1 Область, к которой относится изобретение
Настоящее изобретение относится к иммуноглобулинам, которые связываются с MMP13, и более конкретно, к полипептидам, которые включают или по существу состоят из одного или более таких иммуноглобулинов (также указаны в настоящей заявке как “иммуноглобулин(иммуноглобулины) по изобретению” и “полипептиды по изобретению”, соответственно). Изобретение также относится к конструкциям, включающим такие иммуноглобулины или полипептиды, а также к нуклеиновым кислотам, кодирующим такие иммуноглобулины или полипептиды (также указаны в настоящей заявке как “нуклеиновая кислота (кислоты) по изобретению”; к способам получения таких иммуноглобулинов, полипептидов и конструкций; к клеткам–хозяевам, экспрессирующим или способным экспрессировать такие иммуноглобулины или полипептиды; к композициям, и в частности, к фармацевтическим композициям, которые включают такие иммуноглобулины, полипептиды, конструкции, нуклеиновые кислоты и/или клетки–хозяева; и к применениям иммуноглобулинов, полипептидов, конструкций, нуклеиновых кислот, клеток–хозяев и/или композиций, в частности, для профилактических и/или терапевтических целей, таких как профилактические и/или терапевтические цели, указанные в настоящей заявке. Другие аспекты, варианты осуществления, преимущества и применения изобретения будут понятны из представленного ниже описания.
2 Предпосылки к созданию изобретения
Остеоартрит (ОА) является одной из самых распространенных причин инвалидности во всем мире. Им страдают 30 миллионов американцев, и он является наиболее распространенным заболеванием суставов. По прогнозам, к 2025 году он затронет более 20 процентов населения США. Болезнь не системная и обычно ограничивается несколькими суставами. Однако заболевание может возникать во всех суставах, чаще всего в коленях, бедрах, руках и позвоночнике. ОА характеризуется прогрессирующей эрозией суставного хряща (хряща, который покрывает кости), что приводит к хронической боли и инвалидности. В конце концов, болезнь приводит к полному разрушению суставного хряща, склерозу лежащей ниже кости, образованию остеофитов и т.д., все это приводит к потере движения и боли. Боль является наиболее заметным симптомом ОА, и именно поэтому пациенты чаще всего обращаются за медицинской помощью. ОА не излечивается; лечение болезни ограничивается лечением, которое в лучшем случае является паллиативным и мало влияет на основную причину прогрессирования заболевания.
Идет интенсивный поиск препаратов, модифицирующих течение остеоартрита (DMOAD), которые можно определить как лекарственные средства, которые ингибируют прогрессирование структурных изменений при заболевании и в идеале также улучшают симптомы и/или функцию. DMOAD, вероятно, должны назначаться на длительные периоды при этом хроническом заболевании стареющей популяции, поэтому для этого необходимо получить отличные данные, касающиеся безопасности в целевой популяции с множественными сопутствующими заболеваниями и потенциальных межлекарственных взаимодействий.
Остеоартрит можно определить как разнообразную группу состояний, характеризующихся комбинацией симптомов в суставах, признаками, обусловленными дефектами в суставном хряще, и изменениями смежных тканей, включая кость, сухожилия и мышцы. Хотя начало заболевания может быть многофакторным, разрушение хряща, по–видимому, является результатом неконтролируемого протеолитического разрушения внеклеточного матрикса (ECM).
Как указано выше, основным компонентом хрящевого внеклеточного матрикса является Аггрекан (Kiani et al. 2002 Cell Research 12:19–32). Эта молекула важна для правильного функционирования суставного хряща, поскольку она обеспечивает гидратированную гелевую структуру, которая придает хрящу способность нести нагрузку. Аггрекан представляет собой большую мультимодальную молекулу (2317 аминокислот), экспрессируемую хондроцитами. Его коровый белок состоит из трех глобулярных доменов (G1, G2 и G3) и большой протяженной области между G2 и G3 для прикрепления цепи гликозаминогликана. Эта расширенная область содержит два домена, один из которых замещен кератансульфатными цепями (KS домен), а другой – хондроитинсульфатными цепями (CS домен). Домен CS имеет 100–150 гликозаминогликановых цепей (GAG), прикрепленных к нему. Аггрекан образует большие комплексы с гиалуронаном, в которых 50–100 молекул Аггрекана взаимодействуют через домен G1 и связывающий белок с одной молекулой гиалуронана. При поглощении воды (из–за содержания GAG) эти комплексы образуют обратимо деформируемый гель, который сопротивляется сжатию. Структура, удержание жидкости и функции суставного хряща связаны с содержанием в матриксе Аггрекана и количеством хондроитинсульфата, связанного с интактным коровым белком.
Коллаген типа II (Коллаген II, Col II) составляет 50% суставного хряща. Коллагеновые фибриллы образуют сеть, которая позволяет хрящу захватывать протеогликан, а также обеспечивает прочность ткани. Коллаген является структурным белком, который состоит из правого пучка из трех параллельных левосторонних спиралей типа полипролина II (PPII). Из–за плотной упаковки спиралей PPII в тройной спирали каждый третий остаток, который представляет собой аминокислоту, представляет собой Gly (глицин). Поскольку глицин является самой маленькой аминокислотой без боковой цепи, он играет уникальную роль в белках с волокнистой структурой. В коллагене Gly требуется в каждом третьем положении, поскольку сборка тройной спирали помещает этот остаток во внутреннюю часть (ось) спирали, где нет места для большей боковой группы, чем один атом водорода глицина.
ОА характеризуется 1) разрушением Аггрекана, постепенным высвобождением доменов G3 и G2 (что приводит к “дефляции” хряща) и в конечном итоге высвобождением домена G1 и 2) разрушением коллагена, с необратимым разрушением структуры хряща.
Имеются убедительные доказательства того, что матриксные металлопротеиназы (MMP) играют главную роль в разрушении тканей, связанных с ОА. MMP представляют собой семейство цинк–зависимых эндопептидаз, участвующих в разрушении внеклеточного матрикса и ремоделировании тканей. Существует около 28 членов семейства MMP, которые можно подразделить на различные подгруппы, включая коллагеназы, желатиназы, стромелизины, MMP мембранного типа, матрилизины, эмализины и другие. Коллагеназы, включающие MMP1, MMP8, MMP13 и MMP18, способны разлагать трехспиральные фибриллярные коллагены на различающиеся 3/4 и 1/4 фрагменты. Кроме того, было показано, что MMP14 расщепляет фибриллярный коллаген, и есть доказательства того, что MMP2 также способна к коллагенолизу. MMP давно считаются привлекательными терапевтическими мишенями для лечения ОА. Однако ингибиторы MMP широкого спектра действия, разработанные для лечения артрита, не прошли клинические испытания из–за болезненных сковывающих суставы побочных эффектов, называемых мышечно–скелетным синдромом (MSS). Считается, что причиной, вызывающей MSS, является неселективное ингибирование множества MMP.
Nam et al. (2017 Proc Natl Acad Sci USA 113:14970–14975) описывают Нанотела, которые очевидно специфически направлены против активного сайта MMP14.
Терапевтические вмешательства в OA также было затруднено из–за сложности направленной доставки лекарственных средств в суставной хрящ. Поскольку суставной хрящ является лишенной кровеносных и лимфатических сосудов тканью, традиционные пути доставки лекарственных средств (пероральный, внутривенный, внутримышечный) в конечном итоге зависят от транссиновиального переноса лекарственных средств из синовиальных капилляров в хрящ путем пассивной диффузии. Таким образом, в отсутствие механизма селективного направленного воздействия лекарственного средства на хрящ, необходимо системно воздействовать на организм высокими концентрациями лекарственных средств для достижения устойчивой интраартикулярной терапевтической дозы. В результате высокого системного воздействия большинство традиционных терапий для OA оказались вредными из–за серьезной токсичности.
Кроме того, большинство из новых разработанных DMOAD имеют короткое время удерживания в суставе, даже при введении интраартикулярно (Edwards 2011 Vet. J. 190:15–21; Larsen et al. 2008 J Pham Sci 97:4622–4654). Интраартикулярная (и/а) доставка терапевтических белков ограничена тем, что они быстро выводятся из суставного пространства и недостаточно долго удерживаются в хряще. Время присутствия лекарственного средства в синовиальной жидкости сустава часто составляет менее 24 ч. Из–за быстрого клиренса большинства лекарственных средств, вводимых и/а путем, для поддержания эффективной концентрации потребуются частые инъекции (Owen et al., 1994 Br J Clin Pharmacol 38: 349–355). Однако частые и/а инъекции нежелательны из–за боли и дискомфорта, что может вызвать проблемы с комплаентностью пациента, а также из–за риска внесения инфекций в сустав.
Сохраняется потребность в эффективных DMOAD.
3 Сущность изобретения
Настоящее изобретение направлено на получение полипептидов против OA с улучшенными профилактическими, терапевтическими и/или фармакологическими свойствами, в дополнение к другим полезным свойствам (таким как, например, более простое получение, хорошая стабильность и/или более низкая стоимость продуктов), по сравнению аминокислотными последовательностями и антителами предшествующего уровня техники. В частности, настоящее изобретение направлено на получение одиночных вариабельных доменов иммуноглобулинов (ISVD) и полипептидов, включающих их, для ингибирования MMPs, и в частности, ингибирования MMP13.
Авторы настоящего изобретения предположили, что наилучшей областью для ингибирования ферментативной активности MMP13 была бы индукция ISVDs против каталитического кармана. Однако это оказалось серьезной проблемой. В частности, MMP13 секретируется в виде неактивной проформы (про–MMP13), в которой про–домен маскирует каталитический карман, из–за чего карман недоступен для усиления иммунного ответа. С другой стороны, активированная MMP13 имеет короткий период полужизни, что в основном связано с аутопротеолизом. Кроме того, даже после того, как авторы изобретения преодолели две предыдущие проблемы, оказалось, что высокая консервативность последовательности каталитического домена между различными видами препятствует устойчивому иммунному ответу.
В конце концов, авторы изобретения смогли решить эти проблемы благодаря оригинальной разработке новых инструментов и нетрадиционных методов скрининга.
В различных процедурах скрининга были выделены ISVD, которые далее разрабатывали для получения разнообразных и благоприятных свойств, включая стабильность, аффинность и ингибирующую активность. Одновалентные ISVD по изобретению, связывающие MMP13, превосходили препарат сравнения. Бипаратопные полипептиды, включающие ISVD, который был менее подходящим для ингибирования активности MMP13, были даже более эффективными.
Соответственно, настоящее изобретение относится к полипептиду, включающему по меньшей мере 1 одиночный вариабельный домен иммуноглобулина (ISVD), связывающийся с матриксной металлопротеиназой (MMP) и предпочтительно связывающийся с матриксной металлопротеиназой MMP13. Изобретение также включает полипептид, включающий два или более ISVD, каждый из которых индивидуально специфически связывается с MMP13, где
a) по меньшей мере "первый" ISVD специфически связывается с первой антигенной детерминантой, эпитопом, частью, доменом, субъединицей или конформацией MMP13; и где
b) по меньшей мере "второй" ISVD специфически связывается с второй антигенной детерминантой, эпитопом, частью, доменом, субъединицей или конформацией MMP13, отличных от первой антигенной детерминанты, эпитопа, части, домена, субъединицы или конформации, соответственно.
Также изобретение относится к полипептиду по изобретению, включающему одиночный вариабельный домен (ISVD), который связывается с матриксной металлопротеиназой (MMP), и еще один одиночный вариабельный домен (ISVD), который связывается с протеогликаном хряща и предпочтительно Аггреканом.
Еще один аспект относится к полипептиду в соответствии с изобретением для применения в качестве лекарственного средства. И еще один аспект относится к способу лечения профилактики заболеваний или расстройств у индивидуума, например, которые связаны с активностью MMP13, при этом способ включает введение полипептида в соответствии с изобретением указанному индивидууму в количестве, эффективном для лечения или профилактики симптома указанного заболевания или расстройства.
Другие аспекты, преимущества, применения и использования полипептидов и композиций станут ясны из дальнейшего раскрытия. Некоторые документы цитируется в различных разделах описания настоящего изобретения. Каждый из документов, процитированных выше или ниже в настоящей заявке (включая все патенты, патентные заявки, научные публикации, спецификации изготовителей, инструкции и т.д.), включены в настоящую заявку посредством ссылки во всей их полноте. Ничто в настоящей заявке не должно истолковываться как признание того, что изобретение не имеет права датировать задним числом такое раскрытие в силу предшествующего изобретения.
4. Описание чертежей
Фиг. 1: Кривые доза–ответ Нанотел профиля 1 (левый график) и Нанотел профиля 2 (правый график) в анализе флуорогенного коллагена.
Фиг. 2: Селективность ведущих Нанотел в отношении MMP13.
Фиг. 3: Конкурентный ELISA с 0,6 нМ биотинилированного 40E09 против панели Нанотел профиля 1 и профиля 2 на человеческой полноразмерной MMP13, покрытой мышиным mAb против человеческой MMP13 (R&D Systems #MAB511). MMP13 активировали через инкубацию с APMA в течение 90 мин при 37°C.
Фиг. 4: Ингибирование деградации хряща Нанотелами в крысиной MMT модели.
5 Подробное описание изобретения
Сохраняется потребность в безопасных и эффективных лекарственных средствах для лечения ОА. Эти лекарственные средства должны соответствовать различным и часто противоречащим требованиям, особенно когда предполагается широко применяемый формат. Такой формат предпочтительно должен быть полезен широкому кругу пациентов. Формат предпочтительно должен быть безопасным и не вызывать инфекции из–за частого и/а введения. Кроме того, формат предпочтительно должен быть удобен для пациента. Например, формат должен иметь продолжительный период полужизни в суставах, чтобы такой формат не удалялся мгновенно после введения. Однако продление периода полужизни предпочтительно не должно приводить к нецелевой активности и побочным эффектам или ограничивать эффективность.
Настоящее изобретение реализует по меньшей мере одно из этих требований.
Основываясь на нетрадиционных скрининговых, характеризационных и комбинаторных стратегиях, авторы настоящего изобретения неожиданно обнаружили, что одиночные вариабельные домены иммуноглобулинов (ISVD) показали исключительно хорошие результаты в экспериментах in vitro, ex vivo и in vivo.
Кроме того, авторы настоящего изобретения смогли реконструировать ISVD так, чтобы они превосходили лекарственный препарат сравнения. В бипаратопной конструкции такие характеристики на только сохраняются, но даже улучшаются.
С другой стороны, также было продемонстрировано, что ISVDs по изобретению значительно более эффективны, чем сравнительные молекулы.
Настоящее изобретение относится к полипептидам, являющимся антагонистами MMP, в частности MMP13, с улучшенными профилактическими, терапевтическими и/или фармакологическими свойствами, включая более безопасный профиль, по сравнению с сравнительными молекулами.
Соответственно, настоящее изобретение относится к ISVD и полипептидам, которые направлены против и/или которые могут специфически связываться (как определено в настоящей заявке) с MMP, предпочтительно указанная MMP выбрана из группы, состоящей из MMP13 (коллагеназа), MMP8 (коллагеназа), MMP1 (коллагеназа), MMP19 (матриксная металлопротеиназа RASI) и MMP20 (энамелизин), предпочтительно указанная MMP представляет собой MMP13, и модулируют ее активность, в частности к полипептиду, включающему по меньшей мере один одиночный вариабельный домен иммуноглобулина (ISVD), специфически связывающийся с MMP13, где связывание с MMP13 модулирует активность MMP13.
Определения
Если не указано или не определено иное, все используемые термины имеют их обычное известное в данной области значение, которое будет понятно специалисту. Например, см. справочники, такие как (Molecular Cloning: A Laboratory Manual (2nd Ed.) Vols. 1–3, Cold Spring Harbor Laboratory Press, 1989), F. Ausubel et al. (Current protocols in Molecular biology, Green Publishing and Wiley Interscience, New York, 1987), Lewin (Genes II, John Wiley & Sons, New York, N.Y., 1985), Old et al. (Principles of Gene Manipulation: An Introduction to Genetic Engineering (2nd edition) University of California Press, Berkeley, CA, 1981); Roitt et al. (Immunology (6th Ed.) Mosby/Elsevier, Edinburgh, 2001), Roitt et al. (Roitt’s Essential Immunology (10th Ed.) Blackwell Publishing, UK, 2001), и Janeway et al. (Immunobiology (6th Ed.) Garland Science Publishing/Churchill Livingstone, New York, 2005), а также известный уровень техники, цитируемый в настоящей заявке.
Если не указано иное, все способы, стадии, процедуры и манипуляции, которые не описаны подробно конкретным образом, можно осуществить и осуществляются способом, известным per se, как будет понятно квалифицированному специалисту. Также см. справочники и общую информацию, известную из уровня техники, указанные в настоящей заявке, и дополнительные ссылочные документы, цитируемые в них; а также, например, следующие обзоры Presta (Adv. Drug Deliv. Rev. 58 (5–6): 640–56, 2006), Levin and Weiss (Mol. Biosyst. 2(1): 49–57, 2006), Irving et al. (J. Immunol. Methods 248(1–2): 31–45, 2001), Schmitz et al. (Placenta 21 Suppl. A: S106–12, 2000), Gonzales et al. (Tumour Biol. 26(1): 31–43, 2005), которые описывают методы конструирования белков, такие как созревание аффинности и другие методы для улучшения специфичности и других желаемых свойств белков, таких как иммуноглобулины.
Следует указать, что в контексте настоящей заявки формы единственного числа, включают также и множественное число, если только из контекста явно не следует иное. Таким образом, например, ссылка на "реагент" включает один или несколько из таких различных реагентов, и ссылка на "способ" включает ссылку на эквивалентные стадии и способы, известные специалистам в данной области, которые можно было бы модифицировать или заменить ими способы, описанные в настоящей заявке.
Если не указано иное, термин "по меньшей мере", предшествующий серии элементов, следует понимать как относящийся к каждому элементу в серии. Специалистам в данной области техники будут понятны, или они смогут установить, используя не более чем обычные эксперименты, множество эквивалентов конкретных вариантов осуществления изобретения, описанных в настоящей заявке. Такие эквиваленты предназначены для охвата настоящим изобретением.
Термин "и/или" везде, где он используется в настоящей заявке, включает значение "и", "или" и "все или любая другая комбинация элементов, связанных указанным термином".
Термин "около" или "приблизительно" в контексте настоящей заявки означает в пределах 20%, предпочтительно в пределах 15%, более предпочтительно в пределах 10% и наиболее предпочтительно в пределах 5% от данного значения или диапазона.
Во всех разделах описания и в формуле изобретения, которая следует за ним, если контекст не требует иного, слово "включать" и варианты, такие как "включает" и "включающий", подразумевают включение указанного целого или стадии или группы целых или стадий, но не исключение любого другого целого или стадии или группы целых или стадий. В контексте настоящей заявки термин "включающий" может быть заменен термином "содержащий" или "включающий в себя", или иногда термином "имеющий".
Термин “последовательность” в контексте настоящей заявки (например в терминах, таких как “последовательность иммуноглобулина”, “последовательность антитела”, “последовательность вариабельного домена”, “последовательность VHH” или “последовательность белка”) в основном следует понимать как включающую релевантную аминокислотную последовательность, а также кодирующие ее нуклеиновые кислоты или нуклеотидные последовательности, если только контекст не требует более ограниченной интерпретации.
Аминокислотные последовательности интерпретируются как обозначающие одну аминокислоту или неразветвленную последовательность из двух или более аминокислот, в зависимости от контекста. Нуклеотидные последовательности интерпретируются как обозначающие неразветвленную последовательность из 3 или более нуклеотидов.
Аминокислоты представляют собой такие L–аминокислоты, которые обычно присутствуют в природных белках. Аминокислотные остатки будут указаны в соответствии со стандартным трехбуквенным или однобуквенным обозначением аминокислот. См. Таблицу A–2 на стр. 48 WO 08/020079. Те аминокислотные последовательности, которые содержат D–аминокислоты, не рассматриваются как охватываемые этим определением. Любая аминокислотная последовательность, которая содержит посттрансляционно модифицированные аминокислоты, может быть описана как аминокислотная последовательность, которая первоначально транслирована, с использованием символов, показанных в этой Таблице A–2 с модифицированными положениями; например гидроксилированиями или гликозилированиями, но эти модификации не должны быть прямо показаны в аминокислотной последовательности. Любой пептид или белок, который может быть выражен как последовательность с модифицированными связями, поперечными связями и концевыми кэпами, непептидильными связями и т.д., охватывается этим определением, как это все известно из уровня техники.
Термины "белок", "пептид", "белок/пептид" и "полипептид" используются взаимозаменяемо повсеместно в настоящем раскрытии и каждый имеет одинаковое значение для целей настоящего раскрытия. Каждый термин относится к органическому соединению, образованному линейной цепью из двух или более аминокислот. Соединение может иметь десять или более аминокислот; двадцать пять или более аминокислот; пятьдесят или более аминокислот; сто или более аминокислот, двести или более аминокислот и даже триста или более аминокислот. Специалистам в данной области должно быть понятно, что полипептиды, как правило, включают меньше аминокислот, чем белки, хотя в данной области нет никакой признанной точки, разграничивающей полипептид и белок на основании количества аминокислот; что полипептиды могут быть получены путем химического синтеза или рекомбинантными методами; и что белки, как правило, получают in vitro или in vivo рекомбинантными методами, известными из уровня техники. Согласно правилам, амидная связь в первичной структуре полипептидов расположена в порядке, в котором записываются аминокислоты, где амино–конец (N–конец) полипептида всегда находится слева, тогда как кислотный конец (C–конец) находится справа.
Считается, что нуклеиновокислотная или аминокислотная последовательность находится “(в) (по существу) выделенной (форме)” – например, по сравнению с реакционной средой или средой культивирования, из которой она была получена – когда она отделена от по меньшей мере одного другого компонента, с которым она обычно ассоциирована в указанном источнике или среде, такого как другая нуклеиновая кислота, другой белок/полипептид, другой биологический компонент или макромолекула или по меньшей мере одно загрязняющее вещество, примесь или второстепенный компонент. В частности, нуклеиновокислотная или аминокислотная последовательность считается “(по существу) выделенной”, когда очищена по меньшей мере 2–кратно, в частности по меньшей мере 10–кратно, более конкретно по меньшей мере 100–кратно, и даже 1000–кратно или более. Нуклеиновая кислота или аминокислота, которая находится “в (по существу) выделенной форме”, предпочтительно является по существу гомогенной, как определено с использованием подходящего метода, такого как подходящий хроматографический метод, такой как электрофорез в полиакриламидном геле.
Когда указано, что нуклеотидная последовательность или аминокислотная последовательность “включают” другую нуклеотидную последовательность или аминокислотную последовательность, соответственно, или “по существу состоят из” другой нуклеотидной последовательности или аминокислотной последовательности, это может означать, что последняя нуклеотидная последовательность или аминокислотная последовательность инкорпорирована в первую указанную нуклеотидную последовательность или аминокислотную последовательность, соответственно, но более типично это, как правило, означает, что первая указанная нуклеотидная последовательность или аминокислотная последовательность включает в своей последовательности участок из нуклеотидов или аминокислотных остатков, соответственно, который имеет такую же нуклеотидную последовательность или аминокислотную последовательность, соответственно, как последняя последовательность, независимо от того, как первая указанная последовательность в действительности была образована или получена (например, это может быть с использованием любого подходящего способа, описанного в настоящей заявке). В качестве не ограничивающего примера, когда указано, что полипептид по изобретению включает одиночный вариабельный домен иммуноглобулина ("ISVD"), это может означать, что указанная последовательность одиночного вариабельного домена иммуноглобулина была инкорпорирована в последовательность полипептида по изобретению, но более типично это, как правило, означает, что полипептид по изобретению содержит в своей последовательности последовательность одиночных вариабельных доменов иммуноглобулина, независимо от того, как указанный полипептид по изобретению был образован или получен. Также, когда нуклеиновая кислота или нуклеотидная последовательность указана как включающая другую нуклеотидную последовательность, первая указанная нуклеиновая кислота или нуклеотидная последовательность предпочтительно является такой, что когда она экспрессируется в продукт экспрессии (например, полипептид), аминокислотная последовательность, кодируемая последней нуклеотидной последовательностью, образует часть указанного продукта экспрессии (иными словами, последняя нуклеотидная последовательность находится в той же рамке считывания, что и первая указанная, более крупная нуклеиновая кислота или нуклеотидная последовательность). Также, когда указано, что конструкция по изобретению включает полипептид или ISVD, это может означать, что указанная конструкция по меньшей мере включает указанный полипептид или ISVD, соответственно, но более типично это означает, что указанная конструкция включает группы, остатки (например, аминокислотные остатки), фрагменты и/или связывающие элементы в дополнение к указанному полипептиду или ISVD, независимо от того, как указанный полипептид или ISVD связан с указанными группами, остатками (например, аминокислотными остатками), фрагментами и/или связывающими элементами, и независимо от того, как указанная конструкция была образована или получена.
Термин “по существу состоят из” означает, что ISVD, используемый в изобретении, либо является точно таким же, как ISVD по изобретению, либо соответствует ISVD по изобретению, который имеет ограниченное количество аминокислотных остатков, такое как 1–20 аминокислотных остатков, например 1–10 аминокислотных остатков и предпочтительно 1–6 аминокислотных остатков, например 1, 2, 3, 4, 5 или 6 аминокислотных остатков, добавленных на амино–концевом участке, на карбокси–концевом участке или на обоих амино–концевом участке и карбокси–концевом участке одиночного вариабельного домена иммуноглобулина.
Для целей сравнения двух или более нуклеотидных последовательностей процент “идентичности последовательностей” между первой нуклеотидной последовательностью и второй нуклеотидной последовательностью можно рассчитать путем деления [количества нуклеотидов в первой нуклеотидной последовательности, которые идентичны нуклеотидам в соответствующих положениях во второй нуклеотидной последовательности] на [общее число нуклеотидов в первой нуклеотидной последовательности] и умножения на [100%], где каждая делеция, вставка, замена или добавление нуклеотида во второй нуклеотидной последовательности – по сравнению с первой нуклеотидной последовательностью – считается отличием по одному нуклеотиду (положению). Альтернативно, степень идентичности последовательностей между двумя или более нуклеотидными последовательностями можно рассчитать с использованием известного компьютерного алгоритма для выравнивания последовательностей, такого как NCBI Blast v2.0, с использованием стандартных установочных параметров. Некоторые другие методы, компьютерные алгоритмы и установочные параметры для определения степени идентичности последовательностей описаны, например, в WO 04/037999, EP 0967284, EP 1085089, WO 00/55318, WO 00/78972, WO 98/49185 и GB 2357768. Обычно для целей определения процента “идентичности последовательностей” между двумя нуклеотидными последовательностями в соответствии с методом расчета, описанным выше, нуклеотидную последовательность с наибольшим числом нуклеотидов принимают за “первую” нуклеотидную последовательность, а другую нуклеотидную последовательность принимают за “вторую” нуклеотидную последовательность.
Для целей сравнения двух или более аминокислотных последовательностей процент “идентичности последовательностей” между первой аминокислотной последовательностью и второй аминокислотной последовательностью (также указан в настоящей заявке как “идентичность аминокислот”) можно рассчитать путем деления [количества аминокислотных остатков в первой аминокислотной последовательности, которые идентичны аминокислотным остаткам в соответствующих положениях во второй аминокислотной последовательности] на [общее число аминокислотных остатков в первой аминокислотной последовательности] и умножения на [100%], где каждая делеция, вставка, замена или добавление аминокислотного остатка во второй аминокислотной последовательности – по сравнению с первой аминокислотной последовательностью – считается отличием по одному аминокислотному остатку (положению), т.е. “аминокислотным отличием”, как определено в настоящей заявке. Альтернативно, степень идентичности последовательностей между двумя аминокислотными последовательностями можно рассчитать с использованием известного компьютерного алгоритма, такого как указанные выше для определения степени идентичности последовательностей для нуклеотидных последовательностей, также с использованием стандартных установочных параметров. Обычно для целей определения процента “идентичности последовательностей” между двумя аминокислотными последовательностями в соответствии с методом расчета, описанным выше, аминокислотную последовательность с наибольшим количеством аминокислотных остатков принимают за “первую” аминокислотную последовательность, а другую аминокислотную последовательность принимают за “вторую” аминокислотную последовательность.
Также, при определении степени идентичности последовательностей между двумя аминокислотными последовательностями специалист в данной области может принять во внимание так называемые “консервативные” аминокислотные замены, которые, как правило, могут быть описаны как аминокислотные замены, в которых аминокислотный остаток заменяют другим аминокислотным остатком подобной химической структуры и которые имеют незначительное или не имеют по существу никакого влияния на функцию, активность или другие биологические свойства полипептида. Такие консервативные аминокислотные замены хорошо известны из уровня техники, например из WO 04/037999, GB 335768, WO 98/49185, WO 00/46383 и WO 01/09300; и (предпочтительные) типы и/или комбинации таких замен можно выбрать на основании соответствующих указаний в WO 04/037999, а также WO 98/49185 и других ссылочных документах, цитируемых в них.
Такие консервативные замены предпочтительно представляют собой замены, в которых одну аминокислоту в следующих группах (a) – (e) заменяют другим аминокислотным остатком в той же группе: (a) малые алифатические неполярные или слегка полярные остатки: Ala, Ser, Thr, Pro и Gly; (b) полярные отрицательно заряженные остатки и их (незаряженные) амиды: Asp, Asn, Glu и Gln; (c) полярные положительно заряженные остатки: His, Arg и Lys; (d) крупные алифатические неполярные остатки: Met, Leu, Ile, Val и Cys; и (e) ароматические остатки: Phe, Tyr и Trp. Особенно предпочтительными консервативными заменами являются следующие: Ala на Gly или на Ser; Arg на Lys; Asn на Gln или на His; Asp на Glu; Cys на Ser; Gln на Asn; Glu на Asp; Gly на Ala или на Pro; His на Asn или на Gln; Ile на Leu или на Val; Leu на Ile или на Val; Lys на Arg, на Gln или на Glu; Met на Leu, на Tyr или на Ile; Phe на Met, на Leu или на Tyr; Ser на Thr; Thr на Ser; Trp на Tyr; Tyr на Trp; и/или Phe на Val, на Ile или на Leu.
Любые аминокислотные замены, применимые к полипептидам, описанным в настоящей заявке, могут также основываться на анализе частот аминокислотных вариаций между гомологичными белками разных видов, разработанном Schulz et al. (“Principles of Protein Structure”, Springer–Verlag, 1978), на анализах структурообразующих потенциалов, разработанных Chou и Fasman (Biochemistry 13: 211, 1974; Adv. Enzymol., 47: 45–149, 1978), и на анализе паттернов гидрофобности в белках, разработанных Eisenberg et al. (Proc. Natl. Acad Sci. USA 81: 140–144, 1984), Kyte and Doolittle (J. Molec. Biol. 157: 105–132, 1981) и Goldman et al. (Ann. Rev. Biophys. Chem. 15: 321–353, 1986), все они включены в настоящую заявку посредством ссылки во всей полноте. Информация о первичной, вторичной и третичной структуре нанотел представлена в описании настоящего изобретения и в общем уровне техники, указанном выше. Кроме того, для этой цели кристаллическая структура VHH домена ламы, например, представлена в Desmyter et al. (Nature Structural Biology, 3: 803, 1996), Spinelli et al. (Natural Structural Biology, 3: 752–757, 1996) и Decanniere et al. (Structure, 7 (4): 361, 1999). Дополнительную информацию о некоторых аминокислотных остатках, которые в обычных VH доменах образуют границу раздела VH/VL, и потенциальных заменах верблюжьего происхождения в этих положениях можно найти в предшествующем уровне техники, указанном выше.
Аминокислотные последовательности и последовательности нуклеиновых кислот указаны как “абсолютно одинаковые”, если они имеют идентичность последовательностей 100% (как определено в настоящей заявке) по всей их длине.
При сравнении двух аминокислотных последовательностей, термин “аминокислотное(аминокислотные) отличие” относится к вставке, делеции или замене одного аминокислотного остатка в определенном положении в первой последовательности по сравнению со второй последовательностью; должно быть понятно, что две аминокислотные последовательности могут содержать одно, два или более таких аминокислотных отличий. Более конкретно, в ISVD и/или полипептидах по настоящему изобретению термин “аминокислотное(аминокислотные) отличие” относится к вставке, делеции или замене одного аминокислотного остатка в определенном положении последовательности CDR, определенной в (b), (d) или (f), по сравнению с последовательностью CDR соответственно (a), (c) или (e); должно быть понятно, что последовательность CDR (b), (d) и (f) может содержать одно, два, три, четыре или максимально пять таких аминокислотных отличий по сравнению с последовательностью CDR соответственно (a), (c) или (e).
“Аминокислотное(аминокислотные) отличие” может представлять собой любое одно, два, три, четыре или максимально пять замен, делеций или вставок, или любую их комбинацию, которые либо улучшают свойства MMP13–связывающего агента по изобретению, такого как полипептид по изобретению, либо которые по меньшей мере не намного ухудшают желаемые свойства или баланс или комбинацию желаемых свойств MMP13–связывающего агента по изобретению, такого как полипептид по изобретению. В этой связи, полученный MMP13–связывающий агент по изобретению, такой как полипептид по изобретению, должен по меньшей мере связываться с MMP13 с такой же, почти такой же или более высокой аффинностью по сравнению с полипептидом, включающим одну или несколько CDR последовательностей без одной, двух, трех, четырех или максимально пяти замен, делеций или вставок. Аффинность можно измерить любым подходящим способом, известным из уровня техники, но предпочтительно ее измеряют способом, описанным в разделе Примеры.
В этой связи, аминокислотная последовательность CDRs в соответствии с (b), (d) и/или (f) может представлять собой аминокислотную последовательность, которая получена из аминокислотной последовательности в соответствии с (a), (c) и/или (e), соответственно, путем созревания аффинности с использованием одного или более методов созревания аффинности, известных per se или описанных в примерах. Например, и в зависимости от используемого организма–хозяина для экспрессии полипептида по изобретению, такие делеции и/или замены могут быть рассчитаны таким образом, чтобы удалить один или несколько сайтов для посттрансляционной модификации (таких как один или несколько сайтов гликозилирования), что должно быть известно специалистам в данной области (см. Примеры).
В контексте настоящей заявки термин “представленный” какой–либо из SEQ ID NO эквивалентен “включает или состоит из” указанной SEQ ID NO, и предпочтительно эквивалентен “состоит из” указанной SEQ ID NO.
“Семейство нанотел”, “ семейство VHH” или “семейство”, как используется в настоящем описании, относится к группе нанотел и/или последовательностей VHH, которые имеют одинаковую длину (т.е. они имеют одинаковое количество аминокислот в их последовательности) и у которых аминокислотные последовательности между положением 8 и положением 106 (в соответствии с нумерацией Kabat) имеют идентичность аминокислотных последовательностей 89% или более.
Термины “эпитоп” и “антигенная детерминанта”, которые можно использовать взаимозаменяемо, относятся к части макромолекулы, такой как полипептид или белок, которая распознается антиген–связывающими молекулами, такими как иммуноглобулины, традиционные антитела, одиночные вариабельные домены иммуноглобулинов и/или полипептиды по изобретению, и более конкретно антиген–связывающим сайтом указанных молекул. Эпитопы определяют минимальный сайт связывания для иммуноглобулина и, таким образом, представляют собой мишень специфичности иммуноглобулина.
Часть антиген–связывающей молекулы (такой как иммуноглобулин, традиционное антитело, одиночный вариабельный домен иммуноглобулина и/или полипептид по изобретению), которая распознает эпитоп, называется “паратопом”.
Аминокислотная последовательность (такая как одиночный вариабельный домен иммуноглобулина, антитело, полипептид по изобретению или, как правило, антиген–связывающий белок или полипептид или его фрагмент), которая может “связываться с” или “специфически связываться с”, которая “обладает аффинностью к” и/или которая “обладает специфичностью к” определенному эпитопу, антигену или белку (или по меньшей мере к одной его части, фрагменту или эпитопу), называется "против" или “направленная против” указанного эпитопа, антигена или белка, или представляет собой “связывающую” молекулу по отношению к такому эпитопу, антигену или белку, или называется “анти”–эпитоп, “анти”–антиген или “анти”–белок (например, “анти”–MMP13).
Аффинность означает силу или стабильность молекулярного взаимодействия. Аффинность обычно представляют как KD, или константу диссоциации, которую представляют в единицах моль/литр (или M). Аффинность также можно выразить как константу ассоциации, KA, которая равна 1/KD и которую представляют в единицах (моль/литр)–1 (или M–1). В настоящем описании стабильность взаимодействия между двумя молекулами в основном может быть выражена как KD значение их взаимодействия; квалифицированному специалисту будет понятно, что исходя из отношения KA=1/KD, определяющего силу молекулярного взаимодействия по его KD значению, также можно использовать для расчета соответствующее KA значение. KD–значение характеризует силу молекулярного взаимодействия также с термодинамической точки зрения, поскольку оно связано с изменением свободной энергии (DG) связывания хорошо известным отношением DG=RT.ln(KD) (эквиваленто DG=–RT.ln(KA)), где R=газовая постоянная, T=абсолютная температура и ln означает натуральный логарифм.
KD для биологических взаимодействий, которые считаются значимыми (например, специфическими), типично находятся в пределах от 10–12 M (0,001 нМ) до 10–5 M (10000 нМ). Чем сильнее взаимодействие, тем ниже его KD.
KD также можно выразить как отношение константы скорости диссоциации комплекса, обозначаемой как koff, к скорости его ассоциации, обозначаемой как kon (таким образом, KD=koff/kon и KA=kon/koff). Скорость диссоциации koff выражают в единицах сек–1 (где сек означает секунду (единица системы СИ)). Скорость ассоциации kon выражают в единицах M–1сек–1. Скорость ассоциации может варьироваться в пределах от 102 M–1сек–1 до около 107 M–1сек–1, приближаясь к диффузионно–ограниченной константе скорости ассоциации для бимолекулярных взаимодействий. Скорость диссоциации связана с периодом полужизни данного молекулярного взаимодействия отношением t1/2=ln(2)/koff. Скорость диссоциации может варьироваться в пределах от 10–6 сек–1 (близко к необратимому комплексу с t1/2=несколько дней) до 1 сек–1 (t1/2=0,69 сек).
Специфическое связывание антиген–связывающего белка, такого как ISVD, с антигеном или антигенной детерминантой можно определить любым подходящим способом, известным per se, включая, например, анализы насыщения при связывании и/или анализы конкурентного связывания, такие как радиоиммуноанализы (RIA), иммуноферментные анализы (EIA) и конкурентные сэндвич–анализы, и их различные варианты, известные per se в данной области техники; а также другие методы, указанные в настоящей заявке.
Аффинность молекулярного взаимодействия между двумя молекулами можно измерить разными способами, известными per se, такими как хорошо известный биосенсорный метод поверхностного плазмонного резонанса (SPR) (см., например, Ober et al. 2001, Intern. Immunology 13: 1551–1559), где одна молекула иммобилизована на биосенсорном чипе, а другую молекулу пропускают над иммобилизованной молекулой в режиме течения, с получением kon, koff значений и, следовательно, KD (или KA) значений. Это, например, можно осуществить с использованием хорошо известных устройств BIACORE® i (Pharmacia Biosensor AB, Uppsala, Sweden). Кинетический эксклюзионный анализ (KINEXA®) (Drake et al. 2004, Analytical Biochemistry 328: 35–43) измеряет события связывания в растворе без мечения партнеров по связыванию и основан на кинетическом исключении диссоциации комплекса. Анализ аффинности в растворе также можно осуществить с использованием системы иммуноанализа GYROLAB®, которая обеспечивает платформу для автоматического биоанализа и быструю оборачиваемость образцов (Fraley et al. 2013, Bioanalysis 5: 1765–74).
Также, квалифицированному специалисту должно быть понятно, что измеренная KD может соответствовать кажущейся KD, если способ измерения как–либо влияет на истинную аффинность связывания потенциальных молекул, например, посредством артефактов, связанных с нанесением на биосенсор одной молекулы. Также, кажущуюся KD можно измерить, если одна молекула содержит более одного сайта распознавания для другой молекулы. В такой ситуации на измеряемую аффинность может влиять авидность взаимодействия двух таких молекул. В частности, точное измерение KD может быть очень трудозатратным, и в результате часто кажущиеся KD значения определяют для оценки силы связывания двух молекул. Следует отметить, что при условии, что все измерения осуществляют согласованным образом (например, поддерживая условия анализа неизменными), кажущиеся KD значения можно использовать в качестве приближения к истинной KD, и, следовательно, в настоящем документе KD и кажущуюся KD следует рассматривать как равным образом важные или актуальные.
Термин “специфичность” относится к количеству различных типов антигенов или антигенных детерминант, с которыми может связываться конкретная антиген–связывающая молекула или антиген–связывающий белок (такой как ISVD или полипептид по изобретению), например, как описано в параграфе n) на стр. 53–56 WO 08/020079. Специфичность антиген–связывающего белка можно определить на основании аффинности и/или авидности, например, как описано на стр. 53–56 WO 08/020079 (включенной в настоящую заявку посредством ссылки), которая также описывает некоторые предпочтительные методы для измерения связывания между антиген–связывающей молекулой (такой как полипептид или ISVD по изобретению) и соответствующим антигеном. Типично, антиген–связывающие белки (такие как ISVD и/или полипептиды по изобретению) будут связываться с их антигеном с константой диссоциации (KD) от 10–5 до 10–12 моль/литр или меньше, и предпочтительно от 10–7 до 10–12 моль/литр или меньше, и более предпочтительно от 10–8 до 10–12 моль/литр (т.е. с константой ассоциации (KA) от 105 до 1012 литр/моль или более, и предпочтительно от 107 до 1012 литр/моль или более, и более предпочтительно от 108 до 1012 литр/моль). Любое KD значение больше чем 10–4 моль/литр (или любое KA значение меньше чем 104 литр/моль), как правило, считается как указывающее на неспецифическое связывание. Предпочтительно, одновалентный ISVD по изобретению будет связываться с желаемым антигеном с аффинностью меньше чем 500 нМ, предпочтительно меньше чем 200 нМ, более предпочтительно меньше чем 10 нМ, такой как меньше чем 500 пМ, например между 10 и 5 пМ или меньше.
Одиночный вариабельный домен иммуноглобулина и/или полипептид называют “специфическим в отношении” (первой) мишени или антигена по сравнению с другой (второй) мишенью или антигеном, когда он связывается с первым антигеном с аффинностью (как описано выше, и соответствующим образом выраженной как KD значение, KA значение, Koff скорость и/или Kon скорость), которая больше по меньшей мере в 10 раз, например, по меньшей мере в 100 раз, и предпочтительно по меньшей мере в 1000 или более раз, чем аффинность, с которой ISVD и/или полипептид связывается со второй мишенью или антигеном. Например, одиночный вариабельный домен иммуноглобулина и/или полипептид может связываться с первой мишенью или антигеном с KD значением, которое по меньшей мере в 10 раз меньше, например, по меньшей мере в 100 раз меньше, и предпочтительно по меньшей мере в 1000 раз меньше или даже еще меньше, чем KD, с которой указанный одиночный вариабельный домен иммуноглобулина и/или полипептид связывается со второй мишенью или антигеном. Предпочтительно, когда одиночный вариабельный домен иммуноглобулина и/или полипептид является “специфическим в отношении” первой мишени или антигена по сравнению со второй мишенью или антигеном, он направлен против (как определено в настоящей заявке) указанной первой мишени или антигена, но не направлен против указанной второй мишени или антигена.
Специфическое связывание антиген–связывающего белка с антигеном или антигенной детерминантой можно определить любым подходящим способом, известным per se, включая, например, анализы насыщения при связывании и/или анализы конкурентного связывания, такие как радиоиммуноанализы (RIA), иммуноферментные анализы (EIA) конкурентный сэндвич–анализы, и их различные варианты, известные из уровня техники; а также другие методы, указанные в настоящей заявке. Как будет понятно квалифицированному специалисту, и как описано на стр. 53–56 WO 08/020079, константа диссоциации может быть действительной или кажущейся константой диссоциации. Способы для определения константы диссоциации будут очевидны квалифицированному специалисту и, например, включают методы, указанные на стр. 53–56 WO 08/020079.
Другой предпочтительный подход, который можно использовать для оценки аффинности, представляет собой 2–стадийную процедуру ELISA (Твердофазный иммуноферментный анализ) Friguet et al. 1985 (J. Immunol. Methods 77: 305–19). Этот способ устанавливает измерение равновесия связывания в фазе раствора и избегает возможных артефактов, связанных с адсорбцией одной из молекул на подложке, такой как пластик. Как будет понятно квалифицированному специалисту, например, как описано на стр. 53–56 WO 08/020079, константа диссоциации может представлять собой действительную или кажущуюся константу диссоциации. Способы для определения константы диссоциации будут понятны квалифицированным специалистам и, например, включают способы, указанные на стр. 53–56 WO 08/020079.
В одном аспекте изобретение относится к MMP13–связывающему агенту, такому как an ISVD и полипептид по изобретению, где указанный MMP13–связывающий агент не связывается с MMP1 или MMP14 (мембранного типа).
Наконец, следует отметить, что во многих ситуациях опытный специалист может решить, что удобно определять аффинность связывания по сравнению с некоторой референсной молекулой. Например, для оценки силы связывания между молекулами A и B можно, например, использовать референсную молекулу C, известную как связывающуюся с B и соответствующим образом меченную группой флуорофора или хромофора или другой химической группой, такой как биотин, чтобы легко можно было осуществить детекцию в ELISA или FACS (флуоресцентно–активируемый клеточный сортинг) или в другом формате (флуорофор для флуоресцентной детекции, хромофор для детекции на основе поглощения света, биотин для стрептавидин–опосредованной ELISA детекции). Типично, референсную молекулу C поддерживают при фиксированной концентрации, а концентрация A варьируется в соответствии с заданной концентрацией или количеством B. В результате, получают IC50 значение, соответствующее концентрации A, при которой сигнал, измеренный для C в отсутствие A, уменьшается наполовину. При условии, что известна KD ref, KD референсной молекулы, а также общая концентрация cref референсной молекулы, кажущуюся KD для взаимодействия A–B можно получить с использованием следующей формулы: KD =IC50/(1+cref/KDref). Следует отметить, что, если cref << KDref, KD ≈ IC50. При условии, что измерение IC50 осуществляют единообразным образом (например, поддерживая фиксированную cref) для связующих, которые сравнивают, разницу в силе или стабильность молекулярного взаимодействия можно оценить путем сравнения IC50, и этот показатель считается эквивалентным KD или кажущейся KD повсеместно в тексте настоящего описания.
Полумаксимальная ингибирующая концентрация (IC50) также может быть показателем эффективности соединения в ингибировании биологической или биохимической функции, например фармакологического эффекта. Этот количественный показатель указывает какое количество полипептида или ISVD (например, Нанотела) необходимо для ингибирования наполовину данного биологического процесса (или компонента процесса, т.е. фермента, клетки, клеточного рецептора, хемотаксиса, анаплазии, метастазов, инвазивности и т.д.). Иначе говоря, это полумаксимальная (50%) ингибирующая концентрация (IC) вещества (50% IC, или IC50). IC50 значения можно рассчитать для данного антагониста, такого как полипептид или ISVD (например, Нанотело) по изобретению, путем определения концентрации, необходимой для ингибирования наполовину максимального биологического ответа агониста. KD лекарственного средства можно определить путем построения кривой доза–ответ и изучения эффекта различных концентраций антагониста, такого как полипептид или ISVD (например, Нанотело) по изобретению, на реверсию активности агониста.
Термин "полумаксимальная эффективная концентрация" (ЕС50) относится к концентрации соединения, которая индуцирует ответ на полпути между исходным уровнем и максимумом после определенного времени воздействия. В контексте настоящей заявки он используется в качестве показателя эффективности полипептида или ISVD (например, Нанотела). ЕС50 значение, полученное из кривой доза–ответ при постепенном увеличении дозы, представляет собой концентрацию соединения, при которой наблюдается 50% его максимального эффекта. Концентрацию предпочтительно выражают в молярных единицах.
В биологических системах небольшие изменения в концентрации лиганда обычно приводят к быстрым изменениям ответа в соответствии с сигмоидальной функцией. Точка перегиба, в которой усиление ответа с увеличением концентрации лиганда начинает замедляться, представляет собой значение EC50. Это можно определить математически путем выведения наиболее подходящей линии. В большинстве случаев удобно осуществлять оценку на основании графика. В случае, если в разделе Примеры указана EC50, эксперименты были разработаны так, чтобы максимально точно отразить KD. Другими словами, EC50 значения могут затем рассматриваться как KD значения. Термин "среднее значение KD" относится к среднему значению KD, полученному по меньшей мере в 1, но предпочтительно более чем в 1, например по меньшей мере в 2 экспериментах. Термин "средний" относится к математическому термину "средний" (сумма данных, деленная на количество элементов в данных).
Это также связано с значением IC50, которое является критерием оценки соединения, его ингибирующего действия (ингибирование 50%). Для конкурентных анализов связывания и анализов функциональных антагонистов IC50 является наиболее типичным итоговым показателем кривой доза–ответ. Для анализов агонистов/стимуляторов наиболее типичным итоговым показателем является EC50.
Константа ингибирования (Ki) является показателем того, насколько сильным является ингибитор; это концентрация, необходимая для обеспечения полумаксимального ингибирования. В отличие от IC50, которая может изменяться в зависимости от условий эксперимента, Ki является абсолютной величиной и часто указывается как константа ингибирования лекарственного средства. Константу ингибирования Ki можно рассчитать с использованием уравнения Ченга–Прусоффа:
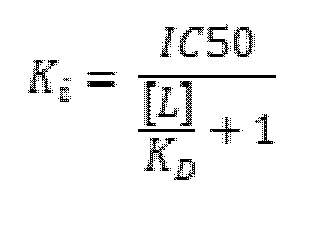
в котором [L] представляет собой фиксированную концентрацию лиганда.
Термин “активность” полипептида по изобретению, в контексте настоящей заявки, означает функцию количества полипептида по изобретению, необходимого для проявления его специфического эффекта. Это значение измеряется просто как обратное значению IC50 для данного полипептида. Это относится к способности указанного полипептида по изобретению модулировать и/или частично или полностью ингибировать активность MMP13. Более конкретно, это может относиться к способности указанного полипептида снижать или даже полностью ингибировать активность MMP13, как определено в настоящей заявке. Таким образом, это может относиться к способности указанного полипептида ингибировать протеолиз, например, протеазную активность, активности эндопептидаз и/или связывание с субстратом, таким как, например, Аггрекан, Коллаген II, Коллаген I, Коллаген III, Коллаген IV, Коллаген IX, Коллаген X, Коллаген XIV и желатин. Действенность можно измерить при помощи любого подходящего анализа, известного из уровня техники или описанного в настоящей заявке.
“Эффективность” полипептида по изобретению определяет максимальную силу его эффекта как такового, при насыщающих концентрациях полипептида. Эффективность означает максимальный ответ, достигаемый полипептидом по изобретению. Это относится к способности полипептида обеспечивать желаемый (терапевтический) эффект.
В одном аспекте изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид связывается с MMP13 с KD между 1E–07 M и 1E–13 M, например между 1E–08 M и 1E–12 M, предпочтительно максимально 1E–07 M, предпочтительно меньше чем 1E–08 M или 1E–09 M, или даже меньше чем 1E–10 M, например 5E–11 M, 4E=11 M, 3E–11 M, 2E–11 M, 1,7E–11 M, 1E–11 M, или даже 5E–12 M, 4E–12 M, 3E–12 M, 1E–12 M, например, как определено методом KinExA.
В одном аспекте изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид ингибирует активность MMP13 с значением IC50 между 1E–07 M и 1E–12 M, таким как между 1E–08 M и 1E–11 M, например, как определено при помощи конкурентного ELISA, конкурентного TIMP–2 ELISA, анализа флуорогенного пептида, анализа флуорогенного коллагена или коллагенолитического анализа, таких как, например, анализы, подробно описанные в разделе Примеры.
В одном аспекте изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид ингибирует активность MMP13 с значением IC50 максимально 1E–07 M, предпочтительно 1E–08 M, 5E–09 M или 4E–9 M, 3E–9 M, 2E–9 M, например 1E–9 M.
В одном аспекте изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид связывается с MMP13 с значением EC50 между 1E–07 M и 1E–12 M, таким как между 1E–08 M и 1E–11 M, например, как определено методом ELISA, конкурентным TIMP–2 ELISA, анализом флуорогенного пептида, анализом флуорогенного коллагена или коллагенолитическим анализом.
В одном аспекте изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид связывается с MMP13 со скоростью диссоциации меньше чем 5E–04 (сек–1), например, как определено методом SPR.
Аминокислотная последовательность, такая как an ISVD или полипептид, называется “перекрестно–реактивной” в отношении двух разных антигенов или антигенных детерминант (таких как например, MMP13 из разных видов млекопитающих, таких как например, MMP13 человека, MMP13 собаки, MMP13 быка, MMP13 крысы, MMP13 свиньи, MMP13 мыши, MMP13 кролика, MMP13 яванского макака и/или MMP13 макака–резуса), если она является специфической в отношении (как определено в настоящей заявке) этих разных антигенов или антигенных детерминант. Должно быть понятно, что ISVD или полипептид может считаться перекрестно–реактивным, хотя аффинность связывания в отношении двух разных антигенов может различаться, например в 2, 5, 10, 50, 100 раз или даже больше, при условии, что он является специфическим в отношении (как определено в настоящей заявке) этих разных антигенов или антигенных детерминант.
MMP13 также известна как CLG3 или Коллагеназа 3, MANDP1, MMP–13, Матриксная металлопептидаза 13 или MDST.
Соответствующую информацию о структуре MMP13 можно найти, например, по номерам доступа UniProt, как показано в таблице 1 ниже (см. Таблицу B).
"MMP13 человека" относится к MMP13, включающей аминокислотную последовательность SEQ ID NO: 115. В одном аспекте полипептид по изобретению специфически связывается с MMP13 из Human sapiens, Mus musculus, Canis lupus, Bos taurus, Macaca mulatta, Rattus norvegicus, Gallus gallus и/или P.troglodytes, предпочтительно MMP13 человека, предпочтительно SEQ ID NO: 115.
Термины “(перекрестно)–блокировать”, “(перекрестно)–блокированный”, “(перекрестное)–блокирование”, “конкурентное связывание”, “(перекрестно)–конкурировать”, “(перекрестно)–конкурирующий” и “(перекрестно)–конкурентный” используются взаимозаменяемо в настоящей заявке как обозначающие способность иммуноглобулина, антитела, ISVD, полипептида или другого связывающего агента препятствовать связыванию других иммуноглобулинов, антител, ISVD, полипептидов или связывающих агентов с данной мишенью. Степень, в которой иммуноглобулин, антитело, ISVD, полипептид или другой связывающий агент способен препятствовать связыванию другого агента с мишенью, а, соответственно, то, можно ли назвать это перекрестным блокированием в соответствии с изобретением, можно определить с использованием конкурентных анализов связывания, которые являются обычными в данной области техники, таких как, например, скрининг очищенных ISVD против ISVD, экспонированных на фаге, в конкурентном ELISA, как описано в примерах. Способы определения действительно ли иммуноглобулин, антитело, одиночный вариабельный домен иммуноглобулина, полипептид или другой связывающий агент (перекрестно)–блокирует, способен (перекрестно)–блокировать, конкурентно связывается или является (перекрестно)–конкурентным в отношении мишеней, как это определено в настоящей заявке, описаны, например, в Xiao–Chi Jia et al. (Journal of Immunological Methods 288: 91–98, 2004), Miller et al. (Journal of Immunological Methods 365: 118–125, 2011), и/или представляют собой способы, описанные в настоящей заявке (см. например, Пример 7).
Настоящее изобретение относится к полипептиду, описанному в настоящей заявке, такому как представленный SEQ ID NO: 111, 11, 112, 12, 109, 9, 110, 10, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2, 3, 4, 5, 6, 7 или 8, где указанный полипептид конкурирует с полипептидом, например, как определено в конкурентном ELISA.
Настоящее изобретение относится к способу определения конкурентов, таких как полипептиды, конкурирующие с полипептидом, описанным в настоящей заявке, таким как представленный любой из SEQ ID NO: 111, 11, 112, 12, 109, 9, 110, 10, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2, 3, 4, 5, 6, 7 или 8, где полипептид, описанный в настоящей заявке, перекрестно блокирует конкурента, такого как полипептид, или конкурирует с ним за связывание с MMP13, например MMP13 человека (SEQ ID NO: 115), где связывание конкурента с MMP13 уменьшается на по меньшей мере 5%, например 10%, 20%, 30%, 40%, 50% или даже больше, например 80%, 90% или даже 100% (т.е. фактически неопределяемо в данном анализе) в присутствии полипептида по изобретению, по сравнению с связыванием конкурента с MMP13 в отсутствие полипептида по изобретению. Конкурентное и перекрестное блокирование можно определить любым способом, известным из уровня техники, таким как, например, конкурентный ELISA. В одном аспекте настоящее изобретение относится к полипептиду по изобретению, где указанный полипептид перекрестно блокирует связывание с MMP13 по меньшей мере одного из полипептидов, представленных SEQ ID NO: 111, 11, 112, 12, 109, 9, 110, 10, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2, 3, 4, 5, 6, 7 или 8, и/или перекрестно блокируется от связывания с MMP13 по меньшей мере одним из полипептидов, представленных SEQ ID NO: 111, 11, 112, 12, 109, 9, 110, 10, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2, 3, 4, 5, 6, 7 или 8.
Настоящее изобретение также относится к конкурентам, конкурирующим с полипептидом, описанным в настоящей заявке, таким как SEQ ID NO: 111, 11, 112, 12, 109, 9, 110, 10, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2, 3, 4, 5, 6, 7 или 8, где конкурент перекрестно блокирует полипептид, описанный в настоящей заявке, или конкурирует с ним за связывание с MMP13, где связывание с MMP13 полипептида по изобретению уменьшается на по меньшей мере 5%, например 10%, 20%, 30%, 40%, 50% или даже больше, например 80% или еще больше, например по меньшей мере на 90% или даже 100% (т.е. фактически неопределяемо в данном анализе) в присутствии указанного конкурента, по сравнению с связыванием полипептида по изобретению с MMP13 в отсутствие указанного конкурента. В одном аспекте настоящее изобретение относится к полипептиду, перекрестно блокирующему связывание MMP13 полипептидом по изобретению, таким как один из SEQ ID NO: 111, 11, 112, 12, 109, 9, 110, 10, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2, 3, 4, 5, 6, 7 или 8, и/или который перекрестно блокируется от связывания с MMP13 по меньшей мере одним из SEQ ID NO: 111, 11, 112, 12, 109, 9, 110, 10, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2, 3, 4, 5, 6, 7 или 8, предпочтительно где указанный полипептид включает по меньшей мере один VH, VL, dAb, одиночный вариабельный домен иммуноглобулина (ISVD), специфически связывающийся с MMP13, где связывание с MMP13 модулирует активность MMP13.
"MMP13 активность" и "активность MMP13" (эти термины используются взаимозаменяемо в настоящей заявке) включают, но не ограничиваются этим, протеолиз, такой как протеазная активность (также называемая протеиназной или пептидазной активностью) и эндопептидазные активности, с одной стороны, и связывание с субстратом, например посредством Гемопексин–подобного домена и пептидогликан–связывающего домена. MMP13 активность включает связывание и/или протеолиз субстратов, таких как Аггрекан, Коллаген II, Коллаген I, Коллаген III, Коллаген IV, Коллаген IX, Коллаген X, Коллаген XIV и Желатин. В контексте настоящей заявки протеолиз представляет собой расщепление белков на более мелкие полипептиды или аминокислоты путем гидролиза пептидных связей, которые связывают аминокислоты вместе в полипептидной цепи.
В контексте настоящего изобретения “модулирующий” или “модулировать”, как правило, означает изменение активности MMP13, измеренное с использованием подходящего in vitro, клеточного или in vivo анализа (такого как анализы, указанные в настоящей заявке). В частности, “модулирующий” или “модулировать” может означать либо снижение или ингибирование активности, либо, альтернативно, повышение активности MMP13, измеренное с использованием подходящего in vitro, клеточного или in vivo анализа (например, такого, как анализы, указанные в настоящей заявке), на по меньшей мере 1%, предпочтительно по меньшей мере 5%, например по меньшей мере 10% или по меньшей мере 25%, например по меньшей мере 50%, по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80% или 90% или более, по сравнению с активностью MMP13 в этом же анализе в таких же условиях, но без присутствия ISVD или полипептида по изобретению.
Соответственно, настоящее изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид модулирует активность MMP13, предпочтительно ингибируя активность MMP13.
Соответственно, настоящее изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид ингибирует протеазную активность MMP13, например, ингибирует протеолиз субстрата, такого как Аггрекан, Коллаген II, Коллаген I, Коллаген III, Коллаген IV, Коллаген IX, Коллаген X, Коллаген XIV и/или желатин.
Соответственно, настоящее изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид блокирует связывание MMP13 с субстратом, таким как Аггрекан, Коллаген II, Коллаген I, Коллаген III, Коллаген IV, Коллаген IX, Коллаген X, Коллаген XIV и/или желатин, где указанный Коллаген предпочтительно представляет собой Коллаген II.
В одном аспекте изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид блокирует связывание MMP13 с Коллагеном и/или Аггреканом по меньшей мере на 20%, например, по меньшей мере на 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95% или даже больше, например, как определено в конкурентных анализах на основе ELISA (см. Howes et al. 2014 J. Biol. Chem. 289:24091–24101).
В одном аспекте изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид антагонизирует или ингибирует активность MMP13, такую как (i) протеазная активность, предпочтительно расщепление Аггрекана и/или Коллагена, где указанный Коллаген предпочтительно представляет собой Коллаген II; (ii) связывание Коллагена с гемопексин–подобным доменом.
Соответственно, настоящее изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид ингибирует протеазную активность MMP13, предпочтительно по меньшей мере на 5%, например на 10%, 20%, 30%, 40%, 50% или даже больше, например по меньшей мере на 60%, 70%, 80%, 90%, 95% или даже больше, как определено любым подходящим способом, известным из уровня техники, таким как, например, конкурентные анализы, или как описано в разделе Примеры.
ISVD
Если не указано иное, термины “иммуноглобулин” и “последовательность иммуноглобулина” – независимо от того, используются ли они в настоящей заявке как относящиеся к антителу только с тяжелыми цепями или к традиционному 4–цепочечному антителу – используются как общие термины, включающие как полноразмерное антитело, так и его отдельные цепи, а также все их части, домены или фрагменты (включая, но не ограничиваясь этим, антиген–связывающие домены или фрагменты, такие как VHH домены или VH/VL домены, соответственно).
Термин “домен” (полипептида или белка) в контексте настоящей заявки относится к свернутой белковой структуре, которая обладает способностью сохранять свою третичную структуру независимо от остальной части белка. Как правило, домены ответственны за определенные функциональные свойства белков, и во многих случаях могут быть добавлены, удалены или перенесены в другие белки без потери функции остальной части белка и/или домена.
Термин “домен иммуноглобулина” в контексте настоящей заявки относится к глобулярной области цепи антитела (такой как например, цепь традиционного 4–цепочечного антитела или антитела только с тяжелыми цепями) или к полипептиду, который по существу состоит из такой глобулярной области. Домены иммуноглобулинов характеризуются тем, что они сохраняют характерную для иммуноглобулинов укладку молекул антител, которая состоит из двухслойного сэндвича из примерно семи антипараллельных бета–цепей, расположенных в виде двух бета–листов, необязательно стабилизированных консервативной дисульфидной связью.
Термин “вариабельный домен иммуноглобулина” в контексте настоящей заявки означает домен иммуноглобулина по существу состоящий из четырех “каркасных областей”, которые указываются в данной области техники и ниже в настоящей заявке как “каркасная область 1” или “FR1”; как “каркасная область 2” или “FR2”; как “каркасная область 3” или “FR3”; и как “каркасная область 4” или “FR4”, соответственно; при этом указанные каркасные области прерываются тремя “определяющими комплементарность областями” или “CDR”, которые указываются в данной области техники и ниже в настоящей заявке как “определяющая комплементарность область 1” или “CDR1”; как “определяющая комплементарность область 2” или “CDR2”; и как “определяющая комплементарность область 3” или “CDR3”, соответственно. Таким образом, общая структура или последовательность вариабельного домена иммуноглобулина может быть указана следующим образом: FR1 – CDR1 – FR2 – CDR2 – FR3 – CDR3 – FR4. Это вариабельный домен (домены) иммуноглобулина, который сообщает антителу специфичность к антигену, поскольку содержит антиген–связывающий сайт. В предпочтительных вариантах осуществления всех аспектов изобретения одиночный вариабельный домен иммуноглобулина (ISVD) в соответствии с изобретением предпочтительно состоит из или по существу состоит из 4 каркасных областей (FR1–FR4, соответственно) и 3 определяющих комплементарность областей CDR1, CDR2 и CDR3 в указанной общей структуре, как описано выше. Предпочтительные каркасные последовательности представлены, например, в таблице A–2 ниже, и их можно использовать как ISVD по изобретению. Предпочтительно, CDR, представленные в таблице A–2, соответствуют соответствующим каркасным областям такой же ISVD конструкции.
Термин “одиночный вариабельный домен иммуноглобулина” (сокращенно указан как "ISVD" или "ISV"), взаимозаменяемо используемый с “одиночным вариабельным доменом”, означает молекулы, где сайт связывания антигена присутствует на, и образован им, одиночном домене иммуноглобулина. Это отличает одиночные вариабельные домены иммуноглобулинов от “традиционных” иммуноглобулинов или их фрагментов, где два домена иммуноглобулина, в частности два вариабельных домена, взаимодействуют с образованием сайта связывания антигена. Типично, в традиционных иммуноглобулинах вариабельный домен тяжелой цепи (VH) и вариабельный домен легкой цепи (VL) взаимодействуют с образованием сайта связывания антигена. В последнем случае определяющие комплементарность области (CDR) обоих VH и VL будут вносить свой вклад в сайт связывания антигена, т.е. в общей сложности 6 CDR будут вовлечены в образование сайта связывания антигена.
В соответствии с представленным выше определением, антиген–связывающий домен традиционного 4–цепочечного антитела (такого как молекула IgG, IgM, IgA, IgD или IgE; известного из уровня техники) или Fab фрагмента, F(ab')2 фрагмента, Fv фрагмента, такого как дисульфид–связанный Fv или scFv фрагмент, или диатела (все известны из уровня техники), происходящего из такого традиционного 4–цепочечного антитела, обычно не будет считаться одиночным вариабельным доменом иммуноглобулина, поскольку в этих случаях связывание с соответствующим эпитопом антигена обычно происходит не посредством одного (одиночного) домена иммуноглобулина, а пары (ассоциирующихся) доменов иммуноглобулина, таких как вариабельные домены легкой и тяжелой цепи, т.е. посредством VH–VL пары доменов иммуноглобулина, которые совместно связываются с эпитопом соответствующего антигена.
В отличие от этого, ISVD способны специфически связываться с эпитопом антигена без спаривания с дополнительным вариабельным доменом иммуноглобулина. Сайт связывания ISVD образован одиночным VHH, VH или VL доменом. Следовательно, антиген–связывающий сайт ISVD образован не больше чем тремя CDR.
Таким образом, одиночный вариабельный домен может представлять собой последовательность вариабельного домена легкой цепи (например, VL–последовательность) или ее подходящий фрагмент; или последовательность вариабельного домена тяжелой цепи (например, VH–последовательность или VHH последовательность) или ее подходящий фрагмент; при условии, что она способна образовывать отдельную антигенсвязывающую единицу (т.е. функциональную антигенсвязывающую единицу, которая по существу состоит из одиночного вариабельного домена, таким образом, чтобы одиночный антигенсвязывающий домен не нуждался во взаимодействии с другим вариабельным доменом для образования функциональной антигенсвязывающей единицы).
В одном варианте осуществления изобретения ISVD представляют собой последовательности вариабельных доменов тяжелых цепей (например, VH–последовательность); более конкретно, ISVD могут представлять собой последовательности вариабельных доменов тяжелых цепей, которые происходят из традиционного четырехцепочечного антитела, или последовательности вариабельных доменов тяжелых цепей, которые происходят из антитела только с тяжелыми цепями.
Например, ISVD может представлять собой (одно)–доменное антитело (или пептид, который является подходящим для использования в качестве (одно)–доменного антитела), "dAb" или sdAb (или пептид, который является подходящим для использования в качестве dAb) или Нанотело (определенное в настоящей заявке и включающее, но не ограничивающееся этим, VHH); другие одиночные вариабельные домены, или любой подходящий фрагмент любого из вышеуказанных.
В частности, ISVD может представлять собой Нанотело® (как определено в настоящей заявке) или его подходящий фрагмент. [Примечание: Нанотело® и Нанотела® являются зарегистрированными торговыми марками Ablynx N.V.]. Что касается общего описания нанотел, см. дальнейшее описание, представленное ниже, а также предшествующий уровень техники, цитируемый в настоящей заявке, например, WO 08/020079 (стр. 16).
“VHH домены”, также известные как VHH, VHH домены, фрагменты VHH антител и VHH антитела, первоначально были описаны как антигенсвязывающий (вариабельный) домен иммуноглобулина “антител с только тяжелыми цепями” (т.е. “антител, лишенных легких цепей”; Hamers–Casterman et al. 1993 Nature 363: 446–448). Термин “VHH домен” выбран, чтобы можно было отличить эти вариабельные домены от вариабельных доменов тяжелых цепей, которые присутствуют в традиционных 4–цепочечных антителах (которые указаны в настоящей заявке как “VH домены” или “VH домены”), и от вариабельных доменов легких цепей, которые присутствуют в традиционных 4–цепочечных антителах (которые указаны в настоящей заявке как “VL домены” или “VL домены”). Более подробное описание VHH и Нанотел можно найти в обзорной статье Muyldermans (Reviews in Molecular Biotechnology 74: 277–302, 2001), а также в следующих патентных заявках, которые указаны как общеизвестный уровень техники: WO 94/04678, WO 95/04079 и WO 96/34103 Vrije Universiteit Brussel; WO 94/25591, WO 99/37681, WO 00/40968, WO 00/43507, WO 00/65057, WO 01/40310, WO 01/44301, EP 1134231 и WO 02/48193 Unilever; WO 97/49805, WO 01/21817, WO 03/035694, WO 03/054016 и WO 03/055527 Vlaams Instituut voor Biotechnologie (VIB); WO 03/050531 Algonomics N.V. и Ablynx N.V.; WO 01/90190 National Research Council of Canada; WO 03/025020 (= EP 1433793) Institute of Antibodiesа, а также WO 04/041867, WO 04/041862, WO 04/041865, WO 04/041863, WO 04/062551, WO 05/044858, WO 06/40153, WO 06/079372, WO 06/122786, WO 06/122787 и WO 06/122825 Ablynx N.V. и другие опубликованные патентные заявки Ablynx N.V. Также можно сослаться на другие документы предшествующего уровня техники, указанные в этих заявках, и, в частности, на перечень ссылочных документов на стр. 41–43 международной заявки WO 06/040153, при этом этот перечень и ссылочные документы включены в настоящую заявку посредством ссылки. Как описано в этих ссылочных документах, Нанотела (в частности, VHH последовательности и частично гуманизированные Нанотела) могут, в частности, характеризоваться присутствием одного или более “Уникальных остатков” в одной или нескольких каркасных последовательностях. Более подробное описание Нанотел, включая гуманизацию и/или камелизацию нанотел, а также другие модификации, части или фрагменты, производные или “слияния Нанотел”, мультивалентные конструкции (включая некоторые неограничивающие примеры линкерных последовательностей) и различные модификации для увеличения периода полужизни Нанотел и их препаратов можно найти, например, в WO 08/101985 и WO 08/142164. Также общее описание Нанотел можно найти в предшествующем уровне техники, цитируемом в настоящей заявке, например, описанном в WO 08/020079 (стр. 16).
В частности, каркасные последовательности, присутствующие в MMP13–связывающих агентах по изобретению, таких как ISVD и/или полипептиды по изобретению, могут содержать один или несколько уникальных остатков (например, как описано в WO 08/020079 (Таблицы A–3 – A–8)), таким образом MMP13–связывающий агент по изобретению представляет собой Нанотело. Некоторые предпочтительные, но не ограничивающие примеры (подходящих комбинаций) таких каркасных последовательностей будут понятны из дальнейшего раскрытия, представленного в настоящей заявке (см., например, Таблицу A–2). Как правило, Нанотела (в частности VHH последовательности и частично гуманизированные Нанотела) могут, в частности, характеризоваться присутствием одного или более “Уникальных остатков” в одной или нескольких их каркасных последовательностях (как, например, более подробно описано в WO 08/020079, стр. 61 строка 24 – стр. 98 строка 3).
Более конкретно, изобретение обеспечивает MMP13–связывающие агенты, включающий по меньшей мере один одиночный вариабельный домен иммуноглобулина, который представляет собой аминокислотную последовательность с (общей) структурой
FR1 – CDR1 – FR2 – CDR2 – FR3 – CDR3 – FR4
в которой FR1–FR4 относятся к каркасным областям 1–4, соответственно, и в которой CDR1–CDR3 относятся к определяющим комплементарность областям 1–3, соответственно, и при этом указанные ISVD:
i) имеют по меньшей мере 80%, более предпочтительно 90%, еще более предпочтительно 95% идентичности аминокислот с по меньшей мере одной из аминокислотных последовательностей SEQ ID NO: 111, 11, 112, 12, 109, 9, 110, 10, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2, 3, 4, 5, 6, 7 или 8 (см. Таблицу A–1), где в целях определения степени идентичности аминокислот аминокислотные остатки, которые образуют последовательности CDR, не учитываются. В этой связи, ссылка также делается на Таблицу A–2, в которой перечислены каркасные последовательности 1 (SEQ ID NO: 67–79), каркасные последовательности 2 (SEQ ID NO: 80–87 и 108), каркасные последовательности 3 (SEQ ID NO: 88–99 и 113–114) и каркасные последовательности 4 (SEQ ID NO: 100–104) одиночных вариабельных доменов иммуноглобулинов SEQ ID NO: 1–22 и 109–112; или
ii) комбинации каркасных последовательностей, которые представлены в таблице A–2;
и в которых:
iii) предпочтительно один или несколько аминокислотных остатков в положениях 11, 37, 44, 45, 47, 83, 84, 103, 104 и 108 в соответствии с нумерацией Kabat выбраны из Уникальных остатков, например, таких, которые указаны в Таблице A–3 –Таблице A–8 WO 08/020079.
Связывающие MMP13 агенты по изобретению, такие как ISVD и/или полипептиды по изобретению, также могут содержать специфические мутации/аминокислотные остатки, описанные в следующих находящихся на одновременном рассмотрении предварительных заявках США, которые все озаглавлены “Improved immunoglobulin variable domains”: US 61/994552 подана 16 мая 2014 г.; US 61/014015 подана 18 июня 2014 г.; US 62/040167 подана 21 августа 2014 г.; и US 62/047560 подана 8 сентября 2014 г. (все принадлежат Ablynx N.V.).
В частности, связывающие MMP13 агенты по изобретению, такие как ISVD и/или полипептиды по изобретению, могут соответственно содержать (i) K или Q в положении 112; или (ii) K или Q в положении 110 в комбинации с V в положении 11; или (iii) T в положении 89; или (iv) L в положении 89 с K или Q в положении 110; или (v) V в положении 11 и L в положении 89; или любую подходящую комбинацию (i) – (v).
Как также описано в указанных находящихся на одновременном рассмотрении предварительных заявках США, когда связывающие MMP13 агенты по изобретению, такие как ISVD и/или полипептиды по изобретению, содержат мутации в соответствии с одним из указанных выше (i) – (v) (или их подходящую комбинацию):
– аминокислотный остаток в положении 11 предпочтительно выбран из L, V или K (и наиболее предпочтительно представляет собой V); и/или
– аминокислотный остаток в положении 14 предпочтительно соответственно выбран из A или P; и/или
– аминокислотный остаток в положении 41 предпочтительно соответственно выбран из A или P; и/или
– аминокислотный остаток в положении 89 предпочтительно соответственно выбран из T, V или L; и/или
– аминокислотный остаток в положении 108 предпочтительно соответственно выбран из Q или L; и/или
– аминокислотный остаток в положении 110 предпочтительно соответственно выбран из T, K или Q; и/или
– аминокислотный остаток в положении 112 предпочтительно соответственно выбран из S, K или Q.
Как описано в указанных находящихся на одновременном рассмотрении предварительных заявках США, указанные мутации эффективны для предотвращения или уменьшения связывания так называемых “предсуществующих антител” с иммуноглобулинами и соединениями по изобретению. Для этой цели MMP13–связывающие агенты по изобретению, такие как ISVD и/или полипептиды по изобретению, также могут содержать (необязательно в комбинации с указанными мутациями) C–концевое удлинение (X)n (где n имеет значение от 1 до 10, предпочтительно от 1 до 5, такое как 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, такое как 1); и каждый X представляет собой (предпочтительно природный) аминокислотный остаток, который независимо выбран, и предпочтительно независимо выбран из группы, состоящей из аланина (A), глицина (G), валина (V), лейцина (L) или изолейцина (I)), см., например, предварительные заявки США, а также WO 12/175741. В частности, связывающий MMP13 агент по изобретению, такой как ISVD и/или полипептид по изобретению, может содержать такое C–концевое удлинение, когда он образует C–концевую область белка, полипептида или другого соединения, или включающей их конструкции (см. например, указанные предварительные заявки США, а также WO 12/175741).
Связывающий MMP13 агент по изобретению может представлять собой иммуноглобулин, такой как одиночный вариабельный домен иммуноглобулина, полученный любым подходящим способом и из любого подходящего источника, и может, например, представлять собой природные VHH последовательности (т.е. из подходящего вида верблюдовых) или синтетические или полусинтетические аминокислотные последовательности, включая, но не ограничиваясь этим, “гуманизированные” (как определено в настоящей заявке) Нанотела или VHH последовательности, “камелизированные” (как определено в настоящей заявке) последовательности иммуноглобулинов (и, в частности, камелизированные последовательности вариабельных доменов тяжелых цепей), а также Нанотела, которые получены методами, такими как созревание аффинности (например, исходя из синтетических, рандомизированных или природных последовательностей иммуноглобулинов), CDR–прививка, маскировка поверхностных остатков, объединение фрагментов, происходящих из различных последовательностей иммуноглобулинов, ПЦР–сборка с использованием перекрывающихся праймеров и подобные методы для конструирования последовательностей иммуноглобулинов, хорошо известные квалифицированным специалистам; или с использованием любой подходящей комбинации любых из вышеуказанных, как описано далее в настоящей заявке. Также, когда иммуноглобулин включает VHH последовательность, указанный иммуноглобулин может быть соответствующим образом гуманизирован, как описано далее в настоящей заявке, для обеспечения одного или более дополнительных (частично или полностью) гуманизированных иммуноглобулинов по изобретению. Подобным образом, когда иммуноглобулин включает синтетическую или полусинтетическую последовательность (такую как частично гуманизированная последовательность), указанный иммуноглобулин необязательно может быть дополнительно соответствующим образом гуманизирован, также как описано в настоящей заявке, также для обеспечения одного или более дополнительных (частично или полностью) гуманизированных иммуноглобулинов по изобретению.
“Доменные антитела”, также известные как “Dab”, “Доменные Антитела” и “dAb” (термины “Доменные Антитела” и “dAb” используются как торговые марки группой компаний GlaxoSmithKline) описаны, например, в EP 0368684, Ward et al. (Nature 341: 544–546, 1989), Holt et al. (Tends in Biotechnology 21: 484–490, 2003) и WO 03/002609, а также, например, в WO 04/068820, WO 06/030220, WO 06/003388 и других опубликованных патентных заявках Domantis Ltd. Доменные антитела по существу соответствуют VH или VL доменам не–верблюдовых млекопитающих, в частности человеческим 4–цепочечным антителам. Для связывания с эпитопом в качестве одиночного антиген–связывающего домена, т.е. без спаривания с VL или VH доменом, соответственно, необходим специфический отбор на основании таких антиген–связывающих свойств, например, с использованием библиотек последовательностей человеческих одиночных VH или VL доменов. Доменные антитела имеют, подобно VHH, молекулярную массу от приблизительно 13 до приблизительно 16 кДа и, если они образованы из полностью человеческих последовательностей, не требуют гуманизации, например, для терапевтического применения для человека.
Также следует отметить, что, хотя и менее предпочтительно в контексте настоящего изобретения, поскольку они происходят не из млекопитающих, одиночные вариабельные домены могут происходить из некоторых видов акул (например, так называемые “IgNAR домены”, см., например, WO 05/18629).
Настоящее изобретение относится, в частности, к ISVD, где указанные ISVD выбраны из группы, состоящей из VHH, гуманизированных VHH и камелизированных VH.
Аминокислотные остатки VHH домена пронумерованы в соответствии с общей нумерацией для VH доменов в соответствии с Kabat et al. ("Sequence of proteins of immunological interest", US Public Health Services, NIH Bethesda, MD, Publication No. 91), применимой к VHH доменам из верблюдовых, как показано например, на Фиг. 2 в Riechmann and Muyldermans (J. Immunol. Methods 231: 25–38, 1999). Альтернативные способы нумерации аминокислотных остатков VH доменов, которые также можно применять аналогичным образом к VHH доменам, известны из уровня техники. Однако в настоящем описании, формуле изобретения и чертежах следуют нумерации в соответствии с Kabat, применяемой к VHH доменам, как описано выше, если не указано иное.
Следует отметить, что – как это хорошо известно из уровня техники для VH доменов и для VHH доменов – общее число аминокислотных остатков в каждой из CDR может варьироваться и может не соответствовать общему количеству аминокислотных остатков, указанному нумерацией по Kabat (т.е. в действительной последовательности одно или несколько положений в соответствии с нумерацией по Kabat могут быть незанятыми, или действительная последовательность может содержать больше аминокислотных остатков, чем количество, которое является возможным согласно нумерации по Kabat). Это означает, что, как правило, нумерация в соответствии с Kabat может соответствовать или не соответствовать действительной нумерации аминокислотных остатков в действительной последовательности. Общее число аминокислотных остатков в VH домене и VHH домене обычно должно быть в пределах от 110 до 120, часто от 112 до 115. Однако следует отметить, что более короткие и более длинные последовательности также могут быть подходящими для целей, описанных в настоящей заявке.
Что касается CDR, как хорошо известно из уровня техники, существует множество общепринятых способов для определения и описания CDR VH или VHH фрагмента, таких как определение по Kabat (которое основано на вариабельности последовательностей и наиболее широко используется) и определение по Chothia (которое основано на локализации структурных петлевых областей). См., например, веб–сайт http://www.bioinf.org.uk/abs/. Для целей настоящего описания и формулы изобретения CDR наиболее предпочтительно определяют на основании Abm определения (которое основано на программе моделирования антител “AbM” Oxford Molecular), поскольку это считается оптимальным компромиссом между определениями Kabat и Chothia (см. http://www.bioinf.org.uk/abs/). В контексте настоящей заявки, FR1 включает аминокислотные остатки в положениях 1–25, CDR1 включает аминокислотные остатки в положениях 26–35, FR2 включает аминокислоты в положениях 36–49, CDR2 включает аминокислотные остатки в положениях 50–58, FR3 включает аминокислотные остатки в положениях 59–94, CDR3 включает аминокислотные остатки в положениях 95–102, и FR4 включает аминокислотные остатки в положениях 103–113.
В контексте настоящего изобретения термин “одиночный вариабельный домен иммуноглобулина” или “одиночный вариабельный домен” включает полипептиды, которые происходят из не–человеческого источника, предпочтительно из верблюдовых, предпочтительно из антитела верблюдовых только с тяжелыми цепями. Они могут быть гуманизированными, как описано в настоящей заявке. Кроме того, термин включает полипептиды, происходящие из не–верблюдовых источников, например, мыши или человека, которые были “камелизированы”, как описано в настоящей заявке.
Следовательно, ISVD, такие как Доменные антитела и Нанотела (включая VHH домены) можно подвергнуть гуманизации. В частности, гуманизированные ISVD, такие как Нанотела (включая VHH домены), могут представлять собой ISVD, которые в общем виде определены в настоящей заявке, но в которых присутствует по меньшей мере один аминокислотный остаток (и, в частности, в по меньшей мере в одном из каркасных остатков), который является и/или который соответствует гуманизирующей замене (как определено в настоящей заявке). Потенциально полезные гуманизирующие замены можно определить путем сравнения последовательности каркасных областей природной VHH последовательности с соответствующей каркасной последовательностью одной или нескольких близкородственных человеческих VH последовательностей, после чего одну или несколько потенциально полезных гуманизирующих замен (или их комбинации), определенных таким образом, можно ввести в указанную VHH последовательность (любым способом, известным per se, как описано далее в настоящей заявке) и полученные гуманизированные VHH последовательности можно испытать на аффинность в отношении мишени, на стабильность, на легкость и уровень экспрессии и/или на другие желаемые свойства. Таким путем, при ограниченной степени проб и ошибок, специалист в данной области сможет определить другие подходящие гуманизирующие замены (или их подходящие комбинации) на основании раскрытия, представленного в настоящей заявке. Также, на основании вышеизложенного, (каркасные области) ISVD, такого как Нанотело (включая VHH домены), могут быть частично гуманизированными или полностью гуманизированными.
Другой особенно предпочтительный класс ISVD по изобретению включает ISVD с аминокислотной последовательностью, которая соответствует аминокислотной последовательности природного VH домена, но которая была “камелизированна”, т.е. путем замены одного или более аминокислотных остатков в аминокислотной последовательности природного VH домена из традиционного 4–цепочечного антитела одним или несколькими аминокислотными остатками, которые присутствуют в соответствующем положении (положениях) в VHH домене антитела только с тяжелыми цепями. Это можно осуществить способом, известным per se, что должно быть понятно квалифицированному специалисту, например, на основании описания, представленного в настоящей заявке. Такие “камелизирующие” замены предпочтительно вводятся в аминокислотных положениях, которые образуют и/или присутствуют на границе раздела VH–VL, и/или в положениях так называемых происходящих из Верблюдовых уникальных остатков, как определено в настоящей заявке (см. также например WO 94/04678 и Davies and Riechmann (1994 и 1996)). Предпочтительно, VH последовательность, которую используют в качестве исходного материала или исходной точки для образования или конструирования камелизированных одиночных вариабельных доменов иммуноглобулинов, предпочтительно представляет собой VH последовательность из млекопитающего, более предпочтительно VH последовательность человека, такую как VH3 последовательность. Однако следует отметить, что такие камелизированные одиночные вариабельные домены иммуноглобулинов по изобретению можно получить любым подходящим способом, известным per se, и, таким образом, они строго не ограничиваются полипептидами, которые получены с использованием полипептида, который включает природный VH домен, в качестве исходного материала. См. Davies and Riechmann (FEBS 339: 285–290, 1994; Biotechnol. 13: 475–479, 1995; Prot. Eng. 9: 531–537, 1996) и Riechmann and Muyldermans (J. Immunol. Methods 231: 25–38, 1999).
Например, опять же как описано далее в настоящей заявке, как “гуманизацию”, так и “камелизацию” можно осуществить путем обеспечения нуклеотидной последовательности, которая кодирует природный VHH домен или VH домен, соответственно, и затем замены способом, известным per se, одного или более кодонов в указанной нуклеотидной последовательности таким образом, чтобы новая нуклеотидная последовательность кодировала “гуманизированный” или “камелизированный” ISVD по изобретению, соответственно. Эту нуклеиновую кислоту затем можно экспрессировать способом, известным per se, чтобы обеспечить желаемые ISVD по изобретению. Альтернативно, на основании аминокислотной последовательности природного VHH домена или VH домена, соответственно, аминокислотную последовательность желаемых гуманизированных или камелизированных ISVD по изобретению, соответственно, можно сконструировать и затем синтезировать de novo с использованием методов пептидного синтеза, известных per se. Также, на основании аминокислотной последовательности или нуклеотидной последовательности природного VHH домена или VH домена, соответственно, нуклеотидную последовательность, кодирующую желаемые гуманизированные или камелизированные ISVD по изобретению, соответственно, можно сконструировать и затем синтезировать de novo с использованием методов синтеза нуклеиновых кислот, известных per se, после чего полученную таким образом нуклеиновую кислоту можно экспрессировать способом, известным per se, чтобы обеспечить желаемые ISVD по изобретению.
ISVD, такие как Доменные антитела и Нанотела (включая VHH домены и гуманизированные VHH домены), также можно подвергнуть созреванию аффинности путем внесения одного или более изменений в аминокислотную последовательность одной или нескольких CDR, где такие изменения приводят к улучшенной аффинности полученного ISVD в отношении его соответствующего антигена, по сравнению с соответствующей исходной молекулой. Молекулы ISVD с созревшей аффинностью по изобретению можно получить способами, известными из уровня техники, например, как описано by Marks et al. (Biotechnology 10:779–783, 1992), Barbas, et al. (Proc. Nat. Acad. Sci, USA 91: 3809–3813, 1994), Shier et al. (Gene 169: 147–155, 1995), Yelton et al. (Immunol. 155: 1994–2004, 1995), Jackson et al. (J. Immunol. 154: 3310–9, 1995), Hawkins et al. (J. Mol. Biol. 226: 889 896, 1992), Johnson and Hawkins (Affinity maturation of antibodies using phage display, Oxford University Press, 1996).
Способ конструирования/выбора и/или получения полипептида, исходя из ISVD, такого как VH, VL, VHH, Доменное антитело или Нанотело, также указан в настоящей заявке как “задание формата” указанного ISVD; и ISVD, который является частью полипептида, указан как “с заданным форматом” или находящийся “в формате” указанного полипептида. Примеры способов, которыми можно задать формат ISVD, и примеры таких форматов будут понятны квалифицированным специалистам на основании раскрытия, представленного в настоящей заявке; и такой одиночный вариабельный домен иммуноглобулина в заданном формате составляет еще один аспект изобретения.
Предпочтительные CDR представлены в Таблице A–2.
В частности, настоящее изобретение относится к ISVD, описанному в настоящей заявке, где указанный ISVD специфически связывается с MMP13 и по существу состоит из 4 каркасных областей (FR1–FR4, соответственно) и 3 определяющих комплементарность областей (CDR1–CDR3, соответственно), в котором
(i) CDR1 выбрана из группы, состоящей из
(a) SEQ ID NO: 27, 28, 25, 26, 23, 29, 30, 31, 32, 33, 34, 35, 36 и 24; и
(b) аминокислотных последовательностей, которые имеют 1, 2 или 3 аминокислотных отличия от SEQ ID NO: 27, 28, 25, 26, 23, 29, 30, 31, 32, 33, 34, 35, 36 и 24;
(ii) CDR2 выбрана из группы, состоящей из
(c) SEQ ID NO: 42, 43, 40, 41, 37, 44, 45, 46, 47, 48, 49, 50, 51, 38 и 39; и
(d) аминокислотных последовательностей, которые имеют 1, 2 или 3 аминокислотных отличия от SEQ ID NO: 42, 43, 40, 41, 37, 44, 45, 46, 47, 48, 49, 50, 51, 38 и 39; и
(iii) CDR3 выбрана из группы, состоящей из
(e) SEQ ID NO: SEQ ID NO: 56, 107, 57, 54, 106, 55, 52, 58, 59, 60, 61, 62, 63, 64, 65, 66 и 53; и
(f) аминокислотных последовательностей, которые имеют 1, 2, 3 или 4 аминокислотных отличия от SEQ ID NO: 56, 107, 57, 54, 106, 55, 52, 58, 59, 60, 61, 62, 63, 64, 65, 66 и 53.
В частности, настоящее изобретение относится к ISVD, описанному в настоящей заявке, где указанный ISVD специфически связывается с MMP13 и по существу состоит из 4 каркасных областей (FR1–FR4, соответственно) и 3 определяющих комплементарность областей (CDR1–CDR3, соответственно), в котором
(i) CDR1 выбрана из группы, состоящей из
(a) SEQ ID NO: 23; и
(b) аминокислотной последовательности, которая имеет 1 аминокислотное отличие от SEQ ID NO: 23, где в положении 7 Y заменен на R;
(ii) CDR2 выбрана из группы, состоящей из
(c) SEQ ID NO: 37; и
(d) аминокислотных последовательностей, которые имеют 1, 2 или 3 аминокислотных отличия от SEQ ID NO: 37, где
– в положении 4 V заменен на T;
– в положении 5 G заменен на A; и/или
– в положении 9 N заменен на H;
(iii) CDR3 выбрана из группы, состоящей из
(e) SEQ ID NO: 52; и
(f) аминокислотной последовательности, которая имеет 1 аминокислотное отличие от SEQ ID NO: 52, где в положении 6 Y заменен на S.
В частности, настоящее изобретение относится к ISVD, описанному в настоящей заявке, где указанный ISVD специфически связывается с MMP13 и по существу состоит из 4 каркасных областей (FR1–FR4, соответственно) и 3 определяющих комплементарность областей (CDR1–CDR3, соответственно), в котором
(i) CDR1 представляет собой SEQ ID NO: 26;
(ii) CDR2 представляет собой SEQ ID NO: 41; и
(iii) CDR3 выбрана из группы, состоящей из
(e) SEQ ID NO: 55; и
(f) аминокислотной последовательности, которая имеет 1 или 2 аминокислотных отличия от SEQ ID NO: 55, где
– в положении 8 N заменен на Q или S; и/или
– в положении 19 N заменен на V или Q.
В частности, настоящее изобретение относится к ISVD, описанному в настоящей заявке, где указанный ISVD специфически связывается с MMP13 и по существу состоит из 4 каркасных областей (FR1–FR4, соответственно) и 3 определяющих комплементарность областей (CDR1–CDR3, соответственно), в котором
(i) CDR1 представляет собой SEQ ID NO: 28;
(ii) CDR2 представляет собой SEQ ID NO: 43; и
(iii) CDR3 выбрана из группы, состоящей из
(e) SEQ ID NO: 57; и
(f) аминокислотной последовательности, которая имеет 1, 2, 3 или 4 аминокислотных отличия от SEQ ID NO: 57, где
– в положении 10 D заменен на E, G, A, P, T, R, M, W или Y;
– в положении 16 M заменен на A, R, N, D, E, Q, Z, G, I, L, K, F, P, S, W, Y или V;
– в положении 17 D заменен на A, R, N, C, E, Q, Z, G, H, I, L, K, M, S, T, W, Y или V; и/или
– в положении 18 Y заменен на A, R, N, D, C, E, Q, Z, G, H, I, L, K, M, F, P, S, T, W или V.
В частности, настоящее изобретение относится к ISVD, описанному в настоящей заявке, где указанный ISVD специфически связывается с MMP13 и по существу состоит из 4 каркасных областей (FR1–FR4, соответственно) и 3 определяющих комплементарность областей (CDR1–CDR3, соответственно), в котором
– CDR1 выбрана из группы, состоящей из SEQ ID NO: 27, 28, 25, 26, 23, 29, 30, 31, 32, 33, 34, 35, 36 и 24;
– CDR2 выбрана из группы, состоящей из SEQ ID NO: 42, 43, 40, 41, 37, 44, 45, 46, 47, 48, 49, 50, 51, 38 и 39; и
– CDR3 выбрана из группы, состоящей из SEQ ID NO: 56, 107, 57, 54, 106, 55, 52, 58, 59, 60, 61, 62, 63, 64, 65, 66 и 53.
В частности, настоящее изобретение относится к ISVD, описанному в настоящей заявке, где указанный ISVD специфически связывается с MMP13 и по существу состоит из 4 каркасных областей (FR1–FR4, соответственно) и 3 определяющих комплементарность областей (CDR1–CDR3, соответственно), в котором указанный ISVD выбран из группы ISVD, где:
– CDR1 представляет собой SEQ ID NO: 27, CDR2 представляет собой SEQ ID NO: 42 и CDR3 представляет собой SEQ ID NO: 56;
– CDR1 представляет собой SEQ ID NO: 28, CDR2 представляет собой SEQ ID NO: 43 и CDR3 представляет собой SEQ ID NO: 107;
– CDR1 представляет собой SEQ ID NO: 28, CDR2 представляет собой SEQ ID NO: 43 и CDR3 представляет собой SEQ ID NO: 57;
– CDR1 представляет собой SEQ ID NO: 25, CDR2 представляет собой SEQ ID NO: 40 и CDR3 представляет собой SEQ ID NO: 54;
– CDR1 представляет собой SEQ ID NO: 26, CDR2 представляет собой SEQ ID NO: 41 и CDR3 представляет собой SEQ ID NO: 106;
– CDR1 представляет собой SEQ ID NO: 26, CDR2 представляет собой SEQ ID NO: 41 и CDR3 представляет собой SEQ ID NO: 55;
– CDR1 представляет собой SEQ ID NO: 23, CDR2 представляет собой SEQ ID NO: 37 и CDR3 представляет собой SEQ ID NO: 52;
– CDR1 представляет собой SEQ ID NO: 26, CDR2 представляет собой SEQ ID NO: 48 и CDR3 представляет собой SEQ ID NO: 62;
– CDR1 представляет собой SEQ ID NO: 26, CDR2 представляет собой SEQ ID NO: 41 и CDR3 представляет собой SEQ ID NO: 63;
– CDR1 представляет собой SEQ ID NO: 29, CDR2 представляет собой SEQ ID NO: 44 и CDR3 представляет собой SEQ ID NO: 58;
– CDR1 представляет собой SEQ ID NO: 30, CDR2 представляет собой SEQ ID NO: 45 и CDR3 представляет собой SEQ ID NO: 58;
– CDR1 представляет собой SEQ ID NO: 31, CDR2 представляет собой SEQ ID NO: 46 и CDR3 представляет собой SEQ ID NO: 59;
– CDR1 представляет собой SEQ ID NO: 32, CDR2 представляет собой SEQ ID NO: 47 и CDR3 представляет собой SEQ ID NO: 60;
– CDR1 представляет собой SEQ ID NO: 33, CDR2 представляет собой SEQ ID NO: 41 и CDR3 представляет собой SEQ ID NO: 61;
– CDR1 представляет собой SEQ ID NO: 34, CDR2 представляет собой SEQ ID NO: 49, и CDR3 представляет собой SEQ ID NO: 64;
– CDR1 представляет собой SEQ ID NO: 35, CDR2 представляет собой SEQ ID NO: 50 и CDR3 представляет собой SEQ ID NO: 65;
– CDR1 представляет собой SEQ ID NO: 36, CDR2 представляет собой SEQ ID NO: 51 и CDR3 представляет собой SEQ ID NO: 66;
– CDR1 представляет собой SEQ ID NO: 23, CDR2 представляет собой SEQ ID NO: 39 и CDR3 представляет собой SEQ ID NO: 53; и
– CDR1 представляет собой SEQ ID NO: 24, CDR2 представляет собой SEQ ID NO: 38 и CDR3 представляет собой SEQ ID NO: 52.
В частности, настоящее изобретение относится к ISVD, описанному в настоящей заявке, где указанный ISVD специфически связывается с MMP13 и по существу состоит из 4 каркасных областей (FR1–FR4, соответственно) и 3 определяющих комплементарность областей (CDR1–CDR3, соответственно), в котором CDR1 представляет собой SEQ ID NO: 27, CDR2 представляет собой SEQ ID NO: 42 и CDR3 представляет собой SEQ ID NO: 56.
В частности, настоящее изобретение относится к ISVD, описанному в настоящей заявке, где указанный ISVD специфически связывается с MMP13 и по существу состоит из 4 каркасных областей (FR1–FR4, соответственно) и 3 определяющих комплементарность областей (CDR1–CDR3, соответственно), где указанный ISVD выбран из группы, состоящей из SEQ ID NO: 111, 11, 112, 12, 109, 9, 110, 10, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2, 3, 4, 5, 6, 7 и 8.
Должно быть понятно, что, без ограничения, одиночные вариабельные домены иммуноглобулинов по настоящему изобретению можно использовать в качестве "структурного блока" для получения полипептида, который, необязательно, может содержать один или более дополнительных одиночных вариабельных доменов иммуноглобулина, которые могут служить в качестве структурного блока (т.е. против того же самого или другого эпитопа на MMP13 и/или против одного или более других антигенов, белков или мишеней, отличных от MMP13).
ПОЛИПЕПТИД
Полипептид по изобретению включает по меньшей мере один ISVD, связывающийся с MMP, предпочтительно MMP13, например два ISVD, связывающиеся с MMP13, и предпочтительно также по меньшей мере один ISVD, связывающийся Аггреканом, более предпочтительно два ISVD, связывающиеся с Аггреканомом. В полипептиде по изобретению ISVD могут быть непосредственно связаны или связаны через линкер. Еще более предпочтительно, полипептид по изобретению включает C–концевое удлинение. Как будет подробно описано ниже, C–концевое удлинение по существу предотвращает/удаляет связывание предсуществующих антител/факторов в большинстве образцов от субъектов–людей/пациентов. C–концевое удлинение присутствует C–терминально от последнего аминокислотного остатка (обычно серинового остатка) последнего (наиболее C–терминально расположенного) ISVD.
Как более подробно описано ниже, ISVD могут происходить из VHH, VH или VL домена, однако, ISVD выбирают таким образом, чтобы они не образовывали комплементарных пар из VH и VL доменов в полипептидах по изобретению. Нанотело, VHH и гуманизированный VHH необычны тем, что они происходят из природных верблюдовых антител, которые не содержат легких цепей, и действительно эти домены неспособны к ассоциации с легкими цепями верблюдовых с образованием комплементарных VHH и VL пар. Таким образом, полипептиды по настоящему изобретению не включают комплементарные ISVD и/или не образуют комплементарных ISVD пар, таких как, например, комплементарные VH/VL пары.
Как правило, полипептиды или конструкции, которые включают или по существу состоят из одного структурного блока, например одного ISVD или одного Нанотела, будут указаны как “одновалентные” полипептиды и “одновалентные конструкции”, соответственно. Полипептиды или конструкции, которые включают два или более структурных блоков (таких как, например, ISVD), также будут указаны как “мультивалентные” полипептиды или конструкции, и структурные блоки/ISVD, присутствующие в таких полипептидах или конструкциях, также будут далее указаны как находящиеся в “мультивалентном формате”. Например, “двухвалентный” полипептид может включать два ISVD, необязательно связанных через линкерную последовательность, тогда как “трехвалентный” полипептид может включать три ISVD, необязательно связанные через две линкерные последовательности; при этом “четырехвалентный” полипептид может включать четыре ISVD, необязательно связанные через три линкерные последовательности, и т.д.
В мультивалентном полипептиде два или более ISVD могут быть одинаковыми или отличными друг от друга и могут быть направлены против одного и того же антигена или антигенной детерминанты (например против одной и той же части (частей) или эпитопа (эпитопов) или против разных частей или эпитопов) или, альтернативно, могут быть направлены против разных антигенов или антигенных детерминант; или могут включать любую подходящую комбинацию вышеуказанного. Полипептиды и конструкции, которые содержат по меньшей мере два структурных блока (таких как, например, ISVD), в которых по меньшей мере один структурный блок направлен против первого антигена (например, MMP13) и по меньшей мере один структурный блок направлен против второго антигена (т.е. отличного от MMP13), также будут указаны как “мультиспецифические” полипептиды и конструкции, и структурные блоки (такие как, например, ISVD), присутствующие в таких полипептидах и конструкциях, также будут указаны далее как находящиеся в “мультиспецифическом формате”. Таким образом, например, “биспецифический” полипептид по изобретению представляет собой полипептид, который включает по меньшей мере один ISVD, направленный против первого антигена (например, MMP13), и по меньшей мере еще один ISVD, направленный против второго антигена (т.е. отличного от MMP13), тогда как “триспецифический” полипептид по изобретению представляет собой полипептид, который включает по меньшей мере один ISVD, направленный против первого антигена (например, MMP13), по меньшей мере еще один ISVD, направленный против второго антигена (т.е. отличного от MMP13), и по меньшей мере еще один ISVD, направленный против третьего антигена (т.е. отличного и от MMP13 и от второго антигена); и т.д.
В одном аспекте настоящее изобретение относится к полипептиду, включающему два или более ISVD, которые специфически связываются с MMP13, где
a) по меньшей мере "первый" ISVD специфически связывается с первой антигенной детерминантой, эпитопом, частью, доменом, субъединицей или конформацией MMP13; предпочтительно указанный "первый" ISVD, специфически связывающийся с MMP13, выбран из группы, состоящей из SEQ ID NO: 111, 11, 110, 10, 112, 12, 109, 9, 13, 14, 15, 16, 17, 18, 19, 20, 21 и 22; и где
b) по меньшей мере "второй" ISVD специфически связывается с второй антигенной детерминантой, эпитопом, частью, доменом, субъединицей или конформацией MMP13, отлично от первой антигенной детерминанты, эпитопа, части, домена, субъединицы или конформации, соответственно, предпочтительно указанный "второй" ISVD, специфически связывающийся с MMP13, выбран из группы, состоящей из SEQ ID NO: 1, 2, 3, 4, 5, 6, 7 и 8.
В одном аспекте, настоящее изобретение относится к полипептиду, включающему два или более ISVD, которые специфически связываются с MMP13, выбранному из группы, состоящей из SEQ ID NO: 160–165, предпочтительно SEQ ID NO: 160 (см. Таблицу A–3).
"Мультипаратопные" полипептиды и "мультипаратопные" конструкции, такие как, например, "бипаратопные" полипептиды или конструкции и "трипаратопные" полипептиды или конструкции, включают или по существу состоят из двух или более структурных блоков, каждый из которых имеет разный паратоп.
Соответственно, ISVD по изобретению, которые связываются с MMP13, могут быть в по существу выделенной форме (как определено в настоящей заявке), или они могут образовывать часть конструкции или полипептида, которая может включать или по существу состоять из одного или более ISVD, которые связываются с MMP13 и которые, необязательно, могут также включать одну или несколько дополнительных аминокислотных последовательностей (все необязательно связаны через один или несколько подходящих линкеров). Настоящее изобретение относится к полипептиду или конструкции, которая включает или по существу состоит из по меньшей мере одного ISVD в соответствии с изобретением, например одного или более ISVD по изобретению (или их подходящих фрагментов), связывающихся с MMP13.
Один или несколько ISVD по изобретению можно использовать в качестве структурного блока в таком полипептиде или конструкции для получения одновалентного, мультивалентного или мультипаратопного полипептида или конструкции по изобретению, соответственно, как описано в настоящей заявке. Настоящее изобретение, таким образом, также относится к полипептиду, который представляет собой одновалентную конструкцию, включающую или по существу состоящую из одного одновалентного полипептида или ISVD по изобретению.
Настоящее изобретение, таким образом, также относится к полипептиду или конструкции, которые представляют собой мультивалентный полипептид или мультивалентную конструкцию, соответственно, например, двухвалентный или трехвалентный полипептид или конструкцию, включающий или по существу состоящий из двух или более ISVD по изобретению (что касается мультивалентных и мультиспецифических полипептидов, содержащих один или несколько VHH доменов, и их получения, см. также Conrath et al. (J. Biol. Chem. 276: 7346–7350, 2001), а также, например, WO 96/34103, WO 99/23221 и WO 2010/115998).
В одном аспекте, в его самой простой форме, мультивалентный полипептид или конструкция по изобретению представляет собой двухвалентный полипептид или конструкцию по изобретению, включающую первый ISVD, такой как Нанотело, направленное против MMP13, и идентичный второй ISVD, такой как Нанотело, направленное против MMP13, где указанный первый и указанный второй ISVD, такие как Нанотела, необязательно могут быть связаны через линкерную последовательность (как определено в настоящей заявке). В его самой простой форме мультивалентный полипептид или конструкция по изобретению может представлять собой трехвалентный полипептид или конструкцию по изобретению, включающую первый ISVD, такой как Нанотело, направленное против MMP13, идентичный второй ISVD, такой как Нанотело, направленное против MMP13, и идентичный третий ISVD, такой как Нанотело, направленное против MMP13, где указанные первый, второй и третий ISVD, такие как Нанотела, необязательно могут быть связаны через одну или несколько и, в частности, две линкерные последовательности. В одном аспекте изобретение относится к полипептиду или конструкции, которые включают или по существу состоят из по меньшей мере двух ISVD в соответствии с изобретением, например 2, 3 или 4 ISVD (или их подходящих фрагментов), связывающих MMP13. Два или более ISVD необязательно могут быть связаны через один или несколько пептидных линкеров.
В другом аспекте мультивалентный полипептид или конструкция по изобретению может представлять собой биспецифический полипептид или конструкцию по изобретению, включающие первый ISVD, такой как Нанотело, направленное против MMP13, и второй ISVD, такой как Нанотело, направленное против второго антигена, такого как, например, Аггрекан, где указанные первый и второй ISVD, такие как Нанотела, необязательно могут быть связаны через линкерную последовательность (как определено в настоящей заявке); при этом мультивалентный полипептид или конструкция по изобретению также может представлять собой триспецифический полипептид или конструкцию по изобретению, включающие первый ISVD, такой как Нанотело, направленное против MMP13, второй ISVD, такой как Нанотело, направленное против второго антигена, такого как, например, Аггрекан, и третий ISVD, такой как Нанотело, направленное против третьего антигена, где указанные первый, второй и третий ISVD, такие как Нанотела, необязательно могут быть связаны через одну или несколько, в частности, две линкерные последовательности.
Изобретение также относится к мультивалентному полипептиду, который включает или (по существу) состоит из по меньшей мере одного ISVD (или его подходящих фрагментов), связывающегося с MMP13, предпочтительно MMP13 человека, и по меньшей мере одного дополнительного ISVD, такого как ISVD, связывающийся с Аггреканом.
Особенно предпочтительные трехвалентные биспецифические полипептиды или конструкции в соответствии с изобретением представляют собой такие, которые показаны в примерах, описанных в настоящей заявке, и в Таблице A–3.
В предпочтительном аспекте полипептид или конструкция по изобретению включает или по существу состоит из по меньшей мере двух ISVD, где указанные по меньшей мере два ISVD могут быть одинаковыми или отличными друг от друга, но из которых по меньшей мере один ISVD направлен против MMP13.
Два или более ISVD, присутствующих в мультивалентном полипептиде или конструкции по изобретению, могут состоять из последовательности вариабельного домена легкой цепи (например, VL–последовательности) или последовательности вариабельного домена тяжелой цепи (например, VH–последовательности); они могут состоять из последовательности вариабельного домена тяжелой цепи, которая происходит из традиционного четырехцепочечного антитела, или из последовательности вариабельного домена тяжелой цепи, которая происходит из антитела только с тяжелыми цепями. В предпочтительном аспекте они состоят из Доменного антитела (или пептида, который является подходящим для использования в качестве доменного антитела), из однодоменного антитела (или пептида, который является подходящим для использования в качестве однодоменного антитела), из “dAb” (или пептида, который является подходящим для использования в качестве dAb), из Нанотела® (включая, но не ограничиваясь этим, VHH), из гуманизированной VHH последовательности, из камелизированной VH последовательности; или из VHH последовательности, которая получена методом созревания аффинности. Два или более одиночных вариабельных доменов иммуноглобулина могут состоять из частично или полностью гуманизированного Нанотела или частично или полностью гуманизированной VHH.
В одном аспекте изобретения первый ISVD и второй ISVD, присутствующие в мультипаратопном (предпочтительно бипаратопном или трипаратопном) полипептиде или конструкции по изобретению, не конкурируют (перекрестно) друг с другом за связывание с MMP13 и, таким образом, относятся к разным семействам. Соответственно, настоящее изобретение относится к мультипаратопному (предпочтительно бипаратопному) полипептиду или конструкции, включающим два или более ISVD, где каждый ISVD относится к разному семейству. В одном аспекте первый ISVD этого мультипаратопного (предпочтительно бипаратопного) полипептида или конструкции по изобретению не блокирует перекрестным образом связывание с MMP13 второго ISVD этого мультипаратопного (предпочтительно бипаратопного) полипептида или конструкции по изобретению, и/или связывание первого ISVD с MMP13 не блокируется перекрестным образом вторым ISVD. Еще в одном аспекте первый ISVD мультипаратопного (предпочтительно бипаратопного) полипептида или конструкции по изобретению перекрестно блокирует связывание MMP13 вторым ISVD этого мультипаратопного (предпочтительно бипаратопного) полипептида или конструкции по изобретению, и/или связывание MMP13 первым ISVD перекрестно блокируется вторым ISVD.
В особенно предпочтительном аспекте полипептид или конструкция по изобретению включает или по существу состоит из трех или более ISVD, из которых по меньшей мере два ISVD направлены против MMP13. Должно быть понятно, что указанные по меньшей мере два ISVD, направленные против MMP13, могут быть одинаковыми или отличными друг от друга, могут быть направлены против одного и того же эпитопа или разных эпитопов MMP13, могут принадлежать к одной и той же эпитопной группе или к разным эпитопным группам и/или могут связываются с одним и тем же или с разными доменами MMP13.
В предпочтительном аспекте полипептид или конструкция по изобретению включает или по существу состоит из по меньшей мере двух ISVD, связывающихся с MMP13, где указанные по меньшей мере два ISVD могут быть одинаковыми или отличными друг от друга, которые независимо выбраны из группы, состоящей из SEQ ID NO: 111, 11, 110, 10, 112, 12, 109, 9, 13, 14, 15, 16, 17, 18, 19, 20, 21 и 22 и SEQ ID NO: 1, 2, 3, 4, 5, 6, 7 и 8, более предпочтительно указанные по меньшей мере два ISVD независимо выбраны из группы, состоящей из SEQ ID NO: 111, 11, 110, 10, 112, 12, 109, 9 и 1, и/или по меньшей мере один ISVD выбран из группы, состоящей из SEQ ID NO: 111, 11, 110, 10, 112, 12, 109, 9, 13, 14, 15, 16, 17, 18, 19, 20, 21 и 22, и по меньшей мере один ISVD выбран из группы, состоящей из SEQ ID NO: 1, 2, 3, 4, 5, 6, 7 и 8.
Еще в одном аспекте изобретение относится к мультипаратопному (предпочтительно бипаратопному) полипептиду или конструкции, включающим два или более ISVD, направленных против MMP13, которые связываются с тем же эпитопом (эпитопами), с которым связывается любая из SEQ ID NO: 111, 11, 110, 10, 112, 12, 109, 9, 13, 14, 15, 16, 17, 18, 19, 20, 21 и 22, или с которым связывается любая из SEQ ID NOs: 1, 2, 3, 4, 5, 6, 7 и 8.
Еще в одном аспекте изобретение относится к полипептиду, описанному в настоящей заявке, где указанный полипептид имеет идентичность последовательности по меньшей мере 80%, 90%, 95% или 100% (более предпочтительно по меньшей мере 95% и наиболее предпочтительно 100%) с любой из SEQ ID NO: 160–165 (т.е. 160, 161, 162, 163, 164 или 165) и 176–192 (т.е. 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191 или 192), предпочтительно SEQ ID NO: 192.
УДЕРЖИВАНИЕ
В данной области техники существует потребность в эффективных методах лечения расстройств, поражающих хрящ в суставах, таких как остеоартрит. Даже при введении интраартикулярно, время удерживания большинства лекарственных средств для лечения пораженного хряща является недостаточным. Авторы настоящего изобретения предположили, что эффективность терапевтического препарата, такого как конструкция, полипептид и ISVD по изобретению, можно было бы значительно повысить путем связывания терапевтического препарата с группой, которая могла бы "заякорить" лекарственное средство в суставе и, следовательно, увеличить период удерживания лекарственного средства, но которая не должна негативно влиять на эффективность указанного терапевтического препарата (эта группа в настоящей заявке также указана как "заякоривающийся в хряще белок" или "CAP"). Эта концепция заякоривания повышает не только эффективность лекарственного средства, но также функциональную специфичность в отношении больного сустава путем снижения токсичности и побочных эффектов, расширяя таким образом количество возможных полезных лекарственных средств.
Предполагается, что формат молекулы для клинического использования включает один или два структурных блока, таких как ISVD, связывающие MMP13, и один или несколько структурных блоков, например ISVD, с таким удерживающим способом действия, и возможно другие компоненты. В настоящем изобретении продемонстрировано, что такие форматы поддерживают как связывание MMP13, так и терапевтический эффект, например, ингибиторную активность, а также свойства удерживания. Один или несколько структурных блоков, таких как ISVD, с удерживающим способом действия могут представлять собой любой структурный блок, обладающий удерживающим эффектом ("CAP структурный блок") в заболеваниях, в которые вовлечен MMP13, таких как артритное заболевание, остеоартрит, спондилоэпиметафизарная дисплазия, дегенерация поясничного диска, дегенеративное заболевание суставов, ревматоидный артрит, рассекающий остеохондрит, аггреканопатии и метастазы опухолей.
"CAP структурный блок" используется для направления, заякоривания и/или удерживания других, например терапевтических, структурных блоков, таких как ISVD, связывающихся с MMP13 на желаемом участке, например в суставе, где указанный другой, например терапевтический, структурный блок, должен проявлять свой эффект, например связывание и/или ингибирование активности MMP13.
Авторы настоящего изобретения также предположили, что Аггрекан–связывающие агенты, такие как ISVD, связывающие Аггрекан, потенциально могут функционировать как такой якорь, хотя Аггрекан сильно гликозилируется и разрушается при различных расстройствах, поражающих хрящ в суставах. Кроме того, учитывая высокие затраты и трудоемкие испытания в различных животных моделях, которые необходимы до того, как лекарственное средство может быть одобрено для клинического применения, такие Аггрекан– связывающие агенты предпочтительно должны обладать широкой перекрестной реактивностью, например, Аггрекан–связывающие агенты должны связываться с Аггреканом из различных видов.
С использованием различных оригинальных способов иммунизации, скрининга и характеризации авторы настоящего изобретения смогли идентифицировать различные Аггрекан–связывающие агенты с превосходными свойствами селективности, стабильности и специфичности, которые обеспечивали возможность пролонгированного удерживания и активности в суставе.
В одном аспекте настоящее изобретение относится к способу для уменьшения и/или ингибирования оттока композиции, полипептида или конструкции из сустава, где указанный способ включает введение фармацевтически активного количества по меньшей мере одного полипептида в соответствии с изобретением, конструкции в соответствии с изобретением или композиции в соответствии с изобретением субъекту, нуждающемуся в этом.
В настоящем изобретении термин "уменьшение и/или ингибирование оттока" означает уменьшение и/или ингибирование выходящего потока композиции, полипептида или конструкции из сустава наружу. Предпочтительно, отток уменьшается и/или ингибируется по меньшей мере на 10%, например, по меньшей мере на 20%, 30%, 40% или 50% или даже более, например, по меньшей мере на 60%, 70%, 80%, 90% или даже 100%, по сравнению с оттоком вышеуказанной композиции, полипептида или конструкции из сустава в таких же условиях, но без присутствия Аггрекан–связывающего агента по изобретению, например ISVD(s), связывающего Аггрекан.
Наряду с заболеваниями, в которые вовлечен MMP13, такими как артритное заболевание, остеоартрит, спондилоэпиметафизарная дисплазия, дегенерация поясничного диска, дегенеративное заболевание суставов, ревматоидный артрит, рассекающий остеохондрит, аггреканопатии и метастазы опухолей, предполагается, что Аггрекан–связывающий агент по изобретению также можно использовать при других различных заболеваниях, поражающих хрящ, таких как артропатии и хондродистрофии, артритное заболевание (такое как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отслоение), ахондроплазия, реберный хондрит, спондилоэпиметафизарная дисплазия, межпозвоночная грыжа, дегенерация поясничного диска, дегенеративное заболевание суставов и рецидивирующий полихондрит (в общем виде указаны в настоящей заявке как "Аггрекан–ассоциированные заболевания").
CAP структурный блок, например, ISVD(s), связывающий Аггрекан, предпочтительно связывается с хрящевой тканью, такой как хрящ и/или мениск. В предпочтительном аспекте CAP структурный блок является перекрестно–реагирующим в отношении других видов и специфически связывается с одним или несколькими из Аггрекана человека (SEQ ID NO: 105), Аггрекана собаки, Аггрекана быка, Аггрекана крысы; Аггрекана свиньи; Аггрекана мыши, Аггрекана кролика; Аггрекана яванского макака и/или Аггрекана макака–резус. Соответствующую информацию о структуре Аггрекана можно найти, например, по номерам доступа (UniProt), показанным в Таблице 2 ниже.
Предпочтительный CAP структурный блок представляет собой ISVD, связывающийся с Аггреканом, предпочтительно Аггреканом человека, предпочтительно представленный SEQ ID NO: 105, как показано в Таблице B.
Настоящее изобретение, таким образом, относится к полипептиду или конструкции в соответствии с изобретением, дополнительно включающим по меньшей мере один CAP структурный блок.
Настоящее изобретение, таким образом, относится к полипептиду или конструкции в соответствии с изобретением, дополнительно включающим по меньшей мере один ISVD, специфически связывающийся с Аггреканом, такой, который показан в таблице E, и предпочтительно выбранный из ISVD, представленных SEQ ID NO: 166 до 168.
В частности, настоящее изобретение относится к ISVD, специфически связывающемуся с Аггреканом, где указанный ISVD по существу состоит из 4 каркасных областей (FR1–FR4, соответственно) и 3 определяющих комплементарность областей (CDR1–CDR3, соответственно), где указанный ISVD выбран из группы ISVD, где (a) CDR1 представляет собой SEQ ID NO: 169, CDR2 представляет собой SEQ ID NO: 170 и CDR3 представляет собой SEQ ID NO: 171; и (b) CDR1 представляет собой SEQ ID NO: 172, CDR2 представляет собой SEQ ID NO: 173 и CDR3 представляет собой SEQ ID NO: 174.
В одном аспекте настоящее изобретение относится к полипептиду, описанному в настоящей заявке, включающему по меньшей мере 2 ISVD, специфически связывающихся с Аггреканом.
В одном аспекте настоящее изобретение относится к полипептиду, описанному в настоящей заявке, включающему по меньшей мере 2 ISVD, специфически связывающихся Аггреканом, где указанные по меньшей мере 2 ISVD, специфически связывающиеся Аггреканом, могут быть одинаковыми или отличными друг от друга.
В одном аспекте настоящее изобретение относится к полипептиду, описанному в настоящей заявке, включающему по меньшей мере 2 ISVD, специфически связывающихся с Аггреканом, где указанные по меньшей мере 2 ISVD, специфически связывающиеся с Аггреканом, независимо выбраны из группы, состоящей из SEQ ID NO: 166–168.
В одном аспекте настоящее изобретение относится к полипептиду, описанному в настоящей заявке, включающему по меньшей мере 2 ISVD, специфически связывающихся с Аггреканом, где указанные по меньшей мере 2 ISVD, специфически связывающиеся с Аггреканом, представлены SEQ ID NO: 166–168.
В одном аспекте настоящее изобретение относится к полипептиду, описанному в настоящей заявке, включающему ISVD, специфически связывающийся с Аггреканом, где указанный ISVD, специфически связывающийся с Аггреканом, специфически связывается с Аггреканом человека [SEQ ID NO: 105].
В одном аспекте настоящее изобретение относится к полипептиду, описанному в настоящей заявке, где указанный ISVD, специфически связывающийся с Аггреканом, специфически связывается с Аггреканом человека (SEQ ID NO: 105), Аггреканом собаки, Аггреканом быка, Аггреканом крысы; Аггреканом свиньи; Аггреканом мыши, Аггреканом кролика; Аггреканом яванского макака и/или Аггреканом макака–резус.
В одном аспекте настоящее изобретение относится к полипептиду, описанному в настоящей заявке, где указанный ISVD, специфически связывающийся с Аггреканом, предпочтительно связывается с хрящевой тканью, такой как хрящ и/или мениск.
Должно быть понятно, что ISVD, полипептид и конструкция по изобретению предпочтительно являются стабильными. Стабильность полипептида, конструкции или ISVD по изобретению можно измерить при помощи обычных анализов, известных специалистам в данной области. Типичные анализы включают (без ограничения) анализы, в которых определяют активность указанного полипептида, конструкции или ISVD, с последующей инкубацией в синовиальной жидкости в течение желаемого периода времени, после чего снова определяют активность, например, как подробно описано в разделе Примеры.
В одном аспекте настоящее изобретение относится к ISVD, полипептиду или конструкции по изобретению со стабильностью в течение по меньшей мере 7 дней, например по меньшей мере в течение 14 дней, 21 дня, 1 месяца, 2 месяцев или даже 3 месяцев в синовиальной жидкости (SF) при 37°C.
В одном аспекте настоящее изобретение относится к ISVD, полипептиду или конструкции по изобретению, проникающей в хрящ по меньшей мере на 5 мкм, например по меньшей мере 10 мкм, 20 мкм, 30 мкм, 40 мкм, 50 мкм или даже больше.
Желаемую активность терапевтического структурного блока, например ISVD, связывающего MMP13 в мультивалентном полипептиде или конструкции по изобретению можно измерить при помощи обычных анализов, известных специалистам в данной области. Типичные анализы включают (без ограничения) анализы высвобождения GAG, подробно описанные в разделе Примеры.
Относительные аффинности могут зависеть от локализации ISVDs в полипептиде. Должно быть понятно, что порядок ISVDs в полипептиде по изобретению (ориентацию) можно выбрать в соответствии с тем, как необходимо специалисту в данной области. Расположение индивидуальных ISVD, а также то, включает полипептид линкер или нет, является вопросом выбора конструкции. Некоторые ориентации, с или без линкеров, могут обеспечивать предпочтительные характеристики связывания по сравнению с другими ориентациями. Например, порядок расположения первого ISVD (например ISVD 1) и второго ISVD (например ISVD 2) в полипептиде по изобретению может быть следующим (от N–конца к C–концу): (i) ISVD 1 (например Нанотело 1) – [линкер] – ISVD 2 (например Нанотело 2) – [C–концевое удлинение]; или (ii) ISVD 2 (например Нанотело 2) – [линкер]– ISVD 1 (например Нанотело 1) – [C–концевое удлинение]; (где фрагменты в квадратных скобках, т.е. линкер и C–концевое удлинение, являются необязательными). Все ориентации охватываются изобретением. Полипептиды, которые содержат ориентацию ISVDs, которая обеспечивает желаемые характеристики связывания, легко можно идентифицировать при помощи рутинного скрининга, например, как проиллюстрировано в разделе Примеры. Предпочтительный порядок от N–конца к C–концу является следующим: ISVD, связывающийся с MMP13 – [линкер]– ISVD, связывающийся с Аггреканом – [C–концевое удлинение], где фрагменты в квадратных скобках являются необязательными. Еще один порядок от N–конца к C–концу является следующим: ISVD, связывающийся с MMP13 – [линкер] – ISVD, связывающийся с Аггреканом– [линкер] – ISVD, связывающийся с Аггреканом – [C–концевое удлинение], где фрагменты в квадратных скобках являются необязательными. См., например, Таблицу F.
ПЕРИОД ПОЛУЖИЗНИ
В специальном аспекте изобретения конструкция или полипептид по изобретению может содержать фрагмент, придающий такое свойство, как больший период полужизни, по сравнению с соответствующей конструкцией или полипептидом по изобретению без указанного фрагмента. Некоторые предпочтительные, но не ограничивающие примеры таких конструкций и полипептидов по изобретению будут понятны квалифицированному специалисту на основании дальнейшего раскрытия, представленного в настоящей заявке, и, например, включают ISVDs или полипептиды по изобретению, которые были химически модифицированны для увеличения их периода полужизни (например, путем пегилирования); связывающие MMP13 агенты по изобретению, такие как ISVD и/или полипептиды по изобретению, которые включают по меньшей мере один дополнительный сайт связывания для связывания с белком сыворотки (таким как сывороточный альбумин); или полипептиды по изобретению, которые включают по меньшей мере один ISVD по изобретению, который связан по меньшей мере с одним фрагментом (и, в частности, по меньшей мере одной аминокислотной последовательностью), который увеличивает период полужизни аминокислотной последовательности по изобретению. Примеры конструкций по изобретению, таких как полипептиды по изобретению, которые включают такие увеличивающие период полужизни фрагменты или ISVDs, будут понятны квалифицированному специалисту на основании дальнейшего раскрытия, представленного в настоящей заявке; и, например, включают, без ограничения, полипептиды, в которых один или несколько ISVD по изобретению подходящим образом связаны с одним или несколькими сывороточными белками или их фрагментами (такими как (человеческий) сывороточный альбумин или его подходящие фрагменты) или с одним или несколькими связывающими элементами, которые могут связываться с сывороточными белками (такими как, например, доменные антитела, одиночные вариабельные домены иммуноглобулинов, которые являются подходящими для применения в качестве доменного антитела, однодоменные антитела, одиночные вариабельные домены иммуноглобулинов, которые являются подходящими для применения в качестве однодоменного антитела, dAbs, одиночные вариабельные домены иммуноглобулинов, которые являются подходящими для применения в качестве dAb, или Нанотела, которые могут связываться с сывороточными белками, такими как сывороточный альбумин (такой как человеческий сывороточный альбумин), сывороточными иммуноглобулинами, такими как IgG, или трансферрин; см. дальнейшее описание и указанные в нем ссылки); полипептиды, в которых аминокислотная последовательность по изобретению связана с Fc частью (такой как человеческий Fc) или ее подходящей частью или фрагментом; или полипептиды, в которых один или несколько одиночных вариабельных доменов иммуноглобулина по изобретению подходящим образом связаны с одним или несколькими небольшими белками или пептидами, которые могут связываться с сывороточными белками, такими как, например, белки и пептиды, описанные в WO 91/01743, WO 01/45746, WO 02/076489, WO2008/068280, WO2009/127691 и PCT/EP2011/051559.
В одном аспекте настоящее изобретение обеспечивает полипептид и конструкцию по изобретению, где указанная конструкция или указанный полипептид дополнительно включает сывороточный белок–связывающий фрагмент или сывороточный белок. Предпочтительно, указанный сывороточный белок–связывающий фрагмент связывается с сывороточным альбумином, таким как человеческий сывороточный альбумин.
В одном аспекте настоящее изобретение относится к полипептиду, описанному в настоящей заявке, включающему ISVD, связывающийся с сывороточным альбумином.
Как правило, конструкции или полипептиды по изобретению с увеличенным периодом полужизни предпочтительно имеют период полужизни, который больше по меньшей мере в 1,5 раза, предпочтительно по меньшей мере в 2 раза, например по меньшей мере в 5 раз, например по меньшей мере в 10 раз или более чем в 20 раз, чем период полужизни соответствующих конструкций или полипептидов по изобретению per se, т.е. без фрагмента, обеспечивающего больший период полужизни. Например, конструкции или полипептиды по изобретению с увеличенным периодом полужизни могут иметь период полужизни, например, у человека, который увеличен больше чем на 1 час, предпочтительно больше чем на 2 часа, более предпочтительно больше чем на 6 часов, например больше чем на 12 часов, или даже больше чем на 24, 48 или 72 часа, по сравнению с соответствующими конструкциями или полипептидами по изобретению per se, т.е. без фрагмента, обеспечивающего больший период полужизни.
В предпочтительном, но не ограничивающем, аспекте изобретения конструкции по изобретению и полипептиды по изобретению имеют период полужизни в сыворотке, например, у человека, который увеличен больше чем на 1 час, предпочтительно больше чем на 2 часа, более предпочтительно больше чем на 6 часов, например больше чем на 12 часов или даже больше чем на 24, 48 или 72 часа, по сравнению с соответствующими конструкциями или полипептидами по изобретению per se, т.е. без фрагмента, обеспечивающего больший период полужизни.
В другом предпочтительном, но не ограничивающем, аспекте изобретения такие конструкции по изобретению, такие как полипептиды по изобретению, демонстрируют период полужизни в сыворотке человека по меньшей мере около 12 часов, предпочтительно по меньшей мере 24 часа, более предпочтительно по меньшей мере 48 часов, еще более предпочтительно по меньшей мере 72 часа или более. Например, конструкции или полипептиды по изобретению могут иметь период полужизни по меньшей мере 5 дней (например около 5–10 дней), предпочтительно по меньшей мере 9 дней (например около 9–14 дней), более предпочтительно по меньшей мере около 10 дней (например около 10–15 дней) или по меньшей мере около 11 дней (например около 11–16 дней), более предпочтительно по меньшей мере около 12 дней (например около 12 до 18 дней или более) или больше чем 14 дней (например около 14–19 дней).
В особенно предпочтительном аспекте изобретения, изобретение обеспечивает конструкцию по изобретению и полипептид по изобретению, включающие, помимо одного или более структурных блоков, связывающихся с MMP13, и возможно одного или более структурных блоков, связывающиеся с Аггреканом, по меньшей мере один структурный блок, связывающийся с сывороточным альбумином, такой как ISVD, связывающийся с сывороточным альбумином, таким как человеческий сывороточный альбумин, как описано в настоящей заявке. Предпочтительно указанный ISVD, связывающийся с сывороточным альбумином, включает или по существу состоит из 4 каркасных областей (FR1–FR4, соответственно) и 3 определяющих комплементарность областей (CDR1–CDR3, соответственно), в которых CDR1 SFGMS, CDR2 представляет собой SISGSGSDTLYADSVKG и CDR3 представляет собой GGSLSR. Предпочтительно, указанный ISVD, связывающийся с человеческим сывороточным альбумином, выбран из группы, состоящей из Alb8, Alb23, Alb129, Alb132, Alb11, Alb11 (S112K)–A, Alb82, Alb82–A, Alb82–AA, Alb82–AAA, Alb82–G, Alb82–GG, Alb82–GGG, Alb92, Alb135 или Alb223 (см. Таблицу D).
В одном варианте осуществления настоящее изобретение относится к конструкциям по изобретению, таким как полипептид, включающий связывающийся с сывороточным белком фрагмент, где указанный связывающийся с сывороточным белком фрагмент представляет собой полипептид не на основе антитела.
ДРУГИЕ ФРАГМЕНТЫ
В одном аспекте настоящее изобретение относится к конструкции, описанной в настоящей заявке, включающей одну или несколько других групп, остатков, фрагментов или связывающих элементов. Одна или несколько других групп, остатков, фрагментов или связывающих элементов предпочтительно выбраны из группы, состоящей из молекулы полиэтиленгликоля, сывороточных белков или их фрагментов, связывающих элементов, которые могут связываться с сывороточными белками, Fc части и небольших белков или пептидов, которые могут связываться с сывороточными белками, других аминокислотных остатков, маркеров или других функциональных фрагментов, например, токсинов, меток, радиохимических веществ и т.д.
В одном варианте осуществления, как указано ниже, настоящее изобретение относится к конструкции по изобретению, такой как полипептид, включающий фрагмент, придающий свойство увеличения периода полужизни, где указанный фрагмент представляет собой ПЭГ. Следовательно, настоящее изобретение относится также конструкции или полипептиду по изобретению, включающему ПЭГ.
Дополнительные аминокислотные остатки могут или не могут изменять, модифицировать или иным образом влиять на другие (биологические) свойства полипептида по изобретению и могут или не могут добавлять дополнительную функциональность полипептиду по изобретению. Например, такие аминокислотные остатки:
a) могут включать N–концевой Met остаток, например в результате экспрессии в гетерологичной клетке–хозяине или организме–хозяине;
b) могут образовывать сигнальную последовательность или лидерную последовательность, которая направляет секрецию полипептида из клетки–хозяина при синтезе (например, для получения пре–, про– или препро– формы полипептида по изобретению, в зависимости от используемой клетки–хозяина для экспрессии полипептида по изобретению). Подходящие секреторные лидерные пептиды будут очевидны квалифицированным специалистам и могут представлять собой такие, которые описаны далее в настоящей заявке. Обычно такая лидерная последовательность будет связана с N–концом полипептида, хотя изобретение в его самом широком смысле не ограничивается этим;
c) могут образовывать “метку”, например аминокислотную последовательность или остаток, который позволяет осуществлять или облегчает очистку полипептида, например, с использованием аффинных методов, направленных против указанной последовательности или остатка. Затем указанную последовательность или остаток можно удалить (например, путем химического или ферментативного расщепления) с получением полипептида (для этой цели метка необязательно может быть связана с аминокислотной последовательностью или последовательностью полипептида через расщепляемую линкерную последовательность или содержать расщепляемый мотив). Некоторые предпочтительные, но не ограничивающие примеры таких остатков представляют собой несколько гистидиновых остатков, глутатионовых остатков и myc–метку, такую как AAAEQKLISEEDLNGAA (SEQ ID NO:175), MYC–HIS–tag (SEQ ID NO: 123) или FLAG–HIS6–tag (SEQ ID NO: 124) (см. Таблицу B);
d) может быть один или несколько аминокислотных остатков, которые были функционализированы и/или которые могут служить в качестве сайта для присоединения функциональных групп. Подходящие аминокислотные остатки и функциональные группы будут очевидны квалифицированному специалисту и включают, но не ограничиваются этим, аминокислотные остатки и функциональные группы, указанные в настоящей заявке для производных полипептидов по изобретению.
Также настоящим изобретением охватываются конструкции и/или полипептиды, включающие и/или ISVD по изобретению, которые дополнительно включают другие функциональные фрагменты, например, токсины, метки, радиохимические вещества и т.д.
Другие группы, остатки, фрагменты или связывающие элементы могут, например, представлять собой химические группы, остатки, фрагменты, которые сами могут быть, или могут не быть, биологически и/или фармакологически активными. Например, и без ограничения, такие группы могут быть связаны с одним или несколькими ISVD или полипептидами по изобретению таким образом, чтобы обеспечить “производное” полипептида или конструкции по изобретению.
Соответственно, изобретение в его самом широком смысле также включает конструкции и/или полипептиды, которые являются производными конструкций и/или полипептидов по изобретению. Такие производные, как правило, можно получить путем модификации, и в частности путем химической и/или биологической (например, ферментативной) модификации, конструкций и/или полипептидов по изобретению и/или одного или более аминокислотных остатков, которые образуют полипептид по изобретению.
Примеры таких модификаций, а также примеры аминокислотных остатков в последовательностях полипептидов, которые могут быть модифицированы таким образом (т.е. либо в основной цепи белка, но предпочтительно в боковой цепи), способы и процедуры, которые можно использовать для введения таких модификаций, и потенциальные применения и преимущества таких модификаций будут очевидны квалифицированному специалисту (см. также Zangi et al., Nat Biotechnol 31(10):898–907, 2013).
Например, такая модификация может включать введение (например, путем ковалентного связывания или любым другим подходящим способом) одной или нескольких (функциональных) групп, остатков или фрагментов в или на полипептид по изобретению, в частности, одной или нескольких функциональных групп, остатков или фрагментов, которые придают одно или несколько желаемых свойств или функциональностей конструкции и/или полипептиду по изобретению. Примеры таких функциональных групп будут очевидны квалифицированному специалисту.
Например, такая модификация может включать введение (например, путем ковалентного связывания или любым другим подходящим способом) одного или более функциональных фрагментов, которые увеличивают период полужизни, растворимость и/или абсорбцию конструкции или полипептида по изобретению, которые уменьшают иммуногенность и/или токсичность конструкции или полипептида по изобретению, которые устраняют или уменьшают любые нежелательные побочные эффекты конструкции или полипептида по изобретению и/или которые придают другие полезные свойства конструкции или полипептиду по изобретению и/или уменьшают их нежелательные свойства; или любую комбинацию из двух или более из вышеуказанных. Примеры функциональных фрагментов и методов их введения будут очевидны квалифицированному специалисту, и они, как правило, включают все функциональные фрагменты и методы, описанные в предшествующем уровне техники, цитируемом в настоящей заявке выше, а также функциональные фрагменты и методы, известные per se для модификации фармацевтических белков и, в частности, для модификации антител или фрагментов антител (включая ScFv’s и однодоменные антитела), например, см. Remington (Pharmaceutical Sciences, 16th ed., Mack Publishing Co., Easton, PA, 1980). Такие функциональные фрагменты, например, могут быть связаны непосредственно (например ковалентно) с полипептидом по изобретению или, необязательно, через подходящий линкер или спейсер, как также будет очевидно квалифицированному специалисту.
Одним конкретным примером является производное полипептида или конструкции по изобретению, где полипептид или конструкция по изобретению были химически модифицированы для увеличения их периода полужизни (например, путем пегилирования). Это один из наиболее широко используемых методов для увеличения периода полужизни и/или уменьшения иммуногенности фармацевтических белков и включает присоединение подходящего фармакологически приемлемого полимера, такого как поли(этиленгликоль) (ПЭГ) или его производных (таких как метоксиполи(этиленгликоль) или мПЭГ). Как правило, можно использовать любую подходящую форму пегилирования, такую как пегилирование, используемое в данной области техники для антител и фрагментов антител (включая, но не ограничиваясь этим, (одно)доменные антитела и ScFv); см., например, Chapman (Nat. Biotechnol. 54: 531–545, 2002), Veronese and Harris (Adv. Drug Deliv. Rev. 54: 453–456, 2003), Harris and Chess (Nat. Rev. Drug. Discov. 2: 214–221, 2003) и WO 04/060965. Различные реагенты для пегилирования белков также являются коммерчески доступными, например от Nektar Therapeutics, USA.
Предпочтительно используют сайт–направленное пегилирование, в частности через цистеиновый остаток (см., например, Yang et al. (Protein Engineering 16: 761–770, 2003). Например, для этой цели ПЭГ можно присоединить к цистеиновому остатку, который естественным образом присутствует в полипептиде по изобретению, конструкцию или полипептид по изобретению можно модифицировать так, чтобы подходящим образом ввести один или несколько цистеиновых остатков для присоединения ПЭГ, или аминокислотную последовательность, включающую один или несколько цистеиновых остатков для присоединения ПЭГ, можно слить с N– и/или C–концом конструкции или полипептида по изобретению – во всех случаях с использованием методов белковой инженерии, известных per se квалифицированным специалистам.
Предпочтительно, для конструкций или полипептидов по изобретению используют ПЭГ с молекулярной массой больше чем 5000, такой как больше чем 10000 и меньше чем 200000, такой как меньше чем 100000; например в пределах от 20000–80000.
Еще одна, обычно менее предпочтительная, модификация включает N–связанное или O–связанное гликозилирование, обычно как часть ко–трансляционной и/или посттрансляционной модификации, в зависимости от клетки–хозяина, используемой для экспрессии полипептида по изобретению.
Еще одна модификация может включать введение одной или нескольких обнаруживаемых меток или других генерирующих сигнал групп или фрагментов, в зависимости от предполагаемого применения полипептида или конструкции по изобретению. Подходящие метки и способы их прикрепления, применения и детекции будут понятны специалистам в данной области и, например, включают, но не ограничиваются этим, флуоресцентные метки (такие как флуоресцеин, изотиоцианат, родамин, фикоэритрин, фикоцианин, аллофикоцианин, о–фтальдегид и флуорескамин и флуоресцентные металлы, такие как 152Eu или другие металлы из ряда лантаноидов), фосфоресцентные метки, хемилюминесцентные метки или биолюминесцентные метки (такие как люминал, изолюминол, ароматический сложный эфир акридиния, имидазол, соли акридиния, оксалатный эфир, диоксетан или GFP и его аналоги), радиоизотопы (такие как 3H, 125I, 32P, 35S, 14C, 51Cr, 36Cl, 57Co, 58Co, 59Fe и 75Se), металлы, металло–хелаты или металлические катионы (например, металлические катионы, такие как 99mTc, 123I, 111In, 131I, 97Ru, 67Cu, 67Ga и 68Ga, или другие металлы или металлические катионы, которые являются особенно подходящими для применения в in vivo, in vitro или in situ диагностике и визуализации, такие как (157Gd, 55Mn, 162Dy, 52Cr и 56Fe)), а также хромофоры и ферменты (такие как малатдегидрогеназа, стафилококковая нуклеаза, дельта–V–стероид–изомераза, алкогольдегидрогеназа дрожжей, альфа–глицерофосфатдегидрогеназа, триозофосфатизомераза, биотинавидинпероксидаза, пероксидаза хрена, щелочная фосфатаза, глюкозооксидаза, β–галактозидаза, рибонуклеаза, уреаза, каталаза, глюкозо–VI–фосфатдегидрогеназа, глюкоамилаза и ацетилхолинэстераза). Другие подходящие метки будут очевидны специалистам в данной области и, например, включают фрагменты, которые могут быть обнаружены с использованием ЯМР или ЭПР–спектроскопии.
Такие меченные полипептиды и конструкции по изобретению, например, можно использовать для анализов in vitro, in vivo или in situ (включая иммуноанализы, известные per se, такие как ELISA, RIA, EIA и другие “сэндвич–анализы” и т.д.), а также для диагностики и визуализации in vivo, в зависимости от выбора конкретной метки.
Как будет понятно квалифицированному специалисту, другая модификация может включать введение хелатирующей группы, например для хелатирования одного из металлов или металлических катионов, указанных выше. Подходящие хелатирующие группы, например, включают, без ограничения, диэтилентриаминпентауксусную кислоту (DTPA) или этилендиаминтетрауксусную кислоту (EDTA).
Еще одна модификация может включать введение функционального фрагмента, который является одной частью специфической связывающейся пары, такой как биотин–(стрепт)авидин связывающейся пары. Такой функциональный фрагмент можно использовать для связывания полипептида по изобретению с другим белком, полипептидом или химическим соединением, который связан с другой половиной связывающейся пары, т.е. через образование связывающейся пары. Например, конструкцию или полипептид по изобретению можно конъюгировать с биотином и связать с другим белком, полипептидом, соединением или носителем, конъюгированным с авидином или стрептавидином. Например, такую конъюгированную конструкцию или полипептид по изобретению можно использовать в качестве репортера, например в системе диагностики, где детектируемый сигнал–испускающий агент конъюгирован с авидином или стрептавидином. Такие связывающиеся пары, например, также можно использовать для связывания конструкции или полипептида по изобретению с носителем, в том числе с носителями, подходящими для фармацевтических целей. Одним неограничивающим примером являются липосомальные композиции, описанные Cao и Suresh (Journal of Drug Targeting 8: 257, 2000). Такие связывающиеся пары также можно использовать для связывания терапевтически активного средства с полипептидом по изобретению.
Другие потенциальные химические и ферментативные модификации будут очевидны квалифицированным специалистам. Такие модификации также могут быть введены для исследовательских целей (например, для исследования взаимосвязи функции–активности). Например, см. Lundblad и Bradshaw (Biotechnol. Appl. Biochem. 26: 143–151, 1997).
Предпочтительно конструкции, полипептиды и/или производные являются такими, которые связываются с MMP13 с аффинностью (соответствующим образом измеренной и/или выраженной как KD–значение (действительное или кажущееся), KA–значение (действительное или кажущееся), kon–скорость(скорость ассоциации) и/или koff–скорость(скорость диссоциации), или альтернативно как IC50 значение, как описано далее в настоящей заявке), которая является такой, как определено в настоящей заявке (например, как определено для полипептидов по изобретению).
Такие конструкции и/или полипептиды по изобретению и их производные также могут быть в по существу выделенной форме (как определено в настоящей заявке).
В одном аспекте настоящее изобретение относится к конструкции по изобретению, которая включает или по существу состоит из ISVD в соответствии с изобретением или полипептида в соответствии с изобретением и которая дополнительно включает одну или несколько других групп, остатков, фрагментов или связывающих элементов, которые необязательно связаны через один или несколько пептидных линкеров.
В одном аспекте настоящее изобретение относится к конструкции по изобретению, в которой одна или несколько других групп, остатков, фрагментов или связывающих элементов выбраны из группы, состоящей из молекулы полиэтиленгликоля, сывороточных белков или их фрагментов, связывающих элементов, которые могут связываться с сывороточными белками, Fc части и небольших белков или пептидов, которые могут связываться с сывороточными белками.
ЛИНКЕРЫ
В конструкциях по изобретению, таких как полипептиды по изобретению, два или более структурных блока, например, такие как ISVD, и необязательно одна или несколько других групп, лекарственных средств, агентов, остатков, фрагментов или связывающих элементов могут быть непосредственно связаны друг с другом (как, например, описано в WO 99/23221) и/или могут быть связаны друг с другом через один или несколько подходящих спейсеров или линкеров, или любую их комбинацию. Подходящие спейсеры или линкеры для применения в мультивалентных и мультиспецифических полипептидах будут очевидны квалифицированным специалистам и, как правило, могут представлять собой любой линкер или спейсер, используемый в данной области техники для связывания аминокислотных последовательностей. Предпочтительно, указанный линкер или спейсер является подходящим для применения в конструировании конструкций, белков или полипептидов, предполагаемых для фармацевтического применения.
Например, полипептид по изобретению, например, может представлять собой трехвалентный триспецифический полипептид, включающий один структурный блок, такой как ISVD, связывающийся с MMP13, САР структурный блок, такой как ISVD, связывающийся с Аггреканом, и потенциально еще один структурный блок, такой как третий ISVD, в котором указанные первый, второй и третий структурные блоки, такие как ISVD, необязательно могут быть связаны через одну или несколько и, в частности, 2 линкерные последовательности. Также, настоящее изобретение обеспечивает конструкцию или полипептид по изобретению, включающий первый ISVD, связывающийся с MMP13, и возможно второй ISVD, связывающийся с Аггреканом, и/или возможно третий ISVD и/или возможно четвертый ISVD, где указанный первый ISVD и/или указанный второй ISVD, и/или возможно указанный третий ISVD, и/или возможно указанный четвертый ISVD связаны через линкеры, в частности 3 линкера.
Некоторые особенно предпочтительные линкеры включают линкеры, которые используются в данной области для связывания фрагментов антител или доменов антител. Они включают линкеры, описанные в общем уровне техники, указанном выше, а также, например, линкеры, которые используются в данной области для конструирования диател или ScFv фрагментов (в этой связи, однако, следует отметить, что, в то время как в диателах и в ScFv фрагментах используемая линкерная последовательность должна иметь длину, степень гибкости и другие свойства, которые позволяют соответствующим VH и VL доменам объединяться для образования полного антигенсвязывающего сайта, нет никаких конкретных ограничений, что касается длины или гибкости линкера, используемого в полипептиде по изобретению, поскольку каждый ISVD, такой как Нанотела, сам как таковой образует полный антигенсвязывающий сайт).
Например, линкер может представлять собой подходящую аминокислотную последовательность и, в частности, аминокислотные последовательности из 1–50, предпочтительно 1–30, например 1–10 аминокислотных остатков. Некоторые предпочтительные примеры таких аминокислотных последовательностей включают gly–ser линкеры, например типа (glyxsery)2, такие как (например (gly4ser)3 или (gly3ser2)3, как описано в WO 99/42077, и GS30, GS15, GS9 и GS7 линкеры, описанные в заявках Ablynx, указанных выше (см., например, WO 06/040153 и WO 06/122825), а также шарнир–подобные области, такие как шарнирные области природных антител, состоящих только из тяжелых цепей, или подобные последовательности (такие как описанные в WO 94/04678). Предпочтительные линкеры представлены в Таблице C.
Некоторые другие особенно предпочтительные линкеры представляют собой поли–аланин (такой как AAA), а также линкеры GS30 (SEQ ID NO: 85 в WO 06/122825) и GS9 (SEQ ID NO: 84 в WO 06/122825).
Другие подходящие линкеры, как правило, включают органические соединения или полимеры, в частности, которые являются подходящими для использования в белках для фармацевтического применения. Например, поли(этиленгликолевые) фрагменты используются для связывания доменов антител, см., например, WO 04/081026.
Объемoм настоящего изобретения охватывается то, что длина, степень гибкости и/или другие свойства используемого линкера(линкеров) (хотя они не являются критическими, как обычно бывает для линкеров, используемых в ScFv фрагментах) могут иметь некоторое влияние на свойства готовой конструкции по изобретению, такой как полипептид по изобретению, включая, но не ограничиваясь этим, аффинность, специфичность или авидность в отношении MMP13 или в отношении одного или более других антигенов. На основании раскрытия, представленного в настоящей заявке, специалист в данной области сможет определить оптимальный линкер(линкеры) для применения в конкретной конструкции по изобретению, такой как полипептид по изобретению, необязательно после нескольких ограниченных рутинных экспериментов.
Например, в мультивалентных полипептидах по изобретению, которые включают структурные блоки, ISVD или Нанотела, направленные против MMP13 и другой мишени, длина и гибкость линкера предпочтительно являются такими, которые позволяют каждому структурному блоку, такому как ISVD по изобретению, присутствующему в полипептиде, связываться с его родственной мишенью, например, антигенной детерминантой на каждой из мишеней. Также, на основании раскрытия, представленного в настоящей заявке, специалист в данной области сможет определить оптимальный линкер(линкеры) для применения в конкретной конструкции по изобретению, такой как полипептид по изобретению, необязательно после нескольких ограниченных рутинных экспериментов.
Объемoм настоящего изобретения также охватывается то, что используемый линкер(линкеры) придает одно или несколько других полезных свойств или функциональностей конструкциям по изобретению, таким как полипептиды по изобретению, и/или обеспечивает один или несколько участков для образования производных и/или для присоединения функциональных групп (например, как описано в настоящей заявке для производных ISVDs по изобретению). Например, линкеры, содержащие один или несколько заряженных аминокислотных остатков, могут обеспечить улучшенные гидрофильные свойства, тогда как линкеры, которые образуют или содержат небольшие эпитопы или метки, можно использовать для целей детекции, идентификации и/или очистки. И в этом случае также на основании раскрытия, представленного в настоящей заявке, специалист в данной области сможет определить оптимальные линкеры для применения в конкретном полипептиде по изобретению, необязательно после нескольких ограниченных рутинных экспериментов.
Конечно, когда два или более линкеров используют в конструкциях, таких как полипептиды по изобретению, эти линкеры могут быть одинаковыми или отличными друг от друга. И в этом случае также на основании раскрытия, представленного в настоящей заявке, специалист в данной области сможет определить оптимальные линкеры для применения в конкретной конструкции или полипептиде по изобретению, необязательно после нескольких ограниченных рутинных экспериментов.
Обычно, чтобы обеспечить более легкую экспрессию и продуцирование, конструкция по изобретению, такая как полипептид по изобретению, может представлять собой линейный полипептид. Однако изобретение в его самом широком смысле не ограничивается этим. Например, когда конструкция по изобретению, такая как полипептид по изобретению, включает три или более структурных блоков, ISVD или Нанотел, их можно связать при помощи линкера с тремя или более “ответвлениями”, где каждое “ответвление” связывается со структурным блоком, ISVD или Нанотелом так, чтобы образовалась “звездообразная” конструкция. Также можно, хотя обычно менее предпочтительно, использовать кольцеобразные конструкции.
Соответственно, настоящее изобретение относится к конструкции по изобретению, такой как полипептид по изобретению, где указанные ISVD непосредственно связаны друг с другом или связаны через линкер.
Соответственно, настоящее изобретение относится к конструкции по изобретению, такой как полипептид по изобретению, где первый ISVD и/или второй ISVD и/или возможно ISVD, связывающийся с сывороточным альбумином, связаны через линкер.
Соответственно, настоящее изобретение относится к конструкции по изобретению, такой как полипептид по изобретению, где указанный линкер выбран из группы, состоящей из линкеров A3, 5GS, 7GS, 8GS, 9GS, 10GS, 15GS, 18GS, 20GS, 25GS, 30GS, 35GS, 40GS, G1 шарнир, 9GS–G1 шарнир, верхняя длинная шарнирная область ламы и G3 шарнир, таких как, например, показанные в Таблице C.
Соответственно, настоящее изобретение относится к конструкции по изобретению, такой как полипептид по изобретению, где указанный полипептид выбран из группы, показанной в Таблице A–3 и Таблице F, например, выбран из группы, состоящей из SEQ ID NO: 164–165, 160, 161, 162, 163, и SEQ ID NO:s 176, 192 и 175–191 (т.е. 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190 или 191).
ПОЛУЧЕНИЕ
Изобретение также относится к способам для получения конструкций, полипептидов, ISVD, нуклеиновых кислот, клеток–хозяев и композиций, описанных в настоящей заявке.
Мультивалентные полипептиды по изобретению, как правило, можно получить способом, который включает по меньшей мере стадию связывания подходящим образом ISVD и/или одновалентного полипептида по изобретению с одним или несколькими другими ISVD, необязательно через один или несколько подходящих линкеров, чтобы обеспечить мультивалентный полипептид по изобретению. Полипептиды по изобретению также можно получить способом, который, как правило, включает по меньшей мере стадии обеспечения нуклеиновой кислоты, которая кодирует полипептид по изобретению, экспрессии указанной нуклеиновой кислоты подходящим способом и выделения экспрессированного полипептида по изобретению. Это можно осуществить способом, известным per se, что должно быть понятно квалифицированному специалисту, например, на основании способов и процедур, описанных далее в настоящей заявке.
Способ получения мультивалентных полипептидов по изобретению может включать по меньшей мере стадии связывания двух или более ISVD по изобретению и, например, одного или более линкеров вместе подходящим способом. ISVDs по изобретению (и линкеры) можно связать любым способом, известным из уровня техники, и как описано далее в настоящей заявке. Предпочтительные способы включают связывание нуклеиновокислотных последовательностей, которые кодируют ISVDs по изобретению (и линкеры) с получением генетической конструкции, которая экспрессирует мультивалентный полипептид. Способы связывания аминокислот или нуклеиновых кислот будут очевидны квалифицированному специалисту, и в этом случае также можно сделать ссылку на справочники, такие как Sambrook et al. и Ausubel et al., указанные выше, а также Примеры, представленные ниже.
Соответственно, настоящее изобретение также относится к применению ISVD по изобретению для получения мультивалентного полипептида по изобретению. Способ получения мультивалентного полипептида будет включать связывание ISVD по изобретению с по меньшей мере одним дополнительным ISVD по изобретению, необязательно через один или несколько линкеров. ISVD по изобретению затем используют в качестве связывающего домена или структурного блока для обеспечения и/или получения мультивалентного полипептида, включающего 2 (например, в двухвалентном полипептиде), 3 (например, в трехвалентном полипептиде), 4 (например, в четырехвалентном) или более (например, в мультивалентном полипептиде) структурных блоков. В этой связи, ISVD по изобретению можно использовать в качестве связывающего домена или связывающего элемента для обеспечения и/или получения мультивалентного, такого как двухвалентный, трехвалентный или четырехвалентный, полипептида по изобретению, включающего 2, 3, 4 или более структурных блоков.
Соответственно, настоящее изобретение также относится к применению ISVD полипептида по изобретению (как описано в настоящей заявке) для получения мультивалентного полипептида. Способ получения мультивалентного полипептида будет включать связывание ISVD по изобретению с по меньшей мере одним другим ISVD по изобретению, необязательно через один или несколько линкеров.
Полипептиды и нуклеиновые кислоты по изобретению можно получить способом, известным per se, как будет понятно квалифицированному специалисту из представленного ниже описания. Например, полипептиды по изобретению можно получить любым способом, известным per se для получения антител и, в частности, для получения фрагментов антител (в том числе, но не ограничиваясь этим, (одно)доменных антител и ScFv фрагментов). Некоторые предпочтительные, но не ограничивающие способы для получения полипептидов и нуклеиновых кислот включают способы и процедуры, описанные в настоящей заявке.
Способ получения полипептида по изобретению может включать следующие стадии:
– экспрессию, в подходящей клетке–хозяине или организме–хозяине (также указан в настоящей заявке как “хозяин по изобретению”), или в другой подходящей системе экспрессии нуклеиновой кислоты, которая кодирует указанный полипептид по изобретению (также указана в настоящей заявке как “нуклеиновая кислота по изобретению”);
необязательно с последующим:
– выделением и/или очисткой полипептида по изобретению, полученного таким образом.
В частности, такой способ может включать стадии:
– культивирования и/или поддержания хозяина по изобретению в условиях, которые являются такими, чтобы указанный хозяин по изобретению экспрессировал и/или продуцировал по меньшей мере один полипептид по изобретению;
необязательно с последующим:
– выделением и/или очисткой полипептида по изобретению, полученного таким образом.
Соответственно, настоящее изобретение также относится к нуклеиновой кислоте или нуклеотидной последовательности, которая кодирует полипептид, ISVD или конструкцию по изобретению (также указана как “нуклеиновая кислота по изобретению”).
Нуклеиновая кислота по изобретению может быть в форме одно– или двухцепочечной ДНК или РНК. В соответствии с одним вариантом осуществления изобретения, нуклеиновая кислота по изобретению находится в по существу выделенной форме, как определено в настоящей заявке. Нуклеиновая кислота по изобретению также может быть в форме вектора, может присутствовать в векторе и/или быть частью вектора, например вектора экспрессии, такого как, например, плазмида, космида или YAC, который также может быть в по существу выделенной форме. Соответственно, настоящее изобретение также относится к вектору экспрессии, включающему нуклеиновую кислоту или нуклеотидную последовательность по изобретению.
Нуклеиновые кислоты по изобретению могут быть изготовлены или получены способом, известным per se, на основании информации по полипептидам по изобретению, представленной в настоящей заявке, и/или они могут быть выделены из подходящего природного источника. Также, как будет понятно квалифицированному специалисту, чтобы получить нуклеиновую кислоту по изобретению, также несколько нуклеотидных последовательностей, например, по меньшей мере две нуклеиновые кислоты, кодирующие ISVD по изобретению, и, например, нуклеиновые кислоты, кодирующие один или несколько линкеров, можно связать вместе подходящим способом. Способы для получения нуклеиновых кислот по изобретению будут очевидны квалифицированному специалисту, и они могут, например, включать, но не ограничиваются этим, автоматический синтез ДНК; сайт–направленный мутагенез; объединение двух или более природных и/или синтетических последовательностей (или двух или более их частей), введение мутаций, которые приводят к экспрессии усеченного продукта экспрессии; введение одного или более рестрикционных сайтов (например, для создания кассет и/или областей, которые легко можно расщепить и/или лигировать с использованием подходящих рестрикционных ферментов), и/или введение мутаций путем ПЦР с использованием одного или более “ошибочно спаренных” праймеров. Эти и другие методы будут очевидны квалифицированному специалисту, и в этом случае снова можно сослаться на справочники, такие как Sambrook et al. и Ausubel et al., указанные выше, а также на представленные ниже Примеры.
В предпочтительном, но не ограничивающем варианте осуществления, генетическая конструкция по изобретению включает
a) по меньшей мере одну нуклеиновую кислоту по изобретению;
b) функционально связанную с одним или несколькими регуляторными элементами, такими как промотор и, необязательно, подходящий терминатор; и необязательно также
c) один или несколько дополнительных элементов генетических конструкций, известных per se;
где термины “регуляторный элемент”, “промотор”, “терминатор” и “функционально связанный” имеют свое обычное значение в данной области техники.
Генетические конструкции по изобретению, как правило, можно получить путем связывания подходящим образом нуклеотидной последовательности(последовательностей) по изобретению с одним или несколькими другими элементами, описанными выше, например с использованием методов, описанных в общих справочниках, таких как Sambrook et al. и Ausubel et al., указанных выше.
Нуклеиновые кислоты по изобретению и/или генетические конструкции по изобретению можно использовать для трансформирования клетки–хозяина или организма–хозяина, т.е. для экспрессии и/или продукции полипептида по изобретению. Подходящие хозяева или клетки–хозяева будут очевидны квалифицированному специалисту, и могут, например, представлять собой любую подходящую грибковую, прокариотическую или эукариотическую клетку или клеточную линию или любой подходящий грибковый, прокариотический или (не человеческий) эукариотический организм, а также все другие клетки–хозяева или (отличные от человека) хозяева, известные per se для экспрессии и продукции антител и фрагментов антител (включая, но не ограничиваясь этим, (одно)доменные антитела и ScFv фрагменты), что должно быть понятно квалифицированному специалисту. См. также ссылку на известный уровень техники, приведенную выше, а также, например, WO 94/29457; WO 96/34103; WO 99/42077; Frenken et al. (Res Immunol. 149: 589–99, 1998); Riechmann and Muyldermans (1999), supra; van der Linden (J. Biotechnol. 80: 261–70, 2000); Joosten et al. (Microb. Cell Fact. 2: 1, 2003); Joosten et al. (Appl. Microbiol. Biotechnol. 66: 384–92, 2005); и другие ссылочные документы, указанные в настоящей заявке. Кроме того, полипептиды по изобретению также могут экспрессироваться и/или продуцироваться в бесклеточных системах экспрессии, и подходящие примеры таких систем будут очевидны квалифицированным специалистам. Подходящие методы трансформирования хозяина или клетки–хозяина по изобретению будут очевидны квалифицированному специалисту и могут зависеть от предполагаемой клетки–хозяина/организма–хозяина и генетической конструкции, которую используют. См. также справочники и патентные заявки, указанные выше. Трансформированная клетка–хозяин (которая может быть в форме стабильной клеточной линии) или организмы–хозяева (которые могут быть в форме стабильной мутантной линии или штамма) составляют другие аспекты настоящего изобретения. Соответственно, настоящее изобретение относится к хозяину или клетке–хозяину, включающему нуклеиновую кислоту в соответствии с изобретением или вектор экспрессии в соответствии с изобретением. Предпочтительно, эти клетки–хозяева или организмы–хозяева являются такими, которые экспрессируют, или (по меньшей мере) способны экспрессировать (например, в подходящих условиях), полипептид по изобретению (и в случае организма–хозяина: в по меньшей мере одной его клетке, части, ткани или органе). Изобретение также включает дальнейшие поколения, потомство и/или дочерние продукты клетки–хозяина или организма–хозяина по изобретению, которые, например, можно получить клеточным делением или половым или бесполым размножением.
Для получения/достижения экспрессии полипептидов по изобретению трансформированную клетку–хозяин или трансформированный организм–хозяин обычно можно хранить, поддерживать и/или культивировать в условиях, в которых (желательный) полипептид по изобретению экспрессируется/продуцируется. Подходящие условия будут очевидны специалистам в данной области и обычно зависят от используемой клетки–хозяина/организма–хозяина, а также от регуляторных элементов, которые контролируют экспрессию (соответствующей) нуклеотидной последовательности по изобретению. Опять же, делается ссылка на справочники и патентные заявки, указанные выше в параграфах, раскрывающих генетические конструкции по изобретению.
Затем полипептид по изобретению может быть выделен из клетки–хозяина/организма–хозяина и/или из среды, в которой культивировали указанную клетку–хозяин или организм–хозяин, с использованием методов выделения и/или очистки белка, известных per se, таких как, (препаративная) хроматография и/или электрофорез, методы дифференциального осаждения, аффинные методы (например, с использованием специфической расщепляемой аминокислотной последовательности, слитой с полипептидом по изобретению) и/или препаративные иммунологические методы (т.е. использование антител против подлежащего выделению полипептида).
В одном аспекте изобретение относится к способу получения конструкции, полипептида или ISVD в соответствии с изобретением, включающему по меньшей мере стадии: (a) экспрессии, в подходящей клетке–хозяине или организме–хозяине, или в другой подходящей системе экспрессии, последовательности нуклеиновой кислоты в соответствии с изобретением; необязательно с последующим (b) выделением и/или очисткой конструкции, полипептида, ISVD в соответствии с изобретением.
В одном аспекте изобретение относится к композиции, включающей конструкцию, полипептид, ISVD или нуклеиновую кислоту в соответствии с изобретением.
Лекарственные средства (применения ISVD, полипептидов, конструкций по изобретению)
Как указано выше, все еще остается потребность в безопасных и эффективных лекарственных средствах для лечения OA. Основываясь на нетрадиционных скрининговых, характеризационных и комбинаторных стратегиях, авторы настоящего изобретения идентифицировали ISVD, связывающие и ингибирующие MMP13. Эти связывающие MMP13 агенты показали исключительно хорошие результаты в экспериментах in vitro, ex vivo и in vivo. Кроме того, также было продемонстрировано, что ISVDs по изобретению значительно более эффективны, чем сравнительные молекулы. Настоящее изобретение, таким образом, обеспечивает композиции, конструкции и/или полипептиды с улучшенными профилактическими, терапевтическими и/или фармакологическими свойствами, включая более безопасный профиль по сравнению с молекулами сравнения. Кроме того, эти связывающие MMP13 агенты, когда они связаны с САР структурными блоками, имели больший период удерживания в суставе, и, с другой стороны, сохраняли активность.
В одном аспекте настоящее изобретение относится к композиции в соответствии с изобретением, полипептиду в соответствии с изобретением и/или конструкции в соответствии с изобретением для применения в качестве лекарственного средства.
В другом аспекте изобретение относится к применению ISVD, полипептида и/или конструкции в соответствии с изобретением для получения фармацевтической композиции для профилактики и/или лечения по меньшей мере MMP13–ассоциированного заболевания; и/или для применения в одном или нескольких способах лечения, указанных в настоящей заявке.
Изобретение также относится к применению ISVD, полипептида, соединения и/или конструкции в соответствии с изобретением для получения фармацевтической композиции для профилактики и/или лечения по меньшей мере одного заболевания или расстройства, которое можно предотвратить и/или лечить путем модуляции активности MMP, предпочтительно MMP13, например, путем ингибирования разрушения Аггрекана и/или Коллагена.
Изобретение также относится к применению ISVD, полипептида, соединения и/или конструкции в соответствии с изобретением для получения фармацевтической композиции для профилактики и/или лечения по меньшей мере одного заболевания или расстройства, которое можно предотвратить и/или лечить путем введения пациенту ISVD, полипептида, соединения и/или конструкции по изобретению.
Изобретение также относится к ISVD, полипептиду, соединению и/или конструкции по изобретению, или к фармацевтической композиции, включающей их, для применения в профилактике и/или лечении по меньшей мере MMP13–ассоциированного заболевания.
Предполагается, что MMP13–связывающие агенты по изобретению можно использовать при различных заболеваниях, поражающих хрящ, таких как артропатии и хондродистрофии, артритное заболевание, такое как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отслоение, ахондроплазия, реберный хондрит, спондилоэпиметафизарная дисплазия, межпозвоночная грыжа, дегенерация поясничного диска, дегенеративное заболевание суставов и рецидивирующий полихондрит, рассекающий остеохондрит и аггреканопатии (обобщенно указаны в настоящей заявке как "MMP13–ассоциированные заболевания").
В одном аспекте настоящее изобретение относится к композиции, ISVD, полипептиду и/или конструкции в соответствии с изобретением для применения в лечении или профилактике симптома MMP13–ассоциированного заболевания, такого как, например, артропатии и хондродистрофии, артритное заболевание, такое как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отслоение, ахондроплазия, реберный хондрит, спондилоэпиметафизарная дисплазия, межпозвоночная грыжа, дегенерация поясничного диска, дегенеративное заболевание суставов, рецидивирующий полихондрит, рассекающий остеохондрит и аггреканопатии. Более предпочтительно, указанное заболевание или расстройство представляет собой артритное заболевание, и наиболее предпочтительно остеоартрит.
В одном аспекте настоящее изобретение относится к способу профилактики или лечения артропатий и хондродистрофий, артритного заболевания, такого как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматического разрыва или отслоения, ахондроплазии, реберного хондрита, спондилоэпиметафизарной дисплазии, межпозвоночной грыжи, дегенерации поясничного диска, дегенеративного заболевания суставов и рецидивирующего полихондрита, где указанный способ включает введение субъекту, нуждающемуся в этом, фармацевтически активного количества по меньшей мере композиции, иммуноглобулина, полипептида и/или конструкции в соответствии с изобретением. Более предпочтительно, указанное заболевание или расстройство представляет собой артритное заболевание, и наиболее предпочтительно остеоартрит.
В одном аспекте настоящее изобретение относится к применению ISVD, полипептида, композиции и/или конструкции в соответствии с изобретением для получения фармацевтической композиции для лечения или профилактики заболевания или расстройства, такого как артропатии и хондродистрофии, артритное заболевание, такое как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отслоение, ахондроплазия, реберный хондрит, спондилоэпиметафизарная дисплазия, межпозвоночная грыжа, дегенерация поясничного диска, дегенеративное заболевание суставов, рецидивирующий полихондрит, рассекающий остеохондрит и аггреканопатии. Более предпочтительно, указанное заболевание или расстройство представляет собой артритное заболевание, и наиболее предпочтительно остеоартрит.
Связываясь с Аггреканом, конструкции и/или полипептиды по изобретению могут снижать или ингибировать активность члена семейства сериновых протеаз, катепсинов, матриксных металлопротеиназ (MMP)/Матриксинов или А дезинтегрина и металлопротеиназы с мотивами тромбоспондина (ADAMTS), MMP20, ADAMTS5 (Аггреканаза–2) ADAMTS4 (Аггреканаза–1) и/или ADAMTS11, связанную с разрушением Аггрекана.
В контексте настоящего изобретения термин “профилактика и/или лечение” включает не только профилактику и/или лечение заболевания, но также обычно включает предотвращение возникновения заболевания, замедление или изменение хода заболевания, предотвращение или замедление возникновение одного или более симптомов, связанных с заболеванием, уменьшение и/или ослабление одного или более симптомов, связанных с заболеванием, уменьшение тяжести и/или продолжительности заболевания и/или любых симптомов, связанных с ним, и/или предотвращение дальнейшего усиления тяжести заболевания и/или любых связанных с ним симптомов, предотвращение, уменьшение или реверсию любого физиологического повреждения, вызванного заболеванием, и, как правило, любое фармакологическое действие, которое полезно для пациента, которого лечат.
Схема введения должна определяться лечащим врачом и клиническими факторами. Как хорошо известно в медицине, дозировка для любого пациента зависит от многих факторов, включая размер, массу тела, площадь поверхности тела, возраст пациента, конкретное вводимое соединение, активность используемого полипептида (включая антитела), время и путь введения, общее состояние здоровья и комбинацию с другими терапиями или лечениями. Белковое фармацевтически активное вещество может присутствовать в количествах между 1 г и 100 мг/кг массы тела на дозу; однако, также предусматриваются дозы ниже или выше этого приведенного в качестве примера диапазона. Если используют непрерывную инфузию, количество может быть в пределах от 1 пг до 100 мг на килограмм массы тела в минуту.
ISVD, полипептид или конструкцию по изобретению можно использовать при концентрации, например, 0,01, 0,1, 0,5, 1, 2, 5, 10, 20 или 50 пг/мл для ингибирования и/или нейтрализации биологической функции MMP13 по меньшей мере на около 50%, предпочтительно 75%, более предпочтительно 90%, 95% или вплоть до 99%, и наиболее предпочтительно приблизительно 100% (по существу полностью), как определяют способами, хорошо известными из уровня техники.
ISVD, полипептид или конструкцию по изобретению можно использовать при концентрации, например, 1, 2, 5, 10, 20, 25, 30, 40, 50, 75, 100, 200, 250 или 500 нг/мг хряща для ингибирования и/или нейтрализации биологической функции MMP13 по меньшей мере на около 50%, предпочтительно 75%, более предпочтительно 90%, 95% или вплоть до 99%, и наиболее предпочтительно приблизительно 100% (по существу полностью), как определяют способами, хорошо известными из уровня техники.
Как правило, схема лечения будет включать введение одного или более ISVD, полипептидов и/или конструкций по изобретению, или одной или нескольких включающей их композиций, в одном или более фармацевтически эффективных количествах или дозах. Конкретные вводимые количества или дозы может определить клиницист, опять же на основании факторов, перечисленных выше. Полезные дозы конструкций, полипептидов и/или ISVD по изобретению можно определить путем сравнения их in vitro активности и in vivo активности в животных моделях. Способы экстраполяции эффективных доз с мышей и других животных на человека известны из уровня техники; например, см. US 4938949.
Как правило, в зависимости от конкретного заболевания, расстройства или состояния, подлежащего лечению, активности конкретного используемого ISVD, полипептида и/или конструкции по изобретению, конкретного пути введения и конкретного используемого фармацевтического состава или композиции, клиницист сможет определить подходящую суточную дозу.
Количество композиций, полипептидов и/или ISVD по изобретению, необходимое для применения в лечении, будет варьироваться не только в зависимости от конкретного иммуноглобулина, полипептида, соединения и/или конструкции, но также от пути введения, природы состояния, подлежащего лечению, и возраста и состояния пациента, и в конечном счете это будет определять лечащий врач или клиницист. Также дозировка конструкций, полипептидов и/или ISVD по изобретению варьируется в зависимости от клетки–мишени, ткани, трансплантата, сустава или органа.
Желаемая доза может удобно предоставляться в виде одной дозы или в виде дробных доз, вводимых через соответствующие интервалы, например, в виде двух, трех, четырех или более субдоз в день. Саму субдозу далее можно разделить, например, на несколько отдельных свободно распределенных введений. Предпочтительно дозу вводят раз в неделю или даже реже, например раз в две недели, раз в три недели, раз в месяц или даже раз в два месяца.
Схема введения может включать долгосрочное лечение. Под “долгосрочным” подразумевается по меньшей мере две недели, а предпочтительно несколько недель, месяцев или лет. Необходимые модификации в этом диапазоне доз могут быть определены специалистом в данной области с использованием только рутинного экспериментирования, с учетом настоящего раскрытия. См. Remington's Pharmaceutical Sciences (Martin, E.W., ed. 4), Mack Publishing Co., Easton, PA. Дозировка также может быть скорректирована лечащим врачом в случае каких–либо осложнений.
Обычно, в описанном выше способе можно использовать ISVD, полипептид и/или конструкцию по изобретению. Однако объемом изобретения охватывается использование двух или более ISVD, полипептидов и/или конструкций по изобретению в комбинации.
ISVD, полипептиды и/или конструкции по изобретению можно использовать в комбинации с одним или несколькими другими фармацевтически активными соединениями или активными веществами, т.е. в виде комбинированной схемы лечения, которая может привести или не привести к синергетическому эффекту.
Фармацевтическая композиция также может включать по меньшей мере еще одно активное вещество, например, одно или несколько других антител или их антиген–связывающих фрагментов, пептидов, белков, нуклеиновых кислот, органических и неорганических молекул.
И в этом случае также клиницист сможет выбрать такие другие соединения или активные вещества, а также подходящую комбинированную схему лечения на основании факторов, перечисленных выше, и его экспертного заключения.
В частности, ISVD, полипептиды и/или конструкции по изобретению можно использовать в комбинации с другими фармацевтически активными соединениями или активными веществами, которые предназначены или которые можно использовать для профилактики и/или лечения заболеваний, расстройств и состояний, перечисленных в настоящей заявке, в результате чего может достигаться или не достигаться синергетический эффект. Примеры таких соединений и активных веществ, а также пути, способы и фармацевтические составы или композиции для их введения будут очевидны клиницисту.
Когда два или более веществ или активных начал используют как часть комбинированной схемы лечения, их можно вводить одним и тем же путем введения или разными путями введения, по существу одновременно или в разное время (например, по существу одновременно, последовательно или в чередующемся режиме). Когда вещества или активные начала можно вводить одновременно одним и тем же путем введения, их можно вводить в виде разных фармацевтических составов или композиций или части комбинированного фармацевтического состава или композиции, как будет понятно квалифицированному специалисту.
Также, когда два или более активных веществ или активных начал используют в виде части комбинированной схемы лечения, каждое из веществ или активных начал можно вводить в таком же количестве и в соответствии с такой же схемой введения, которые используются при введении соединения или активного начала как такового, и такое комбинированное введение может приводить или не приводить к синергетическому эффекту. Однако, когда комбинированное использование двух или более активных веществ или активных начал приводит к синергетическому эффекту, тогда можно будет уменьшить количество одного, нескольких или всех веществ или активных начал, которые следует вводить, с достижением при этом желаемого терапевтического действия. Это может, например, быть полезным для предотвращения, ограничения или уменьшения любых нежелательных побочных эффектов, которые связаны с использованием одного или более веществ или активных начал, когда они используются в их обычных количествах, при одновременном получении желаемого фармацевтического или терапевтического эффекта.
Эффективность схемы лечения, используемой в соответствии с изобретением, можно определить и/или отследить любым способом, известным per se для заболевания, расстройства или состояния, как будет понятно клиницисту. Клиницист также сможет, при необходимости и в каждом конкретном случае, изменять или модифицировать конкретную схему лечения, чтобы достичь желаемого терапевтического эффекта, чтобы избежать, ограничить или уменьшить нежелательные побочные эффекты, и/или чтобы достичь подходящего баланса между достижением желаемого терапевтического эффекта, с одной стороны, и предотвращением, ограничением или уменьшением нежелательных побочных эффектов, с другой стороны.
Как правило, схема лечения должна соблюдаться до тех пор, пока не будет достигнут желаемый терапевтический эффект и/или до тех пор, пока должен поддерживаться желаемый терапевтический эффект. Опять же, это может определить клиницист.
Таким образом, еще в одном аспекте изобретение относится к фармацевтической композиции, которая содержит по меньшей мере одну конструкцию по изобретению, по меньшей мере один полипептид по изобретению, по меньшей мере один ISVD по изобретению или по меньшей мере одну нуклеиновую кислоту по изобретению и по меньшей мере один подходящий носитель, разбавитель или эксципиент (т.е. подходящий для фармацевтического применения) и, необязательно, одно или несколько дополнительных активных веществ. В конкретном аспекте изобретение относится к фармацевтической композиции, которая включает конструкцию, полипептид, ISVD или нуклеиновую кислоту в соответствии с изобретением, предпочтительно по меньшей мере одну из SEQ ID NO: 111, 11, 112, 12, 109, 9, 110, 10, 1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 2, 3, 4, 5, 6, 7, 8, 160 –165 (т.е. SEQ ID NO: 160, 161, 162, 163, 164 или 165) и 176–192 (т.е. SEQ ID NO: 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191 или 192) и по меньшей мере один подходящий носитель, разбавитель или эксципиент (т.е. подходящий для фармацевтического применения) и, необязательно, одно или несколько дополнительных активных веществ.
Субъектом, подлежащим лечению, может быть любое теплокровное животное, но, в частности, млекопитающее и, в частности, человек. При применениях в ветеринарии субъект, подлежащий лечению, включает любое животное, выращенное в коммерческих целях или содержащееся в качестве домашнего животного. Как будет понятно специалисту в данной области, субъектом, подлежащим лечению, будет, в частности, человек, страдающий или подверженный риску заболеваний, расстройств и состояний, указанных в настоящей заявке. Следовательно, в предпочтительном варианте осуществления изобретения фармацевтические композиции, включающие полипептид по изобретению, предназначены для применения в лечении или диагностике. Предпочтительно, фармацевтические композиции предназначены для применения в медицине, но они также могут использоваться в ветеринарии.
Опять же, в такой фармацевтической композиции один или несколько иммуноглобулинов, полипептидов, соединений и/или конструкций по изобретению, или нуклеотид, кодирующий их, и/или фармацевтическую композицию, включающую их, также можно подходящим образом объединить с одним или несколькими другими активными веществами, такими как указанные в настоящей заявке.
Изобретение также относится к композиции (такой как, без ограничения, фармацевтическая композиция или препарат, как далее описано в настоящей заявке) для применения либо in vitro (например, в анализе in vitro или клеточном анализе), либо in vivo (например, в отдельной клетке или многоклеточном организме, и, в частности, для млекопитающего и, более конкретно, человека, такого как человек, который имеет риск развития или страдает от заболевания, расстройства или состояния по настоящему изобретению).
Следует понимать, что ссылка на лечение включает как лечение установленных симптомов, так и профилактическое лечение, если прямо не указано иное.
Как правило, для фармацевтического применения конструкции, полипептиды и/или ISVD по изобретению могут быть сформулированы в виде фармацевтического препарата или композиции, включающей по меньшей мере одну конструкцию, полипептид и/или ISVD по изобретению и по меньшей мере один фармацевтически приемлемый носитель, разбавитель или эксципиент и/или адъювант и, необязательно, один или несколько фармацевтически активных полипептидов и/или соединений. В качестве неограничивающих примеров, такая композиция может быть в форме, подходящей для перорального введения, для парентерального введения (например, посредством внутривенной, внутримышечной или подкожной инъекции или внутривенной инфузии), для местного введения (такого как интраартикулярное введение), для введения путем ингаляция, при помощи кожного пластыря, имплантата, суппозитория и т.д., при этом интраартикулярное введение является предпочтительным. Такие подходящие формы введения, которые могут быть твердыми, полутвердыми или жидкими, в зависимости от способа введения, а также способы и носители для использования при их получении, будут понятны специалисту в данной области и далее описаны в настоящей заявке. Такой фармацевтический препарат или композиция в общем виде будут указаны как “фармацевтическая композиция”.
В качестве примеров эксципиентов можно указать разрыхлители, связующие, наполнители и смазывающие вещества. Примеры разрыхлителей включают агар–агар, альгины, карбонат кальция, целлюлозу, коллоидный диоксид кремния, камеди, алюмосиликат магния, метилцеллюлозу и крахмал. Примеры связующих включают микрокристаллическую целлюлозу, гидроксиметилцеллюлозу, гидроксипропилцеллюлозу и поливинилпирролидон. Примеры наполнителей включают карбонат кальция, фосфат кальция, трехосновный сульфат кальция, кальций карбоксиметилцеллюлозу, целлюлозу, декстрин, декстрозу, фруктозу, лактит, лактозу, карбонат магния, оксид магния, мальтит, мальтодекстрины, мальтозу, сорбит, крахмал, сахарозу, сахар и ксилит. Примеры смазывающих веществ включают агар, этилолеат, этиллаурат, глицерин, глицерилпальмитостеарат, гидрированное растительное масло, оксид магния, стеараты, маннит, полоксамер, гликоли, бензоат натрия, лаурилсульфат натрия, стеарил натрия, сорбит и тальк. Обычные стабилизаторы, консерванты, смачивающие вещества и эмульгаторы, улучшающие консистенцию агенты, улучшающие вкус вещества, соли для изменения осмотического давления, буферные вещества, солюбилизаторы, разбавители, смягчающие вещества, красители и маскирующие агенты и антиоксиданты рассматриваются в качестве фармацевтических адъювантов.
Подходящие носители включают, но не ограничиваются этим, карбонат магния, стеарат магния, тальк, сахар, лактозу, пектин, декстрин, крахмал, желатин, трагакант, метилцеллюлозу, натрий карбоксиметилцеллюлозу, низкоплавкий воск, масло какао, воду, спирты, полиолы, глицерин, растительные масла и т.п.
Как правило, конструкции, полипептиды и/или ISVD по изобретению можно сформулировать в композицию и вводить любым подходящим способом, известным per se. См., например, известный уровень техники, указанный выше (и, в частности, WO 04/041862, WO 04/041863, WO 04/041865, WO 04/041867 и WO 08/020079), а также справочники, такие как Remington’s Pharmaceutical Sciences, 18th Ed., Mack Publishing Company, USA (1990), Remington, the Science and Practice of Pharmacy, 21st Edition, Lippincott Williams and Wilkins (2005); или the Handbook of Therapeutic Antibodies (S. Dubel, Ed.), Wiley, Weinheim, 2007 (см., например, стр. 252–255).
В специальном аспекте изобретение относится к фармацевтической композиции, которая включает конструкцию, полипептид, ISVD или нуклеиновую кислоту в соответствии с изобретением, и которая дополнительно включает по меньшей мере один фармацевтически приемлемый носитель, разбавитель или эксципиент и/или адъювант и, необязательно, включает один или несколько дополнительных фармацевтически активных полипептидов и/или соединений.
Композиции, конструкции, полипептиды и/или ISVD по изобретению можно сформулировать в композицию и вводить любым известным способом для обычных антител и фрагментов антител (включая ScFv и диатела) и других фармацевтически активных белков. Такие композиции и способы их получения будут понятны специалистам и, например, включают препараты, предпочтительные для парентерального введения (например, внутривенного, интраперитонеального, подкожного, внутримышечного, интралюминального, интраартериального, интратекального, интраназального или интрабронхиального введения), но также для местного (т.е. интраартикулярного, трансдермального или интрадермального) введения.
Препараты для парентерального введения могут, например, представлять собой стерильные растворы, суспензии, дисперсии или эмульсии, которые подходят для инфузии или инъекции. Подходящие носители или разбавители для таких препаратов, например, включают, без ограничения, те, которые указаны на странице 143 WO 08/020079. Обычно водные растворы или суспензии будут предпочтительными.
Конструкции, полипептиды и/или ISVD по изобретению также можно вводить с использованием способов доставки, известных из генной терапии, см., например, патент США № 5399346, который включен в качестве ссылки, что касается генно–терапевтических способов доставки. При использовании генно–терапевтического способа доставки первичные клетки, трансфицированные геном, кодирующим конструкцию, полипептид и/или ISVD по изобретению, могут быть дополнительно трансфицированы тканеспецифическими промоторами для нацеливания на конкретные органы, ткани, трансплантаты, опухоли или клетки и могут быть дополнительно трансфицированы сигнальными и стабилизирующими последовательностями для субклеточно локализованной экспрессии.
В соответствии с другими аспектами изобретения, полипептид по изобретению можно использовать в дополнительных применениях in vivo и in vitro. Например, полипептиды по изобретению можно использовать для диагностических целей, например в анализах, предназначенных для детекции и/или количественного определения присутствия MMP13 и/или для очистки MMP13. Полипептиды и также могут быть испытаны на животных моделях конкретных заболеваний и в испытаниях для оценки токсичности, безопасности и дозировки.
Наконец, изобретение относится к набору, включающему по меньшей мере один полипептид по изобретению, по меньшей мере одну последовательность нуклеиновой кислоты, кодирующую указанные компоненты, вектор или векторную систему по изобретению и/или клетку–хозяин в соответствии с изобретением. Предполагается, что набор может быть представлен в различных формах, например в виде диагностического набора.
Далее изобретение будет дополнительно описано при помощи следующих неограничивающих предпочтительных аспектов, примеров и чертежей.
Полное содержание всех ссылок (включая ссылки на литературу, выданные патенты, опубликованные патентные заявки и находящиеся на одновременном рассмотрении патентные заявки), процитированных в настоящей заявке, явным образом включено в настоящую заявку посредством ссылки, в частности, что касается основополагающих ссылочных документов, указанных выше.
Последовательности раскрыты в основной части описания и в отдельном перечне последовательностей в соответствии со стандартом WIPO ST.25. SEQ ID с указанием конкретного номера должен быть одинаковым в основной части описания и в отдельном перечне последовательностей. В качестве примера, SEQ ID №: 1 должен определять одну и ту же последовательность как в основной части описания, так и в отдельном перечне последовательностей. В случае несоответствия между определением последовательности в основном тексте описания и отдельном перечне последовательностей (если, например, SEQ ID №: 1 в основном тексте описания ошибочно соответствует SEQ ID №: 2 в отдельном перечне последовательностей), ссылку на конкретную последовательность в заявке, в частности на конкретные варианты осуществления, следует понимать как ссылку на последовательность в основном тексте заявки, а не на отдельный перечень последовательностей. Другими словами, несоответствие между определением/обозначением последовательности в основной части описания и в отдельном перечне последовательностей должно быть устранено путем исправления отдельного перечня последовательностей в соответствии с последовательностями и их обозначениями, раскрытыми в основной части заявки, которая включает описание, примеры, чертежи и формулу изобретения.
6 ПРИМЕРЫ
Следующие примеры иллюстрируют способы и продукты по изобретению. Подходящие модификации и адаптации описанных условий и параметров, с которыми обычно сталкиваются в области молекулярной и клеточной биологии, которые очевидны специалистам в данной области техники, охватываются сущностью и объемом настоящего изобретения.
6.1 Способы
6.1.1 Иммунизация лам
Иммунизацию лам осуществляли в соответствии со стандартными процедурами, с варьированием количества антигена, типа адъюванта и используемого способа инъекции. Эти варьирования подробно описаны в соответствующих разделах ниже. Все эксперименты по иммунизации были одобрены местным колитетом по этике.
6.1.2 Конструирование библиотеки
кДНК получали с использованием тотальной РНК, экстрагированной из образцов крови всех лам/альпак, иммунизированных MMP13. Нуклеотидные последовательности, кодирующие Нанотела, амплифицировали из кДНК в одностадийной ОТ–ПЦР реакции и лигировали в соответствующие сайты рестрикции фагмидного вектора pAX212, с последующим трансформацией E. coli штамма TG–1 продуктом лигирования через электропорацию.
NNK библиотеки получали методом ПЦР с перекрывающимися праймерами с использованием вырожденного праймера. ПЦР продукты клонировали в вектор экспрессии (pAX129) и трансформировали E. coli TG–1 компетентные клетки. В рамке с Нанотело–кодирующей последовательностью вектор кодирует C–концевой FLAG3– и His6–tag.
Последовательности клонов, представляющих интерес, верифицировали.
6.1.3 Селекции
Фаг–дисплейные библиотеки зондировали с использованием рекомбинантной MMP13. В разных циклах селекции использовали разные антигены, как подробно описано в разделе Результаты, т.е. в Примере 6.2 и далее.
Селекции состояли из инкубации антигена с фаговыми частицами библиотеки в течение 2 часов (в PBS, дополненном 2% Marvel и 0,05% Tween 20). Биотинилированные антигены захватывали с использованием покрытых стрептавидином магнитных шариков (Invitrogen, 112–05D). Небиотинилированные антигены наносили на планшеты MaxiSorp (Nunc, 430341). Несвязанный фаг удаляли промывкой (PBS, дополненный 0,05% Tween 20); связанный фаг элюировали путем добавления трипсина (1 мг/мл в PBS) в течение 15 мин. Элюированные фаги использовали для инфицирования экспоненциально растущих E. coli TG–1 клеток для спасения фага. Фаг, полученный из выбранных выходящих продуктов, использовали в качестве исходного материала в последующих циклах селекции.
6.1.4 ELISA Непосредственно наносимые антигены
MaxiSorp планшеты (Nunc, 430341) покрывали в течение ночи человеческим про–MMP13 при 4°C с последующим блокированием в течение одного часа (PBS, 1% казеина) при комнатной температуре. После стадии промывки в PBS+0,05% Tween20, 10–кратные разведения периплазматических экстрактов в PBS, 0,1% казеина, 0,05% Tween 20 добавляли в течение одного часа при комнатной температуре. Детекцию связанных Нанотел осуществляли с использованием мышиного анти–FLAG–HRP (Sigma (A8592)).
Захваченные антигены
– активированный MMP13 человека ELISA
– активированный MMP13 крысы ELISA
– активированный MMP13 собаки ELISA
MaxiSorp планшеты (Nunc, 430341) покрывали в течение ночи антителом mAb511 против MMP13 человека при 4°C с последующим блокированием в течение одного часа (PBS, 1% казеина) при комнатной температуре. После стадии промывки в PBS+0,05% Tween20, 20 нМ активированного MMP13 человека, крысы или собаки добавляли в течение одного часа при комнатной температуре. После второй стадии промывки добавляли 10–кратные разведения периплазматических экстрактов или серию разведений очищенных Нанотел в PBS, 0,1% казеина, 0,05% Tween 20 в течение одного часа при комнатной температуре. Детекцию связанных Нанотел осуществляли с использованием мышиного анти–FLAG–HRP (Sigma (A8592)).
6.1.5 Анализ флуорогенного пептида
Вкратце, схема флуорогенных пептидных анализов MMP13 человека, яванского макака, крысы, собаки и быка, а также флуорогенных пептидных анализов MMP1 и MMP14 человека является следующей: активированный MMP инкубировали с флуорогенным пептидным субстратом Mca–PLGL–Dpa–AR–NH2 (R&D Systems # ES001) и 1/5 разведением периплазматического экстракта или серией разведений очищенного Нанотела/положительного контроля (общий объем=20 мкл в аналитическом буфере 50 мМ Трис, рН 7,5, 100 мМ NaCl, 10 мМ CaCl2, 0,01% Твин 20) в течение 2 ч при 37°С. Линейное увеличение флуоресценции (v0– между 15 и 45 мин инкубации) использовали в качестве показателя ферментативной активности, и % ингибирования рассчитывали по формуле 100–100 (v0 в присутствии испытываемого Нанотела/v0 в присутствии отрицательного контрольного Нанотела (Cablys)).
6.1.6 Коллагенолитический анализ
Краткое описание процедуры коллагенолитического анализа: 250 нг/мл человеческого коллагена II для иммунизации (Chondrex # 20052) инкубировали с 5 нМ активированного MMP13 в 100 мкл буфера для анализа (50 мМ Tris–Cl pH 7,5, 100 мМ NaCl, 10 мМ CaCl2, 0,01% Твин–20). После 1,5 ч инкубации при 35°С реакцию нейтрализовали при помощи EDTA (10 мкл 30 мМ исходного раствора). MMP13–расщепленный Коллаген дополнительно расщепляли эластазой в течение 20 мин при 38°C, чтобы избежать повторного отжига разрушенного Коллагена II (10 мкл 1/3 разбавленного исходного раствора, предоставленного в наборе для детекции Коллагена типа II (Chondrex # 6009)). Оставшийся неповрежденным Коллаген определяли методом ELISA (реагенты, предоставленные в наборе для детекции Коллагена типа II (Chondrex # 6009))
6.1.7 Анализ флуорогенного коллагена
Вкратце, схема анализа по существу следующая: 100 мкг/мл DQ™ Коллагена типа I из бычьей кожи (конъюгат с флуоресцеином; Molecular Probes #D–12060 партия 1149062) инкубировали с 10 нМ активированного MMP13 и серией разведений очищенного Нанотела/положительного контроля в течение 2 ч при 37°С в 40 мкл буфера для анализа (50 мМ Трис–Cl, рН 7,5, 100 мМ NaCl, 10 мМ CaCl2, 0,01% Твин–20). Линейное увеличение флуоресценции (v0– между 15 и 45 мин инкубации) использовали в качестве показателя ферментативной активности, и % ингибирования рассчитывали по формуле 100–100 (v0 в присутствии испытываемого Нанотела/v0 в присутствии отрицательного контрольного Нанотела (Cablys)).
6.1.8 TIMP–2 конкурентный анализ
50 мкл TIMP–2 (0,63 нМ; R&D Systems #971–TM) захватывали (1ч при комнатной температуре) на покрытом антителом против человеческого TIMP–2 (R&D Systems #MAB9711) планшете (2 мкг/мл в PBS; в течение ночи). Во время этого захватывания 1,26 нМ активированного MMP–13–биотин предварительно инкубировали с серийным разведением Нанотело/TIMP–3/MSC2392891A в 70 мкл аналитическом буфере (50 мМ Tris–Cl pH 7,5, 100 мМ NaCl, 10 мМ CaCl2, 0,01% Tween–20). 50 мкл этой смеси добавляли к захваченному TIMP–2 и инкубировали в течение 1ч при комнатной температуре. Детекцию MMP13–биотина осуществляли с использованием 50 мкл стрептавидин–HRP (1:5000 DakoCytomation #P0397).
6.1.9 Анализ теплового сдвига (TSA)
TSA осуществляли с использованием 5 мкл очищенных одновалентных Нанотел по существу в соответствии с Ericsson et al. (2006 Anals of Biochemistry, 357: 289–298).
6.1.10 Аналитическая эксклюзионная хроматография (Аналитическая SEC)
Эксперименты методом аналитической SEC осуществляли на устройстве Ultimate 3000 (Dionex) в комбинации с колонкой Biosep–SEC–3 (Agilent).
6.1.11 Принудительное окисление
Образцы Нанотел (1 мг/мл) подвергали воздействию 10 мМ H2O2 в PBS в течение четырех часов при комнатной температуре и в темноте, параллельно с контрольными образцами без H2O2, с последующей заменой буфера на PBS с использованием обессоливающих спин–колонок Zeba (0,5 мл) (Thermo Scientific). Образцы, подвергнутые стрессовым воздействиям, и контрольные образцы затем анализировали при помощи RPC на устройстве Series 1200 или 1290 (Agilent Technologies) на колонке Zorbax 300SB–C3 (Agilent Technologies) при 70°C. Окисление Нанотел определяли количественно путем определения % площади пика для пиков, расположенных перед главным пиком, возникающих в результате окислительного стресса, по сравнению с главным пиком белка.
6.1.12 Температурный стресс
Образцы Нанотел (1–2 мг/мл) хранили в PBS в течение четырех недель при –20°C (отрицательный контроль) 25 и 40°C. После этого инкубационного периода Нанотела расщепляли Трипсином или LysC. Пептиды из образцов, подвергнутых стрессовым воздействиям, и контрольных образцов затем анализировали при помощи RPC на устройстве Series 1290 (Agilent Technologies) с колонкой Acquity UPLC BEH300–C18 (Agilent Technologies) при 60°C, соединенной с Q–TOF масс–спектрометром (6530 Accurate Mass Q–TOF (Agilent))
6.2 Иммунизации
MMP13 секретировался в виде неактивной про–формы (про–MMP13). Он активируется сразу после того, как про–домен расщепляется, оставляя активный фермент, состоящий из каталитического домена, который образует каталитический карман, и гемопексин–подобного домена (PDB: 1PEX), который описан как выполняющий функцию в качестве докинга/взаимодействующего домена Коллагенового II субстрата (Col II).
Было сделано предположение, что лучшей областью для ингибирования ферментативной активности MMP13 мог бы быть каталитический карман. Однако, индукция иммунного ответа против каталитического кармана связана с различными серьезными проблемами.
Во–первых, в про–MMP13 про–домен маскирует каталитический карман, из–за этого карман недостижим для индукции иммунного ответа.
Во–вторых, активированный MMP13 имеет короткий период полужизни, преимущественно из–за автопротеолиза. Этот короткий период полужизни препятствует развитию сильного иммунного ответа.
В–третьих, последовательность каталитического домена является высококонсервативной в различных видах. Следовательно, ожидаемый иммунный ответ будет слабым, если вообще будет проявляться.
6.2.1 Стратегия иммунизации
Для решения этих проблем и повышения шансов на успех в получении ингибиторов MMP13, связывающихся с каталитическим карманом, были разработаны сложные и продуманные стратегии иммунизации, включающие различные форматы MMP13. В конечном счете, были осуществлены следующие иммунизации:
(a) 3 лам иммунизировали усеченным вариантом MMP13, состоящим из каталитического домена и содержащим мутацию F72D, которая защищает MMP13 от автопротеолиза;
(b) 3 лам иммунизировали таким же усеченным вариантом MMP13, как (a), который в дополнение к мутации F72D, содержал мутацию E120A, которая инактивирует ферментативную функцию;
(c) еще 3 лам иммунизировали полноразмерным про–MMP13 белком; и
(d) 3 лам иммунизировали смесью плазмид, которые кодировали либо секретируемый про–MMP13 вариант (V123A), либо GPI–заякоренный про–MMP13 вариант (V123A). V123A мутация описана для MMP13 как вызывающая слабое взаимодействие Cys104 с каталитическим цинковым ионом, приводя к спонтанной авто–активации.
6.2.2 Сывороточные титры
Сывороточные титры определяли в отношении про–MMP13 и каталитического домена (F72D).
Как правило, животные, иммунизированные белком про–MMP13 (c) или ДНК, кодирующей про–MMP13 V123A (d), показали хороший иммунный ответ против про–MMP13, но только лишь слабо отвечали на каталитический домен (F72D). Животные, иммунизированные каталитическим доменом (F72D) (a) или неактивным каталитическим доменом (F72D, E120A) (b), не показали никакого или только слабый иммунный ответ против каталитического домена.
6.2.3 Конструирование библиотеки
Несмотря на низкие сывороточные титры против каталитического домена, авторы настоящего изобретения были убеждены, что экстенсивный скрининг позволит идентифицировать ингибиторы, связывающиеся с каталитическим карманом.
РНК экстрагировали из PBLs (первичные лимфоциты крови) и использовали в качестве матрицы для ОТ–ПЦР для амплификации Нанотело–кодирующих генных фрагментов. Эти фрагменты клонировали в фагмидный вектор pAX212, обеспечивая возможность продукции фаговых частиц, экспонирующих Нанотела, слитые с His6– и FLAG3–метками. Фаги получали и хранили в соответствии со стандартными протоколами (Phage Display of Peptides and Proteins: A Laboratory Manual 1st Edition, Brian K. Kay, Jill Winter, John McCafferty, Academic Press, 1996).
Средний размер полученных в результате 18 иммунных библиотек составил около 5 * 108 индивидуальных клонов.
6.3 Первичный скрининг
Селекции с использованием фагового дисплея осуществляли с использованием 18 иммунных библиотек и двух библиотек синтетических Нанотел. Библиотеки подвергали двум–четырем циклам обогащения против различных комбинаций человеческого про–MMP13, активированного MMP13 человека, крысы и собаки, а также каталитического домена MMP13 человека (F72D) с использованием различных форматов презентации антигена. Отдельные клоны из результатов селекции подвергали скринингу на связывание в ELISA (с использованием периплазматических экстрактов из клеток E.coli, экспрессирующих Нанотела) против MMP13 человека и крысы и на ингибирующую активность в анализе флуорогенного пептида, измеряющем увеличение флуоресценции при гидролизе пептида с использованием флуорогенного пептидного субстрата MMP широкого спектра. Нанотела, которые показали связывание в ELISA, но не проявляли ингибирующую активность в анализе флуорогенного пептида, дополнительно подвергали скринингу в коллагенолитическом анализе. В коллагенолитическом анализе используют природный субстрат вместо пептидного суррогата. Поскольку коллаген имеет гораздо бóльшую поверхность взаимодействия с ММР13, чем флуорогенный пептид, предполагалось, что Нанотела будут препятствовать разрушению Коллагена, но не разрушению пептида. Однако коллагенолитический анализ не был совместим с периплазматическими экстрактами и требовал использования очищенных Нанотел.
6.3.1 Кампания 1
В первой селекционной кампании MMP13 был представлен в виде непосредственно покрывающего антигена. Это привело к высокой результативности в ELISA MMP13 человека и крысы (анализ связывания), включая хорошее разнообразие Нанотел, связывающихся с MMP13 человека, с широким диапазоном сигналов связывания в ELISA. Было обнаружено, что большинство Нанотел являются перекрестно–реактивными в отношении MMP13 крысы. Однако в анализе флуорогенного пептида (анализ ингибирования) была чрезвычайно низкая результативность. Более того, наблюдаемое ингибирование было неполным, и некоторые из этих нанотел не показали перекрестную реактивность в отношении белка крысы.
Поскольку не было получено ни одного одновалентного полностью ингибирующего нанотела, авторы изобретения предположили, что не было нацеливания на правильный эпитоп, а условия, используемые в процессе селекций, не были оптимальными. Однако проверке условий отбора препятствовало отсутствие положительного контроля.
В конце концов было обнаружено, что непосредственное покрытие мешает активности фермента.
6.3.2 Кампания 2
В кампании 2 селекции осуществляли в растворе с биотинилированным MMP13. При использовании активированного человеческого и крысиного MMP13, захваченного при помощи ненейтрализующего антитела, вместо непосредственного покрытия про–MMP13, результативность ELISA однако была намного ниже, чем для кампании 1. Результативность также снова была очень низкой в анализе флуорогенного пептида. Однако было обнаружено одно Нанотело, полностью ингибирующее в коллагенолитическом анализе. Поскольку про–форму фермента использовали для обогащения связующим, было выдвинуто предположение, что критические эпитопы были замаскированы про–пептидом.
6.3.3 Кампания 3
Ввиду разочаровывающих результатов кампаний 1 и 2 авторы изобретения решили оптимизировать презентацию критических эпитопов в каталитическом домене, используя активированный MMP13, захваченный ненейтрализующим антителом. Тот же формат захвата был также использован для ELISA. Это привело к более высокой результативности в ELISA для MMP13 человека и крысы. Однако, хотя результативность в анализе флуорогенного пептида была несколько выше по сравнению с предыдущими кампаниями, Нанотела все еще показывали только неполное ингибирование и демонстрировали слабую перекрестную реактивность в отношении крысиного белка или вообще ее отсутствие, что позволяет предположить, что презентация захваченного ММР13 все еще была неоптимальной.
Три клона, включая C0101040E09 (“40E09”), несмотря на то, что показали неполное ингибирование в анализе флуорогенного пептида, были определены как положительные в коллагенолитическом анализе. Члены семейства 40E09 были клонированы и секвенированы: C0101PMP040E08, C0101PMP042A04, C0101PMP040B05, C0101PMP042D12, C0101PMP042A03, C0101PMP024A08 и C0101PMP040D01 (см. Таблицы A–1 и A–2). Вариабельность последовательностей CDR областей показана в Таблицах 6.3.3A, 6.3.3B и 6.3.3C ниже. Аминокислотные последовательности CDR клона 40E09 использовали в качестве эталона, с которым сравнивали CDR членов семейства (CDR1 начинается в положении 26 по Kabat, CDR2 начинается в положении 50 по Kabat, а CDR3 начинается в положении 95 по Kabat.
6.3.4 Кампания 4
В 4–й кампании, в дополнение к иммунным библиотекам фагового дисплея Нанотел, полученным при применении стратегий иммунизации (a) и (c), были также исследованы библиотеки, полученные при применении стратегий селекции (b) и (d) (см. Пример 6.2.1). Стратегия селекции была сфокусирована на каталитическом домене MMP13 (F72D), который использовали в растворе. Результативность в анализе флуорогенного пептида увеличивалась во всех библиотеках, и многие Нанотела показали полное ингибирование. Ингибирующие Нанотела показали лишь слабое связывание в ELISA, подтверждая, что также презентация захваченного MMP13, используемая в кампании 3, была субоптимальной для доступности критических эпитопов. Следовательно, для оценки перекрестной реактивности в отношении крысиного белка использовали ELISA для анализа крысиного флуорогенного пептида. Все представители семейства нанотел с подтвержденным ингибирующим потенциалом были перекрестно реактивными в отношении крысиного белка, что свидетельствует о том, что эпитопы, распознаваемые этим конкретным набором клонов, находятся в консервативном каталитическом кармане MMP13.
Таким образом, было обнаружено, что любые рутинные манипуляции с MMP13 влияли на активность фермента и связывание TIMP–2 (данные не показаны). После варьирования и оценки различных параметров, включая различные антигены (например, про–MMP13, каталитический домен (F72D), активированный человеческий MMP13, активированный крысиный MMP13, активированный собачий MMP13, различные анализы, включая ELISA, анализ флуорогенного пептида человека, анализ флуорогенного пептида крысы и коллагенолитический анализ человеческого белка, различные схемы анализа, включая изменения условий нанесения покрытия, в растворе и захвата MMP13), было обнаружено, что единственными успешными стратегиями для идентификации полностью ингибирующих Нанотел были селекции с использованием каталитического домена (F72D) или активированных видов MMP13 (кампания 4).
6.3.5 Панель лидеров
Ингибирующие Нанотела, идентифицированные в анализе флуорогенного пептида или коллагенолитическом анализе, секвенировали. На основе информации о последовательности, Нанотела могут быть подразделены на различные семейства. 4 семейства, полученные в результате скрининговых кампаний 2 и 3, показали полное ингибирование в коллагенолитическом анализе, но не показали активности в анализе флуорогенного пептида; далее обозначены как клоны “профиля 1” (см. 40E09 и члены семейства). 10 семейств, полученных в результате скрининговой кампании 4, показали ингибирующую активность как в коллагенолитическом анализе, так и в анализе флуорогенного пептида; далее обозначены как клоны “профиля 2”.
Для каждого семейства нанотел был выбран репрезентативный клон, всего 14 представителей. Последовательности репрезентативных клонов показаны в Таблице A–1.
6.4 Характеристика панели одновалентных лидеров in vitro
Чтобы дополнительно охарактеризовать репрезентативные клоны Нанотел функционально, их реклонировали в pAX129, трансформировали в E.coli и экспрессировали и очищали в соответствии со стандартными протоколами (например, Maussang et al. 2013 J Biol Chem 288 (41): 29562–72). Затем эти клоны подвергали различным функциональным анализам in vitro.
6.4.1 Ферментативные анализы
Активность/эффективность Нанотел испытывали в анализе флуорогенного пептида, установленном для различных ортологов ММР13 и в коллагенолитическом анализе человеческого белка (оба анализа также использовали во время скрининга, см. Пример 6.3). Кроме того, второй анализ на основе коллагена (анализ флуорогенного коллагена) с использованием более высоких концентраций коллагена по сравнению с коллагенолитическим анализом был установлен для имитации условий высоких концентраций Коллагена в хряще, в которых, как ожидается, ингибитор ММР13 будет активным. В этом анализе флуоресценция интактного FITC–меченного Коллагенового субстрата является низкой из–за эффекта взаимного гашения флуорофоров. При расщеплении гашение теряется, а флуоресценция увеличивается.
Активности в ферментативных анализах представлены в Таблице 6.4.1.
Активность панели лидеров в ферментативных анализах MMP13. Активности указаны только тогда, когда эффективность составляет ͂100%
2891A
На Фиг. 1 представлены кривые доза–ответ для ингибирования активированного MMP13 человека с использванием высоких концентраций бычьего Коллагена I (анализ флуорогенного коллагена).
Фиг. 1: Кривые доза–ответ Нанотел профиля 1 (левый график) и Нанотел профиля 2 (правый график) в анализе флуорогенного Коллагена
Хотя Нанотела профиля 1 показали полную эффективность в коллагенолитическом анализе в условиях низких концентраций Коллагена, их эффективность снижалась в анализе флуорогенного Коллагена в условиях высоких концентраций Коллагена (Фиг. 1, левая панель).
Также препарат сравнения MSC2392891A показал более слабую эффективность в анализе флуорогенного Коллагена (Фиг. 1).
Репрезентативные Нанотела профиля 2 были активными и полностью эффективными как в коллагенолитическом анализе, так и в анализе флуорогенного Коллагена. В этом анализе большинство Нанотел были более активными, чем препарат сравнения. Эти представители профиля 2 показали сопоставимые активности (см. Таблицу 6.4.1) и эффективности (Фиг. 1, правая панель) в анализах флуорогенного пептида человека, яванского макака, крысы, собаки и быка.
6.4.2 Анализы связывания
Для оценки аффинности связывания использовали схему анализа ELISA. Однако было обнаружено, что этот анализ пригоден только для оценки аффинности Нанотел профиля 1, но не Нанотел профиля 2 (см. Пример 6.3)
Результаты представлены в Таблице 6.4.2A.
Аффинности связывания (EC50), определенные методом ELISA для Нанотел профиля 1
В заключение следует отметить, что аффинность связывания Нанотел профиля 1 сопоставима для трех протестированных видов (т.е. разница менее чем в 10 раз). Хотя клон 40E09 имеет только вторую лучшую аффинность связывания с человеческим MMP13, он демонстрирует наилучшую аффинность среди видов.
Поскольку было обнаружено, что Нанотела профиля 2 конкурировали с TIMP–2 за связывание с MMP13, был установлен конкурентный ELISA для анализа TIMP–2 и использован для оценки аффиностей Нанотел профиля 2. Примечательно, что Нанотела профиля 1 не конкурируют с TIMP–2.
Результаты представлены в Таблице 6.4.2B.
Активности (IC50), оцененные в TIMP–2 конкурентном ELISA для Нанотел профиля 2
В заключение, рейтинг был аналогичен активностям, полученным в ферментных анализах, где Нанотела 516G08, 529C12 и 62CO2 показывают лучший ингибиторный потенциал, тогда как Нанотела 59F06, 525C04 и 63F01 были на втором месте.
6.4.3 Анализы селективности
Чтобы определить селективность Нанотел по отношению к MMP13 по сравнению с MMP1 и MMP14, использовали анализы флуорогенных пептидов. MMP1 и MMP14 являются двумя близкородственными членами семейства MMP. Поскольку Нанотела профиля 1 не показали ингибирования в анализе флуорогенного пептида ММР13, можно было протестировать только Нанотела профиля 2. TIMP–2, неселективный ингибитор ММР, использовали в качестве положительного контроля в этих анализах
Результаты представлены на Фиг. 2.
Фиг. 2. Селективность в отношении MMP13 Нанотел–лидеров
Все Нанотела были высокоселективными. Они не показали ингибирования MMP1, и только очень незначительное ингибирование наблюдали при высоких концентрациях MMP14 для некоторых Нанотел.
6.4.4 Связывание с эпитопом
Панель одновалентных Нанотел профиля 1 и профиля 2 испытывали на связывание с эпитопом в конкурентном ELISA против очищенного Нанотела 40E09 (профиль 1).
Результаты конкурентного ELISA показаны на Фиг. 3.
Фиг. 3. Конкурентный ELISA с 0,6 нМ биотинилированного 40E09 против панели Нанотел профиля 1 и профиля 2 на человеческом полноразмерном MMP13, захваченном посредством мышиного mAb против человеческого MMP13 (R&D Systems #MAB511). MMP13 активировали путем инкубации с APMA в течение 1ч 30 мин при 37°C.
Нанотела профиля 1 32B08, 43B05, 43E10 и 40E09 (положительный контроль) все конкурируют с 40E09. С другой стороны, ни Нанотела профиля 2 59F06, 62C02, 63F01, 513C04, 516G08 и 517A01, ни отрицательный контроль cAbLys не конкурируют с 40E09.
Следовательно, Нанотела профиля 1, по–видимому, принадлежат к другой эпитопной группе (предварительно называемой “группой 1”), чем Нанотела профиля 2 (предварительно называемые “группой 2”), что также может отражать стратегии иммунизации и селекции.
6.5 Двухвалентные конструкции
Как показано в Примере 6.4.1 выше, Нанотела профиля 1 не показали ингибирования в анализах флуорогенных пептидов (см. Таблицу 6.4.1). Авторы изобретения намеревались исследовать эффект комбинации Нанотел профиля 1 и Нанотел профиля 2.
В качестве наилучшего вида перекрестно–реактивного связующего (см. Пример 6.4.2) Нанотело 40E09 было выбрано в качестве репрезентативного Нанотела профиля 1. Для профиля 2 были выбраны три Нанотела: 516G08, 62C02 и 517A01. Нанотела профиля 1 и профиля 2 объединяли в двухвалентном формате с линкером 35GS (см. Таблицу 6.5; Nb(A)–35GS–Nb(B)). Двухвалентные Нанотела клонировали в pAX205, трансформировали в P.pastoris, экспрессировали и очищали в соответствии со стандартными процедурами.
Для оценки активности этих двухвалентных конструкций использовали анализ флуорогенного пептида крысы, но с более низкой концентрацией MMP13 по сравнению с процедурой скрининга (0,15 нМ вместо 1,33 нМ) для улучшения чувствительности анализа. Двухвалентные конструкции тестировали в этом адаптированном анализе флуорогенного пептида, а также в анализе флуорогенного коллагена человека.
Полученные данные представлены в Таблице 6.5.
Активность двухвалентных Нанотел в анализе флуорогенного пептида крысы (адаптированный для большей чувствительности) и анализе флуорогенного коллагена человека
Результаты показывают, что двухвалентные конструкции, состоящие из Нанотела профиля 1 в комбинации с Нанотелом профиля 2, более эффективны, чем их одновалентные структурные блоки в адаптированном анализе крысиного флуорогенного пептида, с улучшением активности вплоть до в 40 раз. Также в анализе человеческого флуорогенного коллагена наблюдали улучшение эффективности (вплоть до в 4 раза). В обоих анализах двухвалентные конструкции были одинаково эффективны по сравнению с положительным неселективным контролем TIMP–2.
Следовательно, хотя Нанотела профиля 1 сами по себе не являются особенно ингибирующими, они улучшают активность Нанотел профиля 2 при комбинировании в виде двухвалентной конструкции.
6.6 Определение биофизических характеристик
Для удобства пациента предпочтительными являются низкая частота введения и высокое удерживание терапевтического соединения. Следовательно, предпочтительно, чтобы нанотела обладали высокой стабильностью.
Для проверки стабильности определяли биофизические характеристики 5 репрезентативных Нанотел профиля 2 и одного репрезентативного Нанотела профиля 1.
6.6.1. Анализ термического сдвига
Термостабильность анти–ММР13 Нанотел дикого типа исследовали в анализе термического сдвига (TSA)
Результаты представлены в таблице 6.6.1.
Т.пл. при pH 7 для одновалентных Нанотел
Т.пл. значения при pH 7 в диапазоне от 65°C до 83°C указывают на характеристики стабильности от хороших до очень хороших.
6.6.2 Аналитическая SEC
Тенденцию к мультимеризации и агрегации выбранной панели из 5 репрезентативных анти–MMP13 Нанотел исследовали методом аналитической эксклюзионной хроматографии (aSEC).
Результаты показаны в таблице 6.6.2.
Аналитические SEC параметры для лидерных Нанотел к MMP13
5 репрезентативных Нанотел имели время удерживания в ожидаемом диапазоне для одновалентных Нанотел (7,6–8,2 мин), и относительная площадь главного пика и общий выход были выше 90% для всех Нанотел.
Биофизические свойства на основании TSA и aSEC считались подходящими для дальнейшей разработки для всех испытанных Нанотел.
6.7 Селекция клонов для дальнейшей разработки и оптимизации последовательностей
На основании функциональных и биофизических характеристик репрезентативных Нанотел и двухвалентных конструкций, 4 иллюстративных лидерных Нанотела: 62C02, 529C12, 80A01 и двухвалентная конструкция C01010080 ("0080", состоящая из Нанотела профиля 2 517A01 и Нанотела профиля 1 40E09) были выбраны для дальнейшей разработки.
Авторы настоящего изобретения поставили своей целью оптимизировать аминокислотную последовательность ("Оптимизация Последовательности (Sequence Optimization)" или "SO") панели лидеров. В процессе оптимизации последовательности предпринимаются попытки осуществления (1) нокаута сайтов для посттрансляционных модификаций (PTM); (2) гуманизации исходного Нанотела; а также (3) нокаута эпитопов для потенциальных предсуществующих антител. В то же время, функциональные и биофизические характеристики Нанотел предпочтительно должны сохраняться или даже улучшаться.
6.7.1 Посттрансляционные модификации (PTM)
Были оценены следующие посттрансляционные модификации (PTM): Met–окисление, Asn–дезамидирование, Asp–изомеризация, Asn–гликозилирование и образование пироглутамата.
Хотя мутацию E1D (обычно включаемая для предотвращения образования пироглутамата) не анализировали во время оптимизации последовательности, она была включена в отформатированные нанотела. Мутация была принята для всех лидерных Нанотел MMP13, кроме 62CO2, для которого наблюдалось 12–кратное снижение активности. Поэтому было решено не включать мутацию E1D в структурный блок 62C02.
Для оценки потенциальных PTM к панели лидеров применяли принудительное окисление и температурный стресс. За исключением C0101517A01 (“517A01”) и C0101080A01 (“80A01”) никаких модификаций для панели лидеров не наблюдали.
В условиях принудительного окисления и температурного стресса C0101080A01 имел тенденцию к Asp–изомеризации и Met–окислению. Однако степень изомеризации и окисления различалась в анализируемых условиях и была чуть ниже или выше применяемого порога в каждом случае. В конце концов, аминокислотные остатки 54–55, 100d–100e, M100j и 101–102 были идентифицированы как остатки, ответственные за PTM. Примечательно, что все эти остатки расположены либо в CDR2, либо в CDR3 области и, следовательно, потенциально вовлечены в связывание с мишенью. Для предпринятия попыток соответствия различным требованиям были сконструированы библиотеки NKK, в которых эти остатки были мутированы, а затем скрининированы в анализе флуорогенного пептида для оценки возможных потерь активности, а также скрининированы на биофизические свойства (Tm). Неожиданно было обнаружено, что в этих CDR различные положения могут быть мутированы без какой–либо значительной потери активности, то есть сохраняя более 80% ингибирования.
Для D100dX библиотеки, 9 аминокислотных ("AA") замен показали ингибирование > 80% (E, G, A, P, T, R, M, W и Y).
Для M100jX библиотеки, 16 AA замен показали ингибирование > 85% (все, за исключением T, C и H).
Для D101X библиотеки, 16 AA замен показали ингибирование >90% (все, за исключением D, F и P).
Для Y102X библиотеки, большинство клонов показали ингибирование >90%. Следовательно, считают, что аминокислотное положение 102 может мутировать в любой остаток.
Следующие консервативные мутации были особенно предпочтительными: D100dE и M100jL.
Обзор предпочтительных мутаций в областях CDR представлен в Таблицах 6.7.1А, 6.7.1В и 6.7.1С ниже. Аминокислотные последовательности CDR клона 80A01 использовали в качестве эталона, с которым сравнивали CDR членов семейства. CDR1 начинается с аминокислотного остатка 26, CDR2 начинается с аминокислотного остатка 50, CDR3 начинается с аминокислотного остатка 95, в соответствии с нумерацией Kabat.
X1=E, G, A, P, T, R, M, W, Y
X2=A, R, N, D, E, Q, Z, G, I, L, K, F, P, S, W, Y и V
X3=A, R, N, C, E, Q, Z, G, H, I, L, K, M, S, T, W, Y и V
X4=A, R, N, D, C, E, Q, Z, G, H, I, L, K, M, F, P, S, T, W и V
В условиях принудительного окисления и температурного стресса C0101517A01 имел предрасположенность к дезамидированию. В результате, в экспериментах в условиях температурного стресса аминокислотные остатки N100b и N101 были идентифицированы как остатки, чувствительные к дезамидированию. Однако эти остатки расположены в CDR3 области и потенциально вовлечены в связывание с мишенью. Таким образом, “нокаут” участков дезамидирования может иметь влияние на связывание. Также в этом случае были сконструированы библиотеки NKK, в которых остатки, склонные к дезамидированию, были мутированы, затем их подвергали скринингу в анализе флуорогенного пептида для оценки возможных потерь активности, а также скринингу на биофизические свойства (Т.пл.).
Совершенно неожиданно было показано, что мутирование N100b в Q или S или мутирование N101 в Q или V подавляет дезамидирование, но в то же время приводит к увеличению Т.пл. на 1–3°C по сравнению с исходным Нанотелом C0101517A01, в то же время эффективность была сопоставимой. 4 предпочтительных варианта показаны в Таблице 6.7.1D, в которой также обобщены результаты TSA и анализа флуорогенного пептида. Обзор предпочтительных мутаций в CDR представлен в таблицах ниже.
Данные вариантов 2–го цикла оптимизации последовательности C0101517A01
Обзор предпочтительных мутаций в CDR областях представлен в Таблицах 6.7.1E, 6.7.1F и 6.7.1G ниже. Аминокислотные последовательности CDR клона 517A01 использовали в качестве эталона, с которым сравнивали CDR других клонов. CDR1 начинается с аминокислотного остатка 26, CDR2 начинается с аминокислотного остатка 50, CDR3 начинается с аминокислотного остатка 95, в соответствии с нумерацией Kabat.
6.7.2 Гуманизация
Для гуманизации последовательность Нанотела делают более гомологичной консенсусной последовательности зародышевой линии IGHV3–IGHJ человека. За исключением "уникальных" остатков Нанотела, специфические аминокислоты в каркасных областях, которые различаются между последовательностью Нанотела и консенсусной последовательностью зародышевой линии IGHV3–IGHJ человека, были заменены человеческим аналогом таким образом, чтобы при этом структура белка, активность и стабильность не изменялись.
6.7.3 Предсуществующие антитела и антитела против лекарственных средств
Авторы изобретения провели раннюю оценку риска клинических последствий, связанных с иммуногенностью, руководствуясь стратегией оптимизации последовательности. Оценка включала как иммуногенный потенциал лекарственного средства–кандидата, так и возможное влияние антител против лекарственного средства, основанное на способе действия и природе потенциальной биотерапевтической молекулы. Для этого оценивали последовательность Нанотела для того, чтобы потенциально (i) минимизировать связывание любых природных предсуществующих антител и (ii) уменьшить потенциальную возможность вызывать возникающую при лечении реакцию иммуногенности.
Мутации L11V и V89L были введены во все Нанотела к MMP13.
6.7.4 Предпочтительные SO–клоны
В таблицах A–1 и A–2 последовательности представлены на основе оптимизации последовательностей панели лидеров, в которой последовательности были разработаны с учетом PTM, гуманизации и эпитопов для потенциальных предсуществующих антител и антител против лекарственных средств.
6.8 Биспецифичные конструкции
Нанотела против MMP13 предпочтительно должны быть активными на участках, представляющих интерес, таких как суставы, чтобы ингибировать разрушающую хрящ функцию MMP13. Аггрекан в изобилии присутствует в суставах и основном протеогликане во внеклеточном матриксе (ECM), составляя около 50% от общего содержания белка. Следовательно, по меньшей мере в теории, прикрепление нанотел против анти–ММР13 к связывающему Аггрекан агенту позволило бы направить анти–ММР13 Нанотело в соответствующую ткань и улучшить его удерживание.
Было предложено объединить анти–ММР13 связующие по настоящему изобретению с этими Аггрекан–связующими и испытать активность полученных биспецифических конструкций в анализе флуорогенного пептида человека и в конкурентном анализе ELISA. Различные биспецифичные конструкции, включающие связывающий Аггрекан агент(агенты) и ингибитор(ингибиторы) MMP13, были получены и испытаны, как указано в таблицах.
Формат и активность типичных результатов представлены в таблице 6.8А и таблице 6.8В
Анализ флуорогенного пептида человека (MMP13)
Биспецифические MMP13–CAP Нанотела были испытаны в конкурентном анализе ELISA. Активности сравнивали с их соответствующим моноспецифическим аналогом (ALB26 слияние). SO: последовательность–оптимизированное (исключая пред–Ab мутации). SOvar: не окончательный SO вариант.
Результаты, показанные в Таблице 6.8A и 6.8B демонстрируют, что объединение Аггрекан–связывающего агента(агентов) с ингибитором(ингибиторами) MMP13 не имеет никакого негативного влияния на активность ингибитора MMP13. Примечательно, что в большинстве случаев панель лидерных соединений–ингибиторов MMP13 имеет такую же эффективность, как TIMP–2, являющийся неселективным ингибитором MMP.
Пример 6.9 Исследование DMOAD в крысиной ММT модели in vivo
Чтобы дополнительно продемонстрировать in vivo эффективность ингибиторов ММР13, слитых с CAP связующим по изобретению, использовали модель хирургически индуцированного разрыва медиального мениска (MMT) у крыс. Вкратце, анти–MMP13 Нанотело связывали с CAP связующим (“754” или C010100754). Крыс оперировали на одном колене для индукции ОА–подобных симптомов. Лечение начинали через 3 дня после операции путем введения и/а инъекции. Гистопатологию осуществляли на 42 день после операции. Промежуточные и конечные образцы сыворотки отбирали для исследовательского анализа биомаркеров. Определяли среднюю и общую ширину значительной дегенерации хряща, а также процент снижения дегенерации хряща. Использовали по 20 животных на группу.
Ингибирование деградации хряща в медиальной большеберцовой кости показано на Фиг. 4.
Результаты показывают, что ширина хряща существенно уменьшалась с использованием конструкции MMP13–CAP через 42 дня по сравнению с носителем. Эти результаты предполагают, что
(а) CAP–фрагмент не оказывает отрицательного влияния на активность анти–MMP13 Нанотела (754), в соответствии с результатами Примера 6.8;
(b) CAP–фрагмент обеспечивает возможность удерживания анти–ММР13 Нанотела; а также
(c) анти–MMP13 Нанотело положительно влияет на ширину хряща
Фиг. 4: Ингибирование деградации хряща Нанотелами в крысиной модели ММT
Полное содержание всех ссылок (включая ссылки на литературу, выданные патенты, опубликованные патентные заявки и находящиеся на одновременном рассмотрении патентные заявки), процитированные в настоящей заявке, явным образом включены в настоящую заявку посредством ссылки, в частности, что касается информации, на которую есть ссылки выше.
Аминокислотные последовательности анти–MMP13 ингибиторов (“ID” относится к SEQ ID NO, как используется в настоящем описании)
040E09
040E08
042A04
040B05
042D12
042A03
024A08
040D01
529C12
517A01
062C02
080A01
516G08
529G11
513C04
521F02
519E04
520B06
520C04
525C04
063F01
059F06
FLAGHis
Последовательности для CDR и каркасных областей, плюс предпочтительные комбинации, представленные в формуле I, т.е. FR1–CDR1–FR2–CDR2–FR3–CDR3–FR4 (следующие термины: “ID” относится к данной SEQ ID NO; первая колонка относится к ID всего ISVD)
Аминокислотные последовательности анти–MMP13 конструкций (“ID” относится к SEQ ID NO, как используется в настоящем описании)
клон 80
клон 76
клон 72
клон 71
клон 70
клон 69
NP_002418.1
Различные линкерные последовательности (“ID” относится к SEQ ID NO, как используется в настоящем описании)
Связывающиеся с сывороточным альбумином последовательности ISVD (“ID” относится к SEQ ID NO, как используется в настоящем описании) , включая последовательности CDR
Аггрекан–связывающие последовательности ISVD (“ID” относится к SEQ ID NO, как используется в настоящем описании), включая последовательности CDR
Мультивалентные конструкции (“ID” относится к SEQ ID NO, как используется в настоящем описании) , включая последовательности CDR
114F08SO
114F08SO–
114F08SO
604F02SO
114F08SO
114F08SO–
114F08SO
604F02SO
40E09SO–
604F02SO–A
40E09SOvar–
114F08SO
40E09SOvar–
114F08SO–
114F08SO
40E09SOvar–
604F02SO
40E09SOvar
40E09SO
604F02SO–A
114F08SO
114F08SO–
114F08SO
604F02SO
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Merck Patent GmbH
Ablynx N.V.
<120> MMP13-связывающие иммуноглобулины
<130> MEPAT.0104
<150> EP17174402.2
<151> 2017-06-02
<160> 197
<170> BiSSAP 1.3.6
<210> 1
<211> 114
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 1
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Tyr
20 25 30
Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val
35 40 45
Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Arg
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr Gln Val Thr Val
100 105 110
Ser Ser
<210> 2
<211> 114
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 2
Lys Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Arg
20 25 30
Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val
35 40 45
Ala Gly Ile Ser Thr Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr Gln Val Thr Val
100 105 110
Ser Ser
<210> 3
<211> 114
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 3
Glu Val Gln Leu Val Glu Ser Gly Arg Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Arg
20 25 30
Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val
35 40 45
Ala Gly Ile Ser Thr Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr Gln Val Thr Val
100 105 110
Ser Ser
<210> 4
<211> 114
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 4
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Thr Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Arg
20 25 30
Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val
35 40 45
Ala Gly Ile Ser Thr Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr Gln Val Thr Val
100 105 110
Ser Ser
<210> 5
<211> 114
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 5
Glu Val Gln Leu Val Glu Ser Glu Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Tyr
20 25 30
Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val
35 40 45
Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Arg
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr Gln Val Thr Val
100 105 110
Ser Ser
<210> 6
<211> 114
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 6
Glu Val Gln Leu Val Glu Ser Arg Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Tyr
20 25 30
Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val
35 40 45
Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr Gln Val Thr Val
100 105 110
Ser Ser
<210> 7
<211> 114
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 7
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Tyr
20 25 30
Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val
35 40 45
Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Phe Leu
65 70 75 80
Gln Met Asn Gly Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr Gln Val Thr Val
100 105 110
Ser Ser
<210> 8
<211> 114
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 8
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Tyr
20 25 30
Ser Met Asn Trp Tyr Arg Gln Ala Pro Arg Lys Gln Arg Glu Phe Val
35 40 45
Ala Gly Ile Ser Thr Ala Arg Ile Thr His Tyr Ala Val Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Gly Gly Leu Gln Gly Ser Trp Gly Leu Gly Thr Leu Val Thr Val
100 105 110
Ser Ser
<210> 9
<211> 123
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 9
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Ser Ile Phe Ser Ile Asn
20 25 30
Ala Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Ser Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Ala Val Asp Ala Ser Arg Gly Leu Pro Tyr Glu Leu Tyr Tyr Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 10
<211> 129
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 10
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Leu Ala Val Tyr Gly Pro Asn Arg Tyr Arg Tyr Gly Pro
100 105 110
Val Gly Glu Tyr Asn Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
115 120 125
Ser
<210> 11
<211> 121
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 11
Glu Val Gln Leu Val Glu Ser Gly Gly Ala Leu Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ala Ala
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Arg Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Asp Asp Gly Ser Lys Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Asn Leu Lys Pro Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Thr Gly Tyr Gly Ala Thr Thr Thr Arg Pro Gly Arg Tyr Trp Gly
100 105 110
Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 12
<211> 128
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 12
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Leu Ala Tyr Tyr
20 25 30
Ser Ile Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ser Cys Ile Ser Ser Gly Ile Asp Gly Ser Thr Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Met
65 70 75 80
Tyr Leu Gln Met Asn Asn Leu Lys Pro Glu Asp Thr Gly Val Tyr Tyr
85 90 95
Cys Ala Ala Asp Pro Ser His Tyr Tyr Ser Glu Tyr Asp Cys Gly Tyr
100 105 110
Tyr Gly Met Asp Tyr Trp Gly Lys Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 13
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 13
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Gly Ser Gly Ser Ile Phe Arg Ile Asn
20 25 30
Val Met Ala Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Thr Ser Gly Gly Thr Thr Asn Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Tyr
85 90 95
Ala Asp Ile Gly Trp Pro Tyr Val Leu Asp Tyr Asp Phe Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 14
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 14
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Arg Ile Asn
20 25 30
Ala Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Ile Ser Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Tyr
85 90 95
Ala Asp Ile Gly Trp Pro Tyr Val Leu Asp Tyr Asp Phe Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 15
<211> 126
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 15
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Arg Tyr
20 25 30
Val Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Asn Trp Ser Ser Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Asp Arg Arg Val Tyr Tyr Asp Thr Tyr Pro Asn Leu Arg Gly
100 105 110
Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 16
<211> 124
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 16
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Leu Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Arg Gly Pro Gly Ser Val Gly Pro Ser Glu Glu Tyr Asn
100 105 110
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 17
<211> 127
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 17
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Pro Thr Phe Ser Asp Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Arg Gly Gly Gly Tyr Arg Ala Ser Gly Gly Pro Leu Ser
100 105 110
Glu Tyr Asn Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 18
<211> 126
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 18
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Gly Gly Gly Ser Thr Tyr Tyr Ser Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Leu Gly Ser Thr Gly Ser Gly Ser Thr Pro Val Pro Glu
100 105 110
Tyr Arg Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 19
<211> 126
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 19
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ser Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Arg Gly Gly Val Ala Gly Thr Asp Gly Pro Leu Gly Asp
100 105 110
Tyr Asn Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 20
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 20
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Gly Ser Gly Ser Ile Phe Ser Gly Asn
20 25 30
Ala Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Thr Ser Gly Gly Val Thr Asn Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Ala Asp Ile Arg Tyr Pro Thr Gly Leu Val Gly Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 21
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 21
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ser Ala Ser Thr Gly Ile Phe Arg Ile Asn
20 25 30
Thr Met Gly Trp His Arg Gln Ala Pro Gly Lys Gln Arg Asp Leu Val
35 40 45
Ala Thr Phe Thr Ser Asp Asp Asn Thr Lys Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Asp Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys His
85 90 95
Ala Thr Thr Val Met Tyr Asp Ser Asn Ser Pro Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 22
<211> 128
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 22
Glu Val Gln Leu Val Glu Ser Glu Gly Gly Thr Val Glu Pro Gly Glu
1 5 10 15
Ser Leu Arg Leu Ala Cys Ala Ala Pro Gly Pro Gly Ile Arg Thr Asn
20 25 30
Phe Met Ala Trp Tyr Arg Gln Ala Pro Glu Lys Glu Arg Glu Met Val
35 40 45
Ala Ser Ile Ser Arg Asp Gly Ser Thr His Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Ser Asp Asn Ala Thr Ser Thr Phe Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Gln Val Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Thr Asp Pro His Ile Leu His Asn Asp Arg Ala Gly Ala Phe Leu Val
100 105 110
Glu Asp Tyr Asp His Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 23
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 23
Gly Ser Thr Phe Ser Arg Tyr Ser Met Asn
1 5 10
<210> 24
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 24
Gly Ser Thr Phe Ser Arg Arg Ser Met Asn
1 5 10
<210> 25
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 25
Gly Ser Ile Phe Ser Ile Asn Ala Met Gly
1 5 10
<210> 26
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 26
Gly Arg Thr Phe Ser Ser Tyr Ala Met Gly
1 5 10
<210> 27
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 27
Gly Phe Ala Phe Ser Ala Ala Tyr Met Ser
1 5 10
<210> 28
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 28
Gly Phe Thr Leu Ala Tyr Tyr Ser Ile Gly
1 5 10
<210> 29
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 29
Gly Ser Ile Phe Arg Ile Asn Val Met Ala
1 5 10
<210> 30
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 30
Gly Ser Ile Phe Arg Ile Asn Ala Met Gly
1 5 10
<210> 31
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 31
Gly Arg Thr Phe Ser Arg Tyr Val Met Gly
1 5 10
<210> 32
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 32
Gly Leu Thr Phe Ser Ser Tyr Ala Met Gly
1 5 10
<210> 33
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 33
Gly Pro Thr Phe Ser Asp Tyr Ala Met Gly
1 5 10
<210> 34
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 34
Gly Ser Ile Phe Ser Gly Asn Ala Met Gly
1 5 10
<210> 35
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 35
Thr Gly Ile Phe Arg Ile Asn Thr Met Gly
1 5 10
<210> 36
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 36
Gly Pro Gly Ile Arg Thr Asn Phe Met Ala
1 5 10
<210> 37
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 37
Gly Ile Ser Val Gly Arg Ile Thr Asn
1 5
<210> 38
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 38
Gly Ile Ser Thr Gly Arg Ile Thr Asn
1 5
<210> 39
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 39
Gly Ile Ser Thr Ala Arg Ile Thr His
1 5
<210> 40
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 40
Ala Ile Ser Ser Gly Gly Ser Thr Tyr
1 5
<210> 41
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 41
Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr
1 5 10
<210> 42
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 42
Ser Ile Ser Asp Asp Gly Ser Lys Thr Tyr
1 5 10
<210> 43
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 43
Cys Ile Ser Ser Gly Ile Asp Gly Ser Thr Tyr
1 5 10
<210> 44
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 44
Ala Ile Thr Ser Gly Gly Thr Thr Asn
1 5
<210> 45
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 45
Ala Ile Ile Ser Gly Gly Thr Thr Tyr
1 5
<210> 46
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 46
Ala Ile Asn Trp Ser Ser Gly Ser Thr Tyr
1 5 10
<210> 47
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 47
Ala Ile Ser Trp Ser Gly Gly Arg Thr Tyr
1 5 10
<210> 48
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 48
Ala Ile Ser Trp Gly Gly Gly Ser Thr Tyr
1 5 10
<210> 49
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 49
Ala Ile Thr Ser Gly Gly Val Thr Asn
1 5
<210> 50
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 50
Thr Phe Thr Ser Asp Asp Asn Thr Lys
1 5
<210> 51
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 51
Ser Ile Ser Arg Asp Gly Ser Thr His
1 5
<210> 52
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 52
Gly Gly Leu Gln Gly Tyr
1 5
<210> 53
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 53
Gly Gly Leu Gln Gly Ser
1 5
<210> 54
<211> 15
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 54
Ala Val Asp Ala Ser Arg Gly Leu Pro Tyr Glu Leu Tyr Tyr Tyr
1 5 10 15
<210> 55
<211> 20
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 55
Ala Leu Ala Val Tyr Gly Pro Asn Arg Tyr Arg Tyr Gly Pro Val Gly
1 5 10 15
Glu Tyr Asn Tyr
20
<210> 56
<211> 12
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 56
Gly Tyr Gly Ala Thr Thr Thr Arg Pro Gly Arg Tyr
1 5 10
<210> 57
<211> 18
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 57
Asp Pro Ser His Tyr Tyr Ser Glu Tyr Asp Cys Gly Tyr Tyr Gly Met
1 5 10 15
Asp Tyr
<210> 58
<211> 12
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 58
Asp Ile Gly Trp Pro Tyr Val Leu Asp Tyr Asp Phe
1 5 10
<210> 59
<211> 17
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 59
Asp Arg Arg Val Tyr Tyr Asp Thr Tyr Pro Asn Leu Arg Gly Tyr Asp
1 5 10 15
Tyr
<210> 60
<211> 15
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 60
Ala Arg Gly Pro Gly Ser Val Gly Pro Ser Glu Glu Tyr Asn Tyr
1 5 10 15
<210> 61
<211> 18
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 61
Ala Arg Gly Gly Gly Tyr Arg Ala Ser Gly Gly Pro Leu Ser Glu Tyr
1 5 10 15
Asn Tyr
<210> 62
<211> 17
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 62
Ala Leu Gly Ser Thr Gly Ser Gly Ser Thr Pro Val Pro Glu Tyr Arg
1 5 10 15
Tyr
<210> 63
<211> 17
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 63
Ala Arg Gly Gly Val Ala Gly Thr Asp Gly Pro Leu Gly Asp Tyr Asn
1 5 10 15
Tyr
<210> 64
<211> 12
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 64
Asp Ile Arg Tyr Pro Thr Gly Leu Val Gly Asp Tyr
1 5 10
<210> 65
<211> 12
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 65
Thr Thr Val Met Tyr Asp Ser Asn Ser Pro Asp Tyr
1 5 10
<210> 66
<211> 20
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 66
Asp Pro His Ile Leu His Asn Asp Arg Ala Gly Ala Phe Leu Val Glu
1 5 10 15
Asp Tyr Asp His
20
<210> 67
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 67
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 68
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 68
Lys Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 69
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 69
Glu Val Gln Leu Val Glu Ser Gly Arg Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 70
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 70
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Thr Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 71
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 71
Glu Val Gln Leu Val Glu Ser Glu Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 72
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 72
Glu Val Gln Leu Val Glu Ser Arg Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 73
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 73
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser
20 25
<210> 74
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 74
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 75
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 75
Glu Val Gln Leu Val Glu Ser Gly Gly Ala Leu Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 76
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 76
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 77
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 77
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Gly Ser
20 25
<210> 78
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 78
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ser Ala Ser
20 25
<210> 79
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 79
Glu Val Gln Leu Val Glu Ser Glu Gly Gly Thr Val Glu Pro Gly Glu
1 5 10 15
Ser Leu Arg Leu Ala Cys Ala Ala Pro
20 25
<210> 80
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 80
Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val Ala
1 5 10
<210> 81
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 81
Trp Tyr Arg Gln Ala Pro Arg Lys Gln Arg Glu Phe Val Ala
1 5 10
<210> 82
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 82
Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val Ala
1 5 10
<210> 83
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 83
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala
1 5 10
<210> 84
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 84
Trp Val Arg Gln Ala Pro Gly Arg Gly Leu Glu Trp Val Ser
1 5 10
<210> 85
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 85
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val Ser
1 5 10
<210> 86
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 86
Trp His Arg Gln Ala Pro Gly Lys Gln Arg Asp Leu Val Ala
1 5 10
<210> 87
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 87
Trp Tyr Arg Gln Ala Pro Glu Lys Glu Arg Glu Met Val Ala
1 5 10
<210> 88
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 88
Tyr Ala Val Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Glu Gly Thr Gly Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Ala
35
<210> 89
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 89
Tyr Ala Val Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Glu Gly Thr Gly Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Ala
35
<210> 90
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 90
Tyr Ala Val Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Glu Gly Thr Gly Phe Leu Gln Met Asn Gly Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Ala
35
<210> 91
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 91
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Ala
35
<210> 92
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 92
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Thr Ala
35
<210> 93
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 93
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Asn Leu Lys Pro Asp Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Thr
35
<210> 94
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 94
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Lys Asn Thr Met Tyr Leu Gln Met Asn Asn Leu Lys Pro Glu Asp Thr
20 25 30
Gly Val Tyr Tyr Cys Ala Ala
35
<210> 95
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 95
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Tyr Ala
35
<210> 96
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 96
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Ala Ala
35
<210> 97
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 97
Tyr Ser Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Thr Ala
35
<210> 98
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 98
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Glu Asn Thr Val Tyr Leu Gln Met Asn Asp Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys His Ala
35
<210> 99
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 99
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Ser Asp Asn Ala
1 5 10 15
Thr Ser Thr Phe Tyr Leu Gln Met Asn Ser Leu Gln Val Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Ala Thr
35
<210> 100
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 100
Trp Gly Leu Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 101
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 101
Trp Gly Leu Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 102
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 102
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 103
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 103
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 104
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 104
Trp Gly Lys Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 105
<211> 2415
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 105
Met Thr Thr Leu Leu Trp Val Phe Val Thr Leu Arg Val Ile Thr Ala
1 5 10 15
Ala Val Thr Val Glu Thr Ser Asp His Asp Asn Ser Leu Ser Val Ser
20 25 30
Ile Pro Gln Pro Ser Pro Leu Arg Val Leu Leu Gly Thr Ser Leu Thr
35 40 45
Ile Pro Cys Tyr Phe Ile Asp Pro Met His Pro Val Thr Thr Ala Pro
50 55 60
Ser Thr Ala Pro Leu Ala Pro Arg Ile Lys Trp Ser Arg Val Ser Lys
65 70 75 80
Glu Lys Glu Val Val Leu Leu Val Ala Thr Glu Gly Arg Val Arg Val
85 90 95
Asn Ser Ala Tyr Gln Asp Lys Val Ser Leu Pro Asn Tyr Pro Ala Ile
100 105 110
Pro Ser Asp Ala Thr Leu Glu Val Gln Ser Leu Arg Ser Asn Asp Ser
115 120 125
Gly Val Tyr Arg Cys Glu Val Met His Gly Ile Glu Asp Ser Glu Ala
130 135 140
Thr Leu Glu Val Val Val Lys Gly Ile Val Phe His Tyr Arg Ala Ile
145 150 155 160
Ser Thr Arg Tyr Thr Leu Asp Phe Asp Arg Ala Gln Arg Ala Cys Leu
165 170 175
Gln Asn Ser Ala Ile Ile Ala Thr Pro Glu Gln Leu Gln Ala Ala Tyr
180 185 190
Glu Asp Gly Phe His Gln Cys Asp Ala Gly Trp Leu Ala Asp Gln Thr
195 200 205
Val Arg Tyr Pro Ile His Thr Pro Arg Glu Gly Cys Tyr Gly Asp Lys
210 215 220
Asp Glu Phe Pro Gly Val Arg Thr Tyr Gly Ile Arg Asp Thr Asn Glu
225 230 235 240
Thr Tyr Asp Val Tyr Cys Phe Ala Glu Glu Met Glu Gly Glu Val Phe
245 250 255
Tyr Ala Thr Ser Pro Glu Lys Phe Thr Phe Gln Glu Ala Ala Asn Glu
260 265 270
Cys Arg Arg Leu Gly Ala Arg Leu Ala Thr Thr Gly His Val Tyr Leu
275 280 285
Ala Trp Gln Ala Gly Met Asp Met Cys Ser Ala Gly Trp Leu Ala Asp
290 295 300
Arg Ser Val Arg Tyr Pro Ile Ser Lys Ala Arg Pro Asn Cys Gly Gly
305 310 315 320
Asn Leu Leu Gly Val Arg Thr Val Tyr Val His Ala Asn Gln Thr Gly
325 330 335
Tyr Pro Asp Pro Ser Ser Arg Tyr Asp Ala Ile Cys Tyr Thr Gly Glu
340 345 350
Asp Phe Val Asp Ile Pro Glu Asn Phe Phe Gly Val Gly Gly Glu Glu
355 360 365
Asp Ile Thr Val Gln Thr Val Thr Trp Pro Asp Met Glu Leu Pro Leu
370 375 380
Pro Arg Asn Ile Thr Glu Gly Glu Ala Arg Gly Ser Val Ile Leu Thr
385 390 395 400
Val Lys Pro Ile Phe Glu Val Ser Pro Ser Pro Leu Glu Pro Glu Glu
405 410 415
Pro Phe Thr Phe Ala Pro Glu Ile Gly Ala Thr Ala Phe Ala Glu Val
420 425 430
Glu Asn Glu Thr Gly Glu Ala Thr Arg Pro Trp Gly Phe Pro Thr Pro
435 440 445
Gly Leu Gly Pro Ala Thr Ala Phe Thr Ser Glu Asp Leu Val Val Gln
450 455 460
Val Thr Ala Val Pro Gly Gln Pro His Leu Pro Gly Gly Val Val Phe
465 470 475 480
His Tyr Arg Pro Gly Pro Thr Arg Tyr Ser Leu Thr Phe Glu Glu Ala
485 490 495
Gln Gln Ala Cys Pro Gly Thr Gly Ala Val Ile Ala Ser Pro Glu Gln
500 505 510
Leu Gln Ala Ala Tyr Glu Ala Gly Tyr Glu Gln Cys Asp Ala Gly Trp
515 520 525
Leu Arg Asp Gln Thr Val Arg Tyr Pro Ile Val Ser Pro Arg Thr Pro
530 535 540
Cys Val Gly Asp Lys Asp Ser Ser Pro Gly Val Arg Thr Tyr Gly Val
545 550 555 560
Arg Pro Ser Thr Glu Thr Tyr Asp Val Tyr Cys Phe Val Asp Arg Leu
565 570 575
Glu Gly Glu Val Phe Phe Ala Thr Arg Leu Glu Gln Phe Thr Phe Gln
580 585 590
Glu Ala Leu Glu Phe Cys Glu Ser His Asn Ala Thr Ala Thr Thr Gly
595 600 605
Gln Leu Tyr Ala Ala Trp Ser Arg Gly Leu Asp Lys Cys Tyr Ala Gly
610 615 620
Trp Leu Ala Asp Gly Ser Leu Arg Tyr Pro Ile Val Thr Pro Arg Pro
625 630 635 640
Ala Cys Gly Gly Asp Lys Pro Gly Val Arg Thr Val Tyr Leu Tyr Pro
645 650 655
Asn Gln Thr Gly Leu Pro Asp Pro Leu Ser Arg His His Ala Phe Cys
660 665 670
Phe Arg Gly Ile Ser Ala Val Pro Ser Pro Gly Glu Glu Glu Gly Gly
675 680 685
Thr Pro Thr Ser Pro Ser Gly Val Glu Glu Trp Ile Val Thr Gln Val
690 695 700
Val Pro Gly Val Ala Ala Val Pro Val Glu Glu Glu Thr Thr Ala Val
705 710 715 720
Pro Ser Gly Glu Thr Thr Ala Ile Leu Glu Phe Thr Thr Glu Pro Glu
725 730 735
Asn Gln Thr Glu Trp Glu Pro Ala Tyr Thr Pro Val Gly Thr Ser Pro
740 745 750
Leu Pro Gly Ile Leu Pro Thr Trp Pro Pro Thr Gly Ala Glu Thr Glu
755 760 765
Glu Ser Thr Glu Gly Pro Ser Ala Thr Glu Val Pro Ser Ala Ser Glu
770 775 780
Glu Pro Ser Pro Ser Glu Val Pro Phe Pro Ser Glu Glu Pro Ser Pro
785 790 795 800
Ser Glu Glu Pro Phe Pro Ser Val Arg Pro Phe Pro Ser Val Glu Leu
805 810 815
Phe Pro Ser Glu Glu Pro Phe Pro Ser Lys Glu Pro Ser Pro Ser Glu
820 825 830
Glu Pro Ser Ala Ser Glu Glu Pro Tyr Thr Pro Ser Pro Pro Glu Pro
835 840 845
Ser Trp Thr Glu Leu Pro Ser Ser Gly Glu Glu Ser Gly Ala Pro Asp
850 855 860
Val Ser Gly Asp Phe Thr Gly Ser Gly Asp Val Ser Gly His Leu Asp
865 870 875 880
Phe Ser Gly Gln Leu Ser Gly Asp Arg Ala Ser Gly Leu Pro Ser Gly
885 890 895
Asp Leu Asp Ser Ser Gly Leu Thr Ser Thr Val Gly Ser Gly Leu Thr
900 905 910
Val Glu Ser Gly Leu Pro Ser Gly Asp Glu Glu Arg Ile Glu Trp Pro
915 920 925
Ser Thr Pro Thr Val Gly Glu Leu Pro Ser Gly Ala Glu Ile Leu Glu
930 935 940
Gly Ser Ala Ser Gly Val Gly Asp Leu Ser Gly Leu Pro Ser Gly Glu
945 950 955 960
Val Leu Glu Thr Ser Ala Ser Gly Val Gly Asp Leu Ser Gly Leu Pro
965 970 975
Ser Gly Glu Val Leu Glu Thr Thr Ala Pro Gly Val Glu Asp Ile Ser
980 985 990
Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Thr Ala Pro Gly Val Glu
995 1000 1005
Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Thr Ala Pro
1010 1015 1020
Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr
1025 1030 1035 1040
Thr Ala Pro Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val
1045 1050 1055
Leu Glu Thr Thr Ala Pro Gly Val Glu Asp Ile Ser Gly Leu Pro Ser
1060 1065 1070
Gly Glu Val Leu Glu Thr Ala Ala Pro Gly Val Glu Asp Ile Ser Gly
1075 1080 1085
Leu Pro Ser Gly Glu Val Leu Glu Thr Ala Ala Pro Gly Val Glu Asp
1090 1095 1100
Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ala Ala Pro Gly
1105 1110 1115 1120
Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ala
1125 1130 1135
Ala Pro Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu
1140 1145 1150
Glu Thr Ala Ala Pro Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly
1155 1160 1165
Glu Val Leu Glu Thr Ala Ala Pro Gly Val Glu Asp Ile Ser Gly Leu
1170 1175 1180
Pro Ser Gly Glu Val Leu Glu Thr Ala Ala Pro Gly Val Glu Asp Ile
1185 1190 1195 1200
Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ala Ala Pro Gly Val
1205 1210 1215
Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ala Ala
1220 1225 1230
Pro Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu
1235 1240 1245
Thr Ala Ala Pro Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu
1250 1255 1260
Val Leu Glu Thr Ala Ala Pro Gly Val Glu Asp Ile Ser Gly Leu Pro
1265 1270 1275 1280
Ser Gly Glu Val Leu Glu Thr Thr Ala Pro Gly Val Glu Glu Ile Ser
1285 1290 1295
Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Thr Ala Pro Gly Val Asp
1300 1305 1310
Glu Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Thr Ala Pro
1315 1320 1325
Gly Val Glu Glu Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr
1330 1335 1340
Ser Thr Ser Ala Val Gly Asp Leu Ser Gly Leu Pro Ser Gly Gly Glu
1345 1350 1355 1360
Val Leu Glu Ile Ser Val Ser Gly Val Glu Asp Ile Ser Gly Leu Pro
1365 1370 1375
Ser Gly Glu Val Val Glu Thr Ser Ala Ser Gly Ile Glu Asp Val Ser
1380 1385 1390
Glu Leu Pro Ser Gly Glu Gly Leu Glu Thr Ser Ala Ser Gly Val Glu
1395 1400 1405
Asp Leu Ser Arg Leu Pro Ser Gly Glu Glu Val Leu Glu Ile Ser Ala
1410 1415 1420
Ser Gly Phe Gly Asp Leu Ser Gly Val Pro Ser Gly Gly Glu Gly Leu
1425 1430 1435 1440
Glu Thr Ser Ala Ser Glu Val Gly Thr Asp Leu Ser Gly Leu Pro Ser
1445 1450 1455
Gly Arg Glu Gly Leu Glu Thr Ser Ala Ser Gly Ala Glu Asp Leu Ser
1460 1465 1470
Gly Leu Pro Ser Gly Lys Glu Asp Leu Val Gly Ser Ala Ser Gly Asp
1475 1480 1485
Leu Asp Leu Gly Lys Leu Pro Ser Gly Thr Leu Gly Ser Gly Gln Ala
1490 1495 1500
Pro Glu Thr Ser Gly Leu Pro Ser Gly Phe Ser Gly Glu Tyr Ser Gly
1505 1510 1515 1520
Val Asp Leu Gly Ser Gly Pro Pro Ser Gly Leu Pro Asp Phe Ser Gly
1525 1530 1535
Leu Pro Ser Gly Phe Pro Thr Val Ser Leu Val Asp Ser Thr Leu Val
1540 1545 1550
Glu Val Val Thr Ala Ser Thr Ala Ser Glu Leu Glu Gly Arg Gly Thr
1555 1560 1565
Ile Gly Ile Ser Gly Ala Gly Glu Ile Ser Gly Leu Pro Ser Ser Glu
1570 1575 1580
Leu Asp Ile Ser Gly Arg Ala Ser Gly Leu Pro Ser Gly Thr Glu Leu
1585 1590 1595 1600
Ser Gly Gln Ala Ser Gly Ser Pro Asp Val Ser Gly Glu Ile Pro Gly
1605 1610 1615
Leu Phe Gly Val Ser Gly Gln Pro Ser Gly Phe Pro Asp Thr Ser Gly
1620 1625 1630
Glu Thr Ser Gly Val Thr Glu Leu Ser Gly Leu Ser Ser Gly Gln Pro
1635 1640 1645
Gly Val Ser Gly Glu Ala Ser Gly Val Leu Tyr Gly Thr Ser Gln Pro
1650 1655 1660
Phe Gly Ile Thr Asp Leu Ser Gly Glu Thr Ser Gly Val Pro Asp Leu
1665 1670 1675 1680
Ser Gly Gln Pro Ser Gly Leu Pro Gly Phe Ser Gly Ala Thr Ser Gly
1685 1690 1695
Val Pro Asp Leu Val Ser Gly Thr Thr Ser Gly Ser Gly Glu Ser Ser
1700 1705 1710
Gly Ile Thr Phe Val Asp Thr Ser Leu Val Glu Val Ala Pro Thr Thr
1715 1720 1725
Phe Lys Glu Glu Glu Gly Leu Gly Ser Val Glu Leu Ser Gly Leu Pro
1730 1735 1740
Ser Gly Glu Ala Asp Leu Ser Gly Lys Ser Gly Met Val Asp Val Ser
1745 1750 1755 1760
Gly Gln Phe Ser Gly Thr Val Asp Ser Ser Gly Phe Thr Ser Gln Thr
1765 1770 1775
Pro Glu Phe Ser Gly Leu Pro Ser Gly Ile Ala Glu Val Ser Gly Glu
1780 1785 1790
Ser Ser Arg Ala Glu Ile Gly Ser Ser Leu Pro Ser Gly Ala Tyr Tyr
1795 1800 1805
Gly Ser Gly Thr Pro Ser Ser Phe Pro Thr Val Ser Leu Val Asp Arg
1810 1815 1820
Thr Leu Val Glu Ser Val Thr Gln Ala Pro Thr Ala Gln Glu Ala Gly
1825 1830 1835 1840
Glu Gly Pro Ser Gly Ile Leu Glu Leu Ser Gly Ala His Ser Gly Ala
1845 1850 1855
Pro Asp Met Ser Gly Glu His Ser Gly Phe Leu Asp Leu Ser Gly Leu
1860 1865 1870
Gln Ser Gly Leu Ile Glu Pro Ser Gly Glu Pro Pro Gly Thr Pro Tyr
1875 1880 1885
Phe Ser Gly Asp Phe Ala Ser Thr Thr Asn Val Ser Gly Glu Ser Ser
1890 1895 1900
Val Ala Met Gly Thr Ser Gly Glu Ala Ser Gly Leu Pro Glu Val Thr
1905 1910 1915 1920
Leu Ile Thr Ser Glu Phe Val Glu Gly Val Thr Glu Pro Thr Ile Ser
1925 1930 1935
Gln Glu Leu Gly Gln Arg Pro Pro Val Thr His Thr Pro Gln Leu Phe
1940 1945 1950
Glu Ser Ser Gly Lys Val Ser Thr Ala Gly Asp Ile Ser Gly Ala Thr
1955 1960 1965
Pro Val Leu Pro Gly Ser Gly Val Glu Val Ser Ser Val Pro Glu Ser
1970 1975 1980
Ser Ser Glu Thr Ser Ala Tyr Pro Glu Ala Gly Phe Gly Ala Ser Ala
1985 1990 1995 2000
Ala Pro Glu Ala Ser Arg Glu Asp Ser Gly Ser Pro Asp Leu Ser Glu
2005 2010 2015
Thr Thr Ser Ala Phe His Glu Ala Asn Leu Glu Arg Ser Ser Gly Leu
2020 2025 2030
Gly Val Ser Gly Ser Thr Leu Thr Phe Gln Glu Gly Glu Ala Ser Ala
2035 2040 2045
Ala Pro Glu Val Ser Gly Glu Ser Thr Thr Thr Ser Asp Val Gly Thr
2050 2055 2060
Glu Ala Pro Gly Leu Pro Ser Ala Thr Pro Thr Ala Ser Gly Asp Arg
2065 2070 2075 2080
Thr Glu Ile Ser Gly Asp Leu Ser Gly His Thr Ser Gln Leu Gly Val
2085 2090 2095
Val Ile Ser Thr Ser Ile Pro Glu Ser Glu Trp Thr Gln Gln Thr Gln
2100 2105 2110
Arg Pro Ala Glu Thr His Leu Glu Ile Glu Ser Ser Ser Leu Leu Tyr
2115 2120 2125
Ser Gly Glu Glu Thr His Thr Val Glu Thr Ala Thr Ser Pro Thr Asp
2130 2135 2140
Ala Ser Ile Pro Ala Ser Pro Glu Trp Lys Arg Glu Ser Glu Ser Thr
2145 2150 2155 2160
Ala Ala Ala Pro Ala Arg Ser Cys Ala Glu Glu Pro Cys Gly Ala Gly
2165 2170 2175
Thr Cys Lys Glu Thr Glu Gly His Val Ile Cys Leu Cys Pro Pro Gly
2180 2185 2190
Tyr Thr Gly Glu His Cys Asn Ile Asp Gln Glu Val Cys Glu Glu Gly
2195 2200 2205
Trp Asn Lys Tyr Gln Gly His Cys Tyr Arg His Phe Pro Asp Arg Glu
2210 2215 2220
Thr Trp Val Asp Ala Glu Arg Arg Cys Arg Glu Gln Gln Ser His Leu
2225 2230 2235 2240
Ser Ser Ile Val Thr Pro Glu Glu Gln Glu Phe Val Asn Asn Asn Ala
2245 2250 2255
Gln Asp Tyr Gln Trp Ile Gly Leu Asn Asp Arg Thr Ile Glu Gly Asp
2260 2265 2270
Phe Arg Trp Ser Asp Gly His Pro Met Gln Phe Glu Asn Trp Arg Pro
2275 2280 2285
Asn Gln Pro Asp Asn Phe Phe Ala Ala Gly Glu Asp Cys Val Val Met
2290 2295 2300
Ile Trp His Glu Lys Gly Glu Trp Asn Asp Val Pro Cys Asn Tyr His
2305 2310 2315 2320
Leu Pro Phe Thr Cys Lys Lys Gly Thr Val Ala Cys Gly Glu Pro Pro
2325 2330 2335
Val Val Glu His Ala Arg Thr Phe Gly Gln Lys Lys Asp Arg Tyr Glu
2340 2345 2350
Ile Asn Ser Leu Val Arg Tyr Gln Cys Thr Glu Gly Phe Val Gln Arg
2355 2360 2365
His Met Pro Thr Ile Arg Cys Gln Pro Ser Gly His Trp Glu Glu Pro
2370 2375 2380
Arg Ile Thr Cys Thr Asp Ala Thr Thr Tyr Lys Arg Arg Leu Gln Lys
2385 2390 2395 2400
Arg Ser Ser Arg His Pro Arg Arg Ser Arg Pro Ser Thr Ala His
2405 2410 2415
<210> 106
<211> 20
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 106
Ala Leu Ala Val Tyr Gly Pro Ser Arg Tyr Arg Tyr Gly Pro Val Gly
1 5 10 15
Glu Tyr Gln Tyr
20
<210> 107
<211> 18
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 107
Asp Pro Ser His Tyr Tyr Ser Glu Tyr Glu Cys Gly Tyr Tyr Gly Met
1 5 10 15
Asp Tyr
<210> 108
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 108
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser
1 5 10
<210> 109
<211> 123
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 109
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Ser Ile Asn
20 25 30
Ala Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Ser Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Ala Val Asp Ala Ser Arg Gly Leu Pro Tyr Glu Leu Tyr Tyr Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 110
<211> 129
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 110
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Leu Ala Val Tyr Gly Pro Ser Arg Tyr Arg Tyr Gly Pro
100 105 110
Val Gly Glu Tyr Gln Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
115 120 125
Ser
<210> 111
<211> 121
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 111
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ala Ala
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Asp Asp Gly Ser Lys Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Thr Gly Tyr Gly Ala Thr Thr Thr Arg Pro Gly Arg Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 112
<211> 128
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 112
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Leu Ala Tyr Tyr
20 25 30
Ser Ile Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ser Cys Ile Ser Ser Gly Ile Asp Gly Ser Thr Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Ala Asp Pro Ser His Tyr Tyr Ser Glu Tyr Glu Cys Gly Tyr
100 105 110
Tyr Gly Met Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120 125
<210> 113
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 113
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Thr
35
<210> 114
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 114
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Ala Ala
35
<210> 115
<211> 471
<212> Белок
<213> Homo sapiens
<220>
<223> Аминокислотная последовательность
<400> 115
Met His Pro Gly Val Leu Ala Ala Phe Leu Phe Leu Ser Trp Thr His
1 5 10 15
Cys Arg Ala Leu Pro Leu Pro Ser Gly Gly Asp Glu Asp Asp Leu Ser
20 25 30
Glu Glu Asp Leu Gln Phe Ala Glu Arg Tyr Leu Arg Ser Tyr Tyr His
35 40 45
Pro Thr Asn Leu Ala Gly Ile Leu Lys Glu Asn Ala Ala Ser Ser Met
50 55 60
Thr Glu Arg Leu Arg Glu Met Gln Ser Phe Phe Gly Leu Glu Val Thr
65 70 75 80
Gly Lys Leu Asp Asp Asn Thr Leu Asp Val Met Lys Lys Pro Arg Cys
85 90 95
Gly Val Pro Asp Val Gly Glu Tyr Asn Val Phe Pro Arg Thr Leu Lys
100 105 110
Trp Ser Lys Met Asn Leu Thr Tyr Arg Ile Val Asn Tyr Thr Pro Asp
115 120 125
Met Thr His Ser Glu Val Glu Lys Ala Phe Lys Lys Ala Phe Lys Val
130 135 140
Trp Ser Asp Val Thr Pro Leu Asn Phe Thr Arg Leu His Asp Gly Ile
145 150 155 160
Ala Asp Ile Met Ile Ser Phe Gly Ile Lys Glu His Gly Asp Phe Tyr
165 170 175
Pro Phe Asp Gly Pro Ser Gly Leu Leu Ala His Ala Phe Pro Pro Gly
180 185 190
Pro Asn Tyr Gly Gly Asp Ala His Phe Asp Asp Asp Glu Thr Trp Thr
195 200 205
Ser Ser Ser Lys Gly Tyr Asn Leu Phe Leu Val Ala Ala His Glu Phe
210 215 220
Gly His Ser Leu Gly Leu Asp His Ser Lys Asp Pro Gly Ala Leu Met
225 230 235 240
Phe Pro Ile Tyr Thr Tyr Thr Gly Lys Ser His Phe Met Leu Pro Asp
245 250 255
Asp Asp Val Gln Gly Ile Gln Ser Leu Tyr Gly Pro Gly Asp Glu Asp
260 265 270
Pro Asn Pro Lys His Pro Lys Thr Pro Asp Lys Cys Asp Pro Ser Leu
275 280 285
Ser Leu Asp Ala Ile Thr Ser Leu Arg Gly Glu Thr Met Ile Phe Lys
290 295 300
Asp Arg Phe Phe Trp Arg Leu His Pro Gln Gln Val Asp Ala Glu Leu
305 310 315 320
Phe Leu Thr Lys Ser Phe Trp Pro Glu Leu Pro Asn Arg Ile Asp Ala
325 330 335
Ala Tyr Glu His Pro Ser His Asp Leu Ile Phe Ile Phe Arg Gly Arg
340 345 350
Lys Phe Trp Ala Leu Asn Gly Tyr Asp Ile Leu Glu Gly Tyr Pro Lys
355 360 365
Lys Ile Ser Glu Leu Gly Leu Pro Lys Glu Val Lys Lys Ile Ser Ala
370 375 380
Ala Val His Phe Glu Asp Thr Gly Lys Thr Leu Leu Phe Ser Gly Asn
385 390 395 400
Gln Val Trp Arg Tyr Asp Asp Thr Asn His Ile Met Asp Lys Asp Tyr
405 410 415
Pro Arg Leu Ile Glu Glu Asp Phe Pro Gly Ile Gly Asp Lys Val Asp
420 425 430
Ala Val Tyr Glu Lys Asn Gly Tyr Ile Tyr Phe Phe Asn Gly Pro Ile
435 440 445
Gln Phe Glu Tyr Ser Ile Trp Ser Asn Arg Ile Val Arg Val Met Pro
450 455 460
Ala Asn Ser Ile Leu Trp Cys
465 470
<210> 116
<211> 471
<212> Белок
<213> Pan troglodytes
<220>
<223> Аминокислотная последовательность
<400> 116
Met His Pro Gly Val Leu Ala Ala Phe Leu Phe Leu Ser Trp Ala His
1 5 10 15
Cys Arg Ala Leu Pro Leu Pro Ser Gly Gly Asp Glu Asp Asp Leu Ser
20 25 30
Glu Glu Asp Leu Gln Phe Ala Glu Arg Tyr Leu Arg Ser Tyr Tyr His
35 40 45
Pro Thr Asn Leu Ala Gly Ile Leu Lys Glu Asn Ala Ala Ser Ser Met
50 55 60
Thr Glu Arg Leu Arg Glu Met Gln Ser Phe Phe Gly Leu Glu Val Thr
65 70 75 80
Gly Lys Leu Asp Asp Asn Thr Leu Asp Val Met Lys Lys Pro Arg Cys
85 90 95
Gly Val Pro Asp Val Gly Glu Tyr Asn Val Phe Pro Arg Thr Leu Lys
100 105 110
Trp Ser Lys Met Asn Leu Thr Tyr Arg Ile Val Asn Tyr Thr Pro Asp
115 120 125
Met Thr His Ser Glu Val Glu Lys Ala Phe Lys Lys Ala Phe Lys Val
130 135 140
Trp Ser Asp Val Thr Pro Leu Asn Phe Thr Arg Leu His Asp Gly Ile
145 150 155 160
Ala Asp Ile Met Ile Ser Phe Gly Ile Lys Glu His Gly Asp Phe Tyr
165 170 175
Pro Phe Asp Gly Pro Ser Gly Leu Leu Ala His Ala Phe Pro Pro Gly
180 185 190
Pro Asn Tyr Gly Gly Asp Ala His Phe Asp Asp Asp Glu Thr Trp Thr
195 200 205
Ser Ser Ser Lys Gly Tyr Asn Leu Phe Leu Val Ala Ala His Glu Phe
210 215 220
Gly His Ser Leu Gly Leu Asp His Ser Lys Asp Pro Gly Ala Leu Met
225 230 235 240
Phe Pro Ile Tyr Thr Tyr Thr Gly Lys Ser His Phe Met Leu Pro Asp
245 250 255
Asp Asp Val Gln Gly Ile Gln Ser Leu Tyr Gly Pro Gly Asp Glu Asp
260 265 270
Pro Asn Pro Lys His Pro Lys Thr Pro Asp Lys Cys Asp Pro Ser Leu
275 280 285
Ser Leu Asp Ala Ile Thr Ser Leu Arg Gly Glu Thr Met Ile Phe Lys
290 295 300
Asp Arg Phe Phe Trp Arg Leu His Pro Gln Gln Val Asp Ala Glu Leu
305 310 315 320
Phe Leu Thr Lys Ser Phe Trp Pro Glu Leu Pro Asn Arg Ile Asp Ala
325 330 335
Ala Tyr Glu His Pro Ser His Asp Leu Ile Phe Ile Phe Arg Gly Arg
340 345 350
Lys Phe Trp Ala Leu Asn Gly Tyr Asp Ile Leu Glu Gly Tyr Pro Lys
355 360 365
Lys Ile Ser Glu Leu Gly Leu Pro Lys Glu Val Lys Lys Ile Ser Ala
370 375 380
Thr Val His Phe Glu Asp Thr Gly Lys Thr Leu Leu Phe Ser Gly Asn
385 390 395 400
Gln Val Trp Arg Tyr Asp Asp Thr Asn His Ile Met Asp Lys Asp Tyr
405 410 415
Pro Arg Leu Ile Glu Glu Glu Phe Pro Gly Ile Gly Asp Lys Val Asp
420 425 430
Ala Val Tyr Glu Lys Asn Gly Tyr Ile Tyr Phe Phe Asn Gly Pro Ile
435 440 445
Gln Phe Glu Tyr Ser Ile Trp Ser Asn Arg Ile Val Arg Val Met Pro
450 455 460
Ala Asn Ser Ile Leu Trp Cys
465 470
<210> 117
<211> 471
<212> Белок
<213> Macaca mulatta
<220>
<223> Аминокислотная последовательность
<400> 117
Met His Pro Gly Val Leu Ala Ala Phe Leu Phe Leu Ser Trp Thr His
1 5 10 15
Cys Arg Ala Leu Pro Leu Pro Ser Gly Gly Asp Glu Asp Asp Leu Ser
20 25 30
Glu Glu Asp Leu Gln Phe Ala Glu Arg Tyr Leu Arg Ser Tyr Tyr Tyr
35 40 45
Pro Thr Asn Leu Ala Gly Ile Leu Lys Glu Asn Ala Ala Ser Ser Met
50 55 60
Thr Asp Arg Leu Arg Glu Met Gln Ser Phe Phe Gly Leu Glu Val Thr
65 70 75 80
Gly Lys Leu Asp Asp Asn Thr Leu Asp Val Met Lys Lys Pro Arg Cys
85 90 95
Gly Val Pro Asp Val Gly Glu Tyr Asn Val Phe Pro Arg Thr Leu Lys
100 105 110
Trp Ser Lys Met Asn Leu Thr Tyr Arg Ile Val Asn Tyr Thr Pro Asp
115 120 125
Met Thr His Ser Glu Val Glu Lys Ala Phe Lys Lys Ala Phe Lys Val
130 135 140
Trp Ser Asp Val Thr Pro Leu Asn Phe Thr Arg Leu His Asp Gly Ile
145 150 155 160
Ala Asp Ile Met Ile Ser Phe Gly Thr Lys Glu His Gly Asp Phe Tyr
165 170 175
Pro Phe Asp Gly Pro Ser Gly Leu Leu Ala His Ala Phe Pro Pro Gly
180 185 190
Pro Asn Tyr Gly Gly Asp Ala His Phe Asp Asp Asp Glu Thr Trp Thr
195 200 205
Ser Ser Ser Lys Gly Tyr Asn Leu Phe Leu Val Ala Ala His Glu Phe
210 215 220
Gly His Ser Leu Gly Leu Asp His Ser Lys Asp Pro Gly Ala Leu Met
225 230 235 240
Phe Pro Ile Tyr Thr Tyr Thr Gly Lys Ser His Phe Met Leu Pro Asp
245 250 255
Asp Asp Val Gln Gly Ile Gln Ser Leu Tyr Gly Pro Gly Asp Glu Asp
260 265 270
Pro Asn Pro Lys His Pro Lys Thr Pro Asp Lys Cys Asp Pro Ser Leu
275 280 285
Ser Leu Asp Ala Ile Thr Ser Leu Arg Gly Glu Thr Met Ile Phe Lys
290 295 300
Asp Arg Phe Phe Trp Arg Leu His Pro Gln Gln Val Asp Ala Glu Leu
305 310 315 320
Phe Leu Thr Lys Ser Phe Trp Pro Glu Leu Pro Asn Arg Ile Asp Ala
325 330 335
Ala Tyr Glu His Pro Ser His Asp Leu Ile Phe Ile Phe Arg Gly Arg
340 345 350
Lys Phe Trp Ala Leu Asn Gly Tyr Asp Ile Leu Glu Gly Tyr Pro Lys
355 360 365
Lys Ile Ser Glu Leu Gly Phe Pro Lys Glu Val Lys Lys Ile Ser Ala
370 375 380
Ala Val His Phe Glu Asp Thr Gly Lys Thr Leu Leu Phe Ser Gly Asn
385 390 395 400
Gln Val Trp Arg Tyr Asp Asp Thr Asn His Ile Met Asp Lys Asp Tyr
405 410 415
Pro Arg Leu Ile Glu Glu Asp Phe Pro Gly Ile Gly Asp Lys Val Asp
420 425 430
Ala Val Tyr Glu Lys Asn Gly Tyr Ile Tyr Phe Phe Asn Gly Pro Ile
435 440 445
Gln Phe Glu Tyr Ser Ile Trp Ser Asn Arg Ile Val Arg Val Met Pro
450 455 460
Ala Asn Ser Ile Leu Trp Cys
465 470
<210> 118
<211> 496
<212> Белок
<213> Canis lupus
<220>
<223> Аминокислотная последовательность
<400> 118
Met Ser His His Cys Arg Ser Ile Lys Val Lys Val Leu Val Trp Glu
1 5 10 15
Arg Gln Gln Ala Pro Gly Thr Thr Thr Lys Met Leu Pro Gly Ile Leu
20 25 30
Ala Ala Phe Leu Cys Leu Ser Trp Thr Gln Cys Trp Ser Leu Pro Leu
35 40 45
Pro Ser Asp Gly Asp Asp Asp Leu Ser Glu Glu Asp Phe Gln Leu Ala
50 55 60
Glu Arg Tyr Leu Lys Ser Tyr Tyr Tyr Pro Leu Asn Pro Ala Gly Ile
65 70 75 80
Leu Lys Lys Ser Ala Ala Gly Ser Val Ala Asp Arg Leu Arg Glu Met
85 90 95
Gln Ser Phe Phe Gly Leu Glu Val Thr Gly Lys Leu Asp Asp Asn Thr
100 105 110
Leu Asp Ile Met Lys Lys Pro Arg Cys Gly Val Pro Asp Val Gly Glu
115 120 125
Tyr Asn Val Phe Pro Arg Thr Leu Lys Trp Ser Lys Thr Asn Leu Thr
130 135 140
Tyr Arg Ile Val Asn Tyr Thr Pro Asp Leu Thr His Ser Glu Val Glu
145 150 155 160
Lys Ala Phe Lys Lys Ala Phe Lys Val Trp Ser Asp Val Thr Pro Leu
165 170 175
Asn Phe Thr Arg Leu His Asp Gly Thr Ala Asp Ile Met Ile Ser Phe
180 185 190
Gly Thr Lys Glu His Gly Asp Phe Tyr Pro Phe Asp Gly Pro Ser Gly
195 200 205
Leu Leu Ala His Ala Phe Pro Pro Gly Pro Asn Tyr Gly Gly Asp Ala
210 215 220
His Phe Asp Asp Asp Glu Thr Trp Thr Ser Ser Ser Lys Gly Tyr Asn
225 230 235 240
Leu Phe Leu Val Ala Ala His Glu Phe Gly His Ser Leu Gly Leu Asp
245 250 255
His Ser Lys Asp Pro Gly Ala Leu Met Phe Pro Ile Tyr Thr Tyr Thr
260 265 270
Gly Lys Ser His Phe Met Leu Pro Asp Asp Asp Val Gln Gly Ile Gln
275 280 285
Ser Leu Tyr Gly Pro Gly Asp Glu Asp Pro Asn Pro Arg His Pro Lys
290 295 300
Thr Pro Asp Lys Cys Asp Pro Ser Leu Ser Leu Asp Ala Ile Thr Ser
305 310 315 320
Leu Arg Gly Glu Thr Met Ile Phe Lys Asp Arg Phe Phe Trp Arg Leu
325 330 335
His Pro Gln Gln Val Asp Ala Glu Leu Phe Leu Thr Lys Ser Phe Trp
340 345 350
Pro Glu Leu Pro Asn Arg Ile Asp Ala Ala Tyr Glu His Pro Ser Arg
355 360 365
Asp Leu Ile Phe Ile Phe Arg Gly Arg Lys Tyr Trp Ala Leu Asn Gly
370 375 380
Tyr Asp Ile Leu Glu Gly Tyr Pro Gln Lys Ile Ser Glu Leu Gly Phe
385 390 395 400
Pro Lys Glu Val Lys Lys Ile Ser Ala Ala Val His Phe Glu Asp Thr
405 410 415
Gly Lys Thr Leu Phe Phe Ser Gly Asn Gln Val Trp Ser Tyr Asp Asp
420 425 430
Thr Asn Gln Ile Met Asp Lys Asp Tyr Pro Arg Leu Ile Glu Glu Asp
435 440 445
Phe Pro Gly Ile Gly Asp Lys Val Asp Ala Val Tyr Glu Lys Asn Gly
450 455 460
Tyr Ile Tyr Phe Phe Asn Gly Pro Ile Gln Phe Glu Tyr Asn Ile Trp
465 470 475 480
Ser Lys Arg Ile Val Arg Val Met Pro Ala Asn Ser Leu Leu Trp Cys
485 490 495
<210> 119
<211> 471
<212> Белок
<213> Bos taurus
<220>
<223> Аминокислотная последовательность
<400> 119
Met His Pro Arg Val Leu Ala Gly Phe Leu Phe Phe Ser Trp Thr Ala
1 5 10 15
Cys Trp Ser Leu Pro Leu Pro Ser Asp Gly Asp Ser Glu Asp Leu Ser
20 25 30
Glu Glu Asp Phe Gln Phe Ala Glu Ser Tyr Leu Lys Ser Tyr Tyr Tyr
35 40 45
Pro Gln Asn Pro Ala Gly Ile Leu Lys Lys Thr Ala Ala Ser Ser Val
50 55 60
Ile Asp Arg Leu Arg Glu Met Gln Ser Phe Phe Gly Leu Glu Val Thr
65 70 75 80
Gly Arg Leu Asp Asp Asn Thr Leu Asp Ile Met Lys Lys Pro Arg Cys
85 90 95
Gly Val Pro Asp Val Gly Glu Tyr Asn Val Phe Pro Arg Thr Leu Lys
100 105 110
Trp Ser Lys Met Asn Leu Thr Tyr Arg Ile Val Asn Tyr Thr Pro Asp
115 120 125
Leu Thr His Ser Glu Val Glu Lys Ala Phe Arg Lys Ala Phe Lys Val
130 135 140
Trp Ser Asp Val Thr Pro Leu Asn Phe Thr Arg Ile His Asn Gly Thr
145 150 155 160
Ala Asp Ile Met Ile Ser Phe Gly Thr Lys Glu His Gly Asp Phe Tyr
165 170 175
Pro Phe Asp Gly Pro Ser Gly Leu Leu Ala His Ala Phe Pro Pro Gly
180 185 190
Pro Asn Tyr Gly Gly Asp Ala His Phe Asp Asp Asp Glu Thr Trp Thr
195 200 205
Ser Ser Ser Lys Gly Tyr Asn Leu Phe Leu Val Ala Ala His Glu Phe
210 215 220
Gly His Ser Leu Gly Leu Asp His Ser Lys Asp Pro Gly Ala Leu Met
225 230 235 240
Phe Pro Ile Tyr Thr Tyr Thr Gly Lys Ser His Phe Met Leu Pro Asp
245 250 255
Asp Asp Val Gln Gly Ile Gln Ser Leu Tyr Gly Pro Gly Asp Glu Asp
260 265 270
Pro Tyr Ser Lys His Pro Lys Thr Pro Asp Lys Cys Asp Pro Ser Leu
275 280 285
Ser Leu Asp Ala Ile Thr Ser Leu Arg Gly Glu Thr Leu Ile Phe Lys
290 295 300
Asp Arg Phe Phe Trp Arg Leu His Pro Gln Gln Val Glu Ala Glu Leu
305 310 315 320
Phe Leu Thr Lys Ser Phe Gly Pro Glu Leu Pro Asn Arg Ile Asp Ala
325 330 335
Ala Tyr Glu His Pro Ser His Asp Leu Ile Phe Ile Phe Arg Gly Arg
340 345 350
Lys Phe Trp Ala Leu Ser Gly Tyr Asp Ile Leu Glu Asp Tyr Pro Lys
355 360 365
Lys Ile Ser Glu Leu Gly Phe Pro Lys His Val Lys Lys Ile Ser Ala
370 375 380
Ala Leu His Phe Glu Asp Ser Gly Lys Thr Leu Phe Phe Ser Glu Asn
385 390 395 400
Gln Val Trp Ser Tyr Asp Asp Thr Asn His Val Met Asp Lys Asp Tyr
405 410 415
Pro Arg Leu Ile Glu Glu Val Phe Pro Gly Ile Gly Asp Lys Val Asp
420 425 430
Ala Val Tyr Gln Lys Asn Gly Tyr Ile Tyr Phe Phe Asn Gly Pro Ile
435 440 445
Gln Phe Glu Tyr Ser Ile Trp Ser Asn Arg Ile Val Arg Val Met Thr
450 455 460
Thr Asn Ser Leu Leu Trp Cys
465 470
<210> 120
<211> 472
<212> Белок
<213> Mus musculus
<220>
<223> Аминокислотная последовательность
<400> 120
Met His Ser Ala Ile Leu Ala Thr Phe Phe Leu Leu Ser Trp Thr Pro
1 5 10 15
Cys Trp Ser Leu Pro Leu Pro Tyr Gly Asp Asp Asp Asp Asp Asp Leu
20 25 30
Ser Glu Glu Asp Leu Val Phe Ala Glu His Tyr Leu Lys Ser Tyr Tyr
35 40 45
His Pro Ala Thr Leu Ala Gly Ile Leu Lys Lys Ser Thr Val Thr Ser
50 55 60
Thr Val Asp Arg Leu Arg Glu Met Gln Ser Phe Phe Gly Leu Glu Val
65 70 75 80
Thr Gly Lys Leu Asp Asp Pro Thr Leu Asp Ile Met Arg Lys Pro Arg
85 90 95
Cys Gly Val Pro Asp Val Gly Glu Tyr Asn Val Phe Pro Arg Thr Leu
100 105 110
Lys Trp Ser Gln Thr Asn Leu Thr Tyr Arg Ile Val Asn Tyr Thr Pro
115 120 125
Asp Met Ser His Ser Glu Val Glu Lys Ala Phe Arg Lys Ala Phe Lys
130 135 140
Val Trp Ser Asp Val Thr Pro Leu Asn Phe Thr Arg Ile Tyr Asp Gly
145 150 155 160
Thr Ala Asp Ile Met Ile Ser Phe Gly Thr Lys Glu His Gly Asp Phe
165 170 175
Tyr Pro Phe Asp Gly Pro Ser Gly Leu Leu Ala His Ala Phe Pro Pro
180 185 190
Gly Pro Asn Tyr Gly Gly Asp Ala His Phe Asp Asp Asp Glu Thr Trp
195 200 205
Thr Ser Ser Ser Lys Gly Tyr Asn Leu Phe Ile Val Ala Ala His Glu
210 215 220
Leu Gly His Ser Leu Gly Leu Asp His Ser Lys Asp Pro Gly Ala Leu
225 230 235 240
Met Phe Pro Ile Tyr Thr Tyr Thr Gly Lys Ser His Phe Met Leu Pro
245 250 255
Asp Asp Asp Val Gln Gly Ile Gln Phe Leu Tyr Gly Pro Gly Asp Glu
260 265 270
Asp Pro Asn Pro Lys His Pro Lys Thr Pro Glu Lys Cys Asp Pro Ala
275 280 285
Leu Ser Leu Asp Ala Ile Thr Ser Leu Arg Gly Glu Thr Met Ile Phe
290 295 300
Lys Asp Arg Phe Phe Trp Arg Leu His Pro Gln Gln Val Glu Ala Glu
305 310 315 320
Leu Phe Leu Thr Lys Ser Phe Trp Pro Glu Leu Pro Asn His Val Asp
325 330 335
Ala Ala Tyr Glu His Pro Ser Arg Asp Leu Met Phe Ile Phe Arg Gly
340 345 350
Arg Lys Phe Trp Ala Leu Asn Gly Tyr Asp Ile Leu Glu Gly Tyr Pro
355 360 365
Arg Lys Ile Ser Asp Leu Gly Phe Pro Lys Glu Val Lys Arg Leu Ser
370 375 380
Ala Ala Val His Phe Glu Asn Thr Gly Lys Thr Leu Phe Phe Ser Glu
385 390 395 400
Asn His Val Trp Ser Tyr Asp Asp Val Asn Gln Thr Met Asp Lys Asp
405 410 415
Tyr Pro Arg Leu Ile Glu Glu Glu Phe Pro Gly Ile Gly Asn Lys Val
420 425 430
Asp Ala Val Tyr Glu Lys Asn Gly Tyr Ile Tyr Phe Phe Asn Gly Pro
435 440 445
Ile Gln Phe Glu Tyr Ser Ile Trp Ser Asn Arg Ile Val Arg Val Met
450 455 460
Pro Thr Asn Ser Ile Leu Trp Cys
465 470
<210> 121
<211> 472
<212> Белок
<213> Rattus norvegicus
<220>
<223> Аминокислотная последовательность
<400> 121
Met His Ser Ala Ile Leu Ala Thr Phe Phe Leu Leu Ser Trp Thr His
1 5 10 15
Cys Trp Ser Leu Pro Leu Pro Tyr Gly Asp Asp Asp Asp Asp Asp Leu
20 25 30
Ser Glu Glu Asp Leu Glu Phe Ala Glu His Tyr Leu Lys Ser Tyr Tyr
35 40 45
His Pro Val Thr Leu Ala Gly Ile Leu Lys Lys Ser Thr Val Thr Ser
50 55 60
Thr Val Asp Arg Leu Arg Glu Met Gln Ser Phe Phe Gly Leu Asp Val
65 70 75 80
Thr Gly Lys Leu Asp Asp Pro Thr Leu Asp Ile Met Arg Lys Pro Arg
85 90 95
Cys Gly Val Pro Asp Val Gly Glu Tyr Asn Val Phe Pro Arg Thr Leu
100 105 110
Lys Trp Ser Gln Thr Asn Leu Thr Tyr Arg Ile Val Asn Tyr Thr Pro
115 120 125
Asp Ile Ser His Ser Glu Val Glu Lys Ala Phe Arg Lys Ala Phe Lys
130 135 140
Val Trp Ser Asp Val Thr Pro Leu Asn Phe Thr Arg Ile His Asp Gly
145 150 155 160
Thr Ala Asp Ile Met Ile Ser Phe Gly Thr Lys Glu His Gly Asp Phe
165 170 175
Tyr Pro Phe Asp Gly Pro Ser Gly Leu Leu Ala His Ala Phe Pro Pro
180 185 190
Gly Pro Asn Leu Gly Gly Asp Ala His Phe Asp Asp Asp Glu Thr Trp
195 200 205
Thr Ser Ser Ser Lys Gly Tyr Asn Leu Phe Ile Val Ala Ala His Glu
210 215 220
Leu Gly His Ser Leu Gly Leu Asp His Ser Lys Asp Pro Gly Ala Leu
225 230 235 240
Met Phe Pro Ile Tyr Thr Tyr Thr Gly Lys Ser His Phe Met Leu Pro
245 250 255
Asp Asp Asp Val Gln Gly Ile Gln Ser Leu Tyr Gly Pro Gly Asp Glu
260 265 270
Asp Pro Asn Pro Lys His Pro Lys Thr Pro Glu Lys Cys Asp Pro Ala
275 280 285
Leu Ser Leu Asp Ala Ile Thr Ser Leu Arg Gly Glu Thr Met Ile Phe
290 295 300
Lys Asp Arg Phe Phe Trp Arg Leu His Pro Gln Gln Val Glu Pro Glu
305 310 315 320
Leu Phe Leu Thr Lys Ser Phe Trp Pro Glu Leu Pro Asn His Val Asp
325 330 335
Ala Ala Tyr Glu His Pro Ser Arg Asp Leu Met Phe Ile Phe Arg Gly
340 345 350
Arg Lys Phe Trp Ala Leu Asn Gly Tyr Asp Ile Met Glu Gly Tyr Pro
355 360 365
Arg Lys Ile Ser Asp Leu Gly Phe Pro Lys Glu Val Lys Arg Leu Ser
370 375 380
Ala Ala Val His Phe Glu Asp Thr Gly Lys Thr Leu Phe Phe Ser Gly
385 390 395 400
Asn His Val Trp Ser Tyr Asp Asp Ala Asn Gln Thr Met Asp Lys Asp
405 410 415
Tyr Pro Arg Leu Ile Glu Glu Glu Phe Pro Gly Ile Gly Asp Lys Val
420 425 430
Asp Ala Val Tyr Glu Lys Asn Gly Tyr Ile Tyr Phe Phe Asn Gly Pro
435 440 445
Ile Gln Phe Glu Tyr Ser Ile Trp Ser Asn Arg Ile Val Arg Val Met
450 455 460
Pro Thr Asn Ser Leu Leu Trp Cys
465 470
<210> 122
<211> 471
<212> Белок
<213> Gallus gallus
<220>
<223> Аминокислотная последовательность
<400> 122
Met Gln Pro Arg Leu Ser Ala Val Phe Phe Phe Leu Leu Gly Leu Ser
1 5 10 15
Phe Cys Leu Thr Val Pro Ile Pro Leu Asp Asp Ser His Glu Phe Thr
20 25 30
Glu Glu Asp Leu Arg Phe Ala Glu Arg Tyr Leu Arg Thr His Tyr Asp
35 40 45
Leu Arg Pro Asn Pro Thr Gly Ile Met Lys Lys Ser Ala Asn Thr Met
50 55 60
Ala Ser Lys Leu Arg Glu Met Gln Ala Phe Phe Gly Leu Glu Val Thr
65 70 75 80
Gly Lys Leu Asp Glu Glu Thr Tyr Glu Leu Met Gln Lys Pro Arg Cys
85 90 95
Gly Val Pro Asp Val Gly Glu Tyr Asn Phe Phe Pro Arg Lys Leu Lys
100 105 110
Trp Ser Asn Thr Asn Leu Thr Tyr Arg Ile Met Ser Tyr Thr Ser Asp
115 120 125
Leu Arg Arg Ala Glu Val Glu Arg Ala Phe Lys Arg Ala Phe Lys Val
130 135 140
Trp Ser Asp Val Thr Pro Leu Asn Phe Thr Arg Ile Arg Ser Gly Thr
145 150 155 160
Ala Asp Ile Met Ile Ser Phe Gly Thr Lys Glu His Gly Asp Phe Tyr
165 170 175
Pro Phe Asp Gly Pro Ser Gly Leu Leu Ala His Ala Phe Pro Pro Gly
180 185 190
Pro Asp Tyr Gly Gly Asp Ala His Phe Asp Asp Asp Glu Thr Trp Ser
195 200 205
Asp Asp Ser Arg Gly Tyr Asn Leu Phe Leu Val Ala Ala His Glu Phe
210 215 220
Gly His Ser Leu Gly Leu Glu His Ser Arg Asp Pro Gly Ala Leu Met
225 230 235 240
Phe Pro Ile Tyr Thr Tyr Thr Gly Lys Ser Gly Phe Val Leu Pro Asp
245 250 255
Asp Asp Val Gln Gly Ile Gln Glu Leu Tyr Gly Ala Gly Asp Arg Asp
260 265 270
Pro Asn Pro Lys His Pro Lys Thr Pro Glu Lys Cys Ala Ala Asp Leu
275 280 285
Ser Ile Asp Ala Ile Thr Lys Leu Arg Gly Glu Met Leu Val Phe Lys
290 295 300
Asp Arg Phe Phe Trp Arg Leu His Pro Gln Met Val Glu Ala Glu Leu
305 310 315 320
Val Leu Ile Lys Ser Phe Trp Pro Glu Leu Pro Asn Lys Ile Asp Ala
325 330 335
Ala Tyr Glu Asn Pro Ile Lys Asp Leu Val Phe Met Phe Lys Gly Lys
340 345 350
Lys Val Trp Ala Met Asn Gly Tyr Asp Ile Val Glu Gly Phe Pro Lys
355 360 365
Lys Ile Tyr Glu Met Gly Phe Pro Lys Glu Met Lys Arg Ile Asp Ala
370 375 380
Val Val His Ile Asp Asp Thr Gly Lys Thr Leu Phe Phe Thr Gly Asn
385 390 395 400
Lys Tyr Trp Ser Tyr Asp Glu Glu Thr Glu Val Met Asp Thr Gly Tyr
405 410 415
Pro Lys Phe Ile Glu Asp Glu Phe Ala Gly Ile Gly Asp Arg Val Asp
420 425 430
Ala Val Tyr His Arg Asn Gly Tyr Leu Tyr Phe Phe Asn Gly Pro Leu
435 440 445
Gln Phe Glu Tyr Ser Ile Trp Ser Lys Arg Ile Val Arg Ile Leu His
450 455 460
Thr Asn Ser Leu Phe Trp Cys
465 470
<210> 123
<211> 23
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 123
Ala Ala Ala Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu Asn Gly Ala
1 5 10 15
Ala His His His His His His
20
<210> 124
<211> 34
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 124
Ala Ala Ala Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp
1 5 10 15
Ile Asp Tyr Lys Asp Asp Asp Asp Lys Gly Ala Ala His His His His
20 25 30
His His
<210> 125
<400> 125
000
<210> 126
<211> 5
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 126
Gly Gly Gly Gly Ser
1 5
<210> 127
<211> 7
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 127
Ser Gly Gly Ser Gly Gly Ser
1 5
<210> 128
<211> 8
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 128
Gly Gly Gly Gly Gly Gly Gly Ser
1 5
<210> 129
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 129
Gly Gly Gly Gly Ser Gly Gly Gly Ser
1 5
<210> 130
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 130
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10
<210> 131
<211> 15
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 131
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 132
<211> 18
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 132
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Ser
<210> 133
<211> 20
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 133
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser
20
<210> 134
<211> 25
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 134
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25
<210> 135
<211> 30
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 135
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25 30
<210> 136
<211> 35
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 136
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser
35
<210> 137
<211> 40
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 137
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser
35 40
<210> 138
<211> 15
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 138
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
1 5 10 15
<210> 139
<211> 24
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 139
Gly Gly Gly Gly Ser Gly Gly Gly Ser Glu Pro Lys Ser Cys Asp Lys
1 5 10 15
Thr His Thr Cys Pro Pro Cys Pro
20
<210> 140
<211> 12
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 140
Glu Pro Lys Thr Pro Lys Pro Gln Pro Ala Ala Ala
1 5 10
<210> 141
<211> 62
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 141
Glu Leu Lys Thr Pro Leu Gly Asp Thr Thr His Thr Cys Pro Arg Cys
1 5 10 15
Pro Glu Pro Lys Ser Cys Asp Thr Pro Pro Pro Cys Pro Arg Cys Pro
20 25 30
Glu Pro Lys Ser Cys Asp Thr Pro Pro Pro Cys Pro Arg Cys Pro Glu
35 40 45
Pro Lys Ser Cys Asp Thr Pro Pro Pro Cys Pro Arg Cys Pro
50 55 60
<210> 142
<211> 115
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 142
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 143
<211> 115
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 143
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 144
<211> 116
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 144
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala
115
<210> 145
<211> 116
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 145
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala
115
<210> 146
<211> 115
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 146
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 147
<211> 116
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 147
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Lys
100 105 110
Val Ser Ser Ala
115
<210> 148
<211> 115
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 148
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 149
<211> 116
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 149
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala
115
<210> 150
<211> 117
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 150
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala Ala
115
<210> 151
<211> 118
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 151
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala Ala Ala
115
<210> 152
<211> 116
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 152
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly
115
<210> 153
<211> 117
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 153
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly Gly
115
<210> 154
<211> 118
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 154
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly Gly Gly
115
<210> 155
<211> 115
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 155
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 156
<211> 116
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 156
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala
115
<210> 157
<211> 5
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 157
Ser Phe Gly Met Ser
1 5
<210> 158
<211> 17
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 158
Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 159
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 159
Gly Gly Ser Leu Ser Arg
1 5
<210> 160
<211> 278
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 160
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Leu Ala Val Tyr Gly Pro Asn Arg Tyr Arg Tyr Gly Pro
100 105 110
Val Gly Glu Tyr Asn Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val
165 170 175
Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr
180 185 190
Phe Ser Arg Tyr Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln
195 200 205
Arg Glu Phe Val Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala
210 215 220
Val Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly
225 230 235 240
Thr Gly Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val
245 250 255
Tyr Tyr Cys Asn Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr
260 265 270
Leu Val Thr Val Ser Ser
275
<210> 161
<211> 269
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 161
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Gly Ser Gly Ser Ile Phe Arg Ile Asn
20 25 30
Val Met Ala Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Thr Ser Gly Gly Thr Thr Asn Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Tyr
85 90 95
Ala Asp Ile Gly Trp Pro Tyr Val Leu Asp Tyr Asp Phe Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
130 135 140
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val
145 150 155 160
Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly Ser Leu Arg Leu Ser
165 170 175
Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Tyr Ser Met Asn Trp Tyr
180 185 190
Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val Ala Gly Ile Ser Val
195 200 205
Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Arg Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn Ala Gly Gly Leu Gln
245 250 255
Gly Tyr Trp Gly Leu Gly Thr Leu Val Thr Val Ser Ser
260 265
<210> 162
<211> 270
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 162
Glu Val Gln Leu Val Glu Ser Gly Gly Ala Leu Val Arg Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ala Ala
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Arg Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Asp Asp Gly Ser Lys Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Asn Leu Lys Pro Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Thr Gly Tyr Gly Ala Thr Thr Thr Arg Pro Gly Arg Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu
145 150 155 160
Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly Ser Leu Arg Leu
165 170 175
Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Tyr Ser Met Asn Trp
180 185 190
Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val Ala Gly Ile Ser
195 200 205
Val Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Arg Gly Arg Phe Thr
210 215 220
Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu Gln Met Asn Ser
225 230 235 240
Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn Ala Gly Gly Leu
245 250 255
Gln Gly Tyr Trp Gly Leu Gly Thr Leu Val Thr Val Ser Ser
260 265 270
<210> 163
<211> 278
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 163
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Tyr
20 25 30
Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val
35 40 45
Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Arg
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr Leu Val Thr Val
100 105 110
Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu
145 150 155 160
Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg
165 170 175
Thr Phe Ser Ser Tyr Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys
180 185 190
Glu Arg Glu Phe Val Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr
195 200 205
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
210 215 220
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
225 230 235 240
Ala Val Tyr Tyr Cys Thr Ala Ala Leu Ala Val Tyr Gly Pro Asn Arg
245 250 255
Tyr Arg Tyr Gly Pro Val Gly Glu Tyr Asn Tyr Trp Gly Gln Gly Thr
260 265 270
Leu Val Thr Val Ser Ser
275
<210> 164
<211> 269
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 164
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Tyr
20 25 30
Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val
35 40 45
Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Arg
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr Leu Val Thr Val
100 105 110
Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu
145 150 155 160
Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Gly Ser Gly Ser
165 170 175
Ile Phe Arg Ile Asn Val Met Ala Trp Tyr Arg Gln Ala Pro Gly Lys
180 185 190
Gln Arg Glu Leu Val Ala Ala Ile Thr Ser Gly Gly Thr Thr Asn Tyr
195 200 205
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
210 215 220
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
225 230 235 240
Val Tyr Tyr Cys Tyr Ala Asp Ile Gly Trp Pro Tyr Val Leu Asp Tyr
245 250 255
Asp Phe Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
260 265
<210> 165
<211> 270
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 165
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ser Arg Tyr
20 25 30
Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Phe Val
35 40 45
Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala Val Ser Val Arg
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly Thr Gly Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr Leu Val Thr Val
100 105 110
Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Ala Leu
145 150 155 160
Val Arg Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe
165 170 175
Ala Phe Ser Ala Ala Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Arg
180 185 190
Gly Leu Glu Trp Val Ser Ser Ile Ser Asp Asp Gly Ser Lys Thr Tyr
195 200 205
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
210 215 220
Lys Asn Thr Val Tyr Leu Gln Met Asn Asn Leu Lys Pro Asp Asp Thr
225 230 235 240
Ala Val Tyr Tyr Cys Asn Thr Gly Tyr Gly Ala Thr Thr Thr Arg Pro
245 250 255
Gly Arg Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
260 265 270
<210> 166
<211> 121
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 166
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn
20 25 30
Val Val Arg Trp Tyr Arg Arg Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Thr Ile Ser Ser Gly Gly Asn Ala Asn Tyr Val Asp Ser Val Arg
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Val Pro Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 167
<211> 122
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 167
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn
20 25 30
Val Val Arg Trp Tyr Arg Arg Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Thr Ile Ser Ser Gly Gly Asn Ala Asn Tyr Val Asp Ser Val Arg
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Asn
85 90 95
Val Pro Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Ala
115 120
<210> 168
<211> 125
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 168
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Thr Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Tyr Arg Arg Arg Arg Ala Ser Ser Asn Arg Gly Leu Trp Asp
100 105 110
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala
115 120 125
<210> 169
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 169
Gly Ser Thr Phe Ile Ile Asn Val Val Arg
1 5 10
<210> 170
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 170
Thr Ile Ser Ser Gly Gly Asn Ala Asn
1 5
<210> 171
<211> 13
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 171
Pro Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr
1 5 10
<210> 172
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 172
Gly Arg Thr Phe Ser Ser Tyr Thr Met Gly
1 5 10
<210> 173
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 173
Ala Ile Ser Trp Ser Gly Gly Arg Thr Tyr
1 5 10
<210> 174
<211> 15
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 174
Tyr Arg Arg Arg Arg Ala Ser Ser Asn Arg Gly Leu Trp Asp Tyr
1 5 10 15
<210> 175
<211> 17
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 175
Ala Ala Ala Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu Asn Gly Ala
1 5 10 15
Ala
<210> 176
<211> 277
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 176
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ala Ala
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Asp Asp Gly Ser Lys Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Thr Gly Tyr Gly Ala Thr Thr Thr Arg Pro Gly Arg Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu
145 150 155 160
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu
165 170 175
Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn Val Val Arg Trp
180 185 190
Tyr Arg Arg Ala Pro Gly Lys Gln Arg Glu Leu Val Ala Thr Ile Ser
195 200 205
Ser Gly Gly Asn Ala Asn Tyr Val Asp Ser Val Arg Gly Arg Phe Thr
210 215 220
Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser
225 230 235 240
Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn Val Pro Thr Thr
245 250 255
His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly Gln Gly Thr Leu
260 265 270
Val Thr Val Ser Ser
275
<210> 177
<211> 433
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 177
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ala Ala
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Asp Asp Gly Ser Lys Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Thr Gly Tyr Gly Ala Thr Thr Thr Arg Pro Gly Arg Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu
145 150 155 160
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu
165 170 175
Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn Val Val Arg Trp
180 185 190
Tyr Arg Arg Ala Pro Gly Lys Gln Arg Glu Leu Val Ala Thr Ile Ser
195 200 205
Ser Gly Gly Asn Ala Asn Tyr Val Asp Ser Val Arg Gly Arg Phe Thr
210 215 220
Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser
225 230 235 240
Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn Val Pro Thr Thr
245 250 255
His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly Gln Gly Thr Leu
260 265 270
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
305 310 315 320
Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
325 330 335
Ser Gly Ser Thr Phe Ile Ile Asn Val Val Arg Trp Tyr Arg Arg Ala
340 345 350
Pro Gly Lys Gln Arg Glu Leu Val Ala Thr Ile Ser Ser Gly Gly Asn
355 360 365
Ala Asn Tyr Val Asp Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp
370 375 380
Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu
385 390 395 400
Asp Thr Ala Val Tyr Tyr Cys Asn Val Pro Thr Thr His Tyr Gly Gly
405 410 415
Val Tyr Tyr Gly Pro Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
420 425 430
Ser
<210> 178
<211> 280
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 178
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ala Ala
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Asp Asp Gly Ser Lys Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Thr Gly Tyr Gly Ala Thr Thr Thr Arg Pro Gly Arg Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu
145 150 155 160
Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu
165 170 175
Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr Thr Met Gly Trp
180 185 190
Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile Ser
195 200 205
Trp Ser Gly Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe
210 215 220
Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn
225 230 235 240
Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ala Tyr Arg
245 250 255
Arg Arg Arg Ala Ser Ser Asn Arg Gly Leu Trp Asp Tyr Trp Gly Gln
260 265 270
Gly Thr Leu Val Thr Val Ser Ser
275 280
<210> 179
<211> 284
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 179
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Leu Ala Tyr Tyr
20 25 30
Ser Ile Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ser Cys Ile Ser Ser Gly Ile Asp Gly Ser Thr Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Met
65 70 75 80
Tyr Leu Gln Met Asn Asn Leu Lys Pro Glu Asp Thr Gly Val Tyr Tyr
85 90 95
Cys Ala Ala Asp Pro Ser His Tyr Tyr Ser Glu Tyr Asp Cys Gly Tyr
100 105 110
Tyr Gly Met Asp Tyr Trp Gly Lys Gly Thr Leu Val Thr Val Ser Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
145 150 155 160
Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
165 170 175
Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe
180 185 190
Ile Ile Asn Val Val Arg Trp Tyr Arg Arg Ala Pro Gly Lys Gln Arg
195 200 205
Glu Leu Val Ala Thr Ile Ser Ser Gly Gly Asn Ala Asn Tyr Val Asp
210 215 220
Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr
225 230 235 240
Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr
245 250 255
Tyr Cys Asn Val Pro Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro
260 265 270
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
275 280
<210> 180
<211> 440
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 180
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Leu Ala Tyr Tyr
20 25 30
Ser Ile Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ser Cys Ile Ser Ser Gly Ile Asp Gly Ser Thr Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Met
65 70 75 80
Tyr Leu Gln Met Asn Asn Leu Lys Pro Glu Asp Thr Gly Val Tyr Tyr
85 90 95
Cys Ala Ala Asp Pro Ser His Tyr Tyr Ser Glu Tyr Asp Cys Gly Tyr
100 105 110
Tyr Gly Met Asp Tyr Trp Gly Lys Gly Thr Leu Val Thr Val Ser Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
145 150 155 160
Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
165 170 175
Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe
180 185 190
Ile Ile Asn Val Val Arg Trp Tyr Arg Arg Ala Pro Gly Lys Gln Arg
195 200 205
Glu Leu Val Ala Thr Ile Ser Ser Gly Gly Asn Ala Asn Tyr Val Asp
210 215 220
Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr
225 230 235 240
Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr
245 250 255
Tyr Cys Asn Val Pro Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro
260 265 270
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly
275 280 285
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
290 295 300
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu
305 310 315 320
Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser
325 330 335
Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn Val
340 345 350
Val Arg Trp Tyr Arg Arg Ala Pro Gly Lys Gln Arg Glu Leu Val Ala
355 360 365
Thr Ile Ser Ser Gly Gly Asn Ala Asn Tyr Val Asp Ser Val Arg Gly
370 375 380
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
385 390 395 400
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn Val
405 410 415
Pro Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly Gln
420 425 430
Gly Thr Leu Val Thr Val Ser Ser
435 440
<210> 181
<211> 287
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 181
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Leu Ala Tyr Tyr
20 25 30
Ser Ile Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ser Cys Ile Ser Ser Gly Ile Asp Gly Ser Thr Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Met
65 70 75 80
Tyr Leu Gln Met Asn Asn Leu Lys Pro Glu Asp Thr Gly Val Tyr Tyr
85 90 95
Cys Ala Ala Asp Pro Ser His Tyr Tyr Ser Glu Tyr Asp Cys Gly Tyr
100 105 110
Tyr Gly Met Asp Tyr Trp Gly Lys Gly Thr Leu Val Thr Val Ser Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
145 150 155 160
Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln
165 170 175
Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe
180 185 190
Ser Ser Tyr Thr Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg
195 200 205
Glu Phe Val Ala Ala Ile Ser Trp Ser Gly Gly Arg Thr Tyr Tyr Ala
210 215 220
Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn
225 230 235 240
Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val
245 250 255
Tyr Tyr Cys Ala Ala Tyr Arg Arg Arg Arg Ala Ser Ser Asn Arg Gly
260 265 270
Leu Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
275 280 285
<210> 182
<211> 438
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 182
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Leu Ala Val Tyr Gly Pro Ser Arg Tyr Arg Tyr Gly Pro
100 105 110
Val Gly Glu Tyr Gln Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
165 170 175
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr
180 185 190
Phe Ser Arg Tyr Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln
195 200 205
Arg Glu Phe Val Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala
210 215 220
Val Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn
225 230 235 240
Thr Gly Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val
245 250 255
Tyr Tyr Cys Asn Ala Gly Gly Leu Gln Gly Tyr Trp Gly Gln Gly Thr
260 265 270
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser
305 310 315 320
Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala
325 330 335
Ala Ser Gly Arg Thr Phe Ser Ser Tyr Thr Met Gly Trp Phe Arg Gln
340 345 350
Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile Ser Trp Ser Gly
355 360 365
Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser
370 375 380
Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg
385 390 395 400
Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ala Tyr Arg Arg Arg Arg
405 410 415
Ala Ser Ser Asn Arg Gly Leu Trp Asp Tyr Trp Gly Gln Gly Thr Leu
420 425 430
Val Thr Val Ser Ser Ala
435
<210> 183
<211> 434
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 183
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Leu Ala Val Tyr Gly Pro Ser Arg Tyr Arg Tyr Gly Pro
100 105 110
Val Gly Glu Tyr Gln Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val
165 170 175
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr
180 185 190
Phe Ser Arg Tyr Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln
195 200 205
Arg Glu Phe Val Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala
210 215 220
Val Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Glu Gly
225 230 235 240
Thr Gly Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val
245 250 255
Tyr Tyr Cys Asn Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr
260 265 270
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser
305 310 315 320
Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala
325 330 335
Ala Ser Gly Ser Thr Phe Ile Ile Asn Val Val Arg Trp Tyr Arg Arg
340 345 350
Ala Pro Gly Lys Gln Arg Glu Leu Val Ala Thr Ile Ser Ser Gly Gly
355 360 365
Asn Ala Asn Tyr Val Asp Ser Val Arg Gly Arg Phe Thr Ile Ser Arg
370 375 380
Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro
385 390 395 400
Glu Asp Thr Ala Val Tyr Tyr Cys Asn Val Pro Thr Thr His Tyr Gly
405 410 415
Gly Val Tyr Tyr Gly Pro Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
420 425 430
Ser Ser
<210> 184
<211> 590
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 184
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Leu Ala Val Tyr Gly Pro Ser Arg Tyr Arg Tyr Gly Pro
100 105 110
Val Gly Glu Tyr Gln Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val
165 170 175
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr
180 185 190
Phe Ser Arg Tyr Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln
195 200 205
Arg Glu Phe Val Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala
210 215 220
Val Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Glu Gly
225 230 235 240
Thr Gly Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val
245 250 255
Tyr Tyr Cys Asn Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr
260 265 270
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser
305 310 315 320
Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala
325 330 335
Ala Ser Gly Ser Thr Phe Ile Ile Asn Val Val Arg Trp Tyr Arg Arg
340 345 350
Ala Pro Gly Lys Gln Arg Glu Leu Val Ala Thr Ile Ser Ser Gly Gly
355 360 365
Asn Ala Asn Tyr Val Asp Ser Val Arg Gly Arg Phe Thr Ile Ser Arg
370 375 380
Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro
385 390 395 400
Glu Asp Thr Ala Val Tyr Tyr Cys Asn Val Pro Thr Thr His Tyr Gly
405 410 415
Gly Val Tyr Tyr Gly Pro Tyr Trp Gly Gln Gly Thr Leu Val Thr Val
420 425 430
Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
435 440 445
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
450 455 460
Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu
465 470 475 480
Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser
485 490 495
Thr Phe Ile Ile Asn Val Val Arg Trp Tyr Arg Arg Ala Pro Gly Lys
500 505 510
Gln Arg Glu Leu Val Ala Thr Ile Ser Ser Gly Gly Asn Ala Asn Tyr
515 520 525
Val Asp Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
530 535 540
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
545 550 555 560
Val Tyr Tyr Cys Asn Val Pro Thr Thr His Tyr Gly Gly Val Tyr Tyr
565 570 575
Gly Pro Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
580 585 590
<210> 185
<211> 437
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 185
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Leu Ala Val Tyr Gly Pro Ser Arg Tyr Arg Tyr Gly Pro
100 105 110
Val Gly Glu Tyr Gln Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val
165 170 175
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr
180 185 190
Phe Ser Arg Tyr Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln
195 200 205
Arg Glu Phe Val Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala
210 215 220
Val Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Glu Gly
225 230 235 240
Thr Gly Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val
245 250 255
Tyr Tyr Cys Asn Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr
260 265 270
Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser
305 310 315 320
Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala
325 330 335
Ala Ser Gly Arg Thr Phe Ser Ser Tyr Thr Met Gly Trp Phe Arg Gln
340 345 350
Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Ala Ile Ser Trp Ser Gly
355 360 365
Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser
370 375 380
Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg
385 390 395 400
Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ala Tyr Arg Arg Arg Arg
405 410 415
Ala Ser Ser Asn Arg Gly Leu Trp Asp Tyr Trp Gly Gln Gly Thr Leu
420 425 430
Val Thr Val Ser Ser
435
<210> 186
<211> 278
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 186
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Leu Ala Val Tyr Gly Pro Ser Arg Tyr Arg Tyr Gly Pro
100 105 110
Val Gly Glu Tyr Gln Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
165 170 175
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr
180 185 190
Phe Ser Arg Tyr Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln
195 200 205
Arg Glu Phe Val Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala
210 215 220
Val Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn
225 230 235 240
Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val
245 250 255
Tyr Tyr Cys Asn Ala Gly Gly Leu Gln Gly Tyr Trp Gly Gln Gly Thr
260 265 270
Leu Val Thr Val Ser Ser
275
<210> 187
<211> 278
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 187
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Leu Ala Val Tyr Gly Pro Ser Arg Tyr Arg Tyr Gly Pro
100 105 110
Val Gly Glu Tyr Gln Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
165 170 175
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr
180 185 190
Phe Ser Arg Tyr Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln
195 200 205
Arg Glu Phe Val Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala
210 215 220
Val Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn
225 230 235 240
Thr Gly Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val
245 250 255
Tyr Tyr Cys Asn Ala Gly Gly Leu Gln Gly Tyr Trp Gly Gln Gly Thr
260 265 270
Leu Val Thr Val Ser Ser
275
<210> 188
<211> 283
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 188
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Ser Ile Asn
20 25 30
Ala Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Ser Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Ala Val Asp Ala Ser Arg Gly Leu Pro Tyr Glu Leu Tyr Tyr Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
145 150 155 160
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu
165 170 175
Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr Thr Met
180 185 190
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Ala
195 200 205
Ile Ser Trp Ser Gly Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly
210 215 220
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
225 230 235 240
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ala
245 250 255
Tyr Arg Arg Arg Arg Ala Ser Ser Asn Arg Gly Leu Trp Asp Tyr Trp
260 265 270
Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala
275 280
<210> 189
<211> 279
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 189
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Ser Ile Asn
20 25 30
Ala Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Ser Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Ala Val Asp Ala Ser Arg Gly Leu Pro Tyr Glu Leu Tyr Tyr Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
145 150 155 160
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu
165 170 175
Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn Val Val
180 185 190
Arg Trp Tyr Arg Arg Ala Pro Gly Lys Gln Arg Glu Leu Val Ala Thr
195 200 205
Ile Ser Ser Gly Gly Asn Ala Asn Tyr Val Asp Ser Val Arg Gly Arg
210 215 220
Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met
225 230 235 240
Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn Val Pro
245 250 255
Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly Gln Gly
260 265 270
Thr Leu Val Thr Val Ser Ser
275
<210> 190
<211> 435
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 190
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Ser Ile Asn
20 25 30
Ala Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Ser Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Ala Val Asp Ala Ser Arg Gly Leu Pro Tyr Glu Leu Tyr Tyr Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
145 150 155 160
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu
165 170 175
Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn Val Val
180 185 190
Arg Trp Tyr Arg Arg Ala Pro Gly Lys Gln Arg Glu Leu Val Ala Thr
195 200 205
Ile Ser Ser Gly Gly Asn Ala Asn Tyr Val Asp Ser Val Arg Gly Arg
210 215 220
Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met
225 230 235 240
Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn Val Pro
245 250 255
Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly Gln Gly
260 265 270
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
275 280 285
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
290 295 300
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
305 310 315 320
Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
325 330 335
Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn Val Val Arg Trp Tyr Arg
340 345 350
Arg Ala Pro Gly Lys Gln Arg Glu Leu Val Ala Thr Ile Ser Ser Gly
355 360 365
Gly Asn Ala Asn Tyr Val Asp Ser Val Arg Gly Arg Phe Thr Ile Ser
370 375 380
Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg
385 390 395 400
Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn Val Pro Thr Thr His Tyr
405 410 415
Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly Gln Gly Thr Leu Val Thr
420 425 430
Val Ser Ser
435
<210> 191
<211> 282
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 191
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Ser Ile Asn
20 25 30
Ala Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Ser Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Ala Val Asp Ala Ser Arg Gly Leu Pro Tyr Glu Leu Tyr Tyr Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
130 135 140
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
145 150 155 160
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu
165 170 175
Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr Thr Met
180 185 190
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Ala
195 200 205
Ile Ser Trp Ser Gly Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly
210 215 220
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
225 230 235 240
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala Ala
245 250 255
Tyr Arg Arg Arg Arg Ala Ser Ser Asn Arg Gly Leu Trp Asp Tyr Trp
260 265 270
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
275 280
<210> 192
<211> 434
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 192
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ala Ala
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Asp Asp Gly Ser Lys Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Asn Thr Gly Tyr Gly Ala Thr Thr Thr Arg Pro Gly Arg Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
130 135 140
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu
145 150 155 160
Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu
165 170 175
Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn Val Val Arg Trp
180 185 190
Tyr Arg Arg Ala Pro Gly Lys Gln Arg Glu Leu Val Ala Thr Ile Ser
195 200 205
Ser Gly Gly Asn Ala Asn Tyr Val Asp Ser Val Arg Gly Arg Phe Thr
210 215 220
Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser
225 230 235 240
Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Asn Val Pro Thr Thr
245 250 255
His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly Gln Gly Thr Leu
260 265 270
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
275 280 285
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
290 295 300
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
305 310 315 320
Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
325 330 335
Ser Gly Ser Thr Phe Ile Ile Asn Val Val Arg Trp Tyr Arg Arg Ala
340 345 350
Pro Gly Lys Gln Arg Glu Leu Val Ala Thr Ile Ser Ser Gly Gly Asn
355 360 365
Ala Asn Tyr Val Asp Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp
370 375 380
Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu
385 390 395 400
Asp Thr Ala Leu Tyr Tyr Cys Asn Val Pro Thr Thr His Tyr Gly Gly
405 410 415
Val Tyr Tyr Gly Pro Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
420 425 430
Ser Ala
<210> 193
<211> 116
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 193
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Lys Ser Ala
115
<210> 194
<211> 155
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 194
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Ala Phe Ser Ala Ala
20 25 30
Tyr Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Asp Asp Gly Ser Lys Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Asn Thr Gly Tyr Gly Ala Thr Thr Thr Arg Pro Gly Arg Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp
115 120 125
His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp
130 135 140
Asp Lys Gly Ala Ala His His His His His His
145 150 155
<210> 195
<211> 162
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 195
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Leu Ala Tyr Tyr
20 25 30
Ser Ile Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Gly Val
35 40 45
Ser Cys Ile Ser Ser Gly Ile Asp Gly Ser Thr Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Met
65 70 75 80
Tyr Leu Gln Met Asn Asn Leu Lys Pro Glu Asp Thr Gly Val Tyr Tyr
85 90 95
Cys Ala Ala Asp Pro Ser His Tyr Tyr Ser Glu Tyr Asp Cys Gly Tyr
100 105 110
Tyr Gly Met Asp Tyr Trp Gly Lys Gly Thr Leu Val Thr Val Ser Ser
115 120 125
Gly Ala Ala Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp
130 135 140
Ile Asp Tyr Lys Asp Asp Asp Asp Lys Gly Ala Ala His His His His
145 150 155 160
His His
<210> 196
<211> 312
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 196
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Ala Leu Ala Val Tyr Gly Pro Asn Arg Tyr Arg Tyr Gly Pro
100 105 110
Val Gly Glu Tyr Asn Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
145 150 155 160
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Val
165 170 175
Gln Ala Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr
180 185 190
Phe Ser Arg Tyr Ser Met Asn Trp Tyr Arg Gln Ala Pro Gly Lys Gln
195 200 205
Arg Glu Phe Val Ala Gly Ile Ser Val Gly Arg Ile Thr Asn Tyr Ala
210 215 220
Val Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Glu Gly
225 230 235 240
Thr Gly Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val
245 250 255
Tyr Tyr Cys Asn Ala Gly Gly Leu Gln Gly Tyr Trp Gly Leu Gly Thr
260 265 270
Leu Val Thr Val Ser Ser Gly Ala Ala Asp Tyr Lys Asp His Asp Gly
275 280 285
Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys Gly
290 295 300
Ala Ala His His His His His His
305 310
<210> 197
<211> 157
<212> Белок
<213> Искусственная последовательность
<220>
<223> Аминокислотная последовательность
<400> 197
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Ser Ile Asn
20 25 30
Ala Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Ser Ser Gly Gly Ser Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Ala Val Asp Ala Ser Arg Gly Leu Pro Tyr Glu Leu Tyr Tyr Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr
115 120 125
Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp
130 135 140
Asp Asp Asp Lys Gly Ala Ala His His His His His His
145 150 155
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| ПОЛИПЕПТИДЫ, СВЯЗЫВАЮЩИЕСЯ С ADAMTS5, MMP13 И АГГРЕКАНОМ | 2018 |
|
RU2786659C2 |
| УСОВЕРШЕНСТВОВАННЫЕ АГЕНТЫ, СВЯЗЫВАЮЩИЕ СЫВОРОТОЧНЫЙ АЛЬБУМИН | 2018 |
|
RU2797270C2 |
| СВЯЗЫВАЮЩИЕ ADAMTS ИММУНОГЛОБУЛИНЫ | 2018 |
|
RU2781182C2 |
| УСОВЕРШЕНСТВОВАННЫЕ СВЯЗЫВАЮЩИЕСЯ С СЫВОРОТОЧНЫМ АЛЬБУМИНОМ ВЕЩЕСТВА | 2018 |
|
RU2789495C2 |
| УЛУЧШЕННЫЕ ОДИНОЧНЫЕ ВАРИАБЕЛЬНЫЕ ДОМЕНЫ ИММУНОГЛОБУЛИНА, СВЯЗЫВАЮЩИЕСЯ С СЫВОРОТОЧНЫМ АЛЬБУМИНОМ | 2017 |
|
RU2765384C2 |
| PD1/CTLA4-СВЯЗЫВАЮЩИЕ ВЕЩЕСТВА | 2016 |
|
RU2755724C2 |
| УСОВЕРШЕНСТВОВАННЫЕ АГЕНТЫ, СВЯЗЫВАЮЩИЕ TNF | 2016 |
|
RU2774823C2 |
| УЛУЧШЕННЫЕ ВАРИАБЕЛЬНЫЕ ДОМЕНЫ ИММУНОГЛОБУЛИНА | 2015 |
|
RU2746738C2 |
| УЛУЧШЕННЫЕ ВАРИАБЕЛЬНЫЕ ДОМЕНЫ ИММУНОГЛОБУЛИНА | 2015 |
|
RU2809788C2 |
| ИММУНОГЛОБУЛИНЫ, СВЯЗЫВАЮЩИЕ АГГРЕКАН | 2018 |
|
RU2771818C2 |
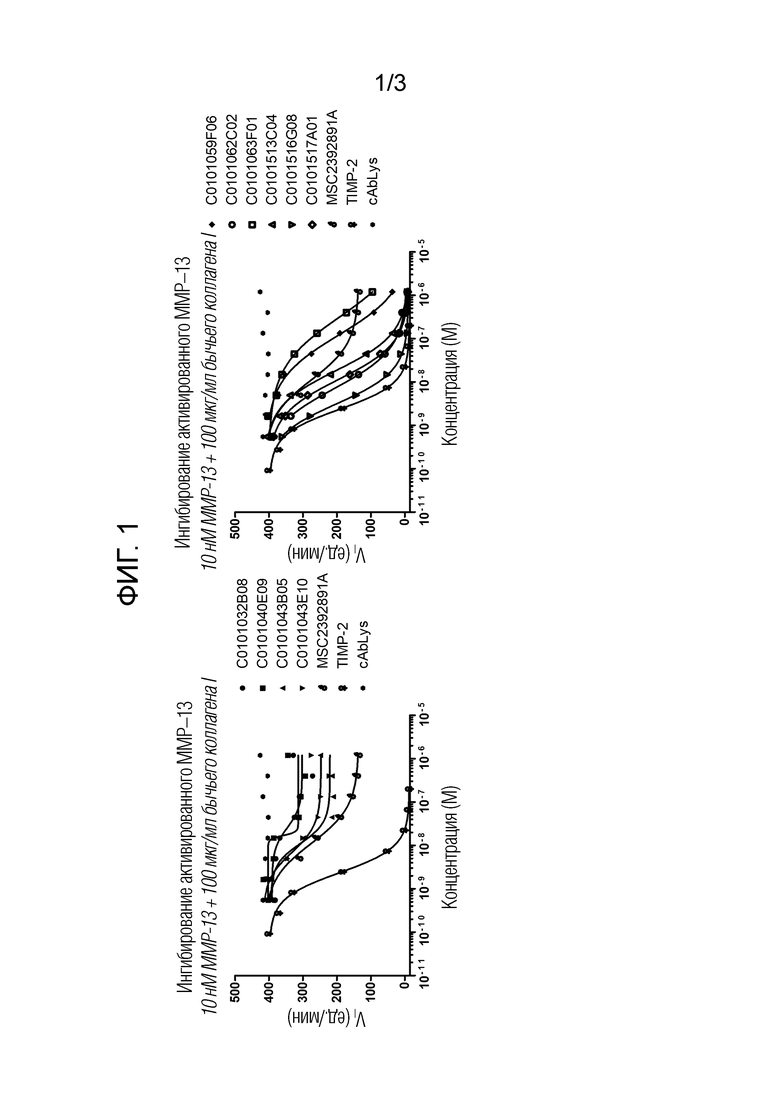
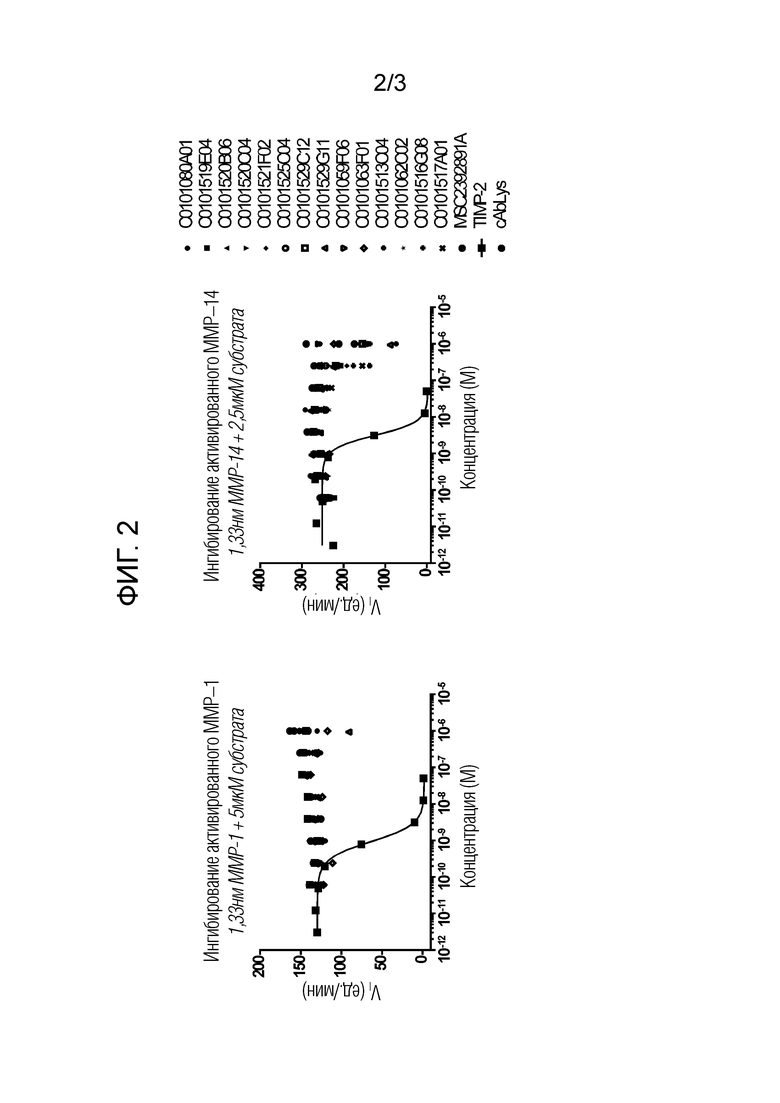
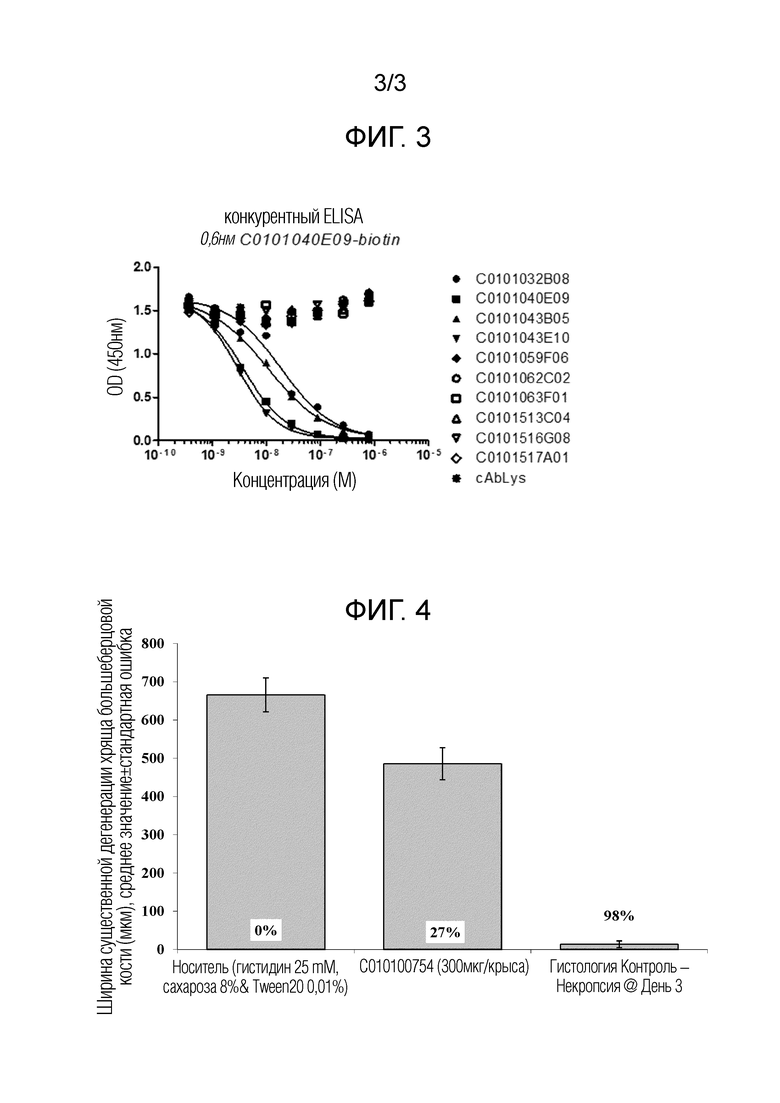
Настоящее изобретение относится к области биотехнологии, конкретно к иммуноглобулинам, которые специфически связываются с матриксной металлопротеиназой 13 (MMP13), и может быть использовано в медицине для лечения и профилактики заболеваний или расстройств у индивидуума, которые связаны с активностью MMP13. Предложенные полипептиды, включающие по меньшей мере 1 одиночный вариабельный домен иммуноглобулина (ISVD), связывающийся с матриксной металлопротеиназой 13, являются антагонистами MMP13 с улучшенными профилактическими, терапевтическими и/или фармакологическими свойствами, включая более безопасный профиль по сравнению со сравнительными молекулами. 3 н. и 42 з.п. ф-лы, 4 ил., 28 табл., 6 пр.
1. Полипептид, связывающийся с матриксной металлопротеиназой 13, включающий по меньшей мере 1 одиночный вариабельный домен иммуноглобулина (ISVD), связывающийся с матриксной металлопротеиназой 13, то есть MMP13, где указанный ISVD, связывающийся с MMP13, включает 3 определяющие комплементарность области (CDR1–CDR3 соответственно), в котором
(i) CDR1 выбрана из группы, состоящей из
(a) SEQ ID NO: 23; и
(b) аминокислотной последовательности, которая имеет 1 аминокислотное отличие от SEQ ID NO: 23, где
– в положении 7 Y заменен на R;
(ii) CDR2 выбрана из группы, состоящей из
(c) SEQ ID NO: 37; и
(d) аминокислотных последовательностей, которые имеют 1, 2 или 3 аминокислотных отличия от SEQ ID NO: 37, где аминокислотное отличие (отличия) определено следующим образом:
– в положении 4 V заменен на T; и/или
– в положении 5 G заменен на A; и/или
– в положении 9 N заменен на H;
и
(iii) CDR3 выбрана из группы, состоящей из
(e) SEQ ID NO: 52; и
(f) аминокислотной последовательности, которая имеет 1 аминокислотное отличие от SEQ ID NO: 52, а именно, в которой в положении 6 Y заменен на S.
2. Полипептид по п. 1, где указанный ISVD, связывающийся с MMP13, не связывается с MMP1 или MMP14 мембранного типа.
3. Полипептид по п. 1 или 2, где указанный ISVD включает комбинацию CDR1, CDR2 и CDR3, которая выбрана из группы, состоящей из:
– CDR1 представляет собой SEQ ID NO: 23, CDR2 представляет собой SEQ ID NO: 37 и CDR3 представляет собой SEQ ID NO: 52;
– CDR1 представляет собой SEQ ID NO: 24, CDR2 представляет собой SEQ ID NO: 38 и CDR3 представляет собой SEQ ID NO: 52;
- CDR1 представляет собой SEQ ID NO: 23, CDR2 представляет собой SEQ ID NO: 39 и CDR3 представляет собой SEQ ID NO: 53.
4. Полипептид по п. 1, где указанный полипептид представляет собой SEQ ID NO: 1 или полипептид, который имеет по меньшей мере 95% идентичности последовательности с SEQ ID NO: 1.
5. Полипептид по п. 1, в котором указанный ISVD выбран из группы, состоящей из SEQ ID NO: 1, 2, 3, 4, 5, 6, 7 и 8.
6. Полипептид по любому из пп. 1–5, где указанный полипептид связывается с MMP13 с KD значением между 1E–07 M и 1E–13 M, таким как между 1E–08 M и 1E–12 M, как определено методом KinExA.
7. Полипептид по п. 6, где указанный полипептид связывается с MMP13 с KD значением, выбранным из группы, состоящей из: максимально 1E–07 M, меньше чем 1E–08 M, меньше чем 1E–09 M, меньше чем 1E–10 M, меньше чем 5E–11 M, меньше чем 4E–11 M, меньше чем 3E–11 M, меньше чем 2E–11 M, меньше чем 1,7E–11 M, меньше чем 1E–11 M, меньше чем 5E–12 M, меньше чем 4E–12 M, меньше чем 3E–12 M и меньше чем 1E–12 M.
8. Полипептид по любому из пп. 1–5, где указанный полипептид ингибирует активность MMP13 с IC50 значением между 1E–07 M и 1E–12 M, таким как между 1E–08 M и 1E–11 M, как определено в конкурентном ELISA, TIMP–2 конкурентном ELISA, анализе флуорогенного пептида, анализе флуорогенного коллагена или коллагенолитическом анализе.
9. Полипептид по п. 8, где указанный полипептид ингибирует активность MMP13 с IC50 значением максимально 1E–07 M.
10. Полипептид по п. 7, где указанный полипептид ингибирует активность MMP13 с IC50 значением 1E–08 M, 5E–09 M или 4E–9 M, 3E–9 M, 2E–9 M, таким как 1E–9 M.
11. Полипептид по любому из пп. 1–10, где указанный полипептид связывается с MMP13 с EC50 значением между 1E–07 M и 1E–12 M, таким как между 1E–08 M и 1E–11 M, как определено методом ELISA.
12. Полипептид по любому из пп. 1–5, где указанный полипептид связывается с MMP13 со скоростью диссоциации меньше чем 5E–04 с–1, как определено методом SPR.
13. Полипептид по любому из пп. 1–5, где указанный MMP13 представляет собой MMP13 человека, MMP13 крысы, MMP13 собаки, MMP13 быка, MMP13 яванского макака.
14. Полипептид по п. 13, где указанный MMP13 представляет собой MMP13 человека.
15. Полипептид по п. 14, где указанный MMP13 представляет собой SEQ ID NO: 115.
16. Полипептид по любому из пп. 1–5, где указанный полипептид антагонизирует активность MMP13, такую как (i) протеазная активность; (ii) связывание коллагена с гемопексин–подобным доменом.
17. Полипептид по п. 16, где указанный полипептид блокирует связывание MMP13 с коллагеном и/или аггреканом по меньшей мере на 20%, по меньшей мере на 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95% или даже больше.
18. Полипептид по любому из пп. 1–5, где указанный полипептид ингибирует протеазную активность MMP13, такую как протеолиз субстрата, такого как аггрекан, коллаген II, коллаген I, коллаген III, коллаген IV, коллаген IX, коллаген X, коллаген XIV и/или желатин.
19. Полипептид по п. 18, где указанный субстрат представляет собой коллаген типа II.
20. Полипептид по п. 1, включающий по меньшей мере 2 ISVD, где по меньшей мере 1 ISVD специфически связывается с MMP13,
и где
(i) указанные по меньшей мере 2 ISVD связаны непосредственно; или
(ii) указанные по меньшей мере 2 ISVD связаны друг с другом через линкер.
21. Полипептид по п. 20, где указанные по меньшей мере 2 ISVD специфически связываются с MMP13.
22. Полипептид по п. 1, включающий два, то есть первый и второй, или более ISVD, каждый из которых индивидуально специфически связывается с MMP13, где
указанный второй ISVD содержит последовательности CDR, определенные в п. 1, где
a) по меньшей мере первый ISVD специфически связывается с первой антигенной детерминантой, эпитопом, частью, доменом, субъединицей или конформацией MMP13; и где
b) по меньшей мере второй ISVD специфически связывается с второй антигенной детерминантой, эпитопом, частью, доменом, субъединицей или конформацией MMP13, отличной от первой антигенной детерминанты, эпитопа, части, домена, субъединицы или конформации соответственно;
и где
(i) указанные по меньшей мере 2 ISVD связаны непосредственно; или
(ii) указанные по меньшей мере 2 ISVD связаны друг с другом через линкер.
23. Полипептид по п. 22, где указанный второй ISVD имеет аминокислотную последовательность SEQ ID NO: 1.
24. Полипептид по любому из пп. 22 или 23, где указанный первый ISVD, специфически связывающийся с MMP13, выбран из группы, состоящей из SEQ ID NO: 111, 11, 110, 10, 112, 12, 109, 9, 13, 14, 15, 16, 17, 18, 19, 20, 21 и 22.
25. Полипептид по любому из пп. 22 или 24, где указанный второй ISVD, специфически связывающийся с MMP13, выбран из группы, состоящей из SEQ ID NO: 1, 2, 3, 4, 5, 6, 7 и 8.
26. Полипептид по п. 1, дополнительно включающий по меньшей мере один ISVD, специфически связывающийся с аггреканом.
27. Полипептид по п. 26, включающий по меньшей мере 2 ISVD, специфически связывающихся с аггреканом.
28. Полипептид по п. 27, где указанные по меньшей мере 2 ISVD, специфически связывающиеся с аггреканом, могут быть одинаковыми или отличными друг от друга.
29. Полипептид по п. 27 или 28, где указанные по меньшей мере 2 ISVD, специфически связывающиеся с аггреканом, независимо выбраны из группы, состоящей из SEQ ID NO: 166–168.
30. Полипептид по любому из пп. 26-28, где указанный ISVD, специфически связывающийся с аггреканом, специфически связывается с аггреканом человека в соответствии с SEQ ID NO: 105.
31. Полипептид по любому из пп. 26-28, где указанный ISVD, специфически связывающийся с аггреканом, специфически связывается с аггреканом собаки, аггреканом быка, аггреканом крысы; аггреканом свиньи; аггреканом мыши, аггреканом кролика; аггреканом яванского макака и/или аггреканом макака–резус.
32. Полипептид по любому из пп. 26-28, где указанный ISVD, специфически связывающийся с аггреканом, связывается с хрящевой тканью, такой как хрящ и/или мениск.
33. Полипептид по любому из пп. 1–32, где указанный полипептид имеет стабильность по меньшей мере 7 дней, такую как 14 дней, 21 день, 1 месяц, 2 месяца или даже 3 месяца, в синовиальной жидкости (SF) при 37°C.
34. Полипептид по п. 1, дополнительно включающий ISVD, связывающийся с сывороточным альбумином.
35. Полипептид по п. 34, где указанный ISVD, связывающийся с сывороточным альбумином, по существу состоит из 4 каркасных областей (FR1–FR4 соответственно) и 3 определяющих комплементарность областей (CDR1–CDR3 соответственно), в котором CDR1 представляет собой SEQ ID NO: 157, CDR2 представляет собой SEQ ID NO: 158 и CDR3 представляет собой SEQ ID NO: 159.
36. Полипептид по п. 35, где указанный ISVD, связывающийся с сывороточным альбумином, выбран из группы, состоящей из ALB135 в соответствии с SEQ ID NO: 193, ALB129 в соответствии с SEQ ID NO: 144, ALB8 в соответствии с SEQ ID NO: 142, ALB23 в соответствии с SEQ ID NO: 143 и ALB132 в соответствии с SEQ ID NO: 145.
37. Полипептид по любому из пп. 20-23, где указанный линкер выбран из группы, состоящей из SEQ ID NO: 125–141.
38. Полипептид по п. 37, где линкер представляет собой SEQ ID NO: 129.
39. Полипептид по любому из пп. 1–38, дополнительно включающий C–концевое удлинение.
40. Полипептид по п. 39, где указанное C–концевое удлинение представляет собой C–концевое удлинение (X)n, где n имеет значение 1–10 и каждый X представляет собой независимо выбранный аминокислотный остаток.
41. Полипептид по п. 40, где указанный аминокислотный остаток независимо выбран из группы, состоящей из аланина (A), глицина (G), валина (V), лейцина (L) или изолейцина (I).
42. Полипептид по любому из пп. 1–5, где указанный полипептид имеет по меньшей мере 80%, 90%, 95% или 100% идентичность последовательности с любой из SEQ ID NO: 1, 2, 3, 4, 5, 6, 7, 8, 160, 161, 162, 163, 164, 165, 183, 184, 185, 186, 187.
43. Способ лечения профилактики заболеваний или расстройств у индивидуума, которые связаны с активностью MMP13, включающий введение указанному индивидууму полипептида по любому из пп. 1–42 в количестве, эффективном для лечения или профилактики симптома указанного заболевания или расстройства,
где указанные заболевания или расстройства выбраны из группы, состоящей из артропатий и хондродистрофий, артритного заболевания, такого как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматического разрыва или отслоения, ахондроплазии, реберного хондрита, спондилоэпиметафизарной дисплазии, межпозвоночной грыжи, дегенерации поясничного диска, дегенеративного заболевания суставов и рецидивирующего полихондрита, рассекающего остеохондрита и аггреканопатий.
44. Применение полипептида по любому из пп. 1–42 в качестве лекарственного средства для лечения или профилактики симптома заболеваний, включающих артропатии и хондродистрофии, артритное заболевание, такое как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отслоение, ахондроплазию, реберный хондрит, спондилоэпиметафизарную дисплазию, межпозвоночную грыжу, дегенерацию поясничного диска, дегенеративное заболевание суставов и рецидивирующий полихондрит, рассекающий остеохондрит и аггреканопатии.
45. Полипептид по любому из пп. 1–5, где указанный полипептид перекрестно блокирует связывание с MMP13 по меньшей мере одного из полипептидов в соответствии с любой из SEQ ID NO: 1, 2, 3, 4, 5, 6, 7 и 8 и/или перекрестно блокируется от связывания с MMP13 по меньшей мере полипептидом в соответствии с любой из SEQ ID NO: 1, 2, 3, 4, 5, 6, 7 и 8.
| DEMEESTERE D | |||
| et al | |||
| Топка с несколькими решетками для твердого топлива | 1918 |
|
SU8A1 |
| Пишущая машина для тюркско-арабского шрифта | 1922 |
|
SU24A1 |
| Кипятильник для воды | 1921 |
|
SU5A1 |
| МУЗЫКАЛЬНЫЙ ПРИБОР С КАТОДНЫМИ ЛАМПАМИ | 1921 |
|
SU890A1 |
| MOHAN V | |||
| et al | |||
| Matrix metalloproteinase protein inhibitors: highlighting a new beginning for metalloproteinases in medicine, METALLOPROTEINASES IN MEDICINE, | |||

