Заявленное техническое решение относится к области технологий идентификации и детектирования документов, удостоверяющих личность.
Из уровня техники известны различные способы идентификации и детектирования документов, удостоверяющих личность.
Например, патент US 11574492 В2, опублик. 03.03.2022, из которого известен подход поиска документа заключается в следующем: поиск особых точек, поиск четырехугольников и линий, и сопоставление с базой данных.
Из документа US 11818303 В2, опублик. 14.11.2023, известен подход поиска документа, который заключается в следующем: поиск идентификационных особенностей и краев документа, и сопоставление с базой данных. Из документа US 11055524 В2, опублик. 06.07.2021, известен подход поиска документа, который заключается в следующем: попытка найти машиночитаемую запись (МЧЗ) и классифицировать по информации оттуда. Если не нашлась МЧЗ, то пытаться найти баркод и классифицировать по информации оттуда. Если не нашлись МЧЗ и баркод, то ищутся ключевые слова и сопоставляются с темплейтами. Если же не удалось сопоставить ключевые слова с темплейтами, то запускается классификация, используя сверточную нейронную сеть. Если и так не удалось классифицировать документ, то запускается поиск особых точек и сопоставление с базой. После того как документ классифицирован вычисляется угол наклона документа.
Недостатками известных решений является низкая достоверность системы идентификации и длительное времени на выполнение процесса идентификации и детектирования документов, удостоверяющих личность.
Задачей заявленного изобретения является устранение недостатков известного уровня техники. Технический результат заключается в обеспечении способа идентификации и детектирования документов, удостоверяющих личность, который позволяет обеспечить повышение эффективности и достоверности системы идентификации, а также сокращение времени на выполнение данного процесса.
Поставленная задача решается, а заявленный технический результат достигается посредством заявленного способа идентификации и детектирования документов, удостоверяющих личность.
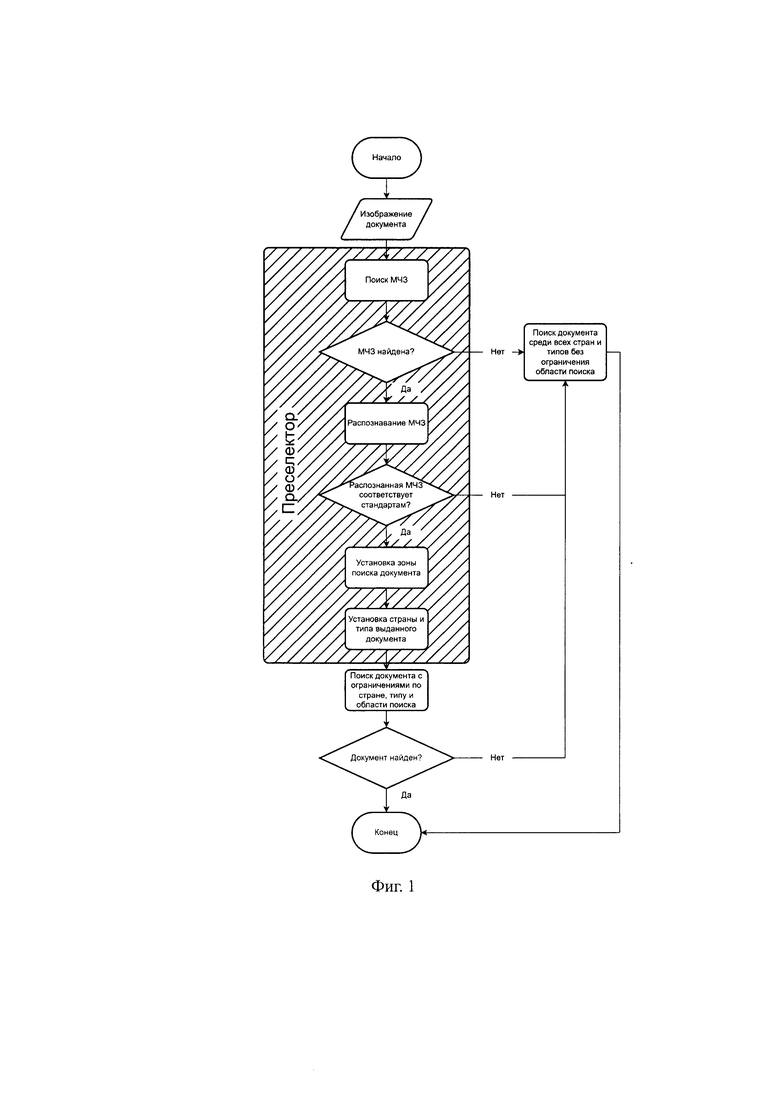
Заявленный способ идентификации и детектирования документов, удостоверяющих личность, заключается в том, что на первом этапе на вход поступает изображение документа, удостоверяющего личность, на втором этапе проводят детектирование МЧЗ на изображении:
а) применяют методы компьютерного зрения и машинного обучения для поиска потенциальной МЧЗ на изображении,
б) если МЧЗ не обнаружена, происходит переход к пятому этапу; на третьем этапе проводят распознавание МЧЗ:
а) применяют оптическое распознавание символов для распознавания и декодирования информации в МЧЗ,
б) если МЧЗ не соответствует стандарту (стандарт ICAO Doc 9303 Part 3: Specifications Common to all MRTDs, Machine Readable Travel Documents), происходит переход к пятому этапу,
в) производят извлечение данных о стране издательства и типе документа из распознанных данных;
на четвертом этапе производят поиск документа с использованием преселектора:
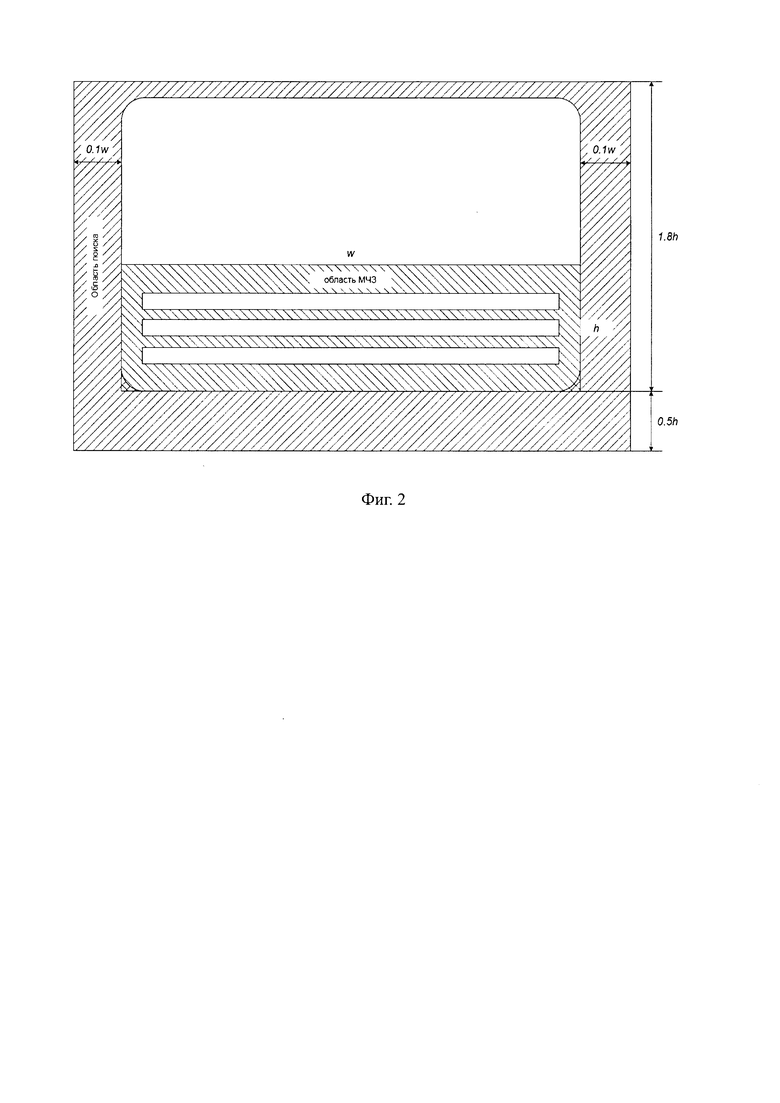
а) на основе координат найденной МЧЗ задают область поиска документа на изображении, при этом, чтобы получить область поиска документа увеличивают область найденной МЧЗ следующим образом: вверх по вертикали область расширяют в 4 раза, если это МЧЗ из двух строк, и в 1,8 раз, если из трех, вниз на половину высоты МЧЗ и по горизонтали расширяют зону на 20%,
б) используя извлеченную информацию о стране и типе документа, применяют преселектор для поиска только среди документов соответствующего типа и страны,
в) если совпадение найдено, возвращают результат и завершают алгоритм;
на пятом этапе производят поиск среди всех типов документов и всех стран:
а) если МЧЗ не обнаружена или не распознана, осуществляют поиск среди всех доступных типов документов и всех стран,
б) если совпадение найдено, возвращают результат;
на шестом этапе получают результат идентификации документа или сообщение о том, что документ не был распознан.
На Фиг. 1 представлена блок-схема процесса привязки документа с преселектором.
На Фиг. 2 представлена схема задачи области поиска документа для МЧЗ, состоящей из 3-х строк.
Заявленный способ оптимизирует процесс идентификации документов, так как сначала делает попытку извлечения информации из МЧЗ и ее координат на изображении и уже на основании этой информации сужает область поиска и убирает несогласованные типы документов из рассмотрения, что увеличивает скорость и точность распознавания.
Предложенный способ улучшения детектирования документов способен повысить качество и ускорить распознавание только в том случае, если в выборке присутствуют документы с МЧЗ.
Примеры: Датасеты:
Три открытых датасета были использованы для эксперимента:
1. midv500 [l]
2. midv2019 [2]
3. midv2020 [3]
Эти датасеты представляют собой коллекции изображений искусственно сгенерированных документов, удостоверяющих личность из различных стран.
Процедура:
Каждый датасет был распознан двумя способами: с подходом привязки без преселектора (п.1) и с подходом с использованием преселектора (модификация п. 1), который опирается на информацию из машиночитаемой зоны (МЧЗ) для оптимизации процесса привязки.
Полем считаем текстовую единицу документа, например: имя, пол, дату рождения и т.д.
Качество распознавания поля в результате прогона датасета - отношение правильно распознанных полей ко всем полям. Правильно распознанными полями считаются поля, совпадающие с разметкой датасета.
Качество распознавания датасета - среднее значение качества распознавания полей, присутствующих в датасете.
Время обработки датасета - время, затраченное на его полное распознавание, то есть распознавание всех изображений.
Результаты эксперимента:
midv2020:
Качество распознавания датасета без преселектора: 36.14%
Качество распознавания датасета с преселектором: 36.15%
Время обработки датасета без преселектора: 401 минута
Время обработки датасета с преселектором: 297 минут
midv2019:
Качество распознавания датасета без преселектора: 44.95%
Качество распознавания датасета с преселектором: 45.3%
Время обработки датасета без преселектора: 32 минуты
Время обработки датасета с преселектором: 26.1 минуты
midv500:
Качество распознавания датасета без преселектора: 54.97%
Качество распознавания полдатасетаей с преселектором: 54.99%
Время обработки датасета без преселектора: 91 минута
Время обработки датасета с преселектором: 71 минута.
Изобретение относится к области технологий идентификации и детектирования документов, удостоверяющих личность. Технический результат заключается в повышении точности идентификации документа. В способе на первом этапе на вход поступает изображение документа, удостоверяющего личность, на втором этапе проводят детектирование машиночитаемой записи (МЧЗ) на изображении: а) применяют методы компьютерного зрения и машинного обучения для поиска потенциальной МЧЗ на изображении; б) если МЧЗ не обнаружена, происходит переход к пятому этапу; на третьем этапе проводят распознавание МЧЗ: а) применяют оптическое распознавание символов для распознавания и декодирования информации в МЧЗ; б) если МЧЗ не соответствует стандарту, происходит переход к пятому этапу; в) производят извлечение данных о стране издательства и типе документа из распознанных данных; на четвертом этапе производят поиск документа с использованием преселектора: а) на основе координат найденной МЧЗ задают область поиска документа на изображении, при этом, чтобы получить область поиска документа, увеличивают область найденной МЧЗ следующим образом: вверх по вертикали область расширяют в 4 раза, если это МЧЗ из двух строк, и в 1,8 раз, если из трех, вниз на половину высоты МЧЗ и по горизонтали расширяют зону на 20%; б) используя извлеченную информацию о стране и типе документа, применяют преселектор для поиска только среди документов соответствующего типа и страны; в) если совпадение найдено, возвращают результат и завершают алгоритм; на пятом этапе производят поиск среди всех типов документов и всех стран: а) если МЧЗ не обнаружена или не распознана, осуществляют поиск среди всех доступных типов документов и всех стран; б) если совпадение найдено, возвращают результат; на шестом этапе получают результат идентификации документа или сообщение о том, что документ не был распознан. 2 ил.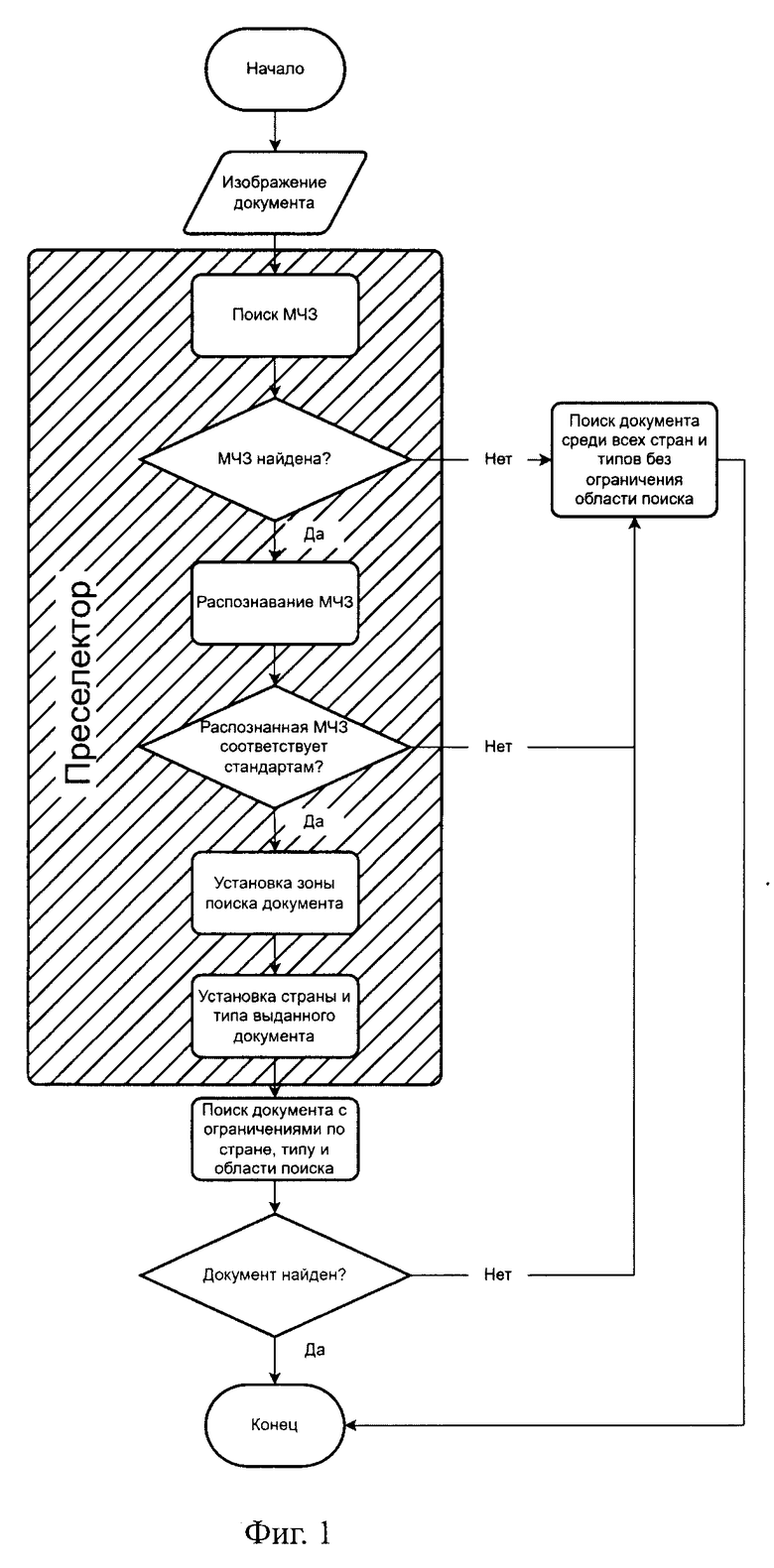
Способ идентификации и детектирования документов, удостоверяющих личность, заключающийся в том, что на первом этапе на вход поступает изображение документа, удостоверяющего личность, на втором этапе проводят детектирование машиночитаемой записи (МЧЗ) на изображении:
а) применяют методы компьютерного зрения и машинного обучения для поиска потенциальной МЧЗ на изображении;
б) если МЧЗ не обнаружена, происходит переход к пятому этапу;
на третьем этапе проводят распознавание МЧЗ:
а) применяют оптическое распознавание символов для распознавания и декодирования информации в МЧЗ;
б) если МЧЗ не соответствует стандарту, происходит переход к пятому этапу;
в) производят извлечение данных о стране издательства и типе документа из распознанных данных;
на четвертом этапе производят поиск документа с использованием преселектора:
а) на основе координат найденной МЧЗ задают область поиска документа на изображении, при этом, чтобы получить область поиска документа, увеличивают область найденной МЧЗ следующим образом: вверх по вертикали область расширяют в 4 раза, если это МЧЗ из двух строк, и в 1,8 раз, если из трех, вниз на половину высоты МЧЗ и по горизонтали расширяют зону на 20%;
б) используя извлеченную информацию о стране и типе документа, применяют преселектор для поиска только среди документов соответствующего типа и страны;
в) если совпадение найдено, возвращают результат и завершают алгоритм;
на пятом этапе производят поиск среди всех типов документов и всех стран:
а) если МЧЗ не обнаружена или не распознана, осуществляют поиск среди всех доступных типов документов и всех стран;
б) если совпадение найдено, возвращают результат;
на шестом этапе получают результат идентификации документа или сообщение о том, что документ не был распознан.
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| Способ оценки действительности документа при помощи оптического распознавания текста на изображении круглого оттиска печати/штампа на цифровом изображении документа | 2020 |
|
RU2750395C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ ЭЛЕКТРОННОГО КОМПЛЕКТА ДОКУМЕНТОВ | 2019 |
|
RU2702967C1 |
| СРАВНЕНИЕ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ ДОСТОВЕРНОГО ИСТОЧНИКА | 2014 |
|
RU2597163C2 |
| КЛАССИФИКАЦИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ НА ОСНОВАНИИ КОНТЕНТА | 2014 |
|
RU2571545C1 |
| Контактное приспособление для соединения обмотки трехфазного ротора асинхронного двигателя с пусковым реостатом | 1931 |
|
SU28580A1 |
| US 11055524 B2, 06.07.2021 | |||
| US 11818303 B2, 14.11.2023 | |||
| US 11574492 B2, 07.02.2023 | |||
| KR 1020160061528 A, 01.06.2016 | |||
| US 20040081332 A1, 29.04.2004 | |||
| US 20160110597 A1, 21.04.2016 | |||
| GB | |||

