ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Изобретение относится к области биотехнологии и молекулярной биологии, в частности генной инженерии, а именно к мини-белку USH2A, к нуклеиновой кислоте, кодирующей мини-белок USH2A, к содержащему её экспрессионному вектору, и может найти применение при генной терапии синдрома Ашера II типа.
УРОВЕНЬ ТЕХНИКИ
Синдром Ашера (синдром Ушера, Usher syndrome) характеризуется врожденной двусторонней сенсоневральной тугоухостью и прогрессирующим пигментным ретинитом, имеет аутосомно-рецессивный тип наследования (Наследственные и врожденные заболевания сетчатки и зрительного нерва. Рук. для врачей. Под ред. Шамшиновой А.М. М.: Медицина; 2001). По данным ряда авторов, распространенность синдрома Ашера составляет 4,4 на 100 тыс. населения, среди новорожденных - 4-5 на 100 тыс. (Boughman JA, Vernon M, Shaver KA. Usher syndrome: definition and estimate of prevalence from two high-risk populations. Journal of Chronic Diseases. 1983;36(8):595-603).
Главной проблемой изучения и поиска лечения синдрома Ашера является его значительная клиническая и генетическая гетерогенность, то есть наличие разных клинических форм и большое число генов, ответственных за данный синдром (Lenarduzzi S., Vozzi D., Morgan A., Rubinato E., D’Eustacchio A., Osland T.M., Rossi C., Graziano C., Castorina P., Ambrosetti U., Morgutti M., Girotto G. Usher syndrome: an effective sequencing approach to establish a genetic and clinical diagnosis. Hearing Research. 2015;320:18-23). В ходе углубленных клинических исследований одновременно с попытками поиска генов-кандидатов на основании клинических различий выделены четыре типа синдрома Ашера.
Самый распространенный из выделенных четырех типов - II тип, ассоциированный с геном USH2A. При синдроме Ашера II типа ребенок с раннего детства имеет тугоухость или полностью не слышит, иногда имеет отставание в развитии. Зрение постепенно ухудшается, поля зрения сужаются, развивается ночная слепота. Основными клиническими признаками синдрома Ашера являются - дезориентация в темноте, частые спотыкания, столкновения с препятствиями.
В настоящее время не существует медицинских средств для предотвращения, лечения или замедления прогрессирования заболевания. Компенсировать потерю слуха позволяет кохлеарная имплантация – операция по установке протеза людям с нейросенсорной тугоухостью. Лечения для пигментного ретинита также не существует (Тихомирова М.А. Синдром Ушера // ГЕНОКАРТА Генетическая энциклопедия. 2019).
В последние годы заместительная генная терапия рассматривалась как потенциальное решение проблемы лечения синдрома Ашера. Суть заместительной терапии заключается в замещении всего гена его здоровой копией, путем клонирования его в вирусный вектор, например, в вектор аденоассоциированного вируса (AAV), и доставки этой копии в нужные клетки.
Синдром Ашера является сложной моделью для разработки геннотерапевтических препаратов, так как пациенты с этой патологией страдают не только от последствий дегенерации сетчатки, но и от потери слуха, многие исследователи в таком случае сосредотачиваются на одной из этих проблем.
Из уровня техники известно, что первым клиническим исследованием генной терапии синдрома Ашера было исследование фазы I/II под номером #NTC01505062, спонсируемое компанией Sanofi, представляющая собой субретинальную лентивирусную доставку гена USH1B, MYO7A. Клинические исследования не были продолжены. Несмотря на то, что лентивирусы способны упаковывать более крупные трансгены, их использование сопряжено с потенциальными рисками. Лентивирусы имеют свойство вызывать нежелательные иммунные реакции, у них ограниченная способность к трансдукции, а также они способны интегрировать несущий трансген в ДНК пациента, что несет в себе риски инсерционного мутагенеза или активации онкогенов. (Ahmed, H., Shubina-Oleinik, O., Holt, J.R. 2017. Emerging gene therapies for genetic hearing loss. J Assoc Res Otolaryngol 18, 649-670).
Для повышения безопасности пациентов в уровне техники известны подходы использования AAV векторов. Принимая во внимание ограничение в емкости AAV вектора, на данный момент существует несколько направлений для решения этой проблемы: двойные AAV векторы и мини-генный подход.
Было описано применение различных двойных AAV векторов для оценки успешной экспрессии функционального миозина VIIa (Dyka, F.M., Boye, S.L., Chiodo, V.A., Hauswirth, W.W., Boye, S.E. 2014. Dual adeno-associated virus vectors result in efficient in vitro and in vivo expression of an oversized gene, MYO7A. Hum Gene Ther Methods 25, 166-77). Исследования были успешны на модельной системе in vitro, однако этот успех не отразился на экспериментах in vivo. Использование двойных векторов имело слабый успех в экспериментах на животных моделях при попытке доставлять большие гены в сетчатку (Ferreira, M.V.; Fernandes, S.; Almeida, A.I.; Neto, S.; Mendes, J.P.; Silva, R.J.S.; Peixoto, C.; Coroadinha, A.S. Extending AAV Packaging Cargo through Dual Co-Transduction: Efficient Protein Trans-Splicing at Low Vector Doses. Int. J. Mol. Sci. 2023, 24, 10524).
Мини-генный подход был использован для создания укороченной версии гена USH2A. Ген кодирующий белок USH2A расположен на хромосоме 1 (chr1:215,622,891-216,423,448 (GRCh38/hg38)) и имеет размер 800 558 пар оснований. Белок USH2A имеет сложную доменную организацию и состоит из 5202 аминокислотных остатков (SEQ ID NO:1). Гены (SEQ ID NO:2) такого размера не могут быть доставлены в составе вирусных векторов.
Были предложены несколько конструктов длиной 6,8kb и 4,1kb, данные конструкции были клонированы в Tol2 транспозонный вектор pDestTol2CG2 (Vona B, Doll J, Hofrichter M., Haaf T., Varshney G.K., Small fish, big prospects: using zebrafish to unravel the mechanisms of hereditary hearing loss, Hearing Research, Volume 397, 2020; Dona, M. (2018). Towards gene therapy for USH2A-associated retinitis pigmentosa (Doctoral thesis, Radboud Institute for Molecular Life Sciences. Radboud Repository. https://repository.ubn.ru.nl/handle/2066/196854). В результате авторам удалось добиться частичного восстановления функции сетчатки у мутантных линий рыб Данио Рерио. Но необходимо учесть, что модель Данио Рерио не является оптимальной для изучения патологий сетчатки и обладаем рядом физиологических особенностей, что не позволяет использовать ее в полной мере для изучения дистрофий сетчатки. И полученные конструкции мини-генов USH2A все еще слишком велики для упаковывания их в AAV вектор для проведения терапии.
Как можно заметить, мини-генные структуры белка USH2A, предлагаемые другими исследовательскими группами, зачастую содержат участок фибронектинового домена F17-F31 (CN114402075A). По имеющимся данным в базе ClinVar на участке фибронектинового домена F17-F31 белка USH2A сосредоточено наибольшее количество патогенных мутаций, чем на первой половине фибронектинового домена.
Анализируя последовательности, приведенные в патенте WO2019166549, где авторы предлагают две основные мини-последовательности белка USH2A, в первом случае, при сохранности основных важных участков размер последовательности составляет 6786 п.о. (пар оснований), что не удовлетворяет дальнейшим условиям упаковки такой последовательности в AAV, из-за ограничения в емкости. Вторая мини-последовательность белка USH2A 4125 п.о., однако в данной последовательности, отсутствуют домены LamGL, LamNT, LamG. Удаление из последовательности 13-го экзона, который чаще всего упоминается как таргетный участок для антисмысловой терапии, приводит к удалению части белкового домена LamEGF, который необходим для специфического функционирования фоторецепторных клеток.
Ближайшим аналогом изобретения является техническое решение, представленное в патентной заявке WO2020214796A1, где авторами сконструированы несколько мини-генов USH2A, которые планируется упаковать в AAV, при этом в заявке не приводятся данные о тестировании этой конструкции и эффективной экспрессии. Приведенные последовательности мини-генов USH2A не содержат ключевых структур, которые по литературным данным отвечают за функционирование белка, как например домены EGF-Like, Lam-G, таким образом высокий уровень экспресcии от таких структур невозможен. Дополнительно, экспрессия мини-вариантов USH2A контролируется промотором родопсин киназы человека (hGRK) который не является аутотентичным для гена USH2A, не является индуцибельным и обладает относительно слабым уровнем экспрессии.
Таким образом, на данный момент не существует зарегистрированной эффективной и безопасной терапии синдрома Ашера II типа. И, несмотря на прогресс в разработке генной терапии указанного заболевания, все еще остается необходимость в получении подходящей нуклеотидной последовательности, кодирующей подходящий белок USH2A. Такая последовательность, белок и вектор представлены в настоящем изобретении.
Было обнаружено, что полученные последовательности мини-белка USH2A, которые содержат уникальную комбинацию доменов, учитывают мутационный профиль и структурные особенности, как на уровне гена, так и белка. Наличие LamGL, LamNT, EGF Lam, FN3 доменов и PDZ-связывающего мотива обеспечивает требуемый функционал белка USH2A, сигнальная последовательность и трансмембранный домен в структуре мини-белка USH2A обеспечивает его физиологическую локализацию. Длина последовательности соответствующего белку мини-гена USH2A позволяет успешно доставлять ее в клетки в составе вирусных векторов.
Представленное изобретение касается мини-белка USH2A, нуклеиновой кислоты, кодирующей мини-белок USH2A, и экспрессионного вектора для экспрессии в эукариотических клетках, содержащий нуклеиновую кислоту. Применение векторов для генной терапии синдрома Ашера II типа.
Нуклеиновая кислота, кодирующая мини-белок USH2A, по представленному изобретению эффективно упаковывалась в состав ААV вектора в общем, а в частности в ААV векторы серотипов 9, 5 или 2.7m8. Минимальный размер трансгена позволил получать ААV вектор в высоком титре (>1.0x10^12 вг/мл), что позволит упростить процесс их массового производства и очистки.
Настоящее изобретение основано на том открытии, что комбинация доменов белка USH2А в мини-белке, позволяет уменьшить размер природной нуклеотидной последовательности гена USH2A на 74% от природной, при этом длина последовательности нуклеиновой кислоты позволяет успешно доставлять ее в клетки в составе вирусных векторов. Предложенная нуклеиновая последовательность сохраняет основные функциональные домены белка USH2A c cеквестрацией количества доменов в разных вариациях.
Неожиданно было обнаружено, что именно после трансфекции плазмидными векторами и трансдукции векторами согласно изобретению, происходит увеличение экспрессии мини-гена USH2A более чем в 80 раз в клетках пигментного эпителия сетчатки человека, а также продемонстрировано наличие мини-белка USH2A в клетках пигментного эпителия сетчатки в клетках после трансдукции. Согласно данным (de Joya E.M., Colbert B.M., Tang P.C., Lam B.L., Yang J., Blanton S.H., Dykxhoorn DM, Liu X. Usher Syndrome in the Inner Ear: Etiologies and Advances in Gene Therapy. Int J Mol Sci. 2021 Apr 10;22(8):3910) наличие белка USH2A необходимо для функционирования волосковых клеток внутреннего уха. Тем самым доставка мини-белка USH2A в эти клетки потенциально может быть использована для генной терапии наследственной глухоты ассоциированной с мутациями в гене USH2A. Применение векторов, содержащих нуклеиновую кислоту, кодирующую мини-белок USH2A, приводит к стабильной экспрессии мини-белка USH2A. В тканях глаза - восполнение недостатка белка в клетках и тканях глаза, и, следовательно, восстановление его функции и стабилизации зрения при пигментном ретините. В тканях уха, а именно в волосковых клетках – экспрессия мини-гена USH2A позволит получить функциональный мини-белок USH2A необходимый для функционирования USH2A комплекса с WHRN, PDZD7, GPR98 и тем самым восполнить недостающую функцию.
Нуклеиновая кислота также обладает низкой иммуногенностью. Таким образом, мини-белку USH2A, нуклеиновой кислоте и вектору удалось преодолеть все недостатки раскрытых в уровне техники технических решений для генной терапии синдрома Ашера II типа.
О применении подобного мини-белка, нуклеиновой кислоты и вектора, ее содержащего, для генной терапии пигментного ретинита, тугоухости при синдроме Ашера II типа до последнего времени не сообщалось.
РАСКРЫТИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Изобретение относится к мини-белку USH2A для генной терапии Синдрома Ашера II типа, содержащему аминокислотную последовательность, выбранную из SEQ ID NO 4, 6, 8, 10, 12. Предпочтительно, изобретение относится к мини-белку USH2A для генной терапии Синдрома Ашера II типа, содержащему аминокислотную последовательность SEQ ID NO 4, 6.
В другом аспекте, изобретение относится к нуклеиновой кислоте, кодирующей мини-белок USH2A. Предпочтительно, нуклеиновой кислоте, кодирующей мини-белок USH2A, содержащей последовательность нуклеотидов, выбранную из SEQ ID NO 3, 7, 9, 11, 13. В частности, нуклеиновой кислоте, кодирующей мини-белок USH2A, содержащей последовательность нуклеотидов SEQ ID NO 3, 7.
Экспрессионный вектор для экспрессии в эукариотических клетках, содержит нуклеиновую кислоту, кодирующую мини-белок USH2A. Предпочтительно, вектор, представляющий собой плазмидный экспрессионный вектор, содержащий следующие элементы:
- участок начала репликации ori;
- левый инвертированный концевой повтор ITR;
- CMV энхансер цитомегаловирусного промотора;
- цитомегаловирусный промотор CMV promoter;
- последовательность интрона гена b-глобина человека;
- оптимизированную последовательность гена fUSH2A SEQ ID NO 3;
- последовательность сигнала полиаденилирования hGH poly(A) signal;
- правый инвертированный концевой повтор ITR;
- участок начала репликации для упаковки в фаговые частицы f1 ori;
- промотор гена устойчивости к ампициллину AmpR promoter;
- ген устойчивости к антибиотику ампициллину AmpR.
В другом аспекте, вектор представляет собой вирусный экспрессионный вектор. В частности, вектор представляет собой аденоассоциированный вирус. В следующем аспекте, вектор представляет собой аденоассоциированный вирус 9 серотипа, 2.7m8 серотипа или 5 серотипа. В другом аспекте, вектор нарабатывается в адгезионных клеточных культурах HEK293T.
Применение вектора в настоящем изобретении для генной терапии Синдрома Ашера II типа. В другом аспекте, применение вектора для генной терапии пигментного ретинита и тугоухости Синдрома Ашера II типа.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
На Фиг. 1 представлена схема строения экспрессионного вектора pAAV-fUSH2A. Рекомбинантный плазмидный экспрессионный вектор pAAV_fUSH2A, экспрессирующий оптимизированную последовательность fUSH2A размером 4011 п.о., состоящий из следующих элементов: участок начала репликации ori; левый инвертированный концевой повтор ITR; CMV энхансер цитомегаловирусного промотора; цитомегаловирусный промотор CMV promoter; последовательность интрона гена b-глобина человека (интрон гена hBG1 - субъединицы гемоглобина гамма-1); последовательность fUSH2A SEQ ID NO 1; последовательность сигнала полиаденилирования hGH poly(A) signal (hGH poly(A) signal, сигнал полиаденилирования гена гормона роста человека); правый инвертированный концевой повтор ITR; участок начала репликации для упаковки в фаговые частицы f1 ori; промотор гена устойчивости к ампициллину AmpR promoter; ген устойчивости к антибиотику ампициллину AmpR.
На Фиг. 2 представлена доменная организация белка USH2A человека и мини-гена fUSH2A.
На Фиг. 3 представлен график амплификации клеточных лизатов с праймерами на ген fUSH2A и ген домашнего хозяйства PPIA. По оси абсцисс значения номера цикла амплификации, по оси ординат - относительная интенсивность флуоресцентного сигнала. Control, eGFP - контрольные образцы в виде клеточных лизатов без трансфекции и трансфицированные плазмидой eGFP, pUSH2A, fUSH2A - клетки трансфицированные плазмидами pUSH2A или fUSH2A, PPIA - все образцы с праймерами на PPIA.
На Фиг. 4 представлены результаты анализа методом ПААГ в невосстанавливающих условиях представлены на рисунке. Анализируемые образцы: 11 - молекулярный маркер, 1 - исходный клеточный лизат, 2 - концентрированный клеточный лизат, 3 - проскок исходного лизата, 4 - проскок концентрированного лизата, 5 - элюат фракция 1 (здесь и далее для концентрированного образца лизата), 6 - элюат фракция 2, 7 - элюат фракция 3, 8 - элюат фракция 4, 9 - элюат фракция 5, 10 - элюат фракция 3 (для неконцентрированного образца лизата). В левой части графика указано распределение по массам молекулярных маркеров, справа от графика указано положение капсидных белков VP1, VP2 и VP3.
На Фиг. 5 представлена стандартная кривая для оценки уровня получения мини-белка методом иммуноферментного анализа (ELISA), построенная на основании измерений оптической плотности стандартных образцов мини-белка USH2A с концентрацией от 1000 пг/мл до 15,1 пг/мл. Линия прогностического тренда указана на графике, значение коэффициента корреляции составило 0,97. По оси абсцисс указана концентрация белка USH2A (пг/мл), по оси ординат указана оптическая плотность (450 нм).
На Фиг. 6 представлены результаты измерений синтеза мини-белков fUSH2A и uUSH2A на 72 часа после трансфекции клеток HEK293T вектором pAAV- fUSH2A и pAAV- uUSH2A, а также в лизате нетрансфицированных клеток HEK293T.
На Фиг. 7 представлен график амплификации геномов ААV методом цифровой капельной ПЦР с использованием флуоресцентного зонда (А). Диапазон значений температур отжига праймеров 52.8 – 62.7 °С. Детекция флуоресцентного сигнала проводилась по каналу FAM.
На Фиг. 8 представлен график амплификации геномов ААV методом цифровой капельной ПЦР с использованием интеркалирующего красителя (EvaGreen) (В). Диапазон значений температур отжига праймеров 52.8 – 62.7 °С. Детекция флуоресцентного сигнала проводилась по каналу FAM.
На Фиг. 9 представлено распределение капель по интенсивности сигнала по каналу FAM (Green). Высокая плотность положительных капель (отмеченных синим цветом) свидетельствует о наличие геномов AAV. Каждая положительная капля на графике свидетельствует о наличие в ней одной копии генома ААV.
На Фиг. 10 представлен график корреляции сигнала по каналу FAM полученного методом qPCR и методом ddPCR. Линейная зависимость на графике отражает сходимость методом qPCR и ddPCR использованных для получения AAV векторов. Коэффициент корреляции (R) составил 0.99. Результаты проведенного анализа свидетельствуют о возможности взаимозаменяемого использования методов qPCR и ddPCR для обнаружения геномов AAV в выбранном диапазоне числовых значений вг/мл.
На Фиг. 11 представлен результаты биоинформатического анализа мини-белка fUSH2А. Аминокислотная последовательность мини-белка USH2A была использована для построения модели на основе подобия используя программу I-TASSER (https://zhanggroup.org/I-TASSER/) Дата запроса 28.10.2023. На рисунке представлены домены и их вторичная структура ( бета листы, альфа спирали и неструктурные петли). Доменная организация представленной структуры полностью воспроизводит расчетную последовательность мини-белка на Фиг. 2. Цветовая схема выбрано произвольно.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Если не указано иначе, предполагается, что все термины, обозначения и другие научные термины, используемые в данной заявке, имеют значения, которые обычно понимают специалисты в области, к которой относится настоящее изобретение. В некоторых случаях определения терминов с общепринятыми значениями приведены в данной заявке для ясности и/или для быстрой справки и понимания, и включение таких определений в настоящее описание не должно истолковываться как наличие существенного отличия значения термина от обычно подразумеваемого в данной области.
Кроме того, если по контексту не требуется иное, термины в единственном числе включают в себя термины во множественном числе, и термины во множественном числе включают в себя термины в единственном числе. Как правило, используемая классификация и методы культивирования клеток, молекулярной биологии, иммунологии, микробиологии, генетики, аналитической химии, химии органического синтеза, медицинской и фармацевтической химии, а также гибридизации и химии белка и нуклеиновых кислот, описанные в настоящем документе, хорошо известны специалистам и широко применяются в данной области. Ферментативные реакции и способы очистки осуществляют в соответствии с инструкциями производителя, как это обычно осуществляется в данной области, или как описано в настоящем документе.
Все публикации, патенты и патентные заявки, а также номера доступа, процитированные в настоящем документе, выше или ниже, включены, таким образом, посредством ссылки в полном объеме.
Термины «содержит», «содержат» и «содержащий» должны интерпретироваться как включающие, а не исключающие, т.е. такие, которые включают в себя другие неуказанные компоненты или этапы процесса. Термины «состоит», «состоящий» и их варианты должны интерпретироваться как исключающие, а не включающие, т.е. такие, которые исключают компоненты или этапы, которые специально не указаны.
Как используют в настоящем документе, «синдром Ашера» ( «синдром Ушера») - это наследственное заболевание, характеризующееся врожденными нарушениями слуха различной степени (тугоухостью), вестибулярной дисфункцией и прогрессирующей пигментной дегенерацией сетчатки (ПДС) (пигментным ретинитом), приводящей к постепенному сужению полей зрения и слепоте, но характер поражения органов свето- и звуковосприятия может быть различным.
Под «генной терапией» понимают группу методов, направленных на модификацию последовательности генов или управление их экспрессией, а также на изменение биологических свойств клеток для их терапевтического или профилактического использования.
«Мини-белок USH2A» («мини-ушерин», «мини-белок ушерин») представляет собой укороченный вариант природного белка USH2A, который получается в результате трансляции матричной РНК рибосомами с мини-гена USH2A полипептидного продукта.
В одном из вариантов осуществления настоящего изобретения мини-белок USH2A для генной терапии синдрома Ашера II типа содержит последовательность SEQ ID NO 12. В еще одном варианте осуществления изобретения мини-белок USH2A для генной терапии синдрома Ашера II типа содержит последовательность SEQ ID NO 10. В еще одном варианте осуществления изобретения мини-белок USH2A для генной терапии синдрома Ашера II типа содержит последовательность SEQ ID NO 8. В еще одном варианте осуществления изобретения мини-белок USH2A для генной терапии синдрома Ашера II типа содержит последовательность SEQ ID NO 6. В еще одном варианте осуществления изобретения мини-белок USH2A для генной терапии синдрома Ашера II типа содержит последовательность SEQ ID NO 4.
В частных вариантах изобретения, мини-белок USH2A для генной терапии синдрома Ашера II типа содержит последовательность SEQ ID NO 4 или SEQ ID NO 6.
Термин «кодон-оптимизированный» обозначает последовательность нуклеотидов, в которой была произведена замена одного или более кодонов на синонимичные без изменения последовательности белка, синтезированного с матрицы этой последовательности.
Термин «оптимизация кодонов» означает экспериментальный подход для улучшения кодонного состава рекомбинантного гена на основе различных критериев без изменения аминокислотной последовательности. Оптимизация кодонов возможна благодаря вырожденному генетическому коду, означающему, что большинство аминокислот кодируется более чем одним кодоном. Большинство подходов к оптимизации кодонов заключается в избегании использования редких кодонов. Также направлением оптимизации кодонов может быть выявление элементов нестабильности мРНК, вторичных структур мРНК, повторов последовательностей, внутренних сайтов входа в рибосому, промоторных последовательностей, предполагаемых сайтов сплайсинга и пр. примеры технологий такой оптимизации писаны в статье (Gao, W. et al. (2004) UpGene: Application of a web-based DNA codon optimization algorithm. Biotechnol. Prog. 20, 443 448; Raab, D. et al. (2010) The GeneOptimizer Algorithm: using a sliding window approach to cope with the vast sequence space in multiparameter DNA sequence optimization. Syst. Synth. Biol. 4, 215-225; Gaspar, P. et al. (2012) EuGene: maximizing synthetic gene design for heterologous expression. Bioinformatics 28, 2683-2684; Fath, S. et al. (2011) Multiparameter RNA and codon optimization: a standardized tool to assess and enhance autologous mammalian gene expression. PLoS ONE 6, e17596). Частоты встречаемости синонимических кодонов различаются у разных организмов и даже в разных клетках одного и того же организма. Они декодируются рибосомами с разной скоростью, так как соответствующие им тРНК также присутствуют в разных клетках в разных количествах, как показано в статье [Dana A., Tuller Т. (2014) The effect of tRNA levels on decoding times of mRNA codons. Nucl. Acids Res. 42, 9171-9181], текст которой инкорпорирован в настоящее описание посредством ссылки. Трансляция в митохондриях отклоняется от универсального генетического кода, используя механизмы и частоты кодонов, более сходные с их α-протеобактериальными предками, чем с ядерным геномом млекопитающих, поэтому для успешной экспрессии в цитозоле митохондриальных генов используется оптимизация кодонов для перекодирования последовательности митохондриального гена в универсальный код (Lewis CJ, Dixit В, Batiuk Е, et al. Codon optimization is an essential parameter for the efficient allotopic expression of mtDNA genes. Redox Biol. 2020 Feb;30:101429. doi: 10.1016/j.redox.2020.101429).
Оптимизация кодонов была выполнена с учетом представленности кодонов и тРНК в клетках человека с уровнем относительной адаптивности не менее 50%. Разработанная кодон-оптимизированная последовательность лишь на 73% идентична последовательности USH2A человека.
Термин «нуклеиновая кислота» относится к последовательности ДНК или РНК. Термин охватывает последовательности, которые содержат какие-либо из известных аналогов оснований для ДНК и РНК, такие как, но не ограничиваясь этим, 4-ацетилцитозин, 8-гидрокси-N6-метиладенозин, азиридинилцитозин, псевдоизоцитозин, 5-(карбоксигидроксилметил)урацил, 5-фторурацил, 5-бромурацил, 5 карбоксиметиламинометил-2-тиоурацил, 5-карбоксиметил аминометилурацил, дигидроурацил, инозин, N6-изопентениладенин, 1-метиладенин, 1-метилпсевдоурацил, 1-метилгуанин, 1-метилинозин, 2,2-диметилгуанин, 2-метиладенин, 2-метилгуанин, 3-метилцитозин, 5-метилцитозин, N6-метиладенин, 7-метилгуанин, 5-метиламинометилурацил, 5-метоксиаминометил-2-тиоурацил, β-D-маннозилквеуозин, 5'-метоксикарбонилметилурацил, 5-метоксиурацил, 2-метилтио-N6-изопентениладенин, сложный метиловый эфир урацил-5-оксиуксусной кислоты, урацил-5-оксиуксусная кислота, оксибутоксозин, псевдоурацил, квеуозин, 2-тиоцитозин, 5-метил-2-тиоурацил, 2-тиоурацил, 4-тиоурацил, 5-метилурацил, сложный метиловый эфир -урацил-5-оксиуксусной кислоты, урацил-5-оксиуксусная кислота, псевдоурацил, квеуозин, 2-тиоцитозин и 2,6-диаминопурин.
Термин «мини-ген USH2A» – это минимальная функционирующая копия гена USH2а, полученная с помощью направленного биодизайна по удалению экзонов из нативной структуры природного гена USH2a. Нуклеотидная последовательность в составе мини-гена кодон-оптимизирована для экспрессии в клетках человека. Полученные последовательности мини-белка USH2A, по изобретению, которые содержат уникальную комбинацию доменов, учитывают мутационный профиль и структурные особенности, как на уровне гена, так и белка. Наличие LamGL, LamNT, EGF Lam, FN3 доменов и PDZ-связывающего мотива обеспечивает требуемый функционал белка USH2A, сигнальная последовательность и трансмембранный домен в структуре мини-белка USH2A обеспечивает его физиологическую локализацию. Длина последовательности соответствующего белку мини-гена USH2A позволяет успешно доставлять ее в клетки в составе вирусных векторов.
Нуклеиновая кислота с заявленной последовательностью может быть получена любым известным из уровня техники способом, включая, в качестве неограничивающих примеров, рекомбинантные способы, такие как клонирование последовательностей нуклеиновой кислоты из рекомбинантной библиотеки или генома клетки, использование обычной технологии клонирования и ПЦР и другими, а также способами химического синтеза.
В вариантах осуществления настоящего изобретения, нуклеиновая кислота содержит последовательность нуклеотидов, выбранную из SEQ ID NO 3, 7, 9, 11, 13. В предпочтительных вариантах, нуклеиновая кислота содержит последовательность нуклеотидов SEQ ID NO 3 или SEQ ID NO 7.
Нуклеотидная последовательность по настоящему изобретению может быть введена в плазмидный экспрессионный вектор, например, на основе pAAV. Введение плазмидного экспрессионного вектора, содержащего последовательность нуклеотидов по настоящему изобретению, в клетки НЕК293Т путем трансфекции приводит к экспрессии мини-гена USH2A.
Нуклеиновая кислота также обладает низкой иммуногенностью. Кодон-оптимизированные последовательности трансгенов обладают меньшей способность индуцировать внутриклеточный иммунный ответ за счет минимальной активации экспрессии интерферонстимулирующих генов (Galieva A., Egorov A., Malogolovkin A., Brovin A., Karabelsky A. RNA-Seq Analysis of Trans-Differentiated ARPE-19 Cells Transduced by AAV9-AIPL1 Vectors. International Journal of Molecular Sciences. 2024; 25(1):197). Более того, сами ААV векторы обладают меньшей иммуногенностью по сравнению с аденовирусами (Rabinowitz J., Chan Y.K., Samulski R.J. Adeno-associated Virus (AAV) versus Immune Response. Viruses. 2019 Jan 25;11(2):102). Дополнительно, введение ААV вектора под сетчатку глаза значительно ограничивает его системное распространение и как результат активацию иммунного ответа. Глаз, как известно, отграничен гематоофтальмическим барьером, также отсутствует интраокулярная лимфатическая система, а на поверхности стромальных клеток глаза наблюдается слабая экспрессия молекул МНС I и II классов или вовсе ее отсутствие. Все это обуславливает лидирующее положение разработок препаратов генной терапии в области офтальмологии. Представленная аминокислотная последовательность белка не обладает высокой иммуногенностью, так как является по сути миниатюризованной версией нативного белка Ушерина, в структуру мини-ушерина не были добавлены новые домены или линкеры, которые могли бы быть интерпретированы иммунной системой пациента как чужеродные.
«Кодирующая последовательность» или последовательность, которая «кодирует» выбранный полипептид, представляет собой молекулу нуклеиновой кислоты, которую транскрибируют (в случае ДНК) и транслируют (в случае мРНК) в полипептид, когда помещают под управление подходящих регуляторных последовательностей. Границы кодирующей последовательности определяет инициирующий кодон на 5' (амино) конце и терминирующий трансляцию кодон на 3' (карбокси) конце. Последовательность терминации транскрипции может быть расположена 3' относительно кодирующей последовательности.
Под «вектором» понимают какой-либо генетический элемент, такой как плазмида, фаг, транспозон, космида, хромосома, вирус, вирион и т.д., который способен к репликации, когда связан с надлежащими управляющими элементами, и который может переносить последовательности генов в клетки. Таким образом, термин включает носители для клонирования и экспрессии, а также вирусные векторы.
Термин «трансфекция» используют, чтобы отослать к накоплению инородной ДНК клеткой, и клетка «трансфицирована», когда экзогенная ДНК введена внутрь клеточной мембраны. Множество способов трансфекции в целом известно в данной области. См., например, Graham et al. (1973) Virology, 52:456, Sambrook et al. (1989) Molecular Cloning, a laboratory manual, Cold Spring Harbor Laboratories, New York, Davis et al. (1986) Basic Methods in Molecular Biology, Elsevier, и Chu et al. (1981) Gene 13:197. Такие способы можно использовать для того, чтобы вводить одну или несколько экзогенных молекул в подходящие клетки-хозяева.
Термин «экспрессионный вектор» («вектор экспрессии») обозначает вектор, содержащий промоторную и другие регуляторные последовательности, обеспечивающие эффективную транскрипцию рекомбинантного гена с последующей трансляцией мРНК и образованием рекомбинантного белка. Используемые плазмидные и экспрессионные векторы, приведенные ниже, используются для примера и не ограничивают объем прав настоящего изобретения.
В варианте осуществления изобретения предлагается плазмидный экспрессионный вектор, содержащий элементы в соответствии с физической и генетической картой, представленной на Фиг. 1. Экспрессионный вектор для экспрессии в эукариотических клетках, содержащий нуклеиновую кислоту, которая содержит последовательность нуклеотидов, выбранную из SEQ ID NO 3, 7, 9, 11, 13. В предпочтительных вариантах, нуклеиновая кислота содержит последовательность нуклеотидов SEQ ID NO 3 или SEQ ID NO 7.
Термин «промотор», используемый в настоящем документе, в частности, относится к последовательности нуклеотидов ДНК, узнаваемой РНК-полимеразой, на которой происходит инициация транскрипции элемента, с которым функционально связан промотор. Промотор может также сопровождаться энхансером.
Энхансеры усиливают активность промотора и стимулируют процесс транскрипции. Для получения большого количества белка в эукариотических клетках и, в частности, в клетках человека, целесообразно использовать сильные промоторы, активные в клетках-мишенях. Сильные конститутивные промоторы, способные инициировать экспрессию рекомбинантного гена в разных типах клеток, хорошо известны в данной области. В одном из вариантов осуществления изобретения в качестве промотора используют промотор цитомегаловируса (CMV promoter).
В варианте осуществления изобретения плазмидный экспрессионный вектор включает следующие элементы в направлении от 5'-конца к 3'-концу:
- участок начала репликации ori;
- левый инвертированный концевой повтор ITR;
- CMV энхансер цитомегаловирусного промотора;
- цитомегаловирусный промотор CMV promoter;
- последовательность интрона гена b-глобина человека;
- оптимизированную последовательность гена fUSH2A SEQ ID NO 3;
- последовательность сигнала полиаденилирования hGH poly(A) signal;
- правый инвертированный концевой повтор ITR;
- промотор гена устойчивости к ампициллину AmpR promoter;
- ген устойчивости к антибиотику ампициллину AmpR.
В еще одном из вариантов осуществления изобретения упомянутый вектор содержит последовательность SEQ ID NO 7 в качестве последовательности, кодирующей мини-белок USH2A (uUSH2A, SEQ ID NO 6). В еще одном из вариантов осуществления изобретения упомянутый вектор содержит последовательность SEQ ID NO 9 в качестве последовательности, кодирующей мини-белок USH2A (сUSH2A, SEQ ID NO 8). В еще одном из вариантов осуществления изобретения упомянутый вектор содержит последовательность SEQ ID NO 11 в качестве последовательности, кодирующей мини-белок USH2A (kUSH2A, SEQ ID NO 10). В еще одном из вариантов осуществления изобретения упомянутый вектор содержит последовательность SEQ ID NO 13 в качестве последовательности, кодирующей мини-белок USH2A (yUSH2A, SEQ ID NO 12).
Трансфекция клеток плазмидными экспрессионными векторами по настоящему изобретению, приводит к стабильной и высокой экспрессии мини-белка USH2A, подходящего для терапии синдрома Ашера II типа.
Термин «экспрессия гена» обозначает преобразование наследственной информации, зашифрованной в последовательности нуклеотидов гена, в функциональный продукт - РНК или белок.
Под «полипептидом» или «пептидом», как используется в настоящем описании, понимается две или более независимо выбранных природных или неприродных аминокислоты, соединенных ковалентной связью (например, пептидной связью). Пептид может включать 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 или более природных или ненатуральных аминокислот, соединенных пептидными связями. Полипептиды, как описано в настоящем описании, включают полноразмерные белки (например, полностью процессированные белки), а также более короткие аминокислотные последовательности (например, фрагменты встречающихся в природе белков или синтетические полипептидные фрагменты).
В одном из вариантов осуществления изобретения предлагается экспрессионный вектор для экспрессии в эукариотических клетках, содержащий нуклеиновую кислоту по настоящему изобретению. Нуклеиновая кислота по настоящему изобретению может быть введена в любой известный из уровня техники вектор, в том числе в плазмидный, вирусный, в том числе на основе вируса SV40, аденовирусов, герпесвирусов, ретровирусов, лентивирусов, аденоассоциированного и других вирусов. Векторы, в которые может быть введена нуклеиновая кислота по настоящему изобретению, не ограничивается этим списком. Выбор экспрессионного вектора определяется задачами, для которых вектор будет в дальнейшем использован и не ограничивает объем настоящего изобретения, способы получения векторов известны из уровня техники, векторы, содержащие нуклеиновую кислоту по настоящему изобретению могут быть получены специалистами в области генетической инженерии.
Аденоассоциированный вирус является непатогенным парвовирусом, состоящим из генома одноцепочечной ДНК размером 4,7 кб, с без оболочечным икосаэдрическим капсидом. Геном содержит три открытых рамки считывания (ORF), фланкированные инвертированными терминальными повторами (ITR), которые функционируют как сигнал репликации и упаковки вирусного происхождения. Rep ORF кодирует четыре неструктурных белка, которые играют роль в репликации вируса, регуляции транскрипции, сайт-специфической интеграции и сборки вириона. Сap ORF кодирует три структурных белка (VP 1-3), которые собираются, чтобы образовать 60-мерный вирусный капсид. Наконец, ORF, присутствует в качестве альтернативной рамки считывания в гене cap, продуцирует активирующий сборку белок (AAP), вирусный белок, который локализует капсидные белки AAV в ядрышко и функционирует в процессе сборки капсида.
Существует несколько природных («дикого типа») серотипов и более 100 известных вариантов AAV, каждый из которых отличается аминокислотной последовательностью, особенно в гипервариабельных областях капсидных белков, и, таким образом, по своим свойствам доставки генов. Не было выявлено связи между любым AAV и какой-либо болезнью человека, что делает рекомбинантный AAV привлекательным для клинических применений.
Для целей описания в данном документе, термин «AAV» является аббревиатурой для аденоассоциированного вируса, включая, без ограничения, сам вирус и его производные. За исключением случаев, когда указано иное, терминология относится ко всем подтипам или серотипам и как репликационно-компетентные, так и рекомбинантные формы. Термин «AAV» включает, без ограничения, AAV типа 1 (AAV-1 или AAV1), AAV типа 2 (AAV-2 или AAV2), AAV типа 3A (AAV-3A или AAV3A), AAV типа 3B (AAV-3B или AAV3B), AAV типа 4 (AAV-4 или AAV4), AAV типа 5 (AAV-5 или AAV5), AAV типа 6 (AAV-6 или AAV6), AAV типа 7 (AAV-7 или AAV7), типа AAV 8 (AAV-8 или AAV8), AAV типа 9 (AAV-9 или AAV9), AAV типа 10 (AAV-10 или AAV10 или AAVrh10), птичий AAV, бычий AAV, собачий AAV, козий AAV, лошадиный AAV, AAV примата, AAV не примата, и овечий AAV. «AAV примата» относится к AAV, который заражает приматов, «AAV не примата» относится к AAV, который заражает млекопитающих, не относящихся к приматам, «бычий AAV» относится к AAV, которые заражают бычьих млекопитающих и т. д.
В данной области техники известны геномные последовательности различных серотипов AAV, а также последовательности нативных терминальных повторов (TRs), белков Rep и капсидных субъединиц. Такие последовательности можно найти в литературе или в публичных базах данных, таких как GenBank. См., например, номера доступа GenBank NC_002077.1 (AAV1), AF063497.1 (AAV1), NC_001401.2 (AAV2), AF043303.1 (AAV2), J01901.1 (AAV2), U48704.1 (AAV3A), NC_001729.1 (AAV3A), AF028705.1 (AAV3B), NC_001829.1 (AAV4), U89790.1 (AAV4), NC_006152.1 (AA5), AF085716.1 (AAV-5), AF028704.1 (AAV6), NC_006260.1 (AAV7), AF513851.1 (AAV7), AF513852.1 (AAV8) NC_006261.1 (AAV-8), AY530579.1 (AAV9), AAT46337 (AAV10) и AAO88208 (AAVrh10); описание которых включено в данный документ в качестве ссылки для обучения нуклеиновой кислоты ААВ и аминокислотных последовательностей. См. также, например, Srivistava et al. (1983) J. Virology 45:555; Chiorini et al. (1998) J. Virology 71:6823; Chiorini et al. (1999) J. Virology 73:1309; Bantel-Schaal et al. (1999) J. Virology 73:939; Xiao et al. (1999) J. Virology 73:3994; Muramatsu et al. (1996) Virology 221:208; Shade et. и др. (1986) J. Virol. 58:921; Gao et al. (2002) Proc. Nat. Acad. Sci. USA 99: 11854; Moris et al. (2004) Virology 33:375-383; международные патентные публикации WO 00/28061, WO 99/61601, WO 98/11244; и пат. США № 6156303.
В предпочтительных вариантах изобретения, вектор представляет собой аденоассоциированный вирус 9 серотипа, 2.7m8 серотипа или 5 серотипа.
В одном из вариантов осуществления изобретения в качестве вирусного экспрессионного вектора предлагается аденоассоциированный вирус 9 серотипа, содержащий нуклеиновую кислоту по настоящему изобретению, нарабатываемый в адгезионных клеточных культурах HEK293Т. Введение плазмидного экспрессионного вектора, содержащего нуклеиновую кислоту по настоящему изобретению, совместно с вектором pHelper и упаковочную плазмиду pRC2 в клетки адгезионных клеточных культурах HEK293Т приводит к продукции вирусных экспрессионных векторов, представляющих собой аденоассоциированный вирус серотипа.
В другом варианте осуществления изобретения в качестве вирусного экспрессионного вектора предлагается аденоассоциированный вирус 2.7m8 серотипа, содержащий нуклеиновую кислоту по настоящему изобретению, нарабатываемый в адгезионных клеточных культурах HEK293Т. Введение плазмидного экспрессионного вектора, содержащего нуклеиновую кислоту по настоящему изобретению, совместно с вектором pHelper и упаковочную плазмиду pRC2.7m8 в клетки адгезионных клеточных культурах HEK293Т приводит к продукции вирусных экспрессионных векторов, представляющих собой аденоассоциированный вирус 2.7m8 серотипа.
В следующем варианте осуществления изобретения в качестве вирусного экспрессионного вектора предлагается аденоассоциированный вирус 5 серотипа, содержащий нуклеиновую кислоту по настоящему изобретению, нарабатываемый в адгезионных клеточных культурах HEK293Т. Введение плазмидного экспрессионного вектора, содержащего нуклеиновую кислоту по настоящему изобретению, совместно с вектором pHelper и упаковочную плазмиду pRC2/5 в клетки адгезионных клеточных культурах HEK293Т приводит к продукции вирусных экспрессионных векторов, представляющих собой аденоассоциированный вирус 5 серотипа.
Экспрессионные векторы по настоящему изобретению демонстрируют стабильную и высокую экспрессию мини-белка USH2A в клетках. Это свидетельствует в пользу того, что введение любого из заявленных экспрессионных векторов по настоящему изобретению в ткани глаза, может привести к стабильной экспрессии мини-белка USH2A и восполнению недостатка белка USH2A в клетках и тканях глаза, и, следовательно, восстановлению его функции и стабилизации зрения при пигментном ретините синдрома Ашера II типа. Введение плазмидного и вирусного векторов по настоящему изобретению в клетки с природной мутацией гена USH2А приводят к накоплению мини-белка USH2A.
Термины «индивидуум», «хозяин», «субъект» и «пациент» используются здесь взаимозаменяемо и относятся к млекопитающему, включая, но, не ограничиваясь ими, людей; нечеловеческие приматы, включая обезьян; спортивные животные-млекопитающие (например, лошади); фермерские животные млекопитающих (например, овцы, козы и т.д.); животные млекопитающих (собаки, кошки и т.д.); и грызунов (например, мышей, крыс и т.д.). В некоторых вариантах осуществления изобретения, «индивидуум» является человеком.
Как используется в данном документе, клетка называется «стабильно» измененной, трансдуцированной, генетически модифицированной или трансформированной генетической, нуклеотидной последовательностью, если эта последовательность доступна для выполнения ее функции при длительной культивировании клетки in vitro и/или в течение длительного периода времени in vivo. Как правило, такая клетка «наследуемо» изменяется (генетически модифицирована) тем, что введенное генетическое изменение, которое также наследуется потомством измененной клетки.
Используемые в данном документе термины «терапия», «обработка», «лечение» и т.п. относятся к получению желаемого фармакологического и/или физиологического эффекта. Эффект может быть профилактическим с точки зрения полного или частичного предотвращения заболевания или его симптома и/или может быть терапевтическим с точки зрения частичного или полного лечения заболевания и/или побочного эффекта, связанного с заболеванием.
«Лечение», как используется в данном документе, охватывает любое лечение заболевания у млекопитающего, особенно у человека, и включает: (а) предотвращение возникновения заболевания (и/или симптомов, вызванных заболеванием) у субъекта, который может быть предрасположен к заболеванию или находящееся под угрозой заражения болезнью, но еще не диагностировано как наличие этого заболевания; (b) ингибирование заболевания (и/или симптомов, вызванных заболеванием), т.е. прекращение его развития; и (c) облегчение болезни (и/или симптомов, вызванных заболеванием), то есть вызывание регрессии заболевания (и/или симптомов, вызванных заболеванием), то есть уменьшение интенсивности заболевания и/или одного или более симптомов болезни. Например, предлагаемые мини-белок USH2A, нуклеиновая кислота, кодирующая мини-белок USH2A, содержащий её экспрессионный вектор могут быть направлены на лечение синдрома Ашера II типа.
Используемый в данном документе термин «эффективное количество» представляет собой количество, достаточное для получения полезных или желаемых клинических результатов. Эффективное количество можно вводить в одном или более введениях. Для целей данного описания, эффективное количество соединения (например, инфекционного rAAV-вириона) представляет собой количество, достаточное для временного облегчения, улучшения, стабилизации, реверсии, профилактики, замедления или приостановки прогрессирования (и/или симптомов, связанных с) конкретного состояния болезни (например, пигментного ретинита, тугоухости).
Термин «клетка сетчатки» относится в данном документе к любому из типов клеток, которые содержатся в сетчатке, такие как, без ограничения, ганглиозная клетка сетчатки (RG), амакриновые клетки, горизонтальные клетки, биполярные клетки, фоторецепторные клетки, глиальные клетки Мюллера, клетки микроглии, и пигментный эпителий сетчатки.
Термин «введение», как используется в способах, означает доставку композиции в выбранную клетку-мишень, которая характерна для болезни глаз и/или ушей. В одном варианте осуществляют доставку композиции путем субретинальной инъекции в фоторецепторные клетки или другие глазные клетки. В другом варианте осуществления используется интравитреальная инъекция в глазные клетки. В еще одном варианте осуществления может использоваться инъекция через вену века для доставки в глазные клетки. Специалистом в данной области техники могут быть выбраны и другие способы введения, принимая во внимание данное описание.
«Введение» или «путь введения» - это доставка субъекту композиции, описанной в настоящем документе, с фармацевтическим носителем или вспомогательным веществом, либо без них. Пути введения при желании можно комбинировать. В некоторых вариантах осуществления введение периодически повторяют.
Фармацевтические композиции, описанные в настоящем документе, разработаны для доставки нуждающимся в этом субъектам с помощью любого подходящего пути или комбинации различных путей. Непосредственная доставка в глаз (необязательно путем внутриглазной доставки, интраретинальной инъекции, интравитреальным, местным путем) или доставка через системные пути, внутриартериальный, внутриглазной, внутривенный, внутримышечный, подкожный, внутрикожный и другие пути парентерального введения. Молекулы нуклеиновой кислоты и/или векторы, описанные в настоящем документе, могут быть доставлены в одной композиции или множестве композиций. Необязательно, могут быть доставлены два или более различных AAV или множество вирусов (см., например, WO 202011/126808 и WO 2013/049493). В другом варианте осуществления множество вирусов может содержать различные дефектные по репликации вирусы (например, AAV и аденовирус) отдельно или в комбинации с белками.
В одном варианте осуществления вирусные конструкции могут доставляться в концентрациях от по меньшей мере 1×106 до около по меньшей мере 1×1011 вирусных геномов (вг) в объемах от около 1 мкл до около 3 мкл для мелких животных, таких как мыши. Для более крупных животных с размером глаз почти таким же, как глаза человека, используются большие человеческие дозы и объемы, указанные выше, например от 1×106 до около 1×1015 вг на дозу. Обсуждение надлежащей практики введения субстанций различным животным см., например, у Diehl et al., J. Applied Toxicology, 21:15-23 (2001). Этот документ включен в настоящий документ посредством ссылки.
Предпочтительно, чтобы использовалась наименьшая эффективная концентрация вируса или другого средства доставки, чтобы снизить риск возникновения нежелательных эффектов, таких как токсичность, дисплазия и отслоение сетчатки.
Пока не определено иное, все технические и научные термины, используемые в настоящем документе, имеют те же значения, которые обыкновенно понимает специалист в области, к которой относится это раскрытие. Несмотря на то, что любые способы и материалы, подобные или эквивалентные тем, что описаны в настоящем документе, можно использовать при практическом осуществлении или тестировании настоящего изобретения, далее описаны образцовые способы, устройства и материалы. Все технические и патентные публикации, цитируемые в настоящем документе, включены в настоящий документ посредством ссылки в полном объеме. Ничто в настоящем документе не следует толковать как признание того, что изобретение не имеет права относить к более ранней дате такое раскрытие посредством предшествующего изобретения.
Следует понимать, что всем числовым обозначениям предшествует термин «приблизительно», несмотря на то, что не всегда это указано явно. Также следует понимать, что реактивы, описанные в настоящем документе, лишь являются образцовыми и их эквиваленты известны в данной области, несмотря на то, что это не всегда указано явно.
Прежде чем описывать настоящее изобретение подробно, следует понимать, что это изобретение не ограничено конкретными составами или параметрами процессов, которые по существу, конечно, могут меняться. Также следует понимать, что терминология, используемая в настоящем документе, служит только цели описания конкретных вариантов осуществления изобретения и не предназначена в качестве ограничения.
Следует принимать во внимание, что изобретение не следует толковать как ограниченное примерами, описанными в настоящем документе. Способы и материалы, подобные или эквивалентные тем, что описаны в настоящем документе, можно использовать при практическом осуществлении настоящего изобретения, и изобретение следует толковать как включающее какие-либо и все применения, предусмотренные в настоящем документе, и все вариации эквивалентов в пределах навыков среднего специалиста.
Центральным для настоящего изобретения является открытие того, что мини-белок USH2A и кодирующая его нуклеиновая кислота, упакованная в ААV вектор, демонстрирует стабильную и высокую экспрессию мини-гена USH2A и получение мини-белка USH2A необходимого для терапии синдрома Ашера II типа
ПРИМЕРЫ
Следующие примеры предлагаются с тем, чтобы обеспечить специалистам в данной области техники полное раскрытие и описание того, как получать и применять изобретение, но они не предназначены для ограничения объема того, что изобретатели рассматривают в качестве своего изобретения.
Пример 1. Создание плазмидных экспрессионных векторов
Пример 1.1. Оптимизация кодонов последовательности нуклеотидов, кодирующих ген fUSH2A, uUSH2A, cUSH2A, kUSH2A и yUSH2A
Аннотацию кодирующей последовательности гена USH2A проводили с использованием сервиса NCBI/CCD. Для выравнивания нуклеотидных последовательностей применяли инструмент UniPro UGENE (Okonechnikov K., Golosova O., Fursov M., the UGENE team. Unipro UGENE: a unified bioinformatics toolkit. Bioinformatics, 2012, 28:1166-1167). Трансляцию нуклеотидной последовательности в аминокислотную проводили при помощи инструмента по ссылке: https://web.expasy.org/translate. Поскольку существуют различия в представленности траспортных РНК в клетках разных тканей была проведена оптимизация последовательности нуклеотидов для исключения стоп-кодонов и несинонимичных кодонов. Для изучения стабильности транскрипта была использована программа RNA fold (http://rna.tbi.univie.ac.at/cgi-bin/RNAWebSuite/RNAfold.cgi). Нуклеиновую кислоту с оптимизированной последовательностью гена USH2A (fUSH2A, SEQ ID NO 3), кодирующую последовательность мини-белка USH2A (fUSH2A, SEQ ID NO 4), синтезировали при помощи сервиса в компании TopGenetech (Канада). Дополнительно был проведен анализ неструктурированных регионов белка с целью выбора оптимальных регионов для оптимизации с помощью IUPred2 (https://iupred2a.elte.hu).
Пример 1.2. Получение экспрессионного вектора для экспрессии fUSH2A
В качестве плазмидного экспрессионного вектора использовали pAAV-MCS (cat#VPK-410, Cell biolabs).
Встраивание последовательности fUSH2A и uUSH2A проводили по методике, рекомендуемой производителем вектора, с использованием эндонуклеаз рестрикции BamHI и HindIII (New England Biolabs Inc., США) и T4 ДНК-лигазы по стандартным протоколам.
В результате был получен рекомбинантный плазмидный экспрессионный вектор pAAV-fUSH2A (Фиг. 1).
Трансформацию клеток проводили по стандартному протоколу (Sambrook, J. and Russell, D.W. (2001) Molecular Cloning: A Laboratory Manual. 3rd Edition, Vol. 1, Cold Spring Harbor Laboratory Press, New York). Для проведения трансформации бактерий использовали 100 мкл химически компетентных клеток Escherichia coli DH5α хранящихся при -80 °С и помещали в лёд для медленного оттаивания. Далее к клеткам добавляли по 10 мкл лигазной смеси и инкубировали во льду 30 мин. Методом теплового шока в течение 30 сек при 42 °С на водяной бане проводили доставку плазмидной ДНК в бактериальные клетки, затем перемещали пробирку с клетками в лед и инкубировали 2 мин. Далее добавляли к клеткам по 1 мл предварительно нагретой до 37 °С питательной среды LB и инкубировали в термостате в течение 1 часа при 37 °С и перемешивании со скоростью 180-200 об/мин. Высевали суспензию трансформированных клеток на предварительно подсушенные в термостате при 37 °С чашки Петри с LB-агаром и ампициллином по 100 мкл на чашку. Культивировали клетки в термостате при 37 °С в течение 16-18 часов.
Таблица 1. Условия проведения ПЦР
Для анализа колоний трансформированных клеток проводили ПЦР-скрининг с использованием вектор-специфических праймеров pAAV_For_seq2 и pAAV_Rev_seq2 (Таблица 1) и готовой смеси для ПЦР ScreenMix (Евроген, Россия). Реакционную смесь готовили согласно рекомендациям производителя. В качестве матрицы использовали термолизаты бактериальных моноклонов. Для этого каждый из 8 моноклонов уколом наконечника переносили сначала на чашку Петри с подготовленной матрицей, а затем опускали наконечник в пробирку с 20 мкл воды mQ. Чашку Петри инкубировали в термостате при 37 °С в течение дня, пробирки (стрипы) с водой и бактериями нагревали при 95 °С в течение 5 минут. В ПЦР брали по 2 мкл суспензии. Проводили ПЦР со следующими параметрами: предварительное плавление ДНК при 95 °С в течение 3 минут, 25 циклов амплификации, включающих плавление в течение 20 секунд при 95 °С, отжиг в течение 20 секунд при 55 °С и элонгацию при 72 °С в течение 2 минут, конечную элонгацию при 72 °С в течение 5 минут. Клоны, для которых методом ПЦР было подтверждено наличие вставки корректного размера, передавали на секвенирование. Отбирали клоны с корректной последовательностью по результатам секвенирования.
В результате культивирования отобранных клонов получили рекомбинантные плазмидные экспрессионные векторы, каждый из которых содержал последовательность fUSH2A.
Рекомбинантный плазмидный экспрессионный вектор pAAV-fUSH2A, экспрессирующий кодон-оптимизированную последовательность гена USH2A (fUSH2A, SEQ ID NO 3), содержит следующие элементы (см. Фиг. 1):
- участок начала репликации ori;
- левый инвертированный концевой повтор ITR;
- CMV энхансер цитомегаловирусного промотора;
- цитомегаловирусный промотор CMV promoter;
- последовательность интрона гена b-глобина человека (интрон гена hBG1 - субъединицы гемоглобина гамма-1);
- последовательность fUSH2A SEQ ID NO 3;
- последовательность сигнала полиаденилирования hGH poly(A) signal (hGH poly(A) signal, сигнал полиаденилирования гена гормона роста человека);
- правый инвертированный концевой повтор ITR;
- промотор гена устойчивости к ампициллину AmpR promoter;
- ген устойчивости к антибиотику ампициллину AmpR.
Пример 1.3. Моделирование in silico
В результате отбора in silico из спроектированных вариантов была получена последовательность нуклеотидов fUSH2A (SEQ ID NO 3). Моделирование вторичной структуры белковой молекулы может быть осуществлено de novo, при отсутствие гомологичных структурных моделей, так и методом сравнения с вторичными структурами белков доступных в базах данных, например, Protein Data Bank (https://www.rcsb.org/). Оценка правильность и адекватности модели проводится путем анализа известных доменов белка, или сохранением каталитических центров, или консервативных областей молекулы, необходимых для осуществления белком физиологических функций. ДНК с заявленной последовательностью может быть получена любым известным из уровня техники способом, включая, в качестве не ограничивающих примеров, рекомбинантные способы, такие как клонирование последовательностей нуклеиновой кислоты из рекомбинантной библиотеки или генома клетки, использование обычной технологии клонирования и ПЦР и другими, а также способами химического синтеза.
Ген с кодон-оптимизированной последовательностью нуклеотидов по настоящему изобретению может быть введён в плазмидный экспрессионный вектор, например, в плазмиду или на основе pAAV. Введение плазмидного экспрессионного вектора, содержащего ген с последовательностью нуклеотидов по настоящему изобретению, в эукариотические клетки, например HEK293T путём трансфекции приводит к экспрессии гетерологичного гена fUSH2A.
Введение плазмидного экспрессионного вектора, содержащего ген с последовательностью нуклеотидов по настоящему изобретению, совместно с вектором pHelper и вектором pRC2/9, или pRC2/5 или pRC2.7m8 в клетки HEK293T приводит к продукции вирусного экспрессионного вектора. Введение полученного вирусного экспрессионного вектора в клетки HEK293T путём трансдукции приводит к экспрессии гетерологичного гена fUSH2A.
Пример 2. Оценка уровня экспрессии гена fUSH2A после трансфекции HEK293T
Для проведения трансфекции клетки пересадили в 6-луночный планшет с плотностью 0,5 млн. клеток/лунку. Трансфекцию проводить через 30 часов после посева клеток (по достижении конфлюентности клеток 80%). Трансфекцию проводили комплексом ДНК-ПЭИ в соотношении 1:5, нагрузка ДНК составляет 1 мкг/млн. клеток.
После трансфекции инкубировать клетки 2 суток. Лизировать клетки двумя циклами заморозки/разморозки. После разморозки провести выделение РНК с использованием набора РИБО-ПРеп, АмплиПрайм. Выделенная РНК использовалась в качестве матрицы для получения кДНК.
Полученная кДНК использовалась для постановки ПЦР с применением 2 праймеров: на целевой ген и на хаускипинг ген (PPIA).
По методу ΔΔCt проведена оценка экспрессии.
Для оценки экспрессии гена fUSH2A провели трансфекцию конструкции fUSH2A с использованием PEI в качестве трансфицирующего агента. Получали комплекс fUSH2A-PEI с последующим добавлением его к клеткам. Через 2 суток после проведения трансфекции выделили РНК из клеточной массы. Полученная РНК использовалась в качестве матрицы для наработки кДНК.
Полученные образцы выделенной ДНК из трансфицированных и нетрансфицированных клеток анализировались методом количественной ПЦР с использованием 2 видов праймеров: на целевой ген fUSH2A и ген фермента PPIA в качестве хаускипинга. В качестве контроля использовались нетрансфицированные клетки, а также клетки, трансфицированные геном eGFP. Результаты амплификации представлены на Фиг. 3.
Таблица 2. Результаты расчета по методу ΔΔCt
Для получения вирусного вектора AAV9-fUSH2A использовали тройную трансфекцию клеточной культуры HEK293T. Культивировали клетки в среде DMEM и 5% FBS в присутствии антибиотиков пенициллин/стрептомицин. За 1 час до проведения трансфекции меняли культуральную среду на DMEM с добавление 2% FBS. Трансфекцию проводили добавлением 1,5 мкг общей ДНК/миллион клеток (соотношение плазмид pGOI:pHelper:pRepCap составляет 1:2:5). Плазмида pHelper pRepCap Соотношение ДНК:ПЭИ составляло 1:5. Через 24 часа после трансфекции меняли культуральную среду на DMEM с содержанием 5% FBS. Лизировали клетки через 72 часа после момента трансфекции двумя циклами заморозки/разморозки, а также добавлением тритон Х-100 до конечной концентрации 0,1%.
Концентрировали клеточный лизат на центрифужных кассетах с пределом отсечения 100kDa в 10 раз. Полученный раствор диализовали против раствора PBS 10-кратным избытком исходного концентрированного раствора. В качестве исходного раствора для очистки использовали лизат, профильтрованный через фильтр с диаметром пор 0,22 мкм, а также диализованный концентрированный образец.
Полученный фильтрат использовали для выделения на хроматографическом сорбенте ThermoFisher POROS AAVX.
Предварительно сорбент после хранения промывали очищенной водой, регенерировали раствором 100 mM глицина, рН 3,0 и 10 мМ NaOH, рН 11. После этого промывали водой и уравновешивали раствором PBS. После нанесения клеточного лизата промывали колонку уравновешивающим буфером. Дополнительную промывку проводили в 0,1 М цитратном буферном растворе, рН 6,2. Элюирование проводили раствором 100 мМ глицина, рН 3,0. Стрип-промывку проводили раствором 100 мМ глицина, рН 2,2. Регенерацию сорбента раствором 10 мМ NaOH, рН 11. Описание стадий проводимого процесса очистки представлено в таблице 3.
Таблица 3. Последовательность стадий для очистки вирусных частиц.
Полученные фракции элюата анализировали методом количественной ПЦР и электрофореза в ПААГ. Результаты анализа методом ПААГ показаны на Фиг. 4. Этот рисунок показывает наличие трех капсидных белков, характерных для адено-ассоциированного вируса c массой VP1 равной 84 кДа, VP2 - 69 кДа, VP3 - 62 кДа. Также электрофорез показывает, что отсутствуют примеси других белков во всех фракциях элюата. При этом соотношение белков VP1:VP2:VP3 в вирусном капсиде составляет около 1:1:10, что подтверждается представленной электрофореграммой.
Для клеток, трансфицированных плазмидой pUSH2A, значение экспрессии РНК составило в 50 082 раз выше по сравнению с контрольным образцом клеток, не подвергшихся трансфекции. Для клеток, трансфицированных плазмидой fUSH2A, это значение составило 72 405 (см. Таблицу 2). Это подтверждает то, что происходит синтез РНК доставляемой конструкции в клетках HEK293T. При этом из-за того, что исследуемая клеточная культура не нарабатывает белок USH2A, то наблюдается значительная разница в экспрессии белка относительно нетрансфицированных клеток (десятки тысяч).
Пример 3. Оценка уровня экспрессии последовательности fUSH2A после трансдукции в составе вирусных векторов на основе AAV
Для получения вирусных AAV векторов использовали плазмидные экспрессионные векторы pAAV- fUSH2A, а также коммерчески доступные хелперную плазмиду (pHelper) и упаковочную плазмиду pRC9 для AAV9 (Cell Biolabs Inc., США).
Клетки адгезионной клеточной линии HEK293T размораживали и культивировали согласно стандартным операционным процедурам и методикам. На момент получения расчетная плотность клеточной культуры составила 106 кл/мл, объём клеточной культуры 30 мл. Трансфекцию проводили в колбах Эрленмейера объёмом 500 мл (рабочий объём 175 мл). Посевная доза 5⋅105 клеток/мл. Трансфекцию плазмидами проводили через 12 часов после засева. Условия трансфекции: концентрация клеток при трансфекции 106 кл/мл, жизнеспособность 85–90 %, масса ДНК 1,5 мкг/1 млн клеточной биомассы. Соотношение ДНК:PEI 1:5, объем трансфицирующей смеси 5 % от объема клеточной культуры. После трансфекции клетки инкубировали при 37 °С, 5% СO2, 75% влажности, 100 об/мин в течение 120 ч.
Для лизиса клеток в колбу добавляли Твин-20 до концентрации 0,05 % и инкубировали в течение 1 часа). Далее добавляли бензоназу до 20 МЕ/мл и MgCl2 до 1-2 мМ и инкубировали в течение 1 часа. Центрифугировали лизаты в течение 10 мин при 3000 g и фильтровали через фильтры с размером пор 0,22 мкм. Проводили концентрирование фильтратов методом тангенциальной фильтрации с отсечением молекул размером больше 100 кДа, из 525 мл в 50 мл, при трансмембранном давлении 1,5-2 бар. Аффинную хроматографию проводили на сорбенте AAVХ (Thermo Fisher Scientific, США) в соответствии с рекомендациями производителя.
Оценивали вирусный титр полученных образцов AAV с помощью RT-PCR, а также физический титр и наличие примесей (низкомолекулярных или высокомолекулярных-агрегатов) с помощью метода ПААГ (полиакриламидный гель) и DLS.
Во всех образцах обнаруживали частицы размером преимущественно 20–25 нм и минорное количество высокомолекулярных примесей (агрегатов).
Пример 4. Оценка количества мини-белка USH2A методом иммуноферментного анализа (ELISA) в лизатах клеток
Для оценки уровня белка USH2A использовали набор Human Usherin USH2A ELISA Kit, Abclonal (Cat. № RK12051). Белок получали в культуре клеток HEK293T путем трансфекции плазмидами pAAV-fUSH2A и pAAV-uUSH2A в ААV2.7m8, содержащими последовательности мини-белка fUSH2A (SEQ ID NО 4) и uUSH2A (SEQ ID NO 6).
Культивирование клеток HEK293T. За сутки до проведения трансфекции перенослили клетки в планшет, за 1 час до проведения трансфекции переводили клетки в бессывороточную среду, перед проведением трансфекции инкубировали клетки в бессывороточной среде, через 5 часов после трансфекции заменяли культуральную среду на DMEM с 5% содержанием FBS. Клетки рассевали в шестилуночный планшет в количестве 1 миллион клеток на лунку. Трансфекцию проводили с использованием PEI max (полиэтиленэмина 1 мг/мл Polyscience (Cat. № 24675-1) и 1 мкг плазмидной ДНК на лунку). Соотношение PEI:ДНК составило 5:1. Клетки инкубировали 372 часа после трансфекции. В качестве контроля использовали нетрансфицированные клетки HEK293T. Для лизирования клеточной массы использовали лизирующий буфер следующего состава: 50 mM Tris, 150 mM NaCl, 1% NP-40, pH 8.0 (для корректировки рН использовался раствор соляной кислоты). Предел количественного определения составляет 3,9 пг/мл. Для количественного определения белка предварительно готовили серию стандартных образцов входящих в состав набора (1000 – 15.6 пг/мл). Постановку реакции осуществляли в соответствии с рекомендациями производителя. Измерение оптической плотности проводили на планшетном ридере Allsheng Feyond-A300 (Китай) при длине волны 450нм. Расчет количества мини-белка USH2A проводили с использованием программы Excel.
Результаты измерений синтеза мини-белка fUSH2A (70,22 пг/мл) и uUSH2A (93,58 пг/мл) на 72 часа после трансфекции клеток HEK293T вектором pAAV- fUSH2A и pAAV- uUSH2A, а также в лизате нетрансфицированных клеток HEK293T (30,15).
Результаты, согласно Фиг. 5, 6, свидетельствуют об увеличении количества мини-белка в трансдуцированных клетках HEK293T в 2.5–3 раза по сравнению с нетрансфицированными клетками. Обнаружение мини-белка в клеточных лизатах свидетельствует о наличие мини-белка в аутентичной конформации. Взаимодействие антител с мини-белком дает основание считать, что полученные белки презентируют сайты связывания с антителами, что также подтверждает их правильную вторичную структуры.
В совокупности результаты иммуноферментного анализа подтверждают наличие белка мини-белка в эукариотической клетке, путем доставки его в составе экспрессионной конструкции.
Пример 5. Оценка титра ААV методом цифровой капельной ПЦР (ddPCR)
Образцы ААV для анализа были получены в адгезионной клеточной линии HEK293T c использованием трехплазмидной системы. Детальный протокол получения AAV представлен в примере по наработке AAV. Кратко, лизирование клеточной суспензии проводили добавлением 10% от общего объема буферного раствора 10 мМ Tris, 20 mM MgCl2, 1% Triton X-100, pH 7,5. Также к раствору добавляли 90 U бензонуклеазы на мл клеточной суспензии. Полученный раствор инкубировали 1 час при перемешивании и температуре 37 °С. После инкубации центрифугировать раствор при 3000хg в течение 20 минут. Супернатант отбирали и фильтровали через фильтр PES с размером пор 0,22 мкм. Полученный фильтрат использовали для выделения на хроматографическом сорбенте POROS AAVX (ThermoFisher Scientific, USA). Объем хроматографического сорбента составлял 0,8 мл. Хроматограф Hanbon Bio-lab 30, колонка хроматографическая Diba Omnifit 6,6×150 mm). Предварительно сорбент после хранения промывали очищенной водой, регенерировали раствором 100 mM глицина, рН 3,0 и 10 мМ NaOH, рН 2,2. После этого промывали водой и уравновешивали раствором PBS. После нанесения клеточного лизата промывали колонку уравновешивающим буфером. Элюирование проводили раствором 100 мМ глицина, рН 3,0.
Для анализа количества AAV геномов использовались 2 вида праймеров в зависимости от используемого гена интереса (см. Таблицу 4). Для праймеров, направленных на инвертированные концевые повторы AAV-ITR применяли систему с флуоресцентным зондом, а для детекции трансгена применяли геноспецифические праймеры и систему Eva Green c интеркалирующеим красителем. Реакционная смесь RainSure Supermix ddPCR для зондов (186-3026). Реакционная смесь QX200 ddPCR EvaGreen (186-4033). Амплификатор RainSure QX200 droplet digital PCR (186-4001).
Таблица 4. Состав смеси для ddPCR
Для валидации метода цифровой капельной ПЦР использовались следующие критерии:
1. Температура отжига праймеров.
2. Линейность.
3. Внутрилабораторная прецензионность.
4. Предел количественного определения.
Температура отжига праймеров.
Для определения оптимальной температуры отжига праймеров использовался диапазон температур с центральной точкой 570 °С и разницей температур ±50 °С. В градиентном режиме программного обеспечения амплификатора выбрало 8 точек для проведения скрининга. В качестве образца для постановки использовался клеточный лизат HEK293T, содержащий конструкцию AAV2.7m8-GFP. Поскольку для постановки цифрового ПЦР использовали 2 системы красителей: Eva Green и зонд AAV-P, то для обоих вариантов проведено исследование температуры отжига праймеров в обозначенном диапазоне температур. Полученные результаты представлены в таблице 5 и на Фиг. 7,8.
Таблица 5. Параметры оптимизации температуры отжига праймеров и значения AAV вг/мл
Оптимальная температура праймеров и зонда на ААV ITR, для праймеров на трансген cоставила 55 °С.
Линейность
Для построения линейной зависимости для испытуемого образца элюата выбран диапазон трехкратных разведений от 100 до 220000.
Образцы подготавливались по следующей схеме. В полипропиленовую пробирку объемом 1.5 мл вносили 90 мкл воды очищенной и 10 мкл образца элюата, содержащая ААV2.7m8, кодирующего варианты мини-белка fUSH2A и uUSH2A. Перемешивали полученный раствор (предварительное разведение 10х - раствор 1). В полипропиленовую пробирку объемом 1.5 мл вносили 90 мкл воды очищенной и 10 мкл раствора 1. Перемешивали полученный раствор (разведение 100х - раствор 2). В полипропиленовую пробирку объемом 1.5 мл вносили 20 мкл воды очищенной и 10 мкл раствора 2. Перемешивали полученный раствор (разведение 300х - раствор 3). В полипропиленовую пробирку объемом 1.5 вносили 20 мкл воды очищенной и 10 мкл раствора 3. Перемешивали полученный раствор (разведение 900х - раствор 4). В пробирку вносили 20 мкл воды очищенной и 10 мкл раствора 4. Перемешивали полученный раствор (разведение 2700х - раствор 5). В пробирку вносили 20 мкл воды очищенной и 10 мкл раствора 5. Перемешивали полученный раствор (разведение 8100х - раствор 6). В пробирку вносили 20 мкл воды очищенной и 10 мкл раствора 6. Перемешивали полученный раствор (разведение 24000х - раствор 7). В пробирку вносили 20 мкл воды очищенной и 10 мкл раствора 7. Перемешивали полученный раствор (разведение 73000 - раствор 8). В пробирку вносили 20 мкл воды очищенной и 10 мкл раствора 8. Перемешивали полученный раствор (разведение 220000 - раствор 9). Для процесса амплификации использовались следующие параметры: активация полимеразы при 95 °С в течение 10 минут; плавление ДНК при 95 °С в течение 30 секунд; отжиг праймеров при 55 °С в течение 30 секунд. Количество циклов: 40.
После окончания процесса загружали чипы с образцами в имэджер и сканировали полученные образцы. Результаты анализа представлены на Фиг. 9, 10 и таблице 6.
Таблица 6. Результаты определения предела обнаружения геномов ААV методом цифровой капельной ПЦР
Согласно полученным результатам можно сделать вывод, что линейная зависимость соблюдается при количестве положительных капель от 90% до 1%. При исследовании количеств ААV выше и ниже этого указанного диапазона, полученные значения концентрации будут лежать за пределами линейного диапазона. Cогласно полученным результатам анализа диапазон от 90 до 1% положительных капель позволяет получать сходящийся результат. Для образцов AAV2.7m8-fUSH в диапазоне разведений 900-220000 относительное стандартное отклонение (RSD) составляет 9,06%, среднее значение 1,44+Е10 вг/мл.
Внутрилабораторная прецензионность
Для постановки прецензионности использовался образец AAV-fUSH.
Предварительно готовили серию разведений 10х-80000х. Приготовление смеси для постановки ПЦР проводили по следующей схеме. В полипропиленовую пробирку объемом 1,5 мл вносили следующие реагенты: 44 мкл мастер-микса для флуоресцентного зонда, 8 мкл прямого праймера, 8 мкл обратного праймера, 4,4 флуоресцентного зонда AAV-P, 2 мкл воды очищенной. Перемешивали полученный раствор и хранили на льду.
Для нанесения использовали образцы растворов №12-15 (Таблица 5). Для этого переносили по 5,5 мкл каждого раствора в отдельную пробирку. Далее добавляли в каждую по 16,5 мкл смеси для постановки ПЦР. Тщательно перемешивали. В чип для постановки цифровой ПЦР вносили в прямоугольную лунку 75 мкл масла для зондов, в лунку для образца внести по 20 мкл. Закрывали заглушками и ставили в амплификатор.
Результаты анализа для трех независимых экспериментов представлены в таблице 7.
Для каждого из трех экспериментов коэффициент относительного стандартного отклонения составил 14,5, 11,5, 26,8% при сравнении различных концентраций между собой.
Если взять для каждого измерения среднее значение и сравнить их между собой, то коэффициент RSD составит 12,9%.
Таблица 7. Результаты измерения внутрилабораторной прецензионности и расчет среднеквадратического отклонения
Предел количественного обнаружения геномов ААV методом цифровой капельной ПЦР
Для определения предела обнаружения использовался образец AAV-fUSH. Приготовление смеси для постановки ПЦР проводили по следующей схеме. В полипропиленовую пробирку объемом 1,5 мл вносили следующие реагенты: 44 мкл мастер-микса для флуоресцентного зонда, 8 мкл прямого праймера, 8 мкл обратного праймера, 4,4 флуоресцентного зонда AAV-P, 2 мкл воды очищенной. Перемешивали полученный раствор и хранили на льду. Для нанесения использовали образцы растворов 20-27 (Таблица 8). Для этого переносили по 5,5 мкл каждого раствора в отдельную пробирку. Добавляли в каждую по 16,5 мкл смеси для постановки ПЦР. Тщательно перемещивали.
В чип для постановки цифровой ПЦР вносили в прямоугольную лунку 75 мкл масла для зондов, в лунку для образца внести по 20 мкл. Закрывали заглушками и ставили в амплификатор.
Результаты анализа для трех независимых экспериментов представлены в таблице 8.
Таблица 8. Результаты анализа для трех независимых экспериментов
Таким образом, предел количественного обнаружения цифровой капельной ПЦР с системой флуоресцентного зонда составляет 12,2 AAV вг/мкл, что соответствует разведению 3.0+Е05 и 2,4+Е02 вг/лунку, при 0,8% положительных точек. Предлагаемый метод позволяет с высокой точностью определять количество геномов вирусных векторов на основе ААV что является чрезвычайно важным для дозировки препарата при генной терапии Синдрома Ашера II типа. Несоблюдение режимов дозирования, в частности превышение оптимальной дозы может оказать токсическое влияние на пациента и вызвать нежелательные побочные эффекты связанные с реакцией организма на введение большого количества вирусного вектора. Также, использование дозировки ниже рекомендуемой зачастую приводит к отсутствию терапевтического эффекта от генотерапевтического препарата. Цифровая капельная ПЦР, в отличие от количественной ПЦР позволяет получать точные абсолютные количественные значения титров ААV без сравнительной аппроксимации на стандартные образцы.
Пример 6. In silico моделирование
Для подтверждения правильности и аутентичности вторичной структуры вариантов мини-белков USH2A полученных методом рационального дизайна было проведено in silico моделирование для предсказания вторичной структуры белков. Для этого последовательности мини-генов fUSH2A, uUSH2A, cUSH2A, kUSH2A и yUSH2A были транслированы в аминокислотные последовательности, используя онлайн утилиту EMBOSS TransSeq (https://www.ebi.ac.uk/Tools/st/emboss_transeq/), дата запроса 27.10.2023. Далее полученные аминокислотные последовательности были использованы для построения моделей при помощи сервисов AlphaFold2 (https://github.com/google-deepmind/alphafold), Robettа (https://robetta.bakerlab.org/) и I-TASSER (https://zhanggroup.org/I-TASSER/). В качестве модели сравнения использовали данные о структуре доменов в составе природного белка USH2a человека (LamGL, LamNT, EGF Lam, FN3, LamG, TM, PDZ). Мини-белки SEQ ID NО 4, 6, 8, 10, 12 показали заявленную вторичную структуру в соответствии с доменной организацией и созданной нуклеотидной последовательностью (Фиг.10). Параметры модели для мини-белков SEQ ID NО 4 и 6 были оценены как приемлемые.
Таким образом, описаны создание вариантов мини-генов fUSH2A, uUSH2A, cUSH2A, kUSH2A и yUSH2A, кодирующих мини-белки fUSH2A, uUSH2A, cUSH2A, kUSH2A и yUSH2A. Также описаны результаты оптимизации кодонов для указанных генов, результаты наработки ААV векторов для упаковки мини-генов fUSH2A и uUSH2A. Продемонстрирована доставка и экспрессия мини-гена fUSH2A в составе вирусного вектора ААV2.7m8 в клетки пигментного эпителия сетчатки человека. Получение мини-белка fUSH2A и uUSH2A подтверждено взаимодействием с антителами к белку USH2A в иммуноферментном анализе.
Несмотря на то, что варианты осуществления рассматриваемого изобретения описаны в некоторых деталях, понятно, что можно создавать очевидные вариации, не отступая от сущности и объема изобретения, как определено в настоящем документе.
--->
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE ST26SequenceListing PUBLIC "-//WIPO//DTD Sequence Listing
1.3//EN" "ST26SequenceListing_V1_3.dtd">
<ST26SequenceListing dtdVersion="V1_3" fileName="ГенЛП Ашера.xml"
softwareName="WIPO Sequence" softwareVersion="2.3.0"
productionDate="2023-12-27">
<ApplicantFileReference>1</ApplicantFileReference>
<ApplicantName languageCode="ru">ФОНД ИССЛЕДОВАНИЙ И ЛЕЧЕНИЯ
ЗАБОЛЕВАНИЙ СЕТЧАТКИ ГЛАЗА</ApplicantName>
<ApplicantNameLatin>RETINAFUND</ApplicantNameLatin>
<InventionTitle languageCode="ru">МИНИ-БЕЛОК USH2A, НУКЛЕИНОВАЯ
КИСЛОТА, КОДИРУЮЩАЯ МИНИ-БЕЛОК USH2A, И СОДЕРЖАЩИЙ ЕЕ ЭКСПРЕССИОННЫЙ
ВЕКТОР ДЛЯ ГЕННОЙ ТЕРАПИИ</InventionTitle>
<SequenceTotalQuantity>13</SequenceTotalQuantity>
<SequenceData sequenceIDNumber="1">
<INSDSeq>
<INSDSeq_length>5202</INSDSeq_length>
<INSDSeq_moltype>AA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..5202</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>protein</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q2">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>Homo sapiens</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>MNCPVLSLGSGFLFQVIEMLIFAYFASISLTESRGLFPRLENVGAFKKV
SIVPTQAVCGLPDRSTFCHSSAAAESIQFCTQRFCIQDCPYRSSHPTYTALFSAGLSSCITPDKNDLHPN
AHSNSASFIFGNHKSCFSSPPSPKLMASFTLAVWLKPEQQGVMCVIEKTVDGQIVFKLTISEKETMFYYR
TVNGLQPPIKVMTLGRILVKKWIHLSVQVHQTKISFFINGVEKDHTPFNARTLSGSITDFASGTVQIGQS
LNGLEQFVGRMQDFRLYQVALTNREILEVFSGDLLRLHAQSHCRCPGSHPRVHPLAQRYCIPNDAGDTAD
NRVSRLNPEAHPLSFVNDNDVGTSWVSNVFTNITQLNQGVTISVDLENGQYQVFYIIIQFFSPQPTEIRI
QRKKENSLDWEDWQYFARNCGAFGMKNNGDLEKPDSVNCLQLSNFTPYSRGNVTFSILTPGPNYRPGYNN
FYNTPSLQEFVKATQIRFHFHGQYYTTETAVNLRHRYYAVDEITISGRCQCHGHADNCDTTSQPYRCLCS
QESFTEGLHCDRCLPLYNDKPFRQGDQVYAFNCKPCQCNSHSKSCHYNISVDPFPFEHFRGGGGVCDDCE
HNTTGRNCELCKDYFFRQVGADPSAIDVCKPCDCDTVGTRNGSILCDQIGGQCNCKRHVSGRQCNQCQNG
FYNLQELDPDGCSPCNCNTSGTVDGDITCHQNSGQCKCKANVIGLRCDHCNFGFKFLRSFNDVGCEPCQC
NLHGSVNKFCNPHSGQCECKKEAKGLQCDTCRENFYGLDVTNCKACDCDTAGSLPGTVCNAKTGQCICKP
NVEGRQCNKCLEGNFYLRQNNSFLCLPCNCDKTGTINGSLLCNKSTGQCPCKLGVTGLRCNQCEPHRYNL
TIDNFQHCQMCECDSLGTLPGTICDPISGQCLCVPNRQGRRCNQCQPGFYISPGNATGCLPCSCHTTGAV
NHICNSLTGQCVCQDASIAGQRCDQCKDHYFGFDPQTGRCQPCNCHLSGALNETCHLVTGQCFCKQFVTG
SKCDACVPSASHLDVNNLLGCSKTPFQQPPPRGQVQSSSAINLSWSPPDSPNAHWLTYSLLRDGFEIYTT
EDQYPYSIQYFLDTDLLPYTKYSYYIETTNVHGSTRSVAVTYKTKPGVPEGNLTLSYIIPIGSDSVTLTW
TTLSNQSGPIEKYILSCAPLAGGQPCVSYEGHETSATIWNLVPFAKYDFSVQACTSGGCLHSLPITVTTA
QAPPQRLSPPKMQKISSTELHVEWSPPAELNGIIIRYELYMRRLRSTKETTSEESRVFQSSGWLSPHSFV
ESANENALKPPQTMTTITGLEPYTKYEFRVLAVNMAGSVSSAWVSERTGESAPVFMIPPSVFPLSSYSLN
ISWEKPADNVTRGKVVGYDINMLSEQSPQQSIPMAFSQLLHTAKSQELSYTVEGLKPYRIYEFTITLCNS
VGCVTSASGAGQTLAAAPAQLRPPLVKGINSTTIHLRWFPPEELNGPSPIYQLERRESSLPALMTTMMKG
IRFIGNGYCKFPSSTHPVNTDFTGIKASFRTKVPEGLIVFAASPGNQEEYFALQLKKGRLYFLFDPQGSP
VEVTTTNDHGKQYSDGKWHEIIAIRHQAFGQITLDGIYTGSSAILNGSTVIGDNTGVFLGGLPRSYTILR
KDPEIIQKGFVGCLKDVHFMKNYNPSAIWEPLDWQSSEEQINVYNSWEGCPASLNEGAQFLGAGFLELHP
YMFHGGMNFEISFKFRTDQLNGLLLFVYNKDGPDFLAMELKSGILTFRLNTSLAFTQVDLLLGLSYCNGK
WNKVIIKKEGSFISASVNGLMKHASESGDQPLVVNSPVYVGGIPQELLNSYQHLCLEQGFGGCMKDVKFT
RGAVVNLASVSSGAVRVNLDGCLSTDSAVNCRGNDSILVYQGKEQSVYEGGLQPFTEYLYRVIASHEGGS
VYSDWSRGRTTGAAPQSVPTPSRVRSLNGYSIEVTWDEPVVRGVIEKYILKAYSEDSTRPPRMPSASAEF
VNTSNLTGILTGLLPFKNYAVTLTACTLAGCTESSHALNISTPQEAPQEVQPPVAKSLPSSLLLSWNPPK
KANGIITQYCLYMDGRLIYSGSEENYIVTDLAVFTPHQFLLSACTHVGCTNSSWVLLYTAQLPPEHVDSP
VLTVLDSRTIHIQWKQPRKISGILERYVLYMSNHTHDFTIWSVIYNSTELFQDHMLQYVLPGNKYLIKLG
ACTGGGCTVSEASEALTDEDIPEGVPAPKAHSYSPDSFNVSWTEPEYPNGVITSYGLYLDGILIHNSSEL
SYRAYGFAPWSLHSFRVQACTAKGCALGPLVENRTLEAPPEGTVNVFVKTQGSRKAHVRWEAPFRPNGLL
THSVLFTGIFYVDPVGNNYTLLNVTKVMYSGEETNLWVLIDGLVPFTNYTVQVNISNSQGSLITDPITIA
MPPGAPDGVLPPRLSSATPTSLQVVWSTPARNNAPGSPRYQLQMRSGDSTHGFLELFSNPSASLSYEVSD
LQPYTEYMFRLVASNGFGSAHSSWIPFMTAEDKPGPVVPPILLDVKSRMMLVTWQHPRKSNGVITHYNIY
LHGRLYLRTPGNVTNCTVMHLHPYTAYKFQVEACTSKGCSLSPESQTVWTLPGAPEGIPSPELFSDTPTS
VIISWQPPTHPNGLVENFTIERRVKGKEEVTTLVTLPRSHSMRFIDKTSALSPWTKYEYRVLMSTLHGGT
NSSAWVEVTTRPSRPAGVQPPVVTVLEPDAVQVTWKPPLIQNGDILSYEIHMPDPHITLTNVTSAVLSQK
VTHLIPFTNYSVTIVACSGGNGYLGGCTESLPTYVTTHPTVPQNVGPLSVIPLSESYVVISWQPPSKPNG
PNLRYELLRRKIQQPLASNPPEDLNRWHNIYSGTQWLYEDKGLSRFTTYEYMLFVHNSVGFTPSREVTVT
TLAGLPERGANLTASVLNHTAIDVRWAKPTVQDLQGEVEYYTLFWSSATSNDSLKILPDVNSHVIGHLKP
NTEYWIFISVFNGVHSINSAGLHATTCDGEPQGMLPPEVVIINSTAVRVIWTSPSNPNGVVTEYSIYVNN
KLYKTGMNVPGSFILRDLSPFTIYDIQVEVCTIYACVKSNGTQITTVEDTPSDIPTPTIRGITSRSLQID
WVSPRKPNGIILGYDLLWKTWYPCAKTQKLVQDQSDELCKAVRCQKPESICGHICYSSEAKVCCNGVLYN
PKPGHRCCEEKYIPFVLNSTGVCCGGRIQEAQPNHQCCSGYYARILPGEVCCPDEQHNRVSVGIGDSCCG
RMPYSTSGNQICCAGRLHDGHGQKCCGRQIVSNDLECCGGEEGVVYNRLPGMFCCGQDYVNMSDTICCSA
SSGESKAHIKKNDPVPVKCCETELIPKSQKCCNGVGYNPLKYVCSDKISTGMMMKETKECRILCPASMEA
TEHCGRCDFNFTSHICTVIRGSHNSTGKASIEEMCSSAEETIHTGSVNTYSYTDVNLKPYMTYEYRISAW
NSYGRGLSKAVRARTKEDVPQGVSPPTWTKIDNLEDTIVLNWRKPIQSNGPIIYYILLRNGIERFRGTSL
SFSDKEGIQPFQEYSYQLKACTVAGCATSSKVVAATTQGVPESILPPSITALSAVALHLSWSVPEKSNGV
IKEYQIRQVGKGLIHTDTTDRRQHTVTGLQPYTNYSFTLTACTSAGCTSSEPFLGQTLQAAPEGVWVTPR
HIIINSTTVELYWSLPEKPNGLVSQYQLSRNGNLLFLGGSEEQNFTDKNLEPNSRYTYKLEVKTGGGSSA
SDDYIVQTPMSTPEEIYPPYNITVIGPYSIFVAWIPPGILIPEIPVEYNVLLNDGSVTPLAFSVGHHQST
LLENLTPFTQYEIRIQACQNGSCGVSSRMFVKTPEAAPMDLNSPVLKALGSACIEIKWMPPEKPNGIIIN
YFIYRRPAGIEEESVLFVWSEGALEFMDEGDTLRPFTLYEYRVRACNSKGSVESLWSLTQTLEAPPQDFP
APWAQATSAHSVLLNWTKPESPNGIISHYRVVYQERPDDPTFNSPTVHAFTVKGTSHQAHLYGLEPFTTY
RIGVVAANHAGEILSPWTLIQTLESSPSGLRNFIVEQKENGRALLLQWSEPMRTNGVIKTYNIFSDGFLE
YSGLNRQFLFRRLDPFTLYTLTLEACTRAGCAHSAPQPLWTDEAPPDSQLAPTVHSVKSTSVELSWSEPV
NPNGKIIRYEVIRRCFEGKAWGNQTIQADEKIVFTEYNTERNTFMYNDTGLQPWTQCEYKIYTWNSAGHT
CSSWNVVRTLQAPPEGLSPPVISYVSMNPQKLLISWIPPEQSNGIIQSYRLQRNEMLYPFSFDPVTFNYT
DEELLPFSTYSYALQACTSGGCSTSKPTSITTLEAAPSEVSPPDLWAVSATQMNVCWSPPTVQNGKITKY
LVRYDNKESLAGQGLCLLVSHLQPYSQYNFSLVACTNGGCTASVSKSAWTMEALPENMDSPTLQVTGSES
IEITWKPPRNPNGQIRSYELRRDGTIVYTGLETRYRDFTLTPGVEYSYTVTASNSQGGILSPLVKDRTSP
SAPSGMEPPKLQARGPQEILVNWDPPVRTNGDIINYTLFIRELFERETKIIHINTTHNSFGMQSYIVNQL
KPFHRYEIRIQACTTLGCASSDWTFIQTPEIAPLMQPPPHLEVQMAPGGFQPTVSLLWTGPLQPNGKVLY
YELYRRQIATQPRKSNPVLIYNGSSTSFIDSELLPFTEYEYQVWAVNSAGKAPSSWTWCRTGPAPPEGLR
APTFHVISSTQAVVNISAPGKPNGIVSLYRLFSSSAHGAETVLSEGMATQQTLHGLQAFTNYSIGVEACT
CFNCCSKGPTAELRTHPAPPSGLSSPQIGTLASRTASFRWSPPMFPNGVIHSYELQFHVACPPDSALPCT
PSQIETKYTGLGQKASLGGLQPYTTYKLRVVAHNEVGSTASEWISFTTQKELPQYRAPFSVDSNLSVVCV
NWSDTFLLNGQLKEYVLTDGGRRVYSGLDTTLYIPRTADKTFFFQVICTTDEGSVKTPLIQYDTSTGLGL
VLTTPGKKKGSRSKSTEFYSELWFIVLMAMLGLILLAIFLSLILQRKIHKEPYIRERPPLVPLQKRMSPL
NVYPPGENHMGLADTKIPRSGTPVSIRSNRSACVLRIPSQNQTSLTYSQGSLHRSVSQLMDIQDKKVLMD
NSLWEAIMGHNSGLYVDEEDLMNAIKDFSSVTKERTTFTDTHL</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="2">
<INSDSeq>
<INSDSeq_length>15609</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..15609</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q4">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>Homo sapiens</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>atgaattgcccagttctttcattgggctctggcttcttgtttcaggtca
ttgaaatgttgatctttgcctattttgcttcaatatccttgactgagtcacgaggtcttttcccaaggct
ggagaacgtgggagctttcaagaaagtttccatcgtgccaacccaagcagtatgtggactcccagaccga
agcactttttgtcacagctctgctgctgctgaaagtattcagttctgtacccagcggttttgtattcagg
attgcccatacagatcttcacaccctacctacactgcccttttctcagcaggcctcagtagctgcatcac
accagacaagaatgatctgcatcctaacgcccatagcaattctgcaagttttatttttggaaatcacaag
agctgcttttcttctcctccttctccaaagctgatggcatcatttaccttagctgtatggctgaaacctg
agcaacaaggtgtaatgtgtgttatagaaaagacagtagatgggcagattgtgttcaaacttacaatatc
tgagaaagagaccatgttttattatcgcacagtaaatggtttgcaacctccaataaaagtaatgacactg
gggagaattcttgtgaagaaatggattcatcttagtgtgcaggtgcatcagacaaaaatcagcttcttta
tcaatggcgtggagaaggatcatacacctttcaatgcaagaactctaagtggttcaattacagattttgc
atctggtactgtgcaaataggacagagtttaaatggtttagagcagtttgtcggaagaatgcaagatttt
cgattataccaagtggcacttacaaacagagagattctggaagtcttctctggagatcttctcagattgc
atgcccaatcacattgccgttgccctggcagccacccgcgggtccaccctttggcacagcggtactgcat
tcctaatgatgcaggagacacagctgataatagagtgtcacggttgaatcctgaagcccatcctctctct
tttgtcaatgataatgatgttggtacttcatgggtttcaaatgtgtttacaaacattacacagcttaatc
aaggagtgactatttcagttgatttggaaaatggacagtatcaggtgttttatattatcattcagttctt
tagtccacaaccaacggaaataaggattcaaaggaagaaggaaaatagtttagattgggaggactggcaa
tattttgccaggaattgtggtgcttttggaatgaaaaacaatggagatttggaaaaacctgattctgtca
actgtcttcagctttccaattttactccatattcccgtggcaatgtcacatttagcatcctgacacctgg
accaaattatcgtcctggatacaataacttctataataccccatctcttcaagagttcgtaaaagccacg
caaataaggtttcattttcatgggcagtactatacaactgagactgctgttaacctcagacacagatatt
atgcagtggacgaaatcaccattagtgggagatgtcagtgccatggtcatgccgataactgcgacacaac
aagccagccatatagatgcctctgctcccaggagagcttcactgaaggacttcattgtgatcgctgcttg
cctctttataatgacaagcctttccgccaaggtgatcaagtttacgctttcaattgtaaaccttgtcaat
gcaacagccattccaaaagctgccattacaacatctctgtagacccatttccttttgagcacttcagagg
gggaggaggagtttgtgatgattgtgagcataacactacaggaaggaactgtgagctgtgcaaggattac
tttttccgacaagttggtgcagatccttcggccatagatgtttgcaaaccctgtgactgtgatacagttg
gcactagaaatggtagcattctttgtgatcagattggaggacagtgtaattgtaagagacacgtgtctgg
caggcagtgcaatcagtgccagaatggattctacaatctacaagagttggatcctgatggctgcagtccc
tgtaactgcaatacctctgggacagtggatggagatattacctgtcaccaaaattcaggccagtgcaagt
gcaaagcaaacgttattgggcttaggtgtgatcattgcaattttggatttaaatttctccgaagctttaa
tgatgttggatgtgagccctgccagtgtaacctccatggctcagtgaacaaattctgcaatcctcactct
gggcagtgtgagtgcaaaaaagaagccaaaggacttcagtgtgacacctgcagagaaaacttttatgggt
tagatgtcaccaattgtaaggcctgtgactgtgacacagctggatccctccctgggactgtctgtaatgc
taagacagggcagtgcatctgcaagcccaatgttgaagggagacagtgcaataaatgtttggagggaaac
ttctacctacggcaaaataattctttcctctgtctgccttgcaactgtgataagactgggacaataaatg
gctctctgctgtgtaacaaatcaacaggacaatgtccttgcaaattaggggtaacaggtcttcgctgtaa
tcagtgtgagcctcacaggtacaatttgaccattgacaattttcaacactgccagatgtgtgagtgtgat
tccttggggacattacctgggaccatttgtgacccaatcagtggccagtgcctgtgtgtgcctaatcgtc
aaggaagaaggtgtaatcagtgtcaaccaggtttttatatttctccaggcaatgccactggctgcctgcc
atgctcatgccatacaactggtgcagttaatcacatctgtaatagcctgactggtcagtgtgtttgccaa
gatgcttccattgctgggcaacgttgtgaccaatgcaaagaccattactttggatttgatcctcagactg
gaagatgtcagccttgtaattgtcatctctcaggagccttgaatgaaacctgtcacttggtcacaggcca
gtgtttctgtaaacaatttgtcactggctcaaagtgtgatgcttgtgttcccagtgcaagccacttggat
gtcaacaatctattgggttgcagcaaaactccattccagcaacctccgcccagaggacaagttcaaagtt
cttctgctatcaatctctcctggagtccacctgattctccaaatgcccactggcttacttacagtttact
cagggatggttttgaaatctacacaacagaggatcaatacccatacagtattcaatacttcttagacaca
gacctgttaccatataccaaatattcctattacattgagaccaccaatgtgcatggttcaacaaggagtg
tagctgtcacttacaagacaaaaccaggggtcccagagggaaacttgactttaagttatatcattcctat
tggctcagactctgtgacacttacctggacaacactctcaaatcaatctggtcccatagagaaatatatt
ttgtcctgtgcccctttggctggtggtcagccatgtgtttcctacgaaggtcatgaaacctcagctacca
tctggaatctggttccatttgccaagtacgatttttctgtacaggcgtgtactagcgggggctgtttaca
cagcttgcccattacagtgaccacagcccaggcccctccccaaagactaagtccacctaagatgcagaaa
atcagttctacagaacttcatgtagaatggtctccaccagcggaactaaatggaataattataagatatg
aactatacatgagaagactgagatctactaaagaaaccacatctgaggaaagtcgagtttttcagagcag
tggttggctcagtcctcattcatttgtagaatcggccaatgaaaatgcattaaaacctcctcaaacaatg
acaaccatcactggcttggagccatacaccaagtatgagttcagagtcttagctgtgaatatggctggaa
gtgtgtcttctgcctgggtctcagaaagaacgggagaatcagcacctgtattcatgatccctccttcagt
ctttcccctctcttcgtactctctcaatatctcctgggagaagccagcagataatgttacaagaggaaaa
gttgtggggtatgacatcaatatgctttctgaacaatcacctcaacagtctattcccatggcgttttcac
agctgttgcacactgctaaatcccaagaactatcttacactgtagaaggactgaaaccttataggatata
tgagtttactattactctctgcaattcagttggttgtgtgaccagtgcttcgggagcaggacaaacttta
gcagcagcaccagcacaactgaggccacctctggttaaaggaatcaacagcacaacaatccatcttaggt
ggtttccacctgaagaactgaatggaccctctcctatatatcagctggaaaggagagagtcatctctacc
agctctgatgaccacgatgatgaaaggaatccgtttcataggaaatgggtattgtaaatttcccagctcc
actcacccagtcaatacagacttcactggcattaaggccagctttcgaacaaaagtgcctgaaggtttga
ttgtctttgcagcatcacctggcaatcaggaagagtattttgcacttcagttgaagaagggacgtcttta
ttttctttttgatcctcaggggtcaccagtggaagtaactacaactaatgatcatggcaaacaatatagt
gatggaaaatggcatgaaataattgctattaggcatcaggcttttggccaaatcactctggatgggatat
atacaggttcctctgccatcctgaatggtagtactgttattggagataacacaggagtctttctgggagg
gctcccgcgaagttataccatcctcaggaaggatcctgagataatccaaaaaggttttgtgggctgtctc
aaggatgtacattttatgaagaattacaatccgtcagctatttgggaacctctggattggcagagttctg
aagaacaaatcaacgtgtataacagctgggagggatgtcccgcttcattaaatgagggagctcagttcct
aggagcagggttcctggaacttcatccatatatgtttcatggtggaatgaactttgagatttcctttaag
ttcagaactgaccaattaaatggattgcttcttttcgtttataacaaagatggacctgattttcttgcta
tggagctgaaaagtggaatattgaccttccggttaaataccagtcttgcctttacacaagtggatctatt
gctggggctatcctattgtaatggaaagtggaataaagtcattattaaaaaggaaggctctttcatatca
gcaagtgtgaatggactgatgaagcatgcatcggagtccggagaccagccactggtggtgaattcaccag
tttatgtgggaggaatcccacaggaactgctgaactcttatcaacatttgtgtttggaacaaggtttcgg
tggttgcatgaaggatgttaaatttacacggggtgctgtcgttaacttggcatctgtgtccagcggtgct
gtcagagtcaatctggatggatgcctatcaactgacagtgctgttaactgcaggggaaatgactccatcc
tggtttaccagggaaaagagcagagtgtttacgagggtggtctccagccttttacagaatacctgtatcg
agtgatagcctcgcatgaaggaggttcagtatatagtgattggagtcgaggacgtacaacaggagcagct
ccacaaagtgtgccaactccctcaagagtccgcagcttaaatggatacagcattgaggtgacctgggatg
aacctgttgtcagaggtgtaattgagaagtacattctgaaagcctatagtgaggacagcacccgtccacc
ccgcatgccctctgccagtgctgaatttgtcaatacaagcaacctcacaggcatattgacaggcttgcta
cccttcaaaaactatgcagtaaccctaactgcttgcactttggctggctgtactgagagctcacatgcat
tgaacatctctactccacaagaagccccacaagaggttcagccaccagtagccaaatcccttcccagttc
tttgctgctctcctggaacccacccaaaaaggcaaatggtattataactcagtactgtttatacatggat
gggaggctgatctattcaggcagtgaggagaactacatagtcacagatttagcagtatttacaccccacc
agtttctactaagtgcatgcacacatgtgggctgtacaaacagttcctgggtcctactgtacacagcaca
gctgccaccagaacacgtggattccccagttctgactgtcctggattctagaactatacacatacagtgg
aaacaaccaagaaaaataagtgggattctggaacgctatgtattatatatgtcaaaccatacacatgatt
ttacaatttggagtgtcatctataacagtacagaacttttccaggatcatatgctacaatacgttttacc
tggtaataaatatctcatcaagctgggagcttgcacaggtggtgggtgcacagtgagtgaggccagtgag
gccctaactgacgaggacatacccgaaggcgtgccagcccccaaagcccactcatattcacctgactcct
ttaatgtctcctggactgagcctgaatatccgaatggtgttatcacgagttatggattatatctagatgg
tatattaatccacaattcctcagaactcagctatcgtgcttacggatttgctccttggagtttacattcc
ttcagagtccaagcatgcacggccaaaggttgtgctctgggcccactggtggaaaatcgaactctagaag
ctcctcctgaaggaacagtaaatgtgtttgtcaaaacacagggatcccggaaagcccacgtgaggtggga
agcaccttttcgccctaatggactcttaacacactcagtccttttcactgggatattctatgtagaccca
gtaggtaataactacacccttctgaatgtcacaaaagtcatgtacagcggagaagagacaaacctttggg
tgctcatcgatgggctggttccttttaccaactatactgtacaagtgaatatttcaaatagccaaggcag
cttgataactgatcctataacaattgcaatgcctccaggagctccagatggcgtgctgcctcccaggctt
tcatctgccactccaaccagtcttcaggttgtctggtctacaccagctcgtaataacgctcctggctctc
ccagataccaactccagatgaggtctggcgactccacccatggatttctagagttattttccaatccttc
tgcatcgttaagctatgaagtgagtgatctccaaccgtacacagagtatatgtttcggttggttgcctcc
aatggatttggcagtgcacatagttcttggattccattcatgaccgcagaggacaaacctggacctgtag
ttcctccgattcttctggatgtgaagtcaagaatgatgttggtcacctggcagcatcctagaaaatccaa
tggggttattacccattataacatttatctacatggccgtctatacttgagaactcctggaaatgtcact
aattgcacagtgatgcatttacacccatacactgcctataagtttcaggtagaagcctgcacttcaaaag
gatgttccctttcaccagagtcccagactgtatggacactcccaggggcaccggaagggatcccaagtcc
agagctgttctctgatactccaacatctgtgattatatcttggcaaccccctacccaccccaatggcttg
gtggagaatttcacaattgagagaagagtcaaaggaaaggaagaagttactaccctggtgactctcccga
ggagtcattccatgaggtttattgacaagacttctgctcttagcccatggacaaaatatgaatatcgggt
actgatgagcactcttcatggaggcacaaacagcagtgcttgggtagaagttaccacaagaccctcacga
cctgctggggtgcagccacctgtggtgacagtgctggaacccgatgcagtccaggtcacttggaaacccc
cactcatccagaacggagacatacttagctatgagattcacatgcctgaccctcacatcactttaaccaa
tgtgacttccgcagtgttaagtcaaaaagttactcatctgattcctttcactaattattctgtcaccatt
gttgcttgctcagggggtaatgggtaccttggagggtgcacagagagtttacctacctatgttaccactc
accccaccgtacctcagaatgttggcccattgtctgtgattccactaagtgaatcatatgttgtgatttc
ttggcaaccaccatccaagccaaatggacctaatttgagatatgagcttctgagacgtaaaatccagcag
ccacttgcatcaaatcccccagaagatttaaatcggtggcacaatatttattcaggaactcagtggcttt
atgaagataagggtcttagcaggtttacaacctatgaatatatgctcttcgtacacaacagtgtgggttt
tacaccgagccgagaagtgactgtgacaacgttagctggtcttccagagagaggagccaatctcactgcg
agtgtccttaaccacacagccatcgacgtgaggtgggctaaaccaactgttcaagacctacaaggtgaag
ttgaatattacacacttttttggagttctgctacctcaaacgactctctaaaaatcttgccagatgtaaa
ctctcatgtcattggccacctaaagccaaacacagagtattggatctttatctctgtcttcaatggagtc
cacagcatcaacagtgcaggacttcatgcaaccacttgcgatggggagcctcagggcatgcttcctccag
aggttgtcatcatcaacagtacagctgtacgtgtcatctggacatctccttcaaacccaaatggtgttgt
cactgagtattctatctatgtaaataataagctctacaagactggaatgaatgtgcctgggtcgtttatt
ctgagagacctgtctcccttcactatctatgacattcaggttgaagtctgcacaatatatgcctgcgtga
aaagcaatggaacccaaattaccactgtggaagacactccaagtgatataccaacacccacaattcgtgg
catcacttcaagatctcttcaaattgattgggtgtctccacggaagccaaatggcatcattcttggatat
gatctcctatggaaaacatggtatccatgcgctaaaactcaaaagttagtgcaggatcagagtgatgagc
tctgcaaggcagtgaggtgtcaaaaacctgaatctatctgtggacacatttgctattcttctgaagctaa
ggtttgttgtaacggagtgctctataaccccaagcctggacatcgctgttgtgaagaaaagtatatcccg
tttgttctgaattctactggagtttgttgtggtggccgaatacaggaggcacaaccaaatcatcagtgct
gctctgggtattacgctagaattctaccaggtgaagtatgctgtccagatgaacagcacaatcgggtttc
tgttggcattggtgattcctgctgtggcagaatgccgtactccacctcaggaaaccagatttgctgtgct
gggaggcttcatgatggccatggccagaagtgctgtggcagacagattgtgagcaacgatttagagtgtt
gtggtggagaagaaggagtggtgtacaatcgccttccaggtatgttctgttgtgggcaggattatgtgaa
tatgtcagataccatatgctgctcagcttccagtggagagtctaaagcacatattaaaaagaatgacccg
gtgccagtaaaatgctgtgagactgaacttattccaaagagccagaaatgctgtaatggagttggatata
atcctttgaaatatgtttgctctgacaagatttcaactggaatgatgatgaaggaaaccaaagagtgcag
gatcctctgcccagcatctatggaagccacagaacattgtggcaggtgtgacttcaactttaccagccac
atttgcactgtgataagagggtctcacaattccacagggaaggcatcaattgaagaaatgtgttcatctg
ccgaagaaaccattcatacagggagtgtaaacacgtactcttacacagatgtgaacctcaagccctacat
gacatatgagtacaggatttctgcctggaacagctatgggcgaggactcagcaaagctgtgagagccaga
acaaaagaagatgtgcctcaaggagtgagtccccctacgtggaccaaaatagacaatcttgaagatacaa
ttgtcttaaactggagaaaacctatacaatcaaatggtcctattatttactacatccttcttcgaaatgg
aattgaacgttttcggggaacatcactgagcttctctgataaagagggaattcaaccatttcaggaatat
tcatatcagctgaaagcttgcacggttgctggctgtgccaccagtagcaaggtagttgcagctactaccc
aaggagttccggagagcatcctgccaccaagcatcacagccctaagtgcagtggctctgcatctgagctg
gagtgtccctgagaaatcaaacggcgtcattaaagagtaccagatcaggcaggttgggaaaggtctcatc
cacactgacaccactgacaggagacagcatacggtcacaggtctccagccatacaccaactacagcttca
ctcttacagcttgtacatctgctgggtgcacttcaagcgagccttttctaggtcagacactgcaggcagc
tcctgaaggagtttgggtgacacctcgacacattatcatcaattctacaacagtggaattatattggagt
ctgccagaaaagcccaatggcctcgtttctcaatatcaattgagtcgtaatggaaacttgcttttcctgg
gtggcagtgaggagcagaatttcactgataaaaacctggagcccaatagcagatacacttacaagttaga
agtcaaaactggaggtggcagcagtgctagtgatgattacattgttcaaacacctatgtcaacaccagaa
gaaatctatcctccatataatatcacagtaattgggccttattctatatttgtagcttggataccaccag
ggatcctcatccccgaaattcctgtggagtacaatgtcttactcaatgatggaagtgtaacacctctggc
cttctccgttggtcatcatcaatccacccttctggaaaatttgactccattcacacagtatgagataagg
atacaagcatgtcaaaatggaagttgtggagttagcagtaggatgtttgtcaaaacacctgaagcagccc
caatggatcttaattctcctgttcttaaggcactggggtcagcttgcatagagattaagtggatgccacc
tgaaaaaccaaatggaatcatcatcaactactttatttacagacgccctgctggcattgaagaggagtct
gttttatttgtctggtcagaaggagcccttgaatttatggatgaaggagacaccctgaggcctttcacac
tctacgaatatcgggtcagagcctgtaactccaagggttcagtggagagtctgtggtcattaacacaaac
tctggaagctccacctcaagattttccagctccttgggctcaagccacgagtgctcattcagttctgttg
aattggacaaagccagaatctcccaatggcattatctcccattaccgtgtggtctaccaggagagacccg
acgatcctacatttaacagccctaccgtgcatgctttcacagtgaagggaacaagccatcaagcccacct
gtacgggttagaaccattcacaacatatcgcattggtgttgtggctgcaaaccatgcaggagaaatttta
agcccttggactctgattcaaaccttagaatcttccccaagtggactgagaaactttatagtagaacaga
aagagaatggccgggcattgctactacagtggtcagaacctatgagaaccaatggtgtgattaagacata
caacatcttcagtgacgggttcctggagtactctggtttgaatcgtcagtttctcttccgccgcctggat
cctttcactctctacacactgaccctggaggcctgcaccagagcaggttgtgcacactcggcgcctcagc
ctctgtggacagatgaagcccctccagactctcagctggctcctactgtccactctgtgaagtccaccag
tgttgagctgagctggtctgagcctgttaacccaaatggaaaaataattcgctatgaagtgattcgcaga
tgcttcgagggaaaagcttggggaaatcagacaatccaggccgacgagaaaattgttttcacagaatata
acactgaaaggaatacatttatgtataatgacacaggtttgcaaccatggacgcagtgtgaatataaaat
ctacacttggaattcagctgggcatacctgtagctcttggaatgtggtgaggacattgcaagcacctcca
gaaggtctctctccacctgtgatatcctatgtttctatgaatccccaaaaactgctgatttcctggatcc
caccagaacagtctaatggtattatccagtcctataggcttcaaaggaatgaaatgctctatccttttag
ctttgatcctgtgactttcaattacactgatgaagagcttcttcctttttccacctatagctatgcactc
caagcctgcacgagtggaggatgctccaccagcaaacccaccagcatcacaactctggaggctgctccat
cagaagtcagccctccagatctttgggccgtcagtgccactcaaatgaatgtatgttggtcaccgcccac
agtgcaaaatggaaagattactaaatatttagttagatatgataataaagagtcccttgctggccagggc
ctgtgcctgctggtttcccacctgcagccttactctcagtataacttctcccttgtagcctgcacgaatg
gaggttgcacagctagtgtgtcaaaatctgcctggacaatggaggccctgccagagaacatggactctcc
aacattgcaagtcacaggctcagaatcaatagaaatcacctggaaacctccaagaaacccaaatggccag
atcagaagttatgaacttaggagggatggaaccattgtatatacaggcttggaaacacgctatcgtgatt
ttactctcaccccaggtgtggagtatagctacacagtaactgccagcaacagccaagggggtattttgag
tcctcttgtcaaagatcgaaccagcccctcagcaccctcagggatggaacctccaaaattgcaggccagg
ggtcctcaggagatcttagtgaactgggaccctccagtgagaacaaatggtgatatcatcaattataccc
tcttcatccgtgaactatttgaaagagaaactaaaatcatacacataaacacaactcataattcttttgg
tatgcagtcatatatagtaaaccagctgaagccatttcacaggtatgaaatacgaattcaagcgtgcacc
accctgggatgtgcatcaagtgactggacattcatacagacccctgagattgcacctttgatgcaacccc
ctccacatctggaggtacaaatggctccaggaggattccagccaactgtttctcttttgtggacaggacc
gctgcagccaaatggaaaagttttgtattacgaattatacagaagacaaatagcaactcagcctagaaaa
tccaatccagtcctaatctataacggaagctcaacatcttttatagattccgaactattgcctttcacag
agtatgagtatcaggtctgggcagtgaattctgcaggaaaagcccccagtagctggacatggtgcagaac
cgggccagccccaccagaaggtctcagagcccccacgttccatgtgatctcttctacccaagcagtggtc
aacatcagtgcccctgggaagcccaacgggatcgtcagtctctacaggctgttctccagcagcgcccatg
gggctgagacagtgctatccgaaggcatggccacccagcagactctccatggccttcaagccttcactaa
ctactctattggagtagaggcctgcacctgcttcaactgttgcagcaaaggaccgacagctgaactgaga
acccatcctgccccaccctcaggactgtcctctccacaaatcgggacgctggcctcaaggacggcctcct
tccggtggagtccccccatgttccccaatggtgtcattcacagctatgaactccaattccacgtggcttg
ccctcctgactcagccctcccctgtactcccagccaaatagaaacaaagtacacggggctggggcagaaa
gccagccttgggggtctccagccctacaccacatacaagctgagagtggtggcacacaacgaggtgggca
gtacggcttccgagtggatcagtttcaccacccaaaaagaattgcctcagtaccgagccccattttcggt
ggacagcaatttgtctgtggtgtgtgtgaactggagtgacaccttcctcctgaacggccaactgaaggag
tacgtgttaaccgacggagggcgacgcgtgtacagcggcttggacaccaccctctacataccgagaacgg
cggacaaaaccttctttttccaggtcatctgcacgactgacgaaggaagtgttaagacgccgttgatcca
atatgatacctctactggacttggcttggtcctaacaactcctgggaaaaagaagggatcgcggagcaaa
agcacagagttctacagcgagctgtggttcatagtgttaatggcgatgctgggcttgatcttgttggcca
tttttctgtccctgatactacaaagaaaaatccacaaagagccatatatcagagaaagacctcccttggt
acctcttcagaagaggatgtctccattgaatgtttacccaccgggggaaaaccatatggggttagccgat
accaaaattccccggtctgggacacctgtgagtatccgcagcaaccggagtgcatgtgtcctgcgcatcc
cgagtcaaaaccaaaccagcctaacctactcccagggttctcttcaccgcagcgtcagccagctcatgga
cattcaagacaagaaagtcttgatggacaactcactgtgggaagccatcatgggccacaacagtggactg
tatgtggatgaagaggacctgatgaacgccatcaaggatttcagctcagtgactaaggaacgcaccacat
tcacagacacccacctgtaa</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="3">
<INSDSeq>
<INSDSeq_length>4011</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..4011</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q6">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>atgaactgccccgtgctgtctctgggcagcggcttcctgttccaggtga
tcgagatgctgatcttcgcctacttcgccagcatcagcctgaccgagagcagaggcctgttccccagact
ggagaacgtgggagccttcaagaaggtgagcatcgtgcccacccaggccgtgtgcggcctgcccgacaga
agcaccttctgccacagcagctgccagtgccacggccacgccgacaactgcgacaccaccagccagccct
acagatgcctgtgcagccaggagagcttcaccgagggcctgcactgcgacagatgcctgcccctgtacaa
tgacaagcccttcagacagggcgaccaggtgtacgccttcaactgtaagccttgccagtgcaacagccac
agcaagagctgccactacaacatcagcgtggaccccttccccttcgagcacttcagaggtggcggtggcg
tgtgcgacgactgcgagcacaacaccaccggcagaaactgcgaactgtgtaaagactacttcttcaggca
ggtgggagctgaccccagcgccattgatgtgtgcaagccctgcgactgcgacaccgtgggcaccagaaat
ggcagcatcctgtgcgaccagatcggcggccagtgcaactgcaagagacacgtgtctggcaggcagtgca
accagtgccagaatggcttctacaacctgcaggagctggaccccgacggctgcagcccctgcaactgcaa
caccagcggcaccgtggacggcgacatcacctgccaccagaacagcggccagtgcaagtgcaaggccaat
gtgattggcctgagatgcgaccactgcaacttcggcttcaagttcctgaggtctttcaacgacgtgggct
gcgagcccacccccttccagcagagaggcgccaacctgaccgccagcgtgctgaaccacaccgccatcga
cgtgagatgggccaagcccaccgtgcaggacctgcagggcgaggtggagtactacaccctgttctggagc
agcgccaccagcaacgacagcctgaagatcctgcccgacgtgaacagccacgtgatcggccacctgaagc
ccaacaccgagtactggatcttcatcagcgtgttcaacggcgtgcacagcatcaacagcgccggcctgca
cgccaccacctgcgacggcgagccccagggcatgctgcctcccgaggtggtgatcattaattctaccgcc
gtgagagtgatctggaccagccccagcaatcccaatggcgtggtgaccgagtacagcatctacgtgaaca
acaagctgtacaagaccggcatgaacgtgcctggcagcttcatcctgagagacctgagccccttcaccat
ctacgacatccaggtggaggtgtgcaccatctacgcctgcgtgaagagcaatggcacccagatcaccacc
gtggaggacacccccagcgacatccccacccccaccatcagaggcatcaccagcagaagcctgcagatcg
actgggtgagccccagaaagcccaatggcatcatcctgggctacgacctgctgtggaagacctggtatcc
ctgcgccaagacccagaagctggtgcaggaccagagcgacgagctgtgcaaggccgtgagatgccagaag
cccgagagcatctgcggccacatctgctacagcagcgaggccaaggtttgttgcaacggagtgctgtaca
atcccaagcccggccacagatgctgcgaggagaagtacatccccttcgtgctgaacagcaccggcgtgtg
ctgcggcggcagaatccaggaggcccagcccaatcaccagtgctgcagcggctactacgccagaatcctg
cctggcgaggtgtgctgccccgacgagcagcacaatagagtgagcgtgggcatcggcgacagctgctgcg
gcagaatgccctacagcaccagcggcaaccagatttgctgcgccggcagactgcacgacggccacggcca
gaagtgctgcggcagacagatcgtgagcaacgacctggagtgctgcggaggcgaggagggcgtggtgtac
aacagactgcccggcatgttctgctgcggccaggactacgtgaacatgagcgacaccatctgctgcagcg
ccagcagcggcgagagcaaggcccacatcaagaagaatgaccccgtgcccgtgaagtgctgcgagaccga
gctgatccccaagtctcagaaatgttgcaatggcgtgggctacaatcccctgaagtacgtgtgcagcgac
aagatcagcaccggcatgatgatgaaggagaccaaggagtgcagaatcctgtgccccgccagcatggagg
ccaccgagcactgcggcagatgcgacttcaacttcaccagccacatctgcaccgtgatcagaggcagcca
caacagcaccggcaaggccagcatcgaggagatgtgcagcagcgccgaggagaccatccacaccggcagc
gtgaatacctacagctacaccgacgtgaacctgaagccctacatgacctacgagtacagaatcagcgcct
ggaacagctacggcagaggcctgagcaaggccgtgagagccagaaccaaggaggacgtgccccagggcgt
gagccctcccacctggaccaagatcgacaatctggaggacaccatcgtgctgaactggagaaagcccatc
cagagcaatggccccatcatctactacatcctgctgagaaatggcatcgagagattcagaggcaccagcc
tgagcttcagcgacaaggagggcatccagcccttccaggagtacagctaccagctgaaggcctgcaccgt
ggccggctgcgccaccagcagcaaggtggtggccgccaccacccagggcgtgcccgagagcatcctgccc
cctagcatcaccgccctgagcgccgtggccctgcacctgagctggagcgtgcccgagaagagcaatggcg
tgatcaaggagtaccagatcagacaggtgggcaagggcctgatccacaccgacaccaccgacagaagaca
gcacaccgtgaccggcctgcagccctacaccaactacagcttcaccctgaccgcctgcaccagcgccggc
tgcaccagcagcgagcccttcctgggccagaccctgcaggccgcccccgagggcgtgtgggtgacaccca
gacacatcatcatcaacagcaccaccgtggagctgtactggagcctgcccgagaagcccaatggcctggt
gagccagtaccagctgagcagaaatggcaacctgctgttcctgggaggcagcgaggagcagaacttcacc
gacaagaacctggagcccaacagcagatacacctacaagctggaggtgaagaccggaggcggaagcagcg
ccagcgacgactacatcgtgcagacccagaaggagctgccccagtacagagcccccttcagcgtggacag
caacctgagcgtggtgtgcgtgaactggagcgacaccttcctgctgaatggcttcatcgtgctgatggcc
atgctgggcctgatcctgctggccatcttcctgagcctgatcctgcagagaaagatccacaaggagccct
acatcagagagagacctcccctggtgcccctgcagaagagaatgagccccctgaacgtgtacccccctgg
cgagaaccacatgggcctggccgacaccaagatccccagaagcggcacccccgtgagcatcagaagcaac
agaagcgcctgcgtgctgagaatccccagccagaaccagaccagcctgacctacagccagggcagcctgc
acagaagcgtgtctcagctcatggacatccaggacaagaaggtgctgatggacaacagcctgtgggaggc
catcatgggccacaacagcggcctgtacgtggacgaggaggacctgatgaacgctatcaaggacttcagc
agcgtgaccaaggagagaaccaccttcaccgacacccacctg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="4">
<INSDSeq>
<INSDSeq_length>1337</INSDSeq_length>
<INSDSeq_moltype>AA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..1337</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>protein</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q8">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>MNCPVLSLGSGFLFQVIEMLIFAYFASISLTESRGLFPRLENVGAFKKV
SIVPTQAVCGLPDRSTFCHSSCQCHGHADNCDTTSQPYRCLCSQESFTEGLHCDRCLPLYNDKPFRQGDQ
VYAFNCKPCQCNSHSKSCHYNISVDPFPFEHFRGGGGVCDDCEHNTTGRNCELCKDYFFRQVGADPSAID
VCKPCDCDTVGTRNGSILCDQIGGQCNCKRHVSGRQCNQCQNGFYNLQELDPDGCSPCNCNTSGTVDGDI
TCHQNSGQCKCKANVIGLRCDHCNFGFKFLRSFNDVGCEPTPFQQRGANLTASVLNHTAIDVRWAKPTVQ
DLQGEVEYYTLFWSSATSNDSLKILPDVNSHVIGHLKPNTEYWIFISVFNGVHSINSAGLHATTCDGEPQ
GMLPPEVVIINSTAVRVIWTSPSNPNGVVTEYSIYVNNKLYKTGMNVPGSFILRDLSPFTIYDIQVEVCT
IYACVKSNGTQITTVEDTPSDIPTPTIRGITSRSLQIDWVSPRKPNGIILGYDLLWKTWYPCAKTQKLVQ
DQSDELCKAVRCQKPESICGHICYSSEAKVCCNGVLYNPKPGHRCCEEKYIPFVLNSTGVCCGGRIQEAQ
PNHQCCSGYYARILPGEVCCPDEQHNRVSVGIGDSCCGRMPYSTSGNQICCAGRLHDGHGQKCCGRQIVS
NDLECCGGEEGVVYNRLPGMFCCGQDYVNMSDTICCSASSGESKAHIKKNDPVPVKCCETELIPKSQKCC
NGVGYNPLKYVCSDKISTGMMMKETKECRILCPASMEATEHCGRCDFNFTSHICTVIRGSHNSTGKASIE
EMCSSAEETIHTGSVNTYSYTDVNLKPYMTYEYRISAWNSYGRGLSKAVRARTKEDVPQGVSPPTWTKID
NLEDTIVLNWRKPIQSNGPIIYYILLRNGIERFRGTSLSFSDKEGIQPFQEYSYQLKACTVAGCATSSKV
VAATTQGVPESILPPSITALSAVALHLSWSVPEKSNGVIKEYQIRQVGKGLIHTDTTDRRQHTVTGLQPY
TNYSFTLTACTSAGCTSSEPFLGQTLQAAPEGVWVTPRHIIINSTTVELYWSLPEKPNGLVSQYQLSRNG
NLLFLGGSEEQNFTDKNLEPNSRYTYKLEVKTGGGSSASDDYIVQTQKELPQYRAPFSVDSNLSVVCVNW
SDTFLLNGFIVLMAMLGLILLAIFLSLILQRKIHKEPYIRERPPLVPLQKRMSPLNVYPPGENHMGLADT
KIPRSGTPVSIRSNRSACVLRIPSQNQTSLTYSQGSLHRSVSQLMDIQDKKVLMDNSLWEAIMGHNSGLY
VDEEDLMNAIKDFSSVTKERTTFTDTHL</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="5">
<INSDSeq>
<INSDSeq_length>8605</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..8605</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q10">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cctgcaggcagctgcgcgctcgctcgctcactgaggccgcccgggcgtc
gggcgacctttggtcgcccggcctcagtgagcgagcgagcgcgcagagagggagtggccaactccatcac
taggggttcctgcggccgcacgcgtggagctagttattaatagtaatcaattacggggtcattagttcat
agcccatatatggagttccgcgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacc
cccgcccattgacgtcaataatgacgtatgttcccatagtaacgtcaatagggactttccattgacgtca
atgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccc
cctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttc
ctacttggcagtacatctacgtattagtcatcgctattaccatggtgatgcggttttggcagtacatcaa
tgggcgtggatagcggtttgactcacggggatttccaagtctccaccccattgacgtcaatgggagtttg
ttttgcaccaaaatcaacgggactttccaaaatgtcgtaacaactccgccccattgacgcaaatgggcgg
taggcgtgtacggtgggaggtctatataagcagagctcgtttagtgaaccgtcagatcgcctggagacgc
catccacgctgttttgacctccatagaagacaccgggaccgatccagcctccgcggattcgaatcccggc
cgggaacggtgcattggaacgcggattccccgtgccaagagtgacgtaagtaccgcctatagagtctata
ggcccacaaaaaatgctttcttcttttaatatacttttttgtttatcttatttctaatactttccctaat
ctctttctttcagggcaataatgatacaatgtatcatgcctctttgcaccattctaaagaataacagtga
taatttctgggttaaggcaatagcaatatttctgcatataaatatttctgcatataaattgtaactgatg
taagaggtttcatattgctaatagcagctacaatccagctaccattctgcttttattttatggttgggat
aaggctggattattctgagtccaagctaggcccttttgctaatcatgttcatacctcttatcttcctccc
acagctcctgggcaacgtgctggtctgtgtgctggcccatcactttggcaaagaattgggattcgaacat
cgattgaattcgccaccatgaactgccccgtgctgtctctgggcagcggcttcctgttccaggtgatcga
gatgctgatcttcgcctacttcgccagcatcagcctgaccgagagcagaggcctgttccccagactggag
aacgtgggagccttcaagaaggtgagcatcgtgcccacccaggccgtgtgcggcctgcccgacagaagca
ccttctgccacagcagctgccagtgccacggccacgccgacaactgcgacaccaccagccagccctacag
atgcctgtgcagccaggagagcttcaccgagggcctgcactgcgacagatgcctgcccctgtacaatgac
aagcccttcagacagggcgaccaggtgtacgccttcaactgtaagccttgccagtgcaacagccacagca
agagctgccactacaacatcagcgtggaccccttccccttcgagcacttcagaggtggcggtggcgtgtg
cgacgactgcgagcacaacaccaccggcagaaactgcgaactgtgtaaagactacttcttcaggcaggtg
ggagctgaccccagcgccattgatgtgtgcaagccctgcgactgcgacaccgtgggcaccagaaatggca
gcatcctgtgcgaccagatcggcggccagtgcaactgcaagagacacgtgtctggcaggcagtgcaacca
gtgccagaatggcttctacaacctgcaggagctggaccccgacggctgcagcccctgcaactgcaacacc
agcggcaccgtggacggcgacatcacctgccaccagaacagcggccagtgcaagtgcaaggccaatgtga
ttggcctgagatgcgaccactgcaacttcggcttcaagttcctgaggtctttcaacgacgtgggctgcga
gcccacccccttccagcagagaggcgccaacctgaccgccagcgtgctgaaccacaccgccatcgacgtg
agatgggccaagcccaccgtgcaggacctgcagggcgaggtggagtactacaccctgttctggagcagcg
ccaccagcaacgacagcctgaagatcctgcccgacgtgaacagccacgtgatcggccacctgaagcccaa
caccgagtactggatcttcatcagcgtgttcaacggcgtgcacagcatcaacagcgccggcctgcacgcc
accacctgcgacggcgagccccagggcatgctgcctcccgaggtggtgatcattaattctaccgccgtga
gagtgatctggaccagccccagcaatcccaatggcgtggtgaccgagtacagcatctacgtgaacaacaa
gctgtacaagaccggcatgaacgtgcctggcagcttcatcctgagagacctgagccccttcaccatctac
gacatccaggtggaggtgtgcaccatctacgcctgcgtgaagagcaatggcacccagatcaccaccgtgg
aggacacccccagcgacatccccacccccaccatcagaggcatcaccagcagaagcctgcagatcgactg
ggtgagccccagaaagcccaatggcatcatcctgggctacgacctgctgtggaagacctggtatccctgc
gccaagacccagaagctggtgcaggaccagagcgacgagctgtgcaaggccgtgagatgccagaagcccg
agagcatctgcggccacatctgctacagcagcgaggccaaggtttgttgcaacggagtgctgtacaatcc
caagcccggccacagatgctgcgaggagaagtacatccccttcgtgctgaacagcaccggcgtgtgctgc
ggcggcagaatccaggaggcccagcccaatcaccagtgctgcagcggctactacgccagaatcctgcctg
gcgaggtgtgctgccccgacgagcagcacaatagagtgagcgtgggcatcggcgacagctgctgcggcag
aatgccctacagcaccagcggcaaccagatttgctgcgccggcagactgcacgacggccacggccagaag
tgctgcggcagacagatcgtgagcaacgacctggagtgctgcggaggcgaggagggcgtggtgtacaaca
gactgcccggcatgttctgctgcggccaggactacgtgaacatgagcgacaccatctgctgcagcgccag
cagcggcgagagcaaggcccacatcaagaagaatgaccccgtgcccgtgaagtgctgcgagaccgagctg
atccccaagtctcagaaatgttgcaatggcgtgggctacaatcccctgaagtacgtgtgcagcgacaaga
tcagcaccggcatgatgatgaaggagaccaaggagtgcagaatcctgtgccccgccagcatggaggccac
cgagcactgcggcagatgcgacttcaacttcaccagccacatctgcaccgtgatcagaggcagccacaac
agcaccggcaaggccagcatcgaggagatgtgcagcagcgccgaggagaccatccacaccggcagcgtga
atacctacagctacaccgacgtgaacctgaagccctacatgacctacgagtacagaatcagcgcctggaa
cagctacggcagaggcctgagcaaggccgtgagagccagaaccaaggaggacgtgccccagggcgtgagc
cctcccacctggaccaagatcgacaatctggaggacaccatcgtgctgaactggagaaagcccatccaga
gcaatggccccatcatctactacatcctgctgagaaatggcatcgagagattcagaggcaccagcctgag
cttcagcgacaaggagggcatccagcccttccaggagtacagctaccagctgaaggcctgcaccgtggcc
ggctgcgccaccagcagcaaggtggtggccgccaccacccagggcgtgcccgagagcatcctgcccccta
gcatcaccgccctgagcgccgtggccctgcacctgagctggagcgtgcccgagaagagcaatggcgtgat
caaggagtaccagatcagacaggtgggcaagggcctgatccacaccgacaccaccgacagaagacagcac
accgtgaccggcctgcagccctacaccaactacagcttcaccctgaccgcctgcaccagcgccggctgca
ccagcagcgagcccttcctgggccagaccctgcaggccgcccccgagggcgtgtgggtgacacccagaca
catcatcatcaacagcaccaccgtggagctgtactggagcctgcccgagaagcccaatggcctggtgagc
cagtaccagctgagcagaaatggcaacctgctgttcctgggaggcagcgaggagcagaacttcaccgaca
agaacctggagcccaacagcagatacacctacaagctggaggtgaagaccggaggcggaagcagcgccag
cgacgactacatcgtgcagacccagaaggagctgccccagtacagagcccccttcagcgtggacagcaac
ctgagcgtggtgtgcgtgaactggagcgacaccttcctgctgaatggcttcatcgtgctgatggccatgc
tgggcctgatcctgctggccatcttcctgagcctgatcctgcagagaaagatccacaaggagccctacat
cagagagagacctcccctggtgcccctgcagaagagaatgagccccctgaacgtgtacccccctggcgag
aaccacatgggcctggccgacaccaagatccccagaagcggcacccccgtgagcatcagaagcaacagaa
gcgcctgcgtgctgagaatccccagccagaaccagaccagcctgacctacagccagggcagcctgcacag
aagcgtgtctcagctcatggacatccaggacaagaaggtgctgatggacaacagcctgtgggaggccatc
atgggccacaacagcggcctgtacgtggacgaggaggacctgatgaacgctatcaaggacttcagcagcg
tgaccaaggagagaaccaccttcaccgacacccacctgtagtgaagatctacgggtggcatccctgtgac
ccctccccagtgcctctcctggccctggaagttgccactccagtgcccaccagccttgtcctaataaaat
taagttgcatcattttgtctgactaggtgtccttctataatattatggggtggaggggggtggtatggag
caaggggcaagttgggaagacaacctgtagggcctgcggggtctattgggaaccaagctggagtgcagtg
gcacaatcttggctcactgcaatctccgcctcctgggttcaagcgattctcctgcctcagcctcccgagt
tgttgggattccaggcatgcatgaccaggctcagctaatttttgtttttttggtagagacggggtttcac
catattggccaggctggtctccaactcctaatctcaggtgatctacccaccttggcctcccaaattgctg
ggattacaggcgtgaaccactgctcccttccctgtccttctgattttgtaggtaaccacgtgcggaccga
gcggccgcaggaacccctagtgatggagttggccactccctctctgcgcgctcgctcgctcactgaggcc
gggcgaccaaaggtcgcccgacgcccgggctttgcccgggcggcctcagtgagcgagcgagcgcgcagct
gcctgcaggggcgcctgatgcggtattttctccttacgcatctgtgcggtatttcacaccgcatacgtca
aagcaaccatagtacgcgccctgtagcggcgcattaagcgcggcgggtgtggtggttacgcgcagcgtga
ccgctacacttgccagcgccctagcgcccgctcctttcgctttcttcccttcctttctcgccacgttcgc
cggctttccccgtcaagctctaaatcgggggctccctttagggttccgatttagtgctttacggcacctc
gaccccaaaaaacttgatttgggtgatggttcacgtagtgggccatcgccctgatagacggtttttcgcc
ctttgacgttggagtccacgttctttaatagtggactcttgttccaaactggaacaacactcaaccctat
ctcgggctattcttttgatttataagggattttgccgatttcggcctattggttaaaaaatgagctgatt
taacaaaaatttaacgcgaattttaacaaaatattaacgtttacaattttatggtgcactctcagtacaa
tctgctctgatgccgcatagttaagccagccccgacacccgccaacacccgctgacgcgccctgacgggc
ttgtctgctcccggcatccgcttacagacaagctgtgaccgtctccgggagctgcatgtgtcagaggttt
tcaccgtcatcaccgaaacgcgcgagacgaaagggcctcgtgatacgcctatttttataggttaatgtca
tgataataatggtttcttagacgtcaggtggcacttttcggggaaatgtgcgcggaacccctatttgttt
atttttctaaatacattcaaatatgtatccgctcatgagacaataaccctgataaatgcttcaataatat
tgaaaaaggaagagtatgagtattcaacatttccgtgtcgcccttattcccttttttgcggcattttgcc
ttcctgtttttgctcacccagaaacgctggtgaaagtaaaagatgctgaagatcagttgggtgcacgagt
gggttacatcgaactggatctcaacagcggtaagatccttgagagttttcgccccgaagaacgttttcca
atgatgagcacttttaaagttctgctatgtggcgcggtattatcccgtattgacgccgggcaagagcaac
tcggtcgccgcatacactattctcagaatgacttggttgagtactcaccagtcacagaaaagcatcttac
ggatggcatgacagtaagagaattatgcagtgctgccataaccatgagtgataacactgcggccaactta
cttctgacaacgatcggaggaccgaaggagctaaccgcttttttgcacaacatgggggatcatgtaactc
gccttgatcgttgggaaccggagctgaatgaagccataccaaacgacgagcgtgacaccacgatgcctgt
agcaatggcaacaacgttgcgcaaactattaactggcgaactacttactctagcttcccggcaacaatta
atagactggatggaggcggataaagttgcaggaccacttctgcgctcggcccttccggctggctggttta
ttgctgataaatctggagccggtgagcgtgggtctcgcggtatcattgcagcactggggccagatggtaa
gccctcccgtatcgtagttatctacacgacggggagtcaggcaactatggatgaacgaaatagacagatc
gctgagataggtgcctcactgattaagcattggtaactgtcagaccaagtttactcatatatactttaga
ttgatttaaaacttcatttttaatttaaaaggatctaggtgaagatcctttttgataatctcatgaccaa
aatcccttaacgtgagttttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttga
gatcctttttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggtttgtt
tgccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgcagataccaaatac
tgtccttctagtgtagccgtagttaggccaccacttcaagaactctgtagcaccgcctacatacctcgct
ctgctaatcctgttaccagtggctgctgccagtggcgataagtcgtgtcttaccgggttggactcaagac
gatagttaccggataaggcgcagcggtcgggctgaacggggggttcgtgcacacagcccagcttggagcg
aacgacctacaccgaactgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggaga
aaggcggacaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggggaa
acgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgatttttgtgatgctc
gtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttttacggttcctggccttttgctgg
ccttttgctcacatgt</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="6">
<INSDSeq>
<INSDSeq_length>2778</INSDSeq_length>
<INSDSeq_moltype>AA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..2778</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>protein</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q12">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>MNCPVLSLGSGFLFQVIEMLIFAYFASISLTESRGLFPRLENVGAFKKV
SIVPTQAVCGLPDRSTFCHSSAAAESIQFCTQRFCIQDCPYRSSHPTYTALFSAGLSSCITPDKNDLHPN
AHSNSASFIFGNHKSCFSSPPSPKLMPCNCHLSGALNETCHLVTGQCFCKQFVTGSKCDACVPSASHLDV
NNLLGCSKTPFQQPPPRGQVQSSSAINLSWSPPDSPNAHWLTYSLLRDGFEIYTTEDQYPYSIQYFLDTD
LLPYTKYSYYIETTNVHGSTRSVAVTYKTKPGVPEGNLTLSYIIPIGSDSVTLTWTTLSNQSGPIEKYIL
SCAPLAGGQPCVSYEGHETSATIWNLVPFAKYDFSVQACTSGGCLHSLPITVTTAQAPPQRLSPPKMQKI
SSTELHVEWSPPAELNGIIIRYELYMRRLRSTKETTSEESRVFQSSGWLSPHSFVESANENALKPPQTMT
TITGLEPYTKYEFRVLAVNMAGSVSSAWVSERTGESAPVFMIPNGYLGGCTESLPTYVTTHPTVPQNVGP
LSVIPLSESYVVISWQPPSKPNGPNLRYELLRRKIQQPLASNPPEDLNRWHNIYSGTQWLYEDKGLSRFT
TYEYMLFVHNSVGFTPSREVTVTTLAGLPERGANLTASVLNHTAIDVRWAKPTVQDLQGEVEYYTLFWSS
ATSNDSLKILPDVNSHVIGHLKPNTEYWIFISVFNGVHSINSAGLHATTCDGEPQGMLPPEVVIINSTAV
RVIWTSPSNPNGVVTEYSIYVNNKLYKTGMNVPGSFILRDLSPFTIYDIQVEVCTIYACVKSNGTQITTV
EDTPSDIPTPTIRGITSRSLQIDWVSPRKPNGIILGYDLLWKTWYPCAKTQKLVQDQSDELCKAVRCQKP
ESICGHICYSSEAKVCCNGVLYNPKPGHRCCEEKYIPFVLNSTGVCCGGRIQEAQPNHQCCSGYYARILP
GEVCCPDEQHNRVSVGIGDSCCGRMPYSTSGNQICCAGRLHDGHGQKCCGRQIVSNDLECCGGEEGVVYN
RLPGMFCCGQDYVNMSDTICCSASSGESKAHIKKNDPVPVKCCETELIPKSQKCCNGVGYNPLKYVCSDK
ISTGMMMKETKECRILCPASMEATEHCGRCDFNFTSHICTVIRGSHNSTGKASIEEMCSSAETQGVPESI
LPPSITALSAVALHLSWSVPEKSNGVIKEYQIRQVGKGLIHTDTTDRRQHTVTGLQPYTNYSFTLTACTS
AGCTSSEPFLGQTLQAAPEGVWVTPRHIIINSTTVELYWSLPEKPNGLVSQYQLSRNGNLLFLGGSEEQN
FTDKNLEPNSRYTYKLEVKTGGGSSASDDYIVQTPMSTPEEIYPPYNITVIGPYSIFVAWIPPGILIPEI
PVEYNVLLNDGSVTPLAFSVGHHQSTLLENLTPFTQYEIRIQACQNGSCGVSSRMFVKTPEAAPMDLNSP
VLKALGSACIEIKWMPPEKPNGIIINYFIYRRPAGIEEESVLFVWSEGALEFMDEGDTLRPFTLYEYRVR
ACNSKGSVESLWSLTQTLEAPPQDFPAPWAQATSAHSVLLNWTKPESPNGIISHYRVVYQERPDDPTFNS
PTVHAFTVKGTSHQAHLYGLEPFTTYRIGVVAANHAGEILSPWTLIQTLESSPSGLRNFIVEQKENGRAL
LLQWSEPMRTNGVIKTYNIFSDGFLEYSGLNRQFLFRRLDPFTLYTLTLEACTRAGCAHSAPQPLWTDEA
PPDSQLAPTVHSVKSTSVELSWSEPVNPNGKIIRYEVIRRCFEGKAWGNQTIQADEKIVFTEYNTERNTF
MYNDTGLQPWTQCEYKIYTWNSAGHTCSSWNVVRTLQAPPEGLSPPVISYVSMNPQKLLISWIPPEQSNG
IIQSYRLQRNEMLYPFSFDPVTFNYTDEELLPFSTYSYALQACTSGGCSTSKPTSITTLEAAPSEVSPPD
LWAVSATQMNVCWSPPTVQNGKITKYLVRYDNKESLAGQGLCLLVSHLQPYSQYNFSLVACTNGGCTASV
SKSAWTMEALPENMDSPTLQVTGSESIEITWKPPRNPNGQIRSYELRRDGTIVYTGLETRYRDFTLTPGV
EYSYTVTASNSQGGILSPLVKDRTSPSAPSGMEPPKLQARGPQEILVNWDPPVRTNGDIINYTLFIRELF
ERETKIIHINTTHNSFGMQSYIVNQLKPFHRYEIRIQACTTLGCASSDWTFIQTPEIAPLMQPPPHLEVQ
MAPGGFQPTVSLLWTGPLQPNGKVLYYELYRRQIATQPRKSNPVLIYNGSSTSFIDSELLPFTEYEYQVW
AVNSAGKAPSSWTWCRTGPAPPEGLRAPTFHVISSTQAVVNISAPGKPNGIVSLYRLFSSSAHGAETVLS
EGMATQQTLHGLQAFTNYSIGVEACTCFNCCSKGPTAELRTHPAPPSGLSSPQIGTLASRTASFRWSPPM
FPNGVIHSYELQFHVACPPDSALPCTPSQIETKYTGLGQKASLGGLQPYTTYKLRVVAHNEVGSTASEWI
SFTTQKELPQYRAPFSVDSNLSVVCVNWSDTFLLNGQLKEYVLTDGGRRVYSGLDTTLYIPRTADKTFFF
QVICTTDEGSVKTPLIQYDTSTGLGLVLTTPGKKKGSRSKSTEFYSELWFIVLMAMLGLILLAIFLSLIL
QRKIHKEPYIRERPPLVPLQKRMSPLNVYPPGENHMGLADTKIPRSGTPVSIRSNRSACVLRIPSQNQTS
LTYSQGSLHRSVSQLMDIQDKKVLMDNSLWEAIMGHNSGLYVDEEDLMNAIKDFSSVTKERTTFTDTHL<
/INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="7">
<INSDSeq>
<INSDSeq_length>8334</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..8334</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q14">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>atgaactgccccgtgctgagcctgggcagcggcttcctgttccaggtga
tcgagatgctgatcttcgcctacttcgccagcatcagcctgaccgagagcaggggcctgttccccaggct
ggagaacgtgggcgccttcaagaaggtgagcatcgtgcccacccaggccgtgtgcggcctgcccgacagg
agcaccttctgccacagcagcgccgccgccgagagcatccagttctgcacccagaggttctgcatccagg
actgcccctacaggagcagccaccccacctacaccgccctgttcagcgccggcctgagcagctgcatcac
ccccgacaagaacgacctgcaccccaacgcccacagcaacagcgccagcttcatcttcggcaaccacaag
agctgcttcagcagcccccccagccccaagctgatgccctgcaactgccacctgagcggcgccctgaacg
agacctgccacctggtgaccggccagtgcttctgcaagcagttcgtgaccggcagcaagtgcgacgcctg
cgtgcccagcgccagccacctggacgtgaacaacctgctgggctgcagcaagacccccttccagcagccc
ccccccaggggccaggtgcagagcagcagcgccatcaacctgagctggagcccccccgacagccccaacg
cccactggctgacctacagcctgctgagggacggcttcgagatctacaccaccgaggaccagtaccccta
cagcatccagtacttcctggacaccgacctgctgccctacaccaagtacagctactacatcgagaccacc
aacgtgcacggcagcaccaggagcgtggccgtgacctacaagaccaagcccggcgtgcccgagggcaacc
tgaccctgagctacatcatccccatcggcagcgacagcgtgaccctgacctggaccaccctgagcaacca
gagcggccccatcgagaagtacatcctgagctgcgcccccctggccggcggccagccctgcgtgagctac
gagggccacgagaccagcgccaccatctggaacctggtgcccttcgccaagtacgacttcagcgtgcagg
cctgcaccagcggcggctgcctgcacagcctgcccatcaccgtgaccaccgcccaggcccccccccagag
gctgagcccccccaagatgcagaagatcagcagcaccgagctgcacgtggagtggagcccccccgccgag
ctgaacggcatcatcatcaggtacgagctgtacatgaggaggctgaggagcaccaaggagaccaccagcg
aggagagcagggtgttccagagcagcggctggctgagcccccacagcttcgtggagagcgccaacgagaa
cgccctgaagcccccccagaccatgaccaccatcaccggcctggagccctacaccaagtacgagttcagg
gtgctggccgtgaacatggccggcagcgtgagcagcgcctgggtgagcgagaggaccggcgagagcgccc
ccgtgttcatgatccccaacggctacctgggcggctgcaccgagagcctgcccacctacgtgaccaccca
ccccaccgtgccccagaacgtgggccccctgagcgtgatccccctgagcgagagctacgtggtgatcagc
tggcagccccccagcaagcccaacggccccaacctgaggtacgagctgctgaggaggaagatccagcagc
ccctggccagcaacccccccgaggacctgaacaggtggcacaacatctacagcggcacccagtggctgta
cgaggacaagggcctgagcaggttcaccacctacgagtacatgctgttcgtgcacaacagcgtgggcttc
acccccagcagggaggtgaccgtgaccaccctggccggcctgcccgagaggggcgccaacctgaccgcca
gcgtgctgaaccacaccgccatcgacgtgaggtgggccaagcccaccgtgcaggacctgcagggcgaggt
ggagtactacaccctgttctggagcagcgccaccagcaacgacagcctgaagatcctgcccgacgtgaac
agccacgtgatcggccacctgaagcccaacaccgagtactggatcttcatcagcgtgttcaacggcgtgc
acagcatcaacagcgccggcctgcacgccaccacctgcgacggcgagccccagggcatgctgccccccga
ggtggtgatcatcaacagcaccgccgtgagggtgatctggaccagccccagcaaccccaacggcgtggtg
accgagtacagcatctacgtgaacaacaagctgtacaagaccggcatgaacgtgcccggcagcttcatcc
tgagggacctgagccccttcaccatctacgacatccaggtggaggtgtgcaccatctacgcctgcgtgaa
gagcaacggcacccagatcaccaccgtggaggacacccccagcgacatccccacccccaccatcaggggc
atcaccagcaggagcctgcagatcgactgggtgagccccaggaagcccaacggcatcatcctgggctacg
acctgctgtggaagacctggtacccctgcgccaagacccagaagctggtgcaggaccagagcgacgagct
gtgcaaggccgtgaggtgccagaagcccgagagcatctgcggccacatctgctacagcagcgaggccaag
gtgtgctgcaacggcgtgctgtacaaccccaagcccggccacaggtgctgcgaggagaagtacatcccct
tcgtgctgaacagcaccggcgtgtgctgcggcggcaggatccaggaggcccagcccaaccaccagtgctg
cagcggctactacgccaggatcctgcccggcgaggtgtgctgccccgacgagcagcacaacagggtgagc
gtgggcatcggcgacagctgctgcggcaggatgccctacagcaccagcggcaaccagatctgctgcgccg
gcaggctgcacgacggccacggccagaagtgctgcggcaggcagatcgtgagcaacgacctggagtgctg
cggcggcgaggagggcgtggtgtacaacaggctgcccggcatgttctgctgcggccaggactacgtgaac
atgagcgacaccatctgctgcagcgccagcagcggcgagagcaaggcccacatcaagaagaacgaccccg
tgcccgtgaagtgctgcgagaccgagctgatccccaagagccagaagtgctgcaacggcgtgggctacaa
ccccctgaagtacgtgtgcagcgacaagatcagcaccggcatgatgatgaaggagaccaaggagtgcagg
atcctgtgccccgccagcatggaggccaccgagcactgcggcaggtgcgacttcaacttcaccagccaca
tctgcaccgtgatcaggggcagccacaacagcaccggcaaggccagcatcgaggagatgtgcagcagcgc
cgagacccagggcgtgcccgagagcatcctgccccccagcatcaccgccctgagcgccgtggccctgcac
ctgagctggagcgtgcccgagaagagcaacggcgtgatcaaggagtaccagatcaggcaggtgggcaagg
gcctgatccacaccgacaccaccgacaggaggcagcacaccgtgaccggcctgcagccctacaccaacta
cagcttcaccctgaccgcctgcaccagcgccggctgcaccagcagcgagcccttcctgggccagaccctg
caggccgcccccgagggcgtgtgggtgacccccaggcacatcatcatcaacagcaccaccgtggagctgt
actggagcctgcccgagaagcccaacggcctggtgagccagtaccagctgagcaggaacggcaacctgct
gttcctgggcggcagcgaggagcagaacttcaccgacaagaacctggagcccaacagcaggtacacctac
aagctggaggtgaagaccggcggcggcagcagcgccagcgacgactacatcgtgcagacccccatgagca
cccccgaggagatctaccccccctacaacatcaccgtgatcggcccctacagcatcttcgtggcctggat
cccccccggcatcctgatccccgagatccccgtggagtacaacgtgctgctgaacgacggcagcgtgacc
cccctggccttcagcgtgggccaccaccagagcaccctgctggagaacctgacccccttcacccagtacg
agatcaggatccaggcctgccagaacggcagctgcggcgtgagcagcaggatgttcgtgaagacccccga
ggccgcccccatggacctgaacagccccgtgctgaaggccctgggcagcgcctgcatcgagatcaagtgg
atgccccccgagaagcccaacggcatcatcatcaactacttcatctacaggaggcccgccggcatcgagg
aggagagcgtgctgttcgtgtggagcgagggcgccctggagttcatggacgagggcgacaccctgaggcc
cttcaccctgtacgagtacagggtgagggcctgcaacagcaagggcagcgtggagagcctgtggagcctg
acccagaccctggaggcccccccccaggacttccccgccccctgggcccaggccaccagcgcccacagcg
tgctgctgaactggaccaagcccgagagccccaacggcatcatcagccactacagggtggtgtaccagga
gaggcccgacgaccccaccttcaacagccccaccgtgcacgccttcaccgtgaagggcaccagccaccag
gcccacctgtacggcctggagcccttcaccacctacaggatcggcgtggtggccgccaaccacgccggcg
agatcctgagcccctggaccctgatccagaccctggagagcagccccagcggcctgaggaacttcatcgt
ggagcagaaggagaacggcagggccctgctgctgcagtggagcgagcccatgaggaccaacggcgtgatc
aagacctacaacatcttcagcgacggcttcctggagtacagcggcctgaacaggcagttcctgttcagga
ggctggaccccttcaccctgtacaccctgaccctggaggcctgcaccagggccggctgcgcccacagcgc
cccccagcccctgtggaccgacgaggccccccccgacagccagctggcccccaccgtgcacagcgtgaag
agcaccagcgtggagctgagctggagcgagcccgtgaaccccaacggcaagatcatcaggtacgaggtga
tcaggaggtgcttcgagggcaaggcctggggcaaccagaccatccaggccgacgagaagatcgtgttcac
cgagtacaacaccgagaggaacaccttcatgtacaacgacaccggcctgcagccctggacccagtgcgag
tacaagatctacacctggaacagcgccggccacacctgcagcagctggaacgtggtgaggaccctgcagg
ccccccccgagggcctgagcccccccgtgatcagctacgtgagcatgaacccccagaagctgctgatcag
ctggatcccccccgagcagagcaacggcatcatccagagctacaggctgcagaggaacgagatgctgtac
cccttcagcttcgaccccgtgaccttcaactacaccgacgaggagctgctgcccttcagcacctacagct
acgccctgcaggcctgcaccagcggcggctgcagcaccagcaagcccaccagcatcaccaccctggaggc
cgcccccagcgaggtgagcccccccgacctgtgggccgtgagcgccacccagatgaacgtgtgctggagc
ccccccaccgtgcagaacggcaagatcaccaagtacctggtgaggtacgacaacaaggagagcctggccg
gccagggcctgtgcctgctggtgagccacctgcagccctacagccagtacaacttcagcctggtggcctg
caccaacggcggctgcaccgccagcgtgagcaagagcgcctggaccatggaggccctgcccgagaacatg
gacagccccaccctgcaggtgaccggcagcgagagcatcgagatcacctggaagccccccaggaacccca
acggccagatcaggagctacgagctgaggagggacggcaccatcgtgtacaccggcctggagaccaggta
cagggacttcaccctgacccccggcgtggagtacagctacaccgtgaccgccagcaacagccagggcggc
atcctgagccccctggtgaaggacaggaccagccccagcgcccccagcggcatggagccccccaagctgc
aggccaggggcccccaggagatcctggtgaactgggacccccccgtgaggaccaacggcgacatcatcaa
ctacaccctgttcatcagggagctgttcgagagggagaccaagatcatccacatcaacaccacccacaac
agcttcggcatgcagagctacatcgtgaaccagctgaagcccttccacaggtacgagatcaggatccagg
cctgcaccaccctgggctgcgccagcagcgactggaccttcatccagacccccgagatcgcccccctgat
gcagccccccccccacctggaggtgcagatggcccccggcggcttccagcccaccgtgagcctgctgtgg
accggccccctgcagcccaacggcaaggtgctgtactacgagctgtacaggaggcagatcgccacccagc
ccaggaagagcaaccccgtgctgatctacaacggcagcagcaccagcttcatcgacagcgagctgctgcc
cttcaccgagtacgagtaccaggtgtgggccgtgaacagcgccggcaaggcccccagcagctggacctgg
tgcaggaccggccccgccccccccgagggcctgagggcccccaccttccacgtgatcagcagcacccagg
ccgtggtgaacatcagcgcccccggcaagcccaacggcatcgtgagcctgtacaggctgttcagcagcag
cgcccacggcgccgagaccgtgctgagcgagggcatggccacccagcagaccctgcacggcctgcaggcc
ttcaccaactacagcatcggcgtggaggcctgcacctgcttcaactgctgcagcaagggccccaccgccg
agctgaggacccaccccgccccccccagcggcctgagcagcccccagatcggcaccctggccagcaggac
cgccagcttcaggtggagcccccccatgttccccaacggcgtgatccacagctacgagctgcagttccac
gtggcctgcccccccgacagcgccctgccctgcacccccagccagatcgagaccaagtacaccggcctgg
gccagaaggccagcctgggcggcctgcagccctacaccacctacaagctgagggtggtggcccacaacga
ggtgggcagcaccgccagcgagtggatcagcttcaccacccagaaggagctgccccagtacagggccccc
ttcagcgtggacagcaacctgagcgtggtgtgcgtgaactggagcgacaccttcctgctgaacggccagc
tgaaggagtacgtgctgaccgacggcggcaggagggtgtacagcggcctggacaccaccctgtacatccc
caggaccgccgacaagaccttcttcttccaggtgatctgcaccaccgacgagggcagcgtgaagaccccc
ctgatccagtacgacaccagcaccggcctgggcctggtgctgaccacccccggcaagaagaagggcagca
ggagcaagagcaccgagttctacagcgagctgtggttcatcgtgctgatggccatgctgggcctgatcct
gctggccatcttcctgagcctgatcctgcagaggaagatccacaaggagccctacatcagggagaggccc
cccctggtgcccctgcagaagaggatgagccccctgaacgtgtacccccccggcgagaaccacatgggcc
tggccgacaccaagatccccaggagcggcacccccgtgagcatcaggagcaacaggagcgcctgcgtgct
gaggatccccagccagaaccagaccagcctgacctacagccagggcagcctgcacaggagcgtgagccag
ctgatggacatccaggacaagaaggtgctgatggacaacagcctgtgggaggccatcatgggccacaaca
gcggcctgtacgtggacgaggaggacctgatgaacgccatcaaggacttcagcagcgtgaccaaggagag
gaccaccttcaccgacacccacctg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="8">
<INSDSeq>
<INSDSeq_length>2515</INSDSeq_length>
<INSDSeq_moltype>AA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..2515</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>protein</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q16">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>MNCPVLSLGSGFLFQVIEMLIFAYFASISLTESRGLFPRLENVGAFKKV
SIVPTQAVCGLPDRSTFCHSSAAAESIQFCTQRFCIQDCPYRSSHPTYTALFSAGLSSCITPDKNDLHPN
AHSNSASFIFGNHKSCFSSPPSPKLMASFTLAVWLKPEQQGVMCVIEKTVDGQIVFKLTISEKETMFYYR
TVNGLQPPIKVMTLGRILVKKWIHLSVQVHQTKISFFINGVEKDHTPFNARTLSGSITDFASGTVQIGQS
LNGLEQFVGRMQDFRLYQVALTNREILEVFSGDLLRLHAQSHCRCPGSHPRVHPLAQRYCIPNDAGDTAD
NRVSRLNPEAHPLSFVNDNDVGTSWVSNVFTNITQLNQGVTISVDLENGQYQVFYIIIQFFSPQPTEIRI
QRKKENSLDWEDWQYFARNCGAFGMKNNGDLEKPDSVNCLQLSNFTPYSRGNVTFSILTPGPNYRPGYNN
FYNTPSLQEFVKATQIRFHFHGQYYTTETAVNLRHRYYAVDEITISGRCQCHGHADNCDTTSQPYRCLCS
QESFTEGLHCDRCLPLYNDKPFRQGDQVYAFNCKPCQCNSHSKSCHYNISVDPFPFEHFRGGGGVCDDCE
HNTTGRNCELCKDYFFRQVGADPSAIDVCKPCDCDTVGTRNGSILCDQIGGQCNCKRHVSGRQCNQCQNG
FYNLQELDPDGCSPCNCNTSGTVDGDITCHQNSGQCKCKANVIGLRCDHCNFGFKFLRSFNDVGCEPCQC
NLHGSVNKFCNPHSGQCECKKEAKGLQCDTCRENFYGLDVTNCKACDCDTAGSLPGTVCNAKTGQCICKP
NVEGRQCNKCLEGNFYLRQNNSFLCLPCNCDKTGTINGSLLCNKSTGQCPCKLGVTGLRCNQCEPHRYNL
TIDNFQHCQMCECDSLGTLPGTICDPISGQCLCVPNRQGRRCNQCQPGFYISPGNATGCLPCSCHTTGAV
NHICNSLTGQCVCQDASIAGQRCDQCKDHYFGFDPQTGRCQPCNCHLSGALNETCHLVTGQCFCKQFVTG
SKCDACVPSASHLDVNNLLGCSKTPFQQPPPRGQVQSSSAINLSWSPPDSPNAHWLTYSLLRDGFEIYTT
EDQYPYSIQYFLDTDLLPYTKYSYYIETTNVHGSTRSVAVTYKTKPGVPEGNLTLSYIIPIGSDSVTLTW
TTLSNQSGPIEKYILSCAPLAGGQPCVSYEGHETSATIWNLVPFAKYDFSVQACTSGGCLHSLPITVTTA
QAPPQRLSPPKMQKISSTELHVEWSPPAELNGIIIRYELYMRRLRSTKETTSEESRVFQSSGWLSPHSFV
ESANENALKPPQTMTTITGLEPYTKYEFRVLAVNMAGSVSSAWVSERTGESAPVFMIPPSVFPLSSYSLN
ISWEKPADNVTRGKVVGYDINMLSEQSPQQSIPMAFSQLLHTAKSQELSYTVEGLKPYRIYEFTITLCNS
VGCVTSASGAGQTLAAAPAQLRPPLVKGINSTTIHLRWFPPEELNGPSPIYQLERRESSLPALMTTMMKG
IRFIGNGYCKFPSSTHPVNTDFTGIKASFRTKVPEGLIVFAASPGNQEEYFALQLKKGRLYFLFDPQGSP
VEVTTTNDHGKQYSDGKWHEIIAIRHQAFGQITLDGIYTGSSAILNGSTVIGDNTGVFLGGLPRSYTILR
KDPEIIQKGFVGCLKDVHFMKNYNPSAIWEPLDWQSSEEQINVYNSWEGCPASLNEGAQFLGAGFLELHP
YMFHGGMNFEISFKFRTDQLNGLLLFVYNKDGPDFLAMELKSGILTFRLNTSLAFTQVDLLLGLSYCNGK
WNKVIIKKEGSFISASVNGLMKHASESGDQPLVVNSPVYVGGIPQELLNSYQHLCLEQGFGGCMKDVKFT
RGAVVNLASVSSGAVRVNLDGCLSTDSAVNCRGNDSILVYQGKEQSVYEGGLQPFTEYLYRVIASHEGGS
VYSDWSRGRTTGAAPQSVPTPSRVRSLNGYSIEVTWDEPVVRGVIEKYILKAYSEDSTRPPRMPSASAEF
VNTSNLTGILTGLLPFKNYAVTLTACTLAGCTESSHALNISTPQEAPQEVQPPVAKSLPSSLLLSWNPPK
KANGIITQYCLYMDGRLIYSGSEENYIVTDLAVFTPHQFLLSACTHVGCTNSSWVLLYTAQLPPEHVDSP
VLTVLDSRTIHIQWKQPRKISGILERYVLYMSNHTHDFTIWSVIYNSTELFQDHMLQYVLPGNKYLIKLG
ACTGGGCTVSEASEALTDEDIQKELPQYRAPFSVDSNLSVVCVNWSDTFLLNGQLKEYVLTDGGRRVYSG
LDTTLYIPRTADKTFFFQVICTTDEGSVKTPLIQYDTSTGLGLVLTTPGKKKGSRSKSTEFYSELWFIVL
MAMLGLILLAIFLSLILQRKIHKEPYIRERPPLVPLQKRMSPLNVYPPGENHMGLADTKIPRSGTPVSIR
SNRSACVLRIPSQNQTSLTYSQGSLHRSVSQLMDIQDKKVLMDNSLWEAIMGHNSGLYVDEEDLMNAIKD
FSSVTKERTTFTDTHL</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="9">
<INSDSeq>
<INSDSeq_length>7545</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..7545</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q18">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>atgaactgccccgtgctgagcctgggcagcggcttcctgttccaggtga
tcgagatgctgatcttcgcctacttcgccagcatcagcctgaccgagagcaggggcctgttccccaggct
ggagaacgtgggcgccttcaagaaggtgagcatcgtgcccacccaggccgtgtgcggcctgcccgacagg
agcaccttctgccacagcagcgccgccgccgagagcatccagttctgcacccagaggttctgcatccagg
actgcccctacaggagcagccaccccacctacaccgccctgttcagcgccggcctgagcagctgcatcac
ccccgacaagaacgacctgcaccccaacgcccacagcaacagcgccagcttcatcttcggcaaccacaag
agctgcttcagcagcccccccagccccaagctgatggccagcttcaccctggccgtgtggctgaagcccg
agcagcagggcgtgatgtgcgtgatcgagaagaccgtggacggccagatcgtgttcaagctgaccatcag
cgagaaggagaccatgttctactacaggaccgtgaacggcctgcagccccccatcaaggtgatgaccctg
ggcaggatcctggtgaagaagtggatccacctgagcgtgcaggtgcaccagaccaagatcagcttcttca
tcaacggcgtggagaaggaccacacccccttcaacgccaggaccctgagcggcagcatcaccgacttcgc
cagcggcaccgtgcagatcggccagagcctgaacggcctggagcagttcgtgggcaggatgcaggacttc
aggctgtaccaggtggccctgaccaacagggagatcctggaggtgttcagcggcgacctgctgaggctgc
acgcccagagccactgcaggtgccccggcagccaccccagggtgcaccccctggcccagaggtactgcat
ccccaacgacgccggcgacaccgccgacaacagggtgagcaggctgaaccccgaggcccaccccctgagc
ttcgtgaacgacaacgacgtgggcaccagctgggtgagcaacgtgttcaccaacatcacccagctgaacc
agggcgtgaccatcagcgtggacctggagaacggccagtaccaggtgttctacatcatcatccagttctt
cagcccccagcccaccgagatcaggatccagaggaagaaggagaacagcctggactgggaggactggcag
tacttcgccaggaactgcggcgccttcggcatgaagaacaacggcgacctggagaagcccgacagcgtga
actgcctgcagctgagcaacttcaccccctacagcaggggcaacgtgaccttcagcatcctgacccccgg
ccccaactacaggcccggctacaacaacttctacaacacccccagcctgcaggagttcgtgaaggccacc
cagatcaggttccacttccacggccagtactacaccaccgagaccgccgtgaacctgaggcacaggtact
acgccgtggacgagatcaccatcagcggcaggtgccagtgccacggccacgccgacaactgcgacaccac
cagccagccctacaggtgcctgtgcagccaggagagcttcaccgagggcctgcactgcgacaggtgcctg
cccctgtacaacgacaagcccttcaggcagggcgaccaggtgtacgccttcaactgcaagccctgccagt
gcaacagccacagcaagagctgccactacaacatcagcgtggaccccttccccttcgagcacttcagggg
cggcggcggcgtgtgcgacgactgcgagcacaacaccaccggcaggaactgcgagctgtgcaaggactac
ttcttcaggcaggtgggcgccgaccccagcgccatcgacgtgtgcaagccctgcgactgcgacaccgtgg
gcaccaggaacggcagcatcctgtgcgaccagatcggcggccagtgcaactgcaagaggcacgtgagcgg
caggcagtgcaaccagtgccagaacggcttctacaacctgcaggagctggaccccgacggctgcagcccc
tgcaactgcaacaccagcggcaccgtggacggcgacatcacctgccaccagaacagcggccagtgcaagt
gcaaggccaacgtgatcggcctgaggtgcgaccactgcaacttcggcttcaagttcctgaggagcttcaa
cgacgtgggctgcgagccctgccagtgcaacctgcacggcagcgtgaacaagttctgcaacccccacagc
ggccagtgcgagtgcaagaaggaggccaagggcctgcagtgcgacacctgcagggagaacttctacggcc
tggacgtgaccaactgcaaggcctgcgactgcgacaccgccggcagcctgcccggcaccgtgtgcaacgc
caagaccggccagtgcatctgcaagcccaacgtggagggcaggcagtgcaacaagtgcctggagggcaac
ttctacctgaggcagaacaacagcttcctgtgcctgccctgcaactgcgacaagaccggcaccatcaacg
gcagcctgctgtgcaacaagagcaccggccagtgcccctgcaagctgggcgtgaccggcctgaggtgcaa
ccagtgcgagccccacaggtacaacctgaccatcgacaacttccagcactgccagatgtgcgagtgcgac
agcctgggcaccctgcccggcaccatctgcgaccccatcagcggccagtgcctgtgcgtgcccaacaggc
agggcaggaggtgcaaccagtgccagcccggcttctacatcagccccggcaacgccaccggctgcctgcc
ctgcagctgccacaccaccggcgccgtgaaccacatctgcaacagcctgaccggccagtgcgtgtgccag
gacgccagcatcgccggccagaggtgcgaccagtgcaaggaccactacttcggcttcgacccccagaccg
gcaggtgccagccctgcaactgccacctgagcggcgccctgaacgagacctgccacctggtgaccggcca
gtgcttctgcaagcagttcgtgaccggcagcaagtgcgacgcctgcgtgcccagcgccagccacctggac
gtgaacaacctgctgggctgcagcaagacccccttccagcagcccccccccaggggccaggtgcagagca
gcagcgccatcaacctgagctggagcccccccgacagccccaacgcccactggctgacctacagcctgct
gagggacggcttcgagatctacaccaccgaggaccagtacccctacagcatccagtacttcctggacacc
gacctgctgccctacaccaagtacagctactacatcgagaccaccaacgtgcacggcagcaccaggagcg
tggccgtgacctacaagaccaagcccggcgtgcccgagggcaacctgaccctgagctacatcatccccat
cggcagcgacagcgtgaccctgacctggaccaccctgagcaaccagagcggccccatcgagaagtacatc
ctgagctgcgcccccctggccggcggccagccctgcgtgagctacgagggccacgagaccagcgccacca
tctggaacctggtgcccttcgccaagtacgacttcagcgtgcaggcctgcaccagcggcggctgcctgca
cagcctgcccatcaccgtgaccaccgcccaggcccccccccagaggctgagcccccccaagatgcagaag
atcagcagcaccgagctgcacgtggagtggagcccccccgccgagctgaacggcatcatcatcaggtacg
agctgtacatgaggaggctgaggagcaccaaggagaccaccagcgaggagagcagggtgttccagagcag
cggctggctgagcccccacagcttcgtggagagcgccaacgagaacgccctgaagcccccccagaccatg
accaccatcaccggcctggagccctacaccaagtacgagttcagggtgctggccgtgaacatggccggca
gcgtgagcagcgcctgggtgagcgagaggaccggcgagagcgcccccgtgttcatgatcccccccagcgt
gttccccctgagcagctacagcctgaacatcagctgggagaagcccgccgacaacgtgaccaggggcaag
gtggtgggctacgacatcaacatgctgagcgagcagagcccccagcagagcatccccatggccttcagcc
agctgctgcacaccgccaagagccaggagctgagctacaccgtggagggcctgaagccctacaggatcta
cgagttcaccatcaccctgtgcaacagcgtgggctgcgtgaccagcgccagcggcgccggccagaccctg
gccgccgcccccgcccagctgaggccccccctggtgaagggcatcaacagcaccaccatccacctgaggt
ggttcccccccgaggagctgaacggccccagccccatctaccagctggagaggagggagagcagcctgcc
cgccctgatgaccaccatgatgaagggcatcaggttcatcggcaacggctactgcaagttccccagcagc
acccaccccgtgaacaccgacttcaccggcatcaaggccagcttcaggaccaaggtgcccgagggcctga
tcgtgttcgccgccagccccggcaaccaggaggagtacttcgccctgcagctgaagaagggcaggctgta
cttcctgttcgacccccagggcagccccgtggaggtgaccaccaccaacgaccacggcaagcagtacagc
gacggcaagtggcacgagatcatcgccatcaggcaccaggccttcggccagatcaccctggacggcatct
acaccggcagcagcgccatcctgaacggcagcaccgtgatcggcgacaacaccggcgtgttcctgggcgg
cctgcccaggagctacaccatcctgaggaaggaccccgagatcatccagaagggcttcgtgggctgcctg
aaggacgtgcacttcatgaagaactacaaccccagcgccatctgggagcccctggactggcagagcagcg
aggagcagatcaacgtgtacaacagctgggagggctgccccgccagcctgaacgagggcgcccagttcct
gggcgccggcttcctggagctgcacccctacatgttccacggcggcatgaacttcgagatcagcttcaag
ttcaggaccgaccagctgaacggcctgctgctgttcgtgtacaacaaggacggccccgacttcctggcca
tggagctgaagagcggcatcctgaccttcaggctgaacaccagcctggccttcacccaggtggacctgct
gctgggcctgagctactgcaacggcaagtggaacaaggtgatcatcaagaaggagggcagcttcatcagc
gccagcgtgaacggcctgatgaagcacgccagcgagagcggcgaccagcccctggtggtgaacagccccg
tgtacgtgggcggcatcccccaggagctgctgaacagctaccagcacctgtgcctggagcagggcttcgg
cggctgcatgaaggacgtgaagttcaccaggggcgccgtggtgaacctggccagcgtgagcagcggcgcc
gtgagggtgaacctggacggctgcctgagcaccgacagcgccgtgaactgcaggggcaacgacagcatcc
tggtgtaccagggcaaggagcagagcgtgtacgagggcggcctgcagcccttcaccgagtacctgtacag
ggtgatcgccagccacgagggcggcagcgtgtacagcgactggagcaggggcaggaccaccggcgccgcc
ccccagagcgtgcccacccccagcagggtgaggagcctgaacggctacagcatcgaggtgacctgggacg
agcccgtggtgaggggcgtgatcgagaagtacatcctgaaggcctacagcgaggacagcaccaggccccc
caggatgcccagcgccagcgccgagttcgtgaacaccagcaacctgaccggcatcctgaccggcctgctg
cccttcaagaactacgccgtgaccctgaccgcctgcaccctggccggctgcaccgagagcagccacgccc
tgaacatcagcaccccccaggaggccccccaggaggtgcagccccccgtggccaagagcctgcccagcag
cctgctgctgagctggaacccccccaagaaggccaacggcatcatcacccagtactgcctgtacatggac
ggcaggctgatctacagcggcagcgaggagaactacatcgtgaccgacctggccgtgttcaccccccacc
agttcctgctgagcgcctgcacccacgtgggctgcaccaacagcagctgggtgctgctgtacaccgccca
gctgccccccgagcacgtggacagccccgtgctgaccgtgctggacagcaggaccatccacatccagtgg
aagcagcccaggaagatcagcggcatcctggagaggtacgtgctgtacatgagcaaccacacccacgact
tcaccatctggagcgtgatctacaacagcaccgagctgttccaggaccacatgctgcagtacgtgctgcc
cggcaacaagtacctgatcaagctgggcgcctgcaccggcggcggctgcaccgtgagcgaggccagcgag
gccctgaccgacgaggacatccagaaggagctgccccagtacagggcccccttcagcgtggacagcaacc
tgagcgtggtgtgcgtgaactggagcgacaccttcctgctgaacggccagctgaaggagtacgtgctgac
cgacggcggcaggagggtgtacagcggcctggacaccaccctgtacatccccaggaccgccgacaagacc
ttcttcttccaggtgatctgcaccaccgacgagggcagcgtgaagacccccctgatccagtacgacacca
gcaccggcctgggcctggtgctgaccacccccggcaagaagaagggcagcaggagcaagagcaccgagtt
ctacagcgagctgtggttcatcgtgctgatggccatgctgggcctgatcctgctggccatcttcctgagc
ctgatcctgcagaggaagatccacaaggagccctacatcagggagaggccccccctggtgcccctgcaga
agaggatgagccccctgaacgtgtacccccccggcgagaaccacatgggcctggccgacaccaagatccc
caggagcggcacccccgtgagcatcaggagcaacaggagcgcctgcgtgctgaggatccccagccagaac
cagaccagcctgacctacagccagggcagcctgcacaggagcgtgagccagctgatggacatccaggaca
agaaggtgctgatggacaacagcctgtgggaggccatcatgggccacaacagcggcctgtacgtggacga
ggaggacctgatgaacgccatcaaggacttcagcagcgtgaccaaggagaggaccaccttcaccgacacc
cacctg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="10">
<INSDSeq>
<INSDSeq_length>1805</INSDSeq_length>
<INSDSeq_moltype>AA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..1805</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>protein</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q20">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>MNCPVLSLGSGFLFQVIEMLIFAYFASISLTESRGLFPRLENVGAFKKV
SIVPTQAVCGLPDRSTFCHSSAAAESIQFCTQRFCIQDCPYRSSHPTYTALFSAGLSSCITPDKNDLHPN
AHSNSASFIFGNHKSCFSSPPSPKLMASFTLAVWLKPEQQGVMCVIEKTVDGQIVFKLTISEKETMFYYR
TVNGLQPPIKVMTLGRILVKKWIHLSVQVHQTKISFFINGVEKDHTPFNARTLSGSITDFASGTVQIGQS
LNGLEQFVGRMQDFRLYQVALTNREILEVFSPCNCHLSGALNETCHLVTGQCFCKQFVTGSKCDACVPSA
SHLDVNNLLGCSKTPFQQPPPRGQVQSSSAINLSWSPPDSPNAHWLTYSLLRDGFEIYTTEDQYPYSIQY
FLDTDLLPYTKYSYYIETTNVHGSTRSVAVTYKTKPGVPEGNLTLSYIIPIGSDSVTLTWTTLSNQSGPI
EKYILSCAPLAGGQPCVSYEGHETSATIWNLVPFAKYDFSVQACTSGGCLHSLPITVTTAQAPPQRLSPP
KMQKISSTELHVEWSPPAELNGIIIRYELYMRRLRSTKETTSEESRVFQSSGWLSPHSFVESANENALKP
PQTMTTITGLEPYTKYEFRVLAVNMAGSVSSAWVSERTGESAPVFMIPPSVFPLSSYSLNISWEKPADNV
TRGKVVGYDINMLSEQSPQQSIPMAFSQLLHTAKSQELSYTVEGLKPYRIYEFTITLCNSVGCVTSASGA
GQTLAAAPAQLRPPLVKGINSTTIHLRWFPPEELNGPSPIYQLERRESSLPALMTTMMKGIRFIGNGYCK
FPSSTHPVNTDFTGIKASFRTKVPEGLIVFAASPGNQEEYFALQLKKGRLYFLFDPQGSPVEVTTTNDHG
KQYSDGKWHEIIAIRHQAFGQITLDGIYTGSSAILNGSTVIGDNTGVFLGGLPRSYTILRKDPEIIQKGF
VGCLKDVHFMKNYNPSAIWEPLDWQSSEEQINVYNSWEGCPASLNEGAQFLGAGFLELHPYMFHGGMNFE
ISFKFRTDQLNGLLLFVYNKDGPDFLAMELKSGILTFRLNTSLAFTQVDLLLGLSYCNGKWNKVIIKKEG
SFISASVNGLMKHASESGDQPLVVNSPVYVGGIPQELLNSYQHLCLEQGFGGCMKDVKFTRGAVVNLASV
SSGAVRVNLDGCLSTDSAVNCRGNDSILVYQGKEQSVYEGGLQPFTEYLYRVIASHEGGSVYSDWSRGRT
TGAAPQSVPTPSRVRSLNGYSIEVTWDEPVVRGVIEKYILKAYSEDSTRPPRMPSASAEFVNTSNLTGIL
TGLLPFKNYAVTLTACTLAGCTESSHALNISTPQEAPQEVQPPVAKSLPSSLLLSWNPPKKANGIITQYC
LYMDGRLIYSGSEENYIVTDLAVFTPHQFLLSACTHVGCTNSSWVLLYTAQLPPEHVDSPVLTVLDSRTI
HIQWKQPRKISGILERYVLYMSNHTHDFTIWSVIYNSTELFQDHMLQYVLPGNKYLIKLGACTGGGCTVS
EASEALTDEDIQKELPQYRAPFSVDSNLSVVCVNWSDTFLLNGQLKEYVLTDGGRRVYSGLDTTLYIPRT
ADKTFFFQVICTTDEGSVKTPLIQYDTSTGLGLVLTTPGKKKGSRSKSTEFYSELWFIVLMAMLGLILLA
IFLSLILQRKIHKEPYIRERPPLVPLQKRMSPLNVYPPGENHMGLADTKIPRSGTPVSIRSNRSACVLRI
PSQNQTSLTYSQGSLHRSVSQLMDIQDKKVLMDNSLWEAIMGHNSGLYVDEEDLMNAIKDFSSVTKERTT
FTDTHL</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="11">
<INSDSeq>
<INSDSeq_length>5415</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..5415</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q22">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>atgaactgccccgtgctgagcctgggcagcggcttcctgttccaggtga
tcgagatgctgatcttcgcctacttcgccagcatcagcctgaccgagagcaggggcctgttccccaggct
ggagaacgtgggcgccttcaagaaggtgagcatcgtgcccacccaggccgtgtgcggcctgcccgacagg
agcaccttctgccacagcagcgccgccgccgagagcatccagttctgcacccagaggttctgcatccagg
actgcccctacaggagcagccaccccacctacaccgccctgttcagcgccggcctgagcagctgcatcac
ccccgacaagaacgacctgcaccccaacgcccacagcaacagcgccagcttcatcttcggcaaccacaag
agctgcttcagcagcccccccagccccaagctgatggccagcttcaccctggccgtgtggctgaagcccg
agcagcagggcgtgatgtgcgtgatcgagaagaccgtggacggccagatcgtgttcaagctgaccatcag
cgagaaggagaccatgttctactacaggaccgtgaacggcctgcagccccccatcaaggtgatgaccctg
ggcaggatcctggtgaagaagtggatccacctgagcgtgcaggtgcaccagaccaagatcagcttcttca
tcaacggcgtggagaaggaccacacccccttcaacgccaggaccctgagcggcagcatcaccgacttcgc
cagcggcaccgtgcagatcggccagagcctgaacggcctggagcagttcgtgggcaggatgcaggacttc
aggctgtaccaggtggccctgaccaacagggagatcctggaggtgttcagcccctgcaactgccacctga
gcggcgccctgaacgagacctgccacctggtgaccggccagtgcttctgcaagcagttcgtgaccggcag
caagtgcgacgcctgcgtgcccagcgccagccacctggacgtgaacaacctgctgggctgcagcaagacc
cccttccagcagcccccccccaggggccaggtgcagagcagcagcgccatcaacctgagctggagccccc
ccgacagccccaacgcccactggctgacctacagcctgctgagggacggcttcgagatctacaccaccga
ggaccagtacccctacagcatccagtacttcctggacaccgacctgctgccctacaccaagtacagctac
tacatcgagaccaccaacgtgcacggcagcaccaggagcgtggccgtgacctacaagaccaagcccggcg
tgcccgagggcaacctgaccctgagctacatcatccccatcggcagcgacagcgtgaccctgacctggac
caccctgagcaaccagagcggccccatcgagaagtacatcctgagctgcgcccccctggccggcggccag
ccctgcgtgagctacgagggccacgagaccagcgccaccatctggaacctggtgcccttcgccaagtacg
acttcagcgtgcaggcctgcaccagcggcggctgcctgcacagcctgcccatcaccgtgaccaccgccca
ggcccccccccagaggctgagcccccccaagatgcagaagatcagcagcaccgagctgcacgtggagtgg
agcccccccgccgagctgaacggcatcatcatcaggtacgagctgtacatgaggaggctgaggagcacca
aggagaccaccagcgaggagagcagggtgttccagagcagcggctggctgagcccccacagcttcgtgga
gagcgccaacgagaacgccctgaagcccccccagaccatgaccaccatcaccggcctggagccctacacc
aagtacgagttcagggtgctggccgtgaacatggccggcagcgtgagcagcgcctgggtgagcgagagga
ccggcgagagcgcccccgtgttcatgatcccccccagcgtgttccccctgagcagctacagcctgaacat
cagctgggagaagcccgccgacaacgtgaccaggggcaaggtggtgggctacgacatcaacatgctgagc
gagcagagcccccagcagagcatccccatggccttcagccagctgctgcacaccgccaagagccaggagc
tgagctacaccgtggagggcctgaagccctacaggatctacgagttcaccatcaccctgtgcaacagcgt
gggctgcgtgaccagcgccagcggcgccggccagaccctggccgccgcccccgcccagctgaggcccccc
ctggtgaagggcatcaacagcaccaccatccacctgaggtggttcccccccgaggagctgaacggcccca
gccccatctaccagctggagaggagggagagcagcctgcccgccctgatgaccaccatgatgaagggcat
caggttcatcggcaacggctactgcaagttccccagcagcacccaccccgtgaacaccgacttcaccggc
atcaaggccagcttcaggaccaaggtgcccgagggcctgatcgtgttcgccgccagccccggcaaccagg
aggagtacttcgccctgcagctgaagaagggcaggctgtacttcctgttcgacccccagggcagccccgt
ggaggtgaccaccaccaacgaccacggcaagcagtacagcgacggcaagtggcacgagatcatcgccatc
aggcaccaggccttcggccagatcaccctggacggcatctacaccggcagcagcgccatcctgaacggca
gcaccgtgatcggcgacaacaccggcgtgttcctgggcggcctgcccaggagctacaccatcctgaggaa
ggaccccgagatcatccagaagggcttcgtgggctgcctgaaggacgtgcacttcatgaagaactacaac
cccagcgccatctgggagcccctggactggcagagcagcgaggagcagatcaacgtgtacaacagctggg
agggctgccccgccagcctgaacgagggcgcccagttcctgggcgccggcttcctggagctgcaccccta
catgttccacggcggcatgaacttcgagatcagcttcaagttcaggaccgaccagctgaacggcctgctg
ctgttcgtgtacaacaaggacggccccgacttcctggccatggagctgaagagcggcatcctgaccttca
ggctgaacaccagcctggccttcacccaggtggacctgctgctgggcctgagctactgcaacggcaagtg
gaacaaggtgatcatcaagaaggagggcagcttcatcagcgccagcgtgaacggcctgatgaagcacgcc
agcgagagcggcgaccagcccctggtggtgaacagccccgtgtacgtgggcggcatcccccaggagctgc
tgaacagctaccagcacctgtgcctggagcagggcttcggcggctgcatgaaggacgtgaagttcaccag
gggcgccgtggtgaacctggccagcgtgagcagcggcgccgtgagggtgaacctggacggctgcctgagc
accgacagcgccgtgaactgcaggggcaacgacagcatcctggtgtaccagggcaaggagcagagcgtgt
acgagggcggcctgcagcccttcaccgagtacctgtacagggtgatcgccagccacgagggcggcagcgt
gtacagcgactggagcaggggcaggaccaccggcgccgccccccagagcgtgcccacccccagcagggtg
aggagcctgaacggctacagcatcgaggtgacctgggacgagcccgtggtgaggggcgtgatcgagaagt
acatcctgaaggcctacagcgaggacagcaccaggccccccaggatgcccagcgccagcgccgagttcgt
gaacaccagcaacctgaccggcatcctgaccggcctgctgcccttcaagaactacgccgtgaccctgacc
gcctgcaccctggccggctgcaccgagagcagccacgccctgaacatcagcaccccccaggaggcccccc
aggaggtgcagccccccgtggccaagagcctgcccagcagcctgctgctgagctggaacccccccaagaa
ggccaacggcatcatcacccagtactgcctgtacatggacggcaggctgatctacagcggcagcgaggag
aactacatcgtgaccgacctggccgtgttcaccccccaccagttcctgctgagcgcctgcacccacgtgg
gctgcaccaacagcagctgggtgctgctgtacaccgcccagctgccccccgagcacgtggacagccccgt
gctgaccgtgctggacagcaggaccatccacatccagtggaagcagcccaggaagatcagcggcatcctg
gagaggtacgtgctgtacatgagcaaccacacccacgacttcaccatctggagcgtgatctacaacagca
ccgagctgttccaggaccacatgctgcagtacgtgctgcccggcaacaagtacctgatcaagctgggcgc
ctgcaccggcggcggctgcaccgtgagcgaggccagcgaggccctgaccgacgaggacatccagaaggag
ctgccccagtacagggcccccttcagcgtggacagcaacctgagcgtggtgtgcgtgaactggagcgaca
ccttcctgctgaacggccagctgaaggagtacgtgctgaccgacggcggcaggagggtgtacagcggcct
ggacaccaccctgtacatccccaggaccgccgacaagaccttcttcttccaggtgatctgcaccaccgac
gagggcagcgtgaagacccccctgatccagtacgacaccagcaccggcctgggcctggtgctgaccaccc
ccggcaagaagaagggcagcaggagcaagagcaccgagttctacagcgagctgtggttcatcgtgctgat
ggccatgctgggcctgatcctgctggccatcttcctgagcctgatcctgcagaggaagatccacaaggag
ccctacatcagggagaggccccccctggtgcccctgcagaagaggatgagccccctgaacgtgtaccccc
ccggcgagaaccacatgggcctggccgacaccaagatccccaggagcggcacccccgtgagcatcaggag
caacaggagcgcctgcgtgctgaggatccccagccagaaccagaccagcctgacctacagccagggcagc
ctgcacaggagcgtgagccagctgatggacatccaggacaagaaggtgctgatggacaacagcctgtggg
aggccatcatgggccacaacagcggcctgtacgtggacgaggaggacctgatgaacgccatcaaggactt
cagcagcgtgaccaaggagaggaccaccttcaccgacacccacctg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="12">
<INSDSeq>
<INSDSeq_length>1621</INSDSeq_length>
<INSDSeq_moltype>AA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..1621</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>protein</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q24">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>MNCPVLSLGSGFLFQVIEMLIFAYFASISLTESRGLFPRLENVGAFKKV
SIVPTQAVCGLPDRSTFCHSSAAAESIQFCTQRFCIQDCPYRSSHPTYTALFSAGLSSCITPDKNDLHPN
AHSNSASFIFGNHKSCFSSPPSPKLMASFTLAVWLKPEQQGVMCVIETEGLHCDRCLPLYNDKPFRQGDQ
VYAFNCKPCQCNSHSKSCHYNISVDPFPFEHFRGGGGVCDDCEHNTTGRNCELCKDYFFRQVGADPSAID
VCKPCDCDTVGTRNGSILCDQIGGQCNCKRHVSGRQCNQCQNGFYNLQELDPDGCSPCNCNTSGTVDGDI
TCHQNSGQCKCKANVIGLRCDHCNFGFKFLRSFNDVGCEPCQCNLHGSVNKFCNPHSGQCECKKEAKGLQ
CDTCRENFYGLDVTNCKACDCDTAGSLPGTVCNAKTGQCICKPNVEGRQCNKCLEGNFYLRQNNSFLCLP
CNCDKTGTINGSLLCNKSTGQCPCKLGVTGLRCNQCEPHRYNLTIDNFQHCQMCECDSLGTLPGTICDPI
SGQCLCVPNRQGRRCNQCQPGFYISPGNATGCLPCSCHTTGAVNHICNSLTGQCVCQDASIAGQRCDQCK
DHYFGFDPQTGRCQPCNCHLSGALNETCHLVTGQCFCKQFVTGSKCDACVPSASHLDVNNLLGCSKTPFQ
QPPPRGQVQSSSAINLSWSPPDSPNAHWLTYSLLRDGFEIYTTEDQYPYSIQYFLDTDLLPYTKYSYYIE
TTNVHGSTRSVAVTYKTKPGVPEGNLTLSYIIPIGSDSVTLTWTTLSNQSGPIEKYILSCAPLAGGQPCV
SYEGHETSATIWNLVPFAKYDFSVQACTSGGCLHSLPITVTTAQAPPQRLSPPKMQKISSTELHVEWSPP
AELNGIIIRYELYMRRLRSTKETTSEESRVFQSSGWLSPHSFVESANENALKPPQTMTTITGLEPYTKYE
FRVLAVNMAGSVSSAWVSERTGESAPVFMIPPSVFPLSSYSLNISWEKPADNVTRGKVVGYDINMLSEQS
PQQSIPMAFSQLLHTAKSQELSYTVEGLKPYRIYEFTITLCNSVGCVTSASGAGQTLAAAPAQLRPPLVK
GINSTTIHLRWFPPEELNGPSPIYQLERRESSLPALMTTMMKGIRFIGNGYCKFPSSTHPVNTDFTGIKA
SFRTKVPEGLIVFAASPGNQEEYFALQLKKGRLYFLFDPQGSPVEVTTTNDHGKQYSDGKWHEIIAIRHQ
AFGQITLDGIYTGSSAILNGSTVIGDNTGVFLGGLPRSYTILRKDPEIIQKGFVGCLKDVHFMKNYNPSA
IWEPLDWQSSEEQINVYNSWEGCPASLNEGAQFLGAGFLELHPYMFHGGMNFEISFKFRTDQLNGLLLFV
YNKDGPDFLAMELKSGILTFRLNTSLAFTQVDLLLGLSYCNGKWNKVIIKKEGSFISASVNGLMKHASES
GDQPLVVNSPVYVGGIPQELLNSYQHLCLEQGFGGCMKDVKFTRGAVVNLASVSSGAVRVNLDGCLSTDS
AVNCRGNDSILVYQGKEQSVYEGGLQPFTEYLYRVIASHEGGSVYSDWSRGRTTGAAPQNSLWEAIMGHN
SGLYVDEEDLMNAIKDFSSVTKERTTFTDTHL</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="13">
<INSDSeq>
<INSDSeq_length>4863</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..4863</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q26">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>atgaactgccccgtgctgagcctgggcagcggcttcctgttccaggtga
tcgagatgctgatcttcgcctacttcgccagcatcagcctgaccgagagcaggggcctgttccccaggct
ggagaacgtgggcgccttcaagaaggtgagcatcgtgcccacccaggccgtgtgcggcctgcccgacagg
agcaccttctgccacagcagcgccgccgccgagagcatccagttctgcacccagaggttctgcatccagg
actgcccctacaggagcagccaccccacctacaccgccctgttcagcgccggcctgagcagctgcatcac
ccccgacaagaacgacctgcaccccaacgcccacagcaacagcgccagcttcatcttcggcaaccacaag
agctgcttcagcagcccccccagccccaagctgatggccagcttcaccctggccgtgtggctgaagcccg
agcagcagggcgtgatgtgcgtgatcgagaccgagggcctgcactgcgacaggtgcctgcccctgtacaa
cgacaagcccttcaggcagggcgaccaggtgtacgccttcaactgcaagccctgccagtgcaacagccac
agcaagagctgccactacaacatcagcgtggaccccttccccttcgagcacttcaggggcggcggcggcg
tgtgcgacgactgcgagcacaacaccaccggcaggaactgcgagctgtgcaaggactacttcttcaggca
ggtgggcgccgaccccagcgccatcgacgtgtgcaagccctgcgactgcgacaccgtgggcaccaggaac
ggcagcatcctgtgcgaccagatcggcggccagtgcaactgcaagaggcacgtgagcggcaggcagtgca
accagtgccagaacggcttctacaacctgcaggagctggaccccgacggctgcagcccctgcaactgcaa
caccagcggcaccgtggacggcgacatcacctgccaccagaacagcggccagtgcaagtgcaaggccaac
gtgatcggcctgaggtgcgaccactgcaacttcggcttcaagttcctgaggagcttcaacgacgtgggct
gcgagccctgccagtgcaacctgcacggcagcgtgaacaagttctgcaacccccacagcggccagtgcga
gtgcaagaaggaggccaagggcctgcagtgcgacacctgcagggagaacttctacggcctggacgtgacc
aactgcaaggcctgcgactgcgacaccgccggcagcctgcccggcaccgtgtgcaacgccaagaccggcc
agtgcatctgcaagcccaacgtggagggcaggcagtgcaacaagtgcctggagggcaacttctacctgag
gcagaacaacagcttcctgtgcctgccctgcaactgcgacaagaccggcaccatcaacggcagcctgctg
tgcaacaagagcaccggccagtgcccctgcaagctgggcgtgaccggcctgaggtgcaaccagtgcgagc
cccacaggtacaacctgaccatcgacaacttccagcactgccagatgtgcgagtgcgacagcctgggcac
cctgcccggcaccatctgcgaccccatcagcggccagtgcctgtgcgtgcccaacaggcagggcaggagg
tgcaaccagtgccagcccggcttctacatcagccccggcaacgccaccggctgcctgccctgcagctgcc
acaccaccggcgccgtgaaccacatctgcaacagcctgaccggccagtgcgtgtgccaggacgccagcat
cgccggccagaggtgcgaccagtgcaaggaccactacttcggcttcgacccccagaccggcaggtgccag
ccctgcaactgccacctgagcggcgccctgaacgagacctgccacctggtgaccggccagtgcttctgca
agcagttcgtgaccggcagcaagtgcgacgcctgcgtgcccagcgccagccacctggacgtgaacaacct
gctgggctgcagcaagacccccttccagcagcccccccccaggggccaggtgcagagcagcagcgccatc
aacctgagctggagcccccccgacagccccaacgcccactggctgacctacagcctgctgagggacggct
tcgagatctacaccaccgaggaccagtacccctacagcatccagtacttcctggacaccgacctgctgcc
ctacaccaagtacagctactacatcgagaccaccaacgtgcacggcagcaccaggagcgtggccgtgacc
tacaagaccaagcccggcgtgcccgagggcaacctgaccctgagctacatcatccccatcggcagcgaca
gcgtgaccctgacctggaccaccctgagcaaccagagcggccccatcgagaagtacatcctgagctgcgc
ccccctggccggcggccagccctgcgtgagctacgagggccacgagaccagcgccaccatctggaacctg
gtgcccttcgccaagtacgacttcagcgtgcaggcctgcaccagcggcggctgcctgcacagcctgccca
tcaccgtgaccaccgcccaggcccccccccagaggctgagcccccccaagatgcagaagatcagcagcac
cgagctgcacgtggagtggagcccccccgccgagctgaacggcatcatcatcaggtacgagctgtacatg
aggaggctgaggagcaccaaggagaccaccagcgaggagagcagggtgttccagagcagcggctggctga
gcccccacagcttcgtggagagcgccaacgagaacgccctgaagcccccccagaccatgaccaccatcac
cggcctggagccctacaccaagtacgagttcagggtgctggccgtgaacatggccggcagcgtgagcagc
gcctgggtgagcgagaggaccggcgagagcgcccccgtgttcatgatcccccccagcgtgttccccctga
gcagctacagcctgaacatcagctgggagaagcccgccgacaacgtgaccaggggcaaggtggtgggcta
cgacatcaacatgctgagcgagcagagcccccagcagagcatccccatggccttcagccagctgctgcac
accgccaagagccaggagctgagctacaccgtggagggcctgaagccctacaggatctacgagttcacca
tcaccctgtgcaacagcgtgggctgcgtgaccagcgccagcggcgccggccagaccctggccgccgcccc
cgcccagctgaggccccccctggtgaagggcatcaacagcaccaccatccacctgaggtggttccccccc
gaggagctgaacggccccagccccatctaccagctggagaggagggagagcagcctgcccgccctgatga
ccaccatgatgaagggcatcaggttcatcggcaacggctactgcaagttccccagcagcacccaccccgt
gaacaccgacttcaccggcatcaaggccagcttcaggaccaaggtgcccgagggcctgatcgtgttcgcc
gccagccccggcaaccaggaggagtacttcgccctgcagctgaagaagggcaggctgtacttcctgttcg
acccccagggcagccccgtggaggtgaccaccaccaacgaccacggcaagcagtacagcgacggcaagtg
gcacgagatcatcgccatcaggcaccaggccttcggccagatcaccctggacggcatctacaccggcagc
agcgccatcctgaacggcagcaccgtgatcggcgacaacaccggcgtgttcctgggcggcctgcccagga
gctacaccatcctgaggaaggaccccgagatcatccagaagggcttcgtgggctgcctgaaggacgtgca
cttcatgaagaactacaaccccagcgccatctgggagcccctggactggcagagcagcgaggagcagatc
aacgtgtacaacagctgggagggctgccccgccagcctgaacgagggcgcccagttcctgggcgccggct
tcctggagctgcacccctacatgttccacggcggcatgaacttcgagatcagcttcaagttcaggaccga
ccagctgaacggcctgctgctgttcgtgtacaacaaggacggccccgacttcctggccatggagctgaag
agcggcatcctgaccttcaggctgaacaccagcctggccttcacccaggtggacctgctgctgggcctga
gctactgcaacggcaagtggaacaaggtgatcatcaagaaggagggcagcttcatcagcgccagcgtgaa
cggcctgatgaagcacgccagcgagagcggcgaccagcccctggtggtgaacagccccgtgtacgtgggc
ggcatcccccaggagctgctgaacagctaccagcacctgtgcctggagcagggcttcggcggctgcatga
aggacgtgaagttcaccaggggcgccgtggtgaacctggccagcgtgagcagcggcgccgtgagggtgaa
cctggacggctgcctgagcaccgacagcgccgtgaactgcaggggcaacgacagcatcctggtgtaccag
ggcaaggagcagagcgtgtacgagggcggcctgcagcccttcaccgagtacctgtacagggtgatcgcca
gccacgagggcggcagcgtgtacagcgactggagcaggggcaggaccaccggcgccgccccccagaacag
cctgtgggaggccatcatgggccacaacagcggcctgtacgtggacgaggaggacctgatgaacgccatc
aaggacttcagcagcgtgaccaaggagaggaccaccttcaccgacacccacctg</INSDSeq_sequen
ce>
</INSDSeq>
</SequenceData>
</ST26SequenceListing>
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| Кодон-оптимизированная последовательность нуклеотидов, кодирующая hAIPL1, и её содержащий экспрессионный вектор | 2021 |
|
RU2785621C1 |
| Пептид митохондриальной локализации, нуклеиновая кислота для аллотопической экспрессии гена MT-ND4, содержащий ее экспрессионный вектор и его применение | 2023 |
|
RU2817420C1 |
| Нуклеиновая кислота для аллотопической экспрессии гена MT-ND4 | 2023 |
|
RU2809065C1 |
| АДЕНОАССОЦИИРОВАННЫЙ ВИРУСНЫЙ ВЕКТОР, СОСТОЯЩИЙ ИЗ БЕЛКОВ КАПСИДА РНР.В, НУКЛЕИНОВОЙ КИСЛОТЫ, КОДИРУЮЩЕЙ БЕЛОК SMN, И ЕГО ПРИМЕНЕНИЕ | 2022 |
|
RU2833225C2 |
| Нуклеиновая кислота, предназначенная для снижения массы тела млекопитающего, экспрессионный вектор для экспрессии в клетках млекопитающего, способ его доставки и способ снижения массы тела млекопитающего | 2023 |
|
RU2810191C1 |
| F-БЕЛОК РЕСПИРАТОРНО-СИНЦИТИАЛЬНОГО ВИРУСА И ЕГО ПРИМЕНЕНИЕ | 2007 |
|
RU2464316C2 |
| Кодон-оптимизированная нуклеиновая кислота, которая кодирует белок SMN1, и ее применение | 2020 |
|
RU2742837C1 |
| ГЕННАЯ ТЕРАПИЯ ОФТАЛЬМОЛОГИЧЕСКИХ НАРУШЕНИЙ | 2016 |
|
RU2762747C2 |
| Нуклеиновая кислота, содержащая последовательность гена PRDM16, предназначенная для снижения массы тела млекопитающего, экспрессионный вектор для экспрессии в клетках млекопитающего, способ его доставки и способ снижения массы тела млекопитающего | 2024 |
|
RU2834035C1 |
| Нуклеиновая кислота, имеющая промоторную активность, и ее применение | 2022 |
|
RU2818112C2 |
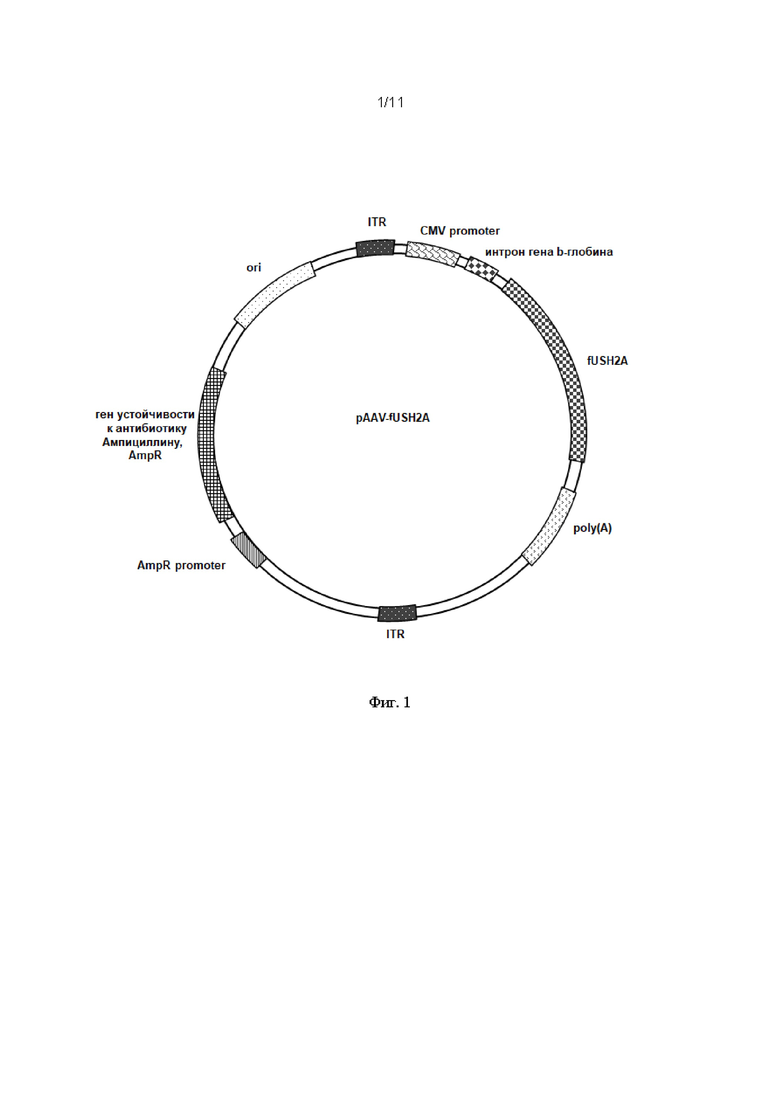

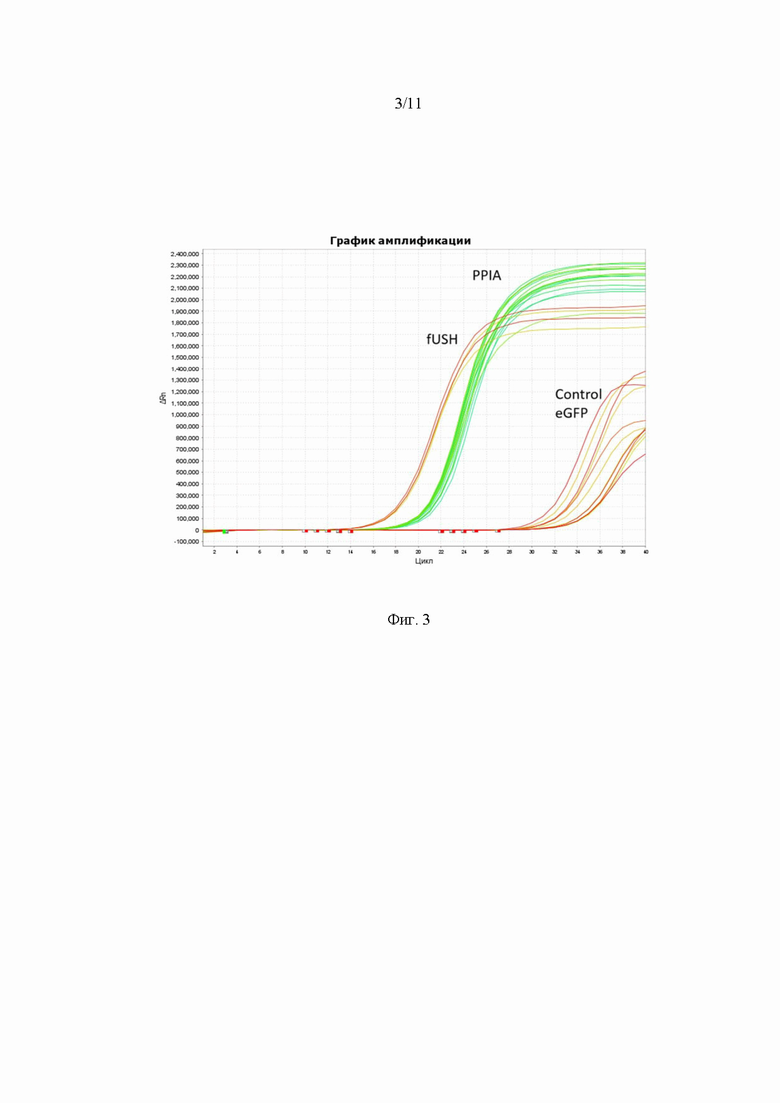
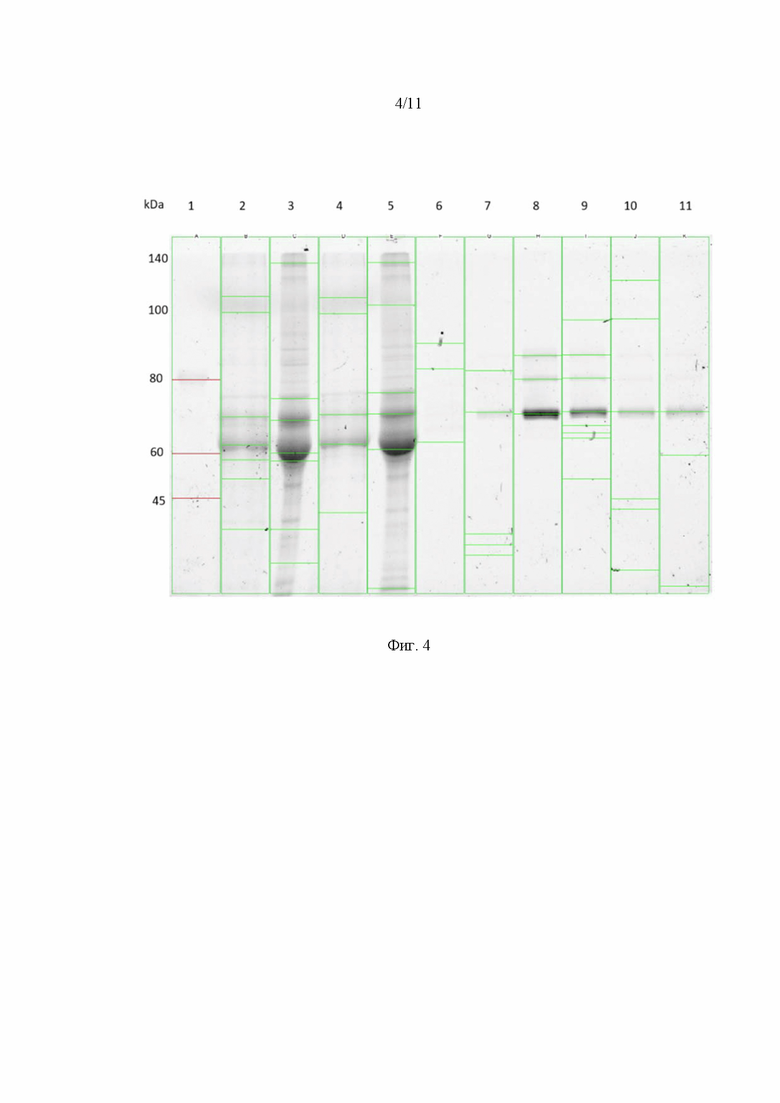
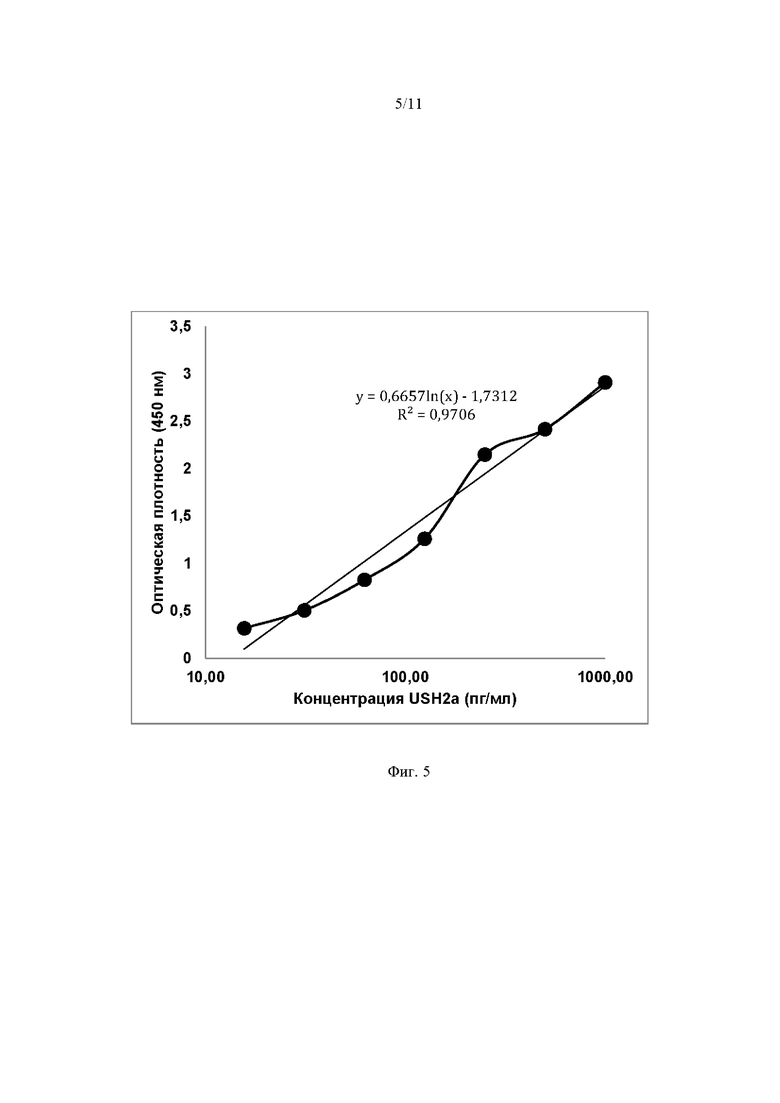
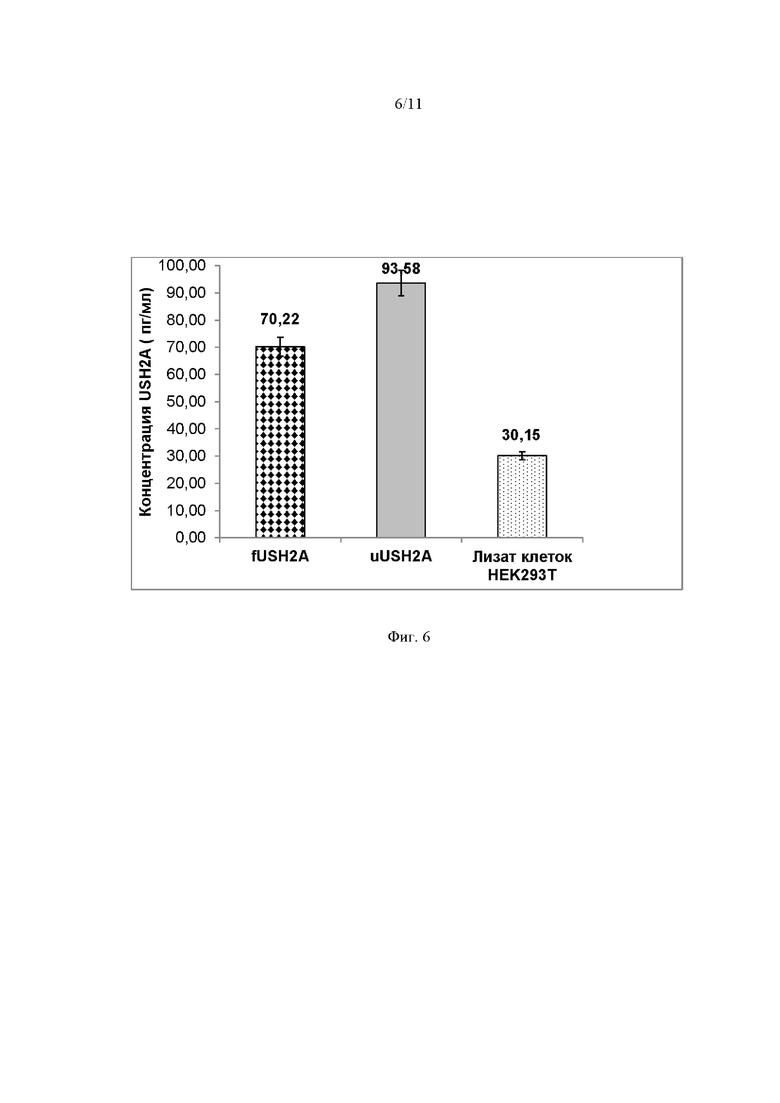
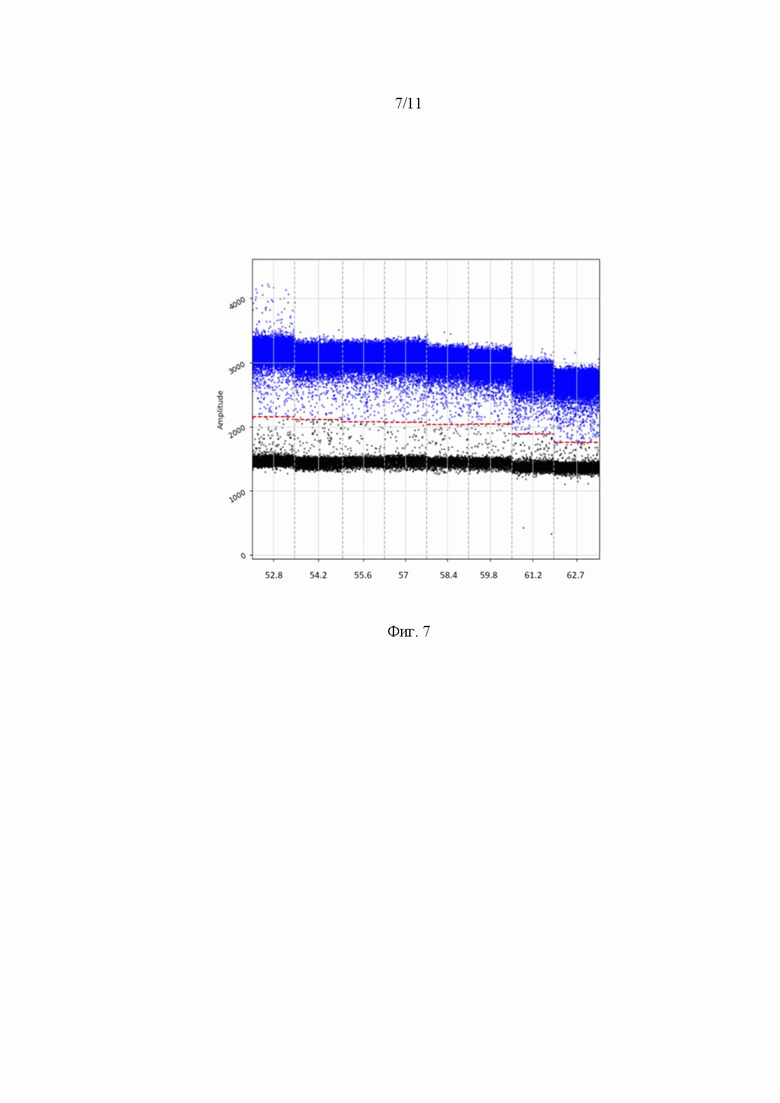
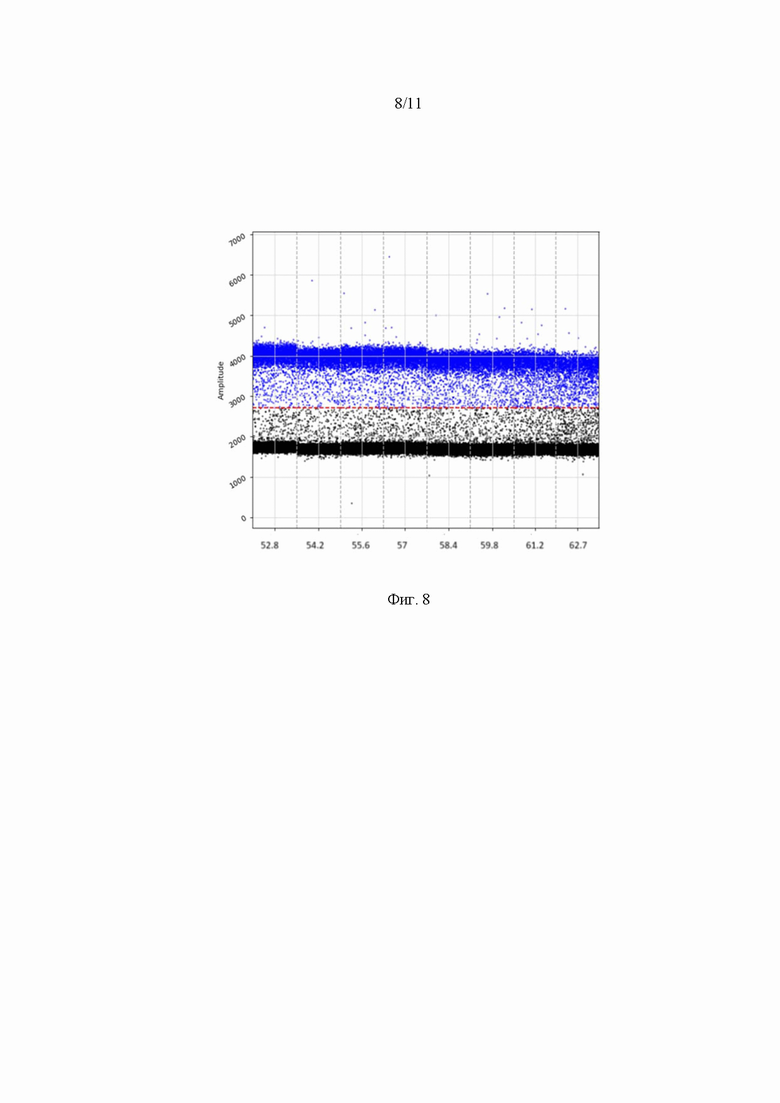
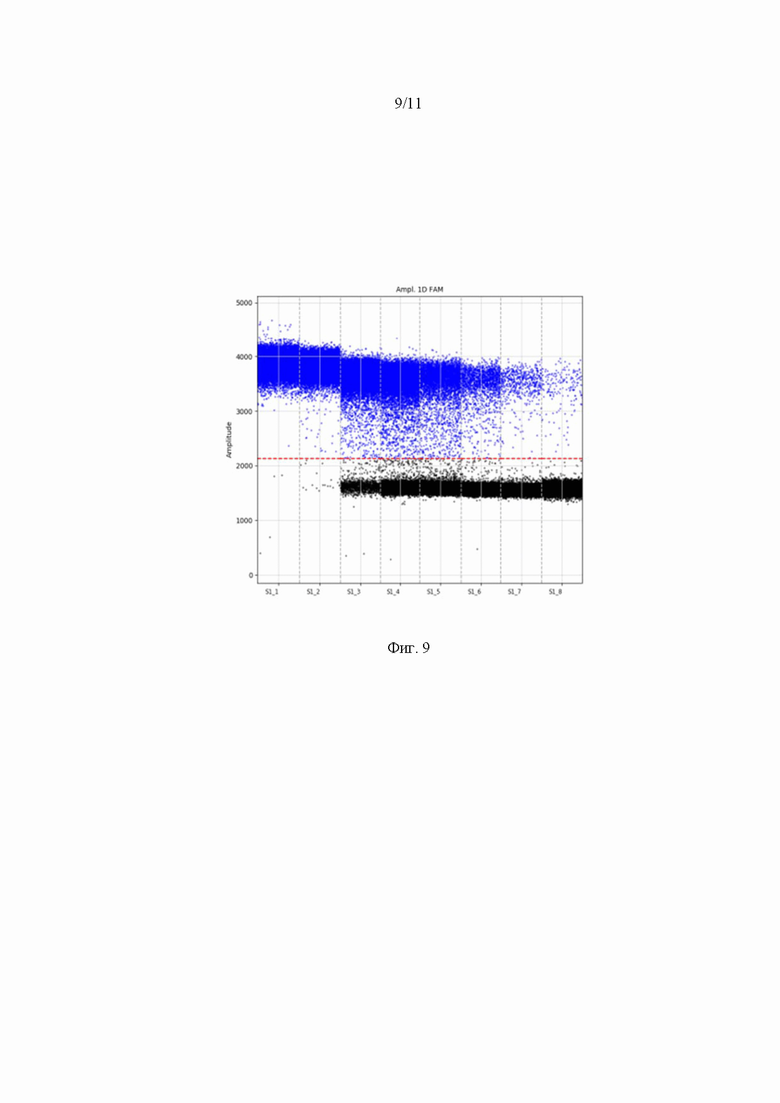
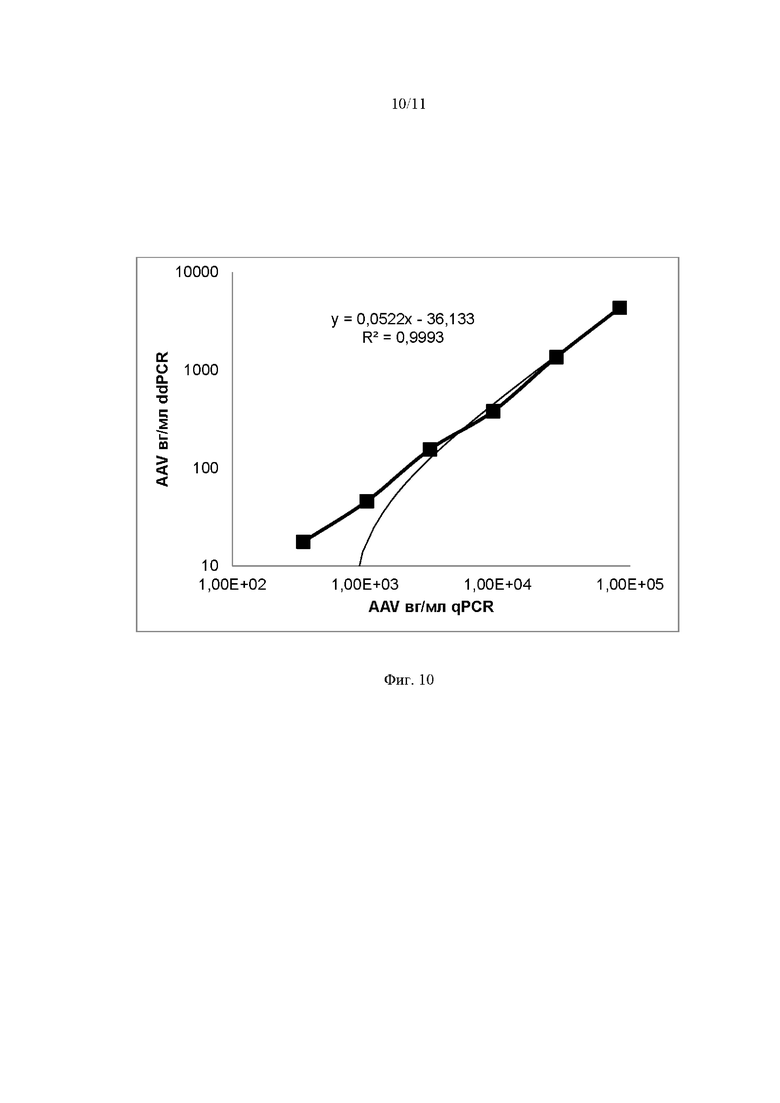

Настоящее изобретение относится к области биотехнологии, а именно к мини-белку USH2A, который при небольшом размере, позволяющем осуществлять доставку в составе вирусных векторов, сохраняет домены полноразмерного белка LamGL, LamNT, EGF Lam, FN3 и PDZ-связывающий мотив, необходимые для функционирования белка USH2A. Также раскрыты нуклеиновая кислота, кодирующая мини-белок USH2A, экспрессионный вектор и применение указанного вектора в генной терапии синдрома Ашера II типа. Изобретение эффективно для стабильной и высокой экспрессии мини-белка USH2A. 4 н. и 9 з.п. ф-лы, 11 ил., 8 табл., 6 пр.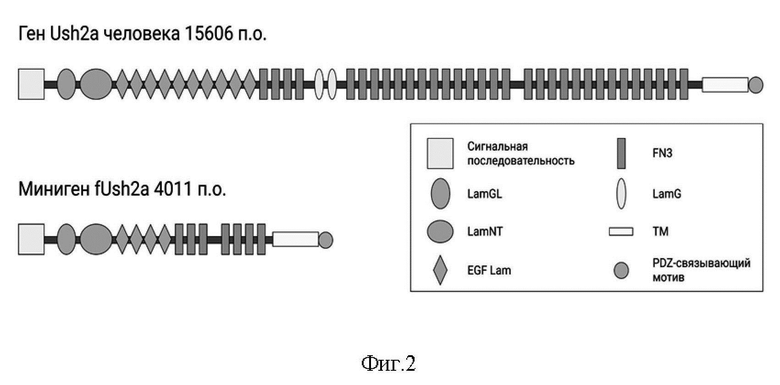
1. Мини-белок USH2A для генной терапии синдрома Ашера II типа, содержащий аминокислотную последовательность, выбранную из SEQ ID NO 4, 6, 8, 10, 12.
2. Мини-белок USH2A по п. 1, содержащий аминокислотную последовательность любую из SEQ ID NO 4, SEQ ID NO 6.
3. Нуклеиновая кислота, кодирующая мини-белок USH2A по п. 1.
4. Нуклеиновая кислота по п. 3, содержащая последовательность нуклеотидов, выбранную из SEQ ID NO 3, 7, 9, 11, 13.
5. Нуклеиновая кислота по п. 4, содержащая последовательность нуклеотидов любую из SEQ ID NO 3, SEQ ID NO 4, 7.
6. Экспрессионный вектор для экспрессии в эукариотических клетках, содержащий нуклеиновую кислоту по пп. 3-5.
7. Вектор по п. 6, представляющий собой плазмидный экспрессионный вектор, содержащий следующие элементы:
- участок начала репликации ori;
- левый инвертированный концевой повтор ITR;
- CMV энхансер цитомегаловирусного промотора;
- цитомегаловирусный промотор CMV promoter;
- последовательность интрона гена b-глобина человека;
- оптимизированную последовательность гена fUSH2A SEQ ID NO 3;
- последовательность сигнала полиаденилирования hGH poly(A) signal;
- правый инвертированный концевой повтор ITR;
- промотор гена устойчивости к ампициллину AmpR promoter;
- ген устойчивости к антибиотику ампициллину AmpR.
8. Вектор по п. 7, представляющий собой вирусный экспрессионный вектор.
9. Вектор по п. 8, представляющий собой аденоассоциированный вирус.
10. Вектор по п. 9, представляющий собой аденоассоциированный вирус 9 серотипа, 2.7m8 серотипа или 5 серотипа.
11. Вектор по п. 10, нарабатываемый в адгезионных клеточных культурах HEK293T.
12. Применение вектора по пп. 6-11 для генной терапии синдрома Ашера II типа.
13. Применение вектора п. 12 для генной терапии пигментного ретинита и тугоухости синдрома Ашера II типа.
| WO 2020214796 A1, 22.10.2020 | |||
| WO 2019166549 A1, 06.09.2019 | |||
| VONA B et al | |||
| Small fish, big prospects: using zebrafish to unravel the mechanisms of hereditary hearing loss, Hearing Research, vol | |||
| СПОСОБ ДЛЯ РАДИОСНОШЕНИЙ С ПОЕЗДАМИ | 1922 |
|
SU397A1 |
| NACHIKET D PENDSE et al | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |

