодирующей их), как определено в данном документе, причем указанный способ, по меньшей мере, включает стадии:
a) экспрессии в подходящей клетке-хозяине или организме-хозяине или в другой подходящей системе экспрессии нуклеиновой кислоты, как определено в данном документе; за которыми необязательно следуют:
b) выделения и/или очистки полипептида или конструкции, как определено в данном документе.
В дополнительном аспекте настоящее изобретение относится к композиции, содержащей, по меньшей мере, один полипептид или конструкцию, определенные в данном документе, или нуклеиновую кислоту, определенную в данном документе. В одном аспекте композиция представляет собой фармацевтическую композицию. В одном аспекте композиция дополнительно содержит, по меньшей мере, один фармацевтически приемлемый носитель, разбавитель или эксципиент и/или адъювант и, необязательно, содержит один или несколько дополнительных фармацевтически активных полипептидов и/или соединений.
Настоящее изобретение также относится к полипептиду, описанному в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе, для применения в качестве лекарственного средства. В дополнительном аспекте настоящее изобретение относится к применению полипептида, описанного в данном документе, или композиции, описанной в данном документе, для изготовления лекарственного средства. В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе, для применения при профилактике, лечении и/или облегчении заболевания или состояния, связанного с CD123. Настоящее изобретение также относится к способу предотвращения, лечения или и/или улучшения ассоциированного с CD123 заболевания или состояния, включающему стадию введения объекту, нуждающемуся в этом, фармацевтически активного количества полипептида, описанного в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе. Настоящее изобретение также относится к применению полипептида, описанного в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе, для изготовления лекарственного средства для профилактики, лечения и/или облегчения заболевания или состояния, связанного с CD123. Без ограничения указанным, CD123-ассоциированное заболевание или состояние может представлять собой пролиферативное заболевание или воспалительное состояние. Соответственно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе, для применения при профилактике, лечении и/или ослаблении пролиферативного заболевания или воспалительного состояния. Настоящее изобретение также относится к способу профилактики, лечения и/или облегчения пролиферативного заболевания или воспалительного состояния, включающему стадию введения объекту, нуждающемуся в этом, фармацевтически активного количества полипептида, описанного в данном документе, конструкцию как описано в данном документе, или композиция, описанная в данном документе. Настоящее изобретение также относится к применению полипептида, описанного в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе, для изготовления лекарственного средства для профилактики, лечения и/или облегчения пролиферативного заболевания или воспалительного состояния.
Без ограничения указанным, пролиферативное заболевание может быть онкологическим заболеванием. Соответственно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе, для применения при профилактике, лечении и/или ослаблении онкологического заболевания. Настоящее изобретение также относится к способу профилактики, лечения и/или облегчения онкологического заболевания, включающему стадию введения объекту, нуждающемуся в этом, фармацевтически активного количества полипептида, описанного в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе. Настоящее изобретение также относится к применению полипептида, описанного в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе, для изготовления лекарственного средства для профилактики, лечения и/или облегчения интенсивности онкологического заболевания.
Онкологическое заболевание, подлежащее лечению способом по изобретению, может быть любым онкологическим заболеванием, о котором известно, что оно лечится посредством уничтожения клеток, путем направленного воздействия через CD123. Злокачественные опухоли, при которых имеет место экспрессия CD123 на аберрантно пролиферирующих клетках, включают (без ограничения указанным) лимфомы (в том числе лимфому Беркитта, лимфому Ходжкина и неходжкинскую лимфому), лейкозы (включая острый миелолейкоз, хронический миелоидный лейкоз, В-клеточный острый лимфобластный лейкоз, хронический лимфолейкоз и волосатоклеточный лейкоз), миелодиспластический синдром, новообразование бластных плазмоцитоидных дендритных клеток, системный мастоцитоз и множественную миелому. Соответственно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, конструкции, описанной в данном документе, композиции, описанной в данном документе, для применения при профилактике, лечении и/или уменьшения интенсивности онкологического заболевания, выбранного из лимфом (включая лимфому Беркитта, лимфому Ходжкина и неходжкинскую лимфому), лейкозов (включая острый миелоидный лейкоз, хронический миелоидный лейкоз, В-клеточный острый лимфобластный лейкоз, хронический лимфолейкоз и волосатоклеточный лейкоз), миелодиспластического синдрома, новообразования бластных плазмоцитоидных дендритных клеток, системного мастоцитоза и множественной миеломы. Настоящее изобретение также относится к способу профилактики, лечения и/или облегчения состояния при онкологическом заболевании, выбранном из лимфом (включая лимфому Беркитта, лимфому Ходжкина и неходжкинскую лимфому), лейкозов (включая острый миелоидный лейкоз, хронический миелоидный лейкоз, В-клеточный острый лимфобластный лейкоз, хронический лимфолейкоз и волосатоклеточный лейкоз), миелодиспластического синдрома, новообразования бластных плазмоцитоидных дендритных клеток, системного мастоцитоза и множественной миеломы, включающего стадию введения объекту, нуждающемуся в этом, фармацевтически активного количества полипептида, описанного в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе. Настоящее изобретение также относится к применению полипептида, описанного в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе, для изготовления лекарственного средства для профилактики, лечения и/или облегчения состояния при онкологическом заболевании, выбранном из группы, состоящей из лимфом (в том числе лимфомы Беркитта, лимфомы Ходжкина и неходжкинской лимфомы), лейкозов (включая острый миелоидный лейкоз, хронический миелоидный лейкоз, В-клеточный острый лимфобластный лейкоз, хронический лимфоцитарный лейкоз и волосатоклеточный лейкоз), миелодиспластического синдрома, новообразования бластных плазмоцитоидных дендритных клеток, системного мастоцитоза и множественной миеломы.
Воспалительное состояние, подлежащее лечению способом по изобретению, может представлять собой любое воспалительное состояние, о котором известно, что оно лечится посредством уничтожения клеток посредством направленного воздействия через CD123. Воспалительные состояния, известные вовлечением экспрессии CD123 на клетках, включают (без ограничения указанным) аутоиммунную волчанку (SLE), аллергию, астму и ревматоидный артрит. Соответственно, в дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, конструкции, описанной в данном документе, композиции, описанной в данном документе, для применения при профилактике, лечении и/или облегчении воспалительного состояния, выбранного из группы, состоящей из аутоиммунной волчанки (SLE), аллергии, астмы и ревматоидного артрита. Настоящее изобретение также относится к способу профилактики, лечения и/или облегчения воспалительного состояния, выбранного из группы, состоящей из аутоиммунной волчанки (SLE), аллергии, астмы и ревматоидного артрита, включающему стадию введения объекту, нуждающемуся в этом фармацевтически активное количество полипептида, описанного в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе. Настоящее изобретение также относится к применению полипептида, описанного в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе, для изготовления лекарственного средства для профилактики, лечения и/или облегчения воспалительного состояния, выбранного из группы, состоящей из аутоиммунной волчанки (SLE), аллергии, астмы и ревматоидного артрита.
Полипептиды, конструкции и композиции по настоящему изобретению также можно использовать в сочетании с другим терапевтическим лекарственным средством. Соответственно, в дополнительном аспекте в настоящем изобретении предлагается полипептид, описанный в данном документе, конструкция, описанная в данном документе, композиция, описанная в данном документе, для применения в комбинированном лечении.
Настоящее изобретение также относится к способу, описанному в данном документе, где лечение представляет собой комбинированное лечение.
В дополнительном аспекте настоящее изобретение относится к применению полипептида, описанного в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе, для изготовления лекарственного средства для профилактики, лечения и/или облегчения состояния, описанного в данном документе, где лечение представляет собой комбинированное лечение.
В дополнительном аспекте настоящее изобретение относится к набору, содержащему полипептид, описанный в данном документе, конструкцию, описанную в данном документе, нуклеиновую кислоту, описанную в данном документе, экспрессирующий вектор, описанный в данном документе, или хозяина или клетку-хозяина, описанные в данном документе.
Краткое описание чертежей
Фигура 1. Оценка экспрессии TCR/CD3 человека и CD3 человека на трансфецированных клеточных линий СНО, HEK293 и Llana с использованием 100 нМ антитела против TCR α/β человека (клон BW242/412) (черный) и 100 нМ антитела против CD3 человека (клон ОКТ-3) (серый). Значение MCF (средняя флуоресценция канала) наносили на график для каждой клеточной линии. Ось X показывает тип клетки и трансфицированные гены; CD3 указывает трансфекцию комплексом CD3 (эпсилон, дельта, гамма и дзета - цепи), huTCR указывает трансфекцию цепями TCR α/β, где используемый вариабельный домен - в скобках.
Фигура 2. Оценка качества растворимых рекомбинантных белков TCR α/β яванского макака с использованием клона R73 антитела, против TCR приматов, отличных от человека/крысы; антитела против TCR α/β человека (сплошные кружки) и нерелевантного нанотела против лизоцима яиц (cAblys) (незакрашенные круги). Значение OD было нанесено на график в зависимости от концентрации нанотела.
Фигура 3. Дозозависимое связывание моновалентного анти-TCR нанотела T0170055A02 с TCR/CD3 человека, экспрессируемым на клетках CHO-K1 (фигура 3A) и с первичными T-клетками человека (фигура 3B). Дозозависимое связывание моновалентного анти-TCR нанотела T0170056G05 с TCR/CD3 человека, экспрессируемым на клетках CHO-K1 (фигура 3C) и с первичными T-клетками человека (фигура 3D). Значение MCF (средняя флуоресценция канала) наносили на график относительно концентрации нанотела.
Фигура 4. Дозозависимое связывание моновалентных нанотел против TCR T0170055A02 (фигура 4A) и T0170056G05 (фигура 4B) с HEK293H с TCR (2IAN)/CD3 человека (закрашенный круг), HEK293H CD3 человека (крест) и с линией контрольных клеток HEK293H (незакрашенные круги). Значение MCF (средняя флуоресценция канала) наносили на график относительно концентрации нанотела.
Фигура 5. Дозозависимое связывание моновалентных нанотел против TCR T0170055A02 (фигура 4A, закрашенные круги) и T0170056G05 (фигура 4B, закрашенные круги) и нерелевантного нанотела (фигура 4A и фигура 4B, незакрашенные круги) с растворимым рекомбинантным TCR человека α/β(2XN9) -белком с «молнией». OD при 450 нм наносили на график относительно концентрации нанотела.
Фигура 6. Кинетический анализ T01700055A02 (фигура 6A) и T01700056G05 (фигура 6B) на взаимодействии растворимого рекомбинантного белка TCR α/β человека (2XN9) -белка с «молнией» с помощью интерферометрии BioLayer на приборе Octet RED384. Применяемые концентрации аналита составляли: 1000, 333, 111, 37, 12,3, 4,1 и 1,4 нМ. Аппроксимация уравнением Ленгмюра к кинетическим данным обозначена черными линиями, тогда как сенсограммы представлены серыми линиями.
Фигура 7. Дозозависимое связывание моновалентных нанотел против TCR T0170055A02 (фигура 7A, закрашенные круги) и T0170056G05 (фигура 7B, закрашенные круги) и нерелевантного нанотела (фигура 7A и фигура 7B, незакрашенные круги) с растворимым рекомбинантным TCR α/β яванского макака - белка с «молнией». OD при 450 нм наносили на график относительно концентрации нанотела.
Фигура 8. Кинетический анализ T0170055A02 (фигура 8A) и T0170056G05 (фигура 8B) по взаимодействию растворимого рекомбинантного TCRα/β яванского макака- белка с «молнией» с помощью интерферометрии BioLayer на приборе Octet RED384. Применяемые концентрации аналита составляли: 1000, 333, 111, 37, 12,3, 4,1 и 1,4 нМ. Аппроксимация уравнением Ленгмюра к кинетическим данным обозначена черными линиями, тогда как сенсограммы представлены серыми линиями.
Фигура 9. Данные активации для моновалентных анти-TCR нанотел, связанных с гранулами (фигура 9А). Данные по активации моновалентными анти-TCR нанотелами, представленными в растворе (фигура 9В). Активацию измеряли путем мониторинга активации CD69 на первичных Т-клетках человека. Значение MCF (средняя флуоресценция канала) наносили на график для каждого нанотела.
Фигура 10. Оценка экспрессии CD123 человека на HEK293 Flp-In, HEK293 Flp-In CD123 яванского макака, CHO Flp-In и CHO Flp-In CD123 человека с использованием антитела против CD123 (BD Biosciences, кат. № 554527) (черный) и изотипического контроля (eBioscience, кат. № 16-4724-85), с последующим мечением PE-меченым козьим антителом против мышиных антител (Jackson Immunoresearch lab. Inc., кат. № 115-116-071) (серый), с использованием проточной цитометрии. Значение MFI (средняя интенсивность флуоресценции канала) наносили на график для каждой клеточной линии.
Фигура 11. Оценка экспрессии CD123 человека в клетках U-937, MOLM-13, KG1a и NCI-H929 с использованием антитела против CD123, меченного APC (BD Biosciences, Cat. № 560087) (черный), и изотипического контроля, меченного APC (Biolegend, кат. № 400220) (серый), с использованием проточной цитометрии. Значение MFI (средняя интенсивность флуоресценции канала) наносили на график для каждой клеточной линии.
Фигура 12. Дозозависимое связывание моновалентного анти-CD123 нанотела A0110056A10 с клетками MOLM-13 (фигура 12A) и клетками KG1a (фигура 12C). Дозозависимое связывание моновалентного анти-CD123 нанотела A0110055F03 с клетками MOLM-13 (фигура 12B) и клетками KG1a (фигура 12D). Значение MFI (средняя интенсивность флуоресценции канала) наносили на график в зависимости от концентрации.
Фигура 13. Дозозависимое связывание Alexa647-меченого A0110056A10 с Flp-In родительскими клетками CHO (незакрашенный символ) и человеческими клетками CHO, трансфицированными CD123 (закрашенный символ) (фигура 13A). Дозозависимое связывание Alexa647-меченого A0110056A10 с родительскими клетками HEK Flp-In (незакрашенный символ) и клетками HEK, трансфицированными CD123 яванского макака (закрашенный символ) (фигура 13B). Значение MFI (средняя интенсивность флуоресценции канала) наносили на график в зависимости от концентрации.
Фигура 14. Дозозависимое связывание A0110055F03 с родительскими клетками СНО Flp-In (незакрашенный символ) и клетками СНО, трансфицированными CD123 человека (закрашенный символ) (фигура 14А). Дозозависимое связывание A0110055F03 с родительскими клетками HEK Flp-In (незакрашенный символ) и клетками HEK, трансфицированными CD123 яванского макака (закрашенный символ) (фигура 14B). Значение MFI (средняя интенсивность флуоресценции канала) наносили на график в зависимости от концентрации.
Фигура 15. Дозозависимое связывание моновалентного анти-CD123 нанотела A0110056A10-Alexa 647 с клетками MOLM-13 (фигура 15А) и с клетками CHO Flp-In, трансфицированными CD123 человека (фигура 15В). Значение MFI (средняя интенсивность флуоресценции канала) наносили на график в зависимости от концентрации.
Фигура 16. Дозозависимая конкуренция моновалентных нанотел A1010056A10 (квадраты) и A0110055F03 (кружки) с меченным Alexa 647 A0110056A10 за связывание с CD123 человека на клетках MOLM-13 (фигура 16A) и на клетках CHO Flp-In, трансфицированных CD123 человека (фигура 16B). Значение MFI (средняя интенсивность флуоресценции канала) наносили на график в зависимости от концентрации.
Фигура 17. Дозозависимое связывание меченного APC мышиного антитела против CD123 человека (клон 7G3) с CD123 человека на клетках MOLM-13 (фигура 17А) и на клетках СНО Flp-In, трансфицированных CD123 человека (фигура 17В). Значение MFI (средняя интенсивность флуоресценции канала) наносили на график в зависимости от концентрации.
Фигура 18. Дозозависимая конкуренция моновалентных нанотел A0110056A10 (квадраты) и A0110055F03 (кружки) с меченным APC мышиным антителом против CD123 человека (клон 7G3) за связывание с CD123, экспрессируемым на клетках MOLM-13 (фигура 18A) или клетках СНО Flp-In, трансфицированных huCD123 (фигура 18В). Значение MFI (средняя интенсивность флуоресценции канала) наносили на график в зависимости от концентрации.
Фигура 19. Дозозависимое связывание мышиного антитела против CD123 человека (клон 7G3) с рекомбинантным белком CD123, биотинилированным собственными силами (R & D Systems, кат. № 301-R3/CF). OD при 450 нм измеряется в зависимости от концентрации.
Фигура 20. Дозозависимая конкуренция моновалентных анти-CD123-нанотел A0110056A10 (квадраты) и A0110055F03 (закрашенные круги) с мышиным моноклональным анти-CD123-антителом (клон 7G3) (BD Biosciences, Cat № 554527) за связывание с белком CD123, в ELISA (фигура 20А). Нерелевантное нанотело против яичного лизоцима cAbLys (незакрашенные круги) и мышиное моноклональное анти-CD123-антитело (клон 7G3) в растворе (звезды) были взяты вместе в качестве отрицательного и положительного контроля, соответственно (фигура 20B). OD при 450 нм измеряется в зависимости от концентрации.
Фигура 21. Дозозависимое связывание моновалентного анти-CD123 нанотела A0110056A10-Alexa 647 с клетками MOLM-13 (фигура 21A), с клетками CHO Flp-In, трансфицированными CD123 человека (фигура 21B) и с клетками HEK Flp-In, трансфицированными CD123 яванского макака (фигура 21С). Значение MFI (средняя интенсивность флуоресценции канала) наносили на график в зависимости от концентрации.
Фигура 22. Дозозависимая конкуренция мультивалентных полипептидов, связывающих CD123/TCR, с Alexa647-A0110056A10 за связывание с CD123, экспрессируемым на клетках MOLM-13 (фигура 22A) и с huCD123, трансфицированным в клетки CHO Flp-In (фигура 22C) или cyCD123, трансфицированным в клетки HEK Flp-In (фигура 22B). Иррелевантный мультивалентный полипептид T017000129 был взят параллельно в качестве отрицательного контроля. Значение MFI (средняя интенсивность флуоресценции канала) наносили на график в зависимости от концентрации.
Фигура 23. Дозозависимая конкуренция мультивалентных полипептидов, связывающих CD123/TCR, с биотинилированным T0170056G05, за связывание с TCR/CD3 человека, экспрессированным на клетках CHO-K1. Значение MFI (средняя интенсивность флуоресценции канала) наносили на график в зависимости от концентрации.
Фигура 24. Дозозависимая конкуренция мультивалентных полипептидов, связывающих CD123/TCR, с T017000099 за связывание с CD3/TCR, экспрессируемых на HSC-F. Моновалентный His-меченный T017000125 был взят в качестве положительного контроля. Значение MFI (средняя интенсивность флуоресценции канала) наносили на график в зависимости от концентрации.
Фигура 25. Дозозависимое перенаправленное уничтожение CD123-экспрессирующих клеток MOLM-13 эффекторными Т-клетками человека, в анализе на основе проточной цитометрии с помощью мультивалентных CD123/TCR-связывающих полипептидов при соотношении эффектора к мишени 10:1. A0110056A10, T017000132 и T017000129 были взяты вместе в качестве отрицательного контроля. Процент гибели клеток (% TOPRO-положительных клеток) наносили на график в зависимости от концентрации конструкции.
Фигура 26. Дозозависимое перенаправленное уничтожение CD123-экспрессирующих клеток KG1a эффекторными Т-клетками человека, в анализе на основе проточной цитометрии с помощью мультивалентных полипептидов, связывающих CD123/TCR, при соотношении эффектора к мишени 10:1. A0110056A10, T017000129 и T017000132 были взяты параллельно в качестве отрицательных контролей. Процент гибели клеток (% TOPRO-положительных клеток) наносили на график в зависимости от концентрации конструкции.
Фигура 27. Дозозависимое перенаправленное уничтожение CD123-экспрессирующих клеток MOLM-13 эффекторными Т-клетками яванского макака в анализе на основе проточной цитометрии с помощью мультивалентных CD123/TCR-связывающих полипептидов при соотношении эффектора к мишени 10:1. A0110056A10 был взят параллельно в качестве отрицательного контроля. Процент гибели клеток (% TOPRO-положительных клеток) наносили на график в зависимости от концентрации конструкции.
Фигура 28. Дозозависимое перенаправленное уничтожение CD123-экспрессирующих клеток KG1a эффекторными Т-клетками яванского макака в анализе на основе проточной цитометрии с мультивалентными CD123/TCR-связывающими полипептидами при соотношении эффектор к мишени равного 8. Несколько иррелевантных конструкций были взяты параллельно в качестве отрицательного контроля. Процент гибели клеток (% TOPRO-положительных клеток) наносили на график в зависимости от концентрации конструкции.
Фигура 29. Дозозависимая активация Т-клеток (положительная регуляция CD25) мультивалентными CD123/TCR-связывающими полипептидами, на отобранных по CD4/CD8+ Т-клетках во время перенаправления уничтожения эффекторными Т-клетками яванского макака клеток MOLM-13 положительных по CD123 человека, после инкубационного периода 72 часа. MFI (средняя интенсивность флуоресценции) отобранных по CD4/CD8+ Т-клеток наносили на график в зависимости от концентрации конструкций.
Фигура 30. Дозозависимое перенаправленное уничтожение эффекторными Т-клетками человека трансфицированных CD123 человека клеток CHO Flp-In в анализе на основе xCELLigence с использованием T017000139 (закрашенные ромбы) при соотношении эффектор и мишень 15:1. Моновалентные нанотела A0110056A10, T0170056G05 и нерелевантная конструкция T017000129 были взяты параллельно в качестве отрицательного контроля. Клеточный индекс (CI) после инкубационного периода 50 ч наносили на график в зависимости от концентрации мультиспецифического полипептида.
Фигура 31. Моновалентные структурные элементы и мультиспецифические полипептиды в анализе перенаправленного уничтожения эффекторными Т-клетками человека с использованием CD123-отрицательной контрольной линии Flp-In CHO в анализе на основе xCELLigence при соотношении эффектор и мишень 15:1. CI после инкубационного периода 50 ч наносили на график в зависимости от концентрации мультиспецифического полипептида.
Фигура 32. Влияние моновалентных структурных элементов и мультиспецифичных полипептидов, связывающих CD123/TCR, на рост линии клеток, трансфицированных CD123 (фигура 32А) и контрольной клеточной линии (фигура 32В) в отсутствие Т-клеток. CI после инкубационного периода 50 ч наносили на график в зависимости от концентрации мультиспецифического полипептида.
Фигура 33. Дозозависимое перенаправленное уничтожение эффекторными Т-клетками яванского макака клеток HEK Flp-In, трансфицированных CD123 яванского макака в анализе на основе xCELLigence с использованием T017000139 (закрашенные ромбы) при соотношении эффектор и мишень 15:1. Моновалентное нанотело, T0170056G05 и нерелевантная конструкция T017000129 были взяты параллельно в качестве отрицательного контроля. CI после инкубационного периода 80 часов наносили на график в зависимости от концентрации мультиспецифического полипептида.
Фигура 34. Моновалентный структурный элемент и мультиспецифические полипептиды в анализе перенаправленного уничтожения Т-клетками яванского макака с использованием CD123-отрицательной контрольной клеточной линии HEK Flp-In. CI после инкубационного периода 80 часов наносили на график в зависимости от концентрации мультиспецифического полипептида.
Фигура 35. Влияние моновалентных структурных элементов и мультиспецифичных полипептидов, связывающих CD123/TCR, на рост линии клеток, трансфицированных CD123 (фигура 35А) и контрольной клеточной линии (фигура 35В) в отсутствие Т-клеток. CI после инкубационного периода 80 часов наносили на график в зависимости от концентрации мультиспецифического полипептида.
Фигура 36. Дозозависимое продуцирование цитокинов эффекторными Т-клетками человека (фигура 36А) или эффекторными Т-клетками яванского макака (фигура 36В) во время перенаправленного уничтожения Т-клетками человека, зависимого от мультиспецифического CD123/TCR-связывающего полипептида, клеток-мишеней CHP Flp-In, экспрессирующих CD123 человека, при соотношении эффектора к мишени 10:1. Продуцирование INF-γ измеряли через 72 ч. Величина OD была нанесена на график в зависимости от концентрации.
Фигура 37. Дозозависимое продуцирование цитокинов эффекторными Т-клетками во время перенаправленного уничтожения Т-клетками, зависимого от мультиспецифического CD123/TCR-связывающего полипептида, клеток-мишеней CHO Flp-In, экспрессирующих CD123 человека, при соотношении эффектора к мишени 10:1. Продуцирование IL-6 измеряли через 72 часа. Значение пг/мл наносили на график в зависимости от концентрации.
Фигура 38. Перенаправленное опосредованное аутологичными Т-клетками истощение CD123+ pDC и базофилов мультивалентными полипептидами, связывающими CD123/TCR, в образцах PBMC здорового человека (фигура 38A) и яванского макака (фигура 38B) после инкубационного периода 5 часов. Процент клеток Lin-/CD123+ (pDC и базофилов) наносили на график в зависимости от концентрации конструкций.
Фигура 39. Перенаправленное истощение аутологичными Т-клетками моноцитов мультивалентными полипептидами, связывающими CD123/TCR, в образцах РВМС здорового человека после инкубационного периода 5 ч (фигура 39A) и 24 ч (фигура 39B). Процент моноцитов (CD14+ клеток) наносили на график в зависимости от концентрации конструкций.
Фигура 40. Дозозависимая положительная регуляция CD69, активация Т-клеток человека мультивалентными полипептидами, связывающими CD123/TCR, на отобранных по CD3+ Т-клетках в ходе перенаправленного уничтожения Т-клетками аутологичных CD123-положительных клеток после инкубационного периода 24 часа. MFI (средняя интенсивность флуоресценции) отобранных по CD3+ Т-клеток наносили на график в зависимости от концентрации конструкций.
Фигура 41. Дозозависимая характеризация моновалентных нанотел и нерелевантного мультивалентного полипептида T017000129 при перенаправленном уничтожении эффекторными T-клетками человека (фигура 41A) или яванского макака (фигура 41B) клеток KG1a с CD123 человека в анализе на основе проточной цитометрии при соотношении эффектора к мишени 10:1. T017000139 (закрашенные ромбы) был взят параллельно в качестве положительного контроля. Процент гибели клеток (% TOPRO-положительных клеток) наносили на график в зависимости от концентрации конструкции.
Фигура 42. Дозозависимая характеризация одновалентных нанотел и нерелевантного мультивалентного полипептида T017000129 для перенаправленного уничтожения эффекторными Т-клетками человека (фигура 42A) или яванского макака (фигура 42В и фигура 42С) клеток MOLM-13 с CD123 человека в анализе на основе проточной цитометрии при соотношении эффектора к мишени 10:1. T017000139 (закрашенные ромбы) был взят параллельно в качестве положительного контроля. Процент гибели клеток (% TOPRO-положительных клеток) наносили на график в зависимости от концентрации конструкции.
Фигура 43. Дозозависимое продуцирование цитокинов эффекторными Т-клетками человека во время зависимого от мультиспецифичных CD123/TCR-связывающих полипептидов перенаправленного уничтожения Т-клетками клеток-мишеней MOLM-13 (фигура 43А и фигура 43C) и KG1a (фигура 43B) при соотношении эффектора к мишени 10:1. Продуцирование IL-6 человека (фигура 43C) и IFN-β человека (фигура 43A и фигура 43B) измеряли через 72 часа. Концентрацию цитокина наносили на график в зависимости от концентрации.
Фигуры 44A и 44B. Дозозависимая характеризация мишень-независимого перенаправленного уничтожения эффекторными Т-клетками человека с помощью мультиспецифичных CD123/TCR-связывающих полипептидов в анализе на основе проточной цитометрии с использованием CD123-отрицательной клеточной линии NCI-H929. Процент гибели клеток (% TOPRO-положительных клеток) наносили на график в зависимости от концентрации конструкции.
Фигура 45. Дозозависимая характеризация мишень-независимого перенаправленного уничтожения эффекторными Т-клетками человека (фигура 45А) или яванского макака (фигура 45В), с помощью мультиспецифичных полипептидов, связывающих CD123/TCR, в анализе на основе проточной цитометрии с использованием CD123-отрицательной клеточной линии U937. Процент гибели клеток (% TOPRO-положительных клеток) наносили на график в зависимости от концентрации конструкции.
Фигура 46. Дозозависимое считывание активации Т-клеток мультивалентными CD123/TCR-связывающими полипептидами на отобранных по CD4/CD8+ Т-клетках во время уничтожения эффекторными Т-клетками отрицательных по CD123 клеток U-937 (фигура 46А) и во время уничтожения эффекторными Т-клетками человека отрицательных по CD123 клеток NCI-H929 (фигура 46B) после инкубационного периода 72 часа. MFI (средняя интенсивность флуоресценции) отобранных по CD4/CD8+ Т-клеток наносили на график в зависимости от концентрации конструкций.
Фигура 47. Влияние мультиспецифичных CD123/TCR-связывающих полипептидов на выработку цитокинов с использованием эффекторных Т-клеток человека и клеток-мишеней NCI-H929 при соотношении эффектора к мишени 10:1. Измеряли выработку IL-6 человека (фигура 47B) и IFN-β человека (фигура 47A). Величина OD количества цитокина была нанесена на график в зависимости от концентрации.
Фигуры 48А и 48В. Дозозависимая пролиферация Т-клеток эффекторных Т-клеток человека из-за мультиспецифичных полипептидов в условиях перенаправленной гибели клеток-мишеней MOLM-13 при соотношении эффектор-мишень 10:1. СРМ (импульсы в минуту) наносили на график относительно концентрации.
Фигура 49. Дозозависимая пролиферация Т-клеток эффекторных Т-клеток человека из-за мультиспецифичных полипептидов в отсутствие клеток-мишеней. СРМ (импульсы в минуту) наносили на график относительно концентрации.
Фигура 50. Литический потенциал неактивированных и предварительно активированных Т-клеток в присутствии клеток T017000114 и MOLM-13 при различных соотношениях E:T. Процент гибели клеток наносили на график в зависимости от концентрации конструкции.
Фигура 51. Литический потенциал неактивированных и предварительно активированных T-клеток в присутствии T017000139 и KG1a клеток при различных соотношениях E:T. Процент гибели клеток наносили на график в зависимости от концентрации конструкции.
Фигура 52. Дозозависимое перенаправленное уничтожение Т-клетками человека (фигура 52А и 52В) и яванского макака (фигура 52С и 52D) клеток MOLM-13 в отсутствие или в присутствие сывороточного альбумина в анализе на основе проточной цитометрии из-за мультивалентных CD123/TCR-связывающих полипептидов при соотношении эффектора к мишени 10:1. Нерелевантный мультивалентный полипептид T017000129 и моновалентные структурные элементы A0110056A10 и T0170056G05 были взяты параллельно в качестве отрицательного контроля. Процент гибели клеток (% TOPRO-положительных клеток) наносили на график в зависимости от концентрации полипептида.
Фигура 53. Дозозависимое перенаправленное уничтожение Т-клетками человека (фигуры 53A, 53B и 53C) и яванского макака (фигура 53D, 53E и 53F) клеток KG1a в отсутствие или в присутствие сывороточного альбумина в анализе на основе проточной цитометрии с помощью мультивалентных CD123/TCR-связывающих полипептидов при соотношении эффектор к мишени 10:1. Нерелевантные мультивалентные полипептиды A022600009 (в присутствии или в отсутствие SA) и T017000129, а также моновалентные структурные элементы A0110056A10 и T0170056G05 были взяты параллельно в качестве отрицательного контроля. Процент гибели клеток (% TOPRO-положительных клеток) наносили на график в зависимости от концентрации конструкции.
Фигура 54. Дозозависимое продуцирование цитокинов Т-клетками человека во время перенаправленного уничтожения Т-клетками MOLM-13 из-за мультиспецифичных полипептидов, связывающих CD123/TCR, при соотношении эффектора к мишени 10:1. Была измерено продуцирование IL-6 человека (фигура 54B) и IFN-β человека (фигура 54A). Количество цитокинов нанесено на график в зависимости от концентрации.
Фигура 55. Дозозависимая пролиферация Т-клеток эффекторных Т-клеток человека из-за мультиспецифичных полипептидов HLE в условиях перенаправленного уничтожения клеток-мишеней MOLM-13 при соотношении эффектора к мишени 10:1. СРМ (импульсы в минуту) наносили на график в зависимости от концентрации.
Фигура 56. Перенаправленное истощение CD123+ pDC и базофилов аутологичными Т-клетками из-за мультивалентных полипептидов HLE, связывающих CD123/TCR, в образцах РВМС здорового человека после инкубационного периода 5 часов. Процент клеток Lin-/CD123+ (pDC и базофилы) наносили на график в зависимости от концентрации конструкций.
Фигура 57. Перенаправленное истощение CD123+ pDC и базофилов аутологичными Т-клетками из-за мультивалентных полипептидов HLE, связывающих CD123/TCR, в здоровых образцах PBMC яванского макака в условиях in vitro после инкубационного периода 5 часов. Процент клеток Lin-/CD123+ (pDC и базофилы) наносили на график в зависимости от концентрации конструкций.
Фигура 58. Перенаправленное истощение моноцитов аутологичными Т-клетками, из-за мультивалентных CD123/TCR-связывающих полипептидов в образцах РВМС здорового человека после инкубационного периода 24 часа. Процент моноцитов (CD14 + клеток) наносили на график в зависимости от концентрации конструкций.
Фигура 59. Подсчет Т-клеток в периферической крови обработанных яванских макак в зависимости от времени. Абсолютное количество CD4+ CD3+ T-клеток (фигура 59A) и CD8+ CD3+ T-клеток (фигура 59B) на мкл крови выражается как среднее значение ± SEM за время для разных групп обработки: положительный контроль (незакрашенные круги, n = 2) нерелевантный полипептид/полипептид TCR (крест, n = 4), полипептид CD123/TCR (черный треугольник, n = 4). Серые столбики отражают периоды непрерывной инфузии.
Фигура 60. Количество CD123+CD14- клеток в периферической крови обработанных яванских макак в зависимости от времени. Абсолютное количество CD123+ CD14- клеток на мкл крови выражается как среднее ± SEM для разных групп обработки: положительный контроль (незакрашенные круги, n = 2), нерелевантный полипептид/полипептид TCR (перекрестный, n = 4), полипептид CD123/TCR (черный треугольник, n = 4). Серые столбики отражают периоды непрерывной инфузии.
Фигура 61. Экспрессия PD-1 на CD4+ CD3+ и CD8+ CD3+ T-клетках в зависимости от времени. Частота CD4+CD3+ T-клеток (фигура 61A) и CD8+CD3+ T-клеток (фигура 61B) в крови выражена как среднее ± SEM для разных групп обработки: положительный контроль (незакрашенные круги, n = 2), нерелевантный полипептид/полипептид TCR (крест, n = 4), полипептид CD123/ TCR (черный треугольник, n = 4). Серые столбики отражают периоды непрерывной инфузии.
Фигура 62. Сывороточный интерлейкин-6 у обработанных яванских макак в зависимости от времени. Концентрация IL-6 в сыворотке выражается в виде среднего значения ± SEM (пг/мл) для разных групп обработки: положительный контроль (незакрашенные круги, n = 2), нерелевантный полипептид/полипептид TCR (перекрестный, n = 4), полипептид CD123/TCR (черный треугольник, n = 4). Серые столбики отражают периоды непрерывной инфузии.
Подробное описание
Определения
Если не указано или не определено иное, все используемые термины имеют обычное значение в данной области техники, которое будет понятно специалисту. Ссылка, например, дается на стандартные руководства, такие как Sambrook et al. (1989, Molecular Cloning: A Laboratory Manual (2nd Ed.) Vols. 1-3, Cold Spring Harbor Laboratory Press), F. Ausubel et al. (1987, Current protocols in molecular biology, Green Publishing and Wiley Interscience, New York), Lewin (1985, Genes II, John Wiley & Sons, New York, N.Y.), Old et al. (1981, Principles of Gene Manipulation: An Introduction to Genetic Engineering (2nd Ed.) University of California Press, Berkeley, CA), Roitt et al. (2001, Immunology (6th Ed.) Mosby/Elsevier, Edinburgh), Roitt et al. (2001, Roitt’s Essential Immunology (10th Ed.) Blackwell Publishing, UK), and Janeway et al. (2005, Immunobiology (6th Ed.) Garland Science Publishing/Churchill Livingstone, New York, 2005), а также общий предшествующий уровень техники, процитированный в данном документе.
Если не указано иное, все способы, стадии, методы и манипуляции, которые конкретно не описаны подробно, могут быть выполнены и были выполнены таким образом, известным per se, как будет понятно специалисту в данной области. Настоящим, например, снова ссылаемся на стандартное руководство и общий предшествующий уровень техники, упомянутый в данном документе, и в других источниках, процитированных в нем; и, например, следующие обзоры Presta (2006, Adv. Drug Deliv. Rev. 58 (5-6): 640-56), Levin and Weiss (2006, Mol. Biosyst. 2(1): 49-57), Irving et al. (2001, J. Immunol. Methods 248(1-2): 31-45), Schmitz et al. (2000, Placenta 21 Suppl. A: S106-12), Gonzales et al. (2005, Tumour Biol. 26(1): 31-43), которые описывают методы белковой инженерии, такие как созревание аффинности и другие методы для улучшения специфичности и других искомых свойств белков, таких как иммуноглобулины.
Используемый в данном документе термин «последовательность» (например, в терминах «последовательность иммуноглобулина», «последовательность антитела», «последовательность вариабельного домена», «последовательность VHH» или «последовательность белка»), как правило, следует понимать как включающий соответствующую аминокислотную последовательность, а также нуклеиновые кислоты или нуклеотидные последовательности, кодирующие их, если только контекст не требует более ограниченной интерпретации.
Аминокислотные последовательности интерпретируются как означающие одиночную аминокислотную или неразветвленную последовательность двух или более аминокислот, в зависимости от контекста. Нуклеотидные последовательности интерпретируются как неразветвленная последовательность из 3 или более нуклеотидов.
Аминокислоты - это те L-аминокислоты, которые обычно встречаются в природных белках и перечислены в таблице B-1 ниже. Те аминокислотные последовательности, которые содержат D-аминокислоты, не должны охватываться этим определением. Любая аминокислотная последовательность, которая содержит посттрансляционно модифицированные аминокислоты, может быть описана как аминокислотная последовательность, которая первоначально транслируется с использованием символов, показанных в таблице ниже, с измененными положениями; например, гидроксилирование или гликозилирование, но эти модификации не должны быть явно показаны в аминокислотной последовательности. Любой пептид или белок, который может быть экспрессирован в виде связей с модифицированными последовательностями, поперечных связей и концевых кэп-структур, непептидильных связей и т.д., охватывается этим определением.
Термины «белок», «пептид», «белок/пептид» и «полипептид» используются взаимозаменяемо по всему описанию, и каждый имеет одно и то же значение для целей настоящего раскрытия. Каждый термин относится к органическому соединению, состоящему из линейной цепи из двух или более аминокислот. Соединение может иметь десять или более аминокислот; двадцать пять или более аминокислот; пятьдесят или более аминокислот; сто или более аминокислот, двести или более аминокислот и даже триста или более аминокислот. Специалисту в данной области будет понятно, что полипептиды обычно содержат меньше аминокислот, чем белки, хотя нет признанной в данной области пороговой точки количества аминокислот, которые различают полипептиды и белки; что полипептиды могут быть получены химическим синтезом или рекомбинантными методами; и что белки обычно получают in vitro или in vivo рекомбинантными способами, известными в данной области.
Аминокислотные остатки будут указаны в соответствии со стандартным трехбуквенным или однобуквенным аминокислотным кодом. Настоящим ссылаемся на таблицу A-2 на стр. 48 в WO 08/020079.
Нуклеиновая кислота или аминокислота считается «(по) (существу) выделенной (формой)», например, по сравнению с реакционной средой или культуральной средой, из которой она была получена, - когда она была отделена, по меньшей мере, от одного другого компонента, с которым она обычно ассоциирована в указанном источнике или среде, такой как другая нуклеиновая кислота, другой белок/полипептид, другой биологический компонент или макромолекула или, по меньшей мере, один загрязнитель, примесь или незначительный компонент. В частности, нуклеиновая кислота или аминокислота считается «(по существу) выделенной», когда она очищена, по меньшей мере, в 2 раза, в частности, по меньшей мере, в 10 раз, более конкретно, по меньшей мере, в 100 раз и до 1000 или более раз. Нуклеиновая кислота или аминокислота, которая находится «(по существу) в выделенной форме», предпочтительно является по существу гомогенной, что определяется с помощью подходящего метода, такого как подходящий хроматографический метод, такой как электрофорез в полиакриламидном геле.
Если контекст явно не требует иного, во всем описании и формуле изобретения слова «включает», «включающий» и тому подобное должны толковаться во всеобъемлющем смысле, а не в исключительном или исчерпывающем смысле; т.е. в смысле «включая, без ограничения указанным».
Например, когда говорят, что нуклеотидная последовательность, аминокислотная последовательность или полипептид «включает» другую нуклеотидную последовательность, аминокислотную последовательность или полипептид или «по существу состоят из» другой нуклеотидной последовательности, аминокислотной последовательности или полипептида, это может означать, что последняя нуклеотидная последовательность, аминокислотная последовательность или полипептид были включены в первую упомянутую нуклеотидную последовательность, аминокислотную последовательность или полипептид, соответственно, но чаще это обычно означает, что первая упомянутая нуклеотидная последовательность, аминокислотная последовательность или полипептид включает в пределах своей последовательности участок нуклеотидов или аминокислотных остатков, соответственно, который имеет такую же нуклеотидную последовательность или аминокислотную последовательность, соответственно, что и последняя последовательность, независимо от того, как первая упомянутая последовательность была фактически создана или получена (которая, например, может быть любым подходящим способом, описанным в данном документе). С помощью неограничивающего примера, когда считается, что полипептид по изобретению содержит иммуноглобулиновый одиночный вариабельный домен, это может означать, что указанная последовательность иммуноглобулинового одиночного вариабельного домена была включена в последовательность полипептида по изобретению, но чаще это обычно означает, что полипептид по изобретению содержит в своей последовательности последовательность иммуноглобулиновых одиночных вариабельных доменов независимо от того, как был создан или получен указанный полипептид по изобретению. Кроме того, когда считается, что нуклеиновая кислота или нуклеотидная последовательность включает другую нуклеотидную последовательность, первая упомянутая нуклеиновая кислота или нуклеотидная последовательность предпочтительно такова, что, когда она экспрессируется в продукт экспрессии (например, полипептид), аминокислотная последовательность, кодируемая последней нуклеотидной последовательностью является частью указанного продукта экспрессии (другими словами, последняя нуклеотидная последовательность находится в той же самой рамке считывания, что и первая упомянутая более крупная нуклеиновая кислота или нуклеотидная последовательность).
Под «по существу состоит из» подразумевается, что иммуноглобулиновый одиночный вариабельный домен, используемый в способе по изобретению, либо точно такой же, как полипептид по изобретению, либо соответствует полипептиду по изобретению, который имеет ограниченное количество аминокислотных остатков, например, 1-20 аминокислотных остатков, например, 1-10 аминокислотных остатков и предпочтительно 1-6 аминокислотных остатков, таких как 1, 2, 3, 4, 5 или 6 аминокислотных остатков, добавленных на амино-конце, на карбокси-конце или и на амино-конце и на карбокси-конце иммуноглобулинового одиночного вариабельного домена.
Под «состоять из» подразумевается, что иммуноглобулиновый одиночный вариабельный домен, используемый в способе по изобретению, является точно таким же, как и полипептид по изобретению.
В целях сравнения двух или более нуклеотидных последовательностей процент «идентичности последовательности» между первой нуклеотидной последовательностью и второй нуклеотидной последовательностью может быть рассчитан путем деления [количества нуклеотидов в первой нуклеотидной последовательности, которые идентичны нуклеотидам в соответствующих положениях во второй нуклеотидной последовательности] на [общее количество нуклеотидов в первой нуклеотидной последовательности] и умножения на [100%], где каждая делеция, вставка, замещение или добавление нуклеотида во второй нуклеотидной последовательности, сравниваемой с первой нуклеотидной последовательностью, рассматривается как различие в одном нуклеотиде (положении). В ином случае степень идентичности последовательности между двумя или более нуклеотидными последовательностями может быть рассчитана с использованием известного компьютерного алгоритма для выравнивания последовательностей, такого как NCBI Blast v2.0, с использованием стандартных настроек. Hекоторые другие методы, компьютерные алгоритмы и настройки для определения степени идентичности последовательности, например, описаны в WO 04/037999, EP 0967284, ЕР 1085089, WO 00/55318, WO 00/78972, WO 98/49185 и GB 2357768. Обычно для определения процента «идентичности последовательности» между двумя нуклеотидными последовательностями в соответствии с описанным выше способом расчета нуклеотидная последовательность с наибольшим количеством нуклеотидов будет приниматься за «первую» нуклеотидную последовательность, а другая нуклеотидная последовательность будет приниматься за «вторую» нуклеотидную последовательность.
В целях сравнения двух или более аминокислотных последовательностей процент «идентичности последовательности» между первой аминокислотной последовательностью и второй аминокислотной последовательностью (также называемой в данном документе «идентичностью аминокислот») может быть рассчитан путем деления [количество аминокислотных остатков в первой аминокислотной последовательности, которые идентичны аминокислотным остаткам в соответствующих положениях во второй аминокислотной последовательности] на [общее количество аминокислотных остатков в первой аминокислотной последовательности] и умножения на [100%], в котором каждая делеция, вставка, замещение или добавление аминокислотного остатка во второй аминокислотной последовательности по сравнению с первой аминокислотной последовательностью рассматривается как различие в одном аминокислотном остатке (положении), т.е. как «аминокислотное различие», как определено в данном документе. В ином случае степень идентичности последовательности между двумя аминокислотными последовательностями может быть рассчитана с использованием известного компьютерного алгоритма, такого как упомянутые выше для определения степени идентичности последовательности для нуклеотидных последовательностей, и в этом случае используя стандартные настройки. Обычно для определения процента «идентичности последовательности» между двумя аминокислотными последовательностями в соответствии с описанным выше способом расчета аминокислотная последовательность с наибольшим количеством аминокислотных остатков будет взята в качестве «первой» аминокислотной последовательности, а другая аминокислотная последовательность будет приниматься за «вторую» аминокислотную последовательность.
Кроме того, при определении степени идентичности последовательности между двумя аминокислотными последовательностями специалист в данной области может принимать во внимание так называемые «консервативные» аминокислотные замены, которые обычно могут быть описаны как аминокислотные замены, в которых аминокислотный остаток заменен на другой аминокислотный остаток с аналогичной химической структурой и который практически не влияет на функцию, активность или другие биологические свойства полипептида. Такие консервативные аминокислотные замены хорошо известны в данной области, например, из WO 04/037999, GB 335768, WO 98/49185, WO 00/46383 и WO 01/09300; и (предпочтительные) типы и/или комбинации таких замен могут быть выбраны на основе соответствующих описаний WO 04/037999, а также WO 98/49185 и из дополнительных источников, цитируемых в них.
Такие консервативные замены предпочтительно представляют собой замены, в которых одна аминокислота в следующих группах (а) - (е) замещена другим аминокислотным остатком в пределах одной и той же группы: (а) небольшие, неполярные или слегка полярные остатки: Ala, Ser, Thr, Pro и Gly; (b) полярные, отрицательно заряженные остатки и их (незаряженные) амиды: Asp, Asn, Glu и Gln; (c) полярные положительно заряженные остатки: His, Arg и Lys; (d) крупные алифатические, неполярные остатки: Met, Leu, Ile, Val и Cys; и (e) ароматические остатки: Phe, Tyr и Trp. Особенно предпочтительными консервативными заменами являются: Ala на Gly или на Ser; Arg на Lys; Asn на Gln или на His; Asp на Glu; Cys на Ser; Gln на Asn; Glu на Asp; Gly на Ala или на Pro; His на Asn или на Gln; Ile на Leu или на Val; Leu на Ile или на Val; Lys на Arg, на Gln или на Glu; Met на Leu, на Tyr или на Ile; Phe на Met, на Leu или на Tyr; Ser на Thr; Thr на Ser; Trp на Tyr; Tyr на Trp; и/или Phe на Val, на Ile или на Leu.
Любые аминокислотные замены, применяемые к описанным в данном документе полипептидам, также могут быть основаны на анализе частот вариаций аминокислот между гомологичными белками разных видов, разработанном Schulz et al. (“Principles of Protein Structure”, Springer-Verlag, 1978), и на анализе структурирующих потенциалов, разработанных Chou и Fasman (Biochemistry 13: 211, 1974; Adv. Enzymol., 47: 45-149, 1978), и на анализе паттернов гидрофобности в белках, разработанном Eisenberg et al. (1984, Proc. Natl. Acad Sci. USA 81: 140-144), Kyte and Doolittle (1981, J. Molec. Biol. 157: 105-132), и Goldman et al. (1986, Ann. Rev. Biophys. Chem. 15: 321-353, 1986), которые все включены в данный документ полностью в качестве ссылки. Информация о первичной, вторичной и третичной структуре нанотел приведена в описании в данном документе и в общем предшествующем уровне техники, упомянутом выше. Кроме того, для этой цели дается кристаллическая структура домена VHH из ламы, например, в Desmyter et al. (1996, Nature Structural Biology, 3: 803), Spinelli et al. (1996, Natural Structural Biology, 3: 752-757) и Decanniere et al. (1999, Structure, 7 (4): 361). Дополнительная информация о HEKоторых аминокислотных остатках, которые в обычных доменах VH образуют интерфейс VH/VL и потенциальные оверблюживающие замены в этих положениях, может быть найдена в предшествующем уровне техники, упомянутом выше.
Аминокислотные последовательности и последовательности нуклеиновых кислот считаются «точно такими же», если они имеют 100% идентичность последовательностей (как определено в данном документе) по всей их длине.
При сравнении двух аминокислотных последовательностей термин «аминокислотное различие» относится к вставке, делеции или замещению одного аминокислотного остатка в положении первой последовательности по сравнению со второй последовательностью; при этом понятно, что две аминокислотные последовательности могут содержать одно, два или более таких аминокислотных различий. Более конкретно, в аминокислотных последовательностях и/или полипептидах по настоящему изобретению термин «аминокислотное различие» относится к вставке, делеции или замене одного аминокислотного остатка в положении последовательности CDR, указанной в b), d) или f) по сравнению с последовательностью CDR, соответственно, a), c) или e); следует понимать, что последовательность CDR b), d) и f) может содержать одну, две или максимальные три таких аминокислотных различия по сравнению с последовательностью CDR, соответственно, а), с) или е).
«Аминокислотное различие» может представлять собой любую одну, две, три или максимально четыре замены, делеции или вставки или любую их комбинацию, которые либо улучшают свойства полипептида по изобретению, либо, по меньшей мере, не слишком сильно отвлекают от искомых свойств или из баланса или комбинации искомых свойств полипептида по изобретению. В этом отношении полученный полипептид по изобретению должен, по меньшей мере, связывать рецептор CD123 или Т-клеток с такой же, примерно такой же или более высокой аффинностью по сравнению с полипептидом, содержащим одну или несколько последовательностей CDR без одной, двух, трех или максимум четыре замены, делеции или вставки, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В этом отношении аминокислотная последовательность в соответствии с b), d) и/или f) может представлять собой аминокислотную последовательность, которая получена из аминокислотной последовательности в соответствии с a), c) и/или e), соответственно, посредством созревание аффинности с использованием одной или нескольких методик созревания аффинности, известных per se.
Например, и в зависимости от организма-хозяина, используемого для экспрессии полипептида по изобретению, такие делеции и/или замены могут быть сконструированы таким образом, что удаляются один или несколько сайтов для посттрансляционной модификации (такие как один или несколько сайтов гликозилирования), что находится в пределах компетенции специалиста в данной области.
«Аффинность» означает прочность или стабильность молекулярного взаимодействия. Аффинность обычно представлена в виде KD, или константы диссоциации, которая имеет единицы моль/литр (или M). Аффинность также может быть выражена в виде константы ассоциации, KA, которая равна 1/KD и имеет единицы измерения (моль/литр)-1 (или M-1). В настоящем описании стабильность взаимодействия между двумя молекулами будет в основном выражаться через величину KD их взаимодействия; специалисту в данной области ясно, что с учетом отношения KA = 1/KD, определение силы молекулярного взаимодействия по его значению KD также может быть использовано для расчета соответствующего значения KA. Значение KD характеризует силу молекулярного взаимодействия также в термодинамическом смысле, поскольку оно связано с изменением свободной энергии (DG) связывания по хорошо известному соотношению DG = RT.ln (KD) (что эквивалентно DG = -RT.ln (KA)), где R равно газовой постоянной, T равно абсолютной температуре, ln - натуральный логарифм.
KD для биологических взаимодействий, которые считаются значимыми (например, специфичными), обычно находятся в диапазоне от 10-10 М (0,1 нМ) до 10-5 М (10000 нМ). Чем сильнее взаимодействие, тем меньше его KD.
KD также можно выразить как отношение константы скорости диссоциации комплекса, обозначенной как koff, к константе скорости его ассоциации, обозначенной как kon (так что KD = koff/kon и KA = kon/Koff). Скорость диссоциации koff имеет единицы с-1 (где с- обозначение секунды в СИ). Скорость ассоциации kon имеет единицы M-1 с-1. Скорость ассоциации может варьировать от 102 М-1 с-1 до около 107 М-1 с-1, приближаясь к константе скорости ассоциации с ограничением диффузии для бимолекулярных взаимодействий. Скорость диссоциации связана с периодом полувыведения данного молекулярного взаимодействия соотношением t1/2 = ln(2)/koff. Скорость диссоциации может варьировать от 10-6 с-1 (около необратимого комплекса с1/2 от нескольких дней) до 1 с-1 (t1/2 = 0,69 с).
Специфическое связывание антиген-связывающего белка, такого как ISVD, с антигеном или антигенной детерминантой может быть определено любым подходящим способом, известным как таковым, в том числе, к примеру, анализом Скэтчарда и/или анализами конкурентного связывания, такие как радио-иммуноанализы (RIA), иммуноферментные анализы (EIA) и сэндвич-анализы конкуренции и их различные варианты, известные per se в данной области; и другими методами, упомянутыми в данном документе.
Аффинность молекулярного взаимодействия между двумя молекулами может быть измерена с помощью различных методов, известных per se, таких как хорошо известный биосенсорный метод поверхностного плазмонного резонанса (SPR) (см., например, Ober et al. 2001, Intern. Immunology 13: 1551-1559). Термин «поверхностный плазмонный резонанс», используемый в данном документе, относится к оптическому явлению, которое позволяет анализировать биоспецифические взаимодействия в реальном времени путем обнаружения изменений в концентрациях белка в матрице биосенсора, где одна молекула иммобилизована на чипе биосенсора и другая молекула проходит над иммобилизованной молекулой в условиях потока, давая значения kon, koff измерений и, следовательно, значения KD (или KA). Это может быть выполнено, например, с использованием хорошо известной системы BIAcore® (BIAcore International AB, GE Healthcare company, Упсала, Швеция и Пискатауэй, Нью-Джерси). Для дальнейших описаний см. Jonsson et al. (1993, Ann. Biol. Clin. 51: 19-26), Jonsson et al. (1991 Biotechniques 11: 620-627), Johnsson et al. (1995, J. Mol. Recognit. 8: 125-131) и Johnnson et al. (1991, Anal. Biochem. 198: 268-277).
Другой хорошо известный биосенсорный метод для определения аффинности биомолекулярных взаимодействий представляет собой биослойную интерферометрию (BLI) (см., например, Abdiche et al. 2008, Anal. Biochem. 377: 209-217). Термин «биослойная интерферометрия» или «BLI», при использовании в настоящем описании, относится к оптическому методу без применения меток, который анализирует интерференционную картину света, отраженного от двух поверхностей: внутреннего эталонного слоя (эталонный луч) и слоя иммобилизованного белка на кончике биосенсора (сигнальный луч). Изменение количества молекул, связанных с наконечником биосенсора, вызывает сдвиг в интерференционной картине, сообщаемый как сдвиг длины волны (нм), величина которого является прямой мерой количества молекул, связанных с поверхностью наконечника биосенсора. Поскольку взаимодействия могут измеряться в режиме реального времени, могут быть определены скорости и ассоциации и диссоциации и аффинности. BLI может, например, выполняться с использованием хорошо известных систем Octet® (ForteBio, подразделение Pall Life Sciences, Менло Парк, США).
В качестве альтернативы, аффинность может быть измерена в анализе кинетического исключения (KinExA) (см., например, Drake et al. 2004, Anal. Biochem., 328: 35-43), используя платформу KinExA® (Sapidyne Instruments Inc, Бойсе, США). Используемый в данном документе термин «KinExA» относится к способу измерения истинного равновесного аффинности связывания и кинетики немодифицированных молекул в растворе. Уравновешенные растворы комплекса антитело/антиген пропускают через колонку с гранулами, предварительно покрытыми антигеном (или антителом), что позволяет свободному антителу (или антигену) связываться с молекулой покрытия. Обнаруженное таким образом антитело (или антиген) захватывается флуоресцентно меченным белком, связывающим антитело (или антиген).
Система иммуноанализа GYROLAB® обеспечивает платформу для автоматического биоанализа и быстрого анализа образцов (Fraley et al. 2013, Bioanalysis 5: 1765-74).
Специалисту в данной области также будет ясно, что измеренный KD может соответствовать кажущемуся KD, если процесс измерения каким-то образом влияет на истинную аффинность связывания предполагаемых молекул, например, на артефакты, связанные с нанесением на биосенсор одной молекулы. Кроме того, кажущийся KD может быть измерен, если одна молекула содержит более одного сайта распознавания для другой молекулы. В такой ситуации на измеренная аффинность может влиять авидность взаимодействия двух молекул. Как будет понятно специалисту в данной области техники, и, как описано на страницах 53-56 WO 08/020079, константа диссоциации может быть фактической или кажущейся константой диссоциации. Специалистам в данной области техники известны способы определения константы диссоциации, которые, например, включают методы, упомянутые на страницах 53-56 WO 08/020079.
Термины «эпитоп» и «антигенная детерминанта», которые могут использоваться взаимозаменяемо, относятся к части макромолекулы, такой как полипептид или белок, который распознается антигенсвязывающими молекулами, такими как иммуноглобулины, обычные антитела, иммуноглобулиновые одиночные вариабельные домены и/или полипептиды по изобретению и, в частности, антигенсвязывающий сайт указанных молекул. Эпитопы определяют минимальный сайт связывания иммуноглобулина и, таким образом, представляют собой мишень специфичности иммуноглобулина.
Часть антигенсвязывающей молекулы (такой как иммуноглобулин, обычное антитело, иммуноглобулиновый одиночный вариабельный домен и/или полипептид по изобретению), которая распознает эпитоп, называется «паратоп».
Полипептид (такой как иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид по изобретению или обычно антигенсвязывающая молекула или ее фрагмент), который может «связываться (с)» или «специфически связываться (с)» то, что «имеет аффинность» и/или «обладает специфичностью» к определенному эпитопу, антигену или белку (или, по меньшей мере, к одной его части, фрагменту или эпитопу), называется «против» или «направленный против» указанного эпитопа, антигена или белка или является «связывающей» молекулой по отношению к такому эпитопу, антигену или белку, или, как говорят, является «анти»эпитопом, «анти»антигеном или «анти»белком (например, «анти»-CD123 или «анти»-TCR).
Термин «специфичность» имеет значение, данное ему в пункте n) на страницах 53-56 в WO 08/020079; и как упомянуто в настоящем документе относится к числу различных типов антигенов или антигенных детерминант, с которыми может связываться конкретная антигенсвязывающая молекула или антигенсвязывающий белок (такой как иммуноглобулиновый одиночный вариабельный домен и/или полипептид по изобретению). Специфичность антигенсвязывающего белка может быть определена на основе аффинности и/или авидности, как описано на стр. 53-56 в WO 08/020079 (включенном в данном документе ссылкой), который также описывает Hекоторые предпочтительные методы для измерения связывания между антиген-связывающей молекулой (такой как иммуноглобулиновый одиночный вариабельный домен и/или полипептид по изобретению) и соответствующим антигеном. Как правило, антигенсвязывающие белки (такие как иммуноглобулиновые одиночные вариабельные домены и/или полипептиды по изобретению) будут связываться с их антигеном с константой диссоциации (K D) от 10-5 до 10-12 моль/л или менее и предпочтительно от 10-7 до 10-12 моль/литр или менее и более предпочтительно от 10-8 до 10-12 моль/литр (т.е. с константой ассоциации (KA) от 105 до 1012 литров/моль или более и предпочтительно 107 до 1012 л/моль или более и более предпочтительно от 108 до 10 12 л/моль). Обычно считается, что любое значение KD больше 104 моль/литр (или любое значение KA ниже 104 М-1) указывает на неспецифическое связывание. Предпочтительно моноспецифичный полипептид по изобретению будет связываться с искомым антигеном с аффинностью менее 500 нМ, предпочтительно менее 200 нМ, более предпочтительно менее 10 нМ, например, например, от 10 до 5 нМ, например, менее 10 нМ. менее 5 нМ, менее 3 нМ, менее 2 нМ, например, 10 нМ - 1 нМ, 5 нМ - 1 нМ или даже менее. Специфическое связывание антиген-связывающего белка с антигеном или антигенной детерминантой может быть определена любым подходящим способом, известным как таковым, в том числе, например, анализом Скэтчарда и/или анализом конкурентного связывания, таким как радиоиммуноанализы (RIA), иммуноферментные анализы (ИФА) и сэндвич-анализы конкуренции, а также различные его варианты, известные per se в данной области; и другие методы, упомянутые в данном документе. Как будет понятно специалисту в данной области техники, и, как описано на страницах 53-56 WO 08/020079, константа диссоциации может быть фактической или кажущейся константой диссоциации. Специалистам в данной области техники известны способы определения константы диссоциации и, например, включают методы, упомянутые на страницах 53-56 WO 08/020079.
Одним из подходов, который можно использовать для оценки аффинности, является процедура двухстадийного ELISA (твердофазного иммуноферментного анализа) из Friguet et al. (1985, J. Immunol. Methods 77: 305-19). Этот способ устанавливает измерение равновесия связывания фазы раствора и позволяет избежать возможных артефактов, связанных с адсорбцией одной из молекул на носителе, таком как пластик.
Однако точное измерение KD может быть довольно трудоемким, и, как следствие, часто кажущиеся значения KD определяются для оценки силы связывания двух молекул. Следует отметить, что, поскольку все измерения выполняются согласованным образом (например, сохраняя неизменными условия анализа), кажущиеся измерения KD можно использовать как приближение к истинному KD и, следовательно, в данном документе KD и кажущееся KD следует рассматривать с равной важностью или актуальностью.
Наконец, следует отметить, что во многих ситуациях опытный ученый может судить об удобстве определения аффинности связывания относительно некоторой контрольной молекулы. Например, для оценки прочности связывания между молекулами А и В можно, например, использовать контрольную молекулу С, которая, как известно, связывается с В и которая соответствующим образом мечена флуорофором или хромофорной группой или другим химическим фрагментом, таким как биотин для легкого обнаружение в ELISA или FACS (клеточная сортировка с активацией флуоресценции) или в другом формате (флуорофор для обнаружения флуоресценции, хромофор для обнаружения поглощения света, биотин для опосредованного стрептавидином ELISA-обнаружения). Обычно эталонную молекулу С выдерживают при фиксированной концентрации и изменяют концентрацию А для данной концентрации или количества В. В результате получается значение IC50, соответствующее концентрации А, при котором сигнал, измеренный для С в отсутствие А уменьшается вдвое. При условии, что KD ref, KD эталонной молекулы, известен, также как и общая концентрация cref эталонной молекулы, кажущееся KD для взаимодействия AB можно получить по следующей формуле: KD = IC50/(1 + cref/KD ref). Заметим, что если c ref << KD ref, KD ≈ IC50. При условии, что измерение IC50 выполняется согласованным образом (например, с сохранением фиксированного значения cref) для сравниваемых связывающих, IC50 может оценить силу или стабильность молекулярного взаимодействия, и это измерение оценивается как эквивалентное KD или кажущееся KD по всему тексту.
Полумаксимальная ингибирующая концентрация (IC50) является мерой эффективности соединения в ингибировании биологической или биохимической функции, например, фармакологического эффекта. Эта количественная мера показывает, сколько ISV (например, нанотела) (ингибитора) необходимо для ингибирования данного биологического процесса (или компонента процесса, т.е. фермента, клетки, клеточного рецептора, хемотаксиса, анаплазии, метастазирования, инвазивности и т.д.) наполовину. Другими словами, это половина максимальной (50%) ингибирующей концентрации (IC) вещества (50% IC или IC50). IC50 лекарственного средства может быть определено путем построения кривой доза-эффект и изучения влияния различных концентраций антагониста, такого как ISVD (например, нанотело) по изобретению, на изменение активности агониста. Значения IC50 можно рассчитать для данного антагониста, такого как ISVD (например, нанотела) по изобретению, путем определения концентрации, необходимой для ингибирования половины максимального биологического ответа агониста.
Термин половинная максимальная эффективная концентрация (ЕС50) относится к концентрации соединения, которая вызывает реакцию на полпути между исходным уровнем и максимумом после определенного времени воздействия. В настоящем контексте он используется в качестве меры эффективности полипептида, ISV (например, нанотела). ЕС50 градуированной кривой доза-ответ представляет концентрацию соединения, при которой наблюдается 50% его максимального эффекта. Концентрация предпочтительно выражается в молярных единицах.
В биологических системах небольшие изменения в концентрации лиганда обычно приводят к быстрым изменениям ответа, следуя сигмоидальной функции. Точка перегиба кривой, в которой увеличение реакции с увеличением концентрации лиганда начинает замедляться, представляет собой ЕС50. Это может быть определено математически путем выведения наиболее подходящей линии. Полагаться на график для оценки удобно в большинстве случаев. В случае, если в разделе примеров приведен EC50, эксперименты были разработаны так, чтобы максимально точно отразить KD. Другими словами, значения ЕС50 могут затем рассматриваться как значения KD.
Это также относится к IC50, которая является мерой ингибирования соединения (50% ингибирования). Для анализов конкурентного связывания и анализов функциональных антагонистов IC50 является наиболее распространенным суммарным показателем кривой доза-ответ. Для анализов агонистов/стимуляторов наиболее распространенной суммарной мерой является EC50.
Ингибиторная константа, Ki, является показателем того, насколько сильным является ингибитор; это концентрация, необходимая для получения половины максимального ингибирования. Абсолютная константа ингибирования Ki может быть рассчитана с использованием уравнения Ченга-Прусоффа:
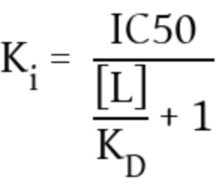 ,
,
в которой [L] является фиксированной концентрацией лиганда.
Считается, что иммуноглобулиновый одиночный вариабельный домен и/или полипептид «специфичен» для первой мишени или антигена по сравнению со второй мишенью или антигеном, когда он связывается с первым антигеном с аффинностью (описанной выше, и, соответственно, выраженной как значение KD, значение KA, скорость koff и/или скорость kon), которая, по меньшей мере, в 10 раз, например, по меньшей мере, в 100 раз, и предпочтительно, по меньшей мере, в 1000 раз, и до 10000 раз или еще лучше, чем аффинность с который иммуноглобулиновый одиночный вариабельный домен и/или полипептид связывает со второй мишенью или антигеном. Например, иммуноглобулиновый одиночный вариабельный домен и/или полипептид может связываться с первой мишенью или антигеном со значением KD, которое, по меньшей мере, в 10 раз меньше, например, по меньшей мере, в 100 раз меньше, и предпочтительно, по меньшей мере, в 1000 раз меньше, например, в 10000 раз меньше или даже менее, чем KD, с которым указанный иммуноглобулиновый одиночный вариабельный домен и/или полипептид связывается со второй мишенью или антигеном. Предпочтительно, если иммуноглобулиновый одиночный вариабельный домен и/или полипептид является «специфичным для» первой мишени или антигена по сравнению со второй мишенью или антигеном, то он направлен против (как определено в данном документе) указанной первой мишени или антигена, но не направлен против указанной второй мишени или антигена.
Считается, что аминокислотная последовательность, такая как, например, иммуноглобулиновый одиночный вариабельный домен или полипептид по изобретению, является «перекрестно-реактивной» для двух разных антигенов или антигенных детерминант (таких как, например, сывороточный альбумин от двух разных видов млекопитающих), таких как, например, сывороточный альбумин человека и сывороточный альбумин яванского макака, такой как, например, CD123 от разных видов млекопитающих, таких как, например, CD123 человека, и CD123 яванского макака, таких как, например, TCR от разных видов млекопитающих, таких как, например, TCR человека и TCR яванского макака), если он специфичен (как определено в данном документе) к этим различным антигенам или антигенным детерминантам.
Термины «(перекрестная) блокировка», «(перекрестно) блокированный», «(перекрестное) блокирование», «конкурентное связывание», «(перекрестно)-конкурировать», «(перекрестно)-конкурирующий» и «(перекрестная) конкуренция» используемые взаимозаменяемо в данном документе, означают способность иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента вмешиваться в связывание других иммуноглобулинов, антител, иммуноглобулиновых одиночных вариабельных доменов, полипептидов или связывающих агентов с заданной мишенью. Степень, в которой иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент способны влиять на связывание другого с мишенью, и, следовательно, можно ли сказать, что он перекрестно блокируется в соответствии с изобретением, может определяться с помощью конкурентных анализов. Один особенно подходящий количественный анализ перекрестного блокирования описан в примерах и включает, например, анализ связывания с сортировкой флуоресцентно-активированных клеток (FACS) с CD123, экспрессированным на клетках. Степень (перекрестного) блокирования может быть измерена по (уменьшенной) флуоресценции канала. Другой подходящий количественный анализ перекрестного блокирования использует прибор Biacore, который может измерять степень взаимодействий с использованием технологии поверхностного плазмонного резонанса. Другой подходящий количественный анализ перекрестного блокирования использует подход, основанный на ELISA, для измерения конкуренции между иммуноглобулинами, антителами, иммуноглобулиновыми одиночными вариабельными доменами, полипептидами или другими связывающими агентами в отношении их связывания с мишенью.
Нижеследующее, как правило, описывает подходящий анализ FACS для определения, перекрестно ли блокирует иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент или способен ли он перекрестно блокироваться в соответствии с изобретением. Понятно, что анализ может быть использован с любым из иммуноглобулинов, антител, иммуноглобулиновых одиночных вариабельных доменов, полипептидов или других связывающих агентов, описанных в данном документе. Прибор FACS (например, FACSArray; Becton Dickinson) работает в соответствии с рекомендациями производителя.
Чтобы оценить «(перекрестное) блокирование» или «(перекрестную) конкуренцию» между двумя связывающими агентами (такими как, например, два иммуноглобулиновых одиночных вариабельных домена и/или нанотела) за связывание с CD123, можно провести конкурентный эксперимент FACS с использованием клеток (таких как, например, эндогенно экспрессирующие CD123 линии клеток MOLM-13 или клетки Flp-In™-CHO, сверхэкспрессирующие CD123 человека). Для обнаружения могут использоваться различные реагенты, включая, например, моноклональное антитело против ANTI-FLAG® M2 (Sigma-Aldrich, кат. № F1804), моноклональное антитело против C-myc (Sigma-Aldrich, кат. № WH0004609M2), моноклональное антитело ANTI-HIS TAG (Sigma -Aldrich, кат. № SAB1305538), каждое из которых помечено по-своему. В качестве меток в проточной цитометрии можно использовать широкий спектр флуорофоров (например, PE (R-фикоэритрин), 7-аминоактиномицин D (7-AAD), акридиновый оранжевый, различные формы Alexa Fluor (такие как, например, Alexa647), аллофикоцианин (APC), AmCyan, аминокумарин, APC Cy5, APC Cy7, APC-H7, APC/Alexa Fluor 750, AsRed2, Azami-Green, Азурит, B ODIPY FL C5-церамид, BCECF-AM, бис-оксонол DiBAC2(3), BODIPY-FL, кальцеин, кальцеин AM, карокси-H2DCFDA, Cascade Blue, Cascade Yellow, Cell Tracker Green, церулеан, CFSE, хромомицин A3, CM-H2DCFDA, Cy2, Cy3, Cy3.5, Cy3B, Cy5, Cy5. 5, Cy7, CyPet, DAF-FM, диацетат DAF-FM, DAPI, DCFH (2'7'-дихородигидрофлуоресцеин), DHR, дигидрокальцеин AM, дигидророадамин, дигидротидий, DiLC1 (5), DiOC6 (3), DiOC7 (3), dOCe-Red, DRAQ5, Dronpa-Green, различные формы DsRed dTomato, различные формы DyLight, E.coli BioParticles AF488, E2-Crimson, E2-Orange, EBFP2, ECFP, различные формы eFluor, EGFP, EGFP*, Emerald, eqFP650, eqFP670, ER-Tracker Blue-White DPX, бромид этидия, Express2, EYFP, Fc OxyBurst Green, Fc OxyBurst Green 123, FITC, Fluo-3, Fluo-4, флуоресцеин, Fura-2, Fura-Red, GFPuv, H2DCFDA, HcRed1, Hoechst Blue (33258), Hoechst Red (33342), гидроксикумарин, HyPer, Indo-1, Indo-1 Blue (низкий Ca2 +), Indo-1 Violet (высокий уровень Ca2+), iRFP, J-Red, JC-1, JC-9, Katushka (TurboFP635), Katushka2 Kusabira-Orange, LDS 751, лиссамин родамин В, различные формы Live/Dead, Lucifer yellow, Lucifer Yellow CH, Lyso Tracker Blue, Lyso Tracker Green, Lyso Tracker Red, mAmertrine, Marina Blue, mBanana, mCFP, mCherry, mCitrine, метоксикумарин, mHoneyDew, Midoriishi-Cyan, митрамицин, Mito Tracker Deep Red, Mito Tracker Green, Mito Tracker Orange, Mito Tracker Red, MitoFluor Green, mKate (TagFP635), mKate2, mKeima, mKeima-Red, mKO, mKOk, mNeptune, монохлоробиман, mOrange2, mRaspberry, mPlum, mRFP1, mStrawberry, mTangerine, mTarquoise, mTFP1, mTFP1 (Teal), NBD, OxyBurst Green H2DCFDA, OxyBurst Green H2HFF BSA, Pacific Blue, PE (R- фикоэритрин), Cy5, PE5, Cy5 ЧП Cy7, PE Texas Red, конъюгаты PE-Cy5, конъюгаты PE-Cy7, PerCP (перидинин-хлорофилл протеин), PerCP Cy5.5, PhiYFP, PhiYFP-m, йодид пропидия (PI), различные формы Qdot, Red 613, томат RFP, Rhod-2, S65A, S65C, S65L, S65T, зеленый сенсор синглетного кислорода, Sirius, SNARF, Superfolder GFP, SYTOX Blue, SYTOX Green, SYTOX Orange, T-Sapphire, TagBFP, TagCFP, TagGFP, TagRFP, TagRFP657, TagYFP, tdTomato, Texas Red, тиазоловый оранжевый, TMRE, TMRM, Topaz, TOTO-1, TO-PRO-1, TRITC, TRITC TruRed, TurboFP602, TurboFP635, TurboGFP, TurboRFP, TurboYFP, Венера, Vybrant CycleDye Violet, GFP дикого типа, X- Родамин, Y66F, Y66H, Y66W, YOYO-1, YPet, ZsGreen1, ZsYellow1, Zymosan A BioParticles AF488 (см. больше на: http://www.thefcn.org/flow-fluorochromes). Флуорофоры или просто «флуоресцирующие агенты», как правило, присоединяются к антителу (например, к иммуноглобулиновым одиночным вариабельным доменам, таким как нанотела), которое распознает CD123, или к антителу, которое используется в качестве реагента для обнаружения. Доступны различные конъюгированные антитела, такие как (без ограничения указанным), например, антитела, конъюгированные с Alexa Fluor®, DyLight®, родамином, PE, FITC и Cy3. Каждый флуорофор имеет характерный пик возбуждения и длину волны излучения. Комбинация меток, которые можно использовать, будет зависеть от длины волны лампы (ламп) или лазера (лазеров), используемых для возбуждения флуорофора, и от доступных детекторов.
Чтобы оценить конкуренцию между двумя тестируемыми связывающими агентами (названными A и B*) за связывание с CD123, серию разведений холодного (без какой-либо метки) связывающего агента A добавляют к клеткам (например, к 100 000) вместе с меченым связывающим агентом B*. Концентрация B* в тестируемой смеси должна быть достаточно высокой, чтобы легко насыщать сайты связывания на CD123, экспрессируемые на клетках. Концентрация связывающего агента B*, которая насыщает сайты связывания для этого связывающего агента на CD123, экспрессируемого на клетках, может быть определена с помощью серии титрования B* на клетках, экспрессирующих CD123, и определения значения EC50 для связывания. Для работы при насыщающей концентрации можно использовать Связывающий агент B* при 100-кратной концентрации EC50.
После инкубации клеток со смесью A и B* и промывания клеток, может быть проведено считывание на FACS. Сначала на инактных клетках устанавливают рамки отбора, определенные по профилю рассеяния, и регистрируют общее количество флуоресценции канала.
Также готовят отдельный раствор связывающего агента B*. Связывающий агент в этих растворах должен находиться в том же буфере и в той же концентрации, что и в тестовой смеси (со связывающими агентами A и B*). Этот отдельный раствор также добавляется к клеткам. После инкубации и промывания клеток, считывание может быть выполнено на FACS. Сначала на инактных клетках устанавливают рамки отбора, определенные по профилю рассеяния, и регистрируют общее количество флуоресценции канала.
Снижение флуоресценции для клеток, инкубированных со смесью A и B*, по сравнению с флуоресценцией для клеток, инкубированных с отдельным раствором B*, указывает на то, что связывающий агент A (перекрестно) блокирует связывание со связывающим агентом B* при связывании с CD123, экспрессируемым на клетках.
Перекрестно-блокирующий иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент по изобретению представляет собой тот, который будет связываться с CD123 в вышеупомянутом анализе перекрестного блокирования FACS, так что во время анализа и в присутствии второго иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента, регистрируемая флуоресценция составляет от 80% до 0,1% (например, от 80% до 4%) от максимальной флуоресценции (измеренной для отдельного меченого иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента), в частности, от 75% до 0,1% (например, от 75% до 4%) от максимальной флуоресценции и, более конкретно, от 70% до 0,1% (например, от 70% до 4%) от максимальной флуоресценции (как только что определено выше).
Конкуренция между двумя тестируемыми связывающими агентами (называемыми A* и B*) за связывание с CD123 также может быть оценена путем добавления обоих связывающих агентов, каждый из которых имеет свой флуорофор, к клеткам, экспрессирующим CD123. После инкубации и промывания клеток, может быть выполнено считывание на FACS. Для каждого флуорофора устанавливаются рамки обнаружения, и записывается общее количество флуоресценции в канале. Уменьшение и/или отсутствие флуоресценции одного из флуорофоров указывают на (перекрестное) блокирование связывающими агентами для связывания с CD123, экспрессируемыми на клетках.
Нижеследующее, как правило, описывает подходящий анализ Biacore для определения того, является ли иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент перекрестными или способными к перекрестной блокировке в соответствии с изобретением. Понятно, что анализ может быть использован с любым из иммуноглобулинов, антител, иммуноглобулиновых одиночных вариабельных доменов, полипептидов или других связывающих агентов, описанных в данном документе. Инструмент Biacore (например, Biacore 3000) управляется в соответствии с рекомендациями производителя. Таким образом, в одном анализе перекрестного блокирования целевой белок (например, CD123) связывают с чипом Biacore CM5 с помощью стандартного сочетания по аминной группе для получения поверхности, которая покрыта мишенью. Как правило, с чипом будут связаны 200-800 резонансных единиц мишени (количество, которое дает легко измеримые уровни связывания, но которое легко насыщается концентрациями используемого тестируемого реагента). Два тестируемых связывающих агента (названных A* и B*), которые должны оцениваться по их способности перекрестно блокировать друг друга, смешиваются при молярном соотношении сайтов связывания один к одному в подходящем буфере для создания тестовой смеси. При расчете концентраций на основе сайтов связывания предполагается, что молекулярная масса связывающего агента равна общей молекулярной массе связывающего агента, деленной на количество целевых сайтов связывания на этом связывающем агенте. Концентрация каждого связывающего агента в тестируемой смеси должна быть достаточно высокой, чтобы легко насыщать сайты связывания этого связывающего агента с молекулами-мишенями, захваченными на чипе Biacore. связывающие агенты в смеси имеют одинаковую молярную концентрацию (на основе связывания), и эта концентрация обычно составляет от 1,00 до 1,5 микромолярной (на основе сайта связывания). Также получают отдельные растворы, содержащие только A* и B*. A* и B* в этих растворах должны находиться в том же буфере и в той же концентрации, что и в тестовой смеси. Тестовую смесь пропускают через покрытый мишенью чип Biacore и записывают общее количество связываний. Затем чип обрабатывается таким образом, чтобы удалить связанные связывающие агенты без повреждения мишени, связанной с чипом. Обычно это делается путем обработки чипа 30 мМ HCl в течение 60 секунд. Затем раствор A* пропускают через покрытую мишенью поверхность и регистрируют количество связываний. Чип снова обрабатывается, чтобы удалить все связанные связывающие агенты, не повреждая цель, связанную с чипом. Затем раствор B* пропускают через покрытую мишенью поверхность и регистрируют количество связывающего. Далее рассчитывается максимальное теоретическое связывание смеси A* и B*, которое представляет собой сумму связывания каждого связывающего агента при прохождении только по поверхности-мишени. Если фактическое регистрируемое связывание смеси меньше этого теоретического максимума, то говорят, что два связывающих агента перекрестно блокируют друг друга. Таким образом, как правило, перекрестно блокирующие иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент по изобретению представляет собой тот, который будет связываться с мишенью в указанном выше анализе перекрестного блокирования Biacore, так что во время анализа и при наличии второго иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента зарегистрированное связывание составляет от 80% до 0,1% (например, от 80% до 4%) от максимального теоретического связывания, в частности, от 75% до 0,1%. (например, от 75% до 4%) от максимального теоретического связывания и, более конкретно, от 70% до 0,1% (например, от 70% до 4%) от максимального теоретического связывания (как только что определено выше) двух иммуноглобулинов, антител, иммуноглобулиновых одиночных вариабельных доменов, полипептидов или связывающих агентов в комбинации. Описанный выше анализ Biacore представляет собой первичный анализ, используемый для определения того, являются ли иммуноглобулины, антитела, иммуноглобулиновые одиночные вариабельные домены, полипептид или другие связывающие агенты перекрестно блокирующими друг друга в соответствии с изобретением. В редких случаях определенные иммуноглобулины, антитела, иммуноглобулиновые одиночные вариабельные домены, полипептиды или другие связывающие агенты могут не связываться с мишенью, химически связанной с помощью амина с чипом CM5 Biacore (это обычно происходит, когда соответствующий сайт связывания на мишени маскируется или разрушается связь с чипом). В таких случаях перекрестное блокирование может быть определено с использованием меченной версии мишени, например, версии, меченной His-меткой по N-концу. В этом конкретном формате антитело против His будет связываться с чипом Biacore, а затем мишень с His-меткой будет проходить над поверхностью чипа и захватываться антителом против His. Анализ перекрестного блокирования должен проводиться, по существу, как описано выше, за исключением того, что после каждого цикла регенерации чипа новая мишень с His-меткой будет загружаться обратно на поверхность, покрытую анти-His-антителом. В дополнение к примеру, приведенному с использованием мишени, меченной по N-концу His-меткой, в качестве альтернативы может использоваться мишень, меченная His-меткой по С-концу. Кроме того, различные другие метки и комбинации белков, связывающих метки, которые известны в данной области, могут быть использованы для такого анализа перекрестного блокирования (например, метка HA с антителами против HA; метка FLAG с антителами против FLAG; биотиновая метка со стрептавидином).
Нижеследующее, как правило, описывает анализ ELISA для определения того, является ли иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент, направленный против мишени (например, CD123), перекрестными или способными к перекрестной блокировке, как определено в данном документе. Понятно, что анализ может быть использован с любым из иммуноглобулинов, антител, иммуноглобулиновых одиночных вариабельных доменов, полипептидов или других связывающих агентов, описанных в данном документе. Общий принцип анализа состоит в том, чтобы иметь иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или связывающий агент, который направлен против мишени, нанесенными на лунки планшета для ELISA. В раствор добавляют избыточное количество второго, потенциально перекрестно блокирующего иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента против мишени (т.е. не связывают с планшетом для ELISA). Затем в лунки добавляется ограниченное количество мишени. Иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент покрытия и иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент в растворе конкурируют за связывание ограниченного числа молекул-мишеней. Планшет промывают для удаления избытка мишени, которая не была связана иммуноглобулином, антителом, иммуноглобулиновым одиночным вариабельным доменом, полипептидом или другим связывающим агентом, а также для удаления второго растворенного иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента, а также любого комплекса, образованного между вторым растворенным иммуноглобулином, антителом, иммуноглобулиновым одиночным вариабельным доменом, полипептидом или другим связывающим агентом и мишенью. Количество связанной цели затем измеряется с использованием реагента, который подходит для обнаружения мишени. Иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент в растворе, который способен перекрестно блокировать покрытый иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент, может вызывать уменьшение количества молекул-мишеней, которые иммуноглобулин с покрытием, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент могут связывать относительно количества молекул-мишеней, которые иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент покрытия могут связывать в отсутствие второго растворенного иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента. В случае, когда первый иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент, например, Ab-X, выбран в качестве иммобилизованного иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента, то его наносят на лунки планшета для ELISA, после чего планшеты блокируют подходящим блокирующим раствором для минимизации неспецифического связывания реагентов, которые добавляют впоследствии. Избыточное количество второго иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента, т.е. Ab-Y, затем добавляют в планшет для ELISA таким образом, чтобы количество молей сайтов связывания мишени Ab-Y на лунку составляло, по меньшей мере, в 10 раз больше, чем количество молей сайтов связывания мишени Ab-X, которые использовались на лунку при покрытии планшета для ELISA. Затем добавляют мишень так, чтобы количество молей мишени, добавленных на лунку, по меньшей мере, в 25 раз ниже, чем количество молей сайтов связывания мишени Ab-X, которые использовались для покрытия каждой лунки. После подходящего периода инкубации планшет для ELISA промывают и добавляют реагент для обнаружения мишени для измерения количества мишени, специфически связанного с покрытым иммуноглобулином, антителом, иммуноглобулиновым одиночным вариабельным доменом, полипептидом или другим связывающим агентом против мишени (в данном случае Ab-X). Фоновый сигнал для анализа определяют как сигнал, полученный в лунках с иммуноглобулином, антителом, иммуноглобулиновым одиночным вариабельным доменом, полипептидом или другим связывающим агентом покрытия (в данном случае Ab-X), вторым иммуноглобулиновым одиночным вариабельным доменом, полипептидом или другим связывающим агентом в жидкой фазе (в данном случае Ab-Y), только буфером для мишени (т. е. без мишени) и реагентами для обнаружения мишени. Сигнал положительного контроля для анализа определяют как сигнал, полученный в лунках с иммуноглобулином, антителом, иммуноглобулиновым одиночным вариабельным доменом, полипептидом или другим связывающим агентом покрытия (в данном случае Ab-X), только буфером для второго иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента в жидкой фазе (т.е. без второго иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента), мишенью и реагентами для определения мишени. Анализ ELISA может проводиться таким образом, чтобы сигнал положительного контроля был, по меньшей мере, в 6 раз больше фонового сигнала. Чтобы избежать каких-либо артефактов (например, существенно различающихся аффинностей между Ab-X и Ab-Y для мишени), возникающих в результате выбора того, какой иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент используется в качестве покрывающего иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента, какой иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент используется в качестве второго (конкурентного), анализ перекрестного блокирования может проводиться в двух форматах: 1) формат 1, в котором Ab-X представляет собой иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент, который нанесен на планшет для ELISA, и в котором Ab-Y представляет собой конкурентный иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент, который находится в растворе, и 2) формат 2, где Ab-Y представляет собой иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент, который нанесен на планшет для ELISA, а Ab-X представляет собой конкурентный иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент, который находится в растворе. Ab-X и Ab-Y определяются как перекрестно блокирующие, если в формате 1 или в формате 2 иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент, направленные против мишени, в жидкой фазе способен вызвать снижение от 60% до 100%, конкретно от 70% до 100% и более конкретно от 80% до 100% сигнала обнаружения мишени (т.е. количества мишени, связанного с покрывающим иммуноглобулином, антителом, иммуноглобулиновым одиночным вариабельным доменом, полипептидом или другим связывающим агентом) по сравнению с сигналом обнаружения мишени, полученным в отсутствие в жидкой фазе иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента, направленных против мишени (т.е. в лунках положительного контроля).
Другие способы определения, является ли иммуноглобулин, антитело, иммуноглобулиновый одиночный вариабельный домен, полипептид или другой связывающий агент, направленный против мишени (перекрестно)-блокирующими, способными к (перекрестному) блокированию, конкурентно связывающимися или являются (перекрестно)-конкурирующими, как определено в данном документе, описаны, например, в Xiao-Chi Jia et al. (2004, Journal of Immunological Methods 288: 91–98), Miller et al. (2011, Journal of Immunological Methods 365: 118-125) и/или в способах, описанных в данном документе (см., например, пример 7).
Используемый в данном документе термин «CD123» относится к α-субъединице рецептора интерлейкина 3 (IL-3R).
Используемый в данном документе термин «TCR» относится к T-клеточному рецептору, который состоит из цепей TCRα и TCRβ. Обе цепи α и β TCR состоят из константного домена и вариабельного домена. Полипептиды и иммуноглобулиновые одиночные вариабельные домены по настоящему изобретению связываются с константным доменом TCR.
«Период полувыведения» полипептида по изобретению обычно можно определить, как описано в пункте o) на стр. 57 в WO 08/020079, и, как упоминалось в нем, относится ко времени, затрачиваемому на то, чтобы концентрация полипептида в сыворотке in vivo снизилась на 50%, например, из-за деградации полипептида и/или клиренса или секвестрации полипептида естественными механизмами. Период полувыведения in vivo полипептида по изобретению может быть определен любым известным способом, таким как фармакокинетический анализ. Подходящие методы будут понятны специалисту в данной области и могут, например, быть, как правило, такими, как описано в пункте o) на стр. 57 в WO 08/020079. Как также упомянуто в пункте o) на странице 57 в WO 08/020079, период полувыведения может быть выражен с использованием таких параметров, как t1/2-альфа, t1/2-бета и площадь под кривой (AUC). Настоящим ссылаемся, например, на стандартные справочники, такие как Kenneth et al. (1986, Chemical Stability of Pharmaceuticals: A Handbook for Pharmacists, John Wiley & Sons Inc) и M Gibaldi and D Perron (1982, Pharmacokinetics, Marcel Dekker, 2nd Rev. Ed., 1982). Термины «увеличение периода полувыведения» или «увеличенный период полувыведения» также определены в пункте o) на стр. 57 в WO 08/020079 и, в частности, относятся к увеличению t1/2-β, либо с или без увеличения t1/2-α и/или AUC или обоих.
Если не указано иное, термины «иммуноглобулин» и «последовательность иммуноглобулина», используемые в данном документе для обозначения антитела с тяжелой цепью или традиционного 4-цепочечного антитела, используются в качестве общего термина для включения как полноразмерного антитела, так и их отдельных цепей, а также всех частей, доменов или их фрагментов (включая, но без ограничения указанным, антигенсвязывающие домены или фрагменты, такие как VHH-домены или VH/VL-домены, соответственно).
Используемый в данном документе термин «домен» (полипептида или белка) относится к сложной белковой структуре, которая обладает способностью сохранять свою третичную структуру независимо от остальной части белка. Как правило, домены ответственны за дискретные функциональные свойства белков и во многих случаях могут быть добавлены, удалены или перенесены в другие белки без потери функции остатка белка и/или домена.
Используемый в данном документе термин «иммуноглобулиновый домен» относится к глобулярной области цепи антитела (такой как, например, цепь обычного антитела из 4 цепей или антитела из тяжелой цепи) или к полипептиду, который по существу состоит из такой глобулярной области. Иммуноглобулиновые домены характеризуются тем, что они сохраняют иммуноглобулиновое сворачивание, характерное для молекул антител, которая состоит из двухслойного сэндвича около семи антипараллельных бета-нитей, расположенных в двух бета-листах, необязательно стабилизированных консервативной дисульфидной связью.
Используемый в данном документе термин «иммуноглобулиновый вариабельный домен» означает иммуноглобулиновый домен, по существу состоящий из четырех «каркасных областей», которые упоминаются в данной области и в данном документе ниже как «каркасная область 1» или «FR1»; как «каркасная область 2» или «FR2»; как «каркасная область 3» или «FR3»; и как «каркасная область 4» или «FR4», соответственно; при этом каркасные области прерываются тремя «определяющими комплементарность областями» или «CDR», которые упоминаются в данной области и ниже, как «область 1 определения комплементарности» или «CDR1»; как «область 2 определения комплементарности» или «CDR2»; и как «область 3 определения комплементарности» или «CDR3», соответственно. Таким образом, общая структура или последовательность вариабельного домена иммуноглобулина может быть указана следующим образом: FR1 - CDR1 - FR2 - CDR2 - FR3 - CDR3 - FR4. Это вариабельный домен (или домены) иммуноглобулина, который придает специфичность антитела к антигену, поскольку заключает в себе антигенсвязывающий сайт.
Термин «иммуноглобулиновый одиночный вариабельный домен», взаимозаменяемо используемый с «одиночным вариабельным доменом», определяет молекулы, в которых сайт связывания антигена присутствует и образован одиночным иммуноглобулиновым доменом. Это ставит иммуноглобулиновые одиночные вариабельные домены отдельно от «обычных» иммуноглобулинов или их фрагментов, в которых два домена иммуноглобулина, в частности два вариабельных домена, взаимодействуют с образованием антигенсвязывающего сайта. Как правило, в обычных иммуноглобулинах вариабельный домен тяжелой цепи (VH) и вариабельный домен легкой цепи (VL) взаимодействуют с образованием сайта связывания антигена. В этом случае определяющие комплементарность области (CDR) как VH, так и VL, будут способствовать созданию сайта связывания антигена, т.е. в создании антигенсвязывающего сайта будет задействовано в общей сложности 6 CDR.
Ввиду вышеприведенного определения антигенсвязывающий домен обычного антитела из 4 цепей (такого как молекула IgG, IgM, IgA, IgD или IgE; известного в данной области) или фрагмента Fab, фрагмента F(ab')2, фрагмента Fv, такого как связанный с дисульфидом Fv или scFv-фрагмент, или диатела (все известные в данной области), полученный из такого обычного антитела из 4 цепей, обычно не считаются иммуноглобулиновым одиночным вариабельным доменом, поскольку, в этих случаях, связывание с соответствующим эпитопом антигена обычно осуществляется не одним (одиночным) иммуноглобулиновым доменом, а парой (ассоциированных) доменов иммуноглобулина, таких как вариабельные домены легкой и тяжелой цепи, т.е. с помощью VH-VL-пары иммуноглобулиновых доменов, которые совместно связываются с эпитопом соответствующего антигена.
Напротив, иммуноглобулиновые одиночные вариабельные домены способны специфически связываться с эпитопом антигена без спаривания с дополнительным иммуноглобулиновым вариабельным доменом. Сайт связывания иммуноглобулинового одиночного вариабельного домена образован одним доменом VH/VHH или VL. Следовательно, сайт связывания антигена иммуноглобулинового одиночного вариабельного домена образуется не более чем тремя CDR.
Таким образом, одиночный вариабельный домен может представлять собой последовательность вариабельной области легкой цепи (например, VL-последовательность) или ее подходящий фрагмент; или последовательность вариабельной области тяжелой цепи (например, VH-последовательность или VHH-последовательность) или ее подходящий фрагмент; поскольку такой домен способен образовывать одиночную антигенсвязывающую единицу (т.е. функциональную антигенсвязывающую единицу, которая по существу состоит из одного вариабельного домена, так что одному антигенсвязывающему домену не требуется взаимодействовать с другим вариабельным доменом для образования функциональной антигенсвязывающей единицы).
В одном аспекте изобретения иммуноглобулиновые одиночные вариабельные домены представляют собой последовательности вариабельного домена тяжелой цепи (например, VH-последовательность); более конкретно, иммуноглобулиновые одиночные вариабельные домены могут представлять собой последовательности вариабельного домена тяжелой цепи, которые получены из обычного четырехцепочечного антитела, или последовательности вариабельного домена тяжелой цепи, которые получены из антитела на основе только тяжелой цепи.
Например, иммуноглобулиновый одиночный вариабельный домен может быть антителом из (одиночного) домена (или аминокислотой, подходящей для применения в качестве антитела из (одиночного) домена), «dAb» или dAb (или аминокислотой, которая подходит для применения в качестве dAb) или нанотелом (как определено в данном документе и включая, без ограничения указанным, VHH); другими одиночными вариабельными доменами или любым подходящим фрагментом любого из них.
В частности, иммуноглобулиновый одиночный вариабельный домен может быть Нанотелом® (как определено в данном документе) или его подходящим фрагментом. [Примечание: Нанотело®, Нанотела® и Наноклон® являются зарегистрированными товарными знаками Ablynx N.V.]. Для общего описания Нанотел настоящим ссылаемся на последующее описание ниже, а также на предшествующий уровень техники, упомянутый в данном документе, например, описанный в WO 08/020079 (стр. 16).
«VHH-домены», также известные как VHH, VHH -домены, антительные фрагменты VHH и VHH-антитела, первоначально были описаны как антигенсвязывающий иммуноглобулиновый (вариабельный) домен «антител, состоящих только из тяжелой цепи» (т.е. «антител, лишенных легких цепей», Hamers-Casterman et al. Nature 363: 446-448, 1993). Термин «домен VHH» был выбран для того, чтобы отличать эти вариабельные домены от вариабельных доменов тяжелой цепи, которые присутствуют в обычных антителах из 4 цепей (которые упоминаются в данном документе как «VH-домены» или «VH-домены») и от вариабельных доменов легкой цепи, которые присутствуют в обычных антителах из 4 цепей (которые называются в данном документе «VL-доменами» или «VL-доменами»). Дальнейшее описание VHH и Нанотел см. в обзорной статье Muyldermans (Reviews in Molecular Biotechnology 74: 277-302, 2001), а также в следующих патентных заявках, которые упоминаются в качестве предшествующего уровня техники: WO 94/04678, WO 95/04079 и WO 96/34103 от Vrije Universiteit Brussel; WO 94/25591, WO 99/37681, WO 00/40968, WO 00/43507, WO 00/65057, WO 01/40310, WO 01/44301, EP 1134231 и WO 02/48193 от Unilever; WO 97/49805, WO 01/21817, WO 03/035694, WO 03/054016 и WO 03/055527 от Vlaams Instituut voor Biotechnologie (VIB); WO 03/050531 от Algonomics NV и Ablynx NV; WO 01/90190 от Национального исследовательского совета Канады; WO 03/025020 (= EP 1433793) от Института антител; и WO 04/041867, WO 04/041862, WO 04/041865, WO 04/041863, WO 04/062551, WO 05/044858, WO 06/40153, WO 06/079372, WO 06/122786, WO 06/122787 и WO 06/122825 от Ablynx NV и дальнейших опубликованных патентных заявках от Ablynx NV. Настоящим также ссылаемся на дополнительный предшествующий уровень техники, упомянутый в этих заявках и, в частности, на список литературы, упомянутый на страницах 41-43 Международной заявки WO 06/040153, перечень и источники которой включены в данный документ ссылкой. Как описано в этих ссылках, Нанотела (в частности, последовательности VHH и частично гуманизированные Нанотела), в частности, могут быть охарактеризованы наличием одного или нескольких «характерных остатков» в одной или нескольких каркасных последовательностях. Дальнейшее описание нанотел, включая гуманизацию и/или оверблюживание нанотел, а также другие модификации, части или фрагменты, производные или «молекулы на основе слияния с нанотелами», мультивалентные конструкции (включая HEKоторые неограничивающие примеры линкерных последовательностей) и различные модификации для увеличения периода полувыведения нанотел и их составов с ними, можно найти, например, в WO 08/101985 и WO 08/142164. Для дальнейшего общего описания Нанотел настоящим ссылаемся на предшествующий уровень техники, процитированный в данном документе, такой как, например, описанный в WO 08/020079 (стр. 16).
«Доменные антитела», также известные как «Dab», «Доменные Антитела» и «dAb» (термины «Доменные Антитела» и «dAb», используются в качестве товарных знаков группой GlaxoSmithKline) были описаны, например, в EP 0368684, Ward et al. (1989, Nature 341: 544-546), Holt et al. (Tends in Biotechnology 21: 484-490, 2003) и WO 03/002609, а также, например, в WO 04/068820, WO 06/030220, WO 06/003388 и других опубликованных патентных заявках Domantis Ltd. Доменные антитела, по существу, соответствуют VH или VL-доменам млекопитающих, отличных от верблюдовых, в частности, из человеческих антител с 4 цепями. Для связывания эпитопа в качестве одиночного антигенсвязывающего домена, т.е. без сопряжения с VL или VH-доменом, соответственно, требуется специфический отбор таких антигенсвязывающих свойств, например, с использованием библиотек последовательностей одиночных VH- или VL-доменов человека. Доменные антитела имеют, подобно VHH, молекулярную массу от около 13 до около 16 кДа и, если они получены из полностью человеческих последовательностей, не требуют гуманизации, например, для терапевтического применения у людей.
Следует также отметить, что отдельные вариабельные домены могут быть получены из HEKоторых видов акул (например, так называемые «домены IgNAR», см. например, WO 05/18629), хотя это менее предпочтительно в контексте настоящего изобретения, поскольку они происходят не из млекопитающих.
Таким образом, по смыслу настоящего изобретения термин «иммуноглобулиновый одиночный вариабельный домен» или «одиночный вариабельный домен» включает полипептиды, которые получены из источника, не являющегося человеком, предпочтительно верблюда, предпочтительно верблюжьего антитела на основе только тяжелой цепи. Они могут быть гуманизированы, как описано выше. Кроме того, этот термин включает полипептиды, полученные из источников, не являющихся верблюдовыми, например, мыши или человека, которые были «оверблюжены», как, например, описано в Davies and Riechmann (FEBS 339: 285-290, 1994; Biotechnol. 13: 475-479; 1996, Prot. Eng. 9: 531-537) и Riechmann and Muyldermans (1999, J. Immunol. Methods 231: 25-38).
Аминокислотные остатки домена VHH пронумерованы в соответствии с общей нумерацией для доменов VH, приведенной в Kabat et al. ("Sequence of proteins of immunological interest", US Public Health Services, NIH Bethesda, MD, Publication No. 91), применительно к доменам VHH верблюдовых, как показано, например, на фигуре 2 в Riechmann and Muyldermans (1999, J. Immunol. Methods 231: 25-38). Альтернативные способы нумерации аминокислотных остатков доменов VH, которые также могут быть применены аналогичным образом к доменам VHH, известны в данной области. Однако в настоящем описании, пунктах формулы и фигурах, будет соблюдаться нумерация согласно Kabat применимая к доменам VHH, как описано выше, если не указано иное.
Следует отметить, что - как хорошо известно в данной области для доменов VH и для доменов VHH - общее количество аминокислотных остатков в каждом из CDR может изменяться и может не соответствовать общему количеству аминокислотных остатков, указанному нумерацией Kabat (т.е. одно или несколько положений в соответствии с нумерацией Kabat могут быть не заняты в реальной последовательности, или фактическая последовательность может содержать больше аминокислотных остатков, чем число, допустимое нумерацией Kabat). Это означает, что, как правило, нумерация по Kabat может соответствовать или не соответствовать фактической нумерации аминокислотных остатков в фактической последовательности. Общее количество аминокислотных остатков в домене VH и домене VHH обычно будет находиться в диапазоне от 110 до 120, часто от 112 до 115. Следует, однако, отметить, что менее и более длинные последовательности также могут быть пригодны для целей, описанных в данном документе.
Определение областей CDR также может быть выполнено в соответствии с различными способами. В определении CDR согласно Kabat FR1 из VHH включает аминокислотные остатки в положениях 1-30, CDR1 из VHH включает аминокислотные остатки в положениях 31-35, FR2 из VHH включает аминокислоты в положениях 36- 49, CDR2 из VHH включает аминокислотные остатки в положениях 50-65, FR3 из VHH включает аминокислотные остатки в положениях 66-94, CDR3 из VHH включает аминокислотные остатки в положениях 95-102 и FR4 из VHH включает аминокислотные остатки в положениях 103-113.
Однако в настоящей заявке последовательности CDR были определены в соответствии с Kontermann и  (Eds., Antibody Engineering, vol 2, Springer Verlag Heidelberg Berlin, Martin, Chapter 3, pp. 33-51, 2010). Согласно этому способу FR1 включает аминокислотные остатки в положениях 1-25, CDR1 включает аминокислотные остатки в положениях 26-35, FR2 включает аминокислоты в положениях 36-49, CDR2 включает аминокислотные остатки в положениях 50- 58, FR3 включает аминокислотные остатки в положениях 59-94, CDR3 включает аминокислотные остатки в положениях 95-102, а FR4 включает аминокислотные остатки в положениях 103-113 (по нумерации Kabat).
(Eds., Antibody Engineering, vol 2, Springer Verlag Heidelberg Berlin, Martin, Chapter 3, pp. 33-51, 2010). Согласно этому способу FR1 включает аминокислотные остатки в положениях 1-25, CDR1 включает аминокислотные остатки в положениях 26-35, FR2 включает аминокислоты в положениях 36-49, CDR2 включает аминокислотные остатки в положениях 50- 58, FR3 включает аминокислотные остатки в положениях 59-94, CDR3 включает аминокислотные остатки в положениях 95-102, а FR4 включает аминокислотные остатки в положениях 103-113 (по нумерации Kabat).
Иммуноглобулиновые одиночные вариабельные домены, такие как доменные антитела и нанотела (включая домены VHH), могут быть подвергнуты гуманизации. В частности, гуманизированные иммуноглобулиновые одиночные вариабельные домены гуманизированного иммуноглобулина, такие как Нанотела (включая VHH-домены), могут быть иммуноглобулиновыми одиночными вариабельными доменами, которые, как правило, определены в предыдущих абзацах, но в которых присутствует, по меньшей мере, один аминокислотный остаток (и, в частности, по меньшей мере, один из остатков каркаса), который является и/или соответствует гуманизирующей замене (как определено в данном документе). Потенциально полезные гуманизирующие замены могут быть установлены путем сравнения последовательности каркасных областей встречающейся в природе последовательности VHH с соответствующей каркасной последовательностью одной или нескольких близко родственных человеческих последовательностей VH, после чего одна или несколько из потенциально полезных гуманизирующих замен (или их комбинации), определенные таким образом, могут быть введены в указанную последовательность VHH (любым способом, известным per se, как дополнительно описано в данном документе), и полученные гуманизированные последовательности VHH можно проверить на аффинность к мишени, на стабильность, на легкость и уровень экспрессии и/или на другие искомые свойства. Таким образом, с помощью ограниченной степени проб и ошибок другие подходящие гуманизирующие замены (или их подходящие сочетания) могут быть определены специалистом в данной области на основании раскрытого в данном документе описания. Кроме того, на основании вышеизложенного (каркасные области) иммуноглобулинового одиночного вариабельного домена, такого как Нанотело (включая домены VHH), могут быть частично гуманизированы или полностью гуманизированы.
Иммуноглобулиновые одиночные вариабельные домены, такие как доменные антитела и Нанотела (включая домены VHH и гуманизированные домены VHH), также могут быть подвергнуты созреванию аффинности путем введения одного или нескольких изменений в аминокислотной последовательности одного или нескольких CDR, причем эти изменения приводят к улучшению аффинности полученного в результате иммуноглобулинового одиночного вариабельного домена к его соответствующему антигену по сравнению с соответствующей исходной молекулой. Молекулы иммуноглобулиновых одиночных вариабельных доменов с созревшей аффинностью по изобретению могут быть получены способами, известными в данной области, например, как описано Marks et al. (1992, Biotechnology 10: 779-783), Barbas, et al. (1994, Proc. Nat. Acad. Sci, USA 91: 3809-3813), Shier et al. (1995, Gene 169: 147-155), Yelton et al. (Immunol. 155: 1994-2004,), Jackson et al. (J. Immunol. 154: 3310-9, 1995), Hawkins et al. (1995, J. MoI. Biol. 226: 889-896), Johnson and Hawkins (1996, Affinity maturation of antibodies using phage display, Oxford University Press).
Процесс конструирования/выбора и/или получения полипептида, начиная с иммуноглобулинового одиночного вариабельного домена, такого как доменное антитело или нанотело, также называют в данном документе «форматированием» указанного иммуноглобулинового одиночного вариабельного домена; и считается, что иммуноглобулиновый одиночный вариабельный домен, который является частью полипептида, «отформатирован» или находится «в формате» указанного полипептида. Примеры способов, в которых может быть отформатирован иммуноглобулиновый одиночный вариабельный домен, и примеры таких форматов будут понятны специалисту в данной области на основе раскрытия в данном документе; и такой форматированный иммуноглобулиновый одиночный вариабельный домен образуют дополнительный аспект изобретения.
Например, и без ограничения указанным, один или несколько иммуноглобулиновых одиночных вариабельных доменов можно использовать в качестве «связывающей единицы», «связывающего домена» или «структурного элемента» (эти термины используются взаимозаменяемо) для получения полипептида, который может необязательно содержит один или несколько дополнительных иммуноглобулиновых одиночных вариабельных доменов, которые могут служить связывающей единицей (т.е. против того же или другого эпитопа на CD123 и/или против одного или нескольких других антигенов, белков или мишеней, чем CD123, таких как, например, TCR).
Моновалентные полипептиды содержат или по существу состоят только из одной единицы связывания (такой как, например, иммуноглобулиновые одиночные вариабельные домены). Полипептиды, которые включают две или более единиц связывания (таких как, например, иммуноглобулиновые одиночные вариабельные домены), будут также упоминаться в данном документе как «мультивалентные» полипептиды, и единицы связывания/иммуноглобулиновые одиночные вариабельные домены, присутствующие в таких полипептидах, будут также упоминаться в данном документе как находящиеся в «мультивалентном формате». Например, «двухвалентный» полипептид может содержать два иммуноглобулиновых одиночных вариабельных доменов, необязательно связанных через линкерную последовательность, тогда как «трехвалентный» полипептид может содержать три иммуноглобулиновых одиночных вариабельных домена, необязательно связанных через две линкерные последовательности; тогда как «четырехвалентный» полипептид может содержать четыре иммуноглобулиновых одиночных вариабельных домена, необязательно связанных через три линкерные последовательности и т.д.
В мультивалентном полипептиде два или несколько иммуноглобулиновых одиночных вариабельных доменов могут быть одинаковыми или разными и могут быть направлены против одного и того же антигена или антигенной детерминанты (например, против одной и той же части (частей) или эпитопа(ов) или против разных частей или эпитопов) или может быть альтернативно направлены против различных антигенов или антигенных детерминант; или любой их подходящей комбинации. Полипептиды, которые содержат, по меньшей мере, две единицы связывания (такие как, например, иммуноглобулиновые одиночные вариабельные домены), в которых, по меньшей мере, одна связывающая единица направлена против первого антигена (т.е. CD123) и, по меньшей мере, одна связывающая единица направлена против второго антигена (т.е., отличного от CD123) также будут называться «мультиспецифичными» полипептидами, и единицы связывания (такие как, например, иммуноглобулиновые одиночные вариабельные домены), присутствующие в таких полипептидах, будут также упоминаться в данном документе как находящиеся в «мультиспецифическом формате». Таким образом, например, «биспецифичный» полипептид по изобретению представляет собой полипептид, который содержит, по меньшей мере, иммуноглобулиновый одиночный вариабельный домен, направленный против первого антигена (т.е. CD123), и один дополнительный иммуноглобулиновый одиночный вариабельный домен, направленный против второго антигена (т.е. отличающегося от CD123, такого как, например, TCR), тогда как «триспецифичный» полипептид по изобретению представляет собой полипептид, который содержит, по меньшей мере, один иммуноглобулиновый одиночный вариабельный домен, направленный против первого антигена (т.е. CD123), еще один иммуноглобулиновый одиночный вариабельный домен, направленный против второго антигена (т.е. отличающегося от CD123, такой как, например, TCR) и, по меньшей мере, один дополнительный иммуноглобулиновый одиночный вариабельный домен, направленный против третьего антигена (т.е. отличающегося как от CD123, так и от второго антигена); и т.п.
Полипептиды, которые направлены против одного антигена, также будут называться «моноспецифичными» полипептидами. Такие «моноспецифичные» полипептиды могут быть моновалентными полипептидами, содержащими только одну связывающую единицу (такую как, например, иммуноглобулиновый одиночный вариабельный домен), направленной против одного антигена (например, TCR или CD123). Такие «моноспецифичные» полипептиды могут также представлять собой мультивалентные полипептиды, содержащие два или более иммуноглобулиновых одиночных вариабельных доменов, направленных против одного и того же антигена. Такие «моноспецифичные» мультивалентные полипептиды могут быть направлены против одной и той же части (частей) или эпитопа (эпитопов) одного и того же антигена или против разных частей или эпитопов одного и того же антигена) (например, CD123).
Полипептиды, которые содержат две или более связывающих единиц, направленных против разных частей или эпитопов на одном и том же антигене, также называют «мультипаратопными» полипептидами. Как таковые, «мультипаратопные» полипептиды, такие как, например, «бипаратопные» полипептиды или «трипаратопные» полипептиды, содержат или, по существу, состоят из двух или более связывающих единиц, каждая из которых имеет различный паратоп (как будет дополнительно описано в данном документе; см. Главу по моноспецифичным полипептидам по изобретению).
Полипептиды по изобретению
Настоящее изобретение относится к полипептидам, которые перенаправляют Т-клетки для уничтожения CD123-экспрессирующих клеток. Способность этих полипептидов осуществлять эту функцию обусловлена их мультиспецифическим форматом. Мультиспецифичные полипептиды, предлагаемые в настоящем изобретении (называемые «мультиспецифичный(ие) полипептид(ы) по настоящему изобретению»)), включают иммуноглобулиновый одиночный вариабельный домен (ISV), который специфически связывает T-клеточный рецептор (TCR), и один или несколько ISV, которые специфически связывают CD123.
Изобретение также относится к одновалентным полипептидам, которые можно использовать в качестве связывающей единицы или структурного элемента в таком мультиспецифическом полипептиде по изобретению. Соответственно, в одном аспекте изобретение предоставляет ISV, которые специфически связывают TCR. В другом аспекте изобретение предоставляет ISV, которые специфически связывают CD123. Эти моновалентные полипептиды связываются только с одним антигеном и поэтому будут называться «моноспецифическим(ими) полипептидом(ами) по изобретению».
ISV, которые специфически связывают CD123, могут быть дополнительно отформатированы с образованием мультивалентных полипептидов, которые также включены в изобретение. Такие мультивалентные полипептиды содержат два или более ISV, которые специфически связывают CD123. Эти мультивалентные полипептиды связывают только один антиген (т.е. CD123) и поэтому также будут называться «моноспецифическим(ими) полипептидом(ами) по изобретению».
Моноспецифичный(ие) полипептид(ы) по изобретению и мультиспецифичный(ие) полипептид(ы) по изобретению дополнительно описаны в данном документе и обычно называются «полипептидом(ами) по изобретению».
1. Моноспецифические полипептиды по изобретению
1.1 Моноспецифические полипептиды, которые связывают TCR
Настоящее изобретение относится к моноспецифичному полипептиду, который специфически связывает TCR. Предпочтительно такой моноспецифичный полипептид по изобретению является одновалентным. В предпочтительном аспекте моноспецифичный полипептид представляет собой иммуноглобулиновый одиночный вариабельный домен, который будет упоминаться в данном документе как «иммуноглобулиновый одиночный вариабельный домен (домены) по изобретению» или «ISV по изобретению».
Т-клеточный рецептор (также называемый в данном документе TCR) представляет собой гетеродимер, который состоит из цепи TCRα и TCRβ. Обе цепи α и β TCR состоят из константного домена и вариабельного домена. Полипептиды по изобретению специфически связываются с константным доменом TCR.
Т-клеточный рецептор является частью комплекса TCR. Используемые в данном документе термины «комплекс TCR» или «комплекс TCRαβ-CD3» относятся к комплексу Т-клеточного рецептора, представленному на поверхности Т-клеток (см. Kuhns et al. 2006, Immunity 24: 133-139). Комплекс TCR состоит из шести различных трансмембранных белков одного типа I: цепей TCRα и TCRβ, которые образуют гетеродимер TCR, ответственный за распознавание лигандов, и HEKовалентно связанных цепей CD3γ, CD3δ, CD3ε и ζ, которые несут мотивы цитоплазматической последовательности, которые фосфорилируются при активации рецептора и рекрутируют большое количество сигнальных компонентов. Последовательности для человеческого CD3 и константных доменов человеческого TCR α/β представлены в таблице А-8 (SEQ ID NO: 70-75; см. также Идентификаторы UniProt: CD3 дельта: P04234, CD3 гамма: P09693, CD3 эпсилон: P07766, CD3 дзета: P20963, TCR альфа: P01848 и TCR бета: относится к P01850).
В одном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, который связывается с константным доменом Т-клеточного рецептора (TCRα) (SEQ ID NO: 74) и/или константным доменом Т-клеточного рецептора (TCRβ) (SEQ ID NO: 75) или их полиморфными вариантами или изоформами.
Изоформы представляют собой альтернативные белковые последовательности, которые могут генерироваться из одного и того же гена одним или комбинацией биологических событий, таких как использование альтернативного промотора, альтернативный сплайсинг, альтернативное инициирование и рибосомное смещение рамки считывания, которые все известны в данной области.
Только после строгих методов иммунизации, скрининга и отбора авторы настоящего изобретения смогли идентифицировать ISV, связывающиеся с константными доменами TCR. Был идентифицирован кластер последовательностей, включающий 104 клона со сходствами и различиями в CDR1, CDR2 и CDR3 (см. таблицу A-5). Представлено соответствующее выравнивание последовательности (таблица A-1).
Соответственно, настоящее изобретение относится к полипептидам, которые являются ISV, выбранными из группы, состоящей из SEQ ID NO: 42 и 78-180 (см. также таблицу A-5). В дополнительном аспекте полипептид выбран из группы, состоящей из SEQ ID NO: 42 и 78-180, или из полипептидов, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 42 и 78-180.
Соответственно, настоящее изобретение относится к полипептиду, который связывает TCR и включает или (по существу) состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых CDR1 имеет аминокислоту последовательность GX1VX2X3X4NX5LX6, в которой X1 представляет собой D, A, S, E или G, X2 представляет собой H или Y, X3 представляет собой K или L, X4 представляет собой I или L, X5 означает F, I или V, а X6 означает G или S.
В дополнительном аспекте настоящее изобретение относится к полипептиду, который связывает TCR и который включает или (по существу) состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых CDR2 имеет аминокислотную последовательность X1IX2IX3DX4X5X6, в которой X1 представляет собой H, T или R, X2 представляет собой S, T или A, X3 представляет собой G, S или A, X4 представляет собой Q, D, E, T, A или V, X5 представляет собой T, A или V и X6 представляет собой D, A, Q, N, V или S.
В дополнительном аспекте настоящее изобретение относится к полипептиду, который связывает TCR и который включает или (по существу) состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых CDR3 имеет аминокислотную последовательность X1SR X2X3PYX4Y, в которой X 1 представляет собой F, Y, G, L или K, X2 представляет собой I или L, X3 представляет собой Y или W и X4 представляет собой D, N или S.
Предпочтительные последовательности CDR для использования в полипептидах по изобретению, а также предпочтительные комбинации последовательностей CDR показаны в таблице A-5.
Соответственно, настоящее изобретение относится к полипептиду, предпочтительно ISV, который специфически связывает TCR и который включает или по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181-191; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 181-191; при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192-217; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 192-217; при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218-225; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 218-225; при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В дополнительном аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181-191; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 181-191; при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192-217; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 192-217; при условии, что полипептид, содержащий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218-225; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 218-225; при условии, что полипептид, содержащий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В частности, настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181-191; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 181-191, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 2, 4, 5, 6, 8 и/или 10 CDR1 (положения 27, 29, 30, 31, 33 и/или 35 согласно нумерации Kabat); при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192-217; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 192-217, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 1, 3, 5, 7, 8 и/или 9 CDR2 (положения 50, 52, 54, 56, 57 и/или 58 согласно нумерации Kabat); при условии, что полипептид, содержащий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218-225; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 218-225, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 1, 4, 5 и/или 8 CDR3 (положения 95, 98, 99 и/или 101 согласно нумерации Kabat); при условии, что полипептид, содержащий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 181, где
- в положении 2 D была изменена на A, S, E или G;
- в положении 4 H была изменена на Y;
- в положении 5 K была изменена на L;
- в положении 6 I была изменена на L;
- в положении 8 F была изменена на I или V; и/или
- в положении 10 G была изменена на S;
при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором CDR2 выбрана из группы, состоящей из:
а) SEQ ID NO: 192; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 192, где
- в положении 1 H была изменена на T или R;
- в положении 3 S была изменена на T или A;
- в положении 5 G была изменена на S или A;
- в положении 7 Q была изменена на D, E, T, A или V;
- в положении 8 Т была изменена на А или V; и/или
- в положении 9 D была изменена на A, Q, N, V или S;
при условии, что полипептид, содержащий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором CDR3 выбрана из группы, состоящей из:
а) SEQ ID NO: 218; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 218, где
- в положении 1 F была изменена на Y, L или G;
- в положении 4 I была изменена на L;
- в положении 5 Y была изменена на W; и/или
- в положении 8 D была изменена на N или S;
при условии, что полипептид, содержащий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Соответственно, настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 181, где
- в положении 2 D была изменена на A, S, E или G;
- в положении 4 H была изменена на Y;
- в положении 5 K была изменена на L;
- в положении 6 I была изменена на L;
- в положении 8 F была изменена на I или V; и/или
- в положении 10 G была изменена на S;
при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 192, где
- в положении 1 H была изменена на T или R;
- в положении 3 S была изменена на T или A;
- в положении 5 G была изменена на S или A;
- в положении 7 Q была изменена на D, E, T, A или V;
- в положении 8 Т была изменена на А или V; и/или
- в положении 9 D была изменена на A, Q, N, V или S;
при условии, что полипептид, содержащий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 218, где
- в положении 1 F была изменена на Y, L или G;
- в положении 4 I была изменена на L;
- в положении 5 Y была изменена на W; и/или
- в положении 8 D была изменена на N или S;
при условии, что полипептид, содержащий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором CDR1 выбрана из группы, состоящей из SEQ ID NO: 181-191, CDR2 выбрана из группы, состоящей из SEQ ID NO: 192-217, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 218-225.
Соответственно, в предпочтительном аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором CDR1 представляет собой SEQ ID NO: 181, CDR2 представляет собой SEQ ID NO: 192 и CDR3 представляет собой SEQ ID NO: 218.
Как правило, комбинации CDR, перечисленные в таблице A-5 (т.е. те, которые указаны в одной строке в таблице A-5), являются предпочтительными. Таким образом, обычно предпочтительно, чтобы, когда CDR в ISV представлял собой последовательность CDR, упомянутую в таблице A-5, или подходящим образом выбирался из группы, состоящей из последовательностей CDR, которые имеют различие в 4, 3, 2 или только 1 аминокислоту с последовательностью CDR, перечисленной в таблице A-5, что, по меньшей мере, один и предпочтительно оба других CDR подходящим образом выбраны из последовательностей CDR, которые принадлежат к той же комбинации в таблице A-5 (т.е. упомянуты в одной строке в таблице A-5) или подходящим образом выбраны из группы, состоящей из последовательностей CDR, которые имеют различие в 4, 3, 2 или только 1 аминокислоту с последовательностью CDR, принадлежащей к той же самой комбинации.
Настоящее изобретение также относится к полипептиду, предпочтительно ISV, который перекрестно блокирует связывание с TCR, по меньшей мере, одного из полипептидов, описанных в данном документе, и/или который перекрестно блокируется от связывания с TCR, по меньшей мере, одним из полипептидов, описанных в данном документе.
Полипептиды по настоящему изобретению специфически связывают TCR на поверхности эффекторных клеток, таких как T-клетки. В «моновалентном» формате моновалентные полипептиды по изобретению, которые связывают TCR, вызывают минимальную или нулевую активацию Т-клеток.
Используемый в данном документе термин «эффекторная клетка» означает клетку, содержащую комплекс TCR, предпочтительно иммунную клетку, такую как T-клетка, предпочтительно CD4+ T-хелперную клетку (также известную как CD4-клетка, T-хелперная клетка или T4-клетка), более предпочтительно цитотоксичную T-клетку (также известную как TC-клетка, CTL или CD8+ T-клетка) или T-клетку естественный киллер (NKT-клетка). В HEKоторых аспектах клетка присутствует in vivo. В HEKоторых аспектах клетка присутствует in vitro. Эффекторная клетка по изобретению относится, в частности, к клеткам млекопитающих, предпочтительно к клеткам приматов и еще более предпочтительно к клеткам человека.
«Активация Т-клеток» в контексте настоящего описания относится к одному или нескольким клеточным ответам Т-клеток, например, цитотоксичных Т-клеток, например, выбранным из: пролиферации, дифференцировки, секреции цитокинов, высвобождения цитотоксичной эффекторной молекулы, цитотоксичной активности, экспрессии маркеров активации и перенаправленного лизиса клеток-мишеней.
Моноспецифичный полипептид по изобретению связывается с константным доменом Т-клеточного рецептора (TCR) со средним значением KD от 100 нМ до 10 пМ, например, со средним значением KD 90 нМ или менее, еще более предпочтительно при среднем значении KD 80 нМ или менее, например, менее 70, 60, 50, 40, 30, 20, 10, 5 нМ или даже менее, например, менее 4, 3, 2 или 1 нМ, например, менее 500, 400, 300, 200, 100, 90, 80, 70, 60, 50, 40, 30, 20 пМ или даже менее, например, менее 10 пМ. Предпочтительно, KD определяется с помощью Kinexa, BLI или SPR, например, как определено с помощью Proteon. Например, указанное KD определяется, как указано в разделе «Примеры».
Моноспецифичный полипептид по изобретению связывается с TCR со значением ЕС50 от 100 нМ до 1 пМ, например, со средним значением ЕС50 100 нМ или менее, еще более предпочтительно со средним значением ЕС50 90 нМ или менее, например, менее 80, 70, 60, 50, 40, 30, 20, 10, 5 нМ или даже менее, например, менее 4, 3, 2 или 1 нМ или даже менее, например, менее 500, 400, 300 200, 100, 90, 80, 70, 60, 50, 40, 30, 20, 10, 5 пМ или даже менее, например, менее 4 пМ. Указанное среднее значение EC50 предпочтительно определяют с помощью FACS, Biacore или ELISA, например, указанное EC50 определяют, как указано в разделе «Примеры».
В примерах показано, что KD хорошо коррелирует с EC50.
В дополнительном аспекте моноспецифичный полипептид, как описано в данном документе, имеет константу скорости ассоциации (kon) для (или для связывания) TCR, выбранную из группы, состоящей из, по меньшей мере, около 102 М-1 с-1, по меньшей мере, около 103 М-1 с-1, по меньшей мере, около 104 М-1 с-1, по меньшей мере, около 105 М-1 с-1, по меньшей мере, около 106 М-1 с-1, 10 7 М-1 с-1, по меньшей мере, около 108 М-1 с-1, по меньшей мере, около 109 М-1 с-1 и, по меньшей мере, около 1010 М-1 с-1, предпочтительно, как измерено поверхностным плазмонным резонансом или как выполнено в разделе примеров.
В дополнительном аспекте моноспецифичный полипептид, как описано в данном документе, имеет константу скорости диссоциации (koff) для (или для связывания) TCR, выбранную из группы, состоящей из, по большей мере, около 10-3 с-1, по большей мере около 10-4 с-1, по большей мере около 10-5 с-1, по большей мере, около 10-6 с-1, по большей мере около 10-7 с-1, по большей мере, около 10-8 с-1, по большей мере, около 10-9 с-1 и самое большее около 10-10 с-1, предпочтительно, как измерено поверхностным плазмонным резонансом или как выполнено в разделе примеров.
Моноспецифические полипептиды и/или иммуноглобулиновые одиночные вариабельные домены по изобретению, которые связывают TCR, могут иметь каркасные последовательности, которые предпочтительно являются (подходящей комбинацией) каркасных последовательностей иммуноглобулина или каркасных последовательностей, которые были получены из каркасных последовательностей иммуноглобулина (например, путем оптимизации последовательности, такие как гуманизация или оверблюживание). Например, каркасные последовательности могут представлять собой каркасные последовательности, полученные из иммуноглобулинового одиночного вариабельного домена, такого как вариабельный домен легкой цепи (например, VL-последовательность), и/или из вариабельного домена тяжелой цепи (например, VH-последовательность). В одном особенно предпочтительном аспекте каркасные последовательности представляют собой либо каркасные последовательности, которые были получены из VHH-последовательности (в которых указанные каркасные последовательности могут быть необязательно частично или полностью гуманизированы), либо представляют собой обычные VH-последовательности, которые были оверблюжены.
Каркасные последовательности предпочтительно могут быть такими, чтобы моноспецифичный полипептид и/или иммуноглобулиновый одиночный вариабельный домен представлял собой доменное антитело (или аминокислотную последовательность, которая подходит для применения в качестве доменного антитела); однодоменное антитело (или аминокислота, которая подходит для применения в качестве однодоменного антитела); «dAb» (или аминокислота, которая подходит для применения в качестве dAb); нанотело; VНН; гуманизированный VHH; оверблюженный VH; или VHH, который был получен путем созревания аффинности. Опять же, подходящие каркасные последовательности будут понятны для специалиста, например, на основе стандартных справочников и дальнейшего раскрытия и предшествующего уровня техники, упомянутых в данном документе.
В частности, каркасные последовательности, присутствующие в моноспецифических полипептидах по изобретению, могут содержать один или несколько характерных остатков (как определено в WO 08/020079 (таблицы A-3-A-8)), так что моноспецифичный полипептид по изобретению является нанотелом. Hекоторые предпочтительные, но не ограничивающие примеры (подходящих комбинаций) таких каркасных последовательностей станут понятны из дальнейшего раскрытия в данном документе (см., например, таблицу A-5). Как правило, нанотела (в частности VHH, частично или полностью гуманизированные VHH и оверблюженные VH) могут, в частности, характеризоваться присутствием одного или нескольких «характерных остатков» в одной или нескольких каркасных последовательностях (например, дополнительно описанных в заявке WO 08/020079, стр. 61, строка 24 - стр. 98, строка 3).
Более конкретно, изобретение относится к полипептидам, содержащим или (по существу) состоящим, по меньшей мере, из иммуноглобулинового одиночного вариабельного домена, который представляет собой аминокислотную последовательность с (общей) структурой
FR1 - CDR1 - FR2 - CDR2 - FR3 - CDR3 - FR4
в которой FR1-FR4 относятся к каркасным областям 1-4, соответственно, и в которой CDR1-CDR3 относятся к областям 1-3, определяющим комплементарность, соответственно, и которая:
i) имеет, по меньшей мере, 80%, более предпочтительно 90%, еще более предпочтительно 95% идентичность аминокислот, по меньшей мере, с одной из аминокислотных последовательностей SEQ ID NO: 42 и 78-180 (см. таблицу A-5), в которой для целей определения степени идентичности аминокислот, аминокислотные остатки, которые образуют последовательности CDR, не учитываются. В этом отношении также настоящим ссылаемся на таблицу A-5, в которой перечислены каркасные последовательности 1 (SEQ ID NO: 226-250), каркасные последовательности 2 (SEQ ID NO: 251-276), каркасные последовательности 3 (SEQ ID NO: 277-319) и каркасные последовательности 4 (SEQ ID NO: 320-324) иммуноглобулиновых одиночных вариабельных доменов SEQ ID NO: 42 и 78-180 (см. таблицу A-5); или
и в которой:
ii) предпочтительно один или несколько аминокислотных остатков в положениях 11, 37, 44, 45, 47, 83, 84, 103, 104 и 108 в соответствии с нумерацией по Kabat выбраны из характерных остатков, упомянутых в таблицах A-3 - A-8 WO 08/020079.
Настоящее изобретение также относится к ряду оптимизированных по последовательности полипептидов и/или иммуноглобулиновых отдельных вариабельных доменов.
В частности, оптимизированные по последовательности полипептиды и/или иммуноглобулиновые одиночные вариабельные домены по изобретению могут представлять собой аминокислотные последовательности, которые, как правило, определены для иммуноглобулиновых одиночных вариабельных доменов в предыдущих абзацах, но в которых присутствует, по меньшей мере, один аминокислотный остаток (и в частности, по меньшей мере, в одном из каркасных остатков), который является и/или который соответствует гуманизирующей замене (как определено в данном документе). Некоторые предпочтительные, но не ограничивающие гуманизирующие замены (и их подходящие комбинации) станут понятными для специалиста на основании раскрытия в данном документе. Кроме того, или в ином случае, другие потенциально полезные гуманизирующие замены могут быть установлены путем сравнения последовательности каркасных областей встречающейся в природе последовательности VHH с соответствующей каркасной последовательностью одной или нескольких близкородственных человеческих последовательностей VH, после чего одна или несколько из потенциально полезных гуманизирующих замен (или их комбинаций), определенных таким образом, могут быть введены в указанную последовательность VHH (любым способом, известным per se, как дополнительно описано в данном документе), и полученные гуманизированные последовательности VHH могут быть проверены на аффинность к мишени, на стабильность, на легкость и уровень экспрессии и/или на другие искомые свойства. Таким образом, с помощью ограниченной степени проб и ошибок другие подходящие гуманизирующие замены (или их подходящие сочетания) могут быть определены специалистом в данной области на основании раскрытого в данном документе описания. Кроме того, на основании вышеизложенного (каркасные области) иммуноглобулиновых отдельных вариабельных доменов могут быть частично гуманизированными или полностью гуманизированными.
Настоящее изобретение также относится к оптимизированным по последовательности полипептидам и/или иммуноглобулиновым одиночным вариабельным доменам, которые могут демонстрировать улучшенную экспрессию и/или повышенную стабильность при хранении во время исследований стабильности. Оптимизированные по последовательности полипептиды и/или ISV по настоящему изобретению могут демонстрировать пониженную посттрансляционную модификацию N-конца пироглутаматом и, следовательно, могут иметь повышенную стабильность продукта. Кроме того, оптимизированные по последовательности полипептиды и/или ISV по настоящему изобретению могут демонстрировать другие улучшенные свойства, такие как, например, меньшая иммуногенность, улучшенные характеристики связывания (подходящим образом измеренные и/или выраженные в виде значения KD (фактического или кажущегося), значения KА (фактического или кажущегося), скорости kon и/или скорости koff или, альтернативно, значения EC50, как дополнительно описано в данном документе) к TCR, улучшенная аффинность и/или улучшенная авидность к TCR.
Некоторыми особенно предпочтительными оптимизированными по последовательности иммуноглобулиновыми одиночными вариабельными доменами по изобретению являются оптимизированные по последовательности варианты иммуноглобулиновых одиночных вариабельных доменов SEQ ID NO: 42 и 78-180.
Таким образом, некоторые другие предпочтительные иммуноглобулиновые одиночные вариабельные домены по изобретению представляют собой нанотела, которые могут связываться (как определено в данном документе) с TCR и которые:
i) представляют собой оптимизированный по последовательности вариант одного из иммуноглобулиновых одиночных вариабельных доменов с последовательностями SEQ ID NO: 42 и 78-180; и/или
ii) имеют, по меньшей мере, 80% идентичности аминокислот, по меньшей мере, с одним из иммуноглобулиновых одиночных вариабельных доменов с SEQ ID NO: 42 и 78-180 (см. таблицу A-5), в которых для целей определения степени аминокислоты идентичность, аминокислотные остатки, которые образуют последовательности CDR, не учитываются; В этом отношении также настоящим ссылаемся на таблицу A-5, в которой перечислены каркасные последовательности 1 (SEQ ID NO: 226-250), каркасные последовательности 2 (SEQ ID NO: 251-276), каркасные последовательности 3 (SEQ ID NO: 277-319) и каркасные последовательности 4 (SEQ ID NO: 320-324) иммуноглобулиновых одиночных вариабельных доменов SEQ ID NO: 42 и 78-180 (см. таблицу A-5);
и в которых:
iii) предпочтительно один или несколько аминокислотных остатков в положениях 11, 37, 44, 45, 47, 83, 84, 103, 104 и 108 в соответствии с нумерацией Kabat выбираются из характерных остатков, упомянутых в таблице A-3 - таблице A-8 WO 08/020079.
Оптимизированные по последовательности полипептиды и/или иммуноглобулиновые одиночные вариабельные домены по изобретению могут также содержать специфические мутации/аминокислотные остатки, описанные в следующих одновременно находящихся на рассмотрении предварительных заявок США, которые все озаглавлены «Улучшенные иммуноглобулиновые вариабельные домены»: US 61/994552, поданная в 16 мае 16 2014 года; US 61/014015, поданная 18 июня 2014 года; патент США 62/040167, поданный 21 августа 2014 года; и US 62/047,560, поданной 8 сентября 2014 года (все закреплены за Ablynx NV), а также в международной заявке WO 2015/173325, которая была основана на этих предварительных заявках и которая была опубликована 19 ноября 2015 года.
В частности, оптимизированные по последовательности полипептиды и/или иммуноглобулиновые одиночные вариабельные домены по изобретению могут подходящим образом содержать (i) K или Q в положении 112; или (ii) K или Q в положении 110 в сочетании с V в положении 11; или (iii) Т в положении 89; или (iv) L в положении 89 с K или Q в положении 110; или (v) V в положении 11 и L в положении 89; или любую подходящую комбинацию (i) - (v).
Как также описано в указанных одновременно находящихся на рассмотрении предварительных заявках США, когда полипептиды и/или иммуноглобулиновые одиночные вариабельные домены по изобретению включают мутации в соответствии с одним из (i) - (v) выше (или их подходящей комбинации):
аминокислотный остаток в положении 11 предпочтительно выбирают из L, V или K (и наиболее предпочтительно V); и
аминокислотный остаток в положении 14 предпочтительно выбирают из А или Р; и
аминокислотный остаток в положении 41 предпочтительно выбирают из А или Р; и
аминокислотный остаток в положении 89 предпочтительно выбирают из Т, V или L; и
аминокислотный остаток в положении 108 предпочтительно выбирают из Q или L; и
аминокислотный остаток в положении 110 предпочтительно выбирают из Т, К или Q; и
аминокислотный остаток в положении 112 предпочтительно выбирают из S, K или Q.
Как упомянуто в указанных одновременно находящихся на рассмотрении предварительных заявках США, указанные мутации эффективны в предотвращении или уменьшении связывания так называемых «ранее существующих антител» с полипептидами, иммуноглобулиновыми одиночными вариабельными доменами и/или конструкциями по изобретению. Для этой цели полипептиды и/или иммуноглобулиновые одиночные вариабельные домены по изобретению также могут содержать (необязательно в комбинации с указанными мутациями) C-концевое удлинение (X)n (в котором n равно от 1 до 10, предпочтительно от 1 до 5, такие как 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например, 1); и каждый X представляет собой (предпочтительно встречающийся в природе) аминокислотный остаток, который независимо выбран и предпочтительно независимо выбран из группы, состоящей из аланина (A), глицина (G), валина (V), лейцина (L) или изолейцина (I)), для которого снова настоящим ссылаемся на упомянутые предварительные заявки США, а также на WO 12/175741. В частности, полипептид и/или иммуноглобулиновый одиночный вариабельный домен по изобретению может включать такое С-концевое удлинение, когда оно формирует С-концевой конец белка, полипептида или другой конструкции, содержащей тоже самое (опять же, как дополнительно описано в упомянутых выше предварительных заявках США, а также WO 12/175741).
Соответственно, настоящее изобретение относится к полипептиду, описанному в данном документе, дополнительно включающему C-концевое удлинение (X)n, в котором n равно от 1 до 5, например, 1, 2, 3, 4 или 5, и в котором X представляет собой встречающуюся в природе аминокислоту, предпочтительно не цистеин.
Эти полипептиды по изобретению и, в частности, иммуноглобулиновые одиночные вариабельные домены, содержащие последовательности CDR по изобретению, особенно подходят для использования в качестве структурного элемента или связывающей единицы для получения мультиспецифичных полипептидов, таких как мультиспецифичные полипептиды по изобретению.
Соответственно, моноспецифичные полипептиды по изобретению, которые связывают TCR, могут быть по существу в выделенной форме (как определено в данном документе), или они могут образовывать часть белка или полипептида, который может включать или по существу состоять из одного полипептида или ISV, который связывает TCR, и которые необязательно может дополнительно включать одну или несколько дополнительных аминокислотных последовательностей (все необязательно связаны через один или несколько подходящих линкеров).
Соответственно, настоящее изобретение также относится к белку или полипептиду, который включает или по существу состоит из одного моноспецифического полипептида по изобретению (или его подходящих фрагментов). В дополнительном аспекте моноспецифические полипептиды по изобретению, которые связывают TCR, могут образовывать часть мультиспецифического полипептида, который может включать или, по существу, состоять из одного ISV, который связывает TCR, и который необязательно может дополнительно содержать один или несколько дополнительных ISV, которые специфически связывают другую мишень, такую как CD123, и который необязательно может дополнительно включать одну или несколько дополнительных аминокислотных последовательностей (все необязательно связаны через один или несколько подходящих линкеров).
Моноспецифические полипептиды по изобретению, таким образом, используются в качестве связывающей единицы или структурного элемента в таком белке или полипептиде, чтобы обеспечить мультиспецифичный полипептид по изобретению, как описано в данном документе (для мультиспецифичных полипептидов, содержащих один или несколько доменов VHH, и их получение, также настоящим ссылаемся на Conrath et al. (2001, J. Biol. Chem. 276: 7346-7350), а также, например, на WO 96/34103, WO 99/23221 и WO 2010/115998). Таким образом, настоящее изобретение также относится к полипептиду, который представляет собой моновалентную конструкцию, включающую или, по существу, состоящую из одного одновалентного полипептида, который связывает TCR.
1.2 CD123-связывающие полипептиды
Настоящее изобретение относится к моноспецифичному полипептиду, который специфически связывает CD123, предпочтительно CD123 человека и/или яванского макака. В предпочтительном аспекте моноспецифичный полипептид представляет собой иммуноглобулиновый одиночный вариабельный домен, также называемый в данном документе «иммуноглобулиновый одиночный вариабельный домен по изобретению» или «ISV по изобретению».
CD123 также известен как α-субъединица рецептора интерлейкина 3 (IL-3Rα). Последовательности CD123 человека и CD123 яванского макака представлены в таблице A-8 (SEQ ID NO: 68-69; см. также CD123 человека: NCBI RefSeq NP_002174 и CD123 яванского макака: NCBI genbank № EHH61867.1).
В одном аспекте настоящее изобретение относится к моноспецифичному полипептиду, описанному в данном документе, который связывается с CD123 человека (SEQ ID NO: 68).
Моноспецифические полипептиды, которые связывают CD123, были тщательно отобраны по их специфичности к CD123. Полипептиды по изобретению проявляют высокоспецифичное связывание с CD123 при форматировании в мультиспецифичный формат по изобретению (т.е. формат, включающий один ISV, который связывает TCR, и один или несколько ISV, которые связывают CD123). Как таковое, связывания вне мишени избегают, и мишень независимая активация Т-клеток минимальна, как дополнительно показано в данном документе.
Авторы идентифицировали 2 кластера нанотел (пример 12), которые проявляли высокоспецифичное связывание с CD123. При форматировании представителей кластеров в мультиспецифичный полипептид по изобретению (как описано далее) наблюдалась только минимальная независимая от мишени активация Т-клеток, что указывает на высокую специфичность представителей кластеров. Соответствующие выравнивания приведены (см. таблицу A-2 для нанотел, связанных с (представителями семейства) нанотела 56A10 (т.е. нанотел, принадлежащих к тому же семейству, что и нанотело 56A10), и таблицу A-3 для нанотел, связанных с (представителями семейства) нанотела 55F03 (т.е. нанотела, принадлежащие к тому же семейству, что и нанотело 55F03).
«Семейство нанотел», «семейство VHH» или «семейство», используемое в настоящем описании, относится к группе последовательностей нанотел и/или VHH, которые имеют одинаковую длину (т.е. они имеют одинаковое количество аминокислот в пределах своих последовательность), и из которых аминокислотная последовательность между положением 8 и положением 106 (согласно нумерации Kabat) имеет идентичность аминокислотной последовательности 89% или более.
Соответственно, настоящее изобретение относится к полипептидам, предпочтительно ISV, выбранным из группы, состоящей из SEQ ID NO: 1-10 (см. также таблицу A-4). В дополнительном аспекте полипептид выбран из группы, состоящей из SEQ ID NO: 1-10 или из полипептидов, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95%, или даже более 99% с одной из SEQ ID NO: 1-10.
Соответственно, настоящее изобретение относится к полипептиду, предпочтительно ISV, который специфически связывает CD123 и который включает или по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16; при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20; при условии, что полипептид, содержащий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2, без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25; при условии, что полипептид, содержащий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В дополнительном аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, который специфически связывает CD123 и который включает или по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в котором:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16; при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20; при условии, что полипептид, содержащий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2, без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25; при условии, что полипептид, содержащий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В дополнительном аспекте полипептид по изобретению, предпочтительно ISV, содержит или по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 3, 6, 7 и/или 8 CDR1 (положения 28, 31, 32 и/или 33 согласно нумерации Kabat); при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20, где различие в 3, 2 или 1 аминокислоту присутствует в положениях 3 6 и/или 10 CDR2 (положения 52, 54 и/или 58 согласно нумерации Kabat); при условии, что полипептид, содержащий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25, где различие в 3, 2 или 1 аминокислоту присутствует в положениях 3, 4 и/или 5 CDR3 (положения 97, 98 и/или 99 согласно нумерации Kabat); при условии, что полипептид, содержащий CDR3 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3, без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В дополнительном аспекте полипептид по изобретению, предпочтительно ISV, содержит или по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 3, 6, 7 и/или 8 CDR1 (положения 28, 31, 32 и/или 33 согласно нумерации Kabat); при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20, где различие в 3, 2 или 1 аминокислоту присутствует в положениях 3 6 и/или 10 CDR2 (положения 52, 54 и/или 58 согласно нумерации Kabat); при условии, что полипептид, содержащий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25, где различие в 3, 2 или 1 аминокислоту присутствует в положениях 3, 4 и/или 5 CDR3 (положения 97, 98 и/или 99 согласно нумерации Kabat); при условии, что полипептид, содержащий CDR3 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3, без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В одном аспекте полипептиды, предпочтительно ISV, по изобретению могут иметь идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одним из SEQ ID NO: 1-6 (см. также таблицу A-4). Эти полипептиды упоминаются в данном документе как «полипептид(ы), относящиеся к 56A10» или «ISV, относящиеся к 56A10».
Соответственно, настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 11, где
- в положении 3 Т была изменена на S или P;
- в положении 6 I была изменена на S;
- в положении 7 N была изменена на D; и/или
- в положении 8 D была изменена на V или A;
при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В дополнительном аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором CDR2 представляет собой SEQ ID NO: 17.
В дополнительном аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором CDR3 выбрана из группы, состоящей из:
а) SEQ ID NO: 21; или
b) аминокислотных последовательностей с различием в 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 21, где
- в положении 3 P была изменена на A;
при условии, что полипептид, содержащий CDR3 с различием в 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Соответственно, настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 11, где
- в положении 3 Т была изменена на S или P;
- в положении 6 I была изменена на S;
- в положении 7 N была изменена на D; и/или
- в положении 8 D была изменена на V или A;
при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 является SEQ ID NO: 17;
и
iii) CDR3 выбрана из группы, состоящей из:
с) SEQ ID NO: 21; или
d) аминокислотных последовательностей с различием в 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 21, где
- в положении 3 P была изменена на A;
при условии, что полипептид, содержащий CDR3 с различием в 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, включающим CDR3 без различия в 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, как описано в данном документе, в котором CDR1 выбрана из группы, состоящей из SEQ ID NO: 11-15, CDR2 представляет собой SEQ ID NO: 17, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 21-22.
Соответственно, в предпочтительном аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, как описано в данном документе, в котором CDR1 представляет собой SEQ ID NO: 11, CDR2 представляет собой SEQ ID NO: 17 и CDR3 представляет собой SEQ ID NO: 21.
Соответственно, настоящее изобретение относится к полипептидам, которые являются ISV, выбранными из группы, состоящей из SEQ ID NO: 1-6.
Полипептиды или ISV, относящиеся к 56A10, были отобраны за их исключительную специфичность для CD123. Связывание полипептидов по изобретению может быть измерено в подходящих анализах связывания, включая, без ограничения указанным, анализ проточной цитометрией. В таком анализе проточной цитометрией можно использовать клетки, которые эндогенно экспрессируют CD123 (такие как, например, клетки MOLM-13 или KG1a). В ином случае, могут быть использованы клетки, которые трансфицированы для сверхэкспрессии CD123 (такие как, например, CHO-K1 huCD123 или HEK293 cyno CD123). Подходящие клеточные линии станут понятны из приведенных в данном документе примеров.
Полипептид, предпочтительно ISV, по изобретению может связываться с CD123, экспрессируемым на клетках, или с клетками, экспрессирующими CD123, со средним значением EC50 между 10 нМ и 100 пМ.
Более конкретно, полипептид, предпочтительно ISV, по изобретению связывается с CD123 человека, экспрессируемым на клетках MOLM-13, со средним значением EC50 между 10 нМ и 100 пМ, например, со средним значением EC50 5 нМ или менее, например, менее чем 4, 3, 2 или 1 нМ или даже менее, предпочтительно по данным проточной цитометрии.
Полипептид, предпочтительно ISV, по изобретению связывается с CD123 человека, экспрессируемым на клетках CHO-K1, со средним значением EC50 от 10 нМ до 100 пМ, например, со средним значением EC50 5 нМ или менее, например, менее 4, 3, 2 или 1 нМ или даже менее, предпочтительно по данным проточной цитометрии.
Полипептид, предпочтительно ISV, по изобретению связывается с CD123 яванского макака, экспрессируемым на клетках HEK293, со средним значением EC50 между 10 нМ и 100 пМ, например, со средним значением EC50 5 нМ или менее, например, менее 4 или 3 нМ или даже менее, предпочтительно по данным проточной цитометрии.
Связывание полипептидов, предпочтительно ISV, по изобретению также может быть измерено с помощью SPR.
Как таковой, полипептид, предпочтительно ISV, по изобретению может связываться с CD123 человека со средним значением KD между 10 нМ и 100 пМ, например, со средним значением KD 5 нМ или менее, например, менее 4, 3 или 2 нМ или даже менее, указанное значение KD предпочтительно определяют поверхностным плазмонным резонансом.
Соответственно, настоящее изобретение относится к полипептиду или ISV, как описано в данном документе, где указанное среднее значение KD или EC50 определяют с помощью проточной цитометрии или SPR, например, указанное KD или EC50 определяют, как изложено в разделе примеров.
В примерах показано, что KD, измеренный в SPR, хорошо коррелирует с EC50, измеренным в проточной цитометрии.
В другом аспекте полипептиды по изобретению могут иметь идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 7- 10 (см. также таблицу A-4). Эти полипептиды упоминаются в данном документе как «полипептид(ы), относящиеся к 55F03» или «ISV, относящиеся к 55F03».
Соответственно, настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором CDR1 представляет собой SEQ ID NO: 16.
В дополнительном аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором CDR2 выбрана из группы, состоящей из:
а) SEQ ID NO: 18; или
b) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 18, где
- в положении 3 Y была изменена на W;
- в положении 6 N была изменена на S; и/или
- в положении 10 Q была изменена на E;
при условии, что полипептид, содержащий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В дополнительном аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором CDR3 выбрана из группы, состоящей из:
а) SEQ ID NO: 23; или
b) аминокислотных последовательностей с различием в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 23, где
- в положении 4 E была изменена на R; и/или
- в положении 5 Т была изменена на D или Y;
при условии, что полипептид, содержащий CDR3 с различием в 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Соответственно, настоящее изобретение относится к полипептиду, предпочтительно ISV, в котором:
i) CDR1 является SEQ ID NO: 16;
и
ii) CDR2 выбрана из группы, состоящей из:
а) SEQ ID NO: 18; или
b) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 18, где
- в положении 3 Y была изменена на W;
- в положении 6 N была изменена на S; и/или
- в положении 10 Q была изменена на E;
при условии, что полипептид, содержащий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
с) SEQ ID NO: 23; или
d) аминокислотных последовательностей с различием в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 23, где
- в положении 4 E была изменена на R; и/или
- в положении 5 Т была изменена на D или Y;
при условии, что полипептид, содержащий CDR3 с различием в 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, как описано в данном документе, в котором CDR1 представляет собой SEQ ID NO: 16, CDR2 выбрана из группы, состоящей из SEQ ID NO: 18-20, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 23-25.
Соответственно, в предпочтительном аспекте настоящее изобретение относится к полипептиду, предпочтительно ISV, как описано в данном документе, в котором CDR1 представляет собой SEQ ID NO: 16, CDR2 представляет собой SEQ ID NO: 18 и CDR3 представляет собой SEQ ID NO: 23.
Предпочтительные полипептиды и/или ISV выбирают из группы, состоящей из SEQ ID NO: 7-10.
Полипептиды или ISV, относящиеся к 55F03, были отобраны за их исключительную специфичность к CD123. Связывание полипептидов по изобретению может быть измерено в подходящих анализах связывания, включая, без ограничения указанным, анализ проточной цитометрией и SPR, как описано в данном документе.
Полипептид, предпочтительно ISV, по изобретению может связываться с CD123, экспрессируемым на клетках, или клетками, экспрессирующими CD123, со средним значением EC50 между 10 мкМ и 100 нМ.
Более конкретно, полипептид, предпочтительно ISV, по изобретению связывается с CD123 человека, экспрессируемым на клетках MOLM-13, со средним значением EC50 от 10 мкМ до 100 нМ, например, со средним значением EC50 5 мкМ или менее, например, менее чем 4, 3, 2 или 1 мкМ или даже менее, предпочтительно по данным проточной цитометрии.
Полипептид, предпочтительно ISV, по изобретению связывается с CD123 человека, экспрессируемым на клетках CHO-K1, со средним значением EC50 между 100 нМ и 1 нМ, например, со средним значением EC50, равным 50 нМ или менее, таким как менее 40, 30, 20 или 10 нМ или даже менее, например, менее 9, 8 или 7 нМ или даже менее, предпочтительно по данным проточной цитометрии.
Полипептид, предпочтительно ISV, по изобретению связывается с CD123 яванского макака, экспрессируемым на клетках HEK293, со средним значением EC50 между 10 нМ и 100 пМ, например, со средним значением EC50 5 нМ или менее, например, менее 4 или 3. нМ или даже менее, предпочтительно по данным проточной цитометрии.
В дополнительном аспекте настоящее изобретение относится к полипептиду или ISV, который связывается с CD123 человека со средним значением KD от 1 мкМ до 10 нМ, таким как среднее значение KD, равное 500 нМ или менее, например, менее чем 400, 300 или 200 нМ или даже менее, указанное значение KD предпочтительно определяют поверхностным плазмонным резонансом.
Соответственно, настоящее изобретение относится к полипептиду или ISV, как описано в данном документе, где указанное среднее значение KD или EC50 определяют с помощью проточной цитометрии или SPR, например, указанное KD или EC50 определяют, как изложено в разделе примеров.
В примерах было показано, что KD, измеренный в SPR, хорошо коррелирует с EC50, как определено в анализе на основе проточной цитометрии с использованием клеток MOLM-13.
Как правило, комбинации CDR, перечисленные в таблице A-4 (т.е. те, которые указаны в одной строке в таблице A-4), являются предпочтительными. Таким образом, обычно предпочтительно, чтобы, когда CDR в ISV представляет собой последовательность CDR, упомянутую в таблице A-4, или подходящим образом выбирается из группы, состоящей из последовательностей CDR, которые имеют различие в 4, 3, 2 или только 1 аминокислоту с последовательностью CDR, перечисленной в таблице A-4, то, по меньшей мере, одна и предпочтительно обе других CDR подходящим образом выбраны из последовательностей CDR, которые принадлежат к той же комбинации в таблице A-4 (т.е. упомянуты в одной строке в таблице A-4) или подходящим образом выбраны из группы, состоящей из последовательностей CDR, которые имеют различие в 4, 3, 2 или только 1 аминокислоту с последовательностью (последовательностями) CDR, принадлежащей к той же самой комбинации. Типичные полипептиды по настоящему изобретению, имеющие CDR, описанные выше, показаны в таблице A-4.
Настоящее изобретение также относится к полипептиду, предпочтительно ISV, который специфически связывает CD123, который перекрестно блокирует связывание с CD123, по меньшей мере, одного из полипептидов, описанных в данном документе и/или выбрано из SEQ ID NO: 1-10, и/или что перекрестно блокируется от связывания с CD123, по меньшей мере, одним из полипептидов, описанных в данном документе и/или выбранных из SEQ ID NO: 1-10.
Изобретение также относится к моноспецифичному полипептиду, который включает или (по существу) состоит из двух или более ISV, которые связывают CD123. В таком мультивалентном (моноспецифическом) полипептиде, также называемом в данном документе «мультивалентным полипептидом(ами) по изобретению», два или более ISV, которые связывают CD123, могут быть необязательно соединены через один или несколько пептидных линкеров, как дополнительно описано в данном документе.
Соответственно, настоящее изобретение относится к полипептиду, включающему два или более ISV, которые специфически связывают CD123, где ISV выбраны из группы ISV, относящихся к 56A10, или из группы ISV, относящихся к 55F03.
В более конкретном аспекте настоящее изобретение относится к полипептидам, содержащим два ISV, которые специфически связывают CD123, где ISV выбраны из группы ISV, относящихся к 56A10, или из группы ISV, относящихся к 55F03.
В таком мультивалентном моноспецифическом полипептиде по изобретению два или более иммуноглобулиновых одиночных вариабельных доменов могут быть одинаковыми или разными и могут быть направлены против одной и той же антигенной детерминанты CD123 (например, против одной и той же части(ей) или эпитопа(ов) CD123) или может быть альтернативно направлен против различных антигенных детерминант CD123 или против различных частей или эпитопов CD123; или любая подходящая их комбинация. Например, двухвалентный полипептид по изобретению может включать (а) два иммуноглобулинового одиночного вариабельного домена; (b) первый иммуноглобулиновый одиночный вариабельный домен, направленный против первой антигенной детерминанты CD123, и второй иммуноглобулиновый одиночный вариабельный домен, направленный против той же антигенной детерминанты CD123, который отличается от первого вариабельного домена иммуноглобулина; или (c) первый вариабельный домен иммуноглобулина, направленный против первой антигенной детерминанты CD123, и второй вариабельный домен иммуноглобулина, направленный против другой антигенной детерминанты CD123.
Трехвалентный полипептид по изобретению может быть любым из указанных выше, дополнительно включающий (а) идентичный иммуноглобулиновый одиночный вариабельный домен; (b) другой иммуноглобулиновый одиночный вариабельный домен, направленный против одной и той же антигенной детерминанты CD123; или (c) другой иммуноглобулиновый одиночный вариабельный домен, направленный против другой антигенной детерминанты CD123.
По существу, в одном аспекте моноспецифичный полипептид по изобретению может представлять собой мультипаратопический полипептид, такой как, например, бипаратопический полипептид. Используемый в данном документе термин «бипаратопическая» (антиген-) связывающая молекула или «бипаратопный» полипептид означает полипептид, содержащий, по меньшей мере, два (т.е. два или более) иммуноглобулинового одиночного вариабельного домена, причем «первый» иммуноглобулиновый одиночный вариабельный домен направлен против CD123 и «второй» иммуноглобулиновый одиночный вариабельный домен направлены против CD123, и где эти «первый» и «второй» иммуноглобулиновые одиночные вариабельные домены имеют различный паратоп. Соответственно, бипаратопический полипептид включает или состоит из двух или более иммуноглобулиновых одиночных вариабельных доменов, которые направлены против CD123, где, по меньшей мере, один «первый» иммуноглобулиновый одиночный вариабельный домен направлен против первого эпитопа на CD123 и, по меньшей мере, один «второй» иммуноглобулиновый одиночный вариабельный домен направлен против второго эпитопа на CD123, отличающегося от первого эпитопа на CD123.
Соответственно, настоящее изобретение относится к полипептидам, где два или более ISV, которые специфически связывают CD123, являются бипаратопными, включающими первый ISV и второй ISV, где первый ISV связывается с эпитопом на CD123, который отличается от эпитопа на CD123, связанного посредством второго ISV. Такой(ие) полипептид(ы) также упоминается в данном документе как «бипаратопный(ые) полипептид(ы) по изобретению».
В дополнительном аспекте настоящее изобретение относится к (бипаратопному) полипептиду, описанному в данном документе, где первый ISV выбран из группы ISV, относящихся к 56A10, и второй ISV выбран из группы ISV, относящихся к 55F03.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где второй ISV расположен на N-конце первого ISV. Такой полипептид включает ISV, относящийся к 55F03, на N-конце ISV, относящегося с 56A10.
В дополнительном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где второй ISV расположен на С-конце первого ISV. Такой полипептид включает ISV, относящийся к 55F03 на С-конце ISV, относящегося с 56A10.
Бипаратопные полипептиды по изобретению могут обладать улучшенной аффинностью к связыванию с CD123 по сравнению с соответствующим одновалентным полипептидом вследствие активного связывания, также называемого «авидностью».
Авидность - это аффинность полипептида, т.е. лиганд способен связываться через два (или более) фармакофоров (ISV), в которых множественные взаимодействия синергизируются для усиления «кажущейся» аффинности. Авидность - это мера силы связывания между полипептидом по изобретению и соответствующими антигенами или антигенными детерминантами. Полипептид по изобретению способен связываться через свои два (или более) структурных элемента, таких как ISV, по меньшей мере, с двумя мишенями или антигенными детерминантами, в которых множественные взаимодействия, например, первого структурного элемента или ISV, связывающегося с первой мишенью или первой антигенной детерминантой, и второго структурного элемента или ISV, связывающегося со второй мишенью или второй антигенной детерминантой, синергизируются для усиления «кажущейся» аффинности. Авидность связана как с аффинностью между антигенной детерминантой и ее антигенсвязывающим сайтом на антигенсвязывающей молекуле, так и с количеством подходящих сайтов связывания, присутствующих на антигенсвязывающих молекулах. Например, и без ограничения указанным, полипептиды, которые содержат два или более структурных элемента, таких как ISV, направленные против разных мишеней в клетке или различных антигенных детерминант, могут (и обычно будут) связываться с более высокой авидностью, чем каждый из отдельных мономеров или отдельных структурных элементов такие как, например, моновалентные ISV, содержащиеся в полипептидах по изобретению.
Моноспецифические полипептиды по изобретению включают или (по существу) состоят из одного или нескольких иммуноглобулиновых одиночных вариабельных доменов. Каркасные последовательности этих ISV предпочтительно представляют собой (подходящую комбинацию) каркасных последовательностей иммуноглобулина или каркасных последовательностей, которые были получены из каркасных последовательностей иммуноглобулина (например, путем оптимизации последовательности, такой как гуманизация или оверблюживание). Например, каркасные последовательности могут представлять собой каркасные последовательности, полученные из иммуноглобулинового одиночного вариабельного домена, такого как вариабельный домен легкой цепи (например, последовательность VL), и/или из вариабельный домена тяжелой цепи (например, последовательность VH). В одном особенно предпочтительном аспекте каркасные последовательности представляют собой либо каркасные последовательности, которые были получены из VHH -последовательности (в которых указанные каркасные последовательности могут быть необязательно частично или полностью гуманизированы), либо представляют собой обычные VH-последовательности, которые были оверблюжены.
Каркасные последовательности предпочтительно могут быть такими, что ISV, включенный в моноспецифичный полипептид по изобретению, представляет собой доменное антитело (или аминокислотную последовательность, которая подходит для применения в качестве доменного антитела); однодоменное антитело (или аминокислота, которая подходит для применения в качестве однодоменного антитела); «dAb» (или аминокислота, которая подходит для применения в качестве dAb); нанотело; VНН; гуманизированный VHH; оверблюженный VH; или VHH, который был получен путем созревания аффинности. Опять же, подходящие каркасные последовательности будут понятны для специалиста, например, на основе стандартных справочников и дальнейшего раскрытия и предшествующего уровня техники, упомянутых в данном документе.
В частности, каркасные последовательности, присутствующие в моноспецифических полипептидах по изобретению, могут включать один или несколько характерных остатка (как определено в WO 08/020079 (таблицы A-3-A-8)), так что моноспецифичный полипептид по изобретению представляет собой нанотело. Некоторые предпочтительные, но не ограничивающие примеры (подходящих комбинаций) таких каркасных последовательностей станут понятными из дальнейшего раскрытия в данном документе (см., например, таблицу A-4). Как правило, нанотела (в частности VHH, частично или полностью гуманизированные VHH и оверблюженные VH) могут, в частности, характеризоваться присутствием одного или нескольких «характерных остатков» в одной или нескольких каркасных последовательностях (как, например, дополнительно описанных в заявке WO 08/020079, стр 61, строка 24 - стр. 98, строка 3).
Более конкретно, изобретение относится к полипептидам, содержащим, по меньшей мере, один иммуноглобулиновый одиночный вариабельный домен, который представляет собой аминокислотную последовательность с (общей) структурой
FR1 - CDR1 - FR2 - CDR2 - FR3 - CDR3 - FR4
в котором FR1-FR4 относятся к каркасным областям 1-4, соответственно, и в которых CDR1-CDR3 относятся к областям 1-3 определения комплементарности, соответственно, и которые:
i) имеют, по меньшей мере, 80%, более предпочтительно 90%, еще более предпочтительно 95% идентичности аминокислот, по меньшей мере, с одной из аминокислотных последовательностей SEQ ID NO: 1-10 (см. таблицу A-4), в которой для целей определения степени идентичности аминокислот аминокислотные остатки, которые образуют последовательности CDR, не учитываются. В этом отношении также настоящим ссылаемся на таблицу A-4, в которой перечислены последовательности структуры 1 (SEQ ID NO: 26-29), последовательности структуры 2 (SEQ ID NO: 30-33), каркасные последовательности 3 (SEQ ID NO: 34-39) и каркасные последовательности 4 (SEQ ID NO: 40-41) иммуноглобулиновых одиночных вариабельных доменов SEQ ID NO: 1-10 (см. таблицу A-4); или
и в котором:
ii) предпочтительно один или несколько аминокислотных остатков в положениях 11, 37, 44, 45, 47, 83, 84, 103, 104 и 108 в соответствии с нумерацией по Kabat выбраны из характерных остатков, упомянутых в таблицах A-3 - A-8 из WO 08/020079.
Настоящее изобретение также относится к ряду оптимизированных по последовательности полипептидов и/или иммуноглобулиновых отдельных вариабельных доменов.
В частности, оптимизированные по последовательности полипептиды и/или иммуноглобулиновые одиночные вариабельные домены по изобретению могут представлять собой аминокислотные последовательности, которые, как правило, определены для иммуноглобулиновых одиночных вариабельных доменов в предыдущих абзацах, но в которых присутствует, по меньшей мере, один аминокислотный остаток (и в в частности, по меньшей мере, в одном из каркасных остатков, который является и/или который соответствует гуманизирующему замещению (как определено в данном документе). Некоторые предпочтительные, но не ограничивающие гуманизирующие замены (и их подходящие комбинации) станут понятными для специалиста на основании раскрытия данного документа. Кроме того, или альтернативно, другие потенциально полезные гуманизирующие замены могут быть установлены путем сравнения последовательности каркасных областей встречающейся в природе последовательности VHH с соответствующей каркасной последовательностью одной или нескольких близкородственных человеческих последовательностей VH, после чего одна или несколько из потенциально полезных гуманизирующих замен (или их комбинаций), определенные таким образом, могут быть введены в указанную последовательность VHH (любым способом, известным per se, как дополнительно описано в данном документе), и полученные гуманизированные последовательности VHH могут быть проверены на аффинность к мишени, на стабильность, на легкость и уровень экспрессии и/или на другие искомые свойства. Таким образом, с помощью ограниченной степени проб и ошибок другие подходящие гуманизирующие замены (или их подходящие сочетания) могут быть определены специалистом в данной области на основании раскрытого в данном документе описания. Кроме того, на основании вышеизложенного (каркасные области) иммуноглобулиновых отдельных вариабельных доменов могут быть частично гуманизированными или полностью гуманизированными.
Настоящее изобретение также относится к оптимизированным по последовательности полипептидам и/или иммуноглобулиновым одиночным вариабельным доменам, которые могут демонстрировать улучшенную экспрессию и/или повышенную стабильность при хранении во время исследований стабильности. Оптимизированные по последовательности полипептиды и/или ISV по настоящему изобретению могут демонстрировать пониженную посттрансляционную модификацию N-конца пироглутаматом и, следовательно, иметь повышенную стабильность продукта. Кроме того, оптимизированные по последовательности полипептиды и/или ISV по настоящему изобретению могут демонстрировать другие улучшенные свойства, такие как, например, меньшая иммуногенность, улучшенные характеристики связывания (подходящим образом измеренные и/или выраженные в виде значения KD (фактического или кажущегося), значения KA (фактического или кажущегося), скорости kon и/или скорости koff, или в качестве альтернативы в качестве значения ЕС50, как дополнительно описано в данном документе) с CD123, улучшенная аффинность и/или улучшенная авидность к CD123.
HEKоторые особенно предпочтительные оптимизированные по последовательности иммуноглобулиновые одиночные вариабельные домены по изобретению представляют собой оптимизированные по последовательности варианты иммуноглобулиновых одиночных вариабельных доменов SEQ ID NO: 1-10.
Таким образом, HEKоторые другие предпочтительные иммуноглобулиновые одиночные вариабельные домены по изобретению представляют собой нанотела, которые могут связываться (как определено в данном документе) с CD123 и которые:
i) представляют собой оптимизированный по последовательности вариант одного из иммуноглобулиновых одиночных вариабельных доменов с последовательностью SEQ ID NO: 1-10; и/или
ii) иметь, по меньшей мере, 80% идентичности аминокислот, по меньшей мере, с одним из иммуноглобулиновых одиночных вариабельных доменов SEQ ID NO: 1-10 (см. таблицу A-4), в которых для целей определения степени идентичности аминокислот, аминокислотные остатки, которые образуют последовательности CDR, не учитываются; в этом отношении также настоящим ссылаемся на таблицу A-4, в которой перечислены каркасные последовательности 1 (SEQ ID NO: 26-29), каркасные последовательности 2 (SEQ ID NO: 30-33), каркасные последовательности 3 (SEQ ID NO: 34-39) и каркасные последовательности 4 (SEQ ID NO: 40-41) иммуноглобулиновых одиночных вариабельных доменов SEQ ID NO: 1-10 (см. таблицу A-4);
и в которых:
iii) предпочтительно один или несколько аминокислотных остатков в положениях 11, 37, 44, 45, 47, 83, 84, 103, 104 и 108 в соответствии с нумерацией Kabat выбираются из характерных остатков, упомянутых в таблице A-3 - таблице A-8 из WO 08/020079.
Полипептиды и/или иммуноглобулиновые одиночные вариабельные домены по изобретению могут также содержать специфические мутации/аминокислотные остатки, описанные в следующих одновременно рассматриваемых предварительных заявках США, все из которых озаглавлены «Улучшенные иммуноглобулиновые вариабельные домены»: US 61/994552, поданная 16 мая, 2014 года; US 61/014015, поданная 18 июня 2014 года; Патент США 62/040167, поданный 21 августа 2014 года; и US 62/047,560, поданной 8 сентября 2014 года (все закреплены за Ablynx NV), а также в международной заявке WO 2015/173325, которая была основана на этих предварительных заявках и которая была опубликована 19 ноября 2015 года.
В частности, полипептиды и/или иммуноглобулиновые одиночные вариабельные домены по изобретению могут подходящим образом содержать (i) K или Q в положении 112; или (ii) K или Q в положении 110 в сочетании с V в положении 11; или (iii) Т в положении 89; или (iv) L в положении 89 с K или Q в положении 110; или (v) V в положении 11 и L в положении 89; или любую подходящую комбинацию (i) - (v).
Как также описано в указанных одновременно находящихся на рассмотрении предварительных заявках США, когда полипептид и/или иммуноглобулиновые одиночные вариабельные домены по изобретению содержат мутации в соответствии с одним из (i) - (v) выше (или их подходящую комбинацию):
аминокислотный остаток в положении 11 предпочтительно выбран из L, V или K (и наиболее предпочтительно V); и
аминокислотный остаток в положении 14 предпочтительно выбирают из А или Р; и
аминокислотный остаток в положении 41 предпочтительно выбирают из А или Р; и
аминокислотный остаток в положении 89 предпочтительно выбирают из Т, V или L; и
аминокислотный остаток в положении 108 предпочтительно выбирают из Q или L; и
аминокислотный остаток в положении 110 предпочтительно выбирают из Т, К или Q; и
аминокислотный остаток в положении 112 предпочтительно выбирают из S, K или Q.
Как упомянуто в указанных одновременно находящихся на рассмотрении предварительных заявках США, указанные мутации эффективны в предотвращении или уменьшении связывания так называемых «ранее существующих антител» с полипептидами и/или одиночными вариабельными доменами иммуноглобулина и/или конструкциями по изобретению. Для этой цели полипептиды и/или иммуноглобулиновые одиночные вариабельные домены по изобретению также могут содержать (необязательно в комбинации с указанными мутациями) C-концевое удлинение (X)n (в котором n равно от 1 до 10, предпочтительно от 1 до 5, такие как 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например, 1); и каждый X представляет собой (предпочтительно встречающийся в природе) аминокислотный остаток, который независимо выбран и предпочтительно независимо выбран из группы, состоящей из аланина (A), глицина (G), валина (V), лейцина (L) или изолейцина (I)), для которого снова настоящим ссылаемся на упомянутые предварительные заявки США, а также на WO 12/175741. В частности, один вариабельный домен полипептида и/или иммуноглобулина по изобретению может содержать такое С-концевое удлинение, когда он образует С-концевой конец белка, полипептида или другой конструкции, содержащей его (опять же, как дополнительно описано в упомянутых выше предварительных заявках США, а также WO 12/175741).
Соответственно, настоящее изобретение относится к полипептиду, описанному в данном документе, дополнительно включающему C-концевое удлинение (X)n, в котором n равно от 1 до 5, например, 1, 2, 3, 4 или 5, и в котором X представляет собой встречающаяся в природе аминокислота, предпочтительно не цистеин.
Эти полипептиды по изобретению и, в частности, иммуноглобулиновые одиночные вариабельные домены, содержащие последовательности CDR по изобретению, особенно подходят для применения в качестве структурного элемента или связывающего звена для получения мультивалентных или мультиспецифичных полипептидов.
Соответственно, моноспецифичные полипептиды по изобретению, которые связывают CD123, могут быть по существу в выделенной форме (как определено в данном документе), или они могут образовывать часть белка или полипептида, который может включать или, по существу, состоять из одного или нескольких ISV, которые связывают CD123, и которые необязательно может дополнительно содержать одну или несколько дополнительных аминокислотных последовательностей (все необязательно связаны через один или несколько подходящих линкеров).
Соответственно, настоящее изобретение также относится к белку или полипептиду, который включает или по существу состоит из одного или нескольких моноспецифических полипептидов по изобретению (или их подходящих фрагментов). В дополнительном аспекте моноспецифические полипептиды по изобретению, которые связывают CD123, могут образовывать часть мультиспецифического полипептида, который может включать или, по существу, состоять из одного или нескольких ISV, которые связывают CD123 и которые могут дополнительно содержать один ISV, который специфически связывает другую мишень, такую как, например, TCR, и который необязательно может дополнительно содержать одну или несколько дополнительных аминокислотных последовательностей (все необязательно связаны через один или несколько подходящих линкеров).
Моноспецифические полипептиды по изобретению, таким образом, используются в качестве связывающей единицы или структурного элемента в таком белке или полипептиде, чтобы обеспечить мультиспецифичный полипептид по изобретению, как описано в данном документе (для мультиспецифичных полипептидов, содержащих один или несколько доменов VHH, и их получение, настоящим также ссылаемся на Conrath et al. (2001, J. Biol. Chem. 276: 7346-7350), а также, например, в WO 96/34103, WO 99/23221 и WO 2010/115998).
2. Мультиспецифичные полипептиды
Изобретение также относится к мультиспецифическим полипептидам, содержащим или (по существу) состоящим из двух или более структурных элементов (таких как, по меньшей мере, два моноспецифических полипептида или ISV по изобретению), в которых, по меньшей мере, один структурный элемент направлен против первого антигена (т.е. CD123) и, по меньшей мере, один структурный элемент направлен против второго антигена (т.е. TCR). Эти мультиспецифичные полипептиды также упоминаются в настоящем описании как «мультиспецифичный(ие) полипептид(ы) по изобретению». Предпочтительными иммуноглобулиновыми одиночными вариабельными доменами для применения в этих мультиспецифичных полипептидах по изобретению являются моноспецифичные полипептиды по изобретению (как описано ранее).
Как описано далее в данном документе, дополнительные связывающие единицы, такие как иммуноглобулиновые одиночные вариабельные домены, имеющие различную антигенную специфичность (т.е. отличную от CD123 и TCR), могут быть связаны с мультиспецифичными полипептидами по изобретению. Комбинируя иммуноглобулиновые одиночные вариабельные домены с тремя или более специфичностями, можно получить триспецифические, тетраспецифичные и т.д. конструкции. Эти мультиспецифичные полипептиды также упоминаются в данном документе как «(мультиспецифичный) полипептид(ы) по изобретению» или «конструкция(ии) по изобретению».
Таким образом, например, «биспецифичный полипептид по изобретению» представляет собой полипептид, который содержит или (по существу) состоит, по меньшей мере, из иммуноглобулинового одиночного вариабельного домена против первого антигена (т.е. CD123) и, по меньшей мере, из одного дополнительного вариабельного домена иммуноглобулина против второго антигена (т.е. TCR), тогда как «триспецифичный полипептид по изобретению» представляет собой полипептид, который содержит или (по существу) состоит, по меньшей мере, из иммуноглобулинового одиночного вариабельного домена против первого антигена (т.е., CD123), по меньшей мере, одного дополнительного иммуноглобулинового одиночного вариабельного домена против второго антигена (т.е. TCR) и, по меньшей мере, одного дополнительного иммуноглобулинового одиночного вариабельного домена против третьего антигена (т.е. отличающегося от CD123 и TCR) и т.д. иммуноглобулиновые одиночные вариабельные домены необязательно могут быть связаны через один или больше пептидных линкеров, как дополнительно описано в данном документе.
Соответственно, настоящее изобретение относится к полипептидам, содержащим или (по существу) состоящим из иммуноглобулинового одиночного вариабельного домена, который специфически связывает TCR, и одного или нескольких ISV, которые специфически связывают CD123. В дополнительном аспекте настоящее изобретение также относится к полипептидам, содержащим или (по существу) состоящим из иммуноглобулинового одиночного вариабельного домена, который специфически связывает TCR, и двух или более ISV, которые специфически связывают CD123. Некоторые неограничивающие примеры таких мультиспецифичных полипептидов или их конструкций станут понятны из дальнейшего описания, приведенного в данном документе.
Понятно (как также продемонстрировано в разделе «Примеры»), что ISV, который специфически связывает TCR, и один или несколько ISV, которые специфически связывают CD123, могут быть расположены в любом порядке в полипептиде по изобретению. Более конкретно, в одном аспекте ISV, связывающий TCR, расположен на N-конце, а ISV, связывающий CD123, расположен на С-конце. В другом аспекте один или несколько ISV, связывающих CD123, расположены на N-конце, а ISV, связывающий TCR, расположены на C-конце. В другом аспекте один или несколько ISV, которые связывают CD123, расположены на N-конце, ISV, который связывает TCR, располагаются центрально, а один или несколько дополнительных ISV, которые связывают CD123, расположены на C-конце. В предпочтительном аспекте изобретение относится к полипептиду, где ISV, который специфически связывает TCR, расположен на N-конце полипептида.
В некоторых аспектах мультиспецифичные полипептиды по изобретению содержат два или более ISV, которые специфически связывают CD123. В одном аспекте два или более ISV, которые специфически связывают CD123, связываются с одним и тем же эпитопом на CD123. В одном аспекте такие мультиспецифичные полипептиды по изобретению могут содержать два или более ISV, относящихся к 56A10. В другом аспекте такие полипептиды по изобретению содержат два или более ISV, относящихся к 55F03.
В более предпочтительном аспекте два или более ISV, которые специфически связывают CD123, связываются с другим эпитопом. Соответственно, настоящее изобретение относится к мультиспецифичному полипептиду, в котором два или более ISV, которые специфически связывают CD123, являются бипаратопными, содержащими первый ISV и второй ISV, где первый ISV связывается с эпитопом на CD123, который отличается от эпитопа на CD123, связываемого вторым ISV.
Более конкретно, настоящее изобретение относится к мультиспецифичному полипептиду по изобретению, где первый ISV, который связывает CD123, выбран из ISV, относящихся к 56A10, и второй ISV, который связывает CD123, выбран из ISV, относящихся к 55F03. Как обсуждалось ранее, эти бипаратопные полипептиды по изобретению обладают улучшенной аффинностью связывания с CD123 по сравнению с моноспецифичными полипептидами по изобретению благодаря активному связыванию, также называемому авидностью.
Понятно (как также продемонстрировано в разделе «Примеры»), что ISV, которые связывают CD123, могут быть расположены в любом порядке в мультиспецифическом полипептиде по изобретению. Более конкретно, в одном аспекте второй ISV (т.е. ISV, относящийся к 55F03) расположен на N-конце первого ISV (т.е. ISV, относящегося к 56A10). В другом аспекте второй ISV (т.е. ISV, относящийся к 55F03) расположен на С-конце первого ISV (т.е. ISV, относящегося к 56A10). Некоторые неограничивающие примеры таких мультиспецифичных конструкций станут понятными из дальнейшего описания, приведенного в данном документе.
Как правило, мультиспецифичные полипептиды по изобретению сочетают в себе высокую аффинность и высокую специфичность распознавания антигена на клетке-мишени с активацией Т-клеток, что приводит к активации, которая не зависит от природной специфичности Т-клеток.
«Клетка-мишень», при упоминании в данном документе, представляет собой клетку, которая представляет конкретный антиген (т.е. CD123) на своей поверхности. В одном аспекте «клетка-мишень» представляет собой клетку, которая характеризуется сверхэкспрессией CD123. В предпочтительном аспекте такая клетка-мишень связана с заболеванием, связанным с CD123. В еще более предпочтительном аспекте клетка-мишень представляет собой злокачественную опухолевую клетку, которая (сверх) экспрессирует CD123. Термин «злокачественное новообразование» относится к патологическому состоянию у млекопитающих, которое обычно характеризуется нарушенной клеточной пролиферацией или выживанием.
«Активация Т-клеток» в контексте настоящего описания относится к одному или нескольким клеточным ответам Т-клеток, например, цитотоксических Т-клеток, таких как выбранные из: пролиферации, дифференцировки, секреции цитокинов, высвобождения цитотоксичной эффекторной молекулы, цитотоксичной активности, экспрессии маркеров активации и перенаправленного лизиса клеток-мишеней. Используемый в данном документе термин «клеточный(ые) ответ(ы)» относится к ответу клетки в результате внутриклеточной передачи сигналов при сборке комплекса TCR.
Способ действия полипептидов, которые связываются как с молекулой клеточной поверхности (такой как, например, CD123) на клетке-мишени, так и с TCR T-клетки, общеизвестен. Приведение Т-клетки в непосредственную близость к целевой клетке (такой как, например, клетка, экспрессирующая CD123), т.е. вовлечение указанной Т-клетки и кластеризацию комплекса TCR, приводит к активации Т-клетки и последующему уничтожению клетки-мишени Т-клеткой. В настоящем изобретении этот процесс используется для борьбы с заболеванием, связанным с CD123, таким как пролиферативное заболевание или воспалительное состояние. Как правило, Т-клетки снабжены гранулами, содержащими смертельную комбинацию порообразующих белков, называемых перфоринами, и протеаз, вызывающих гибель клеток, называемых гранзимами. Предпочтительно, эти белки доставляются в клетки-мишени (такие как, например, клетки, экспрессирующие CD123) через цитолитический синапс, который образуется, если Т-клетки находятся в непосредственной близости от клетки-мишени, которая предназначена для уничтожения. Обычно близкое соседство между Т-клеткой и клеткой-мишенью достигается путем связывания Т-клетки с комплексом МНС/пептид с использованием соответствующего рецептора Т-клетки. Полипептиды по настоящему изобретению переносят Т-клетку в непосредственную близость к клетке-мишени в отсутствие взаимодействия Т-клеточный рецептор/МНС.
Соответственно, настоящее изобретение относится к мультиспецифичному полипептиду, описанному в данном документе, где указанный полипептид направляет Т-клетку к клетке-мишени. Соответственно, полипептид(ы) по настоящему изобретению «перенаправляет(ют) Т-клетки для уничтожения клеток, экспрессирующих CD123», что означает, что полипептид(ы) по настоящему изобретению приводит(ят) Т-клетку в такую непосредственную близость к клетке, экспрессирующей CD123, что она уничтожается.
Одним плечом (ISV, который связывает TCR) мультиспецифичный полипептид по изобретению связывается с константным доменом субъединицы TCR, белковой составляющей сигнально-трансдуцирующего комплекса Т-клеточного рецептора на Т-клетках. Другим плечом (один или несколько ISV, которые связывают CD123), мультиспецифичный полипептид связывается с CD123 на клетках-мишенях. Предпочтительно, активация Т-клеток наблюдается только тогда, когда мультиспецифичные полипептиды представлены Т-клеткам в (сайте) CD123-экспрессирующих клеток. Зависимость антигена от клеток-мишеней (т.е. клеток, экспрессирующих CD123) для активации приводит к благоприятному профилю безопасности. Мультиспецифичные полипептиды по изобретению проявляют высокоспецифичное связывание с CD123. Как такового, нецелевого связывания избегают, и мишень-независимая Т-клеточная активация минимальна, как проиллюстрировано в данном документе. В одном аспекте мультиспецифичные полипептиды временно связывают T-клетки и клетки-мишени. Предпочтительно, мультиспецифичный полипептид может индуцировать активацию покоящихся поликлональных Т-клеток, таких как CD4+ и/или CD8+ Т-клеток, для высокоэффективного перенаправленного лизиса клеток-мишеней (т.е. клеток, экспрессирующих CD123). Предпочтительно, Т-клетка направляется к следующей клетке-мишень после лизиса первой клетки-мишени.
В одном аспекте настоящее изобретение относится к мультиспецифичному полипептиду, как описано в данном документе, где указанный мультиспецифичный полипептид индуцирует активацию Т-клеток.
В дополнительном аспекте настоящее изобретение относится к мультиспецифичному полипептиду, где указанная активация Т-клеток не зависит от распознавания MHC.
«Активация Т-клеток, независимая от распознавания MHC» в контексте настоящего описания относится к активации T-клеток, которая не зависит от связывания комплекса MHC/пептид на клетке-мишени с соответствующим ей рецептором Т-клеток на Т-клетке. Если Т-клетка находится в непосредственной близости от клетки-мишени, клетка-мишень будет убита. Обычно близкое соседство между Т-клеткой и клеткой-мишенью достигается путем связывания Т-клетки с комплексом МНС/пептидом с использованием соответствующего Т-клеточного рецептора. Мультиспецифичные полипептиды по настоящему изобретению переносят Т-клетку в непосредственную близость к клетке-мишени в отсутствие взаимодействия Т-клеточный рецептор/МНС. Мультиспецифичные полипептиды связываются с CD123 на клетке-мишени и, как таковые, презентируются и связываются с Т-клетками, что приводит к активации Т-клеток и уничтожению клетки-мишени.
Соответственно, в дополнительном аспекте настоящее изобретение относится к мультиспецифичному полипептиду, где указанная активация Т-клеток зависит от презентации указанного полипептида, связанного с CD123 на клетке-мишени, Т-клетке.
В дополнительном аспекте настоящее изобретение относится к мультиспецифичному полипептиду, где указанная активация Т-клеток вызывает один или несколько клеточных ответов указанными Т-клетками, причем указанный клеточный ответ выбран из группы, состоящей из пролиферации, дифференцировки, секреции цитокинов, высвобождение молекулы цитотоксического эффектора, цитотоксичной активности, экспрессии маркеров активации и перенаправленного лизиса клеток-мишеней.
Подходящие анализы для измерения активации Т-клеток известны в данной области, например, как описано в WO 99/54440 или Schlereth et al. (2005, Cancer Immunol. Immunother. 20: 1-12) или как показано в примерах или ниже.
Без ограничения указанным, активация Т-клеток полипептидами по изобретению может быть измерена путем мониторинга повышенной регуляции CD69, CD25 и различных молекул клеточной адгезии, экспрессии de novo и/или высвобождения цитокинов (например, IFN-γ, TNF-α, IL -6, IL-2, IL-4 и IL-10), усиление экспрессии гранзима и перфорина и/или пролиферация клеток, мембранный блебинг, активация прокаспаз 3 и/или 7, фрагментация ядерной ДНК и/или расщепление каспазного субстрата, поли (АДФ-рибоза) полимеразы. Предпочтительно, перенаправленный лизис клеток-мишеней мультиспецифичными полипептидами не зависит от специфичности Т-клеточного рецептора, наличия МНС класса I и/или β2 микроглобулина и/или любых костимулирующих стимулов.
Полипептиды по изобретению демонстрируют перенаправленный лизис in vitro с ранее нестимулированными (т.е. не активированными) периферическими поликлональными CD8+ - и CD4+-положительными Т-клетками, как дополнительно поясняется в данном документе. Перенаправленный лизис клеток-мишеней посредством рекрутирования Т-клеток полипептидами по изобретению включает образование цитолитического синапса и доставку перфорина и гранзимов. Клеточный лизис Т-клетками был описан, например, Atkinson and Bleackley (1995, Crit. Rev. Immunol 15(3-4): 359-384). Предпочтительно полипептид по настоящему изобретению обеспечивает уничтожение клеток-мишеней, например, злокачественных опухолевых клеток, путем стимуляции Т-клеток при образовании пор и доставки проапоптотических компонентов гранул цитотоксических Т-клеток. Предпочтительно вовлеченные Т-клетки способны к последовательному лизису клеток-мишеней. In vitro с полипептидами по изобретению перенаправленный лизис наблюдается при низких пикомолярных концентрациях, что позволяет предположить, что очень низкие количества полипептидов по изобретению должны быть связаны с клетками-мишенями для запуска Т-клеток. Как показано в примерах, низкое отношение эффекторных клеток-мишеней может указывать на последовательный лизис клеток-мишеней и демонстрирует высокую активность полипептидов по изобретению.
Используемый в данном документе термин «активность» представляет собой меру биологической активности агента, такого как моноспецифичный или мультиспецифичный полипептид, ISV или нанотело. Специфическая активность является функцией количества полипептида по изобретению, необходимого для его специфического эффекта. Она измеряется просто как обратная величина IC50 для этого полипептида. Что касается мультиспецифичных полипептидов по изобретению, то это относится к способности указанного полипептида по изобретению индуцировать активацию Т-клеток. Эффективность агента может быть определена любым подходящим способом, известным в данной области, таким как, например, как описано в экспериментальном разделе. Анализы активности на основе клеточной культуры часто являются предпочтительным форматом для определения биологической активности, поскольку они измеряют физиологический ответ, вызванный агентом, и могут давать результаты в течение относительно короткого периода времени. Могут быть использованы различные типы клеточных анализов, основанных на механизме действия продукта, включая, помимо прочего, анализы на пролиферацию, анализы на цитотоксичность, анализы уничтожения клеток, анализы репортерных генов, анализы связывания рецепторов на клеточной поверхности и анализы для измерения индукции/ингибирования функционально важных белков или других сигнальных молекул (таких как фосфорилированные белки, ферменты, цитокины, цАМФ и тому подобное), анализ уничтожения опухолевых клеток, опосредованного Т-клетками (например, как изложено в разделе «Примеры»), все хорошо известны в данной области. Результаты анализа эффективности на основе клеток могут быть выражены как «относительная активность», как определено путем сравнения мультиспецифического полипептида по изобретению с ответом, полученным для соответствующего эталонного моновалентного ISV, например, полипептида, содержащего только один ISV или одно нанотело, необязательно дополнительно содержащий нерелевантное нанотело (см. экспериментальный раздел).
«Эффективность» полипептида согласно изобретению измеряет максимальную силу самого эффекта, при насыщающих концентрациях полипептида. Эффективность указывает на максимальный ответ, достигаемый из полипептида по изобретению. Она относится к способности полипептида производить искомый (терапевтический) эффект.
В одном аспекте мультиспецифичный полипептид по изобретению активирует Т-клетки, что приводит к уничтожению клеток, экспрессирующих CD123 (таких как клетки MOLM-13 или KG1a) со средним значением EC50 между 10 нМ и 1 пМ, как определено в анализе на основе проточной цитометрии (см. также пример 25).
Более конкретно, полипептид по настоящему изобретению индуцирует активацию Т-клеток, где указанная активация Т-клеток вызывает гибель экспрессирующих CD123 клеток (таких как клетки MOLM-13) со средним значением ЕС50 от 1 нМ до 1 пМ, например, среднее значение ЕС50 составляет 500 пМ или менее, например, менее 400, 300, 200 или 100 пМ или даже менее, например, менее 90, 80, 70, 60, 50, 40 или 30 пМ или даже менее, указанное значение ЕС50 для примера определено в анализе на основе проточной цитометрии по данным с TOPRO3 с использованием клеток MOLM-13 в качестве клеток-мишеней и Т-клеток человека в качестве эффекторных клеток при соотношении эффекторных клеток и клеток-мишеней 10:1.
Более конкретно, полипептид по изобретению индуцирует активацию Т-клеток, где указанная активация Т-клеток вызывает лизис клеток, экспрессирующих CD123 (таких как клетки MOLM-13), со средним процентом лизиса более чем около 10%, таким как 15%, 16%, 17%, 18%, 19% или 20% или даже более, например, более 25% или даже более 30%, указанный процент лизиса, например, определяется в анализе на основе проточной цитометрии по данным с TOPRO3 с использованием MOLM -13 клеток в качестве клеток-мишеней и человеческих Т-клеток в качестве эффекторных клеток при соотношении эффекторных клеток и клеток-мишеней 10:1.
Более конкретно, полипептид по настоящему изобретению индуцирует активацию Т-клеток, где указанная активация Т-клеток вызывает гибель экспрессирующих CD123 клеток (таких как клетки KG1a) со средним значением ЕС50 от 10 нМ до 10 пМ, например, при среднем значении ЕС50. 5 нМ или менее, например, менее 4, 3, 2 или 1 нМ или даже менее, например, менее 90, 80, 70 или 60 пМ или даже менее, указанное значение EC50, например, определено в анализе на основе проточной цитометрии по данным с TOPRO3 с использованием клеток KG1a в качестве клеток-мишеней и T-клеток человека в качестве эффекторных клеток при соотношении эффекторных клеток и клеток-мишеней 10:1.
Более конкретно, полипептид по изобретению индуцирует активацию Т-клеток, где указанная активация Т-клеток вызывает лизис клеток, экспрессирующих CD123 (таких как клетки KG1a), со средним процентом лизиса более чем около 10%, таким как 15%, 16%, 17% или 18% или даже больше, например, более 24%, указанный процент лизиса, например, определяется в анализе на основе проточной цитометрии по данным с TOPRO3 с использованием клеток KG1a в качестве клеток-мишеней и человеческих Т-клеток в качестве эффекторных клеток при соотношении эффекторных клеток и клеток-мишеней 10:1.
В другом аспекте мультиспецифичные полипептиды по изобретению активируют Т-клетки и могут как таковые индуцировать секрецию цитокинов. Соответственно, полипептиды вызывают секрецию IFN-γ или IL-6 со средним значением EC50 от 100 нМ до 10 пМ. (см. также пример 30).
Более конкретно, полипептид по настоящему изобретению индуцирует активацию Т-клеток, где указанная активация Т-клеток вызывает секрецию IFN-γ со средним значением ЕС50 от 100 нМ до 10 пМ, например, со средним значением ЕС50 50 нМ или менее, например, менее 40, 30, 20, 10 или 9 нМ или даже менее, например, менее 8, 7, 6, 5, 4, 3, 2 или 1 нМ или даже менее, например, менее 500 пМ или даже менее например, менее 400, 300, 200 или 100 пМ или даже менее, указанное значение EC50, например, определено в анализе на основе ELISA, как, например, дополнительно объяснено в примере 30.
Более конкретно, полипептид по настоящему изобретению индуцирует активацию Т-клеток, где указанная активация Т-клеток вызывает секрецию IL-6 со средним значением ЕС50 от 100 нМ до 10 пМ, например, при среднем значении ЕС50 50 нМ или менее, например, менее 40, 30, 20 или 10 нМ или даже менее, например, менее 9, 8, 7, 6, 5, 4, 3, 2 или 1 нМ или даже менее, например, менее 500 пМ или даже менее, например, менее 400, 300, 200 или 100 пМ или даже менее, указанное значение EC50, например, определяют в анализе на основе ELISA, как, например, дополнительно объяснено в примере 30.
В другом аспекте мультиспецифичные полипептиды по изобретению вызывают истощение плазмоцитоидных клеток (pDC) и базофилов (см. также пример 31).
Соответственно, настоящее изобретение относится к полипептиду, где указанная активация Т-клеток вызывает истощение плазмоцитоидных клеток (pDC) и базофилов.
В другом аспекте мультиспецифичные полипептиды по изобретению могут дополнительно вызывать пролиферацию Т-клеток (см. также пример 39).
Соответственно, настоящее изобретение относится к полипептиду, где указанная активация Т-клеток вызывает пролиферацию указанных Т-клеток.
Мультиспецифичные полипептиды по изобретению содержат один или несколько ISV, которые специфически связывают CD123, которые были тщательно отобраны по их специфичности. Как таковые, мультиспецифичные полипептиды по изобретению демонстрируют высокоспецифичное связывание с CD123, что позволяет им убивать CD123-экспрессирующие клетки-мишени. Напротив, в отсутствие клеток, экспрессирующих CD123, наблюдалось только минимальное уничтожение, что подчеркивает безопасность полипептидов по изобретению.
Соответственно, в другом аспекте настоящее изобретение относится к полипептиду, в котором активация Т-клеток в отсутствие CD123-положительных клеток минимальна (см. также примеры с 36 по 38).
Более конкретно, настоящее изобретение относится к полипептиду, в котором индуцированный активацией Т-клеток лизис CD123-отрицательных клеток составляет не более примерно 10%, например, 9% или менее, например, 8, 7 или 6% или даже менее, указанный лизис, например, определяется как средний процент лизиса в анализе на основе проточной цитометрии по данным с TOPRO3 с использованием CD123-отрицательных клеток, таких как клетки U-937 или NCI-H929, в качестве клеток-мишеней и Т-клеток человека в качестве эффекторных клеток при соотношении эффекторных клеток и клеток-мишеней 10:1.
Более конкретно, настоящее изобретение относится к полипептиду, который не индуцирует секрецию IFN-γ и IL-6 в присутствии CD123-отрицательных клеток, причем указанную секрецию определяют, например, в анализе на основе ELISA.
Авторы изобретения обнаружили, что некоторые мультиспецифичные полипептиды по изобретению, содержащие TCR-связывающий ISV по изобретению и один или несколько CD123-связывающих ISV по изобретению, были особенно пригодны для перенаправления Т-клеток для уничтожения CD123-экспрессирующих клеток. С этими мультиспецифичными полипептидами по изобретению активация Т-клеток была минимальной в отсутствие клеток, экспрессирующих CD123.
Соответственно, настоящее изобретение относится к мультиспецифичному полипептиду, который перенаправляет Т-клетки для уничтожения CD123-экспрессирующих клеток, включающему иммуноглобулиновый одиночный вариабельный домен (ISV), который специфически связывает Т-клеточный рецептор (TCR), и один или несколько ISV, которые специфически связывают CD123, где ISV, который специфически связывает TCR, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181-191; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 181-191; при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192-217; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 192-217; при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218-225; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 218-225; при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и где один или несколько ISV, которые специфически связывают CD123, по существу состоят из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16; при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20; при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и/или
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25; при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В дополнительном аспекте настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181-191; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 181-191; при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192-217; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 192-217; при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218-225; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 218-225; при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16; при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20; при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25; при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В конкретном аспекте настоящее изобретение относится к мультиспецифичному полипептиду, в котором ISV, который специфически связывает TCR, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181-191; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 181-191, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 2, 4, 5, 6, 8 и/или 10 CDR1 (положения 27, 29, 30, 31, 33 и/или 35 согласно нумерации Kabat); при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192-217; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 192-217, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 1, 3, 5, 7, 8 и/или 9 CDR2 (положения 50, 52, 54, 56, 57 и/или 58 согласно нумерации Kabat); при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218-225; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 218-225, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 1, 4, 5 и/или 8 CDR3 (положения 95, 98, 99 и/или 101 согласно нумерации Kabat); при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и где ISV, который специфически связывает CD123, является таким, как описано далее в данном документе.
В другом аспекте настоящее изобретение относится к мультиспецифичному полипептиду, как описано выше, где ISV, который специфически связывает TCR, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в какой CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 181, где
- в положении 2 D была изменена на A, S, E или G;
- в положении 4 H была изменена на Y;
- в положении 5 K была изменена на L;
- в положении 6 I была изменена на L;
- в положении 8 F была изменена на I или V; и/или
- в положении 10 G была изменена на S;
при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к мультиспецифичному полипептиду, как описано выше, где ISV, который специфически связывает TCR, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в котором CDR2 выбрана из группы, состоящей из:
а) SEQ ID NO: 192; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 192, где
- в положении 1 H была изменена на T или R;
- в положении 3 S была изменена на T или A;
- в положении 5 G была изменена на S или A;
- в положении 7 Q была изменена на D, E, T, A или V;
- в положении 8 Т была изменена на А или V; и/или
- в положении 9 D была изменена на A, Q, N, V или S;
при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к мультиспецифичному полипептиду, как описано выше, где ISV, который специфически связывает TCR, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в котором CDR3 выбрана из группы, состоящей из:
а) SEQ ID NO: 218; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 218, где
- в положении 1 F была изменена на Y, L или G;
- в положении 4 I была изменена на L;
- в положении 5 Y была изменена на W; и/или
- в положении 8 D была изменена на N или S;
при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Соответственно, настоящее изобретение относится к мультиспецифичному полипептиду, как описано выше, где ISV, который специфически связывает TCR, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 181, где
- в положении 2 D была изменена на A, S, E или G;
- в положении 4 H была изменена на Y;
- в положении 5 K была изменена на L;
- в положении 6 I была изменена на L;
- в положении 8 F была изменена на I или V; и/или
- в положении 10 G была изменена на S;
при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 192, где
- в положении 1 H была изменена на T или R;
- в положении 3 S была изменена на T или A;
- в положении 5 G была изменена на S или A;
- в положении 7 Q была изменена на D, E, T, A или V;
- в положении 8 Т была изменена на А или V; и/или
- в положении 9 D была изменена на A, Q, N, V или S;
при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 218, где
- в положении 1 F была изменена на Y, L или G;
- в положении 4 I была изменена на L;
- в положении 5 Y была изменена на W; и/или
- в положении 8 D была изменена на N или S;
при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и где ISV, который специфически связывает CD123, является таким, как описано далее в данном документе.
В другом аспекте настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых CDR1 представляет собой выбранный из группы, состоящей из SEQ ID NO: 181-191, CDR2 выбрана из группы, состоящей из SEQ ID NO: 192-217, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 218-225 и в которой ISV который специфически связывает CD123, как описано далее в данном документе.
Соответственно, настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых CDR1 представляет собой SEQ ID NO: 181, CDR2 представляет собой SEQ ID NO: 192 и CDR3 представляет собой SEQ ID NO: 218, и где ISV, который специфически связывает CD123, является таким, как описано далее в данном документе.
В предпочтительном аспекте настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, выбран из группы, состоящей из SEQ ID NO: 42 и 78-180, или из ISV, которые имеют идентичность последовательностей более 80%. более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 42 и 78-180 и где ISV, который специфически связывает CD123, является таким, как описано далее в данном документе.
Помимо ISV, связывающего TCR, как описано выше, в мультиспецифичных полипептидах по изобретению один или несколько ISV, которые специфически связывают CD123, относятся к 56A10 и/или 55F03.
Соответственно, настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123, по существу состоят из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в котором:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11-16; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11-16, где различие в 4, 3, 2 или 1 аминокислоту присутствует в положениях 3, 6, 7 и/или 8 CDR1 (положения 28, 31, 32 и/или 33 согласно нумерации Kabat); при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 17-20; или
d) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 17-20, где различие в 3, 2 или 1 аминокислоту присутствует в положениях 3 6 и/или 10 CDR2 (положения 52, 54 и/или 58 согласно нумерации Kabat); при условии, что ISV, включающий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21-25; или
f) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 21-25, где различие в 3, 2 или 1 аминокислоту присутствует в положениях 3, 4 и/или 5 CDR3 (положения 97, 98 и/или 99 согласно нумерации Kabat); при условии, что ISV, включающий CDR3 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR3 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В одном аспекте один или более ISV, который специфически связывает CD123, может быть ISV, относящимся к 56A10.
Соответственно, настоящее изобретение относится к мультиспецифичному полипептиду, как описано выше, где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), где CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 11, где
- в положении 3 Т была изменена на S или P;
- в положении 6 I была изменена на S;
- в положении 7 N была изменена на D; и/или
- в положении 8 D была изменена на V или A;
при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к мультиспецифичному полипептиду, как описано выше, где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), где CDR2 представляет собой SEQ ID NO: 17.
В другом аспекте настоящее изобретение относится к мультиспецифичному полипептиду, как описано выше, где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), где CDR3 выбрана из группы, состоящей из:
а) SEQ ID NO: 21; или
b) аминокислотных последовательностей с различием в 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 21, где
- в положении 3 P была изменена на A;
при условии, что ISV, включающий CDR3 с разницей в 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR3 без различия в 1 аминокислоту, причем указанная аффинность измеряется с помощью поверхностного плазмонного резонанса.
Соответственно, настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в котором:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 11, где
- в положении 3 Т была изменена на S или P;
- в положении 6 I была изменена на S;
- в положении 7 N была изменена на D; и/или
- в положении 8 D была изменена на V или A;
при условии, что полипептид, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 является SEQ ID NO: 17;
и
iii) CDR3 выбрана из группы, состоящей из:
с) SEQ ID NO: 21; или
d) аминокислотных последовательностей с различием в 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 21, где
- в положении 3 P была изменена на A;
при условии, что полипептид, содержащий CDR3 с различием в 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 комплементарности. определяющие регионы (CDR1-CDR3, соответственно), в которых CDR1 выбрана из группы, состоящей из SEQ ID NO: 11-15, CDR2 представляет собой SEQ ID NO: 17, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 21 -22.
Соответственно, настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), где CDR1 представляет собой SEQ ID NO: 11, CDR2 представляет собой SEQ ID NO: 17 и CDR3 представляет собой SEQ ID NO: 21.
В предпочтительном аспекте настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123, выбирают из группы, состоящей из SEQ ID NO: 1-6 или из ISV, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 1-6.
Помимо вышеизложенного или в дополнение, ISV, который специфически связывает CD123, может быть ISV, относящимся к 55F03.
Соответственно, настоящее изобретение также относится к мультиспецифичному полипептиду, как описано выше, где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), где CDR1 представляет собой SEQ ID NO: 16.
В другом аспекте настоящее изобретение относится к мультиспецифичному полипептиду, как описано выше, где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), где CDR2 выбрана из группы, состоящей из:
а) SEQ ID NO: 18; или
b) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 18, где
- в положении 3 Y была изменена на W;
- в положении 6 N была изменена на S; и/или
- в положении 10 Q была изменена на E;
при условии, что ISV, включающий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к мультиспецифичному полипептиду, как описано выше, где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), где CDR3 выбрана из группы, состоящей из:
а) SEQ ID NO: 23; или
b) аминокислотных последовательностей с различием в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 23, где
- в положении 4 E была изменена на R; и/или
- в положении 5 Т была изменена на D или Y;
при условии, что ISV, включающий CDR3 с различием в 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR3 без различия в 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
Соответственно, настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в котором:
i) CDR1 является SEQ ID NO: 16;
и
ii) CDR2 выбрана из группы, состоящей из:
а) SEQ ID NO: 18; или
b) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 18, где
- в положении 3 Y была изменена на W;
- в положении 6 N была изменена на S; и/или
- в положении 10 Q была изменена на E;
при условии, что полипептид, содержащий CDR2 с различием в 3, 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
с) SEQ ID NO: 23; или
d) аминокислотных последовательностей с различием в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 23, где
- в положении 4 E была изменена на R; и/или
- в положении 5 Т была изменена на D или Y;
при условии, что полипептид, содержащий CDR3 с различием в 2 или 1 аминокислоту, связывает CD123 с примерно одинаковой или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR3 без различия в 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
В другом аспекте настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 комплементарности определяющие регионы (CDR1-CDR3, соответственно), в которых CDR1 представляет собой SEQ ID NO: 16, CDR2 выбрана из группы, состоящей из SEQ ID NO: 18-20, и CDR3 выбрана из группы, состоящей из SEQ ID NO: 23 -25.
Соответственно, настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), где CDR1 является SEQ ID NO: 16, CDR2 является SEQ ID NO: 18 и CDR3 является SEQ ID NO: 23.
В предпочтительном аспекте настоящее изобретение относится к мультиспецифичному полипептиду, где ISV, который специфически связывает TCR, является таким, как описано в данном документе, и где один или несколько ISV, которые специфически связывают CD123, выбирают из группы, состоящей из SEQ ID NO: 7-10 или из ISV, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 7-10.
Как подробно описано для моноспецифических полипептидов, иммуноглобулиновые одиночные вариабельные домены, присутствующие в мультиспецифическом полипептиде по изобретению, могут состоять из последовательности вариабельного домена легкой цепи (например, последовательности VL) или последовательности вариабельного домена тяжелой цепи (например, последовательности VH); они могут состоять из последовательности вариабельного домена тяжелой цепи, которая получена из обычного четырехцепочечного антитела, или из последовательности вариабельного домена тяжелой цепи, которая получена из антитела на основе только тяжелой цепи. В предпочтительном аспекте они состоят из доменного антитела (или аминокислоты, которая подходит для применения в качестве доменного антитела), однодоменного антитела (или аминокислоты, которая подходит для применения в качестве однодоменного антитела), «dAb» (или аминокислоты, которая подходит для применения в качестве dAb), нанотела (включая, без ограничения указанным, VHH), гуманизированного VHH, оверблюженного VH или последовательности VHH, полученной созреванием аффинности. Иммуноглобулиновые одиночные вариабельные домены могут состоять из частично или полностью гуманизированного нанотела или частично или полностью гуманизированного VHH. Иммуноглобулиновые одиночные вариабельные домены также могут содержать мутации (как описано в данном документе), которые эффективны для предотвращения или уменьшения связывания так называемых «ранее существовавших антител» с иммуноглобулиновыми одиночными вариабельными доменами и конструкциями по изобретению. В предпочтительном аспекте изобретения иммуноглобулиновые одиночные вариабельные домены, включенные в мультиспецифичный полипептид по изобретению, представляют собой один или несколько моноспецифических полипептидов по изобретению, как определено в данном документе.
Предпочтительные полипептиды по изобретению могут быть выбраны из группы, состоящей из SEQ ID NO: 47, 49, 52, 53, 55, 56 и 58-61 (см. также таблицу A-7). В дополнительном аспекте полипептид выбран из группы, состоящей из SEQ ID NO: 47, 49, 52, 53, 55, 56 и 58-61, или из полипептидов, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 47, 49, 52, 53, 55, 56 и 58-61.
Мультиспецифичные полипептиды по изобретению могут содержать одну или несколько других групп, остатков, фрагментов или связывающих единиц, чтобы образовать «полипептид(ы) по изобретению» или «конструкцию(ии) по изобретению», как дополнительно описано в данном документе. Например, такой связывающей единицей может быть аминокислотная последовательность, которая увеличивает период полувыведения (также называемый в данном документе «удлинением периода полувыведения» и «конструкцией с удлиненным периодом полувыведения») полипептида. В соответствии с конкретным, но не ограничивающим аспектом изобретения, полипептиды по изобретению, таким образом, могут включать, кроме одного или нескольких иммуноглобулиновых одиночных вариабельных доменов против CD123 и одного иммуноглобулинового одиночного вариабельного домена против TCR, по меньшей мере, один иммуноглобулиновый одиночный вариабельный домен против сывороточного альбумина (такого как человеческий сывороточный альбумин). Соответственно, настоящее изобретение относится к конструкции, описанной в данном документе, где указанная связывающая единица, которая обеспечивает полипептиду увеличенный период полувыведения, представляет собой иммуноглобулиновый одиночный вариабельный домен, который связывает сывороточный альбумин. В дополнительном аспекте настоящее изобретение относится к конструкции, описанной в данном документе, где указанный ISV, который связывает сывороточный альбумин, по существу состоит из однодоменного антитела, dAb, нанотела, VHH, гуманизированного VHH или оверблюженного VH.
В предпочтительном аспекте ISV, который связывает сывороточный альбумин, выбран из группы, состоящей из SEQ ID NO 43 или 351-362.
В предпочтительном аспекте ISV напрямую связаны друг с другом или связаны друг с другом через линкер.
Предпочтительные конструкции по изобретению могут быть выбраны из группы конструкций, состоящей из SEQ ID NO: 63-67, или конструкций, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95%, или даже более 99% с одной из SEQ ID NO: 63-67.
В предпочтительном аспекте конструкция выбрана из группы, состоящей из SEQ ID NO: 63-67.
После их введения конструкции с увеличенным периодом полувыведения по изобретению не удаляются мгновенно почечным клиренсом. Таким образом, продление периода полувыведения будет способствовать благоприятному профилю PK. Соответственно, не будет необходимости в непрерывной внутривенной инфузии, и, следовательно, соблюдение пациентом режима и схемы лечения будет улучшено. В конкретном аспекте конструкции по настоящему изобретению не требуют непрерывной инфузии.
Также, как подробно описано для моноспецифических полипептидов, мультиспецифические полипептиды по изобретению или конструкции по изобретению могут дополнительно содержать мутации, которые эффективны в предотвращении или уменьшении связывания так называемых «ранее существующих антител» с полипептидами и конструкциями по изобретению. Для этой цели полипептиды и конструкции по изобретению могут содержать C-концевое удлинение (X)n (в котором n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например, 1), и каждый X представляет собой (предпочтительно встречающийся в природе) аминокислотный остаток, который независимо выбран и предпочтительно независимо выбран из группы, состоящей из аланина (A), глицина (G), валина (V) лейцина (L) или изолейцина (I)), как описано в данном документе.
Соответственно, настоящее изобретение относится к полипептиду или конструкции по изобретению, дополнительно включающей C-концевое удлинение (X)n, в котором n равно от 1 до 5, например, 1, 2, 3, 4 или 5, и в котором Х является природной аминокислотой, предпочтительно без цистеина.
Более конкретно, настоящее изобретение относится к полипептиду или конструкции, где указанный полипептид или конструкция выбран из группы, состоящей из SEQ ID NO: 338-342.
Способ получения мультивалентных или мультиспецифичных полипептидов по изобретению может включать, по меньшей мере, стадии связывания двух или более иммуноглобулиновых одиночных вариабельных доменов, одновалентных полипептидов и/или моноспецифических полипептидов по изобретению и, например, одного или нескольких линкеров вместе подходящим способом. Иммуноглобулиновые одиночные вариабельные домены, моновалентные полипептиды и/или моноспецифические полипептиды по изобретению (и линкеры) могут быть связаны любым способом, известным в данной области, и как дополнительно описано в данном документе. Предпочтительные способы включают связывание последовательностей нуклеиновых кислот, которые кодируют иммуноглобулиновые одиночные вариабельные домены, моновалентные полипептиды и/или моноспецифические полипептиды по изобретению (и линкеры), для получения генетической конструкции, которая экспрессирует мультивалентный или мультиспецифичный полипептид. Методы связывания аминокислот или нуклеиновых кислот будут понятны специалисту в данной области, и снова настоящим ссылаемся на стандартные руководства, такие как Sambrook et al. и Ausubel et al., упомянутые выше, а также примеры ниже.
Соответственно, настоящее изобретение также относится к применению иммуноглобулинового одиночного вариабельного домена, одновалентного полипептида и/или моноспецифического полипептида по изобретению при получении мультивалентного полипептида или мультиспецифического полипептида по изобретению. Способ получения мультивалентного или мультиспецифического полипептида будет включать связывание одного или нескольких иммуноглобулиновых одиночных вариабельных доменов и/или полипептидов по изобретению, по меньшей мере, с одним дополнительным иммуноглобулиновым одиночным вариабельным доменом, моновалентным полипептидом и/или моноспецифическим полипептидом по изобретению необязательно через один или несколько линкеров. Иммуноглобулиновый одиночный вариабельный домен, одновалентный полипептид и/или моноспецифичный полипептид по изобретению затем используют в качестве связывающего домена или связывающего звена при обеспечении и/или получении мультивалентного или мультиспецифического полипептида, включающего два (например, в двухвалентном полипептиде), три (например, в трехвалентном полипептиде) или более (например, в мультивалентном полипептиде) связывающих единиц. В этом отношении иммуноглобулиновый одиночный вариабельный домен, одновалентный полипептид и/или моноспецифичный полипептид по изобретению можно использовать в качестве связывающего домена или связывающей единицы при обеспечении и/или получении мультивалентного или мультиспецифического, такого как биспецифичный или триспецифичный полипептид, содержащего две, три или более связывающих единиц.
Соответственно, настоящее изобретение также относится к применению иммуноглобулинового одиночного вариабельного домена и/или, в частности, моновалентного или моноспецифического полипептида по изобретению (как описано в данном документе) при получении мультивалентного или мультиспецифического полипептида. Способ получения мультивалентного или мультиспецифического полипептида будет включать связывание иммуноглобулинового одиночного вариабельного домена, моновалентного полипептида и/или моноспецифического полипептида по изобретению, по меньшей мере, с одним дополнительным иммуноглобулиновым одиночным вариабельным доменом, моновалентным полипептидом и/или моноспецифическим полипептидом по изобретению, необязательно, через один или несколько линкеров (как дополнительно описано в данном документе).
Конструкции изобретения
Моноспецифичный полипептид по изобретению и мультиспецифичный полипептид по изобретению могут дополнительно содержать или не содержать одну или несколько других групп, остатков, фрагментов или связывающих единиц (эти моновалентные полипептиды, а также мультивалентные полипептиды (с или без дополнительных групп, остатков, фрагментов или связывающих единиц) все упоминаются как «конструкция(ии) изобретения»). В случае присутствия, такие дополнительные группы, остатки, фрагменты или связывающие единицы могут обеспечивать или не обеспечивать дополнительную функциональность для иммуноглобулинового одиночного вариабельного домена (и/или для полипептида, в котором он присутствует) и могут изменять или не изменять свойства иммуноглобулинового одиночного вариабельного домена.
Например, такие дополнительные группы, остатки, фрагменты или связывающие единицы могут представлять собой одну или несколько дополнительных аминокислотных последовательностей, так что полипептид представляет собой (слитый) белок или (слитый) полипептид. В предпочтительном, но не ограничивающем аспекте указанные одна или несколько других групп, остатков, фрагментов или связывающих единиц представляют собой иммуноглобулины. Еще более предпочтительно, если указанные одна или несколько других групп, остатков, фрагментов или связывающих единиц представляют собой иммуноглобулиновые одиночные вариабельные домены, выбранные из группы, состоящей из доменных антител, аминокислот, подходящих для применения в качестве доменных антител, однодоменных антител, аминокислот, подходящих для применения в качестве однодоменного антитела, «dAb», аминокислот, подходящих для применения в качестве dAb, или нанотела (такие как, например, VHH, гуманизированный VHH или оверблюженный VH).
Как описано выше, дополнительные связывающие единицы, такие как иммуноглобулиновые одиночные вариабельные домены, имеющие отличающуюся антигенную специфичность, могут быть связаны с образованием мультиспецифичных конструкций. Комбинируя иммуноглобулиновые одиночные вариабельные домены с двумя или более специфичностями, можно получить биспецифические, триспецифичные и т.д. конструкции. Например, полипептид по изобретению может содержать моноспецифичный или мультиспецифичный полипептид по изобретению и один или несколько иммуноглобулиновых одиночных вариабельных доменов против другой мишени (т.е. отличной от CD123 или TCR). Такие конструкции и их модификации, которые специалист в данной области может легко предвидеть, охватываются термином «конструкция изобретения», используемым в данном документе.
В конструкциях, описанных выше, один, два или более иммуноглобулинового одиночного вариабельного домена и одна или несколько групп, остатков, фрагментов или связывающих единиц могут быть связаны непосредственно друг с другом и/или через один или несколько подходящих линкеров или спейсеров. Например, когда одна или несколько групп, остатков, фрагментов или связывающих единиц представляют собой аминокислотные последовательности, линкеры также могут быть аминокислотными последовательностями, так что получающаяся конструкция представляет собой (белок) слияния или (полипептид) слияния.
Одна или несколько дополнительных групп, остатков, фрагментов или связывающих единиц могут представлять собой любые подходящие и/или искомые аминокислотные последовательности. Дополнительные аминокислотные последовательности могут изменять или не изменять, преобразовывать или иным образом влиять на (биологические) свойства полипептида по изобретению и могут добавлять или не добавлять дополнительную функциональность к полипептиду по изобретению. Предпочтительно дополнительная аминокислотная последовательность такова, что она придает одно или несколько искомых свойств или функциональных возможностей полипептиду по изобретению.
Пример таких аминокислотных последовательностей будет понятен для специалиста и может, как правило, включать все аминокислотные последовательности, которые используются в слитых пептидах на основе обычных антител и их фрагментов (включая, но без ограничения указанным, антитела ScFv и однодоменные антитела). Настоящим ссылаемся, например, на обзор Holliger and Hudson (2005, Nature Biotechnology 23: 1126-1136).
Например, такая аминокислотная последовательность может представлять собой аминокислотную последовательность, которая увеличивает период полувыведения, растворимость или абсорбцию, снижает иммуногенность или токсичность, устраняет или ослабляет нежелательные побочные эффекты и/или придает другие полезные свойства и/или снижает нежелательные свойства конструкции по изобретению по сравнению с полипептидом по изобретению как таковым. Некоторыми неограничивающими примерами таких аминокислотных последовательностей являются сывороточные белки, такие как человеческий сывороточный альбумин (см., например, WO 00/27435) или гаптеновые молекулы (например, гаптены, которые распознаются циркулирующими антителами, см., например, WO 98/22141).
В конкретном, но не ограничивающем аспекте изобретения, который будет дополнительно описан в данном документе, конструкция по изобретению может иметь увеличенный период полувыведения в сыворотке (как дополнительно описано в данном документе) по сравнению с иммуноглобулиновым одиночным вариабельным доменом или полипептидом, из которых они были получены. Например, единственный вариабельный домен или полипептид иммуноглобулина по изобретению может быть связан (химически или иным образом) с одной или несколькими группами или фрагментами, которые увеличивают период полувыведения (такими, как молекула полиэтиленгликоля (PEG)), чтобы обеспечить производное полипептида по изобретению увеличенным периодом полувыведения.
В одном конкретном аспекте изобретения получают конструкцию, которая имеет увеличенный период полувыведения по сравнению с соответствующим полипептидом по изобретению. Примеры конструкций по изобретению, которые содержат такие удлиняющие период полувыведения части, например, включают, без ограничения указанным, конструкции, в которых вариабельные домены одного иммуноглобулина подходящим образом связаны с одним или несколькими белками сыворотки или их фрагментами (такими как (человеческий) сывороточный альбумин или их подходящие фрагменты) или с одним или несколькими связывающими единицами (таким как, например, доменные антитела, аминокислоты, которые подходят для использования в качестве доменного антитела, однодоменные антитела, аминокислоты, которые подходят для использования в качестве однодоменного антитела, «DAb», аминокислоты, которые подходят для использования в качестве dAb, нанотела, VHH, гуманизированные VHH или оверблюженные VH), которые могут связываться с сывороточными белками (такими как сывороточный альбумин (такой как человеческий сывороточный альбумин)), сывороточными иммуноглобулинами (такими как IgG), трансферрином или одним из других сывороточных белков, перечисленных в WO 04/003019; полипептидами, в которых иммуноглобулиновый одиночный вариабельный домен связан с частью Fc (такой как человеческий Fc) или с подходящей частью или ее фрагментом; или конструкции, в которых один или несколько иммуноглобулиновых одиночных вариабельных доменов подходящим образом связаны с одним или несколькими небольшими белками или пептидами, которые могут связываться с белками сыворотки (такими как, без ограничения указанным, белки и пептиды, описанные в WO 91/01743, WO 01/45746 или WO 02/076489). Настоящим также ссылаемся на dAb, описанные в WO 03/002609 и WO 04/003019 и на Harmsen et al. (2005, Vaccine 23: 4926-4942); на ЕР 0368684, а также WO 08/028977, WO 08/043821, WO 08/043822, WO 08/068280, WO 09/127691 и WO 11/095545 от Ablynx NV.
Согласно конкретному, но не ограничивающему аспекту изобретения, конструкции изобретения могут содержать, кроме одного или нескольких иммуноглобулиновых одиночных вариабельных доменов против CD123 и/или иммуноглобулинового одиночного вариабельного домена против TCR, по меньшей мере, один иммуноглобулиновый одиночный вариабельный домен, который связывает сывороточный альбумин (такой как человеческий сывороточный альбумин). Соответственно, настоящее изобретение относится к конструкции, описанной в данном документе, где указанная связывающая единица, которая обеспечивает конструкцию с увеличенным периодом полувыведения, представляет собой иммуноглобулиновый одиночный вариабельный домен, который связывает сывороточный альбумин. В дополнительном аспекте настоящее изобретение относится к конструкции, описанной в данном документе, где указанный ISV, который связывает сывороточный альбумин, по существу состоит из однодоменного антитела, dAb, нанотела, VHH, гуманизированного VHH или оверблюженного VH.
ISV, который связывает сывороточный альбумин, может представлять собой любой ISV, как описано в данной области.
В одном аспекте иммуноглобулиновый одиночный вариабельный домен, который связывает человеческий сывороточный альбумин, может быть таким, как обычно описано в заявках Ablynx NV, процитированных выше (см., например, WO 04/062551). Некоторые предпочтительные нанотела, которые обеспечивают увеличенный период полувыведения и которые могут быть использованы в конструкциях по изобретению, включают нанотела ALB-1-ALB-10, раскрытые в WO 06/122787 (см. таблицы II и III), а также нанотела, раскрытые в WO 2012/175400 или WO 2015/173325 (например, SEQ ID NO: 1-11 в WO 2012/175400, SEQ ID NO: 19 в WO 2015/173325) и нанотела из предварительных заявок US 62/256 841, US 62/335 746, US 62/349 294 и соответствующей международной заявки WO 2017/085172 от Assignee, озаглавленной «Улучшенные агенты, связывающие сывороточный альбумин», которая ссылается на приоритет этих трех предварительных заявок США».
В одном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где указанный ISV, который связывает сывороточный альбумин, по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых CDR1 является GFTFSSFGMS (SEQ ID NO: 363) или GFTFRSFGMS (SEQ ID NO: 364), CDR2 является SISGSGSDTL (SEQ ID NO: 365) и CDR3 является GGSLSR (SEQ ID NO: 366).
Некоторые особенно предпочтительные нанотела, которые обеспечивают увеличенный период полувыведения и которые можно использовать в конструкциях по изобретению, включают иммуноглобулиновые одиночные вариабельные домены, также называемые Alb8, Alb23, Alb129, Alb132, Alb11, Alb11 (S112K) -A, Alb82, Alb82-A, Alb82-AA, Alb82-AAA, Alb82-G, Alb82-GG, Alb82-GGG (таблица B-2).
Соответственно, настоящее изобретение относится к конструкции, описанной в данном документе, где указанный ISV, который связывает сывороточный альбумин, выбран из группы, состоящей из SEQ ID NO 43 или 351-362.
Обычно конструкции по изобретению с увеличенным периодом полувыведения предпочтительно имеют период полувыведения, который составляет, по меньшей мере, в 1,5 раза, предпочтительно, по меньшей мере, в 2 раза, например, по меньшей мере, в 5 раз, например, по меньшей мере, в 10 раз или более, чем в 20 раз, больше, чем период полувыведения соответствующего иммуноглобулинового одиночного вариабельного домена или полипептида по изобретению per se.
Обычно конструкции по изобретению с увеличенным периодом полувыведения предпочтительно имеют период полувыведения, который увеличивается более чем на 1 час, предпочтительно более чем на 2 часа, более предпочтительно более чем на 6 часов, например, более чем на 12 часов или даже более чем через 24, 48 или 72 часа, по сравнению с периодом полувыведения соответствующего вариабельного домена или полипептида соответствующего иммуноглобулина по изобретению per se.
В другом предпочтительном, но не ограничивающем аспекте, такие конструкции по изобретению проявляют период полувыведения в сыворотке у человека, по меньшей мере, около 12 часов, предпочтительно, по меньшей мере, 24 часа, более предпочтительно, по меньшей мере, 48 часов, еще более предпочтительно, по меньшей мере, 72 часа или более. Например, соединения или полипептиды по изобретению могут иметь период полувыведения, по меньшей мере, 5 дней (например, от 5 до 10 дней), предпочтительно, по меньшей мере, 9 дней (например, около от 9 до 14 дней), более предпочтительно, по меньшей мере, около 10 дней (например, от 10 до 15 дней) или, по меньшей мере, около 11 дней (например, от 11 до 16 дней), более предпочтительно, по меньшей мере, около 12 дней (например, от 12 до 18 дней или более) или более 14 дней (например, от 14 до 19 дней).
В настоящем изобретении было продемонстрировано, что включение нацеленной на альбумин связывающей единицы в конструкцию как таковое не оказывает существенного влияния на полученную эффективность или эффективность. Хотя в присутствии HSA наблюдалась незначительная потеря эффективности/активности, время полувыведения TCR-связывающих мультиспецифичных полипептидов все еще было эффективным в уничтожении клеток, экспрессирующих CD123. Было показано, что доставка лекарственных средств на основе альбумина полезна для достижения улучшенной терапии онкологических заболеваний, в основном благодаря ее пассивному нацеливанию на опухоли благодаря усиленной проницаемости и эффекту удержания и повышенной потребности в альбумине опухолевыми клетками в качестве источника энергии и аминокислот.
В соответствии с одним конкретным аспектом один или несколько полипептидов по изобретению могут быть связаны (необязательно через подходящий линкер или шарнирную область) с одним или несколькими константными доменами (например, 2 или 3 константными доменами, которые можно использовать как фрагмент Fc-части/для образования Fc-части), к Fc-части и/или к одной или нескольким частям, фрагментам или доменам антител, которые придают одну или несколько эффекторных функций полипептиду по изобретению и/или могут придавать способность связываться с одним или несколькими Fc-рецепторами. Например, для этой цели и без ограничения указанным, одна или несколько дополнительных аминокислотных последовательностей могут содержать один или несколько доменов CH2 и/или CH3 антитела, такого как антитела на основе только тяжелой цепи (как описано в данном документе) и более предпочтительно из обычного человеческого 4-цепочечного антитела; и/или может образовывать (часть) Fc-области, например, из IgG (например, из IgG1, IgG2, IgG3 или IgG4), из IgE или другого человеческого Ig, такого как IgA, IgD или IgM. Например, в WO 94/04678 описаны антитела на основе только тяжелой цепи, содержащие домен VHH верблюдовых или его гуманизированное производное (т.е. нанотело), в котором домен СH2 и/или CH3 Camelidae C заменен человеческим доменом CH2 и CH3, чтобы обеспечить иммуноглобулин, который состоит из 2 тяжелых цепей, каждая из которых содержит домены нанотела и CH2 и CH3 человека (но без домена CH1), причем иммуноглобулин обладает эффекторной функцией, обеспечиваемой доменами CH2 и CH3 и иммуноглобулин которых может функционировать в отсутствии каких-либо легких цепей. Другие аминокислотные последовательности, которые могут быть подходящим образом связаны с полипептидами по изобретению для обеспечения эффекторной функции, будут понятны специалисту в данной области и могут быть выбраны на основе искомой эффекторной функции(й). Настоящим ссылаемся, например, на WO 04/058820, WO 99/42077, WO 02/056910 и WO 05/017148, а также на обзор Holliger and Hudson, выше; и на WO 09/068628. Связывание полипептида по изобретению с Fc-частью может также привести к увеличению периода полувыведения по сравнению с соответствующим полипептидом по изобретению. Для некоторых применений также может быть подходящим или даже предпочтительным использование Fc-части и/или константных доменов (т.е. доменов CH2 и/или CH3), которые обеспечивают увеличенный период полувыведения без какой-либо биологически значимой эффекторной функции. Другие подходящие конструкции, содержащие один или несколько полипептидов по изобретению и один или несколько константных доменов с увеличенным периодом полувыведения in vivo, будут понятны специалисту в данной области и могут, например, включать полипептиды, связанные с доменом CH3, необязательно через линкерную последовательность. Как правило, любой слитый белок или производные с увеличенным периодом полувыведения предпочтительно будут иметь молекулярную массу более 50 кДа, пороговое значение для почечной абсорбции.
В другом конкретном, но не ограничивающем аспекте полипептиды по изобретению могут быть связаны (необязательно через подходящий линкер или шарнирную область) с встречающимися в природе синтетическими или полусинтетическими константными доменами (или аналогами, вариантами, мутантами, частями или их фрагментами), которые имеют пониженную склонность (или практически не имеют склонности) к самоассоциации в димеры (т.е. по сравнению с константными доменами, которые естественным образом встречаются в обычных 4-цепочечных антителах). Такие мономерные (т.е. не самоассоциирующиеся) варианты Fc-цепи или их фрагменты будут понятны специалисту в данной области. Например, Helm et al. (J. Biol. Chem. 271: 7494, 1996), описывают мономерные варианты Fc-цепей, которые можно использовать в полипептидных цепях по изобретению.
Кроме того, такие варианты мономерной Fc-цепи предпочтительно являются такими, что они все еще способны связываться с комплементом или соответствующими Fc-рецепторами (в зависимости от участка Fc, из которого они получены), и/или такими, что они все еще имеют HEKоторые или все эффекторные функции той Fc-части, из которой они получены (или на пониженном уровне, все еще пригодном для предполагаемого применения). В ином случае, в такой полипептидной цепи по изобретению мономерную Fc-цепь можно использовать для придания увеличенного периода полувыведения полипептидной цепи, и в этом случае мономерная Fc-цепь также может не иметь или по существу не иметь эффекторных функций.
Дополнительные аминокислотные остатки могут изменять или не изменять, преобразовывать или иным образом влиять на другие (биологические) свойства полипептида по изобретению и могут добавлять или не добавлять дополнительную функциональность к полипептиду по изобретению. Например, такие аминокислотные остатки:
а) могут включать N-концевой остаток Met, например, в результате экспрессии в гетерологичной клетке-хозяине или организме-хозяине.
b) могут образовывать сигнальную последовательность или лидерную последовательность, которая направляет секрецию полипептида из клетки-хозяина при синтезе (например, для обеспечения пре-, про- или препроформы полипептида по изобретению, в зависимости от клетки-хозяина, используемой для экспрессии полипептида по изобретению). Подходящие секреторные лидерные пептиды будут понятны специалисту в данной области и могут быть такими, как описано ниже. Обычно такая лидерная последовательность будет связана с N-концом полипептида, хотя изобретение в его самом широком смысле этим не ограничивается;
с) могут образовывать «метку», например, аминокислотную последовательность или остаток, которые позволяют или облегчают очистку полипептида, например, с использованием аффинных методов, направленных против указанной последовательности или остатка. После этого указанную последовательность или остаток можно удалить (например, путем химического или ферментативного расщепления), чтобы получить полипептид (для этой цели метка может быть необязательно связана с аминокислотной последовательностью или полипептидной последовательностью через расщепляемую линкерную последовательность или содержать расщепляемый мотив). Некоторые предпочтительные, но не ограничивающие примеры таких остатков представляют собой множественные остатки гистидина, остатки глутатиона и myc-метку, такую как AAAEQKLISEEDLNGAA (SEQ ID NO: 367);
d) могут быть одним или несколькими аминокислотными остатками, которые были функционализированы и/или которые могут служить в качестве сайта для присоединения функциональных групп. Подходящие аминокислотные остатки и функциональные группы будут понятны специалисту в данной области и включают, без ограничения указанным, аминокислотные остатки и функциональные группы, указанные в данном документе для производных полипептидов по изобретению.
В конструкциях по изобретению два или более структурных элемента, ISV или нанотела и необязательно один или несколько полипептидов, одна или несколько других групп, лекарственные средства, агенты, остатки, фрагменты или связывающие единицы могут быть непосредственно связаны друг с другом (как например, описано в WO 99/23221) и/или могут быть связаны друг с другом через один или несколько подходящих спейсеров или линкеров, или любую их комбинацию.
Подходящие спейсеры или линкеры для применения в конструкциях по изобретению будут понятны специалисту в данной области и обычно могут быть любым линкером или спейсером, используемым в данной области для связывания аминокислотных последовательностей и/или других групп, лекарств, агентов, остатков, фрагментов или связывающих единиц. Предпочтительно, указанный линкер или спейсер подходит для применения при конструировании полипептидов и/или конструкций, которые предназначены для фармацевтического применения.
Некоторые особенно предпочтительные спейсеры включают спейсеры и линкеры, которые используются в данной области для связывания фрагментов антител или доменов антител. Они включают линкеры, упомянутые в общем уровне техники, процитированном выше, а также, например, линкеры, которые используются в данной области для конструирования диатела или фрагментов ScFv (однако в этом отношении следует отметить, что, тогда как в диателах и в ScFv фрагментах используемая линкерная последовательность должна иметь длину, степень гибкости и другие свойства, которые позволяют соответствующим доменам VH и VL объединяться для образования полного антигенсвязывающего сайта, то по длине или гибкости линкера, используемого в полипептиде по изобретению, особых ограничений нет, поскольку каждый иммуноглобулиновый одиночный вариабельный домен сам по себе образует полный антигенсвязывающий сайт).
Например, линкер может представлять собой подходящую аминокислотную последовательность и, в частности, аминокислотные последовательности от 1 до 50, предпочтительно от 1 до 30, например, от 1 до 10 аминокислотных остатков. Некоторые предпочтительные примеры таких аминокислотных последовательностей включают gly-ser линкеры, например, типа (glyxsery)z, такие как (например (gly4ser)3 или (gly3ser2)3, как описано в WO 99/42077 и линкеры GS30, GS15, GS9 и GS7, описанные в заявках Ablynx, упомянутых в данном документе (см., например, WO 06/040153 и WO 06/122825), а также шарнирные области, такие как шарнирные области из встречающихся в природе антител на основе тяжелой цепи или подобных последовательностей (таких как описанные в WO 94/04678).
Некоторые другие особенно предпочтительные линкеры упомянуты в таблице B-3, из которых 35GS (SEQ ID NO: 334) является особенно предпочтительным.
Соответственно, изобретение относится к полипептидам, в которых ISV связаны друг с другом через линкер, выбранный из группы, состоящей из SEQ ID NO: 325-336.
Другие подходящие линкеры обычно включают органические соединения или полимеры, в частности те, которые подходят для применения в белках для фармацевтического применения. Например, для связывания доменов антител были использованы поли(этиленгликолевые) группы, см., например, WO 04/081026.
В объем изобретения входит то, что длина, степень гибкости и/или другие свойства используемого линкера(ов) (хотя и не критично, как это обычно бывает для линкеров, используемых во фрагментах ScFv), могут оказывать HEKоторое влияние на свойства конечного полипептида по изобретению, включая, без ограничения указанным, аффинность, специфичность или авидность к CD123 и/или TCR или к одному или нескольким другим антигенам. На основании раскрытого в данном документе описания специалист в данной области сможет определить оптимальный линкер(ы) для применения в конкретном полипептиде по изобретению, необязательно после некоторых ограниченных рутинных экспериментов.
Например, в мультивалентных или мультиспецифичных полипептидах по изобретению, которые содержат структурные элементы, ISV или нанотела, направленные против первой и второй мишени, длина и гибкость линкера предпочтительно являются такими, что они позволяют каждому структурному элементу, ISV или нанотелу по изобретению, присутствующему в полипептиде, связываться с его когнатной мишенью, например, антигенной детерминантой на каждой из мишеней. Опять же, на основании раскрытого в данном документе описания специалист в данной области сможет определить оптимальные линкеры для применения в конкретном полипептиде по изобретению, необязательно после некоторых ограниченных рутинных экспериментов.
Также в пределах объема изобретения находится то, что используемый линкер(ы) придает одно или несколько других благоприятных свойств или функциональных возможностей полипептидам или конструкциям по изобретению и/или обеспечивает один или несколько сайтов для образования производных и/или для присоединения функциональных групп (например, как описано в данном документе для производных полипептидов по изобретению). Например, линкеры, содержащие один или несколько заряженных аминокислотных остатков, могут обеспечивать улучшенные гидрофильные свойства, тогда как линкеры, которые образуют или содержат небольшие эпитопы или метки, могут использоваться для целей обнаружения, идентификации и/или очистки. Опять же, на основании раскрытого в данном документе описания специалист в данной области сможет определить оптимальные линкеры для применения в конкретном полипептиде по изобретению, необязательно после HEKоторых ограниченных рутинных экспериментов.
Наконец, когда два или более линкера используются в полипептидах или конструкциях по изобретению, эти линкеры могут быть одинаковыми или разными. Опять же, на основании раскрытого в данном документе описания специалист в данной области сможет определить оптимальные линкеры для применения в конкретном полипептиде по изобретению, необязательно после некоторых ограниченных рутинных экспериментов.
Обычно для простоты экспрессии и продуцирования полипептид или конструкция по изобретению будет представлять собой линейный полипептид. Однако изобретение в его самом широком смысле не ограничивается этим. Например, когда полипептид по изобретению содержит три или более аминокислотных последовательностей, ISV или нанотел, их можно связать с использованием линкера с тремя или более «плечами», каждое из которых «связано» с аминокислотной последовательностью, ISV или нанотелом, чтобы обеспечить «звездообразную» конструкцию. Также возможно, хотя обычно и менее предпочтительно, использовать кольцевые конструкции.
Соответственно, настоящее изобретение относится к полипептиду, описанному в данном документе, где указанный первый ISV и указанный второй ISV и, возможно, указанный третий ISV и/или указанный сывороточный альбумин, связывающий ISV, непосредственно связаны друг с другом или связаны через линкер.
В настоящее изобретение также включены конструкции, которые содержат иммуноглобулиновый одиночный вариабельный домен или полипептид по изобретению и, кроме того, содержат метки или другие функциональные фрагменты, например, токсины, метки, радиохимические вещества и т.д.
В ином случае, дополнительные группы, остатки, фрагменты или связывающие единицы могут, например, представлять собой химические группы, остатки, фрагменты, которые сами по себе могут быть или не быть биологически и/или фармакологически активными. Например, и без ограничения указанным, такие группы могут быть связаны с двумя или несколькими вариабельными доменами иммуноглобулина или моновалентными полипептидами, чтобы обеспечить «производное» полипептида по изобретению.
Соответственно, изобретение в его широком смысле также включает производные полипептидов по изобретению. Такие производные обычно могут быть получены путем модификации и, в частности, путем химической и/или биологической (например, ферментативной) модификации полипептидов по изобретению и/или одного или нескольких аминокислотных остатков, которые образуют полипептид по изобретению,
Примеры таких модификаций, а также примеры аминокислотных остатков в полипептидных последовательностях, которые могут быть модифицированы таким образом (т.е. либо на основной цепи белка, но предпочтительно на боковой цепи), способы и методы, которые можно использовать для введения таких модификаций, и потенциальное применение и преимущества таких модификаций будут понятны специалисту (см. также Zangi et al. 2013, Nat. biotechnol. 31: 898-907).
Например, такая модификация может включать введение (например, путем ковалентного связывания или любым другим подходящим способом) одной или нескольких функциональных групп, остатков или фрагментов в или на полипептид по изобретению и, в частности, одной или нескольких функциональных групп, остатков или фрагментов, которые придают одно или несколько искомых свойств или функциональных возможностей полипептиду по изобретению. Пример таких функциональных групп будет понятен специалисту в данной области.
Например, такая модификация может включать введение (например, путем ковалентного связывания или любым другим подходящим способом) одной или нескольких функциональных групп, которые увеличивают время полувыведения, растворимость и/или абсорбцию полипептида по изобретению, которые снижают иммуногенность и/или токсичность полипептида по изобретению, которые устраняют или ослабляют любые нежелательные побочные эффекты полипептида по изобретению, и/или которые придают другие полезные свойства и/или уменьшают нежелательные свойства полипептида изобретения; или любую комбинацию двух или более из вышеперечисленного. Примеры таких функциональных групп и методов их введения будут понятны специалисту в данной области и обычно могут включать все функциональные группы и методы, упомянутые в общем уровне техники, процитированном выше, а также функциональные группы и методики, известные per se для модификации фармацевтических белков и, в частности, для модификации антител или фрагментов антител (включая ScFv и однодоменные антитела), на которые, например, настоящим ссылаемся на Remington (1980, Pharmaceutical Sciences, 16th ed., Mack Publishing Co., Easton, PA, 1980). Такие функциональные группы могут, например, быть связаны непосредственно (например, ковалентно) с полипептидом по изобретению или, необязательно, через подходящий линкер или спейсер, что опять же будет понятно специалисту в данной области.
Одним конкретным примером является производный полипептид по изобретению, где полипептид по изобретению был химически модифицирован для увеличения его периода полувыведения (например, посредством ПЭГилирования). Это один из наиболее широко используемых методов увеличения периода полувыведения и/или снижения иммуногенности фармацевтических белков, который включает присоединение подходящего фармакологически приемлемого полимера, такого как поли (этиленгликоль) (ПЭГ) или его производного (таких как метоксиполи(этиленгликоль) или мПЭГ). Как правило, можно использовать любую подходящую форму ПЭГилирования, такую как ПЭГилирование, используемое в данной области для антител и фрагментов антител (включая, без ограничения указанным (одно)доменные антитела и ScFv; настоящим ссылаемся, например, на Chapman (2002, Nat. Biotechnol. 54: 531-545), Veronese and Harris (2003, Adv. Drug Deliv. Rev. 54: 453-456), Harris and Chess (2003, Nat. Rev. Drug. Discov. 2: 214-221) и WO 04/060965. Различные реагенты для ПЭГилирования белков также коммерчески доступны, например, у Nektar Therapeutics, США.
Предпочтительно используют сайт-направленное ПЭГилирование, в частности, через остаток цистеина (см., например, Yang et al. (2003, Protein Engineering 16: 761-770)). Например, для этой цели ПЭГ может быть присоединен к остатку цистеина, который естественным образом встречается в полипептиде по изобретению, полипептид по изобретению может быть модифицирован таким образом, чтобы соответствующим образом был введен один или несколько остатков цистеина для присоединения ПЭГ, или аминокислотная последовательность, содержащая один или несколько остатков цистеина для присоединения ПЭГ, может быть слита с N- и/или С-концом полипептида по изобретению, причем все с использованием методов белковой инженерии, известных per se специалисту в данной области.
Предпочтительно, для полипептидов по изобретению используют PEG с молекулярной массой более 5000, например, более 10000 и менее 200000, например, менее 100000; например, в диапазоне от 20000 до 80000.
Другая, обычно менее предпочтительная модификация включает N-связанное или O-связанное гликозилирование, обычно как часть котрансляционной и/или посттрансляционной модификации, в зависимости от клетки-хозяина, используемой для экспрессии полипептида по изобретению.
Еще одна модификация может включать введение одной или нескольких обнаруживаемых меток или других генерирующих сигнал групп или фрагментов, в зависимости от предполагаемого применения меченого полипептида по изобретению. Подходящие метки и способы их прикрепления, применения и обнаружения будут понятны специалисту в данной области и, например, включают, без ограничения указанным, флуоресцентные метки (такие как флуоресцеин, изотиоцианат, родамин, фикоэритрин, фикоцианин, аллофикоцианин, о-фтальдегид и флуорескамин и флуоресцентные металлы, такие как 152Eu или другие металлы из серии лантаноидов), фосфоресцентные метки, хемилюминесцентные метки или биолюминесцентные метки (такие как люминал, изолюминол, ароматический эфир акридиния, имидазол, соли акридиния, оксалатный эфир, диоксетан или GFP и его аналоги), радиоизотопы (такие как 3H, 125I, 32P, 35S, 14C, 51Cr, 36Cl, 57Co, 58Co, 59Fe и 75Se), металлы, хелаты металлов или катионы металлов (например, катионы металлов, такие как 99mTc, 123I, 111In, 131I, 97Ru, 67Cu, 67Ga и 68Ga или другие металлы или катионы металлов, которые особенно подходят для применения при диагностике визуализации in vivo, in vitro или in situ, такие как (157Gd, 55Mn, 162Dy, 52Cr и 56Fe)), а также хромофоры и ферменты (такие как малат-дегидрогеназа, стафилококковая нуклеаза, дельта-V-стероид-изомераза, дрожжевая алкогольдегидрогеназа, альфа-глицерофосфатдегидрогеназа, триозофосфатизомераза, биотинавидинпероксидаза, хрен) пероксидаза, щелочная фосфатаза, аспарагиназа, глюкозооксидаза, β-галактозидаза, рибонуклеаза, уреаза, каталаза, глюкозо-VI-фосфатдегидрогеназа, глюкоамилаза и ацетилхолинэстераза). Другие подходящие метки будут понятны специалисту в данной области и, например, включают фрагменты, которые могут быть обнаружены с помощью ЯМР или ЭПР-спектроскопии.
Такие меченые полипептиды по изобретению могут, например, использоваться для анализов in vitro, in vivo или in situ (включая иммуноанализы, известные per se, такие как ELISA, RIA, EIA и другие «сэндвич-анализы» и т.д.), а также для диагностики in vivo. и в целях визуализации, в зависимости от выбора конкретной метки.
Как будет понятно специалисту в данной области, другая модификация может включать введение хелатной группы, например, для хелатирования одного из металлов или катионов металлов, упомянутых выше. Подходящие хелатирующие группы, например, включают, без ограничения указанным, диэтил-энетриаминпентауксусную кислоту (DTPA) или этилендиаминтетрауксусную кислоту (EDTA).
Еще одна модификация может включать введение функциональной группы, которая является одной частью пары специфического связывания, такой как пара связывания биотин-(стрепт)авидин. Такая функциональная группа может быть использована для связывания полипептида по изобретению с другим белком, полипептидом или химическим соединением, которое связано с другой половиной пары связывания, т.е. посредством образования пары связывания. Например, полипептид по изобретению может быть конъюгирован с биотином и связан с другим белком, полипептидом, соединением или носителем, конъюгированным с авидином или стрептавидином. Например, такой конъюгированный полипептид по изобретению может быть использован в качестве репортера, например, в диагностической системе, где детектируемый агент, продуцирующий сигнал, конъюгирован с авидином или стрептавидином. Такие пары связывания могут, например, также использоваться для связывания полипептида по изобретению с носителем, включая носители, подходящие для фармацевтических целей. Одним неограничивающим примером являются липосомные составы, описанные Cao и Suresh (2000, Journal of Drug Targeting 8: 257). Такие пары связывания могут также использоваться для связывания терапевтически активного агента с полипептидом по изобретению.
Другие потенциальные химические и ферментативные модификации будут понятны специалисту. Такие модификации также могут быть введены для исследовательских целей (например, для изучения взаимоотношений функция-активность). Настоящим ссылаемся, например, на Lundblad and Bradshaw (1997, Biotechnol. Appl. Biochem. 26: 143-151).
Предпочтительно, чтобы производные были такими, чтобы они связывались с CD123 и/или TCR с аффинностью (подходящим образом измеренным и/или выраженным в виде значения KD (фактического или кажущегося), значения KA (фактического или кажущегося), скорости kon и/или скорости koff, или, альтернативно, в виде значения IC50, как описано далее в данном документе), как определено в данном документе (т.е. как определено для полипептидов по изобретению).
Такие полипептиды по изобретению и их производные также могут быть по существу в выделенной форме (как определено в данном документе).
Изобретение, кроме того, относится к способам получения полипептидов, нуклеиновых кислот, клеток-хозяев и композиций, описанных в данном документе.
Полипептиды и конструкции по изобретению могут быть получены известным способом, как будет понятно специалисту из дальнейшего описания. Например, полипептиды и конструкции по изобретению могут быть получены любым способом, известным per se для получения антител и, в частности, для получения фрагментов антител (включая, но без ограничения указанным (одно)доменные антитела и фрагменты ScFv). Некоторые предпочтительные, но не ограничивающие способы получения полипептидов, конструкций и нуклеиновых кислот включают способы и методы, описанные в данном документе.
Способ получения полипептида или конструкции (т.е. такой, которая может быть получена путем экспрессии нуклеиновой кислоты, кодирующей ее) по изобретению может включать следующие стадии:
- экспрессии в подходящей клетке-хозяине или организме-хозяине (также называемом в данном документе «хозяином по изобретению») или в другой подходящей системе экспрессии нуклеиновой кислоты, которая кодирует указанный полипептид или конструкцию по изобретению (также называемую в данном документе как «нуклеиновая кислота по изобретению»),
что необязательно сопровождается:
- выделением и/или очисткой полипептида или конструкции по изобретению, полученных таким образом.
В частности, такой способ может включать стадии:
- культивирования и/или поддержания хозяина по изобретению в условиях, которые таковы, что указанный хозяин по изобретению экспрессирует и/или продуцирует, по меньшей мере, один полипептид или конструкцию (т.е. такую, которую можно получить путем экспрессии нуклеиновой кислоты, кодирующей их) по изобретению;
что необязательно сопровождается:
- выделением и/или очисткой полипептида или конструкции по изобретению, полученных таким образом.
Соответственно, настоящее изобретение также относится к нуклеиновой кислоте или нуклеотидной последовательности, которая кодирует полипептид или конструкцию (т.е. такую, которая может быть получена путем экспрессии нуклеиновой кислоты, кодирующей ее) по изобретению (также называемую «нуклеиновая кислота по изобретению»). Нуклеиновая кислота по изобретению может быть в форме одноцепочечной или двухцепочечной ДНК или РНК и предпочтительно в форме двухцепочечной ДНК. Например, нуклеотидные последовательности по изобретению могут быть геномной ДНК, кДНК или синтетической ДНК (такой как ДНК с использованием кодонов, которая была специально адаптирована для экспрессии в предполагаемой клетке-хозяине или организме-хозяине).
Согласно одному аспекту изобретения нуклеиновая кислота по изобретению по существу выделена, как определено в данном документе. Нуклеиновая кислота по изобретению также может быть в форме, присутствовать и/или может быть частью вектора, такого как, например, плазмида, космида или YAC, который также может быть по существу в выделенной форме.
Нуклеиновые кислоты по изобретению могут быть приготовлены или получены способом, который известен per se, на основе информации о полипептидах или конструкциях (которые таковы, что они могут быть получены путем экспрессии нуклеиновой кислоты, кодирующей их) по настоящему изобретению, данной в данном документе и/или могут быть выделены из подходящего природного источника. Также, как будет понятно специалисту в данной области, для получения нуклеиновой кислоты по изобретению также несколько нуклеотидных последовательностей, таких как, по меньшей мере, одна нуклеотидная последовательность, кодирующая иммуноглобулиновый одиночный вариабельный домен по изобретению, и, например, нуклеиновые кислоты, кодирующие один или несколько линкеров, могут быть связаны друг с другом подходящим способом.
Методы получения нуклеиновых кислот по изобретению будут понятны специалисту в данной области и могут, например, включать, без ограничения указанным, автоматический синтез ДНК; сайт-направленный мутагенез; объединение двух или более встречающихся в природе и/или синтетических последовательностей (или двух или более их частей), введение мутаций, которые приводят к экспрессии усеченного продукта экспрессии; введение одного или нескольких сайтов рестрикции (например, для создания кассет и/или областей, которые можно легко переваривать и/или лигировать с использованием подходящих ферментов рестрикции), и/или введение мутаций посредством реакции ПЦР с использованием одного или нескольких «несовпадающих» праймеров. Эти и другие методы будут понятны специалисту, и опять настоящим ссылаемся на стандартные руководства, такие как Sambrook et al. и Ausubel et al., упомянутые выше, а также примеры ниже.
Нуклеиновая кислота по изобретению также может быть в форме, присутствовать и/или быть частью генетической конструкции, как будет понятно специалисту в данной области. Такие генетические конструкции обычно содержат, по меньшей мере, одну нуклеиновую кислоту по изобретению, которая необязательно связана с одним или несколькими элементами генетических конструкций, известных per se, такими как, например, один или несколько подходящих регуляторных элементов (таких как подходящий промотор(ы), энхансер(ы), терминатор(ы) и т.д.) и другими элементами генетических конструкций, упомянутыми в данном документе. Такие генетические конструкции, содержащие, по меньшей мере, одну нуклеиновую кислоту по изобретению, также будут называться в данном документе как «генетические конструкции по изобретению».
Генетические конструкции по изобретению могут представлять собой ДНК или РНК и предпочтительно представляют собой двухцепочечную ДНК. Генетические конструкции по изобретению также могут быть в форме, подходящей для трансформации предполагаемой клетки-хозяина или организма-хозяина, в форме, подходящей для интеграции в геномную ДНК предполагаемой клетки-хозяина, или в форме, подходящей для независимой репликации, поддержания и/или наследование в предполагаемом организме-хозяине. Например, генетические конструкции по изобретению могут быть в форме вектора, такого как, например, плазмида, космида, YAC, вирусный вектор или транспозон. В частности, вектор может представлять собой экспрессирующий вектор, т.е. вектор, который может обеспечивать экспрессию in vitro и/или in vivo (например, в подходящей клетке-хозяине, организме-хозяине и/или системе экспрессии).
В предпочтительном, но не ограничивающем аспекте генетическая конструкция по изобретению включает
а) по меньшей мере, одну нуклеиновую кислоту по изобретению; функционально связанную с
b) одним или несколькими регуляторными элементами, такими как промотор и, необязательно, подходящий терминатор;
и, возможно, также
с) одним или несколькими дополнительными элементами генетических конструкций, известными per se;
в котором термины «регуляторный элемент», «промотор», «терминатор» и «функционально связанный» имеют свое обычное значение в данной области техники (как дополнительно описано в данном документе); и в котором указанные «дополнительные элементы», присутствующие в генетических конструкциях, могут, например, представлять собой 3'- или 5'-последовательности UTR, лидерные последовательности, селективные маркеры, маркеры экспрессии/репортерные гены и/или элементы, которые могут облегчать или увеличивать (эффективность) трансформации или интеграции. Эти и другие подходящие элементы для таких генетических конструкций будут понятны специалисту в данной области и могут, например, зависеть от типа используемой конструкции; предполагаемых клетки-хозяина или организма-хозяина; способа экспрессии представляющих интерес нуклеотидных последовательностей по настоящему изобретению (например, посредством конститутивной, транзиторной или индуцибельной экспрессии); и/или метода трансформации, которые будут использоваться. Например, регуляторные последовательности, промоторы и терминаторы, известные per se для экспрессии и выработки антител и фрагментов антител (включая, но без ограничения указанным (одно)доменные антитела и фрагменты ScFv), могут использоваться по существу аналогичным образом.
Предпочтительно в генетических конструкциях по изобретению указанная, по меньшей мере, одна нуклеиновая кислота по настоящему изобретению и указанные регуляторные элементы и, необязательно, указанные один или несколько дополнительных элементов «функционально связаны» друг с другом, что обычно означает, что они являются в функциональных отношениях друг с другом. Например, промотор считается «функционально связанным» с кодирующей последовательностью, если указанный промотор способен инициировать или иным образом контролировать/регулировать транскрипцию и/или экспрессию кодирующей последовательности (в которой указанную кодирующую последовательность следует понимать «под контролем» указанного промотора). Обычно, когда две нуклеотидные последовательности функционально связаны, они будут иметь одинаковую ориентацию и обычно также будут находиться в одной и той же рамке считывания. Обычно они также будут по существу смежными, хотя это также может не потребоваться.
Предпочтительно регуляторные и дополнительные элементы генетических конструкций по изобретению таковы, что они способны обеспечивать предполагаемую биологическую функцию в предполагаемых клетке-хозяине или организме-хозяине.
Например, промотор, энхансер или терминатор должны быть «функциональными» в предполагаемых клетке-хозяине или организме-хозяине, что подразумевает, что (например) указанный промотор должен быть способен инициировать или иным образом контролировать/регулировать транскрипцию и/или экспрессию нуклеотидной последовательности - например, кодирующей последовательности - с которой она функционально связана (как определено в данном документе).
Некоторые особенно предпочтительные промоторы включают, без ограничения указанным, промоторы, известные per se для экспрессии в клетках-хозяевах, упомянутых в данном документе; и, в частности, промоторы для экспрессии в бактериальных или дрожжевых клетках, такие как упомянутые в данном документе и/или используемые в примерах.
Селективный маркер должен быть таким, чтобы он позволял - т.е. при соответствующих условиях отбора - клетки-хозяева и/или организмы-хозяева, которые были (успешно) трансформированы нуклеотидной последовательностью по изобретению, отличать от клеток-хозяев/организмов, которые не были (успешно) трансформированы. HEKоторые предпочтительные, но не ограничивающие примеры таких маркеров представляют собой гены, которые обеспечивают устойчивость к антибиотикам (таким как канамицин или ампициллин), гены, которые обеспечивают устойчивость к температуре, или гены, которые позволяют поддерживать клетку-хозяина или организм-хозяина в отсутствие определенных факторов, соединений и/или (пищевых) компонентов в среде, которые необходимы для выживания нетрансформированных клеток или организмов.
Лидерная последовательность должна быть такой, чтобы - в предполагаемых клетке-хозяине или организме-хозяине - она делала возможными искомые посттрансляционные модификации и/или такой, чтобы она направляла транскрибированную мРНК в искомую часть или органеллу клетки. Лидерная последовательность также может допускать секрецию продукта экспрессии из указанной клетки. Как таковая, лидерная последовательность может быть любой про-, пре- или препропоследовательностью, действующей в клетке-хозяине или организме-хозяине. Лидерные последовательности могут не требоваться для экспрессии в бактериальной клетке. Например, лидерные последовательности, известные per se для экспрессии и продуцирования антител и фрагментов антител (включая, без ограничения указанным, однодоменные антитела и фрагменты ScFv), могут быть использованы по существу аналогичным образом.
Маркер экспрессии или репортерный ген должен быть таким, чтобы - в клетке-хозяине или организме-хозяине - он позволял обнаруживать экспрессию (гена или нуклеотидной последовательности, присутствующих в) генетической конструкции. Маркер экспрессии может также необязательно делать возможной локализацию экспрессируемого продукта, например, в конкретной части или органелле клетки и/или в (а) конкретной клетке (клетках), ткани (тканях), органе (органах) или части (частях) многоклеточного организма. Такие репортерные гены также могут быть экспрессированы в виде белка, слитого с ISV, полипептидом или конструкцией по изобретению. Некоторые предпочтительные, но не ограничивающие примеры включают флуоресцентные белки, такие как GFP.
Некоторые предпочтительные, но не ограничивающие примеры подходящих промоторов, терминаторов и других элементов включают те, которые могут быть использованы для экспрессии в клетках-хозяевах, упомянутых в данном документе; и, в частности, те, которые подходят для экспрессии в бактериальных или дрожжевых клетках, такие как упомянутые в данном документе и/или те, которые используются в приведенных ниже примерах. Для некоторых (дополнительных) неограничивающих примеров промоторов, селективных маркеров, лидерных последовательностей, маркеров экспрессии и других элементов, которые могут присутствовать/использоваться в генетических конструкциях по изобретению, таких как терминаторы, транскрипционные и/или трансляционные энхансеры и/или факторы интеграции - настоящим ссылаемся на общие руководства, такие как Sambrook et al. и Ausubel et al. упомянутые выше, а также примеры, которые приведены в WO 95/07463, WO 96/23810, WO 95/07463, WO 95/21191, WO 97/11094, WO 97/42320, WO 98/06737, WO 98/21355, US 7207410, US 5693492 и EP 1085089. Другие примеры будут понятны специалисту. Также настоящим ссылаемся на общий уровень техники, процитированный выше, и дополнительные источники, процитированные в данном документе.
Генетические конструкции по изобретению, как правило, могут быть получены путем соответствующего связывания нуклеотидной последовательности (последовательностей) по изобретению с одним или несколькими дополнительными элементами, описанными выше, например, с использованием методов, описанных в общих руководствах, таких как Sambrook et al. и Ausubel et al., которые упомянуты выше.
Часто генетические конструкции по изобретению будут получены путем вставки нуклеотидной последовательности по изобретению в подходящий (экспрессирующий) вектор, известный per se. Некоторые предпочтительные, но не ограничивающие примеры подходящих векторов экспрессии представляют собой те, которые используются в приведенных ниже примерах, а также те, которые упомянуты в данном документе.
Нуклеиновые кислоты по изобретению и/или генетические конструкции по изобретению можно использовать для трансформации клетки-хозяина или организма-хозяина, т.е. для экспрессии и/или продуцирования полипептида или конструкции (т.е. так, чтобы она могла быть получена путем экспрессия нуклеиновой кислоты, кодирующей их) по изобретению. Хозяин предпочтительно не является человеком. Подходящие хозяева или клетки-хозяева будут понятны специалисту и могут, например, представлять собой любые подходящие грибные, прокариотические или эукариотические клетки или клеточные линии или любой подходящий грибной, прокариотический или (не человеческий) эукариотический организм, например:
- бактериальный штамм, включая, без ограничения указанным, грамотрицательные штаммы, такие как штаммы Escherichia coli; Proteus, например, Proteus Mirabilis; из Pseudomonas, например, Pseudomonas fluorescens; и грамположительные штаммы, такие как штаммы Bacillus, например, Bacillus subtilis или Bacillus brevis; Streptomyces, например, Streptomyces lividans; Staphylococcus, например, Staphylococcus carnosus; и Lactococcus, например, Lactococcus lactis;
- грибная клетка, включая, без ограничения указанным, клетки из видов Trichoderma, например, Trichoderma reesei; из Neurospora, например, Neurospora crassa; из Sordaria, например, из Sordaria macrospora; из Aspergillus, например, из Aspergillus niger или из Aspergillus sojae; или из других нитчатых грибов;
- дрожжевая клетка, включая, без ограничения указанным, клетки из видов Saccharomyces, например, Saccharomyces cerevisiae; из Schizosaccharomyces, например, Schizosaccharomyces pombe; из Pichia, например, Pichia pastoris или Pichia methanolica; из Hansenula, например, Hansenula polymorpha; из Kluyveromyces, например, Kluyveromyces lactis; из Arxula, например, Arxula adeninivorans; из Yarrowia, например, Yarrowia lipolytica;
- клетка или клеточная линия амфибии, такую как ооциты Xenopus;
- полученные из насекомых клетки или клеточные линии, такие как клетки/клеточные линии, полученные из чешуекрылых, включая, без ограничения указанным, клетки Spodoptera SF9 и Sf21 или клетки/клеточные линии, полученные из Drosophila, такие как клетки Schneider и Kc;
- растение или растительная клетка, например, из растений табака; и/или
- клетка или клеточная линия млекопитающего, например, клетку или клеточную линию, происходящую из человека, клетку или клеточную линию из млекопитающих, включая, без ограничения указанным, клетки СНО, клетки ВНК (например, клетки ВНК-21) и клетки или клеточные линии человека, такие как клетки HeLa, COS (например, COS-7) и PER.C6;
а также все другие клетки-хозяева или хозяева (не являющиеся человеком), известные per se для экспрессии и продуцирования антител и фрагментов антител (включая, без ограничения указанным (одно)доменные антитела и фрагменты ScFv), понятные специалисту. Ссылка также делается на общий уровень техники, процитированный выше, а также, например, на WO 94/29457; WO 96/34103; WO 99/42077; Frenken et al. (1998, Res Immunol. 149: 589-599); Riechmann and Muyldermans (1999), выше; van der Linden (2000, J. Biotechnol. 80: 261-270); Joosten et al. (2003, Microb. Cell Fact. 2: 1); Joosten et al. 2005 (Appl. Microbiol. Biotechnol. 66: 384-392); и дополнительные источники, процитированные в данном документе.
Полипептиды или конструкции по изобретению также могут быть экспрессированы в виде так называемых «внутриклеточных антител», как, например, описано в WO 94/02610, WO 95/22618 и US 7 004 940; WO 03/014960; в Cattaneo and Biocca (1997, «Внутриклеточные антитела: разработка и применение», Landes and Springer-Verlag); и в Kontermann (2004, Methods 34: 163-170).
Полипептиды или конструкции по изобретению могут, например, также быть получены в молоке трансгенных млекопитающих, например, в молоке кроликов, коров, коз или овец (см., например, US 6 741 957, US 6 304 489 и US 6 849 992 для общих способов введения трансгенов в млекопитающих), в растениях или частях растений, включая, но без ограничения указанным, их листья, цветы, плоды, семена, корни или клубни (например, в табаке, кукурузе, соевых бобах или люцерне) или, например, в куколках шелкопряда Bombix mori.
Кроме того, полипептиды или конструкции по изобретению также могут быть экспрессированы и/или получены в бесклеточных системах экспрессии, и подходящие примеры таких систем будут понятны специалисту в данной области. Некоторые предпочтительные, но не ограничивающие примеры включают экспрессию в системе зародышей пшеницы; в лизатах ретикулоцитов кролика; или в системе E. coli Zubay.
Предпочтительно в изобретении используется система экспрессии (in vivo или in vitro), такая как бактериальная система экспрессии, которая обеспечивает полипептиды или конструкции по изобретению в форме, подходящей для фармацевтического применения, и такие системы экспрессии опять же будут понятны специалисту. Как также будет понятно специалисту в данной области, полипептиды или конструкции по изобретению, подходящие для фармацевтического применения, могут быть получены с использованием методов синтеза пептидов.
Для производства в промышленном масштабе предпочтительные гетерологичные хозяева для (промышленного) производства иммуноглобулинового одиночного вариабельного домена или полипептидных терапевтических средств, содержащих иммуноглобулиновый одиночный вариабельный домен, включают штаммы E.coli, Pichia pastoris, S. cerevisiae, которые подходят для экспрессии/продуцирования/ферментации в большом масштабе, и, в частности, для фармацевтической экспрессии/продуцирования/ферментации в большом масштабе. Подходящие примеры таких штаммов будут понятны специалисту в данной области. Такие штаммы и системы производства/экспрессии также предоставляются такими компаниями, как Biovitrum (Упсала, Швеция).
В ином случае, клеточные линии млекопитающих, в частности клетки яичника китайского хомячка (СНО), можно использовать для экспрессии/продуцирования/ферментации в большом масштабе и, в частности, для фармацевтической экспрессии/продуцирования/ферментации в большом масштабе. Опять же такие системы экспрессии/продуцирования также предоставляются некоторыми из компаний, упомянутых выше.
Выбор конкретной системы экспрессии будет частично зависеть от потребности в определенных посттрансляционных модификациях, более конкретно, в гликозилировании. Получение рекомбинантного белка, содержащего иммуноглобулиновый одиночный вариабельный домен, для которого гликозилирование является желательным или необходимым, потребовало бы использования экспрессирующих хозяев млекопитающих, которые обладают способностью гликозилировать экспрессированный белок. В этом отношении специалисту будет понятно, что полученная картина гликозилирования (т.е. вид, количество и положение прикрепленных остатков) будет зависеть от клетки или клеточной линии, которая используется для экспрессии. Предпочтительно используется либо клетка, либо клеточная линия человека (т.е., приводящие к белку, который по существу имеет паттерн гликозилирования человека), или используется другая клеточная линия млекопитающего, которая может обеспечить паттерн гликозилирования, который по существу и/или функционально такой же, как при гликозилировании человека или, по меньшей мере, имитирует гликозилирование человека. Как правило, прокариотические хозяева, такие как E.coli, не обладают способностью гликозилировать белки, и использование низших эукариот, таких как дрожжи, обычно приводит к паттерну гликозилирования, который отличается от гликозилирования человека. Тем не менее, следует понимать, что все вышеупомянутые клетки-хозяева и системы экспрессии могут быть использованы в изобретении в зависимости от искомого полипептида или конструкции, которую нужно получить.
Таким образом, согласно одному неограничивающему аспекту изобретения, полипептид или конструкция по изобретению являются гликозилированными. Согласно другому неограничивающему аспекту изобретения полипептид или конструкция по изобретению негликозилированы.
Согласно одному предпочтительному, но не ограничивающему аспекту изобретения, полипептид или конструкция по изобретению продуцируется в бактериальной клетке, в частности бактериальной клетке, подходящей для крупномасштабного фармацевтического производства, такой как клетки штаммов, упомянутых выше.
Согласно другому предпочтительному, но не ограничивающему аспекту изобретения, полипептид или конструкцию по изобретению получают в дрожжевой клетке, в частности в дрожжевой клетке, подходящей для крупномасштабного фармацевтического производства, такой как клетки вышеупомянутых видов.
Согласно еще одному предпочтительному, но не ограничивающему аспекту изобретения, полипептид или конструкция по изобретению продуцируется в клетке млекопитающего, в частности в клетке человека или в клетке линии клеток человека, и более конкретно в клетке человека или линии клеток человека, которые подходят для крупномасштабного фармацевтического производства, такая как клеточные линии, упомянутые выше.
Когда экспрессию в клетке-хозяине используют для получения полипептидов или конструкций по изобретению, полипептиды или конструкции по изобретению можно продуцировать либо внутриклеточно (например, в цитозоле, в периплазме или в тельцах включения), а затем выделять из клетки-хозяева и необязательно дополнительно очищать; либо могут быть получены внеклеточно (например, в среде, в которой культивируются клетки-хозяева), а затем выделены из культуральной среды и необязательно дополнительно очищены. Когда используются эукариотические клетки-хозяева, внеклеточное продуцирование обычно является предпочтительным, поскольку это значительно облегчает дальнейшее выделение и последующую обработку полученных полипептидов или конструкций. Бактериальные клетки, такие как штаммы E.coli, упомянутые выше, обычно не секретируют белки внеклеточно, за исключением нескольких классов белков, таких как токсины и гемолизин, а секреторное продуцирование в E.coli относится к транслокации белков через внутреннюю мембрану в периплазматическое пространство. Периплазматическое продуцирование обеспечивает несколько преимуществ по сравнению с цитозольным продуцированием. Например, N-концевая аминокислотная последовательность секретируемого продукта может быть идентичной природному генному продукту после отщепления сигнальной последовательности секреции специфической сигнальной пептидазой. Кроме того, активность протеазы в периплазме значительно ниже, чем в цитоплазме. Кроме того, очистка белка проще из-за меньшего количества загрязняющих белков в периплазме. Другое преимущество состоит в том, что могут образовываться правильные дисульфидные связи, поскольку периплазма обеспечивает более окислительную среду, чем цитоплазма. Белки, сверхэкспрессируемые в E.coli, часто обнаруживаются в нерастворимых агрегатах, так называемых тельца включения. Эти тельца включения могут располагаться в цитозоле или в периплазме; извлечение биологически активных белков из этих телец включения требует процесса денатурации/рефолдинга. Многие рекомбинантные белки, включая терапевтические белки, выделяются из телец включения. В ином случае, как будет понятно специалисту в данной области, могут быть использованы рекомбинантные штаммы бактерий, которые были генетически модифицированы так, чтобы секретировать искомый белок, и, в частности, полипептид или конструкцию по изобретению.
Таким образом, согласно одному неограничивающему аспекту изобретения, полипептид или конструкция по изобретению представляет собой полипептид или конструкцию, которая была продуцирована внутриклеточно и которая была выделена из клетки-хозяина и, в частности, из бактериальной клетки или из тельца включения в бактериальной клетке. Согласно другому неограничивающему аспекту изобретения полипептид или конструкция по изобретению представляет собой полипептид или конструкцию, которая была продуцирована внеклеточно и которая была выделена из среды, в которой культивируется клетка-хозяин.
Некоторые предпочтительные, но не ограничивающие промоторы для применения с этими клетками-хозяевами включают:
- для экспрессии в E.coli: промотор lac (и его производные, такие как промотор lacUV5); промотор арабинозы; левый (PL) и правый (PR) промоторы фага лямбда; промотор оперона trp; гибридные промоторы lac/trp (tac и trc); промотор Т7 (более конкретно, гена 10 фага Т7) и другие промоторы Т-фага; промотор гена устойчивости к тетрациклину Tn10; сконструированные варианты вышеуказанных промоторов, которые включают одну или несколько копий чужеродной регуляторной последовательности оператора;
- для экспрессии в S. cerevisiae: конститутивные: ADH1 (алкогольдегидрогеназа 1), ENO (энолаза), CYC1 (цитохром с изо-1), GAPDH (глицеральдегид-3-фосфатдегидрогеназа), PGK1 (фосфоглицераткиназа), PYK1 (пируваткиназа); регулируемые: GAL1,10,7 (ферменты метаболизма галактозы), ADH2 (алкогольдегидрогеназа 2), PHO5 (кислая фосфатаза), CUP1 (металлотионеин меди); гетерологичные: CaMV (промотор 35S вируса мозаики цветной капусты);
- для экспрессии в Pichia pastoris: промотор AOX1 (алкогольоксидаза I);
- для экспрессии в клетках млекопитающих: предранний энхансер/промотор цитомегаловируса человека (hCMV); предранний вариант промотора цитомегаловируса человека (hCMV), который содержит две последовательности оператора тетрациклина, так что промотор может регулироваться репрессором Tet; промотор тимидинкиназы (TK) вируса простого герпеса; энхансер/промотор длинного концевого повтора вируса саркомы Рауса (RSV LTR); промотор фактора элонгации 1α (hEF-1α) человека, шимпанзе, мыши или крысы; ранний промотор SV40; длинный концевой повторный промотор HIV-1; промотор β актина.
HEKоторые предпочтительные, но не ограничивающие векторы для использования с этими клетками-хозяевами включают:
- векторы для экспрессии в клетках млекопитающих: pMAMneo (Clontech), pcDNA3 (Invitrogen), pMC1neo (Stratagene), pSG5 (Stratagene), EBO-pSV2-neo (ATCC 37593), pBPV-1 (8-2) (ATCC 37110), pdBPV-MMTneo (342-12) (ATCC 37224), pRSVgpt (ATCC37199), pRSVneo (ATCC37198), pSV2-dhfr (ATCC 37146), pUCTag (ATCC 37460) и 1ZD35 (ATCC 37565), а также системы экспрессии на основе вирусов, например, на основе аденовируса;
- векторы для экспрессии в бактериальных клетках: векторы pET (Novagen) и векторы pQE (Qiagen);
- векторы для экспрессии в дрожжевых или других грибных клетках: экспрессирующие векторы pYES2 (Invitrogen) и Pichia (Invitrogen);
- векторы для экспрессии в клетках насекомых: pBlueBacII (Invitrogen) и другие бакуловирусные векторы;
- векторы для экспрессии в растениях или клетках растений: например, векторы на основе вируса мозаики цветной капусты или вируса табачной мозаики, подходящие штаммы Agrobacterium или векторы на основе Ti-плазмиды.
Некоторые предпочтительные, но не ограничивающие секреторные последовательности для применения с этими клетками-хозяевами включают:
- для использования в бактериальных клетках, таких как Е.coli: PelB, Bla, OmpA, OmpC, OmpF, OmpT, StII, PhoA, PhoE, MalE, Lpp, LamB и т.п.; сигнальный пептид ТАТ, сигнал секреции С-конца гемолизина;
- для использования в дрожжах: препропоследовательность фактора спаривания α, фосфатаза (pho1), инвертаза (Suc) и т.д.;
- для использования в клетках млекопитающих: нативный сигнал, если целевой белок имеет эукариотическое происхождение; сигнальный пептид V-J2-C κ-цепи мышиного Ig; и т.п.
Подходящие способы трансформации клетки-хозяина или клетки-хозяина по изобретению будут понятны специалисту в данной области и могут зависеть от предполагаемой клетки-хозяина/организма-хозяина и используемой генетической конструкции. Снова настоящим ссылаемся на упомянутые выше руководства и патентные заявки.
После трансформации может быть выполнена стадия для выявления и отбора тех клеток-хозяев или организмов-хозяев, которые были успешно трансформированы нуклеотидной последовательностью/генетической конструкцией по изобретению. Это может быть, например, стадия отбора на основе селектируемого маркера, присутствующего в генетической конструкции по изобретению, или стадия, включающая обнаружение полипептида или конструкции по изобретению, например, с использованием специфических антител.
Трансформированная клетка-хозяин (которая может быть в форме или стабильной клеточной линии) или организмы-хозяева (которые могут быть в форме стабильной мутантной линии или штамма) образуют дополнительные аспекты настоящего изобретения.
Предпочтительно эти клетки-хозяева или организмы-хозяева таковы, что они экспрессируют или (по меньшей мере) способны экспрессировать (например, в подходящих условиях) полипептид или конструкцию по изобретению (а в случае организма-хозяина: по меньшей мере, в одной клетке, части, ткани или органе). Изобретение также включает следующие поколения, потомство и/или потомки клетки-хозяина или организма-хозяина по изобретению, которые могут быть получены, например, путем деления клеток или путем полового или бесполого размножения.
Соответственно, в другом аспекте изобретение относится к хозяину или клетке-хозяину, которая экспрессирует (или которая при подходящих обстоятельствах способна экспрессировать) полипептид или конструкцию по изобретению; и/или которая содержит нуклеиновую кислоту, кодирующую ее. HEKоторые предпочтительные, но не ограничивающие примеры таких хозяев или клеток-хозяев могут быть такими, как в целом описаны в WO 04/041867, WO 04/041865 или WO 09/068627. Например, полипептиды или конструкции по изобретению могут с преимуществом экспрессироваться, продуцироваться или изготавливаться в штамме дрожжей, таком как штамм Pichia pastoris. Настоящим также ссылаемся на WO 04/25591, WO 10/125187, WO 11/003622 и WO 12/056000, которые также описывают экспрессию/продукцию в Pichia и других хозяевах/клетках-хозяевах иммуноглобулиновых одиночных вариабельных доменов и полипептидов, содержащих их.
Для получения/достижения экспрессии полипептидов или конструкций по изобретению трансформированные клетка-хозяин или трансформированный организм-хозяин, как правило, могут храниться, поддерживаться и/или культивироваться в условиях, при которых (искомый) полипептид или конструкция по изобретению экспрессируется/продуцируется. Подходящие условия будут понятны специалисту в данной области и обычно зависят от используемой клетки-хозяина/организма-хозяина, а также от регуляторных элементов, которые контролируют экспрессию (соответствующей) нуклеотидной последовательности по изобретению. Опять же, настоящим ссылаемся на руководства и заявки на патенты, упомянутые выше в абзацах о генетических конструкциях по изобретению.
Как правило, подходящие условия могут включать использование подходящей среды, присутствие подходящего источника пищи и/или подходящих питательных веществ, использование подходящей температуры и, необязательно, наличие подходящего индуцирующего фактора или соединения (например, когда нуклеотидные последовательности по изобретению находятся под контролем индуцибельного промотора); все из которых могут быть выбраны квалифицированным специалистом. Опять же, в таких условиях полипептиды или конструкции по изобретению могут экспрессироваться конститутивным образом, транзиторным образом или только при соответствующей индукции.
Специалисту в данной области также будет понятно, что полипептид или конструкция по изобретению могут (сначала) быть получены в незрелой форме (как упомянуто выше), которая затем может быть подвергнута посттрансляционной модификации в зависимости от используемых клетки-хозяина/организма хозяина. Также полипептид или конструкция по изобретению могут быть гликозилированы, опять же, в зависимости от используемой клетки-хозяина/организма-хозяина.
Затем полипептид или конструкцию по настоящему изобретению можно выделить из клетки-хозяина/организма-хозяина и/или из среды, в которой культивировали указанную клетку-хозяина или организм-хозяина, с использованием известных per se методов выделения и/или очистки белка, таких как (препаративные) методы хроматографии и/или электрофореза, методы дифференциального осаждения, аффинные методы (например, с использованием специфической, расщепляемой аминокислотной последовательности, слитой с полипептидом или конструкцией по изобретению) и/или препаративные иммунологические методы (т.е. использование антител против полипептида или конструкции, которые должны быть выделены).
Композиции изобретения
Изобретение также относится к продукту или композиции, содержащей или включающей, по меньшей мере, один полипептид или конструкцию по изобретению, и/или, по меньшей мере, одну нуклеиновую кислоту по изобретению, и, необязательно, один или несколько других компонентов таких композиций, известных per se, т.е. к предполагаемому применению композиции.
Как правило, для фармацевтического применения полипептиды или конструкции по изобретению могут быть составлены в виде фармацевтического препарата или композиции, содержащей, по меньшей мере, один полипептид или конструкцию по изобретению и, по меньшей мере, один фармацевтически приемлемый носитель, разбавитель или эксципиент и/или адъювант, и, необязательно, один или несколько других фармацевтически активных полипептидов и/или соединений. Посредством неограничивающих примеров такая композиция может быть в форме, подходящей для перорального введения, для парентерального введения (например, внутривенного, внутрибрюшинного, подкожного, внутримышечного, внутрипросветного, внутриартериального или интратекального введения), для местного введения, для введение ингаляцией, кожным пластырем, имплантатом, суппозиторием и т.д., при этом парентеральное введение является предпочтительным. Такие подходящие формы введения, которые могут быть твердыми, полутвердыми или жидкими, в зависимости от способа введения, а также способы и носители для применения при их приготовлении, будут понятны специалисту в данной области и будут дополнительно описаны в данном документе. Такой фармацевтический препарат или композиция, как правило, будут упоминаться в данном документе как «фармацевтическая композиция». Фармацевтический препарат композиции для применения в организме, отличном от человека, обычно будут называться в данном документе «ветеринарная композиция». Некоторые предпочтительные, но не ограничивающие примеры таких композиций станут понятными из дальнейшего описания, приведенного в данном документе.
Таким образом, в дополнительном аспекте изобретение относится к фармацевтической композиции, которая содержит, по меньшей мере, один полипептид или конструкцию по изобретению и, по меньшей мере, один подходящий носитель, разбавитель или наполнитель (т.е. подходящий для фармацевтического применения), и, необязательно, один или несколько дополнительных активные вещества. В конкретном аспекте изобретение относится к фармацевтической композиции, которая содержит полипептид или конструкцию по изобретению, выбранную из любой из SEQ ID NO: 1-10, 47, 49, 52, 53, 55, 56, 58-61, 63 -67, и 338-342 и, по меньшей мере, один подходящий носитель, разбавитель или наполнитель (т.е. подходящий для фармацевтического применения) и, необязательно, одно или несколько других активных веществ.
Фраза «фармацевтически приемлемый» используется в данном документе для обозначения тех соединений, материалов, композиций и/или дозированных форм, которые в рамках здравого медицинского обоснования пригодны для использования в контакте с тканями людей и животных без чрезмерных токсичности, раздражения, аллергической реакции или других проблем или осложнений, соразмерных с разумным соотношением польза/риск.
Фраза «фармацевтически приемлемый носитель», при использовании в данном документе, означает фармацевтически приемлемый материал, композицию или носитель, такой как жидкий или твердый наполнитель, разбавитель, наполнитель или растворитель, инкапсулирующий материал, участвующий в переносе или транспортировке соединения по настоящему изобретению из одного органа или части тела, в другой орган или часть тела. Каждый носитель должен быть «приемлемым» в смысле совместимости с другими ингредиентами состава и не причинять вреда пациенту.
Как правило, полипептиды и конструкции по изобретению могут быть составлены и введены любым подходящим способом, известным per se. Настоящим ссылаемся, например, на общий уровень техники, упомянутый выше (и, в частности, на WO 04/041862, WO 04/041863, WO 04/041865, WO 04/041867 и WO 08/020079), а также на стандартные руководства, такие как Remington’s Pharmaceutical Sciences, 18th Ed., Mack Publishing Company, USA (1990), Remington, the Science and Practice of Pharmacy, 21st Ed., Lippincott Williams and Wilkins (2005); или the Handbook of Therapeutic Antibodies (S. Dubel, Ed.), Wiley, Weinheim, 2007 (см., например, стр. 252-255).
Например, полипептиды или конструкции по изобретению могут быть составлены и введены любым способом, известным per se для обычных антител и фрагментов антител (включая ScFv и диатела) и других фармацевтически активных белков. Такие составы и способы их приготовления будут понятны специалисту в данной области и, например, включают препараты, подходящие для парентерального введения (например, внутривенного, внутрибрюшинного, подкожного, внутримышечного, внутрипросветного, внутриартериального или интратекального введения).
Препараты для парентерального введения могут, например, представлять собой стерильные растворы, суспензии, дисперсии или эмульсии, которые подходят для инфузии или инъекции. Подходящие носители или разбавители для таких препаратов, например, включают, без ограничения указанным, те, которые упомянуты на странице 143 в WO 08/020079. Обычно водные растворы или суспензии будут предпочтительными.
Полипептиды или конструкции по изобретению можно вводить внутривенно или внутрибрюшинно путем инфузии или инъекции. Растворы полипептидов или конструкций по изобретению могут быть приготовлены в воде, необязательно смешанной с нетоксичным поверхностно-активным веществом. Дисперсии могут быть также получены в глицерине, жидких полиэтиленгликолях, триацетине и в их смесях, и в маслах. При обычных условиях хранения и применения эти препараты могут содержать консервант для предотвращения роста микроорганизмов.
Фармацевтические композиции, подходящие для парентерального введения, включают один или несколько иммуноглобулиновых одиночных вариабельных доменов, полипептидов или конструкций в комбинации с одним или несколькими фармацевтически приемлемыми стерильными изотоническими водными или неводными растворами, дисперсиями, суспензиями или эмульсиями или стерильными порошками, которые могут быть восстановлены в стерильные растворы или дисперсии для инъекций непосредственно перед использованием, которые могут содержать сахара, спирты, антиоксиданты, буферы, бактериостаты, растворенные вещества, которые делают композицию изотонической с кровью предполагаемого реципиента, или суспендирующие или загущающие агенты.
Примеры подходящих водных и неводных носителей, которые могут быть использованы в фармацевтических композициях, включают воду, этанол, полиолы (такие как глицерин, пропиленгликоль, полиэтиленгликоль и тому подобное) и их подходящие смеси, растительные масла, такие как оливковое масло и инъецируемые органические сложные эфиры, такие как этилолеат. Правильную текучесть можно поддерживать, например, путем применения материалов для покрытия, таких как лецитин, путем поддержания требуемого размера частиц в случае дисперсий и с помощью поверхностно-активных веществ.
Эти композиции могут также содержать адъюванты, такие как консерванты, смачивающие агенты, эмульгирующие агенты и диспергирующие агенты. Предотвращение действия микроорганизмов на соединения по настоящему изобретению может быть обеспечено путем включения различных антибактериальных и противогрибковых агентов, например, парабена, хлорбутанола, фенола, сорбиновой кислоты, тимеросала и тому подобного. Также может быть желательно включить в композиции изотонические агенты, такие как сахара, хлорид натрия и тому подобное. Кроме того, длительное всасывание инъецируемой фармацевтической формы может быть вызвано включением агентов, которые замедляют всасывание, таких как моностеарат алюминия и желатин.
В некоторых случаях, чтобы продлить действие лекарственного средства, желательно замедлить всасывание лекарственного средства при подкожных или внутримышечных инъекциях. Это может быть достигнуто путем использования жидкой суспензии кристаллического или аморфного материала, имеющего плохую растворимость в воде. Скорость абсорбции лекарственного средства зависит от скорости его растворения, которая, в свою очередь, может зависеть от размера кристалла и кристаллической формы. В ином случае, отсроченная абсорбция лекарственной формы, вводимой парентерально, достигается путем растворения или суспендирования лекарственного средства в масляном носителе.
Инъецируемые депо-формы получают путем формирования микрокапсульных матриц рассматриваемых соединений в биоразлагаемых полимерах, таких как полилактид-полигликолид. В зависимости от соотношения лекарства и полимера и природы конкретного используемого полимера можно контролировать скорость высвобождения лекарства. Примеры других биодеградируемых полимеров включают поли (ортоэфиры) и поли (ангидриды). Инъекционные депо-составы также готовят путем введения лекарственного средства в липосомы или микроэмульсии, которые совместимы с тканями организма.
Фармацевтические лекарственные формы, подходящие для инъекций или инфузий, могут включать стерильные водные растворы или дисперсии или стерильные порошки, содержащие активный ингредиент, которые адаптированы для немедленного приготовления стерильных инъекционных или инфузионных растворов или дисперсий, необязательно инкапсулированных в липосомы. Во всех случаях конечная лекарственная форма должна быть стерильной, жидкой и стабильной в условиях производства и хранения.
Стерильные растворы для инъекций готовят путем включения полипептидов или конструкций по изобретению в необходимом количестве в соответствующем растворителе с несколькими другими ингредиентами, перечисленными выше, по мере необходимости, с последующей стерилизацией на фильтре. В случае стерильных порошков для приготовления стерильных инъецируемых растворов, способы получения включают способы вакуумной и лиофильной сушки, которые дают порошок активного ингредиента плюс любой дополнительный искомый ингредиент, присутствующий в предварительно стерильно профильтрованных растворах.
Количество полипептидов или конструкций по изобретению, необходимое для применения при лечении, будет варьировать не только в зависимости от конкретного выбранного полипептида или конструкции, но также от пути введения, природы состояния, подвергаемого лечению, а также возраста и состояния пациента и в конечном итоге будет определяться по усмотрению лечащего терапевта или врача. Также дозировка полипептидов или конструкций по изобретению будет варьировать.
Искомая доза может быть удобно представлена в виде одной дозы или в виде разделенных доз, вводимых через соответствующие интервалы, например, в виде двух, трех, четырех или более субдоз в день. Сама субдоза может быть дополнительно разделена, например, на несколько отдельных свободно распределенных введений.
Введение может включать долгосрочное ежедневное лечение. Под «долгосрочным» подразумевается, по меньшей мере, две недели, а предпочтительно несколько недель, месяцев или лет. Необходимые модификации в этом диапазоне доз могут быть определены специалистом в данной области с использованием только обычных экспериментов, приведенных в данном документе. См. Remington's Pharmaceutical Sciences (Martin, EW, ed. 4), Mack Publishing Co., Easton, PA. Дозировка также может быть скорректирована индивидуальным терапевтом в случае каких-либо осложнений.
В другом аспекте предлагаются наборы, содержащие полипептид или конструкцию по изобретению, нуклеиновую кислоту по изобретению, экспрессирующий вектор по изобретению или хозяина или клетку-хозяина по изобретению. Набор также может содержать один или несколько флаконов, содержащих полипептид или конструкцию и инструкции по применению. Набор также может содержать средства для введения полипептида или конструкции по изобретению, такие как шприц, инфузор или тому подобное.
Применение полипептидов, конструкции или композиций по изобретению
Изобретение, кроме того, относится к применениям и использованиям полипептидов, конструкций, нуклеиновых кислот, клеток-хозяев и композиций, описанных в данном документе, а также к способам профилактики и/или лечения заболеваний или состояний, связанных с CD123. Некоторые предпочтительные, но не ограничивающие применения и использования станут понятны из дальнейшего описания, приведенного в данном документе.
Полипептиды, конструкции и композиции по настоящему изобретению обычно можно использовать для активации Т-клеток в (сайте) CD123-экспрессирующих клеток; например, для лизиса клеток, экспрессирующих CD123. Одновременное связывание полипептидов и конструкций по настоящему изобретению с TCR на Т-клетках и CD123 на опухолевых клетках индуцирует активацию клеток и последующий лизис (уничтожение) клеток, экспрессирующих CD123. Когда полипептиды и конструкции по настоящему изобретению не связаны с клетками, экспрессирующими CD123, они практически не активируют Т-клетки. По существу, лизис, не зависящий от мишени (т.е. лизис клеток без экспрессии CD123) полипептидами и конструкциями по настоящему изобретению, является минимальным.
Соответственно, в одном аспекте полипептиды, конструкции и композиции по настоящему изобретению вызывают лизис клеток, экспрессирующих CD123, со средним процентом лизиса, по меньшей мере, 10%, предпочтительно, по меньшей мере, 15%, таким как, по меньшей мере, 16%, 17%, 18%, 19% или 20% или более, например, 30% или более по сравнению с количеством клеток, экспрессирующих CD123, в тех же условиях, но без присутствия полипептида или конструкции по изобретению, измеренных любым подходящим способом, известным per se, например, с использованием одного из описанных в данном документе анализов (таких как анализы перенаправленного уничтожения, опосредованного Т-клетками человека, на основе проточной цитометрии, как описано в разделе «Примеры»).
Помимо этого или в то же время лизис CD123-отрицательных клеток, индуцированный активацией Т-клеток, полипептидами, конструкциями и композициями по настоящему изобретению, составляет не более около 10%, например, 9% или менее, например, 8, 7 или 6% или даже менее количества CD123-отрицательных клеток в тех же условиях, но без присутствия полипептида или конструкции по изобретению, измеренных любым подходящим способом, известным per se, например, с использованием одного из описанных анализов в данном документе (таких как анализы перенаправленного уничтожения, опосредованного Т-клетками человека, на основе проточной цитометрии, как описано в разделе «Примеры»).
Такое уничтожение клеток, экспрессирующих CD123, может быть выгодным при заболеваниях или состояниях, при которых присутствие таких клеток, экспрессирующих CD123, является обильным и/или нежелательным.
Соответственно, в одном аспекте в настоящем изобретении предлагается полипептид, конструкция или композиция для применения в качестве лекарственного средства.
В дополнительном аспекте в настоящем изобретении предлагается полипептид или конструкция по изобретению или композиция, содержащая их, для применения при профилактике, лечении и/или ослаблении ассоциированного с CD123 заболевания или состояния.
Более конкретно, в настоящем изобретении предлагается полипептид или конструкция по изобретению или композиция, содержащая их, для применения при профилактике, лечении и/или облегчении ассоциированного с CD123 заболевания или состояния, где ассоциированное с CD123 заболевание или состояние является пролиферативным заболеванием или воспалительным состоянием.
Изобретение также относится к способу профилактики, лечения и/или облегчения ассоциированного с CD123 заболевания или состояния, причем указанный способ включает введение объекту, нуждающемуся в этом, фармацевтически активного количества полипептида или конструкции по изобретению, и/или композиции, содержащей их.
В частности, настоящее изобретение относится к способу, как описано выше, в котором заболевание или состояние, связанное с CD123, представляет собой пролиферативное заболевание или воспалительное состояние.
Воспалительным состоянием может быть любое воспалительное состояние, которое можно предотвратить, лечить и/или облегчить путем уничтожения клеток, экспрессирующих CD123.
В одном аспекте воспалительное состояние выбрано из группы, состоящей из аутоиммунной волчанки (SLE), аллергии, астмы и ревматоидного артрита.
Соответственно, настоящее изобретение относится к полипептиду, конструкции или композиции для применения при профилактике, лечении и/или уменьшении воспалительного состояния, где указанное воспалительное состояние выбрано из группы, состоящей из аутоиммунной волчанки (SLE), аллергии, астмы и ревматоидного артрита.
Соответственно, настоящее изобретение также относится к способам профилактики, лечения и/или облегчения воспалительного состояния, где указанное воспалительное состояние выбрано из группы, состоящей из аутоиммунной волчанки (SLE), аллергии, астмы и ревматоидного артрита, причем указанный способ включает введение объекту, нуждающемуся в этом, фармацевтически активного количества, по меньшей мере, одного полипептида или конструкции по изобретению или композиции по изобретению.
Пролиферативное заболевание может представлять собой любое пролиферативное заболевание, которое можно предотвратить, лечить и/или облегчить путем уничтожения CD123-экспрессирующих клеток.
В одном аспекте указанное пролиферативное заболевание представляет собой онкологическое заболевание. Примеры онкологических заболеваний, связанных со сверхэкспрессией CD123, будут понятны для специалиста на основании раскрытия в данном документе и, например, включают (без ограничения указанным) следующие злокачественные опухоли: лимфомы (в том числе лимфому Беркитта, лимфому Ходжкина и неходжкинскую лимфому), лейкозы (включая острый миелолейкоз, хронический миелоидный лейкоз, В-клеточный острый лимфобластный лейкоз, хронический лимфолейкоз и волосатоклеточный лейкоз), миелодиспластический синдром, новообразование бластных плазмоцитоидных дендритных клеток, системный мастоцитоз и множественную миелому.
Соответственно, настоящее изобретение относится к полипептиду, конструкции или композиции для применения при профилактике, лечении и/или облегчении онкологического заболевания, где указанное онкологическое заболевание выбрано из группы, состоящей из лимфом (в том числе лимфомы Беркитта, лимфомы Ходжкина и неходжкинской лимфомы), лейкозов (включая острый миелолейкоз, хронический миелоидный лейкоз, В-клеточный острый лимфобластный лейкоз, хронический лимфолейкоз и волосатоклеточный лейкоз), миелодиспластического синдрома, новообразования бластных плазмоцитоидных дендритных клеток, системного мастоцитоза и множественной миеломы.
Соответственно, настоящее изобретение также относится к способам профилактики, лечения и/или облегчения онкологического заболевания, при котором указанное онкологическое заболевание выбирают из группы, состоящей из лимфом (в том числе лимфомы Беркитта, лимфомы Ходжкина и неходжкинской лимфомы), лейкозов (включая острый миелолейкоз, хронический миелоидный лейкоз, В-клеточный острый лимфобластный лейкоз, хронический лимфолейкоз и волосатоклеточный лейкоз), миелодиспластического синдрома, новообразования бластных плазмоцитоидных дендритных клеток, системного мастоцитоза и множественной миеломы, где указанный способ включает введение, объекту, нуждающемуся в этом, фармацевтически активного количества, по меньшей мере, одного полипептида или конструкции по изобретению или композиции по изобретению.
Изобретение также относится к применению полипептида или конструкции по изобретению или композиции по изобретению для изготовления лекарственного средства.
В дополнительном аспекте настоящее изобретение относится к применению полипептида или конструкции по изобретению или композиции, содержащей их, для изготовления лекарственного средства для профилактики, лечения и/или облегчения ассоциированного с CD123 заболевания или состояния.
Более конкретно, настоящее изобретение относится к применению полипептида или конструкции по изобретению или композиции, содержащей их, для изготовления лекарственного средства для профилактики, лечения и/или облегчения заболевания или состояния, связанного с CD123, где связанное с CD123 заболевание или состояние представляет собой пролиферативное заболевание или воспалительное состояние.
В одном аспекте изобретение относится к применению полипептида или конструкции по изобретению или композиции, содержащей его, для изготовления лекарственного средства для профилактики, лечения и/или облегчения воспалительного состояния, при котором указанное воспалительное состояние выбран из группы, состоящей из аутоиммунной волчанки (SLE), аллергии, астмы и ревматоидного артрита.
В другом аспекте изобретение относится к применению полипептида или конструкции по изобретению или композиции, содержащей его, для изготовления лекарственного средства для профилактики, лечения и/или облегчения состояния пролиферативного заболевания, где указанное пролиферативное заболевание - это онкологическое заболевание. Примеры онкологических заболеваний, связанных со сверхэкспрессией CD123, будут понятны для специалиста на основании раскрытия в данном документе и, например, включают (без ограничения указанным) следующие онкологические заболевания: лимфомы (в том числе лимфому Беркитта, лимфому Ходжкина и неходжкинскую лимфому), лейкозы (включая острый миелолейкоз, хронический миелоидный лейкоз, В-клеточный острый лимфобластный лейкоз, хронический лимфолейкоз и волосатоклеточный лейкоз), миелодиспластический синдром, новообразование бластных плазмоцитоидных дендритных клеток, системный мастоцитоз и множественную миелому.
Соответственно, настоящее изобретение также относится к применению полипептида или конструкции по изобретению или композиции, содержащей их, для изготовления лекарственного средства для профилактики, лечения и/или облегчения состояния при онкологическом заболевании, где указанное онкологическое заболевание выбрано из группы, состоящей из лимфом (в том числе лимфомы Беркитта, лимфомы Ходжкина и неходжкинской лимфомы), лейкозов (включая острый миелолейкоз, хронический миелоидный лейкоз, В-клеточный острый лимфобластный лейкоз, хронический лимфолейкоз и волосатоклеточный лейкоз), миелодиспластического синдрома, новообразования бластных плазмоцитоидных дендритных клеток, системного мастоцитоза и множественной миеломы.
В контексте настоящего изобретения термин «профилактика, лечение и/или облегчение» включает не только профилактику, лечение и/или облегчение заболевания, но также обычно включает предотвращение возникновения заболевания, замедление или изменение хода заболевания, предотвращение или замедление появления одного или нескольких симптомов, связанных с заболеванием, уменьшение и/или ослабление одного или нескольких симптомов, связанных с заболеванием, уменьшение тяжести и/или продолжительности заболевания и/или любых симптомов, связанных с ним, и/или предотвращение дальнейшего увеличения тяжести заболевания и/или любых связанных с ним симптомов, предотвращение, уменьшение или устранение любого физиологического повреждения, вызванного заболеванием, и, как правило, любое фармакологическое действие, которое полезно для пациента, которого подвергают лечению.
Используемые в данном документе взаимозаменяемо, термин «фармацевтически эффективное количество» или «фармацевтически активное количество» относится к количеству, достаточному для активации Т-клеток в присутствии экспрессирующих CD123 клеток. В контексте заболевания, ассоциированного с CD123, оно относится к количеству полипептида, конструкции или фармацевтической композиции отдельно или в комбинации с другой терапией, которая обеспечивает терапевтическое преимущество при профилактике, лечении и/или облегчении заболевания, ассоциированного с CD123. Используемый в связи с количеством мультиспецифического полипептида или конструкции по изобретению, этот термин может охватывать количество, которое улучшает общую терапию, уменьшает или позволяет избежать нежелательных эффектов или повышает терапевтическую эффективность или синергизм с другой терапией.
Используемый в данном документе термин «терапия» относится к любому протоколу, способу и/или агенту, который можно использовать для лечения, профилактики и/или лечения ассоциированного с CD123 заболевания, например, воспалительного состояния или пролиферативного заболевания. В некоторых воплощениях термины «терапии» и «терапия» относятся к биологической терапии, поддерживающей терапии и/или другим методам лечения, применимым для лечения, профилактики и/или тактики ведения ассоциированного с CD123 заболевания, например, воспалительного состояния или пролиферативного заболевания или одного или нескольких его симптомов, известных специалисту в данной области, например, медицинскому персоналу.
В другом аспекте изобретение относится к способу иммунотерапии и, в частности, к пассивной иммунотерапии, который включает введение объекту, страдающему или подверженному риску заболевания, связанного с CD123, фармацевтически активного количества полипептида или конструкции по изобретению и/или фармацевтической композиции, содержащей их.
Объектом, подлежащим лечению, может быть любое теплокровное животное, но, в частности, это млекопитающее и, в частности, человек. Как будет понятно специалисту в данной области, объектом, подлежащим лечению, будет, в частности, человек, страдающий или подверженный риску заболеваний и состояний, упомянутых в данном документе.
Как правило, полипептиды или конструкции согласно изобретению и/или композиции, содержащие их, можно вводить любым подходящим способом. Например (без ограничения указанным), полипептиды по изобретению и композиции, содержащие их, можно вводить перорально, парентерально (например, внутривенно, внутрибрюшинно, подкожно, внутримышечно, внутримышечно, внутриартериально или интратекально или любым другим путем введения, который избегает желудочно-кишечный тракт), интраназально, трансдермально, местно, с помощью суппозитория, путем ингаляции, опять же, в зависимости от конкретной фармацевтической композиции или композиции, которая будет использоваться. Врач сможет выбрать подходящий путь введения и подходящую фармацевтическую композицию или композицию для применения при таком введении, в зависимости от заболевания или расстройства, которое нужно предотвратить или лечить, и других факторов, хорошо известных врачу.
В предпочтительном аспекте полипептиды или конструкции по изобретению или композиции, содержащие их, вводят внутривенно (например (но без ограничения указанным), посредством инфузии или болюса) или подкожно.
Полипептиды или конструкции по изобретению и/или композиции, содержащие их, вводят в соответствии с режимом лечения, который подходит для предотвращения, лечения и/или ослабления заболевания, связанного с CD123. Врач, как правило, сможет определить подходящую схему лечения, в зависимости от таких факторов, как тип подлежащего лечению заболевания, стадия заболевания, тяжесть заболевания и/или тяжесть его симптомов, конкретный полипептид или конструкция изобретения, которые следует использовать, конкретный способ введения и фармацевтическая композиция или композиция, которые следует использовать, возраст, пол, масса, рацион, общее состояние пациента и подобные факторы, хорошо известные врачу.
Обычно схема лечения включает введение одного или нескольких полипептидов или конструкций по изобретению или одной или нескольких композиций, содержащих их, в одном или нескольких фармацевтически эффективных количествах или дозах. Конкретное количество или дозы для введения могут быть определены врачом, опять же на основе факторов, указанных выше.
Как правило, для профилактики, лечения и/или облегчения заболевания, связанного с CD123, и в зависимости от типа заболевания, связанного с CD123 (например, пролиферативного расстройства (включая онкологическое заболевание) или воспалительного состояния), подлежащего лечению, стадии заболевания, которая должна быть подвергнута лечению, эффективности полипептида или конструкции по изобретению, которые нужно использовать, конкретного пути введения и конкретного используемого фармацевтического состава или композиции, полипептиды по изобретению, как правило, будут вводить в количестве от 1 грамма до 1 микрограмма на кг массы тела в сутки. Врач, как правило, сможет определить подходящую суточную дозу в зависимости от факторов, упомянутых в данном документе. Также будет ясно, что в определенных случаях врач может выбрать отклонение от этих количеств, например, на основе факторов, упомянутых выше, и своего экспертного заключения. Как правило, некоторые указания относительно вводимых количеств могут быть получены из количеств, обычно вводимых для сопоставимых обычных антител фрагментов антител против одной и той же мишени, по существу, одним и тем же путем, с учетом, однако, различий в аффинности/авидности, эффективности, биораспределении, периода полувыведения и подобных факторов, хорошо известны специалисту.
Обычно в вышеуказанном способе будет использоваться один полипептид или конструкция по изобретению. Однако в объем изобретения входит использование двух или более полипептидов или конструкций по изобретению в комбинации.
Полипептиды или конструкции по изобретению или композиции, содержащие их, также можно использовать в комбинации с одним или несколькими другими фармацевтически активными соединениями или принципами, т.е. в качестве комбинированной схемы лечения, которая может приводить или не приводить к синергетическому эффекту. Опять же, врач сможет выбрать такие дополнительные соединения или принципы, а также подходящую комбинированную схему лечения, основываясь на вышеупомянутых факторах и своем экспертном заключении.
В частности, полипептиды, конструкции и композиции по изобретению могут быть использованы в сочетании с другими фармацевтически активными соединениями или принципами, которые используются или могут быть использованы для профилактики, лечения и/или облегчения ассоциированного с CD123 заболевания (например, пролиферативного расстройства (включая онкологические заболевания) или воспалительного состояния), в результате которого может быть получен или не получен синергетический эффект. Примеры таких соединений и принципов, а также пути, способы и фармацевтические составы или композиции для их введения будут понятны врачу.
Примеры таких соединений и принципов, а также путей, способов и фармацевтических составов или композиций для их введения будут понятны врачу и включают (без ограничения указанным): антрациклины (даунурубицин, доксорубицин, идарубицин, митоксантрон, рубидазон), цитарабин (AML), гематопоэтические факторы роста, деметилирующие агенты (такие как децитабин или азацитидин), политрансретиноевую кислоту, триоксид мышьяка, ингибиторы ДНК-метилтрансферазы, мелфалан, преднизон, леналидомид, циклофосфамид, талидомид, дексаметазон, бортезомиб, флударабин, кортикостероиды, винкристин, расбуриказу, L-аспарагиназу, ПЭГилированную аспарагиназу, кладрибин, пентостатин, адриамицин, блеомицин, винбластин, дакарбазин; или любую их комбинацию.
Когда два или несколько веществ или действующих начал должны использоваться как часть комбинированной схемы лечения, их можно вводить одним и тем же путем введения или разными путями введения, по существу, в одно и то же время или в разные моменты времени (например, по существу, одновременно, последовательно или в соответствии с чередующимся режимом). Когда вещества или действующие начала должны вводиться одновременно посредством одного и того же пути введения, их можно вводить в виде различных фармацевтических композиций или композиций или части комбинированной фармацевтической композиции или композиции, как будет понятно специалисту в данной области.
Кроме того, когда два или несколько активных вещества или действующих начала должны использоваться как часть комбинированного режима лечения, каждое из веществ или действующих начал может вводиться в том же количестве и в соответствии с тем же режимом, который используется, когда соединение или действующее начало применяется само по себе, и такое комбинированное применение может привести или не привести к синергетическому эффекту. Однако когда комбинированное применение двух или более активных веществ или действующих начал приводит к синергетическому эффекту, также может быть возможно уменьшить количество одного, нескольких или всех веществ или действующих начал, которые следует вводить, при этом все еще достигая искомого терапевтического действия. Это может, например, быть полезным для предотвращения, ограничения или уменьшения любых нежелательных побочных эффектов, которые связаны с применением одного или нескольких веществ или действующих начал, когда они используются в их обычных количествах, при одновременном получении искомого фармацевтического или терапевтического эффекта.
Эффективность схемы лечения, используемой в соответствии с изобретением, может быть определена и/или отслежена любым способом, известным per se для данного заболевания или расстройства, как будет понятно врачу. Врач также сможет, в случае необходимости и в каждом конкретном случае, изменять или модифицировать конкретную схему лечения для достижения искомого терапевтического эффекта, чтобы избежать, ограничить или уменьшить нежелательные побочные эффекты, и/или для достижения надлежащего баланса между достижением искомого терапевтического эффекта, с одной стороны, и предотвращением, ограничением или уменьшением нежелательных побочных эффектов, с другой стороны.
Как правило, режим лечения будет соблюдаться до тех пор, пока не будет достигнут искомый терапевтический эффект и/или до тех пор, пока должен поддерживаться искомый терапевтический эффект. Опять же, это может определить врач.
Дальнейшее применение полипептидов или конструкций, нуклеиновых кислот, генетических конструкций и хозяев и клеток-хозяев по изобретению будет понятно для специалиста на основании раскрытия в данном документе.
Аспекты, проиллюстрированные и обсуждаемые в этом описании, предназначены только для обучения специалистов в данной области техники наилучшему способу, известному изобретателям для создания и применения изобретения. Модификации и вариации вышеописанных аспектов изобретения возможны без отступления от изобретения, что понятно специалистам в данной области техники в свете вышеизложенного. Следовательно, следует понимать, что в рамках формулы изобретения и ее эквивалентов изобретение может быть осуществлено на практике иначе, чем конкретно описано.
Далее изобретение будет описано с помощью следующих неограничивающих предпочтительных аспектов, примеров и фигур.
Полное содержание всех источников (включая литературные источники, выпущенные патенты, опубликованные патентные заявки и совместно рассматриваемые патентные заявки), приведенные во всей этой заявке, настоящим полностью включены ссылкой, в частности для описания, ссылка на которое дана выше.
ПРИМЕРЫ
Пример 1. Материалы и методы, относящиеся к TCR
1.1. TCR αβ/CD3-трансфицированные клеточные линии
Были получены транзиторные и стабильные клеточные линии CHO-K1 (ATCC: CCL-61), HEK293H (Life technologies, 11631-017), Llana (фибробластные клетки пуповины ламы) с рекомбинантной сверхэкспрессией всех 6 цепей полного комплекса человеческого Т-клеточного рецептора (TCR). Для этого кодирующие последовательности цепи TCR альфа (α) и TCR бета (β) были клонированы в векторе на основе pcDNA3.1, ниже промотора CMV, а последовательность 2А-подобного вирусного пептида была вставлена между обеими цепями для того, чтобы вызвать перескакивание рибосомы во время трансляции полипротеина. В этом же векторе кодирующие последовательности эпсилон, дельта, гамма и дзета цепей комплекса CD3 клонировали ниже по последовательности от дополнительного промотора CMV, также с использованием последовательности 2А-подобного вирусного пептида между соответствующими цепями. Кроме того, получали стабильный клон HEK293H с рекомбинантной сверхэкспрессией 4 цепей человеческого CD3, как описано выше, с использованием одногенного вектора.
Используемые последовательности для константных доменов CD3 человека и TCR человека были получены из UniProtKB (CD3 дельта: P04234, CD3 гамма: P09693, CD3 эпсилон: P07766, CD3 дзета: P20963, TCR α: P01848 и TCR β: P01850; SEQ ID NO: 70-75, соответственно). Последовательности для вариабельных доменов TCRα/β человека были получены из последовательностей кристаллической структуры (коды PDB: 2IAN, 2XN9 и 3TOE) (вариабельные домены TCRα человека, были получены из 2IAN, 2XN9 и 3TOE с SEQ ID NO: 343, 76 и 345 соответственно; вариабельные домены TCRβ человека, были получены из 2IAN, 2XN9 и 3TOE с SEQ ID NO: 344, 77 и 346, соответственно).
Экспрессия на клеточной поверхности комплекса Т-клеточного рецептора человека была подтверждена проточной цитометрией с использованием функционального мышиного IgG2b антитела против человеческого TCRα/β, клон BW242/412 (Miltenyi, 130-098-219) и функционального антитела IgG2a мыши против CD3, меченного PE, клон ОКТ-3 (eBioscience, 12-0037) (фигура 1).
1.2 Растворимые рекомбинантные белки TCR α/β
Растворимые белка TCRα/β человека и яванского макака/макака-резус были получены собственными силами. Последовательности внеклеточной части константного домена TCRα/β человека были получены из UniProtKB (TCR α: P01848 и TCR β: P01850; SEQ ID NO: 74 и 75, соответственно). Вариабельные домены TCRα/β человека были получены из последовательности кристаллической структуры (код PDB: 2XN9; SEQ ID NO: 76 и 77, соответственно, для цепи α и β).
Последовательности для внеклеточной части константных доменов TCRα/β яванского макака/макака-резус были получены из файлов GenBank EHH63463 и AEA41868, соответственно (SEQ ID NO: 347 и 348). Последовательности для вариабельных доменов TCRα/β яванского макака/макака-резус были получены из AEA41865 и AEA41866 (SEQ ID NO: 349 и 350, соответственно, для α и β цепи).
Внеклеточные домены человеческого TCRα/β(2XN9) или TCRα/β яванского макака/макака-резус сливали с последовательностью, кодирующей белок «молнии» (O'Shea et al. 1993 Curr. Biol. 3 (10): 658-667), экспрессировали в клетках CHOK1SV (Lonza) с использованием системы экспрессии генов GS Lonza™, а затем очищали.
Качество TCR α/β -белок «молнии» оценивали в анализе связывания ELISA. 96-луночные планшеты для ELISA Maxisorp (Nunc) покрывали 2 мкг/мл растворимого рекомбинантного TCRα/β(2XN9) человека - белок «молнии» или растворимого рекомбинантного TCRα/β - белок «молнии». После инкубации в течение ночи планшеты промывали и блокировали PBS + 1% казеина в течение 1 часа при комнатной температуре. Затем планшеты инкубировали с серийными разведениями либо меченного FLAG функционального нанотела, либо функционального IgG-антитела мыши против TCRα/β не являющегося человеком примата/крысы, клон R73 (eBioscience, 16-5960) в течение 1 часа при комнатной температуре, при встряхивании, снова промывали и инкубировали с моноклональным антителом против FLAG, конъюгированного с M2-пероксидазой (HRP) (Sigma, A8592), соответственно, с конъюгированным с пероксидазой кроличьим антителом против мышиных иммуноглобулинов (Dako, P0260). Через 1 час добавляли раствор TMB One (Promega, G7431). Реакцию останавливали с помощью 2 М H2SO4, и дозозависимое связывание определяли путем измерения оптической плотности при 450 нм с использованием Tecan sunrise 4 (фигура 2).
Пример 2. Иммунизация лам TCR/CD3, клонирование репертуаров фрагментов антител, состоящих только из тяжелых цепей, и получение фагов
2.1. Иммунизация
Предполагается, что в камелидах (например, в ламе и альпаке) создаются антитела, содержащие только тяжелые цепи против α и/или β константных цепей Т-клеточного рецептора (TCR). Хотя нативный комплекс Т-клеточного рецептора состоит из цепей CD3 (гамма, дельта, эпсилон и дзета), а также α- и β-цепей TCR, было высказано предположение, что отсутствие цепей CD3 облегчило бы доступ к константным доменам TCR. Тем более что цепи CD3 латерально окружают и ограничивают доступ к константным доменам α- и β-цепей TCR. Вопреки нашему опыту с другими мишенями, получение иммунного ответа против α- или β-цепей TCR оказалось не таким простым, как ожидалось.
В окончательном подходе, после одобрения Этического комитета (CRIA, LA1400575, Belgium-EC2012 # 1), авторы предприняли попытку сложного протокола иммунизации с ДНК, кодирующей Т-клеточный комплекс. Вкратце, 3 дополнительные ламы были иммунизированы плазмидным вектором pVAX1-TCR(2IAN)/CD3 человека (описан в примере 1.1) (Invitrogen, Карлсбад, Калифорния, США) и плазмидным вектором pVAX1- TCRα/β(2XN9)/CD3 человека (описанным в примере 1.1) (Invitrogen, Карлсбад, Калифорния, США) по стандартным протоколам. Две ламы получили дополнительно 1 подкожную инъекцию первичных Т-клеток человека. Человеческие Т-клетки собирали из лейкоцитарной пленки от здоровых добровольцев (банк крови Гента) с использованием RosetteSep (StemCell Technologies, 15061) с последующим обогащением на Ficoll-Paque™ PLUS (GE Healthcare, 17-1440-03) в соответствии с инструкциями производителя и хранили в жидком азоте. После оттаивания клетки промывали и повторно суспендировали в D-PBS от Gibco и хранили на льду до инъекции.
2.2. Клонирование репертуаров фрагментов антител, содержащих только тяжелые цепи, и получение фагов.
Для каждого животного образцы крови собирали после введения одного типа иммунизационного антигена. Из этих образцов крови PBMC готовили с использованием Ficoll-Hypaque в соответствии с инструкциями производителя (Amersham Biosciences, Пискатавэй, Нью-Джерси, США). Для каждой иммунизированной ламы библиотеки конструировали путем объединения всей РНК, выделенной из образцов, происходящих из определенного подмножества схем иммунизации, т.е. после одного типа иммунизационного антигена.
Вкратце, репертуар VHH, амплифицированный с помощью ПЦР, клонировали через специфические сайты рестрикции в вектор, предназначенный для содействия фаговому дисплею библиотеки VHH. Вектор был получен из pUC119. В рамке с кодирующей последовательностью VHH вектор кодирует C-концевой 3xFLAG и метку His6. Фаги готовили в соответствии со стандартными протоколами (см., например, WO 04/041865, WO 04/041863, WO 04/062551, WO 05/044858 и другие источники предшествующего уровня техники и поданные Ablynx NV заявки, процитированные в данном документе).
Пример 3. Отбор VHH, специфичных к TCR/CD3, с помощью фагового дисплея
Подавляющее большинство отобранных VHH было направлено против вариабельных областей цепей TCR α или TCR β. Поэтому авторы должны были разработать различные стратегии отбора и контр-отбора.
Вкратце, репертуары VHH, полученные из всех лам и клонированные в виде фаговой библиотеки, использовали в различных стратегиях отбора, применяя множество условий отбора. Отбор с использованием трансфицированных клеточных линий TCR/CD3 человека с тем же вариабельным доменом, который использовался во время иммунизации, давали только агенты, связывающиеся с вариабельным доменом. По этой причине во время отбора использовали инструменты, включающие трансфецированные клетки, включающие различные вариабельные домены TCRα/β (описанные в примере 1.1), растворимый белок (описанный в примере 1.2) или первичные Т-клетки человека (выделенные, как описано в примере 2.1)), которые доказали свое решающее значение при идентификации константных доменов. Дополнительные переменные во время отбора включали способ презентации антигена (в растворе при использовании клеток или с нанесением на планшеты, при использовании белков), концентрацию антигена, используемый ортолог (рекомбинантный белок TCR α/β человека или яванского макака) и количество раундов отбора. Все отборы с твердофазным покрытием осуществляли в 96-луночных планшетах Maxisorp (Nunc, Висбаден, Германия).
Отбор осуществляли следующим образом. Препараты антигена TCRα/β-CD3 для форматов отбора в твердой фазе и жидкой фазе были представлены, как описано выше, в нескольких концентрациях. После 2 ч инкубации с библиотеками фагов с последующей интенсивной промывкой, связанные фаги элюировали трипсином (1 мг/мл) в течение 15 минут. Активность трипсин-протеазы немедленно нейтрализовали путем применения 0,8 мМ ингибитора протеазы ABSF. В качестве контроля параллельно проводили отборы без антигена.
Полученные в результате фаги были использованы для заражения E. coli для анализа отдельных клонов VHH. Периплазматические экстракты готовили в соответствии со стандартными протоколами (см., например, WO 03/035694, WO 04/041865, WO 04/041863, WO 04/062551 и другие источники предшествующего уровня техники и процитированные в данном документе заявки, поданные Ablynx NV).
Пример 4. Скрининг, анализ последовательности и очистка
4.1. Скрининг TCR/CD3-связывающих нанотел в анализе методом проточной цитометрии
Периплазматические экстракты подвергали скринингу на связывание с клетками, экспрессирующими TCR/CD3 с использованием клеток CHO-K1 или HEK293H, трансфицированных TCR/CD3 человека, и соответствующих контрольных линий CHO-K1 или HEK293H в схеме смешанных клеточных линий. Для этого большую партию контрольных клеточных линий метили 8 мкМ PKH26 и замораживали. 5×104 контрольных клеток, меченных PKH, смешивали с 5×104 клеток-мишеней и инкубировали с периплазматическими экстрактами в течение 30 минут при 4°C и промывали 3 раза. Затем клетки инкубировали с 1 мкг/мл моноклонального антитела ANTI-FLAG® M2 (Sigma-Aldrich, F1804) в течение 30 минут при 4°C, снова промывали и инкубировали в течение 30 минут при 4°C с 5 мкг/мл козьих антител, против мышиных IgG, меченных аллофикоцианином (APC) AffiniPure (Jackson Immunoresearch, 115-135-164). Образцы промывали, ресуспендировали в буфере FACS (D-PBS от Gibco, с 10% FBS от Sigma и 0,05% азида натрия от Merck) и затем анализировали с помощью BD FACSArray. Сначала на основе распределения FSC-SSC была отобрана популяция P1, которая представляла более 80% всей клеточной популяции. В этих рамках отбора («воротах») во время сбора данных насчитали 20 000 клеток. На основании распределения PKH26-SSC была выбрана родительская популяция, меченная PKH, и немеченная целевая популяция TCR/CD3 человека. Для этих двух популяций было рассчитано среднее значение APC.
4.2 Скрининг TCR/CD3-связывающих нанотел в анализе активации Т-клеток человека
После нескольких попыток оказалось, что активация очищенных человеческих Т-клеток антителами или нанотелами в соответствии со стандартными протоколами, т.е. нанесенными в виде покрытия на 96-луночный планшет, была недостаточно чувствительной (данные не показаны).
Для оценки активности был разработан другой анализ, основанный на активации T-клеток, связанных с гранулами. Вкратце, Dynabeads® с козьими антителами, против мышиных IgG (ThermoFisher Scientific, 11033) покрывали моноклональным мышиным антителом ANTI-FLAG® M2 (Sigma-Aldrich, F1804) (15 мкг/1E7 гранул). После 2 ч инкубационного периода при 4°С Dynabeads® промывали и инкубировали с 80 мкл периплазматического экстракта в течение 20 мин при 4°С при встряхивании. Несвязанные нанотела вымывали перед добавлением комплекса гранул вместе с растворимым мышиным анти-CD28 антителом (Pelicluster CD28 - Sanquin, M1650) к очищенным первичным Т-клеткам человека (выделенным, как описано в примере 2.1). В качестве контроля использовали нестимулированные человеческие Т-клетки. Вкратце, Dynabeads® с козьими антителами против мышиных IgG (ThermoFisher Scientific, 11033), связанные с моноклональными мышиными антителами ANTI-FLAG® M2, инкубировали с 80 мкл периплазматического экстракта, содержащего нерелевантные нанотела. После удаления несвязанных нанотел на стадии промывки нерелевантный комплекс нанотел и гранул добавляли к очищенным первичным Т-клеткам человека. После 24-часовой инкубации при 37°С и 5% СО2 статус активации Т-клеток человека определяли путем измерения уровня экспрессии CD69 проточной цитометрией с использованием моноклонального мышиного антитела против CD69PE человека (BD Biosciences, 557050).
4.3 Анализ последовательности полученных нанотел
Нанотела, которые получили положительные результаты в скрининге проточной цитометрии и в анализе активации Т-клеток, секвенировали.
Анализ последовательности привел к идентификации нанотела T0170056G05 и различных представителей его семейства, представляющих в общей сложности 104 различных клона (SEQ ID NO: 42 и 78-180). Проводили соответствующее выравнивание (таблица A-1).
Вариабельность последовательности CDR представителей семейства против T0170056G05, изображена в таблицах ниже.
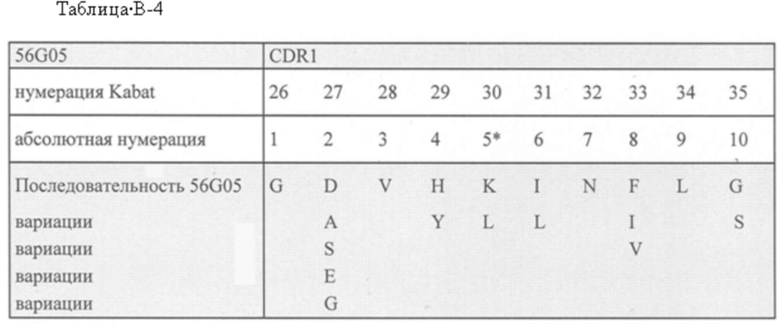
* В случае, если положение 5 - L, тогда положение 6 - также L.
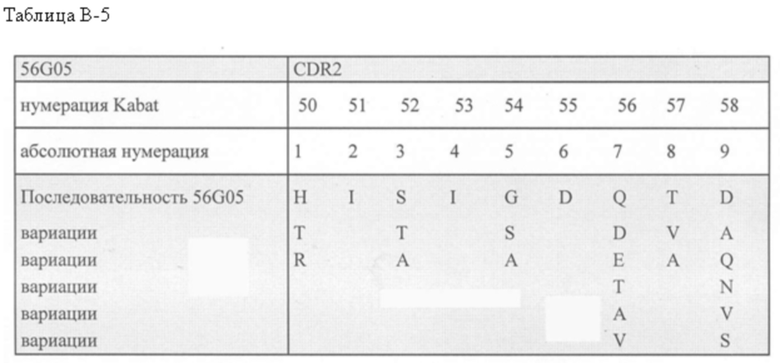
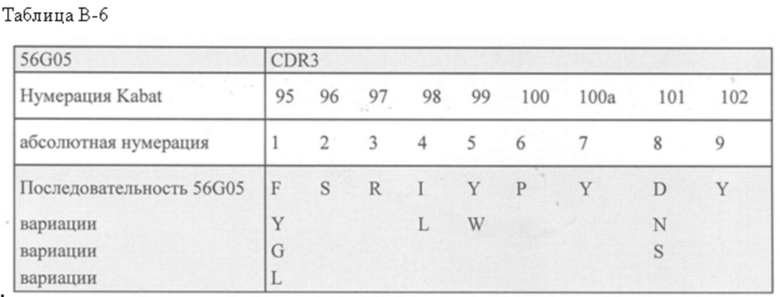
4.4 Очистка моновалентных нанотел
Два репрезентативных нанотела идентифицированного семейства были отобраны и экспрессированы в E.coli TG1 как тройные Flag, His6-меченые белки. Экспрессию индуцировали добавлением 1 мМ IPTG и давали возможность продолжаться в течение 4 часов при 37°C. После центрифугирования клеточных культур периплазматические экстракты готовили путем замораживания-оттаивания осадков. Эти экстракты использовали в качестве исходного материала, а нанотела очищали с помощью IMAC и эксклюзионной хроматографии (SEC).
Нанотела очищали до 95% чистоты, что оценивали с помощью SDS-PAGE (данные не показаны).
Пример 5. Связывание анти-TCR нанотел с TCR/CD3 человека, экспрессированными на клетках CHO-K1, и с очищенными первичными человеческими T-клетками
Дозозависимое связывание очищенных моновалентных анти-TCR нанотел с TCR α/β (2XN9)/CD3 человека, экспрессированным на клетках CHO-K1, и с очищенными первичными человеческими Т-клетками оценивали с помощью проточной цитометрии. Вкратце, клетки собирали и переносили в 96- луночный планшет с V-образным дном (1×105 клеток/лунку), и серийным разведениям нанотел (с 1 мкМ) давали возможность связаться в течение 30 минут при 4°C в буфере FACS. Клетки трижды отмывали центрифугированием и метили моноклональными мышиными антителами ANTI-FLAG® M2 1 мкг/мл (Sigma-Aldrich, F1804) в течение 30 минут при 4°C, снова промывали и инкубировали в течение 30 мин при 4°C с 5 мкг/мл R-фикоэритрин-меченным F(ab') фрагментом козьего антитела против мышиных IgG AffiniPure (Jackson Immunoresearch 115-116-071). После инкубации клетки промывали 3 раза буфером FACS. Затем клетки ресуспендировали в буфере FACS с добавлением 5 нМ TOPRO3 (Molecular Probes, T3605), чтобы отличить живые от мертвых клеток, которые удаляются во время процедуры отбора в «воротах». Клетки анализировали с использованием проточного цитометра FACS Array (BD Biosciences) и программного обеспечения «Flowing Software». Сначала на основе распределения FSC-SSC была отобрана популяция P1, которая представляла более 80% всей клеточной популяции. В этих «воротах» во время сбора данных было подсчитано 10000 клеток. Из этой популяции были исключены клетки TOPRO + (мертвые клетки) и рассчитано среднее значение PE.
Результаты представлены на фигуре 3. Значения ЕС50, полученные из кривой доза-ответ, представлены в таблице С-1.
Нанотела несомненно связаны с TCR/CD3 человека, экспрессируемым на клетках CHO-K1. Нанотела также связываются с очищенными первичными человеческими Т-клетками, хотя и с несколько меньшей эффективностью по сравнению с клетками СНО-К1 с TCR α/β (2XN9)/CD3 человека.
Пример 6. Определение эпитопа связывания
Связывание очищенных моновалентных анти-TCR нанотел с TCRα/β(2IAN)/CD3 человека, экспрессируемым на клетках HEK293H, оценивали и сравнивали со связыванием с клетками HEK293H, трансфицированными CD3 человека, с помощью проточной цитометрии, как описано в примере 5. К клеткам добавляли серии разведений T0170055A02 и T0170056G05, начиная с 1 мкМ. Родительская клеточная линия HEK293H была включена в качестве отрицательной клеточной линии по TCR/CD3.
Результаты представлены на фигуре 4. Значения ЕС50, полученные из кривой доза-ответ, представлены в таблице С-2.
Нанотела четко связываются с TCR (2IAN)/CD3 человека, экспрессируемым на HEK293H, но не с клетками HEK293H, трансфицированными только CD3 человека, или с линией родительских клеток HEK293H. В заключение необходимо отметить, что 2 клона были специфичны по связыванию с TCRα/β человека. Связывание с CD3 человека не наблюдалось.
Пример 7. Связывание анти-TCR нанотел с растворимым рекомбинантным белком TCRα/β человека
7.1. Связывание анти-TCR нанотел с белком Т-клеточного рецептора человека в ELISA
Связывание очищенных моновалентных нанотел TCR с растворимым рекомбинантным белком TCR α/β человека оценивали в ELISA (как описано в примере 1.2), используя 2 мкг/мл растворимого рекомбинантного рекомбинантного белка TCR α/β человека в виде прямого покрытия.
Результаты представлены на фигуре 5. Значения ЕС50, полученные из кривой доза-ответ, представлены в таблице С-3.
α/β (2XN9) человека, определенное в ELISA
Нанотела против TCR связываются с растворимым рекомбинантным белком TCR α/β человека.
7.2. Связывание анти-TCR нанотел с белком Т-клеточного рецептора человека в BLI
Аффинность связывания измеряли с использованием биослойной интерферометрии (BLI) на приборе Octet RED384 (Pall ForteBio Corp.). Рекомбинантный человеческий растворимый белок TCRα/β(2XN9)-белок с «молнией» ковалентно иммобилизовали на аминореактивных сенсорах (ForteBio) посредством химии сочетания NHS/EDC. Для кинетического анализа сенсоры сначала погружали в рабочий буфер (10 мМ Hepes, 150 мМ NaCl, 0,05% р20, рН 7,4 от GE Healthcare Life Sciences), чтобы определить настройки исходного уровня. Затем датчики погружали в лунки, содержащие различные концентрации очищенных нанотел (в диапазоне от 1,4 нМ до 1 мМ) для стадии ассоциации (180 с), и переносили в лунки, содержащие рабочий буфер для стадии диссоциации (15 мин). Константы аффинности (KD) рассчитывали с использованием модели взаимодействия 1:1 с использованием программного обеспечения для анализа данных ForteBio.
Результаты представлены на фигуре 6. Характеристики связывания перечислены в таблице C-4.
Аффинность связывания, определенная с использованием BLI на растворимом TCRα/β (2XN9) человека - белке с «молнией», показала корреляцию с аффинностью, определенной на клетках CHO-K1 TCRα/β(2XN9)/CD3 человека с помощью проточной цитометрии (см. также пример 5).
Пример 8. Связывание анти-TCR нанотел с рекомбинантным растворимым белком TCRα/β
8.1. Связывание анти-TCR нанотел с белком Т-клеточного рецептора яванского макака в ELISA
Связывание очищенных одновалентных анти-TCR нанотел с рекомбинантным растворимым белком TCR α/β яванского макака оценивали в ELISA (как описано в примере 1.2) с помощью 2 мкг/мл, рекомбинантного растворимого TCR α/β яванского макака-белка с «молнией», нанесенного в виде прямого покрытия.
Значения ЕС50, полученные из кривой доза-ответ, представлены в таблице С-5. Примерный результат показан на фигуре 7.
Результаты показали, что анти-TCR нанотела связываются с рекомбинантным TCRα/β яванского макака - белком с «молнией».
8.2. Связывание анти-TCR нанотел с белком T-клеточного рецептора яванского макака в BLI
Аффинность связывания моновалентных анти-TCR нанотел измеряли с использованием биослойной интерферометрии (BLI) на приборе Octet RED384 (Pall ForteBio Corp.), по существу, как описано в примере 7.2, с использованием рекомбинантного растворимого белка TCRα/β яванского макака.
Результаты представлены на фигуре 8. Характеристики связывания анти-TCR нанотел приведены в таблице C-6.
Нанотела связываются с рекомбинантным растворимым белком TCRα/β яванского макака с аффинностью, в 10 раз меньшей по сравнению с рекомбинантным растворимым белком TCRα/β (2XN9) - с «молнией».
Пример 9. Определение способности активации очищенных первичных Т-клеток человека
Функциональность очищенных моновалентных анти-TCR нанотел была оценена в анализе активации Т-клеток человека. Dynabeads® с козьими антителами против мышиных IgG (ThermoFisher Scientific, 11033) покрывали моноклональным мышиным антителом ANTI-FLAG® M2 (Sigma-Aldrich, F1804, 15 мкг/1E7 гранул). После 2 ч инкубационного периода при 4°С Dynabeads® промывали и инкубировали с фиксированным (1 мкг) количеством очищенного Flag-меченного нанотела, в течение 20 мин при 4°С при встряхивании. Несвязанные нанотела вымывали перед добавлением комплекса гранул вместе с растворимым мышиным анти-CD28 антителом (Pelicluster CD28 - Sanquin, M1650) к очищенным первичным Т-клеткам человека, выделенным (выделенным, как описано в примере 2.1) из различных здоровых доноров. Кроме того, эффект моновалентного связывания TCR нанотелами оценивали инкубацией нанотела с очищенными первичными человеческими Т-клетками без предварительного захвата Dynabeads® с антителом против мышиных IgG в присутствии антитела против CD28. Состояние активации очищенных первичных человеческих Т-клеток контролировали путем измерения экспрессии CD69 проточной цитометрией с использованием моноклонального мышиного антитела против CD69PE человека (BD Biosciences, 557050) после инкубации в течение 24 часов при 37°С и 5% СО2.
В заключение необходимо отметить, что нанотела анти-TCR продемонстрировали явную активацию CD69 после захвата на Dynabeads с антителом против мышиных IgG. Нерелевантное нанотело не проявляло никакой положительной регуляции CD69 (фигура 9A). Кроме того, ни одно из нанотел, представленных в растворе, не могло активировать очищенные первичные человеческие Т-клетки, что измерялось по повышенной экспрессии CD69 (фигура 9В).
Пример 10. Иммунизация лам CD123, клонирование репертуаров фрагментов антител, содержащих только тяжелые цепи, и получение фага
10.1. Иммунизация
В соответствии со стандартными протоколами три ламы были иммунизированы рекомбинантным внеклеточным доменом CD123 человека с His-меткой (R & D Systems, 301-R3/CF) посредством внутримышечной инъекции в шею, с использованием Stimune в качестве адъюванта (Cedi Diagnostics, Лелистад, Нидерланды).
Образцы иммунной сыворотки, взятые на 35 день, анализировали на антигенспецифическое связывание с помощью ELISA с адсорбированным hCD123. Все ламы показывают превосходный IgG1-опосредованный сывороточный ответ и хороший или умеренный ответ, опосредованный тяжелой цепью, против hCD123.
10.2 Клонирование репертуаров фрагментов антител, состоящих только из тяжелых цепей, и получение фага
Для каждого животного пробы крови по 100 мл собирали через четыре и восемь дней после последней инъекции иммунизирующего антигена. Из этих образцов крови готовили PBMC с использованием Ficoll-Hypaque в соответствии с инструкциями производителя (Amersham Biosciences, Пискатавэй, Нью-Джерси, США). Для каждой иммунизированной ламы создавали библиотеки путем объединения общей РНК, выделенной из разных образцов крови.
Вкратце, репертуар VHH, амплифицированный с помощью ПЦР, клонировали через специфические сайты рестрикции в фагмидный вектор, предназначенный для содействия фаговому дисплею библиотеки VHH. Вектор был получен из pUC119. В рамке с последовательностью, кодирующей VHH, вектор кодирует C-концевую метку 3xFLAG и HIS6. Фаги готовили в соответствии со стандартными протоколами (см., например, WO 04/041865, WO 04/041863, WO 04/062551, WO 05/044858 и другие источники предшествующего уровня техники и процитированные в данном документе заявки, поданные Ablynx NV).
Пример 11. Отбор CD123-специфичных VHH с помощью фагового дисплея
Репертуары VHH, полученные из всех лам и клонированные в виде фагемидной библиотеки, использовали в различных стратегиях отбора, применяя множество условий отбора. Переменные включали: i) источник антигена CD123 (рекомбинантный белок, продуцируемый в клетках человека или полноразмерный белок, сверхэкспрессируемый на клетках), ii) презентацию антигена (в растворе при использовании биотинилированного рекомбинантного эктодомена, непосредственно нанесенного на планшеты при использовании небиотинилированного эктодомена слитого с Fc) и iii) концентрацию антигена.
Вкратце, клетки HEK293T, сверхэкспрессирующие CD123 (полученные собственными силами), биотинилированные человеческие CD123 (R&D Systems, 301-R3/CF, биотинилированные собственными силами) и нанесенные на планшеты CD123-Fc человека (Sino Biologicals, 10518-H08H), инкубировали в течение 1 ч - 2 ч с 2×Е11 фаговых частиц из разных библиотек с последующей интенсивной промывкой; связанные фаги элюировали трипсином (1 мг/мл) в течение 15 минут, а затем активность протеазы немедленно нейтрализовали путем применения 0,8 мМ ингибитора протеазы ABSF. В качестве контроля параллельно проводили отбор с родительской клеточной линией или без антигена.
Полученные в результате фаги были использованы для заражения E. coli для анализа отдельных клонов VHH. Периплазматические экстракты готовили в соответствии со стандартными протоколами (см., например, WO 03/035694, WO 04/041865, WO 04/041863, WO 04/062551 и другие источники предшествующего уровня техники и процитированные в данном документе заявки, поданные Ablynx NV).
Пример 12. Скрининг на CD123-связывающие нанотела.
12.1. Скрининг в ELISA на связывание
Периплазматические экстракты подвергали скринингу в ELISA на связывание с CD123 человека (R & D Systems, 301-R3). Для этого планшет для микротитрования покрывали CD123 человека (1 мкг/мл) и инкубировали в течение ночи при 4°С. Планшеты блокировали в течение одного часа при комнатной температуре с 4% Marvel в PBS. Планшеты промывали PBS-Tween. Периплазматические экстракты (разведенные 1/10 в PBS с 2% Marvel) инкубировали в течение, по меньшей мере, 1 часа при комнатной температуре. Планшеты промывали PBS-Tween, после чего связывание VHH детектировали моноклональными анти-FLAG M2 антителами с пероксидазой (HRP) (Sigma, A8592, 1/5000) в PBS с 1% Marvel. Окрашивание проводили субстратом esTMB (Nalgene) и сигналы измеряли через 15 минут при 450 нм.
12.2. Скрининг проточной цитометрией
Периплазматические экстракты подвергали скринингу в анализе с помощью проточной цитометрии на транзиторно трансфицированных клетках HEK293T-hCD123 в 96-луночном формате. Кроме того, связывание оценивали для эндогенно экспрессирующих IL-3R клеток MOLM-13, чтобы подтвердить связывание с IL-3Rα в присутствии партнера IL-3Rβ в гетеродимерном рецепторном комплексе. Для этого клетки (1×105 клеток/лунку/0,1 мл) инкубировали с периплазматическими экстрактами (разведения 1:10) в течение 30 минут при 4°C в буфере FACS (D-PBS от Invitrogen, с 10% FBS от Sigma и 0,05% азида натрия от Merck). Клетки промывали 3 раза, и инкубировали с 1 мкг/мл моноклонального ANTI-FLAG® M2 антитела (Sigma-Aldrich, F1804) в течение 30 минут при 4°C, снова промывали и инкубировали в течение 30 минут при 4°C с козьим антителом против мышиных меченых антител, меченным RPE (Jackson) Immunoresearch, 115-116-071, 1: 100). Образцы промывали, инкубировали с TOPRO3 для окрашивания мертвых клеток в буфере FACS и оценивали флуоресценцию на приборе FACSArray (BD).
12.3. Секвенирование нанотел
Секвенировали нанотела, которые имели положительный результат в ELISA на связывание и в анализе проточной цитометрией. Анализ последовательностей привел к идентификации нанотел A0110056A10 и A0110055F03 и различных представителей их семейств. Соответствующие выравнивания приведены в таблице A-2 и таблице A-3 соответственно.
Вариабельность последовательности CDR представителей семейства против A0110056A10, отображена в таблицах ниже.
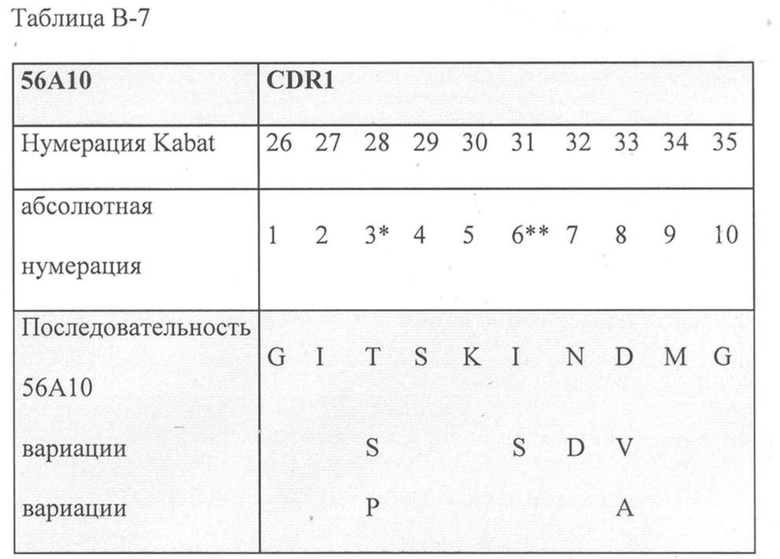
* если положение 3 - это S, то положение 7 - это D;
** если положение 6 - это I, то положение 8 - это D.
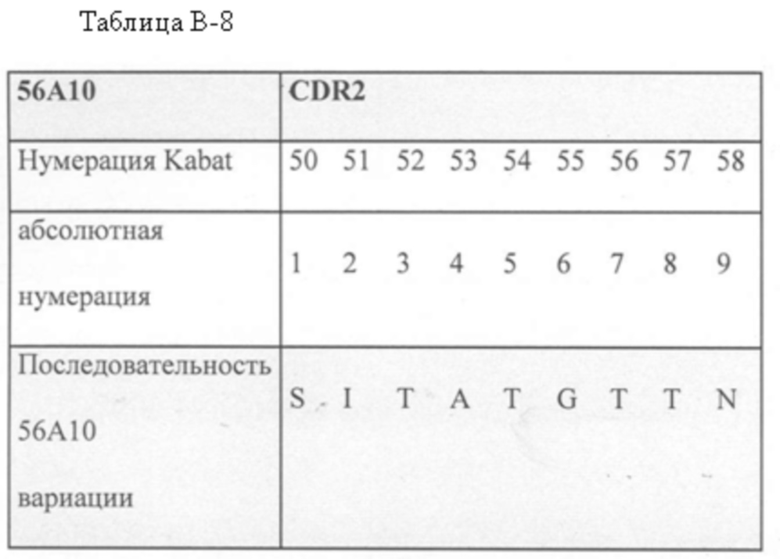
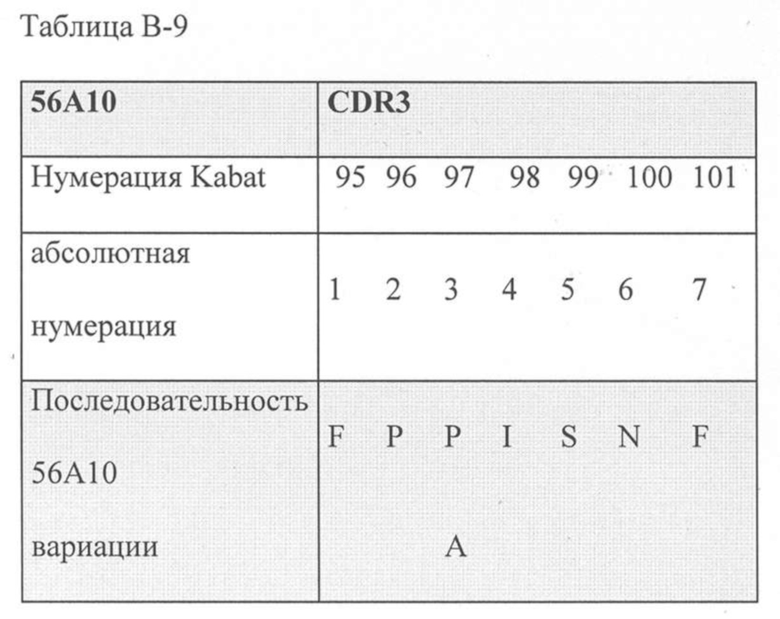
Вариабельность последовательности CDR представителей семейства относительно A011005F03 отображена в таблицах ниже.
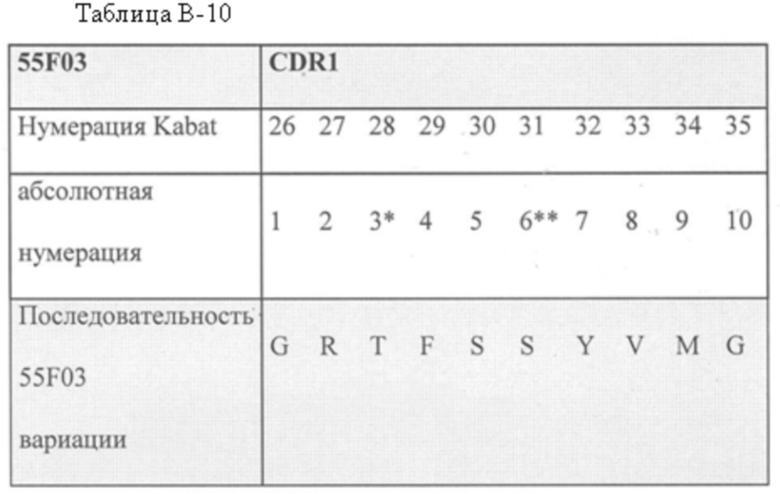
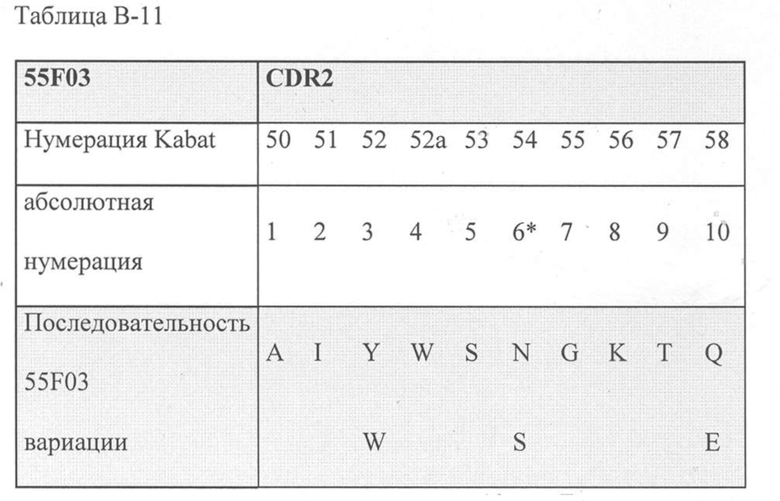
* если положение 6 - это S, то положение 10- это E.

* если положение 4 - это R, то положение 5 - это D или Y.
12.4 Очистка моновалентных нанотел
Репрезентативные нанотела для каждого семейства были отобраны и экспрессированы в E.coli TG1 как тройные Flag, His6-меченые белки. Экспрессию индуцировали добавлением 1 мМ IPTG и проводили в течение 4 часов при 37°C. После центрифугирования клеточных культур периплазматические экстракты готовили путем замораживания-оттаивания осадков. Эти экстракты использовали в качестве исходного материала, а нанотела очищали с помощью IMAC и эксклюзионной хроматографии (SEC). Нанотела очищали до 95% чистоты, как оценивали с помощью SDS-PAGE (данные не показаны).
Пример 13. Дополнительные клеточные линии для описания характеристик
13.1. Клеточные линии, трансфицированные CD123
Стабильные клеточные линии HK293 Flp-In (Invitrogen, R750-07) и CHO Flp-In (Invitrogen, R758-07) с рекомбинантной сверхэкспрессией CD123 были получены с использованием технологии сайт-направленной рекомбинации Flp-In™ (система Flp-In™ для получения стабильных экспрессирующих клеточных линий млекопитающих с помощью Flp-рекомбиназа-опосредованной интеграции (Invitrogen, K601001, K601002)). Таким образом, интеграция ДНК происходит в определенном геномном месте в сайте FRT (мишени рекомбинации Flp) с помощью рекомбиназы Flp (pOG44), полученной из Saccharomyces cerevisiae. И клеточная линия хозяина Flp-In™, и плазмида экспрессии (pcDNA5) содержат этот сайт FRT, что позволяет проводить одиночную гомологичную рекомбинацию ДНК. Последовательность для CD123 человека была получена из NCBI RefSeq NP_002174, последовательность CD123 яванского макака была получена из NCBI genbank no. EHH61867.1 (SEQ ID NO: 68 и 69, соответственно). Экспрессия CD123 человека и яванского макака на клеточной поверхности была подтверждена проточной цитометрией с использованием мышиного моноклонального антитела против CD123 (BD Biosciences, 554527) и контрольного изотипного мышиного IgG2a (BD Bioscience, 16-4724-85). Вкратце, клетки (1×105 клеток/лунку) собирали и переносили в 96-луночный планшет с V-образным дном (Greiner Bio-one, 651 180) и окрашивали при 4°С мышиным моноклональным анти-CD123 антителом (0,25 мкг/мл) и контрольным изотипным мышиным IgG2a (0,25 мкг/мл). После 30 мин инкубации клетки осаждали центрифугированием и 3 раза промывали буфером FACS (D-PBS от Gibco с 10% FBS (Sigma, F7524) и 0,05% азида натрия (Acros органика, 190380050)). Затем клетки инкубировали с 5 мкг/мл козьего F(ab') фрагмента против мышиных IgG, меченного R-фикоэритрином AffiniPure (Jackson Immunoresearch, 115-116-071) в течение 30 минут при 4°C. После инкубации клетки промывали 3 раза буфером FACS. Затем клетки ресуспендировали в буфере FACS, дополненном 5 нМ TOPRO3 (Molecular Probes, T3605), чтобы отличить живые клетки от мертвых. Клетки анализировали с использованием проточного цитометра FACS Array (BD Biosciences) и программного обеспечения Flowing Software. Сначала на основе распределения FSC-SSC была отобрана популяция P1, которая представляла более 80% всей клеточной популяции. Во время накопления данных в этих «воротах» было подсчитано 10000 клеток. Из этой популяции были исключены клетки TOPRO + (мертвые клетки) и рассчитано среднее значение PE. Данные показаны на фигуре 10.
13.2. Клеточные линии U937, MOLM-13, KG1a и NCI-H929
Уровень экспрессии CD123 человека на MOLM-13 (DSMZ, ACC-554), U-937 (ATCC®, CRL-1593.2™), KG1a (ATCC®, CCL246.1™) и NCI-H929 (DSMZ, ACC- 163) определяли, используя меченное APC моноклональное антитело против CD123 (BD Biosciences, 560087) и меченный APC изотипный контроль (Biolegend, 400220) в проточной цитометрии. Вкратце, клетки собирали и суспендировали при плотности 1×107 клеток/мл в буфере FACS с 25 мкг человеческого Fc-блока (BD Biosciences, 564220) и инкубировали в течение 10 минут при комнатной температуре. Затем клетки разбавляли до концентрации клеток 1×106 клеток/мл и переносили в V-образный 96-луночный планшет (1×105 клеток/лунку). Клетки окрашивали при 4°С меченным АРС моноклональным анти-CD123 мышиным антителом (разбавленным в 10 раз) и меченым АРС изотипическим контролем (разбавленным в 10 раз). После 30 минут инкубации клетки промывали 3 раза и ресуспендировали в буфере FACS с добавлением 1 мкг/мл пропидиум иодида (PI) (Sigma, P4170) в течение 30 минут при 4°C, а затем анализировали с помощью программного обеспечения BD FACSCanto и Flowing. Сначала на основе распределения FSC-SSC была отобрана популяция P1, которая представляла более 80% всей клеточной популяции. В P1 были подсчитаны 10000 клеток. Из этой популяции были исключены клетки PI + (мертвые клетки) и рассчитано среднее значение APC. Данные показаны на фигуре 11.
Кроме того, количество рецепторов на клетку определяли с использованием QIFIKIT (Dako, K0078) в соответствии с инструкциями производителя. Данные приведены в таблице C-7.
Пример 14. Связывание моновалентных анти-CD123 нанотел с клеточными линиями, эндогенно экспрессирующими CD123
Дозозависимое связывание очищенных моновалентных анти-CD123 нанотел с клеточными линиями, эндогенно экспрессирующими CD123, MOLM-13 и KG1a оценивали с помощью проточной цитометрии. Вкратце, клетки собирали и переносили в 96- луночный планшет с V-образным дном (1×105 клеток/лунку), и серийным разведениям нанотел (с 1 мкМ) давали возможность связываться в течение 30 минут при 4°C в буфере FACS. Клетки трижды промывали центрифугированием и метили моноклональным мышиным антителом ANTI-FLAG® M2 (Sigma-Aldrich, F1804) в течение 30 минут при 4°C, снова промывали и инкубировали в течение 30 минут при 4°C с 5 мкг/мл козьим F(ab') фрагментом против мышиных IgG, меченных R -фикоэритрином AffiniPure (Jackson Immunoresearch, 115-116-071). После инкубации клетки промывали 3 раза буфером FACS. Затем клетки ресуспендировали в буфере FACS с добавлением 5 нМ TOPRO3 (Molecular Probes, T3605), чтобы отличить живые от мертвых клеток, которые удаляются во время отбора в «воротах». Клетки анализировали с использованием проточного цитометра FACS Array (BD Biosciences) и программного обеспечения Flowing. Сначала на основе распределения FSC-SSC была отобрана популяция P1, которая представляла более 80% всей клеточной популяции. В этих «воротах» было подсчитано 10000 клеток во время сбора данных. Из этой популяции были исключены клетки TOPRO + (мертвые клетки) и рассчитано среднее значение PE .
Связывание нанотел с MOLM-13 и KG1a представлено на фигуре 12. Значения ЕС50, полученные из кривых доза-ответ, представлены в таблице С-8.
Было обнаружено связывание обоих нанотел с клетками, эндогенно экспрессирующими CD123 (MOLM-13, KG1a).
Пример 15. Связывание моновалентных анти-CD123 нанотел с CD123 на трансфицированных клетках
Дозозависимое связывание очищенных моновалентных анти-CD123-нанотел с клетками CHO-K1, сверхэкспрессирующими CD123 человека и HEK293, сверхэкспрессирующими CD123 яванского макака, оценивали с помощью проточной цитометрии.
Для выявления связывания A0110055F03 клетки собирали и переносили в 96-луночный планшет с V-образным дном (1×105 клеток/лунку). Серийные разведения A0110055F03 (начиная с 100 нМ) оставляли для связывания на 30 минут при 4°C в буфере FACS. Клетки промывали 3 раза буфером FACS путем центрифугирования и метили 1 мкг/мл моноклонального мышиного антитела ANTI-FLAG® M2 (Sigma-Aldrich, F1804) в течение 30 минут при 4°C для обнаружения связанного нанотела. Детекцию проводили с помощью 0,5 мкг/мл козьего фрагмента F(ab') против мышиных IgG, меченного R-фикоэритрином AffiniPure (Jackson Immunoresearch, 115-116-071) в течение 30 минут при 4°C. Клетки промывали и инкубировали с TOPRO3 для окрашивания мертвых клеток, которые затем удаляются во время процедуры отбора в «воротах». Затем клетки анализировали с помощью BD FACSArray. Сначала на основе распределения FSC-SSC была отобрана популяция P1, которая представляла более 80% всей клеточной популяции. В этих «воротах» во время сбора данных было подсчитано 10000 клеток. Из этой популяции были исключены клетки TOPRO+ (мертвые клетки) и рассчитано среднее значение PE.
Для выявления связывания A0110056A10 клетки собирали и переносили в 96-луночный планшет с V-образным дном (1×105 клеток/лунку). Последовательные разведения меченного Alexa647 A0110056A10 (начиная с 100 нМ) оставляли для связывания в течение 30 минут при 4°C в буфере FACS. После 30 мин инкубации клетки осаждали центрифугированием и 3 раза промывали буфером FACS. Впоследствии клетки ресуспендировали в буфере FACS с добавлением 1 мкг/мл пропидия иодида для различения живых и мертвых клеток. Клетки анализировали с использованием проточного цитометра FACS Array (BD Biosciences) и программного обеспечения Flowing. Сначала на основе распределения FSC-SSC была отобрана популяция P1, которая представляла более 80% всей клеточной популяции. В этих воротах было подсчитано 10000 клеток во время сбора данных. Из этой популяции были исключены клетки PI + (мертвые клетки), и было рассчитано среднее значение APC.
Связывание нанотел с линиями клеток, трансфицированных CD123, и контрольной клеточной линией представлено на фигуре 13 и фигуре 14 для нанотел A0110056A10 и A0110055F03, соответственно. Значения ЕС50, полученные из кривых доза-ответ, представлены в таблице С-9.
Было обнаружено связывание обоих нанотел с клеточными линиями, трансфицированными CD123. Оба нанотела перекрестно-реактивные между CD123 человека и яванского макака.
Пример 16. Конкуренция нанотел за связывание с CD123, экспрессированным на клетках, по данным проточной цитометрии
Чтобы выяснить, конкурируют ли CD123-нанотела друг с другом, был проведен конкурентный анализ нанотел. С этой целью большая партия A0110056A10 была помечена Alexa647 и заморожена. Затем клетки собирали и переносили в V-дно 96-луночного планшета (1×105 клеток/лунку) и смешивали с последовательным разведением нанотел и фиксированной концентрации A0110056A10-Alexa647 (0,7 нM для MOLM-13, 0,5 нМ для CHO Flp-In CD123 человека). Концентрации A0110056A10-Alexa647, использованные в анализе, были ниже значения EC50 для связывания A0110056A10-Alexa647 с соответствующими клетками (кривые связывания изображены на фигуре 15). После 90-минутного инкубационного периода при 4°C связывание A0110056A10-Alexa647 определяли с помощью проточной цитометрии. Для этого клетки промывали 3 раза и ресуспендировали в буфере FACS с добавлением 1 мкг/мл пропидий иодида, инкубировали в течение 30 минут при 4°C и затем анализировали с помощью BD FACSArray. Сначала на основании распределения FSC-SSC была отобрана популяция P1, которая представляла более 80% всей клеточной популяции. В P1 были подсчитаны 10000 клеток. Из этой популяции были исключены клетки PI + (мертвые клетки) и рассчитано среднее значение APC.
Результаты представлены на фигуре 16. Значения IC50, полученные из кривых доза-ответ, представлены в таблице C-10.
Как и ожидалось, немеченый A0110056A10 конкурировал с A0110056A10-Alexa647 за связывание с CD123 на клетках MOLM-13 и с CD123 человека, экспрессированном на трансфицированных клетках CHO Flp-In. Нанотело A0110055F03 не конкурировало с A0110056A10-Alexa647 за связывание с CD123 на клетках CHO Flp-In, трансфицированных CD123 человека. На линии клеток MOLM-13 A0110055F03 конкурировал только с A0110056A10-Alexa647 при самых высоких протестированных концентрациях.
Пример 17. Конкуренция с мышиным моноклональным анти-CD123-антителом (клон 7G3) за связывание с CD123, экспрессированным на клетках, по данным проточной цитометрии
Чтобы проверить, конкурируют ли анти-CD123-нанотела с мышиным моноклональным анти-CD123-антителом (клон 7G3) за связывание с CD123 человека на клетках, был проведен конкурентный анализ мышиного моноклонального анти-CD123-антитела (клон 7G3) с использованием методики на основе проточной цитометрии, как описано в примере 16. С этой целью серийные разведения нанотел и концентрацию EC30 меченного APC моноклонального антитела против CD123 (клон 7G3) (BD Biosciences, 560087) инкубировали в течение 90 минут с клетками, после чего определяли связывание антитела в проточной цитометрии. Кривые связывания меченного APC моноклонального анти-CD123-антитела мыши (клон 7G3) с MOLM-13 и человеческими клетками CHO Flp-In, трансфицированными CD123, изображены на фигуре 17.
Результаты конкурентных экспериментов представлены на фигуре 18. Значения IC50, полученные из кривых доза-ответ, представлены в таблице C-11.
Нанотело A0110056A10 продемонстрировало конкуренцию с мышиным моноклональным анти-CD123-антителом (клон 7G3) на MOLM-13 и клетками CHO Flp-In, трансфицированными CD123 человека; поэтому эпитопы мышиного моноклонального антитела против CD123 (клон 7G3) и нанотела A0110056A10, по меньшей мере, частично перекрываются. A0110055F03 конкурировал с мышиным моноклональным анти-CD123-антителом (клон 7G3) на клетках MOLM-13. Отсутствие конкуренции с мышиным моноклональным анти-CD123-антителом (клон 7G3) на клеточной линии CHO Flp-In, трансфицированной CD123 человека, может быть результатом более низкой аффинности нанотела A0110055F03 по отношению к CD123 человека.
Пример 18. Конкуренция с мышиным моноклональным анти-CD123-антителом (клон 7G3) за связывание с рекомбинантным CD123 человека по данным ELISA
Чтобы исследовать, конкурируют ли анти-CD123-нанотела с мышиным моноклональным анти-CD123-антителом (клон 7G3) за связывание с рекомбинантным человеческим белком CD123, был проведен конкурентный анализ с использованием методики, основанной на ELISA. Вкратце, мышиное моноклональное анти-CD123-антитело (клон 7G3) (BD Biosciences, 554527) использовали в качестве покрытия в концентрации 1 мкг/мл в PBS. После инкубации в течение ночи при 4°C планшеты блокировали казеином (1% в PBS) при комнатной температуре. Затем добавляли серийное разведение моновалентных анти-CD123 нанотел и 4 нМ рекомбинантного белка CD123, биотинилированного собственными силами (R & D Systems, 301-R3/CF) и инкубировали в течение 1 часа при комнатной температуре в PBS + 0,1% казеина + 0,05% Tween. Концентрация рекомбинантного белка CD123, биотинилированного собственными силами, основывалась на значении EC30, полученном в результате связывания рекомбинантного белка CD123, биотинилированного собственными силами, с мышиным моноклональным анти-CD123 антителом (клон 7G3) (кривая связывания изображена на фигуре 19). Мышиное моноклональное анти-CD123-антитело не использованное в качестве покрытия (клон 7G3) было взято параллельно в качестве положительного контроля, а нерелевантное антитело против лизоцима яйца cAbLys было взято параллельно в качестве отрицательного контроля. Планшеты промывали PBS + 0,05% Tween с использованием мойщика Tecan Hydrospeed и 7G3-связанный биотинилированный-CD123 определяли с помощью 1 мкг/мл экстравидин-пероксидазы (Sigma, E2886) в PBS + 0,1% казеина + 0,05% Tween с последующим проявлением окраски с помощью субстрата esTMB. Реакцию останавливали с помощью 1 М HCl и поглощение при OD 450 нм измеряли с использованием Tecan Infinite M1000.
Результаты представлены на фигуре 20. Значение IC50, полученное из кривой доза-ответ, представлено в таблице C-12.
Конкуренция наблюдалась между A0110056A10 и мышиным моноклональным анти-CD123-антителом (клон 7G3) за связывание с рекомбинантным белком CD123 человека. A0110055F03 не конкурирует с мышиным моноклональным анти-CD123-антителом (клон 7G3) за связывание с рекомбинантным белком CD123 человека.
Пример 19. Связывание моновалентных анти-CD123-нанотел с человеческим белком CD123 (SPR)
Аффинность связывания очищенных CD123-специфических нанотел для CD123 человека оценивали с помощью анализа на основе SPR на приборе ProteOn XPR36. Для этого рекомбинантный CD123 (R&D Systems, 301-R3-025/CF) иммобилизовали на чипе СМ5 с помощью сочетания по аминной группе, используя химию EDC и NHS. Очищенные нанотела инъецировали в течение 2 минут при различных концентрациях (от 4,2 нМ до 1000 нМ) для кинетического анализа с использованием подхода One-shot Kinetics™. Скорость потока составляла 45 мкл/мин, и в качестве рабочего буфера использовали рабочий буфер ProteOn (PBS, pH 7,4, 0,005% Tween 20). Время диссоциации образца 1000 нМ составляло 15 мин. Оценка данных ассоциации/диссоциации проводилась путем подбора модели взаимодействия 1: 1 (модель связывания Ленгмюра).
Значения KD моновалентных анти-CD123 нанотел для связывания с CD123 человека коррелировали с данными по связыванию на клетках. A0110056A10 имеет лучшую аффинность по сравнению с A0110055F03.
Пример 20. Конструирование мультиспецифичных полипептидов CD123/TCR и контрольных полипептидов
Чтобы получить полипептиды, способные вовлекать Т-клетки, CD123-нанотела были связаны с анти-TCR (Т-клеточный рецептор) нанотелом T0170056G05 (SEQ ID NO: 42). Последнее представляет собой нанотело, специфически связывающее константный домен TCRα/β. (см. WO 2016/180969, озаглавленную «Полипептиды рекрутирования Т-клеток на основе реактивности к TCR альфа/бета», поданной 13 мая 2016 г. Ablynx NV).
Терапевтическая активность полипептидов, вовлеченных в Т-клетки, может быть улучшена одновременным нацеливанием нескольких эпитопов на антиген, ассоциированный с опухолью. Опухолевые клетки могут создать механизм ухода от надзора не только путем отрицательной регуляции целевых антигенов в терапии, но также путем введения (точечных) мутаций. Одновременное нацеливание на несколько эпитопов на антигене, вероятно, уменьшит вероятность генерации вариантов ухода опухоли от надзора. Кроме того, нацеливание на нескольких эпитопов в одном антигене может увеличить аффинность связывания (эффект авидности). Для этой концепции мультивалентного нацеливания на опухолевый антиген, два нанотела, реагирующих на антиген CD123, были связаны с нанотелом T0170056G05 против комплекса TCR/CD3.
Конкретный порядок соответствующих нанотел варьировался в пределах формата. Эффекторные и опухолевые нанотела были генетически связаны с линкером 35GS и впоследствии экспрессировались в дрожжевой Pichia в соответствии со стандартными протоколами (мультиспецифичные полипептиды). Параллельно нерелевантные полипептиды получали путем замены одного или обоих реактивных по отношению к опухоли нанотел на нерелевантное нанотело против лизоцима яичного белка cAbLys или анти-RSV нанотела RSV007B02 (Q108L).
Полученные полипептиды перечислены в таблице C-14.
ID NO*
* SEQ ID NO соответствуют последовательностям мультиспецифичных полипептидов без С-концевых меток или Ala-удлинения.
Пример 21. Конкуренция между A0110056A10 и мультиспецифичными полипептидами CD123/TCR за связывание с CD123, экспрессируемым на клетках, по данным проточной цитометрии
Связывание мультиспецифичных полипептидов CD123/TCR с CD123 человека или яванского макака оценивали в конкурентном анализе A0110056A10, как описано в примере 16. После связывания с клетками huCD123 MOLM-13 и CHO Flp-In оценивали связывание с клетками HEK Flp-In, трансфицированными CD123 яванского макака.
С этой целью партия A0110056A10 была помечена Alexa647 и заморожена. Затем клетки собирали и переносили в 96-луночный планшет с V-образным дном (1×105 клеток/лунку) и смешивали с серийным разведением мультиспецифичных связывающих полипептидов (начиная с 1 мкМ) и фиксированной концентрацией A0110056A10-Alexa647. Концентрации, использованные в анализе (0,4 нМ для MOLM-13, 0,9 нМ для CHO Flp-In CD123 человека и для HEK Flp-In CD123 яванского макака) были ниже значения EC50 для связывания A0110056A10-Alexa647 с соответствующими клетками (кривые связывания изображены на фигуре 21). После периода инкубации 90 минут при 4°C связывание A0110056A10-Alexa647 определяли в проточной цитометрии, как описано в примере 16. A0110056A10 и T017000129 были взяты вместе в качестве положительного и отрицательного контроля, соответственно.
Результаты представлены на фигуре 22. Значения IC50, полученные из кривых доза-ответ, представлены в таблице C-15 и таблице C-16.
Все протестированные мультиспецифичные полипептиды показали связывание с клетками, экспрессирующими CD123 человека и яванского макака, подтверждая перекрестную реактивность CD123 человека и яванского макака. Небольшое падение аффинности наблюдалось для полипептидов, у которых A0110056A10 не находился в N-конце.
Пример 22. Конкуренция между T0170056G05 и CD123/TCR мультиспецифичными полипептидами за связывание с TCR/CD3 человека, экспрессированным на клетках, по данным проточной цитометрии
Связывание мультиспецифичных полипептидов CD123/TCR с TCR/CD3 человека оценивали в конкурентном анализе с T0170056G05 методом проточной цитометрии. С этой целью большая партия T0170056G05 была помечена биотином и заморожена. Затем клетки CHO-K1, экспрессирующие TCR/CD3 человека, собирали и переносили в 96-луночный планшет с V-образным дном (1×105 клеток/лунку) и смешивали с серийным разведением мультиспецифичных связывающих полипептидов (начиная с 1 мкМ) и фиксированной концентрацией биотинилированного T0170056G05 в буфере FACS. Концентрация биотинилированного T0170056G05, использованная в анализе (30 нМ), была ниже значения ЕС50 для связывания с клетками (данные не показаны). После 90-минутного инкубационного периода при 4°C связывание биотинилированного нанотела T01700056G05 определяли проточной цитометрией. Для этого клетки промывали 3 раза и ресуспендировали в стрептавидин-РЕ (Ebioscience, 12-4317-87, 1000-кратно разведенный) в буфере FACS и инкубировали в течение 30 мин при 4°С. После этого клетки промывали 3 раза и ресуспендировали в буфере FACS + 1 мкг/мл TOPRO (Molecular Probes, T3605) в течение 30 минут при 4°C, а затем анализировали с помощью BD FACSCanto. Сначала на основе распределения FSC-SSC была отобрана популяция P1, которая представляла более 80% всей клеточной популяции. В P1 были подсчитаны 10000 клеток. Из этой популяции были исключены клетки TOPRO + (мертвые клетки) и рассчитано среднее значение PE. T0170056G05 был взят в качестве положительного контроля.
Результаты представлены на фигуре 23. Значения IC50, полученные из кривых доза-ответ, представлены в таблице C-17.
Было подтверждено связывание мультиспецифичных полипептидов CD123/TCR с TCR/CD3 человека, экспрессированных на клетках. Падение аффинности CD123/TCR мультиспецифического полипептида T017000116 по сравнению с моновалентным TCR-нанотелом наблюдалось из-за С-концевого положения TCR-нанотела.
Пример 23. Конкуренция между T017000099 и мультиспецифичными полипептидами CD123/TCR за связывание с TCR/CD3 яванского макака, экспрессируемым на клетках, по данным проточной цитометрии
Связывание мультиспецифичных полипептидов CD123/TCR с TCR/CD3 яванского макака оценивали в конкурентном анализе с T01700099 (двухвалентный T0170056G01, SEQ ID NO: 337) с помощью проточной цитометрии. С этой целью клетки HSC-F (JCRB, JCRB1164) экспрессирующие TCR/CD3 яванского макака, собирали и переносили в 96- луночный планшет с V-образным дном (1×105 клеток/лунку) и смешивали с серийным разведением мультиспецифичных полипептидов CD123/TCR (начиная с 1 мкМ) и 500 нМ T01700099 в буфере FACS. После 90-минутного инкубационного периода при 4°C клетки промывали 3 раза буфером FACS центрифугированием и метили моноклональными мышиными антителами ANTI-FLAG® M2 1 мкг/мл (Sigma-Aldrich, F1804) в течение 30 минут при 4°С, чтобы обнаружить связанные T01700099. Детекцию проводили с помощью 5 мкг/мл козьих антител против мышиных IgG, меченных аллофикоцианином (APC) AffiniPure (Jackson Immunoresearch, 115-135-164) в течение 30 минут при 4°C. Клетки промывали и инкубировали с пропидиум иодидом для окрашивания мертвых клеток, которые затем удаляли во время процедуры отбора в «воротах». Затем клетки анализировали с помощью BD FACSArray. Сначала на основе распределения FSC-SSC была отобрана популяция P1, которая представляла более 80% всей клеточной популяции. В этих «воротах» было подсчитано 10000 клеток во время сбора данных. Из этой популяции были исключены клетки PI+ (мертвые клетки) и рассчитано среднее значение APC. T017000125 были взяты в качестве положительного контроля.
Результаты представлены на фигуре 24. Значения IC50, полученные из кривых доза-ответ, представлены в таблице C-18.
Для всех мультиспецифичных полипептидов CD123/TCR со связывающим TCR нанотелом на N-конце наблюдалось связывание с TCR/CD3 яванского макака.
Пример 24. Связывание моновалентных нанотел и мультиспецифичных полипептидов с белком CD123 человека (SPR)
Аффинность связывания для мультиспецифичных полипептидов CD123/TCR оценивали с помощью определения аффинности на основе SPR на приборе ProteOn XPR36. Для этого рекомбинантный CD123 (R&D Systems, 301-R3-025/CF) иммобилизовали на чипе СМ5 с помощью сочетания по аминной группе, используя химию EDC и NHS. Очищенные нанотела инъецировали в течение 2 минут при различных концентрациях (от 4,2 нМ до 1000 нМ) с помощью подхода One-shot Kinetics™ для кинетического анализа. Время диссоциации образца 1000 нМ составляло 15 мин. Скорость потока составляла 45 мкл/мин, и в качестве рабочего буфера использовали рабочий буфер ProteOn (PBS, pH 7,4, 0,005% Tween 20). Оценка данных ассоциации/диссоциации проводилась путем подбора модели взаимодействия 1:1 (модель связывания Ленгмюра). Характеристики связывания перечислены в таблице C-19.
KD моновалентных нанотел и мультиспецифичных полипептидов к IL-3Rα человека коррелирует с данными связывания на клетках. Полипептид T017000116, содержащие два структурных элемента против IL-3Rα, имел лучшее KD.
Пример 25. Перенаправленное, опосредованное Т-клетками человека, уничтожение клеток-мишеней с CD123 с помощью мультиспецифичных полипептидов CD123/TCR в анализе на основе проточной цитометрии
Чтобы оценить, способны ли мультиспецифические полипептиды CD123/TCR уничтожать опухолевые клетки, анализы цитотоксичности проводили с выделенными человеческими Т-клетками в качестве эффекторных клеток.
Для этого человеческие Т-клетки собирали из лейкоцитарных пленок крови от здоровых добровольцев (банк крови Гента) с использованием RosetteSep (StemCell Technologies, 15061) с последующим обогащением на Ficoll-Paque™ PLUS (GE Healthcare, 17-1440-03) в соответствии с инструкциями производителя. Качество и чистоту очищенных человеческих Т-клеток проверяли с помощью анти-CD3 (eBioscience, 12-0037-73), анти-CD8 (BDBiosciences, 555367), анти-CD4 (BD Biosciences, 345771), анти-CD45RO (BD Biosciences, 555493), анти-CD45RA (BDBiosciences, 550855), анти-CD19 (BDBiosciences, 555413), анти-CD25 (BDBiosciences, 557138) и анти-CD69 (BDBiosciences, 557050) флуоресцентно меченых антител в анализе проточной цитометрии. Клетки замораживали в жидком азоте.
Клетки MOLM-13 и KG1a, экспрессирующие CD123 человека, метили 8 мкМ мембранного красителя PKH-26 с использованием набора красного флуоресцентного клеточного линкера PKH26 (Sigma, PKH26GL-1KT) в соответствии с инструкцией производителя и использовали в качестве клеток-мишеней. 2,5×105 эффекторных (т.е. первичных Т-клеток человека) и 2,5×104 клеток-мишеней (т.е. меченных PKH клеток MOLM-13 или KG1a) совместно инкубировали в 96-луночных V-образных планшетах (соотношение эффекторов и мишеней 10:1). Для измерения зависимого от концентрации лизиса клеток к клеткам добавляли серийные разведения мультиспецифичных полипептидов CD123/TCR и инкубировали в течение 18 ч в атмосфере с 5% CO2 при 37°C. Нанотело A0110056A10 и полипептиды T017000129 и T017000132 были взяты вместе в качестве отрицательного контроля. После инкубации клетки осаждали центрифугированием и промывали буфером FACS. Затем клетки ресуспендировали в буфере FACS, дополненном 5 нМ TOPRO3 (Molecular Probes, T3605), чтобы отличить живые клетки от мертвых клеток. Клетки анализировали с использованием проточного цитометра FACS Array (BD Biosciences). Для каждой пробы был получен общий объем пробы 80 мкл. Гейтирование было проведено на PKH26-положительных клетках, и в этой популяции были определены TOPRO3-положительные клетки. T017000129, T017000132 и A0110056A10 были взяты параллельно в качестве отрицательного контроля.
Примерные результаты показаны на фигуре 25 и фигуре 26 для клеток MOLM-13 и KG1a, соответственно. Значения EC50 показаны в таблицах C-20 и C-21 для клеток MOLM-13 и KG1a, соответственно.
ультиспецифичные полипептиды CD123/TCR индуцировали опосредованное Т-клетками человека уничтожение CD123-положительных клеточных линий. Было явное предпочтение положению TCR-нанотела в мультиспецифическом полипептиде. В целом, полипептиды с нанотелом против TCR в N-концевом положении показали лучший потенциал уничтожения. Полипептиды T017000135, T017000138 и T013700139 с двумя CD123-реактивными нанотелами показали улучшение специфической активности по сравнению с полипептидом T017000128 только с одним CD123-нанотелом. Эти результаты продемонстрировали, что мультиспецифичные полипептиды CD123/TCR могут индуцировать опосредованное Т-клетками уничтожение клеток, положительных по опухолевой мишени, и что нацеливание на несколько эпитопов на одном антигене улучшает функциональность (эффект авидности).
Кроме того, сравнение полипептидов T017000138 и T017000139, которые оба являются трехвалентными полипептидами с реактивным TCR-нанотелом в N-концевом положении, показало, что существует влияние ориентации нанотел CD123 на активность и эффективность.
Моновалентный структурный элемент CD123 и нерелевантные полипептиды, содержащие структурный элемент TCR, не вызывали никакого уничтожения клетки-мишени, подтверждая необходимость перекрестного связывания Т-клетки и клетки-мишени с мультиспецифичными полипептидами CD123/TCR для индукции уничтожения.
Результаты были подтверждены с использованием очищенных Т-клеток от разных доноров (данные не показаны).
Пример 26. Перенаправленное уничтожение клеток-мишеней CD123, опосредованное Т-клетками яванского макака, мультиспецифичными полипептидами CD123/TCR в анализе на основе проточной цитометрии
Чтобы подтвердить перекрестную реактивность мультиспецифичных полипептидов CD123/TCR для TCR человека и яванского макака, полипептиды оценивали в анализе уничтожения CD123- положительных опухолевых клеток, опосредованного Т-клетками яванского макака. Вкратце, мультиспецифичные полипептиды инкубировали с 2,5×104 меченными PKH клетками-мишенями (т.е. клетками MOLM-13 или KG1a) в присутствии 2,5×105 эффекторных клеток (т.е. первичных Т-клеток яванского макака), соответствующих соотношению эффекторных клеток к клеткам-мишеням (Отношение E: T) 10 к 1, как описано в примере 25. Т-клетки были выделены в LPT Laboratory of Pharmacology and Toxicology GmbH & Co. KG, с помощью набора для выделения Т-клеток (MACS, 130-091-993). Нанотело A0110056A10 и полипептиды T017000129 и T017000132 были взяты вместе в качестве отрицательного контроля.
Примерные результаты показаны на фигурах 27 и фигурах 28 для клеток MOLM-13 и KG1a, соответственно. Значения EC50 представлены в таблице C-22 и таблице C-23 для клеток MOLM-13 и KG1a, соответственно.
Все мультиспецифичные полипептиды CD123/TCR, за исключением T017000134, индуцировали опосредованное Т-клетками яванского макака уничтожение CD123-положительных клеточных линий MOLM-13 или KG1a. Полипептиды с реактивным TCR-нанотелом в N-концевом положении были наиболее сильными и эффективными. Полипептиды T017000138 и T017000139, которые оба являются трехвалентными полипептидами с двумя реактивными нанотелами CD123, показали улучшенную активность по сравнению с полипептидом T017000128, который содержит только одно реактивное нанотело CD123. Моновалентные анти-CD123-нанотела и нерелевантные полипептиды, содержащие структурный элемент TCR, не вызывали уничтожения клеток-мишеней, подтверждая необходимость перекрестного связывания Т-клеток и клеток-мишеней посредством мультиспецифичных полипептидов CD123/TCR для индукции уничтожения.
Результаты были подтверждены с использованием очищенных Т-клеток от разных яванских макак (данные не показаны).
Пример 27. Активация Т-клеток яванского макака мультиспецифичными полипептидами CD123/TCR во время перенаправленного уничтожения клеток-мишеней с CD123, опосредованного Т-клетками яванского макака
Для мониторинга активации Т-клеток после обработки Т-клеток яванского макака и CD123-положительных клеток MOLM-13 мультиспецифичными полипептидами CD123/TCR, полипептиды инкубировали в течение 72 ч при 37°С с 2,5×104 клеток-мишеней в присутствии 2,5×105 первичных Т-клеток (E:T=10:1), как описано в примере 26. Активация Т-клеток яванского макака была измерена путем мониторинга положительной регуляции CD25 в популяции CD4/CD8 Т-клеток с помощью проточной цитометрии.
Для этого после 72-часовой инкубации эффекторные клетки и клетки-мишени собирали центрифугированием и суспендировали в буфере FACS с 25 мкг/мл Human BD Fc Block™(BD Bioscience, 564220) и инкубировали в течение 10 минут при комнатной температуре (RT). Затем клетки окрашивали моноклональными мышиными анти-CD4-APC антителами (Biolegend, 300505) (разведенными в 200 раз), моноклональными мышиными анти-CD8 APC антителами (BDBiosciences, 555366) (разведенными в 50 раз) и моноклональными анти-CD25 PE антителами (BD Biosciences, 557138) (разведенными в 50 раз) в буфере FACS в течение 30 минут при 4°C. После инкубации клетки осаждали центрифугированием и промывали буфером FACS. Затем клетки ресуспендировали в буфере FACS и анализировали с помощью проточного цитометра FACS Canto (BD Biosciences). Для каждого образца был получен общий объем образца 30 мкл. Т-клетки были отсортированы по рамкам отбора на основе графика SSC-APC. Из этой популяции было рассчитано среднее значение PE.
Данные показаны на фигуре 29. Значение ЕС50, полученное для T017000139, изображено в таблице C-24.
Положительной регуляции CD25 не наблюдалось, когда Т-клетки инкубировали с CD123-положительными клетками-мишенями MOLM-13 и моновалентными структурными элементами, связывающими TCR или CD123, T0170056G05, A0110055F03 или A0110056A10 или нерелевантным мультивалентным полипептидом T017000129. Данные показали положительную регуляцию CD25 на первичных Т-клетках яванского макака после инкубации с CD123-положительными клетками-мишенями MOLM-13 и мультиспецифическим полипептидом T017000139.
Клетки MOLM-13 были уничтожены дозозависимым образом (фигура 25, таблица C-22), что указывает на то, что мультиспецифичный связывающий CD123/TCR полипептид индуцировал активацию Т-клеток в процессе перенаправленного уничтожения.
Аналогичным образом, Т-клетки не активировались при инкубации с клетками-мишенями и моновалентными структурными элементами и нерелевантным мультиспецифическим полипептидом, что указывает на необходимость перекрестного связывания Т-клетки и клетки-мишени с мультиспецифичными полипептидами TCR/CD123, чтобы индуцировать активацию CD25.
Пример 28. Перенаправленное опосредованное Т-клетками человека уничтожение CD123-трансфицированных адгезивных клеток-мишеней с помощью мультиспецифичных CD123/TCR-связывающих полипептидов в анализе на основе xCELLigence
TCR/CD123-связывающие полипептиды были охарактеризованы для перенаправленного, опосредованного Т-клетками человека, уничтожения трансфицированных CD123 адгезивных клеток-мишеней в анализе на основе xCELLigence. В этом анализе измеряются флуктуации импеданса, вызванные прилипанием клеток-мишеней к поверхности электрода. Т-клетки не прилипают и, следовательно, не влияют на измерения импеданса. Инструмент xCELLigence (Roche) количественно определяет изменения электрического импеданса, отображая их в виде безразмерного параметра, называемого индексом клеток, который прямо пропорционален общей площади лунки тканевой культуры, которая покрыта клетками. Вкратце, станция xCELLigence была помещена в инкубатор при 37°C при 5% CO2. 50 мкл среды для анализа добавляли в каждую лунку планшета E-plate 96 (ACEA Biosciences; 05 232 368 001) и проводили пустое считывание в системе xCELLigence для измерения импеданса фона в отсутствие клеток. Затем 2×104 клеток CHO Flp-In, трансфицированных CD123 человека, или контрольных клеток CHO Flp-In высевали на планшеты E-plate 96, и добавляли 50 мкл последовательно разведенного мультиспецифического полипептида. Через 30 мин при комнатной температуре в каждую лунку добавляли 50 мкл Т-клеток человека (3×105), чтобы соотношение эффектора к мишени составляло 15:1. Планшет помещали на станцию xCELLigence и измеряли импеданс каждые 15 минут в течение 3 дней. Данные были проанализированы с использованием фиксированного момента времени, указанного в результатах.
Значения IC50, полученные в этом анализе, перечислены в таблице C-25. Результаты представлены на фигуре 30, фигуре 31 и фигуре 32.
Полученные данные подтвердили результаты, полученные в анализе уничтожения на основе проточной цитометрии, т.е. мультиспецифические полипептиды CD123/TCR могут индуцировать опосредованное Т-клетками человека уничтожение CD123-положительных клеточных линий (фигура 30), при этом в отсутствие Т-клеток активность уничтожения не наблюдается (фигура 32). Кроме того, только в присутствии опухолевого антигена-мишени CD123 наблюдалось уничтожение, опосредованное Т-клетками (см. фигуру 31 для отсутствия уничтожения в случае контрольной клеточной линии), что указывает на то, что мультиспецифичные полипептиды критически зависят от своей мишени для индукции цитотоксичности.
Моновалентные нанотела A0110056A10 и T0170056G05 и нерелевантный полипептид T017000129 не индуцируют уничтожение клеток-мишеней, подтверждая необходимость перекрестного связывания Т-клеток и клеток-мишеней с мультиспецифичным связывающим CD123/TCR полипептидом для индукции уничтожения.
Результаты были подтверждены с использованием очищенных Т-клеток от разных доноров (данные не показаны).
Пример 29. Перенаправленное, опосредованное Т-клетками яванского макака, уничтожение CD123-трансфицированных адгезивных клеток-мишеней с помощью мультиспецифичных CD123/TCR-связывающих полипептидов в анализе на основе xCELLigence
Чтобы подтвердить перекрестную реактивность мультиспецифичных полипептидов, полипептиды оценивали в перенаправленном уничтожении Т-клетками яванского макака адгезивных клеток-мишеней, трансфицированных CD123 яванского макака, в анализе на основе xCELLigence, как описано в примере 28.
Значения IC50, полученные в этом анализе, перечислены в таблице C-26. Результаты представлены на фигуре 33, фигуре 34 и фигуре 35.
Мультиспецифичный полипептид CD123/TCR T017000139 мог индуцировать опосредованное Т-клетками яванского макака уничтожение CD123-положительных клеточных линий (фигура 33), при этом в отсутствие Т-клеток активность уничтожения не наблюдалась (фигура 35). Кроме того, в присутствии опухолевого антигена-мишени, CD123 яванского макака, наблюдалось уничтожение, опосредованное Т-клетками (фигура 34), что указывает на то, что мультиспецифичные полипептиды критически зависят от своей мишени для индукции цитотоксичности.
Моновалентные нанотела A0110056A10 и T0170056G05 и нерелевантный полипептид T017000129 не индуцируют уничтожение клеток-мишеней, подтверждая необходимость перекрестного связывания Т-клеток и клеток-мишеней с мультиспецифичным полипептидом, связывающим CD123/TCR, для индукции уничтожения.
Перекрестная реактивность CD123 и TCR человеческого яванского макака мультиспецифического полипептида T017000139 была подтверждена в анализе уничтожения на основе xCELLigence.
Результаты были подтверждены с использованием очищенных Т-клеток от разных доноров (данные не показаны).
Пример 30. Влияние мультиспецифичных полипептидов, связывающих CD123/TCR, на продукцию цитокинов во время перенаправленного уничтожения
Индукцию высвобождения цитокинов контролировали во время CD123-уничтожения, опосредованного Т-клетками человека и яванского макака, на основании анализа xCELLigence. Высвобождение цитокина IFN-γ и IL-6 измеряли с помощью ELISA. Вкратце, клетки CHO-K1, трансфицированные CD123 человека (2×104 клеток/лунку), высевали в планшет E-plate 96 в присутствии очищенных первичных Т-клеток человека или яванского макака (3×105 клеток/лунку) с серийным разведением мультиспецифического TCR/CD123-связывающего полипептида (начиная с 125 нМ) или фиксированной концентрацией (125 нМ) нерелевантных полипептидов, как описано в примере 28. Через 72 ч после добавления первичных Т-клеток человека или яванского макака/полипептидов в планшеты, измеряли продуцирование IFN-γ человека и IL-6 человека первичными Т-клетками человека и IFN-γ яванского макака первичными Т-клетками яванского макака в надосадочной жидкости.
Высвобождение человеческого IL-6 измеряли в ELISA с использованием набора ELISA для человеческого IL-6 Quantikine (R&D systems, D6050) в соответствии с инструкциями производителя. Высвобождение IFN-γ определяли следующим образом: 96-луночные планшеты для ELISA Maxisorp (Nunc) покрывали антителами против IFN-γ человека (BDBiosciences, 551221), и, соответственно, антителами против IFN-γ яванского макака (BioLegend, 507502). После инкубации в течение ночи планшеты промывали и блокировали PBS + 2% BSA в течение 1 часа при комнатной температуре. Затем планшеты инкубировали со 100 мкл надосадочных жидкостей (разбавленных в 2 раза) и 1 мкг/мл биотинилированного антитела против IFN-γ (BD Biosciences, 554550) в течение 2 ч 30 мин при встряхивании, снова промывали и инкубировали со стрептавидином-HRP (Dakocytomation, P0397). Через 30 минут добавляли раствор TMB One (Promega, G7431). Реакцию останавливали с помощью 2 М H2SO4 и определяли продуцирование IFN-γ, зависимое от дозы полипептида, путем измерения оптической плотности при 405 нм с использованием Tecan sunrise 4.
Результаты для IFN-γ показаны на фигуре 36. Результаты для IL-6 показаны на фигуре 37. Значения ЕС50, полученные в этих анализах, перечислены в таблице С-27 и таблице С-28.
Продуцирование цитокинов наблюдали, когда клетки CHO Flp-In, сверхэкспрессирующие CD123, и первичные Т-клетки инкубировали с полипептидами, связывающими CD123/TCR. Нерелевантные полипептиды T017000129 и T017000132 не индуцируют продуцирование цитокинов.
Пример 31. Истощение перенаправленными аутологичными Т-клетками плазмоцитоидных дендритных клеток (pDC) и базофилов мультиспецифичными полипептидами CD123/TCR в здоровых PBMC
Криоконсервированные мононуклеоциты периферической крови (РВМС) оттаивали и промывали средой для анализа (RMPI 1640 + 10% FBS). 2×105 РВМС инкубировали с серийными разведениями мультиспецифичных полипептидов в 200 мкл аналитической среды в 96-луночном V-образном планшете с V-образным дном и инкубировали при 37°C в 5% CO2-инкубаторе. В указанные моменты времени клетки окрашивали при 4°C моноклональными мышиными антителами против CD14-APC (Biolegend, 301808), против CD16-APC (Biolegend, 302012), против CD19-APC (Biolegend, 302212), против CD20-APC (Biolegend, 302312), против CD56-APC (Biolegend, 318310), против CD123-PE (Biolegend, 306006) и против HLA-DR-FITC (Biolegend, 307603). Вкратце, клетки собирали и промывали один раз буфером FACS (D-PBS от Gibco, с 10% FBS от Sigma и 0,05% азида натрия от Merck) и ресуспендировали в 25 мкл Human BD Fc Block™, 0,5 мкг/мл (BD Biosciences, 564220, 1000-кратное разбавление) в течение 10 минут при комнатной температуре. Затем добавляли 25 мкл антител и инкубировали в течение 30 мин при 4°С в соответствии с инструкциями производителя. Отдельную лунку, содержащую РВМС, ресуспендировали в буфере FACS, дополненном 5 нМ TOPRO3 (Molecular Probes, T3605), чтобы отличить мертвые клетки от живых в популяции клеток. Образцы промывали 3 раза, ресуспендировали в буфере FACS (D-PBS от Gibco, с 10% FBS от Sigma и 0,05% азида натрия от Merck) и затем анализировали с помощью цитометра FACS Canto (BD), снабженного программным обеспечением FACS Diva. Для каждой пробы был получен общий объем пробы 75 мкл. Анализ данных проводился с использованием программного обеспечения FACS Diva и Flowing.
По данным лунки, содержащей краситель TOPRO, было проведено гейтирование для исключения мертвых клеток. PDC и базофилы человека и яванского макака были идентифицированы как отрицательная по маркерам дифференцировки (CD16, CD20, CD19, CD56)/CD123-положительная популяция.
Результаты представлены на фигуре 38.
Истощение CD123-положительной популяции человека и, соответственно, яванского макака мультиспецифичными полипептидами CD123/TCR наблюдалось после инкубационного периода 5 часов. Когда таргетное нанотело было заменено нерелевантным нанотелом, то не наблюдалось истощения CD123-положительной популяции, что указывает на необходимость перекрестного связывания Т-клетки и клетки-мишени с мультиспецифичными полипептидами TCR/CD123 для индукции истощения.
Анализ осуществили повтор с использованием PBMC от 3 разных доноров человека и PBMC от 2 разных яванских макаков, подтвердив функциональность мультиспецифичных полипептидов TCR/CD123.
Пример 32. Перенаправленное истощение аутологичными человеческими Т-клетками моноцитов с помощью мультиспецифичных связывающих CD123/TCR полипептидов в образцах РВМС здорового человека
Чтобы оценить истощение моноцитов, анализ проводили, как описано выше, используя криоконсервированные человеческие PBMC, которые были разморожены и промыты средой для анализа (RMPI 1640 + 10% FBS) и инкубированы с серийными разведениями мультиспецифического полипептида в течение 5 или 24 часов. Окрашивание клеток проводили, как описано выше. Моноциты были идентифицированы как популяция CD14+.
Результаты показаны на фигуре 39.
После 5 ч инкубации истощение моноцитов не наблюдалось для мультиспецифического полипептида TCR/CD123 и нерелевантных нанотел. Через 24 часа истощение моноцитов наблюдалось для мультиспецифичных полипептидов TCR/CD123, но не для нерелевантных полипептидов. Анализ повторяли с использованием PBMC от 3 различных доноров, подтверждая функциональность мультиспецифичных полипептидов TCR/CD123.
Пример 33. Активация Т-клеток человека мультиспецифичными полипептидами, связывающими CD123/TCR, в ходе перенаправленного уничтожения Т-клетками аутологичных CD123-положительных клеток в образцах РВМС здорового человека
Чтобы охарактеризовать активацию Т-клеток во время процесса истощения, опосредованного мультиспецифичными полипептидами TCR/CD123, был проведен анализ аутологичных PBMC, как описано выше, и состояние активации Т-клеток человека контролировали путем измерения повышающей регуляции CD69 после 24-часовой инкубации. Вкратце, после 24-часового инкубирования клетки окрашивали 30 минут при 4°С моноклональным мышиным анти-CD3-FITC антителом (BD Biosciences, 555332) для идентификации Т-клеток человека и моноклональным мышиным антителом CD69-PE человека (BD Biosciences, 557050) для оценки активации Т-клеток. Клетки промывали 3 раза, ресуспендировали в буфере FACS (D-PBS от Gibco, с 10% FBS от Sigma и 0,05% азида натрия от Merck) и затем анализировали с помощью цитометра FACS Canto (BD), снабженного программным обеспечением FACS Diva. Для каждой пробы был получен общий объем пробы 75 мкл. Анализ данных проводился с использованием программного обеспечения FACS Diva и Flowing.
Примерные результаты показаны на фигуре 40.
Данные показали дозозависимую активацию CD69 на CD3+ T-клетках человека, когда PBMC инкубировали с мультиспецифичными CD123/TCR-связывающими полипептидами. Инкубация с моновалентными нанотелами или нерелевантными полипептидами не приводила к положительной регуляции CD69.
Пример 34. Описание характеристик нерелевантных полипептидов для перенаправленного уничтожения, опосредованного Т-клетками, клеток-мишеней с CD123 в анализе на основе проточной цитометрии
Чтобы оценить безопасность TCR-нанотела T0170056G05, был проведен углубленный анализ нерелевантных полипептидов (моновалентных нанотел и мультивалентного полипептида T017000129) в анализе перенаправленного уничтожения мишеней, опосредованного Т-клетками, при соотношении E: T 10:1, как описано в примерах 25 и 26. Полипептид T017000139 был взят в качестве положительного контроля.
Результаты с использованием клеток-мишеней KG1a показаны на фигуре 41, результаты с использованием MOLM-13 показаны на фигуре 42. Полученные значения EC50 приведены в таблице C-29 и таблице C-30.
Эксперимент 1
Эксперимент 2
Положительный контроль T017000139 вел себя, как ожидалось при использовании Т-клеток человека и яванского макака. Ни моновалентные структурные элементы, ни нерелевантный полипептид T017000129 (структурные элементы против CD123 были заменены нерелевантными структурными элементами) не вызывали уничтожения CD123-положительных клеток, что подтверждает специфичность мультиспецифичных полипептидов TCR/CD123.
Пример 35. Влияние мультиспецифичных CD123/TCR-связывающих полипептидов на продуцирование цитокинов во время перенаправленного уничтожения клеток человека
Индукцию высвобождения цитокинов контролировали во время анализа уничтожения CD123-клеток, опосредованного Т-клетками человека, на основании данных FACS. Высвобождение цитокинов IFN-γ и IL-6 человека измеряли с помощью ELISA. Вкратце, MOLM-13 или KG1a высевали в 96-луночный планшет с V-образным дном (2×104 клеток/лунка) в присутствии очищенных первичных Т-клеток человека (3×105 клеток/лунку) с серийным разведением мультиспецифичных TCR/CD123-связывающих полипептидов, нерелевантных полипептидов, как описано в примере 25. Через 72 часа после добавления первичных Т-клеток человека/полипептидов в планшеты, продуцирование IFN-γ и IL-6 человека первичными Т-клетками человека измеряли в надосадочной жидкости, как описано в примере 30.
Результаты показаны на фигурах 43А, 43В и 43С. Значения EC50, полученные в этом анализе, перечислены в таблице C-31 и таблице C-32.
Продуцирование цитокинов наблюдали, когда клетки MOLM-13 или KG1a и первичные Т-клетки человека инкубировали с полипептидами, связывающими CD123/TCR. Иррелевантный полипептид T017000129 не индуцирует продуцирование цитокинов.
Пример 36. Описание характеристик мишень-независимого перенаправленного уничтожения эффекторными Т-клетками человека или яванского макака для мультиспецифичных CD123/TCR-связывающих полипептидов в анализе на основе проточной цитометрии с использованием CD123-отрицательных клеточных линий
Для оценки независимого от CD123 перенаправленного уничтожения мультиспецифичными полипептидами, отрицательные по CD123 клеточные линии U-937 и NCI-H929 оценивали в анализе уничтожения на основе проточной цитометрии. Клетки U-937 и NCI-H929 метили 8 мкМ мембранным красителем PKH-26 с использованием набора красного флуоресцентного клеточного линкера PKH26 (Sigma, PKH26GL-1KT) в соответствии с инструкцией производителя и использовали в качестве клеток-мишеней. Анализ проводили, как описано в примерах 25 и 26, с использованием первичных Т-клеток человека или яванского макака (E: T = 10:1).
Примерные результаты показаны на фигурах 44 и 45 для клеток NCI-H929 и U-937, соответственно.
Мультиспецифичные полипептиды TCR/CD123 и нерелевантные полипептиды продемонстрировали только минимальную активность уничтожения клеток U-937 перенаправленными Т-клетками (менее 6%), что указывает на то, что мультиспецифичные полипептиды обладают хорошей специфичностью связывания с CD123.
Пример 37. Описание характеристик активации Т-клеток мультиспецифичными полипептидами, связывающими CD123/TCR, в ходе анализа перенаправленного уничтожения эффекторными Т-клетками с использованием CD123-отрицательных клеточных линий
Для мониторинга активации Т-клеток после обработки Т-клеток и CD123-отрицательных клеток мультиспецифичными полипептидами, связывающими CD123/TCR, полипептиды инкубировали в течение 24 ч при 37°С с 2,5×104 клеток-мишеней U-937, и, соответственно, клеток-мишеней NCI-H929 в присутствии 2,5×105 первичных Т-клеток (E:T = 10:1), как описано в примерах 25 и 26. Активацию Т-клеток оценивали, как описано ранее, путем мониторинга активации CD25 после 72 ч инкубации на популяции CD4/CD8 Т-клеток измеряли с помощью проточной цитометрии, как описано в примере 27, с использованием моноклонального мышиного анти-CD4-APC антитела (Biolegend, 300505), моноклонального мышиного анти-CD8 APC антитела (BD Biosciences, 555366) и моноклонального анти-CD25 антитела (BD Biosciences, 557138).
Примерные результаты показаны на фигуре 46.
Оценка активации Т-клеток после инкубации с мультиспецифичными полипептидами и CD123-отрицательными клеточными линиями U-937 или NCI-929 показала только минимальную активацию CD25 для любого из мультиспецифичных полипептидов. Таким образом, в присутствие CD123-отрицательных клеток-мишеней имели место только минимальные активация Т-клеток и уничтожение Т-клетками.
Пример 38. Описание характеристик продуцирования цитокинов под действием мультиспецифичных CD123/TCR-связывающих полипептидов в ходе перенаправленного уничтожения клетками человека
Аспецифическую индукцию высвобождения цитокинов контролировали во время анализа уничтожения, опосредованного Т-клетками человека, на основании данных FACS. Высвобождение цитокина IFN-γ и IL-6 измеряли с помощью ELISA. Вкратце, NCI-H929 высевали в 96-луночный планшет с V-образным дном (2×104 клеток/лунку) в присутствии очищенных первичных Т-клеток человека (3×105 клеток/лунку) с серийным разведением мультиспецифичных полипептидов, связывающих TCR/CD123, или нерелевантных полипептидов, как описано в примере 25. Через 72 часа после добавления человеческих первичных Т-клеток/полипептидов в планшеты, измеряли продуцирование IFN-γ и IL-6 в человеческих первичных Т-клетках в надосадочной жидкости, как описано в примере 30. Результаты представлены на фигуре 47.
Продуцирование цитокинов не наблюдалось, когда CD123-отрицательную клеточную линию NCI-H929 и первичные Т-клетки человека инкубировали с CD123/TCR-связывающими полипептидами.
Пример 39. Влияние мультиспецифичных полипептидов, связывающих CD123/TCR, на пролиферацию Т-клеток в ходе перенаправленного уничтожения
Чтобы исследовать влияние мультиспецифичных CD123/TCR-связывающих полипептидов на пролиферацию человеческих Т-клеток, облученные гамма-излучением (100Gy) клетки MOLM-13 высевали в 96-луночные планшеты для микротитрования с плоским дном (Greiner bio-one, 655 180, 2×104 клеток/лунку) вместе с мультиспецифичными полипептидами и первичными Т-клетками человека (2×105 клеток/лунку) и инкубировали в течение 72 часов при 37°С в увлажненной атмосфере с 5 × СО2 в воздухе. Затем в клетки вводили в течение приблизительно 18 часов 3H-тимидин (3H-Tdr, New England Nuclear, Бостон, Массачусетс, удельная активность 20 Ки/мМ), собирали на фильтровальные полоски из стекловолокна и затем подсчитывали с помощью жидкостной сцинтилляции.
Примерные результаты показаны на фигуре 48.
Мультиспецифические полипептиды CD123/TCR индуцировали пролиферацию Т-клеток в зависимости от дозы. Для нерелевантного полипептида T017000129 пролиферация Т-клеток не наблюдалась.
Параллельно оценивали влияние мультиспецифичных полипептидов, связывающих CD123/TCR, на пролиферацию Т-клеток человека в отсутствие клеток-мишеней. Для этого мультиспецифичные полипептиды и первичные Т-клетки человека (2×105 клеток/лунку) инкубировали в течение 72 часов при 37°С в увлажненной атмосфере с 5×СО2 в воздухе. Пролиферацию измеряли, как описано выше. Данные показаны на фигуре 49.
Пример 40. Литическая эффективность предварительно активированных Т-клеток по сравнению с неактивированными Т-клетками
Для того, чтобы проверить литическую активность Т-клеток в ответ на многодневный инкубационный период в стимулирующих условиях, первичные человеческие Т-клетки (выделенные, как описано в примере 25) оттаивали и предварительно активировали с использованием Dynabeads® Human T-Activator CD3/CD28 (Gibco - Technologies, 11132D) при соотношении Т-клеток и гранул 2:1. Через 3 дня гранулы заменяли свежими гранулами еще на три дня. Затем гранулы удаляли и предварительно активировали, а неактивированные Т-клетки оценивали в анализе уничтожения клеток-мишеней MOLM-13. Вкратце, неактивированные или предварительно активированные CD3/CD28 первичные Т-клетки от одного и того же донора смешивали с мечеными PKH клетками MOLM-13 при различных соотношениях E: T (8: 1, 2: 1, 1: 2, 1: 4) и с серийными разведениями T017000114 или с меченными PKH клетками KG1A при различных соотношениях E: T (2: 1, 1: 2, 1: 4, 1: 8) и с серийными разведениями T017000139. Считывание цитотоксичности после 24 ч инкубации проводили, как описано выше в примере 25.
Результаты показаны на фигурах 50 и 51 для клеток MOLM-13 и KG1a, соответственно. Значения ЕС50, полученные в этом анализе, перечислены в таблице С-33 и таблице С-34 для клеток MOLM-13 и KG1a, соответственно.
Соотношение E: T 8: 1
Соотношение E: T 2: 1
Соотношение E: T 1: 2
Соотношение E: T 2: 1
Соотношение E: T 1: 2
Соотношение E: T 1: 4
Соотношение E: T 1: 8
Предварительно активированные Т-клетки лизировали клетки-мишени сильнее, чем неактивированные Т-клетки при всех протестированных соотношениях E: T. Предварительная стимуляция эффекторных клеток посредством анти-CD3/анти-CD28 приводила к более высоким скоростям лизиса.
Пример 41. Конструирование мультиспецифичных CD123/TCR-связывающих полипептидов и контрольных полипептидов с увеличенным периодом полувыведения (HLE)
ALB11 (SEQ ID NO: 43), нанотело, связывающееся с человеческим сывороточным альбумином (HSA), было присоединено к CD123/TCR-связывающим полипептидам для увеличения периода полувыведения in vivo у форматированных молекул (WO 06/122787). Ряд форматов был получен с помощью TCR α/β-рекрутирующего нанотела на N-конце и нанотел, нацеленных на опухоли с CD123, или нанотела, нацеленного на альбумин на С-конце, с использованием линкера 35GS и экспрессированных, как указано выше. Нерелевантные полипептиды получали путем замены нанотел, связывающих опухолевый антиген, на нерелевантное нанотело против RSV. Обзор исследованных форматов показан в таблице С-35.
* SEQ ID NO соответствуют последовательностям мультиспецифичных полипептидов без С-концевых меток или Ala-удлинения
Пример 42. Альбуминсвязывающие свойства ALB11 в мультиспецифичных рекрутирующих полипептидах
Аффинность связывания мультиспецифичных полипептидов с увеличенным периодом полувыведения с сывороточным альбумином (SA) человека, и, соответственно, яванского макака, измеряли с помощью определения аффинности на основе SPR на приборе Biacore T100. Для этого SA человека и, соответственно, SA яванского макака (Sigma, A3782) (произведенного собственными силами), иммобилизовали на чипе СМ5 с помощью сочетания по аминной группе, используя химию EDC и NHS. Связывающие TCR/CD123 полипептиды вводили в течение 2 минут при различных концентрациях (от 6,2 до 500 нМ) и оставляли диссоциировать в течение 15 минут при скорости потока 45 мкл/мин. В промежутках между инъекциями образцов поверхности регенерировали 10 мМ глицин-HCl pH 1,5. HBS-EP+ использовали в качестве рабочего буфера. Кинетические константы рассчитывали из сенсограмм с использованием программного обеспечения BIAEvaluation с алгоритмом, использующим модель связывания кинетики одного цикла 1: 1. Константа аффинности KD была рассчитана на основе полученных констант скорости ассоциации и диссоциации ka и kd и показана в таблице C-36.
Форматирование структурного элемента ALB11 в мультиспецифические рекрутирующие полипептиды приводило к допустимому снижению аффинности связывания с сывороточным альбумином человека и яванского макака.
Пример 43. Перенаправленное, опосредованное Т-клетками, уничтожение клеток-мишеней MOLM-13 с помощью связывающих HLE-полипептидов CD123/TCR в анализе на основе проточной цитометрии
Поскольку добавление нанотел ALB11 и связывание с сывороточным альбумином (SA) может влиять на активность полипептидов, HLE-полипептиды, связывающие CD123/TCR, были оценены на предмет перенаправленного уничтожения, опосредованного Т-клетками человека и яванского макака, CD123-положительных клеток-мишеней MOLM-13 на основе анализа проточной цитометрией, как описано в примерах 25 и 26, в отсутствие или в присутствие 30 мкМ SA.
Значения ЕС50, полученные в этом анализе, перечислены в таблице С-37. Результаты представлены на фигуре 52.
лизиса
лизиса
SA
Все мультиспецифичные CD123/TCR-связывающие полипептиды HLE показали дозозависимое уничтожение клеток MOLM-13 как T-клетками человека, так и клетками яванского макака. Включение ALB11 в полипептид не снижало активность. При добавлении HSA или CSA наблюдалось небольшое снижение специфической активности, в то время как на эффективность это не влияло.
Пример 44. Перенаправленное, опосредованное Т-клетками, уничтожение клеток-мишеней KG1a с помощью CD123/TCR-связывающих HLE-полипептидов в анализе на основе проточной цитометрии
Полипептиды с увеличенным периодом полувыведения, связывающие TCR/CD123, также оценивали на предмет перенаправленного уничтожения клеток-мишеней CD123 KG1a, опосредованного Т-клетками человека и яванского макака, на основе анализа проточной цитометрией, как описано в примерах 24 и 25, в отсутствие или в присутствие 30 мкМ сывороточного альбумина.
Значения ЕС50, полученные в этом анализе, перечислены в таблице С-38. Результаты представлены на фигуре 53.
лизиса
лизиса
Все мультиспецифичные CD123/TCR-связывающие HLE-полипептиды продемонстрировали дозозависимое уничтожение клеток KG1a как T-клетками человека, так и яванского макака. Включение ALB11 в полипептид не снижало специфическую активность. При добавлении HSA или CSA наблюдалось небольшое снижение специфической активности, при этом на эффективность это не влияло.
Пример 45. Влияние мультиспецифического CD123/TCR-связывающего HLE-полипептида T017000144 на продуцирование цитокинов во время перенаправленного уничтожения
Индукцию высвобождения цитокинов контролировали во время анализа уничтожения, опосредованного Т-клетками человека, на основе данных FACS. Высвобождение IFN-γ и IL-6 измеряли с помощью ELISA. Вкратце, MOLM-13 (2×104 клеток/лунку) высевали в 96- луночный планшет с V-образным дном в присутствии очищенных первичных Т-клеток человека (3×105 клеток/лунку) с серийным разведением мультиспецифичных полипептидов, связывающихся с TCR/CD123, или нерелевантных полипептидов, как описано в примере 35. Через 72 часа после добавления первичных Т-клеток человека/полипептидов в планшеты, измеряли продуцирование IFN-γ и IL-6, с первичными Т-клетками человека в надосадочной жидкости, как описано в примере 30.
Значения ЕС50, полученные в этом анализе, перечислены в таблице С-39 и таблице С-40. Результаты представлены на фигуре 54.
Продуцирование цитокинов наблюдали, когда клетки MOLM-13 и первичные Т-клетки человека инкубировали с CD123/TCR-связывающим HLE-полипептидом T017000144. Нерелевантный полипептид T017000129 не индуцировал продуцирование цитокинов.
Пример 46. Влияние мультиспецифичных CD123/TCR-связывающих HLE-полипептидов на пролиферацию Т-клеток во время перенаправленного уничтожения
Чтобы исследовать влияние мультиспецифичных CD123/TCR-связывающих HLE-полипептидов на пролиферацию Т-клеток человека, гамма-облученные (100 Гр) клетки MOLM-13 высевали в 96-луночные планшеты для микротитрования с плоским дном (2×104 клеток/лунку) вместе с мультиспецифическим HLE-полипептидом T017000144 и первичными Т-клетками человека (2×105 клеток/лунку) и инкубировали в течение 72 часов при 37°C в увлажненной атмосфере с 5X CO2 в воздухе в отсутствие SA. T017000129 был взят как отрицательный контроль. Затем в клетки вводили в течение приблизительно 18 часов 3H-тимидин (3H-Tdr, New England Nuclear, Бостон, Массачусетс, удельная активность 20 Ки/мМ), собирали на фильтровальные полоски из стекловолокна и затем подсчитывали с помощью жидкостного сцинтилляционного счета.
Примерные результаты показаны на фигуре 55.
Мультиспецифичный CD123/TCR-связывающий HLE-полипептид T017000144 индуцировал пролиферацию Т-клеток дозозависимым образом. Для нерелевантного полипептида T017000129 пролиферация Т-клеток не наблюдалась.
Пример 47. Перенаправленное истощение плазмоцитоидных дендритных клеток (pDC) и базофилов аутологичными Т-клетками при воздействии мультиспецифичных CD123/TCR-связывающих HLE-полипептидов в образцах РВМС здорового человека и РВМС здорового яванского макака
Конструкции HLE дополнительно оценивали в анализе аутологичных PBMC человека и яванского макака в отсутствие SA, как описано в примере 31. Истощение CD123-положительных клеток (pDC: отрицательные по маркерам дифференцировки, CD123-положительные, HLA-DR-положительные и базофилы: отрицательные по маркерам дифференцировки, CD123-положительные, HLA-DR-отрицательные) мультиспецифичными полипептидами оценивали после инкубационного периода 5 ч.
Результаты представлены на фигурах 56 и 57 для PBMC человека и яванского макака, соответственно.
Мультиспецифические HLE-полипептиды, связывающие CD123/TCR, были способны истощить CD123+ pDC и базофилы среди PBMC человека и яванского макака перенаправленными Т-клетками. T017000144 был самым сильным полипептидом. Полипептид T017000142, состоящий из одного структурного элемента TCR, ALB11 и только одного структурного элемента CD123, не показал функциональности в анализе РВМС через 5 часов. Перекрестная реактивность человека и яванского макака мультиспецифичных HLE-полипептидов, связывающих CD123/TCR, была подтверждена в аутологичных условиях.
Пример 48. Перенаправленное истощение аутологичными Т-клетками моноцитов при воздействии мультиспецифичных HLE-полипептидов, связывающих CD123/TCR, в образцах РВМС здорового человека
Истощение моноцитов (CD14+ клеток) мультиспецифичными HLE-полипептидами в условиях аутологичных РВМС человека оценивали после инкубационного периода 24 ч в отсутствие SA. Анализ проводили, как описано в примере 32.
Результаты представлены на фигуре 58.
Мультиспецифичные HLE-полипептиды способны истощать CD123+ моноциты в PBMC человека перенаправленными Т-клетками. T017000144 был самым сильным полипептидом. Полипептид T017000142, состоящий из одного структурного элемента TCR, ALB11 и только одного структурного элемента CD123, продемонстрировал функциональность в анализе истощения аутологичных моноцитов через 24 часа.
Пример 49. Эффективность и безопасность in vivo на модели приматов, отличных от человека
In vivo эффективность и безопасность не-HLE и HLE мультиспецифичных CD123/TCR-связывающих нанотел, оценивали на модели приматов, отличных от человека.
Животных, обработанных контрольным соединением, включали в качестве положительного контроля. Обработку не-HLE IRR/TCR полипептидами использовали в качестве контроля специфичности для фрагмента, нацеленного на CD123, в мультиспецифичных полипептидах. Контрольное соединение и неспецифичные мультиспецифичные полипептиды, связывающие CD123/TCR, вводили яванским макакам путем непрерывной внутривенной инфузии после 7-дневной инфузии NaCl для «предварительной обработки». Не-HLE мультиспецифичные полипептиды, связывающие CD123/TCR, вводили в течение 4 недель в виде 4-дневной/3-дневной инфузии в эквимолярных дозах контрольному соединению в схеме еженедельного повышения дозы в соответствии с таблицей C-41. Мультиспецифичный CD123/TCR-связывающий полипептид HLE вводили яванским макакам посредством болюсных внутривенных инъекций в дни 1, 2, 3, 8, 15 и 22 по схеме еженедельного повышения дозы согласно таблице C-41.
введения
D2: 0,4
D3: 0,34
Перераспределение Т-клеток из крови отслеживали путем измерения подмножеств Т-клеток, как описано в таблице C-42, с использованием проточной цитометрии и дифференциального анализа крови в дни испытаний -7, d-4, d1 (до введения + 4 часа после введения дозы), d4, d8 (до введения + 4 часа после введения дозы), d11, d15 (до введения + 4 часа после введения дозы), d18, d22 (до введения + 4 часа после введения дозы), d25, d29, d32 и d36.
Эффективность in vivo определяли путем оценки процента и количества CD123+ клеток в РВМС, как подробно описано в таблице C-43, с использованием проточной цитометрии и подсчета отдельных видов лейкоцитов в крови в дни испытаний -7, d-4, d1 (до введения дозы + 4 часа после введения дозы, d4, d8 (до введения дозы + 4 часа после введения дозы), d11, d15 (до введения дозы + 4 часа после введения дозы), d18, d22 (до введения дозы + 4 часа после введения дозы) - доза), d25, d29, d32 и d36.
Безопасность определяли путем оценки цитокинов (IL-1β, IL-2, IL-4, IL-5, IL-6, IL-8, IL-10, IL-12 (p70), TNF-α, TNF-β, IFN-γ) в сыворотке крови в дни испытаний -7, d-4, d1 (через 4 часа после введения дозы), d4, d8 (через 4 часа после введения дозы), d11, d15 (через 4 часа после введения дозы), d18, d22 (4 часа после введения дозы), d25, d29, d32 и d36.
запрограммированной клеточной смерти) в Th
Образцы сыворотки для PK-анализа собирали в дни -7, d-4, d1 (до введения + 4 часа после введения дозы), d4, d8 (до введения + 4 часа после введения дозы), d11, d15 (до доза + 4 часа после введения дозы, d18, d22 (до введения дозы + 4 часа после введения дозы), d25, d29, d32 и d36.
Образцы сыворотки для анализа ADA собирали в дни -7, d1 (до введения дозы), d8 (до введения дозы), d15 (до введения дозы), d22 (до введения дозы), d29 и d36.
На 4-й и 25-й день Т-клетки крови выделяли из всех животных и тестировали в тесте на истощение, как описано в примере 25.
На 29 день проводили вскрытие животных 2 группы. На 36 день проводили вскрытие всех оставшихся животных.
Пример 50. Эффективность и безопасность in vivo на модели приматов, не являющихся человеком, - мультиспецифическое нанотело, связывающее CD123/TCR, экспериментальные результаты
In vivo эффективность и безопасность мультиспецифического CD123/TCR-связывающего полипептида T017000139 оценивали на модели приматов, отличных от человека.
Животные, обработанные контрольным соединением (MGD006, Macrogenics), были включены в качестве положительного контроля. Обработку нерелевантным/TCR-связывающим полипептидом T017000129 использовали в качестве контроля специфичности для части мультиспецифического полипептида, нацеливающей на CD123. Контрольное соединение, полипептид, связывающий нерелевантный белок/TCR, и мультиспецифичный CD123/TCR-связывающий полипептид вводили путем непрерывной внутривенной инфузии после 7-дневной инфузии NaCl яванских макак для «предварительной обработки». Полипептид, связывающий нерелевантный белок/TCR, и мультиспецифичный CD123/TCR-связывающий полипептид вводили в течение 4 недель в виде 4-дневной/3-дневной инфузии при равных дозах по отношению к контрольному соединению в схеме еженедельного повышения дозы согласно таблице C-44.
введения
(MGD006)
T=7
Перераспределение Т-клеток из крови отслеживали путем измерения подмножеств Т-клеток с использованием проточной цитометрии в дни испытаний -7, d-4, d1 (до введения + 4 часа после введения дозы), d4, d8 (до введения дозы + 4 часа после введения), d11, d15 (до введения + 4 часа после введения дозы), d18, d22 (до введения + 4 часа после введения дозы), d25, d29, d32 и d36.
Как показано на фигуре 59, в группе положительного контроля, получавшей контрольное соединение, количество циркулирующих CD4+ CD3+ и CD8+ CD3+ Т-клеток колебалось в течение разных циклов дозирования, что указывает на направленную миграцию и/или краевое стояние лейкоцитов, а не на истощение. Напротив, обработка полипептидом CD123/TCR или полипептидом, связывающим нерелевантный белок/TCR, не приводила к сильной флуктуации числа CD4 + CD3 + или CD8 + CD3 + T-клеток.
Количества циркулирующих CD123+CD14- клеток были изучены в качестве фармакодинамической конечной точки для оценки эффективности in vivo путем измерения количества CD123+CD14- клеток в РВМС с использованием проточной цитометрии в крови в дни испытаний -7, d-4, d1 (до введения + 4 часа после введения дозы, d4, d8 (до введения + 4 часа после введения дозы), d11, d15 (до введения + 4 часа после введения дозы), d18, d22 (до введения + 4 часа после введения дозы), d25, d29, d32 и d36.
Результаты представлены на фигуре 60. CD123+CD14- клетки были истощены у животных, которых обрабатывали контрольным соединением MGD006 (положительный контроль), хотя потеря эффективности наблюдалась к 4-му циклу дозирования. Обработка полипептидом CD123/TCR вызывала истощение CD123+CD14- клеток в крови уже с первого цикла дозирования, которое сохранялось в течение 4-го и последнего цикла дозирования. У животных, получавших нерелевантный полипептид/TCR, значительного истощения CD123+CD14- клеток не наблюдалось.
Затем исследовали экспрессию PD-1 в качестве суррогатного маркера для оценки истощения T-клеток in vivo в циркулирующих CD4+CD3+ T-клетках и CD8+CD3+ T-клетках. Для этого экспрессию PD-1 измеряли в PBMC с использованием проточной цитометрии в крови в дни испытаний -7, d-4, d1 (до введения + 4 часа после введения дозы), d4, d8 (до введения + 4 часа после введения дозы), d11, d15 (до введения + 4 часа после введения дозы), d18, d22 (до введения + 4 часа после введения дозы), d25, d29, d32 и d36.
Результаты представлены на фигуре 61. Экспрессия PD-1 была сильно увеличена на большинстве CD4+CD3+ T-клеток и CD8+CD3+ T-клеток у животных, получавших контрольное соединение MGD006 (положительный контроль), и составляла примерно половину у CD4+CD3+ T-клеток и CD8+CD3+ Т-клеток после прекращения введения дозы. Напротив, экспрессия PD-1 оставалась на исходном уровне после обработки полипептидом CD123/TCR или нерелевантным полипептидом/TCR в течение циклов введения дозы.
Безопасность оценивали путем оценки цитокинов (IL-1β, IL-2, IL-4, IL-5, IL-6, IL-10, IL-12 (p70), TNF-α, TNF-β, IFN-γ) в сыворотке крови в дни испытаний -7, d-4, d1 (4 часа после введения дозы), d4, d8 (4 часа после введения дозы), d11, d15 (4 часа после введения дозы), d18, d22 (4 часа после введения дозы) и d25.
Уровни следующих цитокинов оставались ниже предела обнаружения анализа: IL-1β, IL-2, IL-4, IL-5, IL-10, IL-12 (p70), TNF-α, TNF-β и IFN-γ. Интерлейкин-6 был обнаружен в низких концентрациях в группе положительного контроля в начале первого цикла дозирования. Это увеличение было временным и только у одного животного. В группе, получавшей полипептид CD123/TCR, одно животное продемонстрировало обнаруживаемую концентрацию IL-6 перед введением дозы, а одно животное продемонстрировало кратковременное небольшое увеличение в начале второго цикла дозирования, что указывает на стресс, связанный с манипуляциями. В группе, получавшей полипептид, связывающий нерелевантный белок/TCR, одно животное показало кратковременное небольшое увеличение IL-6 в третьем цикле дозирования, что опять же указывает на стресс, связанный с манипуляциями. Результаты измерений IL-6 отображены на фигуре 62.
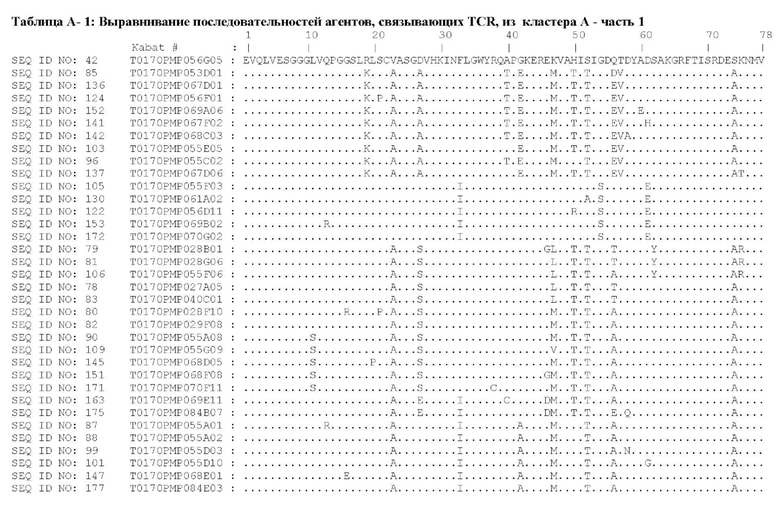



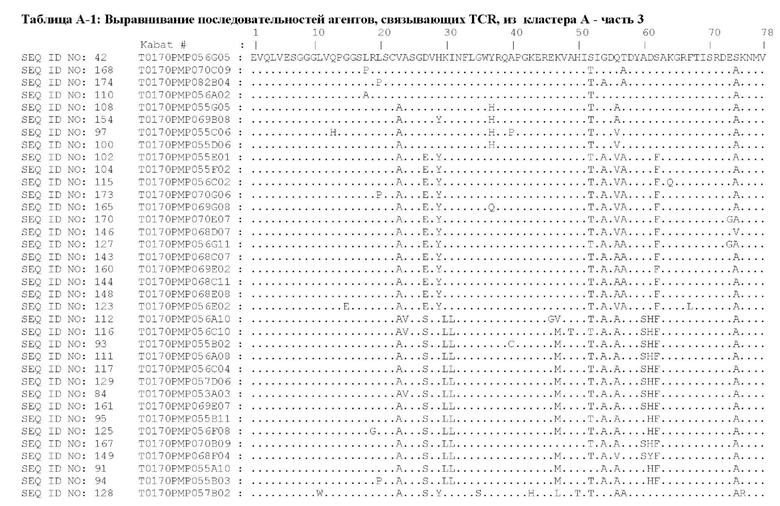



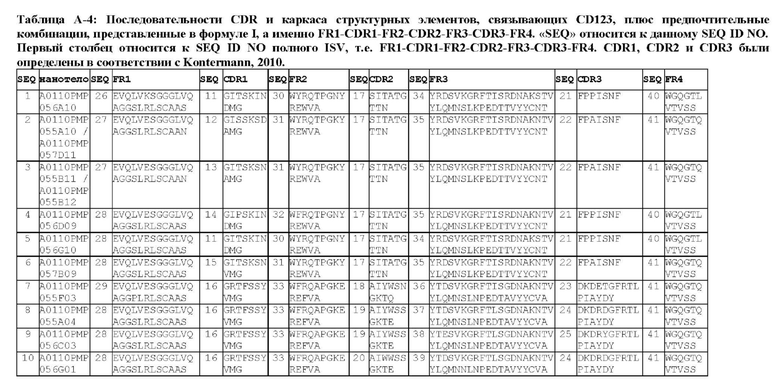
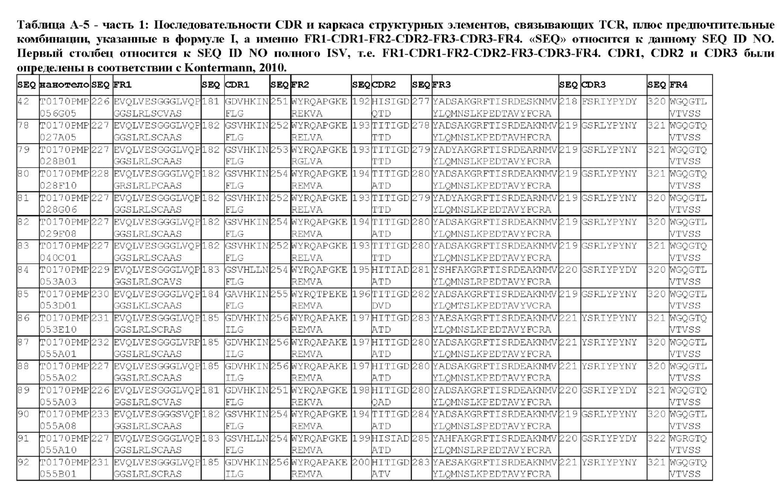
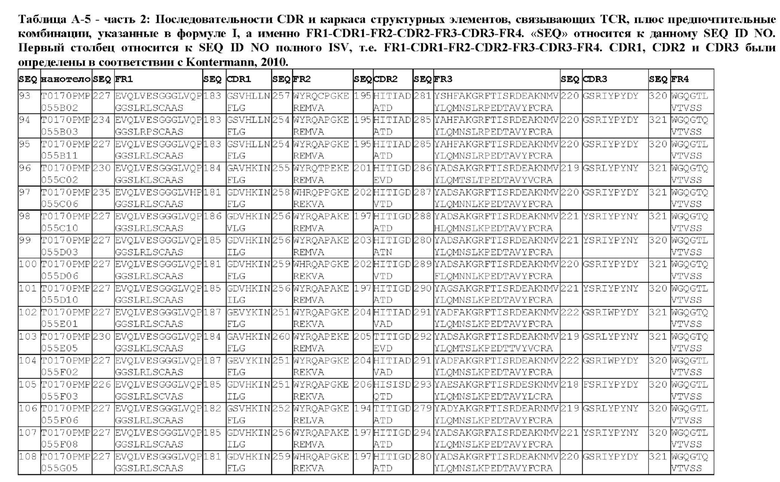
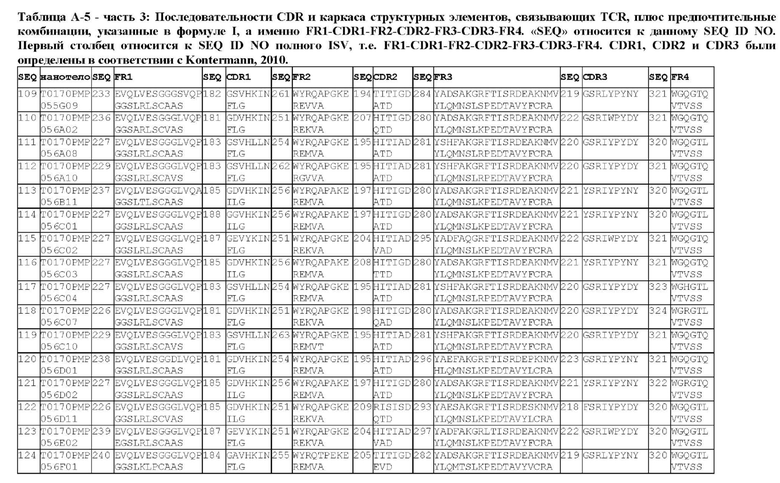
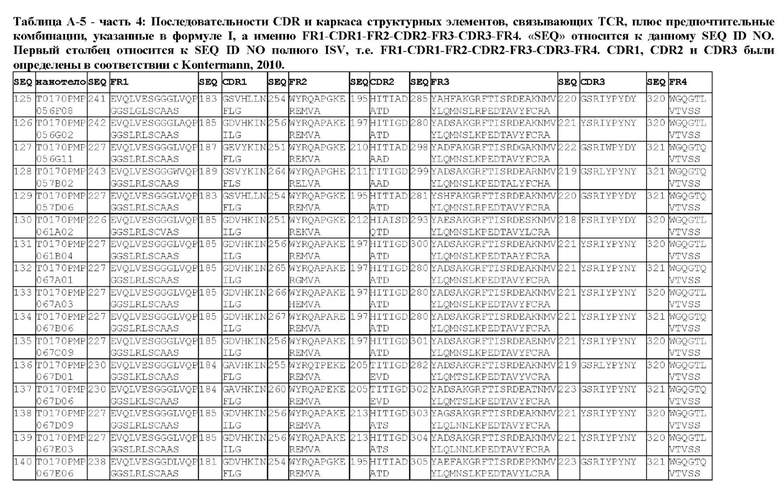
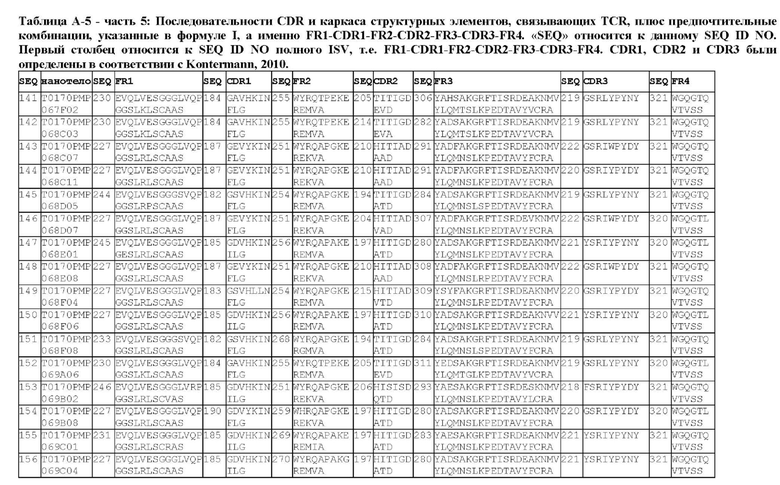
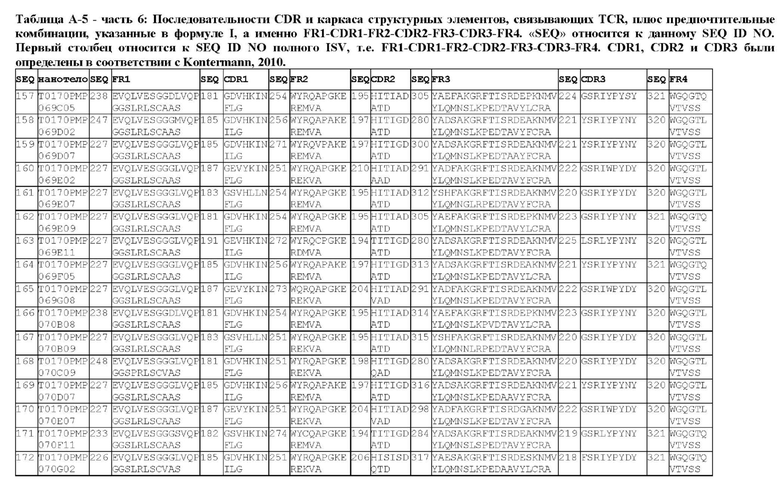
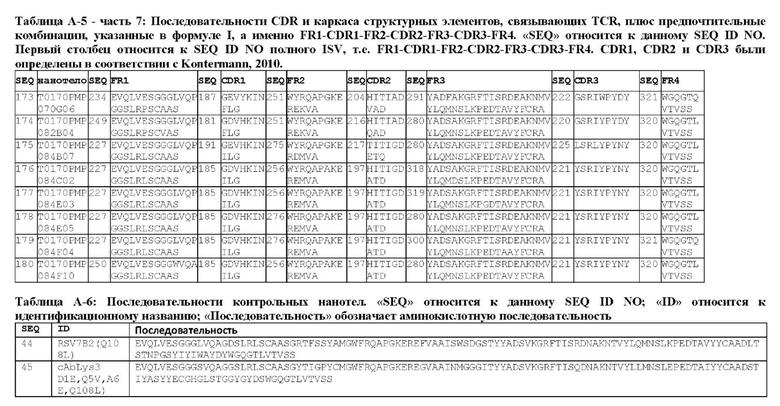










--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Ablynx NV
<120> T - Cell recruiting polypetides capable of binding CD123 and TCR
alpha/beta
<130> P16-014-PCT-1
<150> US 62/422,770
<151> 2016-11-16
<150> US62/557,208
<151> 2017-09-12
<160> 370
<170> PatentIn version 3.5
<210> 1
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 1
Glu Val Gln Leu Val Lys Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ile Asn
20 25 30
Asp Met Gly Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val
35 40 45
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
85 90 95
Thr Phe Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 2
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 2
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Asn Gly Ile Ser Ser Lys Ser Asp
20 25 30
Ala Met Gly Trp Tyr Arg Gln Thr Pro Gly Lys Tyr Arg Glu Trp Val
35 40 45
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
85 90 95
Thr Phe Pro Ala Ile Ser Asn Phe Trp Gly Gln Gly Thr Gln Val Thr
100 105 110
Val Ser Ser
115
<210> 3
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 3
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Asn Gly Ile Thr Ser Lys Ser Asn
20 25 30
Ala Met Gly Trp Tyr Arg Gln Thr Pro Gly Lys Tyr Arg Glu Trp Val
35 40 45
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
85 90 95
Thr Phe Pro Ala Ile Ser Asn Phe Trp Gly Gln Gly Thr Gln Val Thr
100 105 110
Val Ser Ser
115
<210> 4
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 4
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Pro Ser Lys Ile Asn
20 25 30
Asp Met Gly Trp Phe Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val
35 40 45
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
85 90 95
Thr Phe Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 5
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 5
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ile Asn
20 25 30
Asp Met Gly Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val
35 40 45
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
85 90 95
Thr Phe Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 6
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 6
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ser Asn
20 25 30
Val Met Gly Trp Tyr Arg Gln Thr Pro Gly Lys Tyr Arg Glu Trp Val
35 40 45
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
85 90 95
Thr Phe Pro Ala Ile Ser Asn Phe Trp Gly Gln Gly Thr Gln Val Thr
100 105 110
Val Ser Ser
115
<210> 7
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 7
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Val Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Tyr Trp Ser Asn Gly Lys Thr Gln Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Ala Asp Lys Asp Glu Thr Gly Phe Arg Thr Leu Pro Ile Ala Tyr
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 8
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 8
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Val Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Tyr Trp Ser Ser Gly Lys Thr Glu Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Leu Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Ala Asp Lys Asp Arg Asp Gly Phe Arg Thr Leu Pro Ile Ala Tyr
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 9
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 9
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Val Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Tyr Trp Ser Ser Gly Lys Thr Glu Tyr Thr Glu Ser Val
50 55 60
Lys Gly Arg Phe Thr Leu Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Ala Asp Lys Asp Arg Tyr Gly Phe Arg Thr Leu Pro Ile Ala Tyr
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 10
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 10
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Val Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Trp Trp Ser Ser Gly Lys Thr Glu Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Leu Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Asn Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Ala Asp Lys Asp Arg Asp Gly Phe Arg Thr Leu Pro Ile Ala Tyr
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 11
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 11
Gly Ile Thr Ser Lys Ile Asn Asp Met Gly
1 5 10
<210> 12
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 12
Gly Ile Ser Ser Lys Ser Asp Ala Met Gly
1 5 10
<210> 13
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 13
Gly Ile Thr Ser Lys Ser Asn Ala Met Gly
1 5 10
<210> 14
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 14
Gly Ile Pro Ser Lys Ile Asn Asp Met Gly
1 5 10
<210> 15
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 15
Gly Ile Thr Ser Lys Ser Asn Val Met Gly
1 5 10
<210> 16
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 16
Gly Arg Thr Phe Ser Ser Tyr Val Met Gly
1 5 10
<210> 17
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 17
Ser Ile Thr Ala Thr Gly Thr Thr Asn
1 5
<210> 18
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 18
Ala Ile Tyr Trp Ser Asn Gly Lys Thr Gln
1 5 10
<210> 19
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 19
Ala Ile Tyr Trp Ser Ser Gly Lys Thr Glu
1 5 10
<210> 20
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 20
Ala Ile Trp Trp Ser Ser Gly Lys Thr Glu
1 5 10
<210> 21
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 21
Phe Pro Pro Ile Ser Asn Phe
1 5
<210> 22
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 22
Phe Pro Ala Ile Ser Asn Phe
1 5
<210> 23
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 23
Asp Lys Asp Glu Thr Gly Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr
1 5 10 15
<210> 24
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 24
Asp Lys Asp Arg Asp Gly Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr
1 5 10 15
<210> 25
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 25
Asp Lys Asp Arg Tyr Gly Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr
1 5 10 15
<210> 26
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 26
Glu Val Gln Leu Val Lys Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 27
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 27
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Asn
20 25
<210> 28
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 28
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 29
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 29
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 30
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 30
Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val Ala
1 5 10
<210> 31
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 31
Trp Tyr Arg Gln Thr Pro Gly Lys Tyr Arg Glu Trp Val Ala
1 5 10
<210> 32
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 32
Trp Phe Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val Ala
1 5 10
<210> 33
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 33
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala
1 5 10
<210> 34
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 34
Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Thr Val Tyr Tyr Cys Asn Thr
35
<210> 35
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 35
Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Thr Val Tyr Tyr Cys Asn Thr
35
<210> 36
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 36
Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gly Asp Asn Ala
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Val Ala
35
<210> 37
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 37
Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Leu Ser Gly Asp Asn Ala
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Val Ala
35
<210> 38
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 38
Tyr Thr Glu Ser Val Lys Gly Arg Phe Thr Leu Ser Gly Asp Asn Ala
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Val Ala
35
<210> 39
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 39
Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Leu Ser Gly Asp Asn Ala
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Asn Leu Asn Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Val Ala
35
<210> 40
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> FR4
<400> 40
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 41
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> FR4
<400> 41
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 42
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody sequence
<400> 42
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 43
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 43
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 44
<211> 127
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 44
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Asp
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Asp Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Thr Ser Thr Asn Pro Gly Ser Tyr Ile Tyr Ile Trp
100 105 110
Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 45
<211> 133
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 45
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Ile Gly Pro Tyr
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ala Ile Asn Met Gly Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Leu Met Asn Ser Leu Glu Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Ala Asp Ser Thr Ile Tyr Ala Ser Tyr Tyr Glu Cys Gly His Gly
100 105 110
Leu Ser Thr Gly Gly Tyr Gly Tyr Asp Ser Trp Gly Gln Gly Thr Leu
115 120 125
Val Thr Val Ser Ser
130
<210> 46
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 46
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Val Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Tyr Trp Ser Asn Gly Lys Thr Gln Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Ala Asp Lys Asp Glu Thr Gly Phe Arg Thr Leu Pro Ile Ala Tyr
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
145 150 155 160
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
165 170 175
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Ile Gly Pro Tyr
180 185 190
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
195 200 205
Ala Ala Ile Asn Met Gly Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
210 215 220
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
225 230 235 240
Leu Leu Met Asn Ser Leu Glu Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
245 250 255
Ala Ala Asp Ser Thr Ile Tyr Ala Ser Tyr Tyr Glu Cys Gly His Gly
260 265 270
Leu Ser Thr Gly Gly Tyr Gly Tyr Asp Ser Trp Gly Gln Gly Thr Leu
275 280 285
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
305 310 315 320
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
325 330 335
Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Val Ala
340 345 350
Ser Gly Asp Val His Lys Ile Asn Phe Leu Gly Trp Tyr Arg Gln Ala
355 360 365
Pro Gly Lys Glu Arg Glu Lys Val Ala His Ile Ser Ile Gly Asp Gln
370 375 380
Thr Asp Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp
385 390 395 400
Glu Ser Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
405 410 415
Asp Thr Ala Val Tyr Phe Cys Arg Ala Phe Ser Arg Ile Tyr Pro Tyr
420 425 430
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
435 440 445
<210> 47
<211> 427
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 47
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Val Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Tyr Trp Ser Asn Gly Lys Thr Gln Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Ala Asp Lys Asp Glu Thr Gly Phe Arg Thr Leu Pro Ile Ala Tyr
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
145 150 155 160
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
165 170 175
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ile Asn
180 185 190
Asp Met Gly Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val
195 200 205
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
210 215 220
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Val Tyr Leu
225 230 235 240
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
245 250 255
Thr Phe Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr
260 265 270
Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
275 280 285
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
290 295 300
Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly
305 310 315 320
Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Val Ala Ser Gly
325 330 335
Asp Val His Lys Ile Asn Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly
340 345 350
Lys Glu Arg Glu Lys Val Ala His Ile Ser Ile Gly Asp Gln Thr Asp
355 360 365
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser
370 375 380
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
385 390 395 400
Ala Val Tyr Phe Cys Arg Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
420 425
<210> 48
<211> 435
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 48
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ile Asn
20 25 30
Asp Met Gly Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val
35 40 45
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
85 90 95
Thr Phe Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly
145 150 155 160
Ser Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly
165 170 175
Tyr Thr Ile Gly Pro Tyr Cys Met Gly Trp Phe Arg Gln Ala Pro Gly
180 185 190
Lys Glu Arg Glu Gly Val Ala Ala Ile Asn Met Gly Gly Gly Ile Thr
195 200 205
Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn
210 215 220
Ala Lys Asn Thr Val Tyr Leu Leu Met Asn Ser Leu Glu Pro Glu Asp
225 230 235 240
Thr Ala Ile Tyr Tyr Cys Ala Ala Asp Ser Thr Ile Tyr Ala Ser Tyr
245 250 255
Tyr Glu Cys Gly His Gly Leu Ser Thr Gly Gly Tyr Gly Tyr Asp Ser
260 265 270
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
305 310 315 320
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu
325 330 335
Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn Phe Leu
340 345 350
Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val Ala His
355 360 365
Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys Gly Arg
370 375 380
Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu Gln Met
385 390 395 400
Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg Ala Phe
405 410 415
Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
420 425 430
Val Ser Ser
435
<210> 49
<211> 427
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 49
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ile Asn
20 25 30
Asp Met Gly Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val
35 40 45
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
85 90 95
Thr Phe Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly
145 150 155 160
Leu Val Gln Ala Gly Gly Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly
165 170 175
Arg Thr Phe Ser Ser Tyr Val Met Gly Trp Phe Arg Gln Ala Pro Gly
180 185 190
Lys Glu Arg Glu Phe Val Ala Ala Ile Tyr Trp Ser Asn Gly Lys Thr
195 200 205
Gln Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gly Asp Asn
210 215 220
Ala Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro Glu Asp
225 230 235 240
Thr Ala Val Tyr Tyr Cys Val Ala Asp Lys Asp Glu Thr Gly Phe Arg
245 250 255
Thr Leu Pro Ile Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
260 265 270
Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
275 280 285
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
290 295 300
Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly
305 310 315 320
Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Val Ala Ser Gly
325 330 335
Asp Val His Lys Ile Asn Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly
340 345 350
Lys Glu Arg Glu Lys Val Ala His Ile Ser Ile Gly Asp Gln Thr Asp
355 360 365
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser
370 375 380
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
385 390 395 400
Ala Val Tyr Phe Cys Arg Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
420 425
<210> 50
<211> 445
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 50
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Ile Gly Pro Tyr
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ala Ile Asn Met Gly Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Leu Met Asn Ser Leu Glu Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Ala Asp Ser Thr Ile Tyr Ala Ser Tyr Tyr Glu Cys Gly His Gly
100 105 110
Leu Ser Thr Gly Gly Tyr Gly Tyr Asp Ser Trp Gly Gln Gly Thr Leu
115 120 125
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
145 150 155 160
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
165 170 175
Gly Gly Leu Val Gln Ala Gly Gly Pro Leu Arg Leu Ser Cys Ala Ala
180 185 190
Ser Gly Arg Thr Phe Ser Ser Tyr Val Met Gly Trp Phe Arg Gln Ala
195 200 205
Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile Tyr Trp Ser Asn Gly
210 215 220
Lys Thr Gln Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gly
225 230 235 240
Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro
245 250 255
Glu Asp Thr Ala Val Tyr Tyr Cys Val Ala Asp Lys Asp Glu Thr Gly
260 265 270
Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
275 280 285
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
305 310 315 320
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
325 330 335
Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Val Ala
340 345 350
Ser Gly Asp Val His Lys Ile Asn Phe Leu Gly Trp Tyr Arg Gln Ala
355 360 365
Pro Gly Lys Glu Arg Glu Lys Val Ala His Ile Ser Ile Gly Asp Gln
370 375 380
Thr Asp Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp
385 390 395 400
Glu Ser Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
405 410 415
Asp Thr Ala Val Tyr Phe Cys Arg Ala Phe Ser Arg Ile Tyr Pro Tyr
420 425 430
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
435 440 445
<210> 51
<211> 435
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 51
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Tyr Thr Ile Gly Pro Tyr
20 25 30
Cys Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ala Ala Ile Asn Met Gly Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gln Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Leu Met Asn Ser Leu Glu Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Ala Asp Ser Thr Ile Tyr Ala Ser Tyr Tyr Glu Cys Gly His Gly
100 105 110
Leu Ser Thr Gly Gly Tyr Gly Tyr Asp Ser Trp Gly Gln Gly Thr Leu
115 120 125
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
145 150 155 160
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
165 170 175
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
180 185 190
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
195 200 205
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
210 215 220
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
225 230 235 240
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
245 250 255
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
260 265 270
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
305 310 315 320
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu
325 330 335
Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn Phe Leu
340 345 350
Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val Ala His
355 360 365
Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys Gly Arg
370 375 380
Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu Gln Met
385 390 395 400
Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg Ala Phe
405 410 415
Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
420 425 430
Val Ser Ser
435
<210> 52
<211> 427
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 52
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Val Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Tyr Trp Ser Asn Gly Lys Thr Gln Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Ala Asp Lys Asp Glu Thr Gly Phe Arg Thr Leu Pro Ile Ala Tyr
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
145 150 155 160
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
165 170 175
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ile Asn
180 185 190
Asp Met Gly Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val
195 200 205
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
210 215 220
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Val Tyr Leu
225 230 235 240
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
245 250 255
Thr Phe Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr
260 265 270
Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
275 280 285
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
290 295 300
Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly
305 310 315 320
Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Val Ala Ser Gly
325 330 335
Asp Val His Lys Ile Asn Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly
340 345 350
Lys Glu Arg Glu Lys Val Ala His Ile Ser Ile Gly Asp Gln Thr Asp
355 360 365
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser
370 375 380
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
385 390 395 400
Ala Val Tyr Phe Cys Arg Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
420 425
<210> 53
<211> 267
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 53
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
180 185 190
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
195 200 205
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
210 215 220
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
225 230 235 240
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
245 250 255
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
260 265
<210> 54
<211> 279
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 54
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Asp Ser Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Arg Thr Phe Ser Ser Tyr Ala Met Gly Trp Phe Arg Gln Ala
180 185 190
Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile Ser Trp Ser Asp Gly
195 200 205
Ser Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
210 215 220
Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro
225 230 235 240
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ala Asp Leu Thr Ser Thr Asn
245 250 255
Pro Gly Ser Tyr Ile Tyr Ile Trp Ala Tyr Asp Tyr Trp Gly Gln Gly
260 265 270
Thr Leu Val Thr Val Ser Ser
275
<210> 55
<211> 427
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 55
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ile Asn
20 25 30
Asp Met Gly Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val
35 40 45
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
85 90 95
Thr Phe Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly
145 150 155 160
Leu Val Gln Ala Gly Gly Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly
165 170 175
Arg Thr Phe Ser Ser Tyr Val Met Gly Trp Phe Arg Gln Ala Pro Gly
180 185 190
Lys Glu Arg Glu Phe Val Ala Ala Ile Tyr Trp Ser Asn Gly Lys Thr
195 200 205
Gln Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gly Asp Asn
210 215 220
Ala Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro Glu Asp
225 230 235 240
Thr Ala Val Tyr Tyr Cys Val Ala Asp Lys Asp Glu Thr Gly Phe Arg
245 250 255
Thr Leu Pro Ile Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr
260 265 270
Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
275 280 285
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
290 295 300
Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly
305 310 315 320
Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Val Ala Ser Gly
325 330 335
Asp Val His Lys Ile Asn Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly
340 345 350
Lys Glu Arg Glu Lys Val Ala His Ile Ser Ile Gly Asp Gln Thr Asp
355 360 365
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser
370 375 380
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
385 390 395 400
Ala Val Tyr Phe Cys Arg Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
420 425
<210> 56
<211> 267
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 56
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ile Asn
20 25 30
Asp Met Gly Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val
35 40 45
Ala Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn
85 90 95
Thr Phe Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly
145 150 155 160
Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Val Ala Ser Gly
165 170 175
Asp Val His Lys Ile Asn Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly
180 185 190
Lys Glu Arg Glu Lys Val Ala His Ile Ser Ile Gly Asp Gln Thr Asp
195 200 205
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser
210 215 220
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
225 230 235 240
Ala Val Tyr Phe Cys Arg Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr
245 250 255
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
260 265
<210> 57
<211> 279
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 57
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Asp
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Asp Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Asp Leu Thr Ser Thr Asn Pro Gly Ser Tyr Ile Tyr Ile Trp
100 105 110
Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
145 150 155 160
Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro
165 170 175
Gly Gly Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys
180 185 190
Ile Asn Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu
195 200 205
Lys Val Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser
210 215 220
Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val
225 230 235 240
Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe
245 250 255
Cys Arg Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly
260 265 270
Thr Leu Val Thr Val Ser Ser
275
<210> 58
<211> 426
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 58
Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly Ser
1 5 10 15
Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ile Asn Asp
20 25 30
Met Gly Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val Ala
35 40 45
Ser Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys Gly
50 55 60
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Val Tyr Leu Gln
65 70 75 80
Met Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn Thr
85 90 95
Phe Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr Val
100 105 110
Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu
145 150 155 160
Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp
165 170 175
Val His Lys Ile Asn Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys
180 185 190
Glu Arg Glu Lys Val Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr
195 200 205
Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys
210 215 220
Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala
225 230 235 240
Val Tyr Phe Cys Arg Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp
245 250 255
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly
260 265 270
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
275 280 285
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln
290 295 300
Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly Pro Leu Arg
305 310 315 320
Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr Val Met Gly
325 330 335
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile
340 345 350
Tyr Trp Ser Asn Gly Lys Thr Gln Tyr Thr Asp Ser Val Lys Gly Arg
355 360 365
Phe Thr Ile Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln Met
370 375 380
Asn Ser Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys Val Ala Asp
385 390 395 400
Lys Asp Glu Thr Gly Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr Trp
405 410 415
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
420 425
<210> 59
<211> 427
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 59
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Val Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Tyr Trp Ser Asn Gly Lys Thr Gln Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Val Ala Asp Lys Asp Glu Thr Gly Phe Arg Thr Leu Pro Ile Ala Tyr
100 105 110
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
145 150 155 160
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
165 170 175
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
180 185 190
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
195 200 205
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
210 215 220
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
225 230 235 240
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
245 250 255
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
260 265 270
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
305 310 315 320
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
325 330 335
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
340 345 350
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
355 360 365
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
370 375 380
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
385 390 395 400
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
420 425
<210> 60
<211> 427
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 60
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
180 185 190
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
195 200 205
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
210 215 220
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
225 230 235 240
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
245 250 255
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
260 265 270
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
290 295 300
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly Pro Leu
305 310 315 320
Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr Val Met
325 330 335
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Ala
340 345 350
Ile Tyr Trp Ser Asn Gly Lys Thr Gln Tyr Thr Asp Ser Val Lys Gly
355 360 365
Arg Phe Thr Ile Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
370 375 380
Met Asn Ser Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys Val Ala
385 390 395 400
Asp Lys Asp Glu Thr Gly Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
420 425
<210> 61
<211> 427
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 61
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Pro Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Arg Thr Phe Ser Ser Tyr Val Met Gly Trp Phe Arg Gln Ala
180 185 190
Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile Tyr Trp Ser Asn Gly
195 200 205
Lys Thr Gln Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gly
210 215 220
Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro
225 230 235 240
Glu Asp Thr Ala Val Tyr Tyr Cys Val Ala Asp Lys Asp Glu Thr Gly
245 250 255
Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
260 265 270
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
305 310 315 320
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
325 330 335
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
340 345 350
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
355 360 365
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
370 375 380
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
385 390 395 400
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
420 425
<210> 62
<211> 429
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 62
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Asp Ser Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Arg Thr Phe Ser Ser Tyr Ala Met Gly Trp Phe Arg Gln Ala
180 185 190
Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile Ser Trp Ser Asp Gly
195 200 205
Ser Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
210 215 220
Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro
225 230 235 240
Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ala Asp Leu Thr Ser Thr Asn
245 250 255
Pro Gly Ser Tyr Ile Tyr Ile Trp Ala Tyr Asp Tyr Trp Gly Gln Gly
260 265 270
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
275 280 285
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
290 295 300
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
305 310 315 320
Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys
325 330 335
Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg
340 345 350
Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser
355 360 365
Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
370 375 380
Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu
385 390 395 400
Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu
405 410 415
Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser
420 425
<210> 63
<211> 417
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 63
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
180 185 190
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
195 200 205
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
210 215 220
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
225 230 235 240
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
245 250 255
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
260 265 270
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
290 295 300
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
305 310 315 320
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
325 330 335
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
340 345 350
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
355 360 365
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
370 375 380
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
385 390 395 400
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
405 410 415
Ser
<210> 64
<211> 577
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 64
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
180 185 190
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
195 200 205
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
210 215 220
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
225 230 235 240
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
245 250 255
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
260 265 270
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
290 295 300
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly Pro Leu
305 310 315 320
Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr Val Met
325 330 335
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Ala
340 345 350
Ile Tyr Trp Ser Asn Gly Lys Thr Gln Tyr Thr Asp Ser Val Lys Gly
355 360 365
Arg Phe Thr Ile Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
370 375 380
Met Asn Ser Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys Val Ala
385 390 395 400
Asp Lys Asp Glu Thr Gly Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser
<210> 65
<211> 577
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 65
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
180 185 190
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
195 200 205
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
210 215 220
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
225 230 235 240
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
245 250 255
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
260 265 270
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
290 295 300
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
305 310 315 320
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
325 330 335
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
340 345 350
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
355 360 365
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
370 375 380
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
385 390 395 400
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
405 410 415
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
450 455 460
Gln Ala Gly Gly Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr
465 470 475 480
Phe Ser Ser Tyr Val Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
485 490 495
Arg Glu Phe Val Ala Ala Ile Tyr Trp Ser Asn Gly Lys Thr Gln Tyr
500 505 510
Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gly Asp Asn Ala Lys
515 520 525
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr Ala
530 535 540
Val Tyr Tyr Cys Val Ala Asp Lys Asp Glu Thr Gly Phe Arg Thr Leu
545 550 555 560
Pro Ile Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser
<210> 66
<211> 577
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 66
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Pro Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Arg Thr Phe Ser Ser Tyr Val Met Gly Trp Phe Arg Gln Ala
180 185 190
Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile Tyr Trp Ser Asn Gly
195 200 205
Lys Thr Gln Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gly
210 215 220
Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro
225 230 235 240
Glu Asp Thr Ala Val Tyr Tyr Cys Val Ala Asp Lys Asp Glu Thr Gly
245 250 255
Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
260 265 270
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
305 310 315 320
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
325 330 335
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
340 345 350
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
355 360 365
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
370 375 380
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
385 390 395 400
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser
<210> 67
<211> 577
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 67
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Pro Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Arg Thr Phe Ser Ser Tyr Val Met Gly Trp Phe Arg Gln Ala
180 185 190
Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile Tyr Trp Ser Asn Gly
195 200 205
Lys Thr Gln Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gly
210 215 220
Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro
225 230 235 240
Glu Asp Thr Ala Val Tyr Tyr Cys Val Ala Asp Lys Asp Glu Thr Gly
245 250 255
Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
260 265 270
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
305 310 315 320
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
325 330 335
Ser Gly Phe Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala
340 345 350
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
355 360 365
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
370 375 380
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
385 390 395 400
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
405 410 415
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ile Asn Asp Met
485 490 495
Gly Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser
500 505 510
Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg
515 520 525
Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Val Tyr Leu Gln Met
530 535 540
Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe
545 550 555 560
Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser
<210> 68
<211> 378
<212> PRT
<213> Homo sapiens
<400> 68
Met Val Leu Leu Trp Leu Thr Leu Leu Leu Ile Ala Leu Pro Cys Leu
1 5 10 15
Leu Gln Thr Lys Glu Asp Pro Asn Pro Pro Ile Thr Asn Leu Arg Met
20 25 30
Lys Ala Lys Ala Gln Gln Leu Thr Trp Asp Leu Asn Arg Asn Val Thr
35 40 45
Asp Ile Glu Cys Val Lys Asp Ala Asp Tyr Ser Met Pro Ala Val Asn
50 55 60
Asn Ser Tyr Cys Gln Phe Gly Ala Ile Ser Leu Cys Glu Val Thr Asn
65 70 75 80
Tyr Thr Val Arg Val Ala Asn Pro Pro Phe Ser Thr Trp Ile Leu Phe
85 90 95
Pro Glu Asn Ser Gly Lys Pro Trp Ala Gly Ala Glu Asn Leu Thr Cys
100 105 110
Trp Ile His Asp Val Asp Phe Leu Ser Cys Ser Trp Ala Val Gly Pro
115 120 125
Gly Ala Pro Ala Asp Val Gln Tyr Asp Leu Tyr Leu Asn Val Ala Asn
130 135 140
Arg Arg Gln Gln Tyr Glu Cys Leu His Tyr Lys Thr Asp Ala Gln Gly
145 150 155 160
Thr Arg Ile Gly Cys Arg Phe Asp Asp Ile Ser Arg Leu Ser Ser Gly
165 170 175
Ser Gln Ser Ser His Ile Leu Val Arg Gly Arg Ser Ala Ala Phe Gly
180 185 190
Ile Pro Cys Thr Asp Lys Phe Val Val Phe Ser Gln Ile Glu Ile Leu
195 200 205
Thr Pro Pro Asn Met Thr Ala Lys Cys Asn Lys Thr His Ser Phe Met
210 215 220
His Trp Lys Met Arg Ser His Phe Asn Arg Lys Phe Arg Tyr Glu Leu
225 230 235 240
Gln Ile Gln Lys Arg Met Gln Pro Val Ile Thr Glu Gln Val Arg Asp
245 250 255
Arg Thr Ser Phe Gln Leu Leu Asn Pro Gly Thr Tyr Thr Val Gln Ile
260 265 270
Arg Ala Arg Glu Arg Val Tyr Glu Phe Leu Ser Ala Trp Ser Thr Pro
275 280 285
Gln Arg Phe Glu Cys Asp Gln Glu Glu Gly Ala Asn Thr Arg Ala Trp
290 295 300
Arg Thr Ser Leu Leu Ile Ala Leu Gly Thr Leu Leu Ala Leu Val Cys
305 310 315 320
Val Phe Val Ile Cys Arg Arg Tyr Leu Val Met Gln Arg Leu Phe Pro
325 330 335
Arg Ile Pro His Met Lys Asp Pro Ile Gly Asp Ser Phe Gln Asn Asp
340 345 350
Lys Leu Val Val Trp Glu Ala Gly Lys Ala Gly Leu Glu Glu Cys Leu
355 360 365
Val Thr Glu Val Gln Val Val Gln Lys Thr
370 375
<210> 69
<211> 378
<212> PRT
<213> Macaca fascicularis
<400> 69
Met Thr Leu Leu Trp Leu Thr Leu Leu Leu Val Ala Thr Pro Cys Leu
1 5 10 15
Leu Arg Thr Lys Glu Asp Pro Asn Ala Pro Ile Arg Asn Leu Arg Met
20 25 30
Lys Glu Lys Ala Gln Gln Leu Met Trp Asp Leu Asn Arg Asn Val Thr
35 40 45
Asp Val Glu Cys Ile Lys Gly Thr Asp Tyr Ser Met Pro Ala Met Asn
50 55 60
Asn Ser Tyr Cys Gln Phe Gly Ala Ile Ser Leu Cys Glu Val Thr Asn
65 70 75 80
Tyr Thr Val Arg Val Ala Ser Pro Pro Phe Ser Thr Trp Ile Leu Phe
85 90 95
Pro Glu Asn Ser Gly Thr Pro Arg Ala Gly Ala Glu Asn Leu Thr Cys
100 105 110
Trp Val His Asp Val Asp Phe Leu Ser Cys Ser Trp Val Val Gly Pro
115 120 125
Ala Ala Pro Ala Asp Val Gln Tyr Asp Leu Tyr Leu Asn Asn Pro Asn
130 135 140
Ser His Glu Gln Tyr Arg Cys Leu His Tyr Lys Thr Asp Ala Arg Gly
145 150 155 160
Thr Gln Ile Gly Cys Arg Phe Asp Asp Ile Ala Pro Leu Ser Arg Gly
165 170 175
Ser Gln Ser Ser His Ile Leu Val Arg Gly Arg Ser Ala Ala Val Ser
180 185 190
Ile Pro Cys Thr Asp Lys Phe Val Phe Phe Ser Gln Ile Glu Arg Leu
195 200 205
Thr Pro Pro Asn Met Thr Gly Glu Cys Asn Glu Thr His Ser Phe Met
210 215 220
His Trp Lys Met Lys Ser His Phe Asn Arg Lys Phe Arg Tyr Glu Leu
225 230 235 240
Arg Ile Gln Lys Arg Met Gln Pro Val Arg Thr Glu Gln Val Arg Asp
245 250 255
Thr Thr Ser Phe Gln Leu Pro Asn Pro Gly Thr Tyr Thr Val Gln Ile
260 265 270
Arg Ala Arg Glu Thr Val Tyr Glu Phe Leu Ser Ala Trp Ser Thr Pro
275 280 285
Gln Arg Phe Glu Cys Asp Gln Glu Glu Gly Ala Ser Ser Arg Ala Trp
290 295 300
Arg Thr Ser Leu Leu Ile Ala Leu Gly Thr Leu Leu Ala Leu Leu Cys
305 310 315 320
Val Phe Leu Ile Cys Arg Arg Tyr Leu Val Met Gln Arg Leu Phe Pro
325 330 335
Arg Ile Pro His Met Lys Asp Pro Ile Gly Asp Thr Phe Gln Gln Asp
340 345 350
Lys Leu Val Val Trp Glu Ala Gly Lys Ala Gly Leu Glu Glu Cys Leu
355 360 365
Val Ser Glu Val Gln Val Val Glu Lys Thr
370 375
<210> 70
<211> 171
<212> PRT
<213> Homo sapiens
<400> 70
Met Glu His Ser Thr Phe Leu Ser Gly Leu Val Leu Ala Thr Leu Leu
1 5 10 15
Ser Gln Val Ser Pro Phe Lys Ile Pro Ile Glu Glu Leu Glu Asp Arg
20 25 30
Val Phe Val Asn Cys Asn Thr Ser Ile Thr Trp Val Glu Gly Thr Val
35 40 45
Gly Thr Leu Leu Ser Asp Ile Thr Arg Leu Asp Leu Gly Lys Arg Ile
50 55 60
Leu Asp Pro Arg Gly Ile Tyr Arg Cys Asn Gly Thr Asp Ile Tyr Lys
65 70 75 80
Asp Lys Glu Ser Thr Val Gln Val His Tyr Arg Met Cys Gln Ser Cys
85 90 95
Val Glu Leu Asp Pro Ala Thr Val Ala Gly Ile Ile Val Thr Asp Val
100 105 110
Ile Ala Thr Leu Leu Leu Ala Leu Gly Val Phe Cys Phe Ala Gly His
115 120 125
Glu Thr Gly Arg Leu Ser Gly Ala Ala Asp Thr Gln Ala Leu Leu Arg
130 135 140
Asn Asp Gln Val Tyr Gln Pro Leu Arg Asp Arg Asp Asp Ala Gln Tyr
145 150 155 160
Ser His Leu Gly Gly Asn Trp Ala Arg Asn Lys
165 170
<210> 71
<211> 182
<212> PRT
<213> Homo sapiens
<400> 71
Met Glu Gln Gly Lys Gly Leu Ala Val Leu Ile Leu Ala Ile Ile Leu
1 5 10 15
Leu Gln Gly Thr Leu Ala Gln Ser Ile Lys Gly Asn His Leu Val Lys
20 25 30
Val Tyr Asp Tyr Gln Glu Asp Gly Ser Val Leu Leu Thr Cys Asp Ala
35 40 45
Glu Ala Lys Asn Ile Thr Trp Phe Lys Asp Gly Lys Met Ile Gly Phe
50 55 60
Leu Thr Glu Asp Lys Lys Lys Trp Asn Leu Gly Ser Asn Ala Lys Asp
65 70 75 80
Pro Arg Gly Met Tyr Gln Cys Lys Gly Ser Gln Asn Lys Ser Lys Pro
85 90 95
Leu Gln Val Tyr Tyr Arg Met Cys Gln Asn Cys Ile Glu Leu Asn Ala
100 105 110
Ala Thr Ile Ser Gly Phe Leu Phe Ala Glu Ile Val Ser Ile Phe Val
115 120 125
Leu Ala Val Gly Val Tyr Phe Ile Ala Gly Gln Asp Gly Val Arg Gln
130 135 140
Ser Arg Ala Ser Asp Lys Gln Thr Leu Leu Pro Asn Asp Gln Leu Tyr
145 150 155 160
Gln Pro Leu Lys Asp Arg Glu Asp Asp Gln Tyr Ser His Leu Gln Gly
165 170 175
Asn Gln Leu Arg Arg Asn
180
<210> 72
<211> 207
<212> PRT
<213> Homo sapiens
<400> 72
Met Gln Ser Gly Thr His Trp Arg Val Leu Gly Leu Cys Leu Leu Ser
1 5 10 15
Val Gly Val Trp Gly Gln Asp Gly Asn Glu Glu Met Gly Gly Ile Thr
20 25 30
Gln Thr Pro Tyr Lys Val Ser Ile Ser Gly Thr Thr Val Ile Leu Thr
35 40 45
Cys Pro Gln Tyr Pro Gly Ser Glu Ile Leu Trp Gln His Asn Asp Lys
50 55 60
Asn Ile Gly Gly Asp Glu Asp Asp Lys Asn Ile Gly Ser Asp Glu Asp
65 70 75 80
His Leu Ser Leu Lys Glu Phe Ser Glu Leu Glu Gln Ser Gly Tyr Tyr
85 90 95
Val Cys Tyr Pro Arg Gly Ser Lys Pro Glu Asp Ala Asn Phe Tyr Leu
100 105 110
Tyr Leu Arg Ala Arg Val Cys Glu Asn Cys Met Glu Met Asp Val Met
115 120 125
Ser Val Ala Thr Ile Val Ile Val Asp Ile Cys Ile Thr Gly Gly Leu
130 135 140
Leu Leu Leu Val Tyr Tyr Trp Ser Lys Asn Arg Lys Ala Lys Ala Lys
145 150 155 160
Pro Val Thr Arg Gly Ala Gly Ala Gly Gly Arg Gln Arg Gly Gln Asn
165 170 175
Lys Glu Arg Pro Pro Pro Val Pro Asn Pro Asp Tyr Glu Pro Ile Arg
180 185 190
Lys Gly Gln Arg Asp Leu Tyr Ser Gly Leu Asn Gln Arg Arg Ile
195 200 205
<210> 73
<211> 164
<212> PRT
<213> Homo sapiens
<400> 73
Met Lys Trp Lys Ala Leu Phe Thr Ala Ala Ile Leu Gln Ala Gln Leu
1 5 10 15
Pro Ile Thr Glu Ala Gln Ser Phe Gly Leu Leu Asp Pro Lys Leu Cys
20 25 30
Tyr Leu Leu Asp Gly Ile Leu Phe Ile Tyr Gly Val Ile Leu Thr Ala
35 40 45
Leu Phe Leu Arg Val Lys Phe Ser Arg Ser Ala Asp Ala Pro Ala Tyr
50 55 60
Gln Gln Gly Gln Asn Gln Leu Tyr Asn Glu Leu Asn Leu Gly Arg Arg
65 70 75 80
Glu Glu Tyr Asp Val Leu Asp Lys Arg Arg Gly Arg Asp Pro Glu Met
85 90 95
Gly Gly Lys Pro Gln Arg Arg Lys Asn Pro Gln Glu Gly Leu Tyr Asn
100 105 110
Glu Leu Gln Lys Asp Lys Met Ala Glu Ala Tyr Ser Glu Ile Gly Met
115 120 125
Lys Gly Glu Arg Arg Arg Gly Lys Gly His Asp Gly Leu Tyr Gln Gly
130 135 140
Leu Ser Thr Ala Thr Lys Asp Thr Tyr Asp Ala Leu His Met Gln Ala
145 150 155 160
Leu Pro Pro Arg
<210> 74
<211> 142
<212> PRT
<213> Homo sapiens
<400> 74
Pro Asn Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Asp Ser
1 5 10 15
Lys Ser Ser Asp Lys Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Gln
20 25 30
Thr Asn Val Ser Gln Ser Lys Asp Ser Asp Val Tyr Ile Thr Asp Lys
35 40 45
Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Ser Ala Val
50 55 60
Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Ala Asn Ala Phe Asn Asn
65 70 75 80
Ser Ile Ile Pro Glu Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys
85 90 95
Asp Val Lys Leu Val Glu Lys Ser Phe Glu Thr Asp Thr Asn Leu Asn
100 105 110
Phe Gln Asn Leu Ser Val Ile Gly Phe Arg Ile Leu Leu Leu Lys Val
115 120 125
Ala Gly Phe Asn Leu Leu Met Thr Leu Arg Leu Trp Ser Ser
130 135 140
<210> 75
<211> 177
<212> PRT
<213> Homo sapiens
<400> 75
Glu Asp Leu Asn Lys Val Phe Pro Pro Glu Val Ala Val Phe Glu Pro
1 5 10 15
Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu
20 25 30
Ala Thr Gly Phe Phe Pro Asp His Val Glu Leu Ser Trp Trp Val Asn
35 40 45
Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro Leu Lys
50 55 60
Glu Gln Pro Ala Leu Asn Asp Ser Arg Tyr Cys Leu Ser Ser Arg Leu
65 70 75 80
Arg Val Ser Ala Thr Phe Trp Gln Asn Pro Arg Asn His Phe Arg Cys
85 90 95
Gln Val Gln Phe Tyr Gly Leu Ser Glu Asn Asp Glu Trp Thr Gln Asp
100 105 110
Arg Ala Lys Pro Val Thr Gln Ile Val Ser Ala Glu Ala Trp Gly Arg
115 120 125
Ala Asp Cys Gly Phe Thr Ser Val Ser Tyr Gln Gln Gly Val Leu Ser
130 135 140
Ala Thr Ile Leu Tyr Glu Ile Leu Leu Gly Lys Ala Thr Leu Tyr Ala
145 150 155 160
Val Leu Val Ser Ala Leu Val Leu Met Ala Met Val Lys Arg Lys Asp
165 170 175
Phe
<210> 76
<211> 108
<212> PRT
<213> Homo sapiens
<400> 76
Gln Leu Leu Glu Gln Ser Pro Gln Phe Leu Ser Ile Gln Glu Gly Glu
1 5 10 15
Asn Leu Thr Val Tyr Cys Asn Ser Ser Ser Val Phe Ser Ser Leu Gln
20 25 30
Trp Tyr Arg Gln Glu Pro Gly Glu Gly Pro Val Leu Leu Val Thr Val
35 40 45
Val Thr Gly Gly Glu Val Lys Lys Leu Lys Arg Leu Thr Phe Gln Phe
50 55 60
Gly Asp Ala Arg Lys Asp Ser Ser Leu His Ile Thr Ala Ala Gln Pro
65 70 75 80
Gly Asp Thr Gly Leu Tyr Leu Cys Ala Gly Ala Gly Ser Gln Gly Asn
85 90 95
Leu Ile Phe Gly Lys Gly Thr Lys Leu Ser Val Lys
100 105
<210> 77
<211> 112
<212> PRT
<213> Homo sapiens
<400> 77
Asp Gly Gly Ile Thr Gln Ser Pro Lys Tyr Leu Phe Arg Lys Glu Gly
1 5 10 15
Gln Asn Val Thr Leu Ser Cys Glu Gln Asn Leu Asn His Asp Ala Met
20 25 30
Tyr Trp Tyr Arg Gln Asp Pro Gly Gln Gly Leu Arg Leu Ile Tyr Tyr
35 40 45
Ser Gln Ile Val Asn Asp Phe Gln Lys Gly Asp Ile Ala Glu Gly Tyr
50 55 60
Ser Val Ser Arg Glu Lys Lys Glu Ser Phe Pro Leu Thr Val Thr Ser
65 70 75 80
Ala Gln Lys Asn Pro Thr Ala Phe Tyr Leu Cys Ala Ser Ser Ser Arg
85 90 95
Ser Ser Tyr Glu Gln Tyr Phe Gly Pro Gly Thr Arg Leu Thr Val Thr
100 105 110
<210> 78
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 78
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Leu Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Thr Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val His Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 79
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 79
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Gly Leu Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Thr Thr Asp Tyr Ala Asp Tyr Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Arg Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 80
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 80
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Pro Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 81
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 81
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Leu Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Thr Thr Asp Tyr Ala Asp Tyr Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Arg Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 82
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 82
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 83
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 83
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Leu Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Thr Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 84
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 84
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ser His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 85
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 85
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Ala Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Thr Pro Glu Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Asp Val Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Thr Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Val Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 86
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 86
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Arg Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Glu Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 87
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 87
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 88
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 88
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 89
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 89
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Gly Asp Gln Ala Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 90
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 90
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Ser Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 91
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 91
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Ser Ile Ala Asp Ala Thr Asp Tyr Ala His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Arg Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 92
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 92
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Arg Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Val Tyr Ala Glu Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 93
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 93
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Cys Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ser His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 94
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 94
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Pro Ser Cys Ala Ala Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ala His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 95
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 95
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ala His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 96
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 96
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Ala Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Thr Pro Glu Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Glu Val Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Thr Ser Leu Thr Pro Glu Asp Thr Ala Val Tyr Val Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 97
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 97
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val His Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp His Arg Gln Pro Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Gly Asp Val Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Asn Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 98
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 98
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Val Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val His Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 99
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 99
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asn Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 100
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 100
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp His Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Gly Asp Val Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Phe Leu
65 70 75 80
Gln Met Asn Asn Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 101
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 101
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Gly Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 102
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 102
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Val Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 103
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 103
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Ala Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Glu Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Glu Val Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Thr Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Val Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 104
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 104
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Val Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 105
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 105
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Ser Asp Gln Thr Asp Tyr Ala Glu Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Leu Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 106
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 106
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Leu Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Tyr Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Arg Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 107
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 107
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Ala Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 108
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 108
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp His Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 109
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 109
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Val Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Ser Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 110
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 110
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Ala Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 111
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 111
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ser His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 112
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 112
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Gly Val Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ser His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 113
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 113
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 114
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 114
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 115
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 115
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Val Ala Asp Tyr Ala Asp Phe Ala Gln
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 116
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 116
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Thr Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 117
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 117
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ser His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly His Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 118
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 118
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Gly Asp Gln Ala Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Arg Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 119
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 119
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Thr His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ser His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 120
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 120
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ala Glu Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Pro Lys Asn Met Val His Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Leu Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 121
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 121
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Arg Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 122
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 122
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala Arg Ile Ser Ile Ser Asp Gln Thr Asp Tyr Ala Glu Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Leu Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 123
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 123
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Glu Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Val Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Leu Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 124
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 124
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Pro Cys Ala Ala Ser Gly Ala Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Thr Pro Glu Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Glu Val Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Thr Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Val Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 125
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 125
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Gly Leu Ser Cys Ala Ala Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ala His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 126
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 126
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Ala Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 127
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 127
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Gly Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 128
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 128
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Trp Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val Tyr Lys Ile Asn
20 25 30
Phe Leu Ser Trp Tyr Arg Gln Ala Pro Gly His Glu Arg Glu Leu Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Ala Ala Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Arg Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Phe Cys His
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 129
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 129
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ser His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 130
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 130
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ala Ile Ser Asp Gln Thr Asp Tyr Ala Glu Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Leu Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 131
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 131
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ala Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 132
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 132
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Gly Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 133
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 133
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu His Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 134
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 134
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Arg Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 135
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 135
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Glu Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 136
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 136
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Ala Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Thr Pro Glu Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Glu Val Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Thr Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Val Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 137
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 137
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Ala Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Glu Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Glu Val Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Thr Asn Met Val Tyr Leu
65 70 75 80
Gln Met Thr Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 138
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 138
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Ser Tyr Ala Gly Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Leu Asn Asn Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 139
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 139
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Ser Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Leu Asn Asn Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 140
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 140
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ala Glu Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Pro Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Leu Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 141
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 141
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Ala Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Thr Pro Glu Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Glu Val Asp Tyr Ala His Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Thr Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Val Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 142
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 142
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Ala Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Thr Pro Glu Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Glu Val Ala Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Thr Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Val Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 143
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 143
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 144
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 144
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 145
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 145
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Pro Ser Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Ser Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 146
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 146
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Val Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Val Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 147
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 147
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Glu
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 148
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 148
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 149
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 149
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Val Thr Asp Tyr Ser Tyr Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 150
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 150
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Val Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 151
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 151
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Gly Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Ser Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 152
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 152
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser Gly Ala Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Thr Pro Glu Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Glu Val Asp Tyr Glu Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Thr Gly Leu Lys Pro Glu Asp Thr Ala Val Tyr Val Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 153
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 153
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Ser Asp Gln Thr Asp Tyr Ala Glu Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Leu Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 154
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 154
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp His Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 155
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 155
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Arg Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Ile
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Glu Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 156
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 156
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Gly Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 157
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 157
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ala Glu Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Pro Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Leu Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Ser Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 158
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 158
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Met Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 159
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 159
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Val Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ala Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 160
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 160
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 161
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 161
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ser His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Gly Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 162
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 162
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ala Glu Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Pro Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Leu Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 163
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 163
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Cys Pro Gly Lys Glu Arg Asp Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Leu Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 164
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 164
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Leu Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 165
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 165
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Gln Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Val Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 166
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 166
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ala Glu Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Pro Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Val Asp Thr Ala Val Tyr Leu Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 167
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 167
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Leu Leu Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Ala Thr Asp Tyr Ser His Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Asn Leu Arg Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 168
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 168
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Pro Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Gly Asp Gln Ala Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 169
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 169
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Ala Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 170
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 170
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Val Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Gly Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 171
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 171
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Cys Gln Ala Pro Gly Lys Glu Arg Glu Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Ser Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 172
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 172
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Ser Asp Gln Thr Asp Tyr Ala Glu Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Ala Ala Val Tyr Leu Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 173
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 173
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Pro Ser Cys Ala Ala Ser Gly Glu Val Tyr Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Val Ala Asp Tyr Ala Asp Phe Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Trp Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 174
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 174
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Pro Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Thr Ile Ala Asp Gln Ala Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 175
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 175
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Glu Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Asp Met Val
35 40 45
Ala Thr Ile Thr Ile Gly Asp Glu Thr Gln Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Leu Ser Arg Leu Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 176
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 176
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asp Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 177
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 177
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Gly Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 178
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 178
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp His Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 179
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 179
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp His Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ala Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 180
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 180
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Trp Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Ile Leu Gly Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val
35 40 45
Ala His Ile Thr Ile Gly Asp Ala Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser
115
<210> 181
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 181
Gly Asp Val His Lys Ile Asn Phe Leu Gly
1 5 10
<210> 182
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 182
Gly Ser Val His Lys Ile Asn Phe Leu Gly
1 5 10
<210> 183
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 183
Gly Ser Val His Leu Leu Asn Phe Leu Gly
1 5 10
<210> 184
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 184
Gly Ala Val His Lys Ile Asn Phe Leu Gly
1 5 10
<210> 185
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 185
Gly Asp Val His Lys Ile Asn Ile Leu Gly
1 5 10
<210> 186
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 186
Gly Asp Val His Lys Ile Asn Val Leu Gly
1 5 10
<210> 187
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 187
Gly Glu Val Tyr Lys Ile Asn Phe Leu Gly
1 5 10
<210> 188
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 188
Gly Gly Val His Lys Ile Asn Ile Leu Gly
1 5 10
<210> 189
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 189
Gly Ser Val Tyr Lys Ile Asn Phe Leu Ser
1 5 10
<210> 190
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 190
Gly Asp Val Tyr Lys Ile Asn Phe Leu Gly
1 5 10
<210> 191
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 191
Gly Glu Val His Lys Ile Asn Ile Leu Gly
1 5 10
<210> 192
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 192
His Ile Ser Ile Gly Asp Gln Thr Asp
1 5
<210> 193
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 193
Thr Ile Thr Ile Gly Asp Thr Thr Asp
1 5
<210> 194
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 194
Thr Ile Thr Ile Gly Asp Ala Thr Asp
1 5
<210> 195
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 195
His Ile Thr Ile Ala Asp Ala Thr Asp
1 5
<210> 196
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 196
Thr Ile Thr Ile Gly Asp Asp Val Asp
1 5
<210> 197
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 197
His Ile Thr Ile Gly Asp Ala Thr Asp
1 5
<210> 198
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 198
His Ile Thr Ile Gly Asp Gln Ala Asp
1 5
<210> 199
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 199
His Ile Ser Ile Ala Asp Ala Thr Asp
1 5
<210> 200
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 200
His Ile Thr Ile Gly Asp Ala Thr Val
1 5
<210> 201
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 201
His Ile Thr Ile Gly Asp Glu Val Asp
1 5
<210> 202
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 202
His Ile Thr Ile Gly Asp Val Thr Asp
1 5
<210> 203
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 203
His Ile Thr Ile Gly Asp Ala Thr Asn
1 5
<210> 204
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 204
His Ile Thr Ile Ala Asp Val Ala Asp
1 5
<210> 205
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 205
Thr Ile Thr Ile Gly Asp Glu Val Asp
1 5
<210> 206
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 206
His Ile Ser Ile Ser Asp Gln Thr Asp
1 5
<210> 207
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 207
His Ile Thr Ile Gly Asp Gln Thr Asp
1 5
<210> 208
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 208
His Ile Thr Ile Gly Asp Thr Thr Asp
1 5
<210> 209
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 209
Arg Ile Ser Ile Ser Asp Gln Thr Asp
1 5
<210> 210
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 210
His Ile Thr Ile Ala Asp Ala Ala Asp
1 5
<210> 211
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 211
Thr Ile Thr Ile Gly Asp Ala Ala Asp
1 5
<210> 212
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 212
His Ile Ala Ile Ser Asp Gln Thr Asp
1 5
<210> 213
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 213
His Ile Thr Ile Gly Asp Ala Thr Ser
1 5
<210> 214
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 214
Thr Ile Thr Ile Gly Asp Glu Val Ala
1 5
<210> 215
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 215
His Ile Thr Ile Ala Asp Val Thr Asp
1 5
<210> 216
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 216
His Ile Thr Ile Ala Asp Gln Ala Asp
1 5
<210> 217
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 217
Thr Ile Thr Ile Gly Asp Glu Thr Gln
1 5
<210> 218
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 218
Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr
1 5
<210> 219
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 219
Gly Ser Arg Leu Tyr Pro Tyr Asn Tyr
1 5
<210> 220
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 220
Gly Ser Arg Ile Tyr Pro Tyr Asp Tyr
1 5
<210> 221
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 221
Tyr Ser Arg Ile Tyr Pro Tyr Asn Tyr
1 5
<210> 222
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 222
Gly Ser Arg Ile Trp Pro Tyr Asp Tyr
1 5
<210> 223
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 223
Gly Ser Arg Ile Tyr Pro Tyr Asn Tyr
1 5
<210> 224
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 224
Gly Ser Arg Ile Tyr Pro Tyr Ser Tyr
1 5
<210> 225
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 225
Leu Ser Arg Leu Tyr Pro Tyr Asn Tyr
1 5
<210> 226
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 226
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser
20 25
<210> 227
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 227
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 228
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 228
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Pro Cys Ala Ala Ser
20 25
<210> 229
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 229
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Val Ser
20 25
<210> 230
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 230
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Ser Cys Ala Ala Ser
20 25
<210> 231
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 231
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Arg Ala Ser
20 25
<210> 232
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 232
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 233
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 233
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 234
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 234
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Pro Ser Cys Ala Ala Ser
20 25
<210> 235
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 235
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val His Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 236
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 236
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Ala Arg Leu Ser Cys Val Ala Ser
20 25
<210> 237
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 237
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Thr Leu Ser Cys Ala Ala Ser
20 25
<210> 238
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 238
Glu Val Gln Leu Val Glu Ser Gly Gly Asp Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 239
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 239
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Glu Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 240
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 240
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Lys Leu Pro Cys Ala Ala Ser
20 25
<210> 241
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 241
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Gly Leu Ser Cys Ala Ala Ser
20 25
<210> 242
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 242
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Ala Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 243
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 243
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Trp Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 244
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 244
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Pro Ser Cys Ala Ala Ser
20 25
<210> 245
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 245
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Glu
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 246
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 246
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser
20 25
<210> 247
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 247
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Met Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 248
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 248
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Pro Arg Leu Ser Cys Val Ala Ser
20 25
<210> 249
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 249
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Pro Ser Cys Val Ala Ser
20 25
<210> 250
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 250
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Trp Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 251
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 251
Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val Ala
1 5 10
<210> 252
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 252
Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Leu Val Ala
1 5 10
<210> 253
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 253
Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Gly Leu Val Ala
1 5 10
<210> 254
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 254
Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val Ala
1 5 10
<210> 255
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 255
Trp Tyr Arg Gln Thr Pro Glu Lys Glu Arg Glu Met Val Ala
1 5 10
<210> 256
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 256
Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val Ala
1 5 10
<210> 257
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 257
Trp Tyr Arg Gln Cys Pro Gly Lys Glu Arg Glu Met Val Ala
1 5 10
<210> 258
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 258
Trp His Arg Gln Pro Pro Gly Lys Glu Arg Glu Lys Val Ala
1 5 10
<210> 259
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 259
Trp His Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val Ala
1 5 10
<210> 260
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 260
Trp Tyr Arg Gln Ala Pro Glu Lys Glu Arg Glu Met Val Ala
1 5 10
<210> 261
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 261
Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Val Val Ala
1 5 10
<210> 262
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 262
Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Gly Val Val Ala
1 5 10
<210> 263
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 263
Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Met Val Thr
1 5 10
<210> 264
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 264
Trp Tyr Arg Gln Ala Pro Gly His Glu Arg Glu Leu Val Ala
1 5 10
<210> 265
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 265
Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Gly Met Val Ala
1 5 10
<210> 266
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 266
Trp Tyr Arg Gln Ala Pro Ala Lys Glu His Glu Met Val Ala
1 5 10
<210> 267
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 267
Trp Tyr Arg Gln Ala Pro Ala Arg Glu Arg Glu Met Val Ala
1 5 10
<210> 268
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 268
Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Gly Met Val Ala
1 5 10
<210> 269
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 269
Trp Tyr Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Ile Ala
1 5 10
<210> 270
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 270
Trp Tyr Arg Gln Ala Pro Ala Lys Gly Arg Glu Met Val Ala
1 5 10
<210> 271
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 271
Trp Tyr Arg Gln Val Pro Ala Lys Glu Arg Glu Met Val Ala
1 5 10
<210> 272
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 272
Trp Tyr Arg Gln Cys Pro Gly Lys Glu Arg Asp Met Val Ala
1 5 10
<210> 273
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 273
Trp Gln Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val Ala
1 5 10
<210> 274
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 274
Trp Tyr Cys Gln Ala Pro Gly Lys Glu Arg Glu Met Val Ala
1 5 10
<210> 275
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 275
Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Asp Met Val Ala
1 5 10
<210> 276
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 276
Trp His Arg Gln Ala Pro Ala Lys Glu Arg Glu Met Val Ala
1 5 10
<210> 277
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 277
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 278
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 278
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val His Phe Cys Arg Ala
35
<210> 279
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 279
Tyr Ala Asp Tyr Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Arg Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 280
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 280
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 281
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 281
Tyr Ser His Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 282
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 282
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Thr Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Val Cys Arg Ala
35
<210> 283
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 283
Tyr Ala Glu Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 284
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 284
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Ser Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 285
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 285
Tyr Ala His Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 286
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 286
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Thr Ser Leu Thr Pro Glu Asp Thr
20 25 30
Ala Val Tyr Val Cys Arg Ala
35
<210> 287
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 287
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Asn Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 288
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 288
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val His Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 289
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 289
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Phe Leu Gln Met Asn Asn Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 290
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 290
Tyr Ala Gly Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 291
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 291
Tyr Ala Asp Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 292
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 292
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Thr Ser Leu Lys Pro Glu Asp Thr
20 25 30
Thr Val Tyr Val Cys Arg Ala
35
<210> 293
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 293
Tyr Ala Glu Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Leu Cys Arg Ala
35
<210> 294
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 294
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Ala Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 295
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 295
Tyr Ala Asp Phe Ala Gln Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 296
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 296
Tyr Ala Glu Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Pro
1 5 10 15
Lys Asn Met Val His Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Leu Cys Arg Ala
35
<210> 297
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 297
Tyr Ala Asp Phe Ala Lys Gly Arg Leu Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 298
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 298
Tyr Ala Asp Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Gly Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 299
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 299
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Arg Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Leu Tyr Phe Cys His Ala
35
<210> 300
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 300
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Ala Tyr Phe Cys Arg Ala
35
<210> 301
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 301
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Glu Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 302
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 302
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Thr Asn Met Val Tyr Leu Gln Met Thr Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 303
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 303
Tyr Ala Gly Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Leu Asn Asn Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 304
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 304
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Leu Asn Asn Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 305
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 305
Tyr Ala Glu Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Pro
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Leu Cys Arg Ala
35
<210> 306
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 306
Tyr Ala His Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Thr Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Val Cys Arg Ala
35
<210> 307
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 307
Tyr Ala Asp Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Val
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 308
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 308
Tyr Ala Asp Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 309
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 309
Tyr Ser Tyr Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 310
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 310
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Val Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 311
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 311
Tyr Glu Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Thr Gly Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Val Cys Arg Ala
35
<210> 312
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 312
Tyr Ser His Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Gly Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 313
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 313
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Leu Cys Arg Ala
35
<210> 314
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 314
Tyr Ala Glu Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Pro
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Val Asp Thr
20 25 30
Ala Val Tyr Leu Cys Arg Ala
35
<210> 315
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 315
Tyr Ser His Phe Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Asn Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 316
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 316
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Ala
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 317
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 317
Tyr Ala Glu Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Ala
20 25 30
Ala Val Tyr Leu Cys Arg Ala
35
<210> 318
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 318
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asp Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 319
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 319
Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ala
1 5 10 15
Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Gly Asp Thr
20 25 30
Ala Val Tyr Phe Cys Arg Ala
35
<210> 320
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> FR4
<400> 320
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 321
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> FR4
<400> 321
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 322
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> FR4
<400> 322
Trp Gly Arg Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 323
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> FR4
<400> 323
Trp Gly His Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 324
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> FR4
<400> 324
Trp Gly Arg Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 325
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 325
Gly Gly Gly Gly Ser
1 5
<210> 326
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 326
Ser Gly Gly Ser Gly Gly Ser
1 5
<210> 327
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 327
Gly Gly Gly Gly Ser Gly Gly Gly Ser
1 5
<210> 328
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 328
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10
<210> 329
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 329
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 330
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 330
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Ser
<210> 331
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 331
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser
20
<210> 332
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 332
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25
<210> 333
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 333
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25 30
<210> 334
<211> 35
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 334
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser
35
<210> 335
<211> 40
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 335
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser
35 40
<210> 336
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 336
Ala Ala Ala
1
<210> 337
<211> 303
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 337
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Val Ala
165 170 175
Ser Gly Asp Val His Lys Ile Asn Phe Leu Gly Trp Tyr Arg Gln Ala
180 185 190
Pro Gly Lys Glu Arg Glu Lys Val Ala His Ile Ser Ile Gly Asp Gln
195 200 205
Thr Asp Tyr Ala Asp Ser Ala Lys Gly Arg Phe Thr Ile Ser Arg Asp
210 215 220
Glu Ser Lys Asn Met Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
225 230 235 240
Asp Thr Ala Val Tyr Phe Cys Arg Ala Phe Ser Arg Ile Tyr Pro Tyr
245 250 255
Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Ala Ala
260 265 270
Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr
275 280 285
Lys Asp Asp Asp Asp Lys Gly Ala Ala His His His His His His
290 295 300
<210> 338
<211> 418
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 338
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
180 185 190
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
195 200 205
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
210 215 220
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
225 230 235 240
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
245 250 255
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
260 265 270
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
290 295 300
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
305 310 315 320
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
325 330 335
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
340 345 350
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
355 360 365
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
370 375 380
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
385 390 395 400
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
405 410 415
Ser Ala
<210> 339
<211> 578
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 339
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
180 185 190
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
195 200 205
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
210 215 220
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
225 230 235 240
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
245 250 255
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
260 265 270
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
290 295 300
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly Pro Leu
305 310 315 320
Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr Val Met
325 330 335
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Ala
340 345 350
Ile Tyr Trp Ser Asn Gly Lys Thr Gln Tyr Thr Asp Ser Val Lys Gly
355 360 365
Arg Phe Thr Ile Ser Gly Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln
370 375 380
Met Asn Ser Leu Asn Pro Glu Asp Thr Ala Val Tyr Tyr Cys Val Ala
385 390 395 400
Asp Lys Asp Glu Thr Gly Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 340
<211> 578
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 340
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
180 185 190
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
195 200 205
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
210 215 220
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
225 230 235 240
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
245 250 255
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
260 265 270
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
290 295 300
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
305 310 315 320
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
325 330 335
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
340 345 350
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
355 360 365
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
370 375 380
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
385 390 395 400
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
405 410 415
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
450 455 460
Gln Ala Gly Gly Pro Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr
465 470 475 480
Phe Ser Ser Tyr Val Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
485 490 495
Arg Glu Phe Val Ala Ala Ile Tyr Trp Ser Asn Gly Lys Thr Gln Tyr
500 505 510
Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gly Asp Asn Ala Lys
515 520 525
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro Glu Asp Thr Ala
530 535 540
Val Tyr Tyr Cys Val Ala Asp Lys Asp Glu Thr Gly Phe Arg Thr Leu
545 550 555 560
Pro Ile Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 341
<211> 578
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 341
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Pro Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Arg Thr Phe Ser Ser Tyr Val Met Gly Trp Phe Arg Gln Ala
180 185 190
Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile Tyr Trp Ser Asn Gly
195 200 205
Lys Thr Gln Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gly
210 215 220
Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro
225 230 235 240
Glu Asp Thr Ala Val Tyr Tyr Cys Val Ala Asp Lys Asp Glu Thr Gly
245 250 255
Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
260 265 270
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
305 310 315 320
Gly Gly Leu Val Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
325 330 335
Ser Gly Ile Thr Ser Lys Ile Asn Asp Met Gly Trp Tyr Arg Gln Thr
340 345 350
Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser Ile Thr Ala Thr Gly Thr
355 360 365
Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp
370 375 380
Asn Ala Lys Ser Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu
385 390 395 400
Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe Pro Pro Ile Ser Asn Phe
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 342
<211> 578
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 342
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Asp Val His Lys Ile Asn
20 25 30
Phe Leu Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Lys Val
35 40 45
Ala His Ile Ser Ile Gly Asp Gln Thr Asp Tyr Ala Asp Ser Ala Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Met Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Phe Cys Arg
85 90 95
Ala Phe Ser Arg Ile Tyr Pro Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
130 135 140
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
145 150 155 160
Gly Gly Leu Val Gln Ala Gly Gly Pro Leu Arg Leu Ser Cys Ala Ala
165 170 175
Ser Gly Arg Thr Phe Ser Ser Tyr Val Met Gly Trp Phe Arg Gln Ala
180 185 190
Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile Tyr Trp Ser Asn Gly
195 200 205
Lys Thr Gln Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Gly
210 215 220
Asp Asn Ala Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Asn Pro
225 230 235 240
Glu Asp Thr Ala Val Tyr Tyr Cys Val Ala Asp Lys Asp Glu Thr Gly
245 250 255
Phe Arg Thr Leu Pro Ile Ala Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
260 265 270
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
305 310 315 320
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
325 330 335
Ser Gly Phe Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala
340 345 350
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
355 360 365
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
370 375 380
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
385 390 395 400
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
405 410 415
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Ser Lys Ile Asn Asp Met
485 490 495
Gly Trp Tyr Arg Gln Thr Pro Gly Asn Tyr Arg Glu Trp Val Ala Ser
500 505 510
Ile Thr Ala Thr Gly Thr Thr Asn Tyr Arg Asp Ser Val Lys Gly Arg
515 520 525
Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Val Tyr Leu Gln Met
530 535 540
Asn Ser Leu Lys Pro Glu Asp Thr Thr Val Tyr Tyr Cys Asn Thr Phe
545 550 555 560
Pro Pro Ile Ser Asn Phe Trp Gly Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 343
<211> 107
<212> PRT
<213> Homo sapiens
<400> 343
Ile Gln Val Glu Gln Ser Pro Pro Asp Leu Ile Leu Gln Glu Gly Ala
1 5 10 15
Asn Ser Thr Leu Arg Cys Asn Phe Ser Asp Ser Val Asn Asn Leu Gln
20 25 30
Trp Phe His Gln Asn Pro Trp Gly Gln Leu Ile Asn Leu Phe Tyr Ile
35 40 45
Pro Ser Gly Thr Lys Gln Asn Gly Arg Leu Ser Ala Thr Thr Val Ala
50 55 60
Thr Glu Arg Tyr Ser Leu Leu Tyr Ile Ser Ser Ser Gln Thr Thr Asp
65 70 75 80
Ser Gly Val Tyr Phe Cys Ala Ala Leu Ile Gln Gly Ala Gln Lys Leu
85 90 95
Val Phe Gly Gln Gly Thr Arg Leu Thr Ile Asn
100 105
<210> 344
<211> 110
<212> PRT
<213> Homo sapiens
<400> 344
Asn Ala Gly Val Thr Gln Thr Pro Lys Phe Arg Ile Leu Lys Ile Gly
1 5 10 15
Gln Ser Met Thr Leu Gln Cys Thr Gln Asp Met Asn His Asn Tyr Met
20 25 30
Tyr Trp Tyr Arg Gln Asp Pro Gly Met Gly Leu Lys Leu Ile Tyr Tyr
35 40 45
Ser Val Gly Ala Gly Ile Thr Asp Lys Gly Glu Val Pro Asn Gly Tyr
50 55 60
Asn Val Ser Arg Ser Thr Thr Glu Asp Phe Pro Leu Arg Leu Glu Leu
65 70 75 80
Ala Ala Pro Ser Gln Thr Ser Val Tyr Phe Cys Ala Ser Thr Tyr His
85 90 95
Gly Thr Gly Tyr Phe Gly Glu Gly Ser Trp Leu Thr Val Val
100 105 110
<210> 345
<211> 110
<212> PRT
<213> Homo sapiens
<400> 345
Gly Asp Ala Lys Thr Thr Gln Pro Asn Ser Met Glu Ser Asn Glu Glu
1 5 10 15
Glu Pro Val His Leu Pro Cys Asn His Ser Thr Ile Ser Gly Thr Asp
20 25 30
Tyr Ile His Trp Tyr Arg Gln Leu Pro Ser Gln Gly Pro Glu Tyr Val
35 40 45
Ile His Gly Leu Thr Ser Asn Val Asn Asn Arg Met Ala Ser Leu Ala
50 55 60
Ile Ala Glu Asp Arg Lys Ser Ser Thr Leu Ile Leu His Arg Ala Thr
65 70 75 80
Leu Arg Asp Ala Ala Val Tyr Tyr Cys Thr Val Tyr Gly Gly Ala Thr
85 90 95
Asn Lys Leu Ile Phe Gly Thr Gly Thr Leu Leu Ala Val Gln
100 105 110
<210> 346
<211> 114
<212> PRT
<213> Homo sapiens
<400> 346
Val Val Ser Gln His Pro Ser Trp Val Ile Ala Lys Ser Gly Thr Ser
1 5 10 15
Val Lys Ile Glu Cys Arg Ser Leu Asp Phe Gln Ala Thr Thr Met Phe
20 25 30
Trp Tyr Arg Gln Phe Pro Lys Gln Ser Leu Met Leu Met Ala Thr Ser
35 40 45
Asn Glu Gly Ser Lys Ala Thr Tyr Glu Gln Gly Val Glu Lys Asp Lys
50 55 60
Phe Leu Ile Asn His Ala Ser Leu Thr Leu Ser Thr Leu Thr Val Thr
65 70 75 80
Ser Ala His Pro Glu Asp Ser Ser Phe Tyr Ile Cys Ser Ala Arg Gly
85 90 95
Gly Ser Tyr Asn Ser Pro Leu His Phe Gly Asn Gly Thr Arg Leu Thr
100 105 110
Val Thr
<210> 347
<211> 96
<212> PRT
<213> Macaca fascicularis
<400> 347
Pro Tyr Ile Gln Asn Pro Asp Pro Ala Val Tyr Gln Leu Arg Gly Ser
1 5 10 15
Lys Ser Asn Asp Thr Ser Val Cys Leu Phe Thr Asp Phe Asp Ser Val
20 25 30
Met Asn Val Ser Gln Ser Lys Asp Ser Asp Val His Ile Thr Asp Lys
35 40 45
Thr Val Leu Asp Met Arg Ser Met Asp Phe Lys Ser Asn Gly Ala Val
50 55 60
Ala Trp Ser Asn Lys Ser Asp Phe Ala Cys Thr Ser Ala Phe Lys Asp
65 70 75 80
Ser Val Ile Pro Ala Asp Thr Phe Phe Pro Ser Pro Glu Ser Ser Cys
85 90 95
<210> 348
<211> 131
<212> PRT
<213> Macaca mulatta
<400> 348
Glu Asp Leu Lys Lys Val Phe Pro Pro Lys Val Ala Val Phe Glu Pro
1 5 10 15
Ser Glu Ala Glu Ile Ser His Thr Gln Lys Ala Thr Leu Val Cys Leu
20 25 30
Ala Thr Gly Phe Tyr Pro Asp His Val Glu Leu Ser Trp Trp Val Asn
35 40 45
Gly Lys Glu Val His Ser Gly Val Ser Thr Asp Pro Gln Pro Leu Lys
50 55 60
Glu Gln Pro Ala Leu Glu Asp Ser Arg Tyr Ser Leu Ser Ser Arg Leu
65 70 75 80
Arg Val Ser Ala Thr Phe Trp His Asn Pro Arg Asn His Phe Arg Cys
85 90 95
Gln Val Gln Phe Tyr Gly Leu Ser Glu Asp Asp Glu Trp Thr Glu Asp
100 105 110
Arg Asp Lys Pro Ile Thr Gln Lys Ile Ser Ala Glu Ala Trp Gly Arg
115 120 125
Ala Asp Cys
130
<210> 349
<211> 107
<212> PRT
<213> Macaca mulatta
<400> 349
Gln Gln Ile Met Gln Ile Pro Gln Tyr Gln His Val Gln Glu Gly Glu
1 5 10 15
Asp Phe Thr Thr Tyr Cys Asn Ser Ser Thr Thr Leu Ser Asn Ile Gln
20 25 30
Trp Tyr Lys Gln Arg Pro Gly Gly His Pro Val Phe Leu Ile Met Leu
35 40 45
Val Lys Ser Gly Glu Val Lys Lys Gln Lys Arg Leu Ile Phe Gln Phe
50 55 60
Gly Glu Ala Lys Lys Asn Ser Ser Leu His Ile Thr Ala Thr Gln Thr
65 70 75 80
Thr Asp Val Gly Thr Tyr Phe Cys Ala Thr Thr Gly Val Asn Asn Leu
85 90 95
Phe Phe Gly Thr Gly Thr Arg Leu Thr Val Leu
100 105
<210> 350
<211> 118
<212> PRT
<213> Macaca mulatta
<400> 350
Ala Gly Pro Val Asn Ala Gly Val Thr Gln Thr Pro Lys Phe Gln Val
1 5 10 15
Leu Lys Thr Gly Gln Ser Met Thr Leu Gln Cys Ala Gln Asp Met Asn
20 25 30
His Asp Tyr Met Tyr Trp Tyr Arg Gln Asp Pro Gly Met Gly Leu Arg
35 40 45
Leu Ile His Tyr Ser Val Gly Glu Gly Ser Thr Glu Lys Gly Glu Val
50 55 60
Pro Asp Gly Tyr Asn Val Thr Arg Ser Asn Thr Glu Asp Phe Pro Leu
65 70 75 80
Arg Leu Glu Ser Ala Ala Pro Ser Gln Thr Ser Val Tyr Phe Cys Ala
85 90 95
Ser Ser Tyr Trp Thr Gly Arg Ser Tyr Glu Gln Tyr Phe Gly Pro Gly
100 105 110
Thr Arg Leu Thr Val Ile
115
<210> 351
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 351
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 352
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 352
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala
115
<210> 353
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 353
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala
115
<210> 354
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 354
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 355
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 355
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Lys
100 105 110
Val Ser Ser Ala
115
<210> 356
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 356
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 357
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 357
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala
115
<210> 358
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 358
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala Ala
115
<210> 359
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 359
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala Ala Ala
115
<210> 360
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 360
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly
115
<210> 361
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 361
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly Gly
115
<210> 362
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 362
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly Gly Gly
115
<210> 363
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 363
Gly Phe Thr Phe Ser Ser Phe Gly Met Ser
1 5 10
<210> 364
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 364
Gly Phe Thr Phe Arg Ser Phe Gly Met Ser
1 5 10
<210> 365
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 365
Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu
1 5 10
<210> 366
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 366
Gly Gly Ser Leu Ser Arg
1 5
<210> 367
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Myc-Tag
<400> 367
Ala Ala Ala Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu Asn Gly Ala
1 5 10 15
Ala
<210> 368
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<220>
<221> VARIANT
<222> 2
<223> Xaa is D, A, S, E or G
<220>
<221> VARIANT
<222> 4
<223> Xaa is H or Y
<220>
<221> VARIANT
<222> 5
<223> Xaa is K or L
<220>
<221> VARIANT
<222> 6
<223> Xaa is I or L
<220>
<221> VARIANT
<222> 8
<223> Xaa is F, I or V
<220>
<221> VARIANT
<222> 10
<223> Xaa is G or S
<400> 368
Gly Xaa Val Xaa Xaa Xaa Asn Xaa Leu Xaa
1 5 10
<210> 369
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<220>
<221> VARIANT
<222> 1
<223> Xaa is H, T or R
<220>
<221> VARIANT
<222> 3
<223> Xaa is S, T or A
<220>
<221> VARIANT
<222> 5
<223> G, S or A
<220>
<221> VARIANT
<222> 7
<223> Xaa is Q, D, E, T, A or V
<220>
<221> VARIANT
<222> 8
<223> Xaa is T, A or V
<220>
<221> VARIANT
<222> 9
<223> Xaa is D, A, Q, N, V or S
<400> 369
Xaa Ile Xaa Ile Xaa Asp Xaa Xaa Xaa
1 5
<210> 370
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<220>
<221> VARIANT
<222> 1
<223> Xaa is F, Y, G, L or K
<220>
<221> VARIANT
<222> 4
<223> Xaa is I or L
<220>
<221> VARIANT
<222> 5
<223> Xaa is Y or W
<220>
<221> VARIANT
<222> 8
<223> Xaa is D, N or S
<400> 370
Xaa Ser Arg Xaa Xaa Pro Tyr Xaa Tyr
1 5
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| ПОЛИПЕПТИД, ВКЛЮЧАЮЩИЙ АНТИГЕНСВЯЗЫВАЮЩИЙ ДОМЕН И ТРАНСПОРТИРУЮЩИЙ СЕГМЕНТ | 2018 |
|
RU2815452C2 |
| УЛУЧШЕННЫЕ ОДИНОЧНЫЕ ВАРИАБЕЛЬНЫЕ ДОМЕНЫ ИММУНОГЛОБУЛИНА, СВЯЗЫВАЮЩИЕСЯ С СЫВОРОТОЧНЫМ АЛЬБУМИНОМ | 2017 |
|
RU2765384C2 |
| АНТИТЕЛА К C10ORF54 И ИХ ПРИМЕНЕНИЯ | 2015 |
|
RU2819627C1 |
| ПОЛИПЕПТИД, СОДЕРЖАЩИЙ АНТИГЕНСВЯЗЫВАЮЩИЙ ДОМЕН И ТРАНСПОРТИРУЮЩИЙ СЕГМЕНТ | 2017 |
|
RU2827545C2 |
| АНТИТЕЛА К МИОСТАТИНУ, ПОЛИПЕПТИДЫ, СОДЕРЖАЩИЕ ВАРИАНТЫ FC-ОБЛАСТЕЙ, И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2016 |
|
RU2789884C2 |
| СЛИТЫЕ БЕЛКИ С АЛЬБУМИН-СВЯЗЫВАЮЩИМИ ДОМЕНАМИ | 2018 |
|
RU2786444C2 |
| УЛУЧШЕННЫЕ ВАРИАБЕЛЬНЫЕ ДОМЕНЫ ИММУНОГЛОБУЛИНА | 2015 |
|
RU2746738C2 |
| УСОВЕРШЕНСТВОВАННЫЕ АГЕНТЫ, СВЯЗЫВАЮЩИЕ СЫВОРОТОЧНЫЙ АЛЬБУМИН | 2018 |
|
RU2797270C2 |
| АНТИ-PVRIG АНТИТЕЛА И СПОСОБЫ ПРИМЕНЕНИЯ | 2016 |
|
RU2732042C2 |
| ЛИГАНДСВЯЗЫВАЮЩАЯ МОЛЕКУЛА С РЕГУЛИРУЕМОЙ ЛИГАНДСВЯЗЫВАЮЩЕЙ АКТИВНОСТЬЮ | 2017 |
|
RU2803067C2 |
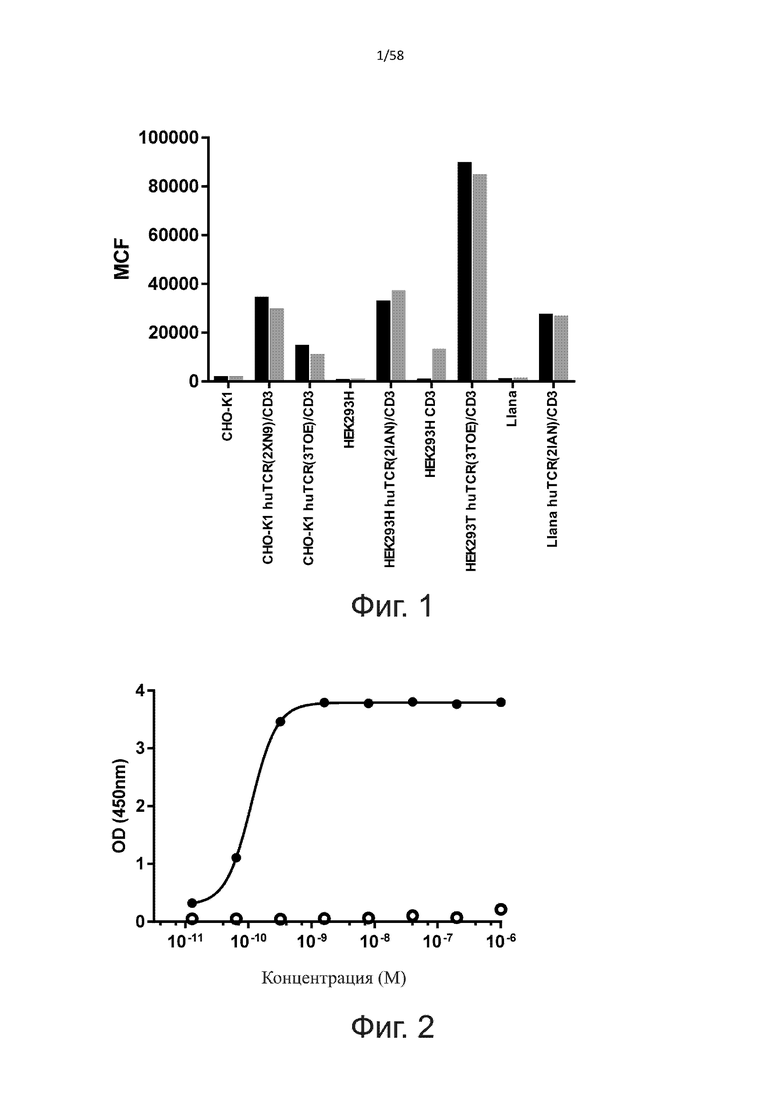
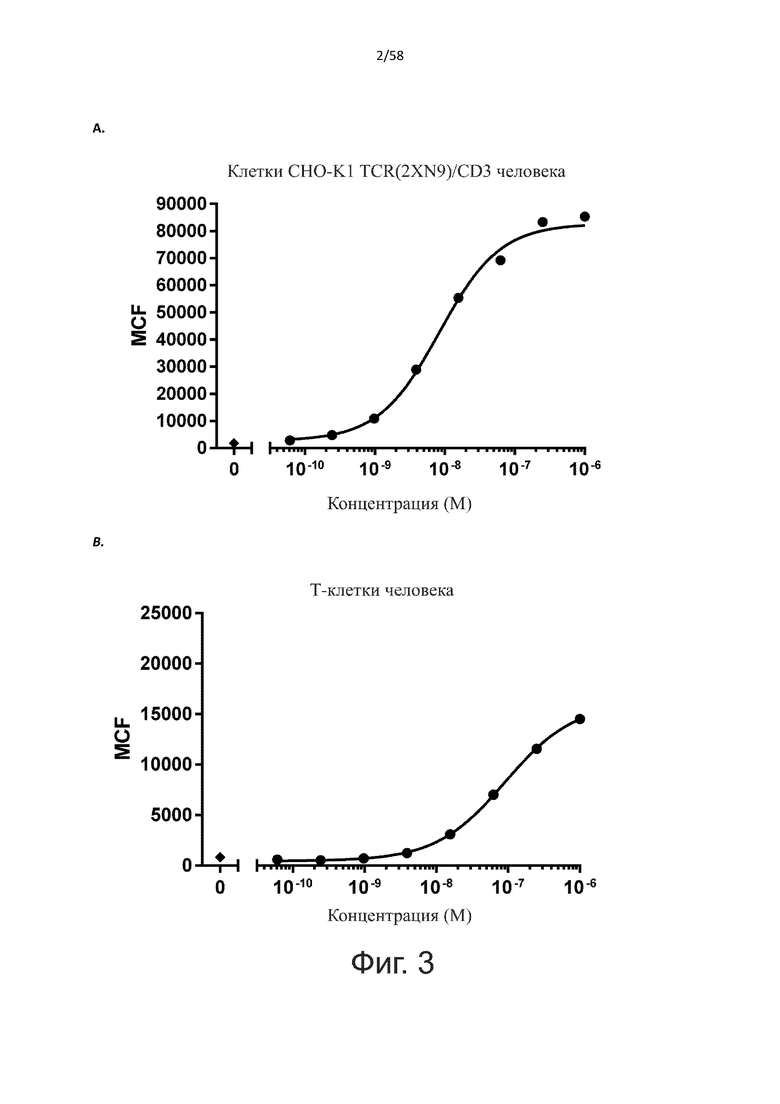
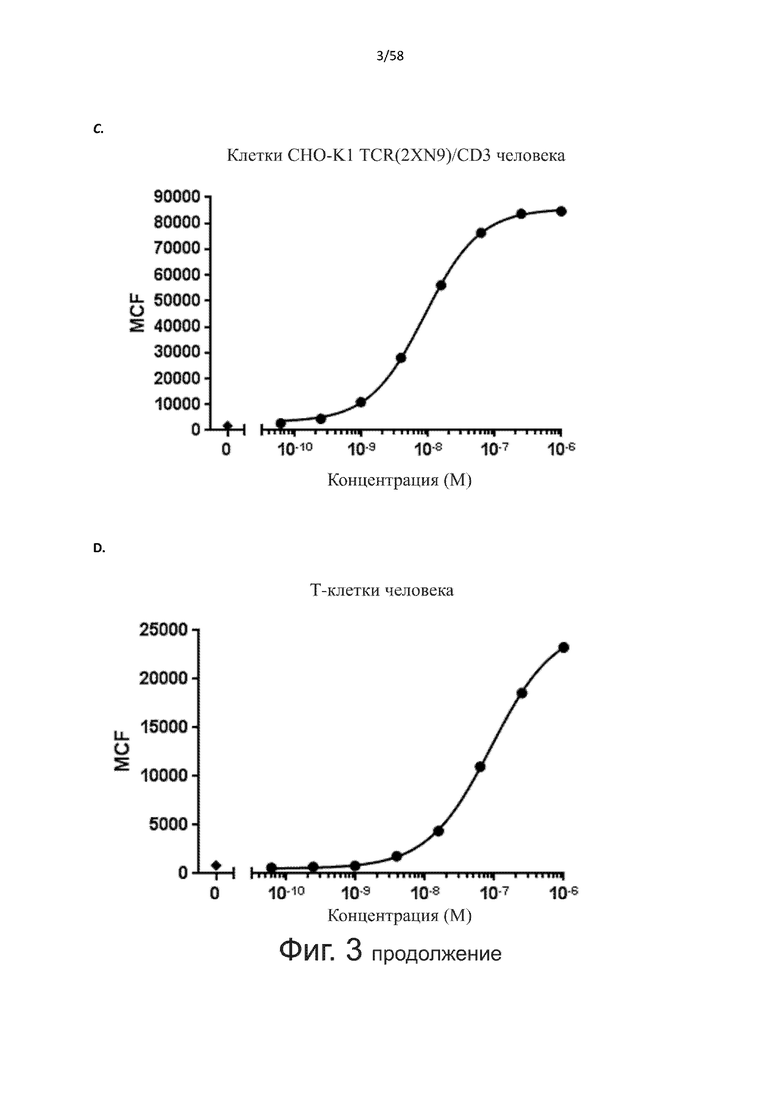
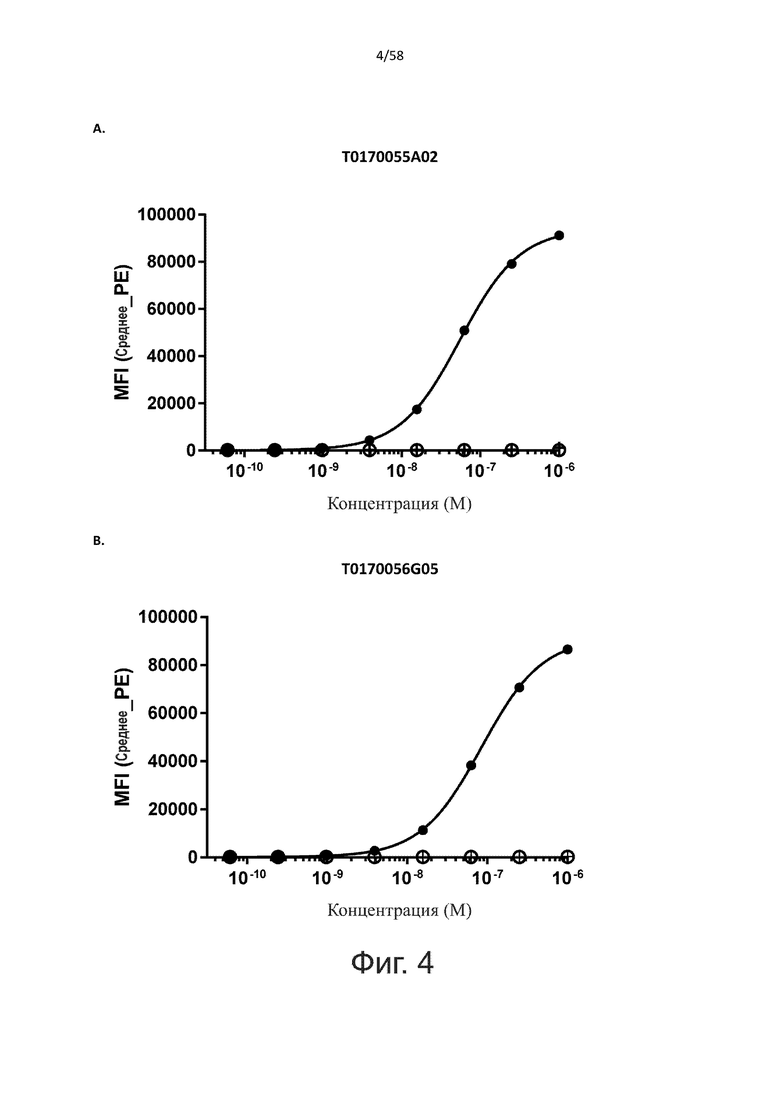
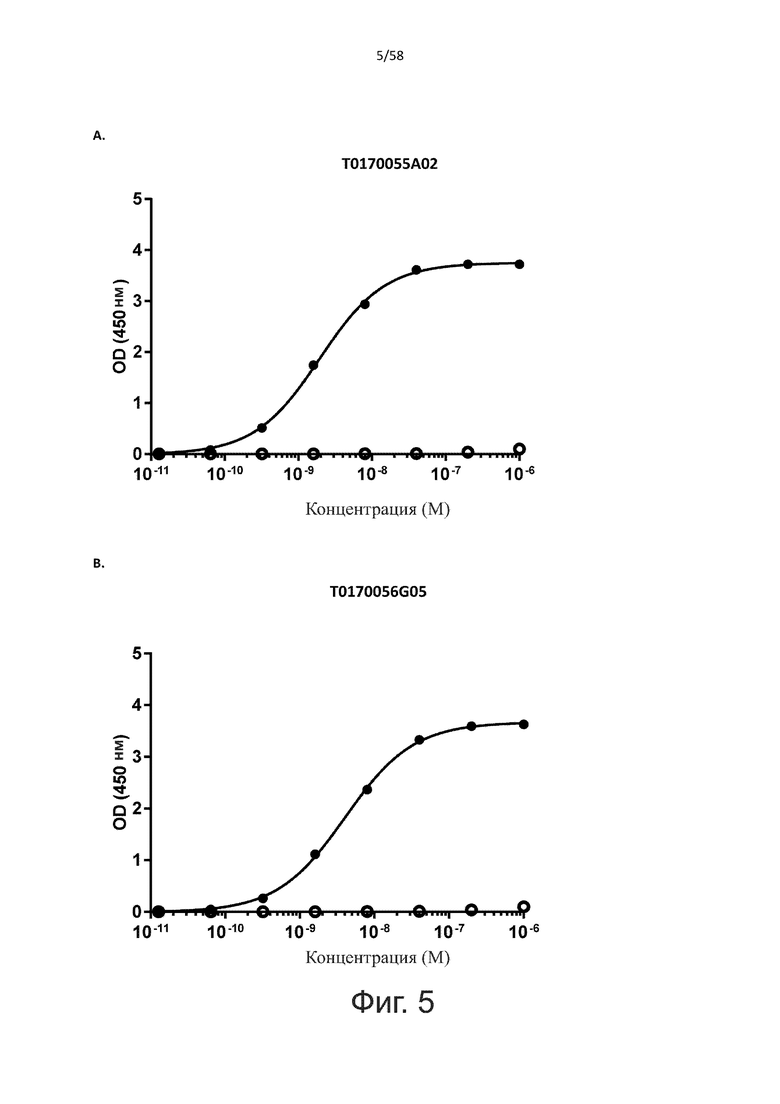
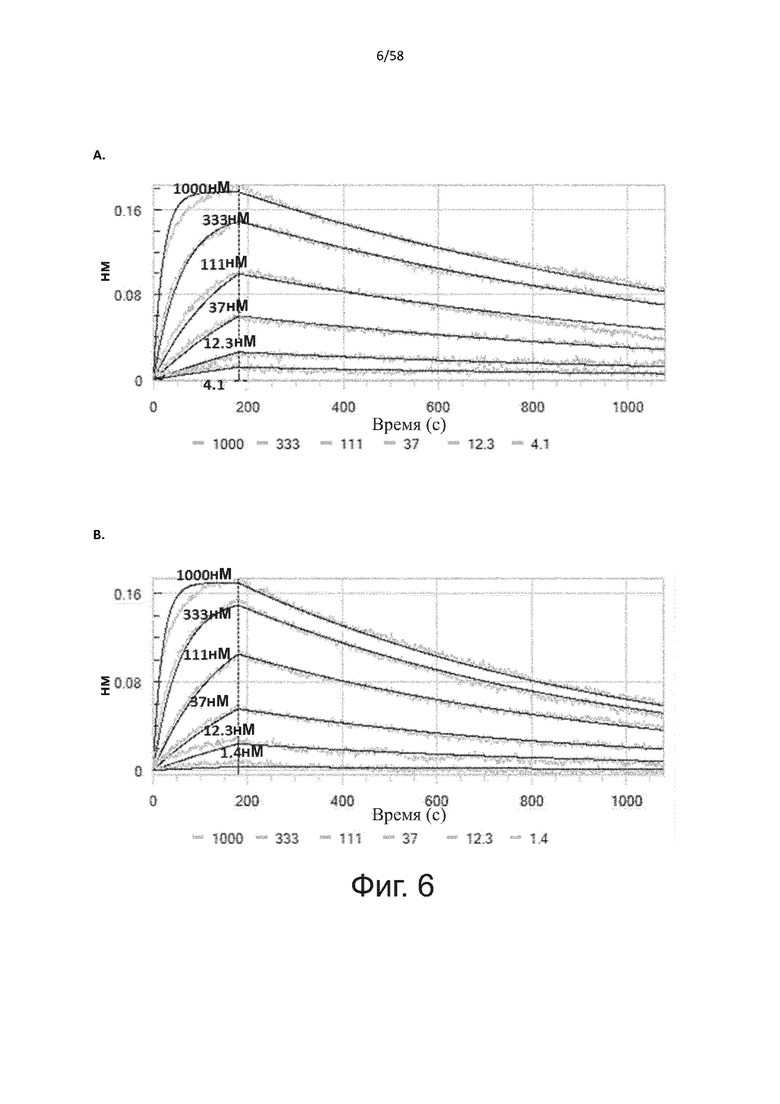
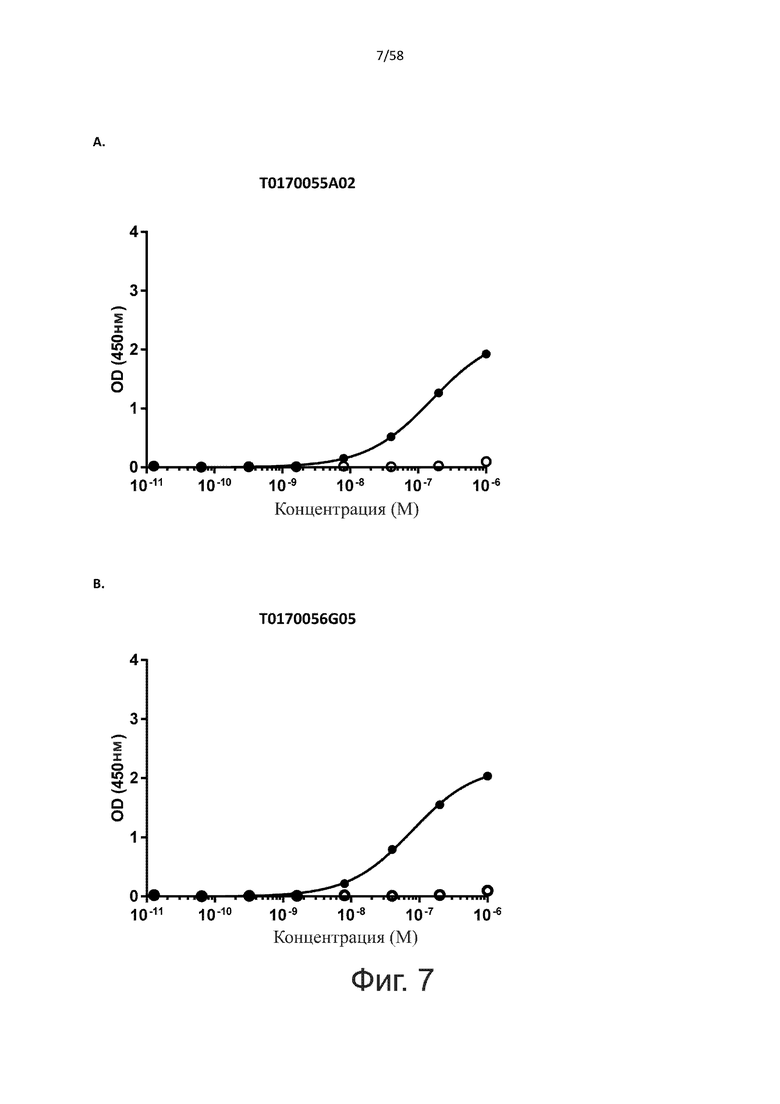
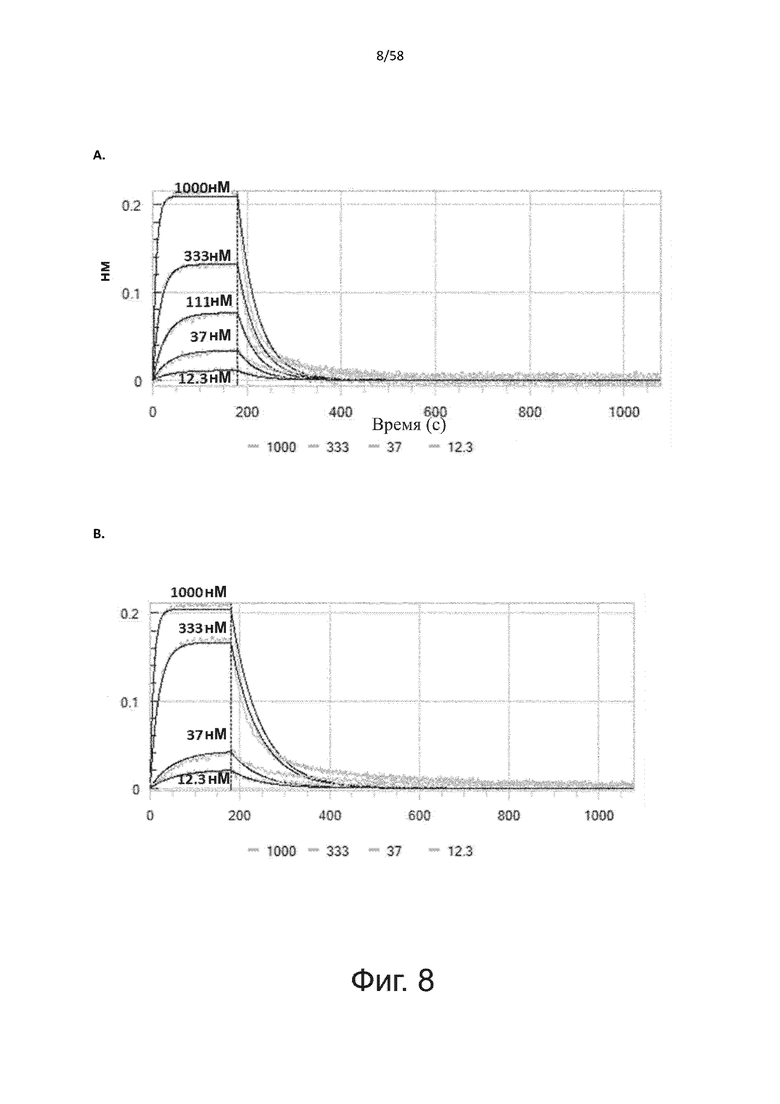
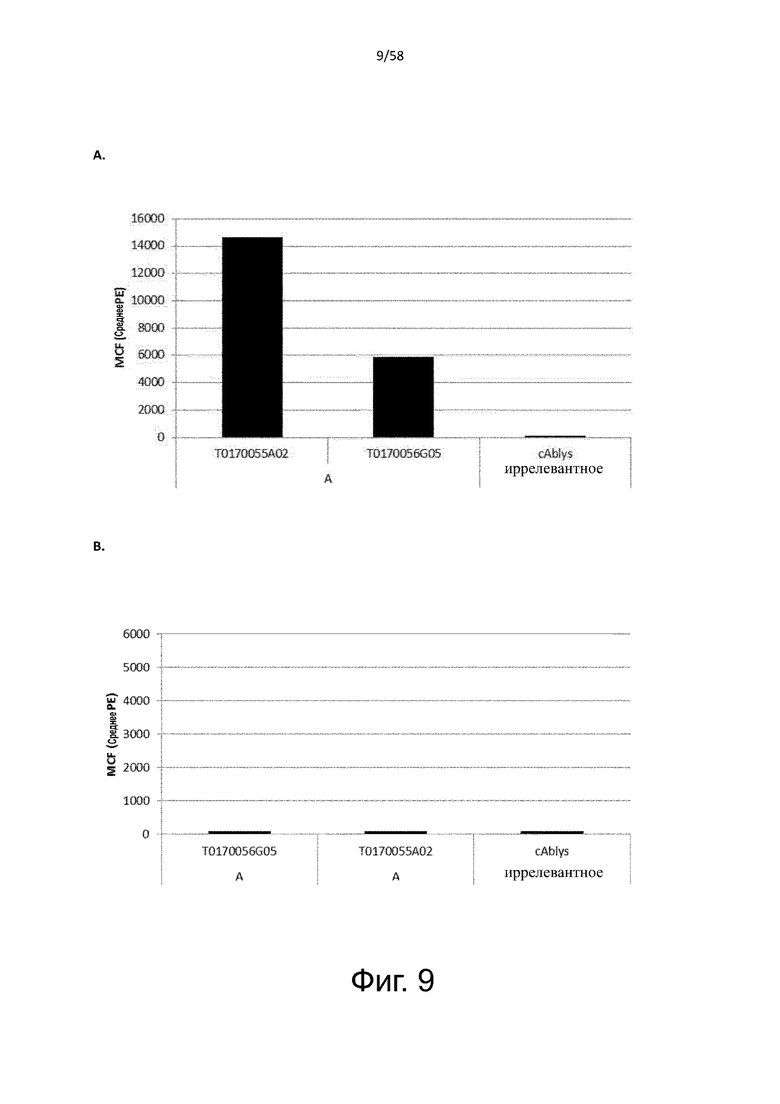
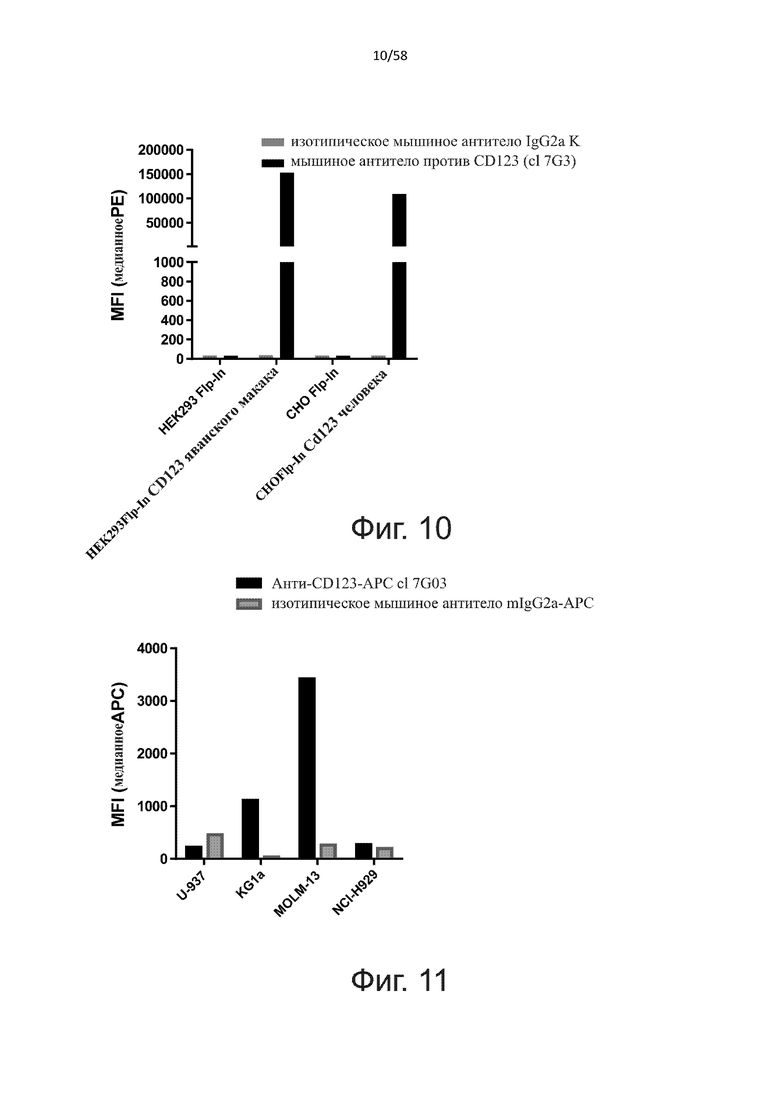
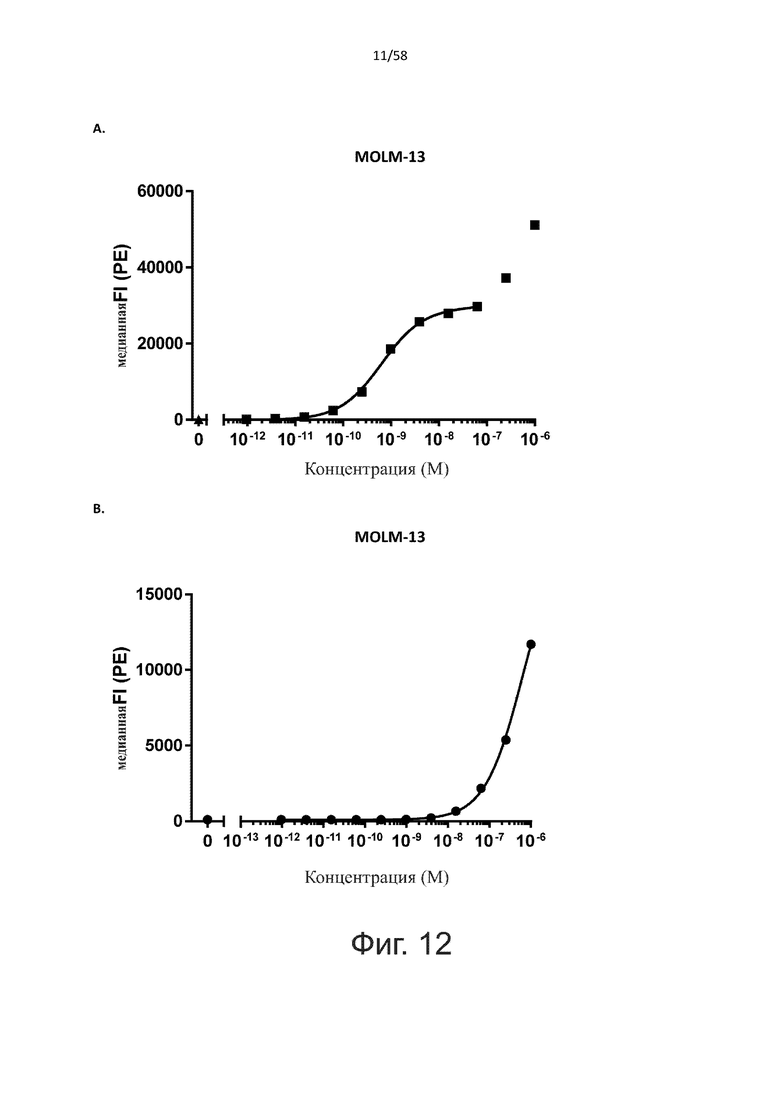
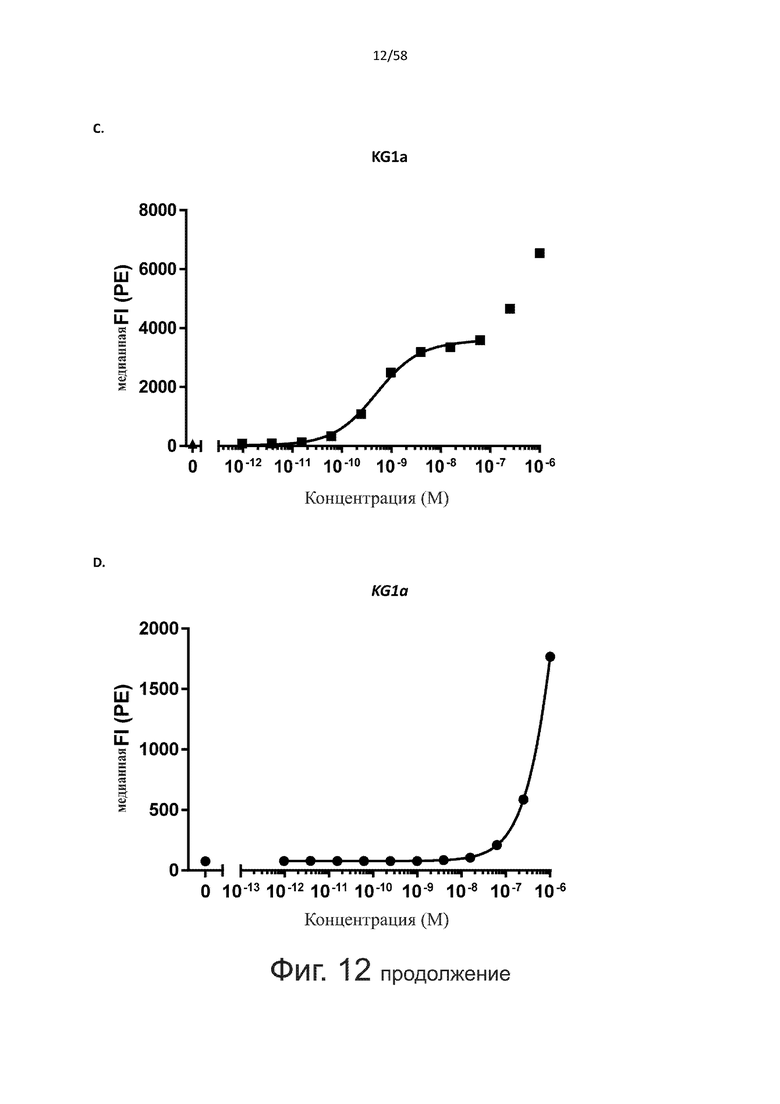
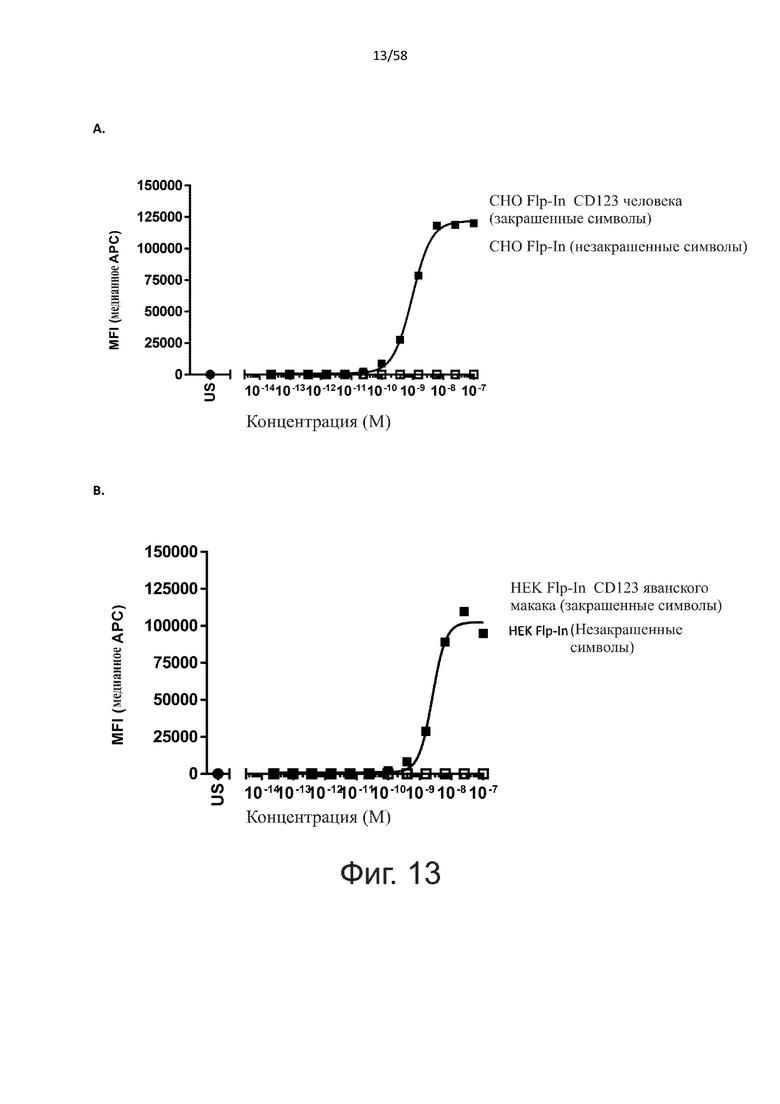
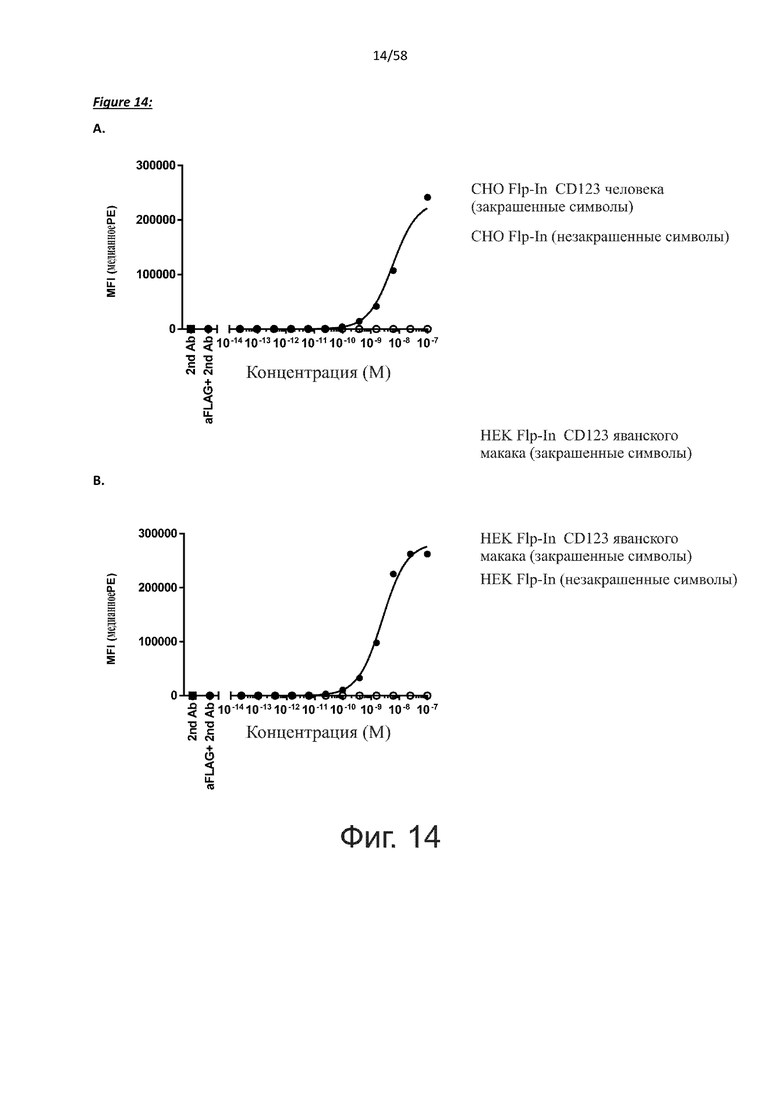
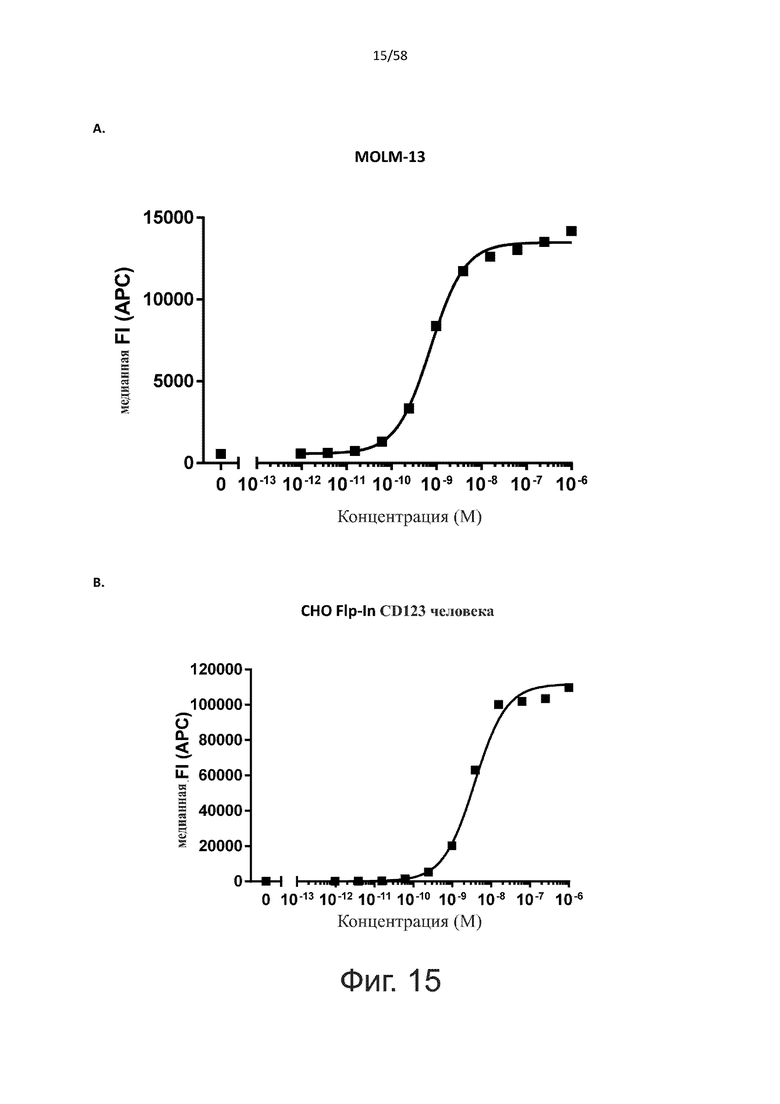
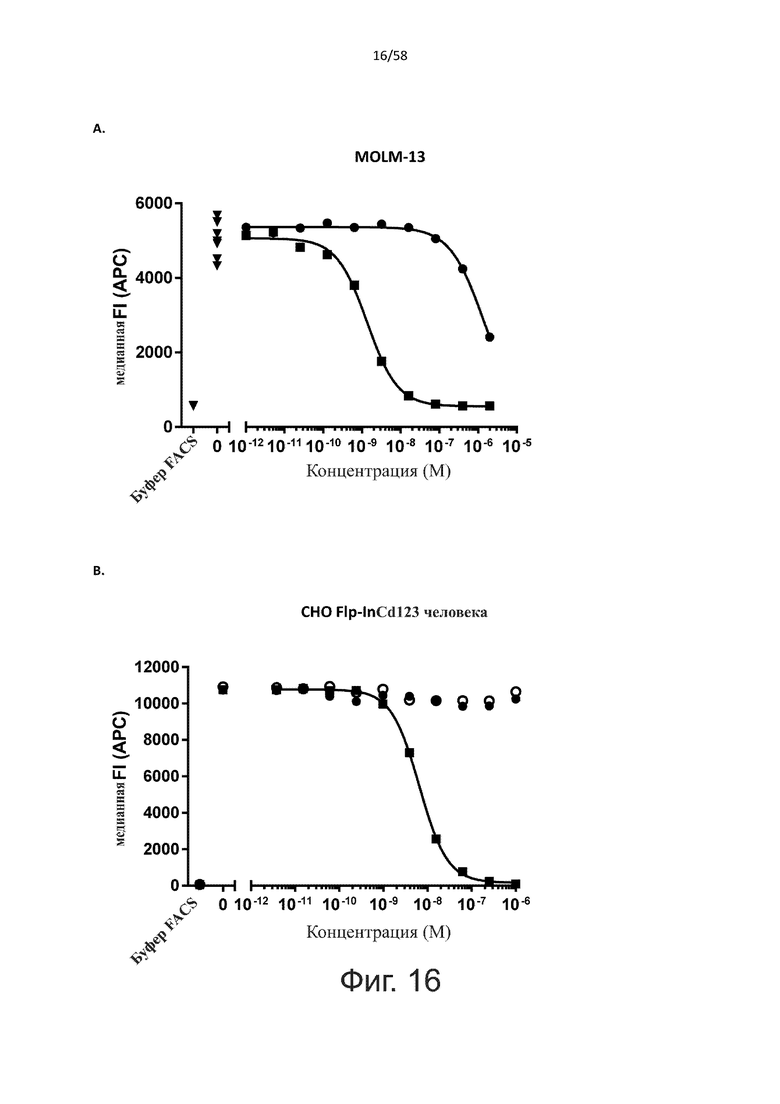
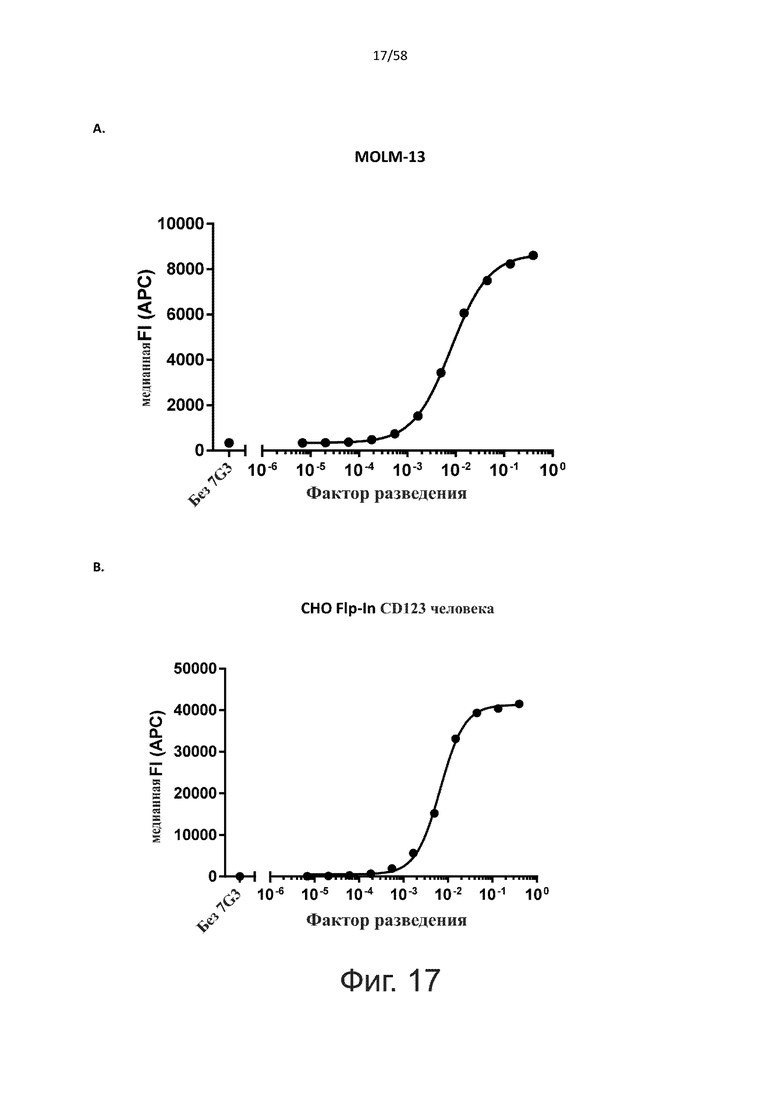
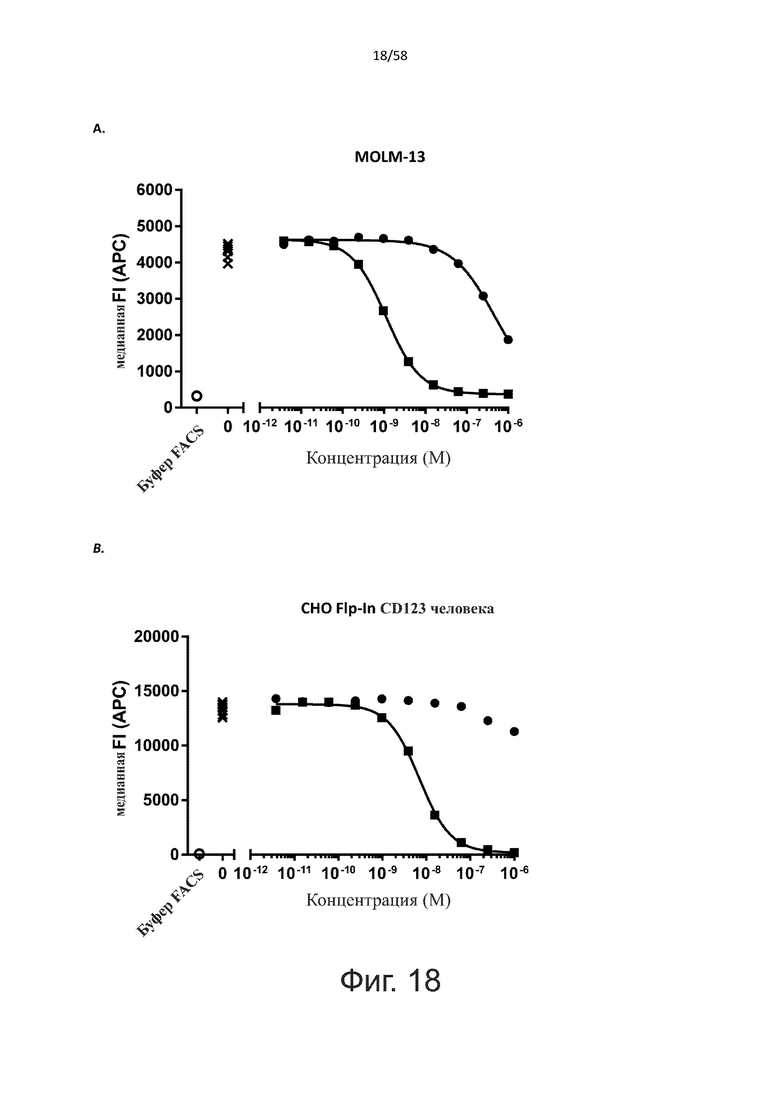

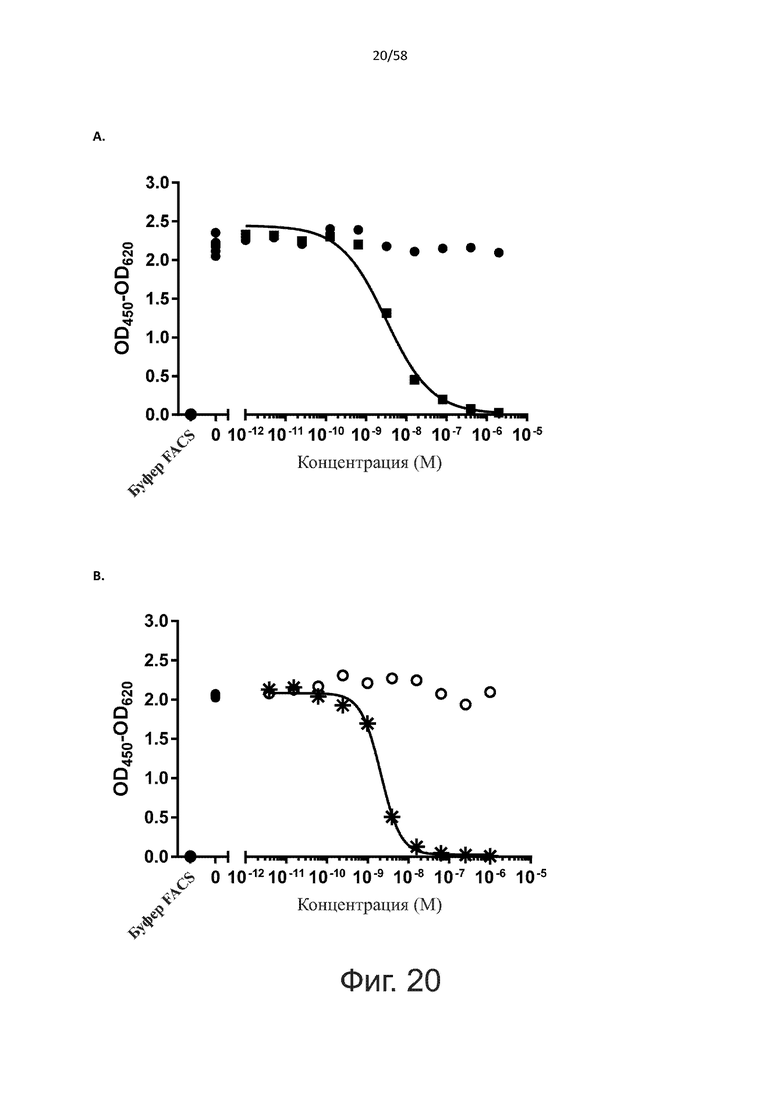
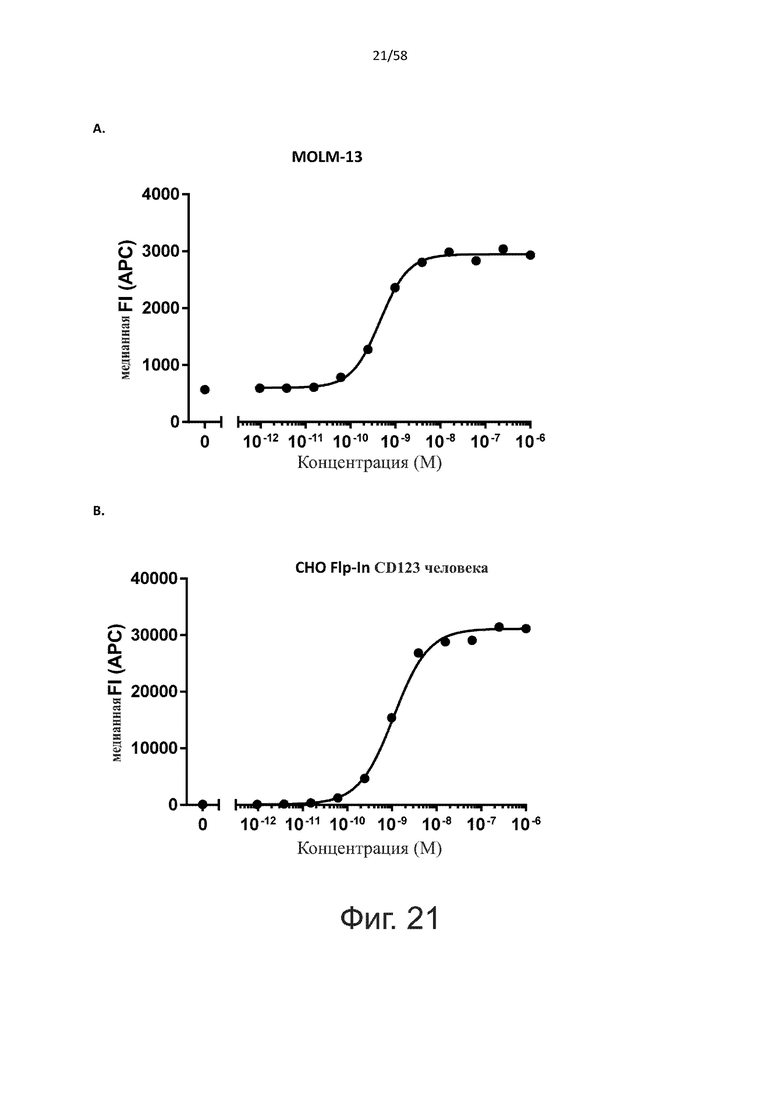
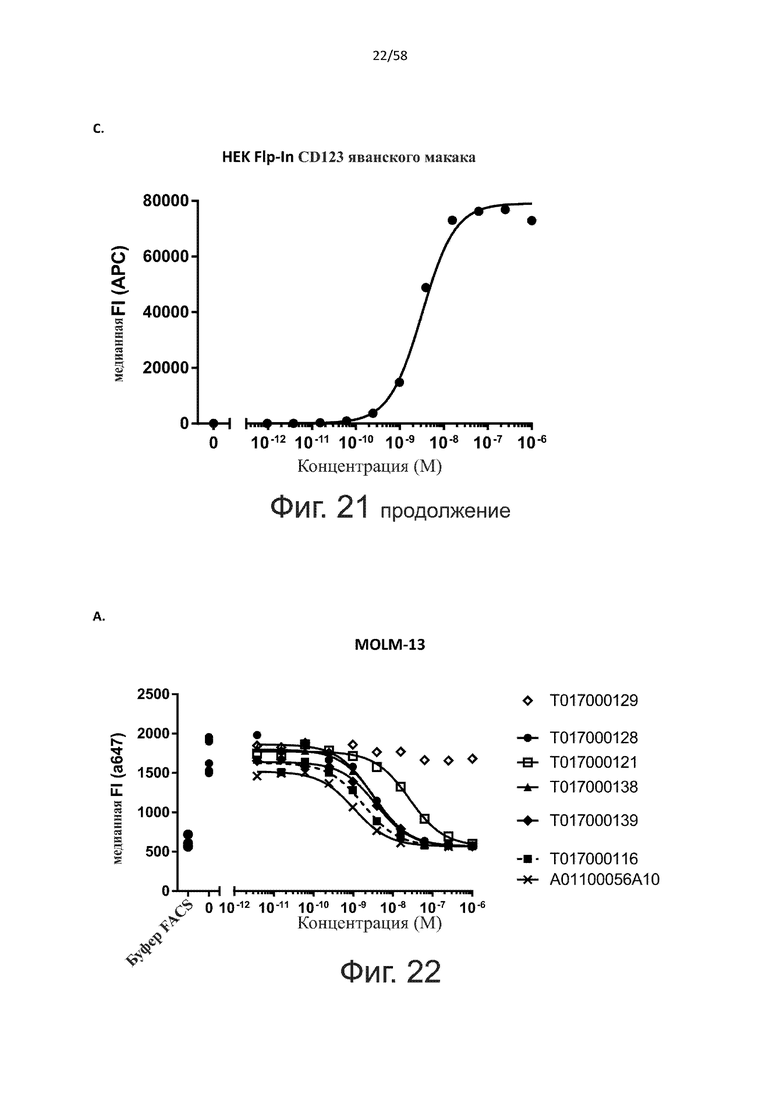
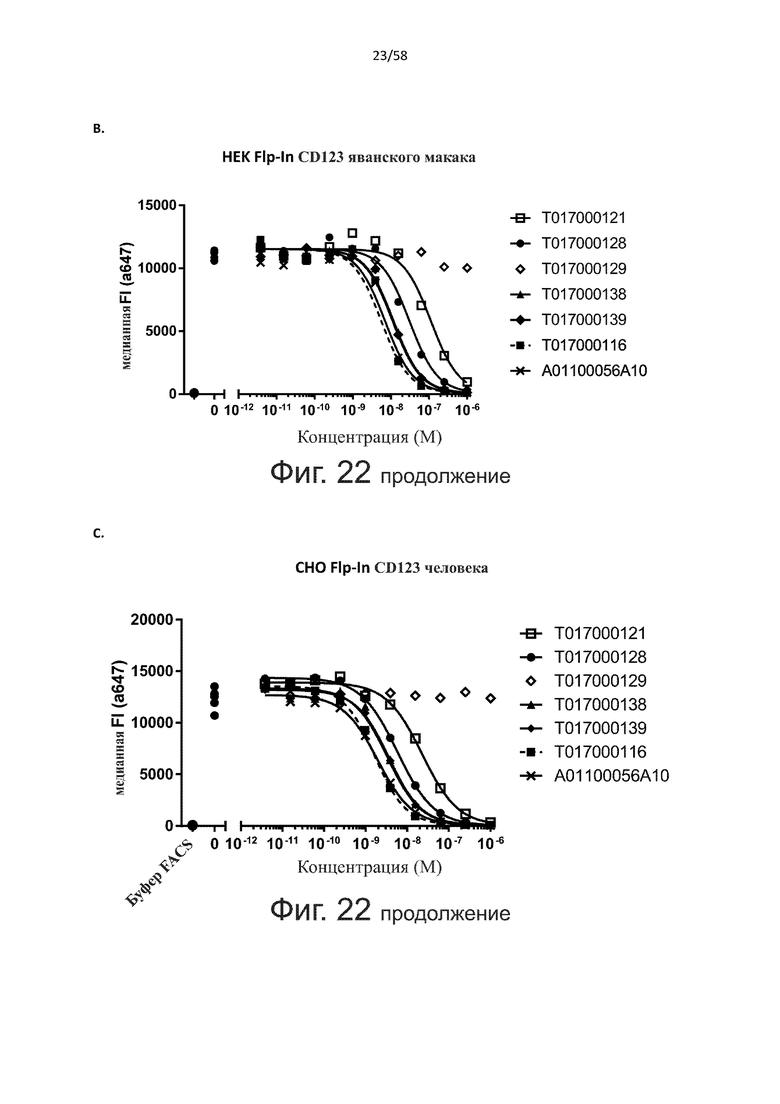
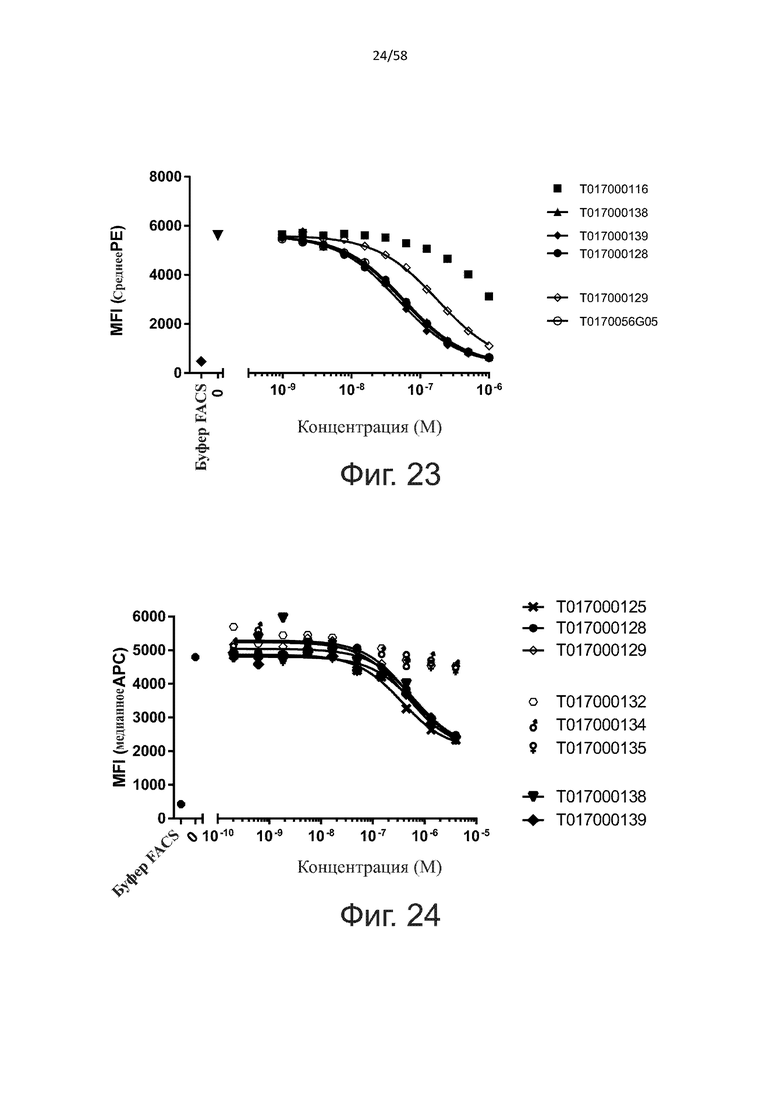
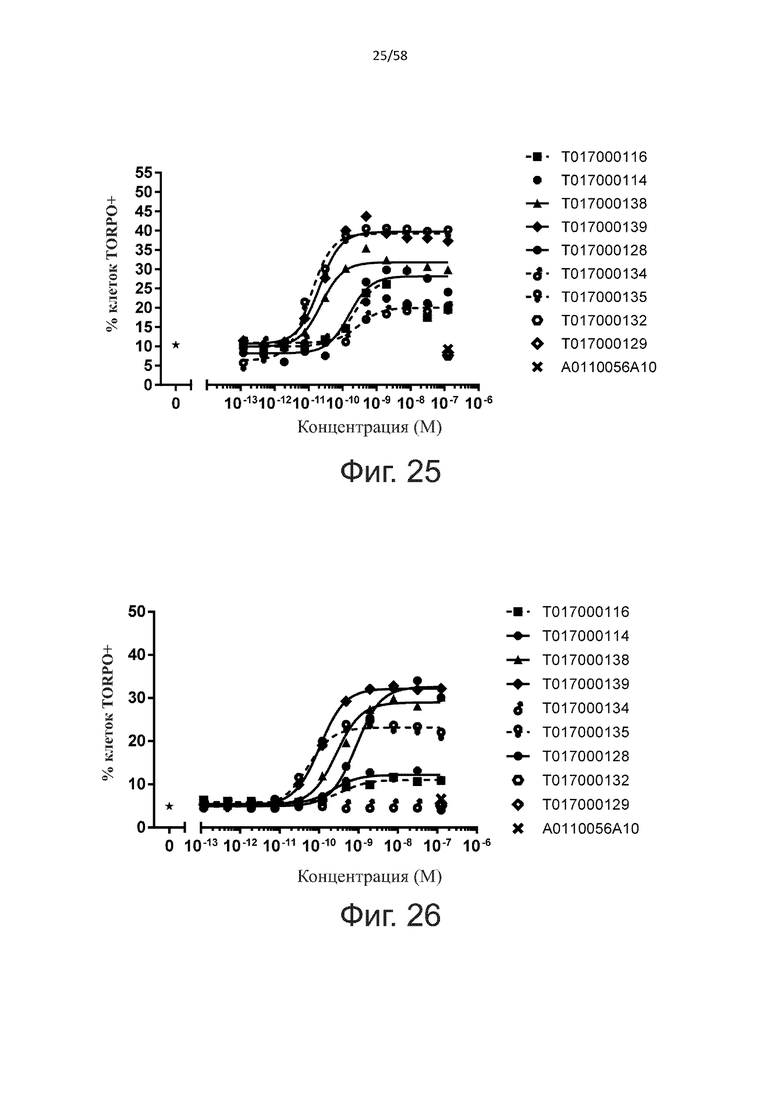
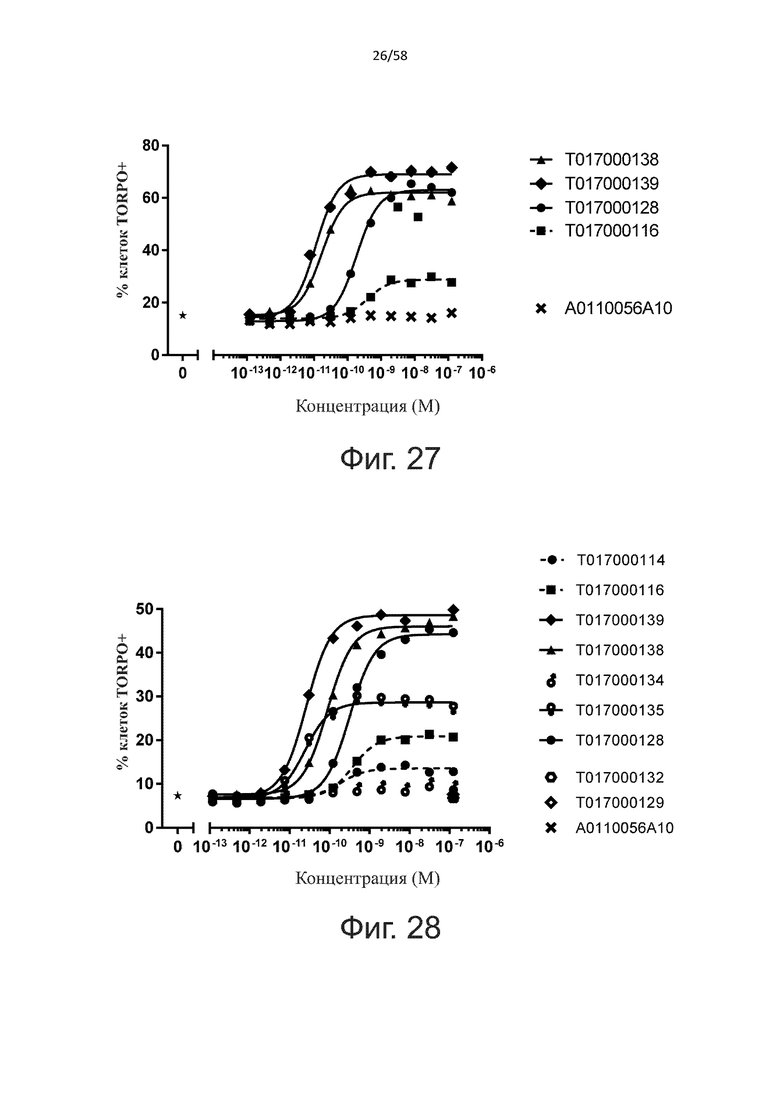
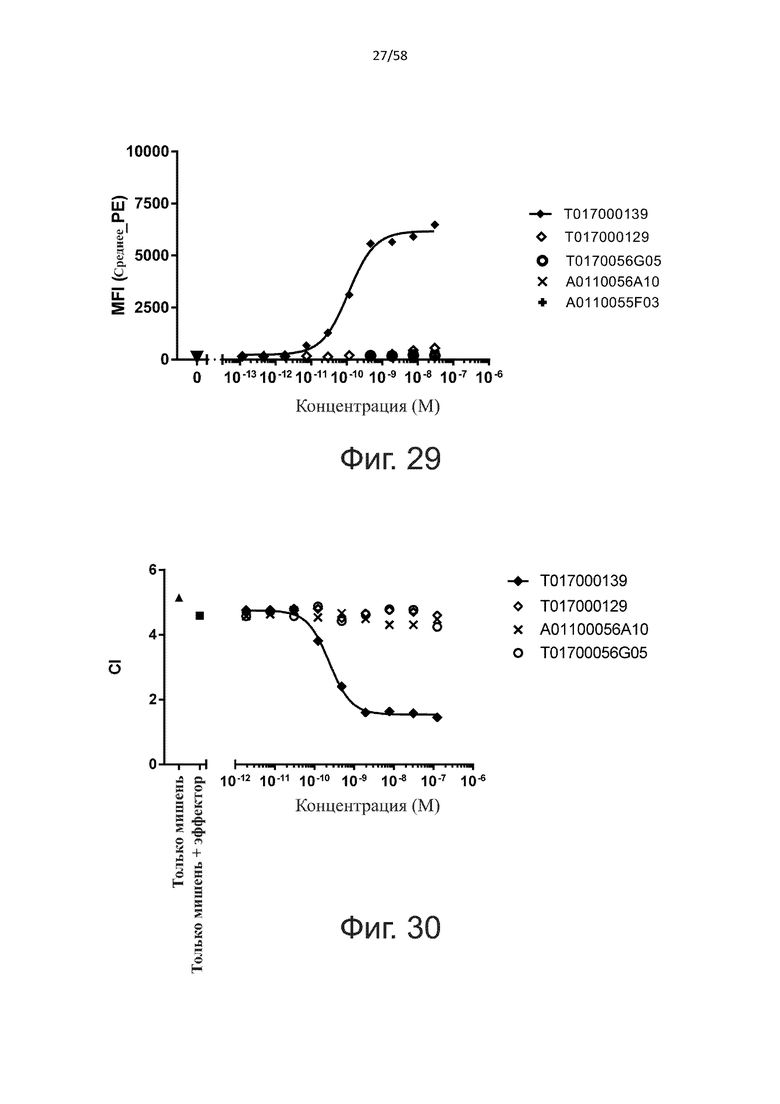
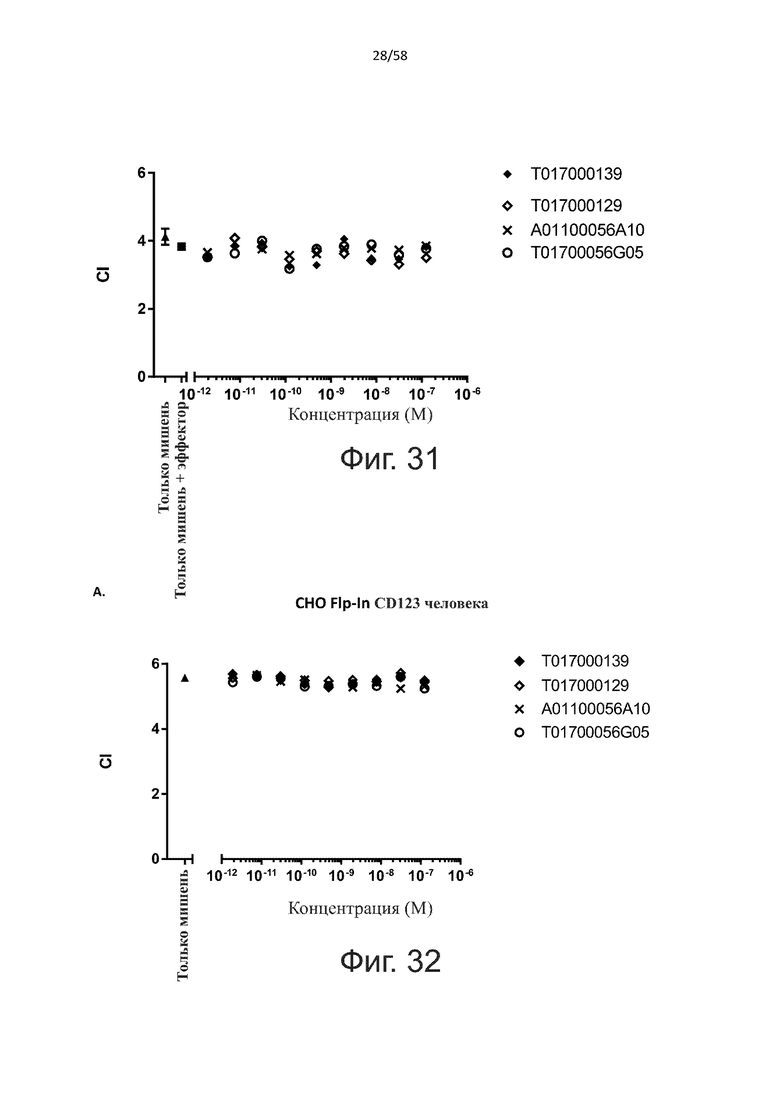
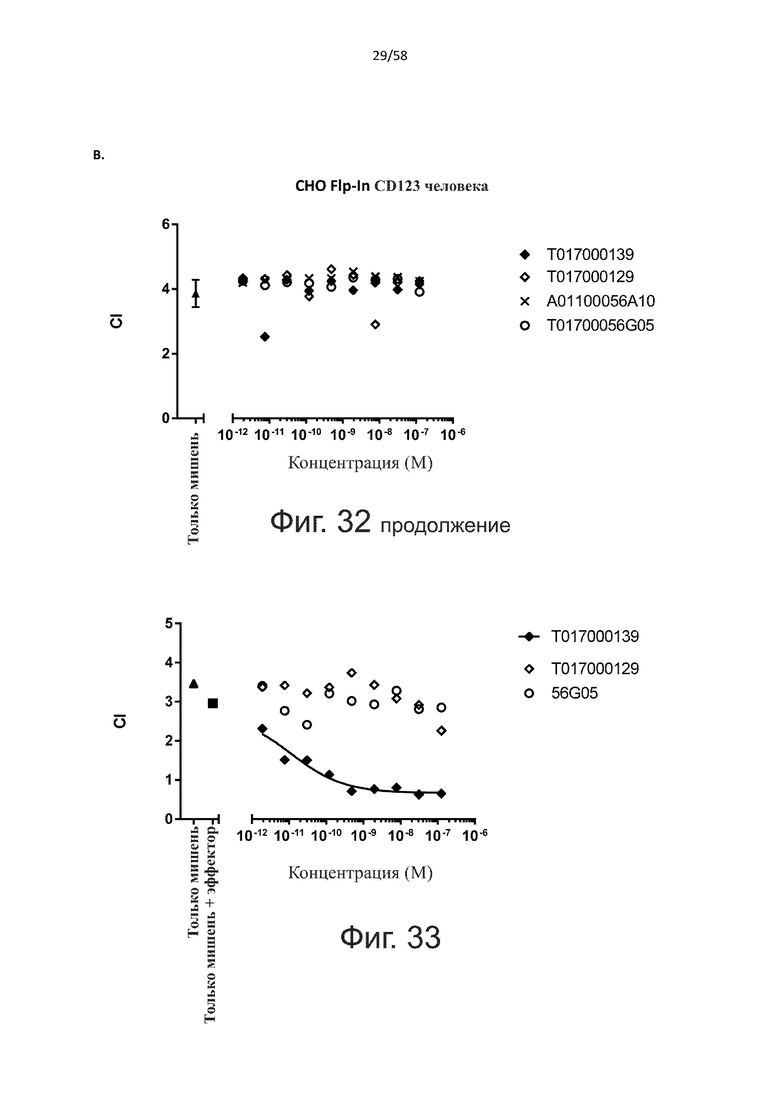
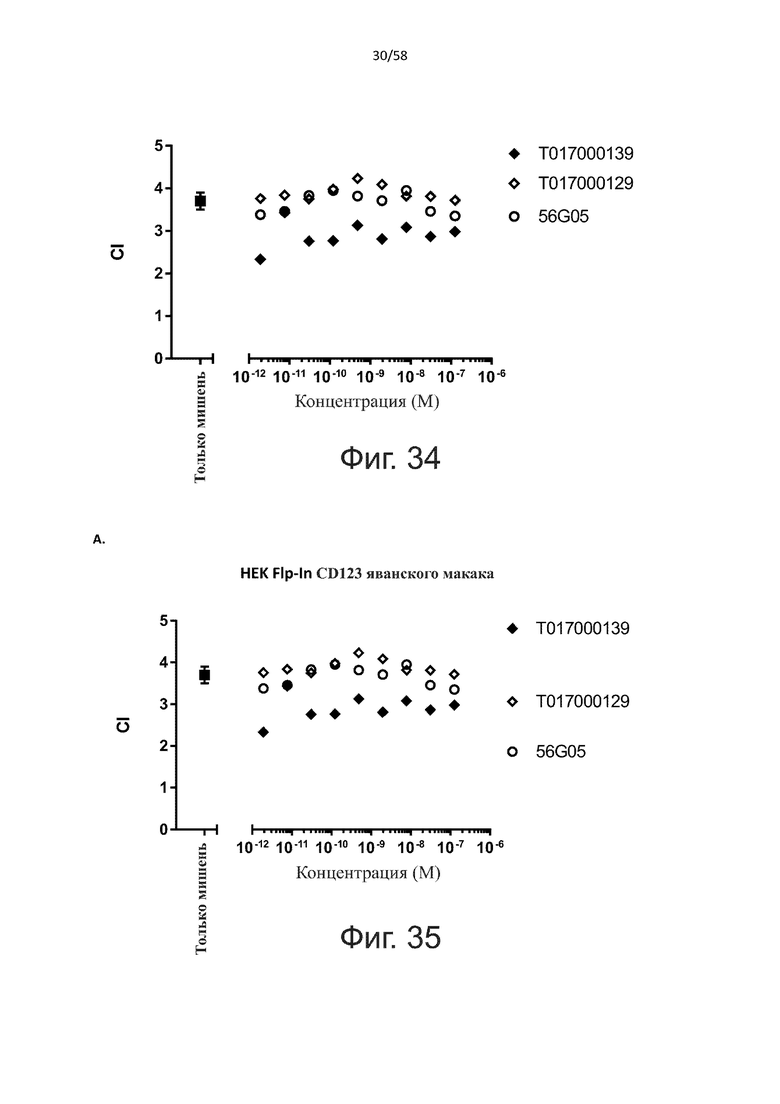
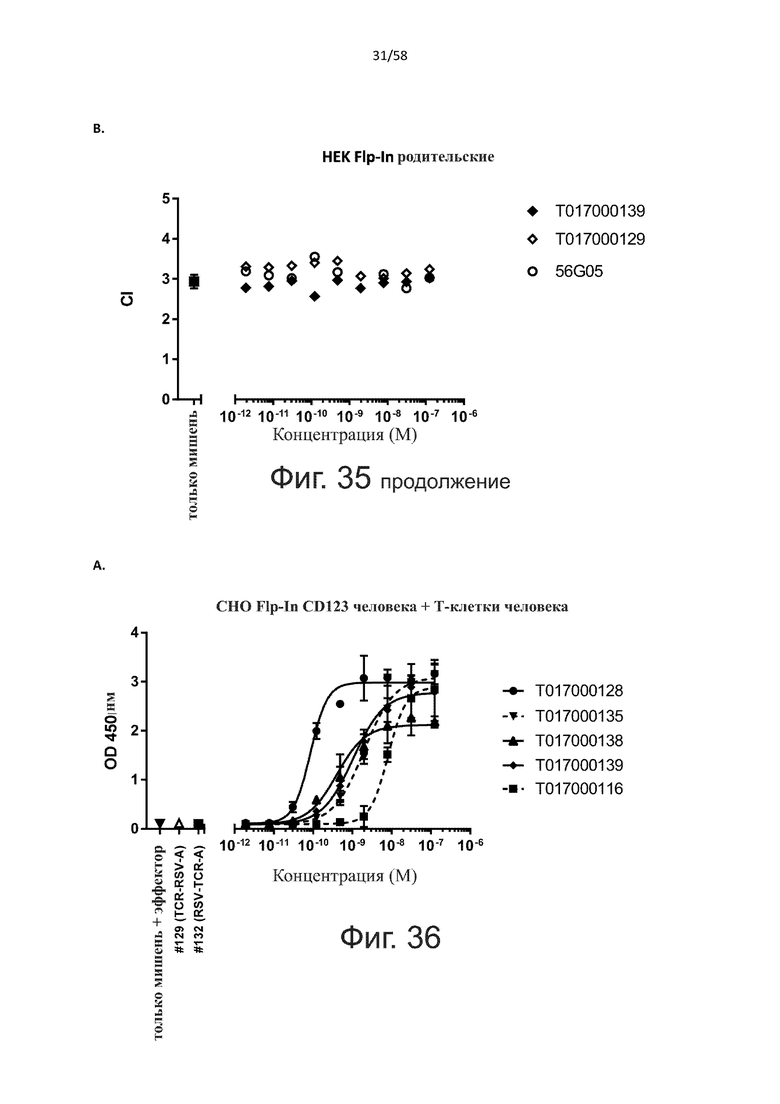
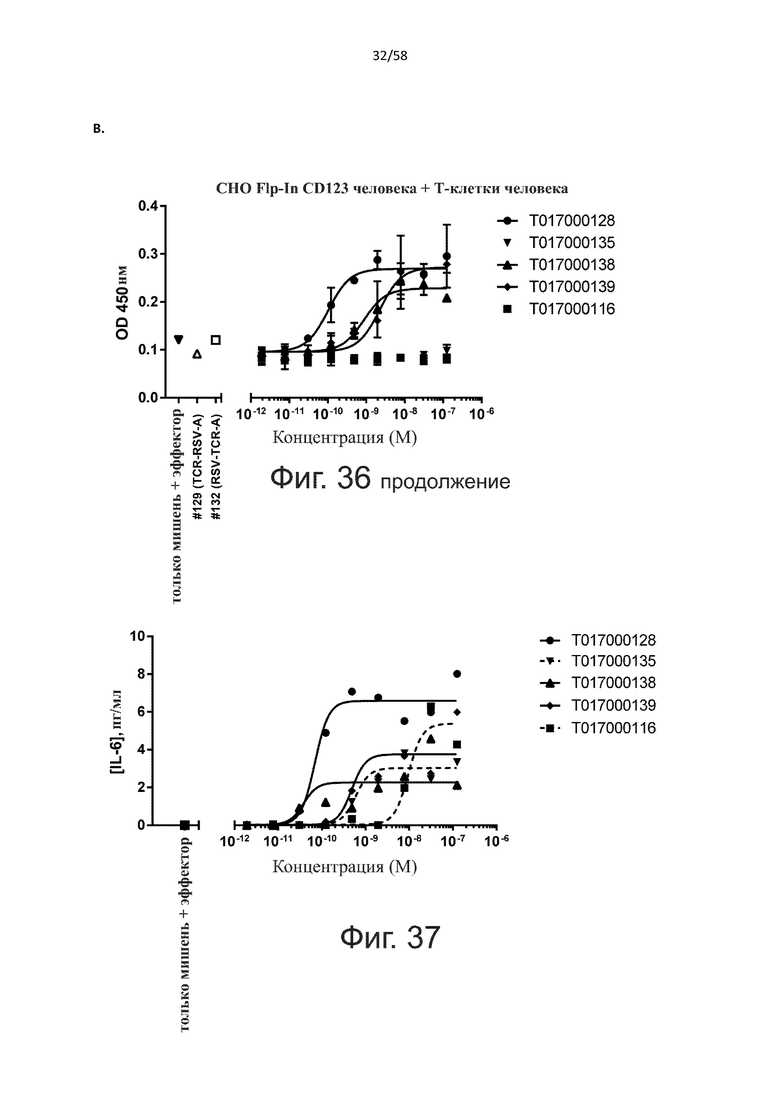
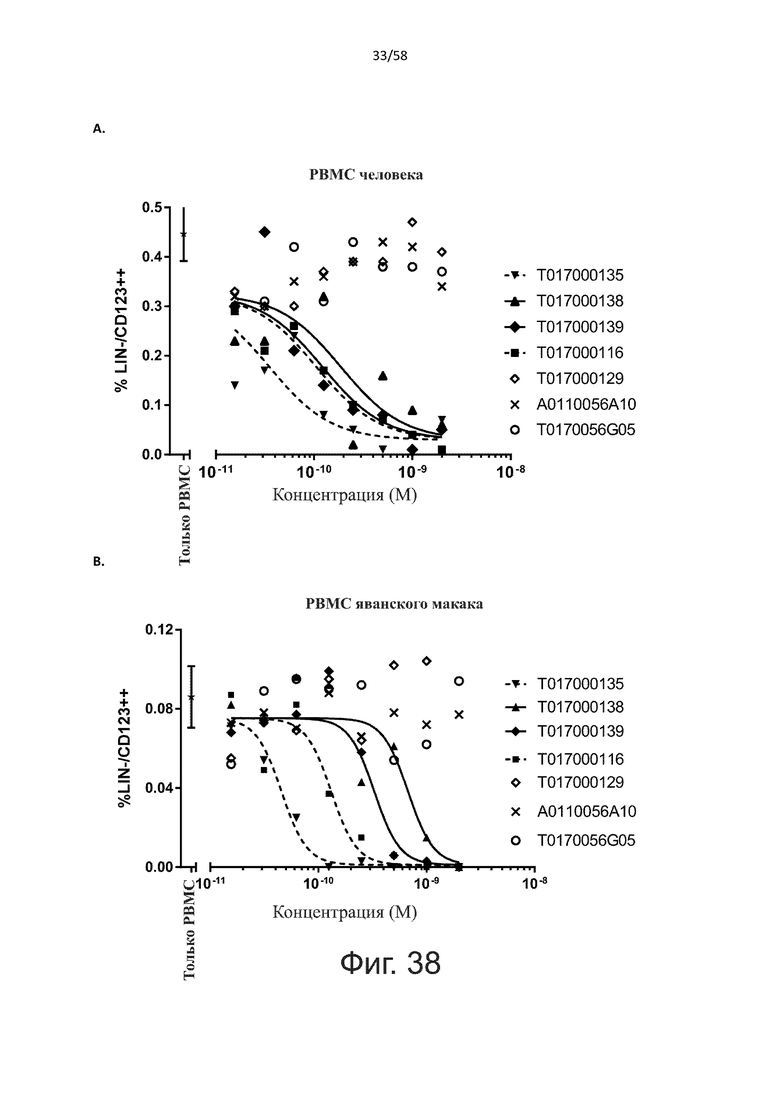
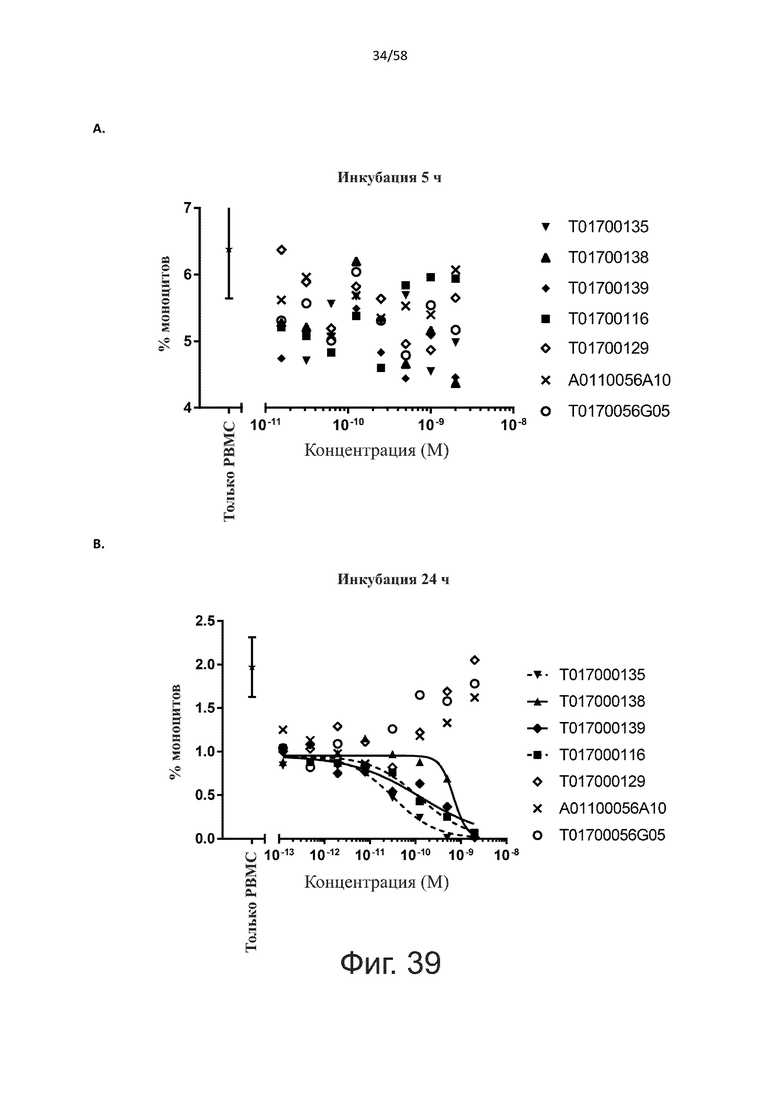
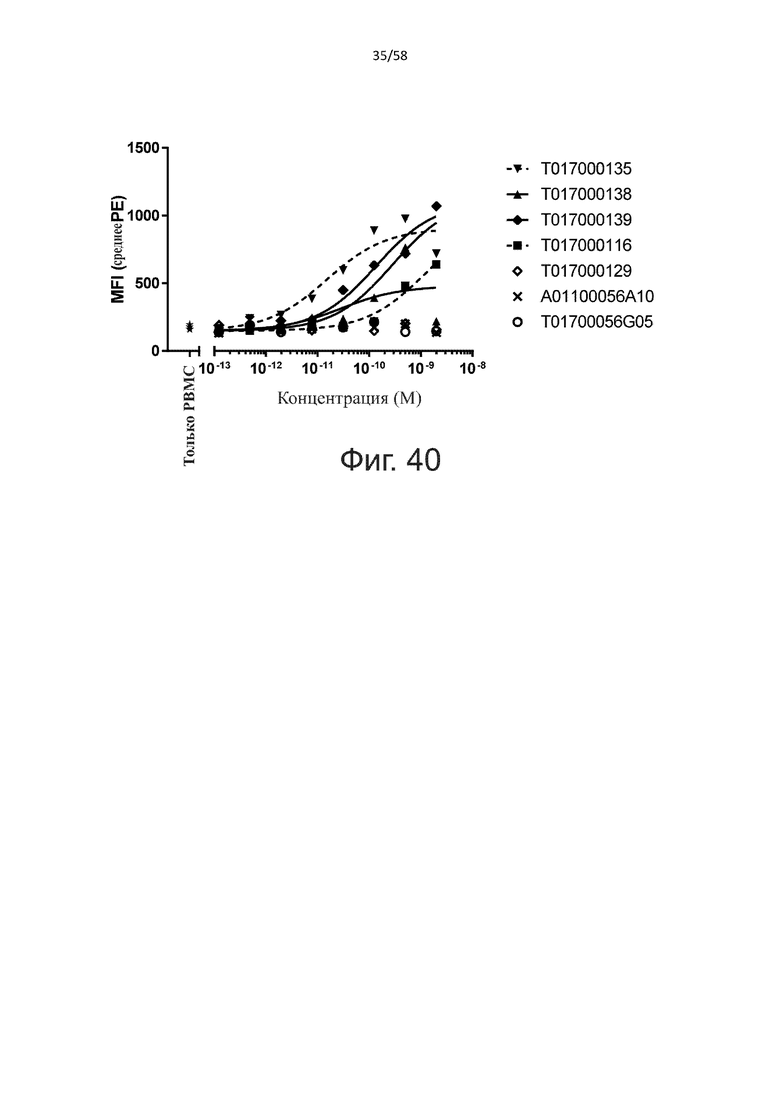
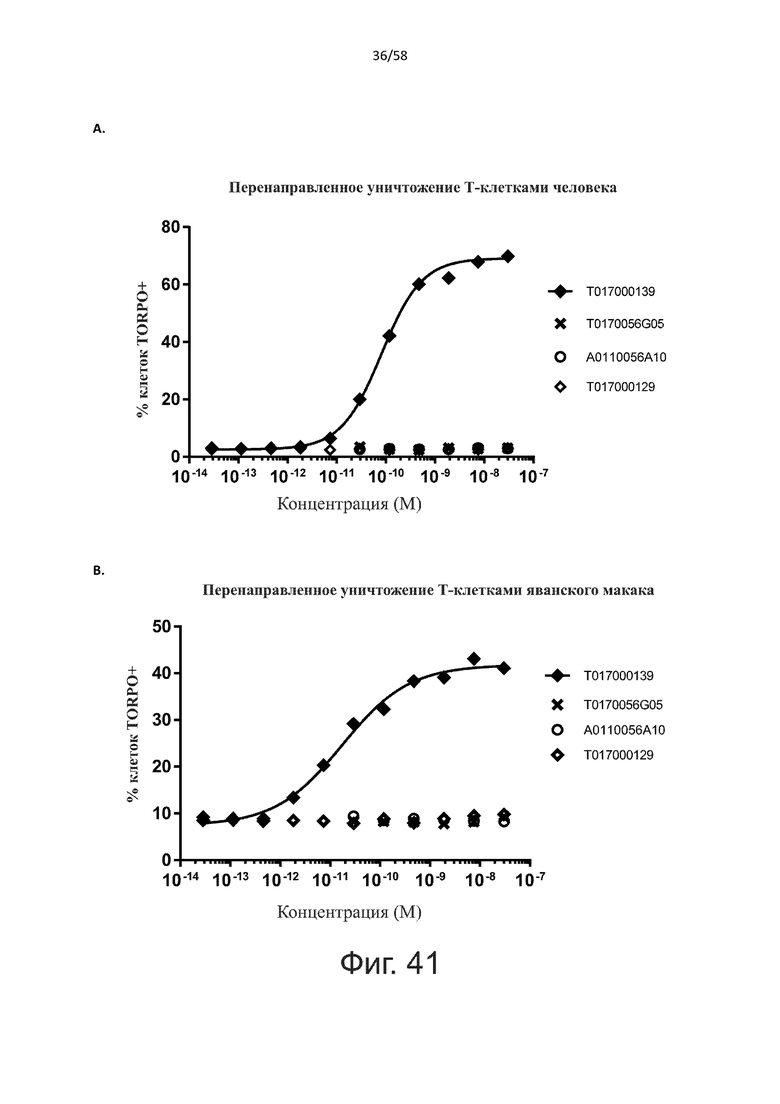
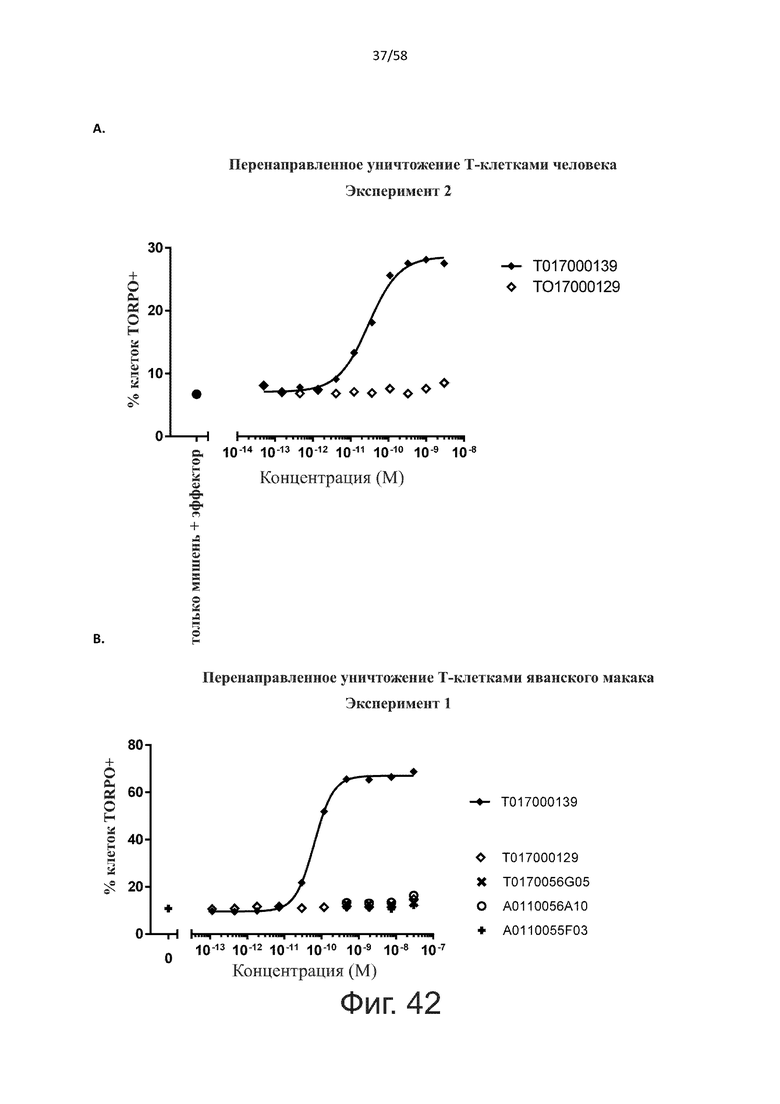
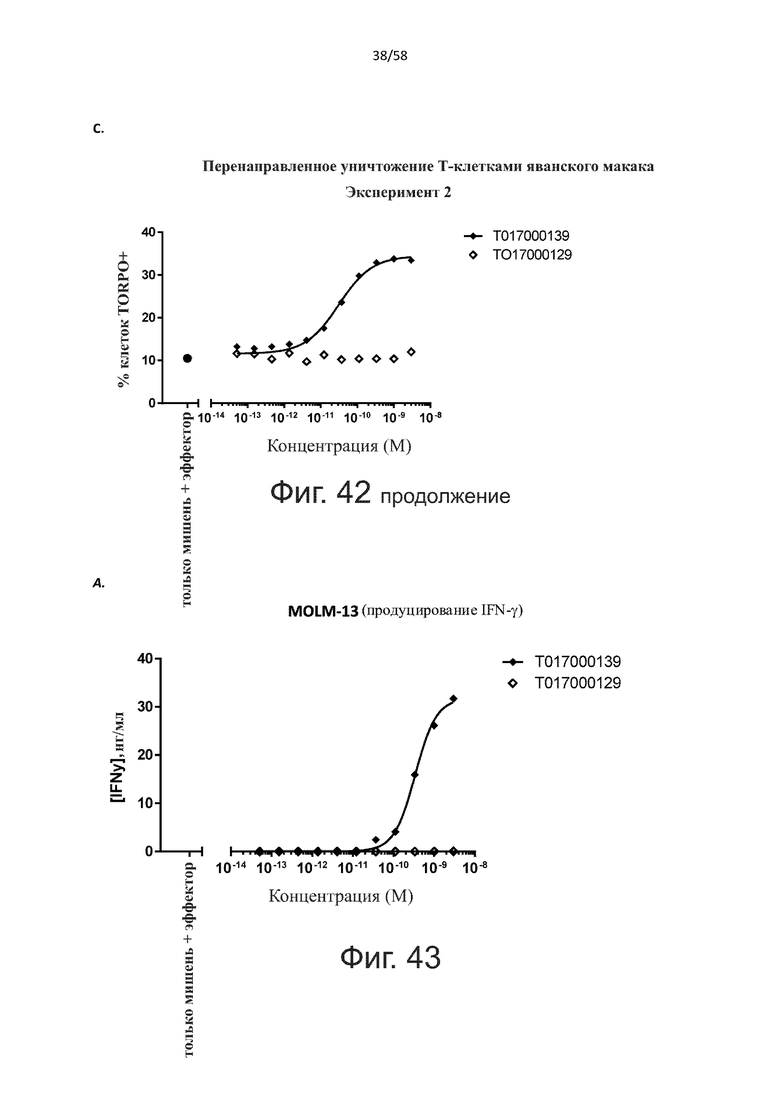
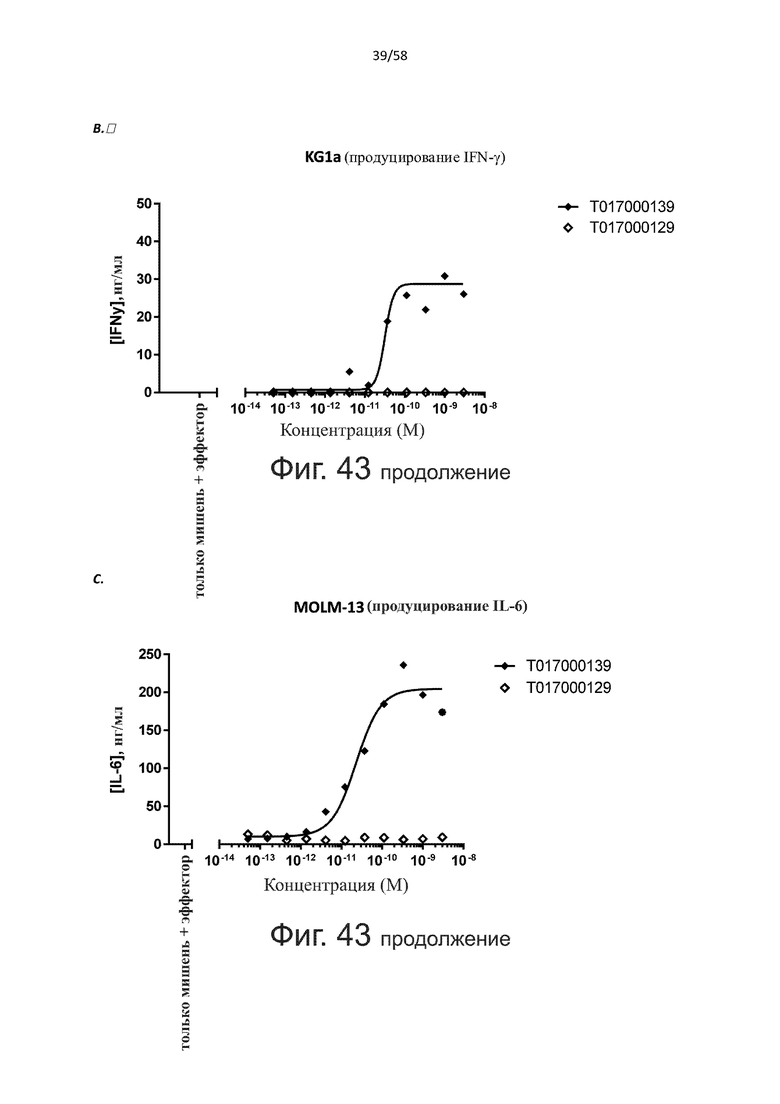
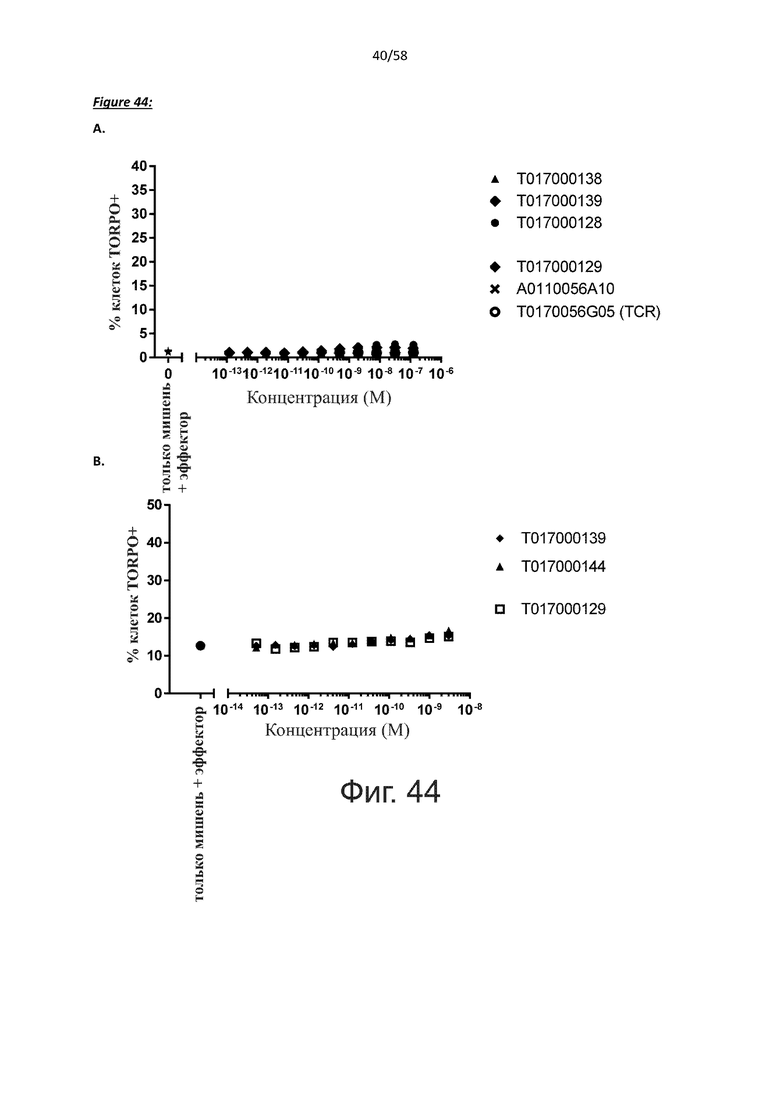
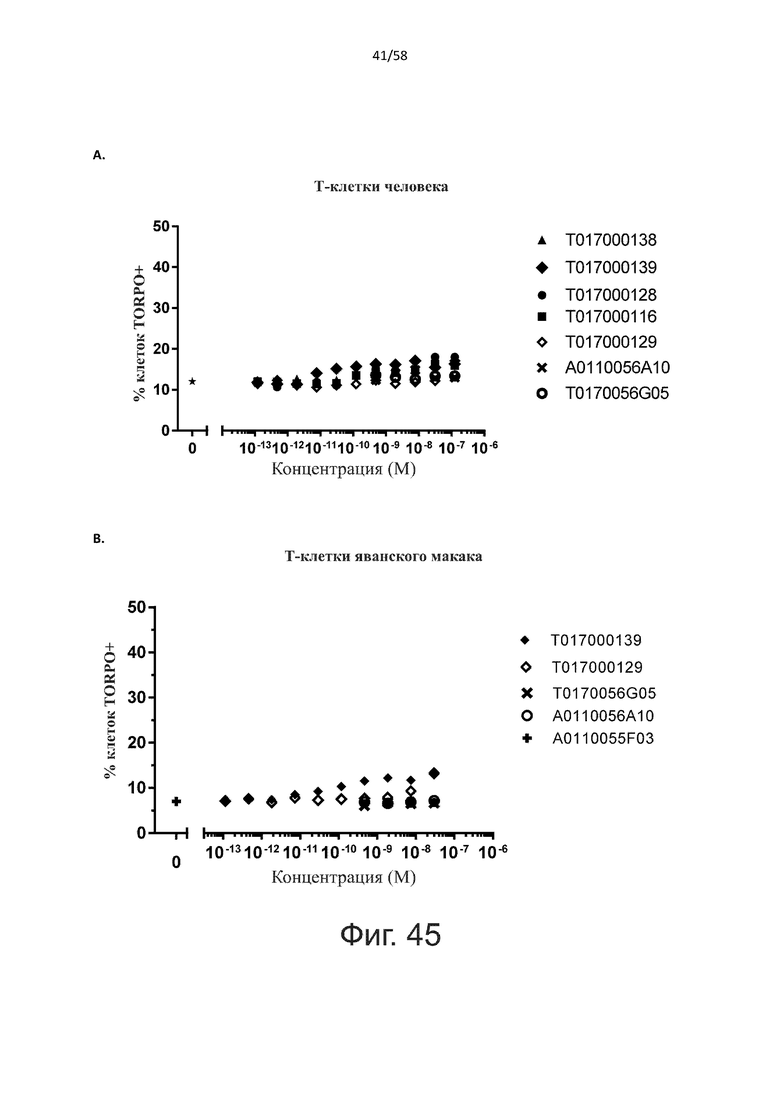
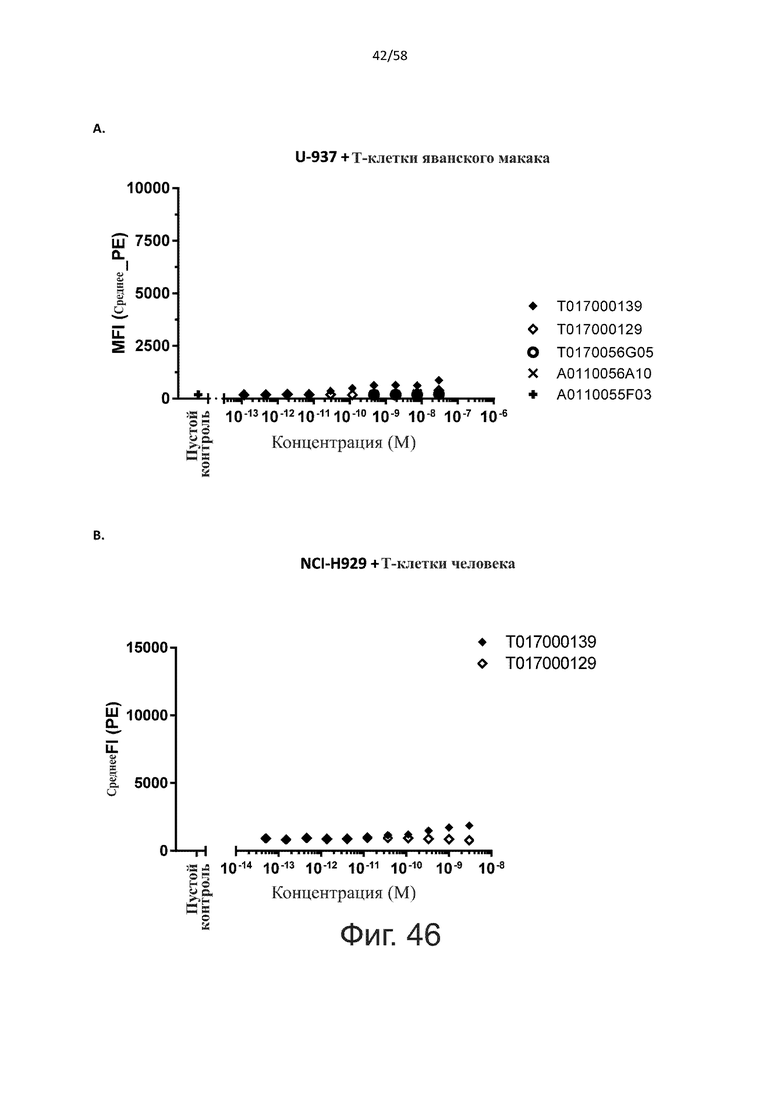
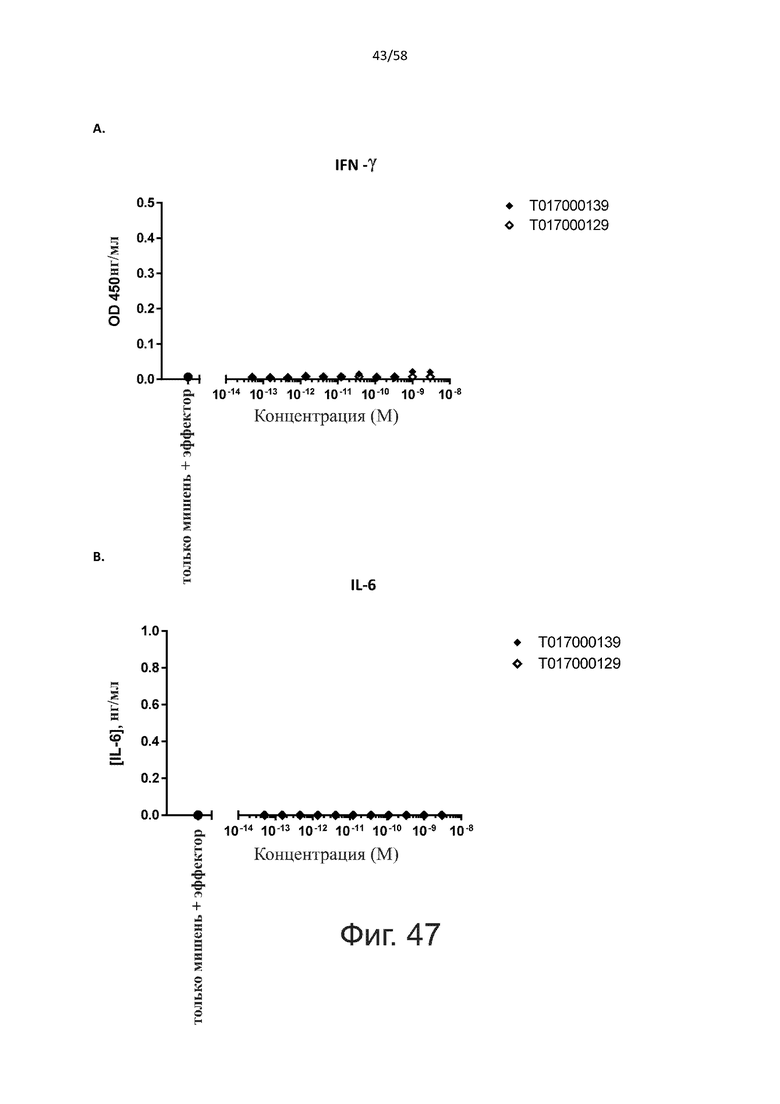
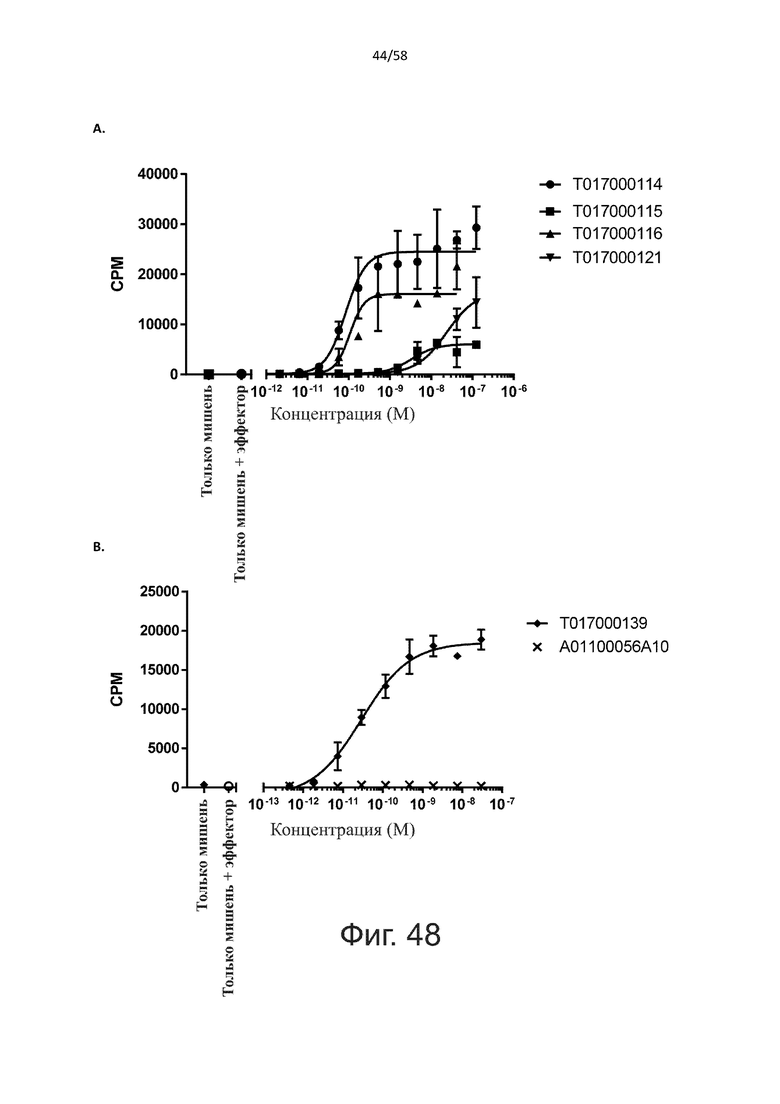
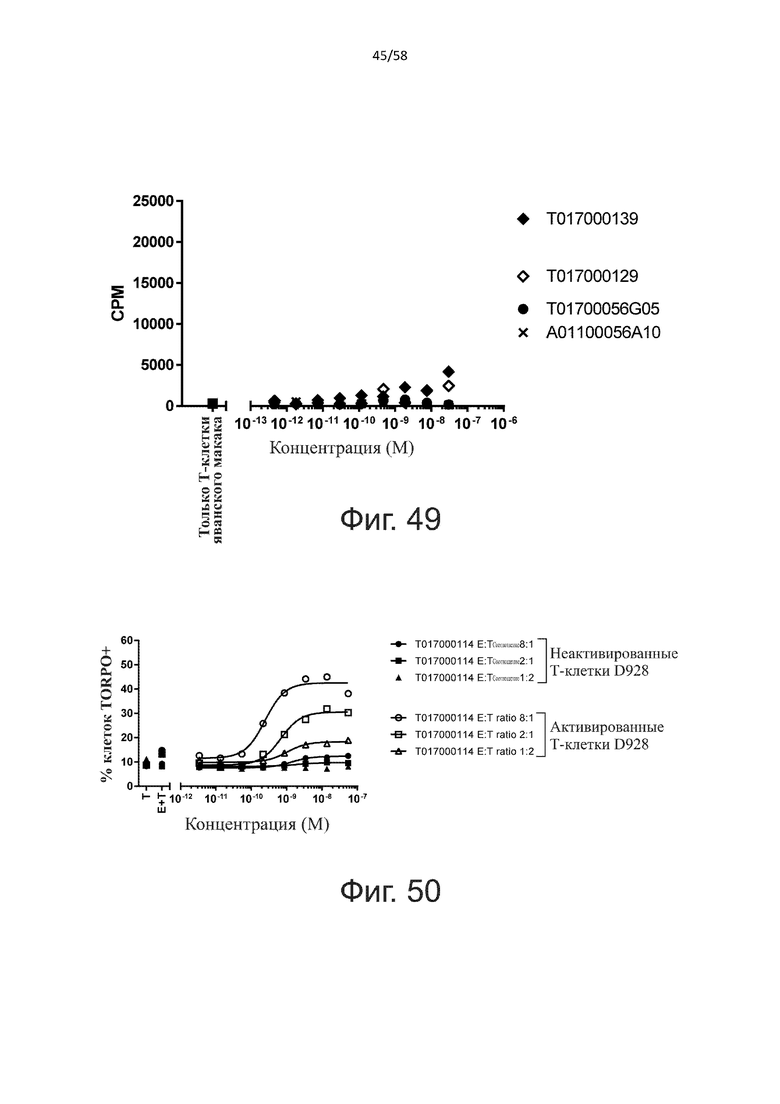

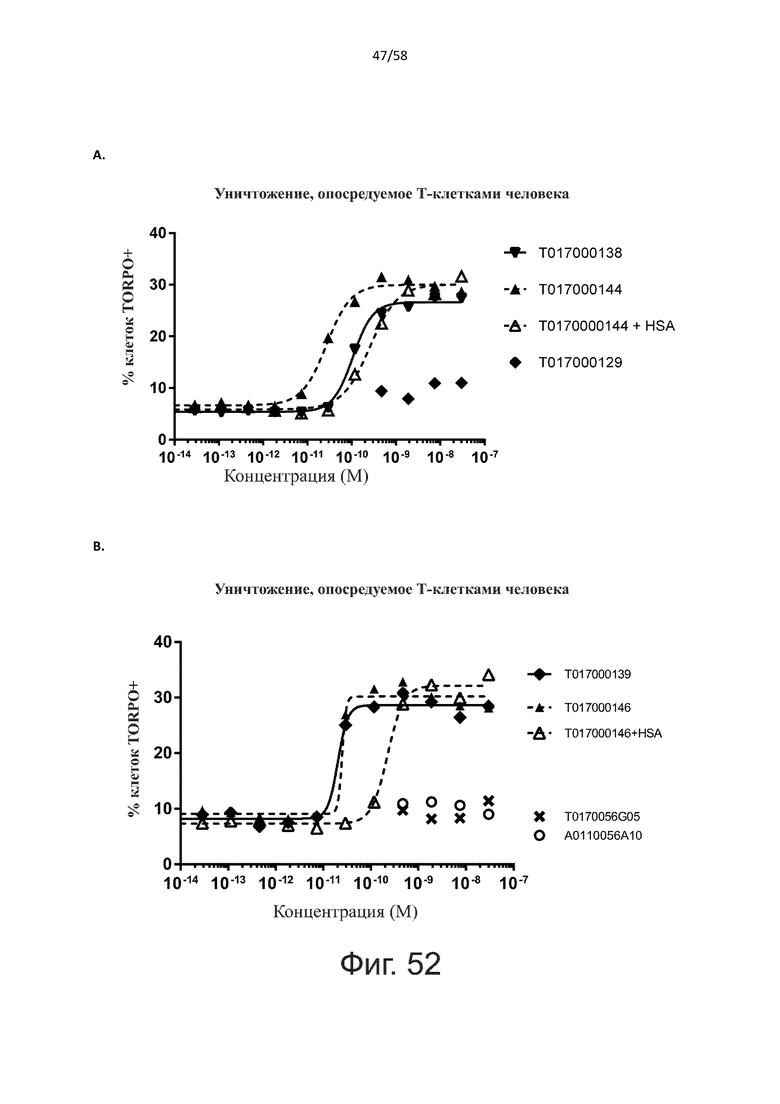

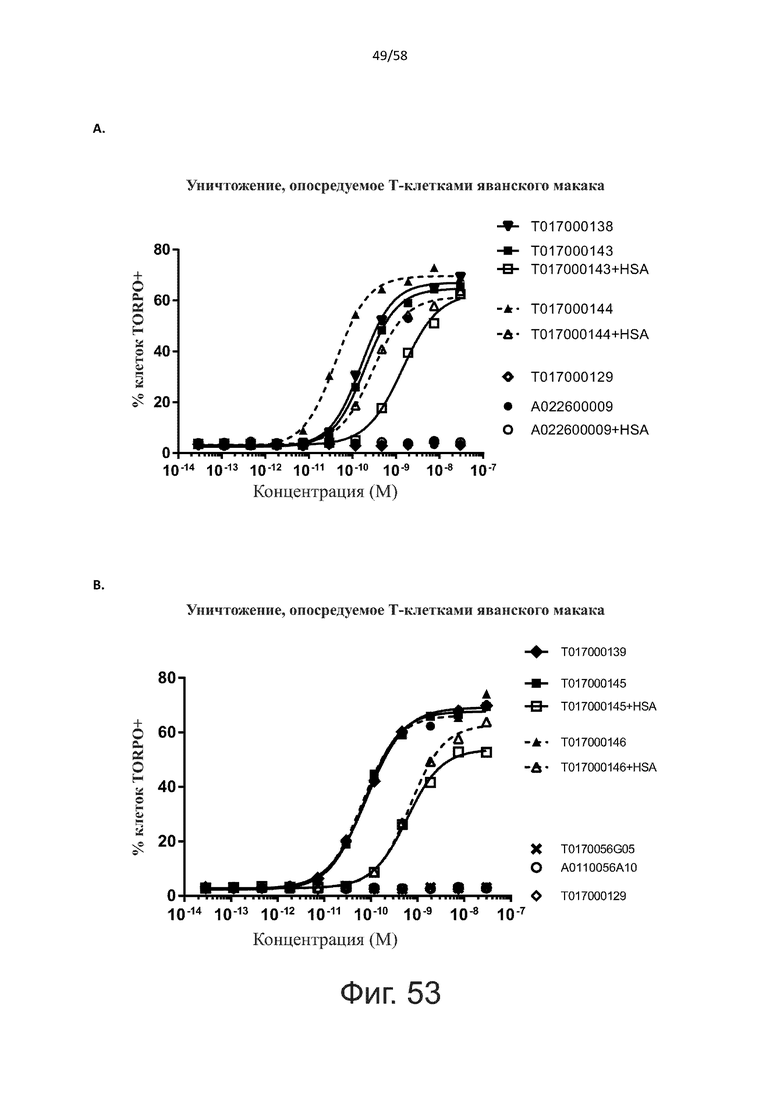
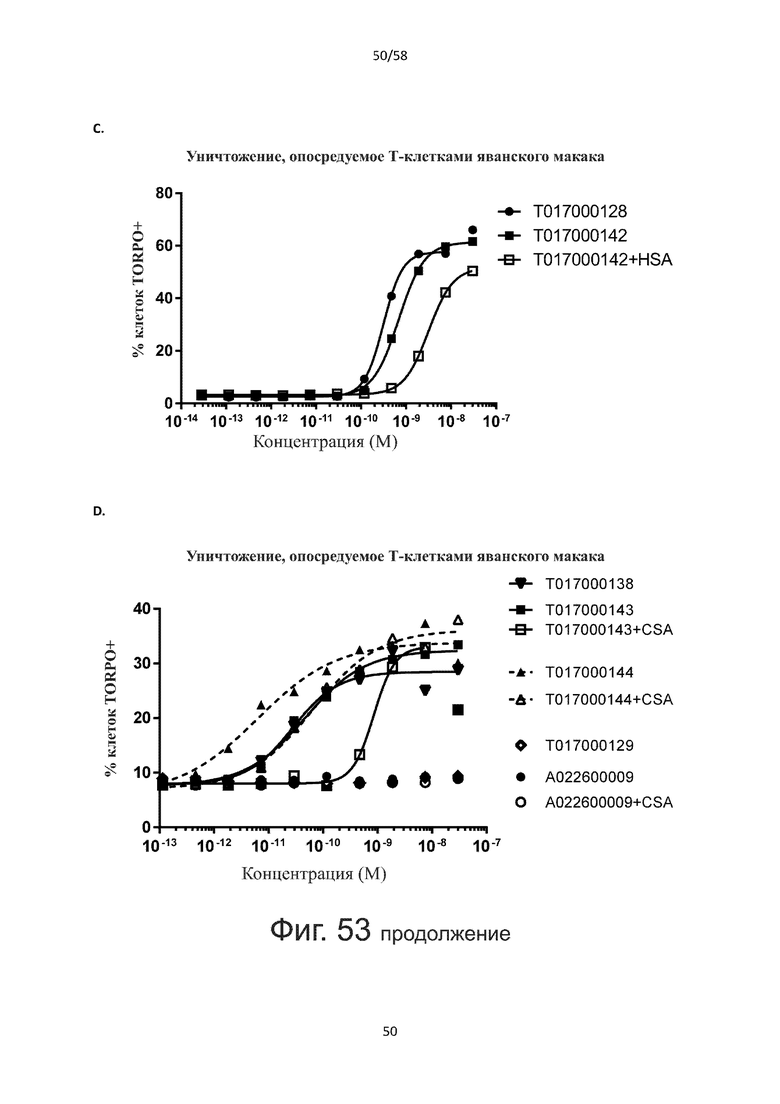
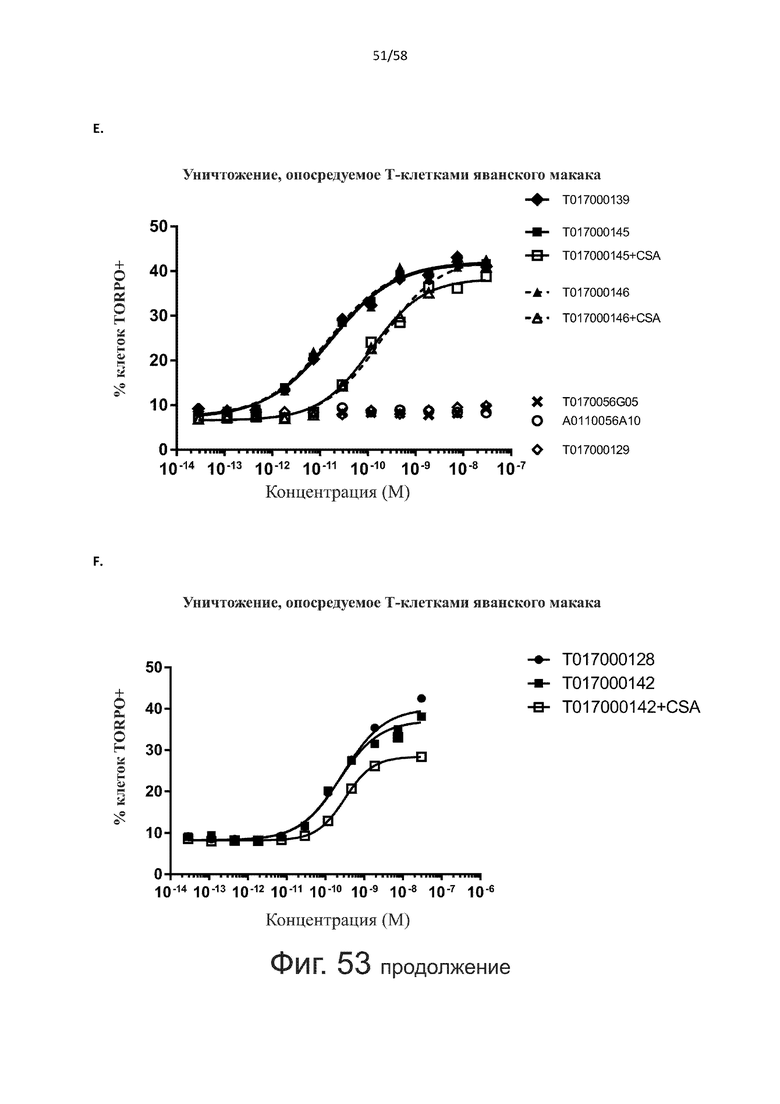
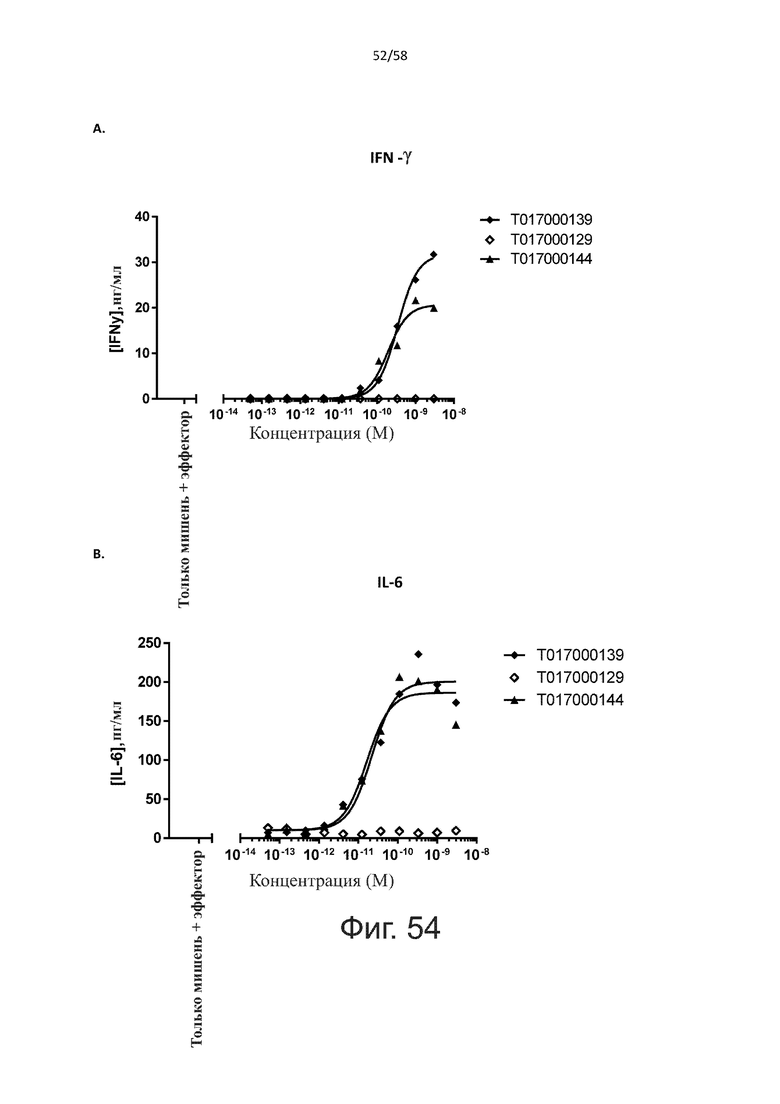
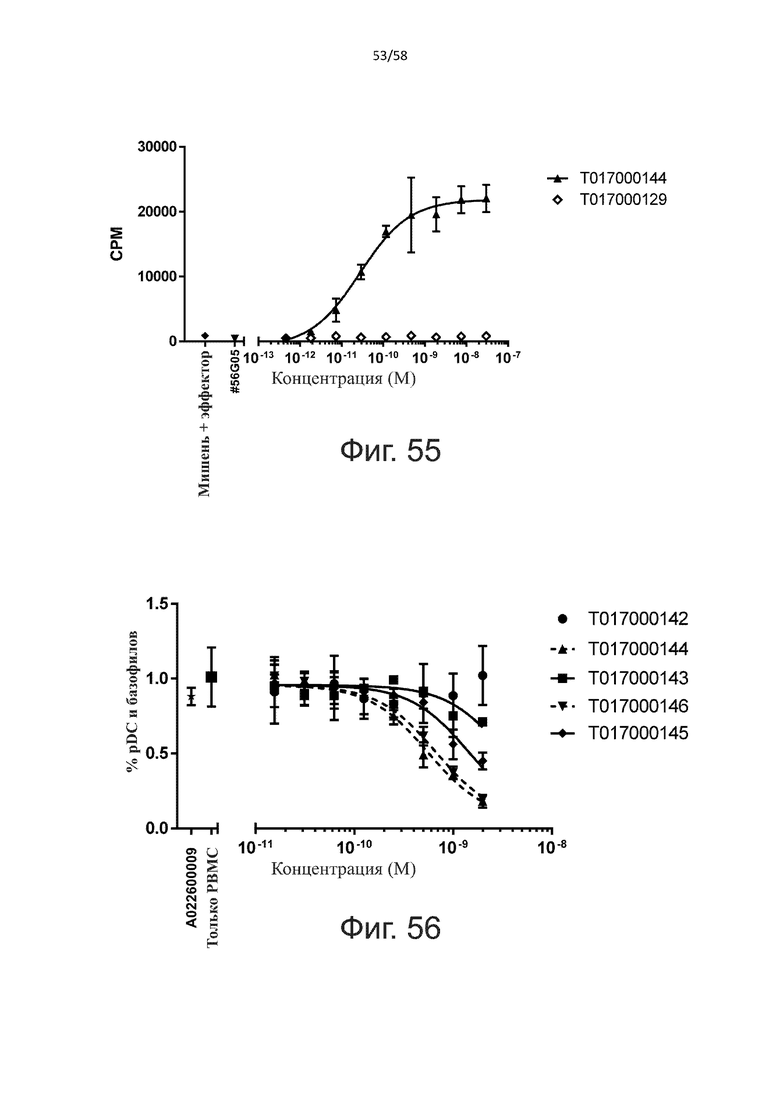
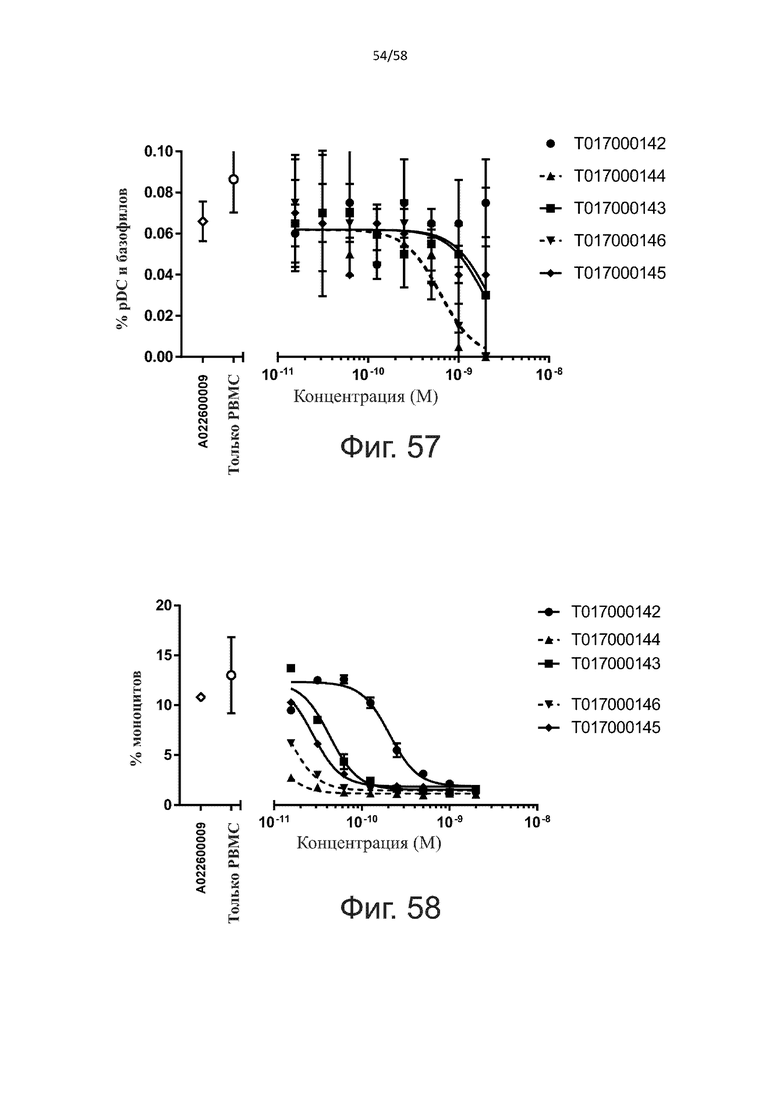
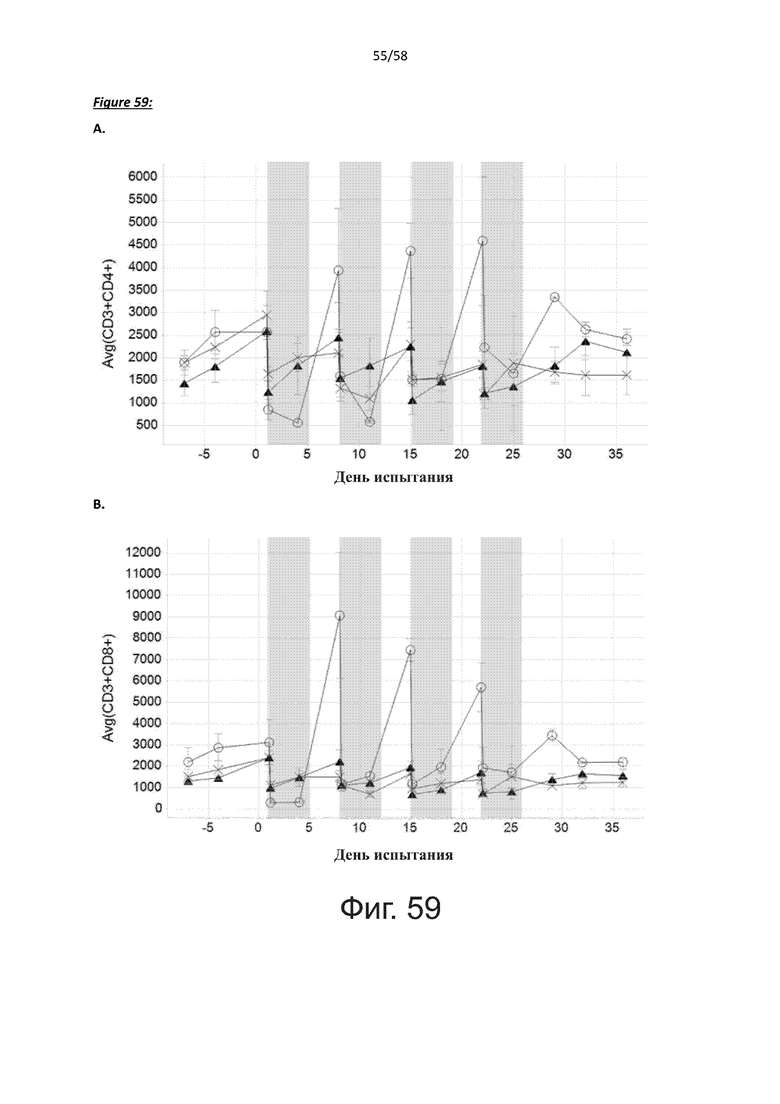
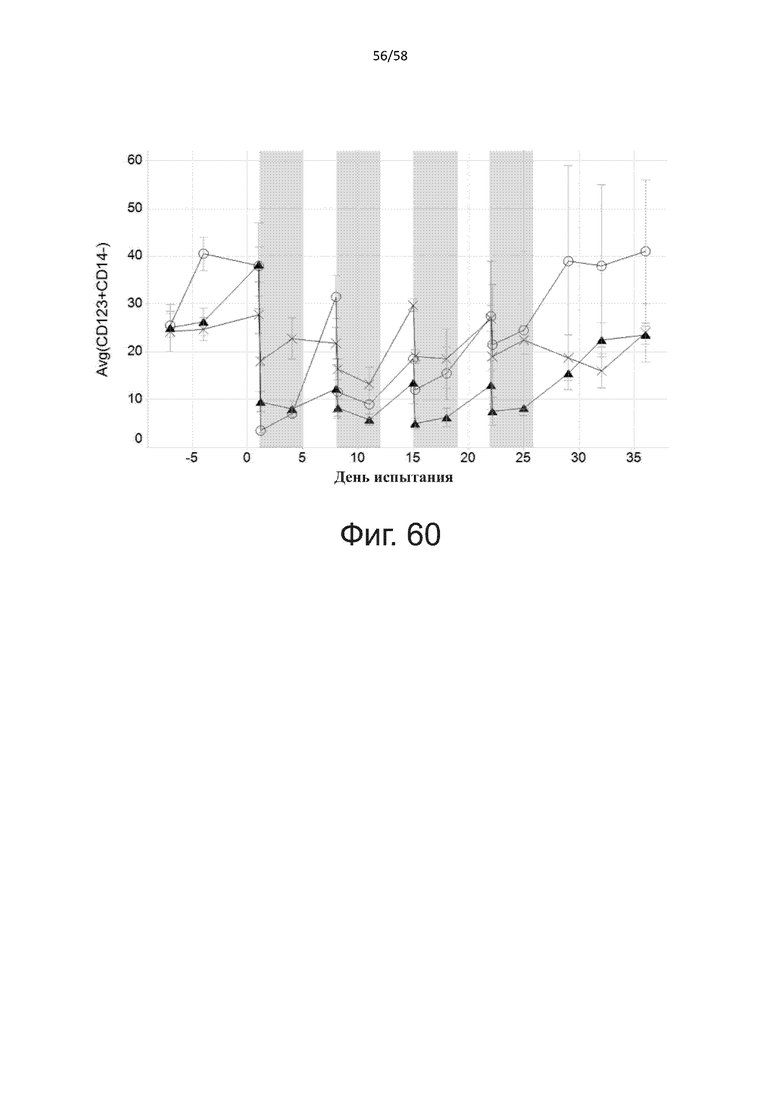
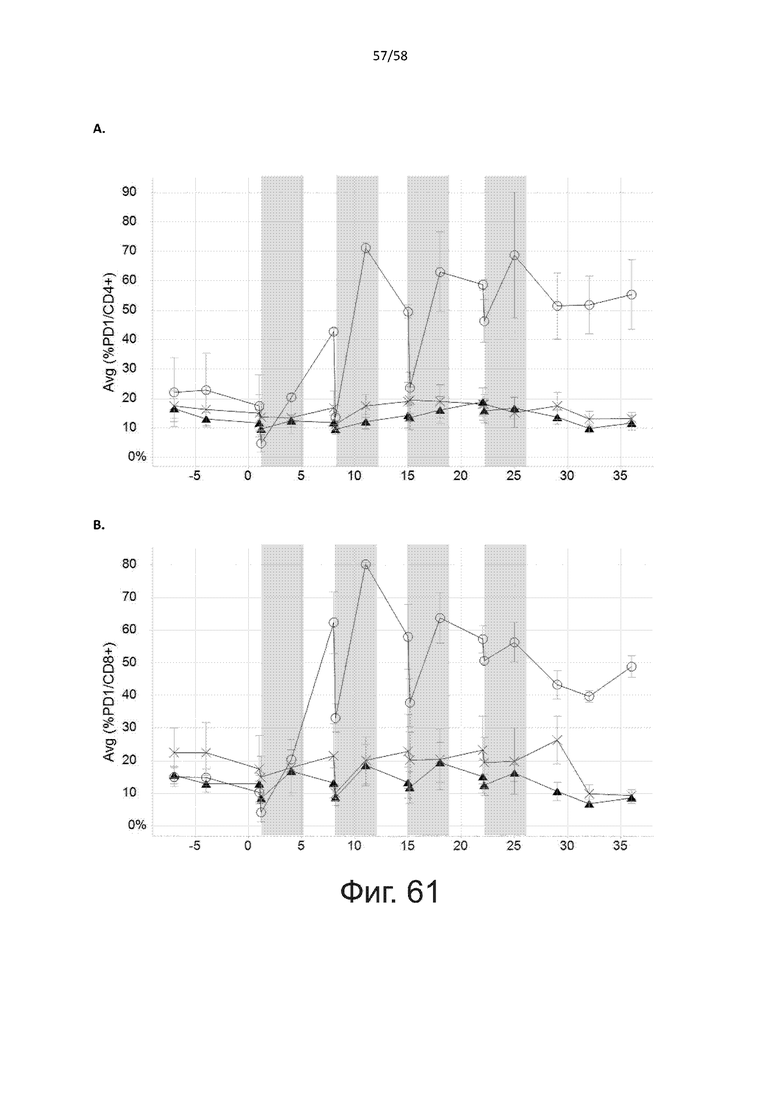
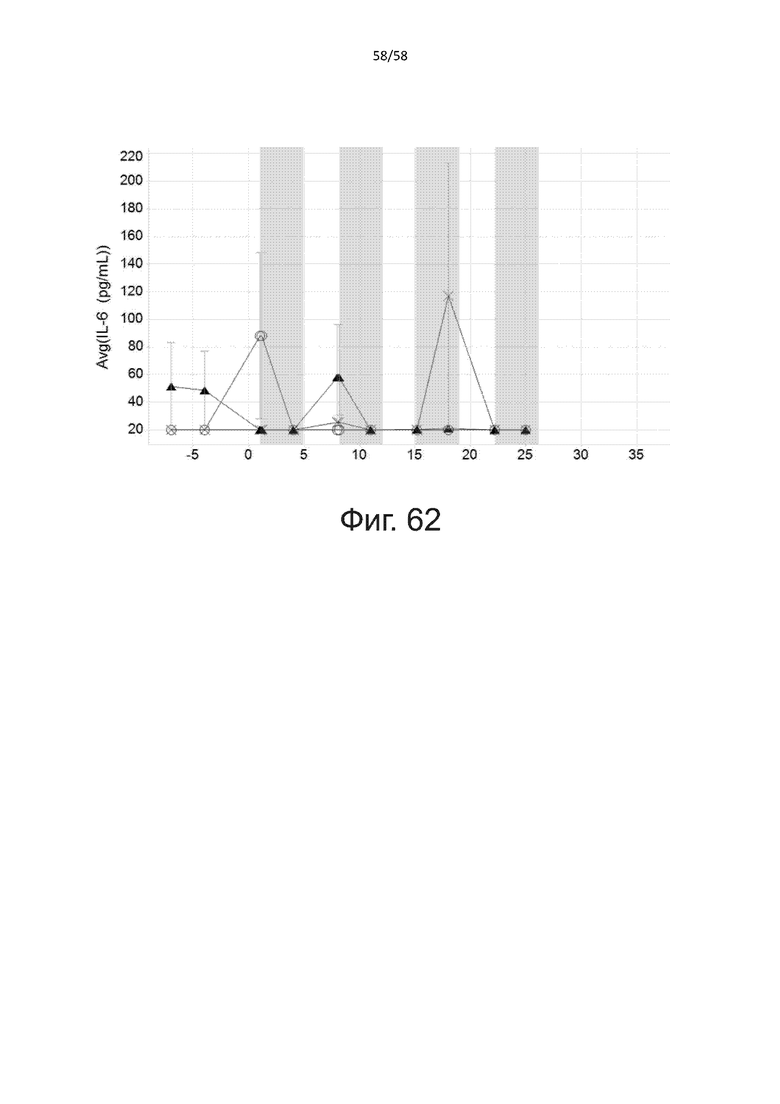
Изобретение относится к области биохимии, в частности к полипептиду, который перенаправляет Т-клетки для уничтожения CD123-экспрессирующих клеток. Также раскрыты конструкция для перенаправления Т-клеток, содержащая указанный полипептид; нуклеиновая кислота, кодирующая указанный полипептид или указанную конструкцию; эксперессионный вектор и клетку-хозяина, содержащие указанную нуклеиновую кислоту; композиция, содержащая указанный полипептид. Раскрыт способ получения указанного полипептида. Изобретение обладает способностью эффективно лечить заболевания, ассоциированные с CD123-экспрессирующих клеток. 8 н. и 12 з.п. ф-лы, 50 пр., 62 ил., 44 табл.
1. Полипептид, который перенаправляет Т-клетки для уничтожения CD123-экспрессирующих клеток, включающий иммуноглобулиновый одиночный вариабельный домен (ISV), который специфически связывает T- клеточный рецептор (TCR), и один или несколько ISV, которые специфически связывают CD123, где ISV, который специфически связывает TCR, состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 181; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 181, где
- в положении 2 D была заменена на A, S, E или G;
- в положении 4 H была заменена на Y;
- в положении 5 K была заменена на L;
- в положении 6 I была заменена на L;
- в положении 8 F была заменена на I или V; и/или
- в положении 10 G была заменена на S;
при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 выбрана из группы, состоящей из:
с) SEQ ID NO: 192; или
d) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 192, где
- в положении 1 H была заменена на T или R;
- в положении 3 S была заменена на T или A;
- в положении 5 G была заменена на S или A;
- в положении 7 Q была заменена на D, E, T, A или V;
- в положении 8 T была заменена на A или V; и/или
- в положении 9 D была заменена на A, Q, N, V или S;
при условии, что ISV, включающий CDR2 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR2 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 218; или
f) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 218, где
- в положении 1 F была заменена на Y, L или G;
- в положении 4 I была заменена на L;
- в положении 5 Y была заменена на W; и/или
- в положении 8 D была заменена на N или S;
при условии, что ISV, включающий CDR3 с различием в 4, 3, 2 или 1 аминокислоту, связывает TCR с одинаковой или более высокой аффинностью по сравнению со связыванием ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и где один или несколько ISV, которые специфически связывают CD123, состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбрана из группы, состоящей из:
а) SEQ ID NO: 11; или
b) аминокислотных последовательностей с различием в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью одной из SEQ ID NO: 11, где
- в положении 3 T была заменена на S или P;
- в положении 6 I была заменена на S;
- в положении 7 N была заменена на D; и/или
- в положении 8 D была заменена на V или A;
при условии, что ISV, включающий CDR1 с различием в 4, 3, 2 или 1 аминокислоту, связывает CD123 с одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR1 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
ii) CDR2 представляет собой с) SEQ ID NO: 17
и
iii) CDR3 выбрана из группы, состоящей из:
е) SEQ ID NO: 21; или
f) аминокислотных последовательностей с различием в 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 21, где
- в положении 3 P была заменена на A;
при условии, что ISV, включающий CDR3 с различием в 1 аминокислоту, связывает CD123 с одинаковой или более высокой аффинностью по сравнению со связыванием с ISV, включающим CDR3 без различия в 4, 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
2. Полипептид по п. 1, отличающийся тем, что ISV, который специфически связывает TCR, состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1- CDR3, соответственно), в которых CDR1 представляет собой SEQ ID NO: 181, CDR2 представляет собой SEQ ID NO: 192, и CDR3 представляет собой SEQ ID NO: 218.
3. Полипептид по любому из пп. 1 или 2, отличающийся тем, что ISV, который специфически связывает TCR, выбран из группы, состоящей из SEQ ID NO: 42 и 78-180, или из ISV, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 42 и 78-180.
4. Полипептид по любому из пп. 1-3, отличающийся тем, что один или несколько ISV, которые специфически связывают CD123, состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 определяющих комплементарность областей (CDR1-CDR3, соответственно), в которых CDR1 представляет собой SEQ ID NO: 11, CDR2 представляет собой SEQ ID NO: 17 и CDR3 представляет собой SEQ ID NO: 21.
5. Полипептид по любому из пп. 1-4, отличающийся тем, что один или несколько ISV, которые специфически связывают CD123, выбирают из группы, состоящей из SEQ ID NO: 1-6 или ISV, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 1-6.
6. Полипептид по любому из пп. 1-5, содержащий дополнительный ISV, который специфически связывает CD123 и по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 областей, определяющих комплементарность (CDR1-CDR3, соответственно), в которых:
i) CDR1 представляет собой SEQ ID NO: 16; и
ii) CDR2 выбрана из группы, состоящей из:
а) SEQ ID NO: 18; или
b) аминокислотных последовательностей с различием в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 18, где
- в положении 3 Y была заменена на W;
- в положении 6 N была заменена на S; и/или
- в положении 10 Q была заменена на E;
при условии, что полипептид, содержащий CDR2 с различием в 3, 2 или 1 аминокислоту(ы), связывает CD123 с такой же или более высокой аффинностью по сравнению со связыванием полипептидом, содержащим CDR2, без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса;
и
iii) CDR3 выбрана из группы, состоящей из:
с) SEQ ID NO: 23; или
d) аминокислотных последовательностей с различием в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 23, где
- в положении 4 E была заменена на R; и/или
- в положении 5 Т была заменена на D или Y;
при условии, что полипептид, содержащий CDR3 с различием в 2 или 1 аминокислоту, связывает CD123 с такой же или более высокой аффинностью по сравнению со связыванием полипептида, содержащего CDR3 без различия в 3, 2 или 1 аминокислоту, где указанная аффинность измерена с помощью поверхностного плазмонного резонанса.
7. Полипептид по п. 6, отличающийся тем, что дополнительный ISV, который специфически связывает CD123, выбран из группы, состоящей из SEQ ID NO: 7-10, или из ISV, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 7-10.
8. Полипептид по любому из пп. 1-7, включающий два или более ISV, которые специфически связывают CD123, отличающийся тем, что два или более ISV, которые специфически связывают CD123, являются бипаратопными, включая первый ISV и второй ISV, где первый ISV связывается с эпитопом на CD123, который отличается от эпитопа на CD123, связываемого вторым ISV.
9. Полипептид по любому из пп. 1-8, отличающийся тем, что ISV, который специфически связывает TCR, и один или несколько ISV, которые специфически связывают CD123, состоят из однодоменного антитела, dAb, нанотела, VHH, гуманизированного VHH, оверблюженного VH или VHH, который был получен путем созревания аффинности.
10. Полипептид по любому из пп. 1-9, отличающийся тем, что указанный полипептид выбран из группы, состоящей из SEQ ID NO: 47, 49, 52, 53, 55, 56 и 58-61, или из полипептидов, которые имеют идентичность последовательностей более 80%, более 85%, более 90%, более 95% или даже более 99% с одной из SEQ ID NO: 47, 49, 52, 53, 55, 56 и 58-61.
11. Конструкция для перенаправления Т-клеток для уничтожения CD123-экспрессирующих клеток с увеличенным периодом полувыведения, содержащая полипептид по любому из пп. 1-10 и одну или более связывающих единиц, которые могут связываться с сывороточным альбумином или сывороточным иммуноглобулином, в которой указанные одна или более связывающих единиц обеспечивают конструкции увеличенный период полувыведения по сравнению с полипептидом по любому из пп. 1-10.
12. Конструкция по п. 11, в которой одна или более связывающие единицы связываются с человеческим сывороточным альбумином или IgG.
13. Нуклеиновая кислота, кодирующая полипептид по любому из пп. 1-10.
14. Нуклеиновая кислота, кодирующая конструкцию по п. 11 или 12.
15. Экспрессирующий вектор, включающий нуклеиновую кислоту по п. 13 или 14.
16. Клетка-хозяин для получения полипептида по любому из пп. 1-10 или конструкции по п. 11 или 12, содержащая нуклеиновую кислоту по п. 13 или 14 или экспрессирующий вектор по п. 15.
17. Способ получения полипептида по любому из пп. 1-10 или конструкции по п. 11 или 12, включающий стадии:
а) экспрессии в подходящей клетке-хозяине или организме-хозяине или в другой подходящей системе экспрессии нуклеиновой кислоты по п. 13 или 14 или экспрессирующего вектора по п. 15 и
b) выделение и/или очистку полипептида по любому из пп. 1-10 или конструкции по п. 11 или 12.
18. Композиция для перенаправления Т-клеток для уничтожения CD123-экспрессирующих клеток, содержащая полипептид по любому из пп. 1-10, или конструкцию по п. 11 или 12, или нуклеиновую кислоту по п. 13 или 14 или экспрессирующий вектор по п. 15 и фармацевтически приемлемый носитель, разбавитель или эксципиент.
19. Полипептид по любому из пп. 1-10, конструкция по п. 11 или 12 или композиция по п. 18 для применения в качестве лекарственного средства.
20. Полипептид по любому из пп. 1-10, конструкция по п. 11 или 12 или композиция по п. 18 для применения при профилактике, лечении и/или облегчении заболевания или состояния, связанного с CD123.
| WO 2016116626 A1, 28.07.2016 | |||
| WO 2012066058 A1, 24.05.2012 | |||
| SHU-RU KUO et al | |||
| Устройство для разметки подлежащих сортированию и резанию лесных материалов | 1922 |
|
SU123A1 |
| Видоизменение пишущей машины для тюркско-арабского шрифта | 1923 |
|
SU25A1 |
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| Регенеративный приемник | 1923 |
|
SU561A1 |
| WO 2013173820 A2, 21.11.2013 | |||
| АНТИ-IFNAR1 АНТИТЕЛА С ПОНИЖЕННЫМ СРОДСТВОМ С ЛИГАНДОМ Fc | 2009 |
|
RU2556125C2 |

