[0001] Согласно настоящей заявке испрашивается приоритет в соответствии с заявкой на выдачу патента Китая № 202011630350.8, поданной 31 декабря 2020 г., которая ссылкой полностью включена в настоящий документ.
Область техники, к которой относится настоящее изобретение
[0002] Настоящее изобретение относится к области обработки естественного языка и, в частности, относится к способу и устройству, вычислительному устройству для расстановки меток языка и носителю данных для расстановки меток языка.
Предшествующий уровень техники настоящего изобретения
[0003] Некоторые платформы видеоданных получают отправленные пользователями видеоданные, например, короткие видеоролики, которые обычно содержат текстовую информацию, и предоставляют для пользователей связанные с языком услуги, например, поиск видеоданных с некоторым языком. Во время обработки видеоданных для расстановки меток с указанием языка в текстовой информации типично используется классификатор.
Краткое описание настоящего изобретения
[0004] В настоящем раскрытии предложены способ и устройство для расстановки меток языка, и вычислительное устройство для расстановки меток языка и носитель данных для решения проблемы низкой эффективности ручной расстановки меток языка в текстовой информации.
[0005] Согласно некоторым вариантам осуществления настоящего раскрытия предложен способ расстановки меток языка. Способ расстановки меток языка предусматривает следующие стадии:
[0006] определение классификатора языка;
[0007] сбор множества элементов информации, относящихся к видеоданным, и определение множества элементов информации в качестве множества элементов видеоинформации;
[0008] разделение множества элементов видеоинформации на целевую информацию и справочную информацию;
[0009] идентификация языков, которые применяются во множестве элементов видеоинформации, с помощью ввода множества элементов видеоинформации в классификатор языка; и
[0010] проверка уровня достоверности целевого языка с помощью справочных языков, причем целевой язык является языком, который применяется для целевой информации, а справочные языки являются множеством языков, которые применяются для справочной информации.
[0011] Согласно некоторым вариантам осуществления настоящего раскрытия предложено устройство для расстановки меток языка. Устройство для расстановки меток языка включает в себя:
[0012] модуль определения классификатора языка, выполненный с возможностью определить классификатор языка;
[0013] модуль сбора видеоинформации, выполненный с возможностью проводить сбор множества элементов информации, относящихся к видеоданным, и определять множество элементов информации в качестве множества элементов видеоинформации;
[0014] модуль разделения видеоинформации, выполненный с возможностью разделять множество элементов видеоинформации на целевую информацию и справочную информацию;
[0015] модуль классификации видеоинформации, выполненный с возможностью идентифицировать языки, которые применяются во множестве элементов видеоинформации, с помощью ввода множества элементов видеоинформации в классификатор языка; и
[0016] модуль проверки уровня достоверности, выполненный с возможностью проверить уровень достоверности целевого языка с помощью справочных языков, причем целевой язык является языком, который применяется для целевой информации, а справочные языки являются множеством языков, которые применяются для справочной информации.
[0017] Согласно некоторым вариантам осуществления настоящего раскрытия предложено вычислительное устройство для расстановки меток языка. Вычислительное устройство для расстановки меток языка содержит в своем составе:
[0018] по меньшей мере, один процессор;
[0019] память, выполненную с возможностью хранить, по меньшей мере, одну программу;
[0020] причем, по меньшей мере, один процессор после загрузки и выполнения, по меньшей мере, одной программы, заставляется выполнять способ расстановки меток языка, как описано выше.
[0021] Согласно некоторым вариантам осуществления настоящего раскрытия предложен машиночитаемый носитель данных. В машиночитаемом носителе данных хранится одна или несколько компьютерных программ, причем одна или несколько компьютерных программ, будучи загруженными и выполняемыми процессором, заставляют процессор выполнить способ расстановки меток языка, как описано выше.
Краткое описание фигур
[0022] На фиг. 1 показана блок-схема алгоритма способа расстановки меток языка согласно первому варианту осуществления настоящего раскрытия;
[0023] На фиг. 2 показана блок-схема алгоритма способа расстановки меток языка согласно второму варианту осуществления настоящего раскрытия;
[0024] На фиг. 3 показана общая блок-схема алгоритма обучения классификатора языка на основе полуконтролируемого обучения согласно второму варианту осуществления настоящего раскрытия;
[0025] На фиг. 4 показана часть блок-схемы алгоритма обучения классификатора языка на основе полуконтролируемого обучения согласно второму варианту осуществления настоящего раскрытия;
[0026] На фиг. 5 показана упрощенная блок-схема устройства для расстановки меток языка согласно третьему варианту осуществления настоящего раскрытия; и
[0027] На фиг. 6 показана упрощенная блок-схема вычислительного устройства согласно четвертому варианту осуществления настоящего раскрытия.
Подробное раскрытие настоящего изобретения
[0028] Настоящее раскрытие подробно описано далее в настоящем документе со ссылками на прилагаемые фигуры и варианты осуществления. Описанные в настоящем документе конкретные варианты осуществления используются только для объяснения настоящего раскрытия. Для упрощения описания на прилагаемых фигурах показаны только части, существенные для настоящего раскрытия.
[0029] Во время обработки видеоданных для расстановки меток с указанием языка в текстовой информации типично используется классификатор. Так как текстовая информация в видеоданных в основном имеет созданный пользователем контент, в ней имеются текстовые несоответствия, например, орфографические ошибки, сокращения, транслитерация, изменение кодировки и тому подобное, что негативно влияет на эффективность работы классификатора.
[0030] Для устранения текстовых несоответствий и обучения классификаторов до уровня высокой точности необходим большой объем текстовой информации с размеченными языками, эта задача в основном возложена на технических специалистов, которые должны вручную расставлять метки языка в текстовой информации. Для каждого языка требуется, по меньшей мере, один технический специалист, знакомый с этим языком. Хороший уровень владения языком приводит к высоким техническим требованиям, а низкая скорость и небольшое количество меток при ручной расстановке меток приводят к низкой эффективности расстановки меток.
[0031] Кроме того, служебные данные содержат сотни различных языков, и классификатор с высокой точностью работы можно получить только за счет обучения, при котором количество выборок для каждого языка достигает определенного количества. В случае редких языков (то есть языков этнических меньшинств) получение высококачественных выборок занимает много времени.
[0032] Первый вариант осуществления
[0033] На фиг. 1 показана блок-схема алгоритма способа расстановки меток языка согласно первому варианту осуществления настоящего раскрытия. Этот вариант осуществления применяется в случае, когда для тех же самых видеоданных конкретная текстовая информация снабжена метками языка с помощью части текстовой информации. Этот способ выполняется с помощью устройства для расстановки меток языка, которое реализовано программными и/или аппаратными средствами и выполнено в виде вычислительного устройства, например, сервера, рабочей станции или персонального компьютера. В способе предусмотрены следующие стадии.
[0034] На стадии 101 определяется классификатор языка.
[0035] Согласно некоторым вариантам осуществления предложен классификатор языка, который выполнен с возможностью идентифицировать язык, который применяется для текстовой информации. Классификатор языка является классификатором, основанном на машинном обучении, например, на методе опорных векторов (SVM) или на байесовской модели; или классификатором, основанном на глубоком обучении, например, классификатор на библиотеке fastText или сверточная нейронная сеть для классификации текста (Text-CNN), классификатор никак не ограничивается в настоящем раскрытии.
[0036] В целом, на вход классификатора языка вводится текстовая информация, и классификатор языка выдает на своем выходе язык и вероятность того, что этот язык применяется для текстовой информации.
[0037] На практике классификатор языка предварительно обучается контролируемым образом. Другими словами, создается учебный набор, и учебный набор является набором данных с тегами.
[0038] Учебный набор включает в себя множество элементов текстовой информации, снабженных метками применяемых языков, или учебный набор включает в себя множество голосовых сигналов, снабженных метками применяемых языков.
[0039] Текстовая информация связана или не связана с видеоданными. Например, некоторые учебные наборы с метками языка с открытым исходным кодом адаптированы для просматривания текстовой информации с веб-страниц и ручной разметки применяемых языков, или для вручную размеченной текстовой информации, связанной с видеоданными с применяемыми языками, это никак не ограничивается в настоящем раскрытии.
[0040] Классификатор языка тренируется с помощью функции потерь перекрестной энтропии и градиентного спуска с использованием текстовой информации из учебного набора в качестве тренировочных выборок и языков в качестве тренировочных тегов.
[0041] Классификатор языка является начальной версией классификатора языка, и он итерационно обновляется в будущем, таким образом, обучение останавливается после i (i является положительным целым числом) сеансов итерационной тренировки, и при этом подтверждается завершение обучение классификатора языка.
[0042] Во время процесса обучения классификатора языка параметры оценки, например, точность, проценты запоминаемости и значения F1 используются в качестве условий для остановки процесса обучения, это никак не ограничивается в настоящем раскрытии.
[0043] На стадии 102 выполняется сбор множества элементов информации, относящихся к видеоданным, и множество элементов информации определяется в качестве множества элементов видеоинформации.
[0044] Согласно некоторым вариантам осуществления, предварительно создается пул видеоданных, в котором хранится множество элементов видеоданных, текстовую информацию которых необходимо снабдить метками языка. Видеоданные имеют формат коротких видеороликов, прямой трансляции, теледрам, фильмов, короткометражек и тому подобного.
[0045] Соответствующие видеоданные отбираются согласно потребностям службы и заносятся в пул видеоданных. Например, в случае, когда необходимо оптимизировать результат внесения видеоданных в некотором регионе, отбираются отправленные из указанного региона видеоданные, или в случае, когда необходимо оптимизировать результат внесения видеоданных за некоторый период времени, отбираются отправленные в указанный период времени видеоданные, это никак не ограничивается в настоящем раскрытии.
[0046] Для каждого экземпляра видеоданных в пуле видеоданных из контекста видеоданных собирается множество элементов (то есть два или более) информации, связанных с видеоданными, и собранная информация рассматривается в качестве видеоинформации.
[0047] Обычно видеоинформация и тренировочные выборки в учебном наборе имеют одинаковый тип. Другими словами, в случае, когда тренировочная выборка в учебном наборе является текстовой информацией, видеоинформация является текстовой информацией; а в случае, когда тренировочная выборка в учебном наборе является голосовым сигналом, видеоинформация является голосовым сигналом.
[0048] Для обновления классификатора языка видеоинформация является набором данных без тегов (то есть она не снабжена метками языка).
[0049] Согласно некоторым примерам, видеоинформация содержит, по меньшей мере, один из следующих элементов.
[0050] 1. Информация описания
[0051] Информация описания обычно является рекламно-маркетинговой информацией с описанием контента видеоданных, введенной создавшим видеоданные пользователем для ознакомления публики с видеоданными.
[0052] 2. Рекламно-маркетинговая информация, согласованная с заставкой
[0053] Создавший видеоданные пользователь выбирает кадр изображения видеоданных в качестве заставки к видеоданным и вводит рекламно-маркетинговую информацию в заставку.
[0054] 3. Информация субтитров
[0055] Информацией субтитров обычно является текст, набранный создавшим видеоданные пользователем, этот текст присутствует в видеоданных согласно нужной заказчику функции.
[0056] 4. Информация первого признака
[0057] Информацией первого признака обычно является текстовая информация, извлеченная из заставки с помощью оптического распознавания символов (OCR).
[0058] 5. Информация второго признака
[0059] Информацией второго признака обычно является текстовая информация, извлеченная из множества кадров изображений видеоданных с помощью функции OCR.
[0060] 6. Информация комментария
[0061] Информацией комментария обычно является сообщение, опубликованное выступившим в качестве зрителя пользователем, после просмотра им видеоданных.
[0062] Приведенные выше элементы видеоинформации являются только примером. На практике согласно фактическим потребностям создаются другие элементы видеоинформации, например, заголовки и голосовые сигналы, это никак не ограничивается в настоящем раскрытии. Более того, в дополнение к описанным выше элементам видеоинформации, специалисты в этой области техники могут использовать другие элементы видеоинформации согласно их фактическим потребностям, это никак не ограничивается в настоящем раскрытии.
[0063] Каждые видеоданные включают в себя значения атрибутов видеоинформации и идентификатор (ID) видеоданных, который упрощает последующий поиск соответствующих видеоданных и видеоинформации.
[0064] На стадии 103 множество элементов видеоинформации разделяется на целевую информацию и справочную информацию.
[0065] В каждой видеоинформации содержится одно или несколько предложений. Для упрощения обработки каждая видеоинформация рассматривается в качестве одного предложения согласно вариантам осуществления во время процесса расстановки меток с языком в видеоинформации, что соответствует соглашениям обработки естественного языка.
[0066] Для каждого предложения (то есть для каждой видеоинформации) следующие операции очистки и фильтрации надлежащим образом выполняются для потребностей процесса расстановки меток с языком.
[0067] 1. Обработка сегментации слов
[0068] Предложение (то есть видеоинформация) сегментируется согласно определенным правилам из непрерывной последовательности в независимые слова с помощью сопоставления символов, методов языкового восприятия и статистических методов.
[0069] 2. Удаление значков эмоций
[0070] Удаляются значки эмоций, например, 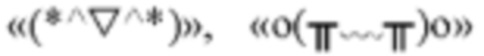 и тому подобные, которые не помогают идентифицировать тип языка.
и тому подобные, которые не помогают идентифицировать тип языка.
[0071] 3. Отбрасывание предложений, которые являются слишком короткими
[0072] Удаляется предложение (то есть видеоинформация), число слов в котором меньше заранее определенного порога слов MIN_WORD_COUNT.
[0073] Указанные выше методы очистки и фильтрации приведены только в качестве примеров. На практике согласно фактическим потребностям используются другие методы очистки и фильтрации, это никак не ограничивается в настоящем раскрытии. Более того, в дополнение к описанным выше методам очистки и фильтрации специалисты в этой области техники могут использовать другие методы очистки и фильтрации согласно их фактическим потребностям, это никак не ограничивается в настоящем раскрытии.
[0074] Согласно некоторым вариантам осуществления, для множества элементов видеоинформации тех же самых видеоданных множество элементов видеоинформации согласно потребностям службы разделяется на целевую информацию и справочную информацию. Целевая информация является видеоинформацией для языка, метки которого необходимо расставить для обновления классификатора языка, а справочная информация является другой видеоинформацией, которая помогает проверить уровень достоверности языка целевой информации.
[0075] Для видеоданных определяются корреляции множества элементов видеоинформации с видеоданными, они определяются согласно свойствам самой видеоинформации. Видеоинформация с наивысшей степенью корреляции настраивается в качестве целевой информации, а отличающаяся от целевой информации видеоинформация настраивается в качестве справочной информации.
[0076] Согласно некоторым примерам, в предположении, что множество элементов видеоинформации включает в себя информацию описания, согласованную с заставкой рекламно-маркетинговую информацию, информацию субтитров, информацию первого признака, информацию второго признака и информацию комментария, информация описания в основном используется для ознакомления с контентом видеоданных, и она имеет наивысшую степень корреляции с видеоданными, и поэтому информация описания настраивается в качестве целевой информации, а справочная информация настраивается для включения в себя, по меньшей мере, одной из:
[0077] согласованной с заставкой рекламно-маркетинговой информации, информации субтитров, информации первого признака, информации второго признака или информации комментария.
[0078] Согласно другому примеру, в предположении, что множество элементов видеоинформации включает в себя голосовой сигнал, информацию описания, согласованную с заставкой рекламно-маркетинговую информацию, информацию субтитров, информацию первого признака, информацию второго признака и информацию комментария, при этом голосовой сигнал в основном включает в себя языковый контент видеоданных и он имеет наивысшую степень корреляции с видеоданными, и поэтому голосовой сигнал настраивается в качестве целевой информации, а справочная информация настраивается для включения в себя, по меньшей мере, одной из:
[0079] информации описания, согласованной с заставкой рекламно-маркетинговой информации, информации субтитров, информации первого признака, информации второго признака и информации комментария.
[0080] На стадии 104 множество элементов видеоинформации вводится в классификатор языка для идентификации языков, которые применяются для множества элементов видеоинформации.
[0081] Множество элементов видеоинформации (включая целевую информацию и справочную информацию), принадлежащих тем же самым видеоданным, вводится в классификатор языка в том же самом пакете для обработки, и классификатор выводит языки, которые применяются для видеоинформации.
[0082] На стадии 105 с помощью справочных языков проверяется уровень достоверности целевого языка.
[0083] Обычно классификатор языка принадлежит к модели многократной классификации, и поэтому классификатор языка способен выводить множество языков, которые применяются для каждых видеоданных, и для каждого языка приводится уровень правдоподобия.
[0084] Целевая информация в основном используется для создания меток языка, и язык является уникальным. Следовательно, язык с наивысшим уровнем правдоподобия из множества языков, выведенных классификатором языка, определяется как язык, применяемый для целевой информации, и игнорируются другие языки, которые с некоторой вероятностью могут применяться для целевой информации. Для упрощения различения этот язык называется целевым языком. Таким образом, целевой язык является языком, который применяется для целевой информации.
[0085] Справочная информация в основном используется для помощи проверки уровня достоверности размеченного языка в целевой информации, и язык с наивысшим уровнем правдоподобия, применяемый в справочной информации, не обязательно должен совпадать с целевым языком. Следовательно, множество языков и их уровни правдоподобия, выводимые классификатором языка, определяются как множество языков, применяемых для справочной информации, и как их уровни правдоподобия. Для упрощения различения эти языки называются справочными языками. Другими словами, справочными языками является множество языков, которое применяется для справочной информации.
[0086] Учитывая, что для тех же самых видеоданных пользователь, который создал видеоданные, является единственным, обычно это отдельный человек или группа, видеоданные в основном выражены как изображения и звуки, которые связаны с культурой и языком, аудитория для видеоданных является единственной, в основном из того же самого региона, как и пользователь, который создал видеоданные, и поэтому обычно в видеоданных используется единственный язык, и связанная с видеоданными видеоинформация в большинстве случаев использует тот же самый язык. Следовательно, уровень достоверности того, что язык целевой информации является целевым языком, проверяется с помощью того факта, что в справочной информации применяется справочный язык (то есть множество справочных языков и их уровни правдоподобия).
[0087] Например, в случае, когда видеоданные являются повседневной сценой, включающей в себя разговор на английском языке, создавший видеоданные пользователь пишет информацию описания на английском языке и добавляет заголовок на английском языке, а пользователь, который просматривает видеоданные и понимает их контент, в большинстве случаев публикует информацию комментария на английском языке.
[0088] На практике диапазон достоверности заранее настроен смещенным к среднему уровню (то есть уровень достоверности является большим). Конечным значением диапазона достоверности является первый порог правдоподобия MIN_PROB_1, а другим конечным значением диапазона является второй порог правдоподобия MIN_PROB_2. Второй порог правдоподобия MIN_PROB_2 больше первого порога правдоподобия MIN_PROB_1.
[0089] Величина вероятности того, что язык целевой информации является целевым языком, определяется из выходных результатов классификатора языка для целевой информации, и эта величина вероятности определяется в качестве целевой вероятности Р_S.
[0090] Целевая вероятность Р_S сравнивается с диапазоном достоверности.
[0091] В случае, когда целевая вероятность Р_S. находится внутри диапазона достоверности, то есть, целевая вероятность Р_S. не меньше первого заранее настроенного порога правдоподобия MIN_PROB_1 и не больше второго заранее настроенного порога правдоподобия MIN_PROB_2, уровень достоверности того, что язык целевой информации является целевым языком, является большим, и язык целевой информации является целевым языком или язык цели не является целевым языком. В каком случае просматривается вся справочная информация, определяется вероятность того, что справочный язык идентичен целевому языку, и эта величина вероятности определяется как справочная вероятность.
[0092] С помощью суммирования, умножения, усреднения и усреднения после применения весовых множителей, уровень достоверности Score того, что целевая информация применяется с целевым языком, вычисляется с помощью объединения с целевой вероятностью и со справочной вероятностью, что позволяет охарактеризовать уровень того, что справочная информация подтверждает, что язык целевой информации является целевым языком.
[0093] Согласно некоторым вариантам осуществления, проверка уровня достоверности выполняется с помощью соответствующей целевой информации, отобранной на основании диапазона достоверности, так что количество элементов целевой информации снижается и благодаря этому объем вычислений снижается и эффективность улучшается.
[0094] Например, язык (то есть целевой язык) с наивысшим уровнем правдоподобия информации описания видеоданных является английским языком, и вероятность английского языка является большой (например, 0,6). Ранее в случае низкой величины вероятности уровень достоверности предсказания обычно определялся как недостаточный, и было возможно, что предсказание не является правильным, и информация описания и целевой язык не использовались в качестве тренировочной выборки для обновления классификатора языка. В случае, когда в тех же самых видеоданных соответствующая заставке рекламно-маркетинговая информация с высокой вероятностью (например, 0,8) предсказывается как имеющая английский язык, такая инкрементальная информация используется для подтверждения, что предсказание о том, что информация описания применяет английский язык, является правильным. В этом случае информация описания, соответствующая заставке рекламно-маркетинговая информация и целевой язык используются в качестве тренировочной выборки для обновления классификатора языка, и поэтому размер стандартной выборки увеличивается.
[0095] В случае, когда целевая вероятность Р_S находится за пределами диапазона достоверности, возможны два следующих случая.
[0096] 1. В случае, когда целевая вероятность Р_S. меньше первого порога правдоподобия MIN_PROB_1, уровень достоверности того, что язык целевой информации является целевым языком, является низким. Другими словами, уровень достоверности недостаточный и язык целевой информации, возможно, не является нормальным языком. Текущие видеоданные и их видеоинформация игнорируются в текущем сеансе итерационного обновления классификатора языка.
[0097] Текущие видеоданные и их видеоинформация в этом сеансе игнорируются и не удаляются. В случае, когда классификатор языка обновляется в последующих итерациях, качество работы классификатора языка улучшается, и целевая вероятность Р_S, возможно, становится не меньше первого порога правдоподобия MIN_PROB_1.
[0098] 2. В случае, когда целевая вероятность Р_S. больше второго порога правдоподобия MIN_PROB_2, уровень достоверности того, что язык целевой информации является целевым языком, является высоким, и язык целевой информации непосредственно идентифицируется в качестве целевого языка без необходимости проверять уровень достоверности того, что язык целевой информации является целевым языком с помощью того факта, что справочная информация использует справочной язык.
[0099] Согласно некоторым вариантам осуществления, проводится определение классификатора языка; сбор множества элементов информации, относящихся к видеоданным; множество элементов информации используется в качестве множества элементов видеоинформации; множество элементов видеоинформации разделяется на целевую информацию и справочную информацию; языки, которые используются для множества элементов видеоинформации, определяются с помощью ввода множества элементов видеоинформации в классификатор языка; и уровень достоверности целевого языка проверяется с помощью справочного языка. Целевой язык является языком, который применяется для целевой информации, а справочные языки являются множеством языков, которые применяются для справочной информации. Для тех же самых видеоданных пользователь, который создал видеоданные, является единственным, аудитория для видеоданных является единственной, применяемый в видеоданных язык также является единственным, и связанная с видеоданными видеоинформация в большинстве случаев применяет тот же самый язык. Следовательно, в случае ситуации, когда справочная информация и применяемый справочный язык используются в качестве помощи, проверяется уровень достоверности того, что язык целевой информации является целевым языком, так что точность предсказания языков улучшается.
[00100] Второй вариант осуществления
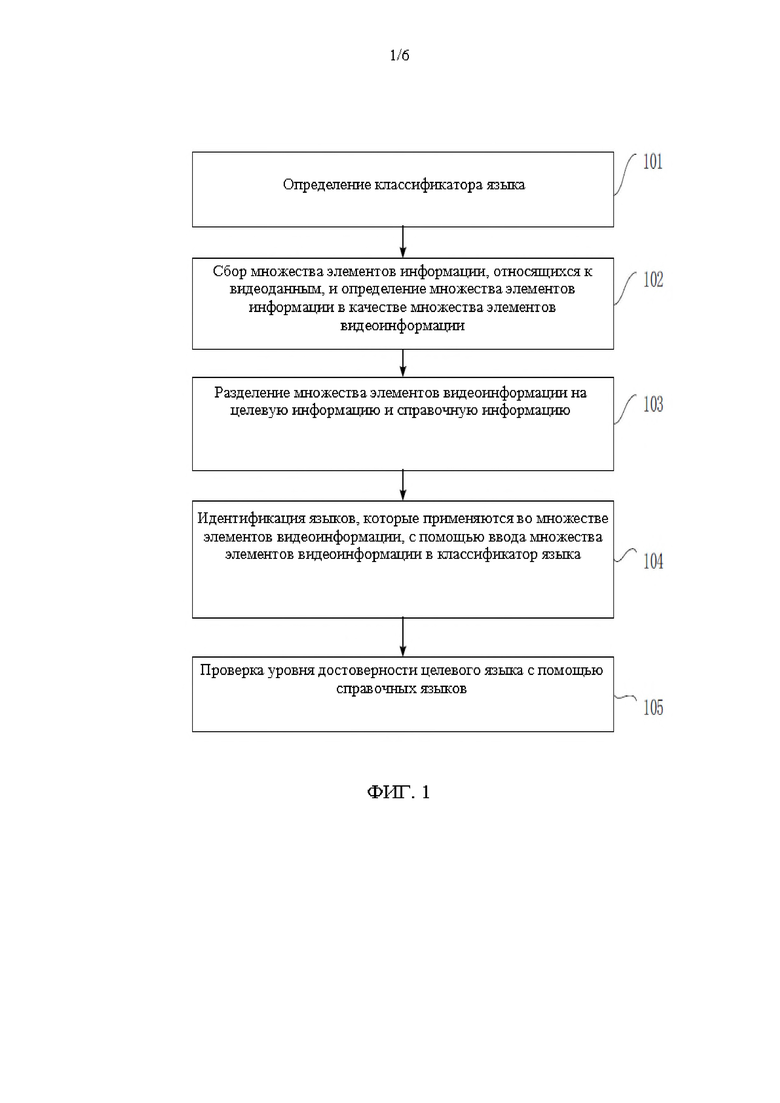
[00101] На фиг. 2 показана блок-схема алгоритма способа расстановки меток языка согласно второму варианту осуществления настоящего раскрытия. Второй вариант осуществления на основании предыдущего варианта осуществления демонстрирует выполнение итерационного обновления классификатора языка на основании полуконтролируемого обучения. В способе предусмотрены следующие стадии.
[00102] На стадии 201 определяется классификатор языка.
[00103] На стадии 202 выполняется сбор множества элементов информации, относящихся к видеоданным, и множество элементов информации определяется в качестве множества элементов видеоинформации.
[00104] На стадии 203 множество элементов видеоинформации разделяется на целевую информацию и справочную информацию.
[00105] На стадии 204 множество элементов видеоинформации вводится в классификатор языка для идентификации языков, которые применяются для множества элементов видеоинформации.
[00106] На стадии 205 с помощью справочных языков проверяется уровень достоверности целевого языка.
[00107] Целевой язык является языком, который применяется для целевой информации, а справочные языки являются множеством языков, которые применяются для справочной информации.
[00108] На стадии 206 в случае, когда уровень достоверности не меньше заранее настроенного порога достоверности, информация, подобная видеоинформации, создается при использовании видеоинформации в качестве образца, и информация используется в качестве инкрементальной информации.
[00109] Согласно некоторым вариантам осуществления, величина уровня достоверности Score сравнивается с заранее настроенным порогом достоверности MIN_SCORE. В случае, когда величина уровня достоверности Score не меньше заранее настроенного порога достоверности MIN_SCORE, величина уровня достоверности Score является высокой и справочная информация имеет высокую степень подтверждения целевой информации. В этом случае информация, подобная видеоинформации, создается при использовании видеоинформации в качестве образца. Для упрощения различения текстовая информация определяется как инкрементальная информация.
[00110] Поскольку инкрементальная информация создается на основании видеоинформации, инкрементальная информация обрабатывается как предложение.
[00111] Согласно некоторым примерам, инкрементальная информация получается при произвольном удалении неполных слов из видеоинформации при условии соблюдения количественного условия.
[00112] Количественное условие заключается в том, что процентное отношение числа слов в инкрементальной информации к числу слов в видеоинформации превышает первый заранее настроенный порог процентного отношения MIN_PERCENT_1.
[00113] Согласно другим примерам, инкрементальная информация получается при преобразовании форматов всех или некоторых слов в видеоинформации с использованием только прописных букв.
[00114] Согласно другим примерам, инкрементальная информация получается при преобразовании форматов всех или некоторых слов в видеоинформации с использованием только строчных букв.
[00115] Согласно другим примерам, инкрементальная информация получается при удалении всех или некоторых знаков препинания в видеоинформации.
[00116] Согласно другим примерам, инкрементальная информация получается при удалении N (N является целым положительным числом, и N < М) слов в диапазоне из М (М является целым положительным числом) слов в видеоинформации.
[00117] Вышеупомянутые методы создания инкрементальной информации являются только примерами и используются по отдельности или в любой комбинации. На практике согласно фактическим потребностям используются другие методы создания инкрементальной информации, это никак не ограничивается в настоящем раскрытии. Более того, в дополнение к описанным выше методам создания инкрементальной информации специалисты в этой области техники могут использовать другие способы создания инкрементальной информации согласно их фактическим потребностям, это никак не ограничивается в настоящем раскрытии.
[00118] На стадии 207 запускается классификатор языка для обнаружения пригодности инкрементальной информации для идентификации целевого языка.
[00119] На практике пользователи в некоторых регионах привыкли к использованию двух или более языков, и поэтому в видеоинформации имеются слова на двух или более языках, что влияет на правильную идентификацию языка классификатором языка.
[00120] В этом случае язык, предсказанный классификатором языка, является языком с большим количеством тренировочных выборок в учебном наборе, что приводит к неправильному предсказанию.
[00121] Например, в видеоинформации содержится 10 слов, и правильный язык этой видеоинформации является языком хинди. Из этих 10 слов 7 слов являются словами на языке хинди, введенными с помощью транслитерации, а остальные 3 слова являются словами на английском языке Поскольку тренировочные выборки со словами на английском языке являются большими, а тренировочные выборки с введенными с помощью транслитерации словами на языке хинди являются редкими, классификатор языка, вероятно, может неправильно предсказать, что язык видеоинформации является английским языком из-за более сильных признаков 3 слов на английском языков.
[00122] Согласно некоторым вариантам осуществления, видеоинформация проверяется с помощью создания нового предложения (то есть инкрементальной информации). Другими словами, запускается классификатор языка для проверки, допустима ли (пригодна ли) инкрементальная информация для идентификации целевого языка, так что точность предсказания языков улучшается.
[00123] На практике язык, который применяется в инкрементальной информации, идентифицируется с помощью ввода инкрементальной информации в классификатор языка для обработки.
[00124] Инкрементальная информация в основном используется для проверки достоверности размеченного языка, и язык является уникальным. Следовательно, язык с наивысшим уровнем правдоподобия из множества языков, выведенных классификатором языка, определяется как язык, применяемый для инкрементальной информации, и игнорируются другие языки, которые с некоторой вероятностью могут применяться для инкрементальной информации. Для упрощения различения этот язык называется инкрементальным языком. Таким образом, инкрементальный язык является языком, который применяется для инкрементальной информации.
[00125] Подсчитывается процентное отношение инкрементальных языков, когда инкрементальные языки идентичны целевым языкам. Другими словами, подсчитывается первое число как число инкрементальных языков, идентичных целевым языкам, и подсчитывается второе число как число всех инкрементальных языков, и отношение первого числа ко второму числу подсчитывается как процентное отношение.
[00126] В случае, когда процентное отношение не меньше второго заранее настроенного порога процентного отношения MIN_PERCENT_2 (например, 80%), сомнения в том, что инкрементальный язык является целевым языком, малы, и инкрементальная информация является допустимой для идентификации языка.
[00127] В случае, когда процентное отношение меньше второго заранее настроенного порога процентного отношения MIN_PERCENT_2 (например, 80%), сомнения в том, что инкрементальный язык является целевым языком, велики, и инкрементальная информация является недопустимой для идентификации языка.
[00128] На стадии 208 в случае, когда инкрементальная информация является допустимой для идентификации целевого языка, классификатор языка обновляется на основе целевого языка и, по меньшей мере, одной из видеоинформации или инкрементальной информации.
[00129] Для автоматического сбора новых данных (видеоинформации, инкрементальной информации) с правильно размеченным языком, и для одновременного улучшения качества работы классификатора языка с помощью использования новых данных в качестве тренировочных выборок (текстовая информация или голосовой сигнал), собранные данные обычно соответствуют следующим двум правилам.
[00130] 1. Новые данные не подобны имеющимся тренировочным выборкам в текущем учебном наборе, так что классификатор языка способен обучиться новым признакам.
[00131] Одним индикатором для определения того, подобны ли новые данные имеющимся тренировочным выборкам, является предсказание величины вероятности языка, который применяется в новых данных, с помощью использования текущего классификатора языка. Другими словами, в случае, когда величина вероятности низкая, классификатор языка не проходил какой тип данных в своем учебном наборе и поэтому предсказана низкая величина вероятности. Следовательно, единственным вариантом является добавление в учебный набор новых данных с низкой величиной вероятности.
[00132] 2. Тег (языка) новых данных является точным, так что классификатор языка обучен для хороших показателей работы.
[00133] Общепринятой практикой для обеспечения наличия точного тега является ручная расстановка меток в новых данных. Для соблюдения требования автоматического сбора, автоматический алгоритм предназначен для обработки языка с высокой величиной вероятности (например, более 0,95) расстановкой правильного тега. Высокая величина вероятности означает, что классификатор языка считает, что применение этого языка в новых данных является правильным. Следовательно, единственным вариантом является добавление в учебный набор новых данных с высокой величиной вероятности
[00134] Используемые в двух вышеупомянутых правилах варианты ранее находились в состоянии конфликта друг с другом. Другими словами, обычно невозможно одновременно добавить в учебный набор данные с низкой величиной вероятности и данные с высокой величиной вероятности.
[00135] Для решения проблемы конфликта между этими двумя вариантами в настоящем раскрытии предложено определить, был ли язык с низкой величиной вероятности правильно предсказан для целевой информации с помощью использования предсказания справочной информации видеоданных в качестве элемента подтверждающего доказательства. В случае, когда предсказанный язык с низкой величиной вероятности был определен как правильный, два вышеупомянутых правила соблюдены, и целевая информация добавляется в учебный набор. Таким образом, в ходе процесса добавления новых признаков, которые ранее не входили или незначительно входили в учебный набор, качество работы классификатора языка улучшается, так что точность предсказания и расстановки меток языков улучшается, и, следовательно, реализована интеграция полуконтролируемого обучения классификатора языка и автоматическая расстановка тегов.
[00136] В случае, когда инкрементальная информация является допустимой для идентификации целевого языка, язык, предсказанный для заново созданной инкрементальной информации, является согласованным с языком видеоинформации. В этом случае предсказание языка видеоинформации определяется как являющееся непротиворечивым, и видеоинформация и ее целевой язык используются для обновления классификатора языка.
[00137] В случае, когда инкрементальная информация является недопустимой для идентификации целевого языка, язык, предсказанный для заново созданной инкрементальной информации, является несогласованным с языком видеоинформации, возможно, вследствие того, что видеоинформации содержит слова на других языках или некоторые слова имеют более сильные признаки. В этом случае, предсказание языка видеоинформации определяется как являющееся противоречивым, и видеоинформация и ее целевой язык не используются для обновления классификатора языка.
[00138] На практике, получается учебный набор для классификатора языка. Учебный набор включает в себя множество элементов текстовой информации (или голосовых сигналов), причем текстовая информация (или голосовые сигналы) в учебном наборе были снабжены метками применяемых языков. Текстовая информация (или голосовые сигналы) в учебном наборе является текстовой информацией (или голосовыми сигналами), которые первоначально были снабжены метками применяемых языков, или видеоинформация и/или инкрементальная информация были впоследствии снабжены метками применяемых языков с помощью классификатора языка, это никак не ограничивается в настоящем документе.
[00139] В процессе обновления классификатора языка с помощью использования видеоинформации и ее целевого языка, видеоинформация добавляется в учебный набор и добавленная видеоинформация используется в качестве текстовой информации (или голосового сигнала) в учебном наборе, и целевая информация снабжается метками языка в качестве языка, который применяется в видеоинформации.
[00140] Более того, в случае, когда инкрементальная информация является допустимой для идентификации целевого языка, надлежащая инкрементальная информация и ее целевой язык используются для обновления классификатора языка.
[00141] Отбирается инкрементальная информация, которая допустима для обновления классификатора языка, и отобранная инкрементальная информация добавляется в учебный набор и используется в качестве текстовой информации (или голосового сигнала) в учебном наборе, и расставляются метки целевого языка как языка, который применяется в инкрементальной информации.
[00142] В качестве примера, величина вероятности того, что в видеоинформации применяется целевой язык, определяется как равная указанному отношению MIN_RATIO (0<MIN RATIO<1), и указанное отношение используется в качестве третьего порога правдоподобия MIN_PROB_3 для инкрементальной информации.
[00143] Величина вероятности того, что целевой язык применяется в инкрементальной информации (она выражена как величина вероятности того, что инкрементальный язык, который используется в инкрементальной информации, идентичен целевому языку), сравнивается с первым заранее настроенным порогом правдоподобия MIN_PROB_1 и с третьим порогом правдоподобия MIN_PROB_3.
[00144] В случае, когда величина вероятности того, что целевой язык применяется в инкрементальной информации, не меньше первого заранее настроенного порога правдоподобия MIN_PROB_1 и не больше третьего порога правдоподобия MIN_PROB_3, инкрементальная информация допустима для обновления классификатора языка. Величина вероятности того, что целевой язык применяется в инкрементальной информации, не меньше первого порога правдоподобия MIN_PROB_1.
[00145] Согласно этому примеру, величина вероятности того, что целевой язык применяется в инкрементальной информации, является большой, и она меньше, чем величина вероятности того, что целевой язык применяется в видеоинформации, это указывает, что инкрементальная информация отличается от видеоинформации тем, что имеются некоторые преобразования инкрементальной информации (например, в инкрементальной информации отсутствуют некоторые слова), что приводит к уменьшению предсказанной величины вероятности, это обусловлено тем фактом, что такие преобразования (например, отсутствующие слова) являются более сильными признаками для классификатора языка в процессе предсказания, а первоначальная информация (например, остальные слова и их комбинации) менее знакомы классификатору языка (например, они не присутствовали в текущем учебном наборе), и поэтому добавление инкрементальной информации помогает улучшить качество работы классификатора языка.
[00146] В дополнение к этому, классификатор языка более чувствителен к тренировочным выборкам из первых h (h является положительным целым числом) сеансов итерационных обновлений, и ошибки при расстановке меток влияют на качество работы классификатора языка и ведут к накоплению большего числа ошибок в последующих итерациях. Следовательно, в первых h сеансах итераций, для итераций использовалась видеоинформация, которая была предварительно снабжена метками языков, и предварительно указанный в метках язык был определен по результатам, выведенным классификатором языка для видеоинформации и инкрементальной информации, и язык определен как фактический язык (то есть фактически язык видеоинформации), и фактический язык сравнивается с целевым языком.
[00147] В случае, когда фактический язык является точно таким же, как целевой язык, видеоинформацию разрешено добавлять в учебный набор и использовать в качестве текстовой информации в учебном наборе, и целевой язык разрешено снабжать метками языка в качестве языка, который применяется в видеоинформации. И/или, инкрементальную информацию разрешено добавлять в учебный набор и использовать в качестве текстовой информации в учебном наборе, и целевой язык разрешено снабжать метками языка в качестве языка, который применяется в инкрементальной информации.
[00148] В случае, когда фактический язык отличается от целевого языка, игнорируются целевой язык и, по меньшей мере, одна из видеоинформации или инкрементальной информации. Другими словами, видеоинформацию запрещено добавлять в учебный набор и использовать в качестве текстовой информации в учебном наборе, и целевой язык запрещено снабжать метками языка в качестве языка, который применяется в видеоинформации. И/или, инкрементальную информацию запрещено добавлять в учебный набор и использовать в качестве текстовой информации в учебном наборе, и целевой язык запрещено снабжать метками языка в качестве языка, который применяется в инкрементальной информации.
[00149] В случае, когда классификатор языка обновляется с использованием целевого языка и, по меньшей мере, одной из видеоинформации или инкрементальной информации, обнаруживается, выполнено ли заранее настроенное условие обучения. В случае, когда заранее настроенное условие обучения выполнено, классификатор языка обновляется с использованием текстовой информации из учебного набора в качестве тренировочной выборки и с использованием размеченных языков в качестве тренировочных тегов. В случае, когда заранее настроенное условие обучения не выполнено, другая видеоинформация и инкрементальная информация будут продолжать добавляться.
[00150] В качестве примера, в ходе процесса обнаружения выполнения условия обучения, подсчитывается полное количество видеоинформации, добавленной к учебному набору после последнего обновления классификатора языка, и это полное количество сравнивается с заранее настроенным порогом количества MAX_SENT_COUNT.
[00151] В случае, когда полное количество больше заранее настроенного порога количества MAX_SENT_COUNT, заранее настроенное условие обучения определяется как выполненное.
[00152] Приведенное выше условие обучения является только примером. На практике согласно фактическим потребностям используются другие условия обучения. Например, с момента последнего обновления классификатора языка игнорируется тот факт, что полное количество видеоинформации превышает другой порог количества, а в случае, когда классификатор языка, возможно, имеет дефекты, проводится ожидание как можно более скорого обновления для улучшения его работы. Условия обучения никак не ограничиваются в настоящем документе. Более того, в дополнение к описанным выше условия обучения, специалисты в этой области техники могут использовать другие условия обучения согласно их фактическим потребностям, это никак не ограничивается в настоящем раскрытии.
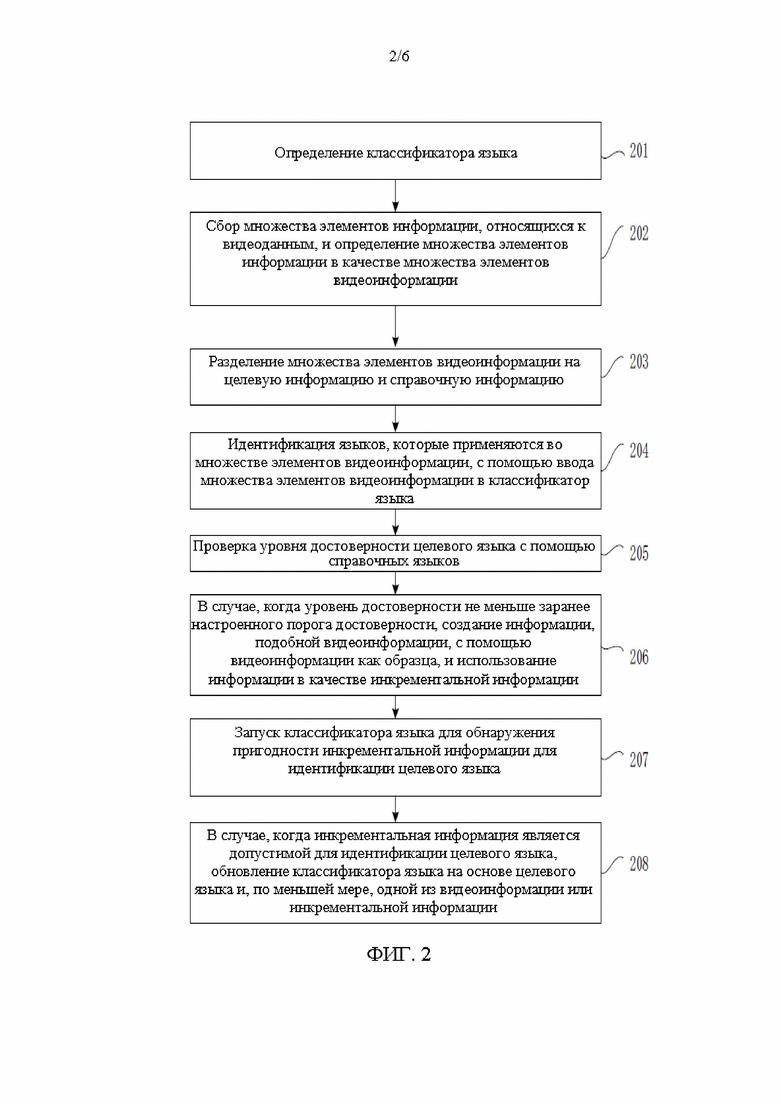
[00153] Для упрощения понимания вариантов осуществления настоящего раскрытия специалистами в этой области техники, способ расстановки меток языка, основанный на полу контролируемом обучении согласно некоторым вариантом осуществления настоящего раскрытия, описан далее в данном документе с помощью примеров.
[00154] Как показано на фиг. 3, количество сеансов итераций i определено как равное 0. На стадии S301 подготавливается размеченный учебный набор L. Учебный набор L содержит в себе предложения (текстовая информация или голосовые сигналы), которые были снабжены метками языка, и неразмеченный набор данных U. Набор данных U содержит в себе предложения (текстовые информация или голосовые сигналы), которые не были снабжены метками языка.
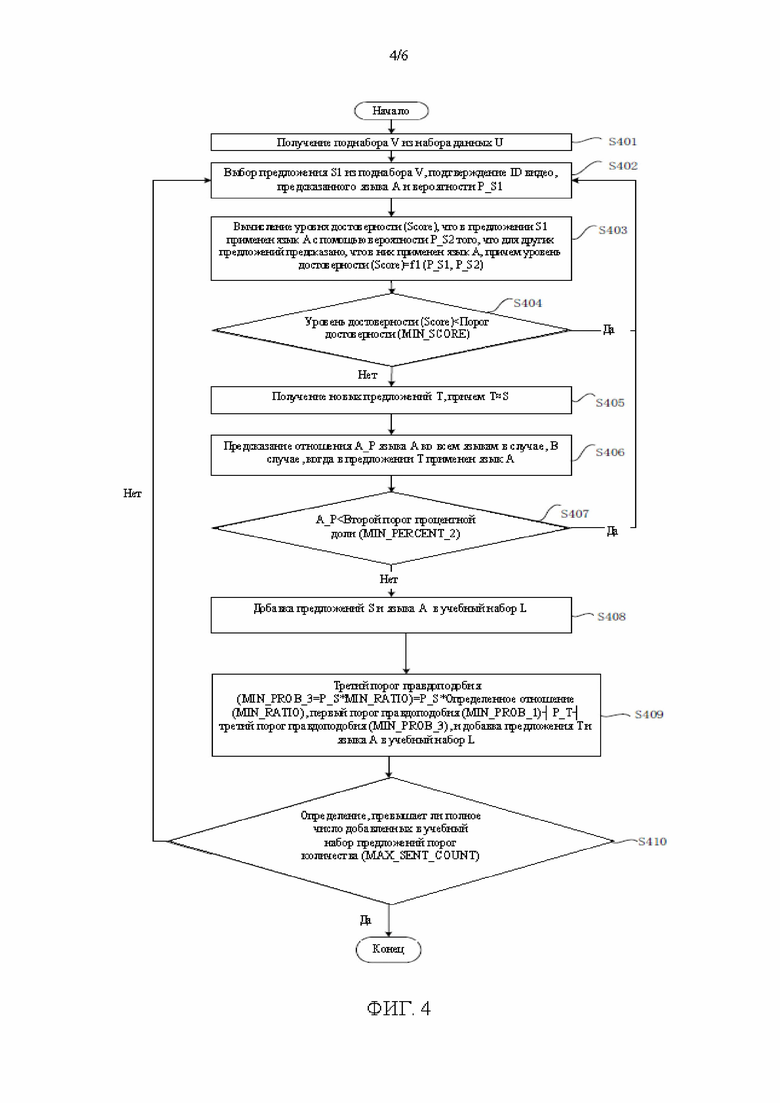
[00155] На стадии S302 классификатор языка Ci тренируется с помощью использования предложений в учебном наборе L и их размеченных языков.
[00156] На стадии S303 определяется, превышает ли значение i порог I. В случае, когда значение i превышает порог I, процесс заканчивается. В случае, когда значение i не превышает порог I, выполняется стадия S304.
[00157] На стадии S304 классификатор языка Ci предсказывает язык, который применяется в каждом предложении S набора данных U, при этом каждому языку указывается величина вероятности.
[00158] На стадии S305 предложения S набора данных снабжаются метками языка, и такие размеченные предложения добавляются в учебный набор L.
[00159] На стадии S306 предложения S, добавленные в учебный набор L, удаляются из набора данных U. В этот момент счетчик итераций увеличивается на единицу (то есть i=i+1) и процесс возвращается на стадию S302.
[00160] Для реализации стадии S304, смотрите фиг. 4, на стадии S401 некоторые предложения S1 (целевая информация) получаются из набора данных U в качестве поднабора V. Наибольшая величина вероятности, среди языков, которые применяются в предложениях S1, лежит между первым порогом правдоподобия MIN_PROB_1 и вторым порогом правдоподобия MIN_PROB_2.
[00161] На стадии S402 предложение S1 случайным образом выбирается из поднабора V, подтверждается идентификатор ID видео видеоданных, в которых расположено предложение S, подтверждается, что предсказанный язык А с наибольшей величиной вероятности применяется в предложении S1, и подтверждается величина вероятности Р_S1 того, что в предложении S1 применяется язык А.
[00162] На стадии S403 другие предложения S2 из видеоданных получаются с помощью использования идентификатора ID видео, и уровень достоверности Score для предложения S1 вычисляется с помощью использования величины вероятности Р_S2 того, что для других предложений предсказано, что в них применяется язык A. Score=f1 (P_S1, Р_S2), где f1 является функцией слияния, например, функцией суммирования, умножения, усреднения, усреднения после применения весовых множителей и тому подобного.
[00163] На стадии S404 определяется, меньше ли уровень достоверности Score порога достоверности MIN_SCORE. В случае, когда уровень достоверности Score меньше порога достоверности MIN_SCORE, предложения S (включая предложения S1 и S2) не выбираются, и процесс возвращается к выполнению стадии S402. В случае, когда уровень достоверности Score не меньше порога достоверности MIN_SCORE, выполняется стадия S405.
[00164] На стадии S405 создается множество новых предложений Т (инкрементальная информация), причем предложения Т подобны предложениям S.
[00165] В качестве примера, предложение Т получается с помощью удаления неполных слов из предложения S. Процентное отношение числа слов в предложении Т к числу слов в предложении S превышает первый порог процентного отношения MIN_PERCENT_1.
[00166] На стадии S406 запускается классификатор языка Ci для соответствующего предсказания множества языков, которые применяются во множестве предложений Т. В случае, когда предсказанным языком является язык А, величина вероятности языка А составляет Р_Т. Вычисляется процентное отношение А_Р языка А ко всем языкам.
[00167] На стадии S407 определяется, меньше ли процентное отношение А_Р второго порога процентного отношения MIN_PERCENT_2. В случае, когда процентное отношение А_Р меньше второго порога процентного отношения MIN_PERCENT_2, предложение S не выбирается и процесс возвращается к выполнению стадии S402. В случае, когда процентное отношение А Р не меньше второго порога процентного отношения MIN_PERCENT_2, выполняется стадия S408.
[00168] На стадии S408 предложения S (включая предложения S1 и S2) снабжаются метками языка А и добавляются в учебный набор L.
[00169] На стадии S409 третий порог правдоподобия MIN_PROB_3 определяется как равный величине P_S*MIN_RATIO. P_S=f2 (P_S1, P_S2), и функция f2 является функцией выбора, например, функцией выбора максимального значения, выбора среднего значения и тому подобного, и 0<MIN_RATIO<l.
[00170] В случае, когда в предложении Т с величиной вероятности MIN_PROB_1≤P_T≤MIN_PROB_3 применяется язык А, предложение Т снабжается меткой языка А и добавляется в учебный набор L.
[00171] На стадии S410 подсчитывается полное количество предложений S и Т, добавленных в учебный набор L, и определяется, превышает ли полное количество величину порога количества MAX_SENT_COUNT. В случае, когда полное количество предложений превышает величину порога количества MAX_SENT_COUNT, процесс останавливается и классификатор языка Ci ожидает обновления с помощью использования учебного набора L. В противном случае процесс возвращается к выполнению стадии S402.
[00172] Для упрощения описания варианты осуществления способа описаны в виде последовательности действий, однако специалисты в этой области техники будут осознавать, что варианты осуществления настоящего раскрытия не ограничены описанной выше последовательностью действий, так как некоторые стадии могут быть выполнены в другой последовательности или одновременно согласно вариантам осуществления настоящего раскрытия. Во-вторых, специалисты в этой области техники также будут осознавать, что описанные в настоящем документе варианты осуществления принадлежат к возможным вариантам осуществления, и выполняемые действия не являются обязательными для вариантов осуществления настоящего раскрытия.
[00173] Третий вариант осуществления
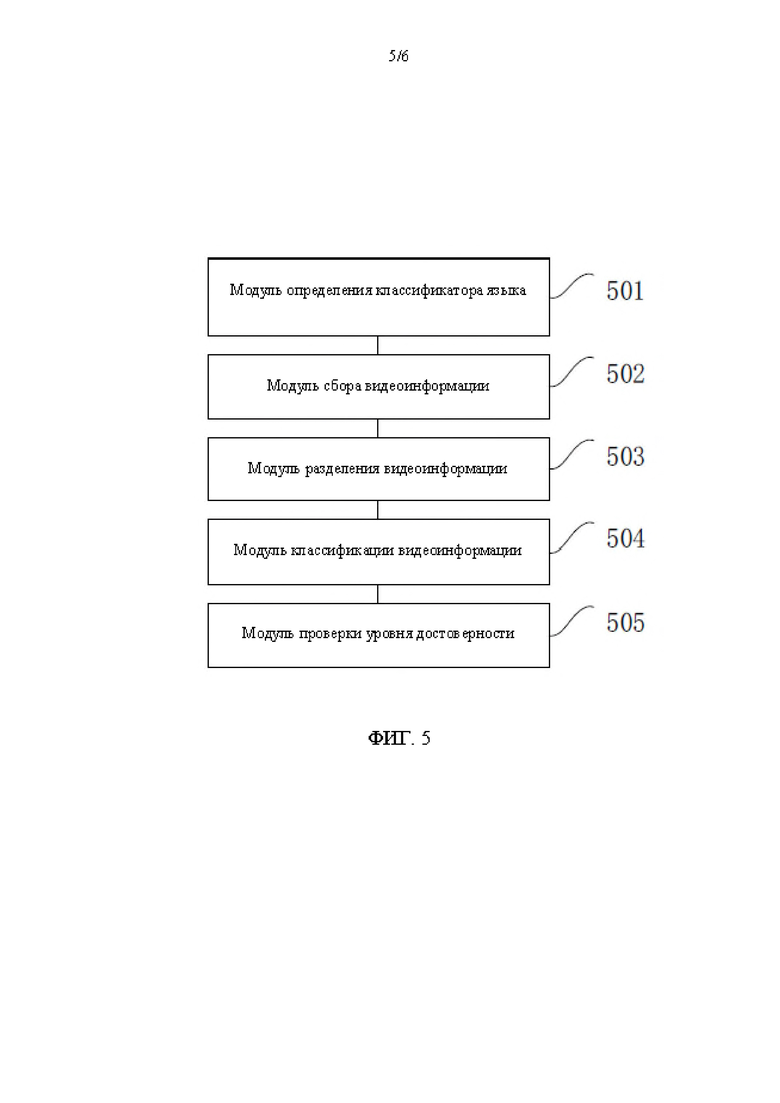
[00174] На фиг. 5 показана упрощенная блок-схема устройства для расстановки меток языка согласно третьему варианту осуществления настоящего раскрытия. Устройство включает в себя:
[00175] модуль 501 определения классификатора языка, выполненный с возможностью определить классификатор языка; модуль 502 сбора видеоинформации, выполненный с возможностью собирать множество элементов информации, связанной с видеоданными, и определить множество элементов информации в качестве множества элементов видеоинформации; модуль 503 разделения видеоинформации, выполненный с возможностью разделять множество элементов видеоинформации на целевую информацию и справочную информацию; модуль 504 классификации видеоинформации, выполненный с возможностью идентифицировать языки, которые применяются во множестве элементов видеоинформации, с помощью ввода множества элементов видеоинформации в классификатор языка; и модуль 505 проверки уровня достоверности, выполненный с возможностью проверить уровень достоверности целевого языка с помощью справочных языков, причем целевой язык является языком, который применяется в целевой информации, а справочные языки являются множеством языков, которые применяются в справочной информации.
[00176] Согласно некоторым вариантам осуществления настоящего раскрытия, модуль 501 определения классификатора языка включает в себя:
[00177] модуль создания учебного набора, выполненный с возможностью создавать учебный набор, причем учебный набор включает в себя множество элементов текстовой информации, и каждый элемент текстовой информации был снабжен меткой примененного языка; и модуль обучения классификатора языка, выполнена с возможностью тренировать классификатор языка с помощью использования каждого элемента текстовой информации в учебном наборе в качестве тренировочной выборки и использования языка, меткой которого была снабжена текстовая информация, в качестве тренировочного тега.
[00178] Согласно некоторым вариантам осуществления настоящего раскрытия, модуль 503 разделения видеоинформации включает в себя:
[00179] модуль определения корреляции, выполненный с возможностью определять корреляции множества элементов видеоинформации с видеоданными; модуль настройки целевой информации, выполненный с возможностью настроить видеоинформацию с наивысшей степенью корреляции в качестве целевой информации; и модуль настройки справочной информации, выполненный с возможностью настроить видеоинформацию, отличающуюся от целевой информации во множестве элементов видеоинформации, в качестве справочной информации.
[00180] Согласно некоторым вариантам осуществления настоящего раскрытия, видеоинформация содержит, по меньшей мере, одну из следующих информаций:
[00181] информация описания, согласованная с заставкой рекламно-маркетинговая информация, информация субтитров, информация первого признака, информация второго признака или информация комментария, причем информация первого признака является текстовой информацией, извлеченной из заставки, а информация второго признака является текстовой информацией, извлеченной из множества элементов кадров изображений видеоданных.
[00182] Целевая информация является информацией описания, а справочная информация включает в себя, по меньшей мере, одну из следующих информаций:
[00183] согласованная с заставкой рекламно-маркетинговая информация, информация субтитров, информация первого признака, информация второго признака или информация комментария.
[00184] Согласно некоторым вариантам осуществления настоящего раскрытия, модуль 505 проверки уровня достоверности включает в себя:
[00185] модуль запроса целевой вероятности, выполненный с возможностью запрашивать вероятность целевого языка и определять вероятность целевого языка в качестве целевой вероятности; модуль запроса справочной вероятности, выполненный с возможностью запрашивать, в случае, когда целевая вероятность не меньше первого заранее настроенного порога правдоподобия и не больше второго заранее настроенного порога правдоподобия, вероятность того, что справочные языки идентичны целевому языку, и использовать вероятность справочных языков в качестве справочной вероятности; модуль слияния вероятности, выполненный с возможностью вычислять уровень достоверности того, что целевой язык назначен целевой информации с помощью комбинирования целевой вероятности со справочной вероятностью.
[00186] Согласно некоторым вариантам осуществления настоящего раскрытия, устройство дополнительно включает в себя:
[00187] модуль создания инкрементальной информации, выполненный с возможностью создавать, в случае, когда уровень достоверности не меньше заранее настроенного порога достоверности, информацию, подобную видеоинформации, для применения в качестве инкрементальной информации; модуль обнаружения пригодности инкрементальной информации для идентификации целевого языка; модуль обновления классификатора языка, выполненный с возможностью обновлять классификатор языка на основе целевого языка и, по меньшей мере, одной из видеоинформации или инкрементальной информации в случае, когда инкрементальная информация допустима для идентификации целевого языка.
[00188] Согласно некоторым вариантам осуществления настоящего раскрытия, модуль создания инкрементальной информации включает в себя:
[00189] первый модуль удаления слов, выполненный с возможностью, в случае соблюдения количественного условия, получать инкрементальную информацию с помощью удаления неполных слов из видеоинформации, причем количественное условие заключается в том, что процентное отношение числа слов в инкрементальной информации к числу слов в видеоинформации превышает первый заранее настроенный порог процентного отношения; и/или первый модуль преобразования букв, выполненный с возможностью получать инкрементальную информацию с помощью преобразования форматов слов в видеоинформации с использованием только прописных букв; и/или второй модуль преобразования букв, выполненный с возможностью получать инкрементальную информацию с помощью преобразования форматов слов в видеоинформации с использованием только строчных букв; и/или модуль удаления знаков пунктуации, выполненный с возможностью получать инкрементальную информацию с помощью удаления знаков пунктуации в видеоинформации; и/или второй модуль удаления слов, выполненный с возможностью получать инкрементальную информацию с помощью удаления N слов, внутри диапазона из М слов, в видеоинформации.
[00190] Согласно некоторым вариантам осуществления настоящего раскрытия, модуль обнаружения пригодности включает в себя:
[00191] модуль классификации инкрементальной информации, выполненный с возможностью идентифицировать язык, который применяется в инкрементальной информации, при помощи ввода инкрементальной информации в классификатор языка, и использовать этот язык в качестве инкрементального языка; модуль подсчета процентного отношения, выполненный с возможностью подсчитывать процентное отношение инкрементальных языков, которые идентичны целевому языку; и модуль определения пригодности, выполненный с возможностью определить, что инкрементальная информация пригодна для идентификация языков в случае, когда процентное отношение не меньше второго заранее настроенного порога процентного отношения.
[00192] Согласно некоторым вариантам осуществления настоящего раскрытия, модуль обновления классификатора языка включает в себя:
[00193] модуль получения учебного набора, выполненный с возможностью получать учебный набор для классификатора языка, причем учебный набор включает в себя множество элементов текстовой информации, и каждый элемент текстовой информации был снабжен меткой языка, примененного в текстовой информации; модуль добавления видеоинформации, выполненный с возможностью добавлять видеоинформацию в учебный набор для использования в качестве текстовой информации в учебном наборе; модуль расстановки меток в видеоинформации, выполненный с возможностью расставлять метки целевого языка в качестве языка, который применен в видеоинформации; модуль обнаружения условия обучения, выполненный с возможностью обнаруживать, выполняется ли заранее настроенное условие обучения, в случае, когда заранее настроенное условие обучения выполнено, запускается модуль итерационного обучения; модуль итерационного обучения, выполненный с возможностью обновить классификатор языка с помощью использования текстовой информации в учебном наборе в качестве тренировочной выборки и использования указанного в метках языка в качестве тренировочного тега.
[00194] Согласно некоторым вариантам осуществления настоящего раскрытия, модуль обнаружения условия обучения включает в себя:
[00195] модуль подсчета полного количества, выполненный с возможностью подсчитывать полное количество видеоинформации, добавленной к учебному набору после последнего обновления классификатора языка; и модуль определения выполнения, выполненный с возможностью определить, что заранее настроенное условие обучения выполнено в случае, когда полное количество больше заранее настроенного порога количества.
[00196] Согласно некоторым вариантам осуществления настоящего раскрытия, модуль обновления классификатора языка дополнительно включает в себя:
[00197] модуль отбора инкрементальной информации, выполненный с возможностью отбирать инкрементальную информацию, которая пригодна для обновления классификатора языка; модуль добавления инкрементальной информации, выполненный с возможностью добавлять отобранную инкрементальную информацию в учебной набор для использования в качестве текстовой информации в учебном наборе; и модуля расстановки меток в инкрементальной информации, выполненный с возможностью расставлять метки целевого языка как языка, который применяется в инкрементальной информации.
[00198] Согласно некоторым вариантам осуществления настоящего раскрытия, модуль отбора инкрементальной информации включает в себя:
[00199] модуль настройки порога правдоподобия, выполненный с возможностью получать указанную процентную долю вероятности того, что целевой язык применяется в видеоинформации, использовать ее в качестве третьего порога правдоподобия для инкрементальной информации; и модуль определения пригодности, выполненный с возможностью определять пригодность инкрементальной информации для обновления классификатора языка в случае, когда величина вероятности того, что целевой язык применяется в инкрементальной информации, не меньше первого заранее настроенного порога правдоподобия и не больше третьего порога правдоподобия, причем величина вероятности того, что целевой язык применяется в целевой информации, не меньше первого порога правдоподобия.
[00200] Согласно некоторым вариантам осуществления настоящего раскрытия, модуль обновления классификатора языка дополнительно включает в себя:
[00201] модуль определения фактического языка, выполненный с возможностью определить язык, метки которого расставлены в видеоинформации, и использовать определенный язык в качестве фактического языка; и модуль игнорирования выборки, выполненный с возможностью игнорировать целевой язык и, по меньшей мере, одну из видеоинформации или инкрементальной информации в случае, когда фактический язык отличается от целевого языка. Устройство для расстановки меток языка согласно некоторым вариантам осуществления настоящего раскрытия способно выполнить способ расстановки меток согласно любому варианту осуществления настоящего раскрытия, и имеет функциональные модули и действия, необходимые для выполнения способа.
[00202] Четвертый вариант осуществления
[00203] На фиг. 6 показана упрощенная блок-схема вычислительного устройства согласно четвертому варианту осуществления настоящего раскрытия. На фиг. 6 показана блок-схема приведенного в качестве примера вычислительного устройства 12, пригодного для реализации вариантов осуществления настоящего раскрытия. Показанное на фиг. 6 вычислительное устройство 12 является только примером и оно не накладывает никаких ограничений на функции или область применения вариантов осуществления настоящего раскрытия.
[00204] Как показано на фиг. 6, вычислительное устройство 12 представлено в виде общего вычислительного устройства. Компоненты вычислительного устройства 12 включают в себя, помимо прочего, один или несколько процессоров или процессорных блоков 16, системную память 28 и шину 18, которая соединяет различные компоненты системы (включая системную память 28 и процессорные блоки 16).
[00205] Системная память 28 включает в себя машиночитаемый носитель данных в виде энергозависимой памяти, например оперативного запоминающего устройства (ОЗУ) 30 и/или кэш-памяти 32. Например, система хранения данных 34 подготовлена для считывания и записи данных на несъемный долговременный энергонезависимый магнитный носитель (не показан на фиг. 6, обычно называется «накопитель на жестком магнитном диске»). В памяти 28 хранится, по меньшей мере, один программный продукт, включающий в себя набор (например, по меньшей мере, один) программных модулей. Программные модули выполнены с возможностью реализовать функции вариантов осуществления настоящего раскрытия.
[00206] Программный продукт/сервисная программа 40 содержит в себе набор (например, по меньшей мере, один) программных модулей 42, и хранится, например, в памяти 28. Программный модуль 42 обычно выполняет функции и/или способы вариантов осуществления, описанных в настоящем раскрытии.
Вычислительное устройство 12 также обменивается данными с одним или несколькими периферийными устройствами 14 (например, клавиатура, указывающее устройство, дисплей 24 и тому подобное). Такая передача данных выполняется с помощью интерфейса 22 ввода - вывода (В-В) 22. Вычислительное устройство 12 также обменивается данными с одной или несколькими сетями (например, локальная вычислительная сеть (ЛВС), глобальная вычислительная сеть (ГВС) и/или сети общего пользования, например, Интернет) с помощью сетевого интерфейса 20.
[00208] Процессорный блок 16 выполняет множество функциональных приложений и обработку данных, например, реализацию способа расстановки меток языка согласно некоторым вариантам осуществления настоящего раскрытия, с помощью выполнения одной или нескольких программ, хранящихся в системной памяти 28.
[00209] Седьмой вариант осуществления
[00210] Согласно седьмому варианту осуществления настоящего раскрытия дополнительно предложен машиночитаемый носитель данных, в котором хранится одна или несколько компьютерных программ. Одна или несколько компьютерных программ, будучи загруженными и выполняемыми процессором, заставляют процессор выполнить множество процессов вышеуказанного способа расстановки меток языка, и при этом достигается тот же самый технический результат, который не повторяется в настоящем описании.
[00211] Машиночитаемый носитель данных включает в себя, помимо прочего, например, электрические, магнитные, оптические, электромагнитные, инфракрасные или полупроводниковые системы, аппаратуру, устройства или их любые комбинации. Примеры машиночитаемого носителя данных включают в себя (неисчерпывающий список) электрическое подключение с помощью одного или нескольких проводов, переносной компьютерный диск, накопитель на жестком магнитном диске, оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), стираемое программируемое постоянное запоминающее устройство (СППЗУ), флэш-память, оптическое волокно, постоянное запоминающее устройство на компакт-диске (CD-ROM), оптическое запоминающее устройство, магнитное запоминающее устройство или их любую пригодную комбинацию. Согласно настоящему раскрытию машиночитаемый носитель данных является любым материальным носителем, содержащим или хранящим одну или несколько программ, причем одна или несколько программ используются системой выполнения команд, аппаратурой или устройством или совместно с ними.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОПРЕДЕЛЕНИЯ ПРОФИЛЯ ПОЛЬЗОВАТЕЛЯ МОБИЛЬНОГО УСТРОЙСТВА НА САМОМ МОБИЛЬНОМ УСТРОЙСТВЕ И СИСТЕМА ДЕМОГРАФИЧЕСКОГО ПРОФИЛИРОВАНИЯ | 2016 |
|
RU2647661C1 |
| ТЕМАТИЧЕСКИЕ МОДЕЛИ С АПРИОРНЫМИ ПАРАМЕТРАМИ ТОНАЛЬНОСТИ НА ОСНОВЕ РАСПРЕДЕЛЕННЫХ ПРЕДСТАВЛЕНИЙ | 2018 |
|
RU2719463C1 |
| Система и способ корректировки орфографических ошибок | 2020 |
|
RU2753183C1 |
| Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации | 2020 |
|
RU2750852C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБУЧЕНИЯ КЛАССИФИКАТОРА И РАСПОЗНАВАНИЯ ТИПА | 2015 |
|
RU2643500C2 |
| ВЫДЕЛЕНИЕ ВРЕМЕННЫХ ВЫРАЖЕНИЙ ДЛЯ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2014 |
|
RU2595489C2 |
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ И ФИЛЬТРАЦИИ ЗАПРЕЩЕННОГО КОНТЕНТА В СЕТИ | 2020 |
|
RU2738335C1 |
| ОБНОВЛЕНИЕ МОДЕЛЕЙ КЛАССИФИКАТОРОВ ПОНИМАНИЯ ЯЗЫКА НА ОСНОВЕ КРАУДСОРСИНГА | 2016 |
|
RU2699587C2 |
| ОБУЧЕНИЕ КЛАССИФИКАТОРОВ, ИСПОЛЬЗУЕМЫХ ДЛЯ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2018 |
|
RU2691855C1 |
| СПОСОБЫ ДЛЯ ПОНИМАНИЯ НЕПОЛНОГО ЗАПРОСА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2710966C2 |
Изобретение относится к способам анализа видеоинформации, в частности к способам определения языка видеоинформации. Технический результат заключается в увеличении точности идентификации языка на видео при сокращении времени. Технический результат достигается за счет того, что способ предусматривает следующие стадии: определение классификатора языка; сбор множества элементов информации, связанной с видеоданными, и определение множества элементов информации в качестве множества элементов видеоинформации; разделение множества элементов видеоинформации на целевую информацию и справочную информацию; идентификация языков, которые применяются во множестве элементов видеоинформации, с помощью ввода множества элементов видеоинформации в классификатор языка; и проверка уровня достоверности целевого языка с помощью справочных языков, причем целевой язык является языком, который применяется в целевой информации, а справочные языки являются множеством языков, которые применяются в справочной информации. 4 н. и 12 з.п. ф-лы, 6 ил.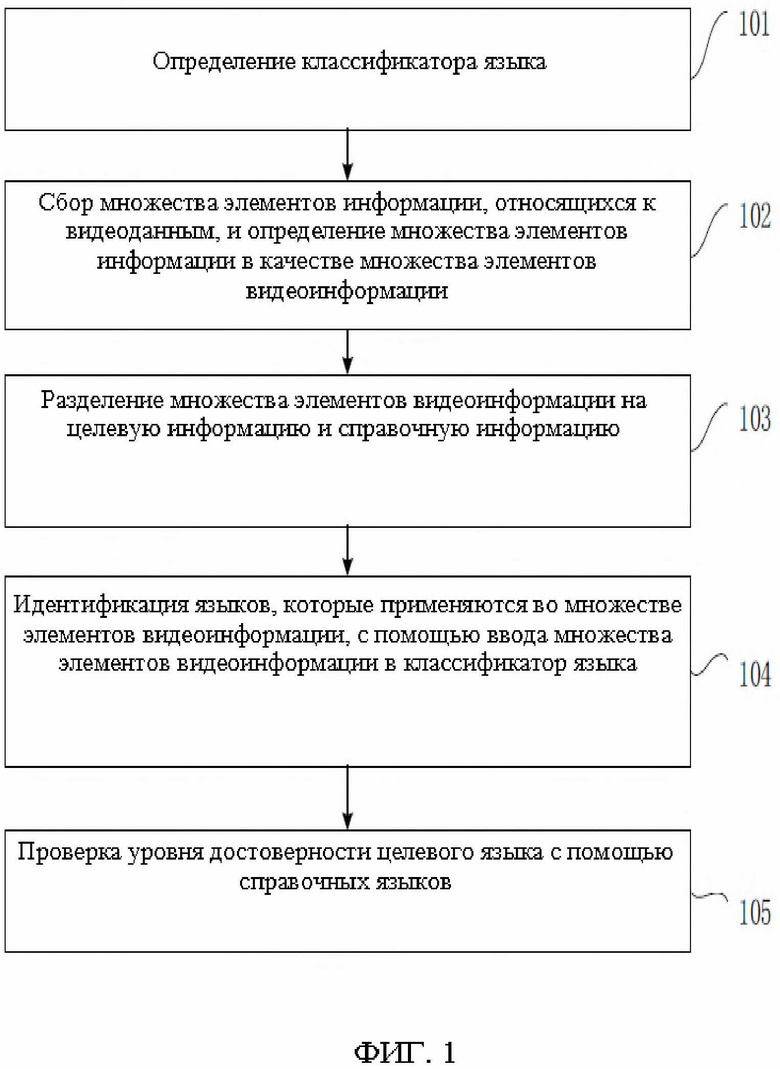
1. Способ расстановки меток языка, предусматривающий следующие стадии:
определение классификатора языка;
сбор множества элементов информации, относящихся к видеоданным, и определение множества элементов информации в качестве множества элементов видеоинформации;
разделение множества элементов видеоинформации на целевую информацию и справочную информацию;
идентификация языков, которые применяются во множестве элементов видеоинформации, с помощью ввода множества элементов видеоинформации в классификатор языка; и
проверка уровня достоверности целевого языка с помощью справочных языков, причем целевой язык является языком, который применяется для целевой информации, а справочные языки являются множеством языков, которые применяются для справочной информации.
2. Способ по п. 1, отличающийся тем, что классификатор языка предусматривает следующие стадии:
создание учебного набора, причем учебный набор включает в себя множество элементов текстовой информации, и каждый элемент текстовой информации был снабжен меткой языка, примененного в текстовой информации; и
тренировка классификатора языка с помощью использования каждого элемента текстовой информации в учебном наборе в качестве тренировочной выборки и использования языка, меткой которого была снабжена текстовая информация, в качестве тренировочного тега.
3. Способ по п. 1, отличающийся тем, что разделение множества элементов видеоинформации на целевую информацию и справочную информацию предусматривает следующие стадии:
определение корреляций множества элементов видеоинформации с видеоданными;
настройка видеоинформации с наивысшей степенью корреляции в качестве целевой информации; и
настройка видеоинформации, отличающейся от целевой информации во множестве элементов видеоинформации, в качестве справочной информации.
4. Способ по п. 3, отличающийся тем, что видеоинформация содержит по меньшей мере одну из следующих информаций: информация описания, согласованная с заставкой рекламно-маркетинговая информация, информация субтитров, информация первого признака, информация второго признака или информация комментария, причем информация первого признака является текстовой информацией, извлеченной из заставки, а информация второго признака является текстовой информацией, извлеченной из множества кадров изображений видеоданных; и
в случае, когда целевая информация является информацией описания, справочная информация включает в себя по меньшей мере одну из следующих информаций: согласованная с заставкой рекламно-маркетинговая информация, информация субтитров, информация первого признака, информация второго признака или информация комментария.
5. Способ по любому из пп. 1-4, отличающийся тем, что проверка уровня достоверности целевого языка с помощью справочных языков предусматривает следующие стадии:
запрашивание вероятности целевого языка и определение вероятности целевого языка в качестве целевой вероятности;
запрашивание, в случае, когда целевая вероятность не меньше первого заранее настроенного порога правдоподобия и не больше второго заранее настроенного порога правдоподобия, вероятности того, что справочные языки идентичны целевому языку, и определение вероятности справочных языков в качестве справочной вероятности; и
вычисление, с помощью объединения с целевой вероятностью и со справочной вероятностью, уровня достоверности того, что целевая информация применяется с целевым языком.
6. Способ по любому из пп. 1-4, в котором дополнительно предусмотрены следующие стадии:
в случае, когда уровень достоверности не меньше заранее настроенного порога достоверности, создание информации, подобной видеоинформации, для использования в качестве инкрементальной информации;
запуск классификатора языка для обнаружения пригодности инкрементальной информации для идентификации целевого языка; и
в случае, когда инкрементальная информация является допустимой для идентификации целевого языка, обновление классификатора языка на основе целевого языка и по меньшей мере одной из видеоинформации или инкрементальной информации.
7. Способ по п. 6, отличающийся тем, что создание информации, подобной видеоинформации, для применения в качестве инкрементальной информации, предусматривает по меньшей мере одну из следующих стадий:
получение инкрементальной информации с помощью удаления неполных слов из видеоинформации при соблюдении количественного условия, причем количественное условие заключается в том, что процентное отношение числа слов в инкрементальной информации к числу слов в видеоинформации превышает первый заранее настроенный порог процентного отношения;
получение инкрементальной информации с помощью преобразования форматов слов в видеоинформации с использованием только прописных букв;
получение инкрементальной информации с помощью преобразования форматов слов в видеоинформации с использованием только строчных букв;
получение инкрементальной информации с помощью удаления знаков препинания в видеоинформации; или
получение инкрементальной информации с помощью удаления N слов внутри диапазона из М слов в видеоинформации, причем М больше N, и оба числа М и N являются положительными целыми числами.
8. Способ по п. 6, отличающийся тем, что запуск классификатора языка для обнаружения пригодности инкрементальной информации для идентификации целевого языка предусматривает следующие стадии:
идентификация языка, который применяется в инкрементальной информации, с помощью ввода инкрементальной информации в классификатор языка, и определение языка как инкрементального языка;
подсчитывание процентного отношения инкрементальных языков, которые идентичны целевому языку; и
в случае, когда процентное отношение не меньше второго заранее настроенного порога процентного отношения, определение, что инкрементальная информация является допустимой для идентификации языков.
9. Способ по п. 6, отличающийся тем, что обновление классификатора языка, которое основано на целевом языке и по меньшей мере одной из видеоинформации или инкрементальной информации, предусматривает следующие стадии:
получение учебного набора для классификатора языка, причем учебный набор включает в себя множество элементов текстовой информации, и каждый элемент текстовой информации был снабжен меткой языка, примененного в текстовой информации;
добавление видеоинформации в учебный набор для использования в качестве текстовой информации в учебном наборе;
расстановка меток целевого языка в качестве языка, который применяется для целевой информации;
определение, выполняется ли заранее настроенное условие обучения; и
в случае выполнения заранее настроенного условия обучения, обновление классификатора языка с использованием текстовой информации из учебного набора в качестве тренировочной выборки и с использованием размеченного языка в качестве тренировочного тега.
10. Способ по п. 9, отличающийся тем, что обнаружение того, удовлетворяет ли учебный набор заранее настроенному условию обучения, предусматривает следующие стадии:
подсчитывание полного количества видеоинформации, добавленной к учебному набору после последнего обновления классификатора языка; и
определение, что заранее настроенное условие обучения выполнено в случае, когда полное количество больше заранее настроенного порога количества.
11. Способ по п. 9, отличающийся тем, что обновление классификатора языка, которое основано на целевом языке и по меньшей мере одной из видеоинформации или инкрементальной информации, дополнительно предусматривает следующие стадии:
проведение отбора инкрементальной информации, которая допустима для обновления классификатора языка;
добавление отобранной инкрементальной информации в учебный набор для использования в качестве текстовой информации в учебном наборе; и
расстановка меток целевого языка в качестве языка, который применяется в инкрементальной информации.
12. Способ по п. 11, отличающийся тем, что проведение отбора инкрементальной информации, которая допустима для обновления классификатора языка, предусматривает следующие стадии:
получение указанного процентного отношения вероятности того, что целевой язык применяется в видеоинформации для использования в качестве третьего порога правдоподобия для инкрементальной информации;
в случае, когда величина вероятности того, что целевой язык применяется в инкрементальной информации, не меньше первого заранее настроенного порога правдоподобия и не больше третьего порога правдоподобия, определение, что инкрементальная информация пригодна для обновления классификатора языка, причем величина вероятности того, что целевой язык применяется в целевой информации, не меньше первого порога.
13. Способ по п. 9 или 11, отличающийся тем, что обновление классификатора языка, которое основано на целевом языке и по меньшей мере одной из видеоинформации или инкрементальной информации, дополнительно предусматривает следующие стадии:
определение языка, указанного в метках видеоинформации, для использования в качестве фактического языка; и
игнорирование целевого языка и по меньшей мере одной из видеоинформации или инкрементальной информации в случае, когда фактический язык отличается от целевого языка.
14. Устройство для расстановки меток языка, включающее в себя:
модуль определения классификатора языка, выполненный с возможностью определить классификатор языка;
модуль сбора видеоинформации, выполненный с возможностью проводить сбор множества элементов информации, относящихся к видеоданным, и определять множество элементов информации в качестве множества элементов видеоинформации;
модуль разделения видеоинформации, выполненный с возможностью разделять множество элементов видеоинформации на целевую информацию и справочную информацию;
модуль классификации видеоинформации, выполненный с возможностью идентифицировать языки, которые применяются во множестве элементов видеоинформации, с помощью ввода множества элементов видеоинформации в классификатор языка; и
модуль проверки уровня достоверности, выполненный с возможностью проверить уровень достоверности целевого языка с помощью справочных языков, причем целевой язык является языком, который применяется для целевой информации, а справочные языки являются множеством языков, которые применяются для справочной информации.
15. Вычислительное устройство для расстановки меток языка, включающее в себя:
по меньшей мере один процессор;
память, выполненную с возможностью хранить по меньшей мере одну программу;
причем по меньшей мере один процессор после загрузки и выполнения по меньшей мере одной программы заставлен выполнять способ расстановки меток языка, как определено согласно любому из пп. 1-13.
16. Машиночитаемый носитель данных, в котором хранится одна или несколько компьютерных программ, причем одна или несколько компьютерных программ, будучи загруженными и выполняемыми процессором, заставляют процессор выполнить способ расстановки меток языка, как определено согласно любому из пп. 1-13.
| CN 112017630 A, 01.12.2020 | |||
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Способ и система перевода исходного предложения на первом языке целевым предложением на втором языке | 2017 |
|
RU2692049C1 |

