ОБЛАСТЬ ТЕХНИКИ
Данное изобретение относится к способам и средствам для получения полипептидов нитрогеназы в митохондриях растительных клеток.
УРОВЕНЬ ТЕХНИКИ
Диазотрофные бактерии вырабатывают аммиак из газа N2 посредством биологической фиксации азота (БФА), катализируемой ферментным комплексом нитрогеназы. Однако требования современного сельского хозяйства выходят далеко за пределы этого источника фиксированного азота и, следовательно, в сельском хозяйстве широко используют производимые в промышленных масштабах азотные удобрения (Smil, 2002). При этом как производство, так и применение удобрений являются причиной загрязнения (Good and Beatty, 2011) и считаются экологически неприемлемыми (Rockstrom et al., 2009). Большинство удобрений, применяемых по всему миру, не полностью поглощаются растениями (Cui et al., 2013; de Bruijn, 2015), приводя к стоку удобрений, распространению сорняков и эвтрофикации водоемов (Good and Beatty, 2011). В результате цветение воды, вызванное массовым развитием водорослей, приводит к нанесению вреда окружающей среде, локальному и прибрежному по всей территории коралловых рифов (De'ath et al., 2012; Glibert et al., 2014; Sutton et al., 2008). Кроме того, хотя избыточное внесение удобрений является проблемой во многих развитых странах, в определенных областях его доступность ограничивает урожаи сельскохозяйственных культур (Mueller et al., 2012). Само производство удобрений требует существенных затрат энергии и средств, по оценкам - 100 миллиардов долларов в год.
Необходимы четкие варианты стратегии снижения зависимости от производимых в промышленных масштабах источников азота. В связи с этим концепция создания растений, способных к биологической фиксации азота долгое время представляла значительный интерес (Merrick and Dixon, 1984), и на ней были сфокусированы недавно опубликованные обзоры (de Bruijn, 2015; Oldroyd and Dixon, 2014). Потенциальные подходы включают i) расширение симбиотической взаимосвязи диазотрофов из бобовых со зерновыми (Santi et al., 2013), ii) переконструирование эндосимбиотических организмов так, чтобы они были способны фиксировать азот (Geddes et al., 2015), и iii) генетическое внесение нитрогеназы в клетки растений (Curatti and Rubio, 2014). Все эти подходы являются амбициозными и спекулятивными вследствие технических трудностей.
Для биосинтеза и функции нитрогеназы, ферментного комплекса из диазотрофных бактерий, способного к биологической фиксации азота, необходим путь мультигенной сборки, как подробно описано в обзорах (Hu and Ribbe, 2013; Rubio and Ludden, 2008; Seefeldt et al., 2009). Компоненты канонической железо-молибденовой нитрогеназы содержат каталитические белки, обозначаемые NifD и NifK, и донор электронов NifH. Около 12 других белков вовлечены в сборку нитрогеназы в диазотрофных бактериях, включая созревание, скаффолдинг и вставку кофактором комплекса, в частности, это NifM, NifS, NifU, NifE, NifN, NifX, NifV, NifJ, NifY, NifF, NifZ и NifQ. Анализ генетических нарушений и комплементации между диазотрофными и недиазотрофными прокариотами, а также филогенетический анализ (Dos Santos et al., 2012; Temme et al., 2012; Wang et al., 2013) привели к выделению подгруппы белков Nif (NifD, NifK, NifB, NifE и NifN), считающихся основными компонентами, тогда как другие полагаются необходимыми для оптимизации активности и считаются вспомогательными. Также для сборки и функции нитрогеназы необходимы специальные биохимические условия. Самым главным среди них является то, что нитрогеназа чрезвычайно чувствительна к кислороду (Robson and Postgate, 1980). Кроме того, для биосинтеза и функции металлопротеинового каталитического центра необходимы большие количества АТФ, восстановителя, легкодоступных Fe, Mo, S-аденозилметионина и гомоцитрата (Hu and Ribbe, 2013; Rubio and Ludden, 2008). Все эти факторы являются причиной технических затруднений при производстве функционального комплекса нитрогеназы в клетках растений.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Авторы данного изобретения определили важность наличия одинаковых количеств NifD и NifK в клетках растений ввиду наблюдаемых затруднений выработки NifD в клетках растений. Подробный анализ полипептидов показал, что их можно экспрессировать в виде слитого белка с сохранением функции, а также важность наличия у компонента NifK C-конца дикого типа. Таким образом, в одном аспекте в данном изобретении предложена растительная клетка, содержащая митохондрии и слитый полипептид, содержащий
(i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец,
(ii) полипептид NifD (ND), который имеет N-конец и C-конец,
(iii) олигопептидный линкер и
(iv) полипептид NifK (NK), который имеет N-конец,
при этом C-конец МНП трансляционно слит с N-концом ND, а
линкер трансляционно слит с C-концом ND и N-концом NK.
В одном варианте реализации C-конец слитого полипептида представляет собой C-конец NK. В предпочтительном варианте реализации C-конец NK является таким же, как и C-конец полипептида NifK дикого типа, т. е. в NK отсутствует какое-либо искусственно добавленное C-концевое удлинение. Наличие C-конца дикого типа важно для сохранения активности NifK.
В другом варианте реализации линкер имеет достаточную длину, чтобы обеспечить возможность ассоциации ND и NK в функциональной конфигурации в растительной клетке или в бактериальной клетке. В одном варианте реализации линкер имеет длину от 8 до 50 аминокислот. Предпочтительно линкер имеет длину по меньшей мере около 20 аминокислот, по меньшей мере около 25 аминокислот или по меньшей мере около 30 аминокислот. Более предпочтительно линкер имеет длину от 25 до 35 аминокислот. Наиболее предпочтительно линкер имеет длину около 30 аминокислот. В этом контексте «около 30» означает 27, 28, 29, 30, 31, 32 или 33 аминокислоты.
В одном варианте реализации полипептид NifD и полипептид NifK в слитом полипептиде имеют такую же функцию, как и полипептид NifD и полипептид NifK, когда они представлены в виде двух отдельных полипептидов. Предпочтительно биохимическая активность слитого полипептида является такой же, как у полипептида NifD дикого типа и полипептида NifK дикого типа.
Авторы данного изобретения также определили важность наличия одинаковых количеств NifE и NifN в клетках растений. Подробный анализ полипептидов показал, что их можно экспрессировать в виде слитого белка с сохранением функции, а также то, что для функциональности полипептидов Nif необходимо наличие линкера. Таким образом, в дополнительном аспекте в данном изобретении предложена растительная клетка, содержащая митохондрии и слитый полипептид, содержащий
(i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец,
(ii) полипептид NifE (NE), который имеет N-конец и C-конец,
(iii) олигопептидный линкер и
(iv) полипептид NifN (NN), который имеет N-конец,
при этом C-конец МНП трансляционно слит с N-концом NE, а
линкер трансляционно слит с C-концом NE и N-концом NN.
В одном варианте реализации вышеуказанного аспекта линкер имеет достаточную длину, чтобы обеспечить возможность ассоциации NE и NN в функциональной конфигурации в растительной клетке или в бактериальной клетке. Например, в одном варианте реализации линкер имеет длину по меньшей мере около 70 Å, по меньшей мере около 100 Å, или от около 70 Å до около 150 Å, или от около 100 Å до около 120 Å, или около 100 Å, или около 104 Å. В одном варианте реализации олигопептидный линкер имеет длину по меньшей мере около 20 аминокислот, или по меньшей мере около 30 аминокислот, или по меньшей мере около 40 аминокислот, или от около 20 аминокислот до около 70 аминокислот, или от около 30 аминокислот до около 70 аминокислот, или от около 30 аминокислот до около 60 аминокислот, или от около 30 аминокислот до около 50 аминокислот, или около 25 аминокислот, или около 30 аминокислот, или около 35 аминокислот, или около 40 аминокислот, или около 45 аминокислот, или около 46 аминокислот, или около 50 аминокислот, или около 55 аминокислот.
В одном варианте реализации полипептид NifE и полипептид NifN в слитом полипептиде имеют такую же функцию, как и полипептид NifE и полипептид NifN, когда они представлены в виде двух отдельных полипептидов. Предпочтительно биохимическая активность слитого полипептида является такой же, как у полипептида NifE дикого типа и полипептида NifN дикого типа.
В одном варианте реализации МНП содержит сайт расщепления протеазой для матриксной процессирующей протеазы (МПП) так, чтобы слитый полипептид мог расщепляться МПП с получением N-концевого отщепленного пептида и процессированного слитого полипептида (CF), содержащего от (ii) до (iv). В одном варианте реализации CF содержит некоторые, но не все C-концевые аминокислоты МНП, предпочтительно от 5 до 45 аминокислот из С-концевых аминокислот МНП. В одном варианте реализации расщепление МПП приводит к удалению 5-50 аминокислот из слитого полипептида с получением CF. В предпочтительном варианте реализации CF содержит от около 5 до около 11 аминокислотных остатков из C-конца МНП, например, 6 или 7 аминокислот, 7 или 8 аминокислот, 8 или 9 аминокислот, 9 или 10 аминокислот или 11 или 12 аминокислот из C-конца МНП.
В одном варианте реализации вышеуказанных двух аспектов растительная клетка дополнительно содержит один или более слитых полипептидов NF (NF), причем каждый NF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид Nif (NP), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом NP, при этом каждый МНП независимо является одинаковым или отличным, а каждый NP независимо является одинаковым или отличным, и при этом митохондрии содержат один или более NF и/или их процессированный продукт (CF), и при этом каждый CF, в случае присутствия, получен посредством расщепления соответствующего NF в пределах его МНП. Предпочтительно по меньшей мере один из полипептидов NF представляет собой NifH. В предпочтительном варианте реализации каждый CF независимо содержит от около 5 до около 11 аминокислотных остатков из C-конца МНП, например, 6 или 7 аминокислот, 7 или 8 аминокислот, 8 или 9 аминокислот, 9 или 10 аминокислот или 11 или 12 аминокислот из C-конца МНП.
В одном варианте реализации экзогенный полинуклеотид(ы), кодирующий слитый полипептид(ы), интегрирован в геном клетки.
Авторы данного изобретения также показали, что все 16 биосинтетических и функциональных белков нитрогеназы (Nif) Klebsiella pneumoniae можно отдельно экспрессировать в виде слияний митохондриального нацеливающего пептида (МНП) и Nif в клетках растений, например, в листьях Nicotiana benthamiana. Авторы данного изобретения продемонстрировали, что эти слияния точно нацелены на митохондриальный матрикс (ММ), субклеточную локацию с биохимическими и генетическими характеристиками, потенциально поддерживающими функцию нитрогеназы. Полипептиды NifJ, NifH, NifD, NifK, NifY, NifE, NifN, NifX, NifU, NifS, NifV, NifM, NifF, NifB и NifQ можно было обнаружить с помощью анализа вестерн-блоттинга. Однако NifD, основной компонент, вовлеченный в катализ, был наименее распространенным. Кристаллическую структуру гетеродимера нитрогеназы NifD-NifK использовали для конструирования трансляционного слитого белка NifD-NifK, что улучшало уровни экспрессии. И наконец, четыре слитых полипептида Nif (NifB, NifS, NifH, NifY) успешно коэкспрессировали, демонстрируя, что на митохондрии можно нацеливать некоторое количество компонентов нитрогеназы. Эти результаты обосновывают возможность воссоздания компонентов нитрогеназы во внутриклеточной среде для поддержания восстановления газообразного азота до аммиака.
Из всех белков Nif, важный компонент каталитического комплекса нитрогеназы NifD было наиболее трудно экспрессировать. Низкие уровни белка NifD контрастировали с высокими уровнями РНК NifD, что позволяет предположить, что уровни трансляции или стабильность белка ограничивали количество белка NifD. Учитывая особую важность NifD при катализе, необходимость его высокой экспрессии в бактериях (Poza-Carrion et al., 2014), и, предпочтительно, в эквимолярном соотношении с NifK, авторы данного изобретения слили эти два ключевых компонента вместе и обнаружили, что количество NifD можно повысить за счет этой стратегии. Это слияние NifD-NifK также обладало преимуществом связи при экспрессии одной кассетой, что обеспечивает возможность трансляции обеих субъединиц при идеальном соотношении 1:1, имитируя стехиометрию нативного гетеродимера. Кроме того, сам линкер был сконструирован так, чтобы обеспечивать достаточную гибкость для двух субъединиц для образования правильной α2β2-гетеротетрамерной структуры, необходимой для катализа. Авторы данного изобретения предполагают, что слитый полипептид NifD-NifK будет, по меньшей мере, функционально замещать экспрессию NifD и NifK по отдельности, возможно, с большей эффективностью, чем было продемонстрировано ранее.
Таким образом, в данном изобретении предложена растительная клетка, содержащая митохондрии и экзогенный полинуклеотид, который кодирует слитый полипептид NifD (NDF), причем NDF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид NifD (ND), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом ND, при этом митохондрии содержат NDF и/или его процессированный продукт NifD (CDF), и при этом CDF, в случае присутствия, получен посредством расщепления NDF в МНП.
В одном варианте реализации МНП содержит сайт расщепления протеазой для матриксной процессирующей протеазы (МПП) так, чтобы NDF мог расщепляться МПП с получением N-концевого отщепленного пептида и CDF. В одном варианте реализации CDF содержит от около 5 до около 11 аминокислотных остатков из C-конца МНП, например, 6 или 7 аминокислот, 7 или 8 аминокислот, 8 или 9 аминокислот, 9 или 10 аминокислот или 11 или 12 аминокислот из C-конца МНП.
В одном аспекте в данном изобретении предложена растительная клетка, которая содержит один или более слитых полипептидов NF (NF), причем каждый NF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид Nif (NP), который имеет N-конец, причем NP выбран из группы, состоящей из NifE, NifF, NifJ, NifM, NifN, NifQ, NifS, NifU, NifV, NifW, NifX, NifY и NifZ, при этом C-конец МНП трансляционно слит с N-концом NP, при этом каждый МНП независимо является одинаковым или отличным, а каждый NP независимо является одинаковым или отличным, и при этом митохондрии содержат один или более NF и/или их процессированный продукт (CF), и при этом каждый CF, в случае присутствия, получен посредством расщепления соответствующего NF в пределах его МНП. В одном варианте реализации полипептиды NF дополнительно содержат один или более, или предпочтительно все полипептиды Nif, выбранные из группы, состоящей из NifD, NifH и NifK. В предпочтительном варианте реализации C-конец NifK и/или NifN является таким же, как и C-конец полипептида NifK дикого типа или полипептида NifN дикого типа, соответственно, т. е. в NifK и/или NifN, предпочтительно в обоих, отсутствует какое-либо искусственно добавленное C-концевое удлинение.
В предпочтительном варианте реализации каждый CF независимо содержит от около 5 до около 11 аминокислотных остатков из C-конца МНП, например, 6 или 7 аминокислот, 7 или 8 аминокислот, 8 или 9 аминокислот, 9 или 10 аминокислот или 11 или 12 аминокислот из C-конца МНП.
В другом аспекте в данном изобретении предложена растительная клетка, содержащая митохондрии, первый экзогенный полинуклеотид, который кодирует первый слитый полипептид Nif (NF), и второй экзогенный полинуклеотид, который кодирует второй NF, причем каждый NF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид Nif (NP), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом NP, при этом каждый МНП независимо является одинаковым или отличным, а каждый NP независимо является одинаковым или отличным, и при этом митохондрии содержат (a) первый NF и/или его процессированный продукт (первый CF) и (b) второй NF и/или его процессированный продукт (второй CF), и при этом каждый CF, в случае присутствия, получен посредством расщепления соответствующего NF в пределах его МНП. В предпочтительном варианте реализации первый и второй NF выбраны из группы, состоящей из NifE, NifF, NifJ, NifM, NifN, NifQ, NifS, NifU, NifV, NifW, NifX, NifY и NifZ. В предпочтительном варианте реализации C-конец NifK (в случае присутствия) и/или NifN является таким же, как и C-конец полипептида NifK дикого типа или полипептида NifN дикого типа, соответственно, т. е. в NifK и/или NifN, предпочтительно в обоих, отсутствует какое-либо искусственно добавленное C-концевое удлинение.
В предпочтительном варианте реализации каждый CF независимо содержит от около 5 до около 11 аминокислотных остатков из C-конца МНП, например, 6 или 7 аминокислот, 7 или 8 аминокислот, 8 или 9 аминокислот, 9 или 10 аминокислот или 11 или 12 аминокислот из C-конца МНП.
В одном варианте реализации растительная клетка дополнительно содержит один или более экзогенных полинуклеотидов, которые кодируют один или более NF, причем каждый NF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид Nif (NP), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом NP, при этом каждый МНП независимо является одинаковым или отличным, а каждый NP независимо является одинаковым или отличным, и при этом митохондрии содержат один или более NF и/или их процессированный продукт (CF), и при этом каждый CF, в случае присутствия, получен посредством расщепления соответствующего NF в пределах его МНП. В предпочтительном варианте реализации один или более NF выбраны из группы, состоящей из NifE, NifF, NifJ, NifM, NifN, NifQ, NifS, NifU, NifV, NifW, NifX, NifY и NifZ. В предпочтительном варианте реализации C-конец NifK (в случае присутствия) и/или NifN является таким же, как и C-конец полипептида NifK дикого типа или полипептида NifN дикого типа, соответственно, т. е. в NifK и/или NifN, предпочтительно в обоих, отсутствует какое-либо искусственно добавленное C-концевое удлинение.
В одном или дополнительном варианте реализации по меньшей мере один МНП, или более одного МНП, или каждый МНП содержит сайт расщепления протеазой для матриксной процессирующей протеазы (МПП) так, чтобы каждый NF, который содержит сайт расщепления протеазой для МПП, мог расщепляться МПП с получением N-концевого отщепленного пептида и соответствующего CF. В предпочтительном варианте реализации каждый CF независимо содержит от около 5 до около 11 аминокислотных остатков из C-конца МНП, например, 6 или 7 аминокислот, 7 или 8 аминокислот, 8 или 9 аминокислот, 9 или 10 аминокислот или 11 или 12 аминокислот из C-конца МНП.
В дополнительном аспекте в данном изобретении предложена растительная клетка, содержащая митохондрии и
(a) первый экзогенный полинуклеотид, который кодирует слитый полипептид NifD (NDF), причем NDF содержит (i) первый митохондриальный нацеливающий пептид (МНП1), который имеет C-конец, и (ii) полипептид NifD (ND), который имеет N-конец, при этом C-конец МНП1 трансляционно слит с N-концом ND,
(b) второй экзогенный полинуклеотид, который кодирует слитый полипептид NifH (NHF), причем NHF содержит (i) второй митохондриальный нацеливающий пептид (МНП2), который имеет C-конец, и (ii) полипептид NifH (NH), который имеет N-конец, при этом C-конец МНП2 трансляционно слит с N-концом NH, и
(с) третий экзогенный полинуклеотид, который кодирует слитый полипептид NifK (NKF), причем NKF содержит (i) третий митохондриальный нацеливающий пептид (МНП3), который имеет C-конец, и (ii) полипептид NifK (NK), который имеет N-конец, при этом C-конец третьего МНП трансляционно слит с N-концом NK,
при этом каждый из МНП1, МНП2 и МНП3 независимо является одинаковым или отличным, а
растительная клетка имеет уровень NDF и/или его процессированного продукта (CDF), больший, чем уровень NDF и/или CDF в соответствующей растительной клетке, которая содержат первый экзогенный полинуклеотид и в которой отсутствуют второй и третий экзогенные полинуклеотиды, и при этом CDF, в случае присутствия, получен посредством расщепления NDF в МНП1. В предпочтительном варианте реализации растительная клетка содержит один или более экзогенных полинуклеотидов, которые кодируют один или более NF, выбранных из группы, состоящей из NifE, NifF, NifJ, NifM, NifN, NifQ, NifS, NifU, NifV, NifW, NifX, NifY и NifZ. В предпочтительном варианте реализации C-конец NifK и/или NifN (в случае присутствия) является таким же, как и C-конец полипептида NifK дикого типа или полипептида NifN дикого типа, соответственно, т. е. в NifK и/или NifN, предпочтительно в обоих, отсутствует какое-либо искусственно добавленное C-концевое удлинение.
В одном варианте реализации CDF присутствует в митохондриях.
В дополнительном варианте реализации митохондрии дополнительно содержат процессированный продукт одного или обоих NHF (CHF) и NKF(CKF), при этом CHF и CKF в случае присутствия получены посредством расщепления NHF и NKF в пределах МНП2 и МНП3, соответственно. В предпочтительном варианте реализации CHF и/или CKF независимо содержит от около 5 до около 11 аминокислотных остатков из C-конца МНП, например, 6 или 7 аминокислот, 7 или 8 аминокислот, 8 или 9 аминокислот, 9 или 10 аминокислот или 11 или 12 аминокислот из C-конца МНП.
В дополнительном варианте реализации растительная клетка характеризуется одним или более, или всем из (i) МНП1 содержит сайт расщепления протеазой для МПП так, чтобы NDF мог расщепляться МПП с получением N-концевого отщепленного пептида и CDF, (ii) МНП2 содержит сайт расщепления протеазой для МПП так, чтобы NHF мог расщепляться МПП с получением N-концевого отщепленного пептида и процессированного продукта NifH (CHF), а (iii) МНП3 содержит сайт расщепления протеазой для МПП так, чтобы NKF мог расщепляться МПП с получением N-концевого отщепленного пептида и процессированного продукта NifK (CKF), при этом митохондрии содержат один или более, или все из CDF, CHF и CKF. В предпочтительном варианте реализации каждый из CDF, CHF и/или CKF независимо содержит от около 5 до около 11 аминокислотных остатков из C-конца МНП, например, 6 или 7 аминокислот, 7 или 8 аминокислот, 8 или 9 аминокислот, 9 или 10 аминокислот или 11 или 12 аминокислот из C-конца МНП.
В дополнительном аспекте в данном изобретении предложена растительная клетка, содержащая митохондрии, первый экзогенный полинуклеотид, который кодирует полипептид NifD (ND), и второй экзогенный полинуклеотид, который кодирует полипептид NifK (NK), при этом один или оба из ND и NK трансляционно слиты в N-конце с митохондриальным нацеливающим пептидом (МНП), который имеет C-конец, при этом, если оба ND и NK трансляционно слиты с МНП, каждый МНП независимо является одинаковым или отличным, и при этом второй экзогенный полинуклеотид ковалентно связан или ковалентно не связан с первым экзогенным полинуклеотидом, и при этом растительная клетка имеет уровень ND и уровень NK, которые являются приблизительно одинаковыми.
В предпочтительном варианте реализации C-конец NifK является таким же, как и C-конец полипептида NifK дикого типа, т. е. в NifK отсутствует какое-либо искусственно добавленное C-концевое удлинение. В предпочтительном варианте реализации результатом расщепления ND и/или NK является полипептид отщепленного продукта, имеющий от около 5 до около 11 аминокислотных остатков из C-конца МНП, например, 6 или 7 аминокислот, 7 или 8 аминокислот, 8 или 9 аминокислот, 9 или 10 аминокислот или 11 или 12 аминокислот из C-конца МНП.
В одном варианте реализации уровень ND и уровень NK включает слияние МНП-Nif и его процессированный продукт.
В дополнительном аспекте в данном изобретении предложена растительная клетка, содержащая митохондрии и экзогенный полинуклеотид, который кодирует слитый полипептид NifH (NHF), содержащий (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид NifH (NH), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом NH, при этом митохондрии содержат NHF и/или его процессированный продукт NifH (CHF), и при этом CHF, в случае присутствия, получен посредством расщепления NHF в МНП.
В одном варианте реализации МНП содержит сайт расщепления протеазой для матриксной процессирующей протеазы (МПП) так, чтобы NHF мог расщепляться МПП с получением N-концевого отщепленного пептида и CHF. В одном варианте реализации CHF содержит от около 5 до около 11 аминокислотных остатков из C-конца МНП, например, 6 или 7 аминокислот, 7 или 8 аминокислот, 8 или 9 аминокислот, 9 или 10 аминокислот или 11 или 12 аминокислот из C-конца МНП.
В дополнительном аспекте в данном изобретении предложена растительная клетка, содержащая митохондрии и экзогенный полинуклеотид, который кодирует слитый полипептид Nif (NF), причем NF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид Nif (NP), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом NP, при этом митохондрии содержат NF и/или его процессированный продукт NP (CF), и при этом CF, в случае присутствия, получен посредством расщепления NF в МНП, и при этом NF и/или CF, предпочтительно оба NF и CF, имеют нативный C-конец по отношению к соответствующему полипептиду Nif дикого типа.
В предпочтительном варианте реализации NP выбран из группы, состоящей из полипептида NifD, полипептида NifK и полипептида NifN. Предпочтительно оба NifK и NifN.
В дополнительном аспекте в данном изобретении предложена растительная клетка, содержащая митохондрии и первый экзогенный полинуклеотид, кодирующий слитый полипептид NifD (NDF), причем NDF содержит (i) первый митохондриальный нацеливающий пептид (МНП1), который имеет C-конец, и (ii) полипептид NifD (ND), который имеет N-конец, при этом C-конец МНП1 трансляционно слит с N-концом ND, и один или более, или все из
(a) второго экзогенного полинуклеотида, кодирующего слитый полипептид NifH (NHF), причем NHF содержит (i) второй митохондриальный нацеливающий пептид (МНП2), который имеет C-конец, и (ii) полипептид NifH (NH), который имеет N-конец, при этом C-конец МНП2 трансляционно слит с N-концом NH,
(b) третьего экзогенного полинуклеотида, кодирующего слитый полипептид NifK (NKF), причем NKF содержит (i) третий митохондриальный нацеливающий пептид (МНП3), который имеет C-конец, и (ii) полипептид NifK (NK), который имеет N-конец, при этом C-конец МНП3 трансляционно слит с N-концом NK, предпочтительно при этом NKF имеет нативный C-конец по отношению к полипептиду NifK дикого типа, и
(с) экзогенного четвертого полинуклеотида, кодирующего слитый полипептид Nif (NF), отличный от NDF, NHF и NKF, причем NF содержит (i) четвертый митохондриальный нацеливающий пептид (МНП4), который имеет C-конец, и (ii) полипептид Nif (NP), который имеет N-конец, при этом C-конец МНП4 трансляционно слит с N-концом NP,
при этом каждый из МНП1, МНП2, МНП3 и МНП4 независимо является одинаковым или отличным. В одном варианте реализации четвертый экзогенный полинуклеотид кодирует один или более NP, выбранных из группы, состоящей из NifE, NifF, NifJ, NifM, NifN, NifQ, NifS, NifU, NifV, NifW, NifX, NifY и NifZ. В предпочтительном варианте реализации C-конец NifK и/или NifN (в случае присутствия) является таким же, как и C-конец полипептида NifK дикого типа или полипептида NifN дикого типа, соответственно, т. е. в NifK и/или NifN, предпочтительно в обоих, отсутствует какое-либо искусственно добавленное C-концевое удлинение.
В одном варианте реализации каждый NF пригоден для транслокации в митохондрии.
В одном варианте реализации любого из вышеуказанных аспектов митохондрии содержат один, по меньшей мере два, по меньшей мере три, по меньшей мере четыре или все полипептиды Nif, выбранные из группы, состоящей из (i) NifD, NifH, NifK, NifB, NifE и NifN, или (ii) NifD, NifH, NifK и NifS.
В одном или дополнительном варианте реализации один или более, или все слитые полипептиды Nif расщепляются в МНП матриксной процессирующей протеазой (МПП) в растительной клетке, предпочтительно при этом по меньшей мере слитый полипептид NifD или слитый полипептид NifH расщепляется МПП.
В одном или дополнительном варианте реализации один или более полипептидов, выбранных из группы, состоящей из ND, NDF, CDF, NH, NHF, CHF, NK, NKF, CKF, NF, CFNB, NE, NN и NS способны к ассоциации с по меньшей мере 1, предпочтительно по меньшей мере 2, или по меньшей мере 3, или по меньшей мере 4, или по меньшей мере 5, или по меньшей мере 6, или по меньшей мере 7 другими полипептидами Nif с образованием белкового комплекса Nif (NPC), предпочтительно так, чтобы NPC обладал активностью нитрогеназы.
В одном или дополнительном варианте реализации CDF, CKF, CHF или CF имеет больший размер, чем ND, NK, NH или NP, соответственно, предпочтительно больше на 5-50 аминокислотных остатков, и/или при этом CDF, CKF, CHF или CF имеет меньший размер, чем NDF, NKF, NHF и NF, соответственно, предпочтительно меньше на 5-45 аминокислотных остатков. В предпочтительном варианте реализации каждый из CDF, CKF, CHF или CF независимо содержит от около 5 до около 11 аминокислотных остатков из C-конца МНП, например, 6 или 7 аминокислот, 7 или 8 аминокислот, 8 или 9 аминокислот, 9 или 10 аминокислот или 11 или 12 аминокислот из C-конца МНП.
В одном или дополнительном варианте реализации МНП содержит по меньшей мере 10 аминокислот, предпочтительно от 10 до 80 аминокислот.
В одном или дополнительном варианте реализации по меньшей мере один или более, или все МНП содержат МНП митохондриального белка-предшественника или его вариант, предпочтительно МНП растения.
В одном или дополнительном варианте реализации экзогенный(ые) полинуклеотид(ы) интегрирован(ы) в геном клетки.
В одном или дополнительном варианте реализации клетка не является протопластом.
В одном или дополнительном варианте реализации клетка представляет собой клетку, отличную от протопласта Arabidopsis thaliana.
В дополнительном аспекте в данном изобретении предложено трансгенное растение, содержащее клетки в соответствии с изобретением, при этом трансгенное растение является трансгенным в отношении экзогенного полинуклеотида(ов) и/или трансгенное растение является трансгенным в отношении экзогенного полинуклеотида(ов), кодирующего(их) слитый(ые) полипептид(ы).
В одном варианте реализации один или более, или все экзогенные полинуклеотиды экспрессируются в корнях растения, предпочтительно экспрессируются на большем уровне в корнях растения, чем в листьях растения.
В одном или дополнительном варианте реализации трансгенное растение имеет измененный фенотип по сравнению с соответствующим растением дикого типа, который состоит в повышении урожайности, биомассы, скорости роста, мощности, поступления азота вследствие биологической фиксации азота, эффективности использования азота, устойчивости к абиотическому стрессу и/или устойчивости к недостатку питательных веществ по сравнению с соответствующим растением дикого типа.
В альтернативном варианте реализации трансгенное растение имеет одинаковые скорость роста и/или фенотип по сравнению с соответствующим растением дикого типа.
В одном или дополнительном варианте реализации трансгенное растение представляет собой зерновое растение, такое как пшеница, рис, кукуруза, тритикале, овес или ячмень, предпочтительно пшеница.
В одном варианте реализации трансгенное растение является гомозиготным или гетерозиготным в отношении экзогенного(ых) полинуклеотида(ов).
В одном или дополнительном варианте реализации трансгенное растение растет в поле.
В дополнительном аспекте в данном изобретении предложена популяция из по меньшей мере 100 растений в соответствии с изобретением, растущая в поле.
В дополнительном аспекте в данном изобретении предложен слитый полипептид NifD (NDF), причем NDF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид NifD (ND), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом ND.
В дополнительном аспекте в данном изобретении предложен слитый полипептид NifH (NHF), причем NHF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид NifH (NH), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом NH.
В дополнительном аспекте в данном изобретении предложен слитый полипептид Nif (NF), причем NF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид Nif (NP), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом NP, и при этом NF имеет нативный C-конец по отношению к полипептиду Nif дикого типа.
В предпочтительном варианте реализации NP выбран из группы, состоящей из полипептида NifD, полипептида NifK и полипептида NifN.
В дополнительном аспекте в данном изобретении предложена комбинация слитых полипептидов Nif (NF), содержащая слитый полипептид NifK (NKF) и слитый полипептид NifN (NNF), причем каждый NF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид Nif (NP), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом NP, при этом МНП каждого NF независимо является одинаковым или отличным, и при этом каждый из NKF и NNF имеет нативный C-конец по отношению к полипептиду Nif дикого типа.
В дополнительном аспекте в данном изобретении предложен слитый полипептид, содержащий
(i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец,
(ii) полипептид NifD (ND), который имеет N-конец и C-конец,
(iii) олигопептидный линкер и
(iv) полипептид NifK (NK), который имеет N-конец,
при этом C-конец МНП трансляционно слит с N-концом ND, а
линкер трансляционно слит с C-концом ND и N-концом NK.
В одном варианте реализации линкер имеет достаточную длину, чтобы обеспечить возможность ассоциации ND и NK в функциональной конфигурации в растительной клетке или в бактериальной клетке. В одном варианте реализации линкер имеет длину от 8 до 50 аминокислот. Предпочтительно линкер имеет длину по меньшей мере около 20 аминокислот, по меньшей мере около 25 аминокислот или по меньшей мере около 30 аминокислот.
В одном варианте реализации C-конец слитого полипептида представляет собой C-конец NK.
В другом аспекте в данном изобретении предложен слитый полипептид, содержащий
(i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец,
(ii) полипептид NifE (NE), который имеет N-конец и C-конец,
(iii) олигопептидный линкер и
(iv) полипептид NifN (NN), который имеет N-конец,
при этом C-конец МНП трансляционно слит с N-концом NE, а
линкер трансляционно слит с C-концом NE и N-концом NN.
В одном варианте реализации линкер имеет достаточную длину, чтобы обеспечить возможность ассоциации NE и NN в функциональной конфигурации в растительной клетке или в бактериальной клетке. Например, в одном варианте реализации линкер имеет длину по меньшей мере около 70 Å, по меньшей мере около 100 Å, или от около 70 Å до около 150 Å, или от около 100 Å до около 120 Å, или около 100 Å, или около 104 Å. В дополнительном варианте реализации олигопептидный линкер имеет длину по меньшей мере около 20 аминокислот, или по меньшей мере около 30 аминокислот, или по меньшей мере около 40 аминокислот, или от около 20 аминокислот до около 70 аминокислот, или от около 30 аминокислот до около 70 аминокислот, или от около 30 аминокислот до около 60 аминокислот, или от около 30 аминокислот до около 50 аминокислот, или около 25 аминокислот, или около 30 аминокислот, или около 35 аминокислот, или около 40 аминокислот, или около 45 аминокислот, или около 46 аминокислот, или около 50 аминокислот, или около 55 аминокислот.
В одном варианте реализации слитый(е) полипептид(ы) по любому из вышеуказанных аспектов может (могут) расщепляться матриксной процессирующей протеазой (МПП) с получением одного или более процессированных продуктов полипептида Nif.
В одном из дополнительных вариантов реализации слитый(е) полипептид(ы) присутствует(ют) в растительной клетке или в бактериальной клетке, предпочтительно в митохондрии растительной клетки.
В дополнительном аспекте в данном изобретении предложен процессированный полипептид Nif, который был получен из слитого(ых) полипептида(ов) в соответствии с изобретением посредством расщепления в МНП слитого(ых) полипептида(ов).
В одном варианте реализации процессированный полипептид Nif был получен посредством расщепления слитого полипептида МПП в митохондриальном матриксе растительной клетки.
В одном или дополнительном варианте реализации процессированный полипептид Nif присутствует в растительной клетке или в бактериальной клетке, предпочтительно в митохондрии растительной клетки, более предпочтительно в митохондриальном матриксе (ММ) митохондрии растительной клетки.
В одном или дополнительном варианте реализации слитый(е) полипептид(ы) или процессированный полипептид Nif имеют такую же биохимическую активность, как и соответствующий полипептид Nif дикого типа, предпочтительно имеют приблизительно такой же уровень биохимической активности, как и соответствующий полипептид Nif дикого типа, необязательно, согласно определению в бактериальной клетке.
В одном или дополнительном варианте реализации слитый(е) полипептид(ы) процессированного полипептида Nif связан(ы) с по меньшей мере 1, предпочтительно по меньшей мере 2, или по меньшей мере 3, или по меньшей мере 4, или по меньшей мере 5, или по меньшей мере 6, или по меньшей мере 7 другими полипептидами Nif с образованием белкового комплекса Nif (NPC), предпочтительно так, чтобы NPC обладал активностью нитрогеназы.
В дополнительном аспекте в данном изобретении предложен полинуклеотид, кодирующий один или более, или все из слитых полипептидов или процессированных полипептидов Nif в соответствии с изобретением.
В одном варианте реализации NF представляет собой слитый полипептид NifD (NDF), а полинуклеотид дополнительно содержит одну или более нуклеотидных последовательностей, которые кодируют один или более, или все из
(i) слитого полипептида NifH (NHF), причем NHF содержит второй митохондриальный нацеливающий пептид (МНП2), который имеет C-конец, и полипептид NifH (NH), который имеет N-конец так, что C-конец МНП2 трансляционно слит с N-концом NH,
(ii) слитого полипептида NifK (NKF), причем NKF содержит третий митохондриальный нацеливающий пептид (МНП3), который имеет C-конец, и полипептид NifK (NK), который имеет N-конец так, что C-конец МНП3 трансляционно слит с N-концом NK,
(iii) слитого полипептида Nif (NF), отличного от NDF, NHF и NKF, причем NF содержит четвертый митохондриальный нацеливающий пептид (МНП4), который имеет C-конец, и полипептид Nif (NP), который имеет N-конец так, что C-конец МНП4 трансляционно слит с N-концом NP,
при этом каждый из МНП1, МНП2, МНП3 и МНП4 независимо является одинаковым или отличным.
В одном или дополнительном варианте реализации полинуклеотид был кодон-модифицированным для экспрессии в растительной клетке.
В одном или дополнительном варианте реализации полинуклеотид содержит промотор, функционально связанный с полинуклеотидом или каждой последовательностью в его составе, кодирующей слитый белок, и/или трансляционные регуляторные элементы, функционально связанные с полинуклеотидом.
В одном варианте реализации промотор обеспечивает экспрессию полинуклеотида в корнях, листьях и/или стебле растения, предпочтительно промотор обеспечивает экспрессию полинуклеотида в одном или более, или всех из корней, листьев или стебля растения по сравнению с семенем растения.
В одном или дополнительном варианте реализации полинуклеотид присутствует в растительной клетке или в бактериальной клетке, предпочтительно интегрирован в геном растительной клетки.
В дополнительном аспекте в данном изобретении предложена конструкция нуклеиновой кислоты, содержащая первый полинуклеотид, который кодирует первый слитый полипептид Nif (NF), и второй полинуклеотид, который кодирует второй NF, причем каждый NF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид Nif (NP), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом NP, и при этом каждый МНП независимо является одинаковым или отличным.
В одном варианте реализации конструкция нуклеиновой кислоты дополнительно содержит один или более полинуклеотидов, которые кодируют один или более NF, причем каждый NF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C-конец, и (ii) полипептид Nif (NP), который имеет N-конец, при этом C-конец МНП трансляционно слит с N-концом NP, при этом каждый МНП независимо является одинаковым или отличным и каждый NP независимо является одинаковым или отличным.
В дополнительном аспекте в данном изобретении предложена конструкция нуклеиновой кислоты, содержащая первый полинуклеотид, кодирующий слитый полипептид NifD (NDF), причем NDF содержит (i) первый митохондриальный нацеливающий пептид (МНП1), который имеет C-конец, и (ii) полипептид NifD (ND), который имеет N-конец, при этом C-конец МНП1 трансляционно слит с N-концом ND, и один или более, или все из
(a) второго полинуклеотида, кодирующего слитый полипептид NifH (NHF), причем NHF содержит (i) второй митохондриальный нацеливающий пептид (МНП2), который имеет C-конец, и (ii) полипептид NifH (NH), который имеет N-конец, при этом C-конец МНП2 трансляционно слит с N-концом NH,
(b) третьего полинуклеотида, кодирующего слитый полипептид NifK (NKF), причем NKF содержит (i) третий митохондриальный нацеливающий пептид (МНП3), который имеет C-конец, и (ii) полипептид NifK (NK), который имеет N-конец, при этом C-конец МНП3 трансляционно слит с N-концом NK, предпочтительно при этом NKF имеет нативный C-конец по отношению к полипептиду NifK дикого типа, и
(с) четвертого полинуклеотида, кодирующего слитый полипептид Nif (NF), отличный от NDF, NHF и NKF, причем NF содержит (i) четвертый митохондриальный нацеливающий пептид (МНП4), который имеет C-конец, и (ii) полипептид Nif (NP), который имеет N-конец, при этом C-конец МНП4 трансляционно слит с N-концом NP,
при этом каждый из МНП1, МНП2, МНП3 и МНП4 независимо является одинаковым или отличным.
В одном варианте реализации каждый NF пригоден для транслокации в митохондрии растительной клетки.
В дополнительном аспекте в данном изобретении предложен химерный вектор, содержащий или кодирующий полинуклеотид в соответствии с изобретением или конструкцию нуклеиновой кислоты в соответствии с изобретением.
В одном варианте реализации полинуклеотид или каждая последовательность в его составе, кодирующие слитый полипептид, функционально связаны с промотором и, необязательно, последовательностью терминации транскрипции.
В одном варианте реализации промотор обеспечивает экспрессию одного или более, или всех полинуклеотидов в корнях, листьях и/или стебле растения, предпочтительно полинуклеотиды экспрессируются преимущественно в одном или более, или всех из корней, листьев или стебля растения по сравнению с семенем растения.
В дополнительном аспекте в данном изобретении предложена клетка, содержащая один или более, или все из слитых полипептидов или процессированных полипептидов Nif в соответствии с изобретением, один или более, или все из полинуклеотидов в соответствии с изобретением, конструкцию нуклеиновой кислоты в соответствии с изобретением и/или вектор в соответствии с изобретением.
В одном варианте реализации клетка является растительной клеткой или бактериальной клеткой.
В дополнительном варианте реализации растительная клетка представляет собой клетку зернового растения, такую как клетка пшеницы, клетка риса, клетка кукурузы, клетка тритикале, клетка овса или клетка ячменя, предпочтительно клетка пшеницы.
В дополнительном аспекте в данном изобретении предложен способ получения слитого(ых) полипептида(ов) или процессированного(ых) полипептида(ов) Nif в соответствии с изобретением, включающий экспрессию в клетке полинуклеотида в соответствии с изобретением.
В дополнительном аспекте в данном изобретении предложен способ получения клетки в соответствии с изобретением, включающий этап внесения полинуклеотида в соответствии с изобретением, конструкции нуклеиновой кислоты в соответствии с изобретением и/или вектора в соответствии с изобретением в клетку.
В дополнительном аспекте в данном изобретении предложен способ получения трансгенного растения в соответствии с изобретением, включающий этапы
i) внесения полинуклеотида в соответствии с изобретением, конструкции нуклеиновой кислоты в соответствии с изобретением и/или вектора в соответствии с изобретением в растительную клетку,
ii) регенерации трансгенного растения из клетки и
iii) необязательно, сбора семян с растения и/или
iv) необязательно, получения одного или более дочерних растений от трансгенного растения, с получением, таким образом, трансгенного растения.
В дополнительном аспекте в данном изобретении предложен способ получения растения, в геном которого интегрирован полинуклеотид в соответствии с изобретением или полинуклеотиды, определенные для любой из конструкций нуклеиновой кислоты в соответствии с изобретением, включающий этапы
i) скрещивания двух родительских растений, при этом по меньшей мере одно растение содержит указанный(е) полинуклеотид(ы),
ii) скрининг одного или более дочерних растений, полученных от скрещивания, в отношении присутствия или отсутствия полинуклеотида(ов) и
iii) отбор дочернего растения, которое содержит указанный(е) полинуклеотид(ы),с получением, таким образом, указанного растения.
В одном варианте реализации полинуклеотид(ы) кодирует(ют) полипептид(ы), который(е) обеспечивает(ют) активность нитрогеназы в растении.
В одном или дополнительном варианте реализации по меньшей мере одно из родительских растений является тетраплоидным или гексаплоидным растением пшеницы.
В одном или дополнительном варианте реализации этап ii) включает анализ образца, содержащего ДНК из одного или более дочерних растений, в отношении указанного(ых) полинуклеотида(ов).
В одном или дополнительном варианте реализации этап iii) включает
i) отбор дочернего растения, которое является гомозиготным в отношении указанного(ых) полинуклеотида(ов), и/или
ii) анализ растения или одного или более его дочерних растений в отношении присутствия и/или экспрессии полинуклеотид(ов) или в отношении измененного фенотипа согласно определению выше.
В одном или дополнительном варианте реализации способ дополнительно включает
iv) обратное скрещивание потомства от скрещивания на этапе i) с растением такого же генотипа, что и первое родительское растение, в котором отсутствует(ют) полинуклеотид(ы), достаточное количество раз, чтобы получить растение с генотипом в основном первого родительского растения, но содержащее указанный полинуклеотид, и
iv) отбор дочернего растения, которое содержит указанный полинуклеотид и/или имеет измененный фенотип согласно определению выше.
В одном или дополнительном варианте реализации способ дополнительно включает этап анализа растения или дочернего растения в отношении по меньшей мере одного генетического маркера.
В дополнительном аспекте в данном изобретении предложено растение, полученное с помощью способа в соответствии с изобретением.
В дополнительном аспекте в данном изобретении предложено применение полинуклеотида в соответствии с изобретением, конструкции нуклеиновой кислоты в соответствии с изобретением и/или вектора в соответствии с изобретением для получения рекомбинантной клетки и/или трансгенного растения.
В одном варианте реализации трансгенное растение имеет измененный фенотип согласно определению выше по сравнению с соответствующим растением, в котором отсутствует экзогенный полинуклеотид, конструкция нуклеиновой кислоты и/или вектор.
В дополнительном аспекте в данном изобретении предложен способ идентификации растения, содержащего полинуклеотид в соответствии с изобретением или полинуклеотиды, определенные для любой из конструкций нуклеиновой кислоты в соответствии с изобретением, включающий этапы
i) получения образца нуклеиновой кислоты от растения и
ii) скрининг образца в отношении присутствия или отсутствия указанного(ых) полинуклеотида(ов).
В одном варианте реализации присутствие полинуклеотида(ов) указывает на то, что растение имеет измененный фенотип согласно определению выше по сравнению с соответствующим растением, в котором отсутствует экзогенный(е) полинуклеотид(ы).
В одном или дополнительном варианте реализации способ позволяет идентифицировать растение в соответствии с изобретением.
В одном или дополнительном варианте реализации способ дополнительно включает получение растения из семян перед этапом i).
В дополнительном аспекте в данном изобретении предложена растительная часть растения в соответствии с изобретением.
В одном варианте реализации часть растения представляет собой семя, которое содержит полинуклеотид в соответствии с изобретением или полинуклеотиды, определенные для любой из конструкций нуклеиновой кислоты в соответствии с изобретением.
В дополнительном аспекте в данном изобретении предложен способ получения части растения, включающий
a) выращивание растения в соответствии с изобретением и
b) сбор части растения.
В дополнительном аспекте в данном изобретении предложен способ получения муки, цельнозерновой муки, крахмала, масла, жмыховой муки или другого продукта, получаемого из семян, включающий:
a) получение семян в соответствии с изобретением и
b) получение муки, цельнозерновой муки, крахмала, масла или другого продукта или получение жмыховой муки.
В дополнительном аспекте в данном изобретении предложен продукт, получаемый из растения и/или части растения в соответствии с изобретением.
В одном варианте реализации часть представляет собой семя.
В одном или дополнительном варианте реализации продукт представляет собой пищевой продукт или питьевой продукт. Предпочтительно i) пищевой продукт выбран из группы, состоящей из муки, крахмала, масла, хлеба из теста на опаре или пресного хлеба, пасты, вермишели, зоокормов, зерновых завтраков, закусочных продуктов, выпечки, солода, кондитерских изделий и пищевых продуктов, содержащих соусы на основе муки, или ii) питьевой продукт представляет собой сок, пиво или солод. Способы получения таких продуктов хорошо известны специалистам в данной области техники.
В альтернативном варианте реализации указанный продукт представляет собой непищевой продукт. Примеры непищевых продуктов включают, но не ограничиваются этим, пленки, покрытия, клеи, строительные материалы и упаковочные материалы. Способы получения таких продуктов хорошо известны специалистам в данной области техники.
В дополнительном аспекте в данном изобретении предложен способ получения пищевого продукта в соответствии с изобретением, включающий смешивание семян или муки, цельнозерновой муки или крахмала из семян с другим пищевым ингредиентом.
В дополнительном аспекте в данном изобретении предложен способ получения солода, включающий этап проращивания семян в соответствии с изобретением.
В дополнительном аспекте в данном изобретении предложено применение растения или его части в соответствии с изобретением в качестве корма для животных или для получения корма для употребления животными или пищи для употребления человеком.
В дополнительном аспекте в данном изобретении предложена композиция, содержащая слитый(е) полипептид(ы) или процессированный(е) полипептид(ы) Nif в соответствии с изобретением, полинуклеотид в соответствии с изобретением, конструкцию нуклеиновой кислоты в соответствии с изобретением, вектор в соответствии с изобретением или клетку в соответствии с изобретением и один или более приемлемых носителей.
В дополнительном аспекте в данном изобретении предложен способ воссоздания белкового комплекса нитрогеназы в растительной клетке, включающий внесение двух или более полинуклеотидов в соответствии с изобретением, двух или более конструкций нуклеиновой кислоты в соответствии с изобретением и/или вектора в соответствии с изобретением в клетку и культивирование растительной клетки в течение времени, достаточного для экспрессии полинуклеотидов или вектора.
В дополнительном аспекте в данном изобретении предложен способ повышения урожайности, биомассы, скорости роста, мощности, поступления азота вследствие биологической фиксации азота, эффективности использования азота, устойчивости к абиотическому стрессу и/или устойчивости недостатку питательных веществ растения, включающий внесение двух или более полинуклеотидов в соответствии с изобретением, двух или более конструкций нуклеиновой кислоты в соответствии с изобретением и/или вектора в соответствии с изобретением в растение или растительную клетку.
Объем данного изобретения не ограничивается конкретными описанными в данном документе вариантами реализации, которые приведены исключительно в качестве примеров. Функционально эквивалентные продукты, композиции и способы явным образом входят в объем изобретения, описанного в данном документе.
В тексте данного описания, если специально не указано иное или иное не следует из контекста, ссылку на один этап, композицию веществ, группу этапов или группу композиций веществ следует воспринимать как включающую один и множество (т. е. один или более) из этих этапов, композиций веществ, групп этапов или групп композиций веществ.
Далее изобретение описано посредством следующих неограничивающих примеров и со ссылкой на прилагающиеся фигуры.
КРАТКОЕ ОПИСАНИЕ ПРИЛАГАЮЩИХСЯ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
Фиг. 1 - Генетическая карта Т-ДНК pCW440. Метки: 35SP, полноразмерный промотор CaMV 35S, показывающий направление транскрипции; промотор T7, промотор для РНК-полимеразы T7; МНП dCoxIV, митохондриальный нацеливающий пептид dCoxIV; AscI, сайт рестрикционного фермента для AscI для вставки слияний, находящихся в одной рамке считывания с МНП; терминатор T7, область терминации транскрипции для РНК-полимеразы T7; модифицированный nos polyA, сигнал полиаденилирования nos 3'.
Фиг. 2 - Фотография анализа методом вестерн-блоттинга слитых полипептидов NifH, NifD, NifK и NifY, вырабатываемых в бактериях и листьях N. benthamiana, причем каждый полипептид слит с МНП dCoxIV и C-концевым удлинением, содержащим эпитоп HA или FLAG. Содержание дорожек: 1, контрольный экстракт листьев (только инфильтрация p19) и маркеры молекулярной массы полипептидов; окрашенная стрелка=72 кДа, стрелки ниже (неокрашенные) соответствуют 55, 40, 33, 25 и 17 кДа; дорожки 2-5, pCW446 dCoxIV-NifH-HA, экспрессируемый в бактериях BL21-Gold (дорожка 2) или двух разных инфильтрациях листьев (дорожки 3, 4); дорожки 5-7, pCW447-dCoxIV-NifD-FLAG, экспрессируемый в бактериях (дорожка 5) или двух разных инфильтрациях листьев (дорожки 6, 7); дорожки 8-10, pCW448-dCoxIV-NifK-HA, экспрессируемый в бактериях (дорожка 8) или двух разных инфильтрациях листьев (дорожки 9, 10); дорожки 11-13, pCW449-dCoxIV-NifY-HA, экспрессируемый в бактериях (дорожка 11) или двух разных инфильтрациях листьев (дорожки 12, 13); дорожки 14-15, комбинация четырех векторов pCW446, pCW447, pCW448 и pCW449, экспрессируемая в инфильтрациях листьев. Дорожка 15 также включает инфильтрацию вектора pCW444, экспрессируемого в локализованном в цитоплазме Lbh. Блот A зондировали двумя первичными антителами, анти-HA и анти-FLAG; блот B зондировали только анти-HA. Большее время экспозиции блота А, полоса 14, позволило выявить сигналы для полипептидов NifH, NifK и NifY, но не NifD.
Фиг. 3 - Схематическое изображение конструкций, применяемых для временной экспрессии слитых полипептидов pFAγ::ЗФБ в листьях N. benthamiana. Аминокислотная последовательность pFAγ дикого типа приведена выше, а мутированная аминокислотная последовательность (mFAγ) приведена ниже. Стрелка указывает на прогнозируемую точку расщепления МПП. 35S Pr, промотор CaMV 35S; T7P, промотор РНК-полимеразы T7; МНП, область pFAγ или mFAγ; ЗФБ, полипептид ЗФБ; T7T, терминатор транскрипции РНК-полимеразы T7; NOS, 3' терминатор транскрипции/область полиаденилирования гена nos.
Фиг. 4 - Фотография вестерн-блота с зондированием антителом к HA (левая панель) или FLAG (правая панель) после ДСН-ПААГ белковых экстрактов из клеток N. benthamiana или E.coli, экспрессирующих конструкции, кодирующие слитые полипептиды pFAγ::NifF::HA или pFAγ::NifZ::FLAG. Символы + и - над дорожками указывают на присутствие или отсутствие, соответственно, белковых экстрактов N. benthamiana или E.coli, наносимых на дорожки; коэффициенты разведения экстрактов, используемые для бактериальных экстрактов, указаны в скобках.
Фиг. 5 - Схема генетической конструкции, используемой для экспрессии pFAγ::NifH::HA в клетках листьев N. benthamiana. Подчеркнутые остатки в нуклеотидной последовательности указывают сайты протеолитического расщепления (карбоксильная сторона) трипсином. Стрелка указывает точку расщепления митохондриальной процессирующей пептидазой (МПП), Пептиды ISTQVVR (SEQ ID NO:44) и AVQGAPTMR (SEQ ID NO:45) были обнаружены методом масс-спектрометрии.
Фиг. 6 - Фотография вестерн-блота с зондированием антителом к HA (верхняя левая панель) или FLAG (верхняя правая панель) после ДСН-ПААГ белковых экстрактов из клеток N. benthamiana, экспрессирующих конструкции, кодирующие слитые полипептиды pFAγ::Nif::HA или pFAγ::Nif::FLAG. Буквами над дорожками (K, B, E, S и т. д.) указан полипептид Nif, включенный в слитый полипептид, кодируемый генетической конструкцией. Слабая дорожка вблизи верхней части блота для pFAγ::NifJ::FLAG указана звездочкой (*). Размер маркеров молекулярной массы (кДа) указан слева. На нижних панелях приведены соответствующие гели после окрашивания кумасси.
Фиг. 7 - Фотография вестерн-блота белковых экстрактов из листьев N. benthamiana или E. coli, содержащих одинаковую конструкцию, кодирующую pFAγ::NifD::FLAG. Блот зондировали антителом против эпитопа FLAG. Указаны значения молекулярной массы маркеров на первой дорожке. Коэффициенты разведения для экстрактов E. coli приведены в скобках.
Фиг. 8 - Фотография вестерн-блота белковых экстрактов из E. coli или листьев N. benthamiana (указано вверху фигуры), содержащих конструкции, кодирующие pFAγ::NifD::HA или mFAγ::NifD::HA, или pFAγ::NifK::HA и pFAγ::ЗФБ в качестве положительного и отрицательного контролей на дорожках 2 и 3 соответственно. Используемые конструкции и кодируемый полипептид Nif (D или K) указаны над каждой дорожкой. Блот зондировали антителом против эпитопа HA. Указаны значения молекулярной массы маркеров на первой дорожке. На нижних панелях приведен окрашенный кумасси гель. Основной дорожкой в окрашенном кумасси геле является Rubisco из образцов листьев N. benthamiana.
Фиг. 9 - Коэкспрессия полипептидов NifK и NifH повышает уровень слитого полипептида NifD in planta. Фотография вестерн-блота полипептидов, вырабатываемых после внесения в клетки листьев конструкций для коэкспрессии слитых полипептидов NifD, NifK и NifH. Дорожка 1, pRA24+pRA10+pRA25; Дорожка 2, pRA22+pRA10+pRA25; Дорожка 3, pRA19+pRA10+pRA25; Дорожка 4, pRA19+pRA25; Дорожка 5, pRA10+pRA25; Дорожка 6, pRA10; Дорожка 7, pRA11; Дорожка 8, pRA25; Дорожка 9, pRA22; Дорожка 10, pRA24; Дорожка 11, pRA19; Дорожка 12, маркеры молекулярной массы, числа справа указаны в кДа. Смотрите Таблицу 4 в отношении перечня конструкций и кодируемых полипептидов, также указанных вверху блота. Звездочкой на 1-ой полосе указана позиция характерной дорожки NifD.
Фиг. 10 - Фотография вестерн-блота полипептидов, вырабатываемых после внесения комбинаций конструкций в клетки листьев для экспрессии слитых полипептидов NifD::FLAG, NifK (без С-концевого удлинения), NifS::HA и NifH::HA. Верхняя панель соответствует зондированию анти-FLAG антителом, нижняя панель соответствует зондированию анти-HA антителом. Дорожки 1 и 12 соответствуют маркерам молекулярной массы с указанными размерами (кДа). Одной звездочкой на дорожке 2 указана позиция характерной дорожки NifD, двойной звездочкой указана позиция меньшего полипептида распада NifD::FLAG или внутреннего полипептида инициации трансляции. Числа в скобках представляют количество характерной дорожки NifD по отношению к фоновой дорожке FLAG. Позиции слитых полипептидов NifK::HA, NifS::HA и Nif::H приведены на нижней панели. Комбинации конструкций и кодируемые полипептиды указаны вверху каждой дорожки. Сокращения: D-FLAG (pRA07; pFAγ::NifD::FLAG), H-HA (pRA10; pFAγ::NifH::HA), K (pRA25; pFAγ::NifK), K-HA (pRA11, pFAγ::NifK::HA), S-HA (pRA16; pFAγ::NifS::HA), D-HA (pRA19, pFAγ::NifD::HA).
Фиг. 11 - Фотография вестерн-блота полипептидов, вырабатываемых после внесения конструкций, отдельно или в комбинациях, в клетки листьев для экспрессии слитых полипептидов NifD::FLAG, NifK (без С-концевого удлинения) или NifK::HA и NifH::HA. Вносимые конструкции приведены над каждой дорожкой, а кодируемый слитый полипептид приведен под каждой дорожкой. Блот разрезали и зондировали анти-HA антителом (дорожки 1-7) или анти-FLAG антителом (дорожки 9-12). Звездочкой указана характерная дорожка NifD::FLAG на дорожках 11 и 12. Большее время экспозиции вестерн-блота было необходимо для наблюдения слабых дорожек NifD для pRA19 и pRA07 (дорожки 2 и 3).
Фиг. 12 - Модель гетеродимера NifD::линкер::NifK с субъединицами NifD и NifK, показанными в зеленом и синем цвете соответственно. Пространственная модель демонстрирует линкерный пептид в красном цвете, связывающий C-конец NifD с N-концом NifK.
Фиг. 13 - Модель гомологии слитого полипептида NifD::линкер::NifK в виде димера, образующего комплекс с двумя полипептидами NifH, с применением аминокислотных последовательностей K. pneumoniae для NifD (зеленый) и NifK (синий) с включенной аминокислотной последовательностью A. vinlandii для субъединиц NifH (пурпурный). Сконструированный линкер показан в красном цвете в ван-дер-Ваальсовом атомарном представлении. Левое и правое изображения повернуты на 90 градусов вокруг вертикальной оси относительно друг друга.
Фиг. 14 - Верхняя панель: Фотография вестерн-блота с применением антитела для обнаружения эпитопа HA полипептидов, вырабатываемых из pRA01 (дорожка 2, ЗФБ), pRA11 (дорожка 3, pFAγ::NifK::HA), pRA19 (дорожка 4, pFAγ::NifD::HA) и pRA20 (дорожка 5, pFAγ::NifD-линкер(FLAG)-NifK::HA). Размеры маркеров молекулярной массы (дорожка 1, кДа) указаны слева. На нижней панели приведен окрашенный кумасси гель.
Фиг. 15 - Схема структуры многокассетных векторов pKT100 и pKT-HC. ЛПО: левая пограничная область Т-ДНК; ППО: правая пограничная область; P1-5/T1-5: Промотор/терминатор экспрессионных кассет 1-5. PS/TS: Промотор/терминатор экспрессионной кассеты, содержащей ген отбора; МАО: матрикс-ассоциированная область. Позиции сайтов рестрикционных ферментов указаны стрелками.
Фиг. 16 - Верхняя панель: Фотография вестерн-блота с зондированием комбинацией анти-HA и анти-ЗФБ антител после гель-электрофореза белковых экстрактов из образцов листьев N. benthamiana, в которые были внесены генетические конструкции. Дорожка 1, маркеры молекулярной массы полипептидов (кДа). Внесенные векторы: дорожка 2, pRA01 (pFAγ::ЗФБ); дорожки 3-7, векторы для экспрессии pFAγ::NifH::HA из кассет 1-5 в дополнение к pRA01. Нижняя панель: Пунцовое окрашивание той же мембраны. Указаны дорожка pFAγ::NifH::HA и дублет дорожек для pFAγ::ЗФБ.
Фиг. 17 - А. Верхняя панель: Фотография вестерн-блота с зондированием анти-HA антителом после гель-электрофореза белковых экстрактов из образцов листьев N. benthamiana, в которые была внесена генетическая конструкция. Дорожки 1 и 3, маркеры молекулярной массы полипептидов (кДа). Внесенные векторы: дорожка 2, pRA01 (pFAγ::ЗФБ); дорожка 4, HC13. Нижняя панель: Пунцовое окрашивание той же мембраны. Указана принадлежность дорожек. B. Идентичный вестерн-блот с зондированием анти-MYC антителом.
Фиг. 18. Верхняя панель: Фотография вестерн-блота белковых экстрактов из листьев N. benthamiana через 4 суток после инфильтрации комбинациями pRA01 (pFAγ::ЗФБ, дорожки, обозначенные G), pRA16 (pFAγ::NifS::HA, дорожки, обозначенные S) и pRA19 (кодон-оптимизированный в соответствии с человеческими кодонами pFAγ::NifD::HA, дорожки, обозначенные D). Вестерн-блот зондировали анти-HA и анти-ЗФБ антителами. Для разрешения NifS и ЗФБ без перенасыщения экспозицию ограничивали. Для обнаружения NifD::HA было необходимо большее время экспозиции блота. Размеры маркеров молекулярной массы (кДа) указаны на дорожке 1. Нижняя панель: Фотография вестерн-блота белковых экстрактов из листьев N. benthamiana через 4 суток после инфильтрации комбинациями pRA01 (pFAγ::ЗФБ, дорожки, обозначенные G), pRA22 (кодон-оптимизированный в соответствии с человеческими кодонами mFAγ::NifD::HA, дорожки, обозначенные D-mMTP), pRA19 (кодон-оптимизированный в соответствии с человеческими кодонами pFAγ::NifD::HA, дорожки, обозначенные D-HA), pRA26 (кодон-оптимизированный в соответствии с человеческими кодонами ΔFAγ::NifD::HA, дорожки, обозначенные D-stop и pRA24 (Arabidopsis, кодон-оптимизированный pFAγ::NifD::HA, дорожки, обозначенные D-alt). Блот зондировали анти-HA и анти-ЗФБ антителами. Для обнаружения NifD-HA было необходимо большее время экспозиции блота.
Фиг. 19 - Фотография вестерн-блота с применением анти-HA антитела после ДСН-ПААГ белковых экстрактов из клеток листьев N. benthamiana после инфильтрации конструкциями, коэкспрессирующими P19 и SN6, SN7, или конструкциями SN8 (пример 20), экспрессирующими NifD::HA, с или без pRA25. Непроц./проц.: непроцессированные и процессированные формы FAγ51::NifD. прод. дегр: NifD-специфический продукт деградации размером приблизительно 48 кДа.
ПОЯСНЕНИЯ К ПЕРЕЧНЮ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
SEQ ID NO:1 - Аминокислотная последовательность нативного МНП субъединицы IV цитохром c-оксидазы (МНП CoxIV).
SEQ ID NO:2 - Аминокислотная последовательность производного МНП субъединицы IV цитохром c-оксидазы (dCoxIV).
SEQ ID NO:3 - Консервативные остатки аргинина и серина в мотиве xRxxxSSx в dCoxIV, принимающие участие в импорте и процессинге МНП.
SEQ ID NO:4 - Нуклеотидная последовательность области Т-ДНК pCW440 с компонентами правой пограничной области Т-ДНК (нуклеотиды 1-164), промотора 35S (нуклеотиды 219-1564), фланкируемого сайтом HindIII и сайтом XhoI, CTCGAG (XhoI), промотора T7 (нуклеотиды 1571-1587), dCoxIV-кодирующей последовательности (нуклеотиды 1650-1742), начинающейся с ATG, сайтом AscI (нуклеотиды 1743-1750), терминатора T7 (нуклеотиды 1810-1856), терминатора nos 3' (нуклеотиды 1861-2084) и левой пограничной области Т-ДНК (нуклеотиды 2186-2346).
SEQ ID NO:5 - Аминокислотная последовательность NifH K. pneumoniae дикого типа.
SEQ ID NO:6 - Аминокислотная последовательность NifD K. pneumoniae дикого типа.
SEQ ID NO:7 - Аминокислотная последовательность NifK K. pneumoniae дикого типа.
SEQ ID NO:8 - Аминокислотная последовательность NifY K. pneumoniae дикого типа.
SEQ ID NO:9 - Аминокислотная последовательность NifB K. pneumoniae дикого типа.
SEQ ID NO:10 - Аминокислотная последовательность NifE K. pneumoniae дикого типа.
SEQ ID NO:11 - Аминокислотная последовательность NifN K. pneumoniae дикого типа.
SEQ ID NO:12 - Аминокислотная последовательность NifQ K. pneumoniae дикого типа.
SEQ ID NO:13 - Аминокислотная последовательность NifS K. pneumoniae дикого типа.
SEQ ID NO:14 - Аминокислотная последовательность NifU K. pneumoniae дикого типа.
SEQ ID NO:15 - Аминокислотная последовательность NifX K. pneumoniae дикого типа.
SEQ ID NO:16 - Аминокислотная последовательность NifF K. pneumoniae дикого типа.
SEQ ID NO:17 - Аминокислотная последовательность NifZ K. pneumoniae дикого типа.
SEQ ID NO:18 - Аминокислотная последовательность NifJ K. pneumoniae дикого типа.
SEQ ID NO:19 - Аминокислотная последовательность NifM K. pneumoniae дикого типа.
SEQ ID NO:20 - Аминокислотная последовательность NifV K. pneumoniae дикого типа.
SEQ ID NO:21 - Аминокислотная последовательность C-концевого удлинения (17 ак), содержащая эпитоп HA (аминокислоты 7-15).
SEQ ID NO:22 - Аминокислотная последовательность C-концевого удлинения (12 ак), содержащая эпитоп FLAG.
SEQ ID NO:23 - Аминокислотная последовательность слитого полипептида dCoxIV::NifH::HA, кодируемого pCW446. Аминокислоты 1-31 соответствуют МНП dCoxIV, аминокислоты 32-34 представляют собой результат клонирования в сайте AscI, аминокислоты 35-326 представляют собой аминокислоты NifH K. pneumoniae (с удаленным стартовым кодоном Met), а аминокислоты 327-343 включают эпитоп HA.
SEQ ID NO:24 - Аминокислотная последовательность слитого полипептида dCoxIV::NifD::FLAG, кодируемого pCW447. Аминокислоты 1-31 соответствуют МНП dCoxIV, аминокислоты 32-34 представляют собой результат клонирования в сайте AscI, аминокислоты 35-515 представляют собой аминокислоты NifD K. pneumoniae (с двумя удаленными N-концевыми остатками Met), а аминокислоты 516-527 включают эпитоп FLAG.
SEQ ID NO:25 - Аминокислотная последовательность слитого полипептида dCoxIV::NifK::HA, кодируемого pCW448. Аминокислоты 1-31 соответствуют МНП dCoxIV, аминокислоты 32-34 представляют собой результат клонирования в сайте AscI, аминокислоты 35-553 представляют собой аминокислоты NifK K. pneumoniae, а аминокислоты 554-570 включают эпитоп HA.
SEQ ID NO:26 - Аминокислотная последовательность слитого полипептида dCoxIV::NifY::HA, кодируемого pCW449. Аминокислоты 1-31 соответствуют МНП dCoxIV, аминокислоты 32-34 представляют собой результат клонирования в сайте AscI, аминокислоты 35-253 представляют собой аминокислоты NifY K. pneumoniae (без стартового кодона Met), а аминокислоты 254-270 включают эпитоп HA.
SEQ ID NO:27 - Нуклеотидная последовательность фрагмента AscI, кодирующего NifH::HA, AscI-NifH-HA-AscI.
SEQ ID NO:28 - Нуклеотидная последовательность фрагмента AscI, кодирующего NifD::FLAG, AscI-NifD-FLAG-AscI.
SEQ ID NO:29 - Нуклеотидная последовательность фрагмента AscI, кодирующего NifK::HA, AscI-NifK-HA-AscI.
SEQ ID NO:30 - Нуклеотидная последовательность фрагмента AscI, кодирующего NifY::HA, AscI-NifY-HA-AscI.
SEQ ID NO:31 - Аминокислотная последовательность слитого полипептида dCoxIV::NifB::HA, кодируемого pCW452. Аминокислоты 1-31 соответствуют МНП dCoxIV, аминокислоты 32-34 представляют собой результат клонирования в сайте AscI, аминокислоты 35-501 представляют собой аминокислоты NifB K. pneumoniae (без стартового кодона Met), а аминокислоты 502-518 включают эпитоп HA.
SEQ ID NO:32 - Аминокислотная последовательность слитого полипептида dCoxIV::NifE::HA, кодируемого pCW454. Аминокислоты 1-31 соответствуют МНП dCoxIV, аминокислоты 32-34 представляют собой результат клонирования в сайте AscI, аминокислоты 35-490 представляют собой аминокислоты NifE K. pneumoniae (без стартового кодона Met), а аминокислоты 491-507 включают эпитоп HA.
SEQ ID NO:33 - Аминокислотная последовательность слитого полипептида dCoxIV::NifN::FLAG, кодируемого pCW455. Аминокислоты 1-31 соответствуют МНП dCoxIV, аминокислоты 32-34 представляют собой результат клонирования в сайте AscI, аминокислоты 35-493 представляют собой аминокислоты NifN K. pneumoniae (без стартового кодона Met), а аминокислоты 494-505 включают эпитоп FLAG.
SEQ ID NO:34 - Аминокислотная последовательность слитого полипептида dCoxIV::NifQ::HA, кодируемого pCW456. Аминокислоты 1-31 соответствуют МНП dCoxIV, аминокислоты 32-34 представляют собой результат клонирования в сайте AscI, аминокислоты 35-200 представляют собой аминокислоты NifQ Klebsiella sp.(без стартового кодона Met), а аминокислоты 201-217 включают эпитоп HA.
SEQ ID NO:35 - Аминокислотная последовательность слитого полипептида dCoxIV::NifS::HA, кодируемого pCW450. Аминокислоты 1-31 соответствуют МНП dCoxIV, аминокислоты 32-34 представляют собой результат клонирования в сайте AscI, аминокислоты 35-433 представляют собой аминокислоты NifS K. pneumoniae (без стартового кодона Met), а аминокислоты 434-450 включают эпитоп HA.
SEQ ID NO:36 - Аминокислотная последовательность слитого полипептида dCoxIV::NifU::FLAG, кодируемого pCW451. Аминокислоты 1-31 соответствуют МНП dCoxIV, аминокислоты 32-34 представляют собой результат клонирования в сайте AscI, аминокислоты 35-493 представляют собой аминокислоты NifU K. pneumoniae (без стартового кодона Met), а аминокислоты 494-505 включают эпитоп FLAG.
SEQ ID NO:37 - Аминокислотная последовательность слитого полипептида dCoxIV::NifX::FLAG, кодируемого pCW453. Аминокислоты 1-31 соответствуют МНП dCoxIV, аминокислоты 32-34 представляют собой результат клонирования в сайте AscI, аминокислоты 35-189 представляют собой аминокислоты NifX K. pneumoniae (без стартового кодона Met), а аминокислоты 190-201 включают эпитоп FLAG.
SEQ ID NO:38 - Аминокислотная последовательность N-концевого удлинения, содержащая МНП pFAγ (аминокислоты 1-77) и аминокислотный триплет GAP (78-80), добавленный вследствие стратегии клонирования в pRA00. Расщепление МПП происходит между аминокислотными остатками 42 и 43.
SEQ ID NO:39 - Аминокислотная последовательность модифицированного N-концевого удлинения, кодируемая в векторе pRA21, содержащая последовательность mFAγ (аминокислоты 1-77) и аминокислотный триплет GAP (78-80), добавленный вследствие стратегии клонирования в pRA21. Аланиновые аминокислотные замены в аминокислотах 12-18, 24-33 и 39-45 относительно SEQ ID NO:38 были сконструированы для устранения расщепления МПП.
SEQ ID NO:40 - Аминокислотная последовательность слитого полипептида pFAγ::NifF::HA, кодируемого pRA05. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования NifX K. pneumoniae в сайте AscI, аминокислоты 81-256 представляют собой аминокислоты NifF K. pneumoniae (SEQ ID NO:16), а аминокислоты 257-267 включают эпитоп HA.
SEQ ID NO:41 - Аминокислотная последовательность слитого полипептида pFAγ::NifZ::FLAG, кодируемого pRA04. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-228 представляют собой аминокислоты NifZ K. pneumoniae (SEQ ID NO:17), а аминокислоты 229-238 включают эпитоп FLAG.
SEQ ID NO:42 - Аминокислотная последовательность слитого полипептида pFAγ::NifH::HA, кодируемого pRA10. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-372 представляют собой аминокислоты NifH K. pneumoniae (SEQ ID NO:5 без инициирующего Met), а аминокислоты 373-389 включают эпитоп HA.
SEQ ID NO:43 - Аминокислотная последовательность триптического пептида из pFAγ, непроцессированного.
SEQ ID NO:44 - Аминокислотная последовательность триптического пептида из pFAγ, после процессинга МПП.
SEQ ID NO:45 - Аминокислотная последовательность триптического пептида из pFAγ, после процессинга МПП.
SEQ ID NO:46 - Аминокислотная последовательность слитого полипептида pFAγ::NifB::HA, кодируемого pRA03. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-547 представляют собой аминокислоты NifB K. pneumoniae (SEQ ID NO:9 без инициирующего Met), а аминокислоты 548-564 включают эпитоп HA.
SEQ ID NO:47 - Аминокислотная последовательность слитого полипептида pFAγ::NifD::FLAG, кодируемого pRA07. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-561 представляют собой аминокислоты NifD K. pneumoniae (SEQ ID NO:6 без инициирующего Met и следующего Met), а аминокислоты 562-573 включают эпитоп FLAG.
SEQ ID NO:48 - Аминокислотная последовательность слитого полипептида pFAγ::NifE::HA, кодируемого pRA09. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-536 представляют собой аминокислоты NifE K. pneumoniae (SEQ ID NO:10 без инициирующего Met), а аминокислоты 537-553 включают эпитоп HA.
SEQ ID NO:49 - Аминокислотная последовательность слитого полипептида pFAγ::NifJ::FLAG, кодируемого pRA06. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-1251 представляют собой аминокислоты NifJ K. pneumoniae (SEQ ID NO:18), а аминокислоты 1252-1261 включают эпитоп FLAG.
SEQ ID NO:50 - Аминокислотная последовательность слитого полипептида pFAγ::NifK::HA, кодируемого pRA11. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-599 представляют собой аминокислоты NifK K. pneumoniae (SEQ ID NO:7 без инициирующего Met), а аминокислоты 600-616 включают эпитоп HA.
SEQ ID NO:51 - Аминокислотная последовательность слитого полипептида pFAγ::NifM::HA, кодируемого pRA18. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-346 представляют собой аминокислоты NifM K. pneumoniae (SEQ ID NO:19), а аминокислоты 347-357 включают эпитоп HA.
SEQ ID NO:52 - Аминокислотная последовательность слитого полипептида pFAγ::NifN::FLAG, кодируемого pRA13. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-539 представляют собой аминокислоты NifN K. pneumoniae (SEQ ID NO:11 без инициирующего Met), а аминокислоты 540-551 включают эпитоп FLAG.
SEQ ID NO:53 - Аминокислотная последовательность слитого полипептида pFAγ::NifQ::HA, кодируемого pRA08. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-246 представляют собой аминокислоты NifQ K. pneumoniae (SEQ ID NO:12 без инициирующего Met), а аминокислоты 247-263 включают эпитоп HA.
SEQ ID NO:54 - Аминокислотная последовательность слитого полипептида pFAγ::NifS::HA, кодируемого pRA16. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-478 представляют собой аминокислоты NifS K. pneumoniae (SEQ ID NO:13 без инициирующего Met), а аминокислоты 479-496 включают эпитоп HA.
SEQ ID NO:55 - Аминокислотная последовательность слитого полипептида pFAγ::NifU::FLAG, кодируемого pRA15. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-353 представляют собой аминокислоты NifU K. pneumoniae (SEQ ID NO:14 без инициирующего Met), а аминокислоты 354-365 включают эпитоп FLAG.
SEQ ID NO:56 - Аминокислотная последовательность слитого полипептида pFAγ::NifV::FLAG, кодируемого pRA17. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-461 представляют собой аминокислоты NifV K. pneumoniae (SEQ ID NO:20), а аминокислоты 462-471 включают эпитоп FLAG.
SEQ ID NO:57 - Аминокислотная последовательность слитого полипептида pFAγ::NifX::FLAG, кодируемого pRA14. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-235 представляют собой аминокислоты NifX K. pneumoniae (SEQ ID NO:15 без инициирующего Met), а аминокислоты 236-247 включают эпитоп FLAG.
SEQ ID NO:58 - Аминокислотная последовательность слитого полипептида pFAγ::NifY::HA, кодируемого pRA12. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-299 представляют собой аминокислоты NifY K. pneumoniae (SEQ ID NO:8 без инициирующего Met), а аминокислоты 300-316 включают эпитоп HA.
SEQ ID NO:59 - Аминокислотная последовательность слитого полипептида pFAγ::NifD::HA, кодируемого pRA19. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-561 представляют собой аминокислоты NifD K. pneumoniae (SEQ ID NO:6 без инициирующего Met и следующего Met), а аминокислоты 562-574 включают эпитоп HA.
SEQ ID NO:60 - Аминокислотная последовательность слитого полипептида pFAγ::NifK (pRA25) с отсутствием какого-либо С-концевого удлинения. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-599 представляют собой аминокислоты NifK K. pneumoniae (SEQ ID NO:7 без инициирующего Met).
SEQ ID NO:61 - Аминокислотная последовательность участка из 11 остатков из известной неструктурированной линкерной области из целлобиогидролазы II Hypocrea jecorina (номер доступа AAG39980.1).
SEQ ID NO:62 - Аминокислотная последовательность эпитопа FLAG из 8 остатков.
SEQ ID NO:63 - Аминокислотная последовательность линкера. Линкер имеет длину 30 остатков и состоит из участка из 11 остатков из известной неструктурированной линкерной области из целлобиогидролазы II Hypocrea jecorina (номер доступа AAG39980.1, ATPPPGSTTTR; SEQ ID NO:61) с заменой последнего аргинина аланином, затем эпитопа FLAG из 8 остатков (DYKDDDDK; SEQ ID NO:62), за которым следует еще одна копия неструктурированной линкерной последовательности из 11 остатков с заменой аргинина аланином.
SEQ ID NO:64 - Аминокислотная последовательность слитого полипептида pFAγ::NifD-линкер-NifK (pRA02) с отсутствием какого-либо С-концевого удлинения для NifK. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-561 представляют собой аминокислоты NifD K. pneumoniae (SEQ ID NO:6 без инициирующего Met и следующего Met), аминокислоты 562-592 представляют собой 30-аминокислотный линкер, а аминокислоты 593-1110 представляют собой аминокислоты NifK K. pneumoniae (SEQ ID NO:7 без инициирующего Met).
SEQ ID NO:65 - Аминокислотная последовательность слитого полипептида pFAγ::NifD-линкер-NifK::HA (pRA20) с отсутствием какого-либо С-концевого удлинения для NifK. Аминокислоты 1-77 соответствуют МНП pFAγ, аминокислоты 78-80 (GAP) представляют собой результат клонирования в сайте AscI, аминокислоты 81-561 представляют собой аминокислоты NifD K. pneumoniae (SEQ ID NO:6 без инициирующего Met и следующего Met), аминокислоты 562-592 представляют собой 30-аминокислотный линкер, аминокислоты 593-1110 представляют собой аминокислоты NifK K. pneumoniae (SEQ ID NO:7 без инициирующего Met), а аминокислоты 1111-1119 включают эпитоп HA.
SEQ ID NO:66 - Аминокислотная последовательность C-концевого удлинения, содержащая эпитоп MYC, соответствующий аминокислотам 347-356 в SEQ ID NO:67.
SEQ ID NO:67 - Аминокислотная последовательность слитого полипептида pFAγ::NifM::MYC.
SEQ ID NO:68 - Нуклеотидная последовательность для слитого полипептида pFAγ::NifD::HA в pRA19, начиная с инициирующего трансляцию кодона.
SEQ ID NO:69 - Аминокислотная последовательность последних четырех аминокислотных остатков в C-конце полипептида NifK из K. pneumoniae.
SEQ ID NO:70. Нуклеотидная последовательность ДНК-фрагмента, кодирующего полипептид pFAγ-C.
SEQ ID NO:71. Аминокислотная последовательность полипептида pFAγ-C.
SEQ ID NO:72. Олигонуклеотидный праймер NifD-F.
SEQ ID NO:73. Олигонуклеотидный праймер NifD-R.
SEQ ID NO:74. Аминокислотная последовательность NifW K. pneumoniae дикого типа.
SEQ ID NO:75. Аминокислотная последовательность полипептида МНП-FAγ51.
SEQ ID NO:76. Аминокислотная последовательность полипептида FAγ-след9.
SEQ ID NO:77. Аминокислотная последовательность МНП CPN60.
SEQ ID NO:78. Аминокислотная последовательность МНП CPN60/без GG-линкера.
SEQ ID NO:79. Аминокислотная последовательность МНП супероксиддисмудазы (SOD) (At3G10920).
SEQ ID NO:80. Аминокислотная последовательность МНП двойной супероксиддисмудазы (2SOD) (At3G10920).
SEQ ID NO:81. Аминокислотная последовательность МНП модифицированной супероксиддисмудазы (SODmod) (At3g10920).
SEQ ID NO:82. Аминокислотная последовательность МНП модифицированной двойной супероксиддисмудазы (2SODmod) (At3g10920).
SEQ ID NO:83. Аминокислотная последовательность МНП L29 (At1G07830).
SEQ ID NO:84. Аминокислотная последовательность МНП субъединицы 9 F0 АТФазы (SU9) Neurospora crassa.
SEQ ID NO:85. Аминокислотная последовательность МНП субъединицы гамма гАТФазы (FAγ51).
SEQ ID NO:86. Аминокислотная последовательность МНП twin strep CoxIV (ABM97483).
SEQ ID NO:87. Аминокислотная последовательность МНП 10xHis CoxIV (ABM97483).
SEQ ID NO:88. Аминокислотная последовательность предсказанного следа для МНП супероксиддисмудазы (SOD) (SEQ ID NO:80).
SEQ ID NO:89. Аминокислотная последовательность предсказанного следа для МНП двойной супероксиддисмудазы (2SOD) (SEQ ID NO:81).
SEQ ID NO:90. Аминокислотная последовательность предсказанного следа для МНП L29 (SEQ ID NO:84).
SEQ ID NO:91. Аминокислотная последовательность предсказанного следа для МНП субъединицы 9 F0 АТФазы (SU9) Neurospora crassa (SEQ ID NO:85).
SEQ ID NO:92. Аминокислотная последовательность предсказанного следа для МНП субъединицы гамма гАТФазы (FAγ51) (SEQ ID NO:86).
SEQ ID NO:93. Аминокислотная последовательность предсказанного следа для МНП twin strep CoxIV (SEQ ID NO:87).
SEQ ID NO:94. Аминокислотная последовательность предсказанного следа для МНП 10xHis CoxIV (SEQ ID NO:88).
SEQ ID NO:95. Аминокислотная последовательность вариантного NifD.
SEQ ID NO:96. Аминокислотная последовательность вариантного NifS.
SEQ ID NO:97. 9-аминокислотное C-концевое удлинение NifK.
SEQ ID NO:98. Олигонуклеотидный праймер.
SEQ ID NO:99. Олигонуклеотидный праймер.
SEQ ID NO:100. Олигонуклеотидный праймер.
SEQ ID NO:101. Олигонуклеотидный праймер.
SEQ ID NO:102. Олигонуклеотидный праймер BO1.
SEQ ID NO:103. Олигонуклеотидный праймер BO2.
SEQ ID NO:104. Аминокислотная последовательность линкера.
SEQ ID NO:105. Олигонуклеотидный праймер pRA31DK-FW.
SEQ ID NO:106. Олигонуклеотидный праймер pRA31DK-RV.
SEQ ID NO:107. Олигонуклеотидный праймер D_start_RV.
SEQ ID NO:108. Олигонуклеотидный праймер K_end_FW.
SEQ ID NO:109. Олигонуклеотидный праймер.
SEQ ID NO:110. Олигонуклеотидный праймер.
SEQ ID NO:111. 9-аминокислотная последовательность N-концевого удлинения полипептида NifD-линкер-NifK.
SEQ ID NO:112. Аминокислотная последовательность эпитопа HA.
SEQ ID NO:113. Аминокислотная последовательность линкера полипептида NifE-NifN HA.
SEQ ID NO:114. Олигонуклеотидный праймер pRAEN-FW. SEQ ID NO:115. Олигонуклеотидный праймер pRAEN-RV.
SEQ ID NO:116. Олигонуклеотидный праймер E_start_RV.
SEQ ID NO:117. Олигонуклеотидный праймер N_end_FW.
SEQ ID NO:118. Олигонуклеотидный праймер.
SEQ ID NO:119. Олигонуклеотидный праймер.
SEQ ID NO:120. Нуклеотидная последовательность промотора SCSV-S4 версии 1.
SEQ ID NO:121. Нуклеотидная последовательность промотора SCSV-S4 версии 2.
SEQ ID NO:122. Нуклеотидная последовательность промотора SCSV-S7.
SEQ ID NO:123. Нуклеотидная последовательность промотора длинной версии CaMV-35S.
SEQ ID NO:124. Нуклеотидная последовательность промотора CaMV-2x25S.
SEQ ID NO:125. Аминокислотная последовательность вирусного супрессорного белка P19.
SEQ ID NO:126. Аминокислотная последовательность пептида P19.
SEQ ID NO:127. Аминокислотная последовательность пептида P19.
SEQ ID NO:128-143. Аминокислотная последовательность пептидов NifK.
SEQ ID NO:144-154. Аминокислотная последовательность пептидов NifH.
SEQ ID NO:155-160. Аминокислотная последовательность пептидов NifB.
SEQ ID NO:161-165. Аминокислотная последовательность пептидов NifJ.
SEQ ID NO:166-174. Аминокислотная последовательность пептидов NifS.
SEQ ID NO:175-182. Аминокислотная последовательность пептидов NifX.
SEQ ID NO:183-186. Аминокислотная последовательность пептидов NifF.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Общие методики и определения
Если специально не указано иное, все используемые в данном документе технические и научные термины следует понимать, как имеющие значение, обычно подразумеваемое специалистом в данной области техники (например, клеточного культивирования, молекулярной генетики, молекулярной биологии растений, белковой химии и биохимии).
Если не указано иное, методики получения рекомбинантных белков, клеточного культивирования и иммунологические методики, применяемые в данном изобретении, являются стандартными процедурами, известными специалистам в данной области техники. Такие методики описаны и разъяснены в таких литературных источниках, как J. Perbal, A Practical Guide to Molecular Cloning, John Wiley and Sons (1984), J. Sambrook et al., Molecular Cloning: A Laboratory Manual, Cold Spring Harbour Laboratory Press (1989), T.A. Brown (editor), Essential Molecular Biology: A Practical Approach, Volumes 1 and 2, IRL Press (1991), D.M. Glover and B.D. Hames (editors), DNA Cloning: A Practical Approach, Volumes 1-4, IRL Press (1995 and 1996), и F.M. Ausubel et al. (editors), Current Protocols in Molecular Biology, Greene Pub. Associates and Wiley-Interscience (1988, включая все обновления вплоть до настоящего времени), Ed Harlow and David Lane (editors) Antibodies: A Laboratory Manual, Cold Spring Harbour Laboratory, (1988), и J.E. Coligan et al. (editors) Current Protocols in Immunology, John Wiley & Sons (включая все обновления вплоть до настоящего времени).
Термин «и/или», например, «X и/или Y», следует понимать, как означающий «X и Y» или «X или Y», и следует воспринимать как прямо предусматривающий оба значения или любое из значений.
В тексте этого описания слово «содержать» или его вариации, такие как «содержит» или «содержащий» следует понимать как подразумевающий включение указанного элемента, целого числа или этапа, или группы элементов, целых чисел или этапов, но не исключение любого другого элемента, целого числа или этапа, или группы элементов, целых чисел или этапов.
Нитрогеназа является ферментом у эубактерий и архебактерий, который катализирует восстановление сильной тройной связи азота (N2) с образованием аммиака (NH3). В природе нитрогеназа присутствует только у бактерий. Это комплекс из двух ферментов, которые можно очищать по отдельности, а именно, динитрогеназы и редуктазы динитрогеназы. Динитрогеназа, также называемая компонентом I или железо-молибденовым (MoFe) белком, представляет собой тетрамер из двух полипептидов NifD и двух полипептидов NifK (α2β2), который также содержит «P-кластеры» и два «FeMo-кофактора» (FeMo-Co). Каждая пара субъединиц NifD-NifK содержит один P-кластер и один FeMo-Co. FeMo-Co представляет собой металлокластер, состоящий из кластера MoFe3-S3, образующего комплекс с молекулой гомоцитрата, координируемого атомом молибдена и соединенного с кластером Fe4-S3 тремя серными лигандами. Сборка FeMo-Co в клетках происходит отдельно, а потом он включается в состав белка apo-MoFe. P-кластер также представляет собой металлокластер и содержит 8 атомов Fe и 7 атомов серы со структурой сходной, но отличной от FeMo-Co. P-кластеры расположены на поверхности контакта субъединицыαβ динитрогеназы и координируются остатками цистеинила из обеих субъединиц. Редуктаза динитрогеназы, также называемая компонентом II или «Fe-белком», представляет собой димер из полипептидов NifH, который также содержит один кластер Fe4-S4 на поверхности контакта субъединицы и два сайта связывания Mg-АТФ, по одному в каждой субъединице. Этот фермент является облигаторным донором электронов для динитрогеназы, при этом электроны переносятся с кластера Fe4-S4 на P-кластер и, в свою очередь, на FeMo-Co, сайт для восстановления N2.
Хотя Mo-содержащая нитрогеназа является наиболее часто встречающейся нитрогеназой у бактерий, существуют две гомологичные нитрогеназы, которые в целом отличны, но имеют аналогичные композиции кофакторов и субъединиц, а именно, ванадий-содержащая нитрогеназа и содержащая только Fe нитрогеназа, кодируемые генами Vnf (ванадиевая фиксация азота) и Anf (альтернативная фиксация азота) соответственно. Некоторые бактерии в природе имеют все три типа нитрогеназ, другие бактерии содержат только Mo- и V-содержащие ферменты или только Mo-содержащий фермент, например, Klebsiella pneumoniae.
Для биосинтеза FeMo-Co и созревания компонентов нитрогеназы до каталитически активных форм необходимы различные гены фиксации азота (Nif). Были описаны роли полипептидов NifB, NifE, NifH, NifN, NifQ, NifV и NifX в синтезе FeMo-Co (Rubio and Ludden, 2005).
Биологическая фиксация N2, катализируемая прокариотическим ферментом нитрогеназой, является альтернативой использованию синтетических N2-удобрений. Чувствительность нитрогеназы к кислороду является основным препятствием для создания растений, например, зерновых культур, с биологической фиксацией азота посредством прямого переноса гена Nif .
Авторы данного изобретения предположили, что нацеливание полипептидов Nif на митохондриальный матрикс (ММ) растительных клеток может помочь преодолеть проблему чувствительности к кислороду. ММ содержит кислород-потребляющие ферменты, которые обеспечивают возможность функционирования других ферментов, которые содержат чувствительный к кислороду кластер Fe-S. Митохондриальный аппарат сборки кластера Fe-S сходен с диазотрофными эквивалентами (Balk and Pilon, 2011; Lill and Mühlenhoff, 2008). Следовательно, некоторые необходимые элементы для биосинтеза нитрогеназы могут уже присутствовать в ММ, уменьшая число генов Nif, необходимых для воссоздания. Кофактор гомоцитрат образуется как часть цикла ТКК. Также присутствуют высокие восстановительный потенциал и концентрация АТФ (Geigenberger and Fernie, 2014; Mackenzie and McIntosh, 1999), которые являются предварительными необходимыми элементами для катализа фермента нитрогеназы. Кроме того, присутствие в митохондриях глутаматсинтазы обеспечивает точку проникновения для любого аммиака, фиксируемого нитрогеназой, для участия в метаболизме растения. Учитывая эти характеристики и тот факт, что сами митохондрии имеют α-протеобактериальное происхождение, авторы данного изобретения предположили, что эта органелла также хорошо подходит в качестве локации для попытки функционального воссоздания нитрогеназы.
В качестве первого шага в направлении воссоздания нитрогеназы в митохондриях растительных клеток были необходимы свидетельства, что отдельные белки Nif можно точно нацеливать на ММ. В этих целях авторы изобретения выбрали модельное растение Nicotiana benthamiana в качестве экспрессионной платформы (Wood et al., 2009), чтобы обеспечить экспрессию трансгенов как по отдельности, так и, что более важно, в комбинациях. Так как большинство локализованных в ММ белков кодируются в ядре, авторы данного изобретения основывались на последних достижениях в понимании субклеточной сигнализации и процесса переноса (Huang et al., 2009; Murcha et al., 2014), используя ранее изученный сигнал, нацеленный на N-концевой пептид (Lee et al., 2012).
В модельном бактериальном диазотрофе Klebsiella pneumoniae используются 16 уникальных белков для биосинтеза и каталитической функции нитрогеназы. Авторы данного изобретения переконструировали все 16 белков Nif из K. pneumoniae для нацеливания на растительный ММ и оценили их экспрессию и процессинг в листьях N. benthamiana. Все 16 полипептидов Nif временно экспрессировали и исследовали в отношении специфического к последовательности ММ-процессинга. Авторы данного изобретения установили, что все 16 полипептидов Nif могут по отдельности экспрессироваться в виде слитых полипептидов МНП:Nif в клетках листьев растений. Кроме того, авторы данного изобретения получили свидетельства, что эти белки могут быть нацелены на митохондриальный матрикс (ММ), субклеточную локацию, потенциально подходящую для функционирования нитрогеназы, и могут расщепляться митохондриальной процессирующей протеазой (МПП). Это является первой демонстрацией на практике возможности реализации такого подхода и представляет важный прогресс в направлении конструирования эндогенной фиксации азота в растениях.
Слитые полипептиды митохондриальный нацеливающий пептид (МНП)-Nif
Данное изобретение относится к слитым полипептидам митохондриальный нацеливающий пептид (МНП)-Nif и полипептидным продуктам их расщепления. Когда слитый полипептид МНП-Nif по изобретению экспрессируется в растительной клетке, слитый полипептид МНП-Nif и/или расщепленный полипептидный продукт нацелен на митохондриальный матрикс (ММ). Предпочтительно слитый полипептид обеспечивает активность редуктазы нитрогеназы и/или нитрогеназы в растительной клетке или активность, являющуюся такой же, которую обеспечивает соответствующий полипептид Nif дикого типа в бактериях.
В контексте данного документа термин «слитый полипептид» означает полипептид, который содержит два или более функциональных полипептидных доменов, ковалентно связанных пептидной связью. Как правило, слитый полипептид кодируется в виде одной полипептидной цепи химерным полинуклеотидом по изобретению. В одном варианте реализации слитые полипептиды по изобретению содержат митохондриальный нацеливающий пептид (МНП) и полипептид Nif (NP). В этом варианте реализации C-конец МНП трансляционно слит с N-концом NP. В альтернативном варианте реализации слитые полипептиды по изобретению содержат C-концевую часть МНП и NP, где C-концевая часть является результатом расщепления МНП МПП. В этом варианте реализации C-конец C-концевой части МНП трансляционно слит с N-концом NP.
В контексте данного документа термин «трансляционно слит с N-концом» означает, что С-конец полипептида МНП ковалентно присоединен пептидной связью к N-концевой аминокислоте NP, таким образом, образуя слитый полипептид. В одном варианте реализации NP не содержит нативный инициирующий трансляцию остаток метионина (Met) или два N-концевых остатка Met по сравнению с соответствующим NP дикого типа. В альтернативном варианте реализации NP содержит инициирующий трансляцию Met или один или оба из двух N-концевых остатков Met полипептида NP дикого типа, например, как в случае NifD.
Такие полипептиды, как правило, получают посредством экспрессии химерной кодирующей белок области, в которой трансляционная рамка считывания нуклеотидов, кодирующих МНП, находится в рамке с рамкой считывания нуклеотидов, кодирующих NP. Специалисту в данной области техники понятно, что C-конец МНП может быть трансляционно слит с N-концевой аминокислотой NP без линкера или посредством линкера из одного или более аминокислотных остатков, например, 1-5 аминокислотных остатков. Такой линкер также может считаться частью МНП. После экспрессии кодирующей белок области может следовать расщепление МНП в ММ растительной клетки и такое расщепление (если оно происходит) включено в концепцию получения слитого полипептида по изобретению.
Слитый полипептид или процессированный полипептид Nif предпочтительно обладает функциональной активностью Nif, сравнимой с соответствующим полипептидом Nif дикого типа. Функциональную активность слитого полипептида или процессированного полипептида Nif можно определять в бактериальном и биохимическом анализе комплементации. В предпочтительном варианте реализации слитый полипептид или процессированный полипептид Nif обладает около 70-100% активности Nif дикого типа.
Слитый полипептид может содержать более одного МНП и/или более одного NP, например, слитый полипептид может содержать МНП, полипептид NifD и полипептид NifK. Слитые полипептиды также могут содержать олигопептидный линкер, например, соединяющий два NP. Предпочтительно линкер имеет достаточную длину, чтобы обеспечить возможность ассоциации двух или более функциональных доменов, например, двух NP, таких как NifD и NifK, в функциональной конфигурации в растительной клетке. Такой линкер может иметь длину от 8 до 50 аминокислотных остатков, предпочтительно длину около 25-35 аминокислот, более предпочтительно длину около 30 аминокислотных остатков. Слитый полипептид можно получать традиционными способами, например, посредством генной экспрессии полинуклеотидной последовательности для указанного слитого полипептида в подходящей клетке.
В контексте данного документа «по существу очищенный полипептид» означает полипептид, который по существу не содержит компонентов (например, липидов, нуклеиновых кислот, углеводов), которые обычно связаны с полипептидом, например, в клетке. Предпочтительно по существу очищенный полипептид является по меньшей мере на 90% свободным от указанных компонентов.
Растительные клетки, трансгенные растения и их части по изобретению сдержат полинуклеотид, кодирующий полипептид по изобретению. Полипептиды по изобретению обычно не встречаются в природе в растительных клетках, в частности, в митохондриях растительных клеток, и, следовательно, полинуклеотид, кодирующий полипептид, может называться в данном документе экзогенным полинуклеотидом, так как он не встречается в природе в растительной клетке, а был внесен в растительную клетку или клетку-предшественницу. Следовательно, можно говорить, что клетки, растения и части растений по изобретению, которые вырабатывают полипептид по изобретению, вырабатывают рекомбинантный полипептид. Термин «рекомбинантный» в контексте полипептида относится к полипептиду, кодируемому экзогенным полинуклеотидом при выработке в клетке, а указанный полинуклеотид был внесен в клетку или клетку-предшественницу с помощью технологии рекомбинантных ДНК или РНК, такой как, например, трансформация. Как правило, растительная клетка, растение или часть растения содержит неэндогенный ген, отвечающий за выработку некоторого количества полипептида, по меньшей мере в течение некоторого времени жизненного цикла растительной клетки или растения.
В одном варианте реализации полипептид по изобретению не является полипептидом природного происхождения. В альтернативном варианте реализации полипептид по изобретению имеет природное происхождение, но присутствует в растительной клетке, предпочтительно в митохондрии растительной клетки, в котором он не встречается в природе.
Полипептид Nif
В контексте данного документа термины «полипептид Nif» и «белок Nif» употребляются взаимозаменяемо и означают полипептид, родственный по аминокислотной последовательности полипептидам природного происхождения, вовлеченным в активность нитрогеназы, при этом полипептид Nif по изобретению выбран из группы, состоящей из полипептида NifD, полипептида NifH, полипептида NifK, полипептида NifB, полипептида NifE, полипептида NifN, полипептида NifF, полипептида NifJ, полипептида NifM, полипептида NifQ, полипептида NifS, полипептида NifU, полипептида NifV, полипептида NifW, полипептида NifX, полипептида NifY и полипептида NifZ, определение каждого из которых приведено в данном документе. Полипептиды Nif по изобретению включают «слитые полипептиды Nif», которые, в контексте данного документа, означают полипептидный гомолог полипептида Nif природного происхождения, который имеет дополнительные аминокислотные остатки, присоединенные к N-концу или С-концу, или к ним обоим, по сравнению с соответствующим полипептидом Nif природного происхождения. Как указано выше, в слитом полипептиде Nif может отсутствовать инициирующий трансляцию Met или два N-концевых остатка Met по сравнению с соответствующим полипептидом Nif дикого типа. Аминокислотные остатки слитого полипептида Nif, которые соответствуют полипептиду Nif природного происхождения, т. е. без дополнительных аминокислотных остатков, присоединенных к N-концу или C-концу, или к ним обоим, также называются в данном документе полипептидом Nif, сокращенно называемым в этом случае «NP», или полипептидом NifD («ND») и т. д. В предпочтительном варианте реализации «дополнительные аминокислотные остатки, присоединенные к N-концу или C-концу, или к ним обоим» содержат митохондриальный нацеливающий пептид (МНП) или процессированный МНП, присоединенный к N-концу NP, или эпитопную последовательность («тэг»), которая расположена с N-конца или C-конца относительно NP, или с обоих концов, или как МНП или процессированный МНП, так и эпитопную последовательность.
Полипептиды Nif природного происхождения встречаются только в некоторых бактериях, включая азотфиксирующие бактерии, в том числе свободно живущие азотфиксирующие бактерии, ассоциативные азотфиксирующие бактерии и симбиотические азотфиксирующие бактерии. Свободно живущие азотфиксирующие бактерии способны фиксировать значительные уровни азота без прямого взаимодействия с другими организмами. Без ограничения, свободно живущие азотфиксирующие бактерии включают представителей видов Azotobacter, Beijerinckia, Klebsiella, Cyanobacteria (классифицируемых как аэробные организмы) и представителей видов Clostridium, Desulfovibrio и упомянутых пурпурных серобактерий, пурпурных несеробактерий и зеленых серобактерий. Ассоциативные азотфиксирующие бактерии представляют собой прокариотические организмы, которые способны образовывать близкие ассоциации с несколькими представителями Poaceae (злаковые). Эти бактерии фиксируют существенное количество азота в ризосфере растений-хозяев. Представители вида Azospirillum являются представителями ассоциативных азотфиксирующих бактерий. Симбиотические азотфиксирующие бактерии представляют собой бактерии, которые фиксируют азот симбиотически в партнерстве с растением-хозяином. Растения обеспечивают сахара, образуемые в процессе фотосинтеза, которые используются азотфиксирующими бактериями для получения энергии, необходимой для фиксации азота. Представители вида Rhizobia являются представителями симбиотических азотфиксирующих бактерий.
Полипептид Nif или слитый полипептид Nif по изобретению выбран из группы, состоящей из полипептидов NifH, NifD, NifK, NifB, NifE, NifN, NifF, NifJ, NifM, NifQ, NifS, NifU, NifV, NifW, NifX, NifY и NifZ.
Полипептид или класс полипептидов можно определить по степени идентичности (% идентичности) его аминокислотной последовательности с референсной аминокислотной последовательностью или по большему % идентичности с одной референсной аминокислотной последовательностью, чем с другой. Полипептид или класс полипептидов также можно определить по наличию такой же биологической активности, как и у полипептида Nif природного происхождения, помимо степени идентичности в последовательности.
% идентичности полипептида определяют с помощью анализа GAP (Needleman and Wunsch, 1970) (программа GCG) со штрафом за создание гэпа=5 и штрафом за продление гэпа=0,3, или с помощью Blastp версии 2.5 или ее обновленных версий (Altschul et al, 1997), где в каждом случае анализ позволяет выровнять две последовательности, включая референсную последовательность, на протяжении всей длины референсной последовательности. В контексте данного документа референсные последовательности включают приведенные для полипептидов Nif природного происхождения из K. pneumoniae, SEQ ID NO:1-20.
В следующих определениях степень идентичности аминокислотной последовательности с референсной последовательностью, приведенной как SEQ ID NO, определяют с помощью Blastp версии 2.5 или ее обновленных версий (Altschul et al, 1997), используя параметры по умолчанию, за исключением максимального числа целевых последовательностей, которое установлено на 10000, и определяют вдоль полной длины референсной аминокислотной последовательности.
Полипептид NifH в существующих в природе бактериях является структурным компонентом комплекса нитрогеназы и часто называется железосодержащим (Fe) белком. Он образует гомодимер с кластером Fe4S4, связанным между субъединицами и двумя АТФ-связывающими доменами. NifH является облигатным донором электронов для белка MoFe (гетеротетрамер NifD/NifK) и, следовательно, функционирует как редуктаза нитрогеназы (EC 1.18.6.1). NifH также принимает участие в биосинтезе FeMo-Co и созревании белка apo-MoFe. В контексте данного документа «полипептид NifH» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 41% идентична аминокислотной последовательности, приведенной как SEQ ID NO:5, и который содержит один или более доменов TIGR01287, PRK13236, PRK13233 и cd02040. Домен TIGR01287 присутствует в каждой из железо-молибденовой редуктазы нитрогеназы (NifH), железо-ванадиевой редуктазы нитрогеназы (VnfH) и железо-железной редуктазы нитрогеназы (AnfH), но исключает гомологичный белок из светонезависимой протохлорофиллидовой редуктазы. Следовательно, в контексте данного документа полипептиды NifH включают подкласс железосвязывающих полипептидов, которые содержат аминокислоты, чья последовательность по меньшей мере на 41% идентична SEQ ID NO:5, железосвязывающие полипептиды VnfH и железосвязывающие полипептиды AnfH. Полипептид NifH природного происхождения, как правило, имеет длину от 260 до 300 аминокислот, а природный мономер имеет молекулярную массу около 30 кДа. Было идентифицировано большое число полипептидов NifH, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifH из Klebsiella michiganensis (№ доступа WP_049123239.1, 99% идентичности с SEQ ID NO:5), Brenneria goodwinii (WP_048638817.1, 93% идентичности), Sideroxydans lithotrophicus (WP_013029017.1, 84% идентичности), Denitrovibrio acetiphilus (WP_013010353.1, 80% идентичности), Desulfovibrio africanus (WP_014258951.1, 72% идентичности), Chlorobium phaeobacteroides (WP_011744626.1, 69% идентичности), Methanosaeta concilii (WP_013718497.1, 64% идентичности), Rhodobacter (WP_009565928.1, 61% идентичности), Methanocaldococcus infernus (WP_013099472.1, 42% идентичности) и Desulfosporosinus youngiae (WP_007781874.1, 41% идентичности). Полипептиды NifH были описаны и рассмотрены в Thiel et al., (1997), Pratte et al., (2006), Boison et al., (2006) и Staples et al., (2007).
В контексте данного документа функциональный полипептид NifH представляет собой полипептид NifH, который способен образовывать функциональный белковый комплекс нитрогеназы вместе с другими необходимыми субъединицами, например, NifD и NifK, и FeMo или другим кофактором.
В контексте данного документа «полипептид NifD» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 33% идентична аминокислотной последовательности, приведенной как SEQ ID NO:6, и который содержит (i) один или оба домена TIGR01282 и COG2710, которые оба встречаются в железо-молибденовых связывающих полипептидах, включая полипептид, имеющий аминокислотную последовательность, приведенную в SEQ ID NO:6, или (ii) железо-ванадиевый связывающий домен TIGR01860, в случае чего полипептид NifD относится к подклассу полипептидов VnfD, или (iii) железо-железный связывающий домен TIGR1861, в случае чего полипептид NifD относится к подклассу полипептидов AnfD.
В контексте данного документа полипептиды NifD включают подкласс железо-молибденовых связывающих (FeMo-Co) полипептидов, содержащих аминокислоты, чья последовательность по меньшей мере на 33% идентична SEQ ID NO:6, железо-ванадиевые полипептиды VnfD и полипептиды AnfD. Полипептид NifD природного происхождения, как правило, имеет длину от 470 до 540 аминокислот. Было идентифицировано большое число полипептидов NifD, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifD из Raoultella ornithinolytica (№ доступа WP_044347161.1, 96% идентичности с SEQ ID NO:6), Kluyvera intermedia (WP_047370273.1, 93% идентичности), Dickeya dadantii (WP_038902190.1, 89% идентичности), Tolumonas sp. BRL6-1 (WP_024872642.1, 81% идентичности), Magnetospirillum gryphiswaldense (WP_024078601.1, 68% идентичности), Thermoanaerobacterium thermosaccharolyticum (WP_013298320.1, 42% идентичности), Methanothermobacter thermautotrophicus (WP_010877172.1, 38% идентичности), Desulfovibrio africanus (WP_014258953.1, 37% идентичности), Desulfotomaculum sp. LMa1 (WP_066665786.1, 37% идентичности), Desulfomicrobium baculatum (WP_015773055.1, 36% идентичности), полипептида VnfD из Fischerella muscicola (WP_016867598.1, 34% идентичности) и полипептида AnfD из Opitutaceae bacterium TAV5 (WP_009512873.1, 33% идентичности). Полипептиды NifD были описаны и рассмотрены в Lawson and Smith (2002), Kim and Rees (1994), Eady (1996), Robson et al., (1989), Dilworth et al., (1988), Dilworth et al., (1993), Miller and Eady (1988), Chiu et al., (2001), Mayer et al., (1999) и Tezcan et al., (2005).
Полипептиды NifD железо-молибденового подкласса являются ключевой субъединицей комплексов нитрогеназы, являясь α-субъединицей белкового комплекса α2β2 MoFe в сердцевине нитрогеназы и сайтом восстановления субстрата с кофактором FeMo. В контексте данного документа функциональный полипептид NifD представляет собой полипептид NifD, который способен образовывать функциональный белковый комплекс нитрогеназы вместе с другими необходимыми субъединицами, например, NifH и NifK, и FeMo или другим кофактором.
В контексте данного документа «полипептид NifK» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 31% идентична аминокислотной последовательности, приведенной как SEQ ID NO:7, и который содержит один или более консервативных доменов c cd01974, TIGR01286 или cd01973, в случае чего полипептид NifK относится к подклассу полипептидов VnfK. В контексте данного документа полипептиды NifK включают полипептиды VnfK из железо-ванадиевой нитрогеназы. Полипептид NifK природного происхождения, как правило, имеет длину от 430 до 530 аминокислот. Было идентифицировано большое число полипептидов NifK, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifK из Klebsiella michiganensis (№ доступа WP_049080161.1, 99% идентичности с SEQ ID NO:7), Raoultella ornithinolytica (WP_044347163.1, 96% идентичности), Klebsiella variicola (SBM87811.1, 94% идентичности), Kluyvera intermedia (WP_047370272.1, 89% идентичности), Rahnella aquatilis (WP_014333919.1, 82% идентичности), Tolumonas auensis (WP_012728880.1, 75% идентичности), Pseudomonas stutzeri (WP_011912506.1, 68% идентичности), Vibrio natriegens (WP_065303473.1, 65% идентичности), Azoarcus toluclasticus (WP_018989051.1, 54% идентичности), Frankia sp., (prf||2106319A, 50% идентичности) и Methanosarcina acetivorans (WP_011021239.1, 31% идентичности). В базах данных есть некоторые примеры полипептидов, обозначенных как «NifK», которые имеют менее 31% идентичности с SEQ ID NO:7, но не содержат какой-либо из доменов, перечисленных выше, и, следовательно, в контексте данного документа они не включены в полипептиды NifK. Полипептиды NifK были описаны и рассмотрены в Kim and Rees (1994), Eady (1996), Robson et al., (1989), Dilworth et al., (1988), Dilworth et al., (1993), Miller and Eady (1988), Igarashi and Seefeldt (2003), Fani et al., (2000) и Rubio and Ludden (2005).
Полипептиды NifK железо-молибденового подкласса являются ключевой субъединицей комплексов нитрогеназы, являясь β-субъединицей белкового комплекса α2β2 MoFe в сердцевине нитрогеназы. В контексте данного документа функциональный полипептид NifK представляет собой полипептид NifK, который способен образовывать функциональный белковый комплекс нитрогеназы вместе с другими необходимыми субъединицами, например, NifD и NifH, и FeMo или другим кофактором. В предпочтительном варианте реализации при выравнивании с аминокислотной последовательностью SEQ ID NO:7 аминокислотная последовательность полипептида NifK по изобретению имеет в С-конце аминокислоты DLVR (остатки 517-520 в SEQ ID NO:7), причем аргинин является С-концевой аминокислотой. Это означает, что полипептид NifK и слитый полипептид NifK по изобретению предпочтительно имеет такой же С-конец, как и полипептиды NifK, т. е. он не содержит искусственное дополнение к С-концу. Такие предпочтительные полипептиды NifK способны лучше образовывать функциональный комплекс нитрогеназы с полипептидами NifD и NifH, как показано в примерах.
Полипептид NifB во встречающихся в природе бактериях представляет собой белок, который принимает участие в синтезе FeMo-Co, преобразуя кластеры [4Fe-4S] в NifB-co, кластер Fe-S с более высокой нуклеарностью с центральным атомом С, который служит в качестве предшественника FeMo-Co (Guo et al., 2016). Следовательно, NifB катализирует первый осуществляемый этап в пути синтеза FeMo-Co. NifB-co-продукт NifB способен связывать комплекс NifE-NifN и может переноситься от NifB к NifE-NifN металлокластерным белком-носителем NifX.
В контексте данного документа «полипептид NifB» означает полипептид, чья аминокислотная последовательность содержит аминокислоты, чья последовательность по меньшей мере на 27% идентична аминокислотной последовательности, приведенной как SEQ ID NO:9. Большинство полипептидов NifB содержат один или более из консервативного домена TIGR01290, консервативного домена NifB cd00852, консервативного домена суперсемейства NifX-NifB cl00252 и консервативного домена Radical_SAM cd01335. В контексте данного документа полипептиды NifB включают полипептиды природного происхождения, которые были описаны как имеющие функцию NifB, но не содержат один из этих доменов. Полипептид NifB природного происхождения, как правило, имеет длину от 440 до 500 аминокислот, а природный мономер имеет молекулярную массу около 50 кДа. Было идентифицировано большое число полипептидов NifB, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifB из Raoultella ornithinolytica (№ доступа WP_041145602.1, 91% идентичности с SEQ ID NO:9), Kosakonia radicincitans (WP_043953592.1, 80% идентичности), Dickeya chrysanthemi (WP_040003311.1, 76% идентичности), Pectobacterium atrosepticum (WP_011094468.1, 70% идентичности), Brenneria goodwinii (WP_048638849.1, 63% идентичности), Halorhodospira halophila (WP_011813098.1, 59% идентичности), Methanosarcina barkeri (WP_048108879.1, 50% идентичности), Clostridium purinilyticum (WP_050355163.1, 40% идентичности), Geofilum rubicundum (GAO28552.1, 35% идентичности) и Desulfovibrio salexigens (WP_015850328.1, 27% идентичности). В контексте данного документа «функциональный полипептид NifB» представляет собой полипептид NifB, способный образовывать NifB-co из кластеров [4Fe-4S]. Полипептиды NifB были описаны и рассмотрены в Curatti et al., (2006) и Allen et al., (1995).
Комплекс NifEN представляет собой каркасный комплекс, необходимый для надлежащей сборки динитрогеназы и также структурно сходный с динитрогеназой (Fay et al., 2016). Комплекс NifEN состоит из двух субъединиц каждого из NifE и NifN, соответственно, образующих гетеротетрамер, называемый в данном случае ENα2β2. Полипептид NifE во встречающихся в природе бактериях представляет собой полипептид, который является субъединицей α тетрамера ENα2β2 с полипептидом NifN, и этот тетрамер ENα2β2 необходим для синтеза FeMo-Co и, предположительно, функционирует как каркас, на который синтезируется FeMo-Co.
В контексте данного документа «полипептид NifE» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 32% идентична аминокислотной последовательности, приведенной как SEQ ID NO:10, и который содержит один или оба домена TIGR01283 и PRK14478. Представители семейства белков домена TIGR01283 также являются представителями суперсемейства cl02775. Полипептид NifE природного происхождения, как правило, имеет длину от 440 до 490 аминокислот, а природный мономер имеет молекулярную массу около 50 кДа. Было идентифицировано большое число полипептидов NifE, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifE из Klebsiella michiganensis (№ доступа WP_049114606.1, 99% идентичности с SEQ ID NO:10), Klebsiella variicola (SBM87755.1, 92% идентичности), Dickeya paradisiaca (WP_012764127.1, 89% идентичности), Tolumonas auensis (WP_012728883.1, 75% идентичности), Pseudomonas stutzeri (WP_003297989.1, 69% идентичности), Azotobacter vinelandii (WP_012698965.1, 62% идентичности), Trichormus azollae (WP_013190624.1, 55% идентичности), Paenibacillus durus (WP_025698318.1, 50% идентичности), Sulfuricurvum kujiense (WP_013460149.1, 44% идентичности), Methanobacterium formicicum (AIS31022.1, 39% идентичности), Anaeromusa acidaminophila (WP_018701501.1, 35% идентичности) и Megasphaera cerevisiae (WP_048514099.1, 32% идентичности). В контексте данного документа «функциональный полипептид NifE» представляет собой полипептид NifE, способный образовывать функциональный тетрамер вместе с NifN так, что полученный комплекс способен синтезировать FeMo-Co. Полипептиды NifE были описаны и рассмотрены в Fay et al., (2016), Hu et al., (2005), Hu et al., (2006) и Hu et al., (2008).
Полипептид NifF во встречающихся в природе бактериях представляет собой флаводоксин, который является донором электронов для NifH. В контексте данного документа «полипептид NifF» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 34% идентична аминокислотной последовательности, приведенной как SEQ ID NO:16, и который содержит один или оба домена TIGR01752 длинного домена флаводоксина и домена FLDA флаводоксина, встречающегося в белках Nif из Azobacter и других бактерий вида PRK09267. Полипептиды NifF включают флаводоксины, связанные с активацией пируватформатлиазы и активностью кобаламин-зависимой метионинсинтазы в не фиксирующих азот бактериях, но исключают другие флаводоксины, вовлеченные в более широкий спектр функций. Полипептид NifF природного происхождения, как правило, имеет длину от 160 до 200 аминокислот, а природный мономер имеет молекулярную массу около 19 кДа. Было идентифицировано большое число полипептидов NifF, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifF из Klebsiella michiganensis (№ доступа WP_004122417.1, 99% идентичности с SEQ ID NO:16), Klebsiella variicola (WP_040968713.1, 85% идентичности), Kosakonia radicincitans (WP_035885760.1, 76% идентичности), Dickeya chrysanthemi (WP_039999438.1, 72% идентичности), Brenneria goodwinii (WP_048638838.1, 62% идентичности), Methylomonas methanica (WP_064006977.1, 56% идентичности), Azotobacter vinelandii (WP_012698862.1, 50% идентичности), Chlorobaculum tepidum (WP_010933399.1, 39% идентичности), Campylobacter showae (WP_002949173.1, 37% идентичности) и Azotobacter chromococcum (WP_039801725.1, 34% идентичности). В контексте данного документа «функциональный полипептид NifF» представляет собой полипептид NifF, способный служить донором электронов для полипептида NifH. Полипептиды NifF были описаны и рассмотрены в Drummond (1985).
Полипептид NifJ во встречающихся в природе бактериях представляет собой пируват:флаводоксин (ферредоксин) оксидоредуктазу, которая является донором электронов для NifH. В контексте данного документа «полипептид NifJ» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 40% идентична аминокислотной последовательности, приведенной как SEQ ID NO:18, и который содержит консервативный домен TIGR02176. Полипептид NifJ природного происхождения, как правило, имеет длину от 1100 до 1200 аминокислот, а природный мономер имеет молекулярную массу около 128 кДа. Было идентифицировано большое число полипептидов NifJ, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifJ из Klebsiella michiganensis (№ доступа WP_024360006.1, 99% идентичности с SEQ DI NO:18), Raoultella ornithinolytica (WP_044347157.1, 95% идентичности), Klebsiella quasipneumoniae (WP_050533844.1, 92% идентичности), Kosakonia oryzae (WP_064566543.1, 82% идентичности), Dickeya solani (WP_057084649.1, 78% идентичности), Rahnella aquatilis (WP_014683040.1, 72% идентичности), Thermoanaerobacter mathranii (WP_013149847.1, 64% идентичности), Clostridium botulinum (WP_053341220.1, 60% идентичности), Spirochaeta africana (WP_014454638.1, 52% идентичности) и Vibrio cholerae (CSA83023.1, 40% идентичности). В контексте данного документа «функциональный полипептид NifJ» представляет собой полипептид NifJ, способный служить донором электронов для полипептида NifH. Полипептиды NifJ были описаны и рассмотрены в Schmitz et al., (2001).
Полипептид NifM во встречающихся в природе бактериях представляет собой полипептид, необходимый для созревания NifH. В отсутствие NifM NifH присутствовал только на низких уровнях в E. coli и дрожжах при гетерологичной экспрессии и не был способен служить донором электронов для NifD-NifK. В контексте данного документа «полипептид NifM» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 26% идентична аминокислотной последовательности, приведенной как SEQ ID NO:19, и который содержит домен TIGR02933. Полипептиды NifM гомологичны пептидил-пролин цис-транс изомеразам и являются акцессорными белками для NifH. Полипептид NifM природного происхождения, как правило, имеет длину от 240 до 300 аминокислот, а природный мономер имеет молекулярную массу около 30 кДа. Было идентифицировано большое число полипептидов NifM, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifM из Klebsiella oxytoca (№ доступа WP_064342940.1, 99% идентичности с SEQ ID NO:19), Klebsiella michiganensis (WP_004122413.1, 97% идентичности), Raoultella ornithinolytica (WP_044347181.1, 85% идентичности), Klebsiella variicola (WP_063105800.1, 75% идентичности), Kosakonia radicincitans (WP_035885759.1, 59% идентичности), Pectobacterium atrosepticum (WP_011094472.1, 42% идентичности), Brenneria goodwinii (WP_048638837.1, 33% идентичности), Pseudomonas aeruginosa PAO1 (CAA75544.1, 28% идентичности), Marinobacterium sp. AK27 (WP_051692859.1, 27% идентичности) и Teredinibacter turnerae (WP_018415157.1, 26% идентичности). В контексте данного документа «функциональный полипептид NifM» представляет собой полипептид NifM, способный образовывать комплекс с полипептидом NifH для созревания полипептида NifH. Полипептиды NifM были описаны и рассмотрены в Petrova et al., (2000).
Полипептид NifN во встречающихся в природе бактериях представляет собой β-субъединицу тетрамера ENα2β2 с полипептидом NifE, и этот тетрамер ENα2β2 необходим для синтеза FeMo-Co и, предположительно, для того, чтобы служить каркасом, на который синтезируется FeMo-Co. В контексте данного документа «полипептид NifN» означает (i) полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 76% идентична последовательности, приведенной как SEQ ID NO:11, и/или (ii) полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 34% идентична последовательности, приведенной как SEQ ID NO:11, и который содержит один или более консервативных доменов TIGR01285, cd01966 и PRK14476. NifN имеет структуру, родственную с NifK β-цепи железо-молибденового белка. Полипептиды, содержащие консервативный TIGR01285, охватывают большинство примеров полипептидов NifN, но исключают некоторые полипептиды NifN, такие как предполагаемый NifN из Chlorobium tepidum, и, следовательно, определение NifN не ограничено полипептидами, содержащими консервативный домен TIGR01285. Представители семейства белков домена PRK14476 также являются представителями суперсемейства cl02775. Полипептид NifN природного происхождения, как правило, имеет длину от 410 до 470 аминокислот, хотя при природном слиянии с NifB он может содержать около 900 аминокислотных остатков, а природный мономер имеет молекулярную массу около 50 кДа. Было идентифицировано большое число полипептидов NifN, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifN из Klebsiella oxytoca (№ доступа WP_064391778.1, 97% идентичности с SEQ ID NO:11), Kluyvera intermedia (WP_047370268.1, 80% идентичности), Rahnella aquatilis (WP_014683026.1, 70% идентичности), Brenneria goodwinii (WP_048638830.1, 65% идентичности), Methylobacter tundripaludum (WP_027147663.1, 46% идентичности), Calothrix parietina (WP_015195966.1, 41% идентичности), Zymomonas mobilis (WP_023593609.1, 37% идентичности), Paenibacillus massiliensis (WP_025677480.1, 35% идентичности) и Desulfitobacterium hafniense (WP_018306265.1, 34% идентичности). В контексте данного документа «функциональный полипептид NifN» представляет собой полипептид NifN, способный образовывать функциональный тетрамер вместе с NifE так, что полученный комплекс способен синтезировать FeMo-Co. Полипептиды NifN были описаны и рассмотрены в Fay et al., (2016), Brigle et al., (1987), Fani et al., (2000) и Hu et al., (2005).
Полипептид NifQ во встречающихся в природе бактериях представляет собой полипептид, который принимает участие в синтезе FeMo-Co, возможно, в раннем процессинге MoO42-. Консервативные C-концевые остатки цистеина могут принимать участие в связывании металла. В контексте данного документа «полипептид NifQ» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 34% идентична аминокислотной последовательности, приведенной как SEQ ID NO:12, и который является представителем семейства белков домена CL04826 и представителем семейства белков домена pfam04891. Полипептид NifQ природного происхождения, как правило, имеет длину от 160 до 250 аминокислот, хотя он может содержать до около 350 аминокислотных остатков, а природный мономер имеет молекулярную массу около 20 кДа. Было идентифицировано большое число полипептидов NifQ, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifQ из Klebsiella oxytoca (№ доступа WP_064391765.1, 95% идентичности с SEQ ID NO:12), Klebsiella variicola (CTQ06350.1, 75% идентичности), Kluyvera intermedia (WP_047370257.1, 63% идентичности), Pectobacterium atrosepticum (WP_043878077.1, 59% идентичности), Mesorhizobium metallidurans (WP_008878174.1, 46% идентичности), Rhodopseudomonas palustris (WP_011501504.1, 42% идентичности), Paraburkholderia sprentiae (WP_027196569.1, 41% идентичности), Burkholderia stabilis (GAU06296.1, 39% идентичности) и Cupriavidus oxalaticus (WP_063239464.1, 34% идентичности). В контексте данного документа «функциональный полипептид NifQ» представляет собой полипептид NifQ, способный осуществлять процессинг MoO42-. Полипептиды NifQ были описаны и рассмотрены в Allen et al., (1995) и Siddavattam et al., (1993).
Полипептид NifS во встречающихся в природе бактериях представляет собой цистеин-десульфуразу, вовлеченную в биосинтез железо-серного кластера (FeS), например, которая принимает участие в мобилизации серы для синтеза и репарации кластера Fe-S. В контексте данного документа «полипептид NifS» означает (i) полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 90% идентична аминокислотной последовательности, приведенной как SEQ ID NO:13, и/или (ii) полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 36% идентична последовательности, приведенной как SEQ ID NO:13, и который содержит один или оба консервативных домена TIGR03402 и COG1104. Семейство белков домена TIGR03402 включает клад, практически всегда встречающийся в расширенных азотфиксирующих системах, плюс второй клад, более близкородственный с первым, чем с IscS, и также часть систем NifS-подобный/NifU-подобный. Семейство белков домена TIGR03402 не распространяется на более отдаленный клад, встречающийся у эпсилон-протеобактерий, таких как Helicobacter pylori, также называемый в литературе NifS, встроенный вместо TIGR03403. Семейство белков домена COG1104 включает цистеин-сульфинат десульфиназу/цистеин-десульфуразу или родственные ферменты. Некоторые полипептиды NifS содержат домен аспартатаминотрансферазы cl18945. Полипептид NifS природного происхождения, как правило, имеет длину от 370 до 440 аминокислот, а природный мономер имеет молекулярную массу около 43 кДа. Было идентифицировано большое число полипептидов NifS, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifS из Klebsiella michiganensis (№ доступа WP_004138780.1, 99% идентичности с SEQ ID NO:13), Raoultella terrigena (WP_045858151.1, 89% идентичности), Kluyvera intermedia (WP_047370265.1, 80% идентичности), Rahnella aquatilis (WP_014333911.1, 73% идентичности), Agarivorans gilvus (WP_055731597.1, 64% идентичности), Azospirillum brasilense (WP_014239770.1, 60% идентичности), Desulfosarcina cetonica (WP_054691765.1, 55% идентичности), Clostridium intestinale (WP_021802294.1, 47% идентичности), Clostridiisalibacter paucivorans (WP_026894054.1, 36% идентичности) и Bacillus coagulans (WP_061575621.1, 42% идентичности и который находится в COG1104). В контексте данного документа «функциональный полипептид NifS» представляет собой полипептид NifS, способный участвовать в биосинтезе и/или репарации железо-серного (FeS) кластера. Полипептиды NifS были описаны и рассмотрены в Clausen et al., (2000), Johnson et al., (2005), Olson et al., (2000) и Yuvaniyama et al., (2000).
Полипептид NifU во встречающихся в природе бактериях представляет собой молекулярный каркасный полипептид, принимающий участие в биосинтезе железо-серного кластера (FeS) для компонентов нитрогеназы. В контексте данного документа «полипептид NifU» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 31% идентична последовательности, приведенной как SEQ ID NO:14, и который содержит домен TIGR02000. Представители семейства белков домена TIGR02000, в частности, принимают участие в созревании нитрогеназы. NifU содержит N-концевой домен (pfam01592) и C-концевой домен (pfam01106). Были описаны три отличные, но частично гомологичные системы сборки кластера Fe-S: Isc, Suf и Nif. Система Nif, частью которой является NifU, связана с донорством кластера Fe-S для нитрогеназы в большом числе азотфиксирующий видов. Гомологи Isc и Suf с эквивалентной доменной архитектурой из Helicobacter и Campylobacter в данном документе исключены из определения NifU. Следовательно, NifU является специфическим для полипептидов NifU, принимающих участие в созревании нитрогеназы. Представители семейства белков родственного домена TIGR01999, которые представляют собой белки IscU (например, из Escherichia. coli и Saccharomyces cerevisiae и Homo sapiens), которые содержат гомолог N-концевой области NifU, в данном документе также исключены из определения NifU. Полипептид NifU природного происхождения, как правило, имеет длину от 260 до 310 аминокислот, а природный мономер имеет молекулярную массу около 29 кДа. Было идентифицировано большое число полипептидов NifU, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifU из Klebsiella michiganensis (№ доступа WP_049136164.1, 97% идентичности с SEQ ID NO:14), Klebsiella variicola (WP_050887862.1, 90% идентичности), Dickeya solani (WP_057084657.1, 80% идентичности), Brenneria goodwinii (WP_048638833.1, 73% идентичности), Tolumonas auensis (WP_012728889.1, 66% идентичности), Agarivorans gilvus (WP_055731596.1, 58% идентичности), Desulfocurvus vexinensis (WP_028587630.1, 54% идентичности), Rhodopseudomonas palustris (WP_044417303.1, 49% идентичности), Helicobacter pylori (WP_001051984.1, 31% идентичности) и Sulfurovum sp. PC08-66 (KIM05011.1, 31% идентичности). В контексте данного документа «функциональный полипептид NifU» представляет собой полипептид NifU, способный функционировать как молекулярный каркасный белок, принимающий участие в биосинтезе железо-серного (FeS) кластера. Полипептиды NifU были описаны и рассмотрены в Hwang et al., (1996), Mühlenhoff et al., (2003) и Ouzounis et al., (1994).
Полипептид NifV во встречающихся в природе бактериях представляет собой гомоцитратсинтазу (EC 2.3.3.14), вырабатывающую гомоцитрат путем переноса ацетильной группы с ацетил-коэнзима A (acetyl-CoA) на 2-оксоглутарат. Затем гомоцитрат используется в синтезе FeMo-Co. В контексте данного документа «полипептид NifV» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 39% идентична аминокислотной последовательности, приведенной как SEQ ID NO:20, и который содержит один или оба домена TIGR02660 и DRE_TIM. Представители семейства белков домена TIGR02660 гомологичны ферментам, которые включают 2-изопропилмлатсинтазу, (R)-цитрамалатсинтазу и гомоцитратсинтазу, связанным с процессами, отличными от фиксации азота. Семейство белков домена cd07939 также включает белки NifV из Heliobacterium chlorum и Gluconacetobacter diazotrophicus, ортологичные с FrbC. Это семейство принадлежит к суперсемейству металлолиаз DRE-TIM. Металлолиазы DRE-TIM включают 2-изопропилмлатсинтазу (IPMS), альфа-изопропилмлатсинтазу (LeuA), 3-гидрокси-3-метилглутарил-CoA лиазу, гомоцитратсинтазу, цитрамалатсинтазу, 4-гидрокси-2-оксовалератадолазу, ре-цитратсинтазу, транскарбоксилазу 5S, пируваткарбоксилазу, AksA и FrbC. Все эти представители имеют общий консервативный триозофосфатизомеразный (TIM) баррель-домен, состоящий из корового мотива бета(8)-альфа(8) с восемью параллельными бета-участками, образующими закрытую баррель-структуру, окруженную восемью альфа-спиралями. Этот домен имеет каталитический центр, содержащий двухвалентный катион-связывающий сайт, образованный кластером из инвариантных остатков, которые закрывают сердцевину барреля. Кроме того, каталитический сайт содержит три инвариантных остатка - аспартат (D), аргинин (R) и глутамат (E), - которые лежат в основе названия домена «DRE-TIM». Полипептид NifV природного происхождения, как правило, имеет длину от 360 до 390 аминокислот, хотя некоторые представители имеют длину около 490 аминокислотных остатков, а природный мономер имеет молекулярную массу около 41 кДа. Было идентифицировано большое число полипептидов NifV, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifV из Klebsiella michiganensis (№ доступа WP_049083341.1, 95% идентичности to SEQ ID NO:20), Raoultella ornithinolytica (WP_045858154.1, 86% идентичности), Kluyvera intermedia (WP_047370264.1, 81% идентичности), Dickeya dadantii (WP_038912041.1, 70% идентичности), Brenneria goodwinii (WP_048638835.1, 59% идентичности), Magnetococcus marinus (WP_011712856.1, 46% идентичности), Sphingomonas wittichii (WP_037528703.1, 43% идентичности), Frankia sp. EI5c (OAA29062.1, 41% идентичности) и Clostridium sp. Maddingley MBC34-26 (EKQ56006.1, 39% идентичности). В контексте данного документа «функциональный полипептид NifV» представляет собой полипептид NifV, способный функционировать как гомоцитратсинтаза. Полипептиды NifV были описаны и рассмотрены в Hu et al., (2008), Lee et al., (2000), Masukawa et al., (2007) и Zheng et al., (1997).
Полипептид NifX во встречающихся в природе бактериях представляет собой полипептид, который принимает участие в синтезе FeMo-Co, по меньшей мере способствуя переносу предшественников FeMo-Co от NifB к NifE-NifN. В контексте данного документа «полипептид NifX» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 29% идентична аминокислотной последовательности, приведенной как SEQ ID NO:15, и который содержит один или оба консервативных домена TIGR02663 и cd00853. NifX включен в состав более крупного семейства железо-молибденовых кластер-связывающих белков, которое включает NifB и NifY, в том отношении, что NifX, NafY и C-концевая область NifB все содержат домен pfam02579 и каждый принимает участие в синтезе FeMo-Co. Следовательно, некоторые полипептиды NifX были обозначены в базах данных как NifY и наоборот. Полипептид NifX природного происхождения, как правило, имеет длину от 110 до 160 аминокислот, а природный мономер имеет молекулярную массу около 15 кДа. Было идентифицировано большое число полипептидов NifX, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifX из Klebsiella michiganensis (№ доступа WP_049070199.1, 97% идентичности с SEQ ID NO:15), Klebsiella oxytoca (WP_064342937.1, 97% идентичности), Raoultella ornithinolytica (WP_044347173.1, 91% идентичности), Klebsiella variicola (WP_044612922.1, 83% идентичности), Kosakonia radicincitans (WP_043953583.1, 75% идентичности), Dickeya chrysanthemi (WP_039999416.1, 68% идентичности), Rahnella aquatilis (WP_047608097.1, 58% идентичности), Azotobacter chroococcum (WP_039800848.1, 34% идентичности), Beggiatoa leptomitiformis (WP_062149047.1, 33% идентичности) и Methyloversatilis discipulorum (WP_020165972.1, 29% идентичности). В контексте данного документа «функциональный полипептид NifX» представляет собой полипептид NifX, способный переносить предшественников FeMo-Co от NifB к NifE-NifN. Полипептиды NifX были описаны и рассмотрены в Allen et al., (1994) и Shah et al., (1999).
Полипептид NifY во встречающихся в природе бактериях представляет собой полипептид, который принимает участие в синтезе FeMo-Co, по меньшей мере способствуя переносу предшественников FeMo-Co от NifB к NifE-NifN. В контексте данного документа «полипептид NifY» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 34% идентична аминокислотной последовательности, приведенной как SEQ ID NO:8, и который содержит один или оба консервативных домена TIGR02663 и cd00853. NifY включен в состав более крупного семейства железо-молибденовых кластер-связывающих белков, которое включает NifB и NifX, в том отношении, что NifX, NafY и C-концевая область NifB все содержат домен pfam02579 и каждый принимает участие в синтезе FeMo-Co. Было идентифицировано большое число полипептидов NifY, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifY из Klebsiella michiganensis (№ доступа WP_049089500.1, 99% идентичности с SEQ ID NO:8), Klebsiella oxytoca (WP_064342935.1, 98% идентичности), Klebsiella quasipneumoniae (WP_044524054.1, 90% идентичности), Klebsiella variicola (WP_049010739.1, 81% идентичности), Kluyvera intermedia (WP_047370270.1, 69% идентичности), Dickeya chrysanthemi (WP_039999411.1, 62% идентичности), Serratia sp. ATCC 39006 (WP_037382461.1, 57% идентичности), Rahnella aquatilis (WP_014683024.1, 47% идентичности), Pseudomonas putida (AEX25784.1, 37% идентичности) и Azotobacter vinelandii (WP_012698835.1, 34% идентичности). В контексте данного документа «функциональный полипептид NifY» представляет собой полипептид NifY, способный переносить предшественников FeMo-Co от NifB к NifE-NifN.
Полипептид NifZ во встречающихся в природе бактериях представляет собой полипептид, который принимает участие в синтезе кластера Fe-S, в частности, необходим для образования второй пары Fe4S4. В контексте данного документа «полипептид NifZ» означает полипептид, содержащий аминокислоты, чья последовательность по меньшей мере на 28% идентична последовательности, приведенной как SEQ ID NO:17, и который содержит консервативный домен pfam04319. Этот домен из около 75 аминокислотных остатков встречается в изоляции у некоторых представителей и в амино-концевой половине более длинных белков NifZ. Полипептид NifZ природного происхождения, как правило, имеет длину от 70 до 150 аминокислот, а природный мономер имеет молекулярную массу от около 9 кДа до около 16 кДа. Было идентифицировано большое число полипептидов NifZ, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifZ из Klebsiella michiganensis (№ доступа WP_057173223.1, 93% идентичности с SEQ ID NO:17), Klebsiella oxytoca (WP_064342939.1, 95% идентичности), Klebsiella variicola (WP_043875005.1, 77% идентичности), Kosakonia radicincitans (WP_043953588.1, 67% идентичности), Kosakonia sacchari (WP_065368553.1, 58% идентичности), Ferriphaselus amnicola (WP_062627625.1, 47% идентичности), Paraburkholderia xenovorans (WP_011491838.1, 41% идентичности), Acidithiobacillus ferrivorans (WP_014029050.1, 35% идентичности) и Bradyrhizobium oligotrophicum (WP_015665422.1, 28% идентичности). В контексте данного документа «функциональный полипептид NifZ» представляет собой полипептид NifZ, способный осуществлять сопряжение кластера Fe4S4 при синтезе кластера Fe-S. Полипептиды NifZ были описаны и рассмотрены в Cotton (2009) и Hu et al., (2004).
Полипептид NifW во встречающихся в природе бактериях представляет собой полипептид, который ассоциирует с полипептидом NifZ с образованием комплексов высшего порядка (Lee et al., 1998), и принимает участие в синтезе или активности белка MoFe (NifD-NifK). NifW и NifZ принимают участие в образовании или накоплении белка MoFe (Paul and Merrick, 1989). В контексте данного документа «полипептид NifW» означает полипептид, чья аминокислотная последовательность содержит аминокислоты, чья последовательность по меньшей мере на 28% идентична аминокислотной последовательности, приведенной как SEQ ID NO:74, и который содержит консервативный белковый домен суперсемейства NifW, архитектурный ID-номер 10505077 и входит в состав Pfamily PF03206. Было идентифицировано некоторое число полипептидов NifW, а многочисленные последовательности доступны в общедоступных базах данных. Например, существуют данные для полипептидов NifW из Klebsiella oxytoca (№ доступа WP_064342938.1, 98% идентичности с SEQ ID NO:74), Klebsiella michiganensis (WP_049080155.1, 94% идентичности), Enterobacter sp. 10-1 (WP_095103586.1, 90% идентичности), Klebsiella quasipneumoniae (WP_065877373.1, 81% идентичности), Pectobacterium polaris (WP_095699971.1, 69% идентичности), Dickeya paradisiaca (WP_012764136.1, 58% идентичности), Brenneria goodwinii (WP_053085547.1, 36% идентичности), Aquaspirillum sp. LM1 (WP_077299824.1, 44% идентичности), Candidatus Muproteobacteria bacterium RBG_16_64_10 (OGI40729, 34% идентичности), Azotobacter vinelandii (ACO76430.1, 32% идентичности) и Methylocaldum marinum (BBA37427.1, 28% идентичности). В контексте данного документа «функциональный полипептид NifW» представляет собой полипептид NifW, который стимулирует или усиливает одно или более из образования, накопления или активности белка MoFe. Функциональный NifW может взаимодействовать с NifZ и/или играть роль в защите от действия кислорода белка MoFe (Gavini et al., (1998)).
В отношении определенного полипептида понятно, что значения % идентичности, большие, чем приведенные выше, будут включать предпочтительные варианты реализации. Таким образом, в соответствующих случаях, в свете минимального значения % идентичности предпочтительно, чтобы полипептид содержал аминокислотную последовательность, которая по меньшей мере на 30%, более предпочтительно по меньшей мере на 35%, более предпочтительно по меньшей мере на 40%, более предпочтительно по меньшей мере на 45%, более предпочтительно по меньшей мере на 50%, более предпочтительно по меньшей мере на 55%, более предпочтительно по меньшей мере на 60%, более предпочтительно по меньшей мере на 65%, более предпочтительно по меньшей мере на 70%, более предпочтительно по меньшей мере на 75%, более предпочтительно по меньшей мере на 80%, более предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, более предпочтительно по меньшей мере на 91%, более предпочтительно по меньшей мере на 92%, более предпочтительно по меньшей мере на 93%, более предпочтительно по меньшей мере на 94%, более предпочтительно по меньшей мере на 95%, более предпочтительно по меньшей мере на 96%, более предпочтительно по меньшей мере на 97%, более предпочтительно по меньшей мере на 98%, более предпочтительно по меньшей мере на 99%, более предпочтительно по меньшей мере на 99,1%, более предпочтительно по меньшей мере на 99,2%, более предпочтительно по меньшей мере на 99,3%, более предпочтительно по меньшей мере на 99,4%, более предпочтительно по меньшей мере на 99,5%, более предпочтительно по меньшей мере на 99,6%, более предпочтительно по меньшей мере на 99,7%, более предпочтительно по меньшей мере на 99,8% и даже более предпочтительно по меньшей мере на 99,9% идентична соответствующей указанной SEQ ID NO.
Определенные в данном документе полипептиды с мутантной аминокислотной последовательностью можно получать путем внесения соответствующих нуклеотидных изменений в определенную в данном документе нуклеиновую кислоту или путем in vitro синтеза необходимого полипептида. Такие мутанты включают, например, одну или более аминокислотных делеций, вставок или замен. Можно осуществлять комбинацию мутаций делеции, вставки и замены для получения конечной конструкции при условии, что конечный полипептидный продукт обладает необходимыми характеристиками. Предпочтительные мутантные аминокислотные последовательности имеют только одно, два, три, четыре или менее 10 аминокислотных изменений по сравнению с референсным полипептидом дикого типа.
Мутантные (измененные) полипептиды можно получать, используя любую известную в данной области техники методику, например, используя стратегии направленной эволюции или рационального дизайна (смотрите ниже). Продукты, полученные из мутированной/измененной ДНК, легко можно исследовать, используя описанные в данном документе методики, для определения, меняет ли их экспрессия в растении его фенотип по сравнению с соответствующим растением дикого типа, например, приводит ли их экспрессия к повышению урожайности, биомассы, скорости роста, мощности, поступления азота вследствие биологической фиксации азот, эффективности использования азота, устойчивости к абиотическому стрессу и/или устойчивости к недостатку питательных веществ по сравнению с соответствующим растением дикого типа.
При конструировании мутантных аминокислотных последовательностей расположение сайта мутации и природа мутации будут зависеть от подлежащих модификации характеристик. Сайты для мутации можно модифицировать по отдельности или группами, например, путем (1) сначала замены выбранной консервативной аминокислотой и затем более радикальной селекции в зависимости от достигнутых результатов, (2) удаления целевого остатка или (3) вставки других остатков, смежный с сайтом локации.
Делеции в аминокислотной последовательности в общем случае находятся в диапазоне от около 1 до 15 остатков, более предпочтительно от около 1 до 10 остатков и, как правило, от около 1 до 5 непрерывных остатков.
В мутантах, содержащих замену, по меньшей мере один аминокислотный остаток в молекуле полипептида удален, а на его место вставлен другой остаток. Если необходимо сохранить определенный вид активности, предпочтительно не делать замены или делать только консервативные замены в аминокислотных позициях, которые являются высококонсервативными в соответствующем семействе белков. Примеры консервативных замен приведены в Таблице 1 под заголовком «типовые замены».
В предпочтительном варианте реализации мутантный/вариантный полипептид имеет одно или два, или три, или четыре консервативные аминокислотные изменения по сравнению с полипептидом природного происхождения. Подробности консервативных аминокислотных изменений приведены в Таблице 1. В предпочтительном варианте реализации изменения не находятся в одном или более мотивах или доменах, которые являются высококонсервативными среди разных полипептидов по изобретению. Специалист в данной области техники должен понимать, что можно объективно предсказать, что такие минимальные изменения не будут менять активность полипептида при экспрессии в рекомбинантной клетке.
Первичную аминокислотную последовательность полипептида по изобретению можно использовать для конструирования ее вариантов/мутантов на основании сравнения с близкородственными полипептидами. Как понятно специалисту в данной области техники, остатки, являющиеся высококонсервативными среди близкородственных белков, менее вероятно можно подвергать изменениям, в особенности неконсервативным заменам, с сохранением активности, чем менее консервативные остатки (смотрите выше). Более строгим исследованием для идентификации консервативных аминокислотных остатков является выравнивание более далеких родственных полипептидов с одной функцией. Высококонсервативные остатки следует сохранять для сохранения функции, тогда как неконсервативные остатки больше подходят для замен или делеций при сохранении функции.
Также в объем изобретения включены полипептиды по данному изобретению, которые модифицированы иным способом во время или после синтеза в клетке, например, путем гликозилирования, ацетилирования, фосфорилирования или протеолитического расщепления.
Таблица 1. Типовые замены.
остаток
замены
Рациональный дизайн
Дизайн белка можно осуществлять рационально на основании известной информации о структуре и сворачивании белка. Это можно осуществлять посредством дизайна с нуля (de novo дизайн) или посредством редизайна на основании нативных каркасов (смотрите, например, Hellinga, 1997; and Lu and Berry, Protein Structure Design and Engineering, Handbook of Proteins 2, 1153-1157 (2007)). Смотрите, например, пример 10 в данном документе. Белковый дизайн, как правило, включает идентификацию последовательностей, которые могут сворачиваться в заданную или целевую структуру, и может быть осуществлен с использованием компьютерных моделей. Алгоритмы компьютерного белкового дизайна осуществляют поиск по пространству последовательность-конформация в отношении последовательностей, имеющих низкую энергию в свернутом в целевую структуру состоянии. Алгоритмы компьютерного белкового дизайна используют модели белковой энергетики для оценки того, как мутации влияли бы на структуру и функцию белка. Эти энергетические функции, как правило, включают комбинацию молекулярной механики, статистических (т. е. на основании знаний) и других эмпирических параметров. Подходящее программное обеспечение включает IPRO (Interative Protein Redesign and Optimization (Итерационный белковый редизайн и оптимизация)), EGAD (A Genetic Algorithm for Protein Design (Генетический алгоритм для белкового дизайна)), Rosetta Design, Sharpen и Abalone.
Митохондриальный белковый импорт в растениях
Почти все митохондриальные белки кодируются в ядре и транслируются в цитозоль, и, следовательно, требуют транслокации в митохондрии. Сигнальные последовательности в полипептидах направляют их импорт в четыре разные внутримитохондриальные локации: внешнюю мембрану (ВншМ), межмембранное пространство (МП), внутреннюю мембрану (ВнтМ) или матрикс (ММ). Эти сигнальные последовательности отличаются своими биохимическими свойствами и направляют перемещение посредством по меньшей мере четырех разных путей импорта, которые направляют полипептиды в одну или более из четырех локаций (Chacinska et al., 2009). Эти четыре пути представляют собой: (1) общий путь импорта, также называемый «классическим» путем препоследовательности, который направляет полипептиды в ММ, МП или ВнтМ; (2) путь импорта за счет носителя, используемый для переноса во ВнтМ, (3) путь сборки митохондриального межмембранного пространства (ММП) и (4) путь аппарата сортировки и сборки (АСС), используемый для переноса полипептидов в ВншМ. Общий путь импорта состоит в импорте полипептидов, имеющих отщепляемую препоследовательность, также известную как сигнальная последовательность. Эти полипептиды также могут иметь сигнал гидрофобной сортировки (СГС). Путь импорта за счет носителя состоит в импорте полипептидов с внутренними подобными препоследовательности сигналами и гидрофобной областью. Путь ММП состоит в импорте полипептидов с двойными цистеиновыми остатками. Путь АСС состоит в импорте полипептидов, которые содержат β-сигнал и предполагаемый сигнал TOM20. Во всех этих путях используется транслоказа внешней мембраны (TOM), а в первом и втором путях также используется транслоказа TIM23 межмембранного комплекса. Только в первом пути используется матриксная процессирующая пептидаза (матриксная процессирущая протеаза, МПП).
Общей характеристикой всех митохондриальных нацеленных полипептидов является присутствие по меньшей мере одного домена в полипептиде, который направляет перенос в надлежащую локацию. Наиболее изученным из них является «классический» N-концевой домен препоследовательности, который отщепляется в матриксе МПП (Murcha et al., 2004). По оценкам около 70% митохондриальных белков растений и животных имеют отщепляемую препоследовательность, но также были обнаружены как внутренняя, так и С-концевая сигнальные последовательности (обзор в Pfanner and Geissler (2001), Schleiff and Soll (2000)). В Arabidopsis эти препоследовательности имеют длину в диапазоне от 11 до 109 аминокислотных остатков со средней длиной 50 аминокислотных остатков. Хотя не существует консенсусной последовательности, которая полностью определяет препоследовательность для первого пути, наблюдается тенденция к содержанию большой доли гидрофобных и положительно заряженных аминокислот. Дополнительной характеристикой является их способность образовывать амфифильную α-спираль, обычно начиная с первых 10 аминокислотных остатков (Roise et al., 1986). Эти домены богаты гидрофобными (Ala, Leu, Phe, Val), гидроксилированными (Ser, Thr) и положительно заряженными (Arg, Lys) аминокислотными остатками и характеризуются дефицитом кислых аминокислот. В большом количестве митохондриальных белков серин (16-17%) и аланин (12-13%) чрезмерно представлены в митохондриальных сигнальных пептидах, а аргинин является распространенным (12%). Точка расщепления МПП определяется для большинства препоследовательностей присутствием консервативного остатка аргинина, обычно в позиции P2 (-2 ак от неустойчивой химической связи) или P3 в большинстве других случаев (Huang et al., 2009).
Митохондиальные препоследовательности взаимодействуют с рецептором Tom20 посредством гидрофобных остатков. Исследования показали, что гидрофобная поверхность α-спирали облегчает распознавание пептида компонентом TOM20 комплекса импорта TOM, тогда как положительные заряды распознаются субъединицей TOM22 (Abe et al., 2000). И наконец, большинство препоследовательностей направляют перенос полипептидов в ассоциации с Hsp70 и, соответственно, практически все растительные препоследовательности содержат по меньшей мере один связывающий мотив для молекулярного шаперона Hsp70 (Zhang and Glaser, 2002). Шаперон Hsp70 принимает участие в сворачивании белка, предотвращает агрегацию белка и функционирует как молекулярный двигатель, проталкивая предшественника через митохондриальные мембраны. Электрический мембранный потенциал (Δψ) (~100 мВ, отрицательный внутри) во внутренней мембране также направляет транслокацию положительно заряженной препоследовательности за счет электрофоретического эффекта.
Большинство белков с отщепляемыми препоследовательностями направляются в митохондриальный матрикс посредством общего пути импорта, в котором используется комплекс транспортера внешней мембраны (TOM) и комплекс транспортера внутренней мембраны 23 (TIM23). При этом некоторые белки с отщепляемыми препоследовательностями могут проходить сборку во внутренней мембране (Murcha et al., 2005) или в межмембранном пространстве, если они также содержат сигнал гидрофобной сортировки (СГС) (Glick et al., 1992). Существует очень мало примеров локализованных в матриксе белков, у которых бы не отщеплялась препоследовательность. В матриксе Arabidopsis была обнаружена только глутаматдегидрогеназа с непроцессированной полноразмерной препоследовательностью (Huang et al., 2009).
В случае белков, которые не нацелены на матрикс, используется ряд внутренних неотщепляемых сигналов локализации. Как правило, они ассоциируются с конкретным путем перемещения и дополнительно приспособлены под конкретный класс белков. В случае растений на сегодняшний день никакие исследования не позволили определить, что точно составляет внутреннюю сигнальную последовательность для белков межмембранного пространства. При этом обнаружено, что мотив с двумя остатками цистеина связан с переносом посредством пути сборки митохондриального межмембранного пространства (ММП) (Carrie et al., 2010; Darshi et al., 2012). И наконец, неотщепляемые внутренние последовательности также используются белками, направленными на внутреннюю мембрану посредством пути носителя, в котором используется аппарат TOM и TIM22 для вставки белков с множественными трансмембранными областями (Kerscher et al., 1997; Sirrenberg et al., 1996). Как правило, эти последовательности содержат гидрофобную область, за которой следует препоследовательность наподобие внутренней последовательности, и, таким образом, они сходны с N-концевыми препоследовательностями, но отличаются своей внутренней локацией в распознаваемом белке.
В случае фотосинтетических организмов для кодируемых в ядре митохондриальных белков существует требование дифференциации между хлоропластным и митохондриальным перемещением, несмотря на большое сходство между этими двумя органеллами и их протеомами. α-спираль, которая присутствует в основном в митохондриальных препоследовательностях, обычно отсутствует в хлоропластных препоследовательностях (Zhang and Glaser, 2002), которые преимущественно являются более неструктурированными и демонстрируют доменную структуру с сильно выраженной β-складчатостью (Bruce, 2001).
В растениях МПП присоединен к внутреннему мембраносвязанному комплексу Cytbc1, хотя активный МПП обращен к матриксу, а функции двух белков являются независимыми (Glaser and Dessi, 1999).
Митохондриальный нацеливающий пептид
В контексте данного документа термин «митохондриальный нацеливающий пептид» или «МНП» означает аминокислотную последовательность, содержащую по меньшей мере 10 аминокислот и предпочтительно от 10 и до около 80 аминокислотных остатков, который направляет целевой белок в митохондрион и который можно использовать гетерологично в трансляционном продукте слияния МНП-целевой белок для направления выбранного целевого белка, такого как полипептид Nif, Gus, ЗФБ и т. д., в митохондрион.
Как правило, МНП содержит в N-конце инициирующий трансляцию метионин полипептида, из которого он получен. МНП трансляционно слит с полипептидом Nif или «целевым белком» пептидной связью с остатком Met, который соответствует инициирующему Met целевого белка, или же этот остаток Met может отсутствовать, а пептидная связь напрямую слита с аминокислотным остатком, который в целевом белке дикого типа является второй аминокислотой. Как правило, МНП богат на основные и гидроксилированные аминокислоты и обычно в нем отсутствуют кислые аминокислоты или удлиненные гидрофобные участки. МНП может образовывать амфифильные спирали.
Без ограничения какой-либо теорией, МНП, как правило, содержит последовательность, нацеливающую на поглощение, которая связывается с рецепторами на внешней мембране митохондрии. После связывания с внешней мембраной слитый полипептид преимущественно подвергается мембранной транслокации к транспортным канальным белкам и проходит через двойную мембрану митохондрии в митохондриальный матрикс (ММ). Затем нацеливающая на поглощение последовательность, как правило, отщепляется и происходит сворачивание зрелого слитого белка.
МНП может содержать дополнительные сигналы, которые впоследствии нацеливают белок на разные области митохондрий, такие как митохондриальный матрикс (ММ). В одном варианте реализации нацеливающая на поглощение последовательность представляет собой нацеливающую на матрикс последовательность.
МНП может быть отщепляемым или неотщепляемым при трансляционном слиянии с полипептидом Nif . В одном варианте реализации по меньшей мере 50% слитого полипептида МНП-Nif, который вырабатывается в клетке, отщепляется в клетке. В альтернативном варианте реализации менее 50% слитого полипептида МНП-Nif отщепляется в клетке, например, МНП не отщепляется. В одном варианте реализации МНП не содержит сайт расщепления для МПП. МНП может содержать сайт расщепления (в пределах последовательности МНП). После расщепления N-концевая часть полученного в результате процессированного продукта (т. е. зрелого NP) может содержать одну или более С-концевых аминокислот МНП. В альтернативном варианте сайт расщепления может располагаться в слитом полипептиде так, что происходит отщепление всей последовательности МНП, например, линкер может содержать последовательность расщепления.
Митохондриальные нацеливающие пептиды расположены в N-конце белков-предшественников, а N-концевая часть, как правило, отщепляется во время или после импорта в митохондрии. Расщепление, как правило, катализируется общей матриксной процессирующей протеазой (МПП), которая, в случае растений, интегрирована в комплекс bc1 респираторной цепи. Эта протеаза распознает сайты расщепления почти 1000 белков-предшественников, которые имеют широкий диапазон аминокислотных последовательностей, демонстрирующих слабую консервативность. В одном варианте реализации МНП содержит сайт расщепления протеазой для МПП. В дополнительном варианте реализации процессированный продукт образуется путем расщепления слитого белка в пределах МНП МПП.
В одном варианте реализации МНП не отщепляется. Авторы данного изобретения продемонстрировали, что включение МНП не всегда приводит к полному процессингу белков Nif. В некоторых случаях (NifX-FLAG, NifD-HAopt1 и NifDK-HA) наблюдали как процессированные, так и непроцессированные белки Nif. Учитывая отсутствие общей консенсусной последовательности для МНП и то, что внутренние белковые последовательности могут влиять на митохондриальное нацеливание (Becker et al., 2012), возможно, не удивительно, что авторы данного изобретения обнаружили различия в эффективности процессинга среди белков Nif.
Подходящие МНП, которые можно использовать в контексте данного изобретения, включают, без ограничения, пептиды, имеющие общую структуру, определенную von Heijne (1986) или Roise and Schatz (1988). Неограничивающими примерами МНП являются митохондриальные нацеливающие пептиды, определенные в Таблице I в von Heijne (1986).
В одном варианте реализации МНП представляет собой γ-субъединицу F1-АТФазы (pFAγ). Примером подходящего МНП pFAγ является таковой из A. thaliana (Lee et al., 2012). В одном варианте реализации МНП pFAγ имеет длину 77 аминокислот, отщепление которых ММП оставляет 38 остатков в N-конце слитого полипептида. В предпочтительном варианте реализации МНП pFAγ имеет длину менее 77 аминокислот. Например, МНП pFAγ имеет длину около 51 аминокислот, отщепление которых ММП оставляет 9 остатков в N-конце слитого полипептида.
Специалисту в данной области понятно, что существует программное обеспечение для предсказания митохондриальных белков и их нацеливающей последовательности, например, MitoProtII, PSORT, TargetP, NNPSL.
MitoProtII является программой, которая позволяет предсказывать митохондриальную локализацию последовательности на основании нескольких физиохимических параметров (например, аминокислотной композиции в N-концевой части или наибольшей общей гидрофобности для окна в 17 остатков). PSORT является программой, которая позволяет предсказывать субклеточные локации на основании различных связанных с последовательностью характеристик, таких как присутствие мотивов последовательностей и аминокислотных композиций. TargetP позволяет предсказывать субклеточную локацию эукариотических белков на основании предсказанного присутствия любой из N-концевых препоследовательностей: хлоропластного транзитного пептида, митохондриального нацеливающего пептида или сигнального пептида секреторного пути. В TargetP необходима N-концевая последовательность в качестве вводных данных в два слоя искусственный нейральных сетей (ИНС) с применением более ранних бинарных прогнозирующих систем SignalP и ChloroP. Для последовательностей, прогнозируемо содержащих N-концевую препоследовательность, также можно предсказать потенциальный сайт расщепления. NNPSL является другим методом на основе ИНС, в котором используется аминокислотная композиция для приписания одной из четырех субклеточных локализаций (цитозольной, внеклеточной, ядерной и митохондриальной) запрашиваемой последовательности.
Специалист в данной области сможет легко определить нацеливает ли выбранный МНП слитый белок на митохондриальный матрикс на основании рутинных способов и способов, описанных в данном документе. Авторы данного изобретения выбрали нацеливающий пептид, который ранее продемонстрировал способность к перемещению ЗФБ в протопластах Arabidopsis (Lee et al., 2012) и который является относительно длинным, чтобы способствовать обнаружению процессированного белка. Как показано в примерах в данном документе, выбранный МНП нацеливал все выбранные белки нитрогеназы на ММ. Это заключение основано на нескольких наборах данных. Во-первых, размеры, наблюдаемые для экспрессируемых N. benthamiana полипептидов Nif, согласовывались с ожидаемым размером в результате процессинга пептидазой ММ. Это также отображалось разницей в размере, наблюдаемой между бактериальными (полноразмерными непроцессированными) и растительными экспрессируемыми в митохондриях Nif малых размеров (NifF и NifZ). Кроме того, мутация МНП, делающая его неспособным к процессингу митохондриальным аппаратом импорта, давала большую полосу для продуктов слияния как NifD, так и ЗФБ, что согласуется с разницей в размере между процессированным и непроцессированным белком. И наконец, масс-спектрометрия для типового слитого полипептида позволила определить, что МНП-NifH расщеплялся между остатками 42-43 МНП, как и предсказывалось для специфического процессинга в матриксе.
В некоторых вариантах реализации этого изобретения может быть целесообразно использовать множественные тандемные копии выбранного МНП. Кодирующую последовательность для удвоенного или приумноженного нацеливающего пептида можно получить путем генетической инженерии из существующего МНП. Количество МНП можно определить с помощью клеточного фракционирования с последующим, например, количественным иммуноблот-анализом. Таким образом, в данном изобретении термин «митохондриальный нацеливающий пептид» или «МНП» включает одну или более копий одного аминокислотного пептида, который направляет целевой белок Nif в митохондрии. В предпочтительном варианте реализации МНП содержит две копии выбранного МНП. В другом варианте реализации МНП содержит три копии выбранного МНП. В другом варианте реализации МНП содержит четыре копии или более выбранного МНП.
Специалисту в данной области понятно, что последовательность МНП не ограничивается нативными последовательностями МНП, но может содержать аминокислотные замены, делеции и/или вставки по сравнению с МНП природного происхождения при условии, что указанный вариант последовательности все еще функционален в отношении митохондриального нацеливания.
Специалисту в данной области понятно, что МНП может фланкироваться аминокислотами в N- или С-конце в результате стратегии клонирования и может функционировать как линкер. Можно считать, что эти дополнительные аминокислоты образуют часть МНП.
Специалисту в данной области также понятно, что МНП может быть слит в N- или С-конце с олигопептидным линкером и/или тэгом, таким как эпитопный тэг. В предпочтительном варианте реализации в одном или более, или во всех слитых полипептидах Nif по изобретению, вырабатываемых в растительной клетке, отсутствуют добавленные эпитопные тэги по сравнению с соответствующим полипептидом Nif дикого типа.
Линкер
В данном документе в контексте полипептидов термин «линкер» или «олигопептидный линкер» означает одну или более аминокислот, которые ковалентно соединяют два или более функциональных доменов, например, МНП и NP, два NP, NP и тэг. Аминокислоты ковалентно соединены посредством пептидных связей, как в линкере, так и между линкером и функциональными доменами. Линкер может обеспечивать свободу перемещения одного функционального домена относительно другого, не оказывая существенное негативное влияние на функцию двух или более доменов. Линкер может помогать стимулировать надлежащее сворачивание и функционирование одного или обоих функциональных доменов. Специалисту в данной области понятно, что размер линкера можно определить эмпирически или можно смоделировать на основании информации о сворачивании белка.
Линкер может содержать сайт расщепления для протеазы, такой как МПП. Такой линкер также может считаться частью МНП.
Специалисту в данной области техники понятно, что C-конец МНП может быть трансляционно слит с N-концевой аминокислотой NP без линкера или посредством линкера из одного или более аминокислотных остатков, например, 1-5 аминокислотных остатков. Такой линкер также может считаться частью МНП.
В некоторых вариантах реализации линкер содержит по меньшей мере 1 аминокислоту, по меньшей мере 2 аминокислоты, по меньшей мере 3 аминокислоты, по меньшей мере 4 аминокислоты, по меньшей мере 5 аминокислот, по меньшей мере 6 аминокислот, по меньшей мере 7 аминокислот, по меньшей мере 8 аминокислот, по меньшей мере 9 аминокислот, по меньшей мере 10 аминокислот, по меньшей мере 12 аминокислот, по меньшей мере 14 аминокислот, по меньшей мере 16 аминокислот, по меньшей мере 18 аминокислот, по меньшей мере 20 аминокислот, по меньшей мере 25 аминокислот, по меньшей мере 30 аминокислот, по меньшей мере 35 аминокислот, по меньшей мере 40 аминокислот, по меньшей мере 45 аминокислот, по меньшей мере 50 аминокислот, по меньшей мере 60 аминокислот, по меньшей мере 70 аминокислот, по меньшей мере 80 аминокислот, по меньшей мере 90 аминокислот или около 100 аминокислот. В некоторых вариантах реализации максимальный размер линкера составляет 100 аминокислот, предпочтительно 60 аминокислот, более предпочтительно 40 аминокислот.
В некоторых вариантах реализации линкер обеспечивает возможность перемещения одного функционального домена относительно другого для повышения стабильности слитого полипептида. При необходимости линкер может включать повторы из полиглицина или комбинации остатков глицина, пролина и аланина.
Линкеры для соединения двух полипептидов Nif, такие как NifD-линкер-NifK и NifE-линкер-NifN, предпочтительно выбирают в отношении числа и последовательности аминокислот в линкере на основании нескольких критериев. А именно: отсутствие остатков цистеина, чтобы избежать образования нежелательных дисульфидных связей, мало или предпочтительно отсутствие заряженных остатков (Glu, Asp, Arg, Lys) для снижения вероятности нежелательных поверхностных взаимодействий с образованием соляных мостиков (Phe, Trp, Tyr, Met, Val, Ile, Leu), так как такие остатки могут стимулировать тенденцию к проникновению через поверхность полипептида, и отсутствие аминокислот, которые могут быть посттрансляционно модифицированы. В этом контексте «мало заряженных остатков» означает менее 10% аминокислотных остатков в линкере, а «мало гидрофобных остатков» означает менее 15% аминокислотных остатков в линкере.
В одном варианте реализации линкер не содержит остаток цистеина.
В одном варианте реализации линкер содержит четыре, три, или два, или один заряженный остаток или не содержит вовсе. Предпочтительно линкер в целом содержит четыре, три, или два, или один остаток глутаминовой кислоты, аспарагиновой кислоты, аргинина и лизина или не содержит вовсе.
В одном варианте реализации линкер содержит четыре, три, или два, или один гидрофобный остаток или не содержит вовсе. Предпочтительно линкер в целом содержит четыре, три, или два, или один остаток фенилаланина, триптофана, тирозина, метионина, валина, изолейцина и лейцина или не содержит вовсе.
В одном варианте реализации по меньшей мере 70%, или по меньшей мере 80%, или по меньшей мере 90% линкера содержит остатки, выбранные из треонина, серина, глицина и аланина.
Обзор по применению олигопептидных линкеров в модификации полипептидов приведен в Chen et al., (2013) и Zhang et al., (2009).
Тэг
В конкретном варианте реализации слитый полипептид содержит по меньшей мере один тэг, пригодный для обнаружения или очистки слитого полипептида или его процессированного продукта. Как правило, тэг связан с С-концевым или N-концевым доменом слитого полипептида. В предпочтительном варианте реализации тэг связан с С-концом полипептида Nif. В общем случае тэг представляет собой пептидную или аминокислотную последовательность, способную связываться с одним или более лигандами, например, одним или более лигандами аффинной матрицы, такой как хроматографическая подложка или гранула, или антитело, с высокой аффинностью. Специалисту в данной области понятно, что тэг предпочтительно расположен в слитом белке в локации, которая не приводит к удалению тэга из NP после отщепления МНП после импорта в митохондрии. Кроме того, тэг не должен мешать работе аппарата импорта в митохондриях. В предпочтительном варианте реализации полинуклеотид по изобретению кодирует слитый полипептид, который содержит, в порядке от N- к С-концу, N-концевой МНП, полипептид Nif и тэг для обнаружения/очистки. В альтернативном варианте реализации слитый полипептид содержит, в порядке от N- к С-концу, N-концевой МНП, тэг для обнаружения/очистки и полипептид Nif.
Дополнительные иллюстративные, неограничивающие примеры тэгов, применимых для обнаружения, выделения или очистки слитого полипептида или его процессированного продукта, включают, тэг человеческого гемагглютинина вируса гриппа (HA), гистидиновые тэги, содержащие, например, 6 или 8 остатков гистидина, флуоресцентные тэги, такие как флуоресцеин, резоруфин и их производные, Arg-тэг, FLAG-тэг, Strep-тэг, эпитоп, который может распознаваться антителом, такой как c-myc-тэг (распознаваемый анти-c-myc антителом), SBP-тэг, S-тэг, кальмодулин-связывающий пептид, целлюлозосвязывающий домен, хитиносвязывающий домен, тэг глутатион S-трансферазы, мальтозосвязывающий белок, NusA, TrxA, DsbA, Avi-тэг и т. д.
Трансляционные продукты слияния, включающие полипептиды Nif
Трансляционные продукты слияния были созданы для нескольких полипептидов Nif, как сообщается в научной литературе. Они обобщены в Таблице 2 и в обзоре Buren and Rubio, (2018). Большинство из них включают искусственное добавление эпитопов или связывающих доменов, таких как гистидиновые тэги или стрептавидиновые тэги, к белкам в целях обнаружения и очистки и только несколько были экспрессированы в растительных клетках. Существует несколько сообщений о продуктах слияния природного происхождения между полипептидами Nif в бактериях. Для анализа в бактериальных организмах-хозяевах His-тэги разной длины (7-10 гистидинов) добавляли к NifD (Christiansen et al., 1998), NifE (Goodwin et al., 1998), NifM (Gavini et al., 2006) и как к полноразмерной, так и к усеченной версиям NifB (Fay et al., 2015).I В каждом случае функция Nif сохранялась для модифицированного полипептида Nif, как было продемонстрировано в бактериях или в in vitro анализе воссоздания нитрогеназы.
Thiel et al., (1995) выявили естественную делецию 29 нуклеотидов и, следовательно, удаление 9 аминокислот и стоп-кодона NifE в межгенной области между генами NifE и NifN в сине-зеленых водорослях Anabaena variabilis. Эта делеция привела к получению полипептидного слияния NifE-NifN, которое сохраняло по меньшей мере некоторую часть функции нитрогеназы полипептидов NifE и NifN. Слитый полипептид NifE-NifN также содержал 19 других аминокислотных замен в области соединения слияния, что могло влиять на функцию Nif, но неизвестным образом. Экспрессия гена слияния происходила, но исключительно в строго анаэробных условиях. Данные о том, было ли снижение активности по сравнению с неслитыми генами, отсутствуют.
Suh et al., (1996) создали искусственное соединение между генами NifD и NifK хромосомы A. vinelandii посредством делеции, включающей стоп-кодон NifD и кодон инициации трансляции (ATG) NifK, получив вектор, обозначенный pBG1404. Эта делеция привела к суммарной потере трех аминокислот и семи аминокислотным заменам в аминокислотах 2-10 полипептида NifK. Клетки-хозяева A. vinelandii, содержащие pBG1404, имели нарушения роста в среде с низким содержанием азота по сравнению с соответствующими бактериями дикого типа.
Wiig at al (2011) использовали естественное трансляционное слияние между генами NifN и NifB, присутствующие в Clostridium pastuerianum, и определили, что оно является функциональным в отношении активности NifN и NifB в бактериальном и биохимическом анализе комплементации. Это слияние было прямым, без какого-либо пептидного линкера, т. е. С-конец NifN был напрямую ковалентно связан с N-концом NifB.
В дрожжевых и растительных клетках трансляционные слияния использовали для направления белков, кодируемых в ядре, в митохондриальный матрикс. В анализе дрожжевой экспрессии было показано, что трансляционные слияния митохондриального нацеливающего пептида (МНП) и некоторых полипептидов Nif (NifH, NifM, NifS и NifU) являются функциональными при росте в аэробных условиях (Lopez-Torrejon et al., 2016). Также было показано, что эпитопные слияния (FLAG и HIS) являются функциональными при слиянии с NifH, NifM, NifS и NifU, хотя эти слияния проявляли тенденцию к локализации в дрожжевой цитоплазме и были функциональными только тогда, когда дрожжи выращивали в анаэробных условиях. Buren et al., (2017) показали, что нацеленная на митохондриальный матрикс версия растворимого варианта NifB была функциональной в in vitro анализе комплементации при повторном выделении из митохондрий дрожжей. Эта версия NifB содержала N-концевой МНП, усеченный вариант NifB (без NifX-подобного домена) и С-концевой эпитопный тэг 10xHis. Также в анализе дрожжевой экспрессии было создано большое количество слияний МНП-Nif. Однако эта большая группа коэкспрессируемых белков не смогла продемонстрировать активность в дрожжах (Buren et al., 2017).
МНП из гена CPN-60 сливали с N-концом NifH, NifM, NifS и NifU и продемонстрировали его функциональность посредством in vitro анализа комплементации при повторном выделении FeProtein из растений, выращиваемых в условиях пониженного кислородного давления при 10% кислорода (US2016/0304842).
Таблица 2. Обобщенные данные по генным слияниям полипептидов Nif по литературным данным
Anabaena variabilis
Clostridium pasteruienum
Полинуклеотиды
Термины «полинуклеотид» и «нуклеиновая кислота» взаимозаменяемо употребляются в данном документе. Они означают полимерную форму нуклеотидов любой длины, как дезоксирибонуклеотидов, так и рибонуклеотидов, или их аналогов. Полинуклеотид по определению данного документа может быть геномного, кДНК, полусинтетического или синтетического происхождения, одноцепочечным или, предпочтительно, двухцепочечным и в соответствии с происхождением или обработкой: (1) не связанным со всем или с частью полинуклеотида, с которым он связан в природе (например, полинуклеотид Nif, который не содержит кодирующую нативный промотор последовательность), (2) связанным с полинуклеотидом, отличным от того, с которым он связан в природе (например, полинуклеотид Nif, связанный с кодирующей МНП нуклеотидной последовательностью и/или кодирующей ненативный промотор последовательностью), или (3) не встречаться в природе (например, полинуклеотиды, кодирующие слитые полипептиды МНП-Nif по изобретению). Далее приведены неограничивающие примеры полинуклеотидов: кодирующие или некодирующие области гена или генного фрагмента, локусы (локус), определенные в анализе связи, экзоны, интроны, матричная РНК (мРНК), транспортная РНК (тРНК), рибосомальная РНК (рРНК), рибозимы, кДНК, рекомбинантные полинуклеотиды, разветвленные полинуклеотиды, плазмиды, векторы, выделенная ДНК любой последовательности, выделенная РНК любой последовательности, химерная ДНК любой последовательности, зонды на основе нуклеиновой кислоты и праймеры. Полинуклеотид может содержать модифицированные нуклеотиды, такие как метилированные нуклеотиды и нуклеотидные аналоги. В случае наличия модификации в структуру нуклеотидов можно вносить до или после сборки полимера. Последовательность нуклеотидов может прерываться ненуклеотидными компонентами. Полинуклеотид можно дополнительно модифицировать после полимеризации, например, путем конъюгации с метящим компонентом.
«Выделенный полинуклеотид» по существу не содержит компонентов, которые обычно связаны (например, регуляторные последовательности) или ассоциированы с полинуклеотидом. Таким образом, выделенный полинуклеотид по существу не содержит другой клеточный материал или культуральную среду при получении с помощью рекомбинантных технологий, или по существу не содержит химических предшественников или другие химические вещества при химическом синтезе. Предпочтительно выделенный полинуклеотид является по меньшей мере на 60% свободным, более предпочтительно по меньшей мере на 75% свободным и более предпочтительно по меньшей мере на 90% свободным от указанных компонентов.
В контексте данного документа термин «ген» следует воспринимать в его самом широком смысле и он включает дезоксирибонуклеотидные последовательности, содержащие транскрибируемую область и, в случае трансляции, кодирующую белок область структурного гена, и в том числе последовательности, смежные с кодирующей областью как в 5', так и в 3' конце на расстояние по меньшей мере около 2 т. о. в любом конце, и которые принимают участие в экспрессии гена. В этом отношении гены содержат регуляторные сигналы, такие как промоторы, энхансеры, сигналы терминации трансляции и транскрипции и/или полиаденилирования, которые в естественном состоянии связаны с данным геном, или гетерологичные регуляторные сигналы, в случае чего ген называется «химерным геном». Последовательности, которые расположены 5' относительно кодирующей белок области и которые присутствуют в мРНК, называются 5' нетранслируемыми последовательностями. Последовательности, которые расположены 3' или ниже кодирующей белок области и которые присутствуют в мРНК, называются 3' нетранслируемыми последовательностями. Термин «ген» включает как кДНК, так и геномные формы гена. Геномная форма или клон гена содержит кодирующую область, которая может прерываться некодирующими последовательностями, называемыми «интронами», «встроенными областями» или «встроенными последовательностями». Интроны представляют собой сегменты гена, которые транскрибируются в ядерную РНК (яРНК). Интроны могут содержать регуляторные элементы, такие как энхансеры. Интроны удаляются или «сплайсируются» из ядерного или первичного транскрипта; следовательно, в мРНК-транскрипте интроны отсутствуют. Функция мРНК во время трансляции состоит в определении последовательности или порядка аминокислот в растущем полипептиде. Термин «ген» включает синтетическую или слитую молекулу, кодирующую все или часть белков по изобретению, описанных в данном документе, и комплементарную нуклеотидную последовательность любого из вышеприведенного.
В контексте данного документа «химерная ДНК», также называемая в данном документе «ДНК-конструкцией», означает любую молекулу ДНК, которая не встречается в природе, но которая искусственным образом соединяет две части ДНК в одну молекулу, каждая часть которой может встречаться в природе, но целиком она в природе не встречается. Например, это ДНК-конструкция, кодирующая слитый полипептид МНП-Nif по изобретению. Как правило, химерная ДНК содержит регуляторные и транскрибируемые или кодирующие белок последовательности, которые не встречаются вместе в природе (например, полинуклеотид Nif, связанный с кодирующей ненативный промотор последовательностью). Соответственно, химерная ДНК может содержать регуляторные последовательности и кодирующие последовательности, которые получены из разных источников, или регуляторные последовательности и кодирующие последовательности, полученные из одного источника, но упорядоченные способом, отличным от встречающегося в природе. Открытая рамка считывания может быть связана или не связана со своими природными вышележащими или нижележащими регуляторными элементами. Открытая рамка считывания может быть включена, например, в геном растения, в отличной от природной локации, или в репликон или вектор, в которых она не встречается в природе, такие как бактериальная плазмида или вирусный вектор. Термин «химерная ДНК» не ограничен молекулами ДНК, способными к репликации в организме-хозяине, но включает ДНК, способные к лигированию в репликон с помощью, например, специальных адапторных последовательностей.
«Трансген» представляет собой ген, который был внесен в геном с помощью процедуры трансформации. Это термин включает ген в дочерних клетке, растении, отличном от человека организме или их части, который был внесен в геном их клетки-предшественника. Такие дочерние клетки и т. д. могут представлять по меньшей мере 3-е или 4-ое поколение относительно клетки-предшественницы, которая была первично трансформированной клеткой. Потомство может быть получено с помощью полового размножения или вегетативно, например, из картофельных клубней или отростков сахарного тростника. Термин «генетически модифицированный» и его вариации является более широким термином, который включает внесение гена в клетку посредством трансформации или трансдукции, мутацию гена в клетке и генетическое изменение или модулирование регуляции гена в клетке, или потомство любой клетки, модифицированной описанным выше образом.
В контексте данного документа «геномная область» относится к позиции в геноме, в которой трансген или группа трансгенов (также называемая в данном документе кластером) были внесены в клетку, или их предшественнику. Такие области содержат только нуклеотиды, которые были включены посредством вмешательства человека, например, описанными в данном документе способами.
«Рекомбинантный полинуклеотид» по изобретению относится к молекуле нуклеиновой кислоты, которая была сконструирована или модифицирована искусственными рекомбинантными способами. Рекомбинантный полинуклеотид может присутствовать в клетке в измененном количестве или экспрессироваться на измененном уровне (например, в случае мРНК) по сравнению с его нативным состоянием. В одном варианте реализации полинуклеотид внесен в клетку, которая не содержит этот полинуклеотид в природном состоянии. Как правило, используют экзогенную ДНК в качестве матрицы для транскрипции мРНК, которая затем транслируется в непрерывную последовательность аминокислотных остатков, кодирующих полипептид по изобретению в трансформированной клетке. В другом варианте реализации полинуклеотид является эндогенным для бактериальной клетки, а его экспрессия изменена рекомбинантными способами, например, внесена экзогенная регуляторная последовательность выше представляющего интерес эндогенного гена, чтобы обеспечить возможность экспрессии трансформированной клеткой полипептида, кодируемого геном.
Рекомбинантный полинуклеотид по изобретению включает полинуклеотиды, которые не были отделены от других компонентов клеточной или бесклеточной экспрессионной системы, в которой он находится, и полинуклеотиды, полученные в указанных клеточных и бесклеточных системах, которые были впоследствии очищены по меньшей мере от некоторых других компонентов. Полинуклеотид представлять собой непрерывный участок из нуклеотидов, существующий в природе (например, полинуклеотид Nif), или содержать два или более непрерывных участков из нуклеотидов из разных источников (природного происхождения и/или синтетических), соединенных с образованием одного полинуклеотида (например, полинуклеотид Nif, связанный с кодирующей МНП нуклеотидной последовательностью и/или кодирующей ненативный промотор последовательностью). Как правило, такие химерные полинуклеотиды содержат по меньшей мере одну открытую рамку считывания, кодирующую полипептид по изобретению, функционально связанную с промотором, подходящим для регуляции транскрипции открытой рамки считывания в представляющей интерес клетке.
В отношении определенных полинуклеотидов понятно, что значения % идентичности, большие, чем приведенные выше, будут включать предпочтительные варианты реализации. Таким образом, в соответствующих случаях, в свете минимального значения % идентичности предпочтительно, чтобы полинуклеотид содержал полинуклеотидную последовательность, которая по меньшей мере на 60%, более предпочтительно по меньшей мере на 65%, более предпочтительно по меньшей мере на 70%, более предпочтительно по меньшей мере на 75%, более предпочтительно по меньшей мере на 80%, более предпочтительно по меньшей мере на 85%, более предпочтительно по меньшей мере на 90%, более предпочтительно по меньшей мере на 91%, более предпочтительно по меньшей мере на 92%, более предпочтительно по меньшей мере на 93%, более предпочтительно по меньшей мере на 94%, более предпочтительно по меньшей мере на 95%, более предпочтительно по меньшей мере на 96%, более предпочтительно по меньшей мере на 97%, более предпочтительно по меньшей мере на 98%, более предпочтительно по меньшей мере на 99%, более предпочтительно по меньшей мере на 99,1%, более предпочтительно по меньшей мере на 99,2%, более предпочтительно по меньшей мере на 99,3%, более предпочтительно по меньшей мере на 99,4%, более предпочтительно по меньшей мере на 99,5%, более предпочтительно по меньшей мере на 99,6%, более предпочтительно по меньшей мере на 99,7%, более предпочтительно по меньшей мере на 99,8% и даже более предпочтительно по меньшей мере на 99,9% идентична соответствующей указанной SEQ ID NO.
Полинуклеотид по данному изобретению или применимый в нем может избирательно гибридизироваться в жестких условиях с полинуклеотидом, определенным в данном документе. В контексте данного документа жесткие условия представляют собой условия, в которых: (1) во время гибридизации используют денатурирующий агент, такой как формамид, например, 50% (об./об.) формамида с 0,1% (масс./об.) бычьего сывороточного альбумина, 0,1% фиколл, 0,1% поливинилпирролидона, 50 мМ фосфатно-натриевого буфера с pH 6,5 с 750 мМ NaCl, 75 мМ цитрата натрия при 42°C; или (2) используют 50% формамида, 5 x SSC (0,75 М NaCl, 0,075 М цитрата натрия), 50 мМ фосфата натрия (pH 6,8), 0,1% пирофосфата натрия, 5 x раствора Денхардта, обработанную ультразвуком ДНК из молок лососевых (50 г/мл), 0,1% ДСН и 10% сульфата декстрана при 42°C в 0,2 x SSC в 0,1% ДСН, и/или (3) используют низкую ионную силу и высокую температуру для промывки, например, 0,015 M NaCl/0,0015 М цитрата натрия/0,1% ДСН при 50°C.
Полинуклеотиды по изобретению могут содержать, по сравнению с молекулами природного происхождения, одну или более мутаций, которые представляют собой делеции, вставки или замены нуклеотидных остатков. Полинуклеотиды, которые имеют мутации относительно референсной последовательности, могут быть как природного происхождения (то есть выделенными из природного источника), так и синтетическими (например, за счет проведения сайт-направленного мутагенеза или перетасовки ДНК в нуклеиновой кислоте, как описано выше).
Полинуклеотиды по изобретению могут быть кодон-оптимизированными в отношении экспрессии в растительной клетке. Специалисту в данной области понятно, что кодирующая белок область может быть кодон-оптимизированной относительно, например, кодирующей области полинуклеотида природного происхождения в азотфиксирующих бактериях.
Конструкции нуклеиновых кислот
В данное изобретение включены конструкции нуклеиновых кислот, содержащие один или более полинуклеотидов по изобретению, и содержащие их векторы и клетки-хозяева, способы их получения и применения, и варианты их применения. Данное изобретение относится к элементам, которые функционально соединены или связаны. Понятия «функционально соединенные» или «функционально связанные» и т. п. относятся к связи полинуклеотидных элементов в функциональной взаимосвязи. Как правило, функционально соединенные последовательности нуклеиновых кислот связаны непрерывно и, в случае необходимости соединения двух кодирующих белок областей, непрерывно и в одной рамке считывания. Кодирующая последовательность «функционально соединена с» другой кодирующей последовательностью, если РНК-полимераза транскрибирует две кодирующие последовательности в одну РНК, которая в случае трансляции транслируется затем в один полипептид, содержащий аминокислоты, кодируемые обеими кодирующими последовательностями. Кодирующие последовательности не обязательно должны быть непрерывными по отношению друг к другу при условии, что в итоге происходит процессинг экспрессируемых последовательностей с получением необходимого белка.
В контексте данного документа термины «цис-действующая последовательность», «цис-действующий элемент» или «цис-регуляторная область», или «регуляторная область», или аналогичный термин, следует воспринимать как означающие любую последовательность нуклеотидов, которая при надлежащем расположении и соединении относительно подлежащей экспрессии генетической последовательности способна регулировать, по меньшей мере частично, экспрессию генетической последовательности. Специалистам в данной области техники известно, что цис-регуляторная область может быть способна осуществлять активацию, сайленсинг, усиление, репрессию или каким-либо иным образом менять уровень экспрессии и/или специфичность к типу клеток, и/или специфичность к стадии развития генной последовательности на транскрипционном или посттранскрипционном уровне. В предпочтительных вариантах реализации данного изобретения цис-действующая последовательность представляет собой активирующую последовательность, которая усиливает или стимулирует экспрессию подлежащей экспрессии генетической последовательности.
«Функциональное соединение» элемента промотора или энхансера с подлежащим транскрипции полинуклеотидом означает помещение подлежащего транскрипции полинуклеотида (например, кодирующего белок полинуклеотида или другого трнскрипта) под регуляторное управление промотора, который затем регулирует транскрипцию этого полинуклеотида. При конструировании комбинаций гетерологичный промотор/структурный ген в общем случае предпочтительно помещать промотор или его вариант на расстоянии от сайта инициации транскрипции подлежащего транскрипции полинуклеотида, которое приблизительно равно расстоянию между этим промотором и кодирующей белок областью, которой он управляет, в его естественном окружении; т. е. гене, из которого получен промотор. Как известно в данной области техники, в это расстояние можно вносить некоторые вариации без потери функции. Аналогично, предпочтительное размещение элемента регуляторной последовательности (например, оператора, энхансера и т. д.) по отношению к подлежащему транскрипции полинуклеотиду, который необходимо поместить под его управление, определяется размещением данного элемента в его естественном окружении; т. е. гене, из которого он получен.
В контексте данного документа «промотор» или «промоторная последовательность» относится к области гена, в общем случае выше (5') РНК-кодирующей области, которая управляет инициацией и уровнем транскрипции в представляющей интерес клетке. «Промотор» содержит транскрипционные регуляторные последовательности классического геномного гена, такие как последовательности TATA-бокс и CCAAT-бокс, а также дополнительные регуляторные элементы (т. е. вышележащие активирующие последовательности, энхансеры и сайленсеры), которые изменяют экспрессию гена в ответ на связанные со стадией развития и/или окружением стимулы или же тканеспецифическим или специфическим относительно клеточного тип образом. Промотор обычно, но не обязательно (например, некоторые промоторы PolIII), размещается выше структурного гена, экспрессию которого он регулирует. Кроме того, регуляторные элементы, содержащие промотор, обычно размещаются в пределах 2 т. о. от сайта инициации транскрипции гена. Промоторы могут содержать дополнительные специфические регуляторные элементы, расположенные более отдаленно от сайта инициации, для дополнительного усиления экспрессии в клетке и/или для изменения времени или индуцибельности экспрессии структурного гена, с которыми они функционально связаны.
«Конститутивный промотор» относится к промотору, который управляет экспрессией функционально связанной транскрибируемой последовательности во многих или всех тканях организма, такого как растение. В контексте данного документа термин «конститутивный» не обязательно указывает на то, что ген экспрессируется на одном уровне во всех типах клеток, на на то, что ген экспрессируется в широком диапазоне типов клеток, хотя часто наблюдаются некоторые вариации уровня. В контексте данного документа «избирательная экспрессия» относится к экспрессии, происходящей практически исключительно в конкретных органах, например, растения, таких как, например, эндосперм, зародыш, листья, плод, клубни или корни. В предпочтительном варианте реализации промотор экспрессируется избирательно или предпочтительно в корнях, листья и/или стеблях растения, предпочтительно зернового растения. Следовательно, избирательную экспрессию можно противопоставить конститутивной экспрессии, которая относится к экспрессии во многих или во всех тканях растения в большинстве или во всех условиях, которым подвергается растение.
Избирательная экспрессия также может приводить к компартментализации продуктов генной экспрессии в конкретных тканях, органах или на конкретных стадиях развития растения. Компартментализацию в конкретных субклеточных локациях, таких как пластида, цитозоль, вакуоль или апопластическое пространство, можно обеспечить путем включения в структуру генного продукта соответствующих сигналов, например, сигнального пептида, для перемещения в необходимый клеточный компартмент, или, в случае полуавтономных органелл (пластид и митохондрий), путем интеграции трансгена с соответствующими регуляторными последовательностями непосредственно в геном органеллы.
«Тканеспецифический промотор» или «органоспецифический промотор» представляет собой промотор, который преимущественно экспрессируется в одной ткани или одном органе по сравнению со многими другими тканями или органами, предпочтительно большинством, если не всеми другими тканями или органами, например, в растении. Как правило, такой промотор экспрессируется на уровне, в 10 раз большем в конкретной ткани или конкретном органе, чем в других тканях или органах.
В одном варианте реализации промотор представляет собой специфический в отношении стебля промотор, специфический в отношении листьев промотор или промотор, который управляет генной экспрессией в наземной части растений (по меньшей мере стеблях и листьях) (специфический в отношении зеленой ткани промотор), такой как промотор рибулозо-1,5-бифосфаткарбоксилазы/оксигеназы (RUBISCO).
Примеры специфических в отношении стебля промоторов включают, но не ограничиваются этим, описанные в US 5625136 и Bam et al. (2008).
В одном варианте реализации промотор представляет собой специфический в отношении корней промотор. Примеры специфических в отношении корней промоторов включают, но не ограничиваются этим, промотор гена кислой хитиназы и специфические субдомены промотора CaMV 35S.
Промоторы, предусмотренные данным изобретением, могут быть нативными для растения-хозяина, подлежащего трансформации, или могут быть получены из альтернативного источника, в котором указанная область функционально в растении-хозяине. Другие источники включают гены Т-ДНК Agrobacterium, такие как промоторы генов для биосинтеза нопалина, октапина, мннопина, или другие опиновые промоторы, тканеспецифические промоторы (смотрите, например, US 5459252 и WO 91/13992); промоторы из вирусов (включая специфические в отношении хозяев вирусы) или же частично или полностью синтетические промоторы. В данной области техники хорошо известны многочисленные промоторы, функциональные в одно- и двудольных растениях (смотрите, например, Greve, 1983; Salomon et al., 1984; Garfinkel et al., 1983; Barker et al., 1983); включая промоторы, выделенные из растений и вирусов, такие как промотор вируса мозаики цветной капусты (CaMV 35S, 19S). Неограничивающие способы оценки активности промоторов описаны в Medberry et al. (1992, 1993), Sambrook et al. (1989, выше) и US 5164316.
В альтернативном или дополнительном варианте промотор может быть индуцибельным промотором или регулируемым в соответствии со стадией развития промотором, который способен управлять экспрессией внесенного полинуклеотида на соответствующей стадии развития, например, растения. Другие цис-действующие последовательности, которые можно применять, включают транскрипционные и/или трансляционные энхансеры. Энхансерные области хорошо известны специалистам в данной области техники и могут включать кодон инициации трансляции ATG и смежные последовательности. В случае включения кодон инициации должен находиться в фазе с рамкой считывания кодирующей последовательности, относящейся к чужеродному или экзогенному полинуклеотиду, чтобы гарантировать трансляцию всей последовательности, если она подлежит трансляции. Области инициации трансляции могут быть получены из источника области инициации транскрипции или из чужеродного или экзогенного полинуклеотида. Эта последовательность также может быть получена из источника промотора, выбранного для управления экспрессией, и может быть специально модифицирована так, чтобы увеличивать трансляцию мРНК.
Конструкция нуклеиновой кислоты по данному изобретению может содержать 3' нетранслируемую последовательность от около 50 до 1000 пар нуклеотидных оснований, которая может включать последовательность терминации транскрипции. 3' нетранслируемая последовательность может содержать сигнал терминации транскрипции, который может включать или не включать сигнал полиаденилирования и любые другие регуляторные сигналы, способные влиять на процессинг мРНК. Функция сигнала полиаденилирования состоит в добавлении трактов полиадениловой кислоты в 3' конец мРНК-предшественницы. Сигналы полиаденилирования обычно можно распознать по наличию гомологии с канонической формой 5' AATAAA-3', хотя вариации не являются редкими. Последовательности терминации транскрипции, которые не содержат сигнал полиаденилирования, включают терминаторы РНК-полимеразы PolI или PolIII, которые содержат участок из четырех или более тимидинов. Примерами подходящих 3' нетранслируемых последовательностей являются 3' транскрибируемые нетранслируемые последовательности, содержащие сигнал полиаденилирования из гена октопинсинтазы (ocs) или гена нопалинсинтазы (nos) из Agrobacterium tumefaciens (Bevan et al., 1983). Подходящие 3' нетранслируемые последовательности также могут быть получены из растительных генов, таких как ген рибулозо-1,5-бифосфаткарбоксилазы (ssRUBISCO), хотя также можно применять другие 3' элементы, известные специалистам в данной области техники.
Так как последовательность ДНК, вставленная между сайтом инициации транскрипции и началом кодирующей последовательности, т. е. нетранслируемая 5' лидерная последовательность (5'НТО), может влиять на экспрессию гена в случае трансляции, а также транскрипции, можно использовать конкретную лидерную последовательность. Подходящие лидерные последовательности включают те, которые содержат последовательности, выбранные для управления оптимальной экспрессией чужеродной или эндогенной последовательности ДНК. Например, такие лидерные последовательности включают предпочтительную консенсусную последовательность, которая может повышать или поддерживать стабильность мРНК и предотвращать неподходящую инициацию трансляции, как описано, например, в Joshi (1987).
Векторы
Данное изобретение включает применение векторов для манипуляции или переноса генетических конструкций. Вектор представляет собой молекулу нуклеиновой кислоты, предпочтительно молекулу ДНК, которую можно использовать для искусственного переноса чужеродного генетического материала в другую клетку, где он может реплицироваться или экспрессироваться. Вектор, содержащий чужеродную ДНК, называется «рекомбинантным вектором». Примеры векторов включают, но не ограничиваются этим, плазмиды, вирусные векторы, космиды, внехромосомные элементы, минихромосомы, искусственные хромосомы. Вектор может содержать подвижный элемент.
Предпочтительно вектор представляет собой двухцепочечную ДНК и содержит один или более уникальных рестрикционных сайтов, и может быть способным к автономной репликации в определенной клетке-хозяине, включая целевую клетку или ткань или ее клетку-предшественницу или ткань, или способным к интеграции в геном, предпочтительно ядерный геном, определенного организма-хозяина так, чтобы клонированная последовательность была репродуцируемой. Соответственно, вектор может представлять собой автономно реплицируемый вектор, т. е. вектор, который существует в виде внехромосомного компонента, репликация которого не зависит от хромосомной репликации, например, линейную или кольцевую плазмиды, внехромосомный элемент, минихромосому или искусственную хромосому. Вектор может содержать любые средства для гарантии саморепликации. В альтернативном варианте вектор может быть таким, который при внесении в клетку интегрируется в геном, предпочтительно ядерный геном, реципиентной клетки и реплицируется вместе с хромосомой(ами) в которую(ые) он был интегрирован. Векторная систем может содержать один вектор или плазмиду, два или более вектора или две или более плазмиды, которые вместе содержат всю ДНК, подлежащую внесению в клетку-хозяина, или транспозон. Выбор вектора, как правило, зависит от совместимости вектора с клеткой, в которую необходимо внести вектор. Вектор также может содержать селективный маркер, такой как ген устойчивости к антибиотикам, ген устойчивости к гербицидам или другой ген, который можно использовать для отбора подходящих трансформантов. Примеры таких генов хорошо известны специалистам в данной области техники.
Конструкцию нуклеиновой кислоты по изобретению можно вносить в вектор, такой как плазмида. Плазмидные векторы, как правило, содержат дополнительные последовательности нуклеиновых кислот, которые обеспечивают легкость отбора, амплификации и трансформации экспрессионной кассеты в прокариотических и эукариотических клетках, например, векторы на основе pUC, векторы на основе pSK, векторы на основе pGEM, векторы на основе pSP, векторы на основе pBS или бинарные векторы, содержащие одну или более областей Т-ДНК.. Дополнительные последовательности нуклеиновых кислот включают точки начала репликации для обеспечения автономной репликации вектора, гены селективных маркеров, предпочтительно кодирующие устойчивость к антибиотикам или гербицидам, уникальные сайты множественного клонирования, обеспечивающие наличие множества сайтов для вставки последовательностей нуклеиновых кислот или генов, кодируемых в конструкции нуклеиновой кислоты, и последовательности, которые усиливают трансформацию прокариотических и эукариотических (в особенности растительных) клеток.
Под «маркерным геном» подразумевается ген, который придает клеткам, экспрессирующим маркерный ген, отличный фенотип и, таким образом, позволяет отличать такие трансформированные клетки от клеток, которые не содержат маркер. Ген селективного маркера обеспечивает признак, по которому можно проводить «отбор» («селекцию») на основании устойчивости к селективному агенту (например, гербициду, антибиотику, излучению, температуре или другой обработке, повреждающей нетрансформированные клетки). Пригодный для скрининга маркерный ген (или репортерный ген) обеспечивает признак, который можно определить с помощью наблюдения или исследования, т. е. путем «скрининга» (например, активность β-глюкуронидазы, люциферазы, ЗФБ или другого фермента, не присутствующая в нетрансформированных клетках). Маркерный ген и представляющая интерес нуклеотидная последовательность не обязательно должны быть связаны.
Чтобы облегчить идентификацию трансформантов, конструкция нуклеиновой кислоты желательно содержит ген селективного или пригодного для скрининга маркера в качестве чужеродного или экзогенного полинуклеотида или в дополнение к нему. Фактический выбор маркера не является критическим при условии, что он является функциональным (т. е. селективным) в комбинации с клеткой-хозяином, предпочтительно растительной клеткой-хозяином. Маркерный ген и представляющий интерес чужеродный или экзогенный полинуклеотид не обязательно должны быть связаны, так как котрансформация несвязанных генов, как описано, например, в US 4399216 также является эффективным способом трансформации растений.
Примерами бактериальных селективных маркеров являются маркеры, которые придают устойчивость к антибиотикам, такую как устойчивость к ампициллину, эритромицину, хлорамфениколу или тетрациклину, предпочтительно устойчивость к канамицину. Примеры селективных маркеров для отбора растительных трансформантов включают, но не ограничиваются этим, ген hyg, который кодирует устойчивость к гигромицину B; ген неомицинфосфотрансферазы (nptII), придающий устойчивость к канамицину, паромомицину, G418; ген глутатион-S-трансферазы из печени крыс, придающий устойчивость к глутатионовым гербицидам, как описано, например, в EP 256223; ген глутаминсинтетазы, придающий, после сверхэкспрессии, устойчивость к ингибиторам глутаминсинтетазы, таким как фосфинотрицин, как описано, например, в WO 87/05327; ген ацетилтрансферазы из Streptomyces viridochromogenes, придающий устойчивость к селективному агенту фосфинотрицину, как описано, например, в EP 275957; ген, кодирующий 5-энолшикимат-3-фосфатсинтазу (EPSPS), придающий стойкость к N-фосфонометилглицину, как описано, например, в Hinchee et al. (1988); ген bar, придающий устойчивость к биалафосу, как описано, например, в WO91/02071; ген нитрилазы, такой как bxn из Klebsiella ozaenae, который придает устойчивость к бромоксинилу (Stalker et al., 1988); ген дигидрофолатредуктазы (DHFR), придающий устойчивость к метотрексату (Thillet et al., 1988); мутантный ген ацетолактатсинтазы (ALS), который придает устойчивость к имидазолинону, сульфонилмочевине или другим ALS-ингибирующим химическим веществам (EP 154,204); мутированный ген антранилатсинтазы, который придает устойчивость к 5-метилтриптофану; или ген далапондегалогеназы, который придает устойчивость к гербициду.
Предпочтительные пригодные для скрининга маркеры включают, но не ограничиваются этим, ген uidA, кодирующий фермент β-глюкуронидазу (GUS), для которого известны различные хромогенные субстраты; ген β-галактозидазы, кодирующий фермент, для которого известны хромогенные субстраты; ген экворина (Prasher et al., 1985), который можно использовать в регистрации кальций-чувствительной биолюминесценции; ген зеленого флуоресцентного белка (Niedz et al., 1995) или его производных; ген люциферазы (luc) (Ow et al., 1986), который позволяет проводить регистрацию биолюминесценции, и другие, известные в данной области техники. В контексте данного описания под «репортерной молекулой» подразумевается молекула, которая по своей химической природе обеспечивает аналитический идентифицируемый сигнал, который облегчает определение промоторной активности относительно белкового продукта.
Предпочтительно конструкция нуклеиновой кислоты стабильно включена в геном, например, растения. Соответственно, нуклеиновая кислота содержит соответствующие элементы, которые обеспечивают возможность включения молекулы в геном, или же конструкция помещена в соответствующий вектор, который может быть включен в хромосому растительной клетки.
Один вариант реализации данного изобретения включает рекомбинантный вектор, который содержит по меньшей мере один полинуклеотид по определению данного документа и способен доставить этот полинуклеотид в клетку-хозяина. Такие векторы содержат гетерологичные последовательности нуклеиновых кислот, то есть последовательности нуклеиновых кислот, которые в природном состоянии не являются смежными с молекулами нуклеиновых кислот по данному изобретению и которые предпочтительно получены от видов, отличных от видов, от которых получены эти молекулы нуклеиновых кислот. Вектор может быть как РНК, так и ДНК, прокариотическим или эукариотическим, и, как правило, представляет собой вирус или плазмиду.
Рекомбинантные векторы по изобретению содержат слитые последовательности, которые приводят к экспрессии молекул нуклеиновых кислот в виде слитых белков.
Рекомбинантные векторы также могут содержать вставочные и/или нетранслируемые последовательности, окружающие и/или находящиеся в пределах последовательности нуклеиновой кислоты полинуклеотида по определению данного документа.
Предпочтительно рекомбинантный вектор стабильно включен в геном клетки-хозяина, такой как растительная клетка. Соответственно, рекомбинантный вектор может содержать соответствующие элементы, которые обеспечивают возможность включения вектора в геном или в хромосому клетки.
Рекомбинантные клетки
Другой вариант данного изобретения включает рекомбинантную клетку, например, рекомбинантную растительную клетку, которая представляет собой клетку-хозяина, трансформированную одним или более полинуклеотидами, конструкциями или векторами по данному изобретению, или потомство клеток. В данном документе термин «рекомбинантная клетка» взаимозаменяемо употребляется с термином «трансгенная клетка».
Трансформацию молекулы нуклеиновой кислоты в клетку можно осуществлять любым способом, посредством которого в клетку можно вносить молекулу нуклеиновой кислоты. Способы трансформации включают, но не ограничиваются этим, трансфекцию, электропорацию, микроинъекцию, липофекцию, адсорбцию и слияние протопластов. Рекомбинантная клетка может оставаться одноклеточной или может вырастать в ткань, орган или многоклеточный организм. Трансформированные молекулы нуклеиновых кислот по данному изобретению могут оставаться внехромосомными или могут интегрироваться в один или более сайтов в хромосоме трансформированной клетки таким образом, чтобы сохранялась их способность к экспрессии.
Предпочтительными клетками-хозяевами являются растительные клетки, более предпочтительно клетки зерновых растений, более предпочтительно клетки ячменя или пшеницы и даже более предпочтительно клетка пшеницы.
Рекомбинантная клетка может быть клеткой in vitro в культуре, клеткой или в организме, таком как, например, растение, или в органе, таком как, например, корень, лист или стебель. Предпочтительно клетка находится в растении, более предпочтительно в корнях, листьях и/или стеблях растения.
В одном варианте реализации для экспрессии активного NifDK в растительной клетке необходима экспрессия NifD, NifK, NifH, NifB, NifE, NifN и, необязательно, NifU, NifS, NifO, NifV, NifY, NifW и/или NifZ.
В другом или дополнительном варианте реализации для экспрессии активного NifH в растительной клетке необходима экспрессия NifH и NifM и, необязательно, NifU и/или NifN.
В одном варианте реализации для воссоздания активности нитрогеназы в растительной клетке необходима экспрессия по меньшей мере NifD, NifK, NifH, NifB, NifE, NifN и NifM.
Специалисту в данной области понятно, что и меньшая подгруппа белков Nif может приводить к воссозданию функциональной нитрогеназы в растительной клетке. Насколько известно авторам изобретения, только в одной работе по переносу гена нитрогеназы в любой фотосинтетический организм описано внесение NifH в хлоропластный геном Chlamydomonas (Cheng et al., 2005). NifH был способен дополнять мутант биосинтеза хлорофилла несмотря на то, что биосинтетические белки-предшественники NifH, а именно NifM, NifS и NifU, не коэкспрессировались. Это демонстрирует, что эндогенные эукариотические эквиваленты могут функционально заменять определенные белки Nif. Действительно, недавняя работа, демонстрирующая, что E.coli может воссоздавать функцию нитрогеназы, используя только восемь белков Nif (Wang et al., 2013), предполагает, что обеспечение функции в растениях может быть менее сложным, чем экспрессия полного комплекта белков Nif. Хотя авторам изобретения еще нужно установить функциональность белков Nif in planta, многообещающим является то, что репертуар биосинтетических и функциональных белков Nif можно экспрессировать в окружении, потенциально поддерживающем функцию нитрогеназы.
Трансгенные растения
В контексте данного документа термин «растение», как существительное, относится к целым растениям и относится к любому представителю царства Растения, но в форме прилагательного (растительный) относится в любому материалу, который присутствует в, получен из или связан с растением, такому как, например, растительные органы (например, листья, стебли, корни, цветки), одиночные клетки (например, пыльца), семена, растительные клетки и т. п. Ростки и пророщенные семена, из которых появились корни и побеги, также включены в значение термина «растение». В контексте данного документа термин «растительные части» относится к одной или более растительным тканям или одному или более растительным органам, которые получены из растения и которые содержат геномную ДНК растения. Растительные части включают вегетативные структуры (например, листья, стебли), корни, цветковые органы/структуры, семена (включая зародыши, семядоли и семенные оболочки), растительные ткани (например, сосудистые ткани, основную паренхиму и т. п.), клетки и их потомство. В контексте данного документа термин «растительная клетка» относится к клетке, полученной из растения или находящейся в растении, и включает протопласты или другие клетки, полученные из растений, гаметообразующие клетки и клетки, которые регенерируют в целые растения. Растительные клетки могут представлять собой клетки в культуре. Под «растительной тканью» подразумевается дифференцированная ткань в растении или полученная из растения («эксплантат»), или недифференцированная ткань, полученная из незрелых или зрелых зародышей, семян, корней, побегов, плодов, клубней, пыльцы, опухолевой ткани, такой как корончатые галлы, и различные формы агрегатов растительных клеток в культуре, такие как каллюс. Примерами растительных тканей, находящихся в семенах или полученных из них, являются семядоли, зародыши и рубчики. Соответственно, данное изобретение также включает растения и растительные части, а также содержащие их продукты.
В контексте данного документа термин «семена» относится к «зрелым семенам» растения, которые готовы к сбору или были собраны с растения, такие как обычно собирают в коммерческих целях с поля, или к «развивающимся семенам», которые присутствуют в растении после оплодотворения и до установления состояния покоя семян, и до сбора.
В контексте данного документа «трансгенное растение» относится к растению, которое содержит конструкцию нуклеиновой кислоты, не встречающуюся в растении дикого типа того же вида, вариетета или культивара. Это означает, что трансгенные растения (трансформированные растения) содержат генетический материал (трансген), который они не содержали до трансформации. Трансген может содержать генетические последовательности, полученные из растительной клетки или клетки другого растения, или нерастительного источника, или синтетическую последовательность. Как правило, трансген внесен в растительную клетку посредством вмешательства человека, например, посредством трансформации, но, как понятно специалисту в данной области техники, можно использовать любой способ. Генетический материал предпочтительно стабильно интегрирован в геном растения, предпочтительно ядерный геном. Внесенный генетический материал может содержать последовательности, которые встречаются в природе в том же виде, но в перестроенном порядке или с отличным упорядочением элементов, например, антисмысловую последовательность. Растения, содержащие такие последовательности, включены в данном документе в определение «трансгенных растений».
В предпочтительном варианте реализации трансгенные растения являются гомозиготными в отношении каждого внесенного гена (трансгена) так, что их потомство не сегрегирует в отношении необходимого фенотипа. Трансгенные растения также могут быть гетерозиготными в отношении внесенного(ых) трансгена(ов), как, например, в потомстве F1, которое было выращено из гибридных семян. Такие растения могут иметь преимущества, такие как мощность гибридов, что хорошо известно в данной области техники.
Трансгенные растения по определению в контексте данного изобретения включают потомство растений, которые были генетически модифицированы с помощью рекомбинантных технологий, причем потомство содержит представляющий интерес трансген. Такое потомство можно получать посредством самоопыления первичного трансгенного растения или посредством скрещивания таких растений с другим растением того же вида. В общем случае это служит для модуляции выработки по меньшей мере одного белка по определению данного документа в необходимом растении или растительном органе. Части трансгенных растений включают все части и клетки указанных растений, содержащие трансген, такие как, например, культивируемые ткани, каллюс и протопласты.
Трансгенные растения можно получать, используя известные в данной области техники методики, такие, как в целом описаны в A. Slater et al., Plant Biotechnology - The Genetic Manipulation of Plants, Oxford University Press (2003) и P. Christou and H. Klee, Handbook of Plant Biotechnology, John Wiley and Sons (2004).
«Нетрансгенным растением» является растение, которое не было генетически модифицировано путем внесения генетического материала с помощью технологий рекомбинантных ДНК. В контексте данного документа термин «по сравнению с изогенным растением» или аналогичные выражения относятся к растению, которое является изогенным по относительно трансгенного растения, но не содержит представляющий интерес трансген. Предпочтительно соответствующее нетрансгенное растение принадлежит тому же культивару или вариетету, что и предшественник представляющего интерес трансгенного растения, или родственной линии растений, в которой отсутствует конструкция, часто называемой «сегрегантом», или это растение того же культивара или вариетета, трансформированное «пустым вектором», и может быть нетрансгенным растением. В контексте данного документа термин «дикого типа» относится к клетке, ткани или растению, которые не были модифицированы в соответствии с изобретением. Клетки, ткани или растения дикого типа можно использовать в качестве контроля для сравнения уровней экспрессии экзогенной нуклеиновой кислоты или степени и природы модификации признаков с клетками, тканями или растениями, модифицированными как описано в данном документе.
Трансгенные растения по определению в контексте данного изобретения включают потомство растений, которые были генетически модифицированы с помощью рекомбинантных технологий, причем потомство содержит представляющий интерес трансген. Такое потомство можно получать посредством самоопыления первичного трансгенного растения или посредством скрещивания таких растений с другим растением того же вида. Части трансгенных растений включают все части и клетки указанных растений, содержащие трансген, такие как, например, культивируемые ткани, каллюс и протопласты.
Растения, предусмотренные для использования при практической реализации данного изобретения, включают как однодольные, так и двудольные. Целевые растения включают, но не ограничиваются этим, следующие: зерновые (например, пшеницу, ячмень, рожь, овес, рис, кукурузу, сорго и родственные зерновые); виноград; свеклу (сахарную свеклу и кормовую свеклу); семечковые, косточковые и ягоды (яблоки, груши, сливы, персики, миндаль, вишни, клубнику, малину и черноягодные); бобовые растения (бобы, чечевицу, горошек, соевые бобы); масличные растения (рапс или другие капустные, горчицу, мак, оливки, подсолнечник, сафлор, лен, кокос, касторовые масличные растения, какао-бобы, арахис); огуречные растения (кабачки, огурцы, дыни); волокнистые растения (хлопок, лен, коноплю, джут); цитрусовые фрукты (апельсины, лимоны, грейпфруты, мандарины); овощи (шпинат, салат, аспарагус, капусту, морковь, лук, томаты, картофель, паприку); лавровые (авокадо, корицу, камфору); или такие растения, как кукуруза, табак, орехи, кофе, сахарный тростник, чай, виноград, хмель, дерн, бананы и природные каучуконосные растения, а также декоративные растения (цветы, кустарники, лиственные деревья и вечнозеленые растения, такие как хвойные). Предпочтительно растение представляет собой зерновое растение, более предпочтительно пшеницу, рис, кукурузу, тритикале, овес или ячмень, даже более предпочтительно пшеницу.
В контексте данного документа термин «пшеница» относится к любым видам рода Triticum, включая их предшественников, а также их потомство, получаемое путем скрещивания с другими видами. Пшеница включает «гексаплоидную пшеницу», которая имеет геномную организацию AABBDD, состоящую из 42 хромосом, и «тетраплоидную пшеницу», которая имеет геномную организацию AABB, состоящую из 28 хромосом. Гексаплоидная пшеница включает T. aestivum, T. spelta, T. macha, T. compactum, T. sphaerococcum, T. vavilovii и их межвидовые гибриды. Предпочтительным видом гексаплоидной пшеницы является T. aestivum ssp aestivum (также называемый «хлебопекарной пшеницей»). Тетраплоидная пшеница включает T. durum (также называемую в данном документе пшеницей дурум или Triticum turgidum ssp. durum), T. dicoccoides, T. dicoccum, T. polonicum и их межвидовые гибриды. Кроме того, термин «пшеница» включает потенциальных предшественников гексаплоидных и тетраплоидных видов Triticum sp., таких как T. uartu, T. monococcum или T. boeoticum в случае генома А, Aegilops speltoides в случае генома B и T. tauschii (также известный как Aegilops squarrosa или Aegilops tauschii) в случае генома D. В особенности предпочтительными предшественниками являются представители генома А, даже более предпочтительно предшественник генома А представляет собой T. monococcum. Культивар пшеницы для применения в данном изобретении может принадлежать, но не ограничиваться ими, любому из вышеперечисленных видов. Также включены растения, которые получают традиционными способами, используя Triticum sp. В качестве родительского растения при пловом скрещивании с не относящимися к Triticum видами (такими, как рожь [Secale cereale]), включая, но не ограничиваясь этим Triticale.
В контексте данного документа термин «ячмень» относится к любым видам рода Hordeum, включая их предшественников, а также их потомство, получаемое путем скрещивания с другими видами. Предпочтительно, чтобы растение принадлежало виду Hordeum, который культивируется в коммерческих целях, такому как, например, штамм или культивар, или вариетет Hordeum vulgare, или подходило для коммерческого производства зерна.
Было описано четыре общих способа прямой доставки гена в клетки: (1) химические способы (Graham et al., 1973); (2) физические способы, такие как микроинъекция (Capecchi, 1980); электропорация (смотрите, например, WO 87/06614, US 5472869, 5384253, WO 92/09696 и WO 93/21335); и технология генной пушки (смотрите, например, US 4945050 и US 5141131); (3) вирусные векторы (Clapp, 1993; Lu et al., 1993; Eglitis et al., 1988); и (4) рецептор-опосредованные механизмы (Curiel et al., 1992; Wagner et al., 1992).
Способы ускорения, которые можно использовать, включают, например, бомбардировку микрочастицами и т. п. Одним из способов доставки трансформирующих молекул нуклеиновых кислот в растительные клетки является бомбардировка микрочастицами. Обзор этого способа приведен в Yang et al., Particle Bombardment Technology for Gene Transfer, Oxford Press, Oxford, England (1994). Небиологические частицы (микрочастицы) можно покрывать нуклеиновыми кислотами и доставлять в клетки, применяя толкающее усилие. Типовые частицы включают частицы, состоящие из вольфрама, золота, платины и т. п. Особенным преимуществом бомбардировки микрочастицами, кроме того, что она является эффективным способом воспроизводимой трансформации однодольных, является отсутствие необходимости как в выделении протопластов, так и в восприимчивости к инфекции Agrobacterium. Системой доставки частиц, подходящей для применения в данном изобретении, является гелиевая пушка-ускоритель PDS-1000/He, доступная от Bio-Rad Laboratories. Для бомбардировки незрелые зародыши или полученные целевые клетки, такие как щитки или каллюс из незрелых зародышей, можно размещать на твердой культуральной среде.
В другом альтернативном варианте реализации можно стабильно трансформировать пластиды. Способ, описанный для трансформации пластид у высших растений, включает доставку ДНК, содержащей селективный маркер, с помощью генной пушки и нацеливание ДНК на геном пластид за счет гомологичной рекомбинации (US 5451513, US 5545818, US 5877402, US 5932479 и WO 99/05265).
Agrobacterium-опосредованный перенос является широко применяемой системой для внесения генов в растительные клетки, так как ДНК можно вносить в цельные растительные ткани, тем самым обходя необходимость регенерации интактного растения из протопласта. Применение Agrobacterium-опосредованной интеграции векторов в растения для внесения ДНК в растительные клетки хорошо известно в данной области техники (смотрите, например, US 5177010, US 5104310, US 5004863, US 5159135). Кроме того, интеграция Т-ДНК является относительно точным способом, приводящим к появлению небольшого количества перестроек. Подлежащая переносу область ДНК определяется пограничными последовательностями, а в растительный геном обычно вставляют вставочную ДНК.
Векторы для Agrobacterium-опосредованной трансформации способны к репликации в E. coli, а также Agrobacterium, что позволяет осуществлять удобные манипуляции, как описано (Klee et al., Plant DNA Infectious Agents, Hohn and Schell, (editors), Springer-Verlag, New York, (1985): 179-203). Кроме того, технологические улучшения в векторах для Agrobacterium-опосредованного переноса генов улучшили упорядочение генов и рестрикционных сайтов в векторах для облегчения конструирования векторов, способных экспрессировать различные кодирующие полипептиды гены. Описанные векторы имеют удобные мультилинкерные области, фланкируемые промотором и сайтом полиаденилирования, для прямой экспрессии вставленных кодирующих полипептиды генов, и подходят для представленных целей. Кроме того, Agrobacterium, содержащие как «вооруженные», так и «безоружные» Ti-гены, можно использовать для трансформации. Для тех вариететов растений, для которых Agrobacterium-опосредованная трансформация является эффективной, она является предпочтительным способом вследствие простой и определенной природы переноса генов.
Трансгенное растение, полученное с помощью Agrobacterium-опосредованных способов трансформации, как правило, содержит один генетический локус в одной хромосоме. Такие трансгенные растения можно называть гомозиготными в отношении добавочного гена. Более предпочтительным является трансгенное растение, гомозиготное в отношении добавочного структурного гена; т. е. трансгенное растение, которое содержит два добавочных гена, по одному гену в одном локусе в каждой хромосоме в паре хромосом. Гомозиготное растение можно получать путем полового скрещивания (самоопыления) независимого сегреганта трансгенного растения, которое содержит один добавочный ген, проращивания некоторых полученных семян и анализа полученных в результате растений в отношении представляющего интерес гена.
Также следует понимать, что два разных трансгенных растения также можно скрещивать для получения потомства, содержащего два независимо сегрегирующих экзогенных гена. Самоопыление соответствующего потомства может дать растения, гомозиготные в отношении обоих экзогенных генов. Также предусматривается обратное скрещивание с родительским растением и перескрещивание с нетрансгенным растением, как и вегетативное размножение. Описание методов селекции, которые обычно используются для разных признаков и культурных растений, можно найти в Fehr, Breeding Methods for Cultivar Development, J. Wilcox (editor) American Society of Agronomy, Madison Wis. (1987).
Трансформацию растительных протопластов можно обеспечивать, используя способы на основании преципитации фосфатом кальция, обработки полиэтиленгликолем, электропорации и комбинаций этих видов обработки. Применение этих систем к разным вариететам растений зависит от способности регенерировать этот конкретный вид растения из протопластов. Описаны иллюстративные способы регенерации зерновых из протопластов (Fujimura et al., 1985; Toriyama et al., 1986; Abdullah et al., 1986).
Также можно применять другие способы трансформации, включая, но не ограничиваясь этим, внесение ДНК в растения путем прямого переноса ДНК в пыльцу, путем прямой инъекции ДНК в репродуктивные органы растения или путем прямой инъекции ДНК в клетки незрелых зародышей с последующей регидратацией высушенных зародышей.
Регенерация, развитие и культивирование растений из состоящих из одного растительного протопласта трансформантов или из различных трансформированных эксплантатов хорошо известны в данной области техники (Weissbach et al., Methods for Plant Molecular Biology, Academic Press, San Diego, (1988)). Процесс регенерации и выращивания, как правило, включает этапы отбора трансформированных клеток, культивирование этих отдельных клеток, проходя все обычные стадии от эмбрионального развития до стадии укоренившихся ростков. Трансгенные зародыши и семена регенерируют аналогично. Полученные в результате укорененные трансгенные побеги после этого высевают в подходящую для роста растения среду, такую как почва.
Развитие или регенерация растений, содержащих чужеродный, экзогенный ген, также хорошо известны в данной области техники. Предпочтительно, регенерированные растения самоопыляют для получения гомозиготных трансгенных растений. В ином случае пыльцой, полученной от регенерированных растений, опыляют выращенные из семян растения сельскохозяйственно важных линий. И наоборот, пыльцу от растений этих важных линий используют для опыления регенерированных растений. Трансгенное растение по данному изобретению, содержащее необходимую экзогенную нуклеиновую кислоту, культивируют, используя способы, хорошо известные специалисту в данной области техники.
Способы трансформации двудольных, главным образом с помощью Agrobacterium tumefaciens, и получения трансгенных растений, были описаны для хлопка (US 5004863, US 5159135, US 5518908); сои (US 5569834, US 5416011); капусты (US 5463174); арахиса (Cheng et al., 1996); и горошка (Grant et al., 1995).
Способы трансформации зерновых растений, таких как пшеница и ячмень, для внесения генетических вариаций в растение путем внесения экзогенной нуклеиновой кислоты и для регенерации растений из протопластов или незрелых растительных зародышей хорошо известны в данной области техники, смотрите, например, CA 2092588, AU 61781/94, AU 667939, US 6100447, WO 97/048814, US 5589617, US 6541257, а другие способы приведены в WO 99/14314. Предпочтительно трансгенные растения пшеницы или ячменя получают с помощью процедур Agrobacterium tumefaciens-опосредованной трансформации. Векторы, несущие необходимую конструкцию нуклеиновой кислоты, можно вносить в пригодные для регенерации клетки пшеницы из подвергаемых тканевому культивированию растений или эксплантатов, или подходящие растительные системы, такие как протопласты. Пригодные для регенерации клетки пшеницы получены предпочтительно из щитка незрелых зародышей, зрелых зародышей, полученного из них каллюса или меристематической ткани.
Для подтверждения наличия трансгенов в трансгенных клетках и растениях можно проводить амплификацию методом полимеразной цепной реакции (ПЦР) или анализа методом саузерн-блоттинга, используя известные специалистам в данной области техники способы. Обнаружение продуктов экспрессии трансгенов можно проводить любым из ряда способов, в зависимости от природы продукта, включая вестерн-блоттинг и ферментативный анализ. В частности, одним из применимых способов для количественной оценки белковой экспрессии и обнаружения репликации в разных растительных тканях является применение репортерного гена, такого как GUS. После получения трансгенных растений их можно выращивать для получения растительных тканей или частей, имеющих необходимый фенотип. Ткани растений или части растений можно собирать и/или же собирать семена. Семена могут служить источником для выращивания дополнительных растений с тканями или частями, имеющими необходимые характеристики.
«Полимеразная цепная реакция» («ПЦР») представляет собой реакцию, в которой получают идентичные копии целевого полинуклеотида, используя «пару праймеров» или «набор праймеров», состоящие из «вышележащего» и «нижележащего» праймера, и катализатор полимеризации, такой как ДНК-полимераза, и, как правило, термически стабильный фермент полимеразы. Способы ПЦР известны в данной области техники и описаны, например, в «PCR» (M.J. McPherson and S.G Moller (editors), BIOS Scientific Publishers Ltd, Oxford, (2000)). ПЦР можно проводить с кДНК, полученной путем обратной транскрипции мРНК, выделенной из растительных клеток, экспрессирующих полинуклеотид по изобретению. Однако в целом будет проще, если проводить ПЦР с геномной ДНК, выделенной из растения.
Праймер представляет собой олигонуклеотидную последовательность, которая способна гибридизироваться специфическим к последовательности образом с целевой последовательностью и продлевается во время ПЦР. Ампликоны или ПЦР-продукты, или ПЦР-фрагменты, или продукты амплификации представляют собой продукты удлинения, которые содержат праймер и новые синтезированные копии целевых последовательностей. Многоканальные ПЦР-системы содержат некоторое количество наборов праймеров, что приводит к одновременному получению более чем одного ампликона. Праймеры могут идеально совпадать с целевой последовательностью или же они могут содержать внутренние несовпадающие основания, которые могут привести к внесению сайтов распознавания/расщепления рестрикционными ферментами или каталитическими нуклеиновыми кислотами в конкретные целевые последовательности. Праймеры также могут содержать дополнительные последовательности и/или содержать модифицированные или меченные нуклеотиды для облегчения захвата или обнаружения ампликонов. Повторяемые циклы температурной денатурации ДНК, гибридизации праймеров с их комплементарными последовательностями и удлинения гибридизированных праймеров полимеразой приводят к экспоненциальной амплификации целевой последовательности. Термины «мишень», или «целевая последовательность», или «матрица» относятся к амплифицируемым последовательностям нуклеиновых кислот.
Способы прямого секвенирования нуклеотидных последовательностей хорошо известны специалистам в данной области техники и представлены, например, в Ausubel et al., (выше) и Sambrook et al., (выше). Секвенирование можно проводить любым подходящим способом, например, дидезокси-секвенирования, химического секвенирования или их вариаций. Преимуществом прямого секвенирования является возможность определения вариации в любой паре оснований конкретной последовательности.
Обработка растений/зерен
Зерна/семена по изобретению, предпочтительно зерна зерновых, или другие части растений по изобретению можно обрабатывать для получения пищевых ингредиентов, пищевых или непищевых продуктов, используя любой из известных в данной области техники способов.
В одном варианте реализации продукт представляет собой цельнозерновую муку, такую как, например, цельнозерновая мука ультрамелкого помола, или муку, полученную из около 100% зерна. Цельнозерновая мука содержит составляющую рафинированной муки (рафинированную муку) и грубую фракцию (грубую фракцию ультрамелкого помола).
Рафинированная мука может представлять собой муку, которую готовят, например, путем измельчения и просеивания очищенного зерна, такого как пшеничное или ячменное зерно. Размер частиц рафинированной муки описывается как мука, в которой не менее 98% проходит через сито с отверстиями, не большими чем у металлотканого сита с обозначением "212 микрометров (U.S. Wire 70)". Грубая фракция содержит по меньшей мере одно из отрубей и зародышей. Например, зародыши представляют собой растение на зародышевой стадии внутри зерна. Зародыши содержат липиды, волокна, витамины, белок, минералы и фитонутриенты, такие как флавоноиды. Отруби содержат несколько клеточных слоев и имеют значительное количество липидов, волокон, витаминов, белка, минералов и фитонутриентов, таких как флавоноиды. Кроме того, грубая фракция может содержать алейроновый слой, который также содержит липиды, волокна, витамины, белок, минералы и фитонутриенты, такие как флавоноиды. Алейроновый слой, хотя технически считается частью эндосперма, демонстрирует многие характеристики, присущие отрубям, и, следовательно, как правило, удаляется вместе с отрубями и зародышами во время процесса помола. Алейроновый слой содержит белки, витамины и фитонутриенты, такие как феруловая кислота.
Кроме того, грубую фракцию можно смешивать с составляющей рафинированной муки. Грубую фракцию можно смешивать с составляющей рафинированной муки для получения цельнозерновой муки, обеспечивая, таким образом, цельнозерновую муку с повышенными питательной ценностью, содержанием волокон и антиокислительной способностью по сравнению с рафинированной мукой. Например, грубую фракцию или цельнозерновую муку можно использовать в различных количествах для замещения рафинированной муки или цельнозерновой муки в пекарских изделиях, закусочных продуктах и пищевых продуктах. Цельнозерновую муку по данному изобретению (т. е. цельнозерновую муку ультрамелкого помола) также можно продавать непосредственно потребителям для использования в домашней выпечке. В типовом варианте реализации профиль грануляции цельнозерновой муки является таким, что 98% частиц по массе цельнозерновой муки имеют размер менее 212 микрометров.
В дополнительных вариантах реализации ферменты, содержащиеся в отрубях и зародышах цельнозерновой муки и/или грубой фракции, инактивированы с целью стабилизации цельнозерновой муки и/или грубой фракции. Стабилизация представляет собой процесс, в котором используется пар, нагрев, облучение или другие варианты обработки для инактивации ферментов, содержащихся в слое отрубей и зародышей. Мука, которая была стабилизирована, сохраняет свои кулинарные характеристики и имеет больший срок годности.
В дополнительных вариантах реализации цельнозерновая мука, грубая фракция или рафинированная мука могут быть компонентами (ингредиентами) пищевых продуктов и могут быть использованы для получения пищевых продуктов. Например, пищевой продукт может представлять собой бублик, бисквит, хлеб, булочку, круассан, пельмени, английский маффин, маффин, хлеб питу, хлеб из теста, приготовленного ускоренным способом, замороженный продукт из теста, тесто, консервированную фасоль, бурито, чили, тако, тамал, тортилью, закрытый пирог, готовое изделие из дробленого зерна, готовую к употреблению пищу, фаршированные продукты, предназначенную для приготовления в СВЧ пищу, брауни, торт, чизкейк, кекс к кофе, печенье, десерт, кондитерские изделия, сдобную булочку, сладкий батончик, корж для пирога, начинку для пирога, детское питание, смесь для выпечки, блинное тесто, панировку, смесь для подливки, мясную добавку, мясной заместитель, смесь специй, суповую смесь, подливку, заправку для соуса, заправку для салата, суп, сметану, лапшу, пасту, лапшу для рамена, лапшу для чоу-мейн, лапшу для ло-мейн, добавку к мороженому, мороженое-эскимо, стаканчик мороженого, брикет мороженого, крекер, сухари, пончик, эгг-ролл, прессованный закусочный продукт, фруктовый и зерновой батончик, предназначенный для приготовления в СВЧ закусочный продукт, питательный батончик, панкейк, полуфабрикат хлебобулочных изделий, крендель, пудинг, продукт на основе гранолы, закуску из чипсов, закусочную пищу, закусочную смесь, вафлю, корж для пиццы, корм для животных или корм для домашних питомцев.
В альтернативных вариантах реализации цельнозерновая мука, рафинированная мука или грубая фракция могут быть компонентами питательных добавок. Например, питательная добавка может представлять собой продукт, который добавляют в рацион, содержащий один или более дополнительных ингредиентов, как правило, содержащий: витамины, минералы, травы, аминокислоты, ферменты, антиоксиданты, травы, специи, пробиотики, экстракты, пребиотики и волокна. Цельнозерновая мука, рафинированная мука или грубая фракция по данному изобретению содержат витамины, минералы, аминокислоты и волокна. Например, грубая фракция содержит концентрированное количество пищевых волокон, а также другие важные питательные вещества, такие как витамины B, селен, хром, марганец, магний и антиоксиданты, которые важны для здорового рациона. Например, 22 грамма грубой фракции по данному изобретению поставляет 33% рекомендуемого суточного потребления волокон для человека. Питательная добавка может содержать любые известные питательные ингредиенты, которые будут способствовать общему здоровью индивида, примеры которых включают, но не ограничиваются этим, витамины, минералы, другие волокнистые компоненты, жирные кислоты, антиоксиданты, аминокислоты, пептиды, белки, лютеин, рибозу, омега-3 жирные кислоты и/или другие питательные ингредиенты. Добавка может быть поставляться, но не ограничивается ими, в следующих формах: быстрорастворимые напитки, готовые напитки, питательные батончики, вафли, печенье, крекеры, желеобразные шоты, капсулы, жвачки, таблетки и пилюли для разжевывания. В одном варианте реализации добавка с клетчаткой поставляется в форме ароматизированного шейка или напитка солодового типа, этот вариант реализации может быть в особенности привлекательным в качестве добавки с клетчаткой для детей.
В дополнительном варианте реализации можно применять процесс помола для получения многозерновой муки или многозерновой грубой фракции. Например, отруби и зародыши из одного типа зерна можно молоть и смешивать с размолотым эндоспермом или цельнозерновой мукой другого типа зернового растения. В альтернативном варианте отруби и зародыши одного типа зерна можно молоть и смешивать с размолотым эндоспермом или цельнозерновой мукой другого типа зерна. Подразумевается, что данное изобретение включает смешивание любой комбинации одного или более из отрубей, зародышей, эндосперма и цельнозерновой муки одного или более видов зерен. Этот многозерновой подход можно использовать для получения специальной муки и делать акцент на качествах и содержании питательных веществ нескольких типов зерна зерновых растений для получения одного вида муки.
Подразумевается, что цельнозерновая мука, грубая фракция и/или зерновые продукты по данному изобретению можно получать с помощью любого процесса помола, известного в данной области техники. Типовой вариант реализации включает помол зерна в одном потоке без разделения эндосперма, отрубей и зародышей зерна на разные потоки. Очищенное и кондиционированное зерно передается на измельчитель для первой проходки, такой как молотковая дробилка, валковая дробилка, штифтовая дробилка, ударная дробилка, дисковая дробилка, воздушная жерновая дробилка, щелевая дробилка и т. п. После измельчения зерно высыпается и передается на просеивающую машину. Кроме того, подразумевается, что цельнозерновая мука, грубая фракция и/или зерновые продукты по данному изобретению могут быть модифицированы или усилены посредством многочисленных других процессов, таких как: ферментация, инстантизация, экструзия, инкапсуляция, обжаривание, зажаривание и т. п.
Солодоращение
Напитки на основе солода, предложенные в данном изобретении, включают алкогольные напитки (включая дистиллированные алкогольные напитки) и безалкогольные напитки, которые получают, используя солод в качестве части или всего исходного материала. Примеры включают пиво, хаппосю (пивной напиток с низким содержанием солода), виски, слабоалкогольные напитки на основе солода (например, напитки на основе солода, содержащие менее 1% алкоголя) и безалкогольные напитки.
Солодоращение представляет собой процесс контролируемого замачивания и проращивания с последующей сушкой зерна, такого как ячменное и пшеничное зерно. Эта последовательность действий важна для синтеза многочисленных ферментов, которые вызывают модификацию зерна, процесс, в котором в первую очередь деполимеризуется клеточные стенки мертвого эндосперма и мобилизуются питательные вещества зерен. Во время последующего процесса сушки получают аромат и цвет благодаря химическим реакциям потемнения. Хотя основное применение солода связано с производством напитков, его также можно использовать в других промышленных процессах, например, в качестве источника ферментов в хлебопекарной промышленности или в качестве ароматизирующего и придающего цвет агента в пищевой промышленности, например, в виде солода или солодовой муки, или непрямым образом в виде солодового сиропа и т. д.
В одном варианте реализации данное изобретение относится к способам получения солодовой композиции. Указанный способ предпочтительно включает такие этапы:
(i) обеспечение зерна, такого как ячменное или пшеничное зерно по изобретению,
(ii) замачивание указанного зерна,
(iii) проращивание замоченного зерна в заданных условиях и
(iv) высушивание указанного пророщенного зерна.
Например, солод можно получать любым из способов, описанных в Hoseney (Principles of Cereal Science and Technology, Second Edition, 1994: American Association of Cereal Chemists, St. Paul, Minn.). При этом в рамках данного изобретения также можно использовать любой другой подходящий способ для получения солода, такой как способы для получения специальных видов солода, включая, но не ограничиваясь этим, способы прожаривания солода.
Солод используется в основном в пивоварении, но также для производства дистиллированных спиртных напитков. Пивоварение включает получение сусла, первичную и вторичную ферментацию и последующую обработку. Сначала солод размалывают, вмешивают в воду и нагревают. Во время этого «заваривания» ферменты, активируемые в солоде, разлагают крахмал ядра на пригодные для ферментации сахара. Полученное сусло осветляют, добавляют дрожжи, смесь ферментируют и проводят последующую обработку.
Обнаружение комплекса нитрогеназы
Обнаружение комплекса нитрогеназы можно проводить любым способом, который позволяет обнаруживать взаимодействие между белковым комплексом NifDK и белком NifH. Способы, подходящие для обнаружения взаимодействия между белковым комплексом NifDK и белком NifH включают любой способ, известный в данной области техники для обнаружения белок-белковых взаимодействий, включая совместную иммунопреципитацию, аффинный блоттинг, аффинную адсорбцию, FRET и т. п.
В альтернативном варианте обнаружение комплекса нитрогеназы можно проводить, измеряя активность получаемого в результате комплекса нитрогеназы.
Способы, подходящие для измерения активности нитрогеназы, включают любой способ, известный в данной области техники для обнаружения ферментативного восстановления молекулярного азота до аммиака, при котором происходит перенос электронов с белка NifH на белковый комплекс NifDK. Например, активность фиксации азота можно оценить с помощью анализа восстановления ацетилена. Вкратце, эта методика представляет непрямой способ, в котором используется способность комплекса нитрогеназы восстанавливать субстраты, содержащие тройные связи. Фермент нитрогеназа восстанавливает ацетилен (C2H2) до этилена (C2H4). Оба газа можно количественно оценивать, используя газовую хроматографию. Фиксацию азота также можно определять в анализе выделения водорода. H2 является обязательным побочным продуктом фиксации N2. Следовательно, непрямое определение активности нитрогеназы можно получить путем количественной оценки концентрации H2 в потоке газа, используя проточный сенсор H2 или газовый хроматограф.
Обнаружение фиксации N2
Фиксацию азота можно оценить, определяя суммарный прирост общего N системы растение-почва (метод баланса N); 2) разделяя растительный N на фракцию, взятую из почвы, и фракцию, полученную вследствие фиксации N2 (методы разницы N, природной распространенности 15N, разведения изотипа 15N и уреида) и 3) определяя активность нитрогеназы (анализ восстановления ацетилена и выделения водорода).
ПРИМЕРЫ
Пример 1. Материалы и методы
Экспрессия генов в растительных клетках в системе с временной экспрессией
Гены экспрессировали в растительных клетках, используя систему с временной экспрессией, преимущественно как описано у Wood et al., (2009). Бинарные векторы, содержащие кодирующую область, подлежащую экспрессии в растительных клетках, под управлением сильного конститутивного промотора 35S, вносили в штамм AGL1 или GV3101 Agrobacterium tumefaciens. Химерный бинарный вектор 35S:p19 для экспрессии вирусного супрессора сайленсинга p19 вносили отдельно в AGL1, как описано в WO2010/057246. Рекомбинантные клетки A. tumefaciens выращивали до стационарной фазы при 28°C в LB-бульоне, дополненном 50 мг/л канамицина и 50 мг/л рифампицина. Затем бактерии осаждали центрифугированием при 5000 g в течение 5 мин при комнатной температуре перед ресуспендированием до ОП600=1,0 в инфильтрационном буфере, содержащем 10 мМ MES pH 5,7, 10 мМ MgCl2 и 100 мкМ ацетосирингона. Затем клетки инкубировали при 28°C с перемешиванием в течение 3 ч, после чего измеряли ОП 600, а объем каждой культуры, включая вирусную супрессорную конструкцию 35S:p19, необходимый для достижения конечной концентрации ОП 600=0,125, добавляли в свежую пробирку. Конечный объем доводили инфильтрационным буфером. Затем листья инфильтрировали культуральной смесью, а растения, как правило, выращивали в течение дополнительных трех-пяти суток после инфильтрации перед получением листовых дисков для анализа.
Для сверхэкспрессии более чем одного представляющего интерес гена каждый дополнительный ген вносили отдельно в штамм A. tumefaciens и выращивали, как описано ранее. Бактериальные суспензии смешивали так, чтобы каждый бактериальный штамм находился в конечной концентрации ОП 600=0,125. Бактериальный штамм, содержащий ген, кодирующий вирусный супрессор сайлесинга 35S:p19, был включен во все смеси в одинаковой концентрации. Например, для экспрессии четырех генов во временном анализе листьев и с включение вирусной супрессорной конструкции конечная ОП 600 инфильтрированной смеси составляла 5×0,125=0,625 единиц. Ранее была продемонстрирована одновременная сверхэкспрессия по меньшей мере пяти генов, каждого из отдельного Т-ДНК-вектора, в растительных клетках в формате временного анализа (Wood et al., 2009).
Экстракция белка из листовой ткани
Для анализа полипептидов, вырабатываемых в растительных клетках после внесения Т-ДНК, собирали образцы листьев Nicotiana benthamiana, вырезая приблизительно 2×2 см кусочки листьев из инфильтрированных областей через 5 суток после инфильтрации (если не указано иное). Их незамедлительно замораживали в жидком азоте и размалывали в порошок в 2 мл пробирках Эппендорфа. В каждый порошковый образец добавляли по 300 мкл буфера. Буфер содержал 125 мМ Трис-HCl, pH 6,8, 4% додецилсульфата натрия (ДСН), 20% глицерина, 60 мМ дитиотреитола (ДТТ). Образцы нагревали при 95°C в течение 3 мин перед центрифугированием при 12000 g в течение 2 мин. Супернатант, содержащий экстрагированные полипептиды, удаляли, и использовали 10 мкл и 100 мкл для вестерн-блоттинга в зависимости от ожидаемого уровня подлежащего обнаружению полипептида.
Анализ методом вестерн-блоттинга
Полипептиды в экстрагированных образцах разделяли с помощью ДСН-полиакриламидного гель-электрофореза (ДСН-ПААГ) на NuPAGE бис-трис 4-12% гелях (ThermoFisher) при 200 В в течение около 1 ч. Разделенные полипептиды переносили из каждого геля на ПВДФ-мембрану, используя полусухой аппарат в соответствии с инструкциями поставщика (Thermofisher). После блоттинга гели окрашивали красителем кумасси в течение 1 ч, затем промывали в воде для визуализации оставшихся белков, чтобы продемонстрировать, что произошел перенос полипептидов. Мембраны со связанными полипептидами блокировали в течение ночи буфером ТБСТ, содержащим 5% сухого обезжиренного молока при 4°C. Буфер ТБСТ представляет собой. Анти-HA и анти-FLAG антитела приобретали от Sigma. Анти-ЗФБ антитело было подарком от Leila Blackman (Australian National University, Canberra, Australia). Антитела добавляли в разведении 1:5000 в ТБСТ с 5% сухого обезжиренного молока и инкубировали мембраны в растворе в течение 2 ч. Затем мембраны промывали 3 х 20 мин ТБСТ. Вторичное антитело, козий антимышиный Immun-Star (GAM)-HRP конъюгат (Biorad) добавляли при 1:5000 в ТБСТ с 5% сухого обезжиренного молока и инкубировали мембраны в течение 1 с с последующей промывкой мембраны 3 х 15 мин ТБСТ. Для обнаружения вторичного антитела использовали ЭХЛ-реагент Amersham и проявляли мембраны с помощью рентгеновского проявителя или на визуализаторе Amersham (Amersham).
Приготовление протопластов
Для выделения протопластов из листовых тканей адаптировали протокол из Breuers et al., (2012) следующим образом. Через трое суток после инфильтрации (3 точки на дюйм) вырезали 2 см квадратный участок инфильтрированного листа, нарезали кусочками и переносили в 5 мл шприц. Добавляли 2 мл раствора для расщепления, содержащего 1,5% (масс./об.) целлюлазы R-10, 0,4% (масс./об.) мацерозима R-10, 0,4 М маннита, 20 мМ KCl, 20 мМ MES, pH 5,6, 10 мМ CaCl2 и 0,1% (масс./об.) БСА и вручную создавали условия слабого вакуума для облегчения попадания раствора в межклеточное пространство в листовой ткани. Раствор и кусочки листьев переносили в 2 мл пробирку Эппендорфа и инкубировали смесь в течение 1 ч при комнатной температуре. Полученные в результате протопласты осторожно экстрагировали, вручную переворачивая пробирку. Листовой дебрис удаляли, используя щипцы, и оставляли протопласты отстояться перед заменой раствора раствором для визуализации (0,4 М маннита, 20 мМ KCl, 20 мМ MES, pH 5,6, 10 мМ CaCl2, 0,1% БСА).
Конфокальная лазерная сканирующая микроскопия и окрашивание митохондрий
Протопласты визуализировали, используя вертикальный конфокальный лазерный сканирующий микроскоп Leica с 40x водно-иммерсионным объективом. ЗФБ возбуждали на 488 нм и записывали испускание на 499-535 нм. Митохондрии окрашивали в течение 10-20 мин, используя 100 нМ раствор MitoTrackerR Red CMXRos (ThermoFisher Scientific). MitoTrackerR Red CMXRos возбуждали на 561 нм и записывали испускание на 570-624 нм.
Экстракция РНК, синтез и анализ кДНК
Для экстракции РНК из клеток N. benthamiana, которые были инфильтрированы Agrobacterium, кусочки листьев площадью около 2×2 см замораживали жидким азотом, измельчали в порошок и добавляли 500 мкл буфера Trizol (Thermo Fisher Scientific) на образец. После этого следовали инструкциям поставщика Trizol за исключением таких модификаций: экстракцию хлороформом повторяли и растворяли РНК при 37°C. Экстрагированную РНК обрабатывали ДНКазой RQ1 (Promega) для удаления какой-либо экстрагированной ДНК. Затем препараты РНК дополнительно очищали, используя колонки Plant RNAeasy (Qiagen). После завершения проводили синтез кДНК, используя обратную транскриптазу Superscript III (Thermo Fisher Scientific) в соответствии с протоколом поставщика с праймером олиго-dT. Для анализа РВ-ПЦР каждого образца РНК проводили три отдельные реакции синтеза кДНК. 20 мкл реакционных раствором кДНК 20-кратно разводили не содержащей нуклеаз водой. кРВ-ПЦР проводили на приборе для ПЦР в режиме реального времени Qiagen rotor gene Q. По 9,6 мкл каждой кДНК добавляли в 10 мкл 2x sensifast без ROX SYBR Taq (Bioline) и 0,4 мкл прямых и обратных праймеров по 10 мкмоль каждого до конечного реакционного объема 20 мкл. Все реакции кПЦР (как для референсных, так и для специфических генов) проводили в трех повторностях в следующих условиях проведения циклов: 1 цикл при 95°C/5 мин, 45 циклов при 95°C/15 с, 60°C/15 с и 72°C/20 с. Флуоресценцию измеряли на этапе 72°C. Затем проводили цикл плавления от 55°C до 99°C. Контрольную амплификацию для конститутивно экспрессируемой мРНК GADPH N. benthamiana использовали для нормализации генной экспрессии, используя программу для сравнительной количественной оценки в пакете программного обеспечения rotor gene. Значения для каждого набора из трех кДНК, представляющие среднее по трем повторным анализам, усредняли, что позволило рассчитать стандартную погрешность среднего (СПС).
Тандемный масс-спектрометрический анализ
Инфильтрированную ткань N. benthamiana измельчали в атмосфере жидкого N2, затем обрабатывали, используя препарат для тканевого лизиса Retsch в 2 мл пробирках Эппендорфа в 50 мМ Трис-HCL, pH 7,5, 1 мМ ЭДТК, 150 мМ NaCl, 0,2% ДСН, 10% глицерина, 5 мМ ДТТ, 0,5 мМ ПМСФ и 1% коктейля из ингибиторов протеаз для растений (Sigma, номер в каталоге P9599). Белковые экстракты очищали центрифугированием, а супернатанты использовали непосредственно в качестве исходного материала для инкубации в течение ночи с моноклональным анти-HA антителом, конъюгированным с агарозными гранулами (Sigma, номер в каталоге A2095). Несвязанные белки удаляли с помощью серии промывок 150 мМ Трис-HCL pH 7,5, 5 мМ ЭДТК, 150 мМ NaCl, 0,1% Тритон X-100, 5% глицерина, 5 мМ ДТТ, 0,5 мМ ПМСФ и 1% коктейля из ингибиторов протеаз. Связанные белки элюировали путем инкубации гранул в буфере Laemmli (50 мМ Трис-HCl, pH 6,8, 2% (масс./об.) ДСН, 0,1% (масс./об.) бромфеноловый синий, 10% (об./об.) глицерин, 100 мМ ДТТ) при 95°C в течение 10 минут. Исходные и иммунопреципитированные образцы белков разделяли с помощью ДСН-ПААГ, а участок геля, содержащий слитый полипептид (МНП::NifH::HA), определяли в параллельном анализе вестерн-блоттинга реплики геля. Область, содержащую слитый полипептид, вырезали, обрабатывали путем триптического расщепления в геле и анализировали триптические продукты с помощью тандемного масс-спектрометрического анализа, используя систему Agilent Chip Cube, сопряженную с масс-спектрометром Agilent Q-TOF 6550 (Campbell et al., 2014). Масс-спектры, полученные от триптических пептидов из обычных примесей, таких как добавленный трипсин и кератин, идентифицировали перед тем, как оставшиеся масс-спектральные данные использовали для поиска по базе данных, содержащей все белковые последовательности для вида Nicotiana из NCBI (номер базы данных 10/3/2015) плюс последовательность HA, используя программное обеспечение SpectrumMill (Agilent Rev B.04.01.141 SP1) с допуском по массе для предшественника 15 м. д., допуском по массе для продукта 50 м. д., оценкой по умолчанию Q-TOF и жесткими настройками «автовалидации» по умолчанию. Модификация остатков цистеина акриламидом была необходимой модификацией, а окисление метионина допускалось как переменная модификация. Изначально было необходимо триптическое расщепление и допускался пропуск до двух расщеплений. После валидации пептидных совпадений поиск повторяли с оставшимися несовпадающими спектрами с допуском нетриптического расщепления.
Программное обеспечение, используемое для молекулярного моделирования
Все модели гомологии конструировали, используя программу MODELLER (Sali and Blundell, 2013), реализованную в Accelrys Discovery Studio 3.5. Подходящие матрицы, на основании которых строили модели гомологии, идентифицировали, используя поиск BLAST по банку данных Brookhaven Protein Databank. Все выравнивания последовательностей проводили, используя алгоритм ClustalW (Sali and Blundell, 2013), реализованный в Discovery Studio 3.5. Все моделирование молекулярной динамики проводили с помощью Amber 12.
Трансформация Azotobacter vinelandii
Плазмиды трансформировали в Azotobacter vinelandii в соответствии со способом Dos Santos (2011). Вкратце, A. vinelandii DJ1271 наносили на твердую среду Берка, в которой отсутствовал молибдат из исходного раствора ДМСО, и пассировали дополнительный раз, чтобы избавить клетки от примеси ДМСО. Петлю для посева клеток использовали для инокуляции 50 мл модифицированной среды Берка, в которой отсутствовал молибдат, и добавляли железо в 125 мл колбу Эрленмейера. Культуру инкубировали при 28°C, перемешивая при 160 об/мин в течение 20-24 ч. 1 нг необходимой плазмидной ДНК добавляли в 50 мкл аликвоты компетентных клеток и инкубировали при комнатной температуре в течение 20 мин. Затем смесь из клеток и ДНК добавляли в 3,8 мл модифицированной среды Берка и восстанавливали в течение 24 ч при 28°C, перемешивая при 160 об/мин. Аликвоты восстановленных клеток высевали на твердую модифицированную среду Берка, содержащую 6 мкг/мл канамицина и 20 мкг/мл ампициллина для проведения отбора в отношении наличия pMMB66EH и его производных. Планшеты инкубировали при 28°C в течение 3-5 суток. Одиночные колонии повторно пассировали на твердой модифицированной среде Берка для получения изолятов одиночных колоний. Повторно пассированные изоляты, которые сохранили устойчивость к ампициллину, использовали для инокуляции твердой модифицированной среды Берка для получения исходных раствором ДМСО и дополнительного исследования.
Пример 2. Применение МНП из гена CoxIV дрожжей для нацеливания полипептидов Nif на растительные митохондрии
Насколько известно авторам изобретения, не существует опубликованных работ по выработке бактериальных полипептидов нитрогеназы Nif в высших растениях, в том числе, например, в растительных митохондриях. Чтобы попытаться осуществить такую выработку в митохондриях, авторы изобретения разработали растительную систему временной экспрессии в листьях Nicotiana benthamiana, чтобы определить, могут ли полипептиды Nif вырабатываться и обнаруживаться в растительных клетках, и чтобы исследовать, какие слитые полипептиды на основе бактериальных полипептидов Nif можно нацеливать на митохондрии в растительных клетках, используя митохондриальные нацеливающие пептиды (МНП). Чтобы исследовать локализацию в митохондрии, выбрали МНП, полученный из N-концевой области белка субъединицы IV дрожжевой цитохром c-оксидазы (CoxIV). Было показано, что МНП CoxIV обеспечивает митохондриальную локализацию и процессинг слитого полипептида с ЗФБ в растительных клетках (Kohler et al., 1997). МНП CoxIV (SEQ ID NO:1) до расщепления составлял в длину всего 29 аминокислот, являясь более коротким, чем многие другие МНП (Huang et al., 2009). Когда этот МНП подвергался процессингу в дрожжевых клетках, происходило удаление 17 или 25 аминокислот (Hurt et al., 1985), потенциально оставляя всего 4 аминокислотных остатка из МНП, присоединенного к N-концу полипептида. В более поздних исследованиях (Huang et al, 2009) в растительных клетках, однако предположили, что процессинг в митохондриальном матриксе (ММ) митохондриальной матриксной протеазой (ММП) приводил бы к расщеплению пептида непосредственно выше серин-серина в аминокислотах 20-21 с созданием процессированного слитого полипептида с добавочными 10 аминокислотными остатками из МНП и N-терминальным концом слитого полипептида. Авторы изобретения учли, что более короткая последовательность МНП может быть преимуществом, в частности, если происходящее после расщепления слияние приводит к добавлению только 10 аминокислот.
Было разработано производное МНП CoxIV, называемое в данном документе dCoxIV (SEQ ID NO:2). dCoxIV содержит консервативные остатки аргинина и серина в мотиве xRxxxSSx (SEQ ID NO:3), вовлеченном в импорт и процессинг полипептидов в митохондрии, в соответствии с Huang et al., (2009), которые в ходе полногеномных исследований в отношении митохондриального нацеливания и сайтов процессинга обнаружили, что большинство важных остатков для импорта и процессинга в растительном митохондриальном матриксе (ММ) были аргинином в позиции на три или четыре остатка выше сайта расщепления(-3R или -4R) и двумя остатками серина непосредственно после сайта расщепления (+1S, +2S). dCoxIV содержит две дополнительные аминокислоты, вставленные в направлении N-терминального конца, и также содержит глутамат в позиции 28 в SEQ ID NO:2, а не соответствующий глутамин в МНП нативного CoxIV. Не ожидалось, что эти изменения могут влиять на локализацию или расщепление пептида dCoxIV.
Конструирование векторов pCW440 и pCW441
Для внесения генов в растительные клетки был разработан и создан многоцелевой растительный/бактериальный экспрессионный вектор pCW440. В его основе лежал бинарный вектор, чтобы обеспечить возможность репликации и отбора в бактериях как Escherichia coli, так и в Agrobacterium tumefaciens, а также содержание области Т-ДНК для переноса генов из A. tumefaciens в растительные клетки. Для создания pCW440 проводили обработку pORE1 (Coutu et al., 2007) для удаления гена растительного селективного маркера, создавая pORE1-ноль. Этот вектор содержал промотор 35S и область терминации транскрипции nos 3'. Синтезировали фрагмент ДНК, содержащий, в следующем порядке, РНК-полимеразу T7, 5'НТО последовательность, нуклеотидную последовательность, кодирующую МНП dCoxIV, инициируемую стартовым кодоном ATG, сайт клонирования для рестрикционного фермента AscI и область терминации транскрипции для РНК-полимеразы T7. Последовательность этого фрагмента была частично основана на векторе pET14b (Novogene). Этот фрагмент фланкировался рестрикционными сайтами, чтобы обеспечить возможность лигирования в pORE-ноль между промотором 35S и 3' областью nos с созданием, таким образом, pCW440. Нуклеотидная последовательность области Т-ДНК pCW440 приведена как SEQ ID NO:4.
Компоненты экспрессионной кассеты в пределах Т-ДНК вектора представляли собой, в порядке в направлении транскрипции, промотор CaMV 35S (нуклеотиды 219-1564 в SEQ ID NO:4), фланкируемый сайтом HindIII и сайтом XhoI в целях клонирования, для управления экспрессией нижележащей кодирующей белок области в растительных клетках для получения слитого полипептида, затем промотор T7 (нуклеотиды 1571-1587), который обеспечивает возможность экспрессии в подходящих клетках E.coli кодирующей области для получения того же полипептида, затем нуклеотиды, кодирующие МНП dCoxIV (нуклеотиды 1650-1742) с инициацией стартовым кодоном ATG, за которыми следовал сайт рестрикционного фермента для AscI (нуклеотиды 1743-1750) в качестве сайта клонирования для вставки кодирующей белок области, затем последовательность терминации транскрипции РНК-полимеразы T7 (нуклеотиды 1810-1856) и, наконец, растительная 3' последовательность терминации транскрипции nos (нуклеотиды 1861-2084). Генетическая карта pCW440 схематически представлена на Фиг. 1.
Нуклеотидную последовательность, кодирующую МНП, вставляли в pCW440 так, чтобы обеспечить возможность вставки любой необходимой кодирующей белок области в сайт AscI для получения слияния в рамке кодируемого белка с С-концом аминокислот dCoxIV в транслируемом полипептиде. Вектор и его производные были стабильными в E. coli и могут быть использованы для получения белков с помощью промоторной системы полимеразы T7 (Studier and Moffatt, 1986). Следовательно, многоцелевой pCW440 был разработан как базовый вектор для экспрессии слитых полипептидов в бактериях с применением коммерчески доступных линий клеток РНК-полимеразы T7, таких как BL21 gold, в которых промотор и терминатор T7 управляют экспрессией слитого белка. Так как в бактериях отсутствуют митохондрии, в E. coli не будет происходить процессинг полноразмерного слитого полипептида, содержащего МНП. Тот же вектор можно использовать в растительных клетках для экспрессии того же слитого полипептида под управлением промотора 35S 3' терминатора nos, управляющих генной экспрессией, используя эндогенный аппарат транскрипции в растительных клетках.
Для создания pCW441 фрагмент ДНК, кодирующий открытую рамку считывания ЗФБ (Brosnan et al., 2007) без исходного остатка метионина, амплифицировали посредством ПЦР, фланкировали сайтами AscI, чтобы обеспечить возможность вставки в сайт AscI pCW440 и позволить трансляционное слияние между dCoxIV и ЗФБ. Вставка в сайте AscI приводила к внесению трех дополнительных аминокислот в соединение слитого полипептида. Этот фрагмент ДНК вставляли в pCW440 для создания pCW441.
Чтобы исследовать, была ли область dCoxIV способна направлять GUS-слитый полипептид на растительные митохондрии, клетки A. tumefaciens, содержащие pCW441 (dCoxIV::ЗФБ), инфильтрировали в листья N. benthamiana, используя способ, описанный в примере 1. Было известно, что N-концевые слияния ЗФБ в общем случае не влияют на его флуоресцентную активность (Kohler et al., 1997), следовательно, ожидалось, что полипептид dCoxIV::ЗФБ сохранит флуоресцентную активность в случае его экспрессии. Контрольную инфильтрацию проводили в то же время с A. tumefaciens, содержащими конструкции для экспрессии локализованного в цитоплазме ЗФБ, pUQ214 (Brosnan et al., 2007). Все варианты инфильтрации включали клетки A. tumefaciens, содержащие конструкцию, кодирующую вирусный супрессор сайленсинга, p19, который также использовали отдельно в качестве контрольной инфильтрации. Через четверо суток после инфильтрации инфильтрированные зоны листьев исследовали в отношении флуоресценции с помощью световой микроскопии с возбуждением синим цветом на 488 нм и ЗФБ-фильтром для обнаружения любого полипептида ЗФБ. Флуоресценцию наблюдали в клетках листьев, инфильтрированных pCW441. Под микроскопом наблюдали флуоресценцию многочисленных мелких субклеточных структур, что согласуется с предыдущими данными (Kohler et al., 1997). Эти структуры были высокомобильными и демонстрировали тенденцию к конгрегации по краям клетки, что согласуется с тем, что они являются митохондриями. В противоположность этому, клетки, в которые был внесен ген, кодирующий цитоплазматический ЗФБ, флуоресцировали более равномерно. Было сделано заключение, что dCoxIV было достаточно для направления полипептида dCoxIV::ЗФБ в растительные митохондрии, что очевидно по перемещению мелких подобных митохондриям частиц в растительной клетке.
Разработка и конструирование векторов pCW446, pCW447, pCW448 и pCW449
На основании наблюдения, что слитый полипептид dCoxIV::ЗФБ вырабатывался в растительных клетках после временной экспрессии и локализовался в митохондриях, был разработан и сконструирован ряд векторов для обеспечения экспрессии слитых полипептидов dCoxIV::Nif. Изначально были разработаны и созданы генетические конструкции для экспрессии слияний в NifH, NifD, NifK и NifY Klebsiella pneumoniae. Аминокислотные последовательности для NifH, NifD, NifK и NifY K. pneumoniae дикого типа приведены как SEQ ID NO:5, 6, 7 и 8 соответственно. В попытке улучшить эффективность трансляции кодирующие белок области для этих полипептидов были кодон-модифицированы с использованием человеческого предпочтения кодонов и криптических сайтов сплайсинга, криптических сигналов полиаденилирования, а последовательности внутренних повторов были удалены из нуклеотидных последовательностей коммерческим поставщиком (Geneart). В случае каждого слитого полипептиды был опущен инициирующий метионин Nif. Кроме того, каждая из открытых рамок считывания включала нуклеотидную последовательность, кодирующую С-концевое удлинение к каждому полипептиду, причем удлинение содержало HA- или FLAG-эпитоп (например, Wood et al., 2006), чтобы обеспечить легкость обнаружения полипептидов с помощью антител к эпитопам из коммерческих источников. Если транслируемые полипептиды имели одинаковый размер, добавляли разные эпитопы, чтобы обеспечить возможность различать белки с помощью разных антител, которые являются коммерчески доступными. Например, слитые полипептиды NifD и NifK имели одинаковый размер и, следовательно, NifD был слит с эпитопом FLAG, а NifK с эпитопом HA. Аминокислотные последовательности, которые были добавлены в каждом С-конце, приведены как SEQ ID NO:21 для эпитопа HA и SEQ ID NO:22 для эпитопа FLAG. Аминокислотные последовательности для слитых полипептидов, включая МНП dCoxIV и эпитопы, приведены как SEQ ID NO:23, 24, 25 и 26, соответственно.
Кодон-оптимизированные нуклеотидные последовательности, кодирующие полипептиды NifH::HA, NifD::FLAG, NifK::HA и NifY::HA, приведены как SEQ ID NO: 27, 28, 29 и 30, соответственно. Фрагменты ДНК, имеющие эти нуклеотидные последовательности, были синтезированы коммерческим поставщиком, причем каждый включал фланкирующие рестрикционные сайты AscI и каждый был вставлен в сайт AscI в pCW440 для создания векторов pCW446 (pCoxIV::NifH::HA), pCW447 (pCoxIV::NifD::FLAG), pCW448 (pCoxIV::NifK::HA) и pCW449 (pCoxIV::NifY::HA).
Экспрессия слитых полипептидов в бактериях
Многоцелевая природа этих векторов обеспечила возможность экспрессии генов и выработки слитых полипептидов в подходящих бактериальных клетках для получения источника полипептидов, которые можно использовать в качестве контроля во время экспериментов с проведением гель-электрофореза и иммунообнаружения. Следовательно, эти векторы вносили в штамм E. coli BL21.1-Gold (Stratagene), который обеспечивает возможность экспрессии из промотора T7 в генетических конструкциях после индукции ростом в среде Overnight Express (EMD-Millipore) при 37°C. Бактериальные культуры, несущие pCW446, pCW447, pCW448 или pCW449, центрифугировали для сбора клеток. Клетки лизировали в половине объема реагента BugBuster (EMD-Millipore) в течение 2 мин при комнатной температуре. Лизат дополнительно центрифугировали, чтобы собрать тельца включения, которые дополнительно два раза промывали в половине объема реагента BugBuster. Тельца включения растворяли в стандартном буфере Laemmli, который содержал ДСН, и дополнительно разводили, как требуется для генерации чистого сигнала при вестерн-блоттинге. Вестерн-блоты зондировали коммерчески доступными антителами, распознающими эпитоп HA или FLAG, при разведении 1:5000 и кроличьим антимышиным вторичным HRP-антителом, а хемилюминесцентный реагент ChemStar (Amersham) служил конечным раствором для обнаружения.
Экспрессия слитых полипептидов в растительных клетках
Каждую из генетических конструкций для экспрессии слитых содержащих тэг полипептидов dCoxIV::Nif::HA или FLAG вносили отдельно в листья N. benthamiana, используя способ, описанный в примере 1. Как было указано выше, все варианты инфильтрации включали клетки A. tumefaciens, содержащие конструкцию, кодирующую вирусный супрессор сайленсинга, p19, для снижения ответов генного сайленсинга. Через 5 суток инфильтрированные зоны собирали и обрабатывали, как описано в примере 1 и выше для бактериальных экстрактов, методом вестерн-блоттинга, используя антитела, которые связывают эпитопы HA или FLAG. Это позволило провести обнаружение полипептидов и оценить их размер и относительные уровни экспрессии. На этапе гель-электрофореза аликвоты бактериальных и растительных экстрактов наносили на смежные дорожки, чтобы обеспечить возможность обнаружения возможных небольших изменений в размере полипептидов, которые были предсказаны в случае расщепления МНП dCoxIV. Например, размер полноразмерного полипептида dCoxIV::NifY::HA составлял приблизительно 30 кДа, тогда как размер процессированного полипептида dCoxIV::NifY::HA по прогнозам должен составлять 28 кДа.
После изучения вестерн-блотов (Фиг. 2) присутствие полосы, соответствующей полипептиду dCoxIV::NifH::HA, четко наблюдалось для образцов, в которых была внесена Т-ДНК pCW446. По наблюдениям этот слитый полипептид NifH экспрессировался сильнее, чем слитые полипептиды NifK и NifY, в клетках листьев на основании интенсивности полос. Размер слитого полипептида NifH, вырабатываемого в растительных клетках, оказался идентичным экспрессируемому в бактериях полипептиду, приблизительно на 40 кДа в гель-электрофорезе. Этот размер соответствовал ожидаемому для слитого белка dCoxIV::NifH::HA. Аналогичным образом, полосу, соответствующую полипептиду dCoxIV::NifK::HA, наблюдали для образцов, в которых была внесена Т-ДНК pCW448 в клетки листьев, а полосу, соответствующую dCoxIV::NifY::HA, наблюдали для образцов, в которых была внесена Т-ДНК pCW449. В каждом случае экспрессируемый в растениях полипептиды был того же размера, что и соответствующий экспрессируемый в бактериях полипептид, составляющего приблизительно 60 кДа для полипептида NifK и приблизительно 30 кДа для полипептида NifY. На основании отсутствия существенной разницы в подвижности экспрессируемых в бактериях и растениях полипептидов авторы изобретения заключили, что в каждом случае МНП dCoxIV не расщеплялся до какого-либо существенного уровня в растительных клетках.
Для слитого полипептида dCoxIV::NifD::FLAG наблюдали достаточно отличающиеся результаты для растительных клеток в сравнении с бактериальными клетками. Когда слитые полипептиды экспрессировали из pCW447 в бактериях, а образцы анализировали методом вестерн-блоттинга, используя антитело для обнаружения полипептидов с FLAG-тэгом, наблюдали выраженную полосу на 55 кДа, как и ожидалось для полноразмерного слитого полипептид (Фиг. 2). Однако, когда Т-ДНК из pCW447 вносили в растительные клетки, пригодная для обнаружения полоса для полипептида dCoxIV::NifD::FLAG отсутствовала, даже после продления обработки вестерн-блотов методами визуализации. Это позволило предположить отсутствие выработки или же очень быстрый оборот слитого полипептида, содержащего последовательность NifD.
Эксперимент с конструкцией NifD повторяли несколько раз, чтобы проверить результат. Снова, полипептид dCoxIV::NifD::FLAG не обнаружили в экстрактах из растительных клеток даже после продления обработки вестерн-блотов. Генетическую конструкцию проверили путем секвенирования с NifD-специфическими и 35S-специфическими праймерами для подтверждения правильности последовательности промотора и фрагмента NifD в остове pCW440. Было понятно, что открытая рамка считывания была интактной, так как та же самая конструкция хорошо экспрессировалась в штамме E. coli.
Экспрессия других слитых полипептидов Nif в растительных клетках
Создавали аналогичные генетические конструкции, кодирующие большую группу слитых полипептидов Nif, в каждом случае используя последовательности K. pneumoniae и используя pCW440 в качестве базового вектора. Это включало оптимизацию кодонов кодирующих белок областей, пропуск инициирующего метионина нативного Nif и добавление С-концевого удлинения, содержащего HA- или FLAG-эпитопный тэг, к каждому слитому полипептиду. Эти конструкции представляли собой pCW452 (dCoxIV::NifB::HA; аминокислотная последовательность SEQ ID NO:31); pCW454 (dCoxIV::NifE::HA; SEQ ID NO:32); pCW455 (dCoxIV::NifN::FLAG; SEQ ID NO:33); pCW456 (dCoxIV::NifQ::HA; SEQ ID NO:34); pCW450 (dCoxIV::NifS::HA; SEQ ID NO:35); pCW451 (dCoxIV::NifU::FLAG; SEQ ID NO:36) и pCW453 (dCoxIV:NifX::FLAG; SEQ ID NO:37).
В случае каждой из них выработку полноразмерного слитого полипептида в клетках N. benthamiana без проблем обнаруживали после внесения релевантной Т-ДНК из Agrobacterium. В каждом случае размер обнаруженного полноразмерного полипептида был таким же, как и размер соответствующего вырабатываемого в бактериях полипептида, что указывает на отсутствие расщепления МНП ММП в растительных клетках. В некоторых случаях в вестерн-блотах наблюдали по несколько полос. В частности, экспрессия трансляционных слитых полипептидов dCoxIV с NifH::HA, NifS::HA и NifN::FLAG приводила к появлению нескольких меньших полос в вестерн-блотах, возможно, вследствие начала трансляции в криптических, внутренних стартовых кодонах в открытых рамках считывания или вследствие расщепления полипептида в растительных клетках, или во время экстракции так, что эпитоп в С-терминальном конце все еще присутствовал в регистрируемой полосе. По результатам этого анализа выработка слитых полипептидов NifH, NifS, NifU и NifX происходила на более высоких уровнях, чем остальных, тогда как слитые полипептиды NifK, NifY, NifE, NifN, NifB и NifQ были обнаружены на уровнях от умеренного до низкого. Опять же, выработка слитого полипептида NifD в растительных клетках обнаружена не была. Авторы изобретения заключили, что все слитые полипептиды Nif за исключением полипептида NifD можно экспрессировать в растительных клетках, используя этот подход, хотя экспрессия происходит на разных уровнях, несмотря на аналогичные параметры частоты использования кодонов и идентичные регуляторные последовательности промоторов и полиаденилирования, или накопление происходит в разном количестве. Что важно, авторы изобретения заключили, что было что-то необычное относительно конструкции слитого полипептида для NifD, так как он очевидно выделялся.
Пример 3. Дополнительные попытки обнаружения слитого полипептида NifD в растительных клетках
Учитывая отсутствие обнаружения слитого полипептида dCoxIV::NifD::FLAG, как описано в примере 2, авторы изобретения предположили, что этот слитый полипептид Nif может быть чувствительным к разложению, связанному, возможно, с концентрацией кислорода, фотосинтезом в клетках листьев или потенциальным неправильным сворачиванием и, следовательно, нестабильностью полипептида, возможно, вследствие отсутствия предполагаемого белка шаперона (Ribbe and Burgess, 2001). Чтобы проверить эту гипотезу, A. tumefaciens, содержащие вектор pCW447, чья Т-ДНК кодировала полипептид pCoxIV::NifD::FLAG, инфильтрировали в листья N. benthamiana. Инфильтрированные растительные ткани вырезали и поддерживали в жидкой культуральной среде в течение 24 ч в переменных условиях. Также исследовали комбинации каждой из этих вариаций. Вариации включали поддержание растительных тканей при концентрациях кислорода 21% (концентрация кислорода окружающей среды), 5% или 1% в темноте или при свете. Также в некоторых инфильтрациях осуществляли совместное внесение генетической конструкции для экспрессии полипептида GroEL (Ribbe and Burgess, 2001) или легтемоглобина (Ott et al., 2005) (Lhb; Фиг. 6 и 3). Этого достигали путем вставки GroEL- и Lbh-кодирующих последовательностей в экспрессионный вектор pORE1-35S (Wood et al., 2009) с созданием конструкций pCW-GroEL и pCW444 соответственно. Обе конструкции трансформировали в агробактерии и использовали для временной листовой экспрессии, как описано ранее.
Ни одна из этих вариаций в условиях или генах не приводила к обнаружению слитого полипептида dCoxIV::NifD::FLAG в клетках N. benthamiana, даже несмотря на то, что контрольные инфильтрации приводили к выработке на высоком уровне других слитых полипептидов Nif, таких как полипептид dCoxIV::NifN:FLAG.
Из этих экспериментов авторы изобретения заключили, что экспрессия слитого полипептида NifD в растительных клетках представляет проблему, которую необходимо решить.
Пример 4. Экспрессия нескольких векторов, экспрессирующих комбинацию полипептидов Nif, в растительных клетках
Авторы изобретения также исследовали, возможна ли коэкспрессия четырех слитых полипептидов Nif в системе из листьев N. benthamiana и может ли это улучшить уровень выработки полипептида dCoxIV::NifD. Эту попытку осуществляли, смешивая четыре клеточные суспензии A. tumefaciens, каждая из которых содержала отличный ген для экспрессии, а именно для слияний dCoxIV с NifY::HA, NifD::FLAG, NifK::HA и NifH::HA, наряду с A. tumefaciens, содержащими конструкцию p19. Когда экстракты из инфильтрированных листовых тканей анализировали, как и ранее, методом вестерн-блоттинга, в этом эксперименте с совместной инфильтрацией четырех генов Nif наблюдали полосы для dCoxIV::NifK, dCoxIV::NifY и dCoxIV::NifH, хотя и с обнаружением каждого на намного меньших уровнях, чем при отдельной экспрессии, но без обнаруживаемой полосы для dCoxIVNifD. Следовательно, слитый полипептид NifD снова оказался отличным от других полипептидов Nif. Комбинация dCoxIV::NifK::HA, dCoxIV::NifH::HA и dCoxIV::NifY::HA не повысила выработку коэкспрессируемого dCoxIV::NifD::FLAG до обнаруживаемых уровней.
Обсуждение.
В экспериментах, описанных выше, синтезировали и использовали генетические конструкции, каждая из которых кодировала производное дрожжевого митохондриального нацеливающего пептида (МНП), dCoxIV, слитого по отдельности с десятью разными полипептидами Nif. Их также сливали с эпитопным тэгом HA или FLAG в каждом С-конце для обнаружения полипептидов при выработке в бактериальных или растительных клетках, и, как было показано, они экспрессировались в листовых тканях после внесения Т-ДНК A. tumefaciens. Процессинг МНП в митохондриях исследовали, скрупулезно сравнивая размеры полипептидов, экстрагированных из клеток бактерий и N. benthamiana. По наблюдениям все десять слитых полипептидов dCoxIV-Nif легко обнаруживались в анализе вестерн-блоттинга после выработки в бактериях E. coli, но только девять полипептидов обнаруживались после внесения в клетки N. benthamiana. Исключение составлял полипептид dCoxIV::NifD::FLAG, который, соответственно, не был обнаружен. Вариация окружающих условий, в которых поддерживали растительные ткани - сниженная концентрация кислорода, поддержание растительных тканей в темноте или при свете или присутствие коэкспрессируемого легтемоглобина или белка шаперона GroEL, - не привело к обнаружению этого полипептида
NifD является важными компонентом ферментного комплекса нитрогеназы. Следовательно, эксперименты в следующих примерах проводили в попытках исправить отсутствие экспрессии слитого полипептида NifD.
Пример 5. Валидация МНП pFAγ для направления белков в растительные митохондрии
Как описано в примерах 2-4, была продемонстрирована выработка десяти из одиннадцати слитых полипептидов Nif в клетках листьев N. benthamiana с применением МНП dCoxIV, единственное исключение составил слитый полипептид NifD. В каждом случае не наблюдали процессинг нацеливающего пептида. Следовательно, авторы изобретения исследовали, смогут ли разные последовательности МНП, слитые с NifD и другими полипептидами Nif, обеспечить обнаруживаемую экспрессию в растительных клетках и расщепление слитого полипептида. Для этой цели авторы изобретения выбрали МНП из γ-субъединицы F1-АТФазы (pFAγ) A. thaliana. Этот МНП длиной 77 аминокислотных остатков был функционально валидирован в протопластах Arabidopsis (Lee et al., 2012) путем слияния с репортерным полипептидом ЗФБ. Расщепление последовательности МНП pFAγ матриксной процессирующей протеазой (МПП) происходит после аминокислоты 42, оставляя С-концевую часть из 35 аминокислот, слитую с N-концом слитого полипептида. Не было известно, сколько из 35 аминокислот требуется для митохондриальной локализации и процессинга в клетках листьев N. benthamiana, следовательно, авторы изобретения решили использовать всю 77-аминокислотную последовательность. Следовательно, способность МНП pFAγ к переносу слитых полипептидов Nif в ММ интактных клеток листьев растений исследовали, используя временную аналитическую систему на основе листьев N. benthamiana.
Химически синтезировали фрагмент ДНК из 970 п. о., который кодировал 319-аминокислотный полипептид, состоящий из 77 аминокислот МНП pFAγ (аминокислоты 1-77 из SEQ ID NO:38), слитый с ЗФБ (GFP 65T, № доступа GenBank U43284; Haas et al., 1996), разделенный тремя аминокислотами gly-ala-pro (GAP), и также содержащий фланкирующие рестрикционные сайты NcoI и AscI. После расщепления NcoI и AscI (частично) этот фрагмент вставляли в сайты NcoI и AscI в pCW441, создавая вектор pRA01. Расщепление pRA01 AscI вырезало ЗФБ-кодирующую область, но оставляло последовательность МНП pFAγ и аминокислоты GAP, создавая вектор pRA00, который использовали в качестве базового вектора для клонирования слитых полипептидов Nif. Когда Nif или другой полипептид был слит ниже МНП pFAγ плюс аминокислоты GAP путем вставки последовательности ДНК в сайте AscI, получаемая в результате генетическая конструкция кодировала МНП pFAγ плюс аминокислоты GAP в месте соединения слияния, тем самым добавляя 80-аминокислотное N-концевое удлинение к Nif или другому полипептиду (SEQ ID NO:38). Ожидалось, что процессинг МНП pFAγ в митохондриях приведет к отщеплению 42 аминокислот с N-конца, включая инициирующий метионин, уменьшая размер экспрессируемого полипептида на около 4,6 кДа. Следовательно, ожидалось, что расщепление МНП оставит 38 аминокислот из С-концевого удлинения, слитых в N-конце с Nif или другим полипептидом.
В качестве контрольного вектора, который бы кодировал N-концевое удлинение такой же длины, но не обеспечивал митохондриальный процессинг МПП, создавали второй вектор, который кодировал нерабочую версию МНП pFAγ. В этом векторе в области МНП, необходимые для его митохондриального распознавания и процессинга, вносили 24 аминокислотные замены (Lee et al., 2012), включая аминокислоты в сайте расщепления pFAγ. Каждая замена замещала аминокислоты дикого типа в МНП pFAγ в pRA1 остатками аланина (Фиг. 3). Следовательно, эта модифицированная версия МНП pFAγ, обозначаемая в данном документе mFAγ, не могла бы быть надлежащим образом процессирована и вместо этого привела бы к получению полноразмерного слитого полипептида, имеющего такое же число аминокислотных остатков, что и соответствующий непроцессированный слитый полипептид pFAγ. Следовательно, этот модифицированный вектор использовали в качестве базового вектора для экспрессии слитых полипептидов, чтобы обеспечить непроцессированный контроль молекулярной массы в анализе вестерн-блоттинга. Оба вектора, pRA00 и его производный mFAγ, были бинарными векторами, обеспечивающими перенос своей Т-ДНК в растительные клетки из A. tumefaciens. Аминокислотная последовательность модифицированного N-концевого удлинения mFAγ, включая триплет GAP в C-терминальном конце, приведена как SEQ ID NO:39.
Чтобы исследовать способность МНП pFAγ локализовать слитые полипептиды в митохондриях растительных клеток, использовали pRA01 во временном анализе с листьями N. benthamiana. В качестве контроля для обнаружения матриксного процессинга слитого полипептида pFAγ::ЗФБ в растительных клетках также создавали соответствующий вектор, кодирующий слитый полипептид mFAγ::ЗФБ, обозначаемый pRA21 (Таблица 3). Через пять суток после инфильтрации листьев A. tumefaciens, содержащими pRA01 или pRA21, собирали образцы листьев из инфильтрированных зон и готовили белковые экстракты, как описано в примере 1. Для белковых экстрактов проводили гель-электрофорез ДСН-ПААГ и вестерн-блоттинг, используя антитело к ЗФБ. При внесении pRA01 (pFAγ::ЗФБ) в вестерн-блотах наблюдали полипептидную полосу, имеющую ожидаемый размер (~30 кДа) для полипептида ЗФБ, который был отщеплен в предсказанном сайте, тогда как для pRA21 (mFAγ::ЗФБ) наблюдали полосу большего размера (~35 кДа), чем ожидаемый для непроцессированного слитого полипептида (Фиг. 4). Более слабую полосу на ~ 28 кДа наблюдали как для pRA01, так и для pRA21, которую не наблюдали в отрицательном контроле, в котором отсутствовал какой-либо ген, кодирующий полипептид ЗФБ. Вероятно она представляет продукт деградации полипептидов ЗФБ или продукт, возникающий при альтернативной транскрипции или трансляции. Оказалось, что процессинг слитого полипептида pFAγ::ЗФБ был эффективным, так как полоса для расщепленной формы была намного интенсивнее, чем полоса для нерасщепленной формы (Фиг. 4). Авторы изобретения заключили, что слитый полипептид pFAγ::ЗФБ процессировался в ММ интактных клеток листьев N. benthamiana, что подразумевает, что по меньшей мере часть МНП слитого полипептида была перенесена в ММ и доступна для МПП.
Для визуализации полипептида ЗФБ готовили протопласты, как описано в примере 1, из листовых тканей, содержащих pRA01 (pFAγ::ЗФБ), и исследовали методом конфокальной микроскопии. Протопласты визуализировали, используя вертикальный конфокальный лазерный сканирующий микроскоп Leica с 40x водно-иммерсионным объективом. ЗФБ возбуждали на 488 нм и записывали испускание на 499-535 нм. В качестве контрокрашивания для идентификации митохондрий протопласты также окрашивали в течение 10-20 мин, используя 100 нМ раствор MitoTrackerR Red CMXRos (ThermoFisher Scientific, кат. № M7512). MitoTrackerR Red CMXRos возбуждали на 561 нм и записывали испускание на 570-624 нм. Таким образом можно проводить наложение изображений флуоресценции для обоих флуорофоров. За счет этого наблюдали, что флуоресценция ЗФБ была колокализована с MitoTrackerR и, следовательно, локализована в митохондриях. Следовательно, авторы изобретения заключили, что по меньшей мере для pFAγ::ЗФБ МНП транслоцировал слитый полипептид в ММ в клетках листьев N. benthamiana и также обеспечивал его расщепление МПП (Фиг. 4). Это заключение основывалось на знании, что процессинг МНП МПП происходит только в ММ.
Таблица 3. Генетические конструкции, кодирующие слитые полипептиды Nif
Пример 6. Транслокация слитых полипептидов Nif в растительные митохондрии
Далее авторы изобретения хотели исследовать, был ли МНП pFAγ способен транслоцировать слитые полипептиды Nif в ММ и мог ли он обеспечивать расщепление МНП МПП. Чтобы сначала исследовать это, были выбраны два белка Nif (NifF и NifZ) для конструирования слитых полипептидов из-за своей относительно небольшой молекулярной массы, что позволило бы четко различать расщепленные и нерасщепленные полипептиды методом вестерн-блоттинга. Кодирующие белок области для полипептидов NifF и NifZ Klebsiella pneumoniae, слитых с эпитопами HA или FLAG в виде C-концевых слияний, были кодон-оптимизированными в соответствии с человеческими кодонами и синтезированными коммерческим поставщиком. Фрагменты ДНК вставляли в сайт AscI pRA00 так, чтобы открытые рамки считывания Nif были трансляционно слиты с N-концевым МНП pFAγ, создавая векторы pRA05 и pRA04 (Таблица 3). Эпитопы HA и FLAG были внесены в С-конец полипептидов NifF и NifZ, соответственно, чтобы обеспечить возможность обнаружения с помощью соответствующих антител. Для создания непроцессированных версий этих слитых полипептидов pFAγ::Nif в качестве контроля те же самые конструкции экспрессировали в E. coli с помощью РНК-полимеразы T7. Учитывая, что МНП не процессируется в бактериях, которые не имеют МПП, разница в размере между экспрессируемыми растениями и бактериями полипептидами позволяла выявлять процессинг методами гель-электрофореза и вестерн-блоттинга. Аминокислотные последовательности слитых полипептидов pFAγ::NifF::HA и pFAγ::NifZ::FLAG до процессинга приведены как SEQ ID NO:40 и 41, соответственно.
Вестерн-блоттинг (Фиг. 4) выявил, что размер полипептидов, обнаруженных в листьях N. benthamiana, в каждом случае был меньшим, чем у соответствующего полипептида, вырабатываемого в E. coli. В случае каждого из pRA05 (pFAγ::NifF::HA) и pRA04 (pFAγ::NifZ::FLAG) полипептиды, обнаруженные в растительных клетках, соответствовали размерам, предсказанным для расщепления слитых полипептидов в их МНП, тогда как полипептиды, обнаруженные в экстрактах E.coli, имели ожидаемые размеры для непроцессированных слитых полипептидов pFAγ::Nif. Из этих данных авторы изобретения заключили, что МНП pFAγ был способен перемещать по меньшей мере часть МНП Nif-слитых полипептидов в ММ и обеспечивать расщепление МНП МПП в растительных клетках.
Пример 7. Демонстрация расщепления МНП с помощью масс-спектрометрии
Чтобы подтвердить, что предсказанный сайт процессинга МНП в части pFAγ слитых полипептидов подвергался расщеплению со стороны МПП в митохондриях, пептидные продукты анализировали с помощью масс-спектрометрии. Для этого авторы изобретения разработали и создали генетическую конструкцию на основе pRA00, которая кодировала слитый полипептид pFAγ::NifH::HA, обозначенную pRA10 (Таблица 3). Аминокислотная последовательность этого слитого полипептида до процессинга приведена как SEQ ID NO:42. Слитый полипептид NifH выбрали благодаря важности NifH в качестве основного компонента ферментного комплекса нитрогеназы и высокого уровня экспрессии полипептида dCoxIV::NifH::HA, наблюдаемого ранее в растительных клетках (пример 2). Конструкцию pRA10 вносили в клетки листьев N. benthamiana, а инфильтрированные ткани собирали через 4 суток. Ткань измельчали в атмосфере жидкого азота, а затем обрабатывали, используя препарат для тканевого лизиса Retsch в 2 мл пробирках Эппендорфа в присутствие буфера для экстракции белков (БЭБ), содержащего 50 мМ Трис-HCL, pH 7,5, 1 мМ ЭДТК, 150 мМ NaCl, 10% глицерина, 5 мМ ДТТ, 0,5 мМ ПМСФ и 1% коктейля из ингибиторов протеаз для растений (Sigma, номер в каталоге P9599). Для улучшения растворимости слитого полипептида NifH, нацеленного на митохондрии, в БЭБ добавляли 0,2% (масс./об.) ДСН. Неочищенные белковые экстракты очищали центрифугированием, а затем инкубировали в присутствии моноклонального анти-HA антитела, конъюгированного с агарозными гранулами (Sigma, номер в каталоге A2095), для иммунопреципитации HA-содержащих полипептидов. Несвязанные белки удаляли с помощью серии промывок 150 мМ Трис-HCL pH 7,5, 5 мМ ЭДТК, 150 мМ NaCl, 0,1% Тритон X-100, 5% глицерина, 5 мМ ДТТ, 0,5 мМ ПМСФ и 1% коктейля из ингибиторов протеаз для растений. Связанные белки элюировали путем инкубации гранул в буфере Laemmli при 95°C в течение 10 мин, а затем дополнительно очищали методом гель-электрофореза на денатурирующем ДСН-ПААГ. Область геля, которая согласно параллельному определению в анализе методом вестерн-блоттинга содержала слитый полипептид pFAγ::NifH::HA, вырезали и подвергали расщеплению трипсином в геле с последующим анализом полученных в результате пептидов методом тандемной масс-спектрометрии, как описано в примере 1, используя систему Agilent Chip Cube, сопряженную с масс-спектрометром Agilent Q-TOF 6550 (Campbell et al., 2014). Этот анализ позволил обнаружить 5 полностью расщепленных триптических пептидов, идентичных областям в NifH, и шесть полутриптических пептидов, что согласуется с точным расщеплением МНП между остатками 42 и 43 (Фиг. 5). Триптический пептид SISTQVVR (SEQ ID NO:43), который мог бы быть получен из непроцессированного МНП, не наблюдали. Вместо этого, самым N-концевым пептидом, который был обнаружен, был полутриптический ISTQVVR (SEQ ID NO:44), подтвержденный полным рядом y-ионов в спектре МС/МС.
Эти данные убедительно продемонстрировали, что по меньшей мере часть МНП полипептида pFAγ::NifH::HA была транслоцирована в ММ и была расщеплена МПП в заданном сайте в МНП в пределах N-концевого удлинения. Эти данные подразумевают, что МНП pFAγ содержал все сигналы, необходимые для транслокации и процессинга в ММ.
Пример 8. Экспрессия нескольких белков нитрогеназы в митохондриальном матриксе растений
Учитывая успешные экспрессию и процессинг в митохондриях ЗФБ, полипептидов NifF, NifZ и NifH, слитых с МНП pFAγ в клетках листьев N. benthamiana, авторы изобретения предприняли попытку экспрессировать оставшиеся 13 полипептидов Nif в виде слитых полипептидов с МНП pFAγ. В модельных диазотрофах Klebsiella pneumoniae 16 белков Nif принимают участие в биосинтезе или функции нитрогеназы, тогда как четверо других имеют неизвестную функцию или вовлечены в регуляцию транскрипции (Oldroyd and Dixon, 2014). В частности, авторы изобретения были заинтересованы в том, будет ли МНП pFAγ обеспечивать выработку и расщепление слитого полипептида NifD с учетом данных, представленных в примерах 2-4.
Получали кодон-оптимизированные версии фрагментов ДНК, кодирующие 16 полипептидов Nif K. pneumonia, и каждую отдельно вставляли в сайте AscI pRA00 для создания ряда генетических конструкций (Таблица 3). Каждая генетическая конструкция кодировала слитый полипептид, содержащий N-концевой МНП pFAγ, затем последовательность Nif (с или без инициирующего метионина), а затем С-концевое удлинение, содержащее эпитоп HA или FLAG для обнаружения с помощью соответствующего антитела. Для экспрессии в растениях каждая конструкция содержала промотор 35S и 3' области терминации транскрипции nos, фланкирующие кодирующую белок область. Аминокислотные последовательности для 16 слитых полипептидов представлены в SEQ ID NO:40-42 и 46-58.
Клетки A. tumefaciens, содержащие каждую из 16 генетических конструкций, отдельно инфильтрировали в листья N. benthamiana и через 4 суток готовили белковые экстракты и анализировали методом гель-электрофореза и вестерн-блоттинга, как и ранее. Для каждой из конструкций, кодирующих содержащие HA-тэг полипептиды pFAγ-Nif, были обнаружены полосы в вестерн-блотах, которые имели размер, приблизительно соответствующий предсказанному для МПП (Таблица 3, Фиг. 6). Распространенность белков варьировалась среди содержащих HA-тэг полипептидов, причем наиболее легко можно было обнаружить слитые полипептиды NifB, NifH, NifK, NifS и NifY. Полипептиды NifF, NifE и NifM присутствовали на низких уровнях, тогда как для обнаружения полипептида NifQ требовалось большее время экспозиции блота, чтобы он был видимым. Интересно, что дополнительные, более высокомолекулярные полосы были обнаружены для инфильтраций конструкциями NifB, NifS, NifH и NifY (Фиг. 6), которые были специфическими в отношении размера для каждой отдельной конструкции Nif::HA. Эти дополнительные полосы соответствовали приблизительно удвоенной молекулярной массе по сравнению с первичной полосой, что позволяет авторам изобретения предположить, что эти полипептиды димеризовались, несмотря на денатурирующие условия во время гель-электрофореза. Сообщалось, что слитые белки NifB, NifS и NifH функционируют в бактериях в виде гомодимеров (Rubio and Ludden, 2008; Yuvaniyama et al., 2000).
Содержащие FLAG-тэг слитые полипептиды pFAγ::Nif::FLAG наблюдали в вестерн-блотах для каждой из конструкций, включая последовательности NifJ, NifN, NifV, NifU, NifX и NifZ (Фиг. 6, верхняя правая панель). Антитело к FLAG давало большее количество фоновых полос из экстрактов N. benthamiana, чем антитело к HA. Несмотря на это, результаты были аналогичны с результатами для содержащих HA-тэг белков. Наблюдали существенную вариацию в интенсивности сигнала для разных слитых полипептидов Nif::FLAG. Наблюдали дополнительную, более высокомолекулярную полосу, специфическую к конструкции NifU (Фиг. 6). Конструкция pFAγ::NifX::FLAG также давала дополнительную, меньшую полосу большей интенсивности, чем ожидалась для предсказанной молекулярной массы после процессинга.
Удивительно, что учитывая то, что 15 из 16 генетических конструкций вырабатывали полипептиды на обнаруживаемом уровне, и несмотря на многочисленные репликации инфильтраций, авторы изобретения не смогли обнаружить какие-либо специфические полосы для конструкции pFAγ::NifD::FLAG (pRA07) в этом растительном анализе, хотя экспрессия одной и той же генетической конструкции в E.coli легко давали видимую полосу ожидаемой молекулярной массы (Фиг. 7). Действительно, даже разведения 1:100 полученного от бактерий экстракта давали полосу, которую легко было наблюдать в вестерн-блотах. Результат по бактериальным экстрактам подтвердил, что генетическая конструкция pRA07 была функциональной, по меньшей мере в отношении кодирующей белок области. Следовательно, с ярким исключением полипептида pFAγ::NifD::FLAG, каждый из полного набора важных полипептидов Nif, необходимых для биосинтеза и функции нитрогеназы, успешно экспрессировали в клетках листьев растений, используя слияния с МНП pFAγ. Кроме того, молекулярная масса наблюдаемых полос согласовалась с процессингом слитых полипептидов в ММ (Таблица 3).
Для активности нитрогеназы требуется совместное действие многих белков Nif, предполагалось, что для функционального воссоздания нитрогеназы в растениях будут необходимы многие из белков Nif, используемых в диазотрофных бактериях для биосинтеза и функции. Следовательно, авторы изобретения хотели определить, можно ли экспрессировать некоторое количество белков Nif в ММ N. benthamiana, используя МНП pFAγ. Для проверки этой концепции выбрали генетические конструкции, кодирующие четыре слитых полипептида Nif разных размеров, что обеспечило бы возможность идентификации получаемых в результате полипептидов в анализе методом вестерн-блоттинга, а именно, конструкции, кодирующие pFAγ::NifB::HA (pRA03), pFAγ::NifS::HA (pRA16), pFAγ::NifH::HA (pRA10) и pFAγ::NifY::HA (pRA12). Четыре культуры A. tumefaciens, трансформированные этими конструкциями, смешивали в одинаковых количествах, а затем смесь инфильтрировали в листья N. benthamiana. Общие уровни полипептидов сравнивали со случаем, когда каждую культуру инфильтрировали отдельно. По наблюдениям каждый полипептид был более многочисленным при экспрессии из одной конструкции, чем в случае комбинации четырех генов. Несмотря на это, все четыре слитые полипептида Nif было легко обнаружить в белковых экстрактах от комбинации генов, а молекулярная масса, наблюдаемая для каждого полипептида, была идентична для отдельных и комбинированных инфильтраций. Это продемонстрировало, что комбинации слитых полипептидов Nif можно получать в растительных клетках с необходимым нацеливанием и процессингом каждого слитого полипептида Nif в митохондриях.
Пример 9. Попытки улучшить выработку слитого полипептида NifD в N. benthamiana
Учитывая ключевую роль NifD в каталитической активности нитрогеназы, авторы изобретения попытались определить причину отсутствия выработки слитого полипептида NifD и проверили несколько подходов для улучшения его присутствия в растительных анализах. Во-первых, они исследовали, могло ли отсутствие выработки/накопления слитого полипептида NifD быть связанным с низкой транскрипцией трансгена или нестабильностью мРНК, путем измерения уровня экспрессии мРНК. Для этого сначала измеряли уровень мРНК в инфильтрированных клетках N. benthamiana из pRA07 с помощью кРВ-ПЦР, как описано в примере 1, и сравнивали с уровнем мРНК, транскрибируемой с конструкции, кодирующей pFAγ::NifU::FLAG (pRA15). Эту вторую конструкцию использовали в качестве контроля, так как она обеспечивала высокие уровни выработки полипептида в растительных клетках, как описано выше. Чтобы устранить любые ошибки в эффективности амплификации, использовали олигонуклеотидные праймеры, которые гибридизировались в пределах области МНП pFAγ, общей для обоих слитых генов Nif. Результаты анализа РВ-ПЦР показали, что уровень мРНК pFAγ::NifD::FLAG более чем в три раза превышал мРНК pFAγ::NifU::FLAG. Во-вторых, синтезировали кДНК из растительной мРНК, транскрибированной с pRA07, клонировали и секвенировали, а ее нуклеотидную последовательность подтвердили как идеально совпадающую по основаниям. Следовательно, отсутствие накопления слитого полипептида pFAγ::NifD::FLAG не было связано с низкой экспрессией или нестабильностью мРНК. Эти эксперименты также показали, что Т-ДНК в pRA07, кодирующей pFAγ::NifD::FLAG, была полностью функциональной, и что промотор 35S в этой конструкции, вероятно, был функциональным. Следовательно, невозможность обнаружить слитый полипептид NifD в клетках N. benthamiana не была связана с какими-либо нарушениями в экспрессии мРНК.
Так как транскрипция гена, кодирующего pFAγ::NifD::FLAG, и накопление мРНК явно не ограничивали выработку слитого полипептида NifD, в генетической конструкции было сделано несколько модификаций в попытке преодолеть недостаток накопления слитого полипептида NifD. Во-первых, учли и проверили возможность того, что присутствие эпитопа FLAG в С-концевом удлинении приводит к отсутствию выработки или к нестабильности слитого полипептида NifD. Чтобы проверить эту возможность, разрабатывали и создавали конструкцию, в которой эпитоп FLAG был заменен эпитопом HA, обозначенную pRA19 (pFAγ::NifD::HA). Эпитоп HA обеспечивал возможность накопления и обнаружения каждого из содержащих тэг слитых полипептидов Nif, которые исследовали с этим эпитопом (Таблица 3). Аминокислотная последовательность этого слитого полипептида приведена как SEQ ID 59. Во-вторых, использование частоты кодонов открытой рамки считывания NifD::HA модифицировали так, чтобы оно больше напоминало использование частоты кодонов в A. thaliana, а не оптимизировали для трансляции в человеческих клетках, в попытке определить, может ли отличная последовательность мРНК улучшить эффективность трансляции. Эту конструкцию обозначили pRA24; она кодировала такой же полипептид pFAγ::NifD::HA (SEQ ID NO:59), что и pRA19. Дополнительно создавали генетическую конструкцию, кодирующую версию слитого полипептида NifD с мутированным N-концевым удлинением mFAγ, а не pFAγ, как описано в примере 5 (mFAγ::NifD::HA). Эту конструкцию (pRA22) создавали, чтобы проверить, были ли митохондриальные нацеливание и/или процессинг, в случае их наличия, по меньшей мере частично ответственны за отсутствие выработки слитого полипептида NifD. Три конструкции, разработанные для решения этого вопроса, перечислены в Таблице 3.
Листья N. benthamiana инфильтрировали A. tumefaciens, содержащими эти конструкции, а из инфильтрированных тканей получали белковые экстракты и анализировали. Интересно, что вестерн-блоттинг показал наличие HA-содержащих полос с молекулярной массой, ожидаемой как для матрикс-процессированных, так и для непроцессированных слитых полипептидов NifD при внесении любой из конструкций pRA19 или pRA24 (pFAγ::NifD::HA) (Фиг. 8). Внесение pRA22 давало только более крупный (непроцессированный) слитый полипептид. В этом эксперименте внесение pRA19 в растительные клетки давало более интенсивные полосы слитого полипептида NifD::HA в вестерн-блоттинге, чем pRA24, но в последующих повторных экспериментах разница в интенсивности не была существенной. Матриксный процессинг подтверждали, сравнивая позицию полос с позициями, получаемыми для вырабатываемых pRA22 (mFAγ::NifD::HA) и бактериями полипептидов (Фиг. 8). Наблюдение двух полос, соответствующих по размеру процессированной и непроцессированной формам pFAγ::NifD::HA, показало, что процессинг этого слитого полипептида NifD не был настолько же эффективным, как в случае других слитых полипептидов Nif, как описано выше. Наблюдаемый уровень полипептида pFAγ::NifD::HA все еще был намного ниже, чем уровень слитого полипептида pFAγ::NifK::HA (дорожка 2), используемого в качестве положительного контроля, несмотря на одинаковые экспрессионную конструкцию и условия экспрессии. Кроме того, для каждой из трех модифицированных конструкций NifD::HA в вестерн-блотах наблюдали дополнительные полосы меньшей молекулярной массы, некоторые из которых были специфическими к конкретной версии pFAγ::NifD::HA. Например, интенсивная полоса на около 50 кДа присутствовала для всех модифицированных конструкций NifD::HA, но другая интенсивная полоса на около 40 кДа оказалась уникальной для образцов при внесении pRA22. Так как эти полосы не присутствовали в случае контролей pFAγ::NifK::HA или ЗФБ, они могут представлять продукты молекулярной деградации NifD::HA или, возможно, продукт альтернативных сигналов инициации транскрипции или трансляции.
Авторы изобретения заключили, что замена эпитопа FLAG эпитопом HA отвечала, по меньшей мере частично, за улучшение накопления слитого полипептида NifD.
Обсуждение
В экспериментах, описанных выше, авторы изобретения продемонстрировали, что все 16 полипептидов Nif, необходимых для функции нитрогеназы в Klebsiella, можно экспрессировать из генетических конструкций в клетках листьев растений в виде слитых полипептидов МНП::Nif и что эти полипептиды накапливались в процессированных формах в митохондриях. Кроме того, эксперименты показали, что эти белки можно нацеливать на ММ, субклеточную локацию, потенциально подходящую для функционирования нитрогеназы. Авторы изобретения считают, что эти эксперименты являются первой практической демонстрацией реализуемости такого подхода.
Заключение по нацеливанию слитых полипептидов Nif на ММ основывалось на нескольких наборах данных. Во-первых, размер каждого из экспрессируемых в растениях полипептидов Nif согласовался с ожидаемым размером, который являлся бы результатом процессинга МПП. Меньшая молекулярная масса, наблюдаемая для экспрессируемых в растениях слитых полипептидов Nif по сравнению с экспрессируемыми в бактериях полипептидами (полноразмерными, непроцессированными) указывала на процессинг слитых полипептидов Nif МПП. Кроме того, когда последовательность МНП была мутирована, делая его неспособным к процессингу митохондриальным аппаратом импорта, наблюдали более крупный полипептид для слитых полипептидов NifD и ЗФБ, что согласуется с разницей в размере между процессированным и непроцессированным полипептидами. Наконец и в заключение, масс-спектрометрия позволила определить, что расщепление pFAγ::NifH происходило между остатками 42-43 МНП, как и предсказывалось для специфического процессинга в матриксе, демонстрируя, что последовательность МНП может расщепляться при слиянии с полипептидами Nif.
Присутствие МНП не всегда приводит к полному процессингу белков Nif. Например, конструкция NifX::FLAG и две из конструкций NifD::HA приводили к накоплению как процессированных, так и непроцессированных слитых полипептидов. Кроме того, несмотря на применение сильного конститутивного промотора 35S, наблюдали значительную степень вариабельности в уровнях накопления полипептидов для различных слитых полипептидов Nif. В случае некоторых из слитых полипептидов Nif наблюдали дополнительные, короче ожидаемых полипептиды, обнаруженные за счет наличия эпитопа в С-конце полипептидов.
Из всех слитых полипептидов Nif полипептид NifD было наиболее трудно получить на обнаруживаемых уровнях. Это не было связано с отсутствием генной экспрессии NifD или нестабильностью мРНК, но слабая трансляция и/или нестабильность белка могли ограничивать количество слитого полипептида NifD. Учитывая особую важность NifD в функции нитрогеназы, включая необходимость его высокой экспрессии в бактериях (Poza-Carrion et al., 2014), эту проблему необходимо преодолеть.
Пример 10. Исследование структуры и функции полипептида нитрогеназы с помощью in silico моделирования
Бактериальная нитрогеназа представляет собой металлопротеиновый комплекс, состоящий из некоторого количества разных полипептидов Nif, которые должны ассоциировать для образования активного фермента. Авторы изобретения рассмотрели, могут ли аминокислотные удлинения в N-конце или С-конце каждого полипептида Nif относительно каждого соответствующего полипептида дикого типа препятствовать биохимической функции каждого отдельного полипептида, а также сборке и функции ферментного комплекса в растительной клетке. В описанных выше примерах слитые полипептиды Nif, кодируемые трансгенами, вносимыми в растительные клетки, направляли на митохондриальный матрикс, используя митохондриальный нацеливающий пептид (МНП). Однако этот процесс удлинял N-конец каждого полипептида нитрогеназы более длинной последовательностью до расщепления МПП или более короткой последовательностью после расщепления. Чтобы проверить, могли ли удлинения влиять на функцию комплекса нитрогеназы, взаимодействуя с каталитическими центрами или белок-белковыми поверхностями раздела, необходимыми для функции, авторы изобретения сначала использовали модели гомологии субъединиц бактериальной нитрогеназы, чтобы предсказать влияние N- и C-концевых удлинений на полипептиды нитрогеназы NifH, NifD, NifK, NifE, NifN, NifS и NifU. Аналогично, эпитопные тэги, такие как эпитопы FLAG, HA и MYC, обычно добавляют в C-конец полипептидов, чтобы обеспечить возможность обнаружения или очистки из клеточных экстрактов. Были кристаллизованы многие отдельные компоненты и белковые комплексы, образующие бактериальную нитрогеназу дикого типа, и были исследованы их структуры в виде одиночных полипептидов или многобелковых комплексов. Следовательно, авторы изобретения использовали эти высокоразрешенные структуры, чтобы смоделировать влияние различных изменений, таких как продления и трансляционные слияния, на каждый полипептид Nif на основании аминокислотных последовательностей K. pneumoniae.
Методы: Программное обеспечение, используемое для молекулярного моделирования
Модели гомологии для каждого полипептида Nif и комплексов, содержащих эти полипептиды, конструировали, используя программу MODELLER (Sali and Blundell, 2013), реализованную в Accelrys Discovery Studio 3.5. Подходящие матрицы, на основании которых строили модели гомологии, идентифицировали, используя поиск BLAST по банку данных Brookhaven Protein Databank. Матричные полипептиды перечислены в Таблице 4, большинство из них получены из A. vinelandii. Выравнивания последовательностей проводили, используя алгоритм ClustalW (Sali and Blundell, 2013), реализованный в Discovery Studio 3.5. Все моделирование молекулярной динамики проводили с помощью Amber 12.
Таблица 4. Матричные полипептиды, применяемые для молекулярного моделирования
1Sorlie et al., (2001); 2Schindelin et al., (1997); 3Kaiser et al.; 4Cupp-Vickery et al., (2003)
Результаты: Структура NifH
Структура NifH A. vinelandii из комплекса NifD-NifK-NifH была на 17 аминокислотных остатков короче в C-конце по сравнению с последовательностью NifH K. pneumoniae, но в остальном эти два полипептида NifH имели более высокую гомологию, чем остальные исследованные полипептиды Nif (Таблица 4). Следовательно, модели гомологии, сконструированные так, как описано ниже, с использованием полипептидной последовательности NifH K. pneumoniae, были сконструированы после исключения этих 17 аминокислотных остатков из последовательности.
Комплексы NifD-NifK и NifD-NifK-NifH
Конструировали модель структуры гетеротетрамера NifD-NifK α2β2, используя полипептиды NifD и NifK из K. pneumoniae, и исследовали методом молекулярно-динамического моделирования. Эту модель конструировали, используя алгоритм MODELLER, реализованный в Accelrys Discovery Studio 3.5, используя кристаллическую структуру комплекса NifD-NifK из A. vinelandii (PDB ID: 1FP4, только NifD и NifK) в качестве матрицы. Идентичность NifD между K. pneumoniae и A. vinelandii составляла 73,2%, а для NifK - 65%. Затем конструировали вторую модель, используя PDB ID: 1N2C для комплекса, содержащего все три полипептида NifD, NifK и NifH K. pneumoniae (гетерооктамер NifD-NifK-NifH α2β2γ4). Это делали, чтобы проверить, выявила ли вторая модель взаимодействия NifD-NifK с субъединицей NifH, на которые могли бы негативно влиять C- или N-концевые удлинения. По второй модели авторы изобретения увидели, что С-конец субъединицы NifK был погружен в сердцевину комплекса и контактировал с несколькими остатками обеих смежных субъединиц NifK и NifD, включая водородные связи и солевые мостики между пятью C-концевыми остатками NifK и смежными субъединицами. Это согласовалось с тем, что наблюдали в модели NifD-NifK. Авторы изобретения заключили, что любое C-концевое удлинение полипептида NifK относительно последовательности K. pneumoniae дикого типа вероятно приводило бы к разрушению комплекса, приводя к получению либо менее стабильной формы, либо полностью нефункционального комплекса в отношении активности нитрогеназы. В противоположность этому C-концы субъединиц NifD и NifH лежат на поверхности комплекса и, следовательно, было предсказано, что можно вносить удлинения в C-концах полипептидов NifD и NifH, не нарушая образование и функцию ферментного комплекса. Модель структуры NifH A. vinelandii позволила предсказать, что 17 аминокислотных остатков, которые были исключены из С-конца K. pneumoniae, также заканчивались бы на поверхности, так как в комплексе NifD-NifK-NifH не было больше «дырок», находящихся в доступности для удлинения из 17 остатков. Аналогично, N-концы субъединиц NifD, NifK и NifH также лежат на поверхности комплекса, и было сделано заключение, что эти N-концы должны быть пригодными для добавления удлинения.
Комплекс NifEN
Тогда как структура гетеротетрамера NifE-NifN α2β2 была доступна в банке данных Brookhaven Protein Databank с приемлемой гомологией с последовательностями NifE-NifN K. pneumoniae, в С-конце структуры NifN отсутствовали 23 остатка, которые вероятно сворачивались бы обратно в ядро комплекса, как видно по эквивалентным структурам гетеротетрамера NifD-NifK α2β2, которые были доступны. Кроме того, в N-конце структуры NifE отсутствовали 22 остатка, которые бы добавляли в модели нежелательную неопределнность. Так как гетеротетрамер NifE-NifN α2β2 характеризуется таким же сворачиванием, что и гетеротетрамер NifD-NifK α2β2 из A. vinelandii (PDB ID: 1N2C, содержащий комплекс NifH-NifD-NifK-NifH, суперпозиция RMSD в 4 Å для комплексов NifE-NifN и NifD-NifK), вместо этого в качестве матрицы использовали структуру NifD-NifK, на основе которой строили модель гомологии NifE-NifN. Дополнительным преимуществом этого было практически полное покрытие концов последовательностей NifE и NifN. Это также обеспечило возможность изучения возможных взаимодействий между концами NifE-NifN и NifH, могут ли они существовать, и того, может ли изменение концевых областей в любой из субъединиц потенциально препятствовать образованию комплекса или доступности активного сайта.
Следовательно, конструировали модель гетеротетрамера NifE-NifN K. pneumoniae α2β2 на основе структуры NifD-NifK A. vinelandii. Аналогично с моделью NifD-NifK, C- и N-концы субъединиц NifE и NifN заканчивались на поверхности комплекса, за исключением С-конца NifN, который заканчивался в сердцевине структуры. N-конец последовательности NifE K. pneumoniae было короче, чем N-конец NifD на 18 аминокислотных остатков с приемлемо высококонсервативным участком из 19 остатков, который контактировал со смежной субъединицей NifK (NifN в модели гомологии). По этой модели было сделано заключение, что удлинение C- или N-концов NifE ожидаемо не будет оказывать негативное действие на структуру или функцию комплекса, но что С-конец NifN вероятно не допускает удлинения. Относительно длинная последовательность из 51 аминокислотного остатка присутствовала в N-конце структуры NifK A. vinelandii, но в последовательности NifN K. pneumoniae не присутствовало соответствующей последовательности. В этой модели дополнительные аминокислотные остатки лежат далеко за пределами поверхности раздела между единицами NifD и NifK. Каталитическое ядро было защищено от этой последовательности. По этим наблюдениям было сделано заключение, что последовательность МНП pFAγ после расщепления МПП, оставляющего N-концевое удлинение из 35 остатков, которое было положительно заряженным (+8) при физиологическом pH, наиболее вероятно сохранит неструктурированную форму и останется гидрофильной. Кроме того, был прецедент, связанный со структурой матрицы NifD-NifK, который подтверждал заключение, что могут допускаться дополнительные аминокислотные остатки в N-конце NifN K. pneumoniae. Не было ничего, что позволило бы предположить, что такое N-концевое удлинение в NifN препятствовало бы каталитической функции или сборке любой из единиц. С другой стороны, ожидалось, что С-конец NifN будет погружен в сердцевину фермента. Следует отметить, что он был на 6 остатков длиннее, чем высококонсервативный С-конец NifK, поэтому точная природа взаимодействий, в которых могут принимать участие эти остатки, остается неизвестной. На основании сходства сворачивания между гетеротетрамером NifD-NifK α2β2 A. vinelandii и гетеротетрамером NifE-NifN α2β2 K. pneumoniae было предсказано, что изменения в С-конце NifN, в частности, продления, оказывали бы отрицательное действие на вторичную структуру и четвертичную структуру комплекса. Было сделано заключение, что следует использовать С-конец такой же, как у полипептида NifN дикого типа.
Модель NifS
Модель гомологии NifS K. pneumoniae конструировали на основании структуры цистеиндесульфуразы E. coli, чьей функциональной единицей был гомодимер. Последние 11 аминокислотных остатков в С-конце NifS K. pneumoniae не были включены при моделировании. Модель гомологии для NifS K. pneumoniae конструировали в виде гомодимера и было видно, что N- и С-концы лежат на поверхности структуры. Как и для большинства анализируемых полипептидов Nif было предсказано, что аминокислотные остатки МНП pFAγ, оставшиеся после процессинга МПП, не оказывали бы отрицательное действие на гомодимер. Было показано, что полипептиды NifU и NifS могут взаимодействовать (Yuvaniyama et al., 2000), однако точная физическая природа взаимодействия остается неизвестной. Возможно, что удлинение любого из N- или С-концов может нарушать физическое взаимодействие между NifU и NifS, в случае его существования.
Модель NifU
Самым близким совпадением с NifU K. pneumoniae в банке данных Brookhaven Protein Databank был PDB ID: 2Z7E, железо-серный кластерный белок (IscU) из Aquifex aeolicus, который кристаллизовался в виде гомотримера. Хотя выравнивание показало хорошую гомологию для мономера 2Z7E, (120 остатков), последовательность NifU была значительно длиннее (271 остаток), оставляя несмоделированными приблизительно 150 остатков в С-конце. Следовательно, модель гомологии NifU K. pneumoniae, за исключением 151 С-концевого остатка, конструировали, используя в качестве матрицы железо-серный кластерный белок (IscU) из Aquifex aeolicus. N-концы имели хорошее покрытие и кластеризовались «вверху» субъединицы. Невозможно было с уверенностью предсказать, обеспечила бы эта структура возможность взаимодействия с полипептидом NifS, если N-конец полипептида NifU был слит с последовательностью МНП.
В целом было сделано заключение, что согласно прогнозам могут допускаться аминокислотные удлинения в N-концах большинства полипептидов Nif без обязательной потери функции. Согласно прогнозам удлинения в С-концах NifK и NifN будут наиболее чувствительными к нарушению образования и функции комплекса. Затем эти результаты использовались авторами изобретения, чтобы помочь в руководстве разработкой функциональных полипептидов нитрогеназы для экспрессии из трансгенов в ядерном геноме и транслокации в матрикс растительных митохондрий.
Пример 11. Коэкспрессия слитых полипептидов NifD и других Nif
Авторы изобретения попробовали дополнительные подходы для улучшения выработки и накопления слитых полипептидов NifD. В азотфиксирующих бактериях NifD, NifK и NifH сильно взаимодействуют посредством водородного связывания, электростатических взаимодействий и гидрофобных взаимодействий ч образованием каталитического ядра комплекса нитрогеназы. Моделирование белковой структуры, описанное в примере 10, позволило выявить, что эффективное образование комплекса между NifK и другими двумя полипептидами, NifD и NifH, зависело от присутствия С-концевой аминокислотной последовательности дикого типа в NifK, а именно аминокислотных остатков DLVR (SEQ ID NO:69) в качестве последних четырех остатков в С-конце (например, остатков 517-520 из SEQ ID NO:7). В описанных выше экспериментах авторы изобретения использовали слитый полипептид NifK, который имел добавочную С-концевую последовательность из 17 аминокислот, включая эпитоп HA из 9 аминокислот. Моделирование, описанное в примере 10, позволило предсказать, что эта последовательность NifK не была бы оптимальной для взаимодействия с NifD из-за С-концевого удлинения. Следовательно, авторы изобретения решили проверить, может ли коэкспрессия полипептида NifK, имеющего С-конец дикого типа, с конструкцией NifD улучшить совместное накопление слитого полипептида NifD.
Создали генетическую конструкцию, которая кодировала слияние pFAγ::NifK без С-концевого удлинения, используя в качестве базового вектора pRA00. Эта конструкция была обозначена pRA25 (Таблица 3). Аминокислотная последовательность этого полипептида приведена как SEQ ID NO:60. Инфильтрации проводили в листьях N. benthamiana комбинациями pRA25 (pFAγ::NifK) с pRA24 (pFAγ::NifD::HA) и сравнивали с ранее использованным pRA11 (pFAγ::NifK::HA) с pRA24. Уровни полипептида NifD сравнивали с помощью гель-электрофореза и вестерн-блоттинга, используя антитело к HA. Неожиданно, совместная инфильтрация с pRA25 (pFAγ::NifK без С-концевого удлинения или эпитопа) существенно повышала накопление слитого полипептида NifD по сравнению с совместной инфильтрацией с pRA11 (pFAγ::NifK с С-концевым удлинением). В этом эксперименте включение pRA11 в смесь не усиливало накопление слитого полипептида NifD, но в повторных экспериментах наблюдалось некоторое повышение при использовании pRA11. Фотография вестерн-блота приведена на Фиг. 9 после инфильтрации конструкции NifD, одной или в комбинации с конструкциями NifK и NifH. В случае блотов, приведенных на Фиг. 9, было необходимо большее время экспозиции, чтобы увидеть полосу для слитого полипептида NifD, когда pRA19 инфильтрировали один (дорожка 11).
В случае других инфильтраций к комбинации NifD и NifK добавляли конструкцию pRA10 pFAγ::NifH::HA (дорожки 1-3 на Фиг. 9). Это дополнительно повышало уровень накопления слитого полипептида NifD. Это показало, что присутствие полипептида NifK с С-концом дикого типа стабилизировало продукт транслокации NifD из pRA19 и что добавление конструкции NifH дополнительно усиливало накопление слитого полипептида NifD, возможно, за счет его защиты от активности протеаз.
Чтобы проверить, происходило ли улучшение накопления слитого полипептида NifD в митохондриальном матриксе, конструкции pFAγ::NifH::HA (pRA10) и pFAγ::NifK (pRA25) коэкспрессировали с версией NifD, имеющей нефункциональный МНП (pRA22, mFAγ::NifD::HA). Этот слитый полипептид отличался от pFAγ::NifD::HA только аминокислотами в N-концевом домене. По наблюдениям, не нацеленный на матрикс слитый полипептид mFAγ::NifD::HA не накапливался на том же уровне, что и нацеленный на матрикс полипептид pFAγ::NifD::HA (сравните дорожки 2 и 3, Фиг. 9). Это подтвердило, что улучшение накопления полипептида NifD вероятно происходило в ММ и позволило предположить, что они взаимодействовали с образованием белкового комплекса. Это заключение поддерживалось наблюдением, что степень процессинга последовательности МНП, слитой с NifD::HA, повышалась в присутствии полипептидов NifK и NifH.
Когда кодон-оптимизированную конструкцию pRA24 использовали с конструкциями NifK (без С-концевого удлинения) и NifH, накопление слитого полипептид NifD происходило даже на более высоких уровнях (дорожка 1, Фиг. 9). В случае другой инфильтрации наблюдали, что коэкспрессия из конструкций NifK и NifH повышала отношение расщепленный:нерасщепленный слитый полипептид pFAγ::NifD::HA.
Чтобы определить, может ли коэкспрессия конструкций, кодирующих NifK, с или без С-концевого удлинения, также усиливать накопление pFAγ::NifD::FLAG, в клетки листьев вносили комбинацию pRA25 и pRA07. Дополнительные комбинации с pRA10 также осуществляли в некоторых инфильтрациях. С помощью антитела, распознающего эпитоп FLAG, в вестерн-блоте был обнаружен слитый полипептид NifD::FLAG (верхняя панель, Фиг. 10), демонстрируя, что накопление полипептида NifD::FLAG было усилено коэкспрессией со слитым полипептидом NifK::HA. Это было первый раз, когда авторы изобретения обнаружили слитый полипептид NifD::FLAG; смотрите результаты, приведенные в примерах 2-5, в отношении отсутствия обнаружения. Уровень накопления полипептида NifD::FLAG был в значительной степени повышен коэкспрессией конструкции, кодирующей NifK с отсутствием С-концевого удлинения. Наибольший уровень слитого полипептида NifD::FLAG наблюдали при совместной инфильтрации с конструкциями NifH и NifK (без С-концевого удлинения) (дорожка 1, Фиг. 10). Это означает, что добавление слитого полипептида NifH к комбинации повышало уровень слитого полипептида NifD даже больше. Этот результат демонстрирует, что несмотря на эпитопный тэг (HA или FLAG) накопление NifD было усилено NifH:HA и NifK без С-концевого удлинения.
Вестерн-блот для дополнительных инфильтраций проиллюстрирован на Фиг. 11. Этот эксперимент также показал, что уровень накопления pFAγ::NifD::FLAG из pRA07 повышался за счет совместного внесения pRA10 (pFAγ::NifH::HA) и pRA25 (pFAγ::NifK). Комбинацию с pRA25 снова сравнивали с комбинацией с pRA11 (NifK, с С-концевым удлинением), смотрите дорожки 10 и 11 на Фиг. 11. Когда интенсивность полос NifD количественно оценили и нормализовали к интенсивности одной из фоновых полос, определили, что уровень накопления NifD::FLAG повысился на около 50% за счет коэкспрессии с pRA25 по сравнению с pRA11. Следовательно, комбинация NifK (без С-концевого удлинения) и NifH способствовала накоплению слитых полипептидов NifD, отличных от содержащих HA-тэг полипептидов NifD, и повышала накопление слитого полипептида NifD больше, чем полипептид NifK с С-концевым удлинением.
Вместе эти результаты указывают, что комбинация полипептидов NifH, NifK и NifD улучшала накопление слитого полипептида NifD в митохондриях растений. Насколько известно авторам изобретения, это первые данные по повышению накопления NifD в растительных клетках, в частности, в случае нацеливания на митохондрии, за счет коэкспрессии с NifH и NifK. Также было сделано заключение, что C-конец дикого типа NifK обеспечивал преимущество в отношении накопления NifD и что NifH дополнительно повышал количество слитого полипептида NifD. Положительный эффект полипептидов NifH и NifK на накопление NifD был дополнительно усилен оптимизацией кодонов NifD-кодирующей области. Также было отмечено, что количество слитого полипептида NifD на дорожке 1 на Фиг. 9 приближалось к количеству полипептида pFAγ::NifK::HA. Авторы изобретения посчитали, что эквимолярные количества этих двух ключевых компонентов будут благоприятны для функции нитрогеназы в растительных клетках.
С учетом благоприятного эффекта NifK и NifH на уровни слитого полипептида NifD, далее авторы изобретения проверили, может ли коэкспрессия слитого полипептида NifS усиливать накопление NifD. NifS представляет собой цистеиндесульфуразу, участвующую на ранних стадиях сборки нитрогеназы, когда она мобилизует серу (S) для образования кластера Fe-S. Эти кластеры Fe-S являются одним целым с комплексом нитрогеназы. Для этого комбинации A. tumefaciens, каждая из которых содержала по одной конструкции, совместно инфильтрировали в листья N. benthamiana. В этом эксперименте использовали конструкцию, кодирующую слитый полипептид pFAγ::NifD::FLAG (pRA07). Неожиданно комбинация конструкции pFAγ::NifS::HA (pRA16) с конструкцией NifD::FLAG также повышала накопление последнего полипептида (сравните дорожки 6 и 11 на Фиг. 10). Было сделано заключение, что совместное получение слитого полипептида NifS повышало накопление слитого полипептида NifD.
Авторы изобретения наблюдали и другое удивительное и неожиданное явление в этом эксперименте. Как видно на Фиг. 10, уровни каждого из слитых полипептидов NifH::HA, NifK::HA и NifS::HA, зарегистрированные из их соответствующих конструкций, были существенно снижены при совместном внесении также конструкции NifD::FLAG по сравнению с вариантами, когда конструкции вносили по отдельности. Если сравнить дорожки 5 и 7, 6 и 9 и 3 и 8, процент снижения составил 42% для NifH::HA, 37% для NifS::HA и 36% для NifK::HA. Оказалось, что совместное внесение конструкции pFAγ::NifD::FLAG (pRA07) имело отрицательный эффект на экспрессию второй слитой конструкции Nif, которую вносили совместно. Это явление исследовали дополнительно.
Чтобы показать, что в растительных клетках эти полипептиды связаны, белковые экстракты после внесения генных комбинаций, включая pRA07, инкубируют с антителом, связывающим эпитоп FLAG, для иммунопреципитации полипептида NifD::FLAG и любого другого полипептида, связанного с ним. Преципитированные полипептиды подвергают электрофорезу, а блоты зондируют антителом, направленным на эпитоп HA. Проводят обнаружение полипептидов, которые были иммунопреципитированы и содержат HA, таких как pFA::NifH::HA. Также можно использовать эксклюзионную хроматографию в неденатурирующих условиях, чтобы продемонстрировать образование многополипептидных белковых комплексов, в частности, ассоциации слитых полипептидов NifD, NifH и NifK.
Пример 12. Конструирование слитого полипептида NifDK
Открытие, что коэкспрессия слитых полипептидов NifH и NifK имела эффект на стабилизацию уровней NifD в растительных клетках, привела к тому, что авторы изобретения разработали способы слияния NifK, гетеротетрамерного партнера NifD в нитрогеназе, с полипептидом NifK. Считалось, что эта стратегия также может защитить полипептид NifD от возможной активности протеаз, которые, как полагали авторы изобретения, обуславливали низкие уровни накопления NifD. Кроме того, в бактериях полипептиды NifD и NifK присутствуют в практически одинаковых количествах (Poza-Carrion et al., 2014), а в кристаллической структуре нитрогеназы эти субъединицы находятся в отношении 1:1 (Schmid et al., 2002). Авторы изобретения посчитали, что прямое слияние этих двух полипептидов гарантировало бы одинаковое соотношение полипептидов.
Однако было обнаружено, что для этой стратегии необходима вставка аминокислотного линкера для соединения единиц NifD и NifK, чтобы обеспечить надлежащее белковое сворачивание одной полипептидной цепи, следующим образом. Модель гомологии гетеротетрамера NifD-K α2β2 из K. pneumoniae конструировали, используя кристаллическую структуру комплекса NifD-K из Azotobacter vinelandii (PDB ID: 1FP4, (Schmid et al., 2002)) в качестве матрицы. Выравнивание K. pneumoniae и соответствующих полипептидов A. vinelandii позволило установить, что идентичность аминокислотных последовательностей составляла 72,2% для полипептидов NifD и 67,3% для полипептидов NifK. В структурной модели для гетеротетрамера D2K2 K. pneumoniae С-конец каждой субъединицы NifD составлял приблизительно 47 Å от N-конца его партнера NifK. Следовательно, был сконструирован линкер такой длины для соединения двух единиц. Линкер имел длину 30 остатков и состоял из участка из 11 остатков из известной неструктурированной линкерной области из целлобиогидролазы II Hypocrea jecorina (номер доступа AAG39980.1, ATPPPGSTTTR; SEQ ID NO:61) с заменой последнего аргинина аланином, затем эпитопа FLAG из 8 остатков (DYKDDDDK; SEQ ID NO:62), за которым следовала еще одна копия неструктурированной линкерной последовательности из 11 остатков с заменой аргинина аланином (полная последовательность линкера: ATPPPGSTTTADYKDDDDKATPPPGSTTTA; SEQ ID NO:63). Замещение аргинина было сделано, чтобы снизить потенциальные электростатические взаимодействия с отрицательно заряженными остатками в центральном эпитопе FLAG линкера. Чтобы гарантировать отсутствие очевидных взаимодействий или конформационных напряжений между любой из единиц NifD-NifK и линкером слитого полипептида или же в самом линкере, которые могут быть вредными для способности единиц D и K к ассоциации в их нативной ориентации, проводили оптимизацию геометрии и уравновешивание для димера композитного слитого полипептида (без включения каких-либо металлических центров) при постоянном давлении в октаэдрической водяной камере TIP3P с минимальным пограничным расстоянием от растворенного компонента, составляющим 10,0 Å. Расчет проводили, используя Amber 12 с применением поля сил ff99SB при 298 К в течение 5 нс всего, используя временной шаг 2 фс и ограничения SHAKE.
Исследовали предсказанную структуру композитного полипептида NifD-линкер-NifK, включая 30-аминокислотный линкер (Фиг. 12), демонстрируя, что добавление линкера обеспечило возможность сворачивания полного слитого полипептида в структуру, которая имитировала нативный комплекс NifD-NifK. Была собрана вторая модель, которая дополнительно содержала две субъединицы NifH, связанные с димером полипептида NifD-линкер-NifK (Фиг. 13), которая продемонстрировала, что добавление линкера не препятствовало связыванию субъединиц NifH. Следовательно, разработали и создали конструкцию, кодирующую слитый полипептид (pRA02), на основе pRA00, которая имела N-концевое удлинение, содержащее МНП pFAγ. Аминокислотная последовательность слитого полипептида pFAγ::NifD-линкер-NifK приведена как SEQ ID NO:64.
Во второй конструкции в С-конец единицы NifK кодируемого полипептида добавляли С-концевое удлинение, содержащее эпитоп HA, чтобы обеспечить возможность обнаружения слитого бека с помощью антитела к HA, в остальном оставшаяся часть кодируемого полипептида была такой же, как для pRA02. Вторая конструкция была обозначена pRA20. Аминокислотная последовательность слитого полипептида pFAγ::NifD-линкер-NifK::HA приведена как SEQ ID NO:65. Первый кодируемый слитый полипептид имел структурные компоненты pFAγ::NifD-линкер (FLAG)-NifK, тогда как второй представлял собой pFAγ::NifD-линкер (FLAG)-NifK::HA.
Когда pRA20 вносили в клетки N. benthamiana и исследовали белковые экстракты методом вестерн-блоттинга (Фиг. 14), были обнаружены две специфические полосы в диапазоне размеров, предсказанном для полипептида приблизительно на 120 кДа. Близость двух полос позволяет предположить, что присутствовали как непроцессированная, так и процессированная формы препоследовательности МНП. Верхняя полоса имела большую интенсивность, чем нижняя полоса, что позволяет предположить, что процессинг происходил только частично. Уровень накопления полипептида pFAγ::NifD-линкер (FLAG)-NifK::HA был существенно большим, чем для pFAγ::NifD::HA в параллельной инфильтрации, но намного меньшим, чем для pFAγ::NifK::HA (Фиг. 14).
Пример 13. Создание мультигенных конструкций для коэкспрессии полипептидов нитрогеназы in planta
Чтобы получить функциональную нитрогеназу в растительных клетках, гены, кодирующие три основных структурных белка NifD, NifH и NifK и ряд вспомогательных белков Nif, включая NifB, NifE и NifN, необходимо будет вносить и координированно экспрессировать в клетках. Геномную интеграцию некоторого количества трансгенов можно обеспечить, используя трансформационную конструкцию, которая содержит некоторое количество экспрессионных кассет в Т-ДНК, причем каждая управляет экспрессией отличного полипептида Nif. Такой дизайн обеспечил бы интеграцию Т-ДНК в одну геномную локацию, в случае необходимости. Следовательно, авторы изобретения разработали и создали три независимые мультигенные конструкции, которые при комбинации в одном трансформационном событии обеспечивали возможность интеграции трех Т-ДНК, содержащих 15 трансгенов, в геном растения. Каждая из трех Т-ДНК содержала отличный селективный маркерный ген, поэтому можно было независимо проводить их отбор следующим образом.
Бинарный вектор pDCOT, полученный от Dr Thomas Vanhercke (CSIRO Agriculture and Food, Canberra, Australia), использовали в качестве стартового вектора. Он имел такую же последовательность остова и левую и правую пограничные последовательности Т-ДНК, как и бинарный вектор pORE_O4 (Coutu et al., 2007; GenBank Accession No. AY562542.1). В дополнение к кассете селективного маркерного гена область Т-ДНК pDCOT содержала четыре экспрессионные кассеты, причем каждая кассета содержала сильный конститутивный промотор и терминатор транскрипции/область полиаденилирования, фланкирующие уникальный рестрикционный сайт, в целях клонирования. После каждого промотора каждая экспрессионная кассета также содержала лидерную последовательность вируса табачной мозаики Ω (TMVΩ) непосредственно перед уникальным сайтом клонирования для оптимизации трансляции с мРНК, которая вырабатывалась бы в растительных клетках. Последовательности промотора и терминатора в разных кассетах варьировали, чтобы ограничить повторяемость последовательности в векторе, посчитав, что это снизило бы сайленсинг экспрессии в растении после трансформации. Дополнительно каждую из кассет 1 и 2 и кассеты 4 и кассеты селективного маркера разделяли последовательностью матрикс-ассоциированной области (МАО), чтобы снизить транскрипционное влияние одной экспрессионной кассеты на другую. Кассетой гена селективного маркера в pDCOT был ген NPTII, придающий устойчивость к антибиотику канамицину. Вектор pDCOT был модулярным по расположению экспрессионных кассет в том, что каждая экспрессионная кассета содержала, в следующем порядке, промотор, TMVΩ, сайт клонирования и последовательность терминатора/полиаденилирования, и фланкировалась уникальными рестрикционными сайтами, обеспечивающими возможность прямого обмена кассетами.
Чтобы увеличить число отдельных кассет для генной экспрессии в трансформационном векторе, в pDCOT вставляли пятую экспрессионную кассету между уникальными сайтами KpnI/AatII, которые существовали в исходном векторе pDCOT, следующим образом. Фрагмент ДНК для пятой экспрессионной кассеты разрабатывали и синтезировали так, чтобы он содержал усиленный промотор CaMV 35S с последующей лидерной последовательностью TMVΩ, затем уникальный сайт клонирования для вставки трансгена (Bstz171/SbfI) и наконец, 3' область терминатора nos. Всю селекционную кассету, фланкируемую 5' сайтом KpnI и 3' сайтом AatII, вставляли в pDCOT, используя рестрикционные сайты для направленного клонирования в pDCOT. Это приводило к вставке пятой экспрессионной кассеты между последовательностью МАО и кассетой селективного маркерного гена. Структура pKT100 схематически представлена на Фиг. 15.
Некоторые из промоторов в pDCOT и его производном pKT100 были из гена малой субъединицы Rubisco A. thaliana (Arath-Rubisco/SSU), что обеспечивало экспрессию трансгена в зеленых тканях на свету, тогда как в других кассетах в векторах использовалась промоторная последовательность CaMV 35S для конститутивной экспрессии. В случае исходных конструкций для экспрессии полипептидов Nif было желательно, чтобы вся экспрессия происходила конститутивно, поэтому промоторы Arath-Rubisco/SSU были заменены другими растительными промоторами на основе вирусов, в то же время снижая повторяемость последовательностей в конечных векторах. Альтернативные выбранные конститутивные промоторы представляли собой производное промотора вируса скручивания желтых листьев цеструма (CmYLCV) Cm4 (Sahoo et al., 2014) и промоторов вируса карликовости клевера подземного (SCSV) S7 и S4 (Schunmann et al., 2003). Применяемая последовательность промотора Cm4 содержала нуклеотиды от -271 до +5 относительно сайта инициации транскрипции CmYLCV (Sahoo et al., 2014), чтобы избежать сайта MluI в 5' конце и присутствия любой ненужной 3' НТО последовательности. Каждая промоторная последовательность содержала лидерную последовательность TMV в 5' НТО и фланкировалась уникальными рестрикционными сайтами, которые совпадали с используемыми для промоторов, которые они замещали, в частности MluI/BamHI для CmYLCV Cm4, NruI/ApaI для SCSV S7 и XmaI/NotI для SCSV S4. Каждая промоторная последовательность была синтезирована коммерческим поставщиком. Стандартное рестрикционное расщепление и направленное клонирование использовали для обмена каждой промоторной последовательности последовательным образом для получения pKT-HC.
Чтобы координированно экспрессировать до 15 трансгенов в растительных клетках, используя три вектора, было желательно, чтобы каждый вектор имел отличный селективный маркерный ген. Селективный маркерный ген в селекционной кассете pDCOT кодировал фермент NptII, придающий устойчивость к канамицину (Bevan et al., 1983). Были отобраны альтернативные гены, кодирующие Hpt (Waldron et al., 1985) и Bar (Block et al., 1987), придающие устойчивость к гигромицину B и глуфосинату аммония/фосфинотрицину (BASTA) соответственно, так как они подходили для применения для отбора в растениях. Фрагменты ДНК, кодирующие эти полипептиды, были созданы коммерческим поставщиком, фланкировались рестрикционными сайтами FseI/AscI, которые совпадали с рестрикционными сайтами, фланкирующими кодирующую область NptII в селекционной кассете pDCOT. Стандартное рестрикционное расщепление и направленное клонирование использовали для замещения кодирующей области NptII в pKT-HC кодирующей областью Hpt или кодирующей областью Bar, создавая набор из трех мультигенных векторов, называемых pKT-HC, pKT-IC и pKT-JC. Каждый имел генетическую конструкцию, проиллюстрированную на Фиг. 15, и компоненты, обобщенные в Таблице 5.
Таблица 5. Компоненты мультиэкспрессионных кассет в Т-ДНК-векторах.
Пример 14. Экспрессия полипептидов Nif в растительных клетках из мультигенных векторов
Чтобы продемонстрировать и оценить способность к экспрессии трансгена каждой экспрессионной кассеты в мультигенных векторах, создавали набор из 5 конструкций, в которых кодирующая белок область, кодирующая слитый полипептид pFAγ::NifH::HA, была отдельно вставлена в каждую из экспрессионных кассет. Конструкции с правильной вставкой МНП-NifH-HA идентифицировали по профилю расщепления рестрикционным ферментом HindIII и использовали для трансформации штамма GV3101 Agrobacterium tumefaciens. Затем использовали систему для временной экспрессии на основе листьев N. benthamiana (Example 1) для оценки белковой экспрессии, при этом листья инфильтрировали смесью из трех штаммов GV3101, а именно, одного, содержащего конструкцию pFAγ::NifH::HA, второго pRA01 и третьего штамма, содержащего вектор для экспрессии белка супрессии сайленсинга p19, каждого под управлением промотора 35S. В этом эксперименте pRA01 служил в качестве положительного контроля для синтеза белка по флуоресценции ЗФБ. Ткань листьев собирали через 4 суток, а белковые экстракты анализировали методом гель-электрофореза и вестерн-блоттинга, как описано выше. Вестерн-блоты зондировали анти-HA и анти-ЗФБ первичными антителами и козьим антимышиным вторичным антителом, связанным с пероксидазой хрена (BioRad). Хемилюминесцентные сигналы генерировали, применяя реагент для обнаружения для ЭХЛ и вестерн-блоттинга Amersham (GE Healthcare Life Sciences) и записывали, используя визуализатор CCD. Экспрессию pFAγ::NifH::HA наблюдали для каждой отдельной экспрессионной кассеты (Фиг. 16), тем самым подтверждая способность каждого промотора в мультигенном векторе экспрессировать слитые полипептиды Nif сильным конститутивным образом в клетках листьев после временного внесения Т-ДНК.
Затем конструировали мультигенный вектор, который кодировал пять отдельных слитых полипептидов Nif в одной Т-ДНК, на основе вектора pKT-HC. Каждую кодирующую область Nif вставляли последовательным образом посредством уникального сайта клонирования в каждой экспрессионной кассете. Кодирующую область для pFAγ::NifH::HA вставляли в кассету 1, область для pFAγ::NifS::HA вставляли в кассету 2, область для pFAγ::NifM::MYC вставляли в кассету 3, область для pFAγ::NifU::HA вставляли в кассету 4 и область для pFAγ::NifZ::MYC вставляли в кассету 5 (Фиг. 4). Аминокислотная последовательность слитого полипептида pFAγ::NifM::MYC приведена как SEQ ID NO:67. Конечную конструкцию, называемую HC13, использовали для трансформации штамма A. tumefaciens штамма GV3101, а трансформированные клетки использовали для инфильтрации листьев N. benthamiana, используя описанный выше способ. Анализ методом вестерн-блоттинга показал, что полипептиды, экспрессируемые из HC13, легко можно обнаружить с ожидаемым размером для pFAγ::NifH::HA, pFAγ:NifM::MYC, pFAγ::NifS::HA и pFAγ::NifU::HA (Фиг. 17). Слитые полипептиды NifM и NifU накапливались на более низких уровнях, чем слитые полипептиды NifH и NifS, но их все еще можно было явно обнаружить. Фоновый сигнал, также наблюдаемый на дорожке для контроля pFAγ::ЗФБ (дорожка 2), находился в той же позиции, что и ожидаемая полоса для конструкции pFAγ::NifZ::MYC (Фиг. 17B), хотя сила сигнала на дорожке 4 была намного большей, чем на дорожке 2. Авторы изобретения сделали заключение, что все пять слитых полипептидов Nif экспрессировались из одной непрерывной генетической конструкции.
Стабильная трансформация растений.
Штаммы Agrobacterium tumefaciens, содержащие генетические конструкции, использовали для трансформации A. thaliana методом погружения (Bechtold et al., 1993), в частности, HC13. С обработанных растений собирали семена. Семена высевали в тканевую культуральную среду, содержащую соответствующий селективный агент для отбора стабильно трансформированных растений, которые переносили в почву для роста до достижения зрелости. Семена с растений, которые оказались трансгенными, собирали и высевали для получения дочерних растений. Проводили идентификацию и отбор дочерних растений, которые являлись гомозиготными в отношении трансгена. Уровни экспрессии трансгенов анализировали стандартными методами кРВ-ПЦР, а уровни накопления слитых полипептидов, которые содержали эпитопы, определяли методами вестерн-блоттинга, как и в случае экспериментов по временной экспрессии, описанных выше.
Пример 15. Эффект конструкции NifD на коэкспрессируемые трансгены
Как описано в примере 11, неожиданно наблюдали, что когда конструкции, кодирующие конкретные слитые полипептиды NifD (pRA07, pRA19), совместно инфильтрировали с другими Nif-экспрессирующими конструкциями, экспрессия всех Nif-экспрессирующих конструкций была существенно снижена (Фиг. 10). Эта конкретная конструкция pRA19 имела нуклеотидную последовательность, которая была оптимизирована в соответствии с человеческой частотой использования кодонов. Следовательно, авторы изобретения пытались понять объем и причину снижения экспрессии в попытке преодолеть эту проблему.
Во-первых, чтобы посмотреть, был ли этот эффект специфическим для комбинации pRA19 и pRA01, Т-ДНК из pRA01 (pFAγ::ЗФБ) вносили в клетки листьев N. benthamiana одну или в комбинации с pRA19 (pFAγ::NifD::HA, человеческая частота оптимизации кодонов) или pRA16 (pFAγ::NifS::HA), или же комбинировали все три pRA01, pRA19 и pRA16. Как и ранее, A. tumefaciens, содержащие конструкцию, экспрессирующую супрессор сайленсинга p19, включали во все инфильтрации, включая контрольные. Через четверо суток после инфильтрации абаксиальную поверхность инфильтрированных листьев N. benthamiana подвергали воздействию ультрафиолетового света (УФ) и фотографировали для определения интенсивности экспрессии ЗФБ. По сравнению с флуоресценцией, наблюдаемой для области, инфильтрированной pRA01, наблюдалось существенное снижение флуоресценции ЗФБ для pRA19+pRA01 с еле видимой флуоресценцией. В противоположность этому, флуоресценция была четко видна для pRA16+pRA01, хотя наблюдалось некоторое снижение флуоресценции по сравнению с одним pRA01, что можно было ожидать при разведении при использовании двух Т-ДНК. Далее сравнивали уровни накопления ЗФБ и слитого полипептида NifS методом гель-электрофореза и вестерн-блоттинга, используя анти-HA и анти-ЗФБ антитела. В соответствии с наблюдаемыми уровнями флуоресценции ЗФБ уровень накопления pFAγ::ЗФБ был снижен при совместной инфильтрации pRA19 с pRA01, тогда как уровень pFAγ::ЗФБ был только немного меньшим при совместном внесении pRA16 и pRA01 (Фиг. 18). При совместном внесении всех трех конструкций уровень накопления pFAγ::NifS::HA также был существенно снижен по сравнению с тем, когда pRA19 не был включен. Следовательно, снижение, вызываемое внесением Т-ДНК из pRA19 не было ограничено снижением pFAγ::ЗФБ из pRA01.
Чтобы дополнительно изучить объем и механизм этой понижающей регуляции, вносили дополнительные конструкции, по отдельности или в комбинации с pRA19 или с другими конструкциями, кодирующими слитый полипептид NifD, и анализировали уровни трансгенной экспрессии белка и мРНК, а также интенсивности флуоресценции под УФ-светом. Как и ранее, внесение Т-ДНК из pRA19 приводило к снижению флуоресценции ЗФБ и белковых уровней как для ЗФБ, так и для слитого полипептида pFAγ::NifS::HA из совместно вносимого pRA16. Однако это не был случай, когда совместно вносили pRA24 (pFAγ::NifD::HA, кодон-оптимизированный на основе частоты использования кодонов Arabidopsis) или pRA20, кодирующие слитый полипептид NifD-NifK (pFAγ::NifD-линкер-NifK::HA). Следует отметить, что pRA24 и pRA20 кодировали идентичную аминокислотную последовательность NifD с pRA19, но использовали разные нуклеотидные последовательности, поскольку они были кодон-оптимизированы на основе частоты использования кодонов Arabidopsis. На основании этих наблюдений авторы изобретения решили, что эффект понижающей регуляции pRA19, возможно, инициировался специфической NifD-кодирующей последовательностью РНК, транскрибируемой с Т-ДНК pRA19.
Чтобы определить, возникал эффект понижающей регуляции на уровне белка и/или РНК, проводили экстракцию РНК из тех же инфильтрированных областей и анализировали методом кРВ-ПЦР. При применение ЗФБ-специфических праймеров было обнаружено, что уровень мРНК ЗФБ для комбинации pRA19+pRA01 был снижен до около 25% относительно уровня для одного pRA01. Когда комбинировали pRA16 и pRA01, снижение составляло менее 50% по сравнению с одним pRA01, как и ожидалось при комбинации двух конструкций. Далее, при применении праймеров, которые гибридизировались с частью РНК, кодирующей пептид pFAγ, причем праймеры амплифицировали бы область мРНК из обоих трансгенов, экспрессируемых одновременно, анализ кРВ-ПЦР позволил определить, что уровень снижения для трансгена был приблизительно на 50% большим для комбинации pRA19+pRA01 по сравнению с pRA16+pRA01. Вместе эти результаты продемонстрировали, что внесение pRA19 в клетки листьев N. benthamiana имело эффект снижения уровней как мРНК, так и белка коэкспрессируемых трансгенов. Это оказался не общий эффект понижающей регуляции мРНК/белка, так как уровень экспрессии контрольного гена (GADPH) был постоянным во всех экспериментах по инфильтрации, а уровни общего синтеза белка оказались аналогичными для всех инфильтраций, на что указывает окрашивание гелей кумасси. Вместе эти результаты показывают, что характерное свойство мРНК, кодирующей полипептид NifD, вырабатываемой из Т-ДНК pRA19, приводило к понижающей регуляции совместно вносимых трансгенов на уровне мРНК и белка.
Известно, что на один из хорошо изученных механизмов РНК-опосредованного генного сайленсинга влияют миРНК длиной 21-24 нуклеотидов, которые направляют белок Argonaute для снижения экспрессии полинуклеотидов с комплементарными или почти комплементарными последовательностями, а этот процесс называется РНК-интерференцией (РНКи). Однако выравнивание последовательностей РНК кодон-оптимизированной в соответствии с человеческой кодирующей области из pRA19 с последовательностями РНК, кодируемыми pRA01 (ЗФБ) или pRA16 (NifS), не выявило ни одного участка гомологии, достаточного для обеспечения комплементарности последовательностей, необходимой для Argonaute-опосредованного сайленсинга. На основании этого открытия предположили, что хотя специфическая последовательность РНК NifD инициировала сайленсинг совместно вносимых трансгенов, эффектор сайленсинга находился в другом месте конструкции pRA19 - в области, которая обладала комплементарностью последовательностей с ЗФБ и другими трансгенами. Чтобы проверить эту гипотезу, pRA22 (mFAγ::NifD::HA), который был идентичен с pRA19, но содержал мМНП и, следовательно, имел отличную последовательность РНК в частях области МНП, совместно вносили с pRA01. Для сравнения также вносили комбинации pRA19+pRA01 и pRA24+pRA01. По данным интенсивности флуоресценции оказалось, что комбинация pRA22+pRA01 экспрессировала ЗФБ приблизительно на том же уровне, что и комбинация pRA24+pRA01. По данным вестерн-блоттинга обе комбинации, pRA24+pRA01 и pRA22+pRA01, демонстрировали небольшое снижение в накоплении белка ЗФБ, тогда как pRA19+pRA01 демонстрировали существенное снижение количество белка ЗФБ. Эти результаты демонстрируют, что модификация последовательности МНП до последовательности со сниженной комплементарностью с другими трансгенами смягчала понижающую регуляцию кодон-оптимизированной в соответствии с человеческими кодонами последовательности NifD. Это позволяет предположить, что кодон-оптимизированная в соответствии с человеческими кодонами РНК NifD в pRA19 в комбинации с последовательностью pFAγ инициировала понижающую регуляцию трансгена. В альтернативном, но не взаимоисключающем варианте, самой нуклеотидной последовательности NifD было достаточно для инициации понижающей регуляции, но было необходимо, чтобы области выше РНК NifD были комплементарными с трансгенами, чтобы вызвать их понижающую регуляцию.
Чтобы подтвердить, что эффект понижающей регуляции кодон-оптимизированного в соответствии с человеческими кодонами NifD на другие белки был свойством РНК NifD, но не белка NifD, разработали конструкцию, которая имела почти идентичную последовательность РНК с pRA19, но с двумя нуклеотидными изменениями, которые создавали преждевременный стоп-кодон и сдвиг рамки в МНП. Ее назвали pRA26 (ΔFAγ::NifD::HA). Если механизм понижающей регуляции был опосредован РНК, но не белком, можно ожидать, что pRA26 приводила бы к понижающей регуляции ЗФБ и других конструкций Nif, аналогичных pRA19. В качестве дополнительной проверки также вносили кодон-оптимизированную в соответствии с человеческими кодонами конструкцию NifD pRA07 (pFAγ::nifD::FLAG). pRA07 экспрессировала бы идентичную последовательность РНК с pRA19 в области NifD, но не в эпитопной области, так как эпитоп HA был заменен на FLAG. Через пять суток наблюдали уровень флуоресценции в инфильтрированных зонах. В соответствии с предыдущими экспериментами флуоресценция ЗФБ была снижена для комбинации pRA19+pRA01. Флуоресценция также была существенно снижена для обеих комбинаций, pRA26+pRA01 и pRA7+pRA01. Вестерн-блоттинг показал, что pRA26 имела аналогичный эффект на снижение ЗФБ по сравнению с pRA19. Было сделано заключение, что кодон-оптимизированная в соответствии с человеческими кодонами мРНК NifD была способна снижать экспрессию других трансгенов, даже в случае отсутствия выработки белка NifD или изменения эпитопа. Совокупно с предыдущими результатами, демонстрирующими, что изменение кодон-оптимизированной в соответствии с человеческими кодонами последовательности РНК NifD предотвращало понижающую регуляцию трансгена, в итоге было продемонстрировано, что снижение экспрессии трансгена последовательностью NifD в pRA19 происходило вследствие наличия специфической кодон-оптимизированной в соответствии с человеческими кодонами последовательности РНК NifD. Нуклеотидная последовательность кодирующей области слитого полипептида pFAγ::NifD::HA в pRA19 приведена как SEQ ID NO:68.
Пример 16. Эксперименты по бактериальной экспрессии для исследования функции полипептида Nif
Как описано в примерах выше, создавали генетические конструкции и исследовали в отношении выработки слитых полипептидов Nif в растительных клетках на примере системы на основе листьев N. benthamiana с внесением синтетических генов с помощью A. tumefaciens. Слитые полипептиды были разработаны так, чтобы содержать находящиеся в рамке слияния митохондриального нацеливающего пептида (МНП), добавляемого в N-конец полипептидов Nif, и эпитопный теэ, добавляемый в С-концевое удлинение. Хотя моделирование сворачивания и ассоциации белков (пример 10) предсказало, что большинство N-концевых и C-концевых удлинений не должны препятствовать образованию и функции комплекса, авторы изобретения хотели проверить в in vivo биологической системе, могут ли эти удлинения влиять на функцию слитых полипептидов по сравнению с нативными полипептидами Nif.
Слитые полипептиды Nif, которые были разработаны для экспрессии в растительных клетках и транслокации в митохондрии, а также их процессированные полипептидные продукты исследовали в отношении их функции в бактериальной экспрессионной системе нитрогеназы. Авторы изобретения создали систему, которая обеспечивала возможность оценки каждого модифицированного полипептида отдельно путем добавления в систему нитрогеназы или итерационно, или даже в комбинациях с другими модифицированными полипептидами Nif. В этой системе в E. coli используется кластер гена нитрогеназы дикого типа, который был модифицирован замены одиночных генов Nif, кодирующих слитые полипептиды Nif, которые необходимо было исследовать, на месте соответствующего гена, кодирующего полипептид Nif дикого типа. За этим следовал анализ активности нитрогеназы или редуктазы нитрогеназы с применением анализа выработки этилена и водорода, соответственно, для определения, может ли слитый полипептид Nif функционировать на месте соответствующего полипептида Nif дикого типа. В основе этого лежала бактериальная векторная система нитрогеназы на основе Smanski et al. (2014). В этой системе все гены дикого типа, необходимые для активности нитрогеназы, находились в одном, рассчитанном на широкий спектр хозяев, экспрессионном векторе pMIT2.1, при этом экспрессия генов находилась под управлением систему индуцибельный промотор/T7-РНК-полимераза из второй плазмиды pN249. При экспрессии в E. coli вырабатывался полный набор бактериальных полипептидов Nif дикого типа, которые вместе обеспечивали наличие комплекса фермента нитрогеназы, чью активность можно было оценить по выработке этилена из ацетилена в стандартном анализе восстановления ацетилена (АВА, de facto измерение активности нитрогеназы) или по выработке водорода для в случае активности редуктазы нитрогеназы.
Способы, в которых использовали pMIT2.1 и ее производные, были следующими. Клетки штамма DH5α E. coli трансформировали двумя плазмидами, pMIT2.1 и pN249, которые придавали устойчивость к антибиотикам, хлорамфениколу и спектиномицину, соответственно. Отбор трансформированных клеток проводили, выращивая их в среде LB (10 г/л триптона, 5 г/л дрожжевого экстракта, 10 г/л NaCl), содержащей хлорамфеникол (34 мг/л) и спектиномицин (80 мг/л). Трансформированные клетки выращивали в аэробных условиях в течение ночи при 37°C в среде LB с антибиотиками до оптической плотности 1,0. Культуры центрифугировали при 10000 g в течение 1 минуты и сливали супернатант. Клетки пересуспендировали в одном объеме индукционной среды, которая не содержала источников N, содержащей 25 г/л Na2HPO4, 3 г/л KH2PO4, 0,25 г/л MgSO4.7H2O, 1 г/л NaCl, 0,1 г/л CaCl2.2H2O, 2,9 мг/л FeCl3, 0,25 мг/л Na2MoO4.2H2O и 20 г/л сахарозы (минимальная среда), дополненной 1,5 мл/л 10% серина. Исходные растворы подвергали стерилизации фильтрацией. Для индукции генной экспрессии Nif среду дополняли изопропил-β-D-1-тиогалактопиранозидом (ИПТГ; Gold Bio #I2481C25 259) в конечной концентрации 0,1 мМ, 0,5 мМ или 1,0 мМ, если не указано иное, в целом 1,0 мМ. Клеточные суспензии переносили в 13 см3 культуральные колбы с закрывали газонепроницаемой резиновой крышкой, используя систему с загибкой краев, а подкрышечное пространство продували чистым газообразным N2 в течение 20 мин. Затем суспензии инкубировали при 30°C с перемешиванием при 200 об/мин в течение 5 часов. После этого начинали проведение анализа восстановления ацетилена (АВА) с введения 1,5 см3 чистого C2H2 (газы BOC, разряд прибора) и дополнительно инкубировали в течение 3 ч, а затем до 18 ч. Выработку этилена в оба момента времениизмеряли с помощью газовой хроматографии с пламенно-ионизационной детекцией (ГХ-ПИД), используя прибор Agilent 6890N GC. Образцы из подкрышечного пространства (0,5 см3) вручную вводили в инжектор с делением/без деления потока в 10:1 режиме разделения. Прибор работал при следующих параметрах: температуры инжектора и ПИД 200°C, средняя скорость носителя He 35 см/с, температура изотермической печи 120°C. Колонку RT-Alumina Bond/MAPD (30 м x 0,32 мм x 5 мкм) использовали с 5 м колонкой для захвата частиц, соединенной с оконечностью детектора. Аналитическую эффективность прибора оценивали, проводя эксперименты с подходящими контрольными и стандартными образцами. В этих условиях происходило выделение этилена из колонки в момент около 2,3 минуты, а ацетилена - в момент около 3,1 минуты. Эта система ГХ могла регистрировать этилен на уровнях до 0,00001% атм с четким отделением от ацетилена, дающего единственный дополнительный регистрируемый пик в этом формате, поэтому была исключительно чувствительной. В случае выработки этилена образцы из подкрышечного пространства 0,5 см3 брали в разные моменты времени после добавления ИПТГ, в целом в моменты 3 ч и 18 ч.
Аналитическая система, в которой использовали pMIT2.1 дикого типа и pN249 в штамме DH5α E. coli в качестве положительного контроля, давала только следовой уровень этилена, когда в среду для роста добавляли ИПТГ, тогда как добавление ИПТГ в среду для роста при 0,1 мМ, 0,5 мМ или 1,0 мМ сильно повышало количество вырабатываемого этилена. Уровень выработки этилена сильно повышался за время от сбора образцов в 3 ч до 18 ч и также при повышении концентрации ИПТГ, что указывает на повышение активности нитрогеназы с повышение генной экспрессии Nif. Эти результаты продемонстрировали, что ИПТГ быстро повышал генную экспрессию Nif и образование нитрогеназы в этой экспрессионной системе, что согласуется в данными Smanski et al., (2014).
Как описано в предыдущих примерах, происходило расщепление аминокислотной последовательности МНП pFAγ в митохондриях растений, оставляя 38 аминокислотных остатков, слитых с N-концом полипептида Nif процессированных слитых полипептидов Nif. Чтобы проверить, будет ли N-концевое удлинение изменять функцию слитых полипептидов, и продемонстрировать, что бактериальная аналитическая система работает, синтезировали фрагмент ДНК (SEQ ID NO:70) длиной 117 п. о. методом ПЦР, используя ДНК pRA10 в качестве матрицы. Этот фрагмент ДНК, кодировал 38 аминокислот той же последовательности, что и С-концевая часть МНП pFAγ, за исключением замены N-концевого остатка Ile на Met для инициации трансляции плюс дополнительный остаток Thr в С-конце. Он был сконструирован так, что при слиянии в рамке непосредственно выше стартового кодона гена, кодирующего любой из полипептидов Nif, химерный ген кодировал бы трансляционное слияние выбранного полипептида Nif. Аминокислотная последовательность 39-аминокислотного полипептида, называемого в данном документе pFAγ-C, приведена как SEQ ID NO:71.
Фрагмент ДНК для pFAγ-C вставляли непосредственно выше кодона инициации трансляции генов, кодирующих NifH, NifM, NifD, NifK, NifE, NifN или NifB, в pMIT2.1 различными методами, включая лигирование тупых концов, ПЦР со сплайс-перекрытием и направленные методы циклизации с лигазой (de Kok et al., 2014). В качестве примера 117 п. о. фрагмент ДНК сливали в рамке с кодирующей белок областью гена NifD в pMIT2.1 следующим образом. ДНК pMIT2.1 амплифицировали, используя праймеры, для создания линейного ДНК-продукта так, чтобы стартовый кодон (ATG) гена NifD находился в 5' конце, а нуклеотидная последовательность гена NifD непосредственно 5' от кодона инициации трансляции образовывала 3' конец продукта. Для этого проводили ПЦР, используя праймеры NifD-F 5'-ATGATG ACTAATGCTACTGGCGAACGTAACCTG-3' (SEQ ID NO:72) и NifD-R 5'-CCGGCTCCTCCGCTAGATAAAAATGTGA-3' (SEQ ID NO:73). Амплификацию проводили, используя полимеразу Phusion-HF Proofreading (NEB, каталог M05081L) с ДНК-матрицей pMIT2.1, со следующим протоколом ПЦР: 96°C в течение 30 с, затем 30 циклов с 92°C в течение 20 с, 55°C в течение 20 с и 72°C в течение 6 мин, затем 72°C в течение 10 мин. Продукты реакции обрабатывали DpnI для удаления векторной матричной ДНК. Продукт ПЦР в целом представлял собой линеаризованную форму pMIT2.1, открытую непосредственно выше кодона инициации трансляции NifD. 117 п. о. фрагмент лигировали в линеаризованную pMIT2.1, используя ДНК-лигазу T4 с созданием pCW1001. Лигирование 117 п. о. фрагмента также осуществляли, используя условия реакции лигирования с циклизацией (LCR), используя Illumina Ampligase (Illumina, A8101) и условия, приведенные в de Kok et al. (2014).
Чтобы определить достоверность и точность реакции амплификации ДНК pMIT2.1 и продемонстрировать, что в генах Nif дикого типа не возникали нуклеотидные замены, лигировали образец линеаризованной ДНК pMIT2.1, чтобы восстановить кольцевые молекулы, и использовали для трансформации DH5α E. coli. Около 10 отдельных колоний, содержащих повторно лигированную pMIT2.1, оценивали в отношении выработки этилена из ацетилена, как описано выше, чтобы продемонстрировать, что мутации инактивации не были включены в ДНК во время реакции ПЦР-амплификации. Также можно проводить секвенирование векторов, чтобы гарантировать точность и достоверность конструкции.
Векторы pCW1001 и pN249 вносили в DH5α, а отбор трансформированных клеток проводили с помощью хлорамфеникола и спектиномицина. Культуры, выращенные из этих клеток в индукционной среде, оценивали в отношении выработки этилена в анализа АВА, используя 1 мМ ИПТГ для индукции генной экспрессии и газообразный N2 в качестве подкрышечного пространства, с добавлением газообразного ацетилена в качестве субстрата. Выработка этилена указывает на то, что 39-аминокислотное N-концевое удлинение в полипептиде NifD в остальном дикого типа допустимо для активности нитрогеназы.
Аналогичный подход используют для модификации других генов Nif в pMIT2.1, включая, например, NifH, NifK, NifB, NifE, NifM и NifN, с применением в каждом случае соответствующих пар праймеров для линеаризации ДНК pMIT2.1 в позиции непосредственно выше кодона инициации трансляции и вставки 117 п. о. фрагмента в этой позиции. Успешные раунды модификации гена Nif также проводят для создания комбинации двух или более модификаций гена Nif в одном векторе, чтобы проверить, сохраняют ли функцию комбинации модифицированных слитых полипептидов Nif в комплексе нитрогеназы в остальном дикого типа.
Альтернативной аналитической системой для исследования биологической функции слитых полипептидов Nif является бактериальный анализ комплементации с использованием мутантов A. vinelandii с мутациями в конкретных генах Nif. Для его осуществления генетические последовательности, кодирующие слитые полипептиды Nif, по отдельности вставляют в рассчитанную на широкий диапазон хозяев плазмиду, такую как pMMB66EH (Furste et al. 1986), которую можно размножать в штаммах бактерии A. vinelandii. Каждую получаемую в результате генетическую конструкцию вносят в мутантный штамм A. vinelandii, например, штамм DJ1271, в котором отсутствуют 200 п. о. в 5' конце эндогенного гена nifH, для исследования функции слитого полипептида NifH. Другие мутантные штаммы, в которых отсутствуют отдельные виды активности Nif, перечислены в Таблице 6. Эти мутации делают мутантов неспособными к фиксации атмосферного азота в соответствующих условиях роста. Экспрессия функционального гена NifH в DJ1271, например, восстанавливает активность нитрогеназы. Следовательно, это является полезной тестовой системой для оценки модифицированных слитых полипептидов NifH в отношении функции при ассоциации с другими полипептидами Nif.
Чтобы оценить функцию этих полипептидов, можно оценивать рост трансформантов в не содержащей азот среде. В отсутствие добавочных источников азота в среде для роста A. vinelandii должны фиксировать атмосферный азот, чтобы расти. Если модифицированные слитые полипептиды NifH являются функциональными, то сверхэкспрессия этих полипептидов в DJ1271 должна восстанавливать способность к росту в твердой среде, не содержащей добавочного азота. В альтернативном варианте функцию нитрогеназы можно оценить с помощью анализа восстановления ацетилена (АВА) способом, описанным выше. АВА позволяет измерять активность нитрогеназы с большей чувствительностью, чем в случае роста в не содержащей азот среде.
Эти экспрессионные системы позволяют исследовать функцию слитых полипептидов Nif в бактериях, когда все другие компоненты Nif, необходимые для функции нитрогеназы, кодируются в бактерии.
Таблица 6. Мутантные штаммы A. vinelandii, которые можно использовать для исследования слитых полипептидов Nif в отношении функции нитрогеназы (бактериальная комплементация).
Пример 17. Модификация последовательностей МНП и их применение с полипептидами Nif
Последовательность МНП pFAγ длиной 77 аминокислотных остатков (аминокислоты 1-77 из SEQ ID NO:38), которая описана и использована в примерах 5-9, получали из гамма-субъединицы F1-АТФазы Arabidopsis thaliana (Lee et al, 2012), фрагмент которой обозначается в данном документе МНП-FAγ77. В протоколе клонирования, используемом в примере 5 для создания генной последовательности, кодирующей трансляционное слияние между МНП-FAγ77 и дистальными полипептидами Nif, использовался вставочный линкер из 9 нуклеотидов в месте соединения слияния, который состоял из сайта клонирования AscI и дополнительного основания для сохранения рамки считывания. Применение этого линкера приводило к наличию дополнительных трех аминокислот, а именно Gly-Ala-Pro (GAP), между С-концом МНП-FAγ77 и N-концом представляющего интерес полипептида (например, ЗФБ или Nif). Следовательно, кодируемые полипептиды содержали, до расщепления в митохондриях, N-концевое удлинение из 80 аминокислот, которое согласно полученным данным было эффективным для перемещения слитых полипептидов в митохондрии и расщепления в предсказанном сайте митохондриальной матриксной пептидазой (ММП). Как описано в примерах 5-9, было сделано заключение, что МНП-FAγ77 был способен направлять 16 разных слитых полипептидов Nif в митохондриальный матрикс растений и что последовательность МНП-FAγ77 процессировалась в митохондриях ММП. Расщепление происходило после 42 аминокислоты, оставляя N-концевое удлинение из 38 аминокислотных остатков, слитое с представляющими интерес полипептидами ЗФБ или Nif, при этом 35 остатков принадлежали МНП-FAγ77 плюс GAP. Это N-концевое удлинение называется в данном документе FAγ-следом38.
Авторы изобретения старались укоротить последовательность МНП от 77 аминокислот МНП-FAγ77 для применения с полипептидами Nif в растительных клетках с сохранением функции МНП. Авторы изобретения исследовали, можно ли вырезать 26 аминокислот из С-конца МНП -FAγ77 для создания МНП, обозначаемого МНП-FAγ51 (SEQ ID NO:75). Авторы изобретения предсказали, что МНП-FAγ51 будет расщепляться МПП после аминокислоты 42, оставляя 9 аминокислот (ISTQVVRNR; SEQ ID NO:76) из МНП-FAγ51 в N-конце процессированного слитого полипептида. Эта 9-аминокислотная последовательность была обозначена как FAγ-след9.
Чтобы исследовать функцию МНП-FAγ51, создавали генетические конструкции, кодирующие МНП, слитый с NifH или с ЗФБ. Эти конструкции содержали модифицированные гены NifH или GFP, которые были идентичными с геном NifH в pRA10 (SEQ ID NO:42) или геном GFP в pRA01 (SEQ ID NO:38), за исключением того, что МНП-FAγ51 был слит с N-концом каждого полипептида вместо МНП-FAγ77 плюс GAP. Полученные в результате конструкции были обозначены pRA34 (МНП-FAγ51::NifH) и pRA35 (МНП-FAγ51::ЗФБ). Усечение проводили посредством реакции лигирования с циклизацией (de Kok et al 2014), используя pRA01 в качестве примера. pRA01 без нуклеотидов, кодирующих 29 С-концевых аминокислот из МНП-FAγ77, и дополнительных 9 нуклеотидов, кодирующих аминокислоты GAP, амплифицировали методом ПЦР, используя праймеры 5'- ATGGTGAGCAAGGGCGAGGAG-3' (SEQ ID NO.xxx) и 5'- GCGGTTACGCACCACTTGAGTTG-3' (SEQ ID NO.xxx) и pRA01 в качестве матрицы. Полученный в результате ПЦР-продукт лигировали с соединительным олиго 5'- CTCCTCGCCCTTGCTCACCATGCGGTTACGCACCACTTGAGTTG-3' и Illumina Ampligase (Illumina, A8101) с условиями, приведенными в de Kok et al. (2014). Эти конструкции исследовали в системе на основе листьев N. benthamiana и сравнивали с соответствующими конструкциями, содержащими МНП-FAγ77 плюс GAP. В случае pRA34 и pRA10 белковые экстракты получали из инфильтрированных листовых тканей. Экстракты подвергали анализу методами ДСН-ПААГ и вестерн-блоттинга, используя антитело к HA, для оценки уровней белковой экспрессии и эффективности процессинга МПП для сравнения.
Белковые экстракты из E.coli, экспрессирующих конструкции, кодирующие МНП-FAγ51::NifH::HA (pRA34) и МНП-FAγ77+GAP::NifH::HA (pRA10), используемые в качестве контроля для непроцессированных слитых полипептидов, давали полипептидные полосы ожидаемого размера для непроцессированного МНП::NifH. Белковые экстракты из тканей листьев N. benthamiana, инфильтрированные этими конструкциями, давали полипептидные полосы меньшего размера, чем соответствующие бактериальные экстракты, соответствующего размеру, ожидаемому для процессированных полипептидов. Например, экспрессия полипептида МНП-FAγ51::NifH::HA дала полосу меньшей ММ, чем МНП-FAγ77+GAP::NifH::HA, в соответствии с разницей в ожидаемом размере между этими двумя полипептидами. Следовательно, было сделано заключение, что аминокислотная последовательность МНП-FAγ51 была способна нацеливать полипептиды Nif на митохондриальный матрикс в растительных клетках и обеспечивала процессинг МПП. Уровни экспрессии полипептидов и эффективность процессинга были такими же, как и в случае более длинного МНП. Кроме того, в блотах для pRA34 с помощью антитела к HA было обнаружено меньше полипептидных полос меньшего размера, которые, как считается, указывают на наличие продуктов деградации. Авторы изобретения заключили, что более короткая последовательность МНП неожиданно снижала деградацию N-концевого МНП::Nif.
Также поводили эксперименты с pRA35, кодирующей ЗФБ-слитый полипептид, для сравнения с pRA01. Для визуализации локализации полипептида с помощью флуоресценции клетки листьев, инфильтрированные кодирующими pRA01 (pFAγ77+GAP::ЗФБ) или pRA35 (FAγ51::ЗФБ) конструкциями, исследовали методом конфокальной микроскопии. Образцы листьев визуализировали, используя вертикальный микроскоп Leica с 40x водно-иммерсионным объективом. ЗФБ возбуждали на 488 нм и записывали испускание флуоресценции. Для обеих конструкция флуоресценция ЗФБ была локализована в небольших субклеточных тельцах с идентичным профилем локализации. На основании сравнения с pRA01, который исследовали в отношении митохондриальной локализации, как описано в примере 1, и по данным по процессингу для pRA34, авторы изобретения заключили, что укороченный МНП-FAγ51 был способен направлять синтетические слитые полипептиды в митохондрии растительных клеток и был способен обеспечивать их процессинг МПП в митохондриях.
Исследовали диапазон разных последовательностей МНП, чтобы оценить их эффективности при транслокации полипептидов Nif в митохондриальный матрикс растительных клеток. Систему для клонирования GoldenGate (Weber et al., 2011) использовали для сборки разных генных элементов, включая промоторы, 5'-НТО, 3'-НТО, N- и C-концевые удлинения и терминаторы. Каждый элемент определял границы, которые обеспечивали возможность модулярной сборки и легкого обмена элементами. Соответственно, эту систему для клонирования с компонентами, описанными в Engler et al., (2014), использовали для исследования большого количества разных генетических конструкций в отношении выработки слитых полипептидов МНП::Nif. Так как в системе для клонирования GoldenGate используются рестрикционные ферменты типа IIS, которые делают надрез за пределами их последовательности распознавания, можно было избежать использования сайтов клонирования для рестрикционных ферментов в соединительных последовательностях. Это позволило сконструировать гены, кодирующие слияния МНП::Nif, без последовательности Gly-Ala-Pro, присутствующей в pRA00, и избежать использования рестрикционных сайтов AscI, как описано в примерах 5-9. Вместо этого использовали мостик Gly-Gly в месте соединения слияний МНП::полипептид для соответствия системе GoldenGate. Глицин был выбран как стандартная аминокислота для этой связи благодаря его обычному наличию в позиции -1 последовательностей МНП.
Был отобран ряд разных МНП различной длины (30-70 аминокислотных остатков), которые по прогнозам должны были оставлять разные аминокислотные остатки («след»), слитые с N-концами полипептидов Nif после расщепления МПП (Таблица 7). Длина следовых последовательностей находилась в диапазоне 0-36 аминокислотных остатков. С помощью системы для клонирования GoldenGate было собрано 17 разных генетических конструкций с использованием комбинаций этих МНП с несколькими Nif (Таблица 8) для экспрессии в растительных клетках. Полипептидные последовательности NifD и NifS, используемые в этих слияниях, были вариантами последовательностей, используемых в примерах 5-9, вместо использования последовательностей в соответствии с Temme et al., (2012). Вариантные аминокислотные последовательности приведены в SEQ ID NO:95 и SEQ ID NO:96, соответственно. Вариантная аминокислотная последовательность NifD (SEQ ID NO:95) отличалась от последовательности из 483 аминокислот, приведенной как SEQ ID NO:6, шестью аминокислотными заменами в позициях 39, 41, 87, 96, 355 и 483. В случае всех этих векторов промоторы, 5' и 3'НТО и терминаторы были идентичными. Культуры Agrobacterium, содержащие эти конструкции, каждая из которых была смешана с конструкцией, вырабатывающей белок-супрессор сайленсинга P19, отдельно вносили в листья N. benthamiana, и получали белковые экстракты через 5 суток после инфильтрации. Для белковых экстрактов проводили анализ методами ДСН-ПААГ и вестерн-блоттинга. В случае инфильтрацией конструкцией МНП::NifD совместно проводили инфильтрацию pRA25 (pFAγ::NifK), так как было показано, что коэкспрессия NifK без С-концевого удлинения повышает количество NifD (пример 11). В Таблице 8 обобщены результаты по обнаружению полипептидов, вырабатываемых в растительных клетках, и расщеплению МПП (процессингу) для каждого слитого полипептида МНП::Nif.
Таблица 7. Подробная информация по МНП, используемым в растениях с применением системы GoldenGate, остатки Gly-Gly в месте соединения выделены жирным (за исключением CPN60/без линкера). кДа С/П: размер процессированного, непроцессированного МНП.
(Prasad and Stewart 1992)
0,13
(Prasad and Stewart 1992)
0
(Huang, Taylor et al. 2009)
0,37
(Huang, Taylor et al. 2009)
0,37
(At3g10920)
(Marques, Santos et al. 2014)
0,13
(Marques, Santos et al. 2014)
0,13
(Huang, Taylor et al. 2009)
1,36
(Burén, Young et al. 2017)
0,38
(Huang, Taylor et al. 2009)
1,19
(ABM97483)
(Burén, Jiang et al. 2017)
3,64
(ABM97483)
(неопубликованные данные)
1,84
Таблица 8. Анализ методом вестерн-блоттинга полипептидов, вырабатываемых после внесения конструкций (обозначенных по номеру SN) в клетки листьев для экспрессии NifH, NifD, NifM, NifS и NifU. Про: процессированный (ч) = частично - менее 50% процессированной формы обнаружено методом вестерн-блоттинга. НР: невозможно распознать процессинг на основании размера полосы.
сигнал?
При трансляционном слиянии в виде слияния МНП::Nif МНП-FAγ51 приводил к получению расщепленного полипептида МНП::Nif в случае всех исследованных полипептидов Nif (Таблица 7). Слитый полипептид NifM был только частично процессирован при слиянии с FAγ51, тогда как другие слитые полипептиды Nif процессировались более эффективно, демонстрируя, что эффективность процессинга для разных Nif может варьироваться для одного МНП. Исследовали версию FAγ51, которая содержала эпитоп HA, слитый в С-конце МНП при слиянии с NifH (SN29). Полипептид, экспрессируемый из этой конструкции, был обнаружен в анализе вестерн-блоттинга (Таблица 8).
Исследовали две версии МНП CPN60, слитого с NifD. В одной версии МНП был слит так, что между МНП CPN60 (SEQ ID:77) и NifD (SN11) находился линкер Gly-Gly. В другой версии (SN4) МНП CPN60 (SEQ ID:78) был слит непосредственно с первым метионином полипептида NifD. По прогнозам CPN60 должен расщепляться непосредственно после С-концевого тирозина в аминокислотной последовательности, и эта конструкция теоретически даст полипептид NifD с N-концом дикого типа, т. е. без «следа», тогда как конструкция SN11 по прогнозам оставит удлинение Gly-Gly после расщепления слияния МНП(GlyGly)::NifD. Неожиданно, эти очень сходные конструкции дали разные результаты, на что указывает анализ методом вестерн-блоттинга: SN11 дала полипептидную полосу с размером, ожидаемым для непроцессированного CPN60(GlyGly)::NifD, тогда как SN4 дала полосы, соответствующие как процессированному, так и непроцессированному полипептидам, при этом непроцессированный полипептид был представлен больше, чем процессированный полипептид. Кроме того, когда белок из инфильтраций SN4 сравнивали методом вестерн-блоттинга с белком, экстрагированным из параллельной инфильтрации pRA24+pRA25 (FAγ77+GAP::NifD::HA+FAγ77+GAP::NifK) (также смотрите пример 11), стало очевидно, что конструкция SN4 приводила к выработке менее корректно процессированного полипептида, чем конструкция pRA24. Следовательно, оказалось, что хотя МНП CPN60 был способен нацеливать слитый полипептид и обеспечивал возможность матриксного процессинга с выработкой полипептида NifD дикого типа, уровень экспрессии и эффективность процессинга были низкими (US2016/0304842). В случае SN11 связь Gly-Gly между CPN60 и NifD могла препятствовать процессингу МНП.
Также исследовали ряд МНП из полипептидов супероксиддисмудазы, как одиночных, так и тандемных МНП, и с или без включения Ile и Gln в С-конце перед связью Gly-Gly. Полипептиды не были обнаружены в анализе методом вестерн-блоттинга в случае версий, содержащих МНП SOD (SN15, SEQ ID NO:81 и SN16, SEQ ID NO:82), которые не содержали остатки Ile и Gln, тогда как версии, в которых сохранились остатки Ile и Gln (SN12, SEQ ID NO:79 и SN13, SEQ ID NO:80) не вырабатывали пригодных для обнаружения полипептидов, хотя оказалось, что они не были процессированы МПП. В противоположность этому, другой исследованный МНП, L29 (SN17, SEQ ID NO:83), давал сильные полипептидные сигналы при слиянии с NifD. Из-за небольшой разницы в размере между процессированной и непроцессированной формами с этим МНП, необходимы дополнительные эксперименты, чтобы определить эффективность процессинга. Ожидается, что МНП L29 приведет к получению расщепленного полипептида Nif эффективным образом. И наконец, авторы изобретения исследовали МНП CoxIV с тэгом twin strep(Burén et al. 2017), слитым в С-конце, но выше связи Gly-Gly(SN19, SEQ ID NO:86). При слиянии с NifD этот МНП давал сильные сигналы в анализе методом вестерн-блоттинга с размером, согласующимся с процессингом в митохондриальном матриксе.
Функциональное исследование разных следовых последовательностей, слитых с полипептидами Nif, в бактериальной системе
Последствия для функции полипептида Nif включения различных МНП и последовательностей, остающихся в N-конце слитых полипептидов Nif после расщепления, оценивали в системе MIT2.1. Например, фрагмент ДНК, кодирующий pFAγ-след9, с Met в качестве первой аминокислоты вместо Ile, вставляли непосредственно выше кодона инициации трансляции генов Nif в pMIT2.1 с помощью методов направленной циклизации с лигазой (de Kok et al., 2014). Способы, применяемые для создания конструкций, были такими, как описаны для NifB в примере 16. 27 п. о. фрагмент ДНК, кодирующий pFAγ-след9 сливали с 5' различных генов Nif в pMIT2.1. Трансформацию E. coli и исследование в отношении функции нитрогеназы с применением анализа восстановления ацетилена проводили как в примере 16.
Этот анализ показал, что добавления 9-аминокислотного удлинения в N-конец NifB не изменяло функцию нитрогеназы по сравнению с уровнем выработки этилена, наблюдаемым для немодифицированной pMIT2.1. Аналогичным образом NifH, NifD, NifK, NifE и NifN также допускали наличие 9-аминокислотного удлинения в их соответствующих N-концах с полной активностью в случае NifH, но с некоторым снижением активности в других случаях. 9-аминокислотные удлинения в N-концах NifD, NifK, NifE и NifN давали уровни активности восстановления ацетилена, которые составляли 50%, 70%, 30% и 50% по сравнению с уровнями немодифицированной pMIT2.1, соответственно. Другие полипептиды Nif, а именно NifJ, NifY, NifQ, NifF, NifU, NifS, NifV, NifW, NifZ и NifM, исследовали аналогичным образом. Используя такие методы анализа, отбирают оптимальные последовательности МНП для каждого полипептида Nif.
Пример 18. Добавление к С-концу NifK нарушает его активность
Как описано в примере 10, из структуры полипептида NifK из K. pneumoniae авторы изобретения заключили, что С-концы субъединиц NifK были погружены в сердцевину белкового комплекса NifD-NifK-NifH и что любой С-концевое удлинение полипептида NifK относительно последовательности дикого типа вероятно приведет к разрушению комплекса. Это исследовали функционально, используя бактериальную систему нитрогеназы, описанную в примере 16, путем модификации плазмиды pMIT2.1. Эту плазмиду модифицировали с целью экспрессии модифицированного полипептида NifK, имеющего 9-аминокислотное С-концевое удлинение относительно последовательности дикого типа, путем добавления аминокислотной последовательности YPYDVPDYA (SEQ ID NO:97) следующим образом.
Для внесения модификации NifK добавляли нуклеотидную последовательность, кодирующую аминокислоты YPYDVPDYA (SEQ ID NO:97), кодон-оптимизированную для экспрессии в E. coli, в 5' обратного праймера в 3' конце NifK. Этот праймер, 5'-TCATCAAGCGTAATCAGG AACATCGTAGGGGTAACGAACCAGATCGAAAGAATAGTCGG-3' (SEQ ID NO:98), и прямой праймер 5'-AAGGGCGAATTCCAGCACACTGG-3' (SEQ ID NO:99) использовали в ПЦР с ДНК pTopoH-J (пример 16) в качестве матрицы, содержащей первую половину pMIT2.1, чтобы получить 7909 п. о. продукт. Оставшиеся 7222 п. о. также амплифицировали методом ПЦР, используя праймеры 5'-CCTGATTGTATCCGCATCTGATGCTAC-3' (SEQ ID NO:100) и 5'-AACCTGCAGGGCTAACTAACTAACCACGGACAAAAAACC-3' (SEQ ID NO:101). Аналогичным образом, как описано в примере 16, затем лигировали два ПЦР-фрагмента, используя реакцию лигирования к циклизацией (LCR) с праймерами BO1, 5'-GGTAGCATCAGATGC GGATACAATCAGGTCATCAAGCGTAATCAGGAACATCGAGG-3' (SEQ ID NO:102) и BO2, 5'-CCAGTGTGCTGGAATTCGCCCTTAACCTGCAGGGCTAACTAACTAAC CACG-3' (SEQ ID NO:103), используя метод de Kok et al., (2014). Лигированный фрагмент ДНК расщепляли SbfI и лигировали в фрагмент SbfI из pB-ori, содержащий немодифицированные гены NifBQFUSVWZM, получая модифицированный вектор MIT2.1, кодирующий слитый полипептид, имеющий С-концевое удлинение, добавленное к NifK.
Полученную в результате генетическую конструкцию вносили в штамм DH5α E. coli, содержащий pN249, а культуры и клетки, трансформированные обоими векторами, выращивали, как описано в примере 16. Эти культуры исследовали в отношении выработки этилена в анализе восстановления ацетилена. Результаты показали, что 9-аминокислотное С-концевое удлинение, добавленное к NifK, полностью устраняло выработку этилена. Контрольный, немодифицированный pMIT2.1 давал положительный результат по выработке этилена. Авторы изобретения заключили, что трансляционно слитое удлинение в С-конце NifK относительно С-конца дикого типа устраняло активность нитрогеназы согласно измерениям восстановления ацетилена, что согласуется и исследованиями моделирования, описанными в примере 10.
Учитывая, что биохимические исследования, описанные выше, продемонстрировали, что удлинение в С-конце NifK устраняло функцию нитрогеназы, а предыдущие эксперименты в растениях показали, что коэкспрессия NifD и NifK с С-концом дикого типа повышала количество NifD (пример 11), авторы изобретения заключили, что С-конец дикого типа в полипептиде NifK был важен как для стабильности, так и для функции гетеротетрамера NifD-NifK и, следовательно, активности нитрогеназы.
Это дополнительно исследовали, экспрессируя разные версии генов, экспрессирующих NifD вместе с NifK, имеющим С-конец дикого типа (pRA25) и оценивая количество NifD. В примере 20 описан ряд генетических конструкций, каждая из которых содержит ген NifD, которые были созданы для оценки количества NifD в N. benthamiana. В этом эксперименте NifD содержал С-концевой эпитоп HA. После совместной инфильтрации этих конструкций (Таблица 8) в присутствии генетической конструкции для экспрессии супрессора сайленсинга P19, что применяли в случае всех инфильтраций N. benthamiana, и с или без совместной инфильтрации pRA25 (NifK), количество белка и процессинг МПП NifD::HA оценивали методами анализа ДСН-ПААГ и вестерн-блоттинга, используя анти-HA антитело. Анализ (Фиг. 19) показал, что в каждом случае добавление pRA25 сильно повышало количество NifD, в частности, для комбинации SN7 и pRA25. Что наиболее важно, отношение процессированного и непроцессированного NifD повышалось добавлением pRA25. Эти результаты дополнительно подтверждают заключение, что стабилизация NifD за счет NifK происходила в митохондриальном матриксе и, что важно, ее осуществление было связано с полипептидом NifK, имеющим С-конец дикого типа.
Дополнительно следует отметить, что в случае всех исследованных конструкций наблюдали полипептидную полосу приблизительно 48 кДа, которая, как полагается, соответствует продукту деградации NifD. Так как этот полипептид был обнаружен с помощью анти-HA антитела и давал четко определенную полипептидную полосу в геле, он должен был представлять конкретный продукт расщепления, содержащий С-конец NifD. Неожиданно, количество этого продукта также повышалось коэкспрессией pRA25 (NifK). Это указывает на взаимодействие между полипептидами NifD и NifK. На основании этих наблюдений авторы изобретения заключили, что деградация NifD была специфической для митохондриального матрикса и обеспечила подтверждение взаимодействия NifD и NifK в ММ.
Одной из возможностей, которую исследовали в отношении полипептида с массой приблизительно 48 кДа, вырабатываемого, когда кодирующие NifD::HA конструкции вносили в растительные клетки, было то, что 48 кДа полипептид был продуктом второго, нижележащего кодона инициации трансляции. Ген NifD имеет некоторое число кодонов ATG, соответствующих остаткам Met, в данной области, что могло привести в появлению 48 кДа трансляционного продукта. Чтобы исследовать эту возможность, создавали генетическую конструкцию (pRA30), которая была идентична с pRA24, за исключением того, что кодоны Met, со второго по пятый, ниже стартового кодона NifD были замещены кодонами Ala. После инфильтрации pRA30 и pRA24 по отдельности в листья N. benthamiana и анализа методами ДСН-ПААГ и вестерн-блоттинга профиль полос для pRA24 и pRA30 оставался таким же с наличием приблизительно 48 кДа полипептидного продукта. Это наблюдение опровергло гипотезу, что полосы размером 48 кДа, видимые при экспрессии гена NifD::HA, были связаны с альтернативной инициацией трансляции. Было сделано заключение, что этот полипептид вырабатывался посредством неизвестного процесса деградации в ММ.
Пример 19. Оценка слитых полипептидов NifD-NifK и NifE-NifN
В примере 12 описаны разработка и конструирование гена, кодирующего слитый полипептид NifD-NifK с применением линкера, состоящего из 30 аминокислотных остатков между С-концом NifD и N-концом NifK. Этот линкер содержал эпитоп FLAG для обнаружения полипептида. Теперь разработали и сконструировали второй ген, который имел такое же упорядочение NifD-(FLAG)линкер-NifK, за исключением того, что эпитоп FLAG был заменен эпитопом HA. Аминокислотная последовательность, также из 30 аминокислотных остатков, кодируемая линкером в этом втором гене, представляла собой ATPPPGSTTTAYPYDVPDYATPPPGSTTTA (SEQ ID NO:104) с эпитопом HA в виде аминокислот 12-20в линкере. Оба эти слитых полипептида исследовали в отношении функциональности в анализе восстановления ацетилена в бактериальной системе на основе вектора pMIT2.1, описанного в примере 16, следующим образом.
Во-первых, ген NifD::HAlinker::NifK из pRA31 амплифицировали методом ПЦР, используя праймеры pRA31DK-FW 5'-ATGATGACTAACGCTACAGGAGAA-3' (SEQ ID NO:105) и pRA31DK-RV 5'-TCATCATCTAACCAAATCAAAACTGTAATCTG-3' (SEQ ID NO:106). Нуклеотидная последовательность этого гена была кодон-оптимизирована для экспрессии в Arabidopsis thaliana. Первую половину pMIT2.1 без генов nifD и nifK также создавали методом ПЦР, используя праймеры D_start_RV 5'-CCGGCTCCTCCGCTAGATAAAAATGTG AATTTTTGCATGCAGCC-3' (SEQ ID NO:107) и K_end_FW 5'-CCTGATTGTATCCGCATCTGATGCTACCGTGGTTGA-3' (SEQ ID NO:108). Амплифицированные ПЦР-продукты лигировали с помощью реакции лигирования к циклизацией, используя соединительные олиго 5'- TTCTCCTGTAGCGTTAGTCATCATCCGGCTCCTCCGCTA-3' (SEQ ID NO:109) и 5'- CAGATGCGGATACAATCAGGTCATCATCTAACCAAATCAAAACTG-3' (SEQ ID NO:110), и расщепляли SbfI. Расщепленный фрагмент ДНК лигировали в ДНК pB-ori, которая также была расщеплена SbfI, содавая модифицированную форму pMIT2.1, содержащую слитый ген NifD::HAlinker::NifK.
Функциональное исследование в клетках E. coli (DH5α) показало, что модифицированный вектор pMIT2.1, содержащий ген NifD::HAlinker::NifK, мог восстанавливать ацетилен до этилена на уровне, составляющем около 10% уровня немодифицированного pMIT2.1. Это означает, что слитый полипептид с 30-аминокислотным линкером между полипептидами NifD и NifK в остальном дикого типа был явно функциональным, хотя и с 10-кратно сниженной активностью, в бактериальной системе.
В попытке повысить активность нитрогеназы слитого полипептида осуществляли два изменения и в целом повторяли эксперимент. Изменения состояли, во-первых, в использовании вариантной аминокислотной последовательности для NifD (Temme et al., 2012), смотрите пример 17, и, во-вторых, в использовании нуклеотидных последовательностей, кодон-оптимизированных в отношении K. pneumoniae, а не A. thaliana. Конструкции создавали таким же образом, как описано выше. То есть, структуру оперона между nifD и nifK в немодифицированном pMIT2.1, кодирующем отдельные полипептиды NifD и NifK, замещали нуклеотидной последовательностью, кодирующей трансляционные слияния NifD-линкер-NifK, создавая, таким образом, гены NifD::linker::NifK в модифицированном pMIT2.1 для каждого из FLAG- и HA-содержащих линкеров. Функциональное исследование в клетках E. coli (DH5α) показало, что модифицированные гены NifD::FLAGlinker::NifK и NifD::HAlinker::NifK в pMIT2.1 восстанавливали ацетилен с получением этилена в количестве, составляющем около 100% и 80%, соответственно, от количества для немодифицированного pMIT2.1. Было сделано заключение, что снижение активности первого слияния NifD-линкер-NifK происходило из-за неидеальной аминокислотной последовательности NifD или оптимизированной для растений частоты использования кодона, или же по обеим причинам. Это демонстрирует важность использования соответствующих полипептидных последовательностей и оптимизации кодонов в соответствии с клетками-хозяевами.
В случае экспрессии в растительных клетках и импорта в митохондриальный матрикс будет необходима последовательность МНП, а N-концевое удлинение согласно прогнозам останется после расщепления в МНП. Например, использование МНП-FAγ51 (пример 17) с последующим расщеплением МПП оставит 9-аминокислотное N-концевое удлинение, слитое с полипептидом Nif. Следовательно, исследовали эффект добавления такого 9-аминокислотного удлинения в полипептид NifD-линкер-NifK, за исключением того, что первый остаток из 9 (Ile) заменяли остатком Met, чтобы обеспечить эффективную трансляцию. 9-аминокислотную последовательность добавляли в N-конец NifD-части слитого полипептида NifD::линкер::NifK, используя подход клонирования, как описано выше. Затем исследовали способность комбинации этих двух модификаций к восстановлению ацетилена в системе pMIT2.1.
Для создания этих конструкций последовательность ДНК из 27 нуклеотидов, кодирующую 9-аминокислотное удлинение (MSTQVVRNR, SEQ ID NO:111), добавляли в 5' конец слитых генов NifD::linker::NifK для каждого из эпитопов FLAG и HA в линкере. Анализ восстановления ацетилена для E. coli, содержащих эти конструкции, показал, что добавление 9-аминокислотного N-концевого удлинения к полипептиду NifD::HAлинкер::NifK приводило приблизительно к такому же уровню выработки этилена, что и NifD::HAлинкер::NifK, в котором отсутствовало 9-аминокислотное удлинение в N-конце, т. е. N-концевое удлинение было вполне допустимым и не снижало активность нитрогеназы. Это согласовалось с ранее полученными данными, что 9-аминокислотное удлинение можно добавлять к NifD дикого типа, не снижая его активность.
Авторы изобретения также исследовали функцию трансляционного слияния между NifD и NifK без какой-либо линкерной последовательности в системе MIT2.1 путем удаления стоп-кодона гена nifD, спейсерной последовательности и сайта связывания рибосомы для кодирующей области nifK из немодифицированного MIT2.1. Это прямое слияние рамок считывания для кодирования полипептида NifD-NifK (называемого в данном документе NifD-без линкера-NifK) снижало активность восстановления ацетилена до 5% по сравнению с положительным контролем. Это снижение функции NifD-без линкера-NifK продемонстрировало преимущество включения гибкого линкера длиной около 30 аминокислотных остатков, который обеспечивал правильную конформационную ассоциацию между частями NifD и NifK слитого полипептида с образованием функциональной структуры динитрогеназы.
Слияния NifE-NifN
Как и NifD и NifK, известно, что NifE и NifN образуют гетеротетрамер. Функцией этого комплекса в отношении активности нитрогеназы является получение ядра кофактора FeMo из NifB, молибдена из NifQ и гомоцитрата из NifV для созревания кофактора FeMo (Hu and Ribbe, 2011). Авторы изобретения понимали, что NifE и NifN должны экспрессироваться на эквимолярном уровне для оптимальной функции нитрогеназы и что слияние двух полипептидов снизит число промоторов, МНП и терминаторов, необходимых для рекомбинантной экспрессии нитрогеназы. Следовательно, был разработан и сконструирован ген, кодирующий слитый полипептид между NifE и NifN, следуя обоснованиям для слияния NifD и NifK (выше), за исключением того, что использовали линкер из 46 аминокислотных остатков вместо 30 аминокислотных остатков в случае слитых полипептидов NifD-линкер-NifK. Его разрабатывали, конструировали и исследовали следующим образом.
Модель гомологии гетеротетрамера NifE-NifN α2β2 из K. pneumoniae конструировали, используя кристаллическую структуру комплекса NifE-NifN из Azotobacter vinelandii (PDB ID: 3PDI, (Kaiser et al., 2011)) в качестве матрицы. Выравнивание K. pneumoniae и соответствующих полипептидов A. vinelandii позволило установить, что идентичность аминокислотных последовательностей составляла 68,1% для полипептидов NifE и 44,2% для полипептидов NifN. Авторы изобретения понимали, что в структурной модели для гетеротетрамера α2β2 (NifE2NifN2) K. pneumoniae С-конец каждой субъединицы NifE составлял приблизительно 70 Å от N-конца его партнера NifN. Следовательно, для соединения двух единиц был разработан линкер подходящей длины, имеющий 46 аминокислотных остатков. Авторы изобретения посчитали, что линкер должен изгибаться вокруг поверхности гетеротетрамера и иметь длину около 104 Å, следовательно, число аминокислотных остатков было выбрано равным 46. Авторы изобретения также посчитали, что линкер должен оптимально иметь несколько других характеристик, включая гибкость.
В основе аминокислотной последовательности выбранного линкера из 46 остатков лежал линкер природного происхождения между углевод-связывающим доменом и каталитическим доменом целлобиогидролазы из Talaromyces funiculosus (UniProtKB: Q8WZJ4). Он был выбран на основании нескольких критериев, включая отсутствие остатков цистеина, чтобы избежать образования нежелательных дисульфидных связей, мало или предпочтительно отсутствие заряженных остатков (Glu, Asp, Arg, Lys) для снижения вероятности нежелательных поверхностных взаимодействий с образованием соляных мостиков (Phe, Trp, Tyr, Met, Val, Ile, Leu), так как такие остатки могут стимулировать тенденцию к проникновению через поверхность полипептида, и в линкерной последовательности отсутствовали посттрансляционно модифицированные аминокислоты - смотрите запись Uniprot на www.uniprot.org/uniprot/Q8WZJ4, в которой линкер составляет остатки 457-493. Остаток Phe в позиции 2 в последовательности целлобиогидролазы заменили на Ser для снижения гидрофобности. Последовательность эпитопа HA YPYDVPDYA (SEQ ID NO:112) вставили между аминокислотами 16 и 17 линкера, исключительно для облегчения обнаружения и количественной оценки слитого полипептида - для функции линкера такой эпитоп не нужен. Эпитоп HA расположили ближе к N-концу, чем к центру линкера, чтобы отдалить его от одного положительно заряженного остатка лизина, который оставался. Полученная в результате линкерная последовательность представляла собой TSSGGTSTGGSTTTTAYPYDVPDYASGTTSTKASTTSTSSTSTGTG (SEQ ID NO:113), содержащую эпитоп HA в виде аминокислот 17-25 и сохранившийся лизин в позиции 32.
Для создания генетической конструкции и исследования функции слитого полипептида NifE-линкер-NifN область между цистронами NifE и NifN в pMIT2.1 заменили нуклеотидной последовательностью, кодирующей трансляционное слияние, содержащее линкер из 46 остатков, используя такой же подход клонирования, как и для предыдущих конструкций при модификации pMIT2.1. Нуклеотидная последовательность была кодон-оптимизирована для Arabidopsis thaliana, хотя слитый ген предполагалось исследовать в E. coli. Ген nifE::HAlinker::nifN амплифицировали методом ПЦР из pRA01-EN, используя праймеры pRAEN-FW 5'-ATGAAGGGAAATGAGATTCTTGCTCTT-3' (SEQ ID NO:114) и pRAEN-RV 5'-TCATCAATCAGCAGCATAAGCACC-3' (SEQ ID NO:115). Первую половину pMIT2.1 без nifE и nifN также создавали методом ПЦР, используя праймеры E_start_RV 5'-TTGTAATAACCTCCAGTGATGAATTGAATA-3' (SEQ ID NO:116) и N_end_FW 5'- CTAGAGATTAATATGGAGAAATTAAGCATG -3' (SEQ ID NO:117). Амплифицированные ПЦР-продукты лигировали с помощью реакции лигирования к циклизацией, используя соединительные олиго 5'- AAGAGCAAGAATCTCATTTCCCTTCATTTGTAATAACCTCCAGTGATGAATTGATAGTG-3' (SEQ ID NO:118) и 5'- TAGTTTTCATGCTTAATTTCTCCATATTAATCTCT AGTCATCAATCAGCAGCATAAGCACC -3' (SEQ ID NO:119), после чего вторую половину pMIT2.1 (pB-ori), которая не была модицифирована, лигировали с модифицированной первой половиной после расщепления обеих ДНК SbfI. Полученная в результате конструкция была обозначена AtNifE::линкер::NifN/MIT2.1.
Функциональное исследование модифицированного вектора MIT2.1, содержащего ген AtNifE::linker::NifN, в клетках E. coli в анализе восстановления ацетилена показало выработку этилена на уровне, составлявшем около 40% от уровня немодифицированного MIT2.1.
В случае экспрессии в растительных клетках и импорта в митохондриальный матрикс будет необходима последовательность МНП, а N-концевое удлинение вероятно останется после расщепления в последовательности МНП МПП. Например, использование МНП-FAγ77 с расщеплением МПП оставит 38-аминокислотное N-концевое удлинение в слитом полипептиде. Следовательно, эффект добавления такого 38-аминокислотного удлинения с заменой первого остатка Ile остатком Met для обеспечения эффективной трансляции исследовали путем добавления нуклеотидной последовательности, кодирующей его в гене AtnifE::linker::nifN. Таким образом, трансляция гена приведет к добавлению 38-аминокислотного удлинения в N-конец NifE слитого полипептида NifE::линкер::NifN. Эффект комбинации этих двух модификаций на активность нитрогеназы исследовали в системе pMIT2.1, используя такой же подход клонирования, как и ранее.
Модифицированный вектор pMIT2.1, содержащий ген 38aa::AtNifE::linker::NifN, в E. coli приводил к выработке этилена на уровне, составлявшем около 25% от уровня немодифицированного pMIT2.1. То есть, использование 38-аминокислотного удлинения в N-конце приводило к положительной, хотя и сниженной активности нитрогеназы по сравнению с немодифицированным pMIT2.1. Авторы изобретения посчитали, что снижение могло быть, по меньшей мере частично, связано с частотой использования кодонов A. thaliana, которая была субоптимальной для эффективной трансляции в E. coli, что легко можно проверить путем создания трансляционного слияния нативных NifE и NifN Klebsiella с бактериальной оптимизацией кодонов. Авторы изобретения рассмотрели другие варианты оптимизации функции слитого полипептида NifE-линкер-NifN следующим образом. 38-аминокислотное удлинение в N-конце NifE может препятствовать эффективному высвобождению кофактора FeMo из гетеротетрамера NifE2NifN2, так как N-конец субъединицы NifE гетеротетрамера находился очень близко к полости, в которой находится кофактор FeMo (Kaiser et al., 2011). Активность гетеротетрамера NifE2NifN2 можно повысить за счет использования МНП, который полностью удаляется после процессинга МПП, или за счет усечения N-концевой кодирующей области NifE для размещения дополнительного удлинения при использовании последовательности МНП, которая полностью не удаляется. Также была рассмотрена возможность, что 46-аминокислотный линкер может выпетливаться с частичным заграждением входа в полость кофактора FeMo, тем самым препятствуя получению ядра кофактора FeMo от NifB или высвобождению зрелого кофактора FeMo. В этом случае линкер можно укоротить или провести усечение С-конца NifE, или оба варианта, чтобы избежать заграждения полости линкерной областью. Варианты в соответствии с этими стратегиями можно легко проверить и оптимизировать, используя систему pMIT2.1.
Краткие выводы
Оба слитых полипептида, NifD-линкер-NifK и NifE-линкер-NifN были способны поддерживать восстановление ацетилена в бактериальной системе pMIT2.1, т. е. они были функциональными для обеспечения активности нитрогеназы. Добавление 9-аминокислотного N-концевого удлинения к NifD-линкер-NifK обеспечивало полную активность нитрогеназы. Добавление более длинного 38-аминокислотного N-концевого удлинения в слитый полипептид NifE-линкер-NifN также было функциональным, хотя и со снижением активности по сравнению с полипептидом без N-концевого удлинения. Авторы изобретения заключили, что стратегия экспрессии этих слитых полипептидов с использованием N-концевой последовательности МНП в растительных клетках в комбинации с другими необходимыми полипептидами Nif обеспечить возможность экспрессии активности нитрогеназы. Дополнительные, проиллюстрированные в данном документе преимущества стратегий слияния NifD-NifK и NifE-NifN включали выработку субъединиц на эквимолярном уровне для оптимальной функции нитрогеназы и то, что слияние двух полипептидов или двух пар полипептидов снизит число промоторов, МНП и терминаторов, необходимых для рекомбинантной экспрессии нитрогеназы в растительных клетках.
Пример 20. Исследование разных промоторов в отношении экспрессии слитого полипептида Nif в растительных клетках
Ряд разных промоторов оценивали в отношении их эффективности для экспрессии генов Nif для выработки полипептидов Nif в растительных клетках на примере клеток листьев N. benthamiana. С этой целью были отобраны пять разных промоторов, а именно две версии промотора S4 из вируса карликовости подземного клевера (SCSV-S4) (Schünmann et al., 2003a; Schünmann et al., 2003b), промотор SCSV-S7 (Schünmann et al., 2003a) и две версии промотора CaMV 35S, а именно более длинная форма промотора 35S и усиленная форма, содержащая двойной энхансер (2x35S) для максимизации генной экспрессии (Таблица 9). Промоторы SCSV экспрессируются на высоком уровне в большинстве растительных тканей и считаются конститутивными промоторами. Полипептид NifD, используемый в этих исследованиях в качестве примера полипептида Nif, представлял собой версию, которую использовали в примере 17 (SEQ ID NO:95). В этом эксперименте NifD выбрали в качестве примера полипептида Nif потому, что из всех исследованных полипептидов Nif (примеры 5-9) его было наиболее трудно экспрессировать. Создали пять векторов, в каждом из которых использовался отличный промотор, но в остальном идентичных, включая последовательность, кодирующую МНП FAγ51 (Таблица 9) для транслокации и процессинга в растительных митохондриях. Методы клонирования GoldenGate (Weber et al., 2011, Engler et al., 2014) использовали для создания этих пяти конструкций, обеспечив возможность подхода модулярной генной сборки.
Клетки Agrobacterium, содержащие эти векторы, смешанные с клетками Agrobacterium, содержащими конструкцию, вырабатывающую белок-супрессор сайленсинга P19, отдельно вносили в листья N. benthamiana, и получали белковые экстракты через 5 суток после инфильтрации. Проводили соответствующие парные инфильтрации вышеуказанными конструкциями с или без добавления pRA25 (pFAγ77+GAP::NifK), так как было показано, что коэкспрессия NifK без С-концевого удлинения повышает количество NifD (пример 11). Для белковых экстрактов проводили анализ методами ДСН-ПААГ и вестерн-блоттинга, используя анти-HA антитело (Фиг. 19, смотрите пример 18). В Таблице 9 обобщены результаты по обнаружению полипептидов, вырабатываемых в растительных клетках, и расщеплению МПП (процессингу) для каждого слитого полипептида FAγ51::NifD.
При внесении в растительные клетки все пять конструкций приводили к выработке полипептидов, обнаруживаемых с помощью антитела (Фиг. 19). В каждом случае наблюдали полипептидные полосы размера, согласующегося как с процессированной, так и с непроцессированной формами of FAγ51::NifD, хотя наблюдалась значительная вариация как в количестве полипептидов, так и в отношении процессированный:непроцессированный полипептид, т. е. эффективности процессинга (Таблица 9). Что наиболее важно, в случае каждой из конструкций SN6, SN7 и SN8 включение pFAγ77+GAP::NifK из pRA25 повышало как абсолютный уровень NifD, так и, неожиданно, отношение процессированной и непроцессированной форм белка NifD. Это было наиболее очевидным для конструкции SN7, для которой уровень непроцессированного NifD был одинаковым с или без pFAγ77+GAP::NifK, но уровень процессированного NifD был сильно повышен присутствием полипептида NifK.
Эти результаты продемонстрировали, что, неожиданно, несмотря на использование одного и того же МНП в случае каждой конструкции, разные промоторы могут иметь существенный эффект не только на уровни белковой экспрессии, но также на эффективность процессинга нацеленных на митохондриальный матрикс белков Nif. Эти результаты также подтвердили повышающую роль в отношении количества NifD экспрессии NifK без С-концевого удлинения.
Таблица 9. Разные промоторы, которые исследовали для оценки экспрессии МНП::NifD::HA в N. benthamiana и эффективности процессинга слитого полипептида.
Пример 21. Исследования избыточности NifS и NifU для функции нитрогеназы
В случае функции нитрогеназы существует два белка Nif, которые обеспечивают железо-серные фрагменты для разных компонентов нитрогеназы для биосинтеза их соответствующего железо-серного (Fe-S) кластера. NifS представляет собой пиридоксаль P-зависимую цистеиндесульфуразу, которая активирует серу для пополнения сульфида (Zheng et al., 1993), а NifU представляет собой молекулярный каркас, который получает сульфид от NifS и осуществляет сборку кластера Fe-S (Agar et al., 2000). Вместе они поставляют кластеры Fe-S NifB для сборки ядра кофактора FeMo (L-кластер) (Hu and Ribbe 2011), а также Fe-белку (NifH) с помощью пептидил-пролил цис/транс-изомеразы NifM (Gavini et al., 2006) для [4Fe-4S] и последующего образования P-кластера ([Fe8-S7]) с помощью NifZ (Lee et al., 2009). В эукариотах существуют ортологи NifS и NifU, которые обеспечивают фрагменты Fe-S для различных ферментов, которые содержат кластеры Fe-S (Couturier et al., 2013). В частности, растительные митохондрии содержат полипептиды NfsI (At5g65720) и IsuI (At4g22220) в качестве ортологов NifS и NifU, соответственно, тогда как в пластидах Nfs2 (At1g08490) и SufB (At4g04770) существуют функциональные эквиваленты для NifS и NifU, соответственно. Как митохондриальным, так и пластидным системам помогают дополнительные вспомогательные белки для полного осуществления сборки кластера Fe-S и переноса к целевым ферментам в окружении их нативной органеллы. Недавно было продемонстрировано в дрожжевых митохондриях и табачных пластидах, что NifS и NifU являются необязательными для активности рекомбинантного Fe-белка (Lopez-Torrejon et al., 2016; Ivleva et al., 2016).
Чтобы исследовать функциональность растительных ортологов NifS и NifU в системе pMIT2.1 в E. coli, гены NifS и NifU Klebsiella заменяют растительными генами NfsI и IsuI, как по одному, так и с двумя заменами в комбинации. Функцию нитрогеназы модифицированного pMIT2.1 оценивают в анализе восстановления ацетилена. Также мутант nfsI A. thaliana (SALK_083681) и мутант isuI (SALK_006332) трансформируют генетическими конструкциями, содержащими гены NifS и NifU Klebsiella, соответственно, нацеленными на митохондриальный матрикс, чтобы посмотреть, могут ли бактериальные ферменты Nif дополнять эти растительные мутации. Этот эксперимент предназначен, чтобы продемонстрировать, что бактериальные белки Nif могут функционально замещать растительные эквиваленты (Frazzon et al., 2007). Успешная комплементация демонстрирует способность выбранного МНП нацеливать белки нитрогеназы на митохондрии в функциональном состоянии. Этот эксперимент обеспечивает первую демонстрацию связанной с нитрогеназой функции полипептида Nif в растениях, в данном случае для NifS и NifU.
Пример 22. Измерение экспрессии полипептида Nif с помощью масс-спектрометрии
Чтобы разработать методы обнаружения и количественной оценки полипептида Nif, в которых не используются методы вестерн-блоттинга и обнаружения с помощью антител и, следовательно, устраняется необходимость использования эпитопов, добавляемых к полипептидам Nif, авторы изобретения постарались напрямую осуществить обнаружение и количественную оценку различных белков Nif, используя методы масс-спектрометрии, в частности, используя протокол МС/МС типа «снизу вверх» с протеолитическим расщеплением. В нем используется масс-спектрометр Oritrap Fusion Tribrid (ThermoFisher), который имеет три масс-анализатора, работающих параллельно, чтобы обеспечить высокое масс-разрешение и масс-точность с масс-анализатором Orbitrap ионов-предшественников на полном скане. Считалось, что методология и чувствительность этого прибора смогут обеспечить большее количество идентификаций белков и пептидов из сложных, неочищенных белковых смесей, чем другие приборы, доступные на сегодняшний день. Сначала этот прибор тестировали, анализируя образцы информационно-зависимым образом, чтобы обеспечить возможность нецелевого обнаружения пептидов и белков в бактериях, экспрессирующих белки Nif , в частности, в клетках E. coli, трансформированных и экспрессирующих pMIT2.1, которая кодирует 16 разных полипептидов Nif. Неочищенные белковые смеси обрабатывали трипсином, чтобы получить пептиды в диапазоне молекулярной массы, пригодном для обнаружения. После идентификации специфических пептидов, которые были получены путем триптического расщепления полипептидов Nif, можно создавать целевые перечни, в которых специально выделена исходная масса представляющих интерес пептидов при их ожидаемом время удержания. Этот нацеленный подход помогал устранить возможность того, что пептиды из белков Nif будут утеряны вследствие низкой представленности или не будут отобраны информационно-зависимым методом вследствие наличия большого числа эндогенных бактериальных или растительных триптических пептидов.
Этот протокол на основе масс-спектрометрии был успешным при обнаружении полного набора из 16 разных белков Nif, экспрессируемых в E. coli, трансформированных плазмидой pMIT2.1. Для каждого из 16 полипептидов Nif был обнаружен по меньшей мере один специфический пептид. По несколько специфических триптических пептидов было обнаружено практически для всех полипептидов Nif, вплоть до максимум 19 пептидов для полипептидов Nif, что покрывает 4-55% общих последовательностей полипептидов Nif (Таблица 10). Оценка Sum PEP для многих из полипептидов Nif была очень высокой (Таблица 10), что указывает на полную достоверность в отношении способности этого метода осуществлять специфическое обнаружение и измерение уровней полипептидов Nif.. В этом контексте оценка суммарной апостериорной вероятности погрешности (PEP) представляет собой сумму отрицательных логарифмов значений PEP для совпадений на пептидном спектре. Чем больше значение Sum PEP, тем менее вероятно появление ложноположительного результата обнаружения.
Затем этот метод проверяли на неочищенных экстрактах из клеток N. benthamiana, экспрессирующих различные генетические конструкции МНП::Nif, используя способ, описанный ниже, для обработки образцов листьев растений, которые инфильтрировали Agrobacterium, содержащими представляющие интерес векторы. Все инфильтрации содержали смесь с Agrobacterium, содержащими генетическую конструкцию для коэкспрессии белка-супрессора сайленсинга P19 (SEQ ID NO:125). Обнаружение двух специфических триптических пептидов (SEQ ID NO:126; SEQ ID NO:127) из вирусного супрессорного белка P19 использовали в качестве положительного контроля для успеха временной экспрессионной системы.
Этот метод был успешным для специфического обнаружения от 3 до 16 специфических триптических пептидов из каждого из полипептидов NifK, NifB, NifH, NifF, NifJ, NifS и NifX при временной экспрессии в растительных клетках. Например, специфические пептиды, обнаруженные в растительных клетках из этих слитых полипептидов Nif, перечислены ниже. В случае каждого из этих экспериментов с временной экспрессией также были обнаружены два специфических пептида из P19. В некоторых экспериментах, в которых применяли гены для экспрессии других полипептидов Nif, в которых специфические пептиды Nif обнаружены не были, два специфических пептида из P19 также обнаружены не были. Это указывает на плохую эффективность трансформации в этих экспериментах, возможно, вследствие субоптимального состояния растений. Эти эксперименты повторяли с лучшими растениями.
Таблица 10. Обнаружение полипептидов Nif, экспрессируемых в E. Coli,, содержащих pMIT2.1
Типовые, специфические пептиды из NifK, обнаруженные в растительных клетках:
INSCYPLFEQDEYQELFR (SEQ ID NO:128)
QLEEAHDAQR (SEQ ID NO:129)
EALTVDPAK (SEQ ID NO:130)
TFTADYQGQPGK (SEQ ID NO:131)
LPKLNLVTGFETYLGNFR (SEQ ID NO:132)
MMEQMAVPCSLLSDPSEVLDTPADGHYR(SEQ ID NO:133)
MYSGGTTQQEMK (SEQ ID NO:134)
EAPDAIDTLLLQPWQLLK (SEQ ID NO:135)
FGLYGDPDFVMGLTR (SEQ ID NO:136)
DSEVFINCDLWHFR (SEQ ID NO:137)
QPDFMIGNSYGK (SEQ ID NO:138)
AFEVPLIR (SEQ ID NO:139)
LGFPLFDR (SEQ ID NO:140)
QTTWGYEGAMNIVTTLVNAVLEK(SEQ ID NO:141)
LDSDTSQLGK (SEQ ID NO:142)
TDYSFDLVR (SEQ ID NO:143)
Специфические пептиды из NifH, обнаруженные в растительных клетках
LGTQMIHFVPR (SEQ ID NO:144)
MTVIEYDPACK (SEQ ID NO:145)
VMIVGCDPK (SEQ ID NO:146)
CAESGGPEPGVGCAGR (SEQ ID NO:147)
STTTQNLVAALAEMGK (SEQ ID NO:148)
STTTQNLVAALAEMGKK (SEQ ID NO:149)
QTDREDELIIALAEK (SEQ ID NO:150)
AQEIYIVCSGEMMAMYAANNISK (SEQ ID NO:151)
AVQGAPTMR (SEQ ID NO:152)
LGGLICNSR (SEQ ID NO:153)
AQNTIMEMAAEVGSVEDLELEDVLQIGYGDVR (SEQ ID NO:154)
Специфические пептиды из NifB, обнаруженные в растительных клетках
LCLSTNGLVLPDAVDR (SEQ ID NO:155)
FAAILELLADVK (SEQ ID NO:156)
GESEADDACLVAVASSR (SEQ ID NO:157)
AVQGAPTSCSSFSGGK (SEQ ID NO:158)
INSVLIPGINDSGMAGVSR (SEQ ID NO:159)
QVAQAIPQLSVVGIAGPGDPLANIAR (SEQ ID NO:160)
Специфические пептиды из NifJ, обнаруженные в растительных клетках
IAGELLPGVFHVSAR (SEQ ID NO:161)
GTAQNPDIYFQER (SEQ ID NO:162)
IPFVNFFDGFR (SEQ ID NO:163)
IEVLEYEQLATLLDRPALDSFR (SEQ ID NO:164)
SGGITVSHLR (SEQ ID NO:165)
Специфические пептиды из NifS, обнаруженные в растительных клетках.
EKEIDYVVATLPPIIDR (SEQ ID NO:166)
EIDYVVATLPPIIDR (SEQ ID NO:167)
IAVDGEGALDMAQFR (SEQ ID NO:168)
EIITSVVEHPATLAACEHMER (SEQ ID NO:169)
IDMLSCSAHK (SEQ ID NO:170)
AMNIPYTAAHGTIR (SEQ ID NO:171)
QVYLDNNATTR (SEQ ID NO:172)
IPIAVGQTR (SEQ ID NO:173)
GVGCLYLR (SEQ ID NO:174)
Специфические пептиды из NifX, обнаруженные в растительных клетках.
VPADTTIVGLLQEIQLYWYDK (SEQ ID NO:175)
QFDMVHSDEWSMK (SEQ ID NO:176)
VVDFSVENGHQTEK (SEQ ID NO:177)
RAGDYKDDDDKPG (SEQ ID NO:178)
ARGDYKDDDDKPG (SEQ ID NO:179)
HVDQHFGATPR (SEQ ID NO:180)
VAFASSDYR (SEQ ID NO:181)
LLQEQEWHGDPDPR (SEQ ID NO:182)
Специфические пептиды из NifF, обнаруженные в растительных клетках
LASWLEEIKR (SEQ ID NO:183)
VLGSWTGDSVNYAASR (SEQ ID NO:184)
QLGELADAPVNINR (SEQ ID NO:185)
FVGLVLDQDNQFDQTEAR (SEQ ID NO:186)
Методы.
Образцы листьев растений замораживали в жидком азоте и измельчали с помощью ступки и пестика в атмосфере жидкого азота. Два объема (об./об.) буфера мочевина/ДСН (6 М мочевины, 2% ДСН, 62,5 мМ Трис-HCl, pH 6,8, 65 мМ ДТТ) добавляли к измельченным листовым дискам и оставляли при комнатной температуре (30 мин) для лизиса клеток и восстановления белков ДТТ. Образцы центрифугировали при 16000 g в течение 5 мин. 10-20 мкл растворимой фракции наносили на фильтр microcon-30 НОММ с 100 мкл буфера мочевины и центрифугировали при 10000 g в течение 10 мин. Остатки цистеина инактивировали акриламидом путем добавления 100 мкл буфера мочевины и 3,5 мкл 40% акриламид, инкубировали при комнатной температуре в течение 30 мин с последующим центрифугированием при10000 g в течение 10 мин. Два этапа промывки с помощью 100 мкл бикарбоната аммония (25 мМ в воде) и центрифугирования, как описано выше, предшествовали триптическому расщеплению 0,5 мкг трипсина (Promega) в 60 мкл ABC и инкубации в течение ночи при 37C. Пептиды после триптического расщепления элюировали центрифугированием при 10000 g в течение 10 мин. Оптическую плотность на 280 нм использовали (Nanodrop) для определения концентрации пептидов, а образцы разводили в загрузочном буфере для ЖХМС до 50 нг/мкл.
250 нг продукта триптического расщепления из каждого образца вводили в нано-ЖХ-систему Dionex Nanomate 3000 (ThermoFisher), прямо подсоединенную к масс-спектрометру Orbitrap Fusion Tribrid. Пептиды обессоливали в течение 5 мин на предколонке Acclaim PepMap C18 (300 Å, 5 мм x 300 мкм) при скорости потока 10 мкл/мин с помощью загрузочного растворителя и разделяли на колонке Acclaim PepMap C18 (100 Å, 150 мм × 0,075 мм) при скорости потока 0,3 мкл/мин при 35C. Применяли линейный градиент от 5% до 40% растворителя B в течение 60 мин с последующей промывкой и повторным уравновешиванием 40-99% B в течение 5 мин, выдержкой 5 мин при 99% B, возвратом к 5% B в течение 6 мин и выдержкой в течение 7 мин. Используемые растворители представляли собой: (A) 0,1% муравьиную кислоту, 99,9% воду; (B) 0,08% муравьиную кислоту, 80% ацетонитрил, 19,92% воду. Нано-ЖХ была напрямую подсоединена к источнику ионов Nanospray Flex масс-спектрометра Orbitrap Fusion. Напряжение ионораспыления было установлено на 2400 В, продувочный газ был установлен на 1 Arb, а температура в трубке для переноса ионов была установлена на 300°C. Данные получали в информационно-зависимом режиме, состоящем из получения скана Orbitap-MS с последующим параллельным получением скана Orbitrap высокого разрешения с разрешением 120000 и множеством событий МС/МС в линейной ионной ловушке в течение 3-секундного периода. МС-анализ первой стадии проводили в режиме положительных ионов в диапазоне масс m/z 400-1500 с AGC-мишенью 4×105 и максимальным временем ввода 50 мс. Тандемные масс-спектры получали в ионной ловушке на ионах-предшественниках, которые превышали порог интенсивности 1000 отсчетов с зарядовым состоянием 2-7. Спектры получали, используя квадрупольное выделение с окном выделения 1,6 m/z и (Higher energy Collisional Dissociation (высокоэнергетическая ударная диссоциация)) HCD, установленным на 28% на основании размера и заряда иона-предшественника для оптимальной фрагментации пептидов. Скорость сканирования ионной ловушки была установлена высокой с AGC-мишенью 4×103 и максимальным временем ввода 300 мс, прибор был установлен на использование максимально параллелизуемого времени для ввода ионов в ловушку во время 3-секундного окна, когда orbitrap записывал МС-спектры высокого разрешения. Динамическое исключение было установлено так, чтобы исключать ионы-предшественники после одного появления с 15 с интервалом и допуском массы 10 м. д.
Идентификацию белков проводили, используя алгоритм Sequest в Proteome Discoverer v2.1 (ThermoFisher). Карбамидометил был выбран в качестве алкилирующего агента, а трипсин был выбран в качестве расщепляющего фермента, были выбраны динамические модификации для окисления на H, M, W и деамидированных N и Q с максимумом в три модификации. Для данных тандемной масс-спектрометрии проводили поиск по внутрилабораторным базам данных конструкций Nif, специальным базам данных обычных примесей и организмов от UniProt. Результаты поиска по базам данных обрабатывали вручную, чтобы получить идентификацию белков, используя 1% глобальный уровень ложноположительных результатов (FDR), определяемый встроенным инструментом FDR в программном обеспечении Proteome Discoverer.
Специалистам в данной области техники понятно, что можно осуществлять многочисленные вариации и/или модификации в отношении вышеописанных вариантов реализации, не отступая от общего широкого объема представленного изобретения. Следовательно, представленные варианты реализации следует воспринимать во всех отношениях как иллюстративные и не ограничительные.
Все публикации, которые обсуждаются и/или на которые приведены ссылки в данном документе, в полном объеме включены в данный документ посредством ссылки.
Любое обсуждение документов, актов, материалов, устройств, статей и т. п., которое было включено в данное описание, имело цель исключительно создания контекста для данного изобретения. Его не следует воспринимать как признание того, что любые или все эти материалы образуют часть основы существующего уровня техники или представляли общие сведения в области, относящейся к данному изобретению, в том виде, в котором они существовали до даты приоритета каждого пункта формулы изобретения этой заявки.
Список литературы
Abe et al., (2000). Cell 100:551-560.
Allen et al., (1994). Crit. Rev. Biotechnol. 14:225-249.
Allen et al., (1995). J. Biol. Chem. 270:26890-26896.
Agar et al., (2000). Journal of Biological Inorganic Chemistry 5:167-177.
Balk and Pilon (2011). Trends Plant Sci 16:218-226.
Bechtold et al., (1993). C.R. Acad. Sci. Paris 316:1194-1199.
Becker et al., (2012). Trends in Biochemical Sciences 37:85-91.
Bevan et al., (1983). Nature 304:184-187.
Boison et al., (2006). Arch. Microbiol. 186:367-376.
Birchler, J.A. (2015). Chromosome Res 23:77-85.
Block et al., (1987). The EMBO journal 6:2513-2518.
Breuers et al., (2012). Front Plant Sci 3.
Brigle et al., (1987). J. Bacteriol. 169:1547-1553.
Brosnan et al., (2007). Proc. Natl. Acad. Sci. USA, 104:14741-14746.
Bruce (2001). Biochimica et Biophysica Acta (BBA) - Molecular Cell Research 1541:2-21.
Burén et al., (2017a). Front Plant Sci 8:1567.
Burén et al. (2017b). ACS Synthetic Biology 6(6):1043-1055.
Buren and Rubio (2018) Fems Microbiol Lett 365:fnx274; doi: 10.1093/femsle/fnx274.
Campbell et al., (2014). Insect Biochem Mol Biol 48:40-50.
Carrie et al., (2010). Journal of Biological Chemistry 285:36138-36148.
Chacinska et al., (2009). Cell 138:628-644.
Chen et al., (2013). Advanced Drug Delivery Reviews 65:1357-1369.
Cheng et al., (2005). Biochemical and Biophysical Research Communications 329:966-975.
Chiu et al., (2001). Biochemistry 40:641-650.
Christiansen et al., (1998) Biochemistry-Us 37: 12611-12623.
Clausen et al., (2000). Proc. Natl. Acad. Sci. U.S.A. 97:3856-3861.
Cotton (2009). J. Am. Chem. Soc. 131: 4558-4559.
Coutu et al., (2007). Transgenic Res 16:771-781.
Couturier et al., (2013). Frontiers in Plant Science 4, art. 259.
Cui et al., (2013). Proceedings of the National Academy of Sciences 110, 2052-2057.
Cupp-Vickery et al., (2003). J. Mol. Biol. 330:1049-1059.
Curatti et al., (2006). Proc. Natl. Acad. Sci. U.S.A. 103:5297-5301.
Curatti and Rubio (2014). Plant Sci 225:130-137.
Darshi et al., (2012). Journal of Biological Chemistry 287:39480-39491.
De'ath et al., (2012). Proc. Natl. Acad. Sci. USA 109:17995-17999.
de Bruijn (2015). In: Biological Nitrogen Fixation pp. 1087-1101. John Wiley & Sons, Inc.
de Kok et al., (2014). ACS Synth. Biol. 3:97-106.
Dilworth et al., (1988). Biochem. J. 249:745-751.
Dilworth et al., (1993). Biochem. J. 289:395-400.
Dos Santos (2011). Methods. Mol. Biol. 766: 81-92.
Dos Santos et al., (2012). Bmc Genomics 13:162.
Drummond (1985). Biochem. J. 232:891-896.
Eady (1996). Chem. Rev. 96:3013-3030.
Engler et al., ACS Synthetic Biology 3(11):839-843.
Fani et al., (2000). J. Mol. Evol. 51:1-11.
Fay et al., (2015) Proc Natl Acad Sci U S A 112: 14829-14833.
Fay et al., (2016). Proc. Natl. Acad. Sci. U.S.A. 2016:9504-9508.
Frazzon et al., (2007). Plant Molecular Biology 64:225-240.
Furste, et al., (1986). Gene 48:119-131.
Gavini et al., (1998). Biochemical and Biophysical Research Communications. 244(2):498-504.
Gavini et al., (2006). Journal of Bacteriology 188:6020-6025.
Geddes et al., (2015). Curr Opin Biotech 32:216-222.
Geigenberger and Fernie (2014). Antioxid Redox Sign 21:1389-1421.
Glaser and Deshi (1999). J Bioenerg Biomembr 31:259-274.
Glibert et al., (2014). Environ Res Lett 9:e105001; doi.org/10.1088/1748-9326/9/10/105001.
Glick et al., (1992). Cell 69:809-822.
Goodwin et al., (1998) Biochemistry-Us 37: 10420-10428.
Good and Beatty (2011). PLoS Biol 9, e1001124.
Hu et al., (2004). J. Biol. Chem. 279:54963-54971.
Hu et al., (2005). Proc. Natl. Acad. Sci. U.S.A. 102:3236-3241.
Hu et al., (2006). Proc. Natl. Acad. Sci. U.S.A. 103:17119-17124.
Hu et al., (2008). Biochemistry 47:3973-3981.
Hu and Ribbe (2011). Coordination Chemistry Reviews 255:1218-1224.
Hu and Ribbe (2013). Bba-Bioenergetics 1827:1112-1122.
Huang et al., (2009). Plant Physiology 150(3):1272-1285.
Hurt et al., (1985). EMBO J. 4:2061-2068.
Hwang et al., (1996). J. Mol. Evol. Nov; 43:536-540.
Igarashi and Seefeldt (2003). Crit. Rev. Biochem. Mol. Biol. 38:351-384.
Ivleva et al., (2016). PLoS ONE 11, e0160951.
Johnson et al., (2005). Biochem. Soc. Trans. 33:90-93.
Kaiser et al., (2011). Science 331:91-94.
Kerscher et al., (1997). The Journal of Cell Biology 139:1663-1675.
Kim and Rees (1994). Biochemistry 33:389-397.
Kohler et al., (1997). Plant J. 11:613-621.
Lahiri et al., (2005). Biochemical and Biophysical Research Communications 337:677-684.
Lawson and Smith (2002). Met Ions Biol Syst; 39:75-119.
Lee et al., (2000). J. Bacteriol. 182:7088-7091.
Lee et al., (2009). Proc. Natl. Acad. Sci. U.S.A. 106, 18474-18478.Lee et al., (2012). Plant Cell 24:5037-5057.
Lill and Mühlenhoff (2008). Annual Review of Biochemistry 77:669-700.
Lopez-Torrejon et al., (2016). Nature Communications 7:11426.
Mackenzie and McIntosh (1999). Plant Cell 11:571-585.
Marques et al., (2014). Acta Crystallographica Section F 70(5):669-672.
Masukawa et al., (2007). Appl. Environ. Microbiol. 73:7562-7570.
Mayer et al., (1999). J. Mol. Biol. 292:871-891.
Merrick and Dixon (1984). Trends Biotechnol 2:162-166.
Miller and Eady (1988). Biochem. J. 256:429-432.
Mueller et al., (2012). Nature 490:254-257.
Mühlenhoff et al., (2003). EMBO J. 22:4815-4825.
Murcha et al., (2004). J Mol Biol 344:443-454.
Murcha et al., (2014). Bba-Gen Subjects 1840:1233-1245.
Oldroyd and Dixon (2014) Curr Opin Biotechnol 26:19-24.
Olson et al., (2000). Biochemistry; 39:16213-16219.
Ormö et al., (1996). Science 273:1392-1395.
Ouzounis et al., (1994). Trends Biochem. Sci. 19:199-200.
Petrie (2014). Plos One 9: Issue 1, e85061.
Petrova et al., (2000). Biochem. Biophys. Res. Commun. 270:863-867.
Pfanner and Geissler (2001) Nat. Rev. Mol. Cell Biol. 2:339-349.
Poza-Carrion et al., (2014). Journal of Bacteriology 196:595-603.
Prasad et al., (1992). Plant Molecular Biology 18(5):873-885.
Pratte et al., (2006). J. Bacteriol. 188:5806-5811.
Rees et al., (2005). Philos Trans A Math Phys Eng Sci. 363:971-984.
Robson and Postgate (1980). Annual Review of Microbiology 34:183-207.
Robson et al., (1989). EMBO J. 8:1217-1224.
Rockstrom et al., (2009). Nature 461:472-475.
Roise et al., (1986) The EMBO Journal 5:1327-1334.
Roise and Schatz (1988). J.Biol.Chem. 263:4509-4511.
Rubio et al., (2004) J Biol Chem 279: 19739-19746.
Rubio and Ludden (2008). Annu Rev Microbiol 62:93-111.
Sahoo et al., (2014). Planta 240:855-875.
Sali and Blundell, (1993). J. Mol. Biol. 234:779-815.
Santi et al., (2013). Ann Bot 111:743-767.
Schleiff and Soll (2000) Planta 211:449-456.
Schmid et al., (2002). Science 296:352-356.
Schmitz et al., (2001). FEMS Microbiol Lett. 195:97-102.
Schunmann et al., (2003a). Functional Plant Biology 30(4):443-452.
Schunmann et al., (2003b). Functional Plant Biology 30(4):453-460.
Seefeldt et al., (2009). Annu Rev Biochem 78:701-722.
Shah et al., (1999). J. Bacteriol. 181:2797-2801.
Siddavattam et al., (1993). Mol. Gen. Genet. 239:435-440.
Smil (2002). Ambio 31:126-131.
Smanski et al., (2014). Nature Biotechnology 32:1241-1249.
Sorlie et al., (2001). Biochem. 40:1540-1549.
Schindelin et al., (1997). Nature 387:370-376.
Staples et al., (2007). J. Bacteriol. 189:7392-7398.
Studier and Moffatt (1986). J Mol Biol 189:113-130.
Suh et al., (2003). Journal of Biological Chemistry 278:5353-5360.
Sutton et al., (2008). Environ Pollut 156:583-604.
Temme et al., (2012). Proc. Natl. Acad. Sci. U.S.A. 109(18):7085-7090.
Tezcan et al., (2005). Science 309:1377-1380.
Thiel et al., (1995) Proc Natl Acad Sci U S A 92: 9358-9362.
Thiel et al., (1997). J. Bacteriol. 179:5222-5225.
Voinnet et al., (2003). Plant Journal 33:949-956.
von Heijne (1986). EMBO J. 5:1335-1342.
Waldron et al., (1985). Plant Mol Biol 5:103-108.
Wang et al., (2013). PLoS Genet 9, e1003865.
Weber et al., (2011) PloS one. 6(2), pp.e16765.
Wiig et al., (2011) Proc Natl Acad Sci USA 108: 8623-8627.
Wood et al., (2006). Proc. Natl. Acad. Sci. USA. 103:14631-14636.
Wood et al., (2009). Plant Biotechnol J. 7:914-924.
Yuvaniyama et al., (2000). Proc. Natl. Acad. Sci. U.S.A. 97:599-604.
Zhang and Glaser (2002). Trends Plant Sci 7:14-21.
Zhang et al., (2009). Progress in Natural Science 19:1197-1200.
Zheng et al., (1993). Proc. Natl. Acad. Sci. U.S.A. 90:2754-2758
Zheng et al., (1997). J. Bacteriol. 179:5963-5966.
--->
Перечень последовательностей
<110> Государственное (commonwealth) объединение научных и прикладных
исследований
<120> Нитрогеназа
<130> 527134
<150> AU2017900359
<151> 2017-02-06
<160> 186
<170> PatentIn версия 3.5
<210> 1
<211> 29
<212> Белок
<213> Saccharomyces cerevisiae
<400> 1
Met Leu Ser Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala Thr Arg
1 5 10 15
Thr Leu Cys Ser Ser Arg Tyr Leu Leu Gln Gln Lys Pro
20 25
<210> 2
<211> 31
<212> Белок
<213> Искусственная последовательность
<220>
<223> Производная последовательность
<400> 2
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro
20 25 30
<210> 3
<211> 8
<212> Белок
<213> Искусственная последовательность
<220>
<223> Мотив
<220>
<221> X
<222> (1)..(1)
<223> Любая аминокислота
<220>
<221> X
<222> (3)..(5)
<223> Любая аминокислота
<220>
<221> X
<222> (8)..(8)
<223> Любая аминокислота
<400> 3
Xaa Arg Xaa Xaa Xaa Ser Ser Xaa
1 5
<210> 4
<211> 2346
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность вектора
<400> 4
ctcctgtggt tggcatgcac atacaaatgg acgaacggat aaaccttttc acgccctttt 60
aaatatccga ttattctaat aaacgctctt ttctcttagg tttacccgcc aatatatcct 120
gtcaaacact gatagtttaa actgaaggcg ggaaacgaca atctgctagt ggatctccca 180
gtcacgacgt tgtaaaacgg gcgccccgcg gaaagctttc gacgaattaa ttccaatccc 240
acaaaaatct gagcttaaca gcacagttgc tcctctcaga gcagaatcgg gtattcaaca 300
ccctcatatc aactactacg ttgtgtataa cggtccacat gccggtatat acgatgactg 360
gggttgtaca aaggcggcaa caaacggcgt tcccggagtt gcacacaaga aatttgccac 420
tattacagag gcaagagcag cagctgacgc gtacacaaca agtcagcaaa cagacaggtt 480
gaacttcatc cccaaaggag aagctcaact caagcccaag agctttgcta aggccctaac 540
aagcccacca aagcaaaaag cccactggct cacgctagga accaaaaggc ccagcagtga 600
tccagcccca aaagagatct cctttgcccc ggagattaca atggacgatt tcctctatct 660
ttacgatcta ggaaggaagt tcgaaggtga aggtgacgac actatgttca ccactgataa 720
tgagaaggtt agcctcttca atttcagaaa gaatgctgac ccacagatgg ttagagaggc 780
ctacgcagca ggtctcatca agacgatcta cccgagtaac aatctccagg agatcaaata 840
ccttcccaag aaggttaaag atgcagtcaa aagattcagg actaattgca tcaagaacac 900
agagaaagac atatttctca agatcagaag tactattcca gtatggacga ttcaaggctt 960
gcttcataaa ccaaggcaag taatagagat tggagtctct aaaaaggtag ttcctactga 1020
atctaaggcc atgcatggag tctaagattc aaatcgagga tctaacagaa ctcgccgtga 1080
agactggcga acagttcata cagagtcttt tacgactcaa tgacaagaag aaaatcttcg 1140
tcaacatggt ggagcacgac actctggtct actccaaaaa tgtcaaagat acagtctcag 1200
aagaccaaag ggctattgag acttttcaac aaaggataat ttcgggaaac ctcctcggat 1260
tccattgccc agctatctgt cacttcatcg aaaggacagt agaaaaggaa ggtggctcct 1320
acaaatgcca tcattgcgat aaaggaaagg ctatcattca agatctctct gccgacagtg 1380
gtcccaaaga tggaccccca cccacgagga gcatcgtgga aaaagaagac gttccaacca 1440
cgtcttcaaa gcaagtggat tgatgtgaca tctccactga cgtaagggat gacgcacaat 1500
cccactatcc ttcgcaagac ccttcctcta tataaggaag ttcatttcat ttggagagga 1560
cacgctcgag taatacgact cactataggg agaccacaac ggtttccctc tagaaataat 1620
tttgtttaac tttaagaagg agatatacca tgggcttgtc actactacgt caatctataa 1680
gatttttcaa gccagccaca agaactttgt gtagctctag atatctgctt gagcaaaaac 1740
ccggcgcgcc ggctgctaac aaagcccgaa aggaagctga gttggctgct gccaccgctg 1800
agcaataact agcataaccc cttggggcct ctaaacgggt cttgaggggt tttttgctgc 1860
ttaagattga atcctgttgc cggtcttgcg atgattatca tataatttct gttgaattac 1920
gttaagcatg taataattaa catgtaatgc atgacgttat ttatgagatg ggtttttatg 1980
attagagtcc cgcaattata catttaatac gcgatagaaa acaaaatata gcgcgcaaac 2040
taggataaat tatcgcgcgc ggtgtcatct atgttactag atccctaggg aagttcctat 2100
tccgaagttc ctattctctg aaaagtatag gaacttcttt gcgtattggg cgctcttggc 2160
ctttttggcc accggtcgta cggttaaaac caccccagta cattaaaaac gtccgcaatg 2220
tgttattaag ttgtctaagc gtcaatttgt ttacaccaca atatatcctg ccaccagcca 2280
gccaacagct ccccgaccgg cagctcggca caaaatcacc actcgataca ggcagcccat 2340
cagtcc 2346
<210> 5
<211> 293
<212> Белок
<213> Klebsiella pneumoniae
<400> 5
Met Thr Met Arg Gln Cys Ala Ile Tyr Gly Lys Gly Gly Ile Gly Lys
1 5 10 15
Ser Thr Thr Thr Gln Asn Leu Val Ala Ala Leu Ala Glu Met Gly Lys
20 25 30
Lys Val Met Ile Val Gly Cys Asp Pro Lys Ala Asp Ser Thr Arg Leu
35 40 45
Ile Leu His Ala Lys Ala Gln Asn Thr Ile Met Glu Met Ala Ala Glu
50 55 60
Val Gly Ser Val Glu Asp Leu Glu Leu Glu Asp Val Leu Gln Ile Gly
65 70 75 80
Tyr Gly Asp Val Arg Cys Ala Glu Ser Gly Gly Pro Glu Pro Gly Val
85 90 95
Gly Cys Ala Gly Arg Gly Val Ile Thr Ala Ile Asn Phe Leu Glu Glu
100 105 110
Glu Gly Ala Tyr Glu Asp Asp Leu Asp Phe Val Phe Tyr Asp Val Leu
115 120 125
Gly Asp Val Val Cys Gly Gly Phe Ala Met Pro Ile Arg Glu Asn Lys
130 135 140
Ala Gln Glu Ile Tyr Ile Val Cys Ser Gly Glu Met Met Ala Met Tyr
145 150 155 160
Ala Ala Asn Asn Ile Ser Lys Gly Ile Val Lys Tyr Ala Lys Ser Gly
165 170 175
Lys Val Arg Leu Gly Gly Leu Ile Cys Asn Ser Arg Gln Thr Asp Arg
180 185 190
Glu Asp Glu Leu Ile Ile Ala Leu Ala Glu Lys Leu Gly Thr Gln Met
195 200 205
Ile His Phe Val Pro Arg Asp Asn Ile Val Gln Arg Ala Glu Ile Arg
210 215 220
Arg Met Thr Val Ile Glu Tyr Asp Pro Ala Cys Lys Gln Ala Asn Glu
225 230 235 240
Tyr Arg Thr Leu Ala Gln Lys Ile Val Asn Asn Thr Met Lys Val Val
245 250 255
Pro Thr Pro Cys Thr Met Asp Glu Leu Glu Ser Leu Leu Met Glu Phe
260 265 270
Gly Ile Met Glu Glu Glu Asp Thr Ser Ile Ile Gly Lys Thr Ala Ala
275 280 285
Glu Glu Asn Ala Ala
290
<210> 6
<211> 483
<212> Белок
<213> Klebsiella pneumoniae
<400> 6
Met Met Thr Asn Ala Thr Gly Glu Arg Asn Leu Ala Leu Ile Gln Glu
1 5 10 15
Val Leu Glu Val Phe Pro Glu Thr Ala Arg Lys Glu Arg Arg Lys His
20 25 30
Met Met Val Ser Asp Pro Lys Met Lys Ser Val Gly Lys Cys Ile Ile
35 40 45
Ser Asn Arg Lys Ser Gln Pro Gly Val Met Thr Val Arg Gly Cys Ala
50 55 60
Tyr Ala Gly Ser Lys Gly Val Val Phe Gly Pro Ile Lys Asp Met Ala
65 70 75 80
His Ile Ser His Gly Pro Ala Gly Cys Gly Gln Tyr Ser Arg Ala Glu
85 90 95
Arg Arg Asn Tyr Tyr Thr Gly Val Ser Gly Val Asp Ser Phe Gly Thr
100 105 110
Leu Asn Phe Thr Ser Asp Phe Gln Glu Arg Asp Ile Val Phe Gly Gly
115 120 125
Asp Lys Lys Leu Ser Lys Leu Ile Glu Glu Met Glu Leu Leu Phe Pro
130 135 140
Leu Thr Lys Gly Ile Thr Ile Gln Ser Glu Cys Pro Val Gly Leu Ile
145 150 155 160
Gly Asp Asp Ile Ser Ala Val Ala Asn Ala Ser Ser Lys Ala Leu Asp
165 170 175
Lys Pro Val Ile Pro Val Arg Cys Glu Gly Phe Arg Gly Val Ser Gln
180 185 190
Ser Leu Gly His His Ile Ala Asn Asp Val Val Arg Asp Trp Ile Leu
195 200 205
Asn Asn Arg Glu Gly Gln Pro Phe Glu Thr Thr Pro Tyr Asp Val Ala
210 215 220
Ile Ile Gly Asp Tyr Asn Ile Gly Gly Asp Ala Trp Ala Ser Arg Ile
225 230 235 240
Leu Leu Glu Glu Met Gly Leu Arg Val Val Ala Gln Trp Ser Gly Asp
245 250 255
Gly Thr Leu Val Glu Met Glu Asn Thr Pro Phe Val Lys Leu Asn Leu
260 265 270
Val His Cys Tyr Arg Ser Met Asn Tyr Ile Ala Arg His Met Glu Glu
275 280 285
Lys His Gln Ile Pro Trp Met Glu Tyr Asn Phe Phe Gly Pro Thr Lys
290 295 300
Ile Ala Glu Ser Leu Arg Lys Ile Ala Asp Gln Phe Asp Asp Thr Ile
305 310 315 320
Arg Ala Asn Ala Glu Ala Val Ile Ala Arg Tyr Glu Gly Gln Met Ala
325 330 335
Ala Ile Ile Ala Lys Tyr Arg Pro Arg Leu Glu Gly Arg Lys Val Leu
340 345 350
Leu Tyr Ile Gly Gly Leu Arg Pro Arg His Val Ile Gly Ala Tyr Glu
355 360 365
Asp Leu Gly Met Glu Ile Ile Ala Ala Gly Tyr Glu Phe Ala His Asn
370 375 380
Asp Asp Tyr Asp Arg Thr Leu Pro Asp Leu Lys Glu Gly Thr Leu Leu
385 390 395 400
Phe Asp Asp Ala Ser Ser Tyr Glu Leu Glu Ala Phe Val Lys Ala Leu
405 410 415
Lys Pro Asp Leu Ile Gly Ser Gly Ile Lys Glu Lys Tyr Ile Phe Gln
420 425 430
Lys Met Gly Val Pro Phe Arg Gln Met His Ser Trp Asp Tyr Ser Gly
435 440 445
Pro Tyr His Gly Tyr Asp Gly Phe Ala Ile Phe Ala Arg Asp Met Asp
450 455 460
Met Thr Leu Asn Asn Pro Ala Trp Asn Glu Leu Thr Ala Pro Trp Leu
465 470 475 480
Lys Ser Ala
<210> 7
<211> 520
<212> Белок
<213> Klebsiella pneumoniae
<400> 7
Met Ser Gln Thr Ile Asp Lys Ile Asn Ser Cys Tyr Pro Leu Phe Glu
1 5 10 15
Gln Asp Glu Tyr Gln Glu Leu Phe Arg Asn Lys Arg Gln Leu Glu Glu
20 25 30
Ala His Asp Ala Gln Arg Val Gln Glu Val Phe Ala Trp Thr Thr Thr
35 40 45
Ala Glu Tyr Glu Ala Leu Asn Phe Arg Arg Glu Ala Leu Thr Val Asp
50 55 60
Pro Ala Lys Ala Cys Gln Pro Leu Gly Ala Val Leu Cys Ser Leu Gly
65 70 75 80
Phe Ala Asn Thr Leu Pro Tyr Val His Gly Ser Gln Gly Cys Val Ala
85 90 95
Tyr Phe Arg Thr Tyr Phe Asn Arg His Phe Lys Glu Pro Ile Ala Cys
100 105 110
Val Ser Asp Ser Met Thr Glu Asp Ala Ala Val Phe Gly Gly Asn Asn
115 120 125
Asn Met Asn Leu Gly Leu Gln Asn Ala Ser Ala Leu Tyr Lys Pro Glu
130 135 140
Ile Ile Ala Val Ser Thr Thr Cys Met Ala Glu Val Ile Gly Asp Asp
145 150 155 160
Leu Gln Ala Phe Ile Ala Asn Ala Lys Lys Asp Gly Phe Val Asp Ser
165 170 175
Ser Ile Ala Val Pro His Ala His Thr Pro Ser Phe Ile Gly Ser His
180 185 190
Val Thr Gly Trp Asp Asn Met Phe Glu Gly Phe Ala Lys Thr Phe Thr
195 200 205
Ala Asp Tyr Gln Gly Gln Pro Gly Lys Leu Pro Lys Leu Asn Leu Val
210 215 220
Thr Gly Phe Glu Thr Tyr Leu Gly Asn Phe Arg Val Leu Lys Arg Met
225 230 235 240
Met Glu Gln Met Ala Val Pro Cys Ser Leu Leu Ser Asp Pro Ser Glu
245 250 255
Val Leu Asp Thr Pro Ala Asp Gly His Tyr Arg Met Tyr Ser Gly Gly
260 265 270
Thr Thr Gln Gln Glu Met Lys Glu Ala Pro Asp Ala Ile Asp Thr Leu
275 280 285
Leu Leu Gln Pro Trp Gln Leu Leu Lys Ser Lys Lys Val Val Gln Glu
290 295 300
Met Trp Asn Gln Pro Ala Thr Glu Val Ala Ile Pro Leu Gly Leu Ala
305 310 315 320
Ala Thr Asp Glu Leu Leu Met Thr Val Ser Gln Leu Ser Gly Lys Pro
325 330 335
Ile Ala Asp Ala Leu Thr Leu Glu Arg Gly Arg Leu Val Asp Met Met
340 345 350
Leu Asp Ser His Thr Trp Leu His Gly Lys Lys Phe Gly Leu Tyr Gly
355 360 365
Asp Pro Asp Phe Val Met Gly Leu Thr Arg Phe Leu Leu Glu Leu Gly
370 375 380
Cys Glu Pro Thr Val Ile Leu Ser His Asn Ala Asn Lys Arg Trp Gln
385 390 395 400
Lys Ala Met Asn Lys Met Leu Asp Ala Ser Pro Tyr Gly Arg Asp Ser
405 410 415
Glu Val Phe Ile Asn Cys Asp Leu Trp His Phe Arg Ser Leu Met Phe
420 425 430
Thr Arg Gln Pro Asp Phe Met Ile Gly Asn Ser Tyr Gly Lys Phe Ile
435 440 445
Gln Arg Asp Thr Leu Ala Lys Gly Lys Ala Phe Glu Val Pro Leu Ile
450 455 460
Arg Leu Gly Phe Pro Leu Phe Asp Arg His His Leu His Arg Gln Thr
465 470 475 480
Thr Trp Gly Tyr Glu Gly Ala Met Asn Ile Val Thr Thr Leu Val Asn
485 490 495
Ala Val Leu Glu Lys Leu Asp Ser Asp Thr Ser Gln Leu Gly Lys Thr
500 505 510
Asp Tyr Ser Phe Asp Leu Val Arg
515 520
<210> 8
<211> 220
<212> Белок
<213> Klebsiella pneumoniae
<400> 8
Met Ser Asp Asn Asp Thr Leu Phe Trp Arg Met Leu Ala Leu Phe Gln
1 5 10 15
Ser Leu Pro Asp Leu Gln Pro Ala Gln Ile Val Asp Trp Leu Ala Gln
20 25 30
Glu Ser Gly Glu Thr Leu Thr Pro Glu Arg Leu Ala Thr Leu Thr Gln
35 40 45
Pro Gln Leu Ala Ala Ser Phe Pro Ser Ala Thr Ala Val Met Ser Pro
50 55 60
Ala Arg Trp Ser Arg Val Met Ala Ser Leu Gln Gly Ala Leu Pro Ala
65 70 75 80
His Leu Arg Ile Val Arg Pro Ala Gln Arg Thr Pro Gln Leu Leu Ala
85 90 95
Ala Phe Cys Ser Gln Asp Gly Leu Val Ile Asn Gly His Phe Gly Gln
100 105 110
Gly Arg Leu Phe Phe Ile Tyr Ala Phe Asp Glu Gln Gly Gly Trp Leu
115 120 125
Tyr Asp Leu Arg Arg Tyr Pro Ser Ala Pro His Gln Gln Glu Ala Asn
130 135 140
Glu Val Arg Ala Arg Leu Ile Glu Asp Cys Gln Leu Leu Phe Cys Gln
145 150 155 160
Glu Ile Gly Gly Pro Ala Ala Ala Arg Pro Ile Arg His Arg Ile His
165 170 175
Pro Met Lys Ala Gln Pro Gly Thr Thr Ile Gln Ala Gln Cys Glu Ala
180 185 190
Ile Asn Thr Leu Leu Ala Gly Arg Leu Pro Pro Trp Leu Ala Lys Arg
195 200 205
Leu Asn Arg Asp Asn Pro Leu Glu Glu Arg Val Phe
210 215 220
<210> 9
<211> 468
<212> Белок
<213> Klebsiella pneumoniae
<400> 9
Met Thr Ser Cys Ser Ser Phe Ser Gly Gly Lys Ala Cys Arg Pro Ala
1 5 10 15
Asp Asp Ser Ala Leu Thr Pro Leu Val Ala Asp Lys Ala Ala Ala His
20 25 30
Pro Cys Tyr Ser Arg His Gly His His Arg Phe Ala Arg Met His Leu
35 40 45
Pro Val Ala Pro Ala Cys Asn Leu Gln Cys Asn Tyr Cys Asn Arg Lys
50 55 60
Phe Asp Cys Ser Asn Glu Ser Arg Pro Gly Val Ser Ser Thr Leu Leu
65 70 75 80
Thr Pro Glu Gln Ala Val Val Lys Val Arg Gln Val Ala Gln Ala Ile
85 90 95
Pro Gln Leu Ser Val Val Gly Ile Ala Gly Pro Gly Asp Pro Leu Ala
100 105 110
Asn Ile Ala Arg Thr Phe Arg Thr Leu Glu Leu Ile Arg Glu Gln Leu
115 120 125
Pro Asp Leu Lys Leu Cys Leu Ser Thr Asn Gly Leu Val Leu Pro Asp
130 135 140
Ala Val Asp Arg Leu Leu Asp Val Gly Val Asp His Val Thr Val Thr
145 150 155 160
Ile Asn Thr Leu Asp Ala Glu Ile Ala Ala Gln Ile Tyr Ala Trp Leu
165 170 175
Trp Leu Asp Gly Glu Arg Tyr Ser Gly Arg Glu Ala Gly Glu Ile Leu
180 185 190
Ile Ala Arg Gln Leu Glu Gly Val Arg Arg Leu Thr Ala Lys Gly Val
195 200 205
Leu Val Lys Ile Asn Ser Val Leu Ile Pro Gly Ile Asn Asp Ser Gly
210 215 220
Met Ala Gly Val Ser Arg Ala Leu Arg Ala Ser Gly Ala Phe Ile His
225 230 235 240
Asn Ile Met Pro Leu Ile Ala Arg Pro Glu His Gly Thr Val Phe Gly
245 250 255
Leu Asn Gly Gln Pro Glu Pro Asp Ala Glu Thr Leu Ala Ala Thr Arg
260 265 270
Ser Arg Cys Gly Glu Val Met Pro Gln Met Thr His Cys His Gln Cys
275 280 285
Arg Ala Asp Ala Ile Gly Met Leu Gly Glu Asp Arg Ser Gln Gln Phe
290 295 300
Thr Gln Leu Pro Ala Pro Glu Ser Leu Pro Ala Trp Leu Pro Ile Leu
305 310 315 320
His Gln Arg Ala Gln Leu His Ala Ser Ile Ala Thr Arg Gly Glu Ser
325 330 335
Glu Ala Asp Asp Ala Cys Leu Val Ala Val Ala Ser Ser Arg Gly Asp
340 345 350
Val Ile Asp Cys His Phe Gly His Ala Asp Arg Phe Tyr Ile Tyr Ser
355 360 365
Leu Ser Ala Ala Gly Met Val Leu Val Asn Glu Arg Phe Thr Pro Lys
370 375 380
Tyr Cys Gln Gly Arg Asp Asp Cys Glu Pro Gln Asp Asn Ala Ala Arg
385 390 395 400
Phe Ala Ala Ile Leu Glu Leu Leu Ala Asp Val Lys Ala Val Phe Cys
405 410 415
Val Arg Ile Gly His Thr Pro Trp Gln Gln Leu Glu Gln Glu Gly Ile
420 425 430
Glu Pro Cys Val Asp Gly Ala Trp Arg Pro Val Ser Glu Val Leu Pro
435 440 445
Ala Trp Trp Gln Gln Arg Arg Gly Ser Trp Pro Ala Ala Leu Pro His
450 455 460
Lys Gly Val Ala
465
<210> 10
<211> 457
<212> Белок
<213> Klebsiella pneumoniae
<400> 10
Met Lys Gly Asn Glu Ile Leu Ala Leu Leu Asp Glu Pro Ala Cys Glu
1 5 10 15
His Asn His Lys Gln Lys Ser Gly Cys Ser Ala Pro Lys Pro Gly Ala
20 25 30
Thr Ala Ala Gly Cys Ala Phe Asp Gly Ala Gln Ile Thr Leu Leu Pro
35 40 45
Ile Ala Asp Val Ala His Leu Val His Gly Pro Ile Gly Cys Ala Gly
50 55 60
Ser Ser Trp Asp Asn Arg Gly Ser Ala Ser Ser Gly Pro Thr Leu Asn
65 70 75 80
Arg Leu Gly Phe Thr Thr Asp Leu Asn Glu Gln Asp Val Ile Met Gly
85 90 95
Arg Gly Glu Arg Arg Leu Phe His Ala Val Arg His Ile Val Thr Arg
100 105 110
Tyr His Pro Ala Ala Val Phe Ile Tyr Asn Thr Cys Val Pro Ala Met
115 120 125
Glu Gly Asp Asp Leu Glu Ala Val Cys Gln Ala Ala Gln Thr Ala Thr
130 135 140
Gly Val Pro Val Ile Ala Ile Asp Ala Ala Gly Phe Tyr Gly Ser Lys
145 150 155 160
Asn Leu Gly Asn Arg Pro Ala Gly Asp Val Met Val Lys Arg Val Ile
165 170 175
Gly Gln Arg Glu Pro Ala Pro Trp Pro Glu Ser Thr Leu Phe Ala Pro
180 185 190
Glu Gln Arg His Asp Ile Gly Leu Ile Gly Glu Phe Asn Ile Ala Gly
195 200 205
Glu Phe Trp His Ile Gln Pro Leu Leu Asp Glu Leu Gly Ile Arg Val
210 215 220
Leu Gly Ser Leu Ser Gly Asp Gly Arg Phe Ala Glu Ile Gln Thr Met
225 230 235 240
His Arg Ala Gln Ala Asn Met Leu Val Cys Ser Arg Ala Leu Ile Asn
245 250 255
Val Ala Arg Ala Leu Glu Gln Arg Tyr Gly Thr Pro Trp Phe Glu Gly
260 265 270
Ser Phe Tyr Gly Ile Arg Ala Thr Ser Asp Ala Leu Arg Gln Leu Ala
275 280 285
Ala Leu Leu Gly Asp Asp Asp Leu Arg Gln Arg Thr Glu Ala Leu Ile
290 295 300
Ala Arg Glu Glu Gln Ala Ala Glu Leu Ala Leu Gln Pro Trp Arg Glu
305 310 315 320
Gln Leu Arg Gly Arg Lys Ala Leu Leu Tyr Thr Gly Gly Val Lys Ser
325 330 335
Trp Ser Val Val Ser Ala Leu Gln Asp Leu Gly Met Thr Val Val Ala
340 345 350
Thr Gly Thr Arg Lys Ser Thr Glu Glu Asp Lys Gln Arg Ile Arg Glu
355 360 365
Leu Met Gly Glu Glu Ala Val Met Leu Glu Glu Gly Asn Ala Arg Thr
370 375 380
Leu Leu Asp Val Val Tyr Arg Tyr Gln Ala Asp Leu Met Ile Ala Gly
385 390 395 400
Gly Arg Asn Met Tyr Thr Ala Tyr Lys Ala Arg Leu Pro Phe Leu Asp
405 410 415
Ile Asn Gln Glu Arg Glu His Ala Phe Ala Gly Tyr Gln Gly Ile Val
420 425 430
Thr Leu Ala Arg Gln Leu Cys Gln Thr Ile Asn Ser Pro Ile Trp Pro
435 440 445
Gln Thr His Ser Arg Ala Pro Trp Arg
450 455
<210> 11
<211> 461
<212> Белок
<213> Klebsiella pneumoniae
<400> 11
Met Ala Asp Ile Phe Arg Thr Asp Lys Pro Leu Ala Val Ser Pro Ile
1 5 10 15
Lys Thr Gly Gln Pro Leu Gly Ala Ile Leu Ala Ser Leu Gly Ile Glu
20 25 30
His Ser Ile Pro Leu Val His Gly Ala Gln Gly Cys Ser Ala Phe Ala
35 40 45
Lys Val Phe Phe Ile Gln His Phe His Asp Pro Val Pro Leu Gln Ser
50 55 60
Thr Ala Met Asp Pro Thr Ser Thr Ile Met Gly Ala Asp Gly Asn Ile
65 70 75 80
Phe Thr Ala Leu Asp Thr Leu Cys Gln Arg Asn Asn Pro Gln Ala Ile
85 90 95
Val Leu Leu Ser Thr Gly Leu Ser Glu Ala Gln Gly Ser Asp Ile Ser
100 105 110
Arg Val Val Arg Gln Phe Arg Glu Glu Tyr Pro Arg His Lys Gly Val
115 120 125
Ala Ile Leu Thr Val Asn Thr Pro Asp Phe Tyr Gly Ser Met Glu Asn
130 135 140
Gly Phe Ser Ala Val Leu Glu Ser Val Ile Glu Gln Trp Val Pro Pro
145 150 155 160
Ala Pro Arg Pro Ala Gln Arg Asn Arg Arg Val Asn Leu Leu Val Ser
165 170 175
His Leu Cys Ser Pro Gly Asp Ile Glu Trp Leu Arg Arg Cys Val Glu
180 185 190
Ala Phe Gly Leu Gln Pro Ile Ile Leu Pro Asp Leu Ala Gln Ser Met
195 200 205
Asp Gly His Leu Ala Gln Gly Asp Phe Ser Pro Leu Thr Gln Gly Gly
210 215 220
Thr Pro Leu Arg Gln Ile Glu Gln Met Gly Gln Ser Leu Cys Ser Phe
225 230 235 240
Ala Ile Gly Val Ser Leu His Arg Ala Ser Ser Leu Leu Ala Pro Arg
245 250 255
Cys Arg Gly Glu Val Ile Ala Leu Pro His Leu Met Thr Leu Glu Arg
260 265 270
Cys Asp Ala Phe Ile His Gln Leu Ala Lys Ile Ser Gly Arg Ala Val
275 280 285
Pro Glu Trp Leu Glu Arg Gln Arg Gly Gln Leu Gln Asp Ala Met Ile
290 295 300
Asp Cys His Met Trp Leu Gln Gly Gln Arg Met Ala Ile Ala Ala Glu
305 310 315 320
Gly Asp Leu Leu Ala Ala Trp Cys Asp Phe Ala Asn Ser Gln Gly Met
325 330 335
Gln Pro Gly Pro Leu Val Ala Pro Thr Gly His Pro Ser Leu Arg Gln
340 345 350
Leu Pro Val Glu Arg Val Val Pro Gly Asp Leu Glu Asp Leu Gln Thr
355 360 365
Leu Leu Cys Ala His Pro Ala Asp Leu Leu Val Ala Asn Ser His Ala
370 375 380
Arg Asp Leu Ala Glu Gln Phe Ala Leu Pro Leu Val Arg Ala Gly Phe
385 390 395 400
Pro Leu Phe Asp Lys Leu Gly Glu Phe Arg Arg Val Arg Gln Gly Tyr
405 410 415
Ser Gly Met Arg Asp Thr Leu Phe Glu Leu Ala Asn Leu Ile Arg Glu
420 425 430
Arg His His His Leu Ala His Tyr Arg Ser Pro Leu Arg Gln Asn Pro
435 440 445
Glu Ser Ser Leu Ser Thr Gly Gly Ala Tyr Ala Ala Asp
450 455 460
<210> 12
<211> 167
<212> Белок
<213> Klebsiella pneumoniae
<400> 12
Met Pro Pro Leu Asp Trp Leu Arg Arg Leu Trp Leu Leu Tyr His Ala
1 5 10 15
Gly Lys Gly Ser Phe Pro Leu Arg Met Gly Leu Ser Pro Arg Asp Trp
20 25 30
Gln Ala Leu Arg Arg Arg Leu Gly Glu Val Glu Thr Pro Leu Asp Gly
35 40 45
Glu Thr Leu Thr Arg Arg Arg Leu Met Ala Glu Leu Asn Ala Thr Arg
50 55 60
Glu Glu Glu Arg Gln Gln Leu Gly Ala Trp Leu Ala Gly Trp Met Gln
65 70 75 80
Gln Asp Ala Gly Pro Met Ala Gln Ile Ile Ala Glu Val Ser Leu Ala
85 90 95
Phe Asn His Leu Trp Gln Asp Leu Gly Leu Ala Ser Arg Ala Glu Leu
100 105 110
Arg Leu Leu Met Ser Asp Cys Phe Pro Gln Leu Val Val Met Asn Glu
115 120 125
His Asn Met Arg Trp Lys Lys Phe Phe Tyr Arg Gln Arg Cys Leu Leu
130 135 140
Gln Gln Gly Glu Val Ile Cys Arg Ser Pro Ser Cys Asp Glu Cys Trp
145 150 155 160
Glu Arg Ser Ala Cys Phe Glu
165
<210> 13
<211> 400
<212> Белок
<213> Klebsiella pneumoniae
<400> 13
Met Lys Gln Val Tyr Leu Asp Asn Asn Ala Thr Thr Arg Leu Asp Pro
1 5 10 15
Met Val Leu Glu Ala Met Met Pro Phe Leu Thr Asp Phe Tyr Gly Asn
20 25 30
Pro Ser Ser Ile His Asp Phe Gly Ile Pro Ala Gln Ala Ala Leu Glu
35 40 45
Arg Ala His Gln Gln Ala Ala Ala Leu Leu Gly Ala Glu Tyr Pro Ser
50 55 60
Glu Ile Ile Phe Thr Ser Cys Ala Thr Glu Ala Thr Ala Thr Ala Ile
65 70 75 80
Ala Ser Ala Ile Ala Leu Leu Pro Glu Arg Arg Glu Ile Ile Thr Ser
85 90 95
Val Val Glu His Pro Ala Thr Leu Ala Ala Cys Glu His Met Glu Arg
100 105 110
Glu Gly Tyr Arg Ile His Arg Ile Ala Val Asp Gly Glu Gly Ala Leu
115 120 125
Asp Met Ala Gln Phe Arg Ala Ala Leu Ser Pro Arg Val Ala Leu Val
130 135 140
Ser Val Met Trp Ala Asn Asn Glu Thr Gly Val Leu Phe Pro Ile Gly
145 150 155 160
Glu Met Ala Glu Leu Ala His Glu Gln Gly Ala Leu Phe His Cys Asp
165 170 175
Ala Val Gln Val Val Gly Lys Ile Pro Ile Ala Val Gly Gln Thr Arg
180 185 190
Ile Asp Met Leu Ser Cys Ser Ala His Lys Phe His Gly Pro Lys Gly
195 200 205
Val Gly Cys Leu Tyr Leu Arg Arg Gly Thr Arg Phe Arg Pro Leu Leu
210 215 220
Arg Gly Gly His Gln Glu Tyr Gly Arg Arg Ala Gly Thr Glu Asn Ile
225 230 235 240
Cys Gly Ile Val Gly Met Gly Ala Ala Cys Glu Leu Ala Asn Ile His
245 250 255
Leu Pro Gly Met Thr His Ile Gly Gln Leu Arg Asn Arg Leu Glu His
260 265 270
Arg Leu Leu Ala Ser Val Pro Ser Val Met Val Met Gly Gly Gly Gln
275 280 285
Pro Ala Val Pro Gly Thr Val Asn Leu Ala Phe Glu Phe Ile Glu Gly
290 295 300
Glu Ala Ile Leu Leu Leu Leu Asn Gln Ala Gly Ile Ala Ala Ser Ser
305 310 315 320
Gly Ser Ala Cys Thr Ser Gly Ser Leu Glu Pro Ser His Val Met Arg
325 330 335
Ala Met Asn Ile Pro Tyr Thr Ala Ala His Gly Thr Ile Arg Phe Ser
340 345 350
Leu Ser Arg Tyr Thr Arg Glu Lys Glu Ile Asp Tyr Val Val Ala Thr
355 360 365
Leu Pro Pro Ile Ile Asp Arg Leu Arg Ala Leu Ser Pro Tyr Trp Gln
370 375 380
Asn Gly Lys Pro Arg Pro Ala Asp Ala Val Phe Thr Pro Val Tyr Gly
385 390 395 400
<210> 14
<211> 274
<212> Белок
<213> Klebsiella pneumoniae
<400> 14
Met Trp Asn Tyr Ser Glu Lys Val Lys Asp His Phe Phe Asn Pro Arg
1 5 10 15
Asn Ala Arg Val Val Asp Asn Ala Asn Ala Val Gly Asp Val Gly Ser
20 25 30
Leu Ser Cys Gly Asp Ala Leu Arg Leu Met Leu Arg Val Asp Pro Gln
35 40 45
Ser Glu Ile Ile Glu Glu Ala Gly Phe Gln Thr Phe Gly Cys Gly Ser
50 55 60
Ala Ile Ala Ser Ser Ser Ala Leu Thr Glu Leu Ile Ile Gly His Thr
65 70 75 80
Leu Ala Glu Ala Gly Gln Ile Thr Asn Gln Gln Ile Ala Asp Tyr Leu
85 90 95
Asp Gly Leu Pro Pro Glu Lys Met His Cys Ser Val Met Gly Gln Glu
100 105 110
Ala Leu Arg Ala Ala Ile Ala Asn Phe Arg Gly Glu Ser Leu Glu Glu
115 120 125
Glu His Asp Glu Gly Lys Leu Ile Cys Lys Cys Phe Gly Val Asp Glu
130 135 140
Gly His Ile Arg Arg Ala Val Gln Asn Asn Gly Leu Thr Thr Leu Ala
145 150 155 160
Glu Val Ile Asn Tyr Thr Lys Ala Gly Gly Gly Cys Thr Ser Cys His
165 170 175
Glu Lys Ile Glu Leu Ala Leu Ala Glu Ile Leu Ala Gln Gln Pro Gln
180 185 190
Thr Thr Pro Ala Val Ala Ser Gly Lys Asp Pro His Trp Gln Ser Val
195 200 205
Val Asp Thr Ile Ala Glu Leu Arg Pro His Ile Gln Ala Asp Gly Gly
210 215 220
Asp Met Ala Leu Leu Ser Val Thr Asn His Gln Val Thr Val Ser Leu
225 230 235 240
Ser Gly Ser Cys Ser Gly Cys Met Met Thr Asp Met Thr Leu Ala Trp
245 250 255
Leu Gln Gln Lys Leu Met Glu Arg Thr Gly Cys Tyr Met Glu Val Val
260 265 270
Ala Ala
<210> 15
<211> 156
<212> Белок
<213> Klebsiella pneumoniae
<400> 15
Met Pro Pro Ile Asn Arg Gln Phe Asp Met Val His Ser Asp Glu Trp
1 5 10 15
Ser Met Lys Val Ala Phe Ala Ser Ser Asp Tyr Arg His Val Asp Gln
20 25 30
His Phe Gly Ala Thr Pro Arg Leu Val Val Tyr Gly Val Lys Ala Asp
35 40 45
Arg Val Thr Leu Ile Arg Val Val Asp Phe Ser Val Glu Asn Gly His
50 55 60
Gln Thr Glu Lys Ile Ala Arg Arg Ile His Ala Leu Glu Asp Cys Val
65 70 75 80
Thr Leu Phe Cys Val Ala Ile Gly Asp Ala Val Phe Arg Gln Leu Leu
85 90 95
Gln Val Gly Val Arg Ala Glu Arg Val Pro Ala Asp Thr Thr Ile Val
100 105 110
Gly Leu Leu Gln Glu Ile Gln Leu Tyr Trp Tyr Asp Lys Gly Gln Arg
115 120 125
Lys Asn Gln Arg Gln Arg Asp Pro Glu Arg Phe Thr Arg Leu Leu Gln
130 135 140
Glu Gln Glu Trp His Gly Asp Pro Asp Pro Arg Arg
145 150 155
<210> 16
<211> 176
<212> Белок
<213> Klebsiella pneumoniae
<400> 16
Met Ala Asn Ile Gly Ile Phe Phe Gly Thr Asp Thr Gly Lys Thr Arg
1 5 10 15
Lys Ile Ala Lys Met Ile His Lys Gln Leu Gly Glu Leu Ala Asp Ala
20 25 30
Pro Val Asn Ile Asn Arg Thr Thr Leu Asp Asp Phe Met Ala Tyr Pro
35 40 45
Val Leu Leu Leu Gly Thr Pro Thr Leu Gly Asp Gly Gln Leu Pro Gly
50 55 60
Leu Glu Ala Gly Cys Glu Ser Glu Ser Trp Ser Glu Phe Ile Ser Gly
65 70 75 80
Leu Asp Asp Ala Ser Leu Lys Gly Lys Thr Val Ala Leu Phe Gly Leu
85 90 95
Gly Asp Gln Arg Gly Tyr Pro Asp Asn Phe Val Ser Gly Met Arg Pro
100 105 110
Leu Phe Asp Ala Leu Ser Ala Arg Gly Ala Gln Met Ile Gly Ser Trp
115 120 125
Pro Asn Glu Gly Tyr Glu Phe Ser Ala Ser Ser Ala Leu Glu Gly Asp
130 135 140
Arg Phe Val Gly Leu Val Leu Asp Gln Asp Asn Gln Phe Asp Gln Thr
145 150 155 160
Glu Ala Arg Leu Ala Ser Trp Leu Glu Glu Ile Lys Arg Thr Val Leu
165 170 175
<210> 17
<211> 148
<212> Белок
<213> Klebsiella pneumoniae
<400> 17
Met Arg Pro Lys Phe Thr Phe Ser Glu Glu Val Arg Val Val Arg Ala
1 5 10 15
Ile Arg Asn Asp Gly Thr Val Ala Gly Phe Ala Pro Gly Ala Leu Leu
20 25 30
Val Arg Arg Gly Ser Thr Gly Phe Val Arg Asp Trp Gly Val Phe Leu
35 40 45
Gln Asp Gln Ile Ile Tyr Gln Ile His Phe Pro Glu Thr Asp Arg Ile
50 55 60
Ile Gly Cys Arg Glu Gln Glu Leu Ile Pro Ile Thr Gln Pro Trp Leu
65 70 75 80
Ala Gly Asn Leu Gln Tyr Arg Asp Ser Val Thr Cys Gln Met Ala Leu
85 90 95
Ala Val Asn Gly Asp Val Val Val Ser Ala Gly Gln Arg Gly Arg Val
100 105 110
Glu Ala Thr Asp Arg Gly Glu Leu Gly Asp Ser Tyr Thr Val Asp Phe
115 120 125
Ser Gly Arg Trp Phe Arg Val Pro Val Gln Ala Ile Ala Leu Ile Glu
130 135 140
Glu Arg Glu Glu
145
<210> 18
<211> 1171
<212> Белок
<213> Klebsiella pneumoniae
<400> 18
Met Ser Gly Lys Met Lys Thr Met Asp Gly Asn Ala Ala Ala Ala Trp
1 5 10 15
Ile Ser Tyr Ala Phe Thr Glu Val Ala Ala Ile Tyr Pro Ile Thr Pro
20 25 30
Ser Thr Pro Met Ala Glu Asn Val Asp Glu Trp Ala Ala Gln Gly Lys
35 40 45
Lys Asn Leu Phe Gly Gln Pro Val Arg Leu Met Glu Met Gln Ser Glu
50 55 60
Ala Gly Ala Ala Gly Ala Val His Gly Ala Leu Gln Ala Gly Ala Leu
65 70 75 80
Thr Thr Thr Tyr Thr Ala Ser Gln Gly Leu Leu Leu Met Ile Pro Asn
85 90 95
Met Tyr Lys Ile Ala Gly Glu Leu Leu Pro Gly Val Phe His Val Ser
100 105 110
Ala Arg Ala Leu Ala Thr Asn Ser Leu Asn Ile Phe Gly Asp His Gln
115 120 125
Asp Val Met Ala Val Arg Gln Thr Gly Cys Ala Met Leu Ala Glu Asn
130 135 140
Asn Val Gln Gln Val Met Asp Leu Ser Ala Val Ala His Leu Ala Ala
145 150 155 160
Ile Lys Gly Arg Ile Pro Phe Val Asn Phe Phe Asp Gly Phe Arg Thr
165 170 175
Ser His Glu Ile Gln Lys Ile Glu Val Leu Glu Tyr Glu Gln Leu Ala
180 185 190
Thr Leu Leu Asp Arg Pro Ala Leu Asp Ser Phe Arg Arg Asn Ala Leu
195 200 205
His Pro Asp His Pro Val Ile Arg Gly Thr Ala Gln Asn Pro Asp Ile
210 215 220
Tyr Phe Gln Glu Arg Glu Ala Gly Asn Arg Phe Tyr Gln Ala Leu Pro
225 230 235 240
Asp Ile Val Glu Ser Tyr Met Thr Gln Ile Ser Ala Leu Thr Gly Arg
245 250 255
Glu Tyr His Leu Phe Asn Tyr Thr Gly Ala Ala Asp Ala Glu Arg Val
260 265 270
Ile Ile Ala Met Gly Ser Val Cys Asp Thr Val Gln Glu Val Val Asp
275 280 285
Thr Leu Asn Ala Ala Gly Glu Lys Val Gly Leu Leu Ser Val His Leu
290 295 300
Phe Arg Pro Phe Ser Leu Ala His Phe Phe Ala Gln Leu Pro Lys Thr
305 310 315 320
Val Gln Arg Ile Ala Val Leu Asp Arg Thr Lys Glu Pro Gly Ala Gln
325 330 335
Ala Glu Pro Leu Cys Leu Asp Val Lys Asn Ala Phe Tyr His His Asp
340 345 350
Asp Ala Pro Leu Ile Val Gly Gly Arg Tyr Ala Leu Gly Gly Lys Asp
355 360 365
Val Leu Pro Asn Asp Ile Ala Ala Val Phe Asp Asn Leu Asn Lys Pro
370 375 380
Leu Pro Met Asp Gly Phe Thr Leu Gly Ile Val Asp Asp Val Thr Phe
385 390 395 400
Thr Ser Leu Pro Pro Arg Gln Gln Thr Leu Ala Val Ser His Asp Gly
405 410 415
Ile Thr Ala Cys Lys Phe Trp Gly Met Gly Ser Asp Gly Thr Val Gly
420 425 430
Ala Asn Lys Ser Ala Ile Lys Ile Ile Gly Asp Lys Thr Pro Leu Tyr
435 440 445
Ala Gln Ala Tyr Phe Ser Tyr Asp Ser Lys Lys Ser Gly Gly Ile Thr
450 455 460
Val Ser His Leu Arg Phe Gly Asp Arg Pro Ile Asn Ser Pro Tyr Leu
465 470 475 480
Ile His Arg Ala Asp Phe Ile Ser Cys Ser Gln Gln Ser Tyr Val Glu
485 490 495
Arg Tyr Asp Leu Leu Asp Gly Leu Lys Pro Gly Gly Thr Phe Leu Leu
500 505 510
Asn Cys Ser Trp Ser Asp Ala Glu Leu Glu Gln His Leu Pro Val Gly
515 520 525
Phe Lys Arg Tyr Leu Ala Arg Glu Asn Ile His Phe Tyr Thr Leu Asn
530 535 540
Ala Val Asp Ile Ala Arg Glu Leu Gly Leu Gly Gly Arg Phe Asn Met
545 550 555 560
Leu Met Gln Ala Ala Phe Phe Lys Leu Ala Ala Ile Ile Asp Pro Gln
565 570 575
Thr Ala Ala Asp Tyr Leu Lys Gln Ala Val Glu Lys Ser Tyr Gly Ser
580 585 590
Lys Gly Ala Ala Val Ile Glu Met Asn Gln Arg Ala Ile Glu Leu Gly
595 600 605
Met Ala Ser Leu His Gln Val Thr Ile Pro Ala His Trp Ala Thr Leu
610 615 620
Asp Glu Pro Ala Ala Gln Ala Ser Ala Met Met Pro Asp Phe Ile Arg
625 630 635 640
Asp Ile Leu Gln Pro Met Asn Arg Gln Cys Gly Asp Gln Leu Pro Val
645 650 655
Ser Ala Phe Val Gly Met Glu Asp Gly Thr Phe Pro Ser Gly Thr Ala
660 665 670
Ala Trp Glu Lys Arg Gly Ile Ala Leu Glu Val Pro Val Trp Gln Pro
675 680 685
Glu Gly Cys Thr Gln Cys Asn Gln Cys Ala Phe Ile Cys Pro His Ala
690 695 700
Ala Ile Arg Pro Ala Leu Leu Asn Gly Glu Glu His Asp Ala Ala Pro
705 710 715 720
Val Gly Leu Leu Ser Lys Pro Ala Gln Gly Ala Lys Glu Tyr His Tyr
725 730 735
His Leu Ala Ile Ser Pro Leu Asp Cys Ser Gly Cys Gly Asn Cys Val
740 745 750
Asp Ile Cys Pro Ala Arg Gly Lys Ala Leu Lys Met Gln Ser Leu Asp
755 760 765
Ser Gln Arg Gln Met Ala Pro Val Trp Asp Tyr Ala Leu Ala Leu Thr
770 775 780
Pro Lys Ser Asn Pro Phe Arg Lys Thr Thr Val Lys Gly Ser Gln Phe
785 790 795 800
Glu Thr Pro Leu Leu Glu Phe Ser Gly Ala Cys Ala Gly Cys Gly Glu
805 810 815
Thr Pro Tyr Ala Arg Leu Ile Thr Gln Leu Phe Gly Asp Arg Met Leu
820 825 830
Ile Ala Asn Ala Thr Gly Cys Ser Ser Ile Trp Gly Ala Ser Ala Pro
835 840 845
Ser Ile Pro Tyr Thr Thr Asn His Arg Gly His Gly Pro Ala Trp Ala
850 855 860
Asn Ser Leu Phe Glu Asp Asn Ala Glu Phe Gly Leu Gly Met Met Leu
865 870 875 880
Gly Gly Gln Ala Val Arg Gln Gln Ile Ala Asp Asp Met Thr Ala Ala
885 890 895
Leu Ala Leu Pro Val Ser Asp Glu Leu Ser Asp Ala Met Arg Gln Trp
900 905 910
Leu Ala Lys Gln Asp Glu Gly Glu Gly Thr Arg Glu Arg Ala Asp Arg
915 920 925
Leu Ser Glu Arg Leu Ala Ala Glu Lys Glu Gly Val Pro Leu Leu Glu
930 935 940
Gln Leu Trp Gln Asn Arg Asp Tyr Phe Val Arg Arg Ser Gln Trp Ile
945 950 955 960
Phe Gly Gly Asp Gly Trp Ala Tyr Asp Ile Gly Phe Gly Gly Leu Asp
965 970 975
His Val Leu Ala Ser Gly Glu Asp Val Asn Ile Leu Val Phe Asp Thr
980 985 990
Glu Val Tyr Ser Asn Thr Gly Gly Gln Ser Ser Lys Ser Thr Pro Val
995 1000 1005
Ala Ala Ile Ala Lys Phe Ala Ala Gln Gly Lys Arg Thr Arg Lys
1010 1015 1020
Lys Asp Leu Gly Met Met Ala Met Ser Tyr Gly Asn Val Tyr Val
1025 1030 1035
Ala Gln Val Ala Met Gly Ala Asp Lys Asp Gln Thr Leu Arg Ala
1040 1045 1050
Ile Ala Glu Ala Glu Ala Trp Pro Gly Pro Ser Leu Val Ile Ala
1055 1060 1065
Tyr Ala Ala Cys Ile Asn His Gly Leu Lys Ala Gly Met Arg Cys
1070 1075 1080
Ser Gln Arg Glu Ala Lys Arg Ala Val Glu Ala Gly Tyr Trp His
1085 1090 1095
Leu Trp Arg Tyr His Pro Gln Arg Glu Ala Glu Gly Lys Thr Pro
1100 1105 1110
Phe Met Leu Asp Ser Glu Glu Pro Glu Glu Ser Phe Arg Asp Phe
1115 1120 1125
Leu Leu Gly Glu Val Arg Tyr Ala Ser Leu His Lys Thr Thr Pro
1130 1135 1140
His Leu Ala Asp Ala Leu Phe Ser Arg Thr Glu Glu Asp Ala Arg
1145 1150 1155
Ala Arg Phe Ala Gln Tyr Arg Arg Leu Ala Gly Glu Glu
1160 1165 1170
<210> 19
<211> 266
<212> Белок
<213> Klebsiella pneumoniae
<400> 19
Met Asn Pro Trp Gln Arg Phe Ala Arg Gln Arg Leu Ala Arg Ser Arg
1 5 10 15
Trp Asn Arg Asp Pro Ala Ala Leu Asp Pro Ala Asp Thr Pro Ala Phe
20 25 30
Glu Gln Ala Trp Gln Arg Gln Cys His Met Glu Gln Thr Ile Val Ala
35 40 45
Arg Val Pro Glu Gly Asp Ile Pro Ala Ala Leu Leu Glu Asn Ile Ala
50 55 60
Ala Ser Leu Ala Ile Trp Leu Asp Glu Gly Asp Phe Ala Pro Pro Glu
65 70 75 80
Arg Ala Ala Ile Val Arg His His Ala Arg Leu Glu Leu Ala Phe Ala
85 90 95
Asp Ile Ala Arg Gln Ala Pro Gln Pro Asp Leu Ser Thr Val Gln Ala
100 105 110
Trp Tyr Leu Arg His Gln Thr Gln Phe Met Arg Pro Glu Gln Arg Leu
115 120 125
Thr Arg His Leu Leu Leu Thr Val Asp Asn Asp Arg Glu Ala Val His
130 135 140
Gln Arg Ile Leu Gly Leu Tyr Arg Gln Ile Asn Ala Ser Arg Asp Ala
145 150 155 160
Phe Ala Pro Leu Ala Gln Arg His Ser His Cys Pro Ser Ala Leu Glu
165 170 175
Glu Gly Arg Leu Gly Trp Ile Ser Arg Gly Leu Leu Tyr Pro Gln Leu
180 185 190
Glu Thr Ala Leu Phe Ser Leu Ala Glu Asn Ala Leu Ser Leu Pro Ile
195 200 205
Ala Ser Glu Leu Gly Trp His Leu Leu Trp Cys Glu Ala Ile Arg Pro
210 215 220
Ala Ala Pro Met Glu Pro Gln Gln Ala Leu Glu Ser Ala Arg Asp Tyr
225 230 235 240
Leu Trp Gln Gln Ser Gln Gln Arg His Gln Arg Gln Trp Leu Glu Gln
245 250 255
Met Ile Ser Arg Gln Pro Gly Leu Cys Gly
260 265
<210> 20
<211> 381
<212> Белок
<213> Klebsiella pneumoniae
<400> 20
Met Glu Arg Val Leu Ile Asn Asp Thr Thr Leu Arg Asp Gly Glu Gln
1 5 10 15
Ser Pro Gly Val Ala Phe Arg Thr Ser Glu Lys Val Ala Ile Ala Glu
20 25 30
Ala Leu Tyr Ala Ala Gly Ile Thr Ala Met Glu Val Gly Thr Pro Ala
35 40 45
Met Gly Asp Glu Glu Ile Ala Arg Ile Gln Leu Val Arg Arg Gln Leu
50 55 60
Pro Asp Ala Thr Leu Met Thr Trp Cys Arg Met Asn Ala Leu Glu Ile
65 70 75 80
Arg Gln Ser Ala Asp Leu Gly Ile Asp Trp Val Asp Ile Ser Ile Pro
85 90 95
Ala Ser Asp Lys Leu Arg Gln Tyr Lys Leu Arg Glu Pro Leu Ala Val
100 105 110
Leu Leu Glu Arg Leu Ala Met Phe Ile His Leu Ala His Thr Leu Gly
115 120 125
Leu Lys Val Cys Ile Gly Cys Glu Asp Ala Ser Arg Ala Ser Gly Gln
130 135 140
Thr Leu Arg Ala Ile Ala Glu Val Ala Gln Asn Ala Pro Ala Ala Arg
145 150 155 160
Leu Arg Tyr Ala Asp Thr Val Gly Leu Leu Asp Pro Phe Thr Thr Ala
165 170 175
Ala Gln Ile Ser Ala Leu Arg Asp Val Trp Ser Gly Glu Ile Glu Met
180 185 190
His Ala His Asn Asp Leu Gly Met Ala Thr Ala Asn Thr Leu Ala Ala
195 200 205
Val Ser Ala Gly Ala Thr Ser Val Asn Thr Thr Val Leu Gly Leu Gly
210 215 220
Glu Arg Ala Gly Asn Ala Ala Ala Trp Lys Pro Ser Ala Leu Gly Leu
225 230 235 240
Glu Arg Cys Leu Gly Val Glu Thr Gly Val His Phe Ser Ala Leu Pro
245 250 255
Ala Leu Cys Gln Arg Val Ala Glu Ala Ala Gln Arg Ala Ile Asp Pro
260 265 270
Gln Gln Pro Leu Val Gly Glu Leu Val Phe Thr His Glu Ser Gly Val
275 280 285
His Val Ala Ala Leu Leu Arg Asp Ser Glu Ser Tyr Gln Ser Ile Ala
290 295 300
Pro Ser Leu Met Gly Arg Ser Tyr Arg Leu Val Leu Gly Lys His Ser
305 310 315 320
Gly Arg Gln Ala Val Asn Gly Val Phe Asp Gln Met Gly Tyr His Leu
325 330 335
Asn Ala Ala Gln Ile Asn Gln Leu Leu Pro Ala Ile Arg Arg Phe Ala
340 345 350
Glu Asn Trp Lys Arg Ser Pro Lys Asp Tyr Glu Leu Val Ala Ile Tyr
355 360 365
Asp Glu Leu Cys Gly Glu Ser Ala Leu Arg Ala Arg Gly
370 375 380
<210> 21
<211> 17
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевое удлинение
<400> 21
Ala Gly Gly Gly Gly Gly Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Pro
1 5 10 15
Gly
<210> 22
<211> 12
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевое удлинение
<400> 22
Ala Gly Asp Tyr Lys Asp Asp Asp Asp Lys Pro Gly
1 5 10
<210> 23
<211> 343
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 23
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro Gly
20 25 30
Ala Pro Thr Met Arg Gln Cys Ala Ile Tyr Gly Lys Gly Gly Ile Gly
35 40 45
Lys Ser Thr Thr Thr Gln Asn Leu Val Ala Ala Leu Ala Glu Met Gly
50 55 60
Lys Lys Val Met Ile Val Gly Cys Asp Pro Lys Ala Asp Ser Thr Arg
65 70 75 80
Leu Ile Leu His Ala Lys Ala Gln Asn Thr Ile Met Glu Met Ala Ala
85 90 95
Glu Val Gly Ser Val Glu Asp Leu Glu Leu Glu Asp Val Leu Gln Ile
100 105 110
Gly Tyr Gly Asp Val Arg Cys Ala Glu Ser Gly Gly Pro Glu Pro Gly
115 120 125
Val Gly Cys Ala Gly Arg Gly Val Ile Thr Ala Ile Asn Phe Leu Glu
130 135 140
Glu Glu Gly Ala Tyr Glu Asp Asp Leu Asp Phe Val Phe Tyr Asp Val
145 150 155 160
Leu Gly Asp Val Val Cys Gly Gly Phe Ala Met Pro Ile Arg Glu Asn
165 170 175
Lys Ala Gln Glu Ile Tyr Ile Val Cys Ser Gly Glu Met Met Ala Met
180 185 190
Tyr Ala Ala Asn Asn Ile Ser Lys Gly Ile Val Lys Tyr Ala Lys Ser
195 200 205
Gly Lys Val Arg Leu Gly Gly Leu Ile Cys Asn Ser Arg Gln Thr Asp
210 215 220
Arg Glu Asp Glu Leu Ile Ile Ala Leu Ala Glu Lys Leu Gly Thr Gln
225 230 235 240
Met Ile His Phe Val Pro Arg Asp Asn Ile Val Gln Arg Ala Glu Ile
245 250 255
Arg Arg Met Thr Val Ile Glu Tyr Asp Pro Ala Cys Lys Gln Ala Asn
260 265 270
Glu Tyr Arg Thr Leu Ala Gln Lys Ile Val Asn Asn Thr Met Lys Val
275 280 285
Val Pro Thr Pro Cys Thr Met Asp Glu Leu Glu Ser Leu Leu Met Glu
290 295 300
Phe Gly Ile Met Glu Glu Glu Asp Thr Ser Ile Ile Gly Lys Thr Ala
305 310 315 320
Ala Glu Glu Asn Ala Ala Ala Gly Gly Gly Gly Gly Tyr Pro Tyr Asp
325 330 335
Val Pro Asp Tyr Ala Pro Gly
340
<210> 24
<211> 527
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 24
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro Gly
20 25 30
Ala Pro Thr Asn Ala Thr Gly Glu Arg Asn Leu Ala Leu Ile Gln Glu
35 40 45
Val Leu Glu Val Phe Pro Glu Thr Ala Arg Lys Glu Arg Arg Lys His
50 55 60
Met Met Val Ser Asp Pro Lys Met Lys Ser Val Gly Lys Cys Ile Ile
65 70 75 80
Ser Asn Arg Lys Ser Gln Pro Gly Val Met Thr Val Arg Gly Cys Ala
85 90 95
Tyr Ala Gly Ser Lys Gly Val Val Phe Gly Pro Ile Lys Asp Met Ala
100 105 110
His Ile Ser His Gly Pro Ala Gly Cys Gly Gln Tyr Ser Arg Ala Glu
115 120 125
Arg Arg Asn Tyr Tyr Thr Gly Val Ser Gly Val Asp Ser Phe Gly Thr
130 135 140
Leu Asn Phe Thr Ser Asp Phe Gln Glu Arg Asp Ile Val Phe Gly Gly
145 150 155 160
Asp Lys Lys Leu Ser Lys Leu Ile Glu Glu Met Glu Leu Leu Phe Pro
165 170 175
Leu Thr Lys Gly Ile Thr Ile Gln Ser Glu Cys Pro Val Gly Leu Ile
180 185 190
Gly Asp Asp Ile Ser Ala Val Ala Asn Ala Ser Ser Lys Ala Leu Asp
195 200 205
Lys Pro Val Ile Pro Val Arg Cys Glu Gly Phe Arg Gly Val Ser Gln
210 215 220
Ser Leu Gly His His Ile Ala Asn Asp Val Val Arg Asp Trp Ile Leu
225 230 235 240
Asn Asn Arg Glu Gly Gln Pro Phe Glu Thr Thr Pro Tyr Asp Val Ala
245 250 255
Ile Ile Gly Asp Tyr Asn Ile Gly Gly Asp Ala Trp Ala Ser Arg Ile
260 265 270
Leu Leu Glu Glu Met Gly Leu Arg Val Val Ala Gln Trp Ser Gly Asp
275 280 285
Gly Thr Leu Val Glu Met Glu Asn Thr Pro Phe Val Lys Leu Asn Leu
290 295 300
Val His Cys Tyr Arg Ser Met Asn Tyr Ile Ala Arg His Met Glu Glu
305 310 315 320
Lys His Gln Ile Pro Trp Met Glu Tyr Asn Phe Phe Gly Pro Thr Lys
325 330 335
Ile Ala Glu Ser Leu Arg Lys Ile Ala Asp Gln Phe Asp Asp Thr Ile
340 345 350
Arg Ala Asn Ala Glu Ala Val Ile Ala Arg Tyr Glu Gly Gln Met Ala
355 360 365
Ala Ile Ile Ala Lys Tyr Arg Pro Arg Leu Glu Gly Arg Lys Val Leu
370 375 380
Leu Tyr Ile Gly Gly Leu Arg Pro Arg His Val Ile Gly Ala Tyr Glu
385 390 395 400
Asp Leu Gly Met Glu Ile Ile Ala Ala Gly Tyr Glu Phe Ala His Asn
405 410 415
Asp Asp Tyr Asp Arg Thr Leu Pro Asp Leu Lys Glu Gly Thr Leu Leu
420 425 430
Phe Asp Asp Ala Ser Ser Tyr Glu Leu Glu Ala Phe Val Lys Ala Leu
435 440 445
Lys Pro Asp Leu Ile Gly Ser Gly Ile Lys Glu Lys Tyr Ile Phe Gln
450 455 460
Lys Met Gly Val Pro Phe Arg Gln Met His Ser Trp Asp Tyr Ser Gly
465 470 475 480
Pro Tyr His Gly Tyr Asp Gly Phe Ala Ile Phe Ala Arg Asp Met Asp
485 490 495
Met Thr Leu Asn Asn Pro Ala Trp Asn Glu Leu Thr Ala Pro Trp Leu
500 505 510
Lys Ser Ala Ala Gly Asp Tyr Lys Asp Asp Asp Asp Lys Pro Gly
515 520 525
<210> 25
<211> 570
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 25
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro Gly
20 25 30
Ala Pro Ser Gln Thr Ile Asp Lys Ile Asn Ser Cys Tyr Pro Leu Phe
35 40 45
Glu Gln Asp Glu Tyr Gln Glu Leu Phe Arg Asn Lys Arg Gln Leu Glu
50 55 60
Glu Ala His Asp Ala Gln Arg Val Gln Glu Val Phe Ala Trp Thr Thr
65 70 75 80
Thr Ala Glu Tyr Glu Ala Leu Asn Phe Arg Arg Glu Ala Leu Thr Val
85 90 95
Asp Pro Ala Lys Ala Cys Gln Pro Leu Gly Ala Val Leu Cys Ser Leu
100 105 110
Gly Phe Ala Asn Thr Leu Pro Tyr Val His Gly Ser Gln Gly Cys Val
115 120 125
Ala Tyr Phe Arg Thr Tyr Phe Asn Arg His Phe Lys Glu Pro Ile Ala
130 135 140
Cys Val Ser Asp Ser Met Thr Glu Asp Ala Ala Val Phe Gly Gly Asn
145 150 155 160
Asn Asn Met Asn Leu Gly Leu Gln Asn Ala Ser Ala Leu Tyr Lys Pro
165 170 175
Glu Ile Ile Ala Val Ser Thr Thr Cys Met Ala Glu Val Ile Gly Asp
180 185 190
Asp Leu Gln Ala Phe Ile Ala Asn Ala Lys Lys Asp Gly Phe Val Asp
195 200 205
Ser Ser Ile Ala Val Pro His Ala His Thr Pro Ser Phe Ile Gly Ser
210 215 220
His Val Thr Gly Trp Asp Asn Met Phe Glu Gly Phe Ala Lys Thr Phe
225 230 235 240
Thr Ala Asp Tyr Gln Gly Gln Pro Gly Lys Leu Pro Lys Leu Asn Leu
245 250 255
Val Thr Gly Phe Glu Thr Tyr Leu Gly Asn Phe Arg Val Leu Lys Arg
260 265 270
Met Met Glu Gln Met Ala Val Pro Cys Ser Leu Leu Ser Asp Pro Ser
275 280 285
Glu Val Leu Asp Thr Pro Ala Asp Gly His Tyr Arg Met Tyr Ser Gly
290 295 300
Gly Thr Thr Gln Gln Glu Met Lys Glu Ala Pro Asp Ala Ile Asp Thr
305 310 315 320
Leu Leu Leu Gln Pro Trp Gln Leu Leu Lys Ser Lys Lys Val Val Gln
325 330 335
Glu Met Trp Asn Gln Pro Ala Thr Glu Val Ala Ile Pro Leu Gly Leu
340 345 350
Ala Ala Thr Asp Glu Leu Leu Met Thr Val Ser Gln Leu Ser Gly Lys
355 360 365
Pro Ile Ala Asp Ala Leu Thr Leu Glu Arg Gly Arg Leu Val Asp Met
370 375 380
Met Leu Asp Ser His Thr Trp Leu His Gly Lys Lys Phe Gly Leu Tyr
385 390 395 400
Gly Asp Pro Asp Phe Val Met Gly Leu Thr Arg Phe Leu Leu Glu Leu
405 410 415
Gly Cys Glu Pro Thr Val Ile Leu Ser His Asn Ala Asn Lys Arg Trp
420 425 430
Gln Lys Ala Met Asn Lys Met Leu Asp Ala Ser Pro Tyr Gly Arg Asp
435 440 445
Ser Glu Val Phe Ile Asn Cys Asp Leu Trp His Phe Arg Ser Leu Met
450 455 460
Phe Thr Arg Gln Pro Asp Phe Met Ile Gly Asn Ser Tyr Gly Lys Phe
465 470 475 480
Ile Gln Arg Asp Thr Leu Ala Lys Gly Lys Ala Phe Glu Val Pro Leu
485 490 495
Ile Arg Leu Gly Phe Pro Leu Phe Asp Arg His His Leu His Arg Gln
500 505 510
Thr Thr Trp Gly Tyr Glu Gly Ala Met Asn Ile Val Thr Thr Leu Val
515 520 525
Asn Ala Val Leu Glu Lys Leu Asp Ser Asp Thr Ser Gln Leu Gly Lys
530 535 540
Thr Asp Tyr Ser Phe Asp Leu Val Arg Ala Gly Gly Gly Gly Gly Tyr
545 550 555 560
Pro Tyr Asp Val Pro Asp Tyr Ala Pro Gly
565 570
<210> 26
<211> 270
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 26
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro Gly
20 25 30
Ala Pro Ser Asp Asn Asp Thr Leu Phe Trp Arg Met Leu Ala Leu Phe
35 40 45
Gln Ser Leu Pro Asp Leu Gln Pro Ala Gln Ile Val Asp Trp Leu Ala
50 55 60
Gln Glu Ser Gly Glu Thr Leu Thr Pro Glu Arg Leu Ala Thr Leu Thr
65 70 75 80
Gln Pro Gln Leu Ala Ala Ser Phe Pro Ser Ala Thr Ala Val Met Ser
85 90 95
Pro Ala Arg Trp Ser Arg Val Met Ala Ser Leu Gln Gly Ala Leu Pro
100 105 110
Ala His Leu Arg Ile Val Arg Pro Ala Gln Arg Thr Pro Gln Leu Leu
115 120 125
Ala Ala Phe Cys Ser Gln Asp Gly Leu Val Ile Asn Gly His Phe Gly
130 135 140
Gln Gly Arg Leu Phe Phe Ile Tyr Ala Phe Asp Glu Gln Gly Gly Trp
145 150 155 160
Leu Tyr Asp Leu Arg Arg Tyr Pro Ser Ala Pro His Gln Gln Glu Ala
165 170 175
Asn Glu Val Arg Ala Arg Leu Ile Glu Asp Cys Gln Leu Leu Phe Cys
180 185 190
Gln Glu Ile Gly Gly Pro Ala Ala Ala Arg Pro Ile Arg His Arg Ile
195 200 205
His Pro Met Lys Ala Gln Pro Gly Thr Thr Ile Gln Ala Gln Cys Glu
210 215 220
Ala Ile Asn Thr Leu Leu Ala Gly Arg Leu Pro Pro Trp Leu Ala Lys
225 230 235 240
Arg Leu Asn Arg Asp Asn Pro Leu Glu Glu Arg Val Phe Ala Gly Gly
245 250 255
Gly Gly Gly Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Pro Gly
260 265 270
<210> 27
<211> 950
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Фрагмент AscI
<400> 27
ggcgcgccaa ctatgagaca atgtgctatc tatggaaagg gtggaatcgg aaagtctact 60
actactcaga accttgttgc tgctcttgct gagatgggaa agaaagttat gatcgttgga 120
tgcgatccta aggctgattc tactagactt atcctccatg ctaaggctca gaacaccatt 180
atggaaatgg ctgctgaggt tggatctgtt gaagatcttg agcttgagga tgttctccaa 240
atcggatacg gtgatgttag atgtgctgaa tctggtggac ctgaacctgg tgttggatgt 300
gctggaagag gtgttattac cgctatcaac ttccttgaag aagagggagc ttacgaggat 360
gatctcgatt tcgttttcta cgatgtgctc ggagatgttg tttgtggtgg atttgctatg 420
cctatcagag agaacaaggc tcaagagatc tacatcgttt gctctggtga gatgatggct 480
atgtatgctg ctaacaacat ctctaaggga atcgtgaagt acgctaagtc tggaaaggtt 540
agacttggag gactcatctg taactctaga cagactgata gagaggatga gcttattatc 600
gctttggctg agaagttggg aactcagatg atccatttcg tgccaagaga taacatcgtt 660
cagagagctg agatcagaag gatgactgtt atcgaatacg atcctgcttg caaacaagct 720
aacgagtata gaactctcgc tcagaagatc gttaacaaca ctatgaaggt ggtgcctact 780
ccttgtacta tggatgaact tgagtctctc ctcatggaat ttggaatcat ggaagaagag 840
gatacctcta tcatcggaaa gactgctgct gaagaaaacg ctgctgccgg cggtggaggt 900
ggataccctt acgacgttcc tgattacgct cccgggtgat gaggcgcgcc 950
<210> 28
<211> 1502
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Фрагмент AscI
<400> 28
ggcgcgccaa ctaatgctac tggtgaaaga aacctcgctc tcatccaaga ggttttggaa 60
gtttttcctg agactgctag gaaagaaagg cgtaagcaca tgatggtgtc tgatcctaag 120
atgaagtctg tgggaaagtg catcatctct aacagaaagt ctcagcctgg tgtgatgact 180
gttagaggat gtgcttatgc tggatctaag ggtgttgttt tcggacctat caaggatatg 240
gctcatatct ctcatggacc tgctggatgt ggacaatatt ctagagctga gcgtaggaac 300
tactacactg gtgtttctgg tgtggattct ttcggaactc tcaacttcac ctctgatttc 360
caagagcgtg atatcgtttt cggaggtgat aagaagctct ctaagttgat cgaagagatg 420
gaactcttgt tcccactcac taagggaatc actatccaat ctgagtgccc tgttggactt 480
atcggagatg atatttctgc tgtggctaac gcttcttcta aggctcttga taagcctgtt 540
atccctgtta gatgtgaagg attcagggga gtttctcagt ctcttggaca tcatatcgct 600
aacgatgtgg tgagagattg gatccttaac aacagagagg gacaaccttt cgagactact 660
ccttacgatg ttgctatcat cggagactac aacattggag gtgatgcttg ggcttctaga 720
atccttcttg aagagatggg actcagagtt gttgctcaat ggtctggtga tggtactctt 780
gttgagatgg aaaacacccc tttcgttaag ctcaacctcg ttcattgcta ccgtagcatg 840
aactacattg ctagacacat ggaagagaag caccaaattc cttggatgga gtacaacttc 900
ttcggaccta ctaagatcgc tgagtctctt agaaagatcg ctgatcagtt cgatgatacc 960
atcagagcta atgctgaggc tgttattgct agatacgagg gacaaatggc tgctattatc 1020
gctaagtaca gacctagact cgagggaaga aaggttttgc tttacatcgg aggactcaga 1080
cctagacatg ttattggagc ttacgaggat ctcggaatgg aaattattgc tgctggatac 1140
gagttcgctc acaacgatga ttacgataga actctccctg acctcaaaga gggaactctt 1200
cttttcgatg acgcttcttc atacgagctt gaggcttttg ttaaggctct taagcctgat 1260
ctcatcggat ctggaatcaa agagaagtac atcttccaga agatgggagt tcctttcaga 1320
cagatgcact cttgggatta ttctggacct taccatggat acgacggatt tgctatcttc 1380
gctagggata tggatatgac tctcaacaat cctgcttgga acgaacttac tgctccttgg 1440
cttaagtctg ctgccggcga ctacaaagac gatgatgaca aacccgggtg atgaggcgcg 1500
cc 1502
<210> 29
<211> 1631
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Фрагмент AscI
<400> 29
ggcgcgccat ctcaaactat tgataagatc aacagctgct acccactctt tgagcaagat 60
gaataccaag agcttttccg taacaagaga cagcttgaag aggctcatga tgctcagaga 120
gttcaagaag ttttcgcttg gactactact gctgaatacg aggctctcaa ctttagaaga 180
gaggctctta ctgttgaccc tgctaaggct tgtcaacctc ttggagctgt tctttgttct 240
cttggattcg ctaacaccct tccttatgtt catggatctc agggatgtgt ggcttacttc 300
agaacctact tcaacaggca cttcaaagaa cctatcgctt gcgttagcga ttctatgact 360
gaagatgctg ctgttttcgg aggtaacaac aacatgaacc ttggacttca gaacgcttct 420
gctctttaca agcctgagat tatcgctgtg tctactactt gcatggctga agttatcgga 480
gatgatctcc aggctttcat tgctaacgct aagaaggatg gattcgtcga ttcttctatc 540
gctgttcctc atgctcacac tccatctttc atcggatctc atgttaccgg atgggataat 600
atgttcgagg gattcgctaa gaccttcact gctgattatc aaggacagcc tggaaagttg 660
cctaagttga atctcgttac cggattcgag acttacctcg gaaacttcag agtgctcaag 720
agaatgatgg aacagatggc tgtgccttgc tctcttcttt ctgatccttc tgaagtgctc 780
gatactcctg ctgatggaca ttataggatg tactctggtg gaactaccca gcaagaaatg 840
aaggaagctc ctgacgctat cgatactctt cttcttcaac cttggcaact cctcaagtct 900
aagaaagttg tgcaagagat gtggaaccag cctgctactg aagttgctat tcctcttgga 960
cttgctgcta ctgatgagct tctcatgact gtttctcagc tttctggaaa gcctatcgct 1020
gatgctctta ctcttgagag aggtagactc gttgatatga tgctcgattc tcatacttgg 1080
ctccacggaa agaagtttgg actttacgga gatcctgact tcgttatggg acttactaga 1140
ttcttgctcg agcttggatg tgagcctact gttatccttt ctcacaacgc taacaagagg 1200
tggcaaaagg ctatgaacaa gatgcttgat gcttctccat acggaaggga ttctgaggtt 1260
ttcatcaact gcgatctctg gcatttccgt tctctcatgt tcactagaca gcctgatttc 1320
atgatcggaa acagctacgg aaagttcatc cagagagata ctctcgctaa gggaaaggct 1380
ttcgaagttc ctcttatcag acttggattc ccactcttcg atagacatca tctccacaga 1440
caaactactt ggggatatga aggtgctatg aacatcgtta ctaccctcgt taacgctgtt 1500
cttgagaagt tggattctga tacttctcag ctcggaaaga ccgattactc tttcgatctc 1560
gtgagagccg gcggtggagg tggataccct tacgacgttc ctgattacgc tcccgggtga 1620
tgaggcgcgc c 1631
<210> 30
<211> 731
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Фрагмент AscI
<400> 30
ggcgcgccat ctgataatga tacacttttt tggaggatgc tcgctctttt ccagtctctt 60
cctgatcttc aacctgctca aatcgttgat tggcttgctc aagaatctgg tgagactctt 120
actcctgaga gacttgctac tcttactcaa cctcaactcg ctgcttcttt tccttctgct 180
actgctgtta tgtctcctgc tagatggtct agagttatgg cttctcttca gggtgctctc 240
ccagctcatc ttagaatcgt tagacctgct caaagaactc ctcaacttct tgctgctttc 300
tgttctcagg atggacttgt tatcaacgga catttcggac agggtagact ctttttcatc 360
tacgcttttg atgagcaggg aggatggctt tacgatctta gaagatatcc ttctgctcct 420
catcagcaag aggctaatga agttagagct agacttatcg aggattgcca gcttttgttc 480
tgtcaagaaa ttggaggacc tgctgctgct agacctatta gacatagaat ccaccctatg 540
aaggctcaac ctggaactac tatccaagct caatgtgagg ctatcaacac tcttcttgct 600
ggtagacttc ctccttggct tgctaaaaga ctcaacagag ataacccgct cgaagagagg 660
gttttcgccg gcggtggagg tggataccct tacgacgttc ctgattacgc tcccgggtga 720
tgaggcgcgc c 731
<210> 31
<211> 518
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 31
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro Gly
20 25 30
Ala Pro Thr Ser Cys Ser Ser Phe Ser Gly Gly Lys Ala Cys Arg Pro
35 40 45
Ala Asp Asp Ser Ala Leu Thr Pro Leu Val Ala Asp Lys Ala Ala Ala
50 55 60
His Pro Cys Tyr Ser Arg His Gly His His Arg Phe Ala Arg Met His
65 70 75 80
Leu Pro Val Ala Pro Ala Cys Asn Leu Gln Cys Asn Tyr Cys Asn Arg
85 90 95
Lys Phe Asp Cys Ser Asn Glu Ser Arg Pro Gly Val Ser Ser Thr Leu
100 105 110
Leu Thr Pro Glu Gln Ala Val Val Lys Val Arg Gln Val Ala Gln Ala
115 120 125
Ile Pro Gln Leu Ser Val Val Gly Ile Ala Gly Pro Gly Asp Pro Leu
130 135 140
Ala Asn Ile Ala Arg Thr Phe Arg Thr Leu Glu Leu Ile Arg Glu Gln
145 150 155 160
Leu Pro Asp Leu Lys Leu Cys Leu Ser Thr Asn Gly Leu Val Leu Pro
165 170 175
Asp Ala Val Asp Arg Leu Leu Asp Val Gly Val Asp His Val Thr Val
180 185 190
Thr Ile Asn Thr Leu Asp Ala Glu Ile Ala Ala Gln Ile Tyr Ala Trp
195 200 205
Leu Trp Leu Asp Gly Glu Arg Tyr Ser Gly Arg Glu Ala Gly Glu Ile
210 215 220
Leu Ile Ala Arg Gln Leu Glu Gly Val Arg Arg Leu Thr Ala Lys Gly
225 230 235 240
Val Leu Val Lys Ile Asn Ser Val Leu Ile Pro Gly Ile Asn Asp Ser
245 250 255
Gly Met Ala Gly Val Ser Arg Ala Leu Arg Ala Ser Gly Ala Phe Ile
260 265 270
His Asn Ile Met Pro Leu Ile Ala Arg Pro Glu His Gly Thr Val Phe
275 280 285
Gly Leu Asn Gly Gln Pro Glu Pro Asp Ala Glu Thr Leu Ala Ala Thr
290 295 300
Arg Ser Arg Cys Gly Glu Val Met Pro Gln Met Thr His Cys His Gln
305 310 315 320
Cys Arg Ala Asp Ala Ile Gly Met Leu Gly Glu Asp Arg Ser Gln Gln
325 330 335
Phe Thr Gln Leu Pro Ala Pro Glu Ser Leu Pro Ala Trp Leu Pro Ile
340 345 350
Leu His Gln Arg Ala Gln Leu His Ala Ser Ile Ala Thr Arg Gly Glu
355 360 365
Ser Glu Ala Asp Asp Ala Cys Leu Val Ala Val Ala Ser Ser Arg Gly
370 375 380
Asp Val Ile Asp Cys His Phe Gly His Ala Asp Arg Phe Tyr Ile Tyr
385 390 395 400
Ser Leu Ser Ala Ala Gly Met Val Leu Val Asn Glu Arg Phe Thr Pro
405 410 415
Lys Tyr Cys Gln Gly Arg Asp Asp Cys Glu Pro Gln Asp Asn Ala Ala
420 425 430
Arg Phe Ala Ala Ile Leu Glu Leu Leu Ala Asp Val Lys Ala Val Phe
435 440 445
Cys Val Arg Ile Gly His Thr Pro Trp Gln Gln Leu Glu Gln Glu Gly
450 455 460
Ile Glu Pro Cys Val Asp Gly Ala Trp Arg Pro Val Ser Glu Val Leu
465 470 475 480
Pro Ala Trp Trp Gln Gln Arg Arg Gly Ser Trp Pro Ala Ala Leu Pro
485 490 495
His Lys Gly Val Ala Ala Gly Gly Gly Gly Gly Tyr Pro Tyr Asp Val
500 505 510
Pro Asp Tyr Ala Pro Gly
515
<210> 32
<211> 507
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 32
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro Gly
20 25 30
Ala Pro Lys Gly Asn Glu Ile Leu Ala Leu Leu Asp Glu Pro Ala Cys
35 40 45
Glu His Asn His Lys Gln Lys Ser Gly Cys Ser Ala Pro Lys Pro Gly
50 55 60
Ala Thr Ala Ala Gly Cys Ala Phe Asp Gly Ala Gln Ile Thr Leu Leu
65 70 75 80
Pro Ile Ala Asp Val Ala His Leu Val His Gly Pro Ile Gly Cys Ala
85 90 95
Gly Ser Ser Trp Asp Asn Arg Gly Ser Ala Ser Ser Gly Pro Thr Leu
100 105 110
Asn Arg Leu Gly Phe Thr Thr Asp Leu Asn Glu Gln Asp Val Ile Met
115 120 125
Gly Arg Gly Glu Arg Arg Leu Phe His Ala Val Arg His Ile Val Thr
130 135 140
Arg Tyr His Pro Ala Ala Val Phe Ile Tyr Asn Thr Cys Val Pro Ala
145 150 155 160
Met Glu Gly Asp Asp Leu Glu Ala Val Cys Gln Ala Ala Gln Thr Ala
165 170 175
Thr Gly Val Pro Val Ile Ala Ile Asp Ala Ala Gly Phe Tyr Gly Ser
180 185 190
Lys Asn Leu Gly Asn Arg Pro Ala Gly Asp Val Met Val Lys Arg Val
195 200 205
Ile Gly Gln Arg Glu Pro Ala Pro Trp Pro Glu Ser Thr Leu Phe Ala
210 215 220
Pro Glu Gln Arg His Asp Ile Gly Leu Ile Gly Glu Phe Asn Ile Ala
225 230 235 240
Gly Glu Phe Trp His Ile Gln Pro Leu Leu Asp Glu Leu Gly Ile Arg
245 250 255
Val Leu Gly Ser Leu Ser Gly Asp Gly Arg Phe Ala Glu Ile Gln Thr
260 265 270
Met His Arg Ala Gln Ala Asn Met Leu Val Cys Ser Arg Ala Leu Ile
275 280 285
Asn Val Ala Arg Ala Leu Glu Gln Arg Tyr Gly Thr Pro Trp Phe Glu
290 295 300
Gly Ser Phe Tyr Gly Ile Arg Ala Thr Ser Asp Ala Leu Arg Gln Leu
305 310 315 320
Ala Ala Leu Leu Gly Asp Asp Asp Leu Arg Gln Arg Thr Glu Ala Leu
325 330 335
Ile Ala Arg Glu Glu Gln Ala Ala Glu Leu Ala Leu Gln Pro Trp Arg
340 345 350
Glu Gln Leu Arg Gly Arg Lys Ala Leu Leu Tyr Thr Gly Gly Val Lys
355 360 365
Ser Trp Ser Val Val Ser Ala Leu Gln Asp Leu Gly Met Thr Val Val
370 375 380
Ala Thr Gly Thr Arg Lys Ser Thr Glu Glu Asp Lys Gln Arg Ile Arg
385 390 395 400
Glu Leu Met Gly Glu Glu Ala Val Met Leu Glu Glu Gly Asn Ala Arg
405 410 415
Thr Leu Leu Asp Val Val Tyr Arg Tyr Gln Ala Asp Leu Met Ile Ala
420 425 430
Gly Gly Arg Asn Met Tyr Thr Ala Tyr Lys Ala Arg Leu Pro Phe Leu
435 440 445
Asp Ile Asn Gln Glu Arg Glu His Ala Phe Ala Gly Tyr Gln Gly Ile
450 455 460
Val Thr Leu Ala Arg Gln Leu Cys Gln Thr Ile Asn Ser Pro Ile Trp
465 470 475 480
Pro Gln Thr His Ser Arg Ala Pro Trp Arg Ala Gly Gly Gly Gly Gly
485 490 495
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Pro Gly
500 505
<210> 33
<211> 505
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 33
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro Gly
20 25 30
Ala Pro Ala Asp Ile Phe Arg Thr Asp Lys Pro Leu Ala Val Ser Pro
35 40 45
Ile Lys Thr Gly Gln Pro Leu Gly Ala Ile Leu Ala Ser Leu Gly Ile
50 55 60
Glu His Ser Ile Pro Leu Val His Gly Ala Gln Gly Cys Ser Ala Phe
65 70 75 80
Ala Lys Val Phe Phe Ile Gln His Phe His Asp Pro Val Pro Leu Gln
85 90 95
Ser Thr Ala Met Asp Pro Thr Ser Thr Ile Met Gly Ala Asp Gly Asn
100 105 110
Ile Phe Thr Ala Leu Asp Thr Leu Cys Gln Arg Asn Asn Pro Gln Ala
115 120 125
Ile Val Leu Leu Ser Thr Gly Leu Ser Glu Ala Gln Gly Ser Asp Ile
130 135 140
Ser Arg Val Val Arg Gln Phe Arg Glu Glu Tyr Pro Arg His Lys Gly
145 150 155 160
Val Ala Ile Leu Thr Val Asn Thr Pro Asp Phe Tyr Gly Ser Met Glu
165 170 175
Asn Gly Phe Ser Ala Val Leu Glu Ser Val Ile Glu Gln Trp Val Pro
180 185 190
Pro Ala Pro Arg Pro Ala Gln Arg Asn Arg Arg Val Asn Leu Leu Val
195 200 205
Ser His Leu Cys Ser Pro Gly Asp Ile Glu Trp Leu Arg Arg Cys Val
210 215 220
Glu Ala Phe Gly Leu Gln Pro Ile Ile Leu Pro Asp Leu Ala Gln Ser
225 230 235 240
Met Asp Gly His Leu Ala Gln Gly Asp Phe Ser Pro Leu Thr Gln Gly
245 250 255
Gly Thr Pro Leu Arg Gln Ile Glu Gln Met Gly Gln Ser Leu Cys Ser
260 265 270
Phe Ala Ile Gly Val Ser Leu His Arg Ala Ser Ser Leu Leu Ala Pro
275 280 285
Arg Cys Arg Gly Glu Val Ile Ala Leu Pro His Leu Met Thr Leu Glu
290 295 300
Arg Cys Asp Ala Phe Ile His Gln Leu Ala Lys Ile Ser Gly Arg Ala
305 310 315 320
Val Pro Glu Trp Leu Glu Arg Gln Arg Gly Gln Leu Gln Asp Ala Met
325 330 335
Ile Asp Cys His Met Trp Leu Gln Gly Gln Arg Met Ala Ile Ala Ala
340 345 350
Glu Gly Asp Leu Leu Ala Ala Trp Cys Asp Phe Ala Asn Ser Gln Gly
355 360 365
Met Gln Pro Gly Pro Leu Val Ala Pro Thr Gly His Pro Ser Leu Arg
370 375 380
Gln Leu Pro Val Glu Arg Val Val Pro Gly Asp Leu Glu Asp Leu Gln
385 390 395 400
Thr Leu Leu Cys Ala His Pro Ala Asp Leu Leu Val Ala Asn Ser His
405 410 415
Ala Arg Asp Leu Ala Glu Gln Phe Ala Leu Pro Leu Val Arg Ala Gly
420 425 430
Phe Pro Leu Phe Asp Lys Leu Gly Glu Phe Arg Arg Val Arg Gln Gly
435 440 445
Tyr Ser Gly Met Arg Asp Thr Leu Phe Glu Leu Ala Asn Leu Ile Arg
450 455 460
Glu Arg His His His Leu Ala His Tyr Arg Ser Pro Leu Arg Gln Asn
465 470 475 480
Pro Glu Ser Ser Leu Ser Thr Gly Gly Ala Tyr Ala Ala Ala Gly Asp
485 490 495
Tyr Lys Asp Asp Asp Asp Lys Pro Gly
500 505
<210> 34
<211> 217
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 34
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro Gly
20 25 30
Ala Pro Pro Pro Leu Asp Trp Leu Arg Arg Leu Trp Leu Leu Tyr His
35 40 45
Ala Gly Lys Gly Ser Phe Pro Leu Arg Met Gly Leu Ser Pro Arg Asp
50 55 60
Trp Gln Ala Leu Arg Arg Arg Leu Gly Glu Val Glu Thr Pro Leu Asp
65 70 75 80
Gly Glu Thr Leu Thr Arg Arg Arg Leu Met Ala Glu Leu Asn Ala Thr
85 90 95
Arg Glu Glu Glu Arg Gln Gln Leu Gly Ala Trp Leu Ala Gly Trp Met
100 105 110
Gln Gln Asp Ala Gly Pro Met Ala Gln Ile Ile Ala Glu Val Ser Leu
115 120 125
Ala Phe Asn His Leu Trp Gln Asp Leu Gly Leu Ala Ser Arg Ala Glu
130 135 140
Leu Arg Leu Leu Met Ser Asp Cys Phe Pro Gln Leu Val Val Met Asn
145 150 155 160
Glu His Asn Met Arg Trp Lys Lys Phe Phe Tyr Arg Gln Arg Cys Leu
165 170 175
Leu Gln Gln Gly Glu Val Ile Cys Arg Ser Pro Ser Cys Asp Glu Cys
180 185 190
Trp Glu Arg Ser Ala Cys Phe Glu Ala Gly Gly Gly Gly Gly Tyr Pro
195 200 205
Tyr Asp Val Pro Asp Tyr Ala Pro Gly
210 215
<210> 35
<211> 450
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 35
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro Gly
20 25 30
Ala Pro Lys Gln Val Tyr Leu Asp Asn Asn Ala Thr Thr Arg Leu Asp
35 40 45
Pro Met Val Leu Glu Ala Met Met Pro Phe Leu Thr Asp Phe Tyr Gly
50 55 60
Asn Pro Ser Ser Ile His Asp Phe Gly Ile Pro Ala Gln Ala Ala Leu
65 70 75 80
Glu Arg Ala His Gln Gln Ala Ala Ala Leu Leu Gly Ala Glu Tyr Pro
85 90 95
Ser Glu Ile Ile Phe Thr Ser Cys Ala Thr Glu Ala Thr Ala Thr Ala
100 105 110
Ile Ala Ser Ala Ile Ala Leu Leu Pro Glu Arg Arg Glu Ile Ile Thr
115 120 125
Ser Val Val Glu His Pro Ala Thr Leu Ala Ala Cys Glu His Met Glu
130 135 140
Arg Glu Gly Tyr Arg Ile His Arg Ile Ala Val Asp Gly Glu Gly Ala
145 150 155 160
Leu Asp Met Ala Gln Phe Arg Ala Ala Leu Ser Pro Arg Val Ala Leu
165 170 175
Val Ser Val Met Trp Ala Asn Asn Glu Thr Gly Val Leu Phe Pro Ile
180 185 190
Gly Glu Met Ala Glu Leu Ala His Glu Gln Gly Ala Leu Phe His Cys
195 200 205
Asp Ala Val Gln Val Val Gly Lys Ile Pro Ile Ala Val Gly Gln Thr
210 215 220
Arg Ile Asp Met Leu Ser Cys Ser Ala His Lys Phe His Gly Pro Lys
225 230 235 240
Gly Val Gly Cys Leu Tyr Leu Arg Arg Gly Thr Arg Phe Arg Pro Leu
245 250 255
Leu Arg Gly Gly His Gln Glu Tyr Gly Arg Arg Ala Gly Thr Glu Asn
260 265 270
Ile Cys Gly Ile Val Gly Met Gly Ala Ala Cys Glu Leu Ala Asn Ile
275 280 285
His Leu Pro Gly Met Thr His Ile Gly Gln Leu Arg Asn Arg Leu Glu
290 295 300
His Arg Leu Leu Ala Ser Val Pro Ser Val Met Val Met Gly Gly Gly
305 310 315 320
Gln Pro Ala Val Pro Gly Thr Val Asn Leu Ala Phe Glu Phe Ile Glu
325 330 335
Gly Glu Ala Ile Leu Leu Leu Leu Asn Gln Ala Gly Ile Ala Ala Ser
340 345 350
Ser Gly Ser Ala Cys Thr Ser Gly Ser Leu Glu Pro Ser His Val Met
355 360 365
Arg Ala Met Asn Ile Pro Tyr Thr Ala Ala His Gly Thr Ile Arg Phe
370 375 380
Ser Leu Ser Arg Tyr Thr Arg Glu Lys Glu Ile Asp Tyr Val Val Ala
385 390 395 400
Thr Leu Pro Pro Ile Ile Asp Arg Leu Arg Ala Leu Ser Pro Tyr Trp
405 410 415
Gln Asn Gly Lys Pro Arg Pro Ala Asp Ala Val Phe Thr Pro Val Tyr
420 425 430
Gly Ala Gly Gly Gly Gly Gly Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
435 440 445
Pro Gly
450
<210> 36
<211> 319
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 36
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro Gly
20 25 30
Ala Pro Trp Asn Tyr Ser Glu Lys Val Lys Asp His Phe Phe Asn Pro
35 40 45
Arg Asn Ala Arg Val Val Asp Asn Ala Asn Ala Val Gly Asp Val Gly
50 55 60
Ser Leu Ser Cys Gly Asp Ala Leu Arg Leu Met Leu Arg Val Asp Pro
65 70 75 80
Gln Ser Glu Ile Ile Glu Glu Ala Gly Phe Gln Thr Phe Gly Cys Gly
85 90 95
Ser Ala Ile Ala Ser Ser Ser Ala Leu Thr Glu Leu Ile Ile Gly His
100 105 110
Thr Leu Ala Glu Ala Gly Gln Ile Thr Asn Gln Gln Ile Ala Asp Tyr
115 120 125
Leu Asp Gly Leu Pro Pro Glu Lys Met His Cys Ser Val Met Gly Gln
130 135 140
Glu Ala Leu Arg Ala Ala Ile Ala Asn Phe Arg Gly Glu Ser Leu Glu
145 150 155 160
Glu Glu His Asp Glu Gly Lys Leu Ile Cys Lys Cys Phe Gly Val Asp
165 170 175
Glu Gly His Ile Arg Arg Ala Val Gln Asn Asn Gly Leu Thr Thr Leu
180 185 190
Ala Glu Val Ile Asn Tyr Thr Lys Ala Gly Gly Gly Cys Thr Ser Cys
195 200 205
His Glu Lys Ile Glu Leu Ala Leu Ala Glu Ile Leu Ala Gln Gln Pro
210 215 220
Gln Thr Thr Pro Ala Val Ala Ser Gly Lys Asp Pro His Trp Gln Ser
225 230 235 240
Val Val Asp Thr Ile Ala Glu Leu Arg Pro His Ile Gln Ala Asp Gly
245 250 255
Gly Asp Met Ala Leu Leu Ser Val Thr Asn His Gln Val Thr Val Ser
260 265 270
Leu Ser Gly Ser Cys Ser Gly Cys Met Met Thr Asp Met Thr Leu Ala
275 280 285
Trp Leu Gln Gln Lys Leu Met Glu Arg Thr Gly Cys Tyr Met Glu Val
290 295 300
Val Ala Ala Ala Gly Asp Tyr Lys Asp Asp Asp Asp Lys Pro Gly
305 310 315
<210> 37
<211> 201
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 37
Met Gly Leu Ser Leu Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala
1 5 10 15
Thr Arg Thr Leu Cys Ser Ser Arg Tyr Leu Leu Glu Gln Lys Pro Gly
20 25 30
Ala Pro Pro Pro Ile Asn Arg Gln Phe Asp Met Val His Ser Asp Glu
35 40 45
Trp Ser Met Lys Val Ala Phe Ala Ser Ser Asp Tyr Arg His Val Asp
50 55 60
Gln His Phe Gly Ala Thr Pro Arg Leu Val Val Tyr Gly Val Lys Ala
65 70 75 80
Asp Arg Val Thr Leu Ile Arg Val Val Asp Phe Ser Val Glu Asn Gly
85 90 95
His Gln Thr Glu Lys Ile Ala Arg Arg Ile His Ala Leu Glu Asp Cys
100 105 110
Val Thr Leu Phe Cys Val Ala Ile Gly Asp Ala Val Phe Arg Gln Leu
115 120 125
Leu Gln Val Gly Val Arg Ala Glu Arg Val Pro Ala Asp Thr Thr Ile
130 135 140
Val Gly Leu Leu Gln Glu Ile Gln Leu Tyr Trp Tyr Asp Lys Gly Gln
145 150 155 160
Arg Lys Asn Gln Arg Gln Arg Asp Pro Glu Arg Phe Thr Arg Leu Leu
165 170 175
Gln Glu Gln Glu Trp His Gly Asp Pro Asp Pro Arg Arg Ala Gly Asp
180 185 190
Tyr Lys Asp Asp Asp Asp Lys Pro Gly
195 200
<210> 38
<211> 80
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 38
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
<210> 39
<211> 80
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 39
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Ala Ala Ala Ala Ala
1 5 10 15
Ala Ala Ala Arg Pro Ile Ala Ala Ala Ala Ala Ala Ala Ala Ala Ala
20 25 30
Ala Glu Glu Gly Leu Leu Ala Ala Ala Ala Ala Ala Ala Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
<210> 40
<211> 267
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 40
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Met Ala Asn Ile Gly Ile Phe Phe Gly Thr Asp Thr Gly Lys Thr Arg
85 90 95
Lys Ile Ala Lys Met Ile His Lys Gln Leu Gly Glu Leu Ala Asp Ala
100 105 110
Pro Val Asn Ile Asn Arg Thr Thr Leu Asp Asp Phe Met Ala Tyr Pro
115 120 125
Val Leu Leu Leu Gly Thr Pro Thr Leu Gly Asp Gly Gln Leu Pro Gly
130 135 140
Leu Glu Ala Gly Cys Glu Ser Glu Ser Trp Ser Glu Phe Ile Ser Gly
145 150 155 160
Leu Asp Asp Ala Ser Leu Lys Gly Lys Thr Val Ala Leu Phe Gly Leu
165 170 175
Gly Asp Gln Arg Gly Tyr Pro Asp Asn Phe Val Ser Gly Met Arg Pro
180 185 190
Leu Phe Asp Ala Leu Ser Ala Arg Gly Ala Gln Met Ile Gly Ser Trp
195 200 205
Pro Asn Glu Gly Tyr Glu Phe Ser Ala Ser Ser Ala Leu Glu Gly Asp
210 215 220
Arg Phe Val Gly Leu Val Leu Asp Gln Asp Asn Gln Phe Asp Gln Thr
225 230 235 240
Glu Ala Arg Leu Ala Ser Trp Leu Glu Glu Ile Lys Arg Thr Val Leu
245 250 255
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Pro Gly
260 265
<210> 41
<211> 238
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 41
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Met Arg Pro Lys Phe Thr Phe Ser Glu Glu Val Arg Val Val Arg Ala
85 90 95
Ile Arg Asn Asp Gly Thr Val Ala Gly Phe Ala Pro Gly Ala Leu Leu
100 105 110
Val Arg Arg Gly Ser Thr Gly Phe Val Arg Asp Trp Gly Val Phe Leu
115 120 125
Gln Asp Gln Ile Ile Tyr Gln Ile His Phe Pro Glu Thr Asp Arg Ile
130 135 140
Ile Gly Cys Arg Glu Gln Glu Leu Ile Pro Ile Thr Gln Pro Trp Leu
145 150 155 160
Ala Gly Asn Leu Gln Tyr Arg Asp Ser Val Thr Cys Gln Met Ala Leu
165 170 175
Ala Val Asn Gly Asp Val Val Val Ser Ala Gly Gln Arg Gly Arg Val
180 185 190
Glu Ala Thr Asp Arg Gly Glu Leu Gly Asp Ser Tyr Thr Val Asp Phe
195 200 205
Ser Gly Arg Trp Phe Arg Val Pro Val Gln Ala Ile Ala Leu Ile Glu
210 215 220
Glu Arg Glu Glu Asp Tyr Lys Asp Asp Asp Asp Lys Pro Gly
225 230 235
<210> 42
<211> 389
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 42
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Thr Met Arg Gln Cys Ala Ile Tyr Gly Lys Gly Gly Ile Gly Lys Ser
85 90 95
Thr Thr Thr Gln Asn Leu Val Ala Ala Leu Ala Glu Met Gly Lys Lys
100 105 110
Val Met Ile Val Gly Cys Asp Pro Lys Ala Asp Ser Thr Arg Leu Ile
115 120 125
Leu His Ala Lys Ala Gln Asn Thr Ile Met Glu Met Ala Ala Glu Val
130 135 140
Gly Ser Val Glu Asp Leu Glu Leu Glu Asp Val Leu Gln Ile Gly Tyr
145 150 155 160
Gly Asp Val Arg Cys Ala Glu Ser Gly Gly Pro Glu Pro Gly Val Gly
165 170 175
Cys Ala Gly Arg Gly Val Ile Thr Ala Ile Asn Phe Leu Glu Glu Glu
180 185 190
Gly Ala Tyr Glu Asp Asp Leu Asp Phe Val Phe Tyr Asp Val Leu Gly
195 200 205
Asp Val Val Cys Gly Gly Phe Ala Met Pro Ile Arg Glu Asn Lys Ala
210 215 220
Gln Glu Ile Tyr Ile Val Cys Ser Gly Glu Met Met Ala Met Tyr Ala
225 230 235 240
Ala Asn Asn Ile Ser Lys Gly Ile Val Lys Tyr Ala Lys Ser Gly Lys
245 250 255
Val Arg Leu Gly Gly Leu Ile Cys Asn Ser Arg Gln Thr Asp Arg Glu
260 265 270
Asp Glu Leu Ile Ile Ala Leu Ala Glu Lys Leu Gly Thr Gln Met Ile
275 280 285
His Phe Val Pro Arg Asp Asn Ile Val Gln Arg Ala Glu Ile Arg Arg
290 295 300
Met Thr Val Ile Glu Tyr Asp Pro Ala Cys Lys Gln Ala Asn Glu Tyr
305 310 315 320
Arg Thr Leu Ala Gln Lys Ile Val Asn Asn Thr Met Lys Val Val Pro
325 330 335
Thr Pro Cys Thr Met Asp Glu Leu Glu Ser Leu Leu Met Glu Phe Gly
340 345 350
Ile Met Glu Glu Glu Asp Thr Ser Ile Ile Gly Lys Thr Ala Ala Glu
355 360 365
Glu Asn Ala Ala Ala Gly Gly Gly Gly Gly Tyr Pro Tyr Asp Val Pro
370 375 380
Asp Tyr Ala Pro Gly
385
<210> 43
<211> 8
<212> Белок
<213> Искусственная последовательность
<220>
<223> Триптический пептид
<400> 43
Ser Ile Ser Thr Gln Val Val Arg
1 5
<210> 44
<211> 7
<212> Белок
<213> Искусственная последовательность
<220>
<223> Триптический пептид
<400> 44
Ile Ser Thr Gln Val Val Arg
1 5
<210> 45
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Триптический пептид
<400> 45
Ala Val Gln Gly Ala Pro Thr Met Arg
1 5
<210> 46
<211> 564
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 46
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Thr Ser Cys Ser Ser Phe Ser Gly Gly Lys Ala Cys Arg Pro Ala Asp
85 90 95
Asp Ser Ala Leu Thr Pro Leu Val Ala Asp Lys Ala Ala Ala His Pro
100 105 110
Cys Tyr Ser Arg His Gly His His Arg Phe Ala Arg Met His Leu Pro
115 120 125
Val Ala Pro Ala Cys Asn Leu Gln Cys Asn Tyr Cys Asn Arg Lys Phe
130 135 140
Asp Cys Ser Asn Glu Ser Arg Pro Gly Val Ser Ser Thr Leu Leu Thr
145 150 155 160
Pro Glu Gln Ala Val Val Lys Val Arg Gln Val Ala Gln Ala Ile Pro
165 170 175
Gln Leu Ser Val Val Gly Ile Ala Gly Pro Gly Asp Pro Leu Ala Asn
180 185 190
Ile Ala Arg Thr Phe Arg Thr Leu Glu Leu Ile Arg Glu Gln Leu Pro
195 200 205
Asp Leu Lys Leu Cys Leu Ser Thr Asn Gly Leu Val Leu Pro Asp Ala
210 215 220
Val Asp Arg Leu Leu Asp Val Gly Val Asp His Val Thr Val Thr Ile
225 230 235 240
Asn Thr Leu Asp Ala Glu Ile Ala Ala Gln Ile Tyr Ala Trp Leu Trp
245 250 255
Leu Asp Gly Glu Arg Tyr Ser Gly Arg Glu Ala Gly Glu Ile Leu Ile
260 265 270
Ala Arg Gln Leu Glu Gly Val Arg Arg Leu Thr Ala Lys Gly Val Leu
275 280 285
Val Lys Ile Asn Ser Val Leu Ile Pro Gly Ile Asn Asp Ser Gly Met
290 295 300
Ala Gly Val Ser Arg Ala Leu Arg Ala Ser Gly Ala Phe Ile His Asn
305 310 315 320
Ile Met Pro Leu Ile Ala Arg Pro Glu His Gly Thr Val Phe Gly Leu
325 330 335
Asn Gly Gln Pro Glu Pro Asp Ala Glu Thr Leu Ala Ala Thr Arg Ser
340 345 350
Arg Cys Gly Glu Val Met Pro Gln Met Thr His Cys His Gln Cys Arg
355 360 365
Ala Asp Ala Ile Gly Met Leu Gly Glu Asp Arg Ser Gln Gln Phe Thr
370 375 380
Gln Leu Pro Ala Pro Glu Ser Leu Pro Ala Trp Leu Pro Ile Leu His
385 390 395 400
Gln Arg Ala Gln Leu His Ala Ser Ile Ala Thr Arg Gly Glu Ser Glu
405 410 415
Ala Asp Asp Ala Cys Leu Val Ala Val Ala Ser Ser Arg Gly Asp Val
420 425 430
Ile Asp Cys His Phe Gly His Ala Asp Arg Phe Tyr Ile Tyr Ser Leu
435 440 445
Ser Ala Ala Gly Met Val Leu Val Asn Glu Arg Phe Thr Pro Lys Tyr
450 455 460
Cys Gln Gly Arg Asp Asp Cys Glu Pro Gln Asp Asn Ala Ala Arg Phe
465 470 475 480
Ala Ala Ile Leu Glu Leu Leu Ala Asp Val Lys Ala Val Phe Cys Val
485 490 495
Arg Ile Gly His Thr Pro Trp Gln Gln Leu Glu Gln Glu Gly Ile Glu
500 505 510
Pro Cys Val Asp Gly Ala Trp Arg Pro Val Ser Glu Val Leu Pro Ala
515 520 525
Trp Trp Gln Gln Arg Arg Gly Ser Trp Pro Ala Ala Leu Pro His Lys
530 535 540
Gly Val Ala Ala Gly Gly Gly Gly Gly Tyr Pro Tyr Asp Val Pro Asp
545 550 555 560
Tyr Ala Pro Gly
<210> 47
<211> 573
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 47
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Thr Asn Ala Thr Gly Glu Arg Asn Leu Ala Leu Ile Gln Glu Val Leu
85 90 95
Glu Val Phe Pro Glu Thr Ala Arg Lys Glu Arg Arg Lys His Met Met
100 105 110
Val Ser Asp Pro Lys Met Lys Ser Val Gly Lys Cys Ile Ile Ser Asn
115 120 125
Arg Lys Ser Gln Pro Gly Val Met Thr Val Arg Gly Cys Ala Tyr Ala
130 135 140
Gly Ser Lys Gly Val Val Phe Gly Pro Ile Lys Asp Met Ala His Ile
145 150 155 160
Ser His Gly Pro Ala Gly Cys Gly Gln Tyr Ser Arg Ala Glu Arg Arg
165 170 175
Asn Tyr Tyr Thr Gly Val Ser Gly Val Asp Ser Phe Gly Thr Leu Asn
180 185 190
Phe Thr Ser Asp Phe Gln Glu Arg Asp Ile Val Phe Gly Gly Asp Lys
195 200 205
Lys Leu Ser Lys Leu Ile Glu Glu Met Glu Leu Leu Phe Pro Leu Thr
210 215 220
Lys Gly Ile Thr Ile Gln Ser Glu Cys Pro Val Gly Leu Ile Gly Asp
225 230 235 240
Asp Ile Ser Ala Val Ala Asn Ala Ser Ser Lys Ala Leu Asp Lys Pro
245 250 255
Val Ile Pro Val Arg Cys Glu Gly Phe Arg Gly Val Ser Gln Ser Leu
260 265 270
Gly His His Ile Ala Asn Asp Val Val Arg Asp Trp Ile Leu Asn Asn
275 280 285
Arg Glu Gly Gln Pro Phe Glu Thr Thr Pro Tyr Asp Val Ala Ile Ile
290 295 300
Gly Asp Tyr Asn Ile Gly Gly Asp Ala Trp Ala Ser Arg Ile Leu Leu
305 310 315 320
Glu Glu Met Gly Leu Arg Val Val Ala Gln Trp Ser Gly Asp Gly Thr
325 330 335
Leu Val Glu Met Glu Asn Thr Pro Phe Val Lys Leu Asn Leu Val His
340 345 350
Cys Tyr Arg Ser Met Asn Tyr Ile Ala Arg His Met Glu Glu Lys His
355 360 365
Gln Ile Pro Trp Met Glu Tyr Asn Phe Phe Gly Pro Thr Lys Ile Ala
370 375 380
Glu Ser Leu Arg Lys Ile Ala Asp Gln Phe Asp Asp Thr Ile Arg Ala
385 390 395 400
Asn Ala Glu Ala Val Ile Ala Arg Tyr Glu Gly Gln Met Ala Ala Ile
405 410 415
Ile Ala Lys Tyr Arg Pro Arg Leu Glu Gly Arg Lys Val Leu Leu Tyr
420 425 430
Ile Gly Gly Leu Arg Pro Arg His Val Ile Gly Ala Tyr Glu Asp Leu
435 440 445
Gly Met Glu Ile Ile Ala Ala Gly Tyr Glu Phe Ala His Asn Asp Asp
450 455 460
Tyr Asp Arg Thr Leu Pro Asp Leu Lys Glu Gly Thr Leu Leu Phe Asp
465 470 475 480
Asp Ala Ser Ser Tyr Glu Leu Glu Ala Phe Val Lys Ala Leu Lys Pro
485 490 495
Asp Leu Ile Gly Ser Gly Ile Lys Glu Lys Tyr Ile Phe Gln Lys Met
500 505 510
Gly Val Pro Phe Arg Gln Met His Ser Trp Asp Tyr Ser Gly Pro Tyr
515 520 525
His Gly Tyr Asp Gly Phe Ala Ile Phe Ala Arg Asp Met Asp Met Thr
530 535 540
Leu Asn Asn Pro Ala Trp Asn Glu Leu Thr Ala Pro Trp Leu Lys Ser
545 550 555 560
Ala Ala Gly Asp Tyr Lys Asp Asp Asp Asp Lys Pro Gly
565 570
<210> 48
<211> 553
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 48
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Lys Gly Asn Glu Ile Leu Ala Leu Leu Asp Glu Pro Ala Cys Glu His
85 90 95
Asn His Lys Gln Lys Ser Gly Cys Ser Ala Pro Lys Pro Gly Ala Thr
100 105 110
Ala Ala Gly Cys Ala Phe Asp Gly Ala Gln Ile Thr Leu Leu Pro Ile
115 120 125
Ala Asp Val Ala His Leu Val His Gly Pro Ile Gly Cys Ala Gly Ser
130 135 140
Ser Trp Asp Asn Arg Gly Ser Ala Ser Ser Gly Pro Thr Leu Asn Arg
145 150 155 160
Leu Gly Phe Thr Thr Asp Leu Asn Glu Gln Asp Val Ile Met Gly Arg
165 170 175
Gly Glu Arg Arg Leu Phe His Ala Val Arg His Ile Val Thr Arg Tyr
180 185 190
His Pro Ala Ala Val Phe Ile Tyr Asn Thr Cys Val Pro Ala Met Glu
195 200 205
Gly Asp Asp Leu Glu Ala Val Cys Gln Ala Ala Gln Thr Ala Thr Gly
210 215 220
Val Pro Val Ile Ala Ile Asp Ala Ala Gly Phe Tyr Gly Ser Lys Asn
225 230 235 240
Leu Gly Asn Arg Pro Ala Gly Asp Val Met Val Lys Arg Val Ile Gly
245 250 255
Gln Arg Glu Pro Ala Pro Trp Pro Glu Ser Thr Leu Phe Ala Pro Glu
260 265 270
Gln Arg His Asp Ile Gly Leu Ile Gly Glu Phe Asn Ile Ala Gly Glu
275 280 285
Phe Trp His Ile Gln Pro Leu Leu Asp Glu Leu Gly Ile Arg Val Leu
290 295 300
Gly Ser Leu Ser Gly Asp Gly Arg Phe Ala Glu Ile Gln Thr Met His
305 310 315 320
Arg Ala Gln Ala Asn Met Leu Val Cys Ser Arg Ala Leu Ile Asn Val
325 330 335
Ala Arg Ala Leu Glu Gln Arg Tyr Gly Thr Pro Trp Phe Glu Gly Ser
340 345 350
Phe Tyr Gly Ile Arg Ala Thr Ser Asp Ala Leu Arg Gln Leu Ala Ala
355 360 365
Leu Leu Gly Asp Asp Asp Leu Arg Gln Arg Thr Glu Ala Leu Ile Ala
370 375 380
Arg Glu Glu Gln Ala Ala Glu Leu Ala Leu Gln Pro Trp Arg Glu Gln
385 390 395 400
Leu Arg Gly Arg Lys Ala Leu Leu Tyr Thr Gly Gly Val Lys Ser Trp
405 410 415
Ser Val Val Ser Ala Leu Gln Asp Leu Gly Met Thr Val Val Ala Thr
420 425 430
Gly Thr Arg Lys Ser Thr Glu Glu Asp Lys Gln Arg Ile Arg Glu Leu
435 440 445
Met Gly Glu Glu Ala Val Met Leu Glu Glu Gly Asn Ala Arg Thr Leu
450 455 460
Leu Asp Val Val Tyr Arg Tyr Gln Ala Asp Leu Met Ile Ala Gly Gly
465 470 475 480
Arg Asn Met Tyr Thr Ala Tyr Lys Ala Arg Leu Pro Phe Leu Asp Ile
485 490 495
Asn Gln Glu Arg Glu His Ala Phe Ala Gly Tyr Gln Gly Ile Val Thr
500 505 510
Leu Ala Arg Gln Leu Cys Gln Thr Ile Asn Ser Pro Ile Trp Pro Gln
515 520 525
Thr His Ser Arg Ala Pro Trp Arg Ala Gly Gly Gly Gly Gly Tyr Pro
530 535 540
Tyr Asp Val Pro Asp Tyr Ala Pro Gly
545 550
<210> 49
<211> 1261
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 49
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Met Ser Gly Lys Met Lys Thr Met Asp Gly Asn Ala Ala Ala Ala Trp
85 90 95
Ile Ser Tyr Ala Phe Thr Glu Val Ala Ala Ile Tyr Pro Ile Thr Pro
100 105 110
Ser Thr Pro Met Ala Glu Asn Val Asp Glu Trp Ala Ala Gln Gly Lys
115 120 125
Lys Asn Leu Phe Gly Gln Pro Val Arg Leu Met Glu Met Gln Ser Glu
130 135 140
Ala Gly Ala Ala Gly Ala Val His Gly Ala Leu Gln Ala Gly Ala Leu
145 150 155 160
Thr Thr Thr Tyr Thr Ala Ser Gln Gly Leu Leu Leu Met Ile Pro Asn
165 170 175
Met Tyr Lys Ile Ala Gly Glu Leu Leu Pro Gly Val Phe His Val Ser
180 185 190
Ala Arg Ala Leu Ala Thr Asn Ser Leu Asn Ile Phe Gly Asp His Gln
195 200 205
Asp Val Met Ala Val Arg Gln Thr Gly Cys Ala Met Leu Ala Glu Asn
210 215 220
Asn Val Gln Gln Val Met Asp Leu Ser Ala Val Ala His Leu Ala Ala
225 230 235 240
Ile Lys Gly Arg Ile Pro Phe Val Asn Phe Phe Asp Gly Phe Arg Thr
245 250 255
Ser His Glu Ile Gln Lys Ile Glu Val Leu Glu Tyr Glu Gln Leu Ala
260 265 270
Thr Leu Leu Asp Arg Pro Ala Leu Asp Ser Phe Arg Arg Asn Ala Leu
275 280 285
His Pro Asp His Pro Val Ile Arg Gly Thr Ala Gln Asn Pro Asp Ile
290 295 300
Tyr Phe Gln Glu Arg Glu Ala Gly Asn Arg Phe Tyr Gln Ala Leu Pro
305 310 315 320
Asp Ile Val Glu Ser Tyr Met Thr Gln Ile Ser Ala Leu Thr Gly Arg
325 330 335
Glu Tyr His Leu Phe Asn Tyr Thr Gly Ala Ala Asp Ala Glu Arg Val
340 345 350
Ile Ile Ala Met Gly Ser Val Cys Asp Thr Val Gln Glu Val Val Asp
355 360 365
Thr Leu Asn Ala Ala Gly Glu Lys Val Gly Leu Leu Ser Val His Leu
370 375 380
Phe Arg Pro Phe Ser Leu Ala His Phe Phe Ala Gln Leu Pro Lys Thr
385 390 395 400
Val Gln Arg Ile Ala Val Leu Asp Arg Thr Lys Glu Pro Gly Ala Gln
405 410 415
Ala Glu Pro Leu Cys Leu Asp Val Lys Asn Ala Phe Tyr His His Asp
420 425 430
Asp Ala Pro Leu Ile Val Gly Gly Arg Tyr Ala Leu Gly Gly Lys Asp
435 440 445
Val Leu Pro Asn Asp Ile Ala Ala Val Phe Asp Asn Leu Asn Lys Pro
450 455 460
Leu Pro Met Asp Gly Phe Thr Leu Gly Ile Val Asp Asp Val Thr Phe
465 470 475 480
Thr Ser Leu Pro Pro Arg Gln Gln Thr Leu Ala Val Ser His Asp Gly
485 490 495
Ile Thr Ala Cys Lys Phe Trp Gly Met Gly Ser Asp Gly Thr Val Gly
500 505 510
Ala Asn Lys Ser Ala Ile Lys Ile Ile Gly Asp Lys Thr Pro Leu Tyr
515 520 525
Ala Gln Ala Tyr Phe Ser Tyr Asp Ser Lys Lys Ser Gly Gly Ile Thr
530 535 540
Val Ser His Leu Arg Phe Gly Asp Arg Pro Ile Asn Ser Pro Tyr Leu
545 550 555 560
Ile His Arg Ala Asp Phe Ile Ser Cys Ser Gln Gln Ser Tyr Val Glu
565 570 575
Arg Tyr Asp Leu Leu Asp Gly Leu Lys Pro Gly Gly Thr Phe Leu Leu
580 585 590
Asn Cys Ser Trp Ser Asp Ala Glu Leu Glu Gln His Leu Pro Val Gly
595 600 605
Phe Lys Arg Tyr Leu Ala Arg Glu Asn Ile His Phe Tyr Thr Leu Asn
610 615 620
Ala Val Asp Ile Ala Arg Glu Leu Gly Leu Gly Gly Arg Phe Asn Met
625 630 635 640
Leu Met Gln Ala Ala Phe Phe Lys Leu Ala Ala Ile Ile Asp Pro Gln
645 650 655
Thr Ala Ala Asp Tyr Leu Lys Gln Ala Val Glu Lys Ser Tyr Gly Ser
660 665 670
Lys Gly Ala Ala Val Ile Glu Met Asn Gln Arg Ala Ile Glu Leu Gly
675 680 685
Met Ala Ser Leu His Gln Val Thr Ile Pro Ala His Trp Ala Thr Leu
690 695 700
Asp Glu Pro Ala Ala Gln Ala Ser Ala Met Met Pro Asp Phe Ile Arg
705 710 715 720
Asp Ile Leu Gln Pro Met Asn Arg Gln Cys Gly Asp Gln Leu Pro Val
725 730 735
Ser Ala Phe Val Gly Met Glu Asp Gly Thr Phe Pro Ser Gly Thr Ala
740 745 750
Ala Trp Glu Lys Arg Gly Ile Ala Leu Glu Val Pro Val Trp Gln Pro
755 760 765
Glu Gly Cys Thr Gln Cys Asn Gln Cys Ala Phe Ile Cys Pro His Ala
770 775 780
Ala Ile Arg Pro Ala Leu Leu Asn Gly Glu Glu His Asp Ala Ala Pro
785 790 795 800
Val Gly Leu Leu Ser Lys Pro Ala Gln Gly Ala Lys Glu Tyr His Tyr
805 810 815
His Leu Ala Ile Ser Pro Leu Asp Cys Ser Gly Cys Gly Asn Cys Val
820 825 830
Asp Ile Cys Pro Ala Arg Gly Lys Ala Leu Lys Met Gln Ser Leu Asp
835 840 845
Ser Gln Arg Gln Met Ala Pro Val Trp Asp Tyr Ala Leu Ala Leu Thr
850 855 860
Pro Lys Ser Asn Pro Phe Arg Lys Thr Thr Val Lys Gly Ser Gln Phe
865 870 875 880
Glu Thr Pro Leu Leu Glu Phe Ser Gly Ala Cys Ala Gly Cys Gly Glu
885 890 895
Thr Pro Tyr Ala Arg Leu Ile Thr Gln Leu Phe Gly Asp Arg Met Leu
900 905 910
Ile Ala Asn Ala Thr Gly Cys Ser Ser Ile Trp Gly Ala Ser Ala Pro
915 920 925
Ser Ile Pro Tyr Thr Thr Asn His Arg Gly His Gly Pro Ala Trp Ala
930 935 940
Asn Ser Leu Phe Glu Asp Asn Ala Glu Phe Gly Leu Gly Met Met Leu
945 950 955 960
Gly Gly Gln Ala Val Arg Gln Gln Ile Ala Asp Asp Met Thr Ala Ala
965 970 975
Leu Ala Leu Pro Val Ser Asp Glu Leu Ser Asp Ala Met Arg Gln Trp
980 985 990
Leu Ala Lys Gln Asp Glu Gly Glu Gly Thr Arg Glu Arg Ala Asp Arg
995 1000 1005
Leu Ser Glu Arg Leu Ala Ala Glu Lys Glu Gly Val Pro Leu Leu
1010 1015 1020
Glu Gln Leu Trp Gln Asn Arg Asp Tyr Phe Val Arg Arg Ser Gln
1025 1030 1035
Trp Ile Phe Gly Gly Asp Gly Trp Ala Tyr Asp Ile Gly Phe Gly
1040 1045 1050
Gly Leu Asp His Val Leu Ala Ser Gly Glu Asp Val Asn Ile Leu
1055 1060 1065
Val Phe Asp Thr Glu Val Tyr Ser Asn Thr Gly Gly Gln Ser Ser
1070 1075 1080
Lys Ser Thr Pro Val Ala Ala Ile Ala Lys Phe Ala Ala Gln Gly
1085 1090 1095
Lys Arg Thr Arg Lys Lys Asp Leu Gly Met Met Ala Met Ser Tyr
1100 1105 1110
Gly Asn Val Tyr Val Ala Gln Val Ala Met Gly Ala Asp Lys Asp
1115 1120 1125
Gln Thr Leu Arg Ala Ile Ala Glu Ala Glu Ala Trp Pro Gly Pro
1130 1135 1140
Ser Leu Val Ile Ala Tyr Ala Ala Cys Ile Asn His Gly Leu Lys
1145 1150 1155
Ala Gly Met Arg Cys Ser Gln Arg Glu Ala Lys Arg Ala Val Glu
1160 1165 1170
Ala Gly Tyr Trp His Leu Trp Arg Tyr His Pro Gln Arg Glu Ala
1175 1180 1185
Glu Gly Lys Thr Pro Phe Met Leu Asp Ser Glu Glu Pro Glu Glu
1190 1195 1200
Ser Phe Arg Asp Phe Leu Leu Gly Glu Val Arg Tyr Ala Ser Leu
1205 1210 1215
His Lys Thr Thr Pro His Leu Ala Asp Ala Leu Phe Ser Arg Thr
1220 1225 1230
Glu Glu Asp Ala Arg Ala Arg Phe Ala Gln Tyr Arg Arg Leu Ala
1235 1240 1245
Gly Glu Glu Asp Tyr Lys Asp Asp Asp Asp Lys Pro Gly
1250 1255 1260
<210> 50
<211> 616
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 50
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Ser Gln Thr Ile Asp Lys Ile Asn Ser Cys Tyr Pro Leu Phe Glu Gln
85 90 95
Asp Glu Tyr Gln Glu Leu Phe Arg Asn Lys Arg Gln Leu Glu Glu Ala
100 105 110
His Asp Ala Gln Arg Val Gln Glu Val Phe Ala Trp Thr Thr Thr Ala
115 120 125
Glu Tyr Glu Ala Leu Asn Phe Arg Arg Glu Ala Leu Thr Val Asp Pro
130 135 140
Ala Lys Ala Cys Gln Pro Leu Gly Ala Val Leu Cys Ser Leu Gly Phe
145 150 155 160
Ala Asn Thr Leu Pro Tyr Val His Gly Ser Gln Gly Cys Val Ala Tyr
165 170 175
Phe Arg Thr Tyr Phe Asn Arg His Phe Lys Glu Pro Ile Ala Cys Val
180 185 190
Ser Asp Ser Met Thr Glu Asp Ala Ala Val Phe Gly Gly Asn Asn Asn
195 200 205
Met Asn Leu Gly Leu Gln Asn Ala Ser Ala Leu Tyr Lys Pro Glu Ile
210 215 220
Ile Ala Val Ser Thr Thr Cys Met Ala Glu Val Ile Gly Asp Asp Leu
225 230 235 240
Gln Ala Phe Ile Ala Asn Ala Lys Lys Asp Gly Phe Val Asp Ser Ser
245 250 255
Ile Ala Val Pro His Ala His Thr Pro Ser Phe Ile Gly Ser His Val
260 265 270
Thr Gly Trp Asp Asn Met Phe Glu Gly Phe Ala Lys Thr Phe Thr Ala
275 280 285
Asp Tyr Gln Gly Gln Pro Gly Lys Leu Pro Lys Leu Asn Leu Val Thr
290 295 300
Gly Phe Glu Thr Tyr Leu Gly Asn Phe Arg Val Leu Lys Arg Met Met
305 310 315 320
Glu Gln Met Ala Val Pro Cys Ser Leu Leu Ser Asp Pro Ser Glu Val
325 330 335
Leu Asp Thr Pro Ala Asp Gly His Tyr Arg Met Tyr Ser Gly Gly Thr
340 345 350
Thr Gln Gln Glu Met Lys Glu Ala Pro Asp Ala Ile Asp Thr Leu Leu
355 360 365
Leu Gln Pro Trp Gln Leu Leu Lys Ser Lys Lys Val Val Gln Glu Met
370 375 380
Trp Asn Gln Pro Ala Thr Glu Val Ala Ile Pro Leu Gly Leu Ala Ala
385 390 395 400
Thr Asp Glu Leu Leu Met Thr Val Ser Gln Leu Ser Gly Lys Pro Ile
405 410 415
Ala Asp Ala Leu Thr Leu Glu Arg Gly Arg Leu Val Asp Met Met Leu
420 425 430
Asp Ser His Thr Trp Leu His Gly Lys Lys Phe Gly Leu Tyr Gly Asp
435 440 445
Pro Asp Phe Val Met Gly Leu Thr Arg Phe Leu Leu Glu Leu Gly Cys
450 455 460
Glu Pro Thr Val Ile Leu Ser His Asn Ala Asn Lys Arg Trp Gln Lys
465 470 475 480
Ala Met Asn Lys Met Leu Asp Ala Ser Pro Tyr Gly Arg Asp Ser Glu
485 490 495
Val Phe Ile Asn Cys Asp Leu Trp His Phe Arg Ser Leu Met Phe Thr
500 505 510
Arg Gln Pro Asp Phe Met Ile Gly Asn Ser Tyr Gly Lys Phe Ile Gln
515 520 525
Arg Asp Thr Leu Ala Lys Gly Lys Ala Phe Glu Val Pro Leu Ile Arg
530 535 540
Leu Gly Phe Pro Leu Phe Asp Arg His His Leu His Arg Gln Thr Thr
545 550 555 560
Trp Gly Tyr Glu Gly Ala Met Asn Ile Val Thr Thr Leu Val Asn Ala
565 570 575
Val Leu Glu Lys Leu Asp Ser Asp Thr Ser Gln Leu Gly Lys Thr Asp
580 585 590
Tyr Ser Phe Asp Leu Val Arg Ala Gly Gly Gly Gly Gly Tyr Pro Tyr
595 600 605
Asp Val Pro Asp Tyr Ala Pro Gly
610 615
<210> 51
<211> 357
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 51
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Met Asn Pro Trp Gln Arg Phe Ala Arg Gln Arg Leu Ala Arg Ser Arg
85 90 95
Trp Asn Arg Asp Pro Ala Ala Leu Asp Pro Ala Asp Thr Pro Ala Phe
100 105 110
Glu Gln Ala Trp Gln Arg Gln Cys His Met Glu Gln Thr Ile Val Ala
115 120 125
Arg Val Pro Glu Gly Asp Ile Pro Ala Ala Leu Leu Glu Asn Ile Ala
130 135 140
Ala Ser Leu Ala Ile Trp Leu Asp Glu Gly Asp Phe Ala Pro Pro Glu
145 150 155 160
Arg Ala Ala Ile Val Arg His His Ala Arg Leu Glu Leu Ala Phe Ala
165 170 175
Asp Ile Ala Arg Gln Ala Pro Gln Pro Asp Leu Ser Thr Val Gln Ala
180 185 190
Trp Tyr Leu Arg His Gln Thr Gln Phe Met Arg Pro Glu Gln Arg Leu
195 200 205
Thr Arg His Leu Leu Leu Thr Val Asp Asn Asp Arg Glu Ala Val His
210 215 220
Gln Arg Ile Leu Gly Leu Tyr Arg Gln Ile Asn Ala Ser Arg Asp Ala
225 230 235 240
Phe Ala Pro Leu Ala Gln Arg His Ser His Cys Pro Ser Ala Leu Glu
245 250 255
Glu Gly Arg Leu Gly Trp Ile Ser Arg Gly Leu Leu Tyr Pro Gln Leu
260 265 270
Glu Thr Ala Leu Phe Ser Leu Ala Glu Asn Ala Leu Ser Leu Pro Ile
275 280 285
Ala Ser Glu Leu Gly Trp His Leu Leu Trp Cys Glu Ala Ile Arg Pro
290 295 300
Ala Ala Pro Met Glu Pro Gln Gln Ala Leu Glu Ser Ala Arg Asp Tyr
305 310 315 320
Leu Trp Gln Gln Ser Gln Gln Arg His Gln Arg Gln Trp Leu Glu Gln
325 330 335
Met Ile Ser Arg Gln Pro Gly Leu Cys Gly Tyr Pro Tyr Asp Val Pro
340 345 350
Asp Tyr Ala Pro Gly
355
<210> 52
<211> 551
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 52
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Ala Asp Ile Phe Arg Thr Asp Lys Pro Leu Ala Val Ser Pro Ile Lys
85 90 95
Thr Gly Gln Pro Leu Gly Ala Ile Leu Ala Ser Leu Gly Ile Glu His
100 105 110
Ser Ile Pro Leu Val His Gly Ala Gln Gly Cys Ser Ala Phe Ala Lys
115 120 125
Val Phe Phe Ile Gln His Phe His Asp Pro Val Pro Leu Gln Ser Thr
130 135 140
Ala Met Asp Pro Thr Ser Thr Ile Met Gly Ala Asp Gly Asn Ile Phe
145 150 155 160
Thr Ala Leu Asp Thr Leu Cys Gln Arg Asn Asn Pro Gln Ala Ile Val
165 170 175
Leu Leu Ser Thr Gly Leu Ser Glu Ala Gln Gly Ser Asp Ile Ser Arg
180 185 190
Val Val Arg Gln Phe Arg Glu Glu Tyr Pro Arg His Lys Gly Val Ala
195 200 205
Ile Leu Thr Val Asn Thr Pro Asp Phe Tyr Gly Ser Met Glu Asn Gly
210 215 220
Phe Ser Ala Val Leu Glu Ser Val Ile Glu Gln Trp Val Pro Pro Ala
225 230 235 240
Pro Arg Pro Ala Gln Arg Asn Arg Arg Val Asn Leu Leu Val Ser His
245 250 255
Leu Cys Ser Pro Gly Asp Ile Glu Trp Leu Arg Arg Cys Val Glu Ala
260 265 270
Phe Gly Leu Gln Pro Ile Ile Leu Pro Asp Leu Ala Gln Ser Met Asp
275 280 285
Gly His Leu Ala Gln Gly Asp Phe Ser Pro Leu Thr Gln Gly Gly Thr
290 295 300
Pro Leu Arg Gln Ile Glu Gln Met Gly Gln Ser Leu Cys Ser Phe Ala
305 310 315 320
Ile Gly Val Ser Leu His Arg Ala Ser Ser Leu Leu Ala Pro Arg Cys
325 330 335
Arg Gly Glu Val Ile Ala Leu Pro His Leu Met Thr Leu Glu Arg Cys
340 345 350
Asp Ala Phe Ile His Gln Leu Ala Lys Ile Ser Gly Arg Ala Val Pro
355 360 365
Glu Trp Leu Glu Arg Gln Arg Gly Gln Leu Gln Asp Ala Met Ile Asp
370 375 380
Cys His Met Trp Leu Gln Gly Gln Arg Met Ala Ile Ala Ala Glu Gly
385 390 395 400
Asp Leu Leu Ala Ala Trp Cys Asp Phe Ala Asn Ser Gln Gly Met Gln
405 410 415
Pro Gly Pro Leu Val Ala Pro Thr Gly His Pro Ser Leu Arg Gln Leu
420 425 430
Pro Val Glu Arg Val Val Pro Gly Asp Leu Glu Asp Leu Gln Thr Leu
435 440 445
Leu Cys Ala His Pro Ala Asp Leu Leu Val Ala Asn Ser His Ala Arg
450 455 460
Asp Leu Ala Glu Gln Phe Ala Leu Pro Leu Val Arg Ala Gly Phe Pro
465 470 475 480
Leu Phe Asp Lys Leu Gly Glu Phe Arg Arg Val Arg Gln Gly Tyr Ser
485 490 495
Gly Met Arg Asp Thr Leu Phe Glu Leu Ala Asn Leu Ile Arg Glu Arg
500 505 510
His His His Leu Ala His Tyr Arg Ser Pro Leu Arg Gln Asn Pro Glu
515 520 525
Ser Ser Leu Ser Thr Gly Gly Ala Tyr Ala Ala Ala Gly Asp Tyr Lys
530 535 540
Asp Asp Asp Asp Lys Pro Gly
545 550
<210> 53
<211> 263
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 53
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Pro Pro Leu Asp Trp Leu Arg Arg Leu Trp Leu Leu Tyr His Ala Gly
85 90 95
Lys Gly Ser Phe Pro Leu Arg Met Gly Leu Ser Pro Arg Asp Trp Gln
100 105 110
Ala Leu Arg Arg Arg Leu Gly Glu Val Glu Thr Pro Leu Asp Gly Glu
115 120 125
Thr Leu Thr Arg Arg Arg Leu Met Ala Glu Leu Asn Ala Thr Arg Glu
130 135 140
Glu Glu Arg Gln Gln Leu Gly Ala Trp Leu Ala Gly Trp Met Gln Gln
145 150 155 160
Asp Ala Gly Pro Met Ala Gln Ile Ile Ala Glu Val Ser Leu Ala Phe
165 170 175
Asn His Leu Trp Gln Asp Leu Gly Leu Ala Ser Arg Ala Glu Leu Arg
180 185 190
Leu Leu Met Ser Asp Cys Phe Pro Gln Leu Val Val Met Asn Glu His
195 200 205
Asn Met Arg Trp Lys Lys Phe Phe Tyr Arg Gln Arg Cys Leu Leu Gln
210 215 220
Gln Gly Glu Val Ile Cys Arg Ser Pro Ser Cys Asp Glu Cys Trp Glu
225 230 235 240
Arg Ser Ala Cys Phe Glu Ala Gly Gly Gly Gly Gly Tyr Pro Tyr Asp
245 250 255
Val Pro Asp Tyr Ala Pro Gly
260
<210> 54
<211> 496
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 54
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Lys Gln Val Tyr Leu Asp Asn Asn Ala Thr Thr Arg Leu Asp Pro Met
85 90 95
Val Leu Glu Ala Met Met Pro Phe Leu Thr Asp Phe Tyr Gly Asn Pro
100 105 110
Ser Ser Ile His Asp Phe Gly Ile Pro Ala Gln Ala Ala Leu Glu Arg
115 120 125
Ala His Gln Gln Ala Ala Ala Leu Leu Gly Ala Glu Tyr Pro Ser Glu
130 135 140
Ile Ile Phe Thr Ser Cys Ala Thr Glu Ala Thr Ala Thr Ala Ile Ala
145 150 155 160
Ser Ala Ile Ala Leu Leu Pro Glu Arg Arg Glu Ile Ile Thr Ser Val
165 170 175
Val Glu His Pro Ala Thr Leu Ala Ala Cys Glu His Met Glu Arg Glu
180 185 190
Gly Tyr Arg Ile His Arg Ile Ala Val Asp Gly Glu Gly Ala Leu Asp
195 200 205
Met Ala Gln Phe Arg Ala Ala Leu Ser Pro Arg Val Ala Leu Val Ser
210 215 220
Val Met Trp Ala Asn Asn Glu Thr Gly Val Leu Phe Pro Ile Gly Glu
225 230 235 240
Met Ala Glu Leu Ala His Glu Gln Gly Ala Leu Phe His Cys Asp Ala
245 250 255
Val Gln Val Val Gly Lys Ile Pro Ile Ala Val Gly Gln Thr Arg Ile
260 265 270
Asp Met Leu Ser Cys Ser Ala His Lys Phe His Gly Pro Lys Gly Val
275 280 285
Gly Cys Leu Tyr Leu Arg Arg Gly Thr Arg Phe Arg Pro Leu Leu Arg
290 295 300
Gly Gly His Gln Glu Tyr Gly Arg Arg Ala Gly Thr Glu Asn Ile Cys
305 310 315 320
Gly Ile Val Gly Met Gly Ala Ala Cys Glu Leu Ala Asn Ile His Leu
325 330 335
Pro Gly Met Thr His Ile Gly Gln Leu Arg Asn Arg Leu Glu His Arg
340 345 350
Leu Leu Ala Ser Val Pro Ser Val Met Val Met Gly Gly Gly Gln Pro
355 360 365
Ala Val Pro Gly Thr Val Asn Leu Ala Phe Glu Phe Ile Glu Gly Glu
370 375 380
Ala Ile Leu Leu Leu Leu Asn Gln Ala Gly Ile Ala Ala Ser Ser Gly
385 390 395 400
Ser Ala Cys Thr Ser Gly Ser Leu Glu Pro Ser His Val Met Arg Ala
405 410 415
Met Asn Ile Pro Tyr Thr Ala Ala His Gly Thr Ile Arg Phe Ser Leu
420 425 430
Ser Arg Tyr Thr Arg Glu Lys Glu Ile Asp Tyr Val Val Ala Thr Leu
435 440 445
Pro Pro Ile Ile Asp Arg Leu Arg Ala Leu Ser Pro Tyr Trp Gln Asn
450 455 460
Gly Lys Pro Arg Pro Ala Asp Ala Val Phe Thr Pro Val Tyr Gly Ala
465 470 475 480
Gly Gly Gly Gly Gly Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Pro Gly
485 490 495
<210> 55
<211> 365
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 55
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Trp Asn Tyr Ser Glu Lys Val Lys Asp His Phe Phe Asn Pro Arg Asn
85 90 95
Ala Arg Val Val Asp Asn Ala Asn Ala Val Gly Asp Val Gly Ser Leu
100 105 110
Ser Cys Gly Asp Ala Leu Arg Leu Met Leu Arg Val Asp Pro Gln Ser
115 120 125
Glu Ile Ile Glu Glu Ala Gly Phe Gln Thr Phe Gly Cys Gly Ser Ala
130 135 140
Ile Ala Ser Ser Ser Ala Leu Thr Glu Leu Ile Ile Gly His Thr Leu
145 150 155 160
Ala Glu Ala Gly Gln Ile Thr Asn Gln Gln Ile Ala Asp Tyr Leu Asp
165 170 175
Gly Leu Pro Pro Glu Lys Met His Cys Ser Val Met Gly Gln Glu Ala
180 185 190
Leu Arg Ala Ala Ile Ala Asn Phe Arg Gly Glu Ser Leu Glu Glu Glu
195 200 205
His Asp Glu Gly Lys Leu Ile Cys Lys Cys Phe Gly Val Asp Glu Gly
210 215 220
His Ile Arg Arg Ala Val Gln Asn Asn Gly Leu Thr Thr Leu Ala Glu
225 230 235 240
Val Ile Asn Tyr Thr Lys Ala Gly Gly Gly Cys Thr Ser Cys His Glu
245 250 255
Lys Ile Glu Leu Ala Leu Ala Glu Ile Leu Ala Gln Gln Pro Gln Thr
260 265 270
Thr Pro Ala Val Ala Ser Gly Lys Asp Pro His Trp Gln Ser Val Val
275 280 285
Asp Thr Ile Ala Glu Leu Arg Pro His Ile Gln Ala Asp Gly Gly Asp
290 295 300
Met Ala Leu Leu Ser Val Thr Asn His Gln Val Thr Val Ser Leu Ser
305 310 315 320
Gly Ser Cys Ser Gly Cys Met Met Thr Asp Met Thr Leu Ala Trp Leu
325 330 335
Gln Gln Lys Leu Met Glu Arg Thr Gly Cys Tyr Met Glu Val Val Ala
340 345 350
Ala Ala Gly Asp Tyr Lys Asp Asp Asp Asp Lys Pro Gly
355 360 365
<210> 56
<211> 471
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 56
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Met Glu Arg Val Leu Ile Asn Asp Thr Thr Leu Arg Asp Gly Glu Gln
85 90 95
Ser Pro Gly Val Ala Phe Arg Thr Ser Glu Lys Val Ala Ile Ala Glu
100 105 110
Ala Leu Tyr Ala Ala Gly Ile Thr Ala Met Glu Val Gly Thr Pro Ala
115 120 125
Met Gly Asp Glu Glu Ile Ala Arg Ile Gln Leu Val Arg Arg Gln Leu
130 135 140
Pro Asp Ala Thr Leu Met Thr Trp Cys Arg Met Asn Ala Leu Glu Ile
145 150 155 160
Arg Gln Ser Ala Asp Leu Gly Ile Asp Trp Val Asp Ile Ser Ile Pro
165 170 175
Ala Ser Asp Lys Leu Arg Gln Tyr Lys Leu Arg Glu Pro Leu Ala Val
180 185 190
Leu Leu Glu Arg Leu Ala Met Phe Ile His Leu Ala His Thr Leu Gly
195 200 205
Leu Lys Val Cys Ile Gly Cys Glu Asp Ala Ser Arg Ala Ser Gly Gln
210 215 220
Thr Leu Arg Ala Ile Ala Glu Val Ala Gln Asn Ala Pro Ala Ala Arg
225 230 235 240
Leu Arg Tyr Ala Asp Thr Val Gly Leu Leu Asp Pro Phe Thr Thr Ala
245 250 255
Ala Gln Ile Ser Ala Leu Arg Asp Val Trp Ser Gly Glu Ile Glu Met
260 265 270
His Ala His Asn Asp Leu Gly Met Ala Thr Ala Asn Thr Leu Ala Ala
275 280 285
Val Ser Ala Gly Ala Thr Ser Val Asn Thr Thr Val Leu Gly Leu Gly
290 295 300
Glu Arg Ala Gly Asn Ala Ala Ala Trp Lys Pro Ser Ala Leu Gly Leu
305 310 315 320
Glu Arg Cys Leu Gly Val Glu Thr Gly Val His Phe Ser Ala Leu Pro
325 330 335
Ala Leu Cys Gln Arg Val Ala Glu Ala Ala Gln Arg Ala Ile Asp Pro
340 345 350
Gln Gln Pro Leu Val Gly Glu Leu Val Phe Thr His Glu Ser Gly Val
355 360 365
His Val Ala Ala Leu Leu Arg Asp Ser Glu Ser Tyr Gln Ser Ile Ala
370 375 380
Pro Ser Leu Met Gly Arg Ser Tyr Arg Leu Val Leu Gly Lys His Ser
385 390 395 400
Gly Arg Gln Ala Val Asn Gly Val Phe Asp Gln Met Gly Tyr His Leu
405 410 415
Asn Ala Ala Gln Ile Asn Gln Leu Leu Pro Ala Ile Arg Arg Phe Ala
420 425 430
Glu Asn Trp Lys Arg Ser Pro Lys Asp Tyr Glu Leu Val Ala Ile Tyr
435 440 445
Asp Glu Leu Cys Gly Glu Ser Ala Leu Arg Ala Arg Gly Asp Tyr Lys
450 455 460
Asp Asp Asp Asp Lys Pro Gly
465 470
<210> 57
<211> 247
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 57
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Pro Pro Ile Asn Arg Gln Phe Asp Met Val His Ser Asp Glu Trp Ser
85 90 95
Met Lys Val Ala Phe Ala Ser Ser Asp Tyr Arg His Val Asp Gln His
100 105 110
Phe Gly Ala Thr Pro Arg Leu Val Val Tyr Gly Val Lys Ala Asp Arg
115 120 125
Val Thr Leu Ile Arg Val Val Asp Phe Ser Val Glu Asn Gly His Gln
130 135 140
Thr Glu Lys Ile Ala Arg Arg Ile His Ala Leu Glu Asp Cys Val Thr
145 150 155 160
Leu Phe Cys Val Ala Ile Gly Asp Ala Val Phe Arg Gln Leu Leu Gln
165 170 175
Val Gly Val Arg Ala Glu Arg Val Pro Ala Asp Thr Thr Ile Val Gly
180 185 190
Leu Leu Gln Glu Ile Gln Leu Tyr Trp Tyr Asp Lys Gly Gln Arg Lys
195 200 205
Asn Gln Arg Gln Arg Asp Pro Glu Arg Phe Thr Arg Leu Leu Gln Glu
210 215 220
Gln Glu Trp His Gly Asp Pro Asp Pro Arg Arg Ala Gly Asp Tyr Lys
225 230 235 240
Asp Asp Asp Asp Lys Pro Gly
245
<210> 58
<211> 316
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 58
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Ser Asp Asn Asp Thr Leu Phe Trp Arg Met Leu Ala Leu Phe Gln Ser
85 90 95
Leu Pro Asp Leu Gln Pro Ala Gln Ile Val Asp Trp Leu Ala Gln Glu
100 105 110
Ser Gly Glu Thr Leu Thr Pro Glu Arg Leu Ala Thr Leu Thr Gln Pro
115 120 125
Gln Leu Ala Ala Ser Phe Pro Ser Ala Thr Ala Val Met Ser Pro Ala
130 135 140
Arg Trp Ser Arg Val Met Ala Ser Leu Gln Gly Ala Leu Pro Ala His
145 150 155 160
Leu Arg Ile Val Arg Pro Ala Gln Arg Thr Pro Gln Leu Leu Ala Ala
165 170 175
Phe Cys Ser Gln Asp Gly Leu Val Ile Asn Gly His Phe Gly Gln Gly
180 185 190
Arg Leu Phe Phe Ile Tyr Ala Phe Asp Glu Gln Gly Gly Trp Leu Tyr
195 200 205
Asp Leu Arg Arg Tyr Pro Ser Ala Pro His Gln Gln Glu Ala Asn Glu
210 215 220
Val Arg Ala Arg Leu Ile Glu Asp Cys Gln Leu Leu Phe Cys Gln Glu
225 230 235 240
Ile Gly Gly Pro Ala Ala Ala Arg Pro Ile Arg His Arg Ile His Pro
245 250 255
Met Lys Ala Gln Pro Gly Thr Thr Ile Gln Ala Gln Cys Glu Ala Ile
260 265 270
Asn Thr Leu Leu Ala Gly Arg Leu Pro Pro Trp Leu Ala Lys Arg Leu
275 280 285
Asn Arg Asp Asn Pro Leu Glu Glu Arg Val Phe Ala Gly Gly Gly Gly
290 295 300
Gly Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Pro Gly
305 310 315
<210> 59
<211> 574
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 59
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Thr Asn Ala Thr Gly Glu Arg Asn Leu Ala Leu Ile Gln Glu Val Leu
85 90 95
Glu Val Phe Pro Glu Thr Ala Arg Lys Glu Arg Arg Lys His Met Met
100 105 110
Val Ser Asp Pro Lys Met Lys Ser Val Gly Lys Cys Ile Ile Ser Asn
115 120 125
Arg Lys Ser Gln Pro Gly Val Met Thr Val Arg Gly Cys Ala Tyr Ala
130 135 140
Gly Ser Lys Gly Val Val Phe Gly Pro Ile Lys Asp Met Ala His Ile
145 150 155 160
Ser His Gly Pro Ala Gly Cys Gly Gln Tyr Ser Arg Ala Glu Arg Arg
165 170 175
Asn Tyr Tyr Thr Gly Val Ser Gly Val Asp Ser Phe Gly Thr Leu Asn
180 185 190
Phe Thr Ser Asp Phe Gln Glu Arg Asp Ile Val Phe Gly Gly Asp Lys
195 200 205
Lys Leu Ser Lys Leu Ile Glu Glu Met Glu Leu Leu Phe Pro Leu Thr
210 215 220
Lys Gly Ile Thr Ile Gln Ser Glu Cys Pro Val Gly Leu Ile Gly Asp
225 230 235 240
Asp Ile Ser Ala Val Ala Asn Ala Ser Ser Lys Ala Leu Asp Lys Pro
245 250 255
Val Ile Pro Val Arg Cys Glu Gly Phe Arg Gly Val Ser Gln Ser Leu
260 265 270
Gly His His Ile Ala Asn Asp Val Val Arg Asp Trp Ile Leu Asn Asn
275 280 285
Arg Glu Gly Gln Pro Phe Glu Thr Thr Pro Tyr Asp Val Ala Ile Ile
290 295 300
Gly Asp Tyr Asn Ile Gly Gly Asp Ala Trp Ala Ser Arg Ile Leu Leu
305 310 315 320
Glu Glu Met Gly Leu Arg Val Val Ala Gln Trp Ser Gly Asp Gly Thr
325 330 335
Leu Val Glu Met Glu Asn Thr Pro Phe Val Lys Leu Asn Leu Val His
340 345 350
Cys Tyr Arg Ser Met Asn Tyr Ile Ala Arg His Met Glu Glu Lys His
355 360 365
Gln Ile Pro Trp Met Glu Tyr Asn Phe Phe Gly Pro Thr Lys Ile Ala
370 375 380
Glu Ser Leu Arg Lys Ile Ala Asp Gln Phe Asp Asp Thr Ile Arg Ala
385 390 395 400
Asn Ala Glu Ala Val Ile Ala Arg Tyr Glu Gly Gln Met Ala Ala Ile
405 410 415
Ile Ala Lys Tyr Arg Pro Arg Leu Glu Gly Arg Lys Val Leu Leu Tyr
420 425 430
Ile Gly Gly Leu Arg Pro Arg His Val Ile Gly Ala Tyr Glu Asp Leu
435 440 445
Gly Met Glu Ile Ile Ala Ala Gly Tyr Glu Phe Ala His Asn Asp Asp
450 455 460
Tyr Asp Arg Thr Leu Pro Asp Leu Lys Glu Gly Thr Leu Leu Phe Asp
465 470 475 480
Asp Ala Ser Ser Tyr Glu Leu Glu Ala Phe Val Lys Ala Leu Lys Pro
485 490 495
Asp Leu Ile Gly Ser Gly Ile Lys Glu Lys Tyr Ile Phe Gln Lys Met
500 505 510
Gly Val Pro Phe Arg Gln Met His Ser Trp Asp Tyr Ser Gly Pro Tyr
515 520 525
His Gly Tyr Asp Gly Phe Ala Ile Phe Ala Arg Asp Met Asp Met Thr
530 535 540
Leu Asn Asn Pro Ala Trp Asn Glu Leu Thr Ala Pro Trp Leu Lys Ser
545 550 555 560
Ala Ala Gly Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Pro Gly
565 570
<210> 60
<211> 599
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 60
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Ser Gln Thr Ile Asp Lys Ile Asn Ser Cys Tyr Pro Leu Phe Glu Gln
85 90 95
Asp Glu Tyr Gln Glu Leu Phe Arg Asn Lys Arg Gln Leu Glu Glu Ala
100 105 110
His Asp Ala Gln Arg Val Gln Glu Val Phe Ala Trp Thr Thr Thr Ala
115 120 125
Glu Tyr Glu Ala Leu Asn Phe Arg Arg Glu Ala Leu Thr Val Asp Pro
130 135 140
Ala Lys Ala Cys Gln Pro Leu Gly Ala Val Leu Cys Ser Leu Gly Phe
145 150 155 160
Ala Asn Thr Leu Pro Tyr Val His Gly Ser Gln Gly Cys Val Ala Tyr
165 170 175
Phe Arg Thr Tyr Phe Asn Arg His Phe Lys Glu Pro Ile Ala Cys Val
180 185 190
Ser Asp Ser Met Thr Glu Asp Ala Ala Val Phe Gly Gly Asn Asn Asn
195 200 205
Met Asn Leu Gly Leu Gln Asn Ala Ser Ala Leu Tyr Lys Pro Glu Ile
210 215 220
Ile Ala Val Ser Thr Thr Cys Met Ala Glu Val Ile Gly Asp Asp Leu
225 230 235 240
Gln Ala Phe Ile Ala Asn Ala Lys Lys Asp Gly Phe Val Asp Ser Ser
245 250 255
Ile Ala Val Pro His Ala His Thr Pro Ser Phe Ile Gly Ser His Val
260 265 270
Thr Gly Trp Asp Asn Met Phe Glu Gly Phe Ala Lys Thr Phe Thr Ala
275 280 285
Asp Tyr Gln Gly Gln Pro Gly Lys Leu Pro Lys Leu Asn Leu Val Thr
290 295 300
Gly Phe Glu Thr Tyr Leu Gly Asn Phe Arg Val Leu Lys Arg Met Met
305 310 315 320
Glu Gln Met Ala Val Pro Cys Ser Leu Leu Ser Asp Pro Ser Glu Val
325 330 335
Leu Asp Thr Pro Ala Asp Gly His Tyr Arg Met Tyr Ser Gly Gly Thr
340 345 350
Thr Gln Gln Glu Met Lys Glu Ala Pro Asp Ala Ile Asp Thr Leu Leu
355 360 365
Leu Gln Pro Trp Gln Leu Leu Lys Ser Lys Lys Val Val Gln Glu Met
370 375 380
Trp Asn Gln Pro Ala Thr Glu Val Ala Ile Pro Leu Gly Leu Ala Ala
385 390 395 400
Thr Asp Glu Leu Leu Met Thr Val Ser Gln Leu Ser Gly Lys Pro Ile
405 410 415
Ala Asp Ala Leu Thr Leu Glu Arg Gly Arg Leu Val Asp Met Met Leu
420 425 430
Asp Ser His Thr Trp Leu His Gly Lys Lys Phe Gly Leu Tyr Gly Asp
435 440 445
Pro Asp Phe Val Met Gly Leu Thr Arg Phe Leu Leu Glu Leu Gly Cys
450 455 460
Glu Pro Thr Val Ile Leu Ser His Asn Ala Asn Lys Arg Trp Gln Lys
465 470 475 480
Ala Met Asn Lys Met Leu Asp Ala Ser Pro Tyr Gly Arg Asp Ser Glu
485 490 495
Val Phe Ile Asn Cys Asp Leu Trp His Phe Arg Ser Leu Met Phe Thr
500 505 510
Arg Gln Pro Asp Phe Met Ile Gly Asn Ser Tyr Gly Lys Phe Ile Gln
515 520 525
Arg Asp Thr Leu Ala Lys Gly Lys Ala Phe Glu Val Pro Leu Ile Arg
530 535 540
Leu Gly Phe Pro Leu Phe Asp Arg His His Leu His Arg Gln Thr Thr
545 550 555 560
Trp Gly Tyr Glu Gly Ala Met Asn Ile Val Thr Thr Leu Val Asn Ala
565 570 575
Val Leu Glu Lys Leu Asp Ser Asp Thr Ser Gln Leu Gly Lys Thr Asp
580 585 590
Tyr Ser Phe Asp Leu Val Arg
595
<210> 61
<211> 11
<212> Белок
<213> Hypocrea jecorina
<400> 61
Ala Thr Pro Pro Pro Gly Ser Thr Thr Thr Arg
1 5 10
<210> 62
<211> 8
<212> Белок
<213> Искусственная последовательность
<220>
<223> Эпитоп FLAG
<400> 62
Asp Tyr Lys Asp Asp Asp Asp Lys
1 5
<210> 63
<211> 30
<212> Белок
<213> Искусственная последовательность
<220>
<223> Линкер
<400> 63
Ala Thr Pro Pro Pro Gly Ser Thr Thr Thr Ala Asp Tyr Lys Asp Asp
1 5 10 15
Asp Asp Lys Ala Thr Pro Pro Pro Gly Ser Thr Thr Thr Ala
20 25 30
<210> 64
<211> 1110
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 64
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Thr Asn Ala Thr Gly Glu Arg Asn Leu Ala Leu Ile Gln Glu Val Leu
85 90 95
Glu Val Phe Pro Glu Thr Ala Arg Lys Glu Arg Arg Lys His Met Met
100 105 110
Val Ser Asp Pro Lys Met Lys Ser Val Gly Lys Cys Ile Ile Ser Asn
115 120 125
Arg Lys Ser Gln Pro Gly Val Met Thr Val Arg Gly Cys Ala Tyr Ala
130 135 140
Gly Ser Lys Gly Val Val Phe Gly Pro Ile Lys Asp Met Ala His Ile
145 150 155 160
Ser His Gly Pro Ala Gly Cys Gly Gln Tyr Ser Arg Ala Glu Arg Arg
165 170 175
Asn Tyr Tyr Thr Gly Val Ser Gly Val Asp Ser Phe Gly Thr Leu Asn
180 185 190
Phe Thr Ser Asp Phe Gln Glu Arg Asp Ile Val Phe Gly Gly Asp Lys
195 200 205
Lys Leu Ser Lys Leu Ile Glu Glu Met Glu Leu Leu Phe Pro Leu Thr
210 215 220
Lys Gly Ile Thr Ile Gln Ser Glu Cys Pro Val Gly Leu Ile Gly Asp
225 230 235 240
Asp Ile Ser Ala Val Ala Asn Ala Ser Ser Lys Ala Leu Asp Lys Pro
245 250 255
Val Ile Pro Val Arg Cys Glu Gly Phe Arg Gly Val Ser Gln Ser Leu
260 265 270
Gly His His Ile Ala Asn Asp Val Val Arg Asp Trp Ile Leu Asn Asn
275 280 285
Arg Glu Gly Gln Pro Phe Glu Thr Thr Pro Tyr Asp Val Ala Ile Ile
290 295 300
Gly Asp Tyr Asn Ile Gly Gly Asp Ala Trp Ala Ser Arg Ile Leu Leu
305 310 315 320
Glu Glu Met Gly Leu Arg Val Val Ala Gln Trp Ser Gly Asp Gly Thr
325 330 335
Leu Val Glu Met Glu Asn Thr Pro Phe Val Lys Leu Asn Leu Val His
340 345 350
Cys Tyr Arg Ser Met Asn Tyr Ile Ala Arg His Met Glu Glu Lys His
355 360 365
Gln Ile Pro Trp Met Glu Tyr Asn Phe Phe Gly Pro Thr Lys Ile Ala
370 375 380
Glu Ser Leu Arg Lys Ile Ala Asp Gln Phe Asp Asp Thr Ile Arg Ala
385 390 395 400
Asn Ala Glu Ala Val Ile Ala Arg Tyr Glu Gly Gln Met Ala Ala Ile
405 410 415
Ile Ala Lys Tyr Arg Pro Arg Leu Glu Gly Arg Lys Val Leu Leu Tyr
420 425 430
Ile Gly Gly Leu Arg Pro Arg His Val Ile Gly Ala Tyr Glu Asp Leu
435 440 445
Gly Met Glu Ile Ile Ala Ala Gly Tyr Glu Phe Ala His Asn Asp Asp
450 455 460
Tyr Asp Arg Thr Leu Pro Asp Leu Lys Glu Gly Thr Leu Leu Phe Asp
465 470 475 480
Asp Ala Ser Ser Tyr Glu Leu Glu Ala Phe Val Lys Ala Leu Lys Pro
485 490 495
Asp Leu Ile Gly Ser Gly Ile Lys Glu Lys Tyr Ile Phe Gln Lys Met
500 505 510
Gly Val Pro Phe Arg Gln Met His Ser Trp Asp Tyr Ser Gly Pro Tyr
515 520 525
His Gly Tyr Asp Gly Phe Ala Ile Phe Ala Arg Asp Met Asp Met Thr
530 535 540
Leu Asn Asn Pro Ala Trp Asn Glu Leu Thr Ala Pro Trp Leu Lys Ser
545 550 555 560
Ala Ala Thr Pro Pro Pro Gly Ser Thr Thr Thr Ala Asp Tyr Lys Asp
565 570 575
Asp Asp Asp Lys Ala Thr Pro Pro Pro Gly Ser Thr Thr Thr Ala Ser
580 585 590
Gln Thr Ile Asp Lys Ile Asn Ser Cys Tyr Pro Leu Phe Glu Gln Asp
595 600 605
Glu Tyr Gln Glu Leu Phe Arg Asn Lys Arg Gln Leu Glu Glu Ala His
610 615 620
Asp Ala Gln Arg Val Gln Glu Val Phe Ala Trp Thr Thr Thr Ala Glu
625 630 635 640
Tyr Glu Ala Leu Asn Phe Arg Arg Glu Ala Leu Thr Val Asp Pro Ala
645 650 655
Lys Ala Cys Gln Pro Leu Gly Ala Val Leu Cys Ser Leu Gly Phe Ala
660 665 670
Asn Thr Leu Pro Tyr Val His Gly Ser Gln Gly Cys Val Ala Tyr Phe
675 680 685
Arg Thr Tyr Phe Asn Arg His Phe Lys Glu Pro Ile Ala Cys Val Ser
690 695 700
Asp Ser Met Thr Glu Asp Ala Ala Val Phe Gly Gly Asn Asn Asn Met
705 710 715 720
Asn Leu Gly Leu Gln Asn Ala Ser Ala Leu Tyr Lys Pro Glu Ile Ile
725 730 735
Ala Val Ser Thr Thr Cys Met Ala Glu Val Ile Gly Asp Asp Leu Gln
740 745 750
Ala Phe Ile Ala Asn Ala Lys Lys Asp Gly Phe Val Asp Ser Ser Ile
755 760 765
Ala Val Pro His Ala His Thr Pro Ser Phe Ile Gly Ser His Val Thr
770 775 780
Gly Trp Asp Asn Met Phe Glu Gly Phe Ala Lys Thr Phe Thr Ala Asp
785 790 795 800
Tyr Gln Gly Gln Pro Gly Lys Leu Pro Lys Leu Asn Leu Val Thr Gly
805 810 815
Phe Glu Thr Tyr Leu Gly Asn Phe Arg Val Leu Lys Arg Met Met Glu
820 825 830
Gln Met Ala Val Pro Cys Ser Leu Leu Ser Asp Pro Ser Glu Val Leu
835 840 845
Asp Thr Pro Ala Asp Gly His Tyr Arg Met Tyr Ser Gly Gly Thr Thr
850 855 860
Gln Gln Glu Met Lys Glu Ala Pro Asp Ala Ile Asp Thr Leu Leu Leu
865 870 875 880
Gln Pro Trp Gln Leu Leu Lys Ser Lys Lys Val Val Gln Glu Met Trp
885 890 895
Asn Gln Pro Ala Thr Glu Val Ala Ile Pro Leu Gly Leu Ala Ala Thr
900 905 910
Asp Glu Leu Leu Met Thr Val Ser Gln Leu Ser Gly Lys Pro Ile Ala
915 920 925
Asp Ala Leu Thr Leu Glu Arg Gly Arg Leu Val Asp Met Met Leu Asp
930 935 940
Ser His Thr Trp Leu His Gly Lys Lys Phe Gly Leu Tyr Gly Asp Pro
945 950 955 960
Asp Phe Val Met Gly Leu Thr Arg Phe Leu Leu Glu Leu Gly Cys Glu
965 970 975
Pro Thr Val Ile Leu Ser His Asn Ala Asn Lys Arg Trp Gln Lys Ala
980 985 990
Met Asn Lys Met Leu Asp Ala Ser Pro Tyr Gly Arg Asp Ser Glu Val
995 1000 1005
Phe Ile Asn Cys Asp Leu Trp His Phe Arg Ser Leu Met Phe Thr
1010 1015 1020
Arg Gln Pro Asp Phe Met Ile Gly Asn Ser Tyr Gly Lys Phe Ile
1025 1030 1035
Gln Arg Asp Thr Leu Ala Lys Gly Lys Ala Phe Glu Val Pro Leu
1040 1045 1050
Ile Arg Leu Gly Phe Pro Leu Phe Asp Arg His His Leu His Arg
1055 1060 1065
Gln Thr Thr Trp Gly Tyr Glu Gly Ala Met Asn Ile Val Thr Thr
1070 1075 1080
Leu Val Asn Ala Val Leu Glu Lys Leu Asp Ser Asp Thr Ser Gln
1085 1090 1095
Leu Gly Lys Thr Asp Tyr Ser Phe Asp Leu Val Arg
1100 1105 1110
<210> 65
<211> 1119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 65
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Thr Asn Ala Thr Gly Glu Arg Asn Leu Ala Leu Ile Gln Glu Val Leu
85 90 95
Glu Val Phe Pro Glu Thr Ala Arg Lys Glu Arg Arg Lys His Met Met
100 105 110
Val Ser Asp Pro Lys Met Lys Ser Val Gly Lys Cys Ile Ile Ser Asn
115 120 125
Arg Lys Ser Gln Pro Gly Val Met Thr Val Arg Gly Cys Ala Tyr Ala
130 135 140
Gly Ser Lys Gly Val Val Phe Gly Pro Ile Lys Asp Met Ala His Ile
145 150 155 160
Ser His Gly Pro Ala Gly Cys Gly Gln Tyr Ser Arg Ala Glu Arg Arg
165 170 175
Asn Tyr Tyr Thr Gly Val Ser Gly Val Asp Ser Phe Gly Thr Leu Asn
180 185 190
Phe Thr Ser Asp Phe Gln Glu Arg Asp Ile Val Phe Gly Gly Asp Lys
195 200 205
Lys Leu Ser Lys Leu Ile Glu Glu Met Glu Leu Leu Phe Pro Leu Thr
210 215 220
Lys Gly Ile Thr Ile Gln Ser Glu Cys Pro Val Gly Leu Ile Gly Asp
225 230 235 240
Asp Ile Ser Ala Val Ala Asn Ala Ser Ser Lys Ala Leu Asp Lys Pro
245 250 255
Val Ile Pro Val Arg Cys Glu Gly Phe Arg Gly Val Ser Gln Ser Leu
260 265 270
Gly His His Ile Ala Asn Asp Val Val Arg Asp Trp Ile Leu Asn Asn
275 280 285
Arg Glu Gly Gln Pro Phe Glu Thr Thr Pro Tyr Asp Val Ala Ile Ile
290 295 300
Gly Asp Tyr Asn Ile Gly Gly Asp Ala Trp Ala Ser Arg Ile Leu Leu
305 310 315 320
Glu Glu Met Gly Leu Arg Val Val Ala Gln Trp Ser Gly Asp Gly Thr
325 330 335
Leu Val Glu Met Glu Asn Thr Pro Phe Val Lys Leu Asn Leu Val His
340 345 350
Cys Tyr Arg Ser Met Asn Tyr Ile Ala Arg His Met Glu Glu Lys His
355 360 365
Gln Ile Pro Trp Met Glu Tyr Asn Phe Phe Gly Pro Thr Lys Ile Ala
370 375 380
Glu Ser Leu Arg Lys Ile Ala Asp Gln Phe Asp Asp Thr Ile Arg Ala
385 390 395 400
Asn Ala Glu Ala Val Ile Ala Arg Tyr Glu Gly Gln Met Ala Ala Ile
405 410 415
Ile Ala Lys Tyr Arg Pro Arg Leu Glu Gly Arg Lys Val Leu Leu Tyr
420 425 430
Ile Gly Gly Leu Arg Pro Arg His Val Ile Gly Ala Tyr Glu Asp Leu
435 440 445
Gly Met Glu Ile Ile Ala Ala Gly Tyr Glu Phe Ala His Asn Asp Asp
450 455 460
Tyr Asp Arg Thr Leu Pro Asp Leu Lys Glu Gly Thr Leu Leu Phe Asp
465 470 475 480
Asp Ala Ser Ser Tyr Glu Leu Glu Ala Phe Val Lys Ala Leu Lys Pro
485 490 495
Asp Leu Ile Gly Ser Gly Ile Lys Glu Lys Tyr Ile Phe Gln Lys Met
500 505 510
Gly Val Pro Phe Arg Gln Met His Ser Trp Asp Tyr Ser Gly Pro Tyr
515 520 525
His Gly Tyr Asp Gly Phe Ala Ile Phe Ala Arg Asp Met Asp Met Thr
530 535 540
Leu Asn Asn Pro Ala Trp Asn Glu Leu Thr Ala Pro Trp Leu Lys Ser
545 550 555 560
Ala Ala Thr Pro Pro Pro Gly Ser Thr Thr Thr Ala Asp Tyr Lys Asp
565 570 575
Asp Asp Asp Lys Ala Thr Pro Pro Pro Gly Ser Thr Thr Thr Ala Ser
580 585 590
Gln Thr Ile Asp Lys Ile Asn Ser Cys Tyr Pro Leu Phe Glu Gln Asp
595 600 605
Glu Tyr Gln Glu Leu Phe Arg Asn Lys Arg Gln Leu Glu Glu Ala His
610 615 620
Asp Ala Gln Arg Val Gln Glu Val Phe Ala Trp Thr Thr Thr Ala Glu
625 630 635 640
Tyr Glu Ala Leu Asn Phe Arg Arg Glu Ala Leu Thr Val Asp Pro Ala
645 650 655
Lys Ala Cys Gln Pro Leu Gly Ala Val Leu Cys Ser Leu Gly Phe Ala
660 665 670
Asn Thr Leu Pro Tyr Val His Gly Ser Gln Gly Cys Val Ala Tyr Phe
675 680 685
Arg Thr Tyr Phe Asn Arg His Phe Lys Glu Pro Ile Ala Cys Val Ser
690 695 700
Asp Ser Met Thr Glu Asp Ala Ala Val Phe Gly Gly Asn Asn Asn Met
705 710 715 720
Asn Leu Gly Leu Gln Asn Ala Ser Ala Leu Tyr Lys Pro Glu Ile Ile
725 730 735
Ala Val Ser Thr Thr Cys Met Ala Glu Val Ile Gly Asp Asp Leu Gln
740 745 750
Ala Phe Ile Ala Asn Ala Lys Lys Asp Gly Phe Val Asp Ser Ser Ile
755 760 765
Ala Val Pro His Ala His Thr Pro Ser Phe Ile Gly Ser His Val Thr
770 775 780
Gly Trp Asp Asn Met Phe Glu Gly Phe Ala Lys Thr Phe Thr Ala Asp
785 790 795 800
Tyr Gln Gly Gln Pro Gly Lys Leu Pro Lys Leu Asn Leu Val Thr Gly
805 810 815
Phe Glu Thr Tyr Leu Gly Asn Phe Arg Val Leu Lys Arg Met Met Glu
820 825 830
Gln Met Ala Val Pro Cys Ser Leu Leu Ser Asp Pro Ser Glu Val Leu
835 840 845
Asp Thr Pro Ala Asp Gly His Tyr Arg Met Tyr Ser Gly Gly Thr Thr
850 855 860
Gln Gln Glu Met Lys Glu Ala Pro Asp Ala Ile Asp Thr Leu Leu Leu
865 870 875 880
Gln Pro Trp Gln Leu Leu Lys Ser Lys Lys Val Val Gln Glu Met Trp
885 890 895
Asn Gln Pro Ala Thr Glu Val Ala Ile Pro Leu Gly Leu Ala Ala Thr
900 905 910
Asp Glu Leu Leu Met Thr Val Ser Gln Leu Ser Gly Lys Pro Ile Ala
915 920 925
Asp Ala Leu Thr Leu Glu Arg Gly Arg Leu Val Asp Met Met Leu Asp
930 935 940
Ser His Thr Trp Leu His Gly Lys Lys Phe Gly Leu Tyr Gly Asp Pro
945 950 955 960
Asp Phe Val Met Gly Leu Thr Arg Phe Leu Leu Glu Leu Gly Cys Glu
965 970 975
Pro Thr Val Ile Leu Ser His Asn Ala Asn Lys Arg Trp Gln Lys Ala
980 985 990
Met Asn Lys Met Leu Asp Ala Ser Pro Tyr Gly Arg Asp Ser Glu Val
995 1000 1005
Phe Ile Asn Cys Asp Leu Trp His Phe Arg Ser Leu Met Phe Thr
1010 1015 1020
Arg Gln Pro Asp Phe Met Ile Gly Asn Ser Tyr Gly Lys Phe Ile
1025 1030 1035
Gln Arg Asp Thr Leu Ala Lys Gly Lys Ala Phe Glu Val Pro Leu
1040 1045 1050
Ile Arg Leu Gly Phe Pro Leu Phe Asp Arg His His Leu His Arg
1055 1060 1065
Gln Thr Thr Trp Gly Tyr Glu Gly Ala Met Asn Ile Val Thr Thr
1070 1075 1080
Leu Val Asn Ala Val Leu Glu Lys Leu Asp Ser Asp Thr Ser Gln
1085 1090 1095
Leu Gly Lys Thr Asp Tyr Ser Phe Asp Leu Val Arg Tyr Pro Tyr
1100 1105 1110
Asp Val Pro Asp Tyr Ala
1115
<210> 66
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевое удлинение
<400> 66
Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu
1 5 10
<210> 67
<211> 356
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 67
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Met Lys Ser Val Lys Asn Ile Gln Lys Ile Thr Lys Ala
50 55 60
Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala Val Gln Gly Ala Pro
65 70 75 80
Met Asn Pro Trp Gln Arg Phe Ala Arg Gln Arg Leu Ala Arg Ser Arg
85 90 95
Trp Asn Arg Asp Pro Ala Ala Leu Asp Pro Ala Asp Thr Pro Ala Phe
100 105 110
Glu Gln Ala Trp Gln Arg Gln Cys His Met Glu Gln Thr Ile Val Ala
115 120 125
Arg Val Pro Glu Gly Asp Ile Pro Ala Ala Leu Leu Glu Asn Ile Ala
130 135 140
Ala Ser Leu Ala Ile Trp Leu Asp Glu Gly Asp Phe Ala Pro Pro Glu
145 150 155 160
Arg Ala Ala Ile Val Arg His His Ala Arg Leu Glu Leu Ala Phe Ala
165 170 175
Asp Ile Ala Arg Gln Ala Pro Gln Pro Asp Leu Ser Thr Val Gln Ala
180 185 190
Trp Tyr Leu Arg His Gln Thr Gln Phe Met Arg Pro Glu Gln Arg Leu
195 200 205
Thr Arg His Leu Leu Leu Thr Val Asp Asn Asp Arg Glu Ala Val His
210 215 220
Gln Arg Ile Leu Gly Leu Tyr Arg Gln Ile Asn Ala Ser Arg Asp Ala
225 230 235 240
Phe Ala Pro Leu Ala Gln Arg His Ser His Cys Pro Ser Ala Leu Glu
245 250 255
Glu Gly Arg Leu Gly Trp Ile Ser Arg Gly Leu Leu Tyr Pro Gln Leu
260 265 270
Glu Thr Ala Leu Phe Ser Leu Ala Glu Asn Ala Leu Ser Leu Pro Ile
275 280 285
Ala Ser Glu Leu Gly Trp His Leu Leu Trp Cys Glu Ala Ile Arg Pro
290 295 300
Ala Ala Pro Met Glu Pro Gln Gln Ala Leu Glu Ser Ala Arg Asp Tyr
305 310 315 320
Leu Trp Gln Gln Ser Gln Gln Arg His Gln Arg Gln Trp Leu Glu Gln
325 330 335
Met Ile Ser Arg Gln Pro Gly Leu Cys Gly Glu Gln Lys Leu Ile Ser
340 345 350
Glu Glu Asp Leu
355
<210> 68
<211> 1723
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 68
atggcaatgg ctgttttccg tcgcgaaggg aggcgtctcc tcccttgaat acgccgctcg 60
cccaatcgct gctatccgat ctcctctctc ttctgaccag gaggaaggac ttcttggagt 120
tcgatctatc tcaactcaag tggtgcgtaa ccgcatgaag agtgttaaga acatccaaaa 180
gatcacaaag gcaatgaaga tggttgctgc ttccaagctt agagcagttc aaggcgcgcc 240
aactaatgct actggtgaaa gaaacctcgc tctcatccaa gaggttttgg aagtttttcc 300
tgagactgct aggaaagaaa ggcgtaagca catgatggtg tctgatccta agatgaagtc 360
tgtgggaaag tgcatcatct ctaacagaaa gtctcagcct ggtgtgatga ctgttagagg 420
atgtgcttat gctggatcta agggtgttgt tttcggacct atcaaggata tggctcatat 480
ctctcatgga cctgctggat gtggacaata ttctagagct gagcgtagga actactacac 540
tggtgtttct ggtgtggatt ctttcggaac tctcaacttc acctctgatt tccaagagcg 600
tgatatcgtt ttcggaggtg ataagaagct ctctaagttg atcgaagaga tggaactctt 660
gttcccactc actaagggaa tcactatcca atctgagtgc cctgttggac ttatcggaga 720
tgatatttct gctgtggcta acgcttcttc taaggctctt gataagcctg ttatccctgt 780
tagatgtgaa ggattcaggg gagtttctca gtctcttgga catcatatcg ctaacgatgt 840
ggtgagagat tggatcctta acaacagaga gggacaacct ttcgagacta ctccttacga 900
tgttgctatc atcggagact acaacattgg aggtgatgct tgggcttcta gaatccttct 960
tgaagagatg ggactcagag ttgttgctca atggtctggt gatggtactc ttgttgagat 1020
ggaaaacacc cctttcgtta agctcaacct cgttcattgc taccgtagca tgaactacat 1080
tgctagacac atggaagaga agcaccaaat tccttggatg gagtacaact tcttcggacc 1140
tactaagatc gctgagtctc ttagaaagat cgctgatcag ttcgatgata ccatcagagc 1200
taatgctgag gctgttattg ctagatacga gggacaaatg gctgctatta tcgctaagta 1260
cagacctaga ctcgagggaa gaaaggtttt gctttacatc ggaggactca gacctagaca 1320
tgttattgga gcttacgagg atctcggaat ggaaattatt gctgctggat acgagttcgc 1380
tcacaacgat gattacgata gaactctccc tgacctcaaa gagggaactc ttcttttcga 1440
tgacgcttct tcatacgagc ttgaggcttt tgttaaggct cttaagcctg atctcatcgg 1500
atctggaatc aaagagaagt acatcttcca gaagatggga gttcctttca gacagatgca 1560
ctcttgggat tattctggac cttaccatgg atacgacgga tttgctatct tcgctaggga 1620
tatggatatg actctcaaca atcctgcttg gaacgaactt actgctcctt ggcttaagtc 1680
tgctgccggc tacccttacg acgttcctga ttacgctccc ggg 1723
<210> 69
<211> 4
<212> Белок
<213> Klebsiella pneumoniae
<400> 69
Asp Leu Arg Val
1
<210> 70
<211> 117
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 70
atgtcaactc aagtggtgcg taaccgcatg aagagtgtta agaacatcca aaagatcaca 60
aaggcaatga agatggttgc tgcttccaag cttagagcag ttcaaggcgc gccaact 117
<210> 71
<211> 39
<212> Белок
<213> Искусственная последовательность
<220>
<223> Слитый полипептид
<400> 71
Met Ser Thr Gln Val Val Arg Asn Arg Lys Ser Val Lys Asn Ile Gln
1 5 10 15
Lys Ile Thr Lys Ala Met Lys Met Val Ala Ala Ser Lys Leu Arg Ala
20 25 30
Val Gln Gly Ala Pro Thr Met
35
<210> 72
<211> 33
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 72
atgatgacta atgctactgg cgaacgtaac ctg 33
<210> 73
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Праймер
<400> 73
ccggctcctc cgctagataa aaatgtga 28
<210> 74
<211> 86
<212> Белок
<213> Klebsiella pneumoniae
<400> 74
Met Met Glu Trp Phe Tyr Gln Ile Pro Gly Val Asp Glu Leu Arg Ser
1 5 10 15
Ala Glu Ser Phe Phe Gln Phe Phe Ala Val Pro Tyr Gln Pro Glu Leu
20 25 30
Leu Gly Arg Cys Ser Leu Pro Val Leu Ala Thr Phe His Arg Lys Leu
35 40 45
Arg Ala Glu Val Pro Leu Gln Asn Arg Leu Glu Asp Asn Asp Arg Ala
50 55 60
Pro Trp Leu Leu Ala Arg Arg Leu Leu Ala Glu Ser Tyr Gln Gln Gln
65 70 75 80
Phe Gln Glu Ser Gly Thr
85
<210> 75
<211> 51
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 75
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg
50
<210> 76
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> МНП-след
<400> 76
Ile Ser Thr Gln Val Val Arg Asn Arg
1 5
<210> 77
<211> 33
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 77
Met Tyr Arg Phe Ala Ser Asn Leu Ala Ser Lys Ala Arg Ile Ala Gln
1 5 10 15
Asn Ala Arg Gln Val Ser Ser Arg Met Ser Trp Ser Arg Asn Tyr Gly
20 25 30
Gly
<210> 78
<211> 31
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 78
Met Tyr Arg Phe Ala Ser Asn Leu Ala Ser Lys Ala Arg Ile Ala Gln
1 5 10 15
Asn Ala Arg Gln Val Ser Ser Arg Met Ser Trp Ser Arg Asn Tyr
20 25 30
<210> 79
<211> 31
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 79
Met Ala Ile Arg Cys Val Ala Ser Arg Lys Thr Leu Ala Gly Leu Lys
1 5 10 15
Glu Thr Ser Ser Arg Leu Leu Arg Ile Arg Gly Ile Gln Gly Gly
20 25 30
<210> 80
<211> 60
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 80
Met Ala Ile Arg Cys Val Ala Ser Arg Lys Thr Leu Ala Gly Leu Lys
1 5 10 15
Glu Thr Ser Ser Arg Leu Leu Arg Ile Arg Gly Ile Gln Met Ala Ile
20 25 30
Arg Cys Val Ala Ser Arg Lys Thr Leu Ala Gly Leu Lys Glu Thr Ser
35 40 45
Ser Arg Leu Leu Arg Ile Arg Gly Ile Gln Gly Gly
50 55 60
<210> 81
<211> 29
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 81
Met Ala Ile Arg Cys Val Ala Ser Arg Lys Thr Leu Ala Gly Leu Lys
1 5 10 15
Glu Thr Ser Ser Arg Leu Leu Arg Ile Arg Gly Gly Gly
20 25
<210> 82
<211> 56
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 82
Met Ala Ile Arg Cys Val Ala Ser Arg Lys Thr Leu Ala Gly Leu Lys
1 5 10 15
Glu Thr Ser Ser Arg Leu Leu Arg Ile Arg Gly Met Ala Ile Arg Cys
20 25 30
Val Ala Ser Arg Lys Thr Leu Ala Gly Leu Lys Glu Thr Ser Ser Arg
35 40 45
Leu Leu Arg Ile Arg Gly Gly Gly
50 55
<210> 83
<211> 34
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 83
Met Phe Leu Thr Arg Phe Val Gly Arg Arg Phe Leu Ala Ala Ala Ser
1 5 10 15
Ala Arg Ser Glu Ser Thr Thr Ala Ala Ala Ala Ala Ser Thr Ile Arg
20 25 30
Gly Gly
<210> 84
<211> 70
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 84
Met Ala Ser Thr Arg Val Leu Ala Ser Arg Leu Ala Ser Gln Met Ala
1 5 10 15
Ala Ser Ala Lys Val Ala Arg Pro Ala Val Arg Val Ala Gln Val Ser
20 25 30
Lys Arg Thr Ile Gln Thr Gly Ser Pro Leu Gln Thr Leu Lys Arg Thr
35 40 45
Gln Met Thr Ser Ile Val Asn Ala Thr Thr Arg Gln Ala Phe Gln Lys
50 55 60
Arg Ala Tyr Ser Gly Gly
65 70
<210> 85
<211> 53
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 85
Met Ala Met Ala Val Phe Arg Arg Glu Gly Arg Arg Leu Leu Pro Ser
1 5 10 15
Ile Ala Ala Arg Pro Ile Ala Ala Ile Arg Ser Pro Leu Ser Ser Asp
20 25 30
Gln Glu Glu Gly Leu Leu Gly Val Arg Ser Ile Ser Thr Gln Val Val
35 40 45
Arg Asn Arg Gly Gly
50
<210> 86
<211> 61
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 86
Met Leu Ser Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala Thr Arg
1 5 10 15
Thr Leu Cys Ser Ser Arg Tyr Leu Leu Gln Gln Lys Pro Ser Ala Trp
20 25 30
Ser His Pro Gln Phe Glu Lys Gly Gly Gly Ser Gly Gly Gly Ser Gly
35 40 45
Gly Ser Ala Trp Ser His Pro Gln Phe Glu Lys Gly Gly
50 55 60
<210> 87
<211> 43
<212> Белок
<213> Искусственная последовательность
<220>
<223> N-концевое удлинение
<400> 87
Met Leu Ser Leu Arg Gln Ser Ile Arg Phe Phe Lys Pro Ala Thr Arg
1 5 10 15
Thr Leu Cys Ser Ser Arg Tyr Leu Leu Gln Gln Lys Pro Gly Gly His
20 25 30
His His His His His His His His His Gly Gly
35 40
<210> 88
<211> 4
<212> Белок
<213> Искусственная последовательность
<220>
<223> Предсказанный след
<400> 88
Ile Gln Gly Gly
1
<210> 89
<211> 4
<212> Белок
<213> Искусственная последовательность
<220>
<223> Предсказанный след
<400> 89
Ile Gln Gly Gly
1
<210> 90
<211> 15
<212> Белок
<213> Искусственная последовательность
<220>
<223> Предсказанный след
<400> 90
Glu Ser Thr Thr Ala Ala Ala Ala Ala Ser Thr Ile Arg Gly Gly
1 5 10 15
<210> 91
<211> 4
<212> Белок
<213> Искусственная последовательность
<220>
<223> Предсказанный след
<400> 91
Tyr Ser Gly Gly
1
<210> 92
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> Предсказанный след
<400> 92
Ile Ser Thr Gln Val Val Arg Asn Arg Gly Gly
1 5 10
<210> 93
<211> 36
<212> Белок
<213> Искусственная последовательность
<220>
<223> Предсказанный след
<400> 93
Gln Gln Lys Pro Ser Ala Trp Ser His Pro Gln Phe Glu Lys Gly Gly
1 5 10 15
Gly Ser Gly Gly Gly Ser Gly Gly Ser Ala Trp Ser His Pro Gln Phe
20 25 30
Glu Lys Gly Gly
35
<210> 94
<211> 16
<212> Белок
<213> Искусственная последовательность
<220>
<223> Предсказанный след
<400> 94
Lys Pro Gly Gly His His His His His His His His His His Gly Gly
1 5 10 15
<210> 95
<211> 488
<212> Белок
<213> Искусственная последовательность
<220>
<223> вариант
<400> 95
Met Met Thr Asn Ala Thr Gly Glu Arg Asn Leu Ala Leu Ile Gln Glu
1 5 10 15
Val Leu Glu Val Phe Pro Glu Thr Ala Arg Lys Glu Arg Arg Lys His
20 25 30
Met Met Val Ser Asp Pro Glu Met Glu Ser Val Gly Lys Cys Ile Ile
35 40 45
Ser Asn Arg Lys Ser Gln Pro Gly Val Met Thr Val Arg Gly Cys Ala
50 55 60
Tyr Ala Gly Ser Lys Gly Val Val Phe Gly Pro Ile Lys Asp Met Ala
65 70 75 80
His Ile Ser His Gly Pro Val Gly Cys Gly Gln Tyr Ser Arg Ala Gly
85 90 95
Arg Arg Asn Tyr Tyr Thr Gly Val Ser Gly Val Asp Ser Phe Gly Thr
100 105 110
Leu Asn Phe Thr Ser Asp Phe Gln Glu Arg Asp Ile Val Phe Gly Gly
115 120 125
Asp Lys Lys Leu Ser Lys Leu Ile Glu Glu Met Glu Leu Leu Phe Pro
130 135 140
Leu Thr Lys Gly Ile Thr Ile Gln Ser Glu Cys Pro Val Gly Leu Ile
145 150 155 160
Gly Asp Asp Ile Ser Ala Val Ala Asn Ala Ser Ser Lys Ala Leu Asp
165 170 175
Lys Pro Val Ile Pro Val Arg Cys Glu Gly Phe Arg Gly Val Ser Gln
180 185 190
Ser Leu Gly His His Ile Ala Asn Asp Val Val Arg Asp Trp Ile Leu
195 200 205
Asn Asn Arg Glu Gly Gln Pro Phe Glu Thr Thr Pro Tyr Asp Val Ala
210 215 220
Ile Ile Gly Asp Tyr Asn Ile Gly Gly Asp Ala Trp Ala Ser Arg Ile
225 230 235 240
Leu Leu Glu Glu Met Gly Leu Arg Val Val Ala Gln Trp Ser Gly Asp
245 250 255
Gly Thr Leu Val Glu Met Glu Asn Thr Pro Phe Val Lys Leu Asn Leu
260 265 270
Val His Cys Tyr Arg Ser Met Asn Tyr Ile Ala Arg His Met Glu Glu
275 280 285
Lys His Gln Ile Pro Trp Met Glu Tyr Asn Phe Phe Gly Pro Thr Lys
290 295 300
Ile Ala Glu Ser Leu Arg Lys Ile Ala Asp Gln Phe Asp Asp Thr Ile
305 310 315 320
Arg Ala Asn Ala Glu Ala Val Ile Ala Arg Tyr Glu Gly Gln Met Ala
325 330 335
Ala Ile Ile Ala Lys Tyr Arg Pro Arg Leu Glu Gly Arg Lys Val Leu
340 345 350
Leu Tyr Met Gly Gly Leu Arg Pro Arg His Val Ile Gly Ala Tyr Glu
355 360 365
Asp Leu Gly Met Glu Ile Ile Ala Ala Gly Tyr Glu Phe Ala His Asn
370 375 380
Asp Asp Tyr Asp Arg Thr Leu Pro Asp Leu Lys Glu Gly Thr Leu Leu
385 390 395 400
Phe Asp Asp Ala Ser Ser Tyr Glu Leu Glu Ala Phe Val Lys Ala Leu
405 410 415
Lys Pro Asp Leu Ile Gly Ser Gly Ile Lys Glu Lys Tyr Ile Phe Gln
420 425 430
Lys Met Gly Val Pro Phe Arg Gln Met His Ser Trp Asp Tyr Ser Gly
435 440 445
Pro Tyr His Gly Tyr Asp Gly Phe Ala Ile Phe Ala Arg Asp Met Asp
450 455 460
Met Thr Leu Asn Asn Pro Ala Trp Asn Glu Leu Thr Ala Pro Trp Leu
465 470 475 480
Lys Ser Gly Val Arg Pro Arg Ser
485
<210> 96
<211> 400
<212> Белок
<213> Искусственная последовательность
<220>
<223> вариант
<400> 96
Met Lys Gln Val Tyr Leu Asp Asn Asn Ala Thr Thr Arg Leu Asp Pro
1 5 10 15
Met Val Leu Glu Ala Met Met Pro Phe Leu Thr Asp Phe Tyr Gly Asn
20 25 30
Pro Ser Ser Ile His Asp Phe Gly Ile Pro Ala Gln Ala Ala Leu Glu
35 40 45
Arg Ala His Gln Gln Ala Ala Ala Leu Leu Gly Ala Glu Tyr Pro Ser
50 55 60
Glu Ile Ile Phe Thr Ser Cys Ala Thr Glu Ala Thr Ala Thr Ala Ile
65 70 75 80
Ala Ser Ala Ile Ala Leu Leu Pro Glu Arg Arg Glu Ile Ile Thr Ser
85 90 95
Val Val Glu His Pro Ala Thr Leu Ala Ala Cys Glu His Leu Glu Arg
100 105 110
Gln Gly Tyr Arg Ile His Arg Ile Ala Val Asp Ser Glu Gly Ala Leu
115 120 125
Asp Met Ala Gln Phe Arg Ala Ala Leu Ser Pro Arg Val Ala Leu Val
130 135 140
Ser Val Met Trp Ala Asn Asn Glu Thr Gly Val Leu Phe Pro Ile Gly
145 150 155 160
Glu Met Ala Glu Leu Ala His Glu Gln Gly Ala Leu Phe His Cys Asp
165 170 175
Ala Val Gln Val Val Gly Lys Ile Pro Ile Ala Val Gly Gln Thr Arg
180 185 190
Ile Asp Met Leu Ser Cys Ser Ala His Lys Phe His Gly Pro Lys Gly
195 200 205
Val Gly Cys Leu Tyr Leu Arg Arg Gly Thr Arg Phe Arg Pro Leu Leu
210 215 220
Arg Gly Gly His Gln Glu Tyr Gly Arg Arg Ala Gly Thr Glu Asn Ile
225 230 235 240
Cys Gly Ile Val Gly Met Gly Ala Ala Cys Glu Leu Ala Asn Ile His
245 250 255
Leu Pro Gly Met Thr His Ile Gly Gln Leu Arg Asn Arg Leu Glu His
260 265 270
Arg Leu Leu Ala Ser Val Pro Ser Val Met Val Met Gly Gly Gly Gln
275 280 285
Pro Arg Val Pro Gly Thr Val Asn Leu Ala Phe Glu Phe Ile Glu Gly
290 295 300
Glu Ala Ile Leu Leu Leu Leu Asn Gln Ala Gly Ile Ala Ala Ser Ser
305 310 315 320
Gly Ser Ala Cys Thr Ser Gly Ser Leu Glu Pro Ser His Val Met Arg
325 330 335
Ala Met Asn Ile Pro Tyr Thr Ala Ala His Gly Thr Ile Arg Phe Ser
340 345 350
Leu Ser Arg Tyr Thr Arg Glu Lys Glu Ile Asp Tyr Val Val Ala Thr
355 360 365
Leu Pro Pro Ile Ile Asp Arg Leu Arg Ala Leu Ser Pro Tyr Trp Gln
370 375 380
Asn Gly Lys Pro Arg Pro Ala Asp Ala Val Phe Thr Pro Val Tyr Gly
385 390 395 400
<210> 97
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевое удлинение
<400> 97
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1 5
<210> 98
<211> 59
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 98
tcatcaagcg taatcaggaa catcgtaggg gtaacgaacc agatcgaaag aatagtcgg 59
<210> 99
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 99
aagggcgaat tccagcacac tgg 23
<210> 100
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 100
cctgattgta tccgcatctg atgctac 27
<210> 101
<211> 39
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 101
aacctgcagg gctaactaac taaccacgga caaaaaacc 39
<210> 102
<211> 56
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 102
ggtagcatca gatgcggata caatcaggtc atcaagcgta atcaggaaca tcgagg 56
<210> 103
<211> 51
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 103
ccagtgtgct ggaattcgcc cttaacctgc agggctaact aactaaccac g 51
<210> 104
<211> 30
<212> Белок
<213> Искусственная последовательность
<220>
<223> линкер
<400> 104
Ala Thr Pro Pro Pro Gly Ser Thr Thr Thr Ala Tyr Pro Tyr Asp Val
1 5 10 15
Pro Asp Tyr Ala Thr Pro Pro Pro Gly Ser Thr Thr Thr Ala
20 25 30
<210> 105
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 105
atgatgacta acgctacagg agaa 24
<210> 106
<211> 32
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 106
tcatcatcta accaaatcaa aactgtaatc tg 32
<210> 107
<211> 44
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 107
ccggctcctc cgctagataa aaatgtgaat ttttgcatgc agcc 44
<210> 108
<211> 36
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 108
cctgattgta tccgcatctg atgctaccgt ggttga 36
<210> 109
<211> 39
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 109
ttctcctgta gcgttagtca tcatccggct cctccgcta 39
<210> 110
<211> 45
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 110
cagatgcgga tacaatcagg tcatcatcta accaaatcaa aactg 45
<210> 111
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> линкер
<400> 111
Met Ser Thr Gln Val Val Arg Asn Arg
1 5
<210> 112
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> Последовательность эпитопа HA
<400> 112
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1 5
<210> 113
<211> 46
<212> Белок
<213> Искусственная последовательность
<220>
<223> линкер
<400> 113
Thr Ser Ser Gly Gly Thr Ser Thr Gly Gly Ser Thr Thr Thr Thr Ala
1 5 10 15
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Ser Gly Thr Thr Ser Thr Lys
20 25 30
Ala Ser Thr Thr Ser Thr Ser Ser Thr Ser Thr Gly Thr Gly
35 40 45
<210> 114
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 114
atgaagggaa atgagattct tgctctt 27
<210> 115
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 115
tcatcaatca gcagcataag cacc 24
<210> 116
<211> 30
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 116
ttgtaataac ctccagtgat gaattgaata 30
<210> 117
<211> 30
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 117
ctagagatta atatggagaa attaagcatg 30
<210> 118
<211> 59
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 118
aagagcaaga atctcatttc ccttcatttg taataacctc cagtgatgaa ttgatagtg 59
<210> 119
<211> 61
<212> ДНК
<213> Искусственная последовательность
<220>
<223> олигонуклеотидный праймер
<400> 119
tagttttcat gcttaatttc tccatattaa tctctagtca tcaatcagca gcataagcac 60
c 61
<210> 120
<211> 545
<212> Белок
<213> Искусственная последовательность
<220>
<223> промотор
<400> 120
Thr Ala Ala Thr Thr Gly Thr Thr Ala Thr Thr Ala Thr Cys Ala Ala
1 5 10 15
Thr Ala Ala Ala Ala Gly Ala Ala Thr Thr Thr Thr Thr Ala Thr Thr
20 25 30
Gly Thr Thr Ala Thr Thr Gly Thr Gly Thr Thr Ala Thr Thr Thr Gly
35 40 45
Gly Thr Ala Ala Thr Thr Thr Ala Thr Gly Cys Thr Thr Ala Thr Ala
50 55 60
Ala Gly Thr Ala Ala Thr Thr Cys Thr Ala Thr Gly Ala Thr Thr Ala
65 70 75 80
Ala Thr Thr Gly Thr Gly Ala Ala Thr Thr Ala Ala Thr Ala Ala Gly
85 90 95
Ala Cys Thr Ala Ala Thr Gly Ala Gly Gly Ala Thr Ala Ala Thr Ala
100 105 110
Ala Thr Thr Gly Ala Ala Thr Thr Thr Gly Ala Thr Thr Ala Ala Ala
115 120 125
Thr Thr Ala Ala Cys Thr Cys Thr Gly Cys Gly Ala Ala Gly Cys Cys
130 135 140
Ala Thr Ala Thr Gly Thr Cys Thr Thr Thr Cys Ala Cys Gly Thr Gly
145 150 155 160
Ala Gly Ala Gly Thr Cys Ala Cys Gly Thr Gly Ala Thr Gly Thr Cys
165 170 175
Thr Cys Cys Gly Cys Gly Ala Cys Ala Gly Gly Cys Thr Gly Gly Cys
180 185 190
Ala Cys Gly Gly Gly Gly Cys Thr Thr Ala Gly Thr Ala Thr Thr Ala
195 200 205
Cys Cys Cys Cys Cys Gly Thr Gly Cys Cys Gly Gly Gly Ala Thr Cys
210 215 220
Ala Gly Ala Gly Ala Cys Ala Thr Thr Thr Gly Ala Cys Thr Ala Ala
225 230 235 240
Ala Thr Gly Thr Thr Gly Ala Cys Thr Thr Gly Gly Ala Ala Thr Ala
245 250 255
Ala Thr Ala Gly Cys Cys Cys Thr Thr Gly Gly Ala Thr Thr Ala Gly
260 265 270
Ala Thr Gly Ala Cys Ala Cys Gly Thr Gly Gly Ala Cys Gly Cys Thr
275 280 285
Cys Ala Gly Gly Ala Thr Cys Thr Gly Thr Gly Ala Thr Gly Cys Thr
290 295 300
Ala Gly Thr Gly Ala Ala Gly Cys Gly Cys Thr Thr Ala Ala Gly Cys
305 310 315 320
Thr Gly Ala Ala Cys Gly Ala Ala Thr Cys Thr Gly Ala Cys Gly Gly
325 330 335
Ala Ala Gly Ala Gly Cys Gly Gly Ala Cys Ala Ala Ala Cys Gly Cys
340 345 350
Ala Cys Ala Thr Gly Gly Ala Cys Thr Ala Thr Gly Gly Cys Cys Cys
355 360 365
Ala Cys Thr Gly Cys Thr Thr Thr Ala Thr Thr Ala Ala Ala Gly Ala
370 375 380
Ala Gly Thr Gly Ala Ala Thr Gly Ala Cys Ala Gly Cys Thr Gly Thr
385 390 395 400
Cys Thr Thr Thr Gly Cys Thr Thr Cys Ala Ala Gly Ala Cys Gly Ala
405 410 415
Ala Gly Thr Ala Ala Ala Gly Ala Ala Thr Ala Gly Thr Gly Gly Ala
420 425 430
Ala Ala Ala Cys Gly Cys Gly Thr Ala Ala Ala Gly Ala Ala Thr Ala
435 440 445
Ala Gly Cys Gly Thr Ala Cys Thr Cys Ala Gly Thr Ala Cys Gly Cys
450 455 460
Thr Thr Cys Gly Thr Gly Gly Cys Thr Thr Thr Ala Thr Ala Ala Ala
465 470 475 480
Thr Ala Gly Thr Gly Cys Thr Thr Cys Gly Thr Cys Thr Thr Ala Thr
485 490 495
Thr Cys Thr Thr Cys Gly Thr Thr Gly Thr Ala Thr Cys Ala Thr Cys
500 505 510
Ala Ala Cys Gly Ala Ala Gly Ala Ala Gly Thr Thr Ala Ala Gly Cys
515 520 525
Thr Thr Thr Gly Thr Thr Cys Thr Gly Cys Gly Thr Thr Thr Thr Ala
530 535 540
Ala
545
<210> 121
<211> 528
<212> Белок
<213> Искусственная последовательность
<220>
<223> промотор
<400> 121
Thr Ala Ala Thr Thr Gly Thr Thr Ala Thr Thr Ala Thr Cys Ala Ala
1 5 10 15
Thr Ala Ala Ala Ala Gly Ala Ala Thr Thr Thr Thr Thr Ala Thr Thr
20 25 30
Gly Thr Thr Ala Thr Thr Gly Thr Gly Thr Thr Ala Thr Thr Thr Gly
35 40 45
Gly Thr Ala Ala Thr Thr Thr Ala Thr Gly Cys Thr Thr Ala Thr Ala
50 55 60
Ala Gly Thr Ala Ala Thr Thr Cys Thr Ala Thr Gly Ala Thr Thr Ala
65 70 75 80
Ala Thr Thr Gly Thr Gly Ala Ala Thr Thr Ala Ala Thr Ala Ala Gly
85 90 95
Ala Cys Thr Ala Ala Thr Gly Ala Gly Gly Ala Thr Ala Ala Thr Ala
100 105 110
Ala Thr Thr Gly Ala Ala Thr Thr Thr Gly Ala Thr Thr Ala Ala Ala
115 120 125
Thr Thr Ala Ala Cys Thr Cys Thr Gly Cys Gly Ala Ala Gly Cys Cys
130 135 140
Ala Thr Ala Thr Gly Thr Cys Thr Thr Thr Cys Ala Cys Gly Thr Gly
145 150 155 160
Ala Gly Ala Gly Thr Cys Ala Cys Gly Thr Gly Ala Thr Gly Thr Cys
165 170 175
Thr Cys Cys Gly Cys Gly Ala Cys Ala Gly Gly Cys Thr Gly Gly Cys
180 185 190
Ala Cys Gly Gly Gly Gly Cys Thr Thr Ala Gly Thr Ala Thr Thr Ala
195 200 205
Cys Cys Cys Cys Cys Gly Thr Gly Cys Cys Gly Gly Gly Ala Thr Cys
210 215 220
Ala Gly Ala Gly Ala Cys Ala Thr Thr Thr Gly Ala Cys Thr Ala Ala
225 230 235 240
Ala Thr Gly Thr Thr Gly Ala Cys Thr Thr Gly Gly Ala Ala Thr Ala
245 250 255
Ala Thr Ala Gly Cys Cys Cys Thr Thr Gly Gly Ala Thr Thr Ala Gly
260 265 270
Ala Thr Gly Ala Cys Ala Cys Gly Thr Gly Gly Ala Cys Gly Cys Thr
275 280 285
Cys Ala Gly Gly Ala Thr Cys Thr Gly Thr Gly Ala Thr Gly Cys Thr
290 295 300
Ala Gly Thr Gly Ala Ala Gly Cys Gly Cys Thr Thr Ala Ala Gly Cys
305 310 315 320
Thr Gly Ala Ala Cys Gly Ala Ala Thr Cys Thr Gly Ala Cys Gly Gly
325 330 335
Ala Ala Gly Ala Gly Cys Gly Gly Ala Cys Ala Ala Ala Cys Gly Cys
340 345 350
Ala Cys Ala Thr Gly Gly Ala Cys Thr Ala Thr Gly Gly Cys Cys Cys
355 360 365
Ala Cys Thr Gly Cys Thr Thr Thr Ala Thr Thr Ala Ala Ala Gly Ala
370 375 380
Ala Gly Thr Gly Ala Ala Thr Gly Ala Cys Ala Gly Cys Thr Gly Thr
385 390 395 400
Cys Thr Thr Thr Gly Cys Thr Thr Cys Ala Ala Gly Ala Cys Gly Ala
405 410 415
Ala Gly Thr Ala Ala Ala Gly Ala Ala Thr Ala Gly Thr Gly Gly Ala
420 425 430
Ala Ala Ala Cys Gly Cys Gly Thr Ala Ala Ala Gly Ala Ala Thr Ala
435 440 445
Ala Gly Cys Gly Thr Ala Cys Thr Cys Ala Gly Thr Ala Cys Gly Cys
450 455 460
Thr Thr Cys Gly Thr Gly Gly Cys Thr Thr Thr Ala Thr Ala Ala Ala
465 470 475 480
Thr Ala Gly Thr Gly Cys Thr Thr Cys Gly Thr Cys Thr Thr Ala Thr
485 490 495
Thr Cys Thr Thr Cys Gly Thr Thr Gly Thr Ala Thr Cys Ala Thr Cys
500 505 510
Ala Ala Cys Gly Ala Ala Gly Ala Ala Gly Thr Thr Ala Ala Gly Cys
515 520 525
<210> 122
<211> 569
<212> Белок
<213> Искусственная последовательность
<220>
<223> промотор
<400> 122
Thr Ala Ala Thr Thr Ala Ala Thr Ala Gly Thr Ala Ala Thr Thr Ala
1 5 10 15
Thr Gly Ala Thr Thr Ala Ala Thr Thr Ala Thr Gly Ala Gly Ala Thr
20 25 30
Ala Ala Gly Ala Gly Thr Thr Gly Thr Thr Ala Thr Thr Ala Ala Thr
35 40 45
Gly Cys Thr Thr Ala Thr Gly Ala Gly Gly Ala Ala Thr Ala Ala Ala
50 55 60
Gly Ala Ala Thr Gly Ala Thr Thr Ala Ala Thr Ala Thr Thr Gly Thr
65 70 75 80
Thr Thr Ala Ala Thr Thr Thr Thr Ala Thr Thr Cys Cys Gly Cys Gly
85 90 95
Ala Ala Gly Cys Gly Gly Thr Gly Thr Gly Thr Thr Ala Thr Gly Thr
100 105 110
Thr Thr Thr Thr Gly Thr Thr Gly Gly Ala Gly Ala Cys Ala Thr Cys
115 120 125
Ala Cys Gly Thr Gly Ala Cys Thr Cys Thr Cys Ala Cys Gly Thr Gly
130 135 140
Ala Thr Gly Thr Cys Thr Cys Cys Gly Cys Gly Ala Cys Ala Gly Gly
145 150 155 160
Cys Thr Gly Gly Cys Ala Cys Gly Gly Gly Gly Cys Thr Thr Ala Gly
165 170 175
Thr Ala Thr Thr Ala Cys Cys Cys Cys Cys Gly Thr Gly Cys Cys Gly
180 185 190
Gly Gly Ala Thr Cys Ala Gly Ala Gly Ala Cys Ala Thr Thr Thr Gly
195 200 205
Ala Cys Thr Ala Ala Ala Thr Ala Thr Thr Gly Ala Cys Thr Thr Gly
210 215 220
Gly Ala Ala Thr Ala Ala Thr Ala Gly Cys Cys Cys Thr Thr Gly Gly
225 230 235 240
Ala Thr Thr Ala Gly Ala Thr Gly Ala Cys Ala Cys Gly Thr Gly Gly
245 250 255
Ala Cys Gly Cys Thr Cys Ala Gly Gly Ala Thr Cys Thr Gly Thr Gly
260 265 270
Ala Thr Gly Cys Thr Ala Gly Thr Gly Ala Ala Gly Cys Gly Cys Thr
275 280 285
Thr Ala Ala Gly Cys Thr Gly Ala Ala Cys Gly Ala Ala Thr Cys Thr
290 295 300
Gly Ala Cys Gly Gly Ala Ala Gly Ala Gly Cys Gly Gly Ala Cys Ala
305 310 315 320
Thr Ala Cys Gly Cys Ala Cys Ala Thr Gly Gly Ala Thr Thr Ala Thr
325 330 335
Gly Gly Cys Cys Cys Ala Cys Ala Thr Gly Thr Cys Thr Ala Ala Ala
340 345 350
Gly Thr Gly Thr Ala Thr Cys Thr Cys Thr Thr Thr Ala Cys Ala Gly
355 360 365
Cys Thr Ala Thr Ala Thr Cys Gly Ala Thr Gly Thr Gly Ala Cys Gly
370 375 380
Thr Ala Ala Gly Ala Thr Gly Cys Thr Thr Thr Ala Cys Thr Thr Cys
385 390 395 400
Gly Cys Thr Thr Cys Gly Ala Ala Gly Thr Ala Ala Ala Gly Thr Ala
405 410 415
Gly Gly Ala Ala Ala Thr Thr Gly Cys Thr Cys Gly Cys Thr Ala Ala
420 425 430
Gly Thr Thr Ala Thr Thr Cys Thr Thr Thr Thr Cys Thr Gly Ala Ala
435 440 445
Ala Gly Ala Ala Ala Thr Thr Ala Ala Thr Thr Thr Ala Ala Thr Thr
450 455 460
Cys Thr Ala Ala Ala Thr Thr Ala Ala Ala Thr Thr Ala Ala Ala Thr
465 470 475 480
Gly Ala Gly Thr Gly Gly Cys Thr Ala Thr Ala Ala Ala Thr Ala Gly
485 490 495
Thr Gly Thr Cys Gly Ala Thr Gly Cys Thr Ala Cys Cys Thr Cys Ala
500 505 510
Cys Ala Thr Cys Gly Thr Ala Thr Thr Cys Thr Thr Cys Thr Thr Cys
515 520 525
Gly Cys Ala Thr Cys Gly Thr Cys Thr Gly Thr Thr Cys Thr Gly Gly
530 535 540
Thr Thr Thr Thr Ala Ala Gly Gly Ala Ala Thr Thr Cys Thr Ala Gly
545 550 555 560
Ala Gly Thr Cys Ala Gly Ala Cys Cys
565
<210> 123
<211> 1428
<212> ДНК
<213> Искусственная последовательность
<220>
<223> промотор
<400> 123
ggaggaattc caatcccaca aaaatctgag cttaacagca cagttgctcc tctcagagca 60
gaatcgggta ttcaacaccc tcatatcaac tactacgttg tgtataacgg tccacatgcc 120
ggtatatacg atgactgggg ttgtacaaag gcggcaacaa acggcgttcc cggagttgca 180
cacaagaaat ttgccactat tacagaggca agagcagcag ctgacgcgta cacaacaagt 240
cagcaaacag acaggttgaa cttcatcccc aaaggagaag ctcaactcaa gcccaagagc 300
tttgctaagg ccctaacaag cccaccaaag caaaaagccc actggctcac gctaggaacc 360
aaaaggccca gcagtgatcc agccccaaaa gagatctcct ttgccccgga gattacaatg 420
gacgatttcc tctatcttta cgatctagga aggaagttcg aaggtgaagg tgacgacact 480
atgttcacca ctgataatga gaaggttagc ctcttcaatt tcagaaagaa tgctgaccca 540
cagatggtta gagaggccta cgcagcaagt ctcatcaaga cgatctaccc gagtaacaat 600
ctccaggaga tcaaatacct tcccaagaag gttaaagatg cagtcaaaag attcaggact 660
aattgcatca agaacacaga gaaagacata tttctcaaga tcagaagtac tattccagta 720
tggacgattc aaggcttgct tcataaacca aggcaagtaa tagagattgg agtctctaaa 780
aaggtagttc ctactgaatc taaggccatg catggagtct aagattcaaa tcgaggatct 840
aacagaactc gccgtcaaga ctggcgaaca gttcatacag agtcttttac gactcaatga 900
caagaagaaa atcttcgtca acatggtgga gcacgacact ctggtctact ccaaaaatgt 960
caaagataca gtctcagaag atcaaagggc tattgagact tttcaacaaa ggataatttc 1020
gggaaacctc ctcggattcc attgcccagc tatctgtcac ttcatcgaaa ggacagtaga 1080
aaaggaaggt ggctcctaca aatgccatca ttgcgataaa ggaaaggcta tcattcaaga 1140
tctctctgcc gacagtggtc ccaaagatgg acccccaccc acgaggagca tcgtggaaaa 1200
agaagaggtt ccaaccacgt ctacaaagca agtggattga tgtgacatct ccactgacgt 1260
aagggatgac gcacaatccc actatccttc gcaagaccct tcctctatat aaggaagttc 1320
atttcatttg gagaggacac gctcgagtat aagagctcat ttttacaaca attaccaaca 1380
acaacaaaca acaaacaaca ttacaattac atttacaatt atcgatac 1428
<210> 124
<211> 839
<212> ДНК
<213> Искусственная последовательность
<220>
<223> промотор
<400> 124
gtcaacatgg tggagcacga cactctggtc tactccaaaa atgtcaaaga tacagtctca 60
gaagatcaaa gggctattga gacttttcaa caaaggataa tttcgggaaa cctcctcgga 120
ttccattgcc cagctatctg tcacttcatc gaaaggacag tagaaaagga aggtggctcc 180
tacaaatgcc atcattgcga taaaggaaag gctatcattc aagatctctc tgccgacagt 240
ggtcccaaag atggaccccc acccacgagg agcatcgtgg aaaaagaaga ggttccaacc 300
acgtctacaa agcaagtgga ttgatgtgat aacatggtgg agcacgacac tctggtctac 360
tccaaaaatg tcaaagatac agtctcagaa gatcaaaggg ctattgagac ttttcaacaa 420
aggataattt cgggaaacct cctcggattc cattgcccag ctatctgtca cttcatcgaa 480
aggacagtag aaaaggaagg tggctcctac aaatgccatc attgcgataa aggaaaggct 540
atcattcaag atctctctgc cgacagtggt cccaaagatg gacccccacc cacgaggagc 600
atcgtggaaa aagaagaggt tccaaccacg tctacaaagc aagtggattg atgtgacatc 660
tccactgacg taagggatga cgcacaatcc cactatcctt cgcaagaccc ttcctctata 720
taaggaagtt catttcattt ggagaggaca cgctcgagta taagagctca tttttacaac 780
aattaccaac aacaacaaac aacaaacaac attacaatta catttacaat tatcgatac 839
<210> 125
<211> 172
<212> Белок
<213> Tombusvirus
<400> 125
Met Glu Arg Ala Ile Gln Gly Asn Asp Ala Arg Glu Gln Ala Asn Ser
1 5 10 15
Glu Arg Trp Asp Gly Gly Ser Gly Ser Ser Thr Ser Pro Phe Gln Leu
20 25 30
Pro Asp Glu Ser Pro Ser Trp Thr Glu Trp Arg Leu His Asn Asp Glu
35 40 45
Thr Asn Ser Asn Gln Asp Asn Pro Leu Gly Phe Lys Glu Ser Trp Gly
50 55 60
Phe Gly Lys Val Val Phe Lys Arg Tyr Leu Arg Tyr Glu Arg Thr Glu
65 70 75 80
Thr Ser Leu His Arg Val Leu Gly Ser Trp Thr Gly Asp Ser Val Asn
85 90 95
Tyr Ala Ala Ser Arg Phe Phe Gly Val Asn Gln Ile Gly Cys Thr Tyr
100 105 110
Ser Ile Arg Phe Arg Gly Val Ser Val Thr Ile Ser Gly Gly Ser Arg
115 120 125
Thr Leu Gln His Leu Cys Glu Met Ala Ile Arg Ser Lys Gln Glu Leu
130 135 140
Leu Gln Leu Thr Pro Val Glu Val Glu Ser Asn Val Ser Arg Gly Cys
145 150 155 160
Pro Glu Gly Val Glu Thr Phe Glu Glu Glu Ser Glu
165 170
<210> 126
<211> 17
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 126
Leu His Asn Asp Glu Thr Asn Ser Asn Gln Asp Asn Pro Leu Gly Phe
1 5 10 15
Lys
<210> 127
<211> 16
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 127
Val Leu Gly Ser Trp Thr Gly Asp Ser Val Asn Tyr Ala Ala Ser Arg
1 5 10 15
<210> 128
<211> 18
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 128
Ile Asn Ser Cys Tyr Pro Leu Phe Glu Gln Asp Glu Tyr Gln Glu Leu
1 5 10 15
Phe Arg
<210> 129
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 129
Gln Leu Glu Glu Ala His Asp Ala Gln Arg
1 5 10
<210> 130
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 130
Glu Ala Leu Thr Val Asp Pro Ala Lys
1 5
<210> 131
<211> 12
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 131
Thr Phe Thr Ala Asp Tyr Gln Gly Gln Pro Gly Lys
1 5 10
<210> 132
<211> 18
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 132
Leu Pro Lys Leu Asn Leu Val Thr Gly Phe Glu Thr Tyr Leu Gly Asn
1 5 10 15
Phe Arg
<210> 133
<211> 28
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 133
Met Met Glu Gln Met Ala Val Pro Cys Ser Leu Leu Ser Asp Pro Ser
1 5 10 15
Glu Val Leu Asp Thr Pro Ala Asp Gly His Tyr Arg
20 25
<210> 134
<211> 12
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 134
Met Tyr Ser Gly Gly Thr Thr Gln Gln Glu Met Lys
1 5 10
<210> 135
<211> 18
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 135
Glu Ala Pro Asp Ala Ile Asp Thr Leu Leu Leu Gln Pro Trp Gln Leu
1 5 10 15
Leu Lys
<210> 136
<211> 15
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 136
Phe Gly Leu Tyr Gly Asp Pro Asp Phe Val Met Gly Leu Thr Arg
1 5 10 15
<210> 137
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 137
Asp Ser Glu Val Phe Ile Asn Cys Asp Leu Trp His Phe Arg
1 5 10
<210> 138
<211> 12
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 138
Gln Pro Asp Phe Met Ile Gly Asn Ser Tyr Gly Lys
1 5 10
<210> 139
<211> 8
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 139
Ala Phe Glu Val Pro Leu Ile Arg
1 5
<210> 140
<211> 8
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 140
Leu Gly Phe Pro Leu Phe Asp Arg
1 5
<210> 141
<211> 23
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 141
Gln Thr Thr Trp Gly Tyr Glu Gly Ala Met Asn Ile Val Thr Thr Leu
1 5 10 15
Val Asn Ala Val Leu Glu Lys
20
<210> 142
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 142
Leu Asp Ser Asp Thr Ser Gln Leu Gly Lys
1 5 10
<210> 143
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 143
Thr Asp Tyr Ser Phe Asp Leu Val Arg
1 5
<210> 144
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 144
Leu Gly Thr Gln Met Ile His Phe Val Pro Arg
1 5 10
<210> 145
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 145
Met Thr Val Ile Glu Tyr Asp Pro Ala Cys Lys
1 5 10
<210> 146
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 146
Val Met Ile Val Gly Cys Asp Pro Lys
1 5
<210> 147
<211> 16
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 147
Cys Ala Glu Ser Gly Gly Pro Glu Pro Gly Val Gly Cys Ala Gly Arg
1 5 10 15
<210> 148
<211> 16
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 148
Ser Thr Thr Thr Gln Asn Leu Val Ala Ala Leu Ala Glu Met Gly Lys
1 5 10 15
<210> 149
<211> 17
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 149
Ser Thr Thr Thr Gln Asn Leu Val Ala Ala Leu Ala Glu Met Gly Lys
1 5 10 15
Lys
<210> 150
<211> 15
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 150
Gln Thr Asp Arg Glu Asp Glu Leu Ile Ile Ala Leu Ala Glu Lys
1 5 10 15
<210> 151
<211> 23
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 151
Ala Gln Glu Ile Tyr Ile Val Cys Ser Gly Glu Met Met Ala Met Tyr
1 5 10 15
Ala Ala Asn Asn Ile Ser Lys
20
<210> 152
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 152
Ala Val Gln Gly Ala Pro Thr Met Arg
1 5
<210> 153
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 153
Leu Gly Gly Leu Ile Cys Asn Ser Arg
1 5
<210> 154
<211> 32
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 154
Ala Gln Asn Thr Ile Met Glu Met Ala Ala Glu Val Gly Ser Val Glu
1 5 10 15
Asp Leu Glu Leu Glu Asp Val Leu Gln Ile Gly Tyr Gly Asp Val Arg
20 25 30
<210> 155
<211> 16
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 155
Leu Cys Leu Ser Thr Asn Gly Leu Val Leu Pro Asp Ala Val Asp Arg
1 5 10 15
<210> 156
<211> 12
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 156
Phe Ala Ala Ile Leu Glu Leu Leu Ala Asp Val Lys
1 5 10
<210> 157
<211> 17
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 157
Gly Glu Ser Glu Ala Asp Asp Ala Cys Leu Val Ala Val Ala Ser Ser
1 5 10 15
Arg
<210> 158
<211> 16
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 158
Ala Val Gln Gly Ala Pro Thr Ser Cys Ser Ser Phe Ser Gly Gly Lys
1 5 10 15
<210> 159
<211> 19
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 159
Ile Asn Ser Val Leu Ile Pro Gly Ile Asn Asp Ser Gly Met Ala Gly
1 5 10 15
Val Ser Arg
<210> 160
<211> 26
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 160
Gln Val Ala Gln Ala Ile Pro Gln Leu Ser Val Val Gly Ile Ala Gly
1 5 10 15
Pro Gly Asp Pro Leu Ala Asn Ile Ala Arg
20 25
<210> 161
<211> 15
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 161
Ile Ala Gly Glu Leu Leu Pro Gly Val Phe His Val Ser Ala Arg
1 5 10 15
<210> 162
<211> 13
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 162
Gly Thr Ala Gln Asn Pro Asp Ile Tyr Phe Gln Glu Arg
1 5 10
<210> 163
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 163
Ile Pro Phe Val Asn Phe Phe Asp Gly Phe Arg
1 5 10
<210> 164
<211> 22
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 164
Ile Glu Val Leu Glu Tyr Glu Gln Leu Ala Thr Leu Leu Asp Arg Pro
1 5 10 15
Ala Leu Asp Ser Phe Arg
20
<210> 165
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 165
Ser Gly Gly Ile Thr Val Ser His Leu Arg
1 5 10
<210> 166
<211> 17
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 166
Glu Lys Glu Ile Asp Tyr Val Val Ala Thr Leu Pro Pro Ile Ile Asp
1 5 10 15
Arg
<210> 167
<211> 15
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 167
Glu Ile Asp Tyr Val Val Ala Thr Leu Pro Pro Ile Ile Asp Arg
1 5 10 15
<210> 168
<211> 15
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 168
Ile Ala Val Asp Gly Glu Gly Ala Leu Asp Met Ala Gln Phe Arg
1 5 10 15
<210> 169
<211> 21
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 169
Glu Ile Ile Thr Ser Val Val Glu His Pro Ala Thr Leu Ala Ala Cys
1 5 10 15
Glu His Met Glu Arg
20
<210> 170
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 170
Ile Asp Met Leu Ser Cys Ser Ala His Lys
1 5 10
<210> 171
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 171
Ala Met Asn Ile Pro Tyr Thr Ala Ala His Gly Thr Ile Arg
1 5 10
<210> 172
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 172
Gln Val Tyr Leu Asp Asn Asn Ala Thr Thr Arg
1 5 10
<210> 173
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 173
Ile Pro Ile Ala Val Gly Gln Thr Arg
1 5
<210> 174
<211> 8
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 174
Gly Val Gly Cys Leu Tyr Leu Arg
1 5
<210> 175
<211> 21
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 175
Val Pro Ala Asp Thr Thr Ile Val Gly Leu Leu Gln Glu Ile Gln Leu
1 5 10 15
Tyr Trp Tyr Asp Lys
20
<210> 176
<211> 13
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 176
Gln Phe Asp Met Val His Ser Asp Glu Trp Ser Met Lys
1 5 10
<210> 177
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 177
Val Val Asp Phe Ser Val Glu Asn Gly His Gln Thr Glu Lys
1 5 10
<210> 178
<211> 13
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 178
Arg Ala Gly Asp Tyr Lys Asp Asp Asp Asp Lys Pro Gly
1 5 10
<210> 179
<211> 13
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 179
Ala Arg Gly Asp Tyr Lys Asp Asp Asp Asp Lys Pro Gly
1 5 10
<210> 180
<211> 11
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 180
His Val Asp Gln His Phe Gly Ala Thr Pro Arg
1 5 10
<210> 181
<211> 9
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 181
Val Ala Phe Ala Ser Ser Asp Tyr Arg
1 5
<210> 182
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 182
Leu Leu Gln Glu Gln Glu Trp His Gly Asp Pro Asp Pro Arg
1 5 10
<210> 183
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 183
Leu Ala Ser Trp Leu Glu Glu Ile Lys Arg
1 5 10
<210> 184
<211> 16
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 184
Val Leu Gly Ser Trp Thr Gly Asp Ser Val Asn Tyr Ala Ala Ser Arg
1 5 10 15
<210> 185
<211> 14
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 185
Gln Leu Gly Glu Leu Ala Asp Ala Pro Val Asn Ile Asn Arg
1 5 10
<210> 186
<211> 18
<212> Белок
<213> Искусственная последовательность
<220>
<223> пептид
<400> 186
Phe Val Gly Leu Val Leu Asp Gln Asp Asn Gln Phe Asp Gln Thr Glu
1 5 10 15
Ala Arg
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| ЭКСПРЕССИЯ ПОЛИПЕПТИДОВ НИТРОГЕНАЗЫ В РАСТИТЕЛЬНЫХ КЛЕТКАХ | 2020 |
|
RU2833880C2 |
| СЛИТЫЕ СЕРПИНОВЫЕ ПОЛИПЕПТИДЫ И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2012 |
|
RU2698655C2 |
| СЛИТЫЕ СЕРПИНОВЫЕ ПОЛИПЕПТИДЫ И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2019 |
|
RU2728861C1 |
| МУЛЬТИВАЛЕНТНЫЕ PD-L1-СВЯЗЫВАЮЩИЕ СОЕДИНЕНИЯ ДЛЯ ЛЕЧЕНИЯ ЗЛОКАЧЕСТВЕННЫХ НОВООБРАЗОВАНИЙ | 2020 |
|
RU2816646C2 |
| СЛИТЫЕ СЕРПИНОВЫЕ ПОЛИПЕПТИДЫ И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2015 |
|
RU2746550C2 |
| КОНСТРУКЦИИ СЛИТОГО БЕЛКА ДЛЯ ЗАБОЛЕВАНИЯ, СВЯЗАННОГО С КОМПЛЕМЕНТОМ | 2019 |
|
RU2824402C2 |
| СЛИТЫЙ ПОЛИПЕПТИД, ВКЛЮЧАЮЩИЙ GDF15 И ПОЛИПЕПТИДНУЮ ОБЛАСТЬ, СПОСОБНУЮ К О-ГЛИКОЗИЛИРОВАНИЮ | 2020 |
|
RU2812049C1 |
| СЛИТЫЙ БЕЛОК GDF15 ДЛИТЕЛЬНОГО ДЕЙСТВИЯ И СОДЕРЖАЩАЯ ЕГО ФАРМАЦЕВТИЧЕСКАЯ КОМПОЗИЦИЯ | 2020 |
|
RU2836280C1 |
| АКТИВИРУЕМЫЕ ПОЛИПЕПТИДЫ ИНТЕРЛЕЙКИНА-2 И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2019 |
|
RU2826454C2 |
| АКТИВИРУЕМЫЕ ПОЛИПЕПТИДЫ ИНТЕРЛЕЙКИНА 12 И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2019 |
|
RU2826183C2 |
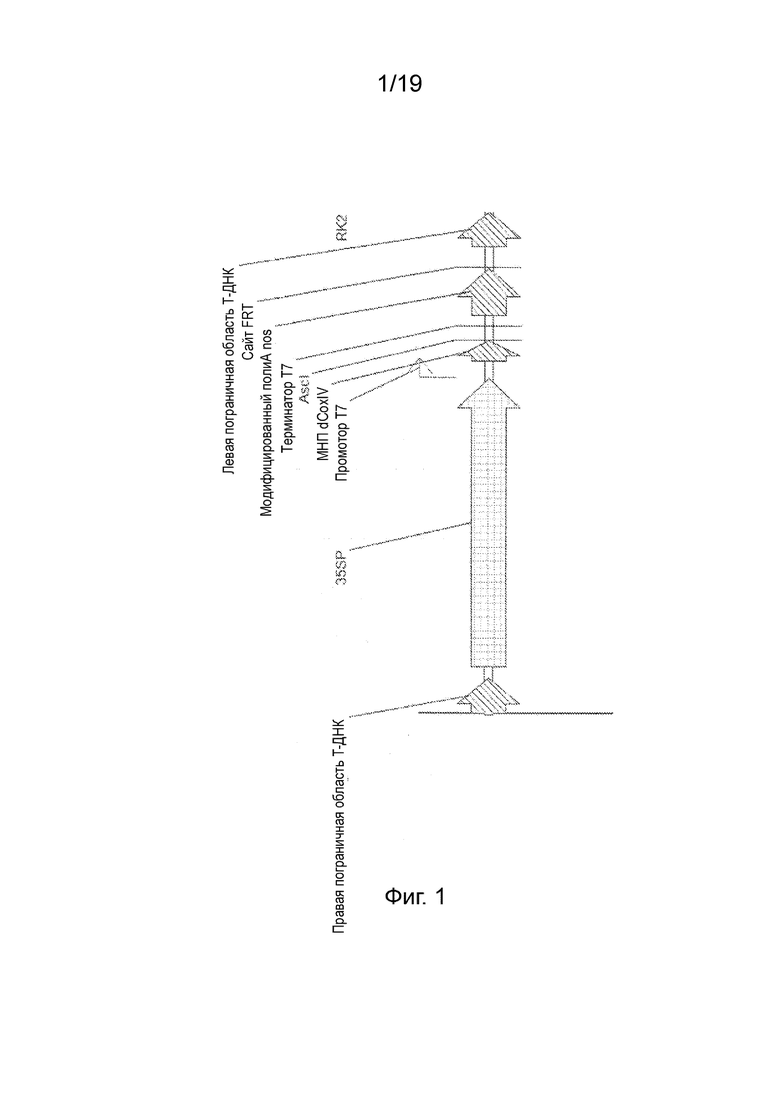

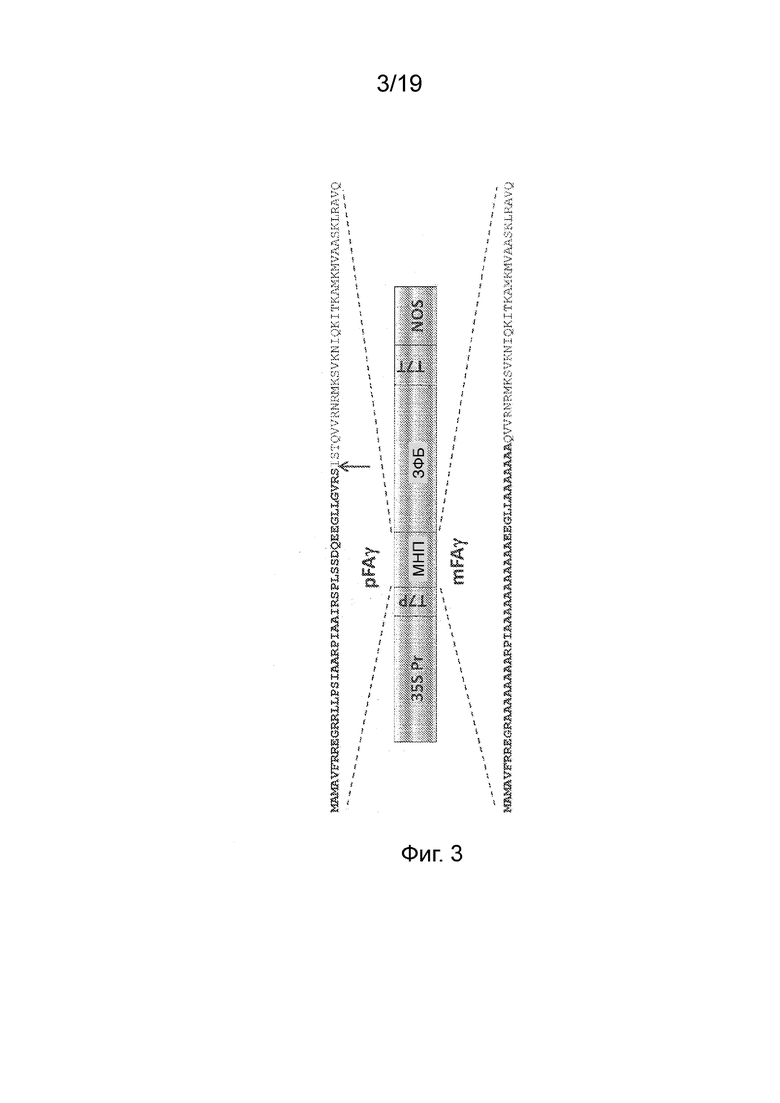
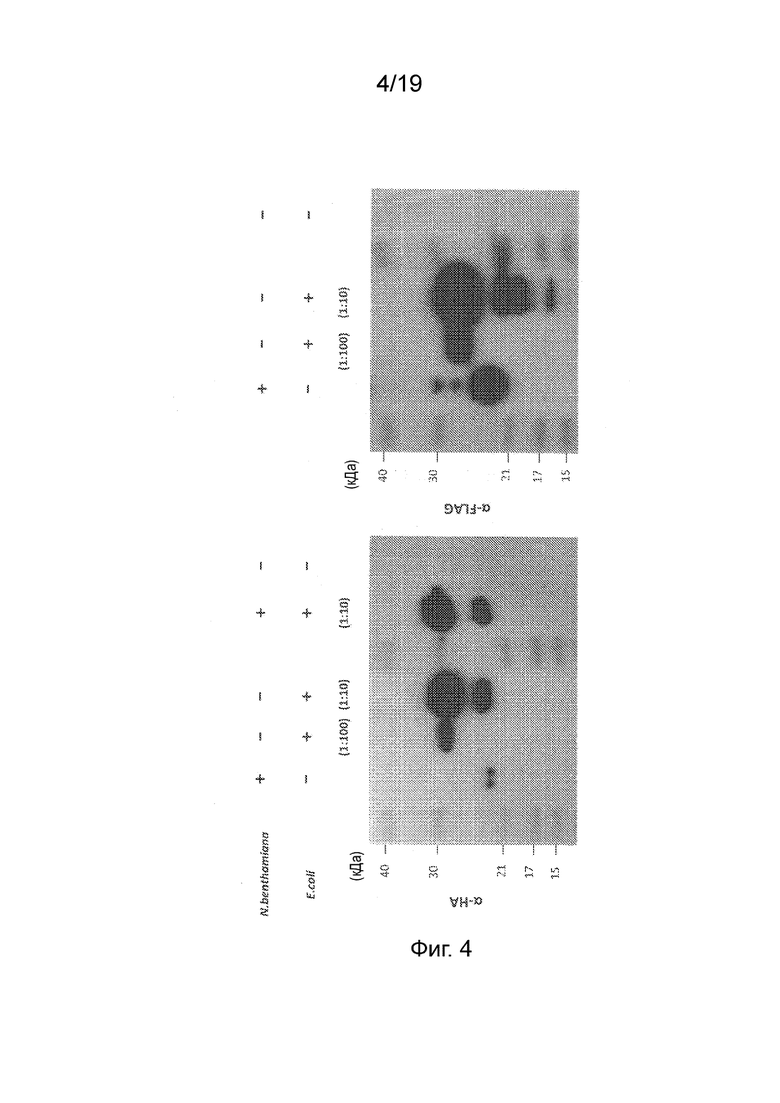
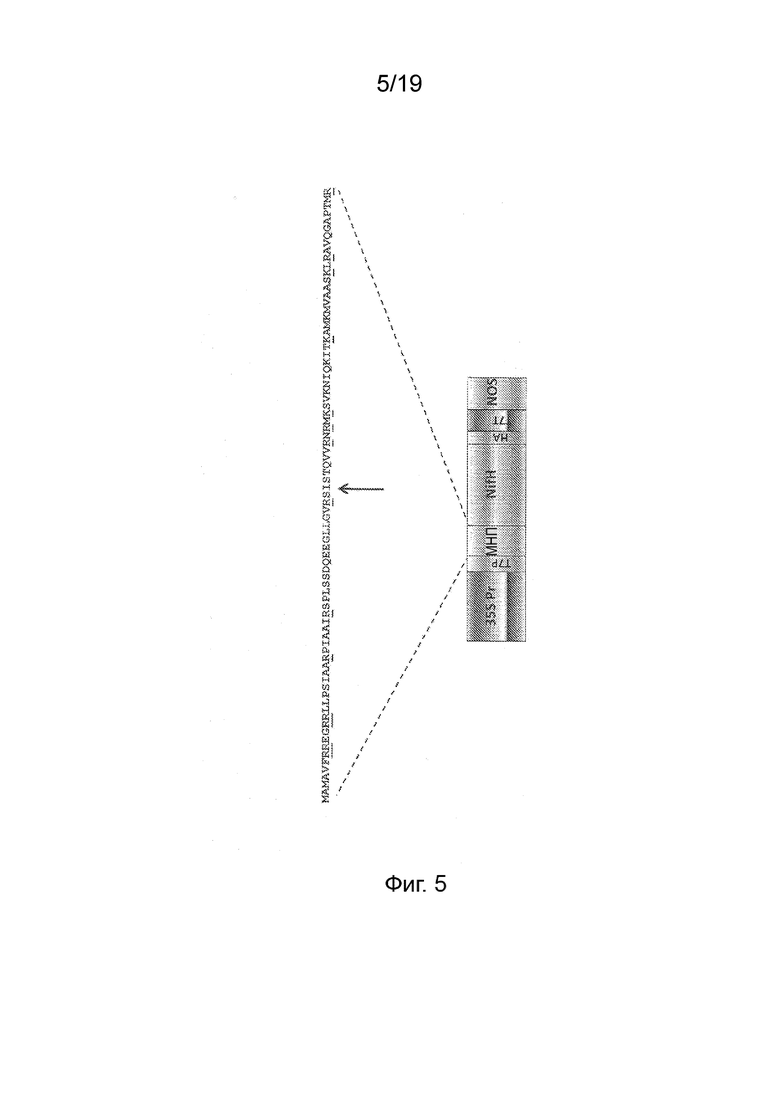
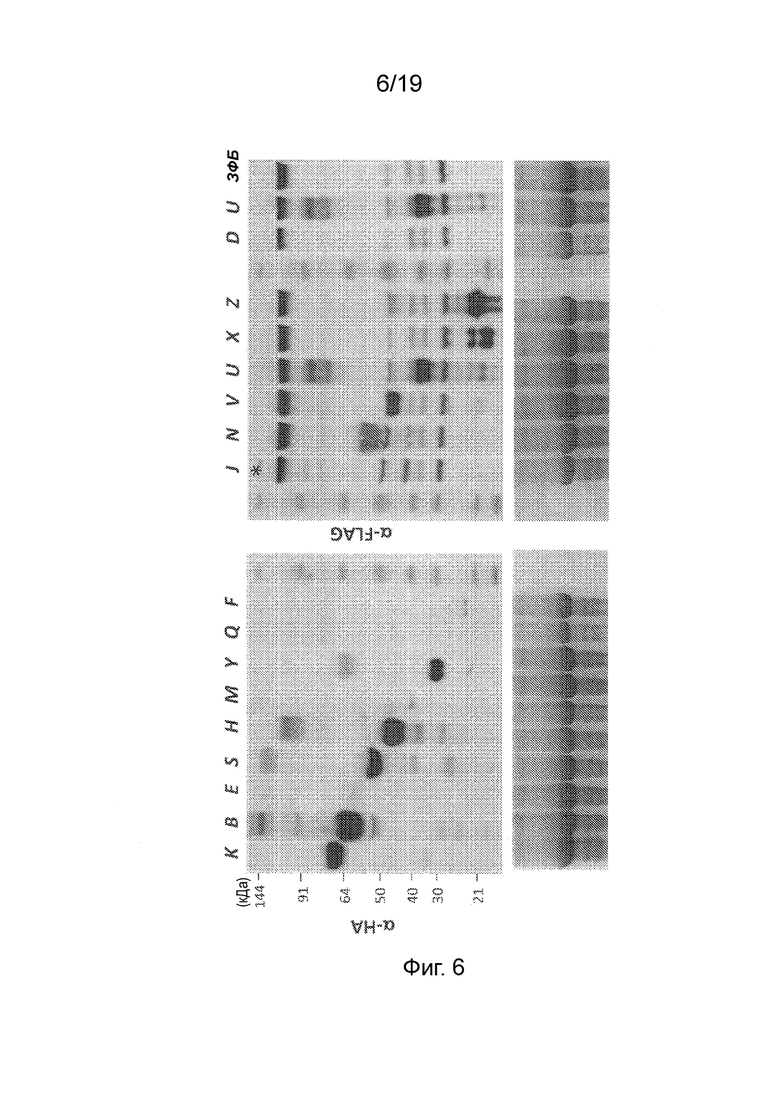
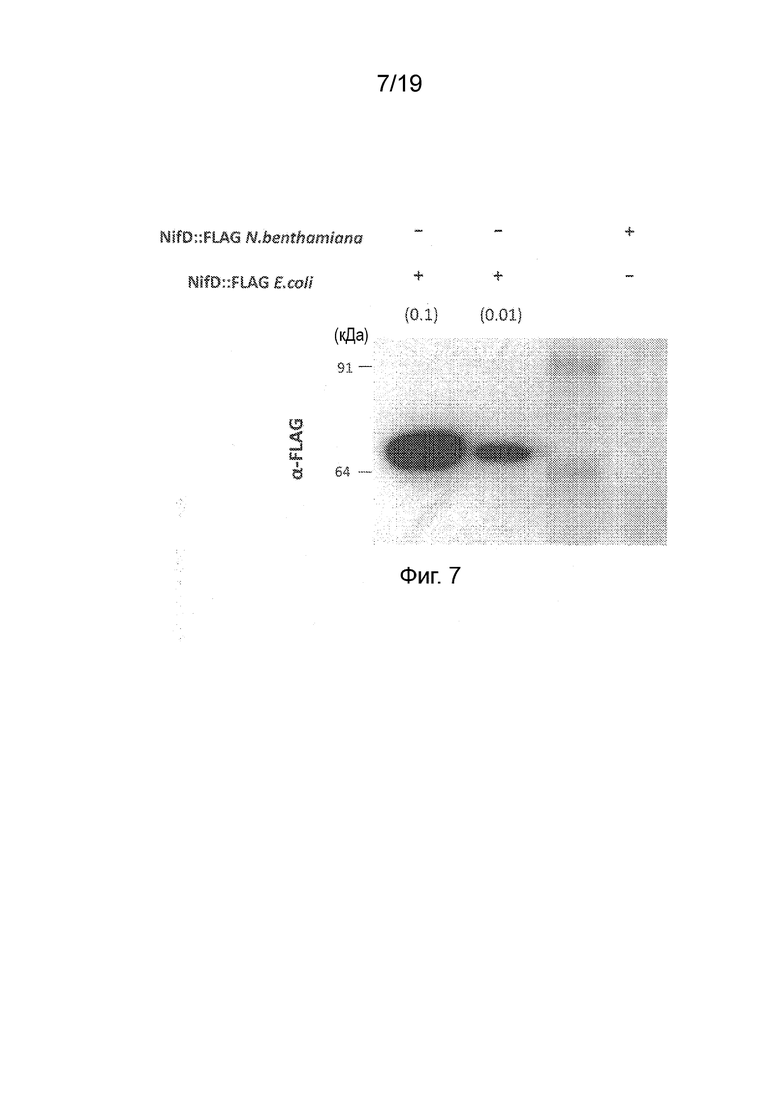

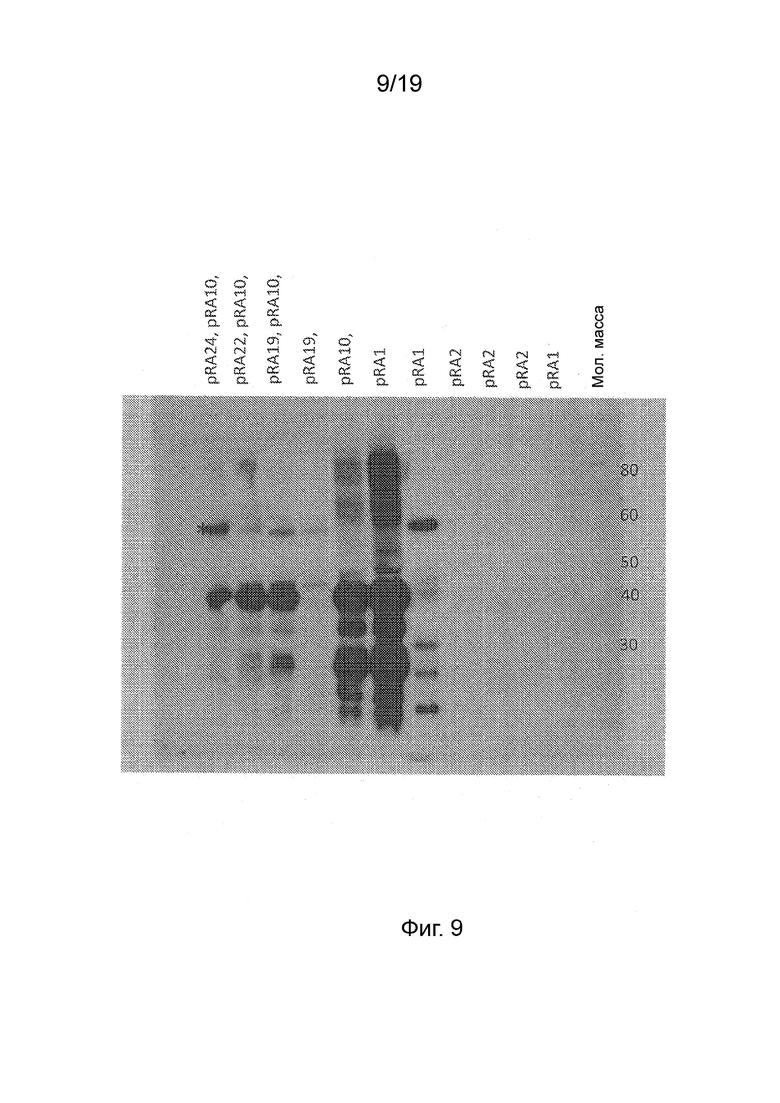
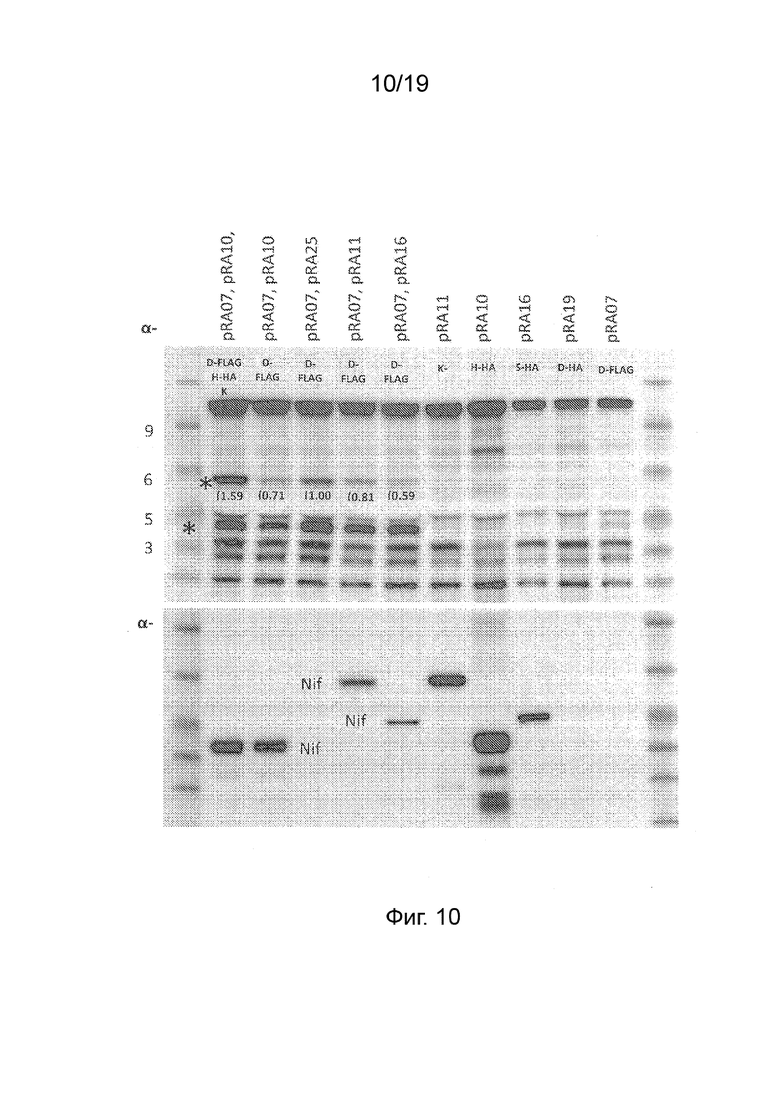
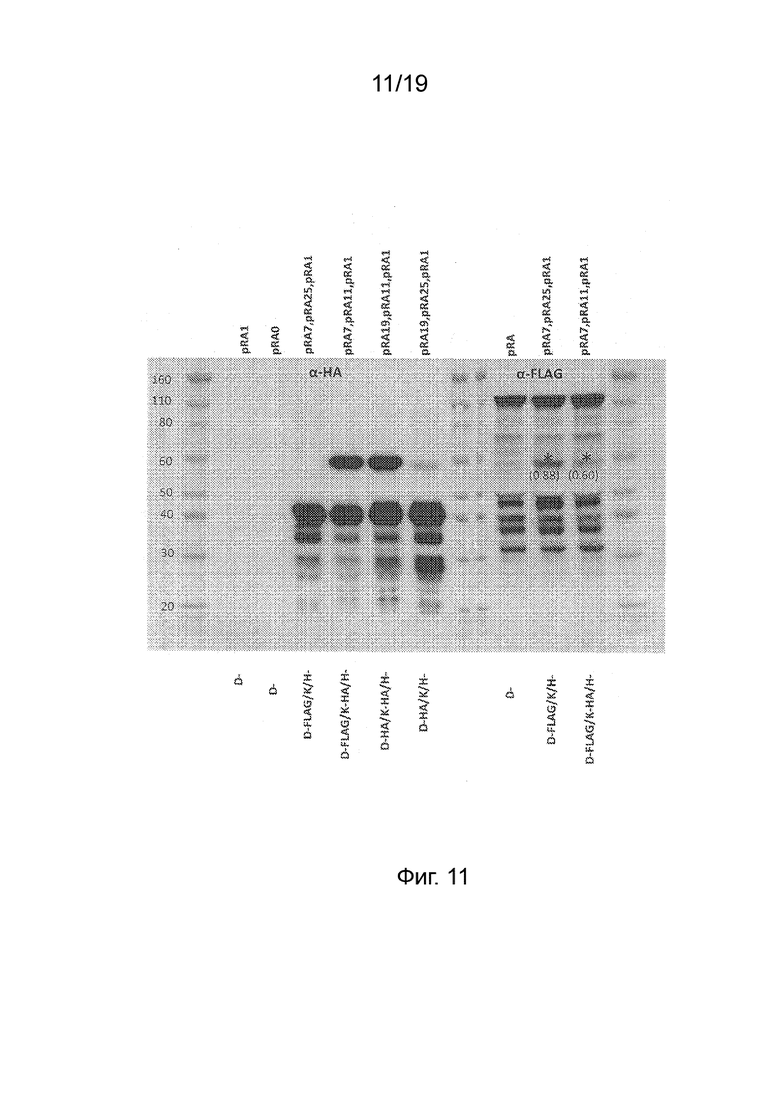
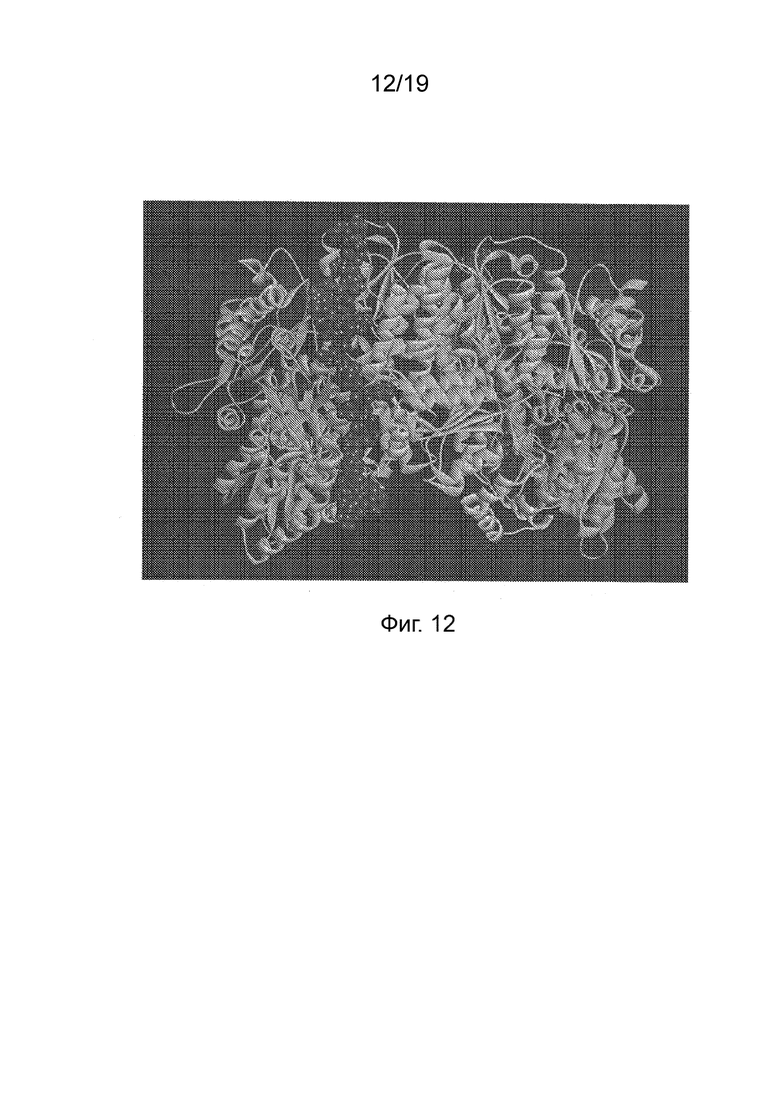


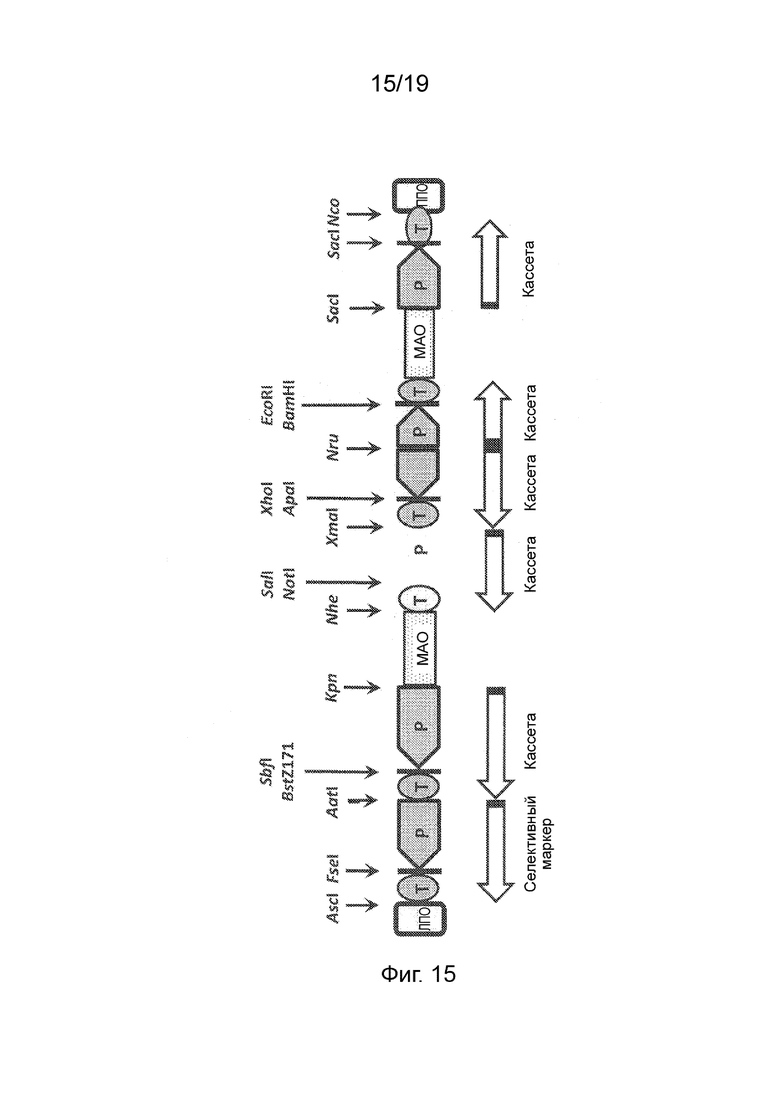
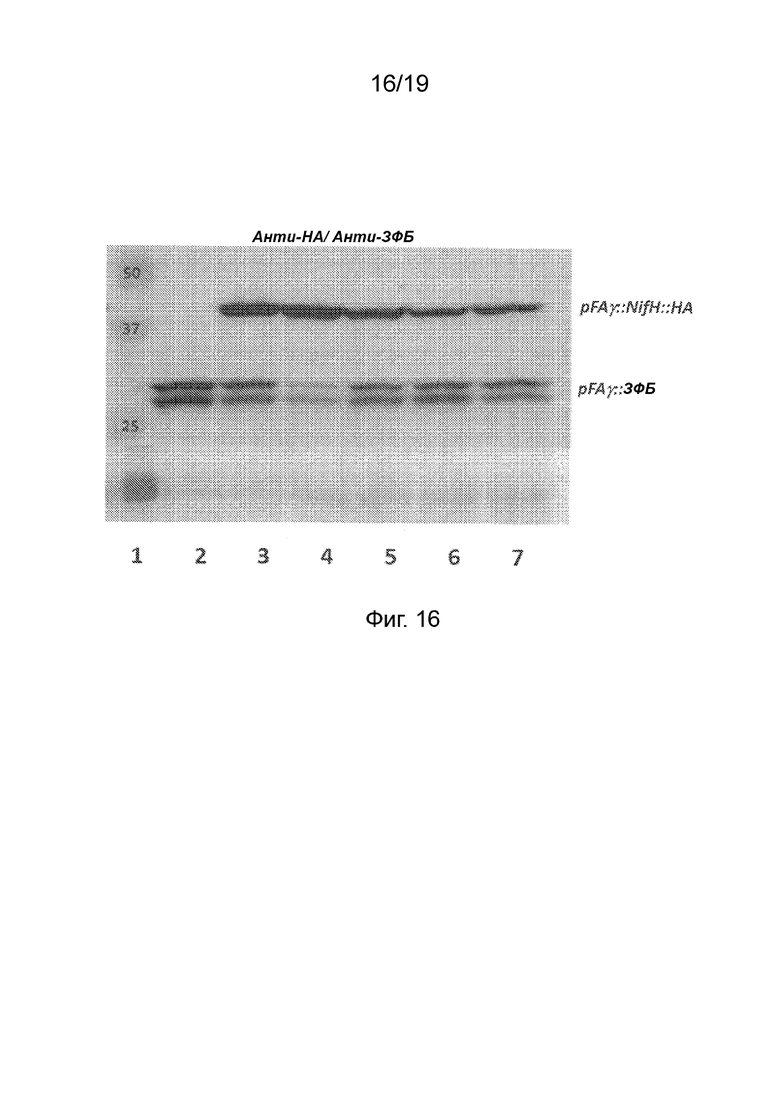
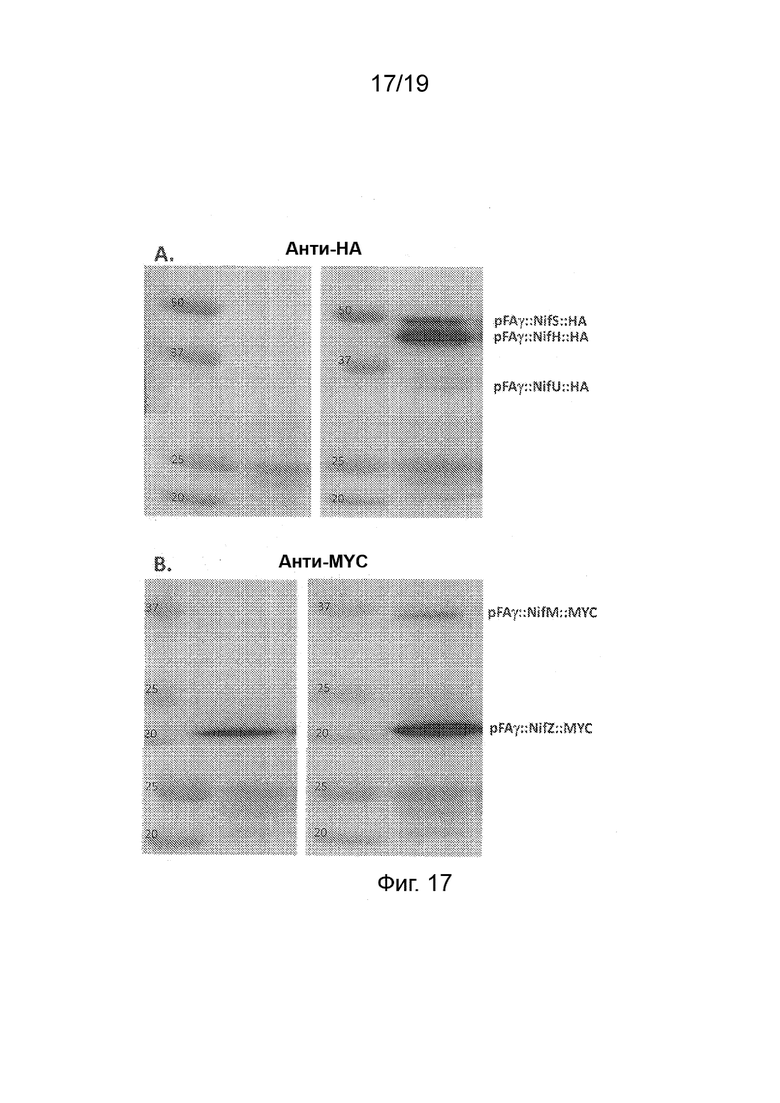
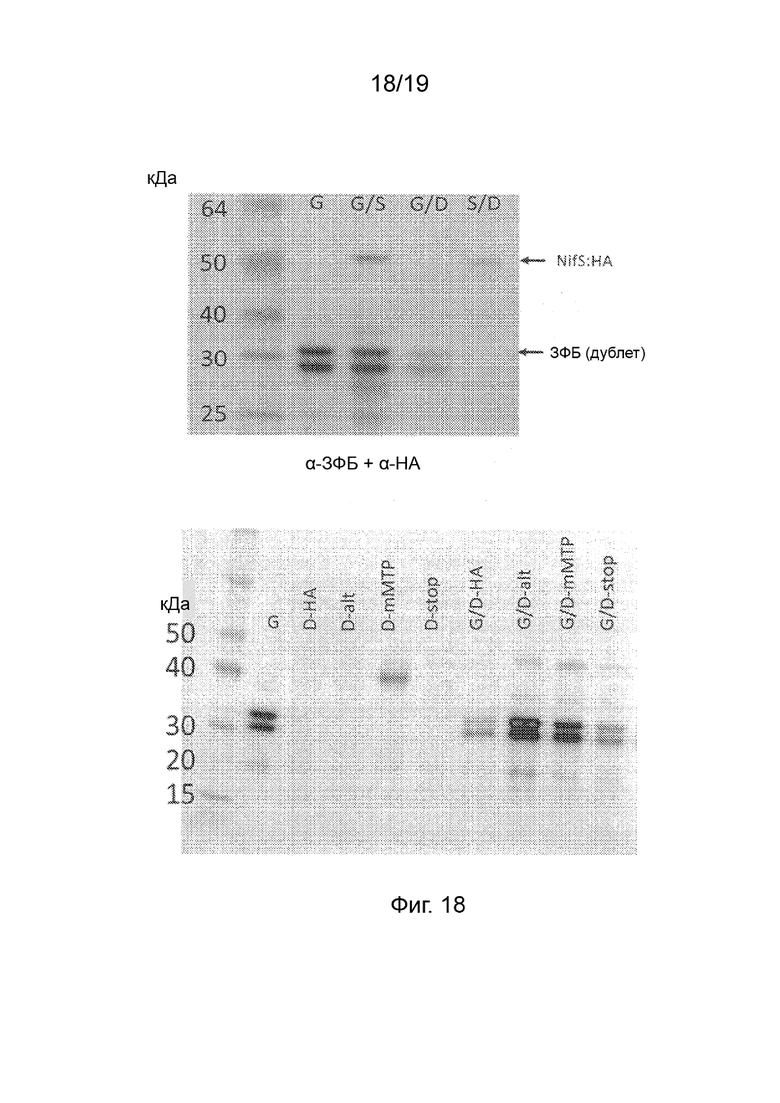
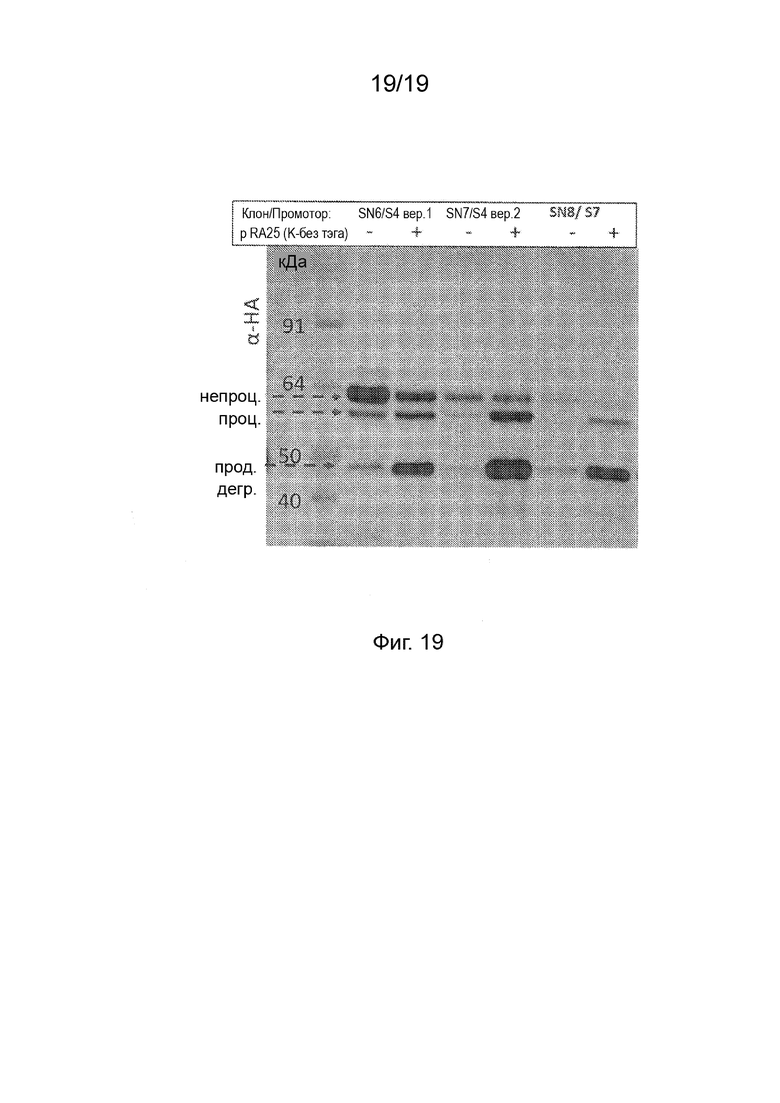
Изобретение относится к области биохимии, в частности к растительной клетке для получения слитого полипептида. Также раскрыты трансгенное растение и часть растения, содержащие указанную растительную клетку; вектор для получения слитого полипептида. Раскрыты способ получения указанного трансгенного растения; способ получения муки; способ получения пищевого продукта. Изобретение позволяет эффективно получать слитый полипептид в клетке растения. 7 н. и 18 з.п. ф-лы, 19 ил., 10 табл., 22 пр.
1. Растительная клетка для получения слитого полипептида, содержащая митохондрии и экзогенный полинуклеотид, кодирующий слитый полипептид, где слитый полипептид содержит
(i) митохондриальный нацеливающий пептид (МНП), который имеет C–конец,
(ii) полипептид NifD (ND), который имеет N–конец и C–конец,
(iii) олигопептидный линкер и
(iv) полипептид NifK (NK), который имеет N–конец,
при этом C–конец МНП трансляционно слит с N–концом ND, а
линкер трансляционно слит с C–концом ND и N–концом NK.
2. Растительная клетка по п. 1, отличающаяся тем, что C–конец слитого полипептида представляет собой C–конец NK, необязательно при этом C–конец NK представляет собой С–конец NifK дикого типа.
3. Растительная клетка по п. 2 или 3, отличающаяся тем, что олигопептидный линкер имеет длину от 8 до 50 аминокислот.
4. Растительная клетка по любому из пп. 1–3, отличающаяся тем, что полипептид NifD и полипептид NifK в слитом полипептиде имеют такую же функцию, как и полипептид NifD и полипептид NifK, когда они представлены в виде двух отдельных полипептидов.
5. Растительная клетка по любому из пп. 1–4, отличающаяся тем, что МНП содержит сайт расщепления протеазой для матриксной процессирующей протеазы (МПП) так, чтобы слитый полипептид мог расщепляться МПП с получением N–концевого отщепленного пептида и процессированного слитого полипептида (CF), содержащего от (ii) до (iv).
6. Растительная клетка по п. 5, отличающаяся тем, что CF содержит некоторые, но не все C–концевые аминокислоты МНП, предпочтительно от 5 до 45 аминокислот из С–концевых аминокислот МНП.
7. Растительная клетка по любому из пп. 1–6, отличающаяся тем, что МНП содержит около 51 аминокислоты F1–АТФазной γ–субъединицы МНП.
8. Растительная клетка по любому из пп. 1–7, дополнительно содержащая один или более слитых полипептидов NF (NF), причем каждый NF содержит (i) митохондриальный нацеливающий пептид (МНП), который имеет C–конец, и (ii) полипептид Nif (NP), который имеет N–конец, при этом C–конец МНП трансляционно слит с N–концом NP, при этом каждый МНП независимо является одинаковым или отличным, а каждый NP независимо является одинаковым или отличным, и при этом митохондрии содержат один или более NF и/или их процессированный продукт (CF), и при этом каждый CF, в случае присутствия, получен посредством расщепления соответствующего NF в пределах его МНП.
9. Растительная клетка по п. 8, отличающаяся тем, что, по меньшей мере, один из полипептидов NF представляет собой NifH.
10. Растительная клетка по любому из пп. 1–9, отличающаяся тем, что митохондрии содержат один, по меньшей мере, два, по меньшей мере, три, по меньшей мере, четыре или все полипептиды Nif, выбранные из группы, состоящей из (i) NifD, NifH, NifK, NifB, NifE и NifN, или (ii) NifD, NifH, NifK и NifS.
11. Растительная клетка по любому из пп. 1–10, отличающаяся тем, что МНП содержит, по меньшей мере, 10 аминокислот, предпочтительно от 10 до 80 аминокислот.
12. Растительная клетка по любому из пп. 1–11, отличающаяся тем, что, по меньшей мере, один или более, или все МНП содержат МНП митохондриального белка–предшественника или его вариант, предпочтительно МНП растения.
13. Растительная клетка по любому из пп. 1–12, отличающаяся тем, что экзогенный(е) полинуклеотид(ы), кодирующий(е) слитый(е) полипептид(ы), интегрирован(ы) в ядерный геном клетки.
14. Растительная клетка по любому из пп. 1–13, отличающаяся тем, что указанная клетка представляет собой клетку, отличную от протопласта Arabidopsis thaliana.
15. Трансгенное растение для получения слитого полипептида, содержащее клетки по любому из пп. 1–14, отличающееся тем, что трансгенное растение является трансгенным в отношении одного или более экзогенных полинуклеотидов, кодирующих слитый полипептид, где слитый полипептид содержит
(i) митохондриальный нацеливающий пептид (МНП), который имеет C–конец,
(ii) полипептид NifD (ND), который имеет N–конец и C–конец,
(iii) олигопептидный линкер и
(iv) полипептид NifK (NK), который имеет N–конец,
где C–конец МНП трансляционно слит с N–концом ND, и
где линкер трансляционно слит с C–концом ND и N–концом NK.
16. Трансгенное растение по п. 15, отличающееся тем, что один или более, или все экзогенные полинуклеотиды экспрессируются в корнях растения, предпочтительно экспрессируются на большем уровне в корнях растения, чем в листьях растения.
17. Трансгенное растение по п. 15 или 16, которое представляет собой зерновое растение, такое как пшеница, рис, кукуруза, тритикале, овес или ячмень, предпочтительно пшеница.
18. Трансгенное растение по любому из пп. 15–17, которое является гомозиготным или гетерозиготным в отношении экзогенного(ых) полинуклеотида(ов).
19. Трансгенное растение по любому из пп. 15–18, которое растет в поле.
20. Химерный вектор для получения слитого полипептида, где химерный вектор содержит экзогенный полинуклеотид, кодирующий слитый полипептид, содержащий
(i) митохондриальный нацеливающий пептид (МНП), который имеет C–конец,
(ii) полипептид NifD (ND), который имеет N–конец и C–конец,
(iii) олигопептидный линкер и
(iv) полипептид NifK (NK), который имеет N–конец,
где C–конец МНП трансляционно слит с N–концом ND, и
где линкер трансляционно слит с C–концом ND и N–концом NK.
21. Способ получения трансгенного растения по любому из пп. 15–19, включающий этапы
i) внесения экзогенного полинуклеотида, кодирующего слитый полипептид, охарактеризованный в п. 20, и/или вектора по п. 20 в клетку растения,
ii) регенерации трансгенного растения из клетки и
iii) необязательно, сбора семян с растения и/или
iv) необязательно, получения одного или более дочерних растений от трансгенного растения,
с получением, таким образом, трансгенного растения.
22. Часть растения, содержащая растительную клетку по любому из пп. 1–14, для получения слитого полипептида, где слитый полипептид содержит
(i) митохондриальный нацеливающий пептид (МНП), который имеет C–конец,
(ii) полипептид NifD (ND), который имеет N–конец и C–конец,
(iii) олигопептидный линкер и
(iv) полипептид NifK (NK), который имеет N–конец,
где C–конец МНП трансляционно слит с N–концом ND, и
где линкер трансляционно слит с C–концом ND и N–концом NK.
23. Часть растения по п. 22 для получения трансгенного растения, где часть растения представляет собой семя, содержащее экзогенный полинуклеотид, кодирующий слитый полипептид, охарактеризованный в п. 20.
24. Способ получения муки, цельнозерновой муки, крахмала, масла, жмыховой муки или другого продукта, получаемого из семян, включающий:
a) получение семян, содержащих полинуклеотид, по п. 23 и
b) получение муки, цельнозерновой муки, крахмала, масла или другого продукта или получение жмыховой муки.
25. Способ получения пищевого продукта, включающий смешивание семян по п. 23, или муки, или цельнозерновой муки из указанных семян с другим пищевым ингредиентом.
| WO 2010025466 A2, 04.03.2010 | |||
| WO 2009034188 A1, 10.01.2014 | |||
| УСТОЙЧИВЫЕ К ГЕРБИЦИДАМ РАСТЕНИЯ ПОДСОЛНЕЧНИКА, ПОЛИНУКЛЕОТИДЫ, КОДИРУЮЩИЕ УСТОЙЧИВЫЕ К ГЕРБИЦИДАМ БЕЛКИ БОЛЬШОЙ СУБЪЕДИНИЦЫ АЦЕТОГИДРОКСИАЦИДСИНТАЗЫ, И СПОСОБЫ ПРИМЕНЕНИЯ | 2005 |
|
RU2415566C2 |

