ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Область изобретения
Примеры осуществления изобретения относятся к управлению потреблением мощности. Более конкретно, в примерах осуществления описывается динамическое управление потреблением мощности источника энергии.
Известный уровень техники
В микропроцессорах обычно используется методика динамического управления потребляемой мощностью для регулирования расхода энергии. Как правило, динамическое управление потребляемой мощностью для микропроцессоров достигается с помощью схемы детектора активности, которая расположена в микропроцессоре и соединена с централизованным функциональным системным блоком (FSB). Схема детектора активности служит для обнаружения условий, при которых должны быть включены или выключены определенные узлы, и для регулирования уровня мощности этих узлов.
Как правило, схема детектора активности обеспечивает достаточно надежную работу, потому что такая схема физически расположена вблизи узлов с управляемой мощностью некоторым расстоянием. Однако архитектуры шин начинают удаляться от архитектуры FSB и в них стали использоваться двухточечные линии связи (рТр). Вместе с тем, такая архитектура рТр связана с трудностями управления потребляемой мощностью.
Одна причина возникновения таких трудностей состоит в том, что архитектура рТр является распределенной системой, которая поддерживает выполнение там, где схема управления потребляемой мощностью и узлы с регулируемой мощностью размещены в различных интегральных схемах, но связаны двухточечными линиями рТр. В результате обычная схема детектора активности не может эффективно скрыть задержку включения/выключения узлов в зависимости от режима работы системы, поскольку она не может обеспечить адекватное время опережения для этих узлов при включении или выключении электропитания.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Изобретение иллюстрируется примерами его осуществления и не ограничивается приложенными чертежами, в которых цифровыми позициями обозначены одинаковые элементы. Следует отметить, что в английском тексте артикль "an" или числительное "один" в примере осуществления необязательно относятся к одному и тому же примеру осуществления, при этом цифровая позиция обозначает, по меньшей мере, один элемент.
Фигура 1 - блок-схема системы со сдвоенным процессором одного примера осуществления изобретения.
Фигура 2 - блок-схема многопроцессорной системы одного примера осуществления изобретения.
Фигура 3 - примерный вариант архитектуры внутреннего блока и кэширующих агентов систем, показанных на фигурах 1-2 в соответствии с примером осуществления изобретения.
Фигура 4 - блок-схема детектора активности, используемого в системе со сдвоенным процессором или в многопроцессорной системе одного примера осуществления изобретения.
Фигура 5 - блок-схема исходной логики способа в одном примере осуществления изобретения.
Фигура 6 - блок-схема способа с деревом решений для детектора активности ядра для одного примера осуществления изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
Настоящая заявка относится к предыдущим заявкам и может включать примеры осуществления из двух ранее поданных заявок. Обе ранние заявки были поданы 29 июня 2006 года той же самой группой изобретателей. Первая заявка с кодом патентного поверенного Р23215 названа "Способ и устройство для динамического управления потребляемой мощностью в распределенной системе", серийный номер 11/479,438. Вторая заявка, с кодом патентного поверенного Р24042, названа "Способ и устройство для динамического регулирования потребления энергии в распределенной системе", серийный номер 11/479,009.
Фигура 1 - блок-схема системы со сдвоенным процессором одного примера осуществления изобретения. Такой сдвоенный процессор (СП) в данном примере осуществления может иметь ряд возможных платформ. Например, этот пример осуществления может быть реализован как настольный или переносный компьютер, сервер, телевизионная приставка, личный цифровой помощник (PDA), алфавитно-цифровой пейджер, мобильный телефон или любой другой тип устройства радиосвязи.
В этом примере осуществления два пункта назначения (процессор 102 и процессор 104) соединены с источником энергии. В этом примере устройство ввода-вывода (IOH) 100 соединено магистральными двухточечными линиями связи 124, 128 с другими устройствами системы. "Линия" в целом определяется как несущая информацию среда, которая устанавливает путь связи для сообщений, а именно информации в предопределенном формате. Двухточечная линия может быть физически токопроводящей средой (такой, как шина, один или несколько электрических проводов, токопроводящая дорожка, кабель и т.д.) или беспроводной средой (например, радиоволны).
В некоторых примерах осуществления могут использоваться двухточечные линии, например, (без ограничения) PCI, PCIX, PCI и т.д. Процессор 102 и процессор 104, в основном, могут быть идентичными и включать контроллеры памяти 110, 112, которые связаны с блоками памяти 106 и 108, соответственно. Таким образом, дальнейшая часть обсуждения этого примера осуществления проводится в контексте раскрытия процессора 102. Однако это обсуждение применимо и к другим компонентам системы, например к процессору 104. Кроме того, предполагается, что некоторые системы могут иметь большее или меньшее количество узлов, связанных с источником.
В дополнение к контроллеру памяти 110 процессор 102 включает некоторые ресурсы 116 и 118, которые могут быть связаны с конкретным источником, таким как устройство IOH 100. В рамках этого обсуждения можно предположить, что ресурс 116 и ресурс 118 не разделены, но уникально подключены к устройству IOH 100. Например, в некоторых примерах осуществления ресурс 116 может представлять собой часть слоя ресурса, который уникально подключен к источнику. Например, ресурсы 116 и 118 могут быть буферами, требуемыми для доступа к памяти, или они могут быть своего рода компонентом исполнения определенного назначения. Ресурсы 116 и 118 дополнительно могут быть подразделены на сегменты (альтернативно называемыми фрагментами) от 172-1 до 172-4 и от 174-1 до 174-4 соответственно. Каждый сегмент определен как сегмент с индивидуально управляемой мощностью, так что сегмент может быть включен или отключен, чтобы в зависимости от энергии, потребляемой ресурсом, можно было бы изменять мощность в зависимости от степени разбиения.
Степень разбиения, при которой может регулироваться мощность, может значительно влиять на эффективность и энергосбережение источника, управляемого схемой динамической мощности (SCDPM). Во многих случаях, если единственным выбором будет полное включение или отключение ресурса, это будет отрицательно влиять на возможную выгоду схемы. Например, если ресурс используется в незначительной степени почти непрерывно с большими периодическими выбросами активности, невозможно сберегать энергию, если единственным выбором является полное включение или полное отключение. В некоторых примерах осуществления необязательно, чтобы все сегменты были бы одного размера или имели бы одну и ту же потребляемую мощность.
В контексте ресурса исполнительного компонента понятие сегментации может быть скорее логическим, чем физическим. Например, исполнительный компонент может иметь ряд дискретных уровней мощности, на которых он может работать, например, в качестве службы регулирования скорости выполнения и т.д. В этом контексте сегменты являются представителями различных возможных уровней мощности.
Доминирующая предпосылка схемы SCDPM состоит в том, что источник использования ресурса лучше позиционируется со знанием того, сколько потребуется этого ресурса, чем с назначением ресурса. Устройство IOH 100 является особенно желательным для использования в схеме SCDPM благодаря относительно высоким характеристикам по времени ожидания устройств IOH, которые предоставляют больше времени от момента, когда был сделан запрос, до момента, когда данные фактически получены, при большом объеме параллельных данных (таких, как DMA) и при отсутствии универсальной кэш-памяти в устройстве IOH.
Ниже будет обсужден детектор активности 150 со ссылкой на фигуру 3.
Например, детектор активности 150 контролирует запросы или события, поступающие от периферийного компонента (шины PCI), соединяющего экспресс-порты 132-0 - 132-N (все вместе 132). В запросе события, пришедшего от PCI 132, экспресс-порты обеспечивают детектор активности показаниями о вероятном будущем использовании ресурса на основании типа запроса или события, и идентификатор пункта назначения, связанного с этим запросом или событием. Экспресс-порты РСI 132 связаны с экспресс-устройствами PCI 130-0 - 130-N (все вместе 130). Экспресс-устройства PCI могут включать жесткие диски или любое другое устройство PCI. Как он используется здесь, термин "устройство" относится к любому электрическому компоненту, соединенному с линией передачи. Контроллер 170 прямого доступа к памяти (DMA) соединен с устройством IOH 100, обеспечивает доступ к DMA и поддерживает действующие мосты и другие периферийные устройства. Схема управления DMA 170 посылает сигналы прерывания в устройство IOH 100, при этом детектор активности может контролировать эти прерывания и данные, аналогичные запросам шины PCI по ожидаемому будущему использованию ресурса в точке назначения, соединенной с источником.
Буфер 152 исходящих запросов в устройстве IOH 100 является внутренней логикой, которая сопровождает все сообщения, поступающие на шину CSI. Путем контроля исходящих запросов буфера 152 детектор активности 150 может получить предварительные сведения о будущем потоке данных, где, например, задача состоит в доступе к устройству IOH 100 для чтения или записи большого количества данных. Кэш записи 154 содержат данные, полученные от различных устройств ввода-вывода, ждущих входа в главную память пункта назначения. Во время обратной записи (WB) запросы ставятся в очередь посылки данных в пункт назначения. Контролируя очередь, детектор активности 150 может оценить трафик, который будет связан с ожиданием обратной записи в пункте назначения. Размер очереди по обратному чтению и обратной записи влияет на окно времени, в котором детектор активности 150 может прогнозировать использование контроля очереди обратной записи.
Наконец, детектор активности может контролировать кредитный пул 156. Кредитный пул 156, прежде всего, выдает информацию о текущем использовании ресурса в точке назначения. Текущее использование необязательно должно быть достоверным показателем будущего использования, но текущее использование может указать на недостаточную мощность используемых ресурсов в одной из точек назначения. В этом случае детектор активности может передать сообщение об аварийном недостатке мощности в этом пункте назначения. Хотя уже были описаны многочисленные компоненты IOH 100, как подходящие для контроля и посылки сигналов детектору активности для будущего использования, в пределах объема и рассмотрения примеров осуществления изобретения выявлено, что и другие компоненты также могут обеспечить полезную информацию для детектора активности, чтобы предвидеть будущее использование ресурса.
Даже в свете большого объема информации, доступной контроллеру активности, детектор активности должен быть разработан так, чтобы прогноз использования был бы достаточно точным, чтобы минимизировать конфликт ресурсов. Например, если устройство IOH 100 готово для передачи потока данных в пункт назначения (например, процессор 102), детектор активности 150 должен обнаружить этот запрос, принять решение и вовремя послать команду на изменение мощности в пункт назначения, чтобы отрегулировать мощность ресурса до прибытия указанного потока данных. Кроме того, детектор активности должен избежать переполнения пункта назначения сообщениями по управлению мощностью, поскольку они занимают всю пропускную способность двухточечной линии и могут вызвать увеличение времени ожидания логики, которая выполняет регулирование мощности.
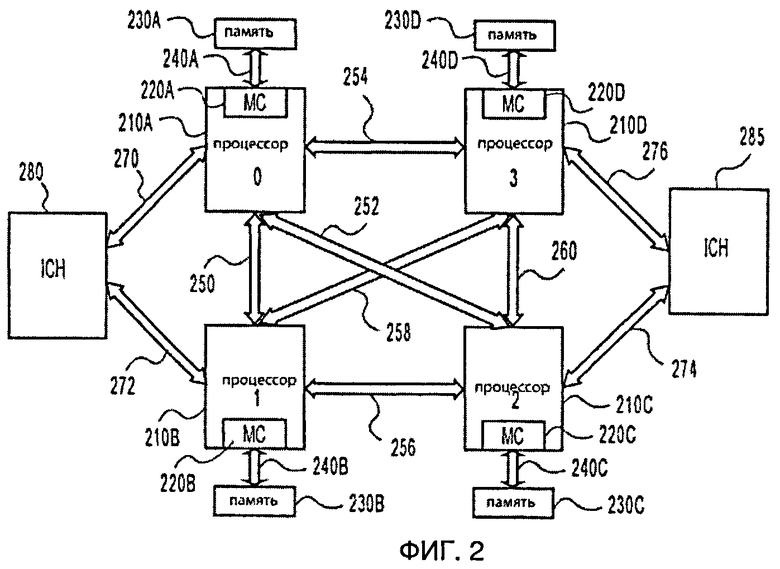
На фигуре 2 показана примерная блок-схема многопроцессорной системы (МР) 200 в соответствии с одним примером осуществления изобретения. Система МР 200 может быть настольным или мобильным компьютером, сервером, цифровым приемником, персональным цифровым помощником (PDA), алфавитно-цифровым пейджером, мобильным телефоном или любым другим типом проводных или беспроводных устройств.
Здесь, согласно одному примеру осуществления изобретения, система МР 200 включает множество процессоров 210А-210Д. Один или несколько процессоров, таких как процессоры 210A-210D, могут включать контроллер памяти (МС) 220A-220D. Эти контроллеры памяти 220A-220D обеспечивают прямую связь с соответствующими блоками памяти 230A-230D через линии передачи 240A-240D соответственно. В частности, как показано на фигуре 2, процессор 210А соединен с памятью 230А через линию передачи 240А, тогда как процессоры 210B-210D соединены с соответствующими устройствами памяти 230B-230D через линии передачи 240B-240D, соответственно. В одном примере осуществления процессоры и устройства IOH, в основном, идентичны описанным выше со ссылкой на фигуру 1.
Кроме того, процессор 210А соединен с каждым из других процессоров 210В-210D через двухточечные линии 250, 252 и 254. Точно также процессор 210В связан с процессором 210А, 210С и 210D через линию рТр, соединяющую 250, 256 и 258. Процессор 210С связан с процессорами 210А, 210В и 210D через линию рТр, соединяющую 252, 256 и 260. Процессор 210D связан с процессорами 210А, 210В и 210С через линию рТр, соединяющую 254, 258 и 260. Процессоры 210А и 210В соединены через двухточечные линии 270 и 272 с первым устройством ввода-вывода (IOH) 280, тогда как процессоры 210С и 210D соединены через двухточечные линии 274 и 276 со вторым устройством IOH 285. В примерах, где нет прямого двухточечного соединения, промежуточное устройство, например процессор, снабжено логической схемой для получения команды, например, от устройства IOH 280 на процессоры 210С и 210D. Это позволяет устройству IOH 280 регулировать мощность ресурса в тех процессорах 210С и 210D, которые согласованы с устройством IOH 280.
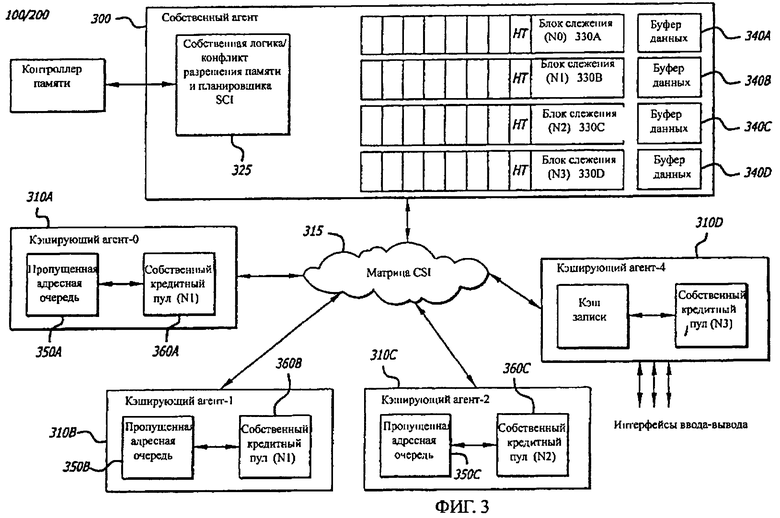
На фигуре 3 показан примерный вариант осуществления архитектуры пункта назначения и источника фигур 1-2. В иллюстративных целях процессор 210D (или процессор 150) сконфигурирован как устройство назначения 300, например собственный агент. Процессоры 210А-210С (или процессор 110) могут быть сформированы как источники 310А-310С, например, как кэширующий агент. Устройство IOH 280 или 285 (или IOH 180 из фигуры 1) могут быть сконфигурированы как устройство ввода-вывода 310D, выполняющее запись/чтение, и как кэширующий агент 320.
Как описано ниже, каждый источник 310А, …, или 310D связан со следящей системой, которая расположена в пункте назначения 300 и имеет предопределенное количество записей. Количество входов в следящей системе ограничено количеством запросов, которые могут быть переданы любым источником 310А, …, или 310D, что равно пропускной способности матрицы CSI 315, поддерживающей двухточечные связи между пунктом назначения 300 и множеством источников (например, источников 310A-310D).
Как показано на фигуре. 3, согласно этому примеру осуществления изобретения, пункт назначения 300 является собственным агентом, который включает собственную логику 325 и множество блоков слежения 3301…330M где М≥1. В комбинации со следящими системами 3301…330M собственная логика 325 адаптирована для работы в качестве планировщика, чтобы помочь при передаче поступающей информации из памяти 230А фигуры 2 и исходящей информации к матрице CSI 315. Кроме того, собственная логика 325 используется для разрешения конфликтов при такой передаче данных.
Для этого примера осуществления изобретения в системе 100/200 используются четыре (4) кэширующих агента 310A-310D и четыре следящих системы (М=4), которые обозначены как "НТ-0" 330А, "НТ-1" 330В, "НТ-2" 330С и "НТ-3" 330D. Каждая из этих следящих систем 330A-330D имеет входы N0, N1, N2 и N3, соответственно, где Ni≥1 (i=1, 2, 3 или 4). Количество записей (N0-N3) может отличаться от одной следящей системы к другой. Каждый вход систем 330A-330D связан с соответствующим буфером данных из буферов данных 340A-340D. Буферы данных 340A-340D обеспечивают временное хранение данных, переданных от контроллера памяти 220А и, в конечном счете, направленных в матрицу CSI 315 для передачи в пункт назначения. Активацией и деактивацией входов следящих систем 330A-330D управляет местная логика 325, описанная ниже.
Кэширующие агенты 310А, 310В и 310С включают пропущенную адресную очередь 350А, 350В и 350С, соответственно. Например, в кэширующем агенте 310А формируется пропущенная адресная очередь 350А, чтобы сохранить все пропущенные входящие сообщения, которые обрабатываются собственным агентом 300.
Кроме того, согласно этому примеру осуществления изобретения, кэширующие агенты 310А, 310В и 310С дополнительно содержат кредитные счетчики 360А, 360В и 360С, соответственно. Каждый кредитный счетчик 360А, 360 В и 360С поддерживает величину отсчета, представляющую число неиспользованных входов в следящих системах 330А, 330В и 330С. Например, когда кэширующим агентом 310А осуществляется новая передача сообщения собственному агенту 300, кредитные счетчики 360А сбрасываются на соответствующую величину. Если передача завершена, показания кредитного счетчика 360А увеличиваются. Во время сброса кредитный счетчик 360А инициализируется на размер пула, равный числу входов следящих систем (N0), связанных с узлом слежения 330А. Та же конфигурация применима и к кредитным счетчикам 360В-360С.
На фигуре 3 также показан пример кэширующего агента 310D, работающего как устройство ввода-вывода, которое считывает информацию из памяти и записывает информацию в интерфейс ввода-вывода. Альтернативно, кэширующий агент 310D может направить информацию в устройство ввода-вывода при записи данных в главную память. Кэширующий агент 310D работает как буфер записи 320, который используется для поддержания высокой пропускной способности при хранении данных, связанных с операциями ввода-вывода.
Аналогично кэширующим агентам 310А-310K, кэширующий агент 310D включает кредитный счетчик 360D, который поддерживает величину счета, отражающую число неиспользованных входов в следящей системе 330D. При сбросе кредитный счетчик 360D инициализируется на размер пула, равный количеству входов в следящей системе (N3), связанных с узлом слежения 330D.
Количество записей на входе следящих систем (N0, N1 и т.д.) рассчитано на работу по сценариям пульсирующего трафика и, таким образом, соответствует пиковой пропускной способности. Иными словами, потенциальные спорадические нагрузки и продолжительное времена ожидания принуждают собственный агент 300 распределять количество ресурсов для кэширующих агентов 310A-310D (запрашивающих агентов) по пессимистическому сценарию. В качестве примера от собственного агента 300 к кэширующему агенту 310А, когда пиковая пропусканная способность по передаче данных составляет ХA гигабайт в секунду (GBps) и задержка входящего сообщения от момента, когда оно было выдано кэширующим агентом 310А собственному агенту 300, до момента, когда сигнал завершения вернется к кэширующему агенту 310А, равна La наносекунд (ns), число (N0) следящих систем дается как (ХA*LA)/64, предполагая, что каждый вход следящих систем имеет размер 64 байта.
Как правило, задержка от (ввода-вывода) кэширующего агента 310D больше порядка 1,5Х раз по сравнению с кэширующими агентами 310А-310K процессора. Это происходит потому, что магистраль для кэширующего агента 310D находится ближе к логике интерфейса ввода-вывода и, как правило, тактовая частота устройства ввода-вывода в 5 раз медленнее этих устройств в процессорах. В таблице 1 показана потенциальная задержка, пиковая пропускная способность данных и число записей следящих систем для системы DP.

Как правило, число ввода данных (Ni) следящих систем выбрано как кратное 2, 4 или 8 и, следовательно, размеры, выбранные для следящих систем, были бы 20, 28 и 36, соответственно. Большое число ввода данных следящих системы и буферов может потребовать существенного объема потребления мощности так, что такая архитектура не является оптимальной.
Во-вторых, в большинстве рабочих режимов трафик во всей системе является весьма неравномерным и не остается в пределах пиковой производительности в течение значительного периода времени. Полное число распределенных записей следящих системы используется редко. Следовательно, использование мощности может быть оптимизировано, модулируя активные вводы данных следящих систем на основе активности, где кэширующие агенты (источники) могут динамически управлять требуемыми ресурсами собственного агента (пункта назначения), используя систему передачи сообщений. Эта система передачи сообщений называется схемой управления динамическим управлением мощностью (SCDPM) и описывается ниже.
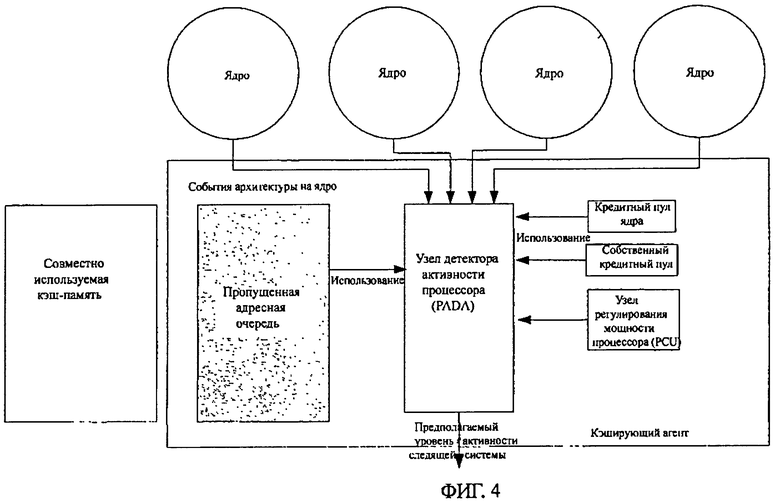
На Фигуре 4 представлена блок-схема многоядерного детектора активности, используемого в системе со сдвоенным процессором или многопроцессорной системой в одном примере осуществления изобретения. В этом примере осуществления основная схема детектора активности находится в кэширующем агенте. В этом примере осуществления кэширующий агент связан с несколькими ядрами и с совместно используемой кэш-памятью. Например, каждый процессор состоит из нескольких ядер и большой совместно используемой кэш-памяти с соответствующей логикой, которая обрабатывает когерентность системы и запросы к подсистеме памяти. На фигуре 4 детектор активности процессора (PADA) связан с несколькими функциональными блоками процессора, чтобы получить полезную информацию. В этом примере блок PADA связан с архитектурой основной шины (линиями от каждого ядра к PADA); используя пропущенную адресную очередь (которая может потреблять ресурс собственного агента), процессор управления мощностью (PCU), который управляет состоянием мощности всего процессора, и индикатор использования кредита от пункта назначения до ядра (ядер). На основе этих входов PADA формирует подробные сообщения, используя интерфейс SCDPM, который связан с собственным агентом (пунктом назначения) для надлежащей настройки мощности. В одном примере осуществления интерфейс SCDPM обсужден в родственных заявках.
Следующая таблица включает множество счетчиков событий архитектуры. В одном примере осуществления поведение одного или нескольких ядер процессора является конкретным приложением. В этом примере осуществления некоторые или все следующие счетчики событий архитектуры используются детектором активности, который эффективно представляет текущий статус ядра и определяет состояние мощности.
В одном примере осуществления счетчики событий архитектуры используются для прогноза пульсирующего поведения. Например, одно ядро может иметь избыток неправильных прогнозов или множество отсутствующих страниц, что может быть хорошей индикацией потоков запросов памяти. Имеются и другие события архитектуры, которые могут помочь понять поведение приложения, которое может быть захвачено и дать достоверную информацию детектору активности о поведении приложения. Например, высокий индекс пропуска LLC предполагает, что требуется больший ресурс для собственного агента. В таблице 1 мы предлагаем, чтобы ресурс собственного агента был бы основан, по меньшей мере, частично на нескольких счетчиках архитектурных событий. Однако заявленный предмет изобретения не ограничен примером использования одного и того же числа счетчиков. Например, некоторые из этих счетчиков соединены каждый со своим ядром, и может быть принято правильное решение, просмотрев накопленные результаты. Квалифицированный специалист в данной области оценит использование различных подсистем счетчиков, основанных на типе пакета, количестве ядер и т.д.
Другим вводом в детектор PADA является использование очереди кредит/запрос. Например, можно использовать потребление кредита ядра и его очередь запросов для того, чтобы понять текущее поведение ядра. Например, имеет место ситуация, когда ядро выдает только несколько запросов кэширующему агенту. Это указывает на эффективное выполнение. В противном случае, когда ядро использует большую часть всего соответствующего кредита ядра, указывает на формирование запросов памяти. Следовательно, собственный агент должен быть включен, чтобы поддерживать запросы ядра.
Еще одним вводом в детектор PADA является собственный кредитный пул. Например, собственный кредит указывает на число вводов данных, которые в настоящее время направлены в соответствующий кэширующий агент. Следовательно, это может быть хорошей индикацией снижения мощности на входах следящих систем пункта назначения, если свободные кредитные счетчики последовательно показывают высокий уровень в течение предопределенного промежутка времени.
Еще один ввод в детектор PADA состоит в использовании пропущенной адресной очереди. Например, использование пропущенной адресной очереди является еще одним указанием на то, испытывает ли ядро избыток пропусков в кэш-памяти и передается ли запрос из памяти собственному агенту. В одном примере осуществления как собственный кредитный пул, так и пропущенная адресная очередь могут использоваться как пороговый механизм для определения состояния мощности собственных агентов.
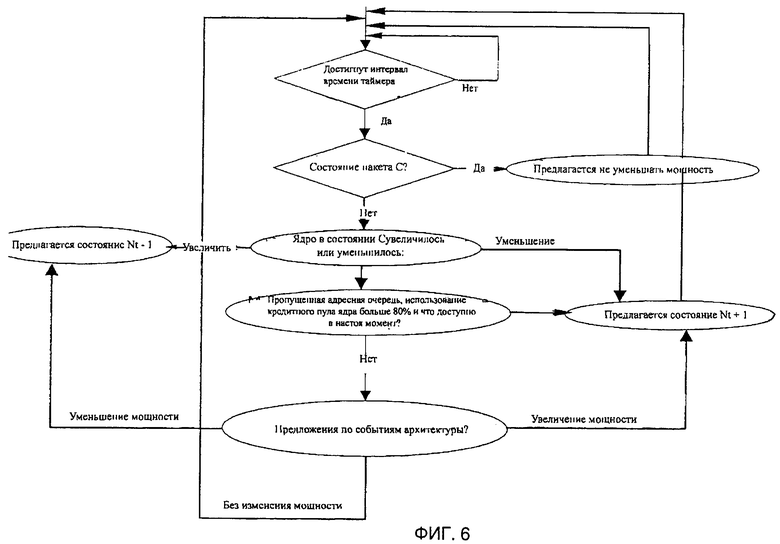
Еще один ввод в детектор PADA - состояние мощности ядер. В одном примере осуществления контроллер PCU посылает сигнал о состоянии мощности ядер в детектор состояния PADA. Состояние мощности каждого ядра может содержать очень полезную информацию для детектора активности. Например, ядро (ядра) с высоким состоянием Р или с низким состоянием С выдает малое или нулевое количество запросов кэширующему агенту. Следовательно, можно определить или даже предсказать возможность использования собственных входов следящих систем. Например, ядро, которое было отобрано в режиме турбо, является показателем относительно большего количества запросов, поступающих от этого конкретного ядра. Когда ядро только вошло в состояние С, ядро не создаст новых запросов в ближайшее время. Кроме того, если все ядра вошли в состояние С, ясно, что можно послать сообщение, чтобы выключить собственную систему слежения, связанную с этим кэширующим агентом.
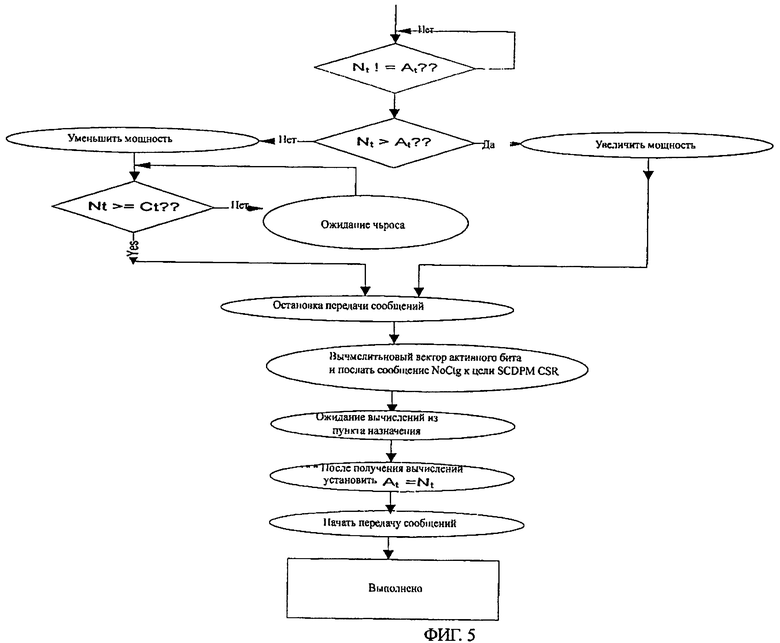
На фигуре 5 представлена блок-схема исходной логики в одном примере осуществления изобретения. В этой блок-схеме показано логическое выполнение детектора активности PADA, облегчающее повысить или понизить уровни Nt в заданный промежуток времени. В одном примере осуществления число уровней Nt определяется пользователем. Например, N0 представляет состояние, когда все ресурсы собственного пункта назначения полностью отключены. Напротив, Nmax предполагает, что все ресурсы собственного пункта назначения включены. Следовательно, логика PADA в каждом интервале времени предполагает повышение или понижение уровней Nt. Схема SCDPM затем будет использовать эту информацию для увеличения/уменьшения ресурса собственного агента, используя предложенный поток, отображенный на фигуре 5. В этом примере осуществления At обозначает текущий активный уровень следящих систем в пункте назначения, a Ct обозначает текущее использование следящих системы в пункте назначения.
На Фигуре 6 представлена блок-схема дерева принятия решений для детектора активности ядра одного примера осуществления изобретения. В одном примере осуществления способ отображает дерево решений для архитектуры PADA. Например, блок-схема изображает приоритетную схему всей информации, полученной детектором активности процессора. Следовательно, она определяет уровень активности собственного агента (Nt). Например, в одном примере осуществления информация о состояния мощности пакета процессоров имеет приоритет относительно всей другой информации. Следовательно, если процессор находится в состоянии С, не будет никакого трафика к собственному агенту. Если пакет является активным, детектор активности PADA выполняет сравнение, чтобы определить, вошли ли ядра в режим энергосбережения. Больше ядер в состоянии С предполагает, что использование собственного ресурса может очень быстро снизиться. Наконец, очередь/кредит и события архитектуры будут использоваться для настройки уровня активности в пункте назначения.
Следует понимать, что ссылка везде в этом описании на "один пример осуществления" или на "пример осуществления" означает, что конкретный признак, структура или характеристика, описанные в связи с примером осуществления, включены, по меньшей мере, в один пример осуществления настоящего изобретения. Поэтому следует подчеркнуть, что две или больше ссылок на "пример осуществления", или "один пример осуществления", или "альтернативный пример осуществления" в различных частях этого описания необязательно относятся к одному и тому же примеру осуществления. Кроме того, конкретные признаки, структуры или характеристики могут быть объединены как подходящие для одного или нескольких примеров осуществления изобретения.
В приведенном выше описании изобретение было раскрыто на определенных примерах его осуществления. Однако специалистам ясно, что могут быть сделаны различные модификации и изменения, не выходя из духа и объема изобретения, как они сформулированы в прилагаемой формуле изобретения. Соответственно, описание и чертежи должны расцениваться в иллюстративном, а не ограничивающем смысле.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРЕДСТАВЛЕНИЕ ФИЛЬТРАЦИИ НАБЛЮДЕНИЯ, АССОЦИИРОВАННОЙ С БУФЕРОМ ДАННЫХ | 2013 |
|
RU2608000C2 |
| НЕЧУВСТВИТЕЛЬНЫЙ К ЗАДЕРЖКЕ БУФЕР ТРАНЗАКЦИИ ДЛЯ СВЯЗИ С КВИТИРОВАНИЕМ | 2014 |
|
RU2598594C2 |
| ПАРЫ ИНСТРУКЦИЙ УСТАНОВЛЕНИЯ ОЧЕРЁДНОСТИ ИСПОЛНЕНИЯ ИНСТРУКЦИЙ, ПРОЦЕССОРЫ, СПОСОБЫ И СИСТЕМЫ | 2014 |
|
RU2630745C2 |
| АРХИТЕКТУРА НАКРИСТАЛЬНОГО МЕЖСОЕДИНЕНИЯ | 2015 |
|
RU2625558C2 |
| УСОВЕРШЕНСТВОВАНИЕ ИНТЕРФЕЙСА PCI EXPRESS | 2013 |
|
RU2645288C2 |
| ФИЗИЧЕСКИЙ УРОВЕНЬ ВЫСОКОПРОИЗВОДИТЕЛЬНОГО МЕЖСОЕДИНЕНИЯ | 2013 |
|
RU2579140C1 |
| МОДУЛЬ СОПРОЦЕССОРА КЭША | 2011 |
|
RU2586589C2 |
| УСТРОЙСТВО И СПОСОБ РЕВЕРСИРОВАНИЯ И ПЕРЕСТАНОВКИ БИТОВ В РЕГИСТРЕ МАСКИ | 2014 |
|
RU2636669C2 |
| ФИЗИЧЕСКИЙ УРОВЕНЬ ВЫСОКОПРОИЗВОДИТЕЛЬНОГО МЕЖСОЕДИНЕНИЯ | 2013 |
|
RU2599971C2 |
| АРХИТЕКТУРА РАСШИРЕНИЯ ОПТИЧЕСКОЙ ПАМЯТИ | 2014 |
|
RU2603553C2 |
Изобретение относится к средствам управления потреблением мощности. Технический результат заключается в уменьшении потребления электроэнергии. Определяют, является ли состояние мощности интегрированного пакета устройства состоянием пониженной мощности, в противном случае определяют, изменилось ли количество ядер процессора, введенных в состояние энергосбережения, от предыдущего промежутка времени. Сравнивают кредитный пул и использование пропущенной адресной очереди с первым порогом. Сравнивают счетчики множества событий архитектуры со вторым порогом и настраивают уровень активной мощности, основанной, по меньшей мере, частично на результатах указанного сравнения. 2 н. и 7 з.п. ф-лы, 6 ил., 2 табл.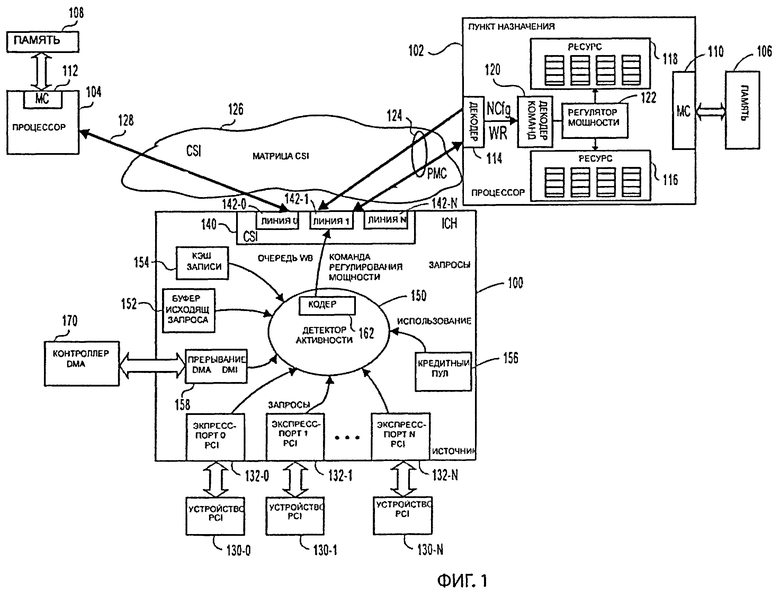
1. Кэширующий агент, связанный с собственным агентом и множеством ядер процессора, содержащий:
блок управления мощностью процессора (PCU), управляющий состоянием мощности множества ядер процессора,
первую логику, имеющую собственный кредитный пул для ряда вводимых данных, используемых кэширующим агентом;
адресную очередь,
вторую логику для хранения индикатора использования кредита ядра;
детектор активности ядра процессора, определяющий уровень активности собственного агента, основанный, по меньшей мере, на входных данных, полученных от блока PCU, первую и вторую логику, счетчики событий архитектуры, полученные от множества ядер процессора, и пропущенную адресную очередь.
2. Кэширующий агент по п.1, в котором индикатор использования кредита ядра выполнен с возможностью определять, следует ли повысить мощность собственного агента по конкретному запросу из памяти ядра, используя большую часть или весь кредит ядра, который превышает предопределенный порог.
3. Кэширующий агент по п.1, в котором счетчики событий архитектуры выполнен с возможностью облегчения прогноза пульсирующих операций, когда ядро процессора с большим числом ветвлений с ошибочным прогнозированием или пропущенными страницами указывает на вероятность множества излишних запросов памяти.
4. Кэширующий агент по п.1, в котором счетчики событий архитектуры выполнены в виде счетчиков предварительной выборки, пропусков протокола LLC, пропусков протокола TLB и пропусков ветвлений.
5. Способ определения уровня активной мощности собственного агента, соединенного с множеством ядер процессора в интегрированном пакете устройства, содержащий:
определение, является ли состояние мощности интегрированного пакета устройства состоянием пониженной мощности, в противном случае, определение, изменилось ли количество ядер процессора, введенных в состояние энергосбережения, от предыдущего промежутка времени;
сравнение кредитного пула и использования пропущенной адресной очереди с первым порогом;
сравнение счетчиков множества событий архитектуры со вторым порогом; и
настройку уровня активной мощности, основанной, по меньшей мере, частично на результатах указанного сравнения.
6. Способ по п.5, в котором уровень активной мощности собственного агента повышают, когда количество ядер процессора, которые введены в состояние энергосбережения, уменьшилось от предыдущего промежутка времени.
7. Способ по п.5, в котором уровень активной мощности собственного агента понижают, когда количество ядер процессора, которые введены в состояние энергосбережения, увеличилось от предыдущего промежутка времени.
8. Способ по п.5, в котором уровень активной мощности собственного агента повышают, когда использование кредитного пула и пропущенной адресной очереди превышает первый порог.
9. Способ по п.5, в котором множество счетчиков событий архитектуры сравнивают со вторым порогом, если кредитный пул и использование пропущенной адресной очереди не превышают первого порога.
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| СИСТЕМА И СПОСОБ ДИАГНОСТИКИ ПЕРИФЕРИЙНЫХ УСТРОЙСТВ | 2005 |
|
RU2298218C2 |

