Область применения изобретения
[0001] Настоящее изобретение в целом относится к вводу данных с помощью оптического или интеллектуального распознавания символов (OCR/ICR) и в частности - к способу и системе для создания описания структуры изображений документов, обладающих фиксированной структурой.
Описание уровня техники
[0002] В большинстве случаев данные из бумажных документов вводятся в компьютерную базу данных с помощью специализированной системы ввода данных, которая преобразует бумажный документ в электронную форму (путем сканирования или фотографирования документов и т.д.) и извлекает данные из полей в изображении документа.
[0003] Для извлечения данных из изображения документа системы ввода данных должны быть обеспечены информацией о полях в изображении документа, из которых будут извлекаться данные. Данная информация может включать расположение полей по отношению, например, к границам документа или другим опорным объектам и т.д. Упоминаемая выше информация называется «шаблоном» или описанием структуры документа.
[0004] Обычно описания структуры документов (шаблоны) создаются экспертами для каждого типа документов заранее. Такие описания документов (шаблоны) загружаются в систему ввода данных и применяются к поступающим изображениям документов. Описания структуры документа (шаблоны) накладываются на поступающие изображения документа, и выполняется извлечение данных из поступающего изображения документа. Основным недостатком существующих специализированных систем ввода данных является то, что они не способны быстро создавать описание структуры документа (шаблоны) для различных типов документов и автоматически извлекать данные, поэтому такие системы не применимы в случаях, когда существует несколько различных типов документов, которые необходимо автоматически обработать, и отсутствует возможность создавать новые шаблоны вручную.
[0005] Кроме того, в настоящее время мобильные устройства (например, смартфоны, мобильные телефоны, планшетные ПК, персональные цифровые помощники и т.д.) становятся все более доступными по всему миру. Более того, производительность мобильных устройств продолжает расти. Они всегда под рукой, и их возможности сопоставимы с возможностями ПК. В результате мобильные электронные устройства стали неотъемлемыми помощниками в бизнесе, образовании, общении, путешествиях и повседневной жизни. В частности, поскольку большинство мобильных электронных устройств оснащено фото- и/или видеокамерами, их можно использовать для получения изображений в высоком качестве и для извлечения данных из этих изображений.
[0006] Также в современном обществе широко используются так называемые документы с фиксированной структурой. Например, примерами таких документов являются водительские удостоверения, удостоверения личности, контрольные списки, договоры и т.д. Документы с фиксированной структурой могут быть жестко структурированы таким образом что, например, поля, которые содержат информацию в документе, всегда находится в одном и том же месте. Если рассмотреть водительские удостоверения, например, поля "first name" («имя»), "last name" («фамилия») и "date of issue" («дата выдачи») могут находиться в одном и том же месте для каждого удостоверения, хотя данные, относящиеся к этим полям, могут отличаться для разных владельцев водительских удостоверений. Существует растущая потребность в быстром и мобильном вводе данных из таких документов с фиксированной структурой.
[0007] С быстрым увеличением и распространением использования документов с фиксированной структурой возникает соответствующая растущая потребность в точном и эффективном извлечении данных, содержащихся в таких документах, с соответствующим высоким уровнем скорости и возможностью воспроизводимости. В настоящее время только специализированные устройства позволяют выполнять обработку и извлечение данных из таких изображений документов. Однако эти специальные устройства обычно являются стационарными или привязанными к стационарным устройствам. На сегодняшний день отсутствуют механизмы, с помощью которых данные из изображения документов с фиксированной структурой могут быть извлечены при помощи мобильных установок, например на контрольно-пропускном пункте. Для описываемого способа не требуется наличие ПК (или другой специализированной системы для извлечения данных), и он может применяться с использованием мобильного устройства с цифровой фотокамерой.
[0008] Наряду с вышеизложенным, зачастую для извлечения данных из изображения документа с фиксированной структурой необходимо предварительно специальным образом обработать документ, из которого будут извлекаться данные. В одном примере обрабатываемый документ можно обработать путем предварительного добавления специальных машиночитаемых знаков, например черных квадратов в углах документа. Преимуществом является то, что для описываемого способа не требуется этап ручной подготовки входящих документов; данный способ может быть использован для любого случайного печатного документа, например удостоверения, договора, чека и т.д. Любому среднему специалисту в данной области техники будет очевидным то, что обстоятельства конкретной ситуации могут не позволить выполнить процесс подготовки для конкретного документа таким способом, так как во многих случаях изображения документов, из которых извлекаются данные, не соответствуют системе, выполняющей извлечение данных. Существует потребность в механизме, посредством которого данные можно эффективно и быстро извлекать из изображений документов с фиксированной структурой в таких условиях, как мобильные установки, что снижает необходимость предварительной обработки, описанной ранее. Для описываемого способа не требуется обученный специалист для разработки и настройки процесса обработки изображения документа. Это может сделать любой пользователь.
[0009] Для решения этой проблемы представлены различные варианты осуществления ввода данных с изображений документов с фиксированной структурой. В одном варианте осуществления, рассматриваемом только в качестве примера, предоставляется способ ввода данных с изображения документа с фиксированной структурой с помощью процессора. Шаблон, выбранный из множества шаблонов, накладывается на изображение документа для извлечения данных. При наложении шаблона используется, по меньшей мере, один опорный объект или опорная точка, указывающие, по меньшей мере, на одну область в изображении документа, откуда следует выполнить ввод данных.
КРАТКИЙ ОБЗОР ОПИСАННЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0010] С одной стороны, данное описание относится к способу ввода данных с изображения документа с фиксированной структурой с помощью процессора. Этот способ включает в себя получение электронного изображения документа с фиксированной структурой. Далее способ включает в себя распознавание ключевых слов на изображении документа и идентификацию, по меньшей мере, одного опорного объекта на основе распознанных ключевых слов, где, по меньшей мере, один опорный объект указывает на, по меньшей мере, одну область изображения документа с фиксированной структурой, откуда следует выполнить ввод данных. В некоторых реализациях в качестве опорного объекта может выступать регулярное выражение. В некоторых реализациях способ может включать в себя создание одного или более шаблонов на основе идентифицированных опорных объектов. Затем выполняется наложение шаблонов из множества шаблонов на документ с фиксированной структурой с помощью идентифицированного, по меньшей мере, одного опорного объекта. Множество шаблонов может включать в себя предварительно созданный шаблон. Далее способ включает в себя выбор шаблона из множества шаблонов с помощью показателя качества распознавания ключевых слов. Выбор шаблона может быть основан на качестве наложения шаблона. Способ может включать в себя выполнение дополнительного распознавания изображения документа с помощью выбранного шаблона. В некоторых реализациях распознавание изображения документа основывается на дополнительной информации о ключевых словах. Далее способ включает в себя извлечение данных из изображения документа с помощью выбранного шаблона.
[0011] В некоторых реализациях способ далее может также содержать вычисление для каждого шаблона качества наложения данного шаблона на изображение документа с фиксированной структурой, что позволит идентифицировать из множества шаблонов те шаблоны, качество наложения которых выше предварительно заданного порога, и сохранить данные идентифицированные шаблоны.
[0012] Более того, в соответствии с описанным изобретением вычисляется качество распознанного текста в распознанном ключевом слове. Рассчитанное качество сравнивается с пороговым значением. Если качество распознанного текста выше порогового значения, распознанный текст экспортируется.
[0013] В некоторых реализациях способ включает в себя выполнение коррекции искажений изображения документа с фиксированной структурой. В качестве коррекции искажений может выступать выравнивание линий, коррекция перекоса, коррекция геометрии документа, цветовая коррекция, восстановление смазанных и несфокусированных областей и удаление шума. В некоторых реализациях способ применяет, по меньшей мере, один фильтр к изображению документа.
[0014] Кроме вышеупомянутого варианта осуществления предоставляются другие варианты осуществления в виде демонстративных систем и компьютерных программ, которые отличаются соответствующими преимуществами.
В приведенном выше кратком обзоре представлены варианты концепций в упрощенной форме, которые более подробно описаны далее в разделе «Подробное описание». Этот краткий обзор не призван идентифицировать основные особенности или важные особенности заявленного объекта изобретения и не предназначен для использования в качестве вспомогательного материала для определения области действия заявленного объекта изобретения. Заявленный объект изобретения не ограничен реализациями, которые устраняют любой или все недостатки, указанные выше.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0015] Чтобы преимущества настоящего изобретения были полностью понятны, более детальное описание изобретения, которое было кратко описано выше, представлено посредством ссылки на определенные варианты осуществления, которые изображены на приложенных чертежах. Подразумевая, что на этих рисунках изображаются варианты осуществления настоящего изобретения, и тем самым их не следует рассматривать как ограничение области применения, изобретение будет описано и объяснено конкретно и подробно посредством применения сопутствующих чертежей, где:
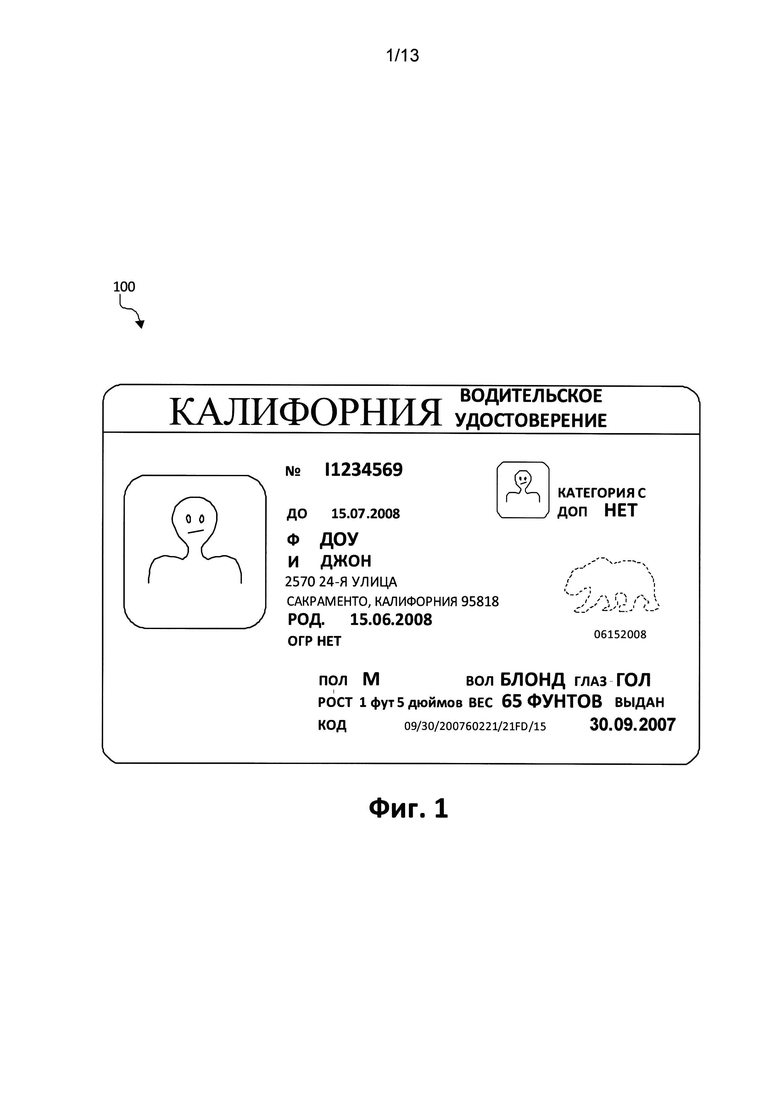
[0016] Фиг. 1 является изображением примера документа с фиксированной структурой, а именно водительского удостоверения штата Калифорния, в котором могут быть реализованы аспекты настоящего изобретения;
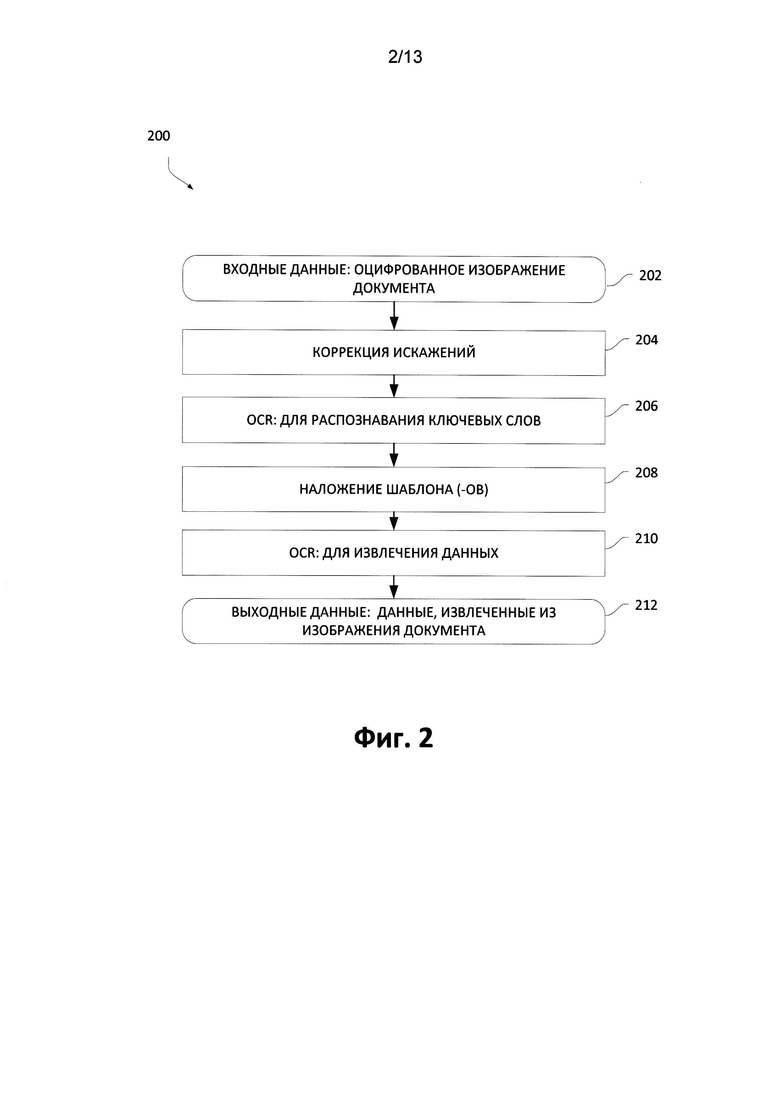
[0017] Фиг. 2 является блок-схемой, изображающей пример способа извлечения данных из изображения документа с фиксированной структурой, в котором могут быть реализованы аспекты настоящего изобретения;
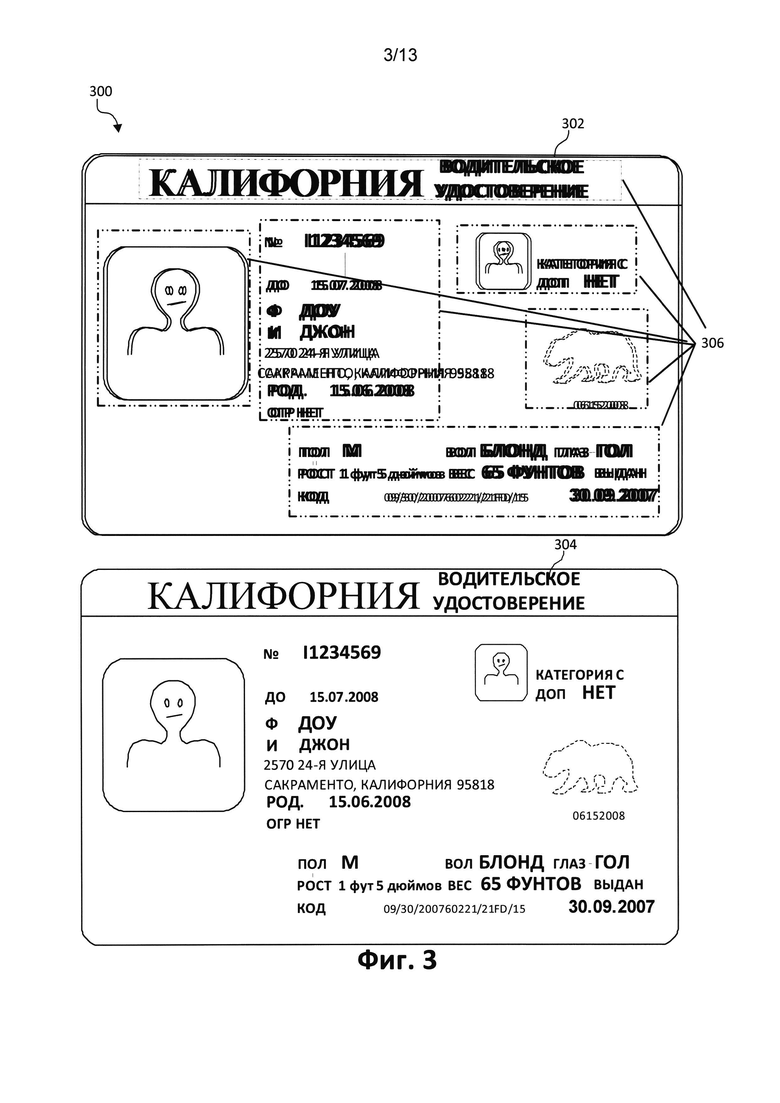
[0018] Фиг. 3 является иллюстрацией действий по коррекции искажений, выполненных на примере изображения документа с фиксированной структурой, где показано состояние изображения до и после применения данных операций, в которых также могут быть реализованы аспекты настоящего изобретения;
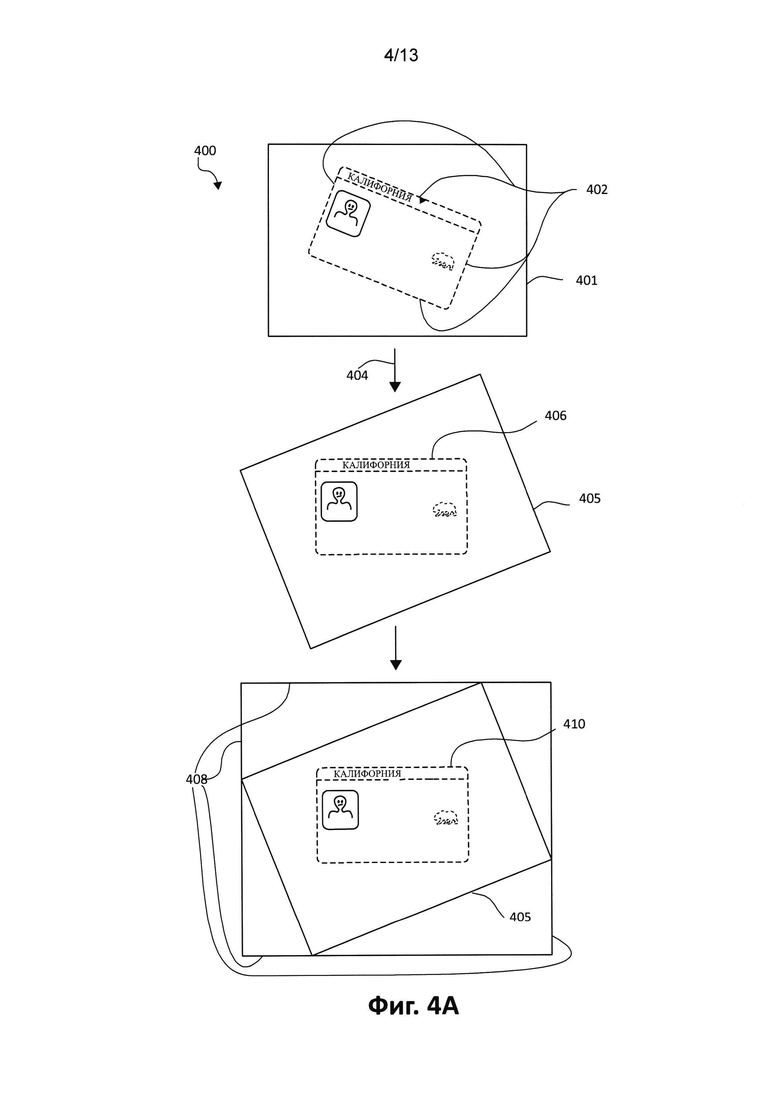
[0019] Фиг. 4А является дополнительным изображением действий коррекции искажений, выполненных на примере изображения документа с фиксированной структурой, а именно коррекция геометрического искажения, в которых также могут быть реализованы аспекты настоящего изобретения;
[0020] Фиг. 4Б является дополнительным изображением действий коррекции геометрических искажений, выполненных на примере изображения документа с фиксированной структурой, в которых также могут быть реализованы аспекты настоящего изобретения;
[0021] Фиг. 5А является блок-схемой первой части подробного примера способа извлечения данных из изображения документа с фиксированной структурой, в котором могут быть реализованы аспекты настоящего изобретения;
[0022] Фиг. 5Б является блок-схемой второй части подробного примера способа извлечения данных из изображения с фиксированной структурой. Продолжение Фиг. 5А; и
[0023] на Фиг. 6 изображены примеры шаблонов, характеризующиеся параметром Qi, в которых могут быть реализованы аспекты настоящего изобретения;
[0024] на Фиг. 7 изображены примеры наложения шаблона на изображение документа с фиксированной структурой, в которых могут быть реализованы аспекты настоящего изобретения.
[0025] Фиг. 8 является блок-схемой, изображающей дополнительный пример способа извлечения данных из изображения документа с фиксированной структурой, в котором также могут быть реализованы аспекты настоящего изобретения;
[0026] на Фиг. 9 показано обработанное изображение документа с фиксированной структурой, в котором также могут быть реализованы аспекты настоящего изобретения;
[0027] Фиг. 10 является изображением примеров отмеченных расположений элементов полей, представленных в подробном описании далее на языке extensible Markup Language (XML);
[0028] на Фиг. 11 представлены изображения примеров применения фильтров к изображению документа с фиксированной структурой в процессе извлечения данных, в которых также могут быть реализованы аспекты настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0029] Как упоминалось ранее, область реализации и применения документов с фиксированной структурой в современном обществе продолжает расти. Удостоверения личности, свидетельства, контрольные списки, договоры и тому подобное присутствуют практически в каждом аспекте жизни. В настоящее время, несмотря на существование специальных механизмов извлечения информации, содержащейся в документах с фиксированной структурой, с помощью систем OCR/ICR, их функциональные возможности привязаны к стационарным системам, а механизм эффективного ввода данных с изображений при помощи мобильной установки без необходимости стадий настройки, предшествующих обработке изображения документа с фиксированной структурой, в настоящий момент недоступен (не существует).
[0030] Чтобы решить проблему потребности в таких функциональных возможностях, различные варианты осуществления настоящего изобретения предоставляют механизмы для эффективного извлечения данных из изображений документов с фиксированной структурой в таких условиях, как мобильная установка, без необходимости в стадиях настройки предварительной обработки изображения. Эти механизмы позволяют извлекать данные из цифровых изображений документов с фиксированной структурой, например, без помощи специализированной системы извлечения данных такой, как ПК; кроме того, эти механизмы можно применять с любыми мобильными устройствами, оснащенными цифровой фотокамерой.
[0031] Также структурированные документы могут включать в себя удостоверения личности, водительские удостоверения или списки различных типов. Механизмы проиллюстрированных вариантов осуществления позволяют определять тип данного входящего изображения документа, делают возможным дальнейшее определение расположения полей, содержащих данные для извлечения, и ввод этих данных в редактируемой форме (например, в форме текста).
[0032] Описанные здесь механизмы проиллюстрированных вариантов осуществления не требуют специальной подготовки документа с фиксированной структурой для извлечения информации. Несмотря на относительно небольшое время, затрачиваемое на описание типа документа, механизмы позволяют осуществлять надежный ввод данных. Для описанного способа не требуется, чтобы обученный сотрудник выполнял разработку и настройку процесса обработки входящих изображений документа. Любой пользователь может выполнить эту задачу. Кроме того, следует заметить, что для описанных далее механизмов не требуется предварительная подготовка документов, то есть нанесение специальных реперных квадратов или других реперных точек, таких как крестов, углов и т.д. Наконец, механизмы проиллюстрированных вариантов осуществления устойчивы к различным типам геометрических и цветовых искажений, которые могут появиться, например, в процессе фотографирования или сканирования. Эти механизмы могут применяться к документам, где есть часть текста, которая не изменяется на различных изображениях одного типа, и для них не требуются специальных меток для точного размещения шаблона.
[0033] Возвращаясь к Фиг. 1, где изображен пример документа с фиксированной структурой 100, а именно водительское удостоверение Джона Доу (штат Калифорния). Как видно, документ с фиксированной структурой 100 содержит различные поля данных, например номер удостоверения («№» / «DL»), срок действия («ДО» / «ЕХР»), категорию («КАТЕГОРИЯ» / «CLASS»), фамилию («Ф» / «LN»), имя («И» / «FN»), дату рождения («РОД» / «DOB»), ограничения («ОГР» / «RSTR»), пол («ПОЛ» / «SEX») и т.п. Каждое из этих полей с данными располагается приблизительно одинаково в документе для каждого владельца водительского удостоверения в штате Калифорния. Как будет понятно любому среднему специалисту в данной области техники, информация, содержащаяся в каждом из полей с данными водительского удостоверения штата Калифорния, будет отличаться в зависимости от конкретного владельца, например, номер удостоверения, срок действия и ранее упоминаемые поля.
[0034] Владелец может предъявить документ 100 лицу, желающему быстро и эффективно проверить информацию, содержащуюся в документе. Например, документ 100 может предъявляться уполномоченному лицу на контрольно-пропускном пункте или другом мобильном учреждении. Желательно, чтобы на месте был внедрен механизм для эффективного, быстрого и точного извлечения информации, содержащейся в документе с фиксированной структурой 100 для различных целей, как было описано ранее.
[0035] Обращаясь теперь к Фиг. 2, где показан пример способа 200 для извлечения данных из документов с фиксированной структурой, в котором могут быть реализованы аспекты настоящего изобретения. Способ 200 начинается с этапа ввода 202, на котором документ оцифровывается, таким образом, получается электронное изображение документа. Электронным изображением документа может быть фотография, результат сканирования или другое цифровое представление. На следующем шаге 204, операции коррекции искажений могут применяться к цифровому изображению, например коррекция геометрических, цветовых и других искажений, которые будут описаны дополнительно. В одном варианте осуществления на этом шаге (204) может быть получено несколько версий исходного цифрового изображения.
[0036] На следующем шаге в способе используются системы OCR для распознавания и обнаружения «ключевых» слов (шаг 206) на изображении(-ях) документа, полученном(-ых) на шаге 204. В одном варианте осуществления все распознанные ключевые слова ищутся в базе данных ключевых слов. Эти распознанные ключевые слова становятся опорными объектами или якорями, которые затем используются для установления пространственного(-ых) расположения(-ий) полей в изображении документа с фиксированной структурой, откуда данные позднее будут считаны и извлечены, что также будет далее описано более подробно. Кроме того, на основе информации о ключевых словах можно создать описание типа документа. Это описание далее будет называться шаблоном. Поэтому для различных изображений документов на этом шаге (206) может быть создано несколько шаблонов. Эти созданные шаблоны можно хранить в памяти электронных устройств или в других запоминающих устройствах и применять для выполнения ввода данных с последующих поступающих изображениях документов. На следующем шаге (208) шаблон (или множество шаблонов) накладывается на электронное изображение документа (202), где шаблон(-ы) можно выбирать из множества шаблонов, созданных на основе информации о ключевых словах на шаге 206, или из множества шаблонов, которые ранее были сохранены в памяти системы ввода данных.
[0037] Как будет описано далее, шаг наложения выбранного шаблона может повторяться, пока не будет определен шаблон, наилучшим образом подходящий для конкретного изображения документа. Данные затем извлекаются с помощью наложенного шаблона (шаг 210), и если устанавливается, что данные извлекаются точно, извлеченные данные формируют результат (шаг 212).
[0038] Далее переходим к Фиг. 3, изображению 300 с действиями по коррекции искажений, проиллюстрированных в демонстративном варианте осуществления. Иллюстрация 300 включает в себя цифровую версию изображения документа 302, на которой присутствует соответствующее количество смазанных областей 306. После обработки изображения 302 смазанные области 306 восстанавливаются, в результате получается изображение 304, в котором восстановлены смазанные области и другие искажения.
[0039] В некоторых реализациях настоящего изобретения изображение документа 202 обрабатывается с помощью методов коррекции дефектов для обнаружения и устранения таких дефектов, как размытость (смаз), расфокусировка или зашумленность. Некоторые методы устранения дефектов описаны в опубликованной заявке на патент США №2012-0243792 "Detecting and Correcting Blur and Defocusing". («Обнаружение и коррекция нечеткого смаза и расфокусировки»).
[0040] Следующий из возможных примеров коррекции геометрических искажений 400 демонстрируется на Фиг. 4А. Сначала происходит обнаружение документа 402 на изображении 401. Документ 402 содержит геометрические искажения (негоризонтальная ориентация) и нуждается в повороте на определенный угол посредством шага 404, как показано на чертеже. Полученное изображение 405 содержит правильно ориентированный документ с фиксированной структурой 406. Обнаружение границ документа можно выполнить с помощью одного из известных способов, например, с помощью, способа, описанного в заявке на патент №14/162,694 "AUTOMATIC CAPTURING OF DOCUMENTS HAVING PRELIMINARILY SPECIFIED GEOMETRIC PROPORTIONS" («Автоматическая съемка документа с заданными геометрическими пропорциями»). Повернутое изображение 405 можно подвергать обработке до тех пор, пока изображение 405 не станет геометрически правильным прямоугольником с границами 408, как показано на рисунке. Правильно ориентированное изображение 410 документа без искаженных линий будет расположено в данном прямоугольнике 408.
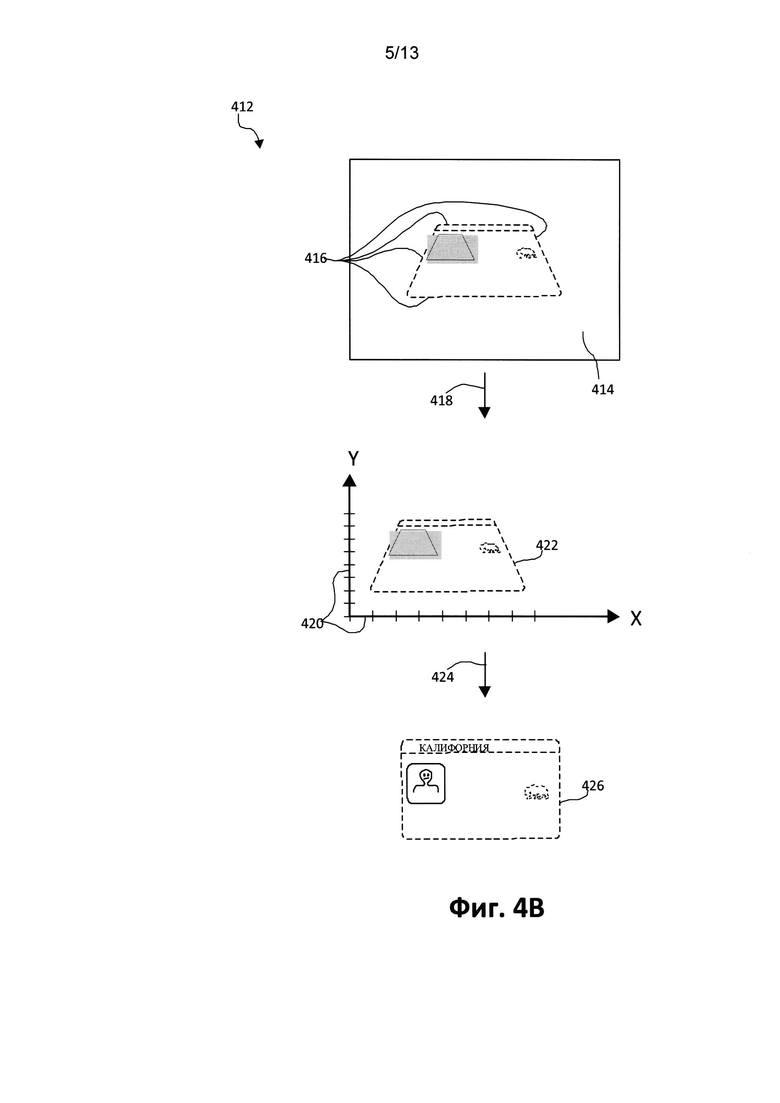
[0041] На Фиг. 4Б изображен следующий пример коррекции геометрических искажений 412, показанных на чертеже. На Фиг. 4Б показан документ с фиксированной структурой с видом, отличающимся от прямоугольного вида (отклоняющаяся от прямоугольной формы, трапециевидная форма) 416. Это изображение можно обработать, например, путем обрезки (418) обнаруженного искаженного документа (416) вдоль границ с отделением фоновой части (414) и последующим сжатием и растяжением (424) обрезанного документа (422) вдоль соответствующих координатных осей (420). В результате документ с искажением перспективы корректируется (426), в результате чего изображение документа подходит для дальнейшего анализа.
[0042] Шаблон:
[0043] В следующих параграфах более подробно описываются механизмы создания шаблонов. Как описано ранее, наше изобретение включает в себя подготовку описания типа(-ов) документа, подвергающегося(-ихся) извлечению данных, и соответствующего(-их) поля(-ей). Для каждого нового типа документа необходимо подготовить описание структуры или шаблон документа.
[0044] В одном варианте осуществления шаблон может состоять из двух частей: описание текста в документе и описание полей, которые будут распознаваться и извлекаться. Эти шаблоны можно подготовить полуавтоматически с участием пользователя. Все данные могут храниться в любой форме, подходящей для использования с системой OCR, например, в стандартном формате XML или других форматах.
[0045] Кратко возвращаясь к Фиг. 2: шаг 202 описывает получение цифрового изображения документа, а шаг 204 описывает выполнение коррекции геометрических, цветовых и других искажений. Можно получить одно или более изображений, хотя следует заметить, что получение только одного эталонного цифрового изображения документа обычно достаточно для применения различных механизмов настоящего изобретения. При наличии геометрических, цветовых или любых других искажений этого изображения их можно корректировать автоматически или вручную таким образом, что изображение, преобразованное в прямоугольную форму, аналогично изображению, полученному, если документ отсканирован без искажений. Кроме того, достаточно даже одного эталонного изображения документа с фиксированной структурой без геометрических или цветовых искажений для создания шаблона.
[0046] Шаблон содержит информацию о тексте, его размерах (опционально) и его расположении на исходном изображении документа. Шаблон также содержит информацию о полях, которые требуется извлечь, и информацию об их координатах. Информация о тексте хранится в форме («слово», координаты слова), где «слово» может являться текстом или регулярным выражением. Как упоминалось выше, шаблон накладывается на поступающие изображения документа, и документы обрабатываются с помощью шаблона для извлечения информации из этих поступающих изображений документа, или, другими словами, для ввода данных.
Создание шаблона:
[0047] Шаблоны, в одном варианте осуществления, можно создать путем распознавания на шаге 206 (Фиг. 2) «ключевых слов» в изображениях документов. Ключевым словом может быть, например, комбинация букв "first name" («имя») или "last name" («фамилия»), (или «И» / "FN" и "LN" / «<D») или дата «$$.$$.$$$$», где $ является любой цифрой. Эти слова можно использовать в качестве опорных объектов для указания областей, где находятся данные для извлечения. Важно заметить, что для описанного изобретения могут не требоваться специальные заранее размещенные реперные точки для ввода данных, например, такие как черные квадраты или схожие символы. В структуре описанных здесь механизмов обычные слова, даты и другие примечания в документе используются в качестве «опорных объектов» или якорей вместо специальных символов. Распознавание ключевых слов можно выполнить на любом портативном электронном устройстве (например, на мобильных устройствах, смартфонах и т.д.) без необходимости в широкополосном соединении и с отсутствием требований к обработке. Например, такое распознавание может быть выполнено в одном варианте осуществления с помощью быстрого режима OCR.
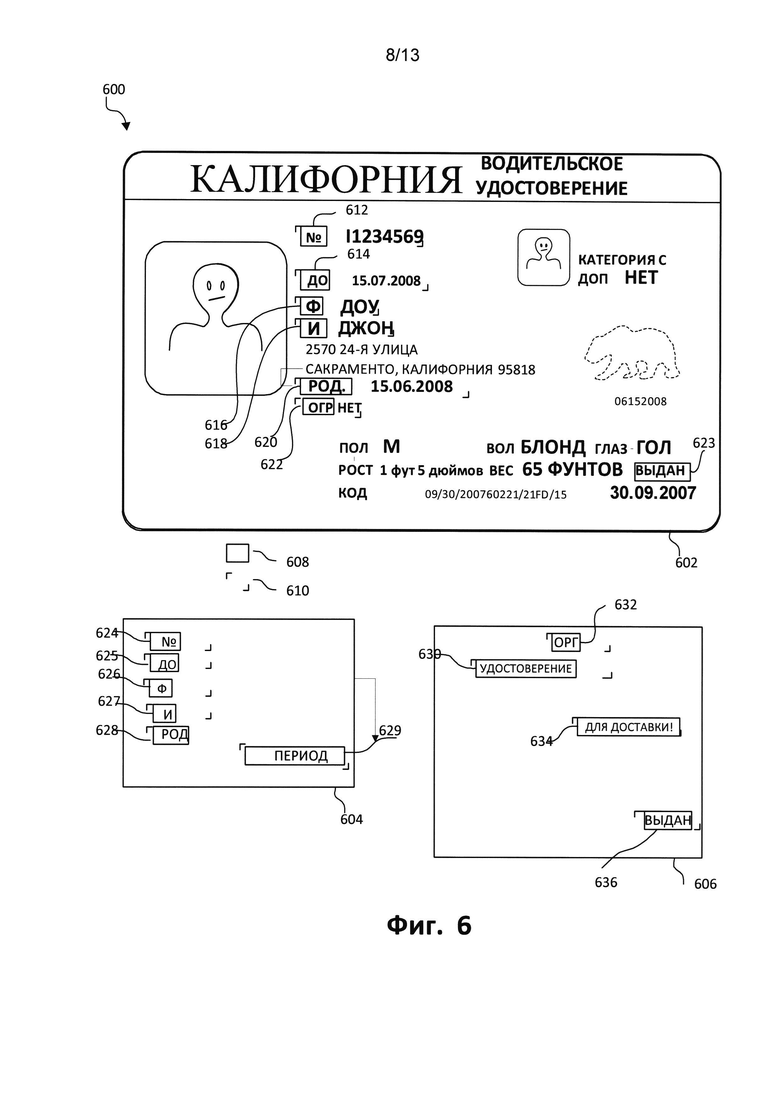
[0048] На Фиг. 6 показаны иллюстрации 600 примеров шаблонов для документа с фиксированной структурой. Изображение 602 является цифровым изображением документа с фиксированной структурой, которое могло подвергаться операциям коррекции искажений для уменьшения геометрических, цветовых и других искажений и улучшения читаемости. Блоки 604 и 606 являются возможными шаблонами, которые могут соответствовать жесткой структуре (описанию документа) документа 602. В одном варианте осуществления распознанные ключевые слова, например названия полей 608 (например, "Last Name" («И», имя) или "Date of Birth" («РОД», дата рождения)) или значения полей (или данные) (например, "Smith" («Смит») или «01/01/1966»), ищутся в базе данных ключевых слов. Ключевые слова 608 в документе 602 могут содержать "DL" («№») (относящийся к номеру удостоверения) 612, "ЕХР'7 «ДО» 614 (для даты истечения срока), "LN" / «Ф» 616 (для фамилии), "FN" / «И» 618 (для имени), "DOB" / «РОД» 620 (для даты рождения), "RSTR" / «ОГР» 622 (для любых ограничений для владельца удостоверения) и "ISS" / «ВЫДАН» 623 (для даты выдачи).
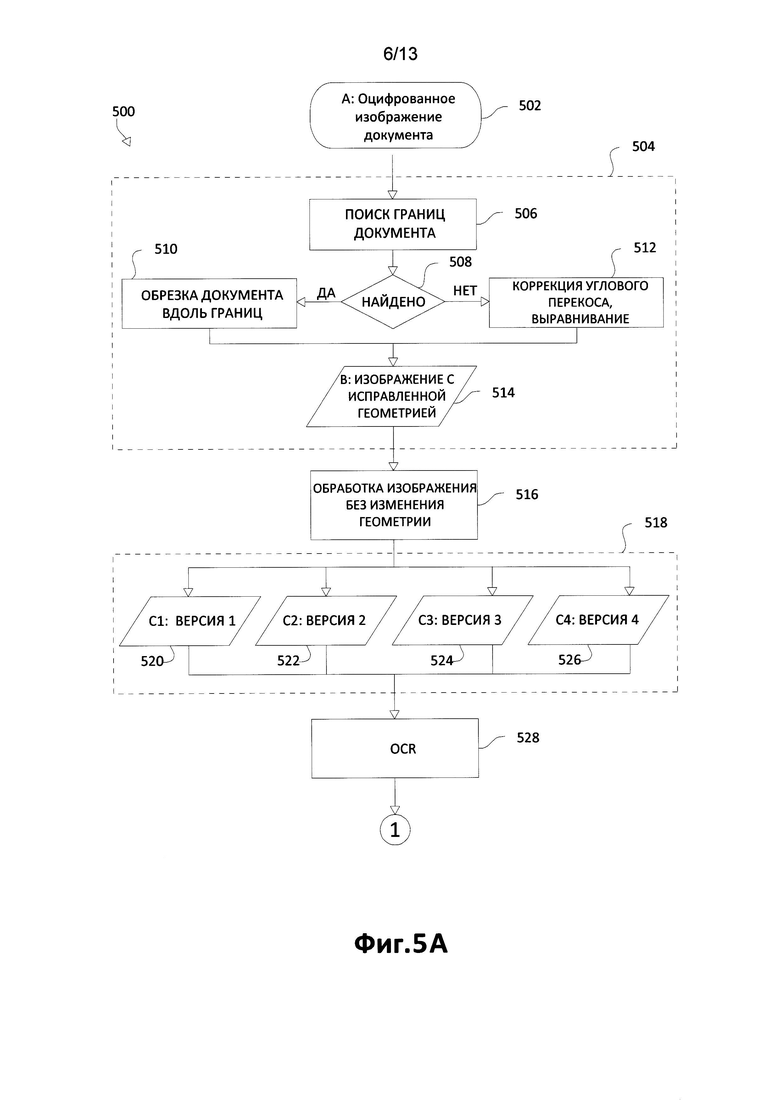
[0049] Шаблон 604 содержит ключевые слова "DL" 624, "ЕХР" 625, "LN" 626, "FN" 627, "DOB" 628, "CADENCE" 629. («№» 624, «ДО» 625, «Ф» 626, «И» 627, «РОД» 628, «ПЕРИОД» 629). Шаблон 606 показан с ключевыми словами "License" («Удостоверение») 630, "ВО" / «ОРГ» 632 (для соответствующих бизнес-организаций, например ООО, Инк. и т.д.), "For Delivery" / «Для доставки» 634 и "158" / «ВЫДАН» 636.
[0050] Полученные шаблоны 604, 606 могут включать в себя вышеупомянутые ключевые слова, найденные на изображении и которые могли быть использованы для создания шаблона. Эти ключевые слова могут быть регулярными выражениями или могут быть описаны другим способом, например, "last name" («фамилия») или "category." («категория»). В одном варианте осуществления пользователь описывает эти ключевые слова, заполняя описание шаблона.
[0051] Задача ввода данных с поступающего изображения документа решается посредством способа, известного как наложение шаблонов (208, Фиг. 2).
Выбор шаблона:
[0052] В одном варианте осуществления качество наложенного шаблона характеризуется параметром Qi Этот параметр шаблона можно рассчитать разными способами.
[0053] Анализируя два наложенных шаблона с изображением 602 на шаге 208 (Фиг. 2), можно заметить, что в качестве кандидата на подходящий шаблон, который будет применен для документа 602, шаблон 604 обладает 5 (пятью) из 7 (семи) ключевых слов или приблизительным показателем точности Qi=71%. В качестве кандидата на подходящий шаблон, который будет использоваться для документа 602, шаблон 606 обладает только одним из семи ключевых слов, или приблизительным показателем точности Qi=14%. Из-за свойственных трудностей в распознавании (например, на шаге 206, Фиг. 2) отдельных символов возможна ситуация, когда несколько ключевых слов не будут найдены, даже если они действительно есть на электронном изображении. В одном из вариантов осуществления - это может объяснить отсутствием 100-процентной точности при определении подходящего шаблона, который будет использоваться на поступающем изображении документа с фиксированной структурой. Кроме описанных ключевых слов можно заметить опорные точки 610, обозначенные показанными угловыми отметками, которые ограничивают область электронного изображения, где будут располагаться ключевые слова и данные. Эти опорные точки нанесены для наглядности.
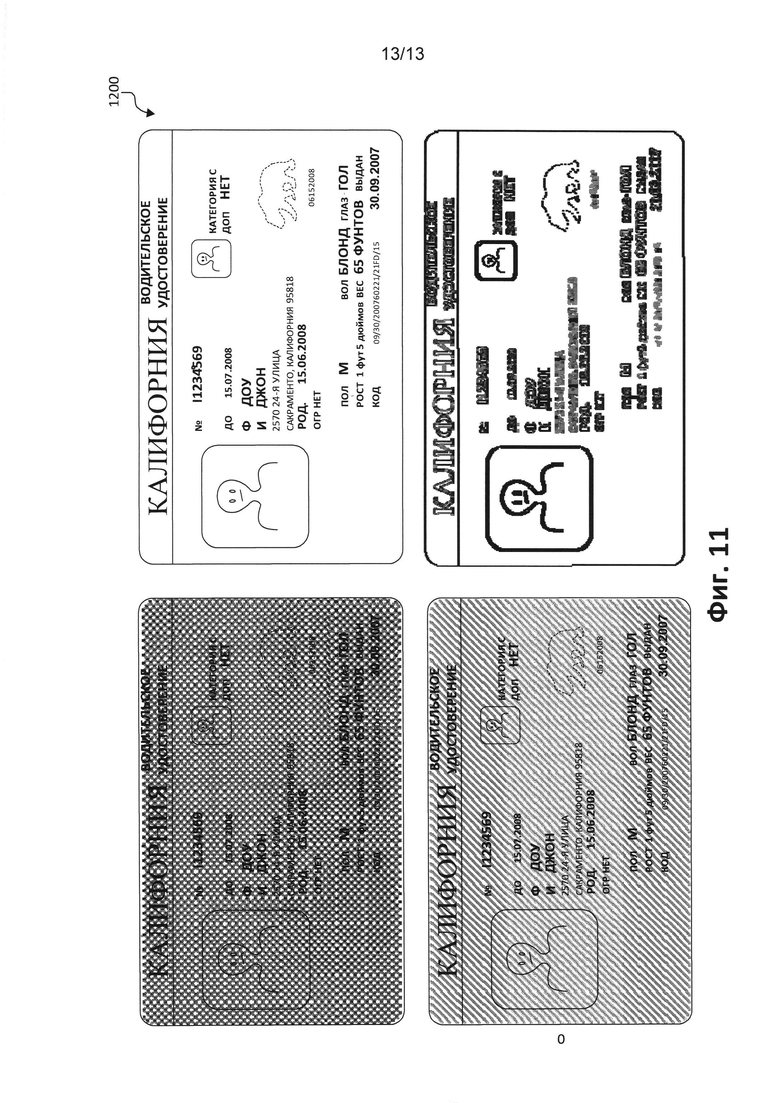
[0054] Пример захваченных с помощью шаблона 604 данных, соответствующих ключевым словам документа 602, включает в себя номер удостоверения 11234569 (соответствующий ключевому слову "DL" / «№»), дату истечения срока 15.07.2008 (соответствующую ключевому слову "ЕХР" / «ДО»), фамилию Доу (соответствующую ключевому слову «Ф» / "LN"), имя Джон (соответствующее ключевому слову «И» / "FN"), дату рождения 15.06.1990 (соответствующую ключевому слову «РОД» / "DOB").
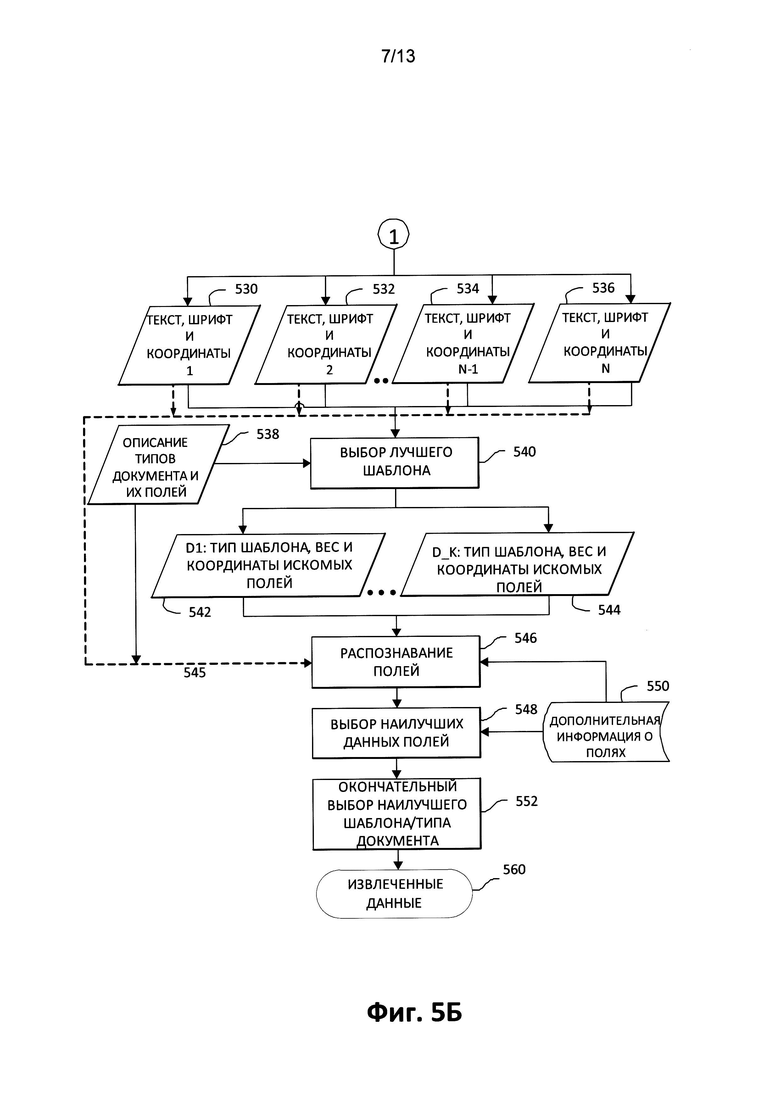
[0055] Теперь обратимся к Фиг. 5, на котором в качестве блок-схемы подробно показан демонстративный способ 500 для ввода данных с изображений документов с фиксированной структурой. В качестве первого шага электронное представление документа (например, фотография) получается путем фотографирования, сканирования или другого метода оцифровывания документа (шаг 502). Создается цифровое (электронное) изображение документа. Цифровое изображение может содержать геометрические и цветовые искажения, которые препятствуют извлечению данных. Шаги, обведенные пунктирной линией 504, соответствуют коррекции геометрической, цветовой и других искажений. Этот шаг не является обязательным.
[0056] Обращаясь к примеру комбинации шагов 504, если изображение содержит геометрические искажения (искажения поворота, перспективы, нелинейные искажения), их можно скорректировать перед следующим шагом. Для коррекции геометрии используются несколько подходов; их можно использовать по отдельности или последовательно в любом порядке. В одном варианте осуществления данного способа геометрические искажения можно скорректировать в соответствии с описанием из заявки на патент США №13/561,242, поданной 30 июля 2012 г., под названием "Straightening Out Distorted Perspective on Images" («Выравнивание искаженного вида изображений»). В другом варианте осуществления способа 500 может быть применена альтернативная процедура коррекции искажений, как описано ниже.
[0057] Выполняется поиск границ документа (506). Например, это можно сделать в соответствии с заявкой на патент №14/162,694 "AUTOMATIC CAPTURING OF DOCUMENTS HAVING PRELIMINARILY SPECIFIED GEOMETRIC PROPORTIONS" («Автоматическая съемка документа с заданными пропорциями»). Если в результате найдены границы (508), документ преобразуется таким образом, чтобы внутри этих границ документ имел прямоугольную форму с указанными пропорциями (510). Например, все границы размещаются в двух стандартных форматах - книжные и альбомные страницы с фиксированными пропорциями. Выбор книжного или альбомного формата может быть основан на ширине и высоте границ, найденных на первоначальном изображении. Выбор книжного или альбомного формата можно осуществить до коррекции геометрических искажений или после нее.
[0058] Другими словами, способ 500 осуществляет поиск одного из нескольких типов документов на основе доступной информации. Например, может быть известно, что страницы всех искомых документов имеют соотношение сторон 3:4 или 4:3. Соответственно, если из найденных границ становится видно, что ширина меньше высоты, геометрия преобразуется к формату 3:4. Если ширина больше высоты, геометрия преобразуется к формату 4:3. В другом примере пропорциями могут быть 16:9, 100:333 или другие числа. В одном варианте осуществления способа 500 изображение может вообще не преобразовываться к стандартному размеру. В этом варианте осуществления границы находятся в соответствии с указанным выше описанием, и вдоль найденных границ изображение обрезается (510) так, чтобы получить горизонтальный (угол поворота не должен отличаться от 90 градусов) прямоугольник. После преобразования изображение выравнивается вдоль границ.
[0059] В одном варианте осуществления способа 500 описанный ранее шаг определения может выполняться, только если границы документа не были найдены в шаге 508. В другом варианте осуществления этот шаг всегда выполняется. Возможны варианты осуществления, в которых выполнение этого шага зависит от других условий. Нарушения геометрии корректируются (512) таким образом, чтобы горизонтальные линии были горизонтальными, а вертикальные линии - вертикальными. Ситуации, в которых искажения перевернуты, также корректируются. Пример корректировки наклонных и неровных линий можно видеть на Фиг. 4А и Фиг. 4Б, описанных ранее. В результате обработки геометрии изображения, получается изображение на этапе 514 для использования в остальных шагах обработки. Первоначальное изображение не используется в дальнейшей обработке.
[0060] Шаги обрезки найденного документа с фиксированной структурой вдоль границ и/или коррекции углового смещения, выравнивания или других геометрических искажений, описанных в приведенных выше примерах, представлены в шагах 508, 510 и 512, как показано на Фиг. 5.
[0061] После коррекции геометрических искажений (или невыполнения коррекции, как в шаге 516) может быть создано несколько изображений С1, С2, … Cn (518), которые геометрически соответствуют изображению В, но отличаются цветовой информацией. В частности, в некоторых случаях цифровое изображение документа может быть нерезким или содержать шумы в областях с данными, или иметь другие искажения цвета. В этих случаях можно создать несколько копий изображения и применить различные фильтры к каждой из копий. Это могут быть разные варианты бинаризации, и в процессе могут использоваться различные фильтры, например, размытие, резкость, яркость, контраст и другие. Затем, например, при использовании фильтра «бинаризация» одно слово, скажем "first name" («имя»), будет более четко видимо (будет распознано системой OCR), а при использовании фильтра «размытие» будет распознано слово "last name" («фамилия»). Хотя на первоначальном изображении слова "first name" («имя») и "last name" («фамилия») могут не распознаваться.
[0062] На Фиг. 11 проиллюстрировано применение фильтров с помощью способа 500 к цифровому изображению. К каждому из показанных четырех цифровых изображений применены разные фильтры, что может привести к тому, что некоторая часть текста становится более видимой в конкретной ситуации. Как будет понятно любому специалисту в данной области техники, применение фильтров совместно с механизмами представленного способа осуществления является дополнительной возможностью.
[0063] Как будет понятно любому среднему специалисту в данной области техники, применение различных типов шагов предварительной обработки (например, 504) может быть более эффективным для различающихся видов изображений. Соответствующим образом в зависимости от типа изображения способ 500 выбирает обработку, которая дает результат наилучшего качества. Если типы изображений известны заранее (например, облачные автоматические системы), может быть выполнена попытка выявления преобразований, которые по предположению обеспечат наилучшее качество.
[0064] Кроме того, можно попробовать автоматизировать выбор типа предварительной обработки. В таком варианте осуществления для каждого типа создается настроенная база данных изображений; а с помощью некоторого алгоритма оптимизации затем может быть выбран некоторый набор действий предварительной обработки, которые обеспечат наилучшее качество.
[0065] Все вариации (520, 522, 524 и 526) С; изображения, полученные на этом шаге, обладают одним общим свойством - текст и другие элементы изображения обладают одинаковыми координатами. Координаты рассчитываются от границ документа. Несколько вариаций создается, чтобы увеличить вероятность того, что содержащийся на изображении текст будет обнаружен и распознан при обработке вариаций. Первоначально все геометрически идентичные вариации Ci изучаемого Ci изображения (и их может быть несколько) распознаются (528) с использованием OCR/ICR, и в результате чего происходит получение информации о тексте, шрифте, используемом в изображении документа, координатах текста и координатах охватывающих различные слова прямоугольников, (530, 532, 534, 536). В одном варианте осуществления изображения документов с фиксированной структурой (520, 522, 524 и 526) распознаются (528) автоматически. Поэтому в итоге создается несколько версий распознавания (530, 532, 534, 536), каждая для соответствующих копий изображения документа В (520, 522, 524 и 526).
[0066] Распознанный текст (530, 532, 534, 536) разбивается на отдельные слова на основе информации о пробелах между ними. Для каждого распознанного слова информация об охватывающем его прямоугольнике сохраняется в памяти. В качестве слова может выступать дата, рисунок, число или что-то схожее. Как будет понятно любому специалисту в данной области техники, здесь термин «слово» относится (как и предполагалось) к широкому диапазону репрезентативной информации.
[0067] На шаге (528) выполняется распознавание изображений C1, C2, …, Cn (518) для поиска опорных объектов или опорных точек (например, точек, слов и т.д.) и областей для каждого опорного объекта (опорной точки). Как уже было описано выше, в соответствии с представленным изобретением распознанные ключевые слова используются в качестве опорных объектов. Например, на этом шаге может происходить процесс поиска ключевого слова "last name" («фамилия») (которое будет опорным объектом) и соответствующего пространственного расположения на документе с фиксированной структурой, которое следует за ключевым словом, где может быть найдена фамилия. Для улучшения обработки документов этого типа пользователь может проверить распознанный текст: например, пользователь может исправить ошибки в распознавании и геометрию распознавания символов и слов или добавить текст, который не был распознан. Например, пользователь может также обработать распознанный текст (530, 532, 534, 536) следующим образом: он может изменять отдельные слова, которые характерны для данной копии документа, на более общие описания (регулярные выражения), которые характерны для этого типа документа. Например, если копия документа содержит дату «2013-03-26», пользователь может изменить распознаваемое ключевое слово на «\д\д\д\д-\д\д-\д\д». Или пользователь может изменить ключевое слово на некоторый предварительно определенный тип, например, путем назначения определенного формата некоторому слову, например, дате, названию, числу или значению.
[0068] Этот тип предварительной обработки распознавания символов может также выполняться автоматически. Формат некоторых полей может быть известен системе (определен заранее). В результате данные могут автоматически заменяться на более общие выражения "уууу-mm-dd" («гпт-мм-дд»). Фамилии и имена также могут обрабатываться аналогичным образом.
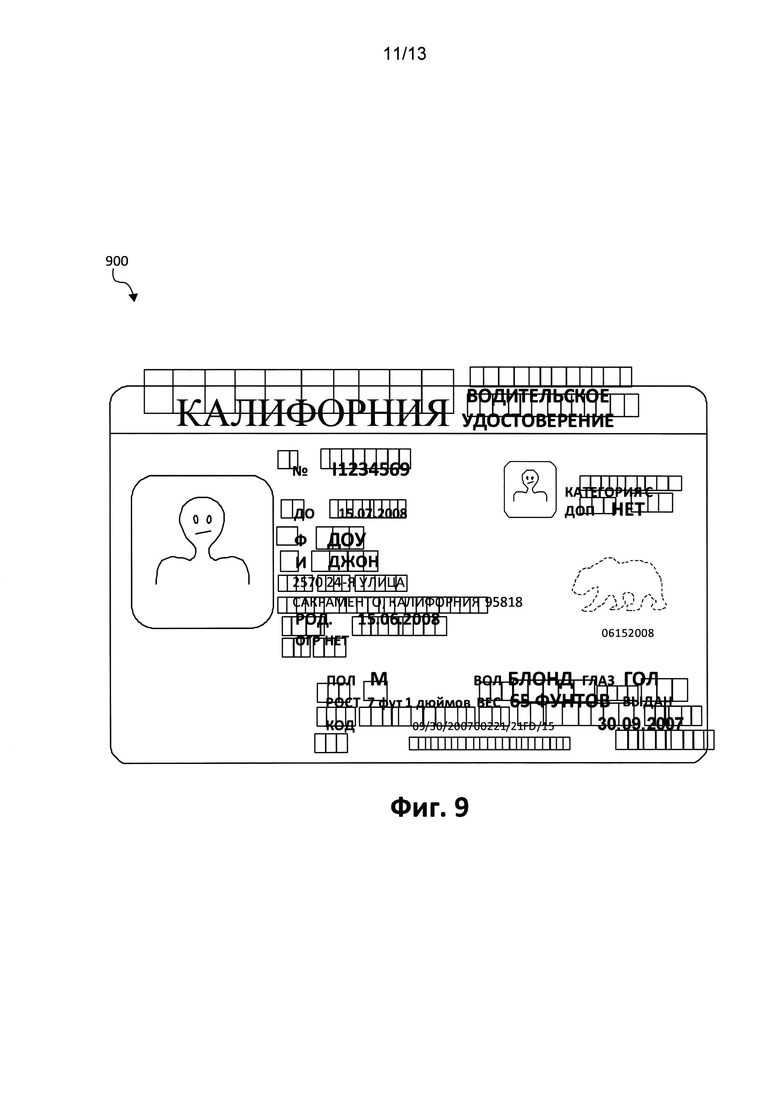
[0069] Рассмотрим следующий пример, где для обрабатываемого изображения 900, показанного на Фиг. 9, представлена репрезентативная часть кода XML.


[0070] Как будет понятно любому среднему специалисту в данной области техники, полный код XML включает в себя буквы и репрезентативную информацию о расположении для всех ключевых слов и соответствующих сведений, найденных в документе с фиксированной структурой, включая "ЕХР" («ДО») и соответствующую дату, считанную из документа, "LN" («Ф») и соответствующую фамилию, считанную из документа, и т.д. Например, как показано выше в репрезентативной части кода XML, описана область изображения, содержащая фамилию "LN" («Ф»). Настройки обработки являются входными данными; тот факт, что область содержит фамилию, словарь или база данных используются для проверки точности извлеченных данных после распознавания.
[0071] В дополнительном примере поле может описываться в коде, содержащем дату, и показан диапазон дат, допустимых для этого поля (в этом примере год выпуска удостоверения не может быть меньше 1930 или больше текущего года).
[0072] После того, как пользователь обработает первоначальные данные из изображения 900 на Фиг. 9, создается шаблон, где данные, связанные с изменяющимися данными от документа к документу, заменяются на регулярные выражения (выделенные полужирным шрифтом), как показано в примерном репрезентативном коде XML:

[0073] Этот процесс продолжается по всему коду, поскольку каждое значение изменяется в схожей манере, как будет понятно любому среднему специалисту в данной области техники. Таким образом, группа типов документов, которые может обработать система, определяется по набору шаблонов, каждый из которых описывает один тип документа.
[0074] На последующем шаге (540) шаблон (или несколько шаблонов) может накладываться на изображение документа. Допустимо использование одного шаблона с максимальным качеством распознавания Qi или нескольких шаблонов. Например, если качество распознавания для полученных шаблонов (на шаге 206 (Фиг. 2), 560 (Фиг. 5) или шаблонов, сохраненных в системе) было 86%, 17% и 75%, было бы логично рассматривать первый и третий шаблоны на этом шаге.
[0075] Целесообразно предоставлять пользователю шаблон, показывающий, какие поля будут извлечены из документа. Например, не обязательно извлекать слово "category" («категория») из водительского удостоверения, но необходимо извлекать букву «В». Чтобы извлечь эту букву, пользователь может описать прямоугольную область на изображении, из которой требуется извлечь данные, и предоставить настройки для обработки этой области вместе с данными, которые требуется извлечь. Все эти данные можно хранить в любой форме, подходящей для использования в системе OCR, например, в формате XML.
Наложение шаблонов:
[0076] Информация, полученная после распознавания с помощью OCR/ICR (530, 532, 534 и 536, Фиг. 5), используется для наложения шаблонов, соответствующих различным типам документов (538, Фиг. 5) и для выбора наилучшего качества Qi (540, Фиг. 5). В одном варианте осуществления качество наложенного шаблона характеризуется параметром Qi. Этот параметр шаблона Qi можно рассчитать разными способами. Например, качество Qi накладываемого шаблона можно рассчитать на основе совпадения распознанных ключевых слов на изображении документа и соответствующих слов в шаблоне. Здесь термин «слова в шаблоне» может относиться к символу, рисунку, слову, регулярному выражению и т.д. В результате возможно наложить шаблон по отдельности на основе результатов распознавания каждого изображения Ci или на основе объединенных результатов распознавания всех изображений или групп изображений.
[0077] Возвращаясь к способу 500 на Фиг. 5, для каждого слова в тексте шаблона способ наложения шаблона 500 выполняет поиск такого же слова в распознанном тексте поступающего изображения документа с фиксированной структурой. Поиск может допускать определенное число ошибок. Мерой количества ошибок может выступать расстояние редактирования. Расстояние редактирования можно рассчитать, например, как метрику Левенштейна. Например, расстояние редактирования может составлять 1/3 от длины искомого слова. В этом случае для опорного объекта, а именно опорного объекта или ключевого слова «some» в шаблоне, может быть найдено слово «come» в распознанном тексте полученного изображения документа с фиксированной структурой. Также можно установить абсолютное ограничение на число ошибок при поиске, например, не более 2 ошибок независимо от длины слова.
[0078] Одно слово на изображении может соответствовать нескольким словам в шаблоне, например, конкретной дате или общему формату - 20-06-2013 и \д\д-\д\д-20\д\д (определенное число и общий формат числа). Таким образом, получается набор слов, описывающих текст в этом типе документа.
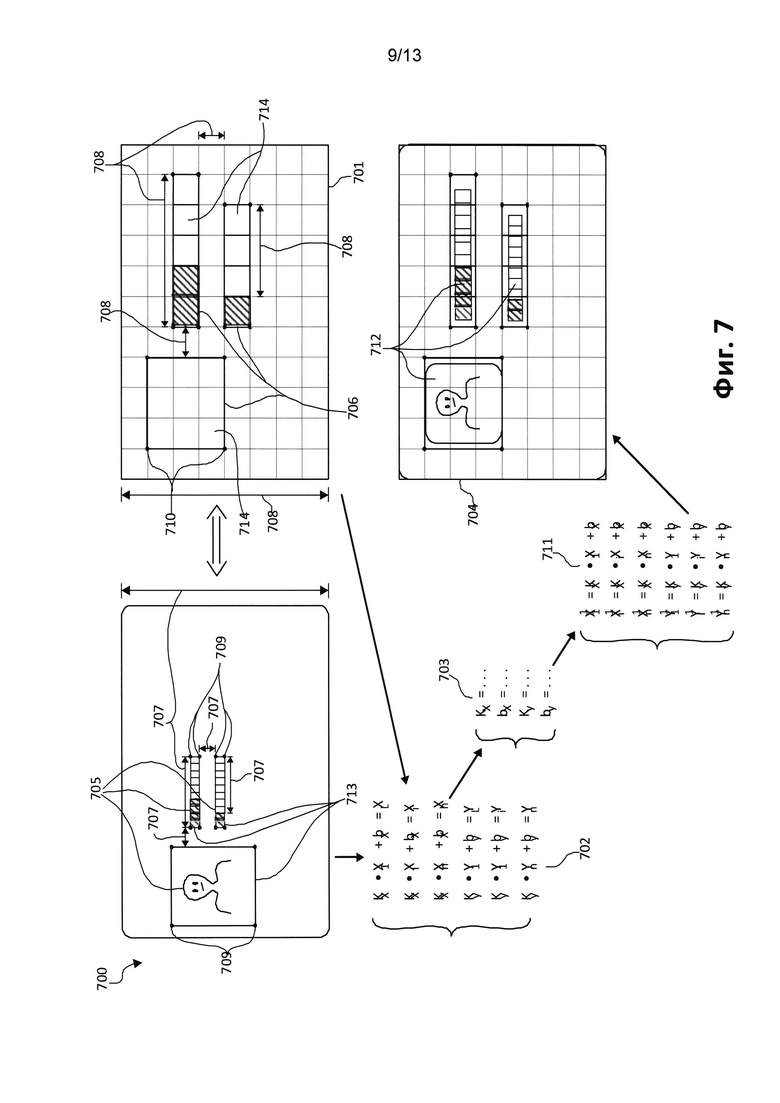
[0079] Если опорный объект (ключевое слово) является регулярным выражением, выполняется поиск части распознанного текста, соответствующего этому регулярному выражению. Когда это происходит, поиск можно выполнять с учетом возможных несоответствий между распознанным текстом и стандартным регулярным выражением. Такой поиск можно выполнить, например, после наложения ограничения на максимальное расстояние редактирования от регулярного выражения.
[0080] Например, номер водительского удостоверения может иметь формат: К-000-00-00. Номер удостоверения можно описать с помощью регулярного выражения К-\д\д\д-\д\д-\д\д, \д = $ в соответствующем пространстве данных (например, см. Фиг. 6). Результатом распознавания изображения документа может быть: K-U00-98-0I. Если выполнять поиск, не допускающий ошибок, ничего не будет найдено. Однако если допустить несоответствия между текстом и шаблоном документа с фиксированной структурой во время поиска, текст будет найден с точностью до двух изменений.
[0081] Для каждого опорного объекта (например, ключевого слова) в шаблоне может быть найдено несколько соответствующих слов в распознанном тексте изображения документа с фиксированной структурой. Для каждого соответствующего найденного слова отмечаются его признаки - координаты начала соответствующих слов в распознанном тексте, координаты конца соответствующих слов, размер шрифта и координаты отдельных букв. Все координаты рассчитываются от границ документа.
[0082] Для каждого соответствия слова из шаблона и из результата распознавания обработанного изображения документа с фиксированной структурой способ 500 находит коэффициенты, уi, 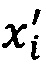 ,
, 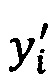 .
.
Примеры таких коэффициентов:
1. х - координата левого края опорного слова, х' - координата левого края слова в распознанном тексте.
2. х - координата правого края опорного слова, х' - координата правого края слова в распознанном тексте.
3. х - координата левого края второй буквы опорного слова, х' - координата левого края второй буквы слова в распознанном тексте.
4. y - координата верхнего края опорного слова, y' - координата верхнего края слова в распознанном тексте.
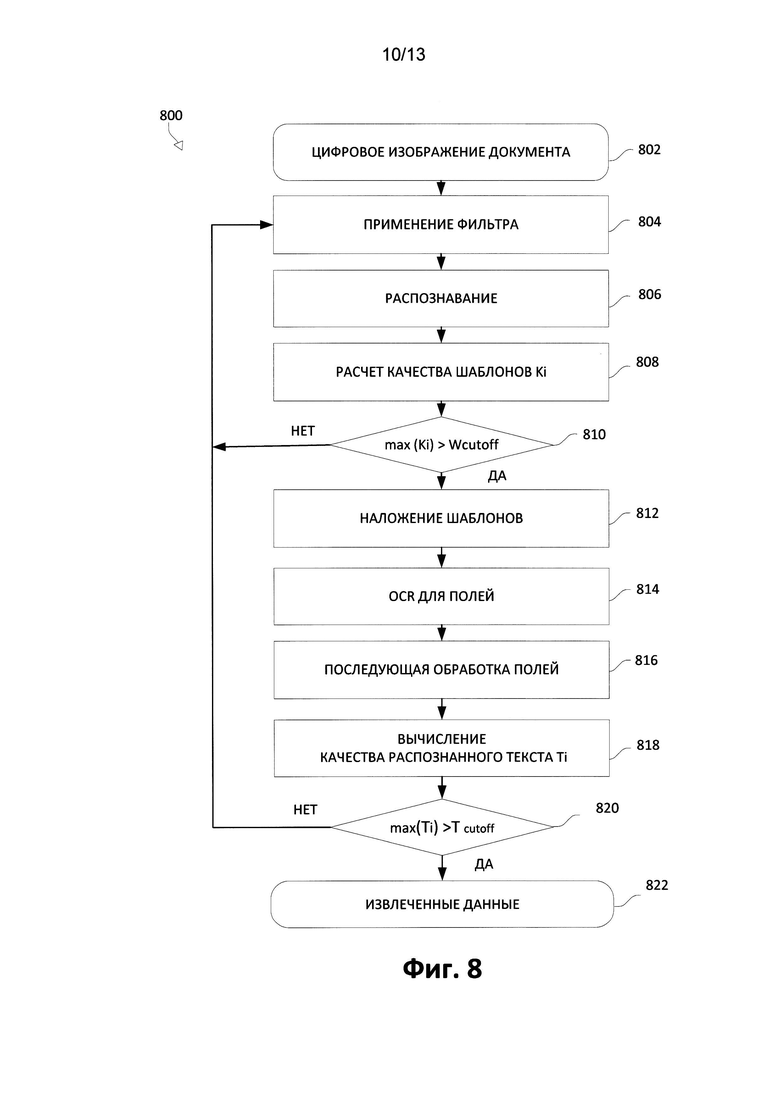
5. y - координата нижнего края опорного слова, у' - координата нижнего края слова в распознанном тексте.
[0083] В результате создается система линейных уравнений, которая не имеет точного решения. Для этого шаблона ищется решение (kx, ky, bx, by) с наименьшей ошибкой с помощью некоторой меры. Например, можно искать решение с помощью метода Гаусса-Зейделя или для другого примера можно искать решение с помощью меры Лебега. Эта ошибка или некоторая монотонная функция от этой ошибки задает показатель качества Q для наложения шаблона на рассматриваемое изображение. Если установлены несколько шаблонов, показатель качества Q и коэффициенты (kx, ky, bx, by) находятся для каждого из доступных шаблонов.
[0084] В одном варианте осуществления при наложении шаблона на изображение документа в способе 500 выполняется попытка поиска оптимального преобразования параллельного переноса и сжатия/растяжения, которое преобразует главное изображение (шаблон создан на основе главного изображения) в обрабатываемое изображение документа. В таких преобразованиях соответствующие поля необходимо переместить ближе друг к другу. Для этого требуется решить систему уравнений следующего типа:
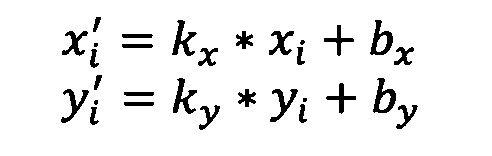
Решение данной системы можно выполнить, например, с помощью метода Гаусса-Жордана или другого метода. Результатом решения системы выступают значения коэффициентов kx, ky, bx, by, которые минимизируют ошибку в определенной метрике, например по методу наименьших квадратов. В другом варианте осуществления способа 1100 может использоваться другая метрика. Это преобразование не включает в себя поворот, поскольку поворот изучаемого изображения корректируется ранее, перед распознаванием текста на изображении.
[0085] Один и тот же текст, например, на рисунках с разными цветами, может распознаваться по-разному. Оптимальный шаблон можно выбрать для каждого изображения документа, учитывая только распознанный текст на этом изображении. Но можно просто объединить распознанный текст на всех изображениях и выбрать наилучший шаблон для всего текста.
[0086] Результатом этого шага является список: качество шаблона Qi и коэффициенты kx, ky, bx, by (которые описывают преобразование изображения, используемое для создания шаблона для текущего изображения документа таким образом, чтобы поля накладывались друг на друга). Качество Qi может быть рассчитано, например как число согласующихся опорных объектов. Например, если ключевыми словами являются "last name" («фамилия»), "date of issue" («дата выдачи»), "category" («категория») и "number" («номер») и найдено 3 слова из 4, качество распознавания составляет 75%; если найдено 1 слово, качество распознавания равно 25%. После наложения шаблонов на основе значения показателя качества наложения выбираются один или более шаблонов с наивысшим качеством Qi. Например, если качество распознавания полученных шаблонов составляет 86%, 17% и 75%, логично изучить первый и третий шаблоны на этом шаге способа 500.
[0087] Демонстративный процесс наложения шаблонов показан на Фиг. 7. Наложение шаблона на изображение документа с фиксированной структурой можно представить как поиск преобразования, которое переводит область 705 документа 700, ограниченную опорными точками, в область 706 шаблона 701, которая ей соответствует. Для этого решается система уравнений (702) в которой опорные точки 709 можно преобразовать в соответствующие опорные точки 710 с минимальной ошибкой. Координатами опорных точек 709 являются xi, а координатами опорных точек 710 являются xi_template. Координаты всегда рассчитываются от границ документа. Важно обратить внимание, что области с данными (713) полностью попадают в области шаблона, который им соответствует (714). Для этого расстояния 707 необходимо преобразовать в расстояния 708.
[0088] Результатом решения системы являются коэффициенты 703 для преобразования изображения документа 700. Коэффициент kx является коэффициентом сжатия вдоль оси х, ky является коэффициентом сжатия вдоль оси y, bx является коэффициентом сдвига вдоль оси х и by является коэффициентом сдвига вдоль оси у. После этого рассчитываются координаты для опорных точек 709, которые получаются после преобразования 703, и получаются новые координаты 711. Координаты 711 могут не совпадать с координатами опорных точек 710, поскольку при наличии более двух опорных точек 709 система (702) не имеет точного решения без погрешностей. После преобразования 703 получается документ, который накладывается на шаблон 704.
[0089] Предпочтительно иметь извлеченные данные полей 712 с минимальным числом ошибок. Этот шаг распознавания также может быть выполнена в облаке или на стационарном устройстве (ПК, сервер и т.д.).
[0090] На основе результатов предыдущего шага (540) выдвигаются гипотезы о типах документа (542, 544, Фиг. 5). Гипотезы содержат информацию о типе шаблона, координаты искомых полей и т.д. Среди этих рекомендованных шаблонов есть шаблон, соответствующий действительному типу изучаемого документа. Однако некоторые типы документов могут быть достаточно схожими между собой, поэтому способ 500 может не ограничиваться простым выбором наилучшего шаблона; например, могут быть наложены несколько доступных шаблонов. После распознавания полей, наконец, выбирается один тип шаблона.
[0091] Каждый из накладываемых шаблонов определяет список координат и настройки обработки для полей в исследуемом изображении, из которых следует извлекать данные. Предположим, например, что необходимо получить данные из определенного поля. Результатом наложения шаблона являются координаты этого поля на изображениях C1, …, Cn. Поскольку все изображения Ci обладают одинаковым расположением элементов (одинаковой геометрией), текстовые данные для поля можно извлекать из любого изображения.
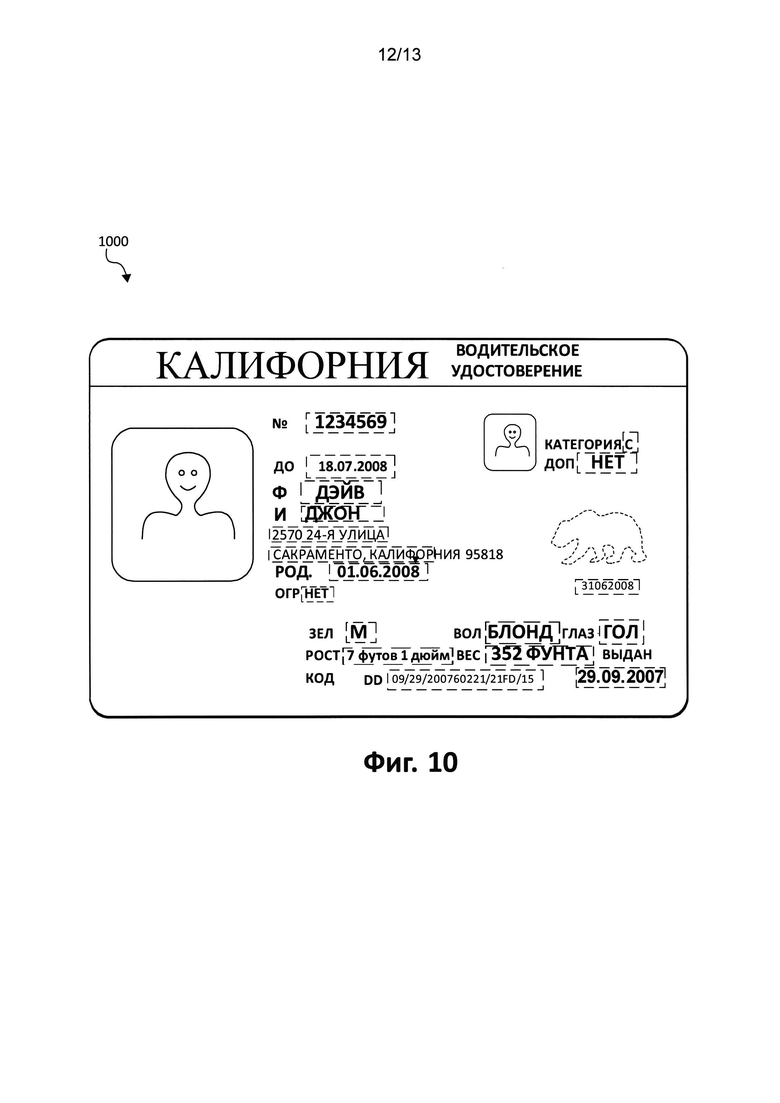
[0092] На Фиг. 10 показано расположение полей, которые содержат извлекаемые данные. Для изображения документа с фиксированной структурой 1000 на Фиг. 10 распознанные данные могут представляться следующей частью примерного кода XML. Как будет понятно любому среднему специалисту в данной области техники, что весь сегмент XML будет представлять общую часть распознаваемых данных:



[0093] Возвращаясь к документу 1000 на Фиг. 10, расположение элементов в примерной части кода XML описывается следующим образом:


[0094] Способ 500 распознает поле на одном или более изображениях Ci (546, Фиг. 5), Распознавание полей может выполняться сразу после того как получены результаты (545) распознавания (530, 532, 534, 536). Затем наилучшие данные для полей выбираются из вариаций распознавания (548, Фиг. 5). Наилучшие данные для поля можно выбирать с помощью различных критериев. Например, наилучшие данные для поля могут основываться на внутреннем показателе качества распознавания, который является выходными данными системы OCR. Кроме того, наилучшие данные для поля могут быть определены с помощью базы данных для имен, фамилий, названий штатов и других данных. В другом альтернативном варианте осуществления способа 500 также можно выбрать поле, которое наилучшим образом подходит к ранее определенному формату. После этого шага выполняется получение списка полей и данных, соответствующих полям, а также данных для каждого шаблона в группе.
[0095] После распознавания полей в изображении документа с фиксированной структурой на основе использования всех шаблонов, наилучший шаблон (552, Фиг. 5) наконец выбирается на основе ранжирования качества распознавания для полей и качества Qi, которое было рассчитано ранее и использовано для сужения списка шаблонов. Выбранный наилучший шаблон может определять тип документа. Этот шаг можно выполнять даже до выбора наилучшего шаблона или во время распознавания поля. Распознанные поля могут затем подвергнуться последующей обработке, как было описано ранее.
[0096] О полях (или ключевых словах) может быть известна дополнительная информация (550, Фиг. 5). Например, если известно, что результатом распознавания поля должна быть дата, результат распознавания модифицируется так, чтобы результатом на самом деле являлась дата. В примере буква «О» заменяется нулем и другие символы, которые часто неправильно распознаются, заменяются таким образом, чтобы результат соответствовал описанному полю. Слова также могут являться регулярными выражениями или описываться другим способом, например, "last name" («фамилия») или "category" («категория»), или, скажем, эти поля обладают собственными словарями. В одном варианте осуществления пользователь описывает их при создании шаблона или указывает, что эти поля связаны с базой данных словаря или что эти поля были найдены в другом месте.
[0097] Результатом шага последующей обработки (или шага выбора шаблона, если последующая обработка была выполнена раньше) являются результаты работы описанного способа 500. В итоге, на входе, получается изображение документа с фиксированной структурой, а на выходе - происходит выбор и наложение одного шаблона из набора шаблонов, в результате чего определяется тип документа и данные в полях (560, Фиг. 5), соответствующих этому типу. Для документа 1000 на Фиг. 10 результат различных операций способа 500 приводит к следующему примерному коду XML:


[0098] В дополнительном варианте осуществления ранее описанные механизмы могут быть реализованы в упрощенной, ускоренной версии, как показано на Фиг. 8. На Фиг. 8 изображен дополнительный примерный способ 800 для извлечения данных с изображений документов с фиксированной структурой в соответствии с механизмами настоящего изобретения.
[0099] После получения цифрового изображения документа (802) к изображению применяется только один фильтр (804) для коррекции искажения. Затем сформированное в результате применения фильтра изображение распознается (806). Качество Ki наложения шаблона рассчитывается (808), например, аналогично тому, как рассчитывалось качество наложения шаблона Qi, как показано на Фиг. 6 выше. На данном этапе шаблон может быть взят из запоминающего устройства системы. На шаге 810 все шаблоны, качество наложения которых К меньше некоторого порогового значения качества наложения шаблона Wcutoff, отбрасываются. Если шаблоны с качеством наложения выше, чем пороговое значение, отсутствуют, способ 800 возвращается к шагу, где применяется фильтр, и используется следующий фильтр.
[00100] Те шаблоны, для которых качество наложения выше порогового значения, теперь накладываются (812) путем преобразования координат. После этого считываются поля (814), где расположены данные. Эти поля затем подвергаются последующей обработке (816). В частности, все слова преобразуются в форму, где они появляются в словаре этого поля (здесь эти слова называются «известными») или вводятся с помощью регулярного выражения, которое описывает это поле. Способ 800 затем рассчитывает качество распознанного текста Ti (818) (также можно рассчитать качество наложения шаблона. Ki) - например, как много слов являются известными. На шаге 820 способ 800 удаляет те шаблоны, качество распознавания которых меньше значения Tcutoff; если шаблонов не остается, способ 800 возвращается к шагу применения фильтров и применяет следующий фильтр. Однако если максимальное значение качества распознавания Ti превышает значение Tfinal cutoff, данные извлекаются и экспортируются. Полученные данные можно использовать в различных ситуациях и обстоятельствах. Способ 800 можно использовать, например, для системы андеррайтинга (гарантийных функциональных возможностей) в страховании. В демонстративном сценарии транспортное средство может быть расположено в удаленном месте от стационарного устройства, для которого предложено автострахование. Страховой агент может взять камеру, смартфон, планшетный ПК или другое портативное устройство с установленным приложением. Результаты обработки извлеченных данных могут быть отображены в графическом интерфейсе пользователя (GUI) страховому агенту, которые могут включать в себя, например, изображение программы, которые подходят для конкретного заявителя и рассматриваемого транспортного средства.
[00101] Как будет понятно специалисту в данной области техники, аспекты настоящего изобретения могут быть воплощены в качестве системы, способа или компьютерной программы. Таким образом, аспекты настоящего изобретения могут принимать форму полностью аппаратного варианта осуществления, полностью программного варианта осуществления (включая прошивки, резидентное программное обеспечение, микропрограммы и т.д.) или варианта осуществления, совмещающего программные и аппаратные аспекты, которые в общем смысле здесь можно называть «схемой», «модулем» или «системой». Более того, аспекты настоящего изобретения могут принимать форму компьютерной программы, размещенной на одном или более машиночитаемом(-ых) носителе(-ях) с размещенным на нем (них) читаемым кодом программы.
[00102] Может использоваться любая комбинация одного или более машиночитаемого(-ых) носителя(-ей). Машиночитаемым носителем может быть машиночитаемый сигнал или машиночитаемый носитель данных. Машиночитаемым носителем данных могут быть, помимо прочего, например, электронные, магнитные, оптические, электромагнитные, инфракрасные или полупроводниковые системы, оборудование или устройства, или любая подходящая комбинация вышеперечисленного. Более конкретные примеры (неполный перечень) машиночитаемых носителей данных могут включать следующее: электрическое соединение с одним или более проводами, переносная компьютерная дискета, жесткий диск, оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), программируемое постоянное запоминающее устройство (ППЗУ или флэш-память), оптоволокно, портативный привод для компакт-дисков (CD-ROM), оптическое запоминающее устройство, магнитное запоминающее устройство или подходящую комбинацию всего вышеуказанного. В контексте этого документа машиночитаемым носителем данных может быть любой материальный носитель, который может содержать или хранить программу для использования вместе с системой выполнения команд, оборудованием или устройством.
[00103] Программный код, реализованный на машиночитаемом носителе, может быть перенесен с помощью любого подходящего носителя, включая, помимо прочего, беспроводное соединение, проводное соединение, оптоволоконный кабель, инфракрасное соединение и т.д. или подходящую комбинацию всего вышеуказанного. Код компьютерной программы для выполнения операций для аспектов настоящего изобретения может быть написан на любой комбинации одного или более языков программирования, включая языки объектно-ориентированного программирования, например, Java, Smalltalk, C++ и т.п., и традиционные языки процедурного программирования, например, язык программирования С или схожие языки программирования. Код программы может полностью исполняться на компьютере пользователя, частично на компьютере пользователя в качестве отдельного программного пакета, частично на компьютере пользователя и частично на удаленном компьютере или полностью на удаленном компьютере или сервере. В последнем сценарии удаленный компьютер может быть подключен к компьютеру пользователя посредством сети любого типа, включая локальную сеть (LAN) или глобальную сеть (WAN), или через соединение с внешним компьютером (например, через Интернет с помощью поставщика услуг Интернета).
[00104] Аспекты настоящего изобретения были описаны выше со ссылкой на графическое представление и/или блок-схемы методов, устройств (систем) и компьютерных программ в соответствии с вариантами реализации изобретения. Подразумевается, что каждый блок графического представления и/или блок-схемы и комбинации блоков в графическом представлении или блок-схемах могут реализовываться командами компьютерных программ. Эти команды компьютерной программы могут быть предоставлены процессору компьютера общего назначения, компьютеру специального назначения или другого программируемого устройства обработки данных для создания такого механизма, в котором команды, исполняемые процессором компьютера или другого программируемого устройства для обработки данных, создают средства для реализации функций/действий, указанных в блоке или блоках графического представления или блок-схемы.
[00105] Эти команды компьютерной программы также могут храниться на машиночитаемом носителе, который может управлять режимами работы компьютеров, других программируемых устройств обработки данных или иных устройств, чтобы команды, хранящиеся на машиночитаемом носителе, создавали готовое изделие, включая команды, которые реализуют функции/действия блока или блоков графического представления, или блок-схемы. Команды компьютерной программы могут также быть загружены на компьютер, другое программируемое устройство обработки данных или иные устройства для вызова серии действий для выполнения на компьютере, другом программируемом устройстве или иных устройствах для создания такого реализованного на компьютере процесса, что команды, которые исполняются на компьютере или другом программируемом устройстве, предоставляют процессы для реализации функций/действий блока или блоков графического представления и/или блок-схемы.
[00106] Графическое представление и блок-схемы на вышеуказанных рисунках демонстрируют архитектуру, функциональные возможности и работу возможных реализации систем, способов и компьютерных программ в соответствии с вариантами осуществления настоящего изобретения. В этом отношении каждый блок в графическом представлении или блок-схеме может представлять модуль, сегмент или часть кода, которые содержат одну или более исполняемых команд для реализации указанной(-ых) логической(-их) функции(-ий). Также следует заметить, что в некоторых альтернативных реализациях упомянутые в блоке функции могут появляться в порядке, отличном от указанного на рисунках. Например, два блока, показанные последовательно, могут на самом деле исполняться практически одновременно, или блоки иногда могут исполняться в обратном порядке в зависимости от задействованных функциональных возможностей. Также следует заметить, что каждый блок блок-схем или графического представления и комбинации блоков в блок-схемах и графическом представлении могут реализовываться в виде систем специального назначения, ориентированных на аппаратное обеспечение, выполняющих указанные функции или действия, или комбинаций оборудования специального назначения и компьютерных команд.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВВОД ДАННЫХ ИЗ СЕРИИ ИЗОБРАЖЕНИЙ, СООТВЕТСТВУЮЩИХ ШАБЛОННОМУ ДОКУМЕНТУ | 2016 |
|
RU2634192C1 |
| Способ обучения классификатора, предназначенного для определения категории документа | 2017 |
|
RU2672395C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| СПОСОБЫ И СИСТЕМЫ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ СЕРИИ ИЗОБРАЖЕНИЙ | 2017 |
|
RU2673016C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ АДАПТИВНЫХ ТЕХНОЛОГИЙ НА ОСНОВЕ НЕЙРОСЕТЕЙ И КОМПЬЮТЕРНОГО ЗРЕНИЯ | 2020 |
|
RU2744769C1 |
| ВЕРИФИКАЦИЯ РЕЗУЛЬТАТОВ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ | 2016 |
|
RU2634194C1 |
| ИДЕНТИФИКАЦИЯ ПОЛЕЙ НА ИЗОБРАЖЕНИИ С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2018 |
|
RU2695489C1 |
| МЕТОД И СИСТЕМА ИЗВЛЕЧЕНИЯ ДАННЫХ ИЗ ИЗОБРАЖЕНИЙ СЛАБОСТРУКТУРИРОВАННЫХ ДОКУМЕНТОВ | 2015 |
|
RU2613846C2 |
| Обработка электронных документов для распознавания инвойсов | 2014 |
|
RU2679209C2 |
Группа изобретений относится к технологиям ввода данных с помощью оптического или интеллектуального распознавания символов. Техническим результатом является обеспечение быстрого и мобильного ввода данных из документов с фиксированной структурой. Предложен способ ввода данных с изображения документа с фиксированной структурой с помощью процессорного устройства. Способ содержит этап, на котором получают электронное изображение документа с фиксированной структурой. Далее, осуществляют распознавание ключевых слов на изображении документа. А также осуществляют идентификацию, по меньшей мере, одного опорного объекта на основе распознанных ключевых слов, где, по меньшей мере, один опорный объект указывает, по меньшей мере, на одну область изображения документа с фиксированной структурой, откуда следует выполнить ввод данных; наложение нескольких шаблонов из множества шаблонов на документ с фиксированной структурой с помощью идентифицированного, по меньшей мере, одного опорного объекта. 3 н. и 45 з.п. ф-лы, 13 ил.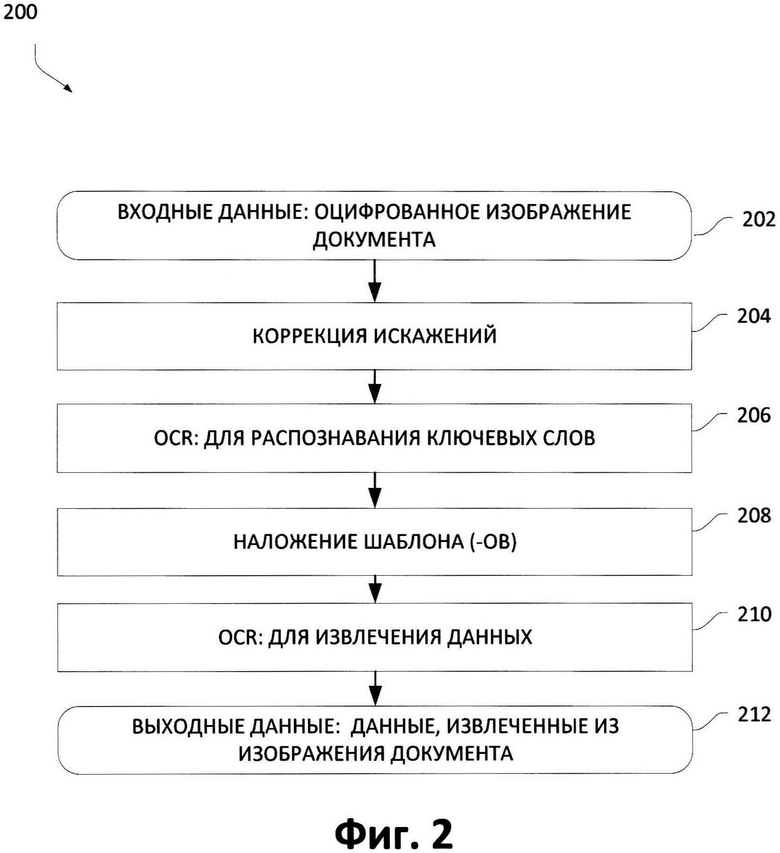
1. Способ ввода данных с изображения документа с фиксированной структурой с помощью процессорного устройства, способ содержит операции:
получение электронного изображения документа с фиксированной структурой;
распознавание ключевых слов на изображении документа;
идентификацию, по меньшей мере, одного опорного объекта на основе распознанных ключевых слов, где, по меньшей мере, один опорный объект указывает, по меньшей мере, на одну область изображения документа с фиксированной структурой, откуда следует выполнить ввод данных;
наложение нескольких шаблонов из множества шаблонов на документ с фиксированной структурой с помощью идентифицированного, по меньшей мере, одного опорного объекта;
выбор шаблона из множества шаблонов с помощью показателя качества распознавания одного или более ключевых слов; и
извлечение данных из изображения документа с помощью выбранного шаблона.
2. Способ по п. 1, дополнительно содержащий выполнение коррекции искажений изображения документа с фиксированной структурой.
3. Способ по п. 2, в котором выполняется коррекция искажений, содержащая, по меньшей мере, одно из следующих:
выравнивание линий, коррекция перекоса, коррекция геометрии документа, цветовая коррекция, восстановление смазанных и несфокусированных областей и удаление шума.
4. Способ по п. 2, в котором выполняется коррекция искажений, содержащая обнаружение границ на изображении документа с фиксированной структурой.
5. Способ по п. 4, дополнительно содержащий обрезку изображения вдоль обнаруженных границ.
6. Способ по п. 1, дополнительно содержащий применение, по меньшей мере, одного фильтра к изображению документа с фиксированной структурой.
7. Способ по п. 1, дополнительно содержащий определение типа документа на основе выбранного шаблона.
8. Способ по п. 7, в котором выбор шаблона основан на показателе качества наложения шаблона.
9. Способ по п. 1, в котором опорным объектом является регулярное выражение.
10. Способ по п. 1, в котором распознавание изображения документа основано на дополнительной информации о распознанных ключевых словах.
11. Способ по п. 1, дополнительно содержащий:
вычисление для каждого шаблона из множества шаблонов показателя качества наложения шаблона на изображение документа с фиксированной структурой и идентификацию шаблонов из множества шаблонов, качество наложения которых выше предварительно заданного порога;
сохранение идентифицированных шаблонов.
12. Способ по п. 1, дополнительно содержащий вычисление показателя качества распознанного текста в распознанном ключевом слове.
13. Способ по п. 12, дополнительно содержащий экспорт распознанного текста, если качество распознанного текста превышает пороговое значение.
14. Способ по п. 1, в котором множество шаблонов содержит, по меньшей мере, один предварительно созданный шаблон.
15. Способ по п. 1, дополнительно содержащий создание одного или более шаблонов на основе, по меньшей мере, одного идентифицированного опорного объекта.
16. Способ по п. 1, дополнительно содержащий распознавание изображения документа с помощью выбранного шаблона.
17. Система ввода данных с изображения документа с фиксированной структурой с помощью процессорного устройства, причем система содержит:
процессорное устройство, причем процессорное устройство выполняет:
получение электронного изображения документа с фиксированной структурой;
распознавание ключевых слов на изображении документа;
идентифицирование, по меньшей мере, одного опорного объекта на основе распознанных ключевых слов, где, по меньшей мере, один опорный объект указывает, по меньшей мере, на одну область изображения документа с фиксированной структурой, откуда следует выполнить ввод данных;
наложение нескольких шаблонов из множества шаблонов документа с фиксированной структурой с помощью идентифицированного, по меньшей мере, одного опорного объекта;
выбор шаблона из множества шаблонов с помощью качества распознанных ключевых слов; и
извлечение данных из изображения документа с помощью выбранного шаблона.
18. Система по п. 17, дополнительно содержащая выполнение коррекции искажений изображения документа с фиксированной структурой.
19. Система по п. 18, в которой выполняется коррекция искажений, содержащая, по меньшей мере, одно из: выравнивание линий, коррекция перекоса, коррекция геометрии документа, коррекция цветов, восстановление смазанных и несфокусированных областей и удаление шума.
20. Система по п. 18, в которой выполняется коррекция искажений, содержащая обнаружение границ на изображении документа с фиксированной структурой.
21. Система по п. 20, дополнительно содержащая обрезку изображения вдоль обнаруженных границ.
22. Система по п. 17, дополнительно содержащая применение, по меньшей мере, одного фильтра к изображению документа с фиксированной структурой.
23. Система по п. 17, дополнительно содержащая определение типа документа на основе выбранного шаблона.
24. Система по п. 23, в которой выбор шаблона основан на показателе качества наложения шаблона.
25. Система по п. 17, в которой опорным объектом является регулярное выражение.
26. Система по п. 17, в которой распознавание изображения документа основано на дополнительной информации о распознанных ключевых словах.
27. Система по п. 17, дополнительно содержащая
вычисление для каждого шаблона из множества шаблонов показателя качества наложения шаблона на изображение документа с фиксированной структурой и идентификацию шаблонов из множества шаблонов, качество наложения которых выше предварительно заданного порога;
сохранение идентифицированных шаблонов.
28. Система по п. 17, дополнительно содержащая вычисление показателя качества распознанного текста в распознанном ключевом слове.
29. Система по п. 28, дополнительно содержащая экспорт распознанного текста, если качество распознанного текста превышает пороговое значение.
30. Система по п. 17, в которой множество шаблонов содержит, по меньшей мере, один предварительно созданный шаблон.
31. Система по п. 17, дополнительно содержащая создание одного или более шаблонов на основе, по меньшей мере, одного идентифицированного опорного объекта.
32. Система по п. 17, дополнительно содержащая распознавание изображения документа с помощью выбранного шаблона.
33. Машиночитаемый носитель данных, имеющий хранящиеся на нем команды, исполнение которых процессором приводит к выполнению процессором операций, содержащих:
получение электронного изображения документа с фиксированной структурой;
распознавание ключевых слов в изображении документа;
идентификацию, по меньшей мере, одного опорного объекта на основе распознанных ключевых слов, где, по меньшей мере, один опорный объект указывает, по меньшей мере, на одну область изображения документа с фиксированной структурой, откуда следует выполнить ввод данных;
наложение нескольких шаблонов из множества шаблонов для документа с фиксированной структурой с помощью идентифицированного, по меньшей мере, одного опорного объекта;
выбор шаблона из множества шаблонов с помощью качества распознанных ключевых слов; и
извлечение данных из изображения документа с помощью выбранного шаблона.
34. Машиночитаемый носитель данных по п. 33, дополнительно содержащий выполнение коррекции искажений изображения документа с фиксированной структурой.
35. Машиночитаемый носитель данных по п. 34, в котором выполняется коррекция искажений, содержащая, по меньшей мере, одно из: выравнивание линий, коррекция перекоса, коррекция геометрии документа, цветовая коррекция, восстановление смазанных и несфокусированных областей и удаление шума.
36. Машиночитаемый носитель данных по п. 34, в котором выполняется коррекция искажений, содержащая обнаружение границ на изображении документа с фиксированной структурой.
37. Машиночитаемый носитель данных по п. 36, дополнительно содержащий обрезку изображения вдоль обнаруженных границ.
38. Машиночитаемый носитель данных по п. 33, дополнительно содержащий применение, по меньшей мере, одного фильтра к изображению документа с фиксированной структурой.
39. Машиночитаемый носитель данных по п. 33, дополнительно содержащий определение типа документа на основе выбранного шаблона.
40. Машиночитаемый носитель данных по п. 39, в котором выбор шаблона основан на показателе качества наложения шаблона.
41. Машиночитаемый носитель данных по п. 33, в котором опорный объект является регулярным выражением.
42. Машиночитаемый носитель данных по п. 33, в котором распознавание изображения документа основано на дополнительной информации о распознанных ключевых словах.
43. Машиночитаемый носитель данных по п. 33, дополнительно содержащий:
вычисление для каждого шаблона из множества шаблонов качества наложения шаблона на изображение документа с фиксированной структурой и идентификацию шаблонов из множества шаблонов, качество наложения которых выше предварительно заданного порога;
сохранение идентифицированных шаблонов.
44. Машиночитаемый носитель данных по п. 33, дополнительно содержащий вычисление показателя качества распознанного текста в распознанных ключевых словах.
45. Машиночитаемый носитель данных по п. 44, дополнительно содержащий экспорт распознанного текста, если качество распознанного текста превышает пороговое значение.
46. Машиночитаемый носитель данных по п. 33, в котором множество шаблонов содержит, по меньшей мере, один предварительно созданный шаблон.
47. Машиночитаемый носитель данных по п. 33, дополнительно содержащий создание одного или более шаблонов на основе, по меньшей мере, одного идентифицированного опорного объекта.
48. Машиночитаемый носитель данных по п. 33, дополнительно содержащий распознавание изображения документа с помощью выбранного шаблона.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 7149347 B1, 12.12.2006 | |||
| СПОСОБ ПРИВЕДЕНИЯ В СООТВЕТСТВИЕ ЗАПОЛНЕННОЙ МАШИНОЧИТАЕМОЙ ФОРМЫ И ЕЕ ШАБЛОНА ПРИ НАЛИЧИИ ИСКАЖЕНИЙ (ВАРИАНТЫ) | 2003 |
|
RU2251738C2 |

