Настоящее изобретение относится к вариантам кислой α-глюкозидазы и их применению.
Болезнь Помпе, также известная как болезнь накопления гликогена (GSD) II типа и недостаточность кислой мальтазы, представляет собой аутосомно-рецессивную метаболическую миопатию, обусловленную недостаточностью лизосомного фермента кислой α-глюкозидазы (GAA). GAA представляет собой экзо-1,4 и 1,6-α-глюкозидазу, которая гидролизует гликоген до глюкозы в лизосоме. Недостаточность GAA ведет к накоплению гликогена в лизосомах и вызывает нарастающее повреждение дыхательных, сердечных и скелетных мышц. Заболевание варьирует от быстро прогрессирующего детского течения, которое обычно фатально к возрасту в 1-2 года, до более медленно прогрессирующего и гетерогенного течения, которое обуславливает значимую распространенность болезни и раннюю смертность у детей и взрослых. Hirschhorn RR, The Metabolic and Molecular Bases of Inherited Disease, 3: 3389-3420 (2001, McGraw-Hill); Van der Ploeg and Reuser, Lancet 372: 1342-1351 (2008).
Существующая терапия человека для лечения болезни Помпе включает введение рекомбинантной GAA человека, которое иначе называют ферментозаместительной терапией (ERT). Продемонстрирован ERT эффект при тяжелой детской GSDII. Однако польза ферментативной терапии ограничена необходимостью частых инфузий и развитием ингибиторных антител против рекомбинантной hGAA (Amalfitano, A., et al. (2001) Genet. In Med. 3:132-138). Кроме того, ERT не обеспечивает эффективную коррекцию во всем организме, вероятно, из-за комбинации плохого биораспределения белка после доставки в периферическую вену, отсутствия захвата из некоторых тканей и высокой иммуногенности.
В качестве альтернативы или вспомогательного средства для ERT исследовали выполнимость подходов генной терапии для того, чтобы лечить GSDII (Amalfitano, A., et al. (1999) Proc. Natl. Acad. Sci. USA 96:8861-8866, Ding, E., et al. (2002) Mol. Ther. 5:436-446, Fraites, T. J., et al. (2002) Mol. Ther. 5:571-578, Tsujino, S., et al. (1998) Hum. Gene Ther. 9:1609-1616). Однако направленный в мышцы перенос генов для того, чтобы корректировать генетический дефект, столкнулся с ограничением системной природой заболевания и тем фактом, что экспрессия трансгена в мышцах обычно бывает более иммуногенной по сравнению с другими тканями.
Doerfler et al., 2016 описывают комбинированное введение двух конструкций, кодирующих GAA человека с оптимизацией кодонов, одна под управлением специфического промотора печени и другая под управлением специфического промотора мышц. Управляемую специфическим промотором печени экспрессию GAA используют для содействия иммунологической толерантности к GAA в модели на Gaa-/- мышах, тогда как управляемая специфическим промотором мышц экспрессия GAA обеспечивает экспрессию терапевтического белка в части тканей, на которые направлена терапия. Однако эта стратегия не является полностью удовлетворительной в том отношении, что она требует использования нескольких конструкций и не ведет к экспрессии GAA по всему организму.
В прошлом предложены модифицированные белки GAA для усовершенствования лечения лизосомной болезни накопления. В частности, в заявке WO2004064750 и Sun et al. 2006 раскрыт химерный полипептид GAA, содержащий сигнальный пептид, функционально связанный с GAA, в качестве способа усиления направленности белка в секреторный путь.
Однако терапия, доступная пациенту, не является полностью удовлетворительной, и в данной области все еще необходимы усовершенствованные полипептиды GAA и продуцирование GAA. В частности, все еще существует потребность в долгосрочном эффекте лечения с использованием GAA, продуцировании GAA на высоком уровне, усовершенствованной иммунологической толерантности к получаемому полипептиду GAA и усовершенствованном захвате GAA клетками и тканями, нуждающимися в нем. Кроме того, в WO2004064750 и Sun et al., 2006, раскрыто распределение химерного полипептида GAA в тканях, которое не является полностью удовлетворительным. Следовательно, все еще существует потребность в полипептиде GAA, который будет полностью терапевтическим, допуская коррекцию накопления гликогена в большинстве, если не во всех, тканей, представляющих интерес.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к вариантам GAA, которые экспрессируют и секретируют на более высоких уровнях по сравнению с белком GAA дикого типа и которые обеспечивают усовершенствованную коррекцию патологического накопления гликогена по всему организму и ведут к индукции иммунологической толерантности к GAA.
По одному из аспектов, изобретение относится к усеченному полипептиду GAA, который содержит делецию по меньшей мере одной аминокислоты с N-конца родительского полипептида GAA, где родительский полипептид соответствует форме предшественника полипептида GAA, свободного от его сигнального пептида. В конкретном варианте осуществления указанный усеченный полипептид GAA имеет по меньшей мере 2, в частности, по меньшей мере 2, в частности, по меньшей мере 3, в частности, по меньшей мере 4, в частности, по меньшей мере 5, в частности, по меньшей мере 6, в частности, по меньшей мере 7, в частности, по меньшей мере 8 последовательных аминокислот, на его N-конце, по сравнению с родительским полипептидом GAA. В другом варианте осуществления указанный усеченный полипептид GAA имеет самое большее 75, в частности самое большее 70, в частности самое большее 60, в частности самое большее 55, в частности самое большее 50, в частности самое большее 47, в частности самое большее 46, в частности самое большее 45, в частности самое большее 44, в частности самое большее 43 последовательных аминокислот, удаленных на его N-конце, по сравнению с родительским полипептидом GAA. В дополнительном конкретном варианте осуществления, указанный усеченный полипептид GAA имеет самое большее 47, в частности самое большее 46, в частности самое большее 45, в частности самое большее 44, в частности самое большее 43 последовательных аминокислот, удаленных на его N-конце, по сравнению с родительским полипептидом GAA. В другом конкретном варианте осуществления указанный усеченный полипептид GAA имеет от 1 до 75, в частности, от 1 до 47, в частности, от 1 до 46, в частности, от 1 до 45, в частности, от 1 до 44, в частности, от 1 до 43 последовательных аминокислот, удаленных на его N-конце, по сравнению с родительским полипептидом GAA. В другом варианте осуществления указанный усеченный полипептид GAA имеет от 2 до 43, в частности, от 3 до 43, в частности, от 4 до 43, в частности, от 5 до 43, в частности, от 6 до 43, в частности, от 7 до 43, в частности, от 8 до 43 последовательных аминокислот, удаленных на его N-конце, по сравнению с родительским полипептидом GAA. В более конкретном варианте осуществления, указанный усеченный полипептид GAA имеет 6, 7, 8, 9, 10, 27, 28, 29, 30, 31, 40, 41, 42, 43, 44, 45, 46 или 47 последовательных аминокислот, удаленных на его N-конце, по сравнению с родительским полипептидом GAA, в частности, 7, 8, 9, 28, 29, 30, 41, 42, 43 или 44, более конкретно 8, 29, 42 или 43 последовательных аминокислот, усеченных на его N-конце, по сравнению с родительским полипептидом GAA. В дополнительном конкретном варианте осуществления, родительский полипептид представляет собой GAA человека (hGAA), в частности hGAA, имеющий аминокислотную последовательность, приведенную в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1.
В конкретном варианте осуществления усеченный полипептид GAA по изобретению имеет последовательность, приведенную в SEQ ID NO: 27, SEQ ID NO: 28, SEQ ID NO: 34 и SEQ ID NO: 35.
Кроме того, усеченный полипептид GAA по изобретению дополнительно может содержать сигнальный пептид, слитый с его N-концом, в частности сигнальный пептид, выбранный в группе, состоящей из SEQ ID NO: с 3 до 7, в частности сигнальный пептид из SEQ ID NO: 3.
В другом аспекте изобретение относится к молекуле нуклеиновой кислоты, кодирующей усеченный полипептид GAA, как описано выше, необязательно слитый с сигнальным пептидом через его N-конец. В некоторых вариантах осуществления молекула нуклеиновой кислоты имеет нуклеотидную последовательность, оптимизированную для того, чтобы усовершенствовать экспрессию и/или усовершенствовать иммунологическую толерантность для усеченного полипептида GAA in vivo, в частности у человеческого субъекта.
В еще одном аспекте изобретение относится к конструкции нуклеиновой кислоты, которая содержит молекулу нуклеиновой кислоты по изобретению, функционально связанную с одной или несколькими регуляторными последовательностями, таким как промотор, интрон, сигнал полиаденилирования и/или энхансер (например, цис-регуляторный модуль, или CRM). В конкретном варианте осуществления промотор представляет собой специфический промотор печени, предпочтительно выбранный в группе, состоящей из промотора α-1-антитрипсина (hAAT), промотора транстиретина, промотора альбумина и промотора тироксинсвязывающего глобулина (TBG). В другом конкретном варианте осуществления промотор представляет собой специфически промотор мышц, такой как промоторы Spc5-12, MCK и десмина. В другом варианте осуществления промотор представляет собой универсальный промотор, такой как промоторы CMV, CAG и PGK. Конструкция нуклеиновой кислоты дополнительно может необязательно содержать интрон, в частности интрон, выбранный в группе, состоящей из интрона β-глобина b2 человека (или HBB2), интрона FIX, интрона β-глобина курицы и интрона SV40, где указанный интрон необязательно представляет собой модифицированный интрон, такой как модифицированный интрон HBB2 из SEQ ID NO: 17, модифицированный интрон FIX из SEQ ID NO: 19 или модифицированный интрон β-глобина курицы из SEQ ID NO: 21. В конкретном варианте осуществления конструкции нуклеиновой кислоты по изобретению указанная конструкция содержит, предпочтительно в этом порядке: энхансер; интрон; промотор, в частности специфический промотор печени; последовательность нуклеиновой кислоты, кодирующую белок GAA; и сигнал полиаденилирования, конструкция содержит, предпочтительно в этом порядке: управляющую область ApoE; интрон HBB2, в частности, модифицированный интрон HBB2; промотор hAAT; последовательность нуклеиновой кислоты, кодирующую усеченный полипептид GAA; и сигнал полиаденилирования бычьего гормона роста. В конкретных вариантах осуществления указанная конструкция нуклеиновой кислоты более конкретно содержит нуклеотидную последовательность из любой одной из SEQ ID NO: с 22 до 26.
В другом аспекте изобретение относится к вектору, содержащему молекулу нуклеиновой кислоты или конструкцию нуклеиновой кислоты, раскрытые в настоящем описании. Вектор по изобретению в частности может представлять собой вирусный вектор, предпочтительно ретровирусный вектор, такой как лентивирусный вектор, или AAV вектор. Предпочтительно, вектор представляет собой одноцепочечный или двухцепочечный самокомплементарный AAV вектор, предпочтительно AAV вектор с происходящим из AAV капсидом, например, капсидом из AAV1, AAV2, варианта AAV2, AAV3, варианта AAV3, AAV3B, варианта AAV3B, AAV4, AAV5, AAV6, варианта AAV6, AAV7, AAV8, AAV9, AAV10, такого как AAVcy10 и AAVrh10, AAVrh74, AAVdj, AAV-Anc80, AAV-LK03, AAV2i8, AAV свиньи, таким как капсид AAVpo4 и AAVpo6, или с химерным капсидом. В конкретном варианте осуществления вектор представляет собой AAV вектор с капсидом AAV8, AAV9, AAVrh74 или AAV2i8, в частности капсидом AAV8, AAV9 или AAVrh74, более конкретно капсидом AAV8.
В еще одном аспекте изобретение относится к клетке, трансформированной молекулой нуклеиновой кислоты, конструкцией нуклеиновой кислоты или вектором по изобретению. Более конкретно, клетка представляет собой клетку печени или клетку мышцы.
В конкретном аспекте, изобретение относится к фармацевтической композиции, которая содержит, в фармацевтически приемлемом носителе, усеченный полипептид GAA, молекулу нуклеиновой кислоты, конструкцию нуклеиновой кислоты, вектор или клетку по изобретению.
Изобретение дополнительно относится к усеченному полипептиду GAA, молекуле нуклеиновой кислоты, конструкции нуклеиновой кислоты, вектору или клетке по изобретению для применения в качестве лекарственного средства.
Изобретение дополнительно предусматривает усеченный полипептид GAA, молекулу нуклеиновой кислоты, конструкцию нуклеиновой кислоты, вектор или клетку по изобретению для применения в способе лечения болезни накопления гликогена. В конкретном варианте осуществления болезнь накопления гликогена представляет собой GSDI, GSDII, GSDIII, GSDIV, GSDV, GSDVI, GSDVII, GSDVIII или летальную врожденную болезнь накопления гликогена в сердце. В более конкретном варианте осуществления, болезнь накопления гликогена выбирают в группе, состоящей из GSDI, GSDII и GSDIII, более конкретно в группе, состоящей из GSDII и GSDIII. В даже более конкретном варианте осуществления болезнь накопления гликогена представляет собой GSDII.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1. Делеция частей hGAA увеличивает ее секрецию in vitro. Часть A. Клетки гепатомы человека (Huh7) трансфицировали с использованием LipofectamineTM и контрольной плазмиды, экспрессирующей зеленый флуоресцентный белок (GFP), или плазмид, экспрессирующих hGAA дикого типа (hGAA) или последовательность hGAA, оптимизированную в соответствии с двумя различными алгоритмами (hGAAco1 и co2, соответственно). Различные конструкции hGAA содержали сигнальный пептид дикого типа или сигнальный пептид α-1-антитрипсина человека (sp2). Усеченную hGAA получали посредством делеции 8 аминокислот после сигнального пептида (Δ8). Через 48 часов после трансфекции, активность hGAA в средах для культивирования измеряли посредством флуорогенного ферментативного анализа и активность GAA оценивали по калибровочной кривой продукта реакции, как указано в Материалах и способах. График гистограммы показывает усредненное±SE для уровней секретируемой hGAA, происходящих из трех различных экспериментов. Статистический анализ выполняли посредством парного критерия Стьюдента, на гистограмме приведены полученные p-значения (*=p<0,05, как указано). Часть B. Клетки гепатомы человека (Huh7) трансфицировали с использованием липофектамина и контрольной плазмиды, экспрессирующей GFP, или плазмид, экспрессирующих hGAAco1 с сигнальным пептидом дикого типа или сигнального пептида химотрипсиногена B1 (sp7). Белок hGAA усекали посредством удаления 8 или 42 аминокислот после сигнального пептида (Δ8 и Δ42, соответственно). Через 48 часов после трансфекции, активность hGAA в средах для культивирования измеряли посредством флуорогенного ферментативного анализа, как указано выше. График гистограммы показывает усредненное±SE для уровней секретируемой hGAA, происходящих из трех различных экспериментов. Статистический анализ выполняли посредством ANOVA (*=p<0,05, как указано).
Фиг. 2. Делеция частей hGAA увеличивает ее секрецию в кровоток в модели болезни Помпе на мышах. В возрасте 3 месяцев GAA-/- мышам (n=4-5 мышей/группа) внутривенно инъецировали PBS или 2E12 вг/кг AAV8 векторов, экспрессирующих hGAA с оптимизированной последовательностью (hGAAco1) под транскрипционным управлением специфического промотора печени. Сигнальный пептид дикого типа из hGAA заменяли на сигнальный пептид химотрипсиногена B1 (sp7), а последовательность hGAA использовали в качестве полноразмерной нативной последовательности или усеченной посредством удаления 8 или 42 аминокислот после сигнального пептида (Δ8 и Δ42, соответственно). Через один месяц после инъекции у мышей брали кровь и измеряли активность hGAA с использованием флуорогенного анализа в сыворотке. Статистический анализ осуществляли посредством ANOVA (*=p<0,05, как указано).
Фиг. 3. Сигнальные пептиды усиливают секрецию hGAA. Клетки гепатомы человека (Huh7) трансфицировали с использованием LipofectamineTM и контрольной плазмиды (GFP), плазмиды, экспрессирующей hGAA дикого типа (обозначено как sp1), или плазмид, экспрессирующих Δ8 hGAA (hGAAco) с оптимизированной последовательностью, слитую с сигнальными пептидами 6-8 (sp6-8). Через 48 часов после трансфекции активность hGAA в средах для культивирования измеряли посредством флуорогенного ферментативного анализа, и активность GAA оценивали по калибровочной кривой для 4-метилумбеллиферона. График гистограммы показывает усредненное±SE для уровней секретируемой hGAA, происходящих из трех различных экспериментов. Статистический анализ выполняли посредством ANOVA (*=p<0,05 в сравнении с клетками с имитированной трансфекцией).
Фиг. 4. Усеченная Δ8 hGAA эффективно корректирует накопление гликогена в модели болезни Помпе на мышах. В возрасте 4 месяцев мышам дикого типа (WT) и GAA-/- мышам (n=4-5 мышей/группа) внутривенно инъецировали PBS или 6E11 вг/кг AAV8 векторов, экспрессирующих Δ8 hGAA (hGAAco) с оптимизированной последовательностью под транскрипционным управлением промотора α-1-антитрипсина человека и слитую с сигнальным пептидом 1, 2, 7 и 8 (sp1, 2, 7, 8). Часть A. Гистограмма показывает активность hGAA, измеряемую посредством флуорогенного анализа в крови через 3 месяца после инъекции векторов. Статистический анализ выполняли посредством ANOVA, на гистограмме приведены полученные p-значения в сравнении с GAA-/- животными, которых лечили PBS (*=p<0,05). Часть B-D. Биохимическая коррекция содержания гликогена в сердце, диафрагме и квадрицепсе. В возрасте 4 месяцев GAA-/- мышей лечили как описано выше. Через 3 месяца после инъекций мышей умерщвляли и оценивали содержание гликогена. Гистограммы показывают содержание гликогена, выражаемое в виде глюкозы, высвобождаемой после ферментативного расщепления гликогена, измеряемого в сердце (часть B), диафрагме (часть C) и квадрицепсе (часть D). Статистический анализ выполняли посредством ANOVA (*=p<0,05 в сравнении с GAA-/- мышами, которым инъецировали PBS).
Фиг. 5. Высоко секретируемая hGAA снижает гуморальный ответ в модели болезни Помпе на мышах. В возрасте 4 месяцев GAA-/- мышам внутривенно инъецировали PBS или две различные дозы (5E11 или 2E12 вг/кг) AAV8 векторов, содержащих оптимизированную последовательность под транскрипционным управлением промотора α-1-антитрипсина человека, которые кодируют Δ8 hGAA, слитой с сигнальным пептидом 1 (co), сигнальным пептидом 2 (sp2-Δ8-co), сигнальным пептидом 7 (sp7-Δ8-co) или сигнальным пептидом 8 (sp8-Δ8-co). Через 1 месяц после инъекций, сыворотки анализировали на присутствие антител против hGAA посредством ELISA. Количественное определение выполняли с использованием очищенного IgG мыши в качестве стандарта. Статистический анализ выполняли посредством ANOVA с использованием апостериорного критерия Даннета (*=p<0,01).
Фиг. 6. Инъекция AAV8-hAAT-sp7-Δ8-hGAAco1 ведет к эффективной секреции hGAA в крови и захвату в мышце у NHP. Двум обезьянам Macaca fascicularis в сутки 0 инъецировали 2E12 вг/кг AAV8-hAAT-sp7-Δ8-hGAAco1. Часть A. Выполняли вестерн-блоттинг hGAA в сыворотке от двух обезьян, которую получали за 12 суток до и через 30 суток после введения вектора. Слева показаны положения полос маркера молекулярной массы, идущего параллельно с образцами. Часть B. Через 3 месяца после инъекции вектора обезьян умерщвляли и собирали ткани для биохимической оценки захвата hGAA. Вестерн-блоттинг hGAA осуществляли в экстрактах тканей, полученных из бицепса и диафрагмы. Антитело против тубулина использовали в качестве контроля загрузки. Слева показаны положения полос маркера молекулярной массы, идущего параллельно с образцами.
Фиг. 7. Биохимическая коррекция содержания гликогена в печени GDE-/- животных, которым инъецировали экспрессирующий hGAA вектор. В возрасте 3 месяцев мышам дикого типа (WT) или GDE-/- мышам внутривенно инъецировали PBS или AAV8 векторы, экспрессирующие hGAA с оптимизированными кодонами под транскрипционным управлением промотора α-1-антитрипсина человека и слитую с сигнальным пептидом 7 (AAV8-hAAT-sp7-Δ8-hGAAco1) в дозе 1E11 или 1E12 вг/мышь. График гистограммы показывает содержание гликогена, выражаемое в виде глюкозы, высвобождаемой после ферментативного расщепления гликогена, измеряемого в печени. Статистический анализ осуществляли посредством ANOVA (*=p<0,05 в сравнении с GDE-/- мышами, которым инъецировали PBS, =p<0,05 в сравнении с животными WT, которым инъецировали PBS).
Фиг. 8. Активность GAA в средах клеток, трансфицированных плазмидами, кодирующими различные варианты GAA. Активность GAA измеряли в средах клеток HuH7 через 24 (часть A) и 48 (часть B) часов после трансфекции плазмидами, содержащими оптимизированные последовательности, кодирующие нативную GAA, комбинированную с нативным сигнальным пептидом sp1 GAA (co), или кодирующие сконструированную GAA, содержащую нативную GAA, комбинированную с гетерологичным сигнальным пептидом sp7 (sp7-co). Оценивали эффект различных делеций в кодирующей последовательности GAA после сигнального пептида sp7 (sp7-Δ8-co, sp7-Δ29-co, sp7-Δ42-co, sp7-Δ43-co, sp7-Δ47-co, sp7-Δ62-co). Плазмиду, кодирующую eGFP, использовали в качестве отрицательного контроля. Статистический анализ осуществляли посредством однофакторного дисперсионного анализа с апостериорным критерием Тьюки. Знак диез (#) в столбцах обозначает статистически значимые различия в сравнении с co; символ тау (τ) обозначает статистически значимые различия в сравнении с sp7-Δ8-co, sp7-Δ29-co, sp7-Δ42-co, sp7-Δ43-co. Данные представляют собой усредненное±SD для двух независимых экспериментов. *p<0,05, **p<0,01, ***p<0,001, ****p<0,0001, за исключением использования различных символов.
Фиг. 9. Внутриклеточная активность GAA различных вариантов GAA. Активность GAA измеряли в лизатах клеток HuH7 через 48 часов после трансфекции плазмидами, содержащими оптимизированные последовательности, кодирующие нативную GAA, комбинированную с нативным сигнальным пептидом sp1 GAA (co), или кодирующие сконструированную GAA, содержащую нативную GAA, комбинированную с гетерологичным сигнальным пептидом sp7 (sp7-co). Оценивали эффект различных делеций в кодирующей последовательности GAA после сигнального пептида (sp7-Δ8-co, sp7-Δ29-co, sp7-Δ42-co, sp7-Δ43-co, sp7-Δ47-co, sp7-Δ62-co). Плазмиду, кодирующую eGFP, использовали в качестве отрицательного контроля. Статистический анализ осуществляли посредством однофакторного дисперсионного анализа с апостериорным критерием Тьюки. Символ тау (τ) обозначает статистически значимые различия в сравнении с sp7-co, sp7-Δ8-co, sp7-Δ29-co, sp7-Δ42-co, sp7-Δ43-co. Данные представляют собой усредненное±SD для двух независимых экспериментов. *p<0,05, **p<0,01, ***p<0,001, ****p<0,0001, за исключением использования различных символов.
Фиг. 10. Увеличенная активность GAA в средах клеток при использовании делеции Δ8, комбинированной с сигнальными пептидами sp6 или sp8. Активность GAA измеряли в средах (часть A) и лизатах (часть B) клеток HuH7 через 48 часов после трансфекции плазмидами, содержащими оптимизированные последовательности, кодирующие нативную GAA, комбинированную с нативным сигнальным пептидом sp1 GAA (co), или кодирующие сконструированную GAA, содержащую нативную GAA, комбинированную с гетерологичным сигнальным пептидом sp6 или sp8 (sp6-co или sp8-co). Оценивали эффект делеции 8 аминокислот в кодирующей последовательности GAA после сигнального пептида (sp6-Δ8-co, sp8-Δ8-co). Плазмиду, кодирующую eGFP, использовали в качестве отрицательного контроля. Статистический анализ осуществляли посредством однофакторного дисперсионного анализа с апостериорным критерием Тьюки. Звездочки в столбцах обозначают статистически значимые различия в сравнении с co. Данные представляют собой усредненное±SD для двух независимых экспериментов. *p<0,05, **p<0,01, ***p<0,001, ****p<0,0001, за исключением использования различных символов.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к усеченному полипептиду GAA, к молекуле нуклеиновой кислоты, кодирующей такой усеченный полипептид GAA, к конструкции нуклеиновой кислоты, содержащей указанную нуклеиновую кислоту, к вектору, содержащему указанную конструкцию нуклеиновой кислоты, к клетке, содержащей указанную молекулу нуклеиновой кислоты или конструкцию или вектор, и к фармацевтической композиции, содержащей полипептид, молекулу нуклеиновой кислоты, конструкцию нуклеиновой кислоты, вектору или клетку в соответствии с изобретением. Авторы изобретения к удивлению показали, что усеченная форма GAA в соответствии с изобретением значительно усовершенствует секрецию GAA, при этом снижая ее иммуногенность.
Лизосомная кислая α-глюкозидаза или «GAA» (E.C. 3.2.1.20) (1,4-α-D-глюканглюкогидролаза) представляет собой экзо-1,4-α-D-глюкозидазу, которая гидролизует как α-1,4, так и α-1,6 связи в олигосахаридах для того, чтобы высвобождать глюкозу. Недостаточность GAA ведет к болезни накопления гликогена II типа (GSDII), также обозначаемой как болезнь Помпе (несмотря на то, что этот термин формально относится к форме заболевания с детским началом). Она катализирует полное разрушение гликогена с замедлением в точках ветвления. ген кислой α-глюкозидазы человека в 28 т. о. на хромосоме 17 кодирует мРНК в 3,6 т. о., которая продуцирует полипептид из 951 аминокислот (Hoefsloot et al., (1988) EMBO J. 7: 1697; Martiniuk et al., (1990) DNA and Cell Biology 9: 85). Фермент допускает котрансляционное N-связанное гликозилирование в эндоплазматическом ретикулуме. Он синтезируются в виде формы предшественника 110 кДа, которая созревает путем обширной модификации гликозилирования, фосфорилирования и путем протеолитического процессинга через эндосомальную промежуточную структуру приблизительно 90 кДа до конечных лизосомных форм 76 и 67 кДа (Hoefsloot, (1988) EMBO J. 7: 1697; Hoefsloot et al., (1990) Biochem. J. 272: 485; Wisselaar et al., (1993) J. Biol. Chem. 268: 2223; Hermans et al., (1993) Biochem. J. 289: 681).
У пациентов с GSDII недостаточность кислой α-глюкозидазы вызывает массовое накопление гликогена в лизосомах, нарушая клеточную функцию (Hirschhorn, R. and Reuser, A. J. (2001), The Metabolic and Molecular Basis for Inherited Disease, (ред. Scriver, C. R. et al.), стр. 3389-3419 (McGraw-Hill, New York). При наиболее распространенной детской форме пациенты демонстрируют нарастающую дегенерацию мышц и кардиомиопатию и погибают до достижения возраста в два года. В формах с ювенильным и взрослым началом имеет место тяжелое истощение.
Кроме того, пациенты, имеющие другие GSD, могут получать пользу от введения оптимизированной формы GAA. Например, показано (Sun et al. (2013) Mol Genet Metab 108(2): 145; WO2010/005565), что введение GAA снижает гликоген в первичных миобластах у пациентов с болезнью накопления гликогена III типа (GSDIII).
В частности, в контексте настоящего изобретения, «форма предшественника GAA» представляет собой форму полипептида GAA, которая содержит ее природный сигнальный пептид. Например, последовательность из SEQ ID NO: 2 представляет собой форму предшественника GAA человека (hGAA). В SEQ ID NO: 2 аминокислотные остатки 1-27 соответствуют сигнальному пептиду из полипептида hGAA. Эта последовательность сигнального пептида hGAA также представлена в SEQ ID NO: 4.
В контексте настоящего изобретения, усеченный полипептид GAA по изобретению происходит из родительского полипептида GAA. В соответствии с настоящим изобретением, «родительский полипептид GAA» представляет собой функциональную последовательность предшественника GAA, как определено выше, но свободную от ее сигнального пептида. Например, со ссылкой на типичный полипептид GAA человека дикого типа, полный полипептид GAA дикого типа (т. е. форма предшественника GAA) представлен в SEQ ID NO: 2 или в SEQ ID NO: 30 и имеет сигнальный пептид (соответствующий аминокислотам 1-27 из SEQ ID NO: 2 или SEQ ID NO: 30), тогда как родительский полипептид GAA, служащий в качестве основы для усеченных форм GAA этих полипептидов GAA человека дикого типа, представлены в SEQ ID NO: 1 и SEQ ID NO: 33, соответственно, и не имеют сигнального пептида. В этом примере, последнее, соответствующее аминокислотам 28-952 из SEQ ID NO: 2 и аминокислотам 28-952 из SEQ ID NO: 30, обозначают как родительский полипептид GAA.
В соответствии с изобретением, усеченный полипептид GAA по изобретению представляет собой функциональный полипептид GAA, т. е. он обладает функциональностью полипептида GAA дикого типа. Как определено выше, функциональность GAA дикого типа состоит в том, чтобы гидролизовать как α-1,4, так и α-1,6 связи олигосахаридов и полисахаридов, более конкретно гликогена, чтобы высвобождать глюкозу. Функциональный белок GAA, кодируемый нуклеиновой кислотой по изобретению, может иметь гидролитическую активность в отношении гликогена по меньшей мере 50%, 60%, 70%, 80%, 90%, 95%, 99% или по меньшей мере 100% по сравнению с полипептидом GAA дикого типа из SEQ ID NO: 1 или SEQ ID NO: 33. Активность белка GAA кодируемого нуклеиновой кислотой по изобретению даже может быть больше чем 100%, например, больше чем 110%, 120%, 130%, 140% или даже больше чем 150% от активности белка GAA дикого типа из SEQ ID NO: 1 или из SEQ ID NO: 33.
Аминокислотная последовательность родительского полипептида GAA или ее кодирующая последовательность могут происходить из любого источника, в том числе биологических видов птиц и млекопитающих. Термин «птицы», как используют в настоящем описании, включает, но не ограничиваясь этим, курицу, утку, гуся, перепелку, индюшку и фазана. Термин «млекопитающее», как используют в настоящем описании, включает, но не ограничиваясь этим, человека, обезьянообразных и других не являющиеся человеком приматов, корову, овцу, козу, лошадь, кошку, собаку, зайцеобразных и т. д. В вариантах осуществления изобретения, родительский полипептид GAA представляет собой полипептид GAA человека, мыши или перепелки, в частности человека.
Кроме того, родительский полипептид GAA может представлять собой функциональный вариант полипептида GAA, который содержит одну или несколько аминокислотных модификаций, таких как аминокислотная инсерция, делеция и/или замена по сравнению с полипептидом GAA. Например, родительский полипептид может представлять собой функциональное производное полипептида GAA человека, такого как полипептид из SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, обладающее по меньшей мере 80, 85, 90, 95, 96, 97, 98 или по меньшей мере 99% идентичностью последовательностей с этим полипептидом GAA человека. Например, в дополнение к усечению, которое определено выше, функциональный вариант полипептида GAA может иметь между 0 и 50, между 0 и 30, между 0 и 20, между 0 и 15, между 0 и 10 или между 0 и 5 аминокислотными изменениями в родительском полипептиде GAA, таком как родительский полипептид GAA, приведенный в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1. В частности, родительский полипептид GAA может состоять из полипептида GAA человека, имеющего аминокислотную последовательность, приведенную в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1.
Термин «идентичный» и его производные относятся к идентичности последовательностей между двумя молекулами нуклеиновой кислоты. Когда положение в обеих из двух сравниваемых последовательностей занимает одно и то же основание, например, если положение в каждой из двух молекул ДНК занимает аденин, то молекулы идентичны в этом положении. % идентичности между двумя последовательностями представляет собой функцию числа совпадающих положений, которыми обладают две последовательности, деленного на число сравниваемых положений, × 100. Например, если 6 из 10 положений в двух последовательностях совпадают, то две последовательности идентичны на 60%. В целом, сравнение выполняют, когда две последовательности выровнены для того, чтобы давать максимальную идентичность. Различные биоинформационные инструменты, известные специалисту в данной области, можно использовать для выравнивания последовательностей нуклеиновой кислоты, например, BLAST или FASTA.
Родительский полипептид GAA также может представлять собой вариант GAA, такой как GAA II, как описано Kunita et al., (1997) Biochemica et Biophysica Acta 1362: 269; полиморфизмы и SNP в GAA описаны Hirschhorn, R. and Reuser, A. J. (2001), The Metabolic and Molecular Basis for Inherited Disease (ред. Scriver, C. R., Beaudet, A. L., Sly, W. S. и Valle, D.), стр. 3389-3419. McGraw-Hill, New York, см. стр. 3403-3405. Любой вариант полипептида GAA, известный в данной области, можно использовать в качестве основы для определения родительского полипептида GAA. Иллюстративные варианты полипептидов GAA включают SEQ ID NO: 2 (эталонная последовательность NCBI NP_000143.2); SEQ ID NO: 29 (GenBank AAA52506.1); SEQ ID NO: 30 (GenBank CAA68763.1); SEQ ID NO: 31 (GenBank: EAW89583.1) и SEQ ID NO: 32 (GenBank ABI53718.1). Другие эффективные варианты включают те, которые описаны в Hoefsloot et al., (1988) EMBO J. 7: 1697; и Van Hove et al., (1996) Proc. Natl. Acad. Sci. USA 93: 65 (человек), и номер доступа Genbank NM_008064 (мышь). Другие варианты полипептидов GAA включают те, которые описаны в WO2012/145644, WO00/34451 и US6858425. В конкретном варианте осуществления родительский полипептид GAA происходит от аминокислотной последовательности, приведенной в SEQ ID NO: 2 или SEQ ID NO: 30.
Усеченная форма GAA в соответствии с изобретением представляет собой усеченную по N-концу форму родительского полипептида GAA, в которой по меньшей мере одна аминокислота удалена с N-конца указанного родительского полипептида GAA.
Под «усеченной формой» понимают полипептид GAA, который содержит одну или несколько последовательных аминокислот, удаленных из N-концевой части родительского полипептида GAA. Например, фрагмент GAA может иметь от 1 до 75 последовательных аминокислот или больше чем 75 последовательных аминокислот, усеченных с ее N-конца, по сравнению с родительским полипептидом GAA. В частности, усеченный полипептид GAA может иметь 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74 или 75 последовательных аминокислот, усеченных с ее N-конца по сравнению с родительским белком GAA (в частности, усеченная форма родительского белка hGAA, приведенная в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1). Используя альтернативную номенклатуру, полипептид GAA в результате усечения 1 аминокислоты в родительском полипептиде GAA обозначают как Δ1 усеченную форму GAA, полипептид GAA в результате усечения 2 последовательных аминокислот с N-конца обозначают как Δ2 усеченную форму GAA, полипептид GAA в результате усечения 3 последовательных аминокислот в родительском полипептиде GAA обозначают как Δ3 усеченную форму GAA) и т. д. В конкретном варианте осуществления усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42, Δ43, Δ44, Δ45, Δ46, Δ47, Δ48, Δ49, Δ50, Δ51, Δ52, Δ53, Δ54, Δ55, Δ56, Δ57, Δ58, Δ59, Δ60, Δ61, Δ62, Δ63, Δ64, Δ65, Δ66, Δ67, Δ68, Δ69, Δ70, Δ71, Δ72, Δ73, Δ74 или Δ75 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В другом конкретном варианте осуществления усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42, Δ43, Δ44, Δ45, Δ46 или Δ47 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В другом конкретном варианте осуществления усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42, Δ43, Δ44, Δ45 или Δ46 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В другом конкретном варианте осуществления усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42, Δ43, Δ44 или Δ45 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42, Δ43 или Δ44 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41 или Δ42 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA (в частности усеченную форму родительского белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ6, Δ7, Δ8, Δ9 или Δ10 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1), в частности Δ7, Δ8 или Δ9 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1), более конкретно Δ8 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ27, Δ28, Δ29, Δ30 или Δ31 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, конкретно в SEQ ID NO: 1), в частности Δ28, Δ29 или Δ30 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1), более конкретно Δ29 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, конкретно в SEQ ID NO: 1).
В другом конкретном варианте осуществления усеченный полипептид GAA по изобретению представляет собой Δ40, Δ41, Δ42, Δ43, или Δ44 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, конкретно в SEQ ID NO: 1), в частности Δ41, Δ42 или Δ43 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1), более конкретно Δ42 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, конкретно в SEQ ID NO: 1).
В дополнительном конкретном варианте осуществления, усеченный полипептид GAA по изобретению представляет собой Δ41, Δ42, Δ43, Δ44 или Δ45 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1), в частности Δ42, Δ43 или Δ44 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1), более конкретно Δ43 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1).
В другом варианте осуществления усеченный полипептид GAA по изобретению представляет собой Δ6, Δ7, Δ8, Δ9, Δ10, Δ27, Δ28, Δ29, Δ30, Δ31, Δ40, Δ41, Δ42, Δ43, Δ44, Δ45, Δ46 или Δ47 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, конкретно в SEQ ID NO: 1).
В другом варианте осуществления усеченный полипептид GAA по изобретению представляет собой Δ7, Δ8, Δ9, Δ28, Δ29, Δ30, Δ41, Δ42, Δ43 или Δ44 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, конкретно в SEQ ID NO: 1).
В другом варианте осуществления усеченный полипептид GAA по изобретению представляет собой Δ6, Δ7, Δ8, Δ9, Δ10, Δ40, Δ41, Δ42, Δ43 или Δ44, усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, конкретно в SEQ ID NO: 1).
В другом варианте осуществления усеченный полипептид GAA по изобретению представляет собой Δ8, Δ29, Δ42, Δ43 или Δ47 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, конкретно в SEQ ID NO: 1).
В другом варианте осуществления усеченный полипептид GAA по изобретению представляет собой Δ8, Δ29, Δ42 или Δ43 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, конкретно в SEQ ID NO: 1).
В другом варианте осуществления усеченный полипептид GAA по изобретению представляет собой Δ8 или Δ42 усеченную форму GAA (в частности белка hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, конкретно в SEQ ID NO: 1).
В конкретном варианте осуществления изобретения, усеченный полипептид GAA по изобретению представляет собой усеченную форму функционального полипептида GAA человека. В дополнительном конкретном варианте осуществления, родительский полипептид hGAA представляет собой полипептид hGAA, приведенный в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1. В варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42, Δ43, Δ44, Δ45, Δ46, Δ47, Δ48, Δ49, Δ50, Δ51, Δ52, Δ53, Δ54, Δ55, Δ56, Δ57, Δ58, Δ59, Δ60, Δ61, Δ62, Δ63, Δ64, Δ65, Δ66, Δ67, Δ68, Δ69, Δ70, Δ71, Δ72, Δ73, Δ74 или Δ75 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42, Δ43, Δ44, Δ45, Δ46 или Δ47 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42, Δ43, Δ44, Δ45 или Δ46 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42, Δ43, Δ44 или Δ45 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42, Δ43 или Δ44 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ1, Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41 или Δ42 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41 или Δ42 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41 или Δ42 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41 или Δ42 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41 или Δ42 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41 или Δ42 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41 или Δ42 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41 или Δ42 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ2, Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ3, Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ4, Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ5, Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ6, Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ7, Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ8, Δ9, Δ10, Δ11, Δ12, Δ13, Δ14, Δ15, Δ16, Δ17, Δ18, Δ19, Δ20, Δ21, Δ22, Δ23, Δ24, Δ25, Δ26, Δ27, Δ28, Δ29, Δ30, Δ31, Δ32, Δ33, Δ34, Δ35, Δ36, Δ37, Δ38, Δ39, Δ40, Δ41, Δ42 или Δ43 усеченную форму GAA полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, даже более конкретно в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, и обладающего по меньшей мере 75, 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 SEQ ID NO: 33, в частности SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ6, Δ7, Δ8, Δ9 или Δ10, в частности Δ7, Δ8 или Δ9, более конкретно Δ8 усеченную форму полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, и обладающего по меньшей мере 80, 85, 90, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ27, Δ28, Δ29, Δ30 или Δ31, в частности Δ28, Δ29 или Δ30, более конкретно Δ29 усеченную форму полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, и обладающего по меньшей мере 80, 85, 90, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ40, Δ41, Δ42, Δ43 или Δ44, в частности Δ41, Δ42 или Δ43, более конкретно Δ42 усеченную форму полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, и обладающего по меньшей мере 80, 85, 90, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ41, Δ42, Δ43, Δ44 или Δ45, в частности Δ42, Δ43 или Δ44, более конкретно Δ43 усеченную форму полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, и обладающего по меньшей мере 80, 85, 90, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ6, Δ7, Δ8, Δ9, Δ10, Δ27, Δ28, Δ29, Δ30, Δ31, Δ40, Δ41, Δ42, Δ43, Δ44 или Δ45, в частности Δ7, Δ8, Δ9, Δ28, Δ29, Δ30, Δ41, Δ42, Δ43 или Δ44, в частности Δ8, Δ29, Δ42 или Δ43 усеченную форму полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, и обладающего по меньшей мере 80, 85, 90, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ6, Δ7, Δ8, Δ9, Δ10, Δ40, Δ41, Δ42, Δ43 или Δ44, в частности Δ8 или Δ42 усеченную форму полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, и обладающего по меньшей мере 80, 85, 90, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ8, Δ29, Δ42, Δ43 или Δ47 усеченную форму полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, и обладающего по меньшей мере 80, 85, 90, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ8, Δ29, Δ42 или Δ43 усеченную форму полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, и обладающего по меньшей мере 80, 85, 90, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1.
В другом варианте по этому варианту осуществления, усеченный полипептид GAA по изобретению представляет собой Δ8 или Δ42 усеченную форму полипептида hGAA, и более конкретно полипептида hGAA, приведенного в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, или его функционального варианта, содержащего замены аминокислот в последовательности, приведенной в SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1, и обладающего по меньшей мере 80, 85, 90, 95, 96, 97, 98 или 99% идентичностью с SEQ ID NO: 1 или SEQ ID NO: 33, в частности в SEQ ID NO: 1.
В конкретном варианте осуществления усеченный полипептид hGAA по изобретению имеет аминокислотную последовательность, состоящую из последовательности, приведенной в SEQ ID NO: 27, SEQ ID NO: 28, SEQ ID NO: 34, SEQ ID NO: 35 или SEQ ID NO: 36, или ее функциональный вариант, содержащий от 1 до 5, в частности от 1 до 4, в частности от 1 до 3, более конкретно от 1 до 2, в частности 1 замену аминокислоты, по сравнению с последовательностью, приведенной в SEQ ID NO: 27, SEQ ID NO: 28, SEQ ID NO: 34, SEQ ID NO: 35 или SEQ ID NO: 36. В другом конкретном варианте осуществления, усеченный полипептид hGAA по изобретению имеет аминокислотную последовательность, состоящую из последовательности, приведенной в SEQ ID NO: 27, SEQ ID NO: 28, SEQ ID NO: 34 или SEQ ID NO: 35, или ее функциональный вариант, содержащий от 1 до 5 замен аминокислот по сравнению с последовательностью, приведенной в SEQ ID NO: 27, SEQ ID NO: 28, SEQ ID NO: 34 или SEQ ID NO: 35. В конкретном варианте осуществления усеченный полипептид hGAA по изобретению имеет аминокислотную последовательность, состоящую из последовательности, приведенной в SEQ ID NO: 27 или SEQ ID NO: 28, или ее функциональный вариант, содержащий от 1 до 5, в частности от 1 до 4, в частности от 1 до 3, более конкретно от 1 до 2, в частности 1 замену аминокислоты, по сравнению с последовательностью, приведенной в SEQ ID NO: 27 или SEQ ID NO: 28.
Усеченный полипептид GAA в соответствии с изобретением дополнительно может содержать сигнальный пептид, такой как природный сигнальный пептид GAA или альтернативный сигнальный пептид, происходящих из другого секретируемого белка. Неограничивающие примеры таких сигнальных пептидов включают те, которые приведены в SEQ ID NO: с 3 до 7. Авторы изобретения к удивлению показали, что слияние усеченного полипептида GAA по изобретению с альтернативным сигнальным пептидом даже дополнительно усиливает его секрецию. Изобретение тем самым предусматривает химерный полипептид GAA, содержащий сигнальный фрагмент и усеченный полипептидный фрагмент GAA, усеченный полипептидный фрагмент GAA представляет собой усеченный полипептид GAA, как определено выше. В конкретном варианте осуществления сигнальный пептид представляет собой природный сигнальный пептид GAA, такой как сигнальный пептид hGAA, приведенный в SEQ ID NO: 4. В другом варианте осуществления сигнальный пептид представляет собой экзогенный (или альтернативный) сигнальный пептид, происходящий из белка, отличного от GAA. В конкретном варианте осуществления альтернативный сигнальный пептид выбирают в группе, состоящей из SEQ ID NO: 3, 5, 6 и 7 или ее функционального производного, как определено далее.
Авторы изобретения показали, что экзогенный сигнальный пептид, слитый с остальной частью белка GAA, увеличивает секрецию получаемого химерного полипептида GAA, по сравнению с соответствующим полипептидом GAA, содержащим свой природный сигнальный пептид. Кроме того, усеченный полипептидный фрагмент GAA также увеличивает секрецию химерного полипептида GAA (включая как сигнальный пептид, так и усеченный полипептид GAA) по сравнению с химерным полипептидом GAA, содержащим тот же сигнальный пептид, слитый с родительским полипептидом GAA.
Конкретные экзогенные сигнальные пептиды, работающие в настоящем изобретении, включают аминокислоты 1-20 из химотрипсиногена B2 (SEQ ID NO: 3), сигнальный пептид α-1-антитрипсина человека (SEQ ID NO: 5), аминокислоты 1-25 из идуронат-2-сульфатазы (SEQ ID NO: 6), и аминокислоты 1-23 из ингибитора протеазы C1 (SEQ ID NO: 7). Сигнальные пептиды из SEQ ID NO: 3 и SEQ ID NO: с 5 до 7 делают возможной более высокую секрецию химерного белка GAA как in vitro, так и in vivo по сравнению с GAA, содержащей ее природный сигнальный пептид. В конкретном варианте осуществления сигнальный пептид имеет последовательность, приведенную в SEQ ID NO: с 3 до 7, или представляет собой ее функциональное производное, т. е. последовательность, содержащую от 1 до 5, в частности от 1 до 4, в частности от 1 до 3, более конкретно от 1 до 2, в частности 1 аминокислотную делецию, инсерцию или замену, по сравнению с последовательностями, приведенными в SEQ ID NO: с 3 до 7, до тех пор, пока получаемая последовательность соответствует функциональному сигнальному пептиду, т. е. сигнальному пептиду, который делает возможной секрецию белка GAA. В конкретном варианте осуществления последовательность фрагмента сигнального пептида состоит из последовательности, выбранной в группе, состоящей из SEQ ID NO: с 3 до 7.
В конкретных вариантах осуществления полипептид GAA по изобретению выбирают из:
- комбинации из SEQ ID NO: 3 с Δ8 усеченной формой GAA, такой как Δ8 усеченная форма hGAA, представленная в SEQ ID NO: 27;
- комбинации из SEQ ID NO: 4 с Δ8 усеченной формой GAA, такой как Δ8 усеченная форма hGAA, представленная в SEQ ID NO: 27;
- комбинации из SEQ ID NO: 5 с Δ8 усеченной формой GAA, такой как Δ8 усеченная форма hGAA, представленная в SEQ ID NO: 27;
- комбинации из SEQ ID NO: 6 с Δ8 усеченной формой GAA, такой как Δ8 усеченная форма hGAA, представленная в SEQ ID NO: 27;
- комбинации из SEQ ID NO: 7 с Δ8 усеченной формой GAA, такой как Δ8 усеченная форма hGAA, представленная в SEQ ID NO: 27;
- комбинации из SEQ ID NO: 3 с Δ29 усеченной формой GAA, такой как Δ29 усеченная форма hGAA, представленная в SEQ ID NO: 34;
- комбинации из SEQ ID NO: 4 с Δ29 усеченной формой GAA, такой как Δ29 усеченная форма hGAA, представленная в SEQ ID NO: 34;
- комбинации из SEQ ID NO: 5 с Δ29 усеченной формой GAA, такой как Δ29 усеченная форма hGAA, представленная в SEQ ID NO: 34;
- комбинация из SEQ ID NO: 6 с Δ29 усеченной формой GAA, такой как Δ29 усеченная форма hGAA, представленная в SEQ ID NO: 34;
- комбинации из SEQ ID NO: 7 с Δ29 усеченной формой GAA, такой как Δ29 усеченная форма hGAA, представленная в SEQ ID NO: 34;
- комбинации из SEQ ID NO: 3 с Δ42 усеченной формой GAA, такой как Δ42 усеченная форма hGAA, представленная в SEQ ID NO: 28;
- комбинации из SEQ ID NO: 4 с Δ42 усеченной формой GAA, такой как Δ42 усеченная форма hGAA, представленная в SEQ ID NO: 28;
- комбинации из SEQ ID NO: 5 с Δ42 усеченной формой GAA, такой как Δ42 усеченная форма hGAA, представленная в SEQ ID NO: 28;
- комбинации из SEQ ID NO: 6 с Δ42 усеченной формой GAA, такой как Δ42 усеченная форма hGAA, представленная в SEQ ID NO: 28;
- комбинации из SEQ ID NO: 7 с Δ42 усеченной формой GAA, такой как Δ42 усеченная форма hGAA, представленная в SEQ ID NO: 28;
- комбинации из SEQ ID NO: 3 с Δ43 усеченной формой GAA, такой как Δ43 усеченная форма hGAA, представленная в SEQ ID NO: 35;
- комбинации из SEQ ID NO: 4 с Δ43 усеченной формой GAA, такой как Δ43 усеченная форма hGAA, представленная в SEQ ID NO: 35;
- комбинации из SEQ ID NO: 5 с Δ43 усеченной формой GAA, такой как Δ43 усеченная форма hGAA, представленная в SEQ ID NO: 35;
- комбинации из SEQ ID NO: 6 с Δ43 усеченной формой GAA, такой как Δ43 усеченная форма hGAA, представленная в SEQ ID NO: 35; и
- комбинации из SEQ ID NO: 7 с Δ43 усеченной формой GAA, такой как Δ43 усеченная форма hGAA, представленная в SEQ ID NO: 35;
- комбинации из SEQ ID NO: 3 с Δ47 усеченной формой GAA, такой как Δ47 усеченная форма hGAA, представленная в SEQ ID NO: 36;
- комбинации из SEQ ID NO: 4 с Δ47 усеченной формой GAA, такой как Δ47 усеченная форма hGAA, представленная в SEQ ID NO: 36;
- комбинации из SEQ ID NO: 5 с Δ47 усеченной формой GAA, такой как Δ47 усеченная форма hGAA, представленная в SEQ ID NO: 36;
- комбинации из SEQ ID NO: 6 с Δ47 усеченной формой GAA, такой как Δ47 усеченная форма hGAA, представленная в SEQ ID NO: 36; и
- комбинации из SEQ ID NO: 7 с Δ47 усеченной формой GAA, такой как Δ47 усеченная форма hGAA, представленная в SEQ ID NO: 36;
или он представляет собой их функциональное производное, обладающее по меньшей мере 90% идентичностью, в частности, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью с получаемой комбинацией последовательностей. В этих вариантах осуществления, как указано выше, фрагмент сигнального пептида может представлять собой последовательность, содержащую от 1 до 5, в частности от 1 до 4, в частности от 1 до 3, более конкретно от 1 до 2, в частности 1 аминокислотную делецию, инсерцию или замену, по сравнению с последовательностями, приведенными в SEQ ID NO: с 3 до 7, до тех пор пока получаемая последовательность соответствует функциональному сигнальному пептиду, т. е. сигнальному пептиду, который допускает секрецию получаемого химерного усеченного белка GAA.
Относительная доля вновь синтезированной GAA, которую секретирует клетка, можно обычным образом определять с помощью известных в данной области способов и как описано в примерах. Секретируемые белки можно обнаруживать путем непосредственного измерения самого белка (например, путем Вестерн-блоттинга) или путем анализа активности белка (например, ферментативный анализ) в клеточной культуральной среде, сыворотке, молоке и т. д.
Специалисты в данной области, кроме того, должны понимать, что усеченный полипептид GAA или химерный полипептид GAA может содержать дополнительные аминокислоты, например, в результате манипуляций с конструкцией нуклеиновой кислоты, таких как добавление участка рестрикции, до тех пор пока эти дополнительные аминокислоты не делают сигнальный пептид или полипептид GAA нефункциональным. Дополнительные аминокислоты могут отщепляться или можно сохраняться в зрелом полипептиде до тех пор, пока сохранение не ведет к нефункциональному полипептиду.
В другом аспекте изобретение относится к молекуле нуклеиновой кислоты, кодирующей усеченный полипептид GAA по изобретению или химерный полипептид GAA по изобретению.
Последовательность молекулы нуклеиновой кислоты по изобретению, кодирующую усеченный GAA, оптимизируют для экспрессии полипептида GAA in vivo. Оптимизация последовательности может включать множество изменений в последовательности нуклеиновой кислоты, в том числе оптимизацию кодонов, увеличение содержания GC, снижение числа островков CpG, снижение числа альтернативных открытых рамок считывания (ARF) и снижение числа участков доноров сплайсинга и акцепторов сплайсинга. По причине вырожденности генетического кода, различные молекулы нуклеиновой кислоты могут кодировать один и тот же белок. Также хорошо известно, что генетические коды различных организмов часто смещены в сторону использования одного из нескольких кодонов, которые кодируют одну и ту же аминокислоту, относительно других. Через оптимизацию кодонов в нуклеотидную последовательность вводят изменения, которые дают преимущество предпочтения кодонов, существующего в заданном клеточном контексте, чтобы экспрессия получаемой нуклеотидной последовательности с оптимизированными кодонами с большей вероятностью происходила в таком заданном клеточном контексте на относительно высоком уровне по сравнению с последовательностью без оптимизированных кодонов. В предпочтительном варианте осуществления изобретения, такая нуклеотидная последовательность с оптимизированной последовательностью, кодирующая усеченную GAA, имеет оптимизацию кодонов для того, чтобы усовершенствовать ее экспрессию в клетках человека по сравнению с нуклеотидными последовательностями без оптимизированных кодонов, кодирующими тот же усеченный белок GAA, например, используя преимущество предпочтения конкретных кодонов у человека.
В конкретном варианте осуществления оптимизированная кодирующая последовательность GAA имеет оптимизированные кодоны и/или имеет повышенное содержание GC и/или имеет сниженное число альтернативных открытых рамок считывания и/или имеет сниженное число участков доноров сплайсинга и/или акцепторов сплайсинга по сравнению с нуклеотидами 82-2859 из кодирующей hGAA дикого типа последовательности из SEQ ID NO: 8. Например, последовательность нуклеиновой кислоты по изобретению ведет к по меньшей мере 2, 3, 4, 5 или 10% увеличению содержания GC в последовательности GAA по сравнению с последовательностью последовательности GAA дикого типа. В конкретном варианте осуществления последовательность нуклеиновой кислоты по изобретению ведет к 2, 3, 4 или, более конкретно, 5% или 10% (в частности 5%) увеличению содержания GC в последовательности GAA по сравнению с последовательность нуклеотидной последовательности GAA дикого типа. В конкретном варианте осуществления последовательность нуклеиновой кислоты по изобретению, кодирующая функциональный полипептид GAA, является «по существу идентичной», то есть приблизительно на 70% идентичной, более предпочтительно приблизительно на 80% идентичной, даже более предпочтительно приблизительно на 90% идентичной, даже более предпочтительно приблизительно на 95% идентичной, даже более предпочтительно приблизительно на 97%, 98% или даже 99% идентичной нуклеотидам 82-2859 из последовательности, приведенной в SEQ ID NO: 8. Как указано выше, в дополнение к содержанию GC и/или числу ARF, оптимизация последовательности также может включать снижение числа островков CpG в последовательности и/или снижение числа участков доноров сплайсинга и акцепторов сплайсинга. Конечно, специалистам в данной области хорошо известно, что оптимизация последовательности представляет собой баланс между всеми этими параметрами, что обозначает, что последовательность можно считать оптимизированной, если по меньшей мере один из вышеуказанных параметров усовершенствован, тогда как один или несколько других параметров нет, до тех пор пока оптимизированная последовательность ведет к усовершенствованию трансгена, такому как усовершенствованная экспрессия и/или сниженный иммунный ответ на трансген in vivo.
Кроме того, адаптивность нуклеотидной последовательности, кодирующей функциональную GAA, к использованию кодонов клетками человека можно выражать в виде коэффициента адаптации кодонов (CAI). Коэффициент адаптации кодонов определяют в настоящем описании как измерение относительной адаптивности к использованию кодонов гена относительно использования кодонов высоко экспрессируемыми генами человека. Относительная адаптивность (w) каждого кодона представляет собой соотношение использования каждого кодона к таковому для наиболее распространенного кодона для одной и той же аминокислоты. CAI определяют как геометрическое среднее этих значений относительной адаптивности. Не синонимические кодоны и терминирующие кодоны (в зависимости от генетического кода) исключают. Значения CAI находятся в диапазоне от 0 до 1, причем более высокие значения указывают на более высокую долю наиболее распространенных кодонов (см. Sharp and Li, 1987, Nucleic Acids Research 15: 1281-1295; также см.: Kim et al, Gen. 1997, 199:293-301; zur Megede et al, Journal of Virology, 2000, 74: 2628-2635). Предпочтительно, молекула нуклеиновой кислоты, кодирующая GAA, имеет CAI по меньшей мере 0,75 (в частности 0,77), 0,8, 0,85, 0,90, 0,92 или 0,94.
Термин «последовательность нуклеиновой кислоты» (или молекула нуклеиновой кислоты) относится к молекуле ДНК или РНК в одно- или двухцепочечной форме, в частности ДНК, кодирующей белок GAA в соответствии с изобретением.
Авторы изобретения обнаружили, что описанный выше усеченный полипептид GAA, при экспрессии с молекулы нуклеиновой кислоты, кодирующей его, обеспечивает к удивлению высокие уровни экспрессии функционального белка GAA как in vitro, так и in vivo по сравнению с кДНК GAA дикого типа. Кроме того, что также показано авторами изобретения, усеченный белок GAA, продуцируемый клетками печени и мышцы, экспрессирующими молекулу нуклеиновой кислоты по изобретению, не индуцирует иммунный ответ. Это обозначает, что эту молекулу нуклеиновой кислоты можно использовать для получения высоких уровней белка GAA, и она обеспечивает терапевтические эффекты, такие как возможность избежать иммуносупрессорного лечения, возможность иммуносупрессорного лечения в низких дозах и возможность повторного введения молекулы нуклеиновой кислоты по изобретению нуждающемуся в этом субъекту. Следовательно, усеченный полипептид GAA по изобретению и молекула нуклеиновой кислоты по изобретению представляют особый интерес в контексте дефицита экспрессии и/или активность GAA или где высокие уровни экспрессии GAA могут улучшать заболевание, например, при болезни накопления гликогена. Конкретно болезнь накопления гликогена может представлять собой GSDI (болезнь Гирке), GSDII (болезнь Помпе), GSDIII (болезнь Кори), GSDIV, GSDV, GSDVI, GSDVII, GSDVIII или летальную врожденную болезнь накопления гликогена в сердце. Более конкретно, болезнь накопления гликогена выбирают в группе, состоящей из GSDI, GSDII и GSDIII, даже более конкретно в группе, состоящей из GSDII и GSDIII. В даже более конкретном варианте осуществления, болезнь накопления гликогена представляет собой GSDII. В частности, молекулы нуклеиновой кислоты по изобретению можно использовать при генной терапии для того, чтобы лечить GAA-дефицитные состояния или другие состояния, ассоциированные с накоплением гликогена, такими как GSDI (болезнь Гирке), GSDII (болезнь Помпе), GSDIII (болезнь Кори), GSDIV, GSDV, GSDVI, GSDVII, GSDVIII и летальная врожденная болезнь накопления гликогена в сердце, более конкретно GSDI, GSDII или GSDIII, даже более конкретно GSDII и GSDIII. В даже более конкретном варианте осуществления, молекулы нуклеиновой кислоты по изобретению можно использовать при генной терапии для того, чтобы лечить GSDII.
В другом варианте осуществления изобретения, часть молекулы нуклеиновой кислоты по изобретению, кодирующей усеченный полипептидный фрагмент GAA, обладает по меньшей мере 75% (например, 77,7%) или по меньшей мере 80% или по меньшей мере 82% (например, 83,1%) идентичностью с соответствующей частью нуклеотидной последовательности, кодирующей SEQ ID NO: 1 или SEQ ID NO: 33, в частности SEQ ID NO: 1, которые представляют собой последовательности полипептидов hGAA дикого типа, свободные от сигнального пептида.
Усеченный фрагмент GAA молекулы нуклеиновой кислоты по изобретению предпочтительно обладает по меньшей мере 85%, более предпочтительно по меньшей мере 90% и даже более предпочтительно по меньшей мере 92% идентичностью, в частности, по меньшей мере 95% идентичностью, например, по меньшей мере 98, 99 или 100% идентичностью с нуклеотидной последовательностью из SEQ ID NO: 10 или 11, которые представляют собой последовательности с оптимизированной последовательностью.
Термин «идентичный» и его производные относятся к идентичности последовательностей между двумя молекулами нуклеиновой кислоты. Когда положение в обеих из двух сравниваемых последовательностей занимает одно и то же основание (например, если положение в каждой из двух молекул ДНК занято аденином), то молекулы идентичны в этом положении. % идентичности между двумя последовательностями представляет собой функцию числа совпадающих положений, которые имеют две последовательности, деленного на число сравниваемых положений, × 100. Например, если совпадает 6 из 10 положений в двух последовательностях, то две последовательности идентичны на 60%. В целом, сравнение выполняют, когда две последовательности выравнивают так, чтобы давать максимальную идентичность. Различные биоинформационные инструменты, известные специалисту в данной области, можно использовать для выравнивания последовательностей нуклеиновой кислоты, например, BLAST или FASTA.
Кроме того, молекула нуклеиновой кислоты по изобретению кодирует функциональный белок GAA, т. е. она кодирует белок GAA человека, который, при экспрессии, обладает функциональностью белка GAA дикого типа. Как определено выше, функциональность GAA дикого типа состоит в том, чтобы гидролизовать как α-1,4, так и α-1,6 связи олигосахаридов и полисахаридов, более конкретно гликогена, чтобы высвобождать глюкозу. Функциональный белок GAA, кодируемый нуклеиновой кислотой по изобретению, может иметь гидролитическую активность в отношении гликогена по меньшей мере 50%, 60%, 70%, 80%, 90%, 95%, 99% или по меньшей мере 100% по сравнению с белком GAA дикого типа из SEQ ID NO: 1, 2, 30 или 33. Активность белка GAA, кодируемого нуклеиновой кислотой по изобретению, даже может составлять больше чем 100%, например, больше чем 110%, 120%, 130%, 140% или даже больше чем 150% от активности белка GAA дикого типа из SEQ ID NO: 1, 2, 30 или 33.
Специалист без труда сможет определять, экспрессирует ли нуклеиновая кислота в соответствии с изобретением функциональный белок GAA. Подходящие способы будут видны специалистам в данной области. Например, один подходящий способ in vitro включает встраивание нуклеиновой кислоты в вектор, такой как плазмида или вирусный вектор, трансфекцию или трансдукцию клеток-хозяев, таких как клетки 293T или HeLa, или других клеток, таких как Huh7, с использованием вектора, и анализ активности GAA. Альтернативно, подходящий способ in vivo включает трансдукцию вектора, содержащего нуклеиновую кислоту, в модели болезни Помпе на мышах или другого нарушения накопления гликогена и анализ функциональной GAA в плазме мыши и присутствия GAA в тканях. Подходящие способы описаны более подробно далее в экспериментальной части.
В конкретном варианте осуществления молекула нуклеиновой кислоты по изобретению содержит последовательность, приведенную в SEQ ID NO: 12 или SEQ ID NO: 13, кодирующую полипептид, имеющий аминокислотную последовательность, приведенную в SEQ ID NO: 27; последовательность, приведенную в SEQ ID NO: 48 или SEQ ID NO: 49, кодирующую полипептид, имеющий аминокислотную последовательность, приведенную в SEQ ID NO: 28; последовательность, приведенную в SEQ ID NO: 50 или SEQ ID NO: 51, кодирующую полипептид, имеющий аминокислотную последовательность, приведенную в SEQ ID NO: 35; или последовательность, приведенную в SEQ ID NO: 52 или SEQ ID NO: 53, кодирующую полипептид, имеющий аминокислотную последовательность, приведенную в SEQ ID NO: 36. В дополнительном варианте осуществления молекула нуклеиновой кислоты по изобретению содержит последовательность, приведенную в SEQ ID NO: 12 или SEQ ID NO: 13, кодирующую полипептид, имеющий аминокислотную последовательность, приведенную в SEQ ID NO: 27; последовательность, приведенную в SEQ ID NO: 48 или SEQ ID NO: 49, кодирующую полипептид, имеющий аминокислотную последовательность, приведенную в SEQ ID NO: 28; или последовательность, приведенную в SEQ ID NO: 50 или SEQ ID NO: 51, кодирующую полипептид, имеющий аминокислотную последовательность, приведенную в SEQ ID NO: 35. В конкретном варианте осуществления молекула нуклеиновой кислоты по изобретению содержит последовательность, приведенную в SEQ ID NO: 12 или SEQ ID NO: 13, кодирующую полипептид, имеющий аминокислотную последовательность, приведенную в SEQ ID NO: 27.
Изобретение также относится к конструкции нуклеиновой кислоты, содержащей молекулу нуклеиновой кислоты по изобретению. Конструкция нуклеиновой кислоты может соответствовать экспрессирующей кассете, содержащей последовательность нуклеиновой кислоты по изобретению, функционально связанную с одной или несколькими управляющими экспрессией последовательностями и/или другими последовательностями, усовершенствующими экспрессию трансгена, и/или последовательностями, усиливающими секрецию кодируемого белка, и/или последовательностями, усиливающими захват кодируемого белка. Как используют в настоящем описании, термин «функционально связанный» относится к связи полинуклеотидных элементов в функциональных отношениях. Нуклеиновая кислота «функционально связана», когда ее помещают в функциональные отношения с другой последовательностью нуклеиновой кислоты. Например, промотор или другая регулирующая транскрипцию последовательность функционально связаны с кодирующей последовательностью, если они влияют на транскрипцию кодирующей последовательности. В данной области известны такие управляющие экспрессией последовательности, например, промоторы, энхансеры (такие как цис-регуляторные модули (CRM)), интроны, сигналы полиА и т. д.
В частности, экспрессирующая кассета может содержать промотор. Промотор может представлять собой универсальный или тканеспецифический промотор, в частности, промотор способен содействовать экспрессии в клетках или тканях, в которых экспрессия GAA желательна, например, в клетках или тканях, в которых экспрессия GAA желательна, у пациентов с дефицитом GAA. В конкретном варианте осуществления промотор представляет собой специфический промотор печени, такой как промотор α-1-антитрипсина (hAAT) (SEQ ID NO: 14), промотор транстиретина, промотор альбумина, промотор тироксинсвязывающего глобулина (TBG), промотор LSP (содержащий последовательность промотора глобулина, связывающего тиреоидный гормон, две копии энхансерной последовательности α1-микроглобулина/бикунина и лидерную последовательность - 34.Ill, C. R., et al. (1997). Optimization of the human factor VIII complementary DNA expression plasmid for gene therapy of hemophilia A. Blood Coag. Fibrinol. 8: S23-S30.) и т. д. Другие эффективные специфические промоторы печени известны в данной области, например, те, которые перечислены в Liver Specific Gene Promoter Database, компилированной Cold Spring Harbor Laboratory (http://rulai.cshl.edu/LSPD/). Предпочтительным промотором в контексте изобретения является промотор hAAT. В другом варианте осуществления промотор представляет собой промотор, управляющий экспрессией в одной ткани или клетке, представляющей интерес, (например, в клетках мышцы), и в клетках печени. Например, в определенной степени, промоторы со специфичностью к клеткам мышцы, такие как промоторы десмина, Spc5-12 и MCK, могут давать некоторую утечку экспрессии в клетки печени, что может быть благоприятно для индукции иммунологической толерантности у субъекта к полипептиду GAA, экспрессируемому с нуклеиновой кислоты по изобретению.
Другие тканеспецифические или не тканеспецифические промоторы можно использовать при практической реализации изобретения. Например, экспрессирующая кассета может содержать тканеспецифический промотор, который представляет собой промотор, отличный от специфического промотора печени. Например, промотор может обладать специфичностью к мышцам, такой как промотор десмина (и вариант промотора десмина, такой как промотор десмина, содержащий природные или искусственные энхансеры), промотор SPc5-12 или MCK. В другом варианте осуществления промотор представляет собой промотор со специфичностью к другой клеточной линии дифференцировки, такой как промотор эритропоэтина, для экспрессии полипептида GAA в клетках эритроидной линии дифференцировки.
В другом варианте осуществления промотор представляет собой универсальный промотор. Репрезентативные универсальные промоторы включают энхансер цитомегаловируса/промотор β-актина курицы (CAG), энхансер/промотор цитомегаловируса (CMV), промотор PGK, ранний промотор SV40 и т. д.
Кроме того, промотор также может представлять собой эндогенный промотор, такой как промотор альбумина или промотор GAA.
В конкретном варианте осуществления промотор ассоциирован с энхансерной последовательностью, такой как цис-регуляторные модули (CRM) или искусственная энхансерная последовательность. Например, промотор может быть ассоциирован с энхансерной последовательностью, такой как управляющая область ApoE человека (или локус гена аполипопротеина E/C-I человека, печеночная управляющая область HCR-1 - номер доступа GenBank U32510, приведена в SEQ ID NO: 15). В конкретном варианте осуществления энхансерная последовательность, такая как последовательность ApoE, ассоциирована со специфическим промотором печени, таким как те, что перечислены выше, и в частности такими, как промотор hAAT. Другие CRM, эффективные при практической реализации настоящего изобретения, включают те, которые описаны в Rincon et al., Mol Ther. 2015 Jan;23(1):43-52, Chuah et al., Mol Ther. 2014 Sep;22(9):1605-13 или Nair et al., Blood. 2014 May 15;123(20):3195-9.
В другом конкретном варианте осуществления конструкция нуклеиновой кислоты содержит интрон, в частности интрон, размещенный между промотором и кодирующей последовательностью GAA. Интрон можно вводить для увеличения стабильности мРНК и продуцирования белка. В дополнительном варианте осуществления конструкция нуклеиновой кислоты содержит интрон β-глобина b2 человека (или HBB2), интрон фактора свертывания IX (FIX), интрон SV40 или интрон β-глобина курицы. В другом дополнительном варианте осуществления, конструкция нуклеиновой кислоты по изобретению содержит модифицированный интрон (в частности, модифицированный интрон HBB2 или FIX), разработанный для уменьшения числа, или даже полного удаления, альтернативных открытых рамок считывания (ARF), найденных в указанном интроне. Предпочтительно, удаляют ARF, длина которых превышает 50 п. о. и которые имеют терминирующий кодон в рамке считывания инициирующего кодона. ARF может быть удалена посредством модификации последовательности интрона. Например, модификацию можно осуществлять посредством нуклеотидной замены, инсерции или делеции, предпочтительно посредством нуклеотидной замены. В качестве иллюстрации, один или несколько нуклеотидов, в частности один нуклеотид, в инициирующем кодоне ATG или GTG, присутствующем в последовательности интрона, представляющего интерес, можно заменить на ведущий к не инициирующему кодону. Например, ATG или GTG можно заменить на CTG, который не является инициирующим кодоном, в последовательности интрона, представляющего интерес.
Классический интрон HBB2, используемый в конструкциях нуклеиновой кислоты, приведен в SEQ ID NO: 16. Например, этот интрон HBB2 можно модифицировать посредством элиминации инициирующих кодонов (кодонов ATG и GTG) в указанном интроне. В конкретном варианте осуществления модифицированный интрон HBB2, содержащийся в конструкции, имеет последовательность, приведенную в SEQ ID NO: 17. Классический интрон FIX, используемый в конструкциях нуклеиновой кислоты, происходит из первого интрона FIX человека и приведен в SEQ ID NO: 18. Интрон FIX можно модифицировать посредством элиминации инициирующих кодонов (кодонов ATG и GTG) в указанном интроне. В конкретном варианте осуществления модифицированный интрон FIX, содержащийся в конструкции по изобретению, имеет последовательность, приведенную в SEQ ID NO: 19. Классический интрон β-глобина курицы, используемый в конструкциях нуклеиновой кислоты, приведен в SEQ ID NO: 20. Интрон β-глобина курицы можно модифицировать посредством элиминации инициирующих кодонов (кодонов ATG и GTG) в указанном интроне. В конкретном варианте осуществления модифицированный интрон β-глобина курицы, содержащийся в конструкции по изобретению, имеет последовательность, приведенную в SEQ ID NO: 21.
Авторы изобретения предварительно показали в WO2015/162302, что такой модифицированный интрон, в частности модифицированный интрон HBB2 или FIX, имеет благоприятные свойства и может значительно усовершенствовать экспрессию трансгена.
В конкретном варианте осуществления конструкция нуклеиновой кислоты по изобретению представляет собой экспрессирующую кассету, содержащую, в ориентации от 5' к 3', промотор, которому необязательно предшествует энхансер, кодирующую последовательность по изобретению (т. е. оптимизированную кодирующую последовательность GAA по изобретению, химерную кодирующую последовательность GAA по изобретению или химерную и оптимизированную кодирующую последовательность GAA по изобретению) и сигнал полиаденилирования (такой как сигнал полиаденилирования бычьего гормона роста, сигнал полиаденилирования SV40 или другой встречаемый в природе или искусственный сигнал полиаденилирования). В конкретном варианте осуществления конструкция нуклеиновой кислоты по изобретению представляет собой экспрессирующую кассету, содержащую, в ориентации от 5' к 3', промотор, которому необязательно предшествует энхансер, (такой как управляющая область ApoE), интрон (в частности, интрон как определено выше), кодирующую последовательность по изобретению и сигнал полиаденилирования. В дополнительном конкретном варианте осуществления, конструкция нуклеиновой кислоты по изобретению представляет собой экспрессирующую кассету, содержащую, в ориентации от 5' к 3', энхансер, такой как управляющая область ApoE, промотор, интрон (в частности, интрон как определено выше), кодирующую последовательность по изобретению и сигнал полиаденилирования. В дополнительном конкретном варианте осуществления изобретения экспрессирующая кассета содержит, в ориентации от 5' к 3', управляющую область ApoE, специфический промотор hAAT печени, интрон HBB2 (в частности, модифицированный интрон HBB2 как определено выше), кодирующую последовательность по изобретению и сигнал полиаденилирования бычьего гормона роста, например, конструкцию, представленную в:
- SEQ ID NO: 22, содержащая не оптимизированную нуклеотидную последовательность, кодирующую Δ8 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 и кодирующую сигнальный пептид из SEQ ID NO: 5;
- SEQ ID NO: 23, содержащая оптимизированную последовательность, кодирующую Δ8 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и кодирующую сигнальный пептид из SEQ ID NO: 5;
- SEQ ID NO: 24, содержащая другую оптимизированную последовательность, кодирующую Δ8 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и кодирующую сигнальный пептид из SEQ ID NO: 5;
- SEQ ID NO: 25, содержащая оптимизированную последовательность, кодирующую Δ8 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и сигнальный пептид из SEQ ID NO: 3;
- SEQ ID NO: 26, содержащая оптимизированную последовательность, кодирующую Δ42 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и сигнальный пептид из SEQ ID NO: 3;
- SEQ ID NO: 37, содержащая не оптимизированную последовательность, кодирующую Δ29 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из не оптимизированной последовательности из SEQ ID NO: 9), и сигнальный пептид из SEQ ID NO: 3;
- SEQ ID NO: 38, содержащая оптимизированную последовательность, кодирующую Δ29 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и сигнальный пептид из SEQ ID NO: 3;
- SEQ ID NO: 39, содержащая другую оптимизированную последовательность, кодирующую Δ29 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и сигнальный пептид из SEQ ID NO: 3;
- SEQ ID NO: 40: содержит не оптимизированную последовательность, кодирующую Δ42 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из не оптимизированной последовательности из SEQ ID NO: 9), и сигнальный пептид из SEQ ID NO: 3;
- SEQ ID NO: 41, содержащая другую оптимизированную последовательность, кодирующую Δ42 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и сигнальный пептид из SEQ ID NO: 3;
- SEQ ID NO: 42, содержащая не оптимизированную последовательность, кодирующую Δ43 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из не оптимизированной последовательности из SEQ ID NO: 9), и сигнальный пептид из SEQ ID NO: 3;
- SEQ ID NO: 43, содержащая оптимизированную последовательность, кодирующую Δ43 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и сигнальный пептид из SEQ ID NO: 3; и
- SEQ ID NO: 44, содержащая другую оптимизированную последовательность, кодирующую Δ43 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и сигнальный пептид из SEQ ID NO: 3;
- SEQ ID NO: 45, содержащая не оптимизированную последовательность, кодирующую Δ47 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из не оптимизированной последовательности из SEQ ID NO: 9), и сигнальный пептид из SEQ ID NO: 3;
- SEQ ID NO: 46, содержащая оптимизированную последовательность, кодирующую Δ47 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и сигнальный пептид из SEQ ID NO: 3; и
- SEQ ID NO: 47, содержащая другую оптимизированную последовательность, кодирующую Δ47 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и сигнальный пептид из SEQ ID NO: 3.
Другие экспрессирующие кассеты по изобретению могут содержать следующие последовательности нуклеиновой кислоты:
- не оптимизированная нуклеотидная последовательность, кодирующая Δ8 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1, и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- не оптимизированная нуклеотидная последовательность, кодирующая Δ29 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1, и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- не оптимизированная нуклеотидная последовательность, кодирующая Δ42 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1, и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- не оптимизированная нуклеотидная последовательность, кодирующая Δ43 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1, и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- не оптимизированная нуклеотидная последовательность, кодирующая Δ47 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1, и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ8 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ8 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ29 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ29 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ42 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ42 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7
- оптимизированная нуклеотидная последовательность, кодирующая Δ43 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ43 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7
- оптимизированная нуклеотидная последовательность, кодирующая Δ47 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ47 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7.
В альтернативных вариантах осуществления этих конкретных конструкций, последовательность, кодирующую SEQ ID NO: 1, заменяют на последовательность, кодирующую SEQ ID NO: 33.
В конкретном варианте осуществления экспрессирующая кассета содержит управляющую область ApoE, специфический промотор hAAT печени, интрон HBB2 с оптимизацией кодонов, кодирующую последовательность по изобретению и сигнал полиаденилирования бычьего гормона роста.
При разработке конструкции нуклеиновой кислоты по изобретению, специалист в данной области уделит внимание ограничению размера вектора, используемого для доставки указанной конструкции в клетку или орган. В частности, специалист в данной области знает, что основное ограничение AAV вектора состоит в его полезной вместимости, которая может варьировать от одного серотипа AAV к другом, но предположительно ограничена приблизительным размером родительского вирусного генома. Например, 5 т. о. Это максимальный размер, который обычно планируют упаковать в капсид AAV8 (Wu Z. et al., Mol Ther., 2010, 18(1): 80-86; Lai Y. et al., Mol Ther., 2010, 18(1): 75-79; Wang Y. et al., Hum Gene Ther Methods, 2012, 23(4): 225-33). Соответственно, специалисты в данной области, при практическом осуществлении настоящего изобретения, уделят внимание тому, чтобы выбирать компоненты конструкции нуклеиновой кислоты по изобретению с тем, чтобы получаемая последовательность нуклеиновой кислоты, в том числе последовательности, кодирующие AAV 5'- и 3'-ITR, предпочтительно не превышала 110% от полезной вместимости внедряемого AAV вектора, в частности, предпочтительно не превышала 5,5 т. о.
Изобретение также относится к вектору, содержащему молекулу нуклеиновой кислоты или конструкцию, как раскрыто в настоящем описании. В частности, вектор по изобретению представляет собой вектор, подходящий для экспрессии белка, предпочтительно для использования в генной терапии. В одном из вариантов осуществления вектор представляет собой плазмидный вектор. В другом варианте осуществления вектор представляет собой наночастицу, содержащую молекулу нуклеиновой кислоты по изобретению, в частности информационную РНК, кодирующую полипептид GAA по изобретению. В другом варианте осуществления вектор представляет собой систему на основе транспозонов, которая делает возможным встраивание молекулы нуклеиновой кислоты или конструкции по изобретению в геном целевой клетки, такой как гиперактивная транспозонная система Sleeping Beauty (SB100X) (Mates et al. 2009). В другом варианте осуществления вектор представляет собой вирусный вектор, подходящий для генной терапии, который направлен на любую клетку, представляющую интерес, такую как ткань или клетки печени, клетка мышцы, клетки CNS (такие как клетки головного мозга) или гематопоэтические стволовые клетки, такие как клетки эритроидной линии дифференцировки (такие как эритроциты). В этом случае, конструкция нуклеиновой кислоты по изобретению также содержит последовательности, подходящие для получения эффективного вирусного вектора, как хорошо известно в данной области. В конкретном варианте осуществления вирусный вектор происходит из интегрирующего вируса. В частности, вирусный вектор может происходить из ретровируса или лентивируса. В дополнительном конкретном варианте осуществления, вирусный вектор представляет собой AAV вектор, такой как AAV вектор, подходящий для трансдукции тканей или клеток печени, более конкретно AAV-1, -2 и варианты AAV-2 (такие как оптимизированный AAV-2 с четверной мутацией капсида, содержащие сконструированный капсид с изменениями Y44+500+730F+T491V, как раскрыто в Ling et al., 2016 Jul 18, Hum Gene Ther Methods [электронная публикация перед печатью]), -3 и варианты AAV-3 (такие как вариант AAV3-ST, содержащий сконструированный капсид AAV3 с двумя аминокислотными изменениями, S663V+T492V, как раскрыто в Vercauteren et al., 2016, Mol. Ther. том 24(6), стр. 1042), -3B и варианты AAV-3B, -4, -5, -6 и варианты AAV-6 (такие как вариант AAV6, содержащий форму капсида AAV6 с тройной мутацией Y731F/Y705F/T492V, как раскрыто в Rosario et al., 2016, Mol Ther Methods Clin Dev. 3, стр. 16026), -7, -8, -9, -10, например, -cy10 и -rh10, -rh74, -dj, Anc80, LK03, AAV2i8, серотипы AAV свиньи, такие как AAVpo4 и AAVpo6 и т. д., вектор или ретровирусный вектор, такой как лентивирусный вектор и альфаретровирус. Как известно в данной области, в зависимости от конкретного вирусного вектора, рассматриваемого для использования, дополнительные подходящие последовательности вводят в конструкцию нуклеиновой кислоты по изобретению для получения функционального вирусного вектора. Подходящие последовательности включают ITR AAV для AAV вектора или LTR для лентивирусных векторов. По существу, изобретение также относится к экспрессирующей кассете, как описано выше, фланкированной с помощью ITR или LTR с каждой стороны.
Преимущества вирусных векторов рассмотрены в следующей части этого раскрытия. Вирусные векторы предпочтительны для доставки молекулы нуклеиновой кислоты или конструкции по изобретению, такой как ретровирусный вектор, например, лентивирусный вектор, или непатогенный парвовирус, более предпочтительно AAV вектор. Парвовирусный аденоассоциированный вирус (AAV) человека представляет собой депендовирус, имеющий природный дефект репликации, который способен встраиваться в геном инфицированной клетки для того, чтобы устанавливать латентную инфекцию. Последнее свойство, по-видимому, является уникальным среди вирусов млекопитающих, поскольку встраивание происходит в конкретном участке в геноме человека, называемом AAVS1, который расположен на хромосоме 19 (19q13.3-qter).
Следовательно, AAV векторы вызывают существенный интерес в качестве потенциальных векторов для генной терапии человека. Среди благоприятных свойств вируса имеют место отсутствие у него связи с любым заболеванием человека, его способность инфицировать делящиеся и не делящиеся клетки, и широкий диапазон клеточных линий, происходящих из различных тканей, которые могут быть инфицированы.
Среди серотипов AAV, выделенных у человека или не являющихся человеком приматов (NHP) и хорошо охарактеризованных, серотип 2 человека представляет собой первый AAV, который разрабатывали в качестве вектора переноса генов. Другие используемые в настоящее время серотипы AAV включают AAV-1, варианты AAV-2 (такие как оптимизированный AAV-2 с четверной мутацией капсида, содержащий сконструированный капсид с изменениями Y44+500+730F+T491V, как раскрыто в Ling et al., 2016 Jul 18, Hum Gene Ther Methods [электронная публикация перед печатью]), -3 и варианты AAV-3 (такие как вариант AAV3-ST, содержащий сконструированный капсид AAV3 с двумя аминокислотными изменениями, S663V+T492V, как раскрыто в Vercauteren et al., 2016, Mol. Ther. том 24(6), стр. 1042), -3B и варианты AAV-3B, -4, -5, -6 и варианты AAV-6 (такие как вариант AAV6, содержащий форму капсида AAV6 с тройной мутацией Y731F/Y705F/T492V, как раскрыто в Rosario et al., 2016, Mol Ther Methods Clin Dev. 3, стр. 16026), -7, -8, -9, -10, например, cy10 и -rh10, -rh74, -dj, Anc80, LK03, AAV2i8, серотипы AAV свиньи, такие как AAVpo4 и AAVpo6, и тирозиновые, лизиновые и сериновые мутантные капсиды серотипов AAV и т. д. Кроме того, другие не природные сконструированные варианты и химерные AAV также могут быть эффективны.
Вирусы AAV можно конструировать с использованием стандартных приемов молекулярной биологии, которые позволяют оптимизировать эти частицы для доставки последовательностей нуклеиновой кислоты в конкретные клетки, для минимизации иммуногенности, для корректировки стабильности и времени жизни частиц, для эффективного разрушения, для точной доставки в ядро.
Желательные фрагменты AAV для сборки в векторы включают белки cap, в том числе vp1, vp2, vp3 и гипервариабельные области, белки rep, в том числе rep 78, rep 68, rep 52 и rep 40, и последовательности, кодирующие эти белки. Эти фрагменты легко можно использовать в различных векторных системах и клетках-хозяевах.
Рекомбинантные векторы на основе AAV, лишенные белка Rep, встраиваются с низким эффектом в геном хозяина и преимущественно представлены в виде стабильных круглых эписом, которые могут персистировать в течение лет в целевых клетках.
Альтернативно использованию природных серотипов AAV, в контексте настоящего изобретения можно использовать искусственные серотипы AAV, в том числе, без ограничения, AAV с не встречаемым в природе белком капсида. Такой искусственный капсид можно создавать с помощью любого подходящего приема, используя выбранную AAV последовательность (например, фрагмент белка капсида vp1) в комбинации с гетерологичными последовательностями, которые можно получать из другого выбранного серотипа AAV, не связанных частей AAV того же серотипа, из не AAV вирусного источника или из не вирусного источника. Искусственный серотип AAV может представлять собой, без ограничения, химерный AAV капсид, рекомбинантный AAV капсид или «гуманизированный» AAV капсид.
Соответственно, настоящее изобретение относится к AAV вектору, содержащему молекулу нуклеиновой кислоты или конструкцию по изобретению. В контексте настоящего изобретения, AAV вектор содержит AAV капсид, способный трансдуцировать целевые клетки, представляющие интерес, в частности, гепатоциты. В соответствии с конкретным вариантом осуществления, AAV вектор относится к AAV-1, -2, вариантам AAV-2 (например, оптимизированный AAV-2 с четверной мутацией капсида, содержащий сконструированный капсид с изменениями Y44+500+730F+T491V, как раскрыто в Ling et al., 2016 Jul 18, Hum Gene Ther Methods [электронная публикация перед печатью]), -3 и варианты AAV-3 (например, вариант AAV3-ST, содержащий сконструированный капсид AAV3 с двумя аминокислотными изменениями, S663V+T492V, как раскрыто в Vercauteren et al., 2016, Mol. Ther. том 24(6), стр. 1042), -3B и варианты AAV-3B, -4, -5, -6 и варианты AAV-6 (например, вариант AAV6, содержащий форму капсида AAV6 с тройной мутацией Y731F/Y705F/T492V, как раскрыто в Rosario et al., 2016, Mol Ther Methods Clin Dev. 3, стр. 16026), -7, -8, -9, -10, например, -cy10 и -rh10, -rh74, -dj, Anc80, LK03, AAV2i8, AAV свиньи, такой как AAVpo4 и AAVpo6, и тирозиновые, лизиновые и сериновые капсидные мутанты серотипов AAV, и т. д., серотип. В конкретном варианте осуществления AAV вектор относится к серотипу AAV8, AAV9, AAVrh74 или AAV2i8 (т. е. AAV вектор имеет капсид серотипа AAV8, AAV9, AAVrh74 или AAV2i8). В дополнительном конкретном варианте осуществления, AAV вектор представляет собой псевдотипированный вектор, т. е. его геном и капсид происходят из AAV различных серотипов. Например, псевдотипированный AAV вектор может представлять собой вектор, геном которого происходит из одного из указанных выше серотипов AAV и капсид которого происходит из другого серотипа. Например, геном псевдотипированного вектора может иметь капсид, происходящий из серотипа AAV8, AAV9, AAVrh74 или AAV2i8, и его геном может происходить из другого серотипа. В конкретном варианте осуществления AAV вектор имеет капсид серотипа AAV8, AAV9 или AAVrh74, в частности серотипа AAV8 или AAV9, более конкретно серотипа AAV8.
В конкретном варианте осуществления, в котором вектор предназначен для использования в доставке трансгена в клетки мышцы, AAV вектор можно выбирать, среди прочих, в группе, состоящей из AAV8, AAV9 и AAVrh74.
В другом конкретном варианте осуществления, в котором вектор предназначен для использования в доставке трансгена в клетки печени, AAV вектор можно выбирать, среди прочих, в группе, состоящей из AAV5, AAV8, AAV9, AAV-LK03, AAV-Anc80 и AAV3B.
В другом варианте осуществления капсид представляет собой модифицированный капсид. В контексте настоящего изобретения, «модифицированный капсид» может представлять собой химерный капсид или капсид, содержащий один или несколько вариантов белков капсида VP, происходящих из одного или нескольких белков капсида VP AAV дикого типа.
В конкретном варианте осуществления AAV вектор представляет собой химерный вектор, т. е. его капсид содержит белки капсида VP, происходящие из по меньшей мере двух различных серотипов AAV, или содержит по меньшей мере один химерный белок VP, объединяющий области или домены белков VP, происходящие из по меньшей мере двух серотипов AAV. Примеры таких химерных AAV векторов, эффективных для трансдукции клеток печени, описаны в Shen et al., Molecular Therapy, 2007 и в Tenney et al., Virology, 2014. Например, химерный AAV вектор может происходить из комбинации последовательности капсида AAV8 с последовательностью серотипа AAV, отличного от серотипа AAV8, такого как любой из тех, что конкретно указаны выше. В другом варианте осуществления капсид AAV вектора содержит один или несколько вариантов белков капсида VP, таких как те, что описаны в WO2015013313, в частности варианты капсида RHM4-1, RHM15-1, RHM15-2, RHM15-3/RHM15-5, RHM15-4 и RHM15-6, которые дают высокий тропизм к печени.
В другом варианте осуществления модифицированный капсид может происходить также из модификаций капсида, вставленных с помощью допускающей ошибки ПЦР и/или инсерции пептида (например, как описано в Bartel et al., 2011). Кроме того, варианты капсида могут содержать изменения одной аминокислоты, такие как тирозиновые мутанты (например, как описано в Zhong et al., 2008)
Кроме того, геном AAV вектора может представлять собой одноцепочечный или самокомплементарный двухцепочечный геном (McCarty et al., Gene Therapy, 2003). Самокомплементарные двухцепочечные AAV векторы создают посредством делеции сайта концевого разрешения (trs) из одного из концевых повторов AAV. Эти модифицированные векторы, реплицирующийся геном которых составляет половину длины от генома AAV дикого типа, обладают склонностью к упаковыванию димеров ДНК. В предпочтительном варианте осуществления AAV вектор, используемый при практической реализации настоящего изобретения, имеет одноцепочечный геном и дополнительно предпочтительно содержит капсид AAV8, AAV9, AAVrh74 или AAV2i8, в частности капсид AAV8, AAV9 или AAVrh74, такой как капсид AAV8 или AAV9, более конкретно капсид AAV8.
В особенно предпочтительном варианте осуществления изобретение относится к AAV вектору, содержащему, в одноцепочечном или двухцепочечном самокомплементарном геноме (например, одноцепочечном геноме), конструкцию нуклеиновой кислоты по изобретению. В одном из вариантов осуществления AAV вектор содержит капсид AAV8, AAV9, AAVrh74 или AAV2i8, в частности капсид AAV8, AAV9 или AAVrh74, такой как капсид AAV8 или AAV9, более конкретно капсид AAV8. В дополнительном конкретном варианте осуществления, указанная нуклеиновая кислота функционально связана с промотором, в частности, универсальным или специфическим промотором печени. В соответствии с вариантом осуществления конкретного варианта, промотор представляет собой универсальный промотор, такой как энхансер цитомегаловируса/промотор β-актина курицы (CAG), энхансер/промотор цитомегаловируса(CMV), промотор PGK и ранний промотор SV40. В конкретном варианте универсальный промотор представляет собой промотор CAG. В соответствии с другим вариантом, промотор представляет собой специфический промотор печени, такой как промотор α-1-антитрипсина (hAAT), промотор транстиретина, промотор альбумина и промотор тироксинсвязывающего глобулина (TBG). В конкретном варианте, специфический промотор печени представляет собой специфический промотор hAAT печени из SEQ ID NO: 14. В дополнительном конкретном варианте осуществления, конструкция нуклеиновой кислоты, содержащаяся в геноме AAV вектора по изобретению, дополнительно содержит интрон, как описано выше, такой как интрон, помещенный между промотором и последовательностью нуклеиновой кислоты, кодирующей кодирующую последовательность GAA (т. е. оптимизированную кодирующую последовательность GAA по изобретению, химерную кодирующую последовательность GAA по изобретению или химерную и оптимизированную кодирующую последовательность GAA по изобретению). Репрезентативные интроны, которые могут быть включены в конструкцию нуклеиновой кислоты, введенную в геном AAV вектора, включают, без ограничения, интрон β-глобина b2 человека (или HBB2), интрон FIX и интрон β-глобина курицы. Указанный интрон в геноме AAV вектора может представлять собой классический (или немодифицированный) интрон или модифицированный интрон, разработанный для снижения числа, или даже полного удаления, альтернативных открытых рамок считывания (ARF) в указанном интроне. Модифицированные и немодифицированные интроны, которые можно использовать при практической реализации этого варианта осуществления, где нуклеиновую кислоту по изобретению вводят в AAV вектор, тщательно описаны выше. В конкретном варианте осуществления AAV вектор, в частности AAV вектор, содержащий капсид AAV8, AAV9, AAVrh74 или AAV2i8, в частности капсид AAV8, AAV9 или AAVrh74, например, капсид AAV8 или AAV9, более конкретно капсид AAV8, по изобретению содержит в своем геноме модифицированный (или оптимизированный) интрон, такой как модифицированный интрон HBB2 из SEQ ID NO: 17, модифицированный интрон FIX из SEQ ID NO: 19 и модифицированный интрон β-глобина курицы из SEQ ID NO: 21. В дополнительном конкретном варианте осуществления, вектор по изобретению представляет собой AAV вектор, содержащий капсид AAV8, AAV9, AAVrh74 или AAV2i8, в частности капсид AAV8, AAV9 или AAVrh74, например, капсид AAV8 или AAV9, более конкретно капсид AAV8, который содержит геном, содержащий, в ориентации от 5' к 3': AAV 5'-ITR (например, AAV2 5'-ITR); управляющую область ApoE; специфический промотор hAAT печени; интрон HBB2 (в частности модифицированный интрон HBB2, как определено выше); кодирующую последовательность GAA по изобретению; сигнал полиаденилирования бычьего гормона роста; и AAV 3'-ITR (например, AAV2 3'-ITR), такой как геном, содержащий конструкцию нуклеиновой кислоты, приведенную в SEQ ID NO: с 22 до 26 и SEQ ID NO: с 37 до 47, фланкированную с помощью AAV 5'-ITR (например, AAV2 5'-ITR) и AAV 3'-ITR (например, AAV2 3'-ITR). Другие конструкции нуклеиновой кислоты, эффективные при практической реализации настоящего изобретения, включают те, которые описаны выше, в том числе:
- не оптимизированная нуклеотидная последовательность, кодирующая Δ8 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1, и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- не оптимизированная нуклеотидная последовательность, кодирующая Δ29 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1, и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- не оптимизированная нуклеотидная последовательность, кодирующая Δ42 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1, и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- не оптимизированная нуклеотидная последовательность, кодирующая Δ43 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1, и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- не оптимизированная нуклеотидная последовательность, кодирующая Δ47 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1, и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7
- оптимизированная нуклеотидная последовательность, кодирующая Δ8 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ8 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ29 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ29 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ42 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и кодирующая сигнальный пептид из SEQ ID NO: 4 или 6;
- оптимизированная нуклеотидная последовательность, кодирующая Δ42 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ43 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ43 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ47 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 12), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7;
- оптимизированная нуклеотидная последовательность, кодирующая Δ47 усеченную форму GAA, происходящую из родительской hGAA из SEQ ID NO: 1 (нуклеотидная последовательность, происходящая из оптимизированной последовательности из SEQ ID NO: 13), и кодирующая сигнальный пептид из SEQ ID NO: 4, 6 или 7.
В альтернативных вариантах осуществления этих конкретных конструкций, последовательность, кодирующую SEQ ID NO: 1, заменяют на последовательность, кодирующую SEQ ID NO: 33.
В конкретном варианте осуществления изобретения, конструкция нуклеиновой кислоты по изобретению содержит специфический промотор печени, как описано выше, и вектор представляет собой вирусный вектор, способный к трансдукции ткани или клеток печени, как описано выше. Авторы изобретения приводят далее данные, показывающие, что протолерогенные и метаболические свойства печени благоприятно реализованы благодаря этому варианту осуществления для разработки высоко эффективных и оптимизированных векторов для экспрессии высоко секретируемых форм GAA в гепатоцитах и индукции иммунологической толерантности на белок.
Кроме того, в дополнительном конкретном варианте осуществления, изобретение относится к комбинации двух векторов, например, двух вирусных векторов, в частности, двух AAV векторов, для усовершенствования доставки гена и эффекта лечения в клетках, представляющих интерес. Например, два вектора могут нести молекулу нуклеиновой кислоты по изобретению, кодирующую белок GAA по изобретению, под управлением одного промотора, различного в каждом из этих двух векторов. В конкретном варианте осуществления один вектор содержит промотор, который представляет собой специфический промотор печени (как один из описанных выше), и другой вектор содержит промотор, который обладает специфичностью к другой ткани, представляющей интерес, для лечения нарушения накопления гликогена, такой как специфический промотор мышц, например, промотор десмина. В конкретном варианте по этому варианту осуществления, эта комбинация векторов соответствует нескольким совместно упакованным AAV векторам, получаемым, как описано в WO2015196179.
Изобретение также относится к клетке, например, клетке печени, которую трансформируют молекулой нуклеиновой кислоты или конструкцией по изобретению, как в случае генной терапии ex vivo. Клетки по изобретению можно доставлять субъекту, нуждающемуся в этом, такому как пациент с дефицитом GAA, с помощью любого подходящего пути введения, например, через инъекцию в печень или в кровоток указанного субъекта. В конкретном варианте осуществления изобретение включает введение молекулы нуклеиновой кислоты, конструкции нуклеиновой кислоты или вектора, в частности лентивирусного вектора, по изобретению в клетки печени, в частности в клетки печени субъекта, подлежащего лечению, и введение указанных трансформированных клеток печени, в которые вводили нуклеиновую кислоту, субъекту. Благоприятно, этот вариант осуществления можно использовать для секреции GAA из указанных клеток. В конкретном варианте осуществления клетки печени представляют собой клетки печени от пациента, подлежащего лечению, или стволовые клетки печени, которые дополнительно трансформируют и дифференцируют in vitro в клетки печени, для последующего введения пациенту.
Настоящее изобретение дополнительно относится к трансгенному не относящемуся к человеку животному, содержащему в своем геноме молекулу нуклеиновой кислоты или конструкцию, кодирующую полипептид GAA в соответствии с изобретением. В конкретном варианте осуществления животным является мышь.
Помимо систем специфической доставки, осуществляемых далее в примерах, известны различные системы доставки, которые можно использовать для того, чтобы вводить молекулу нуклеиновой кислоты или конструкцию по изобретению, например, инкапсулирование в липосомы, микрочастицы, микрокапсулы, рекомбинантные клетки, способные экспрессировать кодирующую последовательность по изобретению, рецептор-опосредованный эндоцитоз, конструкция терапевтической нуклеиновой кислоты в качестве части ретровирусного или другого вектора и т. д.
В соответствии с одним из вариантов осуществления, может быть желательно вводить полипептид GAA, молекулу нуклеиновой кислоты, конструкцию нуклеиновой кислоты или клетку по изобретению в печень субъекта посредством любого подходящего пути. Вдобавок депротеинизированную ДНК, такую как миникольца и транспозоны, можно использовать для векторов доставки или лентивирусных векторов. Дополнительно, технологии редактирования генов, такие как нуклеазы с цинковым пальцем, мегануклеазы, TALEN и CRISPR, также можно использовать для того, чтобы доставлять кодирующую последовательность по изобретению.
Настоящее изобретение также относится к фармацевтическим композициям, содержащим молекулу нуклеиновой кислоты, конструкцию нуклеиновой кислоты, вектор, полипептид GAA или клетку по изобретению. Такие композиции содержат терапевтически эффективное количество терапевтического средства (молекулы нуклеиновой кислоты, конструкции нуклеиновой кислоты, вектора, полипептида GAA или клетки по изобретению) и фармацевтически приемлемый носитель. В конкретном варианте осуществления термин «фармацевтически приемлемый» обозначает одобрение регулирующего органа государственного или регионального правительства или включение в фармакопею США или Европейскую фармакопею или другие общепризнанные фармакопеи для использования у животных и человека. Термин «носитель» относится к разбавителю, адъюванту, эксципиенту или носителю, с которым вводят терапевтическое средство. Такие фармацевтические носители могут представлять собой стерильные жидкости, такие как вода и масла, в том числе те, которые имеют происхождение из нефти, животных, овощей или синтеза, например, арахисовое масло, соевое масло, минеральное масло, сезамовое масло и т. п. Вода является предпочтительным носителем, когда фармацевтическую композицию вводят внутривенно. Солевые растворы и водные растворы декстрозы и глицерина также можно использовать в качестве жидких носителей, в частности, для инъецируемых растворов. Подходящие фармацевтические эксципиенты включают крахмал, глюкозу, лактозу, сахарозу, стеарат натрия, глицерина моностеарат, тальк, хлорид натрия, сухое обезжиренное молоко, глицерин, пропиленгликоль, воду, этанол и т. п.
Композиция, при желании, также может содержать незначительные количества смачивающих или эмульгирующих средств или pH буферных средств. Эти композиции могут принимать форму растворов, суспензий, эмульсий, таблеток, пилюль, капсул, порошков, составов с замедленным высвобождением и т. п. Оральный состав может содержать стандартные носители, такие как маннит, лактоза, крахмал, стеарат магния, сахарин натрия, целлюлоза, карбонат магния фармацевтической степени чистоты и т. д. Примеры подходящих фармацевтических носителей описаны в «Remington's Pharmaceutical Sciences», E. W. Martin. Такие композиции должны содержать терапевтически эффективное количество терапевтического средства, предпочтительно в очищенной форме, вместе с подходящим количеством носителя с тем, чтобы предоставлять форму для надлежащего введения субъекту. В конкретном варианте осуществления нуклеиновую кислоту, вектор или клетку по изобретению формулируют в композиции, содержащей фосфатно-солевой буфер, с добавлением 0,25% сывороточного альбумина человека. В другом конкретном варианте осуществления нуклеиновую кислоту, вектор или клетку по изобретению формулируют в композиции, содержащей лактат Рингера и неионное поверхностно-активное средство, такое как pluronic F68, в конечной концентрации 0,01-0,0001%, например, в концентрации 0,001%, по массе общей композиции. Состав дополнительно может содержать сывороточный альбумин, в частности сывороточный альбумин человека, такой как сывороточный альбумин человека 0,25%. Другие подходящие составы для хранения или введения известны в данной области, в частности, из WO 2005/118792 или Allay et al., 2011.
В предпочтительном варианте осуществления композицию формулируют в соответствии со стандартными процедурами в качестве фармацевтической композиции, адаптированной для внутривенного введения человеку. Обычно композиции для внутривенного введения представляют собой растворы в стерильном изотоническом водном буфере. При необходимости, композиция также может содержать солюбилизирующее средство и местный анестетик, такой как лигнокаин, чтобы снимать боль в месте инъекции.
В одном из вариантов осуществления молекулу нуклеиновой кислоты, конструкцию нуклеиновой кислоты, вектор, полипептид GAA или клетку по изобретению можно доставлять в везикуле, в частности липосоме. В еще одном другом варианте осуществления молекулу нуклеиновой кислоты, конструкцию нуклеиновой кислоты, вектор, полипептид GAA или клетку по изобретению можно доставлять в системе с контролируемым высвобождением.
Способы введения молекулы нуклеиновой кислоты, конструкции нуклеиновой кислоты, вектора, полипептида GAA или клетки по изобретению включают, но не ограничиваясь этим, внутрикожный, внутримышечный, интраперитонеальный, внутривенный, подкожный, интраназальный, эпидуральный и оральный пути. В конкретном варианте осуществления введение происходит через внутривенный или внутримышечный путь. Молекула нуклеиновой кислоты, конструкция нуклеиновой кислоты, вектор, полипептид GAA или клетки по изобретению, в форме вектора или нет, можно вводить с помощью любого удобного пути, например, посредством инфузии или болюсной инъекции, посредством абсорбции через эпителиальные или кожно-слизистые оболочки (например, слизистую оболочку полости рта, слизистую оболочку прямой кишки и кишечника и т. д.), и можно вводить вместе с другими биологически активными средствами. Введение может быть системным или местным.
В конкретном варианте осуществления может быть желательно вводить фармацевтические композиции по изобретению локально в области, нуждающейся в лечении, например, печени. Этого можно достигать, например, посредством имплантата, указанный имплантат из пористого, непористого или гелеобразного материала, в том числе мембран, таких как мембраны «sialastic», или волокон.
Количество терапевтического средства (т. е. молекулы нуклеиновой кислоты, конструкции нуклеиновой кислоты, вектора, полипептида GAA или клетки по изобретению) по изобретению, которое будет эффективным при лечении болезни накопления гликогена, можно определять с помощью стандартных клинических приемов. Кроме того, анализы in vivo и/или in vitro необязательно можно использовать для того, чтобы помогать предсказывать оптимальные диапазоны доз. Точная доза, используемая в составе, также зависит от пути введения и тяжести заболевания, и ее следует выбирать в соответствии с суждением практикующего специалиста и обстоятельствами каждого пациента. Доза молекулы нуклеиновой кислоты, конструкции нуклеиновой кислоты, вектора, полипептида GAA или клетки по изобретению, вводимых субъекту, нуждающемуся в этом, варьирует в зависимости от нескольких факторов, включая, без ограничения, путь введения, конкретное заболевание, которое лечат, возраст субъекта или уровень экспрессии, необходимый для достижения терапевтического эффекта. Специалист в данной области может легко определять, на основе своих знаний в этой области, необходимый диапазон доз на основе этих и других факторов. В случае лечения, включающего введение вирусного вектора, такого как AAV вектор, субъекту, типичные дозы вектор составляют по меньшей мере 1×108 векторных геномов на килограмм массы тела (вг/кг), например, по меньшей мере 1×109 вг/кг, по меньшей мере 1×1010 вг/кг, по меньшей мере 1×1011 вг/кг, по меньшей мере 1×1012 вг/кг по меньшей мере 1×1013 вг/кг или по меньшей мере 1×1014 вг/кг.
Изобретение также относится к способу лечения болезни накопления гликогена, который включает стадию доставки терапевтически эффективного количества нуклеиновой кислоты, вектора, полипептида GAA, фармацевтической композиции или клетки по изобретению нуждающемуся в этом субъекту.
Изобретение также относится к способу лечения болезни накопления гликогена, указанный способ не индуцирует иммунный ответ на трансген (т. е. на полипептид GAA по изобретению) или индуцирует сниженный иммунный ответ на трансген, который включает стадию доставки терапевтически эффективного количества молекулы нуклеиновой кислоты, конструкции нуклеиновой кислоты, вектора, фармацевтической композиции или клетки по изобретению нуждающемуся в этом субъекту. Изобретение также относится к способу лечения болезни накопления гликогена, указанный способ включает повторное введение терапевтически эффективного количества молекулы нуклеиновой кислоты, конструкции нуклеиновой кислоты, вектора, фармацевтической композиции или клетки по изобретению нуждающемуся в этом субъекту. В этом аспекте, молекула нуклеиновой кислоты или конструкция нуклеиновой кислоты по изобретению содержит промотор, который функционален в клетках печени, тем самым делая возможной иммунологическую толерантность к экспрессируемому полипептиду GAA, продуцируемому ими. Также в этом аспекте фармацевтическая композиция, используемая в этом аспекте, содержит молекулу нуклеиновой кислоты или конструкцию нуклеиновой кислоты, содержащую промотор, который функционален в клетках печени. В случае доставки клеток печени, указанные клетки могут представлять собой клетки, предварительно взятые у субъекта, нуждающегося в лечении, и сконструированные посредством введения в них молекулы нуклеиновой кислоты или конструкции нуклеиновой кислоты по изобретению, чтобы тем самым делать их способными продуцировать полипептид GAA по изобретению. В соответствии с одним из вариантов осуществления, в аспекте, включающем повторное введение, указанное введение можно повторять по меньшей мере один раз или больше, и даже можно рассматривать его выполнение в соответствии с периодической схемой, например, раз в неделю, в месяц или в год. Периодическая схема также может включать введение один раз каждые 2, 3, 4, 5, 6, 7, 8, 9 или 10 лет или больше чем 10 лет. В другом конкретном варианте осуществления введение каждого введения вирусного вектора по изобретению выполняют с использованием отличающегося вируса для каждого последующего введения, тем самым избегая снижения эффекта по причине возможного иммунного ответа на ранее введенный вирусный вектор. Например, можно осуществлять первое введение вирусного вектора, содержащего капсид AAV8, после чего следует введение вектора, содержащего AAV9 капсид, или даже введение вируса, не родственного с AAV, такого как ретровирусный или лентивирусный вектор.
В соответствии с настоящим изобретением, лечение может включать излечивающие, облегчающие или профилактические эффекты. Соответственно, терапевтическое и профилактическое лечение включает улучшение симптомов конкретной болезни накопления гликогена или предотвращение или иное снижение риска развития конкретной болезни накопления гликогена. Термин «профилактическое» можно рассматривать в качестве снижения тяжести или начала конкретного состояния. «Профилактическое» также включает предотвращение повторения конкретного состояния у пациента, у которого предварительно диагностировали состояние. «Терапевтическое» также может снижать тяжесть существующего состояния. Термин «лечение» используют в настоящем описании для обозначения любой схемы, которая может принести пользу животному, в частности млекопитающему, более конкретно человеческому субъекту.
Изобретение также относится к способу генной терапии ex vivo для лечения болезни накопления гликогена, который включает введение молекулы нуклеиновой кислоты или конструкции нуклеиновой кислоты по изобретению в выделенную клетку пациента, нуждающегося в этом, например, выделенную гематопоэтическую стволовую клетку, и введение указанной клетки указанному пациенту, нуждающемуся в этом. В конкретном варианте осуществления по этому аспекту, молекулу нуклеиновой кислоты или конструкцию вводят в клетку с использованием вектора, как определено выше. В конкретном варианте осуществления вектор представляет собой интегрирующий вирусный вектор. В дополнительном конкретном варианте осуществления вирусный вектор представляет собой ретровирусный вектор, такой как лентивирусный вектор. Например, лентивирусный вектор, как раскрыто в van Til et al., 2010, Blood, 115(26), стр. 5329, можно использовать при практической реализации способа по настоящему изобретению.
Изобретение также относится к молекуле нуклеиновой кислоты, конструкции нуклеиновой кислоты, вектору, полипептиду GAA или клетке по изобретению для применения в качестве лекарственного средства.
Изобретение также относится к молекуле нуклеиновой кислоты, конструкции нуклеиновой кислоты, вектору, полипептиду GAA или клетке по изобретению для использования в способе лечения заболевания, обусловленного мутацией в гене GAA, в частности, в способе лечения болезнь Помпе. Изобретение дополнительно относится к молекуле нуклеиновой кислоты, конструкции нуклеиновой кислоты, вектору, полипептиду GAA или клетке по изобретению для использования в способе лечения болезни накопления гликогена, такой как GSDI (болезнь Гирке), GSDII (болезнь Помпе), GSDIII (болезнь Кори), GSDIV, GSDV, GSDVI, GSDVII, GSDVIII и летальная врожденная болезнь накопления гликогена в сердце, более конкретно GSDI, GSDII или GSDIII, даже более конкретно GSDII и GSDIII и наиболее конкретно GSDII. Усеченный полипептид GAA по изобретению можно вводить нуждающемуся в этом пациенту для использования в ферментозаместительной терапии (ERT), например, для использования в ферментозаместительной терапии болезни накопления гликогена, такой как GSDI (болезнь Гирке), GSDII (болезнь Помпе), GSDIII (болезнь Кори), GSDIV, GSDV, GSDVI, GSDVII, GSDVIII и летальная врожденная болезнь накопления гликогена в сердце, более конкретно GSDI, GSDII или GSDIII, даже более конкретно GSDII и GSDIII и наиболее конкретно GSDII.
Изобретение дополнительно относится к использованию молекулы нуклеиновой кислоты, конструкции нуклеиновой кислоты, вектора, полипептида GAA или клетки по изобретению при изготовлении лекарственного средства, эффективного для лечения болезни накопления гликогена, такой как GSDI (болезнь Гирке), GSDII (болезнь Помпе), GSDIII (болезнь Кори), GSDIV, GSDV, GSDVI, GSDVII, GSDVIII и летальная врожденная болезнь накопления гликогена в сердце, более конкретно GSDI, GSDII или GSDIII, даже более конкретно GSDII и GSDIII и наиболее конкретно GSDII.
ПРИМЕРЫ
Изобретение дополнительно описано подробно со ссылкой на следующие экспериментальные примеры и приложенные фиг. Эти примеры приведены лишь в иллюстративных целях и не предназначены в качестве ограничения.
МАТЕРИАЛЫ И СПОСОБЫ
Активность GAA
Активность GAA измеряли после гомогенизации замороженных образцов тканей в дистиллированной воде. 50-100 мг ткани взвешивали и гомогенизировали, затем центрифугировали в течение 20 минут на 10000×g. Реакцию проводили с использованием 10 мкл супернатанта и 20 мкл субстрата - 4MUα-D-глюкозида, в 96-луночном планшете. Реакционную смесь инкубировали при 37°C в течение одного часа и затем останавливали добавлением 150 мкл буфера с карбонатом натрия pH 10,5. Калибровочную кривую (4MU 0-2500 пмоль/мкл) использовали для того, чтобы измерять высвобождаемый флуоресцентный 4MU из индивидуальной реакционной смеси, используя считыватель планшетов EnSpire α (Perkin-Elmer) на 449 нм (испускание) и 360 нм (возбуждение). Концентрацию белка осветленного супернатанта количественно определяли с помощью BCA (Thermo Fisher Scientific). Для того чтобы вычислять активность GAA, концентрацию высвобождаемого 4MU делили на концентрацию белка в образце и активность приводили в виде нмоль/час/мг белка.
Исследования мышей
GAA-/- мышь создавали посредством направленного разрушения экзона 6 и поддерживали на фоне C57BL/6J/129X1/SvJ (Raben N. et al 1998). Векторы доставляли через хвостовую вену в объеме 0,2 мл. Образцы сыворотки брали ежемесячно для того, чтобы осуществлять мониторинг уровней секретируемой hGAA. Пораженных животных, которым инъецировали PBS, и однопометников дикого типа использовали в качестве контролей.
Исследование NHP
Самцов яванских макаков содержали в клетках из нержавеющей стали и с поддержанием 12-часового цикла свет/темнота. Все макаки имели титры нейтрализующих антител < 1:5 перед началом исследования дозу 2E12 вг/кг AAV8-hAAT-sp7-Δ8-hGAAco1 инфузировали через подкожную вену. Образцы крови брали за 12 суток до и через 30 суток после инъекции через бедренную вену. Цельную кровь собрали в содержащие EDTA пробирки и центрифугировали для того, чтобы отделять сыворотку. Через 3 месяца после введения вектора всех макаков умерщвляли. Животных сначала анестезировали смесью кетамина/дексмедетомидина и затем эвтаназировали с использованием IV инъекции пентобарбитала натрия. Ткани собирали непосредственно и замораживали в жидком азоте.
Анализ вестерн-блоттинга
Получали полные гомогенаты замороженных мышц. Концентрацию белка определяли в экстрактах с помощью Pierce BCA Protein Assay (Thermo Fisher Scientific), придерживаясь инструкций производителя. Вестерн-блоттинг осуществляли с использованием антитела против hGAA (Abcam). Антитело против тубулина (Sigma Aldrich) использовали в качестве контроля загрузки.
РЕЗУЛЬТАТЫ
С целью разработки новых форм GAA с усовершенствованной секрецией и сниженной иммуногенностью, авторы изобретения решали получать усеченные формы GAA, необязательно комбинируя их с альтернативными сигнальными пептидами.
GAA человека, приведенная в SEQ ID NO: 2, служила в качестве основы для разработки этих новых форм. SEQ ID NO: 1 соответствует последовательности из SEQ ID NO: 2, свободной от соответствующего природного сигнального пептида GAA (аминокислоты 1-27 из SEQ ID NO: 2). Конструкции нуклеиновой кислоты разрабатывали для того, чтобы кодировать полипептиды GAA, происходящие из SEQ ID NO: 1, усеченные по их N-концу. Авторы изобретения начинали с разработки последовательности нуклеиновой кислоты на основе кодирующей последовательности hGAA дикого типа (SEQ ID NO: 9, соответствующая нуклеотидам 82-2859 из SEQ ID NO: 8, которая представляет собой кодирующую последовательность hGAA дикого типа, содержащую кодирующую последовательность сигнального пептида) с делецией кодонов, соответствующих первым 8 аминокислотам из SEQ ID NO: 1 (Δ8). В дополнение к кодирующей последовательности hGAA дикого типа, авторы изобретения разрабатывали оптимизированную последовательность нуклеиновой кислоты, кодирующую Δ8 усеченный полипептид hGAA (SEQ ID NO: 10 и SEQ ID NO: 11 соответствуют оптимизированной кодирующей последовательности hGAAco1 и hGAAco2, соответственно), чтобы исключать возможный эффект конкретной последовательности.
Таблица 1. Описание оптимизированных последовательностей. В таблице приведены характеристики двух оптимизированных последовательностей hGAA по сравнению с последовательностью дикого типа. a) коэффициент адаптации кодонов и b) содержание GC вычисляли с использованием инструмента анализа редких кодонов (http://www.genscript.com). c) и d) соответственно представляют собой альтернативные открытые рамки считывания, вычисленные на 5'-3' (aORF 5'→3') и 3'-5' (aORF 3'→5') нитях. e) и f) соответственно представляют собой участки акцепторов (SA) и доноров (SD) сплайсинга, вычисленные с использованием онлайн-инструмента предсказания участков сплайсинга (http://www.fruitfly.org/seq_tools/splice.html). g) и h) соответственно представляют собой процент идентичности, вычисляемый в сравнении с последовательностью дикого типа (wt) и оптимизированной последовательностью co1. i) островки CpG вычисляли с использованием онлайн-инструмента MethDB (http://www.methdb.de/links.html). Островки CpG представляют собой последовательности длиннее 100 п. о., с содержанием GC > 60% и соотношением наблюдаемые/ожидаемые > 0,6.
Аминокислоты 1-27 из последовательностей hGAA (соответствующие природному сигнальному пептиду hGAA, здесь определены как sp1; их последовательность приведена в SEQ ID NO: 4) заменяли на аминокислоты 1-24 из последовательности α-1-антитрипсина человека (NP_000286.3), здесь определяемую как sp2 (последовательность приведена в SEQ ID NO: 5). Авторы изобретения трансфицировали клетки гепатомы человека (Huh-7) кодирующими усеченную hGAA конструкциями параллельно с их полноразмерными версиями, и авторы изобретения измеряли количество hGAA, высвобождаемой в среду, через 48 часов фиг. 1A). Делеция Δ8 в последовательностях hGAA вела к значимому, 50% увеличению уровня секреции, как для последовательности дикого типа (hGAA), так и для последовательности с оптимизированными кодонами (hGAAco2). То же усечение, выполняемое на другой последовательности с оптимизированными кодонами (hGAAco1), также усовершенствовало секрецию hGAA в той же степени.
Для того чтобы подтверждать, что изменение в последовательности следующего сигнального пептида может усовершенствовать секрецию hGAA, авторы изобретения дополнительно усекали полипептид hGAA. Авторы изобретения устраняли кодоны, соответствующие первым 42 аминокислотам hGAA, из конструкции hGAAco1 (Δ42), и авторы изобретения заменяли их на сигнальный пептид, происходящий из химотрипсиногена B1 (sp7; последовательность приведена в SEQ ID NO: 3). Затем авторы изобретения сравнивали эффект секреции, получаемый с использованием этой новой конструкции с делецией, с ее Δ8 версией, слитой с сигнальным пептидом sp7 и полноразмерной hGAAco1 с sp1 или с sp7. Авторы изобретения трансфицировали клетки Huh-7 этим конструкциями, и авторы изобретения измеряли активность hGAA в среде через 48 часов. Как ожидали, авторы изобретения могли измерять активность hGAA после трансфекции полноразмерной hGAAco1 (p=0,055 в сравнении с GFP), и ее секреция двукратно возрастала при замене сигнального пептида дикого типа на sp7 (p=0,006 в сравнении с hGAAco1). К удивлению, обе последовательности Δ8 и Δ42 hGAA, слитые с сигнальным пептидом sp7, демонстрировали двукратное увеличение секретируемой hGAA по сравнению с полноразмерной последовательностью (p=0,0002 и 0,0003, соответственно, в сравнении с sp7-hGAAco1, фиг. 1B).
В совокупности, эти данные демонстрируют, что усечение последовательности hGAA, соединенной с эффективным сигнальным пептидом, позволяет увеличивать секрецию белка in vitro. Дополнительно, усечение имеет одно важное преимущество по сравнению с мутагенезом нативной последовательности, поскольку при нем не возникают основные неоантигены, что является преимуществом при конструировании терапевтического продукта.
Затем авторы изобретения верифицировали эти находки in vivo, в модели болезни Помпе на мышах. Авторы изобретения инъецировали GAA-/- мышам (Raben et al J. Bio. Chem. 1998) AAV8 векторы, экспрессирующие полноразмерную hGAAco1, Δ8 или Δ42, слитую с сигнальным пептидом sp7 под транскрипционным управлением высоко активного специфического промотора печени, полученного слиянием энхансера аполипопротеин B и промотора α-1-антитрипсина человека (hAAT). Через один месяц после инъекции 2E12 вг/кг векторов, описанных выше, у мышей брали кров и измеряли активность hGAA в сыворотке. Лечение мышей векторами, экспрессирующими полноразмерную hGAAco1, слитую с sp7, показывало повышенный уровень hGAA в кровотоке (p=0,115 в сравнении с PBS). К удивлению, обе усеченные hGAA, Δ8 и Δ42, вели к значимому увеличению уровня hGAA в сыворотке (p=0,014 и 0,013, соответственно).
Эти данные показывают, что делеция первых аминокислот hGAA вела к значимому усовершенствованию уровня hGAA, секретируемой в кровоток.
Кроме того, другой сигнальный пептид сливали с Δ8 усеченной формой hGAA, соответствующий аминокислотам 1-25, из идуронат-2-сульфатазы (sp6; SEQ ID NO: 6). Авторы изобретения трансфицировали клетки гепатомы (Huh-7) плазмидами, экспрессирующими GFP или hGAA дикого типа (hGAA; родительский полипептид, соответствующий аминокислотным остаткам 28-952 из SEQ ID NO: 30), параллельно с плазмидами, экспрессирующими оптимизированную hGAA (hGAAco1), слитую с sp1, sp2, sp6, sp7 или sp8. Через 48 часов после трансфекции, среду для выращивания анализировали на присутствие hGAA. Следует отметить, что эти конструкции вели к значительно более высоким уровням секреции hGAA, чем то, то наблюдали в отрицательном контроле, представленном GFP-трансфицированными клетками (фиг. 3).
Затем авторы изобретения оценивали содержание гликогена в сердце, диафрагме и квадрицепсе GAA-/- мышей, которых лечили, как описано выше, с использованием Δ8-hGAA. Следует отметить, что авторы изобретения наблюдали высокие уровни hGAA в тканях после лечения с использованием экспрессирующих Δ8-hGAAco векторов (данные не представлены), которые коррелировали со значимым снижением содержания гликогена во всех рассматриваемых тканях (фиг. 4B-D). В частности, в сердце (фиг. 4B) уровень гликогена, измеряемый после лечения векторами, несущими высоко эффективные сигнальные пептиды sp7 и 8, неотличим от того, который наблюдали у не пораженных животных (p=0,983 и 0,996 в сравнении с WT, соответственно). Важно, что уровень, наблюдаемый после лечения с использованием векторов sp7 и sp8, значительно снижался по сравнению с GAA-/- животными, которые получали инъекции PBS или лечение вектором, экспрессирующим hGAAco, слитую с сигнальным пептидом sp1.
Авторы изобретения также тестировали, индуцировала ли трансдукция печени с использованием векторов авторов изобретения гуморальный ответ на трансген. Мышам внутривенно инъецировали AAV8 векторы, экспрессирующие hGAAco1 с нативным сигнальным пептидом sp1 (co) или Δ8-hGAAco1, слитую с sp2, sp7 или sp8, под транскрипционным управлением специфического промотора печени. Результаты представлены на фиг. 5. Gaa-/- получали внутримышечную инъекцию AAV, экспрессирующего Δ8-hGAAco1 под транскрипционным управлением конститутивного промотора, который демонстрировал очень высокий уровень общего IgG (~150 мкг/мл), тогда как в целом вектор, экспрессирующий тот же белок в печени, демонстрировал более низкий уровень гуморального ответа. Интересно, что мыши, которым инъецировали экспрессирующий sp1 hGAAco1 (co) вектор, демонстрировали поддающийся обнаружению уровень антител при обеих дозах, тогда как мыши, которым инъецировали сконструированные векторы высокой секреции, имели неподдающиеся обнаружению уровни IgG. Эти данные показывают, что экспрессия трансгена в печени является необходимой для индукции периферической толерантности, также они предоставляют указания на то, что высокие уровни циркулирующей hGAA, которых достигали посредством слияния с эффективным сигнальным пептидом, индуцируют снижение гуморального ответа на сам белок.
Наиболее действенный вектор, выбранный в исследовании на мышах, инъецировали двум не являющимся человеком приматам (NHP, Macaca fascicularis sp.) для того, чтобы верифицировать эффект секреции вектора авторов изобретения и захват в мышцах. Авторы изобретения инъецировали двум обезьянам 2E12 вг/кг AAV8-hAAT-sp7-Δ8-hGAAco1. Через один месяц после инъекции авторы изобретения измеряли уровни hGAA в сыворотке двух животных посредством вестерн-блоттинга с использованием специфического антитела против hGAA. У двух обезьян авторы изобретения наблюдали четкую полосу с размером, совместимым с таковым у hGAA. Эта полоса отсутствовала в образцах сыворотки, полученных за 12 суток до инъекции вектора, что, таким образом, подтверждает специфичность способа обнаружения авторов изобретения (фиг. 6A). Через 3 месяца после инъекции авторы изобретения умерщвляли животных и авторы изобретения получали ткани для того, чтобы верифицировать, если hGAA, секретируемая печенью в кровоток, эффективно захватывалась мышцей. Авторы изобретения выполняли вестерн-блоттинг с использованием антитела со специфичностью к hGAA на общих лизатах, полученных из бицепса и диафрагмы двух обезьян. Интересно, что авторы изобретения могли наблюдать четкую полосу у животного № 2, которое также демонстрировало самые высокие уровни hGAA в кровотоке (фиг. 6B). Также у животного № 1 авторы изобретения могли наблюдать слабую полосу с молекулярной массы, соответствующей таковой у hGAA, в обеих анализируемых мышцах. Эти данные показывают, что вектор AAV8-hAAT-sp7-Δ8-hGAAco1 эффективно трансдуцирует печень у NHP. Также они демонстрируют, что белок, секретируемый в кровоток, эффективно захватывается мышцей и что это захват коррелирует с уровнем hGAA, измеряемой в крови.
Авторы изобретения также определяли эффект наиболее действенного вектора, выбранного в исследовании на мышах (AAV8-hAAT-sp7-Δ8-hGAAco1) в модели GSDIII на мышах. Авторы изобретения разрабатывали модель на мышах с нокаутом для гликоген-деветвящего фермента (GDE). Эта модель повторяет фенотип заболевания, наблюдаемый у людей, пораженных болезнью накопления гликогена III типа (GSDIII). В частности, GDE-/- мыши, у которых полностью отсутствует активность GDE, имеют ослабление силы мышц и накопление гликогена в различных тканях. Также интересно, что они накапливают гликоген в печени, что также наблюдают у человека. Здесь авторы изобретения тестировали, предотвращает ли сверхэкспрессия sp7-Δ8-hGAA в печени накопление гликогена, наблюдаемое у GDE-/- мышей. Авторы изобретения инъецировали GDE-/- мышам 1E11 или 1E12 вг/мышь AAV8-hAAT-sp7-Δ8-hGAAco1. В качестве контролей авторы изобретения параллельно инъецировали PBS мышам дикого типа (WT) и GDE-/- мышам. Через 3 месяца после введения вектора, мышей умерщвляли и количественно определяли уровень гликогена в печени. Результаты приведены на фиг. 7. Как уже сообщалось (Pagliarani et al и модель авторов изобретения), GDE-/- мыши демонстрировали значимое увеличение накопления гликогена в печени (p=1,3E-7) - в 5 раз больше гликогена по сравнению с животными дикого типа. К удивлению, лечение с использованием 1E11 и 1E12 вг/мышь вектора AAV8-hAAT-sp7-Δ8-hGAAco1 вызывало статистически значимое снижение содержания гликогена (p=4,5E-5 и 1,4E-6, соответственно). Важно, что уровни гликогена, измеряемого в печени мышей, которым инъецировали вектор AAV8-hAAT-sp7-Δ8-hGAAco1, не отличались от таковых, измеряемых у животных дикого типа, в частности, в самой высокой дозе (p=0,053 для когорты дозы 1E11 и 0,244 для когорты дозы 1E12).
Авторы изобретения проводили анализ активности GAA в средах и лизатах клеток HuH7, трансфицированных различными версиями GAA (все с оптимизацией кодонов): 1. нативная GAA, содержащая нативный сигнальный пептид sp1 GAA (co), 2. сконструированная GAA, содержащая гетерологичный сигнальный пептид sp7 (sp7-co), и 3. сконструированная GAA, содержащая гетерологичный сигнальный пептид sp7, после которого следует делеция переменного числа аминокислот (sp7-Δ8-co, sp7-Δ29-co, sp7-Δ42-co, sp7-Δ43-co, sp7-Δ47-co и sp7-Δ62-co, в которых удаляют, соответственно, 8, 29, 42, 47 и 62 первых N-концевых аминокислот из SEQ ID NO: 1). Анализ показывал (фиг. 8) значительно более высокую активность GAA в средах клеток, трансфицированных с использованием Δ8, Δ29, Δ42 и Δ43 версий GAA по сравнению как со сконструированной GAA без делеций (sp7-co), так и с нативной GAA (co). Значительно более низкую активность GAA наоборот наблюдали в средах клеток, трансфицированных с использованием Δ47 и Δ62 версий GAA, по сравнению с другими сконструированными версиями GAA [с делециями (sp7-Δ8-co, sp7-Δ29-co, sp7-Δ42-co, sp7-Δ43-co) и без делеций (sp7-co)]. Интересно, что (фиг. 9) внутриклеточная активность GAA не различалась среди продуктивных делеций (sp7-Δ8-co, sp7-Δ29-co, sp7-Δ42-co, sp7-Δ43-co) и версии без делеций (sp7-co), что указывает на то, что все они эффективно продуцируются и процессируются в клетке. Внутриклеточная активность GAA наоборот была очень низкой для версий sp7-Δ47-co и sp7-Δ62-co и значительно ниже по сравнению со всеми другими сконструированными версиями [с делециями (sp7-Δ8-co, sp7-Δ29-co, sp7-Δ42-co, sp7-Δ43-co) и без делеций (sp7-co)].
Авторы изобретения также выполняли анализ активности GAA в средах и лизатах клеток HuH7, трансфицированных различными версиями GAA (все с оптимизированными кодонами): 1. нативная GAA, содержащая нативный сигнальный пептид sp1 GAA (co), 2. сконструированная GAA, содержащая гетерологичный сигнальный пептид sp6 или sp8 (sp6-co, sp8-co), и 3. сконструированная GAA, содержащая гетерологичный сигнальный пептид sp6 или sp8, после которого следует делеция 8 аминокислот (sp6-Δ8-co, sp8-Δ8-co). Анализ показывал (фиг. 10) значительно более высокую активность GAA в средах клеток, трансфицированных Δ8 версиями, по сравнению с: i. соответствующими им сконструированными версиями GAA без делеций (sp6-co или sp8-co); и ii. нативной GAA (co). Интересно, что внутриклеточная активность GAA не различалась среди всех сконструированных версий GAA (как с делециями, так и без делеций), что указывает на то, что все они эффективно продуцируются и процессируются в клетке (часть лизатов клеток). Внутриклеточная активность GAA наоборот была значительно выше при использовании нативной GAA (co) по сравнению со сконструированными версиями, что указывает на то, что нативная GAA преимущественно удерживается в клетке.
--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> GENETHON et al.
<120> ВАРИАНТЫ КИСЛОЙ АЛЬФА-ГЛЮКОЗИДАЗЫ И ИХ ИСПОЛЬЗОВАНИЕ
<130> B2299PC00
<160> 53
<170> PatentIn версии 3.3
<210> 1
<211> 925
<212> Белок
<213> искусственная
<220>
<223> hGAAwt без sp
<400> 1
Gly His Ile Leu Leu His Asp Phe Leu Leu Val Pro Arg Glu Leu Ser
1 5 10 15
Gly Ser Ser Pro Val Leu Glu Glu Thr His Pro Ala His Gln Gln Gly
20 25 30
Ala Ser Arg Pro Gly Pro Arg Asp Ala Gln Ala His Pro Gly Arg Pro
35 40 45
Arg Ala Val Pro Thr Gln Cys Asp Val Pro Pro Asn Ser Arg Phe Asp
50 55 60
Cys Ala Pro Asp Lys Ala Ile Thr Gln Glu Gln Cys Glu Ala Arg Gly
65 70 75 80
Cys Cys Tyr Ile Pro Ala Lys Gln Gly Leu Gln Gly Ala Gln Met Gly
85 90 95
Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu Glu
100 105 110
Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg Thr
115 120 125
Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp Val
130 135 140
Met Met Glu Thr Glu Asn Arg Leu His Phe Thr Ile Lys Asp Pro Ala
145 150 155 160
Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr Pro His Val His Ser Arg
165 170 175
Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe Gly
180 185 190
Val Ile Val Arg Arg Gln Leu Asp Gly Arg Val Leu Leu Asn Thr Thr
195 200 205
Val Ala Pro Leu Phe Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr Ser
210 215 220
Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala Glu His Leu Ser Pro Leu
225 230 235 240
Met Leu Ser Thr Ser Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp Leu
245 250 255
Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr Leu
260 265 270
Ala Leu Glu Asp Gly Gly Ser Ala His Gly Val Phe Leu Leu Asn Ser
275 280 285
Asn Ala Met Asp Val Val Leu Gln Pro Ser Pro Ala Leu Ser Trp Arg
290 295 300
Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu Pro
305 310 315 320
Lys Ser Val Val Gln Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe Met
325 330 335
Pro Pro Tyr Trp Gly Leu Gly Phe His Leu Cys Arg Trp Gly Tyr Ser
340 345 350
Ser Thr Ala Ile Thr Arg Gln Val Val Glu Asn Met Thr Arg Ala His
355 360 365
Phe Pro Leu Asp Val Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser Arg
370 375 380
Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala Met
385 390 395 400
Val Gln Glu Leu His Gln Gly Gly Arg Arg Tyr Met Met Ile Val Asp
405 410 415
Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr Asp
420 425 430
Glu Gly Leu Arg Arg Gly Val Phe Ile Thr Asn Glu Thr Gly Gln Pro
435 440 445
Leu Ile Gly Lys Val Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe Thr
450 455 460
Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp Met Val Ala Glu Phe His
465 470 475 480
Asp Gln Val Pro Phe Asp Gly Met Trp Ile Asp Met Asn Glu Pro Ser
485 490 495
Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu Glu
500 505 510
Asn Pro Pro Tyr Val Pro Gly Val Val Gly Gly Thr Leu Gln Ala Ala
515 520 525
Thr Ile Cys Ala Ser Ser His Gln Phe Leu Ser Thr His Tyr Asn Leu
530 535 540
His Asn Leu Tyr Gly Leu Thr Glu Ala Ile Ala Ser His Arg Ala Leu
545 550 555 560
Val Lys Ala Arg Gly Thr Arg Pro Phe Val Ile Ser Arg Ser Thr Phe
565 570 575
Ala Gly His Gly Arg Tyr Ala Gly His Trp Thr Gly Asp Val Trp Ser
580 585 590
Ser Trp Glu Gln Leu Ala Ser Ser Val Pro Glu Ile Leu Gln Phe Asn
595 600 605
Leu Leu Gly Val Pro Leu Val Gly Ala Asp Val Cys Gly Phe Leu Gly
610 615 620
Asn Thr Ser Glu Glu Leu Cys Val Arg Trp Thr Gln Leu Gly Ala Phe
625 630 635 640
Tyr Pro Phe Met Arg Asn His Asn Ser Leu Leu Ser Leu Pro Gln Glu
645 650 655
Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln Ala Met Arg Lys Ala Leu
660 665 670
Thr Leu Arg Tyr Ala Leu Leu Pro His Leu Tyr Thr Leu Phe His Gln
675 680 685
Ala His Val Ala Gly Glu Thr Val Ala Arg Pro Leu Phe Leu Glu Phe
690 695 700
Pro Lys Asp Ser Ser Thr Trp Thr Val Asp His Gln Leu Leu Trp Gly
705 710 715 720
Glu Ala Leu Leu Ile Thr Pro Val Leu Gln Ala Gly Lys Ala Glu Val
725 730 735
Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val Pro
740 745 750
Val Glu Ala Leu Gly Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg Glu
755 760 765
Pro Ala Ile His Ser Glu Gly Gln Trp Val Thr Leu Pro Ala Pro Leu
770 775 780
Asp Thr Ile Asn Val His Leu Arg Ala Gly Tyr Ile Ile Pro Leu Gln
785 790 795 800
Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg Gln Gln Pro Met Ala Leu
805 810 815
Ala Val Ala Leu Thr Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe Trp
820 825 830
Asp Asp Gly Glu Ser Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr Gln
835 840 845
Val Ile Phe Leu Ala Arg Asn Asn Thr Ile Val Asn Glu Leu Val Arg
850 855 860
Val Thr Ser Glu Gly Ala Gly Leu Gln Leu Gln Lys Val Thr Val Leu
865 870 875 880
Gly Val Ala Thr Ala Pro Gln Gln Val Leu Ser Asn Gly Val Pro Val
885 890 895
Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys Val Leu Asp Ile Cys Val
900 905 910
Ser Leu Leu Met Gly Glu Gln Phe Leu Val Ser Trp Cys
915 920 925
<210> 2
<211> 952
<212> Белок
<213> homo sapiens
<400> 2
Met Gly Val Arg His Pro Pro Cys Ser His Arg Leu Leu Ala Val Cys
1 5 10 15
Ala Leu Val Ser Leu Ala Thr Ala Ala Leu Leu Gly His Ile Leu Leu
20 25 30
His Asp Phe Leu Leu Val Pro Arg Glu Leu Ser Gly Ser Ser Pro Val
35 40 45
Leu Glu Glu Thr His Pro Ala His Gln Gln Gly Ala Ser Arg Pro Gly
50 55 60
Pro Arg Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr
65 70 75 80
Gln Cys Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys
85 90 95
Ala Ile Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro
100 105 110
Ala Lys Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe
115 120 125
Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser
130 135 140
Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe
145 150 155 160
Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu
165 170 175
Asn Arg Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu
180 185 190
Val Pro Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu
195 200 205
Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg
210 215 220
Gln Leu Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe
225 230 235 240
Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr
245 250 255
Ile Thr Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser
260 265 270
Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly
275 280 285
Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly
290 295 300
Gly Ser Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val
305 310 315 320
Val Leu Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile
325 330 335
Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln
340 345 350
Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly
355 360 365
Leu Gly Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr
370 375 380
Arg Gln Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val
385 390 395 400
Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe
405 410 415
Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His
420 425 430
Gln Gly Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser
435 440 445
Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg
450 455 460
Gly Val Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val
465 470 475 480
Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu
485 490 495
Ala Trp Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe
500 505 510
Asp Gly Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly
515 520 525
Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val
530 535 540
Pro Gly Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser
545 550 555 560
Ser His Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly
565 570 575
Leu Thr Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly
580 585 590
Thr Arg Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg
595 600 605
Tyr Ala Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu
610 615 620
Ala Ser Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro
625 630 635 640
Leu Val Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu
645 650 655
Leu Cys Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg
660 665 670
Asn His Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser
675 680 685
Glu Pro Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala
690 695 700
Leu Leu Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly
705 710 715 720
Glu Thr Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser
725 730 735
Thr Trp Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile
740 745 750
Thr Pro Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro
755 760 765
Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val Pro Val Glu Ala Leu Gly
770 775 780
Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser
785 790 795 800
Glu Gly Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val
805 810 815
His Leu Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr
820 825 830
Thr Thr Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr
835 840 845
Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser
850 855 860
Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala
865 870 875 880
Arg Asn Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly
885 890 895
Ala Gly Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala
900 905 910
Pro Gln Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr
915 920 925
Ser Pro Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly
930 935 940
Glu Gln Phe Leu Val Ser Trp Cys
945 950
<210> 3
<211> 18
<212> Белок
<213> искусственная
<220>
<223> sp7
<400> 3
Met Ala Phe Leu Trp Leu Leu Ser Cys Trp Ala Leu Leu Gly Thr Thr
1 5 10 15
Phe Gly
<210> 4
<211> 27
<212> Белок
<213> искусственная
<220>
<223> sp1
<400> 4
Met Gly Val Arg His Pro Pro Cys Ser His Arg Leu Leu Ala Val Cys
1 5 10 15
Ala Leu Val Ser Leu Ala Thr Ala Ala Leu Leu
20 25
<210> 5
<211> 24
<212> Белок
<213> искусственная
<220>
<223> sp2
<400> 5
Met Pro Ser Ser Val Ser Trp Gly Ile Leu Leu Leu Ala Gly Leu Cys
1 5 10 15
Cys Leu Val Pro Val Ser Leu Ala
20
<210> 6
<211> 25
<212> Белок
<213> искусственная
<220>
<223> sp6
<400> 6
Met Pro Pro Pro Arg Thr Gly Arg Gly Leu Leu Trp Leu Gly Leu Val
1 5 10 15
Leu Ser Ser Val Cys Val Ala Leu Gly
20 25
<210> 7
<211> 22
<212> Белок
<213> искусственная
<220>
<223> sp8
<400> 7
Met Ala Ser Arg Leu Thr Leu Leu Thr Leu Leu Leu Leu Leu Leu Ala
1 5 10 15
Gly Asp Arg Ala Ser Ser
20
<210> 8
<211> 2859
<212> ДНК
<213> homo sapiens
<400> 8
atgggagtga ggcacccgcc ctgctcccac cggctcctgg ccgtctgcgc cctcgtgtcc 60
ttggcaaccg cagcgctcct ggggcacatc ctactccatg atttcctgct ggttccccga 120
gagctgagtg gctcctcccc agtcctggag gagactcacc cagctcacca gcagggagcc 180
agcagaccag ggccccggga tgcccaggca caccccgggc ggccgcgagc agtgcccaca 240
cagtgcgacg tcccccccaa cagccgcttc gattgcgccc ctgacaaggc catcacccag 300
gaacagtgcg aggcccgcgg ctgttgctac atccctgcaa agcaggggct gcagggagcc 360
cagatggggc agccctggtg cttcttccca cccagctacc ccagctacaa gctggagaac 420
ctgagctcct ctgaaatggg ctacacggcc accctgaccc gtaccacccc caccttcttc 480
cccaaggaca tcctgaccct gcggctggac gtgatgatgg agactgagaa ccgcctccac 540
ttcacgatca aagatccagc taacaggcgc tacgaggtgc ccttggagac cccgcatgtc 600
cacagccggg caccgtcccc actctacagc gtggagttct ccgaggagcc cttcggggtg 660
atcgtgcgcc ggcagctgga cggccgcgtg ctgctgaaca cgacggtggc gcccctgttc 720
tttgcggacc agttccttca gctgtccacc tcgctgccct cgcagtatat cacaggcctc 780
gccgagcacc tcagtcccct gatgctcagc accagctgga ccaggatcac cctgtggaac 840
cgggaccttg cgcccacgcc cggtgcgaac ctctacgggt ctcacccttt ctacctggcg 900
ctggaggacg gcgggtcggc acacggggtg ttcctgctaa acagcaatgc catggatgtg 960
gtcctgcagc cgagccctgc ccttagctgg aggtcgacag gtgggatcct ggatgtctac 1020
atcttcctgg gcccagagcc caagagcgtg gtgcagcagt acctggacgt tgtgggatac 1080
ccgttcatgc cgccatactg gggcctgggc ttccacctgt gccgctgggg ctactcctcc 1140
accgctatca cccgccaggt ggtggagaac atgaccaggg cccacttccc cctggacgtc 1200
cagtggaacg acctggacta catggactcc cggagggact tcacgttcaa caaggatggc 1260
ttccgggact tcccggccat ggtgcaggag ctgcaccagg gcggccggcg ctacatgatg 1320
atcgtggatc ctgccatcag cagctcgggc cctgccggga gctacaggcc ctacgacgag 1380
ggtctgcgga ggggggtttt catcaccaac gagaccggcc agccgctgat tgggaaggta 1440
tggcccgggt ccactgcctt ccccgacttc accaacccca cagccctggc ctggtgggag 1500
gacatggtgg ctgagttcca tgaccaggtg cccttcgacg gcatgtggat tgacatgaac 1560
gagccttcca acttcatcag gggctctgag gacggctgcc ccaacaatga gctggagaac 1620
ccaccctacg tgcctggggt ggttgggggg accctccagg cggccaccat ctgtgcctcc 1680
agccaccagt ttctctccac acactacaac ctgcacaacc tctacggcct gaccgaagcc 1740
atcgcctccc acagggcgct ggtgaaggct cgggggacac gcccatttgt gatctcccgc 1800
tcgacctttg ctggccacgg ccgatacgcc ggccactgga cgggggacgt gtggagctcc 1860
tgggagcagc tcgcctcctc cgtgccagaa atcctgcagt ttaacctgct gggggtgcct 1920
ctggtcgggg ccgacgtctg cggcttcctg ggcaacacct cagaggagct gtgtgtgcgc 1980
tggacccagc tgggggcctt ctaccccttc atgcggaacc acaacagcct gctcagtctg 2040
ccccaggagc cgtacagctt cagcgagccg gcccagcagg ccatgaggaa ggccctcacc 2100
ctgcgctacg cactcctccc ccacctctac acactgttcc accaggccca cgtcgcgggg 2160
gagaccgtgg cccggcccct cttcctggag ttccccaagg actctagcac ctggactgtg 2220
gaccaccagc tcctgtgggg ggaggccctg ctcatcaccc cagtgctcca ggccgggaag 2280
gccgaagtga ctggctactt ccccttgggc acatggtacg acctgcagac ggtgccagta 2340
gaggcccttg gcagcctccc acccccacct gcagctcccc gtgagccagc catccacagc 2400
gaggggcagt gggtgacgct gccggccccc ctggacacca tcaacgtcca cctccgggct 2460
gggtacatca tccccctgca gggccctggc ctcacaacca cagagtcccg ccagcagccc 2520
atggccctgg ctgtggccct gaccaagggt ggggaggccc gaggggagct gttctgggac 2580
gatggagaga gcctggaagt gctggagcga ggggcctaca cacaggtcat cttcctggcc 2640
aggaataaca cgatcgtgaa tgagctggta cgtgtgacca gtgagggagc tggcctgcag 2700
ctgcagaagg tgactgtcct gggcgtggcc acggcgcccc agcaggtcct ctccaacggt 2760
gtccctgtct ccaacttcac ctacagcccc gacaccaagg tcctggacat ctgtgtctcg 2820
ctgttgatgg gagagcagtt tctcgtcagc tggtgttag 2859
<210> 9
<211> 2778
<212> ДНК
<213> искусственная
<220>
<223> hGAAwt без sp
<400> 9
gggcacatcc tactccatga tttcctgctg gttccccgag agctgagtgg ctcctcccca 60
gtcctggagg agactcaccc agctcaccag cagggagcca gcagaccagg gccccgggat 120
gcccaggcac accccgggcg gccgcgagca gtgcccacac agtgcgacgt cccccccaac 180
agccgcttcg attgcgcccc tgacaaggcc atcacccagg aacagtgcga ggcccgcggc 240
tgttgctaca tccctgcaaa gcaggggctg cagggagccc agatggggca gccctggtgc 300
ttcttcccac ccagctaccc cagctacaag ctggagaacc tgagctcctc tgaaatgggc 360
tacacggcca ccctgacccg taccaccccc accttcttcc ccaaggacat cctgaccctg 420
cggctggacg tgatgatgga gactgagaac cgcctccact tcacgatcaa agatccagct 480
aacaggcgct acgaggtgcc cttggagacc ccgcatgtcc acagccgggc accgtcccca 540
ctctacagcg tggagttctc cgaggagccc ttcggggtga tcgtgcgccg gcagctggac 600
ggccgcgtgc tgctgaacac gacggtggcg cccctgttct ttgcggacca gttccttcag 660
ctgtccacct cgctgccctc gcagtatatc acaggcctcg ccgagcacct cagtcccctg 720
atgctcagca ccagctggac caggatcacc ctgtggaacc gggaccttgc gcccacgccc 780
ggtgcgaacc tctacgggtc tcaccctttc tacctggcgc tggaggacgg cgggtcggca 840
cacggggtgt tcctgctaaa cagcaatgcc atggatgtgg tcctgcagcc gagccctgcc 900
cttagctgga ggtcgacagg tgggatcctg gatgtctaca tcttcctggg cccagagccc 960
aagagcgtgg tgcagcagta cctggacgtt gtgggatacc cgttcatgcc gccatactgg 1020
ggcctgggct tccacctgtg ccgctggggc tactcctcca ccgctatcac ccgccaggtg 1080
gtggagaaca tgaccagggc ccacttcccc ctggacgtcc agtggaacga cctggactac 1140
atggactccc ggagggactt cacgttcaac aaggatggct tccgggactt cccggccatg 1200
gtgcaggagc tgcaccaggg cggccggcgc tacatgatga tcgtggatcc tgccatcagc 1260
agctcgggcc ctgccgggag ctacaggccc tacgacgagg gtctgcggag gggggttttc 1320
atcaccaacg agaccggcca gccgctgatt gggaaggtat ggcccgggtc cactgccttc 1380
cccgacttca ccaaccccac agccctggcc tggtgggagg acatggtggc tgagttccat 1440
gaccaggtgc ccttcgacgg catgtggatt gacatgaacg agccttccaa cttcatcagg 1500
ggctctgagg acggctgccc caacaatgag ctggagaacc caccctacgt gcctggggtg 1560
gttgggggga ccctccaggc ggccaccatc tgtgcctcca gccaccagtt tctctccaca 1620
cactacaacc tgcacaacct ctacggcctg accgaagcca tcgcctccca cagggcgctg 1680
gtgaaggctc gggggacacg cccatttgtg atctcccgct cgacctttgc tggccacggc 1740
cgatacgccg gccactggac gggggacgtg tggagctcct gggagcagct cgcctcctcc 1800
gtgccagaaa tcctgcagtt taacctgctg ggggtgcctc tggtcggggc cgacgtctgc 1860
ggcttcctgg gcaacacctc agaggagctg tgtgtgcgct ggacccagct gggggccttc 1920
taccccttca tgcggaacca caacagcctg ctcagtctgc cccaggagcc gtacagcttc 1980
agcgagccgg cccagcaggc catgaggaag gccctcaccc tgcgctacgc actcctcccc 2040
cacctctaca cactgttcca ccaggcccac gtcgcggggg agaccgtggc ccggcccctc 2100
ttcctggagt tccccaagga ctctagcacc tggactgtgg accaccagct cctgtggggg 2160
gaggccctgc tcatcacccc agtgctccag gccgggaagg ccgaagtgac tggctacttc 2220
cccttgggca catggtacga cctgcagacg gtgccagtag aggcccttgg cagcctccca 2280
cccccacctg cagctccccg tgagccagcc atccacagcg aggggcagtg ggtgacgctg 2340
ccggcccccc tggacaccat caacgtccac ctccgggctg ggtacatcat ccccctgcag 2400
ggccctggcc tcacaaccac agagtcccgc cagcagccca tggccctggc tgtggccctg 2460
accaagggtg gggaggcccg aggggagctg ttctgggacg atggagagag cctggaagtg 2520
ctggagcgag gggcctacac acaggtcatc ttcctggcca ggaataacac gatcgtgaat 2580
gagctggtac gtgtgaccag tgagggagct ggcctgcagc tgcagaaggt gactgtcctg 2640
ggcgtggcca cggcgcccca gcaggtcctc tccaacggtg tccctgtctc caacttcacc 2700
tacagccccg acaccaaggt cctggacatc tgtgtctcgc tgttgatggg agagcagttt 2760
ctcgtcagct ggtgttag 2778
<210> 10
<211> 2778
<212> ДНК
<213> искусственная
<220>
<223> hGAAco1 без sp
<400> 10
ggccatatcc tgctgcacga ctttctacta gtgcccagag agctgagcgg cagctctccc 60
gtgctggaag aaacacaccc tgcccatcag cagggcgcct ctagacctgg acctagagat 120
gcccaggccc accccggcag acctagagct gtgcctaccc agtgtgacgt gccccccaac 180
agcagattcg actgcgcccc tgacaaggcc atcacccagg aacagtgcga ggccagaggc 240
tgctgctaca tccctgccaa gcagggactg cagggcgctc agatgggaca gccctggtgc 300
ttcttcccac cctcctaccc cagctacaag ctggaaaacc tgagcagcag cgagatgggc 360
tacaccgcca ccctgaccag aaccaccccc acattcttcc caaaggacat cctgaccctg 420
cggctggacg tgatgatgga aaccgagaac cggctgcact tcaccatcaa ggaccccgcc 480
aatcggagat acgaggtgcc cctggaaacc ccccacgtgc actctagagc ccccagccct 540
ctgtacagcg tggaattcag cgaggaaccc ttcggcgtga tcgtgcggag acagctggat 600
ggcagagtgc tgctgaacac caccgtggcc cctctgttct tcgccgacca gttcctgcag 660
ctgagcacca gcctgcccag ccagtacatc acaggactgg ccgagcacct gagccccctg 720
atgctgagca catcctggac ccggatcacc ctgtggaaca gggatctggc ccctacccct 780
ggcgccaatc tgtacggcag ccaccctttc tacctggccc tggaagatgg cggatctgcc 840
cacggagtgt ttctgctgaa ctccaacgcc atggacgtgg tgctgcagcc tagccctgcc 900
ctgtcttgga gaagcacagg cggcatcctg gatgtgtaca tctttctggg ccccgagccc 960
aagagcgtgg tgcagcagta tctggatgtc gtgggctacc ccttcatgcc cccttactgg 1020
ggcctgggat tccacctgtg cagatggggc tactccagca ccgccatcac cagacaggtg 1080
gtggaaaaca tgaccagagc ccacttccca ctggatgtgc agtggaacga cctggactac 1140
atggacagca gacgggactt caccttcaac aaggacggct tccgggactt ccccgccatg 1200
gtgcaggaac tgcatcaggg cggcagacgg tacatgatga tcgtggatcc cgccatcagc 1260
tcctctggcc ctgccggctc ttacagaccc tacgacgagg gcctgcggag aggcgtgttc 1320
atcaccaacg agacaggcca gcccctgatc ggcaaagtgt ggcctggcag cacagccttc 1380
cccgacttca ccaatcctac cgccctggct tggtgggagg acatggtggc cgagttccac 1440
gaccaggtgc ccttcgacgg catgtggatc gacatgaacg agcccagcaa cttcatccgg 1500
ggcagcgagg atggctgccc caacaacgaa ctggaaaatc ccccttacgt gcccggcgtc 1560
gtgggcggaa cactgcaggc cgctacaatc tgtgccagca gccaccagtt tctgagcacc 1620
cactacaacc tgcacaacct gtacggcctg accgaggcca ttgccagcca ccgcgctctc 1680
gtgaaagcca gaggcacacg gcccttcgtg atcagcagaa gcacctttgc cggccacggc 1740
agatacgccg gacattggac tggcgacgtg tggtcctctt gggagcagct ggcctctagc 1800
gtgcccgaga tcctgcagtt caatctgctg ggcgtgccac tcgtgggcgc cgatgtgtgt 1860
ggcttcctgg gcaacacctc cgaggaactg tgtgtgcggt ggacacagct gggcgccttc 1920
taccctttca tgagaaacca caacagcctg ctgagcctgc cccaggaacc ctacagcttt 1980
agcgagcctg cacagcaggc catgcggaag gccctgacac tgagatacgc tctgctgccc 2040
cacctgtaca ccctgtttca ccaggcccat gtggccggcg agacagtggc cagacctctg 2100
tttctggaat tccccaagga cagcagcacc tggaccgtgg accatcagct gctgtgggga 2160
gaggctctgc tgattacccc agtgctgcag gcaggcaagg ccgaagtgac cggctacttt 2220
cccctgggca cttggtacga cctgcagacc gtgcctgtgg aagccctggg atctctgcct 2280
ccacctcctg ccgctcctag agagcctgcc attcactctg agggccagtg ggtcacactg 2340
cctgcccccc tggataccat caacgtgcac ctgagggccg gctacatcat accactgcag 2400
ggacctggcc tgaccaccac cgagtctaga cagcagccaa tggccctggc cgtggccctg 2460
accaaaggcg gagaagctag gggcgagctg ttctgggacg atggcgagag cctggaagtg 2520
ctggaaagag gcgcctatac ccaagtgatc ttcctggccc ggaacaacac catcgtgaac 2580
gagctggtgc gcgtgacctc tgaaggcgct ggactgcagc tgcagaaagt gaccgtgctg 2640
ggagtggcca cagcccctca gcaggtgctg tctaatggcg tgcccgtgtc caacttcacc 2700
tacagccccg acaccaaggt gctggacatc tgcgtgtcac tgctgatggg agagcagttt 2760
ctggtgtcct ggtgctga 2778
<210> 11
<211> 2778
<212> ДНК
<213> искусственная
<220>
<223> hGAAco2 без sp
<400> 11
ggacacatcc tgctgcacga cttcctgttg gtgcctagag agctgagcgg atcatcccca 60
gtgctggagg agactcatcc tgctcaccaa cagggagctt ccagaccagg accgagagac 120
gcccaagccc atcctggtag accaagagct gtgcctaccc aatgcgacgt gccacccaac 180
tcccgattcg actgcgcgcc agataaggct attacccaag agcagtgtga agccagaggt 240
tgctgctaca tcccagcgaa gcaaggattg caaggcgccc aaatgggaca accttggtgt 300
ttcttccccc cttcgtaccc atcatataaa ctcgaaaacc tgtcctcttc ggaaatgggt 360
tatactgcca ccctcaccag aactactcct actttcttcc cgaaagacat cttgaccttg 420
aggctggacg tgatgatgga gactgaaaac cggctgcatt tcactatcaa agatcctgcc 480
aatcggcgat acgaggtccc tctggaaacc cctcacgtgc actcacgggc tccttctccg 540
ctttactccg tcgaattctc tgaggaaccc ttcggagtga tcgttagacg ccagctggat 600
ggtagagtgc tgttgaacac tactgtggcc ccacttttct tcgctgacca gtttctgcaa 660
ctgtccactt ccctgccatc ccagtacatt actggactcg ccgaacacct gtcgccactg 720
atgctctcga cctcttggac tagaatcact ttgtggaaca gagacttggc ccctactccg 780
ggagcaaatc tgtacggaag ccaccctttt tacctggcgc tcgaagatgg cggatccgct 840
cacggagtgt tcctgctgaa tagcaacgca atggacgtgg tgctgcaacc ttcccctgca 900
ctcagttgga gaagtaccgg gggtattctg gacgtgtaca tcttcctcgg accagaaccc 960
aagagcgtgg tgcagcaata tctggacgtg gtcggatacc cttttatgcc tccttactgg 1020
ggactgggat tccacctttg ccgttggggc tactcatcca ccgccattac cagacaggtg 1080
gtggagaata tgaccagagc ccacttccct ctcgacgtgc agtggaacga tctggactat 1140
atggactccc ggagagattt caccttcaac aaggacgggt tccgcgattt tcccgcgatg 1200
gttcaagagc tccaccaggg tggtcgaaga tatatgatga tcgtcgaccc agccatttcg 1260
agcagcggac ccgctggatc ttatagacct tacgacgaag gccttaggag aggagtgttc 1320
atcacaaacg agactggaca gcctttgatc ggtaaagtgt ggcctggatc aaccgccttt 1380
cctgacttta ccaatcccac tgccttggct tggtgggagg acatggtggc cgaattccac 1440
gaccaagtcc cctttgatgg aatgtggatc gatatgaacg aaccaagcaa ttttatcaga 1500
ggttccgaag acggttgccc caacaacgaa ctggaaaacc ctccttatgt gcccggagtc 1560
gtgggcggaa cattacaggc cgcgactatt tgcgccagca gccaccaatt cctgtccact 1620
cactacaacc tccacaacct ttatggatta accgaagcta ttgcaagtca cagggctctg 1680
gtgaaggcta gagggactag gccctttgtg atctcccgat ccacctttgc cggacacggg 1740
agatacgccg gtcactggac tggtgacgtg tggagctcat gggaacaact ggcctcctcc 1800
gtgccggaaa tcttacagtt caaccttctg ggtgtccctc ttgtcggagc agacgtgtgt 1860
gggtttcttg gtaacacctc cgaggaactg tgtgtgcgct ggactcaact gggtgcattc 1920
tacccattca tgagaaacca caactccttg ctgtccctgc cacaagagcc ctactcgttc 1980
agcgagcctg cacaacaggc tatgcggaag gcactgaccc tgagatacgc cctgcttcca 2040
cacttataca ctctcttcca tcaagcgcat gtggcaggag aaaccgttgc aaggcctctt 2100
ttccttgaat tccccaagga ttcctcgact tggacggtgg atcatcagct gctgtgggga 2160
gaagctctgc tgattactcc agtgttgcaa gccggaaaag ctgaggtgac cggatacttt 2220
ccgctgggaa cctggtacga cctccagact gtccctgttg aagcccttgg atcactgcct 2280
ccgcctccgg cagctccacg cgaaccagct atacattccg agggacagtg ggttacatta 2340
ccagctcctc tggacacaat caacgtccac ttaagagctg gctacattat ccctctgcaa 2400
ggaccaggac tgactacgac cgagagcaga cagcagccaa tggcactggc tgtggctctg 2460
accaagggag gggaagctag aggagaactc ttctgggatg atggggagtc ccttgaagtg 2520
ctggaaagag gcgcttacac tcaagtcatt ttccttgcac ggaacaacac cattgtgaac 2580
gaattggtgc gagtgaccag cgaaggagct ggacttcaac tgcagaaggt cactgtgctc 2640
ggagtggcta ccgctcctca gcaagtgctg tcgaatggag tccccgtgtc aaactttacc 2700
tactcccctg acactaaggt gctcgacatt tgcgtgtccc tcctgatggg agagcagttc 2760
cttgtgtcct ggtgttga 2778
<210> 12
<211> 2754
<212> ДНК
<213> искусственная
<220>
<223> hGAAco1-дельта-8 без sp
<400> 12
ctactagtgc ccagagagct gagcggcagc tctcccgtgc tggaagaaac acaccctgcc 60
catcagcagg gcgcctctag acctggacct agagatgccc aggcccaccc cggcagacct 120
agagctgtgc ctacccagtg tgacgtgccc cccaacagca gattcgactg cgcccctgac 180
aaggccatca cccaggaaca gtgcgaggcc agaggctgct gctacatccc tgccaagcag 240
ggactgcagg gcgctcagat gggacagccc tggtgcttct tcccaccctc ctaccccagc 300
tacaagctgg aaaacctgag cagcagcgag atgggctaca ccgccaccct gaccagaacc 360
acccccacat tcttcccaaa ggacatcctg accctgcggc tggacgtgat gatggaaacc 420
gagaaccggc tgcacttcac catcaaggac cccgccaatc ggagatacga ggtgcccctg 480
gaaacccccc acgtgcactc tagagccccc agccctctgt acagcgtgga attcagcgag 540
gaacccttcg gcgtgatcgt gcggagacag ctggatggca gagtgctgct gaacaccacc 600
gtggcccctc tgttcttcgc cgaccagttc ctgcagctga gcaccagcct gcccagccag 660
tacatcacag gactggccga gcacctgagc cccctgatgc tgagcacatc ctggacccgg 720
atcaccctgt ggaacaggga tctggcccct acccctggcg ccaatctgta cggcagccac 780
cctttctacc tggccctgga agatggcgga tctgcccacg gagtgtttct gctgaactcc 840
aacgccatgg acgtggtgct gcagcctagc cctgccctgt cttggagaag cacaggcggc 900
atcctggatg tgtacatctt tctgggcccc gagcccaaga gcgtggtgca gcagtatctg 960
gatgtcgtgg gctacccctt catgccccct tactggggcc tgggattcca cctgtgcaga 1020
tggggctact ccagcaccgc catcaccaga caggtggtgg aaaacatgac cagagcccac 1080
ttcccactgg atgtgcagtg gaacgacctg gactacatgg acagcagacg ggacttcacc 1140
ttcaacaagg acggcttccg ggacttcccc gccatggtgc aggaactgca tcagggcggc 1200
agacggtaca tgatgatcgt ggatcccgcc atcagctcct ctggccctgc cggctcttac 1260
agaccctacg acgagggcct gcggagaggc gtgttcatca ccaacgagac aggccagccc 1320
ctgatcggca aagtgtggcc tggcagcaca gccttccccg acttcaccaa tcctaccgcc 1380
ctggcttggt gggaggacat ggtggccgag ttccacgacc aggtgccctt cgacggcatg 1440
tggatcgaca tgaacgagcc cagcaacttc atccggggca gcgaggatgg ctgccccaac 1500
aacgaactgg aaaatccccc ttacgtgccc ggcgtcgtgg gcggaacact gcaggccgct 1560
acaatctgtg ccagcagcca ccagtttctg agcacccact acaacctgca caacctgtac 1620
ggcctgaccg aggccattgc cagccaccgc gctctcgtga aagccagagg cacacggccc 1680
ttcgtgatca gcagaagcac ctttgccggc cacggcagat acgccggaca ttggactggc 1740
gacgtgtggt cctcttggga gcagctggcc tctagcgtgc ccgagatcct gcagttcaat 1800
ctgctgggcg tgccactcgt gggcgccgat gtgtgtggct tcctgggcaa cacctccgag 1860
gaactgtgtg tgcggtggac acagctgggc gccttctacc ctttcatgag aaaccacaac 1920
agcctgctga gcctgcccca ggaaccctac agctttagcg agcctgcaca gcaggccatg 1980
cggaaggccc tgacactgag atacgctctg ctgccccacc tgtacaccct gtttcaccag 2040
gcccatgtgg ccggcgagac agtggccaga cctctgtttc tggaattccc caaggacagc 2100
agcacctgga ccgtggacca tcagctgctg tggggagagg ctctgctgat taccccagtg 2160
ctgcaggcag gcaaggccga agtgaccggc tactttcccc tgggcacttg gtacgacctg 2220
cagaccgtgc ctgtggaagc cctgggatct ctgcctccac ctcctgccgc tcctagagag 2280
cctgccattc actctgaggg ccagtgggtc acactgcctg cccccctgga taccatcaac 2340
gtgcacctga gggccggcta catcatacca ctgcagggac ctggcctgac caccaccgag 2400
tctagacagc agccaatggc cctggccgtg gccctgacca aaggcggaga agctaggggc 2460
gagctgttct gggacgatgg cgagagcctg gaagtgctgg aaagaggcgc ctatacccaa 2520
gtgatcttcc tggcccggaa caacaccatc gtgaacgagc tggtgcgcgt gacctctgaa 2580
ggcgctggac tgcagctgca gaaagtgacc gtgctgggag tggccacagc ccctcagcag 2640
gtgctgtcta atggcgtgcc cgtgtccaac ttcacctaca gccccgacac caaggtgctg 2700
gacatctgcg tgtcactgct gatgggagag cagtttctgg tgtcctggtg ctga 2754
<210> 13
<211> 2754
<212> ДНК
<213> искусственная
<220>
<223> hGAAco2-дельта8 без sp
<400> 13
ctgttggtgc ctagagagct gagcggatca tccccagtgc tggaggagac tcatcctgct 60
caccaacagg gagcttccag accaggaccg agagacgccc aagcccatcc tggtagacca 120
agagctgtgc ctacccaatg cgacgtgcca cccaactccc gattcgactg cgcgccagat 180
aaggctatta cccaagagca gtgtgaagcc agaggttgct gctacatccc agcgaagcaa 240
ggattgcaag gcgcccaaat gggacaacct tggtgtttct tccccccttc gtacccatca 300
tataaactcg aaaacctgtc ctcttcggaa atgggttata ctgccaccct caccagaact 360
actcctactt tcttcccgaa agacatcttg accttgaggc tggacgtgat gatggagact 420
gaaaaccggc tgcatttcac tatcaaagat cctgccaatc ggcgatacga ggtccctctg 480
gaaacccctc acgtgcactc acgggctcct tctccgcttt actccgtcga attctctgag 540
gaacccttcg gagtgatcgt tagacgccag ctggatggta gagtgctgtt gaacactact 600
gtggccccac ttttcttcgc tgaccagttt ctgcaactgt ccacttccct gccatcccag 660
tacattactg gactcgccga acacctgtcg ccactgatgc tctcgacctc ttggactaga 720
atcactttgt ggaacagaga cttggcccct actccgggag caaatctgta cggaagccac 780
cctttttacc tggcgctcga agatggcgga tccgctcacg gagtgttcct gctgaatagc 840
aacgcaatgg acgtggtgct gcaaccttcc cctgcactca gttggagaag taccgggggt 900
attctggacg tgtacatctt cctcggacca gaacccaaga gcgtggtgca gcaatatctg 960
gacgtggtcg gatacccttt tatgcctcct tactggggac tgggattcca cctttgccgt 1020
tggggctact catccaccgc cattaccaga caggtggtgg agaatatgac cagagcccac 1080
ttccctctcg acgtgcagtg gaacgatctg gactatatgg actcccggag agatttcacc 1140
ttcaacaagg acgggttccg cgattttccc gcgatggttc aagagctcca ccagggtggt 1200
cgaagatata tgatgatcgt cgacccagcc atttcgagca gcggacccgc tggatcttat 1260
agaccttacg acgaaggcct taggagagga gtgttcatca caaacgagac tggacagcct 1320
ttgatcggta aagtgtggcc tggatcaacc gcctttcctg actttaccaa tcccactgcc 1380
ttggcttggt gggaggacat ggtggccgaa ttccacgacc aagtcccctt tgatggaatg 1440
tggatcgata tgaacgaacc aagcaatttt atcagaggtt ccgaagacgg ttgccccaac 1500
aacgaactgg aaaaccctcc ttatgtgccc ggagtcgtgg gcggaacatt acaggccgcg 1560
actatttgcg ccagcagcca ccaattcctg tccactcact acaacctcca caacctttat 1620
ggattaaccg aagctattgc aagtcacagg gctctggtga aggctagagg gactaggccc 1680
tttgtgatct cccgatccac ctttgccgga cacgggagat acgccggtca ctggactggt 1740
gacgtgtgga gctcatggga acaactggcc tcctccgtgc cggaaatctt acagttcaac 1800
cttctgggtg tccctcttgt cggagcagac gtgtgtgggt ttcttggtaa cacctccgag 1860
gaactgtgtg tgcgctggac tcaactgggt gcattctacc cattcatgag aaaccacaac 1920
tccttgctgt ccctgccaca agagccctac tcgttcagcg agcctgcaca acaggctatg 1980
cggaaggcac tgaccctgag atacgccctg cttccacact tatacactct cttccatcaa 2040
gcgcatgtgg caggagaaac cgttgcaagg cctcttttcc ttgaattccc caaggattcc 2100
tcgacttgga cggtggatca tcagctgctg tggggagaag ctctgctgat tactccagtg 2160
ttgcaagccg gaaaagctga ggtgaccgga tactttccgc tgggaacctg gtacgacctc 2220
cagactgtcc ctgttgaagc ccttggatca ctgcctccgc ctccggcagc tccacgcgaa 2280
ccagctatac attccgaggg acagtgggtt acattaccag ctcctctgga cacaatcaac 2340
gtccacttaa gagctggcta cattatccct ctgcaaggac caggactgac tacgaccgag 2400
agcagacagc agccaatggc actggctgtg gctctgacca agggagggga agctagagga 2460
gaactcttct gggatgatgg ggagtccctt gaagtgctgg aaagaggcgc ttacactcaa 2520
gtcattttcc ttgcacggaa caacaccatt gtgaacgaat tggtgcgagt gaccagcgaa 2580
ggagctggac ttcaactgca gaaggtcact gtgctcggag tggctaccgc tcctcagcaa 2640
gtgctgtcga atggagtccc cgtgtcaaac tttacctact cccctgacac taaggtgctc 2700
gacatttgcg tgtccctcct gatgggagag cagttccttg tgtcctggtg ttga 2754
<210> 14
<211> 397
<212> ДНК
<213> искусственная
<220>
<223> промотор hAAT
<400> 14
gatcttgcta ccagtggaac agccactaag gattctgcag tgagagcaga gggccagcta 60
agtggtactc tcccagagac tgtctgactc acgccacccc ctccaccttg gacacaggac 120
gctgtggttt ctgagccagg tacaatgact cctttcggta agtgcagtgg aagctgtaca 180
ctgcccaggc aaagcgtccg ggcagcgtag gcgggcgact cagatcccag ccagtggact 240
tagcccctgt ttgctcctcc gataactggg gtgaccttgg ttaatattca ccagcagcct 300
cccccgttgc ccctctggat ccactgctta aatacggacg aggacagggc cctgtctcct 360
cagcttcagg caccaccact gacctgggac agtgaat 397
<210> 15
<211> 321
<212> ДНК
<213> искусственная
<220>
<223> управляющая область ApoE
<400> 15
aggctcagag gcacacagga gtttctgggc tcaccctgcc cccttccaac ccctcagttc 60
ccatcctcca gcagctgttt gtgtgctgcc tctgaagtcc acactgaaca aacttcagcc 120
tactcatgtc cctaaaatgg gcaaacattg caagcagcaa acagcaaaca cacagccctc 180
cctgcctgct gaccttggag ctggggcaga ggtcagagac ctctctgggc ccatgccacc 240
tccaacatcc actcgacccc ttggaatttc ggtggagagg agcagaggtt gtcctggcgt 300
ggtttaggta gtgtgagagg g 321
<210> 16
<211> 441
<212> ДНК
<213> искусственная
<220>
<223> интрон HBB2
<400> 16
gtacacatat tgaccaaatc agggtaattt tgcatttgta attttaaaaa atgctttctt 60
cttttaatat acttttttgt ttatcttatt tctaatactt tccctaatct ctttctttca 120
gggcaataat gatacaatgt atcatgcctc tttgcaccat tctaaagaat aacagtgata 180
atttctgggt taaggcaata gcaatatttc tgcatataaa tatttctgca tataaattgt 240
aactgatgta agaggtttca tattgctaat agcagctaca atccagctac cattctgctt 300
ttattttatg gttgggataa ggctggatta ttctgagtcc aagctaggcc cttttgctaa 360
tcatgttcat acctcttatc ttcctcccac agctcctggg caacgtgctg gtctgtgtgc 420
tggcccatca ctttggcaaa g 441
<210> 17
<211> 441
<212> ДНК
<213> искусственная
<220>
<223> модифицированный интрон HBB2
<400> 17
gtacacatat tgaccaaatc agggtaattt tgcatttgta attttaaaaa atgctttctt 60
cttttaatat acttttttgt ttatcttatt tctaatactt tccctaatct ctttctttca 120
gggcaataat gatacaatgt atcatgcctc tttgcaccat tctaaagaat aacagtgata 180
atttctgggt taaggcaata gcaatatttc tgcatataaa tatttctgca tataaattgt 240
aactgatgta agaggtttca tattgctaat agcagctaca atccagctac cattctgctt 300
ttattttctg gttgggataa ggctggatta ttctgagtcc aagctaggcc cttttgctaa 360
tcttgttcat acctcttatc ttcctcccac agctcctggg caacctgctg gtctctctgc 420
tggcccatca ctttggcaaa g 441
<210> 18
<211> 1438
<212> ДНК
<213> искусственная
<220>
<223> интрон FIX
<400> 18
ggtttgtttc cttttttaaa atacattgag tatgcttgcc ttttagatat agaaatatct 60
gatgctgtct tcttcactaa attttgatta catgatttga cagcaatatt gaagagtcta 120
acagccagca cgcaggttgg taagtactgg ttctttgtta gctaggtttt cttcttcttc 180
atttttaaaa ctaaatagat cgacaatgct tatgatgcat ttatgtttaa taaacactgt 240
tcagttcatg atttggtcat gtaattcctg ttagaaaaca ttcatctcct tggtttaaaa 300
aaattaaaag tgggaaaaca aagaaatagc agaatatagt gaaaaaaaat aaccacatta 360
tttttgtttg gacttaccac tttgaaatca aaatgggaaa caaaagcaca aacaatggcc 420
ttatttacac aaaaagtctg attttaagat atatgacatt tcaaggtttc agaagtatgt 480
aatgaggtgt gtctctaatt ttttaaatta tatatcttca atttaaagtt ttagttaaaa 540
cataaagatt aacctttcat tagcaagctg ttagttatca ccaacgcttt tcatggatta 600
ggaaaaaatc attttgtctc tatgtcaaac atcttggagt tgatatttgg ggaaacacaa 660
tactcagttg agttccctag gggagaaaag cacgcttaag aattgacata aagagtagga 720
agttagctaa tgcaacatat atcactttgt tttttcacaa ctacagtgac tttatgtatt 780
tcccagagga aggcatacag ggaagaaatt atcccatttg gacaaacagc atgttctcac 840
aggaagcatt tatcacactt acttgtcaac tttctagaat caaatctagt agctgacagt 900
accaggatca ggggtgccaa ccctaagcac ccccagaaag ctgactggcc ctgtggttcc 960
cactccagac atgatgtcag ctgtgaaatc gacgtcgctg gaccataatt aggcttctgt 1020
tcttcaggag acatttgttc aaagtcattt gggcaaccat attctgaaaa cagcccagcc 1080
agggtgatgg atcactttgc aaagatcctc aatgagctat tttcaagtga tgacaaagtg 1140
tgaagttaac cgctcatttg agaactttct ttttcatcca aagtaaattc aaatatgatt 1200
agaaatctga ccttttatta ctggaattct cttgactaaa agtaaaattg aattttaatt 1260
cctaaatctc catgtgtata cagtactgtg ggaacatcac agattttggc tccatgccct 1320
aaagagaaat tggctttcag attatttgga ttaaaaacaa agactttctt aagagatgta 1380
aaattttcat gatgttttct tttttgctaa aactaaagaa ttattctttt acatttca 1438
<210> 19
<211> 1438
<212> ДНК
<213> искусственная
<220>
<223> модифицированный интрон FIX
<400> 19
ggtttgtttc cttttttaaa atacattgag tatgcttgcc ttttagatat agaaatatct 60
gatgctgtct tcttcactaa attttgatta catgatttga cagcaatatt gaagagtcta 120
acagccagca cgcaggttgg taagtactgg ttctttgtta gctaggtttt cttcttcttc 180
atttttaaaa ctaaatagat cgacattgct tttgttgcat ttatgtttaa taaacactgt 240
tcagttcatg atttggtcat gtaattcctg ttagaaaaca ttcatctcct tggtttaaaa 300
aaattaaaag tgggaaaaca aagaaatagc agaatatagt gaaaaaaaat aaccacatta 360
tttttgtttg gacttaccac tttgaaatca aattgggaaa caaaagcaca aacaatggcc 420
ttatttacac aaaaagtctg attttaagat atatgacatt tcaaggtttc agaagtatgt 480
aatgaggtgt gtctctaatt ttttaaatta tatatcttca atttaaagtt ttagttaaaa 540
cataaagatt aacctttcat tagcaagctg ttagttatca ccaacgcttt tcatggatta 600
ggaaaaaatc attttgtctc tttgtcaaac atcttggagt tgatatttgg ggaaacacaa 660
tactcagttg agttccctag gggagaaaag cacgcttaag aattgacata aagagtagga 720
agttagctat tgcaacatat atcactttgt tttttcacaa ctacagtgac tttttgtatt 780
tcccagagga aggcatacag ggaagaaatt atcccatttg gacaaacagc ttgttctcac 840
aggaagcatt tatcacactt acttgtcaac tttctagaat caaatctagt agctgacagt 900
accaggatca ggggtgccaa ccctaagcac ccccagaaag ctgactggcc ctgtggttcc 960
cactccagac atgatgtcag ctgtgaaatc gacgtcgctg gaccataatt aggcttctgt 1020
tcttcaggag acatttgttc aaagtcattt gggcaaccat attctgaaaa cagcccagcc 1080
agggtgttgg atcactttgc aaagatcctc attgagctat tttcaagtgt tgacaaagtg 1140
tgaagttaac cgctcatttg agaactttct ttttcatcca aagtaaattc aaatatgatt 1200
agaaatctga ccttttatta ctggaattct cttgactaaa agtaaaattg aattttaatt 1260
cctaaatctc catgtgtata cagtactgtg ggaacatcac agattttggc tccatgccct 1320
aaagagaaat tggctttcag attatttgga ttaaaaacaa agactttctt aagagatgta 1380
aaattttctt gttgttttct tttttgctaa aactaaagaa ttattctttt acatttca 1438
<210> 20
<211> 881
<212> ДНК
<213> искусственная
<220>
<223> интрон бета-глобина курицы
<400> 20
gcgggagtcg ctgcgttgcc ttcgccccgt gccccgctcc gccgccgcct cgcgccgccc 60
gccccggctc tgactgaccg cgttactccc acaggtgagc gggcgggacg gcccttctcc 120
tccgggctgt aattagcgct tggtttaatg acggcttgtt tcttttctgt ggctgcgtga 180
aagccttgag gggctccggg agggcccttt gtgcgggggg agcggctcgg ggggtgcgtg 240
cgtgtgtgtg tgcgtgggga gcgccgcgtg cggctccgcg ctgcccggcg gctgtgagcg 300
ctgcgggcgc ggcgcggggc tttgtgcgct ccgcagtgtg cgcgagggga gcgcggccgg 360
gggcggtgcc ccgcggtgcg gggggggctg cgaggggaac aaaggctgcg tgcggggtgt 420
gtgcgtgggg gggtgagcag ggggtgtggg cgcgtcggtc gggctgcaac cccccctgca 480
cccccctccc cgagttgctg agcacggccc ggcttcgggt gcggggctcc gtacggggcg 540
tggcgcgggg ctcgccgtgc cgggcggggg gtggcggcag gtgggggtgc cgggcggggc 600
ggggccgcct cgggccgggg agggctcggg ggaggggcgc ggcggccccc ggagcgccgg 660
cggctgtcga ggcgcggcga gccgcagcca ttgcctttta tggtaatcgt gcgagagggc 720
gcagggactt cctttgtccc aaatctgtgc ggagccgaaa tctgggaggc gccgccgcac 780
cccctctagc gggcgcgggg cgaagcggtg cggcgccggc aggaaggaaa tgggcgggga 840
gggccttcgt gcgtcgccgc gccgccgtcc ccttctccct c 881
<210> 21
<211> 881
<212> ДНК
<213> искусственная
<220>
<223> модифицированный интрон бета-глобина курицы
<400> 21
gcgggagtcg ctgcgttgcc ttcgccccgt gccccgctcc gccgccgcct cgcgccgccc 60
gccccggctc tgactgaccg cgttactccc acaggtgagc gggcgggacg gcccttctcc 120
tccgggctgt aattagcgct tggtttaatg acggcttgtt tcttttctgt ggctgcgtga 180
aagccttgag gggctccggg agggcccttt gtgcgggggg agcggctcgg ggggtgcgtg 240
cgtgtgtgtg tgcgtgggga gcgccgcgtg cggctccgcg ctgcccggcg gctgtgagcg 300
ctgcgggcgc ggcgcggggc tttgtgcgct ccgcagtgtg cgcgagggga gcgcggccgg 360
gggcggtgcc ccgcggtgcg gggggggctg cgaggggaac aaaggctgcg tgcggggtgt 420
gtgcgtgggg gggtgagcag ggggtgtggg cgcgtcggtc gggctgcaac cccccctgca 480
cccccctccc cgagttgctg agcacggccc ggcttcgggt gcggggctcc gtacggggcg 540
tggcgcgggg ctcgccgtgc cgggcggggg gtggcggcag gtgggggtgc cgggcggggc 600
ggggccgcct cgggccgggg agggctcggg ggaggggcgc ggcggccccc ggagcgccgg 660
cggctgtcga ggcgcggcga gccgcagcca ttgccttttt tggtaatcgt gcgagagggc 720
gcagggactt cctttgtccc aaatctgtgc ggagccgaaa tctgggaggc gccgccgcac 780
cccctctagc gggcgcgggg cgaagcggtg cggcgccggc aggaaggaat tgggcgggga 840
gggccttcgt gcgtcgccgc gccgccgtcc ccttctccct c 881
<210> 22
<211> 4318
<212> ДНК
<213> искусственная
<220>
<223> конструкция: sp2+hGAAwt-дельта-8
<400> 22
aggctcagag gcacacagga gtttctgggc tcaccctgcc cccttccaac ccctcagttc 60
ccatcctcca gcagctgttt gtgtgctgcc tctgaagtcc acactgaaca aacttcagcc 120
tactcatgtc cctaaaatgg gcaaacattg caagcagcaa acagcaaaca cacagccctc 180
cctgcctgct gaccttggag ctggggcaga ggtcagagac ctctctgggc ccatgccacc 240
tccaacatcc actcgacccc ttggaatttc ggtggagagg agcagaggtt gtcctggcgt 300
ggtttaggta gtgtgagagg ggtacccggg gatcttgcta ccagtggaac agccactaag 360
gattctgcag tgagagcaga gggccagcta agtggtactc tcccagagac tgtctgactc 420
acgccacccc ctccaccttg gacacaggac gctgtggttt ctgagccagg tacaatgact 480
cctttcggta agtgcagtgg aagctgtaca ctgcccaggc aaagcgtccg ggcagcgtag 540
gcgggcgact cagatcccag ccagtggact tagcccctgt ttgctcctcc gataactggg 600
gtgaccttgg ttaatattca ccagcagcct cccccgttgc ccctctggat ccactgctta 660
aatacggacg aggacagggc cctgtctcct cagcttcagg caccaccact gacctgggac 720
agtgaataga tcctgagaac ttcagggtga gtctatggga cccttgatgt tttctttccc 780
cttcttttct atggttaagt tcatgtcata ggaaggggag aagtaacagg gtacacatat 840
tgaccaaatc agggtaattt tgcatttgta attttaaaaa atgctttctt cttttaatat 900
acttttttgt ttatcttatt tctaatactt tccctaatct ctttctttca gggcaataat 960
gatacaatgt atcatgcctc tttgcaccat tctaaagaat aacagtgata atttctgggt 1020
taaggcaata gcaatatttc tgcatataaa tatttctgca tataaattgt aactgatgta 1080
agaggtttca tattgctaat agcagctaca atccagctac cattctgctt ttattttctg 1140
gttgggataa ggctggatta ttctgagtcc aagctaggcc cttttgctaa tcttgttcat 1200
acctcttatc ttcctcccac agctcctggg caacctgctg gtctctctgc tggcccatca 1260
ctttggcaaa gcacgcgtgc caccatgccg tcttctgtct cgtggggcat cctcctgctg 1320
gcaggcctgt gctgcctggt ccctgtctcc ctggctctgc tggttccccg agagctgagt 1380
ggctcctccc cagtcctgga ggagactcac ccagctcacc agcagggagc cagcagacca 1440
gggccccggg atgcccaggc acaccccggg cggccgcgag cagtgcccac acagtgcgac 1500
gtccccccca acagccgctt cgattgcgcc cctgacaagg ccatcaccca ggaacagtgc 1560
gaggcccgcg gctgttgcta catccctgca aagcaggggc tgcagggagc ccagatgggg 1620
cagccctggt gcttcttccc acccagctac cccagctaca agctggagaa cctgagctcc 1680
tctgaaatgg gctacacggc caccctgacc cgtaccaccc ccaccttctt ccccaaggac 1740
atcctgaccc tgcggctgga cgtgatgatg gagactgaga accgcctcca cttcacgatc 1800
aaagatccag ctaacaggcg ctacgaggtg cccttggaga ccccgcatgt ccacagccgg 1860
gcaccgtccc cactctacag cgtggagttc tccgaggagc ccttcggggt gatcgtgcgc 1920
cggcagctgg acggccgcgt gctgctgaac acgacggtgg cgcccctgtt ctttgcggac 1980
cagttccttc agctgtccac ctcgctgccc tcgcagtata tcacaggcct cgccgagcac 2040
ctcagtcccc tgatgctcag caccagctgg accaggatca ccctgtggaa ccgggacctt 2100
gcgcccacgc ccggtgcgaa cctctacggg tctcaccctt tctacctggc gctggaggac 2160
ggcgggtcgg cacacggggt gttcctgcta aacagcaatg ccatggatgt ggtcctgcag 2220
ccgagccctg cccttagctg gaggtcgaca ggtgggatcc tggatgtcta catcttcctg 2280
ggcccagagc ccaagagcgt ggtgcagcag tacctggacg ttgtgggata cccgttcatg 2340
ccgccatact ggggcctggg cttccacctg tgccgctggg gctactcctc caccgctatc 2400
acccgccagg tggtggagaa catgaccagg gcccacttcc ccctggacgt ccagtggaac 2460
gacctggact acatggactc ccggagggac ttcacgttca acaaggatgg cttccgggac 2520
ttcccggcca tggtgcagga gctgcaccag ggcggccggc gctacatgat gatcgtggat 2580
cctgccatca gcagctcggg ccctgccggg agctacaggc cctacgacga gggtctgcgg 2640
aggggggttt tcatcaccaa cgagaccggc cagccgctga ttgggaaggt atggcccggg 2700
tccactgcct tccccgactt caccaacccc acagccctgg cctggtggga ggacatggtg 2760
gctgagttcc atgaccaggt gcccttcgac ggcatgtgga ttgacatgaa cgagccttcc 2820
aacttcatca ggggctctga ggacggctgc cccaacaatg agctggagaa cccaccctac 2880
gtgcctgggg tggttggggg gaccctccag gcggccacca tctgtgcctc cagccaccag 2940
tttctctcca cacactacaa cctgcacaac ctctacggcc tgaccgaagc catcgcctcc 3000
cacagggcgc tggtgaaggc tcgggggaca cgcccatttg tgatctcccg ctcgaccttt 3060
gctggccacg gccgatacgc cggccactgg acgggggacg tgtggagctc ctgggagcag 3120
ctcgcctcct ccgtgccaga aatcctgcag tttaacctgc tgggggtgcc tctggtcggg 3180
gccgacgtct gcggcttcct gggcaacacc tcagaggagc tgtgtgtgcg ctggacccag 3240
ctgggggcct tctacccctt catgcggaac cacaacagcc tgctcagtct gccccaggag 3300
ccgtacagct tcagcgagcc ggcccagcag gccatgagga aggccctcac cctgcgctac 3360
gcactcctcc cccacctcta cacactgttc caccaggccc acgtcgcggg ggagaccgtg 3420
gcccggcccc tcttcctgga gttccccaag gactctagca cctggactgt ggaccaccag 3480
ctcctgtggg gggaggccct gctcatcacc ccagtgctcc aggccgggaa ggccgaagtg 3540
actggctact tccccttggg cacatggtac gacctgcaga cggtgccagt agaggccctt 3600
ggcagcctcc cacccccacc tgcagctccc cgtgagccag ccatccacag cgaggggcag 3660
tgggtgacgc tgccggcccc cctggacacc atcaacgtcc acctccgggc tgggtacatc 3720
atccccctgc agggccctgg cctcacaacc acagagtccc gccagcagcc catggccctg 3780
gctgtggccc tgaccaaggg tggggaggcc cgaggggagc tgttctggga cgatggagag 3840
agcctggaag tgctggagcg aggggcctac acacaggtca tcttcctggc caggaataac 3900
acgatcgtga atgagctggt acgtgtgacc agtgagggag ctggcctgca gctgcagaag 3960
gtgactgtcc tgggcgtggc cacggcgccc cagcaggtcc tctccaacgg tgtccctgtc 4020
tccaacttca cctacagccc cgacaccaag gtcctggaca tctgtgtctc gctgttgatg 4080
ggagagcagt ttctcgtcag ctggtgttag ctcgagagat ctaccggtga attcaccgcg 4140
ggtttaaact gtgccttcta gttgccagcc atctgttgtt tgcccctccc ccgtgccttc 4200
cttgaccctg gaaggtgcca ctcccactgt cctttcctaa taaaatgagg aaattgcatc 4260
gcattgtctg agtaggtgtc attctattct ggggggtggg gtgggggcta gctctaga 4318
<210> 23
<211> 4318
<212> ДНК
<213> искусственная
<220>
<223> конструкция: sp2+hGAAco1-дельта-8
<400> 23
aggctcagag gcacacagga gtttctgggc tcaccctgcc cccttccaac ccctcagttc 60
ccatcctcca gcagctgttt gtgtgctgcc tctgaagtcc acactgaaca aacttcagcc 120
tactcatgtc cctaaaatgg gcaaacattg caagcagcaa acagcaaaca cacagccctc 180
cctgcctgct gaccttggag ctggggcaga ggtcagagac ctctctgggc ccatgccacc 240
tccaacatcc actcgacccc ttggaatttc ggtggagagg agcagaggtt gtcctggcgt 300
ggtttaggta gtgtgagagg ggtacccggg gatcttgcta ccagtggaac agccactaag 360
gattctgcag tgagagcaga gggccagcta agtggtactc tcccagagac tgtctgactc 420
acgccacccc ctccaccttg gacacaggac gctgtggttt ctgagccagg tacaatgact 480
cctttcggta agtgcagtgg aagctgtaca ctgcccaggc aaagcgtccg ggcagcgtag 540
gcgggcgact cagatcccag ccagtggact tagcccctgt ttgctcctcc gataactggg 600
gtgaccttgg ttaatattca ccagcagcct cccccgttgc ccctctggat ccactgctta 660
aatacggacg aggacagggc cctgtctcct cagcttcagg caccaccact gacctgggac 720
agtgaataga tcctgagaac ttcagggtga gtctatggga cccttgatgt tttctttccc 780
cttcttttct atggttaagt tcatgtcata ggaaggggag aagtaacagg gtacacatat 840
tgaccaaatc agggtaattt tgcatttgta attttaaaaa atgctttctt cttttaatat 900
acttttttgt ttatcttatt tctaatactt tccctaatct ctttctttca gggcaataat 960
gatacaatgt atcatgcctc tttgcaccat tctaaagaat aacagtgata atttctgggt 1020
taaggcaata gcaatatttc tgcatataaa tatttctgca tataaattgt aactgatgta 1080
agaggtttca tattgctaat agcagctaca atccagctac cattctgctt ttattttctg 1140
gttgggataa ggctggatta ttctgagtcc aagctaggcc cttttgctaa tcttgttcat 1200
acctcttatc ttcctcccac agctcctggg caacctgctg gtctctctgc tggcccatca 1260
ctttggcaaa gcacgcgtgc caccatgcct agctctgtgt cctggggcat tctgctgctg 1320
gccggcctgt gttgtctggt gcctgtgtct ctggccctac tagtgcccag agagctgagc 1380
ggcagctctc ccgtgctgga agaaacacac cctgcccatc agcagggcgc ctctagacct 1440
ggacctagag atgcccaggc ccaccccggc agacctagag ctgtgcctac ccagtgtgac 1500
gtgcccccca acagcagatt cgactgcgcc cctgacaagg ccatcaccca ggaacagtgc 1560
gaggccagag gctgctgcta catccctgcc aagcagggac tgcagggcgc tcagatggga 1620
cagccctggt gcttcttccc accctcctac cccagctaca agctggaaaa cctgagcagc 1680
agcgagatgg gctacaccgc caccctgacc agaaccaccc ccacattctt cccaaaggac 1740
atcctgaccc tgcggctgga cgtgatgatg gaaaccgaga accggctgca cttcaccatc 1800
aaggaccccg ccaatcggag atacgaggtg cccctggaaa ccccccacgt gcactctaga 1860
gcccccagcc ctctgtacag cgtggaattc agcgaggaac ccttcggcgt gatcgtgcgg 1920
agacagctgg atggcagagt gctgctgaac accaccgtgg cccctctgtt cttcgccgac 1980
cagttcctgc agctgagcac cagcctgccc agccagtaca tcacaggact ggccgagcac 2040
ctgagccccc tgatgctgag cacatcctgg acccggatca ccctgtggaa cagggatctg 2100
gcccctaccc ctggcgccaa tctgtacggc agccaccctt tctacctggc cctggaagat 2160
ggcggatctg cccacggagt gtttctgctg aactccaacg ccatggacgt ggtgctgcag 2220
cctagccctg ccctgtcttg gagaagcaca ggcggcatcc tggatgtgta catctttctg 2280
ggccccgagc ccaagagcgt ggtgcagcag tatctggatg tcgtgggcta ccccttcatg 2340
cccccttact ggggcctggg attccacctg tgcagatggg gctactccag caccgccatc 2400
accagacagg tggtggaaaa catgaccaga gcccacttcc cactggatgt gcagtggaac 2460
gacctggact acatggacag cagacgggac ttcaccttca acaaggacgg cttccgggac 2520
ttccccgcca tggtgcagga actgcatcag ggcggcagac ggtacatgat gatcgtggat 2580
cccgccatca gctcctctgg ccctgccggc tcttacagac cctacgacga gggcctgcgg 2640
agaggcgtgt tcatcaccaa cgagacaggc cagcccctga tcggcaaagt gtggcctggc 2700
agcacagcct tccccgactt caccaatcct accgccctgg cttggtggga ggacatggtg 2760
gccgagttcc acgaccaggt gcccttcgac ggcatgtgga tcgacatgaa cgagcccagc 2820
aacttcatcc ggggcagcga ggatggctgc cccaacaacg aactggaaaa tcccccttac 2880
gtgcccggcg tcgtgggcgg aacactgcag gccgctacaa tctgtgccag cagccaccag 2940
tttctgagca cccactacaa cctgcacaac ctgtacggcc tgaccgaggc cattgccagc 3000
caccgcgctc tcgtgaaagc cagaggcaca cggcccttcg tgatcagcag aagcaccttt 3060
gccggccacg gcagatacgc cggacattgg actggcgacg tgtggtcctc ttgggagcag 3120
ctggcctcta gcgtgcccga gatcctgcag ttcaatctgc tgggcgtgcc actcgtgggc 3180
gccgatgtgt gtggcttcct gggcaacacc tccgaggaac tgtgtgtgcg gtggacacag 3240
ctgggcgcct tctacccttt catgagaaac cacaacagcc tgctgagcct gccccaggaa 3300
ccctacagct ttagcgagcc tgcacagcag gccatgcgga aggccctgac actgagatac 3360
gctctgctgc cccacctgta caccctgttt caccaggccc atgtggccgg cgagacagtg 3420
gccagacctc tgtttctgga attccccaag gacagcagca cctggaccgt ggaccatcag 3480
ctgctgtggg gagaggctct gctgattacc ccagtgctgc aggcaggcaa ggccgaagtg 3540
accggctact ttcccctggg cacttggtac gacctgcaga ccgtgcctgt ggaagccctg 3600
ggatctctgc ctccacctcc tgccgctcct agagagcctg ccattcactc tgagggccag 3660
tgggtcacac tgcctgcccc cctggatacc atcaacgtgc acctgagggc cggctacatc 3720
ataccactgc agggacctgg cctgaccacc accgagtcta gacagcagcc aatggccctg 3780
gccgtggccc tgaccaaagg cggagaagct aggggcgagc tgttctggga cgatggcgag 3840
agcctggaag tgctggaaag aggcgcctat acccaagtga tcttcctggc ccggaacaac 3900
accatcgtga acgagctggt gcgcgtgacc tctgaaggcg ctggactgca gctgcagaaa 3960
gtgaccgtgc tgggagtggc cacagcccct cagcaggtgc tgtctaatgg cgtgcccgtg 4020
tccaacttca cctacagccc cgacaccaag gtgctggaca tctgcgtgtc actgctgatg 4080
ggagagcagt ttctggtgtc ctggtgctga ctcgagagat ctaccggtga attcaccgcg 4140
ggtttaaact gtgccttcta gttgccagcc atctgttgtt tgcccctccc ccgtgccttc 4200
cttgaccctg gaaggtgcca ctcccactgt cctttcctaa taaaatgagg aaattgcatc 4260
gcattgtctg agtaggtgtc attctattct ggggggtggg gtgggggcta gctctaga 4318
<210> 24
<211> 4318
<212> ДНК
<213> искусственная
<220>
<223> конструкция: sp2+hGAAco2-дельта-8
<400> 24
aggctcagag gcacacagga gtttctgggc tcaccctgcc cccttccaac ccctcagttc 60
ccatcctcca gcagctgttt gtgtgctgcc tctgaagtcc acactgaaca aacttcagcc 120
tactcatgtc cctaaaatgg gcaaacattg caagcagcaa acagcaaaca cacagccctc 180
cctgcctgct gaccttggag ctggggcaga ggtcagagac ctctctgggc ccatgccacc 240
tccaacatcc actcgacccc ttggaatttc ggtggagagg agcagaggtt gtcctggcgt 300
ggtttaggta gtgtgagagg ggtacccggg gatcttgcta ccagtggaac agccactaag 360
gattctgcag tgagagcaga gggccagcta agtggtactc tcccagagac tgtctgactc 420
acgccacccc ctccaccttg gacacaggac gctgtggttt ctgagccagg tacaatgact 480
cctttcggta agtgcagtgg aagctgtaca ctgcccaggc aaagcgtccg ggcagcgtag 540
gcgggcgact cagatcccag ccagtggact tagcccctgt ttgctcctcc gataactggg 600
gtgaccttgg ttaatattca ccagcagcct cccccgttgc ccctctggat ccactgctta 660
aatacggacg aggacagggc cctgtctcct cagcttcagg caccaccact gacctgggac 720
agtgaataga tcctgagaac ttcagggtga gtctatggga cccttgatgt tttctttccc 780
cttcttttct atggttaagt tcatgtcata ggaaggggag aagtaacagg gtacacatat 840
tgaccaaatc agggtaattt tgcatttgta attttaaaaa atgctttctt cttttaatat 900
acttttttgt ttatcttatt tctaatactt tccctaatct ctttctttca gggcaataat 960
gatacaatgt atcatgcctc tttgcaccat tctaaagaat aacagtgata atttctgggt 1020
taaggcaata gcaatatttc tgcatataaa tatttctgca tataaattgt aactgatgta 1080
agaggtttca tattgctaat agcagctaca atccagctac cattctgctt ttattttctg 1140
gttgggataa ggctggatta ttctgagtcc aagctaggcc cttttgctaa tcttgttcat 1200
acctcttatc ttcctcccac agctcctggg caacctgctg gtctctctgc tggcccatca 1260
ctttggcaaa gcacgcgtgc caccatgcca tcgtcagtgt cttggggcat tcttctgctc 1320
gccggattgt gttgcctggt gcctgtctca ttggccctgt tggtgcctag agagctgagc 1380
ggatcatccc cagtgctgga ggagactcat cctgctcacc aacagggagc ttccagacca 1440
ggaccgagag acgcccaagc ccatcctggt agaccaagag ctgtgcctac ccaatgcgac 1500
gtgccaccca actcccgatt cgactgcgcg ccagataagg ctattaccca agagcagtgt 1560
gaagccagag gttgctgcta catcccagcg aagcaaggat tgcaaggcgc ccaaatggga 1620
caaccttggt gtttcttccc cccttcgtac ccatcatata aactcgaaaa cctgtcctct 1680
tcggaaatgg gttatactgc caccctcacc agaactactc ctactttctt cccgaaagac 1740
atcttgacct tgaggctgga cgtgatgatg gagactgaaa accggctgca tttcactatc 1800
aaagatcctg ccaatcggcg atacgaggtc cctctggaaa cccctcacgt gcactcacgg 1860
gctccttctc cgctttactc cgtcgaattc tctgaggaac ccttcggagt gatcgttaga 1920
cgccagctgg atggtagagt gctgttgaac actactgtgg ccccactttt cttcgctgac 1980
cagtttctgc aactgtccac ttccctgcca tcccagtaca ttactggact cgccgaacac 2040
ctgtcgccac tgatgctctc gacctcttgg actagaatca ctttgtggaa cagagacttg 2100
gcccctactc cgggagcaaa tctgtacgga agccaccctt tttacctggc gctcgaagat 2160
ggcggatccg ctcacggagt gttcctgctg aatagcaacg caatggacgt ggtgctgcaa 2220
ccttcccctg cactcagttg gagaagtacc gggggtattc tggacgtgta catcttcctc 2280
ggaccagaac ccaagagcgt ggtgcagcaa tatctggacg tggtcggata cccttttatg 2340
cctccttact ggggactggg attccacctt tgccgttggg gctactcatc caccgccatt 2400
accagacagg tggtggagaa tatgaccaga gcccacttcc ctctcgacgt gcagtggaac 2460
gatctggact atatggactc ccggagagat ttcaccttca acaaggacgg gttccgcgat 2520
tttcccgcga tggttcaaga gctccaccag ggtggtcgaa gatatatgat gatcgtcgac 2580
ccagccattt cgagcagcgg acccgctgga tcttatagac cttacgacga aggccttagg 2640
agaggagtgt tcatcacaaa cgagactgga cagcctttga tcggtaaagt gtggcctgga 2700
tcaaccgcct ttcctgactt taccaatccc actgccttgg cttggtggga ggacatggtg 2760
gccgaattcc acgaccaagt cccctttgat ggaatgtgga tcgatatgaa cgaaccaagc 2820
aattttatca gaggttccga agacggttgc cccaacaacg aactggaaaa ccctccttat 2880
gtgcccggag tcgtgggcgg aacattacag gccgcgacta tttgcgccag cagccaccaa 2940
ttcctgtcca ctcactacaa cctccacaac ctttatggat taaccgaagc tattgcaagt 3000
cacagggctc tggtgaaggc tagagggact aggccctttg tgatctcccg atccaccttt 3060
gccggacacg ggagatacgc cggtcactgg actggtgacg tgtggagctc atgggaacaa 3120
ctggcctcct ccgtgccgga aatcttacag ttcaaccttc tgggtgtccc tcttgtcgga 3180
gcagacgtgt gtgggtttct tggtaacacc tccgaggaac tgtgtgtgcg ctggactcaa 3240
ctgggtgcat tctacccatt catgagaaac cacaactcct tgctgtccct gccacaagag 3300
ccctactcgt tcagcgagcc tgcacaacag gctatgcgga aggcactgac cctgagatac 3360
gccctgcttc cacacttata cactctcttc catcaagcgc atgtggcagg agaaaccgtt 3420
gcaaggcctc ttttccttga attccccaag gattcctcga cttggacggt ggatcatcag 3480
ctgctgtggg gagaagctct gctgattact ccagtgttgc aagccggaaa agctgaggtg 3540
accggatact ttccgctggg aacctggtac gacctccaga ctgtccctgt tgaagccctt 3600
ggatcactgc ctccgcctcc ggcagctcca cgcgaaccag ctatacattc cgagggacag 3660
tgggttacat taccagctcc tctggacaca atcaacgtcc acttaagagc tggctacatt 3720
atccctctgc aaggaccagg actgactacg accgagagca gacagcagcc aatggcactg 3780
gctgtggctc tgaccaaggg aggggaagct agaggagaac tcttctggga tgatggggag 3840
tcccttgaag tgctggaaag aggcgcttac actcaagtca ttttccttgc acggaacaac 3900
accattgtga acgaattggt gcgagtgacc agcgaaggag ctggacttca actgcagaag 3960
gtcactgtgc tcggagtggc taccgctcct cagcaagtgc tgtcgaatgg agtccccgtg 4020
tcaaacttta cctactcccc tgacactaag gtgctcgaca tttgcgtgtc cctcctgatg 4080
ggagagcagt tccttgtgtc ctggtgttga ctcgagagat ctaccggtga attcaccgcg 4140
ggtttaaact gtgccttcta gttgccagcc atctgttgtt tgcccctccc ccgtgccttc 4200
cttgaccctg gaaggtgcca ctcccactgt cctttcctaa taaaatgagg aaattgcatc 4260
gcattgtctg agtaggtgtc attctattct ggggggtggg gtgggggcta gctctaga 4318
<210> 25
<211> 4300
<212> ДНК
<213> искусственная
<220>
<223> конструкция: sp7+hGAAco1-дельта-8
<400> 25
aggctcagag gcacacagga gtttctgggc tcaccctgcc cccttccaac ccctcagttc 60
ccatcctcca gcagctgttt gtgtgctgcc tctgaagtcc acactgaaca aacttcagcc 120
tactcatgtc cctaaaatgg gcaaacattg caagcagcaa acagcaaaca cacagccctc 180
cctgcctgct gaccttggag ctggggcaga ggtcagagac ctctctgggc ccatgccacc 240
tccaacatcc actcgacccc ttggaatttc ggtggagagg agcagaggtt gtcctggcgt 300
ggtttaggta gtgtgagagg ggtacccggg gatcttgcta ccagtggaac agccactaag 360
gattctgcag tgagagcaga gggccagcta agtggtactc tcccagagac tgtctgactc 420
acgccacccc ctccaccttg gacacaggac gctgtggttt ctgagccagg tacaatgact 480
cctttcggta agtgcagtgg aagctgtaca ctgcccaggc aaagcgtccg ggcagcgtag 540
gcgggcgact cagatcccag ccagtggact tagcccctgt ttgctcctcc gataactggg 600
gtgaccttgg ttaatattca ccagcagcct cccccgttgc ccctctggat ccactgctta 660
aatacggacg aggacagggc cctgtctcct cagcttcagg caccaccact gacctgggac 720
agtgaataga tcctgagaac ttcagggtga gtctatggga cccttgatgt tttctttccc 780
cttcttttct atggttaagt tcatgtcata ggaaggggag aagtaacagg gtacacatat 840
tgaccaaatc agggtaattt tgcatttgta attttaaaaa atgctttctt cttttaatat 900
acttttttgt ttatcttatt tctaatactt tccctaatct ctttctttca gggcaataat 960
gatacaatgt atcatgcctc tttgcaccat tctaaagaat aacagtgata atttctgggt 1020
taaggcaata gcaatatttc tgcatataaa tatttctgca tataaattgt aactgatgta 1080
agaggtttca tattgctaat agcagctaca atccagctac cattctgctt ttattttctg 1140
gttgggataa ggctggatta ttctgagtcc aagctaggcc cttttgctaa tcttgttcat 1200
acctcttatc ttcctcccac agctcctggg caacctgctg gtctctctgc tggcccatca 1260
ctttggcaaa gcacgcgtgc caccatggcc tttctgtggc tgctgagctg ttgggccctg 1320
ctgggcacca ccttcggcct actagtgccc agagagctga gcggcagctc tcccgtgctg 1380
gaagaaacac accctgccca tcagcagggc gcctctagac ctggacctag agatgcccag 1440
gcccaccccg gcagacctag agctgtgcct acccagtgtg acgtgccccc caacagcaga 1500
ttcgactgcg cccctgacaa ggccatcacc caggaacagt gcgaggccag aggctgctgc 1560
tacatccctg ccaagcaggg actgcagggc gctcagatgg gacagccctg gtgcttcttc 1620
ccaccctcct accccagcta caagctggaa aacctgagca gcagcgagat gggctacacc 1680
gccaccctga ccagaaccac ccccacattc ttcccaaagg acatcctgac cctgcggctg 1740
gacgtgatga tggaaaccga gaaccggctg cacttcacca tcaaggaccc cgccaatcgg 1800
agatacgagg tgcccctgga aaccccccac gtgcactcta gagcccccag ccctctgtac 1860
agcgtggaat tcagcgagga acccttcggc gtgatcgtgc ggagacagct ggatggcaga 1920
gtgctgctga acaccaccgt ggcccctctg ttcttcgccg accagttcct gcagctgagc 1980
accagcctgc ccagccagta catcacagga ctggccgagc acctgagccc cctgatgctg 2040
agcacatcct ggacccggat caccctgtgg aacagggatc tggcccctac ccctggcgcc 2100
aatctgtacg gcagccaccc tttctacctg gccctggaag atggcggatc tgcccacgga 2160
gtgtttctgc tgaactccaa cgccatggac gtggtgctgc agcctagccc tgccctgtct 2220
tggagaagca caggcggcat cctggatgtg tacatctttc tgggccccga gcccaagagc 2280
gtggtgcagc agtatctgga tgtcgtgggc taccccttca tgccccctta ctggggcctg 2340
ggattccacc tgtgcagatg gggctactcc agcaccgcca tcaccagaca ggtggtggaa 2400
aacatgacca gagcccactt cccactggat gtgcagtgga acgacctgga ctacatggac 2460
agcagacggg acttcacctt caacaaggac ggcttccggg acttccccgc catggtgcag 2520
gaactgcatc agggcggcag acggtacatg atgatcgtgg atcccgccat cagctcctct 2580
ggccctgccg gctcttacag accctacgac gagggcctgc ggagaggcgt gttcatcacc 2640
aacgagacag gccagcccct gatcggcaaa gtgtggcctg gcagcacagc cttccccgac 2700
ttcaccaatc ctaccgccct ggcttggtgg gaggacatgg tggccgagtt ccacgaccag 2760
gtgcccttcg acggcatgtg gatcgacatg aacgagccca gcaacttcat ccggggcagc 2820
gaggatggct gccccaacaa cgaactggaa aatccccctt acgtgcccgg cgtcgtgggc 2880
ggaacactgc aggccgctac aatctgtgcc agcagccacc agtttctgag cacccactac 2940
aacctgcaca acctgtacgg cctgaccgag gccattgcca gccaccgcgc tctcgtgaaa 3000
gccagaggca cacggccctt cgtgatcagc agaagcacct ttgccggcca cggcagatac 3060
gccggacatt ggactggcga cgtgtggtcc tcttgggagc agctggcctc tagcgtgccc 3120
gagatcctgc agttcaatct gctgggcgtg ccactcgtgg gcgccgatgt gtgtggcttc 3180
ctgggcaaca cctccgagga actgtgtgtg cggtggacac agctgggcgc cttctaccct 3240
ttcatgagaa accacaacag cctgctgagc ctgccccagg aaccctacag ctttagcgag 3300
cctgcacagc aggccatgcg gaaggccctg acactgagat acgctctgct gccccacctg 3360
tacaccctgt ttcaccaggc ccatgtggcc ggcgagacag tggccagacc tctgtttctg 3420
gaattcccca aggacagcag cacctggacc gtggaccatc agctgctgtg gggagaggct 3480
ctgctgatta ccccagtgct gcaggcaggc aaggccgaag tgaccggcta ctttcccctg 3540
ggcacttggt acgacctgca gaccgtgcct gtggaagccc tgggatctct gcctccacct 3600
cctgccgctc ctagagagcc tgccattcac tctgagggcc agtgggtcac actgcctgcc 3660
cccctggata ccatcaacgt gcacctgagg gccggctaca tcataccact gcagggacct 3720
ggcctgacca ccaccgagtc tagacagcag ccaatggccc tggccgtggc cctgaccaaa 3780
ggcggagaag ctaggggcga gctgttctgg gacgatggcg agagcctgga agtgctggaa 3840
agaggcgcct atacccaagt gatcttcctg gcccggaaca acaccatcgt gaacgagctg 3900
gtgcgcgtga cctctgaagg cgctggactg cagctgcaga aagtgaccgt gctgggagtg 3960
gccacagccc ctcagcaggt gctgtctaat ggcgtgcccg tgtccaactt cacctacagc 4020
cccgacacca aggtgctgga catctgcgtg tcactgctga tgggagagca gtttctggtg 4080
tcctggtgct gactcgagag atctaccggt gaattcaccg cgggtttaaa ctgtgccttc 4140
tagttgccag ccatctgttg tttgcccctc ccccgtgcct tccttgaccc tggaaggtgc 4200
cactcccact gtcctttcct aataaaatga ggaaattgca tcgcattgtc tgagtaggtg 4260
tcattctatt ctggggggtg gggtgggggc tagctctaga 4300
<210> 26
<211> 4198
<212> ДНК
<213> искусственная
<220>
<223> sp7+hGAAco1-дельта-42
<400> 26
aggctcagag gcacacagga gtttctgggc tcaccctgcc cccttccaac ccctcagttc 60
ccatcctcca gcagctgttt gtgtgctgcc tctgaagtcc acactgaaca aacttcagcc 120
tactcatgtc cctaaaatgg gcaaacattg caagcagcaa acagcaaaca cacagccctc 180
cctgcctgct gaccttggag ctggggcaga ggtcagagac ctctctgggc ccatgccacc 240
tccaacatcc actcgacccc ttggaatttc ggtggagagg agcagaggtt gtcctggcgt 300
ggtttaggta gtgtgagagg ggtacccggg gatcttgcta ccagtggaac agccactaag 360
gattctgcag tgagagcaga gggccagcta agtggtactc tcccagagac tgtctgactc 420
acgccacccc ctccaccttg gacacaggac gctgtggttt ctgagccagg tacaatgact 480
cctttcggta agtgcagtgg aagctgtaca ctgcccaggc aaagcgtccg ggcagcgtag 540
gcgggcgact cagatcccag ccagtggact tagcccctgt ttgctcctcc gataactggg 600
gtgaccttgg ttaatattca ccagcagcct cccccgttgc ccctctggat ccactgctta 660
aatacggacg aggacagggc cctgtctcct cagcttcagg caccaccact gacctgggac 720
agtgaataga tcctgagaac ttcagggtga gtctatggga cccttgatgt tttctttccc 780
cttcttttct atggttaagt tcatgtcata ggaaggggag aagtaacagg gtacacatat 840
tgaccaaatc agggtaattt tgcatttgta attttaaaaa atgctttctt cttttaatat 900
acttttttgt ttatcttatt tctaatactt tccctaatct ctttctttca gggcaataat 960
gatacaatgt atcatgcctc tttgcaccat tctaaagaat aacagtgata atttctgggt 1020
taaggcaata gcaatatttc tgcatataaa tatttctgca tataaattgt aactgatgta 1080
agaggtttca tattgctaat agcagctaca atccagctac cattctgctt ttattttctg 1140
gttgggataa ggctggatta ttctgagtcc aagctaggcc cttttgctaa tcttgttcat 1200
acctcttatc ttcctcccac agctcctggg caacctgctg gtctctctgc tggcccatca 1260
ctttggcaaa gcacgcgtgc caccatggcc tttctgtggc tgctgagctg ttgggccctg 1320
ctgggcacca ccttcggcgc ccaccccggc agacctagag ctgtgcctac ccagtgtgac 1380
gtgcccccca acagcagatt cgactgcgcc cctgacaagg ccatcaccca ggaacagtgc 1440
gaggccagag gctgctgcta catccctgcc aagcagggac tgcagggcgc tcagatggga 1500
cagccctggt gcttcttccc accctcctac cccagctaca agctggaaaa cctgagcagc 1560
agcgagatgg gctacaccgc caccctgacc agaaccaccc ccacattctt cccaaaggac 1620
atcctgaccc tgcggctgga cgtgatgatg gaaaccgaga accggctgca cttcaccatc 1680
aaggaccccg ccaatcggag atacgaggtg cccctggaaa ccccccacgt gcactctaga 1740
gcccccagcc ctctgtacag cgtggaattc agcgaggaac ccttcggcgt gatcgtgcgg 1800
agacagctgg atggcagagt gctgctgaac accaccgtgg cccctctgtt cttcgccgac 1860
cagttcctgc agctgagcac cagcctgccc agccagtaca tcacaggact ggccgagcac 1920
ctgagccccc tgatgctgag cacatcctgg acccggatca ccctgtggaa cagggatctg 1980
gcccctaccc ctggcgccaa tctgtacggc agccaccctt tctacctggc cctggaagat 2040
ggcggatctg cccacggagt gtttctgctg aactccaacg ccatggacgt ggtgctgcag 2100
cctagccctg ccctgtcttg gagaagcaca ggcggcatcc tggatgtgta catctttctg 2160
ggccccgagc ccaagagcgt ggtgcagcag tatctggatg tcgtgggcta ccccttcatg 2220
cccccttact ggggcctggg attccacctg tgcagatggg gctactccag caccgccatc 2280
accagacagg tggtggaaaa catgaccaga gcccacttcc cactggatgt gcagtggaac 2340
gacctggact acatggacag cagacgggac ttcaccttca acaaggacgg cttccgggac 2400
ttccccgcca tggtgcagga actgcatcag ggcggcagac ggtacatgat gatcgtggat 2460
cccgccatca gctcctctgg ccctgccggc tcttacagac cctacgacga gggcctgcgg 2520
agaggcgtgt tcatcaccaa cgagacaggc cagcccctga tcggcaaagt gtggcctggc 2580
agcacagcct tccccgactt caccaatcct accgccctgg cttggtggga ggacatggtg 2640
gccgagttcc acgaccaggt gcccttcgac ggcatgtgga tcgacatgaa cgagcccagc 2700
aacttcatcc ggggcagcga ggatggctgc cccaacaacg aactggaaaa tcccccttac 2760
gtgcccggcg tcgtgggcgg aacactgcag gccgctacaa tctgtgccag cagccaccag 2820
tttctgagca cccactacaa cctgcacaac ctgtacggcc tgaccgaggc cattgccagc 2880
caccgcgctc tcgtgaaagc cagaggcaca cggcccttcg tgatcagcag aagcaccttt 2940
gccggccacg gcagatacgc cggacattgg actggcgacg tgtggtcctc ttgggagcag 3000
ctggcctcta gcgtgcccga gatcctgcag ttcaatctgc tgggcgtgcc actcgtgggc 3060
gccgatgtgt gtggcttcct gggcaacacc tccgaggaac tgtgtgtgcg gtggacacag 3120
ctgggcgcct tctacccttt catgagaaac cacaacagcc tgctgagcct gccccaggaa 3180
ccctacagct ttagcgagcc tgcacagcag gccatgcgga aggccctgac actgagatac 3240
gctctgctgc cccacctgta caccctgttt caccaggccc atgtggccgg cgagacagtg 3300
gccagacctc tgtttctgga attccccaag gacagcagca cctggaccgt ggaccatcag 3360
ctgctgtggg gagaggctct gctgattacc ccagtgctgc aggcaggcaa ggccgaagtg 3420
accggctact ttcccctggg cacttggtac gacctgcaga ccgtgcctgt ggaagccctg 3480
ggatctctgc ctccacctcc tgccgctcct agagagcctg ccattcactc tgagggccag 3540
tgggtcacac tgcctgcccc cctggatacc atcaacgtgc acctgagggc cggctacatc 3600
ataccactgc agggacctgg cctgaccacc accgagtcta gacagcagcc aatggccctg 3660
gccgtggccc tgaccaaagg cggagaagct aggggcgagc tgttctggga cgatggcgag 3720
agcctggaag tgctggaaag aggcgcctat acccaagtga tcttcctggc ccggaacaac 3780
accatcgtga acgagctggt gcgcgtgacc tctgaaggcg ctggactgca gctgcagaaa 3840
gtgaccgtgc tgggagtggc cacagcccct cagcaggtgc tgtctaatgg cgtgcccgtg 3900
tccaacttca cctacagccc cgacaccaag gtgctggaca tctgcgtgtc actgctgatg 3960
ggagagcagt ttctggtgtc ctggtgctga ctcgagagat ctaccggtga attcaccgcg 4020
ggtttaaact gtgccttcta gttgccagcc atctgttgtt tgcccctccc ccgtgccttc 4080
cttgaccctg gaaggtgcca ctcccactgt cctttcctaa taaaatgagg aaattgcatc 4140
gcattgtctg agtaggtgtc attctattct ggggggtggg gtgggggcta gctctaga 4198
<210> 27
<211> 917
<212> Белок
<213> искусственная
<220>
<223> hGAA-дельта-8
<400> 27
Leu Leu Val Pro Arg Glu Leu Ser Gly Ser Ser Pro Val Leu Glu Glu
1 5 10 15
Thr His Pro Ala His Gln Gln Gly Ala Ser Arg Pro Gly Pro Arg Asp
20 25 30
Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys Asp
35 40 45
Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile Thr
50 55 60
Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys Gln
65 70 75 80
Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro Pro
85 90 95
Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met Gly
100 105 110
Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys Asp
115 120 125
Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg Leu
130 135 140
His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro Leu
145 150 155 160
Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser Val
165 170 175
Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu Asp
180 185 190
Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala Asp
195 200 205
Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr Gly
210 215 220
Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr Arg
225 230 235 240
Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn Leu
245 250 255
Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser Ala
260 265 270
His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu Gln
275 280 285
Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp Val
290 295 300
Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr Leu
305 310 315 320
Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly Phe
325 330 335
His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln Val
340 345 350
Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp Asn
355 360 365
Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys Asp
370 375 380
Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly Gly
385 390 395 400
Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly Pro
405 410 415
Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val Phe
420 425 430
Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro Gly
435 440 445
Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp Trp
450 455 460
Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly Met
465 470 475 480
Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu Asp
485 490 495
Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly Val
500 505 510
Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His Gln
515 520 525
Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr Glu
530 535 540
Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg Pro
545 550 555 560
Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala Gly
565 570 575
His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser Ser
580 585 590
Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val Gly
595 600 605
Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys Val
610 615 620
Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His Asn
625 630 635 640
Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro Ala
645 650 655
Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu Pro
660 665 670
His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr Val
675 680 685
Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp Thr
690 695 700
Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro Val
705 710 715 720
Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly Thr
725 730 735
Trp Tyr Asp Leu Gln Thr Val Pro Val Glu Ala Leu Gly Ser Leu Pro
740 745 750
Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly Gln
755 760 765
Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu Arg
770 775 780
Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr Glu
785 790 795 800
Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly Gly
805 810 815
Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu Val
820 825 830
Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn Asn
835 840 845
Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly Leu
850 855 860
Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln Gln
865 870 875 880
Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro Asp
885 890 895
Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln Phe
900 905 910
Leu Val Ser Trp Cys
915
<210> 28
<211> 883
<212> Белок
<213> искусственная
<220>
<223> hGAA-дельта-42
<400> 28
Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys Asp Val Pro
1 5 10 15
Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile Thr Gln Glu
20 25 30
Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys Gln Gly Leu
35 40 45
Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr
50 55 60
Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr
65 70 75 80
Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu
85 90 95
Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg Leu His Phe
100 105 110
Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr
115 120 125
Pro His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe
130 135 140
Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu Asp Gly Arg
145 150 155 160
Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala Asp Gln Phe
165 170 175
Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala
180 185 190
Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr Arg Ile Thr
195 200 205
Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly
210 215 220
Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser Ala His Gly
225 230 235 240
Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu Gln Pro Ser
245 250 255
Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile
260 265 270
Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr Leu Asp Val
275 280 285
Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly Phe His Leu
290 295 300
Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln Val Val Glu
305 310 315 320
Asn Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp Asn Asp Leu
325 330 335
Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe
340 345 350
Arg Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly Gly Arg Arg
355 360 365
Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly
370 375 380
Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val Phe Ile Thr
385 390 395 400
Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro Gly Ser Thr
405 410 415
Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp
420 425 430
Met Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly Met Trp Ile
435 440 445
Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys
450 455 460
Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly Val Val Gly
465 470 475 480
Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His Gln Phe Leu
485 490 495
Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr Glu Ala Ile
500 505 510
Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg Pro Phe Val
515 520 525
Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala Gly His Trp
530 535 540
Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser Ser Val Pro
545 550 555 560
Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val Gly Ala Asp
565 570 575
Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys Val Arg Trp
580 585 590
Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His Asn Ser Leu
595 600 605
Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln
610 615 620
Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu Pro His Leu
625 630 635 640
Tyr Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr Val Ala Arg
645 650 655
Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp Thr Val Asp
660 665 670
His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro Val Leu Gln
675 680 685
Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr
690 695 700
Asp Leu Gln Thr Val Pro Val Glu Ala Leu Gly Ser Leu Pro Pro Pro
705 710 715 720
Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly Gln Trp Val
725 730 735
Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu Arg Ala Gly
740 745 750
Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg
755 760 765
Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly Gly Glu Ala
770 775 780
Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu Val Leu Glu
785 790 795 800
Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn Asn Thr Ile
805 810 815
Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly Leu Gln Leu
820 825 830
Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln Gln Val Leu
835 840 845
Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys
850 855 860
Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln Phe Leu Val
865 870 875 880
Ser Trp Cys
<210> 29
<211> 952
<212> Белок
<213> homo sapiens
<400> 29
Met Gly Val Arg His Pro Pro Cys Ser His Arg Leu Leu Ala Val Cys
1 5 10 15
Ala Leu Val Ser Leu Ala Thr Ala Ala Leu Leu Gly His Ile Leu Leu
20 25 30
His Asp Phe Leu Leu Val Pro Arg Glu Leu Ser Gly Ser Ser Pro Val
35 40 45
Leu Glu Glu Thr His Pro Ala His Gln Gln Gly Ala Ser Arg Pro Gly
50 55 60
Pro Arg Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr
65 70 75 80
Gln Cys Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys
85 90 95
Ala Ile Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro
100 105 110
Ala Lys Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe
115 120 125
Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser
130 135 140
Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe
145 150 155 160
Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu
165 170 175
Asn Arg Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu
180 185 190
Val Pro Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu
195 200 205
Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg
210 215 220
Gln Leu Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe
225 230 235 240
Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr
245 250 255
Ile Thr Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser
260 265 270
Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly
275 280 285
Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly
290 295 300
Gly Ser Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val
305 310 315 320
Val Leu Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile
325 330 335
Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln
340 345 350
Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly
355 360 365
Leu Gly Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr
370 375 380
Arg Gln Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val
385 390 395 400
Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe
405 410 415
Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His
420 425 430
Gln Gly Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser
435 440 445
Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg
450 455 460
Gly Val Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val
465 470 475 480
Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu
485 490 495
Ala Trp Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe
500 505 510
Asp Gly Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly
515 520 525
Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val
530 535 540
Pro Gly Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser
545 550 555 560
Ser His Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly
565 570 575
Leu Thr Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly
580 585 590
Thr Arg Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg
595 600 605
Tyr Ala Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu
610 615 620
Ala Ser Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro
625 630 635 640
Leu Val Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu
645 650 655
Leu Cys Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg
660 665 670
Asn His Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser
675 680 685
Glu Pro Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala
690 695 700
Leu Leu Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly
705 710 715 720
Glu Thr Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser
725 730 735
Thr Trp Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile
740 745 750
Thr Pro Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro
755 760 765
Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly
770 775 780
Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser
785 790 795 800
Glu Gly Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val
805 810 815
His Leu Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr
820 825 830
Thr Thr Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr
835 840 845
Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser
850 855 860
Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala
865 870 875 880
Arg Asn Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly
885 890 895
Ala Gly Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala
900 905 910
Pro Gln Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr
915 920 925
Ser Pro Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly
930 935 940
Glu Gln Phe Leu Val Ser Trp Cys
945 950
<210> 30
<211> 952
<212> Белок
<213> homo sapiens
<400> 30
Met Gly Val Arg His Pro Pro Cys Ser His Arg Leu Leu Ala Val Cys
1 5 10 15
Ala Leu Val Ser Leu Ala Thr Ala Ala Leu Leu Gly His Ile Leu Leu
20 25 30
His Asp Phe Leu Leu Val Pro Arg Glu Leu Ser Gly Ser Ser Pro Val
35 40 45
Leu Glu Glu Thr His Pro Ala His Gln Gln Gly Ala Ser Arg Pro Gly
50 55 60
Pro Arg Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr
65 70 75 80
Gln Cys Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys
85 90 95
Ala Ile Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro
100 105 110
Ala Lys Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe
115 120 125
Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser
130 135 140
Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe
145 150 155 160
Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu
165 170 175
Asn Arg Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu
180 185 190
Val Pro Leu Glu Thr Pro Arg Val His Ser Arg Ala Pro Ser Pro Leu
195 200 205
Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val His Arg
210 215 220
Gln Leu Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe
225 230 235 240
Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr
245 250 255
Ile Thr Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser
260 265 270
Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly
275 280 285
Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly
290 295 300
Gly Ser Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val
305 310 315 320
Val Leu Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile
325 330 335
Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln
340 345 350
Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly
355 360 365
Leu Gly Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr
370 375 380
Arg Gln Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val
385 390 395 400
Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe
405 410 415
Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His
420 425 430
Gln Gly Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser
435 440 445
Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg
450 455 460
Gly Val Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val
465 470 475 480
Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu
485 490 495
Ala Trp Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe
500 505 510
Asp Gly Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly
515 520 525
Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val
530 535 540
Pro Gly Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser
545 550 555 560
Ser His Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly
565 570 575
Leu Thr Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly
580 585 590
Thr Arg Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg
595 600 605
Tyr Ala Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu
610 615 620
Ala Ser Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro
625 630 635 640
Leu Val Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu
645 650 655
Leu Cys Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg
660 665 670
Asn His Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser
675 680 685
Glu Pro Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala
690 695 700
Leu Leu Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly
705 710 715 720
Glu Thr Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser
725 730 735
Thr Trp Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile
740 745 750
Thr Pro Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro
755 760 765
Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly
770 775 780
Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser
785 790 795 800
Glu Gly Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val
805 810 815
His Leu Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr
820 825 830
Thr Thr Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr
835 840 845
Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser
850 855 860
Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala
865 870 875 880
Arg Asn Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly
885 890 895
Ala Gly Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala
900 905 910
Pro Gln Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr
915 920 925
Ser Pro Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly
930 935 940
Glu Gln Phe Leu Val Ser Trp Cys
945 950
<210> 31
<211> 957
<212> Белок
<213> homo sapiens
<400> 31
Met Gly Val Arg His Pro Pro Cys Ser His Arg Leu Leu Ala Val Cys
1 5 10 15
Ala Leu Val Ser Leu Ala Thr Ala Ala Leu Leu Gly His Ile Leu Leu
20 25 30
His Asp Phe Leu Leu Val Pro Arg Glu Leu Ser Gly Ser Ser Pro Val
35 40 45
Leu Glu Glu Thr His Pro Ala His Gln Gln Gly Ala Ser Arg Pro Gly
50 55 60
Pro Arg Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr
65 70 75 80
Gln Cys Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys
85 90 95
Ala Ile Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro
100 105 110
Ala Lys Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe
115 120 125
Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser
130 135 140
Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe
145 150 155 160
Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu
165 170 175
Asn Arg Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu
180 185 190
Val Pro Leu Glu Thr Pro His Val His Ser Arg Ala Pro Ser Pro Leu
195 200 205
Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val Arg Arg
210 215 220
Gln Leu Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe
225 230 235 240
Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr
245 250 255
Ile Thr Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser
260 265 270
Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly
275 280 285
Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly
290 295 300
Gly Ser Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val
305 310 315 320
Val Leu Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile
325 330 335
Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln
340 345 350
Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly
355 360 365
Leu Gly Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr
370 375 380
Arg Gln Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val
385 390 395 400
Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe
405 410 415
Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His
420 425 430
Gln Gly Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser
435 440 445
Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg
450 455 460
Gly Val Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val
465 470 475 480
Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu
485 490 495
Ala Trp Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe
500 505 510
Asp Gly Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly
515 520 525
Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val
530 535 540
Pro Gly Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser
545 550 555 560
Ser His Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly
565 570 575
Leu Thr Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly
580 585 590
Thr Arg Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg
595 600 605
Tyr Ala Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu
610 615 620
Ala Ser Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro
625 630 635 640
Leu Val Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu
645 650 655
Leu Cys Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg
660 665 670
Asn His Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser
675 680 685
Glu Pro Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala
690 695 700
Leu Leu Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly
705 710 715 720
Glu Thr Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser
725 730 735
Thr Trp Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile
740 745 750
Thr Pro Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro
755 760 765
Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly
770 775 780
Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser
785 790 795 800
Glu Gly Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val
805 810 815
His Leu Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr
820 825 830
Thr Thr Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr
835 840 845
Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser
850 855 860
Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala
865 870 875 880
Arg Asn Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly
885 890 895
Ala Gly Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala
900 905 910
Pro Gln Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr
915 920 925
Ser Pro Asp Thr Lys Ala Arg Gly Pro Arg Val Leu Asp Ile Cys Val
930 935 940
Ser Leu Leu Met Gly Glu Gln Phe Leu Val Ser Trp Cys
945 950 955
<210> 32
<211> 952
<212> Белок
<213> homo sapiens
<400> 32
Met Gly Val Arg His Pro Pro Cys Ser His Arg Leu Leu Ala Val Cys
1 5 10 15
Ala Leu Val Ser Leu Ala Thr Ala Ala Leu Leu Gly His Ile Leu Leu
20 25 30
His Asp Phe Leu Leu Val Pro Arg Glu Leu Ser Gly Ser Ser Pro Val
35 40 45
Leu Glu Glu Thr His Pro Ala His Gln Gln Gly Ala Ser Arg Pro Gly
50 55 60
Pro Arg Asp Ala Gln Ala His Pro Gly Arg Pro Arg Ala Val Pro Thr
65 70 75 80
Gln Cys Asp Val Pro Pro Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys
85 90 95
Ala Ile Thr Gln Glu Gln Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro
100 105 110
Ala Lys Gln Gly Leu Gln Gly Ala Gln Met Gly Gln Pro Trp Cys Phe
115 120 125
Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser
130 135 140
Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe
145 150 155 160
Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp Val Met Met Glu Thr Glu
165 170 175
Asn Arg Leu His Phe Thr Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu
180 185 190
Val Pro Leu Glu Thr Pro Arg Val His Ser Arg Ala Pro Ser Pro Leu
195 200 205
Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe Gly Val Ile Val His Arg
210 215 220
Gln Leu Asp Gly Arg Val Leu Leu Asn Thr Thr Val Ala Pro Leu Phe
225 230 235 240
Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr
245 250 255
Ile Thr Gly Leu Ala Glu His Leu Ser Pro Leu Met Leu Ser Thr Ser
260 265 270
Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly
275 280 285
Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr Leu Ala Leu Glu Asp Gly
290 295 300
Gly Ser Ala His Gly Val Phe Leu Leu Asn Ser Asn Ala Met Asp Val
305 310 315 320
Val Leu Gln Pro Ser Pro Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile
325 330 335
Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu Pro Lys Ser Val Val Gln
340 345 350
Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly
355 360 365
Leu Gly Phe His Leu Cys Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr
370 375 380
Arg Gln Val Val Glu Asn Met Thr Arg Ala His Phe Pro Leu Asp Val
385 390 395 400
Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe
405 410 415
Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala Met Val Gln Glu Leu His
420 425 430
Gln Gly Gly Arg Arg Tyr Met Met Ile Val Asp Pro Ala Ile Ser Ser
435 440 445
Ser Gly Pro Ala Gly Ser Tyr Arg Leu Tyr Asp Glu Gly Leu Arg Arg
450 455 460
Gly Val Phe Ile Thr Asn Glu Thr Gly Gln Pro Leu Ile Gly Lys Val
465 470 475 480
Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu
485 490 495
Ala Trp Trp Glu Asp Met Val Ala Glu Phe His Asp Gln Val Pro Phe
500 505 510
Asp Gly Met Trp Ile Asp Met Asn Glu Pro Ser Asn Phe Ile Arg Gly
515 520 525
Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val
530 535 540
Pro Gly Val Val Gly Gly Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser
545 550 555 560
Ser His Gln Phe Leu Ser Thr His Tyr Asn Leu His Asn Leu Tyr Gly
565 570 575
Leu Thr Glu Ala Ile Ala Ser His Arg Ala Leu Val Lys Ala Arg Gly
580 585 590
Thr Arg Pro Phe Val Ile Ser Arg Ser Thr Phe Ala Gly His Gly Arg
595 600 605
Tyr Ala Gly His Trp Thr Gly Asp Val Trp Ser Ser Trp Glu Gln Leu
610 615 620
Ala Ser Ser Val Pro Glu Ile Leu Gln Phe Asn Leu Leu Gly Val Pro
625 630 635 640
Leu Val Gly Ala Asp Val Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu
645 650 655
Leu Cys Val Arg Trp Thr Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg
660 665 670
Asn His Asn Ser Leu Leu Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser
675 680 685
Glu Pro Ala Gln Gln Ala Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala
690 695 700
Leu Leu Pro His Leu Tyr Thr Leu Phe His Gln Ala His Val Ala Gly
705 710 715 720
Glu Thr Val Ala Arg Pro Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser
725 730 735
Thr Trp Thr Val Asp His Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile
740 745 750
Thr Pro Val Leu Gln Ala Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro
755 760 765
Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val Pro Ile Glu Ala Leu Gly
770 775 780
Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg Glu Pro Ala Ile His Ser
785 790 795 800
Glu Gly Gln Trp Val Thr Leu Pro Ala Pro Leu Asp Thr Ile Asn Val
805 810 815
His Leu Arg Ala Gly Tyr Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr
820 825 830
Thr Thr Glu Ser Arg Gln Gln Pro Met Ala Leu Ala Val Ala Leu Thr
835 840 845
Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser
850 855 860
Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala
865 870 875 880
Arg Asn Asn Thr Ile Val Asn Glu Leu Val Arg Val Thr Ser Glu Gly
885 890 895
Ala Gly Leu Gln Leu Gln Lys Val Thr Val Leu Gly Val Ala Thr Ala
900 905 910
Pro Gln Gln Val Leu Ser Asn Gly Val Pro Val Ser Asn Phe Thr Tyr
915 920 925
Ser Pro Asp Thr Lys Val Leu Asp Ile Cys Val Ser Leu Leu Met Gly
930 935 940
Glu Gln Phe Leu Val Ser Trp Cys
945 950
<210> 33
<211> 925
<212> Белок
<213> искусственная
<220>
<223> вариант hGAAwt без sp
<400> 33
Gly His Ile Leu Leu His Asp Phe Leu Leu Val Pro Arg Glu Leu Ser
1 5 10 15
Gly Ser Ser Pro Val Leu Glu Glu Thr His Pro Ala His Gln Gln Gly
20 25 30
Ala Ser Arg Pro Gly Pro Arg Asp Ala Gln Ala His Pro Gly Arg Pro
35 40 45
Arg Ala Val Pro Thr Gln Cys Asp Val Pro Pro Asn Ser Arg Phe Asp
50 55 60
Cys Ala Pro Asp Lys Ala Ile Thr Gln Glu Gln Cys Glu Ala Arg Gly
65 70 75 80
Cys Cys Tyr Ile Pro Ala Lys Gln Gly Leu Gln Gly Ala Gln Met Gly
85 90 95
Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu Glu
100 105 110
Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg Thr
115 120 125
Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp Val
130 135 140
Met Met Glu Thr Glu Asn Arg Leu His Phe Thr Ile Lys Asp Pro Ala
145 150 155 160
Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr Pro Arg Val His Ser Arg
165 170 175
Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe Gly
180 185 190
Val Ile Val His Arg Gln Leu Asp Gly Arg Val Leu Leu Asn Thr Thr
195 200 205
Val Ala Pro Leu Phe Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr Ser
210 215 220
Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala Glu His Leu Ser Pro Leu
225 230 235 240
Met Leu Ser Thr Ser Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp Leu
245 250 255
Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr Leu
260 265 270
Ala Leu Glu Asp Gly Gly Ser Ala His Gly Val Phe Leu Leu Asn Ser
275 280 285
Asn Ala Met Asp Val Val Leu Gln Pro Ser Pro Ala Leu Ser Trp Arg
290 295 300
Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu Pro
305 310 315 320
Lys Ser Val Val Gln Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe Met
325 330 335
Pro Pro Tyr Trp Gly Leu Gly Phe His Leu Cys Arg Trp Gly Tyr Ser
340 345 350
Ser Thr Ala Ile Thr Arg Gln Val Val Glu Asn Met Thr Arg Ala His
355 360 365
Phe Pro Leu Asp Val Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser Arg
370 375 380
Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala Met
385 390 395 400
Val Gln Glu Leu His Gln Gly Gly Arg Arg Tyr Met Met Ile Val Asp
405 410 415
Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr Asp
420 425 430
Glu Gly Leu Arg Arg Gly Val Phe Ile Thr Asn Glu Thr Gly Gln Pro
435 440 445
Leu Ile Gly Lys Val Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe Thr
450 455 460
Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp Met Val Ala Glu Phe His
465 470 475 480
Asp Gln Val Pro Phe Asp Gly Met Trp Ile Asp Met Asn Glu Pro Ser
485 490 495
Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu Glu
500 505 510
Asn Pro Pro Tyr Val Pro Gly Val Val Gly Gly Thr Leu Gln Ala Ala
515 520 525
Thr Ile Cys Ala Ser Ser His Gln Phe Leu Ser Thr His Tyr Asn Leu
530 535 540
His Asn Leu Tyr Gly Leu Thr Glu Ala Ile Ala Ser His Arg Ala Leu
545 550 555 560
Val Lys Ala Arg Gly Thr Arg Pro Phe Val Ile Ser Arg Ser Thr Phe
565 570 575
Ala Gly His Gly Arg Tyr Ala Gly His Trp Thr Gly Asp Val Trp Ser
580 585 590
Ser Trp Glu Gln Leu Ala Ser Ser Val Pro Glu Ile Leu Gln Phe Asn
595 600 605
Leu Leu Gly Val Pro Leu Val Gly Ala Asp Val Cys Gly Phe Leu Gly
610 615 620
Asn Thr Ser Glu Glu Leu Cys Val Arg Trp Thr Gln Leu Gly Ala Phe
625 630 635 640
Tyr Pro Phe Met Arg Asn His Asn Ser Leu Leu Ser Leu Pro Gln Glu
645 650 655
Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln Ala Met Arg Lys Ala Leu
660 665 670
Thr Leu Arg Tyr Ala Leu Leu Pro His Leu Tyr Thr Leu Phe His Gln
675 680 685
Ala His Val Ala Gly Glu Thr Val Ala Arg Pro Leu Phe Leu Glu Phe
690 695 700
Pro Lys Asp Ser Ser Thr Trp Thr Val Asp His Gln Leu Leu Trp Gly
705 710 715 720
Glu Ala Leu Leu Ile Thr Pro Val Leu Gln Ala Gly Lys Ala Glu Val
725 730 735
Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val Pro
740 745 750
Ile Glu Ala Leu Gly Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg Glu
755 760 765
Pro Ala Ile His Ser Glu Gly Gln Trp Val Thr Leu Pro Ala Pro Leu
770 775 780
Asp Thr Ile Asn Val His Leu Arg Ala Gly Tyr Ile Ile Pro Leu Gln
785 790 795 800
Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg Gln Gln Pro Met Ala Leu
805 810 815
Ala Val Ala Leu Thr Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe Trp
820 825 830
Asp Asp Gly Glu Ser Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr Gln
835 840 845
Val Ile Phe Leu Ala Arg Asn Asn Thr Ile Val Asn Glu Leu Val Arg
850 855 860
Val Thr Ser Glu Gly Ala Gly Leu Gln Leu Gln Lys Val Thr Val Leu
865 870 875 880
Gly Val Ala Thr Ala Pro Gln Gln Val Leu Ser Asn Gly Val Pro Val
885 890 895
Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys Val Leu Asp Ile Cys Val
900 905 910
Ser Leu Leu Met Gly Glu Gln Phe Leu Val Ser Trp Cys
915 920 925
<210> 34
<211> 896
<212> Белок
<213> искусственная
<220>
<223> hGAA-дельта-29
<400> 34
Gln Gln Gly Ala Ser Arg Pro Gly Pro Arg Asp Ala Gln Ala His Pro
1 5 10 15
Gly Arg Pro Arg Ala Val Pro Thr Gln Cys Asp Val Pro Pro Asn Ser
20 25 30
Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile Thr Gln Glu Gln Cys Glu
35 40 45
Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys Gln Gly Leu Gln Gly Ala
50 55 60
Gln Met Gly Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr Pro Ser Tyr
65 70 75 80
Lys Leu Glu Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr Ala Thr Leu
85 90 95
Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu Thr Leu Arg
100 105 110
Leu Asp Val Met Met Glu Thr Glu Asn Arg Leu His Phe Thr Ile Lys
115 120 125
Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr Pro His Val
130 135 140
His Ser Arg Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe Ser Glu Glu
145 150 155 160
Pro Phe Gly Val Ile Val Arg Arg Gln Leu Asp Gly Arg Val Leu Leu
165 170 175
Asn Thr Thr Val Ala Pro Leu Phe Phe Ala Asp Gln Phe Leu Gln Leu
180 185 190
Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala Glu His Leu
195 200 205
Ser Pro Leu Met Leu Ser Thr Ser Trp Thr Arg Ile Thr Leu Trp Asn
210 215 220
Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly Ser His Pro
225 230 235 240
Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser Ala His Gly Val Phe Leu
245 250 255
Leu Asn Ser Asn Ala Met Asp Val Val Leu Gln Pro Ser Pro Ala Leu
260 265 270
Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile Phe Leu Gly
275 280 285
Pro Glu Pro Lys Ser Val Val Gln Gln Tyr Leu Asp Val Val Gly Tyr
290 295 300
Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly Phe His Leu Cys Arg Trp
305 310 315 320
Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln Val Val Glu Asn Met Thr
325 330 335
Arg Ala His Phe Pro Leu Asp Val Gln Trp Asn Asp Leu Asp Tyr Met
340 345 350
Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe Arg Asp Phe
355 360 365
Pro Ala Met Val Gln Glu Leu His Gln Gly Gly Arg Arg Tyr Met Met
370 375 380
Ile Val Asp Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly Ser Tyr Arg
385 390 395 400
Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val Phe Ile Thr Asn Glu Thr
405 410 415
Gly Gln Pro Leu Ile Gly Lys Val Trp Pro Gly Ser Thr Ala Phe Pro
420 425 430
Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp Met Val Ala
435 440 445
Glu Phe His Asp Gln Val Pro Phe Asp Gly Met Trp Ile Asp Met Asn
450 455 460
Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys Pro Asn Asn
465 470 475 480
Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly Val Val Gly Gly Thr Leu
485 490 495
Gln Ala Ala Thr Ile Cys Ala Ser Ser His Gln Phe Leu Ser Thr His
500 505 510
Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr Glu Ala Ile Ala Ser His
515 520 525
Arg Ala Leu Val Lys Ala Arg Gly Thr Arg Pro Phe Val Ile Ser Arg
530 535 540
Ser Thr Phe Ala Gly His Gly Arg Tyr Ala Gly His Trp Thr Gly Asp
545 550 555 560
Val Trp Ser Ser Trp Glu Gln Leu Ala Ser Ser Val Pro Glu Ile Leu
565 570 575
Gln Phe Asn Leu Leu Gly Val Pro Leu Val Gly Ala Asp Val Cys Gly
580 585 590
Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys Val Arg Trp Thr Gln Leu
595 600 605
Gly Ala Phe Tyr Pro Phe Met Arg Asn His Asn Ser Leu Leu Ser Leu
610 615 620
Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln Ala Met Arg
625 630 635 640
Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu Pro His Leu Tyr Thr Leu
645 650 655
Phe His Gln Ala His Val Ala Gly Glu Thr Val Ala Arg Pro Leu Phe
660 665 670
Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp Thr Val Asp His Gln Leu
675 680 685
Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro Val Leu Gln Ala Gly Lys
690 695 700
Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr Asp Leu Gln
705 710 715 720
Thr Val Pro Val Glu Ala Leu Gly Ser Leu Pro Pro Pro Pro Ala Ala
725 730 735
Pro Arg Glu Pro Ala Ile His Ser Glu Gly Gln Trp Val Thr Leu Pro
740 745 750
Ala Pro Leu Asp Thr Ile Asn Val His Leu Arg Ala Gly Tyr Ile Ile
755 760 765
Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg Gln Gln Pro
770 775 780
Met Ala Leu Ala Val Ala Leu Thr Lys Gly Gly Glu Ala Arg Gly Glu
785 790 795 800
Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu Val Leu Glu Arg Gly Ala
805 810 815
Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn Asn Thr Ile Val Asn Glu
820 825 830
Leu Val Arg Val Thr Ser Glu Gly Ala Gly Leu Gln Leu Gln Lys Val
835 840 845
Thr Val Leu Gly Val Ala Thr Ala Pro Gln Gln Val Leu Ser Asn Gly
850 855 860
Val Pro Val Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys Val Leu Asp
865 870 875 880
Ile Cys Val Ser Leu Leu Met Gly Glu Gln Phe Leu Val Ser Trp Cys
885 890 895
<210> 35
<211> 882
<212> Белок
<213> искусственная
<220>
<223> hGAA-дельта-43
<400> 35
His Pro Gly Arg Pro Arg Ala Val Pro Thr Gln Cys Asp Val Pro Pro
1 5 10 15
Asn Ser Arg Phe Asp Cys Ala Pro Asp Lys Ala Ile Thr Gln Glu Gln
20 25 30
Cys Glu Ala Arg Gly Cys Cys Tyr Ile Pro Ala Lys Gln Gly Leu Gln
35 40 45
Gly Ala Gln Met Gly Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr Pro
50 55 60
Ser Tyr Lys Leu Glu Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr Ala
65 70 75 80
Thr Leu Thr Arg Thr Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu Thr
85 90 95
Leu Arg Leu Asp Val Met Met Glu Thr Glu Asn Arg Leu His Phe Thr
100 105 110
Ile Lys Asp Pro Ala Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr Pro
115 120 125
His Val His Ser Arg Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe Ser
130 135 140
Glu Glu Pro Phe Gly Val Ile Val Arg Arg Gln Leu Asp Gly Arg Val
145 150 155 160
Leu Leu Asn Thr Thr Val Ala Pro Leu Phe Phe Ala Asp Gln Phe Leu
165 170 175
Gln Leu Ser Thr Ser Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala Glu
180 185 190
His Leu Ser Pro Leu Met Leu Ser Thr Ser Trp Thr Arg Ile Thr Leu
195 200 205
Trp Asn Arg Asp Leu Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly Ser
210 215 220
His Pro Phe Tyr Leu Ala Leu Glu Asp Gly Gly Ser Ala His Gly Val
225 230 235 240
Phe Leu Leu Asn Ser Asn Ala Met Asp Val Val Leu Gln Pro Ser Pro
245 250 255
Ala Leu Ser Trp Arg Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile Phe
260 265 270
Leu Gly Pro Glu Pro Lys Ser Val Val Gln Gln Tyr Leu Asp Val Val
275 280 285
Gly Tyr Pro Phe Met Pro Pro Tyr Trp Gly Leu Gly Phe His Leu Cys
290 295 300
Arg Trp Gly Tyr Ser Ser Thr Ala Ile Thr Arg Gln Val Val Glu Asn
305 310 315 320
Met Thr Arg Ala His Phe Pro Leu Asp Val Gln Trp Asn Asp Leu Asp
325 330 335
Tyr Met Asp Ser Arg Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe Arg
340 345 350
Asp Phe Pro Ala Met Val Gln Glu Leu His Gln Gly Gly Arg Arg Tyr
355 360 365
Met Met Ile Val Asp Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly Ser
370 375 380
Tyr Arg Pro Tyr Asp Glu Gly Leu Arg Arg Gly Val Phe Ile Thr Asn
385 390 395 400
Glu Thr Gly Gln Pro Leu Ile Gly Lys Val Trp Pro Gly Ser Thr Ala
405 410 415
Phe Pro Asp Phe Thr Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp Met
420 425 430
Val Ala Glu Phe His Asp Gln Val Pro Phe Asp Gly Met Trp Ile Asp
435 440 445
Met Asn Glu Pro Ser Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys Pro
450 455 460
Asn Asn Glu Leu Glu Asn Pro Pro Tyr Val Pro Gly Val Val Gly Gly
465 470 475 480
Thr Leu Gln Ala Ala Thr Ile Cys Ala Ser Ser His Gln Phe Leu Ser
485 490 495
Thr His Tyr Asn Leu His Asn Leu Tyr Gly Leu Thr Glu Ala Ile Ala
500 505 510
Ser His Arg Ala Leu Val Lys Ala Arg Gly Thr Arg Pro Phe Val Ile
515 520 525
Ser Arg Ser Thr Phe Ala Gly His Gly Arg Tyr Ala Gly His Trp Thr
530 535 540
Gly Asp Val Trp Ser Ser Trp Glu Gln Leu Ala Ser Ser Val Pro Glu
545 550 555 560
Ile Leu Gln Phe Asn Leu Leu Gly Val Pro Leu Val Gly Ala Asp Val
565 570 575
Cys Gly Phe Leu Gly Asn Thr Ser Glu Glu Leu Cys Val Arg Trp Thr
580 585 590
Gln Leu Gly Ala Phe Tyr Pro Phe Met Arg Asn His Asn Ser Leu Leu
595 600 605
Ser Leu Pro Gln Glu Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln Ala
610 615 620
Met Arg Lys Ala Leu Thr Leu Arg Tyr Ala Leu Leu Pro His Leu Tyr
625 630 635 640
Thr Leu Phe His Gln Ala His Val Ala Gly Glu Thr Val Ala Arg Pro
645 650 655
Leu Phe Leu Glu Phe Pro Lys Asp Ser Ser Thr Trp Thr Val Asp His
660 665 670
Gln Leu Leu Trp Gly Glu Ala Leu Leu Ile Thr Pro Val Leu Gln Ala
675 680 685
Gly Lys Ala Glu Val Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr Asp
690 695 700
Leu Gln Thr Val Pro Val Glu Ala Leu Gly Ser Leu Pro Pro Pro Pro
705 710 715 720
Ala Ala Pro Arg Glu Pro Ala Ile His Ser Glu Gly Gln Trp Val Thr
725 730 735
Leu Pro Ala Pro Leu Asp Thr Ile Asn Val His Leu Arg Ala Gly Tyr
740 745 750
Ile Ile Pro Leu Gln Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg Gln
755 760 765
Gln Pro Met Ala Leu Ala Val Ala Leu Thr Lys Gly Gly Glu Ala Arg
770 775 780
Gly Glu Leu Phe Trp Asp Asp Gly Glu Ser Leu Glu Val Leu Glu Arg
785 790 795 800
Gly Ala Tyr Thr Gln Val Ile Phe Leu Ala Arg Asn Asn Thr Ile Val
805 810 815
Asn Glu Leu Val Arg Val Thr Ser Glu Gly Ala Gly Leu Gln Leu Gln
820 825 830
Lys Val Thr Val Leu Gly Val Ala Thr Ala Pro Gln Gln Val Leu Ser
835 840 845
Asn Gly Val Pro Val Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys Val
850 855 860
Leu Asp Ile Cys Val Ser Leu Leu Met Gly Glu Gln Phe Leu Val Ser
865 870 875 880
Trp Cys
<210> 36
<211> 878
<212> Белок
<213> искусственная
<220>
<223> hGAA-дельта-47
<400> 36
Pro Arg Ala Val Pro Thr Gln Cys Asp Val Pro Pro Asn Ser Arg Phe
1 5 10 15
Asp Cys Ala Pro Asp Lys Ala Ile Thr Gln Glu Gln Cys Glu Ala Arg
20 25 30
Gly Cys Cys Tyr Ile Pro Ala Lys Gln Gly Leu Gln Gly Ala Gln Met
35 40 45
Gly Gln Pro Trp Cys Phe Phe Pro Pro Ser Tyr Pro Ser Tyr Lys Leu
50 55 60
Glu Asn Leu Ser Ser Ser Glu Met Gly Tyr Thr Ala Thr Leu Thr Arg
65 70 75 80
Thr Thr Pro Thr Phe Phe Pro Lys Asp Ile Leu Thr Leu Arg Leu Asp
85 90 95
Val Met Met Glu Thr Glu Asn Arg Leu His Phe Thr Ile Lys Asp Pro
100 105 110
Ala Asn Arg Arg Tyr Glu Val Pro Leu Glu Thr Pro His Val His Ser
115 120 125
Arg Ala Pro Ser Pro Leu Tyr Ser Val Glu Phe Ser Glu Glu Pro Phe
130 135 140
Gly Val Ile Val Arg Arg Gln Leu Asp Gly Arg Val Leu Leu Asn Thr
145 150 155 160
Thr Val Ala Pro Leu Phe Phe Ala Asp Gln Phe Leu Gln Leu Ser Thr
165 170 175
Ser Leu Pro Ser Gln Tyr Ile Thr Gly Leu Ala Glu His Leu Ser Pro
180 185 190
Leu Met Leu Ser Thr Ser Trp Thr Arg Ile Thr Leu Trp Asn Arg Asp
195 200 205
Leu Ala Pro Thr Pro Gly Ala Asn Leu Tyr Gly Ser His Pro Phe Tyr
210 215 220
Leu Ala Leu Glu Asp Gly Gly Ser Ala His Gly Val Phe Leu Leu Asn
225 230 235 240
Ser Asn Ala Met Asp Val Val Leu Gln Pro Ser Pro Ala Leu Ser Trp
245 250 255
Arg Ser Thr Gly Gly Ile Leu Asp Val Tyr Ile Phe Leu Gly Pro Glu
260 265 270
Pro Lys Ser Val Val Gln Gln Tyr Leu Asp Val Val Gly Tyr Pro Phe
275 280 285
Met Pro Pro Tyr Trp Gly Leu Gly Phe His Leu Cys Arg Trp Gly Tyr
290 295 300
Ser Ser Thr Ala Ile Thr Arg Gln Val Val Glu Asn Met Thr Arg Ala
305 310 315 320
His Phe Pro Leu Asp Val Gln Trp Asn Asp Leu Asp Tyr Met Asp Ser
325 330 335
Arg Arg Asp Phe Thr Phe Asn Lys Asp Gly Phe Arg Asp Phe Pro Ala
340 345 350
Met Val Gln Glu Leu His Gln Gly Gly Arg Arg Tyr Met Met Ile Val
355 360 365
Asp Pro Ala Ile Ser Ser Ser Gly Pro Ala Gly Ser Tyr Arg Pro Tyr
370 375 380
Asp Glu Gly Leu Arg Arg Gly Val Phe Ile Thr Asn Glu Thr Gly Gln
385 390 395 400
Pro Leu Ile Gly Lys Val Trp Pro Gly Ser Thr Ala Phe Pro Asp Phe
405 410 415
Thr Asn Pro Thr Ala Leu Ala Trp Trp Glu Asp Met Val Ala Glu Phe
420 425 430
His Asp Gln Val Pro Phe Asp Gly Met Trp Ile Asp Met Asn Glu Pro
435 440 445
Ser Asn Phe Ile Arg Gly Ser Glu Asp Gly Cys Pro Asn Asn Glu Leu
450 455 460
Glu Asn Pro Pro Tyr Val Pro Gly Val Val Gly Gly Thr Leu Gln Ala
465 470 475 480
Ala Thr Ile Cys Ala Ser Ser His Gln Phe Leu Ser Thr His Tyr Asn
485 490 495
Leu His Asn Leu Tyr Gly Leu Thr Glu Ala Ile Ala Ser His Arg Ala
500 505 510
Leu Val Lys Ala Arg Gly Thr Arg Pro Phe Val Ile Ser Arg Ser Thr
515 520 525
Phe Ala Gly His Gly Arg Tyr Ala Gly His Trp Thr Gly Asp Val Trp
530 535 540
Ser Ser Trp Glu Gln Leu Ala Ser Ser Val Pro Glu Ile Leu Gln Phe
545 550 555 560
Asn Leu Leu Gly Val Pro Leu Val Gly Ala Asp Val Cys Gly Phe Leu
565 570 575
Gly Asn Thr Ser Glu Glu Leu Cys Val Arg Trp Thr Gln Leu Gly Ala
580 585 590
Phe Tyr Pro Phe Met Arg Asn His Asn Ser Leu Leu Ser Leu Pro Gln
595 600 605
Glu Pro Tyr Ser Phe Ser Glu Pro Ala Gln Gln Ala Met Arg Lys Ala
610 615 620
Leu Thr Leu Arg Tyr Ala Leu Leu Pro His Leu Tyr Thr Leu Phe His
625 630 635 640
Gln Ala His Val Ala Gly Glu Thr Val Ala Arg Pro Leu Phe Leu Glu
645 650 655
Phe Pro Lys Asp Ser Ser Thr Trp Thr Val Asp His Gln Leu Leu Trp
660 665 670
Gly Glu Ala Leu Leu Ile Thr Pro Val Leu Gln Ala Gly Lys Ala Glu
675 680 685
Val Thr Gly Tyr Phe Pro Leu Gly Thr Trp Tyr Asp Leu Gln Thr Val
690 695 700
Pro Val Glu Ala Leu Gly Ser Leu Pro Pro Pro Pro Ala Ala Pro Arg
705 710 715 720
Glu Pro Ala Ile His Ser Glu Gly Gln Trp Val Thr Leu Pro Ala Pro
725 730 735
Leu Asp Thr Ile Asn Val His Leu Arg Ala Gly Tyr Ile Ile Pro Leu
740 745 750
Gln Gly Pro Gly Leu Thr Thr Thr Glu Ser Arg Gln Gln Pro Met Ala
755 760 765
Leu Ala Val Ala Leu Thr Lys Gly Gly Glu Ala Arg Gly Glu Leu Phe
770 775 780
Trp Asp Asp Gly Glu Ser Leu Glu Val Leu Glu Arg Gly Ala Tyr Thr
785 790 795 800
Gln Val Ile Phe Leu Ala Arg Asn Asn Thr Ile Val Asn Glu Leu Val
805 810 815
Arg Val Thr Ser Glu Gly Ala Gly Leu Gln Leu Gln Lys Val Thr Val
820 825 830
Leu Gly Val Ala Thr Ala Pro Gln Gln Val Leu Ser Asn Gly Val Pro
835 840 845
Val Ser Asn Phe Thr Tyr Ser Pro Asp Thr Lys Val Leu Asp Ile Cys
850 855 860
Val Ser Leu Leu Met Gly Glu Gln Phe Leu Val Ser Trp Cys
865 870 875
<210> 37
<211> 2745
<212> ДНК
<213> искусственная
<220>
<223> sp7+hGAAwt-дельта-29
<400> 37
atggcctttc tgtggctgct gagctgttgg gccctgctgg gcaccacctt cggccagcag 60
ggagccagca gaccagggcc ccgggatgcc caggcacacc ccgggcggcc gcgagcagtg 120
cccacacagt gcgacgtccc ccccaacagc cgcttcgatt gcgcccctga caaggccatc 180
acccaggaac agtgcgaggc ccgcggctgt tgctacatcc ctgcaaagca ggggctgcag 240
ggagcccaga tggggcagcc ctggtgcttc ttcccaccca gctaccccag ctacaagctg 300
gagaacctga gctcctctga aatgggctac acggccaccc tgacccgtac cacccccacc 360
ttcttcccca aggacatcct gaccctgcgg ctggacgtga tgatggagac tgagaaccgc 420
ctccacttca cgatcaaaga tccagctaac aggcgctacg aggtgccctt ggagaccccg 480
catgtccaca gccgggcacc gtccccactc tacagcgtgg agttctccga ggagcccttc 540
ggggtgatcg tgcgccggca gctggacggc cgcgtgctgc tgaacacgac ggtggcgccc 600
ctgttctttg cggaccagtt ccttcagctg tccacctcgc tgccctcgca gtatatcaca 660
ggcctcgccg agcacctcag tcccctgatg ctcagcacca gctggaccag gatcaccctg 720
tggaaccggg accttgcgcc cacgcccggt gcgaacctct acgggtctca ccctttctac 780
ctggcgctgg aggacggcgg gtcggcacac ggggtgttcc tgctaaacag caatgccatg 840
gatgtggtcc tgcagccgag ccctgccctt agctggaggt cgacaggtgg gatcctggat 900
gtctacatct tcctgggccc agagcccaag agcgtggtgc agcagtacct ggacgttgtg 960
ggatacccgt tcatgccgcc atactggggc ctgggcttcc acctgtgccg ctggggctac 1020
tcctccaccg ctatcacccg ccaggtggtg gagaacatga ccagggccca cttccccctg 1080
gacgtccagt ggaacgacct ggactacatg gactcccgga gggacttcac gttcaacaag 1140
gatggcttcc gggacttccc ggccatggtg caggagctgc accagggcgg ccggcgctac 1200
atgatgatcg tggatcctgc catcagcagc tcgggccctg ccgggagcta caggccctac 1260
gacgagggtc tgcggagggg ggttttcatc accaacgaga ccggccagcc gctgattggg 1320
aaggtatggc ccgggtccac tgccttcccc gacttcacca accccacagc cctggcctgg 1380
tgggaggaca tggtggctga gttccatgac caggtgccct tcgacggcat gtggattgac 1440
atgaacgagc cttccaactt catcaggggc tctgaggacg gctgccccaa caatgagctg 1500
gagaacccac cctacgtgcc tggggtggtt ggggggaccc tccaggcggc caccatctgt 1560
gcctccagcc accagtttct ctccacacac tacaacctgc acaacctcta cggcctgacc 1620
gaagccatcg cctcccacag ggcgctggtg aaggctcggg ggacacgccc atttgtgatc 1680
tcccgctcga cctttgctgg ccacggccga tacgccggcc actggacggg ggacgtgtgg 1740
agctcctggg agcagctcgc ctcctccgtg ccagaaatcc tgcagtttaa cctgctgggg 1800
gtgcctctgg tcggggccga cgtctgcggc ttcctgggca acacctcaga ggagctgtgt 1860
gtgcgctgga cccagctggg ggccttctac cccttcatgc ggaaccacaa cagcctgctc 1920
agtctgcccc aggagccgta cagcttcagc gagccggccc agcaggccat gaggaaggcc 1980
ctcaccctgc gctacgcact cctcccccac ctctacacac tgttccacca ggcccacgtc 2040
gcgggggaga ccgtggcccg gcccctcttc ctggagttcc ccaaggactc tagcacctgg 2100
actgtggacc accagctcct gtggggggag gccctgctca tcaccccagt gctccaggcc 2160
gggaaggccg aagtgactgg ctacttcccc ttgggcacat ggtacgacct gcagacggtg 2220
ccagtagagg cccttggcag cctcccaccc ccacctgcag ctccccgtga gccagccatc 2280
cacagcgagg ggcagtgggt gacgctgccg gcccccctgg acaccatcaa cgtccacctc 2340
cgggctgggt acatcatccc cctgcagggc cctggcctca caaccacaga gtcccgccag 2400
cagcccatgg ccctggctgt ggccctgacc aagggtgggg aggcccgagg ggagctgttc 2460
tgggacgatg gagagagcct ggaagtgctg gagcgagggg cctacacaca ggtcatcttc 2520
ctggccagga ataacacgat cgtgaatgag ctggtacgtg tgaccagtga gggagctggc 2580
ctgcagctgc agaaggtgac tgtcctgggc gtggccacgg cgccccagca ggtcctctcc 2640
aacggtgtcc ctgtctccaa cttcacctac agccccgaca ccaaggtcct ggacatctgt 2700
gtctcgctgt tgatgggaga gcagtttctc gtcagctggt gttag 2745
<210> 38
<211> 2745
<212> ДНК
<213> искусственная
<220>
<223> sp7+hGAAco1-дельта-29
<400> 38
atggcctttc tgtggctgct gagctgttgg gccctgctgg gcaccacctt cggccagcag 60
ggcgcctcta gacctggacc tagagatgcc caggcccacc ccggcagacc tagagctgtg 120
cctacccagt gtgacgtgcc ccccaacagc agattcgact gcgcccctga caaggccatc 180
acccaggaac agtgcgaggc cagaggctgc tgctacatcc ctgccaagca gggactgcag 240
ggcgctcaga tgggacagcc ctggtgcttc ttcccaccct cctaccccag ctacaagctg 300
gaaaacctga gcagcagcga gatgggctac accgccaccc tgaccagaac cacccccaca 360
ttcttcccaa aggacatcct gaccctgcgg ctggacgtga tgatggaaac cgagaaccgg 420
ctgcacttca ccatcaagga ccccgccaat cggagatacg aggtgcccct ggaaaccccc 480
cacgtgcact ctagagcccc cagccctctg tacagcgtgg aattcagcga ggaacccttc 540
ggcgtgatcg tgcggagaca gctggatggc agagtgctgc tgaacaccac cgtggcccct 600
ctgttcttcg ccgaccagtt cctgcagctg agcaccagcc tgcccagcca gtacatcaca 660
ggactggccg agcacctgag ccccctgatg ctgagcacat cctggacccg gatcaccctg 720
tggaacaggg atctggcccc tacccctggc gccaatctgt acggcagcca ccctttctac 780
ctggccctgg aagatggcgg atctgcccac ggagtgtttc tgctgaactc caacgccatg 840
gacgtggtgc tgcagcctag ccctgccctg tcttggagaa gcacaggcgg catcctggat 900
gtgtacatct ttctgggccc cgagcccaag agcgtggtgc agcagtatct ggatgtcgtg 960
ggctacccct tcatgccccc ttactggggc ctgggattcc acctgtgcag atggggctac 1020
tccagcaccg ccatcaccag acaggtggtg gaaaacatga ccagagccca cttcccactg 1080
gatgtgcagt ggaacgacct ggactacatg gacagcagac gggacttcac cttcaacaag 1140
gacggcttcc gggacttccc cgccatggtg caggaactgc atcagggcgg cagacggtac 1200
atgatgatcg tggatcccgc catcagctcc tctggccctg ccggctctta cagaccctac 1260
gacgagggcc tgcggagagg cgtgttcatc accaacgaga caggccagcc cctgatcggc 1320
aaagtgtggc ctggcagcac agccttcccc gacttcacca atcctaccgc cctggcttgg 1380
tgggaggaca tggtggccga gttccacgac caggtgccct tcgacggcat gtggatcgac 1440
atgaacgagc ccagcaactt catccggggc agcgaggatg gctgccccaa caacgaactg 1500
gaaaatcccc cttacgtgcc cggcgtcgtg ggcggaacac tgcaggccgc tacaatctgt 1560
gccagcagcc accagtttct gagcacccac tacaacctgc acaacctgta cggcctgacc 1620
gaggccattg ccagccaccg cgctctcgtg aaagccagag gcacacggcc cttcgtgatc 1680
agcagaagca cctttgccgg ccacggcaga tacgccggac attggactgg cgacgtgtgg 1740
tcctcttggg agcagctggc ctctagcgtg cccgagatcc tgcagttcaa tctgctgggc 1800
gtgccactcg tgggcgccga tgtgtgtggc ttcctgggca acacctccga ggaactgtgt 1860
gtgcggtgga cacagctggg cgccttctac cctttcatga gaaaccacaa cagcctgctg 1920
agcctgcccc aggaacccta cagctttagc gagcctgcac agcaggccat gcggaaggcc 1980
ctgacactga gatacgctct gctgccccac ctgtacaccc tgtttcacca ggcccatgtg 2040
gccggcgaga cagtggccag acctctgttt ctggaattcc ccaaggacag cagcacctgg 2100
accgtggacc atcagctgct gtggggagag gctctgctga ttaccccagt gctgcaggca 2160
ggcaaggccg aagtgaccgg ctactttccc ctgggcactt ggtacgacct gcagaccgtg 2220
cctgtggaag ccctgggatc tctgcctcca cctcctgccg ctcctagaga gcctgccatt 2280
cactctgagg gccagtgggt cacactgcct gcccccctgg ataccatcaa cgtgcacctg 2340
agggccggct acatcatacc actgcaggga cctggcctga ccaccaccga gtctagacag 2400
cagccaatgg ccctggccgt ggccctgacc aaaggcggag aagctagggg cgagctgttc 2460
tgggacgatg gcgagagcct ggaagtgctg gaaagaggcg cctataccca agtgatcttc 2520
ctggcccgga acaacaccat cgtgaacgag ctggtgcgcg tgacctctga aggcgctgga 2580
ctgcagctgc agaaagtgac cgtgctggga gtggccacag cccctcagca ggtgctgtct 2640
aatggcgtgc ccgtgtccaa cttcacctac agccccgaca ccaaggtgct ggacatctgc 2700
gtgtcactgc tgatgggaga gcagtttctg gtgtcctggt gctga 2745
<210> 39
<211> 2745
<212> ДНК
<213> искусственная
<220>
<223> sp7+hGAAco2-дельта-29
<400> 39
atggcctttc tgtggctgct gagctgttgg gccctgctgg gcaccacctt cggccaacag 60
ggagcttcca gaccaggacc gagagacgcc caagcccatc ctggtagacc aagagctgtg 120
cctacccaat gcgacgtgcc acccaactcc cgattcgact gcgcgccaga taaggctatt 180
acccaagagc agtgtgaagc cagaggttgc tgctacatcc cagcgaagca aggattgcaa 240
ggcgcccaaa tgggacaacc ttggtgtttc ttcccccctt cgtacccatc atataaactc 300
gaaaacctgt cctcttcgga aatgggttat actgccaccc tcaccagaac tactcctact 360
ttcttcccga aagacatctt gaccttgagg ctggacgtga tgatggagac tgaaaaccgg 420
ctgcatttca ctatcaaaga tcctgccaat cggcgatacg aggtccctct ggaaacccct 480
cacgtgcact cacgggctcc ttctccgctt tactccgtcg aattctctga ggaacccttc 540
ggagtgatcg ttagacgcca gctggatggt agagtgctgt tgaacactac tgtggcccca 600
cttttcttcg ctgaccagtt tctgcaactg tccacttccc tgccatccca gtacattact 660
ggactcgccg aacacctgtc gccactgatg ctctcgacct cttggactag aatcactttg 720
tggaacagag acttggcccc tactccggga gcaaatctgt acggaagcca ccctttttac 780
ctggcgctcg aagatggcgg atccgctcac ggagtgttcc tgctgaatag caacgcaatg 840
gacgtggtgc tgcaaccttc ccctgcactc agttggagaa gtaccggggg tattctggac 900
gtgtacatct tcctcggacc agaacccaag agcgtggtgc agcaatatct ggacgtggtc 960
ggataccctt ttatgcctcc ttactgggga ctgggattcc acctttgccg ttggggctac 1020
tcatccaccg ccattaccag acaggtggtg gagaatatga ccagagccca cttccctctc 1080
gacgtgcagt ggaacgatct ggactatatg gactcccgga gagatttcac cttcaacaag 1140
gacgggttcc gcgattttcc cgcgatggtt caagagctcc accagggtgg tcgaagatat 1200
atgatgatcg tcgacccagc catttcgagc agcggacccg ctggatctta tagaccttac 1260
gacgaaggcc ttaggagagg agtgttcatc acaaacgaga ctggacagcc tttgatcggt 1320
aaagtgtggc ctggatcaac cgcctttcct gactttacca atcccactgc cttggcttgg 1380
tgggaggaca tggtggccga attccacgac caagtcccct ttgatggaat gtggatcgat 1440
atgaacgaac caagcaattt tatcagaggt tccgaagacg gttgccccaa caacgaactg 1500
gaaaaccctc cttatgtgcc cggagtcgtg ggcggaacat tacaggccgc gactatttgc 1560
gccagcagcc accaattcct gtccactcac tacaacctcc acaaccttta tggattaacc 1620
gaagctattg caagtcacag ggctctggtg aaggctagag ggactaggcc ctttgtgatc 1680
tcccgatcca cctttgccgg acacgggaga tacgccggtc actggactgg tgacgtgtgg 1740
agctcatggg aacaactggc ctcctccgtg ccggaaatct tacagttcaa ccttctgggt 1800
gtccctcttg tcggagcaga cgtgtgtggg tttcttggta acacctccga ggaactgtgt 1860
gtgcgctgga ctcaactggg tgcattctac ccattcatga gaaaccacaa ctccttgctg 1920
tccctgccac aagagcccta ctcgttcagc gagcctgcac aacaggctat gcggaaggca 1980
ctgaccctga gatacgccct gcttccacac ttatacactc tcttccatca agcgcatgtg 2040
gcaggagaaa ccgttgcaag gcctcttttc cttgaattcc ccaaggattc ctcgacttgg 2100
acggtggatc atcagctgct gtggggagaa gctctgctga ttactccagt gttgcaagcc 2160
ggaaaagctg aggtgaccgg atactttccg ctgggaacct ggtacgacct ccagactgtc 2220
cctgttgaag cccttggatc actgcctccg cctccggcag ctccacgcga accagctata 2280
cattccgagg gacagtgggt tacattacca gctcctctgg acacaatcaa cgtccactta 2340
agagctggct acattatccc tctgcaagga ccaggactga ctacgaccga gagcagacag 2400
cagccaatgg cactggctgt ggctctgacc aagggagggg aagctagagg agaactcttc 2460
tgggatgatg gggagtccct tgaagtgctg gaaagaggcg cttacactca agtcattttc 2520
cttgcacgga acaacaccat tgtgaacgaa ttggtgcgag tgaccagcga aggagctgga 2580
cttcaactgc agaaggtcac tgtgctcgga gtggctaccg ctcctcagca agtgctgtcg 2640
aatggagtcc ccgtgtcaaa ctttacctac tcccctgaca ctaaggtgct cgacatttgc 2700
gtgtccctcc tgatgggaga gcagttcctt gtgtcctggt gttga 2745
<210> 40
<211> 2706
<212> ДНК
<213> искусственная
<220>
<223> sp7+hGAAwt-дельта-42
<400> 40
atggcctttc tgtggctgct gagctgttgg gccctgctgg gcaccacctt cggcgcacac 60
cccgggcggc cgcgagcagt gcccacacag tgcgacgtcc cccccaacag ccgcttcgat 120
tgcgcccctg acaaggccat cacccaggaa cagtgcgagg cccgcggctg ttgctacatc 180
cctgcaaagc aggggctgca gggagcccag atggggcagc cctggtgctt cttcccaccc 240
agctacccca gctacaagct ggagaacctg agctcctctg aaatgggcta cacggccacc 300
ctgacccgta ccacccccac cttcttcccc aaggacatcc tgaccctgcg gctggacgtg 360
atgatggaga ctgagaaccg cctccacttc acgatcaaag atccagctaa caggcgctac 420
gaggtgccct tggagacccc gcatgtccac agccgggcac cgtccccact ctacagcgtg 480
gagttctccg aggagccctt cggggtgatc gtgcgccggc agctggacgg ccgcgtgctg 540
ctgaacacga cggtggcgcc cctgttcttt gcggaccagt tccttcagct gtccacctcg 600
ctgccctcgc agtatatcac aggcctcgcc gagcacctca gtcccctgat gctcagcacc 660
agctggacca ggatcaccct gtggaaccgg gaccttgcgc ccacgcccgg tgcgaacctc 720
tacgggtctc accctttcta cctggcgctg gaggacggcg ggtcggcaca cggggtgttc 780
ctgctaaaca gcaatgccat ggatgtggtc ctgcagccga gccctgccct tagctggagg 840
tcgacaggtg ggatcctgga tgtctacatc ttcctgggcc cagagcccaa gagcgtggtg 900
cagcagtacc tggacgttgt gggatacccg ttcatgccgc catactgggg cctgggcttc 960
cacctgtgcc gctggggcta ctcctccacc gctatcaccc gccaggtggt ggagaacatg 1020
accagggccc acttccccct ggacgtccag tggaacgacc tggactacat ggactcccgg 1080
agggacttca cgttcaacaa ggatggcttc cgggacttcc cggccatggt gcaggagctg 1140
caccagggcg gccggcgcta catgatgatc gtggatcctg ccatcagcag ctcgggccct 1200
gccgggagct acaggcccta cgacgagggt ctgcggaggg gggttttcat caccaacgag 1260
accggccagc cgctgattgg gaaggtatgg cccgggtcca ctgccttccc cgacttcacc 1320
aaccccacag ccctggcctg gtgggaggac atggtggctg agttccatga ccaggtgccc 1380
ttcgacggca tgtggattga catgaacgag ccttccaact tcatcagggg ctctgaggac 1440
ggctgcccca acaatgagct ggagaaccca ccctacgtgc ctggggtggt tggggggacc 1500
ctccaggcgg ccaccatctg tgcctccagc caccagtttc tctccacaca ctacaacctg 1560
cacaacctct acggcctgac cgaagccatc gcctcccaca gggcgctggt gaaggctcgg 1620
gggacacgcc catttgtgat ctcccgctcg acctttgctg gccacggccg atacgccggc 1680
cactggacgg gggacgtgtg gagctcctgg gagcagctcg cctcctccgt gccagaaatc 1740
ctgcagttta acctgctggg ggtgcctctg gtcggggccg acgtctgcgg cttcctgggc 1800
aacacctcag aggagctgtg tgtgcgctgg acccagctgg gggccttcta ccccttcatg 1860
cggaaccaca acagcctgct cagtctgccc caggagccgt acagcttcag cgagccggcc 1920
cagcaggcca tgaggaaggc cctcaccctg cgctacgcac tcctccccca cctctacaca 1980
ctgttccacc aggcccacgt cgcgggggag accgtggccc ggcccctctt cctggagttc 2040
cccaaggact ctagcacctg gactgtggac caccagctcc tgtgggggga ggccctgctc 2100
atcaccccag tgctccaggc cgggaaggcc gaagtgactg gctacttccc cttgggcaca 2160
tggtacgacc tgcagacggt gccagtagag gcccttggca gcctcccacc cccacctgca 2220
gctccccgtg agccagccat ccacagcgag gggcagtggg tgacgctgcc ggcccccctg 2280
gacaccatca acgtccacct ccgggctggg tacatcatcc ccctgcaggg ccctggcctc 2340
acaaccacag agtcccgcca gcagcccatg gccctggctg tggccctgac caagggtggg 2400
gaggcccgag gggagctgtt ctgggacgat ggagagagcc tggaagtgct ggagcgaggg 2460
gcctacacac aggtcatctt cctggccagg aataacacga tcgtgaatga gctggtacgt 2520
gtgaccagtg agggagctgg cctgcagctg cagaaggtga ctgtcctggg cgtggccacg 2580
gcgccccagc aggtcctctc caacggtgtc cctgtctcca acttcaccta cagccccgac 2640
accaaggtcc tggacatctg tgtctcgctg ttgatgggag agcagtttct cgtcagctgg 2700
tgttag 2706
<210> 41
<211> 2706
<212> ДНК
<213> искусственная
<220>
<223> sp7-hGAAco2-дельта-42
<400> 41
atggcctttc tgtggctgct gagctgttgg gccctgctgg gcaccacctt cggcgcccat 60
cctggtagac caagagctgt gcctacccaa tgcgacgtgc cacccaactc ccgattcgac 120
tgcgcgccag ataaggctat tacccaagag cagtgtgaag ccagaggttg ctgctacatc 180
ccagcgaagc aaggattgca aggcgcccaa atgggacaac cttggtgttt cttcccccct 240
tcgtacccat catataaact cgaaaacctg tcctcttcgg aaatgggtta tactgccacc 300
ctcaccagaa ctactcctac tttcttcccg aaagacatct tgaccttgag gctggacgtg 360
atgatggaga ctgaaaaccg gctgcatttc actatcaaag atcctgccaa tcggcgatac 420
gaggtccctc tggaaacccc tcacgtgcac tcacgggctc cttctccgct ttactccgtc 480
gaattctctg aggaaccctt cggagtgatc gttagacgcc agctggatgg tagagtgctg 540
ttgaacacta ctgtggcccc acttttcttc gctgaccagt ttctgcaact gtccacttcc 600
ctgccatccc agtacattac tggactcgcc gaacacctgt cgccactgat gctctcgacc 660
tcttggacta gaatcacttt gtggaacaga gacttggccc ctactccggg agcaaatctg 720
tacggaagcc acccttttta cctggcgctc gaagatggcg gatccgctca cggagtgttc 780
ctgctgaata gcaacgcaat ggacgtggtg ctgcaacctt cccctgcact cagttggaga 840
agtaccgggg gtattctgga cgtgtacatc ttcctcggac cagaacccaa gagcgtggtg 900
cagcaatatc tggacgtggt cggataccct tttatgcctc cttactgggg actgggattc 960
cacctttgcc gttggggcta ctcatccacc gccattacca gacaggtggt ggagaatatg 1020
accagagccc acttccctct cgacgtgcag tggaacgatc tggactatat ggactcccgg 1080
agagatttca ccttcaacaa ggacgggttc cgcgattttc ccgcgatggt tcaagagctc 1140
caccagggtg gtcgaagata tatgatgatc gtcgacccag ccatttcgag cagcggaccc 1200
gctggatctt atagacctta cgacgaaggc cttaggagag gagtgttcat cacaaacgag 1260
actggacagc ctttgatcgg taaagtgtgg cctggatcaa ccgcctttcc tgactttacc 1320
aatcccactg ccttggcttg gtgggaggac atggtggccg aattccacga ccaagtcccc 1380
tttgatggaa tgtggatcga tatgaacgaa ccaagcaatt ttatcagagg ttccgaagac 1440
ggttgcccca acaacgaact ggaaaaccct ccttatgtgc ccggagtcgt gggcggaaca 1500
ttacaggccg cgactatttg cgccagcagc caccaattcc tgtccactca ctacaacctc 1560
cacaaccttt atggattaac cgaagctatt gcaagtcaca gggctctggt gaaggctaga 1620
gggactaggc cctttgtgat ctcccgatcc acctttgccg gacacgggag atacgccggt 1680
cactggactg gtgacgtgtg gagctcatgg gaacaactgg cctcctccgt gccggaaatc 1740
ttacagttca accttctggg tgtccctctt gtcggagcag acgtgtgtgg gtttcttggt 1800
aacacctccg aggaactgtg tgtgcgctgg actcaactgg gtgcattcta cccattcatg 1860
agaaaccaca actccttgct gtccctgcca caagagccct actcgttcag cgagcctgca 1920
caacaggcta tgcggaaggc actgaccctg agatacgccc tgcttccaca cttatacact 1980
ctcttccatc aagcgcatgt ggcaggagaa accgttgcaa ggcctctttt ccttgaattc 2040
cccaaggatt cctcgacttg gacggtggat catcagctgc tgtggggaga agctctgctg 2100
attactccag tgttgcaagc cggaaaagct gaggtgaccg gatactttcc gctgggaacc 2160
tggtacgacc tccagactgt ccctgttgaa gcccttggat cactgcctcc gcctccggca 2220
gctccacgcg aaccagctat acattccgag ggacagtggg ttacattacc agctcctctg 2280
gacacaatca acgtccactt aagagctggc tacattatcc ctctgcaagg accaggactg 2340
actacgaccg agagcagaca gcagccaatg gcactggctg tggctctgac caagggaggg 2400
gaagctagag gagaactctt ctgggatgat ggggagtccc ttgaagtgct ggaaagaggc 2460
gcttacactc aagtcatttt ccttgcacgg aacaacacca ttgtgaacga attggtgcga 2520
gtgaccagcg aaggagctgg acttcaactg cagaaggtca ctgtgctcgg agtggctacc 2580
gctcctcagc aagtgctgtc gaatggagtc cccgtgtcaa actttaccta ctcccctgac 2640
actaaggtgc tcgacatttg cgtgtccctc ctgatgggag agcagttcct tgtgtcctgg 2700
tgttga 2706
<210> 42
<211> 2703
<212> ДНК
<213> искусственная
<220>
<223> sp7-hGAAwt-дельта-43
<400> 42
atggcctttc tgtggctgct gagctgttgg gccctgctgg gcaccacctt cggccacccc 60
gggcggccgc gagcagtgcc cacacagtgc gacgtccccc ccaacagccg cttcgattgc 120
gcccctgaca aggccatcac ccaggaacag tgcgaggccc gcggctgttg ctacatccct 180
gcaaagcagg ggctgcaggg agcccagatg gggcagccct ggtgcttctt cccacccagc 240
taccccagct acaagctgga gaacctgagc tcctctgaaa tgggctacac ggccaccctg 300
acccgtacca cccccacctt cttccccaag gacatcctga ccctgcggct ggacgtgatg 360
atggagactg agaaccgcct ccacttcacg atcaaagatc cagctaacag gcgctacgag 420
gtgcccttgg agaccccgca tgtccacagc cgggcaccgt ccccactcta cagcgtggag 480
ttctccgagg agcccttcgg ggtgatcgtg cgccggcagc tggacggccg cgtgctgctg 540
aacacgacgg tggcgcccct gttctttgcg gaccagttcc ttcagctgtc cacctcgctg 600
ccctcgcagt atatcacagg cctcgccgag cacctcagtc ccctgatgct cagcaccagc 660
tggaccagga tcaccctgtg gaaccgggac cttgcgccca cgcccggtgc gaacctctac 720
gggtctcacc ctttctacct ggcgctggag gacggcgggt cggcacacgg ggtgttcctg 780
ctaaacagca atgccatgga tgtggtcctg cagccgagcc ctgcccttag ctggaggtcg 840
acaggtggga tcctggatgt ctacatcttc ctgggcccag agcccaagag cgtggtgcag 900
cagtacctgg acgttgtggg atacccgttc atgccgccat actggggcct gggcttccac 960
ctgtgccgct ggggctactc ctccaccgct atcacccgcc aggtggtgga gaacatgacc 1020
agggcccact tccccctgga cgtccagtgg aacgacctgg actacatgga ctcccggagg 1080
gacttcacgt tcaacaagga tggcttccgg gacttcccgg ccatggtgca ggagctgcac 1140
cagggcggcc ggcgctacat gatgatcgtg gatcctgcca tcagcagctc gggccctgcc 1200
gggagctaca ggccctacga cgagggtctg cggagggggg ttttcatcac caacgagacc 1260
ggccagccgc tgattgggaa ggtatggccc gggtccactg ccttccccga cttcaccaac 1320
cccacagccc tggcctggtg ggaggacatg gtggctgagt tccatgacca ggtgcccttc 1380
gacggcatgt ggattgacat gaacgagcct tccaacttca tcaggggctc tgaggacggc 1440
tgccccaaca atgagctgga gaacccaccc tacgtgcctg gggtggttgg ggggaccctc 1500
caggcggcca ccatctgtgc ctccagccac cagtttctct ccacacacta caacctgcac 1560
aacctctacg gcctgaccga agccatcgcc tcccacaggg cgctggtgaa ggctcggggg 1620
acacgcccat ttgtgatctc ccgctcgacc tttgctggcc acggccgata cgccggccac 1680
tggacggggg acgtgtggag ctcctgggag cagctcgcct cctccgtgcc agaaatcctg 1740
cagtttaacc tgctgggggt gcctctggtc ggggccgacg tctgcggctt cctgggcaac 1800
acctcagagg agctgtgtgt gcgctggacc cagctggggg ccttctaccc cttcatgcgg 1860
aaccacaaca gcctgctcag tctgccccag gagccgtaca gcttcagcga gccggcccag 1920
caggccatga ggaaggccct caccctgcgc tacgcactcc tcccccacct ctacacactg 1980
ttccaccagg cccacgtcgc gggggagacc gtggcccggc ccctcttcct ggagttcccc 2040
aaggactcta gcacctggac tgtggaccac cagctcctgt ggggggaggc cctgctcatc 2100
accccagtgc tccaggccgg gaaggccgaa gtgactggct acttcccctt gggcacatgg 2160
tacgacctgc agacggtgcc agtagaggcc cttggcagcc tcccaccccc acctgcagct 2220
ccccgtgagc cagccatcca cagcgagggg cagtgggtga cgctgccggc ccccctggac 2280
accatcaacg tccacctccg ggctgggtac atcatccccc tgcagggccc tggcctcaca 2340
accacagagt cccgccagca gcccatggcc ctggctgtgg ccctgaccaa gggtggggag 2400
gcccgagggg agctgttctg ggacgatgga gagagcctgg aagtgctgga gcgaggggcc 2460
tacacacagg tcatcttcct ggccaggaat aacacgatcg tgaatgagct ggtacgtgtg 2520
accagtgagg gagctggcct gcagctgcag aaggtgactg tcctgggcgt ggccacggcg 2580
ccccagcagg tcctctccaa cggtgtccct gtctccaact tcacctacag ccccgacacc 2640
aaggtcctgg acatctgtgt ctcgctgttg atgggagagc agtttctcgt cagctggtgt 2700
tag 2703
<210> 43
<211> 2703
<212> ДНК
<213> искусственная
<220>
<223> sp7+hGAAco1-дельта-43
<400> 43
atggcctttc tgtggctgct gagctgttgg gccctgctgg gcaccacctt cggccacccc 60
ggcagaccta gagctgtgcc tacccagtgt gacgtgcccc ccaacagcag attcgactgc 120
gcccctgaca aggccatcac ccaggaacag tgcgaggcca gaggctgctg ctacatccct 180
gccaagcagg gactgcaggg cgctcagatg ggacagccct ggtgcttctt cccaccctcc 240
taccccagct acaagctgga aaacctgagc agcagcgaga tgggctacac cgccaccctg 300
accagaacca cccccacatt cttcccaaag gacatcctga ccctgcggct ggacgtgatg 360
atggaaaccg agaaccggct gcacttcacc atcaaggacc ccgccaatcg gagatacgag 420
gtgcccctgg aaacccccca cgtgcactct agagccccca gccctctgta cagcgtggaa 480
ttcagcgagg aacccttcgg cgtgatcgtg cggagacagc tggatggcag agtgctgctg 540
aacaccaccg tggcccctct gttcttcgcc gaccagttcc tgcagctgag caccagcctg 600
cccagccagt acatcacagg actggccgag cacctgagcc ccctgatgct gagcacatcc 660
tggacccgga tcaccctgtg gaacagggat ctggccccta cccctggcgc caatctgtac 720
ggcagccacc ctttctacct ggccctggaa gatggcggat ctgcccacgg agtgtttctg 780
ctgaactcca acgccatgga cgtggtgctg cagcctagcc ctgccctgtc ttggagaagc 840
acaggcggca tcctggatgt gtacatcttt ctgggccccg agcccaagag cgtggtgcag 900
cagtatctgg atgtcgtggg ctaccccttc atgccccctt actggggcct gggattccac 960
ctgtgcagat ggggctactc cagcaccgcc atcaccagac aggtggtgga aaacatgacc 1020
agagcccact tcccactgga tgtgcagtgg aacgacctgg actacatgga cagcagacgg 1080
gacttcacct tcaacaagga cggcttccgg gacttccccg ccatggtgca ggaactgcat 1140
cagggcggca gacggtacat gatgatcgtg gatcccgcca tcagctcctc tggccctgcc 1200
ggctcttaca gaccctacga cgagggcctg cggagaggcg tgttcatcac caacgagaca 1260
ggccagcccc tgatcggcaa agtgtggcct ggcagcacag ccttccccga cttcaccaat 1320
cctaccgccc tggcttggtg ggaggacatg gtggccgagt tccacgacca ggtgcccttc 1380
gacggcatgt ggatcgacat gaacgagccc agcaacttca tccggggcag cgaggatggc 1440
tgccccaaca acgaactgga aaatccccct tacgtgcccg gcgtcgtggg cggaacactg 1500
caggccgcta caatctgtgc cagcagccac cagtttctga gcacccacta caacctgcac 1560
aacctgtacg gcctgaccga ggccattgcc agccaccgcg ctctcgtgaa agccagaggc 1620
acacggccct tcgtgatcag cagaagcacc tttgccggcc acggcagata cgccggacat 1680
tggactggcg acgtgtggtc ctcttgggag cagctggcct ctagcgtgcc cgagatcctg 1740
cagttcaatc tgctgggcgt gccactcgtg ggcgccgatg tgtgtggctt cctgggcaac 1800
acctccgagg aactgtgtgt gcggtggaca cagctgggcg ccttctaccc tttcatgaga 1860
aaccacaaca gcctgctgag cctgccccag gaaccctaca gctttagcga gcctgcacag 1920
caggccatgc ggaaggccct gacactgaga tacgctctgc tgccccacct gtacaccctg 1980
tttcaccagg cccatgtggc cggcgagaca gtggccagac ctctgtttct ggaattcccc 2040
aaggacagca gcacctggac cgtggaccat cagctgctgt ggggagaggc tctgctgatt 2100
accccagtgc tgcaggcagg caaggccgaa gtgaccggct actttcccct gggcacttgg 2160
tacgacctgc agaccgtgcc tgtggaagcc ctgggatctc tgcctccacc tcctgccgct 2220
cctagagagc ctgccattca ctctgagggc cagtgggtca cactgcctgc ccccctggat 2280
accatcaacg tgcacctgag ggccggctac atcataccac tgcagggacc tggcctgacc 2340
accaccgagt ctagacagca gccaatggcc ctggccgtgg ccctgaccaa aggcggagaa 2400
gctaggggcg agctgttctg ggacgatggc gagagcctgg aagtgctgga aagaggcgcc 2460
tatacccaag tgatcttcct ggcccggaac aacaccatcg tgaacgagct ggtgcgcgtg 2520
acctctgaag gcgctggact gcagctgcag aaagtgaccg tgctgggagt ggccacagcc 2580
cctcagcagg tgctgtctaa tggcgtgccc gtgtccaact tcacctacag ccccgacacc 2640
aaggtgctgg acatctgcgt gtcactgctg atgggagagc agtttctggt gtcctggtgc 2700
tga 2703
<210> 44
<211> 2703
<212> ДНК
<213> искусственная
<220>
<223> sp7+hGAAco2-дельта-43
<400> 44
atggcctttc tgtggctgct gagctgttgg gccctgctgg gcaccacctt cggccatcct 60
ggtagaccaa gagctgtgcc tacccaatgc gacgtgccac ccaactcccg attcgactgc 120
gcgccagata aggctattac ccaagagcag tgtgaagcca gaggttgctg ctacatccca 180
gcgaagcaag gattgcaagg cgcccaaatg ggacaacctt ggtgtttctt ccccccttcg 240
tacccatcat ataaactcga aaacctgtcc tcttcggaaa tgggttatac tgccaccctc 300
accagaacta ctcctacttt cttcccgaaa gacatcttga ccttgaggct ggacgtgatg 360
atggagactg aaaaccggct gcatttcact atcaaagatc ctgccaatcg gcgatacgag 420
gtccctctgg aaacccctca cgtgcactca cgggctcctt ctccgcttta ctccgtcgaa 480
ttctctgagg aacccttcgg agtgatcgtt agacgccagc tggatggtag agtgctgttg 540
aacactactg tggccccact tttcttcgct gaccagtttc tgcaactgtc cacttccctg 600
ccatcccagt acattactgg actcgccgaa cacctgtcgc cactgatgct ctcgacctct 660
tggactagaa tcactttgtg gaacagagac ttggccccta ctccgggagc aaatctgtac 720
ggaagccacc ctttttacct ggcgctcgaa gatggcggat ccgctcacgg agtgttcctg 780
ctgaatagca acgcaatgga cgtggtgctg caaccttccc ctgcactcag ttggagaagt 840
accgggggta ttctggacgt gtacatcttc ctcggaccag aacccaagag cgtggtgcag 900
caatatctgg acgtggtcgg ataccctttt atgcctcctt actggggact gggattccac 960
ctttgccgtt ggggctactc atccaccgcc attaccagac aggtggtgga gaatatgacc 1020
agagcccact tccctctcga cgtgcagtgg aacgatctgg actatatgga ctcccggaga 1080
gatttcacct tcaacaagga cgggttccgc gattttcccg cgatggttca agagctccac 1140
cagggtggtc gaagatatat gatgatcgtc gacccagcca tttcgagcag cggacccgct 1200
ggatcttata gaccttacga cgaaggcctt aggagaggag tgttcatcac aaacgagact 1260
ggacagcctt tgatcggtaa agtgtggcct ggatcaaccg cctttcctga ctttaccaat 1320
cccactgcct tggcttggtg ggaggacatg gtggccgaat tccacgacca agtccccttt 1380
gatggaatgt ggatcgatat gaacgaacca agcaatttta tcagaggttc cgaagacggt 1440
tgccccaaca acgaactgga aaaccctcct tatgtgcccg gagtcgtggg cggaacatta 1500
caggccgcga ctatttgcgc cagcagccac caattcctgt ccactcacta caacctccac 1560
aacctttatg gattaaccga agctattgca agtcacaggg ctctggtgaa ggctagaggg 1620
actaggccct ttgtgatctc ccgatccacc tttgccggac acgggagata cgccggtcac 1680
tggactggtg acgtgtggag ctcatgggaa caactggcct cctccgtgcc ggaaatctta 1740
cagttcaacc ttctgggtgt ccctcttgtc ggagcagacg tgtgtgggtt tcttggtaac 1800
acctccgagg aactgtgtgt gcgctggact caactgggtg cattctaccc attcatgaga 1860
aaccacaact ccttgctgtc cctgccacaa gagccctact cgttcagcga gcctgcacaa 1920
caggctatgc ggaaggcact gaccctgaga tacgccctgc ttccacactt atacactctc 1980
ttccatcaag cgcatgtggc aggagaaacc gttgcaaggc ctcttttcct tgaattcccc 2040
aaggattcct cgacttggac ggtggatcat cagctgctgt ggggagaagc tctgctgatt 2100
actccagtgt tgcaagccgg aaaagctgag gtgaccggat actttccgct gggaacctgg 2160
tacgacctcc agactgtccc tgttgaagcc cttggatcac tgcctccgcc tccggcagct 2220
ccacgcgaac cagctataca ttccgaggga cagtgggtta cattaccagc tcctctggac 2280
acaatcaacg tccacttaag agctggctac attatccctc tgcaaggacc aggactgact 2340
acgaccgaga gcagacagca gccaatggca ctggctgtgg ctctgaccaa gggaggggaa 2400
gctagaggag aactcttctg ggatgatggg gagtcccttg aagtgctgga aagaggcgct 2460
tacactcaag tcattttcct tgcacggaac aacaccattg tgaacgaatt ggtgcgagtg 2520
accagcgaag gagctggact tcaactgcag aaggtcactg tgctcggagt ggctaccgct 2580
cctcagcaag tgctgtcgaa tggagtcccc gtgtcaaact ttacctactc ccctgacact 2640
aaggtgctcg acatttgcgt gtccctcctg atgggagagc agttccttgt gtcctggtgt 2700
tga 2703
<210> 45
<211> 2691
<212> ДНК
<213> искусственная
<220>
<223> sp7+hGAAwt-дельта-47
<400> 45
atggcctttc tgtggctgct gagctgttgg gccctgctgg gcaccacctt cggcccgcga 60
gcagtgccca cacagtgcga cgtccccccc aacagccgct tcgattgcgc ccctgacaag 120
gccatcaccc aggaacagtg cgaggcccgc ggctgttgct acatccctgc aaagcagggg 180
ctgcagggag cccagatggg gcagccctgg tgcttcttcc cacccagcta ccccagctac 240
aagctggaga acctgagctc ctctgaaatg ggctacacgg ccaccctgac ccgtaccacc 300
cccaccttct tccccaagga catcctgacc ctgcggctgg acgtgatgat ggagactgag 360
aaccgcctcc acttcacgat caaagatcca gctaacaggc gctacgaggt gcccttggag 420
accccgcatg tccacagccg ggcaccgtcc ccactctaca gcgtggagtt ctccgaggag 480
cccttcgggg tgatcgtgcg ccggcagctg gacggccgcg tgctgctgaa cacgacggtg 540
gcgcccctgt tctttgcgga ccagttcctt cagctgtcca cctcgctgcc ctcgcagtat 600
atcacaggcc tcgccgagca cctcagtccc ctgatgctca gcaccagctg gaccaggatc 660
accctgtgga accgggacct tgcgcccacg cccggtgcga acctctacgg gtctcaccct 720
ttctacctgg cgctggagga cggcgggtcg gcacacgggg tgttcctgct aaacagcaat 780
gccatggatg tggtcctgca gccgagccct gcccttagct ggaggtcgac aggtgggatc 840
ctggatgtct acatcttcct gggcccagag cccaagagcg tggtgcagca gtacctggac 900
gttgtgggat acccgttcat gccgccatac tggggcctgg gcttccacct gtgccgctgg 960
ggctactcct ccaccgctat cacccgccag gtggtggaga acatgaccag ggcccacttc 1020
cccctggacg tccagtggaa cgacctggac tacatggact cccggaggga cttcacgttc 1080
aacaaggatg gcttccggga cttcccggcc atggtgcagg agctgcacca gggcggccgg 1140
cgctacatga tgatcgtgga tcctgccatc agcagctcgg gccctgccgg gagctacagg 1200
ccctacgacg agggtctgcg gaggggggtt ttcatcacca acgagaccgg ccagccgctg 1260
attgggaagg tatggcccgg gtccactgcc ttccccgact tcaccaaccc cacagccctg 1320
gcctggtggg aggacatggt ggctgagttc catgaccagg tgcccttcga cggcatgtgg 1380
attgacatga acgagccttc caacttcatc aggggctctg aggacggctg ccccaacaat 1440
gagctggaga acccacccta cgtgcctggg gtggttgggg ggaccctcca ggcggccacc 1500
atctgtgcct ccagccacca gtttctctcc acacactaca acctgcacaa cctctacggc 1560
ctgaccgaag ccatcgcctc ccacagggcg ctggtgaagg ctcgggggac acgcccattt 1620
gtgatctccc gctcgacctt tgctggccac ggccgatacg ccggccactg gacgggggac 1680
gtgtggagct cctgggagca gctcgcctcc tccgtgccag aaatcctgca gtttaacctg 1740
ctgggggtgc ctctggtcgg ggccgacgtc tgcggcttcc tgggcaacac ctcagaggag 1800
ctgtgtgtgc gctggaccca gctgggggcc ttctacccct tcatgcggaa ccacaacagc 1860
ctgctcagtc tgccccagga gccgtacagc ttcagcgagc cggcccagca ggccatgagg 1920
aaggccctca ccctgcgcta cgcactcctc ccccacctct acacactgtt ccaccaggcc 1980
cacgtcgcgg gggagaccgt ggcccggccc ctcttcctgg agttccccaa ggactctagc 2040
acctggactg tggaccacca gctcctgtgg ggggaggccc tgctcatcac cccagtgctc 2100
caggccggga aggccgaagt gactggctac ttccccttgg gcacatggta cgacctgcag 2160
acggtgccag tagaggccct tggcagcctc ccacccccac ctgcagctcc ccgtgagcca 2220
gccatccaca gcgaggggca gtgggtgacg ctgccggccc ccctggacac catcaacgtc 2280
cacctccggg ctgggtacat catccccctg cagggccctg gcctcacaac cacagagtcc 2340
cgccagcagc ccatggccct ggctgtggcc ctgaccaagg gtggggaggc ccgaggggag 2400
ctgttctggg acgatggaga gagcctggaa gtgctggagc gaggggccta cacacaggtc 2460
atcttcctgg ccaggaataa cacgatcgtg aatgagctgg tacgtgtgac cagtgaggga 2520
gctggcctgc agctgcagaa ggtgactgtc ctgggcgtgg ccacggcgcc ccagcaggtc 2580
ctctccaacg gtgtccctgt ctccaacttc acctacagcc ccgacaccaa ggtcctggac 2640
atctgtgtct cgctgttgat gggagagcag tttctcgtca gctggtgtta g 2691
<210> 46
<211> 2691
<212> ДНК
<213> искусственная
<220>
<223> sp7+hGAAco1-дельта-47
<400> 46
atggcctttc tgtggctgct gagctgttgg gccctgctgg gcaccacctt cggccctaga 60
gctgtgccta cccagtgtga cgtgcccccc aacagcagat tcgactgcgc ccctgacaag 120
gccatcaccc aggaacagtg cgaggccaga ggctgctgct acatccctgc caagcaggga 180
ctgcagggcg ctcagatggg acagccctgg tgcttcttcc caccctccta ccccagctac 240
aagctggaaa acctgagcag cagcgagatg ggctacaccg ccaccctgac cagaaccacc 300
cccacattct tcccaaagga catcctgacc ctgcggctgg acgtgatgat ggaaaccgag 360
aaccggctgc acttcaccat caaggacccc gccaatcgga gatacgaggt gcccctggaa 420
accccccacg tgcactctag agcccccagc cctctgtaca gcgtggaatt cagcgaggaa 480
cccttcggcg tgatcgtgcg gagacagctg gatggcagag tgctgctgaa caccaccgtg 540
gcccctctgt tcttcgccga ccagttcctg cagctgagca ccagcctgcc cagccagtac 600
atcacaggac tggccgagca cctgagcccc ctgatgctga gcacatcctg gacccggatc 660
accctgtgga acagggatct ggcccctacc cctggcgcca atctgtacgg cagccaccct 720
ttctacctgg ccctggaaga tggcggatct gcccacggag tgtttctgct gaactccaac 780
gccatggacg tggtgctgca gcctagccct gccctgtctt ggagaagcac aggcggcatc 840
ctggatgtgt acatctttct gggccccgag cccaagagcg tggtgcagca gtatctggat 900
gtcgtgggct accccttcat gcccccttac tggggcctgg gattccacct gtgcagatgg 960
ggctactcca gcaccgccat caccagacag gtggtggaaa acatgaccag agcccacttc 1020
ccactggatg tgcagtggaa cgacctggac tacatggaca gcagacggga cttcaccttc 1080
aacaaggacg gcttccggga cttccccgcc atggtgcagg aactgcatca gggcggcaga 1140
cggtacatga tgatcgtgga tcccgccatc agctcctctg gccctgccgg ctcttacaga 1200
ccctacgacg agggcctgcg gagaggcgtg ttcatcacca acgagacagg ccagcccctg 1260
atcggcaaag tgtggcctgg cagcacagcc ttccccgact tcaccaatcc taccgccctg 1320
gcttggtggg aggacatggt ggccgagttc cacgaccagg tgcccttcga cggcatgtgg 1380
atcgacatga acgagcccag caacttcatc cggggcagcg aggatggctg ccccaacaac 1440
gaactggaaa atccccctta cgtgcccggc gtcgtgggcg gaacactgca ggccgctaca 1500
atctgtgcca gcagccacca gtttctgagc acccactaca acctgcacaa cctgtacggc 1560
ctgaccgagg ccattgccag ccaccgcgct ctcgtgaaag ccagaggcac acggcccttc 1620
gtgatcagca gaagcacctt tgccggccac ggcagatacg ccggacattg gactggcgac 1680
gtgtggtcct cttgggagca gctggcctct agcgtgcccg agatcctgca gttcaatctg 1740
ctgggcgtgc cactcgtggg cgccgatgtg tgtggcttcc tgggcaacac ctccgaggaa 1800
ctgtgtgtgc ggtggacaca gctgggcgcc ttctaccctt tcatgagaaa ccacaacagc 1860
ctgctgagcc tgccccagga accctacagc tttagcgagc ctgcacagca ggccatgcgg 1920
aaggccctga cactgagata cgctctgctg ccccacctgt acaccctgtt tcaccaggcc 1980
catgtggccg gcgagacagt ggccagacct ctgtttctgg aattccccaa ggacagcagc 2040
acctggaccg tggaccatca gctgctgtgg ggagaggctc tgctgattac cccagtgctg 2100
caggcaggca aggccgaagt gaccggctac tttcccctgg gcacttggta cgacctgcag 2160
accgtgcctg tggaagccct gggatctctg cctccacctc ctgccgctcc tagagagcct 2220
gccattcact ctgagggcca gtgggtcaca ctgcctgccc ccctggatac catcaacgtg 2280
cacctgaggg ccggctacat cataccactg cagggacctg gcctgaccac caccgagtct 2340
agacagcagc caatggccct ggccgtggcc ctgaccaaag gcggagaagc taggggcgag 2400
ctgttctggg acgatggcga gagcctggaa gtgctggaaa gaggcgccta tacccaagtg 2460
atcttcctgg cccggaacaa caccatcgtg aacgagctgg tgcgcgtgac ctctgaaggc 2520
gctggactgc agctgcagaa agtgaccgtg ctgggagtgg ccacagcccc tcagcaggtg 2580
ctgtctaatg gcgtgcccgt gtccaacttc acctacagcc ccgacaccaa ggtgctggac 2640
atctgcgtgt cactgctgat gggagagcag tttctggtgt cctggtgctg a 2691
<210> 47
<211> 2691
<212> ДНК
<213> искусственная
<220>
<223> sp7+hGAAco2-дельта-47
<400> 47
atggcctttc tgtggctgct gagctgttgg gccctgctgg gcaccacctt cggcccaaga 60
gctgtgccta cccaatgcga cgtgccaccc aactcccgat tcgactgcgc gccagataag 120
gctattaccc aagagcagtg tgaagccaga ggttgctgct acatcccagc gaagcaagga 180
ttgcaaggcg cccaaatggg acaaccttgg tgtttcttcc ccccttcgta cccatcatat 240
aaactcgaaa acctgtcctc ttcggaaatg ggttatactg ccaccctcac cagaactact 300
cctactttct tcccgaaaga catcttgacc ttgaggctgg acgtgatgat ggagactgaa 360
aaccggctgc atttcactat caaagatcct gccaatcggc gatacgaggt ccctctggaa 420
acccctcacg tgcactcacg ggctccttct ccgctttact ccgtcgaatt ctctgaggaa 480
cccttcggag tgatcgttag acgccagctg gatggtagag tgctgttgaa cactactgtg 540
gccccacttt tcttcgctga ccagtttctg caactgtcca cttccctgcc atcccagtac 600
attactggac tcgccgaaca cctgtcgcca ctgatgctct cgacctcttg gactagaatc 660
actttgtgga acagagactt ggcccctact ccgggagcaa atctgtacgg aagccaccct 720
ttttacctgg cgctcgaaga tggcggatcc gctcacggag tgttcctgct gaatagcaac 780
gcaatggacg tggtgctgca accttcccct gcactcagtt ggagaagtac cgggggtatt 840
ctggacgtgt acatcttcct cggaccagaa cccaagagcg tggtgcagca atatctggac 900
gtggtcggat acccttttat gcctccttac tggggactgg gattccacct ttgccgttgg 960
ggctactcat ccaccgccat taccagacag gtggtggaga atatgaccag agcccacttc 1020
cctctcgacg tgcagtggaa cgatctggac tatatggact cccggagaga tttcaccttc 1080
aacaaggacg ggttccgcga ttttcccgcg atggttcaag agctccacca gggtggtcga 1140
agatatatga tgatcgtcga cccagccatt tcgagcagcg gacccgctgg atcttataga 1200
ccttacgacg aaggccttag gagaggagtg ttcatcacaa acgagactgg acagcctttg 1260
atcggtaaag tgtggcctgg atcaaccgcc tttcctgact ttaccaatcc cactgccttg 1320
gcttggtggg aggacatggt ggccgaattc cacgaccaag tcccctttga tggaatgtgg 1380
atcgatatga acgaaccaag caattttatc agaggttccg aagacggttg ccccaacaac 1440
gaactggaaa accctcctta tgtgcccgga gtcgtgggcg gaacattaca ggccgcgact 1500
atttgcgcca gcagccacca attcctgtcc actcactaca acctccacaa cctttatgga 1560
ttaaccgaag ctattgcaag tcacagggct ctggtgaagg ctagagggac taggcccttt 1620
gtgatctccc gatccacctt tgccggacac gggagatacg ccggtcactg gactggtgac 1680
gtgtggagct catgggaaca actggcctcc tccgtgccgg aaatcttaca gttcaacctt 1740
ctgggtgtcc ctcttgtcgg agcagacgtg tgtgggtttc ttggtaacac ctccgaggaa 1800
ctgtgtgtgc gctggactca actgggtgca ttctacccat tcatgagaaa ccacaactcc 1860
ttgctgtccc tgccacaaga gccctactcg ttcagcgagc ctgcacaaca ggctatgcgg 1920
aaggcactga ccctgagata cgccctgctt ccacacttat acactctctt ccatcaagcg 1980
catgtggcag gagaaaccgt tgcaaggcct cttttccttg aattccccaa ggattcctcg 2040
acttggacgg tggatcatca gctgctgtgg ggagaagctc tgctgattac tccagtgttg 2100
caagccggaa aagctgaggt gaccggatac tttccgctgg gaacctggta cgacctccag 2160
actgtccctg ttgaagccct tggatcactg cctccgcctc cggcagctcc acgcgaacca 2220
gctatacatt ccgagggaca gtgggttaca ttaccagctc ctctggacac aatcaacgtc 2280
cacttaagag ctggctacat tatccctctg caaggaccag gactgactac gaccgagagc 2340
agacagcagc caatggcact ggctgtggct ctgaccaagg gaggggaagc tagaggagaa 2400
ctcttctggg atgatgggga gtcccttgaa gtgctggaaa gaggcgctta cactcaagtc 2460
attttccttg cacggaacaa caccattgtg aacgaattgg tgcgagtgac cagcgaagga 2520
gctggacttc aactgcagaa ggtcactgtg ctcggagtgg ctaccgctcc tcagcaagtg 2580
ctgtcgaatg gagtccccgt gtcaaacttt acctactccc ctgacactaa ggtgctcgac 2640
atttgcgtgt ccctcctgat gggagagcag ttccttgtgt cctggtgttg a 2691
<210> 48
<211> 2652
<212> ДНК
<213> искусственная
<220>
<223> hGAAco1-дельта-42
<400> 48
gcccaccccg gcagacctag agctgtgcct acccagtgtg acgtgccccc caacagcaga 60
ttcgactgcg cccctgacaa ggccatcacc caggaacagt gcgaggccag aggctgctgc 120
tacatccctg ccaagcaggg actgcagggc gctcagatgg gacagccctg gtgcttcttc 180
ccaccctcct accccagcta caagctggaa aacctgagca gcagcgagat gggctacacc 240
gccaccctga ccagaaccac ccccacattc ttcccaaagg acatcctgac cctgcggctg 300
gacgtgatga tggaaaccga gaaccggctg cacttcacca tcaaggaccc cgccaatcgg 360
agatacgagg tgcccctgga aaccccccac gtgcactcta gagcccccag ccctctgtac 420
agcgtggaat tcagcgagga acccttcggc gtgatcgtgc ggagacagct ggatggcaga 480
gtgctgctga acaccaccgt ggcccctctg ttcttcgccg accagttcct gcagctgagc 540
accagcctgc ccagccagta catcacagga ctggccgagc acctgagccc cctgatgctg 600
agcacatcct ggacccggat caccctgtgg aacagggatc tggcccctac ccctggcgcc 660
aatctgtacg gcagccaccc tttctacctg gccctggaag atggcggatc tgcccacgga 720
gtgtttctgc tgaactccaa cgccatggac gtggtgctgc agcctagccc tgccctgtct 780
tggagaagca caggcggcat cctggatgtg tacatctttc tgggccccga gcccaagagc 840
gtggtgcagc agtatctgga tgtcgtgggc taccccttca tgccccctta ctggggcctg 900
ggattccacc tgtgcagatg gggctactcc agcaccgcca tcaccagaca ggtggtggaa 960
aacatgacca gagcccactt cccactggat gtgcagtgga acgacctgga ctacatggac 1020
agcagacggg acttcacctt caacaaggac ggcttccggg acttccccgc catggtgcag 1080
gaactgcatc agggcggcag acggtacatg atgatcgtgg atcccgccat cagctcctct 1140
ggccctgccg gctcttacag accctacgac gagggcctgc ggagaggcgt gttcatcacc 1200
aacgagacag gccagcccct gatcggcaaa gtgtggcctg gcagcacagc cttccccgac 1260
ttcaccaatc ctaccgccct ggcttggtgg gaggacatgg tggccgagtt ccacgaccag 1320
gtgcccttcg acggcatgtg gatcgacatg aacgagccca gcaacttcat ccggggcagc 1380
gaggatggct gccccaacaa cgaactggaa aatccccctt acgtgcccgg cgtcgtgggc 1440
ggaacactgc aggccgctac aatctgtgcc agcagccacc agtttctgag cacccactac 1500
aacctgcaca acctgtacgg cctgaccgag gccattgcca gccaccgcgc tctcgtgaaa 1560
gccagaggca cacggccctt cgtgatcagc agaagcacct ttgccggcca cggcagatac 1620
gccggacatt ggactggcga cgtgtggtcc tcttgggagc agctggcctc tagcgtgccc 1680
gagatcctgc agttcaatct gctgggcgtg ccactcgtgg gcgccgatgt gtgtggcttc 1740
ctgggcaaca cctccgagga actgtgtgtg cggtggacac agctgggcgc cttctaccct 1800
ttcatgagaa accacaacag cctgctgagc ctgccccagg aaccctacag ctttagcgag 1860
cctgcacagc aggccatgcg gaaggccctg acactgagat acgctctgct gccccacctg 1920
tacaccctgt ttcaccaggc ccatgtggcc ggcgagacag tggccagacc tctgtttctg 1980
gaattcccca aggacagcag cacctggacc gtggaccatc agctgctgtg gggagaggct 2040
ctgctgatta ccccagtgct gcaggcaggc aaggccgaag tgaccggcta ctttcccctg 2100
ggcacttggt acgacctgca gaccgtgcct gtggaagccc tgggatctct gcctccacct 2160
cctgccgctc ctagagagcc tgccattcac tctgagggcc agtgggtcac actgcctgcc 2220
cccctggata ccatcaacgt gcacctgagg gccggctaca tcataccact gcagggacct 2280
ggcctgacca ccaccgagtc tagacagcag ccaatggccc tggccgtggc cctgaccaaa 2340
ggcggagaag ctaggggcga gctgttctgg gacgatggcg agagcctgga agtgctggaa 2400
agaggcgcct atacccaagt gatcttcctg gcccggaaca acaccatcgt gaacgagctg 2460
gtgcgcgtga cctctgaagg cgctggactg cagctgcaga aagtgaccgt gctgggagtg 2520
gccacagccc ctcagcaggt gctgtctaat ggcgtgcccg tgtccaactt cacctacagc 2580
cccgacacca aggtgctgga catctgcgtg tcactgctga tgggagagca gtttctggtg 2640
tcctggtgct ga 2652
<210> 49
<211> 2652
<212> ДНК
<213> искусственная
<220>
<223> hGAAco2-дельта-42
<400> 49
gcccatcctg gtagaccaag agctgtgcct acccaatgcg acgtgccacc caactcccga 60
ttcgactgcg cgccagataa ggctattacc caagagcagt gtgaagccag aggttgctgc 120
tacatcccag cgaagcaagg attgcaaggc gcccaaatgg gacaaccttg gtgtttcttc 180
cccccttcgt acccatcata taaactcgaa aacctgtcct cttcggaaat gggttatact 240
gccaccctca ccagaactac tcctactttc ttcccgaaag acatcttgac cttgaggctg 300
gacgtgatga tggagactga aaaccggctg catttcacta tcaaagatcc tgccaatcgg 360
cgatacgagg tccctctgga aacccctcac gtgcactcac gggctccttc tccgctttac 420
tccgtcgaat tctctgagga acccttcgga gtgatcgtta gacgccagct ggatggtaga 480
gtgctgttga acactactgt ggccccactt ttcttcgctg accagtttct gcaactgtcc 540
acttccctgc catcccagta cattactgga ctcgccgaac acctgtcgcc actgatgctc 600
tcgacctctt ggactagaat cactttgtgg aacagagact tggcccctac tccgggagca 660
aatctgtacg gaagccaccc tttttacctg gcgctcgaag atggcggatc cgctcacgga 720
gtgttcctgc tgaatagcaa cgcaatggac gtggtgctgc aaccttcccc tgcactcagt 780
tggagaagta ccgggggtat tctggacgtg tacatcttcc tcggaccaga acccaagagc 840
gtggtgcagc aatatctgga cgtggtcgga taccctttta tgcctcctta ctggggactg 900
ggattccacc tttgccgttg gggctactca tccaccgcca ttaccagaca ggtggtggag 960
aatatgacca gagcccactt ccctctcgac gtgcagtgga acgatctgga ctatatggac 1020
tcccggagag atttcacctt caacaaggac gggttccgcg attttcccgc gatggttcaa 1080
gagctccacc agggtggtcg aagatatatg atgatcgtcg acccagccat ttcgagcagc 1140
ggacccgctg gatcttatag accttacgac gaaggcctta ggagaggagt gttcatcaca 1200
aacgagactg gacagccttt gatcggtaaa gtgtggcctg gatcaaccgc ctttcctgac 1260
tttaccaatc ccactgcctt ggcttggtgg gaggacatgg tggccgaatt ccacgaccaa 1320
gtcccctttg atggaatgtg gatcgatatg aacgaaccaa gcaattttat cagaggttcc 1380
gaagacggtt gccccaacaa cgaactggaa aaccctcctt atgtgcccgg agtcgtgggc 1440
ggaacattac aggccgcgac tatttgcgcc agcagccacc aattcctgtc cactcactac 1500
aacctccaca acctttatgg attaaccgaa gctattgcaa gtcacagggc tctggtgaag 1560
gctagaggga ctaggccctt tgtgatctcc cgatccacct ttgccggaca cgggagatac 1620
gccggtcact ggactggtga cgtgtggagc tcatgggaac aactggcctc ctccgtgccg 1680
gaaatcttac agttcaacct tctgggtgtc cctcttgtcg gagcagacgt gtgtgggttt 1740
cttggtaaca cctccgagga actgtgtgtg cgctggactc aactgggtgc attctaccca 1800
ttcatgagaa accacaactc cttgctgtcc ctgccacaag agccctactc gttcagcgag 1860
cctgcacaac aggctatgcg gaaggcactg accctgagat acgccctgct tccacactta 1920
tacactctct tccatcaagc gcatgtggca ggagaaaccg ttgcaaggcc tcttttcctt 1980
gaattcccca aggattcctc gacttggacg gtggatcatc agctgctgtg gggagaagct 2040
ctgctgatta ctccagtgtt gcaagccgga aaagctgagg tgaccggata ctttccgctg 2100
ggaacctggt acgacctcca gactgtccct gttgaagccc ttggatcact gcctccgcct 2160
ccggcagctc cacgcgaacc agctatacat tccgagggac agtgggttac attaccagct 2220
cctctggaca caatcaacgt ccacttaaga gctggctaca ttatccctct gcaaggacca 2280
ggactgacta cgaccgagag cagacagcag ccaatggcac tggctgtggc tctgaccaag 2340
ggaggggaag ctagaggaga actcttctgg gatgatgggg agtcccttga agtgctggaa 2400
agaggcgctt acactcaagt cattttcctt gcacggaaca acaccattgt gaacgaattg 2460
gtgcgagtga ccagcgaagg agctggactt caactgcaga aggtcactgt gctcggagtg 2520
gctaccgctc ctcagcaagt gctgtcgaat ggagtccccg tgtcaaactt tacctactcc 2580
cctgacacta aggtgctcga catttgcgtg tccctcctga tgggagagca gttccttgtg 2640
tcctggtgtt ga 2652
<210> 50
<211> 2649
<212> ДНК
<213> искусственная
<220>
<223> hGAAco1-дельта-43
<400> 50
caccccggca gacctagagc tgtgcctacc cagtgtgacg tgccccccaa cagcagattc 60
gactgcgccc ctgacaaggc catcacccag gaacagtgcg aggccagagg ctgctgctac 120
atccctgcca agcagggact gcagggcgct cagatgggac agccctggtg cttcttccca 180
ccctcctacc ccagctacaa gctggaaaac ctgagcagca gcgagatggg ctacaccgcc 240
accctgacca gaaccacccc cacattcttc ccaaaggaca tcctgaccct gcggctggac 300
gtgatgatgg aaaccgagaa ccggctgcac ttcaccatca aggaccccgc caatcggaga 360
tacgaggtgc ccctggaaac cccccacgtg cactctagag cccccagccc tctgtacagc 420
gtggaattca gcgaggaacc cttcggcgtg atcgtgcgga gacagctgga tggcagagtg 480
ctgctgaaca ccaccgtggc ccctctgttc ttcgccgacc agttcctgca gctgagcacc 540
agcctgccca gccagtacat cacaggactg gccgagcacc tgagccccct gatgctgagc 600
acatcctgga cccggatcac cctgtggaac agggatctgg cccctacccc tggcgccaat 660
ctgtacggca gccacccttt ctacctggcc ctggaagatg gcggatctgc ccacggagtg 720
tttctgctga actccaacgc catggacgtg gtgctgcagc ctagccctgc cctgtcttgg 780
agaagcacag gcggcatcct ggatgtgtac atctttctgg gccccgagcc caagagcgtg 840
gtgcagcagt atctggatgt cgtgggctac cccttcatgc ccccttactg gggcctggga 900
ttccacctgt gcagatgggg ctactccagc accgccatca ccagacaggt ggtggaaaac 960
atgaccagag cccacttccc actggatgtg cagtggaacg acctggacta catggacagc 1020
agacgggact tcaccttcaa caaggacggc ttccgggact tccccgccat ggtgcaggaa 1080
ctgcatcagg gcggcagacg gtacatgatg atcgtggatc ccgccatcag ctcctctggc 1140
cctgccggct cttacagacc ctacgacgag ggcctgcgga gaggcgtgtt catcaccaac 1200
gagacaggcc agcccctgat cggcaaagtg tggcctggca gcacagcctt ccccgacttc 1260
accaatccta ccgccctggc ttggtgggag gacatggtgg ccgagttcca cgaccaggtg 1320
cccttcgacg gcatgtggat cgacatgaac gagcccagca acttcatccg gggcagcgag 1380
gatggctgcc ccaacaacga actggaaaat cccccttacg tgcccggcgt cgtgggcgga 1440
acactgcagg ccgctacaat ctgtgccagc agccaccagt ttctgagcac ccactacaac 1500
ctgcacaacc tgtacggcct gaccgaggcc attgccagcc accgcgctct cgtgaaagcc 1560
agaggcacac ggcccttcgt gatcagcaga agcacctttg ccggccacgg cagatacgcc 1620
ggacattgga ctggcgacgt gtggtcctct tgggagcagc tggcctctag cgtgcccgag 1680
atcctgcagt tcaatctgct gggcgtgcca ctcgtgggcg ccgatgtgtg tggcttcctg 1740
ggcaacacct ccgaggaact gtgtgtgcgg tggacacagc tgggcgcctt ctaccctttc 1800
atgagaaacc acaacagcct gctgagcctg ccccaggaac cctacagctt tagcgagcct 1860
gcacagcagg ccatgcggaa ggccctgaca ctgagatacg ctctgctgcc ccacctgtac 1920
accctgtttc accaggccca tgtggccggc gagacagtgg ccagacctct gtttctggaa 1980
ttccccaagg acagcagcac ctggaccgtg gaccatcagc tgctgtgggg agaggctctg 2040
ctgattaccc cagtgctgca ggcaggcaag gccgaagtga ccggctactt tcccctgggc 2100
acttggtacg acctgcagac cgtgcctgtg gaagccctgg gatctctgcc tccacctcct 2160
gccgctccta gagagcctgc cattcactct gagggccagt gggtcacact gcctgccccc 2220
ctggatacca tcaacgtgca cctgagggcc ggctacatca taccactgca gggacctggc 2280
ctgaccacca ccgagtctag acagcagcca atggccctgg ccgtggccct gaccaaaggc 2340
ggagaagcta ggggcgagct gttctgggac gatggcgaga gcctggaagt gctggaaaga 2400
ggcgcctata cccaagtgat cttcctggcc cggaacaaca ccatcgtgaa cgagctggtg 2460
cgcgtgacct ctgaaggcgc tggactgcag ctgcagaaag tgaccgtgct gggagtggcc 2520
acagcccctc agcaggtgct gtctaatggc gtgcccgtgt ccaacttcac ctacagcccc 2580
gacaccaagg tgctggacat ctgcgtgtca ctgctgatgg gagagcagtt tctggtgtcc 2640
tggtgctga 2649
<210> 51
<211> 2649
<212> ДНК
<213> искусственная
<220>
<223> hGAAco2-дельта-43
<400> 51
catcctggta gaccaagagc tgtgcctacc caatgcgacg tgccacccaa ctcccgattc 60
gactgcgcgc cagataaggc tattacccaa gagcagtgtg aagccagagg ttgctgctac 120
atcccagcga agcaaggatt gcaaggcgcc caaatgggac aaccttggtg tttcttcccc 180
ccttcgtacc catcatataa actcgaaaac ctgtcctctt cggaaatggg ttatactgcc 240
accctcacca gaactactcc tactttcttc ccgaaagaca tcttgacctt gaggctggac 300
gtgatgatgg agactgaaaa ccggctgcat ttcactatca aagatcctgc caatcggcga 360
tacgaggtcc ctctggaaac ccctcacgtg cactcacggg ctccttctcc gctttactcc 420
gtcgaattct ctgaggaacc cttcggagtg atcgttagac gccagctgga tggtagagtg 480
ctgttgaaca ctactgtggc cccacttttc ttcgctgacc agtttctgca actgtccact 540
tccctgccat cccagtacat tactggactc gccgaacacc tgtcgccact gatgctctcg 600
acctcttgga ctagaatcac tttgtggaac agagacttgg cccctactcc gggagcaaat 660
ctgtacggaa gccacccttt ttacctggcg ctcgaagatg gcggatccgc tcacggagtg 720
ttcctgctga atagcaacgc aatggacgtg gtgctgcaac cttcccctgc actcagttgg 780
agaagtaccg ggggtattct ggacgtgtac atcttcctcg gaccagaacc caagagcgtg 840
gtgcagcaat atctggacgt ggtcggatac ccttttatgc ctccttactg gggactggga 900
ttccaccttt gccgttgggg ctactcatcc accgccatta ccagacaggt ggtggagaat 960
atgaccagag cccacttccc tctcgacgtg cagtggaacg atctggacta tatggactcc 1020
cggagagatt tcaccttcaa caaggacggg ttccgcgatt ttcccgcgat ggttcaagag 1080
ctccaccagg gtggtcgaag atatatgatg atcgtcgacc cagccatttc gagcagcgga 1140
cccgctggat cttatagacc ttacgacgaa ggccttagga gaggagtgtt catcacaaac 1200
gagactggac agcctttgat cggtaaagtg tggcctggat caaccgcctt tcctgacttt 1260
accaatccca ctgccttggc ttggtgggag gacatggtgg ccgaattcca cgaccaagtc 1320
ccctttgatg gaatgtggat cgatatgaac gaaccaagca attttatcag aggttccgaa 1380
gacggttgcc ccaacaacga actggaaaac cctccttatg tgcccggagt cgtgggcgga 1440
acattacagg ccgcgactat ttgcgccagc agccaccaat tcctgtccac tcactacaac 1500
ctccacaacc tttatggatt aaccgaagct attgcaagtc acagggctct ggtgaaggct 1560
agagggacta ggccctttgt gatctcccga tccacctttg ccggacacgg gagatacgcc 1620
ggtcactgga ctggtgacgt gtggagctca tgggaacaac tggcctcctc cgtgccggaa 1680
atcttacagt tcaaccttct gggtgtccct cttgtcggag cagacgtgtg tgggtttctt 1740
ggtaacacct ccgaggaact gtgtgtgcgc tggactcaac tgggtgcatt ctacccattc 1800
atgagaaacc acaactcctt gctgtccctg ccacaagagc cctactcgtt cagcgagcct 1860
gcacaacagg ctatgcggaa ggcactgacc ctgagatacg ccctgcttcc acacttatac 1920
actctcttcc atcaagcgca tgtggcagga gaaaccgttg caaggcctct tttccttgaa 1980
ttccccaagg attcctcgac ttggacggtg gatcatcagc tgctgtgggg agaagctctg 2040
ctgattactc cagtgttgca agccggaaaa gctgaggtga ccggatactt tccgctggga 2100
acctggtacg acctccagac tgtccctgtt gaagcccttg gatcactgcc tccgcctccg 2160
gcagctccac gcgaaccagc tatacattcc gagggacagt gggttacatt accagctcct 2220
ctggacacaa tcaacgtcca cttaagagct ggctacatta tccctctgca aggaccagga 2280
ctgactacga ccgagagcag acagcagcca atggcactgg ctgtggctct gaccaaggga 2340
ggggaagcta gaggagaact cttctgggat gatggggagt cccttgaagt gctggaaaga 2400
ggcgcttaca ctcaagtcat tttccttgca cggaacaaca ccattgtgaa cgaattggtg 2460
cgagtgacca gcgaaggagc tggacttcaa ctgcagaagg tcactgtgct cggagtggct 2520
accgctcctc agcaagtgct gtcgaatgga gtccccgtgt caaactttac ctactcccct 2580
gacactaagg tgctcgacat ttgcgtgtcc ctcctgatgg gagagcagtt ccttgtgtcc 2640
tggtgttga 2649
<210> 52
<211> 2637
<212> ДНК
<213> искусственная
<220>
<223> hGAAco1-дельта-47
<400> 52
cctagagctg tgcctaccca gtgtgacgtg ccccccaaca gcagattcga ctgcgcccct 60
gacaaggcca tcacccagga acagtgcgag gccagaggct gctgctacat ccctgccaag 120
cagggactgc agggcgctca gatgggacag ccctggtgct tcttcccacc ctcctacccc 180
agctacaagc tggaaaacct gagcagcagc gagatgggct acaccgccac cctgaccaga 240
accaccccca cattcttccc aaaggacatc ctgaccctgc ggctggacgt gatgatggaa 300
accgagaacc ggctgcactt caccatcaag gaccccgcca atcggagata cgaggtgccc 360
ctggaaaccc cccacgtgca ctctagagcc cccagccctc tgtacagcgt ggaattcagc 420
gaggaaccct tcggcgtgat cgtgcggaga cagctggatg gcagagtgct gctgaacacc 480
accgtggccc ctctgttctt cgccgaccag ttcctgcagc tgagcaccag cctgcccagc 540
cagtacatca caggactggc cgagcacctg agccccctga tgctgagcac atcctggacc 600
cggatcaccc tgtggaacag ggatctggcc cctacccctg gcgccaatct gtacggcagc 660
caccctttct acctggccct ggaagatggc ggatctgccc acggagtgtt tctgctgaac 720
tccaacgcca tggacgtggt gctgcagcct agccctgccc tgtcttggag aagcacaggc 780
ggcatcctgg atgtgtacat ctttctgggc cccgagccca agagcgtggt gcagcagtat 840
ctggatgtcg tgggctaccc cttcatgccc ccttactggg gcctgggatt ccacctgtgc 900
agatggggct actccagcac cgccatcacc agacaggtgg tggaaaacat gaccagagcc 960
cacttcccac tggatgtgca gtggaacgac ctggactaca tggacagcag acgggacttc 1020
accttcaaca aggacggctt ccgggacttc cccgccatgg tgcaggaact gcatcagggc 1080
ggcagacggt acatgatgat cgtggatccc gccatcagct cctctggccc tgccggctct 1140
tacagaccct acgacgaggg cctgcggaga ggcgtgttca tcaccaacga gacaggccag 1200
cccctgatcg gcaaagtgtg gcctggcagc acagccttcc ccgacttcac caatcctacc 1260
gccctggctt ggtgggagga catggtggcc gagttccacg accaggtgcc cttcgacggc 1320
atgtggatcg acatgaacga gcccagcaac ttcatccggg gcagcgagga tggctgcccc 1380
aacaacgaac tggaaaatcc cccttacgtg cccggcgtcg tgggcggaac actgcaggcc 1440
gctacaatct gtgccagcag ccaccagttt ctgagcaccc actacaacct gcacaacctg 1500
tacggcctga ccgaggccat tgccagccac cgcgctctcg tgaaagccag aggcacacgg 1560
cccttcgtga tcagcagaag cacctttgcc ggccacggca gatacgccgg acattggact 1620
ggcgacgtgt ggtcctcttg ggagcagctg gcctctagcg tgcccgagat cctgcagttc 1680
aatctgctgg gcgtgccact cgtgggcgcc gatgtgtgtg gcttcctggg caacacctcc 1740
gaggaactgt gtgtgcggtg gacacagctg ggcgccttct accctttcat gagaaaccac 1800
aacagcctgc tgagcctgcc ccaggaaccc tacagcttta gcgagcctgc acagcaggcc 1860
atgcggaagg ccctgacact gagatacgct ctgctgcccc acctgtacac cctgtttcac 1920
caggcccatg tggccggcga gacagtggcc agacctctgt ttctggaatt ccccaaggac 1980
agcagcacct ggaccgtgga ccatcagctg ctgtggggag aggctctgct gattacccca 2040
gtgctgcagg caggcaaggc cgaagtgacc ggctactttc ccctgggcac ttggtacgac 2100
ctgcagaccg tgcctgtgga agccctggga tctctgcctc cacctcctgc cgctcctaga 2160
gagcctgcca ttcactctga gggccagtgg gtcacactgc ctgcccccct ggataccatc 2220
aacgtgcacc tgagggccgg ctacatcata ccactgcagg gacctggcct gaccaccacc 2280
gagtctagac agcagccaat ggccctggcc gtggccctga ccaaaggcgg agaagctagg 2340
ggcgagctgt tctgggacga tggcgagagc ctggaagtgc tggaaagagg cgcctatacc 2400
caagtgatct tcctggcccg gaacaacacc atcgtgaacg agctggtgcg cgtgacctct 2460
gaaggcgctg gactgcagct gcagaaagtg accgtgctgg gagtggccac agcccctcag 2520
caggtgctgt ctaatggcgt gcccgtgtcc aacttcacct acagccccga caccaaggtg 2580
ctggacatct gcgtgtcact gctgatggga gagcagtttc tggtgtcctg gtgctga 2637
<210> 53
<211> 2637
<212> ДНК
<213> искусственная
<220>
<223> hGAAco2-дельта-47
<400> 53
ccaagagctg tgcctaccca atgcgacgtg ccacccaact cccgattcga ctgcgcgcca 60
gataaggcta ttacccaaga gcagtgtgaa gccagaggtt gctgctacat cccagcgaag 120
caaggattgc aaggcgccca aatgggacaa ccttggtgtt tcttcccccc ttcgtaccca 180
tcatataaac tcgaaaacct gtcctcttcg gaaatgggtt atactgccac cctcaccaga 240
actactccta ctttcttccc gaaagacatc ttgaccttga ggctggacgt gatgatggag 300
actgaaaacc ggctgcattt cactatcaaa gatcctgcca atcggcgata cgaggtccct 360
ctggaaaccc ctcacgtgca ctcacgggct ccttctccgc tttactccgt cgaattctct 420
gaggaaccct tcggagtgat cgttagacgc cagctggatg gtagagtgct gttgaacact 480
actgtggccc cacttttctt cgctgaccag tttctgcaac tgtccacttc cctgccatcc 540
cagtacatta ctggactcgc cgaacacctg tcgccactga tgctctcgac ctcttggact 600
agaatcactt tgtggaacag agacttggcc cctactccgg gagcaaatct gtacggaagc 660
cacccttttt acctggcgct cgaagatggc ggatccgctc acggagtgtt cctgctgaat 720
agcaacgcaa tggacgtggt gctgcaacct tcccctgcac tcagttggag aagtaccggg 780
ggtattctgg acgtgtacat cttcctcgga ccagaaccca agagcgtggt gcagcaatat 840
ctggacgtgg tcggataccc ttttatgcct ccttactggg gactgggatt ccacctttgc 900
cgttggggct actcatccac cgccattacc agacaggtgg tggagaatat gaccagagcc 960
cacttccctc tcgacgtgca gtggaacgat ctggactata tggactcccg gagagatttc 1020
accttcaaca aggacgggtt ccgcgatttt cccgcgatgg ttcaagagct ccaccagggt 1080
ggtcgaagat atatgatgat cgtcgaccca gccatttcga gcagcggacc cgctggatct 1140
tatagacctt acgacgaagg ccttaggaga ggagtgttca tcacaaacga gactggacag 1200
cctttgatcg gtaaagtgtg gcctggatca accgcctttc ctgactttac caatcccact 1260
gccttggctt ggtgggagga catggtggcc gaattccacg accaagtccc ctttgatgga 1320
atgtggatcg atatgaacga accaagcaat tttatcagag gttccgaaga cggttgcccc 1380
aacaacgaac tggaaaaccc tccttatgtg cccggagtcg tgggcggaac attacaggcc 1440
gcgactattt gcgccagcag ccaccaattc ctgtccactc actacaacct ccacaacctt 1500
tatggattaa ccgaagctat tgcaagtcac agggctctgg tgaaggctag agggactagg 1560
ccctttgtga tctcccgatc cacctttgcc ggacacggga gatacgccgg tcactggact 1620
ggtgacgtgt ggagctcatg ggaacaactg gcctcctccg tgccggaaat cttacagttc 1680
aaccttctgg gtgtccctct tgtcggagca gacgtgtgtg ggtttcttgg taacacctcc 1740
gaggaactgt gtgtgcgctg gactcaactg ggtgcattct acccattcat gagaaaccac 1800
aactccttgc tgtccctgcc acaagagccc tactcgttca gcgagcctgc acaacaggct 1860
atgcggaagg cactgaccct gagatacgcc ctgcttccac acttatacac tctcttccat 1920
caagcgcatg tggcaggaga aaccgttgca aggcctcttt tccttgaatt ccccaaggat 1980
tcctcgactt ggacggtgga tcatcagctg ctgtggggag aagctctgct gattactcca 2040
gtgttgcaag ccggaaaagc tgaggtgacc ggatactttc cgctgggaac ctggtacgac 2100
ctccagactg tccctgttga agcccttgga tcactgcctc cgcctccggc agctccacgc 2160
gaaccagcta tacattccga gggacagtgg gttacattac cagctcctct ggacacaatc 2220
aacgtccact taagagctgg ctacattatc cctctgcaag gaccaggact gactacgacc 2280
gagagcagac agcagccaat ggcactggct gtggctctga ccaagggagg ggaagctaga 2340
ggagaactct tctgggatga tggggagtcc cttgaagtgc tggaaagagg cgcttacact 2400
caagtcattt tccttgcacg gaacaacacc attgtgaacg aattggtgcg agtgaccagc 2460
gaaggagctg gacttcaact gcagaaggtc actgtgctcg gagtggctac cgctcctcag 2520
caagtgctgt cgaatggagt ccccgtgtca aactttacct actcccctga cactaaggtg 2580
ctcgacattt gcgtgtccct cctgatggga gagcagttcc ttgtgtcctg gtgttga 2637
<---
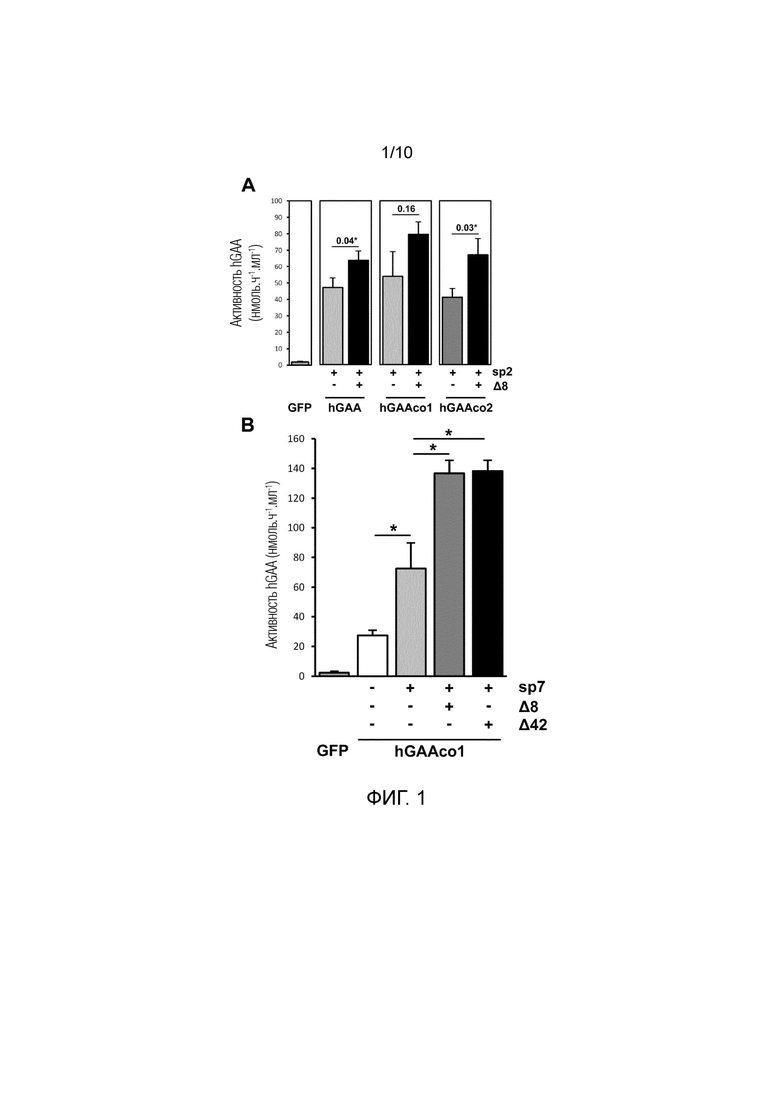
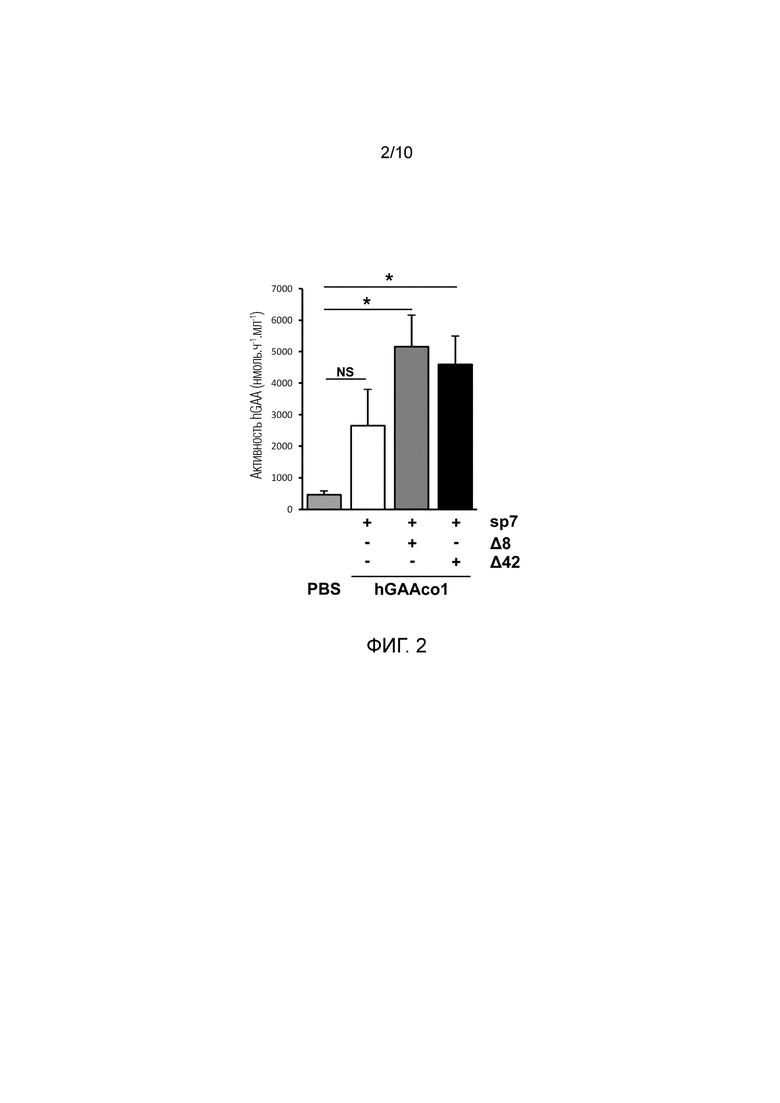

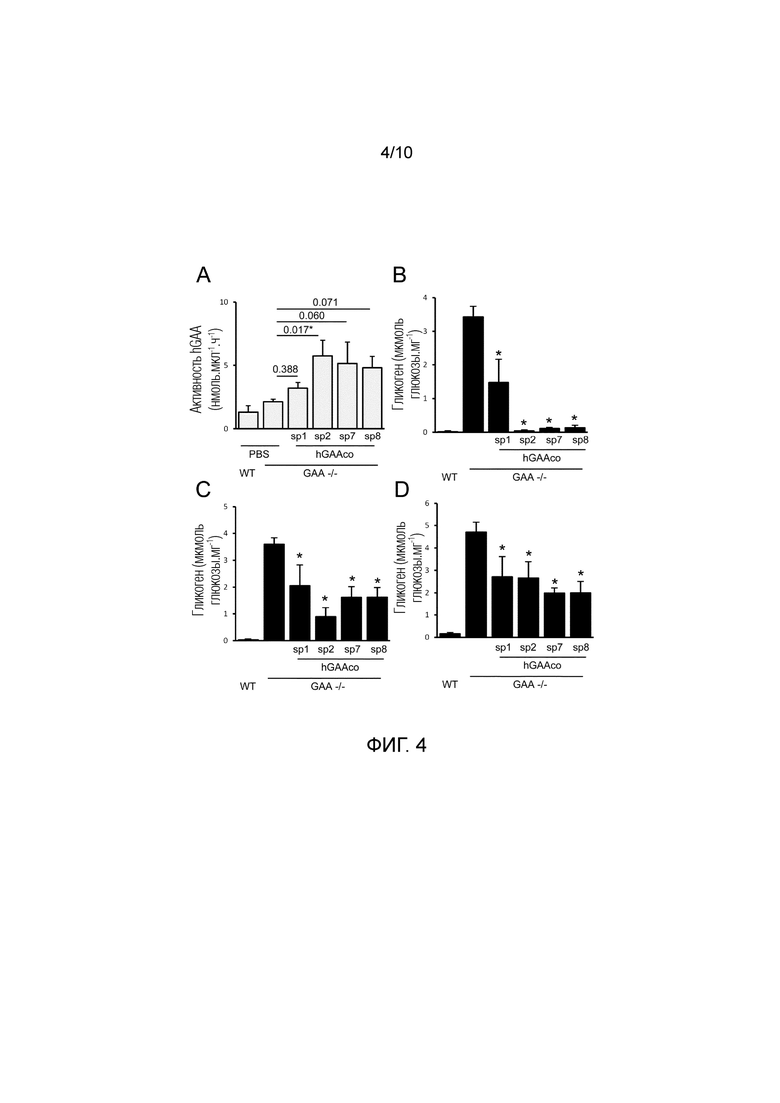
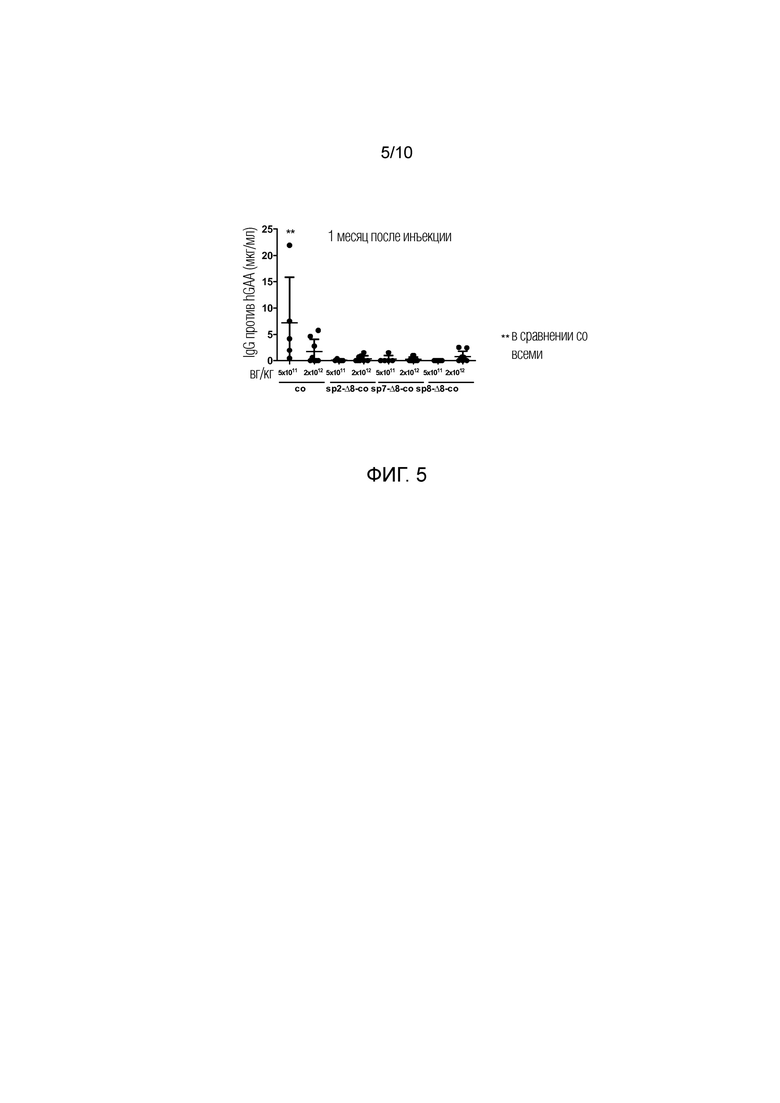
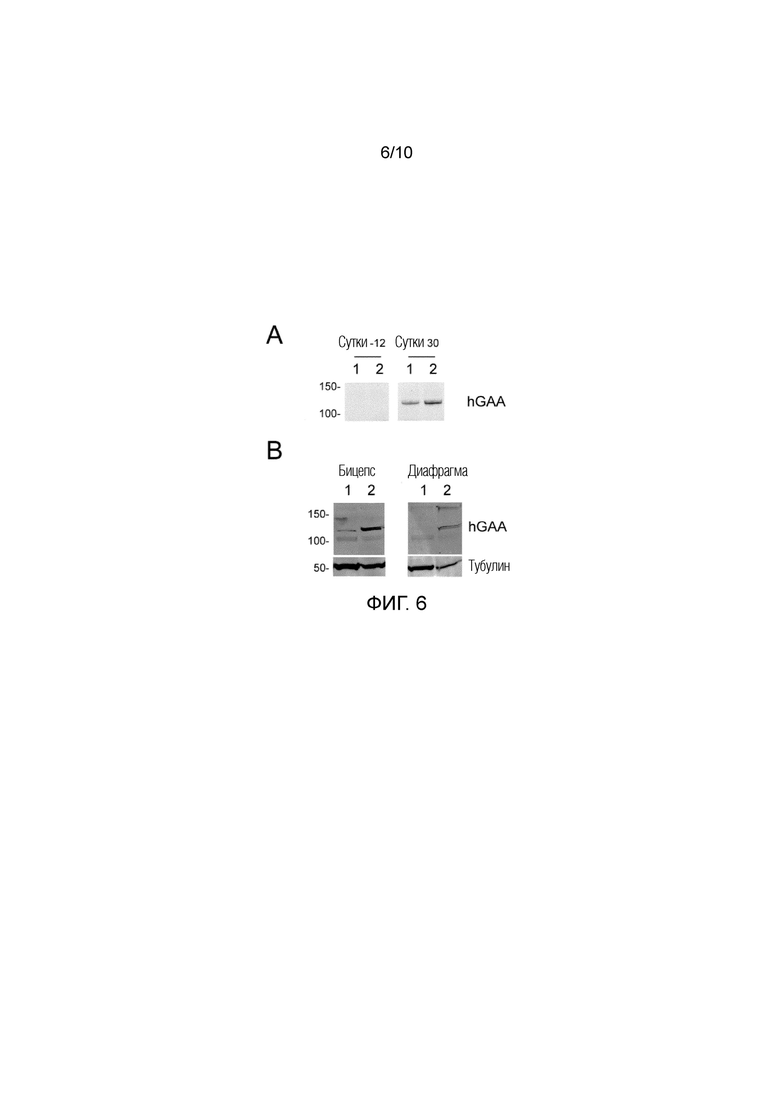


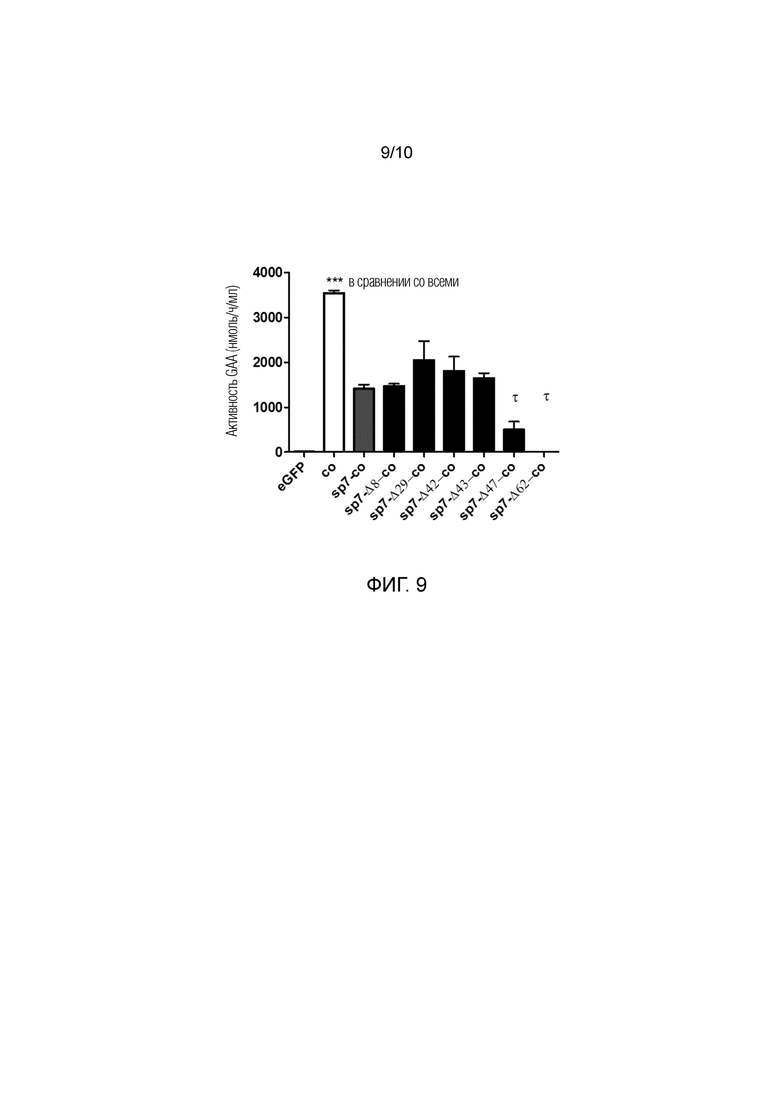
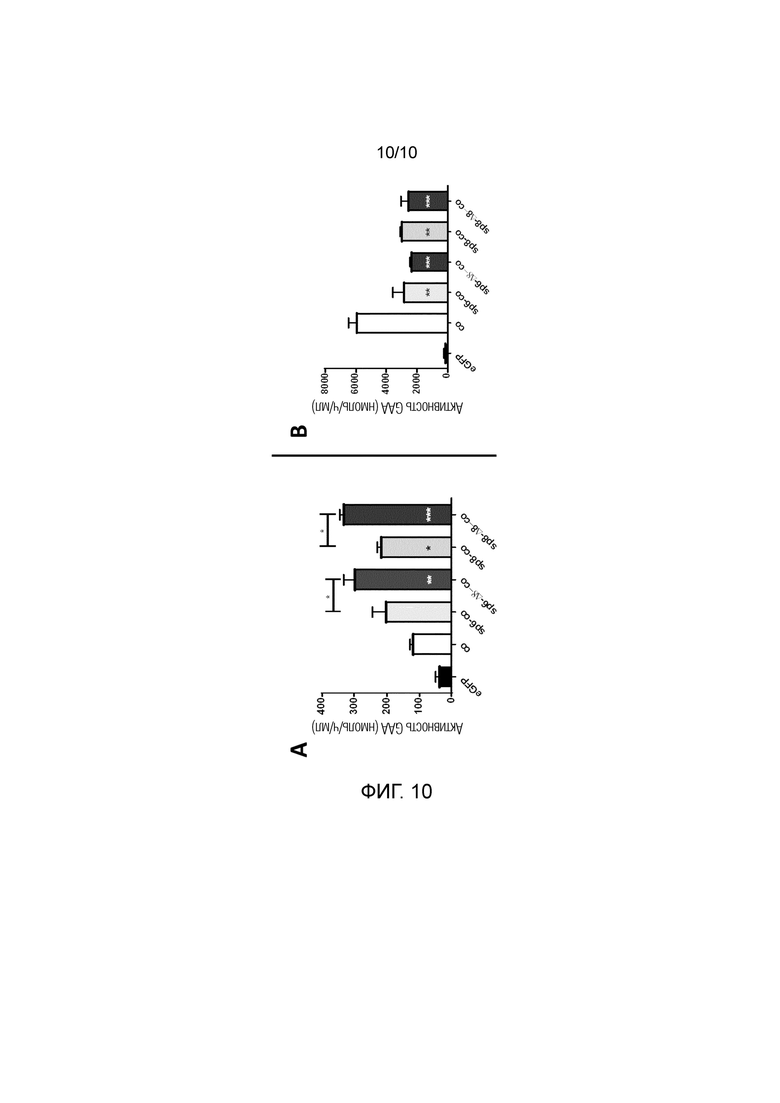
Изобретение относится к области биотехнологии, конкретно к терапевтическим векторам экспрессии, и может быть использовано в медицине для лечения болезни Помпе (GSDII) и болезни Кори (GSDIII). Предложен рекомбинантный вектор на основе аденоассоциированного вируса (AAV) для экспрессии усеченного полипептида альфа-глюкозидазы (GAA). Изобретение обеспечивает экспрессию и секрецию вариантов GAA человека на более высоких уровнях по сравнению с белком GAA человека дикого типа, что обеспечивает усовершенствованную коррекцию патологического накопления гликогена по всему организму и индукцию иммунологической толерантности к GAA. 6 н. и 11 з.п. ф-лы, 1 табл., 10 ил., 1 пр.
1. Рекомбинантный вектор на основе аденоассоциированного вируса (AAV) для экспрессии усеченного полипептида альфа-глюкозидазы (GAA), содержащий экспрессирующую кассету для экспрессии полипептида GAA, при этом экспрессирующая кассета содержит молекулу нуклеиновой кислоты, кодирующую усеченный полипептид GAA, содержащий делецию 1-43 последовательных аминокислот на его N-конце по сравнению с родительским полипептидом GAA, где указанный родительский полипептид соответствует форме предшественника полипептида GAA, свободной от ее сигнального пептида,
где указанный усеченный полипептид GAA дополнительно содержит сигнальный пептид, слитый с его N-концом, и
где указанный родительский полипептид GAA представляет собой полипептид GAA человека, имеющий аминокислотную последовательность, приведенную в SEQ ID NO: 1 или SEQ ID NO: 33.
2. Рекомбинантный AAV вектор по п. 1, где указанный усеченный полипептид GAA имеет 6, 7, 8, 9, 10, 40, 41, 42 или 43 последовательных аминокислот, удаленных на его N-конце, по сравнению с указанным родительским полипептидом GAA.
3. Рекомбинантный AAV вектор по п. 2, где указанный усеченный полипептид GAA имеет 8, 42 или 43 последовательных аминокислоты, удаленных на его N-конце, по сравнению с указанным родительским полипептидом GAA.
4. Рекомбинантный AAV вектор GAA по любому из пп. 1-3, где усеченный полипептид GAA имеет аминокислотную последовательность, приведенную в SEQ ID NO: 27, SEQ ID NO: 28, SEQ ID NO: 34 или SEQ ID NO: 35.
5. Рекомбинантный AAV вектор по любому из пп. 1-4, в котором указанный слитый сигнальный пептид выбирают из группы, состоящей из SEQ ID NO: 3-7, в частности сигнальный пептид с SEQ ID NO: 3.
6. Рекомбинантный AAV вектор по любому из пп. 1-5, где указанная молекула нуклеиновой кислоты, кодирующая усеченный полипептид GAA, представляет собой нуклеотидную последовательность, оптимизированную для того, чтобы усовершенствовать экспрессию и/или иммунологическую толерантность для указанного усеченного полипептида GAA in vivo, при этом указанная молекула нуклеиновой кислоты содержит последовательность нуклеиновой кислоты, приведенную в SEQ ID NO: 12, SEQ ID NO: 13, SEQ ID NO: 48, SEQ ID NO: 49, SEQ ID NO: 50 или SEQ ID NO: 51.
7. Рекомбинантный AAV вектор по любому из пп. 1-6, где указанная молекула нуклеиновой кислоты функционально связана с промотором, в частности промотором, который представляет собой специфический промотор печени, предпочтительно выбранный из группы, состоящей из промотора α-1-антитрипсина (hAAT), промотора транстиретина, промотора альбумина и промотора тироксинсвязывающего глобулина (TBG), где указанная экспрессирующая кассета дополнительно необязательно содержит интрон, в частности интрон, выбранный из группы, состоящей из интрона β-глобина b2 человека (HBB2), интрона FIX, интрона β-глобина курицы и интрона SV40, где указанный интрон необязательно представляет собой модифицированный интрон, такой как модифицированный интрон HBB2 из SEQ ID NO: 17, модифицированный интрон FIX из SEQ ID NO: 19 или модифицированный интрон β-глобина курицы из SEQ ID NO: 21.
8. Рекомбинантный AAV вектор по п. 7, который содержит предпочтительно в этом порядке: энхансер; интрон; промотор, в частности специфический промотор печени; указанную молекулу нуклеиновой кислоты, кодирующую указанный усеченный полипептид GAA; и сигнал полиаденилирования, при этом экспрессирующая кассета содержит предпочтительно в этом порядке: управляющую область ApoE; интрон HBB2, в частности модифицированный интрон HBB2; промотор hAAT; указанную молекулу нуклеиновой кислоты, кодирующую указанный усеченный полипептид GAA; и сигнал полиаденилирования бычьего гормона роста, при этом указанная экспрессирующая кассета более конкретно содержит нуклеотидную последовательность с любой из SEQ ID NO: 22-26.
9. Рекомбинантный AAV вектор по любому из пп. 1-8, который представляет собой одноцепочечный или двухцепочечный самокомплементарный AAV вектор, предпочтительно AAV вектор с происходящим из AAV капсидом, таким как капсид AAV1, AAV2, варианта AAV2, AAV3, варианта AAV3, AAV3B, варианта AAV3B, AAV4, AAV5, AAV6, варианта AAV6, AAV7, AAV8, AAV9, AAV10, например AAVcy10 и AAVrh10, AAVrh74, AAVdj, AAV-Anc80, AAV-LK03, AAV2i8 и AAV свиньи, например AAVpo4 и AAVpo6, или с химерным капсидом.
10. Рекомбинантный AAV вектор по п. 9, где AAV вектор имеет капсид AAV8, AAV9, AAVrh74 или AAV2i8, в частности капсид AAV8, AAV9 или AAVrh74, более конкретно капсид AAV8.
11. Рекомбинантный AAV вектор по п. 1, где указанная молекула нуклеиновой кислоты, кодирующая указанный усеченный полипептид GAA, имеет около 70 процентов, около 80 процентов, около 90 процентов, около 95 процентов, около 97 процентов, около 98 процентов или около 99 процентов идентичности с нуклеотидами 82-2859 SEQ ID NO: 8; или имеет по меньшей мере 75 процентов, по меньшей мере 80 процентов или по меньшей мере 82 процента идентичности последовательности с соответствующей частью нуклеотидной последовательности, кодирующей SEQ ID NO: 1 или SEQ ID NO: 33; или имеет по меньшей мере 85 процентов, по меньшей мере 90 процентов, по меньшей мере 92 процента, по меньшей мере 95 процентов, по меньшей мере 98 процентов, по меньшей мере 99 процентов или 100 процентов идентичности с соответствующей частью нуклеотидной последовательности SEQ ID NO: 10 или SEQ ID NO: 11.
12. Рекомбинантный AAV вектор по п. 1, где указанный усеченный полипептид GAA имеет аминокислотную последовательность SEQ ID NO: 27, где указанный сигнальный пептид имеет аминокислотную последовательность SEQ ID NO: 3 и где указанный рекомбинантный вектор AAV дополнительно содержит один или более из вариантов белков капсида VP, полученных из AAVrh74 или выбранных из группы, состоящей из RHM4-1, RHM15-1, RHM15-2, RHM15-3/RHM15-5, RHM15-4 и RHM15-6.
13. Клетка, трансформированная рекомбинантным AAV вектором по любому из пп. 1-12, для экспрессии усеченного полипептида GAA, где указанная клетка, в частности, представляет собой клетку печени или клетку мышцы.
14. Применение рекомбинантного AAV вектора по любому из пп. 1-12 или клетки по п. 13 в эффективном количестве в фармацевтической композиции с фармацевтически приемлемым носителем для лечения GSDII (болезни Помпе).
15. Применение рекомбинантного AAV вектора по любому из пп. 1-12 или клетки по п. 13 в эффективном количестве в фармацевтической композиции с фармацевтически приемлемым носителем для лечения GSDIII (болезни Кори).
16. Применение рекомбинантного AAV вектора по любому из пп. 1-12 или клетки по п. 13 для изготовления лекарственного средства для лечения GSDII (болезни Помпе).
17. Применение рекомбинантного AAV вектора по любому из пп. 1-12 или клетки по п. 13 для изготовления лекарственного средства для лечения GSDIII (болезни Кори).
| WO 2005078077 A2, 25.08.2005 | |||
| СМЫВНОЙ КЛАПАН ДЛЯ ВАКУУМНОЙ СИСТЕМЫ ДЛЯ ОТХОДОВ | 2009 |
|
RU2471929C1 |
| WO 2014130723 A1, 28.08.2014 | |||
| US 9018001 B2, 28.04.2015 | |||
| SUN B | |||
| ET AL, Enhanced Efficacy of an AAV Vector Encoding Chimeric, Highly Secreted Acid alpha-Glucosidase in Glycogen Storage Disease Type II, MOLECULAR THERAPY, 2006, v.14, n.6, p.822 - 830 | |||
| RU 2014139953 A, 20.05.2016 | |||
| БД GenBank | |||

