Изобретение имеет отношение к способу формирования "отпечатка" для полезного сигнала.
Используемый здесь термин "полезный сигнал" обозначает сигналы, которые представляют собой данные, предназначенные в конечном счете для восприятия пользователем, в частности пользователем-человеком. Обычными примерами полезных сигналов являются звуковые сигналы, представляющие собой развертывание во времени спектра частот для акустических волн (спектр имеет диапазон, например, от 300 Гц до 3400 Гц для телефонии или от 10 Гц до 20 кГц для высококачественного воспроизведения классического концерта) или видеосигналов (одиночных, а также динамических изображений), где частота полезного сигнала, например, для отображения по телевидению или на киноэкране определяется свойствами изображения и лежит между 0 Гц (пустое изображение) и максимальной частотой, определяемой количеством строк и столбцов экрана и частотой обновления для динамических изображений, например, 6,5 МГц для многих систем телевидения.
Полезные сигналы, однако, также могут включать в себя сигналы, представляющие текстовые строки или другие представления, а также перспективы развития таких сигналов, прямо или косвенно предназначенных, в частности, для восприятия человеком.
Полезные сигналы могут быть представлены в аналоговом виде, например как радио или телевизионные сигналы, или могут быть представлены как цифровые сигналы, например сигналы импульсно-кодовой модуляции (ИКМ; PCM), сформированные посредством дискретизации аналогового сигнала с помощью этапов последовательного квантования и, возможно, кодирования. В любом случае подразумевается, что полезный сигнал содержит полное представление значимого набора данных, являющегося отдельным музыкальным произведением или их набором, фонограммами, отдельным изображением или целым фильмом.
Имеется общая потребность сравнивать полезные сигналы друг с другом, например, с целью отличия конкретного сигнала от других сигналов или для проверки идентичности двух полезных сигналов.
Очевидным способом проверки идентичности двух цифровых сигналов является побитовое сравнение. Однако эта процедура не является пригодной во многих случаях: предположим, что сигнал был дублирован при помощи процедуры копирования таким образом, что сигналы являются идентичными друг другу. Если второй сигнал затем изменен, например преобразован в популярный формат MP3 с целью загрузки, после распаковки сравнение двух сигналов приведет к тому, что два сигнала являются различными. То же самое относится к цифроаналоговому и аналого-цифровому преобразованиям.
Кроме того, насколько известно, нет способа автоматической идентификации полезных сигналов, которые не являются идентичными, но только сходны друг с другом, где сходство должно пониматься с точки зрения человека. Например, не известны технические способы идентификации музыкальных фонограмм, которые являются сходными друг с другом по мелодии или ритму.
Как правило, чтобы сделать возможной автоматическую обработку полезных сигналов, вместе с сигналом нужно предоставить идентифицирующие данные. Как пример к музыкальной фонограмме могут быть добавлены поля данных для строк, представляющих авторство, дату записи, тип музыки и т.д. С целью определения идентичных или сходных сигналов должны быть обработаны эти дополнительные поля данных. Однако трудно идентифицировать сходные сигналы, например фонограммы с классической музыкой и рок-музыкой со сходной мелодией.
Данные, идентифицирующие полезный сигнал в одном или более аспектах, далее называются "отпечатком" (иногда такие данные также называют характерным признаком). В частности, данные "отпечатка" могут идентифицировать сигнал относительно человеческого восприятия во время приема сигнала пользователем-человеком.
Задачей изобретения является обеспечение способа формирования "отпечатка" для полезного сигнала, в частности звукового сигнала, который делает возможным автоматическое обнаружение идентичных или сходных полезных сигналов экономичным образом, причем "отпечаток" устойчив к модификациям полезного сигнала, не заметным для пользователей-людей, и который делает возможным эффективное обнаружение идентичных или сходных "отпечатков", и обеспечение соответствующих устройств.
Эта задача решается посредством способа с признаками, описанными в п.1 формулы изобретения, и устройства с признаками, описанными в п.18 формулы изобретения.
В соответствии с изобретением, по меньшей мере, один набор данных, содержащий часть полезного сигнала, обрабатывают анализатором согласно предопределенной анализирующей команде, причем анализатор выдает в качестве результата обработки вектор данных "отпечатка", зависящий от обработанного набора данных и идентифицирующий его.
Одна из фундаментальных идей изобретения заключается в формировании "отпечатка" в результате обработки полезного сигнала или его части посредством анализирующей команды полезного сигнала. Таким образом, "отпечаток" содержит вектор данных "отпечатка, который представляет собой свойства полезного сигнала непосредственно. Не требуется, чтобы администратор-человек вручную добавлял описательные данные к полезному сигналу. Поскольку "отпечаток" связан со свойствами полезного сигнала, идентичные и сходные полезные сигналы могут быть идентифицированы посредством подходящего сравнения соответствующих "отпечатков".
Говоря более подробно, в соответствии с изобретением способ формирования "отпечатка" для полезного сигнала, в частности звукового сигнала, причем полезный сигнал представляет собой развертывание во времени спектра, содержащего частоты полезного сигнала, например звуковые частоты, состоит в том, что, по меньшей мере, один набор данных, содержащий часть полезного сигнала, обрабатывают посредством анализатора в соответствии с предопределенной анализирующей командой, причем анализатор выдает в качестве результата обработки вектор данных "отпечатка", зависящий от обработанного набора данных и идентифицирующий его.
В предпочтительных вариантах воплощения способа изобретения анализирующая команда обрабатывает набор данных с учетом свойств набора данных, которые являются заметными для человеческого ощущения во время восприятия полезного сигнала людьми. Таким образом, идентификация полезных сигналов, которые кажутся сходными человеческому восприятию, является успешно возможной.
В дополнительных предпочтительных вариантах воплощения способа изобретения набор данных обрабатывается двумя или более анализаторами и/или двумя или более анализирующими командами и вектор данных "отпечатка" представляет собой результаты обработки посредством анализаторов и/или анализирующих команд. Таким образом, два или более свойств полезных сигналов могут быть представлены в "отпечатке", например мелодия и ритм.
В других вариантах воплощения изобретения обрабатываются два или более перекрывающихся или не перекрывающихся наборов данных полезного сигнала и вектор данных "отпечатка" представляет собой результаты обработки наборов данных. Таким образом, возможности представления свойств сигнала в векторе данных "отпечатка" значительно расширены.
В дополнительных вариантах воплощения способа изобретения набор данных содержит кадр полезного сигнала, анализирующая команда содержит сравнение набора данных с каждым образцовым кадром предопределенного словаря образцов, причем словарь образцов содержит пронумерованный список образцовых кадров и содержит оценку сходства кадра полезного сигнала с каждым из образцовых кадров, и анализатор выдает в качестве результата обработки набора данных номер образцового кадра, который имеет наибольшее сходство с кадром полезного сигнала. С успехом возможно отображать образцы, встречающиеся в полезном сигнале, которые, например, могут являться типичными для специфического вида сигнала, на известные образцы и заменять образец номером образца. Таким образом, возможно охарактеризовать с помощью маленького набора данных (набора номеров образцов) намного бόльший набор данных полезного сигнала.
В дополнительно проработанном варианте воплощения кадру полезного сигнала присваивается вектор кадра полезного сигнала, каждому из образцовых кадров присваивается вектор образцового кадра и сходство каждой пары кадра полезного сигнала и образцового кадра определяется посредством вычисления расстояния между вектором кадра полезного сигнала и соответствующим вектором образцового кадра. Таким образом, могут быть успешно применены эффективные алгоритмы, известные из векторного анализа.
В еще более проработанном варианте воплощения анализатор является спектральным анализатором, который вычисляет сглаженные параметры спектра, в частности кепстральные коэффициенты для кадра с использованием алгоритма линейного прогнозирования. Кроме того, кепстральные коэффициенты могут быть закодированы с использованием словаря образцов и матрицы расстояний между базисными векторами словаря образцов. В этом случае предпочтительно возможно анализировать относящиеся к тону свойства полезного сигнала (например, для музыкальных фонограмм) и представлять результаты анализа в "отпечатке".
В других предпочтительных вариантах воплощения способа изобретения анализатор содержит частотные фильтры для обработки спектра частот каждого из наборов данных, причем каждый из частотных фильтров выполнен с возможностью фильтровать отдельный тон из спектра частот наборов данных, выдавая в результате набор тонов, и анализирующая команда содержит вычисление амплитуды каждого из тонов каждого из наборов данных. Таким образом, ритм и мелодия или дополнительные относящиеся к тону свойства могут быть легко проанализированы.
В дополнительных вариантах воплощения способа изобретения анализирующие команды дополнительно содержат команды вычисления частоты появления разных тонов, в частности, для определения мелодии полезного сигнала и/или продолжительности одного или более тонов, в частности, для определения ритма и/или значения количества ударов в минуту для полезного сигнала.
В дополнительных вариантах воплощения способа изобретения анализатор содержит дециматор сигнала для дискретизации полезного сигнала с более низкой частотой, причем сохраняется полоса частот, содержащая, по меньшей мере, 90% энергии полезного сигнала. Это уменьшает требования к оборудованию остальной части системы.
В другом варианте воплощения изобретения анализатор содержит датчик активных кадров для обработки полезного сигнала таким образом, что наборы данных с энергией ниже предопределенного порога исключаются из дальнейшей обработки, для которого пороговое значение получено посредством умножения средней энергии сигнала на определяемый пользователем весовой коэффициент. Эта процедура предотвращает ложные срабатывания, вызванные шумом.
В соответствии с изобретением способ идентификации полезных сигналов из предопределенного набора полезных сигналов, которые являются идентичными или сходными входному полезному сигналу, причем каждому из полезных сигналов присвоен "отпечаток", сформированный в соответствии со способом любого из предыдущих пунктов, содержит блок идентификатора, который:
- принимает в качестве входных данных вектор данных "отпечатка" входного полезного сигнала,
- для каждой пары входного полезного сигнала и одного из набора полезных сигналов вычисляет расстояние в соответствии с предопределенной командой вычисления расстояния между соответствующими векторами данных "отпечатка",
- возвращает в качестве результата идентификации список полезных сигналов, расстояние которых является меньшим, чем предопределенное пороговое значение.
Это дает возможность быстрой и надежной идентификации идентичных или сходных сигналов.
В предпочтительном варианте воплощения упомянутого выше способа этап вычисления расстояния содержит следующие подэтапы:
- на первом подэтапе подвекторы полезных сигналов используют при вычислении расстояния для вычисления грубого расстояния и временно идентифицируют полезные сигналы с грубыми расстояниями ниже первого порогового значения,
- на втором подэтапе расстояния временно идентифицированных полезных сигналов до входного полезного сигнала вычисляют с использованием полных векторов полезных данных. В случае большого количества сигналов в наборе полезных сигналов это дает возможность быстрой идентификации сходных полезных сигналов.
Вышеупомянутые способы могут быть осуществлены в компьютерной программе, которая выполнена с возможностью выполняться на программируемом компьютере, в программируемой компьютерной сети или на другом программируемом оборудовании. Это делает возможным дешевую, простую и быструю разработку реализаций способов изобретения. В частности, такая компьютерная программа может быть сохранена на машиночитаемом носителе, например на компакт-диске, предназначенном только для чтения (CD-ROM), или на цифровом универсальном диске, предназначенном только для чтения (DVD-ROM).
Устройства для использования со способами изобретения могут содержаться в специфических программируемых компьютерах, программируемых компьютерных сетях или другом программируемом оборудовании, на которых установлены компьютерные программы, которые осуществляют изобретение.
Дополнительные аспекты и преимущества изобретения станут очевидными из следующего описания вариантов воплощения изобретения в отношении приложенных чертежей, показывающих:
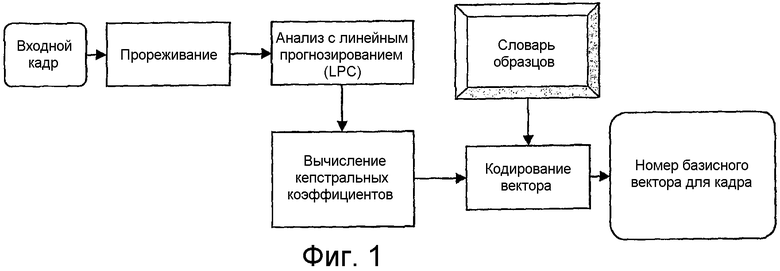
фиг.1 - схематическое представление первого варианта воплощения изобретения;
фиг.2 - схематическое представление второго варианта воплощения изобретения;
фиг.3 - схематическое представление вектора данных "отпечатка" в соответствии с изобретением;
Настоящее изобретение предлагает два независимых анализатора.
Первый анализатор выполняет кодирование вектора с использованием словаря образцов (фиг.1). Для каждого кадра проанализированной последовательности вычисляется N-мерный входной вектор, состоящий из N=12 кепстральных коэффициентов, с использованием алгоритма линейного прогнозирования (LCP).
Представительный набор музыкальных фонограмм был обработан для создания словаря образцов. Для этого набора полезных сигналов был сформирован набор входных векторов. Словарь образцов был создан из этого набора векторов с использованием вычисления центра масс для проектирования кодировочной книги (L. Rabiner, B. Juang. Основные принципы распознавания речи. AT&T, 1993). Приемлемый размер словаря образцов (8192 базисных вектора) был определен экспериментально.
Текущий входной вектор затем заменяется базисным вектором, который является самым близким ко входному вектору по выбранному показателю. Таким образом, каждый кадр полезного сигнала кодируется в один номер базисного вектора. Поэтому целый фрагмент кодируется как последовательность номеров Tan/Tframe базисных векторов из словаря образцов.
Этот алгоритм обеспечивает эффективное кодирование музыкальных файлов с коэффициентом сжатия, превышающим 17500. В компьютерной системе пользователь может установить упомянутые выше параметры в соответствии со свойствами обрабатываемого полезного сигнала. "Отпечатки", основанные на D-кодах (словарных кодах), применимы к широкому диапазону полезных сигналов (звук, видео, медицина и т.д.).
В предпочтительных вариантах воплощения изобретения для использования со звуковыми сигналами полезный сигнал анализируют в отдельных фрагментах, каждый с длиной Tan = 60 секунд. Для каждого фрагмента формируют отдельный код "отпечатка". Соседние фрагменты выбирают с наложением на 1/2Tan.
Предпочтительно сигнал дискретизируют с более низкой частотой 8000 Гц, что по существу срезает его частоты на частоте 4000 Гц. Интервал сигнала, который должен быть проанализирован, разбивают на последовательные кадры по Tfr = 0,2 секунды каждый. В компьютерной системе пользователь может настроить эти параметры в соответствии со свойствами обрабатываемого сигнала.
Второй анализатор основан на реализации быстрого преобразования Фурье (FFT) блока неоднородных фильтров (фиг.2). Блок фильтров с центральными частотами, соответствующими тонам, реализован с использованием алгоритма быстрого преобразования Фурье (FFT) с размерностью Nfft=65536.
Центральные частоты фильтров Fk должны соответствовать частотам нот (тонов):
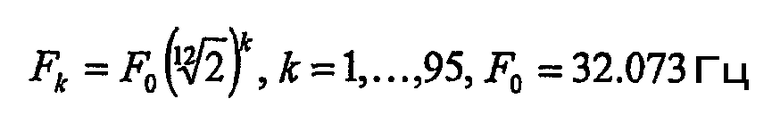
Временные зависимости амплитуд на выходе фильтров, вычисленные для каждого кадра, используются для оценки мелодии и ритма для обрабатываемого кадра полезного сигнала. В предпочтительном варианте воплощения, который рассматривается здесь, алгоритм оценки реализован в следующих этапах:
1) Все ноты (тоны) транспонируют в одну октаву, где они получают номера i = 0, 1, ..., 11, сохраняя максимальную амплитуду A[i] исходной ноты.
2) Номера n[i] нот сортируют в порядке уменьшения амплитуд:
А[n[0]]>А[n[1]]>...> А[n[11]]
3) Из K кадров фрагмента формируют последовательности из трех нот:
{n[0, k]}, {n[1, k]}, {n[2, k]}, где k = 0, 1, ..., K-1.
4) Вычисляют частоту появления первых трех нот Pn[0, i], Pn[1, i], Pn[2, i], i = 0, 1, ..., 11, и вычисляют 36-мерный вектор для обрабатываемого фрагмента. Этот вектор по существу является оценкой мелодии (М-кодом).
5) Компоненты этого 36-мерного вектора записывают как оценку мелодии для обрабатываемого фрагмента.
6) Вычисляют последовательность значений продолжительности нот для последовательности n[0, k].
7) Вычисляют 12-мерный вектор, состоящий из частот появления значений продолжительности в пределах от 0,2 до 4,0 секунд.
8) Вычисляют взвешенный средний интервал и 20-мерный вектор ритма.
9) Оценивают количество ударов в минуту для фрагмента (это, по существу, значение темпа), которое записывают вместе с компонентами 20-мерного вектора ритма.
В варианте воплощения изобретения, содержащем оба анализатора, выполняются следующие этапы:
1) Полезный сигнал сначала обрабатывают посредством дециматора сигнала, какой дискретизирует полезный сигнал с более низкой частотой, но сохраняет полосу частот, содержащую, по меньшей мере, 90% энергии исходного полезного сигнала. Это уменьшает требования к оборудованию остальной части системы.
Фильтр с переменным количеством зависимых от частоты секций и переменной скоростью дискретизации может использоваться для прореживания полезного сигнала; это позволяет пользователю сохранить самые важные свойства полезного сигнала для вычисления данных "отпечатка" после прореживания.
2) После прореживания полезный сигнал, дискретизированный с более низкой частотой, обрабатывают датчиком активных кадров, который исключает кадры с энергией ниже установленного порога из дальнейшей обработки, для которого пороговое значение получено посредством умножения средней энергии сигнала на определяемый пользователем весовой коэффициент. Эта процедура предотвращает ложные срабатывания, вызванные шумом.
В описанном здесь варианте воплощения все кадры текущего фрагмента с энергией ниже определенного порога исключают из дальнейшей обработки в соответствии со следующими этапами:
a) вычисляют порог ThN в соответствии со следующими формулами:
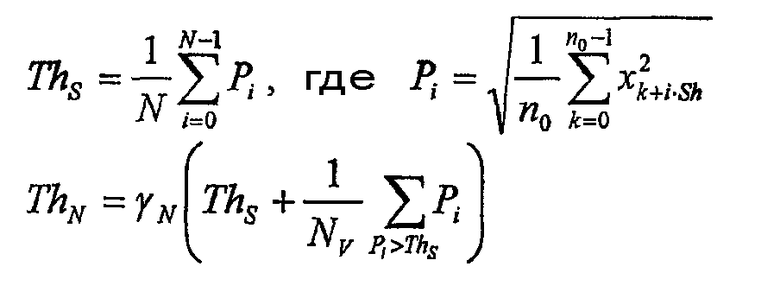
Здесь NV - количество кадров с Pi>ThS, n0 - длина кадра, N - количество кадров во фрагменте, Sh - длина перекрывания, γN - определяемый пользователем весовой коэффициент;
b) для каждого кадра i вычисляют его характеристику Si:
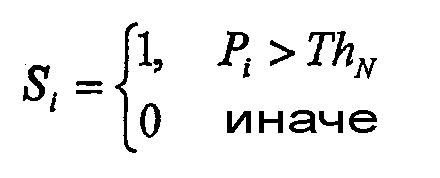
Кадр с порядковым номером i передают на следующие стадии анализа, если
Si-1+Si+Si+1>1.
В ином случае его исключают из дальнейшей обработки.
3) Оставшиеся кадры обрабатывают посредством спектрального анализатора, который вычисляет сглаженные параметры спектра (кепстральные коэффициенты) для каждого кадра с использованием алгоритма линейного прогнозирования.
Здесь описаны методика сравнения образцов и показатели спектрального искажения для кепстральных расстояний. Словарь образцов и матрица расстояний между базисными векторами словаря образцов получены заранее посредством обработки множества полезных сигналов (L. Rabiner, B. Juang. Основные принципы распознавания речи. AT&T, 1993).
Количество базисных векторов в словаре образцов зависит от класса полезных сигналов. Предпочтительные значения составляют 1024-2048 для речи и 4096-8192 для музыки. Если технология изобретения отпечатка применяется для сигналов с разными свойствами, отдельный словарь образцов должен быть сформирован для каждого класса сигналов вместе с соответствующей матрицей расстояний между базисными векторами.
Номер базисного вектора из словаря образцов, соответствующий текущему кадру (то есть словарный код кадра), получают посредством следующих этапов:
a) анализ с линейным прогнозированием (LPС),
b) вычисление N кепстральных коэффициентов,
c) кодирование вектора с использованием словаря образцов.
4) N кепстральных коэффициентов для текущего кадра эффективно кодируют с использованием предварительно вычисленного словаря образцов и матрицы расстояний между базисными векторами словаря образцов. Полученный словарный код текущего кадра является одним номером базисного вектора из словаря образцов. Этот алгоритм обеспечивает высокую степень сжатия и высокую эффективность декодирования. Словарный код целого фрагмента является последовательностью номеров базисных векторов из словаря образцов.
5) Анализ и кодирование отличительных признаков полезного сигнала выполняют с использованием реализации быстрого преобразования Фурье (FFT) блока неоднородных фильтров. Размер быстрого преобразования Фурье (FFT) и ограничивающие частоты блока фильтров определяются пользователем в соответствии с классом полезного сигнала. Для звуковых сигналов предлагается значение Nfft=65536, и ограничивающие частоты выбраны так, чтобы включать в себя тоны в пределах от 32 Гц до 3950 Гц.
Анализ частоты появления разных нот дает соответствующий код мелодии (М-код) для текущего фрагмента полезного сигнала. Анализ продолжительности каждой ноты дает R-код и значение ударов в минуту (Nbpm) для текущего фрагмента.
Для оценки отличительных свойств полезного сигнала, их кодирования и добавления к данным "отпечатка" используется реализация быстрого преобразования Фурье (FFT) блока неоднородных фильтров, причем для музыки блок неоднородных фильтров выбран так, чтобы центральные частоты Fk фильтров соответствовали частотам нот:
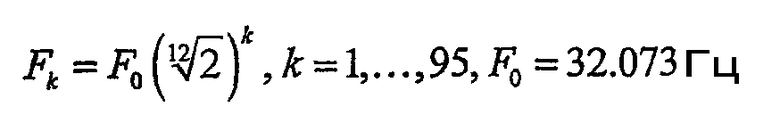
М-код, R-код и Nbpm для текущего фрагмента вычисляют на следующих этапах:
a) блок фильтров быстрого преобразования Фурье (FFT),
b) временные зависимости спектральных амплитуд,
c) транспонирование всех нот в одну октаву (ноты получают номера от 0 до 11) и сортировка нот в порядке уменьшения амплитуды,
d) оценка мелодии (М-код),
e) оценка ритма (R-код),
f) оценка темпа (Nbpm).
Относительно большой размер быстрого преобразования Фурье (FFT) позволяет настраивать блок фильтров на свойства сигнала, только изменяя числа коэффициентов быстрого преобразования Фурье (FFT), которые определяют граничные частоты фильтров.
Структура данных "отпечатка", получающихся из комбинации выходных данных анализатора на фиг.1 и анализатора на фиг.2, показана на фиг.3. Данные "отпечатка" состоят из набора номеров образцов из словаря образцов, 36-мерного вектора, 20-мерного вектора и числа. Конечно, в других вариантах воплощения может использоваться только один анализатор. Получающиеся "отпечатки" соответственно имеют меньше элементов.
Результаты анализа многих полезных сигналов в соответствии с предыдущим описанием могут быть сохранены в базе данных. Каждому полезному сигналу могут быть присвоены уникальные данные "отпечатка", которые записаны в базе данных. "Отпечатки", соответствующие тому же самому сигналу, упорядочены согласно порядку фрагментов в сигнале. Таким образом, сигнал может быть идентифицирован не только целиком, но также и по любым из его фрагментов.
Цель базы данных зависит от цели всей системы, в которой используется технология "отпечатка". Для музыкальных сигналов данные "отпечатка" имеют следующую структуру:
данные "отпечатка" = (D-код, М-код, R-код, Nbpm).
Размер этих данных для одного фрагмента составляет приблизительно 2 килобайта.
Предпочтительный вариант воплощения способа поиска сходного кода "отпечатка" в соответствии с изобретением содержит следующие признаки.
База данных "отпечатка" для большого количества фонограмм хранится на сервере. Эта база данных также содержит атрибуты музыкальной фонограммы (название, автор, жанр и т.д.). Сервер должен также обладать средствами взаимодействия с пользователем, который может хотеть идентифицировать музыкальную фонограмму или ее часть, отправляя на сервер сформированные из нее данные "отпечатка". В ответ пользователь получает сообщение, содержащее названия и другие свойства музыкальных дорожек, отсортированные в порядке их релевантности.
Необходимость такого списка следует из возможного существования многих записей одной и той же музыки при различных условиях и в различном исполнении, которые должны быть возвращены все. Список обновляется в режиме реального времени, пока пользователь прослушивает фонограмму. Так как количество фонограмм в базе данных может достигать сотен тысяч, важно осуществить быстрый способ поиска.
Вариант воплощения, рассмотренный здесь, таким образом, содержит двухступенчатую систему поиска:
Будем обозначать код "отпечатка" текущего фрагмента как {Di, Мi, Ri, Nbpm} и код "отпечатка" из базы данных как {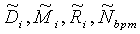 }.
}.
На первом этапе алгоритма поиска осуществляется поиск кодов "отпечатков" из базы данных только по значениям Ri и значениям Nbpm в соответствии со следующим правилом:
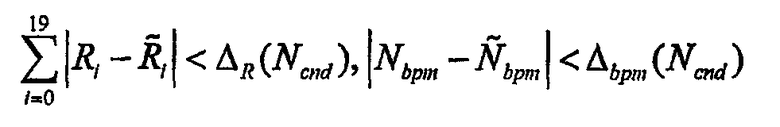
Здесь Ncnd - желаемое значение временных кандидатов и Δbpm, ΔR - настраиваемые пороги, которые зависят от Ncnd.
На втором этапе алгоритма поиска временные кандидаты сортируют в порядке уменьшения взвешенной ошибки:
ε=w1εD+w2εM+w3εR,
где
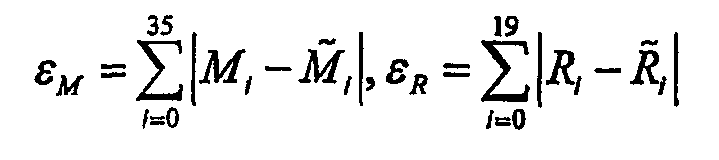
Значение εD ошибки вычисляется с использованием алгоритма динамического программирования, называемого динамическим искажением времени (DTW). Скорость поиска значительно увеличивается посредством предварительного вычисления матрицы расстояний между базисными векторами словаря образцов. Таким образом, значения εD получают суммированием элементов матрицы, соответствующих текущим значениям Di и 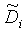 .
.
Пользователь принимает список записей базы данных вместе со значениями подобия, вычисленными с использованием формулы:
Ln=(1-ε)Sn,
где n - номер записи в списке и Sn - монотонно убывающая последовательность.
Компьютерная система позволяет настраивать все вышеупомянутые параметры согласно свойствам полезного сигнала.
Способ поиска сходных "отпечатков" в базе данных, таким образом, содержит следующие этапы:
1) Формируют данные "отпечатка" для текущего фрагмента полезного сигнала.
2) Выбирают K кандидатов из базы данных кодов "отпечатков" с использованием быстрого поиска по одному или нескольким кодам "отпечатков" из всех данных "отпечатка".
3) Сортируют выбранные K кандидатов в порядке уменьшения значений целевой функции, принимая во внимание все коды "отпечатков" сформированных данных "отпечатка".
Выбор K кандидатов обеспечивает быстрый поиск в большой базе данных даже с сотнями тысяч "отпечатков". Целевая функция обеспечивает необходимый компромисс между истинной и ложной идентификацией полезных сигналов.
В применении к музыкальным сигналам текущий фрагмент может быть идентифицирован посредством следующих этапов:
1) Фрагмент обрабатывают и формируют его данные "отпечатка", содержащие D-код, М-код, R-код и Nbpm.
2) Выполняют быстрый выбор K фрагментов-кандидатов из базы данных, для которых
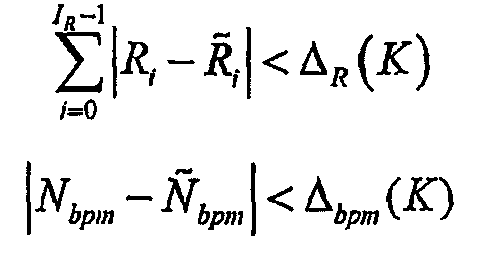
где IR - размерность соответствующего вектора R-кода, 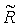 ,
, 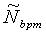 - коды "отпечатка" фрагмента-кандидата из базы данных и пороги ΔR, Δbpm зависят от желаемого количества кандидатов K.
- коды "отпечатка" фрагмента-кандидата из базы данных и пороги ΔR, Δbpm зависят от желаемого количества кандидатов K.
3) Сортируют выбранные K кандидатов в порядке уменьшения ошибки:
ε=w1εD+w2εM+w3εR,
где
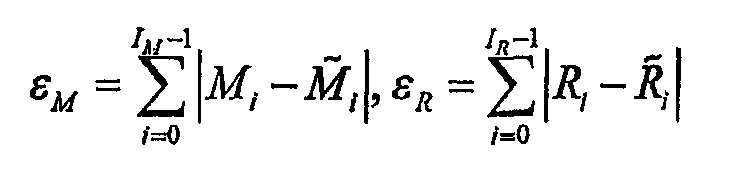
Здесь IM - размерность вектора М-кода.
Ошибка εD вычисляется с использованием алгоритма динамического искажения времени (DTW) с учетом предварительно вычисленных расстояний между базисными векторами словаря образцов.
4) Оценивают значения (L) подобия для всех K кандидатов из базы данных:
L=(1-ε)S%,
где S - функция, определяющая шкалу подобия от 0 до 100%.
В предпочтительных вариантах воплощения изобретения способы формирования "отпечатка" и поиска "отпечатка" могут быть осуществлены в программном обеспечении, в аппаратных средствах или в них обоих. Каждый способ или его компоненты могут быть описаны при помощи соответствующих языков программирования в виде машиночитаемых команд, таких как программы или программные модули. Эти компьютерные программы могут быть установлены на одном или более компьютерах или подобных программируемых устройствах и выполняться ими. Программы могут быть сохранены на сменных носителях (компакт-диски, предназначенные только для чтения (CD-ROM), цифровые универсальные диски, предназначенные только для чтения (DVD-ROM), и т.д.) или других запоминающих устройствах с целью хранения и распространения или могут быть распространены через Интернет.
Устройства, осуществляющие способ изобретения формирования и поиска "отпечатка", могут являться инструментальными средствами аудиопроигрывателя для использования на персональном компьютере (PC). Эти проигрыватели могут являться специализированными аппаратными средствами с соответствующим программным обеспечением, то есть автономным проигрывателем, или могут быть активированы на настольном дисплее персонального компьютера (PC), интегрированные в веб-страницу или загруженные и установленные как дополнение к программе для выполнения в известных проигрывателях.
В качестве примера, рабочий стол прикладной программы реализует способ изобретения формирования и поиска "отпечатка". После запроса пользователя проигрыватель начинает воспроизводить требуемую фонограмму. Сходные фонограммы (то есть фонограммы в базе данных, обслуживающей прикладную программу, со сходными "отпечатками") расположены близко друг к другу. Таким образом, пользователь может легко выбрать фонограммы с сопоставимыми свойствами. То, какие свойства используются для сравнения, также может быть выбрано пользователем.
Здесь были описаны некоторые соответствующие варианты воплощения изобретения. Многие дополнительные варианты воплощения возможны и являются очевидными для специалиста без отступления от объема изобретения, который определен исключительно формулой изобретения.

Изобретение относится к области формирования «отпечатка» для полезного сигнала, представляющего собой данные, предназначенные для восприятия пользователем. Технический результат - повышение экономичности процесса формирования «отпечатка». Изобретение касается способа формирования "отпечатка" для полезного сигнала, причем полезный сигнал представляет собой развертывание во времени спектра, содержащего частоты полезного сигнала, например звуковые частоты, который дает возможность автоматического обнаружения идентичных или сходных полезных сигналов экономичным образом, причем "отпечаток" устойчив к модификациям полезного сигнала, не заметным для пользователя - человека, причем, по меньшей мере, один набор данных, содержащий часть полезного сигнала, обрабатывают анализатором в соответствии с предопределенной анализирующей командой, причем анализатор выдает в качестве результата обработки вектор данных "отпечатка", зависящий от обработанного набора данных и идентифицирующий его. Изобретение касается также способа идентификации полезных сигналов предопределенного набора полезных сигналов, устройства для формирования отпечатка полезного сигнала, устройства для идентификации полезных сигналов предопределенного набора полезных сигналов, системы для идентификации полезных сигналов предопределенного набора полезных сигналов. 5 н. и 21 з.п. ф-лы, 3 ил.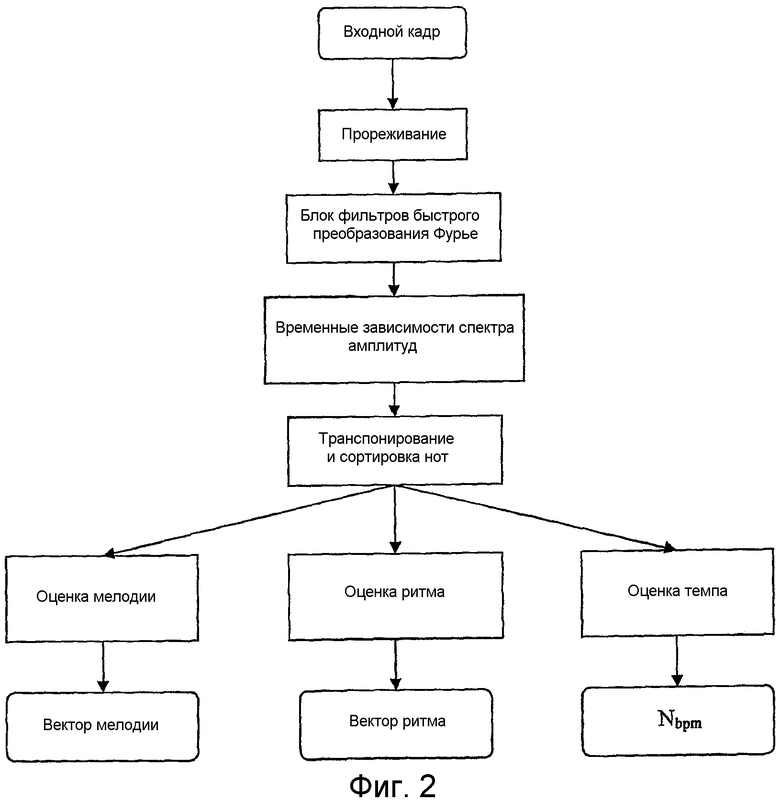
1. Способ формирования «отпечатка» для полезного сигнала, причем полезный сигнал представляет собой развертывание во времени спектра, содержащего частоты полезного сигнала, например аудиочастоты, причем способ содержит этапы, на которых:
осуществляют понижающую дискретизацию набора данных, который содержит, по меньшей мере, часть полезного сигнала, посредством, по меньшей мере, одного дециматора сигнала,
осуществляют фильтрацию дискретизированного набора данных посредством, по меньшей мере, одного фильтра,
выбирают тона наивысшей амплитуды, по меньшей мере, одним анализатором, вычисляют упомянутым, по меньшей мере, одним анализатором, согласно предопределенной анализирующей команде, вектор данных «отпечатка», представляющий выбранные тона.
2. Способ по п.1, отличающийся тем, что анализирующая команда обрабатывает набор данных относительно свойств набора данных, которые являются воспринимаемыми для человеческого ощущения во время восприятия полезного сигнала людьми.
3. Способ по п.1, отличающийся тем, что набор данных обрабатывают посредством двух или более анализаторов и/или двух или более анализирующих команд и вектор данных «отпечатка» представляет собой результаты обработки посредством анализаторов и/или анализирующих команд.
4. Способ по п.2, отличающийся тем, что набор данных обрабатывают посредством двух или более анализаторов и/или двух или более анализирующих команд и вектор данных «отпечатка» представляет собой результаты обработки посредством анализаторов и/или анализирующих команд.
5. Способ по п.1, отличающийся тем, что обрабатывают два или более накладывающихся или ненакладывающихся наборов данных полезного сигнала и вектор данных «отпечатка» представляет собой результаты обработки наборов данных.
6. Способ по п.2, отличающийся тем, что обрабатывают два или более накладывающихся или ненакладывающихся наборов данных полезного сигнала и вектор данных «отпечатка» представляет собой результаты обработки наборов данных.
7. Способ по п.3, отличающийся тем, что обрабатывают два или более накладывающихся или ненакладывающихся наборов данных полезного сигнала и вектор данных «отпечатка» представляет собой результаты обработки наборов данных.
8. Способ по п.1, отличающийся тем, что набор данных содержит кадр полезного сигнала, анализирующая команда содержит сравнение набора данных с каждым образцовым кадром предопределенного словаря образцов, причем словарь образцов содержит пронумерованный список образцовых кадров и содержит оценку сходства кадра полезного сигнала с каждым из образцовых кадров, и анализатор выдает в качестве результата обработки набора данных номер образцового кадра, который имеет наибольшее сходство с кадром полезного сигнала.
9. Способ по п.2, отличающийся тем, что набор данных содержит кадр полезного сигнала, анализирующая команда содержит сравнение набора данных с каждым образцовым кадром предопределенного словаря образцов, причем словарь образцов содержит пронумерованный список образцовых кадров и содержит оценку сходства кадра полезного сигнала с каждым из образцовых кадров, и анализатор выдает в качестве результата обработки набора данных номер образцового кадра, который имеет наибольшее сходство с кадром полезного сигнала.
10. Способ по п.3, отличающийся тем, что набор данных содержит кадр полезного сигнала, анализирующая команда содержит сравнение набора данных с каждым образцовым кадром предопределенного словаря образцов, причем словарь образцов содержит пронумерованный список образцовых кадров и содержит оценку сходства кадра полезного сигнала с каждым из образцовых кадров, и анализатор выдает в качестве результата обработки набора данных номер образцового кадра, который имеет наибольшее сходство с кадром полезного сигнала.
11. Способ по п.8, отличающийся тем, что кадру полезного сигнала присваивают вектор кадра полезного сигнала, каждому из образцовых кадров присваивают вектор образцового кадра и сходство каждой пары кадра полезного сигнала и образцового кадра определяют посредством вычисления расстояния между вектором кадра полезного сигнала и соответствующим вектором образцового кадра.
12. Способ по п.9, отличающийся тем, что кадру полезного сигнала присваивают вектор кадра полезного сигнала, каждому из образцовых кадров присваивают вектор образцового кадра и сходство каждой пары кадра полезного сигнала и образцового кадра определяют посредством вычисления расстояния между вектором кадра полезного сигнала и соответствующим вектором образцового кадра.
13. Способ по п.10, отличающийся тем, что кадру полезного сигнала присваивают вектор кадра полезного сигнала, каждому из образцовых кадров присваивают вектор образцового кадра и сходство каждой пары кадра полезного сигнала и образцового кадра определяют посредством вычисления расстояние между вектором кадра полезного сигнала и соответствующим вектором образцового кадра.
14. Способ по п.8, отличающийся тем, что анализатор является спектральным анализатором, который вычисляет сглаженные параметры спектра, в частности кепстральные коэффициенты для кадра, с использованием алгоритма линейного прогнозирования.
15. Способ по п.11, отличающийся тем, что анализатор является спектральным анализатором, который вычисляет сглаженные параметры спектра, в частности кепстральные коэффициенты для кадра, с использованием алгоритма линейного прогнозирования.
16. Способ по п.14, отличающийся тем, что кепстральные коэффициенты кодируют с использованием словаря образцов и матрицы расстояний между базисными векторами словаря образцов.
17. Способ по п.15, отличающийся тем, что кепстральные коэффициенты кодируют с использованием словаря образцов и матрицы расстояний между базисными векторами словаря образцов.
18. Способ по п.1, отличающийся тем, что анализатор содержит частотные фильтры для обработки спектра частот каждого из наборов данных, причем каждый из частотных фильтров выполнен с возможностью фильтровать конкретный тон из спектра частот наборов данных, выдавая в результате ряд тонов, и анализирующая команда содержит вычисление амплитуды каждого из тонов каждого из наборов данных.
19. Способ по п.18, отличающийся тем, что анализирующие команды также содержат команды вычисления частоты появления разных тонов, в частности, для определения мелодии полезного сигнала и/или продолжительности одного или более тонов, в частности, для определения ритма и/или значения количества ударов в минуту для полезного сигнала.
20. Способ по п.1, отличающийся тем, что упомянутая понижающая дискретизация осуществляется так, что сохраняется полоса частот, содержащая, по меньшей мере, 90% энергии полезного сигнала.
21. Способ по п.1, отличающийся тем, что анализатор содержит датчик активных кадров для обработки полезного сигнала таким образом, чтобы наборы данных с энергией ниже предопределенного порога были исключены из дальнейшей обработки.
22. Способ идентификации полезных сигналов предопределенного набора полезных сигналов, которые являются идентичными или сходными с входным полезным сигналом, причем каждому из полезных сигналов присвоен «отпечаток», сформированный в соответствии со способом по любому из предыдущих пунктов, причем блок идентификатора
принимает в качестве входных данных вектор данных «отпечатка» входного полезного сигнала,
для каждой пары входного полезного сигнала и одного из набора полезных сигналов вычисляет расстояние в соответствии с предопределенной командой вычисления расстояния между соответствующими векторами данных «отпечатка» и
возвращает в качестве результата идентификации список полезных сигналов, расстояние которых меньше, чем предопределенное пороговое значение.
23. Способ по п.22, отличающийся тем, что этап вычисления расстояния содержит следующие подэтапы:
а. на первом подэтапе подвекторы полезных сигналов используют при вычислении расстояния для вычисления грубого расстояния и временно идентифицируют полезные сигналы с грубыми расстояниями ниже первого порогового значения,
b. на втором подэтапе расстояния временно идентифицированных полезных сигналов до входного полезного сигнала вычисляют с использованием полных векторов полезных данных.
24. Устройство для формирования «отпечатка» полезного сигнала, в частности программируемый компьютер, программируемая компьютерная сеть или дополнительное программируемое оборудование, причем устройство содержит машиноисполняемые команды, которые при исполнении устройством побуждают устройство осуществлять способ по любому из пп.1-21.
25. Устройство для идентификации полезных сигналов из предопределенного набора полезных сигналов, в частности программируемый компьютер, программируемая компьютерная сеть или дополнительное программируемое оборудование, причем устройство содержит машиноисполняемые команды, которые при исполнении устройством побуждают устройство осуществлять способ по п.22 или 23.
26. Система для идентификации полезных сигналов из предопределенного набора полезных сигналов, которые являются идентичными или схожими с входным полезным сигналом, содержащая устройство по п.25, отличающаяся базой данных, соединенной с устройством для хранения векторов данных «отпечатков», причем устройство выполнено с возможностью получать доступ к базе данных.
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| US 5918223 A, 29.06.1999 | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| RU 99119985 A, 27.08.2001 | |||
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |

