Родственные заявки и включение посредством ссылки
Настоящая заявка заявляет преимущество и приоритет предварительной заявки на патент США 62/181739, поданной 18 июня 2015 года; предварительной заявки на патент США 62/193507, поданной 16 июля 2015 года, предварительной заявки на патент США 62/201542, поданной 5 августа 2015 года, предварительной заявки на патент США 62/205733, поданной 16 августа 2015 года, предварительной заявки на патент США 62/232067, поданной 24 сентября 2015 года, заявки на патент США с порядковым № 14/975085, поданной 18 декабря 2015 года и заявки на европейский патент № 16150428.7.
Вышеупомянутые заявки и все документы, цитируемые в них или при их рассмотрении ("документы, цитируемые в заявке"), и все документы, цитируемые или приводимые в качестве ссылки в документах, цитируемых в данном документе, вместе с любыми инструкциями производителя, описаниями, спецификациями продукта и технологическими картами для любых продуктов, упомянутых в данном документе или в любом документе, включенном в данный документ посредством ссылки, настоящим включены в данный документ посредством ссылки и могут быть использованы при осуществлении настоящего изобретения на практике. Более конкретно, все документы, приводимые в качестве ссылки, включены посредством ссылки в такой же мере, как если бы конкретно и отдельно было указано, что каждый отдельный документ включен посредством ссылки.
Заявление в отношении финансируемого из федерального бюджета исследования
Настоящее изобретение было выполнено при поддержке правительства в рамках гранта № MH100706, выданного Национальными институтами здоровья. Правительство обладает определенными правами на настоящее изобретение.
Перечень последовательностей
Настоящая заявка содержит перечень последовательностей, который был подан в электронном виде в формате ASCII и настоящим включен посредством ссылки во всей своей полноте. Указанная копия в формате ASCII, созданная 17 декабря 2015 года, имеет название 47627.05.2123_SL.txt и размер 2467205 байт.
Область изобретения
Настоящее изобретение в целом относится к системам, способам и композициям, применяемым для контроля экспрессии генов, включающего нацеливание на последовательность, как, например, внесение изменений в транскрипты генов или редактирование нуклеиновых кислот, при которых могут применяться векторные системы, близкие к коротким палиндромным повторам, регулярно расположенным группами (CRISPR), и их компоненты.
Предпосылки изобретения
Недавние достижения в технологиях секвенирования генома и способах анализа значительно ускорили возможность каталогизации и картирования генетических факторов, ассоциированных с широким разнообразием биологических функций и заболеваний. Технологии точного нацеливания на геном необходимы для обеспечения возможности систематичного обратного конструирования казуальных генетических изменений путем обеспечения селективного внесения изменений в отдельные генетические элементы, а также для продвижения применений в области синтетической биологии, биотехнологии и медицины. Хотя технологии редактирования генома, такие как оригинальные ферменты с "цинковыми пальцами", эффекторы, подобные транскрипционным активаторам (TALE), или хоминг-мегануклеазы, доступны для осуществления нацеленного внесения изменений в геном, все еще существует потребность в новых технологиях конструирования генома, в которых используются новые стратегии и молекулярные механизмы, и которые являются доступными, простыми в осуществлении, масштабируемыми и характеризуются возможностью нацеливания на несколько местоположений в геноме эукариотического организма. Это обеспечит главный ресурс для новых применений в конструировании генома и биотехнологии.
Системы CRISPR-Cas, обеспечивающие адаптивный иммунитет бактерий и архей, демонстрируют чрезвычайное разнообразие состава белков и структуры локусов генома. Локусы системы CRISPR-Cas содержат более 50 семейств генов, и при этом отсутствуют строго универсальные гены, что указывает на быструю эволюцию и чрезвычайное разнообразие структуры локусов. На настоящий момент путем внедрения многоэтапного подхода имеется исчерпывающая идентификация генов cas из приблизительно 395 профилей для 93 белков Cas. Классификация включает сигнатуры генных профилей с сигнатурами структуры локуса. Предложена новая классификация систем CRISPR-Cas, в которой эти системы в широком смысле разделены на два класса, класс 1 с мультисубъединичными эффекторными комплексами и класс 2 с односубъединичными эффекторными модулями, в качестве примера которых приводится белок Cas9. Можно разрабатывать новые эффекторные белки, ассоциированные с системами CRISPR-Cas класса 2, в качестве мощных инструментов для конструирования генома, и важным является прогнозирование предполагаемых новых эффекторных белков и их конструирование и оптимизация.
Цитирование или идентификация любого документа в настоящей заявке не является признанием того, что такой документ предлагается в качестве известного уровня техники для настоящего изобретения.
Краткое описание изобретения
Существует актуальная потребность в альтернативных и надежных системах и методиках для нацеливания на нуклеиновые кислоты или полинуклеотиды (например, ДНК, или РНК, или любой их гибрид или производное) с широким спектром применений. Настоящее изобретение удовлетворяют данную потребность и обеспечивает связанные с этим преимущества. Добавление новых систем нацеливания на ДНК или РНК по настоящей заявке к спектру технологий для геномного и эпигеномного нацеливания может преобразовать исследование и внесение изменений или редактирование специфических целевых сайтов на прямое обнаружение, анализ и манипуляцию. Чтобы эффективно использовать системы нацеливания на ДНК или РНК по настоящей заявке для геномного или эпигеномного нацеливания без вредных эффектов, важно понимать аспекты конструирования и оптимизации этих инструментов для нацеливания на ДНК или РНК.
В настоящем изобретении предусмотрен способ модифицирования последовательностей, ассоциированных с представляющим интерес целевым локусом или находящихся в нем, причем способ включает доставку в указанный локус не встречающейся в природе или сконструированной композиции, содержащей предполагаемый эффекторный белок CRISPR-Cas V типа и один или несколько компонентов на основе нуклеиновой кислоты, где эффекторный белок образует комплекс с одним или несколькими компонентами на основе нуклеиновой кислоты, и после связывания указанного комплекса с представляющим интерес локусом эффекторный белок индуцирует модификацию последовательностей, ассоциированных с представляющим интерес целевым локусом или находящихся в нем. В предпочтительном варианте осуществления модификация представляет собой введение разрыва нити. В предпочтительном варианте осуществления последовательности, ассоциированные с представляющим интерес целевым локусом или находящиеся в нем, предусматривают ДНК, а эффекторный белок кодируется локусом CRISPR-Cas подтипа V-A или локусом CRISPR-Cas подтипа V-B.
Будет понятно, что термины фермент Cas, фермент CRISPR, белок CRISPR, белок Cas и CRISPR Cas в целом используют взаимозаменяемо, и при всех упоминаниях в данном документе относятся по аналогии к новым эффекторным белкам CRISPR, дополнительно описываемым в настоящей заявке, если не очевидно иное, как, например, с помощью специальной ссылки на Cas9. Эффекторные белки CRISPR, описанные в данном документе, предпочтительно представляют собой эффекторные белки Cpf1.
В настоящем изобретении предусмотрен способ модифицирования последовательностей, ассоциированных с представляющим интерес целевым локусом или находящихся в нем, причем способ включает доставку к указанным последовательностям, ассоциированным с локусом или находящихся в нем, не встречающейся в природе или сконструированной композиции, содержащей эффекторный белок Cpf1 и один или несколько компонентов на основе нуклеиновой кислоты, где эффекторный белок Cpf1 образует комплекс с одним или несколькими компонентами на основе нуклеиновой кислоты, и после связывания указанного комплекса с представляющим интерес локусом эффекторный белок индуцирует модификацию последовательностей, ассоциированных с представляющим интерес целевым локусом или находящихся в нем. В предпочтительном варианте осуществления модификация представляет собой введение разрыва нити. В предпочтительном варианте осуществления эффекторный белок Cpf1 образует комплекс с одним компонентом на основе нуклеиновой кислоты; преимущественно компонентом на основе сконструированной или не встречающейся в природе нуклеиновой кислоты. Индукция модификации последовательностей, ассоциированных с представляющим интерес целевым локусом или находящихся в нем, может представлять собой осуществляемую эффекторным белком Cpf1 и направляемую нуклеиновой кислотой. В предпочтительном варианте осуществления один компонент на основе нуклеиновой кислоты представляет собой РНК CRISPR (crRNA). В предпочтительном варианте осуществления один компонент на основе нуклеиновой кислоты представляет собой зрелую crRNA или направляющую РНК, где зрелая crRNA или направляющая РНК содержат спейсерную последовательность (или направляющую последовательность) и последовательность прямого повтора или их производные. В предпочтительном варианте осуществления спейсерная последовательность или ее производное содержат затравочную последовательность, где затравочная последовательность является критически важной для распознавания и/или гибридизации с последовательностью в целевом локусе. В предпочтительном варианте осуществления затравочная последовательность направляющей РНК FnCpf1 находится примерно в пределах первых 5 нуклеотидов на 5'-конце спейсерной последовательности (или направляющей последовательности). В предпочтительном варианте осуществления разрыв нити представляет собой ступенчатый разрез с "липким" 5'-концом. В предпочтительном варианте осуществления последовательности, ассоциированные с представляющим интерес целевым локусом или находящиеся в нем, предусматривают линейную или сверхспирализованную ДНК.
Аспекты настоящего изобретения относятся к комплексам эффекторного белка Cpf1 с одним или несколькими компонентами на основе не встречающейся в природе, или сконструированной, или модифицированной, или оптимизированной нуклеиновой кислоты. В предпочтительном варианте осуществления компонент на основе нуклеиновой кислоты комплекса может предусматривать направляющую последовательность, связанную с последовательностью прямого повтора, где последовательность прямого повтора содержит одну или несколько "петель-на-стебле" или оптимизированных вторичных структур. В предпочтительном варианте осуществления минимальная длина прямого повтора составляет 16 нуклеотидов, и он содержит одну "петлю-на-стебле". В дополнительных вариантах осуществления длина прямого повтора составляет более 16 нуклеотидов, предпочтительно более 17 нуклеотидов, и он содержит более одной "петли-на-стебле" или оптимизированных вторичных структур. В предпочтительном варианте осуществления прямой повтор можно модифицировать так, чтобы он содержал один или несколько белок-связывающих РНК-аптамеров. В предпочтительном варианте осуществления могут быть включены один или несколько аптамеров, как, например, часть оптимизированной вторичной структуры. Такие аптамеры могут быть способны связывать белок оболочки бактериофага. Белок оболочки бактериофага может быть выбран из группы, содержащей Qβ, F2, GA, fr, JP501, MS2, M12, R17, BZ13, JP34, JP500, KU1, M11, MX1, TW18, VK, SP, FI, ID2, NL95, TW19, AP205, φCb5, φCb8r, φCb12r, φCb23r, 7s и PRR1. В предпочтительном варианте осуществления белок оболочки бактериофага представляет собой MS2. В настоящем изобретении также предусмотрен компонент на основе нуклеиновой кислоты комплекса, длина которого составляет 30 или более, 40 или более или 50 или более нуклеотидов.
В настоящем изобретении предусмотрены способы редактирования генома, где способ включает два или более раундов нацеливания и расщепления под действием эффекторного белка Cpf1. В определенных вариантах осуществления первый раунд предусматривает расщепление под действием эффекторного белка Cpf1 последовательностей, ассоциированных с целевым локусом вдали от затравочной последовательности, а второй раунд предусматривает расщепление под действием эффекторного белка Cpf1 последовательностей в целевом локусе. В предпочтительных вариантах осуществления настоящего изобретения первый раунд нацеливания эффекторного белка Cpf1 приводит к образованию вставки/делеции, а второй раунд нацеливания эффекторного белка Cpf1 может подвергаться репарации посредством репарации с помощью гомологичной рекомбинации (HDR). В наиболее предпочтительном варианте осуществления настоящего изобретения один или несколько раундов нацеливания эффекторного белка Cpf1 приводит к ступенчатому расщеплению, которое может подвергаться репарации с помощью вставки матрицы для репарации.
В настоящем изобретении предусмотрены способы редактирования генома или модифицирования последовательностей, ассоциированных с представляющим интерес целевым локусом или находящихся в нем, где способ включает введение комплекса эффекторного белка Cpf1 в любой требуемый тип клеток, прокариотическую или эукариотическую клетку, при этом комплекс эффекторного белка Cpf1 эффективно функционирует с целью интеграции вставки ДНК в геном эукариотической или прокариотической клетки. В предпочтительных вариантах осуществления клетка представляет собой эукариотическую клетку, а геном представляет собой геном млекопитающего. В предпочтительных вариантах осуществления интеграция вставки ДНК облегчается с помощью механизмов вставки гена на основе негомологичного соединения концов (NHEJ). В предпочтительных вариантах осуществления вставка ДНК представляет собой экзогенно вводимую ДНК-матрицу или матрицу для репарации. В одном предпочтительном варианте осуществления экзогенно вводимая ДНК-матрица или матрица для репарации доставляются с комплексом эффекторного белка Cpf1 или одного компонента или полинуклеотидным вектором для экспрессии компонента комплекса. В более предпочтительном варианте осуществления эукариотическая клетка представляет собой неделящуюся клетку (например, неделящуюся клетку, в которой редактирование генома с помощью HDR представляет собой особенную сложность). В предпочтительных способах редактирования генома в клетках человека эффекторные белки Cpf1 могут включать без ограничения эффекторные белки FnCpf1, AsCpf1 и LbCpf1.
В настоящем изобретении также предусмотрен способ модифицирования представляющего интерес целевого локуса, причем способ включает доставку в указанный локус не встречающейся в природе или сконструированной композиции, содержащей эффекторный белок C2c1 и один или несколько компонентов на основе нуклеиновой кислоты, где эффекторный белок C2c1 образует комплекс с одним или несколькими компонентами на основе нуклеиновой кислоты, и после связывания указанного комплекса с представляющим интерес локусом эффекторный белок индуцирует модификацию представляющего интерес целевого локуса. В предпочтительном варианте осуществления модификация представляет собой введение разрыва нити.
В таких способах представляющий интерес целевой локус может содержаться в молекуле ДНК in vitro. В предпочтительном варианте осуществления молекула ДНК представляет собой плазмиду.
В таких способах представляющий интерес целевой локус может содержаться в молекуле ДНК в пределах клетки. Клетка может быть прокариотической клеткой или эукариотической клеткой. Клетка может быть клеткой млекопитающего. Клетка млекопитающего может быть клеткой отличного от человека примата, быка, свиньи, грызуна или мыши. Клетка может быть эукариотической клеткой от организма, отличного от млекопитающего, например, птицы, рыбы или креветки. Клетка также может быть растительной клеткой. Растительная клетка может происходить из сельскохозяйственного растения, такого как маниока, кукуруза, сорго, пшеница или рис. Растительная клетка также может происходить из водоросли, дерева или овощной культуры. Модификация, введенная в клетку с помощью настоящего изобретения, может быть такой, что клетка и потомство клетки изменяются для улучшения продуцирования биологических продуктов, таких как антитело, крахмал, спирт или другой желаемый клеточный продукт. Модификация, введенная в клетку с помощью настоящего изобретения, может быть такой, что клетка и потомство клетки будут включать в себя изменение, которое меняет продуцируемый биологический продукт.
В настоящем изобретении предусмотрен способ модифицирования представляющего интерес целевого локуса, причем способ включает доставку в указанный локус не встречающейся в природе или сконструированной композиции, содержащей эффекторный белок CRISPR-Cas VI типа и один или несколько компонентов на основе нуклеиновой кислоты, где эффекторный белок образует комплекс с одним или несколькими компонентами на основе нуклеиновой кислоты, и после связывания указанного комплекса с представляющим интерес локусом эффекторный белок индуцирует модификацию представляющего интерес целевого локуса. В предпочтительном варианте осуществления модификация представляет собой введение разрыва нити.
В предпочтительном варианте осуществления представляющий интерес целевой локус предусматривает ДНК.
В таких способах представляющий интерес целевой локус может содержаться в молекуле ДНК в пределах клетки. Клетка может быть прокариотической клеткой или эукариотической клеткой. Клетка может быть клеткой млекопитающего. Клетка млекопитающего может представлять собой клетку отличного от человека млекопитающего, например, представителя приматов, бычьих, овечьих, свиных, псовых, грызунов, Leporidae, как, например, обезьяны, коровы, овцы, свиньи, собаки, кролика, крысы или мыши. Клетка может представлять собой эукариотическую клетку от организма, отличного от млекопитающего, как, например, клетку домашней птицы (например, курицы), позвоночной рыбы (например, лосося) или моллюсков и ракообразных (например, устрицы, двустворчатых моллюсков, омара, креветки). Клетка также может быть растительной клеткой. Растительная клетка может быть получена от однодольного или двудольного растения, или от сельскохозяйственного или зернового растения, такого как маниока, кукуруза, сорго, соя, пшеница, овес или рис. Растительная клетка также может быть получена от водоросли, дерева или продуктивного растения, фрукта или овоща (например, деревьев, таких как цитрусовые деревья, например, деревья апельсина, грейпфрута или лимона; деревья персика или нектарина; деревья яблони или груши; орехоплодные деревья, такие как деревья миндаля, или грецкого ореха, или фисташки; пасленовых растений; растений из рода Brassica; растений из рода Lactuca; растений из рода Spinacia; растений из рода Capsicum; хлопчатника, табака, спаржи, моркови, капусты кочанной, брокколи, цветной капусты, томата, баклажана, перца, салата, шпината, земляники, черники, малины, ежевики, винограда, кофе, какао и т.д.).
В любом из описанных способов представляющий интерес целевой локус может представлять собой представляющий интерес локус генома или эпигеномный локус. В любом из описанных способов комплекс может доставляться с множественными направляющими для множественного применения. В любом из описанных способов можно применять более одного белка(белков).
В предпочтительных вариантах осуществления настоящего изобретения биохимическое, или in vitro, или in vivo расщепление последовательностей, ассоциированных с представляющим интерес целевым локусом или находящихся в нем, происходит без последовательности предполагаемой трансактивирующей crRNA (tracr RNA), например, расщепление с помощью эффекторного белка FnCpf1. В других вариантах осуществления настоящего изобретения расщепление может происходить с последовательностью предполагаемой трансактивирующей crRNA (tracr RNA), например, расщепление с помощью других эффекторных белков семейства CRISPR, однако после оценки локуса FnCpf1 заявители сделали вывод, что при расщеплении целевой ДНК с помощью комплекса эффекторного белка Cpf1 не требуется tracrRNA. Заявители определили, что комплексов эффекторного белка Cpf1, содержащих только эффекторный белок Cpf1 и crRNA (направляющая РНК, содержащая последовательность прямого повтора и направляющую последовательность), было достаточно для расщепления целевой ДНК. Соответственно, в настоящем изобретении предусмотрены способы модифицирования представляющего интерес целевого локуса, описанного в данном документе выше, где эффекторный белок представляет собой белок Cpf1, и эффекторный белок образует комплекс с целевой последовательностью без присутствия tracr-последовательности.
В любом из описанных способов эффекторный белок (например, Cpf1) и компоненты на основе нуклеиновой кислоты могут обеспечиваться с помощью одной или нескольких полинуклеотидных молекул, кодирующих белок и/или компонент(компоненты) на основе нуклеиновой кислоты, и где одна или несколько полинуклеотидных молекул функционально сконфигурированы для обеспечения экспрессии белка и/или компонента(компонентов) на основе нуклеиновой кислоты. Одна или несколько полинуклеотидных молекул могут содержать один или несколько регуляторных элементов, функционально сконфигурированных для обеспечения экспрессии белка и/или компонента(компонентов) на основе нуклеиновой кислоты. Одна или несколько полинуклеотидных молекул могут содержаться в одном или нескольких векторах. Настоящее изобретение охватывает такую(такие) полинуклеотидную(полинуклеотидные) молекулу(молекулы), например, такие полинуклеотидные молекулы функционально сконфигурированы для обеспечения экспрессии белка и/или компонента(компонентов) на основе нуклеиновой кислоты, а также такой(такие) вектор(векторы).
В любом из описанных способов разрыв нити может представлять собой однонитевой разрыв или двунитевой разрыв.
Регуляторные элементы могут предусматривать индуцируемые промоторы. Полинуклеотиды и/или векторные системы могут предусматривать индуцируемые системы.
В любом из описанных способов одна или несколько полинуклеотидных молекул могут содержаться в системе доставки, или один или несколько векторов могут содержаться в системе доставки.
В любом из описанных способов не встречающаяся в природе или сконструированная композиция может доставляться с помощью липосом, частиц (например, наночастиц), экзосом, микровезикул, генной пушки или одного или нескольких векторов, например, молекул нуклеиновой кислоты или вирусных векторов.
В настоящем изобретении также предусмотрена не встречающаяся в природе или сконструированная композиция, которая представляет собой композицию с характеристиками, обсуждаемыми в данном документе или определяемыми в любом из способов, описанных в данном документе.
В настоящем изобретении также предусмотрена векторная система, содержащая один или несколько векторов, причем один или несколько векторов содержат одну или несколько полинуклеотидных молекул, кодирующих компоненты не встречающейся в природе или сконструированной композиции, которая представляет собой композицию c характеристиками, обсуждаемыми в данном документе или определяемыми в любом из способов, описанных в данном документе.
В настоящем изобретении также предусмотрена система доставки, содержащая один или несколько векторов или одну или несколько полинуклеотидных молекул, причем один или несколько векторов или полинуклеотидных молекул предусматривают одну или несколько полинуклеотидных молекул, кодирующих компоненты не встречающейся в природе или сконструированной композиции, которая представляет собой композицию c характеристиками, обсуждаемыми в данном документе или определяемыми в любом из способов, описанных в данном документе.
В настоящем изобретении также предусмотрены не встречающаяся в природе или сконструированная композиция, или один или несколько полинуклеотидов, кодирующих компоненты указанной композиции, или вектор или системы доставки, содержащие один или несколько полинуклеотидов, кодирующих компоненты указанной композиции, для применения в терапевтическом способе лечения. Терапевтический способ лечения может предусматривать редактирование гена или генома или генную терапию.
Настоящее изобретение также охватывает компьютерные способы и алгоритмы для прогнозирования новых систем CRISPR-Cas класса 2 и идентификации компонентов в них.
В настоящем изобретении также предусмотрены способы и композиции, где один или несколько аминокислотных остатков эффекторного белка могут быть модифицированы, например, он является сконструированным или не встречающимся в природе эффекторным белком или Cpf1. В одном варианте осуществления модификация может предусматривать мутацию одного или нескольких аминокислотных остатков эффекторного белка. Одна или несколько мутаций могут находиться в одном или нескольких каталитически активных доменах эффекторного белка. Эффекторный белок может характеризоваться сниженной или отмененной нуклеазной активностью по сравнению с эффекторным белком, у которого отсутствует указанная одна или несколько мутаций. Эффекторный белок может не управлять расщеплением одной или другой нити ДНК или РНК в представляющем интерес целевом локусе. Эффекторный белок может не управлять расщеплением одной из нитей ДНК или РНК в представляющем интерес целевом локусе. В предпочтительном варианте осуществления одна или несколько мутаций могут предусматривать две мутации. В предпочтительном варианте осуществления один или несколько аминокислотных остатков модифицированы в эффекторном белке Cpf1, например, сконструированном или не встречающемся в природе эффекторном белке или Cpf1. В предпочтительном варианте осуществления эффекторный белок Cpf1 представляет собой эффекторный белок FnCpf1. В предпочтительном варианте осуществления один или несколько модифицированных или мутированных аминокислотных остатков представляют собой D917A, E1006A или D1255A в соответствии с нумерацией аминокислотных положений в эффекторном белке FnCpf1. В дополнительных предпочтительных вариантах осуществления один или несколько мутированных аминокислотных остатков представляют собой D908A, E993A, D1263A в соответствии с аминокислотными положениями в AsCpf1 или LbD832A, E925A, D947A или D1180A в соответствии с аминокислотными положениями в LbCpf1.
В настоящем изобретении также предусмотрено, что одна или несколько мутаций или две или более мутаций находятся в каталитически активном домене эффекторного белка, предусматривающем домен RuvC. В некоторых вариантах осуществления настоящего изобретения домен RuvC может предусматривать домен RuvCI, RuvCII или RuvCIII или каталитически активный домен, который гомологичен домену RuvCI, RuvCII или RuvCIII и т. д. или любому соответствующему домену, описываемому в любом из способов, описанных в данном документе. Эффекторный белок может содержать один или несколько гетерологичных функциональных доменов. Один или несколько гетерологичных функциональных доменов могут предусматривать один или несколько доменов, представляющих собой сигнал ядерной локализации (NLS). Один или несколько гетерологичных функциональных доменов могут предусматривать по меньшей мере два или более доменов NLS. Один или несколько доменов NLS могут быть расположены на конце эффекторного белка (например, Cpf1), или вблизи, или в непосредственной близости от него, а в случае двух или более NLS каждый из двух может быть расположен на конце эффекторного белка (например, Cpf1), или рядом, или в непосредственной близости от него. Один или несколько гетерологичных функциональных доменов могут предусматривать один или несколько доменов активации транскрипции. В предпочтительном варианте осуществления домен активации транскрипции может предусматривать VP64. Один или несколько гетерологичных функциональных доменов могут предусматривать один или несколько доменов репрессии транскрипции. В предпочтительном варианте осуществления домен репрессии транскрипции предусматривает домен KRAB или домен SID (например, SID4X). Один или несколько гетерологичных функциональных доменов могут предусматривать один или несколько нуклеазных доменов. В предпочтительном варианте осуществления нуклеазный домен предусматривает Fok1.
В настоящем изобретении также предусмотрено, что один или несколько гетерологичных функциональных доменов характеризуются одной или несколькими из следующих видов активности: метилазной активностью, деметилазной активностью, активностью в отношении активации транскрипции, активностью в отношении репрессии транскрипции, активностью фактора освобождения транскрипта, активностью модификации гистонов, нуклеазной активностью, активностью расщепления однонитевой РНК, активностью расщепления двухнитевой ДНК, активностью расщепления однонитевой ДНК, активностью расщепления двухнитевой ДНК и активностью связывания нуклеиновой кислоты. По меньшей мере один или несколько гетерологичных функциональных доменов могут быть расположены на амино-конце эффекторного белка или вблизи него, и/или где по меньшей мере один или несколько гетерологичных функциональных доменов могут быть расположены на кабокси-конце эффекторного белка или вблизи него. Один или несколько гетерологичных функциональных доменов могут быть слиты с эффекторным белком. Один или несколько гетерологичных функциональных доменов могут быть привязаны к эффекторному белку. Один или несколько гетерологичных функциональных доменов могут быть связаны с эффекторным белком с помощью линкерного фрагмента.
В настоящем изобретении также предусмотрен эффекторный белок (например, Cpf1), предусматривающий эффекторный белок (например, Cpf1) от организма из рода, включающего Streptococcus, Campylobacter, Nitratifractor, Staphylococcus, Parvibaculum, Roseburia, Neisseria, Gluconacetobacter, Azospirillum, Sphaerochaeta, Lactobacillus, Eubacterium, Corynebacter, Carnobacterium, Rhodobacter, Listeria, Paludibacter, Clostridium, Lachnospiraceae, Clostridiaridium, Leptotrichia, Francisella, Legionella, Alicyclobacillus, Methanomethyophilus, Porphyromonas, Prevotella, Bacteroidetes, Helcococcus, Letospira, Desulfovibrio, Desulfonatronum, Opitutaceae, Tuberibacillus, Bacillus, Brevibacilus, Methylobacterium или Acidaminococcus.
В настоящем изобретении также предусмотрен эффекторный белок (например, Cpf1), предусматривающий эффекторный белок (например, Cpf1) от организма S. mutans, S. agalactiae, S. equisimilis, S. sanguinis, S. pneumonia; C. jejuni, C. coli; N. salsuginis, N. tergarcus; S. auricularis, S. carnosus; N. meningitides, N. gonorrhoeae; L. monocytogenes, L. ivanovii; C. botulinum, C. difficile, C. tetani, C. sordellii.
Эффекторный белок может предусматривать химерный эффекторный белок, содержащий первый фрагмент из первого ортолога эффекторного белка (например, Cpf1) и второй фрагмент из второго ортолога эффекторного белка (например, Cpf1), и где первый и второй ортологи эффекторного белка являются различными. По меньшей мере один из первого и второго ортологов эффекторного белка (например, Cpf1) может предусматривать эффекторный белок (например, Cpf1) от организма, включающего Streptococcus, Campylobacter, Nitratifractor, Staphylococcus, Parvibaculum, Roseburia, Neisseria, Gluconacetobacter, Azospirillum, Sphaerochaeta, Lactobacillus, Eubacterium, Corynebacter, Carnobacterium, Rhodobacter, Listeria, Paludibacter, Clostridium, Lachnospiraceae, Clostridiaridium, Leptotrichia, Francisella, Legionella, Alicyclobacillus, Methanomethyophilus, Porphyromonas, Prevotella, Bacteroidetes, Helcococcus, Letospira, Desulfovibrio, Desulfonatronum, Opitutaceae, Tuberibacillus, Bacillus, Brevibacilus, Methylobacterium или Acidaminococcus; например, химерный эффекторный белок, содержащий первый фрагмент и второй фрагмент, где каждый из первого и второго фрагментов выбран из Cpf1 организма, включающего Streptococcus, Campylobacter, Nitratifractor, Staphylococcus, Parvibaculum, Roseburia, Neisseria, Gluconacetobacter, Azospirillum, Sphaerochaeta, Lactobacillus, Eubacterium, Corynebacter, Carnobacterium, Rhodobacter, Listeria, Paludibacter, Clostridium, Lachnospiraceae, Clostridiaridium, Leptotrichia, Francisella, Legionella, Alicyclobacillus, Methanomethyophilus, Porphyromonas, Prevotella, Bacteroidetes, Helcococcus, Letospira, Desulfovibrio, Desulfonatronum, Opitutaceae, Tuberibacillus, Bacillus, Brevibacilus, Methylobacterium или Acidaminococcus, где первый и второй фрагменты происходят не от одной и той же бактерии; например, химерный эффекторный белок, содержащий первый фрагмент и второй фрагмент, где каждый из первого и второго фрагментов выбран из Cpf1 S. mutans, S. agalactiae, S. equisimilis, S. sanguinis, S. pneumonia; C. jejuni, C. coli; N. salsuginis, N. tergarcus; S. auricularis, S. carnosus; N. meningitides, N. gonorrhoeae; L. monocytogenes, L. ivanovii; C. botulinum, C. difficile, C. tetani, C. sordellii; Francisella tularensis 1, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens и Porphyromonas macacae, где первый и второй фрагменты происходят не от одной и той же бактерии.
В предпочтительных вариантах осуществления настоящего изобретения эффекторный белок происходит из локуса Cpf1 (в данном документе такие эффекторные белки также обозначаются как "Cpf1p"), например, белка Cpf1 (и такой эффекторный белок, или белок Cpf1, или белок, происходящий из локуса Cpf1, также называются "ферментом CRISPR"). Локусы Cpf1 включают без ограничения локусы Cpf1 видов бактерий, приведенных на фигуре 64. В более предпочтительном варианте осуществления Cpf1p происходит от вида бактерий, выбранного из Francisella tularensis 1, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens и Porphyromonas macacae. В определенных вариантах осуществления Cpf1p происходит от вида бактерий, выбранного из Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020. В определенных вариантах осуществления эффекторный белок происходит от подвида Francisella tularensis 1, включая без ограничения Francisella tularensis subsp. Novicida.
В дополнительных вариантах осуществления настоящего изобретения мотив, смежный с протоспейсером (PAM), или PAM-подобный мотив управляют связыванием комплекса эффекторного белка с представляющим интерес целевым локусом. В предпочтительном варианте осуществления настоящего изобретения PAM представляет собой 5' TTN, где N представляет собой A/C/G или T, а эффекторный белок представляет собой FnCpf1p. В другом предпочтительном варианте осуществления настоящего изобретения PAM представляет собой 5' TTTV, где V представляет собой A/C или G, а эффекторный белок представляет собой AsCpf1, LbCpf1 или PaCpf1p. В определенных вариантах осуществления PAM представляет собой 5' TTN, где N представляет собой A/C/G или T, эффекторный белок представляет собой FnCpf1p, а PAM расположен выше 5'-конца протоспейсера. В определенных вариантах осуществления настоящего изобретения PAM представляет собой 5' CTA, где эффекторный белок представляет собой FnCpf1p, а PAM расположен выше 5'-конца протоспейсера или целевого локуса. В предпочтительных вариантах осуществления настоящего изобретения предусмотрен расширенный диапазон нацеливания для нуклеаз, осуществляющих направляемое РНК редактирование генома, где PAM с высоким содержанием T из семейства Cpf1 обеспечивают возможность нацеливания и редактирования геномов с высоким содержанием AT.
В определенных вариантах осуществления фермент CRISPR является сконструированным, и он может содержать одну или несколько мутаций, которые снижают или устраняют нуклеазную активность. Аминокислотные положения в домене RuvC FnCpf1p включают без ограничения D917A, E1006A, E1028A, D1227A, D1255A, N1257A, D917A, E1006A, E1028A, D1227A, D1255A и N1257A. Заявители также идентифицировали предполагаемый второй нуклеазный домен, который наиболее похож на суперсемейство нуклеаз PD-(D/E)XK и HincII-подобную эндонуклеазу. Точечные мутации, которые необходимо получить в данном предполагаемом нуклеазном домене для значительного снижения нуклеазной активности, включают без ограничения N580A, N584A, T587A, W609A, D610A, K613A, E614A, D616A, K624A, D625A, K627A и Y629A. В предпочтительном варианте осуществления мутация в домене RuvC FnCpf1p представляет собой D917A или E1006A, где мутация D917A или E1006A полностью инактивирует активность расщепления ДНК у эффекторного белка FnCpf1. В другом варианте осуществления мутация в домене RuvC FnCpf1p представляет собой D1255A, где мутированный эффекторный белок FnCpf1 характеризуется значительно сниженной нуклеолитической активностью.
Аминокислотные положения в домене RuvC AsCpf1p включают без ограничения 908, 993 и 1263. В предпочтительном варианте осуществления мутация в домен RuvC AsCpf1p представляет собой D908A, E993A и D1263A, где мутации D908A, E993A и D1263A полностью инактивируют активность расщепления ДНК у эффекторного белка AsCpf1. Аминокислотные положения в домене RuvC LbCpf1p включают без ограничения 832, 947 или 1180. В предпочтительном варианте осуществления мутация в домене RuvC LbCpf1p представляет собой LbD832A, E925A, D947A или D1180A, где мутации LbD832A, E925A, D947A или D1180A полностью инактивируют активность расщепления ДНК у эффекторного белка LbCpf1.
Мутации также можно осуществлять в соседних остатках, например, в аминокислотах вблизи указываемых выше остатков, которые принимают участие в нуклеазной активности. В некоторых вариантах осуществления инактивируется только домен RuvC, а в других вариантах осуществления инактивируется другой предполагаемый нуклеазный домен, где комплекс эффекторного белка функционирует как никаза и расщепляет только одну нить ДНК. В предпочтительном варианте осуществления другой предполагаемый нуклеазный домен представляет собой домен HincII-подобной эндонуклеазы. В некоторых вариантах осуществления два варианта FnCpf1, AsCpf1 или LbCpf1 (каждый из которых представляет собой отличающуюся никазу) применяются для повышения специфичности, два варианта никазы применяются для расщепления ДНК в мишени (где обе никазы расщепляют нить ДНК, при этом сводятся к минимуму или устраняются нецелевые модификации, при которых расщепляется и впоследствии подвергается репарации только одна нить ДНК). В предпочтительных вариантах осуществления эффекторный белок Cpf1 расщепляет последовательности, ассоциированные с представляющим интерес целевым локусом или находящиеся в нем, в виде гомодимера, содержащего две молекулы эффекторного белка Cpf1. В предпочтительном варианте осуществления гомодимер может содержать две молекулы эффекторного белка Cpf1, содержащие свою мутацию в их соответствующих доменах RuvC.
Настоящее изобретение предусматривает способы применения двух или более никаз, в частности, подход двойной или сдвоенной никазы. В некоторых аспектах и вариантах осуществления могут доставляться никазы одного типа FnCpf1, AsCpf1 или LbCpf1, например, модифицированная FnCpf1, AsCpf1 или LbCpf1 или модифицированная никаза FnCpf1, AsCpf1 или LbCpf1, описываемые в данном документе. Это приводит к тому, что целевая ДНК связывается двумя никазами FnCpf1. В дополнение также предусматривается, что можно применять различные ортологи, например, никазу FnCpf1, AsCpf1 или LbCpf1 на одной нити (например, кодирующей нити) ДНК и ортолог на некодирующей или противоположной нити ДНК. Ортолог может представлять собой без ограничения никазу Cas9, такую как никаза SaCas9 или никаза SpCas9. Может иметь преимущество применение двух различных ортологов, для которых требуются различные PAM, и они также могут иметь отличающиеся требования к направляющим, обеспечивая таким образом больший контроль для пользователя. В определенных вариантах осуществления расщепление ДНК будет предусматривать по меньшей мере четыре типа никаз, где каждый тип направляется на отличающуюся последовательность целевой ДНК, где каждая пара вводит первый однонитевой разрез в одну нить ДНК, а вторая вводит однонитевой разрез во вторую нить ДНК. В таких способах по меньшей мере две пары однонитевых разрывов вводятся в целевую ДНК, при этом после введения первой и второй пар однонитевых разрывов целевые последовательности между первой и второй парами однонитевых разрывов вырезаются. В определенных вариантах осуществления один или оба ортолога являются контролируемыми, т. е. индуцируемыми.
В определенных вариантах осуществления настоящего изобретения направляющая РНК или зрелая crRNA предусматривает, состоит, по сути, из или состоит из последовательности прямого повтора и направляющей последовательности или спейсерной последовательности. В определенных вариантах осуществления направляющая РНК или зрелая crRNA предусматривает, состоит, по сути, из или состоит из последовательности прямого повтора, связанной с направляющей последовательностью или спейсерной последовательностью. В определенных вариантах осуществления направляющая РНК или зрелая crRNA содержит 19 нуклеотидов частичного прямого повтора, за которыми следуют 20-30 нуклеотидов направляющей последовательности или спейсерной последовательности, преимущественно приблизительно 20 нуклеотидов, 23-25 нуклеотидов или 24 нуклеотида. В определенных вариантах осуществления эффекторный белок представляет собой эффекторный белок FnCpf1, AsCpf1 или LbCpf1, и требуется направляющая последовательность длиной по меньшей мере 16 нуклеотидов, чтобы достигнуть обнаруживаемого расщепления ДНК, и направляющая последовательность длиной минимум 17 нуклеотидов, чтобы достичь эффективного расщепления ДНК in vitro. В определенных вариантах осуществления последовательность прямого повтора расположена выше (т. е. в направлении 5') направляющей последовательности или спейсерной последовательности. В предпочтительном варианте осуществления затравочная последовательность (т. е. последовательность, критически важная для распознавания и/или гибридизации с последовательностью в целевом локусе) направляющей РНК для FnCpf1, AsCpf1 или LbCpf1 находится примерно в пределах первых 5 нуклеотидов на 5'-конце направляющей последовательности или спейсерной последовательности.
В предпочтительных вариантах осуществления настоящего изобретения зрелая crRNA содержит "петлю-на-стебле", или оптимизированную структуру "петля-на-стебле", или оптимизированную вторичную структуру. В предпочтительных вариантах осуществления зрелая crRNA содержит "петлю-на-стебле" или оптимизированную структуру "петля-на-стебле" в последовательности прямого повтора, где "петля-на-стебле" или оптимизированная структура "петля-на-стебле" важна для активности расщепления. В определенных вариантах осуществления зрелая crRNA предпочтительно содержит одну "петлю-на-стебле". В определенных вариантах осуществления последовательность прямого повтора предпочтительно содержит одну "петлю-на-стебле". В определенных вариантах осуществления активность расщепления комплекса эффекторного белка является модифицированной за счет введения мутаций, которые воздействую на дуплексную структуру РНК "петля-на-стебле". В предпочтительных вариантах осуществления можно вводить мутации, которые поддерживают РНК-дуплекс в "петле-на-стебле", в результате чего сохраняется активность расщепления комплекса эффекторного белка. В других предпочтительных вариантах осуществления можно вводить мутации, которые нарушают дуплексную структуру РНК в "петле-на-стебле", в результате чего активность расщепления комплекса эффекторного белка полностью отменяется.
В настоящем изобретении также предусмотрена нуклеотидная последовательность, кодирующая эффекторный белок, которая является кодон-оптимизированной для экспрессии в эукариотическом организме или эукариотической клетке в любом из способов или композиций, описанных в данном документе. В одном варианте осуществления настоящего изобретения кодон-оптимизированный эффекторный белок представляет собой FnCpf1p, AsCpf1 или LbCpf1, и он является кодон-оптимизированным для функциональности в эукариотической клетке или организме, например, такой клетке или организме, упоминаемом в других разделах данного документа, например, без ограничения клетке дрожжей, или клетке или организме млекопитающего, в том числе клетке мыши, клетке крысы и клетке человека, или эукариотическом организме, отличном от человека, например, в растении.
В определенных вариантах осуществления настоящего изобретения по меньшей мере один сигнал ядерной локализации (NLS) прикреплен к последовательностям нуклеиновой кислоты, кодирующим эффекторные белки Cpf1. В предпочтительных вариантах осуществления прикреплены по меньшей мере один или несколько C-концевых или N-концевых NLS (и, следовательно, молекула(молекулы) нуклеиновой кислоты, кодирующая(кодирующие) эффекторный белок Cpf1, может предусматривать кодирование NLS, вследствие чего экспрессированный продукт имеет прикрепленный(прикрепленные) или присоединенный(присоединенные) NLS). В предпочтительном варианте осуществления C-концевой NLS прикреплен для оптимальной экспрессии и нацеливания в ядро в эукариотических клетках, предпочтительно клетках человека. В предпочтительном варианте осуществления кодон-оптимизированный эффекторный белок представляет собой FnCpf1p, AsCpf1 или LbCpf1, а длина спейсера направляющей РНК составляет от 15 до 35 нуклеотидов. В определенных вариантах осуществления длина спейсера направляющей РНК составляет по меньшей мере 16 нуклеотидов, как, например, по меньшей мере 17 нуклеотидов. В определенных вариантах осуществления длина спейсера составляет от 15 до 17 нуклеотидов, от 17 до 20 нуклеотидов, от 20 до 24 нуклеотидов, например, 20, 21, 22, 23 или 24 нуклеотида, от 23 до 25 нуклеотидов, например, 23, 24 или 25 нуклеотидов, от 24 до 27 нуклеотидов, 27-30 нуклеотидов, 30-35 нуклеотидов, или 35 нуклеотидов или больше. В определенных вариантах осуществления настоящего изобретения кодон-оптимизированный эффекторный белок представляет собой FnCpf1p, а длина прямого повтора направляющей РНК составляет по меньшей мере 16 нуклеотидов. В определенных вариантах осуществления кодон-оптимизированный эффекторный белок представляет собой FnCpf1p, а длина прямого повтора направляющей РНК составляет от 16 до 20 нуклеотидов, например, 16, 17, 18, 19 или 20 нуклеотидов. В определенных предпочтительных вариантах осуществления длина прямого повтора направляющей РНК составляет 19 нуклеотидов.
Настоящее изобретение также охватывает способы доставки множественных компонентов на основе нуклеиновой кислоты, где каждый компонент на основе нуклеиновой кислоты является специфичным к отличающемуся представляющему интерес целевому локусу, за счет чего обеспечивается модифицирование множественных представляющих интерес целевых локусов. Компонент на основе нуклеиновой кислоты комплекса может содержать один или несколько белок-связывающих РНК-аптамеров. Один или несколько аптамеров могут быть способны связывать белок оболочки бактериофага. Белок оболочки бактериофага может быть выбран из группы, содержащей Qβ, F2, GA, fr, JP501, MS2, M12, R17, BZ13, JP34, JP500, KU1, M11, MX1, TW18, VK, SP, FI, ID2, NL95, TW19, AP205, φCb5, φCb8r, φCb12r, φCb23r, 7s и PRR1. В предпочтительном варианте осуществления белок оболочки бактериофага представляет собой MS2. В настоящем изобретении также предусмотрен компонент на основе нуклеиновой кислоты комплекса, длина которого составляет 30 или более, 40 или более или 50 или более нуклеотидов.
Настоящее изобретение также охватывает клетки, компоненты и/или системы по настоящему изобретению со следовыми количествами катионов, присутствующих в клетках, компонентах и/или системах. Преимущественно катион представляет собой магний, как, например, Mg2+. Катион может присутствовать в следовом количестве. Предпочтительный диапазон может составлять от приблизительно 1 мМ до приблизительно 15 мМ в случае катиона, который преимущественно представляет собой Mg2+. Предпочтительная концентрация может составлять приблизительно 1 мМ для клеток, компонентов и/или систем, полученных от человека, и от приблизительно 10 мМ до приблизительно 15 мМ для клеток, компонентов и/или систем, полученных от бактерий. См., например, Gasiunas et al., PNAS, опубликован онлайн 4 сентября 2012 года, www.pnas.org/cgi/doi/10.1073/pnas.1208507109.
Соответственно, целью настоящего изобретения не является охват в пределах настоящего изобретения любого ранее известного продукта, способа получения продукта или способа применения продукта, так что заявители оставляют за собой право и настоящим раскрывают отказ от прав на любой ранее известный продукт, процесс или способ. Следует дополнительно отметить, что настоящее изобретение не предназначено охватывать в пределах объема настоящего изобретения любой продукт, способ получения продукта или способ применения продукта, который не соответствует письменному описанию и требованиям достаточного раскрытия сути изобретения USPTO (первый пункт § 112 статьи 35 USC) или EPO (статья 83 EPC), так что заявители оставляют за собой право и настоящим объявляют отказ от прав на любой ранее описанный продукт, способ получения продукта или способ применения продукта. При осуществлении настоящего изобретения на практике предпочтительным является соответствие статье 53(c) EPC и правилу 28(b), а также (c) EPC. Ничто из содержащегося в данном документе не должно истолковываться как обязательство.
Следует отметить, что в данном раскрытии, и в частности в формуле изобретения и/или параграфах, такие термины, как "содержит", "содержащийся", "содержащий" и т. п., могут иметь значение, приписываемое им в патентном законодательстве США, например, они могут означать "включает", "включенный", "включающий" и т. п., и что такие термины, как "состоящий, по сути, из" и "состоит, по сути, из" имеют значение, приписываемое им в патентном законодательстве США.
Эти и другие варианты осуществления раскрыты или являются очевидными, исходя из следующего подробного описания, а также охвачены им.
Краткое описание графических материалов
Новые признаки настоящего изобретения изложены с характерными особенностями в прилагаемой формуле изобретения. Лучшее понимание признаков и преимуществ настоящего изобретения будет получено при ссылке на следующее подробное описание, в котором изложены иллюстративные варианты осуществления, в которых используются принципы настоящего изобретения, и на сопутствующие графические материалы.
На фиг. 1A-1B изображена новая классификация систем CRISPR-Cas. Класс 2 включает мультисубъединичные комплексы crRNA-эффектор (Cascade), а класс 2 включает односубъединичные комплексы crRNA-эффектор (Cas9-подобные).
На фиг. 2 представлена молекулярная структура CRISPR-Cas.
На фиг. 3A-3D представлены структуры комплексов эффекторов I и III типов: общая структура/общее происхождение, несмотря на существенную дивергенцию последовательности.
На фиг. 4 показана CRISPR-Cas в качестве системы, в центре которой расположен мотив распознавания РНК (RRM).
На фиг. 5A-5D показана филогения Cas1, где главным аспектом эволюции CRISPR-Cas оказывается рекомбинация адаптационного и crRNA-эффекторного модулей.
На фиг. 6 показан полный набор CRISPR-Cas, в частности, распределение типов/подтипов CRISPR-Cas среди архей и бактерий.
На фиг. 7 изображен конвейерный алгоритм идентификации кандидатов Cas.
На фиг. 8A-8D изображена организация полных локусов систем класса 2.
На фиг. 9A-9B изображено соседство C2c1.
На фиг. 10A-10C изображено дерево Cas1.
На фиг. 11A-11B изображена организация доменов у семейств класса 2.
На фиг. 12A-12B изображены участки гомологии с TnpB у белков класса 2 (SEQ ID NO: 246-428 соответственно, по порядку).
На фиг. 13A-13B изображено соседство C2c2.
На фиг. 14A-14E изображен мотив HEPN RxxxxH в семействе C2c2 (SEQ ID NO: 429-1032 соответственно, по порядку).
На фиг. 15 изображен C2C1: 1. Alicyclobacillus acidoterrestris ATCC 49025 (SEQ ID NO: 1034-1037 соответственно, по порядку).
На фиг. 16 изображен C2C1: 4. Desulfonatronum thiodismutans штамма MLF-1 (SEQ ID NO: 1038-1041 соответственно, по порядку).
На фиг. 17 изображен C2C1: 5. Opitutaceae bacterium TAV5 (SEQ ID NO: 1042-1045 соответственно, по порядку).
На фиг. 18 изображен C2C1: 7. Bacillus thermoamylovorans штамма B4166 (SEQ ID NO: 1046-1049 соответственно, по порядку).
На фиг. 19 изображен C2C1: 9. Bacillus sp. NSP2.1 (SEQ ID NO: 1050-1053 соответственно, по порядку).
На фиг. 20 изображен C2C2: 1. Lachnospiraceae bacterium MA2020 (SEQ ID NO: 1054-1057 соответственно, по порядку).
На фиг. 21 изображен C2C2: 2. Lachnospiraceae bacterium NK4A179 (SEQ ID NO: 1058-1064 соответственно, по порядку).
На фиг. 22 изображен C2C2: 3. [Clostridium] aminophilum DSM 10710 (SEQ ID NO: 1065-1068 соответственно, по порядку).
На фиг. 23 изображен C2C2: 4. Lachnospiraceae bacterium NK4A144 (SEQ ID NO: 1069 и 1070 соответственно, по порядку).
На фиг. 24 изображен C2C2: 5. Carnobacterium gallinarum DSM 4847 (SEQ ID NO: 1071-1074 соответственно, по порядку).
На фиг. 25 изображен C2C2: 6. Carnobacterium gallinarum DSM 4847 (SEQ ID NO: 1075-1081 соответственно, по порядку).
На фиг. 26 изображен C2C2: 7. Paludibacter propionicigenes WB4 (SEQ ID NO: 1082).
На фиг. 27 изображен C2C2: 8. Listeria seeligeri serovar 1/2b (SEQ ID NO: 1083-1086 соответственно, по порядку).
На фиг. 28 изображен C2C2: 9. Listeria weihenstephanensis FSL R9-0317 (SEQ ID NO: 1087).
На фиг. 29 изображен C2C2: 10. Listeria bacterium FSL M6-0635 (SEQ ID NO: 1088 и 1091 соответственно, по порядку).
На фиг. 30 изображен C2C2: 11. Leptotrichia wadei F0279 (SEQ ID NO: 1092).
На фиг. 31 изображен C2C2: 12. Leptotrichia wadei F0279 (SEQ ID NO: 1093-1099 соответственно, по порядку).
На фиг. 32 изображен C2C2: 14. Leptotrichia shahii DSM 19757 (SEQ ID NO: 1100-1103 соответственно, по порядку).
На фиг. 33 изображен C2C2: 15. Rhodobacter capsulatus SB 1003 (SEQ ID NO: 1104 и 1105 соответственно, по порядку).
На фиг. 34 изображен C2C2: 16. Rhodobacter capsulatus R121 (SEQ ID NO: 1106 и 1107 соответственно, по порядку).
На фиг. 35 изображен C2C2: 17. Rhodobacter capsulatus DE442 (SEQ ID NO: 1108 и 1109 соответственно, по порядку).
На фиг. 36 изображено дерево DR.
На фиг. 37 изображено дерево C2C2.
На фиг. 38A-38BB показано выравнивание последовательностей ортологов Cas-Cpf1 (SEQ ID NO: 1033 и 1110-1166 соответственно, по порядку).
На фиг. 39A-39B показан обзор выравнивания локусов Cpf1.
На фиг. 40A-40X показана конструкция вектора PACYC184 FnCpf1 (PY001) (SEQ ID NO: 1167 и SEQ ID NO: 1168-1189 соответственно, по порядку).
На фиг. 41A-41I показана последовательность гуманизированного PaCpf1 с нуклеотидной последовательностью под SEQ ID NO: 1190 и белковой последовательностью под SEQ ID NO: 1191.
На фиг. 42 изображен анализ с пробой на PAM.
На фиг. 43 изображена схема эндогенного локуса FnCpf1. pY0001 представляет собой остов pACY184 (от NEB) с частичным локусом FnCpf1. Локус FnCpf1 подвергали ПЦР-амплификации тремя частями и клонировали в pACYC184, разрезанный с помощью Xba1 и Hind3, с применением сборки по Гибсону. PY0001 содержит эндогенный локус FnCpf1 из 255 п. о. в направлении 3' от последовательности ацетилтрансферазы до четвертой спейсерной последовательности. Только спейсеры 1-3 являются потенциально активными, поскольку спейсер 4 больше не фланкирован прямыми повторами.
На фиг. 44 изображены библиотеки PAM, которые раскрыты под SEQ ID NO: 1192-1195 соответственно, по порядку. Обе библиотеки PAM (левые и правые) находятся в pUC19. Сложность библиотеки левых PAM составляет 48 ~ 65 т.о., а сложность библиотеки правых PAM составляет 47 ~ 16 т. о. Обе библиотеки получали с представлением, составляющим > 500.
На фиг. 45A-4E изображен компьютерный анализ для скрининга PAM FnCpf1. После секвенирования подвергнутой скринингу ДНК участки, соответствующие либо левому PAM, либо правому PAM, экстрагировали. Для каждого образца число PAM, присутствующих в секвенированной библиотеке, сравнивали с числом экстрагированных PAM в данной библиотеке (4^8 для левой библиотеки, 4^7 для правой). На фиг. 44A изображена левая библиотека, показывающая истощение PAM. Для количественной оценки данного истощения рассчитывали показатель обогащения. Для обоих состояний (контрольный pACYC или pACYC, содержащий FnCpf1) показатель рассчитывали для каждого PAM в библиотеке как 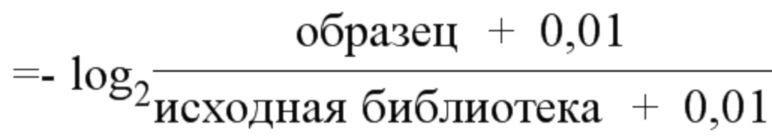 . Нанесение распределения на график показывает небольшое обогащение для контрольного образца и обогащение для обоих биологических повторов. На фиг. 44B-44D изображены распределения показателей PAM. На фиг. 44E показано, что собирали PAM с показателем, превышающим 8, и распределения частот наносили на график для выявления PAM 5' YYN.
. Нанесение распределения на график показывает небольшое обогащение для контрольного образца и обогащение для обоих биологических повторов. На фиг. 44B-44D изображены распределения показателей PAM. На фиг. 44E показано, что собирали PAM с показателем, превышающим 8, и распределения частот наносили на график для выявления PAM 5' YYN.
На фиг. 46 изображен анализ RNAseq локуса Cpf1 Francisella tolerances, который показывает, что локус CRISPR активно экспрессируется. В дополнение к генам Cpf1 и Cas на высоком уровне транскрибируются два небольших некодирующих транскрипта, которые могут быть предполагаемыми tracrRNA. Также экспрессируется массив CRISPR. Как предполагаемые tracrRNA, так и массив CRISPR транскрибируются в том же направлении, что и гены Cpf1 и Cas. В данном случае все РНК-транскрипты, идентифицированные с помощью эксперимента RNAseq, картированы относительно локуса. После дополнительной оценки локуса FnCpf1 заявители сделали вывод, что для расщепления целевой ДНК под действием комплекса эффекторного белка Cpf1 не требуется tracrRNA. Заявители определили, что комплексов эффекторного белка Cpf1, содержащих только эффекторный белок Cpf1 и crRNA (направляющая РНК, содержащая последовательность прямого повтора и направляющую последовательность), было достаточно для расщепления целевой ДНК.
На фиг. 47 изображено увеличение масштаба массива CRISPR c Cpf1. Можно было идентифицировать много различных коротких транскриптов. На данном графике все идентифицированные РНК-транскрипты картированы относительно локуса Cpf1.
На фиг. 48 изображена идентификация двух предполагаемых tracrRNA после отбора транскриптов, длина которых составляет менее 85 нуклеотидов.
На фиг. 49 изображено увеличение масштаба предполагаемой tracrRNA 1 (SEQ ID NO: 1196) и массива CRISPR.
На фиг. 50 изображено увеличение масштаба предполагаемой tracrRNA 2, которая раскрыта под SEQ ID NO: 1197-1203 соответственно, по порядку.
На фиг. 51 изображены предполагаемые последовательности crRNA (повтор обозначен голубым цветом, спейсер обозначен черным цветом) (SEQ ID NO: 1205 и 1206 соответственно, по порядку).
На фиг. 52 показана схема анализа для подтверждения прогнозируемого PAM FnCpf1 in vivo.
На фиг. 53 показаны клетки, несущие локус FnCpf1, и контрольные клетки, трансформированные с помощью pUC19, кодирующего эндогенный спейсер 1 с PAM 5' TTN.
На фиг. 54 показаны схема, указывающая положения последовательности предполагаемой tracrRNA в локусе FnCpf1, crRNA (SEQ ID NO: 1207) и вектор pUC с протоспейсером.
На фиг. 55 представлен гель, на котором показан ПЦР-фрагмент с PAM TTa и последовательностью протоспейсера 1 после инкубации в клеточном лизате.
На фиг. 56 представлен гель, на котором показан pUC-спейсер 1 с различными PAM после инкубации в клеточном лизате.
На фиг. 57 представлен гель, на котором показаны результаты расщепления с помощью BasI после инкубации в клеточном лизате.
На фиг. 58 представлен гель, на котором показаны результаты расщепления трех предполагаемых последовательностей crRNA (SEQ ID NO: 1208).
На фиг. 59 представлен гель, на котором показаны результаты тестирования спейсеров различной длины относительно части целевой ДНК, содержащей целевой сайт: 5'-TTAgagaagtcatttaataaggccactgttaaaa-3' (SEQ ID NO: 1209). Результаты показывают, что crRNA 1-7 опосредовали успешное расщепление целевой ДНК in vitro под действием FnCpf1. crRNA 8-13 не способствовали расщеплению целевой ДНК. SEQ ID NO: 1210-1248 раскрыты соответственно по порядку.
На фиг. 60 представлена схема с указанием минимального локуса FnCpf1.
На фиг. 61 представлена схема с указанием минимальной направляющей Cpf1 (SEQ ID NO: 1249).
На фиг. 62A-62E изображен компьютерный анализ для скрининга PAM PaCpf1. После секвенирования подвергнутой скринингу ДНК участки, соответствующие либо левому PAM, либо правому PAM, экстрагировали. Для каждого образца число PAM, присутствующих в секвенированной библиотеке, сравнивали с числом экстрагированных PAM в данной библиотеке (4^7). (фиг. 62A) Для левой библиотеки показано очень слабое истощение PAM. Для количественной оценки данного истощения рассчитывали показатель обогащения. Для обоих состояний (контрольный pACYC или pACYC, содержащий PaCpf1) показатель рассчитывали для каждого PAM в библиотеке как
показатель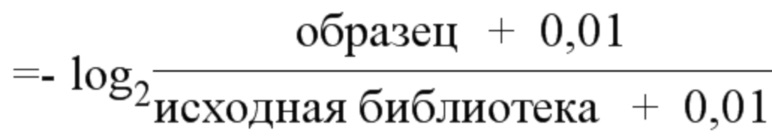 .
.
Нанесение распределения на график показывает небольшое обогащение для контрольного образца и обогащение для обоих биологических повторов. На фиг. 62B-62D изображены распределения показателей PAM. На фиг. 62E показано, что собирали все PAM с показателем, превышающим 4,5, и распределения частот наносили на график, что выявило PAM 5' TTTV, где V представляет собой A, или C, или G.
На фиг. 63 показана карта вектора с последовательностью PaCpf1, кодон-оптимизированной для человека, который изображен как CBh-NLS-huPaCpf1-NLS-3xHA-pA.
На фиг. 64A-64B показано филогенетическое дерево 51 локуса Cpf1 у различных бактерий. Выделение рамкой указывает на №№ эталонных генов: 1-17. Ортологи с рамкой/пронумерованные тестировали в отношении активности расщепления in vitro с прогнозируемой зрелой crRNA; ортологи с рамкой вокруг их номера проявляли активность в анализе in vitro.
На фиг. 65A-65H показаны подробные сведения, относящиеся к последовательности Cpf1 Lachnospiraceae bacterium MC2017 1, кодон-оптимизированной для человека, с длиной гена, составляющей 3849 нуклеотидов (эталон. № 3 на фиг. 64). Фиг. 65A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 65B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 65C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п.о. были удалены. Фиг. 65D. Рестриктазы и цис-действующие элементы. Фиг. 65E. Удаление повторяющихся последовательностей. Фиг. 65F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 3849, GC% 54,70) (SEQ ID NO: 1250). Фиг. 65H. Белковая последовательность (SEQ ID NO: 1251).
На фиг. 66A-66H показаны подробные сведения, относящиеся к последовательности Cpf1 Butyrivibrio proteoclasticus, кодон-оптимизированной для человека, с длиной гена, составляющей 3873 нуклеотида (эталон. № 4 на фиг. 64). Фиг. 66A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 66B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 66C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п. о. были удалены. Фиг. 66D. Рестриктазы и цис-действующие элементы. Фиг. 66E. Удаление повторяющихся последовательностей. Фиг. 66F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 3873, GC% 54,05) (SEQ ID NO: 1252). Фиг. 66H. Белковая последовательность (SEQ ID NO: 1253).
На фиг. 67A-67H показаны подробные сведения, относящиеся к последовательности Cpf1 Peregrinibacteria bacterium GW2011_GWA2_33_10, кодон-оптимизированной для человека, с длиной гена, составляющей 4581 нуклеотид (эталон. № 5 на фиг. 64). Фиг. 67A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 67B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 67C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п.о. были удалены. Фиг. 67D. Рестриктазы и цис-действующие элементы. Фиг. 67E. Удаление повторяющихся последовательностей. Фиг. 67F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 4581, GC% 50,81) (SEQ ID NO: 1254). Фиг. 67H. Белковая последовательность (SEQ ID NO: 1255).
На фиг. 68A-68H показаны подробные сведения, относящиеся к последовательности Cpf1 Parcubacteria bacterium GW2011_GWC2_44_17, кодон-оптимизированной для человека, с длиной гена, составляющей 4206 нуклеотидов (эталон. № 6 на ФИГ. 64). Фиг. 68A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 68B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 68C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п. о. были удалены. Фиг. 68D. Рестриктазы и цис-действующие элементы. Фиг. 68E. Удаление повторяющихся последовательностей. Фиг. 68F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 4206, GC% 52,17) (SEQ ID NO: 1256). Фиг. 68H. Белковая последовательность (SEQ ID NO: 1257).
На фиг. 69A-69H показаны подробные сведения, относящиеся к последовательности Cpf1 Smithella sp. SCADC, кодон-оптимизированной для человека, с длиной гена, составляющей 3900 нуклеотидов (эталон. № 7 на фиг. 64). Фиг. 69A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 69B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 69C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п.о. были удалены. Фиг. 69D. Рестриктазы и цис-действующие элементы. Фиг. 69E. Удаление повторяющихся последовательностей. Фиг. 69F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 3900, GC% 51,56) (SEQ ID NO: 1258). Фиг. 69H. Белковая последовательность (SEQ ID NO: 1259).
На фиг. 70A-70H показаны подробные сведения, относящиеся к последовательности Cpf1 Acidaminococcus sp. BV3L6, кодон-оптимизированной для человека, с длиной гена, составляющей 4071 нуклеотид (эталон. № 8 на фиг. 64). Фиг. 70A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 70B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 70C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п. о. были удалены. Фиг. 70D. Рестриктазы и цис-действующие элементы. Фиг. 70E. Удаление повторяющихся последовательностей. Фиг. 70F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 4071, GC% 54,89) (SEQ ID NO: 1260). Фиг. 70H. Белковая последовательность (SEQ ID NO: 1261).
На фиг. 71A-71H показаны подробные сведения, относящиеся к последовательности Cpf1 Lachnospiraceae bacterium MA2020, кодон-оптимизированной для человека, с длиной гена, составляющей 3768 нуклеотидов (эталон. № 9 на фиг. 64). Фиг. 71A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 71B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 71C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п. о. были удалены. Фиг. 71D. Рестриктазы и цис-действующие элементы. ФИГ. 71E. Удаление повторяющихся последовательностей. Фиг. 71F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 3768, GC% 51,53) (SEQ ID NO: 1262). Фиг. 71H. Белковая последовательность (SEQ ID NO: 1263).
На фиг. 72A-72H показаны подробные сведения, относящиеся к последовательности Cpf1 Candidatus Methanoplasma termitum, кодон-оптимизированной для человека, с длиной гена, составляющей 3864 нуклеотида (эталон. № 10 на фиг. 64). Фиг. 72A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 72B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 72C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п.о. были удалены. Фиг. 72D. Рестриктазы и цис-действующие элементы. Фиг. 72E. Удаление повторяющихся последовательностей. Фиг. 72F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 3864, GC% 52,67) (SEQ ID NO: 1264). Фиг. 72H. Белковая последовательность (SEQ ID NO: 1265).
На фиг. 73A-73H показаны подробные сведения, относящиеся к последовательности Cpf1 Eubacterium eligens, кодон-оптимизированной для человека, с длиной гена, составляющей 3996 нуклеотидов (эталон. № 11 на Фиг. 64). Фиг. 73A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 73B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 73C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п. о. были удалены. Фиг. 73D. Рестриктазы и цис-действующие элементы. Фиг. 73E. Удаление повторяющихся последовательностей. Фиг. 73F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 3996, GC% 50,52) (SEQ ID NO: 1266). Фиг. 73H. Белковая последовательность (SEQ ID NO: 1267).
На фиг. 74A-74H показаны подробные сведения, относящиеся к последовательности Cpf1 Moraxella bovoculi 237, кодон-оптимизированной для человека, с длиной гена, составляющей 4269 нуклеотидов (эталон. № 12 на фиг. 64). Фиг. 74A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 74B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 74C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п.о. были удалены. Фиг. 74D. Рестриктазы и цис-действующие элементы. Фиг. 74E. Удаление повторяющихся последовательностей. Фиг. 74F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 4269, GC% 53,58) (SEQ ID NO: 1268). Фиг. 74H. Белковая последовательность (SEQ ID NO: 1269).
На фиг. 75A-75H показаны подробные сведения, относящиеся к последовательности Cpf1 Leptospira inadai, кодон-оптимизированной для человека, с длиной гена, составляющей 3939 нуклеотидов (эталон. № 13 на фиг. 64). Фиг. 75A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 75B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 75C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п.о. были удалены. Фиг. 75D. Рестриктазы и цис-действующие элементы. Фиг. 75E. Удаление повторяющихся последовательностей. Фиг. 75F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 3939, GC% 51,30) (SEQ ID NO: 1270). Фиг. 75H. Белковая последовательность (SEQ ID NO: 1271).
На фиг. 76A-76H показаны подробные сведения, относящиеся к последовательности Cpf1 Lachnospiraceae bacterium ND2006, кодон-оптимизированной для человека, с длиной гена, составляющей 3834 нуклеотида (эталон. № 14 на фиг. 64). Фиг. 76A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 76B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 76C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п. о. были удалены. Фиг. 76D. Рестриктазы и цис-действующие элементы. Фиг. 76E. Удаление повторяющихся последовательностей. Фиг. 76F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 3834, GC% 51,06) (SEQ ID NO: 1272). Фиг. 76H. Белковая последовательность (SEQ ID NO: 1273).
На фиг. 77A-77H показаны подробные сведения, относящиеся к последовательности Cpf1 Porphyromonas crevioricanis 3, кодон-оптимизированной для человека, с длиной гена, составляющей 3930 нуклеотидов (эталон. № 15 на фиг. 64). Фиг. 77A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 77B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 77C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п. о. были удалены. Фиг. 77D. Рестриктазы и цис-действующие элементы. Фиг. 77E. Удаление повторяющихся последовательностей. Фиг. 77F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 3930, GC% 54,42) (SEQ ID NO: 1274). Фиг. 77H. Белковая последовательность (SEQ ID NO: 1275).
На фиг. 78A-78H показаны подробные сведения, относящиеся к последовательности Cpf1 Prevotella disiens, кодон-оптимизированной для человека, с длиной гена, составляющей 4119 нуклеотидов (эталон. № 16 на фиг. 64). Фиг. 78A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 78B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 78C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п. о. были удалены. Фиг. 78D. Рестриктазы и цис-действующие элементы. Фиг. 78E. Удаление повторяющихся последовательностей. Фиг. 78F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 4119, GC% 51,88) (SEQ ID NO: 1276). Фиг. 78H. Белковая последовательность (SEQ ID NO: 1277).
На фиг. 79A-79H показаны подробные сведения, относящиеся к последовательности Cpf1 Porphyromonas macacae, кодон-оптимизированной для человека, с длиной гена, составляющей 3888 нуклеотидов (эталон. № 17 на фиг. 64). Фиг. 79A. Индекс адаптации кодонов (CAI). Распределение частоты использования кодонов по всей длине последовательности гена. Считается, что CAI, составляющий 1,0, является отличным для организма, в котором требуется экспрессия, а CAI, составляющий > 0,8, считается таким же хорошим с точки зрения высокого уровня экспрессии гена. Фиг. 79B. Частота оптимальных кодонов (FOP). Процентное распределение кодонов в рассчитанных группах качества кодонов. Значение, составляющее 100, установлено для кодонов с наиболее высокой частотой использования для данной аминокислоты в организме, в котором требуется экспрессия. Фиг. 79C. Корректировка содержания GC. Идеальный диапазон процентного содержания GC составляет 30-70%. Пики % содержания GC в окне размером 60 п. о. были удалены. Фиг. 79D. Рестриктазы и цис-действующие элементы. Фиг. 79E. Удаление повторяющихся последовательностей. Фиг. 79F-G. Оптимизированная последовательность (длина оптимизированной последовательности: 3888, GC% 53,26) (SEQ ID NO: 1278). Фиг. 79H. Белковая последовательность (SEQ ID NO: 1279).
На фиг. 80A-80I показаны последовательности прямого повтора (DR) для каждого ортолога (со ссылкой на нумерацию эталон. № 3-17 на фиг. 64) и их прогнозируемая структура укладки. SEQ ID NO: 1280-1313 соответственно раскрыты по порядку.
На фиг. 81 показано расщепление ПЦР-ампликона локуса Emx1 человека. SEQ ID NO: 1314-1318 соответственно раскрыты по порядку.
На фиг. 82A-82B показан эффект усечения 5' DR на активность расщепления. На фиг. 82A показан гель, на котором представлены результаты расщепления с указанием усечений 5' DR. На фиг. 82B показано графическое изображение crDNA deltaDR5, у которой разрушается "петля-на-стебле" на 5'-конце. Это указывает на то, что "петля-на-стебле" на 5'-конце важна для активности расщепления. SEQ ID NO: 1319-1324 соответственно раскрыты по порядку.
На фиг. 83 показан эффект несовпадения crRNA-ДНК-мишень на эффективность расщепления. SEQ ID NO: 1325-1335 соответственно раскрыты по порядку.
На фиг. 84 показано расщепление ДНК с применением очищенного Cpf1 Francisella и Prevotella. Раскрыта SEQ ID NO: 1336.
На фиг. 85A-85B показаны графические изображения вторичных структур DR. На фиг. 85A показана вторичная структура DR FnCpf1 (SEQ ID NO: 1337) ("петля-на-стебле" выделена). На фиг. 85B показана вторичная структура DR PaCpf1 (SEQ ID NO: 1338) ("петля-на-стебле" выделена, она является идентичной за исключением отличия по одному основанию в участке петли).
На фиг. 86 показано дополнительное описание анализа RNAseq локуса FnCp1.
На фиг. 87A-87B показана схема последовательностей зрелой crRNA. На фиг. 87A показаны последовательности зрелой crRNA для FnCpf1. На фиг. 87B показаны последовательности зрелой crRNA для PaCpf1. SEQ ID NO: 1339-1342 соответственно раскрыты по порядку.
На фиг. 88 показано расщепление ДНК с применением FnCpf1 Francisella novicida, кодон-оптимизированной для человека. Верхняя полоска соответствует нерасщепленному полноразмерному фрагменту (606 п.о.). Ожидаемые продукты расщепление размером ~345 п.о. и ~261 п.о. обозначены треугольниками.
На фиг. 89 показан анализ ортологов in vitro, демонстрирующий расщепление под действием ортологов Cpf1.
На фиг. 90A-90C показаны PAM, полученные компьютерным образом на основании анализа разрезания in vitro.
На фиг. 91 показано, что разрезание под действием Cpf1 происходит ступенчатым образом с "липкими" 5'-концами. SEQ ID NO: 1343-1345 соответственно раскрыты по порядку.
На фиг. 92 показан эффект длины спейсера на разрезание. SEQ ID NO: 1346-1352 соответственно раскрыты по порядку.
На фиг. 93 показаны данные SURVEYOR относительно опосредованного FnCpf1 образования вставок/делеций в клетках HEK293T.
На фиг. 94A-94F показан процессинг транскриптов, когда участки локуса FnCpf1 подвергались делеции, в сравнении с процессингом транскриптов в локусе FnCpf1 дикого типа. На фиг. 95B, 95D и 95F увеличен масштаб процессированного спейсера. SEQ ID NO: 1353-1401 соответственно раскрыты по порядку.
На фиг. 95A-95E показано, что локус Cpf1 CRISPR Francisella tularensis subsp. novicida U112 обеспечивает иммунитет от трансформации плазмидами, содержащими протоспейсеры, фланкированные PAM 5'-TTN. На фиг. 95A показана организация двух локусов CRISPR, обнаруженных у Francisella tularensis subsp. novicida U112 (NC_008601). Показано сравнение организации доменов у FnCas9 и FnCpf1. На фиг. 95B представлена схематическая иллюстрация анализа истощения плазмид для обнаружения положения и идентичности PAM. Компетентные E. coli, несущие либо плазмиду с гетерологичным локусом FnCpf1 (pFnCpf1), либо пустой контрольный вектор, трансформировали с помощью библиотеки плазмид, содержащих совпадающий протоспейсер, фланкированный рандомизированными последовательностями 5' или 3' PAM, и проводили отбор с помощью антибиотика для истощения плазмид, несущих успешно подвергаемый нацеливанию PAM. Плазмиды из выживших колоний экстрагировали и секвенировали для определения поверженных истощению последовательностей PAM. На фиг. 95C-95D показаны логотипы последовательностей для PAM FnCpf1, как определено с помощью анализа истощения плазмид. Высота буквы в положении определяется количеством информации; планки погрешностей показывают 95% байесовский доверительный интервал. На фиг. 95E показано, что E. coli, несущие pFnCpf1, демонстрируют устойчивое противодействие плазмидам, несущим PAM 5'-TTN (n = 3, планки погрешностей представляют среднее ± S.E.M.).
На фиг. 96A-96C показано, что гетерологичная экспрессия FnCpf1 и массива CRISPR в E. coli является достаточной для опосредования интерференции в отношении плазмидной ДНК и созревания crRNA. С помощью секвенирования малых РНК Francisella tularensis subsp. novicida U112 (фиг. 96A) обнаружили транскрипцию и процессинг массива CRISPR c FnCpf1. Зрелая crRNA начинается с частичного прямого повтора длиной 19 нуклеотидов, за которым следует 23-25 нуклеотидов спейсерной последовательности. С помощью секвенирования малых РНК E. coli, трансформированной с помощью плазмиды, несущей управляемый синтетическим промотором FnCpf1 и массив CRISPR (фиг. 96B), показано, что процессинг crRNA не зависит от генов Cas и других элементов последовательности в локусе FnCpf1. На фиг. 96C изображены E. coli, несущие различные усечения локуса FnCpf1 CRISPR, и показано, что только FnCpf1 и массив CRISPR требуются для интерференции в отношении плазмидной ДНК (n = 3, планки погрешностей показывают среднее ± S.E.M.). Раскрыта SEQ ID NO: 1580.
На фиг. 97A-97E показано, что FnCpf1 нацеливается с помощью crRNA для расщепления ДНК in vitro. На фиг. 97A представлена схема комплекса нацеливания на ДНК на основе FnCpf1 и crRNA. Сайты расщепления обозначены красными стрелочками (SEQ ID NO: 1402 и 1403 соответственно раскрыты по порядку). FnCpf1 и crRNA отдельно опосредовали направляемое РНК расщепление целевой ДНК зависимым от crRNA и Mg2+ способом (фиг. 97B). На фиг. 97C показано, что FnCpf1 расщепляет как линейную, так и сверхспирализованную ДНК. На фиг. 97D показано, что на записях секвенирования по Сэнгеру мишени, расщепленной под действием FnCpf1, обнаруживаются ступенчатые "липкие" концы (SEQ ID NO: 1404 и 1406 соответственно раскрыты по порядку). Не обусловленное матрицей добавление дополнительного аденина, обозначенного как N, является артефактом, связанным с полимеразой, применяемой при секвенировании. Рид обратного праймера представлен как обратно комплементарная последовательность для лучшей визуализации. На фиг. 97E показано, что расщепление зависит от образования пар оснований в 5' PAM. FnCpf1 может распознавать только PAM в ДНК с правильно образованными парами оснований по Уотсону-Крику.
На фиг. 98A-98B показано, что каталитические остатки в C-концевом домене RuvC FnCpf1 необходимы для расщепления ДНК. На фиг. 98A показана структура доменов FnCpf1, при этом выделены каталитические остатки RuvC. Каталитические остатки идентифицировали на основании гомологии последовательности с RuvC Thermus thermophilus (PDB ID: 4EP5). На фиг. 98B изображен нативный гель TBE PAGE, на котором показано, что мутация каталитических остатков (D917A и E1006A) в RuvC FnCpf1 и мутация каталитического остатка (D10A) в RuvC SpCas9 предотвращает двухнитевое расщепление ДНК. На денатурирующем геле TBE-мочевина PAGE показано, что мутация каталитических остатков (D917A и E1006A) в RuvC FnCpf1 предотвращает активность однонитевого разрыва ДНК, тогда как мутация каталитического остатка (D10A) в RuvC SpCas9 приводит к однонитевому разрыву целевого сайта.
На фиг. 99A-99E показаны требования к crRNA для проявления нуклеазной активности FnCpf1 in vitro. На фиг. 99A показан эффект длины спейсера на активность расщепления у FnCpf1. На фиг. 99B показан эффект несовпадений crRNA-целевая ДНК на активность расщепления у FnCpf1. На фиг. 99C продемонстрирован эффект длины прямого повтора на активность расщепления у FnCpf1. На фиг. 99D показано, что активность расщепления у FnCpf1 зависит от вторичной структуры в стеблевой части структуры РНК прямого повтора. На фиг. 99E показано, что на активность расщепления у FnCpf1 не влияют мутации петлевой части, но она чувствительна к мутации в наиболее 3'-дальнем основании в прямом повторе. SEQ ID NO: 1407-1433 соответственно раскрыты по порядку.
На фиг. 100A-100F представлен анализ разнообразия и функции семейства белков Cpf1. На фиг. 100A-100B показано филогенетическое сравнение 16 ортологов Cpf1, выбранных для функционального анализа. Консервативные последовательности показаны темно-серым цветом. Выделены домен RuvC, мостиковая спираль и цинковый палец. На фиг. 100C показано выравнивание прямых повторов из 16 белков семейства Cpf1. Последовательности, которые удаляются после созревания crRNA, показаны серым цветом. Неконсервативные основания показаны красным цветом. Стеблевой дуплекс выделен серым цветом. На фиг. 100D изображено прогнозирование с помощью RNAfold (Lorenz et al., 2011) последовательности прямого повтора в зрелой crRNA. Показаны результаты прогнозирования для FnCpf1 вместе с тремя наименее консервативными ортологами. На фиг. 100E показано, что ортологи crRNA с подобными последовательностями прямого повтора способны функционировать с FnCpf1 с опосредованием расщепления целевой ДНК. На фиг. 100F показаны последовательности PAM для 8 белков семейства Cpf1, идентифицированные с применением расщепления in vitro плазмидной библиотеки, содержащей рандомизированные PAM, фланкирующие протоспейсер. SEQ ID NO: 1434-1453 соответственно раскрыты по порядку.
На фиг. 101A-101E показано, что Cpf1 опосредует устойчивое редактирование генома в линиях клеток человека. На фиг. 101A представлена схема, на которой показана экспрессия индивидуальных белков семейства Cpf1 в клетках HEK 293FT с применением векторов экспрессии, управляемых промотором CMV. Соответствующая crRNA экспрессировалась с применением ПЦР-фрагмента, содержащего промотор U6, слитый с последовательностью crRNA. Трансфицированные клетки анализировали с применением либо анализа с помощью нуклеазы Surveyor, либо нацеленного глубокого секвенирования. На фиг. 101B (вверху) изображена последовательность crRNA 3, нацеливающейся на DNMT1, и на ридах секвенирования (внизу) показаны типичные вставки/делеции. На фиг. 101B раскрыты SEQ ID NO 1454-1465 соответственно, по порядку. На фиг. 101C представлено сравнение активности расщепления in vitro и in vivo. Целевой участок DNMT1 подвергали ПЦР-амплификации и фрагмент генома применяли для тестирования расщепления, опосредованного Cpf1. Для всех 8 белков семейства Cpf1 показано расщепление ДНК in vitro (вверху). Кандидаты 7 - AsCpf1 и 13 - Lb3Cpf1 облегчали устойчивое образование вставок/делеций в клетках человека (внизу). На фиг. 101D показаны целевые последовательности для Cpf1 и SpCas9 в локусе DNMT1 человека (SEQ ID NO: 1466-1473 соответственно раскрыты по порядку). На фиг. 101E представлено сравнение эффективности редактирования генома под действием Cpf1 и SpCas9. Целевые сайты соответствуют последовательностям, показанным на фиг. 101D.
На фиг. 102A-102D показан анализ истощения плазмид in vivo для идентификации PAM для FnCpf1. (См. также фиг. 95). Фиг. 102A. Трансформация E. coli, несущей pFnCpf1, с помощью библиотеки плазмид, несущих рандомизированные последовательности 5' PAM. Ряд плазмид подвергались истощению. На графике показаны уровни истощения, ранжированные по порядку. Истощение измеряют как отрицательный log2 кратного соотношения нормализованного содержания относительно E. coli, несущих контрольный pACYC184. PAM с пороговым значением, превышающим 3,5, применяли для получения логотипов последовательностей. Фиг. 102B. Трансформация E. coli, несущей pFnCpf1, с помощью библиотеки плазмид, несущих рандомизированные последовательности 3' PAM. Ряд плазмид подвергались истощению. На графике показаны уровни истощения, ранжированные по порядку. Истощение измеряют как отрицательный log2 кратного соотношения нормализованного содержания относительно E. coli, несущих контрольный pACYC184, и PAM с пороговым значением, превышающим 3,5, применяли для получения логотипов последовательностей. Фиг. 102C. Исходная библиотека плазмид, несущих рандомизированные последовательности 5' PAM. На графике показаны уровни истощения, ранжированные по порядку. Истощение измеряют как отрицательный log2 кратного соотношения нормализованного содержания относительно E. coli, несущих контрольный pACYC184. PAM с пороговым значением, превышающим 3,5, применяли для получения логотипов последовательностей. Фиг. 102D. Число уникальных PAM, преодолевших граничное значение значимости для парных комбинаций оснований в положениях 2 и 3 в 5' PAM.
На фиг. 103A-103D показана очистка белка FnCpf1. (См. также фиг. 97). На фиг. 103A изображен акриламидный гель с FnCpf1, окрашенный Кумасси голубым, на котором показана последовательная очистка. Полоска с размером молекул, немного превышающим 160 кДа, элюируемая из колонки Ni-NTA, совпадает с размером продукта слияния MBP-FnCpf1 (189,7 кДа). После добавления протеазы TEV появлялась полоска с меньшей молекулярной массой, совпадающая со свободным FnCpf1 размером 147 кДа. Фиг. 103B. Эксклюзионная гель-фильтрация FnCpf1. FnCpf1 элюировался с размером, составляющим примерно 300 кДа (62,65 мл), что позволяет предположить, что Cpf1 может существовать в растворе в виде димера. На фиг. 103C показаны белковые стандарты, применяемые для калибровки колонки Superdex 200. BDex = голубой декстран (свободный объем), Ald = альдолаза (158 кДа), Ov = овальбумин (44 кДа), RibA = рибонуклеаза A (13,7 кДа), Apr = апротинин (6,5 кДа). Фиг. 103D. Калибровочная кривая колонки Superdex 200. Ka рассчитывают как (элюирующий объем - свободный объем)/(геометрический объем колонки - свободный объем). Стандарты наносили на график и аппроксимировали к логарифмической кривой.
На фиг. 104A-104E показаны паттерны расщепления под действием FnCpf1. (См. также фиг. 97). На записях секвенирования по Сэнгеру ДНК-мишеней, расщепленных под действием FnCpf1, обнаруживаются ступенчатые "липкие" концы. Не обусловленное матрицей добавление дополнительного аденина, обозначенного как N, является артефактом, связанным с полимеразой, применяемой при секвенировании. Записи секвенирования по Сэнгреу показаны для различных PAM TTN с протоспейсером 1 (фиг. 104A), протоспейсером 2 (фиг. 104B) и протоспейсером 3 (фиг. 104C) и мишеней DNMT1 и EMX1 (фиг. 104D). Последовательность (-)-нити является обратно комплементарной, чтобы показать последовательность лучшей нити. Сайты расщепления обозначены красными треугольниками. Более маленькие треугольники обозначают предполагаемые альтернативные сайты расщепления. На фиг. 104E показан эффект несовпадения дистального от PAM остатка при взаимодействии crRNA-целевая ДНК на активность расщепления у FnCpf1. SEQ ID NO: 1474-1494 соответственно раскрыты по порядку.
На фиг. 105A-105B показано выравнивание аминокислотных последовательностей FnCpf1 (SEQ ID NO: 1495), AsCpf1 (SEQ ID NO: 1496) и LbCpf1 (SEQ ID NO: 1497). (См. также фиг. 100). Остатки, которые являются консервативными, выделены красным фоном, а консервативные мутации выделены рамкой и красным шрифтом. Результат прогнозирования вторичной структуры выделен выше (FnCpf1) и ниже (LbCpf1) выравнивания. Альфа-спирали показаны в виде волнистого символа, а бета-нити показаны как черточки. Белковые домены, идентифицированные на фиг. 95A, также выделены.
На фиг. 106A-106D представлены карты локусов генома бактерий, соответствующих 16 белкам семейства Cpf1, выбранных для проведения экспериментов с млекопитающими. (См. также фиг. 100). На фиг. 106A-106D раскрыты SEQ ID NO: 1498-1513 соответственно по порядку.
На фиг. 107A-107E показано определение характеристик белков семейства Cpf1 in vitro. На фиг. 107A представлена схема скрининга PAM in vitro с применением белков семейства Cpf1. Библиотеку плазмид, несущих рандомизированные последовательности 5' PAM, подвергали расщеплению под действием индивидуальных белков семейства Cpf1 и их соответствующих crRNA. Нерасщепленную плазмидную ДНК очищали и секвенировали для идентификации специфических мотивов PAM, которые подвергали истощению. На фиг. 107B указано число уникальных последовательностей, преодолевших граничное значение значимости для парных комбинаций оснований в положениях 2 и 3 в 5' PAM для 7 - AsCpf1. На фиг. 107C указано число уникальных PAM, преодолевших граничное значение значимости для тройных комбинаций оснований в положениях 2, 3 и 4 в 5' PAM для 13 - LbCpf1. На фиг. 107D-107E показаны записи секвенирования по Сэнгеру мишени, расщепленной под действием 7 - AsCpf1 (фиг. 107E), и мишени, расщепленной под действием 13 - LbCpf1 (фиг. 107F), и показаны ступенчатые "липкие" концы. Не обусловленное матрицей добавление дополнительного аденина, обозначенного как N, является артефактом, связанным с полимеразой, применяемой при секвенировании. Сайты расщепления обозначены красными треугольниками. Более маленькие треугольники обозначают предполагаемые альтернативные сайты расщепления. На фиг. 107D-E раскрыты SEQ ID NO: 1514-1519 соответственно, по порядку.
На фиг. 108A-108F указана эффективность редактирования генома клеток человека в дополнительных локусах. На гелях из анализа Surveyor показана количественная оценка эффективности образования вставок/делеций, достигнутой каждым белком семейства Cpf1 в целевых сайтах 1 (фиг. 108A), 2 (фиг. 108B) и 4 (фиг. 108C) DNMT1. На фиг. 108A-108C указана эффективность редактирования генома клеток человека в дополнительных локусах и секвенирование по Сэнгегу подвергнутых расщеплению целевых сайтов DNMT. На гелях из анализа Surveyor показана количественная оценка эффективности образования вставок/делеций, достигнутой каждым белком семейства Cpf1 в целевых сайтах 1 (фиг. 108D) и 2 (фиг. 108E) EMX1. Распределения образования вставок/делеций для AsCpf1 и LbCpf1 и целевых сайтов 2, 3 и 4 DNMT1 (фиг. 108F). Сине-зеленые столбики обозначают общий охват вставок/делеций; голубые столбики обозначают распределение вставок/делеций на 3'-концах. Для каждой мишени последовательность PAM обозначена красным цветом, а целевая последовательность обозначена светло-голубым цветом.
На фиг. 109A-109C изображено, что с помощью компьютерного анализа первичной структуры нуклеаз Cpf1 выявили три отличающихся участка. Первый, C-концевой RuvC-подобный домен, который является единственным охарактеризованным функциональным доменом. Второй, N-концевой альфа-спиральный участок, и третий, участок со смешанной альфа- и бета-структурой, расположенный между RuvC-подобным доменом и альфа-спиральным участком.
На фиг. 110A-110E изображено выравнивание Rad50 AsCpf1 (PDB 4W9M). SEQ ID NO: 1520 и 1521 соответственно раскрыты по порядку. На фиг. 110C изображено выравнивание RuvC AsCpf1 (PDB 4LD0). SEQ ID NO: 1522 и 1523 соответственно раскрыты по порядку. На фиг. 110D-110E изображено выравнивание AsCpf1 и FnCpf1, с помощью которого идентифицируют домен Rad50 в FnCpf1. SEQ ID NO: 1524 и 1525 соответственно раскрыты по порядку.
На фиг. 111 изображена структура Rad50 (4W9M) в комплексе с ДНК. Остатки, взаимодействующие с ДНК, выделены (красным цветом).
На фиг. 112 изображена структура RuvC (4LD0) в комплексе со структурой Холлидея. Остатки, взаимодействующие с ДНК, выделены красным цветом.
На фиг. 113 изображен BLAST-поиск для выравнивания AsCpf1 с участком сайт-специфической рекомбиназы XerD. Участком активного сайта XerD является LYWTGMR (SEQ ID NO: 1), при этом R представляет собой каталитический остаток. SEQ ID NO: 1526-1527 соответственно раскрыты по порядку.
На фиг. 114 изображено, что участок является консервативным у ортологов Cpf1 (желтый прямоугольник), и хотя R не является консервативным, высококонсервативная аспарагиновая кислота (оранжевый прямоугольник) находится просто на C-конце этого участка и вблизи консервативного участка (голубой прямоугольник) с абсолютно консервативным аргинином. Аспарагиновая кислота представляет собой D732 в LbCpf1. SEQ ID NO: 1204 и 1528-1579 соответственно раскрыты по порядку.
На фиг. 115A показан эксперимент, в котором высевали по 150000 клеток HEK293T на лунку 24-луночного планшета за 24 ч. до трансфекции. Клетки трансфицировали с помощью 400 нг плазмиды с huAsCpf1 и 100 нг плазмиды с тандемными направляющими, содержащей одну направляющую последовательность, направленную на GRIN28, и одну, направленную на EMX1, размещенные тандемно за промотором U6, с применением Lipofectamin2000. Клетки собирали через 72 ч. после трансфекции и активность AsCpf1, опосредованную тандемными направляющими, оценивали с применением анализа с помощью нуклеазы SURVEYOR.
На фиг. 115B продемонстрировано образование вставок/делеций как в GRIN28, так и в гене EMX1.
На фиг. 116 показано расщепление под действием FnCpf1 и массива при возрастающих концентрациях EDTA (и снижающихся концентрациях Mg2+). Буфер представляет собой 20 мМ Tris-HCl, pH 7 (комнатная температура), 50 мМ KCl и включает ингибитор мышиной РНКазы для предотвращения разрушения РНК, вследствие возможных следовых количеств неспецифической РНКазы, внесенной в ходе очистки белка.
Фигуры приведены в данном документе только с целью иллюстрации, и они необязательно изображены в масштабе.
Подробное описание изобретения
В настоящей заявке описаны новые направляемые РНК эндонуклеазы (например, эффекторные белки Cpf1), которые функционально отличны от систем CRISPR-Cas9, описанных ранее, и, следовательно, терминология элементов, ассоциированных с этими новыми эндонуклеазами, в данном документе соответственно модифицирована. Cpf1-ассоциированные массивы CRISPR, описанные в данном документе, процессируются в зрелые crRNA без потребности в дополнительной tracrRNA. crRNA, описанные в данном документе, содержат спейсерную последовательность (или направляющую последовательность) и последовательность прямого повтора, и комплекса Cpf1p-crRNA самого по себе достаточно для эффективного расщепления целевой ДНК. Затравочная последовательность, описанная в данном документе, например, затравочная последовательность направляющей РНК для FnCpf1, находится примерно в пределах первых 5 нуклеотидов на 5'-конце спейсерной последовательности (или направляющей последовательности), и мутации в пределах затравочной последовательности негативно влияют на активность расщепления у комплекса эффекторного белка Cpf1.
В целом, система CRISPR характеризуется элементами, которые содействуют образованию комплекса CRISPR в сайте целевой последовательности (также называемой протоспейсер в контексте эндогенной системы CRISPR). В контексте образования комплекса CRISPR "целевая последовательность" обозначает последовательность, для нацеливания на которую разрабатывается направляющая последовательность, например, чтобы обладать комплементарностью, при этом гибридизация между целевой последовательностью и направляющей последовательностью содействует образованию комплекса CRISPR. Отрезок направляющей последовательности, на протяжении которого комплементарность с целевой последовательностью важна для активности расщепления, обозначается в данном документе как затравочная последовательность. Целевая последовательность может предусматривать любой полинуклеотид, как, например, полинуклеотиды ДНК или РНК, и она содержится в пределах представляющего интерес целевого локуса. В некоторых вариантах осуществления целевая последовательность расположена в ядре или цитоплазме клетки. Описанное в данном документе настоящее изобретение охватывает новые эффекторные белки систем CRISPR-Cas класса 2, из которых в качестве примера эффекторного белка приводится Cas9, и, следовательно, термины, используемые в настоящей заявке для описания новых эффекторных белков, могут перекликаться с терминами, используемыми для описания системы CRISPR-Cas9.
Локусы CRISPR-Cas включают более чем 50 семейств генов, и при этом отсутствуют строго универсальные гены. По этой причине невозможно построить единое эволюционное дерево и для идентификации новых семейств нужно применять дифференцированный подход. На настоящий момент имеется исчерпывающая идентификация генов cas из 395 профилей для 93 белков Cas. Классификация включает сигнатуры генных профилей с сигнатурами структуры локуса. Новая классификация систем CRISPR-Cas предложена на фиг. 1. Класс 1 включает мультисубъединичные комплексы crRNA-эффектор (Cascade), а класс 2 включает односубъединичные комплексы crRNA-эффектор (Cas9-подобные). На фиг. 2 представлена молекулярная структура CRISPR-Cas. На фиг. 3 представлены структуры комплексов эффекторов I и III типов: общая структура/общее происхождение, несмотря на существенную дивергенцию последовательности. На фиг. 4 показана CRISPR-Cas в качестве системы, в центре которой расположен мотив распознавания РНК (RRM). На фиг. 5 показана филогения Cas1, где главным аспектом эволюции CRISPR-Cas оказывается рекомбинация адаптационного и crRNA-эффекторного модулей. На фиг. 6 показан полный набор CRISPR-Cas, в частности, распределение типов/подтипов CRISPR-Cas среди архей и бактерий.
Действие системы CRISPR-Cas обычно делится на три стадии: (1) адаптация или интеграция спейсера, (2) процессинг первичного транскрипта локуса CRISPR (pre-crRNA) и созревание crRNA, которая включает спейсер и вариабельные участки, соответствующие 5'- и 3'-фрагментам повторов CRISPR, и (3) ДНК- (или РНК-) интерференция. Двух белков, Cas1 и Cas2, которые присутствуют в подавляющем большинстве известных систем CRISPR-Cas, достаточно для вставки спейсеров в кассеты CRISPR. Эти два белка образуют комплекс, который требуется для данного процесса адаптации; причем эндонуклеазная активность Cas1 требуется для интеграции спейсера, в то время как Cas2, по-видимому, выполняет неферментативную функцию. Комплекс Cas1-Cas2 представляет высококонсервативный модуль "обработки информации" CRISPR-Cas, который, по-видимому, является квазиавтономным от остальной части системы. (См. Annotation and Classification of CRISPR-Cas Systems. Makarova KS, Koonin EV. Methods Mol Biol. 2015;1311:47-75).
Описанные ранее системы класса 2, а именно II типа и предполагаемого V типа, состояли только из трех или четырех генов в опероне cas, а именно генов cas1 и cas2, составляющих адаптационный модуль (пара генов cas1-cas2 не вовлечена в интерференцию), одного мультидоменного эффекторного белка, который отвечает за интерференцию, но также принимает участие в процессинге и адаптации pre-crRNA, и зачастую четвертого гена с неохарактеризованными функциями, который является необязательным по меньшей мере в некоторых системах II типа (и в некоторых случаях четвертый ген представляет собой cas4 (биохимические или in silico доказательства показывают, что Cas4 представляет собой нуклеазу суперсемейства PD-(DE)xK с C-концевым кластером из трех остатков цистеина; он обладает экзонуклеазной активностью в отношении 5'-ssDNA) или csn2, который кодирует инактивированную АТФазу). В большинстве случаев массив CRISPR и ген для отличающейся молекулы РНК, известной как tracrRNA, транс-кодируемая малая РНК CRISPR, расположены вблизи оперонов cas класса 2. tracrRNA является частично гомологичной повторам в пределах соответствующего массива CRISPR, и она необходима для процессинга pre-crRNA, который катализируется РНКазой III, универсальным ферментом бактерий, который не ассоциирован с локусом CRISPR-Cas.
Cas1 является наиболее консервативным белком, который присутствует в большинстве систем CRISPR-Cas и меняется медленнее, чем остальные белки Cas. Соответственно, филогению Cas1 использовали в качестве руководства для классификации системы CRISPR-Cas. Биохимические или in silico доказательства показывают, что Cas1 представляет собой металлозависимую дезоксирибонуклеазу. Удаление Cas1 в E. coli приводит к повышенной чувствительности к повреждению ДНК и нарушенной сегрегации хромосом, как описано в "A dual function of the CRISPR-Cas system in bacterial antivirus immunity and DNA repair", Babu M et al. Mol Microbiol 79:484-502 (2011). Биохимические или in silico доказательства показывают, что Cas 2 представляет собой РНКазу, специфичную к участкам с высоким содержанием U, и является двухнитевой ДНКазой.
Аспекты настоящего изобретения относятся к идентификации и конструированию новых эффекторных белков, ассоциированных с системами CRISPR-Cas класса 2. В предпочтительном варианте осуществления эффекторный белок предусматривает односубъединичный эффекторный модуль. В дополнительном варианте осуществления эффекторный белок является функциональный в прокариотических или эукариотических клетках для применений in vitro, in vivo или ex vivo. Один аспект настоящего изобретения охватывает компьютерные способы и алгоритмы для прогнозирования новых систем CRISPR-Cas класса 2 и идентификации компонентов в них.
В одном варианте осуществления компьютерный способ идентификации новых локусов CRISPR-Cas класса 2 включает следующие стадии: выявление всех контигов, кодирующих белок Cas1; идентификация всех прогнозируемых белок-кодирующих генов в пределах 20 т. о. от гена cas1; сравнение идентифицированных генов с профилями, специфическими для белка Cas, и прогнозирование массивов CRISPR; отбор неклассифицированных кандидатных локусов CRISPR-Cas, содержащих белки из более чем 500 аминокислот (>500 aa); анализ отобранных кандидатов с применением PSI-BLAST и HHPred, за счет чего обеспечивается выделение и идентификация новых локусов CRISPR-Cas класса 2. В дополнение к вышеупомянутым стадиям может проводиться дополнительный анализ кандидатов путем поиска в метагеномных базах данных дополнительных гомологов.
В одном аспекте выявление всех контигов, кодирующих белок Cas1, осуществляют с помощью GenemarkS, которая является программой для прогнозирования генов, дополнительно описанной в "GeneMarkS: a self-training method for prediction of gene starts in microbial genomes. Implications for finding sequence motifs in regulatory regions." John Besemer, Alexandre Lomsadze and Mark Borodovsky, Nucleic Acids Research (2001) 29, pp 2607-2618, включенном в данный документ посредством ссылки.
В одном аспекте идентификацию всех прогнозируемых белок-кодирующих генов проводят путем сравнения идентифицированных генов с профилями, специфическими для белка Cas, и аннотации их в соответствии с базой данных консервативных доменов (CDD) от NCBI, которая представляет собой ресурс для аннотации белков, который состоит из набора хорошо аннотированных моделей множественного выравнивания последовательностей для древних доменов и полноразмерных белков. Они доступны в виде позиционных весовых матриц (PSSM) для быстрой идентификации консервативных доменов в белковых последовательностях с помощью RPS-BLAST. Содержимое CDD включает NCBI-подтвержденные домены, информацию о 3D-структуре которых применяют для точного определения границ доменов и понимания взаимоотношений последовательность/структура/функция, а также модели доменов, импортированные из ряда внешних баз данных (Pfam, SMART, COG, PRK, TIGRFAM). В дополнительном аспекте массивы CRISPR прогнозировали с применением программы PILER-CR, которая представляет собой общедоступное программное обеспечение для нахождения повторов CRISPR, как описано в "PILER-CR: fast and accurate identification of CRISPR repeats", Edgar, R.C., BMC Bioinformatics, Jan 20;8:18(2007), включенном в данный документ посредством ссылки.
В дополнительном аспекте индивидуальный анализ осуществляют с применением PSI-BLAST (позиционно-итеративное средство поиска основного локального выравнивания). PSI-BLAST дает позиционную весовую матрицу (PSSM) или профиль на основании множественного выравнивания последовательностей из выявленных последовательностей, превышающих данное весовое граничное значение c применением поиска BLAST белок-белок. Эту PSSM применяют для дополнительного поиска новых совпадений в базе данных и ее обновляют для последующих итераций с этими новыми выявленными последовательностями. Таким образом, PSI-BLAST обеспечивает средства для выявления отдаленного родства между белками.
В другом аспекте индивидуальный анализ осуществляют с применением HHpred, способа поиска в базах данных последовательностей и прогнозирования структуры, который настолько же прост в применении, как BLAST или PSI-BLAST, и который в то же время является намного более чувствительным в поиске отдаленных гомологов. Фактически, чувствительность HHpred сравнима с наиболее мощными доступными в настоящее время серверами для прогнозирования структуры. HHpred представляет собой первый сервер, который основан на парном сравнении профилей с помощью скрытых Марковских моделей (HMM). В то время как большинство традиционных способов поиска последовательностей проводят поиск в базах данных последовательностей, таких как UniProt или NR, HHpred проводит поиск в базах данных выравниваний, таких как Pfam или SMART. Это значительно сокращает список хитов до числа семейств последовательностей вместо беспорядочной массы отдельных последовательностей. Все главные общедоступные профили и базы данных выравниваний доступны через HHpred. HHpred принимает в качестве вводимой информации одну запрашиваемую последовательность или множественное выравнивание. В течение всего нескольких минут она выдает результаты поиска в легко читаемом формате, напоминающий таковой у PSI-BLAST. Параметры поиска включают локальное или глобальное выравнивание и балльную оценку сходства вторичной структуры. HHpred может проводить парное выравнивание запрашиваемой-матричной последовательностей, слитые множественные выравнивания запрашиваемых-матричной последовательностей (например, для промежуточных поисков), а также модели 3D-структуры, рассчитанные с помощью программного обеспечения MODELLER на основании выравниваний HHpred.
Термин "система нацеливания на нуклеиновую кислоту", где нуклеиновая кислота представляет собой ДНК или РНК, а в некоторых аспектах также может обозначать гибриды ДНК-РНК или их производные, совокупно обозначает транскрипты и другие элементы, вовлеченные в экспрессию или управляющие активностью генов, ассоциированных с нацеливающимся на ДНК или РНК CRISPR ("Cas"), которые могут включать последовательности, кодирующие нацеливающийся на ДНК или РНК белок Cas и нацеливающуюся на ДНК или РНК направляющую РНК, предусматривающую последовательность РНК CRISPR (crRNA) и (в случае системы CRISPR-Cas9, но не во всех системах) последовательность трансактивирующей РНК системы CRISPR-Cas (tracrRNA) или другие последовательности и транскрипты из локуса CRISPR для нацеливания на ДНК или РНК. В Cpf1-системах направляемой РНК эндонуклеазы, нацеливающейся на ДНК, описанных в данном документе, последовательность tracrRNA не требуется. В целом, система нацеливания на РНК характеризуется элементами, которые способствуют образованию комплекса нацеливания на РНК в сайте целевой последовательности РНК. В контексте образования комплекса нацеливания на ДНК или РНК "целевая последовательность" обозначает последовательность ДНК или РНК, относительно которой разрабатывается нацеливающаяся на ДНК или РНК направляющая РНК таким образом, чтобы обладать комплементарностью, при этом гибридизация между целевой последовательностью и нацеливающейся на РНК направляющей РНК содействует образованию комплекса нацеливания на РНК. В некоторых вариантах осуществления целевая последовательность расположена в ядре или цитоплазме клетки.
В одном аспекте настоящего изобретения новые системы нацеливания на ДНК, также называемые CRISPR-Cas для нацеливания на ДНК или система нацеливания на ДНК на основе CRISPR-Cas по настоящей заявке, основаны на идентифицированных белках Cas V типа (например, подтипа V-A и подтипа V-B), в случае которых не требуется получение индивидуальных белков для нацеливания на специфические последовательности ДНК, а скорее один эффекторный белок или фермент может быть запрограммирован молекулой РНК на распознавание специфической ДНК-мишени, другими словами, фермент может быть рекрутирован к специфической ДНК-мишени с помощью указанной молекулы РНК. Аспекты настоящего изобретения, в частности, относятся к направляемым РНК системам нацеливания Cpf1 CRISPR.
В одном аспекте настоящего изобретения новые системы нацеливания на РНК, также называемые CRISPR-Cas для нацеливания на РНК или РНК или система нацеливания на РНК на основе CRISPR-Cas по настоящей заявке, основаны на идентифицированных белках Cas VI типа, в случае которых не требуется получение индивидуальных белков для нацеливания на специфические последовательности РНК, а скорее один фермент может быть запрограммирован молекулой РНК для распознавания специфической РНК-мишени, другими словами, фермент может быть рекрутирован к специфической РНК-мишени с помощью указанной молекулы РНК.
Системы нацеливания на нуклеиновую кислоту, векторные системы, векторы и композиции, описанные в данном документе, можно использовать в различных применениях для нацеливания на нуклеиновую кислоту, изменения или модифицирования синтеза продукта гена, такого как белок, расщепления нуклеиновых кислот, редактирования нуклеиновых кислот, сплайсинга нуклеиновых кислот; направленного перемещения целевых нуклеиновых кислот, отслеживания целевых нуклеиновых кислот, выделения целевых нуклеиновых кислот, визуализации целевых нуклеиновых кислот и т. д.
Используемое в данном документе выражение "белок Cas" или "фермент CRISPR" обозначают любой белок, представленный в новой классификации систем CRISPR-Cas. В преимущественном варианте осуществления настоящее изобретение охватывает эффекторные белки, идентифицированные в локусах CRISPR-Cas V типа, например, локусах, кодирующих Cpf1, обозначенных подтипом V-A. В настоящее время локусы подтипа V-A охватывают cas1, cas2, отдельный ген, обозначенный как cpf1, и массив CRISPR. Cpf1 (CRISPR-ассоциированный белок Cpf1, подтип PREFRAN) представляет собой крупный белок (приблизительно 1300 аминокислот), который содержит домен RuvC-подобной нуклеазы, гомологичный соответствующему домену Cas9, вместе с эквивалентом характерного кластера Cas9 с высоким содержанием аргинина. Однако у Cpf1 отсутствует HNH-нуклеазный домен, который присутствует у всех белков Cas9, а RuvC-подобный домен граничит с последовательностью Cpf1, в отличие от Cas9, где он содержит длинные вставки, включающие домен HNH. Соответственно, в конкретных вариантах осуществления фермент CRISPR-Cas содержит только домен RuvC-подобной нуклеазы.
Ген Cpf1 встречается в геномах нескольких разных бактерий, как правило, в том же локусе, что и гены cas1, cas2 и cas4 и кассета CRISPR (например, FNFX1_1431-FNFX1_1428 из Francisella cf. novicida Fx1). Таким образом, общее устройство этой предполагаемой новой системы CRISPR-Cas, по-видимому, аналогично системе типа II-B. Более того, подобно Cas9, белок Cpf1 содержит легко идентифицируемый C-концевой участок, который гомологичен транспозону ORF-B и включает активную RuvC-подобную нуклеазу, участок с высоким содержанием аргинина и "цинковый палец" (отсутствует у Cas9). Однако, в отличие от Cas9, Cpf1 также присутствует в некоторых геномах без сопутствующего CRISPR-Cas, и его относительно большое сходство с ORF-B позволяет предположить, что он, вероятно, представляет собой компонент транспозона. Было высказано предположение, что если бы это была истинная система CRISPR-Cas, а Cpf1 являлся функциональным аналогом Cas9, они представляли собой новый тип CRISPR-Cas, а именно V тип (см. Annotation and Classification of CRISPR-Cas Systems. Makarova KS, Koonin EV. Methods Mol Biol. 2015;1311:47-75). Однако, как описано в данном документе, Cpf1 обозначен как относящийся к подтипу V-A, чтобы отличать его от C2c1p, который не имеет идентичную структуру доменов и, следовательно, обозначается как относящийся к подтипу V-B.
В преимущественном варианте осуществления настоящее изобретение охватывает композиции и системы, содержащие эффекторные белки, идентифицированные в локусах Cpf1, обозначенных подтипом V-A.
Аспекты настоящего изобретения также охватывают способы и варианты применения композиций и систем, описываемых в данном документе, в конструировании генома, например, для изменения или манипуляции с экспрессией одного или нескольких генов или одного или нескольких продуктов генов в прокариотических или эукариотических клетках in vitro, in vivo или ex vivo.
В вариантах осуществления настоящего изобретения термины "зрелая crRNA" и "направляющая РНК" используются взаимозаменяемо, как и в цитируемых выше документах, таких как WO 2014/093622 (PCT/US2013/074667). В целом, направляющая последовательность представляет собой любую полинуклеотидную последовательность, характеризующуюся достаточной комплементарностью с целевой полинуклеотидной последовательностью для гибридизации с целевой последовательностью и управления специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью. В некоторых вариантах осуществления степень комплементарности между направляющей последовательностью и ее соответствующей целевой последовательностью при оптимальном выравнивании с применением подходящего алгоритма выравнивания составляет приблизительно или более чем приблизительно 50%, 60%, 75%, 80%, 85%, 90%, 95%, 97,5%, 99% или больше. Оптимальное выравнивание можно определять с применением любого подходящего алгоритма для выравнивания последовательностей, к неограничивающим примерам которого относится алгоритм Смита-Ватермана, алгоритм Нидлмана-Вунша, алгоритмы, основанные на преобразовании Барроуза-Уилера (например, Burrows Wheeler Aligner), ClustalW, Clustal X, BLAT, Novoalign (Novocraft Technologies; доступный на сайте www.novocraft.com), ELAND (Illumina, Сан-Диего, Калифорния), SOAP (доступный на сайте soap.genomics.org.cn) и Maq (доступный на сайте maq.sourceforge.net). В некоторых вариантах осуществления длина направляющей последовательности составляет приблизительно или более чем приблизительно 5, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 45, 50, 75 или более нуклеотидов. В некоторых вариантах осуществления длина направляющей последовательности составляет менее чем приблизительно 75, 50, 45, 40, 35, 30, 25, 20, 15, 12 или менее нуклеотидов. Предпочтительно длина направляющей последовательности составляет 10-30 нуклеотидов. Способность направляющей последовательности управлять специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью можно оценить с помощью любого подходящего анализа. Например, компоненты системы CRISPR, достаточные для образования комплекса CRISPR, в том числе направляющая последовательность, подлежащая тестированию, могут обеспечиваться в клетке-хозяине, имеющей соответствующую целевую последовательностью, как, например, с помощью трансфекции векторами, кодирующими компоненты последовательности CRISPR, с последующей оценкой предпочтительного расщепления в пределах целевой последовательности, как, например, с помощью анализа с использованием нуклеазы Surveyor, описываемого в данном документе. Аналогично, расщепление целевой полинуклеотидной последовательности можно определять в пробирке путем обеспечения целевой последовательности, компонентов комплекса CRISPR, в том числе направляющей последовательности, подлежащей тестированию, и контрольной направляющей последовательности, отличной от тестируемой направляющей последовательности, и сравнения связывания или степени расщепления целевой последовательности в случае реакций с тестируемой и контрольной направляющей последовательностью. Возможны и другие анализы, и они могут быть выполнены специалистами в данной области. Направляющая последовательность может быть выбрана для целенаправленного воздействия на любую целевую последовательность. В некоторых вариантах осуществления целевая последовательность является последовательностью в пределах генома клетки. Иллюстративные целевые последовательности включают последовательности, которые являются уникальными в целевом геноме.
В целом и на протяжении данного описания термин "вектор" обозначает молекулу нуклеиновой кислоты, способную переносить другую нуклеиновую кислоту, с которой она была связана. Векторы включают без ограничения молекулы нуклеиновой кислоты, которые являются однонитевыми, двухнитевыми или частично двухнитевыми; молекулы нуклеиновой кислоты, которые содержат один или несколько свободных концов, не содержат свободных концов (например, кольцевые); молекулы нуклеиновой кислоты, которые содержат ДНК, РНК или и ту, и другую; и другие разновидности полинуклеотидов, известные из уровня техники. Одним типом вектора является "плазмида", которая означает кольцевую петлю двухнитевой ДНК, в которую можно встраивать дополнительные сегменты ДНК, как, например, с помощью стандартных методик молекулярного клонирования. Другим типом вектора является вирусный вектор, где полученные из вируса последовательности ДНК или РНК присутствуют в векторе для упаковки в вирус (например, ретровирусы, ретровирусы с дефектной системой репликации, аденовирусы, аденовирусы с дефектной системой репликации и аденоассоциированные вирусы). Вирусные векторы также включают полинуклеотиды, переносимые вирусом для трансфекции в клетку-хозяина. Определенные векторы способны к автономной репликации в клетке-хозяине, в которую они введены (например, бактериальные векторы с бактериальной точкой начала репликации и эписомные векторы для млекопитающих). Другие векторы (например, векторы для млекопитающих, отличные от эписомных) интегрируются в геном клетки-хозяина после введения в клетку-хозяина и, таким образом, реплицируются вместе с геномом хозяина. Более того, определенные векторы способны управлять экспрессией генов, с которыми они функционально связаны. Такие векторы в данном документе обозначены как "векторы экспрессии". Векторы для экспрессии в эукариотической клетке и обеспечивающие таковую в ней могут обозначаться в данном документе как "векторы экспрессии у эукариот". Общепринятые пригодные для методик рекомбинантной ДНК векторы экспрессии часто находятся в форме плазмид.
Рекомбинантные векторы экспрессии могут содержать нуклеиновую кислоту по настоящему изобретению в форме, подходящей для экспрессии нуклеиновой кислоты в клетке-хозяине, что означает, что рекомбинантные векторы экспрессии включают один или несколько регуляторных элементов, которые могут быть выбраны с учетом клеток-хозяев, которые предполагается применять для экспрессии, которые функционально связаны с последовательностью нуклеиновой кислоты, экспрессия которой предполагается. В контексте рекомбинантного вектора экспрессии предполагается, что выражение "функционально связанный" обозначает то, что представляющая интерес нуклеотидная последовательность связана с регуляторным(регуляторными) элементом(элементами), так что обеспечивается возможность экспрессии нуклеотидной последовательности (например, в системе транскрипции/трансляции in vitro или в клетке-хозяине при введении вектора в клетку-хозяина).
Предполагается, что термин "регуляторный элемент" подразумевает промоторы, энхансеры, сайты внутренней посадки рибосомы (IRES) и другие элементы контроля экспрессии (например, сигналы терминации транскрипции, такие как сигналы полиаденилирования и поли-U-последовательности). Такие регуляторные элементы описаны, например, в Goeddel, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990). Регуляторные элементы включают такие элементы, которые управляют конститутивной экспрессией нуклеотидной последовательности во многих типах клеток-хозяев, и такие элементы, которые управляют экспрессией нуклеотидной последовательности только в определенных клетках-хозяевах (например, тканеспецифичные регуляторные последовательности). Тканеспецифичный промотор может управлять экспрессией преимущественно в представляющей интерес целевой ткани, такой как мышца, нейрон, кость, кожа, кровь, конкретных органах (например, печени, поджелудочной железе) или определенных типах клеток (например, лимфоцитах). Регуляторные элементы также могут управлять экспрессией зависимым от времени образом, как, например, зависимым от клеточного цикла или зависимым от стадии развития образом, который также может быть или может не быть тканеспецифичным или специфичным к типу клеток. В некоторых вариантах осуществления вектор содержит один или несколько промоторов pol III (например, 1, 2, 3, 4, 5 или более промоторов pol III), один или несколько промоторов pol II (например, 1, 2, 3, 4, 5 или более промоторов pol II), один или несколько промоторов pol I (например, 1, 2, 3, 4, 5 или более промоторов pol I) или их комбинации. Примеры промоторов pol III включают без ограничения промоторы U6 и H1. Примеры промоторов pol II включают без ограничения ретровирусный промотор LTR вируса саркомы Рауса (RSV) (необязательно с энхансером RSV), промотор цитомегаловируса (CMV) (необязательно с энхансером CMV) [см., например, Boshart et al, Cell, 41:521-530 (1985)], промотор SV40, промотор гена дигидрофолатредуктазы, промотор гена β-актина, промотор гена глицерофосфаткиназы (PGK) и промотор EF1α. Также термином "регуляторный элемент" охватываются энхансерные элементы, такие как энхансеры WPRE; CMV; сегмент R-U5' в LTR из HTLV-I (Mol. Cell. Biol., Vol. 8(1), p. 466-472, 1988); энхансер SV40; а также интронная последовательность между экзонами 2 и 3 гена β-глобина кролика (Proc. Natl. Acad. Sci. USA., Vol. 78(3), p. 1527-31, 1981). Специалистам в данной области техники будет понятно, что конфигурация вектора экспрессии может зависеть от таких факторов, как выбор клетки-хозяина, подлежащей трансформации, требуемый уровень экспрессии и т. п. Вектор можно вводить в клетки-хозяева с получением, таким образом, транскриптов, белков или пептидов, в том числе слитых белков или пептидов, кодируемых нуклеиновыми кислотами, которые описаны в данном документе (например, транскриптов коротких палиндромных повторов, регулярно расположенных группами (CRISPR), белков, ферментов, их мутантных форм, их слитых белков и т. п.).
Преимущественные векторы включают лентивирусы и аденоассоциированные вирусы, и типы таких векторов также могут быть выбраны для нацеливания на определенные типы клеток.
Используемый в данном документе термин "crRNA", или "направляющая РНК", или "одиночная направляющая РНК", или "sgRNA", или "один или несколько компонентов на основе нуклеиновой кислоты" эффекторного белка локуса CRISPR-Cas типа V предусматривает любую полинуклеотидную последовательность, характеризующуюся достаточной комплементарностью с целевой последовательностью нуклеиновой кислоты, чтобы гибридизироваться с целевой последовательностью нуклеиновой кислоты и управлять специфичным к последовательности связыванием комплекса нацеливания на нуклеиновую кислоту с целевой последовательностью нуклеиновой кислоты. В некоторых вариантах осуществления при оптимальном выравнивании с применением подходящего алгоритма выравнивания степень комплементарности составляет приблизительно или более чем приблизительно 50%, 60%, 75%, 80%, 85%, 90%, 95%, 97,5%, 99% или больше. Оптимальное выравнивание можно определять с применением любого подходящего алгоритма для выравнивания последовательностей, к неограничивающим примерам которого относится алгоритм Смита-Ватермана, алгоритм Нидлмана-Вунша, алгоритмы, основанные на преобразовании Барроуза-Уилера (например, Burrows Wheeler Aligner), ClustalW, Clustal X, BLAT, Novoalign (Novocraft Technologies; доступный на сайте www.novocraft.com), ELAND (Illumina, Сан-Диего, Калифорния), SOAP (доступный на сайте soap.genomics.org.cn) и Maq (доступный на сайте maq.sourceforge.net). Способность направляющей последовательности (в рамках направляющей РНК для нацеливания на нуклеиновую кислоту) управлять специфичным к последовательности связыванием комплекса нацеливания на нуклеиновую кислоту с целевой последовательностью нуклеиновой кислоты можно оценивать с помощью любого подходящего анализа. Например, компоненты системы CRISPR для нацеливания на нуклеиновую кислоту, достаточные для образования комплекса нацеливания на нуклеиновую кислоту, в том числе направляющая последовательность, подлежащая тестированию, могут обеспечиваться в клетке-хозяине, имеющей соответствующую целевую последовательность нуклеиновой кислоты, как, например, с помощью трансфекции векторами, кодирующими компоненты комплекса нацеливания на нуклеиновую кислоту, с последующей оценкой предпочтительного нацеливания (например, расщепления) в пределах целевой последовательности нуклеиновой кислоты, как, например, с помощью анализа с использованием нуклеазы Surveyor, описываемого в данном документе. Аналогично, расщепление целевой последовательности нуклеиновой кислоты можно определять в пробирке путем обеспечения целевой последовательности нуклеиновой кислоты, компонентов комплекса нацеливания на нуклеиновую кислоту, в том числе направляющей последовательности, подлежащей тестированию, и контрольной направляющей последовательности, отличной от тестируемой направляющей последовательности, и сравнения связывания или степени расщепления целевой последовательности в случае реакций с тестируемой и контрольной направляющей последовательностью. Возможны и другие анализы, и они могут быть выполнены специалистами в данной области. Направляющая последовательность и, следовательно, направляющая РНК для нацеливания на нуклеиновую кислоту, может быть выбрана для нацеливания на любую целевую последовательность нуклеиновой кислоты. Целевая последовательность может представлять собой ДНК. Целевая последовательность может представлять собой любую последовательность РНК. В некоторых вариантах осуществления целевая последовательность может представлять собой последовательность в пределах молекулы РНК, выбранной из группы, состоящей из матричной RNA (мРНК), pre-mRNA, рибосомальной РНК (rRNA), транспортной РНК (tRNA), микро-РНК (miRNA), малой интерферирующей РНК (siRNA), малой ядерной РНК (snRNA), малой ядрышковой РНК (snoRNA), двухнитевой РНК (dsRNA), некодирующей РНК (ncRNA), длинной некодирующей РНК (lncRNA) и малой цитоплазматической РНК (scRNA). В некоторых предпочтительных вариантах осуществления целевая последовательность может представлять собой последовательность в пределах молекулы РНК, выбранной из группы, состоящей из мРНК, pre-mRNA и rRNA. В некоторых предпочтительных вариантах осуществления целевая последовательность может представлять собой последовательность в пределах молекулы РНК, выбранной из группы, состоящей из ncRNA и lncRNA. В некоторых более предпочтительных вариантах осуществления целевая последовательность может представлять собой последовательность в пределах молекулы мРНК или молекулы pre-mRNA.
В некоторых вариантах осуществления направляющая РНК для нацеливания на нуклеиновую кислоту выбраны для снижения доли вторичной структуры в пределах направляющей РНК для нацеливания на РНК. В некоторых вариантах осуществления приблизительно или менее чем приблизительно 75%, 50%, 40%, 30%, 25%, 20%, 15%, 10%, 5%, 1% или меньше нуклеотидов направляющей РНК для нацеливания на нуклеиновую кислоту участвуют в самокомплементарном образовании пар оснований при оптимальном сворачивании. Оптимальное сворачивание можно определить с помощью любого подходящего алгоритма сворачивания полинуклеотида. Некоторые программы основаны на вычислении минимальной свободной энергии Гиббса. Примером одного такого алгоритма является mFold, который описан Zuker и Stiegler (Nucleic Acids Res. 9 (1981), 133-148). Другим примером алгоритма сворачивания является доступный в режиме онлайн веб-сервер RNAfold, разработанный в Институте теоретической химии при Венском университете, использующий алгоритм прогнозирования структуры на основе центроидного способа (см., например, A.R. Gruber et al., 2008, Cell 106(1): 23-24; и PA Carr and GM Church, 2009, Nature Biotechnology 27(12): 1151-62).
Последовательность "tracrRNA" или аналогичные термины включают любую полинуклеотидную последовательность, которая характеризуется достаточной комплементарностью с последовательностью crRNA для возможности гибридизации. Как указано в данном документе выше, в вариантах осуществления настоящего изобретения tracrRNA не требуется для активности расщепления у комплексов эффекторного белка Cpf1.
Заявители также осуществили эксперимент-пробу для проверки нацеливания и способности расщепления ДНК у белка V типа/VI типа, такого как Cpf1/C2c1/C2c2. Данный эксперимент очень похож на аналогичную работу по гетерологичной экспрессии StCas9 в E. coli (Sapranauskas, R. et al. Nucleic Acids Res 39, 9275-9282 (2011)). Заявители вводили плазмиду, содержащую как PAM, так и ген устойчивости, в гетерологичную E. coli, и затем высевали в присутствии соответствующего антибиотика. Если в плазмиде происходило расщепление ДНК, заявители не наблюдали выживших колоний.
Более подробно, анализ в отношении ДНК-мишени проводится следующим образом. В данном анализе применяли два штамма E.coli. Один несет плазмиду, которая кодирует локус эндогенного эффекторного белка из бактериального штамма. Другой штамм несет пустую плазмиду (например, pACYC184, контрольный штамм). Все возможные последовательности PAM размером 7 или 8 п. о. присутствовали в плазмиде, придающей устойчивость к антибиотику (pUC19 с геном устойчивости к ампициллину). PAM располагается сразу за последовательностью протоспейсера 1 (ДНК-мишень для первого спейсера в локусе эндогенного эффекторного белка). Клонировали две библиотеки PAM. Одну составляли 8 случайных п. о. в направлении 5' от протоспейсера (например, всего 65536 различных последовательностей PAM = сложность). Другую библиотеку составляли 7 случайных п. о. в направлении 3' от протоспейсера (например, общая сложность составляла 16384 различных PAM). Обе библиотеки клонировали так, чтобы получить в среднем 500 плазмид из расчета на один возможный PAM. Тестируемый штамм и контрольный штамм трансформировали с помощью библиотеки 5'PAM и 3'PAM в ходе отдельных трансформаций и трансформированные клетки высевали отдельно на чашки с ампициллином. Распознавание и последующее разрезание/противодействие плазмиде придает клетке чувствительность к ампициллину и предотвращает рост. Примерно через 12 ч. после трансформации все колонии, образованные тестируемым и контрольным штаммами, собирали и плазмидную ДНК выделяли. Плазмидную ДНК использовали в качестве матрицы для ПЦР-амплификации и последующего глубокого секвенирования. Представление всех PAM в нетрансформированных библиотеках показало ожидаемое представление PAM в трансформированных клетках. Представление всех PAM, обнаруженное в контрольных штаммах, показало фактическое представление. Представление всех PAM в тестируемом штамме показало, какие PAM не распознаются ферментом, а сравнение с контрольным штаммом позволило выделить последовательность подвергнутого истощению PAM.
В некоторых вариантах осуществления систем CRISPR-Cas9 степень комплементарности между последовательностью tracrRNA и последовательностью crRNA определяют по всей длине более короткой из двух при оптимальном выравнивании. Как описано в данном документе, в вариантах осуществления настоящего изобретения tracrRNA не требуется. В некоторых вариантах осуществления ранее описанных систем CRISPR-Cas (например, систем CRISPR-Cas9), структуры химерных синтетических направляющих РНК (sgRNA) могут включать дуплексную структуру длиной по меньшей мере 12 п. о. между crRNA и tracrRNA, однако в системах Cpf1 CRISPR, описанных в данном документе, такие химерные РНК (chi-RNA) не являются возможными, поскольку система не использует tracrRNA.
Для сведения к минимуму токсичности и нецелевого эффекта будет важно контролировать концентрацию доставляемой направляющей РНК для нацеливания на нуклеиновую кислоту. Оптимальные концентрации направляющей РНК для нацеливания на нуклеиновую кислоту можно определить путем тестирования различных концентраций на клеточной модели или модели отличного от человека животного-эукариотического организма и применения глубокого секвенирования для анализа степени модификации в потенциальных нецелевых локусах генома. Для доставки in vivo следует выбрать концентрацию, дающую наиболее высокий уровень целевой модификации при сведении к минимуму уровня нецелевой модификации. Систему нацеливания на нуклеиновую кислоту получают преимущественно из системы CRISPR V типа/VI типа. В некоторых вариантах осуществления один или несколько элементов системы нацеливания на нуклеиновую кислоту получены из конкретного организма, содержащего эндогенную систему нацеливания на РНК. В предпочтительных вариантах осуществления настоящего изобретения система нацеливания на РНК представляет собой систему CRISPR V типа/VI типа. В конкретных вариантах осуществления фермент Cas V типа/VI типа для нацеливания на РНК представляет собой Cpf1/C2c1/C2c2. Неограничивающие примеры белков Cas включают Cas1, Cas1B, Cas2, Cas3, Cas4, Cas5, Cas6, Cas7, Cas8, Cas9 (также известный как Csn1 и Csx12), Cas10, Csy1, Csy2, Csy3, Cse1, Cse2, Csc1, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmr1, Cmr3, Cmr4, Cmr5, Cmr6, Csb1, Csb2, Csb3, Csx17, Csx14, Csx10, Csx16, CsaX, Csx3, Csx1, Csx15, Csf1, Csf2, Csf3, Csf4, их гомологи или их модифицированные варианты. В вариантах осуществления белок V типа/VI типа, такой как Cpf1/C2c1/C2c2, упоминаемый в данном документе, также охватывает гомологичный или ортологичный белок для белка V типа/VI типа, такого как Cpf1/C2c1/C2c2. Термины "ортологичный" (также в данном документе называемый "ортолог") и "гомологичный" (также в данном документе называемый "гомолог") хорошо известны из уровня техники. В качестве дополнительного руководства, "гомологичный" белок, как используется в данном документе, представляет собой белок того же вида, который выполняет ту же или подобную функцию, что и белок, которому он гомологичен. Гомологичные белки могут, но не обязательно должны быть структурно родственными, или они являются только частично структурно родственными. "Ортологичный" белок, как используется в настоящем документе, представляет собой белок от другого вида, который выполняет ту же или подобную функцию, что и белок, которому он ортологичен. Ортологичные белки могут, но не обязательно должны быть структурно родственными, или они являются только частично структурно родственными. Гомологи и ортологи могут быть идентифицированы с помощью моделирования гомологии (см., например, Greer, Science vol. 228 (1985) 1055, и Blundell et al. Eur J Biochem vol 172 (1988), 513) или "структурного BLAST" (Dey F, Cliff Zhang Q, Petrey D, Honig B. Toward a "structural BLAST": using structural relationships to infer function. Protein Sci. 2013 Apr;22(4):359-66. doi: 10.1002/pro.2225.). См. также Shmakov et al. (2015) в рамках применения в области локусов CRISPR-Cas. Гомологичные белки могут, но не обязательно должны быть структурно родственными, или они являются только частично структурно родственными. В конкретных вариантах осуществления гомолог или ортолог Cpf1, упоминаемого в данном документе, характеризуется гомологией или идентичностью последовательности, составляющими по меньшей мере 80%, более предпочтительно по меньшей мере 85%, еще более предпочтительно по меньшей мере 90%, как, например, по меньшей мере 95%, с Cpf1. В дополнительных вариантах осуществления гомолог или ортолог Cpf1, упоминаемого в данном документе, характеризуется идентичностью последовательности, составляющей по меньшей мере 80%, более предпочтительно по меньшей мере 85%, еще более предпочтительно по меньшей мере 90%, как, например, по меньшей мере 95%, с Cpf1 дикого типа. Если Cpf1 имеет одну или несколько мутаций (мутированный), то гомолог или ортолог указанного Cpf1, упоминаемого в данном документе, характеризуется идентичностью последовательности, составляющей по меньшей мере 80%, более предпочтительно по меньшей мере 85%, еще более предпочтительно по меньшей мере 90%, как, например, по меньшей мере 95%, с мутированным Cpf1.
- В одном варианте осуществления белок Cas V типа может представлять собой ортолог, происходящий от организма из рода, который включает без ограничения Acidaminococcus sp, Lachnospiraceae bacterium или Moraxella bovoculi; в конкретных вариантах осуществления белок Cas V типа может представлять собой ортолог, происходящий от организма из вида, который включает без ограничения Acidaminococcus sp. BV3L6; Lachnospiraceae bacterium ND2006 (LbCpf1) или Moraxella bovoculi 237. В конкретных вариантах осуществления гомолог или ортолог Cpf1, упоминаемого в данном документе, характеризуется гомологией или идентичностью последовательности, составляющими по меньшей мере 80%, более предпочтительно по меньшей мере 85%, еще более предпочтительно по меньшей мере 90%, как, например, по меньшей мере 95%, с одной или несколькими последовательностями Cpf1, раскрытыми в данном документе. В дополнительных вариантах осуществления гомолог или ортолог Cpf, упоминаемого в данном документе, характеризуется идентичностью последовательности, составляющей по меньшей мере 80%, более предпочтительно по меньшей мере 85%, еще более предпочтительно по меньшей мере 90%, как, например, по меньшей мере 95%, с FnCpf1, AsCpf1 или LbCpf1 дикого типа.
- В конкретных вариантах осуществления белок Cpf1 по настоящему изобретению характеризуется гомологией или идентичностью последовательности, составляющими по меньшей мере 60%, более конкретно, по меньшей мере 70, как, например, по меньшей мере 80%, более предпочтительно по меньшей мере 85%, еще более предпочтительно по меньшей мере 90%, как, например, по меньшей мере 95%, с FnCpf1, AsCpf1 или LbCpf1. В дополнительных вариантах осуществления белок Cpf1, упоминаемый в данном документе, характеризуется идентичностью последовательности, составляющей по меньшей мере 60%, как, например, по меньшей мере 70%, более конкретно по меньшей мере 80%, более предпочтительно по меньшей мере 85%, еще более предпочтительно по меньшей мере 90%, как, например, по меньшей мере 95%, с AsCpf1 или LbCpf1 дикого типа. В конкретных вариантах осуществления белок Cpf1 по настоящему изобретению характеризуется менее чем 60% идентичностью последовательности с FnCpf1. Специалисту в данной области будет понятно, что это подразумевает усеченные формы белка Cpf1, при этом идентичность последовательности определяют по длине усеченной формы.
Некоторые способы идентификации ортологов ферментов системы CRISPR-Cas могут предусматривать идентификацию tracr-последовательностей в представляющих интерес геномах. Идентификация tracr-последовательностей может заключаться в следующих стадиях: поиска прямых повторов или парных tracr-последовательностей в базе данных для идентификации участка CRISPR, содержащего фермент CRISPR; поиска гомологичных последовательностей в участке CRISPR, фланкирующем фермент CRISPR как в смысловом, так и в антисмысловом направлениях; поиска терминаторов транскрипции и вторичных структур; идентификации какой-либо последовательности, которая не является прямым повтором или парной tracr-последовательностью, но характеризуется более чем 50% идентичностью в отношении прямого повтора или парной tracr-последовательности, в качестве потенциальной tracr-последовательности; получения потенциальной tracr-последовательности и анализа на предмет ассоциированных с ней последовательностей терминатора транскрипции. В данной системе с помощью данных по секвенированию РНК обнаружили, что потенциальные tracrRNA, идентифицированные компьютерным способом, экспрессировались только на очень низком уровне, что позволило предположить, что tracrRNA может не быть необходимой для функционирования системы согласно настоящему изобретению. После дополнительной оценки локуса FnCpf1 и добавления результатов расщепления in vitro заявители сделали вывод, что для расщепления целевой ДНК под действием комплекса эффекторного белка Cpf1 не требуется tracrRNA. Заявители определили, что комплексов эффекторного белка Cpf1, содержащих только эффекторный белок Cpf1 и crRNA (направляющая РНК, содержащая последовательность прямого повтора и направляющую последовательность), было достаточно для расщепления целевой ДНК.
Следует понимать, что любое из функциональных свойств, описанных в данном документе, может быть сконструировано в ферментах CRISPR от других ортологов, включая химерные ферменты, содержащие фрагменты из множественных ортологов. Примеры таких ортологов описываются в других разделах данного документа. Таким образом, химерные ферменты могут содержать фрагменты из ортологов фермента CRISPR, происходящих от организмов из рода, который включает без ограничения Corynebacter, Sutterella, Legionella, Treponema, Filifactor, Eubacterium, Streptococcus, Lactobacillus, Mycoplasma, Bacteroides, Flaviivola, Flavobacterium, Sphaerochaeta, Azospirillum, Gluconacetobacter, Neisseria, Roseburia, Parvibaculum, Staphylococcus, Nitratifractor, Mycoplasma и Campylobacter. Химерный фермент может содержать первый фрагмент и второй фрагмент, и при этом фрагменты могут быть из ортологов фермента CRISPR, происходящих от организмов из родов, упоминаемых в данном документе, или из видов, упоминаемых в данном документе; преимущественно фрагменты получены из ортологов фермента CRISPR от различных видов.
В вариантах осуществления эффекторный белок V типа/VI типа для нацеливания на РНК, в частности белок Cpf1/C2c1/C2c2, упоминаемый в данном документе, также охватывает функциональный вариант Cpf1/C2c1/C2c2 или его гомолога или ортолога. "Функциональный вариант" белка, как используется в данном документе, обозначает вариант такого белка, который сохраняет, по меньшей мере частично, активность этого белка. Функциональные варианты могут включать мутантов (которые могут представлять собой мутанты, полученные в результате вставки, делеции или замещения), в том числе полиморфов и т. п. Также функциональные варианты включают продукты слияния такого белка с другими, обычно не родственными, нуклеиновой кислотой, белком, полипептидом или пептидом. Функциональные варианты могут встречаться в природе или могут быть получены человеком. Преимущественные варианты осуществления могут предусматривать сконструированный или не встречающийся в природе эффектoрный белок V типа/VI типа для нацеливания на РНК, например, Cpf1/C2c1/C2c2 или его ортолог или гомолог.
В одном варианте осуществления молекула(молекулы) нуклеиновой кислоты, кодирующая(кодирующие) эффекторный белок V типа/VI типа для нацеливания на РНК, в частности Cpf1/C2c1/C2c2 или его ортолог или гомолог, может(могут) являться кодон-оптимизированной(оптимизированными) для экспрессии в эукариотической клетке. Эукариотический организм может быть таким, как обсуждается в данном документе. Молекула(молекулы) нуклеиновой кислоты может(могут) быть сконструированной(сконструированными) или не встречающейся(не встречающимися) в природе.
В одном варианте осуществления эффекторный белок V типа/VI типа для нацеливания на РНК, в частности Cpf1/C2c1/C2c2 или его ортолог или гомолог, может содержать одну или несколько мутаций (и, следовательно, молекула(молекулы) нуклеиновой кислоты, кодирующая(кодирующие) их, может(могут) иметь мутацию(мутации)). Мутации могут быть искусственно введенными мутациями и могут включать в себя без ограничения одну или несколько мутаций в каталитическом домене. Примеры каталитических доменов в отношении фермента Cas9 могут включать в себя без ограничения домены RuvC I, RuvC II, RuvC III и HNH.
В одном варианте осуществления белок V типа/VI типа, такой как Cpf1/C2c1/C2c2 или его ортолог или гомолог, можно применять как универсальный белок, связывающий нуклеиновую кислоту, с помощью слияния с функциональным доменом или обеспечения функциональной связи с ним. Иллюстративные функциональные домены могут включать без ограничения инициатор трансляции, активатор трансляции, репрессор трансляции, нуклеазы, в частности рибонуклеазы, сплайсосому, гранулы, индуцируемый/контролируемый светом домен или химически индуцируемый/контролируемый домен.
В некоторых вариантах осуществления немодифицированный эффекторный белок для нацеливания на нуклеиновую кислоту может характеризоваться активностью расщепления. В некоторых вариантах осуществления эффекторный белок для нацеливания на РНК может управлять расщеплением одной или обеих нитей нуклеиновой кислоты (ДНК или РНК) в определенном положении целевой последовательностью или вблизи нее, как, например, в пределах целевой последовательности и/или в последовательности, комплементарной целевой последовательности, или в последовательностях, ассоциированных с целевой последовательностью. В некоторых вариантах осуществления эффекторный белок для нацеливания на нуклеиновую кислоту может управлять расщеплением одной или обеих нитей ДНК или РНК в пределах приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 50, 100, 200, 500 или более пар оснований от первого или последнего нуклеотида целевой последовательности. В некоторых вариантах осуществления расщепление может быть ступенчатым, т. е. образующим липкие концы. В некоторых вариантах осуществления расщепление представляет собой ступенчатый разрез с "липким" 5'-концом. В некоторых вариантах осуществления расщепление представляет собой ступенчатый разрез с "липким" 5'-концом из 1-5 нуклеотидов, предпочтительно 4 или 5 нуклеотидов. В некоторых вариантах осуществления сайт расщепления удален от PAM, например, расщепление происходит после 18-го нуклеотида на не подвергаемой нацеливанию нити и после 23-го нуклеотида на подвергаемой нацеливанию нити (фигура 97A). В некоторых вариантах осуществления сайт расщепления располагается после 18-го нуклеотида (считая от PAM) на не подвергаемой нацеливанию нити и после 23-го нуклеотида (считая от PAM) на подвергаемой нацеливанию нити (фигура 97A). В некоторых вариантах осуществления вектор кодирует эффекторный белок для нацеливания на нуклеиновую кислоту, который может быть мутированным по сравнению с соответствующим ферментом дикого типа, так что у мутированного эффекторного белка для нацеливания на нуклеиновую кислоту отсутствует способность расщеплять одну или обе нити ДНК или РНК в целевом полинуклеотиде, содержащем целевую последовательность. В качестве дополнительного примера можно подвергать мутированию два или более каталитических доменов белка Cas (например, RuvC I, RuvC II и RuvC III или домен HNH из белка Cas9) с получением мутированного белка Cas, у которого практически полностью отсутствует активность расщепления ДНК. Как описано в данном документе, соответствующие каталитические домены эффекторного белка Cpf1 также могут быть подвергнуты мутированию с получением мутированного эффекторного белка Cpf1, у которого полностью отсутствует активность расщепления ДНК или который характеризуется значительно сниженной активностью расщепления ДНК. В некоторых вариантах осуществления может считаться, что у эффекторного белка для нацеливания на нуклеиновую кислоту практически полностью отсутствует активность расщепления РНК, если активность расщепления РНК у мутированного фермента составляет не более чем приблизительно 25%, 10%, 5%, 1%, 0,1%, 0,01% или меньше относительно активности расщепления нуклеиновой кислоты у немутированной формы фермента; примером может служить случай, когда активность расщепления нуклеиновой кислоты у мутированной формы отсутствует или несущественна по сравнению с немутированной формой. Эффекторный белок может быть идентифицирован со ссылкой на общий класс ферментов, обладающих гомологией с самой большой нуклеазой с множественными нуклеазными доменами системы CRISPR V типа/VI типа. Наиболее предпочтительно, эффекторный белок представляет собой белок V типа/VI типа, такой как Cpf1/C2c1/C2c2. В дополнительных вариантах осуществления эффекторный белок представляет собой белок V типа. Под происходящим заявители подразумевают, что в основе происходящего фермента главным образом лежит фермент дикого типа в том смысле, что он характеризуется высокой степенью гомологии последовательности с этим ферментом, но он был некоторым образом подвергнут мутации (модифицирован), как известно из уровня техники или описано в данном документе.
Опять-таки, будет понятно, что термины Cas, и фермент CRISPR, и фермент CRISPR, и белок Cas в целом используются взаимозаменяемо, и при всех упоминаниях в данном документе относятся по аналогии к новым эффекторным белкам CRISPR, дополнительно описанным в настоящей заявке, если не очевидно иное, как, например, с помощью специальной ссылки на Cas9. Как упоминается выше, большинство нумераций остатков, используемых в данном документе, относятся к эффекторному белку из локуса CRISPR V типа/VI типа. Однако следует учитывать, что настоящее изобретение включает намного больше эффекторных белков из других видов микроорганизмов. В определенных вариантах осуществления присутствие эффекторных белков может быть постоянным, или их присутствие можно индуцировать, или их присутствие зависит от условий, или их можно вводить или доставлять. Оптимизацию эффекторного белка можно применять для усиления функции или для проявления новых функций, при этом можно получать химерные эффекторные белки. И, как описано в данном документе, эффекторные белки могут быть модифицированы для применения в качестве универсальных белков, связывающих нуклеиновую кислоту.
Как правило, в контексте системы нацеливания на нуклеиновую кислоту образование комплекса нацеливания на нуклеиновую кислоту (содержащего направляющую РНК, гибридизированную с целевой последовательностью и находящуюся в комплексе с одним или несколькими эффекторными белками для нацеливания на нуклеиновую кислоту) приводит к расщеплению одной или обеих нитей ДНК или РНК в целевой последовательности или рядом с ней (например, в пределах 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 50 или более пар оснований). Используемый в данном документе термин "последовательность(последовательности), ассоциированная(ассоциированные) с представляющим интерес целевым локусом" относится к последовательностям рядом с окружающим пространством целевой последовательности (например, в пределах 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 50 или больше пар оснований от целевой последовательности, при этом целевая последовательность содержится в пределах представляющего интерес целевого локуса).
Примером кодон-оптимизированной последовательности в данном случае является последовательность, оптимизированная для экспрессии в эукариотическом организме, например, человека (т. е. которая является оптимизированной для экспрессии у человека), или для экспрессии в другом эукариотическом организме, животном или млекопитающем, как обсуждается в данном документе; см., например, последовательность SaCas9, кодон-оптимизированную для человека, в WO 2014/093622 (PCT/US2013/074667) в качестве примера кодон-оптимизированной последовательности (исходя из сведений из уровня техники и настоящего изобретения, проведение оптимизации кодонов в кодирующей молекуле(молекулах) нуклеиновой кислоты, в частности, эффекторного белка (например, Cpf1), находится в пределах компетентности специалиста в данной области). Хотя это является предпочтительным, следует иметь в виду, что возможны другие примеры и что известна оптимизация кодонов для вида-хозяина, отличного от человека, или оптимизация кодонов для конкретных органов. В некоторых вариантах осуществления фермент-кодирующая последовательность, которая кодирует белок Cas для нацеливания на ДНК/РНК, является кодон-оптимизированной для экспрессии в конкретных клетках, таких как эукариотические клетки. Эукариотические клетки могут быть клетками конкретного организма или полученными из него, как, например, клетками растения или млекопитающего, в том числе без ограничения человека, или отличного от человека эукариотического организма, или животного, или млекопитающего, обсуждаемых в данном документе, например, мыши, крысы, кролика, собаки, крупного рогатого скота или отличного от человека млекопитающего или примата. В некоторых вариантах осуществления могут исключаться способы модифицирования генетической идентичности зародышевой линии человека и/или способы модификации генетической идентичности животных, которые, вероятно, могут причинить им страдания без какой-либо значительной медицинской пользы для человека или животного, а также животные, являющиеся результатом таких способов. В целом, оптимизация кодонов означает способ модифицирования последовательности нуклеиновой кислоты для повышения уровня экспрессии в представляющих интерес клетках-хозяевах путем замещения по меньшей мере одного кодона (например, приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 10, 15, 20, 25, 50 или более кодонов) нативной последовательности на кодоны, которые чаще или наиболее часто используют в генах такой клетки-хозяина, при этом с сохранением нативной аминокислотной последовательности. Разные виды проявляют определенное "предпочтение" в отношении конкретных кодонов определенной аминокислоты. "Предпочтение" кодонов (различия в частоте использования кодонов между организмами) зачастую соотносится с эффективностью трансляции матричной РНК (mRNA), которая, в свою очередь, как полагают, зависит, среди прочего, от свойств кодонов, которые транслируются, и доступности конкретных молекул транспортной РНК (tRNA). Преобладание выбранных tRNA в клетке, как правило, указывает на кодоны, используемые наиболее часто при синтезе пептидов. Соответственно, гены можно приспособить для оптимальной экспрессии генов в данном организме за счет оптимизации кодонов. Таблицы частоты использования кодонов общедоступны, например, в "Базе данных частот использования кодонов", доступной в интернете по адресу www.kazusa.orjp/codon/, и эти таблицы можно адаптировать различными способами. См., Nakamura, Y., et al. "Codon usage tabulated from the international DNA sequence databases: status for the year 2000" Nucl. Acids Res. 28:292 (2000). Также доступны компьютерные алгоритмы для оптимизации кодонов определенной последовательности для экспрессии в определенной клетке-хозяине, как, например, Gene Forge (Aptagen; Джакобус, Пенсильвания). В некоторых вариантах осуществления один или несколько кодонов (например, 1, 2, 3, 4, 5, 10, 15, 20, 25, 50 или более или все кодоны) в последовательности, кодирующей белок Cas для нацеливания на ДНК/РНК, соответствуют наиболее часто используемому кодону для конкретной аминокислоты. Что касается частоты использования кодонов у дрожжей, стоит сослаться на онлайн базу данных генома дрожжей, доступную в интернете по адресу http://www.yeastgenome.org/community/codon_usage.shtml или Codon selection in yeast, Bennetzen and Hall, J Biol Chem. 1982 Mar 25;257(6):3026-31. Что касается частоты использования кодонов у растений, включая водоросли, стоит сослаться на Codon usage in higher plants, green algae, and cyanobacteria, Campbell and Gowri, Plant Physiol. 1990 Jan; 92(1): 1-11; а также Codon usage in plant genes, Murray et al, Nucleic Acids Res. 1989 Jan 25;17(2):477-98; или Selection on the codon bias of chloroplast and cyanelle genes in different plant and algal lineages, Morton BR, J Mol Evol. 1998 Apr;46(4):449-59.
В некоторых вариантах осуществления вектор кодирует эффекторный белок для нацеливания на нуклеиновую кислоту, такой как эффекторный белок V типа/VI типа для нацеливания на РНК, в частности Cpf1/C2c1/C2c2 или его ортолог или гомолог, содержащий одну или несколько последовательностей ядерной локализации (NLS), как, например, приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более NLS. В некоторых вариантах осуществления эффекторный белок для нацеливания на РНК содержит приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более NLS на амино-конце или рядом с ним, приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более NLS на карбокси-конце или рядом с ним, или их комбинацию (например, ни одной или по меньшей мере одну или несколько NLS на амино-конце и ни одной или одну или несколько NLS на карбокси-конце). В тех случаях, когда присутствуют более одной NLS, каждая может быть выбрана независимо от других, так что одна NLS может присутствовать в более чем одной копии и/или в комбинации с одной или несколькими другими NLS, присутствующими в одной или нескольких копиях. В некоторых вариантах осуществления считается, что NLS находится рядом с N- или C-концом в тех случаях, когда наиболее близкая аминокислота NLS находится в пределах приблизительно 1, 2, 3, 4, 5, 10, 15, 20, 25, 30, 40, 50 или более аминокислот вдоль полипетидной цепи от N- или C-конца. Неограничивающие примеры NLS включают последовательность NLS, происходящую из NLS из большого Т-антигена вируса SV40 с аминокислотной последовательностью PKKKRKV(SEQ ID NO: 2); NLS из нуклеоплазмина (например, двусоставная NLS из нуклеоплазмина с последовательностью KRPAATKKAGQAKKKK (SEQ ID NO: 3)); NLS из c-myc с аминокислотной последовательностью PAAKRVKLD (SEQ ID NO: 4) или RQRRNELKRSP (SEQ ID NO: 5); NLS из hRNPA1 M9 с последовательностью NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGY (SEQ ID NO: 6); последовательности RMRIZFKNKGKDTAELRRRRVEVSVELRKAKKDEQILKRRNV (SEQ ID NO: 7) домена IBB из импортина-альфа; последовательностей VSRKRPRP (SEQ ID NO: 8) и PPKKARED (SEQ ID NO: 9) белка T миомы; последовательности POPKKKPL (SEQ ID NO: 10) p53 человека; последовательности SALIKKKKKMAP (SEQ ID NO: 11) c-abl IV мыши; последовательностей DRLRR (SEQ ID NO: 12) и PKQKKRK (SEQ ID NO: 13) из NS1 вируса гриппа; последовательности RKLKKKIKKL (SEQ ID NO: 14) из дельта-антигена вируса гепатита; последовательности REKKKFLKRR (SEQ ID NO: 15) из белка Mx1 мыши; последовательности KRKGDEVDGVDEVAKKKSKK (SEQ ID NO: 16) из поли(АДФ-рибоза)-полимеразы человека и последовательности RKCLQAGMNLEARKTKK (SEQ ID NO: 17) рецепторов стероидных гормонов глюкокортикоидов (человека). В целом, одна или несколько NLS являются достаточно эффективными, чтобы управлять накоплением белка Cas для нацеливания на ДНК/РНК в обнаруживаемом количестве в ядре эукариотической клетки. В целом, степень проявления активности ядерной локализации может быть результатом следующего: числа NLS в эффекторном белке для нацеливания на нуклеиновую кислоту, конкретного(конкретных) используемого(используемых) NLS или комбинации этих факторов. Обнаружение накопления в ядре можно выполнять с помощью любой подходящей методики. Например, с белком для нацеливания на нуклеиновую кислоту может быть слит обнаруживаемый маркер таким образом, чтобы можно было визуализировать данное местоположение в клетке, как, например, в комбинации со средствами для обнаружения местоположения в ядре (например, окрашивающим средством, специфичным к ядру, таким как DAPI). Ядра клеток также можно выделять из клеток, причем их содержимое затем можно анализировать с помощью любого подходящего способа для обнаружения белка, как, например, иммуногистохимического анализа, вестерн-блоттинга или анализа активности фермента. Накопление в ядре также можно определить опосредованно, как, например, с помощью анализа эффекта образования комплекса нацеливания на нуклеиновую кислоту (например, анализа в отношении расщепления ДНК или РНК или мутации в целевой последовательности или анализа в отношении активности экспрессии генов, измененной вследствие образования комплекса нацеливания на РНК и/или активности белка Cas для нацеливания на ДНК или РНК) по сравнению с контролем, который не подвергали воздействию белка Cas для нацеливания на нуклеиновую кислоту или комплекса нацеливания на нуклеиновую кислоту или подвергали воздействию белка Cas для нацеливания на нуклеиновую кислоту, у которого отсутствуют один или несколько NLS. В предпочтительных вариантах осуществления комплексов и систем эффекторного белка Cpf1, описанного в данном документе, кодон-оптимизированные эффекторные белки Cpf1 содержат NLS, прикрепленный к C-концу белка. В определенных вариантах осуществления с белком Cas могут быть слиты другие метки локализации, такие как без ограничения для определения локализации Cas в определенных сайтах в клетке, таких как органеллы, как, например, в митохондриях, пластидах, хлоропласте, везикулах, комплексе Гольджи, (ядерной или клеточной) мембранах, рибосомах, ядрышке, ER, цитоскелете, вакуолях, центросоме, нуклеосоме, гранулах, центриолях и т. д.
В некоторых вариантах осуществления один или несколько векторов, управляющих экспрессией одного или нескольких элементов системы нацеливания на нуклеиновую кислоту, вводят в клетку-хозяина, так что экспрессия элементов системы нацеливания на нуклеиновую кислоту управляет образованием комплекса нацеливания на нуклеиновую кислоту на одном или нескольких целевых сайтах. Например, каждый из эффекторного фермента для нацеливания на нуклеиновую кислоту, и направляющей РНК для нацеливания на нуклеиновую кислоту могут быть функционально связаны с отдельными регуляторными элементами в отдельных векторах. РНК системы нацеливания на нуклеиновую кислоту могут быть доставлены в трансгенное по эффекторному белку для нацеливания на нуклеиновую кислоту животное или млекопитающее, например, животное или млекопитающее, у которого конститутивно, или индуцируемо, или в зависимости от условия экспрессируется эффекторный белок для нацеливания на нуклеиновую кислоту; или животное или млекопитающее, у которого иным образом экспрессируется эффекторный белок для нацеливания на нуклеиновую кислоту или которое имеет клетки, содержащие эффекторный белок для нацеливания на нуклеиновую кислоту, как, например, вследствие предварительного введения в них вектора или векторов, кодирующих и экспрессирующих in vivo эффекторный белок для нацеливания на нуклеиновую кислоту. Альтернативно, два или более элементов, которые экспрессируются за счет одного и того же или разных регуляторных элементов, можно объединять в один вектор, при этом один или несколько дополнительных векторов обеспечивают любые компоненты системы нацеливания на нуклеиновую кислоту, не включенные в первый вектор, при этом компоненты системы нацеливания на нуклеиновую кислоту, которые объединены в одном векторе, могут быть расположены в любой подходящей ориентации, как, например один элемент расположен в направлении 5' ("выше") относительно второго элемента или в направлении 3' ("ниже") относительно него. Кодирующая последовательность одного элемента может быть расположена на одной и той же или противоположной нити по отношению к кодирующей последовательности второго элемента и ориентирована в одном и том же или противоположном направлении. В некоторых вариантах осуществления один промотор управляет экспрессией транскрипта, кодирующего эффекторный белок для нацеливания на нуклеиновую кислоту и направляющую РНК для нацеливания на нуклеиновую кислоту, встроенных в одну или несколько интронных последовательностей (например, каждая в отдельном интроне, две или более по меньшей мере в одном интроне или все в одном интроне). В некоторых вариантах осуществления эффекторный белок для нацеливания на нуклеиновую кислоту и направляющая РНК для нацеливания на нуклеиновую кислоту могут быть функционально связаны с одним и тем же промотором и экспрессироваться от такового. Средства доставки, векторы, частицы, наночастицы, составы и их компоненты для экспрессии одного или нескольких элементов системы нацеливания на нуклеиновую кислоту являются такими, как используемые в вышеизложенных документах, таких как WO 2014/093622 (PCT/US2013/074667). В некоторых вариантах осуществления вектор содержит один или несколько сайтов встраивания, как, например, последовательность узнавания рестрикционной эндонуклеазой (также называемая "сайтом клонирования"). В некоторых вариантах осуществления один или несколько сайтов встраивания (например, приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или больше сайтов встраивания) находятся выше и/или ниже одного или нескольких элементов последовательности одного или нескольких векторов. В тех случаях, когда применяются множественные отличающиеся направляющие последовательности, можно использовать одну экспрессионную конструкцию, чтобы нацеливать активности нацеливания на нуклеиновую кислоту на множественные отличающиеся соответствующие целевые последовательности в клетке. Например, один вектор может содержать приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20 или более направляющих последовательностей. В некоторых вариантах осуществления векторы, содержащие приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более таких направляющих последовательностей, могут быть получены и необязательно доставлены в клетку. В некоторых вариантах осуществления вектор содержит регуляторный элемент, функционально связанный с фермент-кодирующей последовательностью, которая кодирует эффекторный белок для нацеливания на нуклеиновую кислоту. Эффекторный белок для нацеливания на нуклеиновую кислоту или направляющая РНК или направляющие РНК для нацеливания на нуклеиновую кислоту могут доставляться отдельно; и преимущественно по меньшей мере один из них доставляется с помощью комплекса на основе частицы. мРНК эффекторного белка для нацеливания на нуклеиновую кислоту можно доставлять перед доставкой направляющей РНК для нацеливания на нуклеиновую кислоту, чтобы обеспечить время для экспрессии эффекторного белка для нацеливания на нуклеиновую кислоту. мРНК эффекторного белка для нацеливания на нуклеиновую кислоту может быть введена за 1-12 часов (предпочтительно за приблизительно 2-6 часов) до введения направляющей РНК для нацеливания на нуклеиновую кислоту. Альтернативно мРНК эффекторного белка для нацеливания на нуклеиновую кислоту и направляющая РНК для нацеливания на нуклеиновую кислоту могут быть введены вместе. Преимущественно вторую бустерную дозу направляющей РНК можно вводить через 1-12 часов (предпочтительно через около 2-6 часов) после первого введения мРНК эффекторного белка для нацеливания на нуклеиновую кислоту + направляющей РНК. Введение дополнительных доз мРНК эффекторного белка для нацеливания на нуклеиновую кислоту и/или направляющей РНК может быть пригодным для достижения наиболее эффективных уровней модификации генома.
В одном аспекте настоящего изобретения предусмотрены способы применения одного или нескольких элементов системы нацеливания на нуклеиновую кислоту. Комплекс нацеливания на нуклеиновую кислоту по настоящему изобретению обеспечивает эффективное средство для модифицирования целевой ДНК или РНК (одно- или двухнитевой, линейной или сверхспирализированной). Комплекс нацеливания на нуклеиновую кислоту по настоящему изобретению обладает широкой применимостью, включая модифицирование (например, осуществление делеции, встраивания, транслокации, инактивации, активации) целевой ДНК или РНК во множестве типов клеток. Сам по себе комплекс нацеливния на нуклеиновую кислоту по настоящему изобретению имеет широкий спектр применений, например, в генной терапии, скрининге лекарственных средств, диагностике и прогнозировании заболеваний. Иллюстративный комплекс нацеливания на нуклеиновую кислоту содержит эффекторный белок для нацеливания на ДНК или РНК в комплексе с направляющей РНК, гибридизированной с целевой последовательностью в представляющем интерес целевом локусе.
В одном варианте осуществления настоящего изобретения предусмотрен способ расщепления целевой РНК. Способ может включать модифицирование целевой РНК с применением комплекса нацеливания на нуклеиновую кислоту, который связывается с целевой РНК и осуществляет расщепление указанной целевой РНК. В одном варианте осуществления комплекс нацеливания на нуклеиновую кислоту по настоящему изобретению при введении в клетку может образовывать разрыв (например, одно- или двухнитевой разрыв) в последовательности РНК. Например, способ можно применять для расщепления РНК, ответственной за развитие заболевания, в клетке. Например, в клетку может быть введена экзогенная РНК-матрица, содержащая последовательность, подлежащую интеграции, фланкированную последовательностью, расположенной выше, и последовательностью, расположенной ниже. Последовательности, расположенные выше и ниже, характеризуются сходством последовательности с каждой стороной сайта интеграции в РНК. При необходимости донорной РНК может быть мРНК. Экзогенная РНК-матрица содержит последовательность, подлежащую интеграции (например, мутированную РНК). Последовательность, предназначенная для интеграции, может представлять собой последовательность, эндогенную или экзогенную по отношению к клетке. Примеры последовательности, подлежащей интеграции, включают в себя РНК, кодирующую белок, или некодирующую РНК (например, microRNA). Таким образом, последовательность, предназначенная для интеграции, может быть функционально связанной с соответствующей регуляторной последовательностью или соответствующими регуляторными последовательностями. Альтернативно последовательность, подлежащая интеграции, может обеспечивать регуляторную функцию. Последовательности, расположенные выше и ниже в экзогенной РНК-матрице, выбирают таким образом, чтобы способствовать рекомбинации между последовательностью РНК, представляющей интерес, и донорной РНК. Последовательность, расположенная выше, представляет собой последовательность РНК, которая обладает сходством последовательности с последовательностью РНК, расположенной выше подвергаемого нацеливанию сайта интеграции. Аналогично, последовательность, расположенная ниже, представляет собой последовательность РНК, которая обладает сходством последовательности с последовательностью РНК, расположенной ниже подвергаемого нацеливанию сайта интеграции. Последовательности, расположенные выше и ниже в экзогенной РНК-матрице, могут характеризоваться 75%, 80%, 85%, 90%, 95% или 100% идентичностью последовательности с подвергаемой нацеливанию последовательностью РНК. Предпочтительно, последовательности, расположенные выше и ниже в экзогенной РНК-матрице, характеризуются приблизительно 95%, 96%, 97%, 98%, 99% или 100% идентичностью последовательности с подвергаемой нацеливанию последовательностью РНК. В некоторых способах последовательности, расположенные выше и ниже в экзогенной РНК-матрице, характеризуются приблизительно 99% или 100% идентичностью последовательности с подвергаемой нацеливанию последовательностью РНК. Последовательность, расположенная выше или ниже, может содержать от приблизительно 20 п. о. до приблизительно 2500 п. о., например приблизительно 50, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400 или 2500 п. о. В некоторых способах иллюстративная последовательность, расположенная выше или ниже, имеет от приблизительно 200 п. о. до приблизительно 2000 п. о., от приблизительно 600 п. о. до приблизительно 1000 п. о. или, более конкретно, от приблизительно 700 п. о. до приблизительно 1000 п. о. В некоторых способах экзогенная РНК-матрица может дополнительно содержать маркер. Такой маркер может облегчать скрининг в отношении подвергаемых нацеливанию интеграций. Примеры подходящих маркеров включают сайты рестрикции, флуоресцентные белки или селектируемые маркеры. Экзогенную РНК-матрицу по настоящему изобретению можно сконструировать с применением методик рекомбинации (см., например, Sambrook et al., 2001, и Ausubel et al., 1996). В способе модифицирования целевой РНК посредством интеграции экзогенной РНК-матрицы разрыв (например, двух- или однонитевой разрыв в двух- или однонитевой ДНК или РНК) вводится в последовательность ДНК или РНК с помощью комплекса нацеливания на нуклеиновую кислоту, при этом разрыв подвергается репарации с помощью гомологичной рекомбинации с экзогенной РНК-матрицей, так что матрица интегрируется в РНК-мишень. Наличие двухнитевого разрыва способствует интеграции матрицы. В других вариантах осуществления настоящего изобретения предусмотрен способ модифицирования экспрессии РНК в эукариотической клетке. Способ предусматривает повышение или снижение уровня экспрессии целевого полинуклеотида с помощью комплекса нацеливания на нуклеиновую кислоту, который связывается с ДНК или РНК (например, мРНК или pre-mRNA). В некоторых способах целевую РНК можно инактивировать для осуществления модификации экспрессии в клетке. Например, после связывания комплекса нацеливания на РНК с целевой последовательностью в клетке целевая РНК инактивируется, вследствие чего последовательность не транслируется, при этом не вырабатывается закодированный белок или последовательность не функционирует так, как последовательность дикого типа. Например, последовательность, кодирующая белок или микроРНК, может быть инактивирована, вследствие чего не образуется белок, или microRNA или транскрипт pre-microRNA. Целевой РНК для комплекса нацеливания на РНК может быть любая РНК, эндогенная или экзогенная по отношению к эукариотической клетке. Например, целевой РНК может быть РНК, находящаяся в ядре эукариотической клетки. Целевой РНК может быть последовательность (например, мРНК или pre-mRNA), кодирующая продукт гена (например, белок), или некодирующая последовательность (например, ncRNA, lncRNA, tRNA или rRNA). Примеры целевой РНК включают последовательность, ассоциированную с биохимическим путем передачи сигнала, например, РНК, ассоциированную с биохимическим путем передачи сигнала. Примеры целевой РНК включают ассоциированную с заболеванием РНК. "Ассоциированная с заболеванием" РНК обозначает любую РНК, которая обеспечивает продукты трансляции на аномальном уровне или в аномальной форме в клетках, происходящих из пораженных заболеванием тканей, по сравнению с тканями или клетками от контроля без заболевания. Это может быть РНК, транскрибированная с гена, который начинает экспрессироваться на аномально высоком уровне; это может быть РНК, транскрибированная с гена, который начинает экспрессироваться на аномально низком уровне, при этом измененная экспрессия коррелирует с появлением и/или прогрессированием заболевания. Ассоциированная с заболеванием РНК также обозначает РНК, транскрибированную с гена, несущего мутацию(мутации) или генетическое изменение, которое напрямую отвечает за этиологию заболевания или находится в неравновесном сцеплении с геном(генами), ответственным(ответственными) за это. Транслированные продукты могут быть известны или неизвестны и могут присутствовать на нормальном или аномальном уровне. Целевой РНК для комплекса нацеливания на РНК может быть любая РНК, эндогенная или экзогенная по отношению к эукариотической клетке. Например, целевой РНК может быть РНК, находящаяся в ядре эукариотической клетки. Целевой РНК может быть последовательность (например, мРНК или pre-mRNA), кодирующая продукт гена (например, белок), или некодирующая последовательность (например, ncRNA, lncRNA, tRNA или rRNA).
В некоторых вариантах осуществления способ может включать обеспечение связывания комплекса нацеливания на нуклеиновую кислоту с целевой ДНК или РНК для осуществления расщепления указанной целевой ДНК или РНК, за счет чего осуществляется модифицирование целевой ДНК или РНК, где комплекс нацеливания на нуклеиновую кислоту содержит эффекторный белок для нацеливания на нуклеиновую кислоту в комплексе с направляющей РНК, гибридизированной с целевой последовательностью в пределах указанной целевой ДНК или РНК. В одном аспекте настоящего изобретения предусмотрен способ модифицирования экспрессии ДНК или РНК в эукариотической клетке. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса нацеливания на нуклеиновую кислоту с ДНК или РНК, так что указанное связывание приводит к повышенной или сниженной экспрессии указанной ДНК или РНК; где комплекс нацеливания на нуклеиновую кислоту содержит эффекторный белок для нацеливания на нуклеиновую кислоту в комплексе с направляющей РНК. Аналогичные соображения и условия распространяются на способы модифицирования целевой ДНК или РНК, изложенные выше. Фактически, эти варианты отбора образцов, культивирования и повторного введения охватываются аспектами настоящего изобретения. В одном аспекте настоящего изобретения предусмотрены способы модифицирования целевой ДНК или РНК в эукариотической клетке, которые могут осуществляться in vivo, ex vivo или in vitro. В некоторых вариантах осуществления способ включает отбор клетки или популяции клеток у человека или отличного от человека животного и модификацию клетки или клеток. Культивирование можно осуществлять на любой стадии ex vivo. Клетку или клетки можно даже повторно вводить отличному от человека животному или в растение. Что касается повторно вводимых клеток, особенно предпочтительно, чтобы эти клетки являлись стволовыми клетками.
Действительно, в любом аспекте настоящего изобретения комплекс нацеливания на нуклеиновую кислоту может содержать эффекторный белок для нацеливания на нуклеиновую кислоту в комплексе с направляющей РНК, гибридизированной с целевой последовательностью.
Настоящее изобретение относится к конструированию и оптимизации систем, способов и композиций, применяемых для контроля экспрессии гена, предусматривающих нацеливание на последовательность ДНК или РНК, которые связаны с системой нацеливания на нуклеиновую кислоту и ее компонентами. В преимущественных вариантах осуществления эффекторный фермент представляет собой белок V типа/VI типа, такой как Cpf1/C2c1/C2c2. Преимущество способов по настоящему изобретению заключается в том, что система CRISPR сводит к минимуму или исключает нецелевое связывание и возникающие в результате этого побочные эффекты. Это достигается за счет использования систем, устроенных так, чтобы характеризоваться высокой степенью специфичности к последовательности целевой ДНК или РНК.
Что касается комплекса или системы нацеливания на нуклеиновую кислоту, предпочтительно, чтобы последовательность crRNA имела одну или несколько "петель-на-стебле" или шпилек, и ее длина составляла 30 или более нуклеотидов, 40 или более нуклеотидов или 50 или более нуклеотидов; при этом длина последовательность crRNA составляет от 10 до 30 нуклеотидов, а эффекторный белок для нацеливания на нуклеиновую кислоту представляет собой фермент Cas V типа/VI типа. В определенных вариантах осуществления длина последовательности crRNA составляет от 42 до 44 нуклеотида, а белок Cas для нацеливания на нуклеиновую кислоту представляет собой Cpf1 из Francisella tularensis subsp.novocida U112. В определенных вариантах осуществления crRNA содержит, состоит, по сути, из или состоит из 19 нуклеотидов прямого повтора и от 23 до 25 нуклеотидов спейсерной последовательности, а белок Cas для нацеливания на нуклеиновую кислоту представляет собой Cpf1 из Francisella tularensis subsp.novocida U112.
Применение двух различных аптамеров (каждый из которых ассоциирован с отдельной направляющей РНК для нацеливания на нуклеиновую кислоту) обеспечивает возможность применения продукта слияния активатор-адаптерный белок и продукта слияния репрессор-адаптерный белок с различными направляющими РНК для нацеливания на нуклеиновую кислоту, чтобы активировать экспрессию одной ДНК или РНК, в то же время подвергая репрессии другую. Их, вместе с их различными направляющими РНК, можно вводить вместе или практически вместе при подходе мультиплексирования. Одновременно можно применять множество таких модифицированных направляющих РНК для нацеливания на нуклеиновую кислоту, например, 10, или 20, или 30 и т. д., при этом необходимо доставить только одну (или по меньшей мере минимальное количество) молекулу эффекторного белка, поскольку сравнительно небольшое количество молекул эффекторного белка можно применять с большим количеством модифицированных направляющих. Адаптерный белок может быть ассоциирован (предпочтительно связан или слит) с одним или несколькими активаторами или одним или несколькими репрессорами. Например, адаптерный белок может быть ассоциирован с первым активатором и вторым активатором. Первый и второй активаторы могут быть одинаковыми, но предпочтительно они являются различными активаторами. Можно применять три или более или даже четыре или более активаторов (или репрессоров), но размер упаковки может служить ограничением, так что количество не превышает 5 различных функциональных доменов. Предпочтительно применяются линкеры, а не прямое слияние с адаптерным белком, при этом с адаптерным белком ассоциированы два или более функциональных домена. Подходящие линкеры могут включать линкер GlySer.
Также предусмотрено, что комплекс эффекторный белок для нацеливания на нуклеиновую кислоту-направляющая РНК в целом может быть ассоциирован с двумя или более функциональными доменами. Например, два или более функциональных доменов могут быть ассоциированы с эффекторным белком для нацеливания на нуклеиновую кислоту, или два или более функциональных доменов могут быть ассоциированы с направляющей РНК (с помощью одного или нескольких адаптерных белков), или один или несколько функциональных доменов могут быть ассоциированы с эффекторным белком для нацеливания на нуклеиновую кислоту и один или несколько функциональный доменов могут быть ассоциированы с направляющей РНК (с помощью одного или нескольких адаптерных белков).
Продукт слияния между адаптерным белком и активатором или репрессором может включать линкер. Например, можно применять линкеры GlySer, GGGS (SEQ ID NO: 18). Их можно применять в виде повторов по 3 ((GGGGS)3 (SEQ ID NO: 19)) или 6 (SEQ ID NO: 20), 9 (SEQ ID NO: 21) или даже 12 (SEQ ID NO: 22) или более для обеспечения подходящей длины, в случае необходимости. Линкеры можно применять между направляющими РНК и функциональным доменом (активатором или репрессором) или между белком Cas для нацеливания на нуклеиновую кислоту(Cas) и функциональным доменом (активатором или репрессором). Линкеры применяют для конструирования молекулы с достаточной степенью "механической гибкости".
Настоящее изобретение охватывает комплекс нацеливания на нуклеиновую кислоту, содержащий эффекторный белок для нацеливания на нуклеиновую кислоту и направляющую РНК, где эффекторный белок для нацеливания на нуклеиновую кислоту содержит по меньшей мере одну мутацию, вследствие чего эффекторный белок для нацеливания на нуклеиновую кислоту характеризуется не более чем 5% активности эффекторного белка для нацеливания на нуклеиновую кислоту, не имеющего по меньшей мере одной мутации и необязательно по меньшей мере одной или нескольких последовательностей ядерной локализации; направляющая РНК предусматривает направляющую последовательность, способную к гибридизации с целевой последовательностью представляющей интерес РНК в клетке; и где эффекторный белок для нацеливания на нуклеиновую кислоту ассоциирован с двумя или более функциональными доменами; или по меньшей мере одна петля направляющей РНК модифицирована путем вставки отличающейся(отличающихся) последовательности(последовательностей) РНК, которая(которые) связывается(связываются) с одним или несколькими адаптерными белками, и где адаптерный белок ассоциирован с двумя или более функциональными доменами; или белок Cas для нацеливания на нуклеиновую кислоту ассоциирован с одним или несколькими функциональными доменами, и по меньшей мере одна петля направляющей РНК модифицирована путем вставки отличающейся(отличающихся) последовательности(последовательностей) РНК, которая(которые) связывается(связываются) с одним или несколькими адаптерными белками, и где адаптерный белок ассоциирован с одним или несколькими функциональными доменами.
В одном аспекте настоящего изобретения предусмотрен способ получения модельной эукариотической клетки, содержащей мутированный ген, ответственный за развитие заболевания. В некоторых вариантах осуществления ген, ответственный за развитие заболевания, представляет собой любой ген, ассоциированный с повышением риска наличия или развития заболевания. В некоторых вариантах осуществления способ включает (a) введение одного или нескольких векторов в эукариотическую клетку, где один или несколько векторов управляют экспрессией одного или нескольких из: фермента Cpf1 и защищенной направляющей РНК, предусматривающей направляющую последовательность, связанную с последовательностью прямого повтора; и (b) обеспечение связывания комплекса CRISPR с целевым полинуклеотидом для осуществления расщепления целевого полинуклеотида в пределах указанного гена, ответственного за развитие заболевания, где комплекс CRISPR содержит фермент Cpf1 в комплексe с направляющей РНК, предусматривающей последовательность, которая гибридизируется с целевой последовательностью в пределах целевого полинуклеотида, с получением тем самым модельной эукариотической клетки, содержащей мутированный ген, ответственный за развитие заболевания. В некоторых вариантах осуществления указанное расщепление предусматривает расщепление одной или двух нитей в определенном положении целевой последовательности с помощью указанного фермента Cpf1. В некоторых вариантах осуществления указанное расщепление приводит к сниженной транскрипции целевого гена. В некоторых вариантах осуществления способ дополнительно включает репарацию указанного расщепленного целевого полинуклеотида с помощью механизмов генной вставки на основе негомологичного соединения концов (NHEJ) с применением экзогенной полинуклеотидной матрицы, где указанная репарация приводит к мутации, предусматривающей вставку, делецию или замену одного или нескольких нуклеотидов в указанном целевом полинуклеотиде. В некоторых вариантах осуществления указанная мутация приводит к изменению одной или нескольких аминокислот при экспрессии белка с гена, содержащего целевую последовательность.
В одном аспекте настоящего изобретения предусмотрены способы, обсуждаемые в данном документе, где хозяином является эукариотическая клетка. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где хозяином является клетка млекопитающего. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где хозяином является клетка эукариотического организма, отличного от человека. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где клеткой эукариотического организма, отличного от человека, является клетка млекопитающего, отличного от человека. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где клетка млекопитающего, отличного от человека, может представлять собой, включая без ограничения клетку представителя приматов, бычьих, овечьих, свиньих, псовых, грызунов, Leporidae, как, например, обезьяны, коровы, овцы, свиньи, собаки, кролика, крысы или мыши. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, причем клетка может представлять собой эукариотическую клетку от организма, отличного от млекопитающего, как, например, клетку домашней птицы (например, курицы), позвоночной рыбы (например, лосося) или моллюсков и ракообразных (например, устрицы, двустворчатых моллюсков, омара, креветки). В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, причем клеткой эукариотического организма, отличного от человека, является растительная клетка. Растительная клетка может быть получена от однодольного или двудольного растения, или от сельскохозяйственного или зернового растения, такого как маниока, кукуруза, сорго, соя, пшеница, овес или рис. Растительная клетка также может быть получена от водоросли, дерева или продуктивного растения, фрукта или овоща (например, деревьев, таких как цитрусовые деревья, например, деревья апельсина, грейпфрута или лимона; деревья персика или нектарина; деревья яблони или груши; орехоплодные деревья, такие как деревья миндаля, или грецкого ореха, или фисташки; пасленовых растений; растений из рода Brassica; растений из рода Lactuca; растений из рода Spinacia; растений из рода Capsicum; хлопчатника, табака, спаржи, моркови, капусты кочанной, брокколи, цветной капусты, томата, баклажана, перца, салата, шпината, земляники, черники, малины, ежевики, винограда, кофе, какао и т.д.).
В одном аспекте настоящего изобретения предусмотрен способ разработки биологически активного средства, которое модулирует событие передачи сигнала в клетке, ассоциированное с геном, ответственным за развитие заболевания. В некоторых вариантах осуществления ген, ответственный за развитие заболевания, представляет собой любой ген, ассоциированный с повышением риска наличия или развития заболевания. В некоторых вариантах осуществления способ включает (a) приведение тестируемого соединения в контакт с модельной клеткой по любому из описанных выше вариантов осуществления; и (b) обнаружение изменения считываемого показания, что указывает на снижение или возрастание события передачи сигнала в клетке, ассоциированного с указанной мутацией в указанном гене, ответственном за развитие заболевания, с получением тем самым указанного биологически активного средства, которое модулирует указанное событие передачи сигнала в клетке, ассоциированное с указанным геном, ответственным за развитие заболевания.
В одном аспекте настоящего изобретения предусмотрен способ отбора клетки или нескольких клеток путем введения одной или нескольких мутаций в ген в одной или нескольких клетках, причем способ включает введение одного или нескольких векторов в клетку(клетки), где один или несколько векторов управляют экспрессией одного или нескольких из Cpf1, направляющей последовательности, связанной с последовательностью прямого повтора, и матрицы редактирования; где матрица редактирования содержит одну или несколько мутаций, которые прекращают расщепление Cpf1; обеспечение гомологичной рекомбинации матрицы редактирования с целевым полинуклеотидом в клетке(клетках), подлежащей(подлежащих) отбору; обеспечение связывания комплекса CRISPR-Cas на основе Cpf1 с целевым полинуклеотидом для осуществления расщепления целевого полинуклеотида в пределах указанного гена, где комплекс CRISPR-Cas на основе Cpf1 содержит Cpf1 в комплексе с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью в пределах целевого полинуклеотида, и (2) последовательностью прямого повтора, где связывание комплекса CRISPR-Cas на основе Cpf1 с целевым полинуклеотидом индуцирует гибель клетки, тем самым обеспечивая возможность отбора одной или нескольких клеток, в которые были введены одна или несколько мутаций; при этом предусматривается split-Cpf1 по настоящему изобретению. В другом предпочтительном варианте настоящего изобретения клетка, подлежащая отбору, может представлять собой эукариотическую клетку. Аспекты настоящего изобретения предусматривают отбор специфических клеток без необходимости наличия маркера отбора или двухстадийного способа, который может включать систему негативного отбора. В конкретных вариантах осуществления модельная эукариотическая клетка содержится в модельном эукариотическом организме.
В одном аспекте настоящего изобретения предусмотрен рекомбинантный полинуклеотид, содержащий направляющую последовательность ниже последовательности прямого повтора, где направляющая последовательность при экспрессии управляет специфичным к последовательности связыванием комплекса CRISPR-Cas на основе Cpf1 с соответствующей целевой последовательностью, присутствующей в эукариотической клетке. В некоторых вариантах осуществления целевой последовательностью является вирусная последовательность, присутствующая в эукариотической клетке. В некоторых вариантах осуществления целевая последовательность представляет собой протоонкоген или онкоген.
В одном аспекте настоящего изобретения предусмотрена векторная система или эукариотическая клетка-хозяин, содержащие (a) первый регуляторный элемент, функционально связанный с последовательностью прямого повтора и одним или несколькими сайтами встраивания для встраивания одной или нескольких направляющих последовательностей (включая любые из модифицированных направляющих последовательностей, описываемых в данном документе) ниже последовательности DR, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR-Cas на основе Cpf1 с целевой последовательностью в эукариотической клетке, где комплекс CRISPR-Cas на основе Cpf1 содержит Cpf1 (включая любой из модифицированных ферментов, описываемых в данном документе) в комплексе с направляющей последовательностью, которая гибридизируется с целевой последовательностью (и необязательно последовательностью DR); и/или (b) второй регуляторный элемент, функционально связанный с фермент-кодирующей последовательностью, которая кодирует указанный фермент Cpf1, содержащий последовательность ядерной локализации и/или NES. В некоторых вариантах осуществления клетка-хозяин содержит компоненты (a) и (b). В некоторых вариантах осуществления компонент (a), компонент (b) или компоненты (a) и (b) стабильно интегрированы в геном эукариотической клетки-хозяина. В некоторых вариантах осуществления компонент (a) дополнительно содержит две или более направляющих последовательностей, функционально связанных с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR-Cas на основе Cpf1 со своей целевой последовательностью в эукариотической клетке. . В некоторых вариантах осуществления фермент CRISPR содержит одну или несколько последовательностей ядерной локализации и/или последовательностей ядерного экспорта или NES, характеризующихся достаточной эффективностью, чтобы управлять накоплением указанного фермента CRISPR в обнаруживаемом количестве в ядре эукариотической клетки и/или за его пределами. В некоторых вариантах осуществления фермент Cpf1 получен из Cpf1 Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens или Porphyromonas macacae, включая любые модифицированные ферменты, описываемые в данном документе, и он может включать дополнительное изменение или мутацию Cpf1 и может представлять собой химерный Cpf1. . В некоторых вариантах осуществления фермент CRISPR кодон-оптимизирован для экспрессии в эукариотической клетке. В некоторых вариантах осуществления фермент CRISPR управляет расщеплением одной или двух нитей в определенном положении целевой последовательности. В предпочтительном варианте осуществления разрыв нити представляет собой ступенчатый разрез с "липким" 5'-концом. В некоторых вариантах осуществления Cpf1 не обладает активностью расщепления нити ДНК (например, характеризуется не более чем 5% нуклеазной активности по сравнению с ферментом дикого типа или ферментом без мутации или изменения, которые снижают нуклеазную активность). В некоторых вариантах осуществления первый регуляторный элемент является промотором полимеразы III. В некоторых вариантах осуществления второй регуляторный элемент является промотором полимеразы II. В некоторых вариантах осуществления минимальная длина прямого повтора составляет 16 нуклеотидов, и он содержит одну "петлю-на-стебле". В дополнительных вариантах осуществления длина прямого повтора составляет более 16 нуклеотидов, предпочтительно более 17 нуклеотидов, и он содержит более одной "петли-на-стебле" или оптимизированных вторичных структур. В некоторых вариантах осуществления длина направляющей последовательности составляет по меньшей мере 16, 17, 18, 19, 20, 25 нуклеотидов, или 16-30, или 16-25, или 16-20 нуклеотидов.
В одном аспекте настоящего изобретения предусмотрен набор, содержащий один или несколько компонентов, описанных в данном документе. В некоторых вариантах осуществления набор содержит векторную систему или клетку-хозяина, описанные в данном документе, и инструкции по применению набора.
Модифицированные ферменты Cpf1
С помощью компьютерного анализа первичной структуры нуклеаз Cpf1 выявили три отличающихся участка (фигура 1). Первый, C-концевой RuvC-подобный домен, который является единственным охарактеризованным функциональным доменом. Второй, N-концевой альфа-спиральный участок, и третий, участок со смешанной альфа- и бета-структурой, расположенный между RuvC-подобным доменом и альфа-спиральным участком.
Несколько небольших отрезков из неструктурированных участков прогнозируются в первичной структуре Cpf1. Неструктурированные участки, которые подвергаются воздействию растворителя и не являются консервативными в пределах разных ортологов Cpf1, представляют собой предпочтительные стороны для разделений и вставок небольших белковых последовательностей (фигура 2 и 3). Кроме того, эти стороны можно использовать для создания химерных белков между ортологами Cpf1.
На основании приведенной выше информации можно получать мутантов, что подразумевает инактивацию фермента или которые модифицируют нуклеазу, обеспечивающую двухнитевой разрыв, придавая ей активность никазы. В альтернативных вариантах осуществления данную информацию применяют для разработки ферментов со сниженными нецелевыми эффектами (описаны в других разделах данного документа).
В случае определенных описанных выше ферментов Cpf1 фермент является модифицированным с помощью мутации одного или нескольких остатков, включая без ограничения положения D917, E1006, E1028, D1227, D1255A, N1257 согласно положениям в белке FnCpf1 или любом соответствующем ортологе. В одном аспекте настоящего изобретения предусмотрена обсуждаемая в данном документе композиция, где фермент Cpf1 является инактивированным ферментом, который содержит одну или несколько мутаций, выбранных из группы, состоящей из D917A, E1006A, E1028A, D1227A, D1255A, N1257A, D917A, E1006A, E1028A, D1227A, D1255A и N1257A согласно положениям в белке FnCpf1 или соответствующим положениям в ортологе Cpf1. В одном аспекте настоящего изобретения предусмотрена обсуждаемая в данном документе композиция, где фермент CRISPR содержит D917, или E1006 и D917, или D917 и D1255 согласно положениям в белке FnCpf1 или соответствующим положениям в ортологе Cpf1.
В случае определенных описанных выше ферментов Cpf1 фермент модифицируют с помощью мутации одного или нескольких остатков (в домене RuvC), включая без ограничения положения R909, R912, R930, R947, K949, R951, R955, K965, K968, K1000, K1002, R1003, K1009, K1017, K1022, K1029, K1035, K1054, K1072, K1086, R1094, K1095, K1109, K1118, K1142, K1150, K1158, K1159, R1220, R1226, R1242, и/или R1252 в соответствии с нумерацией аминокислотных положений AsCpf1 (Acidaminococcus sp. BV3L6).
В случае определенных описанных выше не встречающихся в природе ферментов CRISPR фермент модифицируют с помощью мутации одного или нескольких остатков (в домене RAD50), включая без ограничения положения K324, K335, K337, R331, K369, K370, R386, R392, R393, K400, K404, K406, K408, K414, K429, K436, K438, K459, K460, K464, R670, K675, R681, K686, K689, R699, K705, R725, K729, K739, K748 и/или K752 в соответствии с нумерацией аминокислотных положений AsCpf1 (Acidaminococcus sp. BV3L6).
В случае определенных ферментов Cpf1 фермент модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения R912, T923, R947, K949, R951, R955, K965, K968, K1000, R1003, K1009, K1017, K1022, K1029, K1072, K1086, F1103, R1226, и/или R1252 в соответствии с нумерацией аминокислотных положений AsCpf1 (Acidaminococcus sp. BV3L6).
В определенных вариантах осуществления фермент Cpf1 модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения R833, R836, K847, K879, K881, R883, R887, K897, K900, K932, R935, K940, K948, K953, K960, K984, K1003, K1017, R1033, R1138, R1165, и/или R1252 в соответствии с нумерацией аминокислотных положений LbCpf1 (Lachnospiraceae bacterium ND2006).
В определенных вариантах осуществления фермент Cpf1 модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения K15, R18, K26, Q34, R43, K48, K51, R56, R84, K85, K87, N93, R103, N104, T118, K123, K134, R176, K177, R192, K200, K226, K273, K275, T291, R301, K307, K369, S404, V409, K414, K436, K438, K468, D482, K516, R518, K524, K530, K532, K548, K559, K570, R574, K592, D596, K603, K607, K613, C647, R681, K686, H720, K739, K748, K757, T766, K780, R790, P791, K796, K809, K815, T816, K860, R862, R863, K868, K897, R909, R912, T923, R947, K949, R951, R955, K965, K968, K1000, R1003, K1009, K1017, K1022, K1029, A1053, K1072, K1086, F1103, S1209, R1226, R1252, K1273, K1282, и/или K1288 в соответствии с нумерацией аминокислотных положений AsCpf1 (Acidaminococcus sp. BV3L6).
В определенных вариантах осуществления фермент модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения K15, R18, K26, R34, R43, K48, K51, K56, K87, K88, D90, K96, K106, K107, K120, Q125, K143, R186, K187, R202, K210, K235, K296, K298, K314, K320, K326, K397, K444, K449, E454, A483, E491, K527, K541, K581, R583, K589, K595, K597, K613, K624, K635, K639, K656, K660, K667, K671, K677, K719, K725, K730, K763, K782, K791, R800, K809, K823, R833, K834, K839, K852, K858, K859, K869, K871, R872, K877, K905, R918, R921, K932, I960, K962, R964, R968, K978, K981, K1013, R1016, K1021, K1029, K1034, K1041, K1065, K1084, и/или K1098 в соответствии с нумерацией аминокислотных положений FnCpf1 (Francisella novicida U112).
В определенных вариантах осуществления фермент модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения K15, R18, K26, K34, R43, K48, K51, R56, K83, K84, R86, K92, R102, K103, K116, K121, R158, E159, R174, R182, K206, K251, K253, K269, K271, K278, P342, K380, R385, K390, K415, K421, K457, K471, A506, R508, K514, K520, K522, K538, Y548, K560, K564, K580, K584, K591, K595, K601, K634, K640, R645, K679, K689, K707, T716, K725, R737, R747, R748, K753, K768, K774, K775, K785, K787, R788, Q793, K821, R833, R836, K847, K879, K881, R883, R887, K897, K900, K932, R935, K940, K948, K953, K960, K984, K1003, K1017, R1033, K1121, R1138, R1165, K1190, K1199, и/или K1208 в соответствии с нумерацией аминокислотных положений LbCpf1 (Lachnospiraceae bacterium ND2006).
В определенных вариантах осуществления фермент модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения K14, R17, R25, K33, M42, Q47, K50, D55, K85, N86, K88, K94, R104, K105, K118, K123, K131, R174, K175, R190, R198, I221, K267, Q269, K285, K291, K297, K357, K403, K409, K414, K448, K460, K501, K515, K550, R552, K558, K564, K566, K582, K593, K604, K608, K623, K627, K633, K637, E643, K780, Y787, K792, K830, Q846, K858, K867, K876, K890, R900, K901, M906, K921, K927, K928, K937, K939, R940, K945, Q975, R987, R990, K1001, R1034, I1036, R1038, R1042, K1052, K1055, K1087, R1090, K1095, N1103, K1108, K1115, K1139, K1158, R1172, K1188, K1276, R1293, A1319, K1340, K1349, и/или K1356 в соответствии с нумерацией аминокислотных положений MbCpf1 (Moraxella bovoculi 237).
Деактивированный/инактивированный белок Cpf1
Если белок Cpf1 характеризуется нуклеазной активностью, белок Cpf1 можно модифицировать, чтобы он характеризовался сниженной нуклеазной активностью, например, инактивация нуклеазы составляет по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 97%, или 100% относительно фермента дикого типа; или, иными словами, фермент Cpf1 характеризуется преимущественно приблизительно 0% нуклеазной активностью относительно немутированного фермента Cpf1 или фермента дикого типа, или фермента CRISPR, или не более приблизительно 3%, или приблизительно 5%, или приблизительно 10% нуклеазной активностью относительно немутированного фермента Cpf1 или фермента дикого типа, например, немутированного фермента Cpf1 или фермента Cpf1 или ферментов дикого типа из Francisella novicida U112 (FnCpf1), Acidaminococcus sp. BV3L6 (AsCpf1), Lachnospiraceae bacterium ND2006 (LbCpf1) или Moraxella bovoculi 237 (фермент MbCpf1 Cpf1 или фермент CRISPR). Это возможно путем введения мутаций в нуклеазные домены Cpf1 и его ортологов.
Более конкретно, инактивированные ферменты Cpf1 включают ферменты, мутированные по аминокислотным положениям As908, As993, As1263 из AsCpf1 или соответствующим положениям в ортологах Cpf1. В дополнение, инактивированные ферменты Cpf1 включают ферменты, мутированные по аминокислотному положению Lb832, 925, 947 или 1180 из LbCpf1 или соответствующим положениям в ортологах Cpf1. Более конкретно, инактивированные ферменты Cpf1 включают ферменты, содержащие одну или несколько мутаций AsD908A, AsE993A, AsD1263A из AsCpf1 или соответствующие мутации в ортологах Cpf1. В дополнение, инактивированные ферменты Cpf1 включают ферменты, содержащие одну или несколько мутаций LbD832A, E925A, D947A или D1180A из LbCpf1 или соответствующие мутации в ортологах Cpf1.
Инактивированный фермент Cpf1 CRISPR может быть ассоциирован (например, посредством образования слитого белка) с одним или несколькими функциональными доменами, в том числе, например, с одним или несколькими доменами из группы, содержащей, состоящей, по сути, из или состоящей из доменов с метилазной активностью, деметилазной активностью, активностью в отношении активации транскрипции, активностью в отношении репрессии транскрипции, активностью фактора освобождения транскрипта, активностью в отношении модификации гистонов, активностью расщепления РНК, активностью расщепления ДНК, активностью связывания нуклеиновой кислоты и молекулярных переключателей (например, индуцируемых светом). Предпочтительными доменами являются Fok1, VP64, P65, HSF1, MyoD1. В случае, когда предусматривается Fok1, преимущественно, чтобы предусматривались множественные функциональные домены Fok1 для обеспечения функционального димера, и чтобы разрабатывались gRNA, обеспечивающие надлежащее расстояние для функционального применения (Fok1), как конкретно описано в Tsai et al. Nature Biotechnology, Vol. 32, Number 6, June 2014). В адаптерном белке можно использовать известные линкеры для прикрепления таких функциональных доменов. В некоторых случаях преимущественным является дополнительное обеспечение по меньшей мере одного NLS. В некоторых случаях предпочтительно положение NLS на N-конце. При включении более чем одного функционального домена функциональные домены могут быть одинаковыми или разными.
В целом, размещение одного или нескольких функциональных доменом в инактивированном ферменте Cpf1 обеспечивает корректную пространственную ориентацию функционального домена для воздействия на мишень с присущим функциональным эффектом. Например, если функциональный домен представляет собой активатор транскрипции (например, VP64 или p65), то активатор транскрипции размещается в пространственной ориентации, которая позволяет ему влиять на транскрипцию мишени. Подобным образом, репрессор транскрипции будет размещаться преимущественно, чтобы воздействовать на транскрипцию мишени, а нуклеаза (например, Fok1) будет размещаться преимущественно для расщепления или частичного расщепления мишени. Могут быть предусмотрены положения, отличные от N-/C-конца фермента CRISPR.
Дестабилизированный Cpf1
В определенных вариантах осуществления эффекторный белок (фермент CRISPR; Cpf1) в соответствии с настоящим изобретением, как описано в данном документе, ассоциирован с доменом дестабилизации (DD) или слит с ним. В некоторых вариантах осуществления DD представляет собой ER50. Соответствующий стабилизирующий лиганд для такого DD в некоторых вариантах осуществления представляет собой 4HT. Таким образом, в некоторых вариантах осуществления один из по меньшей мере одного DD представляет собой ER50, а стабилизирующий лиганд для него представляет собой 4HT или CMP8. В некоторых вариантах осуществления DD представляет собой DHFR50. Соответствующий стабилизирующий лиганд для такого DD в некоторых вариантах осуществления представляет собой TMP. Таким образом, в некоторых вариантах осуществления один из по меньшей мере одного DD представляет собой DHFR50, а стабилизирующий лиганд для него представляет собой TMP. В некоторых вариантах осуществления DD представляет собой ER50. Соответствующий стабилизирующий лиганд для такого DD в некоторых вариантах осуществления представляет собой CMP8. Следовательно, CMP8 может быть стабилизирующим лигандом, являющимся альтернативой 4HT в системе ER50. Хотя возможно, чтобы CMP8 и 4HT могли/должны были применяться конкурентным образом, некоторые типы клеток могут быть более восприимчивыми к одному или другому из этих двух лигандов, и на основании настоящего раскрытия и информации из уровня техники специалист сможет применять CMP8 и/или 4HT.
В некоторых вариантах осуществления один или два DD могут быть слиты с N-концом фермента CRISPR, и один или два DD слиты с C-концом фермента CRISPR. В некоторых вариантах осуществления с ферментом CRISPR ассоциированы по меньшей мере два DD, и при этом DD являются одинаковыми DD, т. е. DD являются гомологичными. Таким образом, оба (или два или более) из DD могут быть DD ER50. Это является предпочтительным в некоторых вариантах осуществления. Альтернативно, оба (или два или более) из DD могут быть DD DHFR50. Это также является предпочтительным в некоторых вариантах осуществления. В некоторых вариантах осуществления с ферментом CRISPR ассоциированы по меньшей мере два DD, и при этом DD являются разными DD, т. е. DD являются гетерологичными. Таким образом, один из DD может представлять собой ER50, тогда как один или несколько из DD или любых других DD могут представлять собой DHFR50. Наличие двух или более DD, которые являются гетерологичными, может быть предпочтительным, поскольку может обеспечивать больший уровень контроля разрушения. Тандемное слияние более чем одного DD на N- или C-конце может усиливать разрушение; и такое тандемное слияние может представлять собой, например, ER50-ER50-C2c2 или DHFR-DHFR-Cpf1. Предусматривается, что высокие уровни разрушения будут наблюдаться в отсутствие обоих стабилизирующих лигандов, промежуточные уровни разложения могут наблюдаться в отсутствие одного стабилизирующего лиганда и в присутствии другого (или иного) стабилизирующего лиганда, тогда как низкие уровни разрушения могут наблюдаться в присутствии обоих (или двух или более) стабилизирующих лигандов. Контроль также может быть обеспечен наличием N-концевого DD ER50 и C-концевого DD DHFR50.
В некоторых вариантах осуществления продукт слияния фермента CRISPR с DD содержит линкер между DD и ферментом CRISPR. В некоторых вариантах осуществления линкер представляет собой линкер GlySer. В некоторых вариантах осуществления фермент DD-CRISPR дополнительно содержит по меньшей мере один сигнал ядерного экспорта (NES). В некоторых вариантах осуществления фермент DD-CRISPR содержит два или более NES. В некоторых вариантах осуществления фермент DD-CRISPR содержит по меньшей мере один сигнал ядерной локализации (NLS). Он может присутствовать наряду с NES. В некоторых вариантах осуществления фермент CRISPR содержит, или состоит, по сути, из, или состоит из сигнала локализации (ядерного импорта или экспорта), в виде линкера между ферментом CRISPR и DD или его части. Метки HA или Flag также охватываются настоящим изобретением в качестве линкеров. Заявители применяют NLS и/или NES в качестве линкера, а также применяют глицин-сериновые линкеры как короткие GS до (GGGGS)3.
Дестабилизирующие домены являются универсальными для придания нестабильности широкому диапазону белков; см., например, Miyazaki, J Am Chem Soc. Mar 7, 2012; 134(9): 3942-3945, включенный в данный документ посредством ссылки. CMP8 или 4-гидрокситамоксифен могут представлять собой дестабилизирующие домены. В более широком смысле, термочувствительный мутант DHFR млекопитающих (DHFRts), дестабилизирующий остаток по правилу N-конца, как оказалось, стабилен при пермиссивной температуре, но нестабилен при 37°C. Добавление метотрексата, высокоаффинного лиганда для DHFR млекопитающих, к клеткам, экспрессирующим DHFRts, частично ингибировало разрушение белка. Это было важным доказательством того, что низкомолекулярный лиганд может стабилизировать белок, в ином случае предназначенный для разрушения в клетках. Производное рапамицина применяли для стабилизации нестабильного мутанта домена FRB в mTOR (FRB*) и восстановления функция слитой киназы, GSK-3β.6,7. Эта система продемонстрировала, что зависимая от лиганда стабильность является привлекательной стратегией для регуляции функции специфического белка в сложной биологической среде. Система для контроля активности белка может включать DD, становящийся функциональным при возникновении комплементации убиквитина с помощью индуцированной рапамицином димеризации белка, связывающего FK506, и FKBP12. Можно сконструировать мутантов FKBP12 человека или белка ecDHFR, которые будут метаболически нестабильны в отсутствии их высокоаффинных лигандов, Shield-1 или триметоприма (TMP) соответственно. Эти мутанты представляют собой некоторые из возможных дестабилизирующих доменов (DD), применимых при осуществлении настоящего изобретения на практике, и нестабильность DD в виде слияния с ферментом CRISPR обеспечивает разрушение белка CRISPR в виде полного слитого белка под действием протеасомы. Shield-1 и TMP связывают и стабилизируют DD дозозависимым образом. Домен связывания лиганда эстрогенового рецептора (ERLBD, остатки 305-549 в ERS1) также может быть сконструирован как дестабилизирующий домен. Поскольку сигнальный путь эстрогенового рецептора вовлечен в ряд заболеваний, таких как рак молочной железы, этот путь был широко изучен, и были разработаны многочисленные агонисты и антагонисты эстрогенового рецептора. Таким образом, известны совместимые пары ERLBD и лекарственных средств. Существуют лиганды, которые связываются с мутантой формой, а не формой дикой типа ERLBD. Путем применения одного из этих мутантных доменов, кодирующих три мутации (L384M, M421G, G521R)12, возможно регулировать стабильность DD, происходящего из ERLBD, с применением лиганда, который не нарушает эндогенные сети, чувствительные к эстрогену. Дополнительная мутация (Y537S) может быть введена для дополнительной дестабилизации ERLBD и для конфигурации его в качестве потенциального кандидата DD. Такой тетра-мутант является предпочтительной разработкой DD. Мутант ERLBD может быть слит с ферментом CRISPR, и его стабильность можно регулировать или нарушать с применением лиганда, при условии что фермент CRISPR имеет DD. Другим DD может быть метка размером 12 кДа (107 аминокислот) на основе мутированного белка FKBP, стабилизируемого лигандом Shield1; см., например, Nature Methods 5, (2008). Например, DD может представлять собой модифицированный связывающий FK506 белок 12 (FKBP12), который связывается и обратимо стабилизируется синтетической биологически инертной малой молекулой Shield-1; см., например, Banaszynski LA, Chen LC, Maynard-Smith LA, Ooi AG, Wandless TJ. A rapid, reversible, and tunable method to regulate protein function in living cells using synthetic small molecules. Cell. 2006;126:995-1004; Banaszynski LA, Sellmyer MA, Contag CH, Wandless TJ, Thorne SH. Chemical control of protein stability and function in living mice. Nat Med. 2008;14:1123-1127; Maynard-Smith LA, Chen LC, Banaszynski LA, Ooi AG, Wandless TJ. A directed approach for engineering conditional protein stability using biologically silent small molecules. The Journal of biological chemistry. 2007;282:24866-24872; и Rodriguez, Chem Biol. Mar 23, 2012; 19(3): 391-398, все из которых включены в данный документ посредством ссылки и могут быть использованы при осуществлении настоящего изобретения на практике в выборе DD для ассоциации с ферментом CRISPR для осуществления настоящего изобретения на практике. Как можно видеть, информация из уровня техники включает целый ряд DD, и DD можно ассоциировать с ферментом CRISPR, например, сливать преимущественно с помощью линкера, в результате чего DD можно стабилизировать в присутствии лиганда, а в случае его отсутствия DD может становиться дестабилизированным, в результате чего полностью дестабилизируется фермент CRISPR, или DD может быть стабилизированным в отсутствие лиганда, а когда лиганд присутствует DD может становиться дестабилизированным; при этом DD обеспечивает возможность регуляции и контроля фермента CRISPR и, следовательно, комплекса или системы CRISPR-Cas - условно говоря, включение или выключение, с обеспечением тем самым средства для регуляции или контроля системы, например, в in vivo или in vitro окружении. Например, если представляющий интерес белок экспрессируется в виде продукта слияния с меткой DD, то он дестабилизируется и быстро разрушается в клетке, например, с помощью протеасом. Таким образом, отсутствие стабилизирующего лиганда приводит к разрушению Cas, ассоциированного с DD. Если с представляющим интерес белком сливают новый DD, его нестабильность предается представляющему интерес белку, что приводит к быстрому разрушению всего слитого белка. Пиковая активность Cas иногда выгодна для снижения нецелевых эффектов. Таким образом, короткие всплески высокой активности являются предпочтительными. Настоящее изобретение может обеспечивать такие пики. В некотором смысле система является индуцируемой. В некотором другом смысле система подвергается репрессии в отсутствие стабилизирующего лиганда и вновь активируется в присутствии стабилизирующего лиганда.
Мутации ферментов, снижающие нецелевые эффекты
В одном аспекте настоящего изобретения предусмотрен не встречающийся в природе или сконструированный фермент CRISPR, предпочтительно фермент CRISPR класса 2, предпочтительно фермент CRISPR V или VI типов, описанный в данном документе, такой как предпочтительно, но без ограничения, Cpf1, описанный в других разделах данного документа, с одной или несколькими мутациями, приводящими к сниженным нецелевым эффектам, т. е. улучшенные ферменты CRISPR для применения в осуществлении модификаций в целевом локусе, но у которых снижена или устранена активность в отношении нецелевых локусов, как, например, будучи в комплексе с направляющими РНК, а также улучшенные ферменты CRISPR для повышения активность ферментов CRISPR, как, например, будучи в комплексе с направляющими РНК. Следует понимать, что мутированные ферменты, описываемые в данном документе ниже, можно применять в любом из способов в соответствии с настоящим изобретением, как описано в других разделах данного документа. Любые из способов, продуктов, композиций и вариантов применения, описываемых в других разделах данного документа, равным образом применимы в случае мутированных ферментов CRISPR, как дополнительно подробно описанного ниже. Следует понимать, что в аспектах и вариантах осуществления, описываемых в данном документе, при ссылке или включении Cpf1 в качестве фермента CRISPR, для восстановления функциональной системы CRISPR-Cas предпочтительно не требуется tracr-последовательность или система не зависит от нее, и/или прямой повтор расположен в направлении 5' (выше) от направляющей (целевой или спейсерной) последовательности.
С целью дополнительного руководства приводятся следующие конкретные аспекты и варианты осуществления.
Авторы настоящего изобретения неожиданно установили, что можно проводить модификации ферментов CRISPR, что обеспечивает сниженную нецелевую активность по сравнению с немодифицированными ферментами CRISPR и/или повышенную целевую активность по сравнению с немодифицированными ферментами CRISPR. Таким образом, в определенных аспектах настоящего изобретения в данном документе предусмотрены улучшенные ферменты CRISPR, которые можно применять в целом ряде применений, связанных с модификациями генов. Также в данном документе предусмотрены комплексы, композиции и системы CRISPR, а также способы и варианты применения, все из которых предусматривают модифицированные ферменты CRISPR, раскрытые в данном документе.
В настоящем изобретении термин "Cas" может означать "Cpf1" или фермент CRISPR. В контексте настоящего изобретения Cpf1 или фермент CRISPR является мутированным или модифицированным, "в результате чего фермент в комплексе CRISPR характеризуется сниженной способностью модифицировать один или несколько нецелевых локусов по сравнению с немодифицированным ферментом" (или подобные выражения); и при чтении настоящего описания подразумевается, что термины "Cpf1", или "Cas", или "фермент CRISPR и т. д. включают мутированный или модифицированный Cpf1, или Cas, или фермент CRISPR в соответствии с настоящим изобретением, т. e."в результате этого фермент в комплексе CRISPR характеризуется сниженной способностью модифицировать один или несколько нецелевых локусов по сравнению с немодифицированным ферментом" (или подобные выражения).
В одном аспекте предусмотрен сконструированный белок Cpf1, определяемый в данном документе, такой как Cpf1, где белок объединяется в комплекс с молекулой нуклеиновой кислоты, предусматривающей РНК, с образованием комплекса CRISPR, при этом находясь в комплексе CRISPR, молекула нуклеиновой кислоты нацеливается на один или несколько целевых полинуклеотидных локусов, причем белок содержит по меньшей мере одну модификацию по сравнению с немодифицированным Cpf1, и где комплекс CRISPR, содержащий модифицированный белок, характеризуется измененной активностью в сравнении с комплексом, содержащим немодифицированный белок Cpf1. Следует понимать, что при ссылке в данном документе на "белок" CRISPR, белок Cpf1 предпочтительно представляет собой модифицированный фермент CRISPR (например, с повышенной или сниженной (или отсутствующей) ферментативной активностью), как, например, без ограничения включающий Cpf1. Термин "белок CRISPR" может использоваться взаимозаменяемо с "фермент CRISPR", независимо от того, был ли белок CRISPR изменен, как, например, характеризуется повышенной или сниженной (или отсутствующей) ферментативной активностью по сравнению с белком CRISPR дикого типа.
В одном аспекте измененная активность сконструированного белка CRISPR предусматривает измененное свойство связывания в отношении молекулы нуклеиновой кислоты, предусматривающей РНК, или целевых полинуклеотидных локусов, измененную кинетику связывания в отношении молекулы нуклеиновой кислоты, предусматривающей РНК, или целевых полинуклеотидных локусов, или измененную специфичность связывания в отношении молекулы нуклеиновой кислоты, предусматривающей РНК, или целевых полинуклеотидных локусов в сравнении с нецелевыми полинуклеотидными локусами.
В некоторых вариантах осуществления немодифицированный Cas характеризуется активностью расщепления ДНК, подобно Cpf1. В некоторых вариантах осуществления Cas управляет расщеплением одной или обеих нитей в определенном положении целевой последовательности, как, например, в пределах целевой последовательности и/или в пределах последовательности, комплементарной целевой последовательности. В некоторых вариантах осуществления Cas управляет расщеплением одной или обеих нитей в пределах приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 50, 100, 200, 500 или более пар оснований от первого или последнего нуклеотида целевой последовательности. В некоторых вариантах осуществления вектор кодирует Cas, который является мутированным по сравнению с соответствующим ферментом дикого типа, так что мутированный Cas не обладает способностью расщеплять одну или обе нити целевого полинуклеотида, содержащего целевую последовательность. В некоторых вариантах осуществления считается, что у фермента Cas практически полностью отсутствует активность расщепления ДНК, если активность расщепления ДНК у мутированного фермента составляет не более чем приблизительно 25%, 10%, 5%, 1%, 0,1%, 0,01% или меньше относительно активности расщепления ДНК у немутированной формы фермента; примером может служить случай, когда активность расщепления ДНК у мутированной формы отсутствует или несущественна по сравнению с немутированной формой. Таким образом, Cas может содержать одну или несколько мутаций и может применяться в качестве универсального ДНК-связывающего белка, слитого или не слитого с функциональным доменом. Мутации могут представлять собой мутации, введенные искусственным образом, или мутации приобретения или потери функции. В одном аспекте настоящего изобретения фермент Cas может быть слит с белком, например TAG, и/или индуцируемым/контролируемым доменом, таким как химически индуцируемый/контролируемый домен. В настоящем изобретении Cas может представлять собой химерные белки Cas, например, Cas, характеризующийся усиленной функцией ввиду того, что он является химерой. Химерные белки Cas могут представлять собой новые Cas, содержащие фрагменты из более чем одного встречающегося в природе Cas. Они могут содержать продукты слияния N-концевого(концевых) фрагмента(фрагментов) одного гомолога Cas9 с C-концевым(концевыми) фрагментом(фрагментами) другого гомолога Cas. Cas может доставляться в клетку в форме мРНК. Экспрессия Cas может находиться под контролем индуцируемого промотора. Очевидно, что цель настоящего изобретения заключается в том, чтобы не охватывать известные мутации. Действительно, фраза "в результате чего фермент в комплексе CRISPR характеризуется сниженной способностью модифицировать один или несколько нецелевых локусов по сравнению немодифицированным ферментом, и/или в результате чего фермент в комплексе CRISPR характеризуется повышенной способностью модифицировать один или несколько целевых локусов по сравнению с немодифицированным ферментом" (или подобная в отношении экспрессии) не подразумевает охват мутаций, которые приводят только к никазе или нефункциональному Cas, или известных мутаций Cas9. ОДНАКО, это не означает, что модификацию(модификации) или мутацию(мутации) по настоящему изобретению "в результате которых фермент в комплексе CRISPR характеризуется сниженной способностью модифицировать один или несколько нецелевых локусов по сравнению с немодифицированным ферментом, и/или в результате которых фермент в комплексе CRISPR характеризуется повышенной способностью модифицировать один или несколько целевых локусов по сравнению с немодифицированным ферментом" (или подобные выражения) нельзя комбинировать с мутациями, которые приводят к тому, что фермент является никазой или он является нефункциональным. Такой нефункциональный фермент может представлять собой улучшенное средство, связывающее молекулу нуклеиновой кислоты. И такая никаза может представлять собой улучшенную никазу. Например, изменение нейтральной(нейтральных) аминокислоты(аминокислот) в бороздке и/или возле нее, и/или других заряженных остатков в других определенных положениях в Cas, которые находятся в непосредственной близости от нуклеиновой кислоты (например, ДНК, cDNA, РНК, gRNA), на положительно заряженную(заряженные) аминокислоту(аминокислоты) может приводить к следующему "в результате чего фермент в комплексе CRISPR характеризуется сниженной способность модифицировать один или несколько нецелевых локусов по сравнению с немодифицированным ферментом и/или в результате чего фермент в комплексе CRISPR характеризуется повышенной способностью модифицировать один или несколько целевые локусов по сравнению с немодифицированным ферментом", например, к большему числу разрезов. Поскольку это могут быть как усиленные целевые, так и нецелевые разрезы (сверхрежущий Cpf1), применение такого фермента с тем, что известно из уровня техники как усеченная направляющая или усеченные sgRNA (см., например, Fu et al., "Improving CRISPR-Cas nuclease specificity using truncated guide RNAs", Nature Biotechnology 32, 279-284 (2014) doi:10.1038/nbt.2808, получен 17 ноября 2013 года, принят 06 января 2014 года, опубликован онлайн 26 января 2014 года, исправлен онлайн 29 января 2014 года), для обеспечения усиленной целевой активности без повышения числа нецелевых разрезов, или для получения сверхрежущих никаз, или для комбинирования с мутацией, которая обеспечивает нефункциональный Cas для сверхсвязывающего средства.
В определенных вариантах осуществления измененная активность сконструированного белка Cpf1 предусматривает повышенную эффективность нацеливания или сниженное нецелевое связывание. В определенных вариантах осуществления измененная активность сконструированного белка Cpf1 предусматривает модифицированную активность расщепления.
В определенных вариантах осуществления измененная активность предусматривает измененное свойство связывания в отношении молекулы нуклеиновой кислоты, предусматривающей РНК, или целевых полинуклеотидных локусов, измененную кинетику связывания в отношении молекулы нуклеиновой кислоты, предусматривающей РНК, или целевых полинуклеотидных локусов, или измененную специфичность связывания в отношении молекулы нуклеиновой кислоты, предусматривающей РНК, или целевых полинуклеотидных локусов в сравнении с нецелевыми полинуклеотидными локусами.
В определенных вариантах осуществления измененная активность предусматривает повышенную эффективность нацеливания или сниженное нецелевое связывание. В определенных вариантах осуществления измененная активность предусматривает модифицированную активность расщепления. В определенных вариантах осуществления измененная активность предусматривает повышенную активность расщепления в отношении целевых полинуклеотидных локусов. В определенных вариантах осуществления измененная активность предусматривает сниженную активность расщепления в отношении целевых полинуклеотидных локусов. В определенных вариантах осуществления измененная активность предусматривает сниженную активность расщепления в отношении нецелевых полинуклеотидных локусов. В определенных вариантах осуществления измененная активность предусматривает повышенную активность расщепления в отношении нецелевых полинуклеотидных локусов.
Соответственно, в определенных вариантах осуществления наблюдается повышенная специфичность в отношении целевых полинуклеотидных локусов по сравнению с нецелевыми полинуклеотидными локусами. В других вариантах осуществления наблюдается сниженная специфичность в отношении целевых полинуклеотидных локусов по сравнению с нецелевыми полинуклеотидными локусами.
В одном аспекте настоящего изобретения измененная активность сконструированного белка Cpf1 предусматривает измененную кинетику хеликазы.
В одном аспекте настоящего изобретения сконструированный белок Cpf1 содержит модификацию, которая изменяет связывание белка с молекулой нуклеиновой кислоты, предусматривающей РНК, или нитью, содержащей целевые полинуклеотидные локусы, или нитью, содержащей нецелевые полинуклеотидные локусы. В одном аспекте настоящего изобретения сконструированный белок Cpf1 содержит модификацию, которая изменяет образование комплекса CRISPR.
В определенных вариантах осуществления модифицированный белок Cpf1 содержит модификацию, которая изменяет нацеливание молекулы нуклеиновой кислоты на полинуклеотидный локус. В определенных вариантах осуществления модификация предусматривает мутацию в участке белка, который связывается с молекулой нуклеиновой кислоты. В определенных вариантах осуществления модификация предусматривает мутацию в участке белка, который связывается с нитью целевого полинуклеотидного локуса. В определенных вариантах осуществления модификация предусматривает мутацию в участке белка, который связывается с нитью нецелевого полинуклеотидного локуса. В определенных вариантах осуществления модификация или мутация предусматривают сниженный положительный заряд в участке белка, который связывается с молекулой нуклеиновой кислоты, предусматривающей РНК, или нитью целевого полинуклеотидного локуса, или нитью нецелевого полинуклеотидного локуса. В определенных вариантах осуществления модификация или мутация предусматривают сниженный отрицательный заряд в участке белка, который связывается с молекулой нуклеиновой кислоты, предусматривающей РНК, или нитью целевого полинуклеотидного локуса, или нитью нецелевого полинуклеотидного локуса. В определенных вариантах осуществления модификация или мутация предусматривают повышенный положительный заряд в участке белка, который связывается с молекулой нуклеиновой кислоты, предусматривающей РНК, или нитью целевого полинуклеотидного локуса, или нитью нецелевого полинуклеотидного локуса. В определенных вариантах осуществления модификация или мутация предусматривают повышенный отрицательный заряд в участке белка, который связывается с молекулой нуклеиновой кислоты, предусматривающей РНК, или нитью целевого полинуклеотидного локуса, или нитью нецелевого полинуклеотидного локуса. В определенных вариантах осуществления модификация или мутация повышают стерическое несоответствие между белком и молекулой нуклеиновой кислоты, предусматривающей РНК, или нитью целевого полинуклеотидного локуса, или нитью целевого полинуклеотидного локуса. В определенных вариантах осуществления модификация или мутация предусматривают замену Lys, His, Arg, Glu, Asp, Ser, Gly или Thr. В определенных вариантах осуществления модификация или мутация предусматривают замену на Gly, Ala, Ile, Glu или Asp. В определенных вариантах осуществления модификация или мутация предусматривают аминокислотную замену в связывающей бороздке.
В одном аспекте настоящего изобретения предусмотрен:
не встречающийся в природе фермент CRISPR, определяемый в данном документе, такой как Cpf1, где
фермент объединяется в комплекс с направляющей РНК с образованием комплекса CRISPR,
при этом находясь в комплексе CRISPR, направляющая РНК нацеливается на один или несколько целевых полинуклеотидных локусов, и фермент изменяет полинуклеотидные локусы, и
фермент содержит по меньшей мере одну модификацию,
в результате чего фермент в комплексе CRISPR характеризуется сниженной способностью модифицировать один или несколько нецелевых локусов по сравнению с немодифицированным ферментом, и/или в результате чего фермент в комплексе CRISPR характеризуется повышенной способностью модифицировать один или несколько целевых локусов по сравнению с немодифицированным ферментом.
В любом таком не встречающемся в природе ферменте CRISPR модификация может предусматривать модификацию одного или нескольких аминокислотных остатков фермента.
В любом таком не встречающемся в природе ферменте CRISPR модификация может предусматривать модификацию одного или нескольких аминокислотных остатков, расположенных в участке, который содержит остатки, которые являются положительно заряженными в немодифицированном ферменте.
В любом таком не встречающемся в природе ферменте CRISPR модификация может предусматривать модификацию одного или нескольких аминокислотных остатков, которые являются положительно заряженными в немодифицированном ферменте.
В любом таком не встречающемся в природе ферменте CRISPR модификация может предусматривать модификацию одного или нескольких аминокислотных остатков, которые не являются положительно заряженными в немодифицированном ферменте.
Модификация может предусматривать модификацию одного или нескольких аминокислотных остатков, которые являются незаряженными в немодифицированном ферменте.
Модификация может предусматривать модификацию одного или нескольких аминокислотных остатков, которые являются отрицательно заряженными в немодифицированном ферменте.
Модификация может предусматривать модификацию одного или нескольких аминокислотных остатков, которые являются гидрофобными в немодифицированном ферменте.
Модификация может предусматривать модификацию одного или нескольких аминокислотных остатков, которые являются полярными в немодифицированном ферменте.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR модификация может предусматривать модификацию одного или нескольких остатков, расположенных в бороздке.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR модификация может предусматривать модификацию одного или нескольких остатков, расположенных за пределами бороздки.
В случае некоторых из описанных выше не встречающихся в природе ферментов CRISPR модификация предусматривает модификацию одного или нескольких остатков, где один или несколько остатков предусматривают аргинин, гистидин или лизин.
В случае любого из описанных выше не встречающихся в природе ферментов CRISPR фермент может быть модифицирован с помощью мутации указанного одного или нескольких остатков.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на аланиновый остаток.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на аспарагиновую кислоту или глутаминовую кислоту.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на серин, треонин, аспарагин или глутамин.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на аланин, глицин, изолейцин, лейцин, метионин, фенилаланин, триптофан, тирозин или валин.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на полярный аминокислотный остаток.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на аминокислотный остаток, который не является полярным аминокислотным остатком.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на отрицательно заряженный аминокислотный остаток.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на аминокислотный остаток, который не является отрицательно заряженным аминокислотным остатком.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на незаряженный аминокислотный остаток.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на аминокислотный остаток, который не является незаряженным аминокислотным остатком.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на гидрофобный аминокислотный остаток.
В случае определенных из описанных выше не встречающихся в природе ферментов CRISPR фермент модифицирован с помощью мутации указанного одного или нескольких остатков, и при этом мутация предусматривает замену остатка в немодифицированном ферменте на аминокислотный остаток, который не является гидрофобным аминокислотным остатком.
В некоторых вариантах осуществления фермент CRISPR, такой как предпочтительно фермент Cpf1, получен из Cpf1 Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacteriu GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens или Porphyromonas macacae (например, Cpf1 одного из этих организмов, модифицированного, как описано в данном документе), и он может включать дополнительные мутации или изменения или может быть химерным Cpf1.
В определенных вариантах осуществления белок Cpf1 содержит один или несколько доменов, представляющих собой сигнал ядерной локализации (NLS). В определенных вариантах осуществления белок Cpf1 содержит по меньшей мере два или более NLS.
В определенных вариантах осуществления белок Cpf1 предусматривает химерный белок CRISPR, содержащий первый фрагмент от первого ортолога CRISPR и второй фрагмент от второго ортолога CIRSPR, и при этом первый и второй ортологи CRISPR являются различными.
В определенных вариантах осуществления фермент является модифицированным или содержит модификацию, например, содержит, состоит, по сути, из или состоит из модификации с помощью мутации любого из остатков, перечисленных в данном документе, или соответствующего остатка в соответственном ортологе; или фермент содержит, состоит, по сути, из или состоит из модификации в любом одном (одиночная), двух (двойная), трех (тройная), четырех (четверная) или большем числе положений в соответствии с раскрытием на протяжении всей настоящей заявки, или соответствующем остатке или положении в ортологе фермента CRISPR, например, фермент содержит, состоит, по сути, из или состоит из модификации в любом из остатков Cpf1, процитированных в данном документе, или соответствующем остатке или положении в ортологе фермента CRISPR. В таком ферменте каждый остаток может быть модифицирован с помощью замены на аланиновый остаток.
Заявители недавно описали способ получения ортологов Cas9 с усиленной специфичностью (Slaymaker et al. 2015 "Rationally engineered Cas9 nucleases with improved specificity"). Данную стратегию можно применять для усиления специфичности ортологов Cpf1. Основными остатками для проведения мутагенеза предпочтительно являются все положительно заряженные остатки в пределах домена RuvC. Дополнительные остатки представляют собой положительно заряженные остатки, которые являются консервативными у различных ортологов.
В определенных вариантах осуществления специфичность Cpf1 может быть улучшена путем мутирования остатков, которые стабилизируют не подвергаемую нацеливанию нить ДНК.
В случае определенных описанных выше не встречающихся в природе ферментов Cpf1 фермент модифицируют с помощью мутации одного или нескольких остатков (в домене RuvC), включая без ограничения положения R909, R912, R930, R947, K949, R951, R955, K965, K968, K1000, K1002, R1003, K1009, K1017, K1022, K1029, K1035, K1054, K1072, K1086, R1094, K1095, K1109, K1118, K1142, K1150, K1158, K1159, R1220, R1226, R1242, и/или R1252 в соответствии с нумерацией аминокислотных положений AsCpf1 (Acidaminococcus sp. BV3L6).
В случае определенных описанных выше не встречающихся в природе ферментов Cpf1 фермент модифицируют с помощью мутации одного или нескольких остатков (в домене RAD50), включая без ограничения положения K324, K335, K337, R331, K369, K370, R386, R392, R393, K400, K404, K406, K408, K414, K429, K436, K438, K459, K460, K464, R670, K675, R681, K686, K689, R699, K705, R725, K729, K739, K748 и/или K752 в соответствии с нумерацией аминокислотных положений AsCpf1 (Acidaminococcus sp. BV3L6).
В случае определенных описанных выше не встречающихся в природе ферментов Cpf1 фермент модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения R912, T923, R947, K949, R951, R955, K965, K968, K1000, R1003, K1009, K1017, K1022, K1029, K1072, K1086, F1103, R1226 и/или R1252 в соответствии с нумерацией аминокислотных положений AsCpf1 (Acidaminococcus sp. BV3L6).
В определенных вариантах осуществления фермент модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения R833, R836, K847, K879, K881, R883, R887, K897, K900, K932, R935, K940, K948, K953, K960, K984, K1003, K1017, R1033, R1138, R1165 и/или R1252 в соответствии с нумерацией аминокислотных положений LbCpf1 (Lachnospiraceae bacterium ND2006).
В определенных вариантах осуществления фермент Cpf1 модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения K15, R18, K26, Q34, R43, K48, K51, R56, R84, K85, K87, N93, R103, N104, T118, K123, K134, R176, K177, R192, K200, K226, K273, K275, T291, R301, K307, K369, S404, V409, K414, K436, K438, K468, D482, K516, R518, K524, K530, K532, K548, K559, K570, R574, K592, D596, K603, K607, K613, C647, R681, K686, H720, K739, K748, K757, T766, K780, R790, P791, K796, K809, K815, T816, K860, R862, R863, K868, K897, R909, R912, T923, R947, K949, R951, R955, K965, K968, K1000, R1003, K1009, K1017, K1022, K1029, A1053, K1072, K1086, F1103, S1209, R1226, R1252, K1273, K1282, и/или K1288 в соответствии с нумерацией аминокислотных положений AsCpf1 (Acidaminococcus sp. BV3L6).
В определенных вариантах осуществления фермент Cpf1 модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения K15, R18, K26, R34, R43, K48, K51, K56, K87, K88, D90, K96, K106, K107, K120, Q125, K143, R186, K187, R202, K210, K235, K296, K298, K314, K320, K326, K397, K444, K449, E454, A483, E491, K527, K541, K581, R583, K589, K595, K597, K613, K624, K635, K639, K656, K660, K667, K671, K677, K719, K725, K730, K763, K782, K791, R800, K809, K823, R833, K834, K839, K852, K858, K859, K869, K871, R872, K877, K905, R918, R921, K932, I960, K962, R964, R968, K978, K981, K1013, R1016, K1021, K1029, K1034, K1041, K1065, K1084, и/или K1098 в соответствии с нумерацией аминокислотных положений FnCpf1 (Francisella novicida U112).
В определенных вариантах осуществления фермент Cpf1 модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения K15, R18, K26, K34, R43, K48, K51, R56, K83, K84, R86, K92, R102, K103, K116, K121, R158, E159, R174, R182, K206, K251, K253, K269, K271, K278, P342, K380, R385, K390, K415, K421, K457, K471, A506, R508, K514, K520, K522, K538, Y548, K560, K564, K580, K584, K591, K595, K601, K634, K640, R645, K679, K689, K707, T716, K725, R737, R747, R748, K753, K768, K774, K775, K785, K787, R788, Q793, K821, R833, R836, K847, K879, K881, R883, R887, K897, K900, K932, R935, K940, K948, K953, K960, K984, K1003, K1017, R1033, K1121, R1138, R1165, K1190, K1199, и/или K1208 в соответствии с нумерацией аминокислотных положений LbCpf1 (Lachnospiraceae bacterium ND2006).
В определенных вариантах осуществления фермент модифицируют с помощью мутации одного или нескольких остатков, включая без ограничения положения K14, R17, R25, K33, M42, Q47, K50, D55, K85, N86, K88, K94, R104, K105, K118, K123, K131, R174, K175, R190, R198, I221, K267, Q269, K285, K291, K297, K357, K403, K409, K414, K448, K460, K501, K515, K550, R552, K558, K564, K566, K582, K593, K604, K608, K623, K627, K633, K637, E643, K780, Y787, K792, K830, Q846, K858, K867, K876, K890, R900, K901, M906, K921, K927, K928, K937, K939, R940, K945, Q975, R987, R990, K1001, R1034, I1036, R1038, R1042, K1052, K1055, K1087, R1090, K1095, N1103, K1108, K1115, K1139, K1158, R1172, K1188, K1276, R1293, A1319, K1340, K1349, и/или K1356 в соответствии с нумерацией аминокислотных положений MbCpf1 (Moraxella bovoculi 237).
В любом из не встречающихся в природе ферментов CRISPR:
одиночное несовпадение может находиться между целевой и соответствующей последовательностью одного или нескольких нецелевых локусов; и/или
два, три или четыре или более несовпадений могут находиться между целевой и соответствующей последовательностью одного или нескольких нецелевых локусов, и/или
где (ii) указанные два, три или четыре или более несовпадения являются смежными.
В случае любого из не встречающихся в природе ферментов CRISPR фермент в комплексе CRISPR может характеризоваться сниженной способностью модифицировать один или несколько нецелевых локусов по сравнению с немодифицированным ферментом, и при этом фермент в комплексе CRISPR характеризуется повышенной способностью модифицировать указанные целевые локусы по сравнению с немодифицированным ферментом.
В случае любого из не встречающихся в природе ферментов CRISPR, когда он находится в комплексе CRISPR, относительная разница модифицирующей способности фермента в отношении целевого и по меньшей мере одного нецелевого локуса может быть увеличена по сравнению с относительной разницей для немодифицированного фермента.
В случае любого из не встречающихся в природе ферментов CRISPR фермент CRISPR может содержать одну или несколько дополнительный мутаций, где одна или несколько дополнительных мутаций находятся в одном или нескольких каталитически активных доменах.
В случае таких не встречающихся в природе ферментов CRISPR фермент CRISPR может характеризоваться сниженной или отмененной нуклеазной активностью в сравнении с ферментом, у которого отсутствует указанная одна или несколько дополнительных мутаций.
В случае некоторых таких не встречающихся в природе ферментов CRISPR фермент CRISPR не управляет расщеплением одной или другой нити ДНК в определенном положении целевой последовательности.
Если фермент CRISPR содержит одну или несколько дополнительных мутаций в одном или нескольких каталитически активных доменах, одна или несколько дополнительных мутаций может находиться в каталитически активном домене фермента CRISPR, содержащего RuvCI, RuvCII или RuvCIII.
Без ограничения теорией, в одном аспекте настоящего изобретения описаны способы и мутации, предусмотренные для улучшения конформационной перегруппировки доменов в ферменте CRISPR (например, доменов Cpf1) в положения, которые обеспечивают расщепление в целевых сайтах, и избегание таких конформационных состояний в случае нецелевых сайтов. Ферменты CRISPR расщепляют целевую ДНК с помощью целого ряда координированных стадий. Вначале PAM-взаимодействующий домен распознает последовательность PAM на 5'-конце целевой ДНК. После связывания PAM первые 10-12 нуклеотидов целевой последовательности (затравочная последовательность) проверяют на комплементарность gRNA:ДНК, причем данный процесс обусловлен разделением ДНК-дуплекса. Если нуклеотиды затравочной последовательности комплементарны gRNA остальная часть ДНК расплетается и полноразмерная gRNA гибридизируется с целевой нитью ДНК. nt-борозки могут стабилизировать не подвергаемую нацеливанию нить ДНК и облегчать раскручивание благодаря неспецифическим взаимодействиям с положительными зарядами фосфатного остова ДНК. Взаимодействия РНК:cDNA и фермент CRISPR:ncDNA управляют раскручиванием ДНК, конкурирующим с повторной гибридизацией cDNA:ncDNA. Другие домены фермента CRISPR могут воздействовать на конформацию нуклеазных доменов, также как, например, линкеры, соединяющие различные домены. Соответственно, предусмотренные способы и мутации охватывают без ограничения RuvCI, RuvCIII, RuvCIII и линкеры. Конформационные изменения, например, в Cpf1, вызванные связыванием целевой ДНК, включая взаимодействия с затравочной последовательностью и взаимодействия с целевой и не подвергаемой нацеливанию нитью ДНК, определяют будут ли домены расположены так, чтобы запустить нуклеазную активность. Таким образом, мутации и способы, предусмотренные в данном документе, демонстрируют и обеспечивают модификации, которые выходят за пределы распознавания PAM и образования пар оснований между РНК-ДНК.
В одном аспекте настоящего изобретения предусмотрены нуклеазы CRISPR, определяемые в данном документе, такие как Cpf1, которые предусматривают улучшенное равновесие, смещенное в направлении конформаций, ассоциированных с активностью расщепления, при вовлечении в целевые взаимодействия, и/или улучшенное равновесие, смещенное в обратную сторону от конформаций, ассоциированных с активностью расщепления, при вовлечении в нецелевые взаимодействия. В одном аспекте настоящего изобретения предусмотрены нуклеазы Cas (например, Cpf1) с улучшенной функцией редактирования, т. е. нуклеаза Cas (например, Cpf1), которая принимает конформацию, обеспечивающую нуклеазную активность в отношении целевого сайта, и при этом такая конформация характеризуется повышенной невыгодностью в отношении нецелевого сайта. Sternberg et al., Nature 527(7576):110-3, doi: 10.1038/nature15544, опубликована онлайн 28 октября 2015 года; электронная публикация 28 октября 2015 года, применяли эксперименты по Ферстеровским резонансным переносом энергии (FRET) для обнаружения относительной ориентации каталитических доменов Cas (например, Cpf1) при связывании с целевой и нецелевой ДНК, и которые можно экстраполировать на ферменты CRISPR по настоящему изобретению (например, Cpf1).
В настоящем изобретении также предусмотрены способы и мутации для модулирования нуклеазной активности и/или специфичности с применением модифицированных направляющих РНК. Как уже обсуждалось, целевая нуклеазная активность может быть повышенной или сниженной. Также, нецелевая нуклеазная активность может быть повышенной или сниженной. Кроме того, может быть повышена или снижена специфичность в отношении целевой активности в сравнении с нецелевой активностью. Модифицированные направляющие РНК включают без ограничения усеченные направляющие РНК, нефункциональные направляющие РНК, химически модифицированные направляющие РНК, направляющие РНК, ассоциированные с функциональными доменами, модифицированные направляющие РНК, содержащие функциональные домены, модифицированные направляющие РНК, содержащие аптамеры, модифицированные направляющие РНК, содержащие адапторные белки, и направляющие РНК, содержащие добавленные или модифицированные петли. В некоторых вариантах осуществления один или несколько функциональных доменов связываются с нефункциональными gRNA (dRNA). В некоторых вариантах осуществления комплекс dRNA с ферментом CRISPR управляет регуляцией гена с помощью функционального домена в локусе гена, тогда как gRNA управляет расщеплением гена с помощью фермента CRISPR в другом локусе. В некоторых вариантах осуществления dRNA отбирают для обеспечения максимальной селективности регуляции для представляющего интерес генного локуса по сравнению с нецелевой регуляцией. В некоторых вариантах осуществления dRNA отбирают для обеспечения максимальной регуляции целевого гена и минимального целевого расщепления.
Для целей следующего обсуждения эталоном функционального домена может быть функциональный домен, ассоциированный с ферментом CRISPR, или функциональный домен, ассоциированный с адаптерным белком.
При осуществлении настоящего изобретения на практике петли в gRNA могут быть увеличены без перекрывания с белком Cas (например, Cpf1) путем вставки отличающейся(отличающихся) петли(петель) РНК или отличающейся(отличающихся) последовательности(последовательностей), которая(которые) могут рекрутировать адаптерные белки, которые могут связываться с отличающейся(отличающимися) петлей(петлями) РНК или отличающейся(отличающимися) последовательностью(последовательностями). Адаптерные белки могут включать без ограничения комбинации ортогональный связывающий РНК белок/аптамер, которые встречаются во множестве белков оболочки бактериофагов. Перечень таких белков оболочки включает без ограничения Qβ, F2, GA, fr, JP501, M12, R17, BZ13, JP34, JP500, KU1, M11, MX1, TW18, VK, SP, FI, ID2, NL95, TW19, AP205, φCb5, φCb8r, φCb12r, φCb23r, 7s и PRR1. Такие адаптерные белки или ортогональные связывающие РНК белки могут дополнительно ректурировать эффекторные белки или продукты слияния, которые содержат один или несколько функциональных доменов. В некоторых вариантах осуществления функциональный домен может быть выбран из группы, состоящей из домена транспозазы, домена интегразы, домена рекомбиназы, домена резольвазы, домена инвертазы, домена протеазы, домена ДНК-метилтрансферазы, домена ДНК-гидроксилметилазы, домена ДНК-деметилазы, домена гистонацетилазы, домена гистондеацетилазы, нуклеазного домена, репрессорного домена, активаторного домена, доменов сигнала ядерной локализации, домена регуляторного белка транскрипции (или вовлечения транскрипционного комплекса), ассоциированного с активностью клеточного поглощения домена, домена связывания нуклеиновой кислоты, домена представления антитела, модифицирующих гистоны ферментов, рекрутера модифицирующих гистоны ферментов; ингибитора модифицирующих гистоны ферментов, гистонметилтрансферазы, гистондеметилазы, гистонкиназы, гистонфосфатазы, гистонрибозилазы, гистондерибозилазы, гистонубиквитиназы, гистондеубиквитиназы, гистонбиотиназы и протеазы гистонового хвоста. В некоторых предпочтительных вариантах осуществления функциональным доменом является домен активации транскрипции, такой как без ограничения VP64, p65, MyoD1, HSF1, RTA, SET7/9 или гистонацетилтрансфераза. В некоторых вариантах осуществления функциональный домен представляет собой домен репрессии транскрипции, предпочтительно KRAB. В некоторых вариантах осуществления домен репрессии транскрипции представляет собой SID или конкатемеры SID (например, SID4X). В некоторых вариантах осуществления функциональный домен представляет собой домен эпигенетического модифицирования, так что обеспечивается фермент эпигенетического модифицирования. В некоторых вариантах осуществления функциональный домен представляет собой домен активации, который может представлять собой домен активации P65. В некоторых вариантах осуществления функциональных домен представляет собой дезаминазу, такую как цитидиндезаминазу. Цитидиндезаминаза может быть направлена на целевую нуклеиновую кислоту, туда, где она управляет превращением цитидина в уридин, что приводит в результате к заменам C на T (G на A в комплементарной нити). В таком варианте осуществления нуклеотидные замены могут быть осуществлены без расщепления ДНК.
В одном аспекте настоящего изобретения также предусмотрены способы и мутации для модулирования активности связывания и/или специфичности связывания Cas (например, Cpf1). В определенных вариантах осуществления применяют белки Cas (например, Cpf1), у которых отсутствует нуклеазная активность. В определенных вариантах осуществления используют модифицированные направляющие РНК, которые содействуют связыванию, но не нуклеазной активности нуклеазы Cas (например, Cpf1). В таких вариантах осуществления целевое связывание может быть повышенным или сниженным. Также, в таких вариантах осуществления нецелевое связывание может быть повышенным или сниженным. Более того, может быть повышена или снижена специфичность в отношении целевого связывания в сравнении с нецелевым связыванием.
В конкретных вариантах осуществления снижение нецелевого расщепления обеспечивается путем дестабилизации разделения нитей, более конкретно путем введения в фермент Cpf1 мутаций, снижающих положительный заряд в участках, взаимодействующих с ДНК (описываемых в данном документе и также приведенных в качестве примера для Cas9 в Slaymaker et al. 2016 (Science, 1;351(6268):84-8). В дополнительных вариантах осуществления снижение нецелевого расщепления обеспечивается путем введения в фермент Cpf1 мутаций, которые влияют на взаимодействие между целевой нитью и последовательностью направляющей РНК, более конкретно нарушают взаимодействия между Cpf1 и фосфатным остовом целевой нити ДНК таким образом, чтобы сохранить целевую специфическую активность, но снизить нецелевую активность (как описано для Cas9 в Kleinstiver et al. 2016, Nature, 28;529(7587):490-5). В конкретных вариантах осуществления нецелевая активность снижается за счет модифицированного Cpf1, при этом взаимодействие как c подвергаемой нацеливанию нитью, так и с не подвергаемой нацеливанию нитью является модифицированным по сравнению с Cpf1 дикого типа.
Способы и мутации, которые можно использовать в различных комбинациях для повышения или снижения активности и/или специфичности целевой в сравнении с нецелевой активностью, или повышения или снижения связывания и/или специфичности целевого в сравнении с нецелевым связыванием, можно применять, чтобы компенсировать или усилить влияние мутаций или модификаций, выполненных для содействия другим эффектам. Такие мутации или модификации, выполненные для содействия другим эффектам, включают мутации или модификацию в Cas (например, Cpf1) и/или мутацию или модификацию, выполненную в направляющей РНК. В определенных вариантах осуществления способы и мутации применяют с химически модифицированными направляющими РНК. Примеры химических модификаций направляющих РНК включают без ограничения введение 2′-O-метила (M), 2′-O-метил-3′-фосфоротиоата (MS) или 2′-O-метил-3′-тио-PACE (MSP) в один или несколько концевых нуклеотидов. Такие химически модифицированные направляющие РНК могут предусматривать повышенную стабильность и повышенную активность по сравнению с немодифицированными направляющими РНК, хотя целевая в сравнении с нецелевой специфичность не является предсказуемой. (См., Hendel, 2015, Nat Biotechnol. 33(9):985-9, doi: 10.1038/nbt.3290, опубликована онлайн 29 июня 2015 года). Химически модифицированные направляющие РНК также включают без ограничения РНК с фосфоротиоатными связями и нуклеотиды закрытых нуклеиновых кислот (LNA), содержащие метиленовый мостик между атомами углерода 2' и 4' в кольце рибозы. Способы и мутации по настоящему изобретению применяют для модулирования нуклеазной активности и/или связывания Cas (например, Cpf1) с химически модифицированными направляющими РНК.
В одном аспекте настоящего изобретения предусмотрены способы и мутации для модулирования связывания и/или специфичности связывания белков Cas (например, Cpf1) согласно настоящему изобретению, как определено в данном документе, которые содержат функциональные домены, такие как нуклеазы, активаторы транскрипции, репрессоры транскрипции и т. п. Например, можно получить белок Cas (например, Cpf1) с отсутствием нуклеазной активности или с измененной или сниженной нуклеазной активностью путем введения мутаций, таких как, например, мутации в Cpf1, описанные в других разделах данного документа, и они включают, например, D917A, E1006A, E1028A, D1227A, D1255A, N1257A, D917A, E1006A, E1028A, D1227A, D1255A и N1257A в соответствии с аминокислотными положениями в домене RuvC FnCpf1p; или, например, N580A, N584A, T587A, W609A, D610A, K613A, E614A, D616A, K624A, D625A, K627A и Y629A в соответствии с предполагаемым вторым нуклеазным доменом, описываемым в других разделах данного документа. Белки Cas (например, Cpf1), лишенные нуклеазной активности, пригодны для РНК-направляемой зависимой от целевой последовательности доставки функциональных доменов. В настоящем изобретении предусмотрены способы и мутации для модулирования связывания белков Cas (например, Cpf1). В одном варианте осуществления функциональный домен предусматривает VP64, обеспечивающий РНК-направляемый фактор транскрипции. В другом варианте осуществления функциональный домен предусматривает Fok I, обеспечивающий РНК-направляемую нуклеазную активность. Здесь следует упомянуть публикацию заявки на патент США 2014/0356959, публикацию заявки на патент США 2014/0342456, публикацию заявки на патент США 2015/0031132, и Mali, P. et al., 2013, Science 339(6121):823-6, doi: 10.1126/science.1232033, опубликованную онлайн 3 января 2013 года, и в идеях, изложенных в данном документе, настоящее изобретение подразумевает способы и материалы этих документов, применяемые в сочетании с идеями, изложенными в данном документе. В определенных вариантах осуществления целевое связывание является повышенным. В определенных вариантах осуществления нецелевое связывание является сниженным. В определенных вариантах осуществления целевое связывание является сниженным. В определенных вариантах осуществления нецелевое связывание является повышенным. Соответственно, в настоящем изобретении также предусмотрено повышение или снижение специфичности целевого связывания в сравнении с нецелевым связыванием у функционализированных связывающих белков Cas (например, Cpf1).
Применение Cas (например, Cpf1) в качестве РНК-направляемого связывающего белка не ограничивается Cas (например, Cpf1) с отсутствием нуклеазной активности. Ферменты Cas (например, Cpf1), имеющие нуклеазную активность, также могут функционировать как РНК-направляемые связывающие белки при применении с определенными направляющими РНК. Например, короткие направляющие РНК и направляющие РНК, содержащие нуклеотиды, не совпадающие с мишенью, могут содействовать управляемому РНК связыванию Cas (например, Cpf1) с целевой последовательностью с небольшим расщеплением мишени или его отсутствием. (См., например, Dahlman, 2015, Nat Biotechnol. 33(11):1159-1161, doi: 10.1038/nbt.3390, опубликованный онлайн 05 октября 2015 года). В одном аспекте настоящего изобретения предусмотрены способы и мутации для модулирования связывания белков Cas (например, Cpf1), которые имеют нуклеазную активность. В определенных вариантах осуществления целевое связывание является повышенным. В определенных вариантах осуществления нецелевое связывание является сниженным. В определенных вариантах осуществления целевое связывание является сниженным. В определенных вариантах осуществления нецелевое связывание является повышенным. В определенных вариантах осуществления имеется повышенная или сниженная специфичность целевого связывания в сравнении с нецелевым связыванием. В определенных вариантах осуществления нуклеазная активность направляющей РНК-фермента Cas (например, Cpf1) также модулирована.
Для активности и специфичности расщепления является важным образование гетеродуплекса РНК-ДНК на протяжении всего целевого участка, а не только участка затравочной последовательности, ближайшего к PAM. Так, усеченные направляющие РНК проявляют сниженную активность и специфичность расщепления. В одном аспекте настоящего изобретения предусмотрены способ и мутации для повышения активности и специфичности расщепления с применением измененных направляющих РНК.
В настоящем изобретении также продемонстрировано, что модификации специфичности нуклеазы Cas (например, Cpf1) могут быть выполнены в сочетании с модификациями в отношении диапазона нацеливания. Могут быть разработаны мутанты Cas (например, Cpf1), которые характеризуются повышенной специфичностью в отношении мишени, а также имеют модификации, обеспечивающие распознавание PAM, например, путем выбора мутаций, который изменяют специфичность в отношении PAM и комбинирования этих мутаций с мутациями nt-бороздки, которые повышают (или, в случае необходимости, снижают) специфичность в отношении целевых последовательностей в сравнении с нецелевыми последовательностями. В одном таком варианте осуществления остаток домена PI подвергают мутированию для обеспечения распознавания требуемой последовательности PAM, при этом одну или несколько аминокислот nt-бороздки подвергают мутированию для изменения специфичности в отношении мишени. Способы и модификации Cas (например, Cpf1), описанные в данном документе, можно применять для противодействия потере специфичности, происходящей в результате изменения распознавания PAM, усиления возрастания специфичности, происходящего в результате изменения распознавания PAM, противодействия возрастанию специфичности, происходящему в результате изменения распознавания PAM, или усиления потери специфичности, происходящей в результате изменения распознавания PAM.
Способы и мутации можно применять в отношении любого фермента Cas (например, Cpf1) с измененным распознаванием PAM. Неограничивающими примерами включаемых PAM являются описанные в других разделах данного документа.
В дополнительных вариантах осуществления способов и мутаций применяют модифицированные белки.
В случае любого из не встречающихся в природе ферментов CRISPR фермент CRISPR может содержать один или несколько гетерологичных функциональных доменов.
Один или несколько гетерологичных функциональных доменов могут предусматривать один или несколько доменов, представляющих собой сигнал ядерной локализации (NLS). Один или несколько гетерологичных функциональных доменов могут предусматривать по меньшей мере два или более NLS.
Один или несколько гетерологичных функциональных доменов могут предусматривать один или несколько доменов активации транскрипции. Домен активации транскрипции может предусматривать VP64.
Один или несколько гетерологичных функциональных доменов могут предусматривать один или несколько доменов репрессии транскрипции. Домен репрессии транскрипции может предусматривать домен KRAB или домен SID.
Один или несколько гетерологичных функциональных доменов могут предусматривать один или несколько нуклеазных доменов. Один или несколько нуклеазных доменов могут предусматривать Fok1.
Один или несколько гетерологичных функциональных доменов могут характеризоваться одной или несколькими из следующих видов активности: метилазной активностью, деметилазной активностью, активностью в отношении активации транскрипции, активностью в отношении репрессии транскрипции, активностью фактора освобождения транскрипта, активностью в отношении модификации гистонов, нуклеазной активностью, активностью расщепления однонитевой РНК, активностью расщепления двухнитевой РНК, активностью расщепления однонитевой ДНК, активностью расщепления двухнитевой ДНК и активностью связывания нуклеиновой кислоты.
По меньшей мере один или несколько гетерологичных функциональных доменов могут быть расположены на амино-конце фермента или вблизи него и/или на карбокси-конце фермента или вблизи него.
Один или несколько гетерологичных функциональных доменов могут быть слиты с ферментом CRISPR, или связаны с ферментом CRISPR, или присоединены к ферменту CRISPR с помощью линкерного фрагмента.
В случае любого из не встречающихся в природе ферментов CRISPR фермент CRISPR может предусматривать фермент CRISPR от организма из рода, включающего Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens, или Porphyromonas macacae (например, Cpf1 одного из данных организмов, модифицированный, как описано в данном документе), и он может включать дополнительные мутации или изменения или представлять собой химерный Cas (например, Cpf1).
В случае любого из не встречающихся в природе ферментов CRISPR фермент CRISPR может предусматривать химерный фермент Cas (например, Cpf1), содержащий первый фрагмент от первого ортолога Cas (например, Cpf1) и второй фрагмент от второго ортолога Cas (например, Cpf1), и при этом первый и второй ортологи Cas (например, Cpf1) являются различными. По меньшей мере один из первого и второго ортологов Cas (например, Cpf1) может предусматривать Cas (например, Cpf1) от организма, включающего Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens, или Porphyromonas macacae.
В случае любого из не встречающихся в природе ферментов CRISPR нуклеотидная последовательность, кодирующая фермент CRISPR может быть подвергнута кодон-оптимизации для экспрессии в эукариотическом организме.
В случае любого из не встречающихся в природе ферментов CRISPR клетка может представлять собой эукариотическую клетку или прокариотическую клетку; причем комплекс CRISPR является функциональным в клетке, и при этом фермент комплекса CRISPR характеризуется сниженной способностью модифицировать один или несколько нецелевых локусов в клетке по сравнению с немодифицированным ферментом, и/или при этом фермент в комплексе CRISPR характеризуется усиленной способностью модифицировать один или нескольких целевых локусов по сравнению с немодифицированным ферментом.
Соответственно, в одном аспекте настоящего изобретения предусмотрена эукариотическая клетка, содержащая сконструированный белок CRISPR или систему, определяемые в данном документе.
В определенных вариантах осуществления способы, описываемые в данном документе, могут включать обеспечение трансгенной по Cas (например, Cpf1) клетки, в которой одна или несколько нуклеиновых кислот, кодирующих одну или несколько направляющих РНК, обеспечивают или вводят функционально связанными в клетку с регуляторным элементом, содержащим промотор одного или нескольких представляющих интерес генов. Используемый в данном документе термин "трансгенная по Cas клетка" обозначает клетку, такую как эукариотическая клетка, в геном которой был интегрирован ген Cas. Природа, тип или происхождение клетки конкретно не ограничиваются в соответствии с настоящим изобретением. Также способ, посредством которого трансген Cas вводят в клетку, может отличаться и может представлять собой любой способ, известный из уровня техники. В определенных вариантах осуществления трансгенную по Cas клетку получают путем введения трансгена Cas в выделенную клетку. В определенных других вариантах осуществления трансгенную по Cas клетку получают путем выделения клеток из трансгенного по Cas организма. В качестве примера и без ограничения, трансгенная по Cas клетка, упоминаемая в данном документе, может быть получена из трансгенного по Cas эукариота, такого как эукариота с нокином по Cas. Ссылка делается на WO 2014/093622 (PCT/US13/74667), который включен в данный документ посредством ссылки. Способы из публикаций заявок на патенты США №№ 20120017290 и 20110265198, закрепленных за Sangamo BioSciences, Inc., относящиеся к нацеливанию на локус Rosa, можно модифицировать для использования системы CRISPR-Cas по настоящему изобретению. Способы из публикации заявки на патент США № 20130236946, закрепленной за Cellectis, относящиеся к нацеливанию на локус Rosa, можно также модифицировать для использования системы CRISPR-Cas по настоящему изобретению. В качестве дополнительного примера ссылка делается на Platt et. al. (Cell; 159(2):440-455 (2014)), где описана мышь с нокином по Cas9, которая включена в данный документ посредством ссылки и которую можно экстраполировать на ферменты CRISPR по настоящему изобретению, определяемые в данном документе. Трансген Cas может дополнительно содержать кассету Lox-Stop-polyA-Lox (LSL), за счет чего обеспечивается возможность индуцирования экспрессии Cas с помощью Cre-рекомбиназы. Альтернативно трансгенная по Cas клетка может быть получена путем введения трансгена Cas в выделенную клетку. Системы доставки для трансгенов хорошо известны из уровня техники. В качестве примера, трансген Cas может быть доставлен, например, в эукариотическую клетку посредством доставки с помощью вектора (например, AAV, аденовируса, лентивируса), и/или частицы, и/или наночастицы, как также описывается в других разделах данного документа.
Специалисту в данной области будет понятно, что клетка, такая как трансгенная по Cas клетка, упоминаемая в данном документе, может содержать дополнительные изменения в геноме помимо наличия интегрированного гена Cas или мутаций, возникающих за счет специфического в отношении последовательности действия Cas при образовании комплекса с РНК, способной направлять Cas в целевой локус, таких как, например, одна или несколько онкогенных мутаций, как в качестве примера и без ограничения описано у Platt et al. (2014), Chen et al. (2014) или Kumar et al. (2009).
В настоящем изобретении также предусмотрена композиция, содержащая сконструированный белок CRISPR, описываемый в данном документе, такая как описана в данном разделе.
В настоящем изобретении также предусмотрена не встречающаяся в природе, сконструированная композиция, содержащая комплекс CRISPR-Cas, содержащий любой не встречающийся в природе фермент CRISPR, описанный выше.
В одном аспекте настоящего изобретения предусмотрена векторная система, содержащая один или несколько векторов, где один или несколько векторов содержат:
a) первый регуляторный элемент, функционально связанный с нуклеотидной последовательностью, кодирующей сконструированный белок CRISPR, определяемый в данном документе; и необязательно
b) второй регуляторный элемент, функционально связанный с одной или несколькими нуклеотидными последовательностями, кодирующими одну или несколько молекул нуклеиновой кислоты, предусматривающих направляющую РНК, содержащую направляющую последовательность, последовательность прямого повтора, необязательно, где компоненты (a) и (b) находятся в одном и том же или в разных векторах.
В настоящем изобретении также предусмотрена не встречающаяся в природе, сконструированная композиция, содержащая:
систему доставки, функционально сконфигурированную с возможностью доставки компонентов комплекса CRISPR-Cas или одной или нескольких полинуклеотидных последовательностей, предусматривающих или кодирующих указанные компоненты, в клетку, и где указанный комплекс CRISPR-Cas является функциональным в клетке,
компоненты комплекса CRISPR-Cas или одну или несколько кодирующих полинуклеотидных последовательностей для транскрипции и/или трансляции в клетке, причем компоненты комплекса CRISPR-Cas предусматривают:
(I) не встречающийся в природе фермент CRISPR (например, сконструированный Cpf1), описываемый в данном документе;
(II) направляющую РНК для CRISPR-Cas, содержащую:
направляющую последовательность и
последовательность прямого повтора,
где фермент в комплексе CRISPR характеризуется сниженной способностью модифицировать один или несколько нецелевых локусов по сравнению с немодифицированным ферментом, и/или в результате чего фермент в комплексе CRISPR характеризуется повышенной способностью модифицировать один или несколько целевых локусов по сравнению с немодифицированным ферментом.
В одном аспекте настоящего изобретения также предусмотрена система, содержащая сконструированный белок CRISPR, описываемый в данном документе, такая как описана в данном разделе.
В случае любой такой композиции система доставки может предусматривать дрожжевую систему, систему на основе липофекции, систему на основе микроинъекции, систему на основе биолистики, виросомы, липосомы, иммунолипосомы, поликатионы, конъюгаты липид:нуклеиновая кислота или искусственные вирионы, определяемые в других разделах данного документа.
В случае любых таких композиций система доставки может предусматривать векторную систему, содержащую один или несколько векторов, и где компонент (II) содержит первый регуляторный элемент, функционально связанный с полинуклеотидной последовательностью, которая содержит направляющую последовательность, последовательность прямого повтора, и, необязательно, где компонент (I) содержит второй регуляторный элемент, функционально связанный с полинуклеотидной последовательностью, кодирующей фермент CRISPR.
В случае любых таких композиций система доставки может предусматривать векторную систему, содержащую один или несколько векторов, и где компонент (II) содержит первый регуляторный элемент, функционально связанный с направляющей последовательностью и последовательностью прямого повтора, и где компонент (I) содержит второй регуляторный элемент, функционально связанный с полинуклеотидной последовательностью, кодирующей фермент CRISPR.
В случае любых таких композиций композиция может предусматривать более одной направляющей РНК, и каждая направляющая РНК имеет свою мишень, в результате чего происходит мультиплексирование.
В случае любых таких композиций полинуклеотидная(полинуклеотидные) последовательность(последовательности) может(могут) находиться на одном векторе.
В настоящем изобретении также предусмотрена сконструированная не встречающаяся в природе векторная система на основе коротких палиндромных повторов, регулярно расположенных группами (CRISPR)-CRISPR-ассоциированного (Cas) (CRISPR-Cas), содержащая один или несколько векторов, содержащих:
a) первый регуляторный элемент, функционально связанный с нуклеотидной последовательностью, кодирующей не встречающийся в природе фермент CRISPR любой из конструкций по настоящему изобретению, изложенных в данном документе; и
b) второй регуляторный элемент, функционально связанный с одной или несколькими нуклеотидными последовательностями, кодирующими одну или несколько направляющих РНК, причем направляющая РНК содержит направляющую последовательность, последовательность прямого повтора,
где
компоненты (a) и (b) находятся в одном и том же или разных векторах,
образуется комплекс CRISPR;
направляющая РНК нацеливается на целевые полинуклеотидные локусы и фермент изменяет полинуклеотидные локусы, и
фермент в комплексе CRISPR характеризуется сниженной способностью модифицировать один или несколько нецелевых локусов по сравнению с немодифицированным ферментом, и/или в результате чего фермент в комплексе CRISPR характеризуется повышенной способностью модифицировать один или несколько целевых локусов по сравнению с немодифицированным ферментом.
В случае такой системы компонент (II) может содержать первый регуляторный элемент, функционально связанный с полинуклеотидной последовательностью, которая содержит направляющую последовательность, последовательность прямого повтора, и где компонент (II) может содержать второй регуляторный элемент, функционально связанный с полинуклеотидной последовательностью, кодирующей фермент CRISPR. В случае такой системы, если применимо, направляющая РНК может предусматривать химерную РНК.
В случае такой системы компонент (I) может содержать первый регуляторный элемент, функционально связанный с направляющей последовательностью и последовательностью прямого повтора, и где компонент (II) может содержать второй регуляторный элемент, функционально связанный с полинуклеотидной последовательностью, кодирующей фермент CRISPR. Такая система может содержать более одной направляющей РНК, и каждая направляющая РНК имеет свою мишень, в результате чего происходит мультиплексирование. Компоненты (a) и (b) могут быть расположены на одном и том же векторе.
В случае любой из таких систем, содержащих векторы, один или несколько векторов могут предусматривать один или несколько вирусных векторов, таких как один или несколько ретровирусных, лентивирусных, аденовирусных векторов, векторов на основе аденоассоциированного вируса или вируса простого герпеса.
В случае любой из таких систем, содержащих регуляторные элементы, по меньшей мере один из указанных регуляторных элементов может предусматривать тканеспецифичный промотор. Тканеспецифичный промотор может управлять экспрессией в клетке крови млекопитающего, в клетке печени млекопитающего или в глазу млекопитающего.
В случае любой из описанных выше композиций или систем последовательность прямого повтора может содержать один или несколько РНК-аптамеров, взаимодействующих с белком. Один или несколько аптамеров могут находиться в тетра-петле. Один или несколько аптамеров могут быть способны связывать белок оболочки бактериофага MS2.
В случае любой из описанных выше композиций или систем клетка может представлять собой эукариотическую клетку или прокариотическую клетку; где комплекс CRISPR является функциональным в клетке, и в результате этого фермент комплекса CRISPR характеризуется сниженной способностью модифицировать один или несколько нецелевых локусов в клетке по сравнению с немодифицированным ферментом и/или в результате этого фермент в комплексе CRISPR характеризуется повышенной способностью модифицировать один или несколько целевых локусов по сравнению с немодифицированным ферментом.
В настоящем изобретении также предусмотрен комплекс CRISPR любой из описанных выше композиций или из любой из описанных выше систем.
В настоящем изобретении также предусмотрен способ модифицирования представляющего интерес локуса в клетке, включающий приведение клетки в контакт с любым из описанных в данном документе сконструированных ферментов CRISPR (например, сконструированным Cpf1), композициями или любыми из описанных в данном документе системами или векторными системами, или где клетка содержит любой из описанных в данном документе комплексов CRISPR, присутствующих в клетке. В случае таких способов клетка может быть прокариотической или эукариотической клеткой, предпочтительно эукариотической клеткой. В случае таких способов организм может содержать клетку. В случае таких способов организм может не представлять собой человека или другое животное.
Любой такой способ может осуществляться ex vivo или in vitro.
В определенных вариантах осуществления нуклеотидная последовательность, кодирующая по меньшей мере одну из указанной направляющей РНК или белка Cas, функционально связана в клетке с регуляторным элементом, предусматривающим промотор представляющего интерес гена, в результате чего экспрессия по меньшей мере одного компонента системы CRISPR-Cas управляется промотором представляющего интерес гена. Подразумевается, что "функционально связанный" означает, что нуклеотидная последовательность, кодирующая направляющую РНК и/или Cas, связана с регуляторным(регуляторными) элементом(элементами) таким способом, который обеспечивает возможность экспрессии нуклеотидной последовательности, как также указано в других разделах данного документа. Термин "регуляторные элементы" также описан в других разделах данного документа. В соответствии с настоящим изобретением регуляторный элемент предусматривает промотор представляющего интерес гена, как, например, предпочтительно промотор представляющего интерес эндогенного гена. В определенных вариантах осуществления промотор находится в своем эндогенном положении в геноме. В таких вариантах осуществления нуклеиновая кислота, кодирующая CRISPR и/или Cas, находится под транскрипционным контролем промотора представляющего интерес гена в своем нативном положении в геноме. В других определенных вариантах осуществления промотор обеспечивается на (отдельной) молекуле нуклеиновой кислоты, такой как вектор или плазмида, или другой внехромосомной нуклеиновой кислоте, т. е. промотор не обеспечивается в своем нативном положении в геноме. В определенных вариантах осуществления промотор интегрирован в геном в ненативном положении в геноме.
Любой такой способ указанного модифицирования может предусматривать модулирование экспрессия гена. Указанное модулирование экспрессии гена может предусматривать активацию экспрессии гена и/или репрессию экспрессии гена. Соответственно, в одном аспекте настоящего изобретения предусмотрен способ модулирования экспрессии гена, где способ включает введение в клетку сконструированного белка CRISPR или системы, описываемых в данном документе.
В настоящем изобретении также предусмотрен способ лечения заболевания, нарушения или инфекции у индивидуума, нуждающегося в этом, включающий введение эффективного количества любого из сконструированных ферментов CRISPR (например, сконструированного Cpf1), композиций, систем или комплексов CRISPR, описываемых в данном документе. Заболевание, нарушение или инфекция могут предусматривать вирусную инфекцию. Вирусная инфекция может представлять собой инфекцию, вызванную HBV.
В настоящем изобретении также предусмотрено применение любого из сконструированных ферментов CRISPR (например, сконструированного Cpf1), композиций, систем или комплексов CRISPR, описанных выше, для редактирования гена или генома.
В настоящем изобретении также предусмотрен способ изменения экспрессии представляющего интерес локуса генома в клетке млекопитающего, включающий приведение клетки в контакт со сконструированными ферментами CRISPR (например, сконструированным Cpf1), композициями, системами или комплексами CRISPR, описываемыми в данном документе, и с доставкой тем самым CRISPR-Cas (вектора) и обеспечением возможности образования комплекса CRISPR-Cas и связывания с мишенью, и определение того, подверглась ли изменению экспрессия локуса генома, как, например, наблюдается ли повышение или снижение экспрессии или модификация продукта гена.
В настоящем изобретении также предусмотрены любые сконструированные ферменты CRISPR (например, сконструированный Cpf1), композиции, системы или комплексы CRISPR, описанные выше, для применения в качестве терапевтического средства. Терапевтическое средство может предназначаться для редактирования гена или генома, или генной терапии.
В определенных вариантах осуществления активность сконструированных ферментов CRISPR (например, сконструированный Cpf1), описываемых в данном документе, предусматривает расщепление геномной ДНК, необязательно приводящее к сниженной транскрипции гена.
В одном аспекте настоящего изобретения предусмотрена выделенная клетка с измененной экспрессией локуса генома, полученная в результате способа, описываемого в данном документе, где экспрессия изменена в сравнении с клеткой, которая не была подвергнута способу изменения экспрессии локуса генома. В связанном аспекте настоящего изобретения предусмотрена линия клеток, основанная такой клеткой.
В одном аспекте настоящего изобретения предусмотрен способ модифицирования организма или организма, отличного от человека, путем манипуляции с целевой последовательностью в представляющем интерес локусе генома, например в HSC (гемопоэтической стволовой клетке), например, где представляющий интерес локус генома ассоциирован с мутацией, ассоциированной с абберантной экспрессией белка или с болезненным состоянием или течением заболевания, включающий:
доставку в HSC, например, путем приведения HSC в контакт с частицей, содержащей не встречающуюся в природе или сконструированную композицию, содержащую:
I. полинуклеотидную последовательность направляющей РНК (gRNA) системы CRISPR-Cas, содержащую:
(a) направляющую последовательность, способную гибридизироваться с целевой последовательностью в HSC,
(b) последовательность прямого повтора, и
II. фермент CRISPR, необязательно содержащий по меньшей мере одну или несколько последовательностей ядерной локализации,
где направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью, и
где комплекс CRISPR содержит фермент CRISPR в комплексе с (1) направляющей последовательностью, которая гибридизирутеся с целевой последовательностью; и
способ также может необязательно включать доставку матрицы для HDR, например, посредством указанной частицы, приводимой в контакт с HSC, которая содержит матрицу для HDR, или посредством приведения HSC в контакт с другой частицей, содержащей матрицу для HDR, где матрица для HDR обеспечивает экспрессию нормальной или менее абберантной формы белка; где "нормальная" относится к дикому типу, а "абберантная" может обозначать экспрессию белка, которая приводит к возникновению патологического состояния или болезненного состояния; и
необязательно способ может включать выделение или получение HSC из организма или организма, отличного от человека, необязательно размножение популяции HSC, осуществление контакта частицы(частиц) с HSC c получением популяции модифицированных HSC, необязательно размножение популяции модифицированных HSC и необязательно введение модифицированных HSC в организм или организм, отличный от человека.
В одном аспекте настоящего изобретения предусмотрен способ модифицирования организма или организма, отличного от человека, путем манипуляции с целевой последовательностью в представляющем интерес локусе генома, например в HSC, например, где представляющий интерес локус генома ассоциирован с мутацией, ассоциированной с абберантной экспрессией белка или с болезненным состоянием или течением заболевания, включающий доставку в HSC, например, путем приведения HSC в контакт с частицей, содержащей не встречающуюся в природе или сконструированную композицию, содержащую: I. (a) направляющую последовательность, способную гибридизироваться с целевой последовательностью в HSC, и (b) по меньшей мере одну или несколько последовательностей прямого повтора, и II. фермент CRISPR, необязательно имеющий одну или несколько NLS, и при этом направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR c целевой последовательностью, и где комплекс CRISPR содержит фермент CRISPR в комплексе с направляющей последовательностью, которая гибридизируется с целевой последовательностью; и
способ также может необязательно включать доставку матрицы для HDR, например, посредством указанной частицы, приводимой в контакт с HSC, которая содержит матрицу для HDR, или посредством приведения HSC в контакт с другой частицей, содержащей матрицу для HDR, где матрица для HDR обеспечивает экспрессию нормальной или менее абберантной формы белка; где "нормальная" относится к дикому типу, а "абберантная" может обозначать экспрессию белка, которая приводит к возникновению патологического состояния или болезненного состояния; и
необязательно способ может включать выделение или получение HSC из организма или организма, отличного от человека, необязательно размножение популяции HSC, осуществление контакта частицы(частиц) с HSC c получением популяции модифицированных HSC, необязательно размножение популяции модифицированных HSC и необязательно введение модифицированных HSC в организм или организм, отличный от человека.
Доставка может представлять собой доставку одного или нескольких полинуклеотидов, кодирующих какой-либо один или несколько или все из CRISPR-комплексов, преимущественно связанных с одним или несколькими регуляторными элементами для экспрессии in vivo, например, посредством частицы(частиц), (содержащей)содержащих вектор, содержащий полинуклеотид(полинуклеотиды), функционально связанный(связанные) с регуляторным(регуляторными) элементом(элементами). Любая или все из полинуклеотидной последовательности, кодирующей фермент CRISPR, направляющую последовательность, последовательность прямого повтора, могут представлять собой РНК. Следует иметь в виду, что если ссылаются на полинуклеотид, который представляет собой РНК, и, как говорят, "содержит" элемент, такой как последовательность прямого повтора, то последовательность РНК включает данный элемент. Если полинуклеотид представляет собой ДНК и, как говорят, содержит элемент, такой как последовательность прямого повтора, то последовательность ДНК транскрибируется или может быть транскрибирована в РНК, содержащую элемент, о котором идет речь. Если элемент представляет собой белок, как, например, фермент CRISPR, то упоминаемая последовательность ДНК или РНК транслируется или может быть транслирована (а в случае ДНК сначала транскрибируется).
В определенных вариантах осуществления настоящего изобретения предусмотрен способ модифицирования организма, например, млекопитающего, включая человека, или отличного от человека млекопитающего или организма путем манипуляции с целевой последовательностью в представляющем интерес локусе генома HSC, например, где представляющий интерес локус генома ассоциирован с мутацией, ассоциированной с абберантной экспрессией белка или с болезненным состоянием или течением заболевания, включающий доставку, например, путем приведения не встречающейся в природе или сконструированной композиция в контакт с HSC, где композиция содержит одну или несколько частиц, содержащих вирусный, плазмидный вектор(векторы) или вектор(векторы) на основе молекул нуклеиновой кислоты (например, РНК), функционально кодирующие композицию для их экспрессии, где композиция содержит: (A) I. первый регуляторный элемент, функционально связанный с полинуклеотидной последовательностью РНК системы CRISPR-Cas, где полинуклеотидная последовательность содержит (a) направляющую последовательность, способную гибридизироваться с целевой последовательностью в эукариотической клетке, (b) последовательность прямого повтора, и II. второй регуляторный элемент, функционально связанный с фермент-кодирующей последовательностью, которая кодирует фермент CRISPR, содержащий по меньшей мере одну или несколько последовательностей ядерной локализации (или необязательно по меньшей мере одну или несколько последовательностей ядерной локализации, поскольку в некоторых вариантах осуществления может не предусматриваться NLS), где (a), (b) и (c) расположены в 5'-3'-ориентации, где компоненты I и II находятся в одном и том же или разных векторах системы, где будучи транскрибированной, направляющая последовательность управляет специфическим к последовательности связыванием комплекса CRISPR с целевой последовательностью, и где комплекс CRISPR содержит фермент CRISPR в комплексе с направляющей последовательностью, которая гибридизирована с целевой последовательностью, или (B) не встречающуюся в природе или сконструированную композицию, содержащую векторную систему, содержащую один или несколько векторов, содержащих I. первый регуляторный элемент, функционально связанный с (a) направляющей последовательностью, способной гибридизироваться с целевой последовательностью в эукариотической клетке, и (b) по меньшей мере одной или несколькими последовательностями прямого повтора, II. второй регуляторный элемент, функционально связанный с фермент-кодирующей последовательностью, которая кодирует фермент CRISPR, и необязательно, если применимо, компоненты I и II находятся в одном и том же или разных векторах системы, где будучи транскрибированной, направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью, и где комплекс CRISPR содержит фермент CRISPR в комплексе с направляющей последовательностью, которая гибридизирована с целевой последовательностью; причем способ также может необязательно включать доставку матрицы для HDR, например, посредством указанной частицы, приводимой в контакт с HSC, которая содержит матрицу для HDR, или посредством приведения HSC в контакт с другой частицей, содержащей матрицу для HDR, где матрица для HDR обеспечивает экспрессию нормальной или менее абберантной формы белка; где "нормальная" относится к дикому типу, а "абберантная" может обозначать экспрессию белка, которая приводит к возникновению патологического состояния или болезненного состояния; и необязательно способ может включать выделение или получение HSC от организма или организма, отличного от человека, необязательно размножение популяции HSC, осуществление контакта частицы(частиц) с HSC с получением популяции модифицированных HSC, необязательно размножение популяции модифицированных HSC и необязательно введение модифицированных HSC в организм или организм, отличный от человека. В некоторых вариантах осуществления компоненты I, II и III находятся в одном и том же векторе. В других вариантах осуществления компоненты I и II находятся в одном и том же векторе, тогда как компонент III находится в другом векторе. В других вариантах осуществления компоненты I и III находятся в одном и том же векторе, тогда как компонент II находится в другом векторе. В других вариантах осуществления компоненты II и III находятся в одном и том же векторе, тогда как компонент I находится в другом векторе. В других вариантах осуществления каждый из компонентов I, II и III находится в отдельных векторах. В настоящем изобретении также предусмотрена вирусная или плазмидная векторная система, описанная в данном документе.
Под манипуляцией с целевой последовательностью заявители также подразумевают эпигенетическую манипуляцию с целевой последовательностью. Она может осуществляться в отношении состояния хроматина целевой последовательности, как, например, путем модификации состояния метилирования целевой последовательности (т. е. добавление или устранение метилирования, или паттернов метилирования, или CpG-островков), модификации гистонов, повышения или снижения доступности целевой последовательности, или путем активации укладки в 3D-структуру. Следует иметь в виду, что если ссылаются на способ модифицирования организма или млекопитающего, включая человека или отличного от человека млекопитающего или организма, путем манипуляции с целевой последовательностью в представляющем интерес локусе генома, то он может применяться в отношении организма (или млекопитающего) в целом или всего лишь одной клетки или популяции клеток из этого организма (если организм является многоклеточным). Например, в случае человека заявители предусматривают, inter alia, одну клетку или популяцию клеток, и их предпочтительно можно модифицировать ex vivo и затем вводить обратно. В этом случае может быть необходим биоптат или другой образец ткани или биологической жидкости. Стволовые клетки также являются особенно предпочтительными в этом отношении. Но, разумеется, также предусматриваются варианты осуществления in vivo. И настоящее изобретение является особенно преимущественным в отношении HSC.
В некоторых вариантах осуществления настоящее изобретение охватывает способ модифицирования организма или организма, отличного от человека, путем манипуляции с первой и второй целевыми последовательностями на противоположных нитях ДНК-дуплекса в представляющем интерес локусе генома в HSC, например, где представляющий интерес локус генома ассоциирован с мутацией, ассоциированной с абберантной экспрессией белка или с болезненным состоянием или течением заболевания, предусматривающей доставку, например, путем приведения HSC в контакт с частицей(частицами), (содержащей)содержащими не встречающуюся в природе или сконструированную композицию, содержащую:
I. первую полинуклеотидную последовательность РНК системы CRISPR-Cas (например, Cpf1), где первая полинуклеотидная последовательность содержит:
(a) первую направляющую последовательность, способную гибридизироваться с первой целевой последовательностью,
(b) первую последовательность прямого повтора, и
II. вторую полинуклеотидную последовательность направляющей РНК системы CRISPR-Cas (например, Cpf1), где вторая полинуклеотидная последовательность содержит:
(a) вторую направляющую последовательность, способную гибридизироваться со второй целевой последовательностью,
(b) вторую последовательность прямого повтора, и
III. полинуклеотидную последовательность, кодирующую фермент CRISPR, содержащий по меньшей мере одну или несколько последовательностей ядерной локализации и содержащий одну или несколько мутаций, где (a), (b) и (c) расположены в 5'-3'-ориентации; или
IV. продукт(продукты) экспрессии одной или нескольких из I. - III., например, первую и вторую последовательности прямого повтора, фермент CRISPR;
где, будучи транскрибированными, первая и вторая направляющие последовательности управляют специфичным к последовательности связыванием первого и второго комплексов CRISPR с первой и второй целевыми последовательностями соответственно, где первый комплекс CRISPR содержит фермент CRISPR в комплексе с (1) первой направляющей последовательностью, которая гибридизирована с первой целевой последовательностью, где второй комплекс CRISPR содержит фермент CRISPR в комплексе с (1) второй направляющей последовательностью, которая гибридизирована со второй целевой последовательностью, где полинуклеотидная последовательность, кодирующая фермент CRISPR, представляет собой ДНК или РНК, и где первая направляющая последовательность управляет расщеплением одной нити ДНК-дуплекса возле первой целевой последовательности, а вторая направляющая последовательность управляет расщеплением другой нити возле второй целевой последовательности, индуцируя двухнитевой разрыв, за счет чего обеспечивается модифицирование организма или организма, отличного от человека; и при этом способ также может необязательно включать доставку матрицы для HDR, например, посредством частицы, приводимой в контакт с HSC, которая содержит матрицу для HDR, или посредством приведения HSC в контакт с другой частицей, содержащей матрицу для HDR, где матрица для HDR обеспечивает экспрессию нормальной или менее абберантной формы белка; где "нормальная" относится к дикому типу, а "абберантная" может обозначать экспрессию белка, которая приводит к возникновению патологического состояния или болезненного состояния; и при этом необязательно способ может включать выделение или получение HSC из организма или организма, отличного от человека, необязательно размножение популяции HSC, осуществление контакта частицы(частиц) с HSC с получением популяции модифицированных HSC, необязательно размножение популяции модифицированных HSC и необязательно введение модифицированных HSC в организм или организм, отличный от человека. В некоторых способах по настоящему изобретению любая или все из полинуклеотидной последовательности, кодирующей фермент CRISPR, первой и второй направляющих последовательностей, первой и второй последовательностей прямого повтора. В дополнительных вариантах осуществления настоящего изобретения полинуклеотиды, кодирующие последовательность, кодирующую фермент CRISPR, первую и вторую направляющие последовательности, первую и вторую последовательности прямого повтора, представляют собой РНК и доставляются с помощью липосом, наночастиц, экзосом, микровезикул или генной пушки; но преимущественно, чтобы доставка осуществлялась посредством частицы. В определенных вариантах осуществления настоящего изобретения первая и вторая последовательности прямого повтора характеризуются 100% идентичностью. В некоторых вариантах осуществления полинуклеотиды могут содержаться в векторной системе, содержащей один или несколько векторов. В предпочтительных вариантах осуществления первый фермент CRISPR имеет одну или несколько мутаций, вследствие которых фермент является ферментом, вносящим однонитевой разрыв в комплементарную нить, а второй фермент CRISPR имеет одну или несколько мутаций, вследствие которых фермент является ферментом, вносящим однонитевой разрыв в некомплементарную нить. Альтернативно первый фермент может являться ферментом, вносящим однонитевой разрыв в некомплементарную нить, а второй фермент может являться ферментом, вносящим однонитевой разрыв в комплементарную нить. В предпочтительных способах по настоящему изобретению первая направляющая последовательность, управляющая расщеплением одной нити ДНК-дуплекса возле первой целевой последовательности, и вторая направляющая последовательность, управляющая расщеплением другой нити возле второй целевой последовательности, приводят к образованию "липкого" 5'-конца. В вариантах осуществления настоящего изобретения "липкий" 5'-конец содержит не более 200 пар оснований, предпочтительно не более 100 пар оснований или более предпочтительно не более 50 пар оснований. В вариантах осуществления настоящего изобретения "липкий" 5'-конец содержит по меньшей мере 26 пар оснований, предпочтительно по меньшей мере 30 пар оснований или более предпочтительно 34-50 пар оснований.
В некоторых вариантах осуществления настоящее изобретение охватывает способ модифицирования организма или организма, отличного от человека, путем манипуляции с первой и второй целевыми последовательностями на противоположных нитях ДНК-дуплекса в представляющем интерес локусе генома, например, в HSC, например, где представляющий интерес локус генома ассоциирован с мутацией, ассоциированной с абберантной экспрессией белка или с болезненным состоянием или течением заболевания, включающий доставку, например, путем приведения HSC в контакт с частицей(частицами), содержащей(содержащими) не встречающуюся в природе или сконструированную композицию, содержащую:
I. первый регуляторный элемент, функционально связанный с
(a) первой направляющей последовательностью, способной гибридизироваться с первой целевой последовательностью, и
(b) по меньшей мере одной или несколькими последовательностями прямого повтора,
II. второй регуляторный элемент, функционально связанный со
(a) второй направляющей последовательностью, способной гибридизироваться со второй целевой последовательностью, и
(b) по меньшей мере одной или несколькими последовательностями прямого повтора,
III. третий регуляторный элемент, функционально связанный с фермент-кодирующей последовательностью, которая кодирует фермент CRISPR (например, Cpf1), и
V. продукт(продукты) экспрессии одной или нескольких из I. - IV., например, первую и вторую последовательности прямого повтора, фермент CRISPR;
где компоненты I, II, III и IV расположены в одном и том же или разных векторах системы, при этом будучи транскрибированными, первая и вторая направляющие последовательности управляют специфичным к последовательности связыванием первого и второго комплексов CRISPR с первой и второй целевыми последовательностями соответственно, где первый комплекс CRISPR содержит фермент CRISPR в комплексе с (1) первой направляющей последовательностью, которая гибридизирована с первой целевой последовательностью, где второй комплекс CRISPR содержит фермент CRISPR в комплексе со второй направляющей последовательностью, которая гибридизирована со второй целевой последовательностью, где полинуклеотидная последовательность, кодирующая фермент CRISPR, представляет собой ДНК или РНК, и где первая направляющая последовательность управляет расщеплением одной нити ДНК-дуплекса возле первой целевой последовательности, а вторая направляющая последовательность управляет расщеплением другой нити возле второй целевой последовательности, индуцируя двухнитевой разрыв, за счет чего осуществляется модифицирование организма или организма, отличного от человека; и при этом способ также может необязательно включать доставку матрицы для HDR, например, посредством указанной частицы, приводимой в контакт с HSC, которая содержит матрицу для HDR, или посредством приведения HSC в контакт с другой частицей, содержащей матрицу для HDR, где матрица для HDR обеспечивает экспрессию нормальной или менее абберантной формы белка; где "нормальная" относится к дикому типу, а "абберантная" может обозначать экспрессию белка, которая приводит к возникновению патологического состояния или болезненного состояния; и при этом необязательно способ может включать выделение или получение HSC из организма или организма, отличного от человека, необязательно размножение популяции HSC, осуществление контакта частицы(частиц) с HSC с получением популяции модифицированных HSC, необязательно размножение популяции модифицированных HSC и необязательно введение модифицированных HSC в организм или организм, отличный от человека.
В настоящем изобретении также предусмотрена векторная система, описанная в данном документе. Система может содержать один, два, три или четыре различных вектора. Компоненты I, II, III и IV, таким образом, могут находиться в одном, двух, трех или четырех разных векторах, и в данном документе предусмотрены все комбинации возможных местоположений компонентов, например, компоненты I, II, III и IV могут находиться в одном и том же векторе; каждый из компонентов I, II, III и IV может находиться в отдельных векторах; компоненты I, II, III и IV могут находиться в общей сложности в двух или трех разных векторах, при этом предусмотрены все комбинации местоположений и т. п. В некоторых способах по настоящему изобретению любая или все из полинуклеотидной последовательности, кодирующей фермент CRISPR, первой и второй направляющих последовательностей, первой и второй последовательностей прямого повтора, представляет собой/представляют собой РНК. В дополнительных вариантах осуществления настоящего изобретения первая и вторая последовательности прямого повтора характеризуются 100% идентичностью. В предпочтительных вариантах осуществления первый фермент CRISPR имеет одну или несколько мутаций, вследствие которых фермент является ферментом, вносящим однонитевой разрыв в комплементарную нить, а второй фермент CRISPR имеет одну или несколько мутаций, вследствие которых фермент является ферментом, вносящим однонитевой разрыв в некомплементарную нить. Альтернативно первый фермент может являться ферментом, вносящим однонитевой разрыв в некомплементарную нить, а второй фермент может являться ферментом, вносящим однонитевой разрыв в комплементарную нить. В дополнительном варианте осуществления настоящего изобретения один или несколько вирусных векторов доставляются посредством липосом, наночастиц, экзосом, микровезикул или генной пушки; но доставка с помощью частиц является преимущественной.
В предпочтительных способах по настоящему изобретению первая направляющая последовательность, управляющая расщеплением одной нити ДНК-дуплекса возле первой целевой последовательности, и вторая направляющая последовательность, управляющая расщеплением другой нити возле второй целевой последовательности, обуславливают образование "липкого" 5'-выступающего конца. В вариантах осуществления настоящего изобретения "липкий" 5'-конец содержит не более 200 пар оснований, предпочтительно не более 100 пар оснований или более предпочтительно не более 50 пар оснований. В вариантах осуществления настоящего изобретения "липкий" 5'-конец содержит по меньшей мере 26 пар оснований, предпочтительно по меньшей мере 30 пар оснований или более предпочтительно 34-50 пар оснований.
В некоторых вариантах осуществления настоящее изобретение охватывает способ модифицирования представляющего интерес локуса генома, например в HSC, например, где представляющий интерес локус генома ассоциирован с мутацией, ассоциированной с абберантной экспрессией белка или с болезненным состоянием или течением заболевания, путем введения в HSC, например, путем приведения HSC в контакт с частицей(частицами), содержащей(содержащими) белок Cas с одной или несколькими мутациями и две направляющие РНК, которые нацеливаются на первую нить и вторую нить молекулы ДНК соответственно в HSC, в результате чего направляющие РНК нацеливаются на молекулу ДНК, а белок Cas вносит однонитевой разрыв в каждую из первой нити и второй нити молекулы ДНК, в результате чего мишень в HSC изменяется; и, где белок Cas и две направляющие РНК не встречаются в природе вместе, и при этом способ необязательно может также включать доставку матрицы для HDR, например, посредством указанной частицы, приводимой в контакт с HSC, которая содержит матрицу для HDR, или посредством приведения HSC в контакт с другой частицей, содержащей матрицу для HDR, где матрица для HDR обеспечивает экспрессию нормальной или менее абберантной формы белка; где "нормальная" относится к дикому типу, а "абберантная" может обозначать экспрессию белка, которая приводит к возникновению патологического состояния или болезненного состояния; и при этом необязательно способ может включать выделение или получение HSC из организма или организма, отличного от человека, необязательно размножение популяции HSC, осуществление контакта частицы(частиц) с HSC получением популяции модифицированных HSC, необязательно размножение популяции модифицированных HSC и необязательно введение модифицированных HSC в организм или организм, отличный от человека. В предпочтительных способах по настоящему изобретению белок Cas вносит однонитевой разрыв в каждую из первой нити и второй нити молекулы ДНК, что приводит к образованию "липкого" 5'-конца. В вариантах осуществления настоящего изобретения "липкий" 5'-конец содержит не более 200 пар оснований, предпочтительно не более 100 пар оснований или более предпочтительно не более 50 пар оснований. В вариантах осуществления настоящего изобретения "липкий" 5'-конец содержит по меньшей мере 26 пар оснований, предпочтительно по меньшей мере 30 пар оснований или более предпочтительно 34-50 пар оснований. В одном аспекте настоящего изобретения белок Cas является кодон-оптимизированным для экспрессии в эукариотической клетке, предпочтительно в клетке млекопитающего или клетке человека. Аспекты настоящего изобретения относятся к снижению экспрессии продукта гена, или к дополнительному введению полинуклеотидной матрицы в молекулу ДНК, кодирующую продукт гена, или к точному вырезанию вставочной последовательности путем обеспечения повторной гибридизации и лигирования двух "липких" 5’-концов, или к изменению активности или функционирования продукта гена, или к повышению экспрессии продукта гена. В одном варианте осуществления настоящего изобретения продукт гена представляет собой белок.
В некоторых вариантах осуществления настоящее изобретение охватывает способ модифицирования представляющего интерес локуса генома, например в HSC, например, где представляющий интерес локус генома ассоциирован с мутацией, ассоциированной с абберантной экспрессией белка или с болезненным состоянием или течением заболевания, путем введения в HSC, например, путем приведения HSC в контакт с частицей(частицами), содержащей(содержащими):
a) первый регуляторный элемент, функционально связанный с каждой из двух направляющих РНК системы CRISPR-Cas, которые нацеливаются на первую нить и вторую нить соответственно двухнитевой молекулы ДНК HSC, и
b) второй регуляторный элемент, функционально связанный с белком Cas (например, Cpf1), или
c) продукт экспрессии(продукты экспрессии) a) или b),
где компоненты (a) и (b) находятся в одном и том же или разных векторах системы, в результате чего направляющие РНК нацеливаются на молекулу ДНК HSC, а белок Cas вносит однонитевой разрыв в каждую из первой нити и второй нити молекулы ДНК HSC; и где белок Cas и две направляющие РНК не встречаются в природе вместе; и при этом способ необязательно может также включать доставку матрицы для HDR, например, посредством указанной частицы, приводимой в контакт с HSC, которая содержит матрицу для HDR, или посредством приведения HSC в контакт с другой частицей, содержащей матрицу для HDR, где матрица для HDR обеспечивает экспрессию нормальной или менее абберантной формы белка; где "нормальная" относится к дикому типу, а "абберантная" может обозначать экспрессию белка, которая приводит к возникновению патологического состояния или болезненного состояния; и при этом необязательно способ может включать выделение или получение HSC из организма или организма, отличного от человека, необязательно размножение популяции HSC, осуществление контакта частицы(частиц) с HSC с получением популяции модифицированных HSC, необязательно размножение популяции модифицированных HSC и необязательно введение модифицированных HSC в организм или организм, отличный от человека. В аспектах настоящего изобретения направляющие РНК могут содержать направляющую последовательность, слитую с последовательностью прямого повтора. Аспекты настоящего изобретения относятся к снижению экспрессии продукта гена, или к дополнительному введению полинуклеотидной матрицы в молекулу ДНК, кодирующую продукт гена, или к точному вырезанию вставочной последовательности путем обеспечения повторной гибридизации и лигирования двух "липких" 5’-концов, или к изменению активности или функционирования продукта гена, или к повышению экспрессии продукта гена. В одном варианте осуществления настоящего изобретения продукт гена представляет собой белок. В предпочтительных вариантах осуществления настоящего изобретения векторы системы являются вирусными векторами. В дополнительном варианте осуществления векторы системы доставляют посредством липосом, наночастиц, экзосом, микровезикул или генной пушки; причем частицы являются предпочтительными. В одном аспекте настоящего изобретения предусмотрен способ модифицирования целевого полинуклеотида в HSC. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса CRISPR с целевым полинуклеотидом для осуществления расщепления указанного целевого полинуклеотида, за счет чего обеспечивается модифицирование целевого полинуклеотида, где комплекс CRISPR содержит фермент CRISPR в комплексе с направляющей последовательностью, гибридизированной с целевой последовательностью в пределах указанного целевого полинуклеотида, где указанная направляющая последовательность связана с последовательностью прямого повтора. В некоторых вариантах осуществления указанное расщепление предусматривает расщепление одной или двух нитей в определенном положении целевой последовательности с помощью указанного фермента CRISPR. В некоторых вариантах осуществления указанное расщепление приводит к сниженной транскрипции целевого гена. В некоторых вариантах осуществления способ дополнительно включает репарацию указанного расщепленного целевого полинуклеотида с помощью гомологичной рекомбинации с экзогенной полинуклеотидной матрицей, где указанная репарация приводит к возникновению мутации, предусматривающей вставку, делецию или замену одного или нескольких нуклеотидов в указанном целевом полинуклеотиде. В некоторых вариантах осуществления указанная мутация приводит к изменению одной или нескольких аминокислот в белке, экспрессируемом с гена, содержащего целевую последовательность. В некоторых вариантах осуществления способ дополнительно включает доставку одного или нескольких векторов или продукта(продуктов) их экспрессии, например, посредством частицы(частиц), например, в указанную HSC, где один или несколько векторов управляют экспрессией одного или нескольких из фермента CRISPR, направляющей последовательности, связанной с последовательностью прямого повтора. В некоторых вариантах осуществления указанные векторы доставляются, например, в HSC, находящуюся в организме субъекта. В некоторых вариантах осуществления указанное модифицирование происходит в указанной HSC, находящей в культуре клеток. В некоторых вариантах осуществления способ дополнительно включает выделение указанной HSC из организма субъекта перед проведением указанного модифицирования. В некоторых вариантах осуществления способ дополнительно включает возвращение указанных HSC и/или клеток, происходящих из них, указанному субъекту.
В одном аспекте настоящего изобретения предусмотрен способ получения, например, HSC, содержащей мутированный ген, ответственный за развитие заболевания. В некоторых вариантах осуществления ген, ответственный за развитие заболевания, является любым геном, ассоциированным с повышением риска наличия или развития заболевания. В некоторых вариантах осуществления способ включает (a) введение одного или нескольких векторов или продукта(продуктов) их экспрессии, например, посредством частицы(частиц) в HSC, где один или несколько векторов управляют экспрессией одного или нескольких из: фермента CRISPR, направляющей последовательности, связанной с парной последовательностью прямого повтора; и (b) обеспечение связывания комплекса CRISPR с целевым полинуклеотидом для осуществления расщепления целевого полинуклеотида в указанном гене, ответственном за развитие заболевания, где комплекс CRISPR содержит фермент CRISPR в комплексе с направляющей последовательностью, которая гибридизирована с целевой последовательностью в целевом полинуклеотиде, и необязательно, если применимо, с получением тем самым HSC, содержащей мутированный ген, ответственный за развитие заболевания. В некоторых вариантах осуществления указанное расщепление предусматривает расщепление одной или двух нитей в определенном положении целевой последовательности с помощью указанного фермента CRISPR. В некоторых вариантах осуществления указанное расщепление приводит к сниженной транскрипции целевого гена. В некоторых вариантах осуществления способ дополнительно включает репарацию указанного расщепленного целевого полинуклеотида с помощью гомологичной рекомбинации с экзогенной полинуклеотидной матрицей, где указанная репарация приводит к возникновению мутации, предусматривающей вставку, делецию или замену одного или нескольких нуклеотидов в указанном целевом полинуклеотиде. В некоторых вариантах осуществления указанная мутация приводит к изменению одной или нескольких аминокислот при экспрессии белка с гена, содержащего целевую последовательность. В некоторых вариантах осуществления модифицированную HSC вводят животному с получением тем самым животной модели.
В одном аспекте настоящего изобретения предусмотрены способы модифицирования целевого полинуклеотида, например, в HSC. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса CRISPR с целевым полинуклеотидом для осуществления расщепления указанного целевого полинуклеотида, за счет чего обеспечивается модифицирование целевого полинуклеотида, где комплекс CRISPR содержит фермент CRISPR в комплексе с направляющей последовательностью, гибридизированной с целевой последовательностью в пределах указанного целевого полинуклеотида, где указанная направляющая последовательность связана с последовательностью прямого повтора. В других вариантах осуществления настоящего изобретения предусмотрен способ модифицирования экспрессии полинуклеотида в эукариотической клетке, которая происходит, например, из HSC. Способ включает повышение или снижение экспрессии целевого полинуклеотида с помощью применения комплекса CRISPR, который связывается с полинуклеотидом в HSC; преимущественно комплекс CRISPR доставляется посредством частицы(частиц).
В некоторых способах целевой полинуклеотид можно инактивировать для осуществления модифицирования экспрессии, например, в HSC. Например, после связывания комплекса CRISPR с целевой последовательностью в клетке целевой полинуклеотид инактивируется, вследствие чего последовательность не транскрибируется, при этом не вырабатывается кодируемый белок или последовательность не функционирует так, как последовательность дикого типа.
В некоторых вариантах осуществления РНК из системы CRISPR-Cas, например, направляющая или gRNA, может быть модифицирована; например, включать аптамер или функциональный домен. Аптамер представляет собой синтетический олигонуклеотид, который связывается со специфической целевой молекулой; к примеру, молекулой нуклеиновой кислоты, которая была сконструирована благодаря повторным раундам in vitro отбора или SELEX (систематическая эволюция лигандов с помощью экспоненциального обогащения) для связывания с различными молекулярными мишенями, такими как малые молекулы, белки, нуклеиновые кислоты и даже клетки, ткани и организмы. Аптамеры являются пригодными в том, что они обеспечивают свойства молекулярного распознавания, что делает их конкурентами антител. В дополнение к их способности дифференциального распознавания, аптамеры предоставляют преимущества в сравнении с антителами, включая то, что при применении в терапевтических целях они вызывают небольшую иммуногенность или не вызывают ее. Соответственно, при осуществлении настоящего изобретения на практике, любое или оба из фермента или РНК могут включать функциональный домен.
В некоторых вариантах осуществления функциональный домен представляет собой домен активации транскрипции, предпочтительно VP64. В некоторых вариантах осуществления функциональный домен представляет собой домен репрессии транскрипции, предпочтительно KRAB. В некоторых вариантах осуществления домен репрессии транскрипции представляет собой SID или конкатемеры SID (например, SID4X). В некоторых вариантах осуществления функциональный домен представляет собой домен эпигенетического модифицирования, так что обеспечивается фермент эпигенетического модифицирования. В некоторых вариантах осуществления функциональный домен представляет собой домен активации, который может представлять собой домен активации P65. В некоторых вариантах осуществления функциональный домен предусматривает нуклеазную активность. В одном таком варианте осуществления функциональный домен предусматривает Fok1.
В настоящем изобретении также предусмотрена in vitro или ex vivo клетка, содержащая любое из модифицированных ферментов CRISPR, композиций, систем или комплексов, описанных выше, или из любого из способов, описанных выше. Клетка может быть эукариотической клеткой или прокариотической клеткой. В настоящем изобретении также предусмотрено потомство таких клеток. В настоящем изобретении также предусмотрен продукт любой такой клетки или любого такого потомства, где продукт представляет собой продукт указанного одного или нескольких целевых локусов, модифицированных с помощью модифицированного фермента CRISPR из комплекса CRISPR. Продукт может представлять собой пептид, полипептид или белок. Некоторые такие продукты могут быть модифицированы с помощью модифицированного фермента CRISPR из комплекса CRISPR. В случае некоторых таких модифицированных продуктов продукт целевого локуса физически отличается от продукта указанного целевого локуса, который не был модифицирован с помощью указанного модифицированного фермента CRISPR.
В настоящем изобретении также предусмотрена полинуклеотидная молекула, содержащая полинуклеотидную последовательность, кодирующую любой из не встречающихся в природе ферментов CRISPR, описанный выше.
Любой такой полинуклеотид может дополнительно содержать один или несколько регуляторных элементов, которые функционально связаны с полинуклеотидной последовательностью, кодирующей не встречающийся в природе фермент CRISPR.
В случае любого такого полинуклеотида, который содержит один или несколько регуляторных элементов, один или несколько регуляторных элементов могут быть функционально сконфигурированы с возможностью экспрессии не встречающегося в природе фермента CRISPR в эукариотической клетке. Эукариотическая клетка может представлять собой клетку человека. Эукариотическая клетка может представлять собой клетку грызуна, необязательно клетку мыши. Эукариотическая клетка может представлять собой клетку дрожжей. Эукариотическая клетка может представлять собой клетку яичника китайского хомячка (CHO). Эукариотическая клетка может представлять собой клетку насекомого.
В случае любого такого полинуклеотида, который содержит один или несколько регуляторных элементов, один или несколько регуляторных элементов могут быть функционально сконфигурированы с возможностью экспрессии не встречающегося в природе фермента CRISPR в прокариотической клетке.
В случае любого такого полинуклеотида, который содержит один или несколько регуляторных элементов, один или несколько регуляторных элементов могут быть функционально сконфигурированы для обеспечения экспрессии не встречающегося в природе фермента CRISPR в in vitro системе.
В настоящем изобретении также предусмотрен вектор экспрессии, содержащий любую из описанных выше полинуклеотидных молекул. В настоящем изобретении также предусмотрена такая полинуклеотидная молекула(молекулы), к примеру, такие полинуклеотидные молекулы, функционально сконфигурированные для обеспечения экспрессии белка и/или компонента(компонентов) на основе нуклеиновой кислоты, а также такой вектор(векторы).
В настоящем изобретении дополнительно предусмотрен способ получения мутаций в Cas (например, Cpf1) или мутированного или модифицированного Cas (например, Cpf1), который является ортологом ферментов CRISPR в соответствии с настоящим изобретением, как описано в данном документе, включающий определение аминокислоты(аминокислот), которые в таком ортологе могут находиться в непосредственной близости или могут касаться молекулы нуклеиновой кислоты, например, ДНК, РНК, gRNA и т. д., и/или аминокислоты(аминокислот), аналогичных или соответствующих идентифицированной в данном документе аминокислоте(аминокислотам) в ферментах CRISPR в соответствии с настоящим изобретением, как описано в данном документе, для осуществления модификации и/или мутации, и синтеза, или получения, или экспрессии ортолога, содержащего, состоящего из или состоящего, по сути, из модификации(модификаций) и/или мутации(мутаций), или осуществления мутирования, как обсуждается в данном документе, например, путем модифицирования, например, изменения или мутирования, нейтральной аминокислоты в заряженную, например положительно заряженную аминокислоту, например, из аланина, например, в лизин. Модифицированный таким образом ортолог можно применять в системах CRISPR-Cas; и молекулу(молекулы) нуклеиновой кислоты, экспрессирующую(экспрессирующие) его, можно применять в векторе или других системах доставки, которые доставляют молекулы или кодируют компоненты системы CRISPR-Cas, как обсуждается в данном документе.
В одном аспекте настоящего изобретения предусмотрены эффективная целевая активность и сведенная к минимуму нецелевая активность. В одном аспекте настоящего изобретения предусмотрено эффективное целевое расщепление с помощью белка CRISPR и сведенное к минимуму нецелевое расщепление под действием белка CRISPR. В одном аспекте настоящего изобретения предусмотрено направленно-специфичное связывание белка CRISPR в генном локусе без расщепления ДНК. В одном аспекте настоящего изобретения предусмотрены эффективное управляемое направляющей последовательностью целевое связывание белка CRISPR в генном локусе и сведенное к минимуму нецелевое связывание белка CRISPR. Соответственно, в одном аспекте настоящего изобретения предусмотрена специфичная к мишени генная регуляция. В одном аспекте настоящего изобретения предусмотрено направленно-специфичное связывание фермента CRISPR в генном локусе без расщепления ДНК. Соответственно, в одном аспекте настоящего изобретения предусмотрено расщепление в одном генном локусе и генная регуляция в другом генном локусе с применением одного фермента CRISPR. В одном аспекте настоящего изобретения предусмотрена ортогональная активация и/или ингибирование и/или расщепление нескольких мишеней с применением одного или нескольких белков и/или ферментов CRISPR.
В другом аспекте настоящего изобретения предусмотрен способ функционального скрининга генов в геноме в пуле клеток ex vivo или in vivo, включающий введение или экспрессию библиотеки, содержащей несколько направляющих РНК (gRNA) системы CRISPR-Cas, и где скрининг дополнительно предусматривает применение фермента CRISPR, где комплекс CRISPR является модифицированным, чтобы содержать гетерологичный функциональный домен. В одном аспекте настоящего изобретения предусмотрен способ скрининга генома, включающий введение хозяину библиотеки или ее экспрессию у хозяина in vivo. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, дополнительно включающий введение хозяину активатора или его экспрессию у хозяина. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где активатор прикреплен к белку CRISPR. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где активатор прикреплен к N-концу или C-концу белка CRISPR. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где активатор прикреплен к петле gRNA. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, дополнительно включающий введение хозяину репрессора или его экспрессию у хозяина. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где скрининг предусматривает воздействие на активацию гена, ингибирование гена или расщепление в локусе, и выявление указанного.
В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где хозяином является эукариотическая клетка. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где хозяином является клетка млекопитающего. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где хозяином является клетка эукариотического организма, отличного от человека. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где клеткой эукариотического организма, отличного от человека, является клетка млекопитающего, отличного от человека. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где клетка млекопитающего, отличного от человека, может представлять собой, включая без ограничения клетку представителя приматов, бычьих, овечьих, свиньих, псовых, грызунов, Leporidae, как, например, обезьяны, коровы, овцы, свиньи, собаки, кролика, крысы или мыши. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, причем клетка может представлять собой эукариотическую клетку от организма, отличного от млекопитающего, как, например, клетку домашней птицы (например, курицы), позвоночной рыбы (например, лосося) или моллюсков и ракообразных (например, устрицы, двустворчатых моллюсков, омара, креветки). В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, причем клеткой эукариотического организма, отличного от человека, является растительная клетка. Растительная клетка может быть получена от однодольного или двудольного растения, или от сельскохозяйственного или зернового растения, такого как маниока, кукуруза, сорго, соя, пшеница, овес или рис. Растительная клетка также может быть получена от водоросли, дерева или продуктивного растения, фрукта или овоща (например, деревьев, таких как цитрусовые деревья, например, деревья апельсина, грейпфрута или лимона; деревья персика или нектарина; деревья яблони или груши; орехоплодные деревья, такие как деревья миндаля, или грецкого ореха, или фисташки; пасленовых растений; растений из рода Brassica; растений из рода Lactuca; растений из рода Spinacia; растений из рода Capsicum; хлопчатника, табака, спаржи, моркови, капусты кочанной, брокколи, цветной капусты, томата, баклажана, перца, салата, шпината, земляники, черники, малины, ежевики, винограда, кофе, какао и т.д.).
В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, включающий доставку комплексов CRISPR-Cas, или их компонента(компонентов), или молекулы(молекул) нуклеиновой кислоты, кодирующей их, где указанная молекула(молекулы) нуклеиновой кислоты функционально связаны с регуляторной последовательностью(последовательностями) и экспрессируются in vivo. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где экспрессия in vivo осуществляется с помощью лентивируса, аденовируса или AAV. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где доставка осуществляется с помощью частицы, наночастицы, липида или пептида, проникающих в клетку (CPP).
В конкретных вариантах осуществления интерес может представлять нацеливание комплекса CRISPR-Cas в хлоропласт. Во многих случаях это нацеливание может достигаться с помощью присутствия N-концевого удлинения, называемого транзитный пептид хлоропласта (CTP) или транзитный пептид пластиды. Хромосомные трансгены из бактериальных источников должны иметь последовательность, кодирующую последовательность CTP, слитую с последовательностью, кодирующей экпрессируемый полипептид, если экпрессируемый полипептид должен быть компартментализован в растительную плазмиду (например, хлоропласт). Соответственно, направление экзогенного полипептида в хлоропласт зачастую 1 осуществляется посредством функционального связывания полинуклеотидной последовательности, кодирующей последовательность CTP, с 5'-участком полинуклеотида, кодирующего экзогенный полипептид. CTP удаляется на стадии процессинга во время транслокации в пластиду. На эффективность процессинга, однако, может воздействовать аминокислотная последовательность CTP и ближайшие последовательности на NH2-конце пептида. Другими элементами для нацеливания в хлоропласт, которые были описаны, являются сигнальная последовательность cab-m7 маиса (патент США № 7022896, WO 97/41228), сигнальная последовательность глутатион-редуктазы гороха (WO 97/41228) и CTP, описанный в US2009029861.
В одном аспекте настоящего изобретения предусмотрена пара комплексов CRISPR-Cas, при этом каждый из них содержит направляющую РНК (gRNA), предусматривающую направляющую последовательность, способную гибридизироваться с целевой последовательностью в представляющем интерес локусе генома в клетке, где по меньшей мере одна петля каждой sgRNA является модифицированной путем вставки отличающейся(отличающихся) последовательности(последовательностей) РНК, которая(которые) связывается(связываются) с одним или несколькими адаптерными белками, и где адаптерный белок ассоциирован с одним или несколькими функциональными доменами, где каждая gRNA из каждого CRISPR-Cas содержит функциональный домен, характеризующийся активностью расщепления ДНК. В одном аспекте настоящего изобретения предусмотрены парные комплексы CRISPR-Cas, обсуждаемые в данном документе, где активность расщепления ДНК обусловлена нуклеазой Fok1.
В одном аспекте настоящего изобретения предусмотрен способ разрезания целевой последовательности в представляющем интерес локусе генома, включающий доставку в клетку комплексов CRISPR-Cas, или их компонента(компонентов), или молекулы(молекул) нуклеиновой кислоты, кодирующей их, где указанная молекула(молекулы) нуклеиновой кислоты функционально связаны с регуляторной последовательностью(последовательностями) и экспрессируются in vivo. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где доставка осуществляется с помощью лентивируса, аденовируса или AAV. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, или парные комплексы CRISPR-Cas, обсуждаемые в данном документе, где целевая последовательность для первого комплекса из пары находится на первой нити двухнитевой ДНК, а целевая последовательность для второго комплекса из пары находится на второй нити двухнитевой ДНК. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, или парные комплексы CRISPR-Cas, обсуждаемые в данном документе, где целевые последовательности первого и второго комплексов расположены близко друг от друга, так что ДНК разрезается таким способом, который облегчает репарацию с помощью гомологичной рекомбинации. В одном аспекте способ, изложенный в данном документе, может дополнительно включать введение в клетку ДНК-матрицы. В одном аспекте способа, изложенного в данном документе, могут подразумеваться парные комплексы CRISPR-Cas, изложенные в данном документе, где каждый комплекс CRISPR-Cas имеет фермент CRISPR, который является мутированным, так что он характеризуется не более, чем приблизительно 5% нуклеазной активности фермента CRISPR, который не является мутированным.
В одном аспекте настоящего изобретения предусмотрены библиотека, способ или комплекс, обсуждаемые в данном документе, где gRNA является модифицированной так, что она имеет по меньшей мере одну некодирующую функциональную петлю, например, где по меньшей мере одна некодирующая функциональная петля является репрессорной; например, где по меньшей мере одна некодирующая функциональная петля содержит Alu.
В одном аспекте настоящего изобретения предусмотрен способ изменения или модифицирования экспрессии продукта гена. Указанный способ может включать введение в клетку, содержащую и экспрессирующую молекулу ДНК, кодирующую продукт гена, сконструированной не встречающейся в природе системы CRISPR-Cas, содержащей белок Cas и направляющую РНК, которая нацеливается на молекулу ДНК, в результате чего направляющая РНК нацеливается на молекулу ДНК, кодирующую продукт гена, а белок Cas расщепляет молекулу ДНК, кодирующую продукт гена, в результате чего экспрессия продукта гена является измененной; и где белок Cas и направляющая РНК не встречаются в природе вместе. Настоящее изобретение дополнительно охватывает белок Cas, который является кодон-оптимизированным для экспрессии в эукариотической клетке. В предпочтительном варианте осуществления эукариотическая клетка является клеткой млекопитающего, и в более предпочтительном варианте осуществления клетка млекопитающего является клеткой человека. В дополнительном варианте осуществления настоящего изобретения экспрессия продукта гена является сниженной.
В одном аспекте настоящего изобретения предусмотрены измененные клетки и потомство таких клеток, а также продукты, производимые клетками. Белки и системы CRISPR-Cas (например, Cpf1) по настоящему изобретению применяют для получения клеток, содержащих модифицированный целевой локус. В некоторых вариантах осуществления способ может включать обеспечение связывания комплекса нацеливания на нуклеиновую кислоту с целевой ДНК или РНК для осуществления расщепления указанной целевой ДНК или РНК, за счет чего осуществляется модифицирование целевой ДНК или РНК, где комплекс нацеливания на нуклеиновую кислоту содержит эффекторный белок для нацеливания на нуклеиновую кислоту в комплексе с направляющей РНК, гибридизированной с целевой последовательностью в пределах указанной целевой ДНК или РНК. В одном аспекте настоящего изобретения предусмотрен способ репарации локуса гена в клетке. В другом аспекте настоящего изобретения предусмотрен способ модифицирования экспрессии ДНК или РНК в эукариотической клетке. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса нацеливания на нуклеиновую кислоту с ДНК или РНК, так что указанное связывание приводит к повышенной или сниженной экспрессии указанной ДНК или РНК; где комплекс нацеливания на нуклеиновую кислоту содержит эффекторный белок для нацеливания на нуклеиновую кислоту в комплексе с направляющей РНК. Аналогичные соображения и условия распространяются на способы модифицирования целевой ДНК или РНК, изложенные выше. Фактически, эти варианты отбора образцов, культивирования и повторного введения охватываются аспектами настоящего изобретения. В одном аспекте настоящего изобретения предусмотрены способы модифицирования целевой ДНК или РНК в эукариотической клетке, которые могут осуществляться in vivo, ex vivo или in vitro. В некоторых вариантах осуществления способ включает отбор клетки или популяции клеток у человека или отличного от человека животного и модификацию клетки или клеток. Культивирование можно осуществлять на любой стадии ex vivo. Такие клетки могут представлять собой без ограничения растительные клетки, клетки животного, конкретные типы клеток любого организма, в том числе стволовые клетки, иммунные клетки, T-клетку, B-клетки, дендритные клетки, клетки сердечно-сосудистой системы, эпителиальные клетки, стволовые клетки и т. п. Клетки могут быть модифицированными в соответствии с настоящим изобретением для получения продуктов гена, например, в контролируемых количествах, которые могут быть повышенными или сниженными, в зависимости от применения, и/или мутированными. В определенных вариантах осуществления локус гена в клетке является репарированным. Клетку или клетки можно даже повторно вводить отличному от человека животному или в растение. Что касается повторно вводимых клеток, может быть предпочтительным, чтобы эти клетки являлись стволовыми клетками.
В одном аспекте настоящего изобретения предусмотрены клетки, которые временно содержат системы CRISPR или их компоненты. Например, белки или ферменты CRISPR, а также нуклеиновые кислоты, временно обеспечиваются в клетке, и локус гена изменяется, после чего происходит снижение количества одного или нескольких компонентов системы CRISPR. Впоследствии клетки, потомство клеток и организмы, которые содержат клетки, которые приобрели генетическое изменение, опосредованное CRISPR, содержат сниженные количества одного или нескольких компонентов системы CRISPR, или более не содержат один или несколько компонентов системы CRISPR. Одним неограничивающим примером является самоинактивирующаяся система CRISPR-Cas, такая как дополнительно описанная в данном документе. Таким образом, в настоящем изобретении предусмотрены клетки, и организмы, и потомство клеток и организмов, которые содержат один или несколько генетических локусов, измененных под действием системы CRISPR-Cas, но, по сути, не содержащие один или несколько компонентов системы CRISPR. В определенных вариантах осуществления компоненты системы CRISPR фактически отсутствуют. Такие клетки, ткани и организмы преимущественно содержат требуемое или выбранное генетическое изменение, но утратили компоненты CRISPR-Cas или их остатки, которые потенциально могли бы действовать неспецифически, что привело бы к вопросам, касающимся безопасности, или затрудняло бы разрешение регуляторного органа. Помимо прочего, в настоящем изобретении предусмотрены продукты, производимые клетками, организмами и потомство клеток и организмов.
Системы CRISPR-Cas на основе индуцируемого Cpf1 ("Split-Cpf1")
В одном аспекте настоящего изобретения предусмотрена не встречающаяся в природе или сконструированная система CRISPR-Cas на основе индуцируемого Cpf1, содержащая:
первую слитую конструкцию на основе Cpf1, к которой прикреплена первая половинка индуцируемого димера, и
вторую слитую конструкцию на основе Cpf1, к которой прикреплена вторая половинка индуцируемого димера,
где первая слитая конструкция на основе Cpf1 функционально связана с одним или несколькими сигналами ядерной локализации,
где вторая слитая конструкция на основе Cpf1 функционально связана с одним или несколькими сигналами ядерного экспорта,
где приведение в контакт с источником энергии, являющимся индуктором, обеспечивает сведение первой и второй половинок индуцируемого димера вместе,
где сведение первой и второй половинок индуцируемого димера вместе позволяет первой и второй слитым конструкциям на основе Cpf1 образовать функциональную систему CRISPR-Cas на основе Cpf1,
где система CRISPR-Cas на основе Cpf1 содержит направляющую РНК (gRNA), предусматривающую направляющую последовательность, способную гибридизироваться с целевой последовательностью в представляющем интерес локусе генома в клетке, и
где функциональная система CRISPR-Cas на основе Cpf1 связывается с целевой последовательностью и необязательно редактирует локус генома для изменения экспрессии генов.
В одном аспекте настоящего изобретения в системе CRISPR-Cas на основе индуцируемого Cpf1 индуцируемый димер представляет собой, или содержит, или состоит, по сути, из, или состоит из индуцируемого гетеродимера. В одном аспекте в системе CRISPR-Cas на основе индуцируемого Cpf1 первая половинка, или первая часть, или первый фрагмент индуцируемого гетеродимера представляет собой, или содержит, или состоит из, или состоит, по сути, из FKBP, необязательно FKBP12. В одном аспекте настоящего изобретения в системе CRISPR-Cas на основе индуцируемого Cpf1 вторая половинка, или вторая часть, или второй фрагмент индуцируемого гетеродимера представляет собой, или содержит, или состоит из, или состоит, по сути, из FRB. В одном аспекте настоящего изобретения в системе CRISPR-Cas на основе индуцируемого Cpf1 порядок расположения в первой слитой конструкции на основе Cpf1 представляет собой, или содержит, или состоит из, или состоит, по сути, из N'-концевая часть Cpf1-FRB-NES. В одном аспекте настоящего изобретения в системе CRISPR-Cas на основе индуцируемого Cpf1 порядок расположения первой слитой конструкции на основе Cpf1 представляет собой, или содержит, или состоит, по сути, из, или состоит из NES-N'-концевая часть Cpf1-FRB-NES. В одном аспекте настоящего изобретения в системе CRISPR-Cas на основе индуцируемого Cpf1 порядок расположения во второй слитой конструкции на основе Cpf1 представляет собой, или содержит, или состоит, по сути, из, или состоит из C'-концевая часть Cpf1-FKBP-NLS. В одном аспекте настоящего изобретения предусмотрена система CRISPR-Cas на основе индуцируемого Cpf1, в которой порядок расположения во второй слитой конструкции на основе Cpf1 представляет собой, или содержит, или состоит из, или состоит, по сути, из NLS-C'-концевая часть Cpf1-FKBP-NLS. В одном аспекте в системе CRISPR-Cas на основе индуцируемого Cpf1 может присутствовать линкер, который отделяет часть Cpf1 от половинки, или части, или фрагмента индуцируемого димера. В одном аспекте в системе CRISPR-Cas на основе индуцируемого Cpf1 источник энергии, являющийся индуктором, представляет собой, или содержит, или состоит, по сути, из, или состоит из рапамицина. В одном аспекте в системе CRISPR-Cas на основе индуцируемого Cpf1 индуцируемый димер представляет собой индуцируемый гомодимер. В одном аспекте в системе CRISPR-Cas на основе индуцируемого Cpf1 - Cpf1 представляет собой FnCpf1. В одном аспекте в системе CRISPR-Cas на основе индуцируемого Cpf1 один или несколько функциональных доменов ассоциированы с одной или обеими частями Cpf1, например, функциональные домены необязательно включают активатор транскрипции, транскрипционный элемент или нуклеазу, такую как нуклеаза Fok1. В одном аспекте системы CRISPR-Cas на основе индуцируемого Cpf1 функциональная система CRISPR-Cas на основе Cpf1 связывается с целевой последовательностью, и при этом фермент представляет собой нефункциональный Cpf1, который необязательно характеризуется нуклеазной активностью, сниженной по меньшей мере на 97% или 100% (или характеризуется не более чем 3% и преимущественно 0% нуклеазной активностью) по сравнению с Cpf1, не имеющим по меньшей мере одной мутации. Настоящее изобретение дополнительно охватывает полинуклеотид, кодирующий систему CRISPR-Cas на основе индуцируемого Cpf1, обсуждаемую в данном документе, и он предусмотрен в одном аспекте настоящего изобретения.
В одном аспекте настоящего изобретения предусмотрен вектор для доставки первой слитой конструкции на основе Cpf1, к которой прикреплена первая половинка, или часть, или фрагмент индуцируемого димера, и которая функционально связана с одним или несколькими сигналами ядерной локализации, в соответствии с обсуждаемым в данном документе. В одном аспекте настоящего изобретения предусмотрен вектор для доставки второй слитой конструкции на основе Cpf1, к которой прикреплена вторая половинка, или часть, или фрагмент индуцируемого димера, и которая функционально связана с одним или несколькими сигналами ядерного экспорта.
В одном аспекте настоящего изобретения предусмотрен вектор для доставки как первой слитой конструкции на основе Cpf1, к которой прикреплена первая половинка, или часть, или фрагмент индуцируемого димера, и которая функционально связана с одним или несколькими сигналами ядерной локализации, обсуждаемыми в данном документе; так и второй слитой конструкции на основе Cpf1, к которой прикреплена вторая половинка, или часть, или фрагмент индуцируемого димера, и которая функционально связана с одним или несколькими сигналами ядерного экспорта, обсуждаемыми в данном документе.
В одном аспекте вектор может представлять отдельную плазмиду или кассету экспрессии.
В одном аспекте настоящего изобретения предусмотрены эукариотическая клетка-хозяин или линия клеток, трансформированные с помощью любого из векторов, обсуждаемых в данном документе, или экспрессирующие систему CRISPR-Cas на основе индуцируемого Cpf1, обсуждаемую в данном документе.
В одном аспекте настоящего изобретения предусмотрен трансгенный организм, трансформированный с помощью любого из векторов, обсуждаемых в данном документе, или экспрессирующий систему CRISPR-Cas на основе индуцируемого Cpf1, обсуждаемую в данном документе, или его потомство. В одном аспекте настоящего изобретения предусмотрен модельный организм, который конститутивно экспрессирует систему CRISPR-Cas на основе индуцируемого Cpf1, обсуждаемую в данном документе.
В одном аспекте настоящего изобретения предусмотрена не встречающаяся в природе или сконструированная система CRISPR-Cas на основе индуцируемого Cpf1, содержащая:
первую слитую конструкцию на основе Cpf1, к которой прикреплена первая половинка индуцируемого гетеродимера, и
вторую слитую конструкцию на основе Cpf1, к которой прикреплена вторая половинка индуцируемого гетеродимера,
где первая слитая конструкция на основе Cpf1 функционально связана с одним или несколькими сигналами ядерной локализации,
где вторая слитая конструкция на основе CPf1 функционально связана с сигналом ядерного экспорта,
где приведение в контакт с источником энергии, являющимся индуктором, обеспечивает сведение первой и второй половинок индуцируемого гетеродимера вместе,
где сведение первой и второй половинок индуцируемого гетеродимера вместе позволяет первой и второй слитым конструкциям на основе Cpf1 образовать функциональную систему CRISPR-Cas на основе Cpf1,
где система CRISPR-Cas на основе Cpf1 содержит направляющую РНК (gRNA), предусматривающую направляющую последовательность, способную гибридизироваться с целевой последовательностью в представляющем интерес локусе генома в клетке, и
где функциональная система CRISPR-Cas на основе Cpf1 редактирует локус генома для изменения экспрессии генов.
В одном аспекте настоящего изобретения предусмотрен способ лечения субъекта, нуждающегося в этом, включающий индуцирование редактирования генов путем трансформации субъекта с помощью полинуклеотида, обсуждаемого в данном документе, или любого из векторов, обсуждаемых в данном документе, и введение субъекту источника энергии, являющегося индуктором. Настоящее изобретение охватывает пути применения такого полинуклеотида или вектора в изготовлении лекарственного препарата, например, такого лекарственного препарата, предназначенного для лечения субъекта или для такого способа лечения субъекта. Настоящее изобретение охватывает полинуклеотид, обсуждаемый в данном документе, или любой из векторов, обсуждаемых в данном документе, для применения в способе лечения субъекта, нуждающегося в этом, предусматривающем индуцирование редактирования генов, где способ дополнительно включает введение субъекту источника энергии, являющегося индуктором. В одном аспекте в способе также обеспечивается матрица для репарации, например, доставляемая вектором, содержащим указанную матрицу для репарации.
В настоящем изобретении также предусмотрен способ лечения субъекта, нуждающегося в этом, включающий индуцирование активации или репрессии транскрипции путем трансформации субъекта с помощью полинуклеотида, обсуждаемого в данном документе, или любого из векторов, обсуждаемых в данном документе, где указанные полинуклеотид или вектор кодируют или содержат каталитически неактивный Cpf1 и один или несколько ассоциированных c ним функциональных доменов, обсуждаемых в данном документе; при этом способ дополнительно включает введение субъекту источника энергии, являющегося индуктором. В настоящем изобретении также предусмотрен полинуклеотид, обсуждаемый в данном документе, или любой из векторов, обсуждаемых в данном документе, для применения в способе лечения субъекта, нуждающегося в этом, включающем индуцирование активации или репрессии транскрипции, где способ дополнительно включает введение субъекту источника энергии, являющегося индуктором.
Соответственно, настоящее изобретение охватывает, помимо прочего, гомодимеры, а также гетеродимеры, нефункциональный Cpf1 или Cpf1, характеризующийся фактически отсутствием нуклеазной активности, например, из-за мутации, системы или комплексы, в которых присутствуют одна или несколько NLS и/или одна или несколько NES; функциональный(функциональные) домен(домены), связанный(связанные) со split-Cpf1; способы, в том числе способы лечения, и пути применения.
Следует понимать, что когда в данном документе ссылаются на Cpf1, белок Cpf1 или фермент Cpf1, то под ними подразумевают split-Cpf1 по настоящему изобретению. В одном аспекте настоящего изобретения предусмотрен способ изменения или модифицирования экспрессии продукта гена. Указанный способ может включать введение в клетку, содержащую и экспрессирующую молекулу ДНК, кодирующую продукт гена, сконструированной не встречающейся в природе системы CRISPR-Cas на основе Cpf1, содержащей белок Cpf1 и направляющую РНК, которая нацеливается на молекулу ДНК, в результате чего направляющая РНК нацеливается на молекулу ДНК, кодирующую продукт гена, а белок Cpf1 расщепляет молекулу ДНК, кодирующую продукт гена, в результате чего изменяется экспрессия продукта гена; и где белок Cpf1 и направляющая РНК не встречаются в природе вместе. Настоящее изобретение охватывает направляющую РНК, предусматривающую направляющую последовательность, связанную с последовательностью прямого повтора (DR). Настоящее изобретение дополнительно охватывает белок Cpf1, который является кодон-оптимизированным для экспрессии в эукариотической клетке. В предпочтительном варианте осуществления эукариотическая клетка является клеткой млекопитающего, и в более предпочтительном варианте осуществления клетка млекопитающего является клеткой человека. В дополнительном варианте осуществления настоящего изобретения экспрессия продукта гена является сниженной.
В одном аспекте настоящего изобретения предусмотрена сконструированная не встречающаяся в природе система CRISPR-Cas на основе Cpf1, содержащая белок Cpf1 и направляющую РНК, которая нацеливается на молекулу ДНК, кодирующую продукт гена в клетке, в результате чего направляющая РНК нацеливается на молекулу ДНК, кодирующую продукт гена, а белок Cpf1 расщепляет молекулу ДНК, кодирующую продукт гена, в результате чего изменяется экспрессия продукта гена; и где белок Cpf1 и направляющая РНК не встречаются в природе вместе; при этом предусматривается split-Cpf1 по настоящему изобретению. Настоящее изобретение охватывает направляющую РНК, предусматривающую направляющую последовательность, связанную с последовательностью DR. Настоящее изобретение дополнительно охватывает белок Cpf1, который является кодон-оптимизированным для экспрессии в эукариотической клетке. В предпочтительном варианте осуществления эукариотическая клетка является клеткой млекопитающего, и в более предпочтительном варианте осуществления клетка млекопитающего является клеткой человека. В дополнительном варианте осуществления настоящего изобретения экспрессия продукта гена является сниженной.
В другом аспекте настоящего изобретения предусмотрена сконструированная не встречающаяся в природе векторная система, содержащая один или несколько векторов, содержащих первый регуляторный элемент, функционально связанный с направляющей РНК системы CRISPR-Cas на основе Cpf1, которая нацеливается на молекулу ДНК, кодирующую продукт гена, и второй регуляторный элемент, функционально связанный с белком Cpf1; при этом предусматривается split-Cpf1 по настоящему изобретению. Компоненты (a) и (b) могут быть расположены в одном и том же или разных векторах системы. Направляющая РНК нацеливается на молекулу ДНК, кодирующую продукт гена в клетке, а белок Cpf1 расщепляет молекулу ДНК, кодирующую продукт гена, в результате чего изменяется экспрессия продукта гена; и где белок Cpf1 и направляющая РНК не встречаются в природе вместе. Настоящее изобретение охватывает направляющую РНК, предусматривающую направляющую последовательность, связанную с последовательностью DR. Настоящее изобретение дополнительно охватывает белок Cpf1, который является кодон-оптимизированным для экспрессии в эукариотической клетке. В предпочтительном варианте осуществления эукариотическая клетка является клеткой млекопитающего, и в более предпочтительном варианте осуществления клетка млекопитающего является клеткой человека. В дополнительном варианте осуществления настоящего изобретения экспрессия продукта гена является сниженной.
В одном аспекте настоящего изобретения предусмотрена векторная система, содержащая один или несколько векторов. В некоторых вариантах осуществления система содержит: (a) первый регуляторный элемент, функционально связанный с последовательностью DR и одним или несколькими сайтами встраивания для встраивания одной или нескольких направляющих последовательностей ниже последовательности DR, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR-Cas на основе Cpf1 с целевой последовательностью в эукариотической клетке, где комплекс CRISPR-Cas на основе Cpf1 содержит Cpf1 в комплексе с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью, и (2) последовательностью DR; и (b) второй регуляторный элемент, функционально связанный с фермент-кодирующей последовательностью, которая кодирует указанный фермент Cpf1, содержащий последовательность ядерной локализации; где компоненты (a) и (b) находятся в одном и том же или разных векторах системы; при этом предусматривается split-Cpf1 по настоящему изобретению. В некоторых вариантах осуществления компонент (a) дополнительно содержит две или более направляющих последовательностей, функционально связанных с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR-Cas на основе Cpf1 со своей целевой последовательностью в эукариотической клетке.
В некоторых вариантах осуществления комплекс CRISPR-Cas на основе Cpf1 содержит одну или несколько последовательностей ядерной локализации, характеризующихся достаточной эффективностью, чтобы управлять накоплением указанного комплекса CRISPR-Cas на основе Cpf1 в обнаруживаемом количестве в ядре эукариотической клетки. Не вдаваясь в теорию полагают, что последовательность ядерной локализации не является необходимой для активности комплекса CRISPR-Cas на основе Cpf1 у эукариот, но включение таких последовательностей повышает активность системы, особенно в отношении нацеливания на молекулы нуклеиновой кислоты в ядре.
В некоторых вариантах осуществления фермент Cpf1 представляет собой Cpf1 от видов бактерий, выбранных из группы, состоящей из Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens и Porphyromonas macacae, и может включать мутированный CPf1, происходящий из этих организмов. Фермент может быть гомологом или ортологом Cpf1. В некоторых вариантах осуществления Cpf1 является кодон-оптимизированным для экспрессии в эукариотической клетке. В некоторых вариантах осуществления Cpf1 управляет расщеплением одной или двух нитей в определенном положении целевой последовательности. В предпочтительном варианте осуществления разрыв нити представляет собой ступенчатый разрез с "липким" 5'-концом. В некоторых вариантах осуществления первый регуляторный элемент является промотором полимеразы III. В некоторых вариантах осуществления второй регуляторный элемент является промотором полимеразы II. В некоторых вариантах осуществления минимальная длина прямого повтора составляет 16 нуклеотидов, и он содержит одну "петлю-на-стебле". В дополнительных вариантах осуществления длина прямого повтора составляет более 16 нуклеотидов, предпочтительно более 17 нуклеотидов, и он содержит более одной "петли-на-стебле" или оптимизированных вторичных структур.
В одном аспекте настоящего изобретения предусмотрена эукариотическая клетка-хозяин, содержащая (a) первый регуляторный элемент, функционально связанный с последовательностью прямого повтора и одним или несколькими сайтами встраивания для встраивания одной или нескольких направляющих последовательностей ниже последовательности DR, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR-Cas на основе Cpf1 с целевой последовательностью в эукариотической клетке, где комплекс CRISPR-Cas на основе Cpf1 содержит Cpf1 в комплексе с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью, и (2) последовательностью DR; и/или (b) второй регуляторный элемент, функционально связанный с фермент-кодирующей последовательностью, которая кодирует указанный фермент Cpf1, содержащий последовательность ядерной локализации. В некоторых вариантах осуществления клетка-хозяин содержит компоненты (a) и (b); при этом предусматривается split-Cpf1 по настоящему изобретению. В некоторых вариантах осуществления компонент (a), компонент (b) или компоненты (a) и (b) стабильно интегрированы в геном эукариотической клетки-хозяина. В некоторых вариантах осуществления компонент (a) дополнительно содержит две или более направляющих последовательностей, функционально связанных с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR-Cas на основе Cpf1 со своей целевой последовательностью в эукариотической клетке. В некоторых вариантах осуществления CPf1 является кодон-оптимизированным для экспрессии в эукариотической клетке. В некоторых вариантах осуществления Cpf1 управляет расщеплением одной или двух нитей в определенном положении целевой последовательности. В предпочтительном варианте осуществления разрыв нити представляет собой ступенчатый разрез с "липким" 5'-концом. В некоторых вариантах осуществления Cpf1 не обладает активностью расщепления нитей ДНК. В некоторых вариантах осуществления первый регуляторный элемент является промотором полимеразы III. В некоторых вариантах осуществления минимальная длина прямого повтора составляет 16 нуклеотидов, и он содержит одну "петлю-на-стебле". В дополнительных вариантах осуществления длина прямого повтора составляет более 16 нуклеотидов, предпочтительно более 17 нуклеотидов, и он содержит более одной "петли-на-стебле" или оптимизированных вторичных структур. В одном аспекте настоящего изобретения предусмотрен эукариотический организм, отличный от человека; предпочтительно многоклеточный эукариотический организм, содержащий эукариотическую клетку-хозяина в соответствии с любым из описанных вариантов осуществления. В других аспектах настоящего изобретения предусмотрен эукариотический организм, предпочтительно многоклеточный эукариотический организм, содержащий эукариотическую клетку-хозяина в соответствии с любым из описанных вариантов осуществления. В некоторых вариантах осуществления этих аспектов организм может представлять собой животное; например, млекопитающее. Также организм может представлять собой членистоногое, такое как насекомое. Организм также может представлять собой растение. Кроме того, организм может представлять собой гриб.
В одном аспекте настоящего изобретения предусмотрен набор, содержащий один или несколько компонентов, описанных в данном документе. В некоторых вариантах осуществления набор содержит векторную систему и инструкции по применению набора. В некоторых вариантах осуществления векторная система содержит (a) первый регуляторный элемент, функционально связанный с последовательностью прямого повтора и одним или несколькими сайтами встраивания для встраивания одной или нескольких направляющих последовательностей ниже последовательности DR, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR-Cas на основе Cpf1 с целевой последовательностью в эукариотической клетке, где комплекс CRISPR-Cas на основе Cpf1 содержит Cpf1 в комплексе с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью, и (2) последовательностью DR; и/или (b) второй регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, которая кодирует указанный фермент Cpf1, содержащий последовательность ядерной локализации, и преимущественно он предусматривает split-Cpf1 по настоящему изобретению. В некоторых вариантах осуществления набор содержит компоненты (a) и (b), находящиеся в одном и том же или разных векторах системы. В некоторых вариантах осуществления компонент (a) дополнительно содержит две или более направляющих последовательностей, функционально связанных с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR-Cas на основе Cpf1 со своей целевой последовательностью в эукариотической клетке. В некоторых вариантах осуществления Cpf1 содержит одну или несколько последовательностей ядерной локализации, характеризующихся достаточной эффективностью, чтобы управлять накоплением указанного Cpf1 в обнаруживаемом количестве в ядре эукариотической клетки. В некоторых вариантах осуществления фермент Cpf1 представляет собой Cpf1 от видов бактерий, выбранных из группы, состоящей из Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens и Porphyromonas macacae, и может включать мутированный CPf1, происходящий из этих организмов. Фермент может быть гомологом или ортологом Cpf1. В некоторых вариантах осуществления Cpf1 является кодон-оптимизированным для экспрессии в эукариотической клетке. В некоторых вариантах осуществления Cpf1 управляет расщеплением одной или двух нитей в определенном положении целевой последовательности. В предпочтительном варианте осуществления разрыв нити представляет собой ступенчатый разрез с "липким" 5'-концом. В некоторых вариантах осуществления фермент CRISPR не обладает активностью расщепления нитей ДНК. В некоторых вариантах осуществления минимальная длина прямого повтора составляет 16 нуклеотидов, и он содержит одну "петлю-на-стебле". В дополнительных вариантах осуществления длина прямого повтора составляет более 16 нуклеотидов, предпочтительно более 17 нуклеотидов, и он содержит более одной "петли-на-стебле" или оптимизированных вторичных структур.
В одном аспекте настоящего изобретения предусмотрен способ модифицирования целевого полинуклеотида в эукариотической клетке. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса CRISPR-Cas на основе Cpf1 с целевым полинуклеотидом для осуществления расщепления указанного целевого полинуклеотида, за счет чего обеспечивается модифицирование целевого полинуклеотида, где комплекс CRISPR-Cas на основе Cpf1 содержит Cpf1 в комплексе с направляющей последовательностью, гибридизированной с целевой последовательностью в пределах указанного целевого полинуклеотида, где указанная направляющая последовательность связана с последовательностью прямого повтора. В некоторых вариантах осуществления указанное расщепление предусматривает расщепление одной или двух нитей в определенном положении целевой последовательности с помощью указанного Cpf1; при этом предусматривается split-Cpf1 по настоящему изобретению. В некоторых вариантах осуществления указанное расщепление приводит к сниженной транскрипции целевого гена. В некоторых вариантах осуществления способ дополнительно включает репарацию указанного расщепленного целевого полинуклеотида с помощью гомологичной рекомбинации с экзогенной полинуклеотидной матрицей, где указанная репарация приводит к возникновению мутации, предусматривающей вставку, делецию или замену одного или нескольких нуклеотидов в указанном целевом полинуклеотиде. В некоторых вариантах осуществления указанная мутация приводит к изменению одной или нескольких аминокислот в белке, экспрессируемом с гена, содержащего целевую последовательность. В некоторых вариантах осуществления способ дополнительно включает доставку одного или нескольких векторов в указанную эукариотическую клетку, где один или несколько векторов управляют экспрессией одного или нескольких из Cpf1 и направляющей последовательности, связанной с последовательностью DR. В некоторых вариантах осуществления указанные векторы доставляются в эукариотическую клетку в субъекте. В некоторых вариантах осуществления указанное модифицирование происходит в указанной эукариотической клетке в культуре клеток. В некоторых вариантах осуществления способ дополнительно включает выделение указанной эукариотической клетки из организма субъекта перед проведением указанного модифицирования. В некоторых вариантах осуществления способ дополнительно включает возвращение указанной эукариотической клетки и/или клеток, происходящих из нее, указанному субъекту.
В одном аспекте настоящего изобретения предусмотрен способ модифицирования экспрессии полинуклеотида в эукариотической клетке. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса CRISPR-Cas на основе Cpf1 с полинуклеотидом, так что указанное связывание приводит к повышенной или сниженной экспрессии указанного полинуклеотида; где комплекс CRISPR-Cas на основе Cpf1 содержит Cpf1 в комплексе с направляющей последовательностью, гибридизирующейся с целевой последовательностью в пределах указанного полинуклеотида, где указанная направляющая последовательность связана с последовательностью прямого повтора; при этом предусматривается split-Cpf1 по настоящему изобретению. В некоторых вариантах осуществления способ дополнительно включает доставку одного или нескольких векторов в указанные эукариотические клетки, где один или несколько векторов управляют экспрессией одного или нескольких из Cpf1 и направляющей последовательности, связанной с последовательностью DR.
В одном аспекте настоящего изобретения предусмотрен способ получения модельной эукариотической клетки, содержащей мутированный ген, ответственный за развитие заболевания. В некоторых вариантах осуществления ген, ответственный за развитие заболевания, представляет собой любой ген, ассоциированный с повышением риска наличия или развития заболевания. В некоторых вариантах осуществления способ включает (a) введение одного или нескольких векторов в эукариотическую клетку, где один или несколько векторов управляют экспрессией одного или нескольких из Cpf1 и направляющей последовательности, связанной с последовательностью прямого повтора; и (b) обеспечение связывания комплекса CRISPR-Cas на основе Cpf1 с целевым полинуклеотидом для осуществления расщепления целевого полинуклеотида в пределах указанного гена, ответственного за развитие заболевания, где комплекс CRISPR-Cas на основе Cpf1 содержит Cpf1 в комплексе с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью в пределах целевого полинуклеотида, и (2) последовательностью DR, с получением тем самым модельной эукариотической клетки, содержащей мутированный ген, ответственный за развитие заболевания; при этом предусматривается split-Cpf1 по настоящему изобретению. В некоторых вариантах осуществления указанное расщепление предусматривает расщепление одной или двух нитей в определенном положении целевой последовательности с помощью указанного Cpf1. В предпочтительном варианте осуществления разрыв нити представляет собой ступенчатый разрез с "липким" 5'-концом. В некоторых вариантах осуществления указанное расщепление приводит к сниженной транскрипции целевого гена. В некоторых вариантах осуществления способ дополнительно включает репарацию указанного расщепленного целевого полинуклеотида с помощью гомологичной рекомбинации с экзогенной полинуклеотидной матрицей, где указанная репарация приводит к возникновению мутации, предусматривающей вставку, делецию или замену одного или нескольких нуклеотидов в указанном целевом полинуклеотиде. В некоторых вариантах осуществления указанная мутация приводит к изменению одной или нескольких аминокислот при экспрессии белка с гена, содержащего целевую последовательность.
В одном аспекте настоящего изобретения предусмотрен способ разработки биологически активного средства, которое модулирует событие передачи сигнала в клетке, ассоциированное с геном, ответственным за развитие заболевания. В некоторых вариантах осуществления ген, ответственный за развитие заболевания, представляет собой любой ген, ассоциированный с повышением риска наличия или развития заболевания. В некоторых вариантах осуществления способ включает (a) приведение тестируемого соединения в контакт с модельной клеткой по любому из описанных вариантов осуществления; и (b) обнаружение изменения считываемого показания, что указывает на снижение или возрастание события передачи сигнала в клетке, ассоциированного с указанной мутацией в указанном гене, ответственном за развитие заболевания, с получением тем самым указанного биологически активного средства, которое модулирует указанное событие передачи сигнала в клетке, ассоциированное с указанным геном, ответственным за развитие заболевания.
В одном аспекте настоящего изобретения предусмотрен рекомбинантный полинуклеотид, содержащий направляющую последовательность ниже последовательности прямого повтора, где направляющая последовательность при экспрессии управляет специфичным к последовательности связыванием комплекса CRISPR-Cas на основе Cpf1 с соответствующей целевой последовательностью, присутствующей в эукариотической клетке. В некоторых вариантах осуществления целевой последовательностью является вирусная последовательность, присутствующая в эукариотической клетке. В некоторых вариантах осуществления целевая последовательность представляет собой протоонкоген или онкоген.
В одном аспекте настоящего изобретения предусмотрен способ отбора клетки или нескольких клеток путем введения одной или нескольких мутаций в ген в одной или нескольких клетках, причем способ включает введение одного или нескольких векторов в клетку(клетки), где один или несколько векторов управляют экспрессией одного или нескольких из Cpf1, направляющей последовательности, связанной с последовательностью прямого повтора, и матрицы редактирования; где матрица редактирования содержит одну или несколько мутаций, которые прекращают расщепление Cpf1; обеспечение гомологичной рекомбинации матрицы редактирования с целевым полинуклеотидом в клетке(клетках), подлежащей(подлежащих) отбору; обеспечение связывания комплекса CRISPR-Cas на основе Cpf1 с целевым полинуклеотидом для осуществления расщепления целевого полинуклеотида в пределах указанного гена, где комплекс CRISPR-Cas на основе Cpf1 содержит Cpf1 в комплексе с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью в пределах целевого полинуклеотида, и (2) последовательностью прямого повтора, где связывание комплекса CRISPR-Cas на основе Cpf1 с целевым полинуклеотидом индуцирует гибель клетки, тем самым обеспечивая возможность отбора одной или нескольких клеток, в которые были введены одна или несколько мутаций; при этом предусматривается split-Cpf1 по настоящему изобретению. В другом предпочтительном варианте настоящего изобретения клетка, подлежащая отбору, может представлять собой эукариотическую клетку. Аспекты настоящего изобретения предусматривают отбор специфических клеток без необходимости наличия маркера отбора или двухстадийного способа, который может включать систему негативного отбора.
В данном документе встречается фраза "при этом предусматривается split-Cpf1 по настоящему изобретению" или подобное выражение; и они указывают на то, что Cpf1 в вариантах осуществления, представленных в данном документе, может представлять собой split-Cpf1, обсуждаемый в данном документе.
В одном аспекте настоящее изобретение относится к не встречающейся в природе или сконструированной системе CRISPR-Cas на основе индуцируемого Cpf1, содержащей первую слитую конструкцию на основе Cpf1, к которой прикреплена первая половинка индуцируемого гетеродимера, и вторую слитую конструкцию на основе Cpf1, к которой прикреплена вторая половинка индуцируемого гетеродимера, где первая слитая конструкция на основе CPf1 функционально связана с одним или несколькими сигналами ядерной локализации, где вторая слитая конструкция на основе CPf1 функционально связана с сигналом ядерного экспорта, где приведение в контакт с источником энергии, являющимся индуктором, обеспечивает сведение первой и второй половинок индуцируемого гетеродимера вместе, где сведение первой и второй половинок индуцируемого гетеродимера вместе позволяет первой и второй слитым конструкциям на основе Cpf1 образовать функциональную систему CRISPR-Cas на основе Cpf1, где система CRISPR-Cas на основе Cpf1 содержит направляющую РНК (gRNA), содержащую направляющую последовательность, способную гибридизироваться с целевой последовательностью в представляющем интерес локусе генома в клетке, и где функциональная система CRISPR-Cas на основе Cpf1 редактирует локус генома для изменения экспрессии генов. В одном варианте осуществления настоящего изобретения первая половинка индуцируемого гетеродимера представляет собой FKBP12, а вторая половинка индуцируемого гетеродимера представляет собой FRB. В другом варианте осуществления настоящего изобретения источником энергии, являющимся индуктором, является рапамицин.
Источником энергии, являющимся индуктором, можно считать просто индуктор или димеризующее средство. Термин "источник энергии, являющийся индуктором" используется по всему данному документу для согласованности. Источник энергии, являющийся индуктором, (или индуктор) действует с восстановлением Cpf1. В некоторых вариантах осуществления источник энергии, являющийся индуктором, обеспечивает сведение двух частей Cpf1 вместе за счет действия двух половинок индуцируемого димера. Две половинки индуцируемого димера, следовательно, сводятся вместе в присутствии источника энергии, являющегося индуктором. Без источника энергии, являющегося индуктором, две половинки димера не будут образовывать димер (димеризоваться).
Таким образом, две половинки индуцируемого димера взаимодействуют с источником энергии, являющимся индуктором, с димеризацией в димер. В свою очередь, это обеспечивает восстановление Cpf1 путем сведения первой и второй частей Cpf1 вместе.
Каждая из слитых конструкций на основе фермента CRISPR содержит одну часть split-Cpf1. Они сливаются, предпочтительно посредством линкера, такого как линкер GlySer, описываемый в данном документе, с одной из двух половин димера. Две половинки димера могут быть, по сути, двумя одинаковыми мономерами, которые вместе образуют гомодимер, или они могут быть разными мономерами, которые вместе образуют гетеродимер. Таким образом, два мономера можно рассматривать как одну половинку полного димера.
Cpf1 является разделенным в том смысле, что две части фермента Cpf1, по сути, составляют функциональный Cpf1. Такой Cpf1 может функционировать как фермент, редактирующий геном (при образовании комплекса с целевой ДНК и направляющей), такой как никаза или нуклеаза (расщепляющая обе нити ДНК), или он может представлять собой нефункциональный Cpf1, который в сущности представляет собой ДНК-связывающий белок с очень небольшой каталитической активностью или с отсутствием таковой, как правило, из-за мутации(мутаций) в его каталитических доменах.
Две части split-Cpf1 можно рассматривать как N'-концевую часть и C'-концевую часть split-Cpf1. Слияние, как правило, происходит в точке разделения Cpf1. Другими словами, С'-конец N'-концевой части split-Cpf1 сливают с одной из половинок димера, тогда как N'-конец C'-концевой части сливают с другой половинкой димера.
Cpf1 не подлежит разделению в том смысле, что разрыв образуется заново. Точку разделения, как правило, разрабатывают in silico и клонируют в конструкции. Вместе две части split-Cpf1, N'-концевая и C'-концевая части, образуют полный Cpf1, содержащий предпочтительно по меньшей мере 70% или больше аминокислот дикого типа (или нуклеотидов, кодирующих их), предпочтительно по меньшей мере 80% или больше, предпочтительно по меньшей мере 90% или больше, предпочтительно по меньшей мере 95% или больше, и наиболее предпочтительно по меньшей мере 99% или больше аминокислот дикого типа (или нуклеотидов, кодирующих их). Может быть возможным некоторое урезание, и при этом предусматриваются мутанты. Нефункциональные домены могут быть полностью удалены. Важно то, что две части могут быть сведены вместе, и что требуемая функция Cpf1 возобновляется или восстанавливается.
Димер может быть гомодимером или гетеродимером.
Один или несколько, предпочтительно два, NLS можно применять в функциональной связи с первой конструкцией на основе Cpf1. Один или несколько, предпочтительно два, NES можно применять в функциональной связи с первой конструкцией на основе Cpf1. NLS и/или NES предпочтительно фланкируют слияние split-Cpf1-димера (т. e. половинку димера), т. e. один NLS может быть расположен на N'-конце первой конструкции на основе Cpf1, и один NLS может быть на C'-конце первой конструкции на основе Cpf1. Аналогично, один NES может быть расположен на N'-конце второй конструкции на основе Cpf1, и один NES может быть на C'-конце второй конструкции на основе Cpf1. Если ссылаются на N'- или C'-концы, следует понимать, что они соответствуют 5'- и 3'-концам в соответствующей нуклеотидной последовательности.
Предпочтительный порядок расположения заключается в том, что первая конструкция на основе Cpf1 устроена так: 5'-NLS-(N'-концевая часть Cpf1)-линкер-(первая половинка димера)-NLS-3'. Предпочтительный порядок расположения заключается в том, что вторая конструкция на основе Cpf1 устроена так: 5'-NES-(вторая половинка димера)-линкер-(C'-концевая часть Cpf1)-NES-3'. Подходящий промотор предпочтительно находится выше каждой из этих конструкций. Две конструкции можно доставлять отдельно или вместе.
В некоторых вариантах осуществления один или все из NES, находящиеся в функциональной связи со второй конструкцией на основе CPf1, могут быть заменены на NLS. Однако это, как правило, может не являться предпочтительным, и в других вариантах осуществления сигнал локализации, находящийся в функциональной связи со второй конструкцией на основе Cpf1, представляет собой один или несколько NES.
Также следует понимать, что NES может быть функционально связан с N'-концевым фрагментом split-Cpf1, и что NLS может быть функционально связан с C'-концевым фрагментом split-Cpf1. Однако порядок расположения, при котором NLS функционально связан с N'-концевым фрагментом split-Cpf1, а NES функционально связан с С'-концевым фрагментом split-Cpf1, может быть предпочтительным.
NES функционирует так, чтобы переместить вторую слитую конструкцию на основе Cpf1 за пределы ядра, по меньшей мере до тех пор, пока будет обеспечиваться источник энергии, являющийся индуктором (например, по меньшей мере до тех пор, пока обеспечивается источник энергии для выполнения индуктором своей функции). Присутствие индуктора стимулирует димеризацию двух продуктов слияния на основе Cpf1 в цитоплазме и делает термодинамически выгодным перемещение в ядро димеризованных первого и второго продуктов слияния на основе Cpf1. Без ограничения теорией, заявители полагают, что NES обеспечивает изоляцию второго продукта слияния на основе Cpf1 в цитоплазме (т. e. вне ядра). NLS в первом продукте слияния на основе Cpf1 обеспечивает его локализацию в ядре. В обоих случаях, заявители используют NES или NLS для сдвига равновесия (равновесия ядерного транспорта) в требуемом направлении. Димеризация, как правило, происходит вне ядра (очень небольшая часть может происходить в ядре), и NLS в димеризованном комплексе сдвигают равновесие ядерного транспорта к ядерной локализации, так что димеризованный и, следовательно, восстановленный Cpf1 проникает в ядро.
Фактически, заявители способны восстанавливать функцию split-Cpf1. Для доказательства концепции применяли транзиентную трансфекцию, и димеризация происходила в фоновом режиме в присутствии источника энергии, являющегося индуктором,. Никакой активности не наблюдали в случае отдельных фрагментов Cpf1. Затем для разработки этого обеспечивали стабильную экспрессию посредством лентивирусной доставки, и было показано, что подход со split-Cpf1 может быть применимым.
Такой подход со split-Cpf1 по настоящему изобретению является полезным, поскольку он обеспечивает возможность обеспечения индуцируемой активности Cpf1, таким образом обеспечивая возможность временного контроля. Более того, для снижения фоновой активности самособирающихся комплексов можно применять разные последовательности локализации (т. e. NES и NLS, что является предпочтительным). Тканеспецифичные промоторы, например, один для каждой из первой и второй слитых конструкций на основе Cpf1, также можно использовать для нацеливания, специфичного к определенной ткани, с обеспечением таким образом пространственного контроля. Два разных тканеспецифичных промотора можно использовать, чтобы обеспечить при необходимости более высокую степень контроля. Тот же подход можно использовать для специфичных к стадии промоторов, или можно применять смесь специфичных к стадии промоторов и тканеспецифичных промоторов, при этом одна из первой и второй слитых конструкций на основе Cpf1 находится под контролем (т. e. функционально связана или содержит) тканеспецифичного промотора, тогда как другая из первой и второй слитых конструкций на основе Cpf1 находится под контролем (т. e. функционально связана или содержит) специфичного к стадии промотора.
Система CRISPR-Cas на основе индуцируемого Cpf1 содержит одну или несколько последовательностей ядерной локализации (NLS), описываемых в данном документе, например, функционально связанные с первой слитой конструкцией на основе Cpf1. Эти последовательности ядерной локализации в идеальном случае характеризуются достаточной эффективностью, чтобы управлять накоплением указанной первой слитой конструкции на основе Cpf1 в обнаруживаемом количестве в ядре эукариотической клетки. Не вдаваясь в теорию полагают, что последовательность ядерной локализации не является необходимой для активности комплекса CRISPR-Cas на основе Cpf1 у эукариот, но включение таких последовательностей повышает активность системы, особенно в отношении нацеливания на молекулы нуклеиновой кислоты в ядре, и содействует функционированию системы из 2 частей согласно настоящему изобретению.
Подобным образом, вторая слитая конструкция на основе Cpf1 функционально связана с последовательностью ядерного экспорта (NES). На самом деле, она может быть связана с одной или несколькими последовательностями ядерного экспорта. Другими словами, число последовательностей экспорта, используемых со второй слитой конструкцией на основе Cpf1, предпочтительно составляет 1, или 2, или 3. Как правило, 2 являются предпочтительными, но 1 достаточна, и поэтому является предпочтительной в некоторых вариантах осуществления. Подходящие примеры NLS и NES известны из уровня техники. Например, предпочтительным сигналом ядерного экспорта (NES) является человеческий белок тирозинкиназа 2. Предпочтительные сигналы будут видоспецифичными.
Если используется система FRB и FKBP, то FKBP предпочтительно фланкируется последовательностями ядерной локализации (NLS). Если используется система FRB и FKBP, то предпочтительный порядок расположения представляет собой N'-концевой Cpf1-FRB-NES: C'-концевой Cpf1-FKBP-NLS. Таким образом, первая слитая конструкция на основе Cpf1 будет содержать C'-концевую часть Cpf1, а вторая слитая конструкция Cpf1 будет содержать N'-концевую часть Cpf1.
Другой полезный аспект настоящего изобретения заключается в том, что она может быть быстро активизироваться, т. е. имеет быструю реакцию. Без ограничения теорией полагают, что активность Cpf1 может быть индуцирована посредством димеризации имеющихся (уже присутствующих) слитых конструкций (за счет приведения в контакт с источником энергии, являющимся индуктором) быстрее, чем посредством экспрессии (в частности, трансляции) новых слитых конструкций. Таким образом, первая и вторая слитые конструкции на основе Cpf1 могут экспрессироваться в целевой клетке заблаговременно, т. е. до того, как потребуется активность Cpf1. Затем активность Cpf1 может временно контролироваться, а потом быстро устанавливаться путем добавления источника энергии, являющегося индуктором, который в идеале действует быстрее (с димеризацией гетеродимера и обеспечением тем самым активности Cpf1), чем посредством экспрессии (в том числе индукции транскрипции) Cpf1, доставленного, например, вектором.
Термины "Cpf1" или "фермент Cpf1" и "фермент CRISPR" используются в данном документе взаимозаменяемо, если не является очевидным иное.
Заявители продемонстрировали, что CPf1 может быть разделен на два компонента, которые при сведении вновь вместе восстанавливают функциональную нуклеазу. С использованием чувствительных к рапамицину доменов димеризации заявители получили химически индуцируемый Cpf1 для временного контроля опосредованного Cpf1 редактирования генома и модулирования транскрипции. Другими словами, заявители продемонстрировали, что Cpf1 можно сделать химически индуцируемым путем разделения на два фрагмента, и что чувствительные к рапамицину домены димеризации можно использовать для контролируемой повторной сборки Cpf1. Заявители показали, что повторно собранный Cpf1 может использоваться для опосредования редактирования генома (посредством нуклеазной/никазной активности), а также для модулирования транскрипции (в качестве ДНК-связывающего домена, так называемого "нефункционального Cpf1").
Таким образом, использование чувствительных к рапамицину доменов димеризации является предпочтительным. Повторная сборка Cpf1 является предпочтительной. Повторная сборка может определяться путем восстановления активности связывания. Если Cpf1 представляет собой никазу или индуцирует двухнитевой разрыв, то проводят подходящее процентное сравнение с диким типом, как описывается в данном документе.
Обработка рапамицином может продолжаться 12 дней. Доза может составлять 200 нM. Такое время обработки и/или молярная дозировка является примером соответствующей дозы для линий клеток эмбриональной почки человека 293FT (HEK293FT), и ее также можно использовать для других линий клеток. Эта схема может быть экстраполирована для терапевтического применения in vivo, например, в мг/кг. Однако в данном случае также предусматривается, что также используется стандартная дозировка для введения рапамицина субъекту. Под "стандартной дозировкой" подразумевают дозировку при обычном терапевтическом применении рапамицина или первичном показании (т. e. дозу, используемую при введении рапамицина для предупреждения отторжения органа).
Следует отметить, что предпочтительным порядком расположения частей Cpf1, содержащих FRB/FKBP, является отдельные части, и они являются неактивными до тех пор, пока индуцируемая рапамицином димеризация FRB и FKBP не приведет к повторной сборке функциональной полноразмерной нуклеазы Cpf1. Таким образом, предпочтительно, чтобы первая слитая конструкция на основе Cpf1, к которой прикреплена первая половина индуцируемого гетеродимера, доставлялась отдельно и/или локализовалась отдельно от второй слитой конструкции на основе Cpf1, к которой присоединена первая половина индуцируемого гетеродимера.
Для обеспечения изоляции фрагмента Cpf1(N)-FRB в цитоплазме, где существует меньшая вероятность димеризации с фрагментом Cpf1(C)-FKBP, локализуемым в ядре, предпочтительно использовать в Cpf1(N)-FRB одну последовательность ядерного экспорта (NES) из человеческой протеинтирозинкиназы 2 (Cpf1(N)-FRB-NES). В присутствии рапамицина Cpf1(N)-FRB-NES димеризуется с Cpf1(C)-FKBP-2xNLS с восстановлением полного белка Cpf1, что сдвигает равновесие ядерного транспорта в направлении ядерного импорта и обеспечивает возможность нацеливания на ДНК.
Высокая дозировка Cpf1 может увеличить частоту образования вставок-делеций в нецелевых (OT) последовательностях, которые характеризуются небольшим числом несовпадений с направляющей нитью. Такие последовательности являются особенно восприимчивыми, если несовпадения являются несмежными и/или находятся за пределами затравочного участка направляющей. Соответственно, временной контроль активности Cpf1 можно применять для снижения дозировки в экспериментах с длительной экспрессией, и это, следовательно, приводит к сниженному образованию нецелевых вставок/делеций по сравнению с конститутивно активным Cpf1.
Доставка с помощью вирусов является предпочтительной. В частности, предусматривается вектор доставки на основе лентивируса или AAV. Заявители получили конструкцию split-Cpf1 на основе лентивируса, подобную плазмиде lentiCRISPR. Части разделенного фермента должны быть достаточно маленькими, чтобы соответствовать ограничению по размеру AAV, составляющему ~4,7 т. о.
Заявители продемонстрировали, что стабильную низкокопийную экспрессию split-Cpf1 можно использовать для индуцирования значительного количества вставок/делеций в целевом локусе без образования значительного числа мутаций в нецелевых сайтах. Заявители клонировали фрагменты Cpf1 (2 части на основе разделения 5, описываемого в настоящем документе).
Также можно использовать нефункциональный Cpf1, содержащий домен трансактивации VP64, например, добавленный к Cpf1(C)-FKBP-2xNLS (нефункциональный Cpf1(C)-FKBP-2xNLS-VP64). Эти фрагменты восстанавливают каталитически неактивный продукт слияния Cpf1-VP64 (нефункциональный Cpf1-VP64). Активация транскрипции индуцируется под действием VP64 в присутствии рапамицина для индукции димеризации продукта слияния Cpf1(C)-FKBP и продукта слияния Cpf1(N)-FRB. Другими словами, заявители тестировали возможность индукции разделенного нефункционального Cpf1-VP64 и показали, что активация транскрипции индуцируется нефункциональным split-Cpf1-VP64 в присутствии рапамицина. Таким образом, индуцируемый Cpf1 по настоящему изобретению может быть ассоциирован с одним или несколькими функциональными доменами, такими как активатор или репрессор транскрипции или нуклеаза (такая как Fok1). Функциональный домен может быть связан или слит с одной частью split-Cpf1.
Предпочтительный порядок расположения заключается в том, что первая конструкция на основе Cpf1 устроена так: 5'-первый сигнал локализации-(N'-концевая часть CPf1)-линкер-(первая половинка димера)-первый сигнал локализации-3', и вторая конструкция на основе Cpf1 устроена так: 5'-второй сигнал локализации-(вторая половинка димера)-линкер-(C'-концевая часть Cpf1)-второй сигнал локализации-функциональный домен-3'. В данном случае функциональный домен помещен на 3'-конце второй конструкции на основе Cpf1. Альтернативно, функциональный домен может быть помещен на 5'-конце первой конструкции на основе Cpf1. Один или несколько функциональных доменов можно использовать на 3'-конце, или 5'-конце, или на обоих концах. Подходящий промотор предпочтительно находится выше каждой из этих конструкций. Две конструкции можно доставлять отдельно или вместе. Сигналами локализации могут быть NLS или NES, при условии, что они не смешаны в каждой конструкции.
В одном аспекте настоящего изобретения предусмотрена система CRISPR-Cas на основе индуцируемого Cpf1, где Cpf1 характеризуется нуклеазной активностью, сниженной по меньшей мере на 97% или 100% по сравнению с ферментом Cpf1, не имеющим по меньшей мере одной мутации.
Соответственно, также предпочтительно, чтобы Cpf1 представлял собой нефункциональный Cpf1. В идеальном случае, разделение всегда должно быть таким, чтобы каталитический(каталитические) домен(домены) не был(были) затронуты. Значение нефункционального Cpf1 состоит в том, что происходит связывание с ДНК, но не происходит расщепление или не проявляется никазная активность.
В одном аспекте настоящего изобретения предусмотрена система CRISPR-Cas на основе индуцируемого Cpf1, обсуждаемая в данном документе, где с Cpf1 ассоциированы один или несколько функциональных доменов. Такой функциональный домен может быть ассоциирован (т. e. связан или слит) с одной или обеими частями split-Cpf1. Он может быть ассоциирован с каждой из двух частей split-Cpf1. Следовательно, они могут быть представлены, как правило, в виде части первой и/или второй слитых конструкций на основе Cpf1, в виде продуктов слияния в пределах этой конструкции. Функциональные домены, как правило, сливают посредством линкера, такого как линкер GlySer, обсуждаемый в данном документе. Один или несколько функциональных доменов могут представлять собой домен активации или домен репрессии транскрипции. Хотя они могут представлять собой разные домены, предпочтительно, чтобы все функциональные домены являлись либо активаторами, либо репрессорами, и чтобы не использовалась смесь двух.
Домен активации транскрипции может предусматривать VP64, p65, MyoD1, HSF1, RTA или SET7/9.
В одном аспекте настоящего изобретения предусмотрена система CRISPR-Cas на основе индуцируемого Cpf1, обсуждаемая в данном документе, где один или несколько функциональных доменов, ассоциированных с Cpf1, представляют собой домен репрессии транскрипции.
В одном аспекте настоящего изобретения предусмотрена система CRISPR-Cas на основе индуцируемого Cpf1, обсуждаемая в данном документе, где домен репрессии транскрипции представляет собой домен KRAB.
В одном аспекте настоящего изобретения предусмотрена система CRISPR-Cas на основе индуцируемого Cpf1, обсуждаемая в данном документе, где домен репрессии транскрипции представляет собой домен NuE, домен NcoR, домен SID или домен SID4X.
В одном аспекте настоящего изобретения предусмотрена система CRISPR-Cas на основе индуцируемого Cpf1, обсуждаемая в данном документе, где один или несколько функциональных доменов, ассоциированных с адаптерным белком, характеризуются одной или несколькими видами активности, предусматривающими метилазную активность, деметилазную активность, активность в отношении активации транскрипции, активность в отношении репрессии транскрипции, активность фактора освобождения транскрипта, активность в отношении модификации гистонов, активность расщепления РНК, активность расщепления ДНК, активность интеграции ДНК или активность связывания нуклеиновой кислоты.
Домены, модифицирующие гистоны, также являются предпочтительными в некоторых вариантах осуществления. Иллюстративные домены, модифицирующие гистоны, обсуждаются ниже. Домены транспозазы, домены механизма HR (гомологичной рекомбинации), домены рекомбиназы и/или домены интегразы также являются предпочтительными в качестве функциональных доменов по настоящему изобретению. В некоторых вариантах осуществления активность интеграции ДНК имеют домены механизма HR, домены интегразы, домены рекомбиназы и/или домены транспозазы.
В одном аспекте настоящего изобретения предусмотрена система CRISPR-Cas на основе индуцируемого Cpf1, обсуждаемая в данном документе, где активность расщепления ДНК обеспечивается нуклеазой.
В одном аспекте настоящего изобретения предусмотрена система CRISPR-Cas на основе индуцируемого Cpf1, обсуждаемая в данном документе, где нуклеаза предусматривает нуклеазу Fok1.
Применение таких функциональных доменов, которые являются предпочтительными для системы на основе split-Cpf1 по настоящему изобретению, также подробно обсуждается в Konermann et al. ("Genome-scale transcriptional activation with an engineered CRISPR-Cas9 complex", опубликованной в Nature 11 декабря 2014 г.).
Система по настоящему изобретению может применяться с любой направляющей.
В определенных вариантах осуществления могут применяться модифицированные направляющие. Особенно предпочтительными являются направляющие в соответствии с идеями вышеупомянутой статьи Konermann, опубликованной в Nature 11 декабря 2014 г. Эти направляющие модифицированы тем, что добавлены связывающиеся с белком части РНК (такие как аптамеры). Такая(такие) часть(части) может(могут) замещать часть направляющей. Соответствующие домены связывающего РНК белка могут использоваться для последующего распознавания РНК и рекрутирования функциональных доменов, таких как описываемые в данном документе, к направляющей. Они, прежде всего, предназначены для применения с нефункциональным Cpf1, что приводит к активации или репрессии транскрипции или расщеплению ДНК посредством нуклеаз, таких как Fok1. Применение таких направляющих в комбинации с нефункциональным Cpf1 является эффективным, и оно особенно эффективно, если сам Cpf1 также ассоциирован со своим собственным функциональным доменом, обсуждаемым в данном документе. Если нефункциональный Cpf1 (с ассоциированным своим собственным функциональным доменом или без него) индуцируется с восстановлением в соответствии с настоящим изобретением, т. e. представляет собой split-Cpf1, то данный инструмент является особенно пригодным.
Направляющая РНК (gRNA), также предпочтительная для применения в соответствии с настоящим изобретением, может содержать направляющую последовательность, способную гибридизироваться с целевой последовательностью в представляющем интерес локусе генома в клетке, где gRNA модифицирована путем вставки отличающейся(отличающихся) последовательности(последовательностей) РНК, которая(которые) связывается(связываются) с одним или несколькими адаптерными белками, и где адаптерный белок ассоциирован с одним или несколькими функциональными доменами. Cpf1 может содержать по меньшей мере одну мутацию, вследствие которой фермент Cpf1 характеризуется не более чем 5% нуклеазной активности фермента Cpf1, не имеющего по меньшей мере одной мутации; и/или по меньшей мере одну или несколько последовательностей ядерной локализации. Также предусмотрена не встречающаяся в природе или сконструированная композиция, содержащая одну или несколько направляющих РНК (gRNA), содержащих направляющую последовательность, способную гибридизироваться с целевой последовательностью в представляющем интерес локусе генома в клетке, фермент Cpf1, содержащий по меньшей мере одну или несколько последовательностей ядерной локализации, где фермент CPf1 содержит по меньшей мере одну мутацию, вследствие которой фермент Cpf1 характеризуется не более чем 5% нуклеазной активности фермента Cpf1, не имеющего по меньшей мере одной мутации, где по меньшей мере одна gRNA модифицирована путем вставки отличающейся(отличающихся) последовательности(последовательностей) РНК, которая(которые) связывается(связываются) с одним или несколькими адаптерными белками, и где адаптерный белок ассоциирован с одним или несколькими функциональными доменами.
gRNA предпочтительно модифицирована путем вставки отличающейся(отличающихся) последовательности(последовательностей) РНК, которая(которые) связывается(связываются) с одним или несколькими адаптерными белками. Вставка отличающейся(отличающихся) последовательности(последовательностей) РНК, которая(которые) связывается(связываются) с одним или несколькими адаптерными белками, предпочтительно представляет собой аптамерную последовательность или две или более аптамерные последовательности, специфичные в отношении одного и того же адаптерного белка или разных адаптерных белков. Адаптерный белок предпочтительно предусматривает MS2, PP7, Qβ, F2, GA, fr, JP501, M12, R17, BZ13, JP34, JP500, KU1, M11, MX1, TW18, VK, SP, FI, ID2, NL95, TW19, AP205, φCb5, φCb8r, φCb12r, φCb23r, 7s, PRR1. Могут быть пригодны линии клеток, стабильно экспрессирующие, помимо прочего, нефункциональный split-Cpf1.
Заявители продемонстрировали, что Cpf1 может быть разделен на два отличающихся фрагмента, которые при сведении вновь вместе с помощью химической индукции восстанавливают функциональную полноразмерную нуклеазу Cpf1. Структура split-Cpf1 будет пригодной для ряда применений. Например, split-CPf1 может обеспечивать возможность осуществления генетических стратегий, направленных на ограничение активности CPf1 популяциями клеток, находящихся на границах, путем помещения каждого фрагмента под контроль разных тканеспецифичных промоторов. Кроме того, также можно использовать различные индуцируемые химическими веществами домены димеризации, как, например, APA и гиббереллин.
Источником энергии, являющимся индуктором, предпочтительно является химическая индукция.
Положением или местоположением разделения является точка, в которой первая часть фермента Cpf1 отделяется от второй части. В некоторых вариантах осуществления первая часть будет содержать или кодировать от 1 до X аминокислоты, тогда как вторая часть будет содержать или кодировать от X+1 аминокислоты до конца. В данном примере нумерация является непрерывной, но это не всегда может быть необходимо, поскольку аминокислоты (или нуклеотиды, кодирующие их) могут быть урезаны с конца любого из разделенных концов при условии, что сохраняются достаточная активность связывания ДНК и, при необходимости, активность никазы или расщепления ДНК, например, по меньшей мере 40%, 50%, 60%, 70%, 80%, 90% или 95% активности по сравнению с Cpf1 дикого типа.
Иллюстративная нумерация, представленная в данном документе, может приводится относительно белка дикого типа, предпочтительно FnCpf1 дикого типа. Однако предусматривается, что могут использоваться мутанты Cpf1 дикого типа, такие как белка FnCpf1. Нумерация также может не полностью соответствовать нумерации FnCpf1, поскольку, например, можно использовать некоторые N'- или C'-концевые усечения или делеции, но это можно решить с помощью стандартных инструментов выравнивания последовательностей. Ортологи также предпочтительны как инструмент выравнивания последовательностей.
Таким образом, положение разделения может быть выбрано средним специалистом в данной области, например, на основании данных о кристаллической структуре и/или результатов компьютерного прогнозирования структуры.
Например, с помощью компьютерного анализа первичной структуры нуклеаз Cpf1 выявили три отличающихся участка (фиг. 1). Первый, C-концевой RuvC-подобный домен, который является единственным охарактеризованным функциональным доменом. Второй, N-концевой альфа-спиральный участок, и третий, участок со смешанной альфа- и бета-структурой, расположенный между RuvC-подобным доменом и альфа-спиральным участком. Несколько небольших отрезков из неструктурированных участков прогнозируются в первичной структуре Cpf1. Неструктурированные участки, которые подвергаются воздействию растворителя и не являются консервативными в пределах разных ортологов Cpf1, могут представлять собой предпочтительные стороны для разделений (фиг. 2 и фиг. 3).
В нижеприведенной таблице представлены неограничивающие потенциальные участки разделения в As и LbCpf1. Сайт разделения в пределах такого участка может быть подходящим.
Для мутантов Cpf1 Fn, As и Lb должно быть совершенно очевидно, что соответствующее положение для потенциального сайта разделения, например, основывается на выравнивании последовательностей. Для отличных от Fn, As и Lb ферментов можно использовать кристаллическую структуру ортолога, если существует относительно высокая степень гомологии между ортологом и предполагаемым Cpf1, или можно использовать компьютерное прогнозирование.
В идеальном случае положение разделения должно быть расположено в пределах участка или петли. Предпочтительно, положение разделения находится там, где прерывание аминокислотной последовательности не приводит к частичному или полному разрушению структурного элемента (например, альфа-спиралей или бета-складчатых структур). Неструктурированные участки (участки, которые не обнаруживаются в кристаллической структуре, поскольку эти участки недостаточно структурированы, чтобы "застывать" в кристалле) часто являются предпочтительными вариантами. Заявители могут, например, проводить разделения в неструктурированных участках, которые доступны на поверхности Cpf1.
Заявители могут придерживаться следующей процедуры, которая представлена в качестве предпочтительного примера и в качестве руководства. Поскольку неструктурированные участки не обнаруживаются в кристаллической структуре, заявители сопоставляют окружающую аминокислотную последовательность в кристалле с первичной аминокислотной последовательностью Cpf1. Каждый неструктурированный участок может состоять, например, из приблизительно 3-10 аминокислот, которые не обнаруживаются в кристалле. Следовательно, заявители выполняют разделение между этими аминокислотами. Для включения большего количества потенциальных сторон разделения заявители включают разделения, расположенные в петлях вне Cpf1, с использованием тех же критериев, что и с неструктурированными участками.
В некоторых вариантах осуществления положение разделения находится во внешней петле Cpf1. В других предпочтительных вариантах осуществления положение разделения находится в неструктурированном участке Cpf1. Неструктурированный участок, как правило, представляет собой очень гибкую внешнюю петлю, структуру которой сложно определить по рентгенограмме кристалла.
После идентификации положения разделения можно разрабатывать подходящие конструкции.
Как правило, NES располагается на N'-конце первой части разделяемой аминокислотной последовательности (или на 5'-конце нуклеотида, кодирующего ее). В таком случае, NLS располагается на С'-конце второй части разделяемой аминокислотной последовательности (или на 3'-конце нуклеотида, кодирующего ее). Таким образом, первая слитая конструкция на основе Cpf1 может быть функционально связана с одним или несколькими сигналами ядерного экспорта, а вторая слитая конструкция на основе Cpf1 может быть функционально связана с сигналом ядерной локализации.
Разумеется, может предусматриваться обратный порядок расположения, при котором NLS располагается на N'-конце первой части разделяемой аминокислотной последовательности (или на 5'-конце нуклеотида, кодирующего ее). В таком случае, NES располагается на С'-конце второй части разделяемой аминокислотной последовательности (или на 3'-конце нуклеотида, кодирующего ее). Таким образом, первая слитая конструкция на основе Cpf1 может быть функционально связана с одним или несколькими сигналами ядерной локализации, а вторая слитая конструкция на основе Cpf1 может быть функционально связана с сигналом ядерного экспорта.
Разделения, которые обеспечивают то, что две части (каждая сторона разделения) имеют примерно одинаковую длину, могут быть полезны для целей упаковки. Например, считается, что легче поддерживать стехиометрию между обеими частями, когда транскрипты имеют примерно одинаковый размер.
В некоторых примерах N- и C-концевые части Cpf1, кодон-оптимизированного для человека, такого как FnCpf1, сливают с доменами димеризации FRB и FKBP соответственно. Такой порядок расположения может быть предпочтительным. Их можно поменять (т. е. N'-конец с FKBP и C'-конец с FRB).
Линкеры, как, например, (GGGGS)3, предпочтительно используют в данном документе для отделения фрагмента Cpf1 от домена димеризации. (GGGGS)3 является предпочтительным, поскольку он является относительно длинным линкером (15 аминокислот). Глициновые остатки являются наиболее гибкими, а сериновые остатки повышают вероятность того, что линкер будет находится на внешней стороне белка. (GGGGS)6, (GGGGS)9 или (GGGGS)12 предпочтительно можно использовать в качестве альтернатив. Другими предпочтительными альтернативами являются (GGGGS)1, (GGGGS)2, (GGGGS)4, (GGGGS)5, (GGGGS)7, (GGGGS)8, (GGGGS)10 или (GGGGS)11.
Например, (GGGGS)3 может быть включен между N'-концевым фрагментом Cpf1 и FRB. Например, (GGGGS)3 может быть включен между FKB и C'-концевым фрагментом Cpf1.
Доступны альтернативные линкеры, но считается, что очень гибкие линкеры лучше обеспечивают максимальную возможность объединения 2 частей Cpf1 и, таким образом, восстановления активности Cpf1. Одной альтернативой является то, что NLS нуклеоплазмина можно использовать в качестве линкера.
Линкер также можно использовать между Cpf1 и любым функциональным доменом. Опять-таки, в данном случае можно использовать линкер (GGGGS)3 (или его варианты с 6, 9 или 12 повторами) или можно использовать NLS нуклеоплазмина в качестве линкера между CPf1 и функциональным доменом.
Предусматриваются альтернативы системы FRB/FKBP. Например, система ABA и гиббереллина.
Соответственно, предпочтительными примерами семейства FKBP являются любые из следующих индуцируемых систем: FKBP, который димеризуется с кальциневрином А (CNA) в присутствии FK506; FKBP, который димеризуется с CyP-Fas в присутствии FKCsA; FKBP, который димеризуется с FRB в присутствии рапамицина; GyrB, который димеризуется с GryB в присутствии кумермицина; GAI, который димеризуется с GID1 в присутствии гиббереллина; или Snap-tag, который димеризуется с HaloTag в присутствии HaXS.
Альтернативы в самом семействе FKBP также являются предпочтительными. Например, FKBP, который гомодимеризуется (т. е. один FKBP димеризуется с другим FKBP) в присутствии FK1012. Таким образом, также предусмотрена не встречающаяся в природе или сконструированная система CRISPR-Cas на основе индуцируемого Cpf1, содержащая:
первую слитую конструкцию на основе Cpf1, к которой прикреплена первая половинка индуцируемого гомодимера, и
вторую слитую конструкцию на основе Cpf1, к которой прикреплена вторая половинка индуцируемого гомодимера,
где первая слитая конструкция на основе Cpf1 функционально связана с одним или несколькими сигналами ядерной локализации,
где вторая слитая конструкция на основе Cpf1 функционально связана с (необязательно одним или несколькими) сигналом(сигналами) ядерного экспорта,
где приведение в контакт с источником энергии, являющимся индуктором, обеспечивает сведение первой и второй половинок индуцируемого гомодимера вместе,
где сведение первой и второй половинок индуцируемого гомодимера вместе позволяет первой и второй слитым конструкциям на основе CPf1 образовать функциональную систему CRISPR-Cas на основе Cpf1,
где система CRISPR-Cas на основе Cpf1 содержит направляющую РНК (gRNA), предусматривающую направляющую последовательность, способную гибридизироваться с целевой последовательностью в представляющем интерес локусе генома в клетке, и
где функциональная система CRISPR-Cas на основе Cpf1 связывается с целевой последовательностью и необязательно редактирует локус генома для изменения экспрессии генов.
В одном варианте осуществления гомодимер предпочтительно представляет собой FKBP, а источник энергии, являющийся индуктором, предпочтительно представляет собой FK1012. В другом варианте осуществления гомодимер предпочтительно представляет собой GryB, а источник энергии, являющийся индуктором, предпочтительно представляет собой кумермицин. В другом варианте осуществления гомодимер предпочтительно представляет собой ABA, а источник энергии, являющийся индуктором, предпочтительно представляет собой гиббереллин.
В других вариантах осуществления димер является гетеродимером. Предпочтительными примерами гетеродимеров являются любые из следующих индуцируемых систем: FKBP, который димеризуется с кальциневрином А (CNA) в присутствии FK506; FKBP, который димеризуется с CyP-Fas в присутствии FKCsA; FKBP, который димеризуется с FRB в присутствии рапамицина в присутствии кумермицина; GAI, который димеризуется с GID1 в присутствии гиббереллина; или Snap-tag, который димеризуется с HaloTag в присутствии HaXS.
Заявители использовали FKBP/FRB, поскольку он хорошо охарактеризован, и оба домена являются достаточно маленькими (<100 аминокислот) для содействия упаковке. Более того, рапамицин использовался долгое время и его побочные эффекты хорошо известны. Крупные домены димеризации (>300 аминокислот) также должны работать, но для обеспечения восстановления Cpf1 могут потребоваться более длинные линкеры.
У Paulmurugan и Gambhir (Cancer Res, August 15, 2005 65; 7413) обсуждаются базовые сведения о системе FRB/FKBP/рапамицин. Другим полезным документом является статья Crabtree et al. (Chemistry & Biology 13, 99-107, Jan 2006).
В данном примере конструируют один вектор, кассету экспрессии (плазмиду). gRNA находится под контролем промотора U6. Используют два разных разделения Cpf1. Конструкция split-Cpf1 основывается на первой слитой конструкции на основе Cpf1, фланкированной NLS, с FKBP, слитым с C'-концевой частью split-Cpf1 посредством линкера GlySer; и второй слитой конструкции на основе Cpf1, фланкированной NES, с FRB, слитым с N'-концевой частью split-Cpf1 посредством линкера GlySer. Для разделения первой и второй слитых конструкций на основе Cpf1 используют P2A, разделяющееся при транскрипции. Split-Cpf1 демонстрирует образование вставок/делеций, подобное таковому у дикого типа, в присутствии рапамицина, но значительно более низкий уровень образования вставок/делеций, чем у дикого типа, в отсутствие рапамицина.
Соответственно, предусматривается один вектор. Вектор содержит:
первую слитую конструкцию на основе Cpf1, к которой прикреплена первая половинка индуцируемого димера, и
вторую слитую конструкцию на основе Cpf1, к которой прикреплена вторая половинка индуцируемого димера,
где первая слитая конструкция на основе Cpf1 функционально связана с одним или несколькими сигналами ядерной локализации,
где вторая слитая конструкция на основе CPf1 функционально связана с одним или несколькими сигналами ядерного экспорта,
где приведение в контакт с источником энергии, являющимся индуктором, обеспечивает сведение первой и второй половинок индуцируемого гетеродимера вместе,
где сведение первой и второй половинок индуцируемого гетеродимера вместе позволяет первой и второй слитым конструкциям на основе CPf1 образовать функциональную систему CRISPR-Cas на основе Cpf1,
где система CRISPR-Cas на основе Cpf1 содержит направляющую РНК (gRNA), предусматривающую направляющую последовательность, способную гибридизироваться с целевой последовательностью в представляющем интерес локусе генома в клетке, и
где функциональная система CRISPR-Cas на основе Cpf1 связывается с целевой последовательностью и необязательно редактирует локус генома для изменения экспрессии генов. Эти элементы предпочтительно представлены в одной конструкции, например, в кассете экспрессии.
Первая слитая конструкция на основе Cpf1 предпочтительно фланкирована по меньшей мере одним сигналом ядерной локализации на каждом конце. Вторая слитая конструкция на основе CPf1 предпочтительно фланкирована по меньшей мере одним сигналом ядерного экспорта на каждом конце.
Также предусмотрен способ лечения субъекта, нуждающегося в этом, включающий индуцирование редактирования генов путем трансформации субъекта с помощью полинуклеотида, кодирующего систему, или любого из векторов согласно настоящему изобретению и введение субъекту источника энергии, являющегося индуктором. Также может предусматриваться подходящая матрица для репарации, например, доставляемая вектором, содержащим указанную матрицу для репарации.
Также предусмотрен способ лечения субъекта, нуждающегося в этом, включающий индуцирование активации или репрессии транскрипции путем трансформации субъекта с помощью полинуклеотида, кодирующего систему согласно настоящему изобретению, или любого из векторов согласно настоящему изобретению, где указанные полинуклеотид или вектор кодируют или содержат каталитически неактивный Cpf1 и один или несколько ассоциированных с ним функциональных доменов; при этом способ дополнительно включает введение субъекту источника энергии, являющегося индуктором.
Также предусмотрены композиции, содержащие систему согласно настоящему изобретению, для применения в указанном способе лечения. Также предусмотрено применение системы согласно настоящему изобретению в изготовлении лекарственного препарата для таких способов лечения.
Примеры состояний, которые можно лечить с помощью системы согласно настоящему изобретению, описаны в данном документе или в документах, цитируемых в данном документе.
Один вектор может содержать средство, разделяющее транскрипты, например, P2A. P2A разделяет транскрипт на два с отделением первой и второй слитых конструкций на основе CPf1. Разделение происходит из-за "рибосомного пропуска". По сути, рибосома пропускает аминокислоту в ходе трансляции, что разрывает цепь белка и дает в результате два отдельных полипептида/белка. Один вектор также пригоден для применений, при которых низкая фоновая активность не представляет проблему, но при этом желательна высокая индуцируемая активность.
Одним примером может быть образование клональных линий эмбриональных стволовых клеток. Обычной процедурой является транзиентная трансфекция плазмидами, кодирующими CPf1 wt или никазы Cpf1. Эти плазмиды обеспечивают образование молекул Cpf1, которые остаются активными в течение нескольких дней и характеризуются более высокой вероятностью нецелевой активности. Использование одного вектора экспрессии для split-Cpf1 позволяет ограничить "высокую" активность Cpf1 более коротким промежутком времени (например, путем применения одной дозы индуктора, такого как рапамицин). Без непрерывных (ежесуточных) обработок индуктором (например, рапамицином) активность отдельных векторов экспрессии split-Cpf1 является низкой и обеспечивает сниженную вероятность возникновения нежелательных нецелевых эффектов.
Пик активности индуцированного Cpf1 полезен в некоторых вариантах осуществления и может быть наиболее легко вызван с использованием одного вектора доставки, но это также возможно с помощью двойной векторной системы (каждый вектор доставляет одну половинку split-Cpf1). Пик может представлять собой высокую активность и длиться в течение короткого срока, как правило, продолжительности действия индуктора.
Соответственно, предусмотрен способ получения клональных линий эмбриональных стволовых клеток, включающий трансфекцию одной или нескольких эмбриональных стволовых клеток с помощью полинуклеотида, кодирующего систему согласно настоящему изобретению, или одного из векторов согласно настоящему изобретению для экспрессии split-Cpf1 согласно настоящему изобретению и введение в одну или несколько стволовых клеток источника энергии, являющегося индуктором, согласно настоящему изобретению или приведение их в контакт с ним для индуцирования восстановления Cpf1. Может предусматриваться матрица для репарации.
Как и во всех способах, описанных в данном документе, следует понимать, что будут необходимы подходящие gRNA или направляющие.
Если функциональные домены и подобные "ассоциированы" с одной или другой частью фермента, то они, как правило, являются продуктами слияния. Термин "ассоциированный с" используется в данном документе в отношении того, как одна молекула "связывается" по отношению к другой, например, между частями Cpf1 и функциональным доменом. В случае таких белок-белковых взаимодействий эту ассоциацию можно рассматривать с точки зрения распознавания как распознавание антителом эпитопа. Альтернативно один белок может быть ассоциирован с другим белком посредством слияния обоих, например, одна субъединица является слитой с другой субъединицей. Слияние обычно происходит путем добавления одной аминокислотной последовательности к другой, например, посредством сплайсинга нуклеотидных последовательностей, которые кодируют каждый белок или субъединицу. Альтернативно, по сути, это можно рассматривать как связывание двух молекул или прямую связь, например, белок слияния. В любом случае слитый белок может включать линкер между двумя представляющими интерес субъединицами (т. е. между ферментом и функциональным доменом или между адаптерным белком и функциональным доменом). Таким образом, в некоторых вариантах осуществления часть CPf1 ассоциирована с функциональным доменом за счет связывания с ним. В других вариантах осуществления CPf1 ассоциирован с функциональным доменом ввиду того, что двое слиты вместе необязательно посредством промежуточного линкера. Примеры линкеров включают линкеры GlySer, обсуждаемые в данном документе.
Другие примеры индукторов включают свет и гормоны. Что касается света, индуцируемые димеры могут быть гетеродимерами и включать первую индуцируемую светом половинку димера и вторую (и комплементарную) индуцируемую светом половинку димера. Предпочтительным примером первой и второй индуцируемых светом половинок димера является система CIB1 и CRY2. Домен CIB1 является гетеродимерным партнером по связыванию чувствительного к свету криптохрома 2 (CRY2).
В другом примере чувствительная к синему свету система димеризации Magnet (pMag и nMag) может быть слита с двумя частями белка split-Cpf1. В ответ на стимуляцию светом pMag и nMag димеризуются и происходит повторная сборка Cpf1. Например, такая система описывается в связи с Cas9 у Nihongaki et al. (Nat. Biotechnol. 33, 755-790, 2015).
В настоящем изобретении подразумевается то, что источником энергии, являющимся индуктором, может быть тепло, ультразвук, электромагнитная энергия или химическое вещество. В предпочтительном варианте осуществления настоящего изобретения источником энергии, являющимся индуктором, может быть антибиотик, малая молекула, гормон, производное гормона, стероид или производное стероида. В более предпочтительном варианте осуществления источником энергии, являющимся индуктором, может быть абсцизовая кислота (ABA), доксициклин (DOX), кумат, рапамицин, 4-гидрокситамоксифен (4OHT), эстроген или экдизон. В настоящем изобретении предусматривается то, что по меньшей мере один "переключатель" может быть выбран из группы, состоящей из индуцируемых на основе антибиотиков систем, индуцируемых на основе электромагнитной энергии систем, индуцируемых на основе малых молекул систем, индуцируемых на основе ядерных рецепторов систем и индуцируемых на основе гормонов систем. В более предпочтительном варианте осуществления по меньшей мере один переключатель может быть выбран из группы, состоящей из индуцируемых тетрациклином (Tet)/DOX систем, индуцируемых светом систем, индуцируемых ABA систем, систем на основе куматного репрессора/оператора, индуцируемых 4OHT/эстрогеном систем, индуцируемых на основе экдизона систем и индуцируемых FKBP12/FRAP (комплекс FKBP12-рапамицин) систем. Такие индукторы также обсуждаются в данном документе и в заявке PCT/US2013/051418, включенной в данный документ посредством ссылки.
В целом, любое применение, которое может касаться Cpf1, будь то фермент дикого типа, никаза или нефункциональный Cpf1 (с ассоциированными функциональными доменами или без них), может быть осуществлено с использованием подхода split-Cpf1 согласно настоящему изобретению. Преимуществом остается индуцируемый характер активности Cpf1.
В качестве дополнительного примера могут быть получены продукты слияния split-CPf1 с флуоресцентными белками, такими как GFP. Это позволит визуализировать локусы генома (см. "Dynamic Imaging of Genomic Loci in Living Human Cells by an Optimized CRISPR/Cas System" Chen B. et al. Cell 2013), но индуцируемым образом. Таким образом, в некоторых вариантах осуществления одна или несколько частей Cpf1 могут быть ассоциированы (и, в частности, слиты с) флуоресцентным белком, например, GFP.
Дополнительные эксперименты касаются того, существует ли разница в нецелевом разрезании среди Cpf1 дикого типа (wt) и split-Cpf1 при аналогичном уровне нецелевого разрезания. Для этого заявители использовали транзиентную трансфекцию плазмидами с Cpf1 wt и split-Cpf1 и осуществляли сбор в разные моменты времени. Заявители определяли нецелевую активацию после выявления ряда образцов, в которых целевое разрезание составляло +/- 5%. Заявители получали линии клеток со стабильной экспрессией Cpf1 wt или split-Cpf1 без направляющих (с применением лентивируса). После отбора с помощью антибиотика направляющие доставляли с помощью отдельного лентивируса и осуществляли сбор в разные моменты времени для измерения целевого/нецелевого разрезания.
Заявители ввели дестабилизирующую последовательность (PEST, см. "Use of mRNA- and protein-destabilizing elements to develop a highly responsive reporter system" Voon DC et al. Nucleic Acids Research 2005) в фрагмент FRB(N)Cpf1-NES для облегчения более быстрого разрушения и, следовательно, для снижения стабильности комплекса нефункциональный split-Cpf1-VP64.
Такие дестабилизирующие последовательности, описываемые в других разделах данного описания (в том числе PEST), могут быть предпочтительными для применения с системами split-Cpf1.
Получали линии клеток, стабильно экспрессирующие нефункциональный split-Cpf1-VP64 и MS2-p65-HSF1 + направляющая. Скрининг на предмет устойчивости к PLX может демонстрировать, что необратимая, регулируемая во времени активация транскрипции может быть применима в скринингах лекарственных средств. Этот подход может быть преимущественным, если активация нефункционального split-Cpf1-VP64 является необратимой.
В одном аспекте настоящего изобретения предусмотрена не встречающаяся в природе или сконструированная система CRISPR-Cas на основе Cpf1, которая может содержать по меньшей мере один "переключатель", при этом активность указанной системы CRISPR-Cas на основе Cpf1 контролируется в отношении "переключателя" путем приведения в контакт по меньшей мере с одним источником энергии, являющимся индуктором. В одном варианте осуществления настоящего изобретения контроль в отношении по меньшей мере одного "переключателя" или активности указанной системы CRISPR-Cas на основе Cpf1 может быть активирован, усилен, прекращен или подавлен. Приведение в контакт по меньшей мере с одним источником энергии, являющимся индуктором, может приводить в результате к первому эффекту и второму эффекту. Первый эффект может представлять собой одно или несколько из ядерного импорта, ядерного экспорта, привлечения вторичного компонента (такого как эффекторная молекула), конформационного изменения (белка, ДНК или РНК), расщепления, высвобождения молекулы-карго (такой как защищенная молекула или кофактор), ассоциации или диссоциации. Второй эффект может представлять собой одно или несколько из активации, усиления, прекращения или подавления контроля в отношении по меньшей мере одного "переключателя" или активности указанной системы CRISPR-Cas на основе Cpf1. В одном варианте осуществления первый эффект и второй эффект могут проявляться в виде каскада.
В другом аспекте настоящего изобретения система CRISPR-Cas на основе Cpf1 может дополнительно содержать по меньшей мере один или несколько из сигнала ядерной локализации (NLS), сигнала ядерного экспорта (NES), функционального домена, гибкого линкера, мутации, делеции, изменения или усечения. Одно или несколько из NLS, NES или функционального домена могут быть активированными в зависимости от условий или инактивированными. В другом варианте осуществления мутацией может быть одна или несколько из мутации в гомологичном участке фактора транскрипции, мутации в ДНК-связывающем домене (как, например, подвергнутые мутации основные остатки в структуре основная спираль-петля-спираль), мутации в эндогенном NLS или мутации в эндогенном NES. В настоящем изобретении подразумевается то, что источником энергии, являющимся индуктором, может быть тепло, ультразвук, электромагнитная энергия или химическое вещество. В предпочтительном варианте осуществления настоящего изобретения источником энергии, являющимся индуктором, может быть антибиотик, малая молекула, гормон, производное гормона, стероид или производное стероида. В более предпочтительном варианте осуществления источником энергии, являющимся индуктором, может быть абсцизовая кислота (ABA), доксициклин (DOX), кумат, рапамицин, 4-гидрокситамоксифен (4OHT), эстроген или экдизон. В настоящем изобретении предусматривается то, что по меньшей мере один "переключатель" может быть выбран из группы, состоящей из индуцируемых на основе антибиотиков систем, индуцируемых на основе электромагнитной энергии систем, индуцируемых на основе малых молекул систем, индуцируемых на основе ядерных рецепторов систем и индуцируемых на основе гормонов систем. В более предпочтительном варианте осуществления по меньшей мере один переключатель может быть выбран из группы, состоящей из индуцируемых тетрациклином (Tet)/DOX систем, индуцируемых светом систем, индуцируемых ABA систем, систем на основе куматного репрессора/оператора, индуцируемых 4OHT/эстрогеном систем, индуцируемых на основе экдизона систем и индуцируемых FKBP12/FRAP (комплекс FKBP12-рапамицин) систем.
Аспекты контроля, подробно описываемые в данной заявке, относятся по меньшей мере к одному или нескольким "переключателям". Термин "переключатель", используемый в данном документе, обозначает систему или набор компонентов, которые действуют согласовано с обеспечением изменения, охватывающего все аспекты биологической функции, такие как активация, подавление, усиление или прекращение этой функции. В одном аспекте термин "переключатель" охватывает "генетические переключатели", которые содержат основные компоненты в виде белков, регулирующих гены, и специфические последовательности ДНК, которые эти белки распознают. В одном аспекте "переключатели" относятся к индуцируемым и репрессируемым системам, используемым в регуляции генов. В целом, индуцируемая система может быть неактивна до тех пор, пока не будет присутствовать определенная молекула (называемая индуктором), которая обеспечивает экспрессию гена. Считается, что молекула "индуцирует экспрессию". Способ, с помощью которого это осуществляется, зависит от механизмов контроля, а также от различий в типе клетки. Репрессируемая система является активной до тех пор, пока отсутствует определенная молекула (называемая корепрессор), которая подавляет экспрессию гена. Считается, что молекула "репрессирует экспрессию". Способ, с помощью которого это осуществляется, зависит от механизмов контроля, а также от различий в типе клетки. Термин "индуцируемый", используемый в данном документе, может охватывать все аспекты "переключателя" независимо от задействованного молекулярного механизма. Соответственно, "переключатель", как подразумевается в настоящем изобретении, может включать без ограничения индуцируемые на основе антибиотиков системы, индуцируемые на основе электромагнитной энергии системы, индуцируемые на основе малых молекул системы, индуцируемые на основе ядерных рецепторов системы и индуцируемые на основе гормонов системы. В предпочтительных вариантах осуществления "переключателем" может быть индуцируемая тетрациклином (Tet)/DOX система, индуцируемые светом системы, индуцируемая абсцизовой кислотой система, система на основе куматного репрессора/оператора, индуцируемая 4OHT/эстрогеном система, индуцируемые на основе экдизона системы и индуцируемая FKBP12/FRAP (комплексом FKBP12-рапамицин) система.
Система CRISPR-Cas на основе Cpf1 согласно настоящему изобретению может быть разработана для модулирования или изменения экспрессии отдельных эндогенных генов точным в пространственном и временном отношении способом. Система CRISPR-Cas на основе Cpf1 может быть разработана так, чтобы связываться с промоторной последовательностью представляющего интерес гена для изменения экспрессии гена. Cpf1 может быть разделен надвое, при этом одну половинку сливают с одной половинкой гетеродимера криптохрома (криптохрома-2 или CIB1), тогда как оставшуюся часть криптохрома сливают с другой половинкой Cpf1. В некоторых аспектах транскрипционный эффекторный домен также может быть включен в систему CRISPR-Cas на основе Cpf1. Эффекторные домены могут быть либо активаторами, такими как VP16, VP64 или p65, либо репрессорами, такими как KRAB, EnR или SID. В нестимулированном состоянии одна половинка белка Cpf1-криптохром-2 локализуется в промоторном участке представляющего интерес гена, но не связывается с CIB1-эффекторным белком. При стимуляция светом синего спектра криптохром-2 активируется, подвергается конформационному изменению и открывает свой домен связывания. CIB1, в свою очередь, связывается с криптохромом-2, что приводит в результате к локализации второй половинки Cpf1 в промоторном участке представляющего интерес гена и инициированию редактирования генома, которое может приводить к сверхэкспрессии или сайленсингу гена. Аспекты LITE дополнительно описываются в Liu, H et al., Science, 2008, и Kennedy M et al., Nature Methods 2010, содержание которых включено в данный документ посредством ссылки во всей своей полноте.
Активаторные и репрессорные домены, которые могут дополнительно модулировать функцию, могут быть выбраны на основании видов, эффективности, механизма, продолжительности, размера или любого ряда других параметров. Предпочтительные эффекторные домены включают без ограничения домен транспозазы, домен интегразы, домен рекомбиназы, домен резольвазы, домен инвертазы, домен протеазы, домен ДНК-метилтрансферазы, домен ДНК-деметилазы, домен гистонацетилазы, домен гистондеацетилазы, нуклеазный домен, репрессорный домен, активаторный домен, домены сигнала ядерной локализации, домен рекрутирования транскрипционного белка, домен, ассоциированный с активностью клеточного поглощения, домен связывания нуклеиновой кислоты или домен презентации антитела.
Существует несколько разных способов получения индуцируемых систем: 1. система на основе ABI-PYL, индуцируемая абсцизовой кислотой (ABA) (см., например, веб-сайт stke.sciencemag.org/cgi/content/abstract/sigtrans;4/164/rs2), 2. система на основе FKBP-FRB, индуцируемая рапамицином (или родственными химическими соединениями на основе рапамицина) (см., например, веб-сайт nature.com/nmeth/journal/v2/n6/full/nmeth763.html), 3. система на основе GID1-GAI, индуцируемая гиббереллином (GA) (см., например, веб-сайт nature.com/nchembio/journal/v8/n5/full/nchembio.922.html).
Другая система, предусматриваемая настоящим изобретением, представляет собой химически индуцируемую систему, основанную на изменении субклеточной локализации. Заявители также предусматривают индуцируемую систему CRISPR-Cas на основе Cpf1, сконструированную для нацеливания на представляющий интерес локус генома, при этом фермент Cpf1 разделен на две слитых конструкции, которые дополнительно связаны с разными частями чувствительного к химическим веществам или энергии белка. Такой чувствительный к химическим веществам или энергии белок будет приводить к изменению субклеточной локализации одной из половинок фермента CPf1 (т. е. транспорту одной из половинок фермента Cpf1 из цитоплазмы в ядро клеток) при связывании химического вещества или при переносе энергии на чувствительный к химическим веществам или энергии белок. Такой транспорт слитых конструкций из одних субклеточных компартментов или органелл, в которых его активность ограничивается из-за отсутствия субстрата для восстановленной системы Cpf1 CRISPR-Cas, в другие, в которых субстрат присутствует, позволит компонентам объединяться и восстанавливать функциональную активность, а затем вступать в контакт с требуемым для них субстратом (т. е. геномной ДНК в ядре клетки млекопитающего) и приводить к активации или подавлению экспрессии целевого гена.
Предусматриваются другие индуцируемые системы, такие как без ограничения регуляция тяжелыми металлами [Mayo KE et al., Cell 1982, 29:99-108; Searle PF et al., Mol Cell Biol 1985, 5:1480-1489, и Brinster RL et al., Nature (London) 1982, 296:39-42], стероидными гормонами [Hynes NE et al., Proc Natl Acad Sci USA 1981, 78:2038-2042; Klock G et al., Nature (London) 1987, 329:734-736, и Lee F et al., Nature (London) 1981, 294:228-232.], тепловым шоком [Nouer L: Heat Shock Response. Boca Raton, FL: CRC; 1991], и были разработаны другие реагенты [Mullick A, Massie B: Transcription, translation and the control of gene expression. в Encyclopedia of Cell Technology, под ред.: Speir RE. Wiley; 2000:1140-1164, и Fussenegger M, Biotechnol Prog 2001, 17:1-51]. Однако в случае таких индуцируемых промоторов млекопитающих существуют ограничения, такие как "утечка" при "выключенном" состоянии и плейотропные эффекты индукторов (теплового шока, тяжелых металлов, глюкокортикоидов и т. д.). Было предложено применение гормонов насекомых (экдизона), с надеждой снизить противодействие клеточными процессам в клетках млекопитающих [No D et al., Proc Natl Acad Sci USA 1996, 93:3346-3351]. В другой превосходной системе в качестве индуктора применяется рапамицин [Rivera VM et al., Nat Med 1996, 2:1028-1032], но роль рапамицина в качестве иммуносупрессора была главным ограничением его применения in vivo и, поэтому, было необходимо найти биологически инертное соединение [Saez E et al., Proc Natl Acad Sci USA 2000, 97:14512-14517] для контроля экспрессии гена.
В конкретных вариантах осуществления системы редактирования генов, описанные в данном документе, помещены под контроль "пароля-выключателя", который представляет собой механизмы, которые эффективно уничтожают клетку-хозяина, если условия в клетке изменяются. Этого достигают путем введения гибридных факторов семейства LacI-GalR, для включения которых требуется присутствие IPTG (Chan et al. 2015 Nature Nature Chemical Biology doi:10.1038/nchembio.1979), которые можно применять для управления геном, кодирующим фермент, критически важный для выживания клетки. Путем комбинирования различных факторов транскрипции, чувствительных к различным химическим веществам, может генерироваться "код". Такую систему можно применять для пространственного и временного контроля степени индуцируемых CRISPR генетических модификаций, которые могут представлять интерес в различных областях техники, включая применение в терапии, и также могут представлять интерес для предотвращения "ускользания" ГМО-организмов из предполагаемой среды.
Самоинактивирующиеся системы
Как только все копии гена в геноме клетки подвергли редактированию, дальнейшая экспрессия CRISRP/Cpf1 в такой клетке более не требуется. В действительности, поддержание экспрессии было бы нежелательным в случае нецелевых эффектов в сайтах генома, не предназначенных для редактирования и т. д. Таким образом, целесообразной была бы ограниченная во времени экспрессия. Индуцируемая экспрессия предоставляет одно решение проблемы, но помимо нее заявители предусматривают самоинактивирующуюся систему CRISPR-Cpf1, которая основана на применении некодирующей направляющей целевой последовательности в самом векторе, несущем CRISPR. Таким образом, после того как экспрессия началась, система CRISPR будет вызывать собственное разрушение, но перед тем как разрушение завершится, у нее будет достаточно времени для редактирования геномных копий целевого гена (для чего, с точки зрения нормальной точечной мутации в диплоидной клетке, потребуется не более двух редактирований). Вкратце, самоинактивирующаяся система CRISPR-Cas включает в себя дополнительную РНК (т. e. направляющую РНК), которая нацеливает кодирующую последовательность для самого фермента CRISPR или которая нацеливает одну или несколько некодирующих направляющих целевых последовательностей, комплементарных уникальным последовательностям, присутствующим в одной или нескольких из следующих:
(a) в промоторе, управляющем экспрессией элементов некодирующей РНК,
(b) в промоторе, управляющем экспрессией гена Cpf1,
(c) в последовательности в 100 п. о. инициирующего трансляцию стартового ATG-кодона в кодирующей последовательности Cpf1,
(d) в инвертированном концевом повторе (iTR) вирусного вектора для доставки, например, в геноме AAV.
Более того, такую РНК можно доставлять посредством вектора, например, отдельного вектора или того же вектора, который кодирует комплекс CRISPR. Когда введение осуществляют при помощи отдельного вектора, то РНК CRISPR, которая целенаправленно воздействует на экспрессию Cpf1, можно вводить последовательно или одновременно. При последовательном введении РНК CRISPR, которая целенаправленно воздействует на экспрессию Cpf1, можно доставлять после РНК CRISPR, которая предназначена, например, для редактирования генов или рекомбинации генов. Данный период может быть периодом, исчисляемым в минутах (например, 5 минут, 10 минут, 20 минут, 30 минут, 45 минут, 60 минут). Данный период может быть периодом, исчисляемым в часах (например, 2 часа, 4 часа, 6 часов, 8 часов, 12 часов, 24 часа). Данный период может быть периодом, исчисляемым в днях (например, 2 дня, 3 дня, 4 дня, 7 дней). Данный период может быть периодом, исчисляемым в неделях (например, 2 недели, 3 недели, 4 недели). Данный период может быть периодом, исчисляемым в месяцах (например, 2 месяца, 4 месяца, 8 месяцев, 12 месяцев). Данный период может быть периодом, исчисляемым в годах (например, 2 года, 3 года, 4 года). Таким путем фермент Cas связывается с первой gRNA, способной гибридизироваться с первой мишенью, такой как представляющие интерес локус или локусы генома, и выполняет функцию(функции), требующиеся для системы CRISPR-Cas (например, рекомбинацию генов); и впоследствии фермент Cpf1 может затем связываться со второй gRNA, способной гибридизироваться с последовательностью, содержащей по меньшей мере часть кассеты Cpf1 или CRISPR. Если gRNA целенаправленно воздействует на последовательности, кодирующие экспрессию белка Cpf1, фермент блокируется, а система становится самоинактивирующейся. Аналогичным образом РНК CRISPR, которая целенаправленно воздействует на экспрессию Cpf1, введенного посредством, например, липосомы, липофекции, наночастиц, микровезикул, что объясняется в данном документе, можно вводить последовательно или одновременно. Проще говоря, самоинактивацию можно применять для инактивации одной или нескольких направляющих РНК, используемых для нацеливания на одну или несколько мишеней.
В ряде аспектов обеспечивается одиночная gRNA, которая способна гибридизироваться с последовательностью, расположенной ниже стартового кодона фермента CRISPR, при этом после определенного периода времени происходит потеря экспрессии фермента CRISPR. В некоторых аспектах предусмотрены одна или несколько gRNA, которые способны гибридизироваться с одной или несколькими кодирующими или некодирующими участками полинуклеотида, кодирующего систему CRISPR-Cas, при этом после определенного периода времени происходит инактивация одной или нескольких, или в ряде случаев, всех систем CRISPR-Cas. В некоторых аспектах системы и не ограничиваясь теорией клетка может содержать множество комплексов CRISPR-Cas, где первое подмножество комплексов CRISPR содержит первую gRNA, способную целенаправленно воздействовать на подлежащие редактированию локус или локусы генома, а второе подмножество комплексов CRISPR содержит по меньшей мере одну вторую gRNA, способную целенаправленно воздействовать на полинуклеотид, кодирующий систему CRISPR-Cas, где первое подмножество комплексов CRISPR-Cas опосредует редактирование целевых локуса или локусов генома, а второе подмножество комплексов CRISPR впоследствии инактивирует систему CRISPR-Cas, инактивируя тем самым в дальнейшем экспрессию CRISPR-Cas в клетке.
Таким образом, настоящее изобретение относится к системе CRISPR-Cas, содержащей один или несколько векторов для доставки в эукариотическую клетку, где вектор(векторы) кодирует(кодируют): (i) фермент CRISPR, в частности, Cpf1; (ii) первую направляющую РНК, способную гибридизироваться с целевой последовательностью в клетке; и (iii) вторую направляющую РНК, способную гибридизироваться с одной или несколькими целевыми последовательностями в векторе, который кодирует фермент CRISPR, где при экспрессии в клетке первая направляющая РНК управляет специфическим к последовательности связыванием первого комплекса CRISPR с целевой последовательностью в клетке; вторая направляющая РНК управляет специфическим к последовательности связыванием второго комплекса CRISPR с целевой последовательностью в векторе, который кодирует фермент CRISPR; при этом комплексы CRISPR содержат фермент CRISPR, связанный с направляющей РНК, при этом направляющая РНК может гибридизироваться со своей целевой последовательностью; а второй комплекс CRISPR инактивирует систему CRISPR-Cas для предупреждения дальнейшей экспрессии клеткой фермента CRISPR.
Дополнительные характеристики вектора(векторов), закодированных ферментов, направляющих последовательностей и т. д. раскрыты в других разделах данного документа. Система может кодировать (i) фермент CRISPR, в частности, Cpf1; (ii) первую gRNA, содержащую последовательность, способную гибридизироваться с первой целевой последовательностью в клетке, (iii) вторую направляющую РНК, способную гибридизироваться с вектором, который кодирует фермент CRISPR. Проще говоря, фермент может включать в себя одну или несколько NLS и т. д.
Разные кодирующие последовательности (фермент CRISPR, направляющие РНК) можно ввести в отдельный вектор или во множество векторов. Например, возможным является кодирование фермента в одном векторе, а последовательностей разных РНК в другом векторе, или кодирование фермента и одной gRNA в одном векторе, а остальной gRNA в другом векторе, или любая другая комбинация. В целом, предпочтительной является система, использующая всего один или два разных вектора.
При использовании множества векторов возможной является их доставка в неравных количествах, а в идеальном варианте с избытком вектора, который кодирует первую направляющую РНК, связанную со второй направляющей РНК, способствуя тем самым задержке конечной инактивации системы CRISPR до момента прохождения редактирования генома.
Первая направляющая РНК может целенаправленно воздействовать на любую представляющую интерес целевую последовательность в геноме, что описано в других частях в данном документе. Вторая направляющая РНК нацеливается на любую последовательность в векторе, который кодирует фермент CRISPR Cas9, и тем самым инактивирует экспрессию фермента, обусловленную данным вектором. Таким образом, целевая последовательность в векторе должна быть способна к инактивации экспрессии. Подходящие целевые последовательности могут находиться, например, рядом с инициирующим трансляцию стартовым кодоном кодирующей последовательности Cpf1 или в его пределах, в некодирующей последовательности в промоторе, управляющем экспрессией элементов некодирующей РНК, в пределах промотора, управляющего экспрессией гена Cpf1, в пределах 100 п. о. инициирующего трансляцию стартового ATG-кодона в кодирующей последовательности Cpf1, и/или в пределах инвертированного концевого повтора (iTR) вирусного вектора для доставки, например, в геноме AAV. Двухнитевой разрыв рядом с данным участком может индуцировать сдвиг рамки в кодирующей последовательности Cpf1, вызывая потерю экспрессии белка. Альтернативой целевой последовательности для "самоинактивирующейся" направляющей РНК было бы нацеливание на редактирование/инактивацию регуляторных участков/последовательностей, которые необходимы для экспрессии системы CRISPR-Cpf1 или для стабильности вектора. К примеру, если нарушена структура промотора для кодирующей последовательности Cpf1, тогда транскрипция будет подавляться или предупреждаться. Проще говоря, если вектор включает в себя последовательности, обеспечивающие репликацию, поддержание или стабильность, тогда можно целенаправленно воздействовать на эти последовательности. К примеру, в векторе на основе AAV приемлемая целевая последовательность находится в пределах iTR. Другими приемлемыми для нацеливания последовательностями могут быть промоторные последовательности, сайты полиаденилирования и т. д.
Более того, если направляющие РНК экспрессируются в формате массива, тогда "самоинактивирующиеся" направляющие РНК, целенаправленно воздействующие одновременно на оба промотора, в результате приведут к вырезанию вставочных нуклеотидов в пределах экспрессионной конструкции CRISPR-Cas, вызывая фактически полную инактивацию. Проще говоря, вырезание вставочных нуклеотидов будет являться результатом целенаправленного воздействия направляющих РНК на оба ITR или одновременного целенаправленного воздействия на два или более компонентов CRISPR-Cas. Как поясняется в данном документе, самоинактивация в целом применима с системами CRISPR-Cpf1 для обеспечения регуляции CRISPR-Cpf1. Например, как поясняется в данном документе, самоинактивацию можно задействовать для CRISPR-опосредованной репарации мутаций, например, нарушений, обусловленных экспансией, как поясняется в данном документе. Результат такой самоинактивации заключается во временной активности CRISPR-опосредованной репарации.
Добавление не воздействующих целенаправленно нуклеотидов к 5'-концу (например, 1-10 нуклеотидов, предпочтительно 1-5 нуклеотидов) "самоинактивирующиейся" направляющей РНК можно использовать для задержки ее процессирования и/или изменения ее эффективности в качестве средства для обеспечения редактирования в целевом локусе генома перед выключением CRISPR-Cpf1.
В одном аспекте самоинактивирующейся системы AAV-CRISPR-Cpf1 плазмиды, которые совместно экспрессируют одну или несколько gRNA, целенаправленно воздействующих на представляющие интерес последовательности в геноме (например, 1-2, 1-5, 1-10, 1-15, 1-20, 1-30), можно создавать с "самоинактивирующимися" gRNA, которые целенаправленно воздействуют на последовательность LbCpf1 в сконструированном стартовом ATG-сайте или рядом с ним (например, в пределах 5 нуклеотидов, в пределах 15 нуклеотидов, в пределах 30 нуклеотидов, в пределах 50 нуклеотидов, в пределах 100 нуклеотидов). На регуляторную последовательность в участке промотора U6 также можно целенаправленно воздействовать при помощи gRNA. U6-контролируемые gRNA можно сконструировать в формате массива с тем, чтобы одновременно могли высвобождаться множество последовательностей gRNA. При первичной доставке в целевые ткань/клетки (клетка слева) gRNA начинают накапливаться, в то же время в ядре повышаются уровни Cpf1. Cpf1 объединяется в комплексы со всеми gRNA для опосредования редактирования генома и самоинактивации плазмид, несущих CRISPR-Cpf1.
Один аспект самоинактивирующейся системы CRISPR-Cpf1 представляет собой экспрессию в отдельном формате или в формате тандемного массива от 1 до 4 или более разных направляющих последовательностей; например, до приблизительно 20 или приблизительно 30 направляющих последовательностей. Каждая отдельная самоинактивирующаяся направляющая последовательность может целенаправленно воздействовать на разные мишени. Такие последовательности могут процессироваться, например, из транскрипта одной химерной pol3. Можно применять промоторы рol3, такие как промоторы U6 или H1. Промоторы рol2 упомянуты во всем данном документе. Последовательности с инвертированными концевыми повторами (iTR) могут фланкировать промотор Pol3 - gRNA - промотор Pol2 - Cpf1.
В одном аспекте химерный транскрипт в формате тандема представляет собой одну или несколько направляющих последовательностей, которые редактируют одну или несколько мишеней, тогда как одна или несколько самоинактивирующихся направляющих последовательностей инактивируют систему CRISPR/Cpf1. Таким образом, например, описываемая система CRISPR-Cpf1 для репарации нарушений, обусловленных экспансией, можно непосредственно объединять с самоинактивирующейся системой CRISPR-Cpf1, описанной в данном документе. Такая система может, например, иметь две направляющие последовательности, направленные на целевой участок для репарации, а также по меньшей мере третью направляющую последовательность, управляющую самоинактивацией CRISPR-Cpf1. Ссылаются на заявку с порядковым № PCT/US2014/069897 под названием "Композиции и способы применения систем CRISPR-Cas при связанных с нуклеотидными повторами нарушениях", опубликованную 12 декабря 2014 г. как WO/2015/089351.
Редактирование генов или изменение целевых локусов с помощью Cpf1
Двухнитевой разрыв или однонитевой разрыв в одной из нитей преимущественно должен находиться достаточно близко к целевому положению так, чтобы происходила коррекция. В одном варианте осуществления расстояние составляет не более 50, 100, 200, 300, 350 или 400 нуклеотидов. Без ограничения какой-либо теорией, полагают, что разрыв должен находиться достаточно близко к целевому положению, так чтобы разрыв находился в участке, который подвергается опосредованному экзонуклеазой удалению в ходе конечной резекции. Если расстояние между целевым положением и разрывом слишком большое, то мутация не может быть включена в конечную резекцию и, поэтому, не может быть исправлена, поскольку только последовательность матричной нуклеиновой кислоты может быть использована для коррекции последовательности в участке конечной резекции.
В одном варианте осуществления, при котором направляющая РНК и молекула V типа/VI типа, в частности, Cpf1/C2c1/C2c2 или его ортолог или гомолог, предпочтительно нуклеаза Cpf1, индуцирует двухнитевой разрыв с целью индуцирования опосредованной HDR коррекции, при этом сайт расщепления находится на расстоянии 0-200 п. о. (например, 0-175, 0-150, 0-125, 0-100, 0-75, 0-50, 0-25, 25-200, 25-175, 25-150, 25-125, 25-100, 25-75, 25-50, 50-200, 50-175, 50-150, 50-125, 50-100, 50-75, 75-200, 75-175, 75-150, 75-125, 75-100 п. о.) от целевого положения. В одном варианте осуществления сайт расщепления находится на расстоянии 0-100 п. о. (например, 0-75, 0-50, 0-25, 25-100, 25-75, 25-50, 50-100, 50-75 или 75-100 п. о.) от целевого положения. В следующем варианте осуществления две или более направляющих РНК, образующих комплекс с Cpf1 или его ортологом или гомологом, можно применять для индуцирования мультиплексных разрывов для индуцирования опосредованной HDR коррекции.
Гомологическое плечо должно протягиваться по меньшей мере до участка, в котором может произойти конечная резекция, например, чтобы позволить резецированному однонитевому "липкому" концу находить комплементарный участок в донорной матрице. Вся длина может быть ограничена параметрами, такими как размер плазмиды или пределы упаковки вируса. В одном варианте осуществления гомологическое плечо может не протягиваться до повторяющихся элементов. Типичная длина гомологического плеча составляет по меньшей мере 50, 100, 250, 500, 750 или 1000 нуклеотидов.
Целевое положение, используемое в данном документе, относится к сайту в целевой нуклеиновой кислоте или целевом гене (например, хромосоме), который модифицирован зависимым от V типа/VI типа, в частности, Cpf1/C2c1/C2c2 или его ортолога или гомолога, предпочтительно молекулы Cpf1 процессом. Например, целевым положением может быть модифицированное расщепление молекулой Cpf1 целевой нуклеиновой кислоты и модификация, направленная на матричную нуклеиновую кислоту, например, коррекция целевого положения. В одном варианте осуществления целевым положением может быть сайт между двумя нуклеотидами, например, смежными нуклеотидами, в целевой нуклеиновой кислоте, в который добавляют один или несколько нуклеотидов. Целевое положение может содержать один или несколько нуклеотидов, которые изменяются, например, корректируются, матричной нуклеиновой кислотой. В одном варианте осуществления целевое положение находится в целевой последовательности (например, в последовательности, с которой связывается направляющая РНК). В одном варианте осуществления целевое положение находится выше или ниже целевой последовательности (например, последовательности, с которой связывается направляющая РНК).
Матричная нуклеиновая кислота, как данный термин используется в данном документе, относится к последовательности нуклеиновой кислоты, которую можно применять в конъюгации с молекулой V типа/VI типа, в частности, с Cpf1/C2c1/C2c2 или его ортологом или гомологом, предпочтительно с молекулой Cpf1 и молекулой направляющей РНК для изменения структуры целевого положения. В одном варианте осуществления целевую нуклеиновую кислоту модифицируют для обеспечения некоторой части или всей последовательности матричной нуклеиновой кислоты, как правило, в сайте(сайтах) расщепления или рядом с таковым(таковыми). В одном варианте осуществления матричная нуклеиновая кислота является однонитевой. В альтернативном варианте осуществления матричная нуклеиновая кислота является двухнитевой. В одном варианте осуществления матричной нуклеиновой кислотой является ДНК, например, двухнитевая ДНК. В альтернативном варианте осуществления матричная нуклеиновая кислота является однонитевой.
В одном варианте осуществления матричная нуклеиновая кислота изменяет структуру целевого положения путем участия в гомологичной рекомбинации. В одном варианте осуществления матричная нуклеиновая кислота изменяет последовательность целевого положения. В одном варианте осуществления матричная нуклеиновая кислота приводит к включению модифицированного или не встречающегося в природе основания в целевую нуклеиновую кислоту.
Матричная последовательность может подвергаться опосредованной или катализируемой разрывом рекомбинации с целевой последовательностью. В одном варианте осуществления матричная нуклеиновая кислота может включать в себя последовательность, которая соответствует сайту в целевой последовательности, который расщепляется опосредованным Cpf1 событием расщепления. В варианте осуществления матричная нуклеиновая кислота может включать в себя последовательность, которая соответствует как первому сайту в целевой последовательности, который расщепляется при первом опосредованном Cpf1 событии, так и второму сайту в целевой последовательности, который расщепляется при втором опосредованном Cpf1 событии.
В определенных вариантах осуществления матричная нуклеиновая кислота может включать в себя последовательность, которая приводит к изменению в кодирующей последовательности транслируемой последовательности, например, последовательность, которая приводит к замене одной аминокислоты на другую в белковом продукте, например, с трансформированием мутантного аллеля в аллель дикого типа, с трансформированием аллеля дикого типа в мутантный аллелль, и/или к введению стоп-кодона, вставки аминокислотного остатка, делеции аминокислотного остатка или нонсенс-мутации. В определенных вариантах осуществления матричная нуклеиновая кислота может включать в себя последовательность, которая приводит к изменению в некодирующей последовательности, например, к изменению в экзоне или в 5'- или 3'-нетранслируемом или нетранскрибируемом участке. Такие изменения включают в себя изменение в контрольном элементе, например, в промоторе, энхансере, и изменение в цис-действующем или транс-действующем контрольном элементе.
Матричную нуклеиновую кислоту, обладающую гомологичностью с целевым положением в целевом гене, можно применять для изменения структуры целевой последовательности. Матричную последовательность можно применять для изменения нежелательной структуры, например, нежелательного или мутантного нуклеотида. Матричная нуклеиновая кислота может включать в себя последовательность, которая при интегрировании приводит к снижению активности положительного контрольного элемента; повышению активности положительного контрольного элемента; снижению активности отрицательного контрольного элемента; повышению активности отрицательного контрольного элемента; снижению экспрессии гена; повышению экспрессии гена; повышению устойчивости к нарушению или заболеванию; повышению устойчивости к проникновению вируса; исправлению мутации или изменению нежелательного аминокислотного остатка, обеспечению, усилению, отмене или снижению биологического свойства продукта гена, например, повышению ферментативной активности фермента, или усилению способности продукта гена взаимодействовать с другой молекулой.
Матричная нуклеиновая кислота может включать в себя последовательность, которая приводит к изменению в последовательности 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 или более нуклеотидов целевой последовательности. В варианте осуществления матричная нуклеиновая кислота может иметь длину 20 +/-10, 30 +/-10, 40 +/-10, 50 +/-10, 60 +/-10, 70 +/-10, 80 +/-10, 90 +/-10, 100 +/-10, 110 +/-10, 120 +/-10, 130 +/-10, 140 +/-10, 150 +/-10, 160 +/-10, 170 +/-10, 180 +/-10, 190 +/-10, 200 +/-10, 210 +/-10 или 220+/-10 нуклеотидов. В варианте осуществления матричная нуклеиновая кислота может иметь длину 30 +/-20, 40 +/-20, 50 +/-20, 60 +/-20, 70 +/-20, 80 +/-20, 90 +/-20, 100 +/-20, 110 +/-20, 120 +/-20, 130 +/-20, 140 +/-20, 150 +/-20, 160 +/-20, 170 +/-20, 180 +/-20, 190 +/-20, 200 +/-20, 210 +/-20 или 220 +/-20 нуклеотидов. В варианте осуществления матричная нуклеиновая кислота имеет длину 10-1000, 20-900, 30-800, 40-700, 50-600, 50-500, 50-400, 50-300, 50-200 или 50-100 нуклеотидов.
Матричная нуклеиновая кислота содержит следующие компоненты: [5'-гомологичное плечо]-[последовательность замены]-[3'-гомологичное плечо]. Гомологичные плечи обеспечивают рекомбинацию в хромосоме, замещая таким образом нежелательный элемент, например, мутацию или сигнатуру, последовательностью замены. В варианте осуществления гомологичные плечи фланкируют наиболее дистальные сайты расщепления. В варианте осуществления 3'-конец 5'-гомологичного плеча представляет собой положение рядом с 5'-концом последовательности замены. В варианте осуществления 5'-гомологичное плечо может протягиваться по меньшей мере на 10, 20, 30, 40, 50, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1500 или 2000 нуклеотидов 5' от 5'-конца последовательности замены. В варианте осуществления 5'-конец 3'-гомологичного плеча представляет собой положение рядом с 3'-концом последовательности замены. В одном варианте осуществления 3'-гомологичное плечо может протягиваться по меньшей мере на 10, 20, 30, 40, 50, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1500 или 2000 нуклеотидов 3' от 3'-конца последовательности замены.
В определенных вариантах осуществления одно или оба гомологичных плеча могут быть укорочены, чтобы избежать включения некоторых повторяющихся элементов последовательности. Например, 5'-гомологичное плечо может быть укорочено, чтобы избежать повторяющегося элемента последовательности. В других вариантах осуществления 3'-гомологичное плечо может быть укорочено, чтобы избежать повторяющегося элемента последовательности. В некоторых вариантах осуществления оба 5'- и 3'-гомологичных плеча могут быть укорочены, чтобы избежать включения некоторых повторяющихся элементов последовательности.
В определенных вариантах осуществления матричные нуклеиновые кислоты для коррекции мутации можно разработать для применения в качестве однонитевого олигонуклеотида. При использовании однонитевого олигонуклеотида длина 5'- и 3'-гомологичных плеч может варьировать до приблизительно 200 пар оснований (п. о.), например, может составлять по меньшей мере 25, 50, 75, 100, 125, 150, 175 или 200 п. о.
Система комплекса с эффекторным белком Cpf1 способстовала негомологичному соединению концов
В определенных вариантах осуществления индуцируемое нуклеазой негомологичное соединение концов (NHEJ) можно применять для целевых ген-специфических нокаутов. Индуцируемое нуклеазой NHEJ также может быть использовано для удаления (например, делеции) последовательности в представляющем интерес гене. Как правило, NHEJ репарирует двухнитевой разрыв в ДНК путем соединения двух концов вместе; однако, как правило, оригинальная последовательность восстанавливается, только если два совместимых конца, точно так же, как если бы они были образованы двухнитевым разрывом, лигированы в полной мере. Концы ДНК двухнитевого разрыва зачастую подвергаются ферментативному процессированию, что приводит к добавлению или удалению нуклеотидов на одной или обеих нитях перед повторным соединением концов. Это приводит в результате к наличию вставочных и/или делеционных (инсерционно-делеционных) мутаций в последовательности ДНК на сайте репарации путем NHEJ. Две третьих таких мутаций, как правило, изменяют рамку считывания и, поэтому, продуцируют нефункциональный белок. Кроме того, мутации, которые сохраняют рамку считывания, но которые вставляют или удаляют значительную часть последовательности, могут нарушать функциональность белка. Это зависит от локуса, поскольку мутации в критических функциональных доменах, вероятно, менее переносимы, чем мутации в некритических участках белка. Мутации по типу вставок/делеций, созданные NHEJ, непредсказуемы по своей природе; однако на данном сайте разрыва некоторые инсерционно-делеционные последовательности являются предпочтительными и чрезмерно представлены в популяции, вероятно, из-за небольших участков микрогомологии. Длины делеций могут широко варьировать; чаще всего в диапазоне 1-50 п. о., но они могут свободно превысить 50 п. о., например, они могут свободно достичь более чем приблизительно 100-200 п. о. Вставки, как правило, короче и зачастую включают в себя короткие повторы последовательностей, непосредственно окружающие сайт разрыва. Однако можно получить крупные вставки, и в этих случаях вставленная последовательность часто проходит к другим участкам генома или к плазмидной ДНК, присутствующей в клетках.
Поскольку NHEJ является мутагенным процессом, оно также может быть использовано для удаления небольших мотивов последовательностей, при условии, что не требуется образование определенной финальной последовательности. Если двухнитевой разрыв намечается рядом с короткой целевой последовательностью, то мутации по типу делеции, вызванные репарацией путем NHEJ, часто охватывают и, поэтому, удаляют нежелательные нуклеотиды. Для делеции более крупных сегментов ДНК введение двух двухнитевых разрывов, по одному с каждой стороны последовательности, может приводить к NHEJ между концами с удалением всей вставочной последовательности. Оба из этих подходов можно применять для удаления определенных последовательностей ДНК; однако, допускающая ошибки природа NHEJ все равно может приводить к мутациям по типу вставок/делеций в сайте репарации.
Как двухнитевая расщепляющая молекула V типа/VI типа, в частности, Cpf1/C2c1/C2c2 или его ортолог или гомолог, предпочтительно молекулы Cpf1, так и однонитевая или никазная молекула V типа/VI типа, в частности, Cpf1/C2c1/C2c2 или его ортолог или гомолог, предпочтительно молекулы Cpf1, могут быть применимы в способах и композициях, описываемых в данном документе, для создания опосредованных NHEJ вставок/делеций. NHEJ-опосредованные вставки/делеции, нацеленные на ген, например, кодирующий участок, например, ранний кодирующий участок представляющего интерес гена, могут быть применимы для нокаута (т. е. для устранения экспрессии) представляющего интерес гена. Например, ранний кодирующий участок представляющего интерес гена включает в себя последовательность сразу после сайта начала транскрипции, в первом экзоне кодирующей последовательности или в пределах 500 п. о. сайта начала транскрипции (например, менее 500, 450, 400, 350, 300, 250, 200, 150, 100 или 50 п. о.).
В одном варианте осуществления, в котором направляющая РНК и молекула V типа/VI типа, в частности, Cpf1/C2c1/C2c2 или его ортолог или гомолог, предпочтительно нуклеаза Cpf1, образует двухнитевой разрыв для индуцирования опосредованных NHEJ вставок/делеций, направляющая РНК может быть сконфигурирована для размещения одного двухнитевого разрыва в непосредственной близости к нуклеотиду целевого положения. В одном варианте осуществления сайт расщепление может находиться в пределах 0-500 п. о. от целевого положения (например, менее 500, 400, 300, 200, 100, 50, 40, 30, 25, 20, 15, 10, 9, 8, 7, 6, 5, 4, 3, 2 или 1 п. о. от целевого положения).
В одном варианте осуществления, в котором две направляющие РНК, образующие комплекс с молекулами V типа/VI типа, в частности, Cpf1/C2c1/C2c2 или его ортологом или гомологом, предпочтительно с никазами Cpf1, индуцируют два однонитевых разрыва для индуцирования опосредованных NHEJ вставок/делеций, две направляющих РНК могут быть сконфигурированы для размещения двух однонитевых разрывов для обеспечения репарации путем NHEJ нуклеотида целевого положения.
Комплексы эффекторного белка Cpf1 могут доставлять функциональные эффекторы
В отличие от нокаута гена, опосредованного CRISPR-Cas, который окончательно устраняет экспрессию путем мутации гена на уровне ДНК, нокдаун с помощью CRISPR-Cas позволяет временно сократить экспрессию гена с использованием искусственных факторов транскрипции. Мутирование ключевых остатков в обоих доменах расщепления ДНК белка Cpf1, такого как белок FnCpf1 (например, мутации D917A и H1006A белка FnCpf1 или D908A, E993A, D1263A в случае белка AsCpf1 или D832A, E925A, D947A или D1180A в случае белка LbCpf1) приводит к образованию каталитически неактивного Cpf1. Кристаллически неактивный Cpf1 объединяется в комплекс с направляющей РНК и локализуется с последовательностью ДНК, определяемой этим нацеливающимся доменом направляющей РНК, однако, он не расщепляет целевую ДНК. Слияние неактивного белка Cpf1, такого как белок FnCpf1 (например, мутации D917A и H1006A) с эффекторным доменом, например, доменом репрессии транскрипции, облегчает рекрутирование эффектора на какой-либо сайт ДНК, определяемый направляющей РНК. В определенных вариантах осуществления Cpf1 может быть слит с доменом транскрипционного подавления и рекрутирован в промоторный участок гена. В частности, для подавления гена в данном документе предусматривается, что блокирование сайта связывания эндогенного фактора транскрипции будет способствовать подавлению экспрессии гена. В другом варианте осуществления неактивный Cpf1 может быть слит с модифицирующим хроматин белком. Изменение состояния хроматина может приводить к пониженной экспрессии целевого гена.
В одном варианте осуществления молекула направляющей РНК может быть нацелена на известные отвечающие за транскрипцию элементы (например, промоторы, энхансеры и т. д.), известные расположенные выше активирующие последовательности и/или последовательности с неизвестной или известной функцией, которые, как предполагается, способны контролировать экспрессию целевой ДНК.
В некоторых способах целевой полинуклеотид можно инактивировать для осуществления модификации экспрессии в клетке. Например, после связывания комплекса CRISPR с целевой последовательностью в клетке целевой полинуклеотид инактивируется, вследствие чего последовательность не транскрибируется, при этом не вырабатывается кодируемый белок или последовательность не функционирует так, как последовательность дикого типа. Например, последовательность, кодирующая белок или microRNA, может быть инактивирована, вследствие чего белок не образуется.
В определенных вариантах осуществления фермент CRISPR содержит одну или несколько мутаций, выбранных из группы, состоящей из D917A, E1006A и D1225A, и/или одна или несколько мутаций находятся в домене RuvC фермента CRISPR или представляют собой другую мутацию, обсуждаемую в данном документе. В некоторых вариантах осуществления фермент CRISPR имеет одну или несколько мутаций в каталитическом домене, где при транскрипции последовательность прямого повтора образует одну "петлю-на-стебле", а направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью, и где фермент дополнительно содержит функциональный домен. В некоторых вариантах осуществления функциональный домен представляет собой домен активации транскрипции, предпочтительно VP64. В некоторых вариантах осуществления функциональный домен представляет собой домен репрессии транскрипции, предпочтительно KRAB. В некоторых вариантах осуществления домен репрессии транскрипции представляет собой SID или конкатемеры SID (например, SID4X). В некоторых вариантах осуществления функциональный домен представляет собой домен эпигенетического модифицирования, так что обеспечивается фермент эпигенетического модифицирования. В некоторых вариантах осуществления функциональный домен представляет собой домен активации, который может представлять собой домен активации P65.
Доставка комплекса эффекторного белка Cpf1 или его компонентов
Благодаря использованию данного раскрытия и сведений из уровня техники, систему CRISPR-Cas, особенно новые системы CRISPR, описанные в данном документе, или ее компоненты, или ее молекулы нуклеиновой кислоты (в том числе, например, матрицу для HDR), или молекулы нуклеиновой кислоты, кодирующие или представляющие собой ее компоненты, можно доставлять с помощью системы доставки, описываемой в данном документе как в целом, так и в подробностях.
Векторная доставка, например, доставка с помощью плазмиды, вируса. Фермент CRISPR, например Cpf1, и/или любую из РНК по настоящему изобретению, например направляющую РНК, можно доставлять с помощью любого подходящего вектора, например плазмиды или вирусных векторов, таких как аденоассоциированный вирус (AAV), лентивирус, аденовирус или другие типы вирусных векторов или их комбинации. Cpf1 и одну или несколько направляющих РНК можно упаковать в один или несколько векторов, например, плазмидный или вирусный векторы. В некоторых вариантах осуществления вектор, например, плазмидный или вирусный вектор, доставляют в представляющую интерес ткань посредством, например, внутримышечной инъекции, тогда как в других случаях доставка осуществляется посредством внутривенного, трансдермального, интраназального, перорального, трансмукозального или других способов доставки. Такая доставка может осуществляться в виде однократной дозы или многократных доз. Специалисту в данной области понятно, что фактическая доза, подлежащая доставке согласно данному документу, может в значительной степени варьировать в зависимости от ряда факторов, таких как выбор вектора, целевые клетка, организм или ткань, общее состояние субъекта, подлежащего лечению, степень требуемой трансформации/модификации, путь введения, способ введения, тип требуемой трансформации/модификации и т. п.
Такая доза может дополнительно содержать, например, носитель (воду, солевой раствор, этанол, глицерин, лактозу, сахарозу, фосфат кальция, желатин, декстран, агар, пектин, арахисовое масло, кунжутное масло и т. д.), разбавитель, фармацевтически приемлемый носитель (например, фосфатно-солевой буфер), фармацевтически приемлемый наполнитель и/или другие соединения, известные из уровня техники. Доза может дополнительно содержать одну или несколько фармацевтически приемлемых солей, таких как, например, соль неорганической кислоты, такая как гидрохлорид, гидробромид, фосфат, сульфат и т. д.; и соли органических кислот, такие как ацетаты, пропионаты, малонаты, бензоаты и т. д. Дополнительно в ней также могут присутствовать вспомогательные вещества, такие как смачивающие или эмульгирующие средства, буферные вещества, поддерживающие pH, гели или гелеобразующие материалы, ароматизаторы, красители, микросферы, полимеры, суспендирующие средства и т. д. Кроме того, также могут присутствовать один или несколько других традиционных фармацевтических ингредиентов, таких как консерванты, увлажнители, суспендирующие средства, поверхностно-активные вещества, антиоксиданты, средства против слеживания, заполнители, хелатообразователи, средства для нанесения покрытий, химические стабилизаторы и т. д., особенно если лекарственная форма представляет собой форму, подлежащую восстановлению. Подходящие иллюстративные ингредиенты включают микрокристаллическую целлюлозу, натрий-карбоксиметилцеллюлозу, полисорбат 80, фенилэтиловый спирт, хлорбутанол, сорбат калия, сорбиновую кислоту, диоксид серы, пропилгаллат, парабены, этилванилин, глицерин, фенол, парахлорфенол, желатин, альбумин и их комбинацию. Подробное обсуждение фармацевтически приемлемых наполнителей доступно в REMINGTON'S PHARMACEUTICAL SCIENCES (Mack Pub. Co., N.J. 1991), включенном в данный документ посредством ссылки.
В одном варианте осуществления согласно данному документу доставку осуществляют посредством аденовируса, который может находиться в однократной бустерной дозе, содержащей по меньшей мере 1 x 105 частиц (также называемых единицами частиц, pu) аденовирусного вектора. В одном варианте осуществления согласно данному документу доза предпочтительно составляет по меньшей мере приблизительно 1 x 106 частиц (например, приблизительно 1 x 106 - 1 x 1012 частиц), более предпочтительно по меньшей мере приблизительно 1 x 107 частиц, более предпочтительно по меньшей мере приблизительно 1 x 108 частиц (например, приблизительно 1 x 108 - 1 x 1011 частиц или приблизительно 1 x 108 - 1 x 1012 частиц) и наиболее предпочтительно по меньшей мере приблизительно 1 x 100 частиц (например, приблизительно 1 x 109 - 1 x 1010 частиц или приблизительно 1 x 109 - 1 x 1012 частиц) или даже по меньшей мере приблизительно 1 x 1010 частиц (например, приблизительно 1 x 1010 - 1 x 1012 частиц) аденовирусного вектора. Альтернативно доза содержит не более чем приблизительно 1 x 1014 частиц, предпочтительно не более чем приблизительно 1 x 1013 частиц, еще более предпочтительно не более чем приблизительно 1 x 1012 частиц, еще более предпочтительно не более чем приблизительно 1 x 1011 частиц и наиболее предпочтительно не более чем приблизительно 1 x 1010 частиц (например, не более чем приблизительно 1 x 109 частиц). Таким образом, доза может включать в себя однократную дозу аденовирусного вектора, например, с приблизительно 1 x 106 единиц частиц (pu), приблизительно 2 x 106 pu, приблизительно 4 x 106 pu, приблизительно 1 x 107 pu, приблизительно 2 x 107 pu, приблизительно 4 x 107 pu, приблизительно 1 x 108 pu, приблизительно 2 x 108 pu, приблизительно 4 x 108 pu, приблизительно 1 x 109 pu, приблизительно 2 x 109 pu, приблизительно 4 x 109 pu, приблизительно 1 x 1010 pu, приблизительно 2 x 1010 pu, приблизительно 4 x 1010 pu, приблизительно 1 x 1011 pu, приблизительно 2 x 1011 pu, приблизительно 4 x 1011 pu, приблизительно 1 x 1012 pu, приблизительно 2 x 1012 pu или приблизительно 4 x 1012 pu аденовирусного вектора. См., например, аденовирусные векторы в патенте США № 8454972 B2 Nabel, et. al., выданном 4 июня 2013 г.; включенном в данный документ посредством ссылки, и дозы в столбце 29, строках 36-58 данного патента. В одном варианте осуществления согласно данному документу аденовирус доставляется посредством многократных доз.
В одном варианте осуществления согласно данному документу доставку осуществляют посредством AAV. Полагают, что терапевтически эффективная доза для in vivo доставки AAV человеку находится в диапазоне от приблизительно 20 до приблизительно 50 мл солевого раствора, содержащего от приблизительно 1 x 1010 до приблизительно 1 x 1010 функциональных частиц AAV/мл раствора. Дозу можно скорректировать для уравновешивания терапевтической пользы и любых побочных эффектов. В одном варианте осуществления согласно данному документу доза AAV, как правило, находится в диапазоне концентраций от приблизительно 1 x 105 до 1 x 1050 геномов AAV, от приблизительно 1 x 108 до 1 x 1020 геномов AAV, от приблизительно 1 x 1010 до приблизительно 1 x 1016 геномов или от приблизительно 1 x 1011 до приблизительно 1 x 1016 геномов AAV. Доза для человека может составлять приблизительно 1 x 1013 геномов AAV. Такие концентрации можно доставлять в дозе от приблизительно 0,001 мл до приблизительно 100 мл, от приблизительно 0,05 до приблизительно 50 мл или от приблизительно 10 до приблизительно 25 мл раствора носителя. Другие эффективные дозы может без труда установить средний специалист в данной области посредством стандартных испытаний с построением кривых зависимости "доза-эффект". См., например, патент США № 8404658 B2 Hajjar, et al., выданный 26 марта 2013 г., в столбце 27, строках 45-60.
В одном варианте осуществления согласно данному документу доставку осуществляют посредством плазмиды. В таких композициях с плазмидами доза должна представлять собой количество плазмид, достаточное для вызывания эффекта. Например, подходящие количества плазмидной ДНК в композициях с плазмидами могут составлять от приблизительно 0,1 до приблизительно 2 мг или от приблизительно 1 мкг до приблизительно 10 мкг из расчет на индивидуума весом 70 кг. Плазмиды по настоящему изобретению в общем будут содержать (i) промотор; (ii) последовательность, кодирующую фермент CRISPR, функционально связанную с указанным промотором; (iii) селектируемый маркер; (iv) точку начала репликациии и (v) расположенный ниже нее терминатор транскрипции, функционально связанный с (ii). Плазмида может также кодировать компоненты РНК комплекса CRISPR, но наряду с этим один или несколько из них могут кодироваться другим вектором.
Дозы в данном документе определяются в расчете на индивидуума со средним весом 70 кг. Частота введения находится в пределах компетенции практикующего врача или ветеринара (например, доктора, ветеринарного врача) или ученого, являющегося специалистом в данной области. Также отмечено, что вес используемых в эксперименте мышей, как правило, составляет приблизительно 20 г, что при проведении экспериментов с мышами пропорционально индивидууму весом 70 кг.
Доза, применяемая для композиций, предусмотренных в данном документе, включает дозы для повторного введения или повторного дозирования. В конкретных вариантах осуществления введение повторяется в течение периода нескольких недель, месяцев или лет. Для получения оптимального режима дозирования могут быть выполнены подходящие анализы. Повторное введение может способствовать применению более низкой дозы, которая может положительно влиять на нецелевые модификации.
В некоторых вариантах осуществления молекулы РНК по настоящему изобретению доставляют в липосомных составах или составах на основе Lipofectin и им подобных, и их можно получить с помощью способов, хорошо известных специалистам в данной области. Такие способы описаны, например, в патентах США №№ 5593972, 5589466 и 5580859, включенных в данный документ посредством ссылки. Были разработаны системы доставки, специально предназначенные для повышения эффективности и улучшения доставки siRNA в клетки млекопитающих (см., например, Shen et al FEBS Let. 2003, 539:111-114; Xia et al., Nat. Biotech. 2002, 20:1006-1010; Reich et al., Mol. Vision. 2003, 9: 210-216; Sorensen et al., J. Mol. Biol. 2003, 327: 761-766; Lewis et al., Nat. Gen. 2002, 32: 107-108 и Simeoni et al., NAR 2003, 31, 11: 2717-2724), и их можно применять в настоящем изобретении. Недавно siRNA успешно применили для ингибирования экспрессии генов у приматов (см., например, Tolentino et al., Retina 24(4):660), и их также можно применять в настоящем изобретении.
И действительно, доставка РНК также является применимым способом доставки in vivo. Возможно доставлять Cpf1 и gRNA (и, например, матрицу для HR-репарации) в клетки с помощью липосом или наночастиц. Таким образом, доставка фермента CRISPR, такого как Cpf1, и/или доставка РНК по настоящему изобретению может осуществляться в форме РНК и посредством микровезикул, липосом, или частиц, или наночастиц. Например, мРНК Cpf1 и gRNA могут быть упакованы в липосомные частицы для доставки in vivo. Реагенты для липосомной трансфекции, такие как Lipofectamine от Life Technologies, и другие реагенты, имеющиеся в продаже, могут эффективно доставлять молекулы РНК в печень.
Также являются предпочтительными другие средства доставки РНК, в том числе доставка РНК посредством частиц (Cho, S., Goldberg, M., Son, S., Xu, Q., Yang, F., Mei, Y., Bogatyrev, S., Langer, R. and Anderson, D., Lipid-like nanoparticles for small interfering RNA delivery to endothelial cells, Advanced Functional Materials, 19: 3112-3118, 2010) или экзосом (Schroeder, A., Levins, C., Cortez, C., Langer, R., and Anderson, D., Lipid-based nanotherapeutics for siRNA delivery, Journal of Internal Medicine, 267: 9-21, 2010, PMID: 20059641). И действительно, как было показано, экзосомы являются особенно применимыми в доставке siRNA, системы, в некоторой степени сходной с системой CRISPR. Например, El-Andaloussi S, et al. ("Exosome-mediated delivery of siRNA in vitro and in vivo." Nat Protoc. 2012 Dec;7(12):2112-26. doi: 10.1038/nprot.2012.131. электронная публикация от 15 ноября 2012 г.) описывают как экзосомы, являющиеся перспективными инструментами доставки лекарственных средств через различные биологические барьеры, можно приспособить для доставки siRNA in vitro и in vivo. Данный подход заключается в создании нацеленных экзосом посредством трансфекции вектором экспрессии, содержащим экзосомный белок, слитый с пептидным лигандом. Экзосомы затем очищают от супернатанта с трансфицированными клетками и характеризуют, а затем в экзосомы загружают РНК. Доставку или введение в соответствии с настоящим изобретением можно осуществлять с помощью экзосом, в частности, без ограничения в головной мозг. Витамин E (α-токоферол) можно конъюгировать с CRISPR-Cas и доставлять в головной мозг вместе с липопротеином высокой плотности (HDL), например, аналогично тому, как это было выполнено Uno et al. (HUMAN GENE THERAPY 22:711-719 (June 2011)) для доставки короткой интерферирующей РНК (siRNA) в головной мозг. Мышам проводили инфузию с помощью осмотических мининасосов (модель 1007D; Alzet, Купертино, Калифорния), наполненных фосфатно-солевым буфером (PBS) или свободной Toc-siBACE или Toc-siBACE/HDL, и соединенных с набором 3 для инфузий в головной мозг (Alzet). Канюлю для инфузий в головной мозг размещали приблизительно на 0,5 мм кзади от брегмы на средней линии для инфузии в дорсальную часть третьего желудочка. Uno et al. обнаружили, что всего 3 нмоль Toc-siRNA с HDL в том же способе ICV инфузии могут индуцировать аналогичную степень целенаправленного снижения. Аналогичная доза CRISPR-Cas, конъюгированной с α-токоферолом и вводимой совместно с HDL, целенаправленно воздействующей на головной мозг, может предусматриваться в настоящем изобретении для людей, например, может предусматриваться в количестве от приблизительно 3 нмоль до приблизительно 3 мкмоль CRISPR-Cas, целенаправленно воздействующей на головной мозг. Zou et al. (HUMAN GENE THERAPY 22:465-475 (April 2011)) описывают способ опосредованной лентивирусами доставки коротких шпилечных РНК, нацеливающихся на PKCγ, для сайленсинга in vivo генов в спинном мозге крыс. Zou et al. вводили приблизительно 10 мкл рекомбинантного лентивируса с титром 1 x 109 трансдуцирующих единиц (TU)/мл с помощью интратекального катетера. Аналогичная доза экспрессируемой CRISPR-Cas в лентивирусном векторе, нацеливающемся на головной мозг, может предусматриваться в настоящем изобретении для людей, например, может предусматриваться приблизительно 10-50 мл CRISPR-Cas, нацеливающейся на головной мозг, в лентивирусе с титром 1 x 109 трансдуцирующих единиц (TU)/мл.
Предварительно собранные рекомбинантные комплексы CRISPR-Cpf1, содержащие Cpf1 и crRNA, могут быть трансфицированы, например, при помощи электропорации, что приводит к высокой частоте мутаций и отсутствию выявляемых нецелевых мутаций. Hur, J.K. et al, Targeted mutagenesis in mice by electroporation of Cpf1 ribonucleoproteins, Nat Biotechnol. 2016 Jun 6. doi: 10.1038/nbt.3596. [Электронная публикация, предшествующая печатной].
Если подразумевают локальную доставку в головной мозг, то этого можно достичь разными способами. Например, материал можно доставлять интрастриатально, например, с помощью инъекции. Инъекцию можно осуществлять стереотаксически посредством краниотомии.
Повышение эффективности NHEJ или HR также способствует доставке. Предпочтительно, чтобы эффективность NHEJ повышали посредством совместной экспрессии ферментов для обработки концов, таких как Trex2 (Dumitrache et al. Genetics. 2011 August; 188(4): 787-797). Предпочтительно, чтобы эффективность HR повышалась путем транзиентного ингибирования компонентов аппарата NHEJ, таких как Ku70 и Ku86. Эффективность HR также можно повысить путем совместной экспрессии прокариотических или эукариотических ферментов гомологичной рекомбинации, таких как RecBCD, RecA.
Упаковка и промоторы
Существуют следующие способы упаковки молекул нуклеиновой кислоты, кодирующих Cpf1 по настоящему изобретению, например ДНК, в векторы, например вирусные векторы, для опосредования модификации генома in vivo.
- Для обеспечения опосредованного NHEJ нокаута гена:
- Один вирусный вектор
- Вектор, содержащий две или более кассет экспрессии:
- промотор-молекула нуклеиновой кислоты, кодирующая Cpf1-терминатор;
- промотор-gRNA1-терминатор;
- промотор-gRNA2-терминатор;
- промотор-gRNA(N)-терминатор (до предельного размера вектора).
- Два вирусных вектора
- вектор 1, содержащий одну кассету экспрессии для управления экспрессией Cpf1:
- Промотор-молекула нуклеиновой кислоты, кодирующая Cpf1-терминатор
- вектор 2, содержащий одну или несколько кассет экспрессии для управления экспрессией одной или нескольких направляющих РНК;
- промотор-gRNA1-терминатор;
- промотор-gRNA(N)-терминатор (до предельного размера вектора).
- Для опосредования репарации с участием гомологичной рекомбинации.
- В дополнение к подходам с одним и двумя вирусными векторами, описанными выше, можно применять дополнительный вектор для доставки матрицы для репарации с участием гомологичной рекомбинации.
Промотор, используемый для управления экспрессии молекулы нуклеиновой кислоты, кодирующей Cpf1, может включать в себя перечисленное ниже.
- ITR AAV может служить в качестве промотора: это является преимущественным для устранения необходимости в дополнительном промоторном элементе (который может занимать пространство в векторе). Освободившееся дополнительное пространство можно задействовать для управления экспрессией дополнительных элементов (gRNA и т. д.). Также активность ITR является относительно более слабой, поэтому ее можно применять для снижения потенциальной токсичности, обусловленной сверхэкспрессией Cpf1.
- Для повсеместной экспрессии промоторы, которые можно применять, включают: CMV, CAG, CBh, PGK, SV40, гены тяжелой или легкой цепей ферритина и т. д.
Для экспрессии в головном мозге или в другом отделе ЦНС можно использовать следующие промоторы: гена синапсина I для всех нейронов, гена CaMKII-альфа для возбуждающих нейронов, GAD67, или GAD65, или VGAT для GABA-эргических нейронов и т. д.
Для экспрессии в печени можно использовать промотор гена альбумина.
Для экспрессии в легких можно использовать SP-B.
Для эндотелиальных клеток можно использовать ICAM.
Для кроветворных клеток можно использовать промотор гена IFN-бета или CD45.
Для остеобластов можно использовать OG-2.
Промотор, используемый для управления направляющей РНК, может включать в себя следующее:
- промоторы Pol III, такие как U6 или H1;
- использование промотора Pol II и интронных кассет для экспрессии gRNA.
Аденоассоциированный вирус (AAV)
Cpf1 и одну или несколько направляющих РНК можно доставлять при помощи аденоассоциированного вируса (AAV), лентивируса, аденовируса или других типов плазмидных или вирусных векторов, в частности, с применением составов и доз согласно, например, патентам США №№ 8454972 (составы, дозы для аденовируса), 8404658 (составы, дозы для AAV) и 5846946 (составы, дозы для плазмидных ДНК) и клиническим испытаниям и публикациям результатов клинических испытаний с использованием лентивируса, AAV и аденовируса. Например, для AAV путь введения, состав и доза могут быть такими, как определено в патенте США № 8454972 и в клинических испытаниях с использованием AAV. Для аденовируса путь введения, состав и доза могут быть такими, как определено в патенте США № 8404658 и в клинических испытаниях с использованием аденовируса. Для доставки с помощью плазмид путь введения, состав и доза могут быть такими, как определено в патенте США № 5846946 и в клинических испытаниях с использованием плазмид. Дозы могут быть определены в расчете на или экстраполированы на индивидуума со средним весом 70 кг (например, взрослый мужчина), и могут быть скорректированы для пациентов, субъектов, млекопитающих с другим весом и другого вида. Частота введения входит в пределы компетенции практикующего врача или ветеринара (например, доктора, ветеринарного врача) и зависит от обычных факторов, в том числе от возраста, пола, общего состояния здоровья, других состояний пациента или субъекта и конкретных рассматриваемых состояний или симптомов. Вирусные векторы можно инъецировать в представляющую интерес ткань. В случае специфичной относительно типа клетки модификации генома, экспрессия Cpf1 может управляться промотором, специфичным к типу клеток. Например, при печеночноспецифической экспрессии может использоваться промотор гена альбумина, а при нейрон-специфической экспрессии (например, для нацеливания на нарушения ЦНС) может использоваться промотор гена синапсина I.
Что касается доставки in vivo, то AAV является преимущественным по сравнению с другими вирусными векторами по двум причинам:
низкая токсичность (она может быть обусловлена способом очистки, не требующим ультрацентрифугирования клеточных частиц, которые могут активировать иммунный ответ) и
низкая вероятность вызова инсерционного мутагенеза, поскольку он не интегрируется в геном хозяина.
AAV имеет предел упаковки, составляющий 4,5 или 4,75 т. о. Это означает, что все из Cpf1, а также промотора и терминатора транскрипции должны помещаться в одном и том же вирусном векторе. Конструкции, размер которых превышает 4,5 или 4,75 т. о., будут обуславливать значительное снижение продуцирования вируса. SpCas9 является достаточно крупным, размер гена самого по себе превышает 4,1 т. о., затрудняя его упаковку в AAV. Следовательно, варианты осуществления настоящего изобретения включают использование более коротких гомологов Cpf1.
Что касается AAV, то AAV может представлять собой AAV1, AAV2, AAV5 или любую их комбинацию. Можно выбрать AAV из AAV с учетом клеток, подлежащих нацеливанию; например, можно выбрать AAV серотипов 1, 2, 5 или гибридный капсид AAV1, AAV2, AAV5 или любую их комбинацию для нацеливания на головной мозг или нейроны; и можно выбрать AAV4 для нацеливания на сердечную ткань. AAV8 применим для доставки в печень. Вышеуказанные промоторы и векторы в данном документе являются предпочтительными по отдельности. Сопоставление определенных серотипов AAV по отношению к определенным клеткам (см. Grimm, D. et al, J. Virol. 82: 5887-5911 (2008)) представлено следующим образом:
Лентивирус
Лентивирусы являются сложными ретровирусами, которые обладают способностью инфицировать как митотические, так и постмитотические клетки и экспрессировать в них свои гены. Наиболее известным лентивирусом является вирус иммунодефицита человека (HIV), который использует гликопротеины оболочки других вирусов для нацеливания на широкий спектр типов клеток.
Лентивирусы можно получить следующим образом. После клонирования pCasES10 (которая содержит остов лентивирусной плазмиды-переносчика) HEK293FT, прошедшие малое количество пассажей (p=5), высевали во флакон T-75 до 50% конфлюэнтности за день до трансфекции в DMEM с 10% фетальной бычьей сывороткой и без антибиотиков. Через 20 часов среду заменяли на среду OptiMEM (бессывороточную) и через 4 часа проводили трансфекцию. Клетки трансфицировали с помощью 10 мкг лентивирусной плазмиды-переносчика (pCasES10) и следующих пакующих плазмид: 5 мкг pMD2.G (псевдотип VSV-g) и 7,5 мкг psPAX2 (gag/pol/rev/tat). Трансфекцию проводили в 4 мл OptiMEM со средством доставки на основе катионного липида (50 мкл Lipofectamine 2000 и 100 мкл реагента Plus). Через 6 часов среду заменяли на DMEM, не содержащую антибиотиков, с 10% фетальной бычьей сыворотки. В данных способах при культивировании клеток использовали сыворотку, но использование бессывороточных способов является предпочтительным.
Лентивирус можно очистить следующим способом. Вируссодержащие супернатанты собирали через 48 часов. Супернатанты сперва очищали от дебриса и фильтровали через фильтр с низкой степенью связывания белка (PVDF) на 0,45 мкм. Затем их центрифугировали на ультрацентрифуге в течение 2 часов при 24000 об./мин. Вируссодержащие супернатанты ресуспендировали в 50 мкл DMEM в течение ночи при 4°C. Затем их разделяли на аликвоты и сразу же замораживали при -80°C.
В другом варианте осуществления также предусмотрены минимальные лентивирусные векторы для отличных от приматов организмов на основе вируса инфекционной анемии лошадей (EIAV), особенно для генной терапии глаз (см., например, Balagaan, J Gene Med 2006; 8: 275-285). В другом варианте осуществления также предусмотрен RetinoStat®, лентивирусный вектор на основе вируса инфекционной анемии лошадей для генной терапии, экспрессирующий ангиостатические белки эндостатин и ангиостатин, который доставляют посредством субретинальной инъекции для лечения влажной формы возрастной дегенерации желтого пятна (см., например, Binley et al., HUMAN GENE THERAPY 23:980-991 (September 2012)), и данный вектор может быть модифицирован для системы CRISPR-Cas по настоящему изобретению.
В другом варианте осуществления самоинактивирующиеся лентивирусные векторы с siRNA, нацеленной на общий экзон, который имеет tat/rev HIV, сигналом ядрышковой локализации TAR-ловушкой и специфичным к CCR5 рибозимом в виде головки молотка (см., например, DiGiusto et al. (2010) Sci Transl Med 2:36ra43) можно использовать и/или адаптировать для системы CRISPR-Cas по настоящему изобретению. Не менее 2,5 × 106 клеток CD34+ на килограмм массы пациента можно собирать и предварительно стимулировать в течение 16-20 часов в среде X-VIVO 15 (Lonza), содержащей 2 мкмоля/L-глутамина, фактор стволовых клеток (100 нг/мл), лиганд Flt-3 (Flt-3L) (100 нг/мл) и тромбопоэтин (10 нг/мл) (CellGenix), при плотности 2 × 106 клеток/мл. Предварительно стимулированные клетки можно трансдуцировать лентивирусом при множественности заражения 5 в течение 16-24 часов во флаконах с культурой тканей на 75 см2, покрытых фибронектином (25 мг/см2) (RetroNectin, Takara Bio Inc.).
Лентивирусные векторы были раскрыты в отношении лечения болезни Паркинсона, см., например, публикацию заявки на патент США № 20120295960 и патенты США №№ 7303910 и 7351585. Лентивирусные векторы также были раскрыты в отношении лечения заболеваний глаз, см., например, публикации заявок на патенты США №№ 20060281180, 20090007284, US20110117189; US20090017543; US20070054961, US20100317109. Лентивирусные векторы также были раскрыты в отношении доставки в головной мозг, см., например, публикации заявок на патенты США №№ US20110293571; US20110293571, US20040013648, US20070025970, US20090111106 и патент США № US7259015.
Доставка РНК
Доставка РНК. фермент CRISPR, например Cpf1, и/или любую из РНК по настоящему изобретению, например направляющую РНК, также можно доставлять в форме РНК. С помощью in vitro транскрипции можно получить мРНК Cpf1. Например, мРНК Cpf1 можно синтезировать с помощью кассеты для ПЦР, содержащей следующие элементы: промотор T7_последовательность Козак (GCCACC)-Cpf1-3’-UTR гена бета-глобина-поли(A)-хвост (цепь из 120 адениновых остатков или более). Кассету можно применять для транскрипции полимеразой T7. Направляющие РНК также можно транскрибировать с помощью транскрипции in vitro с кассеты, содержащей промотор T7-GG-последовательность направляющей РНК.
Для повышения экспрессии и снижения возможной токсичности последовательность, кодирующую фермент CRISPR, и/или направляющую РНК можно модифицировать для включения одного или нескольких модифицированных нуклеозидов, например, с использованием псевдо-U или 5-метил-C.
Способы доставки мРНК в настоящее время являются особенно перспективными для доставки в печень.
Многие клинические работы по доставке РНК были сосредоточены на RNAi или антисмысловых РНК, но данные системы можно адаптировать для доставки РНК для осуществления настоящего изобретения. Соответственно, также ниже необходимо ознакомиться с использованной литературой по RNAi и т. д.
Системы доставки и/или составы на основе частиц
Известно, что несколько типов систем доставки и/или составов на основе частиц являются применимыми в разнообразном спектре биомедицинских применений. Частицу обычно определяют как небольшой объект, ведущий себя как целая единица в том, что касается ее транспорта и свойств. Частицы дополнительно классифицируют по диаметру. Крупные частицы охватывают диапазон от 2500 до 10000 нанометров. Тонкодисперсные частицы имеют размер от 100 до 2500 нанометров. Ультрадисперсные частицы или наночастицы, как правило, имеют размер от 1 до 100 нанометров. Основанием для предела в 100 нм является тот факт, что новые свойства, отличающие частицы от насыпного материала, обычно проявляются в критическом линейном масштабе менее 100 нм.
Используемые в данном документе система доставки и/или состав на основе частиц определяют как любые биологическая система доставки/состав, содержащие частицы в соответствии с настоящим изобретением. Частица в соответствии с настоящим изобретением представляет собой любой объект, имеющий наибольший размер (например, диаметр) менее 100 микрон (мкм). В некоторых вариантах осуществления частицы по настоящему изобретению имеют наибольший размер менее 10 мкм. В некоторых вариантах осуществления частицы по настоящему изобретению имеют наибольший размер менее 2000 нанометров (нм). В некоторых вариантах осуществления частицы по настоящему изобретению имеют наибольший размер менее 1000 нанометров (нм). В некоторых вариантах осуществления частицы по настоящему изобретению имеют наибольший размер менее 900 нм, 800 нм, 700 нм, 600 нм, 500 нм, 400 нм, 300 нм, 200 нм или 100 нм. Частицы по настоящему изобретению, как правило, имеют наибольший размер (например, диаметр) 500 нм или менее. В некоторых вариантах осуществления частицы по настоящему изобретению имеют наибольший размер (например, диаметр) 250 нм или менее. В некоторых вариантах осуществления частицы по настоящему изобретению имеют наибольший размер (например, диаметр) 200 нм или менее. В некоторых вариантах осуществления частицы по настоящему изобретению имеют наибольший размер (например, диаметр) 150 нм или менее. В некоторых вариантах осуществления частицы по настоящему изобретению имеют наибольший размер (например, диаметр) 100 нм или менее. В некоторых вариантах осуществления настоящего изобретения применяют меньшие частицы, например, имеющие наибольший размер 50 нм или менее. В некоторых вариантах осуществления частицы по настоящему изобретению имеют наибольший размер, варьирующий в диапазоне от 25 нм до 200 нм.
Определение характеристик частиц (в том числе, например, определение характеристик морфологии, размеров и т. д.) осуществляют с применением ряда различных методик. Стандартными методиками являются электронная микроскопия (TEM, SEM), атомно-силовая микроскопия (AFM), динамическое рассеяние света (DLS), рентгеновская фотоэлектронная спектроскопия (XPS), порошковая рентгеновская дифракция (XRD), инфракрасная спектроскопия с преобразованием Фурье (FTIR), времяпролетная масс-спектрометрия с лазерной десорбцией и ионизацией из матрицы (MALDI-TOF), спектроскопия в ультрафиолетовой и видимой области спектра, двойная поляризационная интерферометрия и ядерный магнитный резонанс (ЯМР). Получение характеристик (измерения размеров) можно проводить в отношении нативных частиц (т. е. до загрузки) или после загрузки молекулы-карго (в данном документе молекула-карго относится, например, к одному или нескольким компонентам системы CRISPR-Cas, например, ферменту или мРНК CRISPR, или направляющей РНК, или к любой их комбинации, и может включать дополнительные носители и/или наполнители) для получения частиц, имеющих оптимальный размер для доставки, для любого применения настоящего изобретения in vitro, ex vivo и/или in vivo. В определенных предпочтительных вариантах осуществления определение характеристик размеров частиц (например, диаметра) основано на измерениях с применением динамического рассеяния лазерного излучения (DLS). Упоминаются патент США № 8709843; патент США № 6007845; патент США № 5855913; патент США № 5985309; патент США № 5543158 и публикация James E. Dahlman and Carmen Barnes et al. Nature Nanotechnology (2014), опубликованная в интернете 11 мая 2014 года, doi:10.1038/nnano.2014.84, касаются частиц, способов их получения и применения, а также их измерения.
Системы доставки на основе частиц в пределах объема настоящего изобретения могут быть представлены в любой форме, в том числе без ограничения в форме твердых, полутвердых, эмульгированных или коллоидных частиц. В силу этого любые системы доставки, описанные в данном документе, в том числе без ограничения, например, системы на основе липидов, липосомы, мицеллы, микровезикулы, экзосомы или генная пушка, могут быть представлены в качестве систем доставки на основе частиц в пределах объема настоящего изобретения.
Частицы
Будет ясно, что упоминание, выполняемое в данном документе на частицы или наночастицы, при необходимости может быть взаимозаменяемым. мРНК и направляющая РНК фермента CRISPR могут быть доставлены одновременно с использованием частиц или липидных оболочек; например, фермент CRISPR и РНК в соответствии с настоящим изобретением, например, в виде комплекса, могут быть доставлены посредством частицы, как в Dahlman et al., WO 2015089419 A2 и документах, цитируемых там, такой как 7C1 (см., например, James E. Dahlman и Carmen Barnes et al. Nature Nanotechnology (2014), опубликованной онлайн 11 мая 2014 г., doi:10.1038/nnano.2014.84), например, частицы для доставки, содержащей липид или липидоид и гидрофильный полимер, например, катионный липид и гидрофильный полимер, например, при этом катионный липид содержит 1,2-диолеоил-3-триметиламмония-пропан (DOTAP) или 1,2-дитетерадеканоил-sn-глицеро-3-фосфохолин (DMPC), и/или при этом гидрофильный полимер содержит этиленгликоль или полиэтиленгликоль (PEG); и/или при этом частица дополнительно содержит холестерин (например, частица из состава 1 = DOTAP 100, DMPC 0, PEG 0, холестерин 0; состава номер 2 = DOTAP 90, DMPC 0, PEG 10, холестерин 0; состава номер 3 = DOTAP 90, DMPC 0, PEG 5, холестерин 5), где частицы образуются с использованием эффективного многостадийного процесса, при котором первый эффекторный белок и РНК смешивают вместе, например, при молярном отношении 1:1, например, при комнатной температуре, например, в течение 30 минут, например, в стерильном не содержащем нуклеазу 1X PBS; и отдельно DOTAP, DMPC, PEG и холестерин, применимые для состава, растворяют в спирте, например, 100% этаноле; и два раствора смешивают вместе с образованием частиц, содержащих комплексы).
мРНК и направляющая РНК нацеливающихся на нуклеиновую кислоту эффекторных белков (таких как белок V типа, например, Cpf1) могут быть доставлены одновременно при помощи частиц или липидных оболочек. Примеры подходящих частиц включают без ограничений описанные в US 9301923.
Например, у Su X, Fricke J, Kavanagh DG, Irvine DJ ("In vitro and in vivo mRNA delivery using lipid-enveloped pH-responsive polymer nanoparticles" Mol Pharm. 2011 Jun 6;8(3):774-87. doi: 10.1021/mp100390w. Epub 2011 Apr 1) описаны биоразлагаемые наночастицы со структурой ядро-оболочка с ядром из сложного поли(β-аминоэфира) (PBAE), окруженным фосфолипидной двуслойной оболочкой. Они были разработаны для доставки мРНК in vivo. Чувствительный к рН компонент PBAE был выбран для содействия разрушению эндосом, тогда как поверхностный липидный слой был выбран для сведения к минимуму токсичности поликатионного ядра. Таким образом, они являются предпочтительными для доставки РНК по настоящему изобретению.
В одном варианте осуществления предусмотрены частицы/наночастицы на основе самособирающихся биоадгезивных полимеров, которые можно использовать для пероральной доставки пептидов, внутривенной доставки пептидов и интраназальной доставки пептидов, во всех случаях в головной мозг. Также предусмотрены другие варианты осуществления, такие как абсорбция при пероральном применении и внутриглазная доставка гидрофобных лекарственных средств. Технология молекулярных оболочек предусматривает сконструированную полимерную оболочку, защищающую и доставляющую в очаг заболевания (см., например, Mazza, M. et al. ACSNano, 2013. 7(2): 1016-1026; Siew, A., et al. Mol Pharm, 2012. 9(1):14-28; Lalatsa, A., et al. J Contr Rel, 2012. 161(2):523-36; Lalatsa, A., et al., Mol Pharm, 2012. 9(6):1665-80; Lalatsa, A., et al. Mol Pharm, 2012. 9(6):1764-74; Garrett, N.L., et al. J Biophotonics, 2012. 5(5-6):458-68; Garrett, N.L., et al. J Raman Spect, 2012. 43(5):681-688; Ahmad, S., et al. J Royal Soc Interface 2010. 7:S423-33; Uchegbu, I.F. Expert Opin Drug Deliv, 2006. 3(5):629-40; Qu, X.,et al. Biomacromolecules, 2006. 7(12):3452-9 и Uchegbu, I.F., et al. Int J Pharm, 2001. 224:185-199). Предусмотрены дозы, составляющие приблизительно 5 мг/кг, которые в зависимости от целевой ткани будут однократными или многократными дозами.
В одном варианте осуществления частицы/наночастицы, которые могут доставлять РНК в раковые клетки для прекращения роста опухолей, разработанные в лаборатории Дэна Андерсона в MIT, можно использовать для системы CRISPR-Cas по настоящему изобретению и/или приспосабливать к ней. В частности, в лаборатории Андерсона были разработаны полностью автоматизированные, комбинаторные системы для синтеза, очистки, определения характеристик и составления новых биоматериалов и наносоставов. См., например, Alabi et al., Proc Natl Acad Sci U S A. 2013 Aug 6;110(32):12881-6; Zhang et al., Adv Mater. 2013 Sep 6;25(33):4641-5; Jiang et al., Nano Lett. 2013 Mar 13;13(3):1059-64; Karagiannis et al., ACS Nano. 2012 Oct 23;6(10):8484-7; Whitehead et al., ACS Nano. 2012 Aug 28;6(8):6922-9 и Lee et al., Nat Nanotechnol. 2012 Jun 3;7(6):389-93.
Заявка на патент США 20110293703 относится к липидоподобным соединениям, также являющимся особенно применимыми при введении полинуклеотидов, которые можно применять для доставки системы CRISPR-Cas по настоящему изобретению. В одном аспекте аминоспиртовые липидоподобные соединения объединяют со средством, подлежащим доставке в клетку или субъекту, с образованием микрочастиц, наночастиц, липосом или мицелл. Средство, подлежащее доставке с помощью частиц, липосом или мицелл, может быть в форме газа, жидкости или твердого вещества, и средство может представлять собой полинуклеотид, белок, пептид или малую молекулу. Аминоспиртовые липидоподобные соединения можно объединять с другими аминоспиртовыми липидоподобными соединениями, полимерами (синтетическими или природными), поверхностно-активными веществами, холестерином, углеводами, белками, липидами и т. д. с образованием частиц. Эти частицы можно затем необязательно объединять с фармацевтическим наполнителем с образованием фармацевтической композиции.
В публикации заявки на патент США № 20110293703 также представлены способы получения аминоспиртовых липидоподобных соединений. Одному или нескольким эквивалентам амина позволяют вступать в реакцию с одним или несколькими эквивалентами соединения с концевыми эпоксидными группами в подходящих условиях с образованием аминоспиртового липидоподобного соединения по настоящему изобретению. В определенных вариантах осуществления все аминогруппы амина полностью реагируют с соединением с концевыми эпоксидными группами с образованием третичных аминов. В других вариантах осуществления все аминогруппы амина не полностью реагируют с соединением с концевыми эпоксидными группами для образования третичных аминогрупп, в результате чего, таким образом, образуются первичные или вторичные аминогруппы аминоспиртового липидоподобного соединения. Эти первичные или вторичные аминогруппы оставляют в существующем состоянии или могут вводить в реакцию с другим электрофилом, таким как другое соединение с концевыми эпоксидными группами. Специалисту в данной области будет понятно, что введение амина в реакцию с меньшим, чем избыточное, количеством соединения с концевыми эпоксидными группами приведет к получению множества различных аминоспиртовых липидоподобных соединений с различным количеством "хвостов". Определенные амины могут быть полностью функционализированными с помощью двух "хвостов" соединений, полученных из эпоксидов, тогда как другие молекулы могут быть не полностью функционализированными с помощью "хвостов" соединений, полученных из эпоксидов. Например, диамин или полиамин может содержать один, два, три или четыре "хвоста" соединений, полученных из эпоксидов, у различных аминофрагментов молекулы, в результате чего образуются первичные, вторичные и третичные аминогруппы. В определенных вариантах осуществления все аминогруппы являются не полностью функционализированными. В определенных вариантах осуществления используют два соединения с концевыми эпоксидными группами одного типа. В других вариантах осуществления используют два или более различных соединений с концевыми эпоксидными группами. Синтез аминоспиртовых липидоподобных соединений осуществляют с помощью растворителя или без него, и синтез можно осуществлять при более высоких температурах, варьирующих в диапазоне 30-100°C, предпочтительно при примерно 50-90°C. Получаемые аминоспиртовые липидоподобные соединения необязательно можно очищать. Например, смесь аминоспиртовых липидоподобных соединений можно очищать с получением аминоспиртового липидоподобного соединения с определенным количеством "хвостов" соединений, полученных из эпоксидов. Или же смесь можно очищать с получением определенного стерео- или региоизомера. Аминоспиртовые липидоподобные соединения можно также алкилировать с помощью алкилгалогенида (например, йодистого метила) или другого алкилирующего средства и/или их можно ацилировать.
В публикации заявки на патент США № 20110293703 также представлены библиотеки аминоспиртовых липидоподобных соединений, полученных согласно способам по настоящему изобретению. Эти аминоспиртовые липидоподобные соединения можно получать и/или подвергать скринингу с применением высокопроизводительных методик, предусматривающих использование дозаторов жидкостей, автоматических манипуляторов, планшетов для микротитрования, компьютеров и т. д. В определенных вариантах осуществления аминоспиртовые липидоподобные соединения подвергают скринингу в отношении их способности к трансфекции полинуклеотидов или других средств (например, белков, пептидов, малых молекул) в клетку.
Публикация заявки на патент США № 20130302401 относится к классу поли(бета-аминоспиртов) (PBAA), получаемых с помощью комбинаторных методик полимеризации. PBAA по настоящему изобретению можно применять в биотехнологии и биомедицинских применениях в качестве покрытий (таких как пленочные покрытия или многослойные пленки для медицинских инструментов или имплантатов), добавок, материалов, наполнителей, средств, предотвращающих биологическое обрастание, средств для формирования микроструктуры и средств для инкапсулирования клеток. В случае применения в качестве поверхностных покрытий эти PBAA вызывают различные уровни воспаления как in vitro, так и in vivo в зависимости от их химических структур. Большое химическое разнообразие этого класса материалов позволяет идентифицировать полимерные покрытия, ингибирующие активацию макрофагов in vitro. Более того, эти покрытия уменьшают рекрутирование воспалительных клеток и уменьшают выраженность фиброза после подкожной имплантации микрочастиц карбоксилированного полистирола. Эти полимеры можно использовать для образования капсул на основе полиэлектролитных комплексов для инкапсулирования клеток. Настоящее изобретение также может иметь много других применений в биологии, таких как получение антимикробных покрытий, доставка ДНК или siRNA и тканевая инженерия с применением стволовых клеток. Идеи, изложенные в публикации заявки на патент США № 20130302401, можно применять по отношению к системе CRISPR-Cas по настоящему изобретению. В некоторых вариантах осуществления могут быть использованы частицы на основе сахара, например GalNAc, как описывается в данном документе и со ссылкой на WO 2014118272 (включенной в данный документ посредством ссылки) и Nair, JK et al., 2014, Journal of the American Chemical Society 136 (49), 16958-16961), а также согласно идеям в данном документе, особенно в отношении применений в доставке для всех частиц, если не очевидно иное.
В другом варианте осуществления предусмотрены липидные наночастицы (LNP). В частности, малые интерферирующие РНК, воздействующие на транстиретин, инкапсулировали в липидные наночастицы и использовали для доставки у людей (см., например, Coelho et al., N Engl J Med 2013;369:819-29), и такую систему можно приспосабливать и применять в отношении системы CRISPR-Cas по настоящему изобретению. Предусмотрены дозы, составляющие от приблизительно 0,01 до приблизительно 1 мг на кг массы тела, вводимые внутривенно. Предусмотрены лекарственные препараты для снижения риска возникновения инфузионных реакций, такие как дексаметазон, ацетаминофен, дифенгидрамин или цетиризин и ранитидин. Также предусмотрены многократные дозы, состоящие из пяти доз по приблизительно 0,3 мг на килограмм, принимаемых каждые 4 недели.
Было показано, что LNP являются высокоэффективными в доставке siRNA в печень (см., например, Tabernero et al., Cancer Discovery, April 2013, Vol. 3, No. 4, pages 363-470) и, таким образом, предусмотрены для доставки в печень РНК, кодирующей CRISPR-Cas. Может быть предусмотрен режим дозирования с приемом приблизительно четырех доз по 6 мг/кг LNP каждые две недели. Tabernero et al. продемонстрировали, что после первых 2 циклов дозирования LNP при 0,7 мг/кг наблюдалась регрессия опухоли, а к концу 6 циклов у пациента достигался частичный ответ с полной регрессией метастазов в лимфатических узлах и значительным уменьшением размеров опухолей в печени. У данного пациента, у которого сохранялась ремиссия и который завершил лечение после получения доз в течение 26 месяцев, полный ответ достигался после приема 40 доз. У двух пациентов с RCC и внепеченочными очагами заболевания, включающими почку, легкое и лимфатические узлы, в которых наблюдалось прогрессирование после предшествующей терапии ингибиторами сигнального пути VEGF, наблюдалась стабилизация заболевания во всех очагах в течение примерно 8-12 месяцев, а пациент с PNET и метастазами в печени продолжал участие в расширенном исследовании в течение 18 месяцев (36 доз) при стабилизации заболевания.
Однако следует принимать во внимание заряд LNP. Так, объединение катионных липидов с отрицательно заряженными липидами индуцирует образование структур, не являющихся двуслойными, которые облегчают внутриклеточную доставку. Поскольку заряженные LNP быстро выводятся из кровотока после внутривенной инъекции, были разработаны ионизируемые катионные липиды со значениями pKa ниже 7 (см., например, Rosin et al, Molecular Therapy, vol. 19, no. 12, pages 1286-2200, Dec. 2011). Отрицательно заряженные полимеры, такие как РНК, можно загружать в LNP при низких значениях pH (например, pH 4), где ионизируемые липиды проявляют положительный заряд. Однако при физиологических значениях pH LNP проявляют низкий поверхностный заряд, совместимый с большими значениями времени пребывания в кровотоке. Основное внимание сосредоточено на четырех видах молекул ионизируемых катионных липидов, а именно 1,2-дилинолеоил-3-диметиламмонийпропане (DLinDAP), 1,2-дилинолеилокси-3-N,N-диметиламинопропане (DLinDMA), 1,2-дилинолеилоксикето-N,N-диметил-3-аминопропане (DLinKDMA) и 1,2-дилинолеил-4-(2-диметиламиноэтил)-[1,3]-диоксолане (DLinKC2-DMA). Было показано, что системы LNP с siRNA, содержащие эти липиды, проявляют существенно отличающиеся свойства сайленсинга генов в гепатоцитах in vivo, при этом их активность изменяется в ряду DLinKC2-DMA>DLinKDMA>DLinDMA>>DLinDAP при использовании модели сайленсинга гена фактора VII (см., например, Rosin et al, Molecular Therapy, vol. 19, no. 12, pages 1286-2200, Dec. 2011). Может быть предусмотрена доза 1 мкг/мл LNP или РНК CRISPR-Cas в LNP или ассоциированная с ней, в особенности для состава, содержащего DLinKC2-DMA.
Получение LNP и инкапсулирование CRISPR-Cas можно применять и/или адаптировать согласно Rosin et al, Molecular Therapy, vol. 19, no. 12, pages 1286-2200, Dec. 2011. Катионные липиды 1,2-дилинолеоил-3-диметиламмонийпропан (DLinDAP), 1,2-дилинолеилокси-3-N,N-диметиламинопропан (DLinDMA), 1,2-дилинолеилоксикето-N,N-диметил-3-аминопропан (DLinK-DMA), 1,2-дилинолеил-4-(2-диметиламиноэтил)-[1,3]-диоксолан (DLinKC2-DMA), (3-o-[2″-(метоксиполиэтиленгликоль 2000)-сукциноил]-1,2-димиристоил-sn-гликоль (PEG-S-DMG) и R-3-[(ω-метоксиполи(этиленгликоль)2000)-карбамоил]-1,2-димиристилоксипропил-3-амин (PEG-C-DOMG) могут быть предоставлены Tekmira Pharmaceuticals (Ванкувер, Канада) или синтезированы. Холестерин можно приобрести у Sigma (Сент-Луис, Миссури). Конкретную РНК CRISPR-Cas можно инкапсулировать в LNP, содержащую DLinDAP, DLinDMA, DLinK-DMA и DLinKC2-DMA (катионный липид:DSPC:холестерин: PEG-S-DMG или PEG-C-DOMG в молярном соотношении 40:10:40:10). При необходимости можно включать в состав 0,2% SP-DiOC18 (Invitrogen, Берлингтон, Канада) для определения клеточного поглощения, внутриклеточной доставки и биораспределения. Инкапсулирование можно осуществлять путем растворения липидных смесей, содержащих катионный липид:DSPC:холестерин:PEG-C-DOMG (молярное соотношение 40:10:40:10), в этаноле до конечной концентрации липидов 10 ммолей/л. Этот раствор липидов в этаноле можно добавлять по каплям к 50 ммолей/л цитрата, pH 4,0, с образованием многослойных везикул до получения конечной концентрации этанола 30% об./об. Крупные однослойные везикулы могут быть образованы после экструзии многослойных везикул через два установленных один над другим поликарбонатных фильтра Nuclepore на 80 нм с помощью экструдера (Northern Lipids, Ванкувер, Канада). Инкапсулирование можно осуществлять путем добавления РНК, растворенной при 2 мг/мл в 50 ммолей/л цитрата, pH 4,0, содержащего этанола 30% об./об., по каплям к экструдированным предварительно сформированным крупным однослойным везикулам и инкубирования при 31°C в течение 30 минут при постоянном перемешивании до конечного весового соотношения РНК/липид 0,06/1 вес/вес. Удаление этанола и нейтрализацию буфера для получения состава проводили путем диализа против фосфатно-солевого буфера (PBS), pH 7,4, в течение 16 часов с помощью диализных мембран Spectra/Por 2 из регенерированной целлюлозы. Распределение наночастиц по размеру можно определить посредством динамического рассеяния света с использованием измерителя размера частиц NICOMP 370, режимов объема везикул/интенсивности рассеянного света и аппроксимации функцией Гаусса (Nicomp Particle Sizing, Санта-Барбара, Калифорния). Размер частиц для всех трех систем LNP может составлять ~70 нм в диаметре. Эффективность инкапсулирования siRNA можно определить путем удаления свободной РНК из образцов, отобранных до или после диализа, с помощью колонок VivaPureD MiniH (Sartorius Stedim Biotech). Инкапсулированную РНК можно экстрагировать из элюированных наночастиц и подвергнуть количественной оценке при 260 нм. Соотношение РНК и липидов определяли путем измерения содержания холестерина в везикулах с помощью ферментативного анализа Cholesterol E от Wako Chemicals USA (Ричмонд, Виргиния). В связи с обсуждением в данном документе LNP и конъюгатов PEG-липид, ПЭГилированные липосомы или LNP являются также подходящими для доставки системы CRISPR-Cas или ее компонентов.
Получение крупных LNP можно применять и/или адаптировать согласно Rosin et al, Molecular Therapy, vol. 19, no. 12, pages 1286-2200, Dec. 2011. Раствор предварительно приготовленной смеси липидов (общая концентрация липидов 20,4 мг/мл) можно получать в этаноле, содержащем DLinKC2-DMA, DSPC и холестерин в молярном соотношении 50:10:38,5. К предварительно приготовленной смеси липидов можно добавлять ацетат натрия в молярном соотношении 0,75:1 (ацетат натрия:DLinKC2-DMA). Липиды затем можно гидрировать путем объединения смеси с 1,85 объема цитратного буфера (10 ммоль/л, pH 3,0) при энергичном перемешивании, вызывая самопроизвольное образование липосом в водном буфере, содержащем 35% этанол. Раствор липосом можно инкубировать при 37°C для обеспечения зависимого от времени увеличения размера частиц. Можно отбирать аликвоты в различные моменты времени в ходе инкубирования для изучения изменений размера липосом посредством динамического рассеяния света (Zetasizer Nano ZS, Malvern Instruments, Вустершир, Великобритания). По достижении желаемого размера частиц к смеси липосом можно добавлять водный раствор конъюгатов PEG-липид (исходный раствор = 10 мг/мл PEG-DMG в 35% (об./об.) этаноле) с получением конечной молярной концентрации PEG 3,5% от общего количества липидов. После добавления конъюгатов PEG-липид липосомы должны сохранять свой размер с эффективным подавлением дальнейшего роста. К пустым липосомам затем можно добавлять РНК при соотношении РНК и общих липидов, составляющим примерно 1:10 (вес:вес.), с последующим инкубированием в течение 30 минут при 37°C с образованием нагруженных LNP. Смесь затем можно подвергнуть диализу в течение ночи в PBS и отфильтровать через фильтрующий шприц с диаметром пор 0,45 мкм.
Конструкции сферических нуклеиновых кислот (SNA™) и другие наночастицы (в частности, наночастицы золота) также предусмотрены в качестве средства доставки системы CRISPR/Cas к предполагаемым мишеням. Репрезентативные данные показывают, что конструкции сферических нуклеиновых кислот (SNA™) AuraSense лекарственных препаратов на основе наночастиц золота, функционализированных нуклеиновыми кислотами, также являются применимыми.
Литературные источники, которые можно использовать совместно с изложенными в данном документе идеями, включают: Cutler et al., J. Am. Chem. Soc. 2011 133:9254-9257, Hao et al., Small. 2011 7:3158-3162, Zhang et al., ACS Nano. 2011 5:6962-6970, Cutler et al., J. Am. Chem. Soc. 2012 134:1376-1391, Young et al., Nano Lett. 2012 12:3867-71, Zheng et al., Proc. Natl. Acad. Sci. USA. 2012 109:11975-80, Mirkin, Nanomedicine 2012 7:635-638 Zhang et al., J. Am. Chem. Soc. 2012 134:16488-1691, Weintraub, Nature 2013 495:S14-S16, Choi et al., Proc. Natl. Acad. Sci. USA. 2013 110(19):7625-7630, Jensen et al., Sci. Transl. Med. 5, 209ra152 (2013) и Mirkin, et al., Small, 10:186-192.
Самособирающиеся наночастицы с РНК можно конструировать с полиэтиленимином (PEI), который ПЭГилирован с пептидным лигандом Arg-Gly-Asp (RGD), прикрепленным к дистальному концу цепи полиэтиленгликоля (PEG). Данную систему использовали, например, в качестве средства для целенаправленного воздействия на сосудистую сеть опухолей, экспрессирующую интегрины, и для доставки siRNA, подавляющей экспрессию рецептора 2 сосудистого эндотелиального фактора роста (VEGF R2), добиваясь тем самым подавления опухолевого ангиогенеза (см., например, Schiffelers et al., Nucleic Acids Research, 2004, Vol. 32, No. 19). Наноплексы можно получать путем смешивания равных объемов водных растворов катионного полимера и нуклеиновой кислоты с получением чистого молярного избытка ионизируемого азота (полимера) относительно фосфата (нуклеиновой кислоты) в диапазоне от 2 до 6. Электростатические взаимодействия между катионными полимерами и нуклеиновой кислотой приводят в результате к образованию полиплексов, характеризующихся распределением частиц по размеру со средним размером, составляющим приблизительно 100 нм, в связи с чем их называют наноплексами. Для доставки в самособирающихся наночастицах согласно Schiffelers et al. предполагается доза, составляющая приблизительно от 100 до 200 мг CRISPR-Cas.
Наноплексы согласно Bartlett et al. (PNAS, September 25, 2007,vol. 104, no. 39) также можно применять в настоящем изобретении. Наноплексы согласно Bartlett et al. получают путем смешивания равных объемов водных растворов катионного полимера и нуклеиновой кислоты с получением чистого молярного избытка ионизируемого азота (полимера) относительно фосфата (нуклеиновой кислоты) в диапазоне от 2 до 6. Электростатические взаимодействия между катионными полимерами и нуклеиновой кислотой приводят в результате к образованию полиплексов, характеризующихся распределением частиц по размеру со средним размером, составляющим приблизительно 100 нм, в связи с чем их называют наноплексами. Конъюгаты DOTA-siRNA согласно Bartlett et al. синтезировали следующим образом. Сложный моно(N-гидроксисукцинимидный эфир) 1,4,7,10-тетраазациклододекан-1,4,7,10-тетрауксусной кислоты (сложный эфир DOTA-NHS) заказывали у Macrocyclics (Даллас, Техас). В микроцентрифужную пробирку добавляли аминомодифицированную смысловую нить РНК со 100-кратным молярным избытком сложного эфира DOTA-NHS в карбонатном буфере (pH 9). Содержимое вводили в реакцию путем перемешивания в течение 4 ч. при комнатной температуре. Конъюгат DOTA-смысловая нить РНК осаждали этанолом, ресуспендировали в воде и отжигали с немодифицированной антисмысловой нитью с получением конъюгата DOTA-siRNA. Все жидкости предварительно обрабатывали с помощью Chelex-100 (Bio-Rad, Геркулес, Калифорния) для удаления следовых количеств металлических примесей. Нацеленные на Tf или ненацеленные наночастицы с siRNA можно получать с помощью поликатионов, содержащих циклодекстрин. Как правило, наночастицы получают в воде при соотношении зарядов 3 (+/-) и концентрации siRNA 0,5 г/литр. Один процент молекул конъюгатов адамантан-PEG на поверхности нацеленных наночастиц модифицировали с помощью Tf (адамантан-PEG-Tf). Наночастицы суспендировали в 5% (вес./об.) растворе глюкозы в качестве носителя для инъекции.
Davis et al. (Nature, Vol 464, 15 April 2010) проводили клиническое испытание с РНК, в котором использовали систему доставки на основе нацеленных наночастиц (регистрационный номер клинического испытания NCT00689065). Пациентам с солидными формами рака, трудно поддающимися стандартным методикам лечения, вводили дозы целенаправленно воздействующих наночастиц в дни 1, 3, 8 и 10 21-дневного цикла посредством 30-минутной внутривенной инфузии. Наночастицы состоят из синтетической системы доставки, содержащей: (1) линейный полимер на основе циклодекстрина (CDP), (2) лиганд, нацеливающийся на белок трансферрин человека (TF), представленный на внешней поверхности наночастиц, который входит в контакт с рецепторами TF (TFR) на поверхности раковых клеток, (3) гидрофильный полимер (полиэтиленгликоль (PEG), используемый для обеспечения стабильности наночастиц в биологических жидкостях), и (4) siRNA, предназначенную для снижения экспрессии RRM2 (последовательность, применяемая в клинической практике, ранее была обозначена как siR2B+5). Давно известно, что в злокачественных клетках повышена экспрессия TFR, а RRM2 является общепризнанной мишенью для противораковой терапии. Было показано, что эти наночастицы (клинический вариант обозначен как CALAA-01) хорошо переносятся в исследованиях с использованием многократных доз у отличных от человека приматов. Даже при том, что отдельному пациенту с хроническим миелоидным лейкозом вводили siRNA посредством доставки с помощью липосом, клиническое испытание Davis et al. является первым испытанием с участием человека, в котором проводят системную доставку siRNA с помощью системы целенаправленной доставки и лечат пациентов с солидным раком. Для того, чтобы выяснить, может ли система целенаправленной доставки обеспечивать эффективную доставку функциональных siRNA в опухоли человека, Davis et al. исследовали биоптаты от трех пациентов из трех различных групп дозирования; пациентов A, B и C, все из которых имели метастазирующую меланому и получали дозы CALAA-01 с 18, 24 и 30 мг м-2 siRNA соответственно. Аналогичные дозы также могут быть предусмотрены для системы CRISPR-Cas по настоящему изобретению. Доставку по настоящему изобретению можно осуществлять с помощью наночастиц, содержащих линейный полимер на основе циклодекстрина (CDP), лиганд, нацеливающийся на белок трансферрин человека (TF), представленный на внешней поверхности наночастиц, который входит в контакт с рецепторами TF (TFR) на поверхности раковых клеток, и/или гидрофильный полимер (например, полиэтиленгликоль (PEG), применяемый для обеспечения стабильности наночастиц в биологических жидкостях).
В контексте настоящего изобретения предпочтительно, чтобы один или несколько компонентов комплекса CRISPR, например, фермент или мРНК CRISPR или направляющая РНК, были доставлены с помощью наночастиц или липидных оболочек. Вместе с аспектами наночастиц по настоящему изобретению можно применять другие системы доставки или векторы.
В целом, "наночастица" относится к любой частице, имеющей диаметр менее 1000 нм. В определенных предпочтительных вариантах осуществления наночастицы по настоящему изобретению имеют наибольший размер (например, диаметр) 500 нм или менее. В других предпочтительных вариантах осуществления наночастицы по настоящему изобретению имеют наибольший размер, варьирующий в диапазоне от 25 нм до 200 нм. В других предпочтительных вариантах осуществления наночастицы по настоящему изобретению имеют наибольший размер 100 нм или менее. В других предпочтительных вариантах осуществления наночастицы по настоящему изобретению имеют наибольший размер, варьирующий в диапазоне от 35 нм до 60 нм.
Наночастицы, охватываемые настоящим изобретением, могут быть предусмотрены в различных формах, например, в виде твердых наночастиц (например, металла, такого как серебро, золото, железо, титан, неметалла, липидных твердых веществ, полимеров), суспензий наночастиц или их комбинаций. Могут быть получены наночастицы металла, диэлектрика и полупроводника, а также гибридные структуры (например, наночастицы типа ядро/оболочка). Наночастицы, изготовленные из полупроводникового материала, также могут являться меченными квантовыми точками, если они достаточно малы (как правило, менее 10 нм), чтобы происходило квантование уровней энергии электронов. Такие наноразмерные частицы используются в биомедицинских применениях в качестве носителей лекарственных средств или визуализирующих средств и могут быть приспособлены для аналогичных целей в настоящем изобретении.
Были получены полутвердые и мягкие наночастицы, и они находятся в пределах объема настоящего изобретения. Наночастицей-прототипом полутвердой природы является липосома. Различные типы наночастиц-липосом в настоящее время применяют в клинической практике в качестве систем доставки противораковых лекарственных средств и вакцин. Наночастицы, одна полусфера которых является гидрофильной, а другая полусфера - гидрофобной, называются частицами Януса и являются особенно эффективными в стабилизации эмульсий. Они способны к самосборке на поверхностях раздела вода/масло и действовать в качестве твердых поверхностно-активных веществ.
В патенте США № 8709843, включенном в данный документ посредством ссылки, представлена система доставки терапевтических средств для целенаправленной доставки частиц, содержащих терапевтическое средство, в ткани, клетки и внутриклеточные компартменты. Настоящее изобретение относится к подвергнутым нацеливанию частицам, содержащим полимер, конъюгированный с поверхностно-активным веществом, гидрофильным полимером или липидом.
В патенте США № 6007845, включенном в данный документ посредством ссылки, предусмотрены частицы, имеющие ядро из мультиблочного сополимера, образованного путем ковалентного связывания соединения с несколькими функциональными группами с одним или несколькими гидрофобными полимерами и одним или несколькими гидрофильными полимерами, и содержащие биологически активный материал.
В патенте США № 5855913, включенном в данный документ посредством ссылки, предусмотрена композиция в форме частиц, содержащая аэродинамически легкие частицы, имеющие плотность после утряски менее 0,4 г/см3 и средний диаметр от 5 мкм до 30 мкм, содержащие поверхностно-активное вещество на их поверхности, для доставки лекарственных средств в легочную систему.
В патенте США № 5985309, включенном в данный документ посредством ссылки, предусмотрены частицы, содержащие поверхностно-активное вещество и/или гидрофильный или гидрофобный комплекс положительно или отрицательно заряженного терапевтического или диагностического средства и заряженной молекулы, имеющей противоположный заряд, для доставки в легочную систему.
В патенте США № 5543158, включенном в данный документ посредством ссылки, предусмотрены биоразлагаемые инъекционные частицы, имеющие биоразлагаемую твердую сердцевину, содержащую биологически активный материал, и поли(алкиленгликолевые) фрагменты на поверхности.
В WO2012135025 (также опубликованном как US20120251560), включенном в данный документ посредством ссылки, описаны конъюгированные полимеры на основе полиэтиленимина (PEI) и конъюгированные азамакроциклы (совместно именуемые "конъюгированным липополимером" или "липополимерами"). В определенных вариантах осуществления может быть предусмотрено, что такие конъюгированные липополимеры можно применять в случае с системой CRISPR-Cas для осуществления внесения изменений в геном in vitro, ex vivo и in vivo с модификацией экспрессии гена, включающей модулирование экспрессии белка.
В одном варианте осуществления наночастица может представлять собой гибрид липида, модифицированного эпоксидными группами, и полимера, преимущественно 7C1 (см., например, James E. Dahlman and Carmen Barnes et al. Nature Nanotechnology (2014), опубликовано онлайн 11 мая 2014 г., doi:10.1038/nnano.2014.84). C71 синтезировали путем осуществления реакции липидов C15 с концевыми эпоксидными группами с PEI600 в молярном соотношении 14:1 и составляли с C14PEG2000 с получением наночастиц (диаметром от 35 до 60 нм), которые были стабильными в растворе PBS в течение по меньшей мере 40 дней.
Гибрид липида, модифицированного эпоксидными группами, и полимера можно использовать для доставки системы CRISPR-Cas по настоящему изобретению в клетки легких, сердечно-сосудистой системы или почек, однако, специалист в данной области может приспособить систему для доставки в другие целевые органы. Предусмотрена доза, варьирующая в диапазоне от приблизительно 0,05 до приблизительно 0,6 мг/кг. Также предусмотрен прием доз в течение нескольких дней или недель, при этом общая доза составляет приблизительно 2 мг/кг.
Экзосомы
Экзосомы являются эндогенными нановезикулами, переносящими РНК и белки, и которые могут доставлять РНК в головной мозг и другие целевые органы. Для снижения иммуногенности Alvarez-Erviti et al. (2011, Nat Biotechnol 29: 341) использовали аутогенные дендритные клетки для получения экзосом. Нацеливания на головной мозг достигали путем конструирования дендритных клеток, экспрессирующих Lamp2b, мембранный белок экзосом, слитый с нейрон-специфическим пептидом RVG. Очищенные экзосомы нагружали экзогенной РНК путем электропорации. Меченные RVG нацеленные экзосомы, инъецируемые внутривенно, осуществляли специфическую доставку siRNA для GAPDH в нейроны, микроглию, олигодендроциты в головном мозге, обуславливая нокдаун конкретного гена. Предварительное воздействие меченных RVG экзосом не ослабляло выраженность нокдауна, и неспецифическое поглощение в других тканях не наблюдалось. Терапевтические возможности опосредованной экзосомами доставки siRNA были продемонстрированы сильно выраженным нокдауном мРНК (60%) и белка (62%) BACE1, терапевтической мишени при болезни Альцгеймера.
Для получения пула иммунологически инертных экзосом Alvarez-Erviti et al. отбирали костный мозг у инбредных мышей C57BL/6 с гомогенным гаплотипом главного комплекса гистосовместимости (MHC). Поскольку незрелые дендритные клетки вырабатывают большие количества экзосом, лишенных активаторов T-клеток, таких как MHC-II и CD86, Alvarez-Erviti et al. проводили отбор дендритных клеток с помощью гранулоцитарно-макрофагального колониестимулирующего фактора (GM-CSF) в течение 7 дней. Экзосомы очищали от культуральной надосадочной жидкости на следующий день с применением общепринятых протоколов ультрацентрифугирования. Вырабатываемые экзосомы были физически однородными и характеризовались распределением по размеру с пиком при 80 нм в диаметре, как определяли с помощью анализа отслеживания наночастиц (NTA) и электронной микроскопии. Alvarez-Erviti et al. получали 6-12 мкг экзосом (измерено по концентрации белка) на 106 клеток.
Затем Alvarez-Erviti et al. исследовали возможность загрузки модифицированных экзосом экзогенными молекулами-карго с применением протоколов электропорации, приспособленных для применений на наноразмерном уровне. Поскольку электропорация для мембранных частиц в нанометрическом масштабе изучена недостаточно хорошо, для эмпирической оптимизации протокола электропорации использовали неспецифичную меченную Cy5 РНК. Количество инкапсулированной РНК анализировали после ультрацентрифугирования и лизиса экзосом. Электропорация при 400 В и 125 мкФ приводила к наибольшему удержанию РНК и применялась для всех последующих экспериментов.
Alvarez-Erviti et al. вводили по 150 мкг каждой siRNA для BACE1, инкапсулированной в 150 мкг меченных RVG экзосом, нормальным мышам C57BL/6 и сравнивали эффективность нокдауна с таковой в четырех контрольных группах: необработанные мыши, мыши, которым инъецировали только меченные RVG экзосомы, мыши, которым инъецировали siRNA для BACE1, образующую комплекс с реагентом на основе катионных липосом для доставки in vivo, и мыши, которым инъецировали siRNA для BACE1, образующую комплекс с RVG-9R, пептидом RVG, конъюгированным с 9 остатками D-аргинина, который электростатически связывается с siRNA. Образцы кортикальной ткани анализировали через 3 дня после введения, и как у обработанных siRNA-RVG-9R, так и у обработанных меченными RVG экзосомами с siRNA мышей наблюдали значительный нокдаун белка (45%, P < 0,05 и 62%, P < 0,01), обусловленный значительным снижением уровней мРНК BACE1 (66% [+ или -] 15%, P < 0,001 и 61% [+ или -] 13%, P < 0,01 соответственно). Более того, заявители продемонстрировали значительное снижение (55%, P < 0,05) общих уровней [бета]-амилоидного пептида 1-42, основного компонента амилоидных бляшек в патологическом процессе при болезни Альцгеймера у животных, обработанных меченными RVG экзосомами. Наблюдавшееся снижение было большим, чем снижение уровней β-амилоидного пептида 1-40, демонстрируемое у нормальных мышей после внутрижелудочковой инъекции ингибиторов BACE1. Alvarez-Erviti et al. проводили быструю амплификацию 5'-концов кДНК (RACE) в отношении продукта расщепления BACE1, что свидетельствовало об опосредованном RNAi нокдауне с помощью siRNA.
Наконец, Alvarez-Erviti et al. исследовали, индуцируют ли меченные RVG экзосомы с РНК иммунные ответы in vivo, путем определения концентраций IL-6, IP-10, TNFα и IFN-α в сыворотке крови. После обработки экзосомами для всех цитокинов регистрировали незначительные изменения подобно обработке реагентом для трансфекции с siRNA и в отличие от siRNA-RVG-9R, который активно стимулировал секрецию IL-6, что подтверждало иммунологическую инертность как особенность обработки экзосомами. С учетом того, что экзосомы инкапсулируют только 20% siRNA, доставка с помощью меченных RVG экзосом, по-видимому, является более эффективной, чем доставка с помощью RVG-9R, поскольку с использованием в пять раз меньшего количества siRNA без соответствующего уровня стимуляции иммунного ответа достигали сопоставимого нокдауна мРНК и большего нокдауна белка. Данный эксперимент продемонстрировал терапевтические возможности технологии меченных RVG экзосом, которая потенциально подходит для долговременного сайленсинга генов, связанных с нейродегенеративными заболеваниями. Систему доставки на основе экзосом по Alvarez-Erviti et al. можно использовать для доставки системы CRISPR-Cas по настоящему изобретению к терапевтическим мишеням, особенно при нейродегенеративных заболеваниях. В настоящем изобретении может быть предусмотрена доза, составляющая приблизительно 100-1000 мг CRISPR-Cas, инкапсулированных в приблизительно 100-1000 мг меченных RVG экзосом.
El-Andaloussi et al. (Nature Protocols 7, 2112-2126(2012)) раскрывают, как экзосомы, полученные из культивируемых клеток, можно приспособить для доставки РНК in vitro и in vivo. В данном протоколе впервые описано создание нацеленных экзосом посредством трансфекции вектором экспрессии, содержащим экзосомный белок, слитый с пептидным лигандом. Затем El-Andaloussi et al. объясняют, как очищать и характеризовать экзосомы из надосадочной жидкости с трансфицированными клетками. Затем El-Andaloussi et al. подробно описывают важнейшие стадии загрузки РНК в экзосомы. Наконец, El-Andaloussi et al. излагают в общих чертах, как использовать экзосомы для эффективной доставки РНК in vitro и in vivo в головной мозг мышей. Также приведены примеры предполагаемых результатов, в которых опосредованная экзосомами доставка РНК оценивается посредством функциональных анализов и визуализации. Выполнение полного протокола занимает ~3 недели. Доставку или введение согласно настоящему изобретению можно осуществлять с помощью экзосом, полученных из аутогенных дендритных клеток. Среди приведенных в данном документе идей, эту можно использовать в практическом применении настоящего изобретения.
В другом варианте осуществления предполагаются экзосомы плазмы крови согласно Wahlgren et al. (Nucleic Acids Research, 2012, Vol. 40, No. 17 e130). Экзосомы представляют собой наноразмерные везикулы (размером 30-90 нм), вырабатываемые многими типами клеток, в том числе дендритными клетками (DC), B-клетками, T-клетками, тучными клетками, эпителиальными клетками и опухолевыми клетками. Данные везикулы образуются путем внутреннего почкования поздних эндосом, а затем высвобождаются во внеклеточную среду при слиянии с плазматической мембраной. Поскольку в естественных условиях экзосомы переносят РНК между клетками, данное свойство может быть полезным в генной терапии, и согласно данному раскрытию может быть использовано в практическом раскрытии настоящего изобретения.
Экзосомы из плазмы крови могут быть получены путем центрифугирования лейкоцитарной пленки при 900 g в течение 20 мин. для отделения плазмы крови с последующим сбором надосадочных жидкостей культуры клеток, центрифугированием при 300 g в течение 10 мин. для удаления клеток и при 16500 g в течение 30 мин. с последующей фильтрацией через фильтр с диаметром пор 0,22 мм. Экзосомы осаждают путем ультрацентрифугирования при 120000 g в течение 70 мин. Введение siRNA в экзосомы посредством химической трансфекции проводят согласно инструкциям производителя в наборе RNAi Human/Mouse Starter Kit (Quiagen, Хильден, Германия). К 100 мл PBS добавляют siRNA при конечной концентрации 2 ммоля/мл. После добавления реагента для трансфекции HiPerFect смесь инкубируют в течение 10 мин. при КТ. С целью удаления избытка мицелл экзосомы повторно выделяют с помощью латексных частиц с альдегидными/сульфатными группами. Введение CRISPR-Cas в экзосомы посредством химической трансфекции можно проводить аналогично введению siRNA. Экзосомы можно совместно культивировать с моноцитами и лимфоцитами, выделенными из периферической крови здоровых доноров. Таким образом, может быть предусмотрено, чтобы экзосомы, содержащие CRISPR-Cas, можно было вводить в моноциты и лимфоциты и подвергать аутологическому обратному введению в организм человека. Соответственно, доставку или введение согласно настоящему изобретению можно осуществлять с помощью экзосом плазмы крови.
Липосомы
Доставку или введение согласно настоящему изобретению можно осуществлять с помощью липосом. Липосомы являются сферическими везикулярными структурами, содержащими одно- или многослойный липидный бислой, окружающий внутренние водные компартменты, и относительно непроницаемый внешний липофильный фосфолипидный бислой. Липосомы получили значительное внимание в качестве носителей для доставки лекарственных средств, поскольку они являются биологически совместимыми, нетоксичными, могут доставлять как гидрофильные, так и липофильные молекулы лекарственных средств, защищают свою молекулу-карго от разрушения ферментами плазмы крови и переносят свой "груз" через биологические мембраны и гематоэнцефалический барьер (BBB) (для обзора см., например, Spuch and Navarro, Journal of Drug Delivery, vol. 2011, Article ID 469679, 12 pages, 2011. doi:10.1155/2011/469679).
Липосомы можно получать из нескольких различных типов липидов; однако для создания липосом в качестве носителей лекарственных средств чаще всего применяют фосфолипиды. Хотя образование липосом является самопроизвольным при смешивании липидной пленки с водным раствором, его также можно ускорить путем приложения силы в виде встряхивания посредством применения гомогенизатора, ультразвукового диспергатора или экструзионного аппарата (для обзора см., например, Spuch and Navarro, Journal of Drug Delivery, vol. 2011, Article ID 469679, 12 pages, 2011. doi:10.1155/2011/469679).
К липосомам можно добавлять некоторые другие добавки с целью модификации их структуры и свойств. Например, холестерин либо сфингомиелин можно добавлять к смеси липосом в целях содействия стабилизации структуры липосом и предотвращения утечки внутренних молекул-карго липосом. Кроме того, липосомы получают из гидрогенизированного яичного фосфатидилхолина или яичного фосфатидилхолина, холестерина и диацетилфосфата, и их средние размеры везикул доводят до приблизительно 50 и 100 нм. (для обзора см., например, Spuch and Navarro, Journal of Drug Delivery, vol. 2011, Article ID 469679, 12 pages, 2011. doi:10.1155/2011/469679).
Липосомный состав может содержать главным образом природные фосфолипиды и липиды, такие как 1,2-дистеароил-sn-глицеро-3-фосфатидилхолин (DSPC), сфингомиелин, формы яичного фосфатидилхолина и моносиалоганглиозид. Поскольку данный состав состоит только из фосфолипидов, липосомные составы сталкиваются со многими проблемами, одной из которых является нестабильность в плазме. Было предпринято несколько попыток преодоления данных проблем, в частности, посредством манипуляции с липидной мембраной. Одна из этих попыток направлена на манипуляцию с холестерином. Добавление холестерина к традиционным составам уменьшает быстрое высвобождение инкапсулированного биологически активного соединения в плазму крови или 1,2-диолеоил-sn-глицеро-3-фосфоэтаноламин (DOPE) повышает стабильность (для обзора см., например, Spuch and Navarro, Journal of Drug Delivery, vol. 2011, Article ID 469679, 12 pages, 2011. doi:10.1155/2011/469679).
В особенно преимущественном варианте осуществления желательными являются липосомы "троянские кони" (также известные как "молекулярные троянские кони"), и протоколы можно найти на http://cshprotocols.cshlp.org/content/2010/4/pdb.prot5407.long.. Эти частицы обеспечивают доставку трансгена в головной мозг в целом после внутрисосудистой инъекции. Без ограничений полагают, что нейтральные липидные частицы со специфичными антителами, конъюгированными с поверхностью, обеспечивают проникновение через гематоэнцефалический барьер посредством эндоцитоза. Заявитель теоретически допускает использование липосом "троянских коней" для доставки нуклеаз семейства CRISPR в головной мозг посредством внутрисосудистой инъекции, что будет обеспечивать получение животных с трансгенами во всем головном мозге без необходимости в манипуляции с эмбрионами. Для введения in vivo в липосомы может быть предусмотрено приблизительно 1-5 г ДНК или РНК.
В другом варианте осуществления систему CRISPR-Cas или ее компоненты можно вводить в липосомы, такие как стабильная частица из нуклеиновой кислоты и липидов (SNALP) (см., например, Morrissey et al., Nature Biotechnology, Vol. 23, No. 8, August 2005). Предусматриваются ежедневные внутривенные инъекции приблизительно 1, 3 или 5 мг/кг/день специфичной целенаправленно воздействующей CRISPR-Cas в SNALP. Обработку можно осуществлять ежедневно в течение приблизительно трех дней, а затем еженедельно в течение приблизительно пяти недель. В другом варианте осуществления также предусмотрена специфичная CRISPR-Cas, инкапсулированная в SNALP, вводимая посредством внутривенной инъекции в дозах, составляющих приблизительно 1 или 2,5 мг/кг (см., например, Zimmerman et al., Nature Letters, Vol. 441, 4 May 2006). Состав на основе SNALP может содержать липиды 3-N-[(ω-метоксиполи(этиленгликоль)2000)-карбамоил]-1,2-димиристилоксипропиламин (PEG-C-DMA), 1,2-дилинолеилокси-N,N-диметил-3-аминопропан (DLinDMA), 1,2-дистеароил-sn-глицеро-3-фосфохолин (DSPC) и холестерин в молярном процентном соотношении 2:40:10:48 (см., например, Zimmerman et al., Nature Letters, Vol. 441, 4 May 2006).
В другом варианте осуществления было подтверждено, что стабильные частицы из нуклеиновой кислоты и липидов (SNALP) являются эффективными молекулами для доставки в высоковаскуляризированные опухоли печени, происходящие из HepG2, но не в слабо васкуляризированные опухоли печени, происходящие из HCT-116 (см., например, Li, Gene Therapy (2012) 19, 775-780). SNALP-липосомы можно получать путем составления D-Lin-DMA и PEG-C-DMA с дистеароилфосфатидилхолином (DSPC), холестерином и siRNA с использованием соотношения липид/siRNA 25:1 и молярного соотношения холестерин/D-Lin-DMA/DSPC/PEG-C-DMA 48/40/10/2. Полученные в результате SNALP-липосомы имеют размер приблизительно 80-100 нм.
В еще одном варианте осуществления SNALP может содержать синтетический холестерин (Sigma-Aldrich, Сент-Луис, Миссури, США), дипальмитоилфосфатидилхолин (Avanti Polar Lipids, Алабастер, Алабама, США), 3-N-[(ω-метоксиполи(этиленгликоль)2000)карбамоил]-1,2-димиристилоксипропиламин и катионный 1,2-дилинолеилокси-3-N,N-диметиламинопропан (см., например, Geisbert et al., Lancet 2010; 375: 1896-905). Может предусматриваться режим дозирования с приемом приблизительно 2 мг/кг общего количества CRISPR-Cas на дозу, вводимую, например, в виде болюсной внутривенной инфузии.
В еще одном варианте осуществления SNALP может содержать синтетический холестерин (Sigma-Aldrich), 1,2-дистеароил-sn-глицеро-3-фосфохолин (DSPC; Avanti Polar Lipids Inc.), PEG-C-DMA и 1,2-дилинолеилокси-3-(N,N-диметил)аминопропан (DLinDMA) (см., например, Judge, J. Clin. Invest. 119:661-673 (2009)). Составы, используемые для исследований in vivo, могут содержать липиды и РНК в конечном массовом соотношении, составляющем приблизительно 9:1.
Профиль безопасности нанопрепаратов для RNAi был рассмотрен Barros and Gollob из Alnylam Pharmaceuticals (см., например, Advanced Drug Delivery Reviews 64 (2012) 1730-1737). Стабильная частица из нуклеиновой кислоты и липидов (SNALP) содержит четыре различных липида - ионизируемый липид (DLinDMA), который является катионным при низком pH, нейтральный липид-помощник, холестерин и диффундирующий конъюгат полиэтиленгликоль (PEG)-липид. Частица имеет диаметр примерно 80 нм и является электронейтральной при физиологическом значении pH. Во время составления ионизируемый липид служит для конденсации липида с анионной РНК в ходе образования частиц. Будучи положительно заряженным в условиях возрастающей кислотности в эндосомах, ионизируемый липид также опосредует слияние SNALP с мембраной эндосомы, обеспечивая высвобождение РНК в цитоплазму. Конъюгат PEG-липид стабилизирует частицу и уменьшает агрегацию во время составления, а также впоследствии обеспечивает нейтральную гидрофильную наружную поверхность, улучшающую фармакокинетические свойства.
К настоящему времени была начата реализация двух программ клинических исследований с применением составов на основе SNALP с РНК. В Tekmira Pharmaceuticals недавно завершили фазу I однодозового исследования SNALP-ApoB с участием взрослых добровольцев с повышенным уровнем холестерина LDL. ApoB преимущественно экспрессируется в печени и тонкой кишке и является ключевым для сборки и секреции VLDL и LDL. Семнадцать субъектов получали однократную дозу SNALP-ApoB (повышение дозы, охватывающее 7 уровней дозирования). Не наблюдалось свидетельств гепатотоксичности (предполагаемой в качестве возможной дозолимитирующей токсичности на основании доклинических исследований). Один (или два) субъекта при наиболее высокой дозе испытывали симптомы гриппоподобных заболеваний, указывающие на стимуляцию иммунной системы, и было принято решение завершить испытание.
В Alnylam Pharmaceuticals аналогичным образом успешно провели исследование ALN-TTR01, в котором используется технология SNALP, описанная выше, и целенаправленное воздействие на выработку гепатоцитами TTR, как мутантного, так и дикого типа, для лечения опосредованного TTR амилоидоза (ATTR). Были описаны три синдрома при ATTR: семейная амилоидическая полинейропатия (FAP) и семейная амилоидическая кардиомиопатия (FAC) - оба из которых обусловлены аутосомно-доминантными мутациями в TTR; и старческий системный амилоидоз (SSA), обусловленный отложением TTR дикого типа. Недавно завершили I фазу плацебо-контролируемого испытания с повышением однократной дозы ALN-TTR01 с участием пациентов с ATTR. Введение ALN-TTR01 осуществляли в виде 15-минутной IV инфузии 31 пациенту (исследуемое лекарственное средство для 23 и плацебо для 8) в диапазоне доз 0,01-1,0 мг/кг (из расчета по siRNA). Лечение хорошо переносилось без значительного повышения показателей печеночных проб. Инфузионные реакции отмечались у 3 из 23 пациентов при ≥ 0,4 мг/кг; все они реагировали на замедление скорости инфузии и все они продолжали исследование. Минимальные и временные повышения уровней цитокинов IL-6, IP-10 и IL-1ra в сыворотке отмечались у двух пациентов при наиболее высокой дозе 1 мг/кг (как предполагалось на основании доклинических исследований и исследований с участием NHP). Снижение уровня TTR в сыворотке, ожидаемый фармакодинамический эффект ALN-TTR01, наблюдалось при 1 мг/кг.
В еще одном варианте осуществления SNALP можно получить путем солюбилизации катионного липида, DSPC, холестерина и конъюгата PEG-липид, например, в этаноле, например, при молярном соотношении 40:10:40:10 соответственно (см. Semple et al., Nature Biotechnology, Volume 28 Number 2 February 2010, pp. 172-177). Смесь липидов добавляли к водному буферу (50 мМ цитрат, pH 4) с перемешиванием до конечной концентрации этанола и липидов 30% (об./об.) и 6,1 мг/мл соответственно, и ей позволяли уравновешиваться при 22°C в течение 2 мин. перед экструзией. Гидрированные липиды экструдировали через два установленных один над другим фильтра с размером пор 80 нм (Nuclepore) при 22°C с помощью экструдера Lipex (Northern Lipids) до достижения диаметра везикул 70-90 нм, определяемого посредством анализа по методу динамического рассеяния света. Для этого обычно требовалось 1-3 прохождения. Добавляли siRNA (солюбилизированную в водном растворе, содержащем 30% этанол, с 50 мМ цитратом, pH 4) к предварительно уравновешенным (35°C) везикулам со скоростью ~5 мл/мин. при перемешивании. После достижения конечного целевого соотношения siRNA/липиды 0,06 (вес/вес) смесь инкубировали в течение дополнительных 30 мин. при 35°C для обеспечения реорганизации везикул и инкапсулирования siRNA. Этанол затем удаляли, а внешний буфер заменяли на PBS (155 мМ NaCl, 3 мМ Na2HPO4, 1 мМ KH2PO4, pH 7,5) путем диализа либо тангенциальной поточной диафильтрации. В SNALP инкапсулировали siRNA посредством регулируемого способа по методу ступенчатого разведения. Липидные составляющие KC2-SNALP представляли собой DLin-KC2-DMA (катионный липид), дипальмитоилфосфатидилхолин (DPPC; Avanti Polar Lipids), синтетический холестерин (Sigma) и PEG-C-DMA, используемые в молярном соотношении 57,1:7,1:34,3:1,4. После образования нагруженных частиц SNALP подвергали диализу против PBS и стерилизации путем фильтрации через фильтр с диаметром пор 0,2 мкм перед применением. Средние значения размера частиц составляли 75-85 нм, и 90-95% siRNA были инкапсулированы в липидных частицах. Конечное соотношение siRNA/липиды в составах, используемых для тестирования in vivo, составляло ~0,15 (вес/вес). Системы LNP-siRNA, содержащие siRNA для фактора VII, разбавляли до соответствующих концентраций в стерильном PBS непосредственно перед применением, и составы вводили внутривенно через латеральную хвостовую вену в общем объеме 10 мл/кг. Данный способ и данные системы доставки можно экстраполировать на систему CRISPR-Cas по настоящему изобретению.
Другие липиды
Другие катионные липиды, такие как аминолипид 2,2-дилинолеил-4-диметиламиноэтил-[1,3]-диоксолан (DLin-KC2-DMA), можно использовать для инкапсулирования CRISPR-Cas, или ее компонентов, или кодирующих их молекул нуклеиновых кислот, аналогично siRNA (см., например, Jayaraman, Angew. Chem. Int. Ed. 2012, 51, 8529-8533), и, следовательно, можно применять в практическом осуществлении настоящего изобретения. Может быть предусмотрена предварительно сформированная везикула со следующим составом липидов: аминолипид, дистеароилфосфатидилхолин (DSPC), холестерин и (R)-2,3-бис(октадецилокси)пропил-1-(метоксиполи(этиленгликоль)2000)пропилкарбамат (конъюгат PEG-липид) в молярном соотношении 40/10/40/10 соответственно и с соотношением siRNA для FVII/общее количество липидов, составляющим примерно 0,05 (вес./вес.). Для обеспечения узкого распределения частиц по размеру в диапазоне 70-90 нм и низкого коэффициента полидисперсности 0,11+0,04 (n = 56) частицы можно экструдировать до трех раз через мембраны с диаметром пор 80 нм перед добавлением направляющей РНК. Можно использовать частицы, содержащие высокоактивный аминолипид 16, в которых молярное соотношение четырех липидных компонентов 16, DSPC, холестерина и конъюгата PEG-липид (50/10/38,5/1,5) можно дополнительно оптимизировать для повышения активности in vivo.
Michael S D Kormann et al. ("Expression of therapeutic proteins after delivery of chemically modified mRNA in mice: Nature Biotechnology, Volume:29, Pages: 154-157 (2011)) описывают применение липидных оболочек для доставки РНК. Применение липидных оболочек также является предпочтительным в настоящем изобретении.
В другом варианте осуществления липиды можно составлять с системой CRISPR-Cas по настоящему изобретению или ее компонентом(компонентами) или кодирующей(кодирующими) их молекулой(молекулами) нуклеиновой кислоты с образованием липидных наночастиц (LNP). Липиды включают без ограничения DLin-KC2-DMA4, C12-200 и совместно действующие липиды дистеароилфосфатидилхолин, холестерин и PEG-DMG, которые можно составлять с CRISPR-Cas вместо siRNA (см., например, Novobrantseva, Molecular Therapy-Nucleic Acids (2012) 1, e4; doi:10.1038/mtna.2011.3) с помощью процедуры самопроизвольного образования везикул. Молярное соотношение компонентов может составлять приблизительно 50/10/38,5/1,5 (DLin-KC2-DMA или C12-200/дистеароилфосфатидилхолин/холестерин/PEG-DMG). Конечное весовое соотношение липиды:siRNA может составлять ~12:1 и 9:1 в случае липидных наночастиц (LNP) на основе DLin-KC2-DMA и C12-200 соответственно. Составы могут характеризоваться средними диаметрами частиц ~80 нм при >90% эффективности включения. Может быть предусмотрена доза 3 мг/кг.
Tekmira имеет портфель из примерно 95 семейств патентов-аналогов, выданных в США и за границей, которые направлены на различные аспекты LNP и составы на основе LNP (см., например, патенты США №№ 7982027; 7799565; 8058069; 8283333; 7901708; 7745651; 7803397; 8101741; 8188263; 7915399; 8236943 и 7838658 и европейские патенты №№ 1766035; 1519714; 1781593 и 1664316), все из которых можно применять в настоящем изобретении и/или адаптировать к нему.
Систему CRISPR-Cas, или ее компоненты, или кодирующие их молекулы нуклеиновой кислоты можно доставлять инкапсулированными в микросферах на основе PLGA, таких как дополнительно описанные в опубликованных заявках на патенты США 20130252281, и 20130245107, и 20130244279 (закрепленных за Moderna Therapeutics), которые относятся к аспектам составления композиций, содержащих модифицированные молекулы нуклеиновых кислот, которые могут кодировать белок, предшественник белка или частично или полностью процессированную форму белка или предшественника белка. Состав может характеризоваться молярным соотношением 50:10:38,5:1,5-3,0 (катионный липид:фузогенный липид:холестерин:конъюгат PEG-липид). Конъюгат PEG-липид может быть выбран без ограничения из PEG-C-DOMG, PEG-DMG. Фузогенный липид может представлять собой DSPC. См. также Schrum et al., Delivery and Formulation of Engineered Nucleic Acids, опубликованную заявку на патент США 20120251618.
Технология Nanomerics преодолевает проблемы, связанные с биологической доступностью, для широкого спектра терапевтических средств, в том числе низкомолекулярных гидрофобных лекарственных средств, пептидов и терапевтических средств на основе нуклеиновых кислот (плазмид, siRNA, miRNA). Конкретные пути введения, для которых технология продемонстрировала очевидные преимущества, включают пероральный путь, перенос через гематоэнцефалический барьер, доставку в солидные опухоли, а также в глаз. См., например, Mazza et al., 2013, ACS Nano. 2013 Feb 26;7(2):1016-26; Uchegbu and Siew, 2013, J Pharm Sci. 102(2):305-10 и Lalatsa et al., 2012, J Control Release. 2012 Jul 20; 161(2):523-36.
В публикации заявки на патент США № 20050019923 описаны катионные дендримеры для доставки биологически активных молекул, таких как молекулы полинуклеотидов, пептиды и полипептиды и/или фармацевтические средства, в организм млекопитающего. Дендримеры подходят для обеспечения нацеленной доставки биологически активных молекул, например, в печень, селезенку, легкое, почку или сердце (или даже головной мозг). Дендримеры являются синтетическими 3-мерными макромолекулами, получаемыми ступенчатым способом из простых разветвленных мономерных звеньев, природу и количество функциональных групп которых можно легко регулировать и изменять. Дендримеры синтезируют путем повторяющегося присоединения "строительных блоков" в направлении от сердцевины с несколькими функциональными группами (дивергентный подход к синтезу) или к сердцевине с несколькими функциональными группами (конвергентный подход к синтезу), и каждое присоединение 3-мерной оболочки из "строительных блоков" приводит к образованию дендримеров более высокой генерации. Синтез полипропилениминовых дендримеров начинается с диаминобутановой сердцевины, к которой присоединяют удвоенное количество аминогрупп посредством двойного присоединения по Михаэлю ацетонитрила к первичным аминогруппам с последующим гидрированием нитрильных групп. Это обуславливает удвоение количества аминогрупп. Полипропилениминовые дендримеры содержат 100% протонируемых атомов азота и до 64 концевых аминогрупп (генерация 5, DAB 64). Протонируемые группы обычно представляют собой аминогруппы, способные принимать протоны при нейтральном pH. Применение дендримеров в качестве средств для доставки генов в основном ориентировано на использование полиамидоамина и фосфорсодержащих соединений со смесью из амина/амида или N--P(O2)S в качестве конъюгирующих единиц соответственно, при этом в работах не сообщалось о применении полипропилениминовых дендримеров низкой генерации для доставки генов. Полипропилениминовые дендримеры также изучали в качестве pH-чувствительных систем с контролируемым высвобождением для доставки лекарственных средств и для инкапсулирования в них "гостевых" молекул в случае химической модификации периферических аминокислотных групп. Также изучали цитотоксичность и взаимодействие полипропилениминовых дендримеров с ДНК, а также эффективность трансфекции с помощью DAB 64.
Публикация заявки на патент США № 20050019923 основана на наблюдении того, что в противоположность более ранним сообщениям, катионные дендримеры, такие как полипропилениминовые дендримеры, проявляют подходящие свойства, такие как специфичное нацеливание и низкая токсичность, для применения в целенаправленной доставке биологически активных молекул, таких как генетический материал. В дополнение, производные катионного дендримера также проявляют подходящие свойства для нацеленной доставки биологически активных молекул. См. также "Биологически активные полимеры", публикация заявки на патент США 20080267903, в которой раскрыто следующее: "Показано, что различные полимеры, в том числе катионные полиаминные полимеры и дендримерные полимеры, обладают антипролиферативной активностью и могут, таким образом, быть применимыми для лечения нарушений, характеризующихся нежелательной пролиферацией клеток, таких как неоплазии и опухоли, воспалительные нарушения (в том числе аутоиммунные нарушения), псориаз и атеросклероз. Полимеры можно применять в отдельности в качестве активных средств или в качестве средств доставки других терапевтических средств, таких как молекулы лекарственных средств или нуклеиновые кислоты, для генной терапии. В таких случаях присущая полимерам собственная противоопухолевая активность может дополнять активность средства, подлежащего доставке. Раскрытия данных патентных публикаций можно использовать совместно с идеями данного документа для доставки системы(систем) CRISPR Cas, или ее компонента(компонентов), или кодирующей(кодирующих) их молекулы(молекул) нуклеиновой кислоты(нуклеиновых кислот).
Белки с избыточным зарядом
Белки с избыточным зарядом представляют собой класс сконструированных или встречающихся в природе белков, которые обычно имеют высокий положительный или отрицательный суммарный теоретический заряд, и их можно использовать в доставке системы(систем) CRISPR Cas, или ее компонента(компонентов), или кодирующей(кодирующих) их молекулы(молекул) нуклеиновой кислоты(нуклеиновых кислот). Белки как с избыточным отрицательным, так и с избыточным положительным зарядом проявляют особое свойство устойчивости к термически или химически индуцированной агрегации. Белки с избыточным положительным зарядом также способны проникать в клетки млекопитающих. Ассоциация молекул-карго, таких как плазмидная ДНК, РНК, с этими белками или другими белками может обеспечивать функциональную доставку данных макромолекул в клетки млекопитающих как in vitro, так и in vivo. В 2007 г. в лаборатории Дэвида Лю сообщили о создании и определении характеристик белков с избыточным зарядом (Lawrence et al., 2007, Journal of the American Chemical Society 129, 10110-10112).
Невирусная доставка РНК и плазмидной ДНК в клетки млекопитающих является значимой как в исследованиях, так и в терапевтических применениях (Akinc et al., 2010, Nat. Biotech. 26, 561-569). Очищенный белок GFP с зарядом +36 (или другой белок с избыточным положительным зарядом) смешивают с РНК в подходящей бессывороточной среде и обеспечивают возможность образования ими комплекса перед добавлением к клеткам. Включение сыворотки на этой стадии ингибирует образование комплексов белок с избыточным зарядом-РНК и снижает эффективность обработки. Следующий протокол был найден эффективным для ряда линий клеток (McNaughton et al., 2009, Proc. Natl. Acad. Sci. USA 106, 6111-6116) (однако, следовало выполнить пилотные эксперименты с варьирующей дозой белка и РНК для оптимизации процедуры для конкретных линий клеток).
(1) За один день до обработки высеять 1 x 105 клеток на лунку в 48-луночный планшет.
(2) В день обработки развести очищенный белок GFP с зарядом +36 в бессывороточной среде до конечной концентрации 200 нМ. Добавить РНК до конечной концентрации 50 нМ. Перемешать в вихревой мешалке и инкубировать при комнатной температуре в течение 10 мин.
(3) Во время инкубирования аспирировать среду от клеток и промыть один раз с помощью PBS.
(4) После инкубирования GFP с зарядом +36 и РНК добавить к клеткам комплексы белок-РНК.
(5) Инкубировать клетки с комплексами при 37°C в течение 4 ч.
(6) После инкубирования аспирировать среду и промыть три раза с помощью 20 ед./мл гепарина в PBS. Инкубировать клетки в сывороточной среде в течение дополнительных 48 ч. или дольше в зависимости от анализа активности.
(7) Анализировать клетки с помощью иммуноблоттинга, qPCR, фенотипического анализа или другого соответствующего способа.
В лаборатории Дэвида Лю дополнительно обнаружили, что GFP с зарядом +36 является эффективным реагентом для доставки плазмид в ряд клеток. Поскольку плазмидная ДНК является более крупной молекулой-карго, чем siRNA, то для образования эффективного комплекса с плазмидами требуется пропорционально больше белка GFP с зарядом +36. Для эффективной доставки плазмид заявители разработали вариант GFP с зарядом +36, несущий C-концевую пептидную метку HA2, известный пептид, разрушающий эндосомы, происходящий из белка гемагглютинина вируса гриппа. Следующий протокол был эффективным для многих клеток, но, как изложено выше, рекомендуется, чтобы дозы плазмидной ДНК и белка с избыточным зарядом были оптимизированы для конкретных линий клеток и путей применения в доставке.
(1) За один день до обработки высеять 1 x 105 клеток на лунку в 48-луночный планшет. (2) В день
обработки разбавить очищенный белок GFP с зарядом þ36 в бессывороточной среде до конечной концентрации 2 мМ. Добавить 1 мг плазмидной ДНК. Перемешать в вихревой мешалке и инкубировать при комнатной температуре в течение 10 мин.
(3) Во время инкубирования аспирировать среду от клеток и промыть один раз с помощью PBS.
(4) После инкубирования GFP с зарядом þ36 и плазмидной ДНК осторожно добавить к клеткам комплексы белок-ДНК.
(5) Инкубировать клетки с комплексами при 37°C в течение 4 ч.
(6) После инкубирования аспирировать среду и промыть с помощью PBS. Инкубировать клетки в сывороточной среде и инкубировать в течение дополнительных 24-48 ч.
(7) При необходимости проанализировать доставку плазмид (например, посредством экспрессии генов, обусловленной плазмидами).
Cм., например, McNaughton et al., Proc. Natl. Acad. Sci. USA 106, 6111-6116 (2009); Cronican et al., ACS Chemical Biology 5, 747-752 (2010); Cronican et al., Chemistry & Biology 18, 833-838 (2011); Thompson et al., Methods in Enzymology 503, 293-319 (2012); Thompson, D.B., et al., Chemistry & Biology 19 (7), 831-843 (2012). Способы применения белков с избыточным зарядом можно применять для доставки системы CRISPR-Cas по настоящему изобретению и/или приспосабливать к ней. Эти системы согласно Доктору Лю и приведенные в данном документе публикации в связи с идеями данного документа можно использовать в доставке системы(систем) CRISPR Cas, или ее компонента(компонентов), или кодирующей(кодирующих) их молекулы(молекул) нуклеиновой кислоты(нуклеиновых кислот).
Пептиды, приникающие в клетку (CPP)
В еще одном варианте осуществления предусмотрены пептиды, проникающие в клетку (CPP), для доставки системы CRISPR-Cas. CPP представляют собой короткие пептиды, способствующие поглощению клетками различных молекул-карго (от наноразмерных частиц до малых химических молекул и крупных фрагментов ДНК). Термин “молекула-карго”, используемый в данном документе, включает без ограничения группу, состоящую из терапевтических средств, диагностических зондов, пептидов, нуклеиновых кислот, антисмысловых олигонуклеотидов, плазмид, белков, частиц, в том числе наночастиц, липосом, хромофоров, малых молекул и радиоактивных материалов. В аспектах настоящего изобретения молекула-карго может также содержать любой компонент системы CRISPR-Cas или всю функциональную систему CRISPR-Cas. В аспектах настоящего изобретения дополнительно представлены способы доставки желаемой молекулы-карго субъекту, включающие: (a) получение комплекса, содержащего пептид, проникающий в клетку, по настоящему изобретению и требуемую молекулу-карго, и (b) пероральное, внутрисуставное, внутрибрюшинное, интратекальное, внутриартериальное, интраназальное, интрапаренхиматозное, подкожное, внутримышечное, внутривенное, накожное, ректальное или местное введение комплекса субъекту. Молекула-карго связана с пептидами химической связью посредством ковалентных связей либо посредством нековалентных взаимодействий.
Функцией CPP является доставка молекулы-карго в клетки, при этом процесс, который обычно происходит посредством эндоцитоза, приводит к доставке молекулы-карго в эндосомы живых клеток млекопитающих. Пептиды, проникающие в клетку, имеют разные размер, аминокислотные последовательности и заряды, но все CPP имеют одну отличительную характеристику, которая представляет собой способность к перемещению через плазматическую мембрану и содействию доставке различных молекул-карго в цитоплазму или органеллу. Перемещение CPP можно подразделить на три основных механизма поступления: прямое прохождение через мембрану, поступление, опосредованное эндоцитозом, и перемещение посредством образования промежуточной структуры. CPP нашли многочисленные применения в медицине в качестве средств для доставки лекарственных средств при лечении различных заболеваний, в том числе рака, и ингибиторов вирусов, а также контрастных веществ для мечения клеток. Примеры последних включают действие в качестве носителя GFP, контрастных веществ для MRI или квантовых точек. CPP обладают большим потенциалом в качестве векторов доставки in vitro и in vivo для применения в научно-исследовательской работе и медицине. CPP обычно имеют такой аминокислотный состав, при котором они характеризуются высокой относительной распространенностью положительно заряженных аминокислот, таких как лизин или аргинин, либо имеют последовательности, характеризующиеся чередующимся расположением полярных/заряженных аминокислот и неполярных гидрофобных аминокислот. Эти два типа структур называются поликатионными или амфипатическими соответственно. Третьим классом CPP являются гидрофобные пептиды, содержащие только неполярные остатки с низким суммарным зарядом или имеющие гидрофобные группы аминокислот, крайне важные для поглощения клетками. Одним из первых обнаруженных CPP был трансактивирующий активатор транскрипции (Tat) вируса иммунодефицита человека 1 (HIV-1), который, как было выявлено, эффективно поглощался из окружающей среды многочисленными типами клеток в культуре. С тех пор количество известных CPP значительно увеличилось, и были созданы низкомолекулярные синтетические аналоги с более эффективными свойствами белковой трансдукции. CPP включают без ограничения пенетратин, Tat (48-60), транспортан и (R-AhX-R4) (Ahx = аминогексаноил).
В патенте США 8372951 представлен CPP, полученный из катионного белка эозинофилов (ECP), проявляющий высокую эффективность проникновения в клетку и низкую токсичность. Также представлены аспекты доставки CPP со своей молекулой-карго позвоночному субъекту. Дополнительные аспекты, касающиеся CPP и их доставки, описаны в патентах США 8575305; 8614194 и 8044019. CPP можно применять для доставки системы CRISPR-Cas или ее компонентов. Эти CPP можно использовать для доставки системы CRISPR-Cas или ее компонентов, что также представлено в рукописи “Gene disruption by cell-penetrating peptide-mediated delivery of Cas9 protein and guide RNA” Suresh Ramakrishna, Abu-Bonsrah Kwaku Dad, Jagadish Beloor, et al. Genome Res. 2014 Apr 2. [Электронная публикация, предшествующая печатной], включенной посредством ссылки во всей своей полноте, где продемонстрировано, что обработка с помощью рекомбинантного белка Cas9 конъюгированного с CPP, и направляющих РНК, образующих комплекс с CPP, приводит к нарушениям функционирования эндогенных генов в линиях клеток человека. В данной статье белок Cas9 был конъюгирован с CPP с помощью тиоэфирной связи, тогда как направляющая РНК образовывала комплекс с CPP с образованием конденсированных положительно заряженных частиц. Было показано, что одновременная и последовательная обработка клеток человека, в том числе эмбриональных стволовых клеток, дермальных фибробластов, клеток HEK293T, клеток HeLa и клеток эмбриональной карциномы, модифицированным Cas9 и направляющей РНК приводила к эффективным нарушениям функционирования генов со снижением частоты нецелевых мутаций по сравнению с трансфекциями плазмидами.
Имплантируемые устройства
В другом варианте осуществления также предполагаются имплантируемые устройства для доставки системы CRISPR Cas, или ее компонента(компонентов), или кодирующей(кодирующих) их молекулы(молекул) нуклеиновой кислоты(нуклеиновых кислот). Например, в публикации заявки на патент США 20110195123 раскрыто имплантируемое медицинское устройство, высвобождающее лекарственное средство локально и в течение длительного периода, в том числе несколько типов такого устройства, реализуемые способы лечения и способы имплантации. Устройство содержит полимерный субстрат, такой как матрица, например, применяемый в качестве корпуса устройства, и лекарственные средства, и в некоторых случаях дополнительные трехмерные подложки-носители, такие как металлы или дополнительные полимеры, и материалы для улучшения видимости и визуализации. Имплантируемое устройство для доставки может быть преимущественным в обеспечении высвобождения локально и в течение длительного периода, где лекарственное средство высвобождается непосредственно во внеклеточный матрикс (ECM) пораженного заболеванием участка, как, например, в случае опухоли, воспаления, дегенерации, или в целях симптоматической терапии, или в пораженные гладкомышечные клетки, или для предупреждения. Одной разновидностью лекарственного средства является РНК, что раскрыто выше, и данную систему можно применять для системы CRISPR-Cas по настоящему изобретению и/или адаптировать к ней. Способы имплантации в некоторых вариантах осуществления представляют собой существующие процедуры имплантации, разработанные и применяемые в настоящее время для других видов лечения, в том числе для брахитерапии и пункционной биопсии. В таких случаях размеры нового имплантата, описанного в настоящем изобретении, аналогичны размерам первоначального имплантата. Как правило, в ходе одной процедуры лечения имплантируют несколько устройств.
В публикации заявки на патент США 20110195123 предусмотрена имплантируемая или вставная система доставки лекарственных средств, в том числе системы, применимые для введения в полость, такую как брюшная полость, и/или для любого другого типа введения, в которой система доставки лекарственных средств не закреплена и не присоединена, содержащая биоустойчивый, и/или разлагаемый, и/или биопоглощаемый полимерный субстрат, который может, например, необязательно представлять собой матрицу. Следует отметить, что термин "вставка" также включает имплантацию. Система доставки лекарственных средств преимущественно реализуется как "Loder", описанная в публикации заявки на патент США 20110195123.
Полимер или множество полимеров, содержащие средство и/или множество средств, являются биосовместимыми, обеспечивая высвобождение средства с контролируемой скоростью, где общий объем полимерного субстрата, такого как матрица, например, в некоторых вариантах осуществления необязательно и предпочтительно не превосходит максимальный объем, позволяющий достигнуть терапевтического уровня средства. В качестве неограничивающего примера, такой объем предпочтительно находится в диапазоне от 0,1 м3 до 1000 мм3, как того требует объем загруженного средства. Loder необязательно может иметь больший размер, например, будучи включенным в состав устройства, размер которого определяется функциональным назначением, например, без ограничения коленного сустава, внутриматочного или шеечного кольца и т.п.
Система доставки лекарственных средств (для доставки композиции) в некоторых вариантах осуществления предназначена для предпочтительного использования разлагаемых полимеров, где основным механизмом высвобождения является объемная эрозия; или же в некоторых вариантах осуществления применяются неразлагаемые или медленно разлагаемые полимеры, где основным механизмом высвобождения является диффузия, а не объемная эрозия, так что их наружная часть функционирует в качестве мембраны, а их внутренняя часть функционирует в качестве депо лекарственного средства, которое практически не подвергается воздействию окружения в течение продолжительного периода (например, от приблизительно недели до приблизительно нескольких месяцев). Также можно необязательно применять комбинации различных полимеров с различными механизмами высвобождения. Градиент концентраций на поверхности предпочтительно эффективно поддерживается постоянным в течение значительного периода в ходе общего периода высвобождения лекарственного средства, и, таким образом, скорость диффузии (называемой "диффузией нулевого порядка") является эффективно постоянной. Под выражением "постоянный" подразумевают скорость диффузии, которая предпочтительно поддерживается выше нижнего порога терапевтической эффективности, но которая, тем не менее, может необязательно характеризоваться начальным всплеском и/или колебаться, например, повышаясь и понижаясь в некоторой степени. Скорость диффузии предпочтительно поддерживается таким образом в течение длительного периода, и до определенного уровня она может считаться постоянной для оптимизации терапевтически эффективного периода, например, эффективного периода сайленсинга.
Система доставки лекарственных средств необязательно и предпочтительно предназначена для защиты нуклеотидного терапевтического средства от разрушения, химического по своей природе или обусловленного воздействием ферментов и других факторов в организме субъекта.
Система доставки лекарственных средств из публикации заявки на патент США № 20110195123 необязательно связана с чувствительными и/или активирующими приборами, функционирующими во время и/или после имплантации устройства посредством неинвазивных и/или минимально инвазивных способов активации и/или ускорения/замедления, например, необязательно в том числе без ограничения способов или устройств с применением термического нагревания и охлаждения, лазерных пучков и ультразвука, в том числе фокусированного ультразвука, и/или RF (радиочастот).
Согласно некоторым вариантам осуществления публикации заявки на патент США № 20110195123 участок для локальной доставки может необязательно включать целевые участки, характеризующиеся высокой аномальной пролиферацией клеток и подавлением апоптоза, в том числе опухоли, очаги активного и/или хронического воспаления и инфекции, включающих аутоиммунные болезненные состояния, ткань с дегенеративными изменениями, включающую мышечную и нервную ткань, очаги хронической боли, участки с дегенеративными изменениями, и местоположения переломов костей, и другие местоположения ран, для усиления регенерации ткани, а также поврежденные сердечные, гладкие и поперечно-полосатые мышцы.
Участок для имплантации композиции или целевой участок предпочтительно характеризуется радиусом, площадью и/или объемом, достаточно малыми для целенаправленной локальной доставки. Например, целевой участок необязательно имеет диаметр в диапазоне от приблизительно 0,1 мм до приблизительно 5 см.
Местоположение целевого участка предпочтительно выбирают для достижения максимальной терапевтической эффективности. Например, композицию системы доставки лекарственных средств (необязательно вместе с устройством для имплантации, описанным выше) необязательно и предпочтительно имплантируют в опухолевое окружение, или рядом с ним, или в кровеносную сеть, связанную с ним.
Например, композицию (необязательно вместе с устройством) необязательно имплантируют в поджелудочную железу, предстательную железу, молочную железу, печень или рядом с ними, через сосок, в сосудистую систему и т. д.
Целевое местоположение необязательно выбирают из группы, содержащей, состоящей фактически из или состоящей из (только в качестве неограничивающих примеров, поскольку любой участок в организме необязательно может подходить для имплантации Loder): 1. участков головного мозга, таких как базальные ганглии, белое и серое вещество, с дегенеративными изменениями подобными таковым при болезни Паркинсона или Альцгеймера; 2. спинного мозга, как в случае бокового амиотрофического склероза (ALS); 3. шейки матки для предупреждения инфекции, обусловленной HPV; 4. суставов с активным и хроническим воспалением; 5. дермы, как в случае псориаза; 6. участков симпатических и чувствительных нервов для обезболивающего эффекта; 7. участков внутрикостной имплантации; 8. участков острой и хронической инфекции; 9. интравагинальных участков; 10. внутреннего уха слуховой системы, лабиринта внутреннего уха, вестибулярной системы; 11. внутритрахеальных участков; 12. внутрисердечных участков; участков коронарных сосудов, эпикардиальных участков; 13. мочевого пузыря; 14. желчевыделительной системы; 15. участков паренхимной ткани, в том числе без ограничения почки, печени, селезенки; 16. лимфатических узлов; 17. слюнных желез; 18. участков десен вокруг зубов; 19. внутрисуставных участков (имплантация в суставы); 20. внутриглазных участков; 21. ткани головного мозга; 22. желудочков головного мозга; 23. полостей, в том числе брюшной полости (например, без ограничения для лечения рака яичника); 24. внутрипищеводных участков и 25. внутрипрямокишечных участков.
Вставка системы (например, устройства, содержащего композицию) необязательно связана с инъекцией материала в ECM в целевом участке и окруженности этого участка для воздействия на локальные pH, и/или температуру, и/или другие биологические факторы, влияющие на диффузию лекарственного средства и/или кинетику лекарственного средства в ECM целевого участка и окруженности такого участка.
Согласно некоторым вариантам осуществления высвобождение указанного средства необязательно может быть связано с чувствительными и/или активирующими приборами, функционирующими до, и/или во время, и/или после вставки посредством неинвазивных, и/или минимально инвазивных, и/или других способов активации и/или ускорения/замедления, включающих способы или устройства с применением лазерных пучков, ионизирующего излучения, термического нагревания и охлаждения, и ультразвука, в том числе фокусированного ультразвука, и/или RF (радиочастот), а также химических активаторов.
Согласно другим вариантам осуществления в публикации заявки на патент США № 20110195123 лекарственное средство предпочтительно содержит РНК, например, для лечения случаев локализованного рака молочной железы, поджелудочной железы, головного мозга, почки, мочевого пузыря, легкого и предстательной железы, описанных ниже. Несмотря на то, что примеры были приведены с RNAi, многие применимые лекарственные средства подлежат инкапсуляции в Loder, и их можно применять в контексте настоящего изобретения, при условии, что такие лекарственные средства можно инкапсулировать в субстрате Loder, таком как, например, матрица, и данную систему можно использовать и/или приспособить для доставки системы CRISPR Cas по настоящему изобретению.
В качестве другого примера конкретного применения, дегенеративные заболевания нервной системы и мышц развиваются в связи с аномальной экспрессией генов. Локальная доставка РНК может иметь терапевтические свойства, препятствующие такой аномальной экспрессии генов. Локальная доставка антиапоптотических, противовоспалительных и антидегенеративных лекарственных средств, в том числе низкомолекулярных лекарственных средств и макромолекул, может также необязательно быть терапевтической. В таких случаях Loder применяют для пролонгированного высвобождения при постоянной скорости и/или посредством выделенного устройства, которое имплантируют отдельно. Все из этого можно применять для системы CRISPR-Cas по настоящему изобретению и/или приспосабливать к ней.
В качестве еще одного примера конкретного применения, психические и когнитивные нарушения лечат с помощью модификаторов генов. Нокдаун гена является возможным методом лечения. Применение Loder для локальной доставки средств в участки центральной нервной системы является возможным методом терапии психических и когнитивных нарушений, в том числе без ограничения психоза, биполярных расстройств, невротических расстройств и расстройств поведения. Loder могут также обеспечивать локальную доставку лекарственных средств, в том числе низкомолекулярных лекарственных средств и макромолекул, при имплантации в конкретные участки головного мозга. Все из этого можно применять для системы CRISPR-Cas по настоящему изобретению и/или приспосабливать к ней.
В качестве другого примера конкретного применения сайленсинг генов медиаторов врожденного и/или приобретенного иммунного ответа в локальных участках обеспечивает предупреждение отторжения трансплантированного органа. Локальная доставка РНК и иммуномодулирующих реагентов с помощью Loder, имплантированного в трансплантированный орган и/или участок имплантации, активирует подавление местного иммунитета в отношении трансплантированного органа путем отвлечения иммунных клеток, таких как CD8. Все из этого можно применять для системы CRISPR-Cas по настоящему изобретению и/или адаптировать к ней.
В качестве другого примера конкретного применения факторы роста сосудов, в том числе VEGF, и ангиогенин, и другие, являются существенно важными для неоваскуляризации. Локальная доставка факторов, пептидов, пептидомиметиков или подавление их репрессоров является важным терапевтическим воздействием; сайленсинг репрессоров и локальная доставка факторов, пептидов, макромолекул и низкомолекулярных лекарственных средств, стимулирующих ангиогенез, с помощью Loder являются терапевтическими мерами в отношении заболевания периферических сосудов, системного заболевания сосудов и заболевания сосудов сердца.
Способ вставки, такой как имплантация, необязательно можно еще применять для других типов имплантации в ткань, и/или для вставок, и/или для отбора образцов тканей необязательно без модификаций или, в альтернативном случае, необязательно лишь с незначительными модификациями таких способов. Такие способы необязательно включают без ограничения способы брахитерапии, биопсию, эндоскопию с применением ультразвуковых технологий и/или без них, такую как ERCP, стереотаксические способы в отношении тканей головного мозга, лапароскопию, в том числе имплантацию с помощью лапароскопа в суставы, органы брюшной полости, стенку мочевого пузыря и полости тела.
Технологию имплантируемого устройства, описанную в данном документе, можно применять с руководствами в данном документе и, таким образом, с помощью данного раскрытия и знаний в данной области систему CRISPR-Cas, или ее компоненты, или ее молекулы нуклеиновой кислоты, или кодируемые или обеспечиваемые компоненты можно доставлять посредством имплантируемого устройства.
Способы персонифицированного скрининга пациентов
Систему нацеливания на нуклеиновую кислоту, которая целенаправленно воздействуют на ДНК, например, на тринуклеотидные повторы, можно применять для проведения скрининга пациентов или образцов пациентов на присутствие таких повторов. Повторы могут представлять собой мишень для РНК системы нацеливания на нуклеиновую кислоту, и если происходит их связывание с системой нацеливания на нуклеиновую кислоту, то связывание можно выявить, что указывает тем самым на присутствие такого повтора. Таким образом, систему нацеливания на нуклеиновую кислоту можно применять для скрининга пациентов или образцов пациентов на присутствие повторов. Пациенту затем можно вводить подходящее соединение(подходящие соединения), направленное(направленные) на состояние; или можно вводить систему нацеливания на нуклеиновую кислоту для связывания с нуклеотидом и осуществления вставки, делеции или мутации и облегчения тяжести состояния.
В настоящем изобретении нуклеиновые кислоты используются для связывания целевых последовательностей ДНК.
мРНК и направляющая РНК эффекторного белка CRISPR
Направляющую РНК и мРНК фермента CRISPR можно также доставлять по отдельности. мРНК фермента CRISPR можно доставлять перед направляющей РНК, чтобы предоставить время для экспрессии фермента CRISPR. За 1-12 часов (предпочтительно за около 2-6 часов) до введения направляющей РНК можно вводить мРНК фермента CRISPR.
Альтернативно мРНК фермента CRISPR и направляющую РНК можно вводить совместно. Вторую бустерную дозу направляющей РНК можно преимущественно вводить через 1-12 часов (предпочтительно примерно через 2-6 часов) после первого введения мРНК фермента CRISPR + направляющей РНК.
Эффекторный белок CRISPR по настоящему изобретению, т. е. эффекторный белок Cpf1 иногда обозначается в данном документе как фермент CRISPR. Будет ясно, что эффекторный белок основан на ферменте или получен из него, поэтому термин "эффекторный белок" определенно включает "фермент" в некоторых вариантах осуществления. Однако будет ясно, что эффекторный белок, как требуется в некоторых вариантах осуществления, может характеризоваться связыванием с ДНК или РНК, но необязательно разрезанием или никированием, в том числе функцией неработающего эффекторного белка Cas.
Введение дополнительных доз мРНК фермента CRISPR и/или направляющей РНК может быть полезным для достижения наиболее эффективных уровней модификации генома. В некоторых вариантах осуществления фенотипическое изменение предпочтительно является результатом модификации генома при осуществлении нацеливания на генетическое заболевание, особенно в способах терапии, и предпочтительно, если обеспечивается матрица для репарации для коррекции или изменения фенотипа.
В некоторых вариантах осуществления заболевания, на которые можно осуществлять нацеливание, включают заболевания, которые обусловлены патогенными дефектами сплайсинга.
В некоторых вариантах осуществления клеточные цели включают в себя гемопоэтические стволовые клетки/клетки-предшественники (CD34+); человеческие T-клетки и клетки глаза (клетки сетчатки), например, фоторецепторные клетки-предшественники.
В некоторых вариантах осуществления гены-мишени включают: ген бета-глобина человека - HBB (для лечения серповидноклеточной анемии, в том числе путем стимуляции конверсии генов (с использованием близкородственного гена HBD в качестве эндогенной матрицы)); CD3 (T-клетки) и CEP920 - сетчатка (глаза).
В некоторых вариантах осуществления заболевания-мишени также включают: рак; серповидноклеточную анемию (обусловленную точечной мутацией); HIV; бета-талассемию; а также офтальмологическое или глазное заболевание, например, врожденный амавроз Лебера (LCA), вызванный дефектом сплайсинга.
В некоторых вариантах осуществления способы доставки включают опосредованную катионным липидом "прямую" доставку комплекса фермент-направляющая (рибонуклеопротеин) и электропорацию плазмидной ДНК.
Способы по настоящему изобретению могут дополнительно предусматривать доставку матриц, таких как матрицы для репарации, которые могут представлять собой dsODN или ssODN, см. ниже. Доставка матриц может осуществляться одновременно или отдельно от доставки какого-либо или всех из фермента CRISPR или направляющей и с помощью одного и того же или различных механизмов доставки. В некоторых вариантах осуществления предпочтительным является то, что матрицу доставляют вместе с направляющей, а также предпочтительно с ферментом CRISPR. Примером может быть вектор на основе AAV.
Способы по настоящему изобретением могут дополнительно предусматривать: (a) доставку в клетку двухнитевого олигодезоксинуклеотида (dsODN), содержащего "липкие" концы, комплементарные "липким" концам, создаваемым с помощью указанного двухнитевого разрыва, где указанный dsODN интегрируется в представляющий интерес локус; или (b) доставку в клетку однонитевого олигодезоксинуклеотида (ssODN), где указанный ssODN действует как матрица репарации с помощью гомологичной рекомбинации указанного двухнитевого разрыва. Способы по настоящему изобретению можно применять для предупреждения или лечения заболевания у индивидуума, при этом необязательно указанное заболевание вызвано дефектом в указанном представляющем интерес локусе. Способы по настоящему изобретению можно выполнять in vivo у индивидуума или ex vivo в отношении клетки, извлеченной из индивидуума, где необязательно указанную клетку возвращают в организм индивидуума.
Для сведения к минимуму токсичности и нецелевого эффекта будет важной регуляция концентрации доставляемых мРНК фермента CRISPR и направляющей РНК. Оптимальные концентрации мРНК фермента CRISPR и направляющей РНК можно определить путем тестирования различных концентраций в клеточной или животной модели и применения глубокого секвенирования для анализа степени модификации в возможных нецелевых локусах генома. Например, для направляющей последовательности, нацеливающейся на 5’-GAGTCCGAGCAGAAGAAGAA-3’ (SEQ ID NO: 23) в гене EMX1 генома человека, можно применять глубокое секвенирование для определения уровня модификации в следующих двух нецелевых локусах, 1: 5'-GAGTCCTAGCAGGAGAAGAA-3' (SEQ ID NO: 24) и 2: 5'-GAGTCTAAGCAGAAGAAGAA-3' (SEQ ID NO: 25). Для доставки in vivo следует выбрать концентрацию, дающую наиболее высокий уровень точной целевой модификации при сведении к минимуму уровня нецелевой модификации.
Индуцируемые системы
В некоторых вариантах осуществления фермент CRISPR может образовывать компонент индуцируемой системы. Индуцируемая природа системы будет обеспечивать возможность пространственно-временного контроля редактирования генов или экспрессии генов с использованием определенной формы энергии. Форма энергии может включать, но без ограничения, электромагнитное излучение, звуковую энергию, химическую энергию и тепловую энергию. Примеры индуцируемой системы включают индуцируемые тетрациклином промоторы (Tet-On или Tet-Off), двугибридные системы активации транскрипции с использованием малых молекул (FKBP, ABA и т. д.) или индуцируемые светом системы (фитохром, домены LOV или криптохром). В одном варианте осуществления фермент CRISPR может быть частью индуцируемого светом транскрипционного эффектора (LITE) для управления изменениями транскрипционной активности специфичным к последовательности образом. Компоненты индуцируемой светом системы могут включать фермент CRISPR, чувствительный к свету гетеродимер цитохрома (например, из Arabidopsis thaliana) и домен активации/репрессии транскрипции. Дополнительные примеры индуцируемых ДНК-связывающих белков и способы их применения представлены в US 61/736465 и US 61/721283, а также WO 2014/018423 А2, которые включены в данный документ посредством ссылки во всей полноте.
Самоинактивирующиеся системы
Как только все копии гена в геноме клетки подвергли редактированию, дальнейшая экспрессия CRISRP/Cpf1p в такой клетке более не требуется. В действительности, поддержание экспрессии было бы нежелательным в случае нецелевых эффектов в сайтах генома, не предназначенных для редактирования и т. д. Таким образом, целесообразной была бы ограниченная во времени экспрессия. Индуцируемая экспрессия предоставляет одно решение проблемы, но помимо нее заявители сконструировали самоинактивирующуюся систему CRISPR, которая основана на применении некодирующей направляющей целевой последовательности в самом векторе, несущем CRISPR. Таким образом, после того как экспрессия началась, система CRISPR-Cas будет вызывать собственное разрушение, но перед тем как разрушение завершится, у нее будет достаточно времени для редактирования геномных копий целевого гена (для чего, с точки зрения нормальной точечной мутации в диплоидной клетке, потребуется не более двух редактирований). Вкратце, самоинактивирующаяся система CRISPR-Cas включает в себя дополнительную РНК (т. e. направляющую РНК), которая нацеливает кодирующую последовательность для самого фермента CRISPR или которая нацеливает одну или несколько некодирующих направляющих целевых последовательностей, комплементарных уникальным последовательностям, присутствующим в одной или нескольких из следующих:
(a) в промоторе, управляющем экспрессией элементов некодирующей РНК,
(b) в промоторе, управляющем экспрессией гена эффекторного белка Cpf1,
(c) в последовательности в 100 п. о. инициирующего трансляцию стартового ATG-кодона в кодирующей последовательности эффекторного белка Cpf1,
(d) в инвертированном концевом повторе (iTR) вирусного вектора для доставки, например, в геноме AAV.
Более того, такую РНК можно доставлять посредством вектора, например, отдельного вектора или того же вектора, который кодирует комплекс CRISPR. Когда введение осуществляют с помощью отдельного вектора, то РНК CRISPR, которая целенаправленно воздействует на экспрессию Cas, можно вводить последовательно или одновременно. При последовательном введении РНК CRISPR, которая целенаправленно воздействует на экспрессию Cas, можно доставлять после РНК CRISPR, которая предназначена, например, для редактирования генов или рекомбинации генов. Данный период может быть периодом, исчисляемым в минутах (например, 5 минут, 10 минут, 20 минут, 30 минут, 45 минут, 60 минут). Данный период может быть периодом, исчисляемым в часах (например, 2 часа, 4 часа, 6 часов, 8 часов, 12 часов, 24 часа). Данный период может быть периодом, исчисляемым в днях (например, 2 дня, 3 дня, 4 дня, 7 дней). Данный период может быть периодом, исчисляемым в неделях (например, 2 недели, 3 недели, 4 недели). Данный период может быть периодом, исчисляемым в месяцах (например, 2 месяца, 4 месяца, 8 месяцев, 12 месяцев). Данный период может быть периодом, исчисляемым в годах (например, 2 года, 3 года, 4 года). Таким путем фермент Cas связывается с первой gRNA, способной гибридизироваться с первой мишенью, такой как представляющие интерес локус или локусы генома, и выполняет функцию(функции), требующуюся(требующиеся) для системы CRISPR-Cas (например, рекомбинацию генов); и впоследствии фермент Cas может затем связываться со второй gRNA, способной гибридизироваться с последовательностью, содержащей по меньшей мере часть кассеты Cas или CRISPR. Если направляющая РНК целенаправленно воздействуют на последовательности, кодирующие экспрессию белка Cas, фермент блокируется, а система становится самоинактивирующейся. Аналогичным образом РНК CRISPR, которая целенаправленно воздействует на экспрессию Cas, введенного посредством, например, липосомы, липофекции, частиц, микровезикул, что объясняется в данном документе, можно вводить последовательно или одновременно. Проще говоря, самоинактивацию можно применять для инактивации одной или нескольких направляющих РНК, используемых для нацеливания на одну или несколько мишеней.
В ряде аспектов обеспечивается одиночная gRNA, которая способна гибридизироваться с последовательностью, расположенной ниже стартового кодона фермента CRISPR, при этом после определенного периода времени происходит потеря экспрессии фермента CRISPR. В ряде аспектов обеспечиваются одна или несколько gRNA, которые способны гибридизироваться с одной или несколькими кодирующими или некодирующими участками полинуклеотида, кодирующего систему CRISPR-Cas, при этом после определенного периода времени происходит инактивация одной или нескольких, или в ряде случаев, всех систем CRISPR-Cas. В некоторых аспектах системы и не ограничиваясь теорией клетка может содержать множество комплексов CRISPR-Cas, где первое подмножество комплексов CRISPR содержит первую направляющую РНК, способную целенаправленно воздействовать на подлежащие редактированию локус или локусы генома, а второе подмножество комплексов CRISPR содержит по меньшей мере одну вторую направляющую РНК, способную целенаправленно воздействовать на полинуклеотид, кодирующий систему CRISPR-Cas, где первое подмножество комплексов CRISPR-Cas опосредует редактирование целевых локуса или локусов генома, а второе подмножество комплексов CRISPR впоследствии инактивирует систему CRISPR-Cas, инактивируя тем самым в дальнейшем экспрессию CRISPR-Cas в клетке.
Таким образом, настоящее изобретение относится к системе CRISPR-Cas, содержащей один или несколько векторов для доставки в эукариотическую клетку, где вектор(векторы) кодирует(кодируют): (i) фермент CRISPR; (ii) первую направляющую РНК, способную гибридизироваться с целевой последовательностью в клетке; (iii) вторую направляющую РНК, способную гибридизироваться с одной или несколькими целевыми последовательностями в векторе, который кодирует фермент CRISPR; где при экспрессии в клетке первая направляющая РНК управляет специфическим к последовательности связыванием первого комплекса CRISPR с последовательностью в клетке; вторая направляющая РНК управляет специфическим к последовательности связыванием второго комплекса CRISPR с целевой последовательностью в векторе, который кодирует фермент CRISPR; при этом комплексы CRISPR содержат фермент CRISPR, связанный с направляющей РНК, таким образом, что направляющая РНК может гибридизироваться со своей целевой последовательностью; а второй комплекс CRISPR комплекс инактивирует систему CRISPR-Cas для предупреждения дальнейшей экспрессии клеткой фермента CRISPR.
Различные кодирующие последовательности (фермент CRISPR и направляющие РНК) можно ввести в отдельный вектор или во множество векторов. Например, возможным является кодирование фермента в одном векторе, а последовательностей разных РНК в другом векторе, или кодирование фермента и одной направляющей РНК в одном векторе, а остальной направляющей РНК в другом векторе, или любая другая комбинация. В целом, предпочтительной является система, использующая всего один или два разных вектора.
При использовании множества векторов возможной является их доставка в неравных количествах, а в идеальном варианте с избытком вектора, который кодирует первую направляющую РНК, связанную со второй направляющей РНК, способствуя тем самым задержке конечной инактивации системы CRISPR до момента прохождения редактирования генома.
Первая направляющая РНК может целенаправленно воздействовать на любую представляющую интерес целевую последовательность в геноме, что описано в других частях в данном документе. Вторая направляющая РНК нацеливается на любую последовательность в векторе, который кодирует фермент CRISPR Cpf1, и тем самым инактивирует экспрессию фермента, обусловленную данным вектором. Таким образом, целевая последовательность в векторе должна быть способна к инактивации экспрессии. Подходящие целевые последовательности могут находиться, например, рядом с инициирующим трансляцию стартовым кодоном кодирующей последовательности Cpf1p или в его пределах, в некодирующей последовательности в промоторе, управляющим экспрессией элементов некодирующей РНК, в пределах промотора, управляющего экспрессией гена Cpf1p, в пределах 100 п. о. инициирующего трансляцию стартового ATG-кодона в кодирующей последовательности Cas, и/или в пределах инвертированного концевого повтора (iTR) вирусного вектора для доставки, например, в геноме AAV. Двухнитевой разрыв рядом с данным участком может индуцировать сдвиг рамки в кодирующей последовательности Cas, вызывая потерю экспрессии белка. Альтернативой целевой последовательности для "самоинактивирующейся" направляющей РНК было бы нацеливание на редактирование/инактивацию регуляторных участков/последовательностей, которые необходимы для экспрессии системы CRISPR-Cpf1 или для стабильности вектора. Например, если нарушена структура промотора для кодирующей последовательности Cas, тогда транскрипция будет подавляться или предупреждаться. Проще говоря, если вектор включает в себя последовательности, обеспечивающие репликацию, поддержание или стабильность, тогда можно целенаправленно воздействовать на эти последовательности. К примеру, в векторе на основе AAV приемлемая целевая последовательность находится в пределах iTR. Другими приемлемыми для нацеливания последовательностями могут быть промоторные последовательности, сайты полиаденилирования и т. д.
Более того, если направляющие РНК экспрессируются в формате массива, тогда "самоинактивирующиеся" направляющие РНК, целенаправленно воздействующие одновременно на оба промотора, в результате приведут к вырезанию вставочных нуклеотидов в пределах экспрессионной конструкции CRISPR-Cas, вызывая фактически полную инактивацию. Проще говоря, вырезание вставочных нуклеотидов будет являться результатом целенаправленного воздействия направляющих РНК на оба ITR или одновременного целенаправленного воздействия на два или более компонентов CRISPR-Cas. Как поясняется в данном документе, самоинактивация в целом применима с системами CRISPR-Cas для обеспечения регуляции CRISPR-Cas. Например, как поясняется в данном документе, самоинактивацию можно задействовать для CRISPR-опосредованной репарации мутаций, например, нарушений, обусловленных экспансией, как поясняется в данном документе. Результат такой самоинактивации заключается во временной активности CRISPR-опосредованной репарации.
Добавление ненацеливающихся нуклеотидов к 5'-концу (например, 1-10 нуклеотидов, предпочтительно 1-5 нуклеотидов) "самоинактивирующиейся" направляющей РНК можно использовать для задержки ее процессирования и/или модифицирования ее эффективности в качестве средства для обеспечения редактирования в целевом локусе генома перед выключением CRISPR-Cas.
В одном аспекте самоинактивирующейся системы AAV-CRISPR-Cas плазмиды, которые совместно экспрессируют одну или несколько направляющих РНК, целенаправленно воздействующих на представляющие интерес последовательности в геноме (например, 1-2, 1-5, 1-10, 1-15, 1-20, 1-30), можно создавать с "самоинактивирующимися" направляющими РНК, которые нацеливаются на последовательность SpCas9 в сконструированном стартовом ATG-сайте или рядом с ним (например, в пределах 5 нуклеотидов, в пределах 15 нуклеотидов, в пределах 30 нуклеотидов, в пределах 50 нуклеотидов, в пределах 100 нуклеотидов). На регуляторную последовательность в участке промотора U6 также можно целенаправленно воздействовать при помощи направляющей РНК. U6-контролируемые направляющие РНК можно сконструировать в формате массива с тем, чтобы одновременно могли высвобождаться множество последовательностей направляющих РНК. При первичной доставке в целевые ткань/клетки (клетка слева) направляющие РНК начинают накапливаться, в то же время в ядре повышаются уровни Cas. Cas формируют комплексы со всеми направляющими РНК для опосредования редактирования генома и самоинактивации плазмид, несущих CRISPR-Cas.
Один аспект самоинактивирующейся системы CRISPR-Cas представляет собой экспрессию в отдельном формате или в формате тандемного массива от 1 до 4 или более разных направляющих последовательностей; например, до приблизительно 20 или приблизительно 30 направляющих последовательностей. Каждая отдельная самоинактивирующаяся направляющая последовательность может целенаправленно воздействовать на разные мишени. Такие последовательности могут процессироваться, например, из транскрипта одной химерной pol3. Можно применять промоторы рol3, такие как промоторы U6 или H1. Промоторы рol2 упомянуты во всем данном документе. Последовательности с инвертированными концевыми повторами (iTR) могут фланкировать промотор Pol3 - направляющую (направляющие) РНК - промотор Pol2 - Cas.
В одном аспекте транскрипт в формате тандема представляет собой одну или несколько направляющих последовательностей, которые редактируют одну или несколько мишеней, тогда как одна или несколько самоинактивирующихся направляющих последовательностей инактивируют систему CRISPR-Cas. Таким образом, например, описываемая система CRISPR-Cas для репарации нарушений, обусловленных экспансией, можно непосредственно объединять с самоинактивирующейся системой CRISPR-Cas, описанной в данном документе. Такая система может, например, иметь две направляющие последовательности, направленные на целевой участок для репарации, а также по меньшей мере третью направляющую последовательность, управляющую самоинактивацией CRISPR-Cas. Ссылаются на заявку с порядковым № PCT/US2014/069897 под названием "Композиции и способы применения систем CRISPR-Cas при связанных с нуклеотидными повторами нарушениях", опубликованную 12 декабря 2014 г. как WO/2015/089351.
Направляющая РНК может представлять собой контрольную направляющую последовательность. Например, ее можно сконструировать для целенаправленного воздействия на последовательность нуклеиновой кислоты, кодирующую сам фермент CRISPR, как описано в US2015232881A1, раскрытие которого включено в данный документ посредством ссылки. В некоторых вариантах осуществления могут быть предусмотрены система или композиция лишь с направляющей РНК, сконструированной для целенаправленного воздействия на последовательность нуклеиновой кислоты, кодирующую фермент CRISPR. Кроме того, могут быть предусмотрены система или композиция с направляющей РНК, сконструированной для целенаправленного воздействия на последовательность нуклеиновой кислоты, кодирующую фермент CRISPR, а также последовательность нуклеиновой кислоты, кодирующую фермент CRISPR, и необязательно второй направляющей РНК, и дополнительно необязательно матрицей для репарации. Вторая направляющая РНК может представлять собой первичную мишень системы или композиции CRISPR (такой как терапевтической, диагностической, для нокдауна и т. д., как определено выше). В этом отношении система или композиция является самоинактивирующейся. Это показано на примере в отношении Cas9 в US2015232881A1 (также опубликованном как WO2015070083 (A1), на который ссылаются в других местах данного документа, и может быть экстраполировано на Cpf1.
Ферменты в соответствии с настоящим изобретением, используемые в подходе мультиплексного (тандемного) нацеливания
Авторы настоящего изобретения показали, что ферменты CRISPR, определяемые в данном документе, могут использовать более одной направляющей РНК без потери активности. Это делает возможным применение ферментов, систем или комплексов CRISPR, определяемых в данном документе, для нацеливания на множественные ДНК-мишени, гены или генные локусы с помощью одного фермента, системы или комплекса, определяемых в данном документе. Направляющие РНК можно располагать тандемно, необязательно разделенными нуклеотидной последовательностью, такой как прямой повтор, определяемый в данном документе. Положение различных направляющих РНК в тандеме не влияет на активность. Следует отметить, что термины "система CRISPR-Cas", "комплекс CRISP-Cas", "комплекс CRISPR" и "система CRISPR" используются взаимозаменяемо. Также термины "фермент CRISPR", "фермент Cas" или "фермент CRISPR-Cas" могут использоваться взаимозаменяемо. В предпочтительных вариантах осуществления указанный фермент CRISPR, фермент CRISP-Cas или фермент Cas представляет собой Cpf1 или любой из его модифицированных или мутированных вариантов, описанных в других разделах данного документа.
В одном аспекте настоящее изобретение относится к не встречающемуся в природе или сконструированному ферменту CRISPR, предпочтительно ферменту CRISPR 2 класса, предпочтительно ферменту CRISPR V или VI типа, описываемому в данном документе, такому как без ограничений Cpf1, описываемый в других разделах данного документа, применяемый для тандемного или мультиплексного нацеливания. Следует понимать, что в таком подходе может применяться любое из ферментов, комплексов или систем CRISPR (или CRISPR-Cas или Cas) в соответствии с настоящим изобретением, описываемых в других разделах данного документа. Любые из способов, продуктов, композиций и вариантов применения, описываемые в других разделах данного документа, равным образом применимы в подходе мультиплексного или тандемного нацеливания, дополнительно подробно описанного ниже. С целью дополнительного руководства приводятся следующие конкретные аспекты и варианты осуществления.
В одном аспекте настоящее изобретение относится к применению фермента, комплекса или системы Cpf1, определяемых в данном документе, для нацеливания на множественные генные локусы. В одном варианте осуществления это можно осуществить путем применения множественных (тандемных или мультиплексных) последовательностей направляющих РНК (gRNA).
В одном аспекте настоящее изобретение относится к способам применения одного или нескольких элементов фермента, комплекса или системы Cpf1, определяемых в данном документе, для тандемного или мультиплексного нацеливания, где указанная система CRISP содержит множественные последовательности направляющей РНК. Предпочтительно указанные последовательности gRNA разделены нуклеотидной последовательностью, такой как прямой повтор, определяемой в других разделах данного документа.
Фермент, система или комплекс Cpf1, определяемые в данном документе обеспечивают эффективные средства для модифицирования множественных целевых полинуклеотидов. Фермент, система или комплекс Cpf1, определяемые в данном документе, характеризуются большим разнообразием применений, включая модифицирование (например, образование делеции, вставки, транслокации, инактивацию, активацию) одного или нескольких целевых полинуклеотидов в множестве типов клеток. В связи с этим, определяемый в данном документе фермент, система или комплекс Cpf1 по настоящему изобретению имеют широкий спектр применений, например, в генной терапии, скрининге лекарственных средств, диагностике и определении прогноза заболевания, включая нацеливание на множественные генные локусы в пределах одной системы CRISPR.
В одном аспекте настоящее изобретение относится к ферменту, системе или комплексу Cpf1, определяемым в данном документе, т. е. комплексу CRISPR-Cas на основе Cpf1, содержащему белок Cpf1, имеющий по меньшей мере один ассоциированный с ним домен дестабилизации, и множественные направляющие РНК, которые нацеливаются на множественные молекулы нуклеиновой кислоты, такие как молекулы ДНК, в результате чего каждая из указанных множественных направляющих РНК специфически нацеливается на свою соответствующую молекулу нуклеиновой кислоты, например, молекулу ДНК. Каждая целевая молекула нуклеиновой кислоты, например, молекула ДНК, может кодировать продукт гена или охватывать генный локус. Следовательно, применение множественных направляющих РНК дает возможность нацеливания на множественные генные локусы или множественные гены. В некоторых вариантах осуществления фермент Cpf1 может расщеплять молекулу ДНК, кодирующую продукт гена. В некоторых вариантах осуществления экспрессия продукта гена изменена. Белок Cpf1 и направляющие РНК не встречаются в природе вместе. Настоящее изобретение охватывает направляющие РНК, предусматривающие расположенные тандемно направляющие последовательности. Настоящее изобретение дополнительно охватывает кодирующие последовательности для белка Cpf1, который является кодон-оптимизированным для экспрессии в эукариотической клетке. В предпочтительном варианте осуществления эукариотическая клетка представляет собой клетку млекопитающего, растительную клетку или клетку дрожжей, и в более предпочтительном варианте осуществления клетка млекопитающего является клеткой человека. Экспрессия продукта гена может быть снижена. Фермент Cpf1 может образовывать часть системы или комплекса CRISPR, которые дополнительно содержат расположенные тандемно направляющие РНК (gRNA), содержащие серию из 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 25, 25, 30 или более чем 30 направляющих последовательностей, при этом каждая способна специфически гибридизироваться с целевой последовательностью в представляющем интерес локусе генома в клетке. В некоторых вариантах осуществления функциональная система или комплекс Cpf1 CRISPR связываются с множественными целевыми последовательностями. В некоторых вариантах осуществления функциональная система или комплекс CRISPR могут редактировать множественные целевые последовательности, например, целевые последовательности могут предусматривать локус генома, а в некоторых вариантах осуществления может быть предусмотрено изменение экспрессии гена. В некоторых вариантах осуществления функциональная система или комплекс CRISPR могут содержать дополнительные функциональные домены. В некоторых вариантах осуществления настоящее изобретение относится к способу изменения или модифицирования экспрессии множественных продуктов гена. Способ может предусматривать введение в клетку, содержащую указанные целевые нуклеиновые кислоты, например молекулы ДНК, или содержащую и экспрессирующую целевую нуклеиновую кислоту, например молекулы ДНК; к примеру, целевые нуклеиновые кислоты могут кодировать продукты гена или обеспечивать экспрессию продуктов гена (например, регуляторные последовательности).
В предпочтительных вариантах осуществления фермент CRISPR, применяемый для мультиплексного нацеливания, представляет собой Cpf1, или система или комплекс CRISPR содержат Cpf1. В некоторых вариантах осуществления фермент CRISPR, применяемый для мультиплексного нацеливания, представляет собой AsCpf1, или система или комплекс CRISPR, применяемые для мультиплексного нацеливания, содержат AsCpf1. В некоторых вариантах осуществления фермент CRISPR представляет собой LbCpf1, или система или комплекс CRISPR содержат LbCpf1. В некоторых вариантах осуществления фермент Cpf1, применяемый для мультиплексного нацеливания, расщепляет обе нити ДНК с образованием двухнитевого разрыва (DSB). В некоторых вариантах осуществления фермент CRISPR, применяемый для мультиплексного нацеливания, представляет собой никазу. В некоторых вариантах осуществления фермент Cpf1, применяемый для мультиплексного нацеливания, представляет собой двойную никазу. В некоторых вариантах осуществления фермент Cpf1, применяемый для мультиплексного нацеливания, представляет собой фермент Cpf1, такой как фермент DD Cpf1, определяемый в других разделах данного документа.
В некоторых общих вариантах осуществления фермент Cpf1, применяемый для мультиплексного нацеливания, связывается с одним или несколькими функциональными доменами. В некоторых более специфических вариантах осуществления фермент CRISPR, применяемый для мультиплексного нацеливания, представляет собой неработающий Cpf1, определяемый в других разделах данного документа.
В одном аспекте настоящего изобретения предусмотрены средства для доставки фермента, системы или комплекса Cpf1 для применения в множественном нацеливании, как определено в данном документе, или полинуклеотидов, определенных в данном документе. Неограничивающие примеры таких средств доставки представляют собой, например, частицу(частицы), доставляющую(доставляющие) компонент(компоненты) комплекса, вектор(векторы), содержащие полинуклеотид(полинуклеотиды), обсуждаемые в данном документе (например, кодирующие фермент CRISPR, обеспечивающие нуклеотиды, кодирующие комплекс CRISPR). В некоторых вариантах осуществления вектором может быть плазмида или вирусный вектор, такой как AAV или лентивирус. Преимущественной может быть транзиентная трансфекция с помощью плазмид, например, клеток HEK, особенно с учетом ограничений по размеру для AAV и того, что, хотя Cpf1 вмещается в AAV, в случае дополнительных направляющих РНК может быть достигнут верхний предел.
Также предусмотрены модель, в которой конститутивно экспрессируется фермент, комплекс или система Cpf1, применяемые в данном документе, для применения в мультиплексном нацеливании. Организм может быть трансгенным и может быть трансфицирован с помощью векторов по настоящему изобретению или может быть потомством организма, трансфицированного таким образом. В дополнительном аспекте настоящего изобретения предусмотрены композиции, содержащие фермент, систему и комплекс CRISPR, определяемые в данном документе, или полинуклеотиды или векторы, описанные в данном документе. Также предусмотрены системы или комплексы CRISPR на основе Cpf1, содержащие множественные направляющие РНК, предпочтительно в формате тандемного расположения. Указанные различные направляющие РНК могут быть разделены нуклеотидными последовательностями, такими как прямые повторы.
Также предусмотрен способ лечения субъекта, например, субъекта, нуждающегося в этом, предусматривающий индицирование редактирования генов путем трансформации субъекта с помощью полинуклеотида, кодирующего систему или комплекс CRISPR на основе Cpf1, или любого из полинуклеотидов или векторов, описанных в данном документе, и введение их субъекту. Также может предусматриваться подходящая матрица для репарации, например, доставляемая вектором, содержащим указанную матрицу для репарации. Также предусмотрен способ лечения субъекта, например, субъекта, нуждающегося в этом, предусматривающий индуцирование активации или репрессии транскрипции множественных целевых генных локусов путем трансформации субъекта с помощью полинуклеотидов или векторов, описанных в данном документе, где указанный полинуклеотид или вектор кодирует или содержит фермент, комплекс или систему Cpf1, содержащие множественные направляющие РНК, предпочтительно расположенные тандемно. В случае осуществления какой-либо обработки ex vivo, например, в культуре клеток, следует понимать, что термин "субъект" можно заменить фразой "клетка или культура клеток".
Также предусмотрены композиции, содержащие фермент, комплекс или систему Cpf1, содержащие множественные направляющие РНК, предпочтительно расположенные тандемно, или полинуклеотид или вектор, кодирующие или содержащие указанный фермент, комплекс или систему Cpf1, содержащие множественные направляющие РНК, предпочтительно расположенные тандемно, для применения в способах лечения, определяемых в других разделах данного документа. Может предусматриваться набор из частей, включающих такие композиции. Также предусмотрено применение указанной композиции в производстве лекарственного препарата для таких способов лечения. В настоящем изобретении также предусмотрено применение системы CRISPR на основе Cpf1 в скрининге, например, скринингах в отношении мутации приобретения функции. Клетки, в которых искусственным путем обеспечивают сверхэкспрессию гена, могут снижать экспрессию гена с течением времени (восстановление равновесия), например, с помощью отрицательных обратных связей. К моменту начала скрининга уровень экспрессии нерегулируемого гена снова может быть снижен. Применение индуцируемого активатора Cpf1 позволяет индуцировать транскрипцию непосредственно перед скринингом и тем самым сводит к минимуму вероятность ложноотрицательных соответствий. В соответствии с этим, путем применения настоящего изобретения в скрининге, например, скринингах в отношении мутации приобретения функции, вероятность ложноотрицательных результатов может быть сведена к минимуму.
В одном аспекте настоящее изобретение относится к сконструированной, не встречающейся в природе системе CRISPR, содержащей белок Cpf1 и множественные направляющие РНК, каждая из которых специфически нацеливается на молекулу ДНК, кодирующую продукт гена в клетке, в результате чего каждая из множественных направляющих РНК нацеливается на свою специфическую молекулу ДНК, кодирующую продукт гена, и белок Cpf1 расщепляет молекулу целевой ДНК, кодирующую продукт гена, в результате чего экспрессия продукта гена изменяется; и где белок CRISPR и направляющие РНК не встречаются в природе вместе. Настоящее изобретение охватывает множественные направляющие РНК, содержащие множественные направляющие последовательности, предпочтительно разделенные нуклеотидной последовательностью, такой как прямой повтор. В одном варианте осуществления настоящего изобретения белок CRISPR представляет собой белок CRISPR-Cas V или VI типа, и в более предпочтительном варианте осуществления белок CRISPR представляет собой белок Cpf1. Настоящее изобретение дополнительно охватывает белок Cpf1, который является кодон-оптимизированным для экспрессии в эукариотической клетке. В предпочтительном варианте осуществления эукариотическая клетка является клеткой млекопитающего, и в более предпочтительном варианте осуществления клетка млекопитающего является клеткой человека. В дополнительном варианте осуществления настоящего изобретения экспрессия продукта гена является сниженной.
В другом аспекте настоящее изобретение относится к сконструированной, не встречающейся в природе векторной системе, содержащей один или несколько векторов, содержащей первый регуляторный элемент, функционально связанный с множественными направляющими РНК системы CRISPR на основе Cpf1, каждая из которых специфически нацеливается на молекулу ДНК, кодирующую продукт гена, и второй регуляторный элемент, функционально связанный с последовательностью, кодирующей белок CRISPR. Оба регуляторных элемента могут находиться в одном и том же векторе или в разных векторах системы. Множественные направляющие РНК нацеливаются на множественные молекулы ДНК, кодирующие множественные продукты гена в клетке, и белок CRISPR может расщеплять множественные молекулы ДНК, кодирующие продукты гена (он может расщеплять одну или обе нити или фактически не проявлять нуклеазную активность), в результате чего экспрессия множественных продуктов гена изменяется; и где белок CRISPR и множественные направляющие РНК не встречаются в природе вместе. В предпочтительном варианте осуществления белок CRISPR представляет собой белок Cpf1, необязательно кодон-оптимизированный для экспрессии в эукариотической клетке. В предпочтительном варианте осуществления эукариотическая клетка представляет собой клетку млекопитающего, растительную клетку или клетку дрожжей, и в более предпочтительном варианте осуществления клетка млекопитающего является клеткой человека. В дополнительном варианте осуществления настоящего изобретения экспрессия каждого из множественных продуктов гена изменена, предпочтительно снижена.
В одном аспекте настоящего изобретения предусмотрена векторная система, содержащая один или несколько векторов. В некоторых вариантах осуществления система содержит: (a) первый регуляторный элемент, функционально связанный с последовательностью прямого повтора и одним или несколькими сайтами встраивания для встраивания одной или нескольких направляющих последовательностей выше или ниже (в зависимости от того, что является подходящим) последовательности прямого повтора, где при экспрессии одна или несколько направляющих последовательностей управляют специфичным к последовательности связыванием комплекса CRISPR с одной или несколькими целевыми последовательностями в эукариотической клетке, где комплекс CRISPR содержит фермент Cpf1 в комплексе с одной или несколькими направляющими последовательностями, которые гибридизируются с одной или несколькими целевыми последовательностями; и (b) второй регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, которая кодирует указанный фермент Cpf1, предпочтительно содержащей по меньшей мере одну последовательность ядерной локализации и/или по меньшей мере одну NES; где компоненты (a) и (b) находятся в одном и том же или разных векторах системы. В некоторых вариантах осуществления компонент (a) дополнительно содержит две или более направляющих последовательностей, функционально связанных с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR на основе Cpf1 со своей целевой последовательностью в эукариотической клетке. В некоторых вариантах осуществления комплекс CRISPR содержит одну или несколько последовательностей ядерной локализации и/или одну или несколько NES, характеризующихся достаточной эффективностью, чтобы управлять накоплением указанного комплекса CRISPR на основе Cpf1 в обнаруживаемом количестве в ядре эукариотической клетки или за его пределами. В некоторых вариантах осуществления первый регуляторный элемент является промотором полимеразы III. В некоторых вариантах осуществления второй регуляторный элемент является промотором полимеразы II. В некоторых вариантах осуществления длина каждой из направляющих последовательностей составляет по меньшей мере 16, 17, 18, 19, 20, 25 нуклеотидов или 16-30, или 16-25, или 16-20 нуклеотидов.
Рекомбинантные векторы экспрессии могут содержать полинуклеотиды, кодирующие фермент, систему или комплекс Cpf1 для применения в множественном нацеливании, определяемом в данном документе, в форме, подходящей для экспрессии нуклеиновой кислоты в клетке-хозяине, что означает, что рекомбинантные векторы экспрессии включают один или несколько регуляторных элементов, которые могут быть выбраны с учетом клеток-хозяев, которые предполагается применять для экспрессии, которые функционально связаны с последовательностью нуклеиновой кислоты, экспрессия которой предполагается. В контексте рекомбинантного вектора экспрессии предполагается, что выражение "функционально связанный" обозначает то, что представляющая интерес нуклеотидная последовательность связана с регуляторным(регуляторными) элементом(элементами), так что обеспечивается возможность экспрессии нуклеотидной последовательности (например, в системе транскрипции/трансляции in vitro или в клетке-хозяине при введении вектора в клетку-хозяина).
В некоторых вариантах осуществления клетка-хозяин является транзиентно или нетранзиентно трансфицированной с помощью одного или нескольких векторов, содержащих полинуклеотиды, кодирующие фермент, систему или комплекс Cpf1 для применения при множественном нацеливании, определяемом в данном документе. В некоторых вариантах осуществления клетку трансфицируют, когда она находится в естественных условиях в субъекте. В некоторых вариантах осуществления клетка, которую трансфицируют, получена от субъекта. В некоторых вариантах осуществления клетка происходит из клеток, полученных от субъекта, как, например, линии клеток. В данной области техники известен целый ряд линий клеток, применяемых в качестве культуры тканей, и их примеры приведены в других местах данного документа. Линии клеток доступны из множества источников, известных специалистам в данной области (см., например, Американская коллекция типовых культур (ATCC) (Манассас, Вирджиния)). В некоторых вариантах осуществления клетку, трансфицированную с помощью одного или нескольких векторов, содержащих полинуклеотиды, кодирующие фермент, систему или комплекс Cpf1 для применения при множественном нацеливании, определяемом в данном документе, применяют для получения новой линии клеток, содержащей одну или несколько полученных из вектора последовательностей. В некоторых вариантах осуществления клетку, транзиентно трансфицированную с помощью компонентов системы или комплекса CRISPR на основе Cpf1 для применения при множественном нацеливании, описываемом в данном документе (как, например, путем транзиентной трансфекции одного или нескольких векторов, или трансфекции с помощью РНК), и модифицированную при помощи активности системы или комплекса CRISPR на основе Cpf1, применяют для получения новой линии клеток, содержащей клетки, содержащие модификацию, но в которых отсутствует любая другая экзогенная последовательность. В некоторых вариантах осуществления клетки, транзиентно или нетранзиентно трансфицированные с помощью одного или нескольких векторов, содержащих полинуклеотиды, кодирующие фермент, систему или комплекс Cpf1 для применения при множественном нацеливании, определяемом в данном документе, или линии клеток, полученные из таких клеток, применяют в оценке одного или нескольких исследуемых соединений.
Термин "регуляторные элементы" определен в других разделах данного документа.
Преимущественные векторы включают лентивирусы и аденоассоциированные вирусы, и типы таких векторов также могут быть выбраны для нацеливания на определенные типы клеток.
В одном аспекте настоящее изобретение относится к эукариотической клетке-хозяину, содержащей (a) первый регуляторный элемент, функционально связанный с последовательностью прямого повтора и одним или несколькими сайтами встраивания для встраивания одной или нескольких последовательностей направляющей РНК выше или ниже (в зависимости от того, что является подходящим) последовательности прямого повтора, где при экспрессии направляющая(направляющие) последовательность(последовательности) управляет(управляют) специфичным к последовательности связыванием комплекса CRISPR на основе Cpf1 с соответствующей(соответствующими) целевой(целевыми) последовательностью(последовательностями) в эукариотической клетке, где комплекс CRISPR на основе Cpf1 содержит фермент Cpf1 в комплексе с одной или несколькими направляющими последовательностями, которые гибридизируются с соответствующей(соответствующими) целевой(целевыми) последовательностью(последовательностями); и/или (b) второй регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, которая кодирует указанный фермент Cpf1, содержащий предпочтительно по меньшей мере одну последовательность ядерной локализации и/или NES. В некоторых вариантах осуществления клетка-хозяин содержит компоненты (a) и (b). В некоторых вариантах осуществления компонент (a), компонент (b) или компоненты (a) и (b) стабильно интегрированы в геном эукариотической клетки-хозяина. В некоторых вариантах осуществления компонент (a) дополнительно содержит две или более направляющих последовательностей, функционально связанных с первым регуляторным элементом и необязательно разделенных прямым повтором, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR на основе Cpf1 со своей целевой последовательностью в эукариотической клетке. В некоторых вариантах осуществления фермент Cpf1 содержит одну или несколько последовательностей ядерной локализации и/или последовательностей ядерного экспорта или NES, характеризующихся достаточной эффективностью, чтобы управлять накоплением указанного фермента CRISPR в обнаруживаемом количестве в ядре эукариотической клетки и/или за его пределами.
В некоторых вариантах осуществления фермент Cpf1 представляет собой фермент системы CRISPR типа V или VI. В некоторых вариантах осуществления фермент Cpf1 представляет собой фермент Cpf1. В некоторых вариантах осуществления фермент Cpf1 получен из Cpf1 Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens или Porphyromonas macacae, и он может включать дополнительные изменения или мутации Cpf1, определяемые в других разделах данного документа, и он может представлять собой химерный Cpf1. В некоторых вариантах осуществления фермент Cpf1 является кодон-оптимизированным для экспрессии в эукариотической клетке. В некоторых вариантах осуществления фермент CRISPR управляет расщеплением одной или двух нитей в определенном положении целевой последовательности. В некоторых вариантах осуществления первый регуляторный элемент является промотором полимеразы III. В некоторых вариантах осуществления второй регуляторный элемент является промотором полимеразы II. В некоторых вариантах осуществления длина одной или нескольких направляющих последовательностей составляет (или длина каждой составляет) по меньшей мере 16, 17, 18, 19, 20, 25 нуклеотидов, или 16-30, или 16-25, или 16-20 нуклеотидов. При применении множественных направляющих РНК они предпочтительно разделены последовательностью прямого повтора. В одном аспекте настоящего изобретения предусмотрен эукариотический организм, отличный от человека; предпочтительно многоклеточный эукариотический организм, содержащий эукариотическую клетку-хозяина в соответствии с любым из описанных вариантов осуществления. В других аспектах настоящее изобретение предусматривает эукариотический организм, предпочтительно многоклеточный эукариотический организм, содержащий эукариотическую клетку-хозяина согласно любому из описанных вариантов осуществления. В некоторых вариантах осуществления этих аспектов организм может представлять собой животное; например, млекопитающее. Также организм может представлять собой членистоногое, такое как насекомое. Организм также может представлять собой растение. Кроме того, организм может представлять собой гриб.
В одном аспекте настоящее изобретение предусматривает набор, содержащий один или несколько компонентов, описанных в данном документе. В некоторых вариантах осуществления набор содержит векторную систему и инструкции по применению набора. В некоторых вариантах осуществления векторная система содержит (a) первый регуляторный элемент, функционально связанный с последовательностью прямого повтора и одним или несколькими сайтами встраивания для встраивания одной или нескольких направляющих последовательностей выше или ниже (в зависимости от того, что является подходящим) последовательности прямого повтора, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR на основе Cpf1 с целевой последовательностью в эукариотической клетке, где комплекс CRISPR на основе Cpf1 содержит фермент Cpf1 в комплексе с направляющей последовательностью, которая гибридизируется с целевой последовательностью; и/или (b) второй регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, которая кодирует указанный фермент Cpf1, содержащий последовательность ядерной локализации. В некоторых вариантах осуществления набор содержит компоненты (a) и (b), находящиеся в одном и том же или разных векторах системы. В некоторых вариантах осуществления компонент (a) дополнительно содержит две или более направляющих последовательностей, функционально связанных с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR со своей целевой последовательностью в эукариотической клетке. В некоторых вариантах осуществления фермент Cpf1 содержит одну или несколько последовательностей ядерной локализации, характеризующихся достаточной эффективностью, чтобы управлять накоплением указанного фермента CRISPR в обнаруживаемом количестве в ядре эукариотической клетки. В некоторых вариантах осуществления фермент CRISPR представляет собой фермент системы CRISPR V или VI типа. В некоторых вариантах осуществления фермент CRISPR представляет собой фермент Cpf1. В некоторых вариантах осуществления фермент Cpf1 получен из Cpf1 Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens или Porphyromonas macacae (например, модифицированный так, что он имеет по меньшей мере один DD или имеет способность к ассоциации с ним), и он может включать дополнительное изменение или мутацию Cpf1 и может представлять собой химерный Cpf1. В некоторых вариантах осуществления фермент DD-CRISPR является кодон-оптимизированным для экспрессии в эукариотической клетке. В некоторых вариантах осуществления фермент DD-CRISPR управляет расщеплением одной или двух нитей в определенном положении целевой последовательности. В некоторых вариантах осуществления фермент DD-CRISPR не обладает или фактически не обладает активностью расщепления нити ДНК (например, характеризуется не более чем 5% нуклеазной активности по сравнению с ферментом дикого типа или ферментом без мутации или изменения, которые снижают нуклеазную активность). В некоторых вариантах осуществления первый регуляторный элемент является промотором полимеразы III. В некоторых вариантах осуществления второй регуляторный элемент является промотором полимеразы II. В некоторых вариантах осуществления длина направляющей последовательности составляет по меньшей мере 16, 17, 18, 19, 20, 25 нуклеотидов, или 16-30, или 16-25, или 16-20 нуклеотидов.
В одном аспекте настоящее изобретение относится к способу модифицирования множественных целевых полинуклеотидов в клетке-хозяине, такой как эукариотическая клетка. В некоторых вариантах осуществления способ предусматривает обеспечение связывание комплекса CRISPR на основе Cpf1 с множественными целевыми полинуклеотидами, например, для осуществления расщепления указанных множественных целевых полинуклеотидов, тем самым модифицируя множественные целевые полинуклеотиды, где комплекс CRISPR на основе Cpf1 содержит фермент Cpf1 в комплексе с множественными направляющими последовательностями, каждая из которых гибридизируется со специфической целевой последовательностью в пределах указанного целевого полинуклеотида, где указанные множественные направляющие последовательности связаны с последовательностью прямого повтора. В некоторых вариантах осуществления указанное расщепление предусматривает расщепление одной или двух нитей в местоположении каждой целевой последовательности с помощью указанного фермента Cpf1. В некоторых вариантах осуществления указанное расщепление приводит к сниженной транскрипции множественных целевых генов. В некоторых вариантах осуществления способ дополнительно предусматривает репарацию одного или нескольких указанных расщепленных целевых полинуклеотидов с помощью гомологичной рекомбинации с экзогенной полинуклеотидной матрицей, где указанная репарация приводит к мутации, предусматривающей вставку, делецию или замену одного или нескольких нуклеотидов в одном или нескольких указанных целевых полинуклеотидов. В некоторых вариантах осуществления указанная мутация приводит к изменению одной или нескольких аминокислот в белке, экспрессируемом с гена, содержащего одну или несколько целевых последовательностей. В некоторых вариантах осуществления способ дополнительно предусматривает доставку одного или нескольких векторов в указанную эукариотическую клетку, где один или несколько векторов управляют экспрессией одного или нескольких из: фермента Cpf1 и множественных направляющих РНК последовательностей, связанных с последовательностью прямого повтора. В некоторых вариантах осуществления указанные векторы доставляются в эукариотическую клетку в субъекте. В некоторых вариантах осуществления указанное модифицирование происходит в указанной эукариотической клетке в культуре клеток. В некоторых вариантах осуществления способ дополнительно включает выделение указанной эукариотической клетки из организма субъекта перед проведением указанного модифицирования. В некоторых вариантах осуществления способ дополнительно включает возвращение указанной эукариотической клетки и/или клеток, происходящих из нее, указанному субъекту.
В одном аспекте настоящее изобретение относится к способу модифицирования экспрессии множественных полинуклеотидов в эукариотической клетке. В некоторых вариантах осуществления способ предусматривает обеспечение связывания комплекса CRISPR на основе Cpf1 c множественными полинуклеотидами, так что указанное связывание приводит к повышенной или сниженной экспрессии указанных полинуклеотидов; где комплекс CRISPR на основе Cpf1 содержит фермент Cpf1 в комплексе с множественными направляющими последовательностями, каждая из которых специфически гибридизируется с ее собственной целевой последовательностью в пределах указанного полинуклеотида, где указанные направляющие последовательности связаны с последовательностью прямого повтора. В некоторых вариантах осуществления способ дополнительно предусматривает доставку одного или нескольких векторов в указанные эукариотические клетки, где один или несколько векторов управляют экспрессией одного или нескольких из: фермента Cpf1 и множественных направляющих последовательностей, связанных с последовательностями прямого повтора.
В одном аспекте настоящее изобретение относится к рекомбинантному полинуклеотиду, содержащему последовательности множественных направляющих РНК выше или ниже (в зависимости от того, что является подходящим) последовательности прямого повтора, где каждая из направляющих последовательностей при экспрессии управляет специфичным к последовательности связыванием комплекса CRISPR на основе Cpf1 с его соответствующей целевой последовательностью, присутствующей в эукариотической клетке. В некоторых вариантах осуществления целевой последовательностью является вирусная последовательность, присутствующая в эукариотической клетке. В некоторых вариантах осуществления целевая последовательность представляет собой протоонкоген или онкоген.
Аспекты настоящего изобретения охватывают не встречающуюся в природе или сконструированную композицию, которая может содержать направляющую РНК (gRNA), предусматривающую направляющую последовательность, способную гибридизироваться с целевой последовательностью в представляющем интерес локусе генома в клетке, и фермент Cpf1, определяемый в данном документе, который может содержать по меньшей мере одну или более последовательностей ядерной локализации.
Аспект настоящего изобретения охватывает способы модифицирования представляющего интерес локуса генома для изменения экспрессии гена в клетке путем введения в клетку любой из композиций, описанных в данном документе.
Один аспект настоящего изобретения заключается в том, что вышеупомянутые элементы содержатся в одной композиции или содержатся в отдельных композициях. Эти композиции преимущественно могут быть применимы в отношении хозяина для индуцирования функционального эффекта на уровне генома.
Используемый в данном документе термин "направляющая РНК" или "gRNA" имеет значение, применяемое в других разделах данного документа, и предусматривает любую полинуклеотидную последовательность, характеризующуюся достаточной комплементарностью с целевой последовательностью нуклеиновой кислоты, чтобы гибридизироваться с целевой последовательностью нуклеиновой кислоты и управлять специфичным к последовательности связыванием комплекса нацеливания на нуклеиновую кислоту с целевой последовательностью нуклеиновой кислоты. Каждая gRNA может быть разработана с включением множественных связывающих сайтов распознавания (например, аптамеров), специфических в отношении одного и того же или разных адаптерных белков. Каждая gRNA может быть разработана так, чтобы связываться с промоторным участком, расположенным на -1000 - +1 нуклеотидов выше сайта начала транскрипции (т. е. TSS), предпочтительно -200 нуклеотидов. Такое размещение улучшает функциональные домены, которые воздействуют на активацию гена (например, активаторы транскрипции) или ингибирование гена (например, репрессоры транскрипции). Модифицированная gRNA может представлять собой одну или несколько модифицированных gRNA (например, по меньшей мере 1 gRNA, по меньшей мере 2 gRNA, по меньшей мере 5 gRNA, по меньшей мере 10 gRNA, по меньшей мере 20 gRNA, по меньшей мере 30 gRNA, по меньшей мере 50 gRNA), нацеленных на один или несколько целевых локусов, содержащихся в композиции. Указанные последовательности множественных gRNA могут быть расположены тандемно и предпочтительно разделены прямым повтором.
- Таким образом, каждый из gRNA, фермента CRISPR, определяемых в данном документе, могут по отдельности содержаться в композиции, и их можно вводить хозяину по отдельности или совместно. Альтернативно эти компоненты могут обеспечиваться в одной композиции для введения хозяину. Введение хозяину может быть выполнено посредством вирусных векторов, известных специалисту или описываемых в данном документе для доставки хозяину (например, лентивирусного вектора, аденовирусного вектора, вектора на основе AAV). Как объясняется в данном документе, применение различных маркеров отбора (например, для отбора лентивирусной gRNA) и различной концентрации gRNA (например, в зависимости от того, применяются ли множественные gRNA) может быть предпочтительным для индуцирования улучшенного эффекта. Исходя из этой концепции для индукции преобразования в локусе генома подходят несколько вариантов, включая расщепление ДНК, активацию гена или дезактивацию гена. С применением предусмотренных композиций специалист в данной области сможет осуществить эффективное и специфическое нацеливание на один или множественные локусы с помощью одинаковых или различных функциональных доменов для индукции одного или нескольких преобразований в локусе генома. Композиции можно применять в целом ряде способов скрининга библиотек в клетках и функционального моделирования in vivo (например, активации генов lincRNA и идентификации функций; моделирования мутации с приобретением функции; моделирования мутации с потерей функции; применения композиций в соответствии с настоящим изобретением для создания линий клеток и трансгенных животных в целях оптимизации и скрининга).
- Настоящее изобретение охватывает применение композиций по настоящему изобретению для создания и использования трансгенных клеток/животных с зависимой от условия или индуцируемой CRISPR; см, например, Platt et al., Cell (2014), 159(2): 440-455, или патентные публикации согласно PCT, процитированные в данном документе, такие как WO 2014/093622 (PCT/US2013/074667). Например, клетки или животные, такие как отличные от человека животные, например, позвоночные или млекопитающие, такие как грызуны, например, мыши, крысы, или другие лабораторные или внелабораторные животные, например, кошки, собаки, овцы и т.д., могут характеризоваться состоянием "нокин", в результате чего у животного в зависимости от условия или индуцируемо экспрессируется Cpf1, как описано в Platt et al. Таким образом целевая клетка или животное содержат зависимый от условия или индуцируемый (например, в форме Cre-зависимых конструкций) фермент CRISPR (например, Cpf1) (например, в форме Cre-зависимых конструкций), при экспрессии вектора, внедренного в целевую клетку, вектор экспрессирует то, что индуцирует или обеспечивает условие для экспрессии фермента CRISPR (например, Cpf1) в целевой клетке. С применением идей и композиций, определяемых в данном документе, с известным способом создания комплекса CRISPR индуцируемые преобразования генома также являются аспектом настоящего изобретения. Примеры таких индуцируемых преобразований были описаны в других разделах данного документа.
В некоторых вариантах осуществления фенотипическое изменение предпочтительно является результатом модификации генома при осуществлении нацеливания на генетическое заболевание, особенно в способах терапии, и предпочтительно, если обеспечивается матрица для репарации для коррекции или изменения фенотипа.
В некоторых вариантах осуществления заболевания, на которые можно осуществлять нацеливание, включают заболевания, которые обусловлены патогенными дефектами сплайсинга.
В некоторых вариантах осуществления клеточные цели включают в себя гемопоэтические стволовые клетки/клетки-предшественники (CD34+); человеческие T-клетки и клетки глаза (клетки сетчатки), например, фоторецепторные клетки-предшественники.
В некоторых вариантах осуществления гены-мишени включают: ген бета-глобина человека - HBB (для лечения серповидноклеточной анемии, в том числе путем стимуляции конверсии генов (с использованием близкородственного гена HBD в качестве эндогенной матрицы)); CD3 (T-клетки) и CEP920 - сетчатка (глаза).
В некоторых вариантах осуществления заболевания-мишени также включают рак; серповидноклеточную анемию (обусловленную точечной мутацией); HBV, HIV; бета-талассемию; а также офтальмологическое или глазное заболевание, например, врожденный амавроз Лебера (LCA), вызванный дефектом сплайсинга.
В некоторых вариантах осуществления способы доставки включают опосредованную катионным липидом "прямую" доставку комплекса фермент-направляющая (рибонуклеопротеин) и электропорацию плазмидной ДНК.
Способы, продукты и варианты применения, описанные в данном документе, можно применять для целей, не связанных с терапией. Кроме того, любой из способов, описанных в данном документе, можно применять in vitro и ex vivo.
В одном аспекте предусмотрена не встречающаяся в природе или сконструированная композиция, содержащая:
I. две или более полинуклеотидные последовательности системы CRISPR-Cas, предусматривающие
(a) первую направляющую последовательность, способную гибридизироваться с первой целевой последовательностью в полинуклеотидном локусе,
(b) вторую направляющую последовательность, способную гибридизироваться со второй целевой последовательностью в полинуклеотидном локусе,
(c) последовательность прямого повтора,
и
II. фермент Cpf1 или вторую полинуклеотидную последовательность, кодирующую его,
где будучи транскрибированными, первая и вторая направляющая последовательности управляют специфичным к последовательности связыванием первого и второго комплекса CRISPR на основе Cpf1 с первой и второй целевой последовательностями соответственно,
где первый комплекс CRISPR содержит фермент Cpf1 в комплексе с первой направляющей последовательностью, которая может гибридизироваться с первой целевой последовательностью,
где второй комплекс CRISPR содержит фермент Cpf1 в комплексе со второй направляющей последовательностью, которая может гибридизироваться со второй целевой последовательностью, и
где первая направляющая последовательность управляет расщеплением одной нити ДНК-дуплекса возле первой целевой последовательности, и вторая направляющая последовательность управляет расщеплением другой нити возле второй целевой последовательности, при этом индуцируется двухнитевой разрыв, с модификацией тем самым организма, или отличного от человеческого, или отличного от животного организма. Аналогично могут быть предусмотрены композиции, содержащие более двух направляющих РНК, например, каждая из которых специфична в отношении одной мишени, и они расположены тандемно в композиции или системе или комплексе CRISPR, описываемых в данном документе.
В другом варианте осуществления Cpf1 доставляется в клетку в виде белка. В другом и особенно предпочтительном варианте осуществления Cpf1 доставляется в клетку в виде белка или в виде нуклеотидной последовательности, кодирующей его. Доставка в клетку в виде белка может включать доставку рибонуклеопротеинового (RNP) комплекса, в котором белок находится в комплексе с множественными направляющими.
В одном аспекте предусмотрены клетки-хозяева и линии клеток, модифицированные с помощью композиций, систем или модифицированных ферментов по настоящему изобретению или содержащие их, в том числе стволовые клетки и их потомство.
В одном аспекте предусмотрены способы клеточной терапии, при которых, например, отдельную клетку или популяцию клеток отбирают или культивируют, где такую клетку или клетки модифицируют или они были модифицированы ex vivo, как описано в данном документе, а затем возвращают (отобранные клетки) или вводят (культивируемые клетки) в организм. Стволовые клетки, будь то эмбриональные, индуцированные плюрипотентные или тотипотентные стволовые клетки, также особенно предпочтительны в этом отношении. Но, разумеется, также предусматриваются варианты осуществления in vivo.
Способы по настоящему изобретению могут дополнительно предусматривать доставку матриц, таких как матрицы для репарации, которые могут представлять собой dsODN или ssODN, см. ниже. Доставка матриц может осуществляться одновременно или отдельно от доставки какого-либо или всех из фермента CRISPR или направляющих РНК и с помощью одного и того же или различных механизмов доставки. В некоторых вариантах осуществления предпочтительно, чтобы матрица доставлялась вместе с направляющими РНК и, предпочтительно, также с ферментом CRISPR. Примером может служить вектор на основе AAV, при этом фермент CRISPR представляет собой AsCpf1 или LbCpf1.
Способы по настоящему изобретению могут дополнительно предусматривать: (a) доставку в клетку двухнитевого олигодезоксинуклеотида (dsODN), содержащего "липкие" концы, комплементарные "липким" концам, создаваемым с помощью указанного двухнитевого разрыва, где указанный dsODN интегрируется в представляющий интерес локус; или (b) доставку в клетку однонитевого олигодезоксинуклеотида (ssODN), где указанный ssODN действует как матрица репарации с помощью гомологичной рекомбинации указанного двухнитевого разрыва. Способы по настоящему изобретению можно применять для предупреждения или лечения заболевания у индивидуума, при этом необязательно указанное заболевание вызвано дефектом в указанном представляющем интерес локусе. Способы по настоящему изобретению можно выполнять in vivo у индивидуума или ex vivo в отношении клетки, извлеченной из индивидуума, где необязательно указанную клетку возвращают в организм индивидуума.
- Настоящее изобретение также охватывает продукты, полученные в результате применения фермента CRISPR, или фермента Cas, или фермента Cpf1, или фермента CRISPR-CRISPR, или системы CRISPR-Cas, или системы CRISPR-Cpf1, для применения в тандеме или при множественном нацеливании, определяемых в данном документе.
Наборы
В одном аспекте настоящее изобретение относится к наборам, содержащим любой один или несколько из элементов, раскрытых в приведенных выше способах и композициях. В некоторых вариантах осуществления набор содержит векторную систему, описываемую в данном документе, и инструкции по применению набора. Элементы могут быть предоставлены отдельно или в комбинациях и могут быть предоставлены в любом подходящем контейнере, как, например, ампуле, флаконе или пробирке. Наборы могут включать gRNA и несвязанную защитную нить, как описано в данном документе. Наборы могут включать gRNA с защитной нитью, связанной по меньшей мере частично с ведущей последовательностью (т. е. pgRNA). Таким образом, наборы могут включать pgRNA в форме частично двунитевой нуклеотидной последовательности, как описано выше. В некоторых вариантах осуществления набор включает инструкции на одном или нескольких языках, например на нескольких языках. Инструкции могут быть специфичными по отношению к вариантам применения и способам, описанным в данном документе.
В некоторых вариантах осуществления набор содержит один или несколько реагентов для применения в способе, в котором используется один или несколько элементов, описанных в данном документе. Реагенты могут быть предоставлены в любом подходящем контейнере. Например, набор может предусматривать один или несколько реакционных буферов или буферов для хранения. Реагенты могут быть предоставлены в форме, которая применима в конкретном анализе, или в форме, которая предусматривает добавление одного или нескольких других компонентов перед применением (например, в форме концентрата или лиофилизированной форме). Буфер может быть любым буфером, в том числе без ограничения буфером с карбонатом натрия, буфером с бикарбонатом натрия, боратным буфером, Tris-буфером, буфером MOPS, буфером HEPES и их комбинациями. В некоторых вариантах осуществления буфер является щелочным. В некоторых вариантах осуществления буфер имеет значение pH от приблизительно 7 до приблизительно 10. В некоторых вариантах осуществления набор содержит один или несколько олигонуклеотидов, соответствующих направляющей последовательности, для встраивания в вектор, чтобы функционально связать направляющую последовательность и регуляторный элемент. В некоторых вариантах осуществления набор содержит матричный полинуклеотид для гомологичной рекомбинации. В некоторых вариантах осуществления набор содержит один или несколько векторов и/или один или несколько полинуклеотидов, описанных в данном документе. Преимущественно набор может предоставлять все элементы систем по настоящему изобретению.
В одном аспекте настоящее изобретение относится к способам применения одного или нескольких элементов системы CRISPR. Комплекс CRISPR по настоящему изобретению обеспечивает эффективные средства модифицирования целевого полинуклеотида. Комплекс CRISPR по настоящему изобретению обладает широкой применимостью, включая модифицирование (например, осуществление делеции, встраивания, транслокации, инактивации, активации) целевого полинуклеотида во множестве типов клеток. Комплекс CRISPR по настоящему изобретению как таковой имеет широкий спектр применений, например, в генной терапии, скрининге лекарственных средств, диагностике и прогнозировании заболеваний. Иллюстративный комплекс CRISPR содержит эффекторый белок CRISPR, образующий комплекс с направляющей последовательностью, гибридизирующейся с целевой последовательностью в целевом полинуклеотиде. В определенных вариантах осуществления последовательность прямого повтора связана с направляющей последовательностью.
В одном варианте осуществления настоящее изобретение относится к способу расщепления целевого полинуклеотида. Способ включает модификацию целевого полинуклеотида с применением комплекса CRISPR, который связывается с целевым полинуклеотидом и осуществляет расщепление указанного целевого полинуклеотида. Как правило, комплекс CRISPR по настоящему изобретению при введении в клетку создает разрыв (например, однонитевой или двухнитевой разрыв) в геномной последовательности. Например, способ можно применять для расщепления гена, ответственного за развитие заболевания, в клетке.
Репарация разрыва, созданного комплексом CRISPR, может осуществляться посредством процесса репарации, например, путем склонного к ошибкам негомологичного соединения концов (NHEJ) или высокоточной репарацией с помощью гомологичной рекомбинации (HDR). В ходе данного процесса репарации в геномную последовательность может быть введен экзогенный матричный полинуклеотид. В некоторых способах процесс HDR используют для модификации геномной последовательности. Например, в клетку вводят экзогенный матричный полинуклеотид, содержащий последовательность, подлежащую интеграции, фланкированную последовательностью, расположенной выше, и последовательностью, расположенной ниже. Последовательности, расположенные выше и ниже, характеризуются сходством последовательности с каждой стороной сайта интеграции в хромосоме.
При необходимости донорный полинуклеотид может представлять собой ДНК, например плазмидную ДНК, бактериальную искусственную хромосому (BAC), искусственную хромосому дрожжей (YAC), вирусный вектор, линейный фрагмент ДНК, ПЦР-фрагмент, "оголенную" нуклеиновую кислоту или нуклеиновую кислоту в комплексе со средством доставки, таким как липосома или полоксамер.
Экзогенный матричный полинуклеотид содержит последовательность, подлежащую интеграции (например, мутированный ген). Последовательность, предназначенная для интеграции, может представлять собой последовательность, эндогенную или экзогенную по отношению к клетке. Примеры последовательности, подлежащей интеграции, включают полинуклеотиды, кодирующие белок или некодирующую РНК (например, microRNA). Таким образом, последовательность, предназначенная для интеграции, может быть функционально связанной с соответствующей регуляторной последовательностью или соответствующими регуляторными последовательностями. Альтернативно последовательность, подлежащая интеграции, может обеспечивать регуляторную функцию.
Последовательности, расположенные выше и ниже в экзогенном матричном полинуклеотиде, выбирают таким образом, чтобы способствовать рекомбинации между хромосомной последовательностью, представляющей интерес, и донорным полинуклеотидом. Последовательность, расположенная выше, представляет собой последовательность нуклеиновой кислоты, которая обладает сходством последовательности с геномной последовательностью, расположенной выше подвергаемого нацеливанию сайта интеграции. Аналогично последовательность, расположенная ниже, представляет собой последовательность нуклеиновой кислоты, которая обладает сходством последовательности с хромосомной последовательностью, расположенной ниже подвергаемого нацеливанию сайта интеграции. Последовательности, расположенные выше и ниже в экзогенном матричном полинуклеотиде, могут характеризоваться 75%, 80%, 85%, 90%, 95% или 100% идентичностью последовательности с подвергаемой нацеливанию геномной последовательностью. Последовательности, расположенные выше и ниже в экзогенном матричном полинуклеотиде, предпочтительно характеризуются 95%, 96%, 97%, 98%, 99% или 100% идентичностью последовательности с подвергаемой нацеливанию геномной последовательностью. В некоторых способах последовательности, расположенные выше и ниже в экзогенном матричном полинуклеотиде, характеризуются приблизительно 99% или 100% идентичностью последовательности с подвергаемой нацеливанию геномной последовательностью.
Последовательность, расположенная выше или ниже, может содержать от приблизительно 20 п. о. до приблизительно 2500 п. о., например приблизительно 50, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, 2000, 2100, 2200, 2300, 2400 или 2500 п. о. В некоторых способах иллюстративная последовательность, расположенная выше или ниже, имеет от приблизительно 200 п. о. до приблизительно 2000 п. о., от приблизительно 600 п. о. до приблизительно 1000 п. о. или, более конкретно, от приблизительно 700 п. о. до приблизительно 1000 п. о.
В некоторых способах экзогенный матричный полинуклеотид может дополнительно содержать маркер. Такой маркер может облегчать скрининг в отношении подвергаемых нацеливанию интеграций. Примеры подходящих маркеров включают сайты рестрикции, флуоресцентные белки или селектируемые маркеры. Экзогенный матричный полинуклеотид согласно настоящему изобретению можно сконструировать с применением методик рекомбинантной ДНК (см., например, Sambrook et al., 2001 и Ausubel et al., 1996).
В иллюстративном способе модифицирования целевого полинуклеотида посредством интеграции экзогенного матричного полинуклеотида в геномную последовательность вводят двухнитевой разрыв с помощью комплекса CRISPR, осуществляют репарацию разрыва посредством гомологичной рекомбинации с участием экзогенного матричного полинуклеотида, так что матрица интегрируется в геном. Наличие двухнитевого разрыва способствует интеграции матрицы.
В других вариантах осуществления настоящее изобретение относится к способу модификации экспрессии полинуклеотида в эукариотической клетке. Способ включает повышение или снижение экспрессии целевого полинуклеотида с помощью комплекса CRISPR, который связывается с полинуклеотидом.
В некоторых способах целевой полинуклеотид можно инактивировать для осуществления модификации экспрессии в клетке. Например, после связывания комплекса CRISPR с целевой последовательностью в клетке целевой полинуклеотид инактивируется, вследствие чего последовательность не транскрибируется, при этом не вырабатывается кодируемый белок или последовательность не функционирует так, как последовательность дикого типа. Например, последовательность, кодирующая белок или microRNA, может быть инактивирована, вследствие чего белок не образуется.
В некоторых способах регуляторную последовательность можно инактивировать, так что она больше не функционирует в качестве регуляторной последовательности. Используемое в данном документе выражение "регуляторная последовательность" относится к любой последовательности нуклеиновой кислоты, которая оказывает влияние на транскрипцию, трансляцию или доступность последовательности нуклеиновой кислоты. Примеры регуляторной последовательности включают промотор, терминатор транскрипции и энхансер, которые являются регуляторными последовательностями. Инактивированная целевая последовательность может содержать мутацию по типу делеции (т. е. делецию одного или нескольких нуклеотидов), мутацию по типу вставки (т. е. вставку одного или нескольких нуклеотидов) или нонсенс-мутацию (т. е. замену одного нуклеотида на другой нуклеотид, так что вводится стоп-кодон). В некоторых способах инактивация целевой последовательности приводит в результате к "нокауту" целевой последовательности.
Иллюстративные способы применения системы CRISPR Cas
Настоящее изобретение относится к не встречающейся в природе или сконструированной композиции, или одному или нескольким полинуклеотидам, кодирующим компоненты указанной композиции, или вектору или системам доставки, содержащим один или несколько полинуклеотидов, кодирующих компоненты указанной композиции, для применения при модификации целевой клетки in vivo, ex vivo или in vitro, и они могут быть выполнены при помощи способа, который изменяет клетку таким образом, что после модификации потомство или линия клеток клетки, модифицированной при помощи CRISPR, сохраняет измененный фенотип. Модифицированные клетки и потомство могут быть частью многоклеточного организма, такого как растение или животное, с применением ex vivo или in vivo системы CRISPR по отношению к желаемым типам клеток. Изобретение CRISPR может представлять собой терапевтический способ лечения. Терапевтический способ лечения может предусматривать редактирование гена или генома или генную терапию.
Применение инактивированного фермента CRISPR Cpf1 для способов обнаружения, таких как FISH
В одном аспекте настоящее изобретение относится к сконструированной не встречающейся в природе системе CRISPR-Cas, содержащей каталитически неактивный белок Cas, описанный в данном документе, предпочтительно инактивированный Cpf1 (dCpf1), и применению этой системы в способах обнаружения, таких как флуоресцентная гибридизация in situ (FISH). dCpf1, который не обладает способностью выполнять разрывы в двух нитях ДНК, может быть слит с маркером, таким как флуоресцентный белок, такой как усиленный зеленый флуоресцентный белок (eEGFP), и коэкспрессировать с малыми направляющими РНК для нацеливания на перицентрические, центрические и телоцентрические повторы in vivo. Систему dCpf1 можно применять для визуализации повторяющихся последовательностей и отдельных генов в геноме человека. Такие новые варианты применения меченых систем dCpf1 CRISPR-cas могут быть важными в визуализации клеток и изучении функциональной ядерной архитектуры, особенно в случаях с небольшим объемом ядра или сложными 3-D-структурами. (Chen B, Gilbert LA, Cimini BA, Schnitzbauer J, Zhang W, Li GW, Park J, Blackburn EH, Weissman JS, Qi LS, Huang B. 2013. Dynamic imaging of genomic loci in living human cells by an optimized CRISPR/Cas system. Cell 155(7):1479-91. doi: 10.1016/j.cell.2013.12.001.).
Модификация мишени при помощи системы или комплекса CRISPR Cas (например, комплекса Cpf1-РНК)
В одном аспекте настоящее изобретение относится к способам модификации целевого полинуклеотида в эукариотической клетке, что может происходить in vivo, ex vivo или in vitro. В некоторых вариантах осуществления способ включает отбор клетки или популяции клеток у человека или отличного от человека животного и модификацию клетки или клеток. Культивирование можно осуществлять на любой стадии ex vivo. Клетку или клетки можно даже повторно вводить отличному от человека животному или в растение. Что касается повторно вводимых клеток, особенно предпочтительно, чтобы эти клетки являлись стволовыми клетками.
В некоторых вариантах осуществления способ включает обеспечение связывания комплекса CRISPR с целевым полинуклеотидом для осуществления расщепления указанного целевого полинуклеотида, тем самым модифицируя целевой полинуклеотид, где комплекс CRISPR содержит фермент CRISPR в комплексе с направляющей последовательностью, гибридизируемой или способной гибридизироваться с целевой последовательностью в пределах указанного целевого полинуклеотида.
В одном аспекте настоящего изобретения предусмотрен способ модифицирования экспрессии полинуклеотида в эукариотической клетке. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса CRISPR с полинуклеотидом, так что указанное связывание приводит к повышенной или сниженной экспрессии указанного полинуклеотида; где комплекс CRISPR содержит фермент CRISPR в комплексе с направляющей последовательностью, гибридизируемой или способной гибридизироваться с целевой последовательностью в пределах указанного полинуклеотида. Аналогичные факторы и условия распространяются на способы модификации целевого полинуклеотида, как изложено выше. Фактически, эти варианты отбора образцов, культивирования и повторного введения охватываются аспектами настоящего изобретения.
Действительно, в любом аспекте по настоящему изобретению, комплекс CRISPR может содержать фермент CRISPR в комплексе с направляющей последовательностью, гибридизируемой или способной гибридизироваться с целевой последовательностью. Аналогичные факторы и условия распространяются на способы модификации целевого полинуклеотида, как изложено выше.
Таким образом, в любом из не встречающихся в природе ферментов CRISPR, описанных в данном документе, содержится по меньшей мере одна модификация, и тем самым фермент характеризуется определенными улучшенными свойствами. В частности, любой из ферментов способен образовывать комплекс CRISPR с направляющей РНК. При образовании такого комплекса направляющая РНК способна связываться с целевой полинуклеотидной последовательностью, и фермент способен модифицировать целевой локус. Кроме того, фермент в комплексе CRISPR характеризуется сниженной способностью модифицировать один или несколько нецелевых локусов по сравнению с немодифицированным ферментом.
Кроме того, модифицированные ферменты CRISPR, описанные в данном документе, охватывают ферменты, где в комплексе CRISPR фермент характеризуется повышенной способностью модифицировать один или несколько целевых локусов по сравнению с немодифицированным ферментом. Такая функция может быть предусмотрена отдельно или предусмотрена в сочетании с вышеописанной функцией сниженной способности модифицировать один или несколько нецелевых локусов. Любые такие ферменты могут быть предусмотрены с одной из дополнительных модификаций фермента CRISPR, как описано в данном документе, например, в сочетании с активностью, обеспечиваемой одним или несколькими ассоциированными гетерологичными функциональными доменами, любыми дополнительными мутациями с целью снижения нуклеазной активности и т. п.
В предпочтительных вариантах осуществления настоящего изобретения предусмотрен модифицированный фермент CRISPR со сниженной способностью модифицировать один или несколько нецелевых локусов по сравнению с немодифицированным ферментом и повышенной способностью модифицировать один или несколько целевых локусов по сравнению с немодифицированным ферментом. В сочетании с дополнительными модификациями фермента можно достичь существенно усиленной специфичности. Например, предусмотрена комбинация таких предпочтительных вариантов осуществления с одной или несколькими дополнительными мутациями, где одна или несколько дополнительных мутаций находятся в одном или нескольких каталитически активных доменах. Такие дополнительные каталитические мутации могут придавать функциональные свойства никаз, как описано подробно в других частях данного документа. В таких ферментах повышенная специфичность может быть достигнута за счет усиленной специфичности с точки зрения ферментативной активности.
Модификации для снижения нецелевых эффектов и/или повышения целевых эффектов, как описано выше, могут быть выполнены с аминокислотными остатками, расположенными в положительно заряженном участке/бороздке, находящейся между доменами RuvC-III и HNH. Предполагается, что любой из функциональных эффектов, описанных выше, может быть достигнут с помощью модификации аминокислот в вышеупомянутой бороздке, однако также с помощью модификации аминокислот вблизи бороздки или за ее пределами.
Дополнительные функциональные свойства, которые могут быть сконструированы в модифицированных ферментах CRISPR, как описано в данном документе, могут включать следующее. 1. Модифицированные ферменты CRISPR, которые нарушают взаимодействие ДНК и белка без нарушения третичной или вторичной структуры белков. Это включает остатки, которые контактируют с любой частью дуплекса РНК:ДНК. 2. Модифицированные ферменты CRISPR, которые ослабляют взаимодействия между белками, удерживающими Cpf1 в конформации, необходимой для разрезания нуклеазами в ответ на связывание с ДНК (целевые или нецелевые). Например: модификация, которая незначительно ингибирует, но по-прежнему обеспечивает конформацию нуклеазы домена HNH (располагается в поддающемся разрезанию фосфате). 3. Модифицированные ферменты CRISPR, которые усиливают взаимодействия между белками, удерживающими Cpf1 в конформации, ингибирующей активность в ответ на связывание с ДНК (целевые или нецелевые). Например: модификация, которая стабилизирует домен HNH в конформации за пределами поддающегося разрезанию фосфата. Любое такое дополнительное функциональное усиление может быть предусмотрено в комбинации с любой другой модификацией фермента CRISPR, как описано подробно в других местах данного документа.
Любые из описанных в данном документе улучшенных функциональных свойств могут быть выполнены по отношению к любому ферменту CRISPR, такому как фермент Cpf1. Однако предполагается, что любое из функциональных свойств, описанных в данном документе, может быть сконструировано в ферментах Cpf1 от других ортологов, в том числе химерных ферментов, содержащих фрагменты из нескольких ортологов.
Нуклеиновые кислоты, аминокислоты и белки, регуляторные последовательности, векторы и прочие
В настоящем изобретении нуклеиновые кислоты используются для связывания целевых последовательностей ДНК. Это является преимущественным, поскольку получать нуклеиновые кислоты намного легче и дешевле, чем белки, и специфичность может варьировать в зависимости от длины фрагмента, если необходима гомология. Например, не требуется сложное 3-D определение положений многочисленных доменов. Термин "полинуклеотид", "нуклеотид", "нуклеотидная последовательность", "нуклеиновая кислота" и "олигонуклеотид" используют взаимозаменяемо. Они обозначают полимерную форму нуклеотидов любой длины, как дезоксирибонуклеотидов, так и рибонуклеотидов или их аналогов. Полинуклеотиды могут обладать любой пространственной структурой и могут выполнять любую функцию, известную или неизвестную. Неограничивающими примерами полинуклеотидов являются следующие: кодирующие или некодирующие участки гена или фрагмента гена, локусы(локус), определенные(определенный) в результате анализа сцепления, экзоны, интроны, матричная РНК (мРНК), транспортная РНК, рибосомная РНК, короткая интерферирующая РНК (siRNA), короткая шпилечная РНК (shRNA), микроРНК (miRNA), рибозимы, кДНК, рекомбинантные полинуклеотиды, разветвленные полинуклеотиды, плазмиды, векторы, выделенные ДНК любой последовательности, выделенные РНК любой последовательности, нуклеиновые кислоты-зонды и праймеры. Термин также охватывает структуры, подобные нуклеиновым кислотам с синтетическими каркасами, см., например, Eckstein, 1991; Baserga et al., 1992; Milligan, 1993; WO 97/03211; WO 96/39154; Mata, 1997; Strauss-Soukup, 1997 и Samstag, 1996. Полинуклеотид может содержать один или несколько модифицированных нуклеотидов, как, например, метилированные нуклеотиды и аналоги нуклеотидов. При наличии, модификации в нуклеотидную структуру могут быть внесены до или после сборки полимера. Последовательность нуклеотидов может прерываться отличными от нуклеотидов компонентами. Полинуклеотид можно дополнительно модифицировать после полимеризации, как, например, путем соединения с компонентом для мечения. Используемый в данном документе термин "дикий тип" является термином из данной области, понятным специалисту в данной области, и означает типичную форму организма, штамма, гена или характеристики, которая встречаются в природе в отличие от мутантных или вариантных форм. "Дикий тип" может представлять собой основу. Используемый в данном документе термин "вариант" следует понимать как означающее проявление качеств, которые характеризуются паттерном, который отличается от встречающегося в природе. Термины "не встречающийся в природе" или "сконструированный" используют взаимозаменяемо, и они указывают на вмешательство человека. Термины, в тех случаях, когда они касаются молекул нуклеиновых кислот или полипептидов, означают, что молекула нуклеиновой кислоты или полипептид по меньшей мере практически не содержат по меньшей мере один иной компонент, с которым они естественным образом связаны в природе и встречаются в природе. "Комплементарность" означает способность нуклеиновой кислоты образовывать водородную(водородные) связь(связи) с другой последовательностью нуклеиновой кислоты с помощью либо традиционного образования пар по Уотсону-Крику, либо других нетрадиционных типов. Процент комплементарности показывает процентную долю остатков в молекуле нуклеиновой кислоты, которые могут образовывать водородные связи (к примеру, образование пар по Уотсону-Крику) со второй последовательностью нуклеиновой кислоты (к примеру, при этом 5, 6, 7, 8, 9, 10 из 10 будут на 50%, 60%, 70%, 80%, 90% и 100% комплементарны). "Точная комплементарность" означает, что все непрерывные остатки последовательности нуклеиновой кислоты будут связаны водородными связями с таким же количеством непрерывных остатков во второй последовательности нуклеиновой кислоты. Используемое в данном документе выражение "практически комплементарный" означает степень комплементарности, которая составляет по меньшей мере 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 97%, 98%, 99% или 100% в пределах участка из 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40, 45, 50 или более нуклеотидов, или относится к двум нуклеиновым кислотам, которые гибридизируются при жестких условиях. Используемое в данном документе выражение"жесткие условия" в отношении гибридизации означают условия, при которых нуклеиновая кислота с комплементарностью к целевой последовательности преимущественно гибридизируется с целевой последовательностью и практически не гибридизируется с не подвергаемыми нацеливанию последовательностями. Жесткие условия, как правило, являются зависимыми от последовательности и изменяются в зависимости от ряда факторов. В целом, чем длиннее последовательность, тем выше температура, при которой последовательность специфично гибридизируется со своей целевой последовательностью. Неограничивающие примеры жестких условий описаны подробно в Tijssen (1993), Laboratory Techniques In Biochemistry And Molecular Biology-Hybridization With Nucleic Acid Probes Part I, Second Chapter "Overview of principles of hybridization and the strategy of nucleic acid probe assay", Elsevier, N.Y. Если предполагается полинуклеотидная последовательность, то также предусматриваются комплементарные или частично комплементарные последовательности. Эти последовательности предпочтительно способны гибридизироваться с эталонной последовательностью при условиях высокой жесткости. Как правило, для доведения скорости гибридизации до максимума, выбирают условия гибридизации относительно низкой жесткости: температура на приблизительно 20-25°C ниже температуры точки плавления (Tm). Tm представляет собой температуру, при которой 50% специфичной целевой последовательности гибридизируется с точно комплементарным зондом в растворе при определенной ионной силе и pH. Как правило, если требуется по меньшей мере приблизительно 85% нуклеотидная комплементарность гибридизированных последовательностей, выбирают очень жесткие условия отмывки с температурой на приблизительно 5-15°C ниже, чем Tm. Если требуется по меньшей мере приблизительно 70% нуклеотидная комплементарность гибридизированных последовательностей, выбирают умеренно жесткие условия отмывки с температурой на приблизительно 15-30°C ниже, чем Tm. Высоко пермиссивные (очень низкой жесткости) условия отмывки могут характеризоваться наименьшей температурой на 50°C ниже Tm, что допускает высокий уровень несовпадений между гибридизированными последовательностями. Специалисты в данной области поймут, что другие физические и химические параметры на стадиях гибридизации и отмывки также можно изменять для того, чтобы повлиять на получаемый в результате выявляемый сигнал гибридизации исходя из конкретного уровня гомологии между целевой последовательностью и последовательностью зонда. Предпочтительные условия высокой жесткости предусматривают инкубацию в 50% формамиде, 5×SSC и 1% SDS при 42°C, или инкубацию при 5×SSC и 1% SDS при 65°C с отмывкой в 0,2×SSC и 0,1% SDS при 65°C. "Гибридизация" относится к реакции, в которой один или несколько полинуклеотидов вступают в реакцию с образованием комплекса, который стабилизирован посредством образования водородных связей между основаниями остатков нуклеотидов. Образование водородных связей может происходить по принципу образования пар по Уотсону-Крику, Хугстиновского связывания или посредством любого другого специфичного к последовательности способа. Комплекс может содержать две нити, образующие дуплексную структуру, три или более нитей, образующих многонитевой комплекс, одиночную самогибридизирующуюся нить или любую их комбинацию. Реакция гибридизации может представлять собой стадию в более обширном способе, такую как начальная стадия ПЦР или расщепление полинуклеотида с помощью фермента. Последовательность, способную к гибридизации с данной последовательностью, называют "комплементарной последовательностью" для данной последовательности. Используемый в данном документе термин "локус генома" или "локус" (форма множественного числа локусы) представляет собой конкретное положение гена или последовательности ДНК на хромосоме. "Ген" относится к фрагментам ДНК или РНК, которые кодируют цепь полипептида или РНК, которые играют функциональную роль в организме, и, следовательно, он представляет собой молекулярную единицу наследственности в живых организмах. Для цели настоящего изобретения может считаться, что гены содержат участки, которые регулируют образование продукта гена, независимо от того являются ли регуляторные последовательности смежными с кодирующими и/или транскрибируемыми последовательностями или нет. Соответственно, ген содержит, но без обязательного ограничения, промоторные последовательности, терминаторы, регуляторные последовательности трансляции, например, сайты связывания рибосомы и сайты внутренней посадки рибосомы, энхансеры, сайленсеры, инсуляторы, граничные элементы, точки начала репликации, сайты прикрепления к матриксу и регуляторные участки локуса. Используемый в данном документе термин "экспрессия локуса генома" или "экспрессия гена" относится к процессу, в ходе которого информация гена используется в синтезе функционального продукта гена. Продукты экспрессии генов часто представляют собой белки, но у генов, не кодирующих белки, например генов rRNA или генов tRNA, продукт представляет собой функциональную РНК. Процесс экспрессии генов используется всеми известными живыми организмами - эукариотами (в том числе многоклеточными организмами), прокариотами (бактериями и археями) и вирусами для образования функциональных продуктов, необходимых для выживания. Как используется в данном документе, "экспрессия" гена или нуклеиновой кислоты охватывает не только экспрессию генов в клетках, но также транскрипцию и трансляцию нуклеиновой(нуклеиновых) кислоты(кислот) в системах клонирования и в любом другом контексте. Используемый в данном документе термин "экспрессия" также означает процесс, посредством которого полинуклеотид транскрибируется с ДНК-матрицы (как, например, с образованием мРНК или другого РНК-транскрипта), и/или процесс, с помощью которого транскрибированная мРНК далее транслируется с образованием пептидов, полипептидов или белков. Транскрипты и закодированные полипептиды можно в совокупности называть "продуктом гена". Если полинуклеотид получен из геномной ДНК, то экспрессия может включать сплайсинг мРНК в эукариотической клетке. Термины "полипептид", "пептид" и "белок" используются в данном документе взаимозаменяемо для обозначения полимеров из аминокислот любой длины. Полимер может быть линейным или разветвленным, он может содержать модифицированные аминокислоты, и его структура может прерываться отличными от аминокислот компонентами. Термины также охватывают полимер из аминокислот, который был модифицирован; например, образованием дисульфидных связей, гликозилированием, липидизацией, ацетилированием, фосфорилированием или любой другой манипуляцией, как, например, соединением с компонентом для мечения. Используемое в данном документе выражение "аминокислота" включает природные и/или отличные от природных или синтетические аминокислоты, в том числе глицин и как D-, так и L-оптические изомеры, и аналоги аминокислот, и пептидомиметики. Используемое в данном документе выражение "домен" или "белковый домен" относится к части последовательности белка, которая может существовать и функционировать независимо от остальной части белковой цепи. Как описано в аспектах согласно настоящему изобретению, идентичность последовательности относится к гомологии последовательности. Сравнения гомологии можно проводить на глаз или, что делается чаще, с помощью легко доступных программ для сравнения последовательностей. С помощью этих коммерчески доступных компьютерных программ можно рассчитывать процент (%) гомологии между двумя или более последовательностями, а также можно рассчитывать идентичность последовательности между двумя или более аминокислотными последовательностями или последовательностями нуклеиновых кислот.
В аспектах по настоящему изобретению термин "направляющая РНК" относится к полинуклеотидной последовательности, содержащей предположительную или идентифицированную последовательность crRNA или направляющую последовательность.
Используемый в данном документе термин "дикий тип" является термином из данной области, понятным специалисту в данной области, и означает типичную форму организма, штамма, гена или характеристики, которая встречаются в природе в отличие от мутантных или вариантных форм. "Дикий тип" может представлять собой основу.
Используемый в данном документе термин "вариант" следует понимать как означающее проявление качеств, которые характеризуются паттерном, который отличается от встречающегося в природе.
Термины "не встречающийся в природе" или "сконструированный" используют взаимозаменяемо, и они указывают на вмешательство человека. Термины, в тех случаях, когда они касаются молекул нуклеиновых кислот или полипептидов, означают, что молекула нуклеиновой кислоты или полипептид по меньшей мере практически не содержат по меньшей мере один иной компонент, с которым они естественным образом связаны в природе и встречаются в природе. Во всех аспектах и вариантах осуществления, вне зависимости от того, включают ли они эти термины, ясно, что предпочтительно они могут быть необязательными и, таким образом, предпочтительно включены или не предпочтительно не включены. Кроме того, термины "не встречающийся в природе" и "сконструированный" можно употреблять взаимозаменяемо, и, таким образом, можно использовать по отдельности или в сочетании, и одно или другое может замещать упоминание обоих совместно. В частности, "сконструированный" является предпочтительным вместо "не встречающийся в природе" или "не встречающийся в природе и/или сконструированный".
Значения гомологии последовательности можно получить с помощью любой из ряда компьютерных программ, известных из уровня техники, например, BLAST или FASTA и т. д. Подходящей компьютерной программой для осуществления такого выравнивания является пакет программ GCG Wisconsin Bestfit (Университет Висконсина, США; Devereux et al., 1984, Nucleic Acids Research 12:387). Примеры другого программного обеспечения, с помощью которого можно осуществлять сравнения последовательностей, включают без ограничения пакет программ BLAST (см. Ausubel et al., 1999 ibid - Chapter 18), FASTA (Atschul et al., 1990, J. Mol. Biol., 403-410) и пакет программ GENEWORKS в качестве средств для сравнения. Как в BLAST, так и в FASTA доступны оффлайн- и онлайн-поиск (см. Ausubel et al., 1999 ibid, pages 7-58 - 7-60). Однако предпочтительным является использование программы GCG Bestfit. Процентное значение (%) гомологии последовательности можно рассчитывать для непрерывных последовательностей, т. е. одну последовательность выравнивают с другой последовательностью и каждую аминокислоту или нуклеотид в одной последовательности непосредственно сравнивают с соответствующей аминокислотой или нуклеотидом в другой последовательности, один остаток за один раз. Это называется выравниванием "без гэпов". Как правило, такие выравнивания без гэпов осуществляют только для относительно малого числа остатков. Несмотря на то, что этот способ является очень простым и последовательным, при его применении не учитывается то, что, например, в паре последовательностей, которые в остальном являются идентичными, одна вставка или делеция может привести к тому, что следующие за ней аминокислотные остатки не будут учитываться при выравнивании, что, таким образом, потенциально приводит в результате к значительному уменьшению % гомологии при осуществлении глобального выравнивания. Следовательно, большинство способов сравнения последовательностей разработаны для получения оптимальных выравниваний, в которых учитываются возможные вставки и делеции без наложения чрезмерного штрафа на общую гомологию или балл идентичности. Это достигается путем вставки "гэпов" в выравнивание последовательностей в попытке доведения до максимума локальной гомологии или идентичности. Однако в этих более сложных способах назначаются "штрафы за внесения гэпа" для каждого гэпа, который встречается при выравнивании, таким образом, для одинакового количества идентичных аминокислот выравнивание последовательностей с наименьшим возможным количеством гэпов, что отражает более высокую степень родства между двумя сравниваемыми последовательностями, может привести в результате к более высокому баллу, чем выравнивание с большим количеством гэпов. Как правило, используют "значения аффинного штрафа за внесение гэпа для родственных последовательностей", с использованием которых начисляют относительно высокое значение за существование гэпа и меньший штраф за каждый последующий остаток в гэпе. Это наиболее часто используемая система оценки гэпов. Конечно, высокие штрафы за внесение гэпа могут привести к оптимизированным выравниваниям с меньшим количеством гэпов. В большинстве программ выравнивания допускается изменение штрафов за внесение гэпа. Однако предпочтительно использовать значения по умолчанию при использовании такого программного обеспечения для сравнений последовательностей. Например, при использовании пакета программ GCG Wisconsin Bestfit штраф за внесение гэпа по умолчанию для аминокислотных последовательностей составляет -12 для гэпа и -4 за каждый остаток его продолжения. Для расчета максимального % гомологии, следовательно, изначально требуется получение оптимального выравнивания с учетом штрафов за внесение гэпа. Подходящая компьютерная программа для осуществления такого выравнивания представляет собой пакет программ GCG Wisconsin Bestfit (Devereux et al., 1984 Nuc. Acids Research 12 p387). Примеры другого программного обеспечения, с помощью которого можно осуществлять сравнения последовательностей, включают без ограничения пакет программ BLAST (cм. Ausubel et al., 1999 Short Protocols in Molecular Biology, 4th Ed. - Chapter 18), FASTA (Altschul et al., 1990 J. Mol. Biol. 403-410) и пакет программ GENEWORKS в качестве инструментов для сравнения. Как в BLAST, так и в FASTA доступны оффлайн- и онлайн-поиск (см. Ausubel et al., 1999, Short Protocols in Molecular Biology, pages 7-58 - 7-60). Однако для некоторых задач предпочтительно использовать программу GCG Bestfit. Новый инструмент под названием BLAST 2 Sequences также доступен для сравнения белковых и нуклеотидных последовательностей (см. FEMS Microbiol Lett. 1999 174(2): 247-50; FEMS Microbiol Lett. 1999 177(1): 187-8 и веб-сайт Национального центра биотехнологической информации на веб-сайте Национальных институтов здравоохранения). Несмотря на то, что конечный % гомологии можно измерять в единицах идентичности, способ выравнивания сам по себе, как правило, не основывается на сравнении пар по типу "все или ничего". Вместо этого, как правило, используется матрица замен со шкалой сходства, с использованием которой назначаются баллы для каждого попарного сравнения на основании химического сходства или эволюционного расстояния. Примером такой матрицы, используемой чаще всего, является матрица BLOSUM62 - матрица по умолчанию для набора программ BLAST. В программах GCG Wisconsin, как правило, используются либо общедоступные значения по умолчанию, либо специальные таблицы сравнения символов, если предоставляются (дополнительные подробности см. в руководстве пользователя). Для некоторых задач предпочтительным является применение общедоступных значений по умолчанию для пакета программ GCG или, в случае другого программного обеспечения, матрицы по умолчанию, например BLOSUM62. Альтернативно процентные значения гомологии можно рассчитывать с использованием функции множественного выравнивания в DNASISTM (Hitachi Software) с применением алгоритма, аналогичного CLUSTAL (Higgins DG & Sharp PM (1988), Gene 73(1), 237-244). После того, как программное обеспечение предоставит оптимальное выравнивание, возможно рассчитать % гомологии, предпочтительно % идентичности последовательности. Программное обеспечение, как правило, осуществляет это в ходе сравнения последовательностей и выдает численный результат. Последовательности также могут иметь делеции, вставки или замены аминокислотных остатков, которые приводят к молчащему изменению и приводят в результате к функционально эквивалентному веществу. Преднамеренные аминокислотные замены могут быть сделаны исходя из сходства свойств аминокислот (например, полярность, заряд, растворимость, гидрофобность, гидрофильность и/или амфипатическая природа остатков) и, следовательно, они являются применимыми для того, чтобы сгруппировать аминокислоты в функциональные группы. Аминокислоты можно сгруппировать исходя из свойств только их боковых цепей. Однако, также более полезно включить данные о мутациях. Группы аминокислот, полученные таким образом, вероятно, будут консервативными по структурным причинам. Эти группы могут быть описаны в форме диаграммы Венна (Livingstone C.D. and Barton G.J. (1993) "Protein sequence alignments: a strategy for the hierarchical analysis of residue conservation" Comput. Appl. Biosci. 9: 745-756) (Taylor W.R. (1986) "The classification of amino acid conservation" J. Theor. Biol. 119; 205-218). Консервативные замены могут быть сделаны, например, в соответствии с таблицей, представленной ниже, в которой описывается общепринятая группировка аминокислот в форме диаграммы Венна.
Термины "субъект", "индивидуум" и "пациент" используются в данном документе взаимозаменяемо для обозначения позвоночного, предпочтительно млекопитающего, более предпочтительно человека. Млекопитающие включают без ограничения мышей, обезьян, людей, сельскохозяйственных животных, животных для спорта и домашних животных. Также охватываются ткани, клетки и их потомство биологического организма, полученные in vivo или культивированные in vitro.
Термины "терапевтическое средство", "оказывающее терапевтический эффект средство" или "средство для лечения" используются взаимозаменяемо, и они означают молекулу или соединение, которые оказывают некоторое благоприятное воздействие при введении субъекту. Благоприятное воздействие включает возможность осуществления диагностических определений; облегчение заболевания, симптома, нарушения или патологического состояния; ослабление или предупреждение начала проявления заболевания, симптома, нарушения или состояния; а также общее противодействие заболеванию, симптому, нарушению или патологическому состоянию.
Как используется в данном документе, "лечение", или "осуществление лечения", или "временное ослабление", или "облегчение" используются взаимозаменяемо. Эти термины обозначают подход для получения благоприятных или требуемых результатов, в том числе без ограничения терапевтического эффекта и/или профилактического эффекта. Под терапевтическим эффектом понимают любое терапевтически значимое улучшение или воздействие в отношении одного или нескольких заболеваний, состояний или симптомов, лечение которых осуществляют. Для профилактического эффекта композиции можно вводить субъекту с риском развития конкретного заболевания, состояния или симптома или субъекту, который сообщает об одном или нескольких физиологических симптомах заболевания, даже если заболевание, состояние или симптом могли еще не проявиться.
Термин "эффективное количество" или "терапевтически эффективное количество" означает количество средства, которого достаточно для обеспечения благоприятных или желательных результатов. Терапевтически эффективное количество может изменяться в зависимости от одного или нескольких из: субъекта и болезненного состояния, которые подлежат лечению, веса и возраста субъекта, тяжести болезненного состояния, способа введения и подобного, что специалист в данной области легко может определить. Термин также применим к дозе, с помощью которой можно получить изображение для определения любым одним из способов визуализации, описанных в данном документе. Конкретная доза может изменяться в зависимости от одного или нескольких из: конкретного выбранного средства, режима дозирования, которому следуют, того, вводят ли его в комбинации с другими средствами, выбора времени введения, визуализируемой ткани и физической системы доставки, в которой оно заключено.
Некоторые аспекты настоящего изобретения касаются векторных систем, содержащих один или несколько векторов, или векторов как таковых. Векторы могут быть разработаны для экспрессии транскриптов CRISPR (к примеру, транскриптов нуклеиновых кислот, белков или ферментов) в прокариотических или эукариотических клетках. Например, транскрипты CRISPR могут экспрессироваться в бактериальных клетках, например, Escherichia coli, клетках насекомых (с использованием бакуловирусных векторов экспрессии), клетках дрожжей или клетках млекопитающих. Подходящие клетки-хозяева дополнительно рассматриваются в Goeddel, GENE экспрессия TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990). Альтернативно рекомбинантный вектор экспрессии может транскрибироваться и транслироваться in vitro, например, с помощью регуляторных последовательностей промотора T7 и полимеразы T7.
Варианты осуществления согласно настоящему изобретению охватывают последовательности (как полинуклеотидные, так и полипептидные), которые могут содержать гомологичную замену (используемые в данном документе как замена, так и замещение означают обмен существующего аминокислотного остатка или нуклеотида на альтернативный остаток или нуклеотид), которая может происходить, т. е., в случае аминокислот, замену на аналогичную, например, основной на основную, кислой на кислую, полярной на полярную и т. д. Также может происходить негомологичная замена, т. е. остатка из одного класса на остаток из другого или, в альтернативном случае, связанная с включением аминокислот, отличных от природных, например, орнитина (далее в данном документе называемого Z), орнитиндиаминомасляной кислоты (далее в данном документе называемой B), норлейцинорнитина (далее в данном документе называемого O), пиридилаланина, тиенилаланина, нафтилаланина и фенилглицина. Вариантные аминокислотные последовательности могут содержать подходящие спейсерные группы, которые могут быть вставлены между любыми двумя аминокислотными остатками последовательности, в том числе алкильные группы, например, метильную, этильную или пропильную группы, в дополнение к аминокислотным спейсерам, таким как глициновые или β-аланиновые остатки. Другая форма вариации, которая включает присутствие одного или нескольких аминокислотных остатков в пептоидной форме, может быть хорошо понятна специалистам в данной области. Для того, чтобы избежать неопределенности, "пептоидная форма" используется для обозначения вариантных аминокислотных остатков, где замещающая группа для α-углерода расположена на атоме азота остатка, а не на α-углероде. Способы получения пептидов в пептоидной форме известны в данной области, например, Simon RJ et al., PNAS (1992) 89(20), 9367-9371 and Horwell DC, Trends Biotechnol. (1995) 13(4), 132-134.
Моделирование гомологии Соответствующие остатки в других ортологах Cpf1 можно идентифицировать при помощи способов Zhang et al., 2012 (Nature; 490(7421): 556-60) и Chen et al., 2015 (PLoS Comput Biol; 11(5): e1004248)-компьютерного способа белок-белкового взаимодействия (PPI) для прогноза взаимодействий, опосредованных границами домен-мотив. PrePPI (прогнозируемое PPI), структура на основе способа прогнозирования PPI, объединяет структурные доказательства с неструктурными доказательствами с использованием концепции байесовой статистики. Способ включает взятие пары исслудуемых белков и применение структурного выравнивания с целью выявления структурных элементов, которые соответствуют либо по своим экспериментально определенным структурам, либо по гомологичным моделям. Структурное выравнивание дополнительно используют для выявления как расположенных вблизи, так и удаленных структурных соседствующих элементов посредством общих и локальных геометрических связей. Во всех случаях, когда два соседствующих элемента из структурных элементов образуют комплекс, описанный в Protein Data Bank, он определяет матрицу для моделирования взаимодействия между двумя исследуемыми белками. Модели комплекса создают с помощью накладывания структур элементов на их соответствующий структурный соседствующий элемент в матрице. Этот подход дополнительно описан в Dey et al., 2013 (Prot Sci; 22: 359-66).
Для целей настоящего изобретения амплификация означает любой способ с использованием праймера и полимеразы, способной обеспечивать репликацию целевой последовательности с достаточной точностью. Амплификацию можно осуществлять с помощью природных или рекомбинантных ДНК-полимераз, таких как TaqGold™, ДНК-полимераза T7, фрагмент Кленова ДНК-полимеразы E. coli и обратная транскриптаза. Предпочтительным способом амплификации является ПЦР.
В определенных аспектах настоящее изобретение охватывает векторы. Как используется в данном документе, "вектор" представляет собой инструмент, который позволяет или облегчает перенос объекта из одной среды в другую. Он представляет собой репликон, такой как плазмида, фаг или космида, в который может быть встроен другой сегмент ДНК для осуществления таким образом репликации встроенного сегмента. Как правило, вектор способен к репликации, если ассоциирован с соответствующими элементами контроля. В целом, термин "вектор" относится к молекуле нуклеиновой кислоты, способной переносить другую нуклеиновую кислоту, с которой она связана. Векторы включают без ограничения молекулы нуклеиновой кислоты, которые являются однонитевыми, двухнитевыми или частично двухнитевыми; молекулы нуклеиновой кислоты, которые содержат один или несколько свободных концов, не содержат свободных концов (например, кольцевые); молекулы нуклеиновой кислоты, которые содержат ДНК, РНК или и ту, и другую; и другие разновидности полинуклеотидов, известные из уровня техники. Одним типом вектора является "плазмида", которая означает кольцевую петлю двухнитевой ДНК, в которую можно встраивать дополнительные сегменты ДНК, как, например, с помощью стандартных методик молекулярного клонирования. Другим типом вектора является вирусный вектор, где полученные из вируса последовательности ДНК или РНК присутствуют в векторе для упаковки в вирус (например, ретровирусы, ретровирусы с дефектной системой репликации, аденовирусы, аденовирусы с дефектной системой репликации и аденоассоциированные вирусы (AAV)). Вирусные векторы также включают полинуклеотиды, переносимые вирусом для трансфекции в клетку-хозяина. Определенные векторы способны к автономной репликации в клетке-хозяине, в которую они введены (например, бактериальные векторы с бактериальной точкой начала репликации и эписомные векторы для млекопитающих). Другие векторы (например, векторы для млекопитающих, отличные от эписомных) интегрируются в геном клетки-хозяина после введения в клетку-хозяина и, таким образом, реплицируются вместе с геномом хозяина. Более того, определенные векторы способны управлять экспрессией генов, с которыми они функционально связаны. Такие векторы в данном документе обозначены как "векторы экспрессии". Общепринятые пригодные для методик рекомбинантной ДНК векторы экспрессии часто находятся в форме плазмид.
Рекомбинантные векторы экспрессии могут содержать нуклеиновую кислоту по настоящему изобретению в форме, подходящей для экспрессии нуклеиновой кислоты в клетке-хозяине, что означает, что рекомбинантные векторы экспрессии включают один или несколько регуляторных элементов, которые могут быть выбраны с учетом клеток-хозяев, которые предполагается применять для экспрессии, которые функционально связаны с последовательностью нуклеиновой кислоты, экспрессия которой предполагается. В контексте рекомбинантного вектора экспрессии предполагается, что выражение "функционально связанный" обозначает то, что представляющая интерес нуклеотидная последовательность связана с регуляторным(регуляторными) элементом(элементами), так что обеспечивается возможность экспрессии нуклеотидной последовательности (например, в системе транскрипции/трансляции in vitro или в клетке-хозяине при введении вектора в клетку-хозяина). Что касается способов рекомбинации и клонирования, следует упомянуть заявку на патент США № 10/815730, опубликованную 2 сентября 2004 г. как US 2004-0171156 A1, содержание которой включено в данный документ посредством ссылки в полном объеме.
Аспекты настоящего изобретения относятся к бицистронным векторам для направляющей РНК и (необязательно модифицированных или мутантных) ферментов CRISPR (например, Cpf1). Бицистронные векторы экспрессии для направляющей РНК и (необязательно модифицированные или мутантные) ферменты CRISPR являются предпочтительными. В целом и в частности, в данном варианте осуществления (необязательно модифицированные или мутантные) ферменты CRISPR предпочтительно управляются промотором CBh. РНК предпочтительно может управляться промотором Pol III, таким как промотор U6. Оптимальным является их сочетание.
В некоторых вариантах осуществления предусмотрена петля в направляющей РНК. Она может представлять собой петлю на стебле или тетра-петлю. Петля предпочтительно представляет собой GAAA, но не ограничивается этой последовательностью, или действительно ее длина составляет только 4 п.о. Действительно, предпочтительные петлеобразующие последовательности для использования в "шпилечных" структурах имеют длину четыре нуклеотида и наиболее предпочтительно имеют последовательность GAAA. Однако, можно применять более длинные или более короткие последовательности петли, а также альтернативные последовательности. Последовательности предпочтительно включают нуклеотидный триплет (например, AAA) и дополнительный нуклеотид (например, C или G). Примеры петлеобразующих последовательностей включают CAAA и AAAG. При осуществлении на практике любых способов, раскрытых в данном документе, подходящий вектор можно вводить в клетку или эмбрион посредством одного или нескольких способов, известных из уровня техники, в том числе без ограничения микроинъекции, электропорации, сонопорации, баллистической трансфекции, трансфекции, опосредованной фосфатом кальция, трансфекции с помощью катионных липидных частиц, липосомной трансфекции, трансфекции с помощью дендримеров, трансфекции посредством теплового шока, трансфекции посредством нуклеофекции, магнитофекции, липофекции, импалефекции, оптической трансфекции, поглощения нуклеиновых кислот, стимулируемого проприетарным средством, и доставки с помощью липосом, иммунолипосом, виросом или искусственных вирионов. В некоторых способах вектор вводят в эмбрион посредством микроинъекции. Можно осуществлять микроинъекцию вектора или векторов в ядро или цитоплазму эмбриона. В некоторых способах вектор или векторы можно вводить в клетку посредством нуклеофекции.
Термин "регуляторный элемент" предназначен для охвата промоторов, энхансеров, сайтов внутренней посадки рибосомы (IRES) и других контролирующих экспрессию элементов (к примеру, сигналы терминации транскрипции, такие как сигналы полиаденилирования и поли-U-последовательности). Такие регуляторные элементы описаны, например, в Goeddel, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990). Регуляторные элементы включают такие элементы, которые управляют конститутивной экспрессией нуклеотидной последовательности во многих типах клеток-хозяев, и такие элементы, которые управляют экспрессией нуклеотидной последовательности только в определенных клетках-хозяевах (например, тканеспецифичные регуляторные последовательности). Тканеспецифичный промотор может управлять экспрессией преимущественно в представляющей интерес целевой ткани, такой как мышца, нейрон, кость, кожа, кровь, конкретных органах (к примеру, печени, поджелудочной железе) или определенных типах клеток (к примеру, лимфоцитах). Регуляторные элементы также могут управлять экспрессией зависимым от времени образом, как, например, зависимым от клеточного цикла или зависимым от стадии развития образом, который также может быть или может не быть тканеспецифичным или специфичным к типу клеток. В некоторых вариантах осуществления вектор содержит один или несколько промоторов pol III (к примеру, 1, 2, 3, 4, 5 или более промоторов pol III), один или несколько промоторов pol II (к примеру, 1, 2, 3, 4, 5 или более промоторов pol II), один или несколько промоторов pol I (к примеру, 1, 2, 3, 4, 5 или более промоторов pol I) или их комбинации. Примеры промоторов pol III включают без ограничения промоторы U6 и H1. Примеры промоторов pol II включают без ограничения ретровирусный промотор LTR вируса саркомы Рауса (RSV) (необязательно с энхансером RSV), промотор цитомегаловируса (CMV) (необязательно с энхансером CMV) [см., например, Boshart et al, Cell, 41:521-530 (1985)], промотор SV40, промотор гена дигидрофолатредуктазы, промотор гена β-актина, промотор гена глицерофосфаткиназы (PGK) и промотор EF1α. Также термином "регуляторный элемент" охватываются энхансерные элементы, такие как энхансеры WPRE; CMV; сегмент R-U5' в LTR из HTLV-I (Mol. Cell. Biol., Vol. 8(1), p. 466-472, 1988); энхансер SV40; а также интронная последовательность между экзонами 2 и 3 гена β-глобина кролика (Proc. Natl. Acad. Sci. USA., Vol. 78(3), p. 1527-31, 1981). Специалистам в данной области техники будет понятно, что конфигурация вектора экспрессии может зависеть от таких факторов, как выбор клетки-хозяина, подлежащей трансформации, требуемый уровень экспрессии и т. п. Вектор можно вводить в клетки-хозяева с получением, таким образом, транскриптов, белков или пептидов, в том числе слитых белков или пептидов, кодируемых нуклеиновыми кислотами, которые описаны в данном документе (например, транскриптов коротких палиндромных повторов, регулярно расположенных группами (CRISPR), белков, ферментов, их мутантных форм, их слитых белков и т. п.). По отношению к регуляторным последовательностям следует упомянуть заявку на патент США № 10/491026, содержание которой включено в данный документ посредством ссылки в полном объеме. По отношению к промоторам следует упомянуть PCT-публикацию WO 2011/028929 и заявку на патент США № 12/511940, содержание которых включено в данный документ посредством ссылки во их полноте.
Векторы могут быть разработаны для экспрессии транскриптов CRISPR (к примеру, транскриптов нуклеиновых кислот, белков или ферментов) в прокариотических или эукариотических клетках. Например, транскрипты CRISPR могут экспрессироваться в бактериальных клетках, например, Escherichia coli, клетках насекомых (с использованием бакуловирусных векторов экспрессии), клетках дрожжей или клетках млекопитающих. Подходящие клетки-хозяева дополнительно рассматриваются в Goeddel, GENE экспрессия TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990). Альтернативно рекомбинантный вектор экспрессии может транскрибироваться и транслироваться in vitro, например, с помощью регуляторных последовательностей промотора T7 и полимеразы T7.
Векторы можно вводить и размножать в прокариоте или прокариотической клетке. В некоторых вариантах осуществления прокариота используют для амплификации копий вектора, который предполагается вводить в эукариотическую клетку, или в качестве промежуточного вектора при получении вектора, который предполагается вводить в эукариотическую клетку (к примеру, путем амплификации плазмиды как части системы упаковки вирусного вектора). В некоторых вариантах осуществления прокариота используют для амплификации копий вектора и экспрессии одной или нескольких нуклеиновых кислот, как, например, для обеспечения источника одного или нескольких белков для доставки в клетку-хозяин или организм-хозяин. Экспрессию белков в прокариотах наиболее часто осуществляют в Escherichia coli с помощью векторов, содержащих конститутивные или индуцируемые промоторы, управляющие экспрессией либо слитых белков, либо белков, отличных от слитых белков. В слитых векторах добавляют некоторое количество аминокислот к белку, закодированному в них, как, например, к амино-концу рекомбинантного белка. Такие слитые векторы могут служить для одной или нескольких целей, как, например: (i) для повышения экспрессии рекомбинантного белка; (ii) для повышения растворимости рекомбинантного белка и (iii) для содействия очистке рекомбинантного белка путем функционирования в качестве лиганда при аффинной очистке. Часто в слитые векторы экспрессии сайт протеолитического расщепления вводят в место соединения слитого фрагмента и рекомбинантного белка для облегчения отделения рекомбинантного белка от слитого фрагмента после очистки слитого белка. Такие ферменты и их когнатные распознающие последовательности включают фактор Xa, тромбин и энтерокиназу. Иллюстративные слитые векторы экспрессии включают pGEX (Pharmacia Biotech Inc; Smith and Johnson, 1988. Gene 67: 31-40), pMAL (New England Biolabs, Беверли, Массачусетс) и pRIT5 (Pharmacia, Пискатауэй, Нью-Джерси), в которых соответственно глутатион-S-трансфераза (GST), мальтоза-связывающий белок E или белок A слиты с целевым рекомбинантным белком. Примеры подходящих индуцируемых не являющихся слитыми векторов экспрессии для E. coli включают pTrc (Amrann et al., (1988) Gene 69:301-315) и pET 11d (Studier et al., GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990) 60-89). В некоторых вариантах осуществления вектор является дрожжевым вектором экспрессии. Примеры векторов для экспрессии в дрожжах Saccharomyces cerivisae включают pYepSec1 (Baldari, et al., 1987. EMBO J. 6: 229-234), pMFa (Kuijan and Herskowitz, 1982. Cell 30: 933-943), pJRY88 (Schultz et al., 1987. Gene 54: 113-123), pYES2 (Invitrogen Corporation, Сан-Диего, Калифорния) и picZ (InVitrogen Corp, Сан-Диего, Калифорния). В некоторых вариантах осуществления вектор управляет экспрессией белка в клетках насекомых с помощью бакуловирусных векторов экспрессии. Бакуловирусные векторы, доступные для экспрессии белков в культивируемых клетках насекомых (к примеру, клетках SF9), включают группу pAc (Smith, et al., 1983. Mol. Cell. Biol. 3: 2156-2165) и группу pVL (Lucklow and Summers, 1989. Virology 170: 31-39).
В некоторых вариантах осуществления вектор способен управлять экспрессией одной или нескольких последовательностей в клетках млекопитающих с помощью вектора экспрессии для млекопитающих. Примеры векторов экспрессии для млекопитающих включают pCDM8 (Seed, 1987. Nature 329: 840) и pMT2PC (Kaufman, et al., 1987. EMBO J. 6: 187-195). При использовании в клетках млекопитающих функции контроля вектора экспрессии, как правило, обеспечиваются одним или несколькими регуляторными элементами. Например, широко используемые промоторы получают из вируса полиомы, аденовируса 2, цитомегаловируса, обезьяньего вируса 40 и других, раскрытых в данном документе и известных из уровня техники. Что касается других подходящих систем экспрессии как для прокариотических, так и для эукариотических клеток, см., к примеру, главы 16 и 17 в Sambrook, et al., MOLECULAR CLONING: A LABORATORY MANUAL. 2nd ed., Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., 1989.
В некоторых вариантах осуществления рекомбинантные векторы экспрессии для млекопитающих способны управлять экспрессией нуклеиновой кислоты преимущественно в определенном типе клеток (к примеру, тканеспецифичные регуляторные элементы используют для экспрессии нуклеиновой кислоты). Тканеспецифичные регуляторные элементы известны из уровня техники. Неограничивающие примеры подходящих тканеспецифичных промоторов включают промотор гена альбумина (специфичный к печени; Pinkert, et al., 1987. Genes Dev. 1: 268-277), специфичные к лимфоидной ткани промоторы (Calame and Eaton, 1988. Adv. Immunol. 43: 235-275), в частности, промоторы рецепторов T-клеток (Winoto and Baltimore, 1989. EMBO J. 8: 729-733) и иммуноглобулины (Baneiji, et al., 1983. Cell 33: 729-740; Queen and Baltimore, 1983. Cell 33: 741-748), нейрон-специфичные промоторы (к примеру, промотор гена нейрофиламента; Byrne and Ruddle, 1989. Proc. Natl. Acad. Sci. USA 86: 5473-5477), специфичные к клеткам поджелудочной железы промоторы (Edlund, et al., 1985. Science 230: 912-916) и специфичные к клеткам молочной железы промоторы (к примеру, промотор молочной сыворотки; патент США № 4873316 и публикация европейской заявки № 264166). Регулируемые стадией развития промоторы также охвачены, к примеру, промоторы генов hox мыши (Kessel and Gruss, 1990. Science 249: 374-379) и промотор гена α-фетопротеина (Campes and Tilghman, 1989. Genes Dev. 3: 537-546). Что касается этих прокариотических и эукариотических векторов, следует упомянуть патент США № 6750059, содержание которого включено в данный документ посредством ссылки во всей его полноте. Другие варианты осуществления по настоящему изобретению могут относиться к вирусным векторам, которые упоминаются в заявке на патент США № 13/092085, содержание которой включено в данный документ посредством ссылки во всей ее полноте. Тканеспецифичные регуляторные элементы известны из уровня техники и, в связи с этим, следует упомянуть патент США № 7776321, содержание которого включено в данный документ посредством ссылки во всей его полноте. В некоторых вариантах осуществления регуляторный элемент является функционально связанным с одним или несколькими элементами системы CRISPR так, чтобы управлять экспрессией одного или нескольких элементов системы CRISPR. В целом, CRISPR (короткие палиндромные повторы, регулярно расположенные группами), также известные как SPIDR (прерываемые спейсерами прямые повторы), составляют семейство локусов ДНК, которые, как правило, специфичны для определенного вида бактерий. Локус CRISPR включает определенный класс чередующихся коротких повторов последовательностей (SSR), которые были обнаружены у E. coli (Ishino et al., J. Bacteriol., 169:5429-5433 [1987]; и Nakata et al., J. Bacteriol., 171:3553-3556 [1989]), и ассоциированные гены. Подобные чередующиеся SSR были идентифицированы у Haloferax mediterranei, Streptococcus pyogenes, Anabaena и Mycobacterium tuberculosis (см. Groenen et al., Mol. Microbiol., 10:1057-1065 [1993]; Hoe et al., Emerg. Infect. Dis., 5:254-263 [1999]; Masepohl et al., Biochim. Biophys. Acta 1307:26-30 [1996]; и Mojica et al., Mol. Microbiol., 17:85-93 [1995]). Локусы CRISPR, как правило, отличаются от других SSR по структуре повторов, которые были названы короткими повторами с регулярными интервалами (SRSR) (Janssen et al., OMICS J. Integ. Biol., 6:23-33 [2002]; и Mojica et al., Mol. Microbiol., 36:244-246 [2000]). В целом, повторы являются короткими элементами, которые встречаются группами, которые регулярно разделены уникальными вставочными последовательностями с практически постоянной длинной (Mojica et al., [2000], выше). Несмотря на то, что последовательности повторов высоко консервативны между штаммами, некоторое количество чередующихся повторов и последовательностей спейсерных участков, как правило, отличаются от штамма к штамму (van Embden et al., J. Bacteriol., 182:2393-2401 [2000]). Локусы CRISPR идентифицировали у более чем 40 прокариотов (см., например, Jansen et al., Mol. Microbiol., 43:1565-1575 [2002]; и Mojica et al., [2005]), в том числе без ограничения Aeropyrum, Pyrobaculum, Sulfolobus, Archaeoglobus, Halocarcula, Methanobacterium, Methanococcus, Methanosarcina, Methanopyrus, Pyrococcus, Picrophilus, Thermoplasma, Corynebacterium, Mycobacterium, Streptomyces, Aquifex, Porphyromonas, Chlorobium, Thermus, Bacillus, Listeria, Staphylococcus, Clostridium, Thermoanaerobacter, Mycoplasma, Fusobacterium, Azarcus, Chromobacterium, Neisseria, Nitrosomonas, Desulfovibrio, Geobacter, Myxococcus, Campylobacter, Wolinella, Acinetobacter, Erwinia, Escherichia, Legionella, Methylococcus, Pasteurella, Photobacterium, Salmonella, Xanthomonas, Yersinia, Treponema и Thermotoga.
В целом, "система нацеливания на нуклеиновую кислоту", как используется в настоящей заявке, относится собирательно к транскриптам и другим элементам, участвующим в экспрессии или управляющих активностью CRISPR-ассоциированных ("Cas") генов нацеливания на нуклеиновую кислоту (также называемых в данном документе эффекторный белок), в том числе последовательностям, кодирующим белок Cas (эффекторный) нацеливания на нуклеиновую кислоту и направляющую РНК, или другим последовательностям и транскриптам из локуса CRISPR нацеливания на нуклеиновую кислоту. В некоторых вариантах осуществления один или несколько элементов системы нацеливания на нуклеиновую кислоту получены из системы CRISPR типа V/типа VI нацеливания на нуклеиновую кислоту. В некоторых вариантах осуществления один или несколько элементов системы нацеливания на нуклеиновую кислоту получены из конкретного организма, содержащего эндогенную систему CRISPR нацеливания на нуклеиновую кислоту. В целом, система нацеливания на нуклеиновую кислоту характеризуется элементами, которые способствуют образованию комплекса нацеливания на нуклеиновую кислоту в сайте целевой последовательности. В контексте образования комплекса нацеливания на нуклеиновую кислоту "целевая последовательность" относится к последовательности, по отношению к которой направляющая последовательность сконструирована так, чтобы обладать комплементарностью, где гибридизация между целевой последовательностью и направляющей РНК способствует образованию комплекса нацеливания на ДНК или РНК. Полная комплементарность не обязательна при условии, что имеет место достаточная комплементарность для осуществления гибридизации и способствования образованию комплекса нацеливания на нуклеиновую кислоту. Целевая последовательность может содержать полинуклеотиды РНК. В некоторых вариантах осуществления целевая последовательность расположена в ядре или цитоплазме клетки. В некоторых вариантах осуществления целевая последовательность может находиться в органелле эукариотической клетки, например, митохондрии или хлоропласте. Последовательность или матрицу, которую можно применять для рекомбинации в целевом локусе, содержащем целевые последовательности, называют "матрицей редактирования", или "РНК для редактирования" или "последовательностью для редактирования". В аспектах настоящего изобретения экзогенную матричную ДНК можно называть матрицей редактирования. В одном аспекте настоящего изобретения рекомбинация является гомологичной рекомбинацией.
Как правило, в контексте эндогенной системы нацеливания на нуклеиновую кислоту образование комплекса нацеливания на нуклеиновую кислоту (содержащего направляющую РНК, гибридизирующуюся с целевой последовательностью и образующую комплекс с одним или несколькими эффекторными белками для нацеливания на нуклеиновую кислоту) приводит к расщеплению одной или обеих нитей РНК в (к примеру, в пределах 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 50 или более пар оснований) целевой последовательности или рядом с ней. В некоторых вариантах осуществления один или несколько векторов, управляющих экспрессией одного или нескольких элементов системы нацеливания на нуклеиновую кислоту, вводят в клетку-хозяина, так что экспрессия элементов системы нацеливания на нуклеиновую кислоту управляет образованием комплекса нацеливания на нуклеиновую кислоту на одном или нескольких целевых сайтах. Например, и эффекторный белок для нацеливания на нуклеиновую кислоту, и направляющая РНК могут быть функционально связаны с отдельными регуляторными элементами на отдельных векторах. Альтернативно два или более элементов, которые экспрессируются за счет одного и того же или разных регуляторных элементов, можно объединять в один вектор, при этом один или несколько дополнительных векторов обеспечивают любые компоненты системы нацеливания на нуклеиновую кислоту, не включенные в первый вектор, при этом компоненты системы нацеливания на нуклеиновую кислоту, которые объединены в одном векторе, могут быть расположены в любой подходящей ориентации, как, например один элемент расположен в направлении 5' ("выше") относительно второго элемента или в направлении 3’ ("ниже") относительно него. Кодирующая последовательность одного элемента может быть расположена на одной и той же или противоположной нити по отношению к кодирующей последовательности второго элемента и ориентирована в одном и том же или противоположном направлении. В некоторых вариантах осуществления один промотор управляет экспрессией транскрипта, кодирующего эффекторный белок для нацеливания на нуклеиновую кислоту и направляющую РНК, встроенных в одну или несколько интронных последовательностей (к примеру, каждая в разном интроне, две или более по меньшей мере в одном интроне или все в одном интроне). В некоторых вариантах осуществления эффекторный белок нацеливания на нуклеиновую кислоту и направляющая РНК функционально связаны с одним и тем же промотором и экспрессированы от такового.
В целом, направляющая последовательность представляет собой любую полинуклеотидную последовательность, характеризующуюся достаточной комплементарностью с целевой полинуклеотидной последовательностью для гибридизации с целевой последовательностью и управления специфичным к последовательности связыванием комплекса нацеливания на нуклеиновую кислоту с целевой последовательностью. В некоторых вариантах осуществления степень комплементарности между направляющей последовательностью и ее соответствующей целевой последовательностью при оптимальном выравнивании с применением подходящего алгоритма выравнивания составляет приблизительно или более чем приблизительно 50%, 60%, 75%, 80%, 85%, 90%, 95%, 97,5%, 99% или больше. Оптимальное выравнивание можно определять с помощью любого подходящего алгоритма для выравниваемых последовательностей, неограничивающие примеры которого включают алгоритм Смита-Ватермана, алгоритм Нидлмана-Вунша, алгоритмы, основанные на преобразовании Барроуза-Уилера (к примеру, Burrows Wheeler Aligner), ClustalW, Clustal X, BLAT, Novoalign (Novocraft Technologies), ELAND (Illumina, Сан-Диего, Калифорния), SOAP (доступный на soap.genomics.org.cn) и Maq (доступный на maq.sourceforge.net). В некоторых вариантах осуществления длина направляющей последовательности составляет приблизительно или более чем приблизительно 5, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 45, 50, 75 или более нуклеотидов. В некоторых вариантах осуществления длина направляющей последовательности составляет менее чем приблизительно 75, 50, 45, 40, 35, 30, 25, 20, 15, 12 или менее нуклеотидов. Способность направляющей последовательности управлять специфичным к последовательности связыванием комплекса нацеливания на нуклеиновую кислоту с целевой последовательностью можно оценить с помощью любого подходящего анализа. Например, компоненты системы нацеливания на нуклеиновую кислоту, достаточные для образования комплекса нацеливания на нуклеиновую кислоту, в том числе направляющая последовательность, подлежащая тестированию, могут быть доставлены в клетку-хозяина с соответствующей целевой последовательностью, как, например, с помощью трансфекции векторами, кодирующими компоненты последовательности нацеливания на нуклеиновую кислоту CRISPR, с последующей оценкой предпочтительного расщепления в пределах целевой последовательности или рядом с ней, как, например, с помощью анализа с использованием нуклеазы Surveyor, описываемого в данном документе. Аналогично расщепление целевой полинуклеотидной последовательности (или последовательности рядом с ней) может быть оценено в пробирке путем обеспечения целевой последовательности, компонентов комплекса нацеливания на нуклеиновую кислоту, в том числе направляющей последовательности, подлежащей тестированию, и контрольной направляющей последовательности, отличной от тестируемой направляющей последовательности, и сравнения связывания или степени расщепления в целевой последовательности или рядом с ней в случае реакций с тестируемой и контрольной направляющей последовательностью. Возможны и другие анализы, и они могут быть выполнены специалистами в данной области.
Направляющая последовательность может быть выбрана для целенаправленного воздействия на любую целевую последовательность. В некоторых вариантах осуществления целевая последовательность представляет собой последовательность в пределах транскрипта или мРНК.
В некоторых вариантах осуществления целевая последовательность является последовательностью в пределах генома клетки.
В некоторых вариантах осуществления направляющая последовательность выбрана для снижения доли вторичной структуры в направляющей последовательности. Вторичную структуру можно определить с помощью любого подходящего алгоритма сворачивания полинуклеотида. Некоторые программы основаны на вычислении минимальной свободной энергии Гиббса. Примером одного такого алгоритма является mFold, который описан Zuker и Stiegler (Nucleic Acids Res. 9 (1981), 133-148). Другим примером алгоритма сворачивания является доступный в режиме онлайн веб-сервер RNAfold, разработанный в Институте теоретической химии при Венском университете, в котором используется алгоритм прогнозирования структуры на основе центроидного способа (см., к примеру, A.R. Gruber et al., 2008, Cell 106(1): 23-24; и PA Carr and GM Church, 2009, Nature Biotechnology 27(12): 1151-62). Дополнительные алгоритмы можно найти в заявке на патент США с серийным номером TBA (номер дела у патентного поверенного 44790.11.2022; общая ссылка BI-2013/004A); включенной в данный документ при помощи ссылки.
В некоторых вариантах осуществления также предусмотрена матрица для рекомбинации. Матрица для рекомбинации может быть компонентом другого вектора, который описан в данном документе, может содержаться в отдельном векторе или предусматриваться в виде отдельного полинуклеотида. В некоторых вариантах осуществления матрица для рекомбинации разработана так, чтобы служить в качестве матрицы при гомологичной рекомбинации, как, например, в пределах целевой последовательности или рядом с ней, надрезанной или расщепленной ферментом с помощью эффекторного белка для нацеливания на нуклеиновую кислоту в качестве части комплекса нацеливания на нуклеиновую кислоту. Матричный полинуклеотид может иметь любую подходящую длину, как, например, приблизительно или более чем приблизительно 10, 15, 20, 25, 50, 75, 100, 150, 200, 500, 1000 нуклеотидов или более. В некоторых вариантах осуществления матричный полинуклеотид комплементарен части полинуклеотида, содержащего целевую последовательность. При оптимальном выравнивании матричный полинуклеотид может перекрываться с одним или несколькими нуклеотидами целевых последовательностей (к примеру, с приблизительно или более чем приблизительно 1, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100 или более нуклеотидами). В некоторых вариантах осуществления при оптимальном выравнивании матричной последовательности и полинуклеотида, содержащего целевую последовательность, наиболее близкий нуклеотид матричного полинуклеотида находится в пределах приблизительно 1, 5, 10, 15, 20, 25, 50, 75, 100, 200, 300, 400, 500, 1000, 5000, 10000 или более нуклеотидов от целевой последовательности.
В некоторых вариантах осуществления эффекторный белок нацеливания на нуклеиновую кислоту является частью слитого белка, содержащего один или несколько доменов гетерологичного белка (например, приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более доменов в дополнение к эффекторному белку нацеливания на нуклеиновую кислоту). В некоторых вариантах осуществления эффекторный белок CRISPR является частью слитого белка, содержащего один или несколько доменов гетерологичного белка (например, приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более доменов в дополнение к ферменту CRISPR). Слитый белок, содержащий фермент CRISPR, может содержать любую дополнительную последовательность белка и необязательно линкерную последовательность между любыми двумя доменами. Примеры белковых доменов, которые могут быть слиты с ферментом CRISPR, включают без ограничения эпитопные метки, последовательности из генов-репортеров и белковые домены с одной или несколькими из следующих видов активности: метилазная активность, деметилазная активность, активность в отношении активации транскрипции, активность в отношении репрессии транскрипции, активность фактора освобождения транскрипта, активность в отношении модификации гистонов, активность расщепления РНК и активность связывания нуклеиновой кислоты. Неограничивающие примеры эпитопных меток включают гистидиновые (His) метки, V5-метки, FLAG-метки, метки гемагглютинина вируса гриппа (HA), Myc-метки, VSV-G-метки и тиоредоксиновые (Trx) метки. Примеры генов-репортеров включают без ограничения глутатион-S-трансферазу (GST), пероксидазу хрена (HRP), хлорамфеникол-ацетилтрансферазу (CAT), бета-галактозидазу, бета-глюкуронидазу, люциферазу, зеленый флуоресцентный белок (GFP), HcRed, DsRed, голубой флуоресцентный белок (CFP), желтый флуоресцентный белок (YFP) и автофлуоресцирующие белки, в том числе синий флуоресцентный белок (BFP). Фермент CRISPR может быть слит с последовательностью гена, кодирующей белок или фрагмент белка, которые связываются с молекулами ДНК или связываются с другими клеточными молекулами, в том числе без ограничения связывающий мальтозу белок (MBP), S-метка, продукты слияния Lex A и ДНК-связывающего домена (DBD), продукты слияния GAL4 и ДНК-связывающего домена и продукты слияния белка BP16 вируса простого герпеса (HSV). Дополнительные домены, которые могут образовывать часть слитого белка, содержащего фермент CRISPR, описаны в US20110059502, включенном в данный документ с помощью ссылки. В некоторых вариантах осуществления меченый фермент CRISPR используют для идентификации расположения целевой последовательности.
В некоторых вариантах осуществления фермент CRISPR может образовывать компонент индуцируемой системы. Индуцируемая природа системы будет обеспечивать возможность пространственно-временного контроля редактирования генов или экспрессии генов с использованием определенной формы энергии. Форма энергии может включать, но без ограничения, электромагнитное излучение, звуковую энергию, химическую энергию и тепловую энергию. Примеры индуцируемой системы включают индуцируемые тетрациклином промоторы (Tet-On или Tet-Off), двухгибридные системы активации транскрипции с использованием малых молекул (FKBP, ABA и т. д.) или индуцируемые светом системы (фитохром, домены LOV или криптохром). В одном варианте осуществления фермент CRISPR может быть частью индуцируемого светом транскрипционного эффектора (LITE) для управления изменениями транскрипционной активности специфичным к последовательности образом. Компоненты индуцируемой светом системы могут включать фермент CRISPR, чувствительный к свету гетеродимер цитохрома (например, из Arabidopsis thaliana) и домен активации/репрессии транскрипции. Дополнительные примеры индуцируемых ДНК-связывающих белков и способы их применения представлены в US 61/736465 и US 61/721283 и WO 2014/018423 и US8889418, US8895308, US20140186919, US20140242700, US20140273234, US20140335620, WO2014093635, которые включены в данный документ посредством ссылки во всей полноте.
Доставка
В некоторых аспектах настоящее изобретение относится к способам, включающим доставку в клетку-хозяина одного или нескольких полинуклеотидов, как, например, или одного, или нескольких векторов, которые описаны в данном документе, одного или нескольких их транскриптов и/или одного или нескольких белков, транскрибируемых с них. В некоторых аспектах настоящее изобретение дополнительно предусматривает клетки, полученные с помощью таких способов, и организмы (такие как животные, растения или грибы), содержащие такие клетки или полученные из них. В некоторых вариантах осуществления эффекторный белок для нацеливания на нуклеиновую кислоту в комбинации с (и необязательно образующий комплекс с) направляющей РНК доставляют в клетку. Традиционные способы переноса генов с использованием вирусов и без использования вирусов можно применять для введения нуклеиновых кислот в клетки млекопитающих или целевые ткани. Такие способы можно применять для введения нуклеиновых кислот, кодирующих компоненты системы нацеливания на нуклеиновую кислоту, в клетки в культуре или в организме-хозяине. Системы доставки на основе невирусных векторов включают плазмидные ДНК, РНК (например, транскрипт вектора, описанного в данном документе), "оголенную" нуклеиновую кислоту и нуклеиновую кислоту, образующую комплекс со средством доставки, таким как липосома. Системы доставки на основе вирусного вектора включают ДНК- и РНК-содержащие вирусы, которые имеют либо геномы в эписомальной форме, либо интегрированные геномы после доставки в клетку. В отношении обзора процедур генной терапии см. Anderson, Science 256:808-813 (1992); Nabel & Felgner, TIBTECH 11:211-217 (1993); Mitani & Caskey, TIBTECH 11:162-166 (1993); Dillon, TIBTECH 11:167-175 (1993); Miller, Nature 357:455-460 (1992); Van Brunt, Biotechnology 6(10):1149-1154 (1988); Vigne, Restorative Neurology and Neuroscience 8:35-36 (1995); Kremer & Perricaudet, British Medical Bulletin 51(1):31-44 (1995); Haddada et al., в Current Topics in Microbiology and Immunology, Doerfler and Böhm (eds) (1995); и Yu et al., Gene Therapy 1:13-26 (1994).
Способы отличной от вирусной доставки нуклеиновых кислот включают липофекцию, нуклеофекцию, микроинъекцию, баллистическую трансфекцию, виросомы, липосомы, иммунолипосомы, поликатион или конъюгаты липид:нуклеиновая кислота, "оголенную" ДНК, искусственные вирионы и повышенное с помощью средства поглощение ДНК. Липофекция описана, например, в патентах США №№ 5049386, 4946787 и 4897355, и реагенты для липофекции реализуют в промышленных масштабах (к примеру, Transfectam™ и Lipofectin™). Катионные и нейтральные липиды, которые подходят для эффективной липофекции с узнаванием рецепторов полинуклеотидов, включают липиды из Felgner, WO 91/17424; WO 91/16024. Доставка может осуществляться в клетки (к примеру, введение in vitro или ex vivo) или целевые ткани (к примеру, введение in vivo).
Получение комплексов липид:нуклеиновая кислота, в том числе нацеливающих липосом, таких как иммунолипидные комплексы, хорошо известно специалистам в данной области (см., к примеру, Crystal, Science 270:404-410 (1995); Blaese et al., Cancer Gene Ther. 2:291-297 (1995); Behr et al., Bioconjugate Chem. 5:382-389 (1994); Remy et al., Bioconjugate Chem. 5:647-654 (1994); Gao et al., Gene Therapy 2:710-722 (1995); Ahmad et al., Cancer Res. 52:4817-4820 (1992); патенты США №№ 4186183, 4217344, 4235871, 4261975, 4485054, 4501728, 4774085, 4837028 и 4946787).
При применении систем на основе РНК- или ДНК-содержащих вирусов для доставки нуклеиновых кислот используют преимущества тщательно разработанных способов обеспечения нацеливания вируса на конкретные клетки в организме и перемещения полезных последовательностей вируса в ядро. Вирусные векторы можно вводить непосредственно пациентам (in vivo), или их можно применять для обработки клеток in vitro, и модифицированные клетки можно необязательно вводить пациентам (ex vivo). Традиционные системы на основе вирусов для переноса генов могут включать ретровирусные, лентивирусные, аденовирусные векторы, векторы на основе аденоассоциированного вируса и вируса простого герпеса. Интеграция в геном хозяина возможна с применением способов переноса генов на основе ретровируса, лентивируса и аденоассоциированного вируса, что часто приводит к длительной экспрессии встроенного трансгена. Кроме того, высокие показатели эффективности трансдукции наблюдали у многих различных типов клеток и целевых тканей.
Тропизм ретровируса может быть изменен путем включения чужеродных белков оболочки с расширением возможной целевой популяции целевых клеток. Лентивирусные векторы являются ретровирусными векторами, которые способны трансдуцировать или инфицировать неделящиеся клетки и, как правило, дают высокие вирусные титры. Выбор системы переноса генов на основе ретровирусов, таким образом, будет зависеть от целевой ткани. Ретровирусные векторы состоят из действующих в цис-положении длинных концевых повторов с упаковывающей способностью до 6-10 т. о. чужеродной последовательности. Минимальных действующих в цис-положении LTR достаточно для репликации и упаковки векторов, которые затем используют для интеграции терапевтического гена в целевую клетку с получением постоянной экспрессии трансгена. Широко используемые ретровирусные векторы включают такие векторы, как основанные на вирусе лейкоза мышей (MuLV), вирусе лейкоза гиббонов (GaLV), вирусе иммунодефицита обезьян (SIV), вирусе иммунодефицита человека (HIV) и их комбинациях (см., к примеру, Buchscher et al., J. Virol. 66:2731-2739 (1992); Johann et al., J. Virol. 66:1635-1640 (1992); Sommnerfelt et al., Virol. 176:58-59 (1990); Wilson et al., J. Virol. 63:2374-2378 (1989); Miller et al., J. Virol. 65:2220-2224 (1991); PCT/US94/05700). В применениях, в которых транзиентная экспрессия является предпочтительной, можно применять системы на основе аденовирусов. Аденовирусные векторы способны проявлять очень высокую эффективность трансдукции во многих типах клеток и не требуют деления клеток. С применением таких векторов были получены высокие титры и уровни экспрессии. Такой вектор можно получать в больших количествах в относительно простой системе. Векторы на основе аденоассоциированного вируса ("AAV") также можно использовать для трансдукции в клетки целевых нуклеиновых кислот, к примеру, при получении in vitro нуклеиновых кислот и пептидов и для процедур генной терапии in vivo и ex vivo (см., к примеру, West et al., Virology 160:38-47 (1987); патент США № 4797368; WO 93/24641; Kotin, Human Gene Therapy 5:793-801 (1994); Muzyczka, J. Clin. Invest. 94:1351 (1994). Создание рекомбинантных векторов на основе AAV описано в ряде публикаций, в том числе в патенте США № 5173414; Tratschin et al., Mol. Cell. Biol. 5:3251-3260 (1985); Tratschin, et al., Mol. Cell. Biol. 4:2072-2081 (1984); Hermonat & Muzyczka, PNAS 81:6466-6470 (1984); и Samulski et al., J. Virol. 63:03822-3828 (1989).
Варианты для ДНК/РНК, или ДНК/ДНК, или РНК/РНК, или белок/РНК
В некоторых вариантах осуществления компоненты системы CRISPR могут быть доставлены в различной форме, такой как комбинации ДНК/РНК, или РНК/РНК, или белок/РНК. Например, Cpf1 может быть доставлен в виде кодирующего ДНК полинуклеотида, или кодирующего РНК полинуклеотида, или в виде белка. Направляющая может быть доставлена в виде кодирующего ДНК полинуклеотида или РНК. Предусматриваются все возможные комбинации, в том числе смешанные формы доставки.
В некоторых вариантах осуществления предусматриваются все такие комбинации (ДНК/РНК, или ДНК/ДНК, или РНК/РНК, или белок/РНК).
В определенном варианте осуществления, если Cpf1 доставляют в форме белка, то можно предварительно собрать его одной или несколькими направляющими.
Нанококоны
Кроме того, система CRISPR может быть доставлена с использованием нанококонов, например, как описывается у Sun W et al., Cocoon-like self-degradable DNA nanoclew for anticancer drug delivery., J Am Chem Soc. 2014 Oct 22;136(42):14722-5. doi: 10.1021/ja5088024. Epub 2014 Oct 13. ; или у Sun W et al, Self-Assembled DNA Nanoclews for the Efficient Delivery of CRISPR-Cas9 for Genome Editing., Angew Chem Int Ed Engl. 2015 Oct 5;54(41):12029-33. doi: 10.1002/anie.201506030. Epub 2015 Aug 27.
Практическое осуществление настоящего изобретения предусматривает, если не указано иное, традиционные методики иммунологии, биохимии, химии, молекулярной биологии, микробиологии, клеточной биологии, геномики и технологию рекомбинантной ДНК, которые находятся в пределах квалификации специалиста в данной области. См. Sambrook, Fritsch and Maniatis, MOLECULAR CLONING: A LABORATORY MANUAL, 2nd edition (1989); CURRENT PROTOCOLS IN MOLECULAR BIOLOGY (F. M. Ausubel, et al. eds., (1987)); серия METHODS IN ENZYMOLOGY (Academic Press, Inc.): PCR 2: A PRACTICAL APPROACH (M.J. MacPherson, B.D. Hames and G.R. Taylor eds. (1995)), Harlow and Lane, eds. (1988) ANTIBODIES, A LABORATORY MANUAL и ANIMAL CELL CULTURE (R.I. Freshney, ed. (1987)).
Модели генетических и эпигенетических условий
Способ по настоящему изобретению можно использовать для создания растения, животного или клетки, которые могут быть использованы для моделирования и/или изучения представляющих интерес генетических или эпигенетических условий, например, при помощи модели представляющих интерес мутаций или модели заболевания. Используемое в данном документе выражение "заболевание" относится к заболеванию, нарушению или симптому у субъекта. Например, способ по настоящему изобретению можно применять для создания животного или клетки, которые содержат модификацию одной или нескольких последовательностей нуклеиновой кислоты, ассоциированных с заболеванием, или растения, животного или клетки, в которых изменены экспрессии одной или нескольких последовательностей нуклеиновой кислоты, ассоциированных с заболеванием. Такая последовательность нуклеиновой кислоты может кодировать последовательность белка, ассоциированного с заболеванием, или может представлять собой регуляторную последовательность, ассоциированную с заболеванием. Соответственно, подразумевается, что в вариантах осуществления настоящего изобретения растение, субъект, пациент, организм или клетка могут относиться к субъекту, отличному от человека, пациенту, организму или клетке. Таким образом, настоящее изобретение относится к растению, животному или клетке, полученным с помощью способа по настоящему изобретению, или их потомству. Потомство может представлять собой клон полученного растения или животного, или его можно получить с помощью полового размножения посредством скрещивания с другими индивидами того же вида для придания дополнительных желаемых признаков их потомкам. Клетка может находиться in vivo или ex vivo в случае многоклеточных организмов, в частности, животных или растений. В случае, если клетка находится в культуре, можно получить линию клеток при выполнении соответствующих условий культивирования, и предпочтительно, если клетка соответствующим образом приспособлена для этой цели (например, стволовая клетка). Также предусматриваются линии бактериальных клеток, полученные согласно настоящему изобретению. Следовательно, также предусматриваются линии клеток.
В некоторых способах модель заболевания можно применять для изучения влияния мутаций на животное или клетку и развитие и/или прогрессирование заболевания с применением показателей, обычно используемых при изучении заболевания. Альтернативно такая модель заболевания является применимой для изучения влияния фармацевтически активного соединения на заболевание.
В некоторых способах модель заболевания можно применять для оценки эффективности потенциальной стратегии генной терапии. Таким образом, ассоциированные с заболеванием ген или полинуклеотид можно модифицировать, так что развитие и/или прогрессирование заболевания замедляется или уменьшается. В частности, способ включает модификацию ассоциированных с заболеванием гена или полинуклеотида, так что продуцируется измененный белок, и в результате у животного или клетки наблюдается измененный ответ. Соответственно, в некоторых способах генетически модифицированное животное можно сравнивать с животным, предрасположенным к развитию заболевания, так что можно оценить эффект осуществления генной терапии.
В другом варианте осуществления настоящее изобретение относится к способу получения биологически активного средства, которое модулирует процесс передачи сигнала в клетке, ассоциированный с геном, ответственным за развитие заболевания. Способ включает приведение исследуемого соединения в контакт с клеткой, содержащей один или несколько векторов, которые управляют экспрессией одного или нескольких из: фермента CRISPR и последовательности прямого повтора, связанной с направляющей последовательностью; и обнаружение изменения при считывании, которое свидетельствует об ослаблении или усилении процесса передачи сигнала в клетке, ассоциированного, например, с мутацией в гене, ответственном за развитие заболевания, который содержится в клетке.
Клеточную модель или животную модель можно сконструировать в сочетании со способом по настоящему изобретению для скрининга изменения клеточной функции. Такую модель можно применять для исследования влияния геномной последовательности, модифицированной с помощью комплекса CRISPR по настоящему изобретению, на представляющую интерес клеточную функцию. Например, модель клеточной функции можно применять для исследования воздействия модифицированной геномной последовательности на внутриклеточную передачу сигнала или внеклеточную передачу сигнала. Альтернативно модель клеточной функции можно применять для исследования воздействий модифицированной геномной последовательности на сенсорную чувствительность. В некоторых таких моделях одна или несколько геномных последовательностей, ассоциированных с биохимическим путем передачи сигнала, в модели является модифицированной.
Специально было исследовано несколько моделей заболеваний. Они включают гены CHD8, KATNAL2 и SCN2A, связанные с риском развития аутизма de novo, и ген UBE3A, связанный с синдромным аутизмом (синдром Ангельмана). Эти гены и полученные в результате модели аутизма, разумеется, являются предпочтительными, но служат для того, чтобы продемонстрировать широкую применимость настоящего изобретения по отношению к генам и соответствующим моделям. Измененную экспрессию одной или нескольких геномных последовательностей, ассоциированных с биохимическим путем передачи сигнала, можно определять при помощи анализа различия по уровням мРНК соответствующих генов между исследуемой модельной клеткой и контрольной клеткой, при приведении их в контакт с кандидатным средством. Альтернативно различную экспрессию последовательностей, ассоциированных с биохимическим путем передачи сигнала, определяют посредством выявления различия по уровню кодируемого полипептида или продукта гена.
Для анализа индуцированного определенным средством изменения уровня мРНК-транскриптов или соответствующих полинуклеотидов, нуклеиновую кислоту, которая содержится в образце, вначале экстрагируют в соответствии со стандартными способами из уровня техники. Например, матричную РНК можно выделять с применением различных литических ферментов или химических растворов в соответствии с процедурами, изложенными в Sambrook et al. (1989), или экстрагировать с помощью смол, связывающих нуклеиновые кислоты, в соответствии с прилагаемыми инструкциями, предоставленными производителями. Содержащуюся в экстрагированном образце нуклеиновой кислоты мРНК затем выявляют с помощью методик амплификации или традиционных гибридизационных анализов (например, анализа с помощью нозерн-блоттинга) в соответствии со способами, широко известными из уровня техники или основанными на способах, проиллюстрированных в данном документе.
Для целей настоящего изобретения амплификация означает любой способ с использованием праймера и полимеразы, способной обеспечивать репликацию целевой последовательности с достаточной точностью. Амплификацию можно осуществлять с помощью природных или рекомбинантных ДНК-полимераз, таких как TaqGold™, ДНК-полимераза T7, фрагмент Кленова ДНК-полимеразы E. coli и обратная транскриптаза. Предпочтительным способом амплификации является ПЦР. В частности, выделенную РНК можно подвергать анализу с обратной транскрипцией, который объединен с количественной полимеразной цепной реакцией (RT-PCR), для количественного определения уровня экспрессии последовательности, ассоциированной с биохимическим путем передачи сигнала.
Выявление уровня экспрессии генов можно осуществлять в анализе амплификации в режиме реального времени. В одном аспекте амплифицированные продукты можно непосредственно визуализировать с помощью флуоресцентных ДНК-связывающих средств, в том числе без ограничения ДНК-интеркаляторов и средств, связывающихся с бороздкой спирали ДНК. Поскольку количество интеркаляторов, включенных в двухнитевые молекулы ДНК, как правило, является пропорциональным количеству амплифицированных ДНК-продуктов, можно без труда определить количество амплифицированных продуктов путем количественного определения флуоресценции интеркалирующего красителя с применением традиционных оптических систем из уровня техники. ДНК-связывающий краситель, подходящий для этой задачи, охватывает SYBR зеленый, SYBR синий, DAPI, йодид пропидия, Hoeсhst, SYBR золотой, бромид этидия, акридины, профлавин, акридиновый оранжевый, акрифлавин, фторкумарин, эллиптицин, дауномицин, хлорохин, дистамицин D, хромомицин, хомидий, митрамицин, комплексы рутений-полипиридил, антрамицин и т. п.
В другом аспекте можно использовать другие флуоресцентные метки, например, зонды, специфичные по отношению к последовательности, в реакции амплификации для обеспечения выявления и количественного определения амплифицированных продуктов. Количественная амплификация с использованием зонда основана на специфичном по отношению к последовательности выявлении требуемого амплифицированного продукта. Используются флуоресцентные зонды, специфичные по отношению к мишени (например, зонды TaqMan®), что приводит в результате к увеличению специфичности и чувствительности. Способы осуществления количественной амплификации с использованием зонда являются общепринятыми в данной области и описаны в патенте США № 5210015.
В еще одном аспекте можно осуществлять традиционные гибридизационные анализы с использованием гибридизационных зондов, которые характеризуются гомологией последовательности с последовательностями, ассоциированными с биохимическим путем передачи сигнала. Как правило, в реакции гибридизации зондам дают возможность образовать стабильные комплексы с последовательностями, ассоциированными с биохимическим путем передачи сигнала, которые содержатся в биологическом образце, полученном от исследуемого субъекта. Специалисту в данной области будет понятно, что если антисмысловая нуклеиновая кислота используется в качестве зонда, то целевые полинуклеотиды, представленные в образце, выбирают так, чтобы они были комплементарными последовательностям антисмысловых нуклеиновых кислот. Напротив, если нуклеотидный зонд является смысловой нуклеиновой кислотой, то целевой полинуклеотид выбирают так, чтобы он был комплементарным последовательностям смысловой нуклеиновой кислоты.
Гибридизацию можно осуществлять в условиях различной жесткости. Подходящие условия гибридизации для осуществления на практике настоящего изобретения являются такими, что обеспечивающее распознавание взаимодействие зонда с последовательностями, ассоциированными с биохимическим путем передачи сигнала, является как достаточно специфичным, так и достаточно стабильным. Условия, которые приводят к увеличению жесткости реакции гибридизации, хорошо известны из уровня техники и являются опубликованными. См., например (Sambrook, et al., (1989); Nonradioactive In Situ Hybridization Application Manual, Boehringer Mannheim, second edition). Гибридизационный анализ можно осуществлять с применением зондов, иммобилизованных на любой твердой подложке, в том числе без ограничения нитроцеллюлозной, стеклянной, кремниевой, и ряда ДНК-чипов. Предпочтительный гибридизационный анализ проводят на генных чипах высокой плотности, описанных в патенте США № 5445934.
Для удобного выявления комплексов зонд-мишень, образованных в ходе гибридизационного анализа, осуществляют конъюгирование нуклеотидных зондов с детектируемой меткой. Детектируемые метки, подходящие для применения в настоящем изобретении, включают любую композицию, выявляемую с помощью фотохимических, биохимических, спектроскопических, иммунохимических, электрических, оптических или химических средств. Широкий спектр соответствующих детектируемых меток известен из уровня техники, причем он включает флуоресцентные или хемилюминесцентные метки, метки на основе радиоактивных изотопов, ферментные или другие лиганды. В предпочтительных вариантах осуществления, вероятно, предпочтительной будет флуоресцентная метка или ферментная метка, как, например, дигоксигенин, ß-галактозидаза, уреаза, щелочная фосфатаза или пероксидаза, комплекс авидин/биотин.
Способы выявления, применяемые для выявления или количественного определения интенсивности гибридизации, как правило, будут зависеть от метки, выбранной выше. Например, радиоактивные метки можно выявлять с использованием фотографической пленки или фосфовизуализатора. Флуоресцентные маркеры можно выявлять и количественно определять с использованием фотодетектора для выявления излучаемого света. Ферментные метки, как правило, выявляют посредством снабжения фермента субстратом и измерения количества продукта реакции, образованного при воздействии фермента на субстрат; и, наконец, колориметрические метки выявляют посредством простой визуализации цветной метки.
Индуцированное определенным средством изменение экспрессии последовательностей, ассоциированных с биохимическим путем передачи сигнала, также можно определять посредством исследования соответствующих продуктов генов. Определение уровня белка, как правило, включает a) приведение белка, содержащегося в биологическом образце, в контакт со средством, которое специфично связывается с белком, ассоциированным с биохимическим путем передачи сигнала; и (b) идентификацию любого комплекса средство:белок, образованного таким образом. В одном аспекте данного варианта осуществления средство, которое специфически связывает белок, ассоциированный с биохимическим путем передачи сигнала, представляет собой антитело, предпочтительно моноклональное антитело.
Реакцию осуществляют посредством приведения средства в контакт с образцом белков, ассоциированных с биохимическим путем передачи сигнала, полученным из тестируемых образцов, при условиях, которые обеспечивают возможность образования комплекса между средством и белками, ассоциированными с биохимическим путем передачи сигнала. Образование комплекса можно выявлять непосредственно или опосредованно в соответствии со стандартными процедурами из уровня техники. В способе непосредственного выявления средства снабжают детектируемой меткой и непрореагировавшие средства можно удалять от комплекса; количество оставшейся метки, таким образом, отражает количество образованного комплекса. Для такого способа предпочтительно выбирать метки, которые остаются прикрепленными к средствам даже при жестких условиях отмывки. Предпочтительно, чтобы метка не препятствовала реакции связывания. В альтернативном случае, для процедуры опосредованного выявления можно использовать средство, которое содержит метку, введенную либо химическим, либо ферментативным путем. Требуемая метка, как правило, не препятствует связыванию или стабильности полученного в результате комплекса средство:полипептид. Однако, метка, как правило, разработана так, чтобы она была доступной для эффективного связывания антителом и, следовательно, выработки детектируемого сигнала.
Широкий спектр меток, подходящих для выявления уровней белка, известен из уровня техники. Неограничивающие примеры включают радиоактивные изотопы, ферменты, коллоидные металлы, флуоресцентные соединения, биолюминесцентные соединения и хемилюминесцентные соединения.
Количество комплексов средство:полипептид, образованных в ходе реакции связывания, можно количественно определять с помощью стандартных количественных анализов. Как проиллюстрировано выше, образование комплекса средство:полипептид можно измерить непосредственно по количеству метки, оставшейся в сайте связывания. В альтернативном случае белок, ассоциированный с биохимическим путем передачи сигнала, исследуют в отношении его способности конкурировать с меченым аналогом за участки связывания на специфическом средстве. В этом конкурентном анализе количество захваченной метки является обратно пропорциональным количеству последовательностей белка, ассоциированного с биохимическим путем передачи сигнала, присутствующих в исследуемом образце.
Ряд методик анализа белка, основанных на общих принципах, изложенных выше, доступен из уровня техники. Они включают без ограничения радиоиммунные анализы, ELISA (твердофазные ферментные иммунорадиометрические анализы), "сэндвич"-иммуноанализы, иммунорадиометрические анализы, иммуноанализы in situ (с применением, например, коллоидного золота, фермента или радиоизотопных меток), вестерн-блот анализ, иммунопреципитационные анализы, иммунофлуоресцентные анализы и SDS-PAGE.
Антитела, которые обеспечивают специфичное распознавание или связываются с белками, ассоциированными с биохимическим путем передачи сигнала, являются предпочтительными для осуществления вышеупомянутых анализов белка. При необходимости можно применять антитела, которые обеспечивают распознавание конкретного типа посттрансляционных модификаций (например, модификации, индуцируемые биохимическим путем передачи сигнала). Посттрансляционные модификации включают без ограничения гликозилирование, липидизацию, ацетилирование и фосфорилирование. Эти антитела можно приобрести у коммерческих поставщиков. Например, антитела к фосфотирозину, которые обеспечивают специфичное распознавание фосфорилированных по тирозину белков, доступны от ряда поставщиков, включая Invitrogen и Perkin Elmer. Антитела к фосфотирозину являются особенно применимыми при выявлении белков, которые различным образом фосфорилируются по их тирозиновым остаткам в ответ на стресс ER (эндоплазматического ретикулума). Такие белки включают без ограничения эукариотический фактор инициации трансляции 2 альфа (eIF-2α). Альтернативно эти антитела можно получить с помощью традиционных технологий получения поликлональных или моноклональных антител посредством иммунизации животного-хозяина или клетки, продуцирующей антитела, целевым белком, который характеризуется необходимой посттрансляционной модификацией.
При осуществлении заявленного способа на практике может быть необходимо определить профиль экспрессии белка, ассоциированного с биохимическим путем передачи сигнала, в различных тканях организма, в различных типах клеток и/или в различных субклеточных структурах. Данные исследования можно проводить с применением тканеспецифичных, специфичных к определенным клеткам или специфичных к определенным субклеточным структурам антител, способных связываться с белковыми маркерами, которые преимущественно экспрессируются в определенных тканях, типах клеток или субклеточных структурах.
Измененную экспрессию гена, ассоциированного с биохимическим путем передачи сигнала, также можно определять с помощью исследования изменения активности продукта гена по сравнению с контрольной клеткой. Анализ индуцированного определенным средством изменения активности белка, ассоциированного с биохимическим путем передачи сигнала, будет зависеть от биологической активности и/или исследуемого пути передачи сигнала. Например, если белок представляет собой киназу, изменение его способности фосфорилировать субстрат(субстраты) на последующих стадиях можно определять посредством ряда анализов, известных из уровня техники. Иллюстративные анализы включают без ограничения иммуноблоттинг и иммунопреципитацию с использованием антител, таких как антитела к фосфотирозину, которые обеспечивают распознавание фосфорилированных белков. Кроме того, активность киназы можно выявлять с помощью высокопроизводительных хемилюминесцентных анализов, как, например, анализов AlphaScreen™ (доступный от Perkin Elmer) и eTag™ (Chan-Hui, et al. (2003) Clinical Immunology 111: 162-174).
Если белок, ассоциированный с биохимическим путем передачи сигнала, является частью сигнального каскада, который приводит к колебанию внутриклеточных условий pH, молекулы, чувствительные к pH, например, флуоресцентные pH-чувствительные красители, можно применять в качестве репортерных молекул. В другом примере, если белок, ассоциированный с биохимическим путем передачи сигнала, представляет собой ионный канал, можно отслеживать колебания мембранного потенциала и/или внутриклеточной концентрации ионов. Ряд коммерческих наборов и высокопроизводительных устройств являются особенно подходящими для быстрого и надежного скрининга модуляторов ионных каналов. Иллюстративные инструменты включают FLIPRTM (Molecular Devices, Inc.) и VIPR (Aurora Biosciences). Эти инструменты способны обеспечивать одновременное выявление реакций в более чем 1000 лунках с образцом в микропланшете и обеспечивать измерение в реальном времени и функциональные данные в течение секунды или даже миллисекунды.
При осуществлении на практике любых способов, раскрытых в данном документе, подходящий вектор можно вводить в клетку или эмбрион посредством одного или нескольких способов, известных из уровня техники, в том числе без ограничения микроинъекции, электропорации, сонопорации, баллистической трансфекции, трансфекции, опосредованной фосфатом кальция, трансфекции с помощью катионных липидных частиц, липосомной трансфекции, трансфекции с помощью дендримеров, трансфекции посредством теплового шока, трансфекции посредством нуклеофекции, магнитофекции, липофекции, импалефекции, оптической трансфекции, поглощения нуклеиновых кислот, стимулируемого проприетарным средством, и доставки с помощью липосом, иммунолипосом, виросом или искусственных вирионов. В некоторых способах вектор вводят в эмбрион посредством микроинъекции. Можно осуществлять микроинъекцию вектора или векторов в ядро или цитоплазму эмбриона. В некоторых способах вектор или векторы можно вводить в клетку посредством нуклеофекции.
Целевым полинуклеотидом для комплекса CRISPR может быть любой полинуклеотид, эндогенный или экзогенный по отношению к эукариотической клетке. Например, целевой полинуклеотид может быть полинуклеотидом, находящимся в ядре эукариотической клетки. Целевой полинуклеотид может быть последовательностью, кодирующей продукт гена (к примеру, белок), или некодирующей последовательностью (к примеру, регуляторным полинуклеотидом или избыточной ДНК).
Примеры целевых полинуклеотидов включают последовательность, ассоциированную с биохимическим путем передачи сигнала, например, ген или полинуклеотид, ассоциированный с биохимическим путем передачи сигнала. Примеры целевых полинуклеотидов включают ассоциированный с заболеванием ген или полинуклеотид. "Ассоциированный с заболеванием" ген или полинуклеотид означает любой ген или полинуклеотид, который обеспечивает продукты транскрипции или трансляции на аномальном уровне или в аномальной форме в клетках, полученных из пораженных заболеванием тканей, по сравнению с тканями или клетками контроля без заболевания. Это может быть ген, который начинает экспрессироваться при аномально высоком уровне; это может быть ген, который начинает экспрессироваться при аномально низком уровне, где измененная экспрессия коррелирует с появлением и/или прогрессированием заболевания. Ассоциированный с заболеванием ген также означает ген, несущий мутацию(мутации) или генетическую вариацию, который непосредственно ответственен или находится в неравновесном сцеплении с геном(генами), ответственным(ответственными) за этиологию заболевания. Транскрибируемые или транслируемые продукты могут быть известными или неизвестными и могут присутствовать на нормальном или аномальном уровне.
Целевым полинуклеотидом для комплекса CRISPR может быть любой полинуклеотид, эндогенный или экзогенный по отношению к эукариотической клетке. Например, целевой полинуклеотид может быть полинуклеотидом, находящимся в ядре эукариотической клетки. Целевой полинуклеотид может быть последовательностью, кодирующей продукт гена (к примеру, белок), или некодирующей последовательностью (к примеру, регуляторным полинуклеотидом или избыточной ДНК). Не вдаваясь в теорию, полагают, что целевая последовательность должна быть ассоциирована с PAM (мотивом, смежным с протоспейсером); то есть короткой последовательностью, узнаваемой комплексом CRISPR. Определенные требования в отношении последовательности и длины PAM различаются в зависимости от применяемого фермента CRISPR, но PAM, как правило, являются последовательностями в 2-5 пар оснований, смежными с протоспейсером (то есть целевой последовательностью). Примеры последовательностей PAM приведены в разделе "Примеры" ниже, и специалист в данной области техники сможет выявить дополнительные последовательности PAM для применения с данным ферментом CRISPR. Кроме того, конструирование взаимодействующего с PAM (PI) домена может обеспечить программирование PAM специфичности, улучшенную точность сайта распознавания цели и повышенную универсальность платформы конструирования генома Cas, например, Cas9. Белки Cas, такие как белки Cas9, можно конструировать с изменением их специфичности в отношении PAM, например, как описывается у Kleinstiver BP et al. Engineered CRISPR-Cas9 nucleases with altered PAM specificities. Nature. 2015 Jul 23;523(7561):481-5. doi: 10.1038/nature14592.
Целевой полинуклеотид для комплекса CRISPR может включать ряд ассоциированных с заболеваниями генов и полинуклеотидов, а также генов и полинуклеотидов, ассоциированных с биохимическими путями передачи сигнала, которые перечислены в предварительных заявках на патент США 61/736527 и 61/748427 с общей ссылкой BI-2011/008/WSGR, номер в реестре 44063-701.101, и BI-2011/008/WSGR, номер в реестре 44063-701.102, соответственно, обе под названием SYSTEMS METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION, поданные 12 декабря 2012 г. и 2 января 2013 г. соответственно, и заявку согласно PCT/US2013/074667, под названием DELIVERY, ENGINEERING AND OPTIMIZATION OF SYSTEMS, METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION AND THERAPEUTIC APPLICATIONS, поданную 12 декабря 2013 г., каждое содержание из которых включено в данный документ при помощи ссылки во всей их полноте.
Примеры целевых полинуклеотидов включают последовательность, ассоциированную с биохимическим путем передачи сигнала, например, ген или полинуклеотид, ассоциированный с биохимическим путем передачи сигнала. Примеры целевых полинуклеотидов включают ассоциированный с заболеванием ген или полинуклеотид. "Ассоциированный с заболеванием" ген или полинуклеотид означает любой ген или полинуклеотид, который обеспечивает продукты транскрипции или трансляции на аномальном уровне или в аномальной форме в клетках, полученных из пораженных заболеванием тканей, по сравнению с тканями или клетками контроля без заболевания. Это может быть ген, который начинает экспрессироваться при аномально высоком уровне; это может быть ген, который начинает экспрессироваться при аномально низком уровне, где измененная экспрессия коррелирует с появлением и/или прогрессированием заболевания. Ассоциированный с заболеванием ген также означает ген, несущий мутацию(мутации) или генетическую вариацию, который непосредственно ответственен или находится в неравновесном сцеплении с геном(генами), ответственным(ответственными) за этиологию заболевания. Транскрибируемые или транслируемые продукты могут быть известными или неизвестными и могут присутствовать на нормальном или аномальном уровне.
Скрининг полногеномного нокаута
Белки и системы CRISPR, описываемые в настоящем документе, можно применять для выполнения эффективных и рентабельных функциональных геномных тестов. В таких тестах можно использовать эффекторный белок CRISPR на основе полногеномных библиотек. Такие тесты и библиотеки могут обеспечить определение функции генов, вовлечение генов клеточных путей, и того, как какое-либо изменение в экспрессии гена может привести к определенному биологическому процессу. Преимущество настоящего изобретения заключается в том, что система CRISPR исключает нецелевое связывание и возникающие в результате этого побочные эффекты. Это достигается при использовании систем, предусматривающих наличие высокой степени специфичности к последовательности в отношении целевой ДНК. В предпочтительных вариантах осуществления настоящего изобретения комплексы эффекторного белка CRISPR представляют собой комплексы эффекторного белка Cpf1.
В вариантах осуществления настоящего изобретения полногеномная библиотека может содержать множество направляющих РНК Cpf1, описываемых в настоящем документе, содержащих направляющие последовательности, которые способны нацеливаться на множество целевых последовательностей во множестве локусов генома в популяции эукариотических клеток. Популяцией клеток может быть популяция эмбриональных стволовых (ES) клеток. Целевой последовательностью в локусе генома может быть некодирующая последовательность. Некодирующей последовательностью может быть интрон, регуляторная последовательность, сайт сплайсинга, 3'-UTR, 5'-UTR или сигнал полиаденилирования. Функция гена одного или нескольких продуктов генов может быть изменена указанным нацеливанием. Нацеливание может приводить к нокауту функции гена. Нацеливание на продукт гена может предусматривать более чем одну направляющую РНК. На продукт гена можно нацеливаться с помощью 2, 3, 4, 5, 6, 7, 8, 9 или 10 направляющих РНК, предпочтительно 3-4 на ген. Нецелевые модификации можно свести к минимуму при использовании ступенчатых двухнитевых разрывов, созданных при помощи комплексов эффекторного белка Cpf1 или при помощи способов, аналогичных используемым в системах CRISPR-Cas9 (см., специфичность нацеливания на ДНК направляемых РНК нуклеаз Cas9. Hsu, P., Scott, D., Weinstein, J., Ran, FA., Konermann, S., Agarwala, V., Li, Y., Fine, E., Wu, X., Shalem, O., Cradick, TJ., Marraffini, LA., Bao, G., & Zhang, F. Nat Biotechnol doi:10.1038/nbt.2647 (2013)), включенную в данный документ посредством ссылки. Нацеливание может предусматривать приблизительно 100 или более последовательностей. Нацеливание может предусматривать приблизительно 1000 или более последовательностей. Нацеливание может предусматривать приблизительно 20000 или более последовательностей. Нацеливание может предусматривать полный геном. Нацеливание может предусматривать панель целевых последовательностей, ориентированных на релевантном или желательном пути. Путь может быть иммунным путем. Путь может быть путем клеточного деления.
Один аспект настоящего изобретения охватывает полногеномную библиотеку, которая может содержать множество направляющих РНК Cpf1, которое может содержать направляющие последовательности, способные нацеливаться на множество целевых последовательностей во множестве локусов генома, где указанное нацеливание приводит к нокауту/нокдауну генной функции. Эта библиотека потенциально может содержать направляющие РНК, которые нацеливаются на каждый без исключения ген в геноме организма.
В некоторых вариантах осуществления по настоящему изобретению организм или субъект является эукариотом (в том числе млекопитающим, в том числе человеком), или эукариотическим организмом, отличным от человека, или отличным от человека животным, или отличным от человека млекопитающим. В некоторых вариантах осуществления организм или субъект является отличным от человека животным и может быть членистоногим, например, насекомым, или может быть нематодой. В некоторых способах по настоящему изобретению организм или субъект является растением. В некоторых способах по настоящему изобретению организм или субъект является млекопитающим или отличным от человека млекопитающим. Отличное от человека млекопитающее может быть, например, грызуном (предпочтительно мышью или крысой), копытным или приматом. В некоторых способах по настоящему изобретению организм или субъект является водорослью, в том числе микроводорослью, или является грибом.
Нокаут/нокдаун генной функции может предусматривать введение в каждую клетку в популяции клеток векторной системы из одного или нескольких векторов, содержащих сконструированную, не встречающуюся в природе систему эффекторного белка Cpf1, содержащую I. белок Cpf1 и II. одну или несколько направляющих РНК, где компоненты I и II могут находиться на одном и том же или на разных векторах системы, вводящей компоненты I и II в каждую клетку, где направляющая последовательность нацеливается на уникальный ген в каждой клетке, где эффекторный белок Cpf1 функционально связан с регуляторным элементом, где при транскрибировании направляющая РНК, содержащая направляющую последовательность, управляет специфичным к последовательности связыванием системы эффекторного белка Cpf1 с целевой последовательностью, соответствующей локусам генома уникального гена с индуцированием расщепления геномного локуса эффекторным белком Cpf1 и подтверждением разных мутаций нокаута/нокдауна во множестве уникальных генов в каждой клетке популяция клеток с образованием тем самым библиотеки клеток с нокаутом/нокдауном гена. Настоящее изобретение предусматривает, что популяцией клеток является популяция эукариотических клеток, а в предпочтительном варианте осуществления популяцией клеток является популяция эмбриональных стволовых (ES) клеток.
Одним или несколькими векторами могут быть плазмидные векторы. Вектором может быть один вектор, содержащий эффекторный белок Cpf1, gRNA и необязательно маркер отбора в целевых клетках. Без углубления в теорию способность одновременно доставлять эффекторный белок Cpf1 и gRNA при помощи одного вектора обеспечивает применение для любого представляющего интерес типа клеток, без необходимости сначала создавать линии клеток, которые экспрессируют эффекторный белок Cpf1. Регуляторным элементом может быть индуцируемый промотор. Индуцируемый промотор может представлять собой доксициклиновый индуцируемый промотор. В некоторых способах по настоящему изобретению экспрессия направляющей последовательности находится под контролем промотора T7 и управляется экспрессией полимеразы T7. Подтверждение различных мутаций нокаута/нокдауна можно осуществлять полноэкзомным секвенированием. Мутация нокаута/нокдауна может быть достигнута в 100 или более уникальных генов. Мутация нокаута/нокдауна может быть достигнута в 1000 или более уникальных генов. Мутация нокаута/нокдауна может быть достигнута в 20000 или более уникальных генов. Мутация нокаута/нокдауна может быть достигнута во всем геноме. Нокаут/нокдаун генной функции может быть достигнут во множестве уникальных генов, которые функционируют в конкретном физиологическом пути или состоянии. Путь или состояние может быть иммунным путем или состоянием. Путь или состояние может быть путем или состоянием клеточного деления.
Настоящее изобретение также относится к набору, который содержит полногеномные библиотеки, упоминаемые в данном документе. Набор может содержать один контейнер, содержащий векторы или плазмиды, содержащие библиотеку в соответствии с настоящим изобретением. Набор также может содержать панель, предусматривающую отбор уникальных направляющих РНК системы эффекторного белка Cpf1, содержащих направляющие последовательности из библиотеки в соответствии с настоящим изобретением, где отбор указывает на конкретное физиологическое состояние. Настоящее изобретение предусматривает то, что нацеливание составляет приблизительно 100 или больше последовательностей, приблизительно 1000 или больше последовательностей или приблизительно 20000 или больше последовательностей или весь геном. Кроме того, панель целевых последовательностей может быть ориентирована на релевантный или желаемый путь, такой как иммунный путь или клеточное деление.
В дополнительном аспекте настоящего изобретения эффекторный белок Cpf1 может содержать одну или несколько мутаций и может применяться в качестве стандартного ДНК-связывающего белка, слитого или не слитого с функциональным доменом. Мутации могут представлять собой мутации, введенные искусственным образом, или мутации приобретения или потери функции. Мутации характеризовали, как описано в данном документе. В одном аспекте настоящего изобретения функциональным доменом может быть домен активации транскрипции, которым может быть VP64. В других аспектах настоящего изобретения функциональным доменом может быть домен репрессии транскрипции, которым может быть KRAB или SID4X. Другие аспекты настоящего изобретения относятся к мутантному эффекторному белку Cpf1, слитому с доменами, которые включают без ограничения активатор транскрипции, репрессор транскрипции, рекомбиназу, транспозазу, фактор ремоделирования гистонов, деметилазу, ДНК-метилтрансферазу, криптохром, домен, индуцируемый/регулируемый светом, или домен, индуцируемый/регулируемый химическими веществами. Некоторые способы в соответствии с настоящим изобретением могут предусматривать индуцирование экспрессии целевых генов. В одном варианте осуществления индуцирование экспрессии путем нацеливания на множество целевых последовательностей во множестве локусов генома в популяции эукариотических клеток осуществляется путем применения функционального домена.
Применительно к осуществлению настоящего изобретения существуют способы, в которых используются комплексы эффекторного белка Cpf1, применяемые в системах CRISPR-Cas9, и ссылаются на:
Genome-Scale CRISPR-Cas9 Knockout Screening in Human Cells. Shalem, O., Sanjana, NE., Hartenian, E., Shi, X., Scott, DA., Mikkelson, T., Heckl, D., Ebert, BL., Root, DE., Doench, JG., Zhang, F. Science Dec 12. (2013). [Epub ahead of print]; опубликовано в окончательной отредактированной форме как: Science. 2014 Jan 3; 343(6166): 84-87.
Shalem et al. описали новый способ исследования функций генов в полногеномном масштабе. Их исследования показали, что доставка библиотеки CRISPR-Cas9 для нокаута в масштабе генома (GeCKO), целенаправленно воздействующей на 18080 генов, с 64751 уникальной направляющей последовательностью обеспечивала скрининг путем как положительного, так и отрицательного отбора в клетках человека. Во-первых, авторы показали применение библиотеки GeCKO для идентификации генов, существенных для жизнеспособности клеток у раковых и плюрипотентных стволовых клеток. Далее, в модели меланомы, авторы провели скрининг генов, утрата функций которых вовлечена в устойчивость к вемурафенибу, терапевтическому средству, ингибирующему мутантную протеинкиназу BRAF. Их исследования показали, что кандидаты высшего ранга включали ранее подтвержденные гены NF1 и MED12, а также новые хиты NF2, CUL3, TADA2B и TADA1. Авторы наблюдали высокий уровень согласованности между независимыми направляющими РНК, осуществляющими нацеливание на один и тот же ген, и высоким показателем подтверждения хитов и, таким образом, продемонстрировали перспективность скрининга с помощью Cas9 в масштабе генома.
Также можно упомянуть в качестве ссылок заявку на патент США № US20140357530 и патентную публикацию PCT № WO2014093701, включенные тем самым в данный документ посредством ссылки. Также ссылаются на пресс-релиз NIH от 22 октября 2015 г. под названием "Researchers identify potential alternative to CRISPR-Cas genome editing tools: New Cas enzymes shed light on evolution of CRISPR-Cas systems", который включен посредстсвом ссылки.
Функциональное изменение и скрининг
В другом аспекте настоящее изобретение предусматривает способ функциональной оценки и скрининга генов. Применение системы CRISPR по настоящему изобретению для точной доставки функциональных доменов, для активации или репрессии генов или для изменения эпигенетического состояния при помощи точного изменения сайта метилирования в конкретном представляющем интерес локусе можно осуществлять с помощью одной или нескольких направляющих РНК, применяемых к одной клетке или популяции клеток, или с помощью библиотеки, применяемой к геному в пуле клеток ex vivo или in vivo, при этом предусматривается введение или экспрессия библиотеки, содержащей множество направляющих РНК (gRNA), и при этом тестирование дополнительно предусматривает применение эффекторного белка Cpf1, где комплекс CRISPR, содержащий эффекторный белок Cpf1, модифицирован с целью содержания гетерологичного функционального домена. В одном аспекте настоящего изобретения предусмотрен способ скрининга генома, включающий введение хозяину библиотеки или ее экспрессию у хозяина in vivo. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, дополнительно включающий введение хозяину активатора или его экспрессию у хозяина. В одном аспекте настоящее изобретение относится к способу, обсуждаемому в данном документе, где активатор присоединяется к эффекторному белку Cpf1. В одном аспекте настоящее изобретение относится к способу, обсуждаемому в данном документе, где активатор прикреплен к N-концу или C-концу эффекторного белка Cpf1. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где активатор прикреплен к петле gRNA. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, дополнительно включающий введение хозяину репрессора или его экспрессию у хозяина. В одном аспекте настоящеее изобретение относится к способу, обсуждаемому в данном документе, где скрининг предусматривает воздействие на активацию гена, ингибирование гена или расщепление в локусе, и выявление указанного.
В одном аспекте настоящего изобретения предусмотрены эффективная целевая активность и сведенная к минимуму нецелевая активность. В одном аспекте настоящеее изобретение относится к эффективному целевому расщеплению с помощью эффекторного белка Cpf1 и сведенному к минимуму нецелевому расщеплению под действием эффекторного белка Cpf1. В одном аспекте настоящего изобретения предусмотрено направленно-специфичное связывание эффекторного белка Cpf1 в генном локусе без расщепления ДНК. Соответственно, в одном аспекте настоящего изобретения предусмотрена специфичная к мишени генная регуляция. В одном аспекте настоящего изобретения предусмотрено направленно-специфичное связывание эффекторного белка Cpf1 в генном локусе без расщепления ДНК. Соответственно, в одном аспекте настоящее изобретение относится к расщеплению в одном генном локусе и генной регуляции в другом генном локусе с применением одного эффекторного белка Cpf1. В одном аспекте настоящее изобретение относится к ортогональной активации, и/или ингибированию, и/или расщеплению нескольких мишеней с применением одного или нескольких эффекторных белков и/или ферментов Cpf1.
В одном аспекте настоящее изобретение относится к способу, обсуждаемому в данном документе, где хозяином является эукариотическая клетка. В одном аспекте настоящее изобретение относится к способу, обсуждаемому в данном документе, где хозяином является клетка млекопитающего. В одном аспекте настоящее изобретение относится к способу, обсуждаемому в данном документе, где хозяином является эукариотический организм, отличный от человека. В одном аспекте настоящее изобретение относится к способу, обсуждаемому в данном документе, где эукариотическим организмом, отличным от человека, является отличное от человека млекопитающее. В одном аспекте настоящее изобретение относится к способу, обсуждаемому в данном документе, где отличным от человека млекопитающим является мышь. В одном аспекте настоящее изобретение относится к способу, обсуждаемому в данном документе, предусматривающему доставку комплексов эффекторного белка Cpf1, или их компонента(компонентов), или молекулы(молекул) нуклеиновой кислоты, кодирующей их, где указанная(указанные) молекула(молекулы) нуклеиновой кислоты функционально связана(связаны) с регуляторной(регуляторными) последовательностью(последовательностями) и экспрессируется(экспрессируются) in vivo. В одном аспекте настоящее изобретение относится к способу, обсуждаемому в данном документе, где экспрессия in vivo осуществляется с помощью лентивируса, аденовируса или AAV. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где доставка осуществляется с помощью частицы, наночастицы, липида или пептида, проникающих в клетку (CPP).
В одном аспекте настоящее изобретение относится к паре комплексов CRISPR, содержащих эффекторный белок Cpf1, при этом каждый из них содержит направляющую РНК (gRNA), предусматривающую направляющую последовательность, способную гибридизироваться с целевой последовательностью в представляющем интерес локусе генома в клетке, где по меньшей мере одна петля каждой gRNA является модифицированной путем вставки отличающейся(отличающихся) последовательности(последовательностей) РНК, которая(которые) связывается(связываются) с одним или несколькими адаптерными белками, и где адаптерный белок связывается с одним или несколькими функциональными доменами, где каждая gRNA из каждого комплекса эффекторного белка Cpf1 содержит функциональный домен, характеризующийся активностью расщепления ДНК. В одном аспекте настоящее изобретение относится к парным комплексам эффекторного белка Cpf1, обсуждаемым в данном документе, где активность расщепления ДНК обусловлена нуклеазой Fok1.
В одном аспекте настоящее изобретение относится к способу разрезания целевой последовательности в представляющем интерес локусе генома, включающему доставку в клетку комплексов эффекторного белка Cpf1, или их компонента(компонентов), или молекулы(молекул) нуклеиновой кислоты, кодирующей их, где указанная(указанные) молекула(молекулы) нуклеиновой кислоты функционально связана(связаны) с регуляторной(регуляторными) последовательностью(последовательностями) и экспрессируется(экспрессируются) in vivo. В одном аспекте настоящего изобретения предусмотрен способ, обсуждаемый в данном документе, где доставка осуществляется с помощью лентивируса, аденовируса или AAV. В одном аспекте настоящее изобретение относится к способу, обсуждаемому в данном документе, или парным комплексам эффекторного белка Cpf1, обсуждаемым в данном документе, где целевая последовательность для первого комплекса из пары находится на первой нити двухнитевой ДНК, а целевая последовательность для второго комплекса из пары находится на второй нити двухнитевой ДНК. В одном аспекте настоящее изобретение относится к способу, обсуждаемому в данном документе, или парным комплексам эффекторного белка Cpf1, обсуждаемым в данном документе, где целевые последовательности первого и второго комплексов расположены близко друг от друга, так что ДНК разрезается таким способом, который облегчает репарацию с помощью гомологичной рекомбинации. В одном аспекте способ, изложенный в данном документе, может дополнительно включать введение в клетку ДНК-матрицы. В одном аспекте способа, изложенного в данном документе, могут подразумеваться парные комплексы эффекторного белка Cpf1, изложенные в данном документе, где каждый комплекс эффекторного белка Cpf1 имеет эффекторый фермент Cpf1, который является мутированным, так что он характеризуется не более, чем приблизительно 5% нуклеазной активности эффекторного фермента Cpf1, который не является мутированным.
В одном аспекте настоящего изобретения предусмотрены библиотека, способ или комплекс, обсуждаемые в данном документе, где gRNA является модифицированной так, что она имеет по меньшей мере одну некодирующую функциональную петлю, например, где по меньшей мере одна некодирующая функциональная петля является репрессорной; например, где по меньшей мере одна некодирующая функциональная петля содержит Alu.
В одном аспекте настоящего изобретения предусмотрен способ изменения или модифицирования экспрессии продукта гена. Указанный способ может включать введение в клетку, содержащую и экспрессирующую молекулу ДНК, кодирующую продукт гена, сконструированной, не встречающейся в природе системы CRISPR, содержащей эффекторный белок Cpf1 и направляющую РНК, которая нацеливается на молекулу ДНК, в результате чего направляющая РНК нацеливается на молекулу ДНК, кодирующую продукт гена, а эффекторный белок Cpf1 расщепляет молекулу ДНК, кодирующую продукт гена, в результате чего изменяется экспрессия продукта гена; и где эффекторынй белок Cpf1 и направляющая РНК не встречаются в природе вместе. Настоящее изобретение охватывает направляющую РНК, предусматривающую направляющую последовательность, связанную с последовательностью прямого повтора. Настоящее изобретение дополнительно охватывает эффекторный белок Cpf1, который является кодон-оптимизированным для экспрессии в эукариотической клетке. В предпочтительном варианте осуществления эукариотическая клетка является клеткой млекопитающего, и в более предпочтительном варианте осуществления клетка млекопитающего является клеткой человека. В дополнительном варианте осуществления настоящего изобретения экспрессия продукта гена является сниженной.
В некоторых вариантах осуществления один или несколько функциональных доменов ассоциируются с эффекторным белком Cpf1. В некоторых вариантах осуществления один или несколько функциональных доменов ассоциируются с адапторным белком, например, как используется с модифицированными направляющими у Konnerman et al. (Nature 517, 583-588, 29 января 2015 г.). В некоторых вариантах осуществления один или несколько функциональных доменов связываются с нефункциональными gRNA (dRNA). В некоторых вариантах осуществления комплекс dRNA с активным эффекторным белком Cpf1 управляет регуляцией генов с помощью функционального домена в одном генном локусе, тогда как gRNA управляет расщеплением ДНК с помощью активного эффекторного белка Cpf1 в другом локусе, например, как описано аналогично в системах CRISPR-Cas9 у Dahlman et al., ‘Orthogonal gene control with a catalytically active Cas9 nuclease' (in press). В некоторых вариантах осуществления dRNA отбирают для обеспечения максимальной селективности регуляции для представляющего интерес генного локуса по сравнению с нецелевой регуляцией. В некоторых вариантах осуществления dRNA отбирают для обеспечения максимальной регуляции целевого гена и минимального целевого расщепления.
Для целей следующего обсуждения эталоном функционального домена может быть функциональный домен, ассоциированный с эффекторным белком Cpf1, или функциональный домен, ассоциированный с адапторным белком.
При осуществлении настоящего изобретения петли в sgRNA могут быть увеличены без столкновения с белком Cpf1 путем вставки другой(других) петли(петель) РНК или другой(других) последовательности(последовательностей), которая(которые) может(могут) рекрутировать адапторные белки, которые могут связываться с другой(другими) петлей(петлями) РНК или другой(другими) последовательностью(последовательностями). Адаптерные белки могут включать без ограничения комбинации ортогональный связывающий РНК белок/аптамер, которые встречаются во множестве белков оболочки бактериофагов. Перечень таких белков оболочки включает без ограничения Qβ, F2, GA, fr, JP501, M12, R17, BZ13, JP34, JP500, KU1, M11, MX1, TW18, VK, SP, FI, ID2, NL95, TW19, AP205, φCb5, φCb8r, φCb12r, φCb23r, 7s и PRR1. Такие адаптерные белки или ортогональные связывающие РНК белки могут дополнительно ректурировать эффекторные белки или продукты слияния, которые содержат один или несколько функциональных доменов. В некоторых вариантах осуществления функциональный домен может быть выбран из группы, состоящей из домена транспозазы, домена интегразы, домена рекомбиназы, домена резольвазы, домена инвертазы, домена протеазы, домена ДНК-метилтрансферазы, домена ДНК-гидроксилметилазы, домена ДНК-деметилазы, домена гистонацетилазы, домена гистондеацетилазы, нуклеазного домена, репрессорного домена, активаторного домена, доменов сигнала ядерной локализации, домена регуляторного белка транскрипции (или вовлечения транскрипционного комплекса), ассоциированного с активностью клеточного поглощения домена, домена связывания нуклеиновой кислоты, домена представления антитела, модифицирующих гистоны ферментов, рекрутера модифицирующих гистоны ферментов; ингибитора модифицирующих гистоны ферментов, гистонметилтрансферазы, гистондеметилазы, гистонкиназы, гистонфосфатазы, гистонрибозилазы, гистондерибозилазы, гистонубиквитиназы, гистондеубиквитиназы, гистонбиотиназы и протеазы гистонового хвоста. В некоторых предпочтительных вариантах осуществления функциональным доменом является домен активации транскрипции, такой как без ограничения VP64, p65, MyoD1, HSF1, RTA, SET7/9 или гистонацетилтрансфераза. В некоторых вариантах осуществления функциональный домен представляет собой домен репрессии транскрипции, предпочтительно KRAB. В некоторых вариантах осуществления домен репрессии транскрипции представляет собой SID или конкатемеры SID (например, SID4X). В некоторых вариантах осуществления функциональный домен представляет собой домен эпигенетического модифицирования, так что обеспечивается фермент эпигенетического модифицирования. В некоторых вариантах осуществления функциональный домен представляет собой домен активации, который может представлять собой домен активации P65.
В некоторых вариантах осуществления один или несколько функциональных доменов представляют собой NLS (последовательность ядерной локализации) или NES (сигнал ядерного экспорта). В некоторых вариантах осуществления один или несколько функциональных доменов представляют собой домен активации транскрипции, который включает в себя VP64, p65, MyoD1, HSF1, RTA, SET7/9 и гистонацетилтрансферазу. Другие упоминания в данном документе доменов активации (или активатора) в отношении доменов, ассоциированных с ферментом CRISPR, включают в себя любой известный домен активации транскрипции и, в частности, VP64, p65, MyoD1, HSF1, RTA, SET7/9 или гистонацетилтрансферазу.
В некоторых вариантах осуществления один или несколько функциональных доменов представляют собой домен репрессии транскрипции. В некоторых вариантах осуществления домен репрессии транскрипции представляет собой домен KRAB. В определенных вариантах осуществления домен репрессии транскрипции представляет собой домен NuE, домен NcoR, домен SID или домен SID4X.
В некоторых вариантах осуществления один или несколько функциональных доменов характеризуются одной или несколькими видами активности, предусматривающими метилазную активность, деметилазную активность, активность в отношении активации транскрипции, активность в отношении репрессии транскрипции, активность фактора освобождения транскрипта, активность в отношении модификации гистонов, активность расщепления РНК, активность расщепления ДНК, активность интеграции ДНК или активность связывания нуклеиновой кислоты.
Домены, модифицирующие гистоны, также являются предпочтительными в некоторых вариантах осуществления. Иллюстративные домены, модифицирующие гистоны, обсуждаются ниже. Домены транспозазы, домены механизма HR (гомологичной рекомбинации), домены рекомбиназы и/или домены интегразы также являются предпочтительными в качестве функциональных доменов по настоящему изобретению. В некоторых вариантах осуществления активность интеграции ДНК имеют домены механизма HR, домены интегразы, домены рекомбиназы и/или домены транспозазы. Гистонацетилтрансфераза является предпочтительной в некоторых вариантах осуществления.
В определенных вариантах осуществления активность расщепления ДНК обусловлена нуклеазой. В некоторых вариантах осуществления нуклеаза содержит нуклеазу Fok1. См. "Dimeric CRISPR RNA-guided FokI nucleases for highly specific genome editing", Shengdar Q. Tsai, Nicolas Wyvekens, Cyd Khayter, Jennifer A. Foden, Vishal Thapar, Deepak Reyon, Mathew J. Goodwin, Martin J. Aryee, J. Keith Joung Nature Biotechnology 32(6): 569-77 (2014) в отношении направляемых димерной РНК нуклеаз FokI, которые распознают продленные последовательности и могут редактировать эндогенные гены с высокой эффективностью в человеческих клетках.
В некоторых вариантах осуществления один или несколько функциональных доменов присоединяются к эффекторному белку Cpf1 так, что при связывании с sgRNA и мишенью функциональный домен находится в пространственной ориентации, позволяющей функциональному домену функционировать с приписываемой ему функцией.
В некоторых вариантах осуществления один или несколько функциональных доменов присоединяются к адапторному белку так, что при связывании эффекторного белка Cpf1 с gRNA и мишенью функциональный домен находится в пространственной ориентации, позволяющей функциональному домену функционировать с приписываемой ему функцией.
В одном аспекте настоящее изобретение относится к композиции, обсуждаемой в настоящем документе, где один или несколько функциональных доменов присоединяются к эффекторному белку Cpf1 или адапторному белку через линкер, необязательно линкер GlySer, как обсуждается в настоящем документе.
Эндогенная репрессия транскрипции зачастую опосредуется модифицирующими хроматин ферментами, такими как гистонметилтрансферазы (HMT) и деацетилазы (HDAC). Типичная гистоновые эффекторные домены известны, и иллюстративный перечень представлен ниже. В иллюстративной таблице упоминаются белки и функциональные усечения небольших размеров для облегчения эффективной вирусной упаковки (например, посредством AAV). В целом, однако, домены могут включать в себя HDAC, гистонметилтрансферазы (HMT) и ингибиторы гистонацетилтрансферазы (HAT), а также рекрутирующие HDAC и HMT белки. Функциональный домен может представлять собой или включать в некоторых вариантах осуществления эффекторные домены HDAC, рекрутерные эффекторные домены HDAC, эффекторные домены гистонметилтрансферазы (HMT), рекрутерные эффекторные домены гистонметилтрансферазы (HMT) или ингибиторные эффекторные домены гистонацетилтрансферазы.
Эффекторные домены HDAC
Комп-лекс
ние
H4K16Ac
H3K56Ac
H4K16Ac
H3K56Ac
Следовательно, репрессорные домены в соответствии с настоящим изобретением могут быть выбраны из гистонметилтрансфераз (HMT), гистондеацетилаз (HDAC), ингибиторов гистонацетилтрансферазы (HAT), а также рекрутирующих HDAC и HMT белков.
Доменом HDAC может быть любой из доменов в представленной выше таблице, а именно HDAC8, RPD3, MesoLo4, HDAC11, HDT1, SIRT3, HST2, CobB, HST2, SIRT5, Sir2A или SIRT6.
В некотором варианте осуществления функциональным доменом может быть рекрутерный эффекторный домен HDAC. Предпочтительные примеры включают в себя домены в представленной ниже таблице, а именно MeCP2, MBD2b, Sin3a, NcoR, SALL1, RCOR1. NcoR является типичным в примерах настоящего изобретения, и, хотя является предпочтительным, предусматривается, что также будут применимыми и другие домены из класса.
Таблица рекрутерных эффекторных доменов HDAC
Комп-лекс
домен
В некотором варианте осуществления функциональным доменом может быть эффекторный домен метилтрансферазы (HMT). Предпочтительные примеры включают в себя домены в представленной ниже таблице, а именно NUE, vSET, EHMT2/G9A, SUV39H1, dim-5, KYP, SUVR4, SET4, SET1, SETD8 и TgSET8. NUE является типичным в примерах настоящего изобретения, и, хотя является предпочтительным, предусматривается, что также будут применимыми и другие домены из класса.
Таблица эффекторных доменов гистонметилтрансферазы (HMT)
Комп-
Лекс
мер
(aa)
H3, H4
G9A
20
В некотором варианте осуществления функциональным доменом может быть рекрутерный эффекторный домен гистонметилтрансферазы (HMT). Предпочтительные примеры включают в себя домены в представленной ниже таблице, а именно Hp1a, PHF19 и NIPP1.
Таблица рекрутерных эффекторных доменов гистонметилтрансферазы (HMT)
Комп
лекс
домен
В некотором варианте осуществления функциональным доменом может быть ингибиторный эффекторный домен гистонацетилтрансферазы. Предпочтительные примеры включают в себя SET/TAF-1β, приведенные в таблице ниже.
Таблица ингибиторных эффекторных доменов гистонацетилтрансферазы
Комп-лекс
ние
(aa)
ni)
Также предпочтительным является нацеливание на эндогенные (регуляторные) контрольные элементы (такие как энхансеры и сайленсеры) в дополнение к промоторным или промотор-проксимальным элементам. Таким образом, настоящее изобретение также может быть использовано для нацеливания на эндогенные контрольные элементы (в том числе энхансеры и сайленсеры) в дополнение к нацеливанию на промотор. Такие контрольные элементы могут быть расположены выше и ниже сайта начала транскрипции (TSS), начинающегося от 200 т. о. от TSS до 100 т. о. Нацеливание на известные контрольные элементы можно применять для активации или подавления представляющего интерес гена. В некоторых случаях один контрольный элемент может влиять на транскрипцию нескольких целевых генов. Поэтому нацеливание на один контрольный элемент может быть использовано для контроля транскрипции нескольких генов одновременно.
С другой стороны, нацеливание на предполагаемые контрольные элементы (например, путем перекрывания участка предполагаемого контрольного элемента, а также от 200 п. о. до 100 т. о. около элемента) может применяться как средство для подтверждения таких элементов (путем измерения транскрипции представляющего интерес гена) или для выявления новых контрольных элементов (например, путем перекрывания 100 т. о. выше и ниже TSS представляющего интерес гена). Кроме того, нацеливание на предполагаемые контрольные элементы может быть применимо в контексте понимания генетических причин заболевания. Многие мутации и общие варианты SNP, ассоциированные с фенотипами заболеваний, располагаются вне кодирующих участков. После нацеливания на такие области с системами либо активации, либо подавления, описываемыми в данном документе, может следовать считывание транскрипции либо a) ряда предполагаемых мишеней (например, ряда генов, расположенных в тесной близости к контрольному элементу), либо b) полнотранскриптомное считывание, например, с помощью RNAseq или микрочипа. Это позволило бы идентифицировать вероятные кандидатные гены, вовлеченные в фенотип заболевания. Такие кандидатные гены могут быть применимы в качестве новых мишеней лекарственных средств.
В данном документе упоминаются ингибиторы гистонацетилтрансферазы (HAT). Однако альтернативой в некоторых вариантах осуществления является то, что один или несколько функциональных доменов содержат ацетилтрансферазу, предпочтительно гистонацетилтрансферазу. Они применимы в области эпигеномики, например, в способах детального исследования эпигенома. Способы детального исследования эпигенома могут предусматривать, например, нацеливание на эпигеномные последовательности. Нацеливание на эпигеномные последовательности может включать в себя направляющую, направленную на эпигеномную целевую последовательность. Эпигеномная целевая последовательность может включать в себя в некоторых вариантах осуществления промотор, сайленсер или энхансерную последовательность.
Применение функционального домена, связанного с эффекторным белком Cpf1, описываемым в настоящем документе, предпочтительно неработающим эффекторным белком Cpf1, более предпочтительно неработающим эффекторным белком FnCpf1, для нацеливания на эпигеномные последовательности может применяться для активации или подавления промоторов, сайленсера или энхансеров.
Примеры ацетилтрансфераз известны и могут включать в себя в некоторых вариантах осуществления гистонацетилтрансферазы. В некоторых вариантах осуществления гистонацетилтрансфераза может содержать каталитическое ядро человеческой ацетилтрансферазы p300 (Gerbasch & Reddy, Nature Biotech 6th April 2015).
В некоторых предпочтительных вариантах осуществления функциональный домен связывается с эффекторным белком Cpf1 для нацеливания на эпигеномные последовательности, такие как промоторы или энхансеры, и их активации. Одна или несколько направляющих, направленных на такие промоторы или энхансеры, также могут быть обеспечены для управления связывания фермента CRISPR с такими промоторами или энхансерами.
Термин "ассоциированный с" используют в настоящем документе в отношении ассоциации функционального домена с эффекторным белком Cpf1 или адапторным белком. Он используется в отношении того, как одна молекула "связывается" по отношению к другой, например, между адапторным белком и функциональным доменом или между эффекторным белком Cpf1 и функциональным доменом. В случае таких белок-белковых взаимодействий эту ассоциацию можно рассматривать с точки зрения распознавания при распознавании антителом эпитоп. Альтернативно один белок может быть ассоциирован с другим белком посредством слияния обоих, например, одна субъединица является слитой с другой субъединицей. Слияние обычно происходит путем добавления одной аминокислотной последовательности к другой, например, посредством сплайсинга нуклеотидных последовательностей, которые кодируют каждый белок или субъединицу. Альтернативно, по сути, это можно рассматривать как связывание двух молекул или прямую связь, например, белок слияния. В любом случае слитый белок может включать линкер между двумя представляющими интерес субъединицами (т. е. между ферментом и функциональным доменом или между адаптерным белком и функциональным доменом). Таким образом, в некоторых вариантах осуществления эффекторный белок Cpf1 или адапторный белок связывается с функциональным доменом путем связывания с ним. В других вариантах осуществления эффекторный белок Cpf1 или адапторный белок связывается с функциональным доменом, поскольку два сливаются вместе, необязательно через промежуточный линкер.
Прикрепление функционального домена или слитого белка может быть выполнено через линкер, например, гибкий глицин-сериновый (GlyGlyGlySer), или (GGGS)3, или жесткий альфа-спиральный линкер, такой как (Ala(GluAlaAlaAlaLys)Ala). Линкеры, такие как (GGGGS)3, предпочтительно используют в данном документе для отделения белковых или пептидных доменов. (GGGGS)3 является предпочтительным, поскольку он является относительно длинным линкером (15 аминокислот). Глициновые остатки являются наиболее гибкими, а сериновые остатки повышают вероятность того, что линкер будет находится на внешней стороне белка. (GGGGS)6 (GGGGS)9 или (GGGGS)12 предпочтительно могут быть использованы в качестве альтернативных вариантов. Другими предпочтительными альтернативными вариантами являются (GGGGS)1, (GGGGS)2, (GGGGS)4, (GGGGS)5, (GGGGS)7, (GGGGS)8, (GGGGS)10 или (GGGGS)11. Доступны альтернативные линкеры, но считается, что очень гибкие линкеры лучше обеспечивают максимальную возможность объединения 2 частей Cpf1 и, таким образом, восстановления активности Cpf1. Одной альтернативой является то, что NLS нуклеоплазмина можно использовать в качестве линкера. Например, линкер также может быть использован между Cpf1 и каким-либо функциональным доменом. Опять-таки, в данном случае можно применять линкер (GGGGS)3 (или его варианты с 6, 9 или 12 повторами) или можно применять NLS нуклеоплазмина в качестве линкера между Cpf1 и функциональным доменом.
Насыщающий мутагенез
Система(системы) эффекторного белка Cpf1, описанная(описанные) в данном документе, может(могут) применяться для осуществления насыщающего или глубокосканирующего мутагенеза локусов генома вместе с клеточным фенотипом, например, для определения критических минимальных признаков и дискретных повреждаемостей функциональных элементов, необходимых для экспрессии гена, устойчивости к лекарственному средству и обратимости заболевания. Под насыщающим или глубокосканирующим мутагенезом подразумевается то, что каждое или практически каждое основание ДНК разрезается в локусах генома. Библиотека направляющих РНК эффекторного белка Cpf1 может быть введена в популяцию клеток. Библиотека может быть введена так, что каждая клетка получает одну направляющую РНК (gRNA). В том случае, если библиотеку вводят путем трансдукции вирусного вектора, описываемого в данном документе, используется низкая мультиплетность инфекции (MOI). Библиотека может включать в себя gRNA, нацеливающиеся на каждую последовательность выше последовательности РАМ (мотива, смежного с протоспейсером) в геномном локусе. Библиотека может включать в себя по меньшей мере 100 неперекрывающихся геномных последовательностей выше последовательности PAM для каждых 1000 пар оснований в локусе генома. Библиотека может включать в себя нацеливающиеся последовательности gRNA выше по меньшей мере одной другой последовательности PAM. Системы эффекторного белка Cpf1 могут включать в себя более одного белка Cpf1. Может быть использован любой эффекторный белок Cpf1, описываемый в данном документе, в том числе ортологи или сконструированные белки Cpf1, которые распознают другие последовательности PAM. Частота нецелевых сайтов для gRNA может составлять менее 500. Оценки нецелевых событий могут быть получены для отбора gRNA с самым низким числом нецелевых сайтов. Любой фенотип, определенный как ассоциированный с разрезанием по целевому сайту gRNA, может быть подтвержден с использованием нацеливания gRNA на тот же сайт в одном эксперименте. Подтверждение целевого сайта также может быть выполнено с использованием модифицированного эффекторного белка Cpf1, описываемого в данном документе, и двух gRNA, нацеливающихся на представляющий интерес геномный сайт. Без углубления в теорию, целевой сайт представляет собой истинное совпадение, если в подтверждающих экспериментах наблюдают изменение в фенотипе.
Локусы генома могут включать в по меньшей мере один непрерывный участок генома. По меньшей мере один непрерывный участок генома может содержать даже полный геном. По меньшей мере один непрерывный участок генома может содержать функциональный элемент генома. Функциональный элемент может находиться в некодирующем участке, кодирующем участке, интронном участке, промоторе или энхансере. По меньшей мере один непрерывный участок генома может содержать по меньшей мере 1 т. о. предпочтительно по меньшей мере 50 т. о. геномной ДНК. По меньшей мере один непрерывный учаток генома может содержать сайт связывания фактора транскрипции. По меньшей мере один непрерывный учаток генома может содержать участок гиперчувствительности к ДНКазе I. По меньшей мере один непрерывный учаток генома может содержать транскрипционный энхансерный или репрессорный элемент. По меньшей мере один непрерывный учаток генома может содержать сайт, обогащенный эпигенетической сигнатурой. По меньшей мере один непрерывный учаток геномной ДНК может содержать эпигенетический инсулятор. По меньшей мере один непрерывный участок генома может содержать два или более непрерывных участков генома, которые взаимодействуют физически. Участки генома, которые взаимодействуют, могут быть определены с помощью ‘технологии 4C'. 4C технология облегчает тестирование всего генома объективным образом на предмет сегментов ДНК, которые взаимодействуют физически с выбранным фрагментом ДНК, как описано у Zhao et al. ((2006) Nat Genet 38, 1341-7) и в патенте США № 8642295, оба из которых включены в настоящий документ посредством ссылки во всей своей полноте. Эпигенетической сигнатурой может быть гистонацетилирование, гистонметилирование, гистонубиквитинирование, гистонфосфорилирование, метилирование ДНК или отсутствие таковых.
Систему(системы) эффекторного белка Cpf1 для насыщающего или глубокосканирующего мутагенеза можно применять в популяции клеток. Систему(системы) на основе эффекторного белка Cpf1 можно применять в эукариотических клетках, в том числе без ограничения клетках млекопитающих и растений. Популяцией клеток могут быть прокариотические клетки. Популяцией эукариотических клеток может быть популяция эмбриональных стволовых (ES) клеток, нейронных клеток, эпителиальных клеток, иммунных клеток, эндокринных клеток, мышечных клеток, эритроцитов, лимфоцитов, растительных клеток или клеток дрожжей.
В одном аспекте настоящее изобретение относится к способу скрининга на предмет функциональных элементов, ассоциированных с изменением в фенотипе. Библиотека может быть введена в популяцию клеток, которые адаптированы с целью содержания эффекторного белка Cpf1. Клетки могут быть рассортированы по меньшей мере на две группы на основании фенотипа. Фенотипом может быть экспрессия гена, клеточный рост или клеточная жизнеспособность. Определяют относительное представление направляющих РНК, присутствующих в каждой группе, с определением тем самым сайтов генома, ассоциированных с изменением в фенотипе с помощью представления направляющих РНК, присутствующих в каждой группе. Изменением в фенотипе может быть изменение в экспрессии представляющего интерес гена. Представляющий интерес ген может быть активирован, подавлен или нокаутирован. Клетки могут быть рассортированы в группу с высокой экспрессией и группу с низкой экспрессией. Популяция клеток может содержать репортерную конструкцию, которую используют для определения фенотипа. Репортерная конструкция может включать выявляемый маркер. Клетки могут быть рассортированы с использованием выявляемого маркера.
В другом аспекте настоящее изобретение относится к способу скрининга на предмет сайтов генома, ассоциированных с устойчивостью к химическому соединению. Химическим соединением может быть лекарственное средство или пестицид. Библиотека может быть введена в популяцию клеток, которые адаптированы с содержанием эффекторного белка Cpf1, где каждая клетка популяции содержит не более чем одну направляющую РНК; при этом популяцию клеток обрабатывают химическим соединением и определяют представление направляющих РНК после обработки химическим соединением в более поздний момент времени по сравнению с ранним моментом времени, посредством чего определяют геномные сайты, ассоциированные с устойчивостью к химическому соединению с помощью обогащения направляющих РНК. Представление gRNA может быть определено способами глубокого секвенирования.
Применительно к осуществлению настоящего изобретения, существуют способы, в которых используют комплексы эффекторного белка Cpf1, используемые в системах CRISPR-Cas9, и можно упомянуть статью под названием "BCL11A enhancer dissection by Cas9-mediated in situ saturating mutagenesis". Canver, M.C., Smith, E.C., Sher, F., Pinello, L., Sanjana, N.E., Shalem, O., Chen, D.D., Schupp, P.G., Vinjamur, D.S., Garcia, S.P., Luc, S., Kurita, R., Nakamura, Y., Fujiwara, Y., Maeda, T., Yuan, G., Zhang, F., Orkin, S.H., & Bauer, D.E. DOI:10.1038/nature15521, опубликованную онлайн 16 сентября 2015 г., при этом данная статья включена в данный документ посредством ссылки и кратко обсуждается ниже.
Canver et al. включают новую библиотеку объединенных в пулы направляющих РНК CRISPR-Cas9 для выполнения in situ насыщающего мутагенеза человеческих и мышиных энхансеров эритроидного BCL11A, ранее идентифицированных как энхансер, ассоциированный с уровнем фетального гемоглобина (HbF), и мышиный ортолог которого необходим для экспрессии эритроидного BCL11A. Этот подход выявляет критические минимальные признаки и дискретные повреждаемости этих энхансеров. Посредством редактирования первичных клеток-предшественников человека и мышиного трансгеноза авторы подтвердили энхансер эритроидного BCL11A в качестве мишени для повторной индукции HbF. Авторы создали подробную карту энхансеров, которая предоставляет информацию о терапевтическом редактировании генома.
Способ применения систем Cpf1 для модификации клетки или организма
Настоящее изобретение в некоторых вариантах осуществления охватывает способ модифицирования клетки или организма. Клетка может быть прокариотической клеткой или эукариотической клеткой. Клетка может быть клеткой млекопитающего. Клетка млекопитающего может быть клеткой отличного от человека примата, быка, свиньи, грызуна или мыши. Клетка может быть эукариотической клеткой от организма, отличного от млекопитающего, например, птицы, рыбы или креветки. Клетка также может быть растительной клеткой. Растительная клетка может происходить из сельскохозяйственного растения, такого как маниока, кукуруза, сорго, пшеница или рис. Растительная клетка также может происходить из водоросли, дерева или овощной культуры. Модификация, введенная в клетку с помощью настоящего изобретения, может быть такой, что клетка и потомство клетки изменяются для улучшения продуцирования биологических продуктов, таких как антитело, крахмал, спирт или другой желаемый клеточный продукт. Модификация, введенная в клетку с помощью настоящего изобретения, может быть такой, что клетка и потомство клетки будут включать в себя изменение, которое меняет продуцируемый биологический продукт.
Система может содержать один или несколько разных векторов. В аспекте настоящего изобретения белок Cas является кодон-оптимизированным для экспрессии в эукариотической клетке, предпочтительно в клетке млекопитающего или клетке человека.
Упаковывающие клетки, как правило, используют для получения вирусных частиц, которые способны инфицировать клетку-хозяина. Такие клетки включают клетки 293, которые упаковывают аденовирус, и клетки ψ2 или клетки PA317, которые упаковывают ретровирус. Вирусные векторы, используемые в генной терапии, как правило, создают путем получения линии клеток, которые упаковывают вектор на основе нуклеиновой кислоты в вирусную частицу. Векторы, как правило, содержат минимальные вирусные последовательности, необходимые для упаковки и последующей интеграции в хозяина, при этом другие вирусные последовательности замещены кассетой экспрессии для подлежащего экспрессии полинуклеотида(полинуклеотидов). Отсутствующие вирусные функции, как правило, обеспечивают в другом объекте при помощи линии упаковывающих клеток. Например, векторы на основе AAV, применяемые в генной терапии, как правило, имеют только ITR-последовательности из генома AAV, которые необходимы для упаковки и интеграции в геном хозяина. Вирусная ДНК упаковывается в линию клеток, которая содержит плазмиду-помощника, кодирующую другие гены AAV, а именно rep и cap, но без ITR-последовательностей. Линия клеток также может быть инфицирована аденовирусом в качестве вируса-помощника. Вирус-помощник способствует репликации AAV-вектора и экспрессии генов AAV из плазмиды-помощника. Плазмида-помощник не упаковывается в значительном количестве в связи с отсутствием ITR-последовательностей. Контаминация аденовирусом может быть снижена, к примеру, при помощи тепловой обработки, к которой аденовирус более чувствителен, чем AAV.
Доставка
Настоящее изобретение также охватывает по меньшей мере один компонент комплекса CRISPR, например, РНК, доставленную посредством по меньшей мере одного комплекса на основе наночастиц. В некоторых аспектах настоящее изобретение относится к способам, включающим доставку в клетку-хозяина одного или нескольких полинуклеотидов, как, например, или одного, или нескольких векторов, которые описаны в данном документе, одного или нескольких их транскриптов и/или одного или нескольких белков, транскрибируемых с них. В некоторых аспектах настоящее изобретение дополнительно предусматривает клетки, полученные с помощью таких способов, и животных, содержащих такие клетки или полученных из них. В некоторых вариантах осуществления фермент CRISPR в комбинации с (и необязательно образующий комплекс с) направляющей последовательностью доставляют в клетку. Традиционные способы переноса генов с использованием вирусов и без использования вирусов можно применять для введения нуклеиновых кислот в клетки млекопитающих или целевые ткани. Такие способы можно использовать для введения нуклеиновых кислот, кодирующих компоненты системы CRISPR, в клетки в культуре или в организме-хозяине. Системы доставки на основе невирусных векторов включают плазмидные ДНК, РНК (например, транскрипт вектора, описанного в данном документе), "оголенную" нуклеиновую кислоту и нуклеиновую кислоту, образующую комплекс со средством доставки, таким как липосома. Системы доставки на основе вирусного вектора включают ДНК- и РНК-содержащие вирусы, которые имеют либо геномы в эписомальной форме, либо интегрированные геномы после доставки в клетку. В отношении обзора процедур генной терапии см. Anderson, Science 256:808-813 (1992); Nabel & Felgner, TIBTECH 11:211-217 (1993); Mitani & Caskey, TIBTECH 11:162-166 (1993); Dillon, TIBTECH 11:167-175 (1993); Miller, Nature 357:455-460 (1992); Van Brunt, Biotechnology 6(10):1149-1154 (1988); Vigne, Restorative Neurology and Neuroscience 8:35-36 (1995); Kremer & Perricaudet, British Medical Bulletin 51(1):31-44 (1995); Haddada et al. в Current Topics in Microbiology and Immunology, Doerfler and Böhm (eds) (1995) и Yu et al., Gene Therapy 1:13-26 (1994).
Способы отличной от вирусной доставки нуклеиновых кислот включают липофекцию, микроинъекцию, баллистическую трансфекцию, доставка с помощью виросом, липосом, иммунолипосом, поликатион или конъюгатов липид:нуклеиновая кислота, "оголенной" ДНК, искусственных вирионов и повышенное с помощью определенного средства поглощение ДНК. Липофекция описана, например, в патентах США №№ 5049386, 4946787 и 4897355, и реагенты для липофекции реализуют в промышленных масштабах (к примеру, Transfectam™ и Lipofectin™). Катионные и нейтральные липиды, которые подходят для эффективной липофекции с узнаванием рецепторов полинуклеотидов, включают липиды из Felgner, WO 91/17424; WO 91/16024. Доставка может осуществляться в клетки (к примеру, введение in vitro или ex vivo) или целевые ткани (к примеру, введение in vivo).
Получение комплексов липид:нуклеиновая кислота, в том числе нацеливающих липосом, таких как иммунолипидные комплексы, хорошо известно специалистам в данной области (см., к примеру, Crystal, Science 270:404-410 (1995); Blaese et al., Cancer Gene Ther. 2:291-297 (1995); Behr et al., Bioconjugate Chem. 5:382-389 (1994); Remy et al., Bioconjugate Chem. 5:647-654 (1994); Gao et al., Gene Therapy 2:710-722 (1995); Ahmad et al., Cancer Res. 52:4817-4820 (1992); патенты США №№ 4186183, 4217344, 4235871, 4261975, 4485054, 4501728, 4774085, 4837028 и 4946787).
При применении систем на основе РНК- и ДНК-содержащих вирусов для доставки нуклеиновых кислот используют тщательно разработанные способы обеспечения нацеливания вируса на конкретные клетки в организме и перемещения полезных последовательностей вируса в ядро. Вирусные векторы можно вводить непосредственно пациентам (in vivo), или их можно применять для обработки клеток in vitro, и модифицированные клетки можно необязательно вводить пациентам (ex vivo). Традиционные системы на основе вирусов для переноса генов могут включать ретровирусные, лентивирусные, аденовирусные векторы, векторы на основе аденоассоциированного вируса и вируса простого герпеса. Интеграция в геном хозяина возможна с применением способов переноса генов на основе ретровируса, лентивируса и аденоассоциированного вируса, что часто приводит к длительной экспрессии встроенного трансгена. Кроме того, высокие показатели эффективности трансдукции наблюдали у многих различных типов клеток и целевых тканей.
Тропизм ретровируса может быть изменен путем включения чужеродных белков оболочки с расширением возможной целевой популяции целевых клеток. Лентивирусные векторы являются ретровирусными векторами, которые способны трансдуцировать или инфицировать неделящиеся клетки и, как правило, дают высокие вирусные титры. Выбор системы переноса генов на основе ретровирусов, таким образом, будет зависеть от целевой ткани. Ретровирусные векторы состоят из действующих в цис-положении длинных концевых повторов с упаковывающей способностью до 6-10 т. о. чужеродной последовательности. Минимальных действующих в цис-положении LTR достаточно для репликации и упаковки векторов, которые затем используют для интеграции терапевтического гена в целевую клетку с получением постоянной экспрессии трансгена. Широко используемые ретровирусные векторы включают такие векторы, как основанные на вирусе лейкоза мышей (MuLV), вирусе лейкоза гиббонов (GaLV), вирусе иммунодефицита обезьян (SIV), вирусе иммунодефицита человека (HIV) и их комбинациях (см., к примеру, Buchscher et al., J. Virol. 66:2731-2739 (1992); Johann et al., J. Virol. 66:1635-1640 (1992); Sommnerfelt et al., Virol. 176:58-59 (1990); Wilson et al., J. Virol. 63:2374-2378 (1989); Miller et al., J. Virol. 65:2220-2224 (1991); PCT/US94/05700).
В другом варианте осуществления предусматриваются псевдотипированные ретровирусные векторные частицы на основе оболочки везикуловируса Кокал (см., например, публикацию заявки на патент США № 20120164118, закрепленной за Онкологическим исследовательским центром Фреда Хатчинсона). Вирус Кокал относится к роду Vesiculovirus и является возбудителем везикулярного стоматита у млекопитающих. Вирус Кокал изначально был выделен из клещей в Тринидаде (Jonkers et al., Am. J. Vet. Res. 25:236-242 (1964)), и инфекции были идентифицированы в Тринидаде, Бразилии и Аргентине у насекомых, крупного рогатого скота и лошадей. Многие везикуловирусы, которые инфицируют млекопитающих, были выделены у инфицированных в естественных условиях членистоногих, что позволяет предположить, что они являются передаваемыми переносчиками. Антитела к везикуловирусам распространены у людей, живущих в сельской местности, где вирусы являются эндемичными и внутрилабораторными; причем инфекции у людей обычно приводят к гриппоподобным симптомам. Гликопротеин оболочки вируса Кокал обладает идентичностью 71,5% на аминокислотном уровне с VSV-G Индианы, причем филогенетическое сравнение генов оболочки везикуловирусов показало, что вирус Кокал серологически отличается от VSV-G штаммов Индиана, но из везикуловирусов является наиболее близкородственным с ними. Jonkers et al., Am. J. Vet. Res. 25:236-242 (1964) и Travassos da Rosa et al., Am. J. Tropical Med. & Hygiene 33:999-1006 (1984). Псевдотипированные ретровирусные векторные частицы на основе оболочки везикуловируса Кокал могут включать, например, лентивирусные, альфаретровирусные, бетаретровирусные, гаммаретровирусные, дельтаретровирусные и эпсилонретровирусные векторные частицы, которые могут содержать ретровирусный Gag, Pol и/или один или несколько акцессорных белков и белок оболочки везикуловируса Кокал. В определенных аспектах этих вариантов осуществления Gag, Pol и дополнительные белки являются лентивирусными и/или гамма-ретровирусными. Настоящее изобретение предусматривает AAV, которые содержит или состоит фактически из экзогенной молекулы нуклеиновой кислоты, кодирующей систему CRISPR, например, множество кассет, содержащих или состоящих из первой кассеты, содержащей или состоящей фактически из промотора, молекулы нуклеиновой кислоты, кодирующей CRISPR-ассоциированный (Cas) белок (предполагаемые нуклеазные или хеликазные белки), например Cpf1, и терминатор, и две или более, преимущественно до предела упаковки вектора, например, всего (включая первую кассету) пять кассет, содержащих или состоящих фактически из промотора, молекулы нуклеиновой кислоты, кодирующей направляющую РНК (gRNA), и терминатор (например, каждая кассета схематически представлена как промотор-gRNA1-терминатор, промотор-gRNA2-терминатор ... промотор-gRNA(N)-терминатор (где N является количеством, которое можно встроить, находящееся на верхней границе предела упаковки вектора)), или два или более отдельных rAAV, причем каждый содержит одну или несколько кассет системы CRISPR, например первый rAAV, содержащий первую кассету, содержащую или состоящую фактически из промотора, молекулы нуклеиновой кислоты, кодирующей Cas, например, Cas (Cpf1), и терминатора, и второй rAAV, содержащий несколько, четыре кассеты, кассет содержащих или состоящих фактически из промотора, молекулы нуклеиновой кислоты, кодирующей направляющую РНК (gRNA), и терминатора (например, каждая кассета схематически представлена как промотор-gRNA1-терминатор, промотор-gRNA2-терминатор ... промотор-gRNA(N)-терминатор (где N является количеством, которое можно встроить, находящееся на верхней границе предела упаковки вектора)). Поскольку rAAV представляет собой ДНК-содержащий вирус, молекулы нуклеиновой кислоты в изложенном в данном документе обсуждении в отношении AAV или rAAV преимущественно представляют собой ДНК. В некоторых вариантах осуществления промотор преимущественно представляет собой промотор синапсина I человека (hSyn). Дополнительные способы доставки нуклеиновых кислот в клетки известны специалистам в данной области. См., например, US20030087817, включенный в данный документ посредством ссылки.
В некоторых вариантах осуществления клетка-хозяин транзиентно или нетранзиентно трасфицирована одним или несколькими векторами, описанными в данном документе. В некоторых вариантах осуществления клетку трансфицируют, когда она находится в естественных условиях в субъекте. В некоторых вариантах осуществления клетка, которую трансфицируют, получена от субъекта. В некоторых вариантах осуществления клетка происходит из клеток, полученных от субъекта, как, например, линии клеток. Из уровня техники известен целый ряд линий клеток, применяемых в качестве культуры тканей. Примеры линий клеток включают без ограничения C8161, CCRF-CEM, MOLT, mIMCD-3, NHDF, HeLa-S3, Huh1, Huh4, Huh7, HUVEC, HASMC, HEKn, HEKa, MiaPaCell, Panc1, PC-3, TF1, CTLL-2, C1R, Rat6, CV1, RPTE, A10, T24, J82, A375, ARH-77, Calu1, SW480, SW620, SKOV3, SK-UT, CaCo2, P388D1, SEM-K2, WEHI-231, HB56, TIB55, Jurkat, J45.01, LRMB, Bcl-1, BC-3, IC21, DLD2, Raw264.7, NRK, NRK-52E, MRC5, MEF, Hep G2, HeLa B, HeLa T4, COS, COS-1, COS-6, COS-M6A, эпителиальные клетки почки обезьяны BS-C-1, эмбриональные фибробласты мыши BALB/ 3T3, 3T3 Swiss, 3T3-L1, фетальные фибробласты человека 132-d5; фибробласты мыши 10.1, 293-T, 3T3, 721, 9L, A2780, A2780ADR, A2780cis, A172, A20, A253, A431, A-549, ALC, B16, B35, клетки BCP-1, BEAS-2B, bEnd.3, BHK-21, BR 293, BxPC3, C3H-10T1/2, C6/36, Cal-27, CHO, CHO-7, CHO-IR, CHO-K1, CHO-K2, CHO-T, CHO Dhfr -/-, COR-L23, COR-L23/CPR, COR-L23/5010, COR-L23/R23, COS-7, COV-434, CML T1, CMT, CT26, D17, DH82, DU145, DuCaP, EL4, EM2, EM3, EMT6/AR1, EMT6/AR10.0, FM3, H1299, H69, HB54, HB55, HCA2, HEK-293, HeLa, Hepa1c1c7, HL-60, HMEC, HT-29, Jurkat, клетки JY, клетки K562, Ku812, KCL22, KG1, KYO1, LNCap, Ma-Mel 1-48, MC-38, MCF-7, MCF-10A, MDA-MB-231, MDA-MB-468, MDA-MB-435, MDCK II, MDCK II, MOR/0.2R, MONO-MAC 6, MTD-1A, MyEnd, NCI-H69/CPR, NCI-H69/LX10, NCI-H69/LX20, NCI-H69/LX4, NIH-3T3, NALM-1, NW-145, линии клеток OPCN/OPCT, Peer, PNT-1A / PNT 2, RenCa, RIN-5F, RMA/RMAS, клетки Saos-2, Sf-9, SkBr3, T2, T-47D, T84, линию клеток THP1, U373, U87, U937, VCaP, клетки Vero, WM39, WT-49, X63, YAC-1, YAR и их трансгенные разновидности. Линии клеток доступны из множества источников, известных специалистам в данной области (см., например, Американская коллекция типовых культур (ATCC) (Манассас, Вирджиния)). В некоторых вариантах осуществления клетку, трансфицированную с помощью одного или нескольких векторов, описанных в данном документе, используют для получения новой линии клеток, содержащей одну или несколько полученных из вектора последовательностей. В некоторых вариантах осуществления клетку, транзиентно трансфицированную с помощью компонентов системы CRISPR, описанной в данном документе (как, например, путем транзиентной трансфекции с помощью одного или нескольких векторов или трансфекции с использованием РНК), и модифицированную с помощью активности комплекса CRISPR, используют для получения новой линии клеток, содержащей клетки с модификацией, но без любой другой экзогенной последовательности. В некоторых вариантах осуществления клетки, транзиентно или нетранзиентно трансфицированные с помощью одного или нескольких векторов, описанных в данном документе, или линии клеток, полученные из таких клеток, применяют в оценке одного или нескольких тестируемых соединений.
В некоторых вариантах осуществления один или несколько векторов, описанных в данном документе, используют для получения отличного от человека трансгенного животного или трансгенного растения. В некоторых вариантах осуществления трансгенным животным является млекопитающее, как, например, мышь, крыса или кролик. Способы получения трансгенных животных и растений известны из уровня техники и, как правило, начинаются со способа трансфекции клетки, такого как описанный в данном документе. В другом варианте осуществления может предусматриваться устройство для доставки жидкости с матрицей игл (см., например, публикацию заявки на патент США № 20110230839, закрепленной за Онкологическим исследовательским центром Фреда Хатчинсона), для доставки CRISPR-Cas в плотную ткань. Устройство согласно публикации заявки на патент США № 20110230839 для доставки жидкости в плотную ткань может содержать множество игл, расположенных в виде матрицы; множество емкостей, каждая из которых находится в жидкостном соединении с соответствующей одной иглой из множества игл; и множество приводов, функционально связанных с соответствующими емкостями из множества емкостей и выполненных с возможностью регулирования давления жидкости в емкости. В определенных вариантах осуществления каждый из множества приводов может содержать один из множества поршней, причем первая концевая часть каждого из множества поршней находится в соответствующей одной емкости из множества емкостей, и в определенных дополнительных вариантах осуществления поршни из множества поршней функционально связаны вместе по соответствующим вторым концевым частям с обеспечением возможности одновременного нажатия. В определенных других дополнительных вариантах осуществления может предусматриваться управляющий элемент для поршней, сконфигурированный с возможностью нажатия всех из множества поршней с выборочно изменяющейся скоростью. В других вариантах осуществления каждый из множества приводов может содержать одну из множества жидкостных поточных линий, имеющих первую и вторую концевые части, причем первая концевая часть каждой из множества жидкостных поточных линий соединена с соответствующей одной емкостью из множества емкостей. В других вариантах осуществления устройство может содержать источник давления жидкости, и при этом каждый из множества приводов предусматривает гидравлическую муфту между источником давления жидкости и соответствующей одной емкостью из множества емкостей. В дополнительных вариантах осуществления источник давления жидкости может предусматривать по меньшей мере одно из следующих: компрессора, вакуумного накопителя, перистальтического насоса, основного цилиндра, микроструйного насоса и клапана. В другом варианте осуществления каждая из множества игл может содержать множество отверстий, распределенных вдоль ее длины.
В одном аспекте настоящее изобретение относится к способам модификации целевого полинуклеотида в эукариотической клетке. В некоторых вариантах осуществления способ может предусматривать облегчение связывания комплекса нацеливания на нуклеиновую кислоту с целевым полинуклеотидом для осуществления расщепления указанного целевого полинуклеотида, с модифицированием тем самым целевого полинуклеотида, где комплекс нацеливания на нуклеиновую кислоту содержит эффекторный белок нацеливания на нуклеиновую кислоту в комплексе с направляющей РНК, гибридизированной с целевой последовательностью в пределах указанного целевого полинуклеотида.
В одном аспекте настоящего изобретения предусмотрен способ модифицирования экспрессии полинуклеотида в эукариотической клетке. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса нацеливания на нуклеиновую кислоту с полинуклеотидом так, что указанное связывание приводит к повышенной или сниженной экспрессии указанного полинуклеотида; где комплекс нацеливания на нуклеиновую кислоту содержит эффекторный белок нацеливания на нуклеиновую кислоту в комплексе с направляющей РНК, гибридизированной с целевой последовательностью в пределах указанного полинуклеотида.
Компоненты комплекса CRISPR могут быть доставлены с помощью конъюгации или ассоциации с транспортными фрагментами (адаптированными, например, из подходов, раскрытых в патентах США №№ 8106022; 8313772). Стратегии доставки нуклеиновой кислота, например, могут быть использованы для улучшения доставки направляющей РНК, или информационных РНК, или кодирующих ДНК, кодирующих компоненты комплекса CRISPR. Например, РНК могут включать модифицированные нуклеотиды РНК для улучшения стабильности, понижения иммуностимуляции и/или улучшения специфичности (см. Deleavey, Glen F. et al., 2012, Chemistry & Biology , Volume 19 , Issue 8 , 937 - 954; Zalipsky, 1995, Advanced Drug Delivery Reviews 16: 157-182; Caliceti and Veronese, 2003, Advanced Drug Delivery Reviews 55: 1261-1277). Были описаны различные конструкции, которые можно применять для модификации нуклеиновых кислот, таких как gRNA, для более эффективной доставки, например, обратимые нейтрализующие заряд модификации фосфотриэфирного скелета, которые могут быть адаптированы для модификации gRNA так, что они будут более гидрофобными и неанионными, с улучшением тем самым попадания в клетку (Meade BR et al., 2014, Nature Biotechnology 32,1256-1261). В следующих альтернативных вариантах осуществления выбранные мотивы РНК могут быть применимы для опосредования клеточной трансфекции (Magalhães M., et al., Molecular Therapy (2012); 20 3, 616-624). Подобным образом, аптамеры могут быть адаптированы для доставки компонентов комплекса CRISPR, например, с помощью добавления аптамеров к gRNA (Tan W. et al., 2011, Trends in Biotechnology, December 2011, Vol. 29, No. 12).
В некоторых вариантах осуществления конъюгация трехразветвленного N-ацетилгалактозамина (GalNAc) с олигонуклеотидными компонентами может быть использована для улучшения доставки, например, доставки для отбора типов клеток, например, гепатоцитов (см. WO2014118272, включенную в данный документ посредством ссылки; Nair, JK et al., 2014, Journal of the American Chemical Society 136 (49), 16958-16961). Это можно рассматривать как частицу на основе сахара, и дополнительные подробности о других системах доставки в виде частиц и/или составах приведены в данном документе. Поэтому GalNAc можно рассматривать как частицу в том же смысле, что и другие частицы, описываемые в данном документе, так что общие варианты применения и другие соображения, например, доставка указанных частиц, также применимы к частицам GalNAc. Стратегия конъюгации из жидкой фазы, например, может быть использована для присоединения кластеров трехразветвленных GalNAc (молекулярная масса ~2000), активированных как PFP (пентафторфенильные) сложные эфиры, к 5′-гексиламино-модифицированным олигонуклеотидам (5′-HA ASO, молекулярная масса ~8000 Да; Østergaard et al., Bioconjugate Chem., 2015, 26 (8), pp 1451-1455). Подобным образом, были описаны поли(акрилатные) полимеры для доставки нуклеиновой кислоты in vivo (см. WO2013158141, включенную в данный документ посредством ссылки). В следующих альтернативных вариантах осуществления предварительное смешивание наночастиц CRISPR (или белковых комплексов) со встречающимися в природе сывороточными белками можно применять для улучшения доставки (Akinc A et al, 2010, Molecular Therapy vol. 18 no. 7, 1357-1364).
Доступны методики скрининга для идентификации доставленных энхансеров, например, с помощью скрининга химических библиотек (Gilleron J. et al., 2015, Nucl. Acids Res. 43 (16): 7984-8001). Также были описаны подходы для оценивания эффективности средств доставки, таких как липидные наночастицы, которые могут быть использованы для идентификации эффективных носителей доставки для компонентов CRISPR (см. Sahay G. et al., 2013, Nature Biotechnology 31, 653-658).
В некоторых вариантах осуществления доставка компонентов белка CRISPR может быть облегчена добавлением функциональных пептидов к белку, таких как пептиды, которые изменяют гидрофобность белка, например, для улучшения функциональности in vivo. Белковые компоненты CRISPR аналогично могут быть модифицированы для облегчения последующих химических реакций. Например, к белку могут быть добавлены аминокислоты, которые имеют группу, подвергаемую клик-химии (Nikić I. et al., 2015, Nature Protocols 10,780-791). В вариантах осуществления такого рода клик-химическая группа затем может быть использована в широком ряде альтернативных структур, например, поли(этиленгликоль) для стабильности, проникающие в клетку пептиды, аптамеры РНК, липиды или углеводы, такие как GalNAc. В качестве дополнительных альтернатив белковый компонент CRISPR может быть модифицирован для адаптации белка для попадания в клетку (см. Svensen et al., 2012, Trends in Pharmacological Sciences, Vol. 33, No. 4), например, путем добавления проникающих в клетку пептидов к белку (см. Kauffman, W. Berkeley et al., 2015, Trends in Biochemical Sciences, Volume 40, Issue 12 , 749 - 764; Koren and Torchilin, 2012, Trends in Molecular Medicine, Vol. 18, No. 7). В следующих альтернативных вариантах осуществления пациенты или субъекты могут предварительно получать соединения или составы, которые облегчают последующую доставку компонентов CRISPR.
Комплексы эффекторного белка Cpf1 можно применять в растениях
Систему(системы) эффекторного белка Cpf1 (например, одиночную(одиночные) или мультиплексную(мультиплексные)) можно применять в сочетании с последними достижениями в геномике сельскохозяйственных культур. Такие системы, описанные в данном документе, можно применять для осуществления эффективного и рентабельного детального изучения или редактирования гена или генома растений - например, для быстрого исследования, и/или отбора, и/или детальных изучений, и/или сравнения, и/или манипуляций и/или трансформации генов или геномов растений; например, для получения, идентификации, разработки, оптимизации или придания признака(признаков) или характеристики(характеристик) растению(растениям) или для трансформации генома растения. Соответственно, может быть усовершенствовано получение растений, новых растений с новыми комбинациями признаков или характеристик или новых растений с улучшенными признаками. Такую(такие) систему(системы) эффекторного белка Cpf1 можно применять по отношению к растениям в методиках сайт-направленной интеграции (SDI) или редактирования гена (GE) или любой приближенной обратной селекции (NRB) или обратной селекции (RB). Аспекты применения описанных в данном документе систем эффекторного белка Cpf1 могут быть аналогичными применению системы CRISPR-Cas (например, CRISPR-Cas9) у растений, и упоминается веб-сайт Университета Аризоны "CRISPR-PLANT" (http://www.genome.arizona.edu/crispr/) (при поддержке штата Пенсильвания и AGI). Варианты осуществления настоящего изобретения могут быть использованы при редактировании генома в растениях или в случае, когда RNAi или аналогичные методики редактирования генома были использованы ранее; см., например, Nekrasov, "Plant genome editing made easy: targeted mutagenesis in model and crop plants using the CRISPR-Cas system," Plant Methods 2013, 9:39 (doi:10.1186/1746-4811-9-39); Brooks, "Efficient gene editing in tomato in the first generation using the CRISPR/-Сas9 system," Plant Physiology September 2014 pp 114.247577; Shan, "Targeted genome modification of crop plants using a CRISPR-Cas system," Nature Biotechnology 31, 686-688 (2013); Feng, "Efficient genome editing in plants using a CRISPR/Cas system," Cell Research (2013) 23:1229-1232. doi:10.1038/cr.2013.114; опубликовано онлайн 20 августа 2013 г.; Xie, "RNA-guided genome editing in plants using a CRISPR-Cas system," Mol Plant. 2013 Nov;6(6):1975-83. doi: 10.1093/mp/sst119, электронная публикация 17 августа 2013 г.; Xu, "Gene targeting using the Agrobacterium tumefaciens-mediated CRISPR-Cas system in rice", Rice 2014, 7:5 (2014), Zhou et al., "Exploiting SNPs for biallelic CRISPR mutations in the outcrossing woody perennial Populus reveals 4-coumarate: CoA ligase specificity and Redundancy", New Phytologist (2015) (Forum) 1-4 (доступно только онлайн по адресу www.newphytologist.com); Caliando et al, "Targeted DNA degradation using a CRISPR device stably carried in the host genome", NATURE COMMUNICATIONS 6:6989, DOI: 10.1038/ncomms7989, www.nature.com/naturecommunications DOI: 10.1038/ncomms7989; патент США № 6603061 - Agrobacterium-Mediated Plant Transformation Method; патент США № 7868149 - Plant Genome Sequences and Uses Thereof и US 2009/0100536 - Transgenic Plants with Enhanced Agronomic Traits, все содержание и раскрытие каждого из которых включено в данный документ посредством ссылки во всей полноте. При практическом осуществлении настоящего изобретения содержание и раскрытие Morrell et al "Crop genomics: advances and applications", Nat Rev Genet. 2011 Dec 29;13(2):85-96; которое включено в данный документ посредством ссылки, в том числе то, как варианты осуществления в данном документе могут быть использованы по отношению к растениям. Соответственно, ссылка в данном документе на клетки животных может также применяться, с соответствующими изменениями, по отношению к растительным клеткам, если не очевидно иное; и ферменты в данном документе, имеющие ослабленные нецелевые эффекты, и системы, использующие такие ферменты, могут быть использованы в вариантах применения растений, в том числе упомянутых в данном документе.
Применение системы Cpf1-CRISPR в отношении растений и дрожжей
Определения
В целом, термин "растение" относится к любому отличающемуся друг от друга фотосинтезирующему, эукариотическому, одноклеточному или многоклеточному организму царства Растения, характерным образом растущему путем клеточного деления, содержащему хлоропласты и имеющему клеточные стенки, состоящие из целлюлозы. Термин "растение" охватывает однодольные и двудольные растения. В частности, растения включают без ограничения покрытосеменные и голосеменные растения, такие как акация, люцерна, амарант, яблоня, абрикос, артишок, ясень, спаржа, авокадо, банан, ячмень, бобы, свекла, береза, бук, ежевика, голубика, брокколи, брюссельская капуста, капуста, канола, канталупа, морковь, маниок, цветная капуста, кедр, злак, сельдерей, каштан, вишня, китайская капуста, цитрус, клементин, клевер, кофе, кукуруза, хлопчатник, коровий горох, огурец, кипарис, баклажан, вяз, цикорий салатный, эвкалипт, фенхель, инжир, пихта, герань, виноград, грейпфрут, земляной орех, вишня кустарниковая, эвкалипт, болиголов, кария, браунколь, киви, кольраби, лиственница, салат-латук, лук-порей, лимон, лайм, робиния, адиантум, маис, манго, клен, дыня, просо, гриб, горчица, орехи, дуб, овес, масличная пальма, окра, лук репчатый, апельсин, декоративное растение, цветущее растение или дерево, папайя, пальма, петрушка, пастернак, горох, персик, арахис, груша, торф, перец, хурма, голубиный орех, сосна, ананас, подорожник, слива, гранат, картофель, тыква, радиккио, редис, рапс, малина, рис, рожь, сорго, сафлор, ива, соя, шпинат, ель, тыква гигантская, клубника, сахарная свекла, сахарный тростник, подсолнечник, батат, сахарная кукуруза, мандарин, чай, табак, томат, деревья, тритикале, мох, турнепс, ползучее растение, грецкий орех, кресс водяной, арбуз, пшеница, ямс, тис и тыква обыкновенная. Термин "растение" также охватывает водоросли, которые представляют собой главным образом фотоавтотрофов, объединенных преимущественно в связи с отсутствием у них корней, листьев и других органов, которые характеризуют высшие растения.
Способы редактирования генома при помощи системы Cpf1, как описано в данном документе, можно применять для придания желаемых признаков практически любому растению. Широкий спектр растений и систем растительных клеток может быть сконструировано с целью желаемых физиологических и агрономических характеристик, описанных в данном документе, с помощью конструкций нуклеиновой кислоты по настоящему раскрытию и различных способов трансформации, упомянутых выше. В предпочтительных вариантах осуществления целевые растения и растительные клетки для конструирования включают без ограничения такие однодольные и двудольные растения, как зерновые культуры (например, пшеницу, маис, рис, просо, ячмень), плодовые культуры (например, томат, яблоня, груша, клубника, апельсин), кормовые культуры (например, люцерна), корнеплодные овощные культуры (например, морковь, картофель, сахарная свекла, ямс), лиственные овощные культуры (например, салат-латук, шпинат); цветущие растения (например, петуния, роза, хризантема), хвойные и сосновые деревья (например, сосна, пихта, ель); растения, используемые в фиторемедеации (например, растения, поглощающие тяжелые металлы); масляные культуры (например, подсолнечник, рапс) и растения, используемые для экспериментальных целей (например, Arabidopsis). Таким образом, способы и системы CRISPR-Cas могут быть применимы по отношению к широкому диапазону растений, таких как, например, двудольные растения, принадлежащие к порядкам Магнолиецветные, Иллициевые, Лавроцветные, Перечноцветные, Кирказоновые, Кувшинкоцветные, Лютикоцветные, Макоцветные, Саррацениевые, Троходендровые, Гамамелисовые, Эвкомисовые, Лейтнериевые, Мириковые, Букоцветные, Казуариновые, Гвоздичноцветные, Баталовые, Гречихоцветные, Плюмбаговые, Диллениевые, Чайные, Мальвоцветные, Крапивоцветные, Лецитисоцветные, Фиалкоцветные, Ивовые, Каперсоцветные, Верескоцветные, Диапенсиевые, Эбеновые, Примулоцветные, Розоцветные, Бобовоцветные, Подостемовые, Сланоягодникоцветные, Миртоцветные, Кизилоцветные, Протеецветные, Санталоцветные, Раффлезиевые, Бересклетоцветные, Молочаецветные, Крушиновые, Сапиндоцветные, Орехоцветные, Гераниецветные, Истодовые, Аралиецветные, Горечавкоцветные, Синюхоцветные, Ясноткоцветные, Подорожниковые, Норичникоцветные, Колокольчикоцветные, Мареноцветные, Ворсянкоцветные и Астроцветные; способы и системы CRISPR-Cas могут быть применимы по отношению к однодольным растениям, таким как принадлежащие к порядкам Частухоцветные, Панданоцветные, Наядовые, Триурисовые, Коммелиноцветные, Эриокаулоновые, Рестиевые, Тонконогоцветные, Ситниковые, Осокоцветные, Рогозовые, Бромелиецветные, Имбирецветные, Пальмоцветные, Циклантовые, Панданоцветные, Аронниковые, Лилиецветные и Орхидноцветные, или растениям, принадлежащим к голосеменным, например, принадлежащим к порядкам Сосновые, Гинкговые, Саговниковидные, Араукариевые, Кипарисовые и Гнетовидные.
Системы и способы применения Cpf1, описанные в данном документе, могут быть применимы по отношению к широкому диапазону видов растений, включенных в неограничивающий перечень двудольных, однодольных или голосеменных родов, приведенных ниже: Atropa, Alseodaphne, Anacardium, Arachis, Beilschmiedia, Brassica, Carthamus, Cocculus, Croton, Cucumis, Citrus, Citrullus, Capsicum, Catharanthus, Cocos, Coffea, Cucurbita, Daucus, Duguetia, Eschscholzia, Ficus, Fragaria, Glaucium, Glycine, Gossypium, Helianthus, Hevea, Hyoscyamus, Lactuca, Landolphia, Linum, Litsea, Lycopersicon, Lupinus, Manihot, Majorana, Malus, Medicago, Nicotiana, Olea, Parthenium, Papaver, Persea, Phaseolus, Pistacia, Pisum, Pyrus, Prunus, Raphanus, Ricinus, Senecio, Sinomenium, Stephania, Sinapis, Solanum, Theobroma, Trifolium, Trigonella, Vicia, Vinca, Vilis, и Vigna; и род Allium, Andropogon, Aragrostis, Asparagus, Avena, Cynodon, Elaeis, Festuca, Festulolium, Heterocallis, Hordeum, Lemna, Lolium, Musa, Oryza, Panicum, Pannesetum, Phleum, Poa, Secale, Sorghum, Triticum, Zea, Abies, Cunninghamia, Ephedra, Picea, Pinus, и Pseudotsuga.
Системы и способы применения Cpf1 CRISPR могут быть также применимы по отношению к широкому диапазону "водорослей" или "клеток водорослей", в том числе, например, водорослей, выбранных из нескольких эукариотических отделов, в том числе Rhodophyta (красные водоросли), Chlorophyta (зеленые водоросли), Phaeophyta (коричневые водоросли), Bacillariophyta (диатомовые водоросли), Eustigmatophyta и динофлагелляты, а также прокариотическому отделу Cyanobacteria (сине-зеленые водоросли). Термин "водоросли" включает, например, водоросли, выбранные из Amphora, Anabaena, Anikstrodesmis, Botryococcus, Chaetoceros, Chlamydomonas, Chlorella, Chlorococcum, Cyclotella, Cylindrotheca, Dunaliella, Emiliana, Euglena, Hematococcus, Isochrysis, Monochrysis, Monoraphidium, Nannochloris, Nannnochloropsis, Navicula, Nephrochloris, Nephroselmis, Nitzschia, Nodularia, Nostoc, Oochromonas, Oocystis, Oscillartoria, Pavlova, Phaeodactylum, Playtmonas, Pleurochrysis, Porhyra, Pseudoanabaena, Pyramimonas, Stichococcus, Synechococcus, Synechocystis, Tetraselmis, Thalassiosira и Trichodesmium.
Часть растения, т. е., "растительная ткань", может быть обработана в соответствии со способами по настоящему изобретению с целью получения улучшенного растения. Растительная ткань также охватывает растительные клетки. Термин "растительная клетка", как используется в данном документе, относится к отдельным единицам живого растения, как в интактном целом растении, так и в выделенной форме, выращенной в in vitro культурах тканей, на среде или агаре, в суспензии в среде для выращивания или буфере или в виде части более высокоорганизованных единиц, таких как, например, растительная ткань, орган растения или целое растение.
"Протопласт" относится к растительной клетке, у которой защитная клеточная стенка была полностью или частично удалена с помощью, например, механических или ферментативных способов, в результате чего образовалась интактная биохимическая компетентная единица живого растения, которая может сформировать заново свою клеточную стенку, пролиферировать и регенерировать в целое растение в соответствующих условиях роста.
Термин "трансформация" в широком смысле относится к процессу, с помощью которого растение-хозяин генетически модифицируют введением ДНК с помощью Agrobacteria или ряда химических или физических способов. Используемый в данном документе термин "растение-хозяин" относится к любым клеткам, тканям, органам или потомству растений. Многие подходящие растительные ткани или растительные клетки могут быть трансформированы и включают без ограничения протопласты, соматические эмбрионы, пыльцу, листья, сеянцы, стебли, каллюс, столоны, микроклубни и побеги. Растительная ткань также относится к любому клону такого растения, семенам, потомству, побегам, полученным половым или бесполым путем, и потомкам любых из них, таких как черенки или семена.
Термин "трансформированный", как используется в данном документе, относится к клетке, ткани, органу или организму, в которые была введена чужеродная молекула ДНК, такая как конструкция. Введенная молекула ДНК может быть интегрирована в геномную ДНК реципиентной клетки, ткани, органа или организма таким образом, что введенная молекула ДНК передается последующим потокам. В этих вариантах осуществления "трансформированная" или "трансгенная" клетка или растение могут также включать потомство клетки или растения и потомство, полученное в результате программы селекции с применением такой трансформированной клетки в качестве родителя в скрещивании, и характеризующееся измененным фенотипом, полученным в результате присутствия введенной молекулы ДНК. Предпочтительно трансгенное растение является фертильным и способно передавать введенную ДНК потомству в результате полового размножения.
Термин "потомство", такое как потомство трансгенного растения, представляет собой потомство, рожденное, произведенное или полученное из растения или трансгенного растения. Введенная молекула ДНК может также быть временно введенной в реципиентную клетку таким образом, что введенная молекула ДНК не наследуется последующим потомством, и, таким образом, она не считается "трансгенной". Соответственно, как используется в данном документе, "нетрансгенное растение" или растительная клетка представляют собой растение, которое не содержит чужеродную ДНК, стабильно интегрированную в его геном.
Термин "растительный промотор", как используется в данном документе, представляет собой промотор, способный инициировать транскрипцию в растительных клетках, вне зависимости от того, происходит ли он из растительной клетки. Иллюстративные подходящие растительные промоторы включают без ограничения таковые, которые получены из растений, вирусов растений и бактерий, таких как агробактерии или ризобактерии, которые содержат гены, экспрессируемые в растительных клетках.
Используемое в данном документе выражение "грибная клетка" относится к любому типу эукариотической клетки в царстве грибов. Отделы в царстве грибов включают Ascomycota, Basidiomycota, Blastocladiomycota, Chytridiomycota, Glomeromycota, Microsporidia и Neocallimastigomycota. Грибные клетки могут включать дрожжи, плесени и нитчатые грибы. В некоторых вариантах осуществления грибная клетка представляет собой клетку дрожжей.
Используемый в данном документе термин "клетка дрожжей" относится к любой грибной клетке в пределах отделов Ascomycota и Basidiomycota. Клетки дрожжей могут включать почкующиеся клетки дрожжей, делящиеся клетки дрожжей и плесневые клетки. Не ограничиваясь этими организмами, многие типы дрожжей, используемые в лабораторных и промышленных условиях, являются частью отдела Ascomycota. В некоторых вариантах осуществления клетка дрожжей представляет собой клетку S. cerervisiae, Kluyveromyces marxianus или Issatchenkia orientalis. Другие типы клеток дрожжей могут включать без ограничения Candida spp. (например, Candida albicans), Yarrowia spp. (например, Yarrowia lipolytica), Pichia spp. (например, Pichia pastoris), Kluyveromyces spp. (например, Kluyveromyces lactis и Kluyveromyces marxianus), Neurospora spp. (например, Neurospora crassa), Fusarium spp. (например, Fusarium oxysporum) и Issatchenkia spp. (например, Issatchenkia orientalis, также известный как Pichia kudriavzevii, и Candida acidothermophilum). В некоторых вариантах осуществления грибная клетка представляет собой клетку нитчатого гриба. Используемое в данном документе термин "клетка нитчатого гриба" относится к любому типу грибной клетки, которая растет за счет филаментов, т. е. гифов или мицелия. Примеры клеток нитчатых грибов включают без ограничения Aspergillus spp. (например, Aspergillus niger), Trichoderma spp. (например, Trichoderma reesei), Rhizopus spp. (например, Rhizopus oryzae) и Mortierella spp. (например, Mortierella isabellina).
В некоторых вариантах осуществления грибная клетка представляет собой промышленный штамм. Используемое в данном документе выражение "промышленный штамм" относится к любому штамму грибной клетки, используемому в промышленном способе или выделенному из него, например, получении продукта в коммерческом или промышленном масштабе. Промышленный штамм может относиться к виду гриба, который обычно используют в промышленном способе, или он может относиться к изоляту вида гриба, который может быть также использован для некоммерческих целей (например, лабораторное исследование). Примеры промышленных способов могут включать сбраживание (например, при получении пищевых продуктов питания и питьевых продуктов), дистилляцию, получение биотоплива, получение соединения и получение полипептида. Примеры промышленных штаммов могут включать без ограничения JAY270 и ATCC4124.
В некоторых вариантах осуществления грибная клетка представляет собой полиплоидную клетку. Используемое в данном документе выражение "полиплоидная" клетка может относиться к любой клетке, геном которой присутствует в более чем одной копии. Полиплоидная клетка может относиться к типу клетки, которая встречается в природе в полиплоидном состоянии или может относиться к клетке, которая была индуцирована с целью существования в полиплоидном состоянии (например, в результате специфичной регуляции, изменения, инактивации, активации или модификации мейоза, цитокинеза или репликации ДНК). Полиплоидная клетка может относиться к клетке, весь геном которой является полиплоидным, или может относиться к клетке, которая является полиплоидной в определенном представляющем интерес локусе генома. Без углубления в теорию, считается, что избыток направляющей РНК может чаще представлять собой компонент ограничения скорости при конструировании геномов полиплоидных клеток, а не гаплоидных клеток, и, таким образом, способы применения системы Cpf1 CRISPR, описанные в данном документе, могут характеризоваться преимуществом применения определенного типа грибной клетки.
В некоторых вариантах осуществления грибная клетка представляет собой диплоидную клетку. Используемое в данном документе выражение "диплоидная" клетка может относиться к любой клетке, геном которой присутствует в двух копиях. Диплоидная клетка может относиться к типу клетки, которая встречается в природе в диплоидном состоянии, или может относиться к клетке, которая была индуцирована с целью существования в диплоидном состоянии (например, в результате специфичной регуляции, изменения, инактивации, активации или модификации мейоза, цитокинеза или репликации ДНК). Например, штамм S228C S. cerevisiae может поддерживаться в гаплоидном или диплоидном состоянии. Диплоидная клетка может относиться к клетке, весь геном которой является диплоидным, или может относиться к клетке, которая является диплоидной в определенном представляющем интерес локусе генома. В некоторых вариантах осуществления грибная клетка представляет собой гаплоидную клетку. Используемое в данном документе выражение "гаплоидная" клетка может относиться к любой клетке, геном которой присутствует в одной копии. Гаплоидная клетка может относиться к типу клетки, которая встречается в природе в гаплоидном состоянии или может относиться к клетке, которая была индуцирована с целью существования в гаплоидном состоянии (например, в результате специфичной регуляции, изменения, инактивации, активации или модификации мейоза, цитокинеза или репликации ДНК). Например, штамм S228C S. cerevisiae может поддерживаться в гаплоидном или диплоидном состоянии. Гаплоидная клетка может относиться к клетке, весь геном которой является гаплоидным, или может относиться к клетке, которая является гаплоидной в определенном представляющем интерес локусе генома.
Используемое в данном документе выражение "дрожжевой вектор экспрессии" относится к нуклеиновой кислоте, которая содержит одну или несколько последовательностей, кодирующих РНК и/или полипептид, и может дополнительно содержать любые требуемые элементы, которые контролируют экспрессию нуклеиновой кислоты(нуклеиновых кислот), а также любые элементы, которые обеспечивают репликацию и поддержание вектора экспрессии в клетке дрожжей. Многие подходящие дрожжевые векторы экспрессии и их характеристики известны в данной области; например, различные векторы и методики проиллюстрированы в Yeast Protocols, 2nd edition, Xiao, W., ed. (Humana Press, New York, 2007) и Buckholz, R.G. and Gleeson, M.A. (1991) Biotechnology (NY) 9(11): 1067-72. Дрожжевые векторы могут содержать без ограничения центромерную (CEN) последовательность, автономную последовательность репликации (ARS), промотор, такой как промотор РНК-полимеразы III, функционально связанный с представляющими интерес последовательностью или геном, терминатором, таким как терминатор РНК-полимеразы III, точкой начала репликации и маркерным геном (например, селектируемыми маркерами ауксотрофов, селектируемыми маркерами к антибиотикам или другими селектируемыми маркерами). Примеры векторов экспрессии для применения в дрожжах могут включать плазмиды, искусственные хромосомы дрожжей, 2 мкм-плазмиды, дрожжевые интегративные плазмиды, дрожжевые репликативные плазмиды, челночные векторы и эписомальные плазмиды.
Стабильная интеграция компонентов системы Cpf1 CRISPR в геном растений и растительных клеток
В конкретных вариантах осуществления предусмотрено, что полинуклеотиды, кодирующие компоненты системы Cpf1 CRISPR, вводят с целью стабильной интеграции в геном растительной клетки. В этих вариантах осуществления разработка вектора трансформации или системы экспрессии может быть откорректирована в зависимости от того, когда, где и при каких условиях направляющая РНК и/или ген Cpf1 экспрессируются.
В конкретных вариантах осуществления предусмотрено стабильное введение компонентов системы Cpf1 CRISPR в геномную ДНК растительной клетки. Дополнительно или альтернативно предусмотрено введение компонентов системы Cpf1 CRISPR с целью стабильной интеграции в ДНК органеллы растения, такой как без ограничения пластида, митохондрия или хлоропласт.
Система экспрессии для стабильной интеграции в геном растительной клетки может содержать один или несколько из следующих элементов: промоторный элемент, который может быть использован для экспрессии РНК и/или фермента Cpf1 в растительной клетке; 5'-нетранслируемый участок для усиления экспрессии; интронный элемент для дополнительного усиления экспрессии в определенных клетках, таких как клетки однодольных растений; сайт множественного клонирования для обеспечения удобных сайтов рестрикции для вставки последовательностей направляющей РНК и/или гена Cpf1 и другие требуемые элементы; и 3'-нетранслируемый участок для обеспечения эффективной терминации экспрессируемого транскрипта.
Элементы системы экспрессии могут находиться в одной или нескольких конструкциях экспрессии, которые являются кольцевыми, такими как плазмида или вектор трансформации, или некольцевыми, такими как линейная двухнитевая ДНК.
В конкретных вариантах осуществления система экспрессии Cpf1 CRISPR содержит по меньшей мере
- нуклеотидную последовательность, кодирующую направляющую РНК, которая гибридизируется с целевой последовательностью в растении, и где направляющая РНК содержит направляющую последовательность и последовательность прямого повтора, и
- нуклеотидную последовательность, кодирующую белок Cpf1,
где компоненты (a) или (b) расположены в одной и той же или различных конструкциях, и где различные нуклеотидные последовательности могут находиться под контролем одного и того же или различных регуляторных элементов, функционирующих в клетке.
Конструкция(конструкции) ДНК, содержащая(содержащие) компоненты системы Cpf1 CRISPR и при необходимости матричную последовательность, могут быть введены в геном растения, части растения или растительной клетки при помощи ряда стандартных методик. Этот процесс, как правило, предусматривает стадии отбора подходящей клетки-хозяина или ткани-хозяина, введения конструкции(конструкций) в клетку-хозяина или ткань-хозяина и восстановление из них растительных клеток или растений.
В конкретных вариантах осуществления конструкция ДНК может быть введена в растительную клетку с помощью методик, таких как без ограничения электропорация, микроинъекция, введение с помощью аэрозольного пучкового инжектора протопластов растительных клеток, или конструкции ДНК могут быть введены непосредственно в растительную ткань с помощью биолистических способов, таких как бомбардировка частицами с ДНК (см. также Fu et al., Transgenic Res. 2000 Feb;9(1):11-9). Основой бомбардировки частицами является ускорение частиц, покрытых представляющим интерес геном/представляющими интерес генами, в клетки, что приводит к проникновению частиц в протоплазму и, как правило, стабильной интеграции в геном. (См., например, Klein et al, Nature (1987), Klein et ah, Bio/Technology (1992), Casas et ah, Proc. Natl. Acad. Sci. USA (1993)).
В конкретных вариантах осуществления конструкции ДНК, содержащие компоненты системы Cpf1 CRISPR, могут быть введены в растение при помощи опосредованной Agrobacterium трансформации. Конструкции ДНК могут быть комбинированы с подходящими фланкирующими участками T-ДНК и введены в стандартный вектор-хозяин Agrobacterium tumefaciens. Чужеродная ДНК может быть включена в геном растений путем инфицирования растений или инкубирования протопластов растений бактериями Agrobacterium, содержащими одну или несколько Ti (опухоль-индуцирующих) плазмид. (См., например, Fraley et al., (1985), Rogers et al., (1987) и патент США № 5 563 055).
Растительные промоторы
С целью обеспечения подходящей экспрессии в растительной клетке компоненты системы Cpf1 CRISPR, описанные в данном документе, как правило, помещают под контроль растительного промотора, т. е. промотора, функционирующего в растительных клетках. Предусмотрено применение различных типов промоторов.
Конститутивный растительный промотор представляет собой промотор, который способен экспрессировать открытую рамку считывания (ORF), который контролирует ее во всех или почти во всех растительных тканях во время всех или почти всех стадий развития растения (так называемая "конститутивная экспрессия"). Одним неограничивающим примером конститутивного промотора является промотор вируса мозаики цветной капусты 35S. "Регуляторный промотор" относится к промоторам, которые управляют экспрессией генов не конститутивно, а путем временной и/или пространственной регуляции, и включает тканеспецифичные, тканепредпочтительные и индуцируемые промоторы. Различные промоторы могут управлять экспрессией гена в различных тканях или типах клеток, или на различных стадиях развития, или в ответ на различные средовые факторы. В конкретных вариантах осуществления один или несколько из компонентов Cpf1 CRISPR экспрессируются под контролем конститутивного промотора, такого как промотор вируса мозаики цветной капусты 35S, тканеспецифичные промоторы могут быть использованы для нацеливания усиленной экспрессии в определенных типах клеток в конкретной растительной ткани, например, сосудистых тканях или определенных клетках семени. Примеры конкретных промоторов для применения в системе Cpf1 CRISPR встречаются в Kawamata et al., (1997) Plant Cell Physiol 38:792-803; Yamamoto et al., (1997) Plant J 12:255-65; Hire et al, (1992) Plant Mol Biol 20:207-18, Kuster et al, (1995) Plant Mol Biol 29:759-72, и Capana et al., (1994) Plant Mol Biol 25:681 -91.
Примеры промоторов, которые являются индуцируемыми и которые обеспечивают пространственно-временной контроль редактирования генов или экспрессии генов, могут использовать определенную форму энергии. Форма энергии может включать без ограничения звуковую энергию, электромагнитную энергию, химическую энергию и/или тепловую энергию. Примеры индуцируемых систем включают индуцируемые тетрациклином промоторы (Tet-On или Tet-Off), двухгибридные системы активации транскрипции с использованием малых молекул (FKBP, ABA и т. д.) или индуцируемые светом системы (фитохром, домены LOV или криптохром), такие как индуцируемый светом транскрипционный эффектор (LITE), который управляет изменениями транскрипционной активности специфичным к последовательности образом. Компоненты индуцируемой светом системы могут включать фермент Cpf1 CRISPR, чувствительный к свету гетеродимер цитохрома (например, из Arabidopsis thaliana) и домен активации/подавления транскрипции. Дополнительные примеры индуцируемых ДНК-связывающих белков и способы их применения представлены в US 61/736465 и US 61/721283, которые включены в данный документ посредством ссылки во всей полноте.
В конкретных вариантах осуществления транзиентная или индуцируемая экспрессия может быть достигнута, например, с помощью регулируемых химическим путем промоторов, т. е. в случае, когда применение экзогенного химического соединения индуцирует экспрессию генов. Модулирование экспрессии генов также может быть получено с помощью репрессируемого химическим путем промотора, где применение химического соединения репрессирует экспрессию генов. Индуцированные химическим путем промоторы включают без ограничения промотор маиса ln2-2, активируемый антидотами гербицидов на основе бензолсульфамидов (De Veylder et al., (1997) Plant Cell Physiol 38:568-77), промотор маиса GST (GST-ll-27, WO93/01294), активируемый гидрофобными электрофильными соединениями, используемыми в качестве предвсходовых гербицидов, и промотор табака PR-1 (Ono et al., (2004) Biosci Biotechnol Biochem 68:803-7), активируемый салициловой кислотой. Промоторы, которые регулируются антибиотиками, такими как индуцируемые тетрациклином и репрессируемые тетрациклином промоторы (Gatz et al., (1991 ) Mol Gen Genet 227:229-37; патенты США №№ 5814618 и 5789156), также могут быть использованы в данном документе.
Транслокация и/или экспрессия в конкретных органеллах растений
Система экспрессии может содержать элементы для транслокации и/или экспрессии в конкретной органелле растения.
Нацеливание на хлоропласты
В конкретных вариантах осуществления предусмотрено, что система Cpf1 CRISPR используется для специфичной модификации генов хлоропластов или для обеспечения экспрессии в хлоропласте. С этой целью используются способы трансформации хлоропластов или компартментализации компонентов Cpf1 CRISPR в хлоропласте. Например, введение генетических модификаций в геном пластиды может уменьшить проблемы биобезопасности, такие как поток генов через пыльцу.
Способы трансформации хлоропластов известны в данной области и включают бомбардировку частицами, обработку PEG и микроинъекцию. Кроме того, способы, включающие транслокацию кассет для трансформации из ядерного генома в пластиду, можно применять, как описано в WO2010061186.
Альтернативно предусмотрено нацеливание одного или нескольких компонентов системы Cpf1 CRISPR на хлоропласт растения. Это достигается включением в экспрессионную конструкцию последовательности, кодирующей транзитный пептид хлоропласта (CTP) или транзитный пептид пластиды, функционально связанный с 5'-участком последовательности, кодирующей белок Cpf1. CTP удаляется на этапе процессинга во время транслокации в хлоропласт. Нацеливание на хлоропласты экспрессируемых белков хорошо известно специалисту в данной области (см., например, Protein Transport into Chloroplasts, 2010, Annual Review of Plant Biology,Vol. 61: 157-180). В таких вариантах осуществления также является желательным нацеливание направляющей РНК на хлоропласт растения. Способы и конструкции, которые могут быть использованы для транслокации направляющей РНК в хлоропласт пс помощью последовательности локализации в хлоропласте описаны, например, в US 20040142476, включенном в данный документе посредством ссылки. Такие вариации конструкций могут быть включены в системы экспрессии по настоящему изобретению для эффективной транслокации Cpf1-направляющая РНК.
Введение полинуклеотидов, кодирующих систему CRISPR-Cpf1, в клетки водорослей
Трансгенные водоросли (или другие растения, такие как рапс) могут быть особенно полезными в производстве растительных масел или таких видов биотоплива, как, например, спирты (особенно метанол и этанол), или других продуктов. Они могут быть сконструированы для синтеза или избыточного синтеза масла или спиртов на высоких уровнях для применения в масложировой или биотопливной промышленности.
В US 8945839 описан способ конструирования микроводорослей (виды клеток Chlamydomonas reinhardtii) с помощью Cas9. С помощью аналогичных средств способы системы Cpf1 CRISPR, описанной в данном документе, могут быть применимы по отношению к виду Chlamydomonas и другим водорослям. В конкретных вариантах осуществления Cpf1 и направляющую РНК вводят в синтезирующие водоросли при помощи вектора, который экспрессирует Cpf1 под контролем конститутивного промотора, такого как промотор Hsp70A-Rbc S2 или промотор бета 2-тубулина. Направляющую РНК необязательно доставляют при помощи вектора, содержащего промотор T7. Альтернативно мРНК Cas9 и in vitro транскрибируемая направляющая РНК могут быть доставлены в клетки водорослей. Протоколы электропорации доступны специалисту в данной области, такие как стандартный рекомендованный протокол из набора GeneArt Chlamydomonas Engineering.
В конкретных вариантах осуществления эндонуклеаза, используемая в данном документе, представляет собой фермент Split Cpf1. Ферменты Split Cpf1 предпочтительно используют в водорослях для целевой геномной модификации, как было описано для Cas9 в WO 2015086795. Применение системы Cpf1 split является особенно подходящим для индуцируемого способа управления геномом, и в результате этого избегают потенциального токсического эффекта сверхэкспрессии Cpf1 в клетке водорослей. В конкретных вариантах осуществления указанные домены Cpf1 split (домены RuvC и HNH) могут быть одновременно или последовательно введены в клетку таким образом, что указанный домен(указанные домены) split Cpf1 обрабатывает(обрабатывают) целевую последовательность нуклеиновой кислоты в клетке водорослей. Уменьшенный размер split Cpf1 по сравнению с Cpf1 дикого типа облегчает другие способы доставки системы CRISPR в клетки, такие как применение проникающих пептидов, как описано в данном документе. Этот способ представляет особый интерес для получения генетически модифицированных водорослей.
Введение полинуклеотидов, кодирующих компоненты Cpf1, в клетки дрожжей
В конкретных вариантах осуществления настоящее изобретение относится к применению системы Cpf1 CRISPR для редактирования геномов клеток дрожжей. Способы трансформации клеток дрожжей, которые можно применять для введения полинуклеотидов, кодирующих компоненты системы Cpf1 CRISPR, хорошо известны специалисту в данной области и описаны в Kawai et al., 2010, Bioeng Bugs. 2010 Nov-Dec; 1(6): 395-403). Неограничивающие примеры включают трансформацию клеток дрожжей с помощью обработки ацетатом лития (которая может дополнительно включать обработку ДНК-носителем и PEG), бомбардировки или с помощью электропорации.
Транзиентная экспрессия компонентов системы Cpf1 CRISP в растениях и растительных клетках
В конкретных вариантах осуществления предусмотрено, что направляющая РНК и/или ген Cpf1 транзиентно экспрессируются в растительной клетке. В этих вариантах осуществления система Cpf1 CRISPR может обеспечивать модификацию целевого гена только в случае, когда как направляющая РНК, так и белок Cpf1 присутствуют в клетке, таким образом геномную модификацию можно дополнительно контролировать. Поскольку экспрессия фермента Cpf1 является транзиентной, то растения, регенерированные из таких растительных клеток, как правило, не содержат чужеродной ДНК. В конкретных вариантах осуществления фермент Cpf1 стабильно экспрессируется растительной клеткой, а направляющая последовательность экспрессируется транзиентно.
В конкретных вариантах осуществления компоненты системы Cpf1 CRISPR могут быть введены в растительные клетки при помощи вектора на основе вируса растений (Scholthof et al. 1996, Annu Rev Phytopathol. 1996;34:299-323). В дополнительных конкретных вариантах осуществления указанный вирусный вектор представляет собой вектор из ДНК-содержащего вируса. Например, геминивирус (например, вирус курчавости капустного листа, вирус желтой карликовости бобов, вирус карликовости пшеницы, вирус курчавости томатного листа, вирус полосы кукурузы, вирус курчавости листа табака или вирус золотистой мозаики томата) или нановирус (например, вирус желтого некроза конских бобов). В других конкретных вариантах осуществления указанный вирусный вектор представляет собой вектор из РНК-содержащего вируса. Например, тобравирус (например, вирус погремковости табака, вирус табачной мозаики), потексвирус (например, Х-вирус картофеля) или хордейвирус (например, вирус штриховой мозаики ячменя). Реплицирующиеся геномы растительных вирусов представляют собой неинтегративные векторы.
В конкретных вариантах осуществления вектор, используемый для транзиентной экспрессии конструкций Cpf1 CRISPR, представляет собой, например, вектор pEAQ, который подходит для опосредованной Agrobacterium транзиентной экспрессии (Sainsbury F. et al., Plant Biotechnol J. 2009 Sep;7(7):682-93) в протопласте. Точное нацеливание на локализацию в геноме было показано с помощью вектора на основе модифицированного вируса курчавости капустного листа (CaLCuV) с целью экспрессии gRNA в стабильных трансгенных растениях, экспрессирующих фермент CRISPR (Scientific Reports 5, номер статьи: 14926 (2015), doi:10.1038/srep14926).
В конкретных вариантах осуществления фрагменты двухнитевой ДНК, кодирующие направляющую РНК и/или ген Cpf1, могут быть транзиентно введены в растительную клетку. В таких вариантах осуществления введенные фрагменты двухнитевой ДНК предусмотрены в достаточном количестве с целью модификации клетки, однако не сохраняются по прошествии предусмотренного периода времени или после одного или нескольких клеточных делений. Способы прямого переноса ДНК в растения известны специалисту в данной области (см., например, Davey et al. Plant Mol Biol. 1989 Sep;13(3):273-85).
В других вариантах осуществления РНК-полинуклеотид, кодирующий белок Cpf1, вводят в растительную клетку, который затем транслируется и процессируется клеткой-хозяином, образующей белок в достаточном количестве для модификации клетки (в присутствии по меньшей мере одной направляющей РНК), но который не сохраняется по происшествию предусмотренного периода времени или после одного или нескольких клеточных делений. Способы введения мРНК в протопласты растений для транзиентной экспрессии известны специалисту в данной области (см., например, в Gallie, Plant Cell Reports (1993), 13;119-122).
Также предусмотрены комбинации различных способов, описанных выше.
Доставка компонентов Cpf1 CRISPR в растительную клетку
В конкретных вариантах осуществления представляет интерес доставка одного или нескольких компонентов системы Cpf1 СRISPR непосредственно в растительную клетку. Это представляет интерес, помимо прочего, для получения нетрансгенных растений (см. ниже). В конкретных вариантах осуществления один или несколько компонентов Cpf1 получают за пределами растения или растительной клетки и доставляют в клетку. Например, в конкретных вариантах осуществления белок Cpf1 получают in vitro до введения в растительную клетку. Белок Cpf1 может быть получен при помощи различных способов, известных специалисту в данной области, в том числе рекомбинантного получения. После экспрессии белок Cpf1 выделяют, при необходимости повторно подвергают фолдингу, очищают и необязательно обрабатывают для удаления любых меток, таких как His-метка. Непосредственно после получения неочищенного, частично очищенного или более полно очищенного белка Cpf1 белок может быть введен в растительную клетку.
В конкретных вариантах осуществления белок Cpf1 смешивают с направляющей РНК, нацеленной на представляющий интерес ген с получением предварительно собранного рибонуклеопротеина.
Отдельные компоненты или предварительно собранный рибонуклеопротеин могут быть введены в растительную клетку при помощи электропорации, при помощи бомбардировки частицами, покрытыми продуктом гена, ассоциированного с Cpf1, при помощи химической трансфекции или при помощи других средств транспорта через клеточную мембрану. Например, была показана трансфекция протопласта растения предварительно собранным рибонуклеопротеином CRISPR с целью обеспечения целевой модификации генома растения (как описано Woo et al. Nature Biotechnology, 2015; DOI: 10.1038/nbt.3389).
В конкретных вариантах осуществления компоненты системы Cpf1CRISPR вводят в растительные клетки при помощи наночастиц. Компоненты, как в виде белка, так в виде нуклеиновой кислоты или их комбинации, могут быть нагружены или упакованы в наночастицы и нанесены на растения (такие как, например, описаны в WO 2008042156 и US 20130185823). В частности, варианты осуществления по настоящему изобретению предусматривают наночастицы, нагруженные или упакованные молекулой(молекулами) ДНК, кодирующей(кодирующими) белок Cpf1, молекулами ДНК, кодирующими направляющую РНК и/или выделенную направляющую РНК, как описано в WO2015089419.
Дополнительные средства введения одного или нескольких компонентов системы Cpf1 CRISPR в растительную клетку предусматривают проникающие пептиды (CPP). Соответственно, в частности, варианты осуществления по настоящему изобретению предусматривают проникающий пептид, связанный с белком Cpf1. В конкретных вариантах осуществления настоящего изобретения белок Cpf1 и/или направляющая РНК связаны с одним или несколькими CPP с целью эффективной транспортировки в протопласты клеток; см. также Ramakrishna (2014 Genome Res. 2014 Jun;24(6):1020-7 в случае Cas9 в человеческих клетках). В других вариантах осуществления ген Cpf1 и/или направляющая РНК кодируются одной или несколькими кольцевой(кольцевыми) или некольцевой(некольцевыми) молекулой(молекулами) ДНК, которые связаны с одним или несколькими CPP для доставки в протопласты растений. Протопласты растений затем регенерируют до растительных клеток и затем до растений. CPP, как правило, описаны в виде коротких пептидов из менее чем 35 аминокислот, полученных как из белков, так и из химерных последовательностей, которые способны транспортировать биомолекулы через клеточную мембрану рецепторно-зависимым образом. CPP может представлять собой катионные пептиды, пептиды, имеющие гидрофобные последовательности, амфипатические пептиды, пептиды, имеющие последовательность с высоким содержанием пролина и антимикробную последовательность, и химерные или состоящие из двух частей пептиды (Pooga and Langel 2005). CPP способны проникать через биологические мембраны и, таким образом, вызывать движение различных биомолекул через клеточные мембраны в цитоплазму, и улучшать внутриклеточное движение, и, таким образом, облегчать взаимодействие биомолекулы с мишенью. Примеры CPP включают среди прочего Tat, ядерный белок транскрипционный активатор для вирусной репликации HIV 1 типа, пенетратин, сигнальную пептидную последовательность на основе фактора роста фибробластов Капоши (FGF), сигнальную пептидную последовательность на основе интегрина β3; Arg-последовательность на основе полиаргининового пептида, молекулярные транспортеры с высоким содержанием гуанина, пептид "sweet arrow" и др.
Применение системы Cpf1 CRISPR для получения генетически модифицированных нетрансгенных растений
- В конкретных вариантах осуществления способы, описанные в данном документе, используются для модификации эндогенных генов или для модификации их экспрессии без перманентного введения в геном растения какого-либо чужеродного гена, в том числе кодирующих компонентов CRISPR, с тем, чтобы избежать присутствия чужеродной ДНК в геноме растения. Это может представлять интерес, поскольку регуляторные требования для нетрансгенных растений являются менее жесткими.
- В конкретных вариантах осуществления это обеспечивается транзиентной экспрессией компонентов Cpf1 CRISPR. В конкретных вариантах осуществления один или несколько из компонентов CRISPR экспрессируются одним или несколькими вирусными векторами, которые продуцируют достаточно белка Cpf1 и направляющей РНК для стабильного обеспечения модификации представляющего интерес гена в соответствии со способом, описанным в данном документе.
- В конкретных вариантах осуществления транзиентная экспрессия конструкций Cpf1 CRISPR обеспечивается в протопластах растений и, таким образом, не интегрирована в геном. Ограниченное окно экспрессии может быть достаточным для обеспечения того, чтобы система Cpf1 CRISPR обеспечила модификацию целевого гена, как описано в данном документе.
- В конкретных вариантах осуществления различные компоненты системы Cpf1 CRISPR вводят в растительную клетку, протопласт или растительную ткань, как раздельно, так и в смеси, с целью раздельной доставки молекул, таких как наночастицы или молекулы CPP, как описано в данном документ выше.
- Экспрессия компонентов Cpf1 CRISPR может индуцировать целевую модификацию генома, как путем непосредственной активности нуклеазы Cpf1 и необязательного введения матричной ДНК, так и путем модификации целевых генов при помощи системы Cpf1 CRISPR, как описано в данном документе. Различные стратегии, описанные в данном документе выше, обеспечивают Cpf1-опосредованное целевое редактирование генома, требующее введения компонентов Cpf1 CRISPR в геном растений. Компоненты, которые транзиентно вводят в растительную клетку, как правило, удаляют при селекции.
Выявление модификаций в маркерах отбора генома растений
- В конкретных вариантах осуществления, где способ включает модификацию эндогенного целевого гена генома растения, для определения может быть применен любой подходящий способ после того, как растение, часть растения или растительную клетку инфицируют или трансфицируют системой Cpf1 CRISPR, вне зависимости от того, произошло или не произошло нацеливание на ген или направленный мутагенез в целевом сайте. Если способ предусматривает введение трансгена, то трансформированная растительная клетка, каллюс, ткань или растение могут быть идентифицированы и выделены с помощью отбора или скрининга сконструированного растительного материала на наличие трансгена или признаков, кодируемых трансгеном. Физические и биохимические способы могут быть использованы для выявления трансформантов растений или растительных клеток, содержащих вставленные генные конструкции или модификацию эндогенной ДНК. Эти способы включают без ограничения: 1) саузерн-анализ или ПЦР-амплификацию для выявления и определения структуры вставки рекомбинантной ДНК или модифицированных эндогенных генов; 2) нозерн-блоттинг, защиту от S1 РНКазы, достройку праймера или ПЦР-апмлификацию с помощью обратной транскриптазы для выявления и исследования РНК-транскриптов генных конструкций; 3) ферментативные анализы для выявления активности ферментов или рибозимов, где такие продукты генов кодируются генной конструкцией, или экспрессия нарушена в результате генетической модификации; 4) гель-электрофорез белка, методики вестерн-блоттинга, иммуноосаждение или иммуноанализы с иммобилизованными ферментами, где генная конструкция или продукты эндогенных генов представляют собой белки. Дополнительные методики, такие как гибридизация in situ, ферментативное окрашивание и иммуноокрашивание, также могут быть использованы для выявления наличия или экспрессии рекомбинантной конструкции или выявления модификации эндогенного гена в конкретных органах или тканях растений. Способы для выполнения всех этих анализов хорошо известны специалистам в данной области.
- Кроме того (или альтернативно), систему экспрессии, кодирующую компоненты Cpf1 CRISPR, обычно разрабатывают с целью содержания одного или нескольких селектируемых или выявляемых маркеров, которые обеспечивают средство для выделения или эффективного отбора клеток, которые содержат систему Cpf1 CRISPR и/или были модифицированы ею на ранней стадии и в большом объеме.
В случае опосредованной Agrobacterium трансформации кассета с маркерами может находиться вблизи границ фланкирующей T-ДНК или между ними и содержаться в бинарном векторе. В другом варианте осуществления кассета с маркерами может находиться за пределами Т-ДНК. Кассета с селектируемыми маркерами может также находиться на границах той же самой T-ДНК, что и кассета экспрессии, или вблизи них и может находиться в каком-то другом месте во второй Т-ДНК в бинарном векторе (например, системе 2 T-ДНК).
- В случае бомбардировки частицами или трансформации протопласта система экспрессии может содержать один или несколько выделенных линейных фрагментов или может быть частью более крупной конструкции, которая должна содержать элементы репликации бактерий, селектируемые маркеры бактерий или другие выявляемые элементы. Кассета(кассеты) экспрессии, содержащая(содержащие) полинуклеотиды, кодирующие направляющую последовательность и/или Cpf1, может(могут) быть физически связана(связаны) с кассетой с маркерами или может(могут) быть смешана(смешаны) со второй молекулой нуклеиновой кислоты, кодирующей кассету с маркерами. Кассета с маркерами состоит из необходимых элементов для экспрессии выявляемого или селектируемого маркера, который обеспечивает эффективный отбор трансформированных клеток.
- Процедура отбора в случае клеток на основании селектируемого маркера будет зависеть от природы маркерного гена. В конкретных вариантах осуществления применяют селектируемый маркер, т. е. маркер, который обеспечивает непосредственный отбор клеток на основе экспрессии маркера. Маркер отбора может обеспечивать позитивный или негативный отбор и зависит или не зависит от наличия внешних субстратов (Miki et al. 2004, 107(3): 193-232). Как правило, гены устойчивости к антибиотикам или гербицидам используют в качестве маркеров, при этом отбор должен выполняться в зависимости от роста сконструированного растительного материала на средах, содержащих ингибирующее количество антибиотика или гербицида, к которому маркерный ген придает устойчивость. Примерами таких генов являются гены, которые придают устойчивость к антибиотикам, таким как гигромицин (hpt) и канамицин (nptII), и гены, которые придают устойчивость к гербицидам, таким как фосфинотрицин (bar) и хлорсульфурон (als).
- Трансформированные растения и растительные клетки могут также быть идентифицированы при помощи скрининга на виды активности видимого маркера, как правило, фермента, способного обработать окрашенный субстрат (например, β-глюкоронидазу, люциферазу, гены B или C1). Такие методики отбора и скрининга хорошо известны специалистам в данной области.
Культуры и регенерация растений
- В конкретных вариантах осуществления растительные клетки имеют модифицированный геном, и те, которые образованы или получены с помощью любого из способов, описанных в данном документе, могут быть культивированы с регенерацией целого растения, которое обладает трансформированным или модифицированным генотипом и, таким образом, желаемым фенотипом. Стандартные методики регенерации хорошо известны специалистам в данной области. Конкретные примеры таких методик регенерации основаны на действии определенных фитогормонов в среде для роста культуры тканей, и, как правило, основаны на биоцидном и/или гербицидном маркере, который был введен совместно с требуемыми нуклеотидными последовательностями. В дополнительных конкретных вариантах осуществления регенерация растений осуществляется исходя из культивируемых протопластов, каллюса, эксплантов, органов, пыльцы, эмбрионов растений или их частей (см., например, Evans et al. (1983), Handbook of Plant Cell Culture, Klee et al (1987) Ann. Rev. of Plant Phys.).
- В конкретных вариантах осуществления трансформированные или улучшенные растения, как описано в данном документе, могут быть самоопылены с получением семян для гомозитных улучшенных растений по настоящему изобретению (гомозиготных для модификации ДНК) или скрещены с нетрансгенными растениями или различными улучшенными растениями с получением семян для гетерозиготных растений. Если рекомбинантная ДНК была внесена в растительную клетку, то полученное в результате такой селекции растение представляет собой растение, которое является гетерозиготным по рекомбинантной молекуле ДНК. Оба такие гомозиготное и гетерозиготное растения, полученные при скрещивании от улучшенных растений и содержащие генетическую модификацию (которая может представлять собой рекомбинантную ДНК), называются в данном документе "потомство". Дочерние растения представляют собой растения, происходящие от исходного родительского растения и содержащие модификацию генома или молекулу рекомбинантной ДНК, введенную с помощью способов, предусмотренных в данном документе. Альтернативно генетически модифицированные растения могут быть получены при помощи одного из способов, описанных выше, с применением фермента Cfp1, где чужеродная ДНК не вводится в геном. Потомство таких растений, полученных с помощью дополнительной селекции, также может содержать генетическую модификацию. Скрещивания выполняют с помощью любых способов селекции, которые широко применяют для различных сельскохозяйственных культур (например, Allard, Principles of Plant Breeding, John Wiley & Sons, NY, U. of CA, Davis, CA, 50-98 (1960).
Получение растений с улучшенными агрономическими характеристиками
- Системы CRISPR на основе Cpf1, предусмотренные в данном документе, можно применять для введения целевых двунитевых или однонитевых разрывов и/или для введения систем активаторов и/или репрессоров генов и без ограничения могут быть использованы для целенаправленного воздействия на гены, замещения генов, направленного мутагенеза, целевых делеций или вставок, целевых инверсий и/или целевых транслокаций. С помощью коэкспрессии нескольких нацеливающих РНК, направленных на получение нескольких модификаций в одной клетке, может быть обеспечена мультиплексная модификация геномов. Эту технологию можно применять для высокоточного конструирования растений с улучшенными характеристиками, в том числе повышенной пищевой ценностью, повышенной устойчивостью к биотическому и абиотическому стрессу и повышенной продукцией коммерчески ценных растительных продуктов или гетерологичных соединений.
- В конкретных вариантах осуществления система Cpf1 CRISPR, как описано в данном документе, используется для введения целевых двухнитевых разрывов (DSB) в последовательность эндогенной ДНК. DSB активирует клеточные пути репарации ДНК, которые могут быть использованы для достижения требуемых модификаций последовательности ДНК возле сайта разрыва. Это представляет интерес, если инактивация эндогенных генов может придавать желаемый признак или способствует его появлению. В конкретных вариантах осуществления гомологичная рекомбинация матричной последовательностью активизируется в сайте DSB с целью введения представляющего интерес гена.
- В конкретных вариантах осуществления система Cpf1 CRISPR может быть использована в качестве генерического связывающегося с нуклеиновой кислотой белка при слиянии или при функциональном связывании с функциональным доменом для активации и/или репрессии эндогенных генов растений. Иллюстративные функциональные домены могут включать без ограничения инициатор трансляции, активатор трансляции, репрессор трансляции, нуклеазы, в частности рибонуклеазы, сплайсосому, гранулы, индуцируемый/контролируемый светом домен или химически индуцируемый/контролируемый домен. Как правило, в этих вариантах осуществления белок Cpf1 содержит по меньшей мере одну мутацию, например, он характеризуется не более чем 5% активности белка Cpf1, не имеющего по меньшей мере одной мутации; направляющая РНК содержит направляющую последовательность, способную к гибридизации с целевой последовательностью.
- Способы, описанные в данном документе, как правило, приводят к получению "улучшенных растений" в том отношении, что они имеют один или несколько желаемых признаков по сравнению с растением дикого типа. В конкретных вариантах осуществления полученные растения, растительные клетки или части растения представляют собой трансгенные растения, содержащие последовательность экзогенной ДНК, включенную в геном всех или части клеток растения. В конкретных вариантах осуществления нетрансгенные генетически модифицированные растения, части растений или растительные клетки получают таким образом, что никакой последовательности экзогенной ДНК не включено в геном любой из растительных клеток растения. В таких вариантах осуществления улучшенные растения являются нетрансгенными. В случае, если обеспечивают только модификацию экзогенного гена и никаких чужеродных генов не вводят или не сохраняют в геноме растения, то полученные в результате генетически модифицированные сельскохозяйственные культуры не содержат чужеродных генов и могут, таким образом, по существу, считаться нетрансгенными. Различные варианты применения системы Cpf1 CRISPR для редактирования геномов растений описаны более подробно ниже.
a) Введение одного или нескольких чужеродных генов для придания представляющей интерес сельскохозяйственной характеристики
- Настоящее изобретение относится к способам редактирования генома или модификации последовательностей, ассоциированных с представляющим интерес целевым локусом, где способ предусматривает введение комплекса эффекторного белка Cpf1 в растительную клетку, при этом комплекс эффекторного белка Cpf1 эффективно функционирует с целью интеграции вставки ДНК, например, кодирующей представляющий интерес чужеродный ген в геном растительной клетки. В предпочтительных вариантах осуществления интеграция вставки ДНК облегчается с помощью HR с экзогенно введенной ДНК-матрицей или матрицей для репарации. Как правило, экзогенно введенную ДНК-матрицу или матрицу для репарации доставляют совместно с комплексом эффекторного белка Cpf1 или одного компонента или полинуклеотидного вектора для экспрессии компонента комплекса.
Системы Cpf1 CRISPR, предусмотренные в данном документе, обеспечивают целевую доставку генов. Стало более ясно, что экспрессия представляющего интерес гена в большой степени определяется положением интеграции в геном. Способы настоящего изобретения обеспечивают подвергаемую нацеливанию интеграцию чужеродного гена в необходимое положение в геноме. Положение может быть выбрано на основе информации о ранее полученных событиях или может быть выбрано с помощью способов, раскрытых в других местах в данном документе.
- В конкретных вариантах осуществления способы, предусмотренные в данном документе, предусматривают (a) введение в клетку комплекса Cpf1 CRISPR, содержащего направляющую РНК, содержащую прямой повтор и направляющую последовательность, где направляющая последовательность гибридизируется с целевой последовательностью, которая является эндогенной по отношению к растительной клетке; (b) введение в растительную клетку эффекторной молекулы Cpf1, которая образует комплексы с направляющей РНК, когда направляющая последовательность гибридизируется с целевой последовательностью и индуцирует двунитевой разрыв в последовательности, на которую нацеливается направляющая последовательность, или возле нее; и (c) введение в клетку нуклеотидной последовательности, кодирующей матрицу для репарации HDR, которая кодирует представляющий интерес ген, и который вводят в положение DS разрыва в результате HDR. В конкретных вариантах осуществления стадия введения может предусматривать доставку в растительную клетку одного или нескольких полинуклеотидов, кодирующих эффекторный белок Cpf1, направляющую РНК и матрицу для репарации. В конкретных вариантах осуществления полинуклеотиды доставляют в клетку при помощи ДНК-содержащего вируса (например, гемнивируса) или РНК-содержащего вируса (например, тобравируса). В конкретных вариантах осуществления стадии введения предусматривают введение в растительную клетку T-ДНК, содержащей одну или несколько полинуклеотидных последовательностей, кодирующих эффекторный белок Cpf1, направляющую РНК и матрицу для репарации, где доставка осуществляется посредством Agrobacterium. Последовательность нуклеиновой кислоты, кодирующей эффекторный белок Cpf1, может быть функционально связанной с промотором, таким как конститутивный промотор (например, промотор вируса мозаики цветной капусты 35S), или клеточноспецифический, или индуцируемый промотор. В конкретных вариантах осуществления полинуклеотид вводят при помощи бомбардировки микрочастицами. В конкретных вариантах осуществления способ дополнительно предусматривает скрининг растительной клетки после стадий введения с целью определения того, была ли введена матрица для репарации, т. е. представляющий интерес ген. В конкретных вариантах осуществления способы включают стадию регенерации растения из растительной клетки. В дополнительных вариантах осуществления способы включают кроссбридинг растения с получением генетически требуемой линии растений. Примеры чужеродных генов, кодирующих представляющий интерес признак, приведены ниже.
b) Редактирование эндогенных генов для придания представляющей интерес сельскохозяйственной характеристики
- Настоящее изобретение относится к способам редактирования генома или модификации последовательностей, ассоциированных с представляющим интерес целевым локусом, где способ предусматривает введение комплекса эффекторного белка Cpf1 в растительную клетку, при этом комплекс Cpf1 модифицирует экспрессию эндогенного гена растения. Это может быть достигнуто различными путями. В конкретных вариантах осуществления устранение экспрессии эндогенного гена является желательным, и комплекс Cpf1 CRISPR используют для нацеливания на эндогенный ген с целью модификации экспрессии гена и его расщепления. В этих вариантах осуществления способы, предусмотренные в данном документе, предусматривают (a) введение в растительную клетку комплекса Cpf1 CRISPR, содержащего направляющую РНК, содержащую прямой повтор и направляющую последовательность, где направляющая последовательность гибридизируется с целевой последовательность в представляющем интерес гене в геноме растительной клетки; и (b) введение в клетку эффекторного белка Cpf1, который при связывании с направляющей РНК, содержащей направляющую последовательность, которая гибридизируется с целевой последовательностью, обеспечивает двухнитевой разрыв в последовательности, на которую направляющая последовательность оказывает нацеливание, или возле нее. В конкретных вариантах осуществления стадия введения может предусматривать доставку в растительную клетку одного или нескольких полинуклеотидов, кодирующих эффекторный белок Cpf1 и направляющую РНК.
- В конкретных вариантах осуществления полинуклеотиды доставляют в клетку при помощи ДНК-содержащего вируса (например, гемнивируса) или РНК-содержащего вируса (например, тобравируса). В конкретных вариантах осуществления стадии введения предусматривают введение в растительную клетку T-ДНК, содержащей одну или несколько полинуклеотидных последовательностей, кодирующих эффекторный белок Cpf1 и направляющую РНК, где доставка осуществляется посредством Agrobacterium. Полинуклеотидная последовательность, кодирующая компоненты системы Cpf1 CRISPR, может быть функционально связанной с промотором, таким как конститутивный промотор (например, промотор вируса мозаики цветной капусты 35S), или клеточноспецифический, или индуцируемый промотор. В конкретных вариантах осуществления полинуклеотид вводят при помощи бомбардировки микрочастицами. В конкретных вариантах осуществления способ дополнительно предусматривает скрининг растительной клетки после стадий введения с целью определения того, была ли модифицирована экспрессия представляющего интерес гена. В конкретных вариантах осуществления способы включают стадию регенерации растения из растительной клетки. В дополнительных вариантах осуществления способы включают кроссбридинг растения с получением генетически требуемой линии растений.
- В конкретных вариантах осуществления способов, описанных выше, устойчивые к болезням сельскохозяйственные растения получают с помощью целевой мутации генов подверженности к болезням или генов, кодирующих отрицательные регуляторы (например, ген Mlo), из генов, обеспечивающих защиту растений. В конкретном варианте осуществления устойчивые к гербицидам сельскохозяйственные растения получают с помощью целевой замены конкретных нуклеотидов в генах растений, таких как кодирующие ацетолактатсинтазу (ALS) и протопорфириногеноксидазу (PPO). В конкретных вариантах осуществления предусмотрено получение засухоустойчивых и солевыносливых сельскохозяйственных растений с помощью целевой мутации генов, кодирующих отрицательные регуляторы переносимости абиотического стресса, зерновых культур с низким содержанием амилозы с помощью мутации гена Waxy, риса или других зерновых культур со сниженной прогорклостью с помощью целевой мутации основных генов липазы в алейроновом слое и т. д. Более подробный перечень эндогенных генов, кодирующих представляющие интерес признаки, приведен ниже.
c) Модулирование эндогенных генов при помощи системы Cpf1 CRISPR для придания представляющего интерес сельскохозяйственного признака
- В данном документе также предусмотрены способы модулирования (т. е. активации или репрессии) экспрессии эндогенного гена при помощи белка Cpf1, предусмотренного в данном документе. В таких способах применяют различающаяся(различающиеся) последовательность(последовательности) РНК, которая(которые) нацеливаются на геном растений при помощи комплекса Cpf1. В частности, различающаяся(различающиеся) последовательность(последовательности) РНК связывается(связываются) с двумя или более адаптерными белками (например, аптамерами), где каждый адаптерный белок ассоциирован с одним или несколькими функциональными доменами и где по меньшей мере один или несколько функциональных доменов, ассоциированных с адаптерным белком, характеризуются одной или несколькими видами активности, предусматривающими метилазную активность, деметилазную активность, активность в отношении активации транскрипции, активность в отношении репрессии транскрипции, активность фактора освобождения транскрипта, активность в отношении модификации гистонов, активность интеграции ДНК, активность расщепления РНК, активность расщепления ДНК или активность связывания нуклеиновых кислот. Функциональные домены используют для модулирования экспрессии эндогенного гена растений для того, чтобы получить желаемый признак. Как правило, в этих вариантах осуществления эффекторный белок Cpf1 имеет одну или несколько мутаций таким образом, что он имеет не более 5% нуклеазной активности эффекторного белка Cpf1, не имеющего по меньшей мере одной мутации.
- В конкретных вариантах осуществления способы, предусмотренные в данном документе, предусматривают стадии (a) введения в клетку комплекса Cpf1 CRISPR, содержащего направляющую РНК, содержащую прямой повтор и направляющую последовательность, где направляющая последовательность гибридизируется с целевой последовательностью, которая является эндогенной по отношению к растительной клетке; (b) введения в растительную клетку эффекторной молекулы Cpf1, которая образует комплексы с направляющей РНК, когда направляющая последовательность гибридизируется с целевой последовательностью; и где направляющую РНК модифицируют с целью содержания различающейся последовательности РНК (аптамера), связывающейся с функциональным доменом, и/или эффекторный белок Cpf1 модифицируют таким образом, что он связывается с функциональным доменом. В конкретных вариантах осуществления стадия введения может предусматривать доставку в растительную клетку одного или нескольких полинуклеотидов, кодирующих (модифицированный) эффекторный белок Cpf1 и (модифицированную) направляющую РНК. Подробности о компонентах системы Cpf1 CRISPR для применения в этих способах описаны в других местах в данном документе.
- В конкретных вариантах осуществления полинуклеотиды доставляют в клетку при помощи ДНК-содержащего вируса (например, гемнивируса) или РНК-содержащего вируса (например, тобравируса). В конкретных вариантах осуществления стадии введения предусматривают введение в растительную клетку T-ДНК, содержащей одну или несколько полинуклеотидных последовательностей, кодирующих эффекторный белок Cpf1 и направляющую РНК, где доставка осуществляется посредством Agrobacterium. Последовательность нуклеиновой кислоты, кодирующая один или несколько компонентов системы Cpf1 CRISPR, может быть функционально связанной с промотором, таким как конститутивный промотор (например, промотор вируса мозаики цветной капусты 35S), или клеточноспецифический, или индуцируемый промотор. В конкретных вариантах осуществления полинуклеотид вводят при помощи бомбардировки микрочастицами. В конкретных вариантах осуществления способ дополнительно включает скрининг растительной клетки после стадий введения с целью определения того, была ли модифицирована экспрессия представляющего интерес гена. В конкретных вариантах осуществления способы включают стадию регенерации растения из растительной клетки. В дополнительных вариантах осуществления способы включают кроссбридинг растения с получением генетически требуемой линии растений. Более подробный перечень эндогенных генов, кодирующих представляющие интерес признаки, приведен ниже.
Применение Cpf1 для модификации полиплоидных растений
- Многие растения являются полиплоидными, что означает, что они несут двойные копии своих геномов - иногда до шести, как у пшеницы. Способы в соответствии с настоящим изобретением, в которых применяют эффекторный белок Cpf1 CRISPR, могут быть "мультиплексными" с целью воздействия на все копии гена или нацеливания на несколько генов сразу. Например, в конкретных вариантах осуществления способы по настоящему изобретению применяют для одновременного обеспечения мутации потери функции в различных генах, ответственных за подавление защиты по отношению к болезни. В конкретных вариантах осуществления способы по настоящему изобретению применяют для одновременной супрессии экспрессии последовательности нуклеиновой кислоты TaMLO-Al, TaMLO-Bl и TaMLO-Dl в растительной клетке пшеницы и регенерации из нее растения пшеницы, чтобы обеспечить устойчивость растения пшеницы к мучнистой росе (см. также WO2015109752).
Иллюстративные гены, придающие агрономические признаки
- Как описано в данном документе выше, в конкретных вариантах осуществления настоящее изобретение охватывает применение системы Cpf1 CRISPR, как описано в данном документе, для вставки представляющей интерес ДНК, в том числе одного или нескольких экспрессируемых генов растения. В дополнительных конкретных вариантах осуществления настоящее изобретение охватывает способы и средства, в которых применяют систему Cpf1, как описано в данном документе, для частичного или полного удаления одного или нескольких экспрессируемых генов растения. В других дополнительных вариантах осуществления настоящее изобретение охватывает способы и средства, в которых применяют систему Cpf1, как описано в данном документе, для обеспечения модификации одного или нескольких экспрессируемых в растениях генов при помощи мутации, замены, вставки одного или нескольких нуклеотидов. В других конкретных вариантах осуществления настоящее изобретение охватывает применение системы Cpf1 CRISPR, как описано в данном документе, для обеспечения модификации экспрессии одного или нескольких экспрессируемых в растениях генов с помощью специфической модификации одного или нескольких из регуляторных элементов, управляющих экспрессией указанных генов.
- В конкретных вариантах осуществления настоящее изобретение охватывает способы, которые включают введение экзогенных генов и/или воздействия на эндогенные гены и их регуляторные элементы, такие как приведенные ниже:
- 1. Гены, которые придают устойчивость к вредителям или болезням
- Гены, придающие устойчивость к болезням растений. Растение может быть трансформировано клонированными генами устойчивости с целью конструирования растений, которые являются устойчивыми к специфическим патогенным штаммам. См., например, Jones et al., Science 266:789 (1994) (клонирование гена устойчивости томата Cf-9 к Cladosporium fulvum); Martin et al., Science 262:1432 (1993) (ген устойчивости томата Pto к Pseudomonas syringae pv. tomato кодирует протеинкиназу); Mindrinos et al., Cell 78:1089 (1994) (арабидопсис может иметь ген RSP2 устойчивости к Pseudomonas syringae).
- Гены, придающие устойчивость к вредителю, такому как соевая цистообразующая нематода. См., например, заявку согласно PCT WO 96/30517; заявку согласно PCT WO 93/19181.
- Белки Bacillus thuringiensis, см., например, в Geiser et al., Gene 48:109 (1986).
- Лектины, см., например, в Van Damme et al., Plant Molec. Biol. 24:25 (1994).
- Витамин-связывающий белок, такой как авидин, см. в заявке согласно PCT US93/06487, описывающей применение авидина и гомологов авидина в качестве ларвацидов против насекомых-вредителей.
- Ингибиторы ферментов, такие как ингибиторы протеазы или протеиназы или ингибиторы амилазы. См., например, Abe et al., J. Biol. Chem. 262:16793 (1987), Huub et al., Plant Molec. Biol. 21:985 (1993)), Sumitani et al., Biosci. Biotech. Biochem. 57:1243 (1993) и патент США № 5494813.
- Специфичные в отношении насекомых гормоны или феромоны, такие как экдистероид, или ювенильный гормон, его вариант, миметик на его основе или его антагонист или агонист. См., например, Hammock et al., Nature 344:458 (1990).
- Специфичные в отношении насекомых пептиды или нейропептиды, которые при экспрессии нарушают физиологию пораженного вредителя. Например, Regan, J. Biol. Chem. 269:9 (1994) и Pratt et al., Biochem. Biophys. Res. Comm. 163:1243 (1989). См. также патент США № 5266317.
- Специфичный в отношении насекомых яд, вырабатываемый в природе змеей, осой или любым другим организмом. Например, см. Pang et al., Gene 116: 165 (1992).
- Ферменты, ответственные за гипераккумуляцию монотерпена, сесквитерпена, стероида, гидроксамовой кислоты, производного фенилпропаноида или другой небелковой молекулы с инсектицидной активностью.
- Ферменты, участвующие в модификации, в том числе посттрансляционной модификации, биологически активной молекулы; например, гликолитический фермент, протеолитический фермент, липолитический фермент, нуклеаза, циклаза, трансаминаза, эстереза, гидролаза, фосфатаза, киназа, фосфорилаза, полимераза, эластаза, хитиназа и глюканаза, вне зависимости от того являются ли они натуральными или синтетическими. См. заявку согласно PCT WO93/02197, Kramer et al., Insect Biochem. Molec. Biol. 23:691 (1993) и Kawalleck et al., Plant Molec. Biol. 21 :673 (1993).
- Молекулы, которые стимулируют передачу сигнала. Например, см. Botella et al., Plant Molec. Biol. 24:757 (1994) и Griess et al., Plant Physiol. 104:1467 (1994).
- Вирусные инвазивные белки или сложный токсин, полученный из них. См. Beachy et al., Ann. rev. Phytopathol. 28:451 (1990).
- Белки, останавливающие развитие, образуемые в природе патогеном или паразитом. См. Lamb et al., Bio/Technology 10:1436 (1992) и Toubart et al., Plant J. 2:367 (1992).
- Белок, останавливающий развитие, образуемый в природе растением. Например, Logemann et al., Bio/Technology 10:305 (1992).
- У растений патогены часто являются специфичными по отношению к хозяину. Например, некоторые виды Fusarium будут вызывать вилт томата, однако поражают только томат, в то время как другие виды Fusarium поражают только пшеницу. Растения обладают присущими и индуцированными защитными реакциями, обеспечивающими устойчивость к большинству патогенов. Мутации и события рекомбинации в поколениях растений приводят к генетической изменчивости, которая обуславливает восприимчивость, тем более, что патогены размножаются с большей частотой, чем растения. У растений может присутствовать нехозяйская устойчивость, например, хозяин и патоген несовместимы, или может присутствовать частичная устойчивость по отношению ко всем расам патогена, как правило, контролируемая многими генами, и/или также полная устойчивость к некоторым расам патогена, но не к другим расам. Такая устойчивость, как правило, контролируется несколькими генами. При помощи способов и компонентов системы Cpf1 CRISP в настоящее время существует новое средство для индукции предполагаемых мутаций. Соответственно можно проанализировать геном источников генов устойчивости, и в растениях, имеющих желаемые характеристики или признаки, применять способ и компоненты системы Cpf1 CRISPR для индукции образования генов устойчивости. Системы настоящего изобретения могут выполнять это с большей точностью, чем применявшиеся ранее мутагенные средства, и, следовательно, ускорять и улучшать программы селекции растений.
- 2. Гены, участвующие в болезнях растений, таких как приведенные в WO 2013046247.
- Болезни риса: Magnaporthe grisea, Cochliobolus miyabeanus, Rhizoctonia solani, Gibberella fujikuroi; болезни пшеницы: Erysiphe graminis, Fusarium graminearum, F. avenaceum, F. culmorum, Microdochium nivale, Puccinia striiformis, P. graminis, P. recondita, Micronectriella nivale, Typhula sp., Ustilago tritici, Tilletia caries, Pseudocercosporella herpotrichoides, Mycosphaerella graminicola, Stagonospora nodorum, Pyrenophora tritici-repentis; болезни ячменя: Erysiphe graminis, Fusarium graminearum, F. avenaceum, F. culmorum, Microdochium nivale, Puccinia striiformis, P. graminis, P. hordei, Ustilago nuda, Rhynchosporium secalis, Pyrenophora teres, Cochliobolus sativus, Pyrenophora graminea, Rhizoctonia solani; болезни маиса: Ustilago maydis, Cochliobolus heterostrophus, Gloeocercospora sorghi, Puccinia polysora, Cercospora zeae-maydis, Rhizoctonia solani;
- болезни цитрусовых: Diaporthe citri, Elsinoe fawcetti, Penicillium digitatum, P. italicum, Phytophthora parasitica, Phytophthora citrophthora; болезни яблонь: Monilinia mali, Valsa ceratosperma, Podosphaera leucotricha, Alternaria alternata apple pathotype, Venturia inaequalis, Colletotrichum acutatum, Phytophtora cactorum;
- болезни груш: Venturia nashicola, V. pirina, Alternaria alternata Japanese pear pathotype, Gymnosporangium haraeanum, Phytophtora cactorum;
- болезни персиков: Monilinia fructicola, Cladosporium carpophilum, Phomopsis sp.;
- болезни винограда: Elsinoe ampelina, Glomerella cingulata, Uninula necator, Phakopsora ampelopsidis, Guignardia bidwellii, Plasmopara viticola;
- болезни хурмы: Gloesporium kaki, Cercospora kaki, Mycosphaerela nawae;
- болезни тыквы бутылочной: Colletotrichum lagenarium, Sphaerotheca fuliginea, Mycosphaerella melonis, Fusarium oxysporum, Pseudoperonospora cubensis, Phytophthora sp., Pythium sp.;
- болезни томата: Alternaria solani, Cladosporium fulvum, Phytophthora infestans;
- болезни баклажана: Phomopsis vexans, Erysiphe cichoracearum;
- болезни капустных овощей: Alternaria japonica, Cercosporella brassicae, Plasmodiophora brassicae, Peronospora parasitica;
- болезни лука-батуна: Puccinia allii, Peronospora destructor;
- болезни сои: Cercospora kikuchii, Elsinoe glycines, Diaporthe phaseolorum var. sojae, Septoria glycines, Cercospora sojina, Phakopsora pachyrhizi, Phytophthora sojae, Rhizoctonia solani, Corynespora casiicola, Sclerotinia sclerotiorum;
- болезни турецких бобов: Colletrichum lindemthianum;
- болезни арахиса: Cercospora personata, Cercospora arachidicola, Sclerotium rolfsii;
- болезни гороха: Erysiphe pisi;
- болезни картофеля: Alternaria solani, Phytophthora infestans, Phytophthora erythroseptica, Spongospora subterranean, f. sp. Subterranean;
- болезни клубники: Sphaerotheca humuli, Glomerella cingulata;
- болезни чая: Exobasidium reticulatum, Elsinoe leucospila, Pestalotiopsis sp., Colletotrichum theaesinensis;
- болезни табака: Alternaria longipes, Erysiphe cichoracearum, Colletotrichum tabacum, Peronospora tabacina, Phytophthora nicotianae;
- болезни рапса: Sclerotinia sclerotiorum, Rhizoctonia solani;
- болезни хлопчатника: Rhizoctonia solani;
- болезни свеклы: Cercospora beticola, Thanatephorus cucumeris, Thanatephorus cucumeris, Aphanomyces cochlioides;
- болезни роз: Diplocarpon rosae, Sphaerotheca pannosa, Peronospora sparsa;
- болезни хризантем и астровых: Bremia lactuca, Septoria chrysanthemi-indici, Puccinia horiana;
- болезни различных растений: Pythium aphanidermatum, Pythium debarianum, Pythium graminicola, Pythium irregulare, Pythium ultimum, Botrytis cinerea, Sclerotinia sclerotiorum;
- болезни редиса: Alternaria brassicicola;
- болезни цойсии: Sclerotinia homeocarpa, Rhizoctonia solani;
- болезни банана: Mycosphaerella fijiensis, Mycosphaerella musicola;
- болезни подсолнечника: Plasmopara halstedii;
- болезни семян и болезни на начальных стадиях роста различных растений, вызванные Aspergillus spp., Penicillium spp., Fusarium spp., Gibberella spp., Tricoderma spp., Thielaviopsis spp., Rhizopus spp., Mucor spp., Corticium spp., Rhoma spp., Rhizoctonia spp., Diplodia spp. и т. п.;
- вирусные болезни различных растений, опосредованные Polymixa spp., Olpidium spp. и т. п.
- 3. Примеры генов, которые придают устойчивость к гербицидам.
- Устойчивость к гербицидам, которые ингибируют точку роста или меристему, такие как имидазолинон или сульфомочевина, например, Lee et al., EMBO J. 7:1241 (1988), и Miki et al., Theor. Appl. Genet. 80:449 (1990) соответственно.
- Переносимость глифосата (устойчивость, придаваемая, например, генами мутантной 5-енолпирувилшикимат-3-фосфатсинтазы (EPSPS), генами aroA и генами глифосатацетилтрансферазы (GAT) соответственно), или устойчивость к другим фосфоновым соединениям, например, при помощи генов глюфосината (фосфинотрицинацетилтрансферазы (PAT) от видов Streptomyces, в том числе Streptomyces hygroscopicus и Streptomyces viridichromogenes), и к пиридинокси- или феноксипропионовым кислотам и циклогексонам при помощи генов, кодирующих ингибиторы ACCазы. См., например, патент США № 4940835 и патент США № 6248876, патент США № 4769061, EP № 0333033 и патент США № 4975374. См. также EP № 0242246, DeGreef et al., Bio/Technology 7:61 (1989), Marshall et al., Theor. Appl. Genet. 83:435 (1992), WO 2005012515 от Castle et. al. и WO 2005107437.
- Устойчивость к гербицидам, которые ингибируют фотосинтез, такие как триазин (гены psbA и gs+) или бензонитрил (ген нитрилазы), и глутатион-S-трансфераза, в Przibila et al., Plant Cell 3:169 (1991), патент США № 4810648, и Hayes et al., Biochem. J. 285: 173 (1992).
- Гены, кодирующие ферменты, детоксифицирующие гербицид, или мутантный фермент глутаминсинтазу, которая устойчива к ингибированию, например, в заявке на патент США с серийным № 11/760602. Или детоксифицирующий фермент представляет собой фермент, кодирующий фосфинотрицинацетилтрансферазу (такую как белок bar или pat от видов Streptomyces). Фосфинотрицинацетилтрансферазы описаны, например, в патентах США №№ 5561236; 5648477; 5646024; 5273894; 5637489; 5276268; 5739082; 5908810 и 7112665.
- Ингибиторы гидроксифенилпируватдиоксигеназ (HPPD), т. е. встречающиеся в природе устойчивые к HPPD ферменты, или гены, кодирующие мутированный или химерный фермент HPPD, как описано в WO 96/38567, WO 99/24585 и WO 99/24586, WO 2009/144079, WO 2002/046387 или патенте США № 6768044.
- 4. Примеры генов, участвующих в переносимости абиотического стресса.
- Трансген, способный с ослаблению экспрессии и/или активности гена поли(ADP-рибозо)полимеразы (PARP) в растительных клетках или растениях, как описано в WO 00/04173 или WO/2006/045633.
- Трансгены, способные с ослаблению экспрессии и/или активности кодирующих PARG генов растений или растительных клеток, как описано в WO 2004/090140.
- Трансгены, кодирующие функциональный в растениях фермент пути утилизации и синтеза никотинамидадениндинуклеотида, в том числе никотинамидазу, никотинатфосфорибозилтрансферазу, мононуклеотидаденилтрансферазу никотиновой кислоты, никотинамидадениндинуклеотидсинтетазу или никотинамидфосфорибозилтрансферзазу, как описано в EP 04077624.7, WO 2006/133827, PCT/EP07/002,433, EP 1999263 или WO 2007/107326.
- Ферменты, участвующие в биосинтезе углеводов, включают описанные например, в EP 0571427, WO 95/04826, EP 0719338, WO 96/15248, WO 96/19581, WO 96/27674, WO 97/11188, WO 97/26362, WO 97/32985, WO 97/42328, WO 97/44472, WO 97/45545, WO 98/27212, WO 98/40503, WO99/58688, WO 99/58690, WO 99/58654, WO 00/08184, WO 00/08185, WO 00/08175, WO 00/28052, WO 00/77229, WO 01/12782, WO 01/12826, WO 02/101059, WO 03/071860, WO 2004/056999, WO 2005/030942, WO 2005/030941, WO 2005/095632, WO 2005/095617, WO 2005/095619, WO 2005/095618, WO 2005/123927, WO 2006/018319, WO 2006/103107, WO 2006/108702, WO 2007/009823, WO 00/22140, WO 2006/063862, WO 2006/072603, WO 02/034923, EP 06090134.5, EP 06090228.5, EP 06090227.7, EP 07090007.1, EP 07090009.7, WO 01/14569, WO 02/79410, WO 03/33540, WO 2004/078983, WO 01/19975, WO 95/26407, WO 96/34968, WO 98/20145, WO 99/12950, WO 99/66050, WO 99/53072, патенте США № 6734341, WO 00/11192, WO 98/22604, WO 98/32326, WO 01/98509, WO 01/98509, WO 2005/002359, патенте США № 5824790, патенте США № 6013861, WO 94/04693, WO 94/09144, WO 94/11520, WO 95/35026 или WO 97/20936, или ферменты, участвующие в образовании полифруктозы, в частности, из инулина или леванов, как раскрыто в EP 0663956, WO 96/01904, WO 96/21023, WO 98/39460 и WO 99/24593, образовании альфа-1,4-глюканов, как раскрыто в WO 95/31553, US 2002031826, патенте США № 6284479, патенте США № 5712107, WO 97/47806, WO 97/47807, WO 97/47808 и WO 00/14249, образовании альфа-1,6 разветвленных альфа-1,4-глюканов, как раскрыто в WO 00/73422, образовании альтернана, как раскрыто, например, в WO 00/47727, WO 00/73422, EP 06077301.7, патенте США № 5908975 и EP 0728213, образовании гиалуронана, например, как раскрыто в WO 2006/032538, WO 2007/039314, WO 2007/039315, WO 2007/039316, JP 2006304779 и WO 2005/012529.
- Гены, которые повышают засухоустойчивость. Например, в WO 2013122472 раскрыто, что отсутствие или сниженный уровень функционального белка убиквитинпротеинлигазы (UPL), в частности, UPL3, приводит к сниженной потребности в воде или повышенной устойчивости к засухе указанного растения. Другие примеры трансгенных растений с повышенной переносимостью засухи раскрыты, например, в US 2009/0144850, US 2007/0266453 и WO 2002/083911. В US2009/0144850 описано растение, проявляющее фенотип переносимости засухи в результате измененной экспрессии нуклеиновой кислоты DR02. В US 2007/0266453 описано растение, проявляющее фенотип переносимости засухи в результате измененной экспрессии нуклеиновой кислоты DR03, и в WO 2002/08391 1 описано растение, имеющее повышенную переносимость стресса, вызванного засухой, в результате ослабленной активности АВС-транспортера, который экспрессируется в замыкающих клетках. Другим примером является исследование Kasuga и соавторов (1999), которые описывают, что сверхэкспрессия кДНК, кодирующей DREB1 A в трансгенных растениях, активировала экспрессию многих генов переносимости стресса при нормальных условиях роста и приводила к повышенной устойчивости к засухе, солевой нагрузке и замораживанию. Однако экспрессия DREB1A также приводила к тяжелой задержке роста при нормальных условиях роста (Kasuga (1999) Nat Biotechnol 17(3) 287-291).
- В дополнительных конкретных вариантах осуществления сельскохозяйственные растения могут быть улучшены под влиянием определенных признаков растений. Например, путем разработки растений, устойчивых к пестицидам, повышения устойчивости к заболеваниям у растений, повышения устойчивости к вредным для растений насекомым и нематодам, повышения устойчивости растений к паразитирующим сорнякам, повышения засухоустойчивости растений, повышения пищевой ценности растений, повышения переносимости стресса растений, избегания самоопыления, повышения перевариваемости кормовых растений, биомассы, урожая зерна и др. Несколько конкретных неограничивающих примеров предусмотрены в данном документе ниже.
- Кроме целевой мутации единичных генов, комплексы Cpf1CRISPR могут быть разработаны для обеспечения целевой мутации нескольких генов, делеции хромосомного фрагмента, сайт-специфической интеграции трансгена, сайт-направленного мутагенеза in vivo и точного замещения гена или замены аллелей у растений. Таким образом, способы, описанные в данном документе, имеют широкие варианты применения при обнаружении и валидации генов, мутационной и цисгенной селекции и гибридной селекции. Эти варианты применения облегчают получение нового поколения генетически модифицированных сельскохозяйственных культур с различными улучшенными агрономическими признаками, такими как устойчивость к гербицидам, устойчивость к болезням, переносимость абиотического стресса, высокая урожайность и отличное качество.
Применение гена Cpf1 для получения мужских стерильных растений
- Гибридные растения, как правило, имеют предпочтительные агрономические признаки по сравнению с инбредными растениями. Однако для самоопылящихся растений получение гибридов может быть проблематичным. У различных типов растений были идентифицированы гены, которые важны для фертильности растений, в частности, мужской фертильности. Например, у маиса были идентифицированы по меньшей мере два гена, которые важны для фертильности (Amitabh Mohanty International Conference on New Plant Breeding Molecular Technologies Technology Development And Regulation, Oct 9-10, 2014, Jaipur, India; Svitashev et al. Plant Physiol. 2015 Oct;169(2):931-45; Djukanovic et al. Plant J. 2013 Dec;76(5):888-99). Способы, предусмотренные в данном документе, могут быть использованы для нацеливания на гены, необходимые для мужской фертильности, для того, чтобы получить мужские стерильные растения, которые могут быть легко скрещены с получением гибридов. В конкретных вариантах осуществления система Cpf1 CRISPR, предусмотренная в данном документе, используется для направленного мутагенеза цитохром P450-подобного гена (MS26) или гена мегануклеазы (MS45), придавая тем самым мужскую стерильность растению маиса. Растения маиса, которые по этой причине генетически изменены, можно применять в программах селекции гибридов.
Повышение стадии фертильности у растений
- В конкретных вариантах осуществления способы, предусмотренные в данном документе, используют для продления стадии фертильности растения, такого как растение риса. Например, на ген стадии фертильности риса, такой как Ehd3, можно целенаправленно воздействовать с получением мутации в гене, а сеянцы могут быть отобраны в отношении продленной стадии фертильности при регенерации растений (как описано в CN 104004782).
Применение Cpf1 для получения генетической изменчивости у представляющего интерес сельскохозяйственного растения
- Доступность зародышевой плазмы дикого типа и генетические вариации в сельскохозяйственных растениях являются ключевым моментом для программ улучшения сельскохозяйственных культур, однако доступная изменчивость зародышевых плазм от сельскохозяйственных культур является ограниченной. Настоящее изобретение предусматривает способы получения разнообразия генетических вариаций представляющей интерес зародышевой плазмы. В этом применении системы Cpf1 CRISPR предусмотрена библиотека направляющих РНК, нацеленных на различные локусы в геноме растений, и ее вводят в растительные клетки совместно с эффекторным белком Cpf1. В этом отношении может быть получена коллекция точковых мутаций и генных нокаутов в масштабе генома. В конкретных вариантах осуществления способы включают получение части растения или растения из клеток, полученных таким образом, и скрининг клеток на наличие представляющего интерес признака. Целевые гены могут включать кодирующие и некодирующие области. В конкретных вариантах осуществления признак представляет собой переносимость стресса, а способ представляет собой способ получения сортов сельскохозяйственных растений с переносимостью стресса.
Применение Cpf1 для воздействия на созревание плодов
- Созревание представляет собой нормальную фазу в процессе созревания плодов и овощей. Лишь спустя несколько дней после своего начала оно делает плод или овощ несъедобным. Этот процесс приносит значительные убытки как фермерам, так и потребителям. В конкретных вариантах осуществления способы по настоящему изобретению используют для ослабления образования этилена. Это достигается путем обеспечения одного или нескольких из следующего. a. Подавления экспрессии гена ACC-синтазы. ACC-(1-аминоциклопропан-1-карбоновая кислота)-синтаза представляет собой фермент, ответственный за превращение S-аденозилметионина (SAM) в ACC, происходящее со второй до последней стадии в биосинтезе этилена. Экспрессия ферментов нарушена, если антисмысловая ("зеркальное отображение") или усеченная копия гена синтазы вставлена в геном растения; b. вставки гена ACC-дезаминазы. Ген, кодирующий фермент, получают из Pseudomonas chlororaphis, распространенной непатогенной почвенной бактерии. Он превращает ACC в другое соединение, тем самым снижая количество ACC, доступное для образования этилена; c. вставки гена SAM-гидролазы. Этот подход является аналогичным в случае ACC-дезаминазы, где образование этилена нарушается, когда количество его метаболита-предшественника снижено; в этом случае SAM превращается в гомосерин. Ген, кодирующий фермент, получают из бактериофага T3 E. сoli, и d. супрессии экспрессии гена ACC-оксидазы. ACC-оксидаза представляет собой фермент, который катализирует окисление ACC в этилен, являющееся последней стадией в пути биосинтеза этилена. С помощью способов, описанных в данном документе, снижение экспрессии гена ACC-оксидазы приводит к подавлению образования этилена, тем самым происходит задержка созревания плодов. В конкретных вариантах осуществления дополнительно или альтернативно к модификациям, описанным в данном документе, применяют способы, описанные в данном документе, для модификации этиленовых рецепторов с тем, чтобы нарушить сигналы от этилена, получаемые плодом. В конкретных вариантах осуществления экспрессия гена ETR1, кодирующего этилен-связывающий белок, является модифицированной, в частности супрессированной. В конкретных вариантах осуществления дополнительно или альтернативно к модификациям, описанным в данном документе, используют способы, описанные в данном документе, для модификации экспрессии гена, кодирующего полигалактуроназу (PG), которая представляет собой фермент, ответственный за разрушение пектина, соединения, которое поддерживает целостность клеточных стенок растений. Разрушение пектина происходит в начале процесса созревания, приводя к размягчению плода. Соответственно, в конкретных вариантах осуществления способы, описанные в данном документе, используют для введения мутации в ген PG или для супрессии активации гена PG с целью снижения количества образующегося фермента PG, тем самым задерживая разрушение пектина.
- Таким образом, в конкретных вариантах осуществления способы включают применение системы Cpf1 CRISPR для обеспечения одной или нескольких модификаций генома растительной клетки, таких как описаны выше, и регенерации из нее растения. В конкретных вариантах осуществления растение представляет собой растения томата.
Повышение срока хранения растений
- В конкретных вариантах осуществления способы по настоящему изобретению применяют для модификации генов, участвующих в образовании соединений, которые влияют на срок годности растения или части растений. В частности, модификацию осуществляют в гене, которая предупреждает накопление восстанавливающих сахаров в клубнях картофеля. При обработке высокой температурой эти восстанавливающие сахара реагируют со свободными аминокислотами, приводя к образованию продуктов коричневого цвета с горьким вкусом и повышенных уровней акриламида, который является потенциальным канцерогеном. В конкретных вариантах осуществления способы, предусмотренные в данном документе, используют для ослабления или ингибирования экспрессии гена вакуолярной инвертазы (VInv), который кодирует белок, который разрушает сахарозу до глюкозы и фруктозы (Clasen et al. DOI: 10.1111/pbi.12370).
Применение системы Cpf1 CRISPR для обеспечения признака с дополнительным эффектом
- В конкретных вариантах осуществления систему Cpf1 CRISPR применяют для получения сельскохозяйственных культур с улучшенными питательными свойствами. В конкретных вариантах осуществления способы, предусмотренные в данном документе, адаптированы к получению "функциональных продуктов питания", т. е. модифицированного продукта питания или продуктового ингредиента, которые могут обеспечивать пользу для здоровья помимо традиционных нутриентов, которые он содержит, или "нутрицевтиков", т. е. веществ, которые могут рассматриваться продуктом питания или частью продукта питания, и обеспечивают пользу для здоровья, в том числе предупреждение и лечения заболевания. В конкретных вариантах осуществления нутрицевтик является применимым в предупреждении и/или лечении одного или нескольких из рака, диабета, сердечно-сосудистого заболевания или гипертензии.
- Примеры сельскохозяйственных культур с улучшенными питательными свойствами включают (Newell-McGloughlin, Plant Physiology, July 2008, Vol. 147, pp. 939-953):
- модифицированное качество белка, содержание и/состав аминокислот, например, как описано для гречки заметной (Luciani et al. 2005, Florida Genetics Conference Poster), канолы (Roesler et al., 1997, Plant Physiol 113 75-81), маиса (Cromwell et al, 1967, 1969 J Anim Sci 26 1325-1331, O'Quin et al. 2000 J Anim Sci 78 2144-2149, Yang et al. 2002, Transgenic Res 11 11-20, Young et al. 2004, Plant J 38 910-922), картофеля (Yu J and Ao, 1997 Acta Bot Sin 39 329-334; Chakraborty et al. 2000, Proc Natl Acad Sci USA 97 3724-3729; Li et al. 2001) Chin Sci Bull 46 482-484, Rice (Katsube et al. 1999, Plant Physiol 120 1063-1074), сои (Dinkins et al. 2001, Rapp 2002, In Vitro Cell Dev Biol Plant 37 742-747), батата (Egnin and Prakash 1997, In Vitro Cell Dev Biol 33 52A).
- Cодержание незаменимых аминокислот, например, как описано для канолы (Falco et al. 1995, Bio/Technology 13 577-582), Lupin (White et al. 2001, J Sci Food Agric 81 147-154), маиса (Lai and Messing, 2002, Agbios 2008 GM crop database (March 11, 2008)), картофеля (Zeh et al. 2001, Plant Physiol 127 792-802), сорго (Zhao et al. 2003, Kluwer Academic Publishers, Dordrecht, The Netherlands, pp 413-416), сои (Falco et al. 1995 Bio/Technology 13 577-582; Galili et al. 2002 Crit Rev Plant Sci 21 167-204).
- Масла и жирные кислоты, например, для канолы (Dehesh et al. (1996) Plant J 9 167-172 [PubMed] ; Del Vecchio (1996) INFORM International News on Fats, Oils and Related Materials 7 230-243; Roesler et al. (1997) Plant Physiol 113 75-81 [PMC free article] [PubMed]; Froman and Ursin (2002, 2003) Abstracts of Papers of the American Chemical Society 223 U35; James et al. (2003) Am J Clin Nutr 77 1140-1145 [PubMed]; Agbios (2008, выше); хлопчатника (Chapman et al. (2001). J Am Oil Chem Soc 78 941-947; Liu et al. (2002) J Am Coll Nutr 21 205S-211S [PubMed]; O'Neill (2007) Australian Life Scientist. http://www.biotechnews.com.au/index.php/id;866694817;fp;4;fpid;2 (June 17, 2008), льна (Abbadi et al., 2004, Plant Cell 16: 2734-2748), маиса (Young et al., 2004, Plant J 38 910-922), масличной пальмы (Jalani et al. 1997, J Am Oil Chem Soc 74 1451-1455; Parveez, 2003, AgBiotechNet 113 1-8), риса (Anai et al., 2003, Plant Cell Rep 21 988-992), сои (Reddy and Thomas, 1996, Nat Biotechnol 14 639-642; Kinney and Kwolton, 1998, Blackie Academic and Professional, London, pp 193-213), подсолнечника (Arcadia, Biosciences 2008).
- Углеводы, такие как фруктаны, описанные, например, для цикория (Smeekens (1997) Trends Plant Sci 2 286-287, Sprenger et al. (1997) FEBS Lett 400 355-358, Sévenier et al. (1998) Nat Biotechnol 16 843-846), маиса (Caimi et al. (1996) Plant Physiol 110 355-363), картофеля (Hellwege et al. ,1997 Plant J 12 1057-1065), сахарной свеклы (Smeekens et al. 1997, выше), инулин, например, как описано для картофеля (Hellewege et al. 2000, Proc Natl Acad Sci USA 97 8699-8704), крахмал, например, как описано для риса (Schwall et al. (2000) Nat Biotechnol 18 551-554, Chiang et al. (2005) Mol Breed 15 125-143),
- Витамины и каротиноиды, например, описанные для канолы (Shintani and DellaPenna (1998) Science 282 2098-2100), маиса (Rocheford et al. (2002). J Am Coll Nutr 21 191S-198S, Cahoon et al. (2003) Nat Biotechnol 21 1082-1087, Chen et al. (2003) Proc Natl Acad Sci USA 100 3525-3530), семени горчицы (Shewmaker et al. (1999) Plant J 20 401-412, картофеля (Ducreux et al., 2005, J Exp Bot 56 81-89), риса (Ye et al. (2000) Science 287 303-305, клубники (Agius et al. (2003), Nat Biotechnol 21 177-181 ), томата (Rosati et al. (2000) Plant J 24 413-419, Fraser et al. (2001) J Sci Food Agric 81 822-827, Mehta et al. (2002) Nat Biotechnol 20 613-618, Díaz de la Garza et al. (2004) Proc Natl Acad Sci USA 101 13720-13725, Enfissi et al. (2005) Plant Biotechnol J 3 17-27, DellaPenna (2007) Proc Natl Acad Sci USA 104 3675-3676.
- Функциональные вторичные метаболиты, например, описанные для яблони (стильбены, Szankowski et al. (2003) Plant Cell Rep 22: 141-149), люцерны (ресвератрол, Hipskind and Paiva (2000) Mol Plant Microbe Interact 13 551-562), киви (ресвератрол, Kobayashi et al. (2000) Plant Cell Rep 19 904-910), маиса и сои (флавоноиды, Yu et al. (2000) Plant Physiol 124 781-794), картофеля (антоцианин, алкалоид и гликозид, Lukaszewicz et al. (2004) J Agric Food Chem 52 1526-1533), риса (флавоноиды и ресвератрол, Stark-Lorenzen et al. (1997) Plant Cell Rep 16 668-673, Shin et al. (2006) Plant Biotechnol J 4 303-315), томата (+ресвератрол, хлорогеновая кислота, флавоноиды, стильбен; Rosati et al. (2000) выше, Muir et al. (2001) Nature 19 470-474, Niggeweg et al. (2004) Nat Biotechnol 22 746-754, Giovinazzo et al. (2005) Plant Biotechnol J 3 57-69), пшеницы (кофеиновая и феруловая кислоты, ресвератрол; United Press International (2002)); и
- доступность минеральных компонентов, например, как описано для люцерны (фитаза, Austin-Phillips et al. (1999) http://www.molecularfarming.com/nonmedical.html), салата-латука (железо, Goto et al. (2000) Theor Appl Genet 100 658-664), риса (железо, Lucca et al. (2002) J Am Coll Nutr 21 184S-190S), маиса, сои и пшеницы (фитаза, Drakakaki et al. (2005) Plant Mol Biol 59 869-880, Denbow et al. (1998) Poult Sci 77 878-881, Brinch-Pedersen et al. (2000) Mol Breed 6 195-206).
- В конкретных вариантах осуществления признак с дополнительным эффектом относится к предусмотренной пользе для здоровья соединений, присутствующих в растении. Например, в конкретных вариантах осуществления сельскохозяйственную культуру с дополнительным эффектом получают с помощью способов по настоящему изобретению для обеспечения модификации и/или индукции/повышения синтеза одного или нескольких из следующих соединений:
- каротиноиды, такие как α-каротин, присутствующие в моркови, нейтрализуют свободные радикалы, которые могут вызвать разрушение клеток, или β-каротин, присутствующий в различных плодах и овощах, который нейтрализует свободные радикалы.
- Лютеин, присутствующий в зеленых овощах, который способствует сохранению нормального зрения.
- Ликопин, присутствующий в томате и томатных продуктах, который, как считается, снижает риск возникновения рака предстательной железы.
- Зеаксантин, присутствующий в цитрусовых и маисе, который способствует сохранению нормального зрения.
- Пищевые волокна, такие как нерастворимые волокна, присутствующие в пшеничных отрубях, которые могут снижать риск возникновения рака молочной железы и/или колоректального рака, и β-глюкан, присутствующий в овсе, растворимые волокна, присутствующие в псиллуме и цельных зернах, которые могут снижать риск возникновения сердечно-сосудистого заболевания (CVD).
- Жирные кислоты, такие как ω-3 жирные кислоты, которые могут снижать риск возникновения CVD и улучшать умственные и зрительные функции, конъюгированная линолевая кислота, которая может улучшать состав тканей организма, может снижать риск возникновения определенных видов рака, и GLA, которая может снижать риск возникновения воспаления, рака и CVD, может улучшать состав организма.
- Флавоноиды, такие как гидроксициннаматы, присутствующие в пшенице, которые имеют активность, подобную антиоксидантной, могут снижать риск возникновения дегенеративных заболеваний, флавонолы, катехины и таннины, присутствующие в плодах и овощах, которые нейтрализуют свободные радикалы и могут снижать риск возникновения рака.
- Глюкозинолаты, индолы, изотиоцианаты, такие как сульфорафан, присутствующие в овощах семейства крестоцветных (брокколи, браунколь), редьке, которые нейтрализуют свободные радикалы, могут снижать риск возникновения рака.
- Фенольные смолы, такие как стильбены, присутствующие в винограде, которые могут снижать риск возникновения дегенеративных заболеваний, заболевания сердца и рака, могут влиять на продолжительность жизни, кофеиновая кислота и ферулиновая кислота, присутствующие в овощах и цитрусовых, которые имеют подобную антиоксидантной активность, могут снижать риск возникновения дегенеративных заболеваний, заболевания сердца и заболевания глаз, и эпикатехин, присутствующий в какао, который имеет подобную антиоксидантной активность, может снижать риск возникновения дегенеративных заболеваний и заболевания сердца.
- Растительные станолы/стеролы, присутствующие в маисе, сое, пшенице, и древесные смолы могут снижать риск возникновения коронарного заболевания сердца в результате снижения уровней холестерина в крови.
- Фруктаны, инулины, фруктоолигосахариды, присутствующие в топинамбуре, шалоте, луковом порошке, которые могут улучшить состояние желудочно-кишечного тракта.
- Сапонины, присутствующие в сое, которые могут снижать уровень холестерина LDL.
- Белок сои, присутствующий в сое, который может снижать риск возникновения заболевания сердца.
- Фитоэстрогены, такие как изофлавоны, присутствующие в сое, могут снижать симптомы менопаузы, такие как приливы, могут ослаблять остеопороз и CVD, и лигнаны, присутствующие во льне, ржи и овощах, которые могут защищать от заболевания сердца и некоторых видов рака, могут снижать уровень холестерина LDL, общего холестерина.
- Сульфиды и тиолы, такие как диаллилсульфид, присутствующие в луке, чесноке, маслине, луке-порее и зеленом луке, и аллилметилтрисульфид, дитиотионы, присутствующие в овощах семейства крестоцветные, которые могу снижать уровень холестерина LDL, способствуют поддержанию нормального состояния иммунной системы.
- Таннины, такие как проантоцианидины, присутствующие в клюкве, какао, которые могут улучшать состояние мочевыводящих путей, могут снижать риск возникновения CVD и повышенного кровяного давления
- и др.
- Кроме того, способы по настоящему изобретению также предусматривают модифицирование функциональных свойств белков/крахмалов, срока хранения, вкуса/эстетических характеристик, качества волокон, и признаков, связанных со снижением уровня аллергенов, антинутриентов и токсинов.
- Соответственно, настоящее изобретение охватывает способы получения растений с дополнительным питательным эффектом, при этом указанные способы включают введение в растительную клетку гена, кодирующего фермент, участвующий в образовании компонента с дополнительным питательным эффектом при помощи системы Cpf1 CRISPR, как описано в данном документе, и регенерацию растения из указанной растительной клетки, указанного растения, характеризующегося повышением экспрессии указанного компонента с дополнительным питательным эффектом. В конкретных вариантах осуществления систему Cpf1 CRISPR используют для модификации эндогенного синтеза этих соединений опосредованно, например при помощи модификации одного или нескольких факторов транскрипции, которые контролируют метаболизм этого соединения. Способы введения представляющего интерес гена в растительную клетку и/или модификации эндогенного гена при помощи системы Cpf1 CRISPR описаны в данном документе выше.
- Некоторые конкретные примеры модификаций в растениях, которые были модифицированы для придания признаков с дополнительным эффектом, представляют собой растения с модифицированным метаболизмом жирных кислот, например с помощью трансформации растения антисмысловым геном стеарил-ACP-десатуразы с целью повышения содержания стеариновой кислоты в растении. См. Knultzon et al., Proc. Natl. Acad. Sci. U.S.A. 89:2624 (1992). Другой пример включает снижение содержания фитата, например с помощью клонирования и последующего введения ДНК, связанной с одним аллелем, который может отвечать за мутанты маиса, характеризующиеся низким содержанием фитиновой кислоты. См. Raboy et al, Maydica 35:383 (1990).
- Аналогично экспрессия Tfs C1 и R маиса (Zea mays), которые регулируют образование флавоноидов в алейроновых слоях маиса под контролем сильного промотора, приводила к высокой скорости накопления антоцианинов в арабидопсисе (Arabidopsis thaliana), предположительно в результате активации всего пути (Bruce et al., 2000, Plant Cell 12:65-80). DellaPenna (Welsch et al., 2007 Annu Rev Plant Biol 57: 711-738) обнаружил, что Tf RAP2.2 и его взаимодействующий элемент SINAT2 повышали каротиногенез в листьях арабидопсиса. Экспрессия Tf Dof1 индуцировала повышение экспрессии генов, кодирующих ферменты для образования углеродных скелетов, выраженное повышение содержания аминокислот и снижение уровня Glc в трансгенном арабидопсисе (Yanagisawa, 2004 Plant Cell Physiol 45: 386-391), а DOF Tf AtDof1.1 (OBP2) активировал все стадии в пути биосинтеза глюкозинолата в арабидопсисе (Skirycz et al., 2006 Plant J 47: 10-24).
Снижение аллергенов в растениях
- В конкретных вариантах осуществления способы, предусмотренные в данном документе, применяют для получения растений со сниженным уровнем аллергенов, делая их более безопасными для потребителя. В конкретных вариантах осуществления способы предусматривают модификацию экспрессии одного или нескольких генов, ответственных за образование растительных аллергенов. Например, в конкретных вариантах осуществления способы предусматривают снижение экспрессии гена Lol p5 в растительной клетке, такой как растительная клетка райграса, и регенерацию из нее растения, с целью снижения аллергенности пыльцы указанного растения (Bhalla et al. 1999, Proc. Natl. Acad. Sci. USA Vol. 96: 11676-11680).
Аллергические реакции на арахис и аллергические реакции на бобовые растения, как правило, являются реальной и серьезной проблемной для здоровья. Система эффекторного белка Cpf1 по настоящему изобретению может быть использована для выявления и последующего редактирования или сайленсинга генов, кодирующих аллергенные белки таких бобовых растений. Не ограничиваясь такими генами и белками, Nicolaou et al. выявили аллергенные белки в арахисе, сое, чечевице, горохе, люпине, зеленой фасоли и золотистой фасоли. См. Nicolaou et al., Current Opinion in Allergy and Clinical Immunology 2011;11(3):222).
Способы скрининга представляющих интерес эндогенных генов
- Способы, предусмотренные в данном документе, дополнительно обеспечивают выявление ценных генов, кодирующих ферменты, участвующие в образовании компонента с дополнительным питательным эффектом, или в целом генов, влияющих на представляющие интерес агрономические признаки, в пределах вида, типа и растительного царства. В результате избирательного нацеливания, например на гены, кодирующие ферменты метаболических путей в растениях при помощи системы Cpf1 CRISPR, как описано в данном документе, могут быть идентифицированы гены, ответственные за определенные питательные аспекты растения. Аналогично в результате избирательного нацеливания на гены, которые могут влиять на желаемый агрономический признак, могут быть идентифицированы соответствующие гены. Соответственно, настоящее изобретение охватывает способы скрининга генов, кодирующих ферменты, участвующие в образовании соединений с определенной пищевой ценностью и/или агрономическими признаками.
Дополнительные варианты применения системы Cpf1 CRISPR в растениях и дрожжах
Применение системы Cpf1 CRISPR в получении биотоплива
- Термин "биотопливо", как используется в данном документе, представляет собой альтернативное топливо, полученное из растительных ресурсов или ресурсов растительного происхождения. Восполняемые виды биотоплива могут быть экстрагированы из органического вещества, энергия которого была получена в процессе фиксации углерода, или получены в результате использования или превращения биомассы. Эта биомасса может быть использована непосредственно для видов биотоплива или может быть превращена в удобные содержащие энергию вещества с помощью теплового превращения, химического превращения или биохимического превращения. Это превращение биомассы может приводить к образованию топлива в твердой, жидкой или газообразной форме. Существует два типа биотоплива: биоэтанол и биодизель. Биоэтанол образуется главным образом в результате процесса сбраживания сахаров из целлюлозы (крахмала), которую преимущественно получают из маиса и сахарного тростника. Биодизель, с другой стороны, главным образом образуется из масляных сельскохозяйственных культур, таких как семена рапс, пальма и соя. Биотоплива используют главным образом для транспортных средств.
Улучшение свойств растений для получения биотоплива
- В конкретных вариантах осуществления способы с использованием системы Cpf1 CRISPR, как описано в данном документе, применяют для изменения свойств клеточной стенки с целью облегчения доступа при помощи основных гидролизующих средств для более эффективного высвобождения сахаров для сбраживания. В конкретных вариантах осуществления модифицируют биосинтез целлюлозы и/или лигнина. Целлюлоза является основным компонентом клеточной стенки. Биосинтез целлюлозы и лигнина регулируют одновременно. При снижении доли лигнина в растении доля целлюлозы может быть повышена. В конкретных вариантах осуществления способы, описанные в данном документе, используют для снижения биосинтеза лигнина в растении с целью повышения содержания сбраживаемых углеводов. В частности, способы, описанные в данном документе, используют для снижения экспрессии по меньшей мере первого гена биосинтеза лигнина, выбранного из группы, состоящей из 4-кумарат 3-гидроксилазы (C3H), фенилаланин аммонийлиазы (PAL), циннамат 4-гидроксилазы (C4H), гидроксициннамоилтрансферазы (HCT), О-метилтрансферазы кофеиновой кислоты (COMT), кафеол CoA 3-O-метилтрансферазы (CCoAOMT), ферулат 5-гидроксилазы (F5H), циннамилалкогольдегидрогеназы (CAD), циннамоил CoA-редуктазы (CCR), 4-кумарат-CoA лигазы (4CL), монолигнол-лигнин-специфичной гликозилтрансферазы и альдегиддегидрогеназы (ALDH), как раскрыто в WO 2008064289 A2.
- В конкретных вариантах осуществления способы, описанные в данном документе, применяют для получения растительной массы, которая приводит к образованию более низких уровней уксусной кислоты во время сбраживания (см. также WO 2010096488). В частности, способы, раскрытые в данном документе, используют для получения мутаций в гомологах CaslL с целью снижения ацетилирования полисахаридов.
Модификация дрожжей для получения биотоплива
- В конкретных вариантах осуществления фермент Cpf1, предусмотренный в данном документе, используют для получения биотоплива при помощи рекомбинантных микроорганизмов. Например, Cpf1 может быть использован для конструирования микроорганизмов, таких как дрожжи, с целью получения биотоплива или биополимеров из сбраживаемых сахаров и необязательно способности к разрушению лигноцеллюлозы растительного происхождения, полученной из остатков сельскохозяйственного производства, в качестве источника сбраживаемых сахаров. В частности, настоящее изобретение предусматривает способы, в которых применяют комплекс Cpf1 CRISPR для введения чужеродных генов, требуемых для получения биотоплива, в микроорганизмы, и/или для модификации эндогенных генов, которые могут нарушать синтез биотоплива. В частности, способы включают введение в микроорганизм, такой как дрожжи, одной или нескольких нуклеотидных последовательностей, кодирующих ферменты, участвующие в превращении пирувата в этанол или другой представляющий интерес продукт. В конкретных вариантах осуществления способы предусматривают введение одного или нескольких ферментов, которые способствуют разрушению микроорганизмом целлюлозы, такого как целлюлаза. В еще одних дополнительных вариантах осуществления комплекс Cpf1 CRISPR применяют для модификации эндогенных метаболических путей, которые конкурируют с путем образования биотоплива.
- Соответственно, в более конкретных вариантах осуществления способы, описанные в данном документе, применяют для модификации микроорганизма следующим образом:
- введения по меньшей мере одной гетерологичной нуклеиновой кислоты или повышения экспрессии по меньшей мере одной эндогенной нуклеиновой кислоты, кодирующей фермент для разрушения растительной клеточной стенки, таким образом, что указанный микроорганизм способен экспрессировать указанную нуклеиновую кислоту и продуцировать и секретировать указанный фермент для разрушения растительной клеточной стенки;
- введения по меньшей мере одной гетерологичной нуклеиновой кислоты или повышения экспрессии по меньшей мере одной эндогенной нуклеиновой кислоты, кодирующей фермент, который превращает пируват в ацетальдегид, необязательно в сочетании по меньшей мере с одной гетерологичной нуклеиновой кислотой, кодирующей фермент, который превращает ацетальдегид в этанол, таким образом, что указанная клетка-хозяин способна экспрессировать указанную нуклеиновую кислоту; и/или
- модификации по меньшей мере одной нуклеиновой кислоты, кодирующей фермент в метаболическом пути в указанной клетке-хозяине, где указанный путь приводит к образованию метаболита, отличного от ацетальдегида, из пирувата или этанола из ацетальдегида, и где указанная модификация приводит к уменьшенному образованию указанного метаболита, или введения по меньшей мере одной нуклеиновой кислоты, кодирующей ингибитор указанного фермента.
Модификация водорослей и растений для получения растительных масел или видов биотоплива
- Трансгенные водоросли или другие растения, такие как рапс, могут быть особенно полезными в производстве растительных масел или таких видов биотоплива, как, например, спирты (особенно метанол и этанол). Они могут быть сконструированы для синтеза или избыточного синтеза масла или спиртов на высоких уровнях для применения в масложировой или биотопливной промышленности.
- В соответствии с конкретными вариантами настоящего изобретения систему Cpf1 CRISPR используют для получения диатомовых водорослей с высоким содержанием липидов, которые применимы в получении биотоплива.
- В конкретных вариантах осуществления предусмотрено специфично модифицировать гены, которые вовлечены модификацию количества липидов и/или качества липидов, образованных клеткой водорослей. Примеры генов, кодирующих ферменты, участвующие в путях синтеза жирных кислот, могут кодировать белки, имеющие, например, активность ацетил-CoA карбоксилазы, синтазы жирных кислот, 3-кетоацил-синтазы III ацил-белка переносчика, глицерол-3-фосфатдегидрогеназы (G3PDH), еноил-ацил-редуктазы белка-переносчика (еноил-ACP-редуктазы), глицерол-3-фосфатацилтрансферазы, лизофосфатидин ацилтрансферазы или диацилглицеролацилтрансферазы, фосфолипид:диацилглицеролацилтрансферазы, фосфатидинфосфатазы, тиоэстеразы жирной кислоты, такой как пальмитоилпротеинтиоэстеразы, или малатдегидрогеназы. В дополнительных вариантах осуществления предусмотрено получение диатомовых водорослей, которые характеризуются повышенным накоплением липидов. Это может быть достигнуто с помощью нацеливания на гены, которые снижают катаболизм липидов. Особого интереса для применения в способах по настоящему изобретению заслуживают гены, участвующие в активации триглицерола и свободных жирных кислот, а также генов, непосредственно участвующих в β-окислении жирных кислот, таких как ацил-CoA синтетаза, 3-кетоацил-CoA тиолаза, ацил-CoA оксидаза и фосфоглюкомутаза. Система Cpf1 CRISPR и способы, описанные в данном документе, могут быть использованы для специфической активации таких генов в диатомовых водорослях с целью повышения содержания в них липидов.
- Организмы, такие как микроводоросли, широко используют для синтетической биологии. Stovicek et al. (Metab. Eng. Comm., 2015; 2:13 описывает редактирование генома промышленных дрожжей, например Saccharomyces cerevisae, для эффективного получения устойчивых штаммов для промышленного производства. Stovicek использовал систему CRISPR-Cas9, кодон-оптимизированную для дрожжей с целью одновременного разрушения обоих аллелей эндогенного гена и нокина гетерологичного гена. Cas9 и РНК экспрессировали из геномных или эписомальных 2 мкм положений векторов. Авторы также показали, что эффективность нарушения гена можно было повысить при помощи оптимизации уровней экспрессии Cas9 и gRNA. Hlavová et al. (Biotechnol. Adv. 2015) описывают создание видов или штаммов микроводорослей при помощи методик, таких как CRISPR, для нацеливания на ядерные гены и гены хлоропластов с целью инсерционного мутагенеза и тестирования. Способы по Stovicek and Hlavová могут быть применимы в отношении системы эффекторного белка Cpf1 по настоящему изобретению.
- В US 8945839 описан способ конструирования микроводорослей (виды клеток Chlamydomonas reinhardtii) при помощи Cas9. При помощи аналогичных средств способы системы Cpf1 CRISPR, описанной в данном документе, могут быть применимы по отношению к виду Chlamydomonas и другим водорослям. В конкретных вариантах осуществления Cpf1 и направляющую РНК вводят в синтезирующие водоросли при помощи вектора, который экспрессирует Cpf1 под контролем конститутивного промотора, такого как промотор Hsp70A-Rbc S2 или промотор бета 2-тубулина. Направляющую РНК будут доставлять при помощи вектора, содержащего промотор T7. Альтернативно мРНК Cpf1 и in vitro транскрибируемая направляющая РНК могут быть доставлены в клетки водорослей. Протокол электропорации cоответствует стандартному рекомендованному протоколу для набора GeneArt Chlamydomonas Engineering kit.
Применение Cpf1 при получении микроорганизмов, способных к образованию жирных кислот
- В конкретных вариантах осуществления способы по настоящему изобретению применяют для получения генетически модифицированных микроорганизмов, способных к продуцированию жирных сложных эфиров, таких как метиловые сложные эфиры жирных кислот ("FAME") и этиловые сложные эфиры жирных кислот ("FAEE").
- Как правило, клетки-хозяева могут быть сконструированы таким образом, чтобы образовывать жирные сложные эфиры из источника углерода, такого как спирт, присутствующий в среде, в результате экспрессии или сверхэкспрессии гена, кодирующего тиоэстеразу, гена, кодирующего ацил-CoA синтазу, и гена, кодирующего синтазу сложных эфиров. Соответственно, способы, предусмотренные в данном документе, применяют для модификации микроорганизмов с целью сверхэкспрессии или введения гена тиоэстеразы, гена, кодирующего ацит-CoA синтазу и гена, кодирующего синтазу сложных эфиров. В конкретных вариантах осуществления ген тиоэстеразы выбран из tesA, 'tesA, tesB, fatB, fatB2, fatB3, fatAl или fatA. В конкретных вариантах осуществления ген, кодирующий ацил-CoA синтазу, выбран из fadDJadK, BH3103, pfl-4354, EAV15023, fadDl, fadD2, RPC_4074,fadDD35, fadDD22, faa39 или идентифицированного гена, кодирующего фермент, имеющий те же самые свойства. В конкретных вариантах осуществления ген, кодирующий синтазу сложных эфиров, представляет собой ген, кодирующий синтазу/ацил-CoA:диацилглицерилацилтрансферазу из Simmondsia chinensis, Acinetobacter sp. ADP, Alcanivorax borkumensis, Pseudomonas aeruginosa, Fundibacter jadensis, Arabidopsis thaliana или Alkaligenes eutrophus или их вариантов.
- Дополнительно или альтернативно способы, предусмотренные в данном документе, применяют для снижения экспрессии в указанном микроорганизме по меньшей мере одного гена, кодирующего ацил-CoA дегидрогеназу, гена, кодирующего рецептор белка наружной мембраны, и гена, кодирующего регулятор транскрипции биосинтеза жирных кислот. В конкретных вариантах осуществления один или несколько генов являются инактивированными, например, с помощью введения мутации. В конкретных вариантах осуществления ген, кодирующий ацил-CoA дегидрогеназу, представляет собой fadE. В конкретных вариантах осуществления ген, кодирующий регулятор транскрипции биосинтеза жирных кислот, кодирует репрессор транскрипции ДНК, например fabR.
- Дополнительно или альтернативно указанный микроорганизм модифицируют с целью снижения экспрессии по меньшей мере одного гена, кодирующего пируватформатлиазу, гена, кодирующего лактатдегидрогеназу, или их обоих. В конкретных вариантах осуществления ген, кодирующий пируватформатлиазу, представляет собой pflB. В конкретных вариантах осуществления ген, кодирующий лактатдегидрогеназу, представляет собой IdhA. В конкретных вариантах осуществления один или несколько генов являются инактивированными, например, с помощью введения в них мутации.
- В конкретных вариантах осуществления микроорганизм выбирают из рода Escherichia, Bacillus, Lactobacillus, Rhodococcus, Synechococcus, Synechoystis, Pseudomonas, Aspergillus, Trichoderma, Neurospora, Fusarium, Humicola, Rhizomucor, Kluyveromyces, Pichia, Mucor, Myceliophtora, Penicillium, Phanerochaete, Pleurotus, Trametes, Chrysosporium, Saccharomyces, Stenotrophamonas, Schizosaccharomyces, Yarrowia, или Streptomyces.
Применение Cpf1 в получении микроорганизмов, способных к продуцированию органических кислот
- Способы, предусмотренные в данном документе, дополнительно применяют для конструирования микроорганизмов, способных к продуцированию органических кислот, в частности из пентозы или гексозных сахаров. В конкретных вариантах осуществления способы предусматривают введение в микроорганизм эндогенного гена LDH. В конкретных вариантах осуществления продуцирование органических кислот в указанных микроорганизмах дополнительно или альтернативно повышается при инактивации эндогенных генов, кодирующих белки, участвующие в эндогенном метаболическом пути, который приводит к образованию метаболита, отличного от представляющей интерес органической кислоты, и/или в случае, когда в эндогенном метаболическом пути потребляется органическая кислота. В конкретных вариантах осуществления модификация обеспечивает снижение образования метаболита, отличного от представляющей интерес органической кислоты. В соответствии с конкретными вариантами осуществления применяют способы для введения по меньшей мере одной сконструированной делеции гена и/или инактивации эндогенного пути, в котором органическая кислота потребляется, или гена, кодирующего продукт, участвующий в эндогенном пути, который приводит к образованию метаболита, отличного от представляющей интерес органической кислоты. В конкретных вариантах осуществления по меньшей мере одна сконструированная делеция или инактивация гена находится в одном или нескольких генах, кодирующих фермент, выбранный из группы, состоящей из пируватдекарбоксилазы (pdc), фумаратредуктазы, алкогольдегидрогеназы (adh), ацетальдегиддегидрогеназы, фосфоенолпируваткарбоксилазы (ppc), D-лактатдегидрогеназы (d-ldh), L-лактатдегидрогеназы (l-ldh), лактат-2-монооксигеназы.
- В дополнительных вариантах осуществления по меньшей мере одна сконструированная делеция и/или инактивация гена находятся в эндогенном гене, кодирующем пируватдекарбоксилазу (pdc).
- В дополнительных вариантах осуществления микроорганизм конструируют с образованием молочной кислоты, и по меньшей мере одна сконструированная делеция гена и/или инактивация находятся в эндогенном гене, кодирующем лактатдегидрогеназу. Дополнительно или альтернативно микроорганизм содержит по меньшей мере одну сконструированную делецию гена или инактивацию эндогенного гена, кодирующего цитохром-зависимую лактатдегидрогеназу, такую как цитохром B2-зависимая L-лактатдегидрогеназа.
Применение Cpf1 при получении улучшенных штаммов дрожжей, утилизирующих ксилозу и целлобиозу
- В конкретных вариантах осуществления система Cpf1 CRISPR может быть применима для выбора улучшенных штаммов дрожжей, утилизирующих ксилозу или целлобиозу. ПЦР сниженной точности может быть использована для амплификации одного (или нескольких) генов, вовлеченных в пути утилизации ксилозы или целлобиозы. Примеры генов, участвующих в путях утилизации ксилозы и путях утилизации целлобиозы, могут включать без ограничения описанные в Ha, S.J., et al. (2011) Proc. Natl. Acad. Sci. USA 108(2):504-9 и Galazka, J.M., et al. (2010) Science 330(6000):84-6. Полученные библиотеки молекул двухнитевых ДНК, каждая из которых содержит случайную мутацию в таком определенном гене, могли быть котрансформированы компонентами системы Cpf1 CRISPR в штамм дрожжей (например, S288C) и могут быть отобраны штаммы с повышенной способностью к утилизации ксилозы или целлобиозы, как описано в WO2015138855.
Применение Cpf1 при получении улучшенных штаммов дрожжей для использования при биосинтезе изопреноидов
- Tadas Jakočiūnas et al. описали успешное применение мультиплексной системы CRISPR/Cas9 для конструирования генома из различных локусов генома в количестве до 5 на одной стадии трансформации в пекарских дрожжах Saccharomyces cerevisiae (Metabolic Engineering Volume 28, March 2015, Pages 213-222), при этом были получены штаммы с высокой продукцией мевалоната, ключевого посредника для важного в промышленности пути биосинтеза изопреноидов. В конкретных вариантах осуществления система Cpf1 CRISPR может быть применена в способе конструирования мультиплексного генома, как описано в данном документе, для идентификации дополнительных высокопродуктивных штаммов дрожжей для применения в синтезе изопреноидов.
Применение Cpf1 при получении штаммов дрожжей, продуцирующих молочную кислоту
- В другом варианте осуществления охватывается успешное применение мультиплексной системы Cpf1 CRISPR. По аналогии с Vratislav Stovicek et al. (Metabolic Engineering Communications, Volume 2, December 2015, Pages 13-22) улучшенные штаммы, продуцирующие молочную кислоту, могут быть разработаны и получены в одном событии трансформации. В конкретном варианте осуществления систему Cpf1 CRISPR применяют для одновременной вставки гетерологичного гена лактатдегидрогеназы и разрыва двух эндогенных генов PDC1 и PDC5.
Дополнительные варианты применения системы Cpf1 CRISPR в растениях
- В конкретных вариантах осуществления система CRISPR и предпочтительно система Cpf1 CRISPR, описанные в данном документе, могут быть использованы для визуализации динамики генетических элементов. Например, с помощью отображения CRISPR можно визуализировать как повторяющиеся, так и неповторяющиеся геномные последовательности, описывать изменение длины теломеров и движения теломеров и контролировать динамику генных локусов во время клеточного цикла (Chen et al., Cell, 2013). Эти способы могут быть применимы к растениям.
- Другие варианты применения системы CRISPR и предпочтительно системы Cpf1 CRISPR, описанной в данном документе, предусматривают скрининг относительно позитивной селекции разрушения целевого гена in vitro и in vivo (Malina et al., Genes and Development, 2013). Эти способы могут быть применимы к растениям.
- В конкретных вариантах осуществления слияние неактивных эндонуклеаз Cpf1 с модифицирующими гистоны ферментами может вводить специфические изменения в сложном эпигеноме (Rusk et al., Nature Methods, 2014). Эти способы могут быть применимы к растениям.
- В конкретных вариантах осуществления система CRISPR и предпочтительно система Cpf1 CRISPR, описанная в данном документе, могут быть использованы для очистки конкретной части хроматина и выявления ассоциированных белков, при этом устанавливается их регуляторная роль в транскрипции (Waldrip et al., Epigenetics, 2014). Эти способы могут быть применимы к растениям.
- В конкретных вариантах осуществления настоящее изобретение может быть использовано в качестве терапии для удаления вируса в растительных системах, поскольку можно расщеплять как вирусную ДНК, так и РНК. Предыдущие исследования в человеческих системах показали успех применения CRISPR при нацеливании на содержащий однонитевую РНК вирус гепатита С (A. Price, et al., Proc. Natl. Acad. Sci, 2015), а также на содержащий двухнитевую ДНК вирус гепатита B (V. Ramanan, et al., Sci. Rep, 2015). Эти способы могут быть адаптированы для применения системы Cpf1 CRISPR у растений.
- В конкретных вариантах осуществления настоящее изобретение могло бы быть применимо для изменения вариабельности генома. В дополнительных конкретных вариантах осуществления система CRISPR и предпочтительно система Cpf1 CRISPR, описанная в данном документе, могут быть использованы для нарушения или изменения числа хромосом и получения гаплоидных растений, которые содержат хромосомы только от одного родителя. Такие растения могут быть индуцированы с целью осуществления хромосомной дупликации и превращены в диплоидные растения, содержащие только гомозиготные аллели (Karimi-Ashtiyani et al., PNAS, 2015; Anton et al., Nucleus, 2014). Эти способы могут быть применимы к растениям.
- В конкретных вариантах осуществления система Cpf1 CRISPR, описанная в данном документе, может быть использована для саморасщепления. В этих вариантах осуществления промотор фермента Cpf1 и gRNA могут представлять собой конститутивный промотор, а вторую gRNA вводят в ту же самую кассету трансформации, но контролируют при помощи индуцибельного промотора. Эта вторая gRNA может быть сконструирована с целью индукции сайт-специфического расщепления в гене Cpf1 с получением нефункционального Cpf1. В дополнительном конкретном варианте осуществления вторая gRNA индуцирует расщепление на обоих концах кассеты для трансформации, приводя к удалению кассеты из генома хозяина. Эта система обеспечивает контролируемую продолжительность воздействия на клетку фермента Cas и дополнительно сводит к минимуму нецелевое редактирование. Кроме того, расщепление обоих концов кассеты CRISPR/Cas может быть использовано для получения не содержащих трансгенов растений T0 с биаллельными мутациями (как описано для Cas9, например, Moore et al., Nucleic Acids Research, 2014; Schaeffer et al., Plant Science, 2015). Способы из публикации Moore et al. могут быть применены по отношению к системам Cpf1 CRISPR, описанным в данном документе. Sugano et al. (Plant Cell Physiol. 2014 Mar;55(3):475-81. doi: 10.1093/pcp/pcu014. Epub 2014 Jan 18) описывают применение CRISPR-Cas9 по отношению к направленному мутагенезу в печеночном мхе Marchantia polymorpha L., который стал модельным видом для изучения эволюции наземных растений. Промотор U6 M. polymorpha был идентифицирован и клонирован с целью экспрессии gRNA. Целевая последовательность gRNA была разработана с целью нарушения работы гена, кодирующего фактор 1 ответа на ауксин (ARF1) в M. polymorpha. С помощью опосредованной Agrobacterium трансформации Sugano et al. выделили стабильные мутанты в поколении гаметофита M. polymorpha. Сайт-направленный мутагенез на основе CRISPR-Cas9 in vivo был достигнут при помощи вируса 35S мозаики цветной капусты или промотора EF1α M. polymorpha для экспрессии Cas9. Выделенные мутантные особи, проявляющие устойчивый к ауксину фенотип, не были химерными. Кроме того, стабильные мутанты были получены с помощью бесполого размножения растений T1. Несколько аллелей arf1 были легко определены при помощи направленного мутагенеза на основе CRIPSR-Cas9. Способы из публикации Sugano et al. могут быть применимы в отношении системы эффекторного белка Cpf1 по настоящему изобретению.
- Kabadi et al. (Nucleic Acids Res. 2014 Oct 29;42(19):e147. doi: 10.1093/nar/gku749. Epub 2014 Aug 13) разработали одиночную лентивирусную систему с экспрессией варианта Cas9, репортерного гена и до четырех sgRNA включительно из независимых промоторов РНК-полимеразы III, которые включены в вектор с помощью удобного способа клонирования Golden Gate. Каждая sgRNA эффективно экспрессировала и могла опосредовать мультиплексное редактирование генов и длительную активацию транскрипции в иммортализованных и первичных клетках человека. Способы из публикации Kabadi et al. могут быть применимы в отношении системы эффекторного белка Cpf1 по настоящему изобретению.
- Ling et al. (BMC Plant Biology 2014, 14:327) разработали набор бинарных векторов CRISPR-Cas9 на основе каркаса pGreen или pCAMBIA, а также gRNA. Для этого набора инструментов не требуются рестриктазы помимо BsaI для получения конечных конструкций, несущих оптимизированный по кодону маиса Cas9 и одну или несколько gRNA с высокой эффективностью лишь в одной стадии клонирования. Набор инструментов был валидирован с помощью протопластов маиса, линий трансгенного маиса и линий трансгенного арабидопсиса, и, как было показано, характеризовался высокой эффективностью и специфичностью. Что более важно, с помощью этого набора инструментов целевые мутации трех генов арабидопсиса были выявлены в трансгенных сеянцах поколения T1. Кроме того, несколько мутаций генов могли быть унаследованы следующим поколением. (Направляющая РНК) набор модульных векторов, как и набор инструментов для мультиплексного редактирования генома у растений. Набор инструментов из публикации Lin et al. может быть применим в отношении системы эффекторного белка Cpf1 по настоящему изобретению.
- Протоколы для целевого редактирования генома растений посредством CRISP-Cpf1 также доступны на основе раскрытых для системы CRISPR-Cas9 в томе 1284 серии в Methods in Molecular Biology pp 239-255 от 10 февраля 2015 г. Описана подробная процедура разработки, конструирования и оценки двойных gRNA для оптимизированного по кодону растений опосредованного Cas9 (pcoCas9) редактирования генома при помощи клеточных систем на основе модели протопластов Arabidopsis thaliana и Nicotiana benthamiana. Стратегии применения системы CRISPR-Cas9 с целью получения целевых модификаций генома в целых растениях также описаны. Протоколы, описанные в этой главе, могут быть применены по отношению к эффекторному белку Cpf1 по настоящему изобретению.
Petersen ("Towards precisely glycol engineered plants," Plant Biotech Denmark Annual meeting 2015, Copenhagen, Denmark) разработал способ применения CRISPR/Cas9 для конструирования геномных изменений в арабидопсисе, например, глико-конструирования арабидопсиса для получения белков и продуктов, имеющий желаемые посттрансляционные модификации. Hebelstrup et al. (Front Plant Sci. 2015 Apr 23; 6:247) описывает биоинженерию крахмала в растениях, предусматривающую сельскохозяйственные культуры, которые экспрессируют модифицирующие крахмал ферменты и непосредственно дают продукты, которые обычно изготовлены с помощью промышленных химических и/или физических способов обработки крахмалов. Способы по Petersen and Hebelstrup могут быть применимы в отношении системы эффекторного белка Cpf1 по настоящему изобретению.
- Ma et al. (Mol Plant. 2015 Aug 3;8(8):1274-84. doi: 10.1016/j.molp.2015.04.007) описывают устойчивую векторную систему CRISPR-Cas9, используя оптимизированный по кодону растения ген Cas9, для удобного и высокоэффективного мультиплексного редактирования генома в однодольных и двудольных растениях. Ma et al. разработали процедуры на основе ПЦР для быстрого получения нескольких кассет экспрессии sgRNA, которые могут быть собраны в бинарные векторы CRISPR-Cas9 в одном цикле клонирования при помощи лигирования Golden Gate или сборки Gibson. С помощью этой системы Ma et al. редактировали 46 целевых сайтов у риса со средней скоростью мутации, составляющей 85,4%, большей частью в биаллельном и гомозиготном статусе. Ma et al. предложили примеры мутаций генов с потерей функции в растениях риса T0 и растениях арабидопсиса T1 при помощи одновременного нацеливания на несколько (до восьми) представителей семейства генов, несколько генов в пути биосинтеза или нескольких сайтов в одном гене. Способы по Ma et al. могут быть применимы в отношении системы эффекторного белка Cpf1 по настоящему изобретению.
- Lowder et al. (Plant Physiol. 2015 Aug 21. pii: pp.00636.2015) также разработали набор инструментов CRISPR-Cas9, который обеспечивает мультиплексное редактирование генома и регуляцию транскрипции экспрессируемых, выключенных или некодирующих генов в растениях. Этот набор инструментов обеспечивает исследователей протоколом и реагентами для быстрой и эффективной сборки функциональных конструкций T-ДНК CRISPR-Cas9 для однодольных и двудольных при помощи способов клонирования Golden Gate и Gateway. Он поставляется вместе с полным набором возможностей, в том числе мультиплексного редактирования генов и активации или репрессии транскрипции эндогенных генов растений. Технология трансформации на основе T-ДНК является фундаментальной для современной биотехнологии, генетики, молекулярной биологии и физиологии растений. В связи с этим заявители разработали способ сборки Cas9 (WT, никаза или dCas9) и gRNA в представляющий интерес принимающий вектор T-ДНК. Способ сборки основан на сборке Golden Gate и рекомбинации MultiSite Gateway. Для сборки требуется три модуля. Первый модуль представляет собой входящий вектор Cas9, который содержит Cas9 без промотора или его производные гены, фланкированные сайтами attL1 и attR5. Второй модуль представляет собой входящий вектор gRNA, который содержит входящие кассеты экспрессии на основе gRNA, фланкированные сайтами attL5 и attL2. Третий модуль включает attR1-attR2-содержащие векторы назначения T-ДНК, которые предусматривают предпочтительные промоторы для экспрессии Cas9. Набор инструментов из публикации Lowder et al. может быть применим в отношении системы эффекторного белка Cpf1 по настоящему изобретению.
- В предпочтительном варианте осуществления растение может представлять собой дерево. В настоящем изобретении может также применяться раскрытая в данном документе система CRISPR Cas для систем на основе травянистых растений (см., например, Belhaj et al., Plant Methods 9: 39 and Harrison et al., Genes & Development 28: 1859-1872). В особо предпочтительном варианте осуществления система CRISPR Cas по настоящему изобретению может быть направлена на однонуклеотидный полиморфизм (SNP) у деревьев (см., например, Zhou et al., New Phytologist, Volume 208, Issue 2, pages 298-301, October 2015). В исследовании Zhou et al. авторы применяли систему CRISPR Cas для древовидного многолетнего Populus в случае семейства генов 4-кумарат:лигаза CoA (4CL) в качестве примера применения и достигли 100% мутационной эффективности для двух целевых генов 4CL, при этом каждый исследуемый трансформант нес биаллельные модификации. В исследовании Zhou et al. система CRISPR-Cas9 была высокочувствительной по отношению к однонуклеотидным полиморфизмам (SNP), поскольку расщепление для третьего гена 4CL было отменено в результате SNP в целевой последовательности. Эти способы могут быть применимы в отношении системы эффекторного белка Cpf1 по настоящему изобретению.
- Способы Zhou et al. (New Phytologist, Volume 208, Issue 2, pages 298-301, October 2015) могут быть применены по отношению к настоящему изобретению следующим образом. Два гена 4CL, 4CL1 и 4CL2, ассоциированные с биосинтезом лигнина и флавоноидов соответственно, являются мишенями для редактирования с помощью CRISPR-Cas9. Клон 717-1B4 Populus tremula × alba, обычно используемый для трансформации, отличается от Populus trichocarpa с секвенированным геномом. Таким образом, gRNA 4CL1 и 4CL2, разработанные исходя из эталонного генома, детально исследуют в соответствии с внутренними данными секвенирования РНК 717 с целью обеспечения отсутствия SNP, которые могли бы ограничить эффективность Cas. Также включена третья gRNA, разработанная для 4CL5, геномной дупликации 4CL1. Соответствующая последовательность 717 содержит один SNP в каждом аллеле возле/в PAM, оба из которых, как предполагается, устраняют нацеливание со стороны 4CL5-gRNA. Все три целевые сайта gRNA расположены в первом экзоне. Для трансформации последовательности 717 gRNA экспрессируется из промотора Medicago U6.6 совместно с кодон-оптимизированным Cas человека под контролем промотора CaMV 35S в бинарном векторе. Трансформация вектором, содержащим только Cas, может выступать в качестве контроля. Случайным образом выбранные линии 4CL1 и 4CL2 подвергают секвенированию ампликонов. Затем данные обрабатывают и биаллельные мутации подтверждают во всех случаях. Эти способы могут быть применимы в отношении системы эффекторного белка Cpf1 по настоящему изобретению.
- У растений патогены часто являются специфичными по отношению к хозяину. Например, Fusarium oxysporum f. sp. lycopersici вызывает фузариозный вилт томата, но поражает только томат, а F. oxysporum f. dianthii и Puccinia graminis f. sp. tritici поражают только пшеницу. Растения обладают присущими и индуцированными защитными реакциями, обеспечивающими устойчивость к большинству патогенов. Мутации и события рекомбинации в поколениях растений приводят к генетической изменчивости, которая обуславливает восприимчивость, тем более, что патогены размножаются с большей частотой, чем растения. У растений может наблюдаться устойчивость видов, не относящихся к хозяевам, например хозяин и патоген являются несовместимыми. Также может наблюдаться горизонтальная устойчивость, например частичная устойчивость ко всем расам патогена, обычно контролируемая многими генами, и вертикальная устойчивость, например полная устойчивость к некоторым расам патогена, но не к другим расам, обычно контролируемая несколькими генами. На уровне взаимодействия генов растения и патогены эволюционируют совместно, а генетические изменения одного уравновешивают изменения другого. Соответственно, используя естественную изменчивость, селекционеры комбинируют гены, наиболее полезные для урожайности, качества, однородности, выносливости, устойчивости. Источники генов устойчивости включают нативные или чужеродные сорта, старинные сорта, родственные дикорастущие растения и индуцированные мутации, например, при обработке растительного материала мутагенными средствами. Применяя настоящее изобретение, селекционеры растений получают новый инструмент для индукции мутаций. Соответственно, специалист в данной области может проанализировать геном источников генов устойчивости, а в отношении сортов, имеющих желаемые характеристики или признаки, использовать настоящее изобретение для индукции появления генов устойчивости с большей точностью, чем в случае применявшихся ранее мутагенных средств, и, следовательно, для ускорения и улучшения программ селекции растений.
Улучшенные растения и клетки дрожжей
- Настоящее изобретение также предусматривает растения и дрожжевые клетки, получаемые и полученные с помощью способов, предусмотренных в данном документе. Улучшенные растения, полученные с помощью способов, описанных в данном документе, могут быть полезны при получении продуктов питания и кормов посредством экспрессии генов, которые, например, обеспечивают переносимость вредителей растений, гербицидов, засухи, низких или высоких температур, избытка воды и др.
- Улучшенные растения, полученные с помощью способов, описанных в данном документе, в частности, сельскохозяйственные культуры и водоросли, могут быть полезны в производстве продуктов питания и кормов посредством синтеза, например, более высоких уровней белка, углеводов, нутриентов или витаминов, чем в норме наблюдались бы при диком типе. В этом отношении улучшенные растения, в частности, зернобобовые и клубнеплоды, являются предпочтительными.
- Улучшенные водоросли или другие растения, такие как рапс, могут быть особенно полезными в производстве растительных масел или таких видов биотоплива, как, например, спирты (особенно метанол и этанол). Они могут быть сконструированы для синтеза или избыточного синтеза масла или спиртов на высоких уровнях для применения в масложировой или биотопливной промышленности.
- Настоящее изобретение также предусматривает улучшенные части растения. Части растений включают без ограничения листья, стебли, корни, клубни, семена, эндосперм, семяпочку и пыльцу. Части растений, как предусмотрено в данном документе, могут быть жизнеспособными, нежизнеспособными, регенерируемыми и/или нерегенерируемыми.
- В данном документе также охвачены растительные клетки и растения в соответствии со способами по настоящему изобретению. Гаметы, семена, эмбрионы, как зиготические, так и соматические, потомство или гибриды растений, содержащих генетическую модификацию, которые получены с помощью традиционных способов селекции, также включены в объем настоящего изобретения. Такие растения могут содержать гетерологичную последовательность или последовательность чужеродной ДНК, вставленные в целевую последовательность или вместо нее. Альтернативно такие растения могут содержать только изменение (мутацию, делецию, вставку, замену) в одном или нескольких нуклеотидах. Например, такие растения будут отличаться только от своих растений-предшественников по наличию определенной модификации.
- Таким образом, настоящее изобретение относится к растению, животному или клетке, полученным с помощью способа по настоящему изобретению, или их потомству. Потомство может представлять собой клон полученного растения или животного, или его можно получить с помощью полового размножения посредством скрещивания с другими индивидами того же вида для придания дополнительных желаемых признаков их потомкам. Клетка может находиться in vivo или ex vivo в случае многоклеточных организмов, в частности, животных или растений.
Комплексы эффекторного белка Cpf1 могут быть использованы в организмах, отличным от человека/животных
В одном аспекте настоящего изобретения предусмотрен отличный от человеческого эукариотический организм; предпочтительно многоклеточный эукариотический организм, содержащий эукариотическую клетку-хозяина в соответствии с любым из описанных вариантов осуществления. В других аспектах настоящего изобретения предусмотрен эукариотический организм, предпочтительно многоклеточный эукариотический организм, содержащий эукариотическую клетку-хозяина в соответствии с любым из описанных вариантов осуществления. В некоторых вариантах осуществления этих аспектов организм может представлять собой животное; например, млекопитающее. Также организм может представлять собой членистоногое, такое как насекомое. Организм также может представлять собой растение. Кроме того, организм может представлять собой гриб.
- Настоящее изобретение также может распространяться на другие варианты сельскохозяйственного применения, такие как, например, сельскохозяйственные и продуктивные животные. Например, свиньи имеют многие характеристики, которые делают их привлекательными в качестве биомедицинских моделей, в частности, в регенеративной медицине. В частности, свиньи с тяжелым комбинированным иммунодефицитом (SCID) могут обеспечивать полезные модели для регенеративной медицины, ксенотрансплантации (обсуждаемые также в других местах данного документа) и опухолевого развития и будут способствовать разработке терапевтических препаратов для пациентов-людей с SCID. Lee et al. (Proc Natl Acad Sci U S A. 2014 May 20;111(20):7260-5) использовали направляемую репортером систему эффекторной нуклеазы, подобной активаторам транскрипции (TALEN), по отношению к полученным целевым модификациям гена, активирующего рекомбинацию (RAG) 2, в соматических клетках с высокой эффективностью, в том числе некоторым, которые влияли на оба аллеля. Система эффекторного белка Cpf1 может быть применима к аналогичной системе.
- Способы из публикации Lee et al., (Proc Natl Acad Sci U S A. 2014 May 20;111(20):7260-5) могут быть применимы по отношению к настоящему изобретению, аналогично следующему. Мутированных свиней получают с помощью целевой модификации RAG2 в фибробластах плода, после чего происходит SCNT и перенос эмбрионов. Конструкции, кодирующие CRISPR Cas и репортер, электропорируют в фибробласты, полученные из плода. Через 48 часов трансфицированные клетки, экспрессирующие зеленый флуоресцентный белок, сортируют в отдельные лунки 96-луночного планшета при предполагаемом разведении одна клетка на лунку. Целевые модификации RAG2 подвергают скринингу с помощью амплификации фрагмента геномной ДНК, фланкирующей любые сайты рестрикции CRISPR Cas, после чего выполняют секвенирование ПЦР-продуктов. После скрининга и обеспечения отсутствия нецелевых мутаций клетки, несущие целевую модификацию RAG2, используют для SCNT. Полярное тельце вместе с частью прилегающей цитоплазмы ооцита, предположительно содержащего метафазную пластинку II, удаляют, и донорскую клетку помещают в перивителлин. Реконструированные эмбрионы затем электропорируют для слияния донорской клетки с ооцитом и затем химически активируют. Активированные эмбрионы инкубируют в среде для развития свиных зигот 3 (PZM3) с 0,5 мкМ скриптаидом (S7817; Sigma-Aldrich) в течение 14-16 часов. Эмбрионы затем промывают с удалением скриптаида и культивируют в PZM3 до тех пор, пока они не будут перенесены в маточные трубы суррогатных свиней.
- Настоящее изобретение также применимо к модификации SNP других животных, таких как коровы. Tan et al. (Proc Natl Acad Sci U S A. 2013 Oct 8; 110(41): 16526-16531) расширили набор для редактирования генов крупного рогатого скота с включением репарации с участием гомологичной рекомбинации (HDR), стимулированной эффекторной нуклеазой, подобной активаторам транскрипции (TAL) (TALEN) и коротких палиндромных повторов, регулярно расположенных группами (CRISPR)/Cas9, с использованием плазмиды, rAAV и олигонуклеотидных матриц. Геноспецифические последовательности gRNA были клонированы в вектор на основе gRNA Church lab (Addgene ID: 41824) в соответствии с их способами (Mali P, et al. (2013) RNA-Guided Human Genome Engineering via Cas9. Science 339(6121):823-826). Нуклеазу Cas9 получали с помощью котрансфекции плазмиды hCas9 (Addgene ID: 41815) или синтезировали с помощью мРНК из RCIScript-hCas9. Эта система RCIScript-hCas9 была сконструирована с помощью субклонирования фрагмента XbaI-AgeI из плазмиды hCas9 (содержащей кДНК hCas9) в плазмиду RCIScript.
- Heo et al. (Stem Cells Dev. 2015 Feb 1;24(3):393-402. doi: 10.1089/scd.2014.0278. Epub 2014 Nov 3) описали высокоэффективное нацеливание на ген в бычьем геноме с использованием бычьих плюрипотентных клеток и коротких палиндромных повторов, регулярно расположенных группами, (CRISPR)/нуклеазы Cas9. Впервые Heo et al. получили индуцированные плюрипотентные стволовые клетки (iPSC) из бычьих соматических фибробластов с помощью эктопической экспрессии факторов Яманаки и обработки ингибитором GSK3β и MEK (2i). Heo et al. наблюдали, что эти бычьи iPSC очень похожи на наивные плюрипотентные стволовые клетки в отношении экспрессии генов и потенциала развития в тератомы. Кроме того, нуклеаза CRISPR-Cas9, которая была специфичной по отношению к бычьему локусу NANOG, характеризовалась высокоэффективным редактированием бычьего генома в бычьих iPSC и эмбрионах.
- Igenity® предусматривает профильный анализ животных, таких как коровы, для проявления и передачи генов экономически важных признаков, таких как состав туши, качество туши, материнские и репродуктивные признаки и средний суточный прирост. Анализ полного профиля Igenity® начинается с обнаружения ДНК-маркеров (чаще всего однонуклеотидных полиморфизмов или SNP). Все маркеры в рамках профиля Igenity® были обнаружены независимыми учеными в исследовательских институтах, в том числе университетах, исследовательских организациях и государственных организациях, таких как USDA. Затем маркеры анализировали с помощью Igenity® в популяциях для валидации. В Igenity® используют популяции из нескольких ресурсов, которые отражают различные условия производственной среды и биологические типы, при этом часто выполняют работы с промышленными партнерами из маточного, скотоводческого, откормочного и/или упаковочного сегментов скотоводческой промышленности для сбора фенотипов, которые обычно не доступны. Базы данных геномов крупного рогатого скота являются широко доступными, см., например, NAGRP Cattle Genome Coordination Program (http://www.animalgenome.org/cattle/maps/db.html). Таким образом, настоящее изобретение может быть применено для нацеливания на бычьи SNP. Специалист в данной области может использовать вышеупомянутые протоколы для нацеливания на SNP и применения их по отношению к бычьим SNP, как описано, например, Tan et al. или Heo et al.
- Qingjian Zou et al. (Journal of Molecular Cell Biology Advance Access, опубликовано 12 октября 2015 г.) показали повышение мышечной массы у собак с помощью нацеливания на первый экзон гена миостатина собаки (MSTN) (отрицательный регулятор скелетной мышечной массы). Прежде всего, валидировали эффективность sgRNA при помощи котрансфекции sgRNA, нацеленной на MSTN, при помощи вектора Cas9 в собачьих эмбриональных фибробластах (CEF). Затем собак MSTN KO получали с помощью микроинъекции эмбрионам с нормальной морфологией смеси мРНК Cas9 и sgRNA MSTN и аутотрансплантации зигот в маточную трубу той же самой суки. Нокаутированные щенки проявляли выраженный мышечный фенотип в области бедер по сравнению со своим однопометником дикого типа. Это также можно выполнить при помощи систем Cpf1 CRISPR, предусмотренных в данном документе.
Домашний скот - свиньи
- Вирусные мишени в домашнем скоте могут включать в некоторых вариантах осуществления свиной CD163, например, на свиных макрофагах. CD163 ассоциирован с инфекцией (предположительно в результате вхождения вируса в клетку) в результате PRRSv (вируса свиного репродуктивного и респираторного синдрома, артеривируса). Инфекция в результате PRRSv, в частности, свиных альвеолярных макрофагов (встречающихся в легких), приводит к ранее неизлечимому свиному синдрому ("таинственная болезнь свиней" или "болезнь синего уха"), который вызывает болезнь, в том числе репродуктивную недостаточность, потерю веса и высокую смертность у домашних свиней. Оппортунистические инфекции, такие как энзоотическая пневмония, менингит и отечность ушей, часто наблюдаются в результате иммунодефицита вследствие потери активности макрофагов. Это также имеет значительные экономические и средовые последствия в связи с повышенным применением антибиотиков и финансовым ущербом (по оценкам 660 млн. дол. в год).
- Как было описано Kristin M Whitworth and Dr Randall Prather et al. (Nature Biotech 3434, опубликовано онлайн 07 декабря 2015 г.) в Университете штата Миссури и в сотрудничестве с Genus Plc, CD163 подвергали нацеливанию CRISPR-Cas9 и потомство "редактированных" свиней было устойчиво при воздействии PRRSv. Одного хряка-основателя и одну свиноматку-основательницу, оба из которых имели мутации в экзоне 7 CD163, скрещивали с получением потомства. Хряк-основатель характеризовался делецией из 11 п. о. в экзоне 7 в одном аллеле, которая приводила к мутации типа сдвига рамки и миссенс-трансляции в аминокислоте 45 в домене 5 и последующему преждевременному стоп-кодону по аминокислоте 64. Другой аллель характеризовался добавлением из 2 п.о. в экзоне 7 и делецией из 377 п. о. в предшествующем интроне, которые, как предполагалось, приводили к экспрессии первых 49 аминокислот домена 5, затем преждевременного стоп-кодона в аминокислоте 85. Свиноматка характеризовалась добавлением из 7 п. о. в одном аллеле, которое при трансляции, как предполагалось, экспрессировало первые 48 аминокислот домена 5, затем преждевременный стоп-кодон в аминокислоте 70. Другой аллель свиноматки был неамплифицированным. Некоторые потомки, как предполагалось, представляли собой нуль-животное (CD163-/-), т. е. нокаут по CD163.
- Соответственно, в некоторых вариантах осуществления свиные альвеолярные макрофаги могут быть подвергнуты нацеливанию белка CRISPR. В некоторых вариантах осуществления свиной CD163 может быть подвергнут нацеливанию белка CRISPR. В некоторых вариантах осуществления свиной CD163 может быть нокаутирован посредством индукции DSB или в результате вставок или делеций, например, нацеливания на делецию или модификацию экзона 7, в том числе одного или нескольких из описанных выше, или в других областях гена, например, делецию или модификацию экзона 5.
- Также предусмотрены "редактированная" свинья и ее потомство, например, нокаутированная по CD163 свинья. Это может быть предусмотрено для целей скотоводства, селекции и моделирования (т. е., свиная модель). Также предусмотрена семенная жидкость, содержащая нокаут гена.
- CD163 представляет собой представителя суперсемейства фагоцитарных рецепторов с высоким содержанием цистеина (SRCR). На основе in vitro исследований SRCR домен 5 белка представляет собой домен, ответственный за распаковку и высвобождение вирусного генома. Например, другие представители суперсемейства SRCR также могут быть подвергнуты нацеливанию для получения устойчивости к другим вирусам. PRRSV также представляет собой представителя группы артеривирусов млекопитающих, которая также включает вирус, повышающий уровень лактат-дегидрогеназы у мышей, вирус геморрагической лихорадки обезьян и вирус артерита лошадей. Артеривирусы имеют общие важные свойства патогенеза, в том числе макрофагальный тропизм и способность вызывать как тяжелую болезнь, так и хроническую инфекцию. Соответственно, артеривирусы и, в частности, вирус, вызывающий повышение уровня лактат-дегидрогеназы у мышей, вирус геморрагической лихорадки обезьян и вирус артериита лошадей, могут быть подвергнуты нацеливанию, например свиного CD163 или его гомологов у других видов, и также предусмотрены мышиные, обезьяньи и лошадиные модели и нокаут.
- Действительно, этот подход может быть распространен на вирусы или бактерии, которые вызывают другие заболевания домашнего скота, которые могут передаваться человеку, такие как штаммы вируса свиного гриппа (SIV), которые включают грипп C и подтипы гриппа A, известные как H1N1, H1N2, H2N1, H3N1, H3N2 и H2N3, а также пневмонию, менингит и отечность, упомянутые выше.
Терапевтическое нацеливание при помощи направляемого РНК комплекса эффекторного белка Cpf1
- Как будет понятно, предусматривается, что настоящую систему можно использовать для целенаправленного воздействия на любую представляющую интерес полинуклеотидную последовательность. Настоящее изобретение относится к не встречающейся в природе или сконструированной композицию, или одному или нескольким полинуклеотидам, кодирующим компоненты указанной композиции, или вектору или системе доставки, содержащим один или несколько полинуклеотидов, кодирующих компоненты указанной композиции, для применения при модификации целевой клетки in vivo, ex vivo или in vitro, и они могут быть выполнены с помощью способа, который изменяет клетку таким образом, что после модификации потомство или линия клеток клетки, модифицированной с помощью CRISPR, сохраняет измененный фенотип. Модифицированные клетки и потомство могут быть частью многоклеточного организма, такого как растение или животное, с применением ex vivo или in vivo системы CRISPR по отношению к желаемым типам клеток. Изобретение CRISPR может представлять собой терапевтический способ лечения. Терапевтический способ лечения может предусматривать редактирование гена или генома или генную терапию.
Лечение патогенов, например, бактериальных, грибковых и паразитарных патогенов
- Настоящее изобретение также может быть применимо к лечению бактериальных, грибковых и паразитарных патогенов. Большинство исследовательских усилий было сосредоточено на создании новых антибиотиков, которые после создания все равно стали бы предметом аналогичных проблем, связанных с устойчивостью к лекарственному средству. Настоящее изобретение относится к новым альтернативам на основе CRISPR, которые преодолевают эти сложности. Кроме того, в отличие от существующих антибиотиков варианты лечения на основе CRISPR могут быть проведены специфично по отношению к патогенам, с индукцией клеточной смерти целевого патогена, при этом не затрагиваются полезные бактерии.
- Jiang et al. ("RNA-guided editing of bacterial genomes using CRISPR-Cas systems," Nature Biotechnology vol. 31, p. 233-9, March 2013) использовали систему CRISPR-Cas9 для мутирования или уничтожения S. pneumoniae и E. coli. Исследование, в результате которого происходило введение точных мутаций в геномы, опиралось на расщепление в целевом сайте генома под управлением системы двойная РНК:Cas9 для уничтожения немутированных клеток и устраняло необходимость в селектируемых маркерах или системах негативного отбора. Системы CRISPR были использованы для обращения устойчивости к антибиотикам и устранения переноса устойчивости между штаммами. Bickard et al. показали, что Cas9, перепрограммированный для нацеливания на гены вирулентности, уничтожают вирулентный, а не авирулентный S. aureus. Перепрограммирование нуклеазы для нацеливания на гены устойчивости к антибиотиками разрушало плазмиды стафилококков, которые имели гены устойчивости к антибиотикам, и иммунизировало против распространения плазмидных генов устойчивости. (см., Bikard et al., "Exploiting CRISPR-Cas nucleases to produce sequence-specific antimicrobials," Nature Biotechnology vol. 32, 1146-1150, doi:10.1038/nbt.3043, опубликовано онлайн 5 октября 2014 г.) Bikard показал, что антимикробные средства на основе CRISPR-Cas9 функционируют in vivo для уничтожения S. aureus в мышиной модели колонизации кожи. Аналогично, Yosef et al использовали систему CRISPR для нацеливания на гены, кодирующие ферменты, которые придают устойчивость к β-лактамным антибиотикам (см. Yousef et al., "Temperate and lytic bacteriophages programmed to sensitize and kill antibiotic-resistant bacteria," Proc. Natl. Acad. Sci. USA, vol. 112, p. 7267-7272, doi: 10.1073/pnas.1500107112, опубликовано онлайн 18 мая 2015 г.).
- Системы CRISPR могут быть использованы для редактирования геномов паразитов, которые являются устойчивыми к другим генетическим подходам. Например, система CRISPR-Cas9, как было показано, вводит двунитевые разрывы в геном Plasmodium yoelii (см., Zhang et al., "Efficient Editing of Malaria Parasite Genome Using the CRISPR/Cas9 System," mBio. vol. 5, e01414-14, Jul-Aug 2014). Ghorbal et al. ("Genome editing in the human malaria parasite Plasmodium falciparumusing the CRISPR-Cas9 system," Nature Biotechnology, vol. 32, p. 819-821, doi: 10.1038/nbt.2925, опубликовано онлайн 1 июня 2014 г.) модифицировали последовательности двух генов, orc1 и kelch13, которые имеют предположительные функции сайленсинга генов и возникновения устойчивости к артемизинину соответственно. Паразиты, которые были изменены в подходящих сайтах, были восстановлены с очень высокой эффективностью, несмотря на отсутствие прямого отбора в отношении модификации, указывая на то, что нейтральные или даже вредные мутации могут быть получены при помощи этой системы. Систему CRISPR-Cas9 также используют для модификации других патогенных паразитов, в том числе Toxoplasma gondii (см. Shen et al., "Efficient gene disruption in diverse strains of Toxoplasma gondii using CRISPR/CAS9," mBio vol. 5:e01114-14, 2014; and Sidik et al., "Efficient Genome Engineering of Toxoplasma gondii Using CRISPR/Cas9," PLoS One vol. 9, e100450, doi: 10.1371/journal.pone.0100450, опубликовано онлайн 27 июня 2014 г.).
- Vyas et al. ("A Candida albicans CRISPR system permits genetic engineering of essential genes and gene families," Science Advances, vol. 1, e1500248, DOI: 10.1126/sciadv.1500248, от 3 апреля 2015 г.) использовали систему CRISPR для преодоления долго существующих препятствий для генной инженерии в C. albicans и эффективного мутирования в одном эксперименте обеих копий нескольких различных генов. В организме, где несколько механизмов способствуют лекарственной устойчивости, Vyas получал гомозиготные двойные мутанты, которые больше не проявляли гиперустойчивость к флуконазолу или циклогексимиду, обнаруживаемую родительским клиническим изолятом Can90. Vyas также получал гомозиготные мутации потери функции в важных генах C. albicans при помощи создания условных аллелей. Нуль-аллели DCR1, который требуется для процессинга рибосомальной РНК, являются летальными при низкой температуре, но жизнеспособными при высокой температуре. Vyas использовал матрицу дял репарации, которая вводила нонсенс-мутацию, и выделял мутантов dcr1/dcr1, которые не могли расти при 16°C.
- Система CRISPR по настоящему изобретению для применения в P. falciparum посредством разрыва хромосомных локусов. Ghorbal et al. ("Genome editing in the human malaria parasite Plasmodium falciparum using the CRISPR-Cas9 system", Nature Biotechnology, 32, 819-821 (2014), DOI: 10.1038/nbt.2925, от 1 июня 2014 г.) использовали систему CRISPR для введения специфических нокаутов генов и однонуклеотидных замен в геном малярийного плазмодия. Для адаптации системы CRISPR-Cas9 по отношению к P. falciparum Ghorbal et al. получали векторы экспрессии для контроля регуляторных элементов плазмодия в эписоме pUF1-Cas9, которая также несет селектируемый в отношении лекарственного средства маркер ydhodh, который придает устойчивость к DSM1, ингибитору дигидрооротатдегидрогензы (PfDHODH) P. falciparum, и для транскрипции sgRNA использовали регуляторные элементы малых ядерных (sn)RNA U6 P. falciparum, помещая направляющую РНК и матрицу донорской ДНК для гомологичной рекомбинационной репарации на одну и ту же плазмиду pL7. См. также Zhang C. et al. ("Efficient editing of malaria parasite genome using the CRISPR/Cas9 system", MBio, 2014 Jul 1; 5(4):E01414-14, doi: 10.1128/MbIO.01414-14) и Wagner et al. ("Efficient CRISPR-Cas9-mediated genome editing in Plasmodium falciparum, Nature Methods 11, 915-918 (2014), DOI: 10.1038/nmeth.3063).
Лечение патогенов, аналогичных вирусным патогенам, таким как HIV
- Cas-опосредованное редактирование генома может быть использовано для введения защитных мутаций в соматические ткани для лечения негенетических или сложных заболеваний. Например, NHEJ-опосредованная инактивация рецептора CCR5 в лимфоцитах (Lombardo et al., Nat Biotechnol. 2007 Nov; 25(11):1298-306) может представлять собой эффективную стратегию для устранения инфекции, обусловленной HIV, в то время как делеция PCSK9 (Cohen et al., Nat Genet. 2005 Feb; 37(2):161-5) или ангиопоэтина (Musunuru et al., N Engl J Med. 2010 Dec 2; 363(23):2220-7) может обеспечивать терапевтические эффекты по отношению к устойчивой к статинам гиперхолестеринемии или гиперлипидемии. Несмотря на то, что эти мишени могут также подвергаться воздействию с помощью siRNA-опосредованного нокдауна белков, уникальное преимущество NHEJ-опосредованной инактивации генов заключается в способности достигать долговременного терапевтического эффекта без необходимости в продолжении лечения. Как и в случае всех видов генной терапии, это будет, безусловно, важным для установления того, что каждое предлагаемое терапевтическое применение имеет эффективное соотношение "риск-польза".
- Гидродинамическая доставка плазмидной ДНК, кодирующей Cas9 и направляющую РНК, совместно с матрицей для репарации, в печень в модели тирозинемии у взрослых мышей, как было показано, способна корректировать мутантный ген Fah и восстанавливать экспрессию белка Fah дикого типа в ~1 из 250 клеток (Nat Biotechnol. 2014 Jun; 32(6):551-3). Кроме того, в клинических исследованиях успешно применяли нуклеазы ZF для лечения инфекции, обусловленной HIV, с помощью ex vivo нокаута рецептора CCR5. У всех пациентов уровни ДНК HIV снижались, и у одного из четырех пациентов РНК HIV становилась невыявляемой (Tebas et al., N Engl J Med. 2014 Mar 6; 370(10):901-10). Оба из этих результата показывают потенциал программируемых нуклеаз в качестве новой терапевтической платформы.
- В другом варианте осуществления самоинактивирующиеся лентивирусные векторы с siRNA, нацеленной на общий экзон, который имеет tat/rev HIV, сигналом ядрышковой локализации TAR-ловушкой и специфичным к CCR5 рибозимом в виде головки молотка (см., например, DiGiusto et al. (2010) Sci Transl Med 2:36ra43) можно использовать и/или адаптировать для системы CRISPR-Cas по настоящему изобретению. Не менее 2,5 × 106 клеток CD34+ на килограмм массы пациента можно собирать и предварительно стимулировать в течение 16-20 часов в среде X-VIVO 15 (Lonza), содержащей 2 мкмоля/L-глутамина, фактор стволовых клеток (100 нг/мл), лиганд Flt-3 (Flt-3L) (100 нг/мл) и тромбопоэтин (10 нг/мл) (CellGenix), при плотности 2 × 106 клеток/мл. Предварительно стимулированные клетки можно трансдуцировать лентивирусом при множественности заражения 5 в течение 16-24 часов во флаконах с культурой тканей на 75 см2, покрытых фибронектином (25 мг/см2) (RetroNectin, Takara Bio Inc.).
- Специалист в данной области с использованием знаний в данной области и идей настоящего изобретения может корректировать HSC в отношении состояния иммунодефицита, такого как HIV/AIDS, включая приведение HSC в контакт с системой CRISPR-Cas9, которая целенаправленно воздействует на CCR5 и приводит к его нокауту. Направляющую РНК (и преимущественно подход с двумя направляющими последовательностями, например парой различных РНК; например направляющих РНК, нацеленных на два клинически значимых гена, B2M и CCR5, в первичных CD4+ T-клетках человека и CD34+ гемопоэтических стволовых клетках и клетках-предшественниках (HSPC)), которая нацеливается на и нокаутирует частицу, содержащую CCR5 и белок Cpf1, приводят в контакт с HSC. Приведенные таким образом в контакт клетки можно вводить и необязательно обрабатывать и разращивать; см. Cartier. См. также Kiem, "Hematopoietic stem cell-based gene therapy for HIV disease," Cell Stem Cell. Feb 3, 2012; 10(2): 137-147; включенную в данный документ посредством ссылки вместе с документами, которые в ней перечислены; Mandal et al, "Efficient Ablation of Genes in Human Hematopoietic Stem and Effector Cells using CRISPR/Cas9," Cell Stem Cell, Volume 15, Issue 5, p643-652, 6 November 2014; включенную в данный документ посредством ссылки вместе с документами, которые в ней перечислены. Также упоминается публикация Ebina, "CRISPR/Cas9 system to suppress HIV-1 expression by editing HIV-1 integrated proviral DNA" SCIENTIFIC REPORTS | 3 : 2510 | DOI: 10.1038/srep02510, включенная в данный документ посредством ссылки вместе с документами, которые в ней перечислены, в качестве иных средств борьбы с HIV/AIDS с применением системы CRISPR-Cpf1.
- Основание для редактирования генома для лечения HIV исходит из наблюдения того, что индивидуумы, гомозиготные по мутациям с потерей функции в CCR5, клеточном корецепторе для вируса, обладают высокой устойчивостью к инфекции и, в иных случаях, здоровы, что дает основание предполагать, что имитирование этой мутации с редактированием генома может быть безопасной и эффективной терапевтической стратегией [Liu, R., et al. Cell 86, 367-377 (1996)]. Эта идея была подтверждена клинически, когда инфицированному HIV пациенту пересаживали аллогенный трансплантат костного мозга от донора, гомозиготного по мутации с потерей функции в CCR5, что приводило к необнаруживаемым уровням HIV и восстановлению нормальных значений числа клеток CD4 T [Hutter, G., et al. The New England journal of medicine 360, 692-698 (2009)]. Хотя трансплантация костного мозга не является приемлемой стратегией лечения для большинства пациентов с HIV в связи со стоимостью и потенциальной реакцией "трансплантат против хозяина", виды терапии HIV, которые трансформируют собственные T-клетки пациента в CCR5, являются желательными.
- Ранние исследования с применением ZFN и NHEJ для нокаута CCR5 в гуманизированных мышиных моделях HIV показали, что трансплантация CD4 T-клеток с отредактированным CCR5 улучшала вирусную нагрузку и значения числа клеток CD4 T [Perez, E.E., et al. Nature biotechnology 26, 808-816 (2008)]. Важно, что данные модели также показали, что инфекция, обусловленная HIV, приводила к отбору нуль-клеток по CCR5, свидетельствуя о том, что редактирование обеспечивает преимущество пригодности и потенциально предоставляет возможность небольшому количеству редактированных клеток создавать терапевтический эффект.
- Как результат данного и других многообещающих доклинических исследований, терапия с применением редактирования генома, которая обеспечивает нокаут CCR5 в T-клетках пациентов, в настоящее время проходит тестирование на людях [Holt, N., et al. Nature biotechnology 28, 839-847 (2010); Li, L., et al. Molecular therapy : the journal of the American Society of Gene Therapy 21, 1259-1269 (2013)]. В недавно проведенной I фазе клинического испытания CD4+ T-клетки отбирали у пациентов с HIV, редактировали с помощью ZFN, сконструированными для нокаута гена CCR5, и аутологически трансплантировали обратно пациентам [Tebas, P., et al. The New England journal of medicine 370, 901-910 (2014)].
- В другом исследовании (Mandal et al., Cell Stem Cell, Volume 15, Issue 5, p643-652, от 6 ноября 2014 г.) система CRISPR-Cas9 нацеливалась на два клинически значимых гена, B2M и CCR5, в CD4+ T-клетках и CD34+ гемопоэтических стволовых и клетках-предшественниках человека (HSPC). Применение одиночных направляющих РНК приводило к высокоэффективному мутагенезу в HSPC, но не в T-клетках. Подход с двумя направляющими последовательностями повышал эффективность удаления гена в обоих типах клеток. HSPC, которые подвергались редактированию генома с помощью CRISPR-Cas9, сохраняли способность к мультилинейности. Предполагаемые целевые и нецелевые мутации были исследованы посредством целевого секвенирования с захватом в HSPC и низкие уровни нецелевого мутагенеза наблюдали лишь в одном сайте. Эти результаты показывают, что система CRISPR-Cas9 может эффективно удалять гены в HSPC с минимальным нецелевым мутагенезом, что имеет широкую применимость для терапии на основе гемопоэтических клеток.
- Wang et al. (PLoS One. 2014 Dec 26;9(12):e115987. doi: 10.1371/journal.pone.0115987) подвергали сайленсингу CCR5 посредством CRISPR-ассоциированного белка 9 (Cas9) и одиночных направляющих РНК (направяющих РНК) с лентивирусными векторами, экспрессирующими направляющие РНК для Cas9 и CCR5. Wang et al. показали, что трансдукция за один цикл лентивирусных векторов, экспрессирующих направляющие РНК Cas9 и CCR5, в восприимчивых к HIV-1 CD4+ клетках человека приводит к высоким частотам нарушения функционирования гена CCR5. Клетки с разорванным геном CCR5 являются не только устойчивыми к R5-тропному HIV-1, в том числе изолятам передаваемых вирусов/вирусов-основателей (T/F) HIV-1, но также имеют селективное преимущество над клетками с неразорванным геном CCR5 во время инфекции R5-тропным HIV-1. Геномные мутации в потенциальных нецелевых сайтах, которые являются высокогомологичными этим направляющим РНК для CCR5, в стабильно трансдуцированных клетках даже через 84 дня после трансдукции не были обнаружены с помощью анализа T7 эндонуклеазы I.
- Fine et al. (Sci Rep. 2015 Jul 1;5:10777. doi: 10.1038/srep10777) идентифицировали двухкассетную систему, экспрессирующую части белка Cas9 S. pyogenes (SpCas9), который подвергался сплайсингу в клетке с образованием функционального белка, способного к сайт-специфичному расщеплению ДНК. С помощью специфических направляющих нитей CRISPR Fine et al. показали эффективность этой системы в расщеплении генов HBB и CCR5 в клетках HEK-293T человека в виде одного Cas9 и пары никаз Cas9. Транс-сплайсированный SpCas9 (tsSpCas9) характеризовался ~35% от нуклеазной активности по сравнению с SpCas9 дикого типа (wtSpCas9) при стандартных дозах для трансфекции, однако имел значительно сниженную активность при более низких уровнях доз. Существенно уменьшенная длина открытой рамки считывания tsSpCas9 по отношению к wtSpCas9 потенциально способствует упаковке более сложных и длинных генетических элементов в вектор на основе AAV, в том числе тканеспецифичных промоторов, экспрессии мультиплексной направляющей РНК и слиянию эффекторных доменов с SpCas9.
Li et al. (J Gen Virol. 2015 Aug;96(8):2381-93. doi: 10.1099/vir.0.000139. Epub 2015 Apr 8) показали, что система CRISPR-Cas9 может эффективно опосредовать редактирование локуса CCR5 в линиях клеток, приводя к нокауту экспрессии CCR5 на клеточной поверхности. При секвенировании следующего поколения было обнаружено, что различные мутации вводили возле предполагаемого сайта расщепления CCR5. Для каждой из трех наиболее эффективных направляющих РНК, которые были проанализированы, значительных нецелевых эффектов выявлено не было в 15 потенциальных сайтах с наивысшими баллами. С помощью конструирования химерных аденовирусов Ad5F35, несущих компоненты CRISPR-Cas9, Li et al. эффективно трансдуцировали первичные CD4+ T-лимфоциты и нарушали экспрессию CCR5, а положительно трансдуцированным клеткам придавали устойчивость к HIV-1.
- Специалист в данной области может воспользоваться вышеописанными исследованиями, например, Holt, N., et al. Nature biotechnology 28, 839-847 (2010), Li, L., et al. Molecular therapy : the journal of the American Society of Gene Therapy 21, 1259-1269 (2013), Mandal et al., Cell Stem Cell, Volume 15, Issue 5, p643-652, 6 November 2014, Wang et al. (PLoS One. 2014 Dec 26;9(12):e115987. doi: 10.1371/journal.pone.0115987), Fine et al. (Sci Rep. 2015 Jul 1;5:10777. doi: 10.1038/srep10777) и Li et al. (J Gen Virol. 2015 Aug;96(8):2381-93. doi: 10.1099/vir.0.000139. Epub 2015 Apr 8), для нацеливания на CCR5 при помощи системы CRISPR Cas по настоящему изобретению.
Лечение патогенов, аналогичных вирусным патогенам, таким как HBV
- Настоящее изобретение также можно применять для лечения вируса гепатита B (HBV). Однако система CRISPR-Cas должна быть приспособлена для того, чтобы избежать недостатков RNAi, таких как риск перенасыщения эндогенных путей малых РНК, с помощью, например, оптимизации дозы и последовательности (см., например, Grimm et al., Nature vol. 441, 26 May 2006). Например, предусматриваются низкие дозы, такие как приблизительно 1-10 x 1014 частиц на человека. В другом варианте осуществления систему CRISPR-Cas, направленную против HBV, можно вводить в липосомах, таких как стабильная частица из нуклеиновой кислоты и липидов (SNALP) (см., например, Morrissey et al., Nature Biotechnology, Vol. 23, No. 8, August 2005). Предусматриваются ежедневные внутривенные инъекции приблизительно 1, 3 или 5 мг/кг/день CRISPR Cas, целенаправленно воздействующей на РНК HBV в SNALP. Обработку можно осуществлять ежедневно в течение приблизительно трех дней, а затем еженедельно в течение приблизительно пяти недель. В других вариантах осуществления систему согласно Chen et al. (Gene Therapy (2007) 14, 11-19) можно применять к системе CRISPR-Cas согласно настоящему изобретению и/или адаптировать к ней. Chen et al. использовали двухнитевой псевдотипированный вектор на основе аденоассоциированного вируса 8 (dsAAV2/8) для доставки shRNA. Однократное введение вектора dsAAV2/8 (1 x 1012 векторных геномов на мышь), несущего специфичную к HBV shRNA, эффективно подавляло стабильный уровень белка, мРНК и репликативной ДНК HBV в печени трансгенных мышей с HBV, что приводило к снижению нагрузки HBV в кровотоке на вплоть до 2-3 log10. Значительное подавление HBV продолжалось в течение по меньшей мере 120 дней после введения вектора. Терапевтический эффект shRNA зависел от целевой последовательности и не включал активацию интерферона. В соответствии с настоящим изобретением систему CRISPR-Cas, направленную в отношении HBV, можно клонировать в вектор на основе AAV, например, вектор на основе dsAAV2/8, и вводить человеку, например, в дозе от приблизительно 1 x 1015 векторных геномов до приблизительно 1 x 1016 векторных геномов на человека. В другом варианте осуществления способ согласно Wooddell et al. (Molecular Therapy vol. 21 no. 5, 973-985 May 2013) можно применять к системе CRISPR-Cas согласно настоящему изобретению и/или адаптировать к ней. Woodell et al. продемонстрировали, что простая совместная инъекция целенаправленно воздействующего на гепатоциты, конъюгированного с N-ацетилгалактозамином мелиттин-подобного пептида (NAG-MLP) с тропной к печени конъюгированной с холестерином siRNA (chol-siRNA), целенаправленно воздействующей на фактор коагуляции VII (F7), приводит в результате к эффективному нокдауну F7 у мышей и приматов, отличных от человека, без изменений клинических химических показателей или индукции цитокинов. Используя временные и трансгенные мышиные модели инфекции, обусловленной HBV, Wooddell et al. продемонстрировали, что однократная совместная инъекция NAG-MLP с активной chol-siRNA, целенаправленно воздействующей на консервативные последовательности HBV, приводила в результате к многократной репрессии вирусной РНК, белков и вирусной ДНК с большой продолжительностью эффекта. Внутривенные совместные инъекции, например, приблизительно 6 мг/кг NAG-MLP и 6 мг/кг специфичной к HBV CRISPR-Cas, могут предусматриваться в настоящем изобретении. В альтернативном случае, приблизительно 3 мг/кг NAG-MLP и 3 мг/кг специфичной к HBV CRISPR-Cas могут доставляться в первый день с последующим введением приблизительно 2-3 мг/кг NAG-MLP и 2-3 мг/кг специфичной к HBV CRISPR-Cas две недели спустя.
- Lin et al. (Mol Ther Nucleic Acids. 2014 Aug 19;3:e186. doi: 10.1038/mtna.2014.38) разработали восемь gRNA к HBV генотипа A. с помощью специфичных к HBV gRNA система CRISPR-Cas9 значительно снижала образование коровых и поверхностных белков HBV в клетках Huh-7, трансфицированных вектором экспрессии на основе HBV. Среди восьми подвергнутых скринингу gRNA были идентифицированы две эффективные. Одна gRNA, нацеленная на консервативную последовательность HBV, действовала против различных генотипов. С использованием гидродинамической мышиной модели устойчивости HBV Lin et al. дополнительно продемонстрировали, что эта система могла расщеплять плазмиду, содержащую геном HBV, в печени и облегчать ее клиренс in vivo, приводя к снижению уровней поверхностных антигенов сыворотки. Эти данные свидетельствуют о том, что система CRISPR-Cas9 могла разрывать HBV-экспрессирующие матрицы как in vitro, так и in vivo, указывая на потенциал в устранении хронической инфекции, обусловленной HBV.
- Dong et al. (Antiviral Res. 2015 Jun;118:110-7. doi: 10.1016/j.antiviral.2015.03.015. Epub 2015 Apr 3) использовали систему CRISPR-Cas9 для нацеливания на геном HBV и эффективного ингибирования инфекции, обусловленной HBV. Dong et al. синтезировали четыре одиночные направляющие РНК (направляющие РНК), нацеливающиеся на консервативные области HBV. Экспрессия этих направляющих РНК с Cas9 снижала образование вирусов в клетках Huh7, а также в клетках HepG2.2.15, реплицирующих HBV. Dong et al. дополнительно продемонстрировали, что непосредственное расщепление системой CRISPR-Cas9 и опосредованный расщеплением мутагенез происходили в cccDNA HBV трансфицированных клеток. В мышиной модели cccDNA, несущей HBV, инъекция плазмид на основе направляющей РНК и Cas9 в хвостовую вену приводила к низкому уровню cccDNA и белка HBV.
- Liu et al. (J Gen Virol. 2015 Aug;96(8):2252-61. doi: 10.1099/vir.0.000159. Epub 2015 Apr 22) разработали восемь направляющих РНК (gRNA), которые нацеливались на консервативные области различных генотипов HBV, которые могли значительно ингибировать репликацию HBV как in vitro, так и in vivo, с целью исследования возможности применения системы CRISPR-Cas9 для разрыва ДНК-матриц HBV. Специфичная к HBV система gRNA/Cpf1 могла ингибировать репликацию HBV различных генотипов в клетках, а уровень вирусной ДНК значительно снижался в результате действия системы одиночной gRNA/Cpf1 и она выводилась в результате комбинации различных систем gRNA/Cpf1.
- Wang et al. (World J Gastroenterol. 2015 Aug 28;21(32):9554-65. doi: 10.3748/wjg.v21.i32.9554) разработали 15 gRNA к HBV генотипов A-D. Были выбраны одиннадцать комбинаций из двух вышеуказанных gRNA (двойные gRNA), охватывающие регуляторную область HBV. Эффективность каждой gRNA и 11 двойных gRNA по отношению к супрессии репликации HBV (генотипы A-D) исследовали с помощью измерения поверхностного антигена HBV (HBsAg) или антигена e (HBeAg) в супернатанте культуры. Разрушение HBV-экспрессирующих векторов исследовали в клетках HuH7, котрансфицированных вектором, экспрессирующим двойные gRNA и HBV, с помощью метода полимеразной цепной реакции (ПЦР) и секвенирования, а разрушение cccDNA исследовали в клетках HepAD38 с помощью осаждения KCl, переваривания АТФ-зависимой ДНКазой, безопасной для плазмиды (PSAD), комбинированного способа амплификации по типу катящегося кольца и количественной ПЦР. Цитотоксичность этих gRNA определяли с помощью анализа тетразолия в митохондриях. Все из gRNA могли значительно снижать образование HBsAg или HBeAg в супернатанте культуры, которое зависело от области направленности gRNA. Все из двойных gRNA могли эффективно супрессировать образование HBsAg и/или HBeAg в случае HBV генотипов A-D, и эффективность двойных gRNA в супрессии образования HBsAg и/или HBeAg значительно повышалась при сравнении с использованием только одиночных gRNA. Кроме того, при помощи прямого ПЦР-секвенирования подтвердили, что эти двойные gRNA могли специфично разрушать HBV-экспрессирующую матрицу посредством удаления фрагмента между сайтами расщепления двух используемых gRNA. Более важно, что комбинация gRNA-5 и gRNA-12 не только могла эффективно супрессировать образование HBsAg и/или HBeAg, но также разрушать запасы cccDNA в клетках HepAD38.
- Karimova et al. (Sci Rep. 2015 Sep 3;5:13734. doi: 10.1038/srep13734) идентифицировали консервативные последовательности HBV между генотипами в S и X области генома HBV, которые были подвергнуты нацеливанию специфичного и эффективного расщепления с помощью никазы Cas9. С помощью этого подхода нарушали не только эписомальные cccDNA и интегрированные в хромосомы целевые сайты HBV в репортерных линиях клеток, но также репликацию HBV в линиях клеток гепатомы с хронической и de novo инфекцией.
- Специалист в данной области может воспользоваться вышеприведенными исследованиями, например, Lin et al. (Mol Ther Nucleic Acids. 2014 Aug 19;3:e186. doi: 10.1038/mtna.2014.38), Dong et al. (Antiviral Res. 2015 Jun;118:110-7. doi: 10.1016/j.antiviral.2015.03.015. Epub 2015 Apr 3), Liu et al. (J Gen Virol. 2015 Aug;96(8):2252-61. doi: 10.1099/vir.0.000159. Epub 2015 Apr 22), Wang et al. (World J Gastroenterol. 2015 Aug 28;21(32):9554-65. doi: 10.3748/wjg.v21.i32.9554) и Karimova et al. (Sci Rep. 2015 Sep 3;5:13734. doi: 10.1038/srep13734) для нацеливания на HBV с помощью системы CRISPR Cas по настоящему изобретению.
Хроническая инфекция вируса гепатита B (HBV) является распространенной, смертельной и редко излечимой в связи с устойчивостью вирусной эписомальной ДНК (cccDNA) в инфицированных клетках. Ramanan et al. (Ramanan V, Shlomai A, Cox DB, Schwartz RE, Michailidis E, Bhatta A, Scott DA, Zhang F, Rice CM, Bhatia SN, Sci Rep. 2015 Jun 2;5:10833. doi: 10.1038/srep10833, опубликовано онлайн 2 июня 2015 г.) показали, что система CRISPR/Cas9 может специфично нацеливаться и расщеплять консервативные области в геноме HBV, приводя к устойчивой супрессии экспрессии и репликации генов. При длительной экспрессии Cas9 и соответствующим образом выбранных направляющих РНК они показали расщепление cccDNA с помощью Cas9 и существенное снижение cccDNA и других параметров экспрессии и репликации вирусных генов. Таким образом, они показали, что непосредственное нацеливание на эписомальную ДНК является новым терапевтическим подходом к контролю вируса и, возможно, излечению пациентов. Это также описано в WO2015089465 A1, от имени The Broad Institute (института Броада) et al., содержание которого тем самым включено в данный документ посредством ссылки.
В связи с этим нацеливание вирусной эписомальной ДНК в HBV является предпочтительным в некоторых вариантах осуществления.
Настоящее изобретение также может быть применимо для лечения патогенов, например бактериальных, грибковых и паразитарных патогенов. Большинство исследовательских усилий было сосредоточено на создании новых антибиотиков, которые после создания все равно стали бы предметом аналогичных проблем, связанных с устойчивостью к лекарственному средству. Настоящее изобретение относится к новым альтернативам на основе CRISPR, которые преодолевают эти сложности. Кроме того, в отличие от существующих антибиотиков варианты лечения на основе CRISPR могут быть проведены специфично по отношению к патогенам, с индукцией клеточной смерти целевого патогена, при этом не затрагиваются полезные бактерии.
- Настоящее изобретение также можно применять для лечения вируса гепатита C (HCV). Способы согласно Roelvinki et al. (Molecular Therapy vol. 20 no. 9, 1737-1749 Sep 2012) можно применять по отношению к системе CRISPR-Cas. Например, вектор AAV, такой как AAV8, может быть предполагаемым вектором и может предусматриваться, например доза, составляющая от приблизительно 1,25 × 1011 до 1,25 × 1013 векторных геномов на килограмм массы тела (vg/кг).Настоящее изобретение также может быть применимо для лечения патогенов, например бактериальных, грибковых и паразитических патогенов. Большинство исследовательских усилий было сосредоточено на создании новых антибиотиков, которые после создания все равно стали бы предметом аналогичных проблем, связанных с устойчивостью к лекарственному средству. Настоящее изобретение относится к новым альтернативам на основе CRISPR, которые преодолевают эти сложности. Кроме того, в отличие от существующих антибиотиков варианты лечения на основе CRISPR могут быть проведены специфично по отношению к патогенам, с индукцией клеточной смерти целевого патогена, при этом не затрагиваются полезные бактерии.
- Jiang et al. ("RNA-guided editing of bacterial genomes using CRISPR-Cas systems," Nature Biotechnology vol. 31, p. 233-9, March 2013) использовали систему CRISPR-Cas9 для мутирования или уничтожения S. pneumoniae и E. coli. Исследование, в результате которого происходило введение точных мутаций в геномы, опиралось на расщепление в целевом сайте генома под управлением системы двойная РНК:Cas9 для уничтожения немутированных клеток и устраняло необходимость в селектируемых маркерах или системах негативного отбора. Системы CRISPR были использованы для обращения устойчивости к антибиотикам и устранения переноса устойчивости между штаммами. Bickard et al. показали, что Cas9, перепрограммированный для нацеливания на гены вирулентности, уничтожают вирулентный, а не авирулентный S. aureus. Перепрограммирование нуклеазы для нацеливания на гены устойчивости к антибиотиками разрушало плазмиды стафилококков, которые имели гены устойчивости к антибиотикам, и иммунизировало против распространения плазмидных генов устойчивости. (см., Bikard et al., "Exploiting CRISPR-Cas nucleases to produce sequence-specific antimicrobials," Nature Biotechnology vol. 32, 1146-1150, doi:10.1038/nbt.3043, опубликовано онлайн 5 октября 2014 г.) Bikard показал, что антимикробные средства на основе CRISPR-Cas9 функционируют in vivo для уничтожения S. aureus в мышиной модели колонизации кожи. Аналогично, Yosef et al использовали систему CRISPR для нацеливания на гены, кодирующие ферменты, которые придают устойчивость к β-лактамным антибиотикам (см. Yousef et al., "Temperate and lytic bacteriophages programmed to sensitize and kill antibiotic-resistant bacteria," Proc. Natl. Acad. Sci. USA, vol. 112, p. 7267-7272, doi: 10.1073/pnas.1500107112, опубликовано онлайн 18 мая 2015 г.).
- Системы CRISPR могут быть использованы для редактирования геномов паразитов, которые являются устойчивыми к другим генетическим подходам. Например, система CRISPR-Cas9, как было показано, вводит двунитевые разрывы в геном Plasmodium yoelii (см., Zhang et al., "Efficient Editing of Malaria Parasite Genome Using the CRISPR/Cas9 System," mBio. vol. 5, e01414-14, Jul-Aug 2014). Ghorbal et al. ("Genome editing in the human malaria parasite Plasmodium falciparumusing the CRISPR-Cas9 system," Nature Biotechnology, vol. 32, p. 819-821, doi: 10.1038/nbt.2925, опубликовано онлайн 1 июня 2014 г.) модифицировали последовательности двух генов, orc1 и kelch13, которые имеют предположительные функции сайленсинга генов и возникновения устойчивости к артемизинину соответственно. Паразиты, которые были изменены в подходящих сайтах, были восстановлены с очень высокой эффективностью, несмотря на отсутствие прямого отбора в отношении модификации, указывая на то, что нейтральные или даже вредные мутации могут быть получены при помощи этой системы. Систему CRISPR-Cas9 также используют для модификации других патогенных паразитов, в том числе Toxoplasma gondii (см. Shen et al., "Efficient gene disruption in diverse strains of Toxoplasma gondii using CRISPR/CAS9," mBio vol. 5:e01114-14, 2014; and Sidik et al., "Efficient Genome Engineering of Toxoplasma gondii Using CRISPR/Cas9," PLoS One vol. 9, e100450, doi: 10.1371/journal.pone.0100450, опубликовано онлайн 27 июня 2014 г.).
- Vyas et al. ("A Candida albicans CRISPR system permits genetic engineering of essential genes and gene families," Science Advances, vol. 1, e1500248, DOI: 10.1126/sciadv.1500248, от 3 апреля 2015 г.) использовали систему CRISPR для преодоления долго существующих препятствий для генной инженерии в C. albicans и эффективного мутирования в одном эксперименте обеих копий нескольких различных генов. В организме, где несколько механизмов способствуют лекарственной устойчивости, Vyas получал гомозиготные двойные мутанты, которые больше не проявляли гиперустойчивость к флуконазолу или циклогексимиду, обнаруживаемую родительским клиническим изолятом Can90. Vyas также получал гомозиготные мутации потери функции в важных генах C. albicans при помощи создания условных аллелей. Нуль-аллели DCR1, который требуется для процессинга рибосомальной РНК, являются летальными при низкой температуре, но жизнеспособными при высокой температуре. Vyas использовал матрицу дял репарации, которая вводила нонсенс-мутацию, и выделял мутантов dcr1/dcr1, которые не могли расти при 16°C.
Лечение заболеваний с генетическими и эпигенетическими аспектами
- Системы CRISPR-Cas по настоящему раскрытию могут быть использованы для коррекции генетических мутаций, в отношении которых ранее предпринимались попытки с ограниченным успехом при помощи TALEN и ZFN и которые были идентифицированы в качестве потенциальных мишеней для систем Cas9, в том числе, как в опубликованных заявках на патент Editas Medicine, описывающих способы применения систем Cas9 для нацеливания на локусы с целью терапевтической направленности на заболевания при помощи генной терапии, в том числе WO 2015/048577 CRISPR-RELATED METHODS AND COMPOSITIONS Gluckmann et al.; WO 2015/070083 CRISPR-RELATED METHODS AND COMPOSITIONS WITH GOVERNING gRNAS Glucksmann et al. В некоторых вариантах осуществления предусмотрено лечение, профилактика или диагностика первичной открытоугольной глаукомы (POAG). Мишенью предпочтительно является ген MYOC. Это описано в WO2015153780, раскрытие которого включено в данный документе посредством ссылки.
Упоминаются WO 2015/134812 CRISPR/CAS-RELATED METHODS AND COMPOSITIONS FOR TREATING USHER SYNDROME AND RETINITIS PIGMENTOSA, Maeder et al. В идеях, изложенных в данном документе, настоящее изобретение включает способы и материалы этих документов, применяемые в сочетании с идеями, изложенными в данном документе. В одном аспекте генная терапия заболеваний зрения и слуха, способы и композиции для лечения синдрома Ушера и пигментного ретинита могут быть адаптированы к системе CRISPR-Cas по настоящему изобретению (см., например, WO 2015/134812). В варианте осуществления WO 2015/134812 предусматривает лечение или задержку наступления или прогрессирования синдрома Ушера IIA типа (USH2A, USH11A) и пигментного ретинита 39 типа (RP39) при помощи редактирования гена, например при помощи способов, опосредованных системой CRISPR-Cas9, с целью коррекции делеции гуанина в положении 2299 в гене USH2A (например, замены удаленного гуанинового остатка в положении 2299 в гене USH2A). Аналогичный эффект может быть достигнут при помощи Cpf1. В связанном аспекте мутация повергается нацеливанию с помощью расщепления одной или несколькими нуклеазами, одной или несколькими никазами или их комбинацией, например для индукции HDR с донорской матрицей, которая корректирует точковую мутацию (например, однонуклеотидную, например, гуаниновую делецию). Изменение или коррекция мутантного гена USH2A может быть опосредована любым механизмом. Иллюстративные механизмы, которые могут быть ассоциированы с изменением (например, коррекцией) мутантного гена HSH2A, включают без ограничения негомологичное соединение концов, опосредованное микрогомологией связывание концов (MMEJ), репарацию с участием гомологичной рекомбинации (например, опосредованную эндогенной донорской матрицей), SDSA (синтез-зависимый отжиг нитей), однонитевой отжиг и однонитевую инвазию. В варианте осуществления способ, применяемый для лечения синдрома Ушера и пигментного ретинита, может включать получение информации о мутации, переносимой субъектом, например с помощью секвенирования соответствующего участка гена USH2A.
Следует упомянуть WO 2015/138510 и в идеях, изложенных в данном документе, настоящее изобретение (с помощью системы CRISPR-Cas9) подразумевает обеспечение лечения или задержку наступления или прогрессирования врожденного амавроза Лебера 10 типа (LCA 10). LCA 10 вызван мутацией в гене CEP290, например c.2991+1655, мутацией аденина в гуанин в гене CEP290, которая приводит к образованию криптического сайта сплайсинга в интроне 26. Это мутация в нуклеотиде 1655 интрона 26 CEP290, например мутация A в G. CEP290 также известен как CT87; MKS4; POC3; rd16; BBS14; JBTS5; LCAJO; NPHP6; SLSN6 и 3H11Ag (см., например, WO 2015/138510). В одном аспекте генной терапии настоящее изобретение предусматривает введение одного или нескольких разрывов возле сайта целевого положения LCA (например, c.2991 + 1655; A в G) по меньшей мере в одном аллеле гена CEP290. Изменение целевого положения LCA10 относится к (1) индуцированному разрывом введению вставок/делеций (также обозначаемому в данном документе как NHEJ-опосредованное введение вставок/делеций) в непосредственной близости к целевому положению LCA10 или включая его (например, c.2991+1655 A в G), или (2) индуцированной разрывом делеции (также обозначаемой как NHEJ-опосредованная делеция) геномной последовательности, в том числе мутацию в целевом положении LCA10 (например, c.2991+1655 A в G). Оба подхода приводят к потере функции или разрушению криптического сайта сплайсинга, образующегося в результате мутации в целевом положении LCA 10. Соответственно, применение Cpf1 в лечении LCA специально предусмотрено.
- Исследователи рассматривают вопрос о том, можно ли применять генную терапию для лечения широкого диапазона заболеваний. Системы CRISPR по настоящему изобретению, основанные на эффекторном белке Cpf1, предусмотрены для таких вариантов терапевтического применения, включая без ограничения дополнительные приведенные в примерах целевые области и способы доставки, приведенные ниже. Некоторые примеры состояний или заболеваний, которые можно эффективно лечить с использованием системы по настоящему изобретению, включенные в примеры генов и ссылок, включенных в данный документ, и в настоящее время ассоциированные с такими состояниями, также предусмотрены в данном документе. Приведенные в качестве примеров гены и состояния не являются исчерпывающими.
Лечение заболеваний сердечно-сосудистой системы
- Настоящее изобретение также предусматривает доставку системы CRISPR-Cas, в частности новых систем эффекторного белка CRISPR, описанных в данном документе, в кровь или гемопоэтические стволовые клетки. Экзосомы плазмы крови согласно Wahlgren et al. (Nucleic Acids Research, 2012, Vol. 40, No. 17 e130) были описаны ранее и их можно использовать для доставки системы CRISPR-Cas в кровь. Система нацеливания на нуклеиновую кислоту по настоящему изобретению также предусматривается для лечения гемоглобинопатий, таких как формы талассемии и серповидноклеточной анемии. См., например, международную публикацию заявки на патент WO 2013/126794 в отношении потенциальных мишеней, на которые может целенаправленно воздействовать система CRISPR-Cas по настоящему изобретению.
- В публикации Drakopoulou, "Review Article, The Ongoing Challenge of Hematopoietic Stem Cell-Based Gene Therapy for β-Thalassemia", Stem Cells International, Volume 2011, Article ID 987980, 10 pages, doi:10.4061/2011/987980, включенной в данный документ посредством ссылки вместе с документами, которые в ней перечислены так, если бы они были изложены в полном объеме, обсуждается модификация HSC с применением лентивируса, который доставляет ген β-глобина или γ-глобина. В отличие от применения лентивируса специалист в данной области с использованием знаний в данной области и идей настоящего изобретения может корректировать HSC относительно β-талассемии с применением системы CRISPR-Cas, которая нацеливается на мутацию и корректирует ее (например, с помощью подходящей матрицы для HDR, которая доставляет кодирующую последовательность для β-глобина или γ-глобина, преимущественно β-глобина или γ-глобина несерповидных форм эритроцитов); в частности, направляющая РНК может осуществлять нацеливание на мутацию, которая приводит к β-талассемии, и HDR может обеспечивать кодирование, приводящее к надлежащей экспрессии β-глобина или γ-глобина. Направляющая РНК, которая нацеливается на мутацию и частицу, содержащую белок Cas, контактирует с HSC, несущими мутацию. Частица также может содержать подходящую матрицу для HDR для коррекции мутации с целью надлежащей экспрессии β-глобина или γ-глобина; или HSC может быть приведена в контакт со второй частицей или вектором, который содержит или доставляет матрицу для HDR. Приведенные таким образом в контакт клетки можно вводить и необязательно обрабатывать и разращивать; см. Cartier. В этом отношении следует упомянуть публикацию Cavazzana "Outcomes of Gene Therapy for β-Thalassemia Major via Transplantation of Autologous Hematopoietic Stem Cells Transduced Ex Vivo with a Lentiviral βA-T87Q-Globin Vector." tif2014.org/abstractFiles/Jean%20Antoine%20Ribeil_Abstract.pdf; Cavazzana-Calvo "Transfusion independence and HMGA2 activation after gene therapy of human β-thalassaemia", Nature 467, 318-322 (16 сентября 2010 года) doi:10.1038/nature09328; Nienhuis "Development of Gene Therapy for Thalassemia, Cold Spring Harbor Perspectives in Medicine, doi: 10.1101/cshperspect.a011833 (2012), LentiGlobin BB305, лентивирусный вектор, содержащий сконструированный ген β-глобина (βA-T87Q); и Xie et al. "Seamless gene correction of β-thalassaemia mutations in patient-specific iPSCs using CRISPR/Cas9 and piggyback" Genome Research gr.173427.114 (2014) http://www.genome.org/cgi/doi/10.1101/gr.173427.114 (Cold Spring Harbor Laboratory Press); который является предметом исследования Cavazzana, включая β-талассемию человека, и предметом исследования Xie, причем все включены в данный документ посредством ссылки, вместе со всеми документами, которые в них перечислены или связаны с ними. В настоящем изобретении матрица для HDR может обеспечивать экспрессию HSC сконструированного гена β-глобина (например, βA-T87Q) или β-глобина, указанного у Xie.
- Xu et al. (Sci Rep. 2015 Jul 9;5:12065. doi: 10.1038/srep12065) разработали TALEN и CRISPR-Cas9 для непосредственного нацеливания на сайт IVS2-654 мутации интрона 2 в гене глобина. Xu et al. наблюдали различные частоты двунитевых разрывов (DSB) в локусах IVS2-654 при применении TALEN и CRISPR-Cas9, и TALEN опосредовали более высокую эффективность нацеливания на гомологичные гены по сравнению с CRISPR-Cas9 при комбинировании с донором транспозона piggyBac. Кроме того, более очевидные нецелевые события наблюдали в случае CRISPR-Cas9 по сравнению с TALEN. В конечном итоге, откорректированные с помощью TALEN клоны iPSC отбирали на предмет дифференциации эритробластов с помощью системы кокультивирования OP9 и выявляли относительно высокую транскрипцию HBB по сравнению с неоткорректированными клетками.
- Song et al. (Stem Cells Dev. 2015 May 1;24(9):1053-65. doi: 10.1089/scd.2014.0347. Epub 2015 Feb 5) использовали систему CRISPR/ Cas9 для коррекции iPSC с β-Thal; клетки с откорректированными генами характеризовались нормальными кариотипами и полной плюрипотентностью, поскольку эмбриональные стволовые клетки человека (hESC) не проявляли нецелевых эффектов. Впоследствии Song et al. оценивали эффективность дифференцировки iPSC с β-Thal с откорректированными генами. Song et al. обнаружили, что во время дифференцировки гемопоэтических клеток iPSC с β-Thal с откорректированными генами характеризовались повышенным соотношением эмбриоидных телец и различными процентами гемопоэтических клеток-предшественников. Гораздо более важно, линии iPSC с β-Thal с откорректированными генами восстанавливали экспрессию HBB и снижали образование активных форм кислорода по сравнению с неоткорректированной группой. Исследование Song et al. свидетельствовало о том, что эффективность гемопоэтической дифференцировки iPSC с β-Thal была значительно повышена непосредственно после коррекции с помощью системы CRISPR-Cas9. Аналогичные способы могут осуществляться при помощи систем CRISPR-Cas, описанных в данном документе, например, систем, содержащих эффекторные белки Cpf1.
- Серповидноклеточная анемия представляет собой аутосомно-рецессивное наследственное заболевание, при котором красные кровяные тельца приобретают серповидную форму. Оно вызывается заменой одного основания в гене β-глобина, который локализован на коротком плече хромосомы 11. Как результат, валин продуцируется вместо глутаминовой кислоты, что вызывает продуцирование гемоглобина серповидных клеток (HbS). Это приводит к образованию искривленной формы эритроцитов. В связи с аномальной формой небольшие кровеносные сосуды могут блокироваться, вызывая серьезное повреждение кости, селезенки и тканей кожи. Это может приводить к приступам боли, частым инфекциям, ладонно-подошвенному синдрому или даже полиорганной недостаточности. Искривленные эритроциты также являются более восприимчивыми к гемолизу, что приводит к серьезной анемии. Как и в случае β-талассемии, серповидноклеточную анемию можно корректировать путем модификации HSC с использованием системы CRISPR-Cas. Данная система обеспечивает возможность специфического редактирования генома клетки путем разрезания ее ДНК с обеспечением после этого ее самовосстановления. Белок Cas вставляют и направляют с помощью направляющей РНК в точку мутации, а затем он разрезает ДНК в этой точке. Одновременно вставляют нормальный вариант последовательности. Данная система используется собственной системой репарации для исправления индуцированного разреза. В этом отношении система CRISPR-Cas обеспечивает возможность коррекции мутации в ранее полученных стволовых клетках. Специалист в данной области с использованием знаний в данной области и идей настоящего изобретения может корректировать HSC относительно серповидноклеточной анемии с применением системы CRISPR-Cas, которая нацеливается на и корректирует мутацию (например, с помощью подходящей матрицы для HDR, которая доставляет кодирующую последовательность для β-глобина, преимущественно β-глобина не серповидных форм эритроцитов); в частности, направляющая РНК может осуществлять нацеливание на мутацию, которая приводит к серповидноклеточной анемии, и HDR может обеспечивать кодирование, приводящее к правильной экспрессии β-глобина. Направляющая РНК, которая нацеливается на мутацию и частицу, содержащую белок Cas, контактирует с HSC, несущими мутацию. Частица также может содержать подходящую матрицу для HDR для коррекции мутации с целью надлежащей экспрессии β-глобина; или HSC может быть приведена в контакт со второй частицей или вектором, который содержит или доставляет матрицу для HDR. Приведенные таким образом в контакт клетки можно вводить и необязательно обрабатывать и разращивать; см. Cartier. Матрица для HDR может обеспечивать экспрессию HSC сконструированного гена β-глобина (например, βA-T87Q) или β-глобина, указанного у Xie.
- В публикации Williams "Broadening the Indications for Hematopoietic Stem Cell Genetic Therapies," Cell Stem Cell 13:263-264 (2013), включенной в данный документ посредством ссылки вместе с документами, которые в ней перечислены, так, если бы были изложены в полном объеме, сообщается об опосредованном лентивирусами переносе генов в клетки HSC/P из пациентов с лизосомной болезнью накопления, метахроматической лейкодистрофией (MLD), наследственным заболеванием, вызванным дефицитом арилсульфатазы A (ARSA), приводящей к демиелинизации нервов; и опосредованном лентивирусами переносе генов в HSC пациентов с синдром Вискотта-Олдрича (WAS) (пациентов с дефектным белком WAS, эффектором малой ГТФазы CDC42, которая регулирует функцию цитоскелета в линиях клеток крови и, таким образом, они страдают от иммунодефицита при рецидивирующих инфекциях, симптомов аутоиммунных заболеваний и тромбоцитопении с аномально мелкими и функционально неэффективными тромбоцитами, что приводит к обильному кровотечению и повышенному риску возникновения лейкоза и лимфомы). В отличие от применения лентивируса специалист в данной области с использованием знаний в данной области и идей настоящего изобретения может корректировать HSC относительно MLD (недостаточность арилсульфатазы A (ARSA)) с применением системы CRISPR-Cas, которая нацеливается на мутацию и корректирует ее (недостаточность арилсульфатазы A (ARSA)) (например, с помощью подходящей матрицы для HDR, которая доставляет кодирующую последовательность для ARSA); в частности, направляющая РНК может осуществлять нацеливание на мутацию, которая приводит к MLD (недостаточность ARSA), и HDR может обеспечивать кодирование, приводящее к надлежащей экспрессии ARSA. Направляющая РНК, которая нацеливается на мутацию и частицу, содержащую белок Cas, контактирует с HSC, несущими мутацию. Частица также может содержать подходящую матрицу для HDR для коррекции мутации с целью надлежащей экспрессии ARSA; или HSC может быть приведена в контакт со второй частицей или вектором, который содержит или доставляет матрицу для HDR. Приведенные таким образом в контакт клетки можно вводить и необязательно обрабатывать и разращивать; см. Cartier. В отличие от применения лентивируса специалист в данной области с использованием знаний в данной области и идей настоящего изобретения может корректировать HSC относительно WAS с применением системы CRISPR-Cas, которая нацеливается на мутацию и корректирует ее (недостаточность белка WAS) (например, с помощью подходящей матрицы для HDR, которая доставляет кодирующую последовательность для белка WAS); в частности, направляющая РНК может осуществлять нацеливание на мутацию, которая приводит к WAS (дефектный белок WAS), и HDR может обеспечивать кодирование, приводящее к надлежащей экспрессии белка WAS. Направляющая РНК, которая нацеливается на мутацию и частицу, содержащую белок Cpf1, контактирует с HSC, несущими мутацию. Частица также может содержать подходящую матрицу для HDR для коррекции мутации с целью надлежащей экспрессии белка WAS; или HSC может быть приведена в контакт со второй частицей или вектором, который содержит или доставляет матрицу для HDR. Приведенные таким образом в контакт клетки можно вводить и необязательно обрабатывать и разращивать; см. Cartier.
- В публикации Watts "Hematopoietic Stem Cell Expansion and Gene Therapy" Cytotherapy 13(10):1164-1171. doi:10.3109/14653249.2011.620748 (2011), включенной в данный документ посредством ссылки вместе с документами, которые в ней перечислены, так, если бы были изложены в полном объеме, обсуждается генная терапия кроветворных стволовых клеток (HSC), например, опосредованная вирусами генная терапия HSC, как весьма перспективный вариант лечения многих нарушений, в том числе гематологических состояний, типов иммунодефицита, в том числе HIV/AIDS, и других наследственных нарушений, таких как лизосомные болезни накопления, в том числе SCID-X1, ADA-SCID, β-талассемия, сцепленная с Х-хромосомой CGD, синдром Вискотта-Олдрича, анемия Фанкони, адренолейкодистрофия (ALD) и метахроматическая лейкодистрофия (MLD).
- Публикации заявки на патент США №№ 20110225664, 20110091441, 20100229252, 20090271881 и 20090222937, закрепленные за Cellectis, относятся к вариантам CREI, где по меньшей мере один из двух мономеров I-CreI имеет по меньшей мере две замены, по одной в каждой из двух функциональных субдоменов корового домена LAGLIDADG (SEQ ID NO: 26), расположенных соответственно, начиная от положений 26 до 40 и от 44 до 77 I-CreI, при этом указанный вариант способен расщеплять целевую последовательность ДНК из гена гамма-цепи рецептора интерлейкина 2 человека (IL2RG), также обозначаемого геном гамма-цепи общего цитокинового рецептора или геном гамма C. Целевые последовательности, указанные в публикациях заявок на патенты США №№ 20110225664, 20110091441, 20100229252, 20090271881 и 20090222937, могут быть использованы для системы нацеливания на нуклеиновую кислоту по настоящему изобретению.
- Тяжелый комбинированный иммунодефицит (SCID) возникает в результате нарушения созревания T-лимфоцитов, во всех случаях ассоциированного с нарушением функционирования B-лимфоцитов (Cavazzana-Calvo et al., Annu. Rev. Med., 2005, 56, 585-602; Fischer et al., Immunol. Rev., 2005, 203, 98-109). Общая заболеваемость по оценкам составляет 1 на 75 000 родившихся. Пациенты с нелеченным SCID подвержены множественным инфекциям, вызываемым условно-патогенными микроорганизмами, и живут, как правило, не более одного года. SCID можно лечить путем аллогенного переноса кроветворных стволовых клеток от донора-родственника. Степень гистосовместимости с донором может варьировать в широких пределах. В случае аденозиндезаминазной (ADA) недостаточности, одной из форм SCID, пациентов можно лечить с помощью инъекции рекомбинантного фермента аденозиндезаминазы.
- Поскольку было показано, что ген ADA у пациентов с SCID является мутированным (Giblett et al., Lancet, 1972, 2, 1067-1069), были идентифицированы некоторые другие гены, вовлеченные в SCID (Cavazzana-Calvo et al., Annu. Rev. Med., 2005, 56, 585-602; Fischer et al., Immunol. Rev., 2005, 203, 98-109). Существуют четыре основные причины SCID. (i) Наиболее часто встречающуюся форму SCID, SCID-X1 (SCID, сцепленный с X-хромосомой, или X-SCID), вызывает мутация в гене IL2RG, которая приводит к отсутствию зрелых T-лимфоцитов и NK-клеток. IL2RG кодирует белок гамма-C (Noguchi, et al., Cell, 1993, 73, 147-157), общий компонент по меньшей мере пяти рецепторных комплексов интерлейкинов. Данные рецепторы активируют несколько мишеней с помощью киназы JAK3 (Macchi et al., Nature, 1995, 377, 65-68), инактивация которой приводит к возникновению того же синдрома, что и инактивация гамма-C. (ii) Мутация в гене ADA приводит к нарушению метаболизма пуринов, вызывающему гибель предшественников лимфоцитов, что, в свою очередь, приводит к кажущемуся отсутствию B-, T- и NK-клеток. (iii) V(D)J-рекомбинация является существенным этапом созревания иммуноглобулинов и рецепторов T-лимфоцитов (TCR). Мутации в генах, активирующих рекомбинацию, 1 и 2 (RAG1 и RAG2) и Artemis, трех генах, участвующих в этом процессе, приводят к отсутствию зрелых T- и B-лимфоцитов. (iv) Также сообщали о мутациях в других генах, таких как CD45, участвующих в специфичной передаче сигналов в T-клетках, хотя они представляют меньшинство случаев (Cavazzana-Calvo et al., Annu. Rev. Med., 2005, 56, 585-602; Fischer et al., Immunol. Rev., 2005, 203, 98-109). С тех пор, как были идентифицированы их генетические основы, различные формы SCID стали модельными для подходов к генной терапии (Fischer et al., Immunol. Rev., 2005, 203, 98-109) по двум основным причинам. Во-первых, как и при всех заболеваниях крови, может быть предусмотрено лечение ex vivo. Можно выделить гемопоэтические стволовые клетки (HSC) из костного мозга и сохранять их свойства плюрипотентности в течение нескольких клеточных делений. Таким образом, их можно обрабатывать in vitro, а затем повторно инъецировать пациенту, где они повторно заселяют костный мозг. Во-вторых, поскольку созревание лимфоцитов у пациентов с SCID ухудшено, скорректированные клетки имеют селективное преимущество. Таким образом, небольшое количество скорректированных клеток может восстановить функционирование иммунной системы. Данную гипотезу подтверждали несколько раз (i) частичным восстановлением иммунных функций, связанным с реверсией мутаций у пациентов с SCID (Hirschhorn et al., Nat. Genet., 1996, 13, 290-295; Stephan et al., N. Engl. J. Med., 1996, 335, 1563-1567; Bousso et al., Proc. Natl., Acad. Sci. USA, 2000, 97, 274-278; Wada et al., Proc. Natl. Acad. Sci. USA, 2001, 98, 8697-8702; Nishikomori et al., Blood, 2004, 103, 4565-4572), (ii) коррекцией форм недостаточности SCID-X1 in vitro в гемапоэтических клетках (Candotti et al., Blood, 1996, 87, 3097-3102; Cavazzana-Calvo et al., Blood, 1996, Blood, 88, 3901-3909; Taylor et al., Blood, 1996, 87, 3103-3107; Hacein-Bey et al., Blood, 1998, 92, 4090-4097), (iii) коррекцией SCID-X1 (Soudais et al., Blood, 2000, 95, 3071-3077; Tsai et al., Blood, 2002, 100, 72-79), JAK-3 (Bunting et al., Nat. Med., 1998, 4, 58-64; Bunting et al., Hum. Gene Ther., 2000, 11, 2353-2364) и RAG2 (Yates et al., Blood, 2002, 100, 3942-3949) in vivo в животных моделях и (iv) результатом клинических испытаний генной терапии (Cavazzana-Calvo et al., Science, 2000, 288, 669-672; Aiuti et al., Nat. Med., 2002; 8, 423-425; Gaspar et al., Lancet, 2004, 364, 2181-2187).
- Публикация заявки на патент США № 20110182867, закрепленная за Children's Medical Center Corporation и президентом и членами управляющего совета Гарвардского университета, относится к способам модулирования экспрессии фетального гемоглобина (HbF) и ее применениям в гемопоэтических клетках-предшественниках с помощью ингибиторов экспрессии или активности BCL11A, таких как средства для RNAi и антитела. На мишени, раскрытые в публикации заявки на патент США № 20110182867, такие как BCL11A, можно целенаправленно воздействовать с помощью системы CRISPR-Cas по настоящему изобретению для модулирования экспрессии фетального гемоглобина. См. также Bauer et al. (Science 11 October 2013: Vol. 342 no. 6155 pp. 253-257) и Xu et al. (Science 18 November 2011: Vol. 334 no. 6058 pp. 993-996) в отношении дополнительных мишеней BCL11A.
- При наличии знаний в данной области и идей настоящего изобретения специалист в данной области может корректировать HSC по отношению к наследственному гематологическому нарушению, например, β-талассемии, гемофилии или генетической лизосомной болезни накопления.
HSC - доставка в гемопоэтические стволовые клетки и их редактирование; и определенные условия
- Термин "гемопоэтическая стволовая клетка" или "HSC" включает в широком смысле те клетки, которые считаются HSC, например клетки крови, которые приводят к образованию всех других клеток крови и получены из мезодермы; расположены в красном костном мозге, содержащемся во внутренней части большинства костей. HSC по настоящему изобретению включают клетки с фенотипом гемопоэтических стволовых клеток, идентифицированных по небольшому размеру, отсутствию линейных (lin) маркеров и маркеров, которые принадлежат к кластеру серий дифференцировки, например: CD34, CD38, CD90, CD133, CD105, CD45, а также c-kit, - рецептор фактора стволовых клеток. Гемопоэтические стволовые клетки являются отрицательными по отношению к маркерам, которые используют для выявления детерминации дифференцировки, и, таким образом, называются Lin-; и во время их очистки с помощью FACS ряда из до 14 включительно маркеров линий зрелых клеток крови, например, CD13 и CD33 для миелодиных, CD71 - для эритроидных, CD19 - для B-клеток, CD61 - для мегакариоцитарных клеток и т. д., например, для человека; и B220 (мышиный CD45) - для B-клеток, Mac-1 (CD11b/CD18) - для моноцитов, Gr-1 - для гранулоцитов, Ter119 - для эритроидных клеток, Il7Ra, CD3, CD4, CD5, CD8 - для T-клеток и т. д. Маркеры мышиных HSC: CD34lo/-, SCA-1+, Thy1.1+/lo, CD38+, C-kit+, lin-, и маркеры человеческих HSC: CD34+, CD59+, Thy1/CD90+, CD38lo/-, C-kit/CD117+ и lin-. HSC идентифицируют с помощью маркеров. Таким образом, в вариантах осуществления, описанных в данном документе, HSC могут представлять собой CD34+ клетки. HSC также могут представлять собой гемопоэтические стволовые клетки, которые являются CD34-/CD38-. Стволовые клетки, у которых может отсутствовать c-kit на клеточной поверхности, которые считаются в данной области в качестве HSC, находятся в объеме настоящего изобретения, а также CD133+ клетки, аналогично считаются HSC в данной области.
- Система CRISPR-Cas (например, Cpf1) может быть сконструирована для нацеливания на генетический локус или локусы в HSC. Можно получить белок (например, Cpf1), преимущественно кодон-оптимизированный по отношению к эукариотической клетке и, в частности, клетке млекопитающих, например человеческой клетке, например HSC, и sgRNA, нацеливающуюся на локус или локусы в HSC, например ген EMX1. Их можно доставлять посредством частиц. Частицы могут образовываться при помощи белка Cas (например, Cpf1) и добавляемой gRNA. Смесь gRNA и белка Cas (например, Cpf1) можно смешивать, например со смесью, содержащей или состоящей фактически из или состоящей из поверхностно-активного вещества, фосфолипида, биоразлагаемого полимера, липопротеина и спирта, при этом могут образовываться частицы, содержащие gRNA и белок Cas (например, Cpf1). Настоящее изобретение охватывает образованные таким образом частицы и частицы, полученные с помощью такого способа, а также варианты их применения.
- В более общем смысле частицы могут быть образованы с применением эффективного способа. Прежде всего, белок Cas (например, Cpf1) и gRNA, нацеленную на ген EMX1 или контрольный ген LacZ, можно смешивать вместе при подходящем молярном соотношении, например 3:1-1:3, или 2:1-1:2, или 1:1, при подходящей температуре, например, 15-30°C, например, 20-25°C, например, комнатной температуре, в течение подходящего периода времени, например, 15-45, как, например, 30 минут, преимущественно в стерильном буфере без нуклеаз, например 1X PBS. В отдельности, компоненты частиц, такие как или включающие поверхностно-активное вещество, например, катионный липид, например, 1,2-диолеоил-3-триметиламмонийпропан (DOTAP); фосфолипид, например, димиристоилфосфатидилхолин (DMPC); биоразлагаемый полимер, такой как полимер этиленгликоля или PEG, и липопротеин, такой как липопротеин низкой плотности, например, холестерин, можно растворять в спирте, преимущественно C1-6 алкиловом спирте, таком как метанол, этанол, изопропанол, например, 100% этанол. Два раствора можно смешивать вместе с образованием частиц, содержащих комплексы Cas-(например, Cpf1)-gRNA. В определенных вариантах осуществления частица может содержать матрицу для HDR. Это может быть частица, совместно введенная с частицей, содержащей gRNA+белок Cas (например, Cpf1), т. е. в дополнение к приведению HSC в контакт с частицей, содержащей gRNA+белок Cas (например, Cpf1), при этом HSC приводят в контакт с частицей, содержащей матрицу для HDR; или HSC приводят в контакт с частицей, содержащей все из gRNA, Cas (например, Cpf1) и матрицы для HDR. Матрицу для HDR можно вводить с помощью отдельного вектора, при этом в первом случае частица проникает в клетку HSC и отдельный вектор также проникает в клетку, где геном HSC модифицирован gRNA+Cas (например, Cpf1) и также присутствует матрица для HDR, при этом локус генома модифицирован посредством HDR; например, это может приводить к исправлению мутации.
- После образования частицы HSC в 96-луночных планшетах можно трансфицировать при помощи 15 мкг белка Cas (например, Cpf1) на лунку. Через три дня после трансфекции можно собирать HSC и определять количество вставок и делеций (вставок/делеций) в локусе EMX1.
- Это иллюстрирует то, как HSC можно модифицировать при помощи CRISPR-Cas (например, Cpf1), нацеливающейся на представляющий интерес локус в геноме или локусы в HSC. HSC, которые подлежат модификации, могут находиться in vivo, например в организме, например в человеке или отличном от человека эукариотическом организме, например животном, таком как рыба, например данио-рерио, млекопитающем, например примате, например, человекообразной обезьяне, шимпанзе, макаке, грызуне, например мыши, кролике, крысе, кошке или собаке, домашнем скоте (корове/быке, баране/овце, козе или свинье), дикой или домашней птице, например курице. HSC, которые подлежат модификации, могут находиться in vitro, т. е. за пределами такого организма. Также модифицированные HSC можно использовать ex vivo, т. е., одну или нескольких таких HSC такого организма можно получить или выделить из организма, необязательно HSC можно разращивать, HSC модифицируют при помощи композиции, содержащей CRISPR-Cas (например, Cpf1), которая нацеливается на генетический локус или локусы в HSC, например при приведении HSC в контакт с композицией, например, где композиция содержит фермент CRISPR и одну или несколько gRNA, которая нацеливается на генетический локус или локусы в HSC, например частица, полученная или получаемая при смешивании gRNA и белка Cas (например, Cpf1) со смесью, содержащей или состоящей фактически из или состоящей из поверхностно-активного вещества, фосфолипида, биоразлагаемого полимера, липопротеина и спирта (где одна или несколько gRNA нацеливаются на генетический локус или локусы в HSC), необязательно разращивать полученные модифицированные HSC и вводить в организм полученные модифицированные HSC. В некоторых примерах выделенные или полученные HSC могут происходить из первого организма, такого как организм того же самого вида, как и второй организм, и второй организм может представлять собой организм, в который вводят полученные модифицированные HSC, например, первый организм может быть донором (например, родственником, как в случае родителя или сибса) для второго организма. Модифицированные HSC могут иметь генетические мутации для лечения, облегчения или ослабления симптомов заболевания или состояния индивидуума, или субъекта, или пациента. Модифицированные HSC, например, в случае, когда первый организм является донором для второго организма, могут иметь генетические модификации с тем, чтобы HSC имели один или несколько белков, например, поверхностных маркеров или белков, которые более подобны, чем у второго организма. Модифицированные HSC могут иметь генетические модификации для имитации заболевания или состояния индивидуума, или субъекта, или пациента и могут быть повторно введены в отличный от человека организм с получением животной модели. Разращивание HSC находится в пределах компетенции специалиста в данной области исходя из настоящего изобретения и знаний в данной области, см., например, Lee, "Improved ex vivo expansion of adult hematopoietic stem cells by overcoming CUL4-mediated degradation of HOXB4." Blood. 2013 May 16;121(20):4082-9. doi: 10.1182/blood-2012-09-455204. Epub 2013 Mar 21.
- Как указано, для повышения активности gRNA можно обеспечивать предварительное образование комплекса sgRNA с белком Cas (например, Cpf1) перед составлением целого комплекса в частице. Составы можно получать с различным молярным соотношением различных компонентов, известных как способствующие доставке нуклеиновой кислоты в клетки (например, 1,2-диолеоил-3-триметиламмоний-пропан (DOTAP), 1,2-дитетрадеканоил-sn-глицеро-3-фосфохолин (DMPC), полиэтиленгликоль (PEG) и холестерин). Например, молярные соотношения DOTAP: DMPC: PEG: холестерин могут быть следующими: DOTAP 100, DMPC 0, PEG 0, холестерин 0; или DOTAP 90, DMPC 0, PEG 10, холестерин 0; или DOTAP 90, DMPC 0, PEG 5, холестерин 5. DOTAP 100, DMPC 0, PEG 0, холестерин 0. Настоящее изобретение, соответственно, охватывает смешивание gRNA, белка Cas (например, Cpf1) и компонентов, которые образуют частицу; а также частицы в результате такого добавления.
- В предпочтительном варианте осуществления частицы, содержащие комплекс Cas-(например, Cpf1)-gRNA, могут быть образованы путем смешивания белка Cas (например, Cpf1) и одной или нескольких gRNA вместе, предпочтительно при молярном соотношении фермент:направляющая РНК 1:1. В отдельности, различные компоненты, известные как способствующие доставке нуклеиновых кислот (например, DOTAP, DMPC, PEG и холестерин), являются растворенными, предпочтительно в этаноле. Два раствора можно смешивают вместе с образованием частиц, содержащих комплексы Cas-(например, Cpf1)-gRNA. После образования частиц комплексами Cas (например, Cpf1)-gRNA можно трансфицировать клетки (например HSC). Можно наносить штрих-код. На частицы, Cas-9 и/или gRNA можно наносить штрих-код.
- Настоящее изобретение в варианте осуществления предусматривает способ получения частицы, содержащей комплекс gRNA и белка Cas (например, Cpf1), включающий перемешивание смеси gRNA и белка Cas (например, Cpf1) со смесью, содержащей, состоящей по сути из, или состоящей из поверхностно-активного вещества, фосфолипида, биоразлагаемого полимера, липопротеина и спирта. Вариант осуществления охватывает частицу, содержащую комплекс gRNA и белка Cas (например, Cpf1), полученную посредством данного способа. Настоящее изобретение в варианте осуществления охватывает применение частицы в способе модификации представляющего интерес локуса генома, или организма, или отличного от человека организма путем манипуляции с целевой последовательностью в представляющем интерес локусе генома, включающем приведение клетки, содержащей представляющий интерес локус генома, в контакт с частицей, где gRNA осуществляет нацеливание на представляющий интерес локус генома; или способе модификации представляющего интерес локуса генома, или организма, или отличного от человека организма путем манипуляции с целевой последовательностью в представляющем интерес локусе генома, включающем приведение клетки, содержащей представляющий интерес локус генома, в контакт с частицей, где gRNA осуществляет нацеливание на представляющий интерес локус генома. В этих вариантах осуществления представляющий интерес локус генома является преимущественно локусом генома в HSC.
- Факторы, которые следует учитывать для применений в терапии Фактор в терапии на основе редактирования генома представляет собой выбор специфичной по отношению к последовательностям нуклезы, такой как вариант нуклеазы Cpf1. Каждый вариант нуклеазы может обладать своим собственным специфичным набором сильных и слабых сторон, многие из которых должны быть сбалансированы в контексте лечения для сведения к максимуму терапевтического эффекта. До настоящего времени два подхода редактирования с терапевтической целью с применением нуклеаз продемонстрировали значительные перспективы: нарушение функционирования гена и коррекция гена. Нарушение функционирования гена охватывает стимуляцию NHEJ для создания целенаправленных вставок/делеций в генетических элементах, часто приводящих к мутациям с потерей функций, которые являются полезными для пациентов. Напротив, при коррекции гена используется HDR для прямой регрессии мутаций, вызывающих заболевание, с восстановлением функции при сохранении физиологической регуляции cкорректированного элемента. HDR также может применяться для вставки терапевтического трансгена в определенный "безопасный" локус в геноме для восстановления отсутствующей функции гена. С целью обеспечения эффективности специфической терапии с применением редактирования должен достигаться достаточно высокий уровень модификации в целевых клеточных популяциях для вызова обратного развития симптомов заболевания. Этот "порог" терапевтической модификации определяют путем определения пригодности редактированных клеток после обработки и количества продукта гена, необходимого для устранения симптомов. Что касается пригодности, редактирование предусматривает возникновение трех возможных результатов для обработанных клеток по сравнению с их нередактированными аналогами: повышенная, нейтральная или сниженная пригодность. В случае повышенной пригодности, например, при лечении SCID-X1, модифицированные кроветворные клетки-предшественники селективно разрастаются по сравнению с их нередактированными аналогами. SCID-X1 представляет собой заболевание, вызываемое мутациями в гене IL2RG, функция которого требуется для правильного развития лимфоцитарного ростка кроветворения [Leonard, W.J., et al. Immunological reviews 138, 61-86 (1994); Kaushansky, K. & Williams, W.J. Williams hematology, (McGraw-Hill Medical, New York, 2010)]. В клинических испытаниях с пациентами, которые получали генную терапию с использованием вирусов для SCID-X1, и в редком примере спонтанной коррекции мутации SCID-X1 скорректированные кроветворные клетки-предшественники по сравнению с их пораженными заболеванием аналогами могли преодолевать это блокирование развития и разрастались, способствуя терапии [Bousso, P., et al. Proceedings of the National Academy of Sciences of the United States of America 97, 274-278 (2000); Hacein-Bey-Abina, S., et al. The New England journal of medicine 346, 1185-1193 (2002); Gaspar, H.B., et al. Lancet 364, 2181-2187 (2004)]. В данном случае, когда редактированные клетки обладают преимуществом при отборе, даже небольшие количества редактированных клеток можно увеличивать посредством разрастания, обеспечивая терапевтический эффект для пациента. Напротив, редактирование в отношении других заболеваний системы кроветворения, таких как хроническая гранулематозная болезнь (CGD), не будет индуцировать изменений пригодности для редактированных кроветворных клеток-предшественников, повышая порог терапевтической модификации. CGD вызывается мутациями в генах, кодирующих белки фагоцитарной оксидазы, которые обычно используются нейтрофилами для образования активных форм кислорода, уничтожающих патогены [Mukherjee, S. & Thrasher, A.J. Gene 525, 174-181 (2013)]. Поскольку дисфункция этих генов не влияет на пригодность или развитие кроветворных клеток-предшественников, а только на способность гемопоэтических кроветворных зрелого типа бороться с инфекциями, вероятно, не будет наблюдаться предпочтительная экспансия отредактированных клеток при данном заболевании. Действительно, не наблюдалось преимущества при отборе в отношении скорректированных клеток CGD при испытаниях с генной терапией, что приводило к сложностям длительного приживления клеток [Malech, H.L., et al. Proceedings of the National Academy of Sciences of the United States of America 94, 12133-12138 (1997); Kang, H.J., et al. Molecular therapy: the journal of the American Society of Gene Therapy 19, 2092-2101 (2011)]. Как таковые, значительно более высокие уровни редактирования будут требоваться для лечения заболеваний, таких как CGD, где редактирование обуславливает преимущественно нейтральную пригодность, по сравнению с заболеваниями, где редактирование обуславливает повышенную пригодность целевых клеток. Если редактирование вносит недостаток пригодности, как это было бы в случае восстановления функции гена-супрессора опухолевого роста в раковых клетках, пораженные заболеванием аналоги будут вытеснять модифицированные клетки, в результате чего польза от лечения будет ниже по сравнению со скоростью редактирования. Этот последний класс заболеваний было бы особенно сложно лечить с помощью терапии с применением редактирования генома.
- В дополнение к пригодности клеток количество продукта гена, необходимого для лечения заболевания, также влияет на минимальный уровень редактирования генома с терапевтической целью, который должен достигаться для обратного развития симптомов. Гемофилия B является одним из заболеваний, в котором небольшое изменение уровней продукта гена может приводить к значительным изменениям клинических результатов. Данное заболевание вызывается мутациями в гене, кодирующем фактор IX, белок, обычно секретируемый печенью в кровь, где он функционирует в качестве компонента каскада свертывания крови. Клиническая тяжесть гемофилии B связана с величиной активности фактора IX. Ввиду того, что заболевание тяжелой степени ассоциировано с активностью менее 1% от нормальной, более легкие формы заболеваний ассоциированы с более чем 1% активности фактора IX [Kaushansky, K. & Williams, W.J. Williams hematology, (McGraw-Hill Medical, New York, 2010); Lofqvist, T., et al. Journal of internal medicine 241, 395-400 (1997)]. Это позволяет предположить, что варианты терапии с применением редактирования, которые могут восстанавливать экспрессию фактора IX в клетках печени до даже небольшого процента, могут оказывать большое влияние на клинические результаты. Исследование с применением ZFN для коррекции мышиной модели гемофилии B вскоре после рождения продемонстрировало, что 3-7% коррекция была достаточной для устранения симптомов заболевания, обеспечивая доклиническое подтверждение данной гипотезы [Li, H., et al. Nature 475, 217-221 (2011)].
- Нарушения, при которых небольшое изменение уровней продукта гена может влиять на клинические результаты, и заболевания, где имеет место преимущество пригодности редактированных клеток, представляют собой превосходные мишени для терапии с применением редактирования генома, поскольку порог терапевтической модификации является достаточно низким для обеспечения высокой вероятности успеха с учетом современных технологий. Целенаправленное воздействие на данные заболевания на сегодняшний день привело к успехам в терапии с применением редактирования на доклиническом уровне и в фазе I клинического испытания. Усовершенствования в манипуляции путем репарации DSB и доставкой нуклеаз необходимы для распространения данных многообещающих результатов на заболевания с преимуществом нейтральной пригодности отредактированных клеток, или где для лечения необходимы более значительные количества продукта гена. В таблице, приведенной ниже, показаны некоторые примеры вариантов применения редактирования генома по отношению к терапевтическим моделям и ссылки из приведенной ниже таблицы и документы, которые перечислены в этих ссылках, включены в данный документ посредством ссылки, как если бы они были изложены в полном объеме.
- Лечение каждого из таких состояний из предшествующей таблицы при помощи системы CRISPR-Cas (например, Cpf1) для нацеливания при помощи HDR-опосредованной коррекции мутации или HDR-опосредованной вставки надлежащей последовательности гена, предпочтительно посредством системы доставки, как описано в данном документе, например, системы доставки частицы, находится в пределах компетенции специалиста в данной области исходя из раскрытия и знаний в данной области. Таким образом, вариант осуществления охватывает приведение HSC, несущей мутацию, приводящую к гемофилии B, SCID (например, SCID-X1, ADA-SCID) или врожденной тирозинемии, в контакт с gRNA и белком Cas (например, Cpf1), осуществляющими нацеливание нa представляющий интерес локус генома, связанный с гемофилией B, SCID (например, SCID-X1, ADA-SCID) или врожденной тирозинемией (например, как описано в Li, Genovese или Yin). Частица также может содержать подходящую матрицу для HDR для коррекции мутации; или HSC может быть приведена в контакт со второй частицей или вектором, который содержит или доставляет матрицу для HDR. В связи с этим упоминается, что гемофилия B представляет собой сцепленное с Х-хромосомой рецессивное нарушение, вызванное мутациями с потерей функций в гене, кодирующем фактор IX, важный компонент каскада свертывания крови. Восстановление активности фактора IX до приблизительно 1% от его уровней у тяжело пораженных индивидуумов может трансформировать заболевание в значительно более легкую форму, поскольку профилактическая инфузия рекомбинантного фактора IX у таких пациентов с раннего возраста для достижения таких уровней в значительной степени облегчает тяжесть клинических осложнений. Специалист в данной области с использованием знаний в данной области и идей настоящего изобретения может корректировать HSC в отношении гемофилии B с применением системы CRISPR-Cas (например, Cpf1), которая нацеливается на мутацию и корректирует ее (сцепленное с Х-хромосомой рецессивное нарушение, вызванное мутациями с потерей функции гена, кодирующем фактор IX) (например, при помощи подходящей матрицы для HDR, которая доставляет кодирующую последовательность для фактора IX); в частности, gRNA может осуществлять нацеливание на мутацию, которая приводит к возникновению гемофилии B, и HDR может обеспечивать кодирование, приводящее к надлежащей экспрессии фактора IX. gRNA, которая нацеливается на мутацию и частицу, содержащую белок Cas (например, Cpf1), вступает в контакт с HSC, несущими мутацию. Частица также может содержать подходящую матрицу для HDR для коррекции мутации с целью надлежащей экспрессии фактора IX; или HSC может быть приведена в контакт со второй частицей или вектором, который содержит или доставляет матрицу для HDR. Приведенные таким образом в контакт клетки можно вводить и необязательно обрабатывать и разращивать; см. Cartier., описанный в данном документе.
- В публикации Cartier "MINI-SYMPOSIUM: X-Linked Adrenoleukodystrophypa, Hematopoietic Stem Cell Transplantation and Hematopoietic Stem Cell Gene Therapy in X-Linked Adrenoleukodystrophy", Brain Pathology 20 (2010) 857-862, включенной в данный документ посредством ссылки вместе с документами, которые в ней перечислены так, если бы они были изложены в полном объеме, представлено подтверждение того, что аллогенную трансплантацию кроветворных стволовых клеток (HSCT) использовали для доставки нормального лизосомального фермента в головной мозг пациента с болезнью Гурлера, и описание генной терапии HSC для лечения ALD. У двух пациентов периферийные CD34+клетки отбирали после активации гранулоцитарного колониестимулирующего фактора (G-CSF) и трансдуцировали лентивирусным вектором (MND)-ALD с энхансером миелопролиферативного вируса саркомы мышей, удаленным участком отрицательного контроля, замещенным участком связывания праймера dl587rev. CD34+ клетки пациентов трансдуцировали вектором MND-ALD в течение 16 ч в присутствии цитокинов в низких концентрациях. Трансдуцированные CD34+ клетки замораживали после трансдукции для выполнения на 5% клеток ряда испытаний на безопасность, которые включали, в частности, три анализа на присутствие компетентных по репликации лентивирусов (RCL). Эффективность трансдукции CD34+ клеток находилась в диапазоне от 35% до 50% со средним количеством интегрированных копий лентивируса 0,65-0,70. После размораживания трансдуцированных CD34+ клеток пациентам проводили повторную инфузию более чем 4,106 трансдуцированных CD34+ клеток/кг с последующим полным разрушением миелиновых оболочек с применением бусульфана и циклофосфамида. Разрушали HSC пациента для способствования приживлению генетически скорректированных HSC. Гематологическое восстановление для двух пациентов наступало в дни 13-15. Почти полное иммунологическое восстановление наступало через 12 месяцев для первого пациента и через 9 месяцев для второго пациента. В отличие от применения лентивируса специалист в данной области с использованием знаний в данной области и идей настоящего изобретения может корректировать HSC относительно ALD с применением системы CRISPR-Cas (Cpf1), которая нацеливается на мутацию и корректирует ее (например, с помощью подходящей матрицы для HDR); в частности, gRNA может осуществлять нацеливание на мутации в ABCD1, гене, который локализован на X-хромосоме, который кодирует ALD, мембранный транспортный белок пероксисом, и HDR может обеспечивать кодирование, приводящее к надлежащей экспрессии белка. gRNA, которая нацеливается на мутацию и частицу, содержащую белок Cas (Cpf1), вступает в контакт с HSC, например CD34+ клетками, несущими мутацию, как описано в Cartier. Частица также может содержать подходящую матрицу для HDR для коррекции мутации с целью экспрессии пероксисомального мембранного белка-переносчика; или HSC может быть приведена в контакт со второй частицей или вектором, который содержит или доставляет матрицу для HDR. Приводимые таким образом в контакт клетки необязательно можно обрабатывать, как описано в Cartier. Приводимые таким образом в контакт клетки можно вводить, как описано в Cartier.
- Следует упомянуть WO 2015/148860, в идеях, изложенных в данном документе, настоящее изобретение подразумевает способы и материалы этих документов, применяемые в сочетании с идеями, изложенными в данном документе. В одном аспекте генная терапия заболеваний, связанных с кровеносной системой, способы и композиции для лечения бета-талассемии могут быть адаптированы к системе CRISPR-Cas по настоящему изобретению (см., например, WO 2015/148860). В варианте осуществления WO 2015/148860 предусматривает лечение или предупреждение бета-талассемии, или ее симптомов, например, с помощью изменения гена B-клеточного CLL/лимфомы 11A (BCL11A). Ген BCL11A также известен как ген B-клеточного CLL/лимфомы 11A, BCL11A -L, BCL11A -S, BCL11AXL, CTIP 1, HBFQTL5 и ZNF. BCL11A кодирует белок "цинковый палец", который участвует в регуляции экспрессии генов глобинов. При изменении гена BCL11A (например, одного или обоих аллелей гена BCL11A) уровни гамма-глобина могут повышаться. Гамма-глобин может замещать бета-глобин в гемоглобиновом комплексе и эффективно доставлять кислород к тканям, тем самым нормализуя фенотипы заболевания бета-талассемии.
- Следует упомянуть WO 2015/148863, и в идеях, изложенных в данном документе, настоящее изобретение подразумевает способы и материалы этих документов, которые могут быть адаптированы к системе CRISPR-Cas по настоящему изобретению. В аспекте лечения или предупреждения серповидноклеточной анемии, которая представляет собой наследственное гематологическое заболевание крови, WO 2015/148863 предусматривает изменение гена BCL11A. При изменении гена BCL11A (например, одного или обоих аллелей гена BCL11A) уровни гамма-глобина могут повышаться. Гамма-глобин может замещать бета-глобин в гемоглобиновом комплексе и эффективно доставлять кислород к тканям, тем самым нормализуя фенотипы серповидноклеточной анемии.
- В одном аспекте настоящего изобретения способы и композиции, которые включают редактирование целевой последовательности нуклеиновой кислоты или модулирование экспрессии целевой последовательности нуклеиновой кислоты, и варианты их применения в связи с иммунотерапией рака понимают путем адаптации системы CRISPR-Cas по настоящему изобретению. Ссылаются на применение генной терапии в WO 2015/161276, который предусматривает способы и композиции, которые могут быть использованы для нарушения пролиферации, выживания и/или функции T-клеток в результате изменения одного или нескольких экспрессируемых T-клетками генов, например, одного или нескольких из генов FAS, BID, CTLA4, PDCD1, CBLB, PTPN6, TRAC и/или TRBC. В связанных аспектах пролиферация T-клеток может быть нарушена при изменении одного или нескольких экспрессируемых T-клетками генов, например, гена CBLB и/или PTPN6, гена FAS и/или BID, гена CTLA4, и/или PDCDI, и/или TRAC, и/или TRBC.
- T-клетки с химерным антигенным рецептором (CAR)19 характеризуются антилейкозными эффектами в злокачественных образованиях пациентов. Однако пациенты с лейкозом часто имеют недостаточно T-клеток для сбора, следовательно, лечение должно включать модифицированные T-клетки от доноров. Соответственно, существует интерес создания банка донорских T-клеток. Qasim et al. ("First Clinical Application of Talen Engineered Universal CAR19 T Cells in B-ALL" ASH 57th Annual Meeting and Exposition, Dec. 5-8, 2015, Abstract 2046 (https://ash.confex.com/ash/2015/webprogram/Paper81653.html, опубликовано онлайн в ноябре 2015 г.) описывают модификацию T-клеток с CAR19 с целью устранения риска возникновения реакции "трансплантат против хозяина" посредством нарушения экспрессии T-клеточных рецепторов и целенаправленного воздействия на CD52. Кроме того, клетки с CD52 были подвергнуты нацеливанию таким образом, что они стали невосприимчивыми к алемтузумабу, и, таким образом, способствовали тому, что алемтузумаб предупреждал опосредованное хозяином отторжение T-клеток с CAR19, несоответствующих лейкоцитарным антигенам человека (HLA). Исследователи использовали самоинактивирующийся лентивирусный вектор третьего поколения, кодирующий 4g7 CAR19 (CD19 scFv-4-1BB-CD3ζ), связанный с RQR8, затем подвергали электропорации клетки при помощи двух пар мРНК TALEN для мультиплексного целенаправленного воздействия на локус константной альфа-цепи T-клеточного рецептора (TCR) и локус гена CD52. Клетки, которые по-прежнему экспрессировали TCR после ex vivo разращения, подвергали истощению в результате истощения α/β TCR CliniMacs, приводя к образованию T-клеточного продукта (UCART19) с <1% экспрессией TCR, 85% которых приходились на CAR19, а 64% стали негативными по отношению к CD52. Модифицированные T-клетки с CAR19 вводили для лечения рецидивирующего острого лимфобластного лейкоза у пациентов. Идеи, представленные в данном документе, предусматривают эффективные способы получения модифицированных гемопоэтических стволовых клеток и их потомства, в том числе без ограничения клеток миелоидной и лимфоидной линии крови, в том числе T-клеток, B-клеток, моноцитов, макрофагов, нейтрофилов, базофилов, эозинофилов, эритроцитов, дендритных клеток и мегакариоцитов или тромбоцитов, и натуральных клеток-киллеров и их предшественников и потомков. Такие клетки можно модифицировать с помощью нокаута, нокина или иного модулирования мишеней, например, с удалением или модулированием CD52, как описано в данном документе, и других мишеней, таких как без ограничения CXCR4 и PD-1. Такие композиции, клетки и способ по настоящему изобретению можно применять для модулирования иммунных ответов и для лечения без ограничения злокачественных новообразований, вирусных инфекций и иммунных нарушений, в сочетании с введением T-клеток или других клеток пациентам.
- Следует упомянуть WO 2015/148670 и в идеях, изложенных в данном документе, настоящее изобретение подразумевает способы и материалы этого документа, применяемые в сочетании с идеями, изложенными в данном документе. В одном аспекте генной терапии подразумеваются способы и композиции для редактирования целевой последовательности, связанной или находящейся в связи с вирусом иммунодефицита человека (HIV) и синдром приобретенного иммунодефицита (AIDS). В связанном аспекте настоящее изобретение, описанное в данном документе, подразумевает предупреждение и лечение инфекции, обусловленной HIV, и AIDS с помощью введения одной или нескольких мутаций в гене рецептора C-C-хемокина 5 типа (CCR5). Ген CCR5 также известен как CKR5, CCR-5, CD195, CKR-5, CCCKR5, CMKBR5, IDDM22 и CC-CKR-5. В дополнительном аспекте настоящее изобретение, описанное в данном документе, подразумевает применение с целью предупреждения или уменьшения инфекции, обусловленной HIV, и/или предупреждения или уменьшения способности HIV попадать в клетки-хозяева, например у субъектов, которые уже инфицированы. Иллюстративные клетки-хозяева для HIV включают без ограничения CD4-клетки, T-клетки, лимфоидную ткань, ассоциированную с кишечником (GALT), макрофаги, дендритные клетки, миелоидные клетки-предшественники и микроглию. Попадание вируса в клетки-хозяева требует взаимодействия вирусных гликопротеинов gp41 и gp120 с CD4-рецептором и корецептором, например, CCR5. Если корецептор, например CCR5, не присутствует на поверхности клеток-хозяев, то вирус не может связаться и попасть в клетки-хозяева. Таким образом, прогрессирование заболевания затрудняется. С помощью нокаута или нокдауна CCR5 в клетках-хозяевах, например при введении защитной мутации (такой как мутация CCR5 дельта 32), предупреждают проникновение вируса HIV в клетки-хозяева.
- Сцепленная с Х-хромосомой хроническая гранулематозная болезнь (CGD) представляет собой наследственное нарушение иммунной защиты организма в связи с отсутствующей или сниженной активностью фагоцитарной NADPH-оксидазы. При помощи системы CRISPR-Cas (Cpf1), которая нацеливается на мутацию и корректирует ее (отсутствующая или сниженная активность фагоцитарной NADPH-оксидазы) (например, при помощи подходящей матрицы для HDR, которая доставляет кодирующую последовательность для фагоцитарной NADPH-оксидазы); в частности, gRNA может осуществлять нацеливание на мутацию, которая приводит к CGD (дефектная фагоцитарная NADPH-оксидаза), а HDR может обеспечивать кодирование для надлежащей экспрессии фагоцитарной NADPH-оксидазы. gRNA, которая нацеливается на мутацию и частицу, содержащую белок Cas (Cpf1), вступает в контакт с HSC, несущими мутацию. Частица также может содержать подходящую матрицу для HDR для коррекции мутации с целью надлежащей экспрессии фагоцитарной NADPH-оксидазы; или HSC может быть приведена в контакт со второй частицей или вектором, который содержит или доставляет матрицу для HDR. Приведенные таким образом в контакт клетки можно вводить и необязательно обрабатывать и разращивать; см. Cartier.
- Анемия Фанкони Мутации по меньшей мере в 15 генах (FANCA, FANCB, FANCC, FANCD1/BRCA2, FANCD2, FANCE, FANCF, FANCG, FANCI, FANCJ/BACH1/BRIP1, FANCL/PHF9/POG, FANCM, FANCN/PALB2, FANCO/Rad51C и FANCP/SLX4/BTBD12) могут вызывать анемию Фанкони. Белки, продуцируемые в результате экспрессии этих генов, вовлечены в процесс в клетке, известный как путь FA. Путь FA запускается (активируется), когда процесс создания новых копий ДНК, называемый “репликация ДНК”, блокируется в результате повреждения ДНК. Путь FA направляет определенные белки в область повреждения, которые запускают репарацию ДНК, поэтому репликация ДНК может продолжаться. Путь FA, в частности, реагирует на определенный тип повреждения ДНК, известный как межнитевые поперечные сшивки (ICL). ICL происходит в том случае, когда структурные элементы ДНК (нуклеотиды) на противоположных нитях ДНК аномально соединяются или связываются друг с другом, что останавливает репликацию ДНК. ICL могут вызываться накоплением токсических веществ, продуцируемых в организме, или при лечении определенными противоопухолевыми лекарственными средствами. Восемь белков ассоциируются с группой анемии Фанкони с образованием комплекса, известного как коровый комплекс FA. Коровый комплекс FA активирует два белка под названием FANCD2 и FANCI. Активация данных двух белков приводит к доставке белков для репарации ДНК в область ICL, так что поперечная сшивка может быть удалена и репликация ДНК может продолжаться с помощью корового комплекса FA. Более конкретно, коровый комплекс FA, представляющий собой ядерный мультипротеиновый комплекс, состоящий из FANCA, FANCB, FANCC, FANCE, FANCF, FANCG, FANCL и FANCM, функционирует в качестве убиквитинлигазы E3 и опосредует активацию комплекса ID, который представляет собой гетеродимер, состоящий из FANCD2 и FANCI. После моноубиквитинирования он взаимодействует с классическими супрессорами опухолевого роста ниже по пути FA, включая FANCD1/BRCA2, FANCN/PALB2, FANCJ/BRIP1 и FANCO/Rad51C, и, таким образом, участвует в репарации ДНК посредством гомологичной рекомбинации (HR). От восьмидесяти до 90 процентов случаев FA обусловлены мутациями в одном из трех генов, FANCA, FANCC и FANCG. Эти гены несут информацию для продуцирования компонентов корового комплекса FA. Мутации в таких генах, ассоциированные с коровым комплексом FA, будут приводить к потере комплексом функциональности и к разрушению всего пути FA. Как результат, повреждение ДНК не подвергается эффективной репарации, и со временем происходит накопление ICL. В публикации Geiselhart "Review Article, Disrupted Signaling through the Fanconi Anemia Pathway Leads to Dysfunctional Hematopoietic Stem Cell Biology: Underlying Mechanisms and Potential Therapeutic Strategies," Anemia Volume 2012 (2012), Article ID 265790, http://dx.doi.org/10.1155/2012/265790, обсуждается FA и эксперимент с животными, включающий интрафеморальное введение лентивируса, кодирующего ген FANCC, что приводило к коррекции HSC in vivo. При помощи системы CRISPR-Cas (Cpf1), которая нацеливается на одну или несколько мутаций, ассоциированных с FA, например системы CRISPR-Cas (Cpf1), имеющей gRNA и матрицу(матрицы) для HDR, которые соответственно нацеливаются на одну или несколько из мутаций FANCA, FANCC или FANCG, которые приводят к FA и обеспечивают откорректированную экспрессию одного или нескольких из FANCA, FANCC или FANCG; например, gRNA может нацеливаться на мутацию, например FANCC, и HDR может обеспечивать кодирование надлежащей экспрессии FANCC. gRNA, которая нацеливается на мутацию(мутации) (например, одну или несколько, участвующих в FA, такие как мутация(мутации) в частице, содержащей любую один или несколько из FANCA, FANCC или FANCG) и белок Cas (Cpf1), контактирует с HSC, несущими мутацию(мутации). Частица также может содержать подходящую(подходящие) матрицу(матрицы) для HDR для коррекции мутации с целью надлежащей экспрессии одного или нескольких из белков, участвующих в FA, таких как один или несколько из FANCA, FANCC или FANCG; или HSC может быть приведена в контакт со второй частицей или вектором, который содержит или доставляет матрицу для HDR. Приведенные таким образом в контакт клетки можно вводить и необязательно обрабатывать и разращивать; см. Cartier.
- Частица в описании данного документа (например, содержащая gRNA и Cas (Cpf1), необязательно матрицу(матрицы) для HDR, или матрицу(матрицы) для HDR; например, в случае гемофилии B, SCID, SCID-X1, ADA-SCID, наследственной тирозинемии, β-талассемии, сцепленной с X-хромосомой CGD, синдрома Вискотта-Ольдрича, анемии Фанкони, адренолейкодистрофии (ALD), метахроматической лейкодистрофии (MLD), HIV/AIDS, иммунодефицита, гематологичекого состояния или генетической лизосомной болезни накопления) предпочтительно получена или может быть получена в результате смешивания смеси gRNA и белка Cas (Cpf1) (при этом необязательно содержит матрицу(матрицы) для HDR, или такая смесь только содержит матрицу(матрицы) для HDR в том случае, если отдельные частицы по отношению к матрице(матрицам) являются желательными) со смесью, содержащей, или состоящей фактически из, или состоящей из поверхностно-активного вещества, фосфолипида, биоразлагаемого полимера, липопротеина и спирта (где одна или несколько gRNA нацеливаются на генетический локус или локусы в HSC).
- Действительно, настоящее изобретение особенно подходит для лечения гемопоэтических наследственных нарушений при помощи редактирования генома и иммунодефицитов, таких как наследственные иммунодефициты, особенно при помощи технологии на основе частиц, описанной в данном документе. Наследственные иммунодефициты представляют собой заболевания, при которых процедуры редактирования генома по настоящему изобретению могут быть успешными. Причинами являются гемопоэтические клетки, подгруппой которых являются иммунные клетки, являющиеся терапевтически доступными. Их можно удалить из организма и трансплантировать аутологически или аллогенически. Кроме того, определенные наследственные иммунодефициты, например тяжелый комбинированный иммунодефицит (SCID), приводят к дефекту пролиферации иммунных клеток. Коррекция наследственных нарушений, вызывающих SCID, в результате редких спонтанных "обратных" мутаций указывает на то, что коррекция даже одного предшественника лимфоцита может быть достаточной для восстановления иммунной функции у пациентов .../../../Users/t_kowalski/AppData/Local/Microsoft/Windows/Temporary Internet Files/Content.Outlook/GA8VY8LK/Treating SCID for Ellen.docx - _ENREF_1, см. Bousso, P., et al. Diversity, functionality, and stability of the T cell repertoire derived in vivo from a single human T cell precursor. Proceedings of the National Academy of Sciences of the United States of America 97, 274-278 (2000). Селективное преимущество редактированных клеток обеспечивает то, что даже низкие уровни редактирования приводят к терапевтическому эффекту. Этот эффект по настоящему изобретению может наблюдаться при SCID, синдроме Вискотта-Олдрича и других состояниях, упомянутых в данном документе, в том числе наследственных гемопоэтических нарушениях, таких как альфа- и бета-талассемия, при которых недостаточности гемоглобина отрицательно влияют на пригодность предшественников эритроцитов.
- Активность репарации DSB с помощью NHEJ и HDR значительно варьирует в зависимости от типа клетки и состояния клетки. NHEJ не подвергается четкой регуляции клеточным циклом и является эффективным во всех типах клеток, обеспечивая наличие высоких уровней нарушения функционирования гена в доступных целевых клеточных популяциях. Напротив, HDR действует главным образом в течение фазы S/G2, и таким образом ограничена клетками, которые активно делятся, с ограничением применения видов лечения, которые требуют точных модификаций генома до митотических клеток [Ciccia, A. & Elledge, S.J. Molecular cell 40, 179-204 (2010); Chapman, J.R., et al. Molecular cell 47, 497-510 (2012)].
- Эффективность коррекции с применением HDR может контролироваться по эпигенетическому состоянию, или последовательности подверженного целенаправленному воздействию локуса, или применяемой конфигурации специфической матрицы для репарации (однонитевые по сравнению с двухнитевыми, длинные по сравнению с короткими гомологичными плечами) [Hacein-Bey-Abina, S., et al. The New England journal of medicine 346, 1185-1193 (2002); Gaspar, H.B., et al. Lancet 364, 2181-2187 (2004); Beumer, K.J., et al. G3 (2013)]. Относительная активность механизмов NHEJ и HDR в целевых клетках может также оказывать влияние на эффективность коррекции гена, поскольку данные пути могут конкурировать за устранение DSB [Beumer, K.J., et al. Proceedings of the National Academy of Sciences of the United States of America 105, 19821-19826 (2008)]. HDR также вносит проблему доставки, не наблюдаемую в ходе применения стратегий с NHEJ, поскольку она требует одновременой доставки нуклеаз и матриц для репарации. На практике данные ограничения до настоящего времени привели к низким уровням HDR в терапевтически значимых типах клеток. Таким образом, переход к клиническому применению был в основном сосредоточен на стратегиях NHEJ для лечения заболевания, хотя доклинические исследования обоснованности концепции только что были описаны для мышиных моделей гемофилии B и врожденной тирозинемии [Li, H., et al. Nature 475, 217-221 (2011); Yin, H., et al. Nature biotechnology 32, 551-553 (2014)].
- Любое из приведенных применений редактирования генома может включать комбинации белков, малые молекулы РНК и/или матрицы для репарации, что делает доставку данных нескольких частей значительно более проблематичной, чем доставку низкомолекулярных лекарственных средств. Разрабатывали две основные стратегии доставки инструментов для редактирования генома: ex vivo и in vivo. В видах лечения ex vivo пораженные болезнью клетки удаляют из организма, редактируют и затем трансплантируют обратно пациенту. Редактирование ex vivo имеет преимущество в обеспечении возможности должного определения целевой популяции клеток и точного определения дозирования терапевтических молекул. Последний фактор, который следует учитывать, может быть особенно важным, когда нецелевые модификации представляют особый интерес, поскольку подбор количества нуклеазы может приводить к снижению уровня таких мутаций (Hsu et al., 2013). Другим преимуществом подходов ex vivo являются обычно высокие показатели редактирования, которые могут быть достигнуты в связи с разработкой эффективных систем доставки для белков и нуклеиновых кислот в клетки, находящиеся в культуре, для применений в научных исследованиях и генной терапии.
- Существуют два основных недостатка подходов ex vivo, которые ограничивают их применение в отношении небольшого числа заболеваний. Например, целевые клетки должны быть способны к выживанию при манипуляции вне организма. Для многих тканей, как, например, для головного мозга, культивирование клеток вне организма представляет собой большую проблему, поскольку клетки либо не в состоянии выжить, либо теряют свойства, необходимые для их функционирования in vivo. Таким образом, с точки зрения настоящего раскрытия и знаний в данной области, терапия ex vivo по отношению к тканям с популяциями взрослых стволовых клеток, поддающихся ex vivo культивированию и манипуляциям, таким как гемопоэтическая система, при помощи системы CRISPR-Cas (Cpf1) является возможной. [Bunn, H.F. & Aster, J. Pathophysiology of blood disorders, (McGraw-Hill, New York, 2011)]
- Редактирование генома in vivo охватывает прямую доставку систем редактирования в их нативные ткани. Редактирование in vivo допускает лечение заболеваний, в которых пораженная популяция клеток не пригодна для манипуляции ex vivo. Более того, доставка нуклеаз в клетки in situ создает возможность для лечения многих тканей и типов клеток. Данные свойства, вероятно, обеспечивают применение лечения in vivo по отношению к более широкому спектру заболеваний, чем виды терапии ex vivo.
- До настоящего времени редактирования in vivo в значительной степени достигали посредством применения вирусных векторов с определенным, специфичным к тканям тропизмом. Такие векторы в настоящее время ограничены по вместимости и тропизму, ограничивая данный вид терапии системами органов, где трансдукция клинически применимыми векторами является эффективной, как например: печень, мышцы и глаза [Kotterman, M.A. & Schaffer, D.V. Nature reviews. Genetics 15, 445-451 (2014); Nguyen, T.H. & Ferry, N. Gene therapy 11 Suppl 1, S76-84 (2004); Boye, S.E., et al. Molecular therapy : the journal of the American Society of Gene Therapy 21, 509-519 (2013)].
- Главным потенциальным барьером для доставки in vivo является иммунный ответ, который может быть сформирован в ответ на большие количества вируса, необходимого для лечения, но это явление не является уникальным для редактирования генома и наблюдается при других видах генной терапии на основе вирусов [Bessis, N., et al. Gene therapy 11 Suppl 1, S10-17 (2004)]. Также вероятно, что пептиды из осуществляющих редактирование нуклеаз сами по себе презентируются на молекулах MHC класса I для стимулирования иммунного ответа, хотя существует мало доказательств, подтверждающих, что это происходит на доклиническом уровне. Другой основной трудностью данного вида терапии является контроль распространения и, следовательно, дозировки нуклеаз для редактирования генома in vivo, приводящие к образованию профилей нецелевых мутаций, прогнозирование которых может быть затруднительным. Однако с точки зрения настоящего изобретения и знаний в данной области, в том числе применения видов терапии на основе вирусов и частиц, используемых при лечении онкологических заболеваний, in vivo модификация HSC, например с помощью доставки частицы или вируса, находится в пределах компетенции специалиста в данной области.
- Терапия с применением редактирования ex vivo Длительная клиническая экспертиза с очисткой, культивированием и трансплантацией кроветворных клеток определила заболевания, поражающие систему крови, такие как SCID, анемия Фанкони, синдром Вискотта-Олдрича и серповидноклеточная анемия, в приоритетную область терапии с применением редактирования ex vivo. Другой причиной сосредоточения внимания на кроветворных клетках является то, что благодаря предыдущим усилиям по разработке генной терапии нарушений со стороны крови уже существуют системы доставки с относительно высокой эффективностью. С учетом этих преимуществ этот вид терапии может быть применим при заболеваниях, при которых редактированные клетки обладают преимуществом пригодности, в результате чего небольшое количество прижившихся, редактированных клеток могут разрастаться и обеспечивать лечение заболевания. Одним таким заболеванием является HIV, при котором инфекция приводит к недостатку пригодности CD4+ T-клеток.
- Терапию с применением редактирования ex vivo в недавнем времени расширили путем включения стратегий коррекции генов. Барьеры для HDR ex vivo были преодолены, что показано в недавней работе Genovese и соавт., которые достигли коррекции мутированного гена IL2RG в гемопоэтических стволовых клетках (HSC), полученных от пациента, страдающего от SCID-X1 [Genovese, P., et al. Nature 510, 235-240 (2014)]. Genovese et. al. осуществляли коррекцию гена в HSC с применением мультимодальной стратегии. Во-первых, HSC трансдуцировали с использованием лентивируса с дефектом по интеграции, содержащего матрицу для HDR, кодирующую терапевтическую cDNA для IL2RG. После трансдукции клетки подвергали электропорации с применением мРНК, кодирующей ZFN, целенаправленно воздействующие на горячую точку мутагенеза в IL2RG для стимулирования коррекции гена, основанной на HDR. Для повышения показателей HDR условия культивирования оптимизировали путем использования малых молекул, способствующих делению HSC. С применением оптимизированных условий культивирования, нуклеаз и матриц для HDR, HSC со скорректированными генами от пациента с SCID-X1 получали в культуре при терапевтически значимых уровнях. HSC от непораженных индивидуумов, которых подвергали той же процедуре коррекции генов, могли поддерживать длительное кроветворение у мышей, что является золотым стандартом функционирования HSC. HSC способны давать начало всем типам кроветворных клеток, и их можно подвергать аутологической трансплантации, что делает их чрезвычайно важной популяцией клеток для всех наследственных нарушений кроветворения [Weissman, I.L. & Shizuru, J.A. Blood 112, 3543-3553 (2008)]. В принципе, HSC со корректированными генами можно применять для лечения широкого cпектра генетических нарушений со стороны крови, что делает данное исследование важным открытием для редактирования генома с терапевтической целью.
- Терапия с применением редактирования in vivo. Редактирование in vivo можно применять преимущественно исходя из настоящего изобретения и знаний в данной области. Для систем органов, доставка в которые является эффективной, уже существует ряд впечатляющих доклинических терапевтических успехов. Первый пример успешной терапии in vivo с применением редактирования был продемонстрирован на мышиной модели гемофилии B [Li, H., et al. Nature 475, 217-221 (2011)]. Как было отмечено ранее, гемофилия B представляет собой сцепленное с Х-хромосомой рецессивное нарушение, вызванное мутациями с потерей функций в гене, кодирующем фактор IX, важный компонент каскада свертывания крови. Восстановление активности фактора IX до приблизительно 1% от его уровней у тяжело пораженных индивидуумов может трансформировать заболевание в значительно более легкую форму, поскольку профилактическая инфузия рекомбинантного фактора IX у таких пациентов с раннего возраста для получения таких уровней в значительной степени облегчает тяжесть клинических осложнений [Lofqvist, T., et al. Journal of internal medicine 241, 395-400 (1997)]. Таким образом, крайне низкие уровни коррекции гена, опосредованной HDR, являются необходимы для изменения клинических результатов у пациентов. Кроме того, фактор IX синтезируется и секретируется печенью, органом, который может быть эффективно трансдуцирован вирусными векторами, кодирующими системы для редактирования.
- С применением гепатотропных серотипов аденоассоциированного вируса (AAV), кодирующих ZFN и корректирующую матрицу для HDR, получали до 7% коррекции мутированного, гуманизированного гена фактора IX в печени мыши [Li, H., et al. Nature 475, 217-221 (2011)]. Это приводило к улучшению кинетики свертывания крови, меры функционирования каскада свертывания крови, впервые демонстрируя, что терапия in vivo с применением редактирования является не только возможной, но и эффективной Как описано в данном документе, опытный специалист ориентируется на основе идей данного документа и знаний в данной области, например Li в случае лечения гемофилии B частицей, содержащей матрицу HDR и систему CRISPR-Cas (Cpf1), которая нацеливается на мутацию X-сцепленного рецессивного нарушения для обращения мутации потери функции.
- Основываясь на данном исследовании, другие группы с недавнего времени применяют редактирование генома в печени in vivo с использованием CRISPR-Cas для успешного лечения мышиной модели врожденной тирозинемии и для создания мутаций, которые обеспечивают защиту от сердечно-сосудистого заболевания. Эти два отдельных применения демонстрируют универсальность данного подхода для нарушений, которые охватывают дисфункцию печени [Yin, H., et al. Nature biotechnology 32, 551-553 (2014); Ding, Q., et al. Circulation research 115, 488-492 (2014)]. Применения редактирования in vivo других систем органов необходимы для подтверждения того, что данная стратегия широко применима. В настоящее время усилия для оптимизации как вирусных векторов, так и векторов, отличных от вирусных, находятся на пути реализации для расширения спектра нарушений, которые можно лечить с использованием данного метода терапии [Kotterman, M.A. & Schaffer, D.V. Nature reviews. Genetics 15, 445-451 (2014); Yin, H., et al. Nature reviews. Genetics 15, 541-555 (2014)]. Как описано в данном документе, опытный специалист ориентируется на основе идей данного документа и знаний в данной области, например Yin в случае лечения наследственной тирозинемии частицей, содержащей матрицу HDR и систему CRISPR-Cas (Cpf1), которая нацеливается на мутацию.
- Целенаправленная делеция, варианты терапевтического применения. Целенаправленная делеция генов может быть предпочтительной. Таким образом, предпочтительными являются гены, участвующие в иммунодефиците, гематологическом состоянии или генетической лизосомной болезни накопления, например, гемофилии B, SCID, SCID-X1, ADA-SCID, наследственной тирозинемии, β-талассемии, сцепленной с X-хромосомой CGD, синдроме Вискотта-Олдрича, анемии Фанкони, адренолейкодистрофии (ALD), метахромацитной лейкодистрофии (MLD), HIV/AIDS, других метаболических нарушениях, гены, кодирующие неправильно свернутые белки, участвующие в заболеваниях, гены, приводящие к потере функции, участвующей в заболевании, мутации, которые могут подвергаться нацеливанию в HSC, с помощью любой из описанных в данном документе систем доставки, при этом система с использованием частиц является предпочтительной.
- В настоящем изобретении иммуногенность фермента CRISPR, в частности, можно снизить, следуя подходу, впервые изложенному Tangri et al. в отношении эритропоэтина и впоследствии получившему развитие. Соответственно, для снижения иммуногенности фермента CRISPR (например, Cpf1) у вида-хозяина (человека или другого вида) можно применять направленную эволюцию или рациональное конструирование.
- Редактирование генома. Системы CRISPR/Cas (Cpf1) по настоящему изобретению можно применять для коррекции генетических мутаций, попытки которой с ограниченным успехом ранее предпринимались с применением TALEN и ZFN, а также лентивирусов, в том числе, как описано в данном документе; см. также WO2013163628.
Лечение заболеваний мозга, центральной нервной системы и иммунной системы
- Настоящее изобретение также предусматривает доставку системы CRISPR-Cas в головной мозг или нейроны. Например, РНК-интерференция (RNAi) предоставляет терапевтические возможности для лечения этого нарушения посредством уменьшения экспрессии HTT, гена, приводящего к развитию болезни Гентингтона (см., например, McBride et al., Molecular Therapy vol. 19 no. 12 Dec. 2011, pp. 2152-2162), следовательно, автор настоящего изобретения предполагает, что ее можно использовать с системой CRISPR-Cas и/или адаптировать к ней. Систему CRISPR-Cas можно получить с использованием алгоритма для уменьшения возможности нецелевого воздействия антисмысловых последовательностей. Последовательности CRISPR-Cas могут целенаправленно воздействовать на последовательность в экзоне 52 гентингтина мыши, макака-резуса или человека и экспрессироваться вирусным вектором, например на основе AAV. Животным, в том числе человеку, можно вводить путем приблизительно трех микроинъекций на полушарие (всего шесть инъекций): первая на 1 мм рострально от передней спайки (12 мкл) и две оставшиеся инъекции (12 мкл и 10 мкл соответственно) на расстоянии 3 и 6 мм каудально по отношению к первой инъекции, причем с 1e12 vg/мл AAV при скорости приблизительно 1 мкл/минута, при этом иглу оставляли на месте в течение дополнительных 5 минут для обеспечения диффузии вводимого вещества с наконечника иглы.
- DiFiglia et al. (PNAS, October 23, 2007, vol. 104, no. 43, 17204-17209) наблюдали, что однократное введение в полосатое тело взрослого организма siRNA, целенаправленно воздействующей на Htt, может привести к сайленсингу мутированного Htt, ослаблению нейрональной патологии и задержке развития аномального поведенческого фенотипа, наблюдаемого в модели HD на трансгенных мышах, полученной с использованием вируса, с быстрым началом проявления. DiFiglia инъецировал мышам в полосатое тело 2 мкл Cy3-меченых cc-siRNA-Htt или неконъюгированных siRNA-Htt при 10 мкМ. Аналогичная доза CRISPR-Cas, нацеленной на Htt, может быть предусмотрена в настоящем изобретении для человека, например приблизительно 5-10 мл 10 мкМ CRISPR-Cas, нацеленной на Htt, можно инъецировать в полосатое тело.
- В другом примере Boudreau et al. (Molecular Therapy vol. 17 no. 6 june 2009) инъецировали в полосатое тело 5 мкл векторов на основе рекомбинантного AAV серотипа 2/1, экспрессирующих htt-специфичный вирус для RNAi (при 4 x 1012 вирусных геномов/мл). Аналогичная доза CRISPR-Cas, нацеленной на Htt, может быть предусмотрена в настоящем изобретении для человека, например, приблизительно 10-20 мл 4 x 1012 вирусных геномов/мл, причем CRISPR-Cas, нацеленную на Htt, можно инъецировать в полосатое тело.
- В другом примере CRISPR-Cas, целенаправленно воздействующую на HTT, можно вводить непрерывно (см., например, Yu et al., Cell 150, 895-908, August 31, 2012). Yu et al. использовали доставку с помощью осмотических насосов, обеспечивающих скорость 0,25 мл/ч (модель 2004), для доставки 300 мг/день ss-siRNA или фосфатно-солевого буферного раствора (PBS) (Sigma Aldrich) в течение 28 дней и насосы, сконструированные с возможностью доставки 0,5 мкл/ч (модель 2002), использовали для доставки 75 мг/день MOE ASO положительного контроля в течение 14 дней. Насосы (Durect Corporation) заполняли ss-siRNA или MOE, разведенным стерильным PBS, а затем инкубировали при 37 C в течение 24 или 48 (Model 2004) часов перед имплантацией. Мышей анестезировали 2,5% изофлураном и делали срединный разрез у основания черепа. Используя стереотаксические зонды имплантировали канюлю в боковой правый желудочек и закрепляли с помощью клея Loctite. Катетер, прикрепленный к осмотическому мининасосу Alzet, прикрепляли к канюле, и насос размещали подкожно между лопатками. Разрез закрывали швами, используя нейлон 5,0. Аналогичная доза CRISPR-Cas, целенаправленно воздействующей на Htt, может предусматриваться в настоящем изобретении для человека, например, можно вводить от приблизительно 500 до 1000 г/день CRISPR-Cas, целенаправленно воздействующей на Htt.
- В другом примере непрерывной инфузии Stiles et al (Experimental Neurology 233 (2012) 463-471) имплантировали интрапаренхиматозный катетер с титановым наконечником иглы в правую скорлупу. Катетер подсоединяли к насосу SynchroMed® II (Medtronic Neurological, Миннеаполис, Миннесота), подкожно имплантированному в области живота. После 7 дней инфузии фосфатно-солевого буферного раствора при 6 мкл/день насосы повторно заполняли исследуемым препаратом и программировали на непрерывную доставку в течение 7 дней. От приблизительно 2,3 до 11,52 мг/день siRNA вводили путем инфузии при различных значениях скорости инфузии от приблизительно 0,1 до 0,5 мкл/мин. Аналогичная доза CRISPR-Cas, целенаправленно воздействующей на Htt, может предусматриваться в настоящем изобретении для человека, например, можно вводить от приблизительно 20 до 200 мг/день CRISPR-Cas, целенаправленно воздействующей на Htt. В другом примере способы согласно публикации патентного документа США № 20130253040, закрепленной за Sangamo, также можно адаптировать от TALES к системе нацеливания на нуклеиновую кислоту согласно настоящему изобретению для лечения болезни Гентингтона.
В другом примере способы согласно публикации патентного документа США № 20130253040 (WO2013130824), закрепленной за Sangamo, также можно адаптировать от TALES к системе CRISPR-Cas согласно настоящему изобретению для лечения болезни Гентингтона.
WO2015089354 A1 от имени The Broad Institute (института Броада) et al., включенный в данном документ посредством ссылки, описывает мишени для болезни Гентингтона (HP). При болезни Гентингтона потенциальные гены-мишени для комплекса CRISPR: PRKCE; IGF1; EP300; RCOR1; PRKCZ; HDAC4 и TGM2. Соответственно, один или более из PRKCE; IGF1; EP300; RCOR1; PRKCZ; HDAC4 и TGM2 могут быть выбраны в качестве мишеней для болезни Гентингтона в некоторых вариантах осуществления по настоящему изобретению.
Другие нарушения тринуклеотидных повторов. Они могут включать любое из следующего. Категория I включает болезнь Гентингтона (HD) и спиноцеребеллярные атаксии; экспансии категории II являются фенотипически разнообразными с гетерогенными экспансиями, которые, как правило, являются небольшими по величине, но также встречаются в экзонах генов; и категория III включает синдром ломкой X-хромосомы, миотоническую дистрофию, две из спиноцеребеллярных атаксий, ювенильную миоклонус-эпилепсию и атаксию Фридрейха.
- Дополнительный аспект настоящего изобретения относится к использованию системы CRISPR-Cas для корригирования дефектов в генах EMP2A и EMP2B, которые, как было обнаружено, ассоциированы с болезнью Лафора. Болезнь Лафора представляет собой аутосомно-рецессивное состояние, которое характеризуется прогрессирующей миоклонус-эпилепсией, которая может начинаться в виде эпилептических приступов в подростковом возрасте. Некоторые случаи заболевания могут быть вызваны мутациями в генах, которые уже были идентифицированы. Заболевание вызывает судорожные приступы, мышечные спазмы, затрудненную ходьбу, слабоумие и, в конечном итоге, смерть. В настоящее время не существует терапии, которая показала эффективность при прогрессировании заболевания. На другие генетические расстройства, ассоциированные с эпилепсией, также можно целенаправленно воздействовать с помощью системы CRISPR-Cas, и лежащие в основе генетические механизмы дополнительно описаны в Genetics of Epilepsy and Genetic Epilepsies, edited by Giuliano Avanzini, Jeffrey L. Noebels, Mariani Foundation Paediatric Neurology:20; 2009).
- Способы согласно публикации патентного документа США № 20110158957, закрепленного за Sangamo BioSciences, Inc., связанные с инактивацией генов T-клеточного рецептора (TCR), также можно модифицировать для применения с системой CRISPR-Cas согласно настоящему изобретению. В другом примере способы согласно публикации заявки на патент США № 20100311124, закрепленной за Sangamo BioSciences, Inc., и публикации заявки на патент США № 20110225664, закрепленной за Cellectis, оба из которых связаны с инактивацией экспрессии гена глутаминсинтетазы, также можно модифицировать для применения с системой CRISPR-Cas согласно настоящему изобретению.
- Варианты доставки в головной мозг включают инкапсулирование фермента CRISPR и направляющей РНК в форме ДНК или РНК в липосомы и конъюгацию с "молекулярными троянскими конями" для доставки через гематоэнцефалический барьер (BBB). Было показано, что "молекулярные троянские кони" являются эффективными для доставки векторов экспрессии B-gal в головной мозг отличных от человека приматов. Этот же подход можно применять для доставки векторов, содержащих фермент CRISPR и направляющую РНК. Например, Xia CF and Boado RJ, Pardridge WM ("Antibody-mediated targeting of siRNA via the human insulin receptor using avidin-biotin technology." Mol Pharm. 2009 May-Jun;6(3):747-51. doi: 10.1021/mp800194) описывают возможность доставки коротких интерферирующих РНК (siRNA) в клетки в культуре и in vivo в случае комбинированного применения моноклонального антитела (mAb), специфичного к рецептору, и авидин-биотиновой технологии. Авторы также сообщают, что, поскольку в случае применения авидин-биотиновой технологии связь между нацеливающим mAb и siRNA является устойчивой, то после внутривенного введения целенаправленно воздействующей siRNA наблюдаются эффекты RNAi in vivo в отдаленных участках, таких как головной мозг.
- Zhang et al. (Mol Ther. 2003 Jan;7(1):11-8.)) описывают, как экспрессионные плазмиды, кодирующие репортеры, такие как люцифераза, инкапсулировали во внутреннее пространство "искусственного вируса", включающего пегилированную иммунолипосому размером 85 нм, нацеливаемую на головной мозг макака-резуса in vivo с помощью моноклонального антитела (MAb) к рецептору инсулина человека (HIR). MAb к HIR позволяет липосоме, несущей экзогенный ген, подвергаться трансцитозу через гематоэнцефалический барьер и эндоцитозу через плазматическую мембрану нейронов после внутривенной инъекции. Уровень экспрессии гена люциферазы в головном мозге у макака-резуса был в 50 раз выше по сравнению с крысой. Широко распространенная экспрессия гена бета-галактозидазы в нейронах головного мозга приматов была продемонстрирована с помощью как гистохимического анализа, так и конфокальной микроскопии. Авторы указывают, что данный подход позволяет достичь обратимой экспрессии трансгена у взрослых животных в течение 24 часов. Соответственно, применение иммунолипосом является предпочтительным. Их можно использовать в сочетании с антителами для нацеливания на конкретные ткани или белки клеточной поверхности.
Болезнь Альцгеймера
- В публикации заявки на патент США № 20110023153 описывается применение нуклеаз с "цинковыми пальцами" для генетической модификации клеток, животных и белков, ассоциированных с болезнью Альцгеймера. После модификации клетки и животных можно дополнительно исследовать с применением известных способов для исследования воздействия целенаправленных мутаций на развитие и/или прогрессирование AD с использованием показателей, обычно применяемых в исследовании AD - таких как без ограничения обучение и память, тревожность, депрессия, привыкание и сенсомоторные функции, а также анализов, при помощи которых измеряют поведенческие, функциональные, патологические, метаболические и биохимические характеристики.
- Настоящее изобретение предусматривает редактирование любых хромосомных последовательностей, которые кодируют белки, ассоциированные с AD. Белки, связанные с AD, обычно выбирают исходя из экспериментально подтвержденной ассоциации белка, связанного с AD, с заболеванием AD. Например, скорость образования или концентрация в кровотоке белка, связанного с AD, может быть повышенной или пониженной в популяции с заболеванием AD по сравнению с популяцией без заболевания AD. Различия по уровням белка можно оценить с помощью протеомных методик, в том числе без ограничения вестерн-блоттинга, иммуногистохимического окрашивания, твердофазного иммуноферментного анализа (ELISA) и масс-спектрометрии. Альтернативно белки, связанные с AD, можно идентифицировать путем получения профилей генной экспрессии для генов, кодирующих белки, с помощью методик геномного анализа, в том числе без ограничения микроматричного анализа ДНК, последовательного анализа экспрессии генов (SAGE) и количественной полимеразной цепной реакции в режиме реального времени (Q-PCR).
- Примеры ассоциированных с болезнью Альцгеймера белков могут включать, например, белок-рецептор липопротеинов очень низкой плотности (VLDLR), кодируемый геном VLDLR, фермент 1, активирующий убиквитин-подобный модификатор (UBA1), кодируемый геном UBA1, или белок, являющийся каталитической субъединицей NEDD8-активирующего фермента E1 (UBE1C), кодируемый геном UBA3.
- В качестве неограничивающего примера, белки, ассоциированные с AD, включают без ограничения белки, перечисленные ниже: кодируемый хромосомной последовательностью белок ALAS2, дельта-аминолевулинатсинтаза 2 (ALAS2), ABCA1 - ATФ-связывающий кассетный транспортер (ABCA1), ACE - ангиотензин I-превращающий фермент (ACE), APOE - предшественник аполипопротеина E (APOE), APP - белок-предшественник амилоида (APP), AQP1 - белок аквапорин 1 (AQP1), BIN1 - Myc-бокс-зависимый взаимодействующий белок 1 или адаптерный белок-интегратор 1 (BIN1), BDNF - нейротрофический фактор головного мозга (BDNF), BTNL8 - белок 8, подобный бутирофилину (BTNL8), C1ORF49 - белок, кодируемый открытой рамкой считывания 49 хромосомы 1, CDH4 - кадгерин-4, CHRNB2 - нейрональный ацетилхолиновый рецептор, субъединица бета-2, CKLFSF2 - CKLF-подобный белок 2, содержащий трансмембранный домен MARVEL (CKLFSF2), CLEC4E - лектиновый домен C-типа, семейство 4, представитель e (CLEC4E), CLU - кластериновый белок (также известный как аполипопротеин J) CR1 - эритроцитарный рецептор комплемента 1 (CR1, также известный как CD35, рецептор C3b/C4b и рецептор иммунной адгезии), CR1L - эритроцитарный рецептор комплемента 1 (CR1L), CSF3R - рецептор гранулоцитарного колониестимулирующего фактора 3 (CSF3R), CST3 - цистатин C или цистатин 3, CYP2C - цитохром P450 2C, DAPK1 - ассоциированная с клеточной гибелью протеинкиназа 1 (DAPK1), ESR1 - эстрогеновый рецептор 1, FCAR - Fc-фрагмент рецептора для IgA (FCAR, также известный как CD89), FCGR3B - Fc-фрагмент рецептора IIIb для IgG, с низким сродством (FCGR3B или CD16b), FFA2 - рецептор 2 свободных жирных кислот (FFA2), FGA - фибриноген (фактор I), GAB2 - GRB2-ассоциированный связывающий белок 2 (GAB2), GAB2 - GRB2-ассоциированный связывающий белок 2 (GAB2), GALP - галанин-подобный пептид, GAPDHS - глицеральдегид-3-фосфатдегидрогеназа сперматогенных клеток (GAPDHS), GMPB - GMBP, HP - гаптоглобин (HP), HTR7 - 5-гидрокситриптаминовый (серотониновый) рецептор 7 (сопряженный с аденилатциклазой), IDE - фермент, разрушающий инсулин IF127 IF127, IFI6 - интерферон альфа-индуцируемый белок 6 (IFI6), IFIT2 - интерферон-индуцируемый белок с тетратрикопептидными повторами 2 (IFIT2), IL1RN - антагонист рецептора интерлейкина-1 (IL-1RA), IL8RA - рецептор интерлейкина 8, альфа (IL8RA или CD181), IL8RB - рецептор интерлейкина 8, бета (IL8RB), JAG1 - белок Jagged 1 (JAG1), KCNJ15 - входящий калиевый канал, подсемейство J, представитель 15 (KCNJ15), LRP6 - белок 6, родственный рецептору липопротеинов низкой плотности (LRP6), MAPT - белок tau, ассоциированный с микротрубочками (MAPT), MARK4 - киназа 4 MAP/регулирующая сродство к микротрубочкам (MARK4), MPHOSPH1 - фосфобелок 1 M-фазы, MTHFR - 5,10-метилентетрагидрофолатредуктазу, MX2 - интерферон-индуцируемый GTP-связывающий белок Mx2, NBN - нибрин, также известный как NBN, NCSTN - никастрин, NIACR2 - рецептор 2 ниацина (NIACR2, также известный как GPR109B), NMNAT3 - никотинамиднуклеотидаденилилтрансфераза 3, NTM - нейротримин (или HNT), ORM1 - орозомукоид 1 (ORM1) или альфа-1-кислый гликопротеин 1, P2RY13 - пуринергический рецептор P2Y 13 (P2RY13), PBEF1 - никотинамидфосфорибозилтрансфераза (NAmPRTазу или Nampt), также известная как колониестимулирующий фактор 1 пре-B-клеток (PBEF1) или висфатин, PCK1 - -фосфоенолпируваткарбоксикиназа, PICALM - фосфатидилинозит-cвязывающий белок, вовлеченный в формирование клатриновых комплексов (PICALM), PLAU - активатор плазминогена урокиназного типа (PLAU), PLXNC1 - плексин C1 (PLXNC1), PRNP - прионный белок, PSEN1 - белок пресенилин 1 (PSEN1), PSEN2 - белок пресенилин 2 (PSEN2), PTPRA - белок, представляющий собой рецепторную протеинтирозинфосфатазу типа A (PTPRA), RALGPS2 - Ral GEF с доменом PH и SH3-связывающим мотивом 2 (RALGPS2), RGSL2 - белок 2, подобный регулятору передачи сигнала с помощью G-белка (RGSL2), SELENBP1 - селенсвязывающий белок 1 (SELNBP1), SLC25A37 - митоферрин-1, SORL1 - родственный сортилину рецептор L (класс DLR), белок, содержащий повторы A (SORL1), TF - трансферрин, TFAM - митохондриальный транскрипционный фактор A, TNF - фактор некроза опухоли, TNFRSF10C - суперсемейство рецепторов фактора некроза опухоли, представитель 10C (TNFRSF10C), TNFSF10 - суперсемейство рецепторов фактора некроза опухоли (TRAIL), представитель 10a (TNFSF10), UBA1 - фермент 1, активирующий убиквитин-подобный модификатор (UBA1), UBA3 - белок, являющийся каталитической субъединицей NEDD8-активирующего фермента E1 (UBE1C), UBB - белок убиквитин B (UBB), UBQLN1 - убиквилин-1, UCHL1 - белок эстеразу карбокси-конца убиквитина L1 (UCHL1), UCHL3 - белок-изофермент L3 гидролазы карбокси-конца убиквитина (UCHL3), VLDLR - белок-рецептор липопротеинов очень низкой плотности (VLDLR).
- В иллюстративных вариантах осуществления белки, ассоциированные с AD, редактирование хромосомной последовательности которых осуществляют, могут представлять собой белок рецептора липопротеинов очень низкой плотности (VLDLR), кодируемый геном VLDLR, фермент 1, активирующий убиквитин-подобный модификатор (UBA1), кодируемый геном UBA1, белок каталитической субъединицы NEDD8-активирующего фермента E1 (UBE1C), кодируемый геном UBA3, белок аквапорин 1 (AQP1), кодируемый геном AQP1, белок эстеразы карбокси-конца убиквитина L1 (UCHL1), кодируемый геном UCHL1, белок, относящийся к изоферменту L3 гидролазы карбокси-конца убиквитина (UCHL3), кодируемый геном UCHL3, белок убиквитин B (UBB), кодируемый геном UBB, белок tau, ассоциированный с микротрубочками (MAPT), кодируемый геном MAPT, белок рецептора тирозинфосфатазы типа A (PTPRA), кодируемый геном PTPRA, фосфатидилинозит-cвязывающий белок, вовлеченный в формирование клатриновых комплексов (PICALM), кодируемый геном PICALM, кластериновый белок (также известный как аполипопротеин J), кодируемый геном CLU, белок пресенилин 1, кодируемый геном PSEN1, белок пресенилин 2, кодируемый геном PSEN2, родственный сортилину рецептор L (класс DLR), белок, содержащий повторы A (SORL1), кодируемый геном SORL1, белок-предшественник амилоида (APP), кодируемый геном APP, предшественник аполипопротеина E (APOE), кодируемый геном APOE, или нейротрофический фактор головного мозга (BDNF), кодируемый геном BDNF. В иллюстративном варианте осуществления генетически модифицированное животное представляет собой крысу, и редактируемые хромосомные последовательности, кодирующие белок, ассоциированный с AD, являются следующими: APP - белок-предшественник амилоида (APP) - NM_019288, AQP1 - белок аквапорин 1 (AQP1) - NM_012778, BDNF - нейротрофический фактор головного мозга - NM_012513, CLU - кластериновый белок (также известный как аполипопротеин J) - NM_053021, MAPT - белок tau, ассоциированный с микротрубочками (MAPT) - NM_017212, PICALM - фосфатидилинозит-cвязывающий белок, вовлеченный в формирование клатриновых комплексов (PICALM) - NM_053554, PSEN1 - белок пресенилин 1 (PSEN1) - NM_019163, PSEN2 - белок пресенилин 2 (PSEN2) - NM_031087, PTPRA - белок, представляющий собой рецепторную протеинтирозинфосфатазу типа A (PTPRA) - NM_012763, SORL1 - родственный сортилину рецептор L (класс DLR), белок, содержащий повторы A (SORL1) - NM_053519, XM_001065506, XM_217115, UBA1 - фермент 1, активирующий убиквитин-подобный модификатор (UBA1) - NM_001014080, UBA3 - белок, являющийся каталитической субъединицей NEDD8-активирующего фермента E1 (UBE1C) - NM_057205, UBB - белок убиквитин B (UBB) - NM_138895, UCHL1 - белок эстераза карбокси-конца убиквитина L1 (UCHL1) - NM_017237, UCHL3 - белок-изофермент L3 гидролазы карбокси-конца убиквитина (UCHL3) - NM_001110165, VLDLR - белок-рецептор липопротеинов очень низкой плотности (VLDLR) - NM_013155.
- Животное или клетка может содержать 1, 2, 3, 4, 5, 6, 7, 8, 9,10, 11, 12, 13, 14, 15 или более хромосомных последовательностей с нарушенной структурой, кодирующих белок, ассоциированный с AD, и ноль, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 или более интегрированных в хромосомы последовательностей, кодирующих белок, ассоциированный с AD.
- Отредактированную или интегрированную хромосомную последовательность можно модифицировать так, чтобы она кодировала измененный белок, ассоциированный с AD. Ряд мутаций в хромосомных последовательностях, связанных с AD, были ассоциированы с AD. Например, миссенс-мутация V7171 (т. е. валин в положении 717 заменен на изолейцин) в APP приводит к семейной форме AD. Несколько мутаций в белке пресенилин-1, например, H163R (т. е. гистидин в положении 163 заменен на аргинин), A246E (т. е. аланин в положении 246 заменен на глутамат), L286V (т. е. лейцин в положении 286 заменен на валин) и C410Y (т. е. цистеин в положении 410 заменен на тирозин) приводят к семейной форме болезни Альцгеймера 3 типа. Мутации в белке пресенилин-2, например, N141I (т. е. аспарагин в положении 141 заменен на изолейцин), M239V (т. е. метионин в положении 239 заменен на валин) и D439A (т. е. аспартат в положении 439 заменен на аланин) приводят к семейной форме болезни Альцгеймера 4 типа. Другие ассоциации генных вариантов генов, ассоциированных с AD, и заболевания известны из уровня техники. См., например, публикацию Waring et al. (2008) Arch. Neurol. 65:329-334, раскрытие которой включено в данный документ посредством ссылки во всей своей полноте.
Нарушения, связанные с активностью секретазы
- В публикации заявки на патент США № 20110023146 описывается применение нуклеаз с "цинковыми пальцами" для генетической модификации клеток, животных и белков, ассоциированных с нарушением, связанным с активностью секретазы. Секретазы необходимы для процессинга белков-предшественников с образованием их биологически активных форм. Дефекты различных компонентов секретазных путей связаны со многими нарушениями, в частности, с характерным амилоидогенезом или амилоидными бляшками, например, болезнь Альцгеймера (AD).
- Что касается нарушения, связанного с активностью секретазы, белки, ассоциированные с этими нарушениями, представляют собой разнородную группу белков, которые оказывают влияние на восприимчивость ко многим нарушениям, наличие нарушения, тяжесть нарушения или любую их комбинацию. Настоящее изобретение предусматривает редактирование любых хромосомных последовательностей, которые кодируют белки, ассоциированные с нарушением, связанным с активностью секретазы. Белки, ассоциированные с нарушением, связанным с активностью секретазы, как правило, выбирают исходя из экспериментально установленной ассоциации белков, родственных секретазе, с развитием нарушения, связанного с активностью секретазы. Например, скорость образования или концентрация в кровотоке белка, ассоциированного с нарушением, связанным с активностью секретазы, может быть повышенной или пониженной в популяции с нарушением, связанным с активностью секретазы, по сравнению с популяцией без нарушения, связанного с активностью секретазы. Различия по уровням белка можно оценить с помощью протеомных методик, в том числе без ограничения вестерн-блоттинга, иммуногистохимического окрашивания, твердофазного иммуноферментного анализа (ELISA) и масс-спектрометрии. Альтернативно белок, ассоциированный с нарушением, связанным с активностью секретазы, можно идентифицировать путем получения профилей экспрессии генов для генов, кодирующих белки, с помощью методик геномного анализа, в том числе без ограничения микроматричного анализа ДНК, последовательного анализа экспрессии генов (SAGE) и количественной полимеразной цепной реакции в режиме реального времени (Q-PCR).
- При помощи неограничивающего примера белки, ассоциированные с нарушением, связанным с активностью секретазы, включают PSENEN (гомолог 2 энхансера пресенилина (C. elegans)), CTSB (катепсин B), PSEN1 (пресенелин 1), APP (предшественник белка амилоида бета (A4)), APH1B (гомолог В дефекта переднего отдела гортани 1 (C. elegans)), PSEN2 (пресенилин 2 (болезнь Альцгеймера 4 типа)), BACE1 (бета-сайт APP-расщепляющий фермент 1), ITM2B (интегральный мембранный белок 2B), CTSD (катепсин D), NOTCH1 (гомолог 1 Notch, ассоциированный с транслокацией (дрозофилиный)), TNF (фактор некроза опухоли (семейство TNF, представитель 2)), INS (инсулин), DYT10 (фактор 10 дистонии), ADAM17 (домен 17 ADAM металлопептидазы), APOE (аполипопротеин E), ACE (ангиотензин I превращающий фермент (пептидил-дипептидазу A) 1), STN (статин), TP53 (опухолевый белок p53), IL6 (интерлейкин 6 (интерферон, бета 2)), NGFR (рецептор фактора роста нервов (семейство TNFR, представитель 16)), IL1B (интерлейкин 1, бета), ACHE (ацетилхолинэстеразу (группа крови Yt)), CTNNB1 (катенин (кадгерин-ассоциированный белок), бета 1, 88 кДа), IGF1 (инсулин-подобный фактор роста 1 (соматомедин C)), IFNG (интерферон, гамма), NRG1 (неурегулин 1), CASP3 (каспазу 3, связанную с апоптозом цистеинпептидазу), MAPK1 (митоген-активируемую протеинкиназу 1), CDH1 (кадгерин 1, 1 тип, E-кадгерин (эпителиальный)), APBB1 (протеин-связывающий предшественник амилоида бета (A4), семейство B, член 1 (Fe65)), HMGCR (3-гидрокси-3-метилглутарил-коэнзим A редуктазу), CREB1 (связывающий белок 1 чувствительного к cAMP элемента), PTGS2 (простагландин-эндопероксидсинтазу 2 (простагландин G/H синтазу и циклооксигеназу)), HES1 (белок "hairy and enhancer of split 1", (дрозофилиный)), CAT (каталазу), TGFB1 (трансформирующий фактор роста, бета 1), ENO2 (энолазу 2 (гамма, нейрональную)), ERBB4 (гомолог 4 онкогена вируса эритробластического лейкоза v-erb-a (птичий)), TRAPPC10 (комплекс миграции белковых частиц 10), MAOB (моноаминоксидазу B), NGF (фактор роста нервов (бета-полпипептид)), MMP12 (матриксную металлопептидазу 12 (макрофагальную эластазу)), JAG1 (jagged 1 (синдром Алажиля)), CD40LG (лиганд к CD40), PPARG (гамма-рецептор, активируемый пролифератором пероксисом), FGF2 (фактор роста фибробластов 2 (основной)), IL3 (интерлейкин 3 (колониестимулирующий фактор, множественный)), LRP1 (белок 1, связанный с рецептором липопротеина низкой плотности), NOTCH4 (гомолог 4 Notch (дрозофилиный)), MAPK8 (митоген-активируемую протеинкиназу 8), PREP (пролилэндопептидазу), NOTCH3 (гомолог 3 Notch 3 (дрозофильный)), PRNP (прионный белок), CTSG (катапсин G), EGF (эпидермальный фактор роста (бета-урогастрон)), REN (ренин), CD44 (молекулу CD44 (группа крови системы Indian)), SELP (селектин P (гранулярный мембранный белок с массой 140 кДа, антиген CD62)), GHR (рецептор гормона роста), ADCYAP1 (полипептид 1, активирующий адентилатциклазу 1 (гипофизарный)), INSR (инсулиновый рецептор), GFAP (глиофибриллярный кислый белок), MMP3 (матриксную металлопептидазу 3 (стромелизин 1, прожелатиназу)), MAPK10 (митоген-актвивированную протеинкиназу 10), SP1 (фактор транскрипции Sp1), MYC (гомолог онкогена вируса миелоцитоматоза v-myc (птичий)), CTSE (катепсин E), PPARA (альфа-рецептор, активируемый пролифератором пероксисом), JUN (онкоген jun), TIMP1 (ингибитор TIMP металлопептидазы 1), IL5 (интерлейкин 5 (колониестимулирующий фактор, эозинофильный)), IL1A (интерлейкин 1, альфа), MMP9 (матриксную металлопептидазу 9 (желатиназу B, желатиназу с массой 92 кДа, коллагеназу IV типа с массой 92 кДа)), HTR4 (5-гидрокситриптамин (серотониновый) рецептор 4 типа), HSPG2 (гепарасульфатпротеогликан 2), KRAS (гомолог онкогена вируса саркомы крыс Kirsten v-Ki-ras2), CYCS (цитохром c, соматический), SMG1 (гомолог SMG1, киназу, связанную с фосфатидилинозитол-3-киназой (C. elegans)), IL1R1 (рецептор интерлейкина 1, I тип), PROK1 (прокинетицин 1), MAPK3 (митоген-активируемую протеинкиназу 3), NTRK1 (нейротрофическую тироизинкиназу, рецептор, 1 тип), IL13 (интерлейкин 13), MME (мембранную металлоэндопептидазу), TKT (транскетолазу), CXCR2 (хемокиновый рецептор 2 (с мотивом C-X-C)), IGF1R (рецептор 1 инсулин-подобного фактора роста), RARA (рецептор ретиноевой кислоты, альфа), CREBBP (CREB-связывающий белок), PTGS1 (простагландин-эндопероксидсинтазу 1 (простагландин G/H синтазу и циклооксигеназу)), GALT (галактозо-1-фосфатуридилтрансферазу), CHRM1 (холинергический рецептор, мускариновый 1), ATXN1 (атаксин 1), PAWR (PRKC, апоптический, WT1, регулятор), NOTCH2 (гомолог 2 Notch (дрозофилиный)), M6PR (маннозо-6-фосфатный рецептор (катион-зависимый)), CYP46A1 (цитохром P450, семейство 46, подсемейство A, полипептид 1), CSNK1 D (казеинкиназу 1, дельта), MAPK14 (митоген-активируемую протеинкиназу 14), PRG2 (протеогликан 2, костномозговой (активатор натуральных клеток-киллеров, главный основной белок эозинофильных гранул)), PRKCA (протеинкиназу C, альфа), L1 CAM (молекулу клеточной адгезии L1), CD40 (молекулу CD40, член 5 суперсемейства рецепторов TNF), NR1I2 (семейство 1 ядерных рецепторов, I группа, член 2), JAG2 (jagged 2), CTNND1 (катенин (кадгерин-ассоциированный белок), дельта 1), CDH2 (кадгерин 2, 1 тип, N-кадгерин (нейрональный)), CMA1 (химазу 1, тучных клеток), SORT1 (сортилин 1), DLK1 (дельта-подобный 1 гомолог (дрозофилиный)), THEM4 (представитель 4 семейства тиоэстераз 4), JUP (плакоглобин межклеточных контактов), CD46 (молекулу CD46, регуляторный белок комплемента), CCL11 (хемокиновый лиганд 11 (с мотивом C-C)), CAV3 (кавеолин 3), RNASE3 (рибонуклеазу, РНКазу, семейство A, 3 (эозинофильный катионный белок)), HSPA8 (белок 8 теплового шока, с массой 70 кДа), CASP9 (каспазу 9, связанную с апоптозом цистеинпептидазу), CYP3A4 (цитохром P450, семейство 3, подсемейство A, полипептид 4), CCR3 (хемокиновый рецептор 3 (с мотивом C-C)), TFAP2A (фактор транскрипции AP-2 альфа (активирующий энхансер связывающий белок 2 альфа)), SCP2 (белок-переносчик стеринов 2), CDK4 (циклин-зависимую киназу 4), HIF1A (индуцируемый гипоксией фактор 1, альфа-субъединица (основной фактор транскрипции спираль-петля-спираль)), TCF7L2 (фактор 2, подобный фактору транскрипции 7 (специфичный по отношению к T-клеткам, HMG-бокс)), IL1R2 (рецептор интерлейкина 1, II тип), B3GALTL (факторы, подобный бета 1,3-галактозилтрансферазе), MDM2 (гомолог Mdm2 p53-связывающего белка (мышиный)), RELA (гомолог онкогена А вируса ретикулоэндотелиоза v-rel (птичий)), CASP7 (каспазу 7, связанную с апоптозом цистеинпептидазу), IDE (разрушающий инсулин фермент), FABP4 (белок 4, связывающий жирные кислоты, адипоцитарный), CASK (кальций/кальмодулин-зависимую протеинкиназу (семейство MAGUK)), ADCYAP1R1 (аденилатциклазный активирующий рецептор полипептида 1 (гипофизарный), I тип), ATF4 (активирующий фактор транскрипции 4 (чувствительный к tax энхансерный элемент B67)), PDGFA (тромбоцитарный фактор роста, альфа-полипептид), C21 или f33 (открытая рамка считывания 33 хромосомы 21), SCG5 (секретогранин V (белок 7B2)), RNF123 (белок с "цинковыми пальцами" типа ring 123), NFKB1 (ядерный фактор энхансера гена каппа-полипептида легкой цепи в B-клетках 1 типа), ERBB2 (гомолог онкогена 2 вируса эритробластного лейкоза v-erb-b2, гомолог онкогена нейро-/глиобластомного происхождения (птичий)), CAV1 (кавеолин 1, белок кавеол, 22 кДа), MMP7 (матриксную металлопептидазу 7 (матрилизин, маточный)), TGFA (трансформирующий фактор роста, альфа), RXRA (ретиноидный X-рецептор, альфа), STX1A (синтаксин 1A (головного мозга)), PSMC4 (протеасомную субъединицу 26S (просому, макропаин), АТФазу, 4), P2RY2 (пиринергический рецептор P2Y, связанный с G-белком, 2), TNFRSF21 (семейство рецепторов фактора некроза опухоли, представитель 21), DLG1 (discs, большой гомолог 1 (дрозофилиный)), NUMBL (гомолог, подобный numb (дрозофилиный)), SPN (сиалофорин), PLSCR1 (фосфолипидскрамблазу 1), UBQLN2 (убиквитин 2), UBQLN1 (убиквитин 1), PCSK7 (пропротеинконвертазу субтилизин/кексин 7 типа), SPON1 (спондин 1, белок внеклеточного матрикса), SILV (гомолог silver (мышиный)), QPCT (глутаминил-пептид-циклотрансферазу), HESS (белок "hairy and enhancer of split 5" (дрозофильный)), GCC1 (содержащий GRIP двуспиральный домен 1) и их комбинацию.
- Генетически модифицированные животное или клетка могут содержать 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или больше хромосомных последовательностей с нарушенной структурой, кодирующих белок, ассоциированный с нарушением, связанным с активностью секретазы, и ноль, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или больше интегрированных в хромосомы последовательностей, кодирующих белок с нарушенной структурой, ассоциированный с нарушением, связанным с активностью секретазы.
ALS
- В публикации заявки на патент США № 20110023144 описывается применение нуклеаз с "цинковыми пальцами" для генетической модификации клеток, животных и белков, ассоциированных с заболеванием амиотрофическим латеральным склерозом (ALS). ALS характеризуется постепенной прогрессирующей дегенерацией определенных нервных клеток в коре головного мозга, стволе головного мозга и спинном мозге, связанных с произвольными движениями.
- Что касается нарушения, связанного с двигательными нейронами, белки, ассоциированные с этими нарушениями, представляют собой разнородную группу белков, которые оказывают влияние на восприимчивость к развитию нарушения, связанного с двигательными нейронами, наличие нарушения, связанного с двигательными нейронами, тяжесть нарушения, связанного с двигательными нейронами, или любую их комбинацию. Настоящее изобретение предусматривает редактирование любых хромосомных последовательностей, которые кодируют белки, ассоциированные с заболеванием, связанным с ALS, специфическим нарушением, связанным с двигательными нейронами. Белки, ассоциированные с ALS, как правило, выбирают исходя из экспериментально установленной взаимосвязи белков, связанных с ALS, с нарушением по типу ALS. Например, скорость образования или концентрация в кровотоке белка, ассоциированного с ALS, может быть повышенной или пониженной в популяции с ALS по сравнению с популяцией без ALS. Различия по уровням белка можно оценить с помощью протеомных методик, в том числе без ограничения вестерн-блоттинга, иммуногистохимического окрашивания, твердофазного иммуноферментного анализа (ELISA) и масс-спектрометрии. Альтернативно белки, ассоциированные с ALS, можно идентифицировать путем получения профилей экспрессии генов для генов, кодирующих белки, с помощью методик геномного анализа, в том числе без ограничения микроматричного анализа ДНК, последовательного анализа экспрессии генов (SAGE) и количественной полимеразной цепной реакции в режиме реального времени (Q-PCR).
- В качестве неограничивающего примера белки, ассоциированные с ALS, включают без ограничения следующие белки: SOD1 - растворимая супероксиддисмутаза 1, ALS3 - белок 3, связанный с амиотрофическим латеральным склерозом, SETX - сенатаксин, ALS5 - белок 5, связанный с амиотрофическим латеральным склерозом, FUS - РНК-связывающий белок FUS (слит при саркоме), ALS7 - белок 7, связанный с амиотрофическим латеральным склерозом, ALS2 - белок 2, связанный с амиотрофическим латеральным склерозом, DPP6 - дипептидилпептидаза 6, NEFH - тяжелый полипептид нейрофиламента, PTGS1 - простагландин-эндопероксидсинтазы 1, SLC1A2 - семейство 1 переносчиков растворенных веществ (глутаматный транспортер глиальных клеток с высоким сродством), представитель 2, TNFRSF10B - фактор некроза опухоли, суперсемейство рецепторов, представитель 10b, PRPH - периферин, HSP90AA1 - 90 кДа белок теплового шока альфа (цитозольный), класс A представитель 1, GRIA2 - глутаматный рецептор, ионотропный, AMPA 2, IFNG - интерферон, гамма, S100B - S100, кальций-связывающий белок B, FGF2 - фактор 2 роста фибробластов, AOX1 - альдегидоксидаза 1, CS - цитратсинтаза, TARDBP - TAR ДНК-связывающий белок, TXN - тиоредоксин, RAPH1 - Ras-ассоциированный белок, (RaIGDS/AF-6) и киназа 5 с доменами 1, характеризующимися гомологией с плекстрином, MAP3K5 - митоген-активируемая протеинкиназа, NBEAL1 - белок 1, подобный нейробичину, GPX1 - глутатионпероксидаза 1, ICA1L - подобный 1,69 кДа-аутоантигену островковых клеток, RAC1 - ras-родственный белок, подобный субстрату 1 ботулинического C3 токсина, MAPT - белок tau, ассоциированный с микротрубочками, ITPR2 - рецептор инозитол-1,4,5-трифосфата, тип 2, ALS2CR4 - кандидатный участок 4 хромосомы для белка 2, связанного с амиотрофическим латеральным склерозом (ювенильным), GLS - глутаминаза, ALS2CR8 - кандидатный участок 8 хромосомы для белка 2, связанного с амиотрофическим латеральным склерозом (ювенильным), CNTFR - рецептор для цилиарного нейротрофического фактора, ALS2CR11 - кандидатный участок 11 хромосомы для белка 2, связанного с амиотрофическим латеральным склерозом (ювенильным), FOLH1 - фолатгидролаза 1, FAM117B - семейство белков со сходством последовательности с белком 117, представитель B, P4HB - пролил-4-гидроксилаза, полипептид бета, CNTF - цилиарный нейротрофический фактор, SQSTM1 - секвестосома 1, STRADB - STE20-родственная киназа, бета-адаптерная, NAIP - семейство NLR, связанный с апоптозом ингибиторный белок, YWHAQ - тирозиназа/триптофан-5-монооксигеназа активирующий белок, полипептид тета, SLC33A1 - семейство 33 переносчиков растворенных веществ (ацетил-CoA транспортеры), представитель 1, TRAK2 - транспортный белок, кинезин-связывающий 2, фиг. 4, гомолог, содержащий домен фосфатазы липидов SAC1, NIF3L1 - NIF3 NGG1-взаимодействующий фактор 3, подобный 1, INA - интернексин, нейрональный промежуточный филаментный белок, альфа, PARD3B - белок par-3 (partitioning defective 3), гомолога B, COX8A - цитохром c оксидаза, субъединица VIIIA, CDK15 - циклин-зависимая киназа, HECW1 HECT - белок, содержащий домен C2 и WW 15, E3 - лигаза 1 убиквитинового белка, NOS1 - синтаза 1 оксида азота, MET - протоонкоген met, SOD2 - митохондриальная супероксиддисмутаза 2, HSPB1 - 27 кДа белок 1 теплового шока, NEFL - легкий полипептид нейрофиламента, CTSB - катепсин B, ANG - ангиогенин, рибонуклеаза ANG - ангиогенин, рибонуклеаза, РНКаза семейства 5, HSPA8 - 70 кДа белок теплового шока 8, VAPB VAMP (ассоциированный с везикулами мембранный белок)-ассоциированные белки B и C, ESR1 - эстрогеновый рецептор 1, SNCA -синуклеин, альфа, HGF - фактор роста гепатоцитов, CAT - каталаза, ACTB - актин, бета, NEFM - среднего размера полипептид нейрофиламента, TH - тирозингидроксилаза, BCL2 - белок 2 B-клеток, связанный с CLL/лимфомой, FAS - Fas (суперсемейство рецепторов TNF, представитель 6), CASP3 - каспаза 3, связанная с апоптозом цистеинпептидаза, CLU - кластерин, SMN1 - белок, связанный с выживанием двигательных нейронов, G6PD - глюкозо-6-фосфатдегидрогеназа 1, BAX BCL2-ассоциированный белок X, HSF1 - транскрипционный фактор 1 белка теплового шока, RNF19A - белок 19A с доменом ring, JUN - онкоген jun, ALS2CR12 - кандидатный участок 12 хромосомы для белка 2, связанного с амиотрофическим латеральным склерозом (ювенильным), HSPA5 - 70 кДа белок 5 теплового шока, MAPK14 - митоген-активируемая протеинкиназа 14, IL10 - интерлейкин 10, APEX1 - APEX-нуклеаза (мультифункциональный фермент репарации ДНК), TXNRD1 - тиоредоксинредуктаза 1, NOS2 - индуцируемая синтаза 2 оксида азота, TIMP1 - TIMP - ингибитор 1 металлопептидазы, CASP9 - каспаза 9, связанная с апоптозом цистеинпептидаза, XIAP - сцепленный с X-хромосомой ингибитор апоптоза, GLG1 - гликопротеин 1 комплекса Гольджи, EPO - эритропоэтин, VEGFA - фактор роста эндотелия сосудов A, ELN - эластин, GDNF - нейротрофический фактор, полученный из глиальных клеток, NFE2L2 - белок 2, подобный ядерному фактору (эритроидному), SLC6A3 - представитель 3 семейства 6 переносчиков растворенных веществ (транспортер нейротрансмиттеров, допаминовый), HSPA4 - 70 кДа белок 4 теплового шока, APOE - аполипопротеин E, PSMB8 - субъединица протеасомы (просома, макропаин), тип бета, 8, DCTN1 - динактин 1, TIMP3 - TIMP - ингибитор 3 металлопептидазы, KIFAP3 - кинезин-ассоциированный белок 3, SLC1A1 - представитель 1 семейства 1 переносчиков растворенных веществ (глутаматный транспортер нейронов/эпителиальных клеток с высоким сродством, система Xag), SMN2 - центромерный белок 2 выживания двигательных нейронов, CCNC - циклин C, MPP4 - пальмитоилированный мембранный белок 4, STUB1 - белок 1, гомологичный STIP1 и содержащий U-box, ALS2 - белок-предшественник амилоида бета (A4), PRDX6 - пероксиредоксин 6, SYP - синаптофизин, CABIN1 - кальциневрин-связывающий белок 1, CASP1 - каспаза 1, связанная с апоптозом цистеинпептидаза, GART - фосфорибозилглицинамидформилтрансфераза, фосфорибозилглицинамидсинтетаза, фосфорибозиламиноимидазолсинтетаза, CDK5 - циклин-зависимая киназа 5, ATXN3 - атаксин 3, RTN4 - ретикулон 4, C1QB компонент комплемента 1, субкомпонент q, цепь B, VEGFC - рецептор фактора роста нервов, HTT - хантингтин, PARK7 - белок 7, связанный с болезнью Паркинсона, XDH - ксантиндегидрогеназа, GFAP - глиальный фибриллярный кислый белок, MAP2 - белок 2, ассоциированный с микротрубочками, CYCS - цитохром c, соматические клетки, FCGR3B - Fc-фрагмент рецептора IIIb для IgG с низким сродством, CCS - медь-содержащий шаперон супероксиддисмутазы, UBL5 - белок 5, подобный убиквитину, MMP9 - матриксная металлопептидаза 9, SLC18A3 - представитель 3 семейства 18 переносчиков растворенных веществ (везикулярный, ацетилхолиновый), TRPM7 - катионный канал транзиентного рецепторного потенциала, подсемейство M, представитель 7, HSPB2 - 27 кДа белок 2 теплового шока, AKT1 - гомолог 1 онкогена v-akt вируса тимомы мышей, DERL1- представитель 1 семейства белков с Der1-подобным доменом, CCL2 - лиганд 2 хемокина (C--C мотив), NGRN - неугрин, ассоциированный с ростом аксонов, GSR - глутатионредуктаза, TPPP3 - представитель 3 семейства белков, способствующих полимеризации тубулина, APAF1 - фактор 1, активирующий апоптическую пептидазу, BTBD10 - белок 10, содержащий домен BTB (POZ), GLUD1 - глутаматдегидрогеназа 1, CXCR4 - рецептор 4 хемокина (C--X--C мотив), SLC1A3 - представитель 3 семейства 1 переносчиков растворенных веществ (глутаматный транспортер глиальных клеток с высоким сродством), FLT1 - тирозинкиназа 1, родственная fms, PON1 - параоксоназа 1, AR - андрогеновый рецептор, LIF - ингибиторный фактор, связанный с лейкозом, ERBB3 - гомолог 3 онкогена v-erb-b2 вируса эритробластического лейкоза, LGALS1 - лектин, галактозид-связывающий, растворимый, белок 1, CD44 - молекула CD44, TP53 - опухолевый белок p53, TLR3 - толл-подобный рецептор 3, GRIA1 - глутаматный рецептор, ионотропный, AMPA 1, GAPDH - глицеральдегид-3-фосфатдегидрогеназа, GRIK1 - глутаматный рецептор, ионотропный, каинатный белок 1, DES - десмин, CHAT - холинацетилтрансфераза, FLT4 - тирозинкиназа 4, родственная fms, CHMP2B - белок 2B, модифицирующий хроматин, BAG1 - BCL2-ассоциированный атаноген, MT3 - металлотионеин 3, CHRNA4 - холинергический рецептор, никотиновый, альфа 4, GSS - глутатионсинтетаза, BAK1 - BCL2-антагонист/киллер 1, KDR - рецептор вставочного домена киназы (рецептор тирозинкиназы III типа), GSTP1 - глутатион-S-трансфераза пи 1, OGG1 - 8-оксогуанин-ДНК-гликозилаза, IL6 - интерлейкин 6 (интерферон, бета 2).
- Животное или клетка могут содержать 1, 2, 3, 4, 5, 6, 7, 8, 9 10 или больше хромосомных последовательностей с нарушенной структурой, кодирующих белок, ассоциированный с ALS, и нуль, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или больше интегрированных в хромосомы последовательностей, кодирующих белок с нарушенной структурой, ассоциированный с ALS. Предпочтительные белки, ассоциированные с ALS, включают SOD1 (супероксиддисмутазу 1), ALS2 (белок 2, ассоциированный с боковым амиотрофическим склерозом), FUS (РНК-связывающий белок FUS), TARDBP (TAR-ДНК связывающий белок), VAGFA (фактор роста эндотелия сосудов A), VAGFB (фактор роста эндотелия сосудов B) и VAGFC (фактор роста эндотелия сосудов C) и любую их комбинацию.
Аутизм
- В публикации заявки на патент США № 20110023145 описывается применение нуклеаз с "цинковыми пальцами" для генетической модификации клеток, животных и белков, ассоциированных с расстройствами аутистического спектра (ASD). Расстройства аутистического спектра (ASD) представляют собой группу расстройств, характеризующихся качественным нарушением социального взаимодействия и коммуникации, а также ограниченными повторяющимися и стереотипными формами поведения, интересов и видов деятельности. Три расстройства, аутизм, синдром Аспергера (AS) и неспецифическое первазивное расстройство развития (PDD-NOS) относятся к одному и тому же расстройству с различными степенями тяжести, ассоциированными с умственной деятельностью и медицинскими состояниями. ASD преимущественно являются расстройствами, которые предопределены наследственными факторами, с наследуемостью приблизительно 90%.
- В публикации заявки на патент США № 20110023145 предусматривается редактирование любых хромосомных последовательностей, которые кодируют белки, ассоциированные с ASD, что можно применять по отношению к системе CRISPR-Cas согласно настоящему изобретению. Белки, ассоциированные с ASD, как правило, выбирают исходя из экспериментально установленной ассоциации белка, ассоциированного с ASD, с возникновением или симптомом ASD. Например, скорость образования или концентрация в кровотоке белка, связанного с ASD, может быть повышенной или пониженной в популяции с ASD по сравнению с популяцией без ASD. Различия по уровням белка можно оценить с помощью протеомных методик, в том числе без ограничения вестерн-блоттинга, иммуногистохимического окрашивания, твердофазного иммуноферментного анализа (ELISA) и масс-спектрометрии. Альтернативно белки, ассоциированные с ASD, можно идентифицировать путем получения профилей экспрессии генов для генов, кодирующих белки, с помощью методик геномного анализа, в том числе без ограничения микроматричного анализа ДНК, последовательного анализа экспрессии генов (SAGE) и количественной полимеразной цепной реакции в режиме реального времени (Q-PCR).
- Неограничивающие примеры болезненных состояний или расстройств, которые могут быть ассоциированы с белками, ассоциированными с ASD, включают аутизм, синдром Аспергера (AS), неспецифическое первазивное расстройство развития (PDD-NOS), синдром Ретта, туберозный склероз, фенилкетонурию, синдром Смита-Лемли-Опица и синдром ломкой X-хромосомы. В качестве неограничивающего примера белки, ассоциированные с ASD, включают без ограничения следующие белки: ATP10C - аминофосфолипид-транспортирующую АТФазу (ATP10C), MET - MET-рецепторную тирозинкиназу, BZRAP1, MGLUR5 (GRM5) - метаботропный глутаматный рецептор 5 (MGLUR5), CDH10 - кадгерин-10, MGLUR6 (GRM6) - метаботропный глутаматный рецептор 6 (MGLUR6), CDH9 - кадгерин-9, NLGN1 - нейролигин-1, CNTN4 - контактин-4, NLGN2 - нейролигин-2, CNTNAP2 - белок 2, подобный контактин-ассоциированному белку (CNTNAP2), SEMA5A - нейролигин-3, DHCR7 - 7-дегидрохолестеринредуктазу (DHCR7), NLGN4X - нейролигин-4 X-связанный, NLGN4Y - нейролигин-4 Y-связанный, DOC2A - альфа-белок, содержащий двойной C2-подобный домен, DPP6 - белок 6, подобный дипептидиламинопептидазе, NLGN5 - нейролигин-5, EN2 - белок 2, кодируемый гомеобоксом (EN2), NRCAM - молекулу адгезии нейронов (NRCAM), MDGA2, ассоциированный с умственной отсталостью, сцепленной с ломкой X-хромосомой (MDGA2), NRXN1 - нейрексин-1, FMR2 (AFF2) - представитель 2 семейства AF4/FMR2, OR4M2 - рецептор обонятельных луковиц 4M2, FOXP2 - белок, кодируемый Forkhead-боксом P2 (FOXP2), OR4N4 - рецептор обонятельных луковиц 4N4, FXR1 - аутосомный гомолог 1, связанный с умственной отсталостью, сцепленной с ломкой X-хромосомой (FXR1), OXTR - окситоциновый рецептор (OXTR), FXR2 - аутосомный гомолог 2, связанный с умственной отсталостью, сцепленной с ломкой X-хромосомой (FXR2), PAH - фенилаланингидроксилазу (PAH), GABRA1 - субъединицу альфа-1 рецептора гамма-аминомасляной кислоты (GABRA1), PTEN - гомолог фосфатазы и тензина (PTEN), GABRA5 - субъединицу альфа-5 рецептора GABAA (гамма-аминомасляной кислоты) (GABRA5), PTPRZ1 - протеиновую тирозинфосфатазу-дзета рецепторного типа (PTPRZ1), GABRB1 - субъединицу бета-1 рецептора гамма-аминомасляной кислоты (GABRB1), RELN - рилин, GABRB3 - субъединицу бета-3 рецептора GABAA (гамма-аминомасляной кислоты) (GABRB3), RPL10 - рибосомальный белок 60S L10, GABRG1 - субъединицу гамма-1 рецептора гамма-аминомасляной кислоты (GABRG1), SEMA5A - семафорин-5A (SEMA5A), HIRIP3 - HIRA-взаимодействующий белок 3, SEZ6L2 - белок 2, подобный гомологу белка 6, связанного с приступами (мышь), HOXA1 - белок, кодируемый гомеобоксом Hox-A1 (HOXA1), SHANK3 - белок 3, содержащий SH3 и несколько повторяющихся доменов анкирина (SHANK3), IL6 - интерлейкин-6, SHBZRAP1 - белок 3, содержащий SH3 и несколько повторяющихся доменов анкирина (SHBZRAP1), LAMB1 - ламинин, субъединицу бета-1 (LAMB1), SLC6A4 - серотониновый транспортер (SERT), MAPK3 - митоген-активируемую протеинкиназу 3, TAS2R1 - вкусовой рецептор типа 2, представитель 1 (TAS2R1), MAZ - Myc-ассоциированный белок с "цинковыми пальцами", TSC1 - белок 1, ассоциированный с туберозным склерозом, MDGA2 - гликозилфосфатидилинозитол-связанный белок 2, якорная форма 2, содержащий домен MAM (MDGA2), TSC2 - белок 2, ассоциированный с туберозным склерозом, MECP2 - метил-CpG-связывающий белок 2 (MECP2), UBE3A - убиквитинпротеинлигазу E3A (UBE3A), MECP2 - метил-CpG-связывающий белок 2 (MECP2), WNT2 - сайт интеграции MMTV типа Wingless, представитель 2 семейства (WNT2).
- Идентичность белка, ассоциированного с ASD, редактирование хромосомной последовательности которого осуществляют, может и будет варьироваться. В предпочтительных вариантах осуществления белки, ассоциированные с ASD, редактирование хромосомной последовательности которых осуществляют, могут представлять собой белок 1, ассоциированный с периферическим бензодиазепиновым рецептором (BZRAP1), кодируемый геном BZRAP1, белок-представитель 2 семейства AF4/FMR2 (AFF2), кодируемый геном AFF2 (также называемый MFR2), белок-аутосомный гомолог 1, ассоциированный с умственной отсталостью, сцепленной с ломкой X-хромосомой (FXR1), кодируемый геном FXR1, или белок-аутосомный гомолог 2, ассоциированный с умственной отсталостью, сцепленной с ломкой X-хромосомой (FXR2), кодируемый геном FXR2, гликозилфосфатидилинозитол-связанный белок, содержащий домен MAM, якорная форма 2 (MDGA2), кодируемый геном MDGA2, метил-CpG связывающий белок 2 (MECP2), кодируемый геном MECP2, метаботропный глутаматный рецептор 5 (MGLUR5), кодируемый геном MGLUR5-1 (также называемый GRM5), белок нейрексин 1, кодируемый геном NRXN1, или белок семафорин-5A (SEMA5A), кодируемый геном SEMA5A. В иллюстративном варианте осуществления генетически модифицированным животным является крыса, и редактируемые хромосомные последовательности, кодирующие белок, ассоциированный с ASD, перечислены ниже: BZRAP1 - белок 1, ассоциированный с (периферическим) бензодиазепиновым рецептором (BZRAP1) - XM_002727789, XM_213427, XM_002724533, XM_001081125, AFF2 (FMR2) - представитель 2 семейства AF4/FMR2 (AFF2) - XM_219832, XM_001054673, FXR1 - аутосомный гомолог 1, ассоциированный с умственной отсталостью, сцепленной с ломкой X-хромосомой (FXR1) - NM_001012179, FXR2 - аутосомный гомолог 2, ассоциированный с умственной отсталостью, сцепленной с ломкой X-хромосомой (FXR2) - NM_001100647, MDGA2 - гликозилфосфатидилинозитол-связанный белок, содержащий домен MAM, якорная форма 2 (MDGA2) - NM_199269, MECP2 - метил-CpG-связывающий белок 2 (MECP2) - NM_022673, MGLUR5 - метаботропный глутаматный рецептор 5 (GRM5) (MGLUR5) - NM_017012, NRXN1 - нейрексин-1 - NM_021767, SEMA5A - семафорин-5A (SEMA5A) - NM_001107659.
Нарушения, связанные с экспансией тринуклеотидных повторов
- В публикации заявки на патент США № 20110016540 описывается применение нуклеаз с "цинковыми пальцами" для генетической модификации клеток, животных и белков, ассоциированных с нарушениями, связанными с экспансией тринуклеотидных повторов. Нарушения, связанные с экспансией тринуклеотидных повторов, являются комплексными прогрессирующими нарушениями, затрагивающими биологию развития нервной системы и часто нарушающими когнитивные функции, а также сенсомоторные функции.
- Белки, связанные с экспансией тринуклеотидных повторов, представляют собой разнородную группу белков, ассоциированных с восприимчивостью к развитию нарушения, связанного с экспансией тринуклеотидных повторов, наличием нарушения, связанного с экспансией тринуклеотидных повторов, тяжестью нарушения, связанного с экспансией тринуклеотидных повторов, или любой их комбинацией. Нарушения, связанные с экспансией тринуклеотидных повторов, подразделяют на две категории, определяемые типом повтора. Наиболее распространенным повтором является триплет CAG, который, в случае наличия в кодирующем участке гена, кодирует аминокислоту глутамин (Q). Таким образом, эти нарушения называются нарушениями, связанными с экспансией полиглутаминовых повторов (поли-Q), и включают следующие заболевания: болезнь Гентингтона (HD); спинобульбарную мышечную атрофию (SBMA); формы спинально-церебеллярной атаксии (SCA типов 1, 2, 3, 6, 7 и 17) и дентато-рубро-паллидо-льюисову атрофию (DRPLA). Остальные нарушения, связанные с экспансией тринуклеотидных повторов, при которых триплет CAG не вовлечен, либо триплет CAG находится не в кодирующем участке гена, называются таким образом нарушениями, не связанными с экспансией полиглутаминовых повторов. Нарушения, не связанные с экспансией полиглутаминовых повторов, включают синдром ломкой X-хромосомы (FRAXA); синдром умственной отсталости, сцепленный с ломкой X-хромосомой (FRAXE); атаксию Фридрейха (FRDA); миотоническую дистрофию (DM) и формы спинально-церебеллярной атаксии (SCA типов 8 и 12).
- Белки, ассоциированные с нарушениями, связанными с экспансией тринуклеотидных повторов, как правило, выбирают на основании экспериментально установленной ассоциации белка, ассоциированного с нарушением, связанным с экспансией тринуклеотидных повторов, и нарушения, связанного с экспансией тринуклеотидных повторов. Например, скорость образования или концентрация в кровотоке белка, ассоциированного с нарушением, связанным с экспансией тринуклеотидных повторов, может быть повышенной или пониженной в популяции, имеющей нарушение, связанное с экспансией тринуклеотидных повторов, по сравнению с популяцией, не имеющей нарушения, связанного с экспансией тринуклеотидных повторов. Различия по уровням белка можно оценить с помощью протеомных методик, в том числе без ограничения вестерн-блоттинга, иммуногистохимического окрашивания, твердофазного иммуноферментного анализа (ELISA) и масс-спектрометрии. Альтернативно белки, ассоциированные с нарушениями, обусловленными экспансией тринуклеотидных повторов, можно идентифицировать путем получения профилей генной экспрессии для генов, кодирующих белки, с помощью методик геномного анализа, в том числе без ограничения микроматричного анализа ДНК, последовательного анализа экспрессии генов (SAGE) и количественной полимеразной цепной реакции в режиме реального времени (Q-PCR).
- Неограничивающие примеры белков, ассоциированных с нарушениями, связанными с экспансией тринуклеотидных повторов, включают AR (андрогенный рецептор), FMR1 (белок 1, ассоциированный с умственной отсталостью, сцепленной с ломкой X-хромосомой), HTT (гентингтин), DMPK (протеинкиназу, ассоциированную с миотонической дистрофией), FXN (фратаксин), ATXN2 (атаксин 2), ATN1 (атрофин 1), FEN1 (структуроспецифичную флэп-эндонуклеазу 1), TNRC6A (белок, кодируемый геном 6A, содержащим тринуклеотидные повторы), PABPN1 (ядерный поли(A)-связывающий белок 1), JPH3 (юнктофилин 3), MED15 (субъединицу 15 медиаторного комплекса), ATXN1 (атаксин 1), ATXN3 (атаксин 3), TBP (TATA-бокс-связывающий белок), CACNA1A (альфа-1A-субъединицу потенциал-зависимого кальциевого канала P/Q-типа), ATXN80S (белок, синтезируемый с противоположной нити ATXN8 (не кодирующей белок)), PPP2R2B (бета-изоформу регуляторной субъединицы B протеинфосфатазы 2), ATXN7 (атаксин 7), TNRC6B (белок, кодируемый геном 6B, содержащим тринуклеотидные повторы), TNRC6C (белок, кодируемый геном 6C, содержащим тринуклеотидные повторы), CELF3 (CUGBP, представитель 3 семейства Elav-подобных белков), MAB21L1 (mab-21-подобный белок 1 (C. elegans)), MSH2 (гомолог 2 mutS, ассоциированный с неполипозным колоректальным раком 1 типа (E. coli)), TMEM185A (трансмембранный белок 185A), SIX5 (белок, кодируемый гомеобоксом 5 SIX), CNPY3 (гомолог Canopy 3 (данио-рерио)), FRAXE (белок, ассоциированный с "редким" ломким сайтом, проявляющимся при недостатке фолиевой кислоты, fra(X)(q28) E), GNB2 (бета-полипептид 2 белка, связывающего гуаниновые нуклеотиды (G-белка)), RPL14 (рибосомный белок L14), ATXN8 (атаксин 8), INSR (инсулиновый рецептор), TTR (транстиретин), EP400 (E1A-связывающий белок p400), GIGYF2 (белок GYF 2, взаимодействующий с GRB10), OGG1 (8-оксогуанин-ДНК-гликозилазу), STC1 (станниокальцин 1), CNDP1 (карнозиндипептидазу 1 (металлопептидазу семейства M20)), C10orf2 (белок, кодируемый открытой рамкой считывания 2 хромосомы 10), MAML3 (mastermind-подобный белок 3 (Drosophila)), DKC1 (белок 1, ассоциированный с врожденным дискератозом, дискерин), PAXIP1 (белок 1, взаимодействующий с PAX (с доменом активации транскрипции)), CaSK (кальций/кальмодулин-зависимую сериновую протеинкиназу (семейства MAGUK)), MAPT (белок tau, ассоциированный с микротрубочками), SP1 (фактор транскрипции Sp1), POLG (полимеразу гамма (ДНК-направленную)), AFF2 (представитель 2 семейства AF4/FMR2), THBS1 (тромбоспондин 1), TP53 (опухолевый белок p53), ESR1 (эстрогеновый рецептор 1), CGGBP1 (белок 1, связывающий триплетный повтор CGG), ABT1 (активатор 1 базальной транскрипции), KLK3 (родственную калликреину пептидазу 3), PRNP (белок приона), JUN (онкоген jun), KCNN3 (кальций-активируемый калиевый канал средней/малой проводимости, представитель 3 подсемейства N), BAX (BCL2-ассоциированный белок X), FRAXA (белок, ассоциированный с "редким" ломким сайтом, проявляющимся при недостатке фолиевой кислоты, fra(X)(q27.3) A (макроорхидизм, умственная отсталость)), KBTBD10 (белок 10, содержащий повтор Kelch и домен BTB (POZ)), MBNL1 (muscleblind-подобный белок (Drosophila)), RAD51 (гомолог RAD51 (гомолог RecA, E. coli) (S. cerevisiae)), NCOA3 (коактиватор 3 ядерных рецепторов), ERDA1 (белок с экспансией повторяющихся доменов, CAG/CTG 1), TSC1 (белок 1, ассоциированный с туберозным склерозом), COMP (олигомерный матриксный белок хряща), GCLC (каталитическую субъединицу глутаматцистеинлигазы), RRAD (Ras-родственный белок, ассоциированный с сахарным диабетом), MSH3 (гомолог 3 mutS (E. coli)), DRD2 (дофаминовый рецептор D2), CD44 (молекулу CD44 (система групп крови Indian)), CTCF (CCCTC-связывающий фактор (белок с "цинковыми пальцами")), CCND1 (циклин D1), CLSPN (гомолог класпина (Xenopus laevis)), MEF2A (энхансерный фактор 2A миоцитов), PTPRU (протеинтирозинфосфатазу рецепторного типа U), GAPDH (глицеральдегид-3-фосфатдегидрогеназу), TRIM22 (белок 22, содержащий тройной мотив), WT1 (белок 1 опухоли Вильмса), AHR (арил-углеводородный рецептор), GPX1 (глутатионпероксидазу 1), TPMT (тиопурин-S-метилтрансферазу), NDP (белок, ассоциированный с болезнью Норри (псевдоглиомой)), ARX (белок, кодируемый гомеобоксом гена, родственного aristaless), MUS81 (гомолог эндонуклеазы MUS81 (S. cerevisiae)), TYR (тирозиназу (глазокожный альбинизм IA)), EGR1 (белок 1 раннего ростового ответа), UNG (урацил-ДНК-гликозилазу), NUMBL (белок, подобный гомологу numb (Drosophila)), FABP2 (белок 2, связывающий жирные кислоты в кишечнике), EN2 (белок, кодируемый гомеобоксом engrailed 2), CRYGC (гамма-C-кристаллин), SRP14 (гомологичный РНК-связывающий белок Alu размером 14 кДа из частицы узнавания сигнала), CRYGB (гамма-B-кристаллин), PDCD1 (белок 1 запрограммированной гибели клеток), HOXA1 (белок, кодируемый гомеобоксом A1), ATXN2L (атаксин-2-подобный белок), PMS2 (PMS2, белок 2, противодействующий повышению уровня постмейотической сегрегации (S. cerevisiae)), GLA (альфа-галактозидазу), CBL (белок, кодируемый последовательностью, трансформирующей с экотропным ретровирусом Cas-Br-M (мышей)), FTH1 (полипептид 1 тяжелой субъединицы ферритина), IL12RB2 (бета-2-субъединицу рецептора интерлейкина 12), OTX2 (белок, кодируемый гомеобоксом orthodenticle 2), HOXA5 (белок, кодируемый гомеобоксом A5), POLG2 (вспомогательную гамма-2-субъединицу полимеразы (ДНК-направленной)), DLX2 (белок, кодируемый гомеобоксом distal-less 2), SIRPA (сигнально-регуляторный белок альфа), OTX1 (белок, кодируемый гомеобоксом orthodenticle 1), AHRR (репрессор арил-углеводородного рецептора), MANF (мезэнцефальный нейротрофический фактор, происходящий из астроцитов), TMEM158 (трансмембранный белок 158 (ген/псевдоген)) и ENSG00000078687.
- Предпочтительные белки, ассоциированные с нарушениями, обусловленными экспансией тринуклеотидных повторов, включают HTT (гентингтин), AR (андрогенный рецептор), FXN (фратаксин), Atxn3 (атаксин), Atxn1 (атаксин), Atxn2 (атаксин), Atxn7 (атаксин), Atxn10 (атаксин), DMPK (протеинкиназу, ассоциированную с миотонической дистрофией), Atn1 (атрофин 1), CBP (creb-связывающий белок), VLDLR (рецептор липопротеинов очень низкой плотности) и их любую комбинацию.
Лечение заболеваний органов слуха
- Настоящее изобретение также предусматривает доставку системы CRISPR-Cas в одно ухо или оба уха.
- Исследователи рассматривают вопрос о том, можно ли применять генную терапию для содействия существующим способам лечения глухоты - а именно, применению кохлеарных имплантатов. Глухоту часто вызывают утрата или повреждение волосковых клеток, которые не могут передавать сигналы слуховым нейронам. В таких случаях можно применять кохлеарные имплантаты для обеспечения реакции на звук и передачи электрических сигналов нервным клеткам. Однако эти нейроны часто дегенерируют и подвергаются ретракции отростков в улитке, поскольку пораженные волосковые клетки высвобождают меньше факторов роста.
- В заявке на патент США 20120328580 описана инъекция фармацевтической композиции в ухо (например, путем ушного введения), как, например, в просветы улитки (например, в проток улитки, лестницу преддверия и барабанную лестницу улитки), например с помощью шприца, например шприца c однократной дозой. Например, одно или несколько соединений, описанных в данном документе, можно вводить путем интратимпанальной инъекции (например, в среднее ухо) и/или инъекций в наружное, среднее и/или внутреннее ухо. Такие способы регулярно применяются в данной области, например для введения стероидов и антибиотиков в уши людей. Инъекцию можно осуществлять, например, через круглое окно уха или через капсулу улитки. Из уровня техники известны и другие способы введения во внутреннее ухо (см., например, Salt and Plontke, Drug Discovery Today, 10:1299-1306, 2005).
- В другом способе введения фармацевтическую композицию можно вводить in situ с помощью катетера или насоса. Катетер или насос могут, например, направлять фармацевтическую композицию в просветы улитки, или круглое окно уха, и/или просвет толстой кишки. Иллюстративный аппарат для доставки лекарственных средств и способы, подходящие для введения одного или нескольких соединений, описанных в данном документе, в ухо, например, в ухо человека, описаны McKenna et al. (публикация заявки на патент США № 2006/0030837) и Jacobsen et al. (патент США № 7206639). В некоторых вариантах осуществления катетер или насос могут быть расположены, например, в ухе (например, в наружном, среднем и/или внутреннем ухе) пациента во время хирургического вмешательства. В некоторых вариантах осуществления катетер или насос могут быть расположены, например, в ухе (например, в наружном, среднем и/или внутреннем ухе) пациента без необходимости в хирургическом вмешательстве.
- Альтернативно или дополнительно одно или несколько соединений, описанных в данном документе, можно вводить в сочетании с механическим устройством, таким как кохлеарный имплантат или слуховой аппарат, которое носят в наружном ухе. Иллюстративный кохлеарный имплантат, подходящий для применения в настоящем изобретении, описан Edge et al. (публикация заявки на патент США № 2007/0093878).
- В некоторых вариантах осуществления способы введения, описанные выше, можно комбинировать в любом порядке и можно применять одновременно или попеременно.
- Альтернативно или дополнительно настоящее изобретение можно применять согласно любому из способов, одобренных Управлением по контролю качества пищевых продуктов и лекарственных средств, например, описанных в справочнике стандартов CDER, версия номер 004 (доступном по адресу fda.give/cder/dsm/DRG/drg00301.htm).
- В целом способы клеточной терапии, описанные в заявке на патент США 20120328580, можно применять для стимуляции полной или частичной дифференцировки клеток в определенный тип зрелых клеток внутреннего уха (например, в волосковые клетки) или в его направлении in vitro. Клетки, полученные в результате осуществления таких способов, можно затем трансплантировать или имплантировать пациенту, нуждающемуся в таком лечении. Способы культивирования клеток, необходимые для осуществления на практике этих способов, включающие способы идентификации и отбора подходящих типов клеток, способы стимуляции полной или частичной дифференцировки выбранных клеток, способы идентификации полностью или частично дифференцированных типов клеток и способы имплантации полностью или частично дифференцированных клеток, описаны ниже.
- Клетки, подходящие для применения в настоящем изобретении, включают без ограничения клетки, способные к полной или частичной дифференцировке в зрелые клетки внутреннего уха, например в волосковые клетки (например, внутренние и/или наружные волосковые клетки), при контакте, например, in vitro, с одним или несколькими соединениями, описанными в данном документе. Иллюстративные клетки, способные к дифференцировке в волосковые клетки, включают без ограничения стволовые клетки (например, стволовые клетки внутреннего уха, взрослые стволовые клетки, стволовые клетки, полученные из костного мозга, эмбриональные стволовые клетки, мезенхимальные стволовые клетки, стволовые клетки кожи, iPS-клетки и стволовые клетки, полученные из жировой ткани), клетки-предшественники (например, клетки-предшественники внутреннего уха), поддерживающие клетки (например, клетки Дейтерса, столбовые клетки, внутренние фаланговые клетки, тектальные клетки и клетки Гензена) и/или зародышевые клетки. Применение стволовых клеток для замещения чувствительных клеток внутреннего уха описано Li et al. (публикация заявки на патент США № 2005/0287127) и Li et al. (патент США с регистрационным № 11/953797). Применение стволовых клеток, полученных из костного мозга, для замещения чувствительных клеток внутреннего уха описано Edge et al. в PCT/US2007/084654. iPS-клетки описаны, например, в Takahashi et al., Cell, Volume 131, Issue 5, Pages 861-872 (2007); Takahashi and Yamanaka, Cell 126, 663-76 (2006); Okita et al., Nature 448, 260-262 (2007); Yu, J. et al., Science 318(5858):1917-1920 (2007); Nakagawa et al., Nat. Biotechnol. 26:101-106 (2008); и Zaehres and Scholer, Cell 131(5):834-835 (2007). Такие подходящие клетки можно идентифицировать путем анализа (например, качественного или количественного) наличия одного или нескольких тканеспецифичных генов. Например, экспрессию гена можно выявить путем выявления белкового продукта одного или нескольких тканеспецифичных генов. Методики выявления белков включают окрашивание белков (например, с использованием клеточных экстрактов или цельных клеток) с помощью антител к соответствующему антигену. В данном случае соответствующий антиген является белковым продуктом экспрессии тканеспецифичного гена. Хотя, в принципе, меченым может быть первое антитело (т. е. антитело, связывающее антиген), более распространенным (и улучшающим визуализацию) является применение второго антитела, направленного против первого (например, антитела к IgG). Данное второе антитело конъюгируют с флуорохромами, или соответствующими ферментами для колориметрических реакций, или гранулами золота (для электронной микроскопии), или с системой биотин-авидин, так что можно определить местоположение первичного антитела и, следовательно, антигена.
- Молекулы CRISPR-Cas по настоящему изобретению можно доставлять в ухо путем непосредственного нанесения фармацевтической композиции на наружное ухо с применением модифицированных композиций из опубликованной заявки на патент США 20110142917. В некоторых вариантах осуществления фармацевтическую композицию вносят в наружный слуховой проход. Доставка в ухо может также называться внутриушной или ушной доставкой.
- В некоторых вариантах осуществления молекулы РНК по настоящему изобретению доставляют в липосомных составах или составах на основе Lipofectin и им подобных, и их можно получить с помощью способов, хорошо известных специалистам в данной области. Такие способы описаны, например, в патентах США №№ 5593972, 5589466 и 5580859, включенных в данный документ посредством ссылки.
- Были разработаны системы доставки, специально предназначенные для повышения эффективности и улучшения доставки siRNA в клетки млекопитающих (см., например, Shen et al FEBS Let. 2003, 539:111-114; Xia et al., Nat. Biotech. 2002, 20:1006-1010; Reich et al., Mol. Vision. 2003, 9: 210-216; Sorensen et al., J. Mol. Biol. 2003, 327: 761-766; Lewis et al., Nat. Gen. 2002, 32: 107-108 и Simeoni et al., NAR 2003, 31, 11: 2717-2724), и их можно применять в настоящем изобретении. Недавно siRNA успешно применили для ингибирования экспрессии генов у приматов (см., например, Tolentino et al., Retina 24(4):660), и их также можно применять в настоящем изобретении.
- Qi et al. раскрывают способы эффективного введения siRNA во внутреннее ухо через неповрежденное круглое окно путем трансфекции с помощью новой технологии доставки протеидов, которая может быть применена по отношению к системе нацеливания на нуклеиновую кислоту по настоящему изобретению (см., например, Qi et al., Gene Therapy (2013), 1-9). В частности, успешным было применение доменов TAT, связывающих двухнитевую РНК (TAT-DRBD), с помощью которых можно трансфицировать меченную Cy3 siRNA в клетки внутреннего уха, в том числе внутренние и наружные волосковые клетки, ампулярный гребешок, пятно эллиптического мешочка и пятно сферического мешочка, посредством проникновения через неповрежденное круглое окно, для доставки двухнитевых siRNA in vivo для лечения различных болезней внутреннего уха и сохранения слуховой функции. Приблизительно 40 мкл 10 мМ РНК может быть предусмотрено в качестве дозы для введения в ухо.
- В соответствии с Rejali et al. (Hear Res. 2007 Jun;228(1-2):180-7), функционирование кохлеарных имплантатов можно улучшить путем надлежащего сохранения нейронов спирального ганглия, которые являются мишенью для электростимуляции имплантатом, и ранее было показано, что нейротрофический фактор головного мозга (BDNF) повышает выживаемость спирального ганглия в ушах с экспериментально индуцированной глухотой. Rejali et al. тестировали модифицированную конструкцию электрода кохлеарного имплантата, имеющего покрытие из клеток-фибробластов, трансдуцированных вирусным вектором со вставкой гена BDNF. Для осуществления данного типа переноса генов ex vivo Rejali et al. трансдуцировали фибробласты морской свинки аденовирусом со вставкой кассеты с геном BDNF, и определили, что эти клетки секретируют BDNF, а затем прикрепили клетки, секретирующие BDNF, к электроду кохлеарного имплантата с помощью агарозного геля и имплантировали электрод в барабанную лестницу улитки. Rejali et al. определили, что электроды с экспрессией BDNF были способны обеспечивать сохранение значительно большего количества нейронов спирального ганглия в базальных витках улитки через 48 дней после имплантации по сравнению с контрольными электродами и демонстрировали возможность осуществления терапии с применением кохлеарных имплантатов в комбинации с переносом генов ex vivo для повышения выживаемости нейронов спирального ганглия. Такую систему можно применять для доставки системы нацеливания на нуклеиновую кислоту по настоящему изобретению в ухо.
- Mukherjea et al. (Antioxidants & Redox Signaling, Volume 13, Number 5, 2010) документально подтверждают, что нокдаун NOX3 с помощью короткой интерферирующей (si) РНК нейтрализовал ототоксичность цисплатина, о чем свидетельствует защита OHC от повреждения и снижение величин сдвига порогов слуховых вызванных потенциалов ствола мозга (ABR). Крысам вводили различные дозы siNOX3 (0,3, 0,6 и 0,9 мкг) и экспрессию NOX3 оценивали с помощью RT-PCR в режиме реального времени. Наименьшая применяемая доза siRNA для NOX3 (0,3 мкг) не демонстрировала какого-либо ингибирования мРНК NOX3 по сравнению с транстимпанальным введением скремблированной siRNA или отсутствием обработки улиток. Однако введение более высоких доз siRNA для NOX3 (0,6 и 0,9 мкг) снижало экспрессию NOX3 по сравнению с контрольной скремблированной siRNA. Такую систему можно применять для транстимпанального введения системы CRISPR-Cas по настоящему изобретению в дозе от приблизительно 2 мг до приблизительно 4 мг CRISPR-Cas для введения человеку.
- Jung et al. (Molecular Therapy, vol. 21 no. 4, 834-841 apr. 2013) демонстрируют, что уровни Hes5 в эллиптическом мешочке снижались после внесения siRNA и что количество волосковых клеток в этих эллиптических мешочках было значительно большим, чем после контрольной обработки. Данные позволяют предположить, что технология siRNA может быть применимой для индукции восстановления и регенерации во внутреннем ухе и что сигнальный путь Notch является потенциально применимой мишенью для ингибирования экспрессии конкретного гена. Jung et al. в вестибулярный эпителий уха инъецировали 8 мкг siRNA для Hes5 в объеме 2 мкл, полученном путем добавления стерильного нормального физиологического раствора к лиофилизированной siRNA. Такую систему можно применять для введения системы, нацеленной на нуклеиновую кислоту, по настоящему изобретению в вестибулярный эпителий уха в дозе от приблизительно 1 до приблизительно 30 мг CRISPR-Cas для введения человеку.
Нацеливание на ген в неделящихся клетках (нейронах и мышечных)
- Неделящиеся (особенно неделящиеся, полностью дифференцированные) типы клеток являются затруднительными в плане нацеливания на ген или конструирование генома, поскольку, например, гомологичная рекомбинация (HR), как правило, подавляется в фазе G1 клеточного цикла. Однако, исследуя механизмы контроля клетками нормальных систем репарации, Durocher обнаружил ранее неизвестный переключатель, который держит HR "выключенной" в неделящихся клетках, и они разработали стратегию включения этого переключателя. Orthwein et al. (лаборатория Daniel Durocher при Mount Sinai Hospital в Оттаве, Канада, в публикации в Nature 16142, опубликованной онлайн 9 декабря 2015 г.) недавно показали, что подавление HR может быть устранено и нацеливание на ген успешно осуществлено в клетках как почки (293T), так и остеосаркомы (U2OS). Как известно, опухолевые супрессоры BRCA1, PALB2 и BRAC2 обеспечивают репарацию DSB ДНК с помощью HR. Они выяснили, что образование комплекса BRCA1 с PALB2-BRAC2 регулируется убиквитиновым сайтом в PALB2, например действием на сайт убиквитинлигазой E3. Такая убиквитинлигаза E3 состоит из KEAP1 (взаимодействующего с PALB2 белка) в комплексе с циллином-3 (CUL3)-RBX1. Убиквитинилирование PALB2 подавляет его взаимодействие с BRCA1 и нейтрализуется деубиквитилазой USP11, которая сама находится под контролем клеточного цикла. Восстановление взаимодействия BRCA1-PALB2 в комбинации с активацией резекции конца ДНК является достаточным для индуцирования гомологичной рекомбинации в G1, как измерено рядом способов, в том числе анализом основанного на CRISPR-Cas9 нацеливания на ген, направленным на USP11 или KEAP1 (экспрессированные из вектора pX459). Однако, если взаимодействие BRCA1-PALB2 восстанавливалось в перенесших резекцию клетках G1 с использованием либо истощения KEAP1, либо экспрессии мутанта PALB2-KR, выявляли достоверное увеличение числа событий нацеливания на ген.
- Таким образом, реактивация HR в клетках, особенно в неделящихся, полностью дифференцированных типах клеток, является предпочтительной в некоторых вариантах осуществления. В некоторых вариантах осуществления обеспечение взаимодействия BRCA1-PALB2 является предпочтительным в некоторых вариантах осуществления. В некоторых вариантах осуществления целевой клеткой является неделящаяся клетка. В некоторых вариантах осуществления целевой клеткой является нейрон или мышечная клетка. В некоторых вариантах осуществления на целевую клетку нацеливаются in vivo. В некоторых вариантах осуществления клетка находится в G1, при этом HR подавляется. В некоторых вариантах осуществления предпочтительным является применение истощения KEAP1, например, ингибирование активности экспрессии KEAP1. Истощение KEAP1 может быть достигнуто посредством siRNA, например, как показано у Orthwein et al. В качестве альтернативы, предпочтительной является экспрессия мутанта PALB2-KR (не имеющего все восемь остатков Lys в домене взаимодействия с BRCA1) либо в комбинации с истощением KEAP1, либо отдельно. PALB2-KR взаимодействует с BRCA1 не зависимо от положения в клеточном цикле. Таким образом, обеспечение или восстановление взаимодействия BRCA1-PALB2, особенно в клетках G1, является предпочтительным в некоторых вариантах осуществления, особенно, если целевые клетки являются неделящимися, или если удаление и возвращение (ex vivo нацеливания на ген) являются проблематичными, например, в нейронных или мышечных клетках. siRNA KEAP1 доступна от ThermoFischer. В некоторых вариантах осуществления комплекс BRCA1-PALB2 может быть доставлен в G1 клетку. В некоторых вариантах осуществления деубиквитинилирование PALB2 может быть активировано, например, при повышенной экспрессии деубиквитилазы USP11, поэтому может быть предусмотрена конструкция для активации или повышения экспрессии или активности деубиквитилазы USP11.
Лечение заболеваний глаза
Настоящее изобретение также предусматривает доставку системы CRISPR-Cas в один глаз или оба глаза.
В конкретных вариантах осуществления настоящего изобретения систему CRISPR-Cas можно использовать для коррекции дефектов глаз, которые являются результатом нескольких генетических мутаций, дополнительно описанных в Genetic Diseases of the Eye, Second Edition, edited by Elias I. Traboulsi, Oxford University Press, 2012.
Для введения в глаз особенно предпочтительными являются лентивирусные векторы, в частности, вирусы инфекционной анемии лошадей (EIAV).
В другом варианте осуществления также предусмотрены минимальные лентивирусные векторы для отличных от приматов организмов на основе вируса инфекционной анемии лошадей (EIAV), особенно для генной терапии заболеваний глаз (см., например, Balagaan, J Gene Med 2006; 8: 275 - 285, опубликовано онлайн 21 ноября 2005 г. в Wiley InterScience (www.interscience.wiley.com). DOI: 10.1002/jgm.845). Предусмотрено, что векторы имеют промотор цитомегаловируса (CMV), управляющий экспрессией целевого гена. Также предусмотрена любая из внутрикамерной, субретинальной, внутриглазной и интравитреальной инъекций (см., например, Balagaan, J Gene Med 2006; 8: 275 - 285, опубликовано онлайн 21 ноября 2005 г. в Wiley InterScience (www.interscience.wiley.com). DOI: 10.1002/jgm.845). Внутриглазные инъекции можно осуществлять с помощью операционного микроскопа. В случае субретинальной и интравитреальной инъекций можно выпятить глаза путем осторожного надавливания пальцами и визуализировать глазное дно с помощью системы контактных линз, состоящей из капли раствора контактной среды на роговице, накрытой покровным стеклом для микропрепаратов. При субретинальных инъекциях наконечник иглы 34 калибра на 10 мм, закрепленной на 5-мкл шприце Hamilton, можно при непосредственной визуализации продвигать через экваториальную область верхней части склеры тангенциально к заднему полюсу глазного яблока, пока в субретинальном пространстве не будет видна апертура иглы. Затем можно инъецировать 2 мкл суспензии вектора, вызывая буллезное верхнее отслоение сетчатки, что, таким образом, подтверждает субретинальное введение вектора. В данном подходе производят самогерметизирующийся разрез склеры, позволяющий суспензии вектора удерживаться в субретинальном пространстве до поглощения ее RPE, обычно в течение 48 ч. после процедуры. Эту процедуру можно повторить в нижнем полушарии, вызывая нижнее отслоение сетчатки. Данная методика обуславливает воздействие суспензии вектора на приблизительно 70% нейросенсорной части сетчатки и RPE. В случае интравитреальных инъекций можно продвигать наконечник иглы через склеру на 1 мм кзади от корнеосклерального лимба и инъецировать 2 мкл суспензии вектора в полость стекловидного тела. В случае внутрикамерных инъекций можно продвигать наконечник иглы через парацентез корнеосклерального лимба в направлении центральной части роговицы и можно инъецировать 2 мкл суспензии вектора. В случае внутрикамерных инъекций можно продвигать наконечник иглы через парацентез корнеосклерального лимба в направлении центральной части роговицы и можно инъецировать 2 мкл суспензии вектора. Эти векторы можно инъецировать в титрах 1,0-1,4 × 1010 или 1,0-1,4 × 109 трансдуцирующих единиц (ТЕ)/мл.
В другом варианте осуществления также предусмотрен RetinoStat®, лентивирусный вектор на основе вируса инфекционной анемии лошадей для генной терапии, экспрессирующий ангиостатические белки эндостатин и ангиостатин, который доставляют посредством субретинальной инъекции для лечения влажной формы возрастной дегенерации желтого пятна (см., например, Binley et al., HUMAN GENE THERAPY 23:980-991 (September 2012)). Такой вектор может быть модифицирован для системы CRISPR-Cas по настоящему изобретению. Каждый глаз можно обрабатывать любым RetinoStat® в дозе, составляющей 1,1 x 105 трансдуцирующих единиц на глаз (ТЕ/глаз), в общем объеме 100 мкл.
В другом варианте осуществления может быть предусмотрен аденовирусный вектор с делецией E1 и частичной делецией E3 и E4 для доставки в глаз. Двадцать восемь пациентов с неоваскулярной возрастной макулодистрофией на поздней стадии (AMD) получали однократную интравитреальную инъекцию аденовирусного вектора с делецией E1 и частичной делецией E3 и E4, экспрессирующего фактор пигментного эпителия человека (AdPEDF.ll) (см., например, Campochiaro et al., Human Gene Therapy 17:167-176 (February 2006)). Исследовали дозы, варьирующие в диапазоне от 106 до 109,5 единичных частиц (PU), и не наблюдали серьезных нежелательных событий, связанных с AdPEDF.ll, и дозолимитирующей токсичности (см., например, Campochiaro et al., Human Gene Therapy 17:167-176 (February 2006)). Опосредованный аденовирусными векторами перенос генов в глаза, по-видимому, является эффективным подходом для лечения нарушений со стороны органов зрения и может применяться по отношению к системе CRISPR-Cas.
В другом варианте осуществления систему sd-rxRNA® от RXi Pharmaceuticals можно применять для доставки CRISPR-Cas в глаз и/или приспосабливать к ней. В этой системе однократное интравитреальное введение 3 мкг sd-rxRNA приводит к специфичному относительно последовательности снижению уровней мРНК PPIB в течение 14 дней. Систему sd-rxRNA® можно применять по отношению к системе нацеливания на нуклеиновую кислоту по настоящему изобретению, предусматривая введение человеку дозы CRISPR, составляющей от приблизительно 3 до 20 мг.
Millington-Ward et al. (Molecular Therapy, vol. 19 no. 4, 642-649 apr. 2011) описывают векторы на основе аденоассоциированного вируса (AAV) для доставки супрессора родопсина, функционирующего на основе РНК-интерференции (RNAi), и замещающего гена родопсина с модифицированными кодонами, устойчивого к супрессии в связи с нуклеотидными изменениями в вырожденных положениях в целевом сайте для RNAi. Осуществляли субретинальную инъекцию либо 6,0 x 108 vp, либо 1,8 x 1010 vp AAV в глаза согласно Millington-Ward et al. Вектор на основе AAV согласно Millington-Ward et al. можно применять в отношении системы CRISPR-Cas по настоящему изобретению, предусматривая дозу введения человеку от приблизительно 2 x 1011 до приблизительно 6 x 1013 vp.
Dalkara et al. (Sci Transl Med 5, 189ra76 (2013)) также обращаются к направленной эволюции in vivo для конструирования вектора на основе AAV, доставляющего варианты дефектных генов дикого типа по всей сетчатке после безвредной инъекции в жидкую часть стекловидного тела глаза. Dalkara описывает дисплейную библиотеку 7-мерных пептидов и библиотеку AAV, сконструированную посредством ДНК-шаффлинга генов cap AAV1, 2, 4, 5, 6, 8 и 9. Упаковывали библиотеки rcAAV и векторы на основе rAAV, экспрессирующие GFP под контролем промотора CAG или Rho, и с помощью количественной ПЦР получали титры геномов, устойчивых к действию дезоксирибонуклеаз. Библиотеки объединяли, и проводили два цикла эволюции, каждый из которых состоял из диверсификации исходной библиотеки с последующими тремя этапами отбора in vivo. На каждом таком этапе мышам P30, экспрессирующим rho-GFP, интравитреально инъецировали 2 мл очищенной йодиксанолом и подвергнутой диализу против фосфатно-солевого буфера (PBS) библиотеки с титром геномов приблизительно 1 × 1012 vg/мл. Векторы на основе AAV согласно Dalkara et al. можно применять по отношению системы нацеливания на нуклеиновые кислоты по настоящему изобретению, предусматривая введение человеку дозы, составляющей от приблизительно 1 x 1015 до приблизительно 1 x 1016 vg/мл.
В конкретном варианте осуществления можно целенаправленно воздействовать на ген родопсина для лечения пигментного ретинита (RP), при котором систему согласно публикации заявки на патент США № 20120204282, закрепленной за Sangamo BioSciences, Inc., можно модифицировать по образу системы CRISPR-Cas по настоящему изобретению.
В другом варианте осуществления способы согласно публикации заявки на патент США № 20130183282, закрепленной за Cellectis, направленной на способы расщепления целевой последовательности гена родопсина человека, можно также модифицировать для системы нацеливания на нуклеиновую кислоту по настоящему изобретению.
Публикация заявки на патент США № 20130202678, закрепленная за Academia Sinica, относится к способам лечения форм ретинопатии и офтальмологических нарушений с угрозой потери зрения, относящимся к доставке гена Puf-A (экспрессируемого в ганглиозных и пигментных клетках сетчатки в тканях глаза и проявляющего уникальную антиапоптотическую активность) в субретинальное или интравитреальное пространство глаза. В частности, желаемые мишени представляют собой zgc:193933, prdm1a, spata2, tex10, rbb4, ddx3, zp2.2, Blimp-1 и HtrA2, на все из которых можно нацеливаться с помощью системы нацеливания на нуклеиновую кислоту по настоящему изобретению.
Wu (Cell Stem Cell,13:659-62, 2013) разработал направляющую РНК, которая нацеливает Cas9 на местоположение мутации в одной паре оснований, вызывающей формы катаракты у мышей, где он индуцирует расщепление ДНК. Затем с помощью другого аллеля дикого типа или олигонуклеотидов, вводимых в зиготы, механизмы репарации корректируют последовательность поврежденного аллеля и корректируют генетический дефект, вызывающий катаракту, у мутантной мыши.
В публикации заявки на патент США № 20120159653 описывается применение нуклеаз с "цинковыми пальцами" для генетической модификации клеток, животных и белков, ассоциированных с дегенерацией желтого пятна (MD). Дегенерация желтого пятна (MD) является основной причиной ухудшения зрения у лиц пожилого возраста, однако также является характерным симптомом детских заболеваний, таких как болезнь Штаргардта, дистрофия глазного дна Сорсби и летальные детские нейродегенеративные заболевания, при этом начало заболеваний проявляется уже в младенческом возрасте. Дегенерация желтого пятна приводит к потере зрения в центре поля зрения (желтом пятне) по причине поражения сетчатки. Существующие в настоящее время животные модели не воспроизводят основные отличительные признаки заболевания, как это наблюдается у людей. В доступных животных моделях, содержащих мутантные гены, кодирующие белки, ассоциированные с MD, также получают крайне изменчивые фенотипы, переходя к проблематике заболевания человека и разработке способов терапии.
Один аспект публикации заявки на патент США № 20120159653 относится к редактированию любых хромосомных последовательностей, которые кодируют белки, ассоциированные с MD, что можно применять в отношении системы нацеливания на нуклеиновую кислоту по настоящему изобретению. Белки, ассоциированные с MD, как правило, выбирают, исходя из экспериментально установленной взаимосвязи белка, ассоциированного с MD, при нарушении MD. Например, скорость образования или циркулирующая концентрация белка, связанного с MD, может быть повышенной или пониженной в популяции с нарушением с MD по сравнению с популяцией без нарушения с MD. Различия по уровням белка можно оценить с помощью протеомных методик, в том числе без ограничения вестерн-блоттинга, иммуногистохимического окрашивания, твердофазного иммуноферментного анализа (ELISA) и масс-спектрометрии. Альтернативно белки, ассоциированные с MD, можно идентифицировать путем получения профилей экспрессии генов для генов, кодирующих белки, с помощью методик геномного анализа, в том числе без ограничения микроматричного анализа ДНК, последовательного анализа экспрессии генов (SAGE) и количественной полимеразной цепной реакции в режиме реального времени (Q-PCR).
В качестве неограничивающего примера белки, ассоциированные с MD, включают без ограничения следующие белки: представитель 4 (ABCA4) подсемейства A (ABC1) АТФ-связывающей кассеты, ACHM1 - белок 1, ассоциированный с ахроматопсией (палочковым монохроматизмом), ApoE - аполипопротеин E (ApoE), C1QTNF5 (CTRP5) - C1q/белок 5, родственный фактору некроза опухолей (C1QTNF5), C2 - компонент 2 системы комплемента (C2), компонент C3 системы комплемента (C3), CCL2 - хемокиновый лиганд 2 (с мотивом C-C) (CCL2), CCR2 - рецептор хемокина 2 (с мотивом C-C) (CCR2), CD36 - кластер дифференцировки 36, CFB - фактор B системы комплемента, CFH - фактор H системы комплемента (CFH), CFHR1 - белок 1, родственный фактору H системы комплемента, CFHR3 - белок 3, родственный фактору H системы комплемента, CNGB3 - бета-3-субъединица ионного канала, регулируемого циклическими нуклеотидами, CP - церулоплазмин (CP), CRP - C-реактивный белок (CRP) CST3 - цистатин C или цистатин 3 (CST3), CTSD - катепсин D (CTSD), CX3CR1 - рецептор хемокина 1 (с мотивом C-X3-C), ELOVL4 - белок 4, отвечающий за удлинение жирных кислот с очень длинной цепью, ERCC6 - белок эксцизионной репарации, вступающий в перекрестную комплементацию, корректирующий дефицит репарации у грызунов, комплементационная группа 6, FBLN5 - фибулин-5, FBLN5 - фибулин 5, FBLN6 - фибулин 6, FSCN2 - фасцин (FSCN2), HMCN1 - гемицентрин 1, HMCN1 - гемицентрин 1, HTRA1 - сериновая пептидаза HtrA 1 (HTRA1), HTRA1 - сериновая пептидаза HtrA 1, IL-6 - интерлейкин 6, IL-8 - интерлейкин 8, LOC387715 - гипотетический белок, PLEKHA1 - белок, содержащий плекстрин-гомологичный домен, представитель 1 семейства A (PLEKHA1), PROM1 - проминин 1 (PROM1 или CD133), PRPH2 - периферин-2, RPGR - регулятор ГТФазы, ассоциированный с пигментным ретинитом, SERPING1 - ингибитор сериновой пептидазы, представитель 1 клады G (C1-ингибитор), TCOF1 - Treacle, TIMP3 - ингибитор 3 металлопротеиназ (TIMP3), TLR3 - Toll-подобный рецептор 3.
Идентичность белка, ассоциированного с MD, редактирование хромосомной последовательности которого осуществляют, может и будет варьироваться. В предпочтительном варианте осуществления белки, ассоциированные с MD, редактирование хромосомных последовательностей которых осуществляют, могут представлять собой белок представитель 4 (ABCA4) подсемейства A (ABC1) АТФ-связывающей кассеты, кодируемый геном ABCR, белок аполипопротеин E (APOE), кодируемый геном APOE, белок хемокиновый лиганд 2 (с мотивом C-C) (CCL2), кодируемый геном CCL2, белок рецептор хемокина 2 (с мотивом C-C) (CCR2), кодируемый геном CCR2, белок церулоплазмин (CP), кодируемый геном CP, белок катепсин D (CTSD), кодируемый геном CTSD, или белок ингибитор 3 металлопротеиназ (TIMP3), кодируемый геном TIMP3. В иллюстративном варианте осуществления генетически модифицированное животное представляет собой крысу, и редактируемые хромосомные последовательности, кодирующие белок, ассоциированный с MD, могут быть следующими: NM_000350 (ABCA4) для представителя 4 подсемейства A (ABC1) АТФ-связывающей кассеты, NM_138828 (APOE) для аполипопротеина E APOE, NM_031530 (CCL2) для хемокинового лиганда 2 (с мотивом C-C) CCL2, NM_021866 (CCR2) для рецептора хемокина 2 (с мотивом C-C) CCR2, NM_012532 (CP) для церулоплазмина CP, NM_134334 (CTSD) для катепсина D CTSD, NM_012886 (TIMP3) для ингибитора 3 металлопротеиназ TIMP3. Животное или клетка могут содержать 1, 2, 3, 4, 5, 6, 7 или более хромосомных последовательностей с нарушенной структурой, кодирующих белок, ассоциированный с MD, и ноль, 1, 2, 3, 4, 5, 6, 7 или больше интегрированных в хромосомы последовательностей, кодирующих белок с нарушенной структурой, ассоциированный с MD.
Отредактированную или интегрированную хромосомную последовательность можно модифицировать так, чтобы она кодировала измененный белок, ассоциированный с MD. Некоторые мутации в хромосомных последовательностях, связанных с MD, были ассоциированы с MD. Неограничивающие примеры мутаций в хромосомных последовательностях, ассоциированных с MD, включают те мутации, которые могут вызывать MD, в том числе в белке ABCR - E471K (т. е. глутамат в положении 471 заменен на лизин), R1129L (т. е. аргинин в положении 1129 заменен на лейцин), T1428M (т. е. треонин в положении 1428 заменен на метионин), R1517S (т. е. аргинин в положении 1517 заменен на серин), I1562T (т. е. изолейцин в положении 1562 заменен на треонин) и G1578R (т. е. глицин в положении 1578 заменен на аргинин); в белке CCR2 - V64I (т. е. валин в положении 192 заменен на изолейцин); в белке CP - G969B (т. е. глицин в положении 969 заменен на аспарагин или аспартат); в белке TIMP3 - S156C (т. е. серин в положении 156 заменен на цистеин), G166C (т. е. глицин в положении 166 заменен на цистеин), G167C (т. е. глицин в положении 167 заменен на цистеин), Y168C (т. е. тирозин в положении 168 заменен на цистеин), S170C (т. е. серин в положении 170 заменен на цистеин), Y172C (т. е. тирозин в положении 172 заменен на цистеин) и S181C (т. е. серин в положении 181 заменен на цистеин). Из уровня техники известны и другие взаимосвязи генных вариантов генов, ассоциированных с MD, и заболевания.
Системы CRISPR применимы для коррекции заболеваний, возникающих в результате действия аутосомных доминантных генов. Например, CRISPR/Cas9 использовали для удаления аутосомного доминантного гена, который вызывает потерю рецепторов в глазе. Bakondi, B. et al., In Vivo CRISPR/Cas9 Gene Editing Corrects Retinal Dystrophy in the S334ter-3 Rat Model of Autosomal Dominant Retinitis Pigmentosa. Molecular Therapy, 2015; DOI: 10.1038/mt.2015.220.
Лечение сердечно-сосудистых и мышечных заболеваний
Настоящее изобретение также предусматривает доставку системы CRISPR-Cas, описанной в данном документе, например систем эффекторного белка Cpf1, в сердце. Для сердца предпочтительным является тропный к миокарду аденоассоциированный вирус (AAVM), в частности AAVM41, при использовании которого продемонстрирован преимущественный перенос генов в сердце (см., например, Lin-Yanga et al., PNAS, March 10, 2009, vol. 106, no. 10). Введение может быть системным или местным. Доза в приблизительно 1-10 x 1014 векторных геномов предусматривается для системного введения. См. также, например, Eulalio et al. (2012) Nature 492: 376 и Somasuntharam et al. (2013) Biomaterials 34: 7790.
Например, в публикации заявки на патент США № 20110023139 описывается применение нуклеаз с "цинковыми пальцами" для генетической модификации клеток, животных и белков, ассоциированных с сердечно-сосудистым заболеванием. Сердечно-сосудистые заболевания, как правило, включают высокое кровяное давление, сердечные приступы, сердечную недостаточность и инсульт, а также TIA. Любую хромосомную последовательность, связанную с сердечно-сосудистым заболеванием, или белок, кодируемый любой хромосомной последовательностью, связанной с сердечно-сосудистым заболеванием, можно использовать в способах, описанных в настоящем изобретении. Белки, связанные с сердечно-сосудистым заболеванием, как правило, выбирают на основании экспериментально установленной ассоциации белка, связанного с сердечно-сосудистым заболеванием, с развитием сердечно-сосудистого заболевания. Например, скорость образования или концентрация в кровотоке белка, связанного с сердечно-сосудистым заболеванием, может быть повышенной или пониженной в популяции с сердечно-сосудистым заболеванием по сравнению с популяцией без сердечно-сосудистого заболевания. Различия по уровням белка можно оценить с помощью протеомных методик, в том числе без ограничения вестерн-блоттинга, иммуногистохимического окрашивания, твердофазного иммуноферментного анализа (ELISA) и масс-спектрометрии. Альтернативно белки, связанные с сердечно-сосудистым заболеванием, можно идентифицировать путем получения профилей генной экспрессии для генов, кодирующих белки, с помощью методик геномного анализа, в том числе без ограничения микроматричного анализа ДНК, последовательного анализа экспрессии генов (SAGE) и количественной полимеразной цепной реакции в режиме реального времени (Q-PCR).
В качестве примера хромосомная последовательность может включать без ограничения IL1B (интерлейкин 1, бета), XDH (ксантиндегидрогеназу), TP53 (опухолевый белок p53), PTGIS (простагландин 12 (простациклин) синтазу), MB (миоглобин), IL4 (интерлейкин 4), ANGPT1 (ангиопоэтин 1), ABCG8 (АТФ-связывающую кассету, подсемейство G (WHITE), представитель 8), CTSK (катепсин K), PTGIR (рецептор простангландина 12 (простациклина) (IP)), KCNJ11 (калиевый канал внутреннего выпрямления, подсемейство J, представитель 11), INS (инсулин), CRP (C-реактивный белок, связанный с пентраксином), PDGFRB (тромбоцитарный фактор роста, бета-полипептид), CCNA2 (циклин A2), PDGFB (гомолог онкогена бета-полипептида тромбоцитарного фактора роста (вируса саркомы обезьян (v-sis))), KCNJ5 (калиевый канал внутреннего выпрямления, подсемейство J, представитель 5), KCNN3 (калиевый, активируемый кальцием канал, промежуточного/низкого проведения, подсемейство N, представитель 3), CAPN10 (кальпаин 10), PTGES (простагландин E синтаза), ADRA2B (альфа-2B-адренергический рецептор), ABCG5 (АТФ-связывающую кассету, подсемейство G (WHITE), представитель 5), PRDX2 (пероксиредоксин 2), CAPN5 (кальпаин 5), PARP14 (семейство поли (АДФ-рибозо) полимераз, представитель 14), MEX3C (гомолог C mex-3 (C. elegans)), ACE ангиотензин I-конвертирующий фермент (пептидил-дипептидазу A) 1), TNF (фактор некроза опухоли (суперсемейство TNF, представитель 2)), IL6 (интерлейкин 6 (интерферон, бета 2)), STN (статин), SERPINE1 (ингибитор серпинпептидазы, клада E (нексин, ингибитор активатора плазминогена 1 типа), представитель 1), ALB (альбумин), ADIPOQ (адипонектин, содержащий C1Q и коллагеновый домен), APOB (аполипопротеин B (в том числе антиген Ag(x))), APOE (аполипопротеин E), LEP (лептин), MTHFR (5,10-метилентетрагидрофолатредуктаза (NADPH)), APOA1 (аполипопротеин A-I), EDN1 (эндотелин 1), NPPB (предшественник натрийуретического пептида B), NOS3 (синтазу оксида азота 3 типа (эндотелиальная клетка)), PPARG (гамма-рецептор, активируемый пролифератором пероксисом), PLAT (активатор плазминогена, тканевой), PTGS2 (простагландин-эндопероксидсинтазу 2 типа (простагландин G/H синтазу и циклооксигеназу)), CETP (транспортный белок холестериновых эфиров, плазменный), AGTR1 (рецептор антиотензина II, 1 тип), HMGCR (3-гидрокси-3-метилглутарил-кофермент A редуктазу), IGF1 (инсулинподобный фактор роста 1 (соматомедин C)), SELE (селектин E), REN (ренин), PPARA (альфа-рецептор, активируемый пролифератором пероксисом), PON1 (параоксоназу 1), KNG1 (кининоген 1), CCL2 (хемокиновый лиганд 2 (с мотивом C-C)), LPL (липопротеинлипазу), VWF (фактор фон Виллебранда), F2 (фактор коагуляции II (тромбин)), ICAM1 (молекулу межклеточной адгезии 1), TGFB1 (трансформирующий фактор роста, бета 1), NPPA (предшественник натрийуретического пептида A), IL10 (интерлейкин 10), EPO (эритропоэтин), SOD1 (супероксиддисмутазу 1, растворимую), VCAM1 (молекулу адгезии эндотелия сосудов 1 типа), IFNG (интерферон, гамма), LPA (липопротеин, Lp(a)), MPO (миелопероксидазу), ESR1 (эстрогеновый рецептор 1), MAPK1 (митоген-активируемую протеинкиназу 1), HP (гаптоглобин), F3 (фактор коагуляции III (тромбопластин, тканевой фактор)), CST3 (цистатин C), COG2 (компонент олигомерного комплекса Гольджи 2 типа), MMP9 (матриксную металлопептидазу 9 (желатиназу B, желатиназу размером 92 кДа, коллагеназу IV типа размером 92 кДа)), SERPINC1 (ингибитор серпинпептидазы, клада C (антитромбин), представитель 1), F8 (фактор коагуляции VIII, прокоагулянтный компонент), HMOX1 (гемоксигеназу (дециклическую) 1 типа), APOC3 (аполипопротеин C-III), IL8 (интерлейкин 8), PROK1 (прокинетицин 1), CBS (цистатионин-бета-синтазу), NOS2 (синтазу оксида натрия 2 типа, индуцибельную), TLR4 (toll-подобный рецептор 4 типа), SELP (селектин P (гранульный мембранный белок размером 140 кДа, антиген CD62)), ABCA1 (АТФ-связывающую кассету, подсемейство A (ABC1), представитель 1), AGT (ангиотензин (ингибитор серпинпептидазы, клада A, представитель 8)), LDLR (рецептор липопротеина низкой плотности), GPT (глутамат-пируваттрансаминазу (аланинаминотрансферазу)), VEGFA (фактор роста эндотелия сосудов A), NR3C2 (ядерный рецептор, подсемейство 3, группа C, представитель 2), IL18 (интерлейкин 18 (фактор индукции интерферона гамма)), NOS1 (синтазу оксида азота 1 типа (нейрональную)), NR3C1 (ядерный рецептор, подсемейство 3, группа C, представитель 1 (глюкокортикоидный рецептор)), FGB (бета-цепь фибриногена), HGF (фактор роста гепатоцитов (гепатопоэтин A; рассеивающий фактор)), IL1A (интерлейин 1, альфа), RETN (резистин), AKT1 (гомолог онкогена вируса тимомы мышей 1 типа v-akt), LIPC (липазу, печеночную), HSPD1 (белок теплового шока 1 типа размером 60 кДА (шаперонин)), MAPK14 (митоген-активируемую протеинкиназу 14), SPP1 (секретируемый фосфопротеин 1), ITGB3 (интегрин, бета 3 (тромбоцитарный гликопротеин 111a, антиген CD61)), CAT (каталазу), UTS2 (уротензин 2), THBD (тромбомодулин), F10 (фактор коагуляции X), CP (церулоплазмин (ферроксидазу)), TNFRSF11B (суперсемейство фактора некроза опухоли, представитель 11b), EDNRA (рецептор эндотелина типа A), EGFR (рецептор эпидермального фактора роста (гомолог онкогена вируса эритробластического лейкоза (v-erb-b), птичьего)), MMP2 (матриксную металлопептидазу 2 (желатиназу A, желатиназу с массой 72 кДа, коллагеназу IV типа размером 72 кДа)), PLG (плазминоген), NPY (нейропептид Y), RHOD (семейство генов гомологов ras, представитель D), MAPK8 (митоген-активируемую протеинкиназу 8), MYC (гомолог онкогена вируса миелоцистоматоза v-myc (птичьего)), FN1 (фибронектин 1), CMA1 (химазу 1, тучная клетка), PLAU (активатор плазминогена, урокиназу), GNB3 (гуанин-нуклеотид-связывающий белок (G-белок), бета-полипептид 3 типа), ADRB2 (адренергический бета-2-рецептор, поверхностный), APOA5 (аполипопротеин A-V), SOD2 (супероксиддисмутазу 2, митохондриальную), F5 (фактор коагуляции V (проакселерин, лабильный фактор)), VDR (рецептор витамина D (1,25-дигидроксивитамина D3), ALOX5 (арахидонат 5-липооксигеназу), HLA-DRB1 (главный комплекс гистосовместимости, класс II, DR бета 1), PARP1 (поли (АДФ-рибозо) полимеразу 1 типа), CD40LG (лиганд CD40), PON2 (параоксоназу 2), AGER (рецептор, специфичный к конечным продуктам дополнительного гликозилирования), IRS1 (субстрат для инсулинового рецептора 1 типа), PTGS1 (простагландин-эндопероксидсинтазу 1 типа (простагландин G/H синтазу и циклооксигеназу)), ECE1 (эндотелин-превращающий фермент 1 типа), F7 (фактор коагуляции VII (сывороточный ускоритель превращения тромбина)), URN (антагонист рецептора интерлейкина 1), EPHX2 (эпоксидгидролазу 2 типа, цитоплазматическую), IGFBP1 (связывающий белок инсулинподобного фактора роста 1 типа), MAPK10 (митоген-активируемую протеинкиназу 10), FAS (Fas (суперсемейство рецепторов TNF, представитель 6)), ABCB1 (АТФ-связывающую кассету, подсемейство B (MDR/TAP), представитель 1), JUN (онкоген jun), IGFBP3 (связывающий белок инсулинподобного фактора роста 3 типа), CD14 (молекулу CD14), PDE5A (фосфодиэстеразу 5A, cGMP-специфичную), AGTR2 (рецептор ангиотензина II, 2 тип), CD40 (молекулу CD40, представитель 5 суперсемейства рецепторов TNF), LCAT (лецитин-холестерин-ацилтрансферазу), CCR5 (хемокиновый рецептор 5 типа (с мотивом C-C)), MMP1 (матриксную металлопептидазу 1 (интерстициальную коллагеназу)), TIMP1 (ингибитор металлопептидазы TIMP 1 типа), ADM (адреномедуллин), DYT10 (дистонию 10), STAT3 (передатчик сигнала и активатор транскрипции 3 типа (фактор ответа острой фазы)), MMP3 (матриксную металлопептидазу 3 (стромелизин 1, прожелатиназу)), ELN (эластин), USF1 (фактор транскрипции, связывающийся перед сайтом инициации транскрипции 1), CFH (фактор комплемента H), HSPA4 (белок теплового шока 4 размером 70 кДа), MMP12 (матриксную металлопептидазу 12 (макрофагальную эластазу)), MME (мембранную металлоэндопептидазу), F2R (рецептор фактора коагуляции II (тромбина)), SELL (селектин L), CTSB (катепсин B), ANXA5 (аннексин A5), ADRB1 (адренергический бета-1-рецептор), CYBA (цитохром b-245, альфа-пептид), FGA (альфа-цепь фибриногена), GGT1 (гамма-глутамилтрансферазу 1), LIPG (липазу, эндотелиальную), HIF1A (фактор, индуцируемый гипоксией 1, альфа-субъединицу (фактор транскрипции основной структуры спираль-петля-спираль)), CXCR4 (хемокиновый рецептор 4 (с мотивом C-X-C)), PROC (белок C (инактиватор факторов коагуляции Va и VIIIa)), SCARB1 (фагоцитарный рецептор, класс B, представитель 1), CD79A (молекулу CD79a, иммуноглобулин-ассоциированную альфа), PLTP (белок переноса фосфолипидов), ADD1 (аддуцин 1 (альфа)), FGG (гамма-цепь фибриногена), SAA1 (сывороточный амилоид A1), KCNH2 (калиевый потенциалзависимый канал, семейство H (eag-связанный), представитель 2), DPP4 (дипептидилпептидазу 4), G6PD (глюкозо-6-фосфатдегидрогеназу), NPR1 (натрийуретический пептидный рецептор A/гуанилатциклазу A (атрионатрийуретический пептидный рецептор A)), VTN (витронектин), KIAA0101 (KIAA0101), FOS (гомолог онкогена вируса остеосаркомы мышей FBJ), TLR2 (toll-подобный рецептор 2), PPIG (пептидилпролинизомеразу G (циклопролин G)), IL1R1 (рецептор интерлейкина I типа), AR (андрогеновый рецептор), CYP1A1 (цитохром P450, семейство 1, подсемейство A, полипептид 1), SERPINA1 (ингибитор серпинпептидазы, клада A (альфа-1 антипротеиназу, антитрипсин), представитель 1), MTR (5-метилтетрагидрофолат-госоцистеинметилтрансферазу), RBP4 (ретинол-связывающий белок 4 типа, плазменный), APOA4 (аполипопротеин A-IV), CDKN2A (циклин-зависимый ингибитор киназы 2A (меланома, p16, ингибирует CDK4)), FGF2 (фактор роста фибробластов 2 (основной)), EDNRB (эндотелиновый рецептор B типа), ITGA2 (интегрин, альфа 2 (CD49B, альфа 2 субъединицу VLA-2 рецептора)), CABIN1 (кальцинейрин-связывающий белок 1), SHBG (глобулин, связывающийся с половыми гормонами), HMGB1 (группу белков с высокой подвижностью 1 типа), HSP90B2P (белок теплового шока размером 90 кДА, бета (Grp94), представитель 2 (псевдоген)), CYP3A4 (цитохром P450, семейство 3, подсемейство A, полипептид 4), GJA1 (белок межклеточных щелевых контактов, альфа 1, 43 кДа), CAV1 (кавеолин 1, белок кавеол, 22 кДа), ESR2 (эстрогеновый рецептор 2 (ER бета)), LTA (лимфотоксин альфа (суперсемейство TNF, представитель 1)), GDF15 (фактор роста и дифференцировки 15), BDNF (нейротрофический фактор головного мозга), CYP2D6 (цитохром P450, семейство 2, подсемейство D, полипептид 6), NGF (фактор роста нервов (бета-полипептид)), SP1 (фактор транкрипции Sp1), TGIF1 (TGFB-индуцируемый фактор гомеобокс 1), SRC (гомолог онкогена вируса саркомы v-src (Schmidt-Ruppin A-2) (птичьего)), EGF (эпидермальный фактор роста (бета-урогастрон)), PIK3CG (фосфоинозитид-3-киназу, каталитическую, гамма-полипептид), HLA-A (основной комплекс гистосовместимости, класс I, A), KCNQ1 (калиевый потенциалзависимый канал, KQT-подобное семейство, представитель 1), CNR1 (каннабиноидный рецептор 1 (головной мозг)), FBN1 (фибриллин 1), CHKA (холинкиназу альфа), BEST1 (бестрофин 1), APP (белок-предшественник амилоида бета (A4)), CTNNB1 (катенин (кадгерин-ассоциированный беок), бета 1, 88 кДа), IL2 (интерлейкин 2), CD36 (молекулу CD36 (тромбоспондиновый рецептор)), PRKAB1 (протеинкиназу, AMФ-активируемую, бета 1 некаталитическую субъединицу), TPO (тиреоидную перокидазу), ALDH7A1 (семейство альдегиддегидрогеназы 7, представитель A1), CX3CR1 (хемокиновый рецептор 1 (с мотивом C-X3-C)), TH (тирозингидроксилазу), F9 (фактор коагуляции IX), GH1 (гормон роста 1), TF (трансферрин), HFE (гемохроматоз), IL17A (интерлейкин 17A), PTEN (гомолог фосфатазы и тензина), GSTM1 (глутатион S-трансферазу мю 1), DMD (дистрофин), GATA4 (GATA связывающий белок 4 типа), F13A1 (фактор коагуляции XIII, полипептид A1), TTR (транстиретин), FABP4 (связывающий белок жирных кислот 4 типа, адипоцитарный), PON3 (параоксоназу 3), APOC1 (аполипопротеин C-I), INSR (инсулиновый рецептор), TNFRSF1B (суперсемейство рецепторов фактора некроза опухоли, представитель 1B), HTR2A (5-гидрокситриптаминовый (серотониновый) рецептор 2A), CSF3 (колониестимулирующий фактор 3 (гранулоцитарный)), CYP2C9 (цитохром P450, семейство 2, подсемейство C, полипептид 9), TXN (тиоредоксин), CYP11B2 (цитохром P450, семейство 11, подсемейство B, полипептид 2), PTH (паратиреоидный гормон), CSF2 (колониестимулирующий фактор 2 (гранулоцитарно-макрофагальный)), KDR (рецептор, содержащий домен вставки киназы (рецептор тирозинкиназы III типа)), PLA2G2A (фосфолипазу A2, группа IIA (тромбоциты, синовиальная жидкость)), B2M (бета-2-микроглобулин), THBS1 (тромбоспондин 1), GCG (глюкагон), RHOA (семейство генов гомологов ras, представитель A), ALDH2 (семейство альдегиддегидрогеназы 2 (митохондриальной)), TCF7L2 (фактор транскрипции 7, подобный фактору 2 (специфичный по отношению к T-клеткам, HMG-бокс)), BDKRB2 (брадикининовый рецептор B2), NFE2L2 (фактор 2, подобный ядерному фактору (эритроидный 2)), NOTCH1 (гомолог Notch 1, ассоциированный с транслокациями (дрозофилиный)), UGT1A1 (UDP-глюкуронилтрансферазу семейства 1, полипипетид A1), IFNA1 (интерферон, альфа 1), PPARD (дельта-рецептор, активируемый пролифератором пероксисом), SIRT1 (сиртуин 1 (гомолог 2 регуляции молчащей информации совпадающего типа) (S. cerevisiae)), GNRH1 (гонадотропин-рилизинг гормон 1 (лютеинизирующий-рилизинг гормон)), PAPPA (ассоциированный с беременностью белок A плазмы, папализин 1), ARR3 (аррестин 3, ретинальный (X-аррестин)), NPPC (предшественник натрийуретического пептида C), AHSP (альфа-гемоглобин-стабилизирующий белок), PTK2 (протеинтирозинкиназу 2 типа PTK2), IL13 (интерлейкин 13), MTOR (мишень механизма действия рапамицина (серин/треоринкиназу)), ITGB2 (интергрин, бета 2 (субъединицу рецептора 3 и 4 компонента 3 комплемента)), GSTT1 (глутатион-S-трансферазу тета 1), IL6ST (передатчик сигнала интерлейкина 6 (gp130, рецептор онкостатина М)), CPB2 (карбоксипептидазу B2 (плазменную)), CYP1A2 (цитохром P450, семейство 1, подсемейство A, полипептид 2), HNF4A (ядерный фактор гепатоцитов 4, альфа), SLC6A4 (семейство переносчиков растворенных веществ 6 (переносчик нейромедиаторов, серотонина), представитель 4), PLA2G6 (фосфолипазу A2, группа VI (цитозольную, кальций-независимую)), TNFSF11 (суперсемейство фактора роста опухоли (лиганд), представитель 11), SLC8A1 (семейство переносчиков растворенных веществ 8 (натрий-кальциевый антипортер), представитель 1), F2RL1 (рецептор-подобный фактор коагуляции II 1 (тромбин)), AKR1A1 (семейство альдокеторедуктаз 1, представитель A1 (алдегидредуктазу)), ALDH9A1 (семейство альдегиддегирогензы 9, представитель A1), BGLAP (белок гамма-карбоксиглутамата (gla)), MTTP (микросомальный белок переноса триглицеридов), MTRR (редуктаза 5-метилтетрагидрофолат-гомоцистеинметилтрансферазы), SULT1A3 (семейство сульфотрансфераз, цитозолоный, 1A, фенол-предпочтительный, представитель 3), RAGE (антиген опухоли почек), C4B (компонент 4В комплемента (группа крови Chido), P2RY12 (пуринергический рецептор P2Y, связанный с G-белком, 12), RNLS (реналазу, FAD-зависимую аминооксидазу), CREB1 (белок 1, связывающий чувствительный к cAMP элемент), POMC (проопиомеланокортин), RAC1 (связанный с ras субстрат 1 ботулотоксина C3 (семейство rho, малый GTP связывающий белок Rac1)), LMNA (ламин NC), CD59 (молекулу CD59, регуляторный белок комплемента), SCN5A (натриевый канал, потенциалзависимый, V типа, альфа-субъединицу), CYP1B1 (цитохром P450, семейство 1, подсемейство B, полипептид 1), MIF (фактор ингибирования миграции макрофагов (фактор, ингибирующий гликозилирование)), MMP13 (матриксную метталлопептидазу 13 (коллагеназу 3)), TIMP2 (ингибитор металлопептидазы 2 TIMP), CYP19A1 (цитохром P450, семейство 19, подсемейство A, полипептид 1), CYP21A2 (цитохром P450, семейство 21, подсемейство A, полипептид 2), PTPN22 (протеинтирозинфосфатазу, нерецепторную, 22 типа (лимфоидную)), MYH14 (миозин, тяжелую цепь 14, немышечный), MBL2 (маннозо-связывающий лектин (белок C) 2, растворимый (дефект опсонина)), SELPLG (лиганд селектина P), AOC3 (аминоксидазу, медь-содержащую 3 (белок 1 адгезии сосудов)), CTSL1 (катепсин L1), PCNA (ядерный антиген пролиферирующих клеток), IGF2 (инсулинподобный фактор роста 2 (соматомедин A)), ITGB1 (интегрин, бета 1 (фибронектиновый рецептор, бета-полипептид, антиген CD29 включает MDF2, MSK12)), CAST (кальпастатин), CXCL12 (хемокиновый лиганд 12 (с мотивом C-X-C) (стромальный клеточный фактор 1)), IGHE (константную область тяжелой эпсилон-цепи иммуноглобулина), KCNE1 (калиевый потенциалзависимый канал, Isk-связанное семейство, представитель 1), TFRC (трансферриновый рецептор (p90, CD71)), COL1A1 (коллаген 1 типа, альфа 1), COL1A2 (коллаген, I типа, альфа 2), IL2RB (рецептор интерлейкина 2, бета), PLA2G10 (фрсфолипидазу A2, группа X), ANGPT2 (ангиопоэтин 2), PROCR (рецептор протеина C, эндотелиальный (EPCR)), NOX4 (NADPH-оксидазу 4), HAMP (гепцидиновый антимикробный пептид), PTPN11 (протеинтирозинфосфатазу, нерецепторную, 11 типа), SLC2A1 (семейство переносчиков растворенных веществ 2 (переносчик глюкозы посредством облегченной диффузии), представитель 1), IL2RA (рецептор интерлейкина 2, альфа), CCL5 (хемокиновый лиганд 5 (с мотивом C-C)), IRF1 (регуляторный фактор интерферона 1), CFLAR (CASP8 и FADD-подобный регулятор апоптоза), CALCA (кальцитонин-связанный полипептид альфа), EIF4E (фактор инициации трансляции эукариот 4E), GSTP1 (пи-1-глутатин-S-трансферазу), JAK2 (Янус-киназу 2), CYP3A5 (цитохром P450, семейство 3, подсемейство A, полипептид 5), HSPG2 (гепаринсульфатпротеогликан 2), CCL3 (хемокиновый лиганд 3 (с мотивом C-C)), MYD88 (ген первичного ответа миелоидной дифференциации (88)), VIP (вазоактивный пептид кишечника), SOAT1 (стерол-O-ацилтрансферазу 1), ADRBK1 (адренергическую, бета, рецепторную киназу 1), NR4A2 (подсемейство ядерных рецепторов 4, группа A, представитель 2), MMP8 (матриксную металлопептидазу 8 (нейтрофильную коллагеназу)), NPR2 (рецептор натрийуретического пептида B/гуанилатциклазу B (рецептор атрионатрийуретического пептида B)), GCH1 (GTP гидролазу 1), EPRS (глутамил-пропил-тРНК-синтетазу), PPARGC1A (гамма-рецептор, активируемый пролифератором пероксисом, коактиватор 1 альфа), F12 (фактор коагуляции XII (фактор Хагемана)), PECAM1 (молекулу адгезии тромбоцитов/эндотелиальных клеток), CCL4 (хемокиновый лиганд 4 (с мотивом C-C)), SERPINA3 (ингибитор серпинпептидазы, клада A (альфа-1-антипротеиназу, антитрипсин), представитель 3), CASR (кальций-чувствительный рецептор), GJA5 (белок межклеточных щелевых контактов, альфа 5, 40 кДа), FABP2 (связывающий белок жирных кислот 2 типа, кишечный), TTF2 (фактор терминации транскрипции, РНК-полимеразу II), PROS1 (белок S (альфа)), CTF1 (кардиотропин 1), SGCB (саркогликан, бета (дистрофин-ассоциированный гликопротеин размером 43 кДа)), YME1L1 (YME1-подобный фактор 1 (S. cerevisiae)), CAMP (кателицидиновый антимикробный пептид), ZC3H12A (содержащий фактор типа CCCH с цинковыми пальцами 12A), AKR1B1 (семейство альдокеторедуктазы 1, представитель B1 (альдоредуктазу)), DES (десмин), MMP7 (матриксную металлопептидазу 7 (матрилизин, маточный)), AHR (арил-углеводородный рецептор), CSF1 (колониестимулирующий фактор 1 (макрофагальный)), HDAC9 (гистон-деацетилазу 9), CTGF (фактор роста соединительной ткани), KCNMA1 (калиевый, активируемый кальцием канал высокого проведения, подсемейство M, альфа, представитель 1), UGT1A (UDP-глюкуронилтрансферазу семейства 1, локус комплекса полипептида A), PRKCA (протеинкиназу C, альфа), COMT (катехол-бета-метилтрансферазу), S100B (S100 кальций-связывающий белок B), EGR1 (фактор роста раннего ответа 1), PRL (пролактин), IL15 (интерлейкин 15), DRD4 (дофаминовый рецептор D4), CAMK2G (кальций/кальмодулинзависимую протеинкиназу II гамма), SLC22A2 (семейство переносчиков растворенных веществ 22 (переносчик органических катионов), представитель 2), CCL11 (хемокиновый лиганд 11 (с мотивом C-C)), PGF (плацентартный фактор роста B321), THPO (тромбопоэтин), GP6 (гликопротеин VI (тромбоцитарный)), TACR1 (тахикиновый рецептор 1), NTS (нейротензин), HNF1A (HNF1 гомеобокс A), SST (соматостатин), KCND1 (калиевый потенциалзависимый канал, связанное с Shal подсемейство, представитель 1), LOC646627 (ингибитор фосфолипазы), TBXAS1 (тромбоксан A синтазу 1 (тромбоцитарную)), CYP2J2 (цитохром P450, семейство 2, подсемейство J, полипептид 2), TBXA2R (рецептор тромбоксана A2), ADH1C (алкогольдегидрогеназу 1C (класс I), гамма-полипептид), ALOX12 (арахидонат 12-липогеназу), AHSG (альфа-2-HS-гликопротеин), BHMT (бетаин-гомоцистеинметилтрансферазу), GJA4 (белок щелевых межклеточных контактов, альфа 4, 37 кДа), SLC25A4 (семейство переносчиков растворенных веществ 25 (митохондриальный переносчик; аденин-нуклеотид транслокатор), представитель 4), ACLY (АТФ-цитратлиазу), ALOX5AP (белок, активирующий арахидонат-5-липооксигеназу), NUMA1 (ядерный белок митотического аппарата 1), CYP27B1 (цитохром P450, семейство 27, подсемейство B, полипептид 1), CYSLTR2 (цистеинил-лейкотриеновый рецептор 2), SOD3 (супероксиддисмутазу 3, внеклеточную), LTC4S (лейкотриен C4-синтазу), UCN (урокортин), GHRL (препропептид грелина/обестатина), APOC2 (аполипопротеин C-II), CLEC4A (семейство 4 домена лектина C-типа, представитель A), KBTBD10 (содержащий kelch-повтор и домен BTB (POZ) 10), TNC (тенаскин C), TYMS (тимидилатсинтетазу), SHCl (SHC-трансформирующий белок 1 (содержащий домен 2 с Src-гомологией)), LRP1 (белок 1, связанный с рецепторами липопротеина низкой плотности), SOCS3 (супрессор 3 передачи сигнала с участием цитокинов), ADH1B (алкогольдегидрогеназу 1B (I класс), бета-полипептид), KLK3 (связанную с калликреином пептидазу 3), HSD11B1 (гидроксистероид (11-бета) дегидрогеназу 1), VKORC1 (витамин K эпоксид-редуктазный комплекс, субъединица 1), SERPINB2 (ингибитор серпинпептидазы, клада B (овальбумин), представитель 2), TNS1 (тензин 1), RNF19A (белок "цинковый палец" типа ring 19A), EPOR (эритропоэтиновый рецептор), ITGAM (интегрин, альфа M (субъединицу рецептора 3 компонента 3 комплемента)), PITX2 (подобный парному гомеодомен 2), MAPK7 (митоген-активированную протеинкиназу 7), FCGR3A (Fc-фрагмент IgG, с низкой аффинностью 111a, рецептор (CD16a)), LEPR (лептиновый рецептор), ENG (эндоглин), GPX1 (глутатионпероксидазу 1), GOT2 (щавелево-уксусную трансаминазу глутаминовой кислоты 2 типа, митохондриальную (аспартатаминотрансферазу 2 типа)), HRH1 (гистаминовый рецептор H1), NR112 (семейство ядерных рецепторов 1, I группа, представитель 2), CRH (кортикотропин-рилизинг гормон), HTR1A (5-гидрокситриптаминовый (серотониновый) рецептор 1A), VDAC1 (потенциалзависимый анионный канал 1), HPSE (гепараназу), SFTPD (поверхностно-активный белок D), TAP2 (переносчик 2, АТФ-связывающая кассета, подсемейство B (MDR/TAP)), RNF123 (белок "цинковый палец" типа ring 123), PTK2B (PTK2B протеинтирозинкиназу 2 бета), NTRK2 (нейротрофическую тирозинкиназу, рецептор, 2 тип), IL6R (рецептор интерлейкина 6), ACHE (ацетилхолинэстеразу (группу крови Yt)), GLP1R (рецептор глюкагон-подобного пептида 1), GHR (рецептор гормона роста), GSR (глутатионредуктазу), NQO1 (NAD(P)H-дегидрогеназу, хинон 1), NR5A1 (семейство ядерных рецепторов 5, группа A, представитель 1), GJB2 (белок межклеточных щелевых контактов, бета 2, 26 кДа), SLC9A1 (семейство переносчиков растворенных веществ 9 (натрий-водородный антипортер), представитель 1), MAOA (моноаминоксидазу A), PCSK9 (пропротеинконвертазу субтилизин-кексинового 9 типа), FCGR2A (Fc-фрагмент IgG, с низкой аффинностью IIa, рецептор (CD32)), SERPINF1 (ингибитор серпинпептидазы, клада F (альфа-2-антиплазмин, фактор пигментного эпителия), представитель 1), EDN3 (эндотелин 3), DHFR (дигидрофолатредуктазу), GAS6 (специфичный к задержке роста фактор 6), SMPD1 (сфингомиелинфосфодиэстеразу 1, кислую лизосомальную), UCP2 (неспаренный белок 2 (митохондриальный, переносчик протонов)), TFAP2A (транспортный фактор AP-2 альфа (активирующий энхансер связывающий белок 2 альфа)), C4BPA (связывающий белок 4 компонента комплемента, альфа), SERPINF2 (ингибитор серпинпептидазы, клада F (альфа-2-антилазмин, фактор пигментного эпителия), представитель 2), TYMP (тимидинфосфорилазу), ALPP (щелочную фосфатазу, плацентарную (изозим Регана)), CXCR2 (хемокиновый рецептор 2 (с мотивом C-X-C)), SLC39A3 (семейство переносчиков растворенных веществ 39 (переносчик цинка), представитель 3), ABCG2 (АТФ-связывающую кассету, подсемейство G (WHITE), представитель 2), ADA (аденозиндезаминазу), JAK3 (Янус-киназу 3), HSPA1A (белок теплового шока 1А размером 70 кДа), FASN (синтазу жирных кислот), FGF1 (фактор роста фибробластов 1 (кислотный)), F11 (фактор коагуляции XI), ATP7A (АТФазу, транспортирование Cu++, альфа-полипептид), CR1 (рецептор 1 компонента комплемента (3b/4b) (группы крови Knops)), GFAP (глиофибриллярный щелочной белок), ROCK1 (Rho-ассоциированную содержащую двуспиральную протеинкиназу 1), MECP2 (метил CpG-связывающий белок 2 (синдром Ретта)), MYLK (легкую цепь миозина), BCHE (бутирилхолинэстеразу), LIPE (липазу, гормончувствительную), PRDX5 (пероксиредоксин 5), ADORA1 (рецептор аденозина A1), WRN (синдром Вернера, RecQ, подобный хеликазе), CXCR3 (хемокиновый рецептор 3 (с мотивом C-X-C)), CD81 (молекулу CD81), SMAD7 (семейство SMAD, представитель 7), LAMC2 (ламинин, гамма 2), MAP3K5 (митоген-активируемую протеинкиназу киназы 5), CHGA (хромогранин A (паратиреоридный секреторный белок 1)), IAPP (островковый амилоидный пептид), RHO (родопсин), ENPP1 (эктонуклеотидпирофосфатазу/фосфодиэстеразу 1), PTHLH (подобный паратиреоидному гормону гормон), NRG1 (нейрегулин 1), VEGFC (фактор роста эндотелия сосудов C), ENPEP (глутамиламинопептидазу (аминопептидазу A)), CEBPB (CCAAT/энхансерный связывающий белок (C/EBP), бета), NAGLU (N-ацетилглюкозаминидазу, альфа-), F2RL3 (фактор коагуляции II (тромбин), рецептор-подобный 3), CX3CL1 (хемокиновый лиганд 1 (с мотивом C-X3-C)), BDKRB1 (брадикиновый рецептор B1), ADAMTS13 (ADAM металлопептидазу с тромбоспондиновым мотивом 1 типа, 13), ELANE (эластазу, экспрессируемую в нейтрофилах), ENPP2 (эктонуклеотидпирофосфатазу/фосфодиэстеразу 2), CISH (индуцируемый цитокином SH2-содержащий белок), GAST (гастрин), MYOC (миоцилин, индуцируемый трабекулярной сетью глюкокортикоидный ответ), ATP1A2 (АТФазу, Na+/K+ транспорт, альфа 2 полипептид), NF1 (нейрофибромин 1), GJB1 (белок межклеточных щелевых контактов, бета 1, 32 кДа), MEF2A (миоцитарный энхансорный фактор 2A), VCL (винкулин), BMPR2 (рецептор костного морфогенетического белка, тип II (серин/треонинкиназу)), TUBB (тубулин, бета), CDC42 (фактор клеточного цикла 42 (GTP-связывающий белок, 25 кДа)), KRT18 (кератин 18), HSF1 (фактор транскрипции белка теплового шока 1), MYB (гомолог онкогена вируса миелобластоза v-myb (птичьего)), PRKAA2 (протеинкиназу, AMP-активируемую, каталитическую субъединицу альфа 2), ROCK2 (Rho-ассоциированную содержащую двуспиральную протеинкиназу 2), TFPI (ингибитор пути тканевого фактора (липопротеин-ассоциированный ингибитор коагуляции)), PRKG1 (протеинкиназу, cGMP-зависимую, I тип), BMP2 (костный морфогенетический белок 2), CTNND1 (катенин (кадгерин-ассоциированный белок), дельта 1), CTH (цистатионазу (цистатионин-гамма-лиазу)), CTSS (катепсин S), VAV2 (фактор обмена гуаниновых нуклеотидов vav 2), NPY2R (рецептор Y2 нейропептида Y), IGFBP2 (связывающий белок 2 инсулин-подобного фактора роста, 36 кДа), CD28 (молекулу CD28), GSTA1 (глутатион-S-трансферазу, альфа 1), PPIA (пептидилпролилизомеразу A (циклофилин A)), APOH (аполипопротеин H (бета-2-гликопротеин I)), S100A8 (S100 кальций-связывающий белок A8), IL11 (интерлейкин 11), ALOX15 (арахидонат-15-липоксигеназу), FBLN1 (фибулин 1), NR1H3 (семейство ядерных рецепторов 1, группа H, представитель 3), SCD (стеароил-CoA десатуразу (дельта-9-десатуразу)), GIP (желудочный ингибиторный пептид), CHGB (хромогранин B (секретогранин 1)), PRKCB (протеинкиназу C, бета), SRD5A1 (стероид-5-альфа-редуктазу, альфа-полипептид 1 (3-оксо-5 альфа-стероид дельта-4-дегидрогеназу альфа 1)), HSD11B2 (гидроксистероид (11-бета) дегидрогеназу 2), CALCRL (подобный кальцитониновому рецептору), GALNT2 (UDP-N-ацетил-альфа-D-галактозамин:полипептид N-ацетилгалактозаминилтрансферазу 2 (GalNAc-T2)), ANGPTL4 (ангиопоэтинподобный 4), KCNN4 (калиевый, активируемый кальцием канал, промежуточного/низкого проведения, подсемейство N, представитель 4), PIK3C2A (фосфоинозитидин-3-киназу, класс 2, альфа-полипептид), HBEGF (гепарин-связывающий EGF-подобный фактор роста), CYP7A1 (цитохром P450, семейство 7, подсемейство A, полипептид 1), HLA-DRB5 (главный комплекс гистосовместимости, класс II, DR бета 5), BNIP3 (белок 3 с массой 19 кДа, взаимодействующий с BCL2/аденовирусом E1B), GCKR (регулятор глюкокиназы (гексокиназы 4)), S100A12 (S100 кальций-связывающий белок A12), PADI4 (пептидиларгининдеиминазу, тип IV), HSPA14 (белок 14 теплового шока с массой 70 кДа), CXCR1 (хемокиновый рецептор 1 (с мотивом C-X-C)), H19 (H19, экспрессируемый пептид, импринтированный со стороны матери (некодирующий белок)), KRTAP19-3 (кератин-ассоциированный белок 19-3), IDDM2 (фактор инсулин-зависимого сахарного диабета 2 типа), RAC2 (ras-связанный субстрат 2 ботулотоксина C3 (семейство rho, малый GTP связывающий белок Rac2)), RYR1 (рианодиновый рецептор 1 (мышечный)), CLOCK (гомолог гена (мышиный)), NGFR (рецептор фактора роста нервов (суперсемейство TNFR, представитель 16)), DBH (дофамин бета-гидроксилазу (дофамин бета-монооксигеназу)), CHRNA4 (холинергический рецептор, никотиновый, альфа 4), CACNA1C (кальциевый канал, потенциалзависимый, типа L, субъединицу альфа 1C), PRKAG2 (протеинкиназу, AMP-активированную, гамма 2 некаталическую субъединицу), CHAT (холинацетилтрансферазу), PTGDS (простагландин D2 синтазу размером 21 кДа (головного мозга)), NR1H2 (семейство 1 ядерных рецепторов, группа H, представитель 2), TEK (TEK тирозинкиназу, эндотелиальную), VEGFB (фатор роста эндотелия сосудов B), MEF2C (миоцитарный энхансерный фактор 2C), MAPKAPK2 (протеинкиназу 2, активированную митоген-активированной протеинкиназой), TNFRSF11A (суперсемейство рецепторов фактора некроза опухоли, представитель 11a, активатор NFKB), HSPA9 (белок 9 теплового шока размером 70 кДа (морталин)), CYSLTR1 (цистеинил-лейкотриеновый рецептор 1), MAT1A (метионинаденозилтрансферазу I, альфа), OPRL1 (подобный опиатному рецептору 1), IMPA1 (инизитол(мио)-1(или 4)-монофосфатазу 1), CLCN2 (канал-переносчик для ионов хлора 2), DLD (дигидролипоамиддегидрогеназу), PSMA6 (протеасомную субъединицу (просому, макропаин), тип альфа, 6), PSMB8 (протеасомную субъединицу (просому, макропаин), тип бета, 8 (большую мультифункциональную пептидазу 7)), CHI3L1 (фактор 1, подобный хитиназе 3 (хрящевой гликопротеин 39)), ALDH1B1 (альдегиддегидрогеназу, семейство 1, представитель B1), PARP2 (поли (АДФ-рибозо) полимеразу 2), STAR (стероидогенный острый регуляторный белок), LBP (липополисахарид-связывающий белок), ABCC6 (АТФ-связывающую кассету, подсемейство C (CFTR/MRP), представитель 6), RGS2 (регулятор передачи сигнала с участием G-белка 2, 24 кДа), EFNB2 (эфрин-B2), GJB6 (белок межклеточных щелевых контактов, бета 6, 30 кДа), APOA2 (аполипопротеин A-II), AMPD1 (аденозинмонофосфатдезаминазу 1), DYSF (дисферлин, тазо-плечевая мышечная дистрофия 2B (аутосомно-рецессивная)), FDFT1 (фарнезил-дифосфатфарнелизтрансферазу 1), EDN2 (эндотелин 2), CCR6 (хемокиновый рецептор 6 (с мотивом C-C)), GJB3 (белок межклеточных щелевых контактов, бета 3, 31 кДа), IL1RL1 (фактор 1, подобный рецептору интерлейкина 1), ENTPD1 (эктонуклеозидтрифосфат-дифосфогидролазу 1), BBS4 (фактор 4 синдром Барде-Бидля), CELSR2 (кадгерин, семиканальный рецептор 2 G-типа EGF LAG (гомолог flamingo, дрозофилиный)), F11R (рецептор F11), RAPGEF3 (фактор обмена гуаниновых нуклеотидов Rap (GEF) 3), HYAL1 (гиалуроноглюкозаминидазу 1), ZNF259 (белок "цинковый палец" 259), ATOX1 (гомолог антиоксидантного белка 1 ATX1 (дрожжевой)), ATF6 (фактор активации транскрипции 6), KHK (кетогексокиназу (фруктокиназу)), SAT1 (спермидин/спермин N1-ацетилтрансферазу 1), GGH (гамма-глутамилгидролазу (конъюгазу, фолилполигаммаглутамингидролазу)), TIMP4 (ингибитор TIMP металлопептидазы 4), SLC4A4 (семейство переносчиков растворенных белков 4, бикарбонат-натриевый контранспортер, представитель 4), PDE2A (фосфодиэстеразу 2A, cGMP-стимулированную), PDE3B (фосфодиэстеразу 3B, cGMP-ингибированную), FADS1 (десатуразу 1 жирных кислот), FADS2 (десатуразу 2 жирных кислот), TMSB4X (тимозин бета 4, X-сцепленный), TXNIP (белок, взаимодействующий с тиоредоксином), LIMS1 (домены 1, подобные LIM и антигену стареющих клеток), RHOB (семейство генов гомологов ras, представитель B), LY96 (лимфоцитарный антиген 96), FOXO1 (forkhead-бокс О1), PNPLA2 (фактор 2, содержащий домен пататин-подобной фосфолипидазы), TRH (тиротропин-рилизинг гормон), GJC1 (белок межклеточных щелевых контактов, гамма 1, 45 кДа), SLC17A5 (семейство переносчиков растворенных веществ 17 (переносчик анионов и сахаров), представитель 5), FTO (фактор, ассоциированный с жировой массой и ожирением), GJD2 (белок межклеточных щелевых контактов, дельта 2, 36 кДа), PSRC1 (двуспиральный фактор с высоким содержанием пролина и серина 1), CASP12 (каспазу 12 (ген/псевдоген)), GPBAR1 (рецептор 1 желчных кислот, связанный с G-белком), PXK (серин/треонинкиназу, содержащую домен PX), IL33 (интерлейкин 33), TRIB1 (гомолог tribbles 1 (дрозофилиный)), PBX4 (гомеобокс 4 пре-B-клеточного лейкоза), NUPR1 (ядерный белок, регулятор транскрипции, 1), 15-Sep (селенопротеин размером 15 кДа), CILP2 (белок промежуточного слоя хряща 2), TERC (РНК-компонент теломеразы), GGT2 (гамма-глутамилтрансферазу 2), MT-CO1 (цитохром c оксидазу I, кодируемую митохондриальным геномом) и UOX (уратоксидазу, псевдоген). Любая из данных последовательностей может быть мишенью для системы CRISPR-Cas, например, для изучения мутации.
В дополнительном варианте осуществления хромосомная последовательность также может быть выбрана из следующих: Pon1 (параоксоназа 1), LDLR (рецептор LDL), ApoE (аполипопротеин E), Apo B-100 (аполипопротеин B-100), ApoA (аполипопротеин(a)), ApoA1 (аполипопротеин A1), CBS (цистатион-B-синтаза), гликопротеин IIb/IIb, MTHRF (5,10-метилентетрагидрофолатредуктаза (NADPH) и их комбинаций. В одном случае хромосомные последовательности и белки, кодируемые хромосомными последовательностями, связанные с сердечно-сосудистым заболеванием, могут быть выбраны из Cacna1C, Sod1, Pten, Ppar(альфа), Apo E, лептина и их комбинаций в качестве мишени(мишеней) для системы CRISPR-Cas.
Лечение заболеваний печени и почек
Настоящее изобретение также предусматривает доставку системы CRISPR-Cas, описанной в данном документе, например, систем эффекторного белка Cpf1, в печень и/или почки. Стратегии доставки для индукции поглощения клетками терапевтической нуклеиновой кислоты предусматривают использование физических сил или векторных систем, например доставку с использованием вирусов, липидов, или комплексов, или наноносителей. Исходя из первоначальных вариантов применения, имеющих незначительную возможную клиническую значимость, в случае доставки нуклеиновых кислот в клетки почки с помощью гидродинамической системной инъекции с созданием высокого давления, широкий диапазон вирусных терапевтических носителей и носителей, отличных от вирусных, уже применяется для нацеливания на посттранскрипционные события в различных животных моделях заболевания почек in vivo (Csaba Révész and Péter Hamar (2011). Delivery Methods to Target RNAs in the Kidney, Gene Therapy Applications, Prof. Chunsheng Kang (Ed.), ISBN: 978-953-307-541-9, InTech, доступно на: http://www.intechopen.com/books/gene-therapy-applications/delivery-methods-to-target-rnas-inthe-kidney). Способы доставки в почки могут включать таковые в Yuan et al. (Am J Physiol Renal Physiol 295: F605-F617, 2008) исследовали, может ли in vivo доставка малых интерферирующих РНК (siRNA), целенаправленно воздействующих на 12/15-липоксигеназный (12/15-LO) путь метаболизма арахидоновой кислоты, приводить к уменьшению повреждения почек и диабетической нефропатии (DN) в модели диабета 1 типа на мышах, которым вводили стрептозотоцин путем инъекции. Для достижения большей in vivo доступности и экспрессии siRNA в почке Yuan et al. использовали двухнитевые олигонуклеотиды siRNA к 12/15-LO, конъюгированные с холестерином. Приблизительно 400 мкг siRNA вводили мышам путем подкожной инъекции. Способ согласно Yuang et al. можно применять по отношению к системе CRISPR-Cas по настоящему изобретению, что предусматривает подкожную инъекцию человеку 1-2 г CRISPR-Cas, конъюгированной с холестерином, для доставки в почки.
Molitoris et al. (J Am Soc Nephrol 20: 1754-1764, 2009) использовали клетки проксимальных канальцев (PTC) в качестве сайта реабсорбции олигонуклеотидов в почке для исследования эффективности siRNA, целенаправленно воздействующей на p53, ключевой белок в апоптическом пути, для предупреждения повреждения почки. "Оголенная" синтетическая siRNA к p53, которую вводили путем внутривенной инъекции через 4 ч после ишемического повреждения, обеспечивала максимальную защиту как PTC, так и функции почки. Данные Molitoris et al. указывают, что после внутривенного введения следует быстрая доставка siRNA в клетки проксимальных канальцев. Для анализа зависимости эффекта от дозы крысам инъецировали дозы siP53 0,33; 1, 3 или 5 мг/кг, которые вводили в те же четыре момента времени, что давало в результате суммарные дозы 1,32, 4, 12 и 20 мг/кг соответственно. Все протестированные дозы siRNA приводили к эффекту снижения SCr, в день один, причем более высокие дозы являлись эффективными в течение приблизительно пяти дней по сравнению с обработанными PBS контрольными крысами с ишемией. Суммарные дозы 12 и 20 мг/кг обеспечивали наилучший защитный эффект. Способ согласно Molitoris et al. можно применять по отношению к системе нацеливания на нуклеиновую кислоту по настоящему изобретению, что предусматривает введение человеку суммарных доз 12 и 20 мг/кг для доставки в почки.
Thompson et al. (Nucleic Acid Therapeutics, Volume 22, Number 4, 2012) сообщили о токсикологических и фармакокинетических свойствах синтетических малых интерферирующих РНК I5NP после внутривенного введения грызунам и приматам, отличным от человека. I5NP разработан так, чтобы действовать посредством пути РНК-интерференции (RNAi) для временного ингибирования экспрессии проапоптического белка p53 и создан для защиты клеток от повреждений, связанных с острой ишемией/реперфузией, как, например, острое повреждение почки, которое может возникать при обширной операции на сердце, и отсроченная функция трансплантата, которая может возникать после пересадки почки. Дозы 800 мг/кг I5NP для грызунов и 1000 мг/кг I5NP для приматов, отличных от человека, требовались для того, чтобы вызвать нежелательные эффекты, которые у обезьян сводились к непосредственному воздействию на кровь, чтовключало бессимптомную активацию комплемента и несколько увеличенное время свертывания крови. У крыс не наблюдали дополнительных нежелательных эффектов при использовании аналога I5NP, предназначенного для крыс, что указывало на то, что эти эффекты, вероятно, представляют собой эффекты, связанные с классом синтетических РНК-дуплексов, а не с токсичностью, обусловленной целевой фармакологической активностью I5NP. Взятые вместе, эти данные согласуются с клиническим исследованием с внутривенным введением I5NP для сохранения функции почек после повреждения, связанного с острой ишемией/реперфузией. Уровень, при котором не наблюдали нежелательных эффектов (NOAEL) у обезьян, составлял 500 мг/кг. Не наблюдали эффектов в отношении параметров сердечно-сосудистой, дыхательной и нервной системы у обезьян после внутривенного введения при уровнях дозы до 25 мг/кг. Следовательно, аналогичная доза может предусматриваться для внутривенного введения CRISPR-Cas в почки человека.
Shimizu et al. (J Am Soc Nephrol 21: 622-633, 2010) разработали систему для целенаправленной доставки siRNA в клубочки с помощью средств на основе поли(этиленгликоля) и поли(L-лизина). Диаметр комплекса siRNA/наноноситель составлял от приблизительно 10 до 20 нм, причем данный размер будет позволять ему проходить через окончатый эндотелий для того, чтобы попасть в мезангий. После интраперитонеальной инъекции флуоресцентно меченых комплексов siRNA/наноноситель Shimizu et al. выявляли siRNA в кровотоке в течение длительного времени. Повторное интраперитонеальное введение комплекса siRNA к митоген-активируемой протеинкиназе 1 (MAPK1)/наноноситель подавляло экспрессию мРНК и белка MAPK1 в клубочках в мышиной модели гломерулонефрита. Для исследования накопления siRNA Cy5-меченые siRNA в комплексе с PIC наноносителями (0,5 мл, содержание siRNA 5 нмоль), "оголенные" Cy5-меченые siRNA (0,5 мл, 5 нмоль) или Cy5-меченые siRNA, инкапсулированные в HVJ-E (0,5 мл, содержание 5 нмоль siRNA), вводили мышам BALBc. Способ согласно Shimizu et al. можно применять по отношению к системе нацеливания на нуклеиновую кислоту по настоящему изобретению, что предусматривает дозу приблизительно 10-20 мкмоль CRISPR-Cas в комплексе с наноносителями на приблизительно 1-2 литра для интраперитонеального введения человеку и доставки в почки.
Способы доставки в почку обобщены ниже.
липидный
вирусный
липидный
вирусный
pp. (1754-1764)
липидный
поли-L-лизин
квантовая точка/PEI
меланома
mNOX-E36
Нацеливание на печень и клетки печени
Предусмотрено нацеливание на клетки печени. Его можно осуществлять in vitro или in vivo. Гепатоциты являются предпочтительными. Доставка белка CRISPR, такого как Cpf1 в данном документе, может осуществляться посредством вирусных векторов, особенно векторов на основе AAV (и, в частности, AAV2/6). Их можно вводить с помощью внутривенной инъекции.
Предпочтительной мишенью для печени, вне зависимости in vitro или in vivo, является ген альбумина. Он представляет собой так называемую "зону безопасности", поскольку альбумин экспрессируется при очень высоких уровнях, и поэтому некоторое снижение продукции альбумина после успешного редактирования генов является допустимым. Он также является предпочтительным, поскольку высокие уровни экспрессии, наблюдаемые при работе промотора/энхансера альбумина, обеспечивают достижение полезных уровней корректной или трансгенной продукции (из вставленной донорской матрицы) даже в случае, если редактируют лишь небольшую часть гепатоцитов.
Интрон 1 альбумина, как было показано Wechsler et al. (представлено на 57-м ежегодном собрании и выставке Американского общества гематологии - резюме доступно онлайн по адресу https://ash.confex.com/ash/2015/webprogram/Paper86495.html и размещено 6 декабря 2015 г.), является подходящим целевым сайтом. В их исследовании были использованы "цинковые пальцы" для разрезания ДНК в целевом сайте, и подходящие направляющие последовательности можно получить для управления расщеплением в том же сайте с помощью белка CRISPR.
Использование мишеней в высокоэкспрессируемых генах (генах с высокоактивными энхансерами/промоторами), такими как альбумин, может также обеспечивать использование не содержащей промоторов донорской матрицы, как описано Wechsler et al., и это также является широко применимым за пределами нацеливания на печень. Известны другие примеры высокоэкспрессируемых генов.
Другие заболевания печени
В конкретных вариантах осуществления белки CRISPR по настоящему изобретению используют для лечения нарушений печени, таких как транстиретиновый амилоидоз (ATTR), недостаточность альфа-1-антитрипсина и другие врожденные ошибки метаболизма печени. FAP вызван мутацией в гене, который кодирует транстиретин (TTR). Поскольку он является аутосомно-доминантным заболеванием, не у всех носителей развивается заболевание. Существует свыше 100 мутацией в гене TTR, которые, как известно, ассоциированы с заболеванием. Примеры распространенных мутаций включают V30M. Принцип лечения TTR на основе сайленсинга генов был показан исследованиями с применением iRNA (Ueda et al. 2014 Transl Neurogener. 3:19). Болезнь Вильсона (WD) вызвана мутациями в гене, кодирующем ATP7B, который встречается исключительно в гепатоците. Существует свыше 500 мутаций, ассоциированных с WD с повышенной распространенностью в определенных областях, таких как Восточная Азия. Другими примерами являются A1ATD (аутосомно-рецессивное заболевание, вызванное мутациями в гене SERPINA1) и PKU (аутосомно-рецессивное заболевание, вызванное мутациями в гене фенилаланингидроксилазы (PAH)).
Ассоциированые с печенью нарушения крови, в частности, гемофилия, и, в частности, гемофилия B
Успешное редактирование генов гепатоцитов было достигнуто у мышей (как in vitro, так и in vivo) и у отличных от человека приматов (in vivo), показывающее, что лечение нарушений со стороны крови посредством редактирования гена/конструирования генома в гепатоцитах является возможным. В частности, экспрессия человеческого гена F9 (hF9) в гепатоцитах была показана у отличных от человека приматов, указывая на возможность лечения гемофилии B у людей.
Wechsler et al. представили на 57-м ежегодном собрании и выставке Американского общества гематологии (резюме размещено 6 декабря 2015 г. и доступно онлайн по адресу https://ash.confex.com/ash/2015/webprogram/Paper86495.html), что они успешно экспрессировали человеческий F9 (hF9) из гепатоцитов, взятых у отличных от человека приматов, посредством редактирования гена in vivo. Это было достигнуто с помощью 1) двух нуклеаз с "цинковыми пальцами" (ZFN), нацеливающихся на интрон 1 локуса альбумина, и 2) конструкции донорской матрицы человеческого F9. ZFN и донорскую матрицу кодировали на отдельных векторах на основе гепатотропного аденоассоциированного вируса серотипа 2/6 (AAV2/6), вводили внутривенно, что приводило к целевой вставке откорректированной копии гена hF9 в локус альбумина в части гепатоцитов печени.
Локус альбумина выбирали в качестве "предохранителя", поскольку продукция этого наиболее представленного белка плазмы превышает 10 г/день, и умеренные снижения таких уровней являются хорошо переносимыми. Гепатоциты с отредактированным геномом продуцировали hFIX (hF9) в терапевтических количествах, в отличие от альбумина, управляемого высокоактивным энхансером/промотором. Была показана подвергаемая нацеливанию интеграция трансгена hF9 в локус альбумина и сплайсинг этого гена в транскрипт альбумина.
Исследования у мышей: мышам C57BL/6 вводили основу (n=20) или векторы на основе AAV2/6 (n=25), кодирующие мышиные суррогатные реагенты, при 1,0 x1013 векторных геномов (vg)/кг посредством инъекции в хвостовую вену. Анализ ELISA hFIX плазмы у обработанных мышей показал максимальные уровни 50-1053 нг/мл, которые сохранялись в течение 6-месячного исследования. Анализ активности FIX из плазмы мышей подтвердил биоактивность, соразмерную уровням экспрессии.
Исследования у отличных от человека приматов (NHP): одна внутривенная совместная инфузия векторов на основе AAV2/6, кодирующих нацеленные на альбумин-специфичные ZFN NHP, и донорской матрицы человеческого F9 при 1,2x1013 vg/кг (n=5/группа) приводила к уровню >50 нг/мл (>1% от нормы) в этой модели с участием крупных животных. Применение более высоких доз AAV2/6 (до 1,5x1014 vg/кг включительно) приводило к уровням hFIX до 1000 нг/мл включительно (или 20% от нормы) у нескольких животных и до 2000 нг/мл (или 50% от нормы) у одного животного в течение исследования (3 месяца).
Лечение хорошо переносилось у мышей и NHP, без значимых токсикологических результатов, связанных с лечением AAV2/6 ZFN + донор у обоих видов при терапевтических дозах. После этого Sangamo (Калифорния, США) подал заявку в FDA и получил разрешение на проведение первого в мире клинического исследования на человеке с целью применения редактирования генома in vivo. Оно проводится в дополнение к разрешению EMEA лечения на основе генной терапии Glybera недостаточности липопротеинлипазы.
Соответственно, предпочтительно в некоторых вариантах осуществления, что применяют любое или все из следующего:
- векторы на основе AAV (в частности, AAV2/6), предпочтительно вводимые с помощью внутривенной инъекции;
- альбумин в качестве мишени для редактирования гена/вставки трансгена/матрицы - особенно в интроне 1 альбумина;
- донорскую матрицу человеческого F9; и/или
- не содержащую промотора донорскую матрицу.
Гемофилия B
Соответственно, в некоторых вариантах осуществления предпочтительно, что настоящее изобретение применяют для лечения гемофилии B. Например, предпочтительно, что предусмотрена матрица, и что она представляет собой человеческий ген F9. Предполагается, что матрица hF9 содержит wt или "не содержащую ошибок" версию hF9, поэтому лечение является эффективным.
В альтернативном варианте осуществления версия F9, приводящая к гемофилии В, может быть доставлена с тем, чтобы создать модельный организм, клетку или линию клеток (например, модельный организм, клетку или линию клеток мыши или отличных от человека приматов), модельный организм, клетку или линию клеток, имеющую или несущую фенотип гемофилии B, т. е. неспособность продуцировать F9 wt.
Гемофилия A
В некоторых вариантах осуществления ген F9 (фактор IX) может быть замещен геном F8 (фактор VIII), описанным в данном документе, приводя к лечению гемофилии A (посредством получения не содержащего ошибок гена F8) и/или созданию модельного организма, клетки или линии клеток с гемофилией A (посредством получения содержащего ошибки гена F8, версии, приводящей к гемофилии А).
Гемофилия C
В некоторых вариантах осуществления ген F9 (фактор IX) может быть замещен геном F11 (фактор XI), описанным в данном документе, приводя к лечению гемофилии С (посредством получения не содержащего ошибок гена F11) и/или созданию модельного организма, клетки, или линии клеток с гемофилией С (посредством получения содержащего ошибки гена F11, версии, приводящей к гемофилии С).
Лечение заболеваний эпителия и легких
Настоящее изобретение также предусматривает доставку системы CRISPR-Cas, описанной в данном документе, например, систем эффекторного белка Cpf1, в одно легкое или в оба легких.
Несмотря на то, что векторы на основе AAV-2 были изначально предложены для доставки CFTR в дыхательные пути при CF, другие серотипы, например AAV-1, AAV-5, AAV-6 и AAV-9, демонстрировали улучшенную эффективность переноса генов в ряде моделей эпителия легких (см., например, Li et al., Molecular Therapy, vol. 17 no. 12, 2067-2077 Dec 2009). Было продемонстрировано, что AAV-1 являлся в ~100 раз более эффективным, чем AAV-2 и AAV-5 при трансдукции эпителиальных клеток дыхательных путей человека in vitro, хотя эффективность трансдукции эпителия воздухоносных путей трахеи мышей in vivo при использовании помощи AAV-1 была равной таковой для AAV-5. Другие исследования продемонстрировали, что AAV-5 являлся в 50 раз более эффективным, чем AAV-2, при доставке генов в эпителий дыхательных путей человека (HAE) in vitro и значительно более эффективным в эпителии воздухоносных путей легких мышей in vivo. Также было продемонстрировано, что AAV-6 являлся более эффективным, чем AAV-2, в эпителиальных клетках дыхательных путей человека in vitro и дыхательных путях мышей in vivo. Как было показано, изолят, обнаруженный позже, AAV-9, продемонстрировал большую эффективность переноса генов, чем AAV-5, в назальном и альвеолярном эпителии мышей in vivo, причем экспрессию гена выявляли в течение более 9 месяцев, что позволяет предположить, что AAV может обеспечивать длительную экспрессию генов in vivo, являющуюся необходимым свойством для вектора для доставки гена CFTR. Более того, было продемонстрировано, что AAV-9 можно повторно вводить в легкие мышей без потери экспрессии CFTR и с минимальными последствиями, связанными с иммунной системой. Культуры HAE с CF и без CF можно инокулировать на апикальной поверхности с использованием 100 мкл векторов на основе AAV в течение нескольких часов (см., например, Li et al., Molecular Therapy, vol. 17 no. 12, 2067-2077 Dec 2009). MOI может варьировать от 1 × 103 до 4 × 105 векторных геномов/клетка, в зависимости от концентрации вируса и целей экспериментов. Упомянутые выше векторы предусматриваются для доставки и/или введения согласно настоящему изобретению.
Zamora et al. (Am J Respir Crit Care Med Vol 183. pp 531-538, 2011) представили пример применения терапевтического средства на основе РНК-интерференции для лечения инфекционных заболеваний человека, а также рандомизированного исследования противовирусного лекарственного средства у реципиентов трансплантата легкого, инфицированного респираторным синцитиальным вирусом (RSV). Zamora et al. провели рандомизированное, двойное слепое, плацебо-контролируемое исследование у реципиентов LTX с инфекцией дыхательных путей RSV. Пациентам давали возможность получать стандартное лечение против RSV. ALN-RSV01 в форме аэрозоля (0,6 мг/кг) или плацебо вводили ежедневно в течение 3 дней. Это исследование продемонстрировало, что терапевтическое средство на основе RNAi, целенаправленно воздействующее на RSV, можно вводить без риска реципиентам LTX с инфекцией RSV. Три ежедневные дозы ALN-RSV01 не приводили в результате к какому-либо обострению симптомов в дыхательных путях или к нарушению функции легких и не проявляли каких-либо системных провоспалительных эффектов, таких как индукция цитокинов или CRP. Фармакокинетические исследования продемонстрировали только низкий уровень временного системного воздействия после ингаляции, что согласуется с данными доклинических исследований на животных, демонстрирующих, что ALN-RSV01, вводимый внутривенно или путем ингаляции, подвергается быстрому клиренсу из кровотока при помощи опосредованного экзонуклеазами расщепления и почечной экскреции. Способ согласно Zamora et al. можно применять в отношении системы нацеливания на нуклеиновую кислоту по настоящему изобретению, и при этом CRISPR-Cas в форме аэрозоля, например, при дозе 0,6 мг/кг, может предусматриваться в соответствии с настоящим изобретением.
Субъекты, которых лечат от заболевания легкого, например, могут получать фармацевтически эффективное количество векторной системы на основе AAV в форме аэрозоля на легкое, доставляемое эндобронхиально при самостоятельном дыхании. Вследствие этого доставка в форме аэрозоля является предпочтительной для доставки AAV. Аденовирус или частицу AAV можно применять для доставки. Подходящие конструкции с генами, каждый из которых функционально связан с одной или несколькими регуляторными последовательностями, можно клонировать в вектор доставки. В этом случае следующие конструкции представлены в качестве примеров: промотор Cbh или EF1a для Cas (Cpf1), промотор U6 или H1 для направляющей РНК. Предпочтительной схемой является применение направляющей, нацеливающейся на CFTR с мутацией дельта-508, матрицы для репарации мутации дельта-F508 и кодон-оптимизированного фермента Cpf1 необязательно с одним или несколькими сигналами или последовательностями ядерной локализации (NLS), например, с двумя (2) NLS. Также предусматриваются конструкции без NLS.
Лечение заболеваний мышечной системы
В настоящем изобретении также предусмотрена доставка системы CRISPR-Cas, описанной в данном документе, например, систем на основе эффекторного белка Cpf1, в мышцу(мышцы).
Bortolanza et al. (Molecular Therapy vol. 19 no. 11, 2055-2064 Nov. 2011) продемонстрировали, что системная доставка кассет экспрессии для РНК-интерференции у мышей FRG1 после начала проявления плече-лопаточно-лицевой мышечной дистрофии (FSHD) приводила к дозозависимому длительному нокдауну FRG1 без симптомов токсичности. Bortolanza et al. обнаружили, что однократная внутривенная инъекция 5 × 1012 vg (векторных геномов) rAAV6-sh1FRG1 восстанавливает гистопатологические характеристики мышц и функцию мышц у мышей FRG1. Более подробно, 200 мкл, содержащие 2 × 1012 или 5 × 1012 vg вектора в физиологическом растворе, вводили путем инъекции в хвостовую вену с использованием шприца Terumo с иглой 25-ого калибра. Способ согласно Bortolanza et al. можно применять в отношении AAV, экспрессирующему CRISPR Cas, и вводить его человеку путем инъекции в дозе приблизительно 2 × 1015 или 2 × 1016 vg вектора.
Dumonceaux et al. (Molecular Therapy vol. 18 no. 5, 881-887 May 2010) осуществляли ингибирование пути миостатина с применением методики РНК-интерференции, направленной против мРНК рецептора миостатина AcvRIIb (sh-AcvRIIb). Восстановление квази-дистрофина было опосредовано методикой направленного U7 пропуска экзона (U7-DYS). Векторы на основе аденоассоциированных вирусов, несущие либо только конструкцию sh-AcvrIIb, либо только конструкцию U7-DYS, или комбинацию обоих конструкций, вводили путем инъекции в переднюю большеберцовую (TA) мышцу мышей mdx с дистрофией. Инъекции осуществляли с использованием 1011 геномов вируса AAV. Способ согласно Dumonceaux et al. можно применять в отношении AAV, экспрессирующему CRISPR Cas, и вводить его человеку путем инъекции, например, в дозе от приблизительно 1014 до приблизительно 1015 vg вектора.
Kinouchi et al. (генная терапия (2008) 15, 1126-1130) сообщили об эффективности доставки siRNA in vivo в скелетные мышцы нормальных или больных мышей посредством образования наночастиц из химически не модифицированных siRNA с ателоколлагеном (ATCOL). ATCOL-опосредованное местное применение siRNA, целенаправленно воздействующей на миостатин, отрицательный регулятор роста скелетных мышц, при введении в скелетные мышцы мышей или внутривенно приводило к существенному увеличению мышечной массы в течение нескольких недель после применения. Эти результаты указывают на то, что ATCOL-опосредованное применение siRNA является мощным инструментом для дальнейшего терапевтического применения для лечения заболеваний, в том числе мышечной атрофии. Mst-siRNA (конечная концентрация, 10 мМ) смешивали с ATCOL (конечная концентрация для местного введения, 0,5%) (AteloGene, Kohken, Токио, Япония) в соответствии с инструкциями производителя. После проведения анестезии мышей (самцы C57BL/6 в возрасте 20 недель) с помощью нембутала (25 мг/кг, интраперитонеально) комплекс Mst-siRNA/ATCOL инъецировали в жевательные мышцы и двуглавую мышцу бедра. Способ согласно Kinouchi et al. можно применять в отношении CRISPR-Cas и вводить ее человеку путем инъекции, например, в дозе от приблизительно 500 до 1000 мл 40 мкМ раствора в мышцу. Hagstrom et al. (Molecular Therapy Vol. 10, No. 2, August 2004) описывали интраваскулярную методику без использования вируса, которая обеспечивает эффективную и воспроизводимую доставку нуклеиновых кислот в мышечные клетки (мышечные волокна) мышц конечности млекопитающих. Методика включает инъекцию "оголенной" плазмидной ДНК или siRNA в вену дистальной части конечности, временно изолированную с помощью жгута или пневматической манжеты. Доставка нуклеиновой кислоты в мышечные волокна обеспечивается посредством ее быстрого введения путем инъекции при объеме, достаточном для обеспечения просачивания раствора нуклеиновой кислоты в мышечную ткань. Высокие уровни экспрессии трансгена в скелетной мышце достигались как у мелких, так и у крупных животных при минимальной токсичности. Также были получены доказательства доставки siRNA в мышцу конечности. Для внутривенной инъекции плазмидной ДНК макаку-резусу трехходовый кран присоединяли к двум шприцевым насосам (Model PHD 2000; Harvard Instruments), в каждый из которых помещали один шприц. Через пять минут после инъекции папаверина вводили путем инъекции pDNA (15,5-25,7 мг в 40-100 мл физиологического раствора) при скорости 1,7 или 2,0 мл/с. Это можно воспроизводить в увеличенном масштабе для плазмидной ДНК, экспрессирующей CRISPR Cas согласно настоящему изобретению, причем с инъекцией человеку от приблизительно 300 до 500 мг в 800-2000 мл физиологического раствора. Для инъекции аденовирусного вектора крысе 2 x 109 инфекционных частиц в 3 мл физиологического солевого раствора (NSS) вводили путем инъекции. Это можно воспроизводить в увеличенном масштабе для аденовирусного вектора, экспрессирующего CRISPR Cas по настоящему изобретению, причем с инъекцией человеку приблизительно 1 x 1013 инфекционных частиц в 10 литрах NSS. Что касается siRNA, крысе вводили путем инъекции в большую подкожную вену 12,5 мкг siRNA, а примату вводили путем инъекции в большую подкожную вену 750 мкг siRNA. Это можно воспроизводить в увеличенном масштабе для CRISPR Cas согласно настоящему изобретению, например, путем инъекции от приблизительно 15 до приблизительно 50 мг в большую подкожную вену человека.
См. также, например, опубликованную заявку Duke University WO2013163628 A2 "Генетическая коррекция мутированных генов", в которой описаны попытки коррекции, например, мутации по типу сдвига рамки считывания, которая вызывает появление преждевременного стоп-кодона и усечение продукта гена, которую можно откорректировать посредством опосредованного нуклеазами негомологичного соединения концов, как, например, обуславливающей мышечную дистрофию Дюшенна ("DMD"), рецессивное смертельное сцепленное с X-хромосомой нарушение, приводящее к мышечной дегенерации в связи с мутациями гена дистрофина. Большинство мутаций гена дистрофина, вызывающих DMD, представляют собой делеции экзонов, нарушающие рамку считывания и вызывающие преждевременную терминацию трансляции гена дистрофина. Дистрофин представляет собой цитоплазматический белок, обеспечивающий стабильность структуры дистрогликанового комплекса клеточной мембраны, отвечающего за регуляцию целостности и функционирования мышечных клеток. Ген дистрофина или "ген DMD", как взаимозаменяемо используется в данном документе, образован 2,2 миллионами пар оснований в локусе Xp21. Размер первичного транскрипта составляет приблизительно 2400 т.п.о., при этом размер зрелой мРНК составляет приблизительно 14 т.п.о. 79 экзонов кодируют белок, образованный более 3500 аминокислотами. Экзон 51 часто является смежным с положениями делеций, нарушающих рамку считывания, у пациентов с DMD, и в клинических испытаниях на него был направлен пропуск экзона, основанный на применении олигонуклеотидов. Недавно в клиническом испытании с пропуском экзона 51 с помощью соединения этерлипсена сообщали о значительном положительном функциональном эффекте в течение 48 недель со средним количеством дистрофин-положительных волокон 47% по сравнению с исходным уровнем. Мутации в экзоне 51 идеально подходят для устойчивой коррекции посредством редактирования генома на основе NHEJ.
Способы согласно публикации заявки на патент США № 20130145487, закрепленной за Cellectis, которые относятся к вариантам мегануклеаз для расщепления целевой последовательности гена дистрофина человека (DMD), также можно модифицировать для системы нацеливания на нуклеиновую кислоту по настоящему изобретению.
Лечение заболеваний кожи
Настоящее изобретение также предусматривает доставку системы CRISPR-Cas, описанной в данном документе, например, систем эффекторного белка Cpf1, в кожу.
Hickerson et al. (Molecular Therapy-Nucleic Acids (2013) 2, e129) обращаются к снабженному приводом устройству с матрицей микроигл для доставки в кожу, предназначенному для самостоятельной (sd) доставки siRNA в кожу человека и мыши. Основной проблемой, связанной с переносом терапевтических средств на основе siRNA для кожи в клиническую практику, является разработка эффективных систем доставки. Значительные усилия были приложены к созданию ряда методик доставки в кожу, причем с ограниченным успехом. В клиническом исследовании, в котором кожу обрабатывали siRNA, острая боль, связанная с инъекцией с помощью иглы для подкожных инъекций, препятствовала включению дополнительных пациентов в исследование, что придает большое значение потребности в улучшенных, более "удобных для пациента" (т. е. причиняющих слабую боль или не причиняющих ее) средствах доставки. Микроиглы представляют эффективный способ доставки крупных заряженных молекул-карго, включающих siRNA, через первичный барьер, роговой слой, и, как правило, считаются причиняющими меньшую боль, чем обычные иглы для подкожных инъекций. Снабженные приводом устройства "штамповочного типа" с микроиглами, в том числе снабженное приводом устройство с сеткой микроигл (MMNA), используемое Hickerson et al., как было продемонстрировано, были безопасными в исследованиях на бесшерстных мышах и причиняли слабую боль или не причиняли боли, о чем свидетельствует (i) широкое применение в косметологии и (ii) ограниченное тестирование, в котором практически все добровольцы считали применение устройства причиняющим намного меньшую боль, чем при вакцинации против гриппа, что позволяет предположить, что доставка siRNA с применением этого устройства будет намного менее болезненной, чем испытываемая в предшествующих клинических исследованиях с применением игл для подкожных инъекций. Устройство MMNA (имеющееся в продаже как Triple-M или Tri-M от Bomtech Electronic Co, Сеул, Южная Корея) адаптировали для доставки siRNA в кожу мыши и человека. Раствор sd-siRNA (до 300 мкл 0,1 мг/мл РНК) вводили в камеру одноразового инъекционного картриджа с иглами Tri-M (Bomtech), которые устанавливали на глубину 0,1 мм. Для обработки кожи человека деидентифицированную кожу (полученную непосредственно после хирургических вмешательств) растягивали вручную и прикалывали к пробковому столу перед обработкой. Все интрадермальные инъекции осуществляли с помощью инсулинового шприца с 0,5-дюймовой иглой 28 калибра. Устройство MMNA и способ согласно Hickerson et al. можно применять и/или приспосабливать для доставки CRISPR-Cas согласно настоящему изобретению, например, в дозе до 300 мкл 0,1 мг/мл CRISPR-Cas, в кожу.
В Leachman et al. (Molecular Therapy, vol. 18 no. 2, 442-446 Feb. 2010) изложено клиническое исследование фазы Ib, направленное на лечение редкого нарушения кожи врожденной пахионихии (PC), аутосомно-доминантного синдрома, которое предусматривает блокирование подошвенной кератодермии, с использованием первого терапевтического средства на основе короткой интерферирующей РНК (siRNA) для кожи. Эта siRNA, под названием TD101, специфично и эффективно целенаправленно воздействует на мРНК мутантного кератина 6a (K6a) N171K, не оказывая влияния на мРНК K6a дикого типа.
Zheng et al. (PNAS, July 24, 2012, vol. 109, no. 30, 11975-11980) продемонстрировали, что конъюгаты сферических наночастиц с нуклеиновой кислотой (SNA-NC), являющиеся ядрами из золота окружеными плотной оболочкой из строго ориентированных, ковалентно иммобилизованных siRNA, свободно проникают практически в 100% кератиноцитов in vitro, в кожу мыши и в эпидермис человека в течение нескольких часов после применения. Zheng et al. продемонстрировали, что однократное применение 25 нМ SNA-NC к рецептору эпидермального фактора роста (EGFR) в течение 60 ч. продемонстрировало эффективный нокдаун гена в коже человека. Аналогичная доза может предусматриваться для CRISPR-Cas, иммобилизованной в SNA-NC для введения в кожу.
Рак
В некоторых вариантах осуществления предусмотрено лечение, профилактика и диагностика рака. Мишенью предпочтительно является один или несколько из генов FAS, BID, CTLA4, PDCD1, CBLB, PTPN6, TRAC или TRBC. Рак может представлять собой одно или несколько из лимфомы, хронического лимфоцитарного лейкоза (CLL), B-клеточного острого лимфоцитарного лейкоза (B-ALL), острого лимфобластного лейкоза, острого миелоидного лейкоза, неходжкинской лимфомы (NHL), диффузной крупноклеточной лимфомы (DLCL), множественной миеломы, почечно-клеточной карциномы (RCC), нейробластомы, колоректального рака, рака молочной железы, рака яичников, меланомы, саркомы, рака предстательной железы, рака легких, рака пищевода, гепатоцеллюлярной карциномы, рака поджелудочной железы, астроцитомы, мезотелиомы, рака головы и шеи и медуллобластомы. Это можно осуществлять с помощью сконструированной Т-клетки с химерным антигенным рецептором (CAR). Это описано в WO2015161276, раскрытие которого включено в данный документ посредством ссылки, и описано в данном документе ниже.
Целевые гены, подходящие для лечения или профилактики рака, могут включать в некоторых вариантах осуществления описанные в WO2015048577, раскрытие которого включено в данный документ посредством ссылки.
Синдром Ушера или пигментный ретинит-39
В некоторых вариантах осуществления предусмотрено лечение, профилактика и диагностика синдрома Ушера или пигментного ретинита-39. Мишенью предпочтительно является ген USH2A. В некоторых вариантах осуществления предусмотрена коррекция делеции G в положении 2299 (2299delG). Это описано в WO2015134812A1, раскрытие которого включено в данный документе посредством ссылки.
Муковисцидоз (CF)
В некоторых вариантах осуществления предусмотрено лечение, профилактика и диагностика муковисцидоза. Мишенью предпочтительно является ген SCNN1A или CFTR. Это описано в WO2015157070, раскрытие которого включено в данный документ посредством ссылки.
Schwank et al. (Cell Stem Cell, 13:653-58, 2013) использовали CRISPR-Cas9 для коррекции дефекта, ассоциированного с муковисцидозом, в стволовых клетках человека. Целью исследователей являлся ген ионного канала, рецептора трансмембранной проводимости при муковисцидозе (CFTR). Делеция в CFTR приводит к неправильной укладке белка у пациентов с муковисцидозом. С использованием культивируемых стволовых клеток кишечника, полученных из образцов клеток от двух детей с муковисцидозом, Schwank et al. смогли скорректировать дефект с использованием CRISPR вместе с донорной плазмидой, содержащей репаративную последовательность, подлежащую вставке. Исследователи затем вырастили клетки до "органоидов" кишечника или кишок небольшого размера и продемонстрировали, что они нормально функционировали. В этом случае приблизительно половина клональных органоидов подвергалась надлежащей коррекции наследственного материала.
HIV и СПИД
В некоторых вариантах осуществления предусмотрено лечение, профилактика и диагностика HIV и СПИДа. Мишенью предпочтительно является ген CCR5 в HIV. Это описано в WO2015148670A1, раскрытие которого включено в данный документе посредством ссылки.
Бета-талассемия
В некоторых вариантах осуществления предусмотрено лечение, профилактика и диагностика бета-талассемии. Мишенью предпочтительно является ген BCL11A. Это описано в WO2015148860, раскрытие которого включено в данный документе посредством ссылки.
Серповидно-клеточная анемия (SCD)
В некоторых вариантах осуществления предусмотрено лечение, профилактика и диагностика серповидно-клеточной анемии (SCD). Мишенью предпочтительно является ген HBB или BCL11A. Это описано в WO2015148863, раскрытие которого включено в данный документе посредством ссылки.
Вирус простого герпеса 1 и 2 типа
В некоторых вариантах осуществления предусмотрено лечение, профилактика и диагностика HSV-1 (вируса простого герпеса 1). Мишенью предпочтительно является ген UL19, UL30, UL48 или UL50 в HSV-1. Это описано в WO2015153789, раскрытие которого включено в данный документ посредством ссылки.
В других вариантах осуществления предусмотрено лечение, профилактика и диагностика HSV-2 (вируса простого герпеса 2). Мишенью предпочтительно является ген UL19, UL30, UL48 или UL50 в HSV-2. Это описано в WO2015153791, раскрытие которого включено в данный документ посредством ссылки.
В некоторых вариантах осуществления предусмотрено лечение, профилактика и диагностика первичной открытоугольной глаукомы (POAG). Мишенью предпочтительно является ген MYOC. Это описано в WO2015153780, раскрытие которого включено в данный документе посредством ссылки.
Виды адоптивной клеточной терапии
Настоящее изобретение также предусматривает применение системы CRISPR-Cas, описанной в данном документе, например, систем эффекторного белка Cpf1, для модификации клеток с целью адоптивных видов терапии. Аспекты по настоящему изобретению соответственно включают адоптивный перенос клеток иммунной системы, таких как T-клетки, специфичных в отношении определенных антигенов, таких как опухоль-ассоциированные антигены (см. Maus et al., 2014, Adoptive Immunotherapy for Cancer or Viruses, Annual Review of Immunology, Vol. 32: 189-225; Rosenberg and Restifo, 2015, Adoptive cell transfer as personalized immunotherapy for human cancer, Science Vol. 348 no. 6230 pp. 62-68; и Restifo et al., 2015, Adoptive immunotherapy for cancer: harnessing the T cell response. Nat. Rev. Immunol. 12(4): 269-281; и Jenson and Riddell, 2014, Design and implementation of adoptive therapy with chimeric antigen receptor-modified T cells. Immunol Rev. 257(1): 127-144). Например, различные стратегии можно использовать для генетической модификации T-клеток с помощью изменения специфичности T-клеточного рецептора (TCR), например, посредством введения новых α- и β-цепей TCR со специфичностью по отношению к определенным пептидам (см. патент США №8697854; публикации заявок на патент согласно PCT: WO2003020763, WO2004033685, WO2004044004, WO2005114215, WO2006000830, WO2008038002, WO2008039818, WO2004074322, WO2005113595, WO2006125962, WO2013166321, WO2013039889, WO2014018863, WO2014083173; патент США № 8088379).
В качестве альтернативы или дополнительно к модификациям TCR химерные антигенные рецепторы (CAR) можно использовать с целью получения иммунореактивных клеток, таких как T-клетки, специфичные по отношению к определенным мишеням, таким как злокачественные клетки, с широким разнообразием описанных рецепторных химерных конструкций (см. патенты США №№ 5843728; 5851828; 5912170; 6004811; 6284240; 6392013; 6410014; 6753162; 8211422 и публикацию согласно PCT WO9215322). Альтернативные конструкции CAR можно охарактеризовать как принадлежащие к последующим поколениям. CAR первого поколения, как правило, состоят из однонитевого вариабельного фрагмента антитела, специфичного по отношению к антигену, например, содержащего VL, связанную с VH конкретного антитела, связанного с помощью гибкого линкера, например, с помощью шарнирного домена CD8α и трансмембранного домена CD8α с трансмембранными доменами и доменами внутриклеточной передачи сигнала CD3ζ или FcRγ (scFv-CD3ζ или scFv-FcRγ; см. патент США №7741465; патент США №5912172; патент США №5906936). CAR второго поколения охватывают внутриклеточные домены одной или нескольких костимулирующих молекул, таких как CD28, OX40 (CD134) или 4-1BB (CD137) в эндодомене (например, scFv-CD28/OX40/4-1BB-CD3ζ; см. патенты США №№ 8911993; 8916381; 8975071; 9101584; 9102760; 9102761). CAR третьего поколения включают комбинацию костимулирующих эндодоменов, таких как сигнальные домены CD3ζ-цепи, CD97, GDI la-CD18, CD2, ICOS, CD27, CD154, CDS, OX40, 4-1BB или CD28 (например, scFv-CD28-4-1BB-CD3ζ или scFv-CD28-OX40-CD3ζ; см. патент США № 8906682; патент США № 8399645; патент США № 5686281; публикацию согласно PCT № WO2014134165; публикацию согласно PCT № WO2012079000). Альтернативно костимиляцию можно регулировать с помощью экспрессии CAR в антиген-специфичных T-клетках, выбранных с целью активации и размножения в результате вовлечения их нативных αβTCR, например, с помощью антигена на профессиональных антиген-представляющих клетках с помощью сопутствующей костимуляции. Кроме того, дополнительные сконструированные рецепторы могут быть предусмотрены на иммунореактивных клетках, например, для улучшения нацеливания T-клеточной атаки и/или сведения к минимуму побочных эффектов.
Альтернативные методики можно применять для трансформации целевых иммунореактивных клеток, такие как слияние протопласта, липофекция, трансфекция или электропорация. Можно использовать широкое разнообразие векторов, таких как ретровирусные векторы, лентивирусные векторы, аденовирусные векторы, аденоассоциированные вирусные векторы, плазмиды или транспозоны, такие как транспозон "Спящая красавица" (см. патенты США №№ 6489458; 7148203; 7160682; 7985739; 8227432), их можно использовать для введения CAR, например, с помощью получения антиген-специфичных CAR 2-го поколения, передающих сигналы с участием CD3ζ и CD28 или CD137. Вирусные векторы, могут, например, включать векторы на основе HIV, SV40, EBV, HSV или BPV.
Клетки, которые подвергаются нацеливанию с целью трансформации, могут включать, например, T-клетки, натуральные клетки-киллеры (NK), цитотоксические T-лимфоциты (CTL), регуляторные T-клетки, человеческие эмбриональные стволовые клетки, инфильтрующие опухоль лимфоциты (TIL) или плюрипотентную стволовую клетку, из которой лимфоидные клетки могут дифференцироваться. T-клетки, экспрессирующие желаемый CAR, можно, например, выбрать посредством кокультивирования с γ-облученными активирующими и делящимися клетками (AaPC), которые коэкспрессируют раковый антиген и костимулирующие молекулы. Сконструированные CAR Т-клетки можно размножать, например, с помощью кокультивирования на AaPC в присутствии растворенных факторов, таких как IL-2 и IL-21. Такое разращивание, можно, например, проводить с целью получения CAR+ T-клеток памяти (которые можно, например, анализировать при помощи неферментативного цифрового массива и/или многопанельной проточной цитометрии ). В этом отношении можно получить CAR T-клетки, которые характеризуются специфичной цитотоксической активностью по отношению к антиген-несущим опухолям (необязательно в сочетании с образованием желаемых хемокинов, таких как интерферон-γ). CAR T-клетки этого типа, например, можно использовать в животных моделях, например, для лечения ксенотрансплантатов опухолей.
Подходы, такие как вышеизложенные, можно адаптировать для обеспечения способов лечения и/или повышения выживаемости субъекта, имеющего заболевание, такое как новообразование, например, с помощью введения эффективного количества иммунореактивных клеток, содержащих распознающий антиген рецептор, которые связывается с определенным антигеном, где связывание активирует иммунореактивную клетку, тем самым при этом осуществляется лечение или предупреждение заболевания (такого как новообразование, патогенная инфекция, аутоиммунное заболевание или реакция на аллогенный трансплантат). Дозирование в видах лечения на основе CAR T-клеток может, например, предусматривать введение от 106 до 109 клеток/кг, с курсом или без курса противолимфомной терапии, например, с помощью циклофосфамида.
В одном варианте осуществления лечение можно назначать пациентам, проходящим иммуносупрессивное лечение. Клетки или популяцию клеток можно сделать устойчивыми по меньшей мере к одному иммуносупрессивному средству в результате инактивации гена, кодирующего рецептор для такого иммуносупрессивного средства. Не вдаваясь в теорию, иммуносупрессивное лечение должно облегчать отбор и размножение иммунореактивных клеток или T-клеток в соответствии с настоящим изобретением у пациента.
Введение клеток или популяции клеток в соответствии с настоящим изобретением можно выполнять любым удобным способом, в том числе с помощью аэрозольной ингаляции, инъекции, поглощения, трансфузии, имплантации или трансплантации. Клетки или популяцию клеток можно вводить пациенту подкожно, внутрикожно, внутрь опухоли, внутрь узла, интрамедуллярно, внутримышечно, с помощью внутривенной или внутрилимфатической инъекции или внутрибрюшинно. В одном варианте осуществления клеточные композиции по настоящему изобретению предпочтительно вводят с помощью внутривенной инъекции.
Введение клеток или популяции клеток может состоять из введения 104- 109 клеток на кг массы тела, предпочтительно от 105 до 106 клеток/кг массы тела, включая целые значения числа клеток в пределах этих диапазонов. Дозирование в видах лечения на основе CAR T-клеток может, например, предусматривать введение от 106 до 109 клеток/кг, с курсом или без курса противолимфомной терапии, например, с помощью циклофосфамида. Клетки или популяцию клеток можно вводить в одной или нескольких дозах. В другом варианте осуществления эффективное количество клеток вводят в виде одной дозы. В другом варианте осуществления эффективное количество клеток вводят в виде более чем одной дозы в течение периода времени. Определение времени введения находится в пределах компетенции лечащего врача и зависит от клинического состояния пациента. Клетки или популяцию клеток можно получать из любого источника, такого как банк крови или донор. Принимая во внимание то, что потребности индивидуумов варьируют, определение оптимальных диапазонов эффективных количеств определенного типа клеток для определенных заболеваний или состояний находится в пределах компетенции специалиста в данной области. Эффективное количество означает количество, которое обеспечивает терапевтический или профилактический эффект. Вводимая доза может зависеть от возраста, состояния здоровья и веса реципиента, вида сопутствующего лечения, при необходимости, частоты лечения и природы желаемого эффекта.
В другом варианте осуществления эффективное количество клеток или композиции, содержащей такие клетки, вводят парентерально. Введение может представлять собой внутривенное введение. Введение может быть выполнено непосредственно с помощью инъекции в опухоль.
Для предупреждения возможных побочных реакций сконструированные иммунореактивные клетки могут быть оснащены предохранителем в форме трансгена, который делает клетки восприимчивыми к воздействию специфического сигнала. Например, в этом отношении можно использовать ген тимидинкиназы вируса простого герпеса (TK), например, с помощью введения в аллогенные T-лимфоциты, используемые в качестве инфузий донорских лимфоцитов после трансплантации стволовых клеток (Greco, et al., Improving the safety of cell therapy with the TK-suicide gene. Front. Pharmacol. 2015; 6: 95). В таких клетках введение пролекарства на основе нуклеозидов, такого как ганцикловир или ацикловир, вызывает клеточную смерть. Альтернативные конструкции предохранителей включают индуцируемую каспазу 9, например, активируемую введением низкомолекулярного димера, который соединяет две нефункциональные молекулы icasp9 с образованием активного фермента. Было описано широкое разнообразие альтернативных подходов для осуществления контроля пролиферации клеток (см. публикацию заявки на патент США № 20130071414; публикацию заявки на патент согласно PCT WO2011146862; публикацию заявки на патент согласно PCT WO2014011987; публикацию заявки на патент согласно PCT WO2013040371; Zhou et al. BLOOD, 2014, 123/25:3895 - 3905; Di Stasi et al., The New England Journal of Medicine 2011; 365:1673-1683; Sadelain M, The New England Journal of Medicine 2011; 365:1735-173; Ramos et al., Stem Cells 28(6):1107-15 (2010)).
При дополнительном усовершенствовании видов адоптивной терапии редактирование генома с помощью системы CRISPR-Cas, описанной в данном документе, можно применять для приспособления иммунореактивных клеток к альтернативным вариантам осуществления, например, с получением отредактированных CAR T-клеток (см. Poirot et al., 2015, Multiplex genome edited T-cell manufacturing platform for "off-the-shelf" adoptive T-cell immunotherapies, Cancer Res 75 (18): 3853). Например, иммунореактивные клетки можно редактировать с целью устранения экспрессии некоторых или всех из молекул II типа и/или I типа класса HLA, или с целью нокаутирования определенных генов, которые могут ингибировать необходимый иммунный ответ, таких как ген PD1.
Клетки можно редактировать с помощью системы CRISPR и способа ее применения, описанного в данном документе. Системы CRISPR могут быть доставлены в иммунную клетку с помощью любого способа, описанного в данном документе. В предпочтительных вариантах осуществления клетки редактируют ex vivo и переносят в субъекта, нуждающегося в этом. Можно редактировать иммунореактивные клетки, CAR T-клетки или любые клетки для адоптивного клеточного переноса. Редактирование можно выполнять с целью устранения потенциальных аллореактивных T-клеточных рецепторов (TCR), нарушения мишени хемотерапевтического средства, блокирования иммунной контрольной точки, активации T-клетки и/или повышения дифференцировки и/или пролиферации функционально истощенных или дисфункциональных CD8+ T-клеток (см. публикации на патент согласно PCT WO2013176915, WO2014059173, WO2014172606, WO2014184744 и WO2014191128). Редактирование может приводить к инактивации гена.
Под инактивацией гена предполагается, что представляющий интерес ген не экспрессируется в форме функционального белка. В конкретном варианте осуществления система CRISPR специфично катализирует расщепление в одном целевом гене, тем самым инактивируя указанный целевой ген. Вызванные разрывы нити нуклеиновой кислоты обычно репарируются с помощью различных механизмов гомологичной рекомбинации или негомологичного соединения концов (NHEJ). Однако NHEJ представляет собой несовершенный процесс репарации, который часто приводит к изменениям последовательности ДНК в сайте расщепления. Репарация посредством негомологичного соединения концов (NHEJ) часто приводит к небольшим вставкам или делециям (вставкам/делециям) и может быть использована для получения определенных нокаутов генов. Клетки, в которых произошло явление индуцированного расщеплением мутагенеза, можно идентифицировать и/или отобрать с помощью общеизвестных способов в данной области.
T-клеточные рецепторы (TCR) представляют собой рецепторы клеточной поверхности, которые участвуют в активации T-клеток в ответ на представление антигена. TCR, как правило, состоит из двух цепей, α и β, которые собираются с образованием гетеродимера, и ассоциируется с CD3-трансдуцирующими субъединицами, с образованием комплекса T-клеточного рецептора, присутствующего на клеточной поверхности. Каждая α- и β-цель TCR состоит из иммуноглобулин-подобной N-концевой вариабельной (V) и константной (C) области, гидрофобного трансмембранного домена и короткого цитоплазматического участка. Как в случае иммуноглобулиновых молекул, вариабельную область α-и β-целей получают с помощью V(D)J рекомбинации, создавая большое разнообразие антигенных специфичностей в пределах популяции T-клеток. Однако в отличие от иммуноглобулинов, которые распознают интактный антиген, T-клетки активируются с помощью процессированных пептидных фрагментов в сочетании с молекулой MHC, вводящей дополнительную область для распознавания антигенов T-клетками, известную как MHC-рестрикция. Распознавание несовпадений MHC между донором и реципиентом посредством T-клеточного рецептора приводит к T-клеточной пролиферации и потенциальному развитию реакции "трансплантат против хозяина" (GVHD). Инактивация TCRα или TCRβ может приводить к элиминации TCR с поверхности T-клеток, предупреждая распознавание аллоантигена и, таким образом, GVHD. Однако нарушение TCR, как правило, приводит к элиминации CD3 сигнального компонента и изменяет способы дальнейшего разращивания T-клеток.
Аллогенные клетки быстро отторгаются иммунной системой хозяина. Было показано, что аллогенные лейкоциты, присутствующие в необлученных продуктах крови, сохраняются не более 5-6 дней (Boni, Muranski et al. 2008 Blood 1;112(12):4746-54). Таким образом, для предупреждения отторжения аллогенных клеток, иммунную систему хозяина, как правило, необходимо подавлять до некоторой степени. Однако в случае адоптивного клеточного переноса применение иммуносупрессивных препаратов также оказывает вредное воздействие на введенные с терапевтической целью T-клетки. Таким образом, для эффективного применения подхода на основе адоптивной иммунотерапии в этих условиях введенные клетки должны быть устойчивыми к иммуносупрессивному лечению. Таким образом, в конкретном варианте осуществления настоящее изобретение дополнительно предусматривает стадию модификации T-клеток для придания им устойчивости к иммуносупрессивному средству, предпочтительно с помощью инактивации по меньшей мере одного гена, кодирующего иммуносупрессивное средство. Иммуносупрессивное средство представляет собой средство, которое подавляет иммунную функцию посредством одного из нескольких механизмов действия. Иммуносупрессивное средство может представлять собой без ограничения ингибитор кальциневрина, мишень для рапамицина, блокатор α-цепи рецептора интерлейкина 2, ингибитор инозинмонофосфатдегидрогеназы, ингибитор редуктазы дигидрофолиевой кислоты, кортикостероид или иммуносупрессивный антиметаболит. Настоящее изобретение предусматривает придание T-клеткам устойчивости к иммуносупрессорам с целью иммунотерапии с помощью инактивации мишени иммуносупрессивного средства в T-клетках. В качестве неограничивающих примеров мишени для иммуносупрессивного средства могут представлять собой рецептор для иммуносупрессивного средства, такой как CD52, глюкокортикоидный рецептор (GR), представитель семейства генов FKBP и представитель семейства генов циклофилина.
Иммунные контрольные точки представляют собой ингибирующие пути, которые замедляют или останавливают иммунные реакции и предупреждают избыточное разрушение тканей в результате неконтролируемой активности иммунных клеток. В определенных вариантах осуществления целевая иммунная контрольная точка представляет собой ген программируемой смерти 1 (PD-1 или CD279) (PDCD1). В других вариантах осуществления иммунная контрольная точка, на которую оказывают воздействие, представляет собой антиген, ассоциированный с цитотоксическим T-лимфоцитом (CTLA-4). В дополнительных вариантах осуществления целевая иммунная контрольная точка представляет собой другой представитель суперсемейства CD28 и CTLA4 Ig, такой как BTLA, LAG3, ICOS, PDL1 или KIR. В дополнительных вариантах осуществления целевая иммунная контрольная точка представляет собой представителя суперсемейства TNFR, такой как CD40, OX40, CD137, GITR, CD27 или TIM-3.
Дополнительные иммунные контрольные точки включают содержащую домен с гомологией 2 Src протеинтирозинфосфатазу 1 (SHP-1) (Watson HA, et al., SHP-1: the next checkpoint target for cancer immunotherapy? Biochem Soc Trans. 2016 Apr 15;44(2):356-62). SHP-1 представляет собой широко экспрессируемую ингибирующую протеинтирозинфосфатазу (PTP). В T-клетках она является отрицательным регулятором антигензависимой активации и пролиферации. Она представляет собой цитозольный белок и поэтому не пригодна для опосредованных антителами видов терапии, однако ее роль в активации и пролиферации делает ее привлекательной мишенью для генетической манипуляции в стратегиях адоптивного переноса, например, Т-клеток с химерными антигенными рецепторами (CAR). Иммунные контрольные точки могут также включать T-клеточный иммунорецептор с Ig и ITIM доменами (TIGIT/Vstm3/WUCAM/VSIG9) и VISTA (Le Mercier I, et al., (2015) Beyond CTLA-4 and PD-1, the generation Z of negative checkpoint regulators. Front. Immunol. 6:418).
WO2014172606 относится к применению ингибиторов MT1 и/или MT1 для повышения пролиферации и/или активности истощенных CD8+ T-клеток и для снижения CD8+ T-клеточного истощения (например, снижения функциональных свойств истощенных или невосприимчивых CD8+ иммунных клеток). В определенных вариантах осуществления металлотионеины подвергаются нацеливанию с помощью редактирования генов в адоптивно перенесенных T-клетках.
В определенных вариантах осуществления мишени редактирования генов могут представлять собой по меньшей мере один целевой локус, участвующий в экспрессии белка иммунной контрольной точки. Такие мишени могут включают без ограничения CTLA4, PPP2CA, PPP2CB, PTPN6, PTPN22, PDCD1, ICOS (CD278), PDL1, KIR, LAG3, HAVCR2, BTLA, CD160, TIGIT, CD96, CRTAM, LAIR1, SIGLEC7, SIGLEC9, CD244 (2B4), TNFRSF10B, TNFRSF10A, CASP8, CASP10, CASP3, CASP6, CASP7, FADD, FAS, TGFBRII, TGFRBRI, SMAD2, SMAD3, SMAD4, SMAD10, SKI, SKIL, TGIF1, IL10RA, IL10RB, HMOX2, IL6R, IL6ST, EIF2AK4, CSK, PAG1, SIT1, FOXP3, PRDM1, BATF, VISTA, GUCY1A2, GUCY1A3, GUCY1B2, GUCY1B3, MT1, MT2, CD40, OX40, CD137, GITR, CD27, SHP-1 или TIM-3. В предпочтительных вариантах осуществления генный локус, участвующий в экспрессии генов PD-1 или CTLA-4, является целевым. В других предпочтительных вариантах осуществления комбинации генов являются целевыми, такие как без ограничения PD-1 и TIGIT.
В других вариантах осуществления по меньшей мере два гена редактируют. Пары генов могут включать без ограничения PD1 и TCRα, PD1 и TCRβ, CTLA-4 и TCRα, CTLA-4 и TCRβ, LAG3 и TCRα, LAG3 и TCRβ, Tim3 и TCRα, Tim3 и TCRβ, BTLA и TCRα, BTLA и TCRβ, BY55 и TCRα, BY55 и TCRβ, TIGIT и TCRα, TIGIT и TCRβ, B7H5 и TCRα, B7H5 и TCRβ, LAIR1 и TCRα, LAIR1 и TCRβ, SIGLEC10 и TCRα, SIGLEC10 и TCRβ, 2B4 и TCRα, 2B4 и TCRβ.
Вне зависимости от того, является ли модификация Т-клеток предварительной или последующей, T-клетки можно активировать и размножать, как правило, с помощью способов, описанных, например, в патентах США 6352694; 6534055; 6905680; 5858358; 6887466; 6905681; 7144575; 7232566; 7175843; 5883223; 6905874; 6797514; 6867041 и 7572631. T-клетки можно размножать in vitro или in vivo.
Практическое осуществление настоящего изобретения предусматривает, если не указано иное, традиционные методики иммунологии, биохимии, химии, молекулярной биологии, микробиологии, клеточной биологии, геномики и технологию рекомбинантной ДНК, которые находятся в пределах квалификации специалиста в данной области. См. MOLECULAR CLONING: A LABORATORY MANUAL, 2nd edition (1989) (Sambrook, Fritsch and Maniatis); MOLECULAR CLONING: A LABORATORY MANUAL, 4th edition (2012) (Green and Sambrook); CURRENT PROTOCOLS IN MOLECULAR BIOLOGY (1987) (F. M. Ausubel, et al. eds.); серию METHODS IN ENZYMOLOGY (Academic Press, Inc.); PCR 2: A PRACTICAL APPROACH (1995) (M.J. MacPherson, B.D. Hames and G.R. Taylor eds.); ANTIBODIES, A LABORATORY MANUAL (1988) (Harlow and Lane, eds.); ANTIBODIES A LABORATORY MANUAL, 2nd edition (2013) (E.A. Greenfield ed.); и ANIMAL CELL CULTURE (1987) (R.I. Freshney, ed.).
Практическое осуществление настоящего изобретения предусматривает, если не указано иное, стандартные методики получения генетически модифицированных мышей. См. Marten H. Hofker and Jan van Deursen, TRANSGENIC MOUSE METHODS AND PROTOCOLS, 2nd edition (2011).
Генные драйвы
Настоящее изобретение также предусматривает применение системы CRISPR-Cas, описанной в данном документе, например, систем эффекторных белков Cpf1, для обеспечения направляемых РНК генных драйвов, например, в системах, аналогичных генным драйвам, описанным в публикации заявки на патент согласно PCT WO 2015/105928. Системы этого типа, например, могут предусматривать способы изменения эукариотических клеток зародышевой линии с помощью введения в клетку зародышевой линии последовательности нуклеиновой кислоты, кодирующей РНК-направляемую ДНК-нуклеазу и одну или несколько направляющих РНК. Направляющие РНК могут быть разработаны так, что являются комплементарными одной или нескольким целевым локусам в геномной ДНК клетки зародышевой линии. Последовательность нуклеиновой кислоты, кодирующая направляемую РНК ДНК-нуклеазу, и последовательность нуклеиновой кислоты, кодирующая направляющие РНК, могут быть получены в конструкциях между фланкирующими последовательностями, с промоторами, расположенными таким образом, что клетка зародышевой линии может экспрессировать направляемую РНК ДНК-нуклеазу и направляющие РНК, совместно с любыми требуемыми кодирующими молекулы-карго последовательностями, которые также расположены между фланкирующими последовательностями. Фланкирующие последовательности будут, как правило, включать последовательность, которая является идентичной соответствующей последовательности на определенной хромосоме, таким образом, что фланкирующие последовательности функционируют с компонентами, кодируемыми конструкцией для облегчения вставки чужеродных последовательностей конструкций нуклеиновой кислоты в геномную ДНК в целевом сайте для разрезания с помощью механизмов, таких как гомологичная рекомбинация, для воспроизведения клетки зародышевой линии, гомозиготной по чужеродной последовательности нуклеиновой кислоты. Таким образом, системы генного драйва способны к интрогрессии требуемых генов во всей популяции производителей (Gantz et al., 2015, Highly efficient Cas9-mediated gene drive for population modification of the malaria vector mosquito Anopheles stephensi, PNAS 2015, электронная публикация, предшествующая печатной, от 23 ноября 2015 г., doi:10.1073/pnas.1521077112; Esvelt et al., 2014, Concerning RNA-guided gene drives for the alteration of wild populations eLife 2014;3:e03401). В определенных вариантах осуществления могут быть отобраны целевые последовательности, которые имеют мало потенциальных нецелевых сайтов в геноме. Нацеливание на несколько сайтов в целевом локусе с помощью нескольких направляющих РНК может повышать частоту разрезания и замедлять эволюцию устойчивых к драйву генов. Усеченные направляющие РНК могут снижать нецелевое разрезание. Парные никазы могут быть использованы вместо одной нуклеазы для дополнительного повышения специфичности. Конструкции для генного драйва могут включать последовательности молекул-карго, кодирующие регуляторы транскрипции, например, для активации гомологичных рекомбинантных генов и/или репрессии негомологичного соединения концов. Целевые сайты могут быть выбраны в важном гене таким образом, что события негомологичного соединения концов могут вызывать летальность, а не образование устойчивого к драйву аллеля. Конструкции для генного драйва могут быть сконструированы для функционирования в ряде хозяев при диапазоне температур (Cho et al. 2013, Rapid and Tunable Control of Protein Stability in Caenorhabditis elegans Using a Small Molecule, PLoS ONE 8(8): e72393. doi:10.1371/journal.pone.0072393).
Ксенотрасплантация
Настоящее изобретение также предусматривает применение системы CRISPR-Cas, описанной в данном документе, например, систем эффекторного белка Cpf1, для получения направляемых РНК ДНК-нуклеаз, адаптированных для использования с целью получения модифицированных тканей для трансплантации. Например, направляемые РНК ДНК-нуклеазы могут быть использованы для нокаута, нокдауна или разрыва определенных генов у животного, такого как трансгенная свинья (такая как линия трансгенных свиней с гемоксигеназой-1 человека), например, для нарушения экспрессии генов, которые кодируют эпитопы, распознаваемые иммунной системой человека, т. е. генами ксеноантигенов. Кандидатные свиные гены для разрыва, например, могут включать гены α(l,3)-галактозилтрансферазы и гидролазы цитидинмонофосфат-N-ацетилнейраминовой кислоты (см. публикацию заявки на патент согласно PCT WO 2014/066505). Кроме того, гены, кодирующие эндогенные ретровирусы, могут быть разорваны, например, гены, кодирующие все свиные эндогенные ретровирусы (см. Yang et al., 2015, Genome-wide inactivation of porcine endogenous retroviruses (PERVs), Science 27 November 2015: Vol. 350 no. 6264 pp. 1101-1104). Кроме того, РНК-направляемые ДНК-нуклеазы могут быть использованы для нацеливания на сайт с целью интеграции дополнительных генов у животных-доноров с ксенотрансплантатами, таких как ген человеческого CD55, для повышения защиты против сверхострого отторжения.
Общие положения генной терапии
Примеры ассоциированных с заболеваниями генов и полинуклеотидов и конкретная информация в отношении заболеваний доступна от Института генетической медицины МакКьюсика-Натанса (McKusick-Nathans Institute of Genetic Medicine) при Университете Джонса Хопкинса (Johns Hopkins University) (Балтимор, Мэриленд) и Национального центра биотехнологической информации (National Center for Biotechnology Information), Национальной библиотеки медицины (National Library of Medicine) (Бетесда, Мэриленд), доступных во всемирной сети Интернет.
Мутации в этих генах и путях могут приводить к продуцированию несоответствующих белков или белков в несоответствующих количествах, которые воздействуют на функцию. Дополнительные примеры генов, заболеваний и белков, таким образом, включены с помощью ссылки из предварительной заявки на патент США 61/736527, поданной 12 декабря 2012 г. Такие гены, белки и пути могут быть целевым полинуклеотидом для комплекса CRISPR по настоящему изобретению. Примеры ассоциированных с заболеваниями генов и полинуклеотидов приведены в таблицах A и B. Примеры ассоциированных с биохимическими путями передачи сигналов генов и полинуклеотидов приведены в таблице C.
Таблица A
НАРУШЕНИЯ
Таблица B
Таблица C
склерозе
Варианты осуществления настоящего изобретения также относятся к способам и композициям, связанным с нокаутированием генов, амплифицированием генов и репарацией конкретных мутаций, ассоциированных с нестабильностью ДНК-повторов и неврологическими нарушениями (Robert D. Wells, Tetsuo Ashizawa, Genetic Instabilities and Neurological заболевания, Second Edition, Academic Press, Oct 13, 2011 - Medical). Как было обнаружено, определенные аспекты последовательностей тандемных повторов ответственны за более чем двадцать заболеваний человека (New insights into repeat instability: role of RNA•DNA hybrids. McIvor EI, Polak U, Napierala M. RNA Biol. 2010 Sep-Oct;7(5):551-8). Системы эффекторного белка по настоящему изобретению могут быть приспособлены для коррекции таких дефектов геномной нестабильности.
Некоторые дополнительные аспекты настоящего изобретения касаются коррекции дефектов, ассоциированных с широким спектром наследственных заболеваний, которые дополнительно описаны на веб-сайте Национальных институтов здравоохранения (National Institutes of Health) в тематическом подразделе "Наследственные заболевания" ("Genetic Disorders") (веб-сайт по адресу health.nih.gov/topic/GeneticDisorders). Наследственные заболевания головного мозга могут включать без ограничения адренолейкодистрофию, агенезию мозолистого тела, синдром Айкарди, синдром Альперса, болезнь Альцгеймера, синдром Барта, болезнь Баттена, CADASIL, мозжечковую дегенерацию, болезнь Фабри, синдром Герстмана-Штраусслера-Шейнкера, болезнь Гентингтона и другие связанные с триплетными повторами нарушения, болезнь Лея, синдром Леша-Найхана, болезнь Менкеса, типы митохондриальной миопатии и кольпоцефалию по критериям NINDS. Такие заболевания дополнительно описаны на веб-сайте Национальных институтов здравоохранения (National Institutes of Health) в тематическом подразделе "Наследственные заболевания головного мозга" ("Genetic Brain Disorders").
Разработка и применение Cas9
Настоящее изобретение может быть дополнительно проиллюстрировано и расширено на основе аспектов разработки и применения CRISPR-Cas9, как изложено в следующих статьях, и, в частности, он относится к доставке комплекса белка CRISPR и вариантам применения направляемой РНК эндонуклеазы в клетках и организмах:
- Multiplex genome engineering using CRISPR/Cas systems. Cong, L., Ran, F.A., Cox, D., Lin, S., Barretto, R., Habib, N., Hsu, P.D., Wu, X., Jiang, W., Marraffini, L.A., & Zhang, F. Science Feb 15;339(6121):819-23 (2013);
- RNA-guided editing of bacterial genomes using CRISPR-Cas systems. Jiang, W., Bikard, D., Cox, D., Zhang, F., Marraffini, L.A. Nat Biotechnol Mar;31(3):233-9 (2013);
- One-Step Generation of Mice Carrying Mutations in Multiple Genes by CRISPR/Cas-Mediated Genome Engineering. Wang H., Yang H., Shivalila CS., Dawlaty MM., Cheng AW., Zhang F., Jaenisch R. Cell May 9;153(4):910-8 (2013);
- Optical control of mammalian endogenous transcription and epigenetic states. Konermann S, Brigham MD, Trevino AE, Hsu PD, Heidenreich M, Cong L, Platt RJ, Scott DA, Church GM, Zhang F. Nature. Aug 22;500(7463):472-6. doi: 10.1038/Nature12466. Epub 2013 Aug 23 (2013);
- Double Nicking by RNA-Guided CRISPR Cas9 for Enhanced Genome Editing Specificity. Ran, FA., Hsu, PD., Lin, CY., Gootenberg, JS., Konermann, S., Trevino, AE., Scott, DA., Inoue, A., Matoba, S., Zhang, Y., & Zhang, F. Cell Aug 28. pii: S0092-8674(13)01015-5 (2013-A);
- DNA targeting specificity of RNA-guided Cas9 nucleases. Hsu, P., Scott, D., Weinstein, J., Ran, FA., Konermann, S., Agarwala, V., Li, Y., Fine, E., Wu, X., Shalem, O., Cradick, TJ., Marraffini, LA., Bao, G., & Zhang, F. Nat Biotechnol doi:10.1038/nbt.2647 (2013);
- Genome engineering using the CRISPR-Cas9 system. Ran, FA., Hsu, PD., Wright, J., Agarwala, V., Scott, DA., Zhang, F. Nature Protocols Nov;8(11):2281-308 (2013-B);
- Genome-Scale CRISPR-Cas9 Knockout Screening in Human Cells. Shalem, O., Sanjana, NE., Hartenian, E., Shi, X., Scott, DA., Mikkelson, T., Heckl, D., Ebert, BL., Root, DE., Doench, JG., Zhang, F. Science Dec 12. (2013). [Электронная публикация, предшествующая печатной];
- Crystal structure of cas9 in complex with guide RNA and target DNA. Nishimasu, H., Ran, FA., Hsu, PD., Konermann, S., Shehata, SI., Dohmae, N., Ishitani, R., Zhang, F., Nureki, O. Cell Feb 27, 156(5):935-49 (2014);
- Genome-wide binding of the CRISPR endonuclease Cas9 in mammalian cells. Wu X., Scott DA., Kriz AJ., Chiu AC., Hsu PD., Dadon DB., Cheng AW., Trevino AE., Konermann S., Chen S., Jaenisch R., Zhang F., Sharp PA. Nat Biotechnol. Apr 20. doi: 10.1038/nbt.2889 (2014);
- CRISPR-Cas9 Knockin Mice for Genome Editing and Cancer Modeling. Platt RJ, Chen S, Zhou Y, Yim MJ, Swiech L, Kempton HR, Dahlman JE, Parnas O, Eisenhaure TM, Jovanovic M, Graham DB, Jhunjhunwala S, Heidenreich M, Xavier RJ, Langer R, Anderson DG, Hacohen N, Regev A, Feng G, Sharp PA, Zhang F. Cell 159(2): 440-455 DOI: 10.1016/j.cell.2014.09.014(2014);
- Development and Applications of CRISPR-Cas9 for Genome Engineering, Hsu PD, Lander ES, Zhang F., Cell. Jun 5;157(6):1262-78 (2014).
- Genetic screens in human cells using the CRISPR/Cas9 system, Wang T, Wei JJ, Sabatini DM, Lander ES., Science. January 3; 343(6166): 80-84. doi:10.1126/science.1246981 (2014);
- Rational design of highly active sgRNAs for CRISPR-Cas9-mediated gene inactivation, Doench JG, Hartenian E, Graham DB, Tothova Z, Hegde M, Smith I, Sullender M, Ebert BL, Xavier RJ, Root DE., (опубликовано онлайн 3 сентября 2014 г.) Nat Biotechnol. Dec;32(12):1262-7 (2014);
- In vivo interrogation of gene function in the mammalian brain using CRISPR-Cas9, Swiech L, Heidenreich M, Banerjee A, Habib N, Li Y, Trombetta J, Sur M, Zhang F., (опубликовано онлайн 19 октября 2014 г.) Nat Biotechnol. Jan;33(1):102-6 (2015);
- Genome-scale transcriptional activation by an engineered CRISPR-Cas9 complex, Konermann S, Brigham MD, Trevino AE, Joung J, Abudayyeh OO, Barcena C, Hsu PD, Habib N, Gootenberg JS, Nishimasu H, Nureki O, Zhang F., Nature. Jan 29;517(7536):583-8 (2015).
- A split-Cas9 architecture for inducible genome editing and transcription modulation, Zetsche B, Volz SE, Zhang F., (опубликовано онлайн 2 февраля 2015 г.) Nat Biotechnol. Feb;33(2):139-42 (2015);
- Genome-wide CRISPR Screen in a Mouse Model of Tumor Growth and Metastasis, Chen S, Sanjana NE, Zheng K, Shalem O, Lee K, Shi X, Scott DA, Song J, Pan JQ, Weissleder R, Lee H, Zhang F, Sharp PA. Cell 160, 1246-1260, March 12, 2015 (мультиплексный скрининг у мыши), и
- In vivo genome editing using Staphylococcus aureus Cas9, Ran FA, Cong L, Yan WX, Scott DA, Gootenberg JS, Kriz AJ, Zetsche B, Shalem O, Wu X, Makarova KS, Koonin EV, Sharp PA, Zhang F., (опубликовано онлайн 1 апреля 2015 г.), Nature. Apr 9;520(7546):186-91 (2015).
- Shalem et al., "High-throughput functional genomics using CRISPR-Cas9," Nature Reviews Genetics 16, 299-311 (May 2015).
- Xu et al., "Sequence determinants of improved CRISPR sgRNA design," Genome Research 25, 1147-1157 (August 2015).
- Parnas et al., "A Genome-wide CRISPR Screen in Primary Immune Cells to Dissect Regulatory Networks," Cell 162, 675-686 (July 30, 2015).
- Ramanan et al., CRISPR/Cas9 cleavage of viral DNA efficiently suppresses hepatitis B virus," Scientific Reports 5:10833. doi: 10.1038/srep10833 (June 2, 2015)
- Nishimasu et al., Crystal Structure of Staphylococcus aureus Cas9," Cell 162, 1113-1126 (Aug. 27, 2015)
- BCL11A enhancer dissection by Cas9-mediated in situ saturating mutagenesis, Canver et al., Nature 527(7577):192-7 (Nov. 12, 2015) doi: 10.1038/nature15521. Epub 2015 Sep 16.
- Cpf1 Is a Single RNA-Guided Endonuclease of a Class 2 CRISPR-Cas System, Zetsche et al., Cell 163, 759-71 (Sep 25, 2015).
- Discovery and Functional Characterization of Diverse Class 2 CRISPR-Cas Systems, Shmakov et al., Molecular Cell, 60(3), 385-397 doi: 10.1016/j.molcel.2015.10.008 Epub October 22, 2015.
- Rationally engineered Cas9 nucleases with improved specificity, Slaymaker et al., Science 2016 Jan 1 351(6268): 84-88 doi: 10.1126/science.aad5227. Электронная публикация 1 декабря 2015 г. [Электронная публикация, предшествующая печатной],
каждая из которых включена в данный документ посредством ссылки, может быть рассмотрена при практическом осуществлении настоящего изобретения и описана вкратце ниже.
- Cong et al. сконструировали системы CRISPR-Cas II типа на основе как Cas9 Streptococcus thermophilus, так и Cas9 Streptococcus pyogenes для применения в эукариотических клетках и продемонстрировали, что нуклеазы Cas9 могут управляться короткими РНК с индукцией точного расщепления ДНК в клетках человека и мыши. Их исследование дополнительно показало, что Cas9, превращенный в фермент, вносящий однонитевой разрыв, можно применять для облегчения репарации с участием гомологичной рекомбинации в эукариотических клетках с минимальной мутагенной активностью. Кроме того, их исследование продемонстрировало, что в одном массиве CRISPR могут быть закодированы несколько направляющих последовательностей для обеспечения одновременного редактирования в нескольких сайтах эндогенных локусов генома в геноме млекопитающих, что демонстрирует легкую программируемость и широкое применение технологии нуклеаз, направляемых РНК. Эта возможность применения РНК для программирования специфичного к последовательности расщепления ДНК в клетках определила новый класс инструментов для конструирования генома. Данные исследования дополнительно показали, что другие локусы CRISPR, вероятно, можно пересадить в клетки млекопитающих, и они могут также опосредовать расщепление генома млекопитающих. Важно отметить, что можно предусмотреть дополнительное улучшение некоторых аспектов системы CRISPR-Cas для повышения ее эффективности и универсальности.
- Jiang et al. применяли эндонуклеазу Cas9, ассоциированную с короткими палиндромными повторами, регулярно расположенными группами (CRISPR), образующую комплекс с двойными РНК для введения точных мутаций в геномы Streptococcus pneumoniae и Escherichia coli. Подход опирался на расщепление в целевом сайте генома под управлением системы двойная РНК:Cas9 для уничтожения немутированных клеток и устранял необходимость в селектируемых маркерах или системах отрицательного отбора. В исследовании сообщалось о перепрограммировании специфичности системы двойная РНК:Cas9 путем изменения последовательности короткой РНК CRISPR (crRNA) для внесения одно- или многонуклеотидных изменений, выполняемых с помощью матриц редактирования. Исследование показало, что одновременное использование двух crRNA обеспечивало мультиплексный мутагенез. Кроме того, когда подход применяли в сочетании с рекомбинационной инженерией, у S. рneumoniа практически 100% клеток, извлеченных с помощью описанного подхода, содержали желаемую мутацию, а у E. сoli 65% извлеченных клеток содержали мутацию.
- Wang et al. (2013) использовали систему CRISPR-Cas для одностадийного получения мышей, несущих мутации в нескольких генах, которых традиционно получали в несколько стадий, с помощью последовательной рекомбинации в эмбриональных стволовых клетках и/или продолжительного интеркроссинга мышей с одной мутацией. Система CRISPR-Cas будет значительно ускорять исследование функционально избыточных генов и эпистатических генных взаимодействий in vivo.
- Konermann et al. (2013) изучали существующую в данной области необходимость в гибких и надежных технологиях, позволяющих осуществлять оптическое и химическое модулирование фермента Cas9 CRISPR на основе ДНК-связывающих доменов, а также эффекторов, подобных активаторам транскрипции.
- Ran et al. (2013-А) описали подход, в котором мутантную никазу Cas9 применяли в сочетании с парными направляющими РНК для внесения целевых двухнитевых разрывов. Это относится к вопросу о том, что нуклеаза Cas9 из микробной системы CRISPR-Cas направляется на конкретные локусы генома направляющей последовательностью, которая может допускать некоторые несовпадения с ДНК-мишенью и, таким образом, способствует нежелательному нецелевому мутагенезу. Поскольку отдельные однонитевые разрывы в геноме подвергаются высокоточной репарации, одновременное внесение однонитевых разрывов с помощью соответствующим образом смещенных друг относительно друга направляющих РНК является необходимым для образования двухнитевых разрывов и увеличивает количество специфически распознаваемых оснований для расщепления мишени. Авторы продемонстрировали, что применение парного внесения однонитевых разрывов может снижать нецелевую активность в линиях клеток в 50-1500 раз и облегчать нокаут генов в зиготах мышей без уменьшения эффективности целевого расщепления. Данная гибкая стратегия обеспечивает большое разнообразие применений редактирования генома, требующих высокой специфичности.
- Hsu et al. (2013) охарактеризовали специфичность нацеливания SpCas9 в клетках человека, чтобы предоставить информацию для выбора целевых сайтов и избежать нецелевых эффектов. В исследовании оценивали > 700 вариантов направляющей РНК и уровней мутаций по типу вставок/делеций, индуцированных SpCas9, в >100 прогнозируемых нецелевых локусах генома в клетках 293T и 293FT. Авторы показали, что SpCas9 допускает несовпадения между направляющей РНК и целевой ДНК в различных положениях в зависимости от последовательности с чувствительностью к количеству, положению и распределению несовпадений. Авторы дополнительно показали, что на опосредованное SpCas9 расщепление не влияет метилирование ДНК, и что для сведения к минимуму нецелевых модификаций можно подобрать дозу SpCas9 и gRNA. Кроме того, для облегчения применений в геномной инженерии млекопитающих авторы сообщили о получении инструментального программного обеспечения на веб-основе для управления выбором и подтверждением целевых последовательностей, а также анализов нецелевых явлений.
- Ran et al. (2013-B) описали набор инструментов для опосредованного Cas9 редактирования генома посредством негомологичного соединения концов (NHEJ) или репарации с помощью гомологичной рекомбинации (HDR) в клетках млекопитающих, а также создания модифицированных линий клеток для последующих функциональных исследований. Для сведения к минимуму нецелевого расщепления авторы дополнительно описали стратегию внесения двойных однонитевых разрывов с помощью мутантной никазы Cas9 с парными направляющими РНК. Протокол, представленный авторами, является полученным экспериментальным путем руководством по выбору целевых сайтов, оценке эффективности расщепления и анализу нецелевой активности. Исследования показали, что начиная с конструирования мишени, модификации генов можно достигнуть в течение всего лишь 1-2 недель, и модифицированные клональные линии клеток можно получить в течение 2-3 недель.
- Shalem et al. описали новый способ исследования функций генов в полногеномном масштабе. Их исследования показали, что доставка библиотеки CRISPR-Cas9 для нокаута в масштабе генома (GeCKO), целенаправленно воздействующей на 18080 генов, с 64751 уникальной направляющей последовательностью обеспечивала скрининг путем как положительного, так и отрицательного отбора в клетках человека. Во-первых, авторы показали применение библиотеки GeCKO для идентификации генов, существенных для жизнеспособности клеток у раковых и плюрипотентных стволовых клеток. Далее, в модели меланомы, авторы провели скрининг генов, утрата функций которых вовлечена в устойчивость к вемурафенибу, терапевтическому средству, ингибирующему мутантную протеинкиназу BRAF. Их исследования показали, что кандидаты высшего ранга включали ранее подтвержденные гены NF1 и MED12, а также новые хиты NF2, CUL3, TADA2B и TADA1. Авторы наблюдали высокий уровень согласованности между независимыми направляющими РНК, осуществляющими нацеливание на один и тот же ген, и высоким показателем подтверждения хитов и, таким образом, продемонстрировали перспективность скрининга с помощью Cas9 в масштабе генома.
- Nishimasu et al. сообщали о кристаллической структуре Cas9 Streptococcus pyogenes в комплексе с sgRNA и ее целевой ДНК при разрешающей способности в 2,5 A°. В структуре была выявлена двудольная архитектура, образованная долей распознавания мишени и нуклеазной долей, обеспечивающих размещение гетеродуплекса sgRNA:ДНК в положительно заряженной бороздке на поверхности их соприкосновения. При том, что доля распознавания является существенной для связывания sgRNA и ДНК, нуклеазная доля содержит нуклеазные домены HNH и RuvC, расположенные надлежащим образом для расщепления комплементарной и некомплементарной нитей целевой ДНК соответственно. Нуклеазная доля также содержит карбоксиконцевой домен, отвечающий за взаимодействие с мотивом, смежным с протоспейсером (PAM). Эти структурные анализы с высокой разрешающей способностью и сопутствующие функциональные анализы выявили молекулярный механизм нацеливания Cas9, направляемых РНК, на ДНК, с созданием таким образом предпосылок для рационального конструирования новых универсальных технологий редактирования генома.
- Wu et al. производили полногеномное картирование сайтов связывания для каталитически неактивного Cas9 (dCas9) из Streptococcus pyogenes, который вводили с одиночными направляющими РНК (sgRNA) в эмбриональные стволовые клетки мыши (mESC). Авторы показали, что каждая из четырех тестируемых sgRNA осуществляет нацеливание dCas9 на сайты генома в количестве от нескольких десятков до нескольких тысяч, что часто характеризуется наличием 5-нуклеотидного затравочного участка в sgRNA и мотива NGG, смежного с протоспейсером (PAM). Недоступность хроматина снижает связывание dCas9 с другими сайтами с последовательностями, комплементарными затравочной; таким образом, 70% нецелевых сайтов ассоциированы с генами. Авторы показали, что целенаправленное секвенирование 295 сайтов связывания для dCas9 в mESC, трансфицированных каталитически активным Cas9, выявило мутацию, превышающую фоновые уровни, только в одном сайте. Авторы предложили модель связывания с Cas9 и опосредованного им расщепления с двумя состояниями, в которой последовательность, комплементарная затравочной, запускает связывание, но для расщепления необходимо образование многочисленных пар с целевой ДНК.
- Platt et al. получили Cre-зависимую мышь с нокином Cas9. Авторы показали редактирование генома in vivo, а также ex vivo с помощью доставки направляющей РНК на основе аденоассоциированного вируса (AAV), лентивируса или частиц в нейроны, иммунные клетки и эндотелиальные клетки.
- Публикация Hsu et al. (2014) представляет собой обзорную статью, в которой описывается в целом история CRISPR-Cas9 от использования в производстве йогуртовых заквасок до редактирования генома, в том числе генетического скрининга клеток.
- Публикация Wang et al. (2014) связана с подходом на основе объединенного генетического скрининга с изучением потери функции, применимого как для положительного, так и отрицательного отбора, в котором используется библиотека полногеномных лентивирусных одиночных направляющих РНК (sgRNA).
- Doench et al. создали пул sgRNA, покрывающих все возможные целевые сайты панели из шести эндогенных мышиных и трех эндогенных человеческих генов и количественно оценили их способность образовывать нуль-аллели своего целевого гена с помощью окрашивания антител и проточной цитометрии. Авторы показали, что оптимизация PAM повышала активность и также обеспечивала онлайн-средство для конструирования sgRNA.
- Swiech et al. показывают, что AAV-опосредованное редактирование генома SpCas9 может обеспечивать обратные генетические исследования функции гена в головном мозге.
- Konermann et al. (2015) описывают способность присоединять множественные эффекторные домены, например, активатор транскрипции, функциональные и эпигеномные регуляторы в определенных положениях на ведущей последовательности, например, стволе или тетра-петле с линкерами и без них.
- Zetsche et al. показывают, что фермент Cas9 может быть расщеплен на два и, таким образом, сборка Cas9 для активации может быть контролируемой.
- Публикация Chen et al. связана с множественным скринингом посредством демонстрации того, что в результате полногеномного скрининга CRISPR-Cas9 in vivo у мышей обнаружены гены, регулирующие метастазирование в легких.
- Публикация Ran et al. (2015) относится к SaCas9 и его способности редактировать геномы и демонстрирует невозможность экстраполяции исходя из биохимических анализов.
- В публикации Shalem et al. (2015) описаны пути, в которых слияния каталитически неактивного Cas9 (dCas9) используют для синтетической репрессии (CRISPRi) или активации (CRISPRa) экспрессии, показывая успехи применения Cas9 для полногеномного скрининга, в том числе упорядоченных и объединенных скринингов, подходов к нокауту, которые инактивируют геномные локусы, и стратегий, с помощью которых модулируют транскрипционную активность.
- Xu et al. (2015) оценивали характеристики ДНК-последовательности, которые способствуют эффективности одиночной направляющей РНК (sgRNA) при скрининге на основе CRISPR. Авторы исследовали эффективность нокаута с помощью CRISPR/Cas9 и нуклеотидного предпочтения в сайте расщепления. Авторы также обнаружили, что предпочтение последовательности для CRISPRi/a значительно отличается от таковой для нокаута с помощью CRISPR/Cas9.
- Parnas et al. (2015) ввели полногеномные объединенные библиотеки CRISPR-Cas9 в дендритные клетки (DC) с целью выявления генов, которые контролируют индукцию фактора некроза опухоли (Tnf) с помощью бактериального липополисахарида (LPS). Известные регуляторы передачи сигналов с участием Tlr4 и ранее неизвестные кандидаты были идентифицированы и классифицированы на три функциональных модуля с различными эффектами по отношению к классическим ответам на LPS.
- Ramanan et al (2015) показали расщепление вирусной эписомальной ДНК (cccDNA) в инфицированных клетках. Геном HBV существует в ядрах инфицированных гепатоцитов в виде двухнитевых эписомальных молекул ДНК с размером 3,2 т. о., называемых ковалентно связанной кольцевой ДНК (cccDNA), которая является основным компонентов в жизненном цикле HBV, репликация которого не ингибируется при применении существующих видов терапии. Авторы показали, что sgRNA, специфично нацеливающася на высококонсервативные области HBV, устойчиво подавляет вирусную репликацию и расщепляет cccDNA.
- Nishimasu et al. (2015) описали кристаллические структуры SaCas9 в комплексе с одиночной РНК (sgRNA) и ее двухнитевыми ДНК-мишенями, содержащими 5'-TTGAAT-3' PAM и 5'-TTGGGT-3' PAM. Структурное сравнение SaCas9 с SpCas9 указало как на структурную консервативность, так и на изменчивость, объясняя их различные специфичности PAM и ортологическое распознавание sgRNA.
- Canver et al. (2015) продемонстрировали функциональное исследование на основе CRISPR-Cas9 некодирующих геномных элементов. Авторы разработали объединенные библиотеки направляющей РНК CRISPR-Cas9 для выполнения in situ насыщающего мутагенеза человеческих и мышиных энхансеров BCL11A, которые обнаружили критические характеристики энхансеров.
- Zetsche et al. (2015) описали характеристику Cpf1, нуклеазы CRISPR класса 2 из Francisella novicida U112, с признаками, отличными от Cas9. Cpf1 представляет собой одиночную направляемую РНК эндонуклеазу, у которой отсутствует tracrRNA, которая использует мотив, смежный с протоспейсером, с высоким содержанием T и расщепляет ДНК посредством ступенчатого разрыва двухнитевой ДНК.
- Shmakov et al. (2015) описали три различных системы CRISPR-Cas класса 2. Ферменты двух систем CRISPR (C2c1 и C2c3) содержат RuvC-подобные эндонуклеазные домены, отличные от Cpf1. В отличие от Cpf1, C2c1 зависит как от crRNA, так и от tracrRNA, для расщепления ДНК. Третий фермент (C2c2) содержит два предполагаемых домена с HEPN РНКазой и является tracrRNA-независимым.
- Slaymaker et al. (2016) описали применение направляемого структурой конструирования белков для улучшения специфичности Cas9 (SpCas9) Streptococcus pyogenes. Авторы разработали "усиленную специфичность" вариантов SpCas9 (eSpCas9), которые сохраняли устойчивое целевое расщепление при сниженных нецелевых эффектах.
Также публикация "Dimeric CRISPR RNA-guided FokI nucleases for highly specific genome editing", Shengdar Q. Tsai, Nicolas Wyvekens, Cyd Khayter, Jennifer A. Foden, Vishal Thapar, Deepak Reyon, Mathew J. Goodwin, Martin J. Aryee, J. Keith Joung Nature Biotechnology 32(6): 569-77 (2014) в отношении направляемых димерной РНК нуклеаз FokI, которые распознают продленные последовательности и могут редактировать эндогенные гены с высокой эффективностью в человеческих клетках.
Патенты США №№ 8697359, 8771945, 8795965, 8865406, 8871445, 8889356, 8889418, 8895308, 8906616, 8932814, 8945839, 8993233 и 8999641; публикации заявки на патент США US 2014-0310830 (заявка на патент США с регистрационным номером 14/105031), US 2014-0287938 A1 (заявка на патент США с регистрационным номером 14/213991), US 2014-0273234 A1 (заявка на патент США с регистрационным номером 14/293,674), US2014-0273232 A1 (заявка на патент США с регистрационным номером 14/290575), US 2014-0273231 (заявка на патент США с регистрационным номером 14/259420), US 2014-0256046 A1 (заявка на патент США с регистрационным номером 14/226274), US 2014-0248702 A1 (заявка на патент США с регистрационным номером 14/258458), US 2014-0242700 A1 (заявка на патент США с регистрационным номером 14/222930), US 2014-0242699 A1 (заявка на патент США с регистрационным номером 14/183512), US 2014-0242664 A1 (заявка на патент США с регистрационным номером 14/104990), US 2014-0234972 A1 (заявка на патент США с регистрационным номером 14/183471), US 2014-0227787 A1 (заявка на патент США с регистрационным номером 14/256912), US 2014-0189896 A1 (заявка на патент США с регистрационным номером 14/105035), US 2014-0186958 (заявка на патент США с регистрационным номером 14/105017), US 2014-0186919 A1 (заявка на патент США с регистрационным номером 14/104977), US 2014-0186843 A1 (заявка на патент США с регистрационным номером 14/104900), US 2014-0179770 A1 (заявка на патент США с регистрационным номером 14/104837) и US 2014-0179006 A1 (заявка на патент США с регистрационным номером 14/183486), US 2014-0170753 (заявка на патент США с регистрационным номером 14/183429); US 2015-0184139 (заявка на патент США с регистрационным номером 14/324,960); 14/054414 заявки на европейские патенты EP 2 771 468 (EP13818570.7), EP 2 764 103 (EP13824232.6) и EP 2 784 162 (EP14170383.5); и публикации заявки на патенты согласно PCT WO 2014/093661 (PCT/US2013/074743), WO 2014/093694 (PCT/US2013/074790), WO 2014/093595 (PCT/US2013/074611), WO 2014/093718 (PCT/US2013/074825), WO 2014/093709 (PCT/US2013/074812), WO 2014/093622 (PCT/US2013/074667), WO 2014/093635 (PCT/US2013/074691), WO 2014/093655 (PCT/US2013/074736), WO 2014/093712 (PCT/US2013/074819), WO 2014/093701 (PCT/US2013/074800), WO 2014/018423 (PCT/US2013/051418), WO 2014/204723 (PCT/US2014/041790), WO 2014/204724 (PCT/US2014/041800), WO 2014/204725 (PCT/US2014/041803), WO 2014/204726 (PCT/US2014/041804), WO 2014/204727 (PCT/US2014/041806), WO 2014/204728 (PCT/US2014/041808), WO 2014/204729 (PCT/US2014/041809), WO 2015/089351 (PCT/US2014/069897), WO 2015/089354 (PCT/US2014/069902), WO 2015/089364 (PCT/US2014/069925), WO 2015/089427 (PCT/US2014/070068), WO 2015/089462 (PCT/US2014/070127), WO 2015/089419 (PCT/US2014/070057), WO 2015/089465 (PCT/US2014/070135), WO 2015/089486 (PCT/US2014/070175), PCT/US2015/051691, PCT/US2015/051830. Ссылка также делается на предварительные заявки на патенты США 61/758468; 61/802174; 61/806375; 61/814263; 61/819803 и 61/828130, поданные 30 января 2013 г.; 15 марта 2013 г.; 28 марта 2013 г.; 20 апреля 2013 г.; 6 мая 2013 г. и 28 мая 2013 г. соответственно. Ссылка также делается на предварительную заявку на патент США 61/836123, поданную 17 июня 2013 г. Ссылка дополнительно делается на предварительные заявки на патенты США 61/835931, 61/835936, 61/835973, 61/836080, 61/836101 и 61/836127, каждая из которых подана 17 июня 2013 г. Дополнительно ссылаются на предварительные заявки на патенты США 61/862468 и 61/862355, поданные 5 августа 2013 г.; 61/871301, поданную 28 августа 2013 г.; 61/960777, поданную 25 сентября 2013 г., и 61/961980, поданную 28 октября 2013 г. Ссылка еще дополнительно делается на: PCT/US2014/62558, поданный 28 октября 2014 г., и предварительные заявки на патенты США с серийными номерами 61/915148, 61/915150, 61/915153, 61/915203, 61/915251, 61/915301, 61/915267, 61/915260 и 61/915397, каждая из которых подана 12 декабря 2013 г.; 61/757972 и 61/768959, поданные 29 января 2013 г. и 25 февраля 2013 г.; 62/010888 и 62/010879, каждая из которых подана 11 июня 2014 г.; 62/010329, 62/010439 и 62/010441, каждая из которых подана 10 июня 2014 г.; 61/939228 и 61/939242, каждая из которых подана 12 февраля 2014 г.; 61/980012, поданная 15 апреля 2014 г.; 62/038358, поданная 17 августа 2014 г.; 62/055484, 62/055460 и 62/055487, каждая из которых подана 25 сентября 2014 г.; и 62/069243, поданная 27 октября 2014 г. Ссылаются на заявку согласно PCT, в которой, помимо прочих, указаны Соединенные Штаты Америки, заявку под № PCT/US14/41806, поданную 10 июня 2014 г. Ссылаются на предварительную заявку на патент США 61/930214, поданную 22 января 2014 г. Ссылаются на заявку согласно PCT, в которой, помимо прочих, указаны Соединенные Штаты Америки, заявку под № PCT/US14/41806, поданную 10 июня 2014 г.
Также упоминается заявка на патент США 62/180709, поданная 17 июня 2015 г., PROTECTED GUIDE RNAS (PGRNAS); заявка на патент США 62/091455, поданная 12 декабря 2014 г., PROTECTED GUIDE RNAS (PGRNAS); заявка на патент США 62/096708, поданная 24 декабря 2014 г., PROTECTED GUIDE RNAS (PGRNAS); заявки на патент США 62/091462, поданная 12 декабря 2014 г., 62/096324, поданная 23 декабря 2014 г., 62/180681, поданная 17 июня 2015 г., и 62/237496, поданная 5 октября 2015 г., DEAD GUIDES FOR CRISPR TRANSCRIPTION FACTORS; заявки на патент США 62/091456, поданная 12 декабря 2014 г. и 62/180692, поданная 17 июня 2015 г., ESCORTED AND FUNCTIONALIZED GUIDES FOR CRISPR-CAS SYSTEMS; заявки на патент США 62/091461, поданная 12 декабря 2014 г., DELIVERY, USE AND THERAPEUTIC APPLICATIONS OF THE CRISPR-CAS SYSTEMS AND COMPOSITIONS FOR GENOME EDITING AS TO HEMATOPOETIC STEM CELLS (HSC); заявка на патент США 62/094903, поданная 19 декабря 2014 г., UNBIASED IDENTIFICATION OF DOUBLE-STRAND BREAKS AND GENOMIC REARRANGEMENT BY GENOME-WISE INSERT CAPTURE SEQUENCING; заявка на патент США 62/096761, поданная 24 декабря 2014 г., ENGINEERING OF SYSTEMS, METHODS AND OPTIMIZED ENZYME AND GUIDE SCAFFOLDS FOR SEQUENCE MANIPULATION; заявка на патент США 62/098059, поданная 30 декабря 2014 г., 62/181641, поданная 18 июня 2015 г., и 62/181667, поданная 18 июня 2015 г., RNA-TARGETING SYSTEM; заявка на патент США 62/096656, поданная 24 декабря 2014 г., и 62/181151, поданная 17 июня 2015 г., CRISPR HAVING OR ASSOCIATED WITH DESTABILIZATION DOMAINS; заявка на патент США 62/096697, поданная 24 декабря 2014 г., CRISPR HAVING OR ASSOCIATED WITH AAV; заявка на патент США 62/098158, поданная 30 декабря 2014 г., ENGINEERED CRISPR COMPLEX INSERTIONAL TARGETING SYSTEMS; заявка на патент США 62/151052, поданная 22 апреля 2015 г., CELLULAR TARGETING FOR EXTRACELLULAR EXOSOMAL REPORTING; заявка на патент США 62/054490, поданная 24 сентября 2014 г., DELIVERY, USE AND THERAPEUTIC APPLICATIONS OF THE CRISPR-CAS SYSTEMS AND COMPOSITIONS FOR TARGETING DISORDERS AND DISEASES USING PARTICLE DELIVERY COMPONENTS; заявка на патент США 61/939154, поданная 12 февраля 2014 г., SYSTEMS, METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION WITH OPTIMIZED FUNCTIONAL CRISPR-CAS SYSTEMS; заявка на патент США 62/055484, поданная 25 сентября 2014 г., SYSTEMS, METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION WITH OPTIMIZED FUNCTIONAL CRISPR-CAS SYSTEMS; заявка на патент США 62/087537, поданная 4 декабря 2014 г., SYSTEMS, METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION WITH OPTIMIZED FUNCTIONAL CRISPR-CAS SYSTEMS; заявка на патент США 62/054651, поданная 24 сентября 2014 г., DELIVERY, USE AND THERAPEUTIC APPLICATIONS OF THE CRISPR-CAS SYSTEMS AND COMPOSITIONS FOR MODELING COMPETITION OF MULTIPLE CANCER MUTATIONS IN VIVO; заявка на патент США 62/067886, поданная 23 октября 2014 г., DELIVERY, USE AND THERAPEUTIC APPLICATIONS OF THE CRISPR-CAS SYSTEMS AND COMPOSITIONS FOR MODELING COMPETITION OF MULTIPLE CANCER MUTATIONS IN VIVO; заявки на патент США 62/054675, поданная 24 сентября 2014 г., и 62/181002, поданная 17 июня 2015 г., DELIVERY, USE AND THERAPEUTIC APPLICATIONS OF THE CRISPR-CAS SYSTEMS AND COMPOSITIONS IN NEURONAL CELLS/TISSUES; заявка на патент США 62/054528, поданная 24 сентября 2014 г., DELIVERY, USE AND THERAPEUTIC APPLICATIONS OF THE CRISPR-CAS SYSTEMS AND COMPOSITIONS IN IMMUNE DISEASES OR DISORDERS; заявка на патент США 62/055454, поданная 25 сентября 2014 г., DELIVERY, USE AND THERAPEUTIC APPLICATIONS OF THE CRISPR-CAS SYSTEMS AND COMPOSITIONS FOR TARGETING DISORDERS AND DISEASES USING CELL PENETRATION PEPTIDES (CPP); заявка на патент США 62/055460, поданная 25 сентября 2014 г., MULTIFUNCTIONAL-CRISPR COMPLEXES AND/OR OPTIMIZED ENZYME LINKED FUNCTIONAL-CRISPR COMPLEXES; заявка на патент США 62/087475, поданная 4 декабря 2014 г., и 62/181690, поданная 18 июня 2015 г., FUNCTIONAL SCREENING WITH OPTIMIZED FUNCTIONAL CRISPR-CAS SYSTEMS; заявка на патент США 62/055487, поданная 25 сентября 2014 г., FUNCTIONAL SCREENING WITH OPTIMIZED FUNCTIONAL CRISPR-CAS SYSTEMS; заявки на патент США 62/087546, поданная 4 декабря 2014 г., и 62/181687, поданная 18 июня 2015 г., MULTIFUNCTIONAL CRISPR COMPLEXES AND/OR OPTIMIZED ENZYME LINKED FUNCTIONAL-CRISPR COMPLEXES; и заявка на патент США 62/098285, поданная 30 декабря 2014 г., CRISPR MEDIATED IN VIVO MODELING AND GENETIC SCREENING OF TUMOR GROWTH AND METASTASIS.
Упоминаются заявки на патенты США 62/181659, поданная 18 июня 2015 г., и 62/207318, поданная 19 августа 2015 г., ENGINEERING AND OPTIMIZATION OF SYSTEMS, METHODS, ENZYME AND GUIDE SCAFFOLDS OF CAS9 ORTHOLOGS AND VARIANTS FOR SEQUENCE MANIPULATION. Упоминаются заявки на патенты США 62/181663, поданная 18 июня 2015 г., и 62/245264, поданная 22 октября 2015 г., NOVEL CRISPR ENZYMES AND SYSTEMS, заявки на патенты США 62/181675, поданные 18 июня 2015 г., 62/285349, поданная 22 октября 2015 г., 62/296522, поданная 17 февраля 2016 г., и 62/320231, поданная 8 апреля 2016 г., NOVEL CRISPR ENZYMES AND SYSTEMS, заявка на патент США 62/232067, поданная 24 сентября 2015 г., заявка на патент США, 14/975085, поданная 18 декабря 2015 г., европейская заявка на патент №16150428.7, заявка на патент США 62/205733, поданная 16 августа 2015 г., заявка на патент США 62/201542, поданная 5 августа 2015 г., заявка на патент США 62/193507, поданная 16 июля 2015 г., и заявка на патент США 62/181739, поданная 18 июня 2015 г., каждая из которых имеет название NOVEL CRISPR ENZYMES AND SYSTEMS, и заявка на патент США 62/245270, поданная 22 октября 2015 г., NOVEL CRISPR ENZYMES AND SYSTEMS. Также упоминается заявка на патент США 61/939256, поданная 12 февраля 2014 г., и WO 2015/089473 (PCT/US2014/070152), поданная 12 декабря 2014 г., каждая из которых имеет название ENGINEERING OF SYSTEMS, METHODS AND OPTIMIZED GUIDE COMPOSITIONS WITH NEW ARCHITECTURES FOR SEQUENCE MANIPULATION. Также упоминается PCT/US2015/045504, поданная 15 августа 2015 г., заявка на патент США 62/180699, поданная 17 июня 2015 г., и заявка на патент США 62/038358, поданная 17 августа 2014 г., каждая из которых имеет название GENOME EDITING USING CAS9 NICKASES.
- Каждое из данных патентов, публикаций патентов и заявок, а также все документы, цитируемые в них или во время их рассмотрения ("документы, цитируемые в заявке"), и все документы, цитируемые или упомянутые в документах, цитируемых в заявке, вместе с любыми инструкциями, описаниями, характеристиками продукта и технологическими картами для любых продуктов, упомянутыми в них или в любом документе, упомянутом в них и включенном с помощью ссылки в данный документ, настоящим включены в данный документ с помощью ссылки и могут быть использованы в практическом осуществлении настоящего изобретения. Все документы (например, данные патенты, публикации патентов и заявки, а также цитируемые в заявках документы) включены в данный документ посредством ссылки в такой же мере, как если бы конкретно и отдельно было указано, что каждый отдельный документ включен посредством ссылки.
С того времени была показана эффективность настоящего изобретения. Предварительно собранные рекомбинантные комплексы CRISPR-Cpf1, содержащие Cpf1 и crRNA, могут быть трансфицированы, например, при помощи электропорации, что приводит к высокой частоте мутаций и отсутствию выявляемых нецелевых мутаций. Hur, J.K. et al, Targeted mutagenesis in mice by electroporation of Cpf1 ribonucleoproteins, Nat Biotechnol. 2016 Jun 6. doi: 10.1038/nbt.3596. [Электронная публикация, предшествующая печатной], Полногеномные анализы показывают, что Cpf1 является высокоспецифичным. Согласно одному измерению in vitro сайтов расщепления, определенных для SpCas9 в человеческих клетках HEK293T, было значимо меньше, чем для SpCas9. Kim, D. et al., Genome-wide analysis reveals specificities of Cpf1 endonucleases in human cells, Nat Biotechnol. 2016 Jun 6. doi: 10.1038/nbt.3609. [Электронная публикация, предшествующая печатной], Эффективная мультиплексная система с применением Cpf1 была показана у Drosophila, при этом использовали gRNA, обработанные из массива, содержащего разрабатываемые tRNA. Port, F. et al, Expansion of the CRISPR toolbox in an animal with tRNA-flanked Cas9 and Cpf1 gRNAs. doi: http://dx.doi.org/10.1101/046417.
Настоящее изобретение дополнительно будет проиллюстрировано в следующих примерах, которые приведены только для иллюстративных целей и не предназначены для ограничения настоящего изобретения каким-либо образом.
ПРИМЕРЫ
Пример 1. Происхождение и эволюция систем адаптивного иммунитета
Классификация и аннотация систем CRISPR-Cas в геномах архей и бактерий. Локусы CRISPR-Cas включают более чем 50 семейств генов, и при этом отсутствуют строго универсальные гены, наблюдается быстрая эволюция, чрезвычайное разнообразие структуры локусов. По этой причине невозможно построить единое дерево и нужно применять дифференцированный подход. На настоящий момент имеется исчерпывающая идентификация генов cas из 395 профилей для 93 белков Cas. Классификация включает сигнатуры генных профилей с сигнатурами структуры локуса.
Новая классификация систем CRISPR-Cas предложена на фиг. 1. Класс 2 включает мультисубъединичные комплексы crRNA-эффектор (Cascade), а класс 2 включает односубъединичные комплексы crRNA-эффектор (Cas9-подобные). На фиг. 2 представлена молекулярная структура CRISPR-Cas. На фиг. 3 представлены структуры комплексов эффекторов I и III типов: общая структура/общее происхождение, несмотря на существенную дивергенцию последовательности. На фиг. 4 показана CRISPR-Cas в качестве системы, в центре которой расположен мотив распознавания РНК (RRM). На фиг. 5 показана филогения Cas1, где главным аспектом эволюции CRISPR-Cas оказывается рекомбинация адаптационного и crRNA-эффекторного модулей. На фиг. F показан полный набор CRISPR-Cas, в частности, распределение типов/подтипов CRISPR-Cas среди архей и бактерий.
Cas1 не всегда связан с системами CRISPR-Cas, следовательно, возможно, что существует две ветви "самостоятельных" Cas1, что позволяет сделать предположение, что могут существовать различия в функции и происхождении и возможны новые мобильные элементы (см. Makarova, Krupovic, Koonin, Frontiers Genet 2014). Организация генома трех семейств каспозонов может дать некоторую разгадку. В дополнение к Cas1 и PolB каспозоны включают различные гены, в том числе различные нуклеазы (Krupovic et al. BMC Biology 2014). Одно семейство имеет инициируемую белком полимеразу, другое семейства имеет инициируемую РНК полимеразу. Кроме различных Euryarchaeota и Thaumarchaeota каспозоны были обнаружены у некоторых бактерий, что позволяет предположить наличие горизонтального переноса. Предположительно, каспозон Cas1 (транспозаза/интеграза) является базальной кладой в филогении Cas1.
Бактерии и археи используют CRISPR для адаптивного иммунитета у прокариот и эукариот с помощью манипуляций с геномом. Cas 1 обеспечивает готовый инструмент для манипуляций с геномом. У каспозонов и CRISPR существуют аналогичные механизмы интеграции, в частности, зависимое от репликации приобретение с помощью копирования/вставки, а не вырезания-и-вставки (Krupovic et al. BMC Biology 2014). Cas1 является истинной интегразой (Nuñez JK, Lee AS, Engelman A, Doudna JA. Integrase-mediated spacer acquisition during CRISPR-Cas adaptive immunity. Nature. 2015 Feb 18). Существует подобие между концевыми инвертированными повторами каспозонов и CRISPR (Krupovic et al. BMC Biology 2014). CRISPR-Cas может происходит от каспозона и локуса врожденного иммунитета (Koonin, Krupovic, Nature Rev Genet, 2015). Эволюция систем адаптивного иммунитета у прокариот и животных могла проходить параллельно с интеграцией транспозонов в локусы врожденного иммунитета (Koonin, Krupovic, Nature Rev Genet, 2015). Транспозаза RAG1 (ключевой фермент рекомбинации V(D)J у позвоночных) могла произойти из транспозонов Transib (Kapitonov VV, Jurka J. RAG1 core and V(D)J recombination signal sequences were derived from Transib transposons. PLoS Biol. 2005 Jun;3(6):e181), однако, ни один из Transib не кодирует RAG2. Транспозоны, кодирующие RAG1 и RAG2, описаны в Kapitonov, Koonin, Biol Direct 2015, а филогения транспозазы Transib представлена в Kapitonov, Koonin, Biol Direct 2015. Защитное удаление ДНК у ресничных возникло из транспозона PiggyMAc и RNAi, врожденной иммунной системы (Swart EC, Nowacki M. The eukaryotic way to defend and edit genomes by sRNA-targeted DNA deletion. Ann N Y Acad Sci. 2015).
Относительная стабильность классификации подразумевает, что наиболее распространенные варианты систем CRISPR-Cas уже известны. Однако существование редких, в настоящее время неклассифицированных вариантов подразумевает, что остаются дополнительные типы и подтипы, которые необходимо охарактеризовать (Makarova et al. 2015. Evolutionary classification of CRISPR-Cas systems and cas genes).
Транспозоны внесли ключевой вклад в эволюцию адаптивного иммунитета и других систем, вовлеченных в манипуляции с ДНК. CRISPR-Cas класса 1 произошли от транспозонов, но только с точки зрения адаптационного модуля. CRISPR-Cas класса 2 обладают как функцией адаптации, так и эффекторной функцией, при этом модули могли возникнуть из различных транспозонов.
Пример 2. Новые прогнозируемые системы CRISPR-Cas класса 2 и доказательство их независимого происхождения от мобильных генетических элементов
Системы CRISPR-Cas, обеспечивающие адаптивный иммунитет бактерий и архей, демонстрируют чрезвычайное разнообразие состава белков и структуры локусов генома. Эти системы в широком смысле разделены на два класса, класс 1 с мультисубъединичными эффекторными комплексами и класс 2 с односубъединичными эффекторными модулями, в качестве примера которых приводится белок Cas9. Заявители разработали простой компьютерный конвейерный алгоритм для прогнозирования предполагаемых новых систем CRISPR-Cas класса 2. Анализ базы данных полных геномов бактерий с применением данного конвейерного алгоритма привел к идентификации двух новых вариантов, каждый из которых представлен у различных бактерий и содержит гены cas1 и cas2 вместе с третьим геном, кодирующим крупный белок, который, как прогнозируется, функционирует как эффекторный модуль. В случае первого из этих локусов предполагаемый эффекторный белок (C2c1p) содержит домен RuvC-подобной нуклеазы и напоминает описанный ранее белок Cpf1, прогнозируемый эффектор систем CRISPR-Cas V типа; в соответствии с этим, новую предполагаемую систему классифицируют как подтип V-B. При глубоком сравнении белковых последовательностей сделано предположение, что содержащие RuvC эффекторные белки, Cas9, Cpf1 и C2C1p, возникли независимо от различных групп белков TnpB, кодируемых транспозонами. Вторая группа новых предполагаемых локусов CRISPR-Cas включает крупный белок, содержащий два сильно дивергировавшие домена HEPN с прогнозируемой РНКазной активностью. В связи с новизной прогнозируемого эффекторного белка эти локусы классифицируют как новый CRISPR-Cas VI типа, который, по-видимому, нацеливается на мРНК. Совместно результаты данного анализа показывают, что системы CRISPR-Cas класса 2 возникали множество независимых раз путем комбинации различных кодирующих Cas1-Cas2 адаптационных модулей с эффекторными белками, происходящими от других мобильных элементов. Данный путь эволюции наиболее вероятно дал множество вариантов систем класса 2, которые еще предстоит открыть.
Системы адаптивного иммунитета CRISPR-Cas присутствуют в ~45% геномов бактерий и ~90% геномов архей и демонстрируют чрезвычайное разнообразие состава и последовательности белка Cas, а также структуры локусов генома. На основе структурной организации их комплексов crRNA-эффектор эти системы делятся на два класса, а именно класс 1, с мультисубъединичными эффекторными комплексами, и класс 2, с односубъединичными эффекторными комплексами (Makarova, 2015). Системы класса 1 намного более распространены и разнообразны, чем системы класса 2. В настоящее время класс 1 представлен 12 отдельными подтипами, закодированными в геномах многочисленных архей и бактерий, в то же время системы класса 2 включают три подтипа системы II типа и предполагаемого V типа, которые совместно обнаруживаются в приблизительно 10% секвенированных геномов бактерий (с единственным геномом архей, содержащим систему предполагаемого типа). Системы класса 2, как правило, содержат только три или четыре гена в опероне cas, а именно пару генов cas1-cas2, которые вовлечены в адаптацию, но не в интерференцию, один мультидоменный эффекторный белок, который отвечает за интерференцию, но также вносит вклад в процессинг pre-crRNA и адаптацию, и зачастую четвертый ген с неохарактеризованными функциями, который является необязательным по меньшей мере в некоторых системах II типа. В большинстве случаев массив CRISPR и ген для отличающейся молекулы РНК, известной как tracrRNA (транс-кодируемая малая РНК CRISPR), расположены смежно с оперонами cas класса 2 (Chylinski, 2014). tracrRNA является частично гомологичной повторам в пределах соответствующего массива CRISPR, и она необходима для процессинга pre-crRNA, который катализируется РНКазой III, универсальным ферментом бактерий, который не ассоциирован с локусами CRISPR-cas (Deltcheva, 2011), (Chylinski, 2014; Chylinski, 2013).
Мультидоменный эффекторный белок Cas9 II типа был охарактеризован с функциональной и структурной точки зрения в мельчайших деталях. У различных бактерий белки Cas9 содержат от приблизительно 950 до 1400 аминокислот и содержат два нуклеазных домена, а именно RuvC-подобную нуклеазу (РНКаза H) и нуклеазу HNH (McrA-подобная) (Makarova, 2011). Кристаллическая структура Cas9 выявляет двудольную организацию белка с отдельными долей распознавания мишени и нуклеазной долей, при этом на последней расположены оба домена RuvC и HNH (Nishimasu, 2014), (Jinek, 2014). Каждый из нуклеазных доменов Cas9 необходим для расщепления одной из нитей целевой ДНК (Jinek, 2012; Sapranauskas, 2011). Недавно было показано, что Cas9 вносит вклад во все три стадии реакции с участием CRISPR, которые представляют собой не только расщепление целевой ДНК (интерференцию), но также адаптацию и процессинг pre-crRNA (Jinek, 2012). Более конкретно, отдельный домен в нуклеазной доле Cas9, как было показано, распознает и связывает ассоциированный с протоспейсером мотив (PAM) в вирусной ДНК во время стадии адаптации (Nishimasu, 2014), (Jinek, 2014), (Heler, 2015; Wei, 2015). На этой стадии ответа с участием CRISPR Cas9 образует комплекс с Cas1 и Cas2, двумя белками, которые вовлечены в обнаружение спейсера во всех системах CRISPR-Cas (Heler, 2015; Wei, 2015).
Белок Cas9, объединенный с tracrRNA, в недавнее время стал ключевым инструментом для нового поколения способов редактирования и конструирования генома (Gasiunas, 2013; Mali, 2013; Sampson, 2014; Cong, 2015). Данная применимость Cas9 в редактирование генома основывается на том факте, что в системах CRISPR-Cas II типа, в отличие от остальных типов систем CRISPR-Cas, все виды активности, требуемые для распознавания и расщепления целевой ДНК, собраны в одном, хотя и крупном, мультидоменном белке. Этот признак систем типа II в значительной степени облегчает конструирование эффективных инструментов для манипуляций с геномом. Важно отметить, что не все варианты Cas9 являются равноценными. Большинство работ на настоящий момент было выполнено с Cas9 из Streptococcus pyogenes, но другие виды Cas9 могли бы обеспечить значительные преимущества. В качестве примера, недавние эксперименты с Cas9 из Staphylococcus aureus, который на приблизительно 300 аминокислот короче, чем белок S. pyogenes, обеспечили возможность упаковки Cas9 в вектор на основе аденоассоциированного вируса, что привело к значительному улучшению применимости CRISPR-Cas в редактировании генома in vivo (Ran, 2015).
В настоящее время системы CRISPR-Cas II типа разделяют на 3 подтипа (II-A, II-B и II-C) (Makarova, 2011) (Fonfara, 2014; Chylinski, 2013; Chylinski, 2014). В дополнение к генам cas1, cas2 и cas9, которые являются общими для всех локусов типа II, подтип II-A характеризуется дополнительным геном, csn2, который кодирует инактивированную АТФазу (Nam, 2011; Koo, 2012; Lee, 2012), которая играет все еще слабо охарактеризованную роль в обнаружении спейсера (Barrangou, 2007; Arslan, 2013), (Heler, 2015). В системах подтипа II-B отсутствует csn2, но вместо этого содержится ген cas4, который в иных случаях является типичным для систем типа I и кодирует 5'-3'-экзонуклеазу семейства recB, которая вносит вклад в обнаружение спейсера путем образования концов ДНК, способных к рекомбинации (Zhang, 2012), (Lemak, 2013; Lemak, 2014). Гены cas1 и cas2 подтипа II-B наиболее тесно связаны с соответствующими белками систем CRISPR-Cas I типа, что предполагает рекомбинантное происхождение данного подтипа II типа (Chylinski, 2014).
Системы CRISPR-Cas подтипа II-C проявляют минимальное разнообразие, при этом состоят только из генов cas1, cas2 и cas9 (Chylinski, 2013; Koonin, 2013; Chylinski, 2014). Однако, как было показано, примечательно, что у Campylobacter jejuni для обнаружения спейсера с помощью систем типа II-C требуется участие Cas4, кодируемого бактериофагом (Hooton, 2014). Другим отличительным признаком подтипа II-C является то, что образование некоторых crRNA посредством транскрипции подразумевает транскрипцию с внутренних альтернативных промоторов, в отличие от процессинга, наблюдаемого во всех других экспериментально охарактеризованных систем CRISPR-Cas (Zhang, 2013).
Недавно с помощью сравнительного анализа геномов бактерий было спрогнозировано существование систем CRISPR-Cas V типа. Эти предполагаемые новые системы CRISPR-Cas представлены в геномах некоторых бактерий, в частности, принадлежащих роду Francisella, и у одной археи, Methanomethylophilus alvus (Vestergaard, 2014). Все предполагаемые локусы V типа содержат cas1, cas2, отдельный ген, обозначенный cpf1, и массив CRISPR (Schunder, 2013), (Makarova, 2015). Cpf1 представляет собой крупный белок (приблизительно 1300 аминокислот), который содержит домен RuvC-подобной нуклеазы, гомологичный соответствующему домену Cas9, вместе с эквивалентом характерного кластера Cas9 с высоким содержанием аргинина. Однако у Cpf1 отсутствует HNH-нуклеазный домен, который присутствует у всех белков Cas9, а RuvC-подобный домен граничит с последовательностью Cpf1, в отличие от Cas9, где он содержит длинные вставки, включающие домен HNH (Chylinski, 2014; Makarova, 2015). Эти главные отличия в структуре доменов Cas9 и Cpf1 позволяют высказать предположение, что системы, содержащие Cpf1, следует классифицировать как новый тип. Состав предполагаемых систем V типа подразумевает, что Cpf1 является односубъединичным эффекторным комплексом, и, соответственно, эти системы относятся к CRISPR-Cas класса 2. Некоторые из предполагаемых локусов V типа кодируют Cas4 и, соответственно, напоминают локусы подтипа II-B, в то время как в других отсутствует Cas4, и они, таким образом, аналогичны подтипу II-C.
Было показано, что ближайшими гомологами белков Cas9 и Cpf1 являются белки TnpB, которые кодируются транспозонами семейства IS605 и содержат домен RuvC-подобной нуклеазы, а также "цинковый палец", который имеет аналог в Cpf1. Кроме того, были идентифицированы гомологи TnpB, которые содержат домен HNH, вставленный в RuvC-подобный домен, и демонстрируют высокое сходство последовательности с Cas9. Роль TnpB для транспозонов остается неясной, поскольку, как было показано, данный белок не требуется для осуществления транспозиции.
С учетом гомологии Cas9 и Cpf1 с кодируемыми транспозонами белками, заявители высказали гипотезу, что системы CRISPR-Cas класса 2 могли возникать множество раз в результате рекомбинации между транспозоном и локусом cas1-cas2. В соответствии с этим, заявители разработали простую компьютерную стратегию для идентификации локусов генома, которые могли бы быть кандидатами для новых вариантов класса 2. В данном документе заявители описывают первое применение данного подхода, которое привело к идентификации двух групп таких кандидатов, одна из которых, по-видимому, представляет собой отдельный подтип V типа, в то время как вторая группа, видимо, квалифицируется как VI тип. Новые варианты систем CRISPR-Cas класса 2 представляют явный интерес в качестве потенциальных инструментов для редактирования генома и регуляции экспрессии.
Стратегия поиска в базе данных для обнаружения кандидатных новых локусов CRISPR-Cas класса 2. Заявители реализовали прямой компьютерный подход для идентификации кандидатных новых систем CRISPR-Cas класса 2 (ФИГ. 7. Конвейерный алгоритм). Вследствие того, что подавляющее большинство локусов CRISPR-Cas содержат ген cas1 (Makarova, 2011; Makarova, 2015), и последовательность Cas1 является наиболее высококонсервативной среди всех белков Cas (Takeuchi, 2012), заявители заключили, что cas1 представляет собой наилучшую возможную точку привязки для идентификации кандидатных новых локусов с применением транслирующего поиска PSI-BLAST с профилями Cas1. После обнаружения всех контигов, кодирующих Cas1, кодирующие белок гены прогнозировали с применением GenemarkS в пределах участков размером 20 т. о. выше и ниже гена cas1. Эти прогнозируемые гены были аннотированы с применением CDD от NCBI и профилей, специфических для белка Cas, и массивы CRISPR прогнозировали с применением программы PILER-CR. Данную процедуру проводили для отнесения обнаруженных локусов CRISPR-Cas к известным подтипам. Неклассифицированные кандидатные локусы CRISPR-Cas, содержащие крупные (>500 аминокислот) белки, выбирали в качестве кандидатов для новых систем класса 2, при условии характерного присутствия таких белков для II и V типов (Cas9 и Cpf1 соответственно). Все 34 кандидатных локуса, обнаруженные с применением данного критерия, анализировали индивидуальным образом с применением PSI-BLAST и HHpred. Белковые последовательности, кодируемые кандидатными локусами, далее применяли в качестве запрашиваемых последовательностей для поиска дополнительных аналогов в метагеномных базах данных, и длинные контиги, обнаруженные в данных поисках анализировали, как указано выше. Данный анализ с использованием конвейерного алгоритма привел к обнаружению двух групп локусов, прочно связанных с системами CRISPR-Cas.
Предполагаемая система типа V-B. Первая группа кандидатных локусов, предварительно обозначенная названием C2c1 (класс 2, кандидат 1), представлена в геномах бактерий из четырех главных таксономических групп, включая Bacilli, Verrucomicrobia, альфа-протеобактерии и дельта-протеобактерии (фиг. 8 "Организация полных локусов систем класса 2"). Все локусы C2c1 кодируют слияние Cas1-Cas4, Cas2 и крупный белок, который заявители обозначили как C2c1p, и, как правило, они являются смежными с массивом CRISPR (фиг. 9, соседство C2c1). В филогенетическом дереве Cas1 соответствующие белки Cas1 образуют кластер с системой типа I-U (фиг. 10, дерево Cas1), единственной, в которой было обнаружено слияние Cas1-Cas4. Белки C2c1p состоят из примерно 1200 аминокислот, и с помощью поиска HHpred обнаружили значительное сходство между C-концевой частью данного белка и подгруппой белков TnpB, кодируемых транспозонами семейства IS605. В отличие от этого, никакого значительного сходства не обнаружили между C2c1p и Cas9 или Cpf1, которые похожи на другие группы белков TnpB (Chylinski, 2014), (Makarova, 2015; Makarova, 2015). Таким образом, структура доменов C2c1p подобна таковой у Cpf1 и отличается от таковой у Cas9, хотя все три белка Cas, видимо, произошли от семейства TnpB (фиг. 11 "Организация доменов в семействах класса 2"). Для N-концевого участка C2c1p не показано значительное сходство с другими белками. Прогнозирование вторичной структуры показывает, что данный участок принимает, главным образом, конформацию альфа-спирали. Сходство двух сегментов с TnpB охватывает три каталитических мотива RuvC-подобной нуклеазы с сигнатурой D..E..D (фиг. 12, "Участки гомологии с TnpB у белков класса 2"); участок, соответствующий мостиковой спирали (также известный как кластер с высоким содержанием аргинина), который в случае белка Cas9 вовлечен в связывание crRNA; и небольшой участок, который, по-видимому, является аналогом "цинкового пальца" TnpB (однако, связывающие цинк цистеиновые остатки в C2C1p замещены, что указывает на то, что данный белок не связывает цинк). Сходство структуры доменов C2c1p и Cpf1 подразумевает, что локусы C2c1 лучше классифицировать как подтип V-B, в этом случае кодирующие Cpf1 локусы нужно относить к подтипу V-A.
Несмотря на сходство генов cas1, ассоциированных с данной системой, повторы CRISPR в соответствующих массивах являются высоко гетерогенными, хотя все они имеют длину 36-37 п. о. и их можно классифицировать как неструктурированные (энергия сворачивания, ∆G, составляет -0,5-4,5 ккал/моль, в то время как у высоко палиндромных CRISPR ∆G составляет ниже -7). В соответствии со схемой классификации CRISPRmap (Lange, 2013) несколько повторов подтипа V-B обладают некоторым сходством последовательности или структуры с повторами II типа.
Учитывая возможность того, что предполагаемые системы CRISPR-Cas подтипа V-B по механизму аналогичны системам II типа, заявители сделали попытку идентифицировать tracrRNA в соответствующих локусах генома.
С помощью сравнения спейсеров из массивов CRISPR типа V-B с базой данных неизбыточных нуклеотидных последовательностей идентифицировали несколько совпадений с геномами различных бактерий. Значимость этих совпадений трудно оценить, учитывая то, что фаги для бактерий, которые несут предполагаемые системы CRISPR-Cas типа V-B, не известны.
Предполагаемые системы VI типа. Вторую группу кандидатных локусов CRISPR-Cas, обозначенную как C2c2, идентифицировали в геномах из 5 главных таксономических групп бактерий, альфа-протеобактерии, Bacilli, Clostridia, Fusobacteria и Bacteroidetes (фиг. 8 "Организация полных локусов систем класса 2"). Подобно c2c1, локусы C2c2 содержат гены cas1 и cas2 вместе с крупным белком (C2c2p) и массивом CRISPR; однако, в отличие от C2c1 C2c2p зачастую закодирован после массива CRISPR, а не cas1-cas2 (фиг. 13, соседство C2c2). На филогенетическом дереве Cas1 белки Cas1 из локусов C2c2 распределяются по двум кладам. Первая клада включает Cas1 от Clostridia и находится в пределах поддерева II типа вместе с небольшой ветвью типа III-A (фиг. 10, дерево Cas1). Вторая клада состоит из белков Cas1 из локусов C2c2 Leptotrichia, и она располагается внутри смешанной ветви, которая преимущественно содержит белки Cas1 из систем CRISPR-Cas типа III-A. С помощью поисков в базах данных с применением HHpred и PSI-BLAST не обнаружили сходства последовательности между C2c2p и другими белками. Однако просмотр множественных выравниваний белковых последовательностей C2c2p привел к идентификации двух очень консервативных мотивов RxxxxH, которые характерны для доменов HEPN (Anantharaman, 2013). Результаты прогнозирования вторичной структуры показывают, что данные мотивы расположены с пределах сопутствующих структур, сравнимых со структурой домена HEPN, как и при общем прогнозировании вторичной структуры для соответствующих частей C2c2p. Домены HEPN представляют собой небольшие (~150 аминокислот) домены с альфа-структурой, которые, как было показано или прогнозируется, обладают РНКазной активностью и зачастую ассоциированы с различными системами защиты (Anantharaman, 2013) (фиг. 14, мотив RxxxxH HEPN в семействе C2c2). Последовательности доменов HEPN проявляют небольшую консервативность, за исключением каталитического мотива RxxxxH. Таким образом, представляется возможным, что C2c2p содержит два активных домена HEPN. Домен HEPN не является новым для систем CRISPR-Cas, поскольку он часто ассоциирован с доменом CARF (CRISPR-ассоциированная укладка Россмана) у белков Csm6 и Csx1, которые присутствуют во многих системах CRISPR-Cas III типа (Makarova, 2014). Эти белки не принадлежат ни к адаптационным модулям, ни к эффекторным комплексам, а, по-видимому, являются компонентами модуля ассоциированного иммунитета, который присутствует в большинстве систем CRISPR-Cas и задействован в запрограммированной гибели клетки, а также регуляторных функциях во время реакции с участием CRISPR (Koonin, 2013; Makarova, 2012; Makarova, 2013). Однако C2c2p отличается от Csm6 и Csx1 тем, что этот намного более крупный белок является единственным, который закодирован в локусе C2c2, кроме Cas1 и Cas2. Таким образом, представляется возможным, что C2c2p является эффектором этих предполагаемых новых систем CRISPR-Cas, а домены HEPN являются его каталитическими фрагментами. За пределами прогнозируемых доменов HEPN для последовательности C2c1p не показано обнаруживаемого сходства с другими белками, и прогнозируется, что она принимает смешанную вторичную альфа/бета-структуру.
Массивы CRISPR в локусах C2c2 являются высоко гетерогенными, с длиной от 35 до 39 п. о., и неструктурированными (энергия сворачивания составляет от -0,9 до 4,7 ккал/моль). В соответствии с CRISPRmap (Lange, 2013) эти CRISPR не принадлежат ни какому из классов с установленной структурой, и их отнесли к 3 из 6 надклассов. Только CRISPR из Listeria seeligeri отнесли к семейству последовательностей 24, которое обычно ассоциировано с системами типа II-C.
При анализе спейсеров из локуса C2c2 идентифицировали один 30-нуклеотидный участок, идентичный геномной последовательности из Listeria weihenstephanensis и двум несовершенным хитам c геномами бактериофагов.
Учитывая уникальный прогнозируемый эффекторный комплекс C2c2, эти системы видимо следует квалифицировать как предполагаемый CRISPR-Cas VI типа. Кроме того, с учетом того, что все экспериментально охарактеризованные и ферментативно активные домены HEPN представляют собой РНКазы, системы VI типа вероятно действуют на уровне мРНК.
Заявители применили простую прямую компьютерную стратегию для прогнозирования новых систем CRISPR-cas класса 2. Описанные ранее системы класса 2, а именно II типа и предполагаемого V типа, состоят из генов cas1 и cas2 (и в некоторых случаях также cas4), составляющих адаптационный модуль, и одного крупного белка, который составляет эффекторный модуль. Следовательно, заявители выказали предположение, что любой локус генома, содержащий cas1 и крупный белок, может быть потенциальным кандидатом для новой системы класса 2, который заслуживает подробного исследования. Такой анализ с применением чувствительных способов для сравнения белковых последовательностей привел к идентификации двух сильных кандидатов, один из которых представляет собой подтип описанного ранее предполагаемого V типа, тогда как другой квалифицируется как новый предполагаемый VI тип, в силу присутствия нового прогнозируемого эффекторного белка. Многие из этих новых систем встречаются в геномах бактерий, которые не содержат другие локусы CRISPR-Cas, что подразумевает, что системы типа V и типа VI могут функционировать автономно.
В сочетании с результатами предыдущих анализов (Chylinski, 2014; Makarova, 2011), идентификация предполагаемого типа V-B выявляет главную тему в эволюции систем CRISPR-Cas класса 2. Эффекторные белки из всех известных в настоящее время систем данного класса, по-видимому, произошли из группы мобильных генетических элементов, которые кодируют белки TnpB, содержащие RuvC-подобный домен. Последовательности RuvC-подобных доменов TnpB и гомологичных доменов эффекторных белков класса 2 являются слишком дивергировавшими, чтобы провести надежный филогенетический анализ. Несмотря на все это, похоже, что в случае Cas9, эффекторного белка систем II типа, можно с легкостью идентифицировать конкретного предка, а именно семейство TnpB-подобных белков, особенно распространенных у Cyanobacteria, которые демонстрируют относительно высокое сходство последовательностей с Cas9, и имеют общую с ним структуру полных доменов, а именно RuvC-подобного домена и нуклеазного домена HNH и мостиковой спирали с высоким содержанием аргинина (Chylinski, 2014) (фиг. 11, "Организация доменов у семейств класса 2"; фиг. 12, "Участки гомологии с TnpB у белков класса 2"). В отличие от Cas9 было невозможно проследить Cpf1 и C2c1 до конкретного семейства TnpB; при этом несмотря на консервативность всех мотивов, имеющих в центре каталитические остатки RuvC-подобных нуклеаз, для этих белков показано только ограниченное сходство с универсальными профилями TnpB. Однако, учитывая то, что C2c1p не проявляет обнаруживаемое сходство последовательности с Cpf1, содержит отличающиеся вставки между мотивами RuvC и явно неродственные N-концевые участки, представляется наиболее вероятным, что Cpf1 и C2c1 возникли независимо от различных семейств в пределах группы элементов, кодирующих TnpB.
Необычным является то, что белки TnpB кажутся "заранее разработанными" для использования в эффекторных комплексах CRISPR-Cas класса 2, вследствие чего они скорее всего вовлекались множество раз. Вполне возможно, что такая применимость белков TnpB относится к их прогнозируемой способности разрезать однонитевую ДНК, будучи связанными с молекулой РНК через мостиковую спираль с высоким содержанием R, которая, как было показано, в случае Cas9 связывает crRNA (Jinek, 2014; Nishimasu, 2014). Функции TnpB недостаточно понятны. Этот белок не требуется для транспозиции, и в одном случае, как было показано, подавляет транспозицию (Pasternak, 2013), но его механизм действия остается неизвестным. Экспериментальное изучение TnpB вероятно прольет свет на аспекты механизма действия систем CRISPR-Cas класса 2. Следует отметить, что механизмы действия Cpf1 и C2c1 могут быть сходны друг с другом, но их связывание значительно отличается от связывания Cas9, поскольку у первых двух белков отсутствует домен HNH, который у Cas9 отвечает за введение однонитевого разрыва в одну из нитей целевой ДНК (Gasiunas, 2012), (Jinek, 2012), (Chen, 2014). Соответственно, использование Cpf1 и C2c1 могло бы обеспечить дополнительные возможности для редактирования генома.
С точки зрения эволюции, примечательно, что CRISPR-Cas класса 2, по-видимому, полностью происходит от различных мобильных генетических элементов, с учетом недавнего доказательства вероятного происхождения генов cas1 от отдельного семейства транспозонов (Koonin, 2015; Krupovic, 2014). Кроме того, вероятное независимое происхождение эффекторных белков из различных семейств TnpB, вместе с различным филогенетическим родством соответствующих белков cas1, дает веские основания предполагать, что системы класса 2 возникали множество раз вследствие комбинации различных адаптационных модулей и происходящих из транспозонов нуклеаз, дающих эффекторные белки. Этот способ эволюции, по-видимому, является основным проявлением модульного принципа, который характерен для эволюции CRISPR-Cas (Makarova, 2015), при этом подразумевается, что дополнительные комбинации адаптационного и эффекторного модуля, вероятно, существуют в природе.
Предполагаемые системы CRISPR-Cas VI типа содержат прогнозируемый новый эффекторный белок, который содержит два прогнозируемых домена HEPN, которые, вероятно, обладают РНКазной активностью. Домены HEPN не являются частями эффекторных комплексов в других системах CRISPR-Cas, но вовлечены в целый ряд защитных функций, включая прогнозируемую вспомогательную роль в различных системах CRISPR-Cas (Anantharaman, 2013), (Makarova, 2015). Присутствие доменов HEPN в качестве каталитического фрагмента прогнозируемого эффекторного модуля, подразумевает то, что системы VI типа нацеливаются на мРНК и расщепляют ее. Ранее нацеливание на мРНК сообщалось для определенных систем CRISPR-Cas III типа (Hale, 2014; Hale, 2009), (Peng, 2015). Хотя домены HEPN до сих пор не были обнаружены в истинных мобильных генетических элементах, они характеризуются высокой степенью горизонтальной мобильности и являются важным компонентом мобильных элементов, таких как единицы токсин-антитоксин (Anantharaman, 2013). Таким образом, предполагаемые системы VI типа, по-видимому, соответствуют общей парадигме модульной эволюции CRISPR-Cas класса 2 из мобильных компонентов, и, как ожидается, дополнительные варианты и новые типы будут обнаружены с помощью анализа геномных и метагеномных данных.
Модульный принцип эволюции является ключевым признаком систем CRISPR-Cas. Этот способ эволюции, по-видимому, наиболее выражен у систем класса 2, которые возникли благодаря комбинации адаптационных модулей разных других систем CRISPR-Cas с эффекторными белками, которые, по-видимому, привлекались от мобильных элементов независимо множество раз. Учитывая чрезвычайное разнообразие мобильных элементов у бактерий, представляется возможным, что эффекторные модули систем CRISPR-Cas класса 2 также являются очень разнообразными. В данном документе заявители использовали простой компьютерный подход для разграничения двух новых вариантов систем CRISPR-Cas, но с очень большой вероятностью существуют геномы бактерий, которые еще не были подвергнуты секвенированию. Хотя ожидается, что большинство, если не все, из этих новых систем CRISPR-Cas являются редкими, они могут использовать новые стратегии и молекулярные механизмы и будут обеспечивать главный ресурс для новых применений в редактировании генома и биотехнологии.
Программу TBLASTN применяли для поиска в базе данных WGS от NCBI с применением профиля Cas1 в качестве запрашиваемой последовательности. Последовательности контигов или полных областей генома, в которых был идентифицирован хит Cas1, отыскивали в одной базе данных. Участок вокруг гена Cas1 вырезали и подвергали трансляции с применением GENMARK. Проводили поиск для каждого прогнозируемого белка в сравнении с набором профилей из базы данных CDD (Marchler-Bauer, 2009) и специфических профилей Cas, доступных на FTP, с приоритетом хитов с белками Cas. Разработанную ранее процедуру для идентификации полноты локусов CRISPR применяли в отношении каждого локуса.
CRISPRmap (Lange, 2013) применяли для классификации повторов.
Поиски итеративных профилей с помощью PSI-BLAST (Altschul, 1997) и отключенной статистике на основе состава и фильтре низкой сложности, применяли для поиска отдаленно похожих последовательностей в обеих неизбыточных (NR) базах данных от NCBI. Для каждого идентифицированного неизбыточного белка проводили поиск относительно WGS с применением программы TBLAST. HHpred, которую применяли с параметрами по умолчанию, применяли для идентификации отдаленного сходства последовательностей (Soding, 2005). Множественное выравнивание последовательностей разрабатывали с применением MUSCLE (Edgar, 2004). Вторичную структуру белка прогнозировали с применением Jpred 4 (Drozdetskiy, 2015).
Выбранные гены-кандидаты
ID гена: A; тип гена: C2C1; организм: 5. Opitutaceae bacterium TAV5; длина спейсера - мода (диапазон): 34 (от 33 до 37); DR1: GCCGCAGCGAAUGCCGUUUCACGAAUCGUCAGGCGG (SEQ ID NO: 27); DR2: отсутствует; tracrRNA1: GCUGGAGACGUUUUUUGAAACGGCGAGUGCUGCGGAUAGCGAGUUUCUCUUGGGGAGGCGCUCGCGGCCACUUUU (SEQ ID NO: 28); tracrRNA2: отсутствует; белковая последовательность: MSLNRIYQGRVAAVETGTALAKGNVEWMPAAGGDEVLWQHHELFQAAINYYLVALLALADKNNPVLGPLISQMDNPQSPYHVWGSFRRQGRQRTGLSQAVAPYITPGNNAPTLDEVFRSILAGNPTDRATLDAALMQLLKACDGAGAIQQEGRSYWPKFCDPDSTANFAGDPAMLRREQHRLLLPQVLHDPAITHDSPALGSFDTYSIATPDTRTPQLTGPKARARLEQAITLWRVRLPESAADFDRLASSLKKIPDDDSRLNLQGYVGSSAKGEVQARLFALLLFRHLERSSFTLGLLRSATPPPKNAETPPPAGVPLPAASAADPVRIARGKRSFVFRAFTSLPCWHGGDNIHPTWKSFDIAAFKYALTVINQIEEKTKERQKECAELETDFDYMHGRLAKIPVKYTTGEAEPPPILANDLRIPLLRELLQNIKVDTALTDGEAVSYGLQRRTIRGFRELRRIWRGHAPAGTVFSSELKEKLAGELRQFQTDNSTTIGSVQLFNELIQNPKYWPIWQAPDVETARQWADAGFADDPLAALVQEAELQEDIDALKAPVKLTPADPEYSRRQYDFNAVSKFGAGSRSANRHEPGQTERGHNTFTTEIAARNAADGNRWRATHVRIHYSAPRLLRDGLRRPDTDGNEALEAVPWLQPMMEALAPLPTLPQDLTGMPVFLMPDVTLSGERRILLNLPVTLEPAALVEQLGNAGRWQNQFFGSREDPFALRWPADGAVKTAKGKTHIPWHQDRDHFTVLGVDLGTRDAGALALLNVTAQKPAKPVHRIIGEADGRTWYASLADARMIRLPGEDARLFVRGKLVQEPYGERGRNASLLEWEDARNIILRLGQNPDELLGADPRRHSYPEINDKLLVALRRAQARLARLQNRSWRLRDLAESDKALDEIHAERAGEKPSPLPPLARDDAIKSTDEALLSQRDIIRRSFVQIANLILPLRGRRWEWRPHVEVPDCHILAQSDPGTDDTKRLVAGQRGISHERIEQIEELRRRCQSLNRALRHKPGERPVLGRPAKGEEIADPCPALLEKINRLRDQRVDQTAHAILAAALGVRLRAPSKDRAERRHRDIHGEYERFRAPADFVVIENLSRYLSSQDRARSENTRLMQWCHRQIVQKLRQLCETYGIPVLAVPAAYSSRFSSRDGSAGFRAVHLTPDHRHRMPWSRILARLKAHEEDGKRLEKTVLDEARAVRGLFDRLDRFNAGHVPGKPWRTLLAPLPGGPVFVPLGDATPMQADLNAAINIALRGIAAPDRHDIHHRLRAENKKRILSLRLGTQREKARWPGGAPAVTLSTPNNGASPEDSDALPERVSNLFVDIAGVANFERVTIEGVSQKFATGRGLWASVKQRAWNRVARLNETVTDNNRNEEEDDIPM (SEQ ID NO: 29)
ID гена: B; тип гена: C2C1; организм: 7. Bacillus thermoamylovorans штамм B4166; длина спейсера - мода (диапазон): 37 (35-38); DR1: GUCCAAGAAAAAAGAAAUGAUACGAGGCAUUAGCAC (SEQ ID NO: 30); DR2: отсутствует; tracrRNA1: CUGGACGAUGUCUCUUUUAUUUCUUUUUUCUUGGAUCUGAGUACGAGCACCCACAUUGGACAUUUCGCAUGGUGGGUGCUCGUACUAUAGGUAAAACAAACCUUUUU (SEQ ID NO: 31); tracrRNA2: отсутствует; белковая последовательность: MATRSFILKIEPNEEVKKGLWKTHEVLNHGIAYYMNILKLIRQEAIYEHHEQDPKNPKKVSKAEIQAELWDFVLKMQKCNSFTHEVDKDVVFNILRELYEELVPSSVEKKGEANQLSNKFLYPLVDPNSQSGKGTASSGRKPRWYNLKIAGDPSWEEEKKKWEEDKKKDPLAKILGKLAEYGLIPLFIPFTDSNEPIVKEIKWMEKSRNQSVRRLDKDMFIQALERFLSWESWNLKVKEEYEKVEKEHKTLEERIKEDIQAFKSLEQYEKERQEQLLRDTLNTNEYRLSKRGLRGWREIIQKWLKMDENEPSEKYLEVFKDYQRKHPREAGDYSVYEFLSKKENHFIWRNHPEYPYLYATFCEIDKKKKDAKQQATFTLADPINHPLWVRFEERSGSNLNKYRILTEQLHTEKLKKKLTVQLDRLIYPTESGGWEEKGKVDIVLLPSRQFYNQIFLDIEEKGKHAFTYKDESIKFPLKGTLGGARVQFDRDHLRRYPHKVESGNVGRIYFNMTVNIEPTESPVSKSLKIHRDDFPKFVNFKPKELTEWIKDSKGKKLKSGIESLEIGLRVMSIDLGQRQAAAASIFEVVDQKPDIEGKLFFPIKGTELYAVHRASFNIKLPGETLVKSREVLRKAREDNLKLMNQKLNFLRNVLHFQQFEDITEREKRVTKWISRQENSDVPLVYQDELIQIRELMYKPYKDWVAFLKQLHKRLEVEIGKEVKHWRKSLSDGRKGLYGISLKNIDEIDRTRKFLLRWSLRPTEPGEVRRLEPGQRFAIDQLNHLNALKEDRLKKMANTIIMHALGYCYDVRKKKWQAKNPACQIILFEDLSNYNPYEERSRFENSKLMKWSRREIPRQVALQGEIYGLQVGEVGAQFSSRFHAKTGSPGIRCSVVTKEKLQDNRFFKNLQREGRLTLDKIAVLKEGDLYPDKGGEKFISLSKDRKLVTTHADINAAQNLQKRFWTRTHGFYKVYCKAYQVDGQTVYIPESKDQKQKIIEEFGEGYFILKDGVYEWGNAGKLKIKKGSSKQSSSELVDSDILKDSFDLASELKGEKLMLYRDPSGNVFPSDKWMAAGVFFGKLERILISKLTNQYSISTIEDDSSKQSM (SEQ ID NO: 32)
ID гена: C; тип гена: C2C1; организм: 9. Bacillus sp. NSP2.1; длина спейсера - мода (диапазон): 36 (35-42); DR1: GUUCGAAAGCUUAGUGGAAAGCUUCGUGGUUAGCAC (SEQ ID NO: 33); DR2: отсутствует; tracrRNA1: CACGGAUAAUCACGACUUUCCACUAAGCUUUCGAAUUUUAUGAUGCGAGCAUCCUCUCAGGUCAAAAAA (SEQ ID NO: 34); tracrRNA2: отсутствует; белковая последовательность: MAIRSIKLKLKTHTGPEAQNLRKGIWRTHRLLNEGVAYYMKMLLLFRQESTGERPKEELQEELICHIREQQQRNQADKNTQALPLDKALEALRQLYELLVPSSVGQSGDAQIISRKFLSPLVDPNSEGGKGTSKAGAKPTWQKKKEANDPTWEQDYEKWKKRREEDPTASVITTLEEYGIRPIFPLYTNTVTDIAWLPLQSNQFVRTWDRDMLQQAIERLLSWESWNKRVQEEYAKLKEKMAQLNEQLEGGQEWISLLEQYEENRERELRENMTAANDKYRITKRQMKGWNELYELWSTFPASASHEQYKEALKRVQQRLRGRFGDAHFFQYLMEEKNRLIWKGNPQRIHYFVARNELTKRLEEAKQSATMTLPNARKHPLWVRFDARGGNLQDYYLTAEADKPRSRRFVTFSQLIWPSESGWMEKKDVEVELALSRQFYQQVKLLKNDKGKQKIEFKDKGSGSTFNGHLGGAKLQLERGDLEKEEKNFEDGEIGSVYLNVVIDFEPLQEVKNGRVQAPYGQVLQLIRRPNEFPKVTTYKSEQLVEWIKASPQHSAGVESLASGFRVMSIDLGLRAAAATSIFSVEESSDKNAADFSYWIEGTPLVAVHQRSYMLRLPGEQVEKQVMEKRDERFQLHQRVKFQIRVLAQIMRMANKQYGDRWDELDSLKQAVEQKKSPLDQTDRTFWEGIVCDLTKVLPRNEADWEQAVVQIHRKAEEYVGKAVQAWRKRFAADERKGIAGLSMWNIEELEGLRKLLISWSRRTRNPQEVNRFERGHTSHQRLLTHIQNVKEDRLKQLSHAIVMTALGYVYDERKQEWCAEYPACQVILFENLSQYRSNLDRSTKENSTLMKWAHRSIPKYVHMQAEPYGIQIGDVRAEYSSRFYAKTGTPGIRCKKVRGQDLQGRRFENLQKRLVNEQFLTEEQVKQLRPGDIVPDDSGELFMTLTDGSGSKEVVFLQADINAAHNLQKRFWQRYNELFKVSCRVIVRDEEEYLVPKTKSVQAKLGKGLFVKKSDTAWKDVYVWDSQAKLKGKTTFTEESESPEQLEDFQEIIEEAEEAKGTYRTLFRDPSGVFFPESVWYPQKDFWGEVKRKLYGKLRERFLTKAR (SEQ ID NO: 35)
ID гена: D; тип гена: C2C2; организм: 4. Lachnospiraceae bacterium NK4A144 G619; длина спейсера - мода (диапазон): 35; DR1: GUUUUGAGAAUAGCCCGACAUAGAGGGCAAUAGAC (SEQ ID NO: 36); DR2: GUUAUGAAAACAGCCCGACAUAGAGGGCAAUAGACA (SEQ ID NO: 37); tracrRNA1: отсутствует; tracrRNA2: отсутствует; белковая последовательность: MKISKVDHTRMAVAKGNQHRRDEISGILYKDPTKTGSIDFDERFKKLNCSAKILYHVFNGIAEGSNKYKNIVDKVNNNLDRVLFTGKSYDRKSIIDIDTVLRNVEKINAFDRISTEEREQIIDDLLEIQLRKGLRKGKAGLREVLLIGAGVIVRTDKKQEIADFLEILDEDFNKTNQAKNIKLSIENQGLVVSPVSRGEERIFDVSGAQKGKSSKKAQEKEALSAFLLDYADLDKNVRFEYLRKIRRLINLYFYVKNDDVMSLTEIPAEVNLEKDFDIWRDHEQRKEENGDFVGCPDILLADRDVKKSNSKQVKIAERQLRESIREKNIKRYRFSIKTIEKDDGTYFFANKQISVFWIHRIENAVERILGSINDKKLYRLRLGYLGEKVWKDILNFLSIKYIAVGKAVFNFAMDDLQEKDRDIEPGKISENAVNGLTSFDYEQIKADEMLQREVAVNVAFAANNLARVTVDIPQNGEKEDILLWNKSDIKKYKKNSKKGILKSILQFFGGASTWNMKMFEIAYHDQPGDYEENYLYDIIQIIYSLRNKSFHFKTYDHGDKNWNRELIGKMIEHDAERVISVEREKFHSNNLPMFYKDADLKKILDLLYSDYAGRASQVPAFNTVLVRKNFPEFLRKDMGYKVHFNNPEVENQWHSAVYYLYKEIYYNLFLRDKEVKNLFYTSLKNIRSEVSDKKQKLASDDFASRCEEIEDRSLPEICQIIMTEYNAQNFGNRKVKSQRVIEKNKDIFRHYKMLLIKTLAGAFSLYLKQERFAFIGKATPIPYETTDVKNFLPEWKSGMYASFVEEIKNNLDLQEWYIVGRFLNGRMLNQLAGSLRSYIQYAEDIERRAAENRNKLFSKPDEKIEACKKAVRVLDLCIKISTRISAEFTDYFDSEDDYADYLEKYLKYQDDAIKELSGSSYAALDHFCNKDDLKFDIYVNAGQKPILQRNIVMAKLFGPDNILSEVMEKVTESAIREYYDYLKKVSGYRVRGKCSTEKEQEDLLKFQRLKNAVEFRDVTEYAEVINELLGQLISWSYLRERDLLYFQLGFHYMCLKNKSFKPAEYVDIRRNNGTIIHNAILYQIVSMYINGLDFYSCDKEGKTLKPIETGKGVGSKIGQFIKYSQYLYNDPSYKLEIYNAGLEVFENIDEHDNITDLRKYVDHFKYYAYGNKMSLLDLYSEFFDRFFTYDMKYQKNVVNVLENILLRHFVIFYPKFGSGKKDVGIRDCKKERAQIEISEQSLTSEDFMFKLDDKAGEEAKKFPARDERYLQTIAKLLYYPNEIEDMNRFMKKGETINKKVQFNRKKKITRKQKNNSSNEVLSSTMGYLFKNIKL (SEQ ID NO: 38)
ID гена: E; тип гена: C2C2; организм: 8. Listeria seeligeri серовар 1/2b штамм SLCC3954; длина спейсера - мода (диапазон): 30; DR1: GUUUUAGUCCUCUUUCAUAUAGAGGUAGUCUCUUAC (SEQ ID NO: 39); DR2: отсутствует; tracrRNA1: AUGAAAAGAGGACUAAAACUGAAAGAGGACUAAAACACCAGAUGUGGAUAACUAUAUUAGUGGCUAUUAAAAAUUCGUCGAUAUUAGAGAGGAAACUUU (SEQ ID NO: 40); tracrRNA2: отсутствует; белковая последовательность: MWISIKTLIHHLGVLFFCDYMYNRREKKIIEVKTMRITKVEVDRKKVLISRDKNGGKLVYENEMQDNTEQIMHHKKSSFYKSVVNKTICRPEQKQMKKLVHGLLQENSQEKIKVSDVTKLNISNFLNHRFKKSLYYFPENSPDKSEEYRIEINLSQLLEDSLKKQQGTFICWESFSKDMELYINWAENYISSKTKLIKKSIRNNRIQSTESRSGQLMDRYMKDILNKNKPFDIQSVSEKYQLEKLTSALKATFKEAKKNDKEINYKLKSTLQNHERQIIEELKENSELNQFNIEIRKHLETYFPIKKTNRKVGDIRNLEIGEIQKIVNHRLKNKIVQRILQEGKLASYEIESTVNSNSLQKIKIEEAFALKFINACLFASNNLRNMVYPVCKKDILMIGEFKNSFKEIKHKKFIRQWSQFFSQEITVDDIELASWGLRGAIAPIRNEIIHLKKHSWKKFFNNPTFKVKKSKIINGKTKDVTSEFLYKETLFKDYFYSELDSVPELIINKMESSKILDYYSSDQLNQVFTIPNFELSLLTSAVPFAPSFKRVYLKGFDYQNQDEAQPDYNLKLNIYNEKAFNSEAFQAQYSLFKMVYYQVFLPQFTTNNDLFKSSVDFILTLNKERKGYAKAFQDIRKMNKDEKPSEYMSYIQSQLMLYQKKQEEKEKINHFEKFINQVFIKGFNSFIEKNRLTYICHPTKNTVPENDNIEIPFHTDMDDSNIAFWLMCKLLDAKQLSELRNEMIKFSCSLQSTEEISTFTKAREVIGLALLNGEKGCNDWKELFDDKEAWKKNMSLYVSEELLQSLPYTQEDGQTPVINRSIDLVKKYGTETILEKLFSSSDDYKVSAKDIAKLHEYDVTEKIAQQESLHKQWIEKPGLARDSAWTKKYQNVINDISNYQWAKTKVELTQVRHLHQLTIDLLSRLAGYMSIADRDFQFSSNYILERENSEYRVTSWILLSENKNKNKYNDYELYNLKNASIKVSSKNDPQLKVDLKQLRLTLEYLELFDNRLKEKRNNISHFNYLNGQLGNSILELFDDARDVLSYDRKLKNAVSKSLKEILSSHGMEVTFKPLYQTNHHLKIDKLQPKKIHHLGEKSTVSSNQVSNEYCQLVRTLLTMK (SEQ ID NO: 41)
ID гена: F; тип гена: C2C2; организм: 12. Leptotrichia wadei F0279; длина спейсера - мода (диапазон): 31; DR1: GUUUUAGUCCCCUUCGUUUUUGGGGUAGUCUAAAUC (SEQ ID NO: 42); DR2: отсутствует; tracrRNA1: GAUUUAGAGCACCCCAAAAGUAAUGAAAAUUUGCAAUUAAAUAAGGAAUAUUAAAAAAAUGUGAUUUUAAAAAAAUUGAAGAAAUUAAAUGAAAAAUUGUCCAAGUAAAAAAA (SEQ ID NO: 43); tracrRNA2: AUUUAGAUUACCCCUUUAAUUUAUUUUACCAUAUUUUUCUCAUAAUGCAAACUAAUAUUCCAAAAUUUUU (SEQ ID NO: 44); белковая последовательность: MGNLFGHKRWYEVRDKKDFKIKRKVKVKRNYDGNKYILNINENNNKEKIDNNKFIRKYINYKKNDNILKEFTRKFHAGNILFKLKGKEGIIRIENNDDFLETEEVVLYIEAYGKSEKLKALGITKKKIIDEAIRQGITKDDKKIEIKRQENEEEIEIDIRDEYTNKTLNDCSIILRIIENDELETKKSIYEIFKNINMSLYKIIEKIIENETEKVFENRYYEEHLREKLLKDDKIDVILTNFMEIREKIKSNLEILGFVKFYLNVGGDKKKSKNKKMLVEKILNINVDLTVEDIADFVIKELEFWNITKRIEKVKKVNNEFLEKRRNRTYIKSYVLLDKHEKFKIERENKKDKIVKFFVENIKNNSIKEKIEKILAEFKIDELIKKLEKELKKGNCDTEIFGIFKKHYKVNFDSKKFSKKSDEEKELYKIIYRYLKGRIEKILVNEQKVRLKKMEKIEIEKILNESILSEKILKRVKQYTLEHIMYLGKLRHNDIDMTTVNTDDFSRLHAKEELDLELITFFASTNMELNKIFSRENINNDENIDFFGGDREKNYVLDKKILNSKIKIIRDLDFIDNKNNITNNFIRKFTKIGTNERNRILHAISKERDLQGTQDDYNKVINIIQNLKISDEEVSKALNLDVVFKDKKNIITKINDIKISEENNNDIKYLPSFSKVLPEILNLYRNNPKNEPFDTIETEKIVLNALIYVNKELYKKLILEDDLEENESKNIFLQELKKTLGNIDEIDENIIENYYKNAQISASKGNNKAIKKYQKKVIECYIGYLRKNYEELFDFSDFKMNIQEIKKQIKDINDNKTYERITVKTSDKTIVINDDFEYIISIFALLNSNAVINKIRNRFFATSVWLNTSEYQNIIDILDEIMQLNTLRNECITENWNLNLEEFIQKMKEIEKDFDDFKIQTKKEIFNNYYEDIKNNILTEFKDDINGCDVLEKKLEKIVIFDDETKFEIDKKSNILQDEQRKLSNINKKDLKKKVDQYIKDKDQEIKSKILCRIIFNSDFLKKYKKEIDNLIEDMESENENKFQEIYYPKERKNELYIYKKNLFLNIGNPNFDKIYGLISNDIKMADAKFLFNIDGKNIRKNKISEIDAILKNLNDKLNGYSKEYKEKYIKKLKENDDFFAKNIQNKNYKSFEKDYNRVSEYKKIRDLVEFNYLNKIESYLIDINWKLAIQMARFERDMHYIVNGLRELGIIKLSGYNTGISRAYPKRNGSDGFYTTTAYYKFFDEESYKKFEKICYGFGIDLSENSEINKPENESIRNYISHFYIVRNPFADYSIAEQIDRVSNLLSYSTRYNNSTYASVFEVFKKDVNLDYDELKKKFKLIGNNDILERLMKPKKVSVLELESYNSDYIKNLIIELLTKIENTNDTL (SEQ ID NO: 45)
ID гена: G; тип гена: C2C2; организм: 14. Leptotrichia shahii DSM 19757 B031; длина спейсера - мода (диапазон): 30 (30-32); DR1: GUUUUAGUCCCCUUCGAUAUUGGGGUGGUCUAUAUC (SEQ ID NO: 46); DR2: отсутствует; tracrRNA1: AUUGAUGUGGUAUACUAAAAAUGGAAAAUUGUAUUUUUGAUUAGAAAGAUGUAAAAUUGAUUUAAUUUAAAAAUAUUUUAUUAGAUUAAAGUAGA (SEQ ID NO: 47); tracrRNA2: отсутствует; белковая последовательность: MSIYQEFVNKYSLSKTLRFELIPQGKTLENIKARGLILDDEKRAKDYKKAKQIIDKYHQFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSEKFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWTTYFKGFHENRKNVYSSNDIPTSIIYRIVDDNLPKFLENKAKYESLKDKAPEAINYEQIKKDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGENTKRKGINEYINLYSQQINDKTLKKYKMSVLFKQILSDTESKSFVIDKLEDDSDVVTTMQSFYEQIAAFKTVEEKSIKETLSLLFDDLKAQKLDLSKIYFKNDKSLTDLSQQVFDDYSVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDIDKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIKDLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYITQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFDDKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKNGSPQKGYEKFEFNIEDCRKFIDFYKQSISKHPEWKDFGFRFSDTQRYNSIDEFYREVENQGYKLTFENISESYIDSVVNQGKLYLFQIYNKDFSAYSKGRPNLHTLYWKALFDERNLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKRFTEDKFFFHCPITINFKSSGANKFNDEINLLLKEKANDVHILSIDRGERHLAYYTLVDGKGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQVVHEIAKLVIEYNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEFDKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESVSKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKNHNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQMRNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLGRIKNNQEGKKLNLVIKNEEYFEFVQNRNN (SEQ ID NO: 48)
ID гена: H; тип гена: Cpf1; организм: Francisella ularensis subsp. novicida U112; длина спейсера - мода (диапазон): 31; DR1: GUCUAAGAACUUUAAAUAAUUUCUACUGUUGUAGAU (SEQ ID NO: 49); DR2: отсутствует; tracrRNA1: AUCUACAAAAUUAUAAACUAAAUAAAGAUUCUUAUAAUAACUUUAUAUAUAAUCGAAAUGUAGAGAAUUUU (SEQ ID NO: 50); tracrRNA2: отсутствует; белковая последовательность: MSIYQEFVNKYSLSKTLRFELIPQGKTLENIKARGLILDDEKRAKDYKKAKQIIDKYHQFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSEKFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWTTYFKGFHENRKNVYSSNDIPTSIIYRIVDDNLPKFLENKAKYESLKDKAPEAINYEQIKKDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGENTKRKGINEYINLYSQQINDKTLKKYKMSVLFKQILSDTESKSFVIDKLEDDSDVVTTMQSFYEQIAAFKTVEEKSIKETLSLLFDDLKAQKLDLSKIYFKNDKSLTDLSQQVFDDYSVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDIDKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIKDLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYITQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFDDKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKNGSPQKGYEKFEFNIEDCRKFIDFYKQSISKHPEWKDFGFRFSDTQRYNSIDEFYREVENQGYKLTFENISESYIDSVVNQGKLYLFQIYNKDFSAYSKGRPNLHTLYWKALFDERNLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKRFTEDKFFFHCPITINFKSSGANKFNDEINLLLKEKANDVHILSIDRGERHLAYYTLVDGKGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQVVHEIAKLVIEYNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEFDKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESVSKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKNHNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQMRNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLGRIKNNQEGKKLNLVIKNEEYFEFVQNRNN (SEQ ID NO: 51)
Гены для синтеза
В случае генов от A до H следует провести оптимизацию для экспрессии у человека и добавить следующую последовательность ДНК к концу каждого гена. Следует обратить внимание, что эта последовательность ДНК содержит стоп-кодон (подчеркнут), поэтому не следует добавлять какой-либо стоп-кодон к кодон-оптимизированной последовательности гена: AAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGggatccTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAA (SEQ ID NO: 52).
В случае оптимизации следует избегать следующих сайтов рестрикции: BamHI, EcoRI, HindIII, BsmBI, BsaI, BbsI, AgeI, XhoI, NdeI, NotI, KpnI, BsrGI, SpeI, XbaI, NheI
Эти гены клонируют в простой вектор экспрессии для млекопитающих:
>A
MSLNRIYQGRVAAVETGTALAKGNVEWMPAAGGDEVLWQHHELFQAAINYYLVALLALADKNNPVLGPLISQMDNPQSPYHVWGSFRRQGRQRTGLSQAVAPYITPGNNAPTLDEVFRSILAGNPTDRATLDAALMQLLKACDGAGAIQQEGRSYWPKFCDPDSTANFAGDPAMLRREQHRLLLPQVLHDPAITHDSPALGSFDTYSIATPDTRTPQLTGPKARARLEQAITLWRVRLPESAADFDRLASSLKKIPDDDSRLNLQGYVGSSAKGEVQARLFALLLFRHLERSSFTLGLLRSATPPPKNAETPPPAGVPLPAASAADPVRIARGKRSFVFRAFTSLPCWHGGDNIHPTWKSFDIAAFKYALTVINQIEEKTKERQKECAELETDFDYMHGRLAKIPVKYTTGEAEPPPILANDLRIPLLRELLQNIKVDTALTDGEAVSYGLQRRTIRGFRELRRIWRGHAPAGTVFSSELKEKLAGELRQFQTDNSTTIGSVQLFNELIQNPKYWPIWQAPDVETARQWADAGFADDPLAALVQEAELQEDIDALKAPVKLTPADPEYSRRQYDFNAVSKFGAGSRSANRHEPGQTERGHNTFTTEIAARNAADGNRWRATHVRIHYSAPRLLRDGLRRPDTDGNEALEAVPWLQPMMEALAPLPTLPQDLTGMPVFLMPDVTLSGERRILLNLPVTLEPAALVEQLGNAGRWQNQFFGSREDPFALRWPADGAVKTAKGKTHIPWHQDRDHFTVLGVDLGTRDAGALALLNVTAQKPAKPVHRIIGEADGRTWYASLADARMIRLPGEDARLFVRGKLVQEPYGERGRNASLLEWEDARNIILRLGQNPDELLGADPRRHSYPEINDKLLVALRRAQARLARLQNRSWRLRDLAESDKALDEIHAERAGEKPSPLPPLARDDAIKSTDEALLSQRDIIRRSFVQIANLILPLRGRRWEWRPHVEVPDCHILAQSDPGTDDTKRLVAGQRGISHERIEQIEELRRRCQSLNRALRHKPGERPVLGRPAKGEEIADPCPALLEKINRLRDQRVDQTAHAILAAALGVRLRAPSKDRAERRHRDIHGEYERFRAPADFVVIENLSRYLSSQDRARSENTRLMQWCHRQIVQKLRQLCETYGIPVLAVPAAYSSRFSSRDGSAGFRAVHLTPDHRHRMPWSRILARLKAHEEDGKRLEKTVLDEARAVRGLFDRLDRFNAGHVPGKPWRTLLAPLPGGPVFVPLGDATPMQADLNAAINIALRGIAAPDRHDIHHRLRAENKKRILSLRLGTQREKARWPGGAPAVTLSTPNNGASPEDSDALPERVSNLFVDIAGVANFERVTIEGVSQKFATGRGLWASVKQRAWNRVARLNETVTDNNRNEEEDDIPM (SEQ ID NO: 53).
>B
MATRSFILKIEPNEEVKKGLWKTHEVLNHGIAYYMNILKLIRQEAIYEHHEQDPKNPKKVSKAEIQAELWDFVLKMQKCNSFTHEVDKDVVFNILRELYEELVPSSVEKKGEANQLSNKFLYPLVDPNSQSGKGTASSGRKPRWYNLKIAGDPSWEEEKKKWEEDKKKDPLAKILGKLAEYGLIPLFIPFTDSNEPIVKEIKWMEKSRNQSVRRLDKDMFIQALERFLSWESWNLKVKEEYEKVEKEHKTLEERIKEDIQAFKSLEQYEKERQEQLLRDTLNTNEYRLSKRGLRGWREIIQKWLKMDENEPSEKYLEVFKDYQRKHPREAGDYSVYEFLSKKENHFIWRNHPEYPYLYATFCEIDKKKKDAKQQATFTLADPINHPLWVRFEERSGSNLNKYRILTEQLHTEKLKKKLTVQLDRLIYPTESGGWEEKGKVDIVLLPSRQFYNQIFLDIEEKGKHAFTYKDESIKFPLKGTLGGARVQFDRDHLRRYPHKVESGNVGRIYFNMTVNIEPTESPVSKSLKIHRDDFPKFVNFKPKELTEWIKDSKGKKLKSGIESLEIGLRVMSIDLGQRQAAAASIFEVVDQKPDIEGKLFFPIKGTELYAVHRASFNIKLPGETLVKSREVLRKAREDNLKLMNQKLNFLRNVLHFQQFEDITEREKRVTKWISRQENSDVPLVYQDELIQIRELMYKPYKDWVAFLKQLHKRLEVEIGKEVKHWRKSLSDGRKGLYGISLKNIDEIDRTRKFLLRWSLRPTEPGEVRRLEPGQRFAIDQLNHLNALKEDRLKKMANTIIMHALGYCYDVRKKKWQAKNPACQIILFEDLSNYNPYEERSRFENSKLMKWSRREIPRQVALQGEIYGLQVGEVGAQFSSRFHAKTGSPGIRCSVVTKEKLQDNRFFKNLQREGRLTLDKIAVLKEGDLYPDKGGEKFISLSKDRKLVTTHADINAAQNLQKRFWTRTHGFYKVYCKAYQVDGQTVYIPESKDQKQKIIEEFGEGYFILKDGVYEWGNAGKLKIKKGSSKQSSSELVDSDILKDSFDLASELKGEKLMLYRDPSGNVFPSDKWMAAGVFFGKLERILISKLTNQYSISTIEDDSSKQSM (SEQ ID NO: 54).
>C
MAIRSIKLKLKTHTGPEAQNLRKGIWRTHRLLNEGVAYYMKMLLLFRQESTGERPKEELQEELICHIREQQQRNQADKNTQALPLDKALEALRQLYELLVPSSVGQSGDAQIISRKFLSPLVDPNSEGGKGTSKAGAKPTWQKKKEANDPTWEQDYEKWKKRREEDPTASVITTLEEYGIRPIFPLYTNTVTDIAWLPLQSNQFVRTWDRDMLQQAIERLLSWESWNKRVQEEYAKLKEKMAQLNEQLEGGQEWISLLEQYEENRERELRENMTAANDKYRITKRQMKGWNELYELWSTFPASASHEQYKEALKRVQQRLRGRFGDAHFFQYLMEEKNRLIWKGNPQRIHYFVARNELTKRLEEAKQSATMTLPNARKHPLWVRFDARGGNLQDYYLTAEADKPRSRRFVTFSQLIWPSESGWMEKKDVEVELALSRQFYQQVKLLKNDKGKQKIEFKDKGSGSTFNGHLGGAKLQLERGDLEKEEKNFEDGEIGSVYLNVVIDFEPLQEVKNGRVQAPYGQVLQLIRRPNEFPKVTTYKSEQLVEWIKASPQHSAGVESLASGFRVMSIDLGLRAAAATSIFSVEESSDKNAADFSYWIEGTPLVAVHQRSYMLRLPGEQVEKQVMEKRDERFQLHQRVKFQIRVLAQIMRMANKQYGDRWDELDSLKQAVEQKKSPLDQTDRTFWEGIVCDLTKVLPRNEADWEQAVVQIHRKAEEYVGKAVQAWRKRFAADERKGIAGLSMWNIEELEGLRKLLISWSRRTRNPQEVNRFERGHTSHQRLLTHIQNVKEDRLKQLSHAIVMTALGYVYDERKQEWCAEYPACQVILFENLSQYRSNLDRSTKENSTLMKWAHRSIPKYVHMQAEPYGIQIGDVRAEYSSRFYAKTGTPGIRCKKVRGQDLQGRRFENLQKRLVNEQFLTEEQVKQLRPGDIVPDDSGELFMTLTDGSGSKEVVFLQADINAAHNLQKRFWQRYNELFKVSCRVIVRDEEEYLVPKTKSVQAKLGKGLFVKKSDTAWKDVYVWDSQAKLKGKTTFTEESESPEQLEDFQEIIEEAEEAKGTYRTLFRDPSGVFFPESVWYPQKDFWGEVKRKLYGKLRERFLTKAR (SEQ ID NO: 55).
>D
MKISKVDHTRMAVAKGNQHRRDEISGILYKDPTKTGSIDFDERFKKLNCSAKILYHVFNGIAEGSNKYKNIVDKVNNNLDRVLFTGKSYDRKSIIDIDTVLRNVEKINAFDRISTEEREQIIDDLLEIQLRKGLRKGKAGLREVLLIGAGVIVRTDKKQEIADFLEILDEDFNKTNQAKNIKLSIENQGLVVSPVSRGEERIFDVSGAQKGKSSKKAQEKEALSAFLLDYADLDKNVRFEYLRKIRRLINLYFYVKNDDVMSLTEIPAEVNLEKDFDIWRDHEQRKEENGDFVGCPDILLADRDVKKSNSKQVKIAERQLRESIREKNIKRYRFSIKTIEKDDGTYFFANKQISVFWIHRIENAVERILGSINDKKLYRLRLGYLGEKVWKDILNFLSIKYIAVGKAVFNFAMDDLQEKDRDIEPGKISENAVNGLTSFDYEQIKADEMLQREVAVNVAFAANNLARVTVDIPQNGEKEDILLWNKSDIKKYKKNSKKGILKSILQFFGGASTWNMKMFEIAYHDQPGDYEENYLYDIIQIIYSLRNKSFHFKTYDHGDKNWNRELIGKMIEHDAERVISVEREKFHSNNLPMFYKDADLKKILDLLYSDYAGRASQVPAFNTVLVRKNFPEFLRKDMGYKVHFNNPEVENQWHSAVYYLYKEIYYNLFLRDKEVKNLFYTSLKNIRSEVSDKKQKLASDDFASRCEEIEDRSLPEICQIIMTEYNAQNFGNRKVKSQRVIEKNKDIFRHYKMLLIKTLAGAFSLYLKQERFAFIGKATPIPYETTDVKNFLPEWKSGMYASFVEEIKNNLDLQEWYIVGRFLNGRMLNQLAGSLRSYIQYAEDIERRAAENRNKLFSKPDEKIEACKKAVRVLDLCIKISTRISAEFTDYFDSEDDYADYLEKYLKYQDDAIKELSGSSYAALDHFCNKDDLKFDIYVNAGQKPILQRNIVMAKLFGPDNILSEVMEKVTESAIREYYDYLKKVSGYRVRGKCSTEKEQEDLLKFQRLKNAVEFRDVTEYAEVINELLGQLISWSYLRERDLLYFQLGFHYMCLKNKSFKPAEYVDIRRNNGTIIHNAILYQIVSMYINGLDFYSCDKEGKTLKPIETGKGVGSKIGQFIKYSQYLYNDPSYKLEIYNAGLEVFENIDEHDNITDLRKYVDHFKYYAYGNKMSLLDLYSEFFDRFFTYDMKYQKNVVNVLENILLRHFVIFYPKFGSGKKDVGIRDCKKERAQIEISEQSLTSEDFMFKLDDKAGEEAKKFPARDERYLQTIAKLLYYPNEIEDMNRFMKKGETINKKVQFNRKKKITRKQKNNSSNEVLSSTMGYLFKNIKL (SEQ ID NO: 56).
>E
MWISIKTLIHHLGVLFFCDYMYNRREKKIIEVKTMRITKVEVDRKKVLISRDKNGGKLVYENEMQDNTEQIMHHKKSSFYKSVVNKTICRPEQKQMKKLVHGLLQENSQEKIKVSDVTKLNISNFLNHRFKKSLYYFPENSPDKSEEYRIEINLSQLLEDSLKKQQGTFICWESFSKDMELYINWAENYISSKTKLIKKSIRNNRIQSTESRSGQLMDRYMKDILNKNKPFDIQSVSEKYQLEKLTSALKATFKEAKKNDKEINYKLKSTLQNHERQIIEELKENSELNQFNIEIRKHLETYFPIKKTNRKVGDIRNLEIGEIQKIVNHRLKNKIVQRILQEGKLASYEIESTVNSNSLQKIKIEEAFALKFINACLFASNNLRNMVYPVCKKDILMIGEFKNSFKEIKHKKFIRQWSQFFSQEITVDDIELASWGLRGAIAPIRNEIIHLKKHSWKKFFNNPTFKVKKSKIINGKTKDVTSEFLYKETLFKDYFYSELDSVPELIINKMESSKILDYYSSDQLNQVFTIPNFELSLLTSAVPFAPSFKRVYLKGFDYQNQDEAQPDYNLKLNIYNEKAFNSEAFQAQYSLFKMVYYQVFLPQFTTNNDLFKSSVDFILTLNKERKGYAKAFQDIRKMNKDEKPSEYMSYIQSQLMLYQKKQEEKEKINHFEKFINQVFIKGFNSFIEKNRLTYICHPTKNTVPENDNIEIPFHTDMDDSNIAFWLMCKLLDAKQLSELRNEMIKFSCSLQSTEEISTFTKAREVIGLALLNGEKGCNDWKELFDDKEAWKKNMSLYVSEELLQSLPYTQEDGQTPVINRSIDLVKKYGTETILEKLFSSSDDYKVSAKDIAKLHEYDVTEKIAQQESLHKQWIEKPGLARDSAWTKKYQNVINDISNYQWAKTKVELTQVRHLHQLTIDLLSRLAGYMSIADRDFQFSSNYILERENSEYRVTSWILLSENKNKNKYNDYELYNLKNASIKVSSKNDPQLKVDLKQLRLTLEYLELFDNRLKEKRNNISHFNYLNGQLGNSILELFDDARDVLSYDRKLKNAVSKSLKEILSSHGMEVTFKPLYQTNHHLKIDKLQPKKIHHLGEKSTVSSNQVSNEYCQLVRTLLTMK (SEQ ID NO: 57).
>F
MKVTKVDGISHKKYIEEGKLVKSTSEENRTSERLSELLSIRLDIYIKNPDNASEEENRIRRENLKKFFSNKVLHLKDSVLYLKNRKEKNAVQDKNYSEEDISEYDLKNKNSFSVLKKILLNEDVNSEELEIFRKDVEAKLNKINSLKYSFEENKANYQKINENNVEKVGGKSKRNIIYDYYRESAKRNDYINNVQEAFDKLYKKEDIEKLFFLIENSKKHEKYKIREYYHKIIGRKNDKENFAKIIYEEIQNVNNIKELIEKIPDMSELKKSQVFYKYYLDKEELNDKNIKYAFCHFVEIEMSQLLKNYVYKRLSNISNDKIKRIFEYQNLKKLIENKLLNKLDTYVRNCGKYNYYLQVGEIATSDFIARNRQNEAFLRNIIGVSSVAYFSLRNILETENENDITGRMRGKTVKNNKGEEKYVSGEVDKIYNENKQNEVKENLKMFYSYDFNMDNKNEIEDFFANIDEAISSIRHGIVHFNLELEGKDIFAFKNIAPSEISKKMFQNEINEKKLKLKIFKQLNSANVFNYYEKDVIIKYLKNTKFNFVNKNIPFVPSFTKLYNKIEDLRNTLKFFWSVPKDKEEKDAQIYLLKNIYYGEFLNKFVKNSKVFFKITNEVIKINKQRNQKTGHYKYQKFENIEKTVPVEYLAIIQSREMINNQDKEEKNTYIDFIQQIFLKGFIDYLNKNNLKYIESNNNNDNNDIFSKIKIKKDNKEKYDKILKNYEKHNRNKEIPHEINEFVREIKLGKILKYTENLNMFYLILKLLNHKELTNLKGSLEKYQSANKEETFSDELELINLLNLDNNRVTEDFELEANEIGKFLDFNENKIKDRKELKKFDTNKIYFDGENIIKHRAFYNIKKYGMLNLLEKIADKAKYKISLKELKEYSNKKNEIEKNYTMQQNLHRKYARPKKDEKFNDEDYKEYEKAIGNIQKYTHLKNKVEFNELNLLQGLLLKILHRLVGYTSIWERDLRFRLKGEFPENHYIEEIFNFDNSKNVKYKSGQIVEKYINFYKELYKDNVEKRSIYSDKKVKKLKQEKKDLYIRNYIAHFNYIPHAEISLLEVLENLRKLLSYDRKLKNAIMKSIVDILKEYGFVATFKIGADKKIEIQTLESEKIVHLKNLKKKKLMTDRNSEELCELVKVMFEYKALE (SEQ ID NO: 58).
>G
MGNLFGHKRWYEVRDKKDFKIKRKVKVKRNYDGNKYILNINENNNKEKIDNNKFIRKYINYKKNDNILKEFTRKFHAGNILFKLKGKEGIIRIENNDDFLETEEVVLYIEAYGKSEKLKALGITKKKIIDEAIRQGITKDDKKIEIKRQENEEEIEIDIRDEYTNKTLNDCSIILRIIENDELETKKSIYEIFKNINMSLYKIIEKIIENETEKVFENRYYEEHLREKLLKDDKIDVILTNFMEIREKIKSNLEILGFVKFYLNVGGDKKKSKNKKMLVEKILNINVDLTVEDIADFVIKELEFWNITKRIEKVKKVNNEFLEKRRNRTYIKSYVLLDKHEKFKIERENKKDKIVKFFVENIKNNSIKEKIEKILAEFKIDELIKKLEKELKKGNCDTEIFGIFKKHYKVNFDSKKFSKKSDEEKELYKIIYRYLKGRIEKILVNEQKVRLKKMEKIEIEKILNESILSEKILKRVKQYTLEHIMYLGKLRHNDIDMTTVNTDDFSRLHAKEELDLELITFFASTNMELNKIFSRENINNDENIDFFGGDREKNYVLDKKILNSKIKIIRDLDFIDNKNNITNNFIRKFTKIGTNERNRILHAISKERDLQGTQDDYNKVINIIQNLKISDEEVSKALNLDVVFKDKKNIITKINDIKISEENNNDIKYLPSFSKVLPEILNLYRNNPKNEPFDTIETEKIVLNALIYVNKELYKKLILEDDLEENESKNIFLQELKKTLGNIDEIDENIIENYYKNAQISASKGNNKAIKKYQKKVIECYIGYLRKNYEELFDFSDFKMNIQEIKKQIKDINDNKTYERITVKTSDKTIVINDDFEYIISIFALLNSNAVINKIRNRFFATSVWLNTSEYQNIIDILDEIMQLNTLRNECITENWNLNLEEFIQKMKEIEKDFDDFKIQTKKEIFNNYYEDIKNNILTEFKDDINGCDVLEKKLEKIVIFDDETKFEIDKKSNILQDEQRKLSNINKKDLKKKVDQYIKDKDQEIKSKILCRIIFNSDFLKKYKKEIDNLIEDMESENENKFQEIYYPKERKNELYIYKKNLFLNIGNPNFDKIYGLISNDIKMADAKFLFNIDGKNIRKNKISEIDAILKNLNDKLNGYSKEYKEKYIKKLKENDDFFAKNIQNKNYKSFEKDYNRVSEYKKIRDLVEFNYLNKIESYLIDINWKLAIQMARFERDMHYIVNGLRELGIIKLSGYNTGISRAYPKRNGSDGFYTTTAYYKFFDEESYKKFEKICYGFGIDLSENSEINKPENESIRNYISHFYIVRNPFADYSIAEQIDRVSNLLSYSTRYNNSTYASVFEVFKKDVNLDYDELKKKFKLIGNNDILERLMKPKKVSVLELESYNSDYIKNLIIELLTKIENTNDTL (SEQ ID NO: 59).
>H
MSIYQEFVNKYSLSKTLRFELIPQGKTLENIKARGLILDDEKRAKDYKKAKQIIDKYHQFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSEKFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWTTYFKGFHENRKNVYSSNDIPTSIIYRIVDDNLPKFLENKAKYESLKDKAPEAINYEQIKKDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGENTKRKGINEYINLYSQQINDKTLKKYKMSVLFKQILSDTESKSFVIDKLEDDSDVVTTMQSFYEQIAAFKTVEEKSIKETLSLLFDDLKAQKLDLSKIYFKNDKSLTDLSQQVFDDYSVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDIDKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIKDLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYITQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFDDKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKNGSPQKGYEKFEFNIEDCRKFIDFYKQSISKHPEWKDFGFRFSDTQRYNSIDEFYREVENQGYKLTFENISESYIDSVVNQGKLYLFQIYNKDFSAYSKGRPNLHTLYWKALFDERNLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKRFTEDKFFFHCPITINFKSSGANKFNDEINLLLKEKANDVHILSIDRGERHLAYYTLVDGKGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQVVHEIAKLVIEYNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEFDKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESVSKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKNHNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQMRNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLGRIKNNQEGKKLNLVIKNEEYFEFVQNRNN (SEQ ID NO: 60).
В случае от A-локуса до G-локуса эти гены клонировали и вставляли в низкокопийную плазмиду. Применяли вектор, который не содержит ген устойчивости Amp.
>A-локус
TATCCGGTCGAATCGAGAATGACGACCGCTACGTCTTGGACTACGAAGCCGTGGCCCTTGCCGATGCTCTCGGTGTGGATGTTGCCGACCTGTTCCGCAAGATCGATTGCCCCAAGAACCTGCTGCGCAGGCGGGCAGGGTAGGGGAGCGGTTTCCGGCGGAGATTTTCGGAGGCGCCGGTAACGTTATGTCGGGGAATTTGCTATACATCGACGATAATTAGTTTTGTTGATTCAGGATCGAAATGCGCTCAAACAAAGAACGTTCCGCGTTTCCCTCATGCGCTACTACGCCCACACCGCCATCTTTCGGCACGCAAACAAAGCAGATGGGTTGCCTGTCAATGGGTGATCATTGCCTGAAGTTACCATCCATCAATAATATAAATCATCCTTACTCCGAATGTCCCTCAATCGCATCTATCAAGGCCGCGTGGCGGCCGTCGAAACAGGAACGGCCTTAGCGAAAGGTAATGTCGAATGGATGCCTGCCGCAGGAGGCGACGAAGTTCTCTGGCAGCACCACGAACTTTTCCAAGCTGCCATCAACTACTATCTCGTCGCCCTGCTCGCACTCGCCGACAAAAACAATCCCGTACTTGGCCCGCTGATCAGCCAGATGGATAATCCCCAAAGCCCTTACCATGTCTGGGGAAGTTTCCGCCGCCAAGGACGTCAGCGCACAGGTCTCAGTCAAGCCGTTGCACCTTATATCACGCCGGGCAATAACGCTCCCACCCTTGACGAAGTTTTCCGCTCCATTCTTGCGGGCAACCCAACCGACCGCGCAACTTTGGACGCTGCACTCATGCAATTGCTCAAGGCTTGTGACGGCGCGGGCGCTATCCAGCAGGAAGGTCGTTCCTACTGGCCCAAATTCTGCGATCCTGACTCCACTGCCAACTTCGCGGGAGATCCGGCCATGCTCCGGCGTGAACAACACCGCCTCCTCCTTCCGCAAGTTCTCCACGATCCGGCGATTACTCACGACAGTCCTGCCCTTGGCTCGTTCGACACTTATTCGATTGCTACCCCCGACACCAGAACTCCTCAACTCACCGGCCCCAAGGCACGCGCCCGTCTTGAGCAGGCGATCACCCTCTGGCGCGTCCGTCTTCCCGAATCGGCTGCTGACTTCGATCGCCTTGCCAGTTCCCTCAAAAAAATTCCGGACGACGATTCTCGCCTTAACCTTCAGGGCTACGTCGGCAGCAGTGCGAAAGGCGAAGTTCAGGCCCGTCTTTTCGCCCTTCTGCTATTCCGTCACCTGGAGCGTTCCTCCTTTACGCTTGGCCTTCTCCGTTCCGCCACCCCGCCGCCCAAGAACGCTGAAACACCTCCTCCCGCCGGCGTTCCTTTACCTGCGGCGTCCGCAGCCGATCCGGTGCGGATAGCCCGTGGCAAACGCAGTTTTGTTTTTCGCGCATTCACCAGTCTCCCCTGCTGGCATGGCGGTGATAACATCCATCCCACCTGGAAGTCATTCGACATCGCAGCGTTCAAATATGCCCTCACGGTCATCAACCAGATCGAGGAAAAGACGAAAGAACGCCAAAAAGAATGTGCGGAACTTGAAACTGATTTCGACTACATGCACGGACGGCTCGCCAAGATTCCGGTAAAATACACGACCGGCGAAGCCGAACCGCCCCCCATTCTCGCAAACGATCTCCGCATCCCCCTCCTCCGCGAACTTCTCCAGAATATCAAGGTCGACACCGCACTCACCGATGGCGAAGCCGTCTCCTATGGTCTCCAACGCCGCACCATTCGCGGTTTCCGCGAGCTGCGCCGCATCTGGCGCGGCCATGCCCCCGCTGGCACGGTCTTTTCCAGCGAGTTGAAAGAAAAACTAGCCGGCGAACTCCGCCAGTTCCAGACCGACAACTCCACCACCATCGGCAGCGTCCAACTCTTCAACGAACTCATCCAAAACCCGAAATACTGGCCCATCTGGCAGGCTCCTGACGTCGAAACCGCCCGCCAATGGGCCGATGCCGGTTTTGCCGACGATCCGCTCGCCGCCCTTGTGCAAGAAGCCGAACTCCAGGAAGACATCGACGCCCTCAAGGCTCCAGTCAAACTCACTCCGGCCGATCCTGAGTATTCAAGAAGGCAATACGATTTCAATGCCGTCAGCAAATTCGGGGCCGGCTCCCGCTCCGCCAATCGCCACGAACCCGGGCAGACGGAGCGCGGCCACAACACCTTTACCACCGAAATCGCCGCCCGTAACGCGGCGGACGGGAACCGCTGGCGGGCAACCCACGTCCGCATCCATTACTCCGCTCCCCGCCTTCTTCGTGACGGACTCCGCCGACCTGACACCGACGGCAACGAAGCCCTGGAAGCCGTCCCTTGGCTCCAGCCCATGATGGAAGCCCTCGCCCCTCTCCCGACGCTTCCGCAAGACCTCACAGGCATGCCGGTCTTCCTCATGCCCGACGTCACCCTTTCCGGTGAGCGTCGCATCCTCCTCAATCTTCCTGTCACCCTCGAACCAGCCGCTCTTGTCGAACAACTGGGCAACGCCGGTCGCTGGCAAAACCAGTTCTTCGGCTCCCGCGAAGATCCATTCGCTCTCCGATGGCCCGCCGACGGTGCTGTAAAAACCGCCAAGGGGAAAACCCACATACCTTGGCACCAGGACCGCGATCACTTCACCGTACTCGGCGTGGATCTCGGCACGCGCGATGCCGGGGCGCTCGCTCTTCTCAACGTCACTGCGCAAAAACCGGCCAAGCCGGTCCACCGCATCATTGGTGAGGCCGACGGACGCACCTGGTATGCCAGCCTTGCCGACGCTCGCATGATCCGCCTGCCCGGGGAGGATGCCCGGCTCTTTGTCCGGGGAAAACTCGTTCAGGAACCCTATGGTGAACGCGGGCGAAACGCGTCTCTTCTCGAATGGGAAGACGCCCGCAATATCATCCTTCGCCTTGGCCAAAATCCCGACGAACTCCTCGGCGCCGATCCCCGGCGCCATTCGTATCCGGAAATAAACGATAAACTTCTCGTCGCCCTTCGCCGCGCTCAGGCCCGTCTTGCCCGTCTCCAGAACCGGAGCTGGCGGTTGCGCGACCTTGCAGAATCGGACAAGGCCCTTGATGAAATCCATGCCGAGCGTGCCGGGGAGAAGCCTTCTCCGCTTCCGCCCTTGGCTCGCGACGATGCCATCAAAAGCACCGACGAAGCCCTCCTTTCCCAGCGTGACATCATCCGGCGATCCTTCGTTCAGATCGCCAACTTGATCCTTCCCCTTCGCGGACGCCGATGGGAATGGCGGCCCCATGTCGAGGTCCCGGATTGCCACATCCTTGCGCAGAGCGATCCCGGTACGGATGACACCAAGCGTCTTGTCGCCGGACAACGCGGCATCTCTCACGAGCGTATCGAGCAAATCGAAGAACTCCGTCGTCGCTGCCAATCCCTCAACCGTGCCCTGCGTCACAAACCCGGAGAGCGTCCCGTGCTCGGACGCCCCGCCAAGGGCGAGGAAATCGCCGATCCCTGTCCCGCGCTCCTCGAAAAGATCAACCGTCTCCGGGACCAGCGCGTTGACCAAACCGCGCATGCCATCCTCGCCGCCGCTCTCGGTGTTCGACTCCGCGCCCCCTCAAAAGACCGCGCCGAACGCCGCCATCGCGACATCCATGGCGAATACGAACGCTTTCGTGCGCCCGCTGATTTTGTCGTCATCGAAAACCTCTCCCGTTATCTCAGCTCGCAGGATCGTGCTCGTAGTGAAAACACCCGTCTCATGCAGTGGTGCCATCGCCAGATCGTGCAAAAACTCCGTCAGCTCTGCGAGACCTACGGCATCCCCGTCCTCGCCGTCCCGGCGGCCTACTCATCGCGTTTTTCTTCCCGGGACGGCTCGGCCGGATTCCGGGCCGTCCATCTGACACCGGACCACCGTCACCGGATGCCATGGAGCCGCATCCTCGCCCGCCTCAAGGCCCACGAGGAAGACGGAAAAAGACTCGAAAAGACGGTGCTCGACGAGGCTCGCGCCGTCCGGGGACTCTTTGACCGGCTCGACCGGTTCAACGCCGGGCATGTCCCGGGAAAACCTTGGCGCACGCTCCTCGCGCCGCTCCCCGGCGGCCCTGTGTTTGTCCCCCTCGGGGACGCCACACCCATGCAGGCCGATCTGAACGCCGCCATCAACATCGCCCTCCGGGGCATCGCGGCTCCCGACCGCCACGACATCCATCACCGGCTCCGTGCCGAAAACAAAAAACGCATCCTGAGCTTGCGTCTCGGCACTCAGCGCGAGAAAGCCCGCTGGCCTGGAGGAGCTCCGGCGGTGACACTCTCCACTCCGAACAACGGCGCCTCTCCCGAAGATTCCGATGCGTTGCCCGAACGGGTATCCAACCTGTTTGTGGACATCGCCGGTGTCGCCAACTTCGAGCGAGTCACGATCGAAGGAGTCTCGCAAAAATTCGCCACCGGGCGTGGCCTTTGGGCCTCCGTCAAGCAACGTGCATGGAACCGCGTTGCCAGACTCAACGAGACAGTAACAGATAACAACAGGAACGAAGAGGAGGACGACATTCCGATGTAACCATTGCTTCATTACATCTGAGTCTCCCCTCAATCCCTCTGCCCCATGCGTGATATAACCTCCACCTCATGTCCCGGATCGGCGCCGGCAACCTGTAGTTCCCTTCCATCCTCCAACACTCCCGCAGATCGCGATCCGCTGCCGCCGATGCCGGTGCGCCGCCTTCACAACTATCTCTACTGTCCGCGGCTTTTTTATCTCCAGTGGGTCGAGAATCTCTTTGAGGAAAATGCCGACACCATTGCCGGCAGCGCCGTGCATCGTCACGCCGACAAACCTACGCGTTACGATGATGAAAAAGCCGAGGCACTTCGCACTGGTCTCCCTGAAGGCGCGCACATACGCAGCCTTCGCCTGGAAAACGCCCAACTCGGTCTCGTTGGCGTGGTGGATATCGTGGAGGGAGGCCCCGACGGACTCGAACTCGTCGACTACAAAAAAGGTTCCGCCTTCCGCCTCGACGACGGCACGCTCGCTCCCAAGGAAAACGACACCGTGCAACTTGCCGCCTACGCTCTTCTCCTGGCTGCCGATGGTGCGCGCGTTGCGCCCATGGCGACGGTCTATTACGCTGCCGATCGCCGGCGTGTCACCTTCCCGCTCGATGACGCCCTCTACGCCCGCACCCGTTCCGCCCTCGAAGAGGCCCGCGCCGTTGCAACCTCGGGGCGCATACCTCCGCCGCTCGTCTCTGACGTCCGCTGCCTCCATTGTTCCTCCTATGCGCTTTGCCTTCCCCGCGAGTCCGCCTGGTGGTGCCGCCATCGCAGCACGCCGCGGGGAGCCGGCCACACCCCCATGTTGCCGGGCTTTGAGGATGACGCCGCCGCCATTCACCAAATCTCCGAACCTGACACCGAGCCACCACCCGATCTTGCCAGCCAGCCTCCCCGTCCCCCGCGGCTCGATGGAGAATTGTTGGTTGTCCAGACTCCGGGAGCGATGATCGGACAAAGCGGCGGTGAGTTTACCGTGTCCGTCAAGGGTGAGGTTTTGCGCAAGCTTCCGGTTCATCAACTCCGGGCCATTTACGTTTACGGAGCCGTGCAACTCACGGCGCATGCTGTGCAGACCGCCCTTGAGGAGGATATCGACGTCTCCTATTTTGCGCCCAGCGGCCGCTTTCTTGGCCTCCTCCGCGGCCTGCCCGCATCCGGCGTGGATGCGCGTCTCGGGCAATACACCCTGTTTCGCGAACCCTTTGGCCGTCTCCGTCTCGCCTGCGAGGCGATTCGGGCCAAGATCCATAACCAGCGCGTCCTCCTCATGCGTAACGGCGAGCCCGGGGAGGGCGTCTTGCGCGAACTCGCCCGTCTGCGCGACGCCACCAGTGAGGCGACTTCGCTCGACGAACTCCTCGGCATCGAGGGCATCGCCGCGCATTTCTATTTCCAGTATTTTCCCACCATGCTGAAAGAACGGGCGGCCTGGGCCTTTGATTTTTCCGGACGCAATCGCCGCCCGCCGCGCGACCCGGTCAACGCCCTGCTTTCGTTCGGTTACAGCGTGTTGTCCAAGGAACTTGCCGGCGTCTGCCACGCTGTTGGCCTAGACCCGTTTTTCGGCTTCATGCACCAGCCGCGTTACGGGCGCCCCGCACTCGCTCTCGATCTGATGGAGGAGTTTCGCCCTCTCATCGCCGACAGTGTTGCCCTGAATCTCATCAACCGTGGCGAACTCGACGAAGGGGACTTTATCCGGTCGGCCAATGGCACCGCGCTCAATGATCGGGGCCGCCGGCGTTTTTGGGAGGCATGGTTCCGGCGTCTCGACAGCGAAGTCAGCCATCCTGAATTTGGTTACAAGATGAGCTATCGACGGATGCTTGAAGTGCAGGCGCGCCAGCTATGGCGCTATGTGCGCGGTGACGCCTTCCGCTACCACGGATTCACCACCCGTTGATTCCGATGTCAGATCCCCGCCGCCGTTATCTTGTGTGTTACGACATCGCCAATCCGAAGCGATTGCGCCAAGTGGCCAAGCTGCTGGAGAGCTATGGCACGCGTCTGCAATACTCGGTTTTCGAATGTCCTTTGGACGATCTTCGTCTTGAACAGGCGAAGGCTGATTTGCGCGACACGATTAATGCCGACCAAGACCAGGTGTTATTTGTTTCGCTTGGCCCCGAAGCCAACGATGCCACGTTGATCATCGCCACGCTTGGGCTCCCTTATACCGTGCGCTCGCGAGTGACGATTATCTGACCCATAACCCACGTGTTGAAGAGGCTGAAAACAGACGGACCTCTATGAAGAACAATTGACGTTTTGGCCGAACTCAGCAGACCTTTATGCGGCTAAGGCCAATGATCATCCATCCTACCGCCATTGGGCTGGAGACGTTTTTTGAAACGGCGAGTGCTGCGGATAGCGAGTTTCTCTTGGGGAGGCGCTCGCGGCCACTTTTACAGAGGAGATGTTCGGGCGAACTGGCCGACCTAACAAGGCGTACCCGGCTCAAAATCGAGGCACGCTCGCACGGGATGATGTAATTCGTTGTTTTTCAGCATACCGTGCGAGCACGGGCCGCAGCGAATGCCGTTTCACGAATCGTCAGGCGGCGGGGAGAAGTCATTTAATAAGGCCACTGTTAAAAGCCGCAGCGAATGCCGTTTCACGAATCGTCAGGCGGGCAGTGGATGTTTTTCCATGAGGCGAAGAATTTCATCGCCGCAGTGAATGCCGTTTCACCATTGATGAAGAATGCGAGGTGAAAACAGAGAAATTGGGTCAACTCTATCACTCTTATTCAGCCATCGTTTCAAGAAAGGATACCTCGTATTGGATACAACACAGCTCGTTCGTTCTCTCTACCTCCCTCGACAATCTCAAGGA (SEQ ID NO: 61).
>B-локус
TAATAAAATTGAAATATCACTATGGATTATTGTAATATTACCATAAAGATAGGTGACGTTTTTTTGAAAATTGTAAACCTAATTTGAAGAAAACCAATTAAAAATCGCTTCGGCTTTTTTTTAAGTGCCAGGTAGCATTGATGCTAACCCATGTGTAATAAAGGTTTGTTTTCCTTCGGGGCACGAACACATTATAAGGGAAACCTAAAGATTCCCTTTCTTGTTTAATATTATAACCAGTGAAAATAAGAATAATGCACCTAAAACTAATATACAGAAAATAAGAATTAAAAGTACTAATATATACATCATATGTTATCCTCCAATGCTTTATTTTTTAATAATTGATGTTAGTATTAGTTTTATTTTAATTTCTAAACATAAGAATTTGAAAAGGATGTGTTTATTATGGCGACACGCAGTTTTATTTTAAAAATTGAACCAAATGAAGAAGTTAAAAAGGGATTATGGAAGACGCATGAGGTATTGAATCATGGAATTGCCTACTACATGAATATTCTGAAACTAATTAGACAGGAAGCTATTTATGAACATCATGAACAAGATCCTAAAAATCCGAAAAAAGTTTCAAAAGCAGAAATACAAGCCGAGTTATGGGATTTTGTTTTAAAAATGCAAAAATGTAATAGTTTTACACATGAAGTTGACAAAGATGTTGTTTTTAACATCCTGCGTGAACTATATGAAGAGTTGGTCCCTAGTTCAGTCGAGAAAAAGGGTGAAGCCAATCAATTATCGAATAAGTTTCTGTACCCGCTAGTTGATCCGAACAGTCAAAGTGGGAAAGGGACGGCATCATCCGGACGTAAACCTCGGTGGTATAATTTAAAAATAGCAGGCGACCCATCGTGGGAGGAAGAAAAGAAAAAATGGGAAGAGGATAAAAAGAAAGATCCCCTTGCTAAAATCTTAGGTAAGTTAGCAGAATATGGGCTTATTCCGCTATTTATTCCATTTACTGACAGCAACGAACCAATTGTAAAAGAAATTAAATGGATGGAAAAAAGTCGTAATCAAAGTGTCCGGCGACTTGATAAGGATATGTTTATCCAAGCATTAGAGCGTTTTCTTTCATGGGAAAGCTGGAACCTTAAAGTAAAGGAAGAGTATGAAAAAGTTGAAAAGGAACACAAAACACTAGAGGAAAGGATAAAAGAGGACATTCAAGCATTTAAATCCCTTGAACAATATGAAAAAGAACGGCAGGAGCAACTTCTTAGAGATACATTGAATACAAATGAATACCGATTAAGCAAAAGAGGATTACGTGGTTGGCGTGAAATTATCCAAAAATGGCTAAAGATGGATGAAAATGAACCATCAGAAAAATATTTAGAAGTATTTAAAGATTATCAACGGAAACATCCACGAGAAGCCGGGGACTATTCTGTCTATGAATTTTTAAGCAAGAAAGAAAATCATTTTATTTGGCGAAATCATCCTGAATATCCTTATTTGTATGCTACATTTTGTGAAATTGACAAAAAAAAGAAAGACGCTAAGCAACAGGCAACTTTTACTTTGGCTGACCCGATTAACCATCCGTTATGGGTACGATTTGAAGAAAGAAGCGGTTCGAACTTAAACAAATATCGAATTTTAACAGAGCAATTACACACTGAAAAGTTAAAAAAGAAATTAACAGTTCAACTTGATCGTTTAATTTATCCAACTGAATCCGGCGGTTGGGAGGAAAAAGGTAAAGTAGATATCGTTTTGTTGCCGTCAAGACAATTTTATAATCAAATCTTCCTTGATATAGAAGAAAAGGGGAAACATGCTTTTACTTATAAGGATGAAAGTATTAAATTCCCCCTTAAAGGTACACTTGGTGGTGCAAGAGTGCAGTTTGACCGTGACCATTTGCGGAGATATCCGCATAAAGTAGAATCAGGAAATGTTGGACGGATTTATTTTAACATGACAGTAAATATTGAACCAACTGAGAGCCCTGTTAGTAAGTCTTTGAAAATACATAGGGACGATTTCCCCAAGTTCGTTAATTTTAAACCGAAAGAGCTCACCGAATGGATAAAAGATAGTAAAGGGAAAAAATTAAAAAGTGGTATAGAATCCCTTGAAATTGGTCTACGGGTGATGAGTATCGACTTAGGTCAACGTCAAGCGGCTGCTGCATCGATTTTTGAAGTAGTTGATCAGAAACCGGATATTGAAGGGAAGTTATTTTTTCCAATCAAAGGAACTGAGCTTTATGCTGTTCACCGGGCAAGTTTTAACATTAAATTACCGGGTGAAACATTAGTAAAATCACGGGAAGTATTGCGGAAAGCTCGGGAGGACAACTTAAAATTAATGAATCAAAAGTTAAACTTTCTAAGAAATGTTCTACATTTCCAACAGTTTGAAGATATCACAGAAAGAGAGAAGCGTGTAACTAAATGGATTTCTAGACAAGAAAATAGTGATGTTCCTCTTGTATATCAAGATGAGCTAATTCAAATTCGTGAATTAATGTATAAACCCTATAAAGATTGGGTTGCCTTTTTAAAACAACTCCATAAACGGCTAGAAGTCGAGATTGGCAAAGAGGTTAAGCATTGGCGAAAATCATTAAGTGACGGGAGAAAAGGTCTTTACGGAATCTCCCTAAAAAATATTGATGAAATTGATCGAACAAGGAAATTCCTTTTAAGATGGAGCTTACGTCCAACAGAACCTGGGGAAGTAAGACGCTTGGAACCAGGACAGCGTTTTGCGATTGATCAATTAAACCACCTAAATGCATTAAAAGAAGATCGATTAAAAAAGATGGCAAATACGATTATCATGCATGCCTTAGGTTACTGTTATGATGTAAGAAAGAAAAAGTGGCAGGCAAAAAATCCAGCATGTCAAATTATTTTATTTGAAGATTTATCTAACTACAATCCTTACGAGGAAAGGTCCCGTTTTGAAAACTCAAAACTGATGAAGTGGTCACGGAGAGAAATTCCACGACAAGTCGCCTTACAAGGTGAAATTTACGGATTACAAGTTGGGGAAGTAGGTGCCCAATTCAGTTCAAGATTCCATGCGAAAACCGGGTCGCCGGGAATTCGTTGCAGTGTTGTAACGAAAGAAAAATTGCAGGATAATCGCTTTTTTAAAAATTTACAAAGAGAAGGACGACTTACTCTTGATAAAATCGCAGTTTTAAAAGAAGGAGACTTATATCCAGATAAAGGTGGAGAAAAGTTTATTTCTTTATCAAAGGATCGAAAGTTGGTAACTACGCATGCTGATATTAACGCGGCCCAAAATTTACAGAAGCGTTTTTGGACAAGAACACATGGATTTTATAAAGTTTACTGCAAAGCCTATCAGGTTGATGGACAAACTGTTTATATTCCGGAGAGCAAGGACCAAAAACAAAAAATAATTGAAGAATTTGGGGAAGGCTATTTTATTTTAAAAGATGGTGTATATGAATGGGGTAATGCGGGGAAACTAAAAATTAAAAAAGGTTCCTCTAAACAATCATCGAGTGAATTAGTAGATTCGGACATACTGAAAGATTCATTTGATTTAGCAAGTGAACTTAAGGGAGAGAAACTCATGTTATATCGAGATCCGAGTGGAAACGTATTTCCTTCCGACAAGTGGATGGCAGCAGGAGTATTTTTTGGCAAATTAGAAAGAATATTGATTTCTAAGTTAACAAATCAATACTCAATATCAACAATAGAAGATGATTCTTCAAAACAATCAATGTAAAAGTTTGCCCGTATAAGAACTTAATTAATTAGGATGGTAGGATGTTACTAAATATGTCTGTAGGCATCATTCCTACTATCCGTTTTGTCCGAATATCAGAGCATTAGGTGAGGAATGGTAAGAAAGGAAAATTTATATGAACCAACCGATTCCTATTCGAATGTTAAATGAAATACAATATTGTGAGCGACTTTTTTACTTTATGCATGTCCAAAAGCTATTTGATGAGAATGCAGATACAGTTGAAGGAAGTGCACAGCATGAGCGGGCAGAAAGAAGCAAAAGACCAAGTAAAATGGGACCAAAGGAATTATGGGGTGAGGCGCCAAGAAGTCTTAAGCTTGGTGATGAGCTGTTAAATATTACCGGTGTTCTTGATGCCATAAGTCATGAAGAGAACAGTTGGATCCCGGTTGAATCAAAACACAGTTCCGCACCGGATGGATTGAACCCTTTTAAAGTAGATGGCTTTCTACTTGACGGGTCTGCATGGCCAAACGATCAAATTCAACTTTGTGCACAAGGCTTGCTCTTGAATGCCAATGGATACCCGTGTGATTATGGGTATTTATTTTATCGTGGTAATAAGAAAAAGGTGAAAATTTATTTTACTGAAGATTTAATCGCTGCCACAAAGTACTATATTAAAAAAGCACACGAGATACTAGTATTATCTGGTGATGAATCAGCTATTCCTAAGCCTTTAATTGATTCTAATAAGTGTTTTCGCTGTTCTTTAAACTATATCTGTCTTCCGGATGAAACGAACTATCTATTAGGGGCAAGTTCAACAATTCGTAAAATTGTGCCTTCAAGGACAGATGGTGGCGTTTTATATGTATCAGAGTCTGGTACAAAATTAGGAAAATCGGGTGAGGAGTTAATCATTCAGTATAAAGATGGCCAAAAGCAGGGTGTTCCTATAAAAGATATTATTCAAGTTTCGTTAATTGGAAATGTTCAATGCTCAACGCAATTACTTCATTTTTTAATGCAATCAAATATTCCTGTAAGTTATTTATCATCCCACGGTCGTTTGATTGGTGTCAGTTCATCTTTAGTTACAAAAAATGTTTTAACAAGGCAGCAACAGTTCATTAAATTTACAAATCCTGAGTTTGGACTAAATCTAGCAAAACAAATTGTTTATGCCAAGATTCGAAATCAACGAACTTTACTTAGAAGAAATGGGGGGAGTGAGGTAAAGGAGATTTTAACAGATTTAAAATCTTTAAGTGACAGTGCACTGAACGCAATATCAATAGAACAATTACGGGGTATTGAAGGGATTTCTGCAAAACATTATTTCGCAGGATTTCCGTTTATGTTGAAAAATGAATTACGTGAATTGAATTTAATGAAAGGGCGTAATAGGAGACCGCCAAAAGATCCTGTAAATGTACTTCTTTCTCTTGGTTATACTTTATTGACACGTGATATTCATGCTGCGTGTGGTTCAGTCGGATTGGATCCGATGTTTGGTTGTTACCATCGTCCAGAAGCAGGTCGACCGGCTCTAGTATTAGATGTTATGGAAACATTTCGACCACTTATTGTAGACAGTATTGTCATCCGAGCTTTGAATACGGGTGAAATCTCATTAAAAGATTTTTATATAGGAAAAGATAGTTGTCAATTATTAAAACATGGCCGCGATTCCTTTTTTGCCATTTATGAAAGAAGAATGCATGAAACTATTACCGATCCAATTTTCGGCTATAAGATTAGCTATCGCCGTATGCTCGATTTGCACATTCGAATGCTTGCAAGGTTTATTGAAGGGGAACTGCCGGAATATAAACCATTAATGACCCGGTGAGTTTGTTTATTAGGTTAAAAGAAGGTGAAGACATGCAGCAATACGTCCTTGTTTCTTATGATATTTCGGACCAAAAAAGATGGAGAAAAGTATTTAAACTGATGAAAGGATACGGAGAACATGTTCAATATTCCGTATTCATATGCCAGTTAACTGAATTACAGAAGGCAAAATTACAAGCCTCTTTAGAAGACATTATCCATCATAAGAATGACCAAGTAATGTTTGTTCACATCGGGCCAGTGAAAGATGGTCAACTATCTAAAAAAATCTCAACAATTGGGAAAGAATTTGTTCCATTGGATTTAAAGCGGCTTATATTTTGAAAAGATATAGCAAAGAAATCTTATGAAAAAAATACAAAAATATATTGTTAAAAAATAGGGAATATTATATAATGGACTTACGAGGTTCTGTCTTTTGGTCAGGACAACCGTCTAGCTATAAGTGCTGCAGGGGTGTGAGAAACTCCTATTGCTGGACGATGTCTCTTTTATTTCTTTTTTCTTGGATCTGAGTACGAGCACCCACATTGGACATTTCGCATGGTGGGTGCTCGTACTATAGGTAAAACAAACCTTTTTAAGAAGAATACAAAAATAACCACAATATTTTTTAAAAGGAATTTTGATGGATTTACATAACCTCTCGCAACATGCTTCTAAAACCCAAGCCCACCATAGCCCAAAACCCCCTGCGGTCCAAGAAAAAAGAAATGATACGAGGCATTAGCACCGGGGAGAAGTCATTTAATAAGGCCACTGTTAAAAGTCCAAGAAAAAAGAAATGATACGAGGCATTAGCACAACAATATAAACGACTACTTTACCGTGTTCAAGAAAAAAGAAATGATATGAGGCATTAGCACGATGGGATGGGAGAGAGAGGACAGTTCTACTCTTGCTGTATCCAGCTTCTTTTACTTTATCCGGTATCATTTCTTCACTTCTTTCTGCACATAAAAAAGCACCTAACTATTTGGATAAGTTAAGTGCTTTTATTTCCGTTTGAAGTTGTCTATTGCTTTTTTCTTCATATCTTCAAATTTTTTCTGTTTCTCAGAGTCAACTTTACCAACTGTAATCCCTTTTCTTTTTGGCATTGGGGTATCTTTCCACCTTAGTGTGTTCATAAGGCTTATATTTATCACTCATTGTATTCCTCCAACACAATTATAATTTTTCCGTCATCCTCAATCCAACCGTCAACTGTGACAAAAGACGAATCTCTCTTAT (SEQ ID NO: 62).
>C-локус
GTTTCATTTGGAAAGGGAGAGCATTGGCTTTTCTCTTTGTAAATAAAGTGCAAGCTTTGTAATAAGCTTCTAGTGGAGAAGTGATTGTTTGAATCACCCAATGCACACGCACTAAAGTTAGACGAACCTATAATTCGTATTAGTAAGTATAGTACATGAAGAAAAATGCAACAAGCATTTACTCTCTTTTAAATAAAGAATTGATAGCTGTTAATATTGATAGTATATTATACCTTATAGATGTTCGATTTTTTTTGAAATTCAAAAATCATACTTAGTAAAGAAAGGAAATAACGTCATGGACAAGCGAAAGCGTAGAAGTTACGAGTTTAGGTGGGAAGCGGGAGGCACCAGTCATGGCAATCCGTAGCATAAAACTAAAACTAAAAACCCACACAGGCCCGGAAGCGCAAAACCTCCGAAAAGGAATATGGCGGACGCATCGGTTGTTAAATGAAGGCGTCGCCTATTACATGAAAATGCTCCTGCTCTTTCGTCAGGAAAGCACTGGTGAACGGCCAAAAGAAGAACTACAGGAAGAACTGATTTGTCACATACGCGAACAGCAACAACGAAATCAGGCAGATAAAAATACGCAAGCGCTTCCGCTAGATAAGGCACTGGAAGCTTTGCGCCAACTATATGAACTGCTTGTCCCCTCCTCGGTCGGACAAAGTGGCGACGCCCAGATCATCAGCCGAAAGTTTCTCAGCCCGCTCGTCGATCCGAACAGCGAAGGCGGCAAAGGTACTTCGAAGGCAGGGGCAAAACCCACTTGGCAGAAGAAAAAAGAAGCGAACGACCCAACCTGGGAACAGGATTACGAAAAATGGAAAAAAAGACGCGAGGAAGACCCAACCGCTTCTGTGATTACTACTTTGGAGGAATACGGCATTAGACCGATCTTTCCCCTGTACACGAACACCGTAACAGATATCGCGTGGTTGCCACTTCAATCCAATCAGTTTGTGCGAACCTGGGACAGAGACATGCTTCAACAAGCGATTGAAAGACTGCTCAGTTGGGAGAGCTGGAACAAACGTGTCCAGGAAGAGTATGCCAAGCTGAAAGAAAAAATGGCTCAACTGAACGAGCAACTCGAAGGCGGTCAGGAATGGATCAGCTTGCTAGAGCAGTACGAAGAAAACCGAGAGCGAGAGCTTAGGGAAAACATGACCGCTGCCAATGACAAGTATCGGATTACCAAGCGGCAAATGAAAGGCTGGAACGAGCTGTACGAGCTATGGTCAACCTTTCCCGCCAGTGCCAGTCACGAGCAATACAAAGAGGCGCTCAAGCGTGTGCAGCAGCGACTGAGAGGGCGGTTTGGGGATGCTCATTTCTTCCAGTATCTGATGGAAGAGAAGAACCGCCTGATCTGGAAGGGGAATCCGCAGCGTATCCATTATTTTGTCGCGCGCAACGAACTGACGAAACGGCTGGAGGAAGCCAAGCAAAGCGCCACGATGACGTTGCCCAATGCCAGGAAGCATCCATTGTGGGTGCGCTTCGATGCACGGGGAGGAAATTTGCAAGACTACTACTTGACGGCTGAAGCGGACAAACCGAGAAGCAGACGTTTTGTAACGTTTAGTCAGTTGATATGGCCAAGCGAATCGGGATGGATGGAAAAGAAAGACGTCGAGGTCGAGCTAGCTTTGTCCAGGCAGTTTTACCAGCAGGTGAAGTTGCTGAAAAATGACAAAGGCAAGCAGAAAATCGAGTTCAAGGATAAAGGTTCGGGCTCGACGTTTAACGGACACTTGGGGGGAGCAAAGCTACAACTGGAGCGGGGCGATTTGGAGAAGGAAGAAAAAAACTTCGAGGACGGGGAAATCGGCAGCGTTTACCTTAACGTTGTCATTGATTTCGAACCTTTGCAAGAAGTGAAAAATGGCCGCGTGCAGGCGCCGTATGGACAAGTACTGCAACTCATTCGTCGCCCCAACGAGTTTCCCAAGGTCACTACCTATAAGTCGGAGCAACTTGTTGAATGGATAAAAGCTTCGCCACAACACTCGGCTGGGGTGGAGTCGCTGGCATCCGGTTTTCGTGTAATGAGCATAGACCTTGGGCTGCGCGCGGCTGCAGCGACTTCTATTTTTTCTGTAGAAGAGAGTAGCGATAAAAATGCGGCTGATTTTTCCTACTGGATTGAAGGAACGCCGCTGGTCGCTGTCCATCAGCGGAGCTATATGCTCAGGTTGCCTGGTGAACAGGTAGAAAAACAGGTGATGGAAAAACGGGACGAGCGGTTCCAGCTACACCAACGTGTGAAGTTTCAAATCAGAGTGCTCGCCCAAATCATGCGTATGGCAAATAAGCAGTATGGAGATCGCTGGGATGAACTCGACAGCCTGAAACAAGCGGTTGAGCAGAAAAAGTCGCCGCTCGATCAAACAGACCGGACATTTTGGGAGGGGATTGTCTGCGACTTAACAAAGGTTTTGCCTCGAAACGAAGCGGACTGGGAACAAGCGGTAGTGCAAATACACCGAAAAGCAGAGGAATACGTCGGAAAAGCCGTTCAGGCATGGCGCAAGCGCTTTGCTGCTGACGAGCGAAAAGGCATCGCAGGTCTGAGCATGTGGAACATAGAAGAATTGGAGGGCTTGCGCAAGCTGTTGATTTCCTGGAGCCGCAGGACGAGGAATCCGCAGGAGGTTAATCGCTTTGAGCGAGGCCATACCAGCCACCAGCGTCTGTTGACCCATATCCAAAACGTCAAAGAGGATCGCCTGAAGCAGTTAAGTCACGCCATTGTCATGACTGCCTTGGGGTATGTTTACGACGAGCGGAAACAAGAGTGGTGCGCCGAATACCCGGCTTGCCAGGTCATTCTGTTTGAAAATCTGAGCCAGTACCGTTCTAACCTGGATCGCTCGACCAAAGAAAACTCCACCTTGATGAAGTGGGCGCATCGCAGCATTCCGAAATACGTCCACATGCAGGCGGAGCCATACGGGATTCAGATTGGCGATGTCCGGGCGGAATATTCCTCTCGTTTTTACGCCAAGACAGGAACGCCAGGCATTCGTTGTAAAAAGGTGAGAGGCCAAGACCTGCAGGGCAGACGGTTTGAGAACTTGCAGAAGAGGTTAGTCAACGAGCAATTTTTGACGGAAGAACAAGTGAAACAGCTAAGGCCCGGCGACATTGTCCCGGATGATAGCGGAGAACTGTTCATGACCTTGACAGACGGAAGCGGAAGCAAGGAGGTCGTGTTTCTCCAGGCCGATATTAACGCGGCGCACAATCTGCAAAAACGTTTTTGGCAGCGATACAATGAACTGTTCAAGGTTAGCTGCCGCGTCATCGTCCGAGACGAGGAAGAGTATCTCGTTCCCAAGACAAAATCGGTGCAGGCAAAGCTGGGCAAAGGGCTTTTTGTGAAAAAATCGGATACAGCCTGGAAAGATGTATATGTGTGGGACAGCCAGGCAAAGCTTAAAGGTAAAACAACCTTTACAGAAGAGTCTGAGTCGCCCGAACAACTGGAAGACTTTCAGGAGATCATCGAGGAAGCAGAAGAGGCGAAAGGAACATACCGTACACTGTTCCGCGATCCTAGCGGAGTCTTTTTTCCCGAATCCGTATGGTATCCCCAAAAAGATTTTTGGGGCGAGGTGAAAAGGAAGCTGTACGGAAAATTGCGGGAACGGTTTTTGACAAAGGCTCGGTAAGGGTGTGCAAGGAGAGTGAATGGCTTGTCCTGGATACCTGTCCGCATGCTAAATGAAATTCAGTATTGTGAGCGACTGTACCATATTATGCATGTGCAGGGGCTGTTTGAGGAAAGCGCAGACACGGTCGAAGGAGCAGCACAACACAAGCGTGCAGAGACACATCTGCGCAAAAGCAAGGCAGCGCCGGAAGAGATGTGGGGGGACGCTCCGTTTAGCTTGCAGCTCGGCGACCCTGTGCTTGGCATTACGGGAAAGCTGGATGCCGTCTGTCTGGAAGAAGGTAAGCAGTGGATTCCGGTAGAAGGAAAGCATTCGGCGTCGCCAGAAGGCGGGCAGATGTTCACTGTAGGCGTGTATTCGCTGGACGGTTCTGCCTGGCCCAACGACCAAATCCAATTGTGTGCGCAAGGCTTGCTGCTTCGCGCGAATGGATATGAATCCGATTATGGCTACTTATACTACCGTGGCAATAAAAAGAAGGTTCGCATTCCTTTTTCGCAGGAACTCATAGCGGCTACTCACGCCTGCATTCAAAAAGCTCATCAGCTTCGGGAAGCCGAAATTCCCCCTCCGTTGCAGGAGTCGAAAAAGTGCTTTCGATGCTCGTTAAATTACGTATGCATGCCTGACGAGACGAATTACATGTTGGGGTTGAGCGCAAACATCAGAAAGATTGTGCCCAGTCGTCCAGATGGCGGGGTACTGTATGTTACAGAGCAGGGGGCAAAACTGGGCAGAAGCGGAGAAAGCTTGACCATCACCTGCCGGGGCGAAAAGATAGACGAAATCCCGATCAAAGACTTGATTCACGTGAGCTTGATGGGGCATGTGCAATGCTCTACGCAGCTTCTGCACACCTTGATGAACTGTGGCGTCCACGTCAGCTACTTGACTACGCATGGCACATTGACAGGAATAATGACTCCCCCTTTATCGAAAAACATTCGAACAAGAGCCAAGCAGTTTATCAAATTTCAGCACGCGGAGATCGCCCTTGGAATCGCGAGAAGGGTCGTGTATGCGAAAATTTCCAATCAGCGCACGATGCTGCGCCGCAATGGCTCACCAGATAAAGCAGTTTTAAAAGAGTTAAAAGAGCTTAGAGATCGCGCGTGGGAGGCGCCATCACTGGAAATAGTGAGAGGTATCGAGGGACGTGCAGCACAGTTGTACATGCAGTTTTTCCCTACCATGTTAAAGCACCCAGTAGTAGACGGTATGGCGATCATGAACGGTCGCAACCGTCGCCCGCCCAAAGATCCGGTCAATGCGCTGCTCTCCCTCGGCTATACGCTTCTTTCACGGGATGTTTACTCCGCATGTGCCAATGTCGGACTCGATCCACTGTTCGGCTTTTTCCATACGATGGAGCCGGGCAGACCAGCTTTGGCACTCGATCTGATGGAACCGTTCCGCGCCTTGATTGCCGATAGCGTAGCGATACGTACCTTGAATACGGAGGAACTCACCCTCGGGGACTTTTATTGGGGAAAAGACAGTTGTTATTTGAAAAAGGCAGGAAGACAAACGTATTTCGCTGCCTATGAAAGACGGATGAACGAGACGCTGACGCATCCGCAATTTGGGTATAAGCTCAGCTATCGCCGTATGCTGGAGCTGGAAGCAAGGTTTTTGGCCCGGTATCTGGATGGAGAGCTGGTGGAATATACGCCGCTCATGACAAGGTAGGAAATGACCATGCGACAATTTGTTCTGGTAAGCTATGATATTGCCGATCAAAAACGTTGGAGAAAAGTATTCAAGCTGATGAAGGGGCAAGGCGAGCACGTCCAGTACTCGGTGTTTCTGTGCCAACTCACCGAGATTCAGCAAGCCAAGCTAAAGGTAAGCCTGGCGGAGCTGGTTCACCATGGAGAAGACCAGGTCATGTTTGTAAAAATCGGCCCAGTGACGAGAGATCAACTGGACAAGCGGATATCTACTGTTGGCAGGGAGTTTCTGCCTCGCGATTTGACCAAATTTATCTATTAAGGAATGAAGAAAGCTAGTTGTAACAAAAGTGGAAAAAGAGTAAAATAAAGGTGTCAGTCGCACGCTATAGGCCATAAGTCGACTTACATATCCGTGCGTGTGCATTATGGGCCCATCCACAGGTCTATTCCCACGGATAATCACGACTTTCCACTAAGCTTTCGAATTTTATGATGCGAGCATCCTCTCAGGTCAAAAAAGCCGGGGGATGCTCGAACTCTTTGTGGGCGTAGGCTTTCCAGAGTTTTTTAGGGGAAGAGGCAGCCGATGGATAAGAGGAATGGCGATTGAATTTTGGCTTGCTCGAAAAACGGGTCTGTAAGGCTTGCGGCTGTAGGGGTTGAGTGGGAAGGAGTTCGAAAGCTTAGTGGAAAGCTTCGTGGTTAGCACCGGGGAGAAGTCATTTAATAAGGCCACTGTTAAAAGTTCGAAAGCTTAGTGGAAAGCTTCGTGGTTAGCACGCTAAAGTCCGTCTAAACTACTGAGATCTTAAATCGGCGCTCAAATAAAAAACCTCGCTAATGCGAGGTTTCAGC (SEQ ID NO: 63).
>D-локус
GAAGTTATGTTGATAAAATGGTTTATGAAAACGTGAGTCTGTGGTAGTATTATAAACAATGATGGAATAAAGTGTTTTTTGCGCCGCACGGCATGAATTCAGGGGTTAGCTTGGTTTTGTGTATAAATAAATGTTCTACATATTTATTTTGTTTTTTGCGCCGCAAAATGCAACTGAAAGCCGCATCTAGAGCACCCTGTAGAAGACAGGGTTTTGAGAATAGCCCGACATAGAGGGCAATAGACACGGGGAGAAGTCATTTAATAAGGCCACTGTTAAAAGTTTTGAGAATAGCCCGACATAGAGGGCAATAGACTTTTGCTTCGTCACGGATGGACTTCACAATGGCAACAACGTTTTGAGAATAGCCCGACATAGTTATAGAGATGTATAAATATAACCGATAAACATTGACTAATTTGTTGAAGTCAGTGTTTATCGGTTTTTTGTGTAAATATAGGAGTTGTTAGAATGATACTTTTTGCCTAATTTTGGAACTTTATGAGGATATAAGATAGACTTGATAAAAAGGTAAAAGAAAGGTTAAAGAGCATGGCAGGAATAGTGACCTGTGATGAAGATGATGGTAGAATTAAAAGTGTTCTTAAAGAAAAACAATATTGGATAAGGAAAATAATTCAATAGATAAAAAATTTAGGGGGAAAAATGAAAATATCAAAAGTCGATCATACCAGAATGGCGGTTGCTAAAGGTAATCAACACAGGAGAGATGAGATTAGTGGGATTCTCTATAAGGATCCGACAAAGACAGGAAGTATAGATTTTGATGAACGATTCAAAAAACTGAATTGTTCGGCGAAGATACTTTATCATGTATTCAATGGAATTGCTGAGGGAAGCAATAAATACAAAAATATTGTTGATAAAGTAAATAACAATTTAGATAGGGTCTTATTTACAGGTAAGAGCTATGATCGAAAATCTATCATAGACATAGATACTGTTCTTAGAAATGTTGAGAAAATTAATGCATTTGATCGAATTTCAACAGAGGAAAGAGAACAAATAATTGACGATTTGTTAGAAATACAATTGAGGAAGGGGTTAAGGAAAGGAAAAGCTGGATTAAGAGAGGTATTACTAATTGGTGCTGGTGTAATAGTTAGAACCGATAAGAAGCAGGAAATAGCTGATTTTCTGGAGATTTTAGATGAAGATTTCAATAAGACGAATCAGGCTAAGAACATAAAATTGTCTATTGAGAATCAGGGGTTGGTGGTCTCGCCTGTATCAAGGGGAGAGGAACGGATTTTTGATGTCAGTGGCGCACAAAAGGGAAAAAGCAGCAAAAAAGCGCAGGAGAAAGAGGCACTATCTGCATTTCTGTTAGATTATGCTGATCTTGATAAGAATGTCAGGTTTGAGTATTTACGTAAAATTAGAAGACTGATAAATCTATATTTCTATGTCAAAAATGATGATGTTATGTCTTTAACTGAAATTCCGGCAGAAGTGAATCTGGAAAAAGATTTTGATATCTGGAGAGATCACGAACAAAGAAAGGAAGAGAATGGAGATTTTGTTGGATGTCCGGACATACTTTTGGCAGATCGTGATGTGAAGAAAAGTAACAGTAAGCAGGTAAAAATTGCAGAGAGGCAATTAAGGGAGTCAATACGTGAAAAAAATATAAAACGATATAGATTTAGCATAAAAACGATTGAAAAGGATGATGGAACATACTTTTTTGCAAATAAGCAGATAAGTGTATTTTGGATTCATCGCATTGAAAATGCTGTAGAACGTATATTAGGATCTATTAATGATAAAAAACTGTATAGATTACGTTTAGGATATCTAGGAGAAAAAGTATGGAAGGACATACTCAATTTTCTCAGCATAAAATACATTGCAGTAGGCAAGGCAGTATTCAATTTTGCAATGGATGATCTGCAGGAGAAGGATAGAGATATAGAACCCGGCAAGATATCAGAAAATGCAGTAAATGGATTGACTTCGTTTGATTATGAGCAAATAAAGGCAGATGAGATGCTGCAGAGAGAAGTTGCTGTTAATGTAGCATTCGCAGCAAATAATCTTGCTAGAGTAACTGTAGATATTCCGCAAAATGGAGAAAAAGAGGATATCCTTCTTTGGAATAAAAGTGACATAAAAAAATACAAAAAGAATTCAAAGAAAGGTATTCTGAAATCTATACTTCAGTTTTTTGGTGGTGCTTCAACTTGGAATATGAAAATGTTTGAGATTGCATATCATGATCAGCCAGGTGATTACGAAGAAAACTACCTATATGACATTATTCAGATCATTTACTCGCTCAGAAATAAGAGCTTTCATTTCAAGACATATGATCATGGGGATAAGAATTGGAATAGAGAACTGATAGGAAAGATGATTGAGCATGATGCTGAAAGAGTCATTTCTGTTGAGAGGGAAAAGTTTCATTCCAATAACCTGCCGATGTTTTATAAAGACGCTGATCTAAAGAAAATATTGGATCTCTTGTATAGCGATTATGCAGGACGTGCATCTCAGGTTCCGGCATTTAACACTGTCTTGGTTCGAAAGAACTTTCCGGAATTTCTTAGGAAAGATATGGGCTACAAGGTTCATTTTAACAATCCTGAAGTAGAGAATCAGTGGCACAGTGCGGTGTATTACCTATATAAAGAGATTTATTACAATCTATTTTTGAGAGATAAAGAGGTAAAGAATCTTTTTTATACTTCATTAAAAAATATAAGAAGTGAAGTTTCGGACAAAAAACAAAAGTTAGCTTCAGATGATTTTGCATCCAGGTGTGAAGAAATAGAGGATAGAAGTCTTCCGGAAATTTGTCAGATAATAATGACAGAATACAATGCGCAGAACTTTGGTAATAGAAAAGTTAAATCTCAGCGTGTTATTGAAAAAAATAAGGATATTTTCAGACATTATAAAATGCTTTTGATAAAGACTTTAGCAGGTGCTTTTTCTCTTTATTTGAAGCAGGAAAGATTTGCATTTATTGGTAAGGCAACACCTATACCATACGAAACAACCGATGTTAAGAATTTTTTGCCTGAATGGAAATCCGGAATGTATGCATCGTTTGTAGAGGAGATAAAGAATAATCTTGATCTTCAAGAATGGTATATCGTCGGACGATTCCTTAATGGGAGGATGCTCAATCAATTGGCAGGAAGCCTGCGGTCATACATACAGTATGCGGAAGATATAGAACGTCGTGCTGCAGAAAATAGGAATAAGCTTTTCTCCAAGCCTGATGAAAAGATTGAAGCATGTAAAAAAGCGGTCAGAGTGCTTGATTTGTGTATAAAAATTTCAACTAGAATATCTGCGGAATTTACTGACTATTTTGATAGTGAAGATGATTATGCAGATTATCTTGAAAAATATCTCAAGTATCAGGATGATGCCATTAAGGAATTGTCAGGATCTTCGTATGCTGCGTTGGATCATTTTTGCAACAAGGATGATCTGAAATTTGATATCTATGTAAATGCCGGACAGAAGCCTATCTTACAGAGAAATATCGTGATGGCAAAGCTTTTTGGACCAGATAACATTTTGTCTGAAGTTATGGAAAAGGTAACAGAAAGTGCCATACGAGAATACTATGACTATCTGAAGAAAGTTTCAGGATATCGGGTAAGGGGAAAATGTAGTACAGAGAAAGAACAGGAAGATCTGCTAAAGTTCCAAAGATTGAAAAACGCAGTAGAATTCCGGGATGTTACTGAATATGCTGAGGTTATTAATGAGCTTTTAGGACAGTTGATAAGTTGGTCATATCTTAGGGAGAGGGATCTATTATATTTCCAGCTGGGATTCCATTACATGTGTCTGAAAAACAAATCTTTCAAACCGGCAGAATATGTGGATATTCGTAGAAATAATGGTACGATTATACATAATGCGATACTTTACCAGATTGTTTCGATGTATATTAATGGACTGGATTTCTATAGTTGTGATAAAGAAGGGAAAACGCTCAAACCAATTGAAACAGGAAAGGGCGTAGGAAGTAAGATAGGACAATTTATAAAGTATTCCCAGTATTTATACAATGATCCGTCATATAAGCTTGAGATCTATAATGCAGGATTAGAAGTTTTTGAAAACATTGATGAACATGATAATATTACAGATCTTAGAAAGTATGTGGATCATTTTAAGTATTATGCATATGGTAATAAAATGAGCCTGCTTGATCTGTATAGTGAATTCTTCGATCGTTTCTTTACATATGATATGAAGTATCAGAAGAATGTAGTGAATGTGTTGGAGAATATCCTTTTAAGGCATTTTGTAATTTTCTATCCGAAGTTTGGATCAGGAAAAAAAGATGTTGGAATTAGGGATTGTAAAAAAGAAAGAGCTCAGATTGAAATAAGTGAGCAGAGCCTCACATCGGAAGACTTCATGTTTAAGCTTGACGACAAAGCAGGAGAAGAAGCAAAGAAGTTTCCGGCAAGGGATGAACGTTATCTCCAGACAATAGCCAAGTTGCTCTATTATCCTAACGAAATTGAGGATATGAACAGATTCATGAAGAAAGGAGAAACGATAAATAAAAAAGTTCAGTTTAATAGAAAAAAGAAGATAACCAGGAAACAAAAGAATAATTCATCAAACGAGGTATTGTCTTCAACTATGGGTTATTTATTTAAGAACATTAAATTGTAAAAAAGATTCGTTGTAGATAATTGATAGGTAAAAGCTGACCGGAGCCTTTGGCTCCGGACAGTTGTATATAAGAGGATATTAATGACTGAAAATGATTTTTGTTGGAAGTCAGTTTTTTCTGTGGAAAGCGAAATCGAATATGATGAGTATGCATATGGCAGAAGAGCTGTAGAAGGCGAGAATACATATGATTACATTACTAAGGAAGAAAGACCGGAACTTAATGACGAATATGTAGCGAGACGTTGCATTTTCGGTAAAAAAGCAGGAAAAATATCCAGGTCGGATTTTAGTAGGATAAGATCTGCGTTGGATCATGCGATGATAAATAATACACATACAGCATTTGCCAGATTTATCACTGAAAATCTGACGAGACTCAATCACAAAGAACATTTTCTGAATGTGACACGTGCATATTCTAAACCTGATTCTGAAAAATTGATACAACCGAGATACTGGCAGTCGCCTGTAGTTCCAAAGGATAAACAAATATATTATAGCAAGAATGCGATTAAAAAATGGTGTGGTTACGAAGATGATATTCCGCCTCGTTCTGTGATAGTTCAGATGTGTCTATTGTGGGGGACTGATCATGAAGAGGCAGATCATATCCTTCGCAGTTCAGGATACGCGGCGCTTAGTCCTGTTGTACTTCGAGATCTTATCTATATGTATTATCTGGATCATCAGGATTTGCAAAAAAATGAGTTGATATGGGAAGTAAAAAAGCAGTTGGATCACTTCGATTTGACAAATAGAAATTATGATACAAATCCTTTTGATGTAGGGGGCAGCGTAAATGATCATATCTGTGAACTGAGCGAGCATATAGCGAAGGCTCATTATATTTATGAGAGGGCTAAGGAAGGACCATTGCAAAATGTAATTCGGGATATTTTGGGAGATACACCTGCCCTTTATTCTGAAATGGCATTTCCTCAGCTAGCATCTATAAACAGGTGTGCTTGCAATTCGCTTTCTTCATATCAAAAAAATATTTTTGATACTGACATAGCTATATATGCAGATGAAAAGGACACAAGAGGTAAATCAGACCGTATCCTTGTTGAGGGCGCATCTTCGAAATGGTATGAATTGAAGAAACGCGATGCTAATAATGTCAAAATTTCTGAAAAGCTGAGTATACTCAATACTATTCTTAAATTTAATAGTGTTTTTTGGGAAGAATGTTACCTTGATGGAAATATAAAACAATCGAGCGGAAAGCGATCTGAGGCAGGAAAAATTCTTTATGGTCGCGACAACGGAAAAGAAAATGTCGGAGTTTCAAAATTGGAATTGGTGCGGTATATGATAGCTGCAGGTCAGGAACAAAATCTGGGAAATTACCTGGTGAGTTCAGGATTTTGGAGAAAAAATCATATGCTGTCATTTATACAAGGCAATGATATAGCGCTTGATGAGATGGATGAATTGGATCTCTTAGACTATATTCTGATATATGCATGGGGATTTAGGGAAAATATCATTAAAAAGAACAGTAATGTGAATTCTTTGGATGAAAAGACTAGAAAAGTGCAGTTTCCGTTTATAAAGTTACTCATGGCAATTGCAAGAGATATCCAGATACTTATATGTTCAGCACATGAAAAAACAGTCGATGAGTCATCTCGAAATGCAGCAAAGAAGATAGATATATTGGGAAATTATATTCCTTTTCAGATTCATCTTCAGAGAACTAAAAAAGATGGTGGAAGAGTGGTAATGGATACATTGTGTGCTGATTGGATTGCGGATTATGAATGGTACATTGATCTTGAGAAAGGAACACTTGGATGAGCAGTGATGAAAGGATATTTAAAAAATTTTTGGAAAAAGGATCGATTTCTGAGCAGAAAAAGATGCTTTTAGAAGAAAAGAAATGTTCGGATAAACTAACTGCACTGCTTGGGAATTACTGCATACCGATAGACAATATTTCAGAGTCAGACGGAAAAATATATGCGGTCTATAAGCTTCCAAAAAATGTTAAACCTTTGTCCGAAATCATTAATGATGTATCCTTTTCTGATTGTACGATGAGAGTACGTTTGCTTCTCATAAAGAGAATTCTGGAACTCGTGTGTGCTTTTCACGAAAAAAAATGGTATTGTCTCAGTATTTCACCGGGAATGCTCATGGTTGAAGATTTTGATATACCGATGGGAAATGTCGGAAAAGTATTGATATATGATTTCAGAAATCCTGTTCCGTTCGAGTCAGTAAATGAAAGACATAATTTTAACGTTTCAAATAAATACACTTCACCGGAGCTGCTCATCCATTCAAGATATGACGAGTCGAAATCTGTGAGTGAAAAATCAGATTTGTATTCTGTTGCAAAAATTGCGGAAACAATAATAGGAGATTTTAACAGTATTATTGCAAATGGAAATTTGATACTACTTGCAATGCTTAGAGTTTTTATCAGTACAGGGAAAAGTCCGGAACCTGAGTATCGGTTTGAATCGTCGGAAAATATGCTTTCAGTATTTGAAAATTTGATCAAAGAAAATTGTTTTTTTGAAAAAAACGATTATACATCTATGTTTCATCAGGCGTATGACAATTTTTTTGAATGGCAGGAATGTTTGATATCACCGGATCACTTGGATAAAAATATGTTCGAGGCAGCTTTATCAAATCTTGAGGATCAGCTGCTTAGGGTTGATATTGATAAGTATAGAGCAGAGTACTTCTATAAGCTTCTCCGAGAGTTGTCTAATAAATATAAAAATACAATTACTGATGAACAAAAGGTAAGGTTGGCAATACTTGGAATCAGAGCGAAAAATAATCTGGGAAAAAGTTTTGATGCATTGGAAATATATGAGTCAGTACGTGATTTAGAAACTATGTTGGAGGAGATGGCAGAGCTTAGTCCTGTCATTGCTTCGACATATATGGATTGCTACCGATATGCAGATGCGCAGAAAGTGGCGGAAGAAAACATTATCAGGCTTCATAATAGTAATATTCGTATGGAGAAAAAAAGAATACTGCTTGGAAGGTCATATAGTTCAAAAGGGTGCAGCATGGGGTTTCAGCATATTCTTGGTGCGGATGAGTCATTTGAACAGGCTTTATATTTCTTTAACGAAAAGGACAATTTTTGGAAAGAAATATTTGAGAGCAGAAATTTAGAGGACAGCGATAGACTTATAAAGTCTTTACGAAGCAATACGCATATTACGCTGTTTCATTACATGCAATATGCATGTGAAACAAGGAGAAAGGAATTATATGGAGCACTTTCAGACAAATATTTTATAGGTAAAGAATGGACAGAAAGACTCAAAGCATATATAAGCAACAAGGATATATGGAAAAACTATTATGAGATATATATTCTGCTAAAGGGTATTTATTGCTTCTATCCAGAAGTCATGTGTTCGTCTGCGTTTTATGATGAAATCCAAAAAATGTACGATCTTGAATTTGAAAAGGAAAAAATGTTTTACCCATTGAGTCTGATAGAACTGTATCTTGCTCTGATAGAGATAAAAGTTAATGGGAGTCTGACGGAGAATGCCGAGAAGTTGTTTAAACAGGCATTGACACATGACAATGAAGTCAAAAAAGGAAATATGAATATTCAGACCGCCATTTGGTATCGAATATATGCACTGTATAACGATGTAAAAGATGAAACTGATAAGAATAAAAGGCTTTTAAAACGGCTTATGATTCTTTGCCGACGATTTGGTTGGGCGGATATGTATAGTGCTTTGGAGAAGGATGGGAAGTTAATTGATTTTTTGAGATTTGAGGTATGTTAAATGATAACACTTGCATTAGATGAAAATGGCAAATTTGAAGATGCTTTTTCTAAAAAAAATGAAAAACCGATAATGATTGCGGGGATAATCTATGATGACAAGGGGAAAGAGTATGATGCTGAGAATGAACGCTACAGGATATCCAGTTATCTGCGAGCAGTATGTGACAGTTTGGGTGCGAAATACCCTCAGGATCTACATTCAAATAGTAATGGAAATAAGGCGACTGTTGGGAAAGTAAAATGTAAAATTGGTGAAACACTAAAGGAATTCTTGAGAGAAGGAACCTATGAAAAAAAGGAATTGCCGACAAAGAACGGTTATTTAAATAAGAGATCTGGAAAATATGTAATGTTTGCAGAACTCAGGAGTAGTCAGGGAGTTAAAAAGCGTGTTAGTGGTTGGAATGACAATGATCTGACTCAGGATGAAAAGGTCAGCAATCTGTACCTTCATATGGCAGAAAATGCCGTTGTCAGAATGCTCTTCCATAATCCTATATATGAAGATGTAACAGATGTAAATCTCTATTTTCCCACGCGAAAAGTTGTTCTGAAAGATAGAGATAGAGAATACGATAAACAAGATTTCAAAATATATGGTGATAAGGACAAGTGCGAAGCAGAAAGCGGGAGATTGGTGCATTATGATATCGTGTCATCGGATTTTTACCGTACGATAATGGAGAACGAATGTACAAGAATTAATAAAAAGCAATTAAATGTTCATTATATGAACACAAGCCCAATTTCGTACTGGGAGAAAAATGAAAAATATAATACATTTTTATATTTGGCTGACATAGTTTGTTCTATGCTGGATTATTACAAAAAGGGTTCGAGTCCGGCAGAGTGGATGGATTCTTTTGCCGAATGGGGAAACAAATATTTTGGTGATGATCAGATAATCTTATTTGGGTATGATGATATAGATGACAAATACATGGAGGCTGTAGATGCAGTAGGACAGGGAGAGTATTTTCATGCGCTGGATATTATATATGATGCGGAATGTAGTGGAAGTGAATTTGAGAAGCACTACAAAGATTATTGGTTTCCAAAGCTTATAAAAAAGATACGAATAACAGCAACTGTGGATAATTTATGCAGATCGATCTCAGATCTGGAGAGTTTTACATATCGAAGTAATCTTGATCAGCAGAAACTTTTGTGGATTTTTGAGGAAATCAAAGCTATCGTCGATAAGGGAGATTTTGGAAAGAAATATCATACAGATCAGGTTATGTTTGATATGTGTAATGCCGGTATTGCTGTGTACAATCATATCGGAGATTTTGGGACTGCAAAGGAATACTATGATGAGTGCATGAAACACACTGGGGATGTGGATCTGGTAAAGATACTTCGTGCATCAAATAAAATGGTGGTCTTTCTTGACGATGCTTTTAGGTATGGTGACGCGACAGAACGTGCCAGGAAGAATGTTGAATACCAAAAAGCTTTGCACGATATAAAGAGTGAGATTTGTCCGGAAAAGAAAGATGAAGACTTGAACTATGCCATATCGCTCAGTCAATTTGGACAGGCGCTTGCGTGTGAAAAAAATTCTGATGCAGAGAGTGTTTTCCTAGAGTCGTTGCGGCATATGAGGAAAGGGACTGCCAATTATCAGATTACTCTTTCATATTTACTCCATTTTTATCTGGATATGGGAATGACAGATTCTTATCGAGAAAAAACAAAGGACTATTTTGGAAGTGAAAAACCAAAGGAACAGCTGAAAGAATTGCTGAAGTTATCGGGAAAGGATGATAGTATAGTTACTTTCAAATTTGCAATGTATGTCTATTTACGTGCACTTTGGGTATTACAGGAACCGCTTACTGATTTTATCAGAACAAGATTAGAGGACATACGTGAGACTCTTGTAAAGAAGAAAATGAGTGAACATATGGTTGGACATCCGTGGGAGTTGATTTATAAATATCTGGCATTTCTTTTTTATCGTGATGGAAATTGTGAAGCTGCTGAAAAATATATTCATAAAAGTGAAGAGTGCTTGGAAACACAAGGACTGACTATAGATGCGATTATTCATAATGGTAAGTATGAATATGCAGAATTGTCAGGTGACGAGGAGATGATGGCAAGAGAGAAAGCGTACTTTGATGAAAAAGGGATAGATAGAAAAAATGTTTGTACTTTTATGTATCATTGATGTTTAATAAGATTTGACCGAGGAGTGACAGGTAATCGCCGGTATATCTGGTATTACCTGTCATTTTTTGATGAAATAAGCTACTTTTTGCCTAAAAAACGAAACTGTTGGTGTTTTATGATGATTGTGTCAACAAAAGAGAGCAAAAGAAGAGGAGAAAAGTAATGTCAATGATTTCATGTCCGAATTGTGGTGGAGAGATATCTGAAAGGTCAAAGAAATGTGTTCATTGTGGATATGTGTTAGTCGAAGAAGCTAAAGTAGTGTGCACAGAATGTGGAACTGAGGTAGAGAGTGGCGCTGCTGTATGTCCGAAGTGCGGCTGTCCTGTAAATGATAGTGAGACGCCTCAGAAAGTTGAAGTGACTAGGGTAAATGTATCTTCCGTAATCAGCAAAAAAGTCGTTGTAAGCATACTGATCGCAGTGATTACAATTGCAGGTTTTTTCTATGGAGTGAAGTATTCGCAGGAAAAGAAAGCAATTGAAGAGTCAGTAAAGCAGAAGGAAGACTATCAAAGTACGCTAGAGCTTGCTTCGCTAATGATGCTTCAAGGAGCTTCGGATGCAGAAACTTGTGGGAATTTGGTTAGGAAAGTGTGGAGCAACTGCATTTATAAGGAGAGGGATGAAGAAACCGACAAGTATACGTGTGATAGCAGGGGTGCAGGATGGTTTTATGATGATTTTAATGATGCATTAATGGCTCTTTACAGTGACAGCAGTTTTGGCAAGAAGATAAATGAAATCAAAAACGGTCAGGAAACCGTTGCGGCGATGATGAAAGATCTGAAAAATCCGCCGGATGAGATGGCAGATGCCTATGAGGATATTCAAAATTTTTATGTGTCCTATCTAACGCTGACAGAAATGGTTGTGAATCCAACTGGAAGTTTGAGTTCTTTTTCATCTGATTTTTCCGATGCGGATACGGAGGTGTCCAATGCCTATAGCCGGATGAAGTTGTATTTAGATTAAACTATTGAGGAAAAAATGGAGGTGCTTTAATGCGGGGGAGAAACTGTGGAGGGTCATCAGGCGACGGACTGCTGGTACTTCTCGTACTGCTTGTCCTTTTTTATAAAATCATGCCATTCATAGGTTTATGGATTTTAATTTTTGGTGATGCTGAACGTAAAGATCTGGGTATGGGTATGATTATTGTCGGGATAGTTCTATATGTATTATTAGAGGTTTTTTAATGTGAGTTTCTGTGGTAAACTATAAAAGTACAAGCTTTTGCGCCGCACCGCATAAATAGCGGATTTATGACCATTATTTGGTGAAAAAAATGGTGTACACCTGTGTTTTTTTGTTTTGCGCCGCAAAATGCGCCACGGAACCGCATGCAGAGCACCCTGCAAGAGACAGGGTTATGAAAACAGCCCGACATAGAGGGCAATAGACACGGGGAGAAGTCATTTAATAAGGCCACTGTTAAAAGTTATGAAAACAGCCCGACATAGAGGGCAATAGACATAAAGACCAAAAACAGGTCATCTGCATACTGTGTTATGAAAACAGCCCGATATAGAGGGTGTGAGAGATATAGTTCTCGTCACAGTGCAGAAAATGACCTATTATGTGCCGAAAAACAAAATGAAAAAAGAATGGAAAGGCGTATTTAATGAAATGCTGATCTGTTGATTTGAATTAACAAAAAAAGGTCGCCCCACGGATGACAAAAACATCCGGGGGCGACCCTTTT (SEQ ID NO: 64).
>E-локус
TACTGTGTGCATAAGTCTTCCTTAGATCCATAGGTACAGCAGTTTTATTTATTAGCCTTAGAAAATGGAAAATAGAGCTTATAAATGATATGATATTTATGAATAAAATGATTGCATTCTCGTGCAAACTTTAAATATATTGATTATATCCTTTACATTGGTTGTTTTAATTACTATTATTAAGTAGGAATACGATATACCTCTAAATGAAAGAGGACTAAAACCCGCCAAAAGTATCAGAAAATGTTATTGCAGTAAGAGACTACCTCTATATGAAAGAGGACTAAAACTTTTAACAGTGGCCTTATTAAATGACTTCTGTAAGAGACTACCTCTATATGAAAGAGGACTAAAACGTCTAATGTGGATAAGTATAAAAACGCTTATCCATCATTTAGGTGTTTTATTTTTTTGTGATTATATGTACAATAGAAGAGAGAAAAAAATCATTGAGGTGAAAACTATGAGAATTACTAAAGTAGAGGTTGATAGAAAAAAAGTACTAATTTCTAGGGATAAAAACGGGGGCAAGTTAGTTTATGAAAATGAAATGCAAGATAATACAGAACAAATCATGCATCACAAAAAAAGTTCTTTTTACAAAAGTGTGGTAAACAAAACTATTTGTCGTCCTGAACAAAAACAAATGAAAAAATTAGTTCATGGATTATTACAAGAAAATAGTCAAGAAAAAATAAAAGTTTCAGATGTCACTAAACTTAATATCTCAAATTTCTTAAATCATCGTTTCAAAAAAAGTTTATATTATTTTCCTGAAAATAGTCCTGACAAAAGCGAAGAATACAGAATAGAAATAAATCTCTCCCAATTGTTAGAAGATAGCTTAAAAAAACAGCAAGGGACATTTATATGTTGGGAATCTTTTAGCAAAGACATGGAATTATACATTAATTGGGCGGAAAATTATATTTCATCAAAAACGAAGCTAATAAAAAAATCCATTCGAAACAATAGAATTCAATCTACTGAATCAAGAAGTGGACAACTAATGGATAGATATATGAAAGACATTTTAAATAAAAACAAACCTTTCGATATCCAATCAGTTAGCGAAAAGTACCAACTTGAAAAATTGACTAGTGCTTTAAAAGCTACTTTTAAAGAAGCGAAGAAAAACGACAAAGAGATTAACTATAAGCTTAAGTCCACTCTCCAAAACCATGAAAGACAAATAATAGAAGAATTGAAGGAAAATTCCGAACTGAACCAATTTAATATAGAAATAAGAAAACATCTTGAAACTTATTTTCCTATTAAGAAAACAAACAGAAAAGTTGGAGATATAAGGAATTTAGAAATAGGAGAAATCCAAAAAATAGTAAATCATCGGTTGAAAAATAAAATAGTTCAACGCATTCTCCAAGAAGGGAAATTAGCTTCTTATGAGATTGAATCAACAGTTAACTCTAATTCCTTACAAAAAATTAAAATTGAAGAAGCATTTGCCTTAAAGTTTATCAATGCTTGTTTATTTGCTTCTAACAATTTAAGGAATATGGTATATCCTGTTTGCAAAAAGGATATATTAATGATAGGTGAATTTAAAAATAGTTTTAAAGAAATAAAACACAAAAAATTCATTCGTCAATGGTCGCAATTCTTCTCTCAAGAAATAACTGTTGATGACATTGAATTAGCTTCATGGGGGCTGAGAGGAGCCATTGCACCAATAAGAAATGAAATAATTCATTTAAAGAAGCATAGCTGGAAAAAATTTTTTAATAACCCTACTTTCAAAGTGAAAAAAAGTAAAATAATAAATGGGAAAACGAAAGATGTTACATCTGAATTCCTTTATAAAGAAACTTTATTTAAGGATTATTTCTATAGTGAGTTAGATTCTGTTCCAGAATTGATTATTAATAAAATGGAAAGTAGCAAAATTTTAGATTATTATTCCAGTGACCAGCTTAACCAAGTTTTTACAATTCCGAATTTCGAATTATCTTTACTGACTTCGGCCGTTCCCTTTGCACCTAGCTTTAAACGAGTTTATTTGAAAGGCTTTGATTATCAGAATCAAGATGAAGCACAACCGGATTATAATCTTAAATTAAATATCTATAACGAAAAAGCCTTTAATTCGGAGGCATTTCAGGCGCAATATTCATTATTTAAAATGGTTTATTATCAAGTCTTTTTACCGCAATTCACTACAAATAACGATTTATTTAAGTCAAGTGTGGATTTTATTTTAACATTAAACAAAGAACGGAAAGGTTACGCCAAAGCATTTCAAGATATTCGAAAGATGAATAAAGATGAAAAGCCCTCAGAATATATGAGTTACATTCAGAGTCAATTAATGCTCTATCAAAAAAAGCAAGAAGAAAAAGAGAAAATTAATCATTTTGAAAAATTTATAAATCAAGTGTTTATTAAAGGTTTCAATTCTTTTATAGAAAAGAATAGATTAACCTATATTTGCCATCCAACCAAAAACACAGTGCCAGAAAATGATAATATAGAAATACCTTTCCACACGGATATGGATGATTCCAATATTGCATTTTGGCTTATGTGTAAATTATTAGATGCTAAACAACTTAGCGAATTACGTAATGAAATGATAAAATTCAGTTGTTCCTTACAATCAACTGAAGAAATAAGCACATTTACCAAGGCGCGAGAAGTGATTGGTTTAGCTCTTTTAAATGGCGAAAAAGGATGTAATGATTGGAAAGAACTTTTTGATGATAAAGAAGCTTGGAAAAAGAACATGTCCTTATATGTTTCCGAGGAATTGCTTCAATCATTGCCGTACACACAAGAAGATGGTCAAACACCTGTAATTAATCGAAGTATCGATTTAGTAAAAAAATACGGTACAGAAACAATACTAGAGAAATTATTTTCCTCCTCAGATGATTATAAAGTTTCAGCTAAAGATATCGCAAAATTACATGAATATGATGTAACGGAGAAAATAGCACAGCAAGAGAGTCTACATAAGCAATGGATAGAAAAGCCCGGTTTAGCCCGTGACTCAGCATGGACAAAAAAATACCAAAATGTGATTAATGATATTAGTAATTACCAATGGGCTAAGACAAAGGTCGAATTAACACAAGTAAGGCATCTTCATCAATTAACTATTGATTTGCTTTCAAGGTTAGCAGGATATATGTCTATCGCTGACCGTGATTTCCAGTTTTCTAGTAATTATATTTTAGAAAGAGAGAACTCTGAGTATAGAGTTACAAGTTGGATATTATTAAGTGAAAATAAAAATAAAAATAAATATAACGACTACGAATTGTATAATCTAAAAAATGCCTCTATAAAAGTATCATCAAAAAATGATCCCCAGTTAAAAGTTGATCTTAAGCAATTACGATTAACCTTAGAGTACTTAGAACTTTTTGATAACCGATTGAAAGAAAAACGAAATAACATTTCACATTTTAATTACCTTAACGGACAGTTAGGGAACTCTATTTTAGAATTATTTGACGATGCTCGAGATGTACTTTCCTATGATCGTAAACTAAAGAATGCGGTGTCTAAATCTTTGAAAGAAATTTTAAGCTCTCATGGAATGGAAGTGACATTTAAACCACTATATCAAACCAATCATCATTTAAAAATTGATAAACTCCAACCTAAAAAAATACACCACTTAGGTGAAAAAAGTACTGTTTCTTCAAATCAAGTTTCTAATGAATACTGTCAACTAGTAAGAACGCTATTAACGATGAAGTAATTCTTTTAAAGCACATTAATTACCTCTAAATGAAAAGAGGACTAAAACTGAAAGAGGACTAAAACACCAGATGTGGATAACTATATTAGTGGCTATTAAAAATTCGTCGATATTAGAGAGGAAACTTTAGATGAAGATGAAATGGAAATTAAAAGAAAATGACGTTCGCAAAGGGGTGGTGGTCATTGAGTAAAATTGACATCGGAGAAGTAACCCACTTTTTACAAGGTCTAAAGAAAAGTAACGAAAACGCCCGAAAAATGATAGAAGACATTCAATCGGCTGTCAAAGCCTACGCTGATGATACAACTTTAAAAGGAAAAGCAGTGGATTCTTCACAAAGATACTTTGATGAAACGTATACTGTTATTTGTAAAAGTATCATAGAAGCATTAGATGAAAGCGAAGAGAGATTACAACAATATATTCATGATTTTGGAGATCAAGTGGATTCTTCACCTAACGCACGAATTGATGCGGAATTACTACAAGAAGCAATGAGTAGGTTAGCTGACATAAAGCGGAAGCAAGAAGCACTTATGCAATCCTTATCTTCTTCTACAGCAACGCTTTACGAAGGCAAGCAACAAGCGTTACACACTCAATTCACGGATGCGCTGGAGCAAGAAAAAATATTGGAACGCTATATTACTTTTGAACAAACTCACGGGAATTTTTTTGACTCATTTGGAGAACTTGTCTATCGAACGGGACAAGCAGTGCGTGAATTAGCTAATAACGTCACATTCGAGAGCCAAACAGGAAGCTATCATTTTGATAAAATAGATGCTTCTAGATTCCAAACTTTGCAAGAAATGTTGCCAAAGGCAAAGAAAAAAGCATTTAATTTTAATGACTACCAAATAACATGGAATGGCACCACGCACCTTTTATGGAAAAATGGTAAAGTGGATGCAGAAGCAACCAAAGCTTATAACGAGGCGAAACTGAATGGAAAGCTACCAAAGGAAGGTAATGTAGCAACACAAGATGCAGAACTATTAAAAGGCATTTTGGCTTCACTGAAAAACAAGAAAGATCCTATCACTGGAGCAGATATAAGCAGTGTGCATGTATTATCTATCCTTAGCGGGCTCGCATTCTCCTATACAGCTGGGAATTATAAGGGAAGAAAACTTACTGTTCCAAAAAGTTTCTTAGACAAATTAAAGAAAAACCGAAAATCTAAAGTACCTAAACTATCTAGTTTATCAGAAAAACAACAACTAAAACTCGCAAATAAATACAAGAAAAAATCACCTATTCCAATTCCAGATGATGCTAAAATCAAAGCTCAGACGAAAAAGGCTGGTTATGAACAAATATCTTATAAATGGAAAGAGAATGGGATAACCTTTGAAGTTAGATGGCATACTAGGACACCAGGTGCACCAAAGGAACAAGGAAATACGTTTGTTATAGAAAGAAAAATTCAGGGTACAGCAGAAGGGAAAACAAAAGTTCAACAAATATTGGTTGGAGATAATAAGTGGGTGAGTAAAAGTGAGTGGCAAAAGGCTATAACTGATAAGAAAAATGGTGTAAGTACCTCGGAGCAAAATAAAATGTTGTCTGATGGACATTGGAAAGAATAGAAAGGAGCAAAATGATGGAAGATTATTATAAAGGTTTTGAGGGATATCCAGAGATAGATTTTTATACGTATATAGATGATATGAAATTGGGTATAGCAATGTGGGAAGGATACTTTGACAACATTATGAAAGAAATTAATCCAAGTAACGGAAGATGGACTTCATTAGCGTATTATTATCATTTAGATGAGGGGTGGTATGATGAAAGTCCTTGGGAAATACCAAGTAATACAGAAGCATTAGAATTATTGGAAACAATCCATATATCTAATCTAGATACTATCACACAAGAGATATTACTTAAATTAATAAATTTATTAAAGAAGAATATAAATAGACAAGTTTATATTGAATACTCATAAAAAAGATGATTATGATATATTATAGAACAAACGAACAAGCCCCAAATACGAGGTTTGTTCGTTTGTTTTCAATATAATTATTTGCCACCAAGTGAGATATTACGGTTTTAAATAGCTTATTTGACGATACCAAACCCTGATAAGAGAAAGAAGAAAGAGAAAGCTGGTGTAGTTGTTTTAAGTGAACTAGATAAAAAATTAATAGCAAAACTTGAAAAAGATGGTGTGAAAATATCAAAAGAAGATGTTATAGGAATAAAATAATTGCCAGATGATGAGAAATCGTTTGGCTGGAAAAAGGAAATCCATCCGCTGGATTTGAGCATATTCTTATTGAACATGGTGAACAATTTGCTAAATAGGGAATTTCAAAAGCTGAGTTACCTGATTTTTTGATGACTGCTTTAGAAAAGGAAA (SEQ ID NO: 65).
>F-локус
ATTCTTTAAAAATATCTAATAATTTATTTACTATATACTCTAATACATCTTTTAACCTATCTAAAACATCATCACCTACAACATCCCAAAAATCATCTAAAAAGTTAAAAAAATCCATCTTTATCAACTCCTATATCTATTTTTTATTGTGTAATTCCTGAGTTACAAAACCATTATAACACGTATTACACACGTAGTCAATACTTCAAAAAAATTTTTTGTATATTTTTTTGAATAAGTAAATAAAAAGAGCTGTGTAGCTCTTTATTAAAATCAATATTTTTATTTTGTTAACAAACTTAGACAACATTAAATTTAGAAACCTATATATATTTCAGTACTTTTCATTTTTAGGTAGTCTAAATCAGAAATGGTTTTGTCTAAATGATGTATGTAAGTTTTAGTCCCCTTCGTTTTTAGGGTAGTCTAAATCAGAAGTCATTTAATAAGGCCACTGTTAAAAGTTTTAGTCCCCTTCGTTTTTAGGGTAGTCTAAATCCCATCCAAATTATGGGATAATATGTTACTTTTTATTTTAATATTTGATTATTTATTGTTTTTTTACTGATTTAGATTACCCCTTTAATTTATTTTACCATATTTTTCTCATAATGCAAACTAATATTCCAAAATTTTTGTTTCTTTTCTTATGATCTTTTCTCCGATAGTTATTTCTCCAGATAAGATTTTCATTTTTTTGAATTGATCTTCTGTTAGAATTAATGTTCTTACTGATGAATTTTCTGGAACTATCATTGACAACTGATTTTCATAGGAAATTATTTTTTCTTTTGTGCTAGAACTTACAATGTATACTGATTTTTGTACCTGATAATATCCTTTTCTTATAATTTCTTTTCTAAATTTTGCATATTCTTTTTTTTCTTTTCCTGTTTGCATTGGAAAATCATACATTAGAATCCCTACATAATTAGTACTCATAATCCTCTATCCTTAACTCAGGAATTTCTACTTCTGACATTTCTCCTGTAAAATAATTTCTAATATTATCTAAAAAATAATCAATCACTTGAGCCAATTCATATTTTTTATTTTTCCAATAAACTTTTTGTGTTAATACCAATAACAATTTTTGTCTTAATGATTTATTCAAACTTACTTCTTCCTGTTGATTAAAATATACGATATAATCTACCATTGGACGAAATATTTCAATAATATCATCTGCAAAATTATAATTATTAAATTGTGAACTGTGATGTATTCCCAAACTTGGATGAAATCCTTTAGCCACAATTTTTGAAGAGATTAAGCTTCTCAAAACCATATACCCATAATTTAATGCCGAATTTGTCCCGTCTTCACCAAATCTCTTAAATTTTTTCCCAAAAAGTTCACCAAAATACATTCTTGCAGCAATTGCTTCCTGATGTTCCGCTTCTTTTCCTTTTAATCTAATATTATTTTCATATGCTTCCAACTTATATGATACTTCCTGAGATTTTTTCAAAAACTGCAATAAATTTCTTTGATTTTCTATTTTTCTCATTACAATTTTTCTCCAGATTTCTTCTTTTTTATCGTCAATCCAGCTCACTTGCTCATTAATTCTTGTTGTTACTTGAAAATGATTATACAGTCCTAATGAATGTAAAACTGGCTGATGTTTTTCATTACAAATTATCAGTGGAATATTATGTTCTGATAATCTTAACTGTAATATTCCGCTAATTTTACATCTGCAATTTTCAACTACAATTGCCATGATATCATTTAAAGATACTTTATCAGCCTTATTTTCATCATCTTCATTTATCATCACAAGCTGGTTATTTAAAACTGATAATTCATTGACTCTTGTTACATGGATAATATTAGACATTTTTATTACTCCTTTACTCTAAAGCTTTATATTCAAACATAACTTTCACAAGTTCACACAATTCTTCTGAATTTCTATCAGTCATTAATTTTTTCTTTTTTAAATTTTTCAAATGTACAATTTTTTCCGATTCTAAAGTCTGAATTTCTATTTTCTTATCTGCTCCTATTTTAAATGTTGCTACAAAACCATATTCCTTTAATATATCCACTATTGATTTCATAATTGCATTTTTAAGTTTTCTATCATAAGAAAGTAATTTTCTTAAATTTTCCAGCACTTCTAAAAGTGAAATTTCAGCATGCGGAATATAGTTAAAATGTGCAATATAGTTTCGTATATACAAATCTTTTTTCTCTTGTTTTAATTTTTTTACTTTTTTATCAGAATAGATGCTTCTTTTTTCTACATTATCTTTGTATAATTCTTTATAAAAATTTATATATTTTTCAACAATTTGCCCACTTTTATATTTTACATTTTTACTGTTATCAAAATTAAATATTTCTTCAATATAATGATTTTCAGGAAATTCACCTTTCAATCTAAATCTTAAGTCCCTTTCCCAGATCGAAGTATATCCCACAAGTCTGTGGAGTATTTTTAATAACAAGCCTTGCAACAAGTTTAATTCATTAAATTCCACTTTATTTTTCAAATGAGTATATTTTTGTATATTTCCAATTGCTTTTTCATATTCTTTATAATCTTCATCATTAAATTTTTCATCTTTTTTAGGTCTTGCATATTTTCTATGTAAATTTTGCTGCATTGTATAATTTTTTTCTATTTCATTTTTTTTATTGCTGTATTCTTTCAATTCTTTTAAACTTATTTTATACTTCGCTTTATCAGCTATTTTTTCAAGTAAATTTAACATCCCATATTTTTTTATATTATAAAAAGCTCTATGCTTTATAATATTTTCTCCATCAAAATATATTTTATTTGTGTCAAATTTCTTCAATTCTTTCCTATCTTTTATTTTATTTTCATTAAAATCTAAAAATTTTCCAATTTCATTCGCTTCTAATTCAAAATCTTCTGTTACTCTATTATTATCTAAATTTAAAAGATTTATAAGTTCAAGTTCATCTGAAAAAGTTTCTTCTTTATTTGCACTCTGATATTTTTCAAGACTTCCCTTCAAATTAGTCAATTCTTTATGATTAAGCAATTTTAAAATTAAATAAAACATATTCAAATTTTCAGTGTATTTTAATATCTTTCCTAATTTTATCTCTCTTACAAATTCATTTATTTCATGTGGAATTTCTTTATTCCTATTATGTTTTTCATAATTTTTTAAAATTTTATCATATTTTTCTTTATTATCTTTTTTTATTTTTATTTTAGAAAATATATCATTATTATCATTGTTATTATTACTTTCTATATATTTTAAATTATTTTTATTCAAATAATCTATAAAACCTTTTAAAAATATTTGTTGTATAAAATCAATGTATGTATTTTTTTCTTCTTTATCTTGATTATTAATCATCTCCCTACTTTGTATAATAGCAAGATATTCTACTGGTACAGTTTTTTCTATATTTTCAAATTTTTGATATTTATAATGTCCTGTTTTTTGATTTCTTTGTTTATTTATTTTTATTACTTCATTAGTTATTTTAAAAAAAACTTTACTATTTTTAACAAATTTATTAAGAAATTCACCATAATAAATATTTTTCAAAAGATATATTTGAGCATCTTTTTCTTCTTTATCCTTAGGAACACTCCAAAAAAATTTTAAAGTATTTCTTAAATCTTCTATTTTATTATATAATTTCGTAAAAGAAGGAACAAAAGGAATATTCTTATTTACAAAATTAAATTTTGTATTTTTTAAATATTTAATTATCACATCCTTTTCATAATAATTAAATACATTTGCACTATTTAACTGCTTAAATATCTTCAATTTCAATTTTTTCTCATTTATTTCATTTTGAAACATTTTTTTTGAAATTTCAGAAGGAGCTATATTTTTAAATGCAAATATATCTTTCCCTTCTAATTCCAAATTAAAATGCACAATCCCATGTCTAATACTGCTAATAGCTTCATCAATATTTGCAAAAAAATCTTCTATCTCATTTTTATTATCCATATTAAAATCATAACTATAGAACATTTTTAAATTTTCTTTTACTTCATTTTGCTTGTTTTCATTATATATTTTATCAACTTCTCCAGAAACATATTTTTCTTCGCCCTTATTATTTTTTACAGTTTTTCCTCTCATTCTACCTGTAATATCATTCTCATTTTCAGTTTCAAGAATATTTCTCAATGAAAAATATGCAACCGAAGAAACTCCAATTATATTTCGTAAAAATGCTTCATTTTGTCTATTCCTAGCAATAAAATCACTTGTTGCAATCTCTCCAACTTGTAAATAATAATTGTATTTCCCACAATTTCTTACATAAGTATCCAATTTATTTAGTAATTTGTTTTCAATTAATTTTTTTAAATTTTGATATTCAAATATTCTCTTAATTTTATCGTTACTTATGTTACTCAGTCTTTTATACACATAATTTTTCAAAAGCTGACTCATTTCAATTTCCACAAAATGACAAAAAGCATATTTTATATTTTTATCATTAAGTTCTTCTTTATCCAAATAATATTTATAAAACACTTGTGATTTTTTTAATTCACTCATATCCGGAATTTTTTCAATTAATTCTTTTATATTATTTACATTTTGTATTTCTTCGTAAATAATTTTAGCAAAATTTTCTTTATCATTTTTTCTTCCAATTATTTTGTGATAGTATTCTCTTATTTTATATTTTTCATGTTTTTTTGAATTTTCTATTAAAAAAAATAACTTCTCAATATCTTCTTTTTTATACAATTTATCAAATGCTTCCTGTACATTATTTATATAATCATTACGCTTTGCTGATTCTCTATAATAATCATAAATAATATTTCTTTTGCTCTTCCCTCCAACTTTTTCAACATTATTTTCATTAATTTTCTGATAATTAGCCTTATTTTCTTCAAATGAATATTTTAAAGAATTTATCTTATTCAATTTTGCCTCAACATCTTTTCTAAATATTTCTAATTCTTCAGAGTTCACATCTTCATTTAACAATATTTTCTTTAAAACTGAAAAACTATTTTTATTTTTTAAATCATATTCTGAAATATCTTCTTCAGAATAATTTTTATCCTGTACTGCATTTTTCTCTTTCCTATTCTTTAAATACAGAACACTATCTTTTAGATGCAATACTTTATTTGAAAAAAACTTTTTTAAATTTTCTCTTCTTATTCTATTTTCTTCTTCACTTGCATTATCAGGATTTTTTATATATATATCCAGTCTTATACTTAAAAGCTCTGACAATCTCTCACTAGTCCTATTTTCTTCGCTCGTACTTTTTACTAATTTTCCCTCTTCAATATATTTTTTATGCGAAATTCCATCAACTTTTGTAACTTTCATATATAAAAACCTCCTAATATCTATATTTTTTACTCAATACCTAATTCTTTTTTCAATGCTTTTTGTAAAATTTGTGAAAAATTCAGATTTTTTTCCTGTGCCAATATATCTAACCAAACAGGAATTGTTAAAGTTTTCTTTTTAAGTGCATTTGTAACTTTTGCCACTTCATACACTGGATCAACAGATAAAATATACAAATACTGATTTTCTTTCAGTTTCACATCCTCCACTTTTGAAGGCTCAGGAAATTTTTTTCTTACATCCAAAAAATCAGCCAAATGCAGACCCAATGTCTCTCTCAAATTGGAAACAGCCTCCTCCATGCTATCTCCAAATGTAGCATAATAATTTATCTCTCCATCTTCAAACTTATCAAAATCAACAATACAACCATAATAAGTCCCATCTTCCTTAGTTACCACTGCTGGATAAAATACATCCATTTTAATTATCTCCAATCTATACCACGTGTTAAATACGTGTTTAAAAATATTTATAAAATTTTTTAGCATCTCTGCTAAAATAAAACAATTATTTCAAATTTTTCTATTCCTTAATCACTCATTGTTAGTGATTCTTTTTTTACTTGGACAATTTTTCATTTAATTTCTTCAATTTTTTTAAAATCACATTTTTTTAATATTCCTTATTTAATTGCAAATTTTCATTACTTTTGGGGTGCTCTAAATCCCATCCAAATTATGGGATAATAATTTTTAGTGAAAGCAAGAAGGGACTAGAATTTAATCCCAACTTGTTTTTCAATACTTCTTAATGTTCCTACAGGTATATCTTTTGAATATGGTACTGTGACCACACCTTCCACACCTGGGATCATCCATTGATAATGACTACCTCTTATACGCACAACTTTTCCGCCTAATTTTCTAAATCTTTTTTCGAT (SEQ ID NO: 66).
>G-локус
CTTTCTATCTTTTTCAAATAAAATTAGGCTCTAGTTAGCCTAATCGCATAATTATTTATTATAGTATAATTCTTATTTTTTTTCAACCTAAAAATTTAAAACATCTCCAAAAATTTTCGTTTCAGAACAACCAAGCAACCATATTCAAAAAACAATAAAAAATGAGCAAGAATTGAAATTTTATTCTCACTCAGAAGTTATTTTTATTAAATATCACTTTTCGATATTGGGGTGGTCTATATCAATTTAAAAGACAGAATAGATAATTCTTTAGAGTTTTAGTCCCCTTCGATATTGGGGTGGTCTATATCAGAAGTCATTTAATAAGGCCACTGTTAAAAGTTTTAGTCCCCTTCGATATTGGGGTGGTCTATATCCCATCCTAATTTCTTGCTGATGAGATATTTATTTCTAATTTTTCTATTTTGTCTTTATTTTCAATACTTTCAATCCTATTTTTCTCTTTATTAATAATATAGAACCACCCTATACTATTATACCATATTTTTTGATTTTTCAAAATTCCAATATTTTGTTTTGTGAAATTTTTTCTCCCATTGTCACTTCTCCTGCAAGTACCTTCATTTTTTGAAACTGATCTTCTGTCAGGATAATGGAACGGATTGATGAATTTTCTGGAGCGAGCATTGATAACTGTTTTTCTGCCAGTTCGATTTTTTCTTTTGTTTTCGACCTCATTATATATACCGATTTTTGAAGCTGATAATATCCCTTTTCTATCAATTTTTTCCTAAAAGTCCTATATTCAAATCTCTCAACATCTGTCTGCATAGGAAAATCATACATAAGCAGACCAAAATACTCAATACTCATAGTCCATCACGCTCAATGTCGGAATTATCACTTCTTCATCTTTTACAAAATAATTTCGTATACTATCCAAATAATAGTCTACCGCTTGGAAAAAATCATATTTCTTATTGTTAAATAATACCTTCTGCTGTGCTACAAGAAGTATTTTTTGCCTTATTTCCTTACTTAATTTCACTTCATTCAAAATATCCTTGTACATATAAACAAGATAATCCACCATAGGACGAAAAACCTCTATTATATCATCAGAAAAATTATAGGCATTAAACTGTGACTTATGATGTAATCCTAAACTTGGATGAAATCCTTTTGCTACAATCTTTGATGATATTATAGCTCTTAAAATCATATATCCATAATTAAGTGCAGAATTCACTCCATCTTCATCAAATCTTTTAAAACTATTACTATACAATTCCTGAAAATATATCCTTGAAGCTATTGCTTCCTGATGTTCTGCACTCGCATCATCTTTTTTCAAGTTTTCCTTATATGTTTTCAGTCTTTCAATGGAAATATCACTTTTTTCAAGATACTCTAACAATGCTCTTTGATTTTCAATCTTATTCTCCACTATCCTGCTCCACAATTTTTCCTTTTTCTCTTTTTCCCACTCAATCTGCTCATTTATTCGTAAAGTCACTTGAAAATGATTAAATAATCCCAGCGAATGAATTTCAGGCTGATGTTTCTCGTTGCAAATAATAATCGGAATGTTATTTTCCACCAGCCTCAACTGCAAAATCGCACTAATCTTACAATAGCAGTTTTCAATAACTATCGCAGATATATCATTCAAAGAAATCTTATTTTTCTCATCATTATTGTCTTCATCAACCATTATAAGCTGATTATTCGATATTGACAAATCATCAGCCCTTGTTATGTGAATTATATTGGGCATTTTAATCATACTCCTTATAAATTTCATTCTTATAACGTATCATTCGTATTTTCTATTTTTGTTAAAAGTTCTATTATCAAGTTTTTAATATAATCAGAATTATAACTTTCTAATTCTAAAACAGAAACTTTTTTAGGTTTCATTAATCTTTCAAGTATATCATTATTACCGATAAGTTTAAATTTTTTCTTTAATTCATCATAATCTAAATTCACATCTTTTTTAAATACTTCAAATACACTTGCATAAGTTGAATTATTATAACGTGTACTATATGATAATAAATTAGAAACTCTATCAATTTGTTCTGCAATACTGTAATCAGCAAACGGATTTCTTACAATATAGAAATGTGAAATATAGTTTCTAATACTTTCATTTTCCGGCTTATTAATTTCAGAATTTTCAGACAAATCAATTCCAAATCCATAACATATTTTCTCAAATTTTTTATAAGATTCTTCATCAAAAAATTTATAGTATGCTGTTGTTGTATAAAAGCCATCAGATCCATTACGCTTAGGATAAGCTCTACTTATTCCAGTATTGTAGCCACTTAACTTAATAATTCCTAATTCTCTTAGCCCATTTACAATATAGTGCATATCTCTTTCAAATCTAGCCATTTGAATAGCAAGTTTCCAATTTATATCTATCAAATAACTTTCTATTTTATTCAAATAATTAAATTCTACCAAATCTCTAATTTTTTTGTATTCAGAAACTCTATTATAATCTTTTTCAAATGATTTATAGTTTTTATTTTGTATATTTTTTGCAAAAAAGTCATCATTTTCTTTCAATTTTTTTATATACTTCTCTTTGTATTCTTTAGAATATCCATTTAGTTTATCATTTAGATTTTTCAATATTGCATCAATTTCAGATATTTTATTTTTTCTAATATTTTTACCATCAATATTAAATAAAAATTTTGCATCAGCCATTTTAATATCATTTGAAATTAATCCATAAATTTTATCAAAATTTGGATTTCCAATATTTAAAAATAAATTCTTTTTATAAATATATAATTCATTCTTACGTTCTTTAGGATAATATATTTCTTGAAATTTATTTTCATTCTCTGATTCCATATCTTCTATTAAATTATCTATTTCTTTTTTGTATTTTTTTAAAAAATCAGAATTAAATATTATTCTACACAATATTTTACTCTTTATTTCCTGATCTTTATCTTTTATATACTGATCAACCTTTTTTTTCAAATCCTTTTTATTTATGTTTGATAACTTTCTTTGTTCATCTTGTAATATATTCGATTTTTTATCTATCTCAAATTTAGTTTCATCATCAAAAATTACAATTTTTTCTAATTTTTTCTCTAAAACATCACAACCATTAATATCATCTTTAAATTCAGTTAATATATTATTTTTTATATCCTCATAATAATTATTAAAAATTTCTTTTTTAGTTTGTATTTTAAAATCATCAAAGTCTTTTTCTATCTCTTTCATTTTTTGAATAAATTCTTCTAAATTAAGATTCCAATTTTCAGTTATACATTCATTTCTCAAAGTATTTAATTGCATTATTTCATCTAAAATATCTATAATATTTTGATATTCTGAAGTATTTAACCAAACTGATGTTGCAAAAAATCTATTTCTAATTTTATTTATAACCGCATTACTATTTAACAGTGCAAATATTGAAATTATATATTCAAAATCATCATTTATTACTATAGTTTTATCACTAGTCTTTACAGTTATTCTTTCGTAAGTTTTATTATCATTAATGTCTTTTATTTGTTTCTTAATTTCTTGAATATTCATTTTAAAATCTGAAAAATCAAAAAGTTCCTCATAATTTTTTCTCAAATATCCAATATAACATTCTATTACTTTTTTCTGATATTTTTTAATAGCTTTATTATTACCTTTTGAAGCAGAAATCTGAGCATTTTTATAATAATTTTCTATAATATTTTCATCTATTTCATCAATGTTTCCTAAAGTTTTCTTTAATTCTTGTAAAAATATATTCTTACTTTCATTTTCTTCTAAATCATCTTCTAAAATTAATTTCTTATACAATTCTTTATTCACATATATTAAAGCATTTAATACTATTTTTTCTGTTTCTATAGTATCAAATGGTTCATTCTTAGGATTATTCCTATATAAATTTAATATTTCAGGAAGTACTTTAGAAAAGGATGGTAAATATTTAATATCATTATTATTTTCTTCTGAAATTTTAATATCATTTATTTTAGTAATTATATTTTTTTTATCTTTAAATACTACATCTAAATTTAATGCTTTTGACACTTCTTCATCTGATATTTTTAAATTTTGAATTATATTTATGACTTTATTATAGTCATCTTGCGTTCCTTGTAAATCTCTTTCCTTGCTAATCGCATGTAATATCCTGTTTCTTTCATTTGTTCCTATCTTTGTAAATTTCCTAATAAAATTATTTGTAATGTTATTTTTATTATCTATAAAATCTAAGTCTCTTATTATTTTTATTTTTGAATTTAAAATTTTTTTATCAAGTACGTAATTTTTTTCTCGATCTCCTCCAAAGAAATCTATATTTTCATCATTATTTATATTTTCTCTAGAAAAAATCTTATTTAATTCCATATTGGTAGAAGCAAAAAAAGTAATCAATTCTAAATCCAATTCCTCTTTAGCGTGAAGTCTAGAAAAATCATCAGTATTTACTGTTGTCATATCTATATCATTATGTCTTAATTTCCCTAAATACATAATATGCTCTAACGTATATTGCTTAACTCTTTTTAAAATTTTTTCAGATAATATACTTTCATTTAAAATTTTTTCTATTTCTATTTTTTCCATTTTCTTTAATCTGACTTTTTGTTCATTTACCAATATTTTTTCAATTCTTCCTTTCAAATATCGATATATGATTTTATATAGTTCTTTTTCTTCATCAGATTTCTTTGAAAATTTTTTCGAATCAAAATTAACTTTATAATGTTTTTTAAATATTCCAAAAATTTCTGTATCACAATTTCCTTTTTTTAGTTCTTTTTCTAATTTTTTTATTAATTCATCTATTTTAAATTCTGCTAAAATTTTTTCTATTTTTTCTTTTATACTATTATTTTTTATATTTTCTACAAAAAATTTTACAATTTTATCTTTTTTATTTTCTCTTTCTATTTTAAATTTTTCGTGCTTATCTAATAGTACATAAGATTTTATATATGTTCTATTTCTTCTCTTTTCAAGAAATTCATTATTAACTTTTTTTACTTTTTCAATTCTTTTAGTAATATTCCAAAATTCTAACTCTTTTATAACAAAATCAGCTATATCTTCTACTGTTAAATCTACATTTATATTTAAAATTTTTTCAACAAGCATTTTTTTATTTTTAGATTTCTTTTTATCACCACCAACATTAAGATAAAATTTTACAAAACCCAGAATTTCTAAATTACTTTTTATTTTTTCTCTTATTTCCATAAAATTAGTCAAAATAACATCTATTTTATCATCTTTCAATAATTTTTCTCTTAAATGTTCTTCATAATATCGATTTTCAAATACTTTTTCTGTTTCATTTTCAATTATTTTTTCTATAATCTTATATAAACTCATGTTAATATTTTTAAAAATTTCGTAAATTGATTTTTTTGTTTCTAATTCATCATTTTCTATTATTCTTAATATTATTGAACAATCATTTAGTGTTTTATTAGTATACTCATCTCTGATATCTATCTCTATTTCTTCTTCATTCTCTTGTCTCTTTATTTCTATTTTTTTATCATCTTTAGTTATTCCTTGCCTAATTGCTTCATCTATTATTTTCTTTTTTGTAATCCCCAATGCTTTCAATTTCTCAGATTTTCCATATGCTTCTATATATAATACAACTTCTTCTGTTTCCAAAAAATCATCATTATTTTCTATTCTTATGATTCCTTCTTTACCTTTCAACTTAAATAGAATATTTCCTGCATGAAATTTTCTTGTAAATTCTTTAAGAATATTATCATTTTTTTTGTAATTAATATATTTTCTAATAAATTTATTATTATCAATTTTTTCTTTATTATTATTTTCATTAATATTTAAAATGTATTTGTTTCCATCATAGTTCCTTTTAACTTTTACTTTCCGTTTTATTTTAAAATCTTTTTTATCACGAACTTCATACCATCTCTTATGTCCAAATAAATTTCCCATTCCAATCTCCTCGTTTCTACTTTAATCTAATAAAATATTTTTAAATTAAATCAATTTTACATCTTTCTAATCAAAAATACAATTTTCCATTTTTAGTATACCACATCAATATTAAATCTCAAAAAAATAAGGAGCCGTCAAACATAGCTCCCTACTTCTATTTACTCATAATCCCCATCTATCCTTACTTTTCGTAAAATCAATCCTTCTTTCGCCTTTAGATCCAACTTAATTTTCCCATTTGAACCTGTTCTAAATGTTCTGCCTTCTGTTACCAAATCAATAAATCTTTCATCCTGATAATTTGTTTCAAATTCCACATTTTCCCAGCTGTTAAACGAATTATTTATTACAACAATAATTAAATGATCCTCGATTACTCTTTCATACACAATTATTT (SEQ ID NO: 67).
Пример 3. Дополнительная оценка Cpf1 и ассоциированных компонентов
Заявители провели выравнивание последовательностей с ортологами Cas-Cpf1 и сравнили структуру и организацию доменов (фигура 38A-N). Обзор выравнивания локусов Cpf1 показан на фигуре 39.
Последовательности локусов Cpf1 у различных ортологов приведены ниже:
>KKP36646_(модифицированный) гипотетический белок UR27_C0015G0004 [Peregrinibacteria bacterium GW2011_GWA2_33_10]
MSNFFKNFTNLYELSKTLRFELKPVGDTLTNMKDHLEYDEKLQTFLKDQNIDDAYQALKPQFDEIHEEFITDSLESKKAKEIDFSEYLDLFQEKKELNDSEKKLRNKIGETFNKAGEKWKKEKYPQYEWKKGSKIANGADILSCQDMLQFIKYKNPEDEKIKNYIDDTLKGFFTYFGGFNQNRANYYETKKEASTAVATRIVHENLPKFCDNVIQFKHIIKRKKDGTVEKTERKTEYLNAYQYLKNNNKITQIKDAETEKMIESTPIAEKIFDVYYFSSCLSQKQIEEYNRIIGHYNLLINLYNQAKRSEGKHLSANEKKYKDLPKFKTLYKQIGCGKKKDLFYTIKCDTEEEANKSRNEGKESHSVEEIINKAQEAINKYFKSNNDCENINTVPDFINYILTKENYEGVYWSKAAMNTISDKYFANYHDLQDRLKEAKVFQKADKKSEDDIKIPEAIELSGLFGVLDSLADWQTTLFKSSILSNEDKLKIITDSQTPSEALLKMIFNDIEKNMESFLKETNDIITLKKYKGNKEGTEKIKQWFDYTLAINRMLKYFLVKENKIKGNSLDTNISEALKTLIYSDDAEWFKWYDALRNYLTQKPQDEAKENKLKLNFDNPSLAGGWDVNKECSNFCVILKDKNEKKYLAIMKKGENTLFQKEWTEGRGKNLTKKSNPLFEINNCEILSKMEYDFWADVSKMIPKCSTQLKAVVNHFKQSDNEFIFPIGYKVTSGEKFREECKISKQDFELNNKVFNKNELSVTAMRYDLSSTQEKQYIKAFQKEYWELLFKQEKRDTKLTNNEIFNEWINFCNKKYSELLSWERKYKDALTNWINFCKYFLSKYPKTTLFNYSFKESENYNSLDEFYRDVDICSYKLNINTTINKSILDRLVEEGKLYLFEIKNQDSNDGKSIGHKNNLHTIYWNAIFENFDNRPKLNGEAEIFYRKAISKDKLGIVKGKKTKNGTEIIKNYRFSKEKFILHVPITLNFCSNNEYVNDIVNTKFYNFSNLHFLGIDRGEKHLAYYSLVNKNGEIVDQGTLNLPFTDKDGNQRSIKKEKYFYNKQEDKWEAKEVDCWNYNDLLDAMASNRDMARKNWQRIGTIKEAKNGYVSLVIRKIADLAVNNERPAFIVLEDLNTGFKRSRQKIDKSVYQKFELALAKKLNFLVDKNAKRDEIGSPTKALQLTPPVNNYGDIENKKQAGIMLYTRANYTSQTDPATGWRKTIYLKAGPEETTYKKDGKIKNKSVKDQIIETFTDIGFDGKDYYFEYDKGEFVDEKTGEIKPKKWRLYSGENGKSLDRFRGEREKDKYEWKIDKIDIVKILDDLFVNFDKNISLLKQLKEGVELTRNNEHGTGESLRFAINLIQQIRNTGNNERDNDFILSPVRDENGKHFDSREYWDKETKGEKISMPSSGDANGAFNIARKGIIMNAHILANSDSKDLSLFVSDEEWDLHLNNKTEWKKQLNIFSSRKAMAKRKK (SEQ ID NO: 68).
>KKR91555_(модифицированный) гипотетический белок UU43_C0004G0003 [Parcubacteria (Falkowbacteria) bacterium GW2011_GWA2_41_14]
MLFFMSTDITNKPREKGVFDNFTNLYEFSKTLTFGLIPLKWDDNKKMIVEDEDFSVLRKYGVIEEDKRIAESIKIAKFYLNILHRELIGKVLGSLKFEKKNLENYDRLLGEIEKNNKNENISEDKKKEIRKNFKKELSIAQDILLKKVGEVFESNGSGILSSKNCLDELTKRFTRQEVDKLRRENKDIGVEYPDVAYREKDGKEETKSFFAMDVGYLDDFHKNRKQLYSVKGKKNSLGRRILDNFEIFCKNKKLYEKYKNLDIDFSEIERNFNLTLEKVFDFDNYNERLTQEGLDEYAKILGGESNKQERTANIHGLNQIINLYIQKKQSEQKAEQKETGKKKIKFNKKDYPTFTCLQKQILSQVFRKEIIIESDRDLIRELKFFVEESKEKVDKARGIIEFLLNHEENDIDLAMVYLPKSKINSFVYKVFKEPQDFLSVFQDGASNLDFVSFDKIKTHLENNKLTYKIFFKTLIKENHDFESFLILLQQEIDLLIDGGETVTLGGKKESITSLDEKKNRLKEKLGWFEGKVRENEKMKDEEEGEFCSTVLAYSQAVLNITKRAEIFWLNEKQDAKVGEDNKDMIFYKKFDEFADDGFAPFFYFDKFGNYLKRRSRNTTKEIKLHFGNDDLLEGWDMNKEPEYWSFILRDRNQYYLGIGKKDGEIFHKKLGNSVEAVKEAYELENEADFYEKIDYKQLNIDRFEGIAFPKKTKTEEAFRQVCKKRADEFLGGDTYEFKILLAIKKEYDDFKARRQKEKDWDSKFSKEKMSKLIEYYITCLGKRDDWKRFNLNFRQPKEYEDRSDFVRHIQRQAYWIDPRKVSKDYVDKKVAEGEMFLFKVHNKDFYDFERKSEDKKNHTANLFTQYLLELFSCENIKNIKSKDLIESIFELDGKAEIRFRPKTDDVKLKIYQKKGKDVTYADKRDGNKEKEVIQHRRFAKDALTLHLKIRLNFGKHVNLFDFNKLVNTELFAKVPVKILGMDRGENNLIYYCFLDEHGEIENGKCGSLNRVGEQIITLEDDKKVKEPVDYFQLLVDREGQRDWEQKNWQKMTRIKDLKKAYLGNVVSWISKEMLSGIKEGVVTIGVLEDLNSNFKRTRFFRERQVYQGFEKALVNKLGYLVDKKYDNYRNVYQFAPIVDSVEEMEKNKQIGTLVYVPASYTSKICPHPKCGWRERLYMKNSASKEKIVGLLKSDGIKISYDQKNDRFYFEYQWEQEHKSDGKKKKYSGVDKVFSNVSRMRWDVEQKKSIDFVDGTDGSITNKLKSLLKGKGIELDNINQQIVNQQKELGVEFFQSIIFYFNLIMQIRNYDKEKSGSEADYIQCPSCLFDSRKPEMNGKLSAITNGDANGAYNIARKGFMQLCRIRENPQEPMKLITNREWDEAVREWDIYSAAQKIPVLSEEN (SEQ ID NO: 69).
>KDN25524_(модифицированный) гипотетический белок MBO_03467 [Moraxella bovoculi 237]
MLFQDFTHLYPLSKTVRFELKPIDRTLEHIHAKNFLSQDETMADMHQKVKVILDDYHRDFIADMMGEVKLTKLAEFYDVYLKFRKNPKDDELQKQLKDLQAVLRKEIVKPIGNGGKYKAGYDRLFGAKLFKDGKELGDLAKFVIAQEGESSPKLAHLAHFEKFSTYFTGFHDNRKNMYSDEDKHTAIAYRLIHENLPRFIDNLQILTTIKQKHSALYDQIINELTASGLDVSLASHLDGYHKLLTQEGITAYNTLLGGISGEAGSPKIQGINELINSHHNQHCHKSERIAKLRPLHKQILSDGMSVSFLPSKFADDSEMCQAVNEFYRHYADVFAKVQSLFDGFDDHQKDGIYVEHKNLNELSKQAFGDFALLGRVLDGYYVDVVNPEFNERFAKAKTDNAKAKLTKEKDKFIKGVHSLASLEQAIEHYTARHDDESVQAGKLGQYFKHGLAGVDNPIQKIHNNHSTIKGFLERERPAGERALPKIKSGKNPEMTQLRQLKELLDNALNVAHFAKLLTTKTTLDNQDGNFYGEFGVLYDELAKIPTLYNKVRDYLSQKPFSTEKYKLNFGNPTLLNGWDLNKEKDNFGVILQKDGCYYLALLDKAHKKVFDNAPNTGKSIYQKMIYKYLEVRKQFPKVFFSKEAIAINYHPSKELVEIKDKGRQRSDDERLKLYRFILECLKIHPKYDKKFEGAIGDIQLFKKDKKGREVPISEKDLFDKINGIFSSKPKLEMEDFFIGEFKRYNPSQDLVDQYNIYKKIDSNDNRKKENFYNNHPKFKKDLVRYYYESMCKHEEWEESFEFSKKLQDIGCYVDVNELFTEIETRRLNYKISFCNINADYIDELVEQGQLYLFQIYNKDFSPKAHGKPNLHTLYFKALFSEDNLADPIYKLNGEAQIFYRKASLDMNETTIHRAGEVLENKNPDNPKKRQFVYDIIKDKRYTQDKFMLHVPITMNFGVQGMTIKEFNKKVNQSIQQYDEVNVIGIDRGERHLLYLTVINSKGEILEQCSLNDITTASANGTQMTTPYHKILDKREIERLNARVGWGEIETIKELKSGYLSHVVHQISQLMLKYNAIVVLEDLNFGFKRGRFKVEKQIYQNFENALIKKLNHLVLKDKADDEIGSYKNALQLTNNFTDLKSIGKQTGFLFYVPAWNTSKIDPETGFVDLLKPRYENIAQSQAFFGKFDKICYNADKDYFEFHIDYAKFTDKAKNSRQIWTICSHGDKRYVYDKTANQNKGAAKGINVNDELKSLFARHHINEKQPNLVMDICQNNDKEFHKSLMYLLKTLLALRYSNASSDEDFILSPVANDEGVFFNSALADDTQPQNADANGAYHIALKGLWLLNELKNSDDLNKVKLAIDNQTWLNFAQNR (SEQ ID NO: 70).
>KKT48220_(модифицированный) гипотетический белок UW39_C0001G0044 [Parcubacteria bacterium GW2011_GWC2_44_17]
MENIFDQFIGKYSLSKTLRFELKPVGKTEDFLKINKVFEKDQTIDDSYNQAKFYFDSLHQKFIDAALASDKTSELSFQNFADVLEKQNKIILDKKREMGALRKRDKNAVGIDRLQKEINDAEDIIQKEKEKIYKDVRTLFDNEAESWKTYYQEREVDGKKITFSKADLKQKGADFLTAAGILKVLKYEFPEEKEKEFQAKNQPSLFVEEKENPGQKRYIFDSFDKFAGYLTKFQQTKKNLYAADGTSTAVATRIADNFIIFHQNTKVFRDKYKNNHTDLGFDEENIFEIERYKNCLLQREIEHIKNENSYNKIIGRINKKIKEYRDQKAKDTKLTKSDFPFFKNLDKQILGEVEKEKQLIEKTREKTEEDVLIERFKEFIENNEERFTAAKKLMNAFCNGEFESEYEGIYLKNKAINTISRRWFVSDRDFELKLPQQKSKNKSEKNEPKVKKFISIAEIKNAVEELDGDIFKAVFYDKKIIAQGGSKLEQFLVIWKYEFEYLFRDIERENGEKLLGYDSCLKIAKQLGIFPQEKEAREKATAVIKNYADAGLGIFQMMKYFSLDDKDRKNTPGQLSTNFYAEYDGYYKDFEFIKYYNEFRNFITKKPFDEDKIKLNFENGALLKGWDENKEYDFMGVILKKEGRLYLGIMHKNHRKLFQSMGNAKGDNANRYQKMIYKQIADASKDVPRLLLTSKKAMEKFKPSQEILRIKKEKTFKRESKNFSLRDLHALIEYYRNCIPQYSNWSFYDFQFQDTGKYQNIKEFTDDVQKYGYKISFRDIDDEYINQALNEGKMYLFEVVNKDIYNTKNGSKNLHTLYFEHILSAENLNDPVFKLSGMAEIFQRQPSVNEREKITTQKNQCILDKGDRAYKYRRYTEKKIMFHMSLVLNTGKGEIKQVQFNKIINQRISSSDNEMRVNVIGIDRGEKNLLYYSVVKQNGEIIEQASLNEINGVNYRDKLIEREKERLKNRQSWKPVVKIKDLKKGYISHVIHKICQLIEKYSAIVVLEDLЯМРFKQIRGGIERSVYQQFEKALIDKLGYLVFKDNRDLRAPGGVLNGYQLSAPFVSFEKMRKQTGILFYTQAEYTSKTDPITGFRKNVYISNSASLDKIKEAVKKFDAIGWDGKEQSYFFKYNPYNLADEKYKNSTVSKEWAIFASAPRIRRQKGEDGYWKYDRVKVNEEFEKLLKVWNFVNPKATDIKQEIIKKEKAGDLQGEKELDGRLRNFWHSFIYLFNLVLELRNSFSLQIKIKAGEVIAVDEGVDFIASPVKPFFTTPNPYIPSNLCWLAVENADANGAYNIARKGVMILKKIREHAKKDPEFKKLPNLFISNAEWDEAARDWGKYAGTTALNLDH (SEQ ID NO: 71).
>WP_031492824_(модифицированный) гипотетический белок [Succinivibrio dextrinosolvens]
MSSLTKFTNKYSKQLTIKNELIPVGKTLENIKENGLIDGDEQLNENYQKAKIIVDDFLRDFINKALNNTQIGNWRELADALNKEDEDNIEKLQDKIRGIIVSKFETFDLFSSYSIKKDEKIIDDDNDVEEEELDLGKKTSSFKYIFKKNLFKLVLPSYLKTTNQDKLKIISSFDNFSTYFRGFFENRKNIFTKKPISTSIAYRIVHDNFPKFLDNIRCFNVWQTECPQLIVKADNYLKSKNVIAKDKSLANYFTVGAYDYFLSQNGIDFYNNIIGGLPAFAGHEKIQGLNEFINQECQKDSELKSKLKNRHAFKMAVLFKQILSDREKSFVIDEFESDAQVIDAVKNFYAEQCKDNNVIFNLLNLIKNIAFLSDDELDGIFIEGKYLSSVSQKLYSDWSKLRNDIEDSANSKQGNKELAKKIKTNKGDVEKAISKYEFSLSELNSIVHDNTKFSDLLSCTLHKVASEKLVKVNEGDWPKHLKNNEEKQKIKEPLDALLEIYNTLLIFNCKSFNKNGNFYVDYDRCINELSSVVYLYNKTRNYCTKKPYNTDKFKLNFNSPQLGEGFSKSKENDCLTLLFKKDDNYYVGIIRKGAKINFDDTQAIADNTDNCIFKMNYFLLKDAKKFIPKCSIQLKEVKAHFKKSEDDYILSDKEKFASPLVIKKSTFLLATAHVKGKKGNIKKFQKEYSKENPTEYRNSLNEWIAFCKEFLKTYKAATIFDITTLKKAEEYADIVEFYKDVDNLCYKLEFCPIKTSFIENLIDNGDLYLFRINNKDFSSKSTGTKNLHTLYLQAIFDERNLNNPTIMLNGGAELFYRKESIEQKNRITHKAGSILVNKVCKDGTSLDDKIRNEIYQYENKFIDTLSDEAKKVLPNVIKKEATHDITKDKRFTSDKFFFHCPLTINYKEGDTKQFNNEVLSFLRGNPDINIIGIDRGERNLIYVTVINQKGEILDSVSFNTVTNKSSKIEQTVDYEEKLAVREKERIEAKRSWDSISKIATLKEGYLSAIVHEICLLMIKHNAIVVLENLNAGFKRIRGGLSEKSVYQKFEKMLINKLNYFVSKKESDWNKPSGLLNGLQLSDQFESFEKLGIQSGFIFYVPAAYTSKIDPTTGFANVLNLSKVRNVDAIKSFFSNFNEISYSKKEALFKFSFDLDSLSKKGFSSFVKFSKSKWNVYTFGERIIKPKNKQGYREDKRINLTFEMKKLLNEYKVSFDLENNLIPNLTSANLKDTFWKELFFIFKTTLQLRNSVTNGKEDVLISPVKNAKGEFFVSGTHNKTLPQDCDANGAYHIALKGLMILERNNLVREEKDTKKIMAISNVDWFEYVQKRRGVL (SEQ ID NO: 72).
>KKT50231_(модифицированный) гипотетический белок UW40_C0007G0006 [Parcubacteria bacterium GW2011_GWF2_44_17]
MKPVGKTEDFLKINKVFEKDQTIDDSYNQAKFYFDSLHQKFIDAALASDKTSELSFQNFADVLEKQNKIILDKKREMGALRKRDKNAVGIDRLQKEINDAEDIIQKEKEKIYKDVRTLFDNEAESWKTYYQEREVDGKKITFSKADLKQKGADFLTAAGILKVLKYEFPEEKEKEFQAKNQPSLFVEEKENPGQKRYIFDSFDKFAGYLTKFQQTKKNLYAADGTSTAVATRIADNFIIFHQNTKVFRDKYKNNHTDLGFDEENIFEIERYKNCLLQREIEHIKNENSYNKIIGRINKKIKEYRDQKAKDTKLTKSDFPFFKNLDKQILGEVEKEKQLIEKTREKTEEDVLIERFKEFIENNEERFTAAKKLMNAFCNGEFESEYEGIYLKNKAINTISRRWFVSDRDFELKLPQQKSKNKSEKNEPKVKKFISIAEIKNAVEELDGDIFKAVFYDKKIIAQGGSKLEQFLVIWKYEFEYLFRDIERENGEKLLGYDSCLKIAKQLGIFPQEKEAREKATAVIKNYADAGLGIFQMMKYFSLDDKDRKNTPGQLSTNFYAEYDGYYKDFEFIKYYNEFRNFITKKPFDEDKIKLNFENGALLKGWDENKEYDFMGVILKKEGRLYLGIMHKNHRKLFQSMGNAKGDNANRYQKMIYKQIADASKDVPRLLLTSKKAMEKFKPSQEILRIKKEKTFKRESKNFSLRDLHALIEYYRNCIPQYSNWSFYDFQFQDTGKYQNIKEFTDDVQKYGYKISFRDIDDEYINQALNEGKMYLFEVVNKDIYNTKNGSKNLHTLYFEHILSAENLNDPVFKLSGMAEIFQRQPSVNEREKITTQKNQCILDKGDRAYKYRRYTEKKIMFHMSLVLNTGKGEIKQVQFNKIINQRISSSDNEMRVNVIGIDRGEKNLLYYSVVKQNGEIIEQASLNEINGVNYRDKLIEREKERLKNRQSWKPVVKIKDLKKGYISHVIHKICQLIEKYSAIVVLEDLЯМРFKQIRGGIERSVYQQFEKALIDKLGYLVFKDNRDLRAPGGVLNGYQLSAPFVSFEKMRKQTGILFYTQAEYTSKTDPITGFRKNVYISNSASLDKIKEAVKKFDAIGWDGKEQSYFFKYNPYNLADEKYKNSTVSKEWAIFASAPRIRRQKGEDGYWKYDRVKVNEEFEKLLKVWNFVNPKATDIKQEIIKKEKAGDLQGEKELDGRLRNFWHSFIYLFNLVLELRNSFSLQIKIKAGEVIAVDEGVDFIASPVKPFFTTPNPYIPSNLCWLAVENADANGAYNIARKGVMILKKIREHAKKDPEFKKLPNLFISNAEWDEAARDWGKYAGTTALNLDH (SEQ ID NO: 73).
>WP_004356401_(модифицированный) гипотетический белок [Prevotella disiens]
MENYQEFTNLFQLNKTLRFELKPIGKTCELLEEGKIFASGSFLEKDKVRADNVSYVKKEIDKKHKIFIEETLSSFSISNDLLKQYFDCYNELKAFKKDCKSDEEEVKKTALRNKCTSIQRAMREAISQAFLKSPQKKLLAIKNLIENVFKADENVQHFSEFTSYFSGFETNRENFYSDEEKSTSIAYRLVHDNLPIFIKNIYIFEKLKEQFDAKTLSEIFENYKLYVAGSSLDEVFSLEYFNNTLTQKGIDNYNAVIGKIVKEDKQEIQGLNEHINLYNQKHKDRRLPFFISLKKQILSDREALSWLPDMFKNDSEVIKALKGFYIEDGFENNVLTPLATLLSSLDKYNLNGIFIRNNEALSSLSQNVYRNFSIDEAIDANAELQTFNNYELIANALRAKIKKETKQGRKSFEKYEEYIDKKVKAIDSLSIQEINELVENYVSEFNSNSGNMPRKVEDYFSLMRKGDFGSNDLIENIKTKLSAAEKLLGTKYQETAKDIFKKDENSKLIKELLDATKQFQHFIKPLLGTGEEADRDLVFYGDFLPLYEKFEELTLLYNKVRNRLTQKPYSKDKIRLCFNKPKLMTGWVDSKTEKSDNGTQYGGYLFRKKNEIGEYDYFLGISSKAQLFRKNEAVIGDYERLDYYQPKANTIYGSAYEGENSYKEDKKRLNKVIIAYIEQIKQTNIKKSIIESISKYPNISDDDKVTPSSLLEKIKKVSIDSYNGILSFKSFQSVNKEVIDNLLKTISPLKNKAEFLDLINKDYQIFTEVQAVIDEICKQKTFIYFPISNVELEKEMGDKDKPLCLFQISNKDLSFAKTFSANLRKKRGAENLHTMLFKALMEGNQDNLDLGSGAIFYRAKSLDGNKPTHPANEAIKCRNVANKDKVSLFTYDIYKNRRYMENKFLFHLSIVQNYKAANDSAQLNSSATEYIRKADDLHIIGIDRGERNLLYYSVIDMKGNIVEQDSLNIIRNNDLETDYHDLLDKREKERKANRQNWEAVEGIKDLKKGYLSQAVHQIAQLMLKYNAIIALEDLGQMFVTRGQKIEKAVYQQFEKSLVDKLSYLVDKKRPYNELGGILKAYQLASSITKNNSDKQNGFLFYVPAWNTSKIDPVTGFTDLLRPKAMTIKEAQDFFGAFDNISYNDKGYFEFETNYDKFKIRMKSAQTRWTICTFGNRIKRKKDKNYWNYEEVELTEEFKKLFKDSNIDYENCNLKEEIQNKDNRKFFDDLIKLLQLTLQMRNSDDKGNDYIISPVANAEGQFFDSRNGDKKLPLDADANGAYNIARKGLWNIRQIKQTKNDKKLNLSISSTEWLDFVREKPYLK (SEQ ID NO: 74).
>CCB70584_(модифицированный) белок с неизвестной функцией [Flavobacterium branchiophilum FL-15]
MTNKFTNQYSLSKTLRFELIPQGKTLEFIQEKGLLSQDKQRAESYQEMKKTIDKFHKYFIDLALSNAKLTHLETYLELYNKSAETKKEQKFKDDLKKVQDNLRKEIVKSFSDGDAKSIFAILDKKELITVELEKWFENNEQKDIYFDEKFKTFTTYFTGFHQNRKNMYSVEPNSTAIAYRLIHENLPKFLENAKAFEKIKQVESLQVNFRELMGEFGDEGLIFVNELEEMFQINYYNDVLSQNGITIYNSIISGFTKNDIKYKGLNEYINNYNQTKDKKDRLPKLKQLYKQILSDRISLSFLPDAFTDGKQVLKAIFDFYKINLLSYTIEGQEESQNLLLLIRQTIENLSSFDTQKIYLKNDTHLTTISQQVFGDFSVFSTALNYWYETKVNPKFETEYSKANEKKREILDKAKAVFTKQDYFSIAFLQEVLSEYILTLDHTSDIVKKHSSNCIADYFKNHFVAKKENETDKTFDFIANITAKYQCIQGILENADQYEDELKQDQKLIDNLKFFLDAILELLHFIKPLHLKSESITEKDTAFYDVFENYYEALSLLTPLYNMVRNYVTQKPYSTEKIKLNFENAQLLNGWDANKEGDYLTTILKKDGNYFLAIMDKKHNKAFQKFPEGKENYEKMVYKLLPGVNKMLPKVFFSNKNIAYFNPSKELLENYKKETHKKGDTFNLEHCHTLIDFFKDSLNKHEDWKYFDFQFSETKSYQDLSGFYREVEHQGYKINFKNIDSEYIDGLVNEGKLFLFQIYSKDFSPFSKGKPNMHTLYWKALFEEQNLQNVIYKLNGQAEIFFRKASIKPKNIILHKKKIKIAKKHFIDKKTKTSEIVPVQTIKNLNMYYQGKISEKELTQDDLRYIDNFSIFNEKNKTIDIIKDKRFTVDKFQFHVPITMNFKATGGSYINQTVLEYLQNNPEVKIIGLDRGERHLVYLTLIDQQGNILKQESLNTITDSKISTPYHKLLDNKENERDLARKNWGTVENIKELKEGYISQVVHKIATLMLEENAIVVMEDLNFGFKRGRFKVEKQIYQKLEKMLIDKLNYLVLKDKQPQELGGLYNALQLTNKFESFQKMGKQSGFLFYVPAWNTSKIDPTTGFVNYFYTKYENVDKAKAFFEKFEAIRFNAEKKYFEFEVKKYSDFNPKAEGTQQAWTICTYGERIETKRQKDQNNKFVSTPINLTEKIEDFLGKNQIVYGDGNCIKSQIASKDDKAFFETLLYWFKMTLQMRNSETRTDIDYLISPVMNDNGTFYNSRDYEKLENPTLPKDADANGAYHIAKKGLMLLNKIDQADLTKKVDLSISNRDWLQFVQKNK (SEQ ID NO: 75).
>WP_005398606_(модифицированный) гипотетический белок [Helcococcus kunzii]
MFEKLSNIVSISKTIRFKLIPVGKTLENIEKLGKLEKDFERSDFYPILKNISDDYYRQYIKEKLSDLNLDWQKLYDAHELLDSSKKESQKNLEMIQAQYRKVLFNILSGELDKSGEKNSKDLIKNNKALYGKLFKKQFILEVLPDFVNNNDSYSEEDLEGLNLYSKFTTRLKNFWETRKNVFTDKDIVTAIPFRAVNENFGFYYDNIKIFNKNIEYLENKIPNLENELKEADILDDNRSVKDYFTPNGFNYVITQDGIDVYQAIRGGFTKENGEKVQGINEILNLTQQQLRRKPETKNVKLGVLTKLRKQILEYSESTSFLIDQIEDDNDLVDRINKFNVSFFESTEVSPSLFEQIERLYNALKSIKKEEVYIDARNTQKFSQMLFGQWDVIRRGYTVKITEGSKEEKKKYKEYLELDETSKAKRYLNIREIEELVNLVEGFEEVDVFSVLLEKFKMNNIERSEFEAPIYGSPIKLEAIKEYLEKHLEEYHKWKLLLIGNDDLDTDETFYPLLNEVISDYYIIPLYNLTRNYLTRKHSDKDKIKVNFDFPTLADGWSESKISDNRSIILRKGGYYYLGILIDNKLLINKKNKSKKIYEILIYNQIPEFSKSIPNYPFTKKVKEHFKNNVSDFQLIDGYVSPLIITKEIYDIKKEKKYKKDFYKDNNTNKNYLYTIYKWIEFCKQFLYKYKGPNKESYKEMYDFSTLKDTSLYVNLNDFYADVNSCAYRVLFNKIDENTIDNAVEDGKLLLFQIYNKDFSPESKGKKNLHTLYWLSMFSEENLRTRKLKLNGQAEIFYRKKLEKKPIIHKEGSILLNKIDKEGNTIPENIYHECYRYLNKKIGREDLSDEAIALFNKDVLKYKEARFDIIKDRRYSESQFFFHVPITFNWDIKTNKNVNQIVQGMIKDGEIKHIIGIDRGERHLLYYSVIDLEGNIVEQGSLNTLEQNRFDNSTVKVDYQNKLRTREEDRDRARKNWTNINKIKELKDGYLSHVVHKLSRLIIKYEAIVIMENLNQGFKRGRFKVERQVYQKFELALMNKLSALSFKEKYDERKNLEPSGILNPIQACYPVDAYQELQGQNGIVFYLPAAYTSVIDPVTGFTNLFRLKSINSSKYEEFIKKFKNIYFDNEEEDFKFIFNYKDFAKANLVILNNIKSKDWKISTRGERISYNSKKKEYFYVQPTEFLINKLKELNIDYENIDIIPLIDNLEEKAKRKILKALFDTFKYSVQLRNYDFENDYIISPTADDNGNYYNSNEIDIDKTNLPNNGDANGAFNIARKGLLLKDRIVNSNESKVDLKIKNEDWINFIIS (SEQ ID NO: 76).
>WP_021736722_(модифицированный) CRISPR-ассоциированный белок Cpf1, подтип PREFRAN [Acidaminococcus sp. BV3L6]
MTQFEGFTNLYQVSKTLRFELIPQGKTLKHIQEQGFIEEDKARNDHYKELKPIIDRIYKTYADQCLQLVQLDWENLSAAIDSYRKEKTEETRNALIEEQATYRNAIHDYFIGRTDNLTDAINKRHAEIYKGLFKAELFNGKVLKQLGTVTTTEHENALLRSFDKFTTYFSGFYENRKNVFSAEDISTAIPHRIVQDNFPKFKENCHIFTRLITAVPSLREHFENVKKAIGIFVSTSIEEVFSFPFYNQLLTQTQIDLYNQLLGGISREAGTEKIKGLNEVLNLAIQKNDETAHIIASLPHRFIPLFKQILSDRNTLSFILEEFKSDEEVIQSFCKYKTLLRNENVLETAEALFNELNSIDLTHIFISHKKLETISSALCDHWDTLRNALYERRISELTGKITKSAKEKVQRSLKHEDINLQEIISAAGKELSEAFKQKTSEILSHAHAALDQPLPTTLKKQEEKEILKSQLDSLLGLYHLLDWFAVDESNEVDPEFSARLTGIKLEMEPSLSFYNKARNYATKKPYSVEKFKLNFQMPTLASGWDVNKEKNNGAILFVKNGLYYLGIMPKQKGRYKALSFEPTEKTSEGFDKMYYDYFPDAAKMIPKCSTQLKAVTAHFQTHTTPILLSNNFIEPLEITKEIYDLNNPEKEPKKFQTAYAKKTGDQKGYREALCKWIDFTRDFLSKYTKTTSIDLSSLRPSSQYKDLGEYYAELNPLLYHISFQRIAEKEIMDAVETGKLYLFQIYNKDFAKGHHGKPNLHTLYWTGLFSPENLAKTSIKLNGQAELFYRPKSRMKRMAHRLGEKMLNKKLKDQKTPIPDTLYQELYDYVNHRLSHDLSDEARALLPNVITKEVSHEIIKDRRFTSDKFFFHVPITLNYQAANSPSKFNQRVNAYLKEHPETPIIGIDRGERNLIYITVIDSTGKILEQRSLNTIQQFDYQKKLDNREKERVAARQAWSVVGTIKDLKQGYLSQVIHEIVDLMIHYQAVVVLENLNFGFKSKRTGIAEKAVYQQFEKMLIDKLNCLVLKDYPAEKVGGVLNPYQLTDQFTSFAKMGTQSGFLFYVPAPYTSKIDPLTGFVDPFVWKTIKNHESRKHFLEGFDFLHYDVKTGDFILHFKMNRNLSFQRGLPGFMPAWDIVFEKNETQFDAKGTPFIAGKRIVPVIENHRFTGRYRDLYPANELIALLEEKGIVFRDGSNILPKLLENDDSHAIDTMVALIRSVLQMRNSNAATGEDYINSPVRDLNGVCFDSRFQNPEWPMDADANGAYHIALKGQLLLNHLKESKDLKLQNGISNQDWLAYIQELRN (SEQ ID NO: 77).
>WP_004339290_(модифицированный) гипотетический белок [Francisella tularensis]
MSIYQEFVNKYSLSKTLRFELIPQGKTLENIKARGLILDDEKRAKDYKKAKQIIDKYHQFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISKYINDSEKFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWTTYFKGFHENRKNVYSSNDIPTSIIYRIVDDNLPKFLENKAKYESLKDKAPEAINYEQIKKDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGENTKRKGINEYINLYSQQINDKTLKKYKMSVLFKQILSDTESKSFVIDKLEDDSDVVTTMQSFYEQIAAFKTVEEKSIKETLSLLFDDLKAQKLDLSKIYFKNDKSLTDLSQQVFDDYSVIGTAVLEYITQQVAPKNLDNPSKKEQDLIAKKTEKAKYLSLETIKLALEEFNKHRDIDKQCRFEEILSNFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEEDVKAIKDLLDQTNNLLHRLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYITQKPYSDEKFKLNFENSTLASGWDKNKESANTAILFIKDDKYYLGIMDKKHNKIFSDKAIEENKGEGYKKIVYKQIADASKDIQNLMIIDGKTVCKKGRKDRNGVNRQLLSLKRKHLPENIYRIKETKSYLKNEARFSRKDLYDFIDYYKDRLDYYDFEFELKPSNEYSDFNDFTNHIGSQGYKLTFENISQDYINSLVNEGKLYLFQIYSKDFSAYSKGRPNLHTLYWKALFDERNLQDVVYKLNGEAELFYRKQSIPKKITHPAKETIANKNKDNPKKESVFEYDLIKDKRFTEDKFFFHCPITINFKSSGANKFNDEINLLLKEKANDVHILSIDRGERHLAYYTLVDGKGNIIKQDNFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQVVHEIAKLVIEYNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEFDKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESVSKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKNHNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQMRNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLDRIKNNQEGKKLNLVIKNEEYFEFVQNRNN (SEQ ID NO: 78).
>WP_022501477_(модифицированный) гипотетический белок [Eubacterium sp. CAG:76]
MNKAADNYTGGNYDEFIALSKVQKTLRNELKPTPFTAEHIKQRGIISEDEYRAQQSLELKKIADEYYRNYITHKLNDINNLDFYNLFDAIEEKYKKNDKDNRDKLDLVEKSKRGEIAKMLSADDNFKSMFEAKLITKLLPDYVERNYTGEDKEKALETLALFKGFTTYFKGYFKTRKNMFSGEGGASSICHRIVNVNASIFYDNLKTFMRIQEKAGDEIALIEEELTEKLDGWRLEHIFSRDYYNEVLAQKGIDYYNQICGDINKHMNLYCQQNKFKANIFKMMKIQKQIMGISEKAFEIPPMYQNDEEVYASFNEFISRLEEVKLTDRLINILQNINIYNTAKIYINARYYTNVSSYVYGGWGVIDSAIERYLYNTIAGKGQSKVKKIENAKKDNKFMSVKELDSIVAEYEPDYFNAPYIDDDDNAVKAFGGQGVLGYFNKMSELLADVSLYTIDYNSDDSLIENKESALRIKKQLDDIMSLYHWLQTFIIDEVVEKDNAFYAELEDICCELENVVTLYDRIRNYVTKKPYSTQKFKLNFASPTLAAGWSRSKEFDNNAIILLRNNKYYIAIFNVNNKPDKQIIKGSEEQRLSTDYKKMVYNLLPGPNKMLPKVFIKSDTGKRDYNPSSYILEGYEKNRHIKSSGNFDINYCHDLIDYYKACINKHPEWKNYGFKFKETNQYNDIGQFYKDVEKQGYSISWAYISEEDINKLDEEGKIYLFEIYNKDLSAHSTGRDNLHTMYLKNIFSEDNLKNICIELNGEAELFYRKSSMKSNITHKKDTILVNKTYINETGVRVSLSDEDYMKVYNYYNNNYVIDTENDKNLIDIIEKIGHRKSKIDIVKDKRYTEDKYFLYLPITINYGIEDENVNSKIIEYIAKQDNMNVIGIDRGERNLIYISVIDNKGNIIEQKSFNLVNNYDYKNKLKNMEKTRDNARKNWQEIGKIKDVKSGYLSGVISKIARMVIDYNAIIVMEDLNKGFKRGRFKVERQVYQKFENMLISKLNYLVFKERKADENGGILRGYQLTYIPKSIKNVGKQCGCIFYVPAAYTSKIDPATGFINIFDFKKYSGSGINAKVKDKKEFLMSMNSIRYINECSEEYEKIGHRELFAFSFDYNNFKTYNVSSPVNEWTAYTYGERIKKLYKDGRWLRSEVLNLTENLIKLMEQYNIEYKDGHDIREDISHMDETRNADFICSLFEELKYTVQLRNSKSEAEDENYDRLVSPILNSSNGFYDSSDYMENENNTTHTMPKDADANGAYCIALKGLYEINKIKQNWSDDKKFKENELYINVTEWLDYIQNRRFE (SEQ ID NO: 79).
>WP_014550095_(модифицированный) гипотетический белок [Francisella tularensis]
MSIYQEFVNKYSLSKTLRFELIPQGKTLENIKARGLILDDEKRAKDYKKAKQIIDKYHQFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSEKFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWTTYFKGFHENRKNVYSSNDIPTSIIYRIVDDNLPKFLENKAKYESLKDKAPEAINYEQIKKDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGENTKRKGINEYINLYSQQINDKTLKKYKMSVLFKQILSDTESKSFVIDKLEDDSDVVTTMQSFYEQIAAFKTVEEKSIKETLSLLFDDLKAQKLDLSKIYFKNDKSLTDLSQQVFDDYSVIGTAVLEYITQQVAPKNLDNPSKKEQDLIAKKTEKAKYLSLETIKLALEEFNKHRDIDKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIKDLLDQTNNLLHRLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYITQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFDDKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKNGNPQKGYEKFEFNIEDCRKFIDFYKESISKHPEWKDFGFRFSDTQRYNSIDEFYREVENQGYKLTFENISESYIDSVVNQGKLYLFQIYNKDFSAYSKGRPNLHTLYWKALFDERNLQDVVYKLNGEAELFYRKKSIPKKITHPAKEAIANKNKDNPKKESFFEYDLIKDKRFTEDKFFFHCPITINFKSSGANKFNDEINLLLKEKANDVHILSIDRGERHLAYYTLVDGKGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQVVHEIAKLVIEHNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEFDKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESVSKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKNHNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSILNTILQMRNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLDRIKNNQEGKKLNLVIKNEEYFEFVQNRNN (SEQ ID NO: 80).
>WP_003034647_(модифицированный) гипотетический белок [Francisella tularensis]
MSIYQEFVNKYSLSKTLRFELIPQGKTLENIKARGLILDDEKRAKDYKKAKQIIDKYHQFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSEKFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWTTYFKGFHENRKNVYSSDDIPTSIIYRIVDDNLPKFLENKAKYESLKDKAPEAINYEQIKKDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGENTKRKGINEYINLYSQQINDKTLKKYKMSVLFKQILSDTESKSFVIDKLEDDSDVVTTMQSFYEQIAAFKTVEEKSIKETLSLLFDDLKAQKLDLSKIYFKNDKSLTDLSQQVFDDYSVIGTAVLEYITQQVAPKNLDNPSKKEQDLIAKKTEKAKYLSLETIKLALEEFNKHRDIDKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISLKYQNQGKKDLLQASAEEDVKAIKDLLDQTNNLLHRLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYITQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFDDKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKNGNPQKGYEKFEFNIEDCRKFIDFYKESISKHPEWKDFGFRFSDTQRYNSIDEFYREVENQGYKLTFENISESYIDSVVNQGKLYLFQIYNKDFSAYSKGRPNLHTLYWKALFDERNLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKRFTEDKFFFHCPITINFKSSGANKFNDEINLLLKEKANDVHILSIDRGERHLAYYTLVDGKGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQVVHEIAKLVIEHNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEFDKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESVSKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKNHNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQMRNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLDRIKNNQEGKKLNLVIKNEEYFEFVQNRNN (SEQ ID NO: 81).
>FnCpf1 Francisella tularensis subsp. novicida U112, полный геном
MSIYQEFVNKYSLSKTLRFELIPQGKTLENIKARGLILDDEKRAKDYKKAKQIIDKYHQFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSEKFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWTTYFKGFHENRKNVYSSNDIPTSIIYRIVDDNLPKFLENKAKYESLKDKAPEAINYEQIKKDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGENTKRKGINEYINLYSQQINDKTLKKYKMSVLFKQILSDTESKSFVIDKLEDDSDVVTTMQSFYEQIAAFKTVEEKSIKETLSLLFDDLKAQKLDLSKIYFKNDKSLTDLSQQVFDDYSVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDIDKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIKDLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYITQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFDDKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKNGSPQKGYEKFEFNIEDCRKFIDFYKQSISKHPEWKDFGFRFSDTQRYNSIDEFYREVENQGYKLTFENISESYIDSVVNQGKLYLFQIYNKDFSAYSKGRPNLHTLYWKALFDERNLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKRFTEDKFFFHCPITINFKSSGANKFNDEINLLLKEKANDVHILSIDRGERHLAYYTLVDGKGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQVVHEIAKLVIEYNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEFDKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESVSKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKNHNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQMRNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLGRIKNNQEGKKLNLVIKNEEYFEFVQNRNN (SEQ ID NO: 82).
>KKQ38174_(модифицированный) гипотетический белок US54_C0016G0015 [Microgenomates (Roizmanbacteria) bacterium GW2011_GWA2_37_7]
MKSFDSFTNLYSLSKTLKFEMRPVGNTQKMLDNAGVFEKDKLIQKKYGKTKPYFDRLHREFIEEALTGVELIGLDENFRTLVDWQKDKKNNVAMKAYENSLQRLRTEIGKIFNLKAEDWVKNKYPILGLKNKNTDILFEEAVFGILKARYGEEKDTFIEVEEIDKTGKSKINQISIFDSWKGFTGYFKKFFETRKNFYKNDGTSTAIATRIIDQNLKRFIDNLSIVESVRQKVDLAETEKSFSISLSQFFSIDFYNKCLLQDGIDYYNKIIGGETLKNGEKLIGLNELINQYRQNNKDQKIPFFKLLDKQILSEKILFLDEIKNDTELIEALSQFAKTAEEKTKIVKKLFADFVENNSKYDLAQIYISQEAFNTISNKWTSETETFAKYLFEAMKSGKLAKYEKKDNSYKFPDFIALSQMKSALLSISLEGHFWKEKYYKISKFQEKTNWEQFLAIFLYEFNSLFSDKINTKDGETKQVGYYLFAKDLHNLILSEQIDIPKDSKVTIKDFADSVLTIYQMAKYFAVEKKRAWLAEYELDSFYTQPDTGYLQFYDNAYEDIVQVYNKLRNYLTKKPYSEEKWKLNFENSTLANGWDKNKESDNSAVILQKGGKYYLGLITKGHNKIFDDRFQEKFIVGIEGGKYEKIVYKFFPDQAKMFPKVCFSAKGLEFFRPSEEILRIYNNAEFKKGETYSIDSMQKLIDFYKDCLTKYEGWACYTFRHLKPTEEYQNNIGEFFRDVAEDGYRIDFQGISDQYIHEKNEKGELHLFEIHNKDWNLDKARDGKSKTTQKNLHTLYFESLFSNDNVVQNFPIKLNGQAEIFYRPKTEKDKLESKKDKKGNKVIDHKRYSENKIFFHVPLTLNRTKNDSYRFNAQINNFLANNKDINIIGVDRGEKHLVYYSVITQASDILESGSLNELNGVNYAEKLGKKAENREQARRDWQDVQGIKDLKKGYISQVVRKLADLAIKHNAIIILEDLЯМРFKQVRGGIEKSIYQQLEKALIDKLSFLVDKGEKNPEQAGHLLKAYQLSAPFETFQKMGKQTGIIFYTQASYTSKSDPVTGWRPHLYLKYFSAKKAKDDIAKFTKIEFVNDRFELTYDIKDFQQAKEYPNKTVWKVCSNVERFRWDKNLNQNKGGYTHYTNITENIQELFTKYGIDITKDLLTQISTIDEKQNTSFFRDFIFYFNLICQIRNTDDSEIAKKNGKDDFILSPVEPFFDSRKDNGNKLPENGDDNGAYNIARKGIVILNKISQYSEKNENCEKMKWGDLYVSNIDWDNFVTQANARH (SEQ ID NO: 83).
>WP_022097749_(модифицированный) гипотетический белок [Eubacterium eligens CAG:72]
MNGNRSIVYREFVGVTPVAKTLRNELRPVGHTQEHIIQNGLIQEDELRQEKSTELKNIMDDYYREYIDKSLSGLTDLDFTLLFELMNSVQSSLSKDNKKALEKEHNKMREQICTHLQSDSDYKNMFNAKLFKEILPDFIKNYNQYDVKDKAGKLETLALFNGFSTYFTDFFEKRKNVFTKEAVSTSIAYRIVHENSLIFLANMTSYKKISEKALDEIEVIEKNNQDKMGDWELNQIFNPDFYNMVLIQSGIDFYNEICGVVNAHMNLYCQQTKNNYNLFKMRKLHKQILAYTSTSFEVPKMFEDDMSVYNAVNAFIDETEKGNIIGKLKDIVNKYDELDEKRIYISKDFYETLSCFMSGNWNLITGCVENFYDENIHAKGKSKEEKVKKAVKEDKYKSINDVNDLVEKYIDEKERNEFKNSNAKQYIREISNIITDTETAHLEYDEHISLIESEEKADEIKKRLDMYMNMYHWVKAFIVDEVLDRDEMFYSDIDDIYNILENIVPLYNRVRNYVTQKPYTSKKIKLNFQSPTLANGWSQSKEFDNNAIILIRDNKYYLAIFNAKNKPDKKIIQGNSDKKNDNDYKKMVYNLLPGANKMLPKVFLSKKGIETFKPSDYIISGYNAHKHIKTSENFDISFCRDLIDYFKNSIEKHAEWRKYEFKFSATDSYNDISEFYREVEMQGYRIDWTYISEADINKLDEEGKIYLFQIYNKDFAENSTGKENLHTMYFKNIFSEENLKNIVIKLNGQAELFYRKASVKNPVKHKKDSVLVNKTYKNQLDNGDVVRIPIPDDIYNEIYKMYNGYIKESDLSEAAKEYLDKVEVRTAQKDIVKDYRYTVDKYFIHTPITINYKVTARNNVNDMAVKYIAQNDDIHVIGIDRGERNLIYISVIDSHGNIVKQKSYNILNNYDYKKKLVEKEKTREYARKNWKSIGNIKELKEGYISGVVHEIAMLMVEYNAIIAMEDLNYGFKRGRFKVERQVYQKFESMLINKLNYFASKGKSVDEPGGLLKGYQLTYVPDNIKNLGKQCGVIFYVPAAFTSKIDPSTGFISAFNFKSISTNASRKQFFMQFDEIRYCAEKDMFSFGFDYNNFDTYNITMGKTQWTVYTNGERLQSEFNNARRTGKTKSINLTETIKLLLEDNEINYADGHDVRIDMEKMYEDKNSEFFAQLLSLYKLTVQMRNSYTEAEEQEKGISYDKIISPVINDEGEFFDSDNYKESDDKECKMPKDADANGAYCIALKGLYEVLKIKSEWTEDGFDRNCLKLPHAEWLDFIQNKRYE (SEQ ID NO: 84).
>WP_012739647_(модифицированный) гипотетический белок [[Eubacterium] eligens]
MNGNRSIVYREFVGVIPVAKTLRNELRPVGHTQEHIIQNGLIQEDELRQEKSTELKNIMDDYYREYIDKSLSGVTDLDFTLLFELMNLVQSSPSKDNKKALEKEQSKMREQICTHLQSDSNYKNIFNAKLLKEILPDFIKNYNQYDVKDKAGKLETLALFNGFSTYFTDFFEKRKNVFTKEAVSTSIAYRIVHENSLIFLANMTSYKKISEKALDEIEVIEKNNQDKMGDWELNQIFNPDFYNMVLIQSGIDFYNEICGVVNAHMNLYCQQTKNNYNLFKMRKLHKQILAYTSTSFEVPKMFEDDMSVYNAVNAFIDETEKGNIIGKLKDIVNKYDELDEKRIYISKDFYETLSCFMSGNWNLITGCVENFYDENIHAKGKSKEEKVKKAVKEDKYKSINDVNDLVEKYIDEKERNEFKNSNAKQYIREISNIITDTETAHLEYDDHISLIESEEKADEMKKRLDMYMNMYHWAKAFIVDEVLDRDEMFYSDIDDIYNILENIVPLYNRVRNYVTQKPYNSKKIKLNFQSPTLANGWSQSKEFDNNAIILIRDNKYYLAIFNAKNKPDKKIIQGNSDKKNDNDYKKMVYNLLPGANKMLPKVFLSKKGIETFKPSDYIISGYNAHKHIKTSENFDISFCRDLIDYFKNSIEKHAEWRKYEFKFSATDSYSDISEFYREVEMQGYRIDWTYISEADINKLDEEGKIYLFQIYNKDFAENSTGKENLHTMYFKNIFSEENLKDIIIKLNGQAELFYRRASVKNPVKHKKDSVLVNKTYKNQLDNGDVVRIPIPDDIYNEIYKMYNGYIKESDLSEAAKEYLDKVEVRTAQKDIVKDYRYTVDKYFIHTPITINYKVTARNNVNDMVVKYIAQNDDIHVIGIDRGERNLIYISVIDSHGNIVKQKSYNILNNYDYKKKLVEKEKTREYARKNWKSIGNIKELKEGYISGVVHEIAMLIVEYNAIIAMEDLNYGFKRGRFKVERQVYQKFESMLINKLNYFASKEKSVDEPGGLLKGYQLTYVPDNIKNLGKQCGVIFYVPAAFTSKIDPSTGFISAFNFKSISTNASRKQFFMQFDEIRYCAEKDMFSFGFDYNNFDTYNITMGKTQWTVYTNGERLQSEFNNARRTGKTKSINLTETIKLLLEDNEINYADGHDIRIDMEKMDEDKKSEFFAQLLSLYKLTVQMRNSYTEAEEQENGISYDKIISPVINDEGEFFDSDNYKESDDKECKMPKDADANGAYCIALKGLYEVLKIKSEWTEDGFDRNCLKLPHAEWLDFIQNKRYE (SEQ ID NO: 85).
>WP_045971446_(модифицированный) гипотетический белок [Flavobacterium sp. 316]
MKNFSNLYQVSKTVRFELKPIGNTLENIKNKSLLKNDSIRAESYQKMKKTIDEFHKYFIDLALNNKKLSYLNEYIALYTQSAEAKKEDKFKADFKKVQDNLRKEIVSSFTEGEAKAIFSVLDKKELITIELEKWKNENNLAVYLDESFKSFTTYFTGFHQNRKNMYSAEANSTAIAYRLIHENLPKFIENSKAFEKSSQIAELQPKIEKLYKEFEAYLNVNSISELFEIDYFNEVLTQKGITVYNNIIGGRTATEGKQKIQGLNEIINLYNQTKPKNERLPKLKQLYKQILSDRISLSFLPDAFTEGKQVLKAVFEFYKINLLSYKQDGVEESQNLLELIQQVVKNLGNQDVNKIYLKNDTSLTTIAQQLFGDFSVFSAALQYRYETVVNPKYTAEYQKANEAKQEKLDKEKIKFVKQDYFSIAFLQEVVADYVKTLDENLDWKQKYTPSCIADYFTTHFIAKKENEADKTFNFIANIKAKYQCIQGILEQADDYEDELKQDQKLIDNIKFFLDAILEVVHFIKPLHLKSESITEKDNAFYDVFENYYEALNVVTPLYNMVRNYVTQKPYSTEKIKLNFENAQLLNGWDANKEKDYLTTILKRDGNYFLAIMDKKHNKTFQQFTEDDENYEKIVYKLLPGVNKMLPKVFFSNKNIAFFNPSKEILDNYKNNTHKKGATFNLKDCHALIDFFKDSLNKHEDWKYFDFQFSETKTYQDLSGFYKEVEHQGYKINFKKVSVSQIDTLIEEGKMYLFQIYNKDFSPYAKGKPNMHTLYWKALFETQNLENVIYKLNGQAEIFFRKASIKKKNIITHKAHQPIAAKNPLTPTAKNTFAYDLIKDKRYTVDKFQFHVPITMNFKATGNSYINQDVLAYLKDNPEVNIIGLDRGERHLVYLTLIDQKGTILLQESLNVIQDEKTHTPYHTLLDNKEIARDKARKNWGSIESIKELKEGYISQVVHKITKMMIEHNAIVVMEDLNFGFKRGRFKVEKQIYQKLEKMLIDKLNYLVLKDKQPHELGGLYNALQLTNKFESFQKMGKQSGFLFYVPAWNTSKIDPTTGFVNYFYTKYENVEKAKTFFSKFDSILYNKTKGYFEFVVKNYSDFNPKAADTRQEWTICTHGERIETKRQKEQNNNFVSTTIQLTEQFVNFFEKVGLDLSKELKTQLIAQNEKSFFEELFHLLKLTLQMRNSESHTEIDYLISPVANEKGIFYDSRKATASLPIDADANGAYHIAKKGLWIMEQINKTNSEDDLKKVKLAISNREWLQYVQQVQKK (SEQ ID NO: 86).
>WP_044110123_(модифицированный) гипотетический белок [Prevotella brevis]
MKQFTNLYQLSKTLRFELKPIGKTLEHINANGFIDNDAHRAESYKKVKKLIDDYHKDYIENVLNNFKLNGEYLQAYFDLYSQDTKDKQFKDIQDKLRKSIASALKGDDRYKTIDKKELIRQDMKTFLKKDTDKALLDEFYEFTTYFTGYHENRKNMYSDEAKSTAIAYRLIHDNLPKFIDNIAVFKKIANTSVADNFSTIYKNFEEYLNVNSIDEIFSLDYYNIVLTQTQIEVYNSIIGGRTLEDDTKIQGINEFVNLYNQQLANKKDRLPKLKPLFKQILSDRVQLSWLQEEFNTGADVLNAVKEYCTSYFDNVEESVKVLLTGISDYDLSKIYITNDLALTDVSQRMFGEWSIIPNAIEQRLRSDNPKKTNEKEEKYSDRISKLKKLPKSYSLGYINECISELNGIDIADYYATLGAINTESKQEPSIPTSIQVHYNALKPILDTDYPREKNLSQDKLTVMQLKDLLDDFKALQHFIKPLLGNGDEAEKDEKFYGELMQLWEVIDSITPLYNKVRNYCTRKPFSTEKIKVNFENAQLLDGWDENKESTNASIILRKNGMYYLGIMKKEYRNILTKPMPSDGDCYDKVVYKFFKDITTMVPKCTTQMKSVKEHFSNSNDDYTLFEKDKFIAPVVITKEIFDLNNVLYNGVKKFQIGYLNNTGDSFGYNHAVEIWKSFCLKFLKAYKSTSIYDFSSIEKNIGCYNDLNSFYGAVNLLLYNLTYRKVSVDYIHQLVDEDKMYLFMIYNKDFSTYSKGTPNMHTLYWKMLFDESNLNDVVYKLNGQAEVFYRKKSITYQHPTHPANKPIDNKNVNNPKKQSNFEYDLIKDKRYTVDKFMFHVPITLNFKGMGNGDINMQVREYIKTTDDLHFIGIDRGERHLLYICVINGKGEIVEQYSLNEIVNNYKGTEYKTDYHTLLSERDKKRKEERSSWQTIEGIKELKSGYLSQVIHKITQLMIKYNAIVLLEDLNMGFKRGRQKVESSVYQQFEKALIDKLNYLVDKNKDANEIGGLLHAYQLTNDPKLPNKNSKQSGFLFYVPAWNTSKIDPVTGFVNLLDTRYENVAKAQAFFKKFDSIRYNKEYDRFEFKFDYSNFTAKAEDTRTQWTLCTYGTRIETFRNAEKNSNWDSREIDLTTEWKTLFTQHNIPLNANLKEAILLQANKNFYTDILHLMKLTLQMRNSVTGTDIDYMVSPVANECGEFFDSRKVKEGLPVNADANGAYNIARKGLWLAQQIKNANDLSDVKLAITNKEWLQFAQKKQYLKD (SEQ ID NO: 87).
>WP_036388671_(модифицированный) гипотетический белок [Moraxella caprae]
MLFQDFTHLYPLSKTMRFELKPIGKTLEHIHAKNFLSQDETMADMYQKVKAILDDYHRDFIADMMGEVKLTKLAEFYDVYLKFRKNPKDDGLQKQLKDLQAVLRKEIVKPIGNGGKYKAGYDRLFGAKLFKDGKELGDLAKFVIAQEGESSPKLAHLAHFEKFSTYFTGFHDNRKNMYSDEDKHTAITYRLIHENLPRFIDNLQILATIKQKHSALYDQIINELTASGLDVSLASHLDGYHKLLTQEGITAYNTLLGGISGEAGSRKIQGINELINSHHNQHCHKSERIAKLRPLHKQILSDGMGVSFLPSKFADDSEMCQAVNEFYRHYADVFAKVQSLFDGFDDHQKDGIYVEHKNLNELSKQAFGDFALLGRVLDGYYVDVVNPEFNERFAKAKTDNAKAKLTKEKDKFIKGVHSLASLEQAIEHYTARHDDESVQAGKLGQYFKHGLAGVDNPIQKIHNNHSTIKGFLERERPAGERALPKIKSGKNPEMTQLRQLKELLDNALNVAHFAKLLTTKTTLDNQDGNFYGEFGALYDELAKIPTLYNKVRDYLSQKPFSTEKYKLNFGNPTLLNGWDLNKEKDNFGIILQKDGCYYLALLDKAHKKVFDNAPNTGKNVYQKMIYKLLPGPNKMLPKVFFAKSNLDYYNPSAELLDKYAQGTHKKGNNFNLKDCHALIDFFKAGINKHPEWQHFGFKFSPTSSYQDLSDFYREVEPQGYQVKFVDINADYINELVEQGQLYLFQIYNKDFSPKAHGKPNLHTLYFKALFSKDNLANPIYKLNGEAQIFYRKASLDMNETTIHRAGEVLENKNPDNPKKRQFVYDIIKDKRYTQDKFMLHVPITMNFGVQGMTIKEFNKKVNQSIQQYDEVNVIGIDRGERHLLYLTVINSKGEILEQRSLNDITTASANGTQMTTPYHKILDKREIERLNARVGWGEIETIKELKSGYLSHVVHQISQLMLKYNAIVVLEDLNFGFKRGRFKVEKQIYQNFENALIKKLNHLVLKDEADDEIGSYKNALQLTNNFTDLKSIGKQTGFLFYVPAWNTSKIDPETGFVDLLKPRYENIAQSQAFFGKFDKICYNADKDYFEFHIDYAKFTDKAKNSRQIWKICSHGDKRYVYDKTANQNKGATKGINVNDELKSLFARHHINDKQPNLVMDICQNNDKEFHKSLIYLLKTLLALRYSNASSDEDFILSPVANDEGMFFNSALADDTQPQNADANGAYHIALKGLWVLEQIKNSDDLNKVKLAIDNQTWLNFAQNR (SEQ ID NO: 88).
>WP_020988726_(модифицированный) CRISPR-ассоциированный белок Cpf1, подтип PREFRAN [Leptospira inadai]
MEDYSGFVNIYSIQKTLRFELKPVGKTLEHIEKKGFLKKDKIRAEDYKAVKKIIDKYHRAYIEEVFDSVLHQKKKKDKTRFSTQFIKEIKEFSELYYKTEKNIPDKERLEALSEKLRKMLVGAFKGEFSEEVAEKYKNLFSKELIRNEIEKFCETDEERKQVSNFKSFTTYFTGFHSNRQNIYSDEKKSTAIGYRIIHQNLPKFLDNLKIIESIQRRFKDFPWSDLKKNLKKIDKNIKLTEYFSIDGFVNVLNQKGIDAYNTILGGKSEESGEKIQGLNEYINLYRQKNNIDRKNLPNVKILFKQILGDRETKSFIPEAFPDDQSVLNSITEFAKYLKLDKKKKSIIAELKKFLSSFNRYELDGIYLANDNSLASISTFLFDDWSFIKKSVSFKYDESVGDPKKKIKSPLKYEKEKEKWLKQKYYTISFLNDAIESYSKSQDEKRVKIRLEAYFAEFKSKDDAKKQFDLLERIEEAYAIVEPLLGAEYPRDRNLKADKKEVGKIKDFLDSIKSLQFFLKPLLSAEIFDEKDLGFYNQLEGYYEEIDSIGHLYNKVRNYLTGKIYSKEKFKLNFENSTLLKGWDENREVANLCVIFREDQKYYLGVMDKENNTILSDIPKVKPNELFYEKMVYKLIPTPHMQLPRIIFSSDNLSIYNPSKSILKIREAKSFKEGKNFKLKDCHKFIDFYKESISKNEDWSRFDFKFSKTSSYENISEFYREVERQGYNLDFKKVSKFYIDSLVEDGKLYLFQIYNKDFSIFSKGKPNLHTIYFRSLFSKENLKDVCLKLNGEAEMFFRKKSINYDEKKKREGHHPELFEKLKYPILKDKRYSEDKFQFHLPISLNFKSKERLNFNLKVNEFLKRNKDINIIGIDRGERNLLYLVMINQKGEILKQTLLDSMQSGKGRPEINYKEKLQEKEIERDKARKSWGTVENIKELKEGYLSIVIHQISKLMVENNAIVVLEDLNIGFKRGRQKVERQVYQKFEKMLIDKLNFLVFKENKPTEPGGVLKAYQLTDEFQSFEKLSKQTGFLFYVPSWNTSKIDPRTGFIDFLHPAYENIEKAKQWINKFDSIRFNSKMDWFEFTADTRKFSENLMLGKNRVWVICTTNVERYFTSKTANSSIQYNSIQITEKLKELFVDIPFSNGQDLKPEILRKNDAVFFKSLLFYIKTTLSLRQNNGKKGEEEKDFILSPVVDSKGRFFNSLEASDDEPKDADANGAYHIALKGLMNLLVLNETKEENLSRPKWKIKNKDWLEFVWERNR (SEQ ID NO: 89).
>WP_023936172_(модифицированный) экзонуклеаза SbcC [Porphyromonas crevioricanis]
MPWIDLKDFTNLYPVSKTLRFELKPVGKTLENIEKAGILKEDEHRAESYRRVKKIIDTYHKVFIDSSLENMAKMGIENEIKAMLQSFCELYKKDHRTEGEDKALDKIRAVLRGLIVGAFTGVCGRRENTVQNEKYESLFKEKLIKEILPDFVLSTEAESLPFSVEEATRSLKEFDSFTSYFAGFYENRKNIYSTKPQSTAIAYRLIHENLPKFIDNILVFQKIKEPIAKELEHIRADFSAGGYIKKDERLEDIFSLNYYIHVLSQAGIEKYNALIGKIVTEGDGEMKGLNEHINLYNQQRGREDRLPLFRPLYKQILSDREQLSYLPESFEKDEELLRALKEFYDHIAEDILGRTQQLMTSISEYDLSRIYVRNDSQLTDISKKMLGDWNAIYMARERAYDHEQAPKRITAKYERDRIKALKGEESISLANLNSCIAFLDNVRDCRVDTYLSTLGQKEGPHGLSNLVENVFASYHEAEQLLSFPYPEENNLIQDKDNVVLIKNLLDNISDLQRFLKPLWGMGDEPDKDERFYGEYNYIRGALDQVIPLYNKVRNYLTRKPYSTRKVKLNFGNSQLLSGWDRNKEKDNSCVILRKGQNFYLAIMNNRHKRSFENKVLPEYKEGEPYFEKMDYKFLPDPNKMLPKVFLSKKGIEIYEPSPKLLEQYGHGTHKKGDTFSMDDLHELIDFFKHSIEAHEDWKQFGFKFSDTATYENVSSFYREVEDQGYKLSFRKVSESYVYSLIDQGKLYLFQIYNKDFSPCSKGTPNLHTLYWRMLFDERNLADVIYKLDGKAEIFFREKSLKNDHPTHPAGKPIKKKSRQKKGEESLFEYDLVKDRRYTMDKFQFHVPITMNFKCSAGSKVNDMVNAHIREAKDMHVIGIDRGERNLLYICVIDSRGTILDQISLNTINDIDYHDLLESRDKDRQQERRNWQTIEGIKELKQGYLSQAVHRIAELMVAYKAVVALEDLNMGFKRGRQKVESSVYQQFEKQLIDKLNYLVDKKKRPEDIGGLLRAYQFTAPFKSFKEMGKQNGFLFYIPAWNTSNIDPTTGFVNLFHAQYENVDKAKSFFQKFDSISYNPKKDWFEFAFDYKNFTKKAEGSRSMWILCTHGSRIKNFRNSQKNGQWDSEEFALTEAFKSLFVRYEIDYTADLKTAIVDEKQKDFFVDLLKLFKLTVQMRNSWKEKDLDYLISPVAGADGRFFDTREGNKSLPKDADANGAYNIALKGLWALRQIRQTSEGGKLKLAISNKEWLQFVQERSYEKD (SEQ ID NO: 90).
>WP_009217842_(модифицированный) гипотетический белок [Bacteroidetes из ротовой полости, таксон 274]
MRKFNEFVGLYPISKTLRFELKPIGKTLEHIQRNKLLEHDAVRADDYVKVKKIIDKYHKCLIDEALSGFTFDTEADGRSNNSLSEYYLYYNLKKRNEQEQKTFKTIQNNLRKQIVNKLTQSEKYKRIDKKELITTDLPDFLTNESEKELVEKFKNFTTYFTEFHKNRKNMYSKEEKSTAIAFRLINENLPKFVDNIAAFEKVVSSPLAEKINALYEDFKEYLNVEEISRVFRLDYYDELLTQKQIDLYNAIVGGRTEEDNKIQIKGLNQYINEYNQQQTDRSNRLPKLKPLYKQILSDRESVSWLPPKFDSDKNLLIKIKECYDALSEKEKVFDKLESILKSLSTYDLSKIYISNDSQLSYISQKMFGRWDIISKAIREDCAKRNPQKSRESLEKFAERIDKKLKTIDSISIGDVDECLAQLGETYVKRVEDYFVAMGESEIDDEQTDTTSFKKNIEGAYESVKELLNNADNITDNNLMQDKGNVEKIKTLLDAIKDLQRFIKPLLGKGDEADKDGVFYGEFTSLWTKLDQVTPLYNMVRNYLTSKPYSTKKIKLNFENSTLMDGWDLNKEPDNTTVIFCKDGLYYLGIMGKKYNRVFVDREDLPHDGECYDKMEYKLLPGANKMLPKVFFSETGIQRFLPSEELLGKYERGTHKKGAGFDLGDCRALIDFFKKSIERHDDWKKFDFKFSDTSTYQDISEFYREVEQQGYKMSFRKVSVDYIKSLVEEGKLYLFQIYNKDFSAHSKGTPNMHTLYWKMLFDEENLKDVVYKLNGEAEVFFRKSSITVQSPTHPANSPIKNKNKDNQKKESKFEYDLIKDRRYTVDKFLFHVPITMNFKSVGGSNINQLVKRHIRSATDLHIIGIDRGERHLLYLTVIDSRGNIKEQFSLNEIVNEYNGNTYRTDYHELLDTREGERTEARRNWQTIQNIRELKEGYLSQVIHKISELAIKYNAVIVLEDLNFGFMRSRQKVEKQVYQKFEKMLIDKLNYLVDKKKPVAETGGLLRAYQLTGEFESFKTLGKQSGILFYVPAWNTSKIDPVTGFVNLFDTHYENIEKAKVFFDKFKSIRYNSDKDWFEFVVDDYTRFSPKAEGTRRDWTICTQGKRIQICRNHQRNNEWEGQEIDLTKAFKEHFEAYGVDISKDLREQINTQNKKEFFEELLRLLRLTLQMRNSMPSSDIDYLISPVANDTGCFFDSRKQAELKENAVLPMNADANGAYNIARKGLLAIRKMKQEENDSAKISLAISNKEWLKFAQTKPYLED (SEQ ID NO: 91).
>WP_036890108_(модифицированный) гипотетический белок [Porphyromonas crevioricanis]
MDSLKDFTNLYPVSKTLRFELKPVGKTLENIEKAGILKEDEHRAESYRRVKKIIDTYHKVFIDSSLENMAKMGIENEIKAMLQSFCELYKKDHRTEGEDKALDKIRAVLRGLIVGAFTGVCGRRENTVQNEKYESLFKEKLIKEILPDFVLSTEAESLPFSVEEATRSLKEFDSFTSYFAGFYENRKNIYSTKPQSTAIAYRLIHENLPKFIDNILVFQKIKEPIAKELEHIRADFSAGGYIKKDERLEDIFSLNYYIHVLSQAGIEKYNALIGKIVTEGDGEMKGLNEHINLYNQQRGREDRLPLFRPLYKQILSDREQLSYLPESFEKDEELLRALKEFYDHIAEDILGRTQQLMTSISEYDLSRIYVRNDSQLTDISKKMLGDWNAIYMARERAYDHEQAPKRITAKYERDRIKALKGEESISLANLNSCIAFLDNVRDCRVDTYLSTLGQKEGPHGLSNLVENVFASYHEAEQLLSFPYPEENNLIQDKDNVVLIKNLLDNISDLQRFLKPLWGMGDEPDKDERFYGEYNYIRGALDQVIPLYNKVRNYLTRKPYSTRKVKLNFGNSQLLSGWDRNKEKDNSCVILRKGQNFYLAIMNNRHKRSFENKMLPEYKEGEPYFEKMDYKFLPDPNKMLPKVFLSKKGIEIYKPSPKLLEQYGHGTHKKGDTFSMDDLHELIDFFKHSIEAHEDWKQFGFKFSDTATYENVSSFYREVEDQGYKLSFRKVSESYVYSLIDQGKLYLFQIYNKDFSPCSKGTPNLHTLYWRMLFDERNLADVIYKLDGKAEIFFREKSLKNDHPTHPAGKPIKKKSRQKKGEESLFEYDLVKDRRYTMDKFQFHVPITMNFKCSAGSKVNDMVNAHIREAKDMHVIGIDRGERNLLYICVIDSRGTILDQISLNTINDIDYHDLLESRDKDRQQEHRNWQTIEGIKELKQGYLSQAVHRIAELMVAYKAVVALEDLNMGFKRGRQKVESSVYQQFEKQLIDKLNYLVDKKKRPEDIGGLLRAYQFTAPFKSFKEMGKQNGFLFYIPAWNTSNIDPTTGFVNLFHVQYENVDKAKSFFQKFDSISYNPKKDWFEFAFDYKNFTKKAEGSRSMWILCTHGSRIKNFRNSQKNGQWDSEEFALTEAFKSLFVRYEIDYTADLKTAIVDEKQKDFFVDLLKLFKLTVQMRNSWKEKDLDYLISPVAGADGRFFDTREGNKSLPKDADANGAYNIALKGLWALRQIRQTSEGGKLKLAISNKEWLQFVQERSYEKD (SEQ ID NO: 92).
>WP_036887416_(модифицированный) гипотетический белок [Porphyromonas crevioricanis]
MDSLKDFTNLYPVSKTLRFELKPVGKTLENIEKAGILKEDEHRAESYRRVKKIIDTYHKVFIDSSLENMAKMGIENEIKAMLQSFCELYKKDHRTEGEDKALDKIRAVLRGLIVGAFTGVCGRRENTVQNEKYESLFKEKLIKEILPDFVLSTEAESLPFSVEEATRSLKEFDSFTSYFAGFYENRKNIYSTKPQSTAIAYRLIHENLPKFIDNILVFQKIKEPIAKELEHIRADFSAGGYIKKDERLEDIFSLNYYIHVLSQAGIEKYNALIGKIVTEGDGEMKGLNEHINLYNQQRGREDRLPLFRPLYKQILSDREQLSYLPESFEKDEELLRALKEFYDHIAEDILGRTQQLMTSISEYDLSRIYVRNDSQLTDISKKMLGDWNAIYMARERAYDHEQAPKRITAKYERDRIKALKGEESISLANLNSCIAFLDNVRDCRVDTYLSTLGQKEGPHGLSNLVENVFASYHEAEQLLSFPYPEENNLIQDKDNVVLIKNLLDNISDLQRFLKPLWGMGDEPDKDERFYGEYNYIRGALDQVIPLYNKVRNYLTRKPYSTRKVKLNFGNSQLLSGWDRNKEKDNSCVILRKGQNFYLAIMNNRHKRSFENKVLPEYKEGEPYFEKMDYKFLPDPNKMLPKVFLSKKGIEIYKPSPKLLEQYGHGTHKKGDTFSMDDLHELIDFFKHSIEAHEDWKQFGFKFSDTATYENVSSFYREVEDQGYKLSFRKVSESYVYSLIDQGKLYLFQIYNKDFSPCSKGTPNLHTLYWRMLFDERNLADVIYKLDGKAEIFFREKSLKNDHPTHPAGKPIKKKSRQKKGEESLFEYDLVKDRHYTMDKFQFHVPITMNFKCSAGSKVNDMVNAHIREAKDMHVIGIDRGERNLLYICVIDSRGTILDQISLNTINDIDYHDLLESRDKDRQQERRNWQTIEGIKELKQGYLSQAVHRIAELMVAYKAVVALEDLNMGFKRGRQKVESSVYQQFEKQLIDKLNYLVDKKKRPEDIGGLLRAYQFTAPFKSFKEMGKQNGFLFYIPAWNTSNIDPTTGFVNLFHAQYENVDKAKSFFQKFDSISYNPKKDWFEFAFDYKNFTKKAEGSRSMWILCTHGSRIKNFRNSQKNGQWDSEEFALTEAFKSLFVRYEIDYTADLKTAIVDEKQKDFFVDLLKLFKLTVQMRNSWKEKDLDYLISPVAGADGRFFDTREGNKSLPKDADANGAYNIALKGLWALRQIRQTSEGGKLKLAISNKEWLQFVQERSYEKD (SEQ ID NO: 93).
>WP_023941260_(модифицированный) экзонуклеаза SbcC [Porphyromonas cansulci]
MDSLKDFTNLYPVSKTLRFELKPVGKTLENIEKAGILKEDEHRAESYRRVKKIIDTYHKVFIDSSLENMAKMGIENEIKAMLQSFCELYKKDHRTEGEDKALDKIRAVLRGLIVGAFTGVCGRRENTVQNEKYESLFKEKLIKEILPDFVLSTEAESLPFSVEEATRSLKEFDSFTSYFAGFYENRKNIYSTKPQSTAIAYRLIHENLPKFIDNILVFQKIKEPIAKELEHIRADFSAGGYIKKDERLEDIFSLNYYIHVLSQAGIEKYNALIGKIVTEGDGEMKGLNEHINLYNQQRGREDRLPLFRPLYKQILSDREQLSYLPESFEKDEELLRALKEFYDHIAEDILGRTQQLMTSISEYDLSRIYVRNDSQLTDISKKMLGDWNAIYMARERAYDHEQAPKRITAKYERDRIKALKGEESISLANLNSCIAFLDNVRDCRVDTYLSTLGQKEGPHGLSNLVENVFASYHEAEQLLSFPYPEENNLIQDKDNVVLIKNLLDNISDLQRFLKPLWGMGDEPDKDERFYGEYNYIRGALDQVIPLYNKVRNYLTRKPYSTRKVKLNFGNSQLLSGWDRNKEKDNSCVILRKGQNFYLAIMNNRHKRSFENKVLPEYKEGEPYFEKMDYKFLPDPNKMLPKVFLSKKGIEIYKPSPKLLEQYGHGTHKKGDTFSMDDLHELIDFFKHSIEAHEDWKQFGFKFSDTATYENVSSFYREVEDQGYKLSFRKVSESYVYSLIDQGKLYLFQIYNKDFSPCSKGTPNLHTLYWRMLFDERNLADVIYKLDGKAEIFFREKSLKNDHPTHPAGKPIKKKSRQKKGEESLFEYDLVKDRRYTMDKFQFHVPITMNFKCSAGSKVNDMVNAHIREAKDMHVIGIDRGERNLLYICVIDSRGTILDQISLNTINDIDYHDLLESRDKDRQQERRNWQTIEGIKELKQGYLSQAVHRIAELMVAYKAVVALEDLNMGFKRGRQKVESSVYQQFEKQLIDKLNYLVDKKKRPEDIGGLLRAYQFTAPFKSFKEMGKQNGFLFYIPAWNTSNIDPTTGFVNLFHAQYENVDKAKSFFQKFDSISYNPKKDWFEFAFDYKNFTKKAEGSRSMWILCTHGSRIKNFRNSQKNGQWDSEEFALTEAFKSLFVRYEIDYTADLKTAIVDEKQKDFFVDLLKLFKLTVQMRNSWKEKDLDYLISPVAGADGRFFDTREGNKSLPKDADANGAYNIALKGLWALRQIRQTSEGGKLKLAISNKEWLQFVQERSYEKD (SEQ ID NO: 94).
>WP_037975888_(модифицированный) гипотетический белок [Synergistes jonesii]
MANSLKDFTNIYQLSKTLRFELKPIGKTEEHINRKLIIMHDEKRGEDYKSVTKLIDDYHRKFIHETLDPAHFDWNPLAEALIQSGSKNNKALPAEQKEMREKIISMFTSQAVYKKLFKKELFSELLPEMIKSELVSDLEKQAQLDAVKSFDKFSTYFTGFHENRKNIYSKKDTSTSIAFRIVHQNFPKFLANVRAYTLIKERAPEVIDKAQKELSGILGGKTLDDIFSIESFNNVLTQDKIDYYNQIIGGVSGKAGDKKLRGVNEFSNLYRQQHPEVASLRIKMVPLYKQILSDRTTLSFVPEALKDDEQAINAVDGLRSELERNDIFNRIKRLFGKNNLYSLDKIWIKNSSISAFSNELFKNWSFIEDALKEFKENEFNGARSAGKKAEKWLKSKYFSFADIDAAVKSYSEQVSADISSAPSASYFAKFTNLIETAAENGRKFSYFAAESKAFRGDDGKTEIIKAYLDSLNDILHCLKPFETEDISDIDTEFYSAFAEIYDSVKDVIPVYNAVRNYTTQKPFSTEKFKLNFENPALAKGWDKNKEQNNTAIILMKDGKYYLGVIDKNNKLRADDLADDGSAYGYMKMNYKFIPTPHMELPKVFLPKRAPKRYNPSREILLIKENKTFIKDKNFNRTDCHKLIDFFKDSINKHKDWRTFGFDFSDTDSYEDISDFYMEVQDQGYKLTFTRLSAEKIDKWVEEGRLFLFQIYNKDFADGAQGSPNLHTLYWKAIFSEENLKDVVLKLNGEAELFFRRKSIDKPAVHAKGSMKVNRRDIDGNPIDEGTYVEICGYANGKRDMASLNAGARGLIESGLVRITEVKHELVKDKRYTIDKYFFHVPFTINFKAQGQGNINSDVNLFLRNNKDVNIIGIDRGERNLVYVSLIDRDGHIKLQKDFNIIGGMDYHAKLNQKEKERDTARKSWKTIGTIKELKEGYLSQVVHEIVRLAVDNNAVIVMEDLNIGFKRGRFKVEKQVYQKFEKMLIDKLNYLVFKDAGYDAPCGILKGLQLTEKFESFTKLGKQCGIIFYIPAGYTSKIDPTTGFVNLFNINDVSSKEKQKDFIGKLDSIRFDAKRDMFTFEFDYDKFRTYQTSYRKKWAVWTNGKRIVREKDKDGKFRMNDRLLTEDMKNILNKYALAYKAGEDILPDVISRDKSLASEIFYVFKNTLQMRNSKRDTGEDFIISPVLNAKGRFFDSRKTDAALPIDADANGAYHIALKGSLVLDAIDEKLKEDGRIDYKDMAVSNPKWFEFMQTRKFDF (SEQ ID NO: 95).
>EFI70750_(модифицированный) консервативный гипотетический белок [Prevotella bryantii B14]
MQINNLKIIYMKFTDFTGLYSLSKTLRFELKPIGKTLENIKKAGLLEQDQHRADSYKKVKKIIDEYHKAFIEKSLSNFELKYQSEDKLDSLEEYLMYYSMKRIEKTEKDKFAKIQDNLRKQIADHLKGDESYKTIFSKDLIRKNLPDFVKSDEERTLIKEFKDFTTYFKGFYENRENMYSAEDKSTAISHRIIHENLPKFVDNINAFSKIILIPELREKLNQIYQDFEEYLNVESIDEIFHLDYFSMVMTQKQIEVYNAIIGGKSTNDKKIQGLNEYINLYNQKHKDCKLPKLKLLFKQILSDRIAISWLPDNFKDDQEALDSIDTCYKNLLNDGNVLGEGNLKLLLENIDTYNLKGIFIRNDLQLTDISQKMYASWNVIQDAVILDLKKQVSRKKKESAEDYNDRLKKLYTSQESFSIQYLNDCLRAYGKTENIQDYFAKLGAVNNEHEQTINLFAQVRNAYTSVQAILTTPYPENANLAQDKETVALIKNLLDSLKRLQRFIKPLLGKGDESDKDERFYGDFTPLWETLNQITPLYNMVRNYMTRKPYSQEKIKLNFENSTLLGGWDLNKEHDNTAIILRKNGLYYLAIMKKSANKIFDKDKLDNSGDCYEKMVYKLLPGANKMLPKVFFSKSRIDEFKPSENIIENYKKGTHKKGANFNLADCHNLIDFFKSSISKHEDWSKFNFHFSDTSSYEDLSDFYREVEQQGYSISFCDVSVEYINKMVEKGDLYLFQIYNKDFSEFSKGTPNMHTLYWNSLFSKENLNNIIYKLNGQAEIFFRKKSLNYKRPTHPAHQAIKNKNKCNEKKESIFDYDLVKDKRYTVDKFQFHVPITMNFKSTGNTNINQQVIDYLRTEDDTHIIGIDRGERHLLYLVVIDSHGKIVEQFTLNEIVNEYGGNIYRTNYHDLLDTREQNREKARESWQTIENIKELKEGYISQVIHKITDLMQKYHAVVVLEDLNMGFMRGRQKVEKQVYQKFEEMLINKLNYLVNKKADQNSAGGLLHAYQLTSKFESFQKLGKQSGFLFYIPAWNTSKIDPVTGFVNLFDTRYESIDKAKAFFGKFDSIRYNADKDWFEFAFDYNNFTTKAEGTRTNWTICTYGSRIRTFRNQAKNSQWDNEEIDLTKAYKAFFAKHGINIYDNIKEAIAMETEKSFFEDLLHLLKLTLQMRNSITGTTTDYLISPVHDSKGNFYDSRICDNSLPANADANGAYNIARKGLMLIQQIKDSTSSNRFKFSPITNKDWLIFAQEKPYLND (SEQ ID NO: 96).
>WP_024988992_(модифицированный) гипотетический белок [Prevotella albensis]
MNIKNFTGLYPLSKTLRFELKPIGKTKENIEKNGILTKDEQRAKDYLIVKGFIDEYHKQFIKDRLWDFKLPLESEGEKNSLEEYQELYELTKRNDAQEADFTEIKDNLRSSITEQLTKSGSAYDRIFKKEFIREDLVNFLEDEKDKNIVKQFEDFTTYFTGFYENRKNMYSSEEKSTAIAYRLIHQNLPKFMDЯМРSFAKIANSSVSEHFSDIYESWKEYLNVNSIEEIFQLDYFSETLTQPHIEVYNYIIGKKVLEDGTEIKGINEYVNLYNQQQKDKSKRLPFLVPLYKQILSDREKLSWIAEEFDSDKKMLSAITESYNHLHNVLMGNENESLRNLLLNIKDYNLEKINITNDLSLTEISQNLFGRYDVFTNGIKNKLRVLTPRKKKETDENFEDRINKIFKTQKSFSIAFLNKLPQPEMEDGKPRNIEDYFITQGAINTKSIQKEDIFAQIENAYEDAQVFLQIKDTDNKLSQNKTAVEKIKTLLDALKELQHFIKPLLGSGEENEKDELFYGSFLAIWDELDTITPLYNKVRNWLTRKPYSTEKIKLNFDNAQLLGGWDVNKEHDCAGILLRKNDSYYLGIINKKTNHIFDTDITPSDGECYDKIDYKLLPGANKMLPKVFFSKSRIKEFEPSEAIINCYKKGTHKKGKNFNLTDCHRLINFFKTSIEKHEDWSKFGFKFSDTETYEDISGFYREVEQQGYRLTSHPVSASYIHSLVKEGKLYLFQIWNKDFSQFSKGTPNLHTLYWKMLFDKRNLSDVVYKLNGQAEVFYRKSSIEHQNRIIHPAQHPITNKNELNKKHTSTFKYDIIKDRRYTVDKFQFHVPITINFKATGQNNINPIVQEVIRQNGITHIIGIDRGERHLLYLSLIDLKGNIIKQMTLNEIINEYKGVTYKTNYHNLLEKREKERTEARHSWSSIESIKELKDGYMSQVIHKITDMMVKYNAIVVLEDLNGGFMRGRQKVEKQVYQKFEKKLIDKLNYLVDKKLDANEVGGVLNAYQLTNKFESFKKIGKQSGFLFYIPAWNTSKIDPITGFVNLFNTRYESIKETKVFWSKFDIIRYNKEKNWFEFVFDYNTFTTKAEGTRTKWTLCTHGTRIQTFRNPEKNAQWDNKEINLTESFKALFEKYKIDITSNLKESIMQETEKKFFQELHNLLHLTLQMRNSVTGTDIDYLISPVADEDGNFYDSRINGKNFPENADANGAYNIARKGLMLIRQIKQADPQKKFKFETITNKDWLKFAQDKPYLKD (SEQ ID NO: 97).
>WP_039658684_(модифицированный) гипотетический белок [Smithella sp. SC_K08D17]
MQTLFENFTNQYPVSKTLRFELIPQGKTKDFIEQKGLLKKDEDRAEKYKKVKNIIDEYHKDFIEKSLNGLKLDGLEKYKTLYLKQEKDDKDKKAFDKEKENLRKQIANAFRNNEKFKTLFAKELIKNDLMSFACEEDKKNVKEFEAFTTYFTGFHQNRANMYVADEKRTAIASRLIHENLPKFIDNIKIFEKMKKEAPELLSPFNQTLKDMKDVIKGTTLEEIFSLDYFNKTLTQSGIDIYNSVIGGRTPEEGKTKIKGLNEYINTDFNQKQTDKKKRQPKFKQLYKQILSDRQSLSFIAEAFKNDTEILEAIEKFYVNELLHFSNEGKSTNVLDAIKNAVSNLESFNLTKMYFRSGASLTDVSRKVFGEWSIINRALDNYYATTYPIKPREKSEKYEERKEKWLKQDFNVSLIQTAIDEYDNETVKGKNSGKVIADYFAKFCDDKETDLIQKVNEGYIAVKDLLNTPCPENEKLGSNKDQVKQIKAFMDSIMDIMHFVRPLSLKDTDKEKDETFYSLFTPLYDHLTQTIALYNKVRNYLTQKPYSTEKIKLNFENSTLLGGWDLNKETDNTAIILRKDNLYYLGIMDKRHNRIFRNVPKADKKDFCYEKMVYKLLPGANKMLPKVFFSQSRIQEFTPSAKLLENYANETHKKGDNFNLNHCHKLIDFFKDSINKHEDWKNFDFRFSATSTYADLSGFYHEVEHQGYKISFQSVADSFIDDLVNEGKLYLFQIYNKDFSPFSKGKPNLHTLYWKMLFDENNLKDVVYKLNGEAEVFYRKKSIAEKNTTIHKANESIINKNPDNPKATSTFNYDIVKDKRYTIDKFQFHIPITMNFKAEGIFNMNQRVNQFLKANPDINIIGIDRGERHLLYYALINQKGKILKQDTLNVIANEKQKVDYHNLLDKKEGDRATARQEWGVIETIKELKEGYLSQVIHKLTDLMIENNAIIVMEDLNFGFKRGRQKVEKQVYQKFEKMLIDKLNYLVDKNKKANELGGLLNAFQLANKFESFQKMGKQNGFIFYVPAWNTSKTDPATGFIDFLKPRYENLNQAKDFFEKFDSIRLNSKADYFEFAFDFKNFTEKADGGRTKWTVCTTNEDRYAWNRALNNNRGSQEKYDITAELKSLFDGKVDYKSGKDLKQQIASQESADFFKALMKNLSITLSLRHNNGEKGDNEQDYILSPVADSKGRFFDSRKADDDMPKNADANGAYHIALKGLWCLEQISKTDDLKKVKLAISNKEWLEFVQTLKG (SEQ ID NO: 98).
>WP_037385181_(модифицированный) гипотетический белок [Smithella sp. SCADC]
MQTLFENFTNQYPVSKTLRFELIPQGKTKDFIEQKGLLKKDEDRAEKYKKVKNIIDEYHKDFIEKSLNGLKLDGLEEYKTLYLKQEKDDKDKKAFDKEKENLRKQIANAFRNNEKFKTLFAKELIKNDLMSFACEEDKKNVKEFEAFTTYFTGFHQNRANMYVADEKRTAIASRLIHENLPKFIDNIKIFEKMKKEAPELLSPFNQTLKDMKDVIKGTTLEEIFSLDYFNKTLTQSGIDIYNSVIGGRTPEEGKTKIKGLNEYINTDFNQKQTDKKKRQPKFKQLYKQILSDRQSLSFIAEAFKNDTEILEAIEKFYVNELLHFSNEGKSTNVLDAIKNAVSNLESFNLTKIYFRSGTSLTDVSRKVFGEWSIINRALDNYYATTYPIKPREKSEKYEERKEKWLKQDFNVSLIQTAIDEYDNETVKGKNSGKVIVDYFAKFCDDKETDLIQKVNEGYIAVKDLLNTPYPENEKLGSNKDQVKQIKAFMDSIMDIMHFVRPLSLKDTDKEKDETFYSLFTPLYDHLTQTIALYNKVRNYLTQKPYSTEKIKLNFENSTLLGGWDLNKETDNTAIILRKENLYYLGIMDKRHNRIFRNVPKADKKDSCYEKMVYKLLPGANKMLPKVFFSQSRIQEFTPSAKLLENYENETHKKGDNFNLNHCHQLIDFFKDSINKHEDWKNFDFRFSATSTYADLSGFYHEVEHQGYKISFQSIADSFIDDLVNEGKLYLFQIYNKDFSPFSKGKPNLHTLYWKMLFDENNLKDVVYKLNGEAEVFYRKKSIAEKNTTIHKANESIINKNPDNPKATSTFNYDIVKDKRYTIDKFQFHVPITMNFKAEGIFNMNQRVNQFLKANPDINIIGIDRGERHLLYYTLINQKGKILKQDTLNVIANEKQKVDYHNLLDKKEGDRATARQEWGVIETIKELKEGYLSQVIHKLTDLMIENNAIIVMEDLNFGFKRGRQKVEKQVYQKFEKMLIDKLNYLVDKNKKANELGGLLNAFQLANKFESFQKMGKQNGFIFYVPAWNTSKTDPATGFIDFLKPRYENLKQAKDFFEKFDSIRLNSKADYFEFAFDFKNFTGKADGGRTKWTVCTTNEDRYAWNRALNNNRGSQEKYDITAELKSLFDGKVDYKSGKDLKQQIASQELADFFRTLMKYLSVTLSLRHNNGEKGETEQDYILSPVADSMGKFFDSRKAGDDMPKNADANGAYHIALKGLWCLEQISKTDDLKKVKLAISNKEWLEFMQTLKG (SEQ ID NO: 99).
>WP_039871282_(модифицированный) гипотетический белок [Prevotella bryantii]
MKFTDFTGLYSLSKTLRFELKPIGKTLENIKKAGLLEQDQHRADSYKKVKKIIDEYHKAFIEKSLSNFELKYQSEDKLDSLEEYLMYYSMKRIEKTEKDKFAKIQDNLRKQIADHLKGDESYKTIFSKDLIRKNLPDFVKSDEERTLIKEFKDFTTYFKGFYENRENMYSAEDKSTAISHRIIHENLPKFVDNINAFSKIILIPELREKLNQIYQDFEEYLNVESIDEIFHLDYFSMVMTQKQIEVYNAIIGGKSTNDKKIQGLNEYINLYNQKHKDCKLPKLKLLFKQILSDRIAISWLPDNFKDDQEALDSIDTCYKNLLNDGNVLGEGNLKLLLENIDTYNLKGIFIRNDLQLTDISQKMYASWNVIQDAVILDLKKQVSRKKKESAEDYNDRLKKLYTSQESFSIQYLNDCLRAYGKTENIQDYFAKLGAVNNEHEQTINLFAQVRNAYTSVQAILTTPYPENANLAQDKETVALIKNLLDSLKRLQRFIKPLLGKGDESDKDERFYGDFTPLWETLNQITPLYNMVRNYMTRKPYSQEKIKLNFENSTLLGGWDLNKEHDNTAIILRKNGLYYLAIMKKSANKIFDKDKLDNSGDCYEKMVYKLLPGANKMLPKVFFSKSRIDEFKPSENIIENYKKGTHKKGANFNLADCHNLIDFFKSSISKHEDWSKFNFHFSDTSSYEDLSDFYREVEQQGYSISFCDVSVEYINKMVEKGDLYLFQIYNKDFSEFSKGTPNMHTLYWNSLFSKENLNNIIYKLNGQAEIFFRKKSLNYKRPTHPAHQAIKNKNKCNEKKESIFDYDLVKDKRYTVDKFQFHVPITMNFKSTGNTNINQQVIDYLRTEDDTHIIGIDRGERHLLYLVVIDSHGKIVEQFTLNEIVNEYGGNIYRTNYHDLLDTREQNREKARESWQTIENIKELKEGYISQVIHKITDLMQKYHAVVVLEDLNMGFMRGRQKVEKQVYQKFEEMLINKLNYLVNKKADQNSAGGLLHAYQLTSKFESFQKLGKQSGFLFYIPAWNTSKIDPVTGFVNLFDTRYESIDKAKAFFGKFDSIRYNADKDWFEFAFDYNNFTTKAEGTRTNWTICTYGSRIRTFRNQAKNSQWDNEEIDLTKAYKAFFAKHGINIYDNIKEAIAMETEKSFFEDLLHLLKLTLQMRNSITGTTTDYLISPVHDSKGNFYDSRICDNSLPANADANGAYNIARKGLMLIQQIKDSTSSNRFKFSPITNKDWLIFAQEKPYLND (SEQ ID NO: 100).
>EKE28449_(модифицированный) гипотетический белок ACD_3C00058G0015 [некультивируемая бактерия (g-код 4)]
MFKGDAFTGLYEVQKTLRFELVPIGLTQSYLENDWVIQKDKEVEENYGKIKAYFDLIHKEFVRQSLENAWLCQLDDFYEKYIELHNSLETRKDKNLAKQFEKVMKSLKKEFVSFFDAKWNEWKQKFSFLKKWWIDVLNEKEVLDLMAEFYPDEKELFDKFDKFFTYFSNFKESRKNFYADDGRAWAIATRAIDENLITFIKNIEDFKKLNSSFREFVNDNFSEEDKQIFEIDFYNNCLLQPWIDKYNKIVWWYSLENWEKVQWLNEKINNFKQNQNKSNSKDLKFPRMKLLYKQILGDKEKKVYIDEIRDDKNLIDLIDNSKRRNQIKIDNANDIINDFINNNAKFELDKIYLTRQSINTISSKYFSSWDYIRWYFWTGELQEFVSFYDLKETFWKIEYETLENIFKDCYVKGINTESQNNIVFETQGIYENFLNIFKFEFNQNISQISLLEWELDKIQNEDIKKNEKQVEVIKNYFDSVMSVYKMTKYFSLEKWKKRVELDTDNNFYNDFNEYLEGFEIWKDYNLVRNYITKKQVNTDKIKLNFDNSQFLTWWDKDKENERLGIILRREWKYYLWILKKWNTLNFGDYLQKEWEIFYEKMNYKQLNNVYRQLPRLLFPLTKKLNELKWDELKKYLSKYIQNFWYNEEIAQIKIEFDIFQESKEKWEKFDIDKLRKLIEYYKKWVLALYSDLYDLEFIKYKNYDDLSIFYSDVEKKMYNLNFTKIDKSLIDGKVKSWELYLFQIYNKDFSESKKEWSTENIHTKYFKLLFNEKNLQNLVVKLSWWADIFFRDKTENLKFKKDKNGQEILDHRRFSQDKIMFHISITLNANCWDKYWFNQYVNEYMNKERDIKIIWIDRWEKHLAYYCVIDKSWKIFNNEIWTLNELNWVNYLEKLEKIESSRKDSRISWWEIENIKELKNGYISQVINKLTELIVKYNAIIVFEDLNIWFKRWRQKIEKQIYQKLELALAKKLNYLTQKDKKDDEILWNLKALQLVPKVNDYQDIWNYKQSWIMFYVRANYTSVTCPNCWLRKNLYISNSATKENQKKSLNSIAIKYNDWKFSFSYEIDDKSWKQKQSLNKKKFIVYSDIERFVYSPLEKLTKVIDVNKKLLELFRDFNLSLDINKQIQEKDLDSVFFKSLTHLFNLILQLRNSDSKDNKDYISCPSCYYHSNNWLQWFEFNWDANWAYNIARKGIILLDRIRKNQEKPDLYVSDIDWDNFVQSNQFPNTIIPIQNIEKQVPLNIKI (SEQ ID NO: 101).
>WP_018359861_(модифицированный) гипотетический белок [Porphyromonas macacae]
MKTQHFFEDFTSLYSLSKTIRFELKPIGKTLENIKKNGLIRRDEQRLDDYEKLKKVIDEYHEDFIANILSSFSFSEEILQSYIQNLSESEARAKIEKTMRDTLAKAFSEDERYKSIFKKELVKKDIPVWCPAYKSLCKKFDNFTTSLVPFHENRKNLYTSNEITASIPYRIVHVNLPKFIQNIEALCELQKKMGADLYLEMMENLRNVWPSFVKTPDDLCNLKTYNHLMVQSSISEYNRFVGGYSTEDGTKHQGINEWINIYRQRNKEMRLPGLVFLHKQILAKVDSSSFISDTLENDDQVFCVLRQFRKLFWNTVSSKEDDAASLKDLFCGLSGYDPEAIYVSDAHLATISKNIFDRWNYISDAIRRKTEVLMPRKKESVERYAEKISKQIKKRQSYSLAELDDLLAHYSEESLPAGFSLLSYFTSLGGQKYLVSDGEVILYEEGSNIWDEVLIAFRDLQVILDKDFTEKKLGKDEEAVSVIKKALDSALRLRKFFDLLSGTGAEIRRDSSFYALYTDRMDKLKGLLKMYDKVRNYLTKKPYSIEKFKLHFDNPSLLSGWDKNKELNNLSVIFRQNGYYYLGIMTPKGKNLFKTLPKLGAEEMFYEKMEYKQIAEPMLMLPKVFFPKKTKPAFAPDQSVVDIYNKKTFKTGQKGFNKKDLYRLIDFYKEALTVHEWKLFNFSFSPTEQYRNIGEFFDEVREQAYKVSMVNVPASYIDEAVENGKLYLFQIYNKDFSPYSKGIPNLHTLYWKALFSEQNQSRVYKLCGGGELFYRKASLHMQDTTVHPKGISIHKKNLNKKGETSLFNYDLVKDKRFTEDKFFFHVPISINYKNKKITNVNQMVRDYIAQNDDLQIIGIDRGERNLLYISRIDTRGNLLEQFSLNVIESDKGDLRTDYQKILGDREQERLRRRQEWKSIESIKDLKDGYMSQVVHKICNMVVEHKAIVVLENLNLSFMKGRKKVEKSVYEKFERMLVDKLNYLVVDKKNLSNEPGGLYAAYQLTNPLFSFEELHRYPQSGILFFVDPWNTSLTDPSTGFVNLLGRINYTNVGDARKFFDRFNAIRYDGKGNILFDLDLSRFDVRVETQRKLWTLTTFGSRIAKSKKSGKWMVERIENLSLCFLELFEQFNIGYRVEKDLKKAILSQDRKEFYVRLIYLFNLMMQIRNSDGEEDYILSPALNEKNLQFDSRLIEAKDLPVDADANGAYNVARKGLMVVQRIKRGDHESIHRIGRAQWLRYVQEGIVE (SEQ ID NO: 102).
>WP_013282991_(модифицированный) гипотетический белок [Butyrivibrio proteoclasticus]
MLLYENYTKRNQITKSLRLELRPQGKTLRNIKELNLLEQDKAIYALLERLKPVIDEGIKDIARDTLKNCELSFEKLYEHFLSGDKKAYAKESERLKKEIVKTLIKNLPEGIGKISEINSAKYLNGVLYDFIDKTHKDSEEKQNILSDILETKGYLALFSKFLTSRITTLEQSMPKRVIENFEIYAANIPKMQDALERGAVSFAIEYESICSVDYYNQILSQEDIDSYNRLISGIMDEDGAKEKGINQTISEKNIKIKSEHLEEKPFRILKQLHKQILEEREKAFTIDHIDSDEEVVQVTKEAFEQTKEQWENIKKINGFYAKDPGDITLFIVVGPNQTHVLSQLIYGEHDRIRLLLEEYEKNTLEVLPRRTKSEKARYDKFVNAVPKKVAKESHTFDGLQKMTGDDRLFILYRDELARNYMRIKEAYGTFERDILKSRRGIKGNRDVQESLVSFYDELTKFRSALRIINSGNDEKADPIFYNTFDGIFEKANRTYKAENLCRNYVTKSPADDARIMASCLGTPARLRTHWWNGEENFAINDVAMIRRGDEYYYFVLTPDVKPVDLKTKDETDAQIFVQRKGAKSFLGLPKALFKCILEPYFESPEHKNDKNCVIEEYVSKPLTIDRRAYDIFKNGTFKKTNIGIDGLTEEKFKDDCRYLIDVYKEFIAVYTRYSCFNMSGLKRADEYNDIGEFFSDVDTRLCTMEWIPVSFERINDMVDKKEGLLFLVRSMFLYNRPRKPYERTFIQLFSDSNMEHTSMLLNSRAMIQYRAASLPRRVTHKKGSILVALRDSNGEHIPMHIREAIYKMKNNFDISSEDFIMAKAYLAEHDVAIKKANEDIIRNRRYTEDKFFLSLSYTKNADISARTLDYINDKVEEDTQDSRMAVIVTRNLKDLTYVAVVDEKNNVLEEKSLNEIDGVNYRELLKERTKIKYHDKTRLWQYDVSSKGLKEAYVELAVTQISKLATKYNAVVVVESMSSTFKDKFSFLDEQIFKAFEARLCARMSDLSFNTIKEGEAGSISNPIQVSNNNGNSYQDGVIYFLNNAYTRTLCPDTGFVDVFDKTRLITMQSKRQFFAKMKDIRIDDGEMLFTFNLEEYPTKRLLDRKEWTVKIAGDGSYFDKDKGEYVYVNDIVREQIIPALLEDKAVFDGNMAEKFLDKTAISGKSVELIYKWFANALYGIITKKDGEKIYRSPITGTEIDVSKNTTYNFGKKFMFKQEYRGDGDFLDAFLNYMQAQDIAV (SEQ ID NO: 103).
>AIZ56868_(модифицированный) гипотетический белок Mpt1_c09950 [Candidatus Methanoplasma termitum]
MNNYDEFTKLYPIQKTIRFELKPQGRTMEHLETFNFFEEDRDRAEKYKILKEAIDEYHKKFIDEHLTNMSLDWNSLKQISEKYYKSREEKDKKVFLSEQKRMRQEIVSEFKKDDRFKDLFSKKLFSELLKEEIYKKGNHQEIDALKSFDKFSGYFIGLHENRKNMYSDGDEITAISNRIVNENFPKFLDNLQKYQEARKKYPEWIIKAESALVAHNIKMDEVFSLEYFNKVLNQEGIQRYNLALGGYVTKSGEKMMGLNDALNLAHQSEKSSKGRIHMTPLFKQILSEKESFSYIPDVFTEDSQLLPSIGGFFAQIENDKDGNIFDRALELISSYAEYDTERIYIRQADINRVSNVIFGEWGTLGGLMREYKADSINDINLERTCKKVDKWLDSKEFALSDVLEAIKRTGNNDAFNEYISKMRTAREKIDAARKEMKFISEKISGDEESIHIIKTLLDSVQQFLHFFNLFKARQDIPLDGAFYAEFDEVHSKLFAIVPLYNKVRNYLTKNNLNTKKIKLNFKNPTLANGWDQNKVYDYASLIFLRDGNYYLGIINPKRKKNIKFEQGSGNGPFYRKMVYKQIPGPNKNLPRVFLTSTKGKKEYKPSKEIIEGYEADKHIRGDKFDLDFCHKLIDFFKESIEKHKDWSKFNFYFSPTESYGDISEFYLDVEKQGYRMHFENISAETIDEYVEKGDLFLFQIYNKDFVKAATGKKDMHTIYWNAAFSPENLQDVVVKLNGEAELFYRDKSDIKEIVHREGEILVNRTYNGRTPVPDKIHKKLTDYHNGRTKDLGEAKEYLDKVRYFKAHYDITKDRRYLNDKIYFHVPLTLNFKANGKKNLNKMVIEKFLSDEKAHIIGIDRGERNLLYYSIIDRSGKIIDQQSLNVIDGFDYREKLNQREIEMKDARQSWNAIGKIKDLKEGYLSKAVHEITKMAIQYNAIVVMEELNYGFKRGRFKVEKQIYQKFENMLIDKMNYLVFKDAPDESPGGVLNAYQLTNPLESFAKLGKQTGILFYVPAAYTSKIDPTTGFVNLFNTSSKTNAQERKEFLQKFESISYSAKDGGIFAFAFDYRKFGTSKTDHKNVWTAYTNGERMRYIKEKKRNELFDPSKEIKEALTSSGIKYDGGQNILPDILRSNNNGLIYTMYSSFIAAIQMRVYDGKEDYIISPIKNSKGEFFRTDPKRRELPIDADANGAYNIALRGELTMRAIAEKFDPDSEKMAKLELKHKDWFEFMQTRGD (SEQ ID NO: 104).
>WP_027407524_(модифицированный) гипотетический белок [Anaerovibrio sp. RM50]
MVAFIDEFVGQYPVSKTLRFEARPVPETKKWLESDQCSVLFNDQKRNEYYGVLKELLDDYYRAYIEDALTSFTLDKALLENAYDLYCNRDTNAFSSCCEKLRKDLVKAFGNLKDYLLGSDQLKDLVKLKAKVDAPAGKGKKKIEVDSRLINWLNNNAKYSAEDREKYIKAIESFEGFVTYLTNYKQARENMFSSEDKSTAIAFRVIDQNMVTYFGNIRIYEKIKAKYPELYSALKGFEKFFSPTAYSEILSQSKIDEYNYQCIGRPIDDADFKGVNSLINEYRQKNGIKARELPVMSMLYKQILSDRDNSFMSEVINRNEEAIECAKNGYKVSYALFNELLQLYKKIFTEDNYGNIYVKTQPLTELSQALFGDWSILRNALDNGKYDKDIINLAELEKYFSEYCKVLDADDAAKIQDKFNLKDYFIQKNALDATLPDLDKITQYKPHLDAMLQAIRKYKLFSMYNGRKKMDVPENGIDFSNEFNAIYDKLSEFSILYDRIRNFATKKPYSDEKMKLSFNMPTMLAGWDYNNETANGCFLFIKDGKYFLGVADSKSKNIFDFKKNPHLLDKYSSKDIYYKVKYKQVSGSAKMLPKVVFAGSNEKIFGHLISKRILEIREKKLYTAAAGDRKAVAEWIDFMKSAIAIHPEWNEYFKFKFKNTAEYDNANKFYEDIDKQTYSLEKVEIPTEYIDEMVSQHKLYLFQLYTKDFSDKKKKKGTDNLHTMYWHGVFSDENLKAVTEGTQPIIKLNGEAEMFMRNPSIEFQVTHEHNKPIANKNPLNTKKESVFNYDLIKDKRYTERKFYFHCPITLNFRADKPIKYNEKINRFVENNPDVCIIGIDRGERHLLYYTVINQTGDILEQGSLNKISGSYTNDKGEKVNKETDYHDLLDRKEKGKHVAQQAWETIENIKELKAGYLSQVVYKLTQLMLQYNAVIVLENLNVGFKRGRTKVEKQVYQKFEKAMIDKLNYLVFKDRGYEMNGSYAKGLQLTDKFESFDKIGKQTGCIYYVIPSYTSHIDPKTGFVNLLNAKLRYENITKAQDTIRKFDSISYNAKADYFEFAFDYRSFGVDMARNEWVVCTCGDLRWEYSAKTRETKAYSVTDRLKELFKAHGIDYVGGENLVSHITEVADKHFLSTLLFYLRLVLKMRYTVSGTENENDFILSPVEYAPGKFFDSREATSTEPMNADANGAYHIALKGLMTIRGIEDGKLHNYGKGGENAAWFKFMQNQEYKNNG (SEQ ID NO: 105).
>WP_044910712_(модифицированный) гипотетический белок [Lachnospiraceae bacterium MC2017]
MDYGNGQFERRAPLTKTITLRLKPIGETRETIREQKLLEQDAAFRKLVETVTPIVDDCIRKIADNALCHFGTEYDFSCLGNAISKNDSKAIKKETEKVEKLLAKVLTENLPDGLRKVNDINSAAFIQDTLTSFVQDDADKRVLIQELKGKTVLMQRFLTTRITALTVWLPDRVFENFNIFIENAEKMRILLDSPLNEKIMKFDPDAEQYASLEFYGQCLSQKDIDSYNLIISGIYADDEVKNPGINEIVKEYNQQIRGDKDESPLPKLKKLHKQILMPVEKAFFVRVLSNDSDARSILEKILKDTEMLPSKIIEAMKEADAGDIAVYGSRLHELSHVIYGDHGKLSQIIYDKESKRISELMETLSPKERKESKKRLEGLEEHIRKSTYTFDELNRYAEKNVMAAYIAAVEESCAEIMRKEKDLRTLLSKEDVKIRGNRHNTLIVKNYFNAWTVFRNLIRILRRKSEAEIDSDFYDVLDDSVEVLSLTYKGENLCRSYITKKIGSDLKPEIATYGSALRPNSRWWSPGEKFNVKFHTIVRRDGRLYYFILPKGAKPVELEDMDGDIECLQMRKIPNPTIFLPKLVFKDPEAFFRDNPEADEFVFLSGMKAPVTITRETYEAYRYKLYTVGKLRDGEVSEEEYKRALLQVLTAYKEFLENRMIYADLNFGFKDLEEYKDSSEFIKQVETHNTFMCWAKVSSSQLDDLVKSGNGLLFEIWSERLESYYKYGNEKVLRGYEGVLLSILKDENLVSMRTLLNSRPMLVYRPKESSKPMVVHRDGSRVVDRFDKDGKYIPPEVHDELYRFFNNLLIKEKLGEKARKILDNKKVKVKVLESERVKWSKFYDEQFAVTFSVKKNADCLDTTKDLNAEVMEQYSESNRLILIRNTTDILYYLVLDKNGKVLKQRSLNIINDGARDVDWKERFRQVTKDRNEGYNEWDYSRTSNDLKEVYLNYALKEIAEAVIEYNAILIIEKMSNAFKDKYSFLDDVTFKGFETKLLAKLSDLHFRGIKDGEPCSFTNPLQLCQNDSNKILQDGVIFMVPNSMTRSLDPDTGFIFAINDHNIRTKKAKLNFLSKFDQLKVSSEGCLIMKYSGDSLPTHNTDNRVWNCCCNHPITNYDRETKKVEFIEEPVEELSRVLEENGIETDTELNKLNERENVPGKVVDAIYSLVLNYLRGTVSGVAGQRAVYYSPVTGKKYDISFIQAMNLNRKCDYYRIGSKERGEWTDFVAQLIN (SEQ ID NO: 106).
>WP_027216152_(модифицированный) гипотетический белок [Butyrivibrio fibrisolvens]
MYYESLTKLYPIKKTIRNELVPIGKTLENIKKNNILEADEDRKIAYIRVKAIMDDYHKRLINEALSGFALIDLDKAANLYLSRSKSADDIESFSRFQDKLRKAIAKRLREHENFGKIGNKDIIPLLQKLSENEDDYNALESFKNFYTYFESYNDVRLNLYSDKEKSSTVAYRLINENLPRFLDNIRAYDAVQKAGITSEELSSEAQDGLFLVNTFNNVLIQDGINTYNEDIGKLNVAINLYNQKNASVQGFRKVPKMKVLYKQILSDREESFIDEFESDTELLDSLESHYANLAKYFGSNKVQLLFTALRESKGVNVYVKNDIAKTSFSNVVFGSWSRIDELINGEYDDNNNRKKDEKYYDKRQKELKKNKSYTIEKIITLSTEDVDVIGKYIEKLESDIDDIRFKGKNFYEAVLCGHDRSKKLSKNKGAVEAIKGYLDSVKDFERDLKLINGSGQELEKNLVVYGEQEAVLSELSGIDSLYNMTRNYLTKKPFSTEKIKLNFNKPTFLDGWDYGNEEAYLGFFMIKEGNYFLAVMDANWNKEFRNIPSVDKSDCYKKVIYKQISSPEKSIQNLMVIDGKTVKKNGRKEKEGIHSGENLILEELKNTYLPKKINDIRKRRSYLNGDTFSKKDLTEFIGYYKQRVIEYYNGYSFYFKSDDDYASFKEFQEDVGRQAYQISYVDVPVSFVDDLINSGKLYLFRVYNKDFSEYSKGRLNLHTLYFKMLFDERNLKNVVYKLNGQAEVFYRPSSIKKEELIVHRAGEEIKNKNPKRAAQKPTRRLDYDIVKDRRYSQDKFMLHTSIIMNFGAEENVSFNDIVNGVLRNEDKVNVIGIDRGERNLLYVVVIDPEGKILEQRSLNCITDSNLDIETDYHRLLDEKESDRKIARRDWTTIENIKELKAGYLSQVVHIVAELVLKYNAIICLEDLNFGFKRGRQKVEKQVYQKFEKMLIDKLNYLVMDKSREQLSPEKISGALNALQLTPDFKSFKVLGKQTGIIYYVPAYLTSKIDPMTGFANLFYVKYENVDKAKEFFSKFDSIKYNKDGKNWNTKGYFEFAFDYKKFTDRAYGRVSEWTVCTVGERIIKFKNKEKNNSYDDKVIDLTNSLKELFDSYKVTYESEVDLKDAILAIDDPAFYRDLTRRLQQTLQMRNSSCDGSRDYIISPVKNSKGEFFCSDNNDDTTPNDADANGAFNIARKGLWVLNEIRNSEEGSKINLAMSNAQWLEYAQDNTI (SEQ ID NO: 107).
>WP_016301126_(модифицированный) гипотетический белок [Lachnospiraceae bacterium COE1]
MHENNGKIADNFIGIYPVSKTLRFELKPVGKTQEYIEKHGILDEDLKRAGDYKSVKKIIDAYHKYFIDEALNGIQLDGLKNYYELYEKKRDNNEEKEFQKIQMSLRKQIVKRFSEHPQYKYLFKKELIKNVLPEFTKDNAEEQTLVKSFQEFTTYFEGFHQNRKNMYSDEEKSTAIAYRVVHQNLPKYIDЯМРIFSMILNTDIRSDLTELFNNLKTKMDITIVEEYFAIDGFNKVVNQKGIDVYNTILGAFSTDDNTKIKGLNEYINLYNQKNKAKLPKLKPLFKQILSDRDKISFIPEQFDSDTEVLEAVDMFYNRLLQFVIENEGQITISKLLTNFSAYDLNKIYVKNDTTISAISNDLFDDWSYISKAVRENYDSENVDKNKRAAAYEEKKEKALSKIKMYSIEELNFFVKKYSCNECHIEGYFERRILEILDKMRYAYESCKILHDKGLINNISLCQDRQAISELKDFLDSIKEVQWLLKPLMIGQEQADKEEAFYTELLRIWEELEPITLLYNKVRNYVTKKPYTLEKVKLNFYKSTLLDGWDKNKEKDNLGIILLKDGQYYLGIMNRRNNKIADDAPLAKTDNVYRKMEYKLLTKVSANLPRIFLKDKYNPSEEMLEKYEKGTHLKGENFCIDDCRELIDFFKKGIKQYEDWGQFDFKFSDTESYDDISAFYKEVEHQGYKITFRDIDETYIDSLVNEGKLYLFQIYNKDFSPYSKGTKNLHTLYWEMLFSQQNLQNIVYKLNGNAEIFYRKASINQKDVVVHKADLPIKNKDPQNSKKESMFDYDIIKDKRFTCDKYQFHVPITMNFKALGENHFNRKVNRLIHDAENMHIIGIDRGERNLIYLCMIDMKGNIVKQISLNEIISYDKNKLEHKRNYHQLLKTREDENKSARQSWQTIHTIKELKEGYLSQVIHVITDLMVEYNAIVVLEDLNFGFKQGRQKFERQVYQKFEKMLIDKLNYLVDKSKGMDEDGGLLHAYQLTDEFKSFKQLGKQSGFLYYIPAWNTSKLDPTTGFVNLFYTKYESVEKSKEFINNFTSILYNQEREYFEFLFDYSAFTSKAEGSRLKWTVCSKGERVETYRNPKKNNEWDTQKIDLTFELKKLFNDYSISLLDGDLREQMGKIDKADFYKKFMKLFALIVQMRNSDEREDKLISPVLNKYGAFFETGKNERMPLDADANGAYNIARKGLWIIEKIKNTDVEQLDKVKLTISNKEWLQYAQEHIL (SEQ ID NO: 108).
>WP_035635841_(модифицированный) гипотетический белок [Lachnospiraceae bacterium ND2006]
MSKLEKFTNCYSLSKTLRFKAIPVGKTQENIDNKRLLVEDEKRAEDYKGVKKLLDRYYLSFINDVLHSIKLKNLNNYISLFRKKTRTEKENKELENLEINLRKEIAKAFKGNEGYKSLFKKDIIETILPEFLDDKDEIALVNSFNGFTTAFTGFFDNRENMFSEEAKSTSIAFRCINENLTRYISNMDIFEKVDAIFDKHEVQEIKEKILNSDYDVEDFFEGEFFNFVLTQEGIDVYNAIIGGFVTESGEKIKGLNEYINLYNQKTKQKLPKFKPLYKQVLSDRESLSFYGEGYTSDEEVLEVFRNTLNKNSEIFSSIKKLEKLFKNFDEYSSAGIFVKNGPAISTISKDIFGEWNVIRDKWNAEYDDIHLKKKAVVTEKYEDDRRKSFKKIGSFSLEQLQEYADADLSVVEKLKEIIIQKVDEIYKVYGSSEKLFDADFVLEKSLKKNDAVVAIMKDLLDSVKSFENYIKAFFGEGKETNRDESFYGDFVLAYDILLKVDHIYDAIRNYVTQKPYSKDKFKLYFQNPQFMGGWDKDKETDYRATILRYGSKYYLAIMDKKYAKCLQKIDKDDVNGNYEKINYKLLPGPNKMLPKVFFSKKWMAYYNPSEDIQKIYKNGTFKKGDMFNLNDCHKLIDFFKDSISRYPKWSNAYDFNFSETEKYKDIAGFYREVEEQGYKVSFESASKKEVDKLVEEGKLYMFQIYNKDFSDKSHGTPNLHTMYFKLLFDENNHGQIRLSGGAELFMRRASLKKEELVVHPANSPIANKNPDNPKKTTTLSYDVYKDKRFSEDQYELHIPIAINKCPKNIFKINTEVRVLLKHDDNPYVIGIDRGERNLLYIVVVDGKGNIVEQYSLNEIINNFNGIRIKTDYHSLLDKKEKERFEARQNWTSIENIKELKAGYISQVVHKICELVEKYDAVIALEDLNSGFKNSRVKVEKQVYQKFEKMLIDKLNYMVDKKSNPCATGGALKGYQITNKFESFKSMSTQNGFIFYIPAWLTSKIDPSTGFVNLLKTKYTSIADSKKFISSFDRIMYVPEEDLFEFALDYKNFSRTDADYIKKWKLYSYGNRIRIFRNPKKNNVFDWEEVCLTSAYKELFNKYGINYQQGDIRALLCEQSDKAFYSSFMALMSLMLQMRNSITGRTDVDFLISPVKNSDGIFYDSRNYEAQENAILPKNADANGAYNIARKVLWAIGQFKKAEDEKLDKVKIAISNKEWLEYAQTSVKH (SEQ ID NO: 109).
>WP_015504779_(модифицированный) экзонуклеаза SbcC [Candidatus Methanomethylophilus alvus]
MDAKEFTGQYPLSKTLRFELRPIGRTWDNLEASGYLAEDRHRAECYPRAKELLDDNHRAFLNRVLPQIDMDWHPIAEAFCKVHKNPGNKELAQDYNLQLSKRRKEISAYLQDADGYKGLFAKPALDEAMKIAKENGNESDIEVLEAFNGFSVYFTGYHESRENIYSDEDMVSVAYRITEDNFPRFVSNALIFDKLNESHPDIISEVSGNLGVDDIGKYFDVSNYNNFLSQAGIDDYNHIIGGHTTEDGLIQAFNVVLNLRHQKDPGFEKIQFKQLYKQILSVRTSKSYIPKQFDNSKEMVDCICDYVSKIEKSETVERALKLVRNISSFDLRGIFVNKKNLRILSNKLIGDWDAIETALMHSSSSENDKKSVYDSAEAFTLDDIFSSVKKFSDASAEDIGNRAEDICRVISETAPFINDLRAVDLDSLNDDGYEAAVSKIRESLEPYMDLFHELEIFSVGDEFPKCAAFYSELEEVSEQLIEIIPLFNKARSFCTRKRYSTDKIKVNLKFPTLADGWDLNKERDNKAAILRKDGKYYLAILDMKKDLSSIRTSDEDESSFEKMEYKLLPSPVKMLPKIFVKSKAAKEKYGLTDRMLECYDKGMHKSGSAFDLGFCHELIDYYKRCIAEYPGWDVFDFKFRETSDYGSMKEFNEDVAGAGYYMSLRKIPCSEVYRLLDEKSIYLFQIYNKDYSENAHGNKNMHTMYWEGLFSPQNLESPVFKLSGGAELFFRKSSIPNDAKTVHPKGSVLVPRNDVNGRRIPDSIYRELTRYFNRGDCRISDEAKSYLDKVKTKKADHDIVKDRRFTVDKMMFHVPIAMNFKAISKPNLNKKVIDGIIDDQDLKIIGIDRGERNLIYVTMVDRKGNILYQDSLNILNGYDYRKALDVREYDNKEARRNWTKVEGIRKMKEGYLSLAVSKLADMIIENNAIIVMEDLNHGFKAGRSKIEKQVYQKFESMLINKLGYMVLKDKSIDQSGGALHGYQLANHVTTLASVGKQCGVIFYIPAAFTSKIDPTTGFADLFALSNVKNVASMREFFSKMKSVIYDKAEGKFAFTFDYLDYNVKSECGRTLWTVYTVGERFTYSRVNREYVRKVPTDIIYDALQKAGISVEGDLRDRIAESDGDTLKSIFYAFKYALDMRVENREEDYIQSPVKNASGEFFCSKNAGKSLPQDSDANGAYNIALKGILQLRMLSEQYDPNAESIRLPLITNKAWLTFMQSGMKTWKN (SEQ ID NO: 110).
>WP_044910713_(модифицированный) гипотетический белок [Lachnospiraceae bacterium MC2017]
MGLYDGFVNRYSVSKTLRFELIPQGRTREYIETNGILSDDEERAKDYKTIKRLIDEYHKDYISRCLKNVNISCLEEYYHLYNSSNRDKRHEELDALSDQMRGEIASFLTGNDEYKEQKSRDIIINERIINFASTDEELAAVKRFRKFTSYFTGFFTNRENMYSAEKKSTAIAHRIIDVNLPKYVDNIKAFNTAIEAGVFDIAEFESNFKAITDEHEVSDLLDITKYSRFIRNEDIIIYNTLLGGISMKDEKIQGLNELINLHNQKHPGKKVPLLKVLYKQILGDSQTHSFVDDQFEDDQQVINAVKAVTDTFSETLLGSLKIIINNIGHYDLDRIYIKAGQDITTLSKRALNDWHIITECLESEYDDKFPKNKKSDTYEEMRNRYVKSFKSFSIGRLNSLVTTYTEQACFLENYLGSFGGDTDKNCLTDFTNSLMEVEHLLNSEYPVTNRLITDYESVRILKRLLDSEMEVIHFLKPLLGNGNESDKDLVFYGEFEAEYEKLLPVIKVYNRVRNYLTRKPFSTEKIKLNFNSPTLLCGWSQSKEKEYMGVILRKDGQYYLGIMTPSNKKIFSEAPKPDEDCYEKMVLRYIPHPYQMLPKVFFSKSNIAFFNPSDEILRIKKQESFKKGKSFNRDDCHKFIDFYKDSINRHEEWRKFNFKFSDTDSYEDISRFYKEVENQAFSMSFTKIPTVYIDSLVDEGKLYLFKLHNKDFSEHSKGKPNLHTVYWNALFSEYNLQNTVYQLNGSAEIFFRKASIPENERVIHKKNVPITRKVAELNGKKEVSVFPYDIIKNRRYTVDKFQFHVPLKMNFKADEKKRINDDVIEAIRSNKGIHVIGIDRGERNLLYLSLINEEGRIIEQRSLNIIDSGEGHTQNYRDLLDSREKDREKARENWQEIQEIKDLKTGYLSQAIHTITKWMKEYNAIIVLEDLNDRFTNGRKKVEKQVYQKFEKMLIDKLNYYVDKDEEFDRMGGTHRALQLTEKFESFQKLGRQTGFIFYVPAWNTSKLDPTTGFVDLLYPKYKSVDATKDFIKKFDFIRFNSEKNYFEFGLHYSNFTERAIGCRDEWILCSYGNRIVNFRNAAKNNSWDYKEIDITKQLLDLFEKNGIDVKQENLIDSICEMKDKPFFKSLIANIKLILQIRNSASGTDIDYMISPAMNDRGEFFDTRKGLQQLPLDADANGAYNIAKKGLWIVDQIRNTTGNNVKMAMSNREWMHFAQESRLA (SEQ ID NO: 111).
>KKQ36153_(модифицированный) гипотетический белок US52_C0007G0008 [бактерия кандидатного отдела WS6 GW2011_GWA2_37_6]
MKNVFGGFTNLYSLTKTLRFELKPTSKTQKLMKRNNVIQTDEEIDKLYHDEMKPILDEIHRRFINDALAQKIFISASLDNFLKVVKNYKVESAKKNIKQNQVKLLQKEITIKTLGLRREVVSGFITVSKKWKDKYVGLGIKLKGDGYKVLTEQAVLDILKIEFPNKAKYIDKFRGFWTYFSGFNENRKNYYSEEDKATSIANRIVNENLSRYIDNIIAFEEILQKIPNLKKFKQDLDITSYNYYLNQAGIDKYNKIIGGYIVDKDKKIQGINEKVNLYTQQTKKKLPKLKFLFKQIGSERKGFGIFEIKEGKEWEQLGDLFKLQRTKINSNGREKGLFDSLRTMYREFFDEIKRDSNSQARYSLDKIYFNKASVNTISNSWFTNWNKFAELLNIKEDKKNGEKKIPEQISIEDIKDSLSIIPKENLEELFKLTNREKHDRTRFFGSNAWVTFLNIWQNEIEESFNKLEEKEKDFKKNAAIKFQKNNLVQKNYIKEVCDRMLAIERMAKYHLPKDSNLSREEDFYWIIDNLSEQREIYKYYNAFRNYISKKPYNKSKMKLNFENGNLLGGWSDGQERNKAGVILRNGNKYYLGVLINRGIFRTDKINNEIYRTGSSKWERLILSNLKFQTLAGKGFLGKHGVSYGNMNPEKSVPSLQKFIRENYLKKYPQLTEVSNTKFLSKKDFDAAIKEALKECFTMNFINIAENKLLEAEDKGDLYLFEITNKDFSGKKSGKDNIHTIYWKYLFSESNCKSPIIGLNGGAEIFFREGQKDKLHTKLDKKGKKVFDAKRYSEDKLFFHVSITINYGKPKNIKFRDIINQLITSMNVNIIGIDRGEKHLLYYSVIDSNGIILKQGSLNKIRVGDKEVDFNKKLTERANEMKKARQSWEQIGNIKNFKEGYLSQAIHEIYQLMIKYNAIIVLEDLNTEFKAKRLSKVEKSVYKKFELKLARKLNHLILKDRNTNEIGGVLKAYQLTPTIGGGDVSKFEKAKQWGMMFYVRANYTSTTDPVTGWRKHLYISNFSNNSVIKSFFDPTNRDTGIEIFYSGKYRSWGFRYVQKETGKKWELFATKELERFKYNQTTKLCEKINLYDKFEELFKGIDKSADIYSQLCNVLDFRWKSLVYLWNLLNQIRNVDKNAEGNKNDFIQSPVYPFFDSRKTDGKTEPINGDANGALNIARKGLMLVERIKNNPEKYEQLIRDTEWDAWIQNFNKVN (SEQ ID NO: 112).
>WP_044919442_(модифицированный) гипотетический белок [Lachnospiraceae bacterium MA2020]
MYYESLTKQYPVSKTIRNELIPIGKTLDNIRQNNILESDVKRKQNYEHVKGILDEYHKQLINEALDNCTLPSLKIAAEIYLKNQKEVSDREDFNKTQDLLRKEVVEKLKAHENFTKIGKKDILDLLEKLPSISEDDYNALESFRNFYTYFTSYNKVRENLYSDKEKSSTVAYRLINENFPKFLDNVKSYRFVKTAGILADGLGEEEQDSLFIVETFNKTLTQDGIDTYNSQVGKINSSINLYNQKNQKANGFRKIPKMKMLYKQILSDREESFIDEFQSDEVLIDNVESYGSVLIESLKSSKVSAFFDALRESKGKNVYVKNDLAKTAMSNIVFENWRTFDDLLNQEYDLANENKKKDDKYFEKRQKELKKNKSYSLEHLCNLSEDSCNLIENYIHQISDDIENIIINNETFLRIVINEHDRSRKLAKNRKAVKAIKDFLDSIKVLERELKLINSSGQELEKDLIVYSAHEELLVELKQVDSLYNMTRNYLTKKPFSTEKVKLNFNRSTLLNGWDRNKETDNLGVLLLKDGKYYLGIMNTSANKAFVNPPVAKTEKVFKKVDYKLLPVPNQMLPKVFFAKSNIDFYNPSSEIYSNYKKGTHKKGNMFSLEDCHNLIDFFKESISKHEDWSKFGFKFSDTASYNDISEFYREVEKQGYKLTYTDIDETYINDLIERNELYLFQIYNKDFSMYSKGKLNLHTLYFMMLFDQRNIDDVVYKLNGEAEVFYRPASISEDELIIHKAGEEIKNKNPNRARTKETSTFSYDIVKDKRYSKDKFTLHIPITMNFGVDEVKRFNDAVNSAIRIDENVNVIGIDRGERNLLYVVVIDSKGNILEQISLNSIINKEYDIETDYHALLDEREGGRDKARKDWNTVENIRDLKAGYLSQVVNVVAKLVLKYNAIICLEDLNFGFKRGRQKVEKQVYQKFEKMLIDKLNYLVIDKSREQTSPKELGGALNALQLTSKFKSFKELGKQSGVIYYVPAYLTSKIDPTTGFANLFYMKCENVEKSKRFFDGFDFIRFNALENVFEFGFDYRSFTQRACGINSKWTVCTNGERIIKYRNPDKNNMFDEKVVVVTDEMKNLFEQYKIPYEDGRNVKDMIISNEEAEFYRRLYRLLQQTLQMRNSTSDGTRDYIISPVKNKREAYFNSELSDGSVPKDADANGAYNIARKGLWVLEQIRQKSEGEKINLAMTNAEWLEY AQTHLL (SEQ ID NO: 113).
>WP_035798880_(модифицированный) гипотетический белок [Butyrivibrio sp. NC3005]
MYYQNLTKKYPVSKTIRNELIPIGKTLENIRKNNILESDVKRKQDYEHVKGIMDEYHKQLINEALDNYMLPSLNQAAEIYLKKHVDVEDREEFKKTQDLLRREVTGRLKEHENYTKIGKKDILDLLEKLPSISEEDYNALESFRNFYTYFTSYNKVRENLYSDEEKSSTVAYRLINENLPKFLDNIKSYAFVKAAGVLADCIEEEEQDALFMVETFNMTLTQEGIDMYNYQIGKVNSAINLYNQKNHKVEEFKKIPKMKVLYKQILSDREEVFIGEFKDDETLLSSIGAYGNVLMTYLKSEKINIFFDALRESEGKNVYVKNDLSKTTMSNIVFGSWSAFDELLNQEYDLANENKKKDDKYFEKRQKELKKNKSYTLEQMSNLSKEDISPIENYIERISEDIEKICIYNGEFEKIVVNEHDSSRKLSKNIKAVKVIKDYLDSIKELEHDIKLINGSGQELEKNLVVYVGQEEALEQLRPVDSLYNLTRNYLTKKPFSTEKVKLNFNKSTLLNGWDKNKETDNLGILFFKDGKYYLGIMNTTANKAFVNPPAAKTENVFKKVDYKLLPGSNKMLPKVFFAKSNIGYYNPSTELYSNYKKGTHKKGPSFSIDDCHNLIDFFKESIKKHEDWSKFGFEFSDTADYRDISEFYREVEKQGYKLTFTDIDESYINDLIEKNELYLFQIYNKDFSEYSKGKLNLHTLYFMMLFDQRNLDNVVYKLNGEAEVFYRPASIAENELVIHKAGEGIKNKNPNRAKVKETSTFSYDIVKDKRYSKYKFTLHIPITMNFGVDEVRRFNDVINNALRTDDNVNVIGIDRGERNLLYVVVINSEGKILEQISLNSIINKEYDIETNYHALLDEREDDRNKARKDWNTIENIKELKTGYLSQVVNVVAKLVLKYNAIICLEDLNFGFKRGRQKVEKQVYQKFEKMLIEKLNYLVIDKSREQVSPEKMGGALNALQLTSKFKSFAELGKQSGIIYYVPAYLTSKIDPTTGFVNLFYIKYENIEKAKQFFDGFDFIRFNKKDDMFEFSFDYKSFTQKACGIRSKWIVYTNGERIIKYPNPEKNNLFDEKVINVTDEIKGLFKQYRIPYENGEDIKEIIISKAEADFYKRLFRLLHQTLQMRNSTSDGTRDYIISPVKNDRGEFFCSEFSEGTMPKDADANGAYNIARKGLWVLEQIRQKDEGEKVNLSMTNAEWLKYAQLHLL (SEQ ID NO: 114).
>WP_027109509_(модифицированный) гипотетический белок [Lachnospiraceae bacterium NC2008]
MENYYDSLTRQYPVTKTIRQELKPVGKTLENIKNAEIIEADKQKKEAYVKVKELMDEFHKSIIEKSLVGIKLDGLSEFEKLYKIKTKTDEDKNRISELFYYMRKQIADALKNSRDYGYVDNKDLIEKILPERVKDENSLNALSCFKGFTTYFTDYYKNRKNIYSDEEKHSTVGYRCINENLLIFMSNIEVYQIYKKANIKNDNYDEETLDKTFMIESFNECLTQSGVEAYNSVVASIKTATNLYIQKNNKEENFVRVPKMKVLFKQILSDRTSLFDGLIIESDDELLDKLCSFSAEVDKFLPINIDRYIKTLMDSNNGTGIYVKNDSSLTTLSNYLTDSWSSIRNAFNENYDAKYTGKVNDKYEEKREKAYKSNDSFELNYIQNLLGINVIDKYIERINFDIKEICEAYKEMTKNCFEDHDKTKKLQKNIKAVASIKSYLDSLKNIERDIKLLNGTGLESRNEFFYGEQSTVLEEITKVDELYNITRNYLTKKPFSTEKMKLNFNNPQLLGGWDVNKERDCYGVILIKDNNYYLGIMDKSANKSFLNIKESKNENAYKKVNCKLLPGPNKMFPKVFFAKSNIDYYDPTHEIKKLYDKGTFKKGNSFNLEDCHKLIDFYKESIKKNDDWKNFNFNFSDTKDYEDISGFFREVEAQNYKITYTNVSCDFIESLVDEGKLYLFQIYNKDFSEYATGNLNLHTLYLKMLFDERNLKDLCIKMNGEAEVFYRPASILDEDKVVHKANQKITNKNTNSKKKESIFSYDIVKDKRYTVDKFFIHLPITLNYKEQNVSRFNDYIREILKKSKNIRVIGIDRGERNLLYVVVCDSDGSILYQRSINEIVSGSHKTDYHKLLDNKEKERLSSRRDWKTIENIKDLKAGYMSQVVNEIYNLILKYNAIVVLEDLNIGFKNGRKKVEKQVYQNFEKALIDKLNYLCIDKTREQLSPSSPGGVLNAYQLTAKFESFEKIGKQTGCIFYVPAYLTSQIDPTTGFVNLFYQKDTSKQGLQLFFRKFKKINFDKVASNFEFVFDYNDFTNKAEGTKTNWTISTQGTRIAKYRSDDANGKWISRTVHPTDIIKEALNREKINYNDGHDLIDEIVSIEKSAVLKEIYYGFKLTLQLRNSTLANEEEQEDYIISPVKNSSGNYFDSRITSKELPCDADANGAYNIARKGLWALEQIRNSENVSKVKLAISNKEWFEYTQNNIPSL (SEQ ID NO: 1581).
>WP_029202018_(модифицированный) гипотетический белок [Oribacterium sp. NK2B42]
MYYDGLTKQYALSKTIRNELVPIGKTLDNIKKNRILEADIKRKSDYEHVKKLMDMYHKKIINEALDNFKLSVLEDAADIYFNKQNDERDIDAFLKIQDKLRKEIVEQLKGHTDYSKVGNKDFLGLLKAASTEEDRILIESFDNFYTYFTSYNKVRSNLYSAEDKSSTVAYRLINENLPKFFDNIKAYRTVRNAGVISGDMSIVEQDELFEVDTFNHTLTQYGIDTYNHMIGQLNSAINLYNQKMHGAGSFKKLPKMKELYKQLLTEREEEFIEEYTDDEVLITSVHNYVSYLIDYLNSDKVESFFDTLRKSDGKEVFIKNDVSKTTMSNILFDNWSTIDDLINHEYDSAPENVKKTKDDKYFEKRQKDLKKNKSYSLSKIAALCRDTTILEKYIRRLVDDIEKIYTSNNVFSDIVLSKHDRSKKLSKNTNAVQAIKNMLDSIKDFEHDVMLINGSGQEIKKNLNVYSEQEALAGILRQVDHIYNLTRNYLTKKPFSTEKIKLNFNRPTFLDGWDKNKEEANLGILLIKDNRYYLGIMNTSSNKAFVNPPKAISNDIYKKVDYKLLPGPNKMLPKVFFATKNIAYYAPSEELLSKYRKGTHKKGDSFSIDDCRNLIDFFKSSINKNTDWSTFGFNFSDTNSYNDISDFYREVEKQGYKLSFTDIDACYIKDLVDNNELYLFQIYNKDFSPYSKGKLNLHTLYFKMLFDQRNLDNVVYKLNGEAEVFYRPASIESDEQIIHKSGQNIKNKNQKRSNCKKTSTFDYDIVKDRRYCKDKFMLHLPITVNFGTNESGKFNELVNNAIRADKDVNVIGIDRGERNLLYVVVVDPCGKIIEQISLNTIVDKEYDIETDYHQLLDEKEGSRDKARKDWNTIENIKELKEGYLSQVVNIIAKLVLKYDAIICLEDLNFGFKRGRQKVEKQVYQKFEKMLIDKMNYLVLDKSRKQESPQKPGGALNALQLTSAFKSFKELGKQTGIIYYVPAYLTSKIDPTTGFANLFYIKYESVDKARDFFSKFDFIRYNQMDNYFEFGFDYKSFTERASGCKSKWIACTNGERIVKYRNSDKNNSFDDKTVILTDEYRSLFDKYLQNYIDEDDLKDQILQIDSADFYKNLIKLFQLTLQMRNSSSDGKRDYIISPVKNYREEFFCSEFSDDTFPRDADANGAYNIARKGLWVIKQIRETKSGTKINLAMSNSEWLEYAQCNLL (SEQ ID NO: 115).
>WP_028248456_(модифицированный) гипотетический белок [Pseudobutyrivibrio ruminis]
MYYQNLTKMYPISKTLRNELIPVGKTLENIRKNGILEADIQRKADYEHVKKLMDNYHKQLINEALQGVHLSDLSDAYDLY
FNLSKEKNSVDAFSKCQDKLRKEIVSLLKNHENFPKIGNKEIIKLLQSLYDNDTDYKALDSFSNFYTYFSSYNEVRKNLYSDEEKSSTVAYRLINENLPKFLDNIKAYAIAKKAGVRAEGLSEEDQDCLFIIETFERTLTQDGIDNYNAAIGKLNTAINLFNQQNKKQEGFRKVPQMKCLYKQILSDREEAFIDEFSDDEDLITNIESFAENMNVFLNSEIITDFKIALVESDGSLVYIKNDVSKTSFSNIVFGSWNAIDEKLSDEYDLANSKKKKDEKYYEKRQKELKKNKSYDLETIIGLFDDNSDVIGKYIEKLESDITAIAEAKNDFDEIVLRKHDKNKSLRKNTNAVEAIKSYLDTVKDFERDIKLINGSGQEVEKNLVVYAEQENILAEIKNVDSLYNMSRNYLTQKPFSTEKFKLNFNRATLLNGWDKNKETDNLGILFEKDGMYYLGIMNTKANKIFVNIPKATSNDVYHKVNYKLLPGPNKMLPKVFFAQSNLDYYKPSEELLAKYKAGTHKKGDNFSLEDCHALIDFFKASIEKHPDWSSFGFEFSETCTYEDLSGFYREVEKQGYKITYTDVDADYITSLVERDELYLFQIYNKDFSPYSKGNLNLHTIYLQMLFDQRNLNNVVYKLNGEAEVFYRPASINDEEVIIHKAGEEIKNKNSKRAVDKPTSKFGYDIIKDRRYSKDKFMLHIPVTMNFGVDETRRFNDVVNDALRNDEKVRVIGIDRGERNLLYVVVVDTDGTILEQISLNSIINNEYSIETDYHKLLDEKEGDRDRARKNWTTIENIKELKEGYLSQVVNVIAKLVLKYNAIICLEDLNFGFKRGRQKVEKQVYQKFEKMLIDKLNYLVIDKSRKQDKPEEFGGALNALQLTSKFTSFKDMGKQTGIIYYVPAYLTSKIDPTTGFANLFYVKYENVEKAKEFFSRFDSISYNNESGYFEFAFDYKKFTDRACGARSQWTVCTYGERIIKFRNTEKNNSFDDKTIVLSEEFKELFSIYGISYEDGAELKNKIMSVDEADFFRSLTRLFQQTMQMRNSSNDVTRDYIISPIMNDRGEFFNSEACDASKPKDADANGAFNIARKGLWVLEQIRNTPSGDKLNLAMSNAEWLEYAQRNQI (SEQ ID NO: 116).
>WP_028830240_(модифицированный) гипотетический белок [Proteocatella sphenisci]
MENFKNLYPINKTLRFELRPYGKTLENFKKSGLLEKDAFKANSRRSMQAIIDEKFKETIEERLKYTEFSECDLGNMTSKDKKITDKAATNLKKQVILSFDDEIFNNYLKPDKNIDALFKNDPSNPVISTFKGFTTYFVNFFEIRKHIFKGESSGSMAYRIIDENLTTYLNNIEKIKKLPEELKSQLEGIDQIDKLNNYNEFITQSGITHYNEIIGGISKSENVKIQGINEGINLYCQKNKVKLPRLTPLYKMILSDRVSNSFVLDTIENDTELIEMISDLINKTEISQDVIMSDIQNIFIKYKQLGNLPGISYSSIVNAICSDYDNNFGDGKRKKSYENDRKKHLETNVYSINYISELLTDTDVSSNIKMRYKELEQNYQVCKENFNATNWMNIKNIKQSEKTNLIKDLLDILKSIQRFYDLFDIVDEDKNPSAEFYTWLSKNAEKLDFEFNSVYNKSRNYLTRKQYSDKKIKLNFDSPTLAKGWDANKEIDNSTIIMRKFNNDRGDYDYFLGIWNKSTPANEKIIPLEDNGLFEKMQYKLYPDPSKMLPKQFLSKIWKAKHPTTPEFDKKYKEGRHKKGPDFEKEFLHELIDCFKHGLVNHDEKYQDVFGFNLRNTEDYNSYTEFLEDVERCNYNLSFNKIADTSNLINDGKLYVFQIWSKDFSIDSKGTKNLNTIYFESLFSEENMIEKMFKLSGEAEIFYRPASLNYCEDIIKKGHHHAELKDKFDYPIIKDKRYSQDKFFFHVPMVINYKSEKLNSKSLNNRTNENLGQFTHIIGIDRGERHLIYLTVVDVSTGEIVEQKHLDEIINTDTKGVEHKTHYLNKLEEKSKTRDNERKSWEAIETIKELKEGYISHVINEIQKLQEKYNALIVMENLNYGFKNSRIKVEKQVYQKFETALIKKFNYIIDKKDPETYIHGYQLTNPITTLDKIGNQSGIVLYIPAWNTSKIDPVTGFVNLLYADDLKYKNQEQAKSFIQKIDNIYFENGEFKFDIDFSKWNNRYSISKTKWTLTSYGTRIQTFRNPQKNNKWDSAEYDLTEEFKLILNIDGTLKSQDVETYKKFMSLFKLMLQLRNSVTGTDIDYMISPVTDKTGTHFDSRENIKNLPADADANGAYNIARKGIMAIENIMNGISDPLKISNEDYLKYIQNQQE (SEQ ID NO: 117).
Заявители получили векторные конструкции, как показано на фигурах 40A-L (например, PACYC184 fnCpf1 (PY001)) и фигурах 41A-E (например, PaCpf1).
Анализ с пробой на PAM для обнаружения предположительных последовательностей PAM для FnCpf1 (фигура 42): Заявители выделили локус Cpf1 из Francisella novicida (Fn) (фигура 43) и трансформировали его в E.coli. Локус экспрессировался в E.coli из pACYC184, аналогично эксперименту, описанному в Sapranauskas et al.
E.coli с pACYC-локус FnCpf1 = Cpf1+
E.coli с пустым pACYC184 = контроль
Заявители трансформировали Cpf1+ и контрольных E.coli с помощью плазмид с библиотекой PAM. Получали две библиотеки PAM (фигура 44). Библиотеки PAM представляли собой плазмиды pUC19, содержащие последовательность протоспейсера длиной 31 п. о., которая соответствовала спейсеру 1 в локусе FnCpf1. Библиотека левых PAM имела вырожденный PAM длиной 8 п. о. на 5'-конце протоспейсера. Библиотека правых PAM имела вырожденный PAM длиной 7 п. о. на 3'-конце протоспейсера. Заявители высевали Cpf1+ и контрольные E.coli и собирали все колонии через ~12 ч. Каждая колония представляла собой объект трансформации с помощью PAM-pUC19, в котором не произошло разрезание/интерференция под действием Cpf1. Эти плазмиды PAM-pUC19 не несли распознаваемый PAM. Заявители определили с помощью секвенирования колоний, какие плазмиды PAM-pUC19 более не присутствовали в сравнении с контролем, и эти плазмиды идентифицировали как содержащие распознаваемый PAM.
Клонирование pY0001: pY0001 представляет собой остов pACYC184 (от NEB) с частичным локусом FnCpf1. pY0001 содержит эндогенный локус FnCpf1 из 255 п. о. в направлении 3' от последовательности ацетилтрансферазы до 4-ой спейсерной последовательности. Только спейсеры 1-3 являются потенциально активными, поскольку спейсер 4 больше не фланкирован прямыми повторами.
Заявители подвергали ПЦР-амплификации локус FnCpf1 3 кусками и клонировали в pACYC184, разрезанный с помощью Xba1 и Hind3, с применением сборки по Гибсону.
Компьютерный анализ для скрининга PAM Cpf1
После секвенирования подвергнутой скринингу ДНК заявители экстрагировали участки, соответствующие либо левому PAM, либо правому PAM. Для каждого образца число PAM, присутствующих в секвенированной библиотеке, сравнивали с числом экстрагированных PAM в данной библиотеке (4^8 для левой библиотеки, 4^7 для правой).
Для левой библиотеки показано истощение PAM. Для количественной оценки данного истощения заявители рассчитывали показатель обогащения. Для обоих состояний (контрольный pACYC или pACYC, содержащий FnCpf1) заявители рассчитывали показатель для каждого PAM в библиотеке как:
показатель
Заявители определили, что нанесение распределения на график показало небольшое обогащение для контрольного образца и обогащение для обоих биологических повторов. Заявители собирали все PAM с показателем, превышающим 8, и наносили на график распределения частот для выявления PAM 5' YYN (фигуры 45A-E). Заявители подтвердили, что PAM представляет собой TTN, где N представляет собой A/C/G или T.
Заявители проводили секвенирование РНК локуса Cpf1Francisella tolerances, и анализ RNAseq показал, что локус CRISPR активно экспрессировался (фигура 46). Дополнительное описание анализа RNAseq локуса FnCpf1 показано на фигуре 86. В дополнение к генам Cpf1 и Cas на высоком уровне транскрибировались два малых некодирующих транскрипта, которые заявители определили как предполагаемые tracrRNA. Также экспрессируется массив CRISPR. Как предполагаемые tracrRNA, так и массив CRISPR транскрибируются в том же направлении, что и гены Cpf1 и Cas. В данном случае все РНК-транскрипты, идентифицированные с помощью эксперимента RNAseq, картированы относительно локуса. Путем увеличения масштаба массива CRISPR c Cpf1 заявители идентифицировали много различных коротких транскриптов. На данном графике все идентифицированные РНК-транскрипты картированы относительно локуса Cpf1 (фигура 47). После отбора транскриптов, которые имели длину менее 85 нуклеотидов, заявители идентифицировали две предполагаемых tracrRNA (фигура 48). На фигуре 49 показано увеличение масштаба общего вида предполагаемой tracrRNA 1 и массива CRISPR. На фигуре 50 показано увеличение масштаба общего вида предполагаемой tracrRNA 2. Предполагаемые последовательности crRNA указаны на фигуре 51.
Заявители проводили тестирование на предмет функционирования в клетках млекопитающих с применением продуктов ПЦР U6: спейсера (DR-спейсер-DR) (в определенных аспектах спейсеры могут обозначаться как crRNA или направляющая РНК или аналогичным термином, описываемым в настоящей заявке) и tracr для других идентифицированных локусов Cpf1.
Пример 4. Дополнительные эксперименты по подтверждению FnCpf1
Заявители подтвердили, что прогнозируемый PAM FnCpf1 является TTN in vivo, путем применения анализа, изложенного на фигуре 52. Заявители трансформировали клетки, несущие локус FnCpf1, и контрольные клетки, с помощью pUC19, кодирующего эндогенный спейсер 1 с PAM 5' TTN (фигура 53). Вкратце, в in vivo анализе подтверждения PAM 50 мкл компетентных E.coli с локусом FnCpf1 (тестируемый штамм) и с пустым pACYC184 (контрольный штамм) трансформировали с помощью 10 нг плазмид, несущих протоспейсер 1. Перед последовательностью протоспейсера располагались прогнозируемые последовательности PAM (TTC, TTG, TTA и TTT). После трансформации клетки разбавляли 1:2000 и высевали на чашки с LB-агаром, содержащие ампициллин и хлорамфеникол. Только клетки с интактной плазмидой с протоспейсером могли формировать колонии. Чашки с колониями фотографировали через ~14 ч после посева и колонии подсчитывали с применением программного обеспечения ImageJ.
Заявители осуществляли анализы расщепления в клеточных лизатах для дополнительного подтверждения расщепления под действием FnCpf1. Протокол анализа расщепления в клеточных лизатах был следующим.
In vitro реакция расщепления Буфер для расщепления: 100 мМ HEPES, pH 7,5, 500 мМ KCl, 25 мМ MgCl2, 5 мМ DTT, 25% глицерин. Исходный раствор можно готовить без DTT.
Получение клеточных лизатов
Буфер для лизиса: 20 мМ Hepes, pH 7,5, 100 мМ хлорид калия [KCl], 5 мМ хлорид магния [MgCl2], 1 мМ дитиотреитола [DTT], 5% глицерин, 0,1% Triton X-100, дополненный 10x смесью ингибиторов протеаз от Roche. Можно хранить концентрированный исходный раствор буфера для лизиса без ингибитора протеаз от Roche и DTT. Хранить при -20°C.
Трансфицировать клетки HEK с помощью рекомендованного количества ДНК с Lipofectamine 2000
- 500 нг на лунку в 24-луночном планшете
- 2000 нг на лунку в 6-луночном планшете
Собрать клетки с помощью буфера для лизиса через 24-72 часов после трансфекции
- Аспирировать среду
- Аккуратно промыть с помощью DPBS
- Аспирировать DPBS
- Применить 50 мкл буфера для лизиса на лунку в 24-луночном планшете или 250 мкл на лунку в 6-луночном планшете
- Оставить на льду на 5 мин.
- Перенести в пробирку Эппендорф
- Поместить на лед на 15 минут
- Обработать ультразвуком высокой мощности, с 50% коэффициентом заполнения в течение 5-10 мин.
- Осадить центрифугированием на холоде при максимальной скорости в течение 20 мин.
- Перенести супернатант в новую пробирку
- Разделить на аликвоты в пробирки для ПЦР в стрипах, 10 мкл на стрип и заморозить при -80°C
In vitro транскрипция направляющей РНК
Протокол для набора: Доступ к информации можно получить на веб-сайте www.neb.com/products/e2030-hiscribe-t7-in-vitro-transcription-kit
Взять 100 мМ исходного раствора олигонуклеотидов
Выполнить отжиг в реакционной смеси объемом 10 мкл:
1 мкл "прямой" нити T7 = "XRP2649"
1 мкл "обратного" олигонуклеотида T7
1 мкл буфера TaqB
7 мкл воды
Запустить ПЦР-программу PNK без стадии инкубации при 37°C (изначально нагреть до 95°C в течение 5 мин. и осуществить медленное охлаждение до 4°C, но не такое медленное как отжиг в анализе с использование нуклеазы Surveyor). Олигонуклеотиды, подверженные отжигу на нанокаплях: нормализовать водой до 500 нг/мкл (обычно 1000-2000 нг/мкл в случае олигонуклеотидов длиной 120 нуклеотидов)
Для транскрипции T7 следуйте инструкциям из набора (но сократите размер в 4x)
Реакционная смесь объемом 10 мкл
1 мкл 10x буфер
1 мкл транскриптазы T7
0,5 мкл rNTP
0,5 мкл смеси HMW
1 мкл ДНК-матрицы (отожженной)
6 мкл воды
Провести транскрипцию при 42°C (предпочтительно в термоциклере) в течение по меньшей мере 2-3 часов, оставить протекать на протяжение ночи. Выход должен составлять около 1000-2000 нг/мкл РНК. Образование белого осадка является нормальным.
Подготовка ДНК
Для pUC19 линеаризовать с помощью HindIII и провести очистку на колонке
→ для реакции потребуется 300-400 нг плазмиды, поэтому сократите количество, при необходимости
Для gDNA амплифицировать ДНК клеток дикого типа с помощью ПЦР
→ осуществить несколько ПЦР-реакций, объединить и провести очистку на колонке
→ концентрировать продукт до примерно 100-200 нг/мкл
Хранить при -20°C
Реакционная смесь объемом 20 мкл
10 мкл лизата (который был ранее разделен на аликвоты)
2 мкл буфера для расщепления (буфер 3 от NEB)
1 мкл РНК (непосредственно из предыдущей стадии; очистка не требуется)
1 мкл ДНК (из предыдущей стадии)
6 мкл воды
Инкубировать при 37°C в течение 1-2 часа (30 мин. достаточно)
Очистить реакционную смесь на колонке
Пропустить через 2% E-гель
В анализе расщепления в клеточных лизатах применяли tracrRNA в положениях 1, 2, 3, 4 и 5, как указано на фигуре 54. Анализ расщепления в клеточных лизатах (1) (фигура 55). Представлен гель, на котором показан ПЦР-фрагмент с PAM TTa и последовательностью протоспейсера 1 после инкубации в клеточном лизате. Анализ расщепления в клеточных лизатах (2) (фигура 56). Представлен гель, на котором показан pUC-спейсер 1 с различными PAM после инкубации в клеточном лизате. Анализ расщепления в клеточных лизатах (3) (фигура 57). Представлен гель, на котором показаны результаты расщепления с помощью BasI после инкубации в клеточном лизате. Анализ расщепления в клеточных лизатах (4) (фигура 58). Представлен гель, на котором показаны результаты расщепления трех предполагаемых последовательностей crRNA.
Заявители также определяли эффект длины спейсера на эффективность расщепления. Заявители тестировали спейсеры различной длины относительно части целевой ДНК, содержащей целевой сайт: 5'-TTAgagaagtcatttaataaggccactgttaaaa-3' (SEQ ID NO: 119). В случае данного эксперимента плазмиду pUC19, содержащую спейсер (5'-TTcgagaagucauuuaauaaggccacuguuaaaa-3' (SEQ ID NO: 120)), обрабатывали при следующих условиях:
2 мкл клеточный лизат, содержащий Cpf1
2 мкл ДНК pUC19 со спейсером (300 нг)
1 мкл crRNA (500 нг)
2 мкл NEBuffer 3
2 мкл 40 мМ DTT
0,3 мкл BsaI
10,7 мкл ddH2O
Инкубировали при 37°C в течение 30 минут, с последующей обработкой с помощью РНКазы в течение 5 минут. Затем реакционную смесь очищали с применением набора для очистки ПЦР-продуктов от Qiagen и анализировали на 2% E-геле EX от Invitrogen. На фигуре 59 представлен гель, на котором показано, что crRNA 1-7 опосредовали успешное расщепление целевой ДНК in vitro под действием FnCpf1, тогда как crRNA 8-13 не способствовали расщеплению целевой ДНК.
Заявители нашли минимальный локус Fn Cpf1 (фигура 60) и также установили минимальную направляющую для Cpf1 (фигура 61). Заявители также провели расщепление ПЦР-ампликона локуса Emx1 человека (фигура 81). Ампликон EMX обрабатывали при следующих условиях:
2 мкл клеточный лизат, содержащий Cpf1
3 мкл ДНК pUC19 со спейсером (300 нг)
1 мкл crRNA (500 нг)
2 мкл NEBuffer 3
2 мкл 40 мМ DTT
0,3 мкл BsaI
9,7 мкл ddH2O
Инкубировали при 37°C в течение 30 минут, с последующей обработкой с помощью РНКазы в течение 5 минут. Затем реакционную смесь очищали с применением набора для очистки ПЦР-продуктов от Qiagen и анализировали на 2% E-геле EX от Invitrogen.
Заявители дополнительно изучали эффект усечения 5' DR на активность расщепления (фигура 82A-B). В случае данного эксперимента плазмиду pUC19, содержащую спейсер (5'-TTcgagaagucauuuaauaaggccacuguuaaaa-3' (SEQ ID NO: 121)), обрабатывали при следующих условиях:
2 мкл клеточный лизат, содержащий Cpf1
2 мкл ДНК pUC19 со спейсером (300 нг)
1 мкл crRNA (500 нг)
2 мкл NEBuffer 3
2 мкл 40 мМ DTT
0,3 мкл BsaI
10,7 мкл ddH2O
Инкубировали при 37°C в течение 30 минут, с последующей обработкой с помощью РНКазы в течение 5 минут. Затем реакционную смесь очищали с применением набора для очистки ПЦР-продуктов от Qiagen и анализировали на 2% E-геле EX от Invitrogen. Заявители определили, что в crDNA deltaDR5 разрушалась "петля-на-стебле" на 5'-конце, и это показывает, что "петля-на-стебле" на 5'-конце необходима для активности расщепления (фигура 82B).
Заявители исследовали эффект несовпадения crRNA-ДНК-мишень на эффективность расщепления (фигура 83). В случае данного эксперимента плазмиду pUC19, содержащую спейсер (5'-TTcgagaagucauuuaauaaggccacuguuaaaa-3' (SEQ ID NO: 122)), обрабатывали при следующих условиях:
2 мкл клеточный лизат, содержащий Cpf1
2 мкл ДНК pUC19 со спейсером (300 нг)
1 мкл crRNA (500 нг)
2 мкл NEBuffer 3
2 мкл 40 мМ DTT
0,3 мкл BsaI
10,7 мкл ddH2O
Инкубировали при 37°C в течение 30 минут, с последующей обработкой с помощью РНКазы в течение 5 минут. Затем реакционную смесь очищали с применением набора для очистки ПЦР-продуктов от Qiagen и анализировали на 2% E-геле EX от Invitrogen. Каждая дорожка на геле, показанном на фигуре 83, состояла из Cpf1-содержащего клеточного лизата, pUC19 с TTc-протоспейсером и соответствующей crRNA, обозначенной как 1-11.
Заявители изучили домен RuvC FnCpf1p и идентифицировали аминокислотные мутации, которые могут превращать эффекторный белок FnCpf1 в никазу, в результате чего эффекторный белок характеризуется значительно сниженной нуклеазной активностью и только одна нить ДНК подвергается однонитевому разрыву и/или расщеплению. Аминокислотные положения в домене RuvC FnCpf1p включают без ограничения D917A, E1006A, E1028A, D1227A, D1255A, N1257A, D917A, E1006A, E1028A, D1227A, D1255A и N1257A. Аминокислотные положения в AsCpf1 соответствуют AsD908A, AsE993A, AsD1263A. Аминокислотные положения в LbCpf1 соответствуют LbD832A.
Заявители также идентифицировали предполагаемый второй нуклеазный домен, который наиболее похож на суперсемейство нуклеаз PD-(D/E)XK и HincII-подобную эндонуклеазу. Точечные мутации, которые необходимо получить в данном предполагаемом нуклеазном домене для значительного снижения нуклеазной активности, включают без ограничения N580A, N584A, T587A, W609A, D610A, K613A, E614A, D616A, K624A, D625A, K627A и Y629A.
Заявители осуществили эксперименты по расщеплению плазмид с помощью FnCpf1p, и секвенирование указанных плазмид обеспечит информацию относительно того, какой из сайтов разреза является "липким", а какой "тупым". Заявители установят дополнительные подробности о различных доменах FnCpf1p на основании кристаллической структуры данного белка в соответствующем комплексе. Для оптимизации компонентов локуса FnCpf1 в отношении активности в клетках человека заявители проведут испытания crRNA с различной структурой и проведут испытания в отношении большего числа мишеней, чем описано в данном документе.
Заявители проводили расщепление ДНК с применением очищенного Cpf1 Francisella и Prevotella (фигура 84). В случае данного эксперимента плазмиду pUC19, содержащую спейсер (5'-TTcgagaagucauuuaauaaggccacuguuaaaa-3' (SEQ ID NO: 123)), обрабатывали при следующих условиях:
2 мкл очищенного раствора белка
2 мкл ДНК pUC19 со спейсером (300 нг)
1 мкл crRNA (500 нг)
2 мкл NEBuffer 3
2 мкл 40 мМ DTT
0,3 мкл BsaI
10,7 мкл ddH2O
Инкубировали при 37°C в течение 30 минут, с последующей обработкой с помощью РНКазы в течение 5 минут. Затем реакционную смесь очищали с применением набора для очистки ПЦР-продуктов от Qiagen и анализировали на 2% E-геле EX от Invitrogen. Анализ геля, показанного на фигуре 84, показывает, что PaCpf1 может работать с crRNA для FnCpf1, хотя активность не настолько высока, как в случае FnCpf1. Заявители сделали вывод, что это вполне ожидаемо, учитывая то, что последовательности "петли-на-стебле" у PaCpf1 и FnCpf1 являются почти идентичными (отличие только в 1 основание) (см. фигуры 85A-B). Это дополнительно проиллюстрировано в зрелых последовательностях crRNA для FnCpf1 и PaCpf1, показанных на фигурах 87A-B. В предпочтительных вариантах осуществления настоящего изобретения в случае биохимического или in vitro расщепления для эффективного функционирования системы CRISPR на основе Cpf1p может не требоваться tracr-последовательность. Включение "петли-на-стебле" или дополнительно оптимизированной структуры "петля-на-стебле" является важным для активности расщепления.
Расщепление ДНК с помощью FnCpf1p Francisella novicida, кодон-оптимизированной для человека.
Заявители также показали, что FnCpf1p расщепляет ДНК в клетках человека. 400 нг FnCpf1p, кодон-оптимизированной для человека, и 100 нг U6::crRNA трансфицировали в лунке с клетками HEK293T (~240000 клеток) в 24-луночных планшетах. Использовали пять crRNA, содержащих спейсерные последовательности длиной 20-24 нуклеотидов на основе 5'-ctgatggtccatgtctgttactcg-3' (SEQ ID NO: 124) (т. е. первые 20, 21, 22, 23 или все 24 нуклеотида). crRNA дополнительно содержали 20 нуклеотидов последовательности 5’-повтора из PaCpf1 на 5'-конце спейсера. Заявители ранее определили, что последовательность повтора из PaCpf1 может распознаваться FnCpf1.
ДНК собирали через ~60 ч. и анализировали посредством анализа с помощью нуклеазы SURVEYOR. Праймеры SURVEYOR для DNMT1 представляли собой 5'-ctgggactcaggcgggtcac-3' (SEQ ID NO: 125) (прямой) и 5'-cctcacacaacagcttcatgtcagc-3' (SEQ ID NO: 126) (обратный). Фрагменты расщепленной ДНК, совпадающие с ожидаемыми продуктами расщепления длиной ~345 п. о. и ~261 п. о., наблюдали в случае всех пяти crRNA (длина спейсеров составляла 20-24 нуклеотидов) (фигура 88).
Пример 5. Дополнительные эксперименты по подтверждению PaCpf1
Компьютерный скрининг PAM проводили для Cpf1 Prevotella albensis (PaCpf1) аналогично скринингу, проводимому для FnCpf1, как подробно описано в примере 3. После секвенирования подвергнутой скринингу ДНК участки, соответствующие либо левому PAM, либо правому PAM, экстрагировали. Для каждого образца число PAM, присутствующих в секвенированной библиотеке, сравнивали с числом экстрагированных PAM в данной библиотеке (4^7). Для левой библиотеки показано очень слабое истощение PAM. Для количественной оценки данного истощения рассчитывали показатель обогащения. Для обоих состояний (контрольный pACYC или pACYC, содержащий PaCpf1) показатель рассчитывали для каждого PAM в библиотеке как
показатель
Нанесение распределения на график показывает небольшое обогащение для контрольного образца и обогащение для обоих биологических повторов. Собирали все PAM с показателем, превышающим 4,5, и распределения частот наносили на график, что выявило PAM 5' TTTV, где V представляет собой A, или C, или G (фигура 62A-E).
Заявители установят дополнительные подробности о различных доменах PaCpf1p на основании кристаллической структуры данного белка в соответствующем комплексе. Для оптимизации компонентов локуса PaCpf1 в отношении активности в клетках человека заявители проведут работы с crRNA (направляющими RNA) различной структуры и различными оптимизированными эффекторными белками PaCpf1. Заявители провели кодон-оптимизацию последовательности PaCpf1 для человека следующим образом:
NLS (подчеркнут)
GS-линкер (жирный шрифт)
3xHA-метка (курсив)
ATGGCCCCAAAGAAGAAGCGGAAGGTCGGTATCCACGGAGTCCCAGCAGCCggtagtAACATCAAAAACTTTACCGGGCTCTACCCCCTCAGCAAAACTTTGCGCTTTGAACTCAAGCCTATTGGCAAAACCAAGGAAAACATCGAGAAAAATGGCATCCTGACCAAGGACGAGCAACGGGCTAAAGACTACCTCATAGTCAAAGGCTTTATTGACGAGTATCACAAGCAGTTCATCAAAGACAGGCTTTGGGACTTTAAATTGCCTCTCGAAAGTGAGGGGGAGAAGAACAGTCTCGAAGAATACCAGGAACTGTACGAGCTCACTAAGCGCAACGATGCCCAGGAGGCCGACTTCACCGAGATTAAAGATAACCTTCGCAGCTCTATTACCGAACAGCTCACGAAGTCTGGATCTGCGTACGATCGGATTTTTAAAAAAGAGTTCATTAGAGAAGACCTGGTCAACTTCCTCGAAGATGAAAAAGATAAAAATATCGTGAAACAGTTCGAGGACTTTACTACATATTTTACGGGTTTTTATGAAAATAGGAAGAACATGTACTCTAGCGAAGAGAAGTCCACGGCCATCGCATACCGGCTTATCCATCAGAATCTGCCAAAATTCATGGACAACATGAGAAGTTTTGCCAAAATTGCAAATTCCAGTGTTTCCGAGCACTTTAGCGACATCTATGAAAGCTGGAAGGAATATCTGAATGTAAATAGCATCGAGGAAATCTTCCAGCTCGACTATTTTAGCGAAACCTTGACTCAGCCACATATTGAGGTGTATAACTATATTATCGGGAAGAAAGTCCTGGAAGACGGAACCGAGATAAAGGGCATCAACGAGTATGTGAACCTCTACAATCAGCAGCAGAAAGATAAGAGTAAACGACTGCCTTTCCTGGTGCCACTGTATAAGCAAATTTTGTCTGATAGGGAAAAACTCTCCTGGATTGCTGAAGAGTTCGACAGCGACAAGAAGATGCTGAGCGCTATCACCGAGTCTTACAACCACCTGCACAACGTGTTGATGGGTAACGAGAACGAAAGCCTGCGAAATCTGCTGCTGAATATTAAGGACTATAACCTGGAGAAAATTAATATCACAAACGACTTGTCTCTCACCGAAATCTCCCAGAATCTTTTTGGCCGATATGATGTATTCACAAATGGGATCAAAAACAAGCTGAGAGTGTTGACTCCAAGGAAGAAAAAGGAGACGGACGAAAATTTTGAGGACCGCATTAACAAAATTTTTAAGACCCAGAAGTCCTTCAGCATCGCTTTTCTGAACAAGCTGCCTCAGCCCGAAATGGAGGATGGGAAGCCCCGGAACATTGAGGACTATTTCATTACACAGGGGGCGATTAACACCAAATCTATACAGAAAGAAGATATCTTCGCCCAAATTGAGAATGCATACGAGGATGCACAGGTGTTCCTGCAAATTAAGGACACCGACAACAAACTTAGCCAGAACAAGACGGCGGTGGAAAAGATCAAAACTTTGCTGGACGCCTTGAAGGAACTCCAGCACTTCATCAAACCGCTGCTGGGCTCTGGGGAGGAGAACGAGAAAGACGAACTGTTCTACGGTTCCTTCCTGGCCATCTGGGACGAACTGGACACCATTACACCACTTTATAACAAAGTGAGAAATTGGCTGACCCGAAAACCATATTCAACAGAAAAAATCAAATTGAATTTCGACAACGCTCAGCTGCTGGGAGGGTGGGATGTCAATAAAGAACACGACTGTGCAGGTATCTTGTTGCGGAAAAACGATAGCTACTATCTCGGAATTATCAATAAGAAAACCAACCACATCTTTGATACGGATATTACGCCATCAGATGGCGAGTGCTATGACAAAATCGACTACAAGCTCCTTCCCGGGGCGAACAAAATGCTTCCAAAGGTGTTTTTTAGTAAGTCCCGAATCAAAGAGTTCGAGCCATCAGAGGCCATAATCAATTGCTATAAGAAGGGGACACACAAAAAAGGAAAAAACTTTAACCTGACGGACTGTCACCGCCTGATCAACTTTTTTAAGACCTCAATCGAGAAACACGAGGATTGGTCAAAATTCGGATTCAAGTTCTCCGATACCGAAACGTATGAGGATATTAGCGGTTTTTATAGAGAGGTCGAGCAGCAGGGATACAGGCTGACGAGCCATCCAGTCAGTGCCAGCTATATACATAGTCTGGTCAAGGAAGGAAAACTGTACCTCTTCCAAATCTGGAACAAGGACTTTTCTCAATTCTCCAAGGGGACCCCTAACTTGCACACTCTCTATTGGAAGATGCTGTTTGACAAACGGAATCTTAGCGATGTGGTTTATAAGCTGAATGGCCAGGCTGAAGTGTTCTATAGAAAGAGCTCCATTGAACACCAGAACCGAATTATCCACCCCGCTCAGCATCCCATCACAAATAAGAATGAGCTTAACAAAAAGCACACTAGCACCTTCAAATACGATATCATCAAAGATCGCAGATACACGGTGGATAAATTCCAGTTCCATGTGCCCATTACTATAAATTTTAAGGCGACCGGGCAGAACAACATCAACCCAATCGTCCAAGAGGTGATTCGCCAAAACGGTATCACCCACATCATAGGCATCGATCGAGGTGAACGCCATCTTCTGTACCTCTCTCTCATCGATTTGAAAGGCAACATCATCAAGCAGATGACTCTCAACGAAATTATTAATGAGTATAAGGGTGTGACCTATAAGACCAACTACCATAACCTCCTGGAGAAGAGGGAGAAGGAGCGGACCGAGGCCAGACACTCCTGGAGTAGTATTGAAAGCATAAAAGAACTGAAGGATGGATACATGTCACAGGTGATTCACAAAATTACGGACATGATGGTTAAGTACAATGCGATTGTGGTCCTGGAGGACCTCAACGGGGGGTTTATGCGAGGCCGCCAGAAGGTCGAGAAGCAGGTGTACCAGAAATTTGAAAAAAAGTTGATCGACAAGCTGAACTATCTCGTTGACAAGAAACTCGACGCTAACGAGGTCGGCGGAGTACTGAATGCTTATCAGCTGACCAACAAGTTCGAGTCTTTCAAGAAGATTGGGAAACAAAGCGGATTTTTGTTCTACATCCCCGCCTGGAACACAAGCAAAATCGATCCTATAACAGGGTTCGTTAATCTGTTCAACACCAGGTACGAGTCTATCAAGGAGACAAAAGTTTTTTGGTCTAAGTTTGATATTATCCGATACAATAAAGAGAAGAATTGGTTCGAGTTCGTCTTCGATTACAATACCTTTACGACTAAAGCGGAGGGAACACGCACTAAGTGGACTCTGTGCACCCACGGCACTCGCATCCAGACATTCCGGAACCCAGAAAAGAATGCCCAGTGGGACAATAAAGAGATCAATTTGACTGAGTCCTTCAAAGCTCTGTTTGAAAAGTACAAGATCGATATCACCAGTAATCTCAAGGAATCCATCATGCAGGAAACCGAGAAGAAGTTCTTCCAGGAACTGCATAATCTGCTCCACCTGACCCTGCAGATGAGGAATAGCGTTACTGGAACCGACATAGACTATTTGATCAGCCCCGTTGCCGATGAGGATGGAAATTTCTATGATAGTCGCATAAATGGCAAAAATTTTCCGGAGAATGCCGATGCCAATGGCGCGTACAACATCGCACGAAAGGGTCTGATGCTTATTCGGCAGATCAAGCAAGCAGATCCACAGAAGAAATTCAAGTTTGAGACAATCACCAATAAAGACTGGCTGAAATTCGCCCAAGACAAGCCCTATCTTAAAGATggcagcgggAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGggatccTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATACGATGTCCCCGACTATGCCTAA (SEQ ID NO: 127).
Карта вектора для последовательности PaCpf1, кодон-оптимизированной для человека, представлена на фигуре 63.
Пример 6. Ортологи Cpf1
Заявители анализировали расширенную группу ортологов Cpf1 (фигура 64). Последовательности, кодон-оптимизированные для человека, получали для некоторых компонентов локуса Cpf1 (фигуры 65-79). Заявители также получили последовательности прямого повтора (DR) для каждого ортолога и их прогнозируемую структуру укладки (фигура 80A-I).
Заявители дополнительно исследовали ортологи Cpf1 по признаку размера эффекторного белка, т. е. более маленькие эффекторные белки обеспечивают возможность более легкой упаковки в векторы, и по признаку состава PAM. Все аспекты обеспечивают возможность дополнительной оптимизации в прокариотических и эукариотических клетках, предпочтительно для эффективной активности в клетках млекопитающих, т. е. клетках человека.
Заявители показали, что для ортологов эффекторного белка из следующих локусов показана активность в in vitro анализе расщепления: Cpf1 Peregrinibacteria bacterium GW2011_GWA2_33_10, Cpf1 Acidaminococcus sp. BV3L6, Cpf1 Francisalla tularensis 1, Cpf1 Moraxella bovoculi 237, Cpf1 Lachnospiraceae bacterium ND2006, Cpf1 Lachnospiraceaa bacterium MA2020, Cpf1 Porphyromonas macacee, Cpf1 Porphyromonas crevlor1canls 3 , Cpf1 Prevotella albensis (фигура 64).
В in vitro анализе расщепления с помощью ортологов клетки HEK293, экспрессирующие ортологи Cpf1, собирали и лизат инкубировали с прогнозируемой зрелой crRNA, нацеливающейся на искусственный спейсер, клонированный в плазмиды pUC19. Перед спейсером находились 8 вырожденных оснований для обеспечения определения PAM с помощью секвенирования. Нижние полоски указывали на расщепление под действием фермента Cpf1 (фигура 89).
Заявители идентифицировали полученные компьютерным образом PAM в in vitro анализе расщепления (фигура 90). Не подвергнутую разрезанию ДНК из фигуры 89 (самая высокая полоска) вырезали и амплифицировали для секвенирования следующего поколения. Рассчитывали содержание каждого 8-мера, и для количественной оценки обогащения log-показатель сравнивали с исходной библиотекой. Индивидуальные 8-меры с log-показателем, превышающим 4, компилировали и применяли для определения консенсусного PAM с применением Weblogo.
Заявители дополнительно идентифицировали, что эффекторные белки Cpf1p осуществляют разрез ступенчатым образом с "липкими" 5'-концами. Очищенный белок FnCpf1 собирали и инкубировали с crRNA и соответствующей мишенью, клонированной в pUC19. Расщепленный продукт экстрагировали из геля и подвергали секвенированию по Сэнгеру. Асимметричные риды указывают на то, что наблюдается ступенчатый разрез (фигура 91). В предпочтительном варианте осуществления настоящего изобретения заявители демонстрируют ступенчатое in vivo сшивание с матрицей (например, экзогенной матрицей).
Заявители также определяли эффект длины спейсера на способность эффекторного белка к разрезанию (фигура 92). Очищенный белок FnCpf1 собирали и инкубировали с crRNA и соответствующей мишенью, клонированной в pUC19. Спейсеры, длина которых составляла более 17 нуклеотидов, приводили к полному разрезанию, в то время как для спейсера длиной 17 нуклеотидов показана сниженная активность, а спейсеры, длина которых составляла менее 17 нуклеотидов, были неактивными.
Заявители продемонстрировали, что FnCpf1 опосредует образование вставок/делеций в клетках HEK293T.
~280000 клеток HEK/лунка в 24-луночном планшете трансфицировали с помощью 350 нг плазмиды huFnCpf1 и 150 нг U6::crRNA. Клетки собирали через три дня после трансфекции и анализировали посредством анализа с помощью нуклеазы SURVEYOR. Размер нерасщепленного ПЦР-фрагмента составлял 606 п. о. Размеры ожидаемых фрагментов составляли ~418 п. о. и ~188 п. о. в случае crRNA для DNMT1-1 и ~362 п. о. и ~244 п. о. в случае crRNA для DNMT1-3 (фигура 93).
Спейсерная последовательность DNMT1-1: cctcactcctgctcggtgaattt (SEQ ID NO: 128).
Спейсерная последовательность DNMT1-3: ctgatggtccatgtctgttactc (SEQ ID NO: 129).
Заявители идентифицировали компоненты системы Cpf1, требуемые для обеспечения расщепления, путем определения того, подвергались ли процессингу транскрипты, когда удалялись определенные последовательности локуса (фигура 94A-F). Удаленные последовательности могли включать без ограничения ген Cas1, ген Cas2 и tracr-последовательность. Следовательно, в предпочтительном варианте осуществления настоящего изобретения заявители продемонстрировали, что tracr-последовательность не является компонентом функциональной системы или комплекса Cpf1, требуемым для обеспечения расщепления.
Пример 7. Процедуры
Получение гетерологичных плазмид
Чтобы получить локус FnCpf1 для гетерологичной экспрессии, геномную ДНК из Francisella Novicida подвергали ПЦР-амплификации с применением полимеразы Herculase II (Agilent Technologies) и клонировали в pACYC-184 с применением клонирования по Гибсону (New England Biolabs). Клетки, несущие плазмиды, делали компетентными с применением набора Z-competent (Zymo).
Секвенирование бактериальной РНК
РНК выделяли из бактерий на стационарной фазе роста вначале путем ресуспендирования F. novicida (щедрый подарок от David Weiss) или E. coli в TRIzol, а затем гомогенизации бактерий с помощью гранул из циркония/кремнезема (BioSpec Products) в BeadBeater (BioSpec Products) в ходе 3 одноминутных циклов. Общую РНК очищали из гомогенизированных образцов с помощью протокола для набора Direct-Zol RNA miniprep (Zymo), обрабатывали ДНКазой с помощью ДНКазы TURBO (Life Technologies) и подвергали 3'-дефосфорилированию с помощью киназы для полинуклеотидов T4 (New England Biolabs). rRNA удаляли с помощью набора для удаления бактериальной rRNA Ribo-Zero (Illumina). Библиотеки РНК получали из РНК, истощенной по rRNA, с применением набора для получения библиотек малых РНК NEBNext® для Illumina (New England Biolabs) и отбирали по размеру с применением Pippin Prep (Sage Science)
- Для гетерологичной экспрессии локуса FnCpf1 в E. coli , получали библиотеки для секвенирования РНК из РНК, истощенной по rRNA, с применением модифицированного способа секвенирования РНК CRISPR, описанного ранее (Heidrich et al., 2015. Вкратце, к транскриптам добавляли поли-A-хвост с помощью поли(A)-полимеразы E. coli (New England Biolabs), лигировали с 5' РНК-адаптерами с применением РНК-лигазы 1 T4 (лигаза для ssRNA) высокой концентрации (New England Biolabs) и проводили обратную транскрипцию с помощью обратной транскриптазы AffinityScript, активной при разных температурах (Agilent Technologies). cDNA подвергали ПЦР-амплификации с праймерами, снабженными штрих-кодом, с применением полимеразы Herculase II (Agilent Technologies) Анализ с секвенированием РНК
Полученные библиотеки cDNA секвенировали на MiSeq (Illumina). Риды из каждого образца идентифицировали на основании ассоциированного с ними штрих-кода и выравнивали с соответствующим эталонным геномом из RefSeq с применением BWA (Li and Durbin, 2009). Выравнивания спаренных концов применяли для экстракции последовательностей целого транскрипта с применением инструментов Picard (http://broadinstitute.github.io/picard), и эти последовательности анализировали с применением Geneious 8.1.5.
In vivo скрининг PAM FnCpf1
Плазмидные библиотеки с рандомизированными PAM конструировали с применением синтезированных олигонуклеотидов (IDT), состоящих из 7 рандомизированных нуклеотидов либо выше, либо ниже мишени-спейсера 1 (дополнительная таблица S8). Рандомизированные олигонуклеотиды ssDNA превращали в двухнитевые путем отжига с коротким праймером и c применением крупного фрагмента Кленова (New England Biolabs) для синтеза второй нити. Продукт в виде dsDNA собирали в линеаризованный pUC19 с применением клонирования по Гибсону (New England Biolabs). Компетентные Stbl3 E. coli (Invitrogen) трансформировали с помощью клонированных продуктов, и более чем 107 клеток собирали и объединяли. Плазмидную ДНК собирали с применением набора Maxi-prep (Qiagen). 360 нг объединенной библиотеки трансформировали в клетки E. coli, несущие локус FnCpf1 locus или контрольный pACYC184. После трансформации клетки высевали на среду с ампициллином. После роста в течение 16 часов >4*106 клеток собирали и плазмидную ДНК экстрагировали с применением набора Maxi-prep (Qiagen). Целевой участок PAM амплифицировали и секвенировали с помощью MiSeq (Illumina) с 150 циклами для одиночных концов.
Компьютерный конвейерный алгоритм для обнаружения PAM
Участки PAM экстрагировали, подсчитывали и нормализовали к общему числу ридов для каждого образца. В случае данного PAM обогащение измеряли как log-показатель по сравнению с контрольным pACYC184 с поправкой на псевдоотсчет 0,01. PAM с пороговым значением обогащения, превышающим 3,5, собирали и применяли для получения логотипов последовательностей (Crooks et al., 2004).
Подтверждение PAM
Последовательности, как соответствующие PAM, так и не соответствующие PAM, клонировали в подвергнутый разрезанию pUC19 и лигировали с помощью лигазы T4 (Enzymatics). Компетентные E. сoli либо с плазмидой с локусом FnCpf1, либо с контрольной плазмидой pACYC184 трансформировали с помощью 20 нг плазмиды с PAM и высевали на чашки с LB-агаром, дополненным ампициллином и хлорамфениколом. Колонии подсчитывали через 18 часов.
Синтез crRNA и gRNA
Все crRNA и gRNA, применяемые в in vitro анализе, синтезировали с применением набора для синтеза РНК с высоким выходом на основе T7 HiScribe™ (NEB). Олигонуклеотиды ssDNA, соответствующие обратно комплементарной последовательности целевой последовательности РНК, синтезировали из IDT и отжигали с короткой праймерной последовательностью T7. Транскрипцию T7 осуществляли в течение 4 часов и затем РНК очищали с применением набора для очистки продуктов транскрипции MEGAclear™ (Ambion).
Очистка белка Cpf1
Белок FnCpf1 клонировали в вектор экспрессии для бактерий (6-His-MBP-TEV-Cpf1, вектор на основе pET, любезно предоставленный заявителям Doug Daniels) ("6-His" раскрыта как SEQ ID NO: 130). В два литра питательной среды Terrific Broth с 100 мкг/мл ампициллина инокулировали 10 мл ночной культуры клеток Rosetta (DE3) pLyseS (EMD Millipore), содержащих конструкцию для экспрессии Cpf1. Питательную среду с инокулированным материалом культивировали при 37°C до тех пор, пока плотность клеток OD600 не достигла 0,2, затем температуру снижали до 21°C. Выращивание продолжали до тех пор, пока OD600 не достигла 0,6, в этот момент добавляли IPTG из расчета конечной концентрации 500 мкМ для индуцирования экспрессии MBP-Cpf1. Культуру индуцировали в течение 14-18 часов, перед тем как клетки собирали и замораживали при -80°C до осуществления очистки.
Клеточную массу ресуспендировали в 200 мл буфера для лизиса (50 мМ Hepes, pH 7, 2 М NaCl, 5 мМ MgCl2, 20 мМ имидазол), дополненном ингибиторами протеаз (Roche cOmplete, без EDTA) и лизоцимом. Сразу после гомогенизации клетки лизировали путем обработки ультразвуком (Branson Sonifier 450), затем центрифугировали при 10000 g в течение 1 часа для избавления лизата от примесей. Лизат фильтровали через фильтр с размером пор 0,22 микрон (Millipore, Stericup) и вносили в колонку с никелем (HisTrap FF, 5 мл), промывали и затем элюировали с помощью градиента имидазола. Фракции, содержащие белок ожидаемого размера, объединяли, добавляли протеазу TEV (Sigma) и образец подвергали диализу в течение ночи с буфером TEV (500 мМ NaCl, 50 мМ Hepes, pH 7, 5 мМ MgCl, 2 мМ DTT). После диализа расщепление под действием TEV подтверждали с помощью SDS-PAGE и образец концентрировали до 500 мкл до загрузки на колонку для гель-фильтрации (HiLoad 16/600 Superdex 200) с помощью FPLC (AKTA Pure). Фракции, полученные в результате гель-фильтрации, анализировали с помощью SDS-PAGE; фракции, содержащие Cpf1, объединяли и концентрировали до 200 мкл и либо использовали напрямую для биохимических анализов, либо замораживали при -80°C для хранения. Стандарты гель-фильтрации прогоняли на той же колонке, уравновешенной с помощью 2 М NaCl, Hepes, pH 7,0, чтобы рассчитать приблизительный размер FnCpf1.
Получение лизата с белком Cpf1
Синтезировали белки Cpf1, кодон-оптимизированные для экспрессии у человека, с N-концевой метки ядерной локализации и клонировали в плазмиду для экспрессии pcDNA3.1 от Genscript. 2000 нг плазмид для экспрессии Cpf1 трансфицировали в клетки HEK293FT, выращиваемые в 6-луночных планшетах, при 90% конфлюэнтности с применением реагента Lipofectamine 2000 (Life Technologies). Через 48 часов клетки собирали путем однократной промывки с помощью DPBS (Life Technologies) и соскребания в буфере для лизиса [20 мМ Hepes, pH 7,5, 100 мМ KCl, 5 мМ MgCl2, 1 мМ DTT, 5% глицерин, 0,1% Triton X-100, 1X таблетки со смесью ингибиторов протеаз cOmplete (Roche)]. Лизат обрабатывали ультразвуком в течение 10 минут на соникаторе Biorupter (Diagenode) и затем центрифугировали. Супернатант замораживали для последующего использования в in vitro анализах расщепления.
In vitro анализ расщепления
In vitro расщепление осуществляли либо с очищенным белком, либо с лизатом клеток млекопитающих, содержащим белок, при 37°C в буфере для расщепления (NEBuffer 3, 5 мМ DTT) в течение 20 минут. В реакции расщепления использовали 500 нг синтезированной crRNA или sgRNA и 200 нг целевой ДНК. Целевая ДНК включала либо протоспейсеры, клонированные в pUC19, либо ПЦР-ампликоны генных участков из геномной ДНК, выделенной из клеток HEK293. Реакционные смеси очищали с применением колонок для очистки продуктов ПЦР (Qiagen) и прогоняли на 2% агарозных E-гелях (Life Technologies). В случае нативных и денатурирующих гелей для анализа расщепления под действием мутантов нуклеазы, реакционные смеси после очистки прогоняли на 6% полиакриламидных гелях с TBE или 6% полиакриламидных гелях с TBE-мочевиной (Life Technologies).
In vitro скрининг PAM для белков семейства Cpf1
Реакционные смеси после in vitro расщепления с помощью белков семейства Cpf1 прогоняли на 2% агарозных E-гелях (Life Technologies). Полоски, соответствующие не подвергнутой расщеплению мишени, подвергали экстрагированию из геля с применением набора для экстракции из геля QIAquick (Qiagen) и участок с целевым PAM амплифицировали и секвенировали с применением MiSeq (Illumina) с 150 циклами для одиночных концов. Результаты секвенирования вводили в конвейерный алгоритм обнаружения PAM.
Активность расщепления под действием Cpf1 в клетках 293FT
Синтезировали белки Cpf1, кодон-оптимизированные для экспрессии у человека, с N-концевой метки ядерной локализации и клонировали в плазмиду для экспрессии pcDNA3.1 с промотором CMV от Genscript. ПЦР-ампликоны, содержащие промотор U6, управляющий экспрессией последовательности crRNA, получали с помощью Herculase II (Agilent Technologies). 400 нг плазмид для экспрессии Cpf1 и 100 нг продукта ПРЦ crRNA трансфицировали в клетки HEK293FT, выращиваемые в 24-луночных планшетах, при 75-90% конфлюэнтности с применением реагента Lipofectamine 2000 (Life Technologies). Геномную ДНК собирали с применением раствора для экстракции ДНК QuickExtract™ (Epicentre).
Анализ с помощью нуклеазы SURVEYOR на наличие модификации генома
Клетки 293FT трансфицировали с помощью 400 нг плазмиды для экспрессии Cpf1 и 100 нг ПЦР-фрагментов U6::crRNA с применением реагента Lipofectamin 2000 (Life Technologies). Клетки инкубировали при 37ºC в течение 72 ч. после трансфекции до проведения экстракции геномной ДНК. Геномную ДНК экстрагировали с помощью раствора для экстракции ДНК QuickExtract (Epicentre), следуя протоколу производителя. Участок генома, фланкирующий целевой сайт для CRISPR, для каждого гена подвергали ПЦР-амплификации, и продукты очищали с использованием центрифужной колонки QiaQuick (Qiagen), следуя протоколу производителя. В общей сложности 200-500 нг очищенных продуктов ПЦР смешивали с 1 мкл 10× буфера для ПЦР с применением ДНК-полимеразы Taq (Enzymatics) и водой сверхвысокой чистоты до конечного объема 10 мкл и подвергали процессу повторного отжига для обеспечения образования гетеродуплекса: 95°C в течение 10 мин., снижение от 95°C до 85°C со скоростью −2°C/с, снижение от 85°C до 25°C со скоростью −0,25°C/с и удержание 25°C в течение 1 мин. После повторного отжига продукты обрабатывали с помощью нуклеазы SURVEYOR и энхансера S SURVEYOR (Integrated DNA Technologies), следуя рекомендованному производителем протоколу, и анализировали на 4-20% полиакриламидных гелях Novex с TBE (Life Technologies). Гели окрашивали красителем для ДНК SYBR золотой (Life Technologies) в течение 10 мин. и визуализировали с помощью системы для визуализации геля Gel Doc (Bio-rad). Количественный анализ основывался на относительных интенсивностях окраски полосок. Процентное значение частоты вставок/делеций определяли по формуле 100 × (1 − (1 − (b + c)/(a + b + c))1/2), где a представляет собой суммарную интенсивность для нерасщепленного продукта ПЦР, а b и c представляют собой значения суммарной интенсивности для каждого продукта расщепления.
Глубокое секвенирование для определения характеристик паттерна вставок/делеций, образуемого под действием Cpf1 в клетках 293FT
Клетки HEK293FT трансфицировали и собирали как описано для оценки активности расщепления под действием Cpf1. Участок генома, фланкирующий мишени DNMT1, амплифицировали с применением участка, полученного в двух раундах ПЦР, для добавления адаптеров Illumina P5, а также уникальных специфичных для образца штрих-кодов к целевым ампликонам. Продукты ПЦР прогоняли на 2% E-геле (Invitrogen) и экстрагировали из геля с применением центрифужной колонки QiaQuick (Qiagen) согласно рекомендуемому производителем протоколу. Образцы объединяли и проводили количественную оценку с помощью флуорометра Qubit 2.0 (Life Technologies). Полученные библиотеки cDNA секвенировали на MiSeq (Illumina). Вставки/делеции картировали с применением реализованного на языке Питон Geneious 6.0.3 Read Mapper.
Компьютерный анализ локуса Cpf1
Программу PSI-BLAST (Altschul et al., 1997) применяли для идентификации гомологов Cpf1 в базе данных NR от NCBI с применением нескольких известных последовательностей Cpf1 в качестве запрашиваемых последовательностей с Cpf1, при этом граничное E-значение составляет 0,01 и отключены фильтр низкой сложности и статистика на основе состава. Программу TBLASTN со следующими параметрами, граничное E-значение составляет 0,01 и отключен фильтр низкой сложности, применяли для проведения поиска в базе данных WGS от NCBI с применением профиля Cpf1 (Marakova et al., 2015) в качестве запрашиваемой последовательности. Результаты всех поисков объединяли. Программу HHpred использовали с параметрами по умолчанию для идентификации отдаленного сходства последовательностей с применением подгруппы репрезентативных запрашиваемых последовательностей Cpf1 (Soding et al., 2006). Множественное выравнивание последовательностей разрабатывали с применением MUSCLE (Edgar, 2004) с корректировкой вручную, исходя из попарных выравниваний, полученных с применением программ PSI-BLAST и HHpred. Филогенетический анализ проводили с применением программы FastTree с эволюционной моделью WAG и дискретной гамма-моделью с 20 рейтинговыми категориями (Price et al., 2010). Вторичную структуру белка прогнозировали с применением Jpred 4 (Drozdetskiy et al., 2015).
Повторы CRISPR идентифицировали с применением PILER-CR (Edgar, 2007) и CRISPRfinder (Grissa et al, 2007). Поиск спейсерных последовательностей проводили в базах данных NR нуклеотидных последовательностей от NCBI с применением MEGABLAST (Morgulis et al, 2008) с параметрами по умолчанию, за исключением того, что был установлен размер слова 20 и граничное E-значение 0,0001.
NNNNNNNNGAGAAGTCATTTAATAAGGC
CACTGTTAAAAAGCTTGGCGTAATCATGG
TCATAGCTGTTT(SEQ ID NO: 134).
GAGAAGTCATTTAATAAGGCCACTGTTAA
AANNNNNNNNAGCTTGGCGTAATCATGG
TCATAGCTGTTT(SEQ ID NO: 135).
(-)
мишень 1
мишень 2
(SEQ ID NO: 175).
(SEQ ID NO: 176).
мишень 3
(SEQ ID NO: 177).
(SEQ ID NO: 178).
мишень 4
(SEQ ID NO: 179).
(SEQ ID NO: 180).
мишень 1
(SEQ ID NO: 181).
(SEQ ID NO: 182).
мишень 2
(SEQ ID NO: 183).
(SEQ ID NO: 184).
мишень 3
(SEQ ID NO: 185).
(SEQ ID NO: 186).
мишень 4
мишень 1
(SEQ ID NO: 190).
мишень 2
(SEQ ID NO: 191).
мишень 3
(SEQ ID NO: 192).
мишень 4
(SEQ ID NO: 193).
нацеливающихся на протоспейсер 1 и мишень 3 DNMT1
Пример 8. Клонирование Cpf1 Francisella tularensis subsp. novicida U112 (FnCpf1)
Заявители клонировали локус Cpf1 Francisella tularensis subsp. novicida U112 (FnCpf1) (фигура 95A) в низкокопийные плазмиды (pFnCpf1) для обеспечения гетерологичного восстановления в Escherichia coli. Как правило, в системах CRISPR-Cas, охарактеризованных к настоящему времени, имеется два требования к интерференции в отношении ДНК: (i) целевая последовательность должна совпадать с одним из спейсеров, присутствующих в соответствующем массиве CRISPR, и (ii) целевая последовательность, комплементарная спейсеру (далее называемая протоспейсер), должна быть фланкирована соответственным мотивом, смежным с протоспейсером (PAM). Учитывая полностью неохарактеризованные функциональные возможности локуса FnCpf1 CRISPR разработали анализ истощения плазмид для определения активности Cpf1 и идентификации последовательности PAM и ее соответствующего местоположения относительно протоспейсера (5' или 3') (фигура 95B). Разработали две библиотеки плазмид, несущих протоспейсер, совпадающий с первым спейсером в массиве CRISPR c FnCpf1, при этом на 5'- или 3'-конце находились рандомизированые последовательности длиной 7 п. о. Каждую плазмидную библиотеку трансформировали в E. coli, в которых происходила гетерологичная экспрессия локуса FnCpf1, или в контрольный штамм E. coli, несущий пустой вектор. С применением данного анализа определяли последовательность и местоположение PAM путем идентификации нуклеотидных мотивов, которые преимущественно подвергаются истощению в клетках, в которых происходила гетерологичная экспрессия локуса FnCpf1. Обнаружили, что PAM для FnCpf1 расположен выше 5'-конца перемещенной нити протоспейсера и имеет последовательность 5'-TTN (фигуры 95C-D и 102). Местоположение PAM в направлении 5' также наблюдалось в случае систем CRISPR I типа, но не систем II типа, в которых Cas9 использует последовательности PAM, которые находятся на 3'-конце протоспейсера (Mojica et al., 2009; Garneau et al., 2010. Кроме идентификации PAM результаты анализа истощения ясно показали, что гетерологично экспрессированные локусы Cpf1 способны к эффективной интерференции в отношении плазмидной ДНК.
Для определения дополнительных характеристик PAM анализировали активность интерференции в отношении плазмид путем трансформации клеток, экспрессирующих локус cpf1, с помощью плазмид, несущих протоспейсер 1, фланкированный PAM 5'-TTN. В случае всех PAM 5'-TTN происходило эффективное нацеливание (фигура 1E). Кроме того, эффективное нацеливание происходило также в случае 5'-CTA, но не в случае 5'-TCA (фигура 95E), что позволяет предположить, что центральный T является более важным для распознавания PAM, чем первый T, и что, в полном соответствии с мотивами последовательности, подвергнутыми истощению в анализе обнаружения PAM (фигура 102D), PAM может иметь менее строгую последовательность, чем 5'-TTN.
Пример 9. Массив CRISPR c Cpf1 процессируется независимо от tracrRNA
Анализ с секвенированием малых РНК, RNAseq, применяли для точного определения crRNA, образуемой в локусе CRISPR на основе cpf1. Путем секвенирования малых РНК, экстрагированных из культуры Francisella tularensis subsp. novicida U112, обнаружили, что массив CRISPR процессируется в короткие зрелые crRNA длиной 42-44 нуклеотида. Каждая зрелая crRNA начинается с прямого повтора длиной 19 нуклеотидов, за которым следует 23-25 нуклеотидов спейсерной последовательности (фигура 96A). Данный порядок расположения crRNA отличается от такового в системах CRISPR-Cas II типа, в которых зрелая crRNA начинается спейсерной последовательностью длиной 20-24 нуклеотида, за которой следует ~22 нуклеотида прямого повтора (Deltcheva et al., 2011; Chylinski et al., 2013). Неожиданно, за исключением crRNA возле локуса cpf1 Francisella не были обнаружены никакие надежно экспрессируемые небольшие транскрипты, которые могли бы соответствовать tracrRNA, которые ассоциированы с системами на основе Cas9.
- Чтобы подтвердить то, что для созревания crRNA и интерференции в отношении ДНК не требуются дополнительные РНК, разрабатывали плазмиду экспрессии с применением синтетических промоторов для управления экспрессией cpf1 Francisella (FnCpf1) и массива CRISPR (pFnCpf1_min). При анализе с секвенированием малых РНК, RNAseq, у E. coli, экспрессирующих данную плазмиду, все еще наблюдался надежный процессинг массива CRISPR в зрелую crRNA (фигура 96B), что указывает на то, что FnCpf1 и ее массива CRISPR достаточно для обеспечения процессинга crRNA. Кроме того, для E. coli, экспрессирующих pFnCpf1_min, а также pFnCpf1_ΔCas, плазмиду, в которой были удалены все гены cas, но остались нативные промоторы, управляющие экспрессией FnCpf1 и массива CRISPR, также показана надежная интерференция в отношении ДНК, что показывает, что FnCpf1 и crRNA являются достаточными для опосредования нацеливания на ДНК (фигура 96C). В отличие от этого, чтобы опосредовать нацеленную интерференцию в отношении ДНК для Cas9 требуется как crRNA, так и tracrRNA (Deltcheva et al., 2011; Zhang et al., 2013).
Пример 10. Cpf1 представляет собой одиночную эндонуклеазу, направляемую crRNA
Сведения от том, что FnCpf1 может опосредовать интерференцию в отношении ДНК с применением только crRNA, являются очень неожиданными, с учетом того, что Cas9 распознает crRNA благодаря дуплексной структуре, образуемой между crRNA и tracrRNA (Jinek et al., 2012; Nishimasu et al., 2014), а также вторичной структуре tracrRNA на 3'-конце (Hsu et al., 2013; Nishimasu et al., 2014). Чтобы убедиться в том, что crRNA на самом деле достаточно для образования активного комплекса с FnCpf1 и опосредования направляемого РНК расщепления ДНК, FnCpf1, дополненную только crRNA, тестировали в отношении расщепления целевой ДНК in vitro. Очищенный FnCpf1 (фигура 103) оценивали в отношении его способности расщеплять ту же самую плазмиду, содержащую протоспейсер 1, которую применяли в экспериментах по интерференции в отношении бактериальной ДНК (фигура 97A). FnCpf1 с in vitro транскрибированной зрелой crRNA, нацеливающейся на протоспейсер 1, был способен эффективно расщеплять целевую плазмиду способом, зависимым от Mg2+- и crRNA (фигура 97B). Более того, FnCpf1 был способен расщеплять как сверхспирализованную, так и линейную целевую ДНК (фигура 97C). Эти результаты ясно демонстрируют то, что FnCpf1 и crRNA достаточно для направляемого РНК расщепления ДНК.
Сайт расщепления FnCpf1 также картировали с применением секвенирования по Сэнгеру концов подвергнутой расщеплению ДНК. Опосредованное FnCpf1 расщепление приводит к образованию "липкого" 5'-конца длиной 5 нуклеотидов (фигуры 97A, 97D и 104), что отличается от продукта расщепления с "тупыми" концами, образуемого Cas9 (Garneau et al., 2010; Jinek et al., 2012; Gasiunas et al., 2012). Сайт ступенчатого расщепления под действием FnCpf1 отдален от PAM: расщепление происходит после 18-го основания на не подвергаемой нацеливанию (+) нити и после 23-го основания на подвергаемой нацеливанию (-) нити (фигуры 97A, 97D и 104). Путем применения субстратов на основе двухнитевых олигонуклеотидов с различными последовательностями PAM, также обнаружили, что FnCpf1 расщепляет целевую ДНК, когда PAM 5'-TTN находится в дуплексной форме (фигура 97E), в отличие от PAM для Cas9 (Sternberg et al., 2014).
Пример 11. RuvC-подобный домен Cpf1 опосредует направляемое РНК расщепление ДНК
RuvC-подобный домен Cpf1 сохраняет все каталитические остатки из данного семейства эндонуклеаз (фигуры 98A и 105), и, таким образом, прогнозируется как активная нуклеаза. Получали трех мутантов, FnCpf1(D917A), FnCpf1(E1006A), и FnCpf1(D1225A) (фигура 98A), чтобы протестировать, необходимы ли консервативные каталитические остатки для нуклеазной активности FnCpf1. Мутации D917A и E1006A приводили к полному прекращению активности расщепления ДНК у FnCpf1, а D1255A значительно снижала нуклеолитическую активность (фигура 98B). Эти результаты отличаются от результатов мутагенеза Cas9 Streptococcus pyogenes (SpCas9), в котором мутирование нуклеазных доменов RuvC (D10A) и HNH (N863A) превращает SpCas9 в ДНК-никазу (т. е. инактивация каждого из двух нуклеазных доменов отменяет расщепление одной из нитей ДНК) (Jinek et al., 2012; Gasiunas et al., 2012) (фигура 98B). Такие данные позволяют предположить, что RuvC-подобный домен FnCpf1 расщепляет обе нити целевой ДНК, возможно в димерной конфигурации (фигура 103B).
Пример 12. Последовательность и структура crRNA Cpf1
По сравнению с направляющей РНК для Cas9, в которой тщательно проработаны особенности вторичной структуры РНК, которая взаимодействуют с Cas9 (Nishimasu et al., 2014), направляющая РНК для FnCpf1 является значительно более простой и содержит только одну "петлю-на-стебле" в последовательности прямого повтора (фигура 97A).
Исследовали требования к последовательности и структуре crRNA для опосредования расщепления ДНК под действием FnCpf1. Проверяли длину направляющей последовательности. Наблюдали, что направляющая последовательность длиной 16 нуклеотидов, обеспечивала обнаруживаемое расщепление ДНК, а направляющие последовательности длиной 18 нуклеотидов обеспечивали эффективное расщепление ДНК in vitro (фигура 99A). Такие варианты длины аналогичны длинам, показанным для SpCas9, где спейсерная последовательность длиной 16-17 нуклеотидов была достаточной для расщепления ДНК (Cencic et al., 2014; Fu et al., 2014). Затравочный участок направляющей РНК для FnCpf1 отмечали в пределах первых 6 или 7 нуклеотидов на 5'-конце спейсерной последовательности (фигура 99B).
Исследовали эффект мутаций в последовательности прямого повтора на активность направляемого РНК расщепления ДНК. Длина части зрелой crRNA, представляющей собой прямой повтор, составляет 19 нуклеотидов (фигура 96A). Путем усечения прямого повтора выявили, что для эффективного расщепления ДНК достаточно прямого повтора длиной 16 нуклеотидов, но оптимальным является более 17 нуклеотидов. Мутации в "петле-на-стебле", которые сохраняют РНК-дуплекс, не оказывали воздействия на активность расщепления, в то время как мутации, которые нарушали дуплексную структуру "петля-на-стебле", отменяли расщепление (фигура 99D). Наконец, замены основания в участке петли не оказывали воздействия на нуклеазную активность, в то время как замена U, расположенная в направлении 5' от спейсерной последовательности, значительно снижала активность (фигура 5E). В совокупности, эти результаты позволяют предполагать, что FnCpf1 распознает crRNA благодаря комбинации специфичных к последовательности и структурных особенностей "петли-на-стебле".
Пример 13. Белки семейства Cpf1 от различных бактерий характеризуются общей структурой crRNA и PAM
Чтобы исследовать применение Cpf1 в качестве инструмента для редактирования генома, воспользовались разнообразием белков семейства Cpf1, доступных в общедоступных базах данных последовательностей. Поиск BLAST в базе данных WGS на NCBI выявил 46 неизбыточных белков семейства Cpf1 (фигура 64). 16 были выбраны на основе проведенной заявителями филогенетической реконструкции (фигура 64) как представители разнообразия Cpf1 (фигуры 100A-100B и 106). Длина данных белков семейства Cpf1 находится в диапазоне от ~1200 до ~1500 аминокислот.
Для последовательностей прямого повтора в каждом из данных белков семейства Cpf1 показан сильный консерватизм 19 нуклеотидов на 3'-конце прямого повтора, части повтора, которая включается в процессированную crRNA (фигура 100C). Последовательность на 5'-конце прямого повтора является намного более разнообразной. Из 16 белков семейства Cpf1, выбранных для анализа, три (2 - Lachnospiraceae bacterium MC2017, Lb3Cpf1; 3 - Butyrivibrio proteoclasticus, BpCpf1; и 6 - Smithella sp. SC_K08D17, SsCpf1) были ассоциированы с последовательностями прямого повтора, которые заметно отличались от последовательности прямого повтора для FnCpf1 (фигура 100C). Примечательно, что данные последовательности прямого повтора сохраняли структуры "петля-на-стебле", которые были идентичны или почти идентичны последовательностям прямого повтора для FnCpf1 (фигура 100D).
Ортологичные последовательности прямого повтора тестировали в отношении их способности поддерживать нуклеазную активность FnCpf1 in vitro. Прямые повторы, которые содержали консервативные последовательности стеблевой структуры, были способны функционировать взаимозаменяемо с FnCpf1. Прямой повтор от кандидата 3 (BpCpf1) поддерживал низкий уровень нуклеазной активности FnCpf1 (фигура 100E), возможно вследствие сохранения большинства U на 3'-конце.
In vitro анализ идентификации PAM (фигура 107A) применяли для определения последовательности PAM для каждого белка семейства Cpf1. Последовательности PAM идентифицировали для 7 новых белков семейства Cpf1 (фигуры 100E и 107B-C), и путем скрининга подтвердили, что PAM для FnCpf1 представляет собой 5'-TTN. Последовательности PAM для белков семейства Cpf1 преимущественно характеризовались высоким содержанием T, при этом, прежде всего, варьировало число T, составляющих каждый PAM (фигуры 100F и 107B-C).
Пример 14. Cpf1 можно приспособить для содействия редактированию генома в клетках человека
Белки семейства Cpf1 подвергали кодон-оптимизации и к ним прикрепляли C-концевой сигнал ядерной локализации (NLS) для обеспечения оптимальной экспрессии и нацеливания в ядро клеток человека (фигура 101A). Для тестирования активности каждого белка семейства Cpf1 выбирали целевой сайт для направляющей РНК в пределах гена DNMT1 (фигура 101B). Каждый из белков семейства Cpf1 вместе с его соответствующей crRNA, разработанной для нацеливания на DNMT1, был способен расщеплять ПЦР-ампликон геномного участка DNMT1 in vitro (фигура 101C). При тестировании на клетках эмбриональной почки человека 293FT (HEK 293FT) 2 из белков семейства Cpf1 (7 - AsCpf1 и 13 - LbCpf1) проявляли обнаруживаемые уровни индуцированного нуклеазой образования вставок/делеций при используемых условиях (фигуры 101C и D).
Каждый белок семейства Cpf1 тестировали в отношении дополнительных геномных мишеней. AsCpf1 и LbCpf1 стабильно опосредовали надежное редактирование генома в клетках HEK293FT (фигуры 101E и 108). В сравнении с Cas9 AsCpf1 и LbCpf1 опосредовали сравнимые уровни образования вставок/делеций (фигура 101E). В дополнение, применяли in vitro расщепление с последующим секвенированием по Сэнгеру концов подвергнутой расщеплению ДНК и обнаружили, что 7 - AsCpf1 и 13 - LbCpf1 также образовывали ступенчатые сайты расщепления (фигуры 101D и 107E).
Далее представлены нуклеотидные и аминокислотные последовательности конструкций и ортологов FnCpf1:
Последовательности локуса FnCpf1
pFnCpf1
5'-конец эндогенной ацетилтрансферазы F. novicida (выше локуса FnCpf1)
FnCpf1
Cas4
Cas1
Cas2
Прямые повторы
Спейсер
CATCAAGGAATTGGTTCTAAGCTTATAGAAGCAATGATTAAGGAAGCCAAAAAAAATAATATTGATGCAATATTTGTCTTAGGTCATCCAAGTTATTATCCAAAATTTGGTTTTAAACCAGCCACAGAATATCAGATAAAATGTGAATATGATGTCCCAGCGGATGTTTTTATGGTACTAGATTTGTCAGCTAAACTAGCTAGTTTAAAAGGACAAACTGTCTACTATGCCGATGAGTTTGGCAAAATTTTTTAGATCTACAAAATTATAAACTAAATAAAGATTCTTATAATAACTTTATATATAATCGAAATGTAGAGAATTTTATAAGGAGTCTTTATCATGTCAATTTATCAAGAATTTGTTAATAAATATAGTTTAAGTAAAACTCTAAGATTTGAGTTAATCCCACAGGGTAAAACACTTGAAAACATAAAAGCAAGAGGTTTGATTTTAGATGATGAGAAAAGAGCTAAAGACTACAAAAAGGCTAAACAAATAATTGATAAATATCATCAGTTTTTTATAGAGGAGATATTAAGTTCGGTTTGTATTAGCGAAGATTTATTACAAAACTATTCTGATGTTTATTTTAAACTTAAAAAGAGTGATGATGATAATCTACAAAAAGATTTTAAAAGTGCAAAAGATACGATAAAGAAACAAATATCTGAATATATAAAGGACTCAGAGAAATTTAAGAATTTGTTTAATCAAAACCTTATCGATGCTAAAAAAGGGCAAGAGTCAGATTTAATTCTATGGCTAAAGCAATCTAAGGATAATGGTATAGAACTATTTAAAGCCAATAGTGATATCACAGATATAGATGAGGCGTTAGAAATAATCAAATCTTTTAAAGGTTGGACAACTTATTTTAAGGGTTTTCATGAAAATAGAAAAAATGTTTATAGTAGCAATGATATTCCTACATCTATTATTTATAGGATAGTAGATGATAATTTGCCTAAATTTCTAGAAAATAAAGCTAAGTATGAGAGTTTAAAAGACAAAGCTCCAGAAGCTATAAACTATGAACAAATTAAAAAAGATTTGGCAGAAGAGCTAACCTTTGATATTGACTACAAAACATCTGAAGTTAATCAAAGAGTTTTTTCACTTGATGAAGTTTTTGAGATAGCAAACTTTAATAATTATCTAAATCAAAGTGGTATTACTAAATTTAATACTATTATTGGTGGTAAATTTGTAAATGGTGAAAATACAAAGAGAAAAGGTATAAATGAATATATAAATCTATACTCACAGCAAATAAATGATAAAACACTCAAAAAATATAAAATGAGTGTTTTATTTAAGCAAATTTTAAGTGATACAGAATCTAAATCTTTTGTAATTGATAAGTTAGAAGATGATAGTGATGTAGTTACAACGATGCAAAGTTTTTATGAGCAAATAGCAGCTTTTAAAACAGTAGAAGAAAAATCTATTAAAGAAACACTATCTTTATTATTTGATGATTTAAAAGCTCAAAAACTTGATTTGAGTAAAATTTATTTTAAAAATGATAAATCTCTTACTGATCTATCACAACAAGTTTTTGATGATTATAGTGTTATTGGTACAGCGGTACTAGAATATATAACTCAACAAATAGCACCTAAAAATCTTGATAACCCTAGTAAGAAAGAGCAAGAATTAATAGCCAAAAAAACTGAAAAAGCAAAATACTTATCTCTAGAAACTATAAAGCTTGCCTTAGAAGAATTTAATAAGCATAGAGATATAGATAAACAGTGTAGGTTTGAAGAAATACTTGCAAACTTTGCGGCTATTCCGATGATATTTGATGAAATAGCTCAAAACAAAGACAATTTGGCACAGATATCTATCAAATATCAAAATCAAGGTAAAAAAGACCTACTTCAAGCTAGTGCGGAAGATGATGTTAAAGCTATCAAGGATCTTTTAGATCAAACTAATAATCTCTTACATAAACTAAAAATATTTCATATTAGTCAGTCAGAAGATAAGGCAAATATTTTAGACAAGGATGAGCATTTTTATCTAGTATTTGAGGAGTGCTACTTTGAGCTAGCGAATATAGTGCCTCTTTATAACAAAATTAGAAACTATATAACTCAAAAGCCATATAGTGATGAGAAATTTAAGCTCAATTTTGAGAACTCGACTTTGGCTAATGGTTGGGATAAAAATAAAGAGCCTGACAATACGGCAATTTTATTTATCAAAGATGATAAATATTATCTGGGTGTGATGAATAAGAAAAATAACAAAATATTTGATGATAAAGCTATCAAAGAAAATAAAGGCGAGGGTTATAAAAAAATTGTTTATAAACTTTTACCTGGCGCAAATAAAATGTTACCTAAGGTTTTCTTTTCTGCTAAATCTATAAAATTTTATAATCCTAGTGAAGATATACTTAGAATAAGAAATCATTCCACACATACAAAAAATGGTAGTCCTCAAAAAGGATATGAAAAATTTGAGTTTAATATTGAAGATTGCCGAAAATTTATAGATTTTTATAAACAGTCTATAAGTAAGCATCCGGAGTGGAAAGATTTTGGATTTAGATTTTCTGATACTCAAAGATATAATTCTATAGATGAATTTTATAGAGAAGTTGAAAATCAAGGCTACAAACTAACTTTTGAAAATATATCAGAGAGCTATATTGATAGCGTAGTTAATCAGGGTAAATTGTACCTATTCCAAATCTATAATAAAGATTTTTCAGCTTATAGCAAAGGGCGACCAAATCTACATACTTTATATTGGAAAGCGCTGTTTGATGAGAGAAATCTTCAAGATGTGGTTTATAAGCTAAATGGTGAGGCAGAGCTTTTTTATCGTAAACAATCAATACCTAAAAAAATCACTCACCCAGCTAAAGAGGCAATAGCTAATAAAAACAAAGATAATCCTAAAAAAGAGAGTGTTTTTGAATATGATTTAATCAAAGATAAACGCTTTACTGAAGATAAGTTTTTCTTTCACTGTCCTATTACAATCAATTTTAAATCTAGTGGAGCTAATAAGTTTAATGATGAAATCAATTTATTGCTAAAAGAAAAAGCAAATGATGTTCATATATTAAGTATAGATAGAGGTGAAAGACATTTAGCTTACTATACTTTGGTAGATGGTAAAGGCAATATCATCAAACAAGATACTTTCAACATCATTGGTAATGATAGAATGAAAACAAACTACCATGATAAGCTTGCTGCAATAGAGAAAGATAGGGATTCAGCTAGGAAAGACTGGAAAAAGATAAATAACATCAAAGAGATGAAAGAGGGCTATCTATCTCAGGTAGTTCATGAAATAGCTAAGCTAGTTATAGAGTATAATGCTATTGTGGTTTTTGAGGATTTAAATTTTGGATTTAAAAGAGGGCGTTTCAAGGTAGAGAAGCAGGTCTATCAAAAGTTAGAAAAAATGCTAATTGAGAAACTAAACTATCTAGTTTTCAAAGATAATGAGTTTGATAAAACTGGGGGAGTGCTTAGAGCTTATCAGCTAACAGCACCTTTTGAGACTTTTAAAAAGATGGGTAAACAAACAGGTATTATCTACTATGTACCAGCTGGTTTTACTTCAAAAATTTGTCCTGTAACTGGTTTTGTAAATCAGTTATATCCTAAGTATGAAAGTGTCAGCAAATCTCAAGAGTTCTTTAGTAAGTTTGACAAGATTTGTTATAACCTTGATAAGGGCTATTTTGAGTTTAGTTTTGATTATAAAAACTTTGGTGACAAGGCTGCCAAAGGCAAGTGGACTATAGCTAGCTTTGGGAGTAGATTGATTAACTTTAGAAATTCAGATAAAAATCATAATTGGGATACTCGAGAAGTTTATCCAACTAAAGAGTTGGAGAAATTGCTAAAAGATTATTCTATCGAATATGGGCATGGCGAATGTATCAAAGCAGCTATTTGCGGTGAGAGCGACAAAAAGTTTTTTGCTAAGCTAACTAGTGTCCTAAATACTATCTTACAAATGCGTAACTCAAAAACAGGTACTGAGTTAGATTATCTAATTTCACCAGTAGCAGATGTAAATGGCAATTTCTTTGATTCGCGACAGGCGCCAAAAAATATGCCTCAAGATGCTGATGCCAATGGTGCTTATCATATTGGGCTAAAAGGTCTGATGCTACTAGGTAGGATCAAAAATAATCAAGAGGGCAAAAAACTCAATTTGGTTATCAAAAATGAAGAGTATTTTGAGTTCGTGCAGAATAGGAATAACTAATTCATTCAAGAATATATTACCCTGTCAGTTTAGCGACTATTACCTCTTTAATAATTTGCAGGGGAATTATTTTAGTAATAGTAATATACACAAGAGTTATTGATTATATGGAAAATTATATTTAGATAACATGGTTAAATGATTTTATATTCTGTCCTTACTCGATATATTTGCATAATATCTATAGTAATGCCTCAGATACTACATACTATTCATCTAGCCAAACAAAAGGGCGCGATGCTCATAAAAGTATCGATAAAGGAATCTATAGTACCAAAAAAGATGACCTGATCGGTATCGATGTTATTAACCATAAATATGGTTTGGTTGGTAAAATTGATGTTTTTCATAAAGATAAGGGCTTACTTGTGGAGAGAAAAAGGCAAATCAAGACTATCTATGATGGCTATAAATATCAGCTTTATGCGCAATATTTTTGTCTCCAAGAGATGGGCTATGATGTCAAAGCCATTAAATTTTATTCGATGGTTGATAATAAATCATACCCAATAGCTATACCAACTTCAGCTGAGTTAGAAAAGTTTGAAAAACATATTCAAACAATCAAGCAATATAATCCAATGGATAACTCATTTAGGCAAAATATTGAAAAGTGTAAATTTTGTATATATGCAAACTTATGTGATAAAACGGACTTGTAGATTATGTTTAGTAAAAATGATATTGAATCAAAGAATATAGTTTTTGTTAATATTTTTGATGGAGTGAAACTTAGTCTATCATTGGGGAATATAGTTATAAAAGATAAAGAAACTGATGAGGTGAAAACTAAGCTTTCTGTTCATAAAGTTCTTGCATTGTTTATCGTAGGTAATATGACGATGACCTCGCAACTTTTAGAGACCTGTAAGAAAAATGCTATACAGCTAGTTTTTATGAAAAATAGCTTTAGACCATATCTATGTTTTGGTGATATTGCTGAGGCTAATTTTTTAGCTAGATATAAGCAATATAGTGTAGTTGAGCAAGATATAAGTTTAGCAAGGATTTTTATAACATCAAAGATACGCAATCAACATAACTTAGTCAAAAGCCTAAGAGATAAAACTCCAGAGCAGCAAGAGATAGTCAAAAAGAATAAACAGCTAATAGCAGAGTTAGAAAATACAACAAGCCTAGCGGAGCTAATGGGTATAGAGGGCAATGTTGCCAAAAATTTCTTCAAAGGATTCTATGGACATTTAGATAGTTGGCAAGGGCGCAAACCTAGAATAAAACAGGATCCATATAATGTTGTTTTAGACTTGGGCTATAGTATGTTGTTTAATTTTGTAGAGTGTTTTTTGCGACTTTTTGGCTTTGATTTATACAAGGGCTTTTGTCATCAGACTTGGTATAAGCGTAAATCCCTAGTTTGTGACTTTGTTGAGCCATTTAGATGTATAGTGGATAACCAAGTTAGAAAATCATGGAATCTCGGGCAATTTTCTGTAGAGGATTTTGGTTGCAAAAATGAGCAGTTTTATATAAAAAAAGATAAAACAAAAGACTACTCAAAAATACTTTTTGCCGAGATTATCAGCTACAAGCTAGAGATATTTGAATATGTAAGAGAATTTTATCGTGCCTTTATGCGAGGCAAAGAAATTGCAGAGTATCCAATATTTTGTTATGAAACTAGGAGGGTGTATGTTGATAGTCAGTTATGATTTTAGTAATAATAAAGTACGTGCAAAGTTTGCCAAATTTCTAGAAAGTTATGGTGTACGTTTACAATATTCGGTATTTGAGCTCAAATATAGCAAGAGAATGTTAGACTTGATTTTAGCTGAGATAGAAAATAACTATGTACCACTATTTACAAATGCTGATAGTGTTTTAATCTTTAATGCTCCAGATAAAGATGTGATAAAATATGGTTATGCGATTCATAGAGAACAAGAGGTTGTTTTTATAGACTAAAAATTGCAAACCTTAGTCTTTATGTTAAAATAACTACTAAGTTCTTAGAGATATTTAAAAATATGACTGTTGTTATATATCAAAATGCTAAAAAAATCATAGATTTTAGGTCTTTTTTTGCTGATTTAGGCAAAAACGGGTCTAAGAACTTTAAATAATTTCTACTGTTGTAGATGAGAAGTCATTTAATAAGGCCACTGTTAAAAGTCTAAGAACTTTAAATAATTTCTACTGTTGTAGATGCTACTATTCCTGTGCCTTCAGATAATTCAGTCTAAGAACTTTAAATAATTTCTACTGTTGTAGATGTCTAGAGCCTTTTGTATTAGTAGCCGGTCTAAGAACTTTAAATAATTTCTACTGTTGTAGATTAGCGATTTATGAAGGTCATTTTTTTGTCT (SEQ ID NO: 211).
pFnCpf1_min
Промотор Lac
Последовательность Шайна-Дальгарно
FnCpf1
Промотор J23119
Прямые повторы
Спейсер
TTTACACTTTATGCTTCCGGCTCGTATGTTAGGAGGTCTTTATCATGTCAATTTATCAAGAATTTGTTAATAAATATAGTTTAAGTAAAACTCTAAGATTTGAGTTAATCCCACAGGGTAAAACACTTGAAAACATAAAAGCAAGAGGTTTGATTTTAGATGATGAGAAAAGAGCTAAAGACTACAAAAAGGCTAAACAAATAATTGATAAATATCATCAGTTTTTTATAGAGGAGATATTAAGTTCGGTTTGTATTAGCGAAGATTTATTACAAAACTATTCTGATGTTTATTTTAAACTTAAAAAGAGTGATGATGATAATCTACAAAAAGATTTTAAAAGTGCAAAAGATACGATAAAGAAACAAATATCTGAATATATAAAGGACTCAGAGAAATTTAAGAATTTGTTTAATCAAAACCTTATCGATGCTAAAAAAGGGCAAGAGTCAGATTTAATTCTATGGCTAAAGCAATCTAAGGATAATGGTATAGAACTATTTAAAGCCAATAGTGATATCACAGATATAGATGAGGCGTTAGAAATAATCAAATCTTTTAAAGGTTGGACAACTTATTTTAAGGGTTTTCATGAAAATAGAAAAAATGTTTATAGTAGCAATGATATTCCTACATCTATTATTTATAGGATAGTAGATGATAATTTGCCTAAATTTCTAGAAAATAAAGCTAAGTATGAGAGTTTAAAAGACAAAGCTCCAGAAGCTATAAACTATGAACAAATTAAAAAAGATTTGGCAGAAGAGCTAACCTTTGATATTGACTACAAAACATCTGAAGTTAATCAAAGAGTTTTTTCACTTGATGAAGTTTTTGAGATAGCAAACTTTAATAATTATCTAAATCAAAGTGGTATTACTAAATTTAATACTATTATTGGTGGTAAATTTGTAAATGGTGAAAATACAAAGAGAAAAGGTATAAATGAATATATAAATCTATACTCACAGCAAATAAATGATAAAACACTCAAAAAATATAAAATGAGTGTTTTATTTAAGCAAATTTTAAGTGATACAGAATCTAAATCTTTTGTAATTGATAAGTTAGAAGATGATAGTGATGTAGTTACAACGATGCAAAGTTTTTATGAGCAAATAGCAGCTTTTAAAACAGTAGAAGAAAAATCTATTAAAGAAACACTATCTTTATTATTTGATGATTTAAAAGCTCAAAAACTTGATTTGAGTAAAATTTATTTTAAAAATGATAAATCTCTTACTGATCTATCACAACAAGTTTTTGATGATTATAGTGTTATTGGTACAGCGGTACTAGAATATATAACTCAACAAATAGCACCTAAAAATCTTGATAACCCTAGTAAGAAAGAGCAAGAATTAATAGCCAAAAAAACTGAAAAAGCAAAATACTTATCTCTAGAAACTATAAAGCTTGCCTTAGAAGAATTTAATAAGCATAGAGATATAGATAAACAGTGTAGGTTTGAAGAAATACTTGCAAACTTTGCGGCTATTCCGATGATATTTGATGAAATAGCTCAAAACAAAGACAATTTGGCACAGATATCTATCAAATATCAAAATCAAGGTAAAAAAGACCTACTTCAAGCTAGTGCGGAAGATGATGTTAAAGCTATCAAGGATCTTTTAGATCAAACTAATAATCTCTTACATAAACTAAAAATATTTCATATTAGTCAGTCAGAAGATAAGGCAAATATTTTAGACAAGGATGAGCATTTTTATCTAGTATTTGAGGAGTGCTACTTTGAGCTAGCGAATATAGTGCCTCTTTATAACAAAATTAGAAACTATATAACTCAAAAGCCATATAGTGATGAGAAATTTAAGCTCAATTTTGAGAACTCGACTTTGGCTAATGGTTGGGATAAAAATAAAGAGCCTGACAATACGGCAATTTTATTTATCAAAGATGATAAATATTATCTGGGTGTGATGAATAAGAAAAATAACAAAATATTTGATGATAAAGCTATCAAAGAAAATAAAGGCGAGGGTTATAAAAAAATTGTTTATAAACTTTTACCTGGCGCAAATAAAATGTTACCTAAGGTTTTCTTTTCTGCTAAATCTATAAAATTTTATAATCCTAGTGAAGATATACTTAGAATAAGAAATCATTCCACACATACAAAAAATGGTAGTCCTCAAAAAGGATATGAAAAATTTGAGTTTAATATTGAAGATTGCCGAAAATTTATAGATTTTTATAAACAGTCTATAAGTAAGCATCCGGAGTGGAAAGATTTTGGATTTAGATTTTCTGATACTCAAAGATATAATTCTATAGATGAATTTTATAGAGAAGTTGAAAATCAAGGCTACAAACTAACTTTTGAAAATATATCAGAGAGCTATATTGATAGCGTAGTTAATCAGGGTAAATTGTACCTATTCCAAATCTATAATAAAGATTTTTCAGCTTATAGCAAAGGGCGACCAAATCTACATACTTTATATTGGAAAGCGCTGTTTGATGAGAGAAATCTTCAAGATGTGGTTTATAAGCTAAATGGTGAGGCAGAGCTTTTTTATCGTAAACAATCAATACCTAAAAAAATCACTCACCCAGCTAAAGAGGCAATAGCTAATAAAAACAAAGATAATCCTAAAAAAGAGAGTGTTTTTGAATATGATTTAATCAAAGATAAACGCTTTACTGAAGATAAGTTTTTCTTTCACTGTCCTATTACAATCAATTTTAAATCTAGTGGAGCTAATAAGTTTAATGATGAAATCAATTTATTGCTAAAAGAAAAAGCAAATGATGTTCATATATTAAGTATAGATAGAGGTGAAAGACATTTAGCTTACTATACTTTGGTAGATGGTAAAGGCAATATCATCAAACAAGATACTTTCAACATCATTGGTAATGATAGAATGAAAACAAACTACCATGATAAGCTTGCTGCAATAGAGAAAGATAGGGATTCAGCTAGGAAAGACTGGAAAAAGATAAATAACATCAAAGAGATGAAAGAGGGCTATCTATCTCAGGTAGTTCATGAAATAGCTAAGCTAGTTATAGAGTATAATGCTATTGTGGTTTTTGAGGATTTAAATTTTGGATTTAAAAGAGGGCGTTTCAAGGTAGAGAAGCAGGTCTATCAAAAGTTAGAAAAAATGCTAATTGAGAAACTAAACTATCTAGTTTTCAAAGATAATGAGTTTGATAAAACTGGGGGAGTGCTTAGAGCTTATCAGCTAACAGCACCTTTTGAGACTTTTAAAAAGATGGGTAAACAAACAGGTATTATCTACTATGTACCAGCTGGTTTTACTTCAAAAATTTGTCCTGTAACTGGTTTTGTAAATCAGTTATATCCTAAGTATGAAAGTGTCAGCAAATCTCAAGAGTTCTTTAGTAAGTTTGACAAGATTTGTTATAACCTTGATAAGGGCTATTTTGAGTTTAGTTTTGATTATAAAAACTTTGGTGACAAGGCTGCCAAAGGCAAGTGGACTATAGCTAGCTTTGGGAGTAGATTGATTAACTTTAGAAATTCAGATAAAAATCATAATTGGGATACTCGAGAAGTTTATCCAACTAAAGAGTTGGAGAAATTGCTAAAAGATTATTCTATCGAATATGGGCATGGCGAATGTATCAAAGCAGCTATTTGCGGTGAGAGCGACAAAAAGTTTTTTGCTAAGCTAACTAGTGTCCTAAATACTATCTTACAAATGCGTAACTCAAAAACAGGTACTGAGTTAGATTATCTAATTTCACCAGTAGCAGATGTAAATGGCAATTTCTTTGATTCGCGACAGGCGCCAAAAAATATGCCTCAAGATGCTGATGCCAATGGTGCTTATCATATTGGGCTAAAAGGTCTGATGCTACTAGGTAGGATCAAAAATAATCAAGAGGGCAAAAAACTCAATTTGGTTATCAAAAATGAAGAGTATTTTGAGTTCGTGCAGAATAGGAATAACTAATTGACAGCTAGCTCAGTCCTAGGTATAATGCTAGCGCTGATTTAGGCAAAAACGGGTCTAAGAACTTTAAATAATTTCTACTGTTGTAGATGAGAAGTCATTTAATAAGGCCACTGTTAAAAGTCTAAGAACTTTAAATAATTTCTACTGTTGTAGATGCTACTATTCCTGTGCCTTCAGATAATTCAGTCTAAGAACTTTAAATAATTTCTACTGTTGTAGA (SEQ ID NO: 212)
pFnCpf1_∆Cas
5'-конец эндогенной ацетилтрансферазы F. novicida (выше локуса FnCpf1
FnCpf1
Прямые повторы
Спейсер
CTGTCTACTATGCCGATGAGTTTGGCAAAATTTTTTAGATCTACAAAATTATAAACTAAATAAAGATTCTTATAATAACTTTATATATAATCGAAATGTAGAGAATTTTATAAGGAGTCTTTATCATGTCAATTTATCAAGAATTTGTTAATAAATATAGTTTAAGTAAAACTCTAAGATTTGAGTTAATCCCACAGGGTAAAACACTTGAAAACATAAAAGCAAGAGGTTTGATTTTAGATGATGAGAAAAGAGCTAAAGACTACAAAAAGGCTAAACAAATAATTGATAAATATCATCAGTTTTTTATAGAGGAGATATTAAGTTCGGTTTGTATTAGCGAAGATTTATTACAAAACTATTCTGATGTTTATTTTAAACTTAAAAAGAGTGATGATGATAATCTACAAAAAGATTTTAAAAGTGCAAAAGATACGATAAAGAAACAAATATCTGAATATATAAAGGACTCAGAGAAATTTAAGAATTTGTTTAATCAAAACCTTATCGATGCTAAAAAAGGGCAAGAGTCAGATTTAATTCTATGGCTAAAGCAATCTAAGGATAATGGTATAGAACTATTTAAAGCCAATAGTGATATCACAGATATAGATGAGGCGTTAGAAATAATCAAATCTTTTAAAGGTTGGACAACTTATTTTAAGGGTTTTCATGAAAATAGAAAAAATGTTTATAGTAGCAATGATATTCCTACATCTATTATTTATAGGATAGTAGATGATAATTTGCCTAAATTTCTAGAAAATAAAGCTAAGTATGAGAGTTTAAAAGACAAAGCTCCAGAAGCTATAAACTATGAACAAATTAAAAAAGATTTGGCAGAAGAGCTAACCTTTGATATTGACTACAAAACATCTGAAGTTAATCAAAGAGTTTTTTCACTTGATGAAGTTTTTGAGATAGCAAACTTTAATAATTATCTAAATCAAAGTGGTATTACTAAATTTAATACTATTATTGGTGGTAAATTTGTAAATGGTGAAAATACAAAGAGAAAAGGTATAAATGAATATATAAATCTATACTCACAGCAAATAAATGATAAAACACTCAAAAAATATAAAATGAGTGTTTTATTTAAGCAAATTTTAAGTGATACAGAATCTAAATCTTTTGTAATTGATAAGTTAGAAGATGATAGTGATGTAGTTACAACGATGCAAAGTTTTTATGAGCAAATAGCAGCTTTTAAAACAGTAGAAGAAAAATCTATTAAAGAAACACTATCTTTATTATTTGATGATTTAAAAGCTCAAAAACTTGATTTGAGTAAAATTTATTTTAAAAATGATAAATCTCTTACTGATCTATCACAACAAGTTTTTGATGATTATAGTGTTATTGGTACAGCGGTACTAGAATATATAACTCAACAAATAGCACCTAAAAATCTTGATAACCCTAGTAAGAAAGAGCAAGAATTAATAGCCAAAAAAACTGAAAAAGCAAAATACTTATCTCTAGAAACTATAAAGCTTGCCTTAGAAGAATTTAATAAGCATAGAGATATAGATAAACAGTGTAGGTTTGAAGAAATACTTGCAAACTTTGCGGCTATTCCGATGATATTTGATGAAATAGCTCAAAACAAAGACAATTTGGCACAGATATCTATCAAATATCAAAATCAAGGTAAAAAAGACCTACTTCAAGCTAGTGCGGAAGATGATGTTAAAGCTATCAAGGATCTTTTAGATCAAACTAATAATCTCTTACATAAACTAAAAATATTTCATATTAGTCAGTCAGAAGATAAGGCAAATATTTTAGACAAGGATGAGCATTTTTATCTAGTATTTGAGGAGTGCTACTTTGAGCTAGCGAATATAGTGCCTCTTTATAACAAAATTAGAAACTATATAACTCAAAAGCCATATAGTGATGAGAAATTTAAGCTCAATTTTGAGAACTCGACTTTGGCTAATGGTTGGGATAAAAATAAAGAGCCTGACAATACGGCAATTTTATTTATCAAAGATGATAAATATTATCTGGGTGTGATGAATAAGAAAAATAACAAAATATTTGATGATAAAGCTATCAAAGAAAATAAAGGCGAGGGTTATAAAAAAATTGTTTATAAACTTTTACCTGGCGCAAATAAAATGTTACCTAAGGTTTTCTTTTCTGCTAAATCTATAAAATTTTATAATCCTAGTGAAGATATACTTAGAATAAGAAATCATTCCACACATACAAAAAATGGTAGTCCTCAAAAAGGATATGAAAAATTTGAGTTTAATATTGAAGATTGCCGAAAATTTATAGATTTTTATAAACAGTCTATAAGTAAGCATCCGGAGTGGAAAGATTTTGGATTTAGATTTTCTGATACTCAAAGATATAATTCTATAGATGAATTTTATAGAGAAGTTGAAAATCAAGGCTACAAACTAACTTTTGAAAATATATCAGAGAGCTATATTGATAGCGTAGTTAATCAGGGTAAATTGTACCTATTCCAAATCTATAATAAAGATTTTTCAGCTTATAGCAAAGGGCGACCAAATCTACATACTTTATATTGGAAAGCGCTGTTTGATGAGAGAAATCTTCAAGATGTGGTTTATAAGCTAAATGGTGAGGCAGAGCTTTTTTATCGTAAACAATCAATACCTAAAAAAATCACTCACCCAGCTAAAGAGGCAATAGCTAATAAAAACAAAGATAATCCTAAAAAAGAGAGTGTTTTTGAATATGATTTAATCAAAGATAAACGCTTTACTGAAGATAAGTTTTTCTTTCACTGTCCTATTACAATCAATTTTAAATCTAGTGGAGCTAATAAGTTTAATGATGAAATCAATTTATTGCTAAAAGAAAAAGCAAATGATGTTCATATATTAAGTATAGATAGAGGTGAAAGACATTTAGCTTACTATACTTTGGTAGATGGTAAAGGCAATATCATCAAACAAGATACTTTCAACATCATTGGTAATGATAGAATGAAAACAAACTACCATGATAAGCTTGCTGCAATAGAGAAAGATAGGGATTCAGCTAGGAAAGACTGGAAAAAGATAAATAACATCAAAGAGATGAAAGAGGGCTATCTATCTCAGGTAGTTCATGAAATAGCTAAGCTAGTTATAGAGTATAATGCTATTGTGGTTTTTGAGGATTTAAATTTTGGATTTAAAAGAGGGCGTTTCAAGGTAGAGAAGCAGGTCTATCAAAAGTTAGAAAAAATGCTAATTGAGAAACTAAACTATCTAGTTTTCAAAGATAATGAGTTTGATAAAACTGGGGGAGTGCTTAGAGCTTATCAGCTAACAGCACCTTTTGAGACTTTTAAAAAGATGGGTAAACAAACAGGTATTATCTACTATGTACCAGCTGGTTTTACTTCAAAAATTTGTCCTGTAACTGGTTTTGTAAATCAGTTATATCCTAAGTATGAAAGTGTCAGCAAATCTCAAGAGTTCTTTAGTAAGTTTGACAAGATTTGTTATAACCTTGATAAGGGCTATTTTGAGTTTAGTTTTGATTATAAAAACTTTGGTGACAAGGCTGCCAAAGGCAAGTGGACTATAGCTAGCTTTGGGAGTAGATTGATTAACTTTAGAAATTCAGATAAAAATCATAATTGGGATACTCGAGAAGTTTATCCAACTAAAGAGTTGGAGAAATTGCTAAAAGATTATTCTATCGAATATGGGCATGGCGAATGTATCAAAGCAGCTATTTGCGGTGAGAGCGACAAAAAGTTTTTTGCTAAGCTAACTAGTGTCCTAAATACTATCTTACAAATGCGTAACTCAAAAACAGGTACTGAGTTAGATTATCTAATTTCACCAGTAGCAGATGTAAATGGCAATTTCTTTGATTCGCGACAGGCGCCAAAAAATATGCCTCAAGATGCTGATGCCAATGGTGCTTATCATATTGGGCTAAAAGGTCTGATGCTACTAGGTAGGATCAAAAATAATCAAGAGGGCAAAAAACTCAATTTGGTTATCAAAAATGAAGAGTATTTTGAGTTCGTGCAGAATAGGAATAACTAATTCATTCAAGAATATATTACCCTGTCAGTTTAGCGACTATTACCTCTTTAATAATTTGCAGGGGAATTATTTTAGTAATAGTAATATACACAAGAGTTATTGATTATATGGAAAATTATATTTAGATAACATGGTTAAATGATTTTATATTCTGTCCTTACTCGATATATTTTTTATAGACTAAAAATTGCAAACCTTAGTCTTTATGTTAAAATAACTACTAAGTTCTTAGAGATATTTAAAAATATGACTGTTGTTATATATCAAAATGCTAAAAAAATCATAGATTTTAGGTCTTTTTTTGCTGATTTAGGCAAAAACGGGTCTAAGAACTTTAAATAATTTCTACTGTTGTAGATGAGAAGTCATTTAATAAGGCCACTGTTAAAAGTCTAAGAACTTTAAATAATTTCTACTGTTGTAGATGCTACTATTCCTGTGCCTTCAGATAATTCAGTCTAAGAACTTTAAATAATTTCTACTGTTGTAGATGTCTAGAGCCTTTTGTATTAGTAGCCGGTCTAAGAACTTTAAATAATTTCTACTGTTGTAGATTAGCGATTTATGAAGGTCATTTTTTTGTCT (SEQ ID NO: 213).
Нуклеотидные последовательности ортологов Cpf1, кодон-оптимизированных для человека
Сигнал ядерной локализации (NLS)
Глицин-сериновый линкер
3x HA-метка
1- Francisella tularensis subsp. Novicida U112 (FnCpf1)
ATGAGCATCTACCAGGAGTTCGTCAACAAGTATTCACTGAGTAAGACACTGCGGTTCGAGCTGATCCCACAGGGCAAGACACTGGAGAACATCAAGGCCCGAGGCCTGATTCTGGACGATGAGAAGCGGGCAAAAGACTATAAGAAAGCCAAGCAGATCATTGATAAATACCACCAGTTCTTTATCGAGGAAATTCTGAGCTCCGTGTGCATCAGTGAGGATCTGCTGCAGAATTACTCAGACGTGTACTTCAAGCTGAAGAAGAGCGACGATGACAACCTGCAGAAGGACTTCAAGTCCGCCAAGGACACCATCAAGAAACAGATTAGCGAGTACATCAAGGACTCCGAAAAGTTTAAAAATCTGTTCAACCAGAATCTGATCGATGCTAAGAAAGGCCAGGAGTCCGACCTGATCCTGTGGCTGAAACAGTCTAAGGACAATGGGATTGAACTGTTCAAGGCTAACTCCGATATCACTGATATTGACGAGGCACTGGAAATCATCAAGAGCTTCAAGGGATGGACCACATACTTTAAAGGCTTCCACGAGAACCGCAAGAACGTGTACTCCAGCAACGACATTCCTACCTCCATCATCTACCGAATCGTCGATGACAATCTGCCAAAGTTCCTGGAGAACAAGGCCAAATATGAATCTCTGAAGGACAAAGCTCCCGAGGCAATTAATTACGAACAGATCAAGAAAGATCTGGCTGAGGAACTGACATTCGATATCGACTATAAGACTAGCGAGGTGAACCAGAGGGTCTTTTCCCTGGACGAGGTGTTTGAAATCGCCAATTTCAACAATTACCTGAACCAGTCCGGCATTACTAAATTCAATACCATCATTGGCGGGAAGTTTGTGAACGGGGAGAATACCAAGCGCAAGGGAATTAACGAATACATCAATCTGTATAGCCAGCAGATCAACGACAAAACTCTGAAGAAATACAAGATGTCTGTGCTGTTCAAACAGATCCTGAGTGATACCGAGTCCAAGTCTTTTGTCATTGATAAACTGGAAGATGACTCAGACGTGGTCACTACCATGCAGAGCTTTTATGAGCAGATCGCCGCTTTCAAGACAGTGGAGGAAAAATCTATTAAGGAAACTCTGAGTCTGCTGTTCGATGACCTGAAAGCCCAGAAGCTGGACCTGAGTAAGATCTACTTCAAAAACGATAAGAGTCTGACAGACCTGTCACAGCAGGTGTTTGATGACTATTCCGTGATTGGGACCGCCGTCCTGGAGTACATTACACAGCAGATCGCTCCAAAGAACCTGGATAATCCCTCTAAGAAAGAGCAGGAACTGATCGCTAAGAAAACCGAGAAGGCAAAATATCTGAGTCTGGAAACAATTAAGCTGGCACTGGAGGAGTTCAACAAGCACAGGGATATTGACAAACAGTGCCGCTTTGAGGAAATCCTGGCCAACTTCGCAGCCATCCCCATGATTTTTGATGAGATCGCCCAGAACAAAGACAATCTGGCTCAGATCAGTATTAAGTACCAGAACCAGGGCAAGAAAGACCTGCTGCAGGCTTCAGCAGAAGATGACGTGAAAGCCATCAAGGATCTGCTGGACCAGACCAACAATCTGCTGCACAAGCTGAAAATCTTCCATATTAGTCAGTCAGAGGATAAGGCTAATATCCTGGATAAAGACGAACACTTCTACCTGGTGTTCGAGGAATGTTACTTCGAGCTGGCAAACATTGTCCCCCTGTATAACAAGATTAGGAACTACATCACACAGAAGCCTTACTCTGACGAGAAGTTTAAACTGAACTTCGAAAATAGTACCCTGGCCAACGGGTGGGATAAGAACAAGGAGCCTGACAACACAGCTATCCTGTTCATCAAGGATGACAAGTACTATCTGGGAGTGATGAATAAGAAAAACAATAAGATCTTCGATGACAAAGCCATTAAGGAGAACAAAGGGGAAGGATACAAGAAAATCGTGTATAAGCTGCTGCCCGGCGCAAATAAGATGCTGCCTAAGGTGTTCTTCAGCGCCAAGAGTATCAAATTCTACAACCCATCCGAGGACATCCTGCGGATTAGAAATCACTCAACACATACTAAGAACGGGAGCCCCCAGAAGGGATATGAGAAATTTGAGTTCAACATCGAGGATTGCAGGAAGTTTATTGACTTCTACAAGCAGAGCATCTCCAAACACCCTGAATGGAAGGATTTTGGCTTCCGGTTTTCCGACACACAGAGATATAACTCTATCGACGAGTTCTACCGCGAGGTGGAAAATCAGGGGTATAAGCTGACTTTTGAGAACATTTCTGAAAGTTACATCGACAGCGTGGTCAATCAGGGAAAGCTGTACCTGTTCCAGATCTATAACAAAGATTTTTCAGCATACAGCAAGGGCAGACCAAACCTGCATACACTGTACTGGAAGGCCCTGTTCGATGAGAGGAATCTGCAGGACGTGGTCTATAAACTGAACGGAGAGGCCGAACTGTTTTACCGGAAGCAGTCTATTCCTAAGAAAATCACTCACCCAGCTAAGGAGGCCATCGCTAACAAGAACAAGGACAATCCTAAGAAAGAGAGCGTGTTCGAATACGATCTGATTAAGGACAAGCGGTTCACCGAAGATAAGTTCTTTTTCCATTGTCCAATCACCATTAACTTCAAGTCAAGCGGCGCTAACAAGTTCAACGACGAGATCAATCTGCTGCTGAAGGAAAAAGCAAACGATGTGCACATCCTGAGCATTGACCGAGGAGAGCGGCATCTGGCCTACTATACCCTGGTGGATGGCAAAGGGAATATCATTAAGCAGGATACATTCAACATCATTGGCAATGACCGGATGAAAACCAACTACCACGATAAACTGGCTGCAATCGAGAAGGATAGAGACTCAGCTAGGAAGGACTGGAAGAAAATCAACAACATTAAGGAGATGAAGGAAGGCTATCTGAGCCAGGTGGTCCATGAGATTGCAAAGCTGGTCATCGAATACAATGCCATTGTGGTGTTCGAGGATCTGAACTTCGGCTTTAAGAGGGGGCGCTTTAAGGTGGAAAAACAGGTCTATCAGAAGCTGGAGAAAATGCTGATCGAAAAGCTGAATTACCTGGTGTTTAAAGATAACGAGTTCGACAAGACCGGAGGCGTCCTGAGAGCCTACCAGCTGACAGCTCCCTTTGAAACTTTCAAGAAAATGGGAAAACAGACAGGCATCATCTACTATGTGCCAGCCGGATTCACTTCCAAGATCTGCCCCGTGACCGGCTTTGTCAACCAGCTGTACCCTAAATATGAGTCAGTGAGCAAGTCCCAGGAATTTTTCAGCAAGTTCGATAAGATCTGTTATAATCTGGACAAGGGGTACTTCGAGTTTTCCTTCGATTACAAGAACTTCGGCGACAAGGCCGCTAAGGGGAAATGGACCATTGCCTCCTTCGGATCTCGCCTGATCAACTTTCGAAATTCCGATAAAAACCACAATTGGGACACTAGGGAGGTGTACCCAACCAAGGAGCTGGAAAAGCTGCTGAAAGACTACTCTATCGAGTATGGACATGGCGAATGCATCAAGGCAGCCATCTGTGGCGAGAGTGATAAGAAATTTTTCGCCAAGCTGACCTCAGTGCTGAATACAATCCTGCAGATGCGGAACTCAAAGACCGGGACAGAACTGGACTATCTGATTAGCCCCGTGGCTGATGTCAACGGAAACTTCTTCGACAGCAGACAGGCACCCAAAAATATGCCTCAGGATGCAGACGCCAACGGGGCCTACCACATCGGGCTGAAGGGACTGATGCTGCTGGGCCGGATCAAGAACAATCAGGAGGGGAAGAAGCTGAACCTGGTCATTAAGAACGAGGAATACTTCGAGTTTGTCCAGAATAGAAATAACAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCC (SEQ ID NO: 214).
3- Lachnospiraceae bacterium MC2017 (Lb3Cpf1)
ATGGATTACGGCAACGGCCAGTTTGAGCGGAGAGCCCCCCTGACCAAGACAATCACCCTGCGCCTGAAGCCTATCGGCGAGACACGGGAGACAATCCGCGAGCAGAAGCTGCTGGAGCAGGACGCCGCCTTCAGAAAGCTGGTGGAGACAGTGACCCCTATCGTGGACGATTGTATCAGGAAGATCGCCGATAACGCCCTGTGCCACTTTGGCACCGAGTATGACTTCAGCTGTCTGGGCAACGCCATCTCTAAGAATGACAGCAAGGCCATCAAGAAGGAGACAGAGAAGGTGGAGAAGCTGCTGGCCAAGGTGCTGACCGAGAATCTGCCAGATGGCCTGCGCAAGGTGAACGACATCAATTCCGCCGCCTTTATCCAGGATACACTGACCTCTTTCGTGCAGGACGATGCCGACAAGCGGGTGCTGATCCAGGAGCTGAAGGGCAAGACCGTGCTGATGCAGCGGTTCCTGACCACACGGATCACAGCCCTGACCGTGTGGCTGCCCGACAGAGTGTTCGAGAACTTTAATATCTTCATCGAGAACGCCGAGAAGATGAGAATCCTGCTGGACTCCCCTCTGAATGAGAAGATCATGAAGTTTGACCCAGATGCCGAGCAGTACGCCTCTCTGGAGTTCTATGGCCAGTGCCTGTCTCAGAAGGACATCGATAGCTACAACCTGATCATCTCCGGCATCTATGCCGACGATGAGGTGAAGAACCCTGGCATCAATGAGATCGTGAAGGAGTACAATCAGCAGATCCGGGGCGACAAGGATGAGTCCCCACTGCCCAAGCTGAAGAAGCTGCACAAGCAGATCCTGATGCCAGTGGAGAAGGCCTTCTTTGTGCGCGTGCTGTCTAACGACAGCGATGCCCGGAGCATCCTGGAGAAGATCCTGAAGGACACAGAGATGCTGCCCTCCAAGATCATCGAGGCCATGAAGGAGGCAGATGCAGGCGACATCGCCGTGTACGGCAGCCGGCTGCACGAGCTGAGCCACGTGATCTACGGCGATCACGGCAAGCTGTCCCAGATCATCTATGACAAGGAGTCCAAGAGGATCTCTGAGCTGATGGAGACACTGTCTCCAAAGGAGCGCAAGGAGAGCAAGAAGCGGCTGGAGGGCCTGGAGGAGCACATCAGAAAGTCTACATACACCTTCGACGAGCTGAACAGGTATGCCGAGAAGAATGTGATGGCAGCATACATCGCAGCAGTGGAGGAGTCTTGTGCCGAGATCATGAGAAAGGAGAAGGATCTGAGGACCCTGCTGAGCAAGGAGGACGTGAAGATCCGGGGCAACAGACACAATACACTGATCGTGAAGAACTACTTTAATGCCTGGACCGTGTTCCGGAACCTGATCAGAATCCTGAGGCGCAAGTCCGAGGCCGAGATCGACTCTGACTTCTACGATGTGCTGGACGATTCCGTGGAGGTGCTGTCTCTGACATACAAGGGCGAGAATCTGTGCCGCAGCTATATCACCAAGAAGATCGGCTCCGACCTGAAGCCCGAGATCGCCACATACGGCAGCGCCCTGAGGCCTAACAGCCGCTGGTGGTCCCCAGGAGAGAAGTTTAATGTGAAGTTCCACACCATCGTGCGGAGAGATGGCCGGCTGTACTATTTCATCCTGCCCAAGGGCGCCAAGCCTGTGGAGCTGGAGGACATGGATGGCGACATCGAGTGTCTGCAGATGAGAAAGATCCCTAACCCAACAATCTTTCTGCCCAAGCTGGTGTTCAAGGACCCTGAGGCCTTCTTTAGGGATAATCCAGAGGCCGACGAGTTCGTGTTTCTGAGCGGCATGAAGGCCCCCGTGACAATCACCAGAGAGACATACGAGGCCTACAGGTATAAGCTGTATACCGTGGGCAAGCTGCGCGATGGCGAGGTGTCCGAAGAGGAGTACAAGCGGGCCCTGCTGCAGGTGCTGACCGCCTACAAGGAGTTTCTGGAGAACAGAATGATCTATGCCGACCTGAATTTCGGCTTTAAGGATCTGGAGGAGTATAAGGACAGCTCCGAGTTTATCAAGCAGGTGGAGACACACAACACCTTCATGTGCTGGGCCAAGGTGTCTAGCTCCCAGCTGGACGATCTGGTGAAGTCTGGCAACGGCCTGCTGTTCGAGATCTGGAGCGAGCGCCTGGAGTCCTACTATAAGTACGGCAATGAGAAGGTGCTGCGGGGCTATGAGGGCGTGCTGCTGAGCATCCTGAAGGATGAGAACCTGGTGTCCATGCGGACCCTGCTGAACAGCCGGCCCATGCTGGTGTACCGGCCAAAGGAGTCTAGCAAGCCTATGGTGGTGCACCGGGATGGCAGCAGAGTGGTGGACAGGTTTGATAAGGACGGCAAGTACATCCCCCCTGAGGTGCACGACGAGCTGTATCGCTTCTTTAACAATCTGCTGATCAAGGAGAAGCTGGGCGAGAAGGCCCGGAAGATCCTGGACAACAAGAAGGTGAAGGTGAAGGTGCTGGAGAGCGAGAGAGTGAAGTGGTCCAAGTTCTACGATGAGCAGTTTGCCGTGACCTTCAGCGTGAAGAAGAACGCCGATTGTCTGGACACCACAAAGGACCTGAATGCCGAAGTGATGGAGCAGTATAGCGAGTCCAACAGACTGATCCTGATCAGGAATACCACAGATATCCTGTACTATCTGGTGCTGGACAAGAATGGCAAGGTGCTGAAGCAGAGATCCCTGAACATCATCAATGACGGCGCCAGGGATGTGGACTGGAAGGAGAGGTTCCGCCAGGTGACAAAGGATAGAAACGAGGGCTACAATGAGTGGGATTATTCCAGGACCTCTAACGACCTGAAGGAGGTGTACCTGAATTATGCCCTGAAGGAGATCGCCGAGGCCGTGATCGAGTACAACGCCATCCTGATCATCGAGAAGATGTCTAATGCCTTTAAGGACAAGTATAGCTTCCTGGACGACGTGACCTTCAAGGGCTTCGAGACAAAGCTGCTGGCCAAGCTGAGCGATCTGCACTTTAGGGGCATCAAGGACGGCGAGCCATGTTCCTTCACAAACCCCCTGCAGCTGTGCCAGAACGATTCTAATAAGATCCTGCAGGACGGCGTGATCTTTATGGTGCCAAATTCTATGACACGGAGCCTGGACCCCGACACCGGCTTCATCTTTGCCATCAACGACCACAATATCAGGACCAAGAAGGCCAAGCTGAACTTTCTGAGCAAGTTCGATCAGCTGAAGGTGTCCTCTGAGGGCTGCCTGATCATGAAGTACAGCGGCGATTCCCTGCCTACACACAACACCGACAATCGCGTGTGGAACTGCTGTTGCAATCACCCAATCACAAACTATGACCGGGAGACAAAGAAGGTGGAGTTCATCGAGGAGCCCGTGGAGGAGCTGTCCCGCGTGCTGGAGGAGAATGGCATCGAGACAGACACCGAGCTGAACAAGCTGAATGAGCGGGAGAACGTGCCTGGCAAGGTGGTGGATGCCATCTACTCTCTGGTGCTGAATTATCTGCGCGGCACAGTGAGCGGAGTGGCAGGACAGAGGGCCGTGTACTATAGCCCTGTGACCGGCAAGAAGTACGATATCTCCTTTATCCAGGCCATGAACCTGAATAGGAAGTGTGACTACTATAGGATCGGCTCCAAGGAGAGGGGAGAGTGGACCGATTTCGTGGCCCAGCTGATCAACAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCC (SEQ ID NO: 215).
4- Butyrivibrio proteoclasticus (BpCpf1)
ATGAGCATCTACCAGGAGTTCGTCAACAAGTATTCACTGAGTAAGACACTGCGGTTCGAGCTGATCCCACAGGGCAAGACACTGGAGAACATCAAGGCCCGAGGCCTGATTCTGGACGATGAGAAGCGGGCAAAAGACTATAAGAAAGCCAAGCAGATCATTGATAAATACCACCAGTTCTTTATCGAGGAAATTCTGAGCTCCGTGTGCATCAGTGAGGATCTGCTGCAGAATTACTCAGACGTGTACTTCAAGCTGAAGAAGAGCGACGATGACAACCTGCAGAAGGACTTCAAGTCCGCCAAGGACACCATCAAGAAACAGATTAGCGAGTACATCAAGGACTCCGAAAAGTTTAAAAATCTGTTCAACCAGAATCTGATCGATGCTAAGAAAGGCCAGGAGTCCGACCTGATCCTGTGGCTGAAACAGTCTAAGGACAATGGGATTGAACTGTTCAAGGCTAACTCCGATATCACTGATATTGACGAGGCACTGGAAATCATCAAGAGCTTCAAGGGATGGACCACATACTTTAAAGGCTTCCACGAGAACCGCAAGAACGTGTACTCCAGCAACGACATTCCTACCTCCATCATCTACCGAATCGTCGATGACAATCTGCCAAAGTTCCTGGAGAACAAGGCCAAATATGAATCTCTGAAGGACAAAGCTCCCGAGGCAATTAATTACGAACAGATCAAGAAAGATCTGGCTGAGGAACTGACATTCGATATCGACTATAAGACTAGCGAGGTGAACCAGAGGGTCTTTTCCCTGGACGAGGTGTTTGAAATCGCCAATTTCAACAATTACCTGAACCAGTCCGGCATTACTAAATTCAATACCATCATTGGCGGGAAGTTTGTGAACGGGGAGAATACCAAGCGCAAGGGAATTAACGAATACATCAATCTGTATAGCCAGCAGATCAACGACAAAACTCTGAAGAAATACAAGATGTCTGTGCTGTTCAAACAGATCCTGAGTGATACCGAGTCCAAGTCTTTTGTCATTGATAAACTGGAAGATGACTCAGACGTGGTCACTACCATGCAGAGCTTTTATGAGCAGATCGCCGCTTTCAAGACAGTGGAGGAAAAATCTATTAAGGAAACTCTGAGTCTGCTGTTCGATGACCTGAAAGCCCAGAAGCTGGACCTGAGTAAGATCTACTTCAAAAACGATAAGAGTCTGACAGACCTGTCACAGCAGGTGTTTGATGACTATTCCGTGATTGGGACCGCCGTCCTGGAGTACATTACACAGCAGATCGCTCCAAAGAACCTGGATAATCCCTCTAAGAAAGAGCAGGAACTGATCGCTAAGAAAACCGAGAAGGCAAAATATCTGAGTCTGGAAACAATTAAGCTGGCACTGGAGGAGTTCAACAAGCACAGGGATATTGACAAACAGTGCCGCTTTGAGGAAATCCTGGCCAACTTCGCAGCCATCCCCATGATTTTTGATGAGATCGCCCAGAACAAAGACAATCTGGCTCAGATCAGTATTAAGTACCAGAACCAGGGCAAGAAAGACCTGCTGCAGGCTTCAGCAGAAGATGACGTGAAAGCCATCAAGGATCTGCTGGACCAGACCAACAATCTGCTGCACAAGCTGAAAATCTTCCATATTAGTCAGTCAGAGGATAAGGCTAATATCCTGGATAAAGACGAACACTTCTACCTGGTGTTCGAGGAATGTTACTTCGAGCTGGCAAACATTGTCCCCCTGTATAACAAGATTAGGAACTACATCACACAGAAGCCTTACTCTGACGAGAAGTTTAAACTGAACTTCGAAAATAGTACCCTGGCCAACGGGTGGGATAAGAACAAGGAGCCTGACAACACAGCTATCCTGTTCATCAAGGATGACAAGTACTATCTGGGAGTGATGAATAAGAAAAACAATAAGATCTTCGATGACAAAGCCATTAAGGAGAACAAAGGGGAAGGATACAAGAAAATCGTGTATAAGCTGCTGCCCGGCGCAAATAAGATGCTGCCTAAGGTGTTCTTCAGCGCCAAGAGTATCAAATTCTACAACCCATCCGAGGACATCCTGCGGATTAGAAATCACTCAACACATACTAAGAACGGGAGCCCCCAGAAGGGATATGAGAAATTTGAGTTCAACATCGAGGATTGCAGGAAGTTTATTGACTTCTACAAGCAGAGCATCTCCAAACACCCTGAATGGAAGGATTTTGGCTTCCGGTTTTCCGACACACAGAGATATAACTCTATCGACGAGTTCTACCGCGAGGTGGAAAATCAGGGGTATAAGCTGACTTTTGAGAACATTTCTGAAAGTTACATCGACAGCGTGGTCAATCAGGGAAAGCTGTACCTGTTCCAGATCTATAACAAAGATTTTTCAGCATACAGCAAGGGCAGACCAAACCTGCATACACTGTACTGGAAGGCCCTGTTCGATGAGAGGAATCTGCAGGACGTGGTCTATAAACTGAACGGAGAGGCCGAACTGTTTTACCGGAAGCAGTCTATTCCTAAGAAAATCACTCACCCAGCTAAGGAGGCCATCGCTAACAAGAACAAGGACAATCCTAAGAAAGAGAGCGTGTTCGAATACGATCTGATTAAGGACAAGCGGTTCACCGAAGATAAGTTCTTTTTCCATTGTCCAATCACCATTAACTTCAAGTCAAGCGGCGCTAACAAGTTCAACGACGAGATCAATCTGCTGCTGAAGGAAAAAGCAAACGATGTGCACATCCTGAGCATTGACCGAGGAGAGCGGCATCTGGCCTACTATACCCTGGTGGATGGCAAAGGGAATATCATTAAGCAGGATACATTCAACATCATTGGCAATGACCGGATGAAAACCAACTACCACGATAAACTGGCTGCAATCGAGAAGGATAGAGACTCAGCTAGGAAGGACTGGAAGAAAATCAACAACATTAAGGAGATGAAGGAAGGCTATCTGAGCCAGGTGGTCCATGAGATTGCAAAGCTGGTCATCGAATACAATGCCATTGTGGTGTTCGAGGATCTGAACTTCGGCTTTAAGAGGGGGCGCTTTAAGGTGGAAAAACAGGTCTATCAGAAGCTGGAGAAAATGCTGATCGAAAAGCTGAATTACCTGGTGTTTAAAGATAACGAGTTCGACAAGACCGGAGGCGTCCTGAGAGCCTACCAGCTGACAGCTCCCTTTGAAACTTTCAAGAAAATGGGAAAACAGACAGGCATCATCTACTATGTGCCAGCCGGATTCACTTCCAAGATCTGCCCCGTGACCGGCTTTGTCAACCAGCTGTACCCTAAATATGAGTCAGTGAGCAAGTCCCAGGAATTTTTCAGCAAGTTCGATAAGATCTGTTATAATCTGGACAAGGGGTACTTCGAGTTTTCCTTCGATTACAAGAACTTCGGCGACAAGGCCGCTAAGGGGAAATGGACCATTGCCTCCTTCGGATCTCGCCTGATCAACTTTCGAAATTCCGATAAAAACCACAATTGGGACACTAGGGAGGTGTACCCAACCAAGGAGCTGGAAAAGCTGCTGAAAGACTACTCTATCGAGTATGGACATGGCGAATGCATCAAGGCAGCCATCTGTGGCGAGAGTGATAAGAAATTTTTCGCCAAGCTGACCTCAGTGCTGAATACAATCCTGCAGATGCGGAACTCAAAGACCGGGACAGAACTGGACTATCTGATTAGCCCCGTGGCTGATGTCAACGGAAACTTCTTCGACAGCAGACAGGCACCCAAAAATATGCCTCAGGATGCAGACGCCAACGGGGCCTACCACATCGGGCTGAAGGGACTGATGCTGCTGGGCCGGATCAAGAACAATCAGGAGGGGAAGAAGCTGAACCTGGTCATTAAGAACGAGGAATACTTCGAGTTTGTCCAGAATAGAAATAACAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCC (SEQ ID NO: 216).
5- Peregrinibacteria bacterium GW2011_GWA_33_10 (PeCpf1)
ATGTCCAACTTCTTTAAGAATTTCACCAACCTGTATGAGCTGTCCAAGACACTGAGGTTTGAGCTGAAGCCCGTGGGCGACACCCTGACAAACATGAAGGACCACCTGGAGTACGATGAGAAGCTGCAGACCTTCCTGAAGGATCAGAATATCGACGATGCCTATCAGGCCCTGAAGCCTCAGTTCGACGAGATCCACGAGGAGTTTATCACAGATTCTCTGGAGAGCAAGAAGGCCAAGGAGATCGACTTCTCCGAGTACCTGGATCTGTTTCAGGAGAAGAAGGAGCTGAACGACTCTGAGAAGAAGCTGCGCAACAAGATCGGCGAGACATTCAACAAGGCCGGCGAGAAGTGGAAGAAGGAGAAGTACCCTCAGTATGAGTGGAAGAAGGGCTCCAAGATCGCCAATGGCGCCGACATCCTGTCTTGCCAGGATATGCTGCAGTTTATCAAGTATAAGAACCCAGAGGATGAGAAGATCAAGAATTACATCGACGATACACTGAAGGGCTTCTTTACCTATTTCGGCGGCTTTAATCAGAACAGGGCCAACTACTATGAGACAAAGAAGGAGGCCTCCACCGCAGTGGCAACAAGGATCGTGCACGAGAACCTGCCAAAGTTCTGTGACAATGTGATCCAGTTTAAGCACATCATCAAGCGGAAGAAGGATGGCACCGTGGAGAAAACCGAGAGAAAGACCGAGTACCTGAACGCCTACCAGTATCTGAAGAACAATAACAAGATCACACAGATCAAGGACGCCGAGACAGAGAAGATGATCGAGTCTACACCCATCGCCGAGAAGATCTTCGACGTGTACTACTTCAGCAGCTGCCTGAGCCAGAAGCAGATCGAGGAGTACAACCGGATCATCGGCCACTATAATCTGCTGATCAACCTGTATAACCAGGCCAAGAGATCTGAGGGCAAGCACCTGAGCGCCAACGAGAAGAAGTATAAGGACCTGCCTAAGTTCAAGACCCTGTATAAGCAGATCGGCTGCGGCAAGAAGAAGGACCTGTTTTACACAATCAAGTGTGATACCGAGGAGGAGGCCAATAAGTCCCGGAACGAGGGCAAGGAGTCCCACTCTGTGGAGGAGATCATCAACAAGGCCCAGGAGGCCATCAATAAGTACTTCAAGTCTAATAACGACTGTGAGAATATCAACACCGTGCCCGACTTCATCAACTATATCCTGACAAAGGAGAATTACGAGGGCGTGTATTGGAGCAAGGCCGCCATGAACACCATCTCCGACAAGTACTTCGCCAATTATCACGACCTGCAGGATAGACTGAAGGAGGCCAAGGTGTTTCAGAAGGCCGATAAGAAGTCCGAGGACGATATCAAGATCCCAGAGGCCATCGAGCTGTCTGGCCTGTTCGGCGTGCTGGACAGCCTGGCCGATTGGCAGACCACACTGTTTAAGTCTAGCATCCTGAGCAACGAGGACAAGCTGAAGATCATCACAGATTCCCAGACCCCCTCTGAGGCCCTGCTGAAGATGATCTTCAATGACATCGAGAAGAACATGGAGTCCTTTCTGAAGGAGACAAACGATATCATCACCCTGAAGAAGTATAAGGGCAATAAGGAGGGCACCGAGAAGATCAAGCAGTGGTTCGACTATACACTGGCCATCAACCGGATGCTGAAGTACTTTCTGGTGAAGGAGAATAAGATCAAGGGCAACTCCCTGGATACCAATATCTCTGAGGCCCTGAAAACCCTGATCTACAGCGACGATGCCGAGTGGTTCAAGTGGTACGACGCCCTGAGAAACTATCTGACCCAGAAGCCTCAGGATGAGGCCAAGGAGAATAAGCTGAAGCTGAATTTCGACAACCCATCTCTGGCCGGCGGCTGGGATGTGAACAAGGAGTGCAGCAATTTTTGCGTGATCCTGAAGGACAAGAACGAGAAGAAGTACCTGGCCATCATGAAGAAGGGCGAGAATACCCTGTTCCAGAAGGAGTGGACAGAGGGCCGGGGCAAGAACCTGACAAAGAAGTCTAATCCACTGTTCGAGATCAATAACTGCGAGATCCTGAGCAAGATGGAGTATGACTTTTGGGCCGACGTGAGCAAGATGATCCCCAAGTGTAGCACCCAGCTGAAGGCCGTGGTGAACCACTTCAAGCAGTCCGACAATGAGTTCATCTTTCCTATCGGCTACAAGGTGACAAGCGGCGAGAAGTTTAGGGAGGAGTGCAAGATCTCCAAGCAGGACTTCGAGCTGAATAACAAGGTGTTTAATAAGAACGAGCTGAGCGTGACCGCCATGCGCTACGATCTGTCCTCTACACAGGAGAAGCAGTATATCAAGGCCTTCCAGAAGGAGTACTGGGAGCTGCTGTTTAAGCAGGAGAAGCGGGACACCAAGCTGACAAATAACGAGATCTTCAACGAGTGGATCAATTTTTGCAACAAGAAGTATAGCGAGCTGCTGTCCTGGGAGAGAAAGTACAAGGATGCCCTGACCAATTGGATCAACTTCTGTAAGTACTTTCTGAGCAAGTATCCCAAGACCACACTGTTCAACTACTCTTTTAAGGAGAGCGAGAATTATAACTCCCTGGACGAGTTCTACCGGGACGTGGATATCTGTTCTTACAAGCTGAATATCAACACCACAATCAATAAGAGCATCCTGGATAGACTGGTGGAGGAGGGCAAGCTGTACCTGTTTGAGATCAAGAATCAGGACAGCAACGATGGCAAGTCCATCGGCCACAAGAATAACCTGCACACCATCTACTGGAACGCCATCTTCGAGAATTTTGACAACAGGCCTAAGCTGAATGGCGAGGCCGAGATCTTCTATCGCAAGGCCATCTCCAAGGATAAGCTGGGCATCGTGAAGGGCAAGAAAACCAAGAACGGCACCGAGATCATCAAGAATTACAGATTCAGCAAGGAGAAGTTTATCCTGCACGTGCCAATCACCCTGAACTTCTGCTCCAATAACGAGTATGTGAATGACATCGTGAACACAAAGTTCTACAATTTTTCCAACCTGCACTTTCTGGGCATCGATAGGGGCGAGAAGCACCTGGCCTACTATTCTCTGGTGAATAAGAACGGCGAGATCGTGGACCAGGGCACACTGAACCTGCCTTTCACCGACAAGGATGGCAATCAGCGCAGCATCAAGAAGGAGAAGTACTTTTATAACAAGCAGGAGGACAAGTGGGAGGCCAAGGAGGTGGATTGTTGGAATTATAACGACCTGCTGGATGCCATGGCCTCTAACCGGGACATGGCCAGAAAGAATTGGCAGAGGATCGGCACCATCAAGGAGGCCAAGAACGGCTACGTGAGCCTGGTCATCAGGAAGATCGCCGATCTGGCCGTGAATAACGAGCGCCCCGCCTTCATCGTGCTGGAGGACCTGAATACAGGCTTTAAGCGGTCCAGACAGAAGATCGATAAGAGCGTGTACCAGAAGTTCGAGCTGGCCCTGGCCAAGAAGCTGAACTTTCTGGTGGACAAGAATGCCAAGCGCGATGAGATCGGCTCCCCTACAAAGGCCCTGCAGCTGACCCCCCCTGTGAATAACTACGGCGACATTGAGAACAAGAAGCAGGCCGGCATCATGCTGTATACCCGGGCCAATTATACCTCTCAGACAGATCCAGCCACAGGCTGGAGAAAGACCATCTATCTGAAGGCCGGCCCCGAGGAGACAACATACAAGAAGGACGGCAAGATCAAGAACAAGAGCGTGAAGGACCAGATCATCGAGACATTCACCGATATCGGCTTTGACGGCAAGGATTACTATTTCGAGTACGACAAGGGCGAGTTTGTGGATGAGAAAACCGGCGAGATCAAGCCCAAGAAGTGGCGGCTGTACTCCGGCGAGAATGGCAAGTCCCTGGACAGGTTCCGCGGAGAGAGGGAGAAGGATAAGTATGAGTGGAAGATCGACAAGATCGATATCGTGAAGATCCTGGACGATCTGTTCGTGAATTTTGACAAGAACATCAGCCTGCTGAAGCAGCTGAAGGAGGGCGTGGAGCTGACCCGGAATAACGAGCACGGCACAGGCGAGTCCCTGAGATTCGCCATCAACCTGATCCAGCAGATCCGGAATACCGGCAATAACGAGAGAGACAACGATTTCATCCTGTCCCCAGTGAGGGACGAGAATGGCAAGCACTTTGACTCTCGCGAGTACTGGGATAAGGAGACAAAGGGCGAGAAGATCAGCATGCCCAGCTCCGGCGATGCCAATGGCGCCTTCAACATCGCCCGGAAGGGCATCATCATGAACGCCCACATCCTGGCCAATAGCGACTCCAAGGATCTGTCCCTGTTCGTGTCTGACGAGGAGTGGGATCTGCACCTGAATAACAAGACCGAGTGGAAGAAGCAGCTGAACATCTTTTCTAGCAGGAAGGCCATGGCCAAGCGCAAGAAGAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 217).
6- Parcubacteria bacterium GWC2011_GWC2_44_17 (PbCpf1)
ATGGAGAACATCTTCGACCAGTTTATCGGCAAGTACAGCCTGTCCAAGACCCTGAGATTCGAGCTGAAGCCCGTGGGCAAGACAGAGGACTTCCTGAAGATCAACAAGGTGTTTGAGAAGGATCAGACCATCGACGATAGCTACAATCAGGCCAAGTTCTATTTTGATTCCCTGCACCAGAAGTTTATCGACGCCGCCCTGGCCTCCGATAAGACATCCGAGCTGTCTTTCCAGAACTTTGCCGACGTGCTGGAGAAGCAGAATAAGATCATCCTGGATAAGAAGAGAGAGATGGGCGCCCTGAGGAAGCGCGACAAGAACGCCGTGGGCATCGATAGGCTGCAGAAGGAGATCAATGACGCCGAGGATATCATCCAGAAGGAGAAGGAGAAGATCTACAAGGACGTGCGCACCCTGTTCGATAACGAGGCCGAGTCTTGGAAAACCTACTATCAGGAGCGGGAGGTGGACGGCAAGAAGATCACCTTCAGCAAGGCCGACCTGAAGCAGAAGGGCGCCGATTTTCTGACAGCCGCCGGCATCCTGAAGGTGCTGAAGTATGAGTTCCCCGAGGAGAAGGAGAAGGAGTTTCAGGCCAAGAACCAGCCCTCCCTGTTCGTGGAGGAGAAGGAGAATCCTGGCCAGAAGAGGTACATCTTCGACTCTTTTGATAAGTTCGCCGGCTATCTGACCAAGTTTCAGCAGACAAAGAAGAATCTGTACGCAGCAGACGGCACCAGCACAGCAGTGGCCACCCGCATCGCCGATAACTTTATCATCTTCCACCAGAATACCAAGGTGTTCCGGGACAAGTACAAGAACAATCACACAGACCTGGGCTTCGATGAGGAGAACATCTTTGAGATCGAGAGGTATAAGAATTGCCTGCTGCAGCGCGAGATCGAGCACATCAAGAATGAGAATAGCTACAACAAGATCATCGGCCGGATCAATAAGAAGATCAAGGAGTATCGGGACCAGAAGGCCAAGGATACCAAGCTGACAAAGTCCGACTTCCCTTTCTTTAAGAACCTGGATAAGCAGATCCTGGGCGAGGTGGAGAAGGAGAAGCAGCTGATCGAGAAAACCCGGGAGAAAACCGAGGAGGACGTGCTGATCGAGCGGTTCAAGGAGTTCATCGAGAACAATGAGGAGAGGTTCACCGCCGCCAAGAAGCTGATGAATGCCTTCTGTAACGGCGAGTTTGAGTCCGAGTACGAGGGCATCTATCTGAAGAATAAGGCCATCAACACAATCTCCCGGAGATGGTTCGTGTCTGACAGAGATTTTGAGCTGAAGCTGCCTCAGCAGAAGTCCAAGAACAAGTCTGAGAAGAATGAGCCAAAGGTGAAGAAGTTCATCTCCATCGCCGAGATCAAGAACGCCGTGGAGGAGCTGGACGGCGATATCTTTAAGGCCGTGTTCTACGACAAGAAGATCATCGCCCAGGGCGGCTCTAAGCTGGAGCAGTTCCTGGTCATCTGGAAGTACGAGTTTGAGTATCTGTTCCGGGACATCGAGAGAGAGAACGGCGAGAAGCTGCTGGGCTATGATAGCTGCCTGAAGATCGCCAAGCAGCTGGGCATCTTCCCACAGGAGAAGGAGGCCCGCGAGAAGGCAACCGCCGTGATCAAGAATTACGCCGACGCCGGCCTGGGCATCTTCCAGATGATGAAGTATTTTTCTCTGGACGATAAGGATCGGAAGAACACCCCCGGCCAGCTGAGCACAAATTTCTACGCCGAGTATGACGGCTACTACAAGGATTTCGAGTTTATCAAGTACTACAACGAGTTTAGGAACTTCATCACCAAGAAGCCTTTCGACGAGGATAAGATCAAGCTGAACTTTGAGAATGGCGCCCTGCTGAAGGGCTGGGACGAGAACAAGGAGTACGATTTCATGGGCGTGATCCTGAAGAAGGAGGGCCGCCTGTATCTGGGCATCATGCACAAGAACCACCGGAAGCTGTTTCAGTCCATGGGCAATGCCAAGGGCGACAACGCCAATAGATACCAGAAGATGATCTATAAGCAGATCGCCGACGCCTCTAAGGATGTGCCCAGGCTGCTGCTGACCAGCAAGAAGGCCATGGAGAAGTTCAAGCCTTCCCAGGAGATCCTGAGAATCAAGAAGGAGAAAACCTTCAAGCGGGAGAGCAAGAACTTTTCCCTGAGAGATCTGCACGCCCTGATCGAGTACTATAGGAACTGCATCCCTCAGTACAGCAATTGGTCCTTTTATGACTTCCAGTTTCAGGATACCGGCAAGTACCAGAATATCAAGGAGTTCACAGACGATGTGCAGAAGTACGGCTATAAGATCTCCTTTCGCGACATCGACGATGAGTATATCAATCAGGCCCTGAACGAGGGCAAGATGTACCTGTTCGAGGTGGTGAACAAGGATATCTATAACACCAAGAATGGCTCCAAGAATCTGCACACACTGTACTTTGAGCACATCCTGTCTGCCGAGAACCTGAATGACCCAGTGTTCAAGCTGTCTGGCATGGCCGAGATCTTTCAGCGGCAGCCCAGCGTGAACGAAAGAGAGAAGATCACCACACAGAAGAATCAGTGTATCCTGGACAAGGGCGATAGAGCCTACAAGTATAGGCGCTACACCGAGAAGAAGATCATGTTCCACATGAGCCTGGTGCTGAACACAGGCAAGGGCGAGATCAAGCAGGTGCAGTTTAATAAGATCATCAACCAGAGGATCAGCTCCTCTGACAACGAGATGAGGGTGAATGTGATCGGCATCGATCGCGGCGAGAAGAACCTGCTGTACTATAGCGTGGTGAAGCAGAATGGCGAGATCATCGAGCAGGCCTCCCTGAACGAGATCAATGGCGTGAACTACCGGGACAAGCTGATCGAGAGGGAGAAGGAGCGCCTGAAGAACCGGCAGAGCTGGAAGCCTGTGGTGAAGATCAAGGATCTGAAGAAGGGCTACATCTCCCACGTGATCCACAAGATCTGCCAGCTGATCGAGAAGTATTCTGCCATCGTGGTGCTGGAGGACCTGAATATGAGATTCAAGCAGATCAGGGGAGGAATCGAGCGGAGCGTGTACCAGCAGTTCGAGAAGGCCCTGATCGATAAGCTGGGCTATCTGGTGTTTAAGGACAACAGGGATCTGAGGGCACCAGGAGGCGTGCTGAATGGCTACCAGCTGTCTGCCCCCTTTGTGAGCTTCGAGAAGATGCGCAAGCAGACCGGCATCCTGTTCTACACACAGGCCGAGTATACCAGCAAGACAGACCCAATCACCGGCTTTCGGAAGAACGTGTATATCTCTAATAGCGCCTCCCTGGATAAGATCAAGGAGGCCGTGAAGAAGTTCGACGCCATCGGCTGGGATGGCAAGGAGCAGTCTTACTTCTTTAAGTACAACCCTTACAACCTGGCCGACGAGAAGTATAAGAACTCTACCGTGAGCAAGGAGTGGGCCATCTTTGCCAGCGCCCCAAGAATCCGGAGACAGAAGGGCGAGGACGGCTACTGGAAGTATGATAGGGTGAAAGTGAATGAGGAGTTCGAGAAGCTGCTGAAGGTCTGGAATTTTGTGAACCCAAAGGCCACAGATATCAAGCAGGAGATCATCAAGAAGGAGAAGGCAGGCGACCTGCAGGGAGAGAAGGAGCTGGATGGCCGGCTGAGAAACTTTTGGCACTCTTTCATCTACCTGTTTAACCTGGTGCTGGAGCTGCGCAATTCTTTCAGCCTGCAGATCAAGATCAAGGCAGGAGAAGTGATCGCAGTGGACGAGGGCGTGGACTTCATCGCCAGCCCAGTGAAGCCCTTCTTTACCACACCCAACCCTTACATCCCCTCCAACCTGTGCTGGCTGGCCGTGGAGAATGCAGACGCAAACGGAGCCTATAATATCGCCAGGAAGGGCGTGATGATCCTGAAGAAGATCCGCGAGCACGCCAAGAAGGACCCCGAGTTCAAGAAGCTGCCAAACCTGTTTATCAGCAATGCAGAGTGGGACGAGGCAGCCCGGGATTGGGGCAAGTACGCAGGCACCACAGCCCTGAACCTGGACCACAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 218).
7- Smithella sp. SC_K08D17 (SsCpf1)
ATGCAGACCCTGTTTGAGAACTTCACAAATCAGTACCCAGTGTCCAAGACCCTGCGCTTTGAGCTGATCCCCCAGGGCAAGACAAAGGACTTCATCGAGCAGAAGGGCCTGCTGAAGAAGGATGAGGACCGGGCCGAGAAGTATAAGAAGGTGAAGAACATCATCGATGAGTACCACAAGGACTTCATCGAGAAGTCTCTGAATGGCCTGAAGCTGGACGGCCTGGAGAAGTACAAGACCCTGTATCTGAAGCAGGAGAAGGACGATAAGGATAAGAAGGCCTTTGACAAGGAGAAGGAGAACCTGCGCAAGCAGATCGCCAATGCCTTCCGGAACAATGAGAAGTTTAAGACACTGTTCGCCAAGGAGCTGATCAAGAACGATCTGATGTCTTTCGCCTGCGAGGAGGACAAGAAGAATGTGAAGGAGTTTGAGGCCTTCACCACATACTTCACCGGCTTCCACCAGAACCGCGCCAATATGTACGTGGCCGATGAGAAGAGAACAGCCATCGCCAGCAGGCTGATCCACGAGAACCTGCCAAAGTTTATCGACAATATCAAGATCTTCGAGAAGATGAAGAAGGAGGCCCCCGAGCTGCTGTCTCCTTTCAACCAGACCCTGAAGGATATGAAGGACGTGATCAAGGGCACCACACTGGAGGAGATCTTTAGCCTGGATTATTTCAACAAGACCCTGACACAGAGCGGCATCGACATCTACAATTCCGTGATCGGCGGCAGAACCCCTGAGGAGGGCAAGACAAAGATCAAGGGCCTGAACGAGTACATCAATACCGACTTCAACCAGAAGCAGACAGACAAGAAGAAGCGGCAGCCAAAGTTCAAGCAGCTGTATAAGCAGATCCTGAGCGATAGGCAGAGCCTGTCCTTTATCGCCGAGGCCTTCAAGAACGACACCGAGATCCTGGAGGCCATCGAGAAGTTTTACGTGAATGAGCTGCTGCACTTCAGCAATGAGGGCAAGTCCACAAACGTGCTGGACGCCATCAAGAATGCCGTGTCTAACCTGGAGAGCTTTAACCTGACCAAGATGTATTTCCGCTCCGGCGCCTCTCTGACAGACGTGAGCCGGAAGGTGTTTGGCGAGTGGAGCATCATCAATAGAGCCCTGGACAACTACTATGCCACCACATATCCAATCAAGCCCAGAGAGAAGTCTGAGAAGTACGAGGAGAGGAAGGAGAAGTGGCTGAAGCAGGACTTCAACGTGAGCCTGATCCAGACCGCCATCGATGAGTACGACAACGAGACAGTGAAGGGCAAGAACAGCGGCAAAGTGATCGCCGATTATTTTGCCAAGTTCTGCGACGATAAGGAGACAGACCTGATCCAGAAGGTGAACGAGGGCTACATCGCCGTGAAGGATCTGCTGAATACACCCTGTCCTGAGAACGAGAAGCTGGGCAGCAATAAGGACCAGGTGAAGCAGATCAAGGCCTTTATGGATTCTATCATGGACATCATGCACTTCGTGCGCCCCCTGAGCCTGAAGGATACCGACAAGGAGAAGGATGAGACATTCTACTCCCTGTTCACACCTCTGTACGACCACCTGACCCAGACAATCGCCCTGTATAACAAGGTGCGGAACTATCTGACCCAGAAGCCTTACAGCACAGAGAAGATCAAGCTGAACTTCGAGAACAGCACCCTGCTGGGCGGCTGGGATCTGAATAAGGAGACAGACAACACAGCCATCATCCTGAGGAAGGATAACCTGTACTATCTGGGCATCATGGACAAGAGGCACAATCGCATCTTTCGGAACGTGCCCAAGGCCGATAAGAAGGACTTCTGCTACGAGAAGATGGTGTATAAGCTGCTGCCTGGCGCCAACAAGATGCTGCCAAAGGTGTTCTTTTCTCAGAGCAGAATCCAGGAGTTTACCCCTTCCGCCAAGCTGCTGGAGAACTACGCCAATGAGACACACAAGAAGGGCGATAATTTCAACCTGAATCACTGTCACAAGCTGATCGATTTCTTTAAGGACTCTATCAACAAGCACGAGGATTGGAAGAATTTCGACTTTAGGTTCAGCGCCACCTCCACCTACGCCGACCTGAGCGGCTTTTACCACGAGGTGGAGCACCAGGGCTACAAGATCTCTTTTCAGAGCGTGGCCGATTCCTTCATCGACGATCTGGTGAACGAGGGCAAGCTGTACCTGTTCCAGATCTATAATAAGGACTTTTCCCCATTCTCTAAGGGCAAGCCCAACCTGCACACCCTGTACTGGAAGATGCTGTTTGATGAGAACAATCTGAAGGACGTGGTGTATAAGCTGAATGGCGAGGCCGAGGTGTTCTACCGCAAGAAGAGCATTGCCGAGAAGAACACCACAATCCACAAGGCCAATGAGTCCATCATCAACAAGAATCCTGATAACCCAAAGGCCACCAGCACCTTCAACTATGATATCGTGAAGGACAAGAGATACACCATCGACAAGTTTCAGTTCCACATCCCAATCACAATGAACTTTAAGGCCGAGGGCATCTTCAACATGAATCAGAGGGTGAATCAGTTCCTGAAGGCCAATCCCGATATCAACATCATCGGCATCGACAGAGGCGAGAGGCACCTGCTGTACTATGCCCTGATCAACCAGAAGGGCAAGATCCTGAAGCAGGATACCCTGAATGTGATCGCCAACGAGAAGCAGAAGGTGGACTACCACAATCTGCTGGATAAGAAGGAGGGCGACCGCGCAACCGCAAGGCAGGAGTGGGGCGTGATCGAGACAATCAAGGAGCTGAAGGAGGGCTATCTGTCCCAGGTCATCCACAAGCTGACCGATCTGATGATCGAGAACAATGCCATCATCGTGATGGAGGACCTGAACTTTGGCTTCAAGCGGGGCAGACAGAAGGTGGAGAAGCAGGTGTATCAGAAGTTTGAGAAGATGCTGATCGATAAGCTGAATTACCTGGTGGACAAGAATAAGAAGGCAAACGAGCTGGGAGGCCTGCTGAACGCATTCCAGCTGGCCAATAAGTTTGAGTCCTTCCAGAAGATGGGCAAGCAGAACGGCTTTATCTTCTACGTGCCCGCCTGGAATACCTCTAAGACAGATCCTGCCACCGGCTTTATCGACTTCCTGAAGCCCCGCTATGAGAACCTGAATCAGGCCAAGGATTTCTTTGAGAAGTTTGACTCTATCCGGCTGAACAGCAAGGCCGATTACTTTGAGTTCGCCTTTGACTTCAAGAATTTCACCGAGAAGGCCGATGGCGGCAGAACCAAGTGGACAGTGTGCACCACAAACGAGGACAGATATGCCTGGAATAGGGCCCTGAACAATAACAGGGGCAGCCAGGAGAAGTACGACATCACAGCCGAGCTGAAGTCCCTGTTCGATGGCAAGGTGGACTATAAGTCTGGCAAGGATCTGAAGCAGCAGATCGCCAGCCAGGAGTCCGCCGACTTCTTTAAGGCCCTGATGAAGAACCTGTCCATCACCCTGTCTCTGAGACACAATAACGGCGAGAAGGGCGATAATGAGCAGGACTACATCCTGTCCCCTGTGGCCGATTCTAAGGGCCGCTTCTTTGACTCCCGGAAGGCCGACGATGACATGCCAAAGAATGCCGACGCCAACGGCGCCTATCACATCGCCCTGAAGGGCCTGTGGTGTCTGGAGCAGATCAGCAAGACCGATGACCTGAAGAAGGTGAAGCTGGCCATCTCCAACAAGGAGTGGCTGGAGTTCGTGCAGACACTGAAGGGCAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 219).
8- Acidaminococcus sp. BV3L6 (AsCpf1)
ATGACACAGTTCGAGGGCTTTACCAACCTGTATCAGGTGAGCAAGACACTGCGGTTTGAGCTGATCCCACAGGGCAAGACCCTGAAGCACATCCAGGAGCAGGGCTTCATCGAGGAGGACAAGGCCCGCAATGATCACTACAAGGAGCTGAAGCCCATCATCGATCGGATCTACAAGACCTATGCCGACCAGTGCCTGCAGCTGGTGCAGCTGGATTGGGAGAACCTGAGCGCCGCCATCGACTCCTATAGAAAGGAGAAAACCGAGGAGACAAGGAACGCCCTGATCGAGGAGCAGGCCACATATCGCAATGCCATCCACGACTACTTCATCGGCCGGACAGACAACCTGACCGATGCCATCAATAAGAGACACGCCGAGATCTACAAGGGCCTGTTCAAGGCCGAGCTGTTTAATGGCAAGGTGCTGAAGCAGCTGGGCACCGTGACCACAACCGAGCACGAGAACGCCCTGCTGCGGAGCTTCGACAAGTTTACAACCTACTTCTCCGGCTTTTATGAGAACAGGAAGAACGTGTTCAGCGCCGAGGATATCAGCACAGCCATCCCACACCGCATCGTGCAGGACAACTTCCCCAAGTTTAAGGAGAATTGTCACATCTTCACACGCCTGATCACCGCCGTGCCCAGCCTGCGGGAGCACTTTGAGAACGTGAAGAAGGCCATCGGCATCTTCGTGAGCACCTCCATCGAGGAGGTGTTTTCCTTCCCTTTTTATAACCAGCTGCTGACACAGACCCAGATCGACCTGTATAACCAGCTGCTGGGAGGAATCTCTCGGGAGGCAGGCACCGAGAAGATCAAGGGCCTGAACGAGGTGCTGAATCTGGCCATCCAGAAGAATGATGAGACAGCCCACATCATCGCCTCCCTGCCACACAGATTCATCCCCCTGTTTAAGCAGATCCTGTCCGATAGGAACACCCTGTCTTTCATCCTGGAGGAGTTTAAGAGCGACGAGGAAGTGATCCAGTCCTTCTGCAAGTACAAGACACTGCTGAGAAACGAGAACGTGCTGGAGACAGCCGAGGCCCTGTTTAACGAGCTGAACAGCATCGACCTGACACACATCTTCATCAGCCACAAGAAGCTGGAGACAATCAGCAGCGCCCTGTGCGACCACTGGGATACACTGAGGAATGCCCTGTATGAGCGGAGAATCTCCGAGCTGACAGGCAAGATCACCAAGTCTGCCAAGGAGAAGGTGCAGCGCAGCCTGAAGCACGAGGATATCAACCTGCAGGAGATCATCTCTGCCGCAGGCAAGGAGCTGAGCGAGGCCTTCAAGCAGAAAACCAGCGAGATCCTGTCCCACGCACACGCCGCCCTGGATCAGCCACTGCCTACAACCCTGAAGAAGCAGGAGGAGAAGGAGATCCTGAAGTCTCAGCTGGACAGCCTGCTGGGCCTGTACCACCTGCTGGACTGGTTTGCCGTGGATGAGTCCAACGAGGTGGACCCCGAGTTCTCTGCCCGGCTGACCGGCATCAAGCTGGAGATGGAGCCTTCTCTGAGCTTCTACAACAAGGCCAGAAATTATGCCACCAAGAAGCCCTACTCCGTGGAGAAGTTCAAGCTGAACTTTCAGATGCCTACACTGGCCTCTGGCTGGGACGTGAATAAGGAGAAGAACAATGGCGCCATCCTGTTTGTGAAGAACGGCCTGTACTATCTGGGCATCATGCCAAAGCAGAAGGGCAGGTATAAGGCCCTGAGCTTCGAGCCCACAGAGAAAACCAGCGAGGGCTTTGATAAGATGTACTATGACTACTTCCCTGATGCCGCCAAGATGATCCCAAAGTGCAGCACCCAGCTGAAGGCCGTGACAGCCCACTTTCAGACCCACACAACCCCCATCCTGCTGTCCAACAATTTCATCGAGCCTCTGGAGATCACAAAGGAGATCTACGACCTGAACAATCCTGAGAAGGAGCCAAAGAAGTTTCAGACAGCCTACGCCAAGAAAACCGGCGACCAGAAGGGCTACAGAGAGGCCCTGTGCAAGTGGATCGACTTCACAAGGGATTTTCTGTCCAAGTATACCAAGACAACCTCTATCGATCTGTCTAGCCTGCGGCCATCCTCTCAGTATAAGGACCTGGGCGAGTACTATGCCGAGCTGAATCCCCTGCTGTACCACATCAGCTTCCAGAGAATCGCCGAGAAGGAGATCATGGATGCCGTGGAGACAGGCAAGCTGTACCTGTTCCAGATCTATAACAAGGACTTTGCCAAGGGCCACCACGGCAAGCCTAATCTGCACACACTGTATTGGACCGGCCTGTTTTCTCCAGAGAACCTGGCCAAGACAAGCATCAAGCTGAATGGCCAGGCCGAGCTGTTCTACCGCCCTAAGTCCAGGATGAAGAGGATGGCACACCGGCTGGGAGAGAAGATGCTGAACAAGAAGCTGAAGGATCAGAAAACCCCAATCCCCGACACCCTGTACCAGGAGCTGTACGACTATGTGAATCACAGACTGTCCCACGACCTGTCTGATGAGGCCAGGGCCCTGCTGCCCAACGTGATCACCAAGGAGGTGTCTCACGAGATCATCAAGGATAGGCGCTTTACCAGCGACAAGTTCTTTTTCCACGTGCCTATCACACTGAACTATCAGGCCGCCAATTCCCCATCTAAGTTCAACCAGAGGGTGAATGCCTACCTGAAGGAGCACCCCGAGACACCTATCATCGGCATCGATCGGGGCGAGAGAAACCTGATCTATATCACAGTGATCGACTCCACCGGCAAGATCCTGGAGCAGCGGAGCCTGAACACCATCCAGCAGTTTGATTACCAGAAGAAGCTGGACAACAGGGAGAAGGAGAGGGTGGCAGCAAGGCAGGCCTGGTCTGTGGTGGGCACAATCAAGGATCTGAAGCAGGGCTATCTGAGCCAGGTCATCCACGAGATCGTGGACCTGATGATCCACTACCAGGCCGTGGTGGTGCTGGAGAACCTGAATTTCGGCTTTAAGAGCAAGAGGACCGGCATCGCCGAGAAGGCCGTGTACCAGCAGTTCGAGAAGATGCTGATCGATAAGCTGAATTGCCTGGTGCTGAAGGACTATCCAGCAGAGAAAGTGGGAGGCGTGCTGAACCCATACCAGCTGACAGACCAGTTCACCTCCTTTGCCAAGATGGGCACCCAGTCTGGCTTCCTGTTTTACGTGCCTGCCCCATATACATCTAAGATCGATCCCCTGACCGGCTTCGTGGACCCCTTCGTGTGGAAAACCATCAAGAATCACGAGAGCCGCAAGCACTTCCTGGAGGGCTTCGACTTTCTGCACTACGACGTGAAAACCGGCGACTTCATCCTGCACTTTAAGATGAACAGAAATCTGTCCTTCCAGAGGGGCCTGCCCGGCTTTATGCCTGCATGGGATATCGTGTTCGAGAAGAACGAGACACAGTTTGACGCCAAGGGCACCCCTTTCATCGCCGGCAAGAGAATCGTGCCAGTGATCGAGAATCACAGATTCACCGGCAGATACCGGGACCTGTATCCTGCCAACGAGCTGATCGCCCTGCTGGAGGAGAAGGGCATCGTGTTCAGGGATGGCTCCAACATCCTGCCAAAGCTGCTGGAGAATGACGATTCTCACGCCATCGACACCATGGTGGCCCTGATCCGCAGCGTGCTGCAGATGCGGAACTCCAATGCCGCCACAGGCGAGGACTATATCAACAGCCCCGTGCGCGATCTGAATGGCGTGTGCTTCGACTCCCGGTTTCAGAACCCAGAGTGGCCCATGGACGCCGATGCCAATGGCGCCTACCACATCGCCCTGAAGGGCCAGCTGCTGCTGAATCACCTGAAGGAGAGCAAGGATCTGAAGCTGCAGAACGGCATCTCCAATCAGGACTGGCTGGCCTACATCCAGGAGCTGCGCAACAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 220).
9- Lachnospiraceae bacterium MA2020 (Lb2Cpf1)
ATGTACTATGAGTCCCTGACCAAGCAGTACCCCGTGTCTAAGACAATCCGGAATGAGCTGATCCCTATCGGCAAGACACTGGATAACATCCGCCAGAACAATATCCTGGAGAGCGACGTGAAGCGGAAGCAGAACTACGAGCACGTGAAGGGCATCCTGGATGAGTATCACAAGCAGCTGATCAACGAGGCCCTGGACAATTGCACCCTGCCATCCCTGAAGATCGCCGCCGAGATCTACCTGAAGAATCAGAAGGAGGTGTCTGACAGAGAGGATTTCAACAAGACACAGGACCTGCTGAGGAAGGAGGTGGTGGAGAAGCTGAAGGCCCACGAGAACTTTACCAAGATCGGCAAGAAGGACATCCTGGATCTGCTGGAGAAGCTGCCTTCCATCTCTGAGGACGATTACAATGCCCTGGAGAGCTTCCGCAACTTTTACACCTATTTCACATCCTACAACAAGGTGCGGGAGAATCTGTATTCTGATAAGGAGAAGAGCTCCACAGTGGCCTACAGACTGATCAACGAGAATTTCCCAAAGTTTCTGGACAATGTGAAGAGCTATAGGTTTGTGAAAACCGCAGGCATCCTGGCAGATGGCCTGGGAGAGGAGGAGCAGGACTCCCTGTTCATCGTGGAGACATTCAACAAGACCCTGACACAGGACGGCATCGATACCTACAATTCTCAAGTGGGCAAGATCAACTCTAGCATCAATCTGTATAACCAGAAGAATCAGAAGGCCAATGGCTTCAGAAAGATCCCCAAGATGAAGATGCTGTATAAGCAGATCCTGTCCGATAGGGAGGAGTCTTTCATCGACGAGTTTCAGAGCGATGAGGTGCTGATCGACAACGTGGAGTCTTATGGCAGCGTGCTGATCGAGTCTCTGAAGTCCTCTAAGGTGAGCGCCTTCTTTGATGCCCTGAGAGAGTCTAAGGGCAAGAACGTGTACGTGAAGAATGACCTGGCCAAGACAGCCATGAGCAACATCGTGTTCGAGAATTGGAGGACCTTTGACGATCTGCTGAACCAGGAGTACGACCTGGCCAACGAGAACAAGAAGAAGGACGATAAGTATTTCGAGAAGCGCCAGAAGGAGCTGAAGAAGAATAAGAGCTACTCCCTGGAGCACCTGTGCAACCTGTCCGAGGATTCTTGTAACCTGATCGAGAATTATATCCACCAGATCTCCGACGATATCGAGAATATCATCATCAACAATGAGACATTCCTGCGCATCGTGATCAATGAGCACGACAGGTCCCGCAAGCTGGCCAAGAACCGGAAGGCCGTGAAGGCCATCAAGGACTTTCTGGATTCTATCAAGGTGCTGGAGCGGGAGCTGAAGCTGATCAACAGCTCCGGCCAGGAGCTGGAGAAGGATCTGATCGTGTACTCTGCCCACGAGGAGCTGCTGGTGGAGCTGAAGCAGGTGGACAGCCTGTATAACATGACCAGAAATTATCTGACAAAGAAGCCTTTCTCTACCGAGAAGGTGAAGCTGAACTTTAATCGCAGCACACTGCTGAACGGCTGGGATCGGAATAAGGAGACAGACAACCTGGGCGTGCTGCTGCTGAAGGACGGCAAGTACTATCTGGGCATCATGAACACAAGCGCCAATAAGGCCTTCGTGAATCCCCCTGTGGCCAAGACCGAGAAGGTGTTTAAGAAGGTGGATTACAAGCTGCTGCCAGTGCCCAACCAGATGCTGCCAAAGGTGTTCTTTGCCAAGAGCAATATCGACTTCTATAACCCCTCTAGCGAGATCTACTCCAATTATAAGAAGGGCACCCACAAGAAGGGCAATATGTTTTCCCTGGAGGATTGTCACAACCTGATCGACTTCTTTAAGGAGTCTATCAGCAAGCACGAGGACTGGAGCAAGTTCGGCTTTAAGTTCAGCGATACAGCCTCCTACAACGACATCTCCGAGTTCTATCGCGAGGTGGAGAAGCAGGGCTACAAGCTGACCTATACAGACATCGATGAGACATACATCAATGATCTGATCGAGCGGAACGAGCTGTACCTGTTCCAGATCTATAATAAGGACTTTAGCATGTACTCCAAGGGCAAGCTGAACCTGCACACACTGTATTTCATGATGCTGTTTGATCAGCGCAATATCGACGACGTGGTGTATAAGCTGAACGGAGAGGCAGAGGTGTTCTATAGGCCAGCCTCCATCTCTGAGGACGAGCTGATCATCCACAAGGCCGGCGAGGAGATCAAGAACAAGAATCCTAACCGGGCCAGAACCAAGGAGACAAGCACCTTCAGCTACGACATCGTGAAGGATAAGCGGTATAGCAAGGATAAGTTTACCCTGCACATCCCCATCACAATGAACTTCGGCGTGGATGAGGTGAAGCGGTTCAACGACGCCGTGAACAGCGCCATCCGGATCGATGAGAATGTGAACGTGATCGGCATCGACCGGGGCGAGAGAAATCTGCTGTACGTGGTGGTCATCGACTCTAAGGGCAACATCCTGGAGCAGATCTCCCTGAACTCTATCATCAATAAGGAGTACGACATCGAGACAGATTATCACGCACTGCTGGATGAGAGGGAGGGCGGCAGAGATAAGGCCCGGAAGGACTGGAACACCGTGGAGAATATCAGGGACCTGAAGGCCGGCTACCTGAGCCAGGTGGTGAACGTGGTGGCCAAGCTGGTGCTGAAGTATAATGCCATCATCTGCCTGGAGGACCTGAACTTTGGCTTCAAGAGGGGCCGCCAGAAGGTGGAGAAGCAGGTGTACCAGAAGTTCGAGAAGATGCTGATCGATAAGCTGAATTACCTGGTCATCGACAAGAGCCGCGAGCAGACATCCCCTAAGGAGCTGGGAGGCGCCCTGAACGCACTGCAGCTGACCTCTAAGTTCAAGAGCTTTAAGGAGCTGGGCAAGCAGTCCGGCGTGATCTACTATGTGCCTGCCTACCTGACCTCTAAGATCGATCCAACCACAGGCTTCGCCAATCTGTTTTATATGAAGTGTGAGAACGTGGAGAAGTCCAAGAGATTCTTTGACGGCTTTGATTTCATCAGGTTCAACGCCCTGGAGAACGTGTTCGAGTTCGGCTTTGACTACCGGAGCTTCACCCAGAGGGCCTGCGGCATCAATTCCAAGTGGACCGTGTGCACCAACGGCGAGCGCATCATCAAGTATCGGAATCCAGATAAGAACAATATGTTCGACGAGAAGGTGGTGGTGGTGACCGATGAGATGAAGAACCTGTTTGAGCAGTACAAGATCCCCTATGAGGATGGCAGAAATGTGAAGGACATGATCATCAGCAACGAGGAGGCCGAGTTCTACCGGAGACTGTATAGGCTGCTGCAGCAGACCCTGCAGATGAGAAACAGCACCTCCGACGGCACAAGGGATTACATCATCTCCCCTGTGAAGAATAAGAGAGAGGCCTACTTCAACAGCGAGCTGTCCGACGGCTCTGTGCCAAAGGACGCCGATGCCAACGGCGCCTACAATATCGCCAGAAAGGGCCTGTGGGTGCTGGAGCAGATCAGGCAGAAGAGCGAGGGCGAGAAGATCAATCTGGCCATGACCAACGCCGAGTGGCTGGAGTATGCCCAGACACACCTGCTGAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 221).
10- Candidatus Methanoplasma termitum (CMtCpf1)
ATGAACAATTACGACGAGTTCACCAAGCTGTATCCTATCCAGAAAACCATCCGGTTTGAGCTGAAGCCACAGGGCAGAACCATGGAGCACCTGGAGACATTCAACTTCTTTGAGGAGGACCGGGATAGAGCCGAGAAGTATAAGATCCTGAAGGAGGCCATCGACGAGTACCACAAGAAGTTTATCGATGAGCACCTGACCAATATGTCCCTGGATTGGAACTCTCTGAAGCAGATCAGCGAGAAGTACTATAAGAGCAGGGAGGAGAAGGACAAGAAGGTGTTCCTGTCCGAGCAGAAGAGGATGCGCCAGGAGATCGTGTCTGAGTTTAAGAAGGACGATCGCTTCAAGGACCTGTTTTCCAAGAAGCTGTTCTCTGAGCTGCTGAAGGAGGAGATCTACAAGAAGGGCAACCACCAGGAGATCGACGCCCTGAAGAGCTTCGATAAGTTTTCCGGCTATTTCATCGGCCTGCACGAGAATAGGAAGAACATGTACTCCGACGGCGATGAGATCACCGCCATCTCCAATCGCATCGTGAATGAGAACTTCCCCAAGTTTCTGGATAACCTGCAGAAGTACCAGGAGGCCAGGAAGAAGTATCCTGAGTGGATCATCAAGGCCGAGAGCGCCCTGGTGGCCCACAATATCAAGATGGACGAGGTGTTCTCCCTGGAGTACTTTAATAAGGTGCTGAACCAGGAGGGCATCCAGCGGTACAACCTGGCCCTGGGCGGCTATGTGACCAAGAGCGGCGAGAAGATGATGGGCCTGAATGATGCCCTGAACCTGGCCCACCAGTCCGAGAAGAGCTCCAAGGGCAGAATCCACATGACCCCCCTGTTCAAGCAGATCCTGTCCGAGAAGGAGTCCTTCTCTTACATCCCCGACGTGTTTACAGAGGATTCTCAGCTGCTGCCTAGCATCGGCGGCTTCTTTGCCCAGATCGAGAATGACAAGGATGGCAACATCTTCGACCGGGCCCTGGAGCTGATCTCTAGCTACGCCGAGTATGATACCGAGCGGATCTATATCAGACAGGCCGACATCAATAGAGTGTCCAACGTGATCTTTGGAGAGTGGGGCACCCTGGGAGGCCTGATGAGGGAGTACAAGGCCGACTCTATCAATGATATCAACCTGGAGCGCACATGCAAGAAGGTGGACAAGTGGCTGGATTCTAAGGAGTTTGCCCTGAGCGATGTGCTGGAGGCCATCAAGAGGACCGGCAACAATGACGCCTTCAACGAGTATATCTCCAAGATGCGGACAGCCAGAGAGAAGATCGATGCCGCCCGCAAGGAGATGAAGTTCATCAGCGAGAAGATCTCCGGCGATGAGGAGTCTATCCACATCATCAAGACCCTGCTGGACAGCGTGCAGCAGTTCCTGCACTTCTTTAATCTGTTTAAGGCAAGGCAGGACATCCCACTGGATGGAGCCTTCTACGCCGAGTTTGACGAGGTGCACAGCAAGCTGTTTGCCATCGTGCCCCTGTATAACAAGGTGCGGAACTATCTGACCAAGAACAATCTGAACACAAAGAAGATCAAGCTGAATTTCAAGAACCCTACACTGGCCAATGGCTGGGACCAGAACAAGGTGTACGATTATGCCTCCCTGATCTTTCTGCGGGACGGCAATTACTATCTGGGCATCATCAATCCTAAGAGAAAGAAGAACATCAAGTTCGAGCAGGGCTCTGGCAACGGCCCCTTCTACCGGAAGATGGTGTATAAGCAGATCCCCGGCCCTAATAAGAACCTGCCAAGAGTGTTCCTGACCTCCACAAAGGGCAAGAAGGAGTATAAGCCCTCTAAGGAGATCATCGAGGGCTACGAGGCCGACAAGCACATCAGGGGCGATAAGTTCGACCTGGATTTTTGTCACAAGCTGATCGATTTCTTTAAGGAGTCCATCGAGAAGCACAAGGACTGGTCTAAGTTCAACTTCTACTTCAGCCCAACCGAGAGCTATGGCGACATCTCTGAGTTCTACCTGGATGTGGAGAAGCAGGGCTATCGCATGCACTTTGAGAATATCAGCGCCGAGACAATCGACGAGTATGTGGAGAAGGGCGATCTGTTTCTGTTCCAGATCTACAACAAGGATTTTGTGAAGGCCGCCACCGGCAAGAAGGACATGCACACAATCTACTGGAATGCCGCCTTCAGCCCCGAGAACCTGCAGGACGTGGTGGTGAAGCTGAACGGCGAGGCCGAGCTGTTTTATAGGGACAAGTCCGATATCAAGGAGATCGTGCACCGCGAGGGCGAGATCCTGGTGAATAGGACCTACAACGGCCGCACACCAGTGCCCGACAAGATCCACAAGAAGCTGACCGATTATCACAATGGCCGGACAAAGGACCTGGGCGAGGCCAAGGAGTACCTGGATAAGGTGAGATACTTCAAGGCCCACTATGACATCACCAAGGATCGGAGATACCTGAACGACAAGATCTATTTCCACGTGCCTCTGACCCTGAACTTCAAGGCCAACGGCAAGAAGAATCTGAACAAGATGGTCATCGAGAAGTTCCTGTCCGATGAGAAGGCCCACATCATCGGCATCGACAGGGGCGAGCGCAATCTGCTGTACTATTCCATCATCGACAGGTCTGGCAAGATCATCGATCAGCAGAGCCTGAATGTGATCGACGGCTTTGATTATCGGGAGAAGCTGAACCAGAGAGAGATCGAGATGAAGGATGCCCGCCAGTCTTGGAACGCCATCGGCAAGATCAAGGACCTGAAGGAGGGCTACCTGAGCAAGGCCGTGCACGAGATCACCAAGATGGCCATCCAGTATAATGCCATCGTGGTCATGGAGGAGCTGAACTACGGCTTCAAGCGGGGCCGGTTCAAGGTGGAGAAGCAGATCTATCAGAAGTTCGAGAATATGCTGATCGATAAGATGAACTACCTGGTGTTTAAGGACGCACCTGATGAGTCCCCAGGAGGCGTGCTGAATGCCTACCAGCTGACAAACCCACTGGAGTCTTTCGCCAAGCTGGGCAAGCAGACCGGCATCCTGTTTTACGTGCCAGCCGCCTATACATCCAAGATCGACCCCACCACAGGCTTCGTGAATCTGTTTAACACCTCCTCTAAGACAAACGCCCAGGAGCGGAAGGAGTTCCTGCAGAAGTTTGAGAGCATCTCCTATTCTGCCAAGGATGGCGGCATCTTTGCCTTCGCCTTTGACTACAGAAAGTTCGGCACCAGCAAGACAGATCACAAGAACGTGTGGACCGCCTATACAAACGGCGAGAGGATGCGCTACATCAAGGAGAAGAAGCGGAATGAGCTGTTTGACCCTTCTAAGGAGATCAAGGAGGCCCTGACCAGCTCCGGCATCAAGTACGATGGCGGCCAGAACATCCTGCCAGACATCCTGAGGAGCAACAATAACGGCCTGATCTACACAATGTATTCTAGCTTCATCGCCGCCATCCAGATGCGCGTGTACGACGGCAAGGAGGATTATATCATCAGCCCCATCAAGAACTCCAAGGGCGAGTTCTTTAGGACCGACCCCAAGAGGCGCGAGCTGCCTATCGACGCCGATGCCAATGGCGCCTACAACATCGCCCTGAGGGGAGAGCTGACAATGAGGGCAATCGCAGAGAAGTTCGACCCTGATAGCGAGAAGATGGCCAAGCTGGAGCTGAAGCACAAGGATTGGTTCGAGTTTATGCAGACCAGAGGCGACAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 222).
11- Eubacterium eligens (EeCpf1)
ATGAACGGCAATAGGTCCATCGTGTACCGCGAGTTCGTGGGCGTGATCCCCGTGGCCAAGACCCTGAGGAATGAGCTGCGCCCTGTGGGCCACACACAGGAGCACATCATCCAGAACGGCCTGATCCAGGAGGACGAGCTGCGGCAGGAGAAGAGCACCGAGCTGAAGAACATCATGGACGATTACTATAGAGAGTACATCGATAAGTCTCTGAGCGGCGTGACCGACCTGGACTTCACCCTGCTGTTCGAGCTGATGAACCTGGTGCAGAGCTCCCCCTCCAAGGACAATAAGAAGGCCCTGGAGAAGGAGCAGTCTAAGATGAGGGAGCAGATCTGCACCCACCTGCAGTCCGACTCTAACTACAAGAATATCTTTAACGCCAAGCTGCTGAAGGAGATCCTGCCTGATTTCATCAAGAACTACAATCAGTATGACGTGAAGGATAAGGCCGGCAAGCTGGAGACACTGGCCCTGTTTAATGGCTTCAGCACATACTTTACCGACTTCTTTGAGAAGAGGAAGAACGTGTTCACCAAGGAGGCCGTGAGCACATCCATCGCCTACCGCATCGTGCACGAGAACTCCCTGATCTTCCTGGCCAATATGACCTCTTATAAGAAGATCAGCGAGAAGGCCCTGGATGAGATCGAAGTGATCGAGAAGAACAATCAGGACAAGATGGGCGATTGGGAGCTGAATCAGATCTTTAACCCTGACTTCTACAATATGGTGCTGATCCAGTCCGGCATCGACTTCTACAACGAGATCTGCGGCGTGGTGAATGCCCACATGAACCTGTACTGTCAGCAGACCAAGAACAATTATAACCTGTTCAAGATGCGGAAGCTGCACAAGCAGATCCTGGCCTACACCAGCACCAGCTTCGAGGTGCCCAAGATGTTCGAGGACGATATGAGCGTGTATAACGCCGTGAACGCCTTCATCGACGAGACAGAGAAGGGCAACATCATCGGCAAGCTGAAGGATATCGTGAATAAGTACGACGAGCTGGATGAGAAGAGAATCTATATCAGCAAGGACTTTTACGAGACACTGAGCTGCTTCATGTCCGGCAACTGGAATCTGATCACAGGCTGCGTGGAGAACTTCTACGATGAGAACATCCACGCCAAGGGCAAGTCCAAGGAGGAGAAGGTGAAGAAGGCCGTGAAGGAGGACAAGTACAAGTCTATCAATGACGTGAACGATCTGGTGGAGAAGTATATCGATGAGAAGGAGAGGAATGAGTTCAAGAACAGCAATGCCAAGCAGTACATCCGCGAGATCTCCAACATCATCACCGACACAGAGACAGCCCACCTGGAGTATGACGATCACATCTCTCTGATCGAGAGCGAGGAGAAGGCCGACGAGATGAAGAAGCGGCTGGATATGTATATGAACATGTACCACTGGGCCAAGGCCTTTATCGTGGACGAGGTGCTGGACAGAGATGAGATGTTCTACAGCGATATCGACGATATCTATAATATCCTGGAGAACATCGTGCCACTGTATAATCGGGTGAGAAACTACGTGACCCAGAAGCCCTACAACTCTAAGAAGATCAAGCTGAATTTCCAGAGCCCTACACTGGCCAATGGCTGGTCCCAGTCTAAGGAGTTCGACAACAATGCCATCATCCTGATCAGAGATAACAAGTACTATCTGGCCATCTTCAATGCCAAGAACAAGCCAGACAAGAAGATCATCCAGGGCAACTCCGATAAGAAGAACGACAACGATTACAAGAAGATGGTGTATAACCTGCTGCCAGGCGCCAACAAGATGCTGCCCAAGGTGTTTCTGTCTAAGAAGGGCATCGAGACATTCAAGCCCTCCGACTATATCATCTCTGGCTACAACGCCCACAAGCACATCAAGACAAGCGAGAATTTTGATATCTCCTTCTGTCGGGACCTGATCGATTACTTCAAGAACAGCATCGAGAAGCACGCCGAGTGGAGAAAGTATGAGTTCAAGTTTTCCGCCACCGACAGCTACTCCGATATCTCTGAGTTCTATCGGGAGGTGGAGATGCAGGGCTACAGAATCGACTGGACATATATCAGCGAGGCCGACATCAACAAGCTGGATGAGGAGGGCAAGATCTATCTGTTTCAGATCTACAATAAGGATTTCGCCGAGAACAGCACCGGCAAGGAGAATCTGCACACAATGTACTTTAAGAACATCTTCTCCGAGGAGAATCTGAAGGACATCATCATCAAGCTGAACGGCCAGGCCGAGCTGTTTTATCGGAGAGCCTCTGTGAAGAATCCCGTGAAGCACAAGAAGGATAGCGTGCTGGTGAACAAGACCTACAAGAATCAGCTGGACAACGGCGACGTGGTGAGAATCCCCATCCCTGACGATATCTATAACGAGATCTACAAGATGTATAATGGCTACATCAAGGAGTCCGACCTGTCTGAGGCCGCCAAGGAGTACCTGGATAAGGTGGAGGTGAGGACCGCCCAGAAGGACATCGTGAAGGATTACCGCTATACAGTGGACAAGTACTTCATCCACACACCTATCACCATCAACTATAAGGTGACCGCCCGCAACAATGTGAATGATATGGTGGTGAAGTACATCGCCCAGAACGACGATATCCACGTGATCGGCATCGACCGGGGCGAGAGAAACCTGATCTACATCTCCGTGATCGATTCTCACGGCAACATCGTGAAGCAGAAATCCTACAACATCCTGAACAACTACGACTACAAGAAGAAGCTGGTGGAGAAGGAGAAAACCCGGGAGTACGCCAGAAAGAACTGGAAGAGCATCGGCAATATCAAGGAGCTGAAGGAGGGCTATATCTCCGGCGTGGTGCACGAGATCGCCATGCTGATCGTGGAGTACAACGCCATCATCGCCATGGAGGACCTGAATTATGGCTTTAAGAGGGGCCGCTTCAAGGTGGAGCGGCAGGTGTACCAGAAGTTTGAGAGCATGCTGATCAATAAGCTGAACTATTTCGCCAGCAAGGAGAAGTCCGTGGACGAGCCAGGAGGCCTGCTGAAGGGCTATCAGCTGACCTACGTGCCCGATAATATCAAGAACCTGGGCAAGCAGTGCGGCGTGATCTTTTACGTGCCTGCCGCCTTCACCAGCAAGATCGACCCATCCACAGGCTTTATCTCTGCCTTCAACTTTAAGTCTATCAGCACAAATGCCTCTCGGAAGCAGTTCTTTATGCAGTTTGACGAGATCAGATACTGTGCCGAGAAGGATATGTTCAGCTTTGGCTTCGACTACAACAACTTCGATACCTACAACATCACAATGGGCAAGACACAGTGGACCGTGTATACAAACGGCGAGAGACTGCAGTCTGAGTTCAACAATGCCAGGCGCACCGGCAAGACAAAGAGCATCAATCTGACAGAGACAATCAAGCTGCTGCTGGAGGACAATGAGATCAACTACGCCGACGGCCACGATATCAGGATCGATATGGAGAAGATGGACGAGGATAAGAAGAGCGAGTTCTTTGCCCAGCTGCTGAGCCTGTATAAGCTGACCGTGCAGATGCGCAATTCCTATACAGAGGCCGAGGAGCAGGAGAACGGCATCTCTTACGACAAGATCATCAGCCCTGTGATCAATGATGAGGGCGAGTTCTTTGACTCCGATAACTATAAGGAGTCTGACGATAAGGAGTGCAAGATGCCAAAGGACGCCGATGCCAACGGCGCCTACTGTATCGCCCTGAAGGGCCTGTATGAGGTGCTGAAGATCAAGAGCGAGTGGACCGAGGACGGCTTTGATAGGAATTGCCTGAAGCTGCCACACGCAGAGTGGCTGGACTTCATCCAGAACAAGCGGTACGAGAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 223).
12- Moraxella bovoculi 237 (MbCpf1)
ATGCTGTTCCAGGACTTTACCCACCTGTATCCACTGTCCAAGACAGTGAGATTTGAGCTGAAGCCCATCGATAGGACCCTGGAGCACATCCACGCCAAGAACTTCCTGTCTCAGGACGAGACAATGGCCGATATGCACCAGAAGGTGAAAGTGATCCTGGACGATTACCACCGCGACTTCATCGCCGATATGATGGGCGAGGTGAAGCTGACCAAGCTGGCCGAGTTCTATGACGTGTACCTGAAGTTTCGGAAGAACCCAAAGGACGATGAGCTGCAGAAGCAGCTGAAGGATCTGCAGGCCGTGCTGAGAAAGGAGATCGTGAAGCCCATCGGCAATGGCGGCAAGTATAAGGCCGGCTACGACAGGCTGTTCGGCGCCAAGCTGTTTAAGGACGGCAAGGAGCTGGGCGATCTGGCCAAGTTCGTGATCGCACAGGAGGGAGAGAGCTCCCCAAAGCTGGCCCACCTGGCCCACTTCGAGAAGTTTTCCACCTATTTCACAGGCTTTCACGATAACCGGAAGAATATGTATTCTGACGAGGATAAGCACACCGCCATCGCCTACCGCCTGATCCACGAGAACCTGCCCCGGTTTATCGACAATCTGCAGATCCTGACCACAATCAAGCAGAAGCACTCTGCCCTGTACGATCAGATCATCAACGAGCTGACCGCCAGCGGCCTGGACGTGTCTCTGGCCAGCCACCTGGATGGCTATCACAAGCTGCTGACACAGGAGGGCATCACCGCCTACAATACACTGCTGGGAGGAATCTCCGGAGAGGCAGGCTCTCCTAAGATCCAGGGCATCAACGAGCTGATCAATTCTCACCACAACCAGCACTGCCACAAGAGCGAGAGAATCGCCAAGCTGAGGCCACTGCACAAGCAGATCCTGTCCGACGGCATGAGCGTGTCCTTCCTGCCCTCTAAGTTTGCCGACGATAGCGAGATGTGCCAGGCCGTGAACGAGTTCTATCGCCACTACGCCGACGTGTTCGCCAAGGTGCAGAGCCTGTTCGACGGCTTTGACGATCACCAGAAGGATGGCATCTACGTGGAGCACAAGAACCTGAATGAGCTGTCCAAGCAGGCCTTCGGCGACTTTGCACTGCTGGGACGCGTGCTGGACGGATACTATGTGGATGTGGTGAATCCAGAGTTCAACGAGCGGTTTGCCAAGGCCAAGACCGACAATGCCAAGGCCAAGCTGACAAAGGAGAAGGATAAGTTCATCAAGGGCGTGCACTCCCTGGCCTCTCTGGAGCAGGCCATCGAGCACTATACCGCAAGGCACGACGATGAGAGCGTGCAGGCAGGCAAGCTGGGACAGTACTTCAAGCACGGCCTGGCCGGAGTGGACAACCCCATCCAGAAGATCCACAACAATCACAGCACCATCAAGGGCTTTCTGGAGAGGGAGCGCCCTGCAGGAGAGAGAGCCCTGCCAAAGATCAAGTCCGGCAAGAATCCTGAGATGACACAGCTGAGGCAGCTGAAGGAGCTGCTGGATAACGCCCTGAATGTGGCCCACTTCGCCAAGCTGCTGACCACAAAGACCACACTGGACAATCAGGATGGCAACTTCTATGGCGAGTTTGGCGTGCTGTACGACGAGCTGGCCAAGATCCCCACCCTGTATAACAAGGTGAGAGATTACCTGAGCCAGAAGCCTTTCTCCACCGAGAAGTACAAGCTGAACTTTGGCAATCCAACACTGCTGAATGGCTGGGACCTGAACAAGGAGAAGGATAATTTCGGCGTGATCCTGCAGAAGGACGGCTGCTACTATCTGGCCCTGCTGGACAAGGCCCACAAGAAGGTGTTTGATAACGCCCCTAATACAGGCAAGAGCATCTATCAGAAGATGATCTATAAGTACCTGGAGGTGAGGAAGCAGTTCCCCAAGGTGTTCTTTTCCAAGGAGGCCATCGCCATCAACTACCACCCTTCTAAGGAGCTGGTGGAGATCAAGGACAAGGGCCGGCAGAGATCCGACGATGAGCGCCTGAAGCTGTATCGGTTTATCCTGGAGTGTCTGAAGATCCACCCTAAGTACGATAAGAAGTTCGAGGGCGCCATCGGCGACATCCAGCTGTTTAAGAAGGATAAGAAGGGCAGAGAGGTGCCAATCAGCGAGAAGGACCTGTTCGATAAGATCAACGGCATCTTTTCTAGCAAGCCTAAGCTGGAGATGGAGGACTTCTTTATCGGCGAGTTCAAGAGGTATAACCCAAGCCAGGACCTGGTGGATCAGTATAATATCTACAAGAAGATCGACTCCAACGATAATCGCAAGAAGGAGAATTTCTACAACAATCACCCCAAGTTTAAGAAGGATCTGGTGCGGTACTATTACGAGTCTATGTGCAAGCACGAGGAGTGGGAGGAGAGCTTCGAGTTTTCCAAGAAGCTGCAGGACATCGGCTGTTACGTGGATGTGAACGAGCTGTTTACCGAGATCGAGACACGGAGACTGAATTATAAGATCTCCTTCTGCAACATCAATGCCGACTACATCGATGAGCTGGTGGAGCAGGGCCAGCTGTATCTGTTCCAGATCTACAACAAGGACTTTTCCCCAAAGGCCCACGGCAAGCCCAATCTGCACACCCTGTACTTCAAGGCCCTGTTTTCTGAGGACAACCTGGCCGATCCTATCTATAAGCTGAATGGCGAGGCCCAGATCTTCTACAGAAAGGCCTCCCTGGACATGAACGAGACAACAATCCACAGGGCCGGCGAGGTGCTGGAGAACAAGAATCCCGATAATCCTAAGAAGAGACAGTTCGTGTACGACATCATCAAGGATAAGAGGTACACACAGGACAAGTTCATGCTGCACGTGCCAATCACCATGAACTTTGGCGTGCAGGGCATGACAATCAAGGAGTTCAATAAGAAGGTGAACCAGTCTATCCAGCAGTATGACGAGGTGAACGTGATCGGCATCGATCGGGGCGAGAGACACCTGCTGTACCTGACCGTGATCAATAGCAAGGGCGAGATCCTGGAGCAGTGTTCCCTGAACGACATCACCACAGCCTCTGCCAATGGCACACAGATGACCACACCTTACCACAAGATCCTGGATAAGAGGGAGATCGAGCGCCTGAACGCCCGGGTGGGATGGGGCGAGATCGAGACAATCAAGGAGCTGAAGTCTGGCTATCTGAGCCACGTGGTGCACCAGATCAGCCAGCTGATGCTGAAGTACAACGCCATCGTGGTGCTGGAGGACCTGAATTTCGGCTTTAAGAGGGGCCGCTTTAAGGTGGAGAAGCAGATCTATCAGAACTTCGAGAATGCCCTGATCAAGAAGCTGAACCACCTGGTGCTGAAGGACAAGGCCGACGATGAGATCGGCTCTTACAAGAATGCCCTGCAGCTGACCAACAATTTCACAGATCTGAAGAGCATCGGCAAGCAGACCGGCTTCCTGTTTTATGTGCCCGCCTGGAACACCTCTAAGATCGACCCTGAGACAGGCTTTGTGGATCTGCTGAAGCCAAGATACGAGAACATCGCCCAGAGCCAGGCCTTCTTTGGCAAGTTCGACAAGATCTGCTATAATGCCGACAAGGATTACTTCGAGTTTCACATCGACTACGCCAAGTTTACCGATAAGGCCAAGAATAGCCGCCAGATCTGGACAATCTGTTCCCACGGCGACAAGCGGTACGTGTACGATAAGACAGCCAACCAGAATAAGGGCGCCGCCAAGGGCATCAACGTGAATGATGAGCTGAAGTCCCTGTTCGCCCGCCACCACATCAACGAGAAGCAGCCCAACCTGGTCATGGACATCTGCCAGAACAATGATAAGGAGTTTCACAAGTCTCTGATGTACCTGCTGAAAACCCTGCTGGCCCTGCGGTACAGCAACGCCTCCTCTGACGAGGATTTCATCCTGTCCCCCGTGGCAAACGACGAGGGCGTGTTCTTTAATAGCGCCCTGGCCGACGATACACAGCCTCAGAATGCCGATGCCAACGGCGCCTACCACATCGCCCTGAAGGGCCTGTGGCTGCTGAATGAGCTGAAGAACTCCGACGATCTGAACAAGGTGAAGCTGGCCATCGACAATCAGACCTGGCTGAATTTCGCCCAGAACAGGAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 224).
13- Leptospira inadai (LiCpf1)
ATGGAGGACTATTCCGGCTTTGTGAACATCTACTCTATCCAGAAAACCCTGAGGTTCGAGCTGAAGCCAGTGGGCAAGACACTGGAGCACATCGAGAAGAAGGGCTTCCTGAAGAAGGACAAGATCCGGGCCGAGGATTACAAGGCCGTGAAGAAGATCATCGATAAGTACCACAGAGCCTATATCGAGGAGGTGTTTGATTCCGTGCTGCACCAGAAGAAGAAGAAGGACAAGACCCGCTTTTCTACACAGTTCATCAAGGAGATCAAGGAGTTCAGCGAGCTGTACTATAAGACCGAGAAGAACATCCCCGACAAGGAGAGGCTGGAGGCCCTGAGCGAGAAGCTGCGCAAGATGCTGGTGGGCGCCTTTAAGGGCGAGTTCTCCGAGGAGGTGGCCGAGAAGTATAAGAACCTGTTTTCTAAGGAGCTGATCAGGAATGAGATCGAGAAGTTCTGCGAGACAGACGAGGAGCGCAAGCAGGTGTCTAACTTCAAGAGCTTCACCACATACTTTACCGGCTTCCACTCCAACAGGCAGAATATCTATTCCGACGAGAAGAAGTCTACAGCCATCGGCTACCGCATCATCCACCAGAACCTGCCTAAGTTCCTGGATAATCTGAAGATCATCGAGTCCATCCAGCGGCGGTTCAAGGACTTCCCATGGTCTGATCTGAAGAAGAACCTGAAGAAGATCGATAAGAATATCAAGCTGACCGAGTACTTCAGCATCGACGGCTTCGTGAACGTGCTGAATCAGAAGGGCATCGATGCCTACAACACAATCCTGGGCGGCAAGTCCGAGGAGTCTGGCGAGAAGATCCAGGGCCTGAACGAGTACATCAATCTGTATCGGCAGAAGAACAATATCGACAGAAAGAACCTGCCCAATGTGAAGATCCTGTTTAAGCAGATCCTGGGCGATAGGGAGACAAAGAGCTTTATCCCTGAGGCCTTCCCAGACGATCAGTCCGTGCTGAACTCTATCACAGAGTTCGCCAAGTACCTGAAGCTGGATAAGAAGAAGAAGAGCATCATCGCCGAGCTGAAGAAGTTTCTGAGCTCCTTCAATCGCTACGAGCTGGACGGCATCTATCTGGCCAACGATAATAGCCTGGCCTCTATCAGCACCTTCCTGTTTGACGATTGGTCCTTTATCAAGAAGTCCGTGTCTTTCAAGTATGACGAGTCCGTGGGCGACCCCAAGAAGAAGATCAAGTCTCCCCTGAAGTACGAGAAGGAGAAGGAGAAGTGGCTGAAGCAGAAGTACTATACAATCTCTTTCCTGAACGATGCCATCGAGAGCTATTCCAAGTCTCAGGACGAGAAGAGGGTGAAGATCCGCCTGGAGGCCTACTTTGCCGAGTTCAAGAGCAAGGACGATGCCAAGAAGCAGTTCGACCTGCTGGAGAGGATCGAGGAGGCCTATGCCATCGTGGAGCCTCTGCTGGGAGCAGAGTACCCAAGGGACCGCAACCTGAAGGCCGATAAGAAGGAAGTGGGCAAGATCAAGGACTTCCTGGATAGCATCAAGTCCCTGCAGTTCTTTCTGAAGCCTCTGCTGTCCGCCGAGATCTTTGACGAGAAGGATCTGGGCTTCTACAATCAGCTGGAGGGCTACTATGAGGAGATCGATTCTATCGGCCACCTGTATAACAAGGTGCGGAATTATCTGACCGGCAAGATCTACAGCAAGGAGAAGTTTAAGCTGAACTTCGAGAACAGCACCCTGCTGAAGGGCTGGGACGAGAACCGGGAGGTGGCCAATCTGTGCGTGATCTTCAGAGAGGACCAGAAGTACTATCTGGGCGTGATGGATAAGGAGAACAATACCATCCTGTCCGACATCCCCAAGGTGAAGCCTAACGAGCTGTTTTACGAGAAGATGGTGTATAAGCTGATCCCCACACCTCACATGCAGCTGCCCCGGATCATCTTCTCTAGCGACAACCTGTCTATCTATAATCCTAGCAAGTCCATCCTGAAGATCAGAGAGGCCAAGAGCTTTAAGGAGGGCAAGAACTTCAAGCTGAAGGACTGTCACAAGTTTATCGATTTCTACAAGGAGTCTATCAGCAAGAATGAGGACTGGAGCAGATTCGACTTCAAGTTCAGCAAGACCAGCAGCTACGAGAACATCAGCGAGTTTTACCGGGAGGTGGAGAGACAGGGCTATAACCTGGACTTCAAGAAGGTGTCTAAGTTCTACATCGACAGCCTGGTGGAGGATGGCAAGCTGTACCTGTTCCAGATCTATAACAAGGACTTTTCTATCTTCAGCAAGGGCAAGCCCAATCTGCACACCATCTATTTTCGGTCCCTGTTCTCTAAGGAGAACCTGAAGGACGTGTGCCTGAAGCTGAATGGCGAGGCCGAGATGTTCTTTCGGAAGAAGTCCATCAACTACGATGAGAAGAAGAAGCGGGAGGGCCACCACCCCGAGCTGTTTGAGAAGCTGAAGTATCCTATCCTGAAGGACAAGAGATACAGCGAGGATAAGTTTCAGTTCCACCTGCCCATCAGCCTGAACTTCAAGTCCAAGGAGCGGCTGAACTTTAATCTGAAAGTGAATGAGTTCCTGAAGAGAAACAAGGACATCAATATCATCGGCATCGATCGGGGCGAGAGAAACCTGCTGTACCTGGTCATGATCAATCAGAAGGGCGAGATCCTGAAGCAGACCCTGCTGGACAGCATGCAGTCCGGCAAGGGCCGGCCTGAGATCAACTACAAGGAGAAGCTGCAGGAGAAGGAGATCGAGAGGGATAAGGCCCGCAAGAGCTGGGGCACAGTGGAGAATATCAAGGAGCTGAAGGAGGGCTATCTGTCTATCGTGATCCACCAGATCAGCAAGCTGATGGTGGAGAACAATGCCATCGTGGTGCTGGAGGACCTGAACATCGGCTTTAAGCGGGGCAGACAGAAGGTGGAGCGGCAGGTGTACCAGAAGTTCGAGAAGATGCTGATCGATAAGCTGAACTTTCTGGTGTTCAAGGAGAATAAGCCAACCGAGCCAGGAGGCGTGCTGAAGGCCTATCAGCTGACAGACGAGTTTCAGTCTTTCGAGAAGCTGAGCAAGCAGACCGGCTTTCTGTTCTACGTGCCAAGCTGGAACACCTCCAAGATCGACCCCAGAACAGGCTTTATCGATTTCCTGCACCCTGCCTACGAGAATATCGAGAAGGCCAAGCAGTGGATCAACAAGTTTGATTCCATCAGGTTCAATTCTAAGATGGACTGGTTTGAGTTCACCGCCGATACACGCAAGTTTTCCGAGAACCTGATGCTGGGCAAGAATCGGGTGTGGGTCATCTGCACCACAAATGTGGAGCGGTACTTCACCAGCAAGACCGCCAACAGCTCCATCCAGTACAATAGCATCCAGATCACCGAGAAGCTGAAGGAGCTGTTTGTGGACATCCCTTTCAGCAACGGCCAGGATCTGAAGCCAGAGATCCTGAGGAAGAATGACGCCGTGTTCTTTAAGAGCCTGCTGTTTTACATCAAGACCACACTGTCCCTGCGCCAGAACAATGGCAAGAAGGGCGAGGAGGAGAAGGACTTCATCCTGAGCCCAGTGGTGGATTCCAAGGGCCGGTTCTTTAACTCTCTGGAGGCCAGCGACGATGAGCCCAAGGACGCCGATGCCAATGGCGCCTACCACATCGCCCTGAAGGGCCTGATGAACCTGCTGGTGCTGAATGAGACAAAGGAGGAGAACCTGAGCAGACCAAAGTGGAAGATCAAGAATAAGGACTGGCTGGAGTTCGTGTGGGAGAGGAACCGCAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 225).
14- Lachnospiraceae bacterium ND2006 (LbCpf1)
ATGAGCAAGCTGGAGAAGTTTACAAACTGCTACTCCCTGTCTAAGACCCTGAGGTTCAAGGCCATCCCTGTGGGCAAGACCCAGGAGAACATCGACAATAAGCGGCTGCTGGTGGAGGACGAGAAGAGAGCCGAGGATTATAAGGGCGTGAAGAAGCTGCTGGATCGCTACTATCTGTCTTTTATCAACGACGTGCTGCACAGCATCAAGCTGAAGAATCTGAACAATTACATCAGCCTGTTCCGGAAGAAAACCAGAACCGAGAAGGAGAATAAGGAGCTGGAGAACCTGGAGATCAATCTGCGGAAGGAGATCGCCAAGGCCTTCAAGGGCAACGAGGGCTACAAGTCCCTGTTTAAGAAGGATATCATCGAGACAATCCTGCCAGAGTTCCTGGACGATAAGGACGAGATCGCCCTGGTGAACAGCTTCAATGGCTTTACCACAGCCTTCACCGGCTTCTTTGATAACAGAGAGAATATGTTTTCCGAGGAGGCCAAGAGCACATCCATCGCCTTCAGGTGTATCAACGAGAATCTGACCCGCTACATCTCTAATATGGACATCTTCGAGAAGGTGGACGCCATCTTTGATAAGCACGAGGTGCAGGAGATCAAGGAGAAGATCCTGAACAGCGACTATGATGTGGAGGATTTCTTTGAGGGCGAGTTCTTTAACTTTGTGCTGACACAGGAGGGCATCGACGTGTATAACGCCATCATCGGCGGCTTCGTGACCGAGAGCGGCGAGAAGATCAAGGGCCTGAACGAGTACATCAACCTGTATAATCAGAAAACCAAGCAGAAGCTGCCTAAGTTTAAGCCACTGTATAAGCAGGTGCTGAGCGATCGGGAGTCTCTGAGCTTCTACGGCGAGGGCTATACATCCGATGAGGAGGTGCTGGAGGTGTTTAGAAACACCCTGAACAAGAACAGCGAGATCTTCAGCTCCATCAAGAAGCTGGAGAAGCTGTTCAAGAATTTTGACGAGTACTCTAGCGCCGGCATCTTTGTGAAGAACGGCCCCGCCATCAGCACAATCTCCAAGGATATCTTCGGCGAGTGGAACGTGATCCGGGACAAGTGGAATGCCGAGTATGACGATATCCACCTGAAGAAGAAGGCCGTGGTGACCGAGAAGTACGAGGACGATCGGAGAAAGTCCTTCAAGAAGATCGGCTCCTTTTCTCTGGAGCAGCTGCAGGAGTACGCCGACGCCGATCTGTCTGTGGTGGAGAAGCTGAAGGAGATCATCATCCAGAAGGTGGATGAGATCTACAAGGTGTATGGCTCCTCTGAGAAGCTGTTCGACGCCGATTTTGTGCTGGAGAAGAGCCTGAAGAAGAACGACGCCGTGGTGGCCATCATGAAGGACCTGCTGGATTCTGTGAAGAGCTTCGAGAATTACATCAAGGCCTTCTTTGGCGAGGGCAAGGAGACAAACAGGGACGAGTCCTTCTATGGCGATTTTGTGCTGGCCTACGACATCCTGCTGAAGGTGGACCACATCTACGATGCCATCCGCAATTATGTGACCCAGAAGCCCTACTCTAAGGATAAGTTCAAGCTGTATTTTCAGAACCCTCAGTTCATGGGCGGCTGGGACAAGGATAAGGAGACAGACTATCGGGCCACCATCCTGAGATACGGCTCCAAGTACTATCTGGCCATCATGGATAAGAAGTACGCCAAGTGCCTGCAGAAGATCGACAAGGACGATGTGAACGGCAATTACGAGAAGATCAACTATAAGCTGCTGCCCGGCCCTAATAAGATGCTGCCAAAGGTGTTCTTTTCTAAGAAGTGGATGGCCTACTATAACCCCAGCGAGGACATCCAGAAGATCTACAAGAATGGCACATTCAAGAAGGGCGATATGTTTAACCTGAATGACTGTCACAAGCTGATCGACTTCTTTAAGGATAGCATCTCCCGGTATCCAAAGTGGTCCAATGCCTACGATTTCAACTTTTCTGAGACAGAGAAGTATAAGGACATCGCCGGCTTTTACAGAGAGGTGGAGGAGCAGGGCTATAAGGTGAGCTTCGAGTCTGCCAGCAAGAAGGAGGTGGATAAGCTGGTGGAGGAGGGCAAGCTGTATATGTTCCAGATCTATAACAAGGACTTTTCCGATAAGTCTCACGGCACACCCAATCTGCACACCATGTACTTCAAGCTGCTGTTTGACGAGAACAATCACGGACAGATCAGGCTGAGCGGAGGAGCAGAGCTGTTCATGAGGCGCGCCTCCCTGAAGAAGGAGGAGCTGGTGGTGCACCCAGCCAACTCCCCTATCGCCAACAAGAATCCAGATAATCCCAAGAAAACCACAACCCTGTCCTACGACGTGTATAAGGATAAGAGGTTTTCTGAGGACCAGTACGAGCTGCACATCCCAATCGCCATCAATAAGTGCCCCAAGAACATCTTCAAGATCAATACAGAGGTGCGCGTGCTGCTGAAGCACGACGATAACCCCTATGTGATCGGCATCGATAGGGGCGAGCGCAATCTGCTGTATATCGTGGTGGTGGACGGCAAGGGCAACATCGTGGAGCAGTATTCCCTGAACGAGATCATCAACAACTTCAACGGCATCAGGATCAAGACAGATTACCACTCTCTGCTGGACAAGAAGGAGAAGGAGAGGTTCGAGGCCCGCCAGAACTGGACCTCCATCGAGAATATCAAGGAGCTGAAGGCCGGCTATATCTCTCAGGTGGTGCACAAGATCTGCGAGCTGGTGGAGAAGTACGATGCCGTGATCGCCCTGGAGGACCTGAACTCTGGCTTTAAGAATAGCCGCGTGAAGGTGGAGAAGCAGGTGTATCAGAAGTTCGAGAAGATGCTGATCGATAAGCTGAACTACATGGTGGACAAGAAGTCTAATCCTTGTGCAACAGGCGGCGCCCTGAAGGGCTATCAGATCACCAATAAGTTCGAGAGCTTTAAGTCCATGTCTACCCAGAACGGCTTCATCTTTTACATCCCTGCCTGGCTGACATCCAAGATCGATCCATCTACCGGCTTTGTGAACCTGCTGAAAACCAAGTATACCAGCATCGCCGATTCCAAGAAGTTCATCAGCTCCTTTGACAGGATCATGTACGTGCCCGAGGAGGATCTGTTCGAGTTTGCCCTGGACTATAAGAACTTCTCTCGCACAGACGCCGATTACATCAAGAAGTGGAAGCTGTACTCCTACGGCAACCGGATCAGAATCTTCCGGAATCCTAAGAAGAACAACGTGTTCGACTGGGAGGAGGTGTGCCTGACCAGCGCCTATAAGGAGCTGTTCAACAAGTACGGCATCAATTATCAGCAGGGCGATATCAGAGCCCTGCTGTGCGAGCAGTCCGACAAGGCCTTCTACTCTAGCTTTATGGCCCTGATGAGCCTGATGCTGCAGATGCGGAACAGCATCACAGGCCGCACCGACGTGGATTTTCTGATCAGCCCTGTGAAGAACTCCGACGGCATCTTCTACGATAGCCGGAACTATGAGGCCCAGGAGAATGCCATCCTGCCAAAGAACGCCGACGCCAATGGCGCCTATAACATCGCCAGAAAGGTGCTGTGGGCCATCGGCCAGTTCAAGAAGGCCGAGGACGAGAAGCTGGATAAGGTGAAGATCGCCATCTCTAACAAGGAGTGGCTGGAGTACGCCCAGACCAGCGTGAAGCACAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 226).
15- Porphyromonas crevioricanis (PcCpf1)
ATGGACAGCCTGAAGGATTTCACCAACCTGTACCCCGTGTCCAAGACACTGCGGTTTGAGCTGAAGCCTGTGGGCAAGACCCTGGAGAATATCGAGAAGGCCGGCATCCTGAAGGAGGATGAGCACAGAGCCGAGAGCTACCGGAGAGTGAAGAAGATCATCGATACATATCACAAGGTGTTCATCGACAGCTCCCTGGAGAACATGGCCAAGATGGGCATCGAGAATGAGATCAAGGCCATGCTGCAGTCCTTTTGCGAGCTGTATAAGAAGGACCACAGGACCGAGGGAGAGGACAAGGCCCTGGATAAGATCAGGGCCGTGCTGAGGGGCCTGATCGTGGGAGCCTTCACCGGCGTGTGCGGCCGGCGGGAGAACACAGTGCAGAATGAGAAGTATGAGAGCCTGTTTAAGGAGAAGCTGATCAAGGAGATCCTGCCAGATTTCGTGCTGTCTACAGAGGCCGAGTCCCTGCCCTTTTCTGTGGAGGAGGCCACCAGAAGCCTGAAGGAGTTCGACTCCTTTACATCTTACTTCGCCGGCTTTTATGAGAACCGGAAGAATATCTACTCTACCAAGCCCCAGAGCACAGCCATCGCCTATAGACTGATCCACGAGAACCTGCCTAAGTTCATCGATAATATCCTGGTGTTTCAGAAGATCAAGGAGCCAATCGCCAAGGAGCTGGAGCACATCAGGGCAGACTTCAGCGCCGGCGGCTACATCAAGAAGGATGAGCGCCTGGAGGACATCTTTTCCCTGAACTACTATATCCACGTGCTGTCTCAGGCCGGCATCGAGAAGTACAATGCCCTGATCGGCAAGATCGTGACCGAGGGCGATGGCGAGATGAAGGGCCTGAACGAGCACATCAACCTGTATAATCAGCAGAGGGGCCGCGAGGACCGGCTGCCACTGTTCAGACCCCTGTATAAGCAGATCCTGTCTGATAGGGAGCAGCTGTCCTATCTGCCAGAGTCTTTCGAGAAGGACGAGGAGCTGCTGAGGGCCCTGAAGGAGTTTTACGATCACATCGCAGAGGACATCCTGGGAAGGACCCAGCAGCTGATGACAAGCATCTCCGAGTACGATCTGTCCCGGATCTATGTGAGAAACGATAGCCAGCTGACCGACATCTCCAAGAAGATGCTGGGCGATTGGAATGCCATCTACATGGCCCGGGAGAGAGCCTATGACCACGAGCAGGCCCCCAAGCGCATCACAGCCAAGTACGAGAGGGACCGCATCAAGGCCCTGAAGGGCGAGGAGTCTATCAGCCTGGCCAACCTGAACAGCTGCATCGCCTTCCTGGACAACGTGAGGGATTGTCGCGTGGACACCTATCTGTCTACACTGGGACAGAAGGAGGGACCTCACGGCCTGAGCAACCTGGTGGAGAACGTGTTCGCCTCCTACCACGAGGCCGAGCAGCTGCTGTCTTTTCCCTATCCTGAGGAGAACAATCTGATCCAGGACAAGGATAACGTGGTGCTGATCAAGAACCTGCTGGATAATATCAGCGACCTGCAGAGGTTCCTGAAGCCACTGTGGGGCATGGGCGATGAGCCCGACAAGGATGAGAGGTTTTACGGCGAGTACAATTATATCAGGGGCGCCCTGGACCAGGTCATCCCTCTGTATAACAAGGTGCGGAATTATCTGACCCGCAAGCCATACTCCACACGCAAGGTGAAGCTGAACTTCGGCAATAGCCAGCTGCTGTCCGGCTGGGATAGGAACAAGGAGAAGGACAATTCTTGCGTGATCCTGCGCAAGGGCCAGAACTTCTACCTGGCCATCATGAACAATCGGCACAAGCGGAGCTTCGAGAATAAGATGCTGCCCGAGTATAAGGAGGGCGAGCCTTACTTCGAGAAGATGGATTATAAGTTTCTGCCAGACCCCAACAAGATGCTGCCCAAGGTGTTCCTGTCTAAGAAGGGCATCGAGATCTACAAGCCTAGCCCAAAGCTGCTGGAGCAGTATGGCCACGGCACCCACAAGAAGGGCGATACCTTCAGCATGGACGATCTGCACGAGCTGATCGACTTCTTTAAGCACTCCATCGAGGCCCACGAGGATTGGAAGCAGTTCGGCTTTAAGTTCAGCGACACCGCCACATACGAGAACGTGAGCAGCTTCTACCGGGAGGTGGAGGACCAGGGCTACAAGCTGTCTTTTAGAAAGGTGTCCGAGTCTTACGTGTATAGCCTGATCGATCAGGGCAAGCTGTACCTGTTCCAGATCTATAACAAGGACTTTAGCCCTTGTTCCAAGGGCACCCCAAATCTGCACACACTGTACTGGCGGATGCTGTTCGATGAGAGAAACCTGGCCGACGTGATCTATAAGCTGGATGGCAAGGCCGAGATCTTCTTTCGGGAGAAGTCCCTGAAGAATGACCACCCAACCCACCCTGCAGGCAAGCCCATCAAGAAGAAGAGCCGGCAGAAGAAGGGCGAGGAGAGCCTGTTCGAGTACGATCTGGTGAAGGACCGGAGATATACCATGGATAAGTTTCAGTTCCACGTGCCAATCACAATGAACTTTAAGTGCTCTGCCGGCAGCAAGGTGAACGACATGGTGAATGCCCACATCAGGGAGGCCAAGGACATGCACGTGATCGGCATCGATAGGGGCGAGCGCAATCTGCTGTATATCTGCGTGATCGACAGCCGCGGCACCATCCTGGATCAGATCTCCCTGAACACAATCAATGACATCGATTATCACGATCTGCTGGAGTCCAGGGACAAGGATCGCCAGCAGGAGCACAGGAACTGGCAGACCATCGAGGGCATCAAGGAGCTGAAGCAGGGCTACCTGTCTCAGGCCGTGCACCGCATCGCCGAGCTGATGGTGGCCTATAAGGCCGTGGTGGCCCTGGAGGACCTGAACATGGGCTTCAAGCGGGGCAGACAGAAGGTGGAGAGCAGCGTGTACCAGCAGTTTGAGAAGCAGCTGATCGACAAGCTGAATTATCTGGTGGATAAGAAGAAGCGGCCCGAGGACATCGGAGGCCTGCTGAGAGCCTACCAGTTCACCGCCCCTTTCAAGAGCTTTAAGGAGATGGGCAAGCAGAACGGCTTTCTGTTCTATATCCCTGCCTGGAACACATCCAATATCGACCCAACCACAGGCTTCGTGAACCTGTTTCACGTGCAGTACGAGAATGTGGATAAGGCCAAGAGCTTCTTTCAGAAGTTCGACAGCATCTCCTACAACCCTAAGAAGGATTGGTTTGAGTTCGCCTTTGACTATAAGAACTTCACCAAGAAGGCCGAGGGCTCTAGGAGCATGTGGATTCTGTGCACCCACGGCTCCCGGATCAAGAACTTCAGAAATTCTCAGAAGAATGGCCAGTGGGATAGCGAGGAGTTTGCCCTGACCGAGGCCTTCAAGTCCCTGTTTGTGCGGTACGAGATCGATTATACCGCCGACCTGAAAACCGCCATCGTGGACGAGAAGCAGAAGGATTTCTTTGTGGACCTGCTGAAGCTGTTCAAGCTGACCGTGCAGATGAGAAACTCCTGGAAGGAGAAGGACCTGGATTACCTGATCTCTCCAGTGGCCGGCGCCGATGGCAGGTTCTTTGACACACGCGAGGGCAATAAGAGCCTGCCCAAGGACGCAGATGCAAACGGAGCCTATAATATCGCCCTGAAGGGCCTGTGGGCACTGAGGCAGATCAGACAGACCTCCGAGGGCGGCAAGCTGAAGCTGGCCATCTCTAACAAGGAGTGGCTGCAGTTTGTGCAGGAGAGATCCTACGAGAAGGACAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 227).
16- Prevotella disiens (PdCpf1)
ATGGAGAACTATCAGGAGTTCACCAACCTGTTTCAGCTGAATAAGACACTGAGATTCGAGCTGAAGCCCATCGGCAAGACCTGCGAGCTGCTGGAGGAGGGCAAGATCTTCGCCAGCGGCTCCTTTCTGGAGAAGGACAAGGTGAGGGCCGATAACGTGAGCTACGTGAAGAAGGAGATCGACAAGAAGCACAAGATCTTTATCGAGGAGACACTGAGCTCCTTCTCTATCAGCAACGATCTGCTGAAGCAGTACTTTGACTGCTATAATGAGCTGAAGGCCTTCAAGAAGGACTGTAAGAGCGATGAGGAGGAGGTGAAGAAAACCGCCCTGCGCAACAAGTGTACCTCCATCCAGAGGGCCATGCGCGAGGCCATCTCTCAGGCCTTTCTGAAGAGCCCCCAGAAGAAGCTGCTGGCCATCAAGAACCTGATCGAGAACGTGTTCAAGGCCGACGAGAATGTGCAGCACTTCTCCGAGTTTACCAGCTATTTCTCCGGCTTTGAGACAAACAGAGAGAATTTCTACTCTGACGAGGAGAAGTCCACATCTATCGCCTATAGGCTGGTGCACGATAACCTGCCTATCTTCATCAAGAACATCTACATCTTCGAGAAGCTGAAGGAGCAGTTCGACGCCAAGACCCTGAGCGAGATCTTCGAGAACTACAAGCTGTATGTGGCCGGCTCTAGCCTGGATGAGGTGTTCTCCCTGGAGTACTTTAACAATACCCTGACACAGAAGGGCATCGACAACTATAATGCCGTGATCGGCAAGATCGTGAAGGAGGATAAGCAGGAGATCCAGGGCCTGAACGAGCACATCAACCTGTATAATCAGAAGCACAAGGACCGGAGACTGCCCTTCTTTATCTCCCTGAAGAAGCAGATCCTGTCCGATCGGGAGGCCCTGTCTTGGCTGCCTGACATGTTCAAGAATGATTCTGAAGTGATCAAGGCCCTGAAGGGCTTCTACATCGAGGACGGCTTTGAGAACAATGTGCTGACACCTCTGGCCACCCTGCTGTCCTCTCTGGATAAGTACAACCTGAATGGCATCTTTATCCGCAACAATGAGGCCCTGAGCTCCCTGTCCCAGAACGTGTATCGGAATTTTTCTATCGACGAGGCCATCGATGCCAACGCCGAGCTGCAGACCTTCAACAATTACGAGCTGATCGCCAATGCCCTGCGCGCCAAGATCAAGAAGGAGACAAAGCAGGGCCGGAAGTCTTTCGAGAAGTACGAGGAGTATATCGATAAGAAGGTGAAGGCCATCGACAGCCTGTCCATCCAGGAGATCAACGAGCTGGTGGAGAATTACGTGAGCGAGTTTAACTCTAATAGCGGCAACATGCCAAGAAAGGTGGAGGACTACTTCAGCCTGATGAGGAAGGGCGACTTCGGCTCCAACGATCTGATCGAAAATATCAAGACCAAGCTGAGCGCCGCAGAGAAGCTGCTGGGCACAAAGTACCAGGAGACAGCCAAGGACATCTTCAAGAAGGATGAGAACTCCAAGCTGATCAAGGAGCTGCTGGACGCCACCAAGCAGTTCCAGCACTTTATCAAGCCACTGCTGGGCACAGGCGAGGAGGCAGATCGGGACCTGGTGTTCTACGGCGATTTTCTGCCCCTGTATGAGAAGTTTGAGGAGCTGACCCTGCTGTATAACAAGGTGCGGAATAGACTGACACAGAAGCCCTATTCCAAGGACAAGATCCGCCTGTGCTTCAACAAGCCTAAGCTGATGACAGGCTGGGTGGATTCCAAGACCGAGAAGTCTGACAACGGCACACAGTACGGCGGCTATCTGTTTCGGAAGAAGAATGAGATCGGCGAGTACGATTATTTTCTGGGCATCTCTAGCAAGGCCCAGCTGTTCAGAAAGAACGAGGCCGTGATCGGCGACTACGAGAGGCTGGATTACTATCAGCCAAAGGCCAATACCATCTACGGCTCTGCCTATGAGGGCGAGAACAGCTACAAGGAGGACAAGAAGCGGCTGAACAAAGTGATCATCGCCTATATCGAGCAGATCAAGCAGACAAACATCAAGAAGTCTATCATCGAGTCCATCTCTAAGTATCCTAATATCAGCGACGATGACAAGGTGACCCCATCCTCTCTGCTGGAGAAGATCAAGAAGGTGTCTATCGACAGCTACAACGGCATCCTGTCCTTCAAGTCTTTTCAGAGCGTGAACAAGGAAGTGATCGATAACCTGCTGAAAACCATCAGCCCCCTGAAGAACAAGGCCGAGTTTCTGGACCTGATCAATAAGGATTATCAGATCTTCACCGAGGTGCAGGCCGTGATCGACGAGATCTGCAAGCAGAAAACCTTCATCTACTTTCCAATCTCCAACGTGGAGCTGGAGAAGGAGATGGGCGATAAGGACAAGCCCCTGTGCCTGTTCCAGATCAGCAATAAGGATCTGTCCTTCGCCAAGACCTTTAGCGCCAACCTGCGGAAGAAGAGAGGCGCCGAGAATCTGCACACAATGCTGTTTAAGGCCCTGATGGAGGGCAACCAGGATAATCTGGACCTGGGCTCTGGCGCCATCTTCTACAGAGCCAAGAGCCTGGACGGCAACAAGCCCACACACCCTGCCAATGAGGCCATCAAGTGTAGGAACGTGGCCAATAAGGATAAGGTGTCCCTGTTCACCTACGACATCTATAAGAACAGGCGCTACATGGAGAATAAGTTCCTGTTTCACCTGAGCATCGTGCAGAACTATAAGGCCGCCAATGACTCCGCCCAGCTGAACAGCTCCGCCACCGAGTATATCAGAAAGGCCGATGACCTGCACATCATCGGCATCGATAGGGGCGAGCGCAATCTGCTGTACTATTCCGTGATCGATATGAAGGGCAACATCGTGGAGCAGGACTCTCTGAATATCATCAGGAACAATGACCTGGAGACAGATTACCACGACCTGCTGGATAAGAGGGAGAAGGAGCGCAAGGCCAACCGGCAGAATTGGGAGGCCGTGGAGGGCATCAAGGACCTGAAGAAGGGCTACCTGAGCCAGGCCGTGCACCAGATCGCCCAGCTGATGCTGAAGTATAACGCCATCATCGCCCTGGAGGATCTGGGCCAGATGTTTGTGACCCGCGGCCAGAAGATCGAGAAGGCCGTGTACCAGCAGTTCGAGAAGAGCCTGGTGGATAAGCTGTCCTACCTGGTGGACAAGAAGCGGCCTTATAATGAGCTGGGCGGCATCCTGAAGGCCTACCAGCTGGCCTCTAGCATCACCAAGAACAATTCTGACAAGCAGAACGGCTTCCTGTTTTATGTGCCAGCCTGGAATACAAGCAAGATCGATCCCGTGACCGGCTTTACAGACCTGCTGCGGCCCAAGGCCATGACCATCAAGGAGGCCCAGGACTTCTTTGGCGCCTTCGATAACATCTCTTACAATGACAAGGGCTATTTCGAGTTTGAGACAAACTACGACAAGTTTAAGATCAGAATGAAGAGCGCCCAGACCAGGTGGACAATCTGCACCTTCGGCAATCGGATCAAGAGAAAGAAGGATAAGAACTACTGGAATTATGAGGAGGTGGAGCTGACCGAGGAGTTCAAGAAGCTGTTTAAGGACAGCAACATCGATTACGAGAACTGTAATCTGAAGGAGGAGATCCAGAACAAGGACAATCGCAAGTTCTTTGATGACCTGATCAAGCTGCTGCAGCTGACACTGCAGATGCGGAACTCCGATGACAAGGGCAATGATTATATCATCTCTCCTGTGGCCAACGCCGAGGGCCAGTTCTTTGACTCCCGCAATGGCGATAAGAAGCTGCCACTGGATGCAGACGCAAACGGAGCCTACAATATCGCCCGCAAGGGCCTGTGGAACATCCGGCAGATCAAGCAGACCAAGAACGACAAGAAGCTGAATCTGAGCATCTCCTCTACAGAGTGGCTGGATTTCGTGCGGGAGAAGCCTTACCTGAAGAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 228).
17- Porphyromonas macacae (PmCpf1)
ATGAAAACCCAGCACTTCTTTGAGGACTTCACAAGCCTGTACTCTCTGAGCAAGACCATCCGGTTTGAGCTGAAGCCAATCGGCAAGACCCTGGAGAACATCAAGAAGAATGGCCTGATCCGGAGAGATGAGCAGAGACTGGACGATTACGAGAAGCTGAAGAAAGTGATCGACGAGTATCACGAGGATTTCATCGCCAACATCCTGAGCTCCTTTTCCTTCTCTGAGGAGATCCTGCAGTCCTACATCCAGAATCTGAGCGAGTCCGAGGCCAGGGCCAAGATCGAGAAAACCATGCGCGACACACTGGCCAAGGCCTTCTCTGAGGATGAGAGGTACAAGAGCATCTTTAAGAAGGAGCTGGTGAAGAAGGACATCCCCGTGTGGTGCCCTGCCTATAAGAGCCTGTGCAAGAAGTTCGATAACTTTACCACATCTCTGGTGCCCTTCCACGAGAACAGGAAGAACCTGTATACCAGCAATGAGATCACAGCCTCTATCCCTTATCGCATCGTGCACGTGAACCTGCCAAAGTTTATCCAGAATATCGAGGCCCTGTGCGAGCTGCAGAAGAAGATGGGCGCCGACCTGTACCTGGAGATGATGGAGAACCTGCGCAACGTGTGGCCCAGCTTCGTGAAAACCCCAGACGACCTGTGCAACCTGAAAACCTATAATCACCTGATGGTGCAGTCTAGCATCAGCGAGTACAACAGGTTTGTGGGCGGCTATTCCACCGAGGACGGCACAAAGCACCAGGGCATCAACGAGTGGATCAATATCTACAGACAGAGGAATAAGGAGATGCGCCTGCCTGGCCTGGTGTTCCTGCACAAGCAGATCCTGGCCAAGGTGGACTCCTCTAGCTTCATCAGCGATACACTGGAGAACGACGATCAGGTGTTTTGCGTGCTGAGACAGTTCAGGAAGCTGTTTTGGAATACCGTGTCCTCTAAGGAGGACGATGCCGCCTCCCTGAAGGACCTGTTCTGTGGCCTGTCTGGCTATGACCCTGAGGCCATCTACGTGAGCGATGCCCACCTGGCCACAATCTCCAAGAACATCTTTGACAGATGGAATTACATCTCCGATGCCATCAGGCGCAAGACCGAGGTGCTGATGCCACGGAAGAAGGAGAGCGTGGAGAGATATGCCGAGAAGATCTCCAAGCAGATCAAGAAGAGACAGTCTTACAGCCTGGCCGAGCTGGACGATCTGCTGGCCCACTATAGCGAGGAGTCCCTGCCCGCAGGCTTCTCTCTGCTGAGCTACTTTACATCTCTGGGCGGCCAGAAGTATCTGGTGAGCGACGGCGAAGTGATCCTGTACGAGGAGGGCAGCAACATCTGGGACGAGGTGCTGATCGCCTTCAGGGATCTGCAGGTCATCCTGGACAAGGACTTCACCGAGAAGAAGCTGGGCAAGGATGAGGAGGCCGTGTCTGTGATCAAGAAGGCCCTGGACAGCGCCCTGCGCCTGCGGAAGTTCTTTGATCTGCTGTCCGGCACAGGCGCAGAGATCAGGAGAGACAGCTCCTTCTATGCCCTGTATACCGACCGGATGGATAAGCTGAAGGGCCTGCTGAAGATGTATGATAAGGTGAGAAACTACCTGACCAAGAAGCCTTATTCCATCGAGAAGTTCAAGCTGCACTTTGACAACCCATCCCTGCTGTCTGGCTGGGATAAGAATAAGGAGCTGAACAATCTGTCTGTGATCTTCCGGCAGAACGGCTACTATTACCTGGGCATCATGACACCCAAGGGCAAGAATCTGTTCAAGACCCTGCCTAAGCTGGGCGCCGAGGAGATGTTTTATGAGAAGATGGAGTACAAGCAGATCGCCGAGCCTATGCTGATGCTGCCAAAGGTGTTCTTTCCCAAGAAAACCAAGCCAGCCTTCGCCCCAGACCAGAGCGTGGTGGATATCTACAACAAGAAAACCTTCAAGACAGGCCAGAAGGGCTTTAATAAGAAGGACCTGTACCGGCTGATCGACTTCTACAAGGAGGCCCTGACAGTGCACGAGTGGAAGCTGTTTAACTTCTCCTTTTCTCCAACCGAGCAGTATCGGAATATCGGCGAGTTCTTTGACGAGGTGAGAGAGCAGGCCTACAAGGTGTCCATGGTGAACGTGCCCGCCTCTTATATCGACGAGGCCGTGGAGAACGGCAAGCTGTATCTGTTCCAGATCTACAATAAGGACTTCAGCCCCTACTCCAAGGGCATCCCTAACCTGCACACACTGTATTGGAAGGCCCTGTTCAGCGAGCAGAATCAGAGCCGGGTGTATAAGCTGTGCGGAGGAGGAGAGCTGTTTTATAGAAAGGCCAGCCTGCACATGCAGGACACCACAGTGCACCCCAAGGGCATCTCTATCCACAAGAAGAACCTGAATAAGAAGGGCGAGACAAGCCTGTTCAACTACGACCTGGTGAAGGATAAGAGGTTTACCGAGGACAAGTTCTTTTTCCACGTGCCTATCTCTATCAACTACAAGAATAAGAAGATCACCAACGTGAATCAGATGGTGCGCGATTATATCGCCCAGAACGACGATCTGCAGATCATCGGCATCGACCGCGGCGAGCGGAATCTGCTGTATATCAGCCGGATCGATACAAGGGGCAACCTGCTGGAGCAGTTCAGCCTGAATGTGATCGAGTCCGACAAGGGCGATCTGAGAACCGACTATCAGAAGATCCTGGGCGATCGCGAGCAGGAGCGGCTGAGGCGCCGGCAGGAGTGGAAGTCTATCGAGAGCATCAAGGACCTGAAGGATGGCTACATGAGCCAGGTGGTGCACAAGATCTGTAACATGGTGGTGGAGCACAAGGCCATCGTGGTGCTGGAGAACCTGAATCTGAGCTTCATGAAGGGCAGGAAGAAGGTGGAGAAGTCCGTGTACGAGAAGTTTGAGCGCATGCTGGTGGACAAGCTGAACTATCTGGTGGTGGATAAGAAGAACCTGTCCAATGAGCCAGGAGGCCTGTATGCAGCATACCAGCTGACCAATCCACTGTTCTCTTTTGAGGAGCTGCACAGATACCCCCAGAGCGGCATCCTGTTTTTCGTGGACCCATGGAACACCTCTCTGACAGATCCCAGCACAGGCTTCGTGAATCTGCTGGGCAGAATCAACTACACCAATGTGGGCGACGCCCGCAAGTTTTTCGATCGGTTTAACGCCATCAGATATGACGGCAAGGGCAATATCCTGTTCGACCTGGATCTGTCCAGATTTGATGTGAGGGTGGAGACACAGAGGAAGCTGTGGACACTGACCACATTCGGCTCTCGCATCGCCAAATCCAAGAAGTCTGGCAAGTGGATGGTGGAGCGGATCGAGAACCTGAGCCTGTGCTTTCTGGAGCTGTTCGAGCAGTTTAATATCGGCTACAGAGTGGAGAAGGACCTGAAGAAGGCCATCCTGAGCCAGGATAGGAAGGAGTTCTATGTGCGCCTGATCTACCTGTTTAACCTGATGATGCAGATCCGGAACAGCGACGGCGAGGAGGATTATATCCTGTCTCCCGCCCTGAACGAGAAGAATCTGCAGTTCGACAGCAGGCTGATCGAGGCCAAGGATCTGCCTGTGGACGCAGATGCAAACGGAGCATACAATGTGGCCCGCAAGGGCCTGATGGTGGTGCAGAGAATCAAGAGGGGCGACCACGAGTCCATCCACAGGATCGGAAGGGCACAGTGGCTGAGATATGTGCAGGAGGGCATCGTGGAGAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTATCCCTACGACGTGCCTGATTATGCATACCCATATGATGTCCCCGACTATGCCTAAGAATTC (SEQ ID NO: 229).
Аминокислотные последовательности ортологов Cpf1, кодон-оптимизированных для человека
Сигнал ядерной локализации (NLS)
Глицин-сериновый линкер
3x HA-метка
1- Franscisella tularensis subsp. novicida U112 (FnCpf1)
MSIYQEFVNKYSLSKTLRFELIPQGKTLENIKARGLILDDEKRAKDYKKAKQIIDKYHQFFIEEILSSVCISEDLLQNYSDVYFKLKKSDDDNLQKDFKSAKDTIKKQISEYIKDSEKFKNLFNQNLIDAKKGQESDLILWLKQSKDNGIELFKANSDITDIDEALEIIKSFKGWTTYFKGFHENRKNVYSSNDIPTSIIYRIVDDNLPKFLENKAKYESLKDKAPEAINYEQIKKDLAEELTFDIDYKTSEVNQRVFSLDEVFEIANFNNYLNQSGITKFNTIIGGKFVNGENTKRKGINEYINLYSQQINDKTLKKYKMSVLFKQILSDTESKSFVIDKLEDDSDVVTTMQSFYEQIAAFKTVEEKSIKETLSLLFDDLKAQKLDLSKIYFKNDKSLTDLSQQVFDDYSVIGTAVLEYITQQIAPKNLDNPSKKEQELIAKKTEKAKYLSLETIKLALEEFNKHRDIDKQCRFEEILANFAAIPMIFDEIAQNKDNLAQISIKYQNQGKKDLLQASAEDDVKAIKDLLDQTNNLLHKLKIFHISQSEDKANILDKDEHFYLVFEECYFELANIVPLYNKIRNYITQKPYSDEKFKLNFENSTLANGWDKNKEPDNTAILFIKDDKYYLGVMNKKNNKIFDDKAIKENKGEGYKKIVYKLLPGANKMLPKVFFSAKSIKFYNPSEDILRIRNHSTHTKNGSPQKGYEKFEFNIEDCRKFIDFYKQSISKHPEWKDFGFRFSDTQRYNSIDEFYREVENQGYKLTFENISESYIDSVVNQGKLYLFQIYNKDFSAYSKGRPNLHTLYWKALFDERNLQDVVYKLNGEAELFYRKQSIPKKITHPAKEAIANKNKDNPKKESVFEYDLIKDKRFTEDKFFFHCPITINFKSSGANKFNDEINLLLKEKANDVHILSIDRGERHLAYYTLVDGKGNIIKQDTFNIIGNDRMKTNYHDKLAAIEKDRDSARKDWKKINNIKEMKEGYLSQVVHEIAKLVIEYNAIVVFEDLNFGFKRGRFKVEKQVYQKLEKMLIEKLNYLVFKDNEFDKTGGVLRAYQLTAPFETFKKMGKQTGIIYYVPAGFTSKICPVTGFVNQLYPKYESVSKSQEFFSKFDKICYNLDKGYFEFSFDYKNFGDKAAKGKWTIASFGSRLINFRNSDKNHNWDTREVYPTKELEKLLKDYSIEYGHGECIKAAICGESDKKFFAKLTSVLNTILQMRNSKTGTELDYLISPVADVNGNFFDSRQAPKNMPQDADANGAYHIGLKGLMLLGRIKNNQEGKKLNLVIKNEEYFEFVQNRNNKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 230).
3- Lachnospiraceae bacterium MC2017 (Lb3Cpf1)
MDYGNGQFERRAPLTKTITLRLKPIGETRETIREQKLLEQDAAFRKLVETVTPIVDDCIRKIADNALCHFGTEYDFSCLGNAISKNDSKAIKKETEKVEKLLAKVLTENLPDGLRKVNDINSAAFIQDTLTSFVQDDADKRVLIQELKGKTVLMQRFLTTRITALTVWLPDRVFENFNIFIENAEKMRILLDSPLNEKIMKFDPDAEQYASLEFYGQCLSQKDIDSYNLIISGIYADDEVKNPGINEIVKEYNQQIRGDKDESPLPKLKKLHKQILMPVEKAFFVRVLSNDSDARSILEKILKDTEMLPSKIIEAMKEADAGDIAVYGSRLHELSHVIYGDHGKLSQIIYDKESKRISELMETLSPKERKESKKRLEGLEEHIRKSTYTFDELNRYAEKNVMAAYIAAVEESCAEIMRKEKDLRTLLSKEDVKIRGNRHNTLIVKNYFNAWTVFRNLIRILRRKSEAEIDSDFYDVLDDSVEVLSLTYKGENLCRSYITKKIGSDLKPEIATYGSALRPNSRWWSPGEKFNVKFHTIVRRDGRLYYFILPKGAKPVELEDMDGDIECLQMRKIPNPTIFLPKLVFKDPEAFFRDNPEADEFVFLSGMKAPVTITRETYEAYRYKLYTVGKLRDGEVSEEEYKRALLQVLTAYKEFLENRMIYADLNFGFKDLEEYKDSSEFIKQVETHNTFMCWAKVSSSQLDDLVKSGNGLLFEIWSERLESYYKYGNEKVLRGYEGVLLSILKDENLVSMRTLLNSRPMLVYRPKESSKPMVVHRDGSRVVDRFDKDGKYIPPEVHDELYRFFNNLLIKEKLGEKARKILDNKKVKVKVLESERVKWSKFYDEQFAVTFSVKKNADCLDTTKDLNAEVMEQYSESNRLILIRNTTDILYYLVLDKNGKVLKQRSLNIINDGARDVDWKERFRQVTKDRNEGYNEWDYSRTSNDLKEVYLNYALKEIAEAVIEYNAILIIEKMSNAFKDKYSFLDDVTFKGFETKLLAKLSDLHFRGIKDGEPCSFTNPLQLCQNDSNKILQDGVIFMVPNSMTRSLDPDTGFIFAINDHNIRTKKAKLNFLSKFDQLKVSSEGCLIMKYSGDSLPTHNTDNRVWNCCCNHPITNYDRETKKVEFIEEPVEELSRVLEENGIETDTELNKLNERENVPGKVVDAIYSLVLNYLRGTVSGVAGQRAVYYSPVTGKKYDISFIQAMNLNRKCDYYRIGSKERGEWTDFVAQLINKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 231).
4- Butyrivibrio proteoclasticus (BpCpf1)
MLLYENYTKRNQITKSLRLELRPQGKTLRNIKELNLLEQDKAIYALLERLKPVIDEGIKDIARDTLKNCELSFEKLYEHFLSGDKKAYAKESERLKKEIVKTLIKNLPEGIGKISEINSAKYLNGVLYDFIDKTHKDSEEKQNILSDILETKGYLALFSKFLTSRITTLEQSMPKRVIENFEIYAANIPKMQDALERGAVSFAIEYESICSVDYYNQILSQEDIDSYNRLISGIMDEDGAKEKGINQTISEKNIKIKSEHLEEKPFRILKQLHKQILEEREKAFTIDHIDSDEEVVQVTKEAFEQTKEQWENIKKINGFYAKDPGDITLFIVVGPNQTHVLSQLIYGEHDRIRLLLEEYEKNTLEVLPRRTKSEKARYDKFVNAVPKKVAKESHTFDGLQKMTGDDRLFILYRDELARNYMRIKEAYGTFERDILKSRRGIKGNRDVQESLVSFYDELTKFRSALRIINSGNDEKADPIFYNTFDGIFEKANRTYKAENLCRNYVTKSPADDARIMASCLGTPARLRTHWWNGEENFAINDVAMIRRGDEYYYFVLTPDVKPVDLKTKDETDAQIFVQRKGAKSFLGLPKALFKCILEPYFESPEHKNDKNCVIEEYVSKPLTIDRRAYDIFKNGTFKKTNIGIDGLTEEKFKDDCRYLIDVYKEFIAVYTRYSCFNMSGLKRADEYNDIGEFFSDVDTRLCTMEWIPVSFERINDMVDKKEGLLFLVRSMFLYNRPRKPYERTFIQLFSDSNMEHTSMLLNSRAMIQYRAASLPRRVTHKKGSILVALRDSNGEHIPMHIREAIYKMKNNFDISSEDFIMAKAYLAEHDVAIKKANEDIIRNRRYTEDKFFLSLSYTKNADISARTLDYINDKVEEDTQDSRMAVIVTRNLKDLTYVAVVDEKNNVLEEKSLNEIDGVNYRELLKERTKIKYHDKTRLWQYDVSSKGLKEAYVELAVTQISKLATKYNAVVVVESMSSTFKDKFSFLDEQIFKAFEARLCARMSDLSFNTIKEGEAGSISNPIQVSNNNGNSYQDGVIYFLNNAYTRTLCPDTGFVDVFDKTRLITMQSKRQFFAKMKDIRIDDGEMLFTFNLEEYPTKRLLDRKEWTVKIAGDGSYFDKDKGEYVYVNDIVREQIIPALLEDKAVFDGNMAEKFLDKTAISGKSVELIYKWFANALYGIITKKDGEKIYRSPITGTEIDVSKNTTYNFGKKFMFKQEYRGDGDFLDAFLNYMQAQDIAVKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 232).
5- Peregrinibacteria bacterium GW2011_GWA_33_10 (PeCpf1)
MSNFFKNFTNLYELSKTLRFELKPVGDTLTNMKDHLEYDEKLQTFLKDQNIDDAYQALKPQFDEIHEEFITDSLESKKAKEIDFSEYLDLFQEKKELNDSEKKLRNKIGETFNKAGEKWKKEKYPQYEWKKGSKIANGADILSCQDMLQFIKYKNPEDEKIKNYIDDTLKGFFTYFGGFNQNRANYYETKKEASTAVATRIVHENLPKFCDNVIQFKHIIKRKKDGTVEKTERKTEYLNAYQYLKNNNKITQIKDAETEKMIESTPIAEKIFDVYYFSSCLSQKQIEEYNRIIGHYNLLINLYNQAKRSEGKHLSANEKKYKDLPKFKTLYKQIGCGKKKDLFYTIKCDTEEEANKSRNEGKESHSVEEIINKAQEAINKYFKSNNDCENINTVPDFINYILTKENYEGVYWSKAAMNTISDKYFANYHDLQDRLKEAKVFQKADKKSEDDIKIPEAIELSGLFGVLDSLADWQTTLFKSSILSNEDKLKIITDSQTPSEALLKMIFNDIEKNMESFLKETNDIITLKKYKGNKEGTEKIKQWFDYTLAINRMLKYFLVKENKIKGNSLDTNISEALKTLIYSDDAEWFKWYDALRNYLTQKPQDEAKENKLKLNFDNPSLAGGWDVNKECSNFCVILKDKNEKKYLAIMKKGENTLFQKEWTEGRGKNLTKKSNPLFEINNCEILSKMEYDFWADVSKMIPKCSTQLKAVVNHFKQSDNEFIFPIGYKVTSGEKFREECKISKQDFELNNKVFNKNELSVTAMRYDLSSTQEKQYIKAFQKEYWELLFKQEKRDTKLTNNEIFNEWINFCNKKYSELLSWERKYKDALTNWINFCKYFLSKYPKTTLFNYSFKESENYNSLDEFYRDVDICSYKLNINTTINKSILDRLVEEGKLYLFEIKNQDSNDGKSIGHKNNLHTIYWNAIFENFDNRPKLNGEAEIFYRKAISKDKLGIVKGKKTKNGTEIIKNYRFSKEKFILHVPITLNFCSNNEYVNDIVNTKFYNFSNLHFLGIDRGEKHLAYYSLVNKNGEIVDQGTLNLPFTDKDGNQRSIKKEKYFYNKQEDKWEAKEVDCWNYNDLLDAMASNRDMARKNWQRIGTIKEAKNGYVSLVIRKIADLAVNNERPAFIVLEDLNTGFKRSRQKIDKSVYQKFELALAKKLNFLVDKNAKRDEIGSPTKALQLTPPVNNYGDIENKKQAGIMLYTRANYTSQTDPATGWRKTIYLKAGPEETTYKKDGKIKNKSVKDQIIETFTDIGFDGKDYYFEYDKGEFVDEKTGEIKPKKWRLYSGENGKSLDRFRGEREKDKYEWKIDKIDIVKILDDLFVNFDKNISLLKQLKEGVELTRNNEHGTGESLRFAINLIQQIRNTGNNERDNDFILSPVRDENGKHFDSREYWDKETKGEKISMPSSGDANGAFNIARKGIIMNAHILANSDSKDLSLFVSDEEWDLHLNNKTEWKKQLNIFSSRKAMAKRKKKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 233).
6- Parcubacteria bacterium GWC2011_GWC2_44_17 (PbCpf1)
MENIFDQFIGKYSLSKTLRFELKPVGKTEDFLKINKVFEKDQTIDDSYNQAKFYFDSLHQKFIDAALASDKTSELSFQNFADVLEKQNKIILDKKREMGALRKRDKNAVGIDRLQKEINDAEDIIQKEKEKIYKDVRTLFDNEAESWKTYYQEREVDGKKITFSKADLKQKGADFLTAAGILKVLKYEFPEEKEKEFQAKNQPSLFVEEKENPGQKRYIFDSFDKFAGYLTKFQQTKKNLYAADGTSTAVATRIADNFIIFHQNTKVFRDKYKNNHTDLGFDEENIFEIERYKNCLLQREIEHIKNENSYNKIIGRINKKIKEYRDQKAKDTKLTKSDFPFFKNLDKQILGEVEKEKQLIEKTREKTEEDVLIERFKEFIENNEERFTAAKKLMNAFCNGEFESEYEGIYLKNKAINTISRRWFVSDRDFELKLPQQKSKNKSEKNEPKVKKFISIAEIKNAVEELDGDIFKAVFYDKKIIAQGGSKLEQFLVIWKYEFEYLFRDIERENGEKLLGYDSCLKIAKQLGIFPQEKEAREKATAVIKNYADAGLGIFQMMKYFSLDDKDRKNTPGQLSTNFYAEYDGYYKDFEFIKYYNEFRNFITKKPFDEDKIKLNFENGALLKGWDENKEYDFMGVILKKEGRLYLGIMHKNHRKLFQSMGNAKGDNANRYQKMIYKQIADASKDVPRLLLTSKKAMEKFKPSQEILRIKKEKTFKRESKNFSLRDLHALIEYYRNCIPQYSNWSFYDFQFQDTGKYQNIKEFTDDVQKYGYKISFRDIDDEYINQALNEGKMYLFEVVNKDIYNTKNGSKNLHTLYFEHILSAENLNDPVFKLSGMAEIFQRQPSVNEREKITTQKNQCILDKGDRAYKYRRYTEKKIMFHMSLVLNTGKGEIKQVQFNKIINQRISSSDNEMRVNVIGIDRGEKNLLYYSVVKQNGEIIEQASLNEINGVNYRDKLIEREKERLKNRQSWKPVVKIKDLKKGYISHVIHKICQLIEKYSAIVVLEDLЯМРFKQIRGGIERSVYQQFEKALIDKLGYLVFKDNRDLRAPGGVLNGYQLSAPFVSFEKMRKQTGILFYTQAEYTSKTDPITGFRKNVYISNSASLDKIKEAVKKFDAIGWDGKEQSYFFKYNPYNLADEKYKNSTVSKEWAIFASAPRIRRQKGEDGYWKYDRVKVNEEFEKLLKVWNFVNPKATDIKQEIIKKEKAGDLQGEKELDGRLRNFWHSFIYLFNLVLELRNSFSLQIKIKAGEVIAVDEGVDFIASPVKPFFTTPNPYIPSNLCWLAVENADANGAYNIARKGVMILKKIREHAKKDPEFKKLPNLFISNAEWDEAARDWGKYAGTTALNLDHKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 234).
7- Smithella sp. SC_K08D17 (SsCpf1)
MQTLFENFTNQYPVSKTLRFELIPQGKTKDFIEQKGLLKKDEDRAEKYKKVKNIIDEYHKDFIEKSLNGLKLDGLEKYKTLYLKQEKDDKDKKAFDKEKENLRKQIANAFRNNEKFKTLFAKELIKNDLMSFACEEDKKNVKEFEAFTTYFTGFHQNRANMYVADEKRTAIASRLIHENLPKFIDNIKIFEKMKKEAPELLSPFNQTLKDMKDVIKGTTLEEIFSLDYFNKTLTQSGIDIYNSVIGGRTPEEGKTKIKGLNEYINTDFNQKQTDKKKRQPKFKQLYKQILSDRQSLSFIAEAFKNDTEILEAIEKFYVNELLHFSNEGKSTNVLDAIKNAVSNLESFNLTKMYFRSGASLTDVSRKVFGEWSIINRALDNYYATTYPIKPREKSEKYEERKEKWLKQDFNVSLIQTAIDEYDNETVKGKNSGKVIADYFAKFCDDKETDLIQKVNEGYIAVKDLLNTPCPENEKLGSNKDQVKQIKAFMDSIMDIMHFVRPLSLKDTDKEKDETFYSLFTPLYDHLTQTIALYNKVRNYLTQKPYSTEKIKLNFENSTLLGGWDLNKETDNTAIILRKDNLYYLGIMDKRHNRIFRNVPKADKKDFCYEKMVYKLLPGANKMLPKVFFSQSRIQEFTPSAKLLENYANETHKKGDNFNLNHCHKLIDFFKDSINKHEDWKNFDFRFSATSTYADLSGFYHEVEHQGYKISFQSVADSFIDDLVNEGKLYLFQIYNKDFSPFSKGKPNLHTLYWKMLFDENNLKDVVYKLNGEAEVFYRKKSIAEKNTTIHKANESIINKNPDNPKATSTFNYDIVKDKRYTIDKFQFHIPITMNFKAEGIFNMNQRVNQFLKANPDINIIGIDRGERHLLYYALINQKGKILKQDTLNVIANEKQKVDYHNLLDKKEGDRATARQEWGVIETIKELKEGYLSQVIHKLTDLMIENNAIIVMEDLNFGFKRGRQKVEKQVYQKFEKMLIDKLNYLVDKNKKANELGGLLNAFQLANKFESFQKMGKQNGFIFYVPAWNTSKTDPATGFIDFLKPRYENLNQAKDFFEKFDSIRLNSKADYFEFAFDFKNFTEKADGGRTKWTVCTTNEDRYAWNRALNNNRGSQEKYDITAELKSLFDGKVDYKSGKDLKQQIASQESADFFKALMKNLSITLSLRHNNGEKGDNEQDYILSPVADSKGRFFDSRKADDDMPKNADANGAYHIALKGLWCLEQISKTDDLKKVKLAISNKEWLEFVQTLKGKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 235).
8- Acidaminococcus sp. BV3L6 (AsCpf1)
MTQFEGFTNLYQVSKTLRFELIPQGKTLKHIQEQGFIEEDKARNDHYKELKPIIDRIYKTYADQCLQLVQLDWENLSAAIDSYRKEKTEETRNALIEEQATYRNAIHDYFIGRTDNLTDAINKRHAEIYKGLFKAELFNGKVLKQLGTVTTTEHENALLRSFDKFTTYFSGFYENRKNVFSAEDISTAIPHRIVQDNFPKFKENCHIFTRLITAVPSLREHFENVKKAIGIFVSTSIEEVFSFPFYNQLLTQTQIDLYNQLLGGISREAGTEKIKGLNEVLNLAIQKNDETAHIIASLPHRFIPLFKQILSDRNTLSFILEEFKSDEEVIQSFCKYKTLLRNENVLETAEALFNELNSIDLTHIFISHKKLETISSALCDHWDTLRNALYERRISELTGKITKSAKEKVQRSLKHEDINLQEIISAAGKELSEAFKQKTSEILSHAHAALDQPLPTTLKKQEEKEILKSQLDSLLGLYHLLDWFAVDESNEVDPEFSARLTGIKLEMEPSLSFYNKARNYATKKPYSVEKFKLNFQMPTLASGWDVNKEKNNGAILFVKNGLYYLGIMPKQKGRYKALSFEPTEKTSEGFDKMYYDYFPDAAKMIPKCSTQLKAVTAHFQTHTTPILLSNNFIEPLEITKEIYDLNNPEKEPKKFQTAYAKKTGDQKGYREALCKWIDFTRDFLSKYTKTTSIDLSSLRPSSQYKDLGEYYAELNPLLYHISFQRIAEKEIMDAVETGKLYLFQIYNKDFAKGHHGKPNLHTLYWTGLFSPENLAKTSIKLNGQAELFYRPKSRMKRMAHRLGEKMLNKKLKDQKTPIPDTLYQELYDYVNHRLSHDLSDEARALLPNVITKEVSHEIIKDRRFTSDKFFFHVPITLNYQAANSPSKFNQRVNAYLKEHPETPIIGIDRGERNLIYITVIDSTGKILEQRSLNTIQQFDYQKKLDNREKERVAARQAWSVVGTIKDLKQGYLSQVIHEIVDLMIHYQAVVVLENLNFGFKSKRTGIAEKAVYQQFEKMLIDKLNCLVLKDYPAEKVGGVLNPYQLTDQFTSFAKMGTQSGFLFYVPAPYTSKIDPLTGFVDPFVWKTIKNHESRKHFLEGFDFLHYDVKTGDFILHFKMNRNLSFQRGLPGFMPAWDIVFEKNETQFDAKGTPFIAGKRIVPVIENHRFTGRYRDLYPANELIALLEEKGIVFRDGSNILPKLLENDDSHAIDTMVALIRSVLQMRNSNAATGEDYINSPVRDLNGVCFDSRFQNPEWPMDADANGAYHIALKGQLLLNHLKESKDLKLQNGISNQDWLAYIQELRNKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 236).
9- Lachnospiraceae bacterium MA2020 (Lb2Cpf1)
MYYESLTKQYPVSKTIRNELIPIGKTLDNIRQNNILESDVKRKQNYEHVKGILDEYHKQLINEALDNCTLPSLKIAAEIYLKNQKEVSDREDFNKTQDLLRKEVVEKLKAHENFTKIGKKDILDLLEKLPSISEDDYNALESFRNFYTYFTSYNKVRENLYSDKEKSSTVAYRLINENFPKFLDNVKSYRFVKTAGILADGLGEEEQDSLFIVETFNKTLTQDGIDTYNSQVGKINSSINLYNQKNQKANGFRKIPKMKMLYKQILSDREESFIDEFQSDEVLIDNVESYGSVLIESLKSSKVSAFFDALRESKGKNVYVKNDLAKTAMSNIVFENWRTFDDLLNQEYDLANENKKKDDKYFEKRQKELKKNKSYSLEHLCNLSEDSCNLIENYIHQISDDIENIIINNETFLRIVINEHDRSRKLAKNRKAVKAIKDFLDSIKVLERELKLINSSGQELEKDLIVYSAHEELLVELKQVDSLYNMTRNYLTKKPFSTEKVKLNFNRSTLLNGWDRNKETDNLGVLLLKDGKYYLGIMNTSANKAFVNPPVAKTEKVFKKVDYKLLPVPNQMLPKVFFAKSNIDFYNPSSEIYSNYKKGTHKKGNMFSLEDCHNLIDFFKESISKHEDWSKFGFKFSDTASYNDISEFYREVEKQGYKLTYTDIDETYINDLIERNELYLFQIYNKDFSMYSKGKLNLHTLYFMMLFDQRNIDDVVYKLNGEAEVFYRPASISEDELIIHKAGEEIKNKNPNRARTKETSTFSYDIVKDKRYSKDKFTLHIPITMNFGVDEVKRFNDAVNSAIRIDENVNVIGIDRGERNLLYVVVIDSKGNILEQISLNSIINKEYDIETDYHALLDEREGGRDKARKDWNTVENIRDLKAGYLSQVVNVVAKLVLKYNAIICLEDLNFGFKRGRQKVEKQVYQKFEKMLIDKLNYLVIDKSREQTSPKELGGALNALQLTSKFKSFKELGKQSGVIYYVPAYLTSKIDPTTGFANLFYMKCENVEKSKRFFDGFDFIRFNALENVFEFGFDYRSFTQRACGINSKWTVCTNGERIIKYRNPDKNNMFDEKVVVVTDEMKNLFEQYKIPYEDGRNVKDMIISNEEAEFYRRLYRLLQQTLQMRNSTSDGTRDYIISPVKNKREAYFNSELSDGSVPKDADANGAYNIARKGLWVLEQIRQKSEGEKINLAMTNAEWLEYAQTHLLKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 237).
10- Candidatus Methanoplasma termitum (CMtCpf1)
MNNYDEFTKLYPIQKTIRFELKPQGRTMEHLETFNFFEEDRDRAEKYKILKEAIDEYHKKFIDEHLTNMSLDWNSLKQISEKYYKSREEKDKKVFLSEQKRMRQEIVSEFKKDDRFKDLFSKKLFSELLKEEIYKKGNHQEIDALKSFDKFSGYFIGLHENRKNMYSDGDEITAISNRIVNENFPKFLDNLQKYQEARKKYPEWIIKAESALVAHNIKMDEVFSLEYFNKVLNQEGIQRYNLALGGYVTKSGEKMMGLNDALNLAHQSEKSSKGRIHMTPLFKQILSEKESFSYIPDVFTEDSQLLPSIGGFFAQIENDKDGNIFDRALELISSYAEYDTERIYIRQADINRVSNVIFGEWGTLGGLMREYKADSINDINLERTCKKVDKWLDSKEFALSDVLEAIKRTGNNDAFNEYISKMRTAREKIDAARKEMKFISEKISGDEESIHIIKTLLDSVQQFLHFFNLFKARQDIPLDGAFYAEFDEVHSKLFAIVPLYNKVRNYLTKNNLNTKKIKLNFKNPTLANGWDQNKVYDYASLIFLRDGNYYLGIINPKRKKNIKFEQGSGNGPFYRKMVYKQIPGPNKNLPRVFLTSTKGKKEYKPSKEIIEGYEADKHIRGDKFDLDFCHKLIDFFKESIEKHKDWSKFNFYFSPTESYGDISEFYLDVEKQGYRMHFENISAETIDEYVEKGDLFLFQIYNKDFVKAATGKKDMHTIYWNAAFSPENLQDVVVKLNGEAELFYRDKSDIKEIVHREGEILVNRTYNGRTPVPDKIHKKLTDYHNGRTKDLGEAKEYLDKVRYFKAHYDITKDRRYLNDKIYFHVPLTLNFKANGKKNLNKMVIEKFLSDEKAHIIGIDRGERNLLYYSIIDRSGKIIDQQSLNVIDGFDYREKLNQREIEMKDARQSWNAIGKIKDLKEGYLSKAVHEITKMAIQYNAIVVMEELNYGFKRGRFKVEKQIYQKFENMLIDKMNYLVFKDAPDESPGGVLNAYQLTNPLESFAKLGKQTGILFYVPAAYTSKIDPTTGFVNLFNTSSKTNAQERKEFLQKFESISYSAKDGGIFAFAFDYRKFGTSKTDHKNVWTAYTNGERMRYIKEKKRNELFDPSKEIKEALTSSGIKYDGGQNILPDILRSNNNGLIYTMYSSFIAAIQMRVYDGKEDYIISPIKNSKGEFFRTDPKRRELPIDADANGAYNIALRGELTMRAIAEKFDPDSEKMAKLELKHKDWFEFMQTRGDKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 238).
11- Eubacterium eligens (EeCpf1)
MNGNRSIVYREFVGVIPVAKTLRNELRPVGHTQEHIIQNGLIQEDELRQEKSTELKNIMDDYYREYIDKSLSGVTDLDFTLLFELMNLVQSSPSKDNKKALEKEQSKMREQICTHLQSDSNYKNIFNAKLLKEILPDFIKNYNQYDVKDKAGKLETLALFNGFSTYFTDFFEKRKNVFTKEAVSTSIAYRIVHENSLIFLANMTSYKKISEKALDEIEVIEKNNQDKMGDWELNQIFNPDFYNMVLIQSGIDFYNEICGVVNAHMNLYCQQTKNNYNLFKMRKLHKQILAYTSTSFEVPKMFEDDMSVYNAVNAFIDETEKGNIIGKLKDIVNKYDELDEKRIYISKDFYETLSCFMSGNWNLITGCVENFYDENIHAKGKSKEEKVKKAVKEDKYKSINDVNDLVEKYIDEKERNEFKNSNAKQYIREISNIITDTETAHLEYDDHISLIESEEKADEMKKRLDMYMNMYHWAKAFIVDEVLDRDEMFYSDIDDIYNILENIVPLYNRVRNYVTQKPYNSKKIKLNFQSPTLANGWSQSKEFDNNAIILIRDNKYYLAIFNAKNKPDKKIIQGNSDKKNDNDYKKMVYNLLPGANKMLPKVFLSKKGIETFKPSDYIISGYNAHKHIKTSENFDISFCRDLIDYFKNSIEKHAEWRKYEFKFSATDSYSDISEFYREVEMQGYRIDWTYISEADINKLDEEGKIYLFQIYNKDFAENSTGKENLHTMYFKNIFSEENLKDIIIKLNGQAELFYRRASVKNPVKHKKDSVLVNKTYKNQLDNGDVVRIPIPDDIYNEIYKMYNGYIKESDLSEAAKEYLDKVEVRTAQKDIVKDYRYTVDKYFIHTPITINYKVTARNNVNDMVVKYIAQNDDIHVIGIDRGERNLIYISVIDSHGNIVKQKSYNILNNYDYKKKLVEKEKTREYARKNWKSIGNIKELKEGYISGVVHEIAMLIVEYNAIIAMEDLNYGFKRGRFKVERQVYQKFESMLINKLNYFASKEKSVDEPGGLLKGYQLTYVPDNIKNLGKQCGVIFYVPAAFTSKIDPSTGFISAFNFKSISTNASRKQFFMQFDEIRYCAEKDMFSFGFDYNNFDTYNITMGKTQWTVYTNGERLQSEFNNARRTGKTKSINLTETIKLLLEDNEINYADGHDIRIDMEKMDEDKKSEFFAQLLSLYKLTVQMRNSYTEAEEQENGISYDKIISPVINDEGEFFDSDNYKESDDKECKMPKDADANGAYCIALKGLYEVLKIKSEWTEDGFDRNCLKLPHAEWLDFIQNKRYEKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 239).
12- Moraxella bovoculi 237 (MbCpf1)
MLFQDFTHLYPLSKTVRFELKPIDRTLEHIHAKNFLSQDETMADMHQKVKVILDDYHRDFIADMMGEVKLTKLAEFYDVYLKFRKNPKDDELQKQLKDLQAVLRKEIVKPIGNGGKYKAGYDRLFGAKLFKDGKELGDLAKFVIAQEGESSPKLAHLAHFEKFSTYFTGFHDNRKNMYSDEDKHTAIAYRLIHENLPRFIDNLQILTTIKQKHSALYDQIINELTASGLDVSLASHLDGYHKLLTQEGITAYNTLLGGISGEAGSPKIQGINELINSHHNQHCHKSERIAKLRPLHKQILSDGMSVSFLPSKFADDSEMCQAVNEFYRHYADVFAKVQSLFDGFDDHQKDGIYVEHKNLNELSKQAFGDFALLGRVLDGYYVDVVNPEFNERFAKAKTDNAKAKLTKEKDKFIKGVHSLASLEQAIEHYTARHDDESVQAGKLGQYFKHGLAGVDNPIQKIHNNHSTIKGFLERERPAGERALPKIKSGKNPEMTQLRQLKELLDNALNVAHFAKLLTTKTTLDNQDGNFYGEFGVLYDELAKIPTLYNKVRDYLSQKPFSTEKYKLNFGNPTLLNGWDLNKEKDNFGVILQKDGCYYLALLDKAHKKVFDNAPNTGKSIYQKMIYKYLEVRKQFPKVFFSKEAIAINYHPSKELVEIKDKGRQRSDDERLKLYRFILECLKIHPKYDKKFEGAIGDIQLFKKDKKGREVPISEKDLFDKINGIFSSKPKLEMEDFFIGEFKRYNPSQDLVDQYNIYKKIDSNDNRKKENFYNNHPKFKKDLVRYYYESMCKHEEWEESFEFSKKLQDIGCYVDVNELFTEIETRRLNYKISFCNINADYIDELVEQGQLYLFQIYNKDFSPKAHGKPNLHTLYFKALFSEDNLADPIYKLNGEAQIFYRKASLDMNETTIHRAGEVLENKNPDNPKKRQFVYDIIKDKRYTQDKFMLHVPITMNFGVQGMTIKEFNKKVNQSIQQYDEVNVIGIDRGERHLLYLTVINSKGEILEQCSLNDITTASANGTQMTTPYHKILDKREIERLNARVGWGEIETIKELKSGYLSHVVHQISQLMLKYNAIVVLEDLNFGFKRGRFKVEKQIYQNFENALIKKLNHLVLKDKADDEIGSYKNALQLTNNFTDLKSIGKQTGFLFYVPAWNTSKIDPETGFVDLLKPRYENIAQSQAFFGKFDKICYNADKDYFEFHIDYAKFTDKAKNSRQIWTICSHGDKRYVYDKTANQNKGAAKGINVNDELKSLFARHHINEKQPNLVMDICQNNDKEFHKSLMYLLKTLLALRYSNASSDEDFILSPVANDEGVFFNSALADDTQPQNADANGAYHIALKGLWLLNELKNSDDLNKVKLAIDNQTWLNFAQNRKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 240).
13- Leptospira inadai (LiCpf1)
MEDYSGFVNIYSIQKTLRFELKPVGKTLEHIEKKGFLKKDKIRAEDYKAVKKIIDKYHRAYIEEVFDSVLHQKKKKDKTRFSTQFIKEIKEFSELYYKTEKNIPDKERLEALSEKLRKMLVGAFKGEFSEEVAEKYKNLFSKELIRNEIEKFCETDEERKQVSNFKSFTTYFTGFHSNRQNIYSDEKKSTAIGYRIIHQNLPKFLDNLKIIESIQRRFKDFPWSDLKKNLKKIDKNIKLTEYFSIDGFVNVLNQKGIDAYNTILGGKSEESGEKIQGLNEYINLYRQKNNIDRKNLPNVKILFKQILGDRETKSFIPEAFPDDQSVLNSITEFAKYLKLDKKKKSIIAELKKFLSSFNRYELDGIYLANDNSLASISTFLFDDWSFIKKSVSFKYDESVGDPKKKIKSPLKYEKEKEKWLKQKYYTISFLNDAIESYSKSQDEKRVKIRLEAYFAEFKSKDDAKKQFDLLERIEEAYAIVEPLLGAEYPRDRNLKADKKEVGKIKDFLDSIKSLQFFLKPLLSAEIFDEKDLGFYNQLEGYYEEIDSIGHLYNKVRNYLTGKIYSKEKFKLNFENSTLLKGWDENREVANLCVIFREDQKYYLGVMDKENNTILSDIPKVKPNELFYEKMVYKLIPTPHMQLPRIIFSSDNLSIYNPSKSILKIREAKSFKEGKNFKLKDCHKFIDFYKESISKNEDWSRFDFKFSKTSSYENISEFYREVERQGYNLDFKKVSKFYIDSLVEDGKLYLFQIYNKDFSIFSKGKPNLHTIYFRSLFSKENLKDVCLKLNGEAEMFFRKKSINYDEKKKREGHHPELFEKLKYPILKDKRYSEDKFQFHLPISLNFKSKERLNFNLKVNEFLKRNKDINIIGIDRGERNLLYLVMINQKGEILKQTLLDSMQSGKGRPEINYKEKLQEKEIERDKARKSWGTVENIKELKEGYLSIVIHQISKLMVENNAIVVLEDLNIGFKRGRQKVERQVYQKFEKMLIDKLNFLVFKENKPTEPGGVLKAYQLTDEFQSFEKLSKQTGFLFYVPSWNTSKIDPRTGFIDFLHPAYENIEKAKQWINKFDSIRFNSKMDWFEFTADTRKFSENLMLGKNRVWVICTTNVERYFTSKTANSSIQYNSIQITEKLKELFVDIPFSNGQDLKPEILRKNDAVFFKSLLFYIKTTLSLRQNNGKKGEEEKDFILSPVVDSKGRFFNSLEASDDEPKDADANGAYHIALKGLMNLLVLNETKEENLSRPKWKIKNKDWLEFVWERNRKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 241).
14- Lachnospiraceae bacterium ND2006 (LbCpf1)
MSKLEKFTNCYSLSKTLRFKAIPVGKTQENIDNKRLLVEDEKRAEDYKGVKKLLDRYYLSFINDVLHSIKLKNLNNYISLFRKKTRTEKENKELENLEINLRKEIAKAFKGNEGYKSLFKKDIIETILPEFLDDKDEIALVNSFNGFTTAFTGFFDNRENMFSEEAKSTSIAFRCINENLTRYISNMDIFEKVDAIFDKHEVQEIKEKILNSDYDVEDFFEGEFFNFVLTQEGIDVYNAIIGGFVTESGEKIKGLNEYINLYNQKTKQKLPKFKPLYKQVLSDRESLSFYGEGYTSDEEVLEVFRNTLNKNSEIFSSIKKLEKLFKNFDEYSSAGIFVKNGPAISTISKDIFGEWNVIRDKWNAEYDDIHLKKKAVVTEKYEDDRRKSFKKIGSFSLEQLQEYADADLSVVEKLKEIIIQKVDEIYKVYGSSEKLFDADFVLEKSLKKNDAVVAIMKDLLDSVKSFENYIKAFFGEGKETNRDESFYGDFVLAYDILLKVDHIYDAIRNYVTQKPYSKDKFKLYFQNPQFMGGWDKDKETDYRATILRYGSKYYLAIMDKKYAKCLQKIDKDDVNGNYEKINYKLLPGPNKMLPKVFFSKKWMAYYNPSEDIQKIYKNGTFKKGDMFNLNDCHKLIDFFKDSISRYPKWSNAYDFNFSETEKYKDIAGFYREVEEQGYKVSFESASKKEVDKLVEEGKLYMFQIYNKDFSDKSHGTPNLHTMYFKLLFDENNHGQIRLSGGAELFMRRASLKKEELVVHPANSPIANKNPDNPKKTTTLSYDVYKDKRFSEDQYELHIPIAINKCPKNIFKINTEVRVLLKHDDNPYVIGIDRGERNLLYIVVVDGKGNIVEQYSLNEIINNFNGIRIKTDYHSLLDKKEKERFEARQNWTSIENIKELKAGYISQVVHKICELVEKYDAVIALEDLNSGFKNSRVKVEKQVYQKFEKMLIDKLNYMVDKKSNPCATGGALKGYQITNKFESFKSMSTQNGFIFYIPAWLTSKIDPSTGFVNLLKTKYTSIADSKKFISSFDRIMYVPEEDLFEFALDYKNFSRTDADYIKKWKLYSYGNRIRIFRNPKKNNVFDWEEVCLTSAYKELFNKYGINYQQGDIRALLCEQSDKAFYSSFMALMSLMLQMRNSITGRTDVDFLISPVKNSDGIFYDSRNYEAQENAILPKNADANGAYNIARKVLWAIGQFKKAEDEKLDKVKIAISNKEWLEYAQTSVKHKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 242).
15- Porphyromonas crevioricanis (PcCpf1)
MDSLKDFTNLYPVSKTLRFELKPVGKTLENIEKAGILKEDEHRAESYRRVKKIIDTYHKVFIDSSLENMAKMGIENEIKAMLQSFCELYKKDHRTEGEDKALDKIRAVLRGLIVGAFTGVCGRRENTVQNEKYESLFKEKLIKEILPDFVLSTEAESLPFSVEEATRSLKEFDSFTSYFAGFYENRKNIYSTKPQSTAIAYRLIHENLPKFIDNILVFQKIKEPIAKELEHIRADFSAGGYIKKDERLEDIFSLNYYIHVLSQAGIEKYNALIGKIVTEGDGEMKGLNEHINLYNQQRGREDRLPLFRPLYKQILSDREQLSYLPESFEKDEELLRALKEFYDHIAEDILGRTQQLMTSISEYDLSRIYVRNDSQLTDISKKMLGDWNAIYMARERAYDHEQAPKRITAKYERDRIKALKGEESISLANLNSCIAFLDNVRDCRVDTYLSTLGQKEGPHGLSNLVENVFASYHEAEQLLSFPYPEENNLIQDKDNVVLIKNLLDNISDLQRFLKPLWGMGDEPDKDERFYGEYNYIRGALDQVIPLYNKVRNYLTRKPYSTRKVKLNFGNSQLLSGWDRNKEKDNSCVILRKGQNFYLAIMNNRHKRSFENKMLPEYKEGEPYFEKMDYKFLPDPNKMLPKVFLSKKGIEIYKPSPKLLEQYGHGTHKKGDTFSMDDLHELIDFFKHSIEAHEDWKQFGFKFSDTATYENVSSFYREVEDQGYKLSFRKVSESYVYSLIDQGKLYLFQIYNKDFSPCSKGTPNLHTLYWRMLFDERNLADVIYKLDGKAEIFFREKSLKNDHPTHPAGKPIKKKSRQKKGEESLFEYDLVKDRRYTMDKFQFHVPITMNFKCSAGSKVNDMVNAHIREAKDMHVIGIDRGERNLLYICVIDSRGTILDQISLNTINDIDYHDLLESRDKDRQQEHRNWQTIEGIKELKQGYLSQAVHRIAELMVAYKAVVALEDLNMGFKRGRQKVESSVYQQFEKQLIDKLNYLVDKKKRPEDIGGLLRAYQFTAPFKSFKEMGKQNGFLFYIPAWNTSNIDPTTGFVNLFHVQYENVDKAKSFFQKFDSISYNPKKDWFEFAFDYKNFTKKAEGSRSMWILCTHGSRIKNFRNSQKNGQWDSEEFALTEAFKSLFVRYEIDYTADLKTAIVDEKQKDFFVDLLKLFKLTVQMRNSWKEKDLDYLISPVAGADGRFFDTREGNKSLPKDADANGAYNIALKGLWALRQIRQTSEGGKLKLAISNKEWLQFVQERSYEKDKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 243).
16- Prevotella disiens (PdCpf1)
MENYQEFTNLFQLNKTLRFELKPIGKTCELLEEGKIFASGSFLEKDKVRADNVSYVKKEIDKKHKIFIEETLSSFSISNDLLKQYFDCYNELKAFKKDCKSDEEEVKKTALRNKCTSIQRAMREAISQAFLKSPQKKLLAIKNLIENVFKADENVQHFSEFTSYFSGFETNRENFYSDEEKSTSIAYRLVHDNLPIFIKNIYIFEKLKEQFDAKTLSEIFENYKLYVAGSSLDEVFSLEYFNNTLTQKGIDNYNAVIGKIVKEDKQEIQGLNEHINLYNQKHKDRRLPFFISLKKQILSDREALSWLPDMFKNDSEVIKALKGFYIEDGFENNVLTPLATLLSSLDKYNLNGIFIRNNEALSSLSQNVYRNFSIDEAIDANAELQTFNNYELIANALRAKIKKETKQGRKSFEKYEEYIDKKVKAIDSLSIQEINELVENYVSEFNSNSGNMPRKVEDYFSLMRKGDFGSNDLIENIKTKLSAAEKLLGTKYQETAKDIFKKDENSKLIKELLDATKQFQHFIKPLLGTGEEADRDLVFYGDFLPLYEKFEELTLLYNKVRNRLTQKPYSKDKIRLCFNKPKLMTGWVDSKTEKSDNGTQYGGYLFRKKNEIGEYDYFLGISSKAQLFRKNEAVIGDYERLDYYQPKANTIYGSAYEGENSYKEDKKRLNKVIIAYIEQIKQTNIKKSIIESISKYPNISDDDKVTPSSLLEKIKKVSIDSYNGILSFKSFQSVNKEVIDNLLKTISPLKNKAEFLDLINKDYQIFTEVQAVIDEICKQKTFIYFPISNVELEKEMGDKDKPLCLFQISNKDLSFAKTFSANLRKKRGAENLHTMLFKALMEGNQDNLDLGSGAIFYRAKSLDGNKPTHPANEAIKCRNVANKDKVSLFTYDIYKNRRYMENKFLFHLSIVQNYKAANDSAQLNSSATEYIRKADDLHIIGIDRGERNLLYYSVIDMKGNIVEQDSLNIIRNNDLETDYHDLLDKREKERKANRQNWEAVEGIKDLKKGYLSQAVHQIAQLMLKYNAIIALEDLGQMFVTRGQKIEKAVYQQFEKSLVDKLSYLVDKKRPYNELGGILKAYQLASSITKNNSDKQNGFLFYVPAWNTSKIDPVTGFTDLLRPKAMTIKEAQDFFGAFDNISYNDKGYFEFETNYDKFKIRMKSAQTRWTICTFGNRIKRKKDKNYWNYEEVELTEEFKKLFKDSNIDYENCNLKEEIQNKDNRKFFDDLIKLLQLTLQMRNSDDKGNDYIISPVANAEGQFFDSRNGDKKLPLDADANGAYNIARKGLWNIRQIKQTKNDKKLNLSISSTEWLDFVREKPYLKKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 244).
17- Porphyromonas macacae (PmCpf1)
MKTQHFFEDFTSLYSLSKTIRFELKPIGKTLENIKKNGLIRRDEQRLDDYEKLKKVIDEYHEDFIANILSSFSFSEEILQSYIQNLSESEARAKIEKTMRDTLAKAFSEDERYKSIFKKELVKKDIPVWCPAYKSLCKKFDNFTTSLVPFHENRKNLYTSNEITASIPYRIVHVNLPKFIQNIEALCELQKKMGADLYLEMMENLRNVWPSFVKTPDDLCNLKTYNHLMVQSSISEYNRFVGGYSTEDGTKHQGINEWINIYRQRNKEMRLPGLVFLHKQILAKVDSSSFISDTLENDDQVFCVLRQFRKLFWNTVSSKEDDAASLKDLFCGLSGYDPEAIYVSDAHLATISKNIFDRWNYISDAIRRKTEVLMPRKKESVERYAEKISKQIKKRQSYSLAELDDLLAHYSEESLPAGFSLLSYFTSLGGQKYLVSDGEVILYEEGSNIWDEVLIAFRDLQVILDKDFTEKKLGKDEEAVSVIKKALDSALRLRKFFDLLSGTGAEIRRDSSFYALYTDRMDKLKGLLKMYDKVRNYLTKKPYSIEKFKLHFDNPSLLSGWDKNKELNNLSVIFRQNGYYYLGIMTPKGKNLFKTLPKLGAEEMFYEKMEYKQIAEPMLMLPKVFFPKKTKPAFAPDQSVVDIYNKKTFKTGQKGFNKKDLYRLIDFYKEALTVHEWKLFNFSFSPTEQYRNIGEFFDEVREQAYKVSMVNVPASYIDEAVENGKLYLFQIYNKDFSPYSKGIPNLHTLYWKALFSEQNQSRVYKLCGGGELFYRKASLHMQDTTVHPKGISIHKKNLNKKGETSLFNYDLVKDKRFTEDKFFFHVPISINYKNKKITNVNQMVRDYIAQNDDLQIIGIDRGERNLLYISRIDTRGNLLEQFSLNVIESDKGDLRTDYQKILGDREQERLRRRQEWKSIESIKDLKDGYMSQVVHKICNMVVEHKAIVVLENLNLSFMKGRKKVEKSVYEKFERMLVDKLNYLVVDKKNLSNEPGGLYAAYQLTNPLFSFEELHRYPQSGILFFVDPWNTSLTDPSTGFVNLLGRINYTNVGDARKFFDRFNAIRYDGKGNILFDLDLSRFDVRVETQRKLWTLTTFGSRIAKSKKSGKWMVERIENLSLCFLELFEQFNIGYRVEKDLKKAILSQDRKEFYVRLIYLFNLMMQIRNSDGEEDYILSPALNEKNLQFDSRLIEAKDLPVDADANGAYNVARKGLMVVQRIKRGDHESIHRIGRAQWLRYVQEGIVEKRPAATKKAGQAKKKKGSYPYDVPDYAYPYDVPDYAYPYDVPDYA (SEQ ID NO: 245).
Пример 15. Компьютерный анализ структуры Cpf1
С помощью компьютерного анализа первичной структуры нуклеаз Cpf1 выявили три отличающихся участка (фигура 109). Первый, C-концевой RuvC-подобный домен, который является единственным охарактеризованным функциональным доменом. Второй, N-концевой альфа-спиральный участок, и третий, участок со смешанной альфа- и бета-структурой, расположенный между RuvC-подобным доменом и альфа-спиральным участком.
Несколько небольших отрезков из неструктурированных участков прогнозируются в первичной структуре Cpf1. Неструктурированные участки, которые подвергаются воздействию растворителя и не являются консервативными в пределах разных ортологов Cpf1, представляют собой предпочтительные стороны для разделений и вставок небольших белковых последовательностей. Кроме того, эти стороны можно использовать для создания химерных белков между ортологами Cpf1.
Пример 16. Получение мутантов Cpf1 с усиленной специфичностью
Недавно был описан способ получения ортологов Cas9 с усиленной специфичностью (Slaymaker et al. 2015). Данную стратегию можно применять для усиления специфичности ортологов Cpf1.
Основными остатками для проведения мутагенеза являются все положительно заряженные остатки в пределах домена RuvC, поскольку это единственная известная структура в отсутствие кристалла, и известно, что мутанты RuvC с измененной специфичностью функционировали в Cas9 (см таблицу ниже: консервативные лизиновые и аргининовые остатки в пределах RuvC).
Не вдаваясь в теорию, положительно заряженные остатки этого участка Cpf1 могут функционировать для стабилизации взаимодействия между ферментом и ДНК в результате взаимодействия с отрицательно заряженным фосфодиэфирным остовом не подвергаемой нацеливанию нити ДНК. Путем замены положительно заряженных остатков Cpf1 взаимодействия с не подвергаемой нацеливанию нитью могут быть нарушены. При надлежащем нарушении этого взаимодействия может сохраняться соответствующая активность по отношению к целевым сайтам, однако снижаться активность фермента по отношению к нецелевым сайтам (которые, как обычно будет ожидаться, характеризуются более слабыми взаимодействиями с направляющей последовательностью за счет одного или нескольких несовпадений по сравнению с целевой последовательностью).
Другие домены проявляют аналогичные особенности. Представляющим интерес участком является домен REC1, включая без ограничения мутацию одного или нескольких аминокислотных остатков, аналогичных N497, R661, Q695 или Q926 в SpCas9, и включая без ограничения мутации с преобразованием в аланин в этих положениях. Мутации по таким остаткам также нарушают взаимодействие фермент-фосфатный остов ДНК. Более того, можно использовать комбинации мутаций, расположенных в одном или различных доменах.
Таблица. Консервативные лизиновые и аргининовые остатки в пределах RuvC.
Дополнительными кандидатами являются положительно заряженные остатки, которые являются консервативными у различных ортологов, и они представлены в таблице ниже.
Таблица. Консервативные лизиновые и аргининовые остатки

В таблице выше представлены положения консервативных лизиновых и аргининовых остатков в выравнивании нуклеазы Cpf1 от Francisella novicida U112 (FnCpf1), Acidaminococcus sp. BV3L6 (AsCpf1), Lachnospiraceae bacterium ND2006 (LbCpf1) и Moraxella bovoculi 237 (MbCpf1). Их можно использовать для получения мутантов Cpf1 c усиленной специфичностью.
Пример 17. Улучшенная специфичность связывания Cpf1
С помощью стратегии, подобной той, которую применяли для улучшения специфичности Cas9, специфичность Cpf1 может быть улучшена путем мутирования остатков, которые стабилизируют не подвергаемую нацеливанию нить ДНК. Этого можно достичь без определения кристаллической структуры путем применения выравниваний линейной структуры для прогнозирования того, 1) какой домен Cpf1 связывается с какой нитью ДНК и 2) какие остатки в пределах этих доменов контактируют с ДНК.
Однако данный подход может быть ограничен вследствие недостаточной степени консервативности Cpf1 относительно известных белков. Таким образом, может потребоваться исследование функции всех аминокислот, которые, вероятно, взаимодействуют с ДНК (лизин, гистидин и аргинин).
Положительно заряженные остатки в домене RuvC являются более консервативными во всех Cpf1, чем остатки в домене Rad50, что указывает на то, что остатки в RuvC являются менее эволюционно гибкими. Это указывает на то, что в данном домене необходим строгий контроль связывания нуклеиновых кислот (относительно домена Rad50). Следовательно, возможно, что данный домен разрезает подвергаемую нацеливанию нить ДНК, из-за необходимости стабилизировать дуплекс РНК:ДНК (аналогично Cas9). Кроме того, больше остатков аргинина присутствует в домене RuvC (5% из остатков RuvC от 904 до 1307 в сравнении с 3,8% в предположительных доменах Rad50), что снова указывает на то, что RuvC нацеливается на одну из нитей ДНК. Остатки аргинина в большей степени вовлечены в связывание с большой или малой бороздками нуклеиновой кислоты (Rohs Nature 2009: http://rohslab.cmb.usc.edu/Papers/Rohs_etal_Nature.pdf). Большая/малая бороздки будут присутствовать только в дуплексе (таком как дуплекс нацеливания ДНК:РНК), что дополнительно указывает на то, что RuvC может быть вовлечен в разрезание.
На фигурах 110, 111 и 112 представлены кристаллические структуры двух доменов, аналогичных обнаруженным в Cpf1 (RuvC-резольваза структур Холлидея и Rad50-белок для репарации ДНК). На основании этих структур можно сделать вывод, что соответственные домены Cpf1 являются аналогичными, и определить какие участки и остатки могут контактировать с ДНК. В каждой структуре выделены остатки, которые контактируют с ДНК. В выравниваниях на фигуре 113 аннотированы участки AsCpf1, которые соответствуют этим участкам связывания ДНК. В перечне остатков в таблице ниже представлены остатки, обнаруженные в двух связывающих доменах.
Таблица. - Перечень возможных остатков, взаимодействующих с ДНК
На основании этих конкретных сведений про AsCpf1 можно идентифицировать подобные остатки в Cpf1 от других видов путем выравниваний последовательностей. В пример выравнивания AsCpf1 и FnCpf1, приведенном на фигуре 114, идентифицированы связывающие домены Rad50 и остатки аргинина и лизина в них.
Пример 18. Мультиплексирование в случае Cpf1 с применением тандемных направляющих
Анализировали, возможно ли мультиплексирование в случае фермента Cpf1. С этой целью разрабатывали направляющие РНК, причем различные направляющие последовательности располагали тандемно под контролем одного промотора, и определяли способность этих направляющих управлять редактированием генома в отношении их соответствующих мишеней.
По 150000 клеток HEK293T высевали на лунку 24-луночного планшета за 24 ч. перед трансфекцией. Клетки трансфицировали с помощью 400 нг плазмиды с huAsCpf1 и 100 нг плазмиды с тандемными направляющими, содержащей одну направляющую последовательность, направленную на GRIN28, и одну, направленную на EMX1, размещенные тандемно за промотором U6 (фигура 115A), с применением Lipofectamin2000. Клетки собирали через 72 ч. после трансфекции и активность AsCpf1, опосредованную тандемными направляющими, оценивали с применением анализа с помощью нуклеазы SURVEYOR.
Результаты продемонстрированы на фигуре 115B, где продемонстрировано образование вставок/делеций как в GRIN28, так и в гене EMX1.
Таким образом, определили, что AsCpf1 и, по аналогии LbCpf1, могут использовать две направляющие, экспрессированные с одного промотора U6, без потери активности. Положение в пределах тандема не влияет на образование вставок/делеций. Это продемонстрировало, что Cpf1 можно применять для мультиплексирования с применением двух или более направляющих.
Настоящее изобретение дополнительно описано с помощью следующих пронумерованных пунктов:
1. Сконструированная не встречающаяся в природе система на основе коротких палиндромных повторов, регулярно расположенных группами (CRISPR)-CRISPR-ассоциированного фермента (Cas) (CRISPR-Cas), содержащая
a) одну или несколько полинуклеотидных последовательностей CRISPR-Cas V типа, предусматривающих направляющую РНК, которая содержит направляющую последовательность, связанную с последовательностью прямого повтора, где направляющая последовательность способна гибридизироваться с целевой последовательностью, или одну или несколько нуклеотидных последовательностей, кодирующих одну или несколько полинуклеотидных последовательностей CRISPR-Cas V типа, и
b) эффекторный белок Cpf1 или одну или несколько нуклеотидных последовательностей, кодирующих эффекторный белок Cpf1;
где одна или несколько направляющих последовательностей гибридизируются с указанной целевой последовательностью, причем указанная последовательность находится в направлении 3' от мотива, смежного с протоспейсером (PAM), и указанная направляющая РНК образует комплекс с эффекторным белком Cpf1.
2. Сконструированная не встречающаяся в природе векторная система на основе коротких палиндромных повторов, регулярно расположенных группами (CRISPR)-CRISPR-ассоциированного фермента (Cas) (CRISPR-Cas), содержащая один или несколько векторов, содержащих
c) первый регуляторный элемент, функционально связанный с одной или несколькими нуклеотидными последовательностями, кодирующими одну или несколько полинуклеотидных последовательностей CRISPR-Cas V типа, предусматривающих направляющую РНК, которая содержит направляющую последовательность, связанную с последовательностью прямого повтора, где направляющая последовательность способна гибридизироваться с целевой последовательностью,
d) второй регуляторный элемент, функционально связанный с нуклеотидной последовательностью, кодирующей эффекторный белок Cpf1;
где компоненты (a) и (b) находятся в одном и том же или в разных векторах системы,
где, будучи транскрибированными, одна или несколько направляющих последовательностей гибридизируются с указанной целевой последовательностью, причем указанная последовательность находится в направлении 3' от мотива, смежного с протоспейсером (PAM), и при этом указанная направляющая РНК образует комплекс с эффекторным белком Cpf1.
3. Система по пункту 1 или 2, где целевые последовательности находятся в клетке.
4. Система по пункту 3, где клетка предусматривает эукариотическую клетку.
5. Система по любому из пунктов 1-4, где, будучи транскрибированными, одна или несколько направляющих последовательностей гибридизируются с целевой последовательностью, и при этом направляющая РНК образует комплекс c эффекторным белком Cpf1, который вызывает расщепление отдаленно от целевой последовательности.
6. Система по пункту 5, где указанное расщепление приводит к образованию ступенчатого двухнитевого разрыва с "липким" 5'-концом длиной 4 или 5 нуклеотидов.
7. Система по любому из пунктов 1-6, где PAM предусматривает 5'-мотив с высоким содержанием T.
8. Система по любому из пунктов 1-7, где эффекторный белок представляет собой эффекторный белок Cpf1, происходящий от одного из видов бактерий, приведенных на фигуре 64.
9. Система по пункту 8, где эффекторный белок Cpf1 происходит от вида бактерий, выбранного из группы, состоящей из Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens и Porphyromonas macacae.
10. Система по пункту 9, где последовательность PAM представляет собой TTN, где N представляет собой A/C/G или T, а эффекторный белок представляет собой FnCpf1, или где последовательность PAM представляет собой TTTV, где V представляет собой A/C или G, а эффекторный белок представляет собой PaCpf1p, LbCpf1 или AsCpf1.
11. Система по любому из пунктов 1-10, где эффекторный белок Cpf1 содержит один или несколько сигналов ядерной локализации.
12. Система по любому из пунктов 1-11, где последовательности нуклеиновой кислоты, кодирующие эффекторный белок Cpf1, являются кодон-оптимизированными для экспрессии в эукариотической клетке.
13. Система по любому из пунктов 1-12, где компоненты (a) и (b) или нуклеотидные последовательности находятся в одном векторе.
14. Способ модифицирования представляющего интерес целевого локуса, включающий доставку системы по любому из пунктов 1-13 в указанный локус или клетку, содержащую локус.
15. Способ модифицирования представляющего интерес целевого локуса, причем способ включает доставку в указанный локус не встречающейся в природе или сконструированной композиции, содержащей эффекторный белок Cpf1 и один или несколько компонентов на основе нуклеиновой кислоты, где эффекторный белок Cpf1 образует комплекс с одним или несколькими компонентами на основе нуклеиновой кислоты, и после связывания указанного комплекса с представляющим интерес целевым локусом, который находится в направлении 3' от мотива, смежного с протоспейсером (PAM), эффекторный белок индуцирует модификацию представляющего интерес целевого локуса, где комплекс содержит Mg2+.
16. Способ по пункту 14 или 15, где представляющий интерес целевой локус находится в клетке.
17. Способ по пункту 16, где клетка является эукариотической клеткой.
18. Способ по пункту 16, где клетка является клеткой животного или человека.
19. Способ по пункту 16, где клетка является растительной клеткой.
20. Способ по пункту 14 или 15, где представляющий интерес целевой локус содержится в молекуле ДНК in vitro.
21. Способ по любому из пунктов 15-20, где указанную не встречающуюся в природе или сконструированную композицию, содержащую эффекторный белок Cpf1 и один или несколько компонентов на основе нуклеиновой кислоты, доставляют в клетку в виде одной или нескольких полинуклеотидных молекул.
22. Способ по любому из пунктов 14-21, где представляющий интерес целевой локус предусматривает ДНК.
23. Способ по пункту 22, где ДНК является релаксированной или суперспирализованной.
24. Способ по любому из пунктов 14-23, где композиция содержит один компонент на основе нуклеиновой кислоты.
25. Способ по пункту 24, где один компонент на основе нуклеиновой кислоты предусматривает направляющую последовательность, связанную с последовательностью прямого повтора.
26. Способ по любому из пунктов 14-25, где модификация представляющего интерес целевого локуса представляет собой разрыв нити.
27. Способ по пункту 26, где разрыв нити предусматривает ступенчатый двухнитевой разрыв ДНК с "липким" 5'-концом длиной 4 или 5 нуклеотидов.
28. Способ по пункту 26 или 27, где представляющий интерес целевой локус является модифицированным посредством интеграции ДНК-вставки в ступенчатый двухнитевой разрыв ДНК.
29. Способ по любому из пунктов 14-28, где эффекторный белок Cpf1 содержит один или несколько сигналов ядерной локализации (NLS).
30. Способ по любому из пунктов 21-29, где одна или несколько полинуклеотидных молекул содержатся в одном или нескольких векторах.
31. Способ по любому из пунктов 21-30, где одна или несколько полинуклеотидных молекул содержат один или несколько регуляторных элементов, функционально сконфигурированных для обеспечения экспрессии эффекторного белка Cpf1 и/или компонента(компонентов) на основе нуклеиновой кислоты, где один или несколько регуляторных элементов необязательно предусматривают индуцируемые промоторы.
32. Способ по любому из пунктов 21-31, где одна или несколько полинуклеотидных молекул или один или несколько векторов содержатся в системе доставки.
33. Способ по любому из пунктов 14-30, где систему или одну или несколько полинуклеотидных молекул доставляют посредством частиц, везикул или одного или нескольких вирусных векторов.
34. Способ по пункту 33, где частицы предусматривают липид, сахар, металл или белок.
35. Способ по пункту 33, где везикулы предусматривают экзосомы или липосомы.
36. Способ по пункту 33, где один или несколько вирусных векторов предусматривают одно или несколько из аденовируса, одного или нескольких лентивирусов или одного или нескольких аденоассоциированных вирусов.
37. Способ по любому из пунктов 14-36, который представляет собой способ модифицирования клетки, линии клеток или организма путем манипуляции с одной или несколькими целевыми последовательностями в представляющих интерес локусах генома.
38. Клетка, полученная в результате осуществления способа по пункту 37, или ее потомство, где клетка содержит модификацию, не присутствующую в клетке, в отношении которой не осуществляли способ.
39. Клетка по пункту 38 или ее потомство, где клетка, в отношении которой не осуществляли способ, содержит аномалию, а клетка, полученная в результате осуществления способа, характеризуется устраненной или скорректированной аномалией.
40. Продукт клетки, полученный из клетки или ее потомства по пункту 38, где продукт является модифицированным по своей природе или количеству по сравнению с продуктом клетки, полученным из клетки, в отношении которой не осуществляли способ.
41. Продукт клетки по пункту 40, где клетка, в отношении которой не осуществляли способ, содержит аномалию, и при этом продукт клетки отражает аномалию, которая устраняется или корректируется с помощью способа.
42. In vitro, ex vivo или in vivo клетка-хозяин или линия клеток или их потомство, содержащие систему по любому из пунктов 1-13.
43. Клетка-хозяин или линия клеток или их потомство по пункту 42, где клетка является эукариотической клеткой.
44. Клетка-хозяин или линия клеток или их потомство по пункту 43, где клетка является клеткой животного.
45. Клетка-хозяин или линия клеток или их потомство по пункту 33, где клетка является клеткой человека.
46. Клетка-хозяин, линия клеток или их потомство по пункту 31, предусматривающие стволовую клетку или линию стволовых клеток.
47. Клетка-хозяин или линия клеток или их потомство по пункту 30, где клетка является растительной клеткой.
48. Способ получения растения с модифицированным представляющим интерес признаком, кодируемым представляющим интерес геном, причем указанный способ включает приведение растительной клетки в контакт с системой по любому из пунктов 1-13 или осуществление в отношении растительной клетки способа по любому из пунктов 14-17 или 19-37, за счет чего обеспечивается либо модифицирование, либо введение указанного представляющего интерес гена, и регенерацию растения из указанной растительной клетки.
49. Способ идентификации представляющего интерес признака у растения, причем указанный представляющий интерес признак кодируется представляющим интерес геном, причем указанный способ включает приведение растительной клетки в контакт с системой по любому из пунктов 1-13 или осуществление в отношении растительной клетки способа по любому из пунктов 14-17 или 19-37, за счет чего обеспечивается идентификация указанного представляющего интерес гена.
50. Способ по пункту 49, дополнительно включающий введение идентифицированного представляющего интерес гена в растительную клетку, или линию растительных клеток, или растительную зародышевую плазму и получение из них растения, в результате чего растение содержит представляющий интерес ген.
51. Способ по пункту 50, где у растения проявляется представляющий интерес признак.
52. Частица, содержащая систему по любому из пунктов 1-13.
53. Частица по пункту 52, где частица содержит эффекторный белок Cpf1 в комплексе с направляющей РНК.
54. Система или способ по любому из предыдущих пунктов, где комплекс, направляющая РНК или белок конъюгированы по меньшей мере с одним сахарным фрагментом, необязательно N-ацетилгалактозамином (GalNAc), в частности, с трехразветвленным GalNAc.
55. Система или способ по любому из предыдущих пунктов, где концентрация Mg2+ составляет от приблизительно 1 мМ до приблизительно 15 мМ.
56. Выделенный белок, характеризующийся по меньшей мере 60% идентичностью последовательности с AsCpf1 или LbCpf1 и способный связывать целевую ДНК с помощью комплекса с направляющей РНК, содержащей последовательность прямого повтора и направляющую последовательность, при этом не требуется присутствие tracrRNA.
57. Выделенная нуклеиновая кислота, кодирующая белок по пункту 56.
58. Способ по пункту 17, который представляет собой способ лечения заболевания, вызванного генетическим дефектом в указанной клетке.
59. Способ по пункту 58, где указанный способ осуществляют в клетке in vivo или ex vivo.
60. Не встречающаяся в природе или сконструированная композиция, содержащая эффекторный белок Cpf1 и одну или несколько направляющих РНК, содержащих последовательность прямого повтора и направляющую последовательность, способную гибридизироваться с целевой ДНК в представляющем интерес локусе, где эффекторный белок Cpf1 образует комплекс с одной или несколькими направляющими РНК, и после связывания указанного комплекса с представляющим интерес целевым локусом, который находится в направлении 3' от мотива, смежного с протоспейсером (PAM), эффекторный белок индуцирует модификацию представляющего интерес целевого локуса.
61. Не встречающаяся в природе или сконструированная композиция, содержащая полинуклеотидную последовательность, кодирующую эффекторный белок Cpf1 и одну или несколько направляющих РНК, содержащих последовательность прямого повтора и направляющую последовательность, способную гибридизироваться с целевой ДНК в представляющем интерес локусе, где, будучи экспрессированным, эффекторный белок Cpf1 образует комплекс с одной или несколькими направляющими РНК, и после связывания указанного комплекса с представляющим интерес целевым локусом, который находится в направлении 3' от мотива, смежного с протоспейсером (PAM), эффекторный белок индуцирует модификацию представляющего интерес целевого локуса.
62. Композиция по пункту 60 или 61, которая является фармацевтической композицией.
63. Композиция по пункту 60 или 61 для применения в качестве лекарственного препарата.
64. Композиция по пункту 60 или 61 для применения в лечении заболевания или нарушения, вызванных генетическим дефектом в представляющем интерес целевом локусе.
65. Способ по пункту 58 или композиция для применения по пункту 64, где клетка является клеткой HSC.
66. Способ по пункту 58 или композиция для применения по пункту 64, где заболевание или нарушение представляет собой нарушение, связанное с клетками крови.
* * *
Несмотря на то, что предпочтительные варианты осуществления настоящего изобретения были показаны и описаны в данном документе, для специалистов в данной области будет очевидно, что такие варианты осуществления предоставлены только в качестве примера. Многочисленные варианты, изменения и замены теперь будут очевидны для специалистов в данной области без отступления от сути настоящего изобретения. Следует понимать, что различные альтернативы вариантов осуществления настоящего изобретения, раскрытые в данном документе, можно использовать при практическом осуществлении настоящего изобретения. Подразумевается, что следующая формула изобретения определяет объем настоящего изобретения, и что, таким образом, охвачены способы и структуры в пределах объема данной формулы изобретения и их эквиваленты.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> ZHANG, FENG
ZETSCHE, BERND
SLAYMAKER, IAN
GOOTENBERG, JONATHAN S.
ABUDAYYEH, OMAR O.
<120> НОВЫЕ ФЕРМЕНТЫ И СИСТЕМЫ CRISPR
<130> 47627.05.2123
<140> 14/975,085
<141> 2015-12-18
<150> 62/232,067
<151> 2015-09-24
<150> 62/205,733
<151> 2015-08-16
<150> 62/201,542
<151> 2015-08-05
<150> 62/193,507
<151> 2015-07-16
<150> 62/181,739
<151> 2015-06-18
<160> 1595
<170> PatentIn версия 3.5
<210> 1
<211> 7
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность участка активного сайта XerD
<400> 1
Leu Tyr Trp Thr Gly Met Arg
1 5
<210> 2
<211> 7
<212> БЕЛОК
<213> Вирус обезьян 40
<400> 2
Pro Lys Lys Lys Arg Lys Val
1 5
<210> 3
<211> 16
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность двусоставного NLS из нуклеоплазмина
<400> 3
Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1 5 10 15
<210> 4
<211> 9
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность NLS из C-myc
<400> 4
Pro Ala Ala Lys Arg Val Lys Leu Asp
1 5
<210> 5
<211> 11
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность NLS из C-myc
<400> 5
Arg Gln Arg Arg Asn Glu Leu Lys Arg Ser Pro
1 5 10
<210> 6
<211> 38
<212> БЕЛОК
<213> Homo sapiens
<400> 6
Asn Gln Ser Ser Asn Phe Gly Pro Met Lys Gly Gly Asn Phe Gly Gly
1 5 10 15
Arg Ser Ser Gly Pro Tyr Gly Gly Gly Gly Gln Tyr Phe Ala Lys Pro
20 25 30
Arg Asn Gln Gly Gly Tyr
35
<210> 7
<211> 42
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность домена IBB из импортина-альфа
<400> 7
Arg Met Arg Ile Glx Phe Lys Asn Lys Gly Lys Asp Thr Ala Glu Leu
1 5 10 15
Arg Arg Arg Arg Val Glu Val Ser Val Glu Leu Arg Lys Ala Lys Lys
20 25 30
Asp Glu Gln Ile Leu Lys Arg Arg Asn Val
35 40
<210> 8
<211> 8
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность из T-белка миомы
<400> 8
Val Ser Arg Lys Arg Pro Arg Pro
1 5
<210> 9
<211> 8
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность из T-белка миомы
<400> 9
Pro Pro Lys Lys Ala Arg Glu Asp
1 5
<210> 10
<211> 8
<212> БЕЛОК
<213> Homo sapiens
<400> 10
Pro Gln Pro Lys Lys Lys Pro Leu
1 5
<210> 11
<211> 12
<212> БЕЛОК
<213> Mus musculus
<400> 11
Ser Ala Leu Ile Lys Lys Lys Lys Lys Met Ala Pro
1 5 10
<210> 12
<211> 5
<212> БЕЛОК
<213> Вирус гриппа
<400> 12
Asp Arg Leu Arg Arg
1 5
<210> 13
<211> 7
<212> БЕЛОК
<213> Вирус гриппа
<400> 13
Pro Lys Gln Lys Lys Arg Lys
1 5
<210> 14
<211> 10
<212> БЕЛОК
<213> Вирус гепатита дельта
<400> 14
Arg Lys Leu Lys Lys Lys Ile Lys Lys Leu
1 5 10
<210> 15
<211> 10
<212> БЕЛОК
<213> Mus musculus
<400> 15
Arg Glu Lys Lys Lys Phe Leu Lys Arg Arg
1 5 10
<210> 16
<211> 20
<212> БЕЛОК
<213> Homo sapiens
<400> 16
Lys Arg Lys Gly Asp Glu Val Asp Gly Val Asp Glu Val Ala Lys Lys
1 5 10 15
Lys Ser Lys Lys
20
<210> 17
<211> 17
<212> БЕЛОК
<213> Homo sapiens
<400> 17
Arg Lys Cys Leu Gln Ala Gly Met Asn Leu Glu Ala Arg Lys Thr Lys
1 5 10 15
Lys
<210> 18
<211> 4
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический пептид
<400> 18
Gly Gly Gly Ser
1
<210> 19
<211> 15
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический пептид
<400> 19
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 20
<211> 30
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 20
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25 30
<210> 21
<211> 45
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 21
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
35 40 45
<210> 22
<211> 60
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 22
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
50 55 60
<210> 23
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 23
gagtccgagc agaagaagaa 20
<210> 24
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 24
gagtcctagc aggagaagaa 20
<210> 25
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 25
gagtctaagc agaagaagaa 20
<210> 26
<211> 9
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Пептид, относящийся к семейству пептидов, содержащих мотив LAGLIDADG"
<400> 26
Leu Ala Gly Leu Ile Asp Ala Asp Gly
1 5
<210> 27
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 27
gccgcagcga augccguuuc acgaaucguc aggcgg 36
<210> 28
<211> 75
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 28
gcuggagacg uuuuuugaaa cggcgagugc ugcggauagc gaguuucucu uggggaggcg 60
cucgcggcca cuuuu 75
<210> 29
<211> 1388
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Opitutaceae bacterium
<400> 29
Met Ser Leu Asn Arg Ile Tyr Gln Gly Arg Val Ala Ala Val Glu Thr
1 5 10 15
Gly Thr Ala Leu Ala Lys Gly Asn Val Glu Trp Met Pro Ala Ala Gly
20 25 30
Gly Asp Glu Val Leu Trp Gln His His Glu Leu Phe Gln Ala Ala Ile
35 40 45
Asn Tyr Tyr Leu Val Ala Leu Leu Ala Leu Ala Asp Lys Asn Asn Pro
50 55 60
Val Leu Gly Pro Leu Ile Ser Gln Met Asp Asn Pro Gln Ser Pro Tyr
65 70 75 80
His Val Trp Gly Ser Phe Arg Arg Gln Gly Arg Gln Arg Thr Gly Leu
85 90 95
Ser Gln Ala Val Ala Pro Tyr Ile Thr Pro Gly Asn Asn Ala Pro Thr
100 105 110
Leu Asp Glu Val Phe Arg Ser Ile Leu Ala Gly Asn Pro Thr Asp Arg
115 120 125
Ala Thr Leu Asp Ala Ala Leu Met Gln Leu Leu Lys Ala Cys Asp Gly
130 135 140
Ala Gly Ala Ile Gln Gln Glu Gly Arg Ser Tyr Trp Pro Lys Phe Cys
145 150 155 160
Asp Pro Asp Ser Thr Ala Asn Phe Ala Gly Asp Pro Ala Met Leu Arg
165 170 175
Arg Glu Gln His Arg Leu Leu Leu Pro Gln Val Leu His Asp Pro Ala
180 185 190
Ile Thr His Asp Ser Pro Ala Leu Gly Ser Phe Asp Thr Tyr Ser Ile
195 200 205
Ala Thr Pro Asp Thr Arg Thr Pro Gln Leu Thr Gly Pro Lys Ala Arg
210 215 220
Ala Arg Leu Glu Gln Ala Ile Thr Leu Trp Arg Val Arg Leu Pro Glu
225 230 235 240
Ser Ala Ala Asp Phe Asp Arg Leu Ala Ser Ser Leu Lys Lys Ile Pro
245 250 255
Asp Asp Asp Ser Arg Leu Asn Leu Gln Gly Tyr Val Gly Ser Ser Ala
260 265 270
Lys Gly Glu Val Gln Ala Arg Leu Phe Ala Leu Leu Leu Phe Arg His
275 280 285
Leu Glu Arg Ser Ser Phe Thr Leu Gly Leu Leu Arg Ser Ala Thr Pro
290 295 300
Pro Pro Lys Asn Ala Glu Thr Pro Pro Pro Ala Gly Val Pro Leu Pro
305 310 315 320
Ala Ala Ser Ala Ala Asp Pro Val Arg Ile Ala Arg Gly Lys Arg Ser
325 330 335
Phe Val Phe Arg Ala Phe Thr Ser Leu Pro Cys Trp His Gly Gly Asp
340 345 350
Asn Ile His Pro Thr Trp Lys Ser Phe Asp Ile Ala Ala Phe Lys Tyr
355 360 365
Ala Leu Thr Val Ile Asn Gln Ile Glu Glu Lys Thr Lys Glu Arg Gln
370 375 380
Lys Glu Cys Ala Glu Leu Glu Thr Asp Phe Asp Tyr Met His Gly Arg
385 390 395 400
Leu Ala Lys Ile Pro Val Lys Tyr Thr Thr Gly Glu Ala Glu Pro Pro
405 410 415
Pro Ile Leu Ala Asn Asp Leu Arg Ile Pro Leu Leu Arg Glu Leu Leu
420 425 430
Gln Asn Ile Lys Val Asp Thr Ala Leu Thr Asp Gly Glu Ala Val Ser
435 440 445
Tyr Gly Leu Gln Arg Arg Thr Ile Arg Gly Phe Arg Glu Leu Arg Arg
450 455 460
Ile Trp Arg Gly His Ala Pro Ala Gly Thr Val Phe Ser Ser Glu Leu
465 470 475 480
Lys Glu Lys Leu Ala Gly Glu Leu Arg Gln Phe Gln Thr Asp Asn Ser
485 490 495
Thr Thr Ile Gly Ser Val Gln Leu Phe Asn Glu Leu Ile Gln Asn Pro
500 505 510
Lys Tyr Trp Pro Ile Trp Gln Ala Pro Asp Val Glu Thr Ala Arg Gln
515 520 525
Trp Ala Asp Ala Gly Phe Ala Asp Asp Pro Leu Ala Ala Leu Val Gln
530 535 540
Glu Ala Glu Leu Gln Glu Asp Ile Asp Ala Leu Lys Ala Pro Val Lys
545 550 555 560
Leu Thr Pro Ala Asp Pro Glu Tyr Ser Arg Arg Gln Tyr Asp Phe Asn
565 570 575
Ala Val Ser Lys Phe Gly Ala Gly Ser Arg Ser Ala Asn Arg His Glu
580 585 590
Pro Gly Gln Thr Glu Arg Gly His Asn Thr Phe Thr Thr Glu Ile Ala
595 600 605
Ala Arg Asn Ala Ala Asp Gly Asn Arg Trp Arg Ala Thr His Val Arg
610 615 620
Ile His Tyr Ser Ala Pro Arg Leu Leu Arg Asp Gly Leu Arg Arg Pro
625 630 635 640
Asp Thr Asp Gly Asn Glu Ala Leu Glu Ala Val Pro Trp Leu Gln Pro
645 650 655
Met Met Glu Ala Leu Ala Pro Leu Pro Thr Leu Pro Gln Asp Leu Thr
660 665 670
Gly Met Pro Val Phe Leu Met Pro Asp Val Thr Leu Ser Gly Glu Arg
675 680 685
Arg Ile Leu Leu Asn Leu Pro Val Thr Leu Glu Pro Ala Ala Leu Val
690 695 700
Glu Gln Leu Gly Asn Ala Gly Arg Trp Gln Asn Gln Phe Phe Gly Ser
705 710 715 720
Arg Glu Asp Pro Phe Ala Leu Arg Trp Pro Ala Asp Gly Ala Val Lys
725 730 735
Thr Ala Lys Gly Lys Thr His Ile Pro Trp His Gln Asp Arg Asp His
740 745 750
Phe Thr Val Leu Gly Val Asp Leu Gly Thr Arg Asp Ala Gly Ala Leu
755 760 765
Ala Leu Leu Asn Val Thr Ala Gln Lys Pro Ala Lys Pro Val His Arg
770 775 780
Ile Ile Gly Glu Ala Asp Gly Arg Thr Trp Tyr Ala Ser Leu Ala Asp
785 790 795 800
Ala Arg Met Ile Arg Leu Pro Gly Glu Asp Ala Arg Leu Phe Val Arg
805 810 815
Gly Lys Leu Val Gln Glu Pro Tyr Gly Glu Arg Gly Arg Asn Ala Ser
820 825 830
Leu Leu Glu Trp Glu Asp Ala Arg Asn Ile Ile Leu Arg Leu Gly Gln
835 840 845
Asn Pro Asp Glu Leu Leu Gly Ala Asp Pro Arg Arg His Ser Tyr Pro
850 855 860
Glu Ile Asn Asp Lys Leu Leu Val Ala Leu Arg Arg Ala Gln Ala Arg
865 870 875 880
Leu Ala Arg Leu Gln Asn Arg Ser Trp Arg Leu Arg Asp Leu Ala Glu
885 890 895
Ser Asp Lys Ala Leu Asp Glu Ile His Ala Glu Arg Ala Gly Glu Lys
900 905 910
Pro Ser Pro Leu Pro Pro Leu Ala Arg Asp Asp Ala Ile Lys Ser Thr
915 920 925
Asp Glu Ala Leu Leu Ser Gln Arg Asp Ile Ile Arg Arg Ser Phe Val
930 935 940
Gln Ile Ala Asn Leu Ile Leu Pro Leu Arg Gly Arg Arg Trp Glu Trp
945 950 955 960
Arg Pro His Val Glu Val Pro Asp Cys His Ile Leu Ala Gln Ser Asp
965 970 975
Pro Gly Thr Asp Asp Thr Lys Arg Leu Val Ala Gly Gln Arg Gly Ile
980 985 990
Ser His Glu Arg Ile Glu Gln Ile Glu Glu Leu Arg Arg Arg Cys Gln
995 1000 1005
Ser Leu Asn Arg Ala Leu Arg His Lys Pro Gly Glu Arg Pro Val
1010 1015 1020
Leu Gly Arg Pro Ala Lys Gly Glu Glu Ile Ala Asp Pro Cys Pro
1025 1030 1035
Ala Leu Leu Glu Lys Ile Asn Arg Leu Arg Asp Gln Arg Val Asp
1040 1045 1050
Gln Thr Ala His Ala Ile Leu Ala Ala Ala Leu Gly Val Arg Leu
1055 1060 1065
Arg Ala Pro Ser Lys Asp Arg Ala Glu Arg Arg His Arg Asp Ile
1070 1075 1080
His Gly Glu Tyr Glu Arg Phe Arg Ala Pro Ala Asp Phe Val Val
1085 1090 1095
Ile Glu Asn Leu Ser Arg Tyr Leu Ser Ser Gln Asp Arg Ala Arg
1100 1105 1110
Ser Glu Asn Thr Arg Leu Met Gln Trp Cys His Arg Gln Ile Val
1115 1120 1125
Gln Lys Leu Arg Gln Leu Cys Glu Thr Tyr Gly Ile Pro Val Leu
1130 1135 1140
Ala Val Pro Ala Ala Tyr Ser Ser Arg Phe Ser Ser Arg Asp Gly
1145 1150 1155
Ser Ala Gly Phe Arg Ala Val His Leu Thr Pro Asp His Arg His
1160 1165 1170
Arg Met Pro Trp Ser Arg Ile Leu Ala Arg Leu Lys Ala His Glu
1175 1180 1185
Glu Asp Gly Lys Arg Leu Glu Lys Thr Val Leu Asp Glu Ala Arg
1190 1195 1200
Ala Val Arg Gly Leu Phe Asp Arg Leu Asp Arg Phe Asn Ala Gly
1205 1210 1215
His Val Pro Gly Lys Pro Trp Arg Thr Leu Leu Ala Pro Leu Pro
1220 1225 1230
Gly Gly Pro Val Phe Val Pro Leu Gly Asp Ala Thr Pro Met Gln
1235 1240 1245
Ala Asp Leu Asn Ala Ala Ile Asn Ile Ala Leu Arg Gly Ile Ala
1250 1255 1260
Ala Pro Asp Arg His Asp Ile His His Arg Leu Arg Ala Glu Asn
1265 1270 1275
Lys Lys Arg Ile Leu Ser Leu Arg Leu Gly Thr Gln Arg Glu Lys
1280 1285 1290
Ala Arg Trp Pro Gly Gly Ala Pro Ala Val Thr Leu Ser Thr Pro
1295 1300 1305
Asn Asn Gly Ala Ser Pro Glu Asp Ser Asp Ala Leu Pro Glu Arg
1310 1315 1320
Val Ser Asn Leu Phe Val Asp Ile Ala Gly Val Ala Asn Phe Glu
1325 1330 1335
Arg Val Thr Ile Glu Gly Val Ser Gln Lys Phe Ala Thr Gly Arg
1340 1345 1350
Gly Leu Trp Ala Ser Val Lys Gln Arg Ala Trp Asn Arg Val Ala
1355 1360 1365
Arg Leu Asn Glu Thr Val Thr Asp Asn Asn Arg Asn Glu Glu Glu
1370 1375 1380
Asp Asp Ile Pro Met
1385
<210> 30
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 30
guccaagaaa aaagaaauga uacgaggcau uagcac 36
<210> 31
<211> 107
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 31
cuggacgaug ucucuuuuau uucuuuuuuc uuggaucuga guacgagcac ccacauugga 60
cauuucgcau ggugggugcu cguacuauag guaaaacaaa ccuuuuu 107
<210> 32
<211> 1108
<212> БЕЛОК
<213> Bacillus thermoamylovorans
<400> 32
Met Ala Thr Arg Ser Phe Ile Leu Lys Ile Glu Pro Asn Glu Glu Val
1 5 10 15
Lys Lys Gly Leu Trp Lys Thr His Glu Val Leu Asn His Gly Ile Ala
20 25 30
Tyr Tyr Met Asn Ile Leu Lys Leu Ile Arg Gln Glu Ala Ile Tyr Glu
35 40 45
His His Glu Gln Asp Pro Lys Asn Pro Lys Lys Val Ser Lys Ala Glu
50 55 60
Ile Gln Ala Glu Leu Trp Asp Phe Val Leu Lys Met Gln Lys Cys Asn
65 70 75 80
Ser Phe Thr His Glu Val Asp Lys Asp Val Val Phe Asn Ile Leu Arg
85 90 95
Glu Leu Tyr Glu Glu Leu Val Pro Ser Ser Val Glu Lys Lys Gly Glu
100 105 110
Ala Asn Gln Leu Ser Asn Lys Phe Leu Tyr Pro Leu Val Asp Pro Asn
115 120 125
Ser Gln Ser Gly Lys Gly Thr Ala Ser Ser Gly Arg Lys Pro Arg Trp
130 135 140
Tyr Asn Leu Lys Ile Ala Gly Asp Pro Ser Trp Glu Glu Glu Lys Lys
145 150 155 160
Lys Trp Glu Glu Asp Lys Lys Lys Asp Pro Leu Ala Lys Ile Leu Gly
165 170 175
Lys Leu Ala Glu Tyr Gly Leu Ile Pro Leu Phe Ile Pro Phe Thr Asp
180 185 190
Ser Asn Glu Pro Ile Val Lys Glu Ile Lys Trp Met Glu Lys Ser Arg
195 200 205
Asn Gln Ser Val Arg Arg Leu Asp Lys Asp Met Phe Ile Gln Ala Leu
210 215 220
Glu Arg Phe Leu Ser Trp Glu Ser Trp Asn Leu Lys Val Lys Glu Glu
225 230 235 240
Tyr Glu Lys Val Glu Lys Glu His Lys Thr Leu Glu Glu Arg Ile Lys
245 250 255
Glu Asp Ile Gln Ala Phe Lys Ser Leu Glu Gln Tyr Glu Lys Glu Arg
260 265 270
Gln Glu Gln Leu Leu Arg Asp Thr Leu Asn Thr Asn Glu Tyr Arg Leu
275 280 285
Ser Lys Arg Gly Leu Arg Gly Trp Arg Glu Ile Ile Gln Lys Trp Leu
290 295 300
Lys Met Asp Glu Asn Glu Pro Ser Glu Lys Tyr Leu Glu Val Phe Lys
305 310 315 320
Asp Tyr Gln Arg Lys His Pro Arg Glu Ala Gly Asp Tyr Ser Val Tyr
325 330 335
Glu Phe Leu Ser Lys Lys Glu Asn His Phe Ile Trp Arg Asn His Pro
340 345 350
Glu Tyr Pro Tyr Leu Tyr Ala Thr Phe Cys Glu Ile Asp Lys Lys Lys
355 360 365
Lys Asp Ala Lys Gln Gln Ala Thr Phe Thr Leu Ala Asp Pro Ile Asn
370 375 380
His Pro Leu Trp Val Arg Phe Glu Glu Arg Ser Gly Ser Asn Leu Asn
385 390 395 400
Lys Tyr Arg Ile Leu Thr Glu Gln Leu His Thr Glu Lys Leu Lys Lys
405 410 415
Lys Leu Thr Val Gln Leu Asp Arg Leu Ile Tyr Pro Thr Glu Ser Gly
420 425 430
Gly Trp Glu Glu Lys Gly Lys Val Asp Ile Val Leu Leu Pro Ser Arg
435 440 445
Gln Phe Tyr Asn Gln Ile Phe Leu Asp Ile Glu Glu Lys Gly Lys His
450 455 460
Ala Phe Thr Tyr Lys Asp Glu Ser Ile Lys Phe Pro Leu Lys Gly Thr
465 470 475 480
Leu Gly Gly Ala Arg Val Gln Phe Asp Arg Asp His Leu Arg Arg Tyr
485 490 495
Pro His Lys Val Glu Ser Gly Asn Val Gly Arg Ile Tyr Phe Asn Met
500 505 510
Thr Val Asn Ile Glu Pro Thr Glu Ser Pro Val Ser Lys Ser Leu Lys
515 520 525
Ile His Arg Asp Asp Phe Pro Lys Phe Val Asn Phe Lys Pro Lys Glu
530 535 540
Leu Thr Glu Trp Ile Lys Asp Ser Lys Gly Lys Lys Leu Lys Ser Gly
545 550 555 560
Ile Glu Ser Leu Glu Ile Gly Leu Arg Val Met Ser Ile Asp Leu Gly
565 570 575
Gln Arg Gln Ala Ala Ala Ala Ser Ile Phe Glu Val Val Asp Gln Lys
580 585 590
Pro Asp Ile Glu Gly Lys Leu Phe Phe Pro Ile Lys Gly Thr Glu Leu
595 600 605
Tyr Ala Val His Arg Ala Ser Phe Asn Ile Lys Leu Pro Gly Glu Thr
610 615 620
Leu Val Lys Ser Arg Glu Val Leu Arg Lys Ala Arg Glu Asp Asn Leu
625 630 635 640
Lys Leu Met Asn Gln Lys Leu Asn Phe Leu Arg Asn Val Leu His Phe
645 650 655
Gln Gln Phe Glu Asp Ile Thr Glu Arg Glu Lys Arg Val Thr Lys Trp
660 665 670
Ile Ser Arg Gln Glu Asn Ser Asp Val Pro Leu Val Tyr Gln Asp Glu
675 680 685
Leu Ile Gln Ile Arg Glu Leu Met Tyr Lys Pro Tyr Lys Asp Trp Val
690 695 700
Ala Phe Leu Lys Gln Leu His Lys Arg Leu Glu Val Glu Ile Gly Lys
705 710 715 720
Glu Val Lys His Trp Arg Lys Ser Leu Ser Asp Gly Arg Lys Gly Leu
725 730 735
Tyr Gly Ile Ser Leu Lys Asn Ile Asp Glu Ile Asp Arg Thr Arg Lys
740 745 750
Phe Leu Leu Arg Trp Ser Leu Arg Pro Thr Glu Pro Gly Glu Val Arg
755 760 765
Arg Leu Glu Pro Gly Gln Arg Phe Ala Ile Asp Gln Leu Asn His Leu
770 775 780
Asn Ala Leu Lys Glu Asp Arg Leu Lys Lys Met Ala Asn Thr Ile Ile
785 790 795 800
Met His Ala Leu Gly Tyr Cys Tyr Asp Val Arg Lys Lys Lys Trp Gln
805 810 815
Ala Lys Asn Pro Ala Cys Gln Ile Ile Leu Phe Glu Asp Leu Ser Asn
820 825 830
Tyr Asn Pro Tyr Glu Glu Arg Ser Arg Phe Glu Asn Ser Lys Leu Met
835 840 845
Lys Trp Ser Arg Arg Glu Ile Pro Arg Gln Val Ala Leu Gln Gly Glu
850 855 860
Ile Tyr Gly Leu Gln Val Gly Glu Val Gly Ala Gln Phe Ser Ser Arg
865 870 875 880
Phe His Ala Lys Thr Gly Ser Pro Gly Ile Arg Cys Ser Val Val Thr
885 890 895
Lys Glu Lys Leu Gln Asp Asn Arg Phe Phe Lys Asn Leu Gln Arg Glu
900 905 910
Gly Arg Leu Thr Leu Asp Lys Ile Ala Val Leu Lys Glu Gly Asp Leu
915 920 925
Tyr Pro Asp Lys Gly Gly Glu Lys Phe Ile Ser Leu Ser Lys Asp Arg
930 935 940
Lys Leu Val Thr Thr His Ala Asp Ile Asn Ala Ala Gln Asn Leu Gln
945 950 955 960
Lys Arg Phe Trp Thr Arg Thr His Gly Phe Tyr Lys Val Tyr Cys Lys
965 970 975
Ala Tyr Gln Val Asp Gly Gln Thr Val Tyr Ile Pro Glu Ser Lys Asp
980 985 990
Gln Lys Gln Lys Ile Ile Glu Glu Phe Gly Glu Gly Tyr Phe Ile Leu
995 1000 1005
Lys Asp Gly Val Tyr Glu Trp Gly Asn Ala Gly Lys Leu Lys Ile
1010 1015 1020
Lys Lys Gly Ser Ser Lys Gln Ser Ser Ser Glu Leu Val Asp Ser
1025 1030 1035
Asp Ile Leu Lys Asp Ser Phe Asp Leu Ala Ser Glu Leu Lys Gly
1040 1045 1050
Glu Lys Leu Met Leu Tyr Arg Asp Pro Ser Gly Asn Val Phe Pro
1055 1060 1065
Ser Asp Lys Trp Met Ala Ala Gly Val Phe Phe Gly Lys Leu Glu
1070 1075 1080
Arg Ile Leu Ile Ser Lys Leu Thr Asn Gln Tyr Ser Ile Ser Thr
1085 1090 1095
Ile Glu Asp Asp Ser Ser Lys Gln Ser Met
1100 1105
<210> 33
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 33
guucgaaagc uuaguggaaa gcuucguggu uagcac 36
<210> 34
<211> 69
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 34
cacggauaau cacgacuuuc cacuaagcuu ucgaauuuua ugaugcgagc auccucucag 60
gucaaaaaa 69
<210> 35
<211> 1108
<212> БЕЛОК
<213> Bacillus sp.
<400> 35
Met Ala Ile Arg Ser Ile Lys Leu Lys Leu Lys Thr His Thr Gly Pro
1 5 10 15
Glu Ala Gln Asn Leu Arg Lys Gly Ile Trp Arg Thr His Arg Leu Leu
20 25 30
Asn Glu Gly Val Ala Tyr Tyr Met Lys Met Leu Leu Leu Phe Arg Gln
35 40 45
Glu Ser Thr Gly Glu Arg Pro Lys Glu Glu Leu Gln Glu Glu Leu Ile
50 55 60
Cys His Ile Arg Glu Gln Gln Gln Arg Asn Gln Ala Asp Lys Asn Thr
65 70 75 80
Gln Ala Leu Pro Leu Asp Lys Ala Leu Glu Ala Leu Arg Gln Leu Tyr
85 90 95
Glu Leu Leu Val Pro Ser Ser Val Gly Gln Ser Gly Asp Ala Gln Ile
100 105 110
Ile Ser Arg Lys Phe Leu Ser Pro Leu Val Asp Pro Asn Ser Glu Gly
115 120 125
Gly Lys Gly Thr Ser Lys Ala Gly Ala Lys Pro Thr Trp Gln Lys Lys
130 135 140
Lys Glu Ala Asn Asp Pro Thr Trp Glu Gln Asp Tyr Glu Lys Trp Lys
145 150 155 160
Lys Arg Arg Glu Glu Asp Pro Thr Ala Ser Val Ile Thr Thr Leu Glu
165 170 175
Glu Tyr Gly Ile Arg Pro Ile Phe Pro Leu Tyr Thr Asn Thr Val Thr
180 185 190
Asp Ile Ala Trp Leu Pro Leu Gln Ser Asn Gln Phe Val Arg Thr Trp
195 200 205
Asp Arg Asp Met Leu Gln Gln Ala Ile Glu Arg Leu Leu Ser Trp Glu
210 215 220
Ser Trp Asn Lys Arg Val Gln Glu Glu Tyr Ala Lys Leu Lys Glu Lys
225 230 235 240
Met Ala Gln Leu Asn Glu Gln Leu Glu Gly Gly Gln Glu Trp Ile Ser
245 250 255
Leu Leu Glu Gln Tyr Glu Glu Asn Arg Glu Arg Glu Leu Arg Glu Asn
260 265 270
Met Thr Ala Ala Asn Asp Lys Tyr Arg Ile Thr Lys Arg Gln Met Lys
275 280 285
Gly Trp Asn Glu Leu Tyr Glu Leu Trp Ser Thr Phe Pro Ala Ser Ala
290 295 300
Ser His Glu Gln Tyr Lys Glu Ala Leu Lys Arg Val Gln Gln Arg Leu
305 310 315 320
Arg Gly Arg Phe Gly Asp Ala His Phe Phe Gln Tyr Leu Met Glu Glu
325 330 335
Lys Asn Arg Leu Ile Trp Lys Gly Asn Pro Gln Arg Ile His Tyr Phe
340 345 350
Val Ala Arg Asn Glu Leu Thr Lys Arg Leu Glu Glu Ala Lys Gln Ser
355 360 365
Ala Thr Met Thr Leu Pro Asn Ala Arg Lys His Pro Leu Trp Val Arg
370 375 380
Phe Asp Ala Arg Gly Gly Asn Leu Gln Asp Tyr Tyr Leu Thr Ala Glu
385 390 395 400
Ala Asp Lys Pro Arg Ser Arg Arg Phe Val Thr Phe Ser Gln Leu Ile
405 410 415
Trp Pro Ser Glu Ser Gly Trp Met Glu Lys Lys Asp Val Glu Val Glu
420 425 430
Leu Ala Leu Ser Arg Gln Phe Tyr Gln Gln Val Lys Leu Leu Lys Asn
435 440 445
Asp Lys Gly Lys Gln Lys Ile Glu Phe Lys Asp Lys Gly Ser Gly Ser
450 455 460
Thr Phe Asn Gly His Leu Gly Gly Ala Lys Leu Gln Leu Glu Arg Gly
465 470 475 480
Asp Leu Glu Lys Glu Glu Lys Asn Phe Glu Asp Gly Glu Ile Gly Ser
485 490 495
Val Tyr Leu Asn Val Val Ile Asp Phe Glu Pro Leu Gln Glu Val Lys
500 505 510
Asn Gly Arg Val Gln Ala Pro Tyr Gly Gln Val Leu Gln Leu Ile Arg
515 520 525
Arg Pro Asn Glu Phe Pro Lys Val Thr Thr Tyr Lys Ser Glu Gln Leu
530 535 540
Val Glu Trp Ile Lys Ala Ser Pro Gln His Ser Ala Gly Val Glu Ser
545 550 555 560
Leu Ala Ser Gly Phe Arg Val Met Ser Ile Asp Leu Gly Leu Arg Ala
565 570 575
Ala Ala Ala Thr Ser Ile Phe Ser Val Glu Glu Ser Ser Asp Lys Asn
580 585 590
Ala Ala Asp Phe Ser Tyr Trp Ile Glu Gly Thr Pro Leu Val Ala Val
595 600 605
His Gln Arg Ser Tyr Met Leu Arg Leu Pro Gly Glu Gln Val Glu Lys
610 615 620
Gln Val Met Glu Lys Arg Asp Glu Arg Phe Gln Leu His Gln Arg Val
625 630 635 640
Lys Phe Gln Ile Arg Val Leu Ala Gln Ile Met Arg Met Ala Asn Lys
645 650 655
Gln Tyr Gly Asp Arg Trp Asp Glu Leu Asp Ser Leu Lys Gln Ala Val
660 665 670
Glu Gln Lys Lys Ser Pro Leu Asp Gln Thr Asp Arg Thr Phe Trp Glu
675 680 685
Gly Ile Val Cys Asp Leu Thr Lys Val Leu Pro Arg Asn Glu Ala Asp
690 695 700
Trp Glu Gln Ala Val Val Gln Ile His Arg Lys Ala Glu Glu Tyr Val
705 710 715 720
Gly Lys Ala Val Gln Ala Trp Arg Lys Arg Phe Ala Ala Asp Glu Arg
725 730 735
Lys Gly Ile Ala Gly Leu Ser Met Trp Asn Ile Glu Glu Leu Glu Gly
740 745 750
Leu Arg Lys Leu Leu Ile Ser Trp Ser Arg Arg Thr Arg Asn Pro Gln
755 760 765
Glu Val Asn Arg Phe Glu Arg Gly His Thr Ser His Gln Arg Leu Leu
770 775 780
Thr His Ile Gln Asn Val Lys Glu Asp Arg Leu Lys Gln Leu Ser His
785 790 795 800
Ala Ile Val Met Thr Ala Leu Gly Tyr Val Tyr Asp Glu Arg Lys Gln
805 810 815
Glu Trp Cys Ala Glu Tyr Pro Ala Cys Gln Val Ile Leu Phe Glu Asn
820 825 830
Leu Ser Gln Tyr Arg Ser Asn Leu Asp Arg Ser Thr Lys Glu Asn Ser
835 840 845
Thr Leu Met Lys Trp Ala His Arg Ser Ile Pro Lys Tyr Val His Met
850 855 860
Gln Ala Glu Pro Tyr Gly Ile Gln Ile Gly Asp Val Arg Ala Glu Tyr
865 870 875 880
Ser Ser Arg Phe Tyr Ala Lys Thr Gly Thr Pro Gly Ile Arg Cys Lys
885 890 895
Lys Val Arg Gly Gln Asp Leu Gln Gly Arg Arg Phe Glu Asn Leu Gln
900 905 910
Lys Arg Leu Val Asn Glu Gln Phe Leu Thr Glu Glu Gln Val Lys Gln
915 920 925
Leu Arg Pro Gly Asp Ile Val Pro Asp Asp Ser Gly Glu Leu Phe Met
930 935 940
Thr Leu Thr Asp Gly Ser Gly Ser Lys Glu Val Val Phe Leu Gln Ala
945 950 955 960
Asp Ile Asn Ala Ala His Asn Leu Gln Lys Arg Phe Trp Gln Arg Tyr
965 970 975
Asn Glu Leu Phe Lys Val Ser Cys Arg Val Ile Val Arg Asp Glu Glu
980 985 990
Glu Tyr Leu Val Pro Lys Thr Lys Ser Val Gln Ala Lys Leu Gly Lys
995 1000 1005
Gly Leu Phe Val Lys Lys Ser Asp Thr Ala Trp Lys Asp Val Tyr
1010 1015 1020
Val Trp Asp Ser Gln Ala Lys Leu Lys Gly Lys Thr Thr Phe Thr
1025 1030 1035
Glu Glu Ser Glu Ser Pro Glu Gln Leu Glu Asp Phe Gln Glu Ile
1040 1045 1050
Ile Glu Glu Ala Glu Glu Ala Lys Gly Thr Tyr Arg Thr Leu Phe
1055 1060 1065
Arg Asp Pro Ser Gly Val Phe Phe Pro Glu Ser Val Trp Tyr Pro
1070 1075 1080
Gln Lys Asp Phe Trp Gly Glu Val Lys Arg Lys Leu Tyr Gly Lys
1085 1090 1095
Leu Arg Glu Arg Phe Leu Thr Lys Ala Arg
1100 1105
<210> 36
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 36
guuuugagaa uagcccgaca uagagggcaa uagac 35
<210> 37
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 37
guuaugaaaa cagcccgaca uagagggcaa uagaca 36
<210> 38
<211> 1334
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 38
Met Lys Ile Ser Lys Val Asp His Thr Arg Met Ala Val Ala Lys Gly
1 5 10 15
Asn Gln His Arg Arg Asp Glu Ile Ser Gly Ile Leu Tyr Lys Asp Pro
20 25 30
Thr Lys Thr Gly Ser Ile Asp Phe Asp Glu Arg Phe Lys Lys Leu Asn
35 40 45
Cys Ser Ala Lys Ile Leu Tyr His Val Phe Asn Gly Ile Ala Glu Gly
50 55 60
Ser Asn Lys Tyr Lys Asn Ile Val Asp Lys Val Asn Asn Asn Leu Asp
65 70 75 80
Arg Val Leu Phe Thr Gly Lys Ser Tyr Asp Arg Lys Ser Ile Ile Asp
85 90 95
Ile Asp Thr Val Leu Arg Asn Val Glu Lys Ile Asn Ala Phe Asp Arg
100 105 110
Ile Ser Thr Glu Glu Arg Glu Gln Ile Ile Asp Asp Leu Leu Glu Ile
115 120 125
Gln Leu Arg Lys Gly Leu Arg Lys Gly Lys Ala Gly Leu Arg Glu Val
130 135 140
Leu Leu Ile Gly Ala Gly Val Ile Val Arg Thr Asp Lys Lys Gln Glu
145 150 155 160
Ile Ala Asp Phe Leu Glu Ile Leu Asp Glu Asp Phe Asn Lys Thr Asn
165 170 175
Gln Ala Lys Asn Ile Lys Leu Ser Ile Glu Asn Gln Gly Leu Val Val
180 185 190
Ser Pro Val Ser Arg Gly Glu Glu Arg Ile Phe Asp Val Ser Gly Ala
195 200 205
Gln Lys Gly Lys Ser Ser Lys Lys Ala Gln Glu Lys Glu Ala Leu Ser
210 215 220
Ala Phe Leu Leu Asp Tyr Ala Asp Leu Asp Lys Asn Val Arg Phe Glu
225 230 235 240
Tyr Leu Arg Lys Ile Arg Arg Leu Ile Asn Leu Tyr Phe Tyr Val Lys
245 250 255
Asn Asp Asp Val Met Ser Leu Thr Glu Ile Pro Ala Glu Val Asn Leu
260 265 270
Glu Lys Asp Phe Asp Ile Trp Arg Asp His Glu Gln Arg Lys Glu Glu
275 280 285
Asn Gly Asp Phe Val Gly Cys Pro Asp Ile Leu Leu Ala Asp Arg Asp
290 295 300
Val Lys Lys Ser Asn Ser Lys Gln Val Lys Ile Ala Glu Arg Gln Leu
305 310 315 320
Arg Glu Ser Ile Arg Glu Lys Asn Ile Lys Arg Tyr Arg Phe Ser Ile
325 330 335
Lys Thr Ile Glu Lys Asp Asp Gly Thr Tyr Phe Phe Ala Asn Lys Gln
340 345 350
Ile Ser Val Phe Trp Ile His Arg Ile Glu Asn Ala Val Glu Arg Ile
355 360 365
Leu Gly Ser Ile Asn Asp Lys Lys Leu Tyr Arg Leu Arg Leu Gly Tyr
370 375 380
Leu Gly Glu Lys Val Trp Lys Asp Ile Leu Asn Phe Leu Ser Ile Lys
385 390 395 400
Tyr Ile Ala Val Gly Lys Ala Val Phe Asn Phe Ala Met Asp Asp Leu
405 410 415
Gln Glu Lys Asp Arg Asp Ile Glu Pro Gly Lys Ile Ser Glu Asn Ala
420 425 430
Val Asn Gly Leu Thr Ser Phe Asp Tyr Glu Gln Ile Lys Ala Asp Glu
435 440 445
Met Leu Gln Arg Glu Val Ala Val Asn Val Ala Phe Ala Ala Asn Asn
450 455 460
Leu Ala Arg Val Thr Val Asp Ile Pro Gln Asn Gly Glu Lys Glu Asp
465 470 475 480
Ile Leu Leu Trp Asn Lys Ser Asp Ile Lys Lys Tyr Lys Lys Asn Ser
485 490 495
Lys Lys Gly Ile Leu Lys Ser Ile Leu Gln Phe Phe Gly Gly Ala Ser
500 505 510
Thr Trp Asn Met Lys Met Phe Glu Ile Ala Tyr His Asp Gln Pro Gly
515 520 525
Asp Tyr Glu Glu Asn Tyr Leu Tyr Asp Ile Ile Gln Ile Ile Tyr Ser
530 535 540
Leu Arg Asn Lys Ser Phe His Phe Lys Thr Tyr Asp His Gly Asp Lys
545 550 555 560
Asn Trp Asn Arg Glu Leu Ile Gly Lys Met Ile Glu His Asp Ala Glu
565 570 575
Arg Val Ile Ser Val Glu Arg Glu Lys Phe His Ser Asn Asn Leu Pro
580 585 590
Met Phe Tyr Lys Asp Ala Asp Leu Lys Lys Ile Leu Asp Leu Leu Tyr
595 600 605
Ser Asp Tyr Ala Gly Arg Ala Ser Gln Val Pro Ala Phe Asn Thr Val
610 615 620
Leu Val Arg Lys Asn Phe Pro Glu Phe Leu Arg Lys Asp Met Gly Tyr
625 630 635 640
Lys Val His Phe Asn Asn Pro Glu Val Glu Asn Gln Trp His Ser Ala
645 650 655
Val Tyr Tyr Leu Tyr Lys Glu Ile Tyr Tyr Asn Leu Phe Leu Arg Asp
660 665 670
Lys Glu Val Lys Asn Leu Phe Tyr Thr Ser Leu Lys Asn Ile Arg Ser
675 680 685
Glu Val Ser Asp Lys Lys Gln Lys Leu Ala Ser Asp Asp Phe Ala Ser
690 695 700
Arg Cys Glu Glu Ile Glu Asp Arg Ser Leu Pro Glu Ile Cys Gln Ile
705 710 715 720
Ile Met Thr Glu Tyr Asn Ala Gln Asn Phe Gly Asn Arg Lys Val Lys
725 730 735
Ser Gln Arg Val Ile Glu Lys Asn Lys Asp Ile Phe Arg His Tyr Lys
740 745 750
Met Leu Leu Ile Lys Thr Leu Ala Gly Ala Phe Ser Leu Tyr Leu Lys
755 760 765
Gln Glu Arg Phe Ala Phe Ile Gly Lys Ala Thr Pro Ile Pro Tyr Glu
770 775 780
Thr Thr Asp Val Lys Asn Phe Leu Pro Glu Trp Lys Ser Gly Met Tyr
785 790 795 800
Ala Ser Phe Val Glu Glu Ile Lys Asn Asn Leu Asp Leu Gln Glu Trp
805 810 815
Tyr Ile Val Gly Arg Phe Leu Asn Gly Arg Met Leu Asn Gln Leu Ala
820 825 830
Gly Ser Leu Arg Ser Tyr Ile Gln Tyr Ala Glu Asp Ile Glu Arg Arg
835 840 845
Ala Ala Glu Asn Arg Asn Lys Leu Phe Ser Lys Pro Asp Glu Lys Ile
850 855 860
Glu Ala Cys Lys Lys Ala Val Arg Val Leu Asp Leu Cys Ile Lys Ile
865 870 875 880
Ser Thr Arg Ile Ser Ala Glu Phe Thr Asp Tyr Phe Asp Ser Glu Asp
885 890 895
Asp Tyr Ala Asp Tyr Leu Glu Lys Tyr Leu Lys Tyr Gln Asp Asp Ala
900 905 910
Ile Lys Glu Leu Ser Gly Ser Ser Tyr Ala Ala Leu Asp His Phe Cys
915 920 925
Asn Lys Asp Asp Leu Lys Phe Asp Ile Tyr Val Asn Ala Gly Gln Lys
930 935 940
Pro Ile Leu Gln Arg Asn Ile Val Met Ala Lys Leu Phe Gly Pro Asp
945 950 955 960
Asn Ile Leu Ser Glu Val Met Glu Lys Val Thr Glu Ser Ala Ile Arg
965 970 975
Glu Tyr Tyr Asp Tyr Leu Lys Lys Val Ser Gly Tyr Arg Val Arg Gly
980 985 990
Lys Cys Ser Thr Glu Lys Glu Gln Glu Asp Leu Leu Lys Phe Gln Arg
995 1000 1005
Leu Lys Asn Ala Val Glu Phe Arg Asp Val Thr Glu Tyr Ala Glu
1010 1015 1020
Val Ile Asn Glu Leu Leu Gly Gln Leu Ile Ser Trp Ser Tyr Leu
1025 1030 1035
Arg Glu Arg Asp Leu Leu Tyr Phe Gln Leu Gly Phe His Tyr Met
1040 1045 1050
Cys Leu Lys Asn Lys Ser Phe Lys Pro Ala Glu Tyr Val Asp Ile
1055 1060 1065
Arg Arg Asn Asn Gly Thr Ile Ile His Asn Ala Ile Leu Tyr Gln
1070 1075 1080
Ile Val Ser Met Tyr Ile Asn Gly Leu Asp Phe Tyr Ser Cys Asp
1085 1090 1095
Lys Glu Gly Lys Thr Leu Lys Pro Ile Glu Thr Gly Lys Gly Val
1100 1105 1110
Gly Ser Lys Ile Gly Gln Phe Ile Lys Tyr Ser Gln Tyr Leu Tyr
1115 1120 1125
Asn Asp Pro Ser Tyr Lys Leu Glu Ile Tyr Asn Ala Gly Leu Glu
1130 1135 1140
Val Phe Glu Asn Ile Asp Glu His Asp Asn Ile Thr Asp Leu Arg
1145 1150 1155
Lys Tyr Val Asp His Phe Lys Tyr Tyr Ala Tyr Gly Asn Lys Met
1160 1165 1170
Ser Leu Leu Asp Leu Tyr Ser Glu Phe Phe Asp Arg Phe Phe Thr
1175 1180 1185
Tyr Asp Met Lys Tyr Gln Lys Asn Val Val Asn Val Leu Glu Asn
1190 1195 1200
Ile Leu Leu Arg His Phe Val Ile Phe Tyr Pro Lys Phe Gly Ser
1205 1210 1215
Gly Lys Lys Asp Val Gly Ile Arg Asp Cys Lys Lys Glu Arg Ala
1220 1225 1230
Gln Ile Glu Ile Ser Glu Gln Ser Leu Thr Ser Glu Asp Phe Met
1235 1240 1245
Phe Lys Leu Asp Asp Lys Ala Gly Glu Glu Ala Lys Lys Phe Pro
1250 1255 1260
Ala Arg Asp Glu Arg Tyr Leu Gln Thr Ile Ala Lys Leu Leu Tyr
1265 1270 1275
Tyr Pro Asn Glu Ile Glu Asp Met Asn Arg Phe Met Lys Lys Gly
1280 1285 1290
Glu Thr Ile Asn Lys Lys Val Gln Phe Asn Arg Lys Lys Lys Ile
1295 1300 1305
Thr Arg Lys Gln Lys Asn Asn Ser Ser Asn Glu Val Leu Ser Ser
1310 1315 1320
Thr Met Gly Tyr Leu Phe Lys Asn Ile Lys Leu
1325 1330
<210> 39
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 39
guuuuagucc ucuuucauau agagguaguc ucuuac 36
<210> 40
<211> 99
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 40
augaaaagag gacuaaaacu gaaagaggac uaaaacacca gauguggaua acuauauuag 60
uggcuauuaa aaauucgucg auauuagaga ggaaacuuu 99
<210> 41
<211> 1120
<212> БЕЛОК
<213> Listeria seeligeri
<400> 41
Met Trp Ile Ser Ile Lys Thr Leu Ile His His Leu Gly Val Leu Phe
1 5 10 15
Phe Cys Asp Tyr Met Tyr Asn Arg Arg Glu Lys Lys Ile Ile Glu Val
20 25 30
Lys Thr Met Arg Ile Thr Lys Val Glu Val Asp Arg Lys Lys Val Leu
35 40 45
Ile Ser Arg Asp Lys Asn Gly Gly Lys Leu Val Tyr Glu Asn Glu Met
50 55 60
Gln Asp Asn Thr Glu Gln Ile Met His His Lys Lys Ser Ser Phe Tyr
65 70 75 80
Lys Ser Val Val Asn Lys Thr Ile Cys Arg Pro Glu Gln Lys Gln Met
85 90 95
Lys Lys Leu Val His Gly Leu Leu Gln Glu Asn Ser Gln Glu Lys Ile
100 105 110
Lys Val Ser Asp Val Thr Lys Leu Asn Ile Ser Asn Phe Leu Asn His
115 120 125
Arg Phe Lys Lys Ser Leu Tyr Tyr Phe Pro Glu Asn Ser Pro Asp Lys
130 135 140
Ser Glu Glu Tyr Arg Ile Glu Ile Asn Leu Ser Gln Leu Leu Glu Asp
145 150 155 160
Ser Leu Lys Lys Gln Gln Gly Thr Phe Ile Cys Trp Glu Ser Phe Ser
165 170 175
Lys Asp Met Glu Leu Tyr Ile Asn Trp Ala Glu Asn Tyr Ile Ser Ser
180 185 190
Lys Thr Lys Leu Ile Lys Lys Ser Ile Arg Asn Asn Arg Ile Gln Ser
195 200 205
Thr Glu Ser Arg Ser Gly Gln Leu Met Asp Arg Tyr Met Lys Asp Ile
210 215 220
Leu Asn Lys Asn Lys Pro Phe Asp Ile Gln Ser Val Ser Glu Lys Tyr
225 230 235 240
Gln Leu Glu Lys Leu Thr Ser Ala Leu Lys Ala Thr Phe Lys Glu Ala
245 250 255
Lys Lys Asn Asp Lys Glu Ile Asn Tyr Lys Leu Lys Ser Thr Leu Gln
260 265 270
Asn His Glu Arg Gln Ile Ile Glu Glu Leu Lys Glu Asn Ser Glu Leu
275 280 285
Asn Gln Phe Asn Ile Glu Ile Arg Lys His Leu Glu Thr Tyr Phe Pro
290 295 300
Ile Lys Lys Thr Asn Arg Lys Val Gly Asp Ile Arg Asn Leu Glu Ile
305 310 315 320
Gly Glu Ile Gln Lys Ile Val Asn His Arg Leu Lys Asn Lys Ile Val
325 330 335
Gln Arg Ile Leu Gln Glu Gly Lys Leu Ala Ser Tyr Glu Ile Glu Ser
340 345 350
Thr Val Asn Ser Asn Ser Leu Gln Lys Ile Lys Ile Glu Glu Ala Phe
355 360 365
Ala Leu Lys Phe Ile Asn Ala Cys Leu Phe Ala Ser Asn Asn Leu Arg
370 375 380
Asn Met Val Tyr Pro Val Cys Lys Lys Asp Ile Leu Met Ile Gly Glu
385 390 395 400
Phe Lys Asn Ser Phe Lys Glu Ile Lys His Lys Lys Phe Ile Arg Gln
405 410 415
Trp Ser Gln Phe Phe Ser Gln Glu Ile Thr Val Asp Asp Ile Glu Leu
420 425 430
Ala Ser Trp Gly Leu Arg Gly Ala Ile Ala Pro Ile Arg Asn Glu Ile
435 440 445
Ile His Leu Lys Lys His Ser Trp Lys Lys Phe Phe Asn Asn Pro Thr
450 455 460
Phe Lys Val Lys Lys Ser Lys Ile Ile Asn Gly Lys Thr Lys Asp Val
465 470 475 480
Thr Ser Glu Phe Leu Tyr Lys Glu Thr Leu Phe Lys Asp Tyr Phe Tyr
485 490 495
Ser Glu Leu Asp Ser Val Pro Glu Leu Ile Ile Asn Lys Met Glu Ser
500 505 510
Ser Lys Ile Leu Asp Tyr Tyr Ser Ser Asp Gln Leu Asn Gln Val Phe
515 520 525
Thr Ile Pro Asn Phe Glu Leu Ser Leu Leu Thr Ser Ala Val Pro Phe
530 535 540
Ala Pro Ser Phe Lys Arg Val Tyr Leu Lys Gly Phe Asp Tyr Gln Asn
545 550 555 560
Gln Asp Glu Ala Gln Pro Asp Tyr Asn Leu Lys Leu Asn Ile Tyr Asn
565 570 575
Glu Lys Ala Phe Asn Ser Glu Ala Phe Gln Ala Gln Tyr Ser Leu Phe
580 585 590
Lys Met Val Tyr Tyr Gln Val Phe Leu Pro Gln Phe Thr Thr Asn Asn
595 600 605
Asp Leu Phe Lys Ser Ser Val Asp Phe Ile Leu Thr Leu Asn Lys Glu
610 615 620
Arg Lys Gly Tyr Ala Lys Ala Phe Gln Asp Ile Arg Lys Met Asn Lys
625 630 635 640
Asp Glu Lys Pro Ser Glu Tyr Met Ser Tyr Ile Gln Ser Gln Leu Met
645 650 655
Leu Tyr Gln Lys Lys Gln Glu Glu Lys Glu Lys Ile Asn His Phe Glu
660 665 670
Lys Phe Ile Asn Gln Val Phe Ile Lys Gly Phe Asn Ser Phe Ile Glu
675 680 685
Lys Asn Arg Leu Thr Tyr Ile Cys His Pro Thr Lys Asn Thr Val Pro
690 695 700
Glu Asn Asp Asn Ile Glu Ile Pro Phe His Thr Asp Met Asp Asp Ser
705 710 715 720
Asn Ile Ala Phe Trp Leu Met Cys Lys Leu Leu Asp Ala Lys Gln Leu
725 730 735
Ser Glu Leu Arg Asn Glu Met Ile Lys Phe Ser Cys Ser Leu Gln Ser
740 745 750
Thr Glu Glu Ile Ser Thr Phe Thr Lys Ala Arg Glu Val Ile Gly Leu
755 760 765
Ala Leu Leu Asn Gly Glu Lys Gly Cys Asn Asp Trp Lys Glu Leu Phe
770 775 780
Asp Asp Lys Glu Ala Trp Lys Lys Asn Met Ser Leu Tyr Val Ser Glu
785 790 795 800
Glu Leu Leu Gln Ser Leu Pro Tyr Thr Gln Glu Asp Gly Gln Thr Pro
805 810 815
Val Ile Asn Arg Ser Ile Asp Leu Val Lys Lys Tyr Gly Thr Glu Thr
820 825 830
Ile Leu Glu Lys Leu Phe Ser Ser Ser Asp Asp Tyr Lys Val Ser Ala
835 840 845
Lys Asp Ile Ala Lys Leu His Glu Tyr Asp Val Thr Glu Lys Ile Ala
850 855 860
Gln Gln Glu Ser Leu His Lys Gln Trp Ile Glu Lys Pro Gly Leu Ala
865 870 875 880
Arg Asp Ser Ala Trp Thr Lys Lys Tyr Gln Asn Val Ile Asn Asp Ile
885 890 895
Ser Asn Tyr Gln Trp Ala Lys Thr Lys Val Glu Leu Thr Gln Val Arg
900 905 910
His Leu His Gln Leu Thr Ile Asp Leu Leu Ser Arg Leu Ala Gly Tyr
915 920 925
Met Ser Ile Ala Asp Arg Asp Phe Gln Phe Ser Ser Asn Tyr Ile Leu
930 935 940
Glu Arg Glu Asn Ser Glu Tyr Arg Val Thr Ser Trp Ile Leu Leu Ser
945 950 955 960
Glu Asn Lys Asn Lys Asn Lys Tyr Asn Asp Tyr Glu Leu Tyr Asn Leu
965 970 975
Lys Asn Ala Ser Ile Lys Val Ser Ser Lys Asn Asp Pro Gln Leu Lys
980 985 990
Val Asp Leu Lys Gln Leu Arg Leu Thr Leu Glu Tyr Leu Glu Leu Phe
995 1000 1005
Asp Asn Arg Leu Lys Glu Lys Arg Asn Asn Ile Ser His Phe Asn
1010 1015 1020
Tyr Leu Asn Gly Gln Leu Gly Asn Ser Ile Leu Glu Leu Phe Asp
1025 1030 1035
Asp Ala Arg Asp Val Leu Ser Tyr Asp Arg Lys Leu Lys Asn Ala
1040 1045 1050
Val Ser Lys Ser Leu Lys Glu Ile Leu Ser Ser His Gly Met Glu
1055 1060 1065
Val Thr Phe Lys Pro Leu Tyr Gln Thr Asn His His Leu Lys Ile
1070 1075 1080
Asp Lys Leu Gln Pro Lys Lys Ile His His Leu Gly Glu Lys Ser
1085 1090 1095
Thr Val Ser Ser Asn Gln Val Ser Asn Glu Tyr Cys Gln Leu Val
1100 1105 1110
Arg Thr Leu Leu Thr Met Lys
1115 1120
<210> 42
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 42
guuuuagucc ccuucguuuu ugggguaguc uaaauc 36
<210> 43
<211> 113
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 43
gauuuagagc accccaaaag uaaugaaaau uugcaauuaa auaaggaaua uuaaaaaaau 60
gugauuuuaa aaaaauugaa gaaauuaaau gaaaaauugu ccaaguaaaa aaa 113
<210> 44
<211> 70
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 44
auuuagauua ccccuuuaau uuauuuuacc auauuuuucu cauaaugcaa acuaauauuc 60
caaaauuuuu 70
<210> 45
<211> 1389
<212> БЕЛОК
<213> Leptotrichia wadei
<400> 45
Met Gly Asn Leu Phe Gly His Lys Arg Trp Tyr Glu Val Arg Asp Lys
1 5 10 15
Lys Asp Phe Lys Ile Lys Arg Lys Val Lys Val Lys Arg Asn Tyr Asp
20 25 30
Gly Asn Lys Tyr Ile Leu Asn Ile Asn Glu Asn Asn Asn Lys Glu Lys
35 40 45
Ile Asp Asn Asn Lys Phe Ile Arg Lys Tyr Ile Asn Tyr Lys Lys Asn
50 55 60
Asp Asn Ile Leu Lys Glu Phe Thr Arg Lys Phe His Ala Gly Asn Ile
65 70 75 80
Leu Phe Lys Leu Lys Gly Lys Glu Gly Ile Ile Arg Ile Glu Asn Asn
85 90 95
Asp Asp Phe Leu Glu Thr Glu Glu Val Val Leu Tyr Ile Glu Ala Tyr
100 105 110
Gly Lys Ser Glu Lys Leu Lys Ala Leu Gly Ile Thr Lys Lys Lys Ile
115 120 125
Ile Asp Glu Ala Ile Arg Gln Gly Ile Thr Lys Asp Asp Lys Lys Ile
130 135 140
Glu Ile Lys Arg Gln Glu Asn Glu Glu Glu Ile Glu Ile Asp Ile Arg
145 150 155 160
Asp Glu Tyr Thr Asn Lys Thr Leu Asn Asp Cys Ser Ile Ile Leu Arg
165 170 175
Ile Ile Glu Asn Asp Glu Leu Glu Thr Lys Lys Ser Ile Tyr Glu Ile
180 185 190
Phe Lys Asn Ile Asn Met Ser Leu Tyr Lys Ile Ile Glu Lys Ile Ile
195 200 205
Glu Asn Glu Thr Glu Lys Val Phe Glu Asn Arg Tyr Tyr Glu Glu His
210 215 220
Leu Arg Glu Lys Leu Leu Lys Asp Asp Lys Ile Asp Val Ile Leu Thr
225 230 235 240
Asn Phe Met Glu Ile Arg Glu Lys Ile Lys Ser Asn Leu Glu Ile Leu
245 250 255
Gly Phe Val Lys Phe Tyr Leu Asn Val Gly Gly Asp Lys Lys Lys Ser
260 265 270
Lys Asn Lys Lys Met Leu Val Glu Lys Ile Leu Asn Ile Asn Val Asp
275 280 285
Leu Thr Val Glu Asp Ile Ala Asp Phe Val Ile Lys Glu Leu Glu Phe
290 295 300
Trp Asn Ile Thr Lys Arg Ile Glu Lys Val Lys Lys Val Asn Asn Glu
305 310 315 320
Phe Leu Glu Lys Arg Arg Asn Arg Thr Tyr Ile Lys Ser Tyr Val Leu
325 330 335
Leu Asp Lys His Glu Lys Phe Lys Ile Glu Arg Glu Asn Lys Lys Asp
340 345 350
Lys Ile Val Lys Phe Phe Val Glu Asn Ile Lys Asn Asn Ser Ile Lys
355 360 365
Glu Lys Ile Glu Lys Ile Leu Ala Glu Phe Lys Ile Asp Glu Leu Ile
370 375 380
Lys Lys Leu Glu Lys Glu Leu Lys Lys Gly Asn Cys Asp Thr Glu Ile
385 390 395 400
Phe Gly Ile Phe Lys Lys His Tyr Lys Val Asn Phe Asp Ser Lys Lys
405 410 415
Phe Ser Lys Lys Ser Asp Glu Glu Lys Glu Leu Tyr Lys Ile Ile Tyr
420 425 430
Arg Tyr Leu Lys Gly Arg Ile Glu Lys Ile Leu Val Asn Glu Gln Lys
435 440 445
Val Arg Leu Lys Lys Met Glu Lys Ile Glu Ile Glu Lys Ile Leu Asn
450 455 460
Glu Ser Ile Leu Ser Glu Lys Ile Leu Lys Arg Val Lys Gln Tyr Thr
465 470 475 480
Leu Glu His Ile Met Tyr Leu Gly Lys Leu Arg His Asn Asp Ile Asp
485 490 495
Met Thr Thr Val Asn Thr Asp Asp Phe Ser Arg Leu His Ala Lys Glu
500 505 510
Glu Leu Asp Leu Glu Leu Ile Thr Phe Phe Ala Ser Thr Asn Met Glu
515 520 525
Leu Asn Lys Ile Phe Ser Arg Glu Asn Ile Asn Asn Asp Glu Asn Ile
530 535 540
Asp Phe Phe Gly Gly Asp Arg Glu Lys Asn Tyr Val Leu Asp Lys Lys
545 550 555 560
Ile Leu Asn Ser Lys Ile Lys Ile Ile Arg Asp Leu Asp Phe Ile Asp
565 570 575
Asn Lys Asn Asn Ile Thr Asn Asn Phe Ile Arg Lys Phe Thr Lys Ile
580 585 590
Gly Thr Asn Glu Arg Asn Arg Ile Leu His Ala Ile Ser Lys Glu Arg
595 600 605
Asp Leu Gln Gly Thr Gln Asp Asp Tyr Asn Lys Val Ile Asn Ile Ile
610 615 620
Gln Asn Leu Lys Ile Ser Asp Glu Glu Val Ser Lys Ala Leu Asn Leu
625 630 635 640
Asp Val Val Phe Lys Asp Lys Lys Asn Ile Ile Thr Lys Ile Asn Asp
645 650 655
Ile Lys Ile Ser Glu Glu Asn Asn Asn Asp Ile Lys Tyr Leu Pro Ser
660 665 670
Phe Ser Lys Val Leu Pro Glu Ile Leu Asn Leu Tyr Arg Asn Asn Pro
675 680 685
Lys Asn Glu Pro Phe Asp Thr Ile Glu Thr Glu Lys Ile Val Leu Asn
690 695 700
Ala Leu Ile Tyr Val Asn Lys Glu Leu Tyr Lys Lys Leu Ile Leu Glu
705 710 715 720
Asp Asp Leu Glu Glu Asn Glu Ser Lys Asn Ile Phe Leu Gln Glu Leu
725 730 735
Lys Lys Thr Leu Gly Asn Ile Asp Glu Ile Asp Glu Asn Ile Ile Glu
740 745 750
Asn Tyr Tyr Lys Asn Ala Gln Ile Ser Ala Ser Lys Gly Asn Asn Lys
755 760 765
Ala Ile Lys Lys Tyr Gln Lys Lys Val Ile Glu Cys Tyr Ile Gly Tyr
770 775 780
Leu Arg Lys Asn Tyr Glu Glu Leu Phe Asp Phe Ser Asp Phe Lys Met
785 790 795 800
Asn Ile Gln Glu Ile Lys Lys Gln Ile Lys Asp Ile Asn Asp Asn Lys
805 810 815
Thr Tyr Glu Arg Ile Thr Val Lys Thr Ser Asp Lys Thr Ile Val Ile
820 825 830
Asn Asp Asp Phe Glu Tyr Ile Ile Ser Ile Phe Ala Leu Leu Asn Ser
835 840 845
Asn Ala Val Ile Asn Lys Ile Arg Asn Arg Phe Phe Ala Thr Ser Val
850 855 860
Trp Leu Asn Thr Ser Glu Tyr Gln Asn Ile Ile Asp Ile Leu Asp Glu
865 870 875 880
Ile Met Gln Leu Asn Thr Leu Arg Asn Glu Cys Ile Thr Glu Asn Trp
885 890 895
Asn Leu Asn Leu Glu Glu Phe Ile Gln Lys Met Lys Glu Ile Glu Lys
900 905 910
Asp Phe Asp Asp Phe Lys Ile Gln Thr Lys Lys Glu Ile Phe Asn Asn
915 920 925
Tyr Tyr Glu Asp Ile Lys Asn Asn Ile Leu Thr Glu Phe Lys Asp Asp
930 935 940
Ile Asn Gly Cys Asp Val Leu Glu Lys Lys Leu Glu Lys Ile Val Ile
945 950 955 960
Phe Asp Asp Glu Thr Lys Phe Glu Ile Asp Lys Lys Ser Asn Ile Leu
965 970 975
Gln Asp Glu Gln Arg Lys Leu Ser Asn Ile Asn Lys Lys Asp Leu Lys
980 985 990
Lys Lys Val Asp Gln Tyr Ile Lys Asp Lys Asp Gln Glu Ile Lys Ser
995 1000 1005
Lys Ile Leu Cys Arg Ile Ile Phe Asn Ser Asp Phe Leu Lys Lys
1010 1015 1020
Tyr Lys Lys Glu Ile Asp Asn Leu Ile Glu Asp Met Glu Ser Glu
1025 1030 1035
Asn Glu Asn Lys Phe Gln Glu Ile Tyr Tyr Pro Lys Glu Arg Lys
1040 1045 1050
Asn Glu Leu Tyr Ile Tyr Lys Lys Asn Leu Phe Leu Asn Ile Gly
1055 1060 1065
Asn Pro Asn Phe Asp Lys Ile Tyr Gly Leu Ile Ser Asn Asp Ile
1070 1075 1080
Lys Met Ala Asp Ala Lys Phe Leu Phe Asn Ile Asp Gly Lys Asn
1085 1090 1095
Ile Arg Lys Asn Lys Ile Ser Glu Ile Asp Ala Ile Leu Lys Asn
1100 1105 1110
Leu Asn Asp Lys Leu Asn Gly Tyr Ser Lys Glu Tyr Lys Glu Lys
1115 1120 1125
Tyr Ile Lys Lys Leu Lys Glu Asn Asp Asp Phe Phe Ala Lys Asn
1130 1135 1140
Ile Gln Asn Lys Asn Tyr Lys Ser Phe Glu Lys Asp Tyr Asn Arg
1145 1150 1155
Val Ser Glu Tyr Lys Lys Ile Arg Asp Leu Val Glu Phe Asn Tyr
1160 1165 1170
Leu Asn Lys Ile Glu Ser Tyr Leu Ile Asp Ile Asn Trp Lys Leu
1175 1180 1185
Ala Ile Gln Met Ala Arg Phe Glu Arg Asp Met His Tyr Ile Val
1190 1195 1200
Asn Gly Leu Arg Glu Leu Gly Ile Ile Lys Leu Ser Gly Tyr Asn
1205 1210 1215
Thr Gly Ile Ser Arg Ala Tyr Pro Lys Arg Asn Gly Ser Asp Gly
1220 1225 1230
Phe Tyr Thr Thr Thr Ala Tyr Tyr Lys Phe Phe Asp Glu Glu Ser
1235 1240 1245
Tyr Lys Lys Phe Glu Lys Ile Cys Tyr Gly Phe Gly Ile Asp Leu
1250 1255 1260
Ser Glu Asn Ser Glu Ile Asn Lys Pro Glu Asn Glu Ser Ile Arg
1265 1270 1275
Asn Tyr Ile Ser His Phe Tyr Ile Val Arg Asn Pro Phe Ala Asp
1280 1285 1290
Tyr Ser Ile Ala Glu Gln Ile Asp Arg Val Ser Asn Leu Leu Ser
1295 1300 1305
Tyr Ser Thr Arg Tyr Asn Asn Ser Thr Tyr Ala Ser Val Phe Glu
1310 1315 1320
Val Phe Lys Lys Asp Val Asn Leu Asp Tyr Asp Glu Leu Lys Lys
1325 1330 1335
Lys Phe Lys Leu Ile Gly Asn Asn Asp Ile Leu Glu Arg Leu Met
1340 1345 1350
Lys Pro Lys Lys Val Ser Val Leu Glu Leu Glu Ser Tyr Asn Ser
1355 1360 1365
Asp Tyr Ile Lys Asn Leu Ile Ile Glu Leu Leu Thr Lys Ile Glu
1370 1375 1380
Asn Thr Asn Asp Thr Leu
1385
<210> 46
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 46
guuuuagucc ccuucgauau uggggugguc uauauc 36
<210> 47
<211> 95
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 47
auugaugugg uauacuaaaa auggaaaauu guauuuuuga uuagaaagau guaaaauuga 60
uuuaauuuaa aaauauuuua uuagauuaaa guaga 95
<210> 48
<211> 1300
<212> БЕЛОК
<213> Leptotrichia shahii
<400> 48
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Ile Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Glu Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Asp Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Lys Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Ser Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr Lys Gln Ser Ile Ser Lys His Pro Glu Trp Lys Asp
725 730 735
Phe Gly Phe Arg Phe Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu
740 745 750
Phe Tyr Arg Glu Val Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn
755 760 765
Ile Ser Glu Ser Tyr Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr
770 775 780
Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg
785 790 795 800
Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn
805 810 815
Leu Gln Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr
820 825 830
Arg Lys Gln Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
835 840 845
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Val Phe Glu
850 855 860
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
865 870 875 880
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
885 890 895
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
900 905 910
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
915 920 925
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
930 935 940
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
945 950 955 960
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
965 970 975
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
980 985 990
Ala Lys Leu Val Ile Glu Tyr Asn Ala Ile Val Val Phe Glu Asp Leu
995 1000 1005
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
1010 1015 1020
Tyr Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu
1025 1030 1035
Val Phe Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg
1040 1045 1050
Ala Tyr Gln Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly
1055 1060 1065
Lys Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser
1070 1075 1080
Lys Ile Cys Pro Val Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys
1085 1090 1095
Tyr Glu Ser Val Ser Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp
1100 1105 1110
Lys Ile Cys Tyr Asn Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe
1115 1120 1125
Asp Tyr Lys Asn Phe Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr
1130 1135 1140
Ile Ala Ser Phe Gly Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp
1145 1150 1155
Lys Asn His Asn Trp Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu
1160 1165 1170
Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly
1175 1180 1185
Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe
1190 1195 1200
Phe Ala Lys Leu Thr Ser Val Leu Asn Thr Ile Leu Gln Met Arg
1205 1210 1215
Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val
1220 1225 1230
Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
1235 1240 1245
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly
1250 1255 1260
Leu Lys Gly Leu Met Leu Leu Gly Arg Ile Lys Asn Asn Gln Glu
1265 1270 1275
Gly Lys Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu
1280 1285 1290
Phe Val Gln Asn Arg Asn Asn
1295 1300
<210> 49
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 49
gucuaagaac uuuaaauaau uucuacuguu guagau 36
<210> 50
<211> 71
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 50
aucuacaaaa uuauaaacua aauaaagauu cuuauaauaa cuuuauauau aaucgaaaug 60
uagagaauuu u 71
<210> 51
<211> 1300
<212> БЕЛОК
<213> Francisella ularensis
<400> 51
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Ile Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Glu Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Asp Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Lys Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Ser Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr Lys Gln Ser Ile Ser Lys His Pro Glu Trp Lys Asp
725 730 735
Phe Gly Phe Arg Phe Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu
740 745 750
Phe Tyr Arg Glu Val Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn
755 760 765
Ile Ser Glu Ser Tyr Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr
770 775 780
Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg
785 790 795 800
Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn
805 810 815
Leu Gln Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr
820 825 830
Arg Lys Gln Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
835 840 845
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Val Phe Glu
850 855 860
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
865 870 875 880
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
885 890 895
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
900 905 910
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
915 920 925
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
930 935 940
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
945 950 955 960
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
965 970 975
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
980 985 990
Ala Lys Leu Val Ile Glu Tyr Asn Ala Ile Val Val Phe Glu Asp Leu
995 1000 1005
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
1010 1015 1020
Tyr Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu
1025 1030 1035
Val Phe Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg
1040 1045 1050
Ala Tyr Gln Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly
1055 1060 1065
Lys Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser
1070 1075 1080
Lys Ile Cys Pro Val Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys
1085 1090 1095
Tyr Glu Ser Val Ser Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp
1100 1105 1110
Lys Ile Cys Tyr Asn Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe
1115 1120 1125
Asp Tyr Lys Asn Phe Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr
1130 1135 1140
Ile Ala Ser Phe Gly Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp
1145 1150 1155
Lys Asn His Asn Trp Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu
1160 1165 1170
Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly
1175 1180 1185
Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe
1190 1195 1200
Phe Ala Lys Leu Thr Ser Val Leu Asn Thr Ile Leu Gln Met Arg
1205 1210 1215
Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val
1220 1225 1230
Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
1235 1240 1245
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly
1250 1255 1260
Leu Lys Gly Leu Met Leu Leu Gly Arg Ile Lys Asn Asn Gln Glu
1265 1270 1275
Gly Lys Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu
1280 1285 1290
Phe Val Gln Asn Arg Asn Asn
1295 1300
<210> 52
<211> 138
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 52
aaaaggccgg cggccacgaa aaaggccggc caggcaaaaa agaaaaaggg atcctaccca 60
tacgatgttc cagattacgc ttatccctac gacgtgcctg attatgcata cccatatgat 120
gtccccgact atgcctaa 138
<210> 53
<211> 1388
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 53
Met Ser Leu Asn Arg Ile Tyr Gln Gly Arg Val Ala Ala Val Glu Thr
1 5 10 15
Gly Thr Ala Leu Ala Lys Gly Asn Val Glu Trp Met Pro Ala Ala Gly
20 25 30
Gly Asp Glu Val Leu Trp Gln His His Glu Leu Phe Gln Ala Ala Ile
35 40 45
Asn Tyr Tyr Leu Val Ala Leu Leu Ala Leu Ala Asp Lys Asn Asn Pro
50 55 60
Val Leu Gly Pro Leu Ile Ser Gln Met Asp Asn Pro Gln Ser Pro Tyr
65 70 75 80
His Val Trp Gly Ser Phe Arg Arg Gln Gly Arg Gln Arg Thr Gly Leu
85 90 95
Ser Gln Ala Val Ala Pro Tyr Ile Thr Pro Gly Asn Asn Ala Pro Thr
100 105 110
Leu Asp Glu Val Phe Arg Ser Ile Leu Ala Gly Asn Pro Thr Asp Arg
115 120 125
Ala Thr Leu Asp Ala Ala Leu Met Gln Leu Leu Lys Ala Cys Asp Gly
130 135 140
Ala Gly Ala Ile Gln Gln Glu Gly Arg Ser Tyr Trp Pro Lys Phe Cys
145 150 155 160
Asp Pro Asp Ser Thr Ala Asn Phe Ala Gly Asp Pro Ala Met Leu Arg
165 170 175
Arg Glu Gln His Arg Leu Leu Leu Pro Gln Val Leu His Asp Pro Ala
180 185 190
Ile Thr His Asp Ser Pro Ala Leu Gly Ser Phe Asp Thr Tyr Ser Ile
195 200 205
Ala Thr Pro Asp Thr Arg Thr Pro Gln Leu Thr Gly Pro Lys Ala Arg
210 215 220
Ala Arg Leu Glu Gln Ala Ile Thr Leu Trp Arg Val Arg Leu Pro Glu
225 230 235 240
Ser Ala Ala Asp Phe Asp Arg Leu Ala Ser Ser Leu Lys Lys Ile Pro
245 250 255
Asp Asp Asp Ser Arg Leu Asn Leu Gln Gly Tyr Val Gly Ser Ser Ala
260 265 270
Lys Gly Glu Val Gln Ala Arg Leu Phe Ala Leu Leu Leu Phe Arg His
275 280 285
Leu Glu Arg Ser Ser Phe Thr Leu Gly Leu Leu Arg Ser Ala Thr Pro
290 295 300
Pro Pro Lys Asn Ala Glu Thr Pro Pro Pro Ala Gly Val Pro Leu Pro
305 310 315 320
Ala Ala Ser Ala Ala Asp Pro Val Arg Ile Ala Arg Gly Lys Arg Ser
325 330 335
Phe Val Phe Arg Ala Phe Thr Ser Leu Pro Cys Trp His Gly Gly Asp
340 345 350
Asn Ile His Pro Thr Trp Lys Ser Phe Asp Ile Ala Ala Phe Lys Tyr
355 360 365
Ala Leu Thr Val Ile Asn Gln Ile Glu Glu Lys Thr Lys Glu Arg Gln
370 375 380
Lys Glu Cys Ala Glu Leu Glu Thr Asp Phe Asp Tyr Met His Gly Arg
385 390 395 400
Leu Ala Lys Ile Pro Val Lys Tyr Thr Thr Gly Glu Ala Glu Pro Pro
405 410 415
Pro Ile Leu Ala Asn Asp Leu Arg Ile Pro Leu Leu Arg Glu Leu Leu
420 425 430
Gln Asn Ile Lys Val Asp Thr Ala Leu Thr Asp Gly Glu Ala Val Ser
435 440 445
Tyr Gly Leu Gln Arg Arg Thr Ile Arg Gly Phe Arg Glu Leu Arg Arg
450 455 460
Ile Trp Arg Gly His Ala Pro Ala Gly Thr Val Phe Ser Ser Glu Leu
465 470 475 480
Lys Glu Lys Leu Ala Gly Glu Leu Arg Gln Phe Gln Thr Asp Asn Ser
485 490 495
Thr Thr Ile Gly Ser Val Gln Leu Phe Asn Glu Leu Ile Gln Asn Pro
500 505 510
Lys Tyr Trp Pro Ile Trp Gln Ala Pro Asp Val Glu Thr Ala Arg Gln
515 520 525
Trp Ala Asp Ala Gly Phe Ala Asp Asp Pro Leu Ala Ala Leu Val Gln
530 535 540
Glu Ala Glu Leu Gln Glu Asp Ile Asp Ala Leu Lys Ala Pro Val Lys
545 550 555 560
Leu Thr Pro Ala Asp Pro Glu Tyr Ser Arg Arg Gln Tyr Asp Phe Asn
565 570 575
Ala Val Ser Lys Phe Gly Ala Gly Ser Arg Ser Ala Asn Arg His Glu
580 585 590
Pro Gly Gln Thr Glu Arg Gly His Asn Thr Phe Thr Thr Glu Ile Ala
595 600 605
Ala Arg Asn Ala Ala Asp Gly Asn Arg Trp Arg Ala Thr His Val Arg
610 615 620
Ile His Tyr Ser Ala Pro Arg Leu Leu Arg Asp Gly Leu Arg Arg Pro
625 630 635 640
Asp Thr Asp Gly Asn Glu Ala Leu Glu Ala Val Pro Trp Leu Gln Pro
645 650 655
Met Met Glu Ala Leu Ala Pro Leu Pro Thr Leu Pro Gln Asp Leu Thr
660 665 670
Gly Met Pro Val Phe Leu Met Pro Asp Val Thr Leu Ser Gly Glu Arg
675 680 685
Arg Ile Leu Leu Asn Leu Pro Val Thr Leu Glu Pro Ala Ala Leu Val
690 695 700
Glu Gln Leu Gly Asn Ala Gly Arg Trp Gln Asn Gln Phe Phe Gly Ser
705 710 715 720
Arg Glu Asp Pro Phe Ala Leu Arg Trp Pro Ala Asp Gly Ala Val Lys
725 730 735
Thr Ala Lys Gly Lys Thr His Ile Pro Trp His Gln Asp Arg Asp His
740 745 750
Phe Thr Val Leu Gly Val Asp Leu Gly Thr Arg Asp Ala Gly Ala Leu
755 760 765
Ala Leu Leu Asn Val Thr Ala Gln Lys Pro Ala Lys Pro Val His Arg
770 775 780
Ile Ile Gly Glu Ala Asp Gly Arg Thr Trp Tyr Ala Ser Leu Ala Asp
785 790 795 800
Ala Arg Met Ile Arg Leu Pro Gly Glu Asp Ala Arg Leu Phe Val Arg
805 810 815
Gly Lys Leu Val Gln Glu Pro Tyr Gly Glu Arg Gly Arg Asn Ala Ser
820 825 830
Leu Leu Glu Trp Glu Asp Ala Arg Asn Ile Ile Leu Arg Leu Gly Gln
835 840 845
Asn Pro Asp Glu Leu Leu Gly Ala Asp Pro Arg Arg His Ser Tyr Pro
850 855 860
Glu Ile Asn Asp Lys Leu Leu Val Ala Leu Arg Arg Ala Gln Ala Arg
865 870 875 880
Leu Ala Arg Leu Gln Asn Arg Ser Trp Arg Leu Arg Asp Leu Ala Glu
885 890 895
Ser Asp Lys Ala Leu Asp Glu Ile His Ala Glu Arg Ala Gly Glu Lys
900 905 910
Pro Ser Pro Leu Pro Pro Leu Ala Arg Asp Asp Ala Ile Lys Ser Thr
915 920 925
Asp Glu Ala Leu Leu Ser Gln Arg Asp Ile Ile Arg Arg Ser Phe Val
930 935 940
Gln Ile Ala Asn Leu Ile Leu Pro Leu Arg Gly Arg Arg Trp Glu Trp
945 950 955 960
Arg Pro His Val Glu Val Pro Asp Cys His Ile Leu Ala Gln Ser Asp
965 970 975
Pro Gly Thr Asp Asp Thr Lys Arg Leu Val Ala Gly Gln Arg Gly Ile
980 985 990
Ser His Glu Arg Ile Glu Gln Ile Glu Glu Leu Arg Arg Arg Cys Gln
995 1000 1005
Ser Leu Asn Arg Ala Leu Arg His Lys Pro Gly Glu Arg Pro Val
1010 1015 1020
Leu Gly Arg Pro Ala Lys Gly Glu Glu Ile Ala Asp Pro Cys Pro
1025 1030 1035
Ala Leu Leu Glu Lys Ile Asn Arg Leu Arg Asp Gln Arg Val Asp
1040 1045 1050
Gln Thr Ala His Ala Ile Leu Ala Ala Ala Leu Gly Val Arg Leu
1055 1060 1065
Arg Ala Pro Ser Lys Asp Arg Ala Glu Arg Arg His Arg Asp Ile
1070 1075 1080
His Gly Glu Tyr Glu Arg Phe Arg Ala Pro Ala Asp Phe Val Val
1085 1090 1095
Ile Glu Asn Leu Ser Arg Tyr Leu Ser Ser Gln Asp Arg Ala Arg
1100 1105 1110
Ser Glu Asn Thr Arg Leu Met Gln Trp Cys His Arg Gln Ile Val
1115 1120 1125
Gln Lys Leu Arg Gln Leu Cys Glu Thr Tyr Gly Ile Pro Val Leu
1130 1135 1140
Ala Val Pro Ala Ala Tyr Ser Ser Arg Phe Ser Ser Arg Asp Gly
1145 1150 1155
Ser Ala Gly Phe Arg Ala Val His Leu Thr Pro Asp His Arg His
1160 1165 1170
Arg Met Pro Trp Ser Arg Ile Leu Ala Arg Leu Lys Ala His Glu
1175 1180 1185
Glu Asp Gly Lys Arg Leu Glu Lys Thr Val Leu Asp Glu Ala Arg
1190 1195 1200
Ala Val Arg Gly Leu Phe Asp Arg Leu Asp Arg Phe Asn Ala Gly
1205 1210 1215
His Val Pro Gly Lys Pro Trp Arg Thr Leu Leu Ala Pro Leu Pro
1220 1225 1230
Gly Gly Pro Val Phe Val Pro Leu Gly Asp Ala Thr Pro Met Gln
1235 1240 1245
Ala Asp Leu Asn Ala Ala Ile Asn Ile Ala Leu Arg Gly Ile Ala
1250 1255 1260
Ala Pro Asp Arg His Asp Ile His His Arg Leu Arg Ala Glu Asn
1265 1270 1275
Lys Lys Arg Ile Leu Ser Leu Arg Leu Gly Thr Gln Arg Glu Lys
1280 1285 1290
Ala Arg Trp Pro Gly Gly Ala Pro Ala Val Thr Leu Ser Thr Pro
1295 1300 1305
Asn Asn Gly Ala Ser Pro Glu Asp Ser Asp Ala Leu Pro Glu Arg
1310 1315 1320
Val Ser Asn Leu Phe Val Asp Ile Ala Gly Val Ala Asn Phe Glu
1325 1330 1335
Arg Val Thr Ile Glu Gly Val Ser Gln Lys Phe Ala Thr Gly Arg
1340 1345 1350
Gly Leu Trp Ala Ser Val Lys Gln Arg Ala Trp Asn Arg Val Ala
1355 1360 1365
Arg Leu Asn Glu Thr Val Thr Asp Asn Asn Arg Asn Glu Glu Glu
1370 1375 1380
Asp Asp Ile Pro Met
1385
<210> 54
<211> 1108
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 54
Met Ala Thr Arg Ser Phe Ile Leu Lys Ile Glu Pro Asn Glu Glu Val
1 5 10 15
Lys Lys Gly Leu Trp Lys Thr His Glu Val Leu Asn His Gly Ile Ala
20 25 30
Tyr Tyr Met Asn Ile Leu Lys Leu Ile Arg Gln Glu Ala Ile Tyr Glu
35 40 45
His His Glu Gln Asp Pro Lys Asn Pro Lys Lys Val Ser Lys Ala Glu
50 55 60
Ile Gln Ala Glu Leu Trp Asp Phe Val Leu Lys Met Gln Lys Cys Asn
65 70 75 80
Ser Phe Thr His Glu Val Asp Lys Asp Val Val Phe Asn Ile Leu Arg
85 90 95
Glu Leu Tyr Glu Glu Leu Val Pro Ser Ser Val Glu Lys Lys Gly Glu
100 105 110
Ala Asn Gln Leu Ser Asn Lys Phe Leu Tyr Pro Leu Val Asp Pro Asn
115 120 125
Ser Gln Ser Gly Lys Gly Thr Ala Ser Ser Gly Arg Lys Pro Arg Trp
130 135 140
Tyr Asn Leu Lys Ile Ala Gly Asp Pro Ser Trp Glu Glu Glu Lys Lys
145 150 155 160
Lys Trp Glu Glu Asp Lys Lys Lys Asp Pro Leu Ala Lys Ile Leu Gly
165 170 175
Lys Leu Ala Glu Tyr Gly Leu Ile Pro Leu Phe Ile Pro Phe Thr Asp
180 185 190
Ser Asn Glu Pro Ile Val Lys Glu Ile Lys Trp Met Glu Lys Ser Arg
195 200 205
Asn Gln Ser Val Arg Arg Leu Asp Lys Asp Met Phe Ile Gln Ala Leu
210 215 220
Glu Arg Phe Leu Ser Trp Glu Ser Trp Asn Leu Lys Val Lys Glu Glu
225 230 235 240
Tyr Glu Lys Val Glu Lys Glu His Lys Thr Leu Glu Glu Arg Ile Lys
245 250 255
Glu Asp Ile Gln Ala Phe Lys Ser Leu Glu Gln Tyr Glu Lys Glu Arg
260 265 270
Gln Glu Gln Leu Leu Arg Asp Thr Leu Asn Thr Asn Glu Tyr Arg Leu
275 280 285
Ser Lys Arg Gly Leu Arg Gly Trp Arg Glu Ile Ile Gln Lys Trp Leu
290 295 300
Lys Met Asp Glu Asn Glu Pro Ser Glu Lys Tyr Leu Glu Val Phe Lys
305 310 315 320
Asp Tyr Gln Arg Lys His Pro Arg Glu Ala Gly Asp Tyr Ser Val Tyr
325 330 335
Glu Phe Leu Ser Lys Lys Glu Asn His Phe Ile Trp Arg Asn His Pro
340 345 350
Glu Tyr Pro Tyr Leu Tyr Ala Thr Phe Cys Glu Ile Asp Lys Lys Lys
355 360 365
Lys Asp Ala Lys Gln Gln Ala Thr Phe Thr Leu Ala Asp Pro Ile Asn
370 375 380
His Pro Leu Trp Val Arg Phe Glu Glu Arg Ser Gly Ser Asn Leu Asn
385 390 395 400
Lys Tyr Arg Ile Leu Thr Glu Gln Leu His Thr Glu Lys Leu Lys Lys
405 410 415
Lys Leu Thr Val Gln Leu Asp Arg Leu Ile Tyr Pro Thr Glu Ser Gly
420 425 430
Gly Trp Glu Glu Lys Gly Lys Val Asp Ile Val Leu Leu Pro Ser Arg
435 440 445
Gln Phe Tyr Asn Gln Ile Phe Leu Asp Ile Glu Glu Lys Gly Lys His
450 455 460
Ala Phe Thr Tyr Lys Asp Glu Ser Ile Lys Phe Pro Leu Lys Gly Thr
465 470 475 480
Leu Gly Gly Ala Arg Val Gln Phe Asp Arg Asp His Leu Arg Arg Tyr
485 490 495
Pro His Lys Val Glu Ser Gly Asn Val Gly Arg Ile Tyr Phe Asn Met
500 505 510
Thr Val Asn Ile Glu Pro Thr Glu Ser Pro Val Ser Lys Ser Leu Lys
515 520 525
Ile His Arg Asp Asp Phe Pro Lys Phe Val Asn Phe Lys Pro Lys Glu
530 535 540
Leu Thr Glu Trp Ile Lys Asp Ser Lys Gly Lys Lys Leu Lys Ser Gly
545 550 555 560
Ile Glu Ser Leu Glu Ile Gly Leu Arg Val Met Ser Ile Asp Leu Gly
565 570 575
Gln Arg Gln Ala Ala Ala Ala Ser Ile Phe Glu Val Val Asp Gln Lys
580 585 590
Pro Asp Ile Glu Gly Lys Leu Phe Phe Pro Ile Lys Gly Thr Glu Leu
595 600 605
Tyr Ala Val His Arg Ala Ser Phe Asn Ile Lys Leu Pro Gly Glu Thr
610 615 620
Leu Val Lys Ser Arg Glu Val Leu Arg Lys Ala Arg Glu Asp Asn Leu
625 630 635 640
Lys Leu Met Asn Gln Lys Leu Asn Phe Leu Arg Asn Val Leu His Phe
645 650 655
Gln Gln Phe Glu Asp Ile Thr Glu Arg Glu Lys Arg Val Thr Lys Trp
660 665 670
Ile Ser Arg Gln Glu Asn Ser Asp Val Pro Leu Val Tyr Gln Asp Glu
675 680 685
Leu Ile Gln Ile Arg Glu Leu Met Tyr Lys Pro Tyr Lys Asp Trp Val
690 695 700
Ala Phe Leu Lys Gln Leu His Lys Arg Leu Glu Val Glu Ile Gly Lys
705 710 715 720
Glu Val Lys His Trp Arg Lys Ser Leu Ser Asp Gly Arg Lys Gly Leu
725 730 735
Tyr Gly Ile Ser Leu Lys Asn Ile Asp Glu Ile Asp Arg Thr Arg Lys
740 745 750
Phe Leu Leu Arg Trp Ser Leu Arg Pro Thr Glu Pro Gly Glu Val Arg
755 760 765
Arg Leu Glu Pro Gly Gln Arg Phe Ala Ile Asp Gln Leu Asn His Leu
770 775 780
Asn Ala Leu Lys Glu Asp Arg Leu Lys Lys Met Ala Asn Thr Ile Ile
785 790 795 800
Met His Ala Leu Gly Tyr Cys Tyr Asp Val Arg Lys Lys Lys Trp Gln
805 810 815
Ala Lys Asn Pro Ala Cys Gln Ile Ile Leu Phe Glu Asp Leu Ser Asn
820 825 830
Tyr Asn Pro Tyr Glu Glu Arg Ser Arg Phe Glu Asn Ser Lys Leu Met
835 840 845
Lys Trp Ser Arg Arg Glu Ile Pro Arg Gln Val Ala Leu Gln Gly Glu
850 855 860
Ile Tyr Gly Leu Gln Val Gly Glu Val Gly Ala Gln Phe Ser Ser Arg
865 870 875 880
Phe His Ala Lys Thr Gly Ser Pro Gly Ile Arg Cys Ser Val Val Thr
885 890 895
Lys Glu Lys Leu Gln Asp Asn Arg Phe Phe Lys Asn Leu Gln Arg Glu
900 905 910
Gly Arg Leu Thr Leu Asp Lys Ile Ala Val Leu Lys Glu Gly Asp Leu
915 920 925
Tyr Pro Asp Lys Gly Gly Glu Lys Phe Ile Ser Leu Ser Lys Asp Arg
930 935 940
Lys Leu Val Thr Thr His Ala Asp Ile Asn Ala Ala Gln Asn Leu Gln
945 950 955 960
Lys Arg Phe Trp Thr Arg Thr His Gly Phe Tyr Lys Val Tyr Cys Lys
965 970 975
Ala Tyr Gln Val Asp Gly Gln Thr Val Tyr Ile Pro Glu Ser Lys Asp
980 985 990
Gln Lys Gln Lys Ile Ile Glu Glu Phe Gly Glu Gly Tyr Phe Ile Leu
995 1000 1005
Lys Asp Gly Val Tyr Glu Trp Gly Asn Ala Gly Lys Leu Lys Ile
1010 1015 1020
Lys Lys Gly Ser Ser Lys Gln Ser Ser Ser Glu Leu Val Asp Ser
1025 1030 1035
Asp Ile Leu Lys Asp Ser Phe Asp Leu Ala Ser Glu Leu Lys Gly
1040 1045 1050
Glu Lys Leu Met Leu Tyr Arg Asp Pro Ser Gly Asn Val Phe Pro
1055 1060 1065
Ser Asp Lys Trp Met Ala Ala Gly Val Phe Phe Gly Lys Leu Glu
1070 1075 1080
Arg Ile Leu Ile Ser Lys Leu Thr Asn Gln Tyr Ser Ile Ser Thr
1085 1090 1095
Ile Glu Asp Asp Ser Ser Lys Gln Ser Met
1100 1105
<210> 55
<211> 1108
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 55
Met Ala Ile Arg Ser Ile Lys Leu Lys Leu Lys Thr His Thr Gly Pro
1 5 10 15
Glu Ala Gln Asn Leu Arg Lys Gly Ile Trp Arg Thr His Arg Leu Leu
20 25 30
Asn Glu Gly Val Ala Tyr Tyr Met Lys Met Leu Leu Leu Phe Arg Gln
35 40 45
Glu Ser Thr Gly Glu Arg Pro Lys Glu Glu Leu Gln Glu Glu Leu Ile
50 55 60
Cys His Ile Arg Glu Gln Gln Gln Arg Asn Gln Ala Asp Lys Asn Thr
65 70 75 80
Gln Ala Leu Pro Leu Asp Lys Ala Leu Glu Ala Leu Arg Gln Leu Tyr
85 90 95
Glu Leu Leu Val Pro Ser Ser Val Gly Gln Ser Gly Asp Ala Gln Ile
100 105 110
Ile Ser Arg Lys Phe Leu Ser Pro Leu Val Asp Pro Asn Ser Glu Gly
115 120 125
Gly Lys Gly Thr Ser Lys Ala Gly Ala Lys Pro Thr Trp Gln Lys Lys
130 135 140
Lys Glu Ala Asn Asp Pro Thr Trp Glu Gln Asp Tyr Glu Lys Trp Lys
145 150 155 160
Lys Arg Arg Glu Glu Asp Pro Thr Ala Ser Val Ile Thr Thr Leu Glu
165 170 175
Glu Tyr Gly Ile Arg Pro Ile Phe Pro Leu Tyr Thr Asn Thr Val Thr
180 185 190
Asp Ile Ala Trp Leu Pro Leu Gln Ser Asn Gln Phe Val Arg Thr Trp
195 200 205
Asp Arg Asp Met Leu Gln Gln Ala Ile Glu Arg Leu Leu Ser Trp Glu
210 215 220
Ser Trp Asn Lys Arg Val Gln Glu Glu Tyr Ala Lys Leu Lys Glu Lys
225 230 235 240
Met Ala Gln Leu Asn Glu Gln Leu Glu Gly Gly Gln Glu Trp Ile Ser
245 250 255
Leu Leu Glu Gln Tyr Glu Glu Asn Arg Glu Arg Glu Leu Arg Glu Asn
260 265 270
Met Thr Ala Ala Asn Asp Lys Tyr Arg Ile Thr Lys Arg Gln Met Lys
275 280 285
Gly Trp Asn Glu Leu Tyr Glu Leu Trp Ser Thr Phe Pro Ala Ser Ala
290 295 300
Ser His Glu Gln Tyr Lys Glu Ala Leu Lys Arg Val Gln Gln Arg Leu
305 310 315 320
Arg Gly Arg Phe Gly Asp Ala His Phe Phe Gln Tyr Leu Met Glu Glu
325 330 335
Lys Asn Arg Leu Ile Trp Lys Gly Asn Pro Gln Arg Ile His Tyr Phe
340 345 350
Val Ala Arg Asn Glu Leu Thr Lys Arg Leu Glu Glu Ala Lys Gln Ser
355 360 365
Ala Thr Met Thr Leu Pro Asn Ala Arg Lys His Pro Leu Trp Val Arg
370 375 380
Phe Asp Ala Arg Gly Gly Asn Leu Gln Asp Tyr Tyr Leu Thr Ala Glu
385 390 395 400
Ala Asp Lys Pro Arg Ser Arg Arg Phe Val Thr Phe Ser Gln Leu Ile
405 410 415
Trp Pro Ser Glu Ser Gly Trp Met Glu Lys Lys Asp Val Glu Val Glu
420 425 430
Leu Ala Leu Ser Arg Gln Phe Tyr Gln Gln Val Lys Leu Leu Lys Asn
435 440 445
Asp Lys Gly Lys Gln Lys Ile Glu Phe Lys Asp Lys Gly Ser Gly Ser
450 455 460
Thr Phe Asn Gly His Leu Gly Gly Ala Lys Leu Gln Leu Glu Arg Gly
465 470 475 480
Asp Leu Glu Lys Glu Glu Lys Asn Phe Glu Asp Gly Glu Ile Gly Ser
485 490 495
Val Tyr Leu Asn Val Val Ile Asp Phe Glu Pro Leu Gln Glu Val Lys
500 505 510
Asn Gly Arg Val Gln Ala Pro Tyr Gly Gln Val Leu Gln Leu Ile Arg
515 520 525
Arg Pro Asn Glu Phe Pro Lys Val Thr Thr Tyr Lys Ser Glu Gln Leu
530 535 540
Val Glu Trp Ile Lys Ala Ser Pro Gln His Ser Ala Gly Val Glu Ser
545 550 555 560
Leu Ala Ser Gly Phe Arg Val Met Ser Ile Asp Leu Gly Leu Arg Ala
565 570 575
Ala Ala Ala Thr Ser Ile Phe Ser Val Glu Glu Ser Ser Asp Lys Asn
580 585 590
Ala Ala Asp Phe Ser Tyr Trp Ile Glu Gly Thr Pro Leu Val Ala Val
595 600 605
His Gln Arg Ser Tyr Met Leu Arg Leu Pro Gly Glu Gln Val Glu Lys
610 615 620
Gln Val Met Glu Lys Arg Asp Glu Arg Phe Gln Leu His Gln Arg Val
625 630 635 640
Lys Phe Gln Ile Arg Val Leu Ala Gln Ile Met Arg Met Ala Asn Lys
645 650 655
Gln Tyr Gly Asp Arg Trp Asp Glu Leu Asp Ser Leu Lys Gln Ala Val
660 665 670
Glu Gln Lys Lys Ser Pro Leu Asp Gln Thr Asp Arg Thr Phe Trp Glu
675 680 685
Gly Ile Val Cys Asp Leu Thr Lys Val Leu Pro Arg Asn Glu Ala Asp
690 695 700
Trp Glu Gln Ala Val Val Gln Ile His Arg Lys Ala Glu Glu Tyr Val
705 710 715 720
Gly Lys Ala Val Gln Ala Trp Arg Lys Arg Phe Ala Ala Asp Glu Arg
725 730 735
Lys Gly Ile Ala Gly Leu Ser Met Trp Asn Ile Glu Glu Leu Glu Gly
740 745 750
Leu Arg Lys Leu Leu Ile Ser Trp Ser Arg Arg Thr Arg Asn Pro Gln
755 760 765
Glu Val Asn Arg Phe Glu Arg Gly His Thr Ser His Gln Arg Leu Leu
770 775 780
Thr His Ile Gln Asn Val Lys Glu Asp Arg Leu Lys Gln Leu Ser His
785 790 795 800
Ala Ile Val Met Thr Ala Leu Gly Tyr Val Tyr Asp Glu Arg Lys Gln
805 810 815
Glu Trp Cys Ala Glu Tyr Pro Ala Cys Gln Val Ile Leu Phe Glu Asn
820 825 830
Leu Ser Gln Tyr Arg Ser Asn Leu Asp Arg Ser Thr Lys Glu Asn Ser
835 840 845
Thr Leu Met Lys Trp Ala His Arg Ser Ile Pro Lys Tyr Val His Met
850 855 860
Gln Ala Glu Pro Tyr Gly Ile Gln Ile Gly Asp Val Arg Ala Glu Tyr
865 870 875 880
Ser Ser Arg Phe Tyr Ala Lys Thr Gly Thr Pro Gly Ile Arg Cys Lys
885 890 895
Lys Val Arg Gly Gln Asp Leu Gln Gly Arg Arg Phe Glu Asn Leu Gln
900 905 910
Lys Arg Leu Val Asn Glu Gln Phe Leu Thr Glu Glu Gln Val Lys Gln
915 920 925
Leu Arg Pro Gly Asp Ile Val Pro Asp Asp Ser Gly Glu Leu Phe Met
930 935 940
Thr Leu Thr Asp Gly Ser Gly Ser Lys Glu Val Val Phe Leu Gln Ala
945 950 955 960
Asp Ile Asn Ala Ala His Asn Leu Gln Lys Arg Phe Trp Gln Arg Tyr
965 970 975
Asn Glu Leu Phe Lys Val Ser Cys Arg Val Ile Val Arg Asp Glu Glu
980 985 990
Glu Tyr Leu Val Pro Lys Thr Lys Ser Val Gln Ala Lys Leu Gly Lys
995 1000 1005
Gly Leu Phe Val Lys Lys Ser Asp Thr Ala Trp Lys Asp Val Tyr
1010 1015 1020
Val Trp Asp Ser Gln Ala Lys Leu Lys Gly Lys Thr Thr Phe Thr
1025 1030 1035
Glu Glu Ser Glu Ser Pro Glu Gln Leu Glu Asp Phe Gln Glu Ile
1040 1045 1050
Ile Glu Glu Ala Glu Glu Ala Lys Gly Thr Tyr Arg Thr Leu Phe
1055 1060 1065
Arg Asp Pro Ser Gly Val Phe Phe Pro Glu Ser Val Trp Tyr Pro
1070 1075 1080
Gln Lys Asp Phe Trp Gly Glu Val Lys Arg Lys Leu Tyr Gly Lys
1085 1090 1095
Leu Arg Glu Arg Phe Leu Thr Lys Ala Arg
1100 1105
<210> 56
<211> 1334
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 56
Met Lys Ile Ser Lys Val Asp His Thr Arg Met Ala Val Ala Lys Gly
1 5 10 15
Asn Gln His Arg Arg Asp Glu Ile Ser Gly Ile Leu Tyr Lys Asp Pro
20 25 30
Thr Lys Thr Gly Ser Ile Asp Phe Asp Glu Arg Phe Lys Lys Leu Asn
35 40 45
Cys Ser Ala Lys Ile Leu Tyr His Val Phe Asn Gly Ile Ala Glu Gly
50 55 60
Ser Asn Lys Tyr Lys Asn Ile Val Asp Lys Val Asn Asn Asn Leu Asp
65 70 75 80
Arg Val Leu Phe Thr Gly Lys Ser Tyr Asp Arg Lys Ser Ile Ile Asp
85 90 95
Ile Asp Thr Val Leu Arg Asn Val Glu Lys Ile Asn Ala Phe Asp Arg
100 105 110
Ile Ser Thr Glu Glu Arg Glu Gln Ile Ile Asp Asp Leu Leu Glu Ile
115 120 125
Gln Leu Arg Lys Gly Leu Arg Lys Gly Lys Ala Gly Leu Arg Glu Val
130 135 140
Leu Leu Ile Gly Ala Gly Val Ile Val Arg Thr Asp Lys Lys Gln Glu
145 150 155 160
Ile Ala Asp Phe Leu Glu Ile Leu Asp Glu Asp Phe Asn Lys Thr Asn
165 170 175
Gln Ala Lys Asn Ile Lys Leu Ser Ile Glu Asn Gln Gly Leu Val Val
180 185 190
Ser Pro Val Ser Arg Gly Glu Glu Arg Ile Phe Asp Val Ser Gly Ala
195 200 205
Gln Lys Gly Lys Ser Ser Lys Lys Ala Gln Glu Lys Glu Ala Leu Ser
210 215 220
Ala Phe Leu Leu Asp Tyr Ala Asp Leu Asp Lys Asn Val Arg Phe Glu
225 230 235 240
Tyr Leu Arg Lys Ile Arg Arg Leu Ile Asn Leu Tyr Phe Tyr Val Lys
245 250 255
Asn Asp Asp Val Met Ser Leu Thr Glu Ile Pro Ala Glu Val Asn Leu
260 265 270
Glu Lys Asp Phe Asp Ile Trp Arg Asp His Glu Gln Arg Lys Glu Glu
275 280 285
Asn Gly Asp Phe Val Gly Cys Pro Asp Ile Leu Leu Ala Asp Arg Asp
290 295 300
Val Lys Lys Ser Asn Ser Lys Gln Val Lys Ile Ala Glu Arg Gln Leu
305 310 315 320
Arg Glu Ser Ile Arg Glu Lys Asn Ile Lys Arg Tyr Arg Phe Ser Ile
325 330 335
Lys Thr Ile Glu Lys Asp Asp Gly Thr Tyr Phe Phe Ala Asn Lys Gln
340 345 350
Ile Ser Val Phe Trp Ile His Arg Ile Glu Asn Ala Val Glu Arg Ile
355 360 365
Leu Gly Ser Ile Asn Asp Lys Lys Leu Tyr Arg Leu Arg Leu Gly Tyr
370 375 380
Leu Gly Glu Lys Val Trp Lys Asp Ile Leu Asn Phe Leu Ser Ile Lys
385 390 395 400
Tyr Ile Ala Val Gly Lys Ala Val Phe Asn Phe Ala Met Asp Asp Leu
405 410 415
Gln Glu Lys Asp Arg Asp Ile Glu Pro Gly Lys Ile Ser Glu Asn Ala
420 425 430
Val Asn Gly Leu Thr Ser Phe Asp Tyr Glu Gln Ile Lys Ala Asp Glu
435 440 445
Met Leu Gln Arg Glu Val Ala Val Asn Val Ala Phe Ala Ala Asn Asn
450 455 460
Leu Ala Arg Val Thr Val Asp Ile Pro Gln Asn Gly Glu Lys Glu Asp
465 470 475 480
Ile Leu Leu Trp Asn Lys Ser Asp Ile Lys Lys Tyr Lys Lys Asn Ser
485 490 495
Lys Lys Gly Ile Leu Lys Ser Ile Leu Gln Phe Phe Gly Gly Ala Ser
500 505 510
Thr Trp Asn Met Lys Met Phe Glu Ile Ala Tyr His Asp Gln Pro Gly
515 520 525
Asp Tyr Glu Glu Asn Tyr Leu Tyr Asp Ile Ile Gln Ile Ile Tyr Ser
530 535 540
Leu Arg Asn Lys Ser Phe His Phe Lys Thr Tyr Asp His Gly Asp Lys
545 550 555 560
Asn Trp Asn Arg Glu Leu Ile Gly Lys Met Ile Glu His Asp Ala Glu
565 570 575
Arg Val Ile Ser Val Glu Arg Glu Lys Phe His Ser Asn Asn Leu Pro
580 585 590
Met Phe Tyr Lys Asp Ala Asp Leu Lys Lys Ile Leu Asp Leu Leu Tyr
595 600 605
Ser Asp Tyr Ala Gly Arg Ala Ser Gln Val Pro Ala Phe Asn Thr Val
610 615 620
Leu Val Arg Lys Asn Phe Pro Glu Phe Leu Arg Lys Asp Met Gly Tyr
625 630 635 640
Lys Val His Phe Asn Asn Pro Glu Val Glu Asn Gln Trp His Ser Ala
645 650 655
Val Tyr Tyr Leu Tyr Lys Glu Ile Tyr Tyr Asn Leu Phe Leu Arg Asp
660 665 670
Lys Glu Val Lys Asn Leu Phe Tyr Thr Ser Leu Lys Asn Ile Arg Ser
675 680 685
Glu Val Ser Asp Lys Lys Gln Lys Leu Ala Ser Asp Asp Phe Ala Ser
690 695 700
Arg Cys Glu Glu Ile Glu Asp Arg Ser Leu Pro Glu Ile Cys Gln Ile
705 710 715 720
Ile Met Thr Glu Tyr Asn Ala Gln Asn Phe Gly Asn Arg Lys Val Lys
725 730 735
Ser Gln Arg Val Ile Glu Lys Asn Lys Asp Ile Phe Arg His Tyr Lys
740 745 750
Met Leu Leu Ile Lys Thr Leu Ala Gly Ala Phe Ser Leu Tyr Leu Lys
755 760 765
Gln Glu Arg Phe Ala Phe Ile Gly Lys Ala Thr Pro Ile Pro Tyr Glu
770 775 780
Thr Thr Asp Val Lys Asn Phe Leu Pro Glu Trp Lys Ser Gly Met Tyr
785 790 795 800
Ala Ser Phe Val Glu Glu Ile Lys Asn Asn Leu Asp Leu Gln Glu Trp
805 810 815
Tyr Ile Val Gly Arg Phe Leu Asn Gly Arg Met Leu Asn Gln Leu Ala
820 825 830
Gly Ser Leu Arg Ser Tyr Ile Gln Tyr Ala Glu Asp Ile Glu Arg Arg
835 840 845
Ala Ala Glu Asn Arg Asn Lys Leu Phe Ser Lys Pro Asp Glu Lys Ile
850 855 860
Glu Ala Cys Lys Lys Ala Val Arg Val Leu Asp Leu Cys Ile Lys Ile
865 870 875 880
Ser Thr Arg Ile Ser Ala Glu Phe Thr Asp Tyr Phe Asp Ser Glu Asp
885 890 895
Asp Tyr Ala Asp Tyr Leu Glu Lys Tyr Leu Lys Tyr Gln Asp Asp Ala
900 905 910
Ile Lys Glu Leu Ser Gly Ser Ser Tyr Ala Ala Leu Asp His Phe Cys
915 920 925
Asn Lys Asp Asp Leu Lys Phe Asp Ile Tyr Val Asn Ala Gly Gln Lys
930 935 940
Pro Ile Leu Gln Arg Asn Ile Val Met Ala Lys Leu Phe Gly Pro Asp
945 950 955 960
Asn Ile Leu Ser Glu Val Met Glu Lys Val Thr Glu Ser Ala Ile Arg
965 970 975
Glu Tyr Tyr Asp Tyr Leu Lys Lys Val Ser Gly Tyr Arg Val Arg Gly
980 985 990
Lys Cys Ser Thr Glu Lys Glu Gln Glu Asp Leu Leu Lys Phe Gln Arg
995 1000 1005
Leu Lys Asn Ala Val Glu Phe Arg Asp Val Thr Glu Tyr Ala Glu
1010 1015 1020
Val Ile Asn Glu Leu Leu Gly Gln Leu Ile Ser Trp Ser Tyr Leu
1025 1030 1035
Arg Glu Arg Asp Leu Leu Tyr Phe Gln Leu Gly Phe His Tyr Met
1040 1045 1050
Cys Leu Lys Asn Lys Ser Phe Lys Pro Ala Glu Tyr Val Asp Ile
1055 1060 1065
Arg Arg Asn Asn Gly Thr Ile Ile His Asn Ala Ile Leu Tyr Gln
1070 1075 1080
Ile Val Ser Met Tyr Ile Asn Gly Leu Asp Phe Tyr Ser Cys Asp
1085 1090 1095
Lys Glu Gly Lys Thr Leu Lys Pro Ile Glu Thr Gly Lys Gly Val
1100 1105 1110
Gly Ser Lys Ile Gly Gln Phe Ile Lys Tyr Ser Gln Tyr Leu Tyr
1115 1120 1125
Asn Asp Pro Ser Tyr Lys Leu Glu Ile Tyr Asn Ala Gly Leu Glu
1130 1135 1140
Val Phe Glu Asn Ile Asp Glu His Asp Asn Ile Thr Asp Leu Arg
1145 1150 1155
Lys Tyr Val Asp His Phe Lys Tyr Tyr Ala Tyr Gly Asn Lys Met
1160 1165 1170
Ser Leu Leu Asp Leu Tyr Ser Glu Phe Phe Asp Arg Phe Phe Thr
1175 1180 1185
Tyr Asp Met Lys Tyr Gln Lys Asn Val Val Asn Val Leu Glu Asn
1190 1195 1200
Ile Leu Leu Arg His Phe Val Ile Phe Tyr Pro Lys Phe Gly Ser
1205 1210 1215
Gly Lys Lys Asp Val Gly Ile Arg Asp Cys Lys Lys Glu Arg Ala
1220 1225 1230
Gln Ile Glu Ile Ser Glu Gln Ser Leu Thr Ser Glu Asp Phe Met
1235 1240 1245
Phe Lys Leu Asp Asp Lys Ala Gly Glu Glu Ala Lys Lys Phe Pro
1250 1255 1260
Ala Arg Asp Glu Arg Tyr Leu Gln Thr Ile Ala Lys Leu Leu Tyr
1265 1270 1275
Tyr Pro Asn Glu Ile Glu Asp Met Asn Arg Phe Met Lys Lys Gly
1280 1285 1290
Glu Thr Ile Asn Lys Lys Val Gln Phe Asn Arg Lys Lys Lys Ile
1295 1300 1305
Thr Arg Lys Gln Lys Asn Asn Ser Ser Asn Glu Val Leu Ser Ser
1310 1315 1320
Thr Met Gly Tyr Leu Phe Lys Asn Ile Lys Leu
1325 1330
<210> 57
<211> 1120
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 57
Met Trp Ile Ser Ile Lys Thr Leu Ile His His Leu Gly Val Leu Phe
1 5 10 15
Phe Cys Asp Tyr Met Tyr Asn Arg Arg Glu Lys Lys Ile Ile Glu Val
20 25 30
Lys Thr Met Arg Ile Thr Lys Val Glu Val Asp Arg Lys Lys Val Leu
35 40 45
Ile Ser Arg Asp Lys Asn Gly Gly Lys Leu Val Tyr Glu Asn Glu Met
50 55 60
Gln Asp Asn Thr Glu Gln Ile Met His His Lys Lys Ser Ser Phe Tyr
65 70 75 80
Lys Ser Val Val Asn Lys Thr Ile Cys Arg Pro Glu Gln Lys Gln Met
85 90 95
Lys Lys Leu Val His Gly Leu Leu Gln Glu Asn Ser Gln Glu Lys Ile
100 105 110
Lys Val Ser Asp Val Thr Lys Leu Asn Ile Ser Asn Phe Leu Asn His
115 120 125
Arg Phe Lys Lys Ser Leu Tyr Tyr Phe Pro Glu Asn Ser Pro Asp Lys
130 135 140
Ser Glu Glu Tyr Arg Ile Glu Ile Asn Leu Ser Gln Leu Leu Glu Asp
145 150 155 160
Ser Leu Lys Lys Gln Gln Gly Thr Phe Ile Cys Trp Glu Ser Phe Ser
165 170 175
Lys Asp Met Glu Leu Tyr Ile Asn Trp Ala Glu Asn Tyr Ile Ser Ser
180 185 190
Lys Thr Lys Leu Ile Lys Lys Ser Ile Arg Asn Asn Arg Ile Gln Ser
195 200 205
Thr Glu Ser Arg Ser Gly Gln Leu Met Asp Arg Tyr Met Lys Asp Ile
210 215 220
Leu Asn Lys Asn Lys Pro Phe Asp Ile Gln Ser Val Ser Glu Lys Tyr
225 230 235 240
Gln Leu Glu Lys Leu Thr Ser Ala Leu Lys Ala Thr Phe Lys Glu Ala
245 250 255
Lys Lys Asn Asp Lys Glu Ile Asn Tyr Lys Leu Lys Ser Thr Leu Gln
260 265 270
Asn His Glu Arg Gln Ile Ile Glu Glu Leu Lys Glu Asn Ser Glu Leu
275 280 285
Asn Gln Phe Asn Ile Glu Ile Arg Lys His Leu Glu Thr Tyr Phe Pro
290 295 300
Ile Lys Lys Thr Asn Arg Lys Val Gly Asp Ile Arg Asn Leu Glu Ile
305 310 315 320
Gly Glu Ile Gln Lys Ile Val Asn His Arg Leu Lys Asn Lys Ile Val
325 330 335
Gln Arg Ile Leu Gln Glu Gly Lys Leu Ala Ser Tyr Glu Ile Glu Ser
340 345 350
Thr Val Asn Ser Asn Ser Leu Gln Lys Ile Lys Ile Glu Glu Ala Phe
355 360 365
Ala Leu Lys Phe Ile Asn Ala Cys Leu Phe Ala Ser Asn Asn Leu Arg
370 375 380
Asn Met Val Tyr Pro Val Cys Lys Lys Asp Ile Leu Met Ile Gly Glu
385 390 395 400
Phe Lys Asn Ser Phe Lys Glu Ile Lys His Lys Lys Phe Ile Arg Gln
405 410 415
Trp Ser Gln Phe Phe Ser Gln Glu Ile Thr Val Asp Asp Ile Glu Leu
420 425 430
Ala Ser Trp Gly Leu Arg Gly Ala Ile Ala Pro Ile Arg Asn Glu Ile
435 440 445
Ile His Leu Lys Lys His Ser Trp Lys Lys Phe Phe Asn Asn Pro Thr
450 455 460
Phe Lys Val Lys Lys Ser Lys Ile Ile Asn Gly Lys Thr Lys Asp Val
465 470 475 480
Thr Ser Glu Phe Leu Tyr Lys Glu Thr Leu Phe Lys Asp Tyr Phe Tyr
485 490 495
Ser Glu Leu Asp Ser Val Pro Glu Leu Ile Ile Asn Lys Met Glu Ser
500 505 510
Ser Lys Ile Leu Asp Tyr Tyr Ser Ser Asp Gln Leu Asn Gln Val Phe
515 520 525
Thr Ile Pro Asn Phe Glu Leu Ser Leu Leu Thr Ser Ala Val Pro Phe
530 535 540
Ala Pro Ser Phe Lys Arg Val Tyr Leu Lys Gly Phe Asp Tyr Gln Asn
545 550 555 560
Gln Asp Glu Ala Gln Pro Asp Tyr Asn Leu Lys Leu Asn Ile Tyr Asn
565 570 575
Glu Lys Ala Phe Asn Ser Glu Ala Phe Gln Ala Gln Tyr Ser Leu Phe
580 585 590
Lys Met Val Tyr Tyr Gln Val Phe Leu Pro Gln Phe Thr Thr Asn Asn
595 600 605
Asp Leu Phe Lys Ser Ser Val Asp Phe Ile Leu Thr Leu Asn Lys Glu
610 615 620
Arg Lys Gly Tyr Ala Lys Ala Phe Gln Asp Ile Arg Lys Met Asn Lys
625 630 635 640
Asp Glu Lys Pro Ser Glu Tyr Met Ser Tyr Ile Gln Ser Gln Leu Met
645 650 655
Leu Tyr Gln Lys Lys Gln Glu Glu Lys Glu Lys Ile Asn His Phe Glu
660 665 670
Lys Phe Ile Asn Gln Val Phe Ile Lys Gly Phe Asn Ser Phe Ile Glu
675 680 685
Lys Asn Arg Leu Thr Tyr Ile Cys His Pro Thr Lys Asn Thr Val Pro
690 695 700
Glu Asn Asp Asn Ile Glu Ile Pro Phe His Thr Asp Met Asp Asp Ser
705 710 715 720
Asn Ile Ala Phe Trp Leu Met Cys Lys Leu Leu Asp Ala Lys Gln Leu
725 730 735
Ser Glu Leu Arg Asn Glu Met Ile Lys Phe Ser Cys Ser Leu Gln Ser
740 745 750
Thr Glu Glu Ile Ser Thr Phe Thr Lys Ala Arg Glu Val Ile Gly Leu
755 760 765
Ala Leu Leu Asn Gly Glu Lys Gly Cys Asn Asp Trp Lys Glu Leu Phe
770 775 780
Asp Asp Lys Glu Ala Trp Lys Lys Asn Met Ser Leu Tyr Val Ser Glu
785 790 795 800
Glu Leu Leu Gln Ser Leu Pro Tyr Thr Gln Glu Asp Gly Gln Thr Pro
805 810 815
Val Ile Asn Arg Ser Ile Asp Leu Val Lys Lys Tyr Gly Thr Glu Thr
820 825 830
Ile Leu Glu Lys Leu Phe Ser Ser Ser Asp Asp Tyr Lys Val Ser Ala
835 840 845
Lys Asp Ile Ala Lys Leu His Glu Tyr Asp Val Thr Glu Lys Ile Ala
850 855 860
Gln Gln Glu Ser Leu His Lys Gln Trp Ile Glu Lys Pro Gly Leu Ala
865 870 875 880
Arg Asp Ser Ala Trp Thr Lys Lys Tyr Gln Asn Val Ile Asn Asp Ile
885 890 895
Ser Asn Tyr Gln Trp Ala Lys Thr Lys Val Glu Leu Thr Gln Val Arg
900 905 910
His Leu His Gln Leu Thr Ile Asp Leu Leu Ser Arg Leu Ala Gly Tyr
915 920 925
Met Ser Ile Ala Asp Arg Asp Phe Gln Phe Ser Ser Asn Tyr Ile Leu
930 935 940
Glu Arg Glu Asn Ser Glu Tyr Arg Val Thr Ser Trp Ile Leu Leu Ser
945 950 955 960
Glu Asn Lys Asn Lys Asn Lys Tyr Asn Asp Tyr Glu Leu Tyr Asn Leu
965 970 975
Lys Asn Ala Ser Ile Lys Val Ser Ser Lys Asn Asp Pro Gln Leu Lys
980 985 990
Val Asp Leu Lys Gln Leu Arg Leu Thr Leu Glu Tyr Leu Glu Leu Phe
995 1000 1005
Asp Asn Arg Leu Lys Glu Lys Arg Asn Asn Ile Ser His Phe Asn
1010 1015 1020
Tyr Leu Asn Gly Gln Leu Gly Asn Ser Ile Leu Glu Leu Phe Asp
1025 1030 1035
Asp Ala Arg Asp Val Leu Ser Tyr Asp Arg Lys Leu Lys Asn Ala
1040 1045 1050
Val Ser Lys Ser Leu Lys Glu Ile Leu Ser Ser His Gly Met Glu
1055 1060 1065
Val Thr Phe Lys Pro Leu Tyr Gln Thr Asn His His Leu Lys Ile
1070 1075 1080
Asp Lys Leu Gln Pro Lys Lys Ile His His Leu Gly Glu Lys Ser
1085 1090 1095
Thr Val Ser Ser Asn Gln Val Ser Asn Glu Tyr Cys Gln Leu Val
1100 1105 1110
Arg Thr Leu Leu Thr Met Lys
1115 1120
<210> 58
<211> 1152
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 58
Met Lys Val Thr Lys Val Asp Gly Ile Ser His Lys Lys Tyr Ile Glu
1 5 10 15
Glu Gly Lys Leu Val Lys Ser Thr Ser Glu Glu Asn Arg Thr Ser Glu
20 25 30
Arg Leu Ser Glu Leu Leu Ser Ile Arg Leu Asp Ile Tyr Ile Lys Asn
35 40 45
Pro Asp Asn Ala Ser Glu Glu Glu Asn Arg Ile Arg Arg Glu Asn Leu
50 55 60
Lys Lys Phe Phe Ser Asn Lys Val Leu His Leu Lys Asp Ser Val Leu
65 70 75 80
Tyr Leu Lys Asn Arg Lys Glu Lys Asn Ala Val Gln Asp Lys Asn Tyr
85 90 95
Ser Glu Glu Asp Ile Ser Glu Tyr Asp Leu Lys Asn Lys Asn Ser Phe
100 105 110
Ser Val Leu Lys Lys Ile Leu Leu Asn Glu Asp Val Asn Ser Glu Glu
115 120 125
Leu Glu Ile Phe Arg Lys Asp Val Glu Ala Lys Leu Asn Lys Ile Asn
130 135 140
Ser Leu Lys Tyr Ser Phe Glu Glu Asn Lys Ala Asn Tyr Gln Lys Ile
145 150 155 160
Asn Glu Asn Asn Val Glu Lys Val Gly Gly Lys Ser Lys Arg Asn Ile
165 170 175
Ile Tyr Asp Tyr Tyr Arg Glu Ser Ala Lys Arg Asn Asp Tyr Ile Asn
180 185 190
Asn Val Gln Glu Ala Phe Asp Lys Leu Tyr Lys Lys Glu Asp Ile Glu
195 200 205
Lys Leu Phe Phe Leu Ile Glu Asn Ser Lys Lys His Glu Lys Tyr Lys
210 215 220
Ile Arg Glu Tyr Tyr His Lys Ile Ile Gly Arg Lys Asn Asp Lys Glu
225 230 235 240
Asn Phe Ala Lys Ile Ile Tyr Glu Glu Ile Gln Asn Val Asn Asn Ile
245 250 255
Lys Glu Leu Ile Glu Lys Ile Pro Asp Met Ser Glu Leu Lys Lys Ser
260 265 270
Gln Val Phe Tyr Lys Tyr Tyr Leu Asp Lys Glu Glu Leu Asn Asp Lys
275 280 285
Asn Ile Lys Tyr Ala Phe Cys His Phe Val Glu Ile Glu Met Ser Gln
290 295 300
Leu Leu Lys Asn Tyr Val Tyr Lys Arg Leu Ser Asn Ile Ser Asn Asp
305 310 315 320
Lys Ile Lys Arg Ile Phe Glu Tyr Gln Asn Leu Lys Lys Leu Ile Glu
325 330 335
Asn Lys Leu Leu Asn Lys Leu Asp Thr Tyr Val Arg Asn Cys Gly Lys
340 345 350
Tyr Asn Tyr Tyr Leu Gln Val Gly Glu Ile Ala Thr Ser Asp Phe Ile
355 360 365
Ala Arg Asn Arg Gln Asn Glu Ala Phe Leu Arg Asn Ile Ile Gly Val
370 375 380
Ser Ser Val Ala Tyr Phe Ser Leu Arg Asn Ile Leu Glu Thr Glu Asn
385 390 395 400
Glu Asn Asp Ile Thr Gly Arg Met Arg Gly Lys Thr Val Lys Asn Asn
405 410 415
Lys Gly Glu Glu Lys Tyr Val Ser Gly Glu Val Asp Lys Ile Tyr Asn
420 425 430
Glu Asn Lys Gln Asn Glu Val Lys Glu Asn Leu Lys Met Phe Tyr Ser
435 440 445
Tyr Asp Phe Asn Met Asp Asn Lys Asn Glu Ile Glu Asp Phe Phe Ala
450 455 460
Asn Ile Asp Glu Ala Ile Ser Ser Ile Arg His Gly Ile Val His Phe
465 470 475 480
Asn Leu Glu Leu Glu Gly Lys Asp Ile Phe Ala Phe Lys Asn Ile Ala
485 490 495
Pro Ser Glu Ile Ser Lys Lys Met Phe Gln Asn Glu Ile Asn Glu Lys
500 505 510
Lys Leu Lys Leu Lys Ile Phe Lys Gln Leu Asn Ser Ala Asn Val Phe
515 520 525
Asn Tyr Tyr Glu Lys Asp Val Ile Ile Lys Tyr Leu Lys Asn Thr Lys
530 535 540
Phe Asn Phe Val Asn Lys Asn Ile Pro Phe Val Pro Ser Phe Thr Lys
545 550 555 560
Leu Tyr Asn Lys Ile Glu Asp Leu Arg Asn Thr Leu Lys Phe Phe Trp
565 570 575
Ser Val Pro Lys Asp Lys Glu Glu Lys Asp Ala Gln Ile Tyr Leu Leu
580 585 590
Lys Asn Ile Tyr Tyr Gly Glu Phe Leu Asn Lys Phe Val Lys Asn Ser
595 600 605
Lys Val Phe Phe Lys Ile Thr Asn Glu Val Ile Lys Ile Asn Lys Gln
610 615 620
Arg Asn Gln Lys Thr Gly His Tyr Lys Tyr Gln Lys Phe Glu Asn Ile
625 630 635 640
Glu Lys Thr Val Pro Val Glu Tyr Leu Ala Ile Ile Gln Ser Arg Glu
645 650 655
Met Ile Asn Asn Gln Asp Lys Glu Glu Lys Asn Thr Tyr Ile Asp Phe
660 665 670
Ile Gln Gln Ile Phe Leu Lys Gly Phe Ile Asp Tyr Leu Asn Lys Asn
675 680 685
Asn Leu Lys Tyr Ile Glu Ser Asn Asn Asn Asn Asp Asn Asn Asp Ile
690 695 700
Phe Ser Lys Ile Lys Ile Lys Lys Asp Asn Lys Glu Lys Tyr Asp Lys
705 710 715 720
Ile Leu Lys Asn Tyr Glu Lys His Asn Arg Asn Lys Glu Ile Pro His
725 730 735
Glu Ile Asn Glu Phe Val Arg Glu Ile Lys Leu Gly Lys Ile Leu Lys
740 745 750
Tyr Thr Glu Asn Leu Asn Met Phe Tyr Leu Ile Leu Lys Leu Leu Asn
755 760 765
His Lys Glu Leu Thr Asn Leu Lys Gly Ser Leu Glu Lys Tyr Gln Ser
770 775 780
Ala Asn Lys Glu Glu Thr Phe Ser Asp Glu Leu Glu Leu Ile Asn Leu
785 790 795 800
Leu Asn Leu Asp Asn Asn Arg Val Thr Glu Asp Phe Glu Leu Glu Ala
805 810 815
Asn Glu Ile Gly Lys Phe Leu Asp Phe Asn Glu Asn Lys Ile Lys Asp
820 825 830
Arg Lys Glu Leu Lys Lys Phe Asp Thr Asn Lys Ile Tyr Phe Asp Gly
835 840 845
Glu Asn Ile Ile Lys His Arg Ala Phe Tyr Asn Ile Lys Lys Tyr Gly
850 855 860
Met Leu Asn Leu Leu Glu Lys Ile Ala Asp Lys Ala Lys Tyr Lys Ile
865 870 875 880
Ser Leu Lys Glu Leu Lys Glu Tyr Ser Asn Lys Lys Asn Glu Ile Glu
885 890 895
Lys Asn Tyr Thr Met Gln Gln Asn Leu His Arg Lys Tyr Ala Arg Pro
900 905 910
Lys Lys Asp Glu Lys Phe Asn Asp Glu Asp Tyr Lys Glu Tyr Glu Lys
915 920 925
Ala Ile Gly Asn Ile Gln Lys Tyr Thr His Leu Lys Asn Lys Val Glu
930 935 940
Phe Asn Glu Leu Asn Leu Leu Gln Gly Leu Leu Leu Lys Ile Leu His
945 950 955 960
Arg Leu Val Gly Tyr Thr Ser Ile Trp Glu Arg Asp Leu Arg Phe Arg
965 970 975
Leu Lys Gly Glu Phe Pro Glu Asn His Tyr Ile Glu Glu Ile Phe Asn
980 985 990
Phe Asp Asn Ser Lys Asn Val Lys Tyr Lys Ser Gly Gln Ile Val Glu
995 1000 1005
Lys Tyr Ile Asn Phe Tyr Lys Glu Leu Tyr Lys Asp Asn Val Glu
1010 1015 1020
Lys Arg Ser Ile Tyr Ser Asp Lys Lys Val Lys Lys Leu Lys Gln
1025 1030 1035
Glu Lys Lys Asp Leu Tyr Ile Arg Asn Tyr Ile Ala His Phe Asn
1040 1045 1050
Tyr Ile Pro His Ala Glu Ile Ser Leu Leu Glu Val Leu Glu Asn
1055 1060 1065
Leu Arg Lys Leu Leu Ser Tyr Asp Arg Lys Leu Lys Asn Ala Ile
1070 1075 1080
Met Lys Ser Ile Val Asp Ile Leu Lys Glu Tyr Gly Phe Val Ala
1085 1090 1095
Thr Phe Lys Ile Gly Ala Asp Lys Lys Ile Glu Ile Gln Thr Leu
1100 1105 1110
Glu Ser Glu Lys Ile Val His Leu Lys Asn Leu Lys Lys Lys Lys
1115 1120 1125
Leu Met Thr Asp Arg Asn Ser Glu Glu Leu Cys Glu Leu Val Lys
1130 1135 1140
Val Met Phe Glu Tyr Lys Ala Leu Glu
1145 1150
<210> 59
<211> 1389
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 59
Met Gly Asn Leu Phe Gly His Lys Arg Trp Tyr Glu Val Arg Asp Lys
1 5 10 15
Lys Asp Phe Lys Ile Lys Arg Lys Val Lys Val Lys Arg Asn Tyr Asp
20 25 30
Gly Asn Lys Tyr Ile Leu Asn Ile Asn Glu Asn Asn Asn Lys Glu Lys
35 40 45
Ile Asp Asn Asn Lys Phe Ile Arg Lys Tyr Ile Asn Tyr Lys Lys Asn
50 55 60
Asp Asn Ile Leu Lys Glu Phe Thr Arg Lys Phe His Ala Gly Asn Ile
65 70 75 80
Leu Phe Lys Leu Lys Gly Lys Glu Gly Ile Ile Arg Ile Glu Asn Asn
85 90 95
Asp Asp Phe Leu Glu Thr Glu Glu Val Val Leu Tyr Ile Glu Ala Tyr
100 105 110
Gly Lys Ser Glu Lys Leu Lys Ala Leu Gly Ile Thr Lys Lys Lys Ile
115 120 125
Ile Asp Glu Ala Ile Arg Gln Gly Ile Thr Lys Asp Asp Lys Lys Ile
130 135 140
Glu Ile Lys Arg Gln Glu Asn Glu Glu Glu Ile Glu Ile Asp Ile Arg
145 150 155 160
Asp Glu Tyr Thr Asn Lys Thr Leu Asn Asp Cys Ser Ile Ile Leu Arg
165 170 175
Ile Ile Glu Asn Asp Glu Leu Glu Thr Lys Lys Ser Ile Tyr Glu Ile
180 185 190
Phe Lys Asn Ile Asn Met Ser Leu Tyr Lys Ile Ile Glu Lys Ile Ile
195 200 205
Glu Asn Glu Thr Glu Lys Val Phe Glu Asn Arg Tyr Tyr Glu Glu His
210 215 220
Leu Arg Glu Lys Leu Leu Lys Asp Asp Lys Ile Asp Val Ile Leu Thr
225 230 235 240
Asn Phe Met Glu Ile Arg Glu Lys Ile Lys Ser Asn Leu Glu Ile Leu
245 250 255
Gly Phe Val Lys Phe Tyr Leu Asn Val Gly Gly Asp Lys Lys Lys Ser
260 265 270
Lys Asn Lys Lys Met Leu Val Glu Lys Ile Leu Asn Ile Asn Val Asp
275 280 285
Leu Thr Val Glu Asp Ile Ala Asp Phe Val Ile Lys Glu Leu Glu Phe
290 295 300
Trp Asn Ile Thr Lys Arg Ile Glu Lys Val Lys Lys Val Asn Asn Glu
305 310 315 320
Phe Leu Glu Lys Arg Arg Asn Arg Thr Tyr Ile Lys Ser Tyr Val Leu
325 330 335
Leu Asp Lys His Glu Lys Phe Lys Ile Glu Arg Glu Asn Lys Lys Asp
340 345 350
Lys Ile Val Lys Phe Phe Val Glu Asn Ile Lys Asn Asn Ser Ile Lys
355 360 365
Glu Lys Ile Glu Lys Ile Leu Ala Glu Phe Lys Ile Asp Glu Leu Ile
370 375 380
Lys Lys Leu Glu Lys Glu Leu Lys Lys Gly Asn Cys Asp Thr Glu Ile
385 390 395 400
Phe Gly Ile Phe Lys Lys His Tyr Lys Val Asn Phe Asp Ser Lys Lys
405 410 415
Phe Ser Lys Lys Ser Asp Glu Glu Lys Glu Leu Tyr Lys Ile Ile Tyr
420 425 430
Arg Tyr Leu Lys Gly Arg Ile Glu Lys Ile Leu Val Asn Glu Gln Lys
435 440 445
Val Arg Leu Lys Lys Met Glu Lys Ile Glu Ile Glu Lys Ile Leu Asn
450 455 460
Glu Ser Ile Leu Ser Glu Lys Ile Leu Lys Arg Val Lys Gln Tyr Thr
465 470 475 480
Leu Glu His Ile Met Tyr Leu Gly Lys Leu Arg His Asn Asp Ile Asp
485 490 495
Met Thr Thr Val Asn Thr Asp Asp Phe Ser Arg Leu His Ala Lys Glu
500 505 510
Glu Leu Asp Leu Glu Leu Ile Thr Phe Phe Ala Ser Thr Asn Met Glu
515 520 525
Leu Asn Lys Ile Phe Ser Arg Glu Asn Ile Asn Asn Asp Glu Asn Ile
530 535 540
Asp Phe Phe Gly Gly Asp Arg Glu Lys Asn Tyr Val Leu Asp Lys Lys
545 550 555 560
Ile Leu Asn Ser Lys Ile Lys Ile Ile Arg Asp Leu Asp Phe Ile Asp
565 570 575
Asn Lys Asn Asn Ile Thr Asn Asn Phe Ile Arg Lys Phe Thr Lys Ile
580 585 590
Gly Thr Asn Glu Arg Asn Arg Ile Leu His Ala Ile Ser Lys Glu Arg
595 600 605
Asp Leu Gln Gly Thr Gln Asp Asp Tyr Asn Lys Val Ile Asn Ile Ile
610 615 620
Gln Asn Leu Lys Ile Ser Asp Glu Glu Val Ser Lys Ala Leu Asn Leu
625 630 635 640
Asp Val Val Phe Lys Asp Lys Lys Asn Ile Ile Thr Lys Ile Asn Asp
645 650 655
Ile Lys Ile Ser Glu Glu Asn Asn Asn Asp Ile Lys Tyr Leu Pro Ser
660 665 670
Phe Ser Lys Val Leu Pro Glu Ile Leu Asn Leu Tyr Arg Asn Asn Pro
675 680 685
Lys Asn Glu Pro Phe Asp Thr Ile Glu Thr Glu Lys Ile Val Leu Asn
690 695 700
Ala Leu Ile Tyr Val Asn Lys Glu Leu Tyr Lys Lys Leu Ile Leu Glu
705 710 715 720
Asp Asp Leu Glu Glu Asn Glu Ser Lys Asn Ile Phe Leu Gln Glu Leu
725 730 735
Lys Lys Thr Leu Gly Asn Ile Asp Glu Ile Asp Glu Asn Ile Ile Glu
740 745 750
Asn Tyr Tyr Lys Asn Ala Gln Ile Ser Ala Ser Lys Gly Asn Asn Lys
755 760 765
Ala Ile Lys Lys Tyr Gln Lys Lys Val Ile Glu Cys Tyr Ile Gly Tyr
770 775 780
Leu Arg Lys Asn Tyr Glu Glu Leu Phe Asp Phe Ser Asp Phe Lys Met
785 790 795 800
Asn Ile Gln Glu Ile Lys Lys Gln Ile Lys Asp Ile Asn Asp Asn Lys
805 810 815
Thr Tyr Glu Arg Ile Thr Val Lys Thr Ser Asp Lys Thr Ile Val Ile
820 825 830
Asn Asp Asp Phe Glu Tyr Ile Ile Ser Ile Phe Ala Leu Leu Asn Ser
835 840 845
Asn Ala Val Ile Asn Lys Ile Arg Asn Arg Phe Phe Ala Thr Ser Val
850 855 860
Trp Leu Asn Thr Ser Glu Tyr Gln Asn Ile Ile Asp Ile Leu Asp Glu
865 870 875 880
Ile Met Gln Leu Asn Thr Leu Arg Asn Glu Cys Ile Thr Glu Asn Trp
885 890 895
Asn Leu Asn Leu Glu Glu Phe Ile Gln Lys Met Lys Glu Ile Glu Lys
900 905 910
Asp Phe Asp Asp Phe Lys Ile Gln Thr Lys Lys Glu Ile Phe Asn Asn
915 920 925
Tyr Tyr Glu Asp Ile Lys Asn Asn Ile Leu Thr Glu Phe Lys Asp Asp
930 935 940
Ile Asn Gly Cys Asp Val Leu Glu Lys Lys Leu Glu Lys Ile Val Ile
945 950 955 960
Phe Asp Asp Glu Thr Lys Phe Glu Ile Asp Lys Lys Ser Asn Ile Leu
965 970 975
Gln Asp Glu Gln Arg Lys Leu Ser Asn Ile Asn Lys Lys Asp Leu Lys
980 985 990
Lys Lys Val Asp Gln Tyr Ile Lys Asp Lys Asp Gln Glu Ile Lys Ser
995 1000 1005
Lys Ile Leu Cys Arg Ile Ile Phe Asn Ser Asp Phe Leu Lys Lys
1010 1015 1020
Tyr Lys Lys Glu Ile Asp Asn Leu Ile Glu Asp Met Glu Ser Glu
1025 1030 1035
Asn Glu Asn Lys Phe Gln Glu Ile Tyr Tyr Pro Lys Glu Arg Lys
1040 1045 1050
Asn Glu Leu Tyr Ile Tyr Lys Lys Asn Leu Phe Leu Asn Ile Gly
1055 1060 1065
Asn Pro Asn Phe Asp Lys Ile Tyr Gly Leu Ile Ser Asn Asp Ile
1070 1075 1080
Lys Met Ala Asp Ala Lys Phe Leu Phe Asn Ile Asp Gly Lys Asn
1085 1090 1095
Ile Arg Lys Asn Lys Ile Ser Glu Ile Asp Ala Ile Leu Lys Asn
1100 1105 1110
Leu Asn Asp Lys Leu Asn Gly Tyr Ser Lys Glu Tyr Lys Glu Lys
1115 1120 1125
Tyr Ile Lys Lys Leu Lys Glu Asn Asp Asp Phe Phe Ala Lys Asn
1130 1135 1140
Ile Gln Asn Lys Asn Tyr Lys Ser Phe Glu Lys Asp Tyr Asn Arg
1145 1150 1155
Val Ser Glu Tyr Lys Lys Ile Arg Asp Leu Val Glu Phe Asn Tyr
1160 1165 1170
Leu Asn Lys Ile Glu Ser Tyr Leu Ile Asp Ile Asn Trp Lys Leu
1175 1180 1185
Ala Ile Gln Met Ala Arg Phe Glu Arg Asp Met His Tyr Ile Val
1190 1195 1200
Asn Gly Leu Arg Glu Leu Gly Ile Ile Lys Leu Ser Gly Tyr Asn
1205 1210 1215
Thr Gly Ile Ser Arg Ala Tyr Pro Lys Arg Asn Gly Ser Asp Gly
1220 1225 1230
Phe Tyr Thr Thr Thr Ala Tyr Tyr Lys Phe Phe Asp Glu Glu Ser
1235 1240 1245
Tyr Lys Lys Phe Glu Lys Ile Cys Tyr Gly Phe Gly Ile Asp Leu
1250 1255 1260
Ser Glu Asn Ser Glu Ile Asn Lys Pro Glu Asn Glu Ser Ile Arg
1265 1270 1275
Asn Tyr Ile Ser His Phe Tyr Ile Val Arg Asn Pro Phe Ala Asp
1280 1285 1290
Tyr Ser Ile Ala Glu Gln Ile Asp Arg Val Ser Asn Leu Leu Ser
1295 1300 1305
Tyr Ser Thr Arg Tyr Asn Asn Ser Thr Tyr Ala Ser Val Phe Glu
1310 1315 1320
Val Phe Lys Lys Asp Val Asn Leu Asp Tyr Asp Glu Leu Lys Lys
1325 1330 1335
Lys Phe Lys Leu Ile Gly Asn Asn Asp Ile Leu Glu Arg Leu Met
1340 1345 1350
Lys Pro Lys Lys Val Ser Val Leu Glu Leu Glu Ser Tyr Asn Ser
1355 1360 1365
Asp Tyr Ile Lys Asn Leu Ile Ile Glu Leu Leu Thr Lys Ile Glu
1370 1375 1380
Asn Thr Asn Asp Thr Leu
1385
<210> 60
<211> 1300
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 60
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Ile Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Glu Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Asp Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Lys Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Ser Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr Lys Gln Ser Ile Ser Lys His Pro Glu Trp Lys Asp
725 730 735
Phe Gly Phe Arg Phe Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu
740 745 750
Phe Tyr Arg Glu Val Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn
755 760 765
Ile Ser Glu Ser Tyr Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr
770 775 780
Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg
785 790 795 800
Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn
805 810 815
Leu Gln Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr
820 825 830
Arg Lys Gln Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
835 840 845
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Val Phe Glu
850 855 860
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
865 870 875 880
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
885 890 895
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
900 905 910
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
915 920 925
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
930 935 940
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
945 950 955 960
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
965 970 975
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
980 985 990
Ala Lys Leu Val Ile Glu Tyr Asn Ala Ile Val Val Phe Glu Asp Leu
995 1000 1005
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
1010 1015 1020
Tyr Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu
1025 1030 1035
Val Phe Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg
1040 1045 1050
Ala Tyr Gln Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly
1055 1060 1065
Lys Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser
1070 1075 1080
Lys Ile Cys Pro Val Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys
1085 1090 1095
Tyr Glu Ser Val Ser Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp
1100 1105 1110
Lys Ile Cys Tyr Asn Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe
1115 1120 1125
Asp Tyr Lys Asn Phe Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr
1130 1135 1140
Ile Ala Ser Phe Gly Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp
1145 1150 1155
Lys Asn His Asn Trp Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu
1160 1165 1170
Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly
1175 1180 1185
Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe
1190 1195 1200
Phe Ala Lys Leu Thr Ser Val Leu Asn Thr Ile Leu Gln Met Arg
1205 1210 1215
Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val
1220 1225 1230
Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
1235 1240 1245
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly
1250 1255 1260
Leu Lys Gly Leu Met Leu Leu Gly Arg Ile Lys Asn Asn Gln Glu
1265 1270 1275
Gly Lys Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu
1280 1285 1290
Phe Val Gln Asn Arg Asn Asn
1295 1300
<210> 61
<211> 7403
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 61
tatccggtcg aatcgagaat gacgaccgct acgtcttgga ctacgaagcc gtggcccttg 60
ccgatgctct cggtgtggat gttgccgacc tgttccgcaa gatcgattgc cccaagaacc 120
tgctgcgcag gcgggcaggg taggggagcg gtttccggcg gagattttcg gaggcgccgg 180
taacgttatg tcggggaatt tgctatacat cgacgataat tagttttgtt gattcaggat 240
cgaaatgcgc tcaaacaaag aacgttccgc gtttccctca tgcgctacta cgcccacacc 300
gccatctttc ggcacgcaaa caaagcagat gggttgcctg tcaatgggtg atcattgcct 360
gaagttacca tccatcaata atataaatca tccttactcc gaatgtccct caatcgcatc 420
tatcaaggcc gcgtggcggc cgtcgaaaca ggaacggcct tagcgaaagg taatgtcgaa 480
tggatgcctg ccgcaggagg cgacgaagtt ctctggcagc accacgaact tttccaagct 540
gccatcaact actatctcgt cgccctgctc gcactcgccg acaaaaacaa tcccgtactt 600
ggcccgctga tcagccagat ggataatccc caaagccctt accatgtctg gggaagtttc 660
cgccgccaag gacgtcagcg cacaggtctc agtcaagccg ttgcacctta tatcacgccg 720
ggcaataacg ctcccaccct tgacgaagtt ttccgctcca ttcttgcggg caacccaacc 780
gaccgcgcaa ctttggacgc tgcactcatg caattgctca aggcttgtga cggcgcgggc 840
gctatccagc aggaaggtcg ttcctactgg cccaaattct gcgatcctga ctccactgcc 900
aacttcgcgg gagatccggc catgctccgg cgtgaacaac accgcctcct ccttccgcaa 960
gttctccacg atccggcgat tactcacgac agtcctgccc ttggctcgtt cgacacttat 1020
tcgattgcta cccccgacac cagaactcct caactcaccg gccccaaggc acgcgcccgt 1080
cttgagcagg cgatcaccct ctggcgcgtc cgtcttcccg aatcggctgc tgacttcgat 1140
cgccttgcca gttccctcaa aaaaattccg gacgacgatt ctcgccttaa ccttcagggc 1200
tacgtcggca gcagtgcgaa aggcgaagtt caggcccgtc ttttcgccct tctgctattc 1260
cgtcacctgg agcgttcctc ctttacgctt ggccttctcc gttccgccac cccgccgccc 1320
aagaacgctg aaacacctcc tcccgccggc gttcctttac ctgcggcgtc cgcagccgat 1380
ccggtgcgga tagcccgtgg caaacgcagt tttgtttttc gcgcattcac cagtctcccc 1440
tgctggcatg gcggtgataa catccatccc acctggaagt cattcgacat cgcagcgttc 1500
aaatatgccc tcacggtcat caaccagatc gaggaaaaga cgaaagaacg ccaaaaagaa 1560
tgtgcggaac ttgaaactga tttcgactac atgcacggac ggctcgccaa gattccggta 1620
aaatacacga ccggcgaagc cgaaccgccc cccattctcg caaacgatct ccgcatcccc 1680
ctcctccgcg aacttctcca gaatatcaag gtcgacaccg cactcaccga tggcgaagcc 1740
gtctcctatg gtctccaacg ccgcaccatt cgcggtttcc gcgagctgcg ccgcatctgg 1800
cgcggccatg cccccgctgg cacggtcttt tccagcgagt tgaaagaaaa actagccggc 1860
gaactccgcc agttccagac cgacaactcc accaccatcg gcagcgtcca actcttcaac 1920
gaactcatcc aaaacccgaa atactggccc atctggcagg ctcctgacgt cgaaaccgcc 1980
cgccaatggg ccgatgccgg ttttgccgac gatccgctcg ccgcccttgt gcaagaagcc 2040
gaactccagg aagacatcga cgccctcaag gctccagtca aactcactcc ggccgatcct 2100
gagtattcaa gaaggcaata cgatttcaat gccgtcagca aattcggggc cggctcccgc 2160
tccgccaatc gccacgaacc cgggcagacg gagcgcggcc acaacacctt taccaccgaa 2220
atcgccgccc gtaacgcggc ggacgggaac cgctggcggg caacccacgt ccgcatccat 2280
tactccgctc cccgccttct tcgtgacgga ctccgccgac ctgacaccga cggcaacgaa 2340
gccctggaag ccgtcccttg gctccagccc atgatggaag ccctcgcccc tctcccgacg 2400
cttccgcaag acctcacagg catgccggtc ttcctcatgc ccgacgtcac cctttccggt 2460
gagcgtcgca tcctcctcaa tcttcctgtc accctcgaac cagccgctct tgtcgaacaa 2520
ctgggcaacg ccggtcgctg gcaaaaccag ttcttcggct cccgcgaaga tccattcgct 2580
ctccgatggc ccgccgacgg tgctgtaaaa accgccaagg ggaaaaccca cataccttgg 2640
caccaggacc gcgatcactt caccgtactc ggcgtggatc tcggcacgcg cgatgccggg 2700
gcgctcgctc ttctcaacgt cactgcgcaa aaaccggcca agccggtcca ccgcatcatt 2760
ggtgaggccg acggacgcac ctggtatgcc agccttgccg acgctcgcat gatccgcctg 2820
cccggggagg atgcccggct ctttgtccgg ggaaaactcg ttcaggaacc ctatggtgaa 2880
cgcgggcgaa acgcgtctct tctcgaatgg gaagacgccc gcaatatcat ccttcgcctt 2940
ggccaaaatc ccgacgaact cctcggcgcc gatccccggc gccattcgta tccggaaata 3000
aacgataaac ttctcgtcgc ccttcgccgc gctcaggccc gtcttgcccg tctccagaac 3060
cggagctggc ggttgcgcga ccttgcagaa tcggacaagg cccttgatga aatccatgcc 3120
gagcgtgccg gggagaagcc ttctccgctt ccgcccttgg ctcgcgacga tgccatcaaa 3180
agcaccgacg aagccctcct ttcccagcgt gacatcatcc ggcgatcctt cgttcagatc 3240
gccaacttga tccttcccct tcgcggacgc cgatgggaat ggcggcccca tgtcgaggtc 3300
ccggattgcc acatccttgc gcagagcgat cccggtacgg atgacaccaa gcgtcttgtc 3360
gccggacaac gcggcatctc tcacgagcgt atcgagcaaa tcgaagaact ccgtcgtcgc 3420
tgccaatccc tcaaccgtgc cctgcgtcac aaacccggag agcgtcccgt gctcggacgc 3480
cccgccaagg gcgaggaaat cgccgatccc tgtcccgcgc tcctcgaaaa gatcaaccgt 3540
ctccgggacc agcgcgttga ccaaaccgcg catgccatcc tcgccgccgc tctcggtgtt 3600
cgactccgcg ccccctcaaa agaccgcgcc gaacgccgcc atcgcgacat ccatggcgaa 3660
tacgaacgct ttcgtgcgcc cgctgatttt gtcgtcatcg aaaacctctc ccgttatctc 3720
agctcgcagg atcgtgctcg tagtgaaaac acccgtctca tgcagtggtg ccatcgccag 3780
atcgtgcaaa aactccgtca gctctgcgag acctacggca tccccgtcct cgccgtcccg 3840
gcggcctact catcgcgttt ttcttcccgg gacggctcgg ccggattccg ggccgtccat 3900
ctgacaccgg accaccgtca ccggatgcca tggagccgca tcctcgcccg cctcaaggcc 3960
cacgaggaag acggaaaaag actcgaaaag acggtgctcg acgaggctcg cgccgtccgg 4020
ggactctttg accggctcga ccggttcaac gccgggcatg tcccgggaaa accttggcgc 4080
acgctcctcg cgccgctccc cggcggccct gtgtttgtcc ccctcgggga cgccacaccc 4140
atgcaggccg atctgaacgc cgccatcaac atcgccctcc ggggcatcgc ggctcccgac 4200
cgccacgaca tccatcaccg gctccgtgcc gaaaacaaaa aacgcatcct gagcttgcgt 4260
ctcggcactc agcgcgagaa agcccgctgg cctggaggag ctccggcggt gacactctcc 4320
actccgaaca acggcgcctc tcccgaagat tccgatgcgt tgcccgaacg ggtatccaac 4380
ctgtttgtgg acatcgccgg tgtcgccaac ttcgagcgag tcacgatcga aggagtctcg 4440
caaaaattcg ccaccgggcg tggcctttgg gcctccgtca agcaacgtgc atggaaccgc 4500
gttgccagac tcaacgagac agtaacagat aacaacagga acgaagagga ggacgacatt 4560
ccgatgtaac cattgcttca ttacatctga gtctcccctc aatccctctg ccccatgcgt 4620
gatataacct ccacctcatg tcccggatcg gcgccggcaa cctgtagttc ccttccatcc 4680
tccaacactc ccgcagatcg cgatccgctg ccgccgatgc cggtgcgccg ccttcacaac 4740
tatctctact gtccgcggct tttttatctc cagtgggtcg agaatctctt tgaggaaaat 4800
gccgacacca ttgccggcag cgccgtgcat cgtcacgccg acaaacctac gcgttacgat 4860
gatgaaaaag ccgaggcact tcgcactggt ctccctgaag gcgcgcacat acgcagcctt 4920
cgcctggaaa acgcccaact cggtctcgtt ggcgtggtgg atatcgtgga gggaggcccc 4980
gacggactcg aactcgtcga ctacaaaaaa ggttccgcct tccgcctcga cgacggcacg 5040
ctcgctccca aggaaaacga caccgtgcaa cttgccgcct acgctcttct cctggctgcc 5100
gatggtgcgc gcgttgcgcc catggcgacg gtctattacg ctgccgatcg ccggcgtgtc 5160
accttcccgc tcgatgacgc cctctacgcc cgcacccgtt ccgccctcga agaggcccgc 5220
gccgttgcaa cctcggggcg catacctccg ccgctcgtct ctgacgtccg ctgcctccat 5280
tgttcctcct atgcgctttg ccttccccgc gagtccgcct ggtggtgccg ccatcgcagc 5340
acgccgcggg gagccggcca cacccccatg ttgccgggct ttgaggatga cgccgccgcc 5400
attcaccaaa tctccgaacc tgacaccgag ccaccacccg atcttgccag ccagcctccc 5460
cgtcccccgc ggctcgatgg agaattgttg gttgtccaga ctccgggagc gatgatcgga 5520
caaagcggcg gtgagtttac cgtgtccgtc aagggtgagg ttttgcgcaa gcttccggtt 5580
catcaactcc gggccattta cgtttacgga gccgtgcaac tcacggcgca tgctgtgcag 5640
accgcccttg aggaggatat cgacgtctcc tattttgcgc ccagcggccg ctttcttggc 5700
ctcctccgcg gcctgcccgc atccggcgtg gatgcgcgtc tcgggcaata caccctgttt 5760
cgcgaaccct ttggccgtct ccgtctcgcc tgcgaggcga ttcgggccaa gatccataac 5820
cagcgcgtcc tcctcatgcg taacggcgag cccggggagg gcgtcttgcg cgaactcgcc 5880
cgtctgcgcg acgccaccag tgaggcgact tcgctcgacg aactcctcgg catcgagggc 5940
atcgccgcgc atttctattt ccagtatttt cccaccatgc tgaaagaacg ggcggcctgg 6000
gcctttgatt tttccggacg caatcgccgc ccgccgcgcg acccggtcaa cgccctgctt 6060
tcgttcggtt acagcgtgtt gtccaaggaa cttgccggcg tctgccacgc tgttggccta 6120
gacccgtttt tcggcttcat gcaccagccg cgttacgggc gccccgcact cgctctcgat 6180
ctgatggagg agtttcgccc tctcatcgcc gacagtgttg ccctgaatct catcaaccgt 6240
ggcgaactcg acgaagggga ctttatccgg tcggccaatg gcaccgcgct caatgatcgg 6300
ggccgccggc gtttttggga ggcatggttc cggcgtctcg acagcgaagt cagccatcct 6360
gaatttggtt acaagatgag ctatcgacgg atgcttgaag tgcaggcgcg ccagctatgg 6420
cgctatgtgc gcggtgacgc cttccgctac cacggattca ccacccgttg attccgatgt 6480
cagatccccg ccgccgttat cttgtgtgtt acgacatcgc caatccgaag cgattgcgcc 6540
aagtggccaa gctgctggag agctatggca cgcgtctgca atactcggtt ttcgaatgtc 6600
ctttggacga tcttcgtctt gaacaggcga aggctgattt gcgcgacacg attaatgccg 6660
accaagacca ggtgttattt gtttcgcttg gccccgaagc caacgatgcc acgttgatca 6720
tcgccacgct tgggctccct tataccgtgc gctcgcgagt gacgattatc tgacccataa 6780
cccacgtgtt gaagaggctg aaaacagacg gacctctatg aagaacaatt gacgttttgg 6840
ccgaactcag cagaccttta tgcggctaag gccaatgatc atccatccta ccgccattgg 6900
gctggagacg ttttttgaaa cggcgagtgc tgcggatagc gagtttctct tggggaggcg 6960
ctcgcggcca cttttacaga ggagatgttc gggcgaactg gccgacctaa caaggcgtac 7020
ccggctcaaa atcgaggcac gctcgcacgg gatgatgtaa ttcgttgttt ttcagcatac 7080
cgtgcgagca cgggccgcag cgaatgccgt ttcacgaatc gtcaggcggc ggggagaagt 7140
catttaataa ggccactgtt aaaagccgca gcgaatgccg tttcacgaat cgtcaggcgg 7200
gcagtggatg tttttccatg aggcgaagaa tttcatcgcc gcagtgaatg ccgtttcacc 7260
attgatgaag aatgcgaggt gaaaacagag aaattgggtc aactctatca ctcttattca 7320
gccatcgttt caagaaagga tacctcgtat tggatacaac acagctcgtt cgttctctct 7380
acctccctcg acaatctcaa gga 7403
<210> 62
<211> 6789
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 62
taataaaatt gaaatatcac tatggattat tgtaatatta ccataaagat aggtgacgtt 60
tttttgaaaa ttgtaaacct aatttgaaga aaaccaatta aaaatcgctt cggctttttt 120
ttaagtgcca ggtagcattg atgctaaccc atgtgtaata aaggtttgtt ttccttcggg 180
gcacgaacac attataaggg aaacctaaag attccctttc ttgtttaata ttataaccag 240
tgaaaataag aataatgcac ctaaaactaa tatacagaaa ataagaatta aaagtactaa 300
tatatacatc atatgttatc ctccaatgct ttatttttta ataattgatg ttagtattag 360
ttttatttta atttctaaac ataagaattt gaaaaggatg tgtttattat ggcgacacgc 420
agttttattt taaaaattga accaaatgaa gaagttaaaa agggattatg gaagacgcat 480
gaggtattga atcatggaat tgcctactac atgaatattc tgaaactaat tagacaggaa 540
gctatttatg aacatcatga acaagatcct aaaaatccga aaaaagtttc aaaagcagaa 600
atacaagccg agttatggga ttttgtttta aaaatgcaaa aatgtaatag ttttacacat 660
gaagttgaca aagatgttgt ttttaacatc ctgcgtgaac tatatgaaga gttggtccct 720
agttcagtcg agaaaaaggg tgaagccaat caattatcga ataagtttct gtacccgcta 780
gttgatccga acagtcaaag tgggaaaggg acggcatcat ccggacgtaa acctcggtgg 840
tataatttaa aaatagcagg cgacccatcg tgggaggaag aaaagaaaaa atgggaagag 900
gataaaaaga aagatcccct tgctaaaatc ttaggtaagt tagcagaata tgggcttatt 960
ccgctattta ttccatttac tgacagcaac gaaccaattg taaaagaaat taaatggatg 1020
gaaaaaagtc gtaatcaaag tgtccggcga cttgataagg atatgtttat ccaagcatta 1080
gagcgttttc tttcatggga aagctggaac cttaaagtaa aggaagagta tgaaaaagtt 1140
gaaaaggaac acaaaacact agaggaaagg ataaaagagg acattcaagc atttaaatcc 1200
cttgaacaat atgaaaaaga acggcaggag caacttctta gagatacatt gaatacaaat 1260
gaataccgat taagcaaaag aggattacgt ggttggcgtg aaattatcca aaaatggcta 1320
aagatggatg aaaatgaacc atcagaaaaa tatttagaag tatttaaaga ttatcaacgg 1380
aaacatccac gagaagccgg ggactattct gtctatgaat ttttaagcaa gaaagaaaat 1440
cattttattt ggcgaaatca tcctgaatat ccttatttgt atgctacatt ttgtgaaatt 1500
gacaaaaaaa agaaagacgc taagcaacag gcaactttta ctttggctga cccgattaac 1560
catccgttat gggtacgatt tgaagaaaga agcggttcga acttaaacaa atatcgaatt 1620
ttaacagagc aattacacac tgaaaagtta aaaaagaaat taacagttca acttgatcgt 1680
ttaatttatc caactgaatc cggcggttgg gaggaaaaag gtaaagtaga tatcgttttg 1740
ttgccgtcaa gacaatttta taatcaaatc ttccttgata tagaagaaaa ggggaaacat 1800
gcttttactt ataaggatga aagtattaaa ttccccctta aaggtacact tggtggtgca 1860
agagtgcagt ttgaccgtga ccatttgcgg agatatccgc ataaagtaga atcaggaaat 1920
gttggacgga tttattttaa catgacagta aatattgaac caactgagag ccctgttagt 1980
aagtctttga aaatacatag ggacgatttc cccaagttcg ttaattttaa accgaaagag 2040
ctcaccgaat ggataaaaga tagtaaaggg aaaaaattaa aaagtggtat agaatccctt 2100
gaaattggtc tacgggtgat gagtatcgac ttaggtcaac gtcaagcggc tgctgcatcg 2160
atttttgaag tagttgatca gaaaccggat attgaaggga agttattttt tccaatcaaa 2220
ggaactgagc tttatgctgt tcaccgggca agttttaaca ttaaattacc gggtgaaaca 2280
ttagtaaaat cacgggaagt attgcggaaa gctcgggagg acaacttaaa attaatgaat 2340
caaaagttaa actttctaag aaatgttcta catttccaac agtttgaaga tatcacagaa 2400
agagagaagc gtgtaactaa atggatttct agacaagaaa atagtgatgt tcctcttgta 2460
tatcaagatg agctaattca aattcgtgaa ttaatgtata aaccctataa agattgggtt 2520
gcctttttaa aacaactcca taaacggcta gaagtcgaga ttggcaaaga ggttaagcat 2580
tggcgaaaat cattaagtga cgggagaaaa ggtctttacg gaatctccct aaaaaatatt 2640
gatgaaattg atcgaacaag gaaattcctt ttaagatgga gcttacgtcc aacagaacct 2700
ggggaagtaa gacgcttgga accaggacag cgttttgcga ttgatcaatt aaaccaccta 2760
aatgcattaa aagaagatcg attaaaaaag atggcaaata cgattatcat gcatgcctta 2820
ggttactgtt atgatgtaag aaagaaaaag tggcaggcaa aaaatccagc atgtcaaatt 2880
attttatttg aagatttatc taactacaat ccttacgagg aaaggtcccg ttttgaaaac 2940
tcaaaactga tgaagtggtc acggagagaa attccacgac aagtcgcctt acaaggtgaa 3000
atttacggat tacaagttgg ggaagtaggt gcccaattca gttcaagatt ccatgcgaaa 3060
accgggtcgc cgggaattcg ttgcagtgtt gtaacgaaag aaaaattgca ggataatcgc 3120
ttttttaaaa atttacaaag agaaggacga cttactcttg ataaaatcgc agttttaaaa 3180
gaaggagact tatatccaga taaaggtgga gaaaagttta tttctttatc aaaggatcga 3240
aagttggtaa ctacgcatgc tgatattaac gcggcccaaa atttacagaa gcgtttttgg 3300
acaagaacac atggatttta taaagtttac tgcaaagcct atcaggttga tggacaaact 3360
gtttatattc cggagagcaa ggaccaaaaa caaaaaataa ttgaagaatt tggggaaggc 3420
tattttattt taaaagatgg tgtatatgaa tggggtaatg cggggaaact aaaaattaaa 3480
aaaggttcct ctaaacaatc atcgagtgaa ttagtagatt cggacatact gaaagattca 3540
tttgatttag caagtgaact taagggagag aaactcatgt tatatcgaga tccgagtgga 3600
aacgtatttc cttccgacaa gtggatggca gcaggagtat tttttggcaa attagaaaga 3660
atattgattt ctaagttaac aaatcaatac tcaatatcaa caatagaaga tgattcttca 3720
aaacaatcaa tgtaaaagtt tgcccgtata agaacttaat taattaggat ggtaggatgt 3780
tactaaatat gtctgtaggc atcattccta ctatccgttt tgtccgaata tcagagcatt 3840
aggtgaggaa tggtaagaaa ggaaaattta tatgaaccaa ccgattccta ttcgaatgtt 3900
aaatgaaata caatattgtg agcgactttt ttactttatg catgtccaaa agctatttga 3960
tgagaatgca gatacagttg aaggaagtgc acagcatgag cgggcagaaa gaagcaaaag 4020
accaagtaaa atgggaccaa aggaattatg gggtgaggcg ccaagaagtc ttaagcttgg 4080
tgatgagctg ttaaatatta ccggtgttct tgatgccata agtcatgaag agaacagttg 4140
gatcccggtt gaatcaaaac acagttccgc accggatgga ttgaaccctt ttaaagtaga 4200
tggctttcta cttgacgggt ctgcatggcc aaacgatcaa attcaacttt gtgcacaagg 4260
cttgctcttg aatgccaatg gatacccgtg tgattatggg tatttatttt atcgtggtaa 4320
taagaaaaag gtgaaaattt attttactga agatttaatc gctgccacaa agtactatat 4380
taaaaaagca cacgagatac tagtattatc tggtgatgaa tcagctattc ctaagccttt 4440
aattgattct aataagtgtt ttcgctgttc tttaaactat atctgtcttc cggatgaaac 4500
gaactatcta ttaggggcaa gttcaacaat tcgtaaaatt gtgccttcaa ggacagatgg 4560
tggcgtttta tatgtatcag agtctggtac aaaattagga aaatcgggtg aggagttaat 4620
cattcagtat aaagatggcc aaaagcaggg tgttcctata aaagatatta ttcaagtttc 4680
gttaattgga aatgttcaat gctcaacgca attacttcat tttttaatgc aatcaaatat 4740
tcctgtaagt tatttatcat cccacggtcg tttgattggt gtcagttcat ctttagttac 4800
aaaaaatgtt ttaacaaggc agcaacagtt cattaaattt acaaatcctg agtttggact 4860
aaatctagca aaacaaattg tttatgccaa gattcgaaat caacgaactt tacttagaag 4920
aaatgggggg agtgaggtaa aggagatttt aacagattta aaatctttaa gtgacagtgc 4980
actgaacgca atatcaatag aacaattacg gggtattgaa gggatttctg caaaacatta 5040
tttcgcagga tttccgttta tgttgaaaaa tgaattacgt gaattgaatt taatgaaagg 5100
gcgtaatagg agaccgccaa aagatcctgt aaatgtactt ctttctcttg gttatacttt 5160
attgacacgt gatattcatg ctgcgtgtgg ttcagtcgga ttggatccga tgtttggttg 5220
ttaccatcgt ccagaagcag gtcgaccggc tctagtatta gatgttatgg aaacatttcg 5280
accacttatt gtagacagta ttgtcatccg agctttgaat acgggtgaaa tctcattaaa 5340
agatttttat ataggaaaag atagttgtca attattaaaa catggccgcg attccttttt 5400
tgccatttat gaaagaagaa tgcatgaaac tattaccgat ccaattttcg gctataagat 5460
tagctatcgc cgtatgctcg atttgcacat tcgaatgctt gcaaggttta ttgaagggga 5520
actgccggaa tataaaccat taatgacccg gtgagtttgt ttattaggtt aaaagaaggt 5580
gaagacatgc agcaatacgt ccttgtttct tatgatattt cggaccaaaa aagatggaga 5640
aaagtattta aactgatgaa aggatacgga gaacatgttc aatattccgt attcatatgc 5700
cagttaactg aattacagaa ggcaaaatta caagcctctt tagaagacat tatccatcat 5760
aagaatgacc aagtaatgtt tgttcacatc gggccagtga aagatggtca actatctaaa 5820
aaaatctcaa caattgggaa agaatttgtt ccattggatt taaagcggct tatattttga 5880
aaagatatag caaagaaatc ttatgaaaaa aatacaaaaa tatattgtta aaaaataggg 5940
aatattatat aatggactta cgaggttctg tcttttggtc aggacaaccg tctagctata 6000
agtgctgcag gggtgtgaga aactcctatt gctggacgat gtctctttta tttctttttt 6060
cttggatctg agtacgagca cccacattgg acatttcgca tggtgggtgc tcgtactata 6120
ggtaaaacaa acctttttaa gaagaataca aaaataacca caatattttt taaaaggaat 6180
tttgatggat ttacataacc tctcgcaaca tgcttctaaa acccaagccc accatagccc 6240
aaaaccccct gcggtccaag aaaaaagaaa tgatacgagg cattagcacc ggggagaagt 6300
catttaataa ggccactgtt aaaagtccaa gaaaaaagaa atgatacgag gcattagcac 6360
aacaatataa acgactactt taccgtgttc aagaaaaaag aaatgatatg aggcattagc 6420
acgatgggat gggagagaga ggacagttct actcttgctg tatccagctt cttttacttt 6480
atccggtatc atttcttcac ttctttctgc acataaaaaa gcacctaact atttggataa 6540
gttaagtgct tttatttccg tttgaagttg tctattgctt ttttcttcat atcttcaaat 6600
tttttctgtt tctcagagtc aactttacca actgtaatcc cttttctttt tggcattggg 6660
gtatctttcc accttagtgt gttcataagg cttatattta tcactcattg tattcctcca 6720
acacaattat aatttttccg tcatcctcaa tccaaccgtc aactgtgaca aaagacgaat 6780
ctctcttat 6789
<210> 63
<211> 6214
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 63
gtttcatttg gaaagggaga gcattggctt ttctctttgt aaataaagtg caagctttgt 60
aataagcttc tagtggagaa gtgattgttt gaatcaccca atgcacacgc actaaagtta 120
gacgaaccta taattcgtat tagtaagtat agtacatgaa gaaaaatgca acaagcattt 180
actctctttt aaataaagaa ttgatagctg ttaatattga tagtatatta taccttatag 240
atgttcgatt ttttttgaaa ttcaaaaatc atacttagta aagaaaggaa ataacgtcat 300
ggacaagcga aagcgtagaa gttacgagtt taggtgggaa gcgggaggca ccagtcatgg 360
caatccgtag cataaaacta aaactaaaaa cccacacagg cccggaagcg caaaacctcc 420
gaaaaggaat atggcggacg catcggttgt taaatgaagg cgtcgcctat tacatgaaaa 480
tgctcctgct ctttcgtcag gaaagcactg gtgaacggcc aaaagaagaa ctacaggaag 540
aactgatttg tcacatacgc gaacagcaac aacgaaatca ggcagataaa aatacgcaag 600
cgcttccgct agataaggca ctggaagctt tgcgccaact atatgaactg cttgtcccct 660
cctcggtcgg acaaagtggc gacgcccaga tcatcagccg aaagtttctc agcccgctcg 720
tcgatccgaa cagcgaaggc ggcaaaggta cttcgaaggc aggggcaaaa cccacttggc 780
agaagaaaaa agaagcgaac gacccaacct gggaacagga ttacgaaaaa tggaaaaaaa 840
gacgcgagga agacccaacc gcttctgtga ttactacttt ggaggaatac ggcattagac 900
cgatctttcc cctgtacacg aacaccgtaa cagatatcgc gtggttgcca cttcaatcca 960
atcagtttgt gcgaacctgg gacagagaca tgcttcaaca agcgattgaa agactgctca 1020
gttgggagag ctggaacaaa cgtgtccagg aagagtatgc caagctgaaa gaaaaaatgg 1080
ctcaactgaa cgagcaactc gaaggcggtc aggaatggat cagcttgcta gagcagtacg 1140
aagaaaaccg agagcgagag cttagggaaa acatgaccgc tgccaatgac aagtatcgga 1200
ttaccaagcg gcaaatgaaa ggctggaacg agctgtacga gctatggtca acctttcccg 1260
ccagtgccag tcacgagcaa tacaaagagg cgctcaagcg tgtgcagcag cgactgagag 1320
ggcggtttgg ggatgctcat ttcttccagt atctgatgga agagaagaac cgcctgatct 1380
ggaaggggaa tccgcagcgt atccattatt ttgtcgcgcg caacgaactg acgaaacggc 1440
tggaggaagc caagcaaagc gccacgatga cgttgcccaa tgccaggaag catccattgt 1500
gggtgcgctt cgatgcacgg ggaggaaatt tgcaagacta ctacttgacg gctgaagcgg 1560
acaaaccgag aagcagacgt tttgtaacgt ttagtcagtt gatatggcca agcgaatcgg 1620
gatggatgga aaagaaagac gtcgaggtcg agctagcttt gtccaggcag ttttaccagc 1680
aggtgaagtt gctgaaaaat gacaaaggca agcagaaaat cgagttcaag gataaaggtt 1740
cgggctcgac gtttaacgga cacttggggg gagcaaagct acaactggag cggggcgatt 1800
tggagaagga agaaaaaaac ttcgaggacg gggaaatcgg cagcgtttac cttaacgttg 1860
tcattgattt cgaacctttg caagaagtga aaaatggccg cgtgcaggcg ccgtatggac 1920
aagtactgca actcattcgt cgccccaacg agtttcccaa ggtcactacc tataagtcgg 1980
agcaacttgt tgaatggata aaagcttcgc cacaacactc ggctggggtg gagtcgctgg 2040
catccggttt tcgtgtaatg agcatagacc ttgggctgcg cgcggctgca gcgacttcta 2100
ttttttctgt agaagagagt agcgataaaa atgcggctga tttttcctac tggattgaag 2160
gaacgccgct ggtcgctgtc catcagcgga gctatatgct caggttgcct ggtgaacagg 2220
tagaaaaaca ggtgatggaa aaacgggacg agcggttcca gctacaccaa cgtgtgaagt 2280
ttcaaatcag agtgctcgcc caaatcatgc gtatggcaaa taagcagtat ggagatcgct 2340
gggatgaact cgacagcctg aaacaagcgg ttgagcagaa aaagtcgccg ctcgatcaaa 2400
cagaccggac attttgggag gggattgtct gcgacttaac aaaggttttg cctcgaaacg 2460
aagcggactg ggaacaagcg gtagtgcaaa tacaccgaaa agcagaggaa tacgtcggaa 2520
aagccgttca ggcatggcgc aagcgctttg ctgctgacga gcgaaaaggc atcgcaggtc 2580
tgagcatgtg gaacatagaa gaattggagg gcttgcgcaa gctgttgatt tcctggagcc 2640
gcaggacgag gaatccgcag gaggttaatc gctttgagcg aggccatacc agccaccagc 2700
gtctgttgac ccatatccaa aacgtcaaag aggatcgcct gaagcagtta agtcacgcca 2760
ttgtcatgac tgccttgggg tatgtttacg acgagcggaa acaagagtgg tgcgccgaat 2820
acccggcttg ccaggtcatt ctgtttgaaa atctgagcca gtaccgttct aacctggatc 2880
gctcgaccaa agaaaactcc accttgatga agtgggcgca tcgcagcatt ccgaaatacg 2940
tccacatgca ggcggagcca tacgggattc agattggcga tgtccgggcg gaatattcct 3000
ctcgttttta cgccaagaca ggaacgccag gcattcgttg taaaaaggtg agaggccaag 3060
acctgcaggg cagacggttt gagaacttgc agaagaggtt agtcaacgag caatttttga 3120
cggaagaaca agtgaaacag ctaaggcccg gcgacattgt cccggatgat agcggagaac 3180
tgttcatgac cttgacagac ggaagcggaa gcaaggaggt cgtgtttctc caggccgata 3240
ttaacgcggc gcacaatctg caaaaacgtt tttggcagcg atacaatgaa ctgttcaagg 3300
ttagctgccg cgtcatcgtc cgagacgagg aagagtatct cgttcccaag acaaaatcgg 3360
tgcaggcaaa gctgggcaaa gggctttttg tgaaaaaatc ggatacagcc tggaaagatg 3420
tatatgtgtg ggacagccag gcaaagctta aaggtaaaac aacctttaca gaagagtctg 3480
agtcgcccga acaactggaa gactttcagg agatcatcga ggaagcagaa gaggcgaaag 3540
gaacataccg tacactgttc cgcgatccta gcggagtctt ttttcccgaa tccgtatggt 3600
atccccaaaa agatttttgg ggcgaggtga aaaggaagct gtacggaaaa ttgcgggaac 3660
ggtttttgac aaaggctcgg taagggtgtg caaggagagt gaatggcttg tcctggatac 3720
ctgtccgcat gctaaatgaa attcagtatt gtgagcgact gtaccatatt atgcatgtgc 3780
aggggctgtt tgaggaaagc gcagacacgg tcgaaggagc agcacaacac aagcgtgcag 3840
agacacatct gcgcaaaagc aaggcagcgc cggaagagat gtggggggac gctccgttta 3900
gcttgcagct cggcgaccct gtgcttggca ttacgggaaa gctggatgcc gtctgtctgg 3960
aagaaggtaa gcagtggatt ccggtagaag gaaagcattc ggcgtcgcca gaaggcgggc 4020
agatgttcac tgtaggcgtg tattcgctgg acggttctgc ctggcccaac gaccaaatcc 4080
aattgtgtgc gcaaggcttg ctgcttcgcg cgaatggata tgaatccgat tatggctact 4140
tatactaccg tggcaataaa aagaaggttc gcattccttt ttcgcaggaa ctcatagcgg 4200
ctactcacgc ctgcattcaa aaagctcatc agcttcggga agccgaaatt ccccctccgt 4260
tgcaggagtc gaaaaagtgc tttcgatgct cgttaaatta cgtatgcatg cctgacgaga 4320
cgaattacat gttggggttg agcgcaaaca tcagaaagat tgtgcccagt cgtccagatg 4380
gcggggtact gtatgttaca gagcaggggg caaaactggg cagaagcgga gaaagcttga 4440
ccatcacctg ccggggcgaa aagatagacg aaatcccgat caaagacttg attcacgtga 4500
gcttgatggg gcatgtgcaa tgctctacgc agcttctgca caccttgatg aactgtggcg 4560
tccacgtcag ctacttgact acgcatggca cattgacagg aataatgact ccccctttat 4620
cgaaaaacat tcgaacaaga gccaagcagt ttatcaaatt tcagcacgcg gagatcgccc 4680
ttggaatcgc gagaagggtc gtgtatgcga aaatttccaa tcagcgcacg atgctgcgcc 4740
gcaatggctc accagataaa gcagttttaa aagagttaaa agagcttaga gatcgcgcgt 4800
gggaggcgcc atcactggaa atagtgagag gtatcgaggg acgtgcagca cagttgtaca 4860
tgcagttttt ccctaccatg ttaaagcacc cagtagtaga cggtatggcg atcatgaacg 4920
gtcgcaaccg tcgcccgccc aaagatccgg tcaatgcgct gctctccctc ggctatacgc 4980
ttctttcacg ggatgtttac tccgcatgtg ccaatgtcgg actcgatcca ctgttcggct 5040
ttttccatac gatggagccg ggcagaccag ctttggcact cgatctgatg gaaccgttcc 5100
gcgccttgat tgccgatagc gtagcgatac gtaccttgaa tacggaggaa ctcaccctcg 5160
gggactttta ttggggaaaa gacagttgtt atttgaaaaa ggcaggaaga caaacgtatt 5220
tcgctgccta tgaaagacgg atgaacgaga cgctgacgca tccgcaattt gggtataagc 5280
tcagctatcg ccgtatgctg gagctggaag caaggttttt ggcccggtat ctggatggag 5340
agctggtgga atatacgccg ctcatgacaa ggtaggaaat gaccatgcga caatttgttc 5400
tggtaagcta tgatattgcc gatcaaaaac gttggagaaa agtattcaag ctgatgaagg 5460
ggcaaggcga gcacgtccag tactcggtgt ttctgtgcca actcaccgag attcagcaag 5520
ccaagctaaa ggtaagcctg gcggagctgg ttcaccatgg agaagaccag gtcatgtttg 5580
taaaaatcgg cccagtgacg agagatcaac tggacaagcg gatatctact gttggcaggg 5640
agtttctgcc tcgcgatttg accaaattta tctattaagg aatgaagaaa gctagttgta 5700
acaaaagtgg aaaaagagta aaataaaggt gtcagtcgca cgctataggc cataagtcga 5760
cttacatatc cgtgcgtgtg cattatgggc ccatccacag gtctattccc acggataatc 5820
acgactttcc actaagcttt cgaattttat gatgcgagca tcctctcagg tcaaaaaagc 5880
cgggggatgc tcgaactctt tgtgggcgta ggctttccag agttttttag gggaagaggc 5940
agccgatgga taagaggaat ggcgattgaa ttttggcttg ctcgaaaaac gggtctgtaa 6000
ggcttgcggc tgtaggggtt gagtgggaag gagttcgaaa gcttagtgga aagcttcgtg 6060
gttagcaccg gggagaagtc atttaataag gccactgtta aaagttcgaa agcttagtgg 6120
aaagcttcgt ggttagcacg ctaaagtccg tctaaactac tgagatctta aatcggcgct 6180
caaataaaaa acctcgctaa tgcgaggttt cagc 6214
<210> 64
<211> 12338
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 64
gaagttatgt tgataaaatg gtttatgaaa acgtgagtct gtggtagtat tataaacaat 60
gatggaataa agtgtttttt gcgccgcacg gcatgaattc aggggttagc ttggttttgt 120
gtataaataa atgttctaca tatttatttt gttttttgcg ccgcaaaatg caactgaaag 180
ccgcatctag agcaccctgt agaagacagg gttttgagaa tagcccgaca tagagggcaa 240
tagacacggg gagaagtcat ttaataaggc cactgttaaa agttttgaga atagcccgac 300
atagagggca atagactttt gcttcgtcac ggatggactt cacaatggca acaacgtttt 360
gagaatagcc cgacatagtt atagagatgt ataaatataa ccgataaaca ttgactaatt 420
tgttgaagtc agtgtttatc ggttttttgt gtaaatatag gagttgttag aatgatactt 480
tttgcctaat tttggaactt tatgaggata taagatagac ttgataaaaa ggtaaaagaa 540
aggttaaaga gcatggcagg aatagtgacc tgtgatgaag atgatggtag aattaaaagt 600
gttcttaaag aaaaacaata ttggataagg aaaataattc aatagataaa aaatttaggg 660
ggaaaaatga aaatatcaaa agtcgatcat accagaatgg cggttgctaa aggtaatcaa 720
cacaggagag atgagattag tgggattctc tataaggatc cgacaaagac aggaagtata 780
gattttgatg aacgattcaa aaaactgaat tgttcggcga agatacttta tcatgtattc 840
aatggaattg ctgagggaag caataaatac aaaaatattg ttgataaagt aaataacaat 900
ttagataggg tcttatttac aggtaagagc tatgatcgaa aatctatcat agacatagat 960
actgttctta gaaatgttga gaaaattaat gcatttgatc gaatttcaac agaggaaaga 1020
gaacaaataa ttgacgattt gttagaaata caattgagga aggggttaag gaaaggaaaa 1080
gctggattaa gagaggtatt actaattggt gctggtgtaa tagttagaac cgataagaag 1140
caggaaatag ctgattttct ggagatttta gatgaagatt tcaataagac gaatcaggct 1200
aagaacataa aattgtctat tgagaatcag gggttggtgg tctcgcctgt atcaagggga 1260
gaggaacgga tttttgatgt cagtggcgca caaaagggaa aaagcagcaa aaaagcgcag 1320
gagaaagagg cactatctgc atttctgtta gattatgctg atcttgataa gaatgtcagg 1380
tttgagtatt tacgtaaaat tagaagactg ataaatctat atttctatgt caaaaatgat 1440
gatgttatgt ctttaactga aattccggca gaagtgaatc tggaaaaaga ttttgatatc 1500
tggagagatc acgaacaaag aaaggaagag aatggagatt ttgttggatg tccggacata 1560
cttttggcag atcgtgatgt gaagaaaagt aacagtaagc aggtaaaaat tgcagagagg 1620
caattaaggg agtcaatacg tgaaaaaaat ataaaacgat atagatttag cataaaaacg 1680
attgaaaagg atgatggaac atactttttt gcaaataagc agataagtgt attttggatt 1740
catcgcattg aaaatgctgt agaacgtata ttaggatcta ttaatgataa aaaactgtat 1800
agattacgtt taggatatct aggagaaaaa gtatggaagg acatactcaa ttttctcagc 1860
ataaaataca ttgcagtagg caaggcagta ttcaattttg caatggatga tctgcaggag 1920
aaggatagag atatagaacc cggcaagata tcagaaaatg cagtaaatgg attgacttcg 1980
tttgattatg agcaaataaa ggcagatgag atgctgcaga gagaagttgc tgttaatgta 2040
gcattcgcag caaataatct tgctagagta actgtagata ttccgcaaaa tggagaaaaa 2100
gaggatatcc ttctttggaa taaaagtgac ataaaaaaat acaaaaagaa ttcaaagaaa 2160
ggtattctga aatctatact tcagtttttt ggtggtgctt caacttggaa tatgaaaatg 2220
tttgagattg catatcatga tcagccaggt gattacgaag aaaactacct atatgacatt 2280
attcagatca tttactcgct cagaaataag agctttcatt tcaagacata tgatcatggg 2340
gataagaatt ggaatagaga actgatagga aagatgattg agcatgatgc tgaaagagtc 2400
atttctgttg agagggaaaa gtttcattcc aataacctgc cgatgtttta taaagacgct 2460
gatctaaaga aaatattgga tctcttgtat agcgattatg caggacgtgc atctcaggtt 2520
ccggcattta acactgtctt ggttcgaaag aactttccgg aatttcttag gaaagatatg 2580
ggctacaagg ttcattttaa caatcctgaa gtagagaatc agtggcacag tgcggtgtat 2640
tacctatata aagagattta ttacaatcta tttttgagag ataaagaggt aaagaatctt 2700
ttttatactt cattaaaaaa tataagaagt gaagtttcgg acaaaaaaca aaagttagct 2760
tcagatgatt ttgcatccag gtgtgaagaa atagaggata gaagtcttcc ggaaatttgt 2820
cagataataa tgacagaata caatgcgcag aactttggta atagaaaagt taaatctcag 2880
cgtgttattg aaaaaaataa ggatattttc agacattata aaatgctttt gataaagact 2940
ttagcaggtg ctttttctct ttatttgaag caggaaagat ttgcatttat tggtaaggca 3000
acacctatac catacgaaac aaccgatgtt aagaattttt tgcctgaatg gaaatccgga 3060
atgtatgcat cgtttgtaga ggagataaag aataatcttg atcttcaaga atggtatatc 3120
gtcggacgat tccttaatgg gaggatgctc aatcaattgg caggaagcct gcggtcatac 3180
atacagtatg cggaagatat agaacgtcgt gctgcagaaa ataggaataa gcttttctcc 3240
aagcctgatg aaaagattga agcatgtaaa aaagcggtca gagtgcttga tttgtgtata 3300
aaaatttcaa ctagaatatc tgcggaattt actgactatt ttgatagtga agatgattat 3360
gcagattatc ttgaaaaata tctcaagtat caggatgatg ccattaagga attgtcagga 3420
tcttcgtatg ctgcgttgga tcatttttgc aacaaggatg atctgaaatt tgatatctat 3480
gtaaatgccg gacagaagcc tatcttacag agaaatatcg tgatggcaaa gctttttgga 3540
ccagataaca ttttgtctga agttatggaa aaggtaacag aaagtgccat acgagaatac 3600
tatgactatc tgaagaaagt ttcaggatat cgggtaaggg gaaaatgtag tacagagaaa 3660
gaacaggaag atctgctaaa gttccaaaga ttgaaaaacg cagtagaatt ccgggatgtt 3720
actgaatatg ctgaggttat taatgagctt ttaggacagt tgataagttg gtcatatctt 3780
agggagaggg atctattata tttccagctg ggattccatt acatgtgtct gaaaaacaaa 3840
tctttcaaac cggcagaata tgtggatatt cgtagaaata atggtacgat tatacataat 3900
gcgatacttt accagattgt ttcgatgtat attaatggac tggatttcta tagttgtgat 3960
aaagaaggga aaacgctcaa accaattgaa acaggaaagg gcgtaggaag taagatagga 4020
caatttataa agtattccca gtatttatac aatgatccgt catataagct tgagatctat 4080
aatgcaggat tagaagtttt tgaaaacatt gatgaacatg ataatattac agatcttaga 4140
aagtatgtgg atcattttaa gtattatgca tatggtaata aaatgagcct gcttgatctg 4200
tatagtgaat tcttcgatcg tttctttaca tatgatatga agtatcagaa gaatgtagtg 4260
aatgtgttgg agaatatcct tttaaggcat tttgtaattt tctatccgaa gtttggatca 4320
ggaaaaaaag atgttggaat tagggattgt aaaaaagaaa gagctcagat tgaaataagt 4380
gagcagagcc tcacatcgga agacttcatg tttaagcttg acgacaaagc aggagaagaa 4440
gcaaagaagt ttccggcaag ggatgaacgt tatctccaga caatagccaa gttgctctat 4500
tatcctaacg aaattgagga tatgaacaga ttcatgaaga aaggagaaac gataaataaa 4560
aaagttcagt ttaatagaaa aaagaagata accaggaaac aaaagaataa ttcatcaaac 4620
gaggtattgt cttcaactat gggttattta tttaagaaca ttaaattgta aaaaagattc 4680
gttgtagata attgataggt aaaagctgac cggagccttt ggctccggac agttgtatat 4740
aagaggatat taatgactga aaatgatttt tgttggaagt cagttttttc tgtggaaagc 4800
gaaatcgaat atgatgagta tgcatatggc agaagagctg tagaaggcga gaatacatat 4860
gattacatta ctaaggaaga aagaccggaa cttaatgacg aatatgtagc gagacgttgc 4920
attttcggta aaaaagcagg aaaaatatcc aggtcggatt ttagtaggat aagatctgcg 4980
ttggatcatg cgatgataaa taatacacat acagcatttg ccagatttat cactgaaaat 5040
ctgacgagac tcaatcacaa agaacatttt ctgaatgtga cacgtgcata ttctaaacct 5100
gattctgaaa aattgataca accgagatac tggcagtcgc ctgtagttcc aaaggataaa 5160
caaatatatt atagcaagaa tgcgattaaa aaatggtgtg gttacgaaga tgatattccg 5220
cctcgttctg tgatagttca gatgtgtcta ttgtggggga ctgatcatga agaggcagat 5280
catatccttc gcagttcagg atacgcggcg cttagtcctg ttgtacttcg agatcttatc 5340
tatatgtatt atctggatca tcaggatttg caaaaaaatg agttgatatg ggaagtaaaa 5400
aagcagttgg atcacttcga tttgacaaat agaaattatg atacaaatcc ttttgatgta 5460
gggggcagcg taaatgatca tatctgtgaa ctgagcgagc atatagcgaa ggctcattat 5520
atttatgaga gggctaagga aggaccattg caaaatgtaa ttcgggatat tttgggagat 5580
acacctgccc tttattctga aatggcattt cctcagctag catctataaa caggtgtgct 5640
tgcaattcgc tttcttcata tcaaaaaaat atttttgata ctgacatagc tatatatgca 5700
gatgaaaagg acacaagagg taaatcagac cgtatccttg ttgagggcgc atcttcgaaa 5760
tggtatgaat tgaagaaacg cgatgctaat aatgtcaaaa tttctgaaaa gctgagtata 5820
ctcaatacta ttcttaaatt taatagtgtt ttttgggaag aatgttacct tgatggaaat 5880
ataaaacaat cgagcggaaa gcgatctgag gcaggaaaaa ttctttatgg tcgcgacaac 5940
ggaaaagaaa atgtcggagt ttcaaaattg gaattggtgc ggtatatgat agctgcaggt 6000
caggaacaaa atctgggaaa ttacctggtg agttcaggat tttggagaaa aaatcatatg 6060
ctgtcattta tacaaggcaa tgatatagcg cttgatgaga tggatgaatt ggatctctta 6120
gactatattc tgatatatgc atggggattt agggaaaata tcattaaaaa gaacagtaat 6180
gtgaattctt tggatgaaaa gactagaaaa gtgcagtttc cgtttataaa gttactcatg 6240
gcaattgcaa gagatatcca gatacttata tgttcagcac atgaaaaaac agtcgatgag 6300
tcatctcgaa atgcagcaaa gaagatagat atattgggaa attatattcc ttttcagatt 6360
catcttcaga gaactaaaaa agatggtgga agagtggtaa tggatacatt gtgtgctgat 6420
tggattgcgg attatgaatg gtacattgat cttgagaaag gaacacttgg atgagcagtg 6480
atgaaaggat atttaaaaaa tttttggaaa aaggatcgat ttctgagcag aaaaagatgc 6540
ttttagaaga aaagaaatgt tcggataaac taactgcact gcttgggaat tactgcatac 6600
cgatagacaa tatttcagag tcagacggaa aaatatatgc ggtctataag cttccaaaaa 6660
atgttaaacc tttgtccgaa atcattaatg atgtatcctt ttctgattgt acgatgagag 6720
tacgtttgct tctcataaag agaattctgg aactcgtgtg tgcttttcac gaaaaaaaat 6780
ggtattgtct cagtatttca ccgggaatgc tcatggttga agattttgat ataccgatgg 6840
gaaatgtcgg aaaagtattg atatatgatt tcagaaatcc tgttccgttc gagtcagtaa 6900
atgaaagaca taattttaac gtttcaaata aatacacttc accggagctg ctcatccatt 6960
caagatatga cgagtcgaaa tctgtgagtg aaaaatcaga tttgtattct gttgcaaaaa 7020
ttgcggaaac aataatagga gattttaaca gtattattgc aaatggaaat ttgatactac 7080
ttgcaatgct tagagttttt atcagtacag ggaaaagtcc ggaacctgag tatcggtttg 7140
aatcgtcgga aaatatgctt tcagtatttg aaaatttgat caaagaaaat tgtttttttg 7200
aaaaaaacga ttatacatct atgtttcatc aggcgtatga caattttttt gaatggcagg 7260
aatgtttgat atcaccggat cacttggata aaaatatgtt cgaggcagct ttatcaaatc 7320
ttgaggatca gctgcttagg gttgatattg ataagtatag agcagagtac ttctataagc 7380
ttctccgaga gttgtctaat aaatataaaa atacaattac tgatgaacaa aaggtaaggt 7440
tggcaatact tggaatcaga gcgaaaaata atctgggaaa aagttttgat gcattggaaa 7500
tatatgagtc agtacgtgat ttagaaacta tgttggagga gatggcagag cttagtcctg 7560
tcattgcttc gacatatatg gattgctacc gatatgcaga tgcgcagaaa gtggcggaag 7620
aaaacattat caggcttcat aatagtaata ttcgtatgga gaaaaaaaga atactgcttg 7680
gaaggtcata tagttcaaaa gggtgcagca tggggtttca gcatattctt ggtgcggatg 7740
agtcatttga acaggcttta tatttcttta acgaaaagga caatttttgg aaagaaatat 7800
ttgagagcag aaatttagag gacagcgata gacttataaa gtctttacga agcaatacgc 7860
atattacgct gtttcattac atgcaatatg catgtgaaac aaggagaaag gaattatatg 7920
gagcactttc agacaaatat tttataggta aagaatggac agaaagactc aaagcatata 7980
taagcaacaa ggatatatgg aaaaactatt atgagatata tattctgcta aagggtattt 8040
attgcttcta tccagaagtc atgtgttcgt ctgcgtttta tgatgaaatc caaaaaatgt 8100
acgatcttga atttgaaaag gaaaaaatgt tttacccatt gagtctgata gaactgtatc 8160
ttgctctgat agagataaaa gttaatggga gtctgacgga gaatgccgag aagttgttta 8220
aacaggcatt gacacatgac aatgaagtca aaaaaggaaa tatgaatatt cagaccgcca 8280
tttggtatcg aatatatgca ctgtataacg atgtaaaaga tgaaactgat aagaataaaa 8340
ggcttttaaa acggcttatg attctttgcc gacgatttgg ttgggcggat atgtatagtg 8400
ctttggagaa ggatgggaag ttaattgatt ttttgagatt tgaggtatgt taaatgataa 8460
cacttgcatt agatgaaaat ggcaaatttg aagatgcttt ttctaaaaaa aatgaaaaac 8520
cgataatgat tgcggggata atctatgatg acaaggggaa agagtatgat gctgagaatg 8580
aacgctacag gatatccagt tatctgcgag cagtatgtga cagtttgggt gcgaaatacc 8640
ctcaggatct acattcaaat agtaatggaa ataaggcgac tgttgggaaa gtaaaatgta 8700
aaattggtga aacactaaag gaattcttga gagaaggaac ctatgaaaaa aaggaattgc 8760
cgacaaagaa cggttattta aataagagat ctggaaaata tgtaatgttt gcagaactca 8820
ggagtagtca gggagttaaa aagcgtgtta gtggttggaa tgacaatgat ctgactcagg 8880
atgaaaaggt cagcaatctg taccttcata tggcagaaaa tgccgttgtc agaatgctct 8940
tccataatcc tatatatgaa gatgtaacag atgtaaatct ctattttccc acgcgaaaag 9000
ttgttctgaa agatagagat agagaatacg ataaacaaga tttcaaaata tatggtgata 9060
aggacaagtg cgaagcagaa agcgggagat tggtgcatta tgatatcgtg tcatcggatt 9120
tttaccgtac gataatggag aacgaatgta caagaattaa taaaaagcaa ttaaatgttc 9180
attatatgaa cacaagccca atttcgtact gggagaaaaa tgaaaaatat aatacatttt 9240
tatatttggc tgacatagtt tgttctatgc tggattatta caaaaagggt tcgagtccgg 9300
cagagtggat ggattctttt gccgaatggg gaaacaaata ttttggtgat gatcagataa 9360
tcttatttgg gtatgatgat atagatgaca aatacatgga ggctgtagat gcagtaggac 9420
agggagagta ttttcatgcg ctggatatta tatatgatgc ggaatgtagt ggaagtgaat 9480
ttgagaagca ctacaaagat tattggtttc caaagcttat aaaaaagata cgaataacag 9540
caactgtgga taatttatgc agatcgatct cagatctgga gagttttaca tatcgaagta 9600
atcttgatca gcagaaactt ttgtggattt ttgaggaaat caaagctatc gtcgataagg 9660
gagattttgg aaagaaatat catacagatc aggttatgtt tgatatgtgt aatgccggta 9720
ttgctgtgta caatcatatc ggagattttg ggactgcaaa ggaatactat gatgagtgca 9780
tgaaacacac tggggatgtg gatctggtaa agatacttcg tgcatcaaat aaaatggtgg 9840
tctttcttga cgatgctttt aggtatggtg acgcgacaga acgtgccagg aagaatgttg 9900
aataccaaaa agctttgcac gatataaaga gtgagatttg tccggaaaag aaagatgaag 9960
acttgaacta tgccatatcg ctcagtcaat ttggacaggc gcttgcgtgt gaaaaaaatt 10020
ctgatgcaga gagtgttttc ctagagtcgt tgcggcatat gaggaaaggg actgccaatt 10080
atcagattac tctttcatat ttactccatt tttatctgga tatgggaatg acagattctt 10140
atcgagaaaa aacaaaggac tattttggaa gtgaaaaacc aaaggaacag ctgaaagaat 10200
tgctgaagtt atcgggaaag gatgatagta tagttacttt caaatttgca atgtatgtct 10260
atttacgtgc actttgggta ttacaggaac cgcttactga ttttatcaga acaagattag 10320
aggacatacg tgagactctt gtaaagaaga aaatgagtga acatatggtt ggacatccgt 10380
gggagttgat ttataaatat ctggcatttc ttttttatcg tgatggaaat tgtgaagctg 10440
ctgaaaaata tattcataaa agtgaagagt gcttggaaac acaaggactg actatagatg 10500
cgattattca taatggtaag tatgaatatg cagaattgtc aggtgacgag gagatgatgg 10560
caagagagaa agcgtacttt gatgaaaaag ggatagatag aaaaaatgtt tgtactttta 10620
tgtatcattg atgtttaata agatttgacc gaggagtgac aggtaatcgc cggtatatct 10680
ggtattacct gtcatttttt gatgaaataa gctacttttt gcctaaaaaa cgaaactgtt 10740
ggtgttttat gatgattgtg tcaacaaaag agagcaaaag aagaggagaa aagtaatgtc 10800
aatgatttca tgtccgaatt gtggtggaga gatatctgaa aggtcaaaga aatgtgttca 10860
ttgtggatat gtgttagtcg aagaagctaa agtagtgtgc acagaatgtg gaactgaggt 10920
agagagtggc gctgctgtat gtccgaagtg cggctgtcct gtaaatgata gtgagacgcc 10980
tcagaaagtt gaagtgacta gggtaaatgt atcttccgta atcagcaaaa aagtcgttgt 11040
aagcatactg atcgcagtga ttacaattgc aggttttttc tatggagtga agtattcgca 11100
ggaaaagaaa gcaattgaag agtcagtaaa gcagaaggaa gactatcaaa gtacgctaga 11160
gcttgcttcg ctaatgatgc ttcaaggagc ttcggatgca gaaacttgtg ggaatttggt 11220
taggaaagtg tggagcaact gcatttataa ggagagggat gaagaaaccg acaagtatac 11280
gtgtgatagc aggggtgcag gatggtttta tgatgatttt aatgatgcat taatggctct 11340
ttacagtgac agcagttttg gcaagaagat aaatgaaatc aaaaacggtc aggaaaccgt 11400
tgcggcgatg atgaaagatc tgaaaaatcc gccggatgag atggcagatg cctatgagga 11460
tattcaaaat ttttatgtgt cctatctaac gctgacagaa atggttgtga atccaactgg 11520
aagtttgagt tctttttcat ctgatttttc cgatgcggat acggaggtgt ccaatgccta 11580
tagccggatg aagttgtatt tagattaaac tattgaggaa aaaatggagg tgctttaatg 11640
cgggggagaa actgtggagg gtcatcaggc gacggactgc tggtacttct cgtactgctt 11700
gtcctttttt ataaaatcat gccattcata ggtttatgga ttttaatttt tggtgatgct 11760
gaacgtaaag atctgggtat gggtatgatt attgtcggga tagttctata tgtattatta 11820
gaggtttttt aatgtgagtt tctgtggtaa actataaaag tacaagcttt tgcgccgcac 11880
cgcataaata gcggatttat gaccattatt tggtgaaaaa aatggtgtac acctgtgttt 11940
ttttgttttg cgccgcaaaa tgcgccacgg aaccgcatgc agagcaccct gcaagagaca 12000
gggttatgaa aacagcccga catagagggc aatagacacg gggagaagtc atttaataag 12060
gccactgtta aaagttatga aaacagcccg acatagaggg caatagacat aaagaccaaa 12120
aacaggtcat ctgcatactg tgttatgaaa acagcccgat atagagggtg tgagagatat 12180
agttctcgtc acagtgcaga aaatgaccta ttatgtgccg aaaaacaaaa tgaaaaaaga 12240
atggaaaggc gtatttaatg aaatgctgat ctgttgattt gaattaacaa aaaaaggtcg 12300
ccccacggat gacaaaaaca tccgggggcg accctttt 12338
<210> 65
<211> 6098
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 65
tactgtgtgc ataagtcttc cttagatcca taggtacagc agttttattt attagcctta 60
gaaaatggaa aatagagctt ataaatgata tgatatttat gaataaaatg attgcattct 120
cgtgcaaact ttaaatatat tgattatatc ctttacattg gttgttttaa ttactattat 180
taagtaggaa tacgatatac ctctaaatga aagaggacta aaacccgcca aaagtatcag 240
aaaatgttat tgcagtaaga gactacctct atatgaaaga ggactaaaac ttttaacagt 300
ggccttatta aatgacttct gtaagagact acctctatat gaaagaggac taaaacgtct 360
aatgtggata agtataaaaa cgcttatcca tcatttaggt gttttatttt tttgtgatta 420
tatgtacaat agaagagaga aaaaaatcat tgaggtgaaa actatgagaa ttactaaagt 480
agaggttgat agaaaaaaag tactaatttc tagggataaa aacgggggca agttagttta 540
tgaaaatgaa atgcaagata atacagaaca aatcatgcat cacaaaaaaa gttcttttta 600
caaaagtgtg gtaaacaaaa ctatttgtcg tcctgaacaa aaacaaatga aaaaattagt 660
tcatggatta ttacaagaaa atagtcaaga aaaaataaaa gtttcagatg tcactaaact 720
taatatctca aatttcttaa atcatcgttt caaaaaaagt ttatattatt ttcctgaaaa 780
tagtcctgac aaaagcgaag aatacagaat agaaataaat ctctcccaat tgttagaaga 840
tagcttaaaa aaacagcaag ggacatttat atgttgggaa tcttttagca aagacatgga 900
attatacatt aattgggcgg aaaattatat ttcatcaaaa acgaagctaa taaaaaaatc 960
cattcgaaac aatagaattc aatctactga atcaagaagt ggacaactaa tggatagata 1020
tatgaaagac attttaaata aaaacaaacc tttcgatatc caatcagtta gcgaaaagta 1080
ccaacttgaa aaattgacta gtgctttaaa agctactttt aaagaagcga agaaaaacga 1140
caaagagatt aactataagc ttaagtccac tctccaaaac catgaaagac aaataataga 1200
agaattgaag gaaaattccg aactgaacca atttaatata gaaataagaa aacatcttga 1260
aacttatttt cctattaaga aaacaaacag aaaagttgga gatataagga atttagaaat 1320
aggagaaatc caaaaaatag taaatcatcg gttgaaaaat aaaatagttc aacgcattct 1380
ccaagaaggg aaattagctt cttatgagat tgaatcaaca gttaactcta attccttaca 1440
aaaaattaaa attgaagaag catttgcctt aaagtttatc aatgcttgtt tatttgcttc 1500
taacaattta aggaatatgg tatatcctgt ttgcaaaaag gatatattaa tgataggtga 1560
atttaaaaat agttttaaag aaataaaaca caaaaaattc attcgtcaat ggtcgcaatt 1620
cttctctcaa gaaataactg ttgatgacat tgaattagct tcatgggggc tgagaggagc 1680
cattgcacca ataagaaatg aaataattca tttaaagaag catagctgga aaaaattttt 1740
taataaccct actttcaaag tgaaaaaaag taaaataata aatgggaaaa cgaaagatgt 1800
tacatctgaa ttcctttata aagaaacttt atttaaggat tatttctata gtgagttaga 1860
ttctgttcca gaattgatta ttaataaaat ggaaagtagc aaaattttag attattattc 1920
cagtgaccag cttaaccaag tttttacaat tccgaatttc gaattatctt tactgacttc 1980
ggccgttccc tttgcaccta gctttaaacg agtttatttg aaaggctttg attatcagaa 2040
tcaagatgaa gcacaaccgg attataatct taaattaaat atctataacg aaaaagcctt 2100
taattcggag gcatttcagg cgcaatattc attatttaaa atggtttatt atcaagtctt 2160
tttaccgcaa ttcactacaa ataacgattt atttaagtca agtgtggatt ttattttaac 2220
attaaacaaa gaacggaaag gttacgccaa agcatttcaa gatattcgaa agatgaataa 2280
agatgaaaag ccctcagaat atatgagtta cattcagagt caattaatgc tctatcaaaa 2340
aaagcaagaa gaaaaagaga aaattaatca ttttgaaaaa tttataaatc aagtgtttat 2400
taaaggtttc aattctttta tagaaaagaa tagattaacc tatatttgcc atccaaccaa 2460
aaacacagtg ccagaaaatg ataatataga aatacctttc cacacggata tggatgattc 2520
caatattgca ttttggctta tgtgtaaatt attagatgct aaacaactta gcgaattacg 2580
taatgaaatg ataaaattca gttgttcctt acaatcaact gaagaaataa gcacatttac 2640
caaggcgcga gaagtgattg gtttagctct tttaaatggc gaaaaaggat gtaatgattg 2700
gaaagaactt tttgatgata aagaagcttg gaaaaagaac atgtccttat atgtttccga 2760
ggaattgctt caatcattgc cgtacacaca agaagatggt caaacacctg taattaatcg 2820
aagtatcgat ttagtaaaaa aatacggtac agaaacaata ctagagaaat tattttcctc 2880
ctcagatgat tataaagttt cagctaaaga tatcgcaaaa ttacatgaat atgatgtaac 2940
ggagaaaata gcacagcaag agagtctaca taagcaatgg atagaaaagc ccggtttagc 3000
ccgtgactca gcatggacaa aaaaatacca aaatgtgatt aatgatatta gtaattacca 3060
atgggctaag acaaaggtcg aattaacaca agtaaggcat cttcatcaat taactattga 3120
tttgctttca aggttagcag gatatatgtc tatcgctgac cgtgatttcc agttttctag 3180
taattatatt ttagaaagag agaactctga gtatagagtt acaagttgga tattattaag 3240
tgaaaataaa aataaaaata aatataacga ctacgaattg tataatctaa aaaatgcctc 3300
tataaaagta tcatcaaaaa atgatcccca gttaaaagtt gatcttaagc aattacgatt 3360
aaccttagag tacttagaac tttttgataa ccgattgaaa gaaaaacgaa ataacatttc 3420
acattttaat taccttaacg gacagttagg gaactctatt ttagaattat ttgacgatgc 3480
tcgagatgta ctttcctatg atcgtaaact aaagaatgcg gtgtctaaat ctttgaaaga 3540
aattttaagc tctcatggaa tggaagtgac atttaaacca ctatatcaaa ccaatcatca 3600
tttaaaaatt gataaactcc aacctaaaaa aatacaccac ttaggtgaaa aaagtactgt 3660
ttcttcaaat caagtttcta atgaatactg tcaactagta agaacgctat taacgatgaa 3720
gtaattcttt taaagcacat taattacctc taaatgaaaa gaggactaaa actgaaagag 3780
gactaaaaca ccagatgtgg ataactatat tagtggctat taaaaattcg tcgatattag 3840
agaggaaact ttagatgaag atgaaatgga aattaaaaga aaatgacgtt cgcaaagggg 3900
tggtggtcat tgagtaaaat tgacatcgga gaagtaaccc actttttaca aggtctaaag 3960
aaaagtaacg aaaacgcccg aaaaatgata gaagacattc aatcggctgt caaagcctac 4020
gctgatgata caactttaaa aggaaaagca gtggattctt cacaaagata ctttgatgaa 4080
acgtatactg ttatttgtaa aagtatcata gaagcattag atgaaagcga agagagatta 4140
caacaatata ttcatgattt tggagatcaa gtggattctt cacctaacgc acgaattgat 4200
gcggaattac tacaagaagc aatgagtagg ttagctgaca taaagcggaa gcaagaagca 4260
cttatgcaat ccttatcttc ttctacagca acgctttacg aaggcaagca acaagcgtta 4320
cacactcaat tcacggatgc gctggagcaa gaaaaaatat tggaacgcta tattactttt 4380
gaacaaactc acgggaattt ttttgactca tttggagaac ttgtctatcg aacgggacaa 4440
gcagtgcgtg aattagctaa taacgtcaca ttcgagagcc aaacaggaag ctatcatttt 4500
gataaaatag atgcttctag attccaaact ttgcaagaaa tgttgccaaa ggcaaagaaa 4560
aaagcattta attttaatga ctaccaaata acatggaatg gcaccacgca ccttttatgg 4620
aaaaatggta aagtggatgc agaagcaacc aaagcttata acgaggcgaa actgaatgga 4680
aagctaccaa aggaaggtaa tgtagcaaca caagatgcag aactattaaa aggcattttg 4740
gcttcactga aaaacaagaa agatcctatc actggagcag atataagcag tgtgcatgta 4800
ttatctatcc ttagcgggct cgcattctcc tatacagctg ggaattataa gggaagaaaa 4860
cttactgttc caaaaagttt cttagacaaa ttaaagaaaa accgaaaatc taaagtacct 4920
aaactatcta gtttatcaga aaaacaacaa ctaaaactcg caaataaata caagaaaaaa 4980
tcacctattc caattccaga tgatgctaaa atcaaagctc agacgaaaaa ggctggttat 5040
gaacaaatat cttataaatg gaaagagaat gggataacct ttgaagttag atggcatact 5100
aggacaccag gtgcaccaaa ggaacaagga aatacgtttg ttatagaaag aaaaattcag 5160
ggtacagcag aagggaaaac aaaagttcaa caaatattgg ttggagataa taagtgggtg 5220
agtaaaagtg agtggcaaaa ggctataact gataagaaaa atggtgtaag tacctcggag 5280
caaaataaaa tgttgtctga tggacattgg aaagaataga aaggagcaaa atgatggaag 5340
attattataa aggttttgag ggatatccag agatagattt ttatacgtat atagatgata 5400
tgaaattggg tatagcaatg tgggaaggat actttgacaa cattatgaaa gaaattaatc 5460
caagtaacgg aagatggact tcattagcgt attattatca tttagatgag gggtggtatg 5520
atgaaagtcc ttgggaaata ccaagtaata cagaagcatt agaattattg gaaacaatcc 5580
atatatctaa tctagatact atcacacaag agatattact taaattaata aatttattaa 5640
agaagaatat aaatagacaa gtttatattg aatactcata aaaaagatga ttatgatata 5700
ttatagaaca aacgaacaag ccccaaatac gaggtttgtt cgtttgtttt caatataatt 5760
atttgccacc aagtgagata ttacggtttt aaatagctta tttgacgata ccaaaccctg 5820
ataagagaaa gaagaaagag aaagctggtg tagttgtttt aagtgaacta gataaaaaat 5880
taatagcaaa acttgaaaaa gatggtgtga aaatatcaaa agaagatgtt ataggaataa 5940
aataattgcc agatgatgag aaatcgtttg gctggaaaaa ggaaatccat ccgctggatt 6000
tgagcatatt cttattgaac atggtgaaca atttgctaaa tagggaattt caaaagctga 6060
gttacctgat tttttgatga ctgctttaga aaaggaaa 6098
<210> 66
<211> 6222
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 66
attctttaaa aatatctaat aatttattta ctatatactc taatacatct tttaacctat 60
ctaaaacatc atcacctaca acatcccaaa aatcatctaa aaagttaaaa aaatccatct 120
ttatcaactc ctatatctat tttttattgt gtaattcctg agttacaaaa ccattataac 180
acgtattaca cacgtagtca atacttcaaa aaaatttttt gtatattttt ttgaataagt 240
aaataaaaag agctgtgtag ctctttatta aaatcaatat ttttattttg ttaacaaact 300
tagacaacat taaatttaga aacctatata tatttcagta cttttcattt ttaggtagtc 360
taaatcagaa atggttttgt ctaaatgatg tatgtaagtt ttagtcccct tcgtttttag 420
ggtagtctaa atcagaagtc atttaataag gccactgtta aaagttttag tccccttcgt 480
ttttagggta gtctaaatcc catccaaatt atgggataat atgttacttt ttattttaat 540
atttgattat ttattgtttt tttactgatt tagattaccc ctttaattta ttttaccata 600
tttttctcat aatgcaaact aatattccaa aatttttgtt tcttttctta tgatcttttc 660
tccgatagtt atttctccag ataagatttt catttttttg aattgatctt ctgttagaat 720
taatgttctt actgatgaat tttctggaac tatcattgac aactgatttt cataggaaat 780
tattttttct tttgtgctag aacttacaat gtatactgat ttttgtacct gataatatcc 840
ttttcttata atttcttttc taaattttgc atattctttt ttttcttttc ctgtttgcat 900
tggaaaatca tacattagaa tccctacata attagtactc ataatcctct atccttaact 960
caggaatttc tacttctgac atttctcctg taaaataatt tctaatatta tctaaaaaat 1020
aatcaatcac ttgagccaat tcatattttt tatttttcca ataaactttt tgtgttaata 1080
ccaataacaa tttttgtctt aatgatttat tcaaacttac ttcttcctgt tgattaaaat 1140
atacgatata atctaccatt ggacgaaata tttcaataat atcatctgca aaattataat 1200
tattaaattg tgaactgtga tgtattccca aacttggatg aaatccttta gccacaattt 1260
ttgaagagat taagcttctc aaaaccatat acccataatt taatgccgaa tttgtcccgt 1320
cttcaccaaa tctcttaaat tttttcccaa aaagttcacc aaaatacatt cttgcagcaa 1380
ttgcttcctg atgttccgct tcttttcctt ttaatctaat attattttca tatgcttcca 1440
acttatatga tacttcctga gattttttca aaaactgcaa taaatttctt tgattttcta 1500
tttttctcat tacaattttt ctccagattt cttctttttt atcgtcaatc cagctcactt 1560
gctcattaat tcttgttgtt acttgaaaat gattatacag tcctaatgaa tgtaaaactg 1620
gctgatgttt ttcattacaa attatcagtg gaatattatg ttctgataat cttaactgta 1680
atattccgct aattttacat ctgcaatttt caactacaat tgccatgata tcatttaaag 1740
atactttatc agccttattt tcatcatctt catttatcat cacaagctgg ttatttaaaa 1800
ctgataattc attgactctt gttacatgga taatattaga catttttatt actcctttac 1860
tctaaagctt tatattcaaa cataactttc acaagttcac acaattcttc tgaatttcta 1920
tcagtcatta attttttctt ttttaaattt ttcaaatgta caattttttc cgattctaaa 1980
gtctgaattt ctattttctt atctgctcct attttaaatg ttgctacaaa accatattcc 2040
tttaatatat ccactattga tttcataatt gcatttttaa gttttctatc ataagaaagt 2100
aattttctta aattttccag cacttctaaa agtgaaattt cagcatgcgg aatatagtta 2160
aaatgtgcaa tatagtttcg tatatacaaa tcttttttct cttgttttaa tttttttact 2220
tttttatcag aatagatgct tcttttttct acattatctt tgtataattc tttataaaaa 2280
tttatatatt tttcaacaat ttgcccactt ttatatttta catttttact gttatcaaaa 2340
ttaaatattt cttcaatata atgattttca ggaaattcac ctttcaatct aaatcttaag 2400
tccctttccc agatcgaagt atatcccaca agtctgtgga gtatttttaa taacaagcct 2460
tgcaacaagt ttaattcatt aaattccact ttatttttca aatgagtata tttttgtata 2520
tttccaattg ctttttcata ttctttataa tcttcatcat taaatttttc atctttttta 2580
ggtcttgcat attttctatg taaattttgc tgcattgtat aatttttttc tatttcattt 2640
tttttattgc tgtattcttt caattctttt aaacttattt tatacttcgc tttatcagct 2700
attttttcaa gtaaatttaa catcccatat ttttttatat tataaaaagc tctatgcttt 2760
ataatatttt ctccatcaaa atatatttta tttgtgtcaa atttcttcaa ttctttccta 2820
tcttttattt tattttcatt aaaatctaaa aattttccaa tttcattcgc ttctaattca 2880
aaatcttctg ttactctatt attatctaaa tttaaaagat ttataagttc aagttcatct 2940
gaaaaagttt cttctttatt tgcactctga tatttttcaa gacttccctt caaattagtc 3000
aattctttat gattaagcaa ttttaaaatt aaataaaaca tattcaaatt ttcagtgtat 3060
tttaatatct ttcctaattt tatctctctt acaaattcat ttatttcatg tggaatttct 3120
ttattcctat tatgtttttc ataatttttt aaaattttat catatttttc tttattatct 3180
ttttttattt ttattttaga aaatatatca ttattatcat tgttattatt actttctata 3240
tattttaaat tatttttatt caaataatct ataaaacctt ttaaaaatat ttgttgtata 3300
aaatcaatgt atgtattttt ttcttcttta tcttgattat taatcatctc cctactttgt 3360
ataatagcaa gatattctac tggtacagtt ttttctatat tttcaaattt ttgatattta 3420
taatgtcctg ttttttgatt tctttgttta tttattttta ttacttcatt agttatttta 3480
aaaaaaactt tactattttt aacaaattta ttaagaaatt caccataata aatatttttc 3540
aaaagatata tttgagcatc tttttcttct ttatccttag gaacactcca aaaaaatttt 3600
aaagtatttc ttaaatcttc tattttatta tataatttcg taaaagaagg aacaaaagga 3660
atattcttat ttacaaaatt aaattttgta ttttttaaat atttaattat cacatccttt 3720
tcataataat taaatacatt tgcactattt aactgcttaa atatcttcaa tttcaatttt 3780
ttctcattta tttcattttg aaacattttt tttgaaattt cagaaggagc tatattttta 3840
aatgcaaata tatctttccc ttctaattcc aaattaaaat gcacaatccc atgtctaata 3900
ctgctaatag cttcatcaat atttgcaaaa aaatcttcta tctcattttt attatccata 3960
ttaaaatcat aactatagaa catttttaaa ttttctttta cttcattttg cttgttttca 4020
ttatatattt tatcaacttc tccagaaaca tatttttctt cgcccttatt attttttaca 4080
gtttttcctc tcattctacc tgtaatatca ttctcatttt cagtttcaag aatatttctc 4140
aatgaaaaat atgcaaccga agaaactcca attatatttc gtaaaaatgc ttcattttgt 4200
ctattcctag caataaaatc acttgttgca atctctccaa cttgtaaata ataattgtat 4260
ttcccacaat ttcttacata agtatccaat ttatttagta atttgttttc aattaatttt 4320
tttaaatttt gatattcaaa tattctctta attttatcgt tacttatgtt actcagtctt 4380
ttatacacat aatttttcaa aagctgactc atttcaattt ccacaaaatg acaaaaagca 4440
tattttatat ttttatcatt aagttcttct ttatccaaat aatatttata aaacacttgt 4500
gattttttta attcactcat atccggaatt ttttcaatta attcttttat attatttaca 4560
ttttgtattt cttcgtaaat aattttagca aaattttctt tatcattttt tcttccaatt 4620
attttgtgat agtattctct tattttatat ttttcatgtt tttttgaatt ttctattaaa 4680
aaaaataact tctcaatatc ttctttttta tacaatttat caaatgcttc ctgtacatta 4740
tttatataat cattacgctt tgctgattct ctataataat cataaataat atttcttttg 4800
ctcttccctc caactttttc aacattattt tcattaattt tctgataatt agccttattt 4860
tcttcaaatg aatattttaa agaatttatc ttattcaatt ttgcctcaac atcttttcta 4920
aatatttcta attcttcaga gttcacatct tcatttaaca atattttctt taaaactgaa 4980
aaactatttt tattttttaa atcatattct gaaatatctt cttcagaata atttttatcc 5040
tgtactgcat ttttctcttt cctattcttt aaatacagaa cactatcttt tagatgcaat 5100
actttatttg aaaaaaactt ttttaaattt tctcttctta ttctattttc ttcttcactt 5160
gcattatcag gattttttat atatatatcc agtcttatac ttaaaagctc tgacaatctc 5220
tcactagtcc tattttcttc gctcgtactt tttactaatt ttccctcttc aatatatttt 5280
ttatgcgaaa ttccatcaac ttttgtaact ttcatatata aaaacctcct aatatctata 5340
ttttttactc aatacctaat tcttttttca atgctttttg taaaatttgt gaaaaattca 5400
gatttttttc ctgtgccaat atatctaacc aaacaggaat tgttaaagtt ttctttttaa 5460
gtgcatttgt aacttttgcc acttcataca ctggatcaac agataaaata tacaaatact 5520
gattttcttt cagtttcaca tcctccactt ttgaaggctc aggaaatttt tttcttacat 5580
ccaaaaaatc agccaaatgc agacccaatg tctctctcaa attggaaaca gcctcctcca 5640
tgctatctcc aaatgtagca taataattta tctctccatc ttcaaactta tcaaaatcaa 5700
caatacaacc ataataagtc ccatcttcct tagttaccac tgctggataa aatacatcca 5760
ttttaattat ctccaatcta taccacgtgt taaatacgtg tttaaaaata tttataaaat 5820
tttttagcat ctctgctaaa ataaaacaat tatttcaaat ttttctattc cttaatcact 5880
cattgttagt gattcttttt ttacttggac aatttttcat ttaatttctt caattttttt 5940
aaaatcacat ttttttaata ttccttattt aattgcaaat tttcattact tttggggtgc 6000
tctaaatccc atccaaatta tgggataata atttttagtg aaagcaagaa gggactagaa 6060
tttaatccca acttgttttt caatacttct taatgttcct acaggtatat cttttgaata 6120
tggtactgtg accacacctt ccacacctgg gatcatccat tgataatgac tacctcttat 6180
acgcacaact tttccgccta attttctaaa tcttttttcg at 6222
<210> 67
<211> 6337
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 67
ctttctatct ttttcaaata aaattaggct ctagttagcc taatcgcata attatttatt 60
atagtataat tcttattttt tttcaaccta aaaatttaaa acatctccaa aaattttcgt 120
ttcagaacaa ccaagcaacc atattcaaaa aacaataaaa aatgagcaag aattgaaatt 180
ttattctcac tcagaagtta tttttattaa atatcacttt tcgatattgg ggtggtctat 240
atcaatttaa aagacagaat agataattct ttagagtttt agtccccttc gatattgggg 300
tggtctatat cagaagtcat ttaataaggc cactgttaaa agttttagtc cccttcgata 360
ttggggtggt ctatatccca tcctaatttc ttgctgatga gatatttatt tctaattttt 420
ctattttgtc tttattttca atactttcaa tcctattttt ctctttatta ataatataga 480
accaccctat actattatac catatttttt gatttttcaa aattccaata ttttgttttg 540
tgaaattttt tctcccattg tcacttctcc tgcaagtacc ttcatttttt gaaactgatc 600
ttctgtcagg ataatggaac ggattgatga attttctgga gcgagcattg ataactgttt 660
ttctgccagt tcgatttttt cttttgtttt cgacctcatt atatataccg atttttgaag 720
ctgataatat cccttttcta tcaatttttt cctaaaagtc ctatattcaa atctctcaac 780
atctgtctgc ataggaaaat catacataag cagaccaaaa tactcaatac tcatagtcca 840
tcacgctcaa tgtcggaatt atcacttctt catcttttac aaaataattt cgtatactat 900
ccaaataata gtctaccgct tggaaaaaat catatttctt attgttaaat aataccttct 960
gctgtgctac aagaagtatt ttttgcctta tttccttact taatttcact tcattcaaaa 1020
tatccttgta catataaaca agataatcca ccataggacg aaaaacctct attatatcat 1080
cagaaaaatt ataggcatta aactgtgact tatgatgtaa tcctaaactt ggatgaaatc 1140
cttttgctac aatctttgat gatattatag ctcttaaaat catatatcca taattaagtg 1200
cagaattcac tccatcttca tcaaatcttt taaaactatt actatacaat tcctgaaaat 1260
atatccttga agctattgct tcctgatgtt ctgcactcgc atcatctttt ttcaagtttt 1320
ccttatatgt tttcagtctt tcaatggaaa tatcactttt ttcaagatac tctaacaatg 1380
ctctttgatt ttcaatctta ttctccacta tcctgctcca caatttttcc tttttctctt 1440
tttcccactc aatctgctca tttattcgta aagtcacttg aaaatgatta aataatccca 1500
gcgaatgaat ttcaggctga tgtttctcgt tgcaaataat aatcggaatg ttattttcca 1560
ccagcctcaa ctgcaaaatc gcactaatct tacaatagca gttttcaata actatcgcag 1620
atatatcatt caaagaaatc ttatttttct catcattatt gtcttcatca accattataa 1680
gctgattatt cgatattgac aaatcatcag cccttgttat gtgaattata ttgggcattt 1740
taatcatact ccttataaat ttcattctta taacgtatca ttcgtatttt ctatttttgt 1800
taaaagttct attatcaagt ttttaatata atcagaatta taactttcta attctaaaac 1860
agaaactttt ttaggtttca ttaatctttc aagtatatca ttattaccga taagtttaaa 1920
ttttttcttt aattcatcat aatctaaatt cacatctttt ttaaatactt caaatacact 1980
tgcataagtt gaattattat aacgtgtact atatgataat aaattagaaa ctctatcaat 2040
ttgttctgca atactgtaat cagcaaacgg atttcttaca atatagaaat gtgaaatata 2100
gtttctaata ctttcatttt ccggcttatt aatttcagaa ttttcagaca aatcaattcc 2160
aaatccataa catattttct caaatttttt ataagattct tcatcaaaaa atttatagta 2220
tgctgttgtt gtataaaagc catcagatcc attacgctta ggataagctc tacttattcc 2280
agtattgtag ccacttaact taataattcc taattctctt agcccattta caatatagtg 2340
catatctctt tcaaatctag ccatttgaat agcaagtttc caatttatat ctatcaaata 2400
actttctatt ttattcaaat aattaaattc taccaaatct ctaatttttt tgtattcaga 2460
aactctatta taatcttttt caaatgattt atagttttta ttttgtatat tttttgcaaa 2520
aaagtcatca ttttctttca atttttttat atacttctct ttgtattctt tagaatatcc 2580
atttagttta tcatttagat ttttcaatat tgcatcaatt tcagatattt tattttttct 2640
aatattttta ccatcaatat taaataaaaa ttttgcatca gccattttaa tatcatttga 2700
aattaatcca taaattttat caaaatttgg atttccaata tttaaaaata aattcttttt 2760
ataaatatat aattcattct tacgttcttt aggataatat atttcttgaa atttattttc 2820
attctctgat tccatatctt ctattaaatt atctatttct tttttgtatt tttttaaaaa 2880
atcagaatta aatattattc tacacaatat tttactcttt atttcctgat ctttatcttt 2940
tatatactga tcaacctttt ttttcaaatc ctttttattt atgtttgata actttctttg 3000
ttcatcttgt aatatattcg attttttatc tatctcaaat ttagtttcat catcaaaaat 3060
tacaattttt tctaattttt tctctaaaac atcacaacca ttaatatcat ctttaaattc 3120
agttaatata ttatttttta tatcctcata ataattatta aaaatttctt ttttagtttg 3180
tattttaaaa tcatcaaagt ctttttctat ctctttcatt ttttgaataa attcttctaa 3240
attaagattc caattttcag ttatacattc atttctcaaa gtatttaatt gcattatttc 3300
atctaaaata tctataatat tttgatattc tgaagtattt aaccaaactg atgttgcaaa 3360
aaatctattt ctaattttat ttataaccgc attactattt aacagtgcaa atattgaaat 3420
tatatattca aaatcatcat ttattactat agttttatca ctagtcttta cagttattct 3480
ttcgtaagtt ttattatcat taatgtcttt tatttgtttc ttaatttctt gaatattcat 3540
tttaaaatct gaaaaatcaa aaagttcctc ataatttttt ctcaaatatc caatataaca 3600
ttctattact tttttctgat attttttaat agctttatta ttaccttttg aagcagaaat 3660
ctgagcattt ttataataat tttctataat attttcatct atttcatcaa tgtttcctaa 3720
agttttcttt aattcttgta aaaatatatt cttactttca ttttcttcta aatcatcttc 3780
taaaattaat ttcttataca attctttatt cacatatatt aaagcattta atactatttt 3840
ttctgtttct atagtatcaa atggttcatt cttaggatta ttcctatata aatttaatat 3900
ttcaggaagt actttagaaa aggatggtaa atatttaata tcattattat tttcttctga 3960
aattttaata tcatttattt tagtaattat atttttttta tctttaaata ctacatctaa 4020
atttaatgct tttgacactt cttcatctga tatttttaaa ttttgaatta tatttatgac 4080
tttattatag tcatcttgcg ttccttgtaa atctctttcc ttgctaatcg catgtaatat 4140
cctgtttctt tcatttgttc ctatctttgt aaatttccta ataaaattat ttgtaatgtt 4200
atttttatta tctataaaat ctaagtctct tattattttt atttttgaat ttaaaatttt 4260
tttatcaagt acgtaatttt tttctcgatc tcctccaaag aaatctatat tttcatcatt 4320
atttatattt tctctagaaa aaatcttatt taattccata ttggtagaag caaaaaaagt 4380
aatcaattct aaatccaatt cctctttagc gtgaagtcta gaaaaatcat cagtatttac 4440
tgttgtcata tctatatcat tatgtcttaa tttccctaaa tacataatat gctctaacgt 4500
atattgctta actcttttta aaattttttc agataatata ctttcattta aaattttttc 4560
tatttctatt ttttccattt tctttaatct gactttttgt tcatttacca atattttttc 4620
aattcttcct ttcaaatatc gatatatgat tttatatagt tctttttctt catcagattt 4680
ctttgaaaat tttttcgaat caaaattaac tttataatgt tttttaaata ttccaaaaat 4740
ttctgtatca caatttcctt tttttagttc tttttctaat ttttttatta attcatctat 4800
tttaaattct gctaaaattt tttctatttt ttcttttata ctattatttt ttatattttc 4860
tacaaaaaat tttacaattt tatctttttt attttctctt tctattttaa atttttcgtg 4920
cttatctaat agtacataag attttatata tgttctattt cttctctttt caagaaattc 4980
attattaact ttttttactt tttcaattct tttagtaata ttccaaaatt ctaactcttt 5040
tataacaaaa tcagctatat cttctactgt taaatctaca tttatattta aaattttttc 5100
aacaagcatt tttttatttt tagatttctt tttatcacca ccaacattaa gataaaattt 5160
tacaaaaccc agaatttcta aattactttt tattttttct cttatttcca taaaattagt 5220
caaaataaca tctattttat catctttcaa taatttttct cttaaatgtt cttcataata 5280
tcgattttca aatacttttt ctgtttcatt ttcaattatt ttttctataa tcttatataa 5340
actcatgtta atatttttaa aaatttcgta aattgatttt tttgtttcta attcatcatt 5400
ttctattatt cttaatatta ttgaacaatc atttagtgtt ttattagtat actcatctct 5460
gatatctatc tctatttctt cttcattctc ttgtctcttt atttctattt ttttatcatc 5520
tttagttatt ccttgcctaa ttgcttcatc tattattttc ttttttgtaa tccccaatgc 5580
tttcaatttc tcagattttc catatgcttc tatatataat acaacttctt ctgtttccaa 5640
aaaatcatca ttattttcta ttcttatgat tccttcttta cctttcaact taaatagaat 5700
atttcctgca tgaaattttc ttgtaaattc tttaagaata ttatcatttt ttttgtaatt 5760
aatatatttt ctaataaatt tattattatc aattttttct ttattattat tttcattaat 5820
atttaaaatg tatttgtttc catcatagtt ccttttaact tttactttcc gttttatttt 5880
aaaatctttt ttatcacgaa cttcatacca tctcttatgt ccaaataaat ttcccattcc 5940
aatctcctcg tttctacttt aatctaataa aatattttta aattaaatca attttacatc 6000
tttctaatca aaaatacaat tttccatttt tagtatacca catcaatatt aaatctcaaa 6060
aaaataagga gccgtcaaac atagctccct acttctattt actcataatc cccatctatc 6120
cttacttttc gtaaaatcaa tccttctttc gcctttagat ccaacttaat tttcccattt 6180
gaacctgttc taaatgttct gccttctgtt accaaatcaa taaatctttc atcctgataa 6240
tttgtttcaa attccacatt ttcccagctg ttaaacgaat tatttattac aacaataatt 6300
aaatgatcct cgattactct ttcatacaca attattt 6337
<210> 68
<211> 1477
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Peregrinibacteria bacterium
<400> 68
Met Ser Asn Phe Phe Lys Asn Phe Thr Asn Leu Tyr Glu Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Asp Thr Leu Thr Asn Met
20 25 30
Lys Asp His Leu Glu Tyr Asp Glu Lys Leu Gln Thr Phe Leu Lys Asp
35 40 45
Gln Asn Ile Asp Asp Ala Tyr Gln Ala Leu Lys Pro Gln Phe Asp Glu
50 55 60
Ile His Glu Glu Phe Ile Thr Asp Ser Leu Glu Ser Lys Lys Ala Lys
65 70 75 80
Glu Ile Asp Phe Ser Glu Tyr Leu Asp Leu Phe Gln Glu Lys Lys Glu
85 90 95
Leu Asn Asp Ser Glu Lys Lys Leu Arg Asn Lys Ile Gly Glu Thr Phe
100 105 110
Asn Lys Ala Gly Glu Lys Trp Lys Lys Glu Lys Tyr Pro Gln Tyr Glu
115 120 125
Trp Lys Lys Gly Ser Lys Ile Ala Asn Gly Ala Asp Ile Leu Ser Cys
130 135 140
Gln Asp Met Leu Gln Phe Ile Lys Tyr Lys Asn Pro Glu Asp Glu Lys
145 150 155 160
Ile Lys Asn Tyr Ile Asp Asp Thr Leu Lys Gly Phe Phe Thr Tyr Phe
165 170 175
Gly Gly Phe Asn Gln Asn Arg Ala Asn Tyr Tyr Glu Thr Lys Lys Glu
180 185 190
Ala Ser Thr Ala Val Ala Thr Arg Ile Val His Glu Asn Leu Pro Lys
195 200 205
Phe Cys Asp Asn Val Ile Gln Phe Lys His Ile Ile Lys Arg Lys Lys
210 215 220
Asp Gly Thr Val Glu Lys Thr Glu Arg Lys Thr Glu Tyr Leu Asn Ala
225 230 235 240
Tyr Gln Tyr Leu Lys Asn Asn Asn Lys Ile Thr Gln Ile Lys Asp Ala
245 250 255
Glu Thr Glu Lys Met Ile Glu Ser Thr Pro Ile Ala Glu Lys Ile Phe
260 265 270
Asp Val Tyr Tyr Phe Ser Ser Cys Leu Ser Gln Lys Gln Ile Glu Glu
275 280 285
Tyr Asn Arg Ile Ile Gly His Tyr Asn Leu Leu Ile Asn Leu Tyr Asn
290 295 300
Gln Ala Lys Arg Ser Glu Gly Lys His Leu Ser Ala Asn Glu Lys Lys
305 310 315 320
Tyr Lys Asp Leu Pro Lys Phe Lys Thr Leu Tyr Lys Gln Ile Gly Cys
325 330 335
Gly Lys Lys Lys Asp Leu Phe Tyr Thr Ile Lys Cys Asp Thr Glu Glu
340 345 350
Glu Ala Asn Lys Ser Arg Asn Glu Gly Lys Glu Ser His Ser Val Glu
355 360 365
Glu Ile Ile Asn Lys Ala Gln Glu Ala Ile Asn Lys Tyr Phe Lys Ser
370 375 380
Asn Asn Asp Cys Glu Asn Ile Asn Thr Val Pro Asp Phe Ile Asn Tyr
385 390 395 400
Ile Leu Thr Lys Glu Asn Tyr Glu Gly Val Tyr Trp Ser Lys Ala Ala
405 410 415
Met Asn Thr Ile Ser Asp Lys Tyr Phe Ala Asn Tyr His Asp Leu Gln
420 425 430
Asp Arg Leu Lys Glu Ala Lys Val Phe Gln Lys Ala Asp Lys Lys Ser
435 440 445
Glu Asp Asp Ile Lys Ile Pro Glu Ala Ile Glu Leu Ser Gly Leu Phe
450 455 460
Gly Val Leu Asp Ser Leu Ala Asp Trp Gln Thr Thr Leu Phe Lys Ser
465 470 475 480
Ser Ile Leu Ser Asn Glu Asp Lys Leu Lys Ile Ile Thr Asp Ser Gln
485 490 495
Thr Pro Ser Glu Ala Leu Leu Lys Met Ile Phe Asn Asp Ile Glu Lys
500 505 510
Asn Met Glu Ser Phe Leu Lys Glu Thr Asn Asp Ile Ile Thr Leu Lys
515 520 525
Lys Tyr Lys Gly Asn Lys Glu Gly Thr Glu Lys Ile Lys Gln Trp Phe
530 535 540
Asp Tyr Thr Leu Ala Ile Asn Arg Met Leu Lys Tyr Phe Leu Val Lys
545 550 555 560
Glu Asn Lys Ile Lys Gly Asn Ser Leu Asp Thr Asn Ile Ser Glu Ala
565 570 575
Leu Lys Thr Leu Ile Tyr Ser Asp Asp Ala Glu Trp Phe Lys Trp Tyr
580 585 590
Asp Ala Leu Arg Asn Tyr Leu Thr Gln Lys Pro Gln Asp Glu Ala Lys
595 600 605
Glu Asn Lys Leu Lys Leu Asn Phe Asp Asn Pro Ser Leu Ala Gly Gly
610 615 620
Trp Asp Val Asn Lys Glu Cys Ser Asn Phe Cys Val Ile Leu Lys Asp
625 630 635 640
Lys Asn Glu Lys Lys Tyr Leu Ala Ile Met Lys Lys Gly Glu Asn Thr
645 650 655
Leu Phe Gln Lys Glu Trp Thr Glu Gly Arg Gly Lys Asn Leu Thr Lys
660 665 670
Lys Ser Asn Pro Leu Phe Glu Ile Asn Asn Cys Glu Ile Leu Ser Lys
675 680 685
Met Glu Tyr Asp Phe Trp Ala Asp Val Ser Lys Met Ile Pro Lys Cys
690 695 700
Ser Thr Gln Leu Lys Ala Val Val Asn His Phe Lys Gln Ser Asp Asn
705 710 715 720
Glu Phe Ile Phe Pro Ile Gly Tyr Lys Val Thr Ser Gly Glu Lys Phe
725 730 735
Arg Glu Glu Cys Lys Ile Ser Lys Gln Asp Phe Glu Leu Asn Asn Lys
740 745 750
Val Phe Asn Lys Asn Glu Leu Ser Val Thr Ala Met Arg Tyr Asp Leu
755 760 765
Ser Ser Thr Gln Glu Lys Gln Tyr Ile Lys Ala Phe Gln Lys Glu Tyr
770 775 780
Trp Glu Leu Leu Phe Lys Gln Glu Lys Arg Asp Thr Lys Leu Thr Asn
785 790 795 800
Asn Glu Ile Phe Asn Glu Trp Ile Asn Phe Cys Asn Lys Lys Tyr Ser
805 810 815
Glu Leu Leu Ser Trp Glu Arg Lys Tyr Lys Asp Ala Leu Thr Asn Trp
820 825 830
Ile Asn Phe Cys Lys Tyr Phe Leu Ser Lys Tyr Pro Lys Thr Thr Leu
835 840 845
Phe Asn Tyr Ser Phe Lys Glu Ser Glu Asn Tyr Asn Ser Leu Asp Glu
850 855 860
Phe Tyr Arg Asp Val Asp Ile Cys Ser Tyr Lys Leu Asn Ile Asn Thr
865 870 875 880
Thr Ile Asn Lys Ser Ile Leu Asp Arg Leu Val Glu Glu Gly Lys Leu
885 890 895
Tyr Leu Phe Glu Ile Lys Asn Gln Asp Ser Asn Asp Gly Lys Ser Ile
900 905 910
Gly His Lys Asn Asn Leu His Thr Ile Tyr Trp Asn Ala Ile Phe Glu
915 920 925
Asn Phe Asp Asn Arg Pro Lys Leu Asn Gly Glu Ala Glu Ile Phe Tyr
930 935 940
Arg Lys Ala Ile Ser Lys Asp Lys Leu Gly Ile Val Lys Gly Lys Lys
945 950 955 960
Thr Lys Asn Gly Thr Glu Ile Ile Lys Asn Tyr Arg Phe Ser Lys Glu
965 970 975
Lys Phe Ile Leu His Val Pro Ile Thr Leu Asn Phe Cys Ser Asn Asn
980 985 990
Glu Tyr Val Asn Asp Ile Val Asn Thr Lys Phe Tyr Asn Phe Ser Asn
995 1000 1005
Leu His Phe Leu Gly Ile Asp Arg Gly Glu Lys His Leu Ala Tyr
1010 1015 1020
Tyr Ser Leu Val Asn Lys Asn Gly Glu Ile Val Asp Gln Gly Thr
1025 1030 1035
Leu Asn Leu Pro Phe Thr Asp Lys Asp Gly Asn Gln Arg Ser Ile
1040 1045 1050
Lys Lys Glu Lys Tyr Phe Tyr Asn Lys Gln Glu Asp Lys Trp Glu
1055 1060 1065
Ala Lys Glu Val Asp Cys Trp Asn Tyr Asn Asp Leu Leu Asp Ala
1070 1075 1080
Met Ala Ser Asn Arg Asp Met Ala Arg Lys Asn Trp Gln Arg Ile
1085 1090 1095
Gly Thr Ile Lys Glu Ala Lys Asn Gly Tyr Val Ser Leu Val Ile
1100 1105 1110
Arg Lys Ile Ala Asp Leu Ala Val Asn Asn Glu Arg Pro Ala Phe
1115 1120 1125
Ile Val Leu Glu Asp Leu Asn Thr Gly Phe Lys Arg Ser Arg Gln
1130 1135 1140
Lys Ile Asp Lys Ser Val Tyr Gln Lys Phe Glu Leu Ala Leu Ala
1145 1150 1155
Lys Lys Leu Asn Phe Leu Val Asp Lys Asn Ala Lys Arg Asp Glu
1160 1165 1170
Ile Gly Ser Pro Thr Lys Ala Leu Gln Leu Thr Pro Pro Val Asn
1175 1180 1185
Asn Tyr Gly Asp Ile Glu Asn Lys Lys Gln Ala Gly Ile Met Leu
1190 1195 1200
Tyr Thr Arg Ala Asn Tyr Thr Ser Gln Thr Asp Pro Ala Thr Gly
1205 1210 1215
Trp Arg Lys Thr Ile Tyr Leu Lys Ala Gly Pro Glu Glu Thr Thr
1220 1225 1230
Tyr Lys Lys Asp Gly Lys Ile Lys Asn Lys Ser Val Lys Asp Gln
1235 1240 1245
Ile Ile Glu Thr Phe Thr Asp Ile Gly Phe Asp Gly Lys Asp Tyr
1250 1255 1260
Tyr Phe Glu Tyr Asp Lys Gly Glu Phe Val Asp Glu Lys Thr Gly
1265 1270 1275
Glu Ile Lys Pro Lys Lys Trp Arg Leu Tyr Ser Gly Glu Asn Gly
1280 1285 1290
Lys Ser Leu Asp Arg Phe Arg Gly Glu Arg Glu Lys Asp Lys Tyr
1295 1300 1305
Glu Trp Lys Ile Asp Lys Ile Asp Ile Val Lys Ile Leu Asp Asp
1310 1315 1320
Leu Phe Val Asn Phe Asp Lys Asn Ile Ser Leu Leu Lys Gln Leu
1325 1330 1335
Lys Glu Gly Val Glu Leu Thr Arg Asn Asn Glu His Gly Thr Gly
1340 1345 1350
Glu Ser Leu Arg Phe Ala Ile Asn Leu Ile Gln Gln Ile Arg Asn
1355 1360 1365
Thr Gly Asn Asn Glu Arg Asp Asn Asp Phe Ile Leu Ser Pro Val
1370 1375 1380
Arg Asp Glu Asn Gly Lys His Phe Asp Ser Arg Glu Tyr Trp Asp
1385 1390 1395
Lys Glu Thr Lys Gly Glu Lys Ile Ser Met Pro Ser Ser Gly Asp
1400 1405 1410
Ala Asn Gly Ala Phe Asn Ile Ala Arg Lys Gly Ile Ile Met Asn
1415 1420 1425
Ala His Ile Leu Ala Asn Ser Asp Ser Lys Asp Leu Ser Leu Phe
1430 1435 1440
Val Ser Asp Glu Glu Trp Asp Leu His Leu Asn Asn Lys Thr Glu
1445 1450 1455
Trp Lys Lys Gln Leu Asn Ile Phe Ser Ser Arg Lys Ala Met Ala
1460 1465 1470
Lys Arg Lys Lys
1475
<210> 69
<211> 1403
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Falkowbacteria bacterium
<400> 69
Met Leu Phe Phe Met Ser Thr Asp Ile Thr Asn Lys Pro Arg Glu Lys
1 5 10 15
Gly Val Phe Asp Asn Phe Thr Asn Leu Tyr Glu Phe Ser Lys Thr Leu
20 25 30
Thr Phe Gly Leu Ile Pro Leu Lys Trp Asp Asp Asn Lys Lys Met Ile
35 40 45
Val Glu Asp Glu Asp Phe Ser Val Leu Arg Lys Tyr Gly Val Ile Glu
50 55 60
Glu Asp Lys Arg Ile Ala Glu Ser Ile Lys Ile Ala Lys Phe Tyr Leu
65 70 75 80
Asn Ile Leu His Arg Glu Leu Ile Gly Lys Val Leu Gly Ser Leu Lys
85 90 95
Phe Glu Lys Lys Asn Leu Glu Asn Tyr Asp Arg Leu Leu Gly Glu Ile
100 105 110
Glu Lys Asn Asn Lys Asn Glu Asn Ile Ser Glu Asp Lys Lys Lys Glu
115 120 125
Ile Arg Lys Asn Phe Lys Lys Glu Leu Ser Ile Ala Gln Asp Ile Leu
130 135 140
Leu Lys Lys Val Gly Glu Val Phe Glu Ser Asn Gly Ser Gly Ile Leu
145 150 155 160
Ser Ser Lys Asn Cys Leu Asp Glu Leu Thr Lys Arg Phe Thr Arg Gln
165 170 175
Glu Val Asp Lys Leu Arg Arg Glu Asn Lys Asp Ile Gly Val Glu Tyr
180 185 190
Pro Asp Val Ala Tyr Arg Glu Lys Asp Gly Lys Glu Glu Thr Lys Ser
195 200 205
Phe Phe Ala Met Asp Val Gly Tyr Leu Asp Asp Phe His Lys Asn Arg
210 215 220
Lys Gln Leu Tyr Ser Val Lys Gly Lys Lys Asn Ser Leu Gly Arg Arg
225 230 235 240
Ile Leu Asp Asn Phe Glu Ile Phe Cys Lys Asn Lys Lys Leu Tyr Glu
245 250 255
Lys Tyr Lys Asn Leu Asp Ile Asp Phe Ser Glu Ile Glu Arg Asn Phe
260 265 270
Asn Leu Thr Leu Glu Lys Val Phe Asp Phe Asp Asn Tyr Asn Glu Arg
275 280 285
Leu Thr Gln Glu Gly Leu Asp Glu Tyr Ala Lys Ile Leu Gly Gly Glu
290 295 300
Ser Asn Lys Gln Glu Arg Thr Ala Asn Ile His Gly Leu Asn Gln Ile
305 310 315 320
Ile Asn Leu Tyr Ile Gln Lys Lys Gln Ser Glu Gln Lys Ala Glu Gln
325 330 335
Lys Glu Thr Gly Lys Lys Lys Ile Lys Phe Asn Lys Lys Asp Tyr Pro
340 345 350
Thr Phe Thr Cys Leu Gln Lys Gln Ile Leu Ser Gln Val Phe Arg Lys
355 360 365
Glu Ile Ile Ile Glu Ser Asp Arg Asp Leu Ile Arg Glu Leu Lys Phe
370 375 380
Phe Val Glu Glu Ser Lys Glu Lys Val Asp Lys Ala Arg Gly Ile Ile
385 390 395 400
Glu Phe Leu Leu Asn His Glu Glu Asn Asp Ile Asp Leu Ala Met Val
405 410 415
Tyr Leu Pro Lys Ser Lys Ile Asn Ser Phe Val Tyr Lys Val Phe Lys
420 425 430
Glu Pro Gln Asp Phe Leu Ser Val Phe Gln Asp Gly Ala Ser Asn Leu
435 440 445
Asp Phe Val Ser Phe Asp Lys Ile Lys Thr His Leu Glu Asn Asn Lys
450 455 460
Leu Thr Tyr Lys Ile Phe Phe Lys Thr Leu Ile Lys Glu Asn His Asp
465 470 475 480
Phe Glu Ser Phe Leu Ile Leu Leu Gln Gln Glu Ile Asp Leu Leu Ile
485 490 495
Asp Gly Gly Glu Thr Val Thr Leu Gly Gly Lys Lys Glu Ser Ile Thr
500 505 510
Ser Leu Asp Glu Lys Lys Asn Arg Leu Lys Glu Lys Leu Gly Trp Phe
515 520 525
Glu Gly Lys Val Arg Glu Asn Glu Lys Met Lys Asp Glu Glu Glu Gly
530 535 540
Glu Phe Cys Ser Thr Val Leu Ala Tyr Ser Gln Ala Val Leu Asn Ile
545 550 555 560
Thr Lys Arg Ala Glu Ile Phe Trp Leu Asn Glu Lys Gln Asp Ala Lys
565 570 575
Val Gly Glu Asp Asn Lys Asp Met Ile Phe Tyr Lys Lys Phe Asp Glu
580 585 590
Phe Ala Asp Asp Gly Phe Ala Pro Phe Phe Tyr Phe Asp Lys Phe Gly
595 600 605
Asn Tyr Leu Lys Arg Arg Ser Arg Asn Thr Thr Lys Glu Ile Lys Leu
610 615 620
His Phe Gly Asn Asp Asp Leu Leu Glu Gly Trp Asp Met Asn Lys Glu
625 630 635 640
Pro Glu Tyr Trp Ser Phe Ile Leu Arg Asp Arg Asn Gln Tyr Tyr Leu
645 650 655
Gly Ile Gly Lys Lys Asp Gly Glu Ile Phe His Lys Lys Leu Gly Asn
660 665 670
Ser Val Glu Ala Val Lys Glu Ala Tyr Glu Leu Glu Asn Glu Ala Asp
675 680 685
Phe Tyr Glu Lys Ile Asp Tyr Lys Gln Leu Asn Ile Asp Arg Phe Glu
690 695 700
Gly Ile Ala Phe Pro Lys Lys Thr Lys Thr Glu Glu Ala Phe Arg Gln
705 710 715 720
Val Cys Lys Lys Arg Ala Asp Glu Phe Leu Gly Gly Asp Thr Tyr Glu
725 730 735
Phe Lys Ile Leu Leu Ala Ile Lys Lys Glu Tyr Asp Asp Phe Lys Ala
740 745 750
Arg Arg Gln Lys Glu Lys Asp Trp Asp Ser Lys Phe Ser Lys Glu Lys
755 760 765
Met Ser Lys Leu Ile Glu Tyr Tyr Ile Thr Cys Leu Gly Lys Arg Asp
770 775 780
Asp Trp Lys Arg Phe Asn Leu Asn Phe Arg Gln Pro Lys Glu Tyr Glu
785 790 795 800
Asp Arg Ser Asp Phe Val Arg His Ile Gln Arg Gln Ala Tyr Trp Ile
805 810 815
Asp Pro Arg Lys Val Ser Lys Asp Tyr Val Asp Lys Lys Val Ala Glu
820 825 830
Gly Glu Met Phe Leu Phe Lys Val His Asn Lys Asp Phe Tyr Asp Phe
835 840 845
Glu Arg Lys Ser Glu Asp Lys Lys Asn His Thr Ala Asn Leu Phe Thr
850 855 860
Gln Tyr Leu Leu Glu Leu Phe Ser Cys Glu Asn Ile Lys Asn Ile Lys
865 870 875 880
Ser Lys Asp Leu Ile Glu Ser Ile Phe Glu Leu Asp Gly Lys Ala Glu
885 890 895
Ile Arg Phe Arg Pro Lys Thr Asp Asp Val Lys Leu Lys Ile Tyr Gln
900 905 910
Lys Lys Gly Lys Asp Val Thr Tyr Ala Asp Lys Arg Asp Gly Asn Lys
915 920 925
Glu Lys Glu Val Ile Gln His Arg Arg Phe Ala Lys Asp Ala Leu Thr
930 935 940
Leu His Leu Lys Ile Arg Leu Asn Phe Gly Lys His Val Asn Leu Phe
945 950 955 960
Asp Phe Asn Lys Leu Val Asn Thr Glu Leu Phe Ala Lys Val Pro Val
965 970 975
Lys Ile Leu Gly Met Asp Arg Gly Glu Asn Asn Leu Ile Tyr Tyr Cys
980 985 990
Phe Leu Asp Glu His Gly Glu Ile Glu Asn Gly Lys Cys Gly Ser Leu
995 1000 1005
Asn Arg Val Gly Glu Gln Ile Ile Thr Leu Glu Asp Asp Lys Lys
1010 1015 1020
Val Lys Glu Pro Val Asp Tyr Phe Gln Leu Leu Val Asp Arg Glu
1025 1030 1035
Gly Gln Arg Asp Trp Glu Gln Lys Asn Trp Gln Lys Met Thr Arg
1040 1045 1050
Ile Lys Asp Leu Lys Lys Ala Tyr Leu Gly Asn Val Val Ser Trp
1055 1060 1065
Ile Ser Lys Glu Met Leu Ser Gly Ile Lys Glu Gly Val Val Thr
1070 1075 1080
Ile Gly Val Leu Glu Asp Leu Asn Ser Asn Phe Lys Arg Thr Arg
1085 1090 1095
Phe Phe Arg Glu Arg Gln Val Tyr Gln Gly Phe Glu Lys Ala Leu
1100 1105 1110
Val Asn Lys Leu Gly Tyr Leu Val Asp Lys Lys Tyr Asp Asn Tyr
1115 1120 1125
Arg Asn Val Tyr Gln Phe Ala Pro Ile Val Asp Ser Val Glu Glu
1130 1135 1140
Met Glu Lys Asn Lys Gln Ile Gly Thr Leu Val Tyr Val Pro Ala
1145 1150 1155
Ser Tyr Thr Ser Lys Ile Cys Pro His Pro Lys Cys Gly Trp Arg
1160 1165 1170
Glu Arg Leu Tyr Met Lys Asn Ser Ala Ser Lys Glu Lys Ile Val
1175 1180 1185
Gly Leu Leu Lys Ser Asp Gly Ile Lys Ile Ser Tyr Asp Gln Lys
1190 1195 1200
Asn Asp Arg Phe Tyr Phe Glu Tyr Gln Trp Glu Gln Glu His Lys
1205 1210 1215
Ser Asp Gly Lys Lys Lys Lys Tyr Ser Gly Val Asp Lys Val Phe
1220 1225 1230
Ser Asn Val Ser Arg Met Arg Trp Asp Val Glu Gln Lys Lys Ser
1235 1240 1245
Ile Asp Phe Val Asp Gly Thr Asp Gly Ser Ile Thr Asn Lys Leu
1250 1255 1260
Lys Ser Leu Leu Lys Gly Lys Gly Ile Glu Leu Asp Asn Ile Asn
1265 1270 1275
Gln Gln Ile Val Asn Gln Gln Lys Glu Leu Gly Val Glu Phe Phe
1280 1285 1290
Gln Ser Ile Ile Phe Tyr Phe Asn Leu Ile Met Gln Ile Arg Asn
1295 1300 1305
Tyr Asp Lys Glu Lys Ser Gly Ser Glu Ala Asp Tyr Ile Gln Cys
1310 1315 1320
Pro Ser Cys Leu Phe Asp Ser Arg Lys Pro Glu Met Asn Gly Lys
1325 1330 1335
Leu Ser Ala Ile Thr Asn Gly Asp Ala Asn Gly Ala Tyr Asn Ile
1340 1345 1350
Ala Arg Lys Gly Phe Met Gln Leu Cys Arg Ile Arg Glu Asn Pro
1355 1360 1365
Gln Glu Pro Met Lys Leu Ile Thr Asn Arg Glu Trp Asp Glu Ala
1370 1375 1380
Val Arg Glu Trp Asp Ile Tyr Ser Ala Ala Gln Lys Ile Pro Val
1385 1390 1395
Leu Ser Glu Glu Asn
1400
<210> 70
<211> 1373
<212> БЕЛОК
<213> Moraxella bovoculi
<400> 70
Met Leu Phe Gln Asp Phe Thr His Leu Tyr Pro Leu Ser Lys Thr Val
1 5 10 15
Arg Phe Glu Leu Lys Pro Ile Asp Arg Thr Leu Glu His Ile His Ala
20 25 30
Lys Asn Phe Leu Ser Gln Asp Glu Thr Met Ala Asp Met His Gln Lys
35 40 45
Val Lys Val Ile Leu Asp Asp Tyr His Arg Asp Phe Ile Ala Asp Met
50 55 60
Met Gly Glu Val Lys Leu Thr Lys Leu Ala Glu Phe Tyr Asp Val Tyr
65 70 75 80
Leu Lys Phe Arg Lys Asn Pro Lys Asp Asp Glu Leu Gln Lys Gln Leu
85 90 95
Lys Asp Leu Gln Ala Val Leu Arg Lys Glu Ile Val Lys Pro Ile Gly
100 105 110
Asn Gly Gly Lys Tyr Lys Ala Gly Tyr Asp Arg Leu Phe Gly Ala Lys
115 120 125
Leu Phe Lys Asp Gly Lys Glu Leu Gly Asp Leu Ala Lys Phe Val Ile
130 135 140
Ala Gln Glu Gly Glu Ser Ser Pro Lys Leu Ala His Leu Ala His Phe
145 150 155 160
Glu Lys Phe Ser Thr Tyr Phe Thr Gly Phe His Asp Asn Arg Lys Asn
165 170 175
Met Tyr Ser Asp Glu Asp Lys His Thr Ala Ile Ala Tyr Arg Leu Ile
180 185 190
His Glu Asn Leu Pro Arg Phe Ile Asp Asn Leu Gln Ile Leu Thr Thr
195 200 205
Ile Lys Gln Lys His Ser Ala Leu Tyr Asp Gln Ile Ile Asn Glu Leu
210 215 220
Thr Ala Ser Gly Leu Asp Val Ser Leu Ala Ser His Leu Asp Gly Tyr
225 230 235 240
His Lys Leu Leu Thr Gln Glu Gly Ile Thr Ala Tyr Asn Thr Leu Leu
245 250 255
Gly Gly Ile Ser Gly Glu Ala Gly Ser Pro Lys Ile Gln Gly Ile Asn
260 265 270
Glu Leu Ile Asn Ser His His Asn Gln His Cys His Lys Ser Glu Arg
275 280 285
Ile Ala Lys Leu Arg Pro Leu His Lys Gln Ile Leu Ser Asp Gly Met
290 295 300
Ser Val Ser Phe Leu Pro Ser Lys Phe Ala Asp Asp Ser Glu Met Cys
305 310 315 320
Gln Ala Val Asn Glu Phe Tyr Arg His Tyr Ala Asp Val Phe Ala Lys
325 330 335
Val Gln Ser Leu Phe Asp Gly Phe Asp Asp His Gln Lys Asp Gly Ile
340 345 350
Tyr Val Glu His Lys Asn Leu Asn Glu Leu Ser Lys Gln Ala Phe Gly
355 360 365
Asp Phe Ala Leu Leu Gly Arg Val Leu Asp Gly Tyr Tyr Val Asp Val
370 375 380
Val Asn Pro Glu Phe Asn Glu Arg Phe Ala Lys Ala Lys Thr Asp Asn
385 390 395 400
Ala Lys Ala Lys Leu Thr Lys Glu Lys Asp Lys Phe Ile Lys Gly Val
405 410 415
His Ser Leu Ala Ser Leu Glu Gln Ala Ile Glu His Tyr Thr Ala Arg
420 425 430
His Asp Asp Glu Ser Val Gln Ala Gly Lys Leu Gly Gln Tyr Phe Lys
435 440 445
His Gly Leu Ala Gly Val Asp Asn Pro Ile Gln Lys Ile His Asn Asn
450 455 460
His Ser Thr Ile Lys Gly Phe Leu Glu Arg Glu Arg Pro Ala Gly Glu
465 470 475 480
Arg Ala Leu Pro Lys Ile Lys Ser Gly Lys Asn Pro Glu Met Thr Gln
485 490 495
Leu Arg Gln Leu Lys Glu Leu Leu Asp Asn Ala Leu Asn Val Ala His
500 505 510
Phe Ala Lys Leu Leu Thr Thr Lys Thr Thr Leu Asp Asn Gln Asp Gly
515 520 525
Asn Phe Tyr Gly Glu Phe Gly Val Leu Tyr Asp Glu Leu Ala Lys Ile
530 535 540
Pro Thr Leu Tyr Asn Lys Val Arg Asp Tyr Leu Ser Gln Lys Pro Phe
545 550 555 560
Ser Thr Glu Lys Tyr Lys Leu Asn Phe Gly Asn Pro Thr Leu Leu Asn
565 570 575
Gly Trp Asp Leu Asn Lys Glu Lys Asp Asn Phe Gly Val Ile Leu Gln
580 585 590
Lys Asp Gly Cys Tyr Tyr Leu Ala Leu Leu Asp Lys Ala His Lys Lys
595 600 605
Val Phe Asp Asn Ala Pro Asn Thr Gly Lys Ser Ile Tyr Gln Lys Met
610 615 620
Ile Tyr Lys Tyr Leu Glu Val Arg Lys Gln Phe Pro Lys Val Phe Phe
625 630 635 640
Ser Lys Glu Ala Ile Ala Ile Asn Tyr His Pro Ser Lys Glu Leu Val
645 650 655
Glu Ile Lys Asp Lys Gly Arg Gln Arg Ser Asp Asp Glu Arg Leu Lys
660 665 670
Leu Tyr Arg Phe Ile Leu Glu Cys Leu Lys Ile His Pro Lys Tyr Asp
675 680 685
Lys Lys Phe Glu Gly Ala Ile Gly Asp Ile Gln Leu Phe Lys Lys Asp
690 695 700
Lys Lys Gly Arg Glu Val Pro Ile Ser Glu Lys Asp Leu Phe Asp Lys
705 710 715 720
Ile Asn Gly Ile Phe Ser Ser Lys Pro Lys Leu Glu Met Glu Asp Phe
725 730 735
Phe Ile Gly Glu Phe Lys Arg Tyr Asn Pro Ser Gln Asp Leu Val Asp
740 745 750
Gln Tyr Asn Ile Tyr Lys Lys Ile Asp Ser Asn Asp Asn Arg Lys Lys
755 760 765
Glu Asn Phe Tyr Asn Asn His Pro Lys Phe Lys Lys Asp Leu Val Arg
770 775 780
Tyr Tyr Tyr Glu Ser Met Cys Lys His Glu Glu Trp Glu Glu Ser Phe
785 790 795 800
Glu Phe Ser Lys Lys Leu Gln Asp Ile Gly Cys Tyr Val Asp Val Asn
805 810 815
Glu Leu Phe Thr Glu Ile Glu Thr Arg Arg Leu Asn Tyr Lys Ile Ser
820 825 830
Phe Cys Asn Ile Asn Ala Asp Tyr Ile Asp Glu Leu Val Glu Gln Gly
835 840 845
Gln Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Pro Lys Ala
850 855 860
His Gly Lys Pro Asn Leu His Thr Leu Tyr Phe Lys Ala Leu Phe Ser
865 870 875 880
Glu Asp Asn Leu Ala Asp Pro Ile Tyr Lys Leu Asn Gly Glu Ala Gln
885 890 895
Ile Phe Tyr Arg Lys Ala Ser Leu Asp Met Asn Glu Thr Thr Ile His
900 905 910
Arg Ala Gly Glu Val Leu Glu Asn Lys Asn Pro Asp Asn Pro Lys Lys
915 920 925
Arg Gln Phe Val Tyr Asp Ile Ile Lys Asp Lys Arg Tyr Thr Gln Asp
930 935 940
Lys Phe Met Leu His Val Pro Ile Thr Met Asn Phe Gly Val Gln Gly
945 950 955 960
Met Thr Ile Lys Glu Phe Asn Lys Lys Val Asn Gln Ser Ile Gln Gln
965 970 975
Tyr Asp Glu Val Asn Val Ile Gly Ile Asp Arg Gly Glu Arg His Leu
980 985 990
Leu Tyr Leu Thr Val Ile Asn Ser Lys Gly Glu Ile Leu Glu Gln Cys
995 1000 1005
Ser Leu Asn Asp Ile Thr Thr Ala Ser Ala Asn Gly Thr Gln Met
1010 1015 1020
Thr Thr Pro Tyr His Lys Ile Leu Asp Lys Arg Glu Ile Glu Arg
1025 1030 1035
Leu Asn Ala Arg Val Gly Trp Gly Glu Ile Glu Thr Ile Lys Glu
1040 1045 1050
Leu Lys Ser Gly Tyr Leu Ser His Val Val His Gln Ile Ser Gln
1055 1060 1065
Leu Met Leu Lys Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn
1070 1075 1080
Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Ile Tyr
1085 1090 1095
Gln Asn Phe Glu Asn Ala Leu Ile Lys Lys Leu Asn His Leu Val
1100 1105 1110
Leu Lys Asp Lys Ala Asp Asp Glu Ile Gly Ser Tyr Lys Asn Ala
1115 1120 1125
Leu Gln Leu Thr Asn Asn Phe Thr Asp Leu Lys Ser Ile Gly Lys
1130 1135 1140
Gln Thr Gly Phe Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys
1145 1150 1155
Ile Asp Pro Glu Thr Gly Phe Val Asp Leu Leu Lys Pro Arg Tyr
1160 1165 1170
Glu Asn Ile Ala Gln Ser Gln Ala Phe Phe Gly Lys Phe Asp Lys
1175 1180 1185
Ile Cys Tyr Asn Ala Asp Lys Asp Tyr Phe Glu Phe His Ile Asp
1190 1195 1200
Tyr Ala Lys Phe Thr Asp Lys Ala Lys Asn Ser Arg Gln Ile Trp
1205 1210 1215
Thr Ile Cys Ser His Gly Asp Lys Arg Tyr Val Tyr Asp Lys Thr
1220 1225 1230
Ala Asn Gln Asn Lys Gly Ala Ala Lys Gly Ile Asn Val Asn Asp
1235 1240 1245
Glu Leu Lys Ser Leu Phe Ala Arg His His Ile Asn Glu Lys Gln
1250 1255 1260
Pro Asn Leu Val Met Asp Ile Cys Gln Asn Asn Asp Lys Glu Phe
1265 1270 1275
His Lys Ser Leu Met Tyr Leu Leu Lys Thr Leu Leu Ala Leu Arg
1280 1285 1290
Tyr Ser Asn Ala Ser Ser Asp Glu Asp Phe Ile Leu Ser Pro Val
1295 1300 1305
Ala Asn Asp Glu Gly Val Phe Phe Asn Ser Ala Leu Ala Asp Asp
1310 1315 1320
Thr Gln Pro Gln Asn Ala Asp Ala Asn Gly Ala Tyr His Ile Ala
1325 1330 1335
Leu Lys Gly Leu Trp Leu Leu Asn Glu Leu Lys Asn Ser Asp Asp
1340 1345 1350
Leu Asn Lys Val Lys Leu Ala Ile Asp Asn Gln Thr Trp Leu Asn
1355 1360 1365
Phe Ala Gln Asn Arg
1370
<210> 71
<211> 1352
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность бактерии группы Parcubacteria
<400> 71
Met Glu Asn Ile Phe Asp Gln Phe Ile Gly Lys Tyr Ser Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Glu Asp Phe Leu
20 25 30
Lys Ile Asn Lys Val Phe Glu Lys Asp Gln Thr Ile Asp Asp Ser Tyr
35 40 45
Asn Gln Ala Lys Phe Tyr Phe Asp Ser Leu His Gln Lys Phe Ile Asp
50 55 60
Ala Ala Leu Ala Ser Asp Lys Thr Ser Glu Leu Ser Phe Gln Asn Phe
65 70 75 80
Ala Asp Val Leu Glu Lys Gln Asn Lys Ile Ile Leu Asp Lys Lys Arg
85 90 95
Glu Met Gly Ala Leu Arg Lys Arg Asp Lys Asn Ala Val Gly Ile Asp
100 105 110
Arg Leu Gln Lys Glu Ile Asn Asp Ala Glu Asp Ile Ile Gln Lys Glu
115 120 125
Lys Glu Lys Ile Tyr Lys Asp Val Arg Thr Leu Phe Asp Asn Glu Ala
130 135 140
Glu Ser Trp Lys Thr Tyr Tyr Gln Glu Arg Glu Val Asp Gly Lys Lys
145 150 155 160
Ile Thr Phe Ser Lys Ala Asp Leu Lys Gln Lys Gly Ala Asp Phe Leu
165 170 175
Thr Ala Ala Gly Ile Leu Lys Val Leu Lys Tyr Glu Phe Pro Glu Glu
180 185 190
Lys Glu Lys Glu Phe Gln Ala Lys Asn Gln Pro Ser Leu Phe Val Glu
195 200 205
Glu Lys Glu Asn Pro Gly Gln Lys Arg Tyr Ile Phe Asp Ser Phe Asp
210 215 220
Lys Phe Ala Gly Tyr Leu Thr Lys Phe Gln Gln Thr Lys Lys Asn Leu
225 230 235 240
Tyr Ala Ala Asp Gly Thr Ser Thr Ala Val Ala Thr Arg Ile Ala Asp
245 250 255
Asn Phe Ile Ile Phe His Gln Asn Thr Lys Val Phe Arg Asp Lys Tyr
260 265 270
Lys Asn Asn His Thr Asp Leu Gly Phe Asp Glu Glu Asn Ile Phe Glu
275 280 285
Ile Glu Arg Tyr Lys Asn Cys Leu Leu Gln Arg Glu Ile Glu His Ile
290 295 300
Lys Asn Glu Asn Ser Tyr Asn Lys Ile Ile Gly Arg Ile Asn Lys Lys
305 310 315 320
Ile Lys Glu Tyr Arg Asp Gln Lys Ala Lys Asp Thr Lys Leu Thr Lys
325 330 335
Ser Asp Phe Pro Phe Phe Lys Asn Leu Asp Lys Gln Ile Leu Gly Glu
340 345 350
Val Glu Lys Glu Lys Gln Leu Ile Glu Lys Thr Arg Glu Lys Thr Glu
355 360 365
Glu Asp Val Leu Ile Glu Arg Phe Lys Glu Phe Ile Glu Asn Asn Glu
370 375 380
Glu Arg Phe Thr Ala Ala Lys Lys Leu Met Asn Ala Phe Cys Asn Gly
385 390 395 400
Glu Phe Glu Ser Glu Tyr Glu Gly Ile Tyr Leu Lys Asn Lys Ala Ile
405 410 415
Asn Thr Ile Ser Arg Arg Trp Phe Val Ser Asp Arg Asp Phe Glu Leu
420 425 430
Lys Leu Pro Gln Gln Lys Ser Lys Asn Lys Ser Glu Lys Asn Glu Pro
435 440 445
Lys Val Lys Lys Phe Ile Ser Ile Ala Glu Ile Lys Asn Ala Val Glu
450 455 460
Glu Leu Asp Gly Asp Ile Phe Lys Ala Val Phe Tyr Asp Lys Lys Ile
465 470 475 480
Ile Ala Gln Gly Gly Ser Lys Leu Glu Gln Phe Leu Val Ile Trp Lys
485 490 495
Tyr Glu Phe Glu Tyr Leu Phe Arg Asp Ile Glu Arg Glu Asn Gly Glu
500 505 510
Lys Leu Leu Gly Tyr Asp Ser Cys Leu Lys Ile Ala Lys Gln Leu Gly
515 520 525
Ile Phe Pro Gln Glu Lys Glu Ala Arg Glu Lys Ala Thr Ala Val Ile
530 535 540
Lys Asn Tyr Ala Asp Ala Gly Leu Gly Ile Phe Gln Met Met Lys Tyr
545 550 555 560
Phe Ser Leu Asp Asp Lys Asp Arg Lys Asn Thr Pro Gly Gln Leu Ser
565 570 575
Thr Asn Phe Tyr Ala Glu Tyr Asp Gly Tyr Tyr Lys Asp Phe Glu Phe
580 585 590
Ile Lys Tyr Tyr Asn Glu Phe Arg Asn Phe Ile Thr Lys Lys Pro Phe
595 600 605
Asp Glu Asp Lys Ile Lys Leu Asn Phe Glu Asn Gly Ala Leu Leu Lys
610 615 620
Gly Trp Asp Glu Asn Lys Glu Tyr Asp Phe Met Gly Val Ile Leu Lys
625 630 635 640
Lys Glu Gly Arg Leu Tyr Leu Gly Ile Met His Lys Asn His Arg Lys
645 650 655
Leu Phe Gln Ser Met Gly Asn Ala Lys Gly Asp Asn Ala Asn Arg Tyr
660 665 670
Gln Lys Met Ile Tyr Lys Gln Ile Ala Asp Ala Ser Lys Asp Val Pro
675 680 685
Arg Leu Leu Leu Thr Ser Lys Lys Ala Met Glu Lys Phe Lys Pro Ser
690 695 700
Gln Glu Ile Leu Arg Ile Lys Lys Glu Lys Thr Phe Lys Arg Glu Ser
705 710 715 720
Lys Asn Phe Ser Leu Arg Asp Leu His Ala Leu Ile Glu Tyr Tyr Arg
725 730 735
Asn Cys Ile Pro Gln Tyr Ser Asn Trp Ser Phe Tyr Asp Phe Gln Phe
740 745 750
Gln Asp Thr Gly Lys Tyr Gln Asn Ile Lys Glu Phe Thr Asp Asp Val
755 760 765
Gln Lys Tyr Gly Tyr Lys Ile Ser Phe Arg Asp Ile Asp Asp Glu Tyr
770 775 780
Ile Asn Gln Ala Leu Asn Glu Gly Lys Met Tyr Leu Phe Glu Val Val
785 790 795 800
Asn Lys Asp Ile Tyr Asn Thr Lys Asn Gly Ser Lys Asn Leu His Thr
805 810 815
Leu Tyr Phe Glu His Ile Leu Ser Ala Glu Asn Leu Asn Asp Pro Val
820 825 830
Phe Lys Leu Ser Gly Met Ala Glu Ile Phe Gln Arg Gln Pro Ser Val
835 840 845
Asn Glu Arg Glu Lys Ile Thr Thr Gln Lys Asn Gln Cys Ile Leu Asp
850 855 860
Lys Gly Asp Arg Ala Tyr Lys Tyr Arg Arg Tyr Thr Glu Lys Lys Ile
865 870 875 880
Met Phe His Met Ser Leu Val Leu Asn Thr Gly Lys Gly Glu Ile Lys
885 890 895
Gln Val Gln Phe Asn Lys Ile Ile Asn Gln Arg Ile Ser Ser Ser Asp
900 905 910
Asn Glu Met Arg Val Asn Val Ile Gly Ile Asp Arg Gly Glu Lys Asn
915 920 925
Leu Leu Tyr Tyr Ser Val Val Lys Gln Asn Gly Glu Ile Ile Glu Gln
930 935 940
Ala Ser Leu Asn Glu Ile Asn Gly Val Asn Tyr Arg Asp Lys Leu Ile
945 950 955 960
Glu Arg Glu Lys Glu Arg Leu Lys Asn Arg Gln Ser Trp Lys Pro Val
965 970 975
Val Lys Ile Lys Asp Leu Lys Lys Gly Tyr Ile Ser His Val Ile His
980 985 990
Lys Ile Cys Gln Leu Ile Glu Lys Tyr Ser Ala Ile Val Val Leu Glu
995 1000 1005
Asp Leu Asn Met Arg Phe Lys Gln Ile Arg Gly Gly Ile Glu Arg
1010 1015 1020
Ser Val Tyr Gln Gln Phe Glu Lys Ala Leu Ile Asp Lys Leu Gly
1025 1030 1035
Tyr Leu Val Phe Lys Asp Asn Arg Asp Leu Arg Ala Pro Gly Gly
1040 1045 1050
Val Leu Asn Gly Tyr Gln Leu Ser Ala Pro Phe Val Ser Phe Glu
1055 1060 1065
Lys Met Arg Lys Gln Thr Gly Ile Leu Phe Tyr Thr Gln Ala Glu
1070 1075 1080
Tyr Thr Ser Lys Thr Asp Pro Ile Thr Gly Phe Arg Lys Asn Val
1085 1090 1095
Tyr Ile Ser Asn Ser Ala Ser Leu Asp Lys Ile Lys Glu Ala Val
1100 1105 1110
Lys Lys Phe Asp Ala Ile Gly Trp Asp Gly Lys Glu Gln Ser Tyr
1115 1120 1125
Phe Phe Lys Tyr Asn Pro Tyr Asn Leu Ala Asp Glu Lys Tyr Lys
1130 1135 1140
Asn Ser Thr Val Ser Lys Glu Trp Ala Ile Phe Ala Ser Ala Pro
1145 1150 1155
Arg Ile Arg Arg Gln Lys Gly Glu Asp Gly Tyr Trp Lys Tyr Asp
1160 1165 1170
Arg Val Lys Val Asn Glu Glu Phe Glu Lys Leu Leu Lys Val Trp
1175 1180 1185
Asn Phe Val Asn Pro Lys Ala Thr Asp Ile Lys Gln Glu Ile Ile
1190 1195 1200
Lys Lys Glu Lys Ala Gly Asp Leu Gln Gly Glu Lys Glu Leu Asp
1205 1210 1215
Gly Arg Leu Arg Asn Phe Trp His Ser Phe Ile Tyr Leu Phe Asn
1220 1225 1230
Leu Val Leu Glu Leu Arg Asn Ser Phe Ser Leu Gln Ile Lys Ile
1235 1240 1245
Lys Ala Gly Glu Val Ile Ala Val Asp Glu Gly Val Asp Phe Ile
1250 1255 1260
Ala Ser Pro Val Lys Pro Phe Phe Thr Thr Pro Asn Pro Tyr Ile
1265 1270 1275
Pro Ser Asn Leu Cys Trp Leu Ala Val Glu Asn Ala Asp Ala Asn
1280 1285 1290
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Val Met Ile Leu Lys Lys
1295 1300 1305
Ile Arg Glu His Ala Lys Lys Asp Pro Glu Phe Lys Lys Leu Pro
1310 1315 1320
Asn Leu Phe Ile Ser Asn Ala Glu Trp Asp Glu Ala Ala Arg Asp
1325 1330 1335
Trp Gly Lys Tyr Ala Gly Thr Thr Ala Leu Asn Leu Asp His
1340 1345 1350
<210> 72
<211> 1334
<212> БЕЛОК
<213> Succinivibrio dextrinosolvens
<400> 72
Met Ser Ser Leu Thr Lys Phe Thr Asn Lys Tyr Ser Lys Gln Leu Thr
1 5 10 15
Ile Lys Asn Glu Leu Ile Pro Val Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Glu Asn Gly Leu Ile Asp Gly Asp Glu Gln Leu Asn Glu Asn Tyr Gln
35 40 45
Lys Ala Lys Ile Ile Val Asp Asp Phe Leu Arg Asp Phe Ile Asn Lys
50 55 60
Ala Leu Asn Asn Thr Gln Ile Gly Asn Trp Arg Glu Leu Ala Asp Ala
65 70 75 80
Leu Asn Lys Glu Asp Glu Asp Asn Ile Glu Lys Leu Gln Asp Lys Ile
85 90 95
Arg Gly Ile Ile Val Ser Lys Phe Glu Thr Phe Asp Leu Phe Ser Ser
100 105 110
Tyr Ser Ile Lys Lys Asp Glu Lys Ile Ile Asp Asp Asp Asn Asp Val
115 120 125
Glu Glu Glu Glu Leu Asp Leu Gly Lys Lys Thr Ser Ser Phe Lys Tyr
130 135 140
Ile Phe Lys Lys Asn Leu Phe Lys Leu Val Leu Pro Ser Tyr Leu Lys
145 150 155 160
Thr Thr Asn Gln Asp Lys Leu Lys Ile Ile Ser Ser Phe Asp Asn Phe
165 170 175
Ser Thr Tyr Phe Arg Gly Phe Phe Glu Asn Arg Lys Asn Ile Phe Thr
180 185 190
Lys Lys Pro Ile Ser Thr Ser Ile Ala Tyr Arg Ile Val His Asp Asn
195 200 205
Phe Pro Lys Phe Leu Asp Asn Ile Arg Cys Phe Asn Val Trp Gln Thr
210 215 220
Glu Cys Pro Gln Leu Ile Val Lys Ala Asp Asn Tyr Leu Lys Ser Lys
225 230 235 240
Asn Val Ile Ala Lys Asp Lys Ser Leu Ala Asn Tyr Phe Thr Val Gly
245 250 255
Ala Tyr Asp Tyr Phe Leu Ser Gln Asn Gly Ile Asp Phe Tyr Asn Asn
260 265 270
Ile Ile Gly Gly Leu Pro Ala Phe Ala Gly His Glu Lys Ile Gln Gly
275 280 285
Leu Asn Glu Phe Ile Asn Gln Glu Cys Gln Lys Asp Ser Glu Leu Lys
290 295 300
Ser Lys Leu Lys Asn Arg His Ala Phe Lys Met Ala Val Leu Phe Lys
305 310 315 320
Gln Ile Leu Ser Asp Arg Glu Lys Ser Phe Val Ile Asp Glu Phe Glu
325 330 335
Ser Asp Ala Gln Val Ile Asp Ala Val Lys Asn Phe Tyr Ala Glu Gln
340 345 350
Cys Lys Asp Asn Asn Val Ile Phe Asn Leu Leu Asn Leu Ile Lys Asn
355 360 365
Ile Ala Phe Leu Ser Asp Asp Glu Leu Asp Gly Ile Phe Ile Glu Gly
370 375 380
Lys Tyr Leu Ser Ser Val Ser Gln Lys Leu Tyr Ser Asp Trp Ser Lys
385 390 395 400
Leu Arg Asn Asp Ile Glu Asp Ser Ala Asn Ser Lys Gln Gly Asn Lys
405 410 415
Glu Leu Ala Lys Lys Ile Lys Thr Asn Lys Gly Asp Val Glu Lys Ala
420 425 430
Ile Ser Lys Tyr Glu Phe Ser Leu Ser Glu Leu Asn Ser Ile Val His
435 440 445
Asp Asn Thr Lys Phe Ser Asp Leu Leu Ser Cys Thr Leu His Lys Val
450 455 460
Ala Ser Glu Lys Leu Val Lys Val Asn Glu Gly Asp Trp Pro Lys His
465 470 475 480
Leu Lys Asn Asn Glu Glu Lys Gln Lys Ile Lys Glu Pro Leu Asp Ala
485 490 495
Leu Leu Glu Ile Tyr Asn Thr Leu Leu Ile Phe Asn Cys Lys Ser Phe
500 505 510
Asn Lys Asn Gly Asn Phe Tyr Val Asp Tyr Asp Arg Cys Ile Asn Glu
515 520 525
Leu Ser Ser Val Val Tyr Leu Tyr Asn Lys Thr Arg Asn Tyr Cys Thr
530 535 540
Lys Lys Pro Tyr Asn Thr Asp Lys Phe Lys Leu Asn Phe Asn Ser Pro
545 550 555 560
Gln Leu Gly Glu Gly Phe Ser Lys Ser Lys Glu Asn Asp Cys Leu Thr
565 570 575
Leu Leu Phe Lys Lys Asp Asp Asn Tyr Tyr Val Gly Ile Ile Arg Lys
580 585 590
Gly Ala Lys Ile Asn Phe Asp Asp Thr Gln Ala Ile Ala Asp Asn Thr
595 600 605
Asp Asn Cys Ile Phe Lys Met Asn Tyr Phe Leu Leu Lys Asp Ala Lys
610 615 620
Lys Phe Ile Pro Lys Cys Ser Ile Gln Leu Lys Glu Val Lys Ala His
625 630 635 640
Phe Lys Lys Ser Glu Asp Asp Tyr Ile Leu Ser Asp Lys Glu Lys Phe
645 650 655
Ala Ser Pro Leu Val Ile Lys Lys Ser Thr Phe Leu Leu Ala Thr Ala
660 665 670
His Val Lys Gly Lys Lys Gly Asn Ile Lys Lys Phe Gln Lys Glu Tyr
675 680 685
Ser Lys Glu Asn Pro Thr Glu Tyr Arg Asn Ser Leu Asn Glu Trp Ile
690 695 700
Ala Phe Cys Lys Glu Phe Leu Lys Thr Tyr Lys Ala Ala Thr Ile Phe
705 710 715 720
Asp Ile Thr Thr Leu Lys Lys Ala Glu Glu Tyr Ala Asp Ile Val Glu
725 730 735
Phe Tyr Lys Asp Val Asp Asn Leu Cys Tyr Lys Leu Glu Phe Cys Pro
740 745 750
Ile Lys Thr Ser Phe Ile Glu Asn Leu Ile Asp Asn Gly Asp Leu Tyr
755 760 765
Leu Phe Arg Ile Asn Asn Lys Asp Phe Ser Ser Lys Ser Thr Gly Thr
770 775 780
Lys Asn Leu His Thr Leu Tyr Leu Gln Ala Ile Phe Asp Glu Arg Asn
785 790 795 800
Leu Asn Asn Pro Thr Ile Met Leu Asn Gly Gly Ala Glu Leu Phe Tyr
805 810 815
Arg Lys Glu Ser Ile Glu Gln Lys Asn Arg Ile Thr His Lys Ala Gly
820 825 830
Ser Ile Leu Val Asn Lys Val Cys Lys Asp Gly Thr Ser Leu Asp Asp
835 840 845
Lys Ile Arg Asn Glu Ile Tyr Gln Tyr Glu Asn Lys Phe Ile Asp Thr
850 855 860
Leu Ser Asp Glu Ala Lys Lys Val Leu Pro Asn Val Ile Lys Lys Glu
865 870 875 880
Ala Thr His Asp Ile Thr Lys Asp Lys Arg Phe Thr Ser Asp Lys Phe
885 890 895
Phe Phe His Cys Pro Leu Thr Ile Asn Tyr Lys Glu Gly Asp Thr Lys
900 905 910
Gln Phe Asn Asn Glu Val Leu Ser Phe Leu Arg Gly Asn Pro Asp Ile
915 920 925
Asn Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Ile Tyr Val Thr
930 935 940
Val Ile Asn Gln Lys Gly Glu Ile Leu Asp Ser Val Ser Phe Asn Thr
945 950 955 960
Val Thr Asn Lys Ser Ser Lys Ile Glu Gln Thr Val Asp Tyr Glu Glu
965 970 975
Lys Leu Ala Val Arg Glu Lys Glu Arg Ile Glu Ala Lys Arg Ser Trp
980 985 990
Asp Ser Ile Ser Lys Ile Ala Thr Leu Lys Glu Gly Tyr Leu Ser Ala
995 1000 1005
Ile Val His Glu Ile Cys Leu Leu Met Ile Lys His Asn Ala Ile
1010 1015 1020
Val Val Leu Glu Asn Leu Asn Ala Gly Phe Lys Arg Ile Arg Gly
1025 1030 1035
Gly Leu Ser Glu Lys Ser Val Tyr Gln Lys Phe Glu Lys Met Leu
1040 1045 1050
Ile Asn Lys Leu Asn Tyr Phe Val Ser Lys Lys Glu Ser Asp Trp
1055 1060 1065
Asn Lys Pro Ser Gly Leu Leu Asn Gly Leu Gln Leu Ser Asp Gln
1070 1075 1080
Phe Glu Ser Phe Glu Lys Leu Gly Ile Gln Ser Gly Phe Ile Phe
1085 1090 1095
Tyr Val Pro Ala Ala Tyr Thr Ser Lys Ile Asp Pro Thr Thr Gly
1100 1105 1110
Phe Ala Asn Val Leu Asn Leu Ser Lys Val Arg Asn Val Asp Ala
1115 1120 1125
Ile Lys Ser Phe Phe Ser Asn Phe Asn Glu Ile Ser Tyr Ser Lys
1130 1135 1140
Lys Glu Ala Leu Phe Lys Phe Ser Phe Asp Leu Asp Ser Leu Ser
1145 1150 1155
Lys Lys Gly Phe Ser Ser Phe Val Lys Phe Ser Lys Ser Lys Trp
1160 1165 1170
Asn Val Tyr Thr Phe Gly Glu Arg Ile Ile Lys Pro Lys Asn Lys
1175 1180 1185
Gln Gly Tyr Arg Glu Asp Lys Arg Ile Asn Leu Thr Phe Glu Met
1190 1195 1200
Lys Lys Leu Leu Asn Glu Tyr Lys Val Ser Phe Asp Leu Glu Asn
1205 1210 1215
Asn Leu Ile Pro Asn Leu Thr Ser Ala Asn Leu Lys Asp Thr Phe
1220 1225 1230
Trp Lys Glu Leu Phe Phe Ile Phe Lys Thr Thr Leu Gln Leu Arg
1235 1240 1245
Asn Ser Val Thr Asn Gly Lys Glu Asp Val Leu Ile Ser Pro Val
1250 1255 1260
Lys Asn Ala Lys Gly Glu Phe Phe Val Ser Gly Thr His Asn Lys
1265 1270 1275
Thr Leu Pro Gln Asp Cys Asp Ala Asn Gly Ala Tyr His Ile Ala
1280 1285 1290
Leu Lys Gly Leu Met Ile Leu Glu Arg Asn Asn Leu Val Arg Glu
1295 1300 1305
Glu Lys Asp Thr Lys Lys Ile Met Ala Ile Ser Asn Val Asp Trp
1310 1315 1320
Phe Glu Tyr Val Gln Lys Arg Arg Gly Val Leu
1325 1330
<210> 73
<211> 1331
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность бактерии группы Parcubacteria
<400> 73
Met Lys Pro Val Gly Lys Thr Glu Asp Phe Leu Lys Ile Asn Lys Val
1 5 10 15
Phe Glu Lys Asp Gln Thr Ile Asp Asp Ser Tyr Asn Gln Ala Lys Phe
20 25 30
Tyr Phe Asp Ser Leu His Gln Lys Phe Ile Asp Ala Ala Leu Ala Ser
35 40 45
Asp Lys Thr Ser Glu Leu Ser Phe Gln Asn Phe Ala Asp Val Leu Glu
50 55 60
Lys Gln Asn Lys Ile Ile Leu Asp Lys Lys Arg Glu Met Gly Ala Leu
65 70 75 80
Arg Lys Arg Asp Lys Asn Ala Val Gly Ile Asp Arg Leu Gln Lys Glu
85 90 95
Ile Asn Asp Ala Glu Asp Ile Ile Gln Lys Glu Lys Glu Lys Ile Tyr
100 105 110
Lys Asp Val Arg Thr Leu Phe Asp Asn Glu Ala Glu Ser Trp Lys Thr
115 120 125
Tyr Tyr Gln Glu Arg Glu Val Asp Gly Lys Lys Ile Thr Phe Ser Lys
130 135 140
Ala Asp Leu Lys Gln Lys Gly Ala Asp Phe Leu Thr Ala Ala Gly Ile
145 150 155 160
Leu Lys Val Leu Lys Tyr Glu Phe Pro Glu Glu Lys Glu Lys Glu Phe
165 170 175
Gln Ala Lys Asn Gln Pro Ser Leu Phe Val Glu Glu Lys Glu Asn Pro
180 185 190
Gly Gln Lys Arg Tyr Ile Phe Asp Ser Phe Asp Lys Phe Ala Gly Tyr
195 200 205
Leu Thr Lys Phe Gln Gln Thr Lys Lys Asn Leu Tyr Ala Ala Asp Gly
210 215 220
Thr Ser Thr Ala Val Ala Thr Arg Ile Ala Asp Asn Phe Ile Ile Phe
225 230 235 240
His Gln Asn Thr Lys Val Phe Arg Asp Lys Tyr Lys Asn Asn His Thr
245 250 255
Asp Leu Gly Phe Asp Glu Glu Asn Ile Phe Glu Ile Glu Arg Tyr Lys
260 265 270
Asn Cys Leu Leu Gln Arg Glu Ile Glu His Ile Lys Asn Glu Asn Ser
275 280 285
Tyr Asn Lys Ile Ile Gly Arg Ile Asn Lys Lys Ile Lys Glu Tyr Arg
290 295 300
Asp Gln Lys Ala Lys Asp Thr Lys Leu Thr Lys Ser Asp Phe Pro Phe
305 310 315 320
Phe Lys Asn Leu Asp Lys Gln Ile Leu Gly Glu Val Glu Lys Glu Lys
325 330 335
Gln Leu Ile Glu Lys Thr Arg Glu Lys Thr Glu Glu Asp Val Leu Ile
340 345 350
Glu Arg Phe Lys Glu Phe Ile Glu Asn Asn Glu Glu Arg Phe Thr Ala
355 360 365
Ala Lys Lys Leu Met Asn Ala Phe Cys Asn Gly Glu Phe Glu Ser Glu
370 375 380
Tyr Glu Gly Ile Tyr Leu Lys Asn Lys Ala Ile Asn Thr Ile Ser Arg
385 390 395 400
Arg Trp Phe Val Ser Asp Arg Asp Phe Glu Leu Lys Leu Pro Gln Gln
405 410 415
Lys Ser Lys Asn Lys Ser Glu Lys Asn Glu Pro Lys Val Lys Lys Phe
420 425 430
Ile Ser Ile Ala Glu Ile Lys Asn Ala Val Glu Glu Leu Asp Gly Asp
435 440 445
Ile Phe Lys Ala Val Phe Tyr Asp Lys Lys Ile Ile Ala Gln Gly Gly
450 455 460
Ser Lys Leu Glu Gln Phe Leu Val Ile Trp Lys Tyr Glu Phe Glu Tyr
465 470 475 480
Leu Phe Arg Asp Ile Glu Arg Glu Asn Gly Glu Lys Leu Leu Gly Tyr
485 490 495
Asp Ser Cys Leu Lys Ile Ala Lys Gln Leu Gly Ile Phe Pro Gln Glu
500 505 510
Lys Glu Ala Arg Glu Lys Ala Thr Ala Val Ile Lys Asn Tyr Ala Asp
515 520 525
Ala Gly Leu Gly Ile Phe Gln Met Met Lys Tyr Phe Ser Leu Asp Asp
530 535 540
Lys Asp Arg Lys Asn Thr Pro Gly Gln Leu Ser Thr Asn Phe Tyr Ala
545 550 555 560
Glu Tyr Asp Gly Tyr Tyr Lys Asp Phe Glu Phe Ile Lys Tyr Tyr Asn
565 570 575
Glu Phe Arg Asn Phe Ile Thr Lys Lys Pro Phe Asp Glu Asp Lys Ile
580 585 590
Lys Leu Asn Phe Glu Asn Gly Ala Leu Leu Lys Gly Trp Asp Glu Asn
595 600 605
Lys Glu Tyr Asp Phe Met Gly Val Ile Leu Lys Lys Glu Gly Arg Leu
610 615 620
Tyr Leu Gly Ile Met His Lys Asn His Arg Lys Leu Phe Gln Ser Met
625 630 635 640
Gly Asn Ala Lys Gly Asp Asn Ala Asn Arg Tyr Gln Lys Met Ile Tyr
645 650 655
Lys Gln Ile Ala Asp Ala Ser Lys Asp Val Pro Arg Leu Leu Leu Thr
660 665 670
Ser Lys Lys Ala Met Glu Lys Phe Lys Pro Ser Gln Glu Ile Leu Arg
675 680 685
Ile Lys Lys Glu Lys Thr Phe Lys Arg Glu Ser Lys Asn Phe Ser Leu
690 695 700
Arg Asp Leu His Ala Leu Ile Glu Tyr Tyr Arg Asn Cys Ile Pro Gln
705 710 715 720
Tyr Ser Asn Trp Ser Phe Tyr Asp Phe Gln Phe Gln Asp Thr Gly Lys
725 730 735
Tyr Gln Asn Ile Lys Glu Phe Thr Asp Asp Val Gln Lys Tyr Gly Tyr
740 745 750
Lys Ile Ser Phe Arg Asp Ile Asp Asp Glu Tyr Ile Asn Gln Ala Leu
755 760 765
Asn Glu Gly Lys Met Tyr Leu Phe Glu Val Val Asn Lys Asp Ile Tyr
770 775 780
Asn Thr Lys Asn Gly Ser Lys Asn Leu His Thr Leu Tyr Phe Glu His
785 790 795 800
Ile Leu Ser Ala Glu Asn Leu Asn Asp Pro Val Phe Lys Leu Ser Gly
805 810 815
Met Ala Glu Ile Phe Gln Arg Gln Pro Ser Val Asn Glu Arg Glu Lys
820 825 830
Ile Thr Thr Gln Lys Asn Gln Cys Ile Leu Asp Lys Gly Asp Arg Ala
835 840 845
Tyr Lys Tyr Arg Arg Tyr Thr Glu Lys Lys Ile Met Phe His Met Ser
850 855 860
Leu Val Leu Asn Thr Gly Lys Gly Glu Ile Lys Gln Val Gln Phe Asn
865 870 875 880
Lys Ile Ile Asn Gln Arg Ile Ser Ser Ser Asp Asn Glu Met Arg Val
885 890 895
Asn Val Ile Gly Ile Asp Arg Gly Glu Lys Asn Leu Leu Tyr Tyr Ser
900 905 910
Val Val Lys Gln Asn Gly Glu Ile Ile Glu Gln Ala Ser Leu Asn Glu
915 920 925
Ile Asn Gly Val Asn Tyr Arg Asp Lys Leu Ile Glu Arg Glu Lys Glu
930 935 940
Arg Leu Lys Asn Arg Gln Ser Trp Lys Pro Val Val Lys Ile Lys Asp
945 950 955 960
Leu Lys Lys Gly Tyr Ile Ser His Val Ile His Lys Ile Cys Gln Leu
965 970 975
Ile Glu Lys Tyr Ser Ala Ile Val Val Leu Glu Asp Leu Asn Met Arg
980 985 990
Phe Lys Gln Ile Arg Gly Gly Ile Glu Arg Ser Val Tyr Gln Gln Phe
995 1000 1005
Glu Lys Ala Leu Ile Asp Lys Leu Gly Tyr Leu Val Phe Lys Asp
1010 1015 1020
Asn Arg Asp Leu Arg Ala Pro Gly Gly Val Leu Asn Gly Tyr Gln
1025 1030 1035
Leu Ser Ala Pro Phe Val Ser Phe Glu Lys Met Arg Lys Gln Thr
1040 1045 1050
Gly Ile Leu Phe Tyr Thr Gln Ala Glu Tyr Thr Ser Lys Thr Asp
1055 1060 1065
Pro Ile Thr Gly Phe Arg Lys Asn Val Tyr Ile Ser Asn Ser Ala
1070 1075 1080
Ser Leu Asp Lys Ile Lys Glu Ala Val Lys Lys Phe Asp Ala Ile
1085 1090 1095
Gly Trp Asp Gly Lys Glu Gln Ser Tyr Phe Phe Lys Tyr Asn Pro
1100 1105 1110
Tyr Asn Leu Ala Asp Glu Lys Tyr Lys Asn Ser Thr Val Ser Lys
1115 1120 1125
Glu Trp Ala Ile Phe Ala Ser Ala Pro Arg Ile Arg Arg Gln Lys
1130 1135 1140
Gly Glu Asp Gly Tyr Trp Lys Tyr Asp Arg Val Lys Val Asn Glu
1145 1150 1155
Glu Phe Glu Lys Leu Leu Lys Val Trp Asn Phe Val Asn Pro Lys
1160 1165 1170
Ala Thr Asp Ile Lys Gln Glu Ile Ile Lys Lys Glu Lys Ala Gly
1175 1180 1185
Asp Leu Gln Gly Glu Lys Glu Leu Asp Gly Arg Leu Arg Asn Phe
1190 1195 1200
Trp His Ser Phe Ile Tyr Leu Phe Asn Leu Val Leu Glu Leu Arg
1205 1210 1215
Asn Ser Phe Ser Leu Gln Ile Lys Ile Lys Ala Gly Glu Val Ile
1220 1225 1230
Ala Val Asp Glu Gly Val Asp Phe Ile Ala Ser Pro Val Lys Pro
1235 1240 1245
Phe Phe Thr Thr Pro Asn Pro Tyr Ile Pro Ser Asn Leu Cys Trp
1250 1255 1260
Leu Ala Val Glu Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala
1265 1270 1275
Arg Lys Gly Val Met Ile Leu Lys Lys Ile Arg Glu His Ala Lys
1280 1285 1290
Lys Asp Pro Glu Phe Lys Lys Leu Pro Asn Leu Phe Ile Ser Asn
1295 1300 1305
Ala Glu Trp Asp Glu Ala Ala Arg Asp Trp Gly Lys Tyr Ala Gly
1310 1315 1320
Thr Thr Ala Leu Asn Leu Asp His
1325 1330
<210> 74
<211> 1323
<212> БЕЛОК
<213> Prevotella disiens
<400> 74
Met Glu Asn Tyr Gln Glu Phe Thr Asn Leu Phe Gln Leu Asn Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Cys Glu Leu Leu Glu
20 25 30
Glu Gly Lys Ile Phe Ala Ser Gly Ser Phe Leu Glu Lys Asp Lys Val
35 40 45
Arg Ala Asp Asn Val Ser Tyr Val Lys Lys Glu Ile Asp Lys Lys His
50 55 60
Lys Ile Phe Ile Glu Glu Thr Leu Ser Ser Phe Ser Ile Ser Asn Asp
65 70 75 80
Leu Leu Lys Gln Tyr Phe Asp Cys Tyr Asn Glu Leu Lys Ala Phe Lys
85 90 95
Lys Asp Cys Lys Ser Asp Glu Glu Glu Val Lys Lys Thr Ala Leu Arg
100 105 110
Asn Lys Cys Thr Ser Ile Gln Arg Ala Met Arg Glu Ala Ile Ser Gln
115 120 125
Ala Phe Leu Lys Ser Pro Gln Lys Lys Leu Leu Ala Ile Lys Asn Leu
130 135 140
Ile Glu Asn Val Phe Lys Ala Asp Glu Asn Val Gln His Phe Ser Glu
145 150 155 160
Phe Thr Ser Tyr Phe Ser Gly Phe Glu Thr Asn Arg Glu Asn Phe Tyr
165 170 175
Ser Asp Glu Glu Lys Ser Thr Ser Ile Ala Tyr Arg Leu Val His Asp
180 185 190
Asn Leu Pro Ile Phe Ile Lys Asn Ile Tyr Ile Phe Glu Lys Leu Lys
195 200 205
Glu Gln Phe Asp Ala Lys Thr Leu Ser Glu Ile Phe Glu Asn Tyr Lys
210 215 220
Leu Tyr Val Ala Gly Ser Ser Leu Asp Glu Val Phe Ser Leu Glu Tyr
225 230 235 240
Phe Asn Asn Thr Leu Thr Gln Lys Gly Ile Asp Asn Tyr Asn Ala Val
245 250 255
Ile Gly Lys Ile Val Lys Glu Asp Lys Gln Glu Ile Gln Gly Leu Asn
260 265 270
Glu His Ile Asn Leu Tyr Asn Gln Lys His Lys Asp Arg Arg Leu Pro
275 280 285
Phe Phe Ile Ser Leu Lys Lys Gln Ile Leu Ser Asp Arg Glu Ala Leu
290 295 300
Ser Trp Leu Pro Asp Met Phe Lys Asn Asp Ser Glu Val Ile Lys Ala
305 310 315 320
Leu Lys Gly Phe Tyr Ile Glu Asp Gly Phe Glu Asn Asn Val Leu Thr
325 330 335
Pro Leu Ala Thr Leu Leu Ser Ser Leu Asp Lys Tyr Asn Leu Asn Gly
340 345 350
Ile Phe Ile Arg Asn Asn Glu Ala Leu Ser Ser Leu Ser Gln Asn Val
355 360 365
Tyr Arg Asn Phe Ser Ile Asp Glu Ala Ile Asp Ala Asn Ala Glu Leu
370 375 380
Gln Thr Phe Asn Asn Tyr Glu Leu Ile Ala Asn Ala Leu Arg Ala Lys
385 390 395 400
Ile Lys Lys Glu Thr Lys Gln Gly Arg Lys Ser Phe Glu Lys Tyr Glu
405 410 415
Glu Tyr Ile Asp Lys Lys Val Lys Ala Ile Asp Ser Leu Ser Ile Gln
420 425 430
Glu Ile Asn Glu Leu Val Glu Asn Tyr Val Ser Glu Phe Asn Ser Asn
435 440 445
Ser Gly Asn Met Pro Arg Lys Val Glu Asp Tyr Phe Ser Leu Met Arg
450 455 460
Lys Gly Asp Phe Gly Ser Asn Asp Leu Ile Glu Asn Ile Lys Thr Lys
465 470 475 480
Leu Ser Ala Ala Glu Lys Leu Leu Gly Thr Lys Tyr Gln Glu Thr Ala
485 490 495
Lys Asp Ile Phe Lys Lys Asp Glu Asn Ser Lys Leu Ile Lys Glu Leu
500 505 510
Leu Asp Ala Thr Lys Gln Phe Gln His Phe Ile Lys Pro Leu Leu Gly
515 520 525
Thr Gly Glu Glu Ala Asp Arg Asp Leu Val Phe Tyr Gly Asp Phe Leu
530 535 540
Pro Leu Tyr Glu Lys Phe Glu Glu Leu Thr Leu Leu Tyr Asn Lys Val
545 550 555 560
Arg Asn Arg Leu Thr Gln Lys Pro Tyr Ser Lys Asp Lys Ile Arg Leu
565 570 575
Cys Phe Asn Lys Pro Lys Leu Met Thr Gly Trp Val Asp Ser Lys Thr
580 585 590
Glu Lys Ser Asp Asn Gly Thr Gln Tyr Gly Gly Tyr Leu Phe Arg Lys
595 600 605
Lys Asn Glu Ile Gly Glu Tyr Asp Tyr Phe Leu Gly Ile Ser Ser Lys
610 615 620
Ala Gln Leu Phe Arg Lys Asn Glu Ala Val Ile Gly Asp Tyr Glu Arg
625 630 635 640
Leu Asp Tyr Tyr Gln Pro Lys Ala Asn Thr Ile Tyr Gly Ser Ala Tyr
645 650 655
Glu Gly Glu Asn Ser Tyr Lys Glu Asp Lys Lys Arg Leu Asn Lys Val
660 665 670
Ile Ile Ala Tyr Ile Glu Gln Ile Lys Gln Thr Asn Ile Lys Lys Ser
675 680 685
Ile Ile Glu Ser Ile Ser Lys Tyr Pro Asn Ile Ser Asp Asp Asp Lys
690 695 700
Val Thr Pro Ser Ser Leu Leu Glu Lys Ile Lys Lys Val Ser Ile Asp
705 710 715 720
Ser Tyr Asn Gly Ile Leu Ser Phe Lys Ser Phe Gln Ser Val Asn Lys
725 730 735
Glu Val Ile Asp Asn Leu Leu Lys Thr Ile Ser Pro Leu Lys Asn Lys
740 745 750
Ala Glu Phe Leu Asp Leu Ile Asn Lys Asp Tyr Gln Ile Phe Thr Glu
755 760 765
Val Gln Ala Val Ile Asp Glu Ile Cys Lys Gln Lys Thr Phe Ile Tyr
770 775 780
Phe Pro Ile Ser Asn Val Glu Leu Glu Lys Glu Met Gly Asp Lys Asp
785 790 795 800
Lys Pro Leu Cys Leu Phe Gln Ile Ser Asn Lys Asp Leu Ser Phe Ala
805 810 815
Lys Thr Phe Ser Ala Asn Leu Arg Lys Lys Arg Gly Ala Glu Asn Leu
820 825 830
His Thr Met Leu Phe Lys Ala Leu Met Glu Gly Asn Gln Asp Asn Leu
835 840 845
Asp Leu Gly Ser Gly Ala Ile Phe Tyr Arg Ala Lys Ser Leu Asp Gly
850 855 860
Asn Lys Pro Thr His Pro Ala Asn Glu Ala Ile Lys Cys Arg Asn Val
865 870 875 880
Ala Asn Lys Asp Lys Val Ser Leu Phe Thr Tyr Asp Ile Tyr Lys Asn
885 890 895
Arg Arg Tyr Met Glu Asn Lys Phe Leu Phe His Leu Ser Ile Val Gln
900 905 910
Asn Tyr Lys Ala Ala Asn Asp Ser Ala Gln Leu Asn Ser Ser Ala Thr
915 920 925
Glu Tyr Ile Arg Lys Ala Asp Asp Leu His Ile Ile Gly Ile Asp Arg
930 935 940
Gly Glu Arg Asn Leu Leu Tyr Tyr Ser Val Ile Asp Met Lys Gly Asn
945 950 955 960
Ile Val Glu Gln Asp Ser Leu Asn Ile Ile Arg Asn Asn Asp Leu Glu
965 970 975
Thr Asp Tyr His Asp Leu Leu Asp Lys Arg Glu Lys Glu Arg Lys Ala
980 985 990
Asn Arg Gln Asn Trp Glu Ala Val Glu Gly Ile Lys Asp Leu Lys Lys
995 1000 1005
Gly Tyr Leu Ser Gln Ala Val His Gln Ile Ala Gln Leu Met Leu
1010 1015 1020
Lys Tyr Asn Ala Ile Ile Ala Leu Glu Asp Leu Gly Gln Met Phe
1025 1030 1035
Val Thr Arg Gly Gln Lys Ile Glu Lys Ala Val Tyr Gln Gln Phe
1040 1045 1050
Glu Lys Ser Leu Val Asp Lys Leu Ser Tyr Leu Val Asp Lys Lys
1055 1060 1065
Arg Pro Tyr Asn Glu Leu Gly Gly Ile Leu Lys Ala Tyr Gln Leu
1070 1075 1080
Ala Ser Ser Ile Thr Lys Asn Asn Ser Asp Lys Gln Asn Gly Phe
1085 1090 1095
Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro Val
1100 1105 1110
Thr Gly Phe Thr Asp Leu Leu Arg Pro Lys Ala Met Thr Ile Lys
1115 1120 1125
Glu Ala Gln Asp Phe Phe Gly Ala Phe Asp Asn Ile Ser Tyr Asn
1130 1135 1140
Asp Lys Gly Tyr Phe Glu Phe Glu Thr Asn Tyr Asp Lys Phe Lys
1145 1150 1155
Ile Arg Met Lys Ser Ala Gln Thr Arg Trp Thr Ile Cys Thr Phe
1160 1165 1170
Gly Asn Arg Ile Lys Arg Lys Lys Asp Lys Asn Tyr Trp Asn Tyr
1175 1180 1185
Glu Glu Val Glu Leu Thr Glu Glu Phe Lys Lys Leu Phe Lys Asp
1190 1195 1200
Ser Asn Ile Asp Tyr Glu Asn Cys Asn Leu Lys Glu Glu Ile Gln
1205 1210 1215
Asn Lys Asp Asn Arg Lys Phe Phe Asp Asp Leu Ile Lys Leu Leu
1220 1225 1230
Gln Leu Thr Leu Gln Met Arg Asn Ser Asp Asp Lys Gly Asn Asp
1235 1240 1245
Tyr Ile Ile Ser Pro Val Ala Asn Ala Glu Gly Gln Phe Phe Asp
1250 1255 1260
Ser Arg Asn Gly Asp Lys Lys Leu Pro Leu Asp Ala Asp Ala Asn
1265 1270 1275
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Trp Asn Ile Arg Gln
1280 1285 1290
Ile Lys Gln Thr Lys Asn Asp Lys Lys Leu Asn Leu Ser Ile Ser
1295 1300 1305
Ser Thr Glu Trp Leu Asp Phe Val Arg Glu Lys Pro Tyr Leu Lys
1310 1315 1320
<210> 75
<211> 1318
<212> БЕЛОК
<213> Flavobacterium branchiophilum
<400> 75
Met Thr Asn Lys Phe Thr Asn Gln Tyr Ser Leu Ser Lys Thr Leu Arg
1 5 10 15
Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Phe Ile Gln Glu Lys
20 25 30
Gly Leu Leu Ser Gln Asp Lys Gln Arg Ala Glu Ser Tyr Gln Glu Met
35 40 45
Lys Lys Thr Ile Asp Lys Phe His Lys Tyr Phe Ile Asp Leu Ala Leu
50 55 60
Ser Asn Ala Lys Leu Thr His Leu Glu Thr Tyr Leu Glu Leu Tyr Asn
65 70 75 80
Lys Ser Ala Glu Thr Lys Lys Glu Gln Lys Phe Lys Asp Asp Leu Lys
85 90 95
Lys Val Gln Asp Asn Leu Arg Lys Glu Ile Val Lys Ser Phe Ser Asp
100 105 110
Gly Asp Ala Lys Ser Ile Phe Ala Ile Leu Asp Lys Lys Glu Leu Ile
115 120 125
Thr Val Glu Leu Glu Lys Trp Phe Glu Asn Asn Glu Gln Lys Asp Ile
130 135 140
Tyr Phe Asp Glu Lys Phe Lys Thr Phe Thr Thr Tyr Phe Thr Gly Phe
145 150 155 160
His Gln Asn Arg Lys Asn Met Tyr Ser Val Glu Pro Asn Ser Thr Ala
165 170 175
Ile Ala Tyr Arg Leu Ile His Glu Asn Leu Pro Lys Phe Leu Glu Asn
180 185 190
Ala Lys Ala Phe Glu Lys Ile Lys Gln Val Glu Ser Leu Gln Val Asn
195 200 205
Phe Arg Glu Leu Met Gly Glu Phe Gly Asp Glu Gly Leu Ile Phe Val
210 215 220
Asn Glu Leu Glu Glu Met Phe Gln Ile Asn Tyr Tyr Asn Asp Val Leu
225 230 235 240
Ser Gln Asn Gly Ile Thr Ile Tyr Asn Ser Ile Ile Ser Gly Phe Thr
245 250 255
Lys Asn Asp Ile Lys Tyr Lys Gly Leu Asn Glu Tyr Ile Asn Asn Tyr
260 265 270
Asn Gln Thr Lys Asp Lys Lys Asp Arg Leu Pro Lys Leu Lys Gln Leu
275 280 285
Tyr Lys Gln Ile Leu Ser Asp Arg Ile Ser Leu Ser Phe Leu Pro Asp
290 295 300
Ala Phe Thr Asp Gly Lys Gln Val Leu Lys Ala Ile Phe Asp Phe Tyr
305 310 315 320
Lys Ile Asn Leu Leu Ser Tyr Thr Ile Glu Gly Gln Glu Glu Ser Gln
325 330 335
Asn Leu Leu Leu Leu Ile Arg Gln Thr Ile Glu Asn Leu Ser Ser Phe
340 345 350
Asp Thr Gln Lys Ile Tyr Leu Lys Asn Asp Thr His Leu Thr Thr Ile
355 360 365
Ser Gln Gln Val Phe Gly Asp Phe Ser Val Phe Ser Thr Ala Leu Asn
370 375 380
Tyr Trp Tyr Glu Thr Lys Val Asn Pro Lys Phe Glu Thr Glu Tyr Ser
385 390 395 400
Lys Ala Asn Glu Lys Lys Arg Glu Ile Leu Asp Lys Ala Lys Ala Val
405 410 415
Phe Thr Lys Gln Asp Tyr Phe Ser Ile Ala Phe Leu Gln Glu Val Leu
420 425 430
Ser Glu Tyr Ile Leu Thr Leu Asp His Thr Ser Asp Ile Val Lys Lys
435 440 445
His Ser Ser Asn Cys Ile Ala Asp Tyr Phe Lys Asn His Phe Val Ala
450 455 460
Lys Lys Glu Asn Glu Thr Asp Lys Thr Phe Asp Phe Ile Ala Asn Ile
465 470 475 480
Thr Ala Lys Tyr Gln Cys Ile Gln Gly Ile Leu Glu Asn Ala Asp Gln
485 490 495
Tyr Glu Asp Glu Leu Lys Gln Asp Gln Lys Leu Ile Asp Asn Leu Lys
500 505 510
Phe Phe Leu Asp Ala Ile Leu Glu Leu Leu His Phe Ile Lys Pro Leu
515 520 525
His Leu Lys Ser Glu Ser Ile Thr Glu Lys Asp Thr Ala Phe Tyr Asp
530 535 540
Val Phe Glu Asn Tyr Tyr Glu Ala Leu Ser Leu Leu Thr Pro Leu Tyr
545 550 555 560
Asn Met Val Arg Asn Tyr Val Thr Gln Lys Pro Tyr Ser Thr Glu Lys
565 570 575
Ile Lys Leu Asn Phe Glu Asn Ala Gln Leu Leu Asn Gly Trp Asp Ala
580 585 590
Asn Lys Glu Gly Asp Tyr Leu Thr Thr Ile Leu Lys Lys Asp Gly Asn
595 600 605
Tyr Phe Leu Ala Ile Met Asp Lys Lys His Asn Lys Ala Phe Gln Lys
610 615 620
Phe Pro Glu Gly Lys Glu Asn Tyr Glu Lys Met Val Tyr Lys Leu Leu
625 630 635 640
Pro Gly Val Asn Lys Met Leu Pro Lys Val Phe Phe Ser Asn Lys Asn
645 650 655
Ile Ala Tyr Phe Asn Pro Ser Lys Glu Leu Leu Glu Asn Tyr Lys Lys
660 665 670
Glu Thr His Lys Lys Gly Asp Thr Phe Asn Leu Glu His Cys His Thr
675 680 685
Leu Ile Asp Phe Phe Lys Asp Ser Leu Asn Lys His Glu Asp Trp Lys
690 695 700
Tyr Phe Asp Phe Gln Phe Ser Glu Thr Lys Ser Tyr Gln Asp Leu Ser
705 710 715 720
Gly Phe Tyr Arg Glu Val Glu His Gln Gly Tyr Lys Ile Asn Phe Lys
725 730 735
Asn Ile Asp Ser Glu Tyr Ile Asp Gly Leu Val Asn Glu Gly Lys Leu
740 745 750
Phe Leu Phe Gln Ile Tyr Ser Lys Asp Phe Ser Pro Phe Ser Lys Gly
755 760 765
Lys Pro Asn Met His Thr Leu Tyr Trp Lys Ala Leu Phe Glu Glu Gln
770 775 780
Asn Leu Gln Asn Val Ile Tyr Lys Leu Asn Gly Gln Ala Glu Ile Phe
785 790 795 800
Phe Arg Lys Ala Ser Ile Lys Pro Lys Asn Ile Ile Leu His Lys Lys
805 810 815
Lys Ile Lys Ile Ala Lys Lys His Phe Ile Asp Lys Lys Thr Lys Thr
820 825 830
Ser Glu Ile Val Pro Val Gln Thr Ile Lys Asn Leu Asn Met Tyr Tyr
835 840 845
Gln Gly Lys Ile Ser Glu Lys Glu Leu Thr Gln Asp Asp Leu Arg Tyr
850 855 860
Ile Asp Asn Phe Ser Ile Phe Asn Glu Lys Asn Lys Thr Ile Asp Ile
865 870 875 880
Ile Lys Asp Lys Arg Phe Thr Val Asp Lys Phe Gln Phe His Val Pro
885 890 895
Ile Thr Met Asn Phe Lys Ala Thr Gly Gly Ser Tyr Ile Asn Gln Thr
900 905 910
Val Leu Glu Tyr Leu Gln Asn Asn Pro Glu Val Lys Ile Ile Gly Leu
915 920 925
Asp Arg Gly Glu Arg His Leu Val Tyr Leu Thr Leu Ile Asp Gln Gln
930 935 940
Gly Asn Ile Leu Lys Gln Glu Ser Leu Asn Thr Ile Thr Asp Ser Lys
945 950 955 960
Ile Ser Thr Pro Tyr His Lys Leu Leu Asp Asn Lys Glu Asn Glu Arg
965 970 975
Asp Leu Ala Arg Lys Asn Trp Gly Thr Val Glu Asn Ile Lys Glu Leu
980 985 990
Lys Glu Gly Tyr Ile Ser Gln Val Val His Lys Ile Ala Thr Leu Met
995 1000 1005
Leu Glu Glu Asn Ala Ile Val Val Met Glu Asp Leu Asn Phe Gly
1010 1015 1020
Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Ile Tyr Gln Lys
1025 1030 1035
Leu Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Leu Lys
1040 1045 1050
Asp Lys Gln Pro Gln Glu Leu Gly Gly Leu Tyr Asn Ala Leu Gln
1055 1060 1065
Leu Thr Asn Lys Phe Glu Ser Phe Gln Lys Met Gly Lys Gln Ser
1070 1075 1080
Gly Phe Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile Asp
1085 1090 1095
Pro Thr Thr Gly Phe Val Asn Tyr Phe Tyr Thr Lys Tyr Glu Asn
1100 1105 1110
Val Asp Lys Ala Lys Ala Phe Phe Glu Lys Phe Glu Ala Ile Arg
1115 1120 1125
Phe Asn Ala Glu Lys Lys Tyr Phe Glu Phe Glu Val Lys Lys Tyr
1130 1135 1140
Ser Asp Phe Asn Pro Lys Ala Glu Gly Thr Gln Gln Ala Trp Thr
1145 1150 1155
Ile Cys Thr Tyr Gly Glu Arg Ile Glu Thr Lys Arg Gln Lys Asp
1160 1165 1170
Gln Asn Asn Lys Phe Val Ser Thr Pro Ile Asn Leu Thr Glu Lys
1175 1180 1185
Ile Glu Asp Phe Leu Gly Lys Asn Gln Ile Val Tyr Gly Asp Gly
1190 1195 1200
Asn Cys Ile Lys Ser Gln Ile Ala Ser Lys Asp Asp Lys Ala Phe
1205 1210 1215
Phe Glu Thr Leu Leu Tyr Trp Phe Lys Met Thr Leu Gln Met Arg
1220 1225 1230
Asn Ser Glu Thr Arg Thr Asp Ile Asp Tyr Leu Ile Ser Pro Val
1235 1240 1245
Met Asn Asp Asn Gly Thr Phe Tyr Asn Ser Arg Asp Tyr Glu Lys
1250 1255 1260
Leu Glu Asn Pro Thr Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala
1265 1270 1275
Tyr His Ile Ala Lys Lys Gly Leu Met Leu Leu Asn Lys Ile Asp
1280 1285 1290
Gln Ala Asp Leu Thr Lys Lys Val Asp Leu Ser Ile Ser Asn Arg
1295 1300 1305
Asp Trp Leu Gln Phe Val Gln Lys Asn Lys
1310 1315
<210> 76
<211> 1310
<212> БЕЛОК
<213> Helcococcus kunzii
<400> 76
Met Phe Glu Lys Leu Ser Asn Ile Val Ser Ile Ser Lys Thr Ile Arg
1 5 10 15
Phe Lys Leu Ile Pro Val Gly Lys Thr Leu Glu Asn Ile Glu Lys Leu
20 25 30
Gly Lys Leu Glu Lys Asp Phe Glu Arg Ser Asp Phe Tyr Pro Ile Leu
35 40 45
Lys Asn Ile Ser Asp Asp Tyr Tyr Arg Gln Tyr Ile Lys Glu Lys Leu
50 55 60
Ser Asp Leu Asn Leu Asp Trp Gln Lys Leu Tyr Asp Ala His Glu Leu
65 70 75 80
Leu Asp Ser Ser Lys Lys Glu Ser Gln Lys Asn Leu Glu Met Ile Gln
85 90 95
Ala Gln Tyr Arg Lys Val Leu Phe Asn Ile Leu Ser Gly Glu Leu Asp
100 105 110
Lys Ser Gly Glu Lys Asn Ser Lys Asp Leu Ile Lys Asn Asn Lys Ala
115 120 125
Leu Tyr Gly Lys Leu Phe Lys Lys Gln Phe Ile Leu Glu Val Leu Pro
130 135 140
Asp Phe Val Asn Asn Asn Asp Ser Tyr Ser Glu Glu Asp Leu Glu Gly
145 150 155 160
Leu Asn Leu Tyr Ser Lys Phe Thr Thr Arg Leu Lys Asn Phe Trp Glu
165 170 175
Thr Arg Lys Asn Val Phe Thr Asp Lys Asp Ile Val Thr Ala Ile Pro
180 185 190
Phe Arg Ala Val Asn Glu Asn Phe Gly Phe Tyr Tyr Asp Asn Ile Lys
195 200 205
Ile Phe Asn Lys Asn Ile Glu Tyr Leu Glu Asn Lys Ile Pro Asn Leu
210 215 220
Glu Asn Glu Leu Lys Glu Ala Asp Ile Leu Asp Asp Asn Arg Ser Val
225 230 235 240
Lys Asp Tyr Phe Thr Pro Asn Gly Phe Asn Tyr Val Ile Thr Gln Asp
245 250 255
Gly Ile Asp Val Tyr Gln Ala Ile Arg Gly Gly Phe Thr Lys Glu Asn
260 265 270
Gly Glu Lys Val Gln Gly Ile Asn Glu Ile Leu Asn Leu Thr Gln Gln
275 280 285
Gln Leu Arg Arg Lys Pro Glu Thr Lys Asn Val Lys Leu Gly Val Leu
290 295 300
Thr Lys Leu Arg Lys Gln Ile Leu Glu Tyr Ser Glu Ser Thr Ser Phe
305 310 315 320
Leu Ile Asp Gln Ile Glu Asp Asp Asn Asp Leu Val Asp Arg Ile Asn
325 330 335
Lys Phe Asn Val Ser Phe Phe Glu Ser Thr Glu Val Ser Pro Ser Leu
340 345 350
Phe Glu Gln Ile Glu Arg Leu Tyr Asn Ala Leu Lys Ser Ile Lys Lys
355 360 365
Glu Glu Val Tyr Ile Asp Ala Arg Asn Thr Gln Lys Phe Ser Gln Met
370 375 380
Leu Phe Gly Gln Trp Asp Val Ile Arg Arg Gly Tyr Thr Val Lys Ile
385 390 395 400
Thr Glu Gly Ser Lys Glu Glu Lys Lys Lys Tyr Lys Glu Tyr Leu Glu
405 410 415
Leu Asp Glu Thr Ser Lys Ala Lys Arg Tyr Leu Asn Ile Arg Glu Ile
420 425 430
Glu Glu Leu Val Asn Leu Val Glu Gly Phe Glu Glu Val Asp Val Phe
435 440 445
Ser Val Leu Leu Glu Lys Phe Lys Met Asn Asn Ile Glu Arg Ser Glu
450 455 460
Phe Glu Ala Pro Ile Tyr Gly Ser Pro Ile Lys Leu Glu Ala Ile Lys
465 470 475 480
Glu Tyr Leu Glu Lys His Leu Glu Glu Tyr His Lys Trp Lys Leu Leu
485 490 495
Leu Ile Gly Asn Asp Asp Leu Asp Thr Asp Glu Thr Phe Tyr Pro Leu
500 505 510
Leu Asn Glu Val Ile Ser Asp Tyr Tyr Ile Ile Pro Leu Tyr Asn Leu
515 520 525
Thr Arg Asn Tyr Leu Thr Arg Lys His Ser Asp Lys Asp Lys Ile Lys
530 535 540
Val Asn Phe Asp Phe Pro Thr Leu Ala Asp Gly Trp Ser Glu Ser Lys
545 550 555 560
Ile Ser Asp Asn Arg Ser Ile Ile Leu Arg Lys Gly Gly Tyr Tyr Tyr
565 570 575
Leu Gly Ile Leu Ile Asp Asn Lys Leu Leu Ile Asn Lys Lys Asn Lys
580 585 590
Ser Lys Lys Ile Tyr Glu Ile Leu Ile Tyr Asn Gln Ile Pro Glu Phe
595 600 605
Ser Lys Ser Ile Pro Asn Tyr Pro Phe Thr Lys Lys Val Lys Glu His
610 615 620
Phe Lys Asn Asn Val Ser Asp Phe Gln Leu Ile Asp Gly Tyr Val Ser
625 630 635 640
Pro Leu Ile Ile Thr Lys Glu Ile Tyr Asp Ile Lys Lys Glu Lys Lys
645 650 655
Tyr Lys Lys Asp Phe Tyr Lys Asp Asn Asn Thr Asn Lys Asn Tyr Leu
660 665 670
Tyr Thr Ile Tyr Lys Trp Ile Glu Phe Cys Lys Gln Phe Leu Tyr Lys
675 680 685
Tyr Lys Gly Pro Asn Lys Glu Ser Tyr Lys Glu Met Tyr Asp Phe Ser
690 695 700
Thr Leu Lys Asp Thr Ser Leu Tyr Val Asn Leu Asn Asp Phe Tyr Ala
705 710 715 720
Asp Val Asn Ser Cys Ala Tyr Arg Val Leu Phe Asn Lys Ile Asp Glu
725 730 735
Asn Thr Ile Asp Asn Ala Val Glu Asp Gly Lys Leu Leu Leu Phe Gln
740 745 750
Ile Tyr Asn Lys Asp Phe Ser Pro Glu Ser Lys Gly Lys Lys Asn Leu
755 760 765
His Thr Leu Tyr Trp Leu Ser Met Phe Ser Glu Glu Asn Leu Arg Thr
770 775 780
Arg Lys Leu Lys Leu Asn Gly Gln Ala Glu Ile Phe Tyr Arg Lys Lys
785 790 795 800
Leu Glu Lys Lys Pro Ile Ile His Lys Glu Gly Ser Ile Leu Leu Asn
805 810 815
Lys Ile Asp Lys Glu Gly Asn Thr Ile Pro Glu Asn Ile Tyr His Glu
820 825 830
Cys Tyr Arg Tyr Leu Asn Lys Lys Ile Gly Arg Glu Asp Leu Ser Asp
835 840 845
Glu Ala Ile Ala Leu Phe Asn Lys Asp Val Leu Lys Tyr Lys Glu Ala
850 855 860
Arg Phe Asp Ile Ile Lys Asp Arg Arg Tyr Ser Glu Ser Gln Phe Phe
865 870 875 880
Phe His Val Pro Ile Thr Phe Asn Trp Asp Ile Lys Thr Asn Lys Asn
885 890 895
Val Asn Gln Ile Val Gln Gly Met Ile Lys Asp Gly Glu Ile Lys His
900 905 910
Ile Ile Gly Ile Asp Arg Gly Glu Arg His Leu Leu Tyr Tyr Ser Val
915 920 925
Ile Asp Leu Glu Gly Asn Ile Val Glu Gln Gly Ser Leu Asn Thr Leu
930 935 940
Glu Gln Asn Arg Phe Asp Asn Ser Thr Val Lys Val Asp Tyr Gln Asn
945 950 955 960
Lys Leu Arg Thr Arg Glu Glu Asp Arg Asp Arg Ala Arg Lys Asn Trp
965 970 975
Thr Asn Ile Asn Lys Ile Lys Glu Leu Lys Asp Gly Tyr Leu Ser His
980 985 990
Val Val His Lys Leu Ser Arg Leu Ile Ile Lys Tyr Glu Ala Ile Val
995 1000 1005
Ile Met Glu Asn Leu Asn Gln Gly Phe Lys Arg Gly Arg Phe Lys
1010 1015 1020
Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Leu Ala Leu Met Asn
1025 1030 1035
Lys Leu Ser Ala Leu Ser Phe Lys Glu Lys Tyr Asp Glu Arg Lys
1040 1045 1050
Asn Leu Glu Pro Ser Gly Ile Leu Asn Pro Ile Gln Ala Cys Tyr
1055 1060 1065
Pro Val Asp Ala Tyr Gln Glu Leu Gln Gly Gln Asn Gly Ile Val
1070 1075 1080
Phe Tyr Leu Pro Ala Ala Tyr Thr Ser Val Ile Asp Pro Val Thr
1085 1090 1095
Gly Phe Thr Asn Leu Phe Arg Leu Lys Ser Ile Asn Ser Ser Lys
1100 1105 1110
Tyr Glu Glu Phe Ile Lys Lys Phe Lys Asn Ile Tyr Phe Asp Asn
1115 1120 1125
Glu Glu Glu Asp Phe Lys Phe Ile Phe Asn Tyr Lys Asp Phe Ala
1130 1135 1140
Lys Ala Asn Leu Val Ile Leu Asn Asn Ile Lys Ser Lys Asp Trp
1145 1150 1155
Lys Ile Ser Thr Arg Gly Glu Arg Ile Ser Tyr Asn Ser Lys Lys
1160 1165 1170
Lys Glu Tyr Phe Tyr Val Gln Pro Thr Glu Phe Leu Ile Asn Lys
1175 1180 1185
Leu Lys Glu Leu Asn Ile Asp Tyr Glu Asn Ile Asp Ile Ile Pro
1190 1195 1200
Leu Ile Asp Asn Leu Glu Glu Lys Ala Lys Arg Lys Ile Leu Lys
1205 1210 1215
Ala Leu Phe Asp Thr Phe Lys Tyr Ser Val Gln Leu Arg Asn Tyr
1220 1225 1230
Asp Phe Glu Asn Asp Tyr Ile Ile Ser Pro Thr Ala Asp Asp Asn
1235 1240 1245
Gly Asn Tyr Tyr Asn Ser Asn Glu Ile Asp Ile Asp Lys Thr Asn
1250 1255 1260
Leu Pro Asn Asn Gly Asp Ala Asn Gly Ala Phe Asn Ile Ala Arg
1265 1270 1275
Lys Gly Leu Leu Leu Lys Asp Arg Ile Val Asn Ser Asn Glu Ser
1280 1285 1290
Lys Val Asp Leu Lys Ile Lys Asn Glu Asp Trp Ile Asn Phe Ile
1295 1300 1305
Ile Ser
1310
<210> 77
<211> 1307
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 77
Met Thr Gln Phe Glu Gly Phe Thr Asn Leu Tyr Gln Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Lys His Ile Gln
20 25 30
Glu Gln Gly Phe Ile Glu Glu Asp Lys Ala Arg Asn Asp His Tyr Lys
35 40 45
Glu Leu Lys Pro Ile Ile Asp Arg Ile Tyr Lys Thr Tyr Ala Asp Gln
50 55 60
Cys Leu Gln Leu Val Gln Leu Asp Trp Glu Asn Leu Ser Ala Ala Ile
65 70 75 80
Asp Ser Tyr Arg Lys Glu Lys Thr Glu Glu Thr Arg Asn Ala Leu Ile
85 90 95
Glu Glu Gln Ala Thr Tyr Arg Asn Ala Ile His Asp Tyr Phe Ile Gly
100 105 110
Arg Thr Asp Asn Leu Thr Asp Ala Ile Asn Lys Arg His Ala Glu Ile
115 120 125
Tyr Lys Gly Leu Phe Lys Ala Glu Leu Phe Asn Gly Lys Val Leu Lys
130 135 140
Gln Leu Gly Thr Val Thr Thr Thr Glu His Glu Asn Ala Leu Leu Arg
145 150 155 160
Ser Phe Asp Lys Phe Thr Thr Tyr Phe Ser Gly Phe Tyr Glu Asn Arg
165 170 175
Lys Asn Val Phe Ser Ala Glu Asp Ile Ser Thr Ala Ile Pro His Arg
180 185 190
Ile Val Gln Asp Asn Phe Pro Lys Phe Lys Glu Asn Cys His Ile Phe
195 200 205
Thr Arg Leu Ile Thr Ala Val Pro Ser Leu Arg Glu His Phe Glu Asn
210 215 220
Val Lys Lys Ala Ile Gly Ile Phe Val Ser Thr Ser Ile Glu Glu Val
225 230 235 240
Phe Ser Phe Pro Phe Tyr Asn Gln Leu Leu Thr Gln Thr Gln Ile Asp
245 250 255
Leu Tyr Asn Gln Leu Leu Gly Gly Ile Ser Arg Glu Ala Gly Thr Glu
260 265 270
Lys Ile Lys Gly Leu Asn Glu Val Leu Asn Leu Ala Ile Gln Lys Asn
275 280 285
Asp Glu Thr Ala His Ile Ile Ala Ser Leu Pro His Arg Phe Ile Pro
290 295 300
Leu Phe Lys Gln Ile Leu Ser Asp Arg Asn Thr Leu Ser Phe Ile Leu
305 310 315 320
Glu Glu Phe Lys Ser Asp Glu Glu Val Ile Gln Ser Phe Cys Lys Tyr
325 330 335
Lys Thr Leu Leu Arg Asn Glu Asn Val Leu Glu Thr Ala Glu Ala Leu
340 345 350
Phe Asn Glu Leu Asn Ser Ile Asp Leu Thr His Ile Phe Ile Ser His
355 360 365
Lys Lys Leu Glu Thr Ile Ser Ser Ala Leu Cys Asp His Trp Asp Thr
370 375 380
Leu Arg Asn Ala Leu Tyr Glu Arg Arg Ile Ser Glu Leu Thr Gly Lys
385 390 395 400
Ile Thr Lys Ser Ala Lys Glu Lys Val Gln Arg Ser Leu Lys His Glu
405 410 415
Asp Ile Asn Leu Gln Glu Ile Ile Ser Ala Ala Gly Lys Glu Leu Ser
420 425 430
Glu Ala Phe Lys Gln Lys Thr Ser Glu Ile Leu Ser His Ala His Ala
435 440 445
Ala Leu Asp Gln Pro Leu Pro Thr Thr Leu Lys Lys Gln Glu Glu Lys
450 455 460
Glu Ile Leu Lys Ser Gln Leu Asp Ser Leu Leu Gly Leu Tyr His Leu
465 470 475 480
Leu Asp Trp Phe Ala Val Asp Glu Ser Asn Glu Val Asp Pro Glu Phe
485 490 495
Ser Ala Arg Leu Thr Gly Ile Lys Leu Glu Met Glu Pro Ser Leu Ser
500 505 510
Phe Tyr Asn Lys Ala Arg Asn Tyr Ala Thr Lys Lys Pro Tyr Ser Val
515 520 525
Glu Lys Phe Lys Leu Asn Phe Gln Met Pro Thr Leu Ala Ser Gly Trp
530 535 540
Asp Val Asn Lys Glu Lys Asn Asn Gly Ala Ile Leu Phe Val Lys Asn
545 550 555 560
Gly Leu Tyr Tyr Leu Gly Ile Met Pro Lys Gln Lys Gly Arg Tyr Lys
565 570 575
Ala Leu Ser Phe Glu Pro Thr Glu Lys Thr Ser Glu Gly Phe Asp Lys
580 585 590
Met Tyr Tyr Asp Tyr Phe Pro Asp Ala Ala Lys Met Ile Pro Lys Cys
595 600 605
Ser Thr Gln Leu Lys Ala Val Thr Ala His Phe Gln Thr His Thr Thr
610 615 620
Pro Ile Leu Leu Ser Asn Asn Phe Ile Glu Pro Leu Glu Ile Thr Lys
625 630 635 640
Glu Ile Tyr Asp Leu Asn Asn Pro Glu Lys Glu Pro Lys Lys Phe Gln
645 650 655
Thr Ala Tyr Ala Lys Lys Thr Gly Asp Gln Lys Gly Tyr Arg Glu Ala
660 665 670
Leu Cys Lys Trp Ile Asp Phe Thr Arg Asp Phe Leu Ser Lys Tyr Thr
675 680 685
Lys Thr Thr Ser Ile Asp Leu Ser Ser Leu Arg Pro Ser Ser Gln Tyr
690 695 700
Lys Asp Leu Gly Glu Tyr Tyr Ala Glu Leu Asn Pro Leu Leu Tyr His
705 710 715 720
Ile Ser Phe Gln Arg Ile Ala Glu Lys Glu Ile Met Asp Ala Val Glu
725 730 735
Thr Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Lys
740 745 750
Gly His His Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Thr Gly Leu
755 760 765
Phe Ser Pro Glu Asn Leu Ala Lys Thr Ser Ile Lys Leu Asn Gly Gln
770 775 780
Ala Glu Leu Phe Tyr Arg Pro Lys Ser Arg Met Lys Arg Met Ala His
785 790 795 800
Arg Leu Gly Glu Lys Met Leu Asn Lys Lys Leu Lys Asp Gln Lys Thr
805 810 815
Pro Ile Pro Asp Thr Leu Tyr Gln Glu Leu Tyr Asp Tyr Val Asn His
820 825 830
Arg Leu Ser His Asp Leu Ser Asp Glu Ala Arg Ala Leu Leu Pro Asn
835 840 845
Val Ile Thr Lys Glu Val Ser His Glu Ile Ile Lys Asp Arg Arg Phe
850 855 860
Thr Ser Asp Lys Phe Phe Phe His Val Pro Ile Thr Leu Asn Tyr Gln
865 870 875 880
Ala Ala Asn Ser Pro Ser Lys Phe Asn Gln Arg Val Asn Ala Tyr Leu
885 890 895
Lys Glu His Pro Glu Thr Pro Ile Ile Gly Ile Asp Arg Gly Glu Arg
900 905 910
Asn Leu Ile Tyr Ile Thr Val Ile Asp Ser Thr Gly Lys Ile Leu Glu
915 920 925
Gln Arg Ser Leu Asn Thr Ile Gln Gln Phe Asp Tyr Gln Lys Lys Leu
930 935 940
Asp Asn Arg Glu Lys Glu Arg Val Ala Ala Arg Gln Ala Trp Ser Val
945 950 955 960
Val Gly Thr Ile Lys Asp Leu Lys Gln Gly Tyr Leu Ser Gln Val Ile
965 970 975
His Glu Ile Val Asp Leu Met Ile His Tyr Gln Ala Val Val Val Leu
980 985 990
Glu Asn Leu Asn Phe Gly Phe Lys Ser Lys Arg Thr Gly Ile Ala Glu
995 1000 1005
Lys Ala Val Tyr Gln Gln Phe Glu Lys Met Leu Ile Asp Lys Leu
1010 1015 1020
Asn Cys Leu Val Leu Lys Asp Tyr Pro Ala Glu Lys Val Gly Gly
1025 1030 1035
Val Leu Asn Pro Tyr Gln Leu Thr Asp Gln Phe Thr Ser Phe Ala
1040 1045 1050
Lys Met Gly Thr Gln Ser Gly Phe Leu Phe Tyr Val Pro Ala Pro
1055 1060 1065
Tyr Thr Ser Lys Ile Asp Pro Leu Thr Gly Phe Val Asp Pro Phe
1070 1075 1080
Val Trp Lys Thr Ile Lys Asn His Glu Ser Arg Lys His Phe Leu
1085 1090 1095
Glu Gly Phe Asp Phe Leu His Tyr Asp Val Lys Thr Gly Asp Phe
1100 1105 1110
Ile Leu His Phe Lys Met Asn Arg Asn Leu Ser Phe Gln Arg Gly
1115 1120 1125
Leu Pro Gly Phe Met Pro Ala Trp Asp Ile Val Phe Glu Lys Asn
1130 1135 1140
Glu Thr Gln Phe Asp Ala Lys Gly Thr Pro Phe Ile Ala Gly Lys
1145 1150 1155
Arg Ile Val Pro Val Ile Glu Asn His Arg Phe Thr Gly Arg Tyr
1160 1165 1170
Arg Asp Leu Tyr Pro Ala Asn Glu Leu Ile Ala Leu Leu Glu Glu
1175 1180 1185
Lys Gly Ile Val Phe Arg Asp Gly Ser Asn Ile Leu Pro Lys Leu
1190 1195 1200
Leu Glu Asn Asp Asp Ser His Ala Ile Asp Thr Met Val Ala Leu
1205 1210 1215
Ile Arg Ser Val Leu Gln Met Arg Asn Ser Asn Ala Ala Thr Gly
1220 1225 1230
Glu Asp Tyr Ile Asn Ser Pro Val Arg Asp Leu Asn Gly Val Cys
1235 1240 1245
Phe Asp Ser Arg Phe Gln Asn Pro Glu Trp Pro Met Asp Ala Asp
1250 1255 1260
Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Gln Leu Leu Leu
1265 1270 1275
Asn His Leu Lys Glu Ser Lys Asp Leu Lys Leu Gln Asn Gly Ile
1280 1285 1290
Ser Asn Gln Asp Trp Leu Ala Tyr Ile Gln Glu Leu Arg Asn
1295 1300 1305
<210> 78
<211> 1307
<212> БЕЛОК
<213> Francisella tularensis
<400> 78
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Lys Tyr
100 105 110
Ile Asn Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Val Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Asp Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ser
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Glu Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Arg Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Ser Gly
595 600 605
Trp Asp Lys Asn Lys Glu Ser Ala Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Ile Met Asp Lys Lys His Asn Lys Ile
625 630 635 640
Phe Ser Asp Lys Ala Ile Glu Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Gln Ile Ala Asp Ala Ser Lys Asp Ile Gln Asn Leu
660 665 670
Met Ile Ile Asp Gly Lys Thr Val Cys Lys Lys Gly Arg Lys Asp Arg
675 680 685
Asn Gly Val Asn Arg Gln Leu Leu Ser Leu Lys Arg Lys His Leu Pro
690 695 700
Glu Asn Ile Tyr Arg Ile Lys Glu Thr Lys Ser Tyr Leu Lys Asn Glu
705 710 715 720
Ala Arg Phe Ser Arg Lys Asp Leu Tyr Asp Phe Ile Asp Tyr Tyr Lys
725 730 735
Asp Arg Leu Asp Tyr Tyr Asp Phe Glu Phe Glu Leu Lys Pro Ser Asn
740 745 750
Glu Tyr Ser Asp Phe Asn Asp Phe Thr Asn His Ile Gly Ser Gln Gly
755 760 765
Tyr Lys Leu Thr Phe Glu Asn Ile Ser Gln Asp Tyr Ile Asn Ser Leu
770 775 780
Val Asn Glu Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Ser Lys Asp Phe
785 790 795 800
Ser Ala Tyr Ser Lys Gly Arg Pro Asn Leu His Thr Leu Tyr Trp Lys
805 810 815
Ala Leu Phe Asp Glu Arg Asn Leu Gln Asp Val Val Tyr Lys Leu Asn
820 825 830
Gly Glu Ala Glu Leu Phe Tyr Arg Lys Gln Ser Ile Pro Lys Lys Ile
835 840 845
Thr His Pro Ala Lys Glu Thr Ile Ala Asn Lys Asn Lys Asp Asn Pro
850 855 860
Lys Lys Glu Ser Val Phe Glu Tyr Asp Leu Ile Lys Asp Lys Arg Phe
865 870 875 880
Thr Glu Asp Lys Phe Phe Phe His Cys Pro Ile Thr Ile Asn Phe Lys
885 890 895
Ser Ser Gly Ala Asn Lys Phe Asn Asp Glu Ile Asn Leu Leu Leu Lys
900 905 910
Glu Lys Ala Asn Asp Val His Ile Leu Ser Ile Asp Arg Gly Glu Arg
915 920 925
His Leu Ala Tyr Tyr Thr Leu Val Asp Gly Lys Gly Asn Ile Ile Lys
930 935 940
Gln Asp Asn Phe Asn Ile Ile Gly Asn Asp Arg Met Lys Thr Asn Tyr
945 950 955 960
His Asp Lys Leu Ala Ala Ile Glu Lys Asp Arg Asp Ser Ala Arg Lys
965 970 975
Asp Trp Lys Lys Ile Asn Asn Ile Lys Glu Met Lys Glu Gly Tyr Leu
980 985 990
Ser Gln Val Val His Glu Ile Ala Lys Leu Val Ile Glu Tyr Asn Ala
995 1000 1005
Ile Val Val Phe Glu Asp Leu Asn Phe Gly Phe Lys Arg Gly Arg
1010 1015 1020
Phe Lys Val Glu Lys Gln Val Tyr Gln Lys Leu Glu Lys Met Leu
1025 1030 1035
Ile Glu Lys Leu Asn Tyr Leu Val Phe Lys Asp Asn Glu Phe Asp
1040 1045 1050
Lys Thr Gly Gly Val Leu Arg Ala Tyr Gln Leu Thr Ala Pro Phe
1055 1060 1065
Glu Thr Phe Lys Lys Met Gly Lys Gln Thr Gly Ile Ile Tyr Tyr
1070 1075 1080
Val Pro Ala Gly Phe Thr Ser Lys Ile Cys Pro Val Thr Gly Phe
1085 1090 1095
Val Asn Gln Leu Tyr Pro Lys Tyr Glu Ser Val Ser Lys Ser Gln
1100 1105 1110
Glu Phe Phe Ser Lys Phe Asp Lys Ile Cys Tyr Asn Leu Asp Lys
1115 1120 1125
Gly Tyr Phe Glu Phe Ser Phe Asp Tyr Lys Asn Phe Gly Asp Lys
1130 1135 1140
Ala Ala Lys Gly Lys Trp Thr Ile Ala Ser Phe Gly Ser Arg Leu
1145 1150 1155
Ile Asn Phe Arg Asn Ser Asp Lys Asn His Asn Trp Asp Thr Arg
1160 1165 1170
Glu Val Tyr Pro Thr Lys Glu Leu Glu Lys Leu Leu Lys Asp Tyr
1175 1180 1185
Ser Ile Glu Tyr Gly His Gly Glu Cys Ile Lys Ala Ala Ile Cys
1190 1195 1200
Gly Glu Ser Asp Lys Lys Phe Phe Ala Lys Leu Thr Ser Val Leu
1205 1210 1215
Asn Thr Ile Leu Gln Met Arg Asn Ser Lys Thr Gly Thr Glu Leu
1220 1225 1230
Asp Tyr Leu Ile Ser Pro Val Ala Asp Val Asn Gly Asn Phe Phe
1235 1240 1245
Asp Ser Arg Gln Ala Pro Lys Asn Met Pro Gln Asp Ala Asp Ala
1250 1255 1260
Asn Gly Ala Tyr His Ile Gly Leu Lys Gly Leu Met Leu Leu Asp
1265 1270 1275
Arg Ile Lys Asn Asn Gln Glu Gly Lys Lys Leu Asn Leu Val Ile
1280 1285 1290
Lys Asn Glu Glu Tyr Phe Glu Phe Val Gln Asn Arg Asn Asn
1295 1300 1305
<210> 79
<211> 1305
<212> БЕЛОК
<213> Eubacterium sp.
<400> 79
Met Asn Lys Ala Ala Asp Asn Tyr Thr Gly Gly Asn Tyr Asp Glu Phe
1 5 10 15
Ile Ala Leu Ser Lys Val Gln Lys Thr Leu Arg Asn Glu Leu Lys Pro
20 25 30
Thr Pro Phe Thr Ala Glu His Ile Lys Gln Arg Gly Ile Ile Ser Glu
35 40 45
Asp Glu Tyr Arg Ala Gln Gln Ser Leu Glu Leu Lys Lys Ile Ala Asp
50 55 60
Glu Tyr Tyr Arg Asn Tyr Ile Thr His Lys Leu Asn Asp Ile Asn Asn
65 70 75 80
Leu Asp Phe Tyr Asn Leu Phe Asp Ala Ile Glu Glu Lys Tyr Lys Lys
85 90 95
Asn Asp Lys Asp Asn Arg Asp Lys Leu Asp Leu Val Glu Lys Ser Lys
100 105 110
Arg Gly Glu Ile Ala Lys Met Leu Ser Ala Asp Asp Asn Phe Lys Ser
115 120 125
Met Phe Glu Ala Lys Leu Ile Thr Lys Leu Leu Pro Asp Tyr Val Glu
130 135 140
Arg Asn Tyr Thr Gly Glu Asp Lys Glu Lys Ala Leu Glu Thr Leu Ala
145 150 155 160
Leu Phe Lys Gly Phe Thr Thr Tyr Phe Lys Gly Tyr Phe Lys Thr Arg
165 170 175
Lys Asn Met Phe Ser Gly Glu Gly Gly Ala Ser Ser Ile Cys His Arg
180 185 190
Ile Val Asn Val Asn Ala Ser Ile Phe Tyr Asp Asn Leu Lys Thr Phe
195 200 205
Met Arg Ile Gln Glu Lys Ala Gly Asp Glu Ile Ala Leu Ile Glu Glu
210 215 220
Glu Leu Thr Glu Lys Leu Asp Gly Trp Arg Leu Glu His Ile Phe Ser
225 230 235 240
Arg Asp Tyr Tyr Asn Glu Val Leu Ala Gln Lys Gly Ile Asp Tyr Tyr
245 250 255
Asn Gln Ile Cys Gly Asp Ile Asn Lys His Met Asn Leu Tyr Cys Gln
260 265 270
Gln Asn Lys Phe Lys Ala Asn Ile Phe Lys Met Met Lys Ile Gln Lys
275 280 285
Gln Ile Met Gly Ile Ser Glu Lys Ala Phe Glu Ile Pro Pro Met Tyr
290 295 300
Gln Asn Asp Glu Glu Val Tyr Ala Ser Phe Asn Glu Phe Ile Ser Arg
305 310 315 320
Leu Glu Glu Val Lys Leu Thr Asp Arg Leu Ile Asn Ile Leu Gln Asn
325 330 335
Ile Asn Ile Tyr Asn Thr Ala Lys Ile Tyr Ile Asn Ala Arg Tyr Tyr
340 345 350
Thr Asn Val Ser Ser Tyr Val Tyr Gly Gly Trp Gly Val Ile Asp Ser
355 360 365
Ala Ile Glu Arg Tyr Leu Tyr Asn Thr Ile Ala Gly Lys Gly Gln Ser
370 375 380
Lys Val Lys Lys Ile Glu Asn Ala Lys Lys Asp Asn Lys Phe Met Ser
385 390 395 400
Val Lys Glu Leu Asp Ser Ile Val Ala Glu Tyr Glu Pro Asp Tyr Phe
405 410 415
Asn Ala Pro Tyr Ile Asp Asp Asp Asp Asn Ala Val Lys Ala Phe Gly
420 425 430
Gly Gln Gly Val Leu Gly Tyr Phe Asn Lys Met Ser Glu Leu Leu Ala
435 440 445
Asp Val Ser Leu Tyr Thr Ile Asp Tyr Asn Ser Asp Asp Ser Leu Ile
450 455 460
Glu Asn Lys Glu Ser Ala Leu Arg Ile Lys Lys Gln Leu Asp Asp Ile
465 470 475 480
Met Ser Leu Tyr His Trp Leu Gln Thr Phe Ile Ile Asp Glu Val Val
485 490 495
Glu Lys Asp Asn Ala Phe Tyr Ala Glu Leu Glu Asp Ile Cys Cys Glu
500 505 510
Leu Glu Asn Val Val Thr Leu Tyr Asp Arg Ile Arg Asn Tyr Val Thr
515 520 525
Lys Lys Pro Tyr Ser Thr Gln Lys Phe Lys Leu Asn Phe Ala Ser Pro
530 535 540
Thr Leu Ala Ala Gly Trp Ser Arg Ser Lys Glu Phe Asp Asn Asn Ala
545 550 555 560
Ile Ile Leu Leu Arg Asn Asn Lys Tyr Tyr Ile Ala Ile Phe Asn Val
565 570 575
Asn Asn Lys Pro Asp Lys Gln Ile Ile Lys Gly Ser Glu Glu Gln Arg
580 585 590
Leu Ser Thr Asp Tyr Lys Lys Met Val Tyr Asn Leu Leu Pro Gly Pro
595 600 605
Asn Lys Met Leu Pro Lys Val Phe Ile Lys Ser Asp Thr Gly Lys Arg
610 615 620
Asp Tyr Asn Pro Ser Ser Tyr Ile Leu Glu Gly Tyr Glu Lys Asn Arg
625 630 635 640
His Ile Lys Ser Ser Gly Asn Phe Asp Ile Asn Tyr Cys His Asp Leu
645 650 655
Ile Asp Tyr Tyr Lys Ala Cys Ile Asn Lys His Pro Glu Trp Lys Asn
660 665 670
Tyr Gly Phe Lys Phe Lys Glu Thr Asn Gln Tyr Asn Asp Ile Gly Gln
675 680 685
Phe Tyr Lys Asp Val Glu Lys Gln Gly Tyr Ser Ile Ser Trp Ala Tyr
690 695 700
Ile Ser Glu Glu Asp Ile Asn Lys Leu Asp Glu Glu Gly Lys Ile Tyr
705 710 715 720
Leu Phe Glu Ile Tyr Asn Lys Asp Leu Ser Ala His Ser Thr Gly Arg
725 730 735
Asp Asn Leu His Thr Met Tyr Leu Lys Asn Ile Phe Ser Glu Asp Asn
740 745 750
Leu Lys Asn Ile Cys Ile Glu Leu Asn Gly Glu Ala Glu Leu Phe Tyr
755 760 765
Arg Lys Ser Ser Met Lys Ser Asn Ile Thr His Lys Lys Asp Thr Ile
770 775 780
Leu Val Asn Lys Thr Tyr Ile Asn Glu Thr Gly Val Arg Val Ser Leu
785 790 795 800
Ser Asp Glu Asp Tyr Met Lys Val Tyr Asn Tyr Tyr Asn Asn Asn Tyr
805 810 815
Val Ile Asp Thr Glu Asn Asp Lys Asn Leu Ile Asp Ile Ile Glu Lys
820 825 830
Ile Gly His Arg Lys Ser Lys Ile Asp Ile Val Lys Asp Lys Arg Tyr
835 840 845
Thr Glu Asp Lys Tyr Phe Leu Tyr Leu Pro Ile Thr Ile Asn Tyr Gly
850 855 860
Ile Glu Asp Glu Asn Val Asn Ser Lys Ile Ile Glu Tyr Ile Ala Lys
865 870 875 880
Gln Asp Asn Met Asn Val Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu
885 890 895
Ile Tyr Ile Ser Val Ile Asp Asn Lys Gly Asn Ile Ile Glu Gln Lys
900 905 910
Ser Phe Asn Leu Val Asn Asn Tyr Asp Tyr Lys Asn Lys Leu Lys Asn
915 920 925
Met Glu Lys Thr Arg Asp Asn Ala Arg Lys Asn Trp Gln Glu Ile Gly
930 935 940
Lys Ile Lys Asp Val Lys Ser Gly Tyr Leu Ser Gly Val Ile Ser Lys
945 950 955 960
Ile Ala Arg Met Val Ile Asp Tyr Asn Ala Ile Ile Val Met Glu Asp
965 970 975
Leu Asn Lys Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Arg Gln Val
980 985 990
Tyr Gln Lys Phe Glu Asn Met Leu Ile Ser Lys Leu Asn Tyr Leu Val
995 1000 1005
Phe Lys Glu Arg Lys Ala Asp Glu Asn Gly Gly Ile Leu Arg Gly
1010 1015 1020
Tyr Gln Leu Thr Tyr Ile Pro Lys Ser Ile Lys Asn Val Gly Lys
1025 1030 1035
Gln Cys Gly Cys Ile Phe Tyr Val Pro Ala Ala Tyr Thr Ser Lys
1040 1045 1050
Ile Asp Pro Ala Thr Gly Phe Ile Asn Ile Phe Asp Phe Lys Lys
1055 1060 1065
Tyr Ser Gly Ser Gly Ile Asn Ala Lys Val Lys Asp Lys Lys Glu
1070 1075 1080
Phe Leu Met Ser Met Asn Ser Ile Arg Tyr Ile Asn Glu Cys Ser
1085 1090 1095
Glu Glu Tyr Glu Lys Ile Gly His Arg Glu Leu Phe Ala Phe Ser
1100 1105 1110
Phe Asp Tyr Asn Asn Phe Lys Thr Tyr Asn Val Ser Ser Pro Val
1115 1120 1125
Asn Glu Trp Thr Ala Tyr Thr Tyr Gly Glu Arg Ile Lys Lys Leu
1130 1135 1140
Tyr Lys Asp Gly Arg Trp Leu Arg Ser Glu Val Leu Asn Leu Thr
1145 1150 1155
Glu Asn Leu Ile Lys Leu Met Glu Gln Tyr Asn Ile Glu Tyr Lys
1160 1165 1170
Asp Gly His Asp Ile Arg Glu Asp Ile Ser His Met Asp Glu Thr
1175 1180 1185
Arg Asn Ala Asp Phe Ile Cys Ser Leu Phe Glu Glu Leu Lys Tyr
1190 1195 1200
Thr Val Gln Leu Arg Asn Ser Lys Ser Glu Ala Glu Asp Glu Asn
1205 1210 1215
Tyr Asp Arg Leu Val Ser Pro Ile Leu Asn Ser Ser Asn Gly Phe
1220 1225 1230
Tyr Asp Ser Ser Asp Tyr Met Glu Asn Glu Asn Asn Thr Thr His
1235 1240 1245
Thr Met Pro Lys Asp Ala Asp Ala Asn Gly Ala Tyr Cys Ile Ala
1250 1255 1260
Leu Lys Gly Leu Tyr Glu Ile Asn Lys Ile Lys Gln Asn Trp Ser
1265 1270 1275
Asp Asp Lys Lys Phe Lys Glu Asn Glu Leu Tyr Ile Asn Val Thr
1280 1285 1290
Glu Trp Leu Asp Tyr Ile Gln Asn Arg Arg Phe Glu
1295 1300 1305
<210> 80
<211> 1300
<212> БЕЛОК
<213> Francisella tularensis
<400> 80
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Val Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Asp Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Asp Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Arg Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Asn Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr Lys Glu Ser Ile Ser Lys His Pro Glu Trp Lys Asp
725 730 735
Phe Gly Phe Arg Phe Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu
740 745 750
Phe Tyr Arg Glu Val Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn
755 760 765
Ile Ser Glu Ser Tyr Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr
770 775 780
Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg
785 790 795 800
Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn
805 810 815
Leu Gln Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr
820 825 830
Arg Lys Lys Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
835 840 845
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Phe Phe Glu
850 855 860
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
865 870 875 880
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
885 890 895
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
900 905 910
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
915 920 925
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
930 935 940
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
945 950 955 960
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
965 970 975
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
980 985 990
Ala Lys Leu Val Ile Glu His Asn Ala Ile Val Val Phe Glu Asp Leu
995 1000 1005
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
1010 1015 1020
Tyr Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu
1025 1030 1035
Val Phe Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg
1040 1045 1050
Ala Tyr Gln Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly
1055 1060 1065
Lys Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser
1070 1075 1080
Lys Ile Cys Pro Val Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys
1085 1090 1095
Tyr Glu Ser Val Ser Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp
1100 1105 1110
Lys Ile Cys Tyr Asn Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe
1115 1120 1125
Asp Tyr Lys Asn Phe Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr
1130 1135 1140
Ile Ala Ser Phe Gly Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp
1145 1150 1155
Lys Asn His Asn Trp Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu
1160 1165 1170
Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly
1175 1180 1185
Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe
1190 1195 1200
Phe Ala Lys Leu Thr Ser Ile Leu Asn Thr Ile Leu Gln Met Arg
1205 1210 1215
Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val
1220 1225 1230
Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
1235 1240 1245
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly
1250 1255 1260
Leu Lys Gly Leu Met Leu Leu Asp Arg Ile Lys Asn Asn Gln Glu
1265 1270 1275
Gly Lys Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu
1280 1285 1290
Phe Val Gln Asn Arg Asn Asn
1295 1300
<210> 81
<211> 1300
<212> БЕЛОК
<213> Francisella tularensis
<400> 81
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asp Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Val Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Asp Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Leu Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Glu Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Arg Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Asn Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr Lys Glu Ser Ile Ser Lys His Pro Glu Trp Lys Asp
725 730 735
Phe Gly Phe Arg Phe Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu
740 745 750
Phe Tyr Arg Glu Val Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn
755 760 765
Ile Ser Glu Ser Tyr Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr
770 775 780
Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg
785 790 795 800
Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn
805 810 815
Leu Gln Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr
820 825 830
Arg Lys Gln Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
835 840 845
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Val Phe Glu
850 855 860
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
865 870 875 880
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
885 890 895
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
900 905 910
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
915 920 925
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
930 935 940
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
945 950 955 960
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
965 970 975
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
980 985 990
Ala Lys Leu Val Ile Glu His Asn Ala Ile Val Val Phe Glu Asp Leu
995 1000 1005
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
1010 1015 1020
Tyr Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu
1025 1030 1035
Val Phe Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg
1040 1045 1050
Ala Tyr Gln Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly
1055 1060 1065
Lys Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser
1070 1075 1080
Lys Ile Cys Pro Val Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys
1085 1090 1095
Tyr Glu Ser Val Ser Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp
1100 1105 1110
Lys Ile Cys Tyr Asn Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe
1115 1120 1125
Asp Tyr Lys Asn Phe Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr
1130 1135 1140
Ile Ala Ser Phe Gly Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp
1145 1150 1155
Lys Asn His Asn Trp Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu
1160 1165 1170
Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly
1175 1180 1185
Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe
1190 1195 1200
Phe Ala Lys Leu Thr Ser Val Leu Asn Thr Ile Leu Gln Met Arg
1205 1210 1215
Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val
1220 1225 1230
Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
1235 1240 1245
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly
1250 1255 1260
Leu Lys Gly Leu Met Leu Leu Asp Arg Ile Lys Asn Asn Gln Glu
1265 1270 1275
Gly Lys Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu
1280 1285 1290
Phe Val Gln Asn Arg Asn Asn
1295 1300
<210> 82
<211> 1300
<212> БЕЛОК
<213> Francisella tularensis
<400> 82
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Ile Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Glu Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Asp Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Lys Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Ser Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr Lys Gln Ser Ile Ser Lys His Pro Glu Trp Lys Asp
725 730 735
Phe Gly Phe Arg Phe Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu
740 745 750
Phe Tyr Arg Glu Val Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn
755 760 765
Ile Ser Glu Ser Tyr Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr
770 775 780
Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg
785 790 795 800
Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn
805 810 815
Leu Gln Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr
820 825 830
Arg Lys Gln Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
835 840 845
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Val Phe Glu
850 855 860
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
865 870 875 880
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
885 890 895
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
900 905 910
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
915 920 925
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
930 935 940
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
945 950 955 960
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
965 970 975
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
980 985 990
Ala Lys Leu Val Ile Glu Tyr Asn Ala Ile Val Val Phe Glu Asp Leu
995 1000 1005
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
1010 1015 1020
Tyr Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu
1025 1030 1035
Val Phe Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg
1040 1045 1050
Ala Tyr Gln Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly
1055 1060 1065
Lys Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser
1070 1075 1080
Lys Ile Cys Pro Val Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys
1085 1090 1095
Tyr Glu Ser Val Ser Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp
1100 1105 1110
Lys Ile Cys Tyr Asn Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe
1115 1120 1125
Asp Tyr Lys Asn Phe Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr
1130 1135 1140
Ile Ala Ser Phe Gly Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp
1145 1150 1155
Lys Asn His Asn Trp Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu
1160 1165 1170
Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly
1175 1180 1185
Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe
1190 1195 1200
Phe Ala Lys Leu Thr Ser Val Leu Asn Thr Ile Leu Gln Met Arg
1205 1210 1215
Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val
1220 1225 1230
Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
1235 1240 1245
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly
1250 1255 1260
Leu Lys Gly Leu Met Leu Leu Gly Arg Ile Lys Asn Asn Gln Glu
1265 1270 1275
Gly Lys Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu
1280 1285 1290
Phe Val Gln Asn Arg Asn Asn
1295 1300
<210> 83
<211> 1285
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Roizmanbacteria bacterium
<400> 83
Met Lys Ser Phe Asp Ser Phe Thr Asn Leu Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Lys Phe Glu Met Arg Pro Val Gly Asn Thr Gln Lys Met Leu Asp
20 25 30
Asn Ala Gly Val Phe Glu Lys Asp Lys Leu Ile Gln Lys Lys Tyr Gly
35 40 45
Lys Thr Lys Pro Tyr Phe Asp Arg Leu His Arg Glu Phe Ile Glu Glu
50 55 60
Ala Leu Thr Gly Val Glu Leu Ile Gly Leu Asp Glu Asn Phe Arg Thr
65 70 75 80
Leu Val Asp Trp Gln Lys Asp Lys Lys Asn Asn Val Ala Met Lys Ala
85 90 95
Tyr Glu Asn Ser Leu Gln Arg Leu Arg Thr Glu Ile Gly Lys Ile Phe
100 105 110
Asn Leu Lys Ala Glu Asp Trp Val Lys Asn Lys Tyr Pro Ile Leu Gly
115 120 125
Leu Lys Asn Lys Asn Thr Asp Ile Leu Phe Glu Glu Ala Val Phe Gly
130 135 140
Ile Leu Lys Ala Arg Tyr Gly Glu Glu Lys Asp Thr Phe Ile Glu Val
145 150 155 160
Glu Glu Ile Asp Lys Thr Gly Lys Ser Lys Ile Asn Gln Ile Ser Ile
165 170 175
Phe Asp Ser Trp Lys Gly Phe Thr Gly Tyr Phe Lys Lys Phe Phe Glu
180 185 190
Thr Arg Lys Asn Phe Tyr Lys Asn Asp Gly Thr Ser Thr Ala Ile Ala
195 200 205
Thr Arg Ile Ile Asp Gln Asn Leu Lys Arg Phe Ile Asp Asn Leu Ser
210 215 220
Ile Val Glu Ser Val Arg Gln Lys Val Asp Leu Ala Glu Thr Glu Lys
225 230 235 240
Ser Phe Ser Ile Ser Leu Ser Gln Phe Phe Ser Ile Asp Phe Tyr Asn
245 250 255
Lys Cys Leu Leu Gln Asp Gly Ile Asp Tyr Tyr Asn Lys Ile Ile Gly
260 265 270
Gly Glu Thr Leu Lys Asn Gly Glu Lys Leu Ile Gly Leu Asn Glu Leu
275 280 285
Ile Asn Gln Tyr Arg Gln Asn Asn Lys Asp Gln Lys Ile Pro Phe Phe
290 295 300
Lys Leu Leu Asp Lys Gln Ile Leu Ser Glu Lys Ile Leu Phe Leu Asp
305 310 315 320
Glu Ile Lys Asn Asp Thr Glu Leu Ile Glu Ala Leu Ser Gln Phe Ala
325 330 335
Lys Thr Ala Glu Glu Lys Thr Lys Ile Val Lys Lys Leu Phe Ala Asp
340 345 350
Phe Val Glu Asn Asn Ser Lys Tyr Asp Leu Ala Gln Ile Tyr Ile Ser
355 360 365
Gln Glu Ala Phe Asn Thr Ile Ser Asn Lys Trp Thr Ser Glu Thr Glu
370 375 380
Thr Phe Ala Lys Tyr Leu Phe Glu Ala Met Lys Ser Gly Lys Leu Ala
385 390 395 400
Lys Tyr Glu Lys Lys Asp Asn Ser Tyr Lys Phe Pro Asp Phe Ile Ala
405 410 415
Leu Ser Gln Met Lys Ser Ala Leu Leu Ser Ile Ser Leu Glu Gly His
420 425 430
Phe Trp Lys Glu Lys Tyr Tyr Lys Ile Ser Lys Phe Gln Glu Lys Thr
435 440 445
Asn Trp Glu Gln Phe Leu Ala Ile Phe Leu Tyr Glu Phe Asn Ser Leu
450 455 460
Phe Ser Asp Lys Ile Asn Thr Lys Asp Gly Glu Thr Lys Gln Val Gly
465 470 475 480
Tyr Tyr Leu Phe Ala Lys Asp Leu His Asn Leu Ile Leu Ser Glu Gln
485 490 495
Ile Asp Ile Pro Lys Asp Ser Lys Val Thr Ile Lys Asp Phe Ala Asp
500 505 510
Ser Val Leu Thr Ile Tyr Gln Met Ala Lys Tyr Phe Ala Val Glu Lys
515 520 525
Lys Arg Ala Trp Leu Ala Glu Tyr Glu Leu Asp Ser Phe Tyr Thr Gln
530 535 540
Pro Asp Thr Gly Tyr Leu Gln Phe Tyr Asp Asn Ala Tyr Glu Asp Ile
545 550 555 560
Val Gln Val Tyr Asn Lys Leu Arg Asn Tyr Leu Thr Lys Lys Pro Tyr
565 570 575
Ser Glu Glu Lys Trp Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn
580 585 590
Gly Trp Asp Lys Asn Lys Glu Ser Asp Asn Ser Ala Val Ile Leu Gln
595 600 605
Lys Gly Gly Lys Tyr Tyr Leu Gly Leu Ile Thr Lys Gly His Asn Lys
610 615 620
Ile Phe Asp Asp Arg Phe Gln Glu Lys Phe Ile Val Gly Ile Glu Gly
625 630 635 640
Gly Lys Tyr Glu Lys Ile Val Tyr Lys Phe Phe Pro Asp Gln Ala Lys
645 650 655
Met Phe Pro Lys Val Cys Phe Ser Ala Lys Gly Leu Glu Phe Phe Arg
660 665 670
Pro Ser Glu Glu Ile Leu Arg Ile Tyr Asn Asn Ala Glu Phe Lys Lys
675 680 685
Gly Glu Thr Tyr Ser Ile Asp Ser Met Gln Lys Leu Ile Asp Phe Tyr
690 695 700
Lys Asp Cys Leu Thr Lys Tyr Glu Gly Trp Ala Cys Tyr Thr Phe Arg
705 710 715 720
His Leu Lys Pro Thr Glu Glu Tyr Gln Asn Asn Ile Gly Glu Phe Phe
725 730 735
Arg Asp Val Ala Glu Asp Gly Tyr Arg Ile Asp Phe Gln Gly Ile Ser
740 745 750
Asp Gln Tyr Ile His Glu Lys Asn Glu Lys Gly Glu Leu His Leu Phe
755 760 765
Glu Ile His Asn Lys Asp Trp Asn Leu Asp Lys Ala Arg Asp Gly Lys
770 775 780
Ser Lys Thr Thr Gln Lys Asn Leu His Thr Leu Tyr Phe Glu Ser Leu
785 790 795 800
Phe Ser Asn Asp Asn Val Val Gln Asn Phe Pro Ile Lys Leu Asn Gly
805 810 815
Gln Ala Glu Ile Phe Tyr Arg Pro Lys Thr Glu Lys Asp Lys Leu Glu
820 825 830
Ser Lys Lys Asp Lys Lys Gly Asn Lys Val Ile Asp His Lys Arg Tyr
835 840 845
Ser Glu Asn Lys Ile Phe Phe His Val Pro Leu Thr Leu Asn Arg Thr
850 855 860
Lys Asn Asp Ser Tyr Arg Phe Asn Ala Gln Ile Asn Asn Phe Leu Ala
865 870 875 880
Asn Asn Lys Asp Ile Asn Ile Ile Gly Val Asp Arg Gly Glu Lys His
885 890 895
Leu Val Tyr Tyr Ser Val Ile Thr Gln Ala Ser Asp Ile Leu Glu Ser
900 905 910
Gly Ser Leu Asn Glu Leu Asn Gly Val Asn Tyr Ala Glu Lys Leu Gly
915 920 925
Lys Lys Ala Glu Asn Arg Glu Gln Ala Arg Arg Asp Trp Gln Asp Val
930 935 940
Gln Gly Ile Lys Asp Leu Lys Lys Gly Tyr Ile Ser Gln Val Val Arg
945 950 955 960
Lys Leu Ala Asp Leu Ala Ile Lys His Asn Ala Ile Ile Ile Leu Glu
965 970 975
Asp Leu Asn Met Arg Phe Lys Gln Val Arg Gly Gly Ile Glu Lys Ser
980 985 990
Ile Tyr Gln Gln Leu Glu Lys Ala Leu Ile Asp Lys Leu Ser Phe Leu
995 1000 1005
Val Asp Lys Gly Glu Lys Asn Pro Glu Gln Ala Gly His Leu Leu
1010 1015 1020
Lys Ala Tyr Gln Leu Ser Ala Pro Phe Glu Thr Phe Gln Lys Met
1025 1030 1035
Gly Lys Gln Thr Gly Ile Ile Phe Tyr Thr Gln Ala Ser Tyr Thr
1040 1045 1050
Ser Lys Ser Asp Pro Val Thr Gly Trp Arg Pro His Leu Tyr Leu
1055 1060 1065
Lys Tyr Phe Ser Ala Lys Lys Ala Lys Asp Asp Ile Ala Lys Phe
1070 1075 1080
Thr Lys Ile Glu Phe Val Asn Asp Arg Phe Glu Leu Thr Tyr Asp
1085 1090 1095
Ile Lys Asp Phe Gln Gln Ala Lys Glu Tyr Pro Asn Lys Thr Val
1100 1105 1110
Trp Lys Val Cys Ser Asn Val Glu Arg Phe Arg Trp Asp Lys Asn
1115 1120 1125
Leu Asn Gln Asn Lys Gly Gly Tyr Thr His Tyr Thr Asn Ile Thr
1130 1135 1140
Glu Asn Ile Gln Glu Leu Phe Thr Lys Tyr Gly Ile Asp Ile Thr
1145 1150 1155
Lys Asp Leu Leu Thr Gln Ile Ser Thr Ile Asp Glu Lys Gln Asn
1160 1165 1170
Thr Ser Phe Phe Arg Asp Phe Ile Phe Tyr Phe Asn Leu Ile Cys
1175 1180 1185
Gln Ile Arg Asn Thr Asp Asp Ser Glu Ile Ala Lys Lys Asn Gly
1190 1195 1200
Lys Asp Asp Phe Ile Leu Ser Pro Val Glu Pro Phe Phe Asp Ser
1205 1210 1215
Arg Lys Asp Asn Gly Asn Lys Leu Pro Glu Asn Gly Asp Asp Asn
1220 1225 1230
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Ile Val Ile Leu Asn Lys
1235 1240 1245
Ile Ser Gln Tyr Ser Glu Lys Asn Glu Asn Cys Glu Lys Met Lys
1250 1255 1260
Trp Gly Asp Leu Tyr Val Ser Asn Ile Asp Trp Asp Asn Phe Val
1265 1270 1275
Thr Gln Ala Asn Ala Arg His
1280 1285
<210> 84
<211> 1282
<212> БЕЛОК
<213> Eubacterium eligens
<400> 84
Met Asn Gly Asn Arg Ser Ile Val Tyr Arg Glu Phe Val Gly Val Thr
1 5 10 15
Pro Val Ala Lys Thr Leu Arg Asn Glu Leu Arg Pro Val Gly His Thr
20 25 30
Gln Glu His Ile Ile Gln Asn Gly Leu Ile Gln Glu Asp Glu Leu Arg
35 40 45
Gln Glu Lys Ser Thr Glu Leu Lys Asn Ile Met Asp Asp Tyr Tyr Arg
50 55 60
Glu Tyr Ile Asp Lys Ser Leu Ser Gly Leu Thr Asp Leu Asp Phe Thr
65 70 75 80
Leu Leu Phe Glu Leu Met Asn Ser Val Gln Ser Ser Leu Ser Lys Asp
85 90 95
Asn Lys Lys Ala Leu Glu Lys Glu His Asn Lys Met Arg Glu Gln Ile
100 105 110
Cys Thr His Leu Gln Ser Asp Ser Asp Tyr Lys Asn Met Phe Asn Ala
115 120 125
Lys Leu Phe Lys Glu Ile Leu Pro Asp Phe Ile Lys Asn Tyr Asn Gln
130 135 140
Tyr Asp Val Lys Asp Lys Ala Gly Lys Leu Glu Thr Leu Ala Leu Phe
145 150 155 160
Asn Gly Phe Ser Thr Tyr Phe Thr Asp Phe Phe Glu Lys Arg Lys Asn
165 170 175
Val Phe Thr Lys Glu Ala Val Ser Thr Ser Ile Ala Tyr Arg Ile Val
180 185 190
His Glu Asn Ser Leu Ile Phe Leu Ala Asn Met Thr Ser Tyr Lys Lys
195 200 205
Ile Ser Glu Lys Ala Leu Asp Glu Ile Glu Val Ile Glu Lys Asn Asn
210 215 220
Gln Asp Lys Met Gly Asp Trp Glu Leu Asn Gln Ile Phe Asn Pro Asp
225 230 235 240
Phe Tyr Asn Met Val Leu Ile Gln Ser Gly Ile Asp Phe Tyr Asn Glu
245 250 255
Ile Cys Gly Val Val Asn Ala His Met Asn Leu Tyr Cys Gln Gln Thr
260 265 270
Lys Asn Asn Tyr Asn Leu Phe Lys Met Arg Lys Leu His Lys Gln Ile
275 280 285
Leu Ala Tyr Thr Ser Thr Ser Phe Glu Val Pro Lys Met Phe Glu Asp
290 295 300
Asp Met Ser Val Tyr Asn Ala Val Asn Ala Phe Ile Asp Glu Thr Glu
305 310 315 320
Lys Gly Asn Ile Ile Gly Lys Leu Lys Asp Ile Val Asn Lys Tyr Asp
325 330 335
Glu Leu Asp Glu Lys Arg Ile Tyr Ile Ser Lys Asp Phe Tyr Glu Thr
340 345 350
Leu Ser Cys Phe Met Ser Gly Asn Trp Asn Leu Ile Thr Gly Cys Val
355 360 365
Glu Asn Phe Tyr Asp Glu Asn Ile His Ala Lys Gly Lys Ser Lys Glu
370 375 380
Glu Lys Val Lys Lys Ala Val Lys Glu Asp Lys Tyr Lys Ser Ile Asn
385 390 395 400
Asp Val Asn Asp Leu Val Glu Lys Tyr Ile Asp Glu Lys Glu Arg Asn
405 410 415
Glu Phe Lys Asn Ser Asn Ala Lys Gln Tyr Ile Arg Glu Ile Ser Asn
420 425 430
Ile Ile Thr Asp Thr Glu Thr Ala His Leu Glu Tyr Asp Glu His Ile
435 440 445
Ser Leu Ile Glu Ser Glu Glu Lys Ala Asp Glu Ile Lys Lys Arg Leu
450 455 460
Asp Met Tyr Met Asn Met Tyr His Trp Val Lys Ala Phe Ile Val Asp
465 470 475 480
Glu Val Leu Asp Arg Asp Glu Met Phe Tyr Ser Asp Ile Asp Asp Ile
485 490 495
Tyr Asn Ile Leu Glu Asn Ile Val Pro Leu Tyr Asn Arg Val Arg Asn
500 505 510
Tyr Val Thr Gln Lys Pro Tyr Thr Ser Lys Lys Ile Lys Leu Asn Phe
515 520 525
Gln Ser Pro Thr Leu Ala Asn Gly Trp Ser Gln Ser Lys Glu Phe Asp
530 535 540
Asn Asn Ala Ile Ile Leu Ile Arg Asp Asn Lys Tyr Tyr Leu Ala Ile
545 550 555 560
Phe Asn Ala Lys Asn Lys Pro Asp Lys Lys Ile Ile Gln Gly Asn Ser
565 570 575
Asp Lys Lys Asn Asp Asn Asp Tyr Lys Lys Met Val Tyr Asn Leu Leu
580 585 590
Pro Gly Ala Asn Lys Met Leu Pro Lys Val Phe Leu Ser Lys Lys Gly
595 600 605
Ile Glu Thr Phe Lys Pro Ser Asp Tyr Ile Ile Ser Gly Tyr Asn Ala
610 615 620
His Lys His Ile Lys Thr Ser Glu Asn Phe Asp Ile Ser Phe Cys Arg
625 630 635 640
Asp Leu Ile Asp Tyr Phe Lys Asn Ser Ile Glu Lys His Ala Glu Trp
645 650 655
Arg Lys Tyr Glu Phe Lys Phe Ser Ala Thr Asp Ser Tyr Asn Asp Ile
660 665 670
Ser Glu Phe Tyr Arg Glu Val Glu Met Gln Gly Tyr Arg Ile Asp Trp
675 680 685
Thr Tyr Ile Ser Glu Ala Asp Ile Asn Lys Leu Asp Glu Glu Gly Lys
690 695 700
Ile Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Glu Asn Ser Thr
705 710 715 720
Gly Lys Glu Asn Leu His Thr Met Tyr Phe Lys Asn Ile Phe Ser Glu
725 730 735
Glu Asn Leu Lys Asn Ile Val Ile Lys Leu Asn Gly Gln Ala Glu Leu
740 745 750
Phe Tyr Arg Lys Ala Ser Val Lys Asn Pro Val Lys His Lys Lys Asp
755 760 765
Ser Val Leu Val Asn Lys Thr Tyr Lys Asn Gln Leu Asp Asn Gly Asp
770 775 780
Val Val Arg Ile Pro Ile Pro Asp Asp Ile Tyr Asn Glu Ile Tyr Lys
785 790 795 800
Met Tyr Asn Gly Tyr Ile Lys Glu Ser Asp Leu Ser Glu Ala Ala Lys
805 810 815
Glu Tyr Leu Asp Lys Val Glu Val Arg Thr Ala Gln Lys Asp Ile Val
820 825 830
Lys Asp Tyr Arg Tyr Thr Val Asp Lys Tyr Phe Ile His Thr Pro Ile
835 840 845
Thr Ile Asn Tyr Lys Val Thr Ala Arg Asn Asn Val Asn Asp Met Ala
850 855 860
Val Lys Tyr Ile Ala Gln Asn Asp Asp Ile His Val Ile Gly Ile Asp
865 870 875 880
Arg Gly Glu Arg Asn Leu Ile Tyr Ile Ser Val Ile Asp Ser His Gly
885 890 895
Asn Ile Val Lys Gln Lys Ser Tyr Asn Ile Leu Asn Asn Tyr Asp Tyr
900 905 910
Lys Lys Lys Leu Val Glu Lys Glu Lys Thr Arg Glu Tyr Ala Arg Lys
915 920 925
Asn Trp Lys Ser Ile Gly Asn Ile Lys Glu Leu Lys Glu Gly Tyr Ile
930 935 940
Ser Gly Val Val His Glu Ile Ala Met Leu Met Val Glu Tyr Asn Ala
945 950 955 960
Ile Ile Ala Met Glu Asp Leu Asn Tyr Gly Phe Lys Arg Gly Arg Phe
965 970 975
Lys Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Ser Met Leu Ile Asn
980 985 990
Lys Leu Asn Tyr Phe Ala Ser Lys Gly Lys Ser Val Asp Glu Pro Gly
995 1000 1005
Gly Leu Leu Lys Gly Tyr Gln Leu Thr Tyr Val Pro Asp Asn Ile
1010 1015 1020
Lys Asn Leu Gly Lys Gln Cys Gly Val Ile Phe Tyr Val Pro Ala
1025 1030 1035
Ala Phe Thr Ser Lys Ile Asp Pro Ser Thr Gly Phe Ile Ser Ala
1040 1045 1050
Phe Asn Phe Lys Ser Ile Ser Thr Asn Ala Ser Arg Lys Gln Phe
1055 1060 1065
Phe Met Gln Phe Asp Glu Ile Arg Tyr Cys Ala Glu Lys Asp Met
1070 1075 1080
Phe Ser Phe Gly Phe Asp Tyr Asn Asn Phe Asp Thr Tyr Asn Ile
1085 1090 1095
Thr Met Gly Lys Thr Gln Trp Thr Val Tyr Thr Asn Gly Glu Arg
1100 1105 1110
Leu Gln Ser Glu Phe Asn Asn Ala Arg Arg Thr Gly Lys Thr Lys
1115 1120 1125
Ser Ile Asn Leu Thr Glu Thr Ile Lys Leu Leu Leu Glu Asp Asn
1130 1135 1140
Glu Ile Asn Tyr Ala Asp Gly His Asp Val Arg Ile Asp Met Glu
1145 1150 1155
Lys Met Tyr Glu Asp Lys Asn Ser Glu Phe Phe Ala Gln Leu Leu
1160 1165 1170
Ser Leu Tyr Lys Leu Thr Val Gln Met Arg Asn Ser Tyr Thr Glu
1175 1180 1185
Ala Glu Glu Gln Glu Lys Gly Ile Ser Tyr Asp Lys Ile Ile Ser
1190 1195 1200
Pro Val Ile Asn Asp Glu Gly Glu Phe Phe Asp Ser Asp Asn Tyr
1205 1210 1215
Lys Glu Ser Asp Asp Lys Glu Cys Lys Met Pro Lys Asp Ala Asp
1220 1225 1230
Ala Asn Gly Ala Tyr Cys Ile Ala Leu Lys Gly Leu Tyr Glu Val
1235 1240 1245
Leu Lys Ile Lys Ser Glu Trp Thr Glu Asp Gly Phe Asp Arg Asn
1250 1255 1260
Cys Leu Lys Leu Pro His Ala Glu Trp Leu Asp Phe Ile Gln Asn
1265 1270 1275
Lys Arg Tyr Glu
1280
<210> 85
<211> 1282
<212> БЕЛОК
<213> Eubacterium eligens
<400> 85
Met Asn Gly Asn Arg Ser Ile Val Tyr Arg Glu Phe Val Gly Val Ile
1 5 10 15
Pro Val Ala Lys Thr Leu Arg Asn Glu Leu Arg Pro Val Gly His Thr
20 25 30
Gln Glu His Ile Ile Gln Asn Gly Leu Ile Gln Glu Asp Glu Leu Arg
35 40 45
Gln Glu Lys Ser Thr Glu Leu Lys Asn Ile Met Asp Asp Tyr Tyr Arg
50 55 60
Glu Tyr Ile Asp Lys Ser Leu Ser Gly Val Thr Asp Leu Asp Phe Thr
65 70 75 80
Leu Leu Phe Glu Leu Met Asn Leu Val Gln Ser Ser Pro Ser Lys Asp
85 90 95
Asn Lys Lys Ala Leu Glu Lys Glu Gln Ser Lys Met Arg Glu Gln Ile
100 105 110
Cys Thr His Leu Gln Ser Asp Ser Asn Tyr Lys Asn Ile Phe Asn Ala
115 120 125
Lys Leu Leu Lys Glu Ile Leu Pro Asp Phe Ile Lys Asn Tyr Asn Gln
130 135 140
Tyr Asp Val Lys Asp Lys Ala Gly Lys Leu Glu Thr Leu Ala Leu Phe
145 150 155 160
Asn Gly Phe Ser Thr Tyr Phe Thr Asp Phe Phe Glu Lys Arg Lys Asn
165 170 175
Val Phe Thr Lys Glu Ala Val Ser Thr Ser Ile Ala Tyr Arg Ile Val
180 185 190
His Glu Asn Ser Leu Ile Phe Leu Ala Asn Met Thr Ser Tyr Lys Lys
195 200 205
Ile Ser Glu Lys Ala Leu Asp Glu Ile Glu Val Ile Glu Lys Asn Asn
210 215 220
Gln Asp Lys Met Gly Asp Trp Glu Leu Asn Gln Ile Phe Asn Pro Asp
225 230 235 240
Phe Tyr Asn Met Val Leu Ile Gln Ser Gly Ile Asp Phe Tyr Asn Glu
245 250 255
Ile Cys Gly Val Val Asn Ala His Met Asn Leu Tyr Cys Gln Gln Thr
260 265 270
Lys Asn Asn Tyr Asn Leu Phe Lys Met Arg Lys Leu His Lys Gln Ile
275 280 285
Leu Ala Tyr Thr Ser Thr Ser Phe Glu Val Pro Lys Met Phe Glu Asp
290 295 300
Asp Met Ser Val Tyr Asn Ala Val Asn Ala Phe Ile Asp Glu Thr Glu
305 310 315 320
Lys Gly Asn Ile Ile Gly Lys Leu Lys Asp Ile Val Asn Lys Tyr Asp
325 330 335
Glu Leu Asp Glu Lys Arg Ile Tyr Ile Ser Lys Asp Phe Tyr Glu Thr
340 345 350
Leu Ser Cys Phe Met Ser Gly Asn Trp Asn Leu Ile Thr Gly Cys Val
355 360 365
Glu Asn Phe Tyr Asp Glu Asn Ile His Ala Lys Gly Lys Ser Lys Glu
370 375 380
Glu Lys Val Lys Lys Ala Val Lys Glu Asp Lys Tyr Lys Ser Ile Asn
385 390 395 400
Asp Val Asn Asp Leu Val Glu Lys Tyr Ile Asp Glu Lys Glu Arg Asn
405 410 415
Glu Phe Lys Asn Ser Asn Ala Lys Gln Tyr Ile Arg Glu Ile Ser Asn
420 425 430
Ile Ile Thr Asp Thr Glu Thr Ala His Leu Glu Tyr Asp Asp His Ile
435 440 445
Ser Leu Ile Glu Ser Glu Glu Lys Ala Asp Glu Met Lys Lys Arg Leu
450 455 460
Asp Met Tyr Met Asn Met Tyr His Trp Ala Lys Ala Phe Ile Val Asp
465 470 475 480
Glu Val Leu Asp Arg Asp Glu Met Phe Tyr Ser Asp Ile Asp Asp Ile
485 490 495
Tyr Asn Ile Leu Glu Asn Ile Val Pro Leu Tyr Asn Arg Val Arg Asn
500 505 510
Tyr Val Thr Gln Lys Pro Tyr Asn Ser Lys Lys Ile Lys Leu Asn Phe
515 520 525
Gln Ser Pro Thr Leu Ala Asn Gly Trp Ser Gln Ser Lys Glu Phe Asp
530 535 540
Asn Asn Ala Ile Ile Leu Ile Arg Asp Asn Lys Tyr Tyr Leu Ala Ile
545 550 555 560
Phe Asn Ala Lys Asn Lys Pro Asp Lys Lys Ile Ile Gln Gly Asn Ser
565 570 575
Asp Lys Lys Asn Asp Asn Asp Tyr Lys Lys Met Val Tyr Asn Leu Leu
580 585 590
Pro Gly Ala Asn Lys Met Leu Pro Lys Val Phe Leu Ser Lys Lys Gly
595 600 605
Ile Glu Thr Phe Lys Pro Ser Asp Tyr Ile Ile Ser Gly Tyr Asn Ala
610 615 620
His Lys His Ile Lys Thr Ser Glu Asn Phe Asp Ile Ser Phe Cys Arg
625 630 635 640
Asp Leu Ile Asp Tyr Phe Lys Asn Ser Ile Glu Lys His Ala Glu Trp
645 650 655
Arg Lys Tyr Glu Phe Lys Phe Ser Ala Thr Asp Ser Tyr Ser Asp Ile
660 665 670
Ser Glu Phe Tyr Arg Glu Val Glu Met Gln Gly Tyr Arg Ile Asp Trp
675 680 685
Thr Tyr Ile Ser Glu Ala Asp Ile Asn Lys Leu Asp Glu Glu Gly Lys
690 695 700
Ile Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Glu Asn Ser Thr
705 710 715 720
Gly Lys Glu Asn Leu His Thr Met Tyr Phe Lys Asn Ile Phe Ser Glu
725 730 735
Glu Asn Leu Lys Asp Ile Ile Ile Lys Leu Asn Gly Gln Ala Glu Leu
740 745 750
Phe Tyr Arg Arg Ala Ser Val Lys Asn Pro Val Lys His Lys Lys Asp
755 760 765
Ser Val Leu Val Asn Lys Thr Tyr Lys Asn Gln Leu Asp Asn Gly Asp
770 775 780
Val Val Arg Ile Pro Ile Pro Asp Asp Ile Tyr Asn Glu Ile Tyr Lys
785 790 795 800
Met Tyr Asn Gly Tyr Ile Lys Glu Ser Asp Leu Ser Glu Ala Ala Lys
805 810 815
Glu Tyr Leu Asp Lys Val Glu Val Arg Thr Ala Gln Lys Asp Ile Val
820 825 830
Lys Asp Tyr Arg Tyr Thr Val Asp Lys Tyr Phe Ile His Thr Pro Ile
835 840 845
Thr Ile Asn Tyr Lys Val Thr Ala Arg Asn Asn Val Asn Asp Met Val
850 855 860
Val Lys Tyr Ile Ala Gln Asn Asp Asp Ile His Val Ile Gly Ile Asp
865 870 875 880
Arg Gly Glu Arg Asn Leu Ile Tyr Ile Ser Val Ile Asp Ser His Gly
885 890 895
Asn Ile Val Lys Gln Lys Ser Tyr Asn Ile Leu Asn Asn Tyr Asp Tyr
900 905 910
Lys Lys Lys Leu Val Glu Lys Glu Lys Thr Arg Glu Tyr Ala Arg Lys
915 920 925
Asn Trp Lys Ser Ile Gly Asn Ile Lys Glu Leu Lys Glu Gly Tyr Ile
930 935 940
Ser Gly Val Val His Glu Ile Ala Met Leu Ile Val Glu Tyr Asn Ala
945 950 955 960
Ile Ile Ala Met Glu Asp Leu Asn Tyr Gly Phe Lys Arg Gly Arg Phe
965 970 975
Lys Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Ser Met Leu Ile Asn
980 985 990
Lys Leu Asn Tyr Phe Ala Ser Lys Glu Lys Ser Val Asp Glu Pro Gly
995 1000 1005
Gly Leu Leu Lys Gly Tyr Gln Leu Thr Tyr Val Pro Asp Asn Ile
1010 1015 1020
Lys Asn Leu Gly Lys Gln Cys Gly Val Ile Phe Tyr Val Pro Ala
1025 1030 1035
Ala Phe Thr Ser Lys Ile Asp Pro Ser Thr Gly Phe Ile Ser Ala
1040 1045 1050
Phe Asn Phe Lys Ser Ile Ser Thr Asn Ala Ser Arg Lys Gln Phe
1055 1060 1065
Phe Met Gln Phe Asp Glu Ile Arg Tyr Cys Ala Glu Lys Asp Met
1070 1075 1080
Phe Ser Phe Gly Phe Asp Tyr Asn Asn Phe Asp Thr Tyr Asn Ile
1085 1090 1095
Thr Met Gly Lys Thr Gln Trp Thr Val Tyr Thr Asn Gly Glu Arg
1100 1105 1110
Leu Gln Ser Glu Phe Asn Asn Ala Arg Arg Thr Gly Lys Thr Lys
1115 1120 1125
Ser Ile Asn Leu Thr Glu Thr Ile Lys Leu Leu Leu Glu Asp Asn
1130 1135 1140
Glu Ile Asn Tyr Ala Asp Gly His Asp Ile Arg Ile Asp Met Glu
1145 1150 1155
Lys Met Asp Glu Asp Lys Lys Ser Glu Phe Phe Ala Gln Leu Leu
1160 1165 1170
Ser Leu Tyr Lys Leu Thr Val Gln Met Arg Asn Ser Tyr Thr Glu
1175 1180 1185
Ala Glu Glu Gln Glu Asn Gly Ile Ser Tyr Asp Lys Ile Ile Ser
1190 1195 1200
Pro Val Ile Asn Asp Glu Gly Glu Phe Phe Asp Ser Asp Asn Tyr
1205 1210 1215
Lys Glu Ser Asp Asp Lys Glu Cys Lys Met Pro Lys Asp Ala Asp
1220 1225 1230
Ala Asn Gly Ala Tyr Cys Ile Ala Leu Lys Gly Leu Tyr Glu Val
1235 1240 1245
Leu Lys Ile Lys Ser Glu Trp Thr Glu Asp Gly Phe Asp Arg Asn
1250 1255 1260
Cys Leu Lys Leu Pro His Ala Glu Trp Leu Asp Phe Ile Gln Asn
1265 1270 1275
Lys Arg Tyr Glu
1280
<210> 86
<211> 1273
<212> БЕЛОК
<213> Flavobacterium sp.
<400> 86
Met Lys Asn Phe Ser Asn Leu Tyr Gln Val Ser Lys Thr Val Arg Phe
1 5 10 15
Glu Leu Lys Pro Ile Gly Asn Thr Leu Glu Asn Ile Lys Asn Lys Ser
20 25 30
Leu Leu Lys Asn Asp Ser Ile Arg Ala Glu Ser Tyr Gln Lys Met Lys
35 40 45
Lys Thr Ile Asp Glu Phe His Lys Tyr Phe Ile Asp Leu Ala Leu Asn
50 55 60
Asn Lys Lys Leu Ser Tyr Leu Asn Glu Tyr Ile Ala Leu Tyr Thr Gln
65 70 75 80
Ser Ala Glu Ala Lys Lys Glu Asp Lys Phe Lys Ala Asp Phe Lys Lys
85 90 95
Val Gln Asp Asn Leu Arg Lys Glu Ile Val Ser Ser Phe Thr Glu Gly
100 105 110
Glu Ala Lys Ala Ile Phe Ser Val Leu Asp Lys Lys Glu Leu Ile Thr
115 120 125
Ile Glu Leu Glu Lys Trp Lys Asn Glu Asn Asn Leu Ala Val Tyr Leu
130 135 140
Asp Glu Ser Phe Lys Ser Phe Thr Thr Tyr Phe Thr Gly Phe His Gln
145 150 155 160
Asn Arg Lys Asn Met Tyr Ser Ala Glu Ala Asn Ser Thr Ala Ile Ala
165 170 175
Tyr Arg Leu Ile His Glu Asn Leu Pro Lys Phe Ile Glu Asn Ser Lys
180 185 190
Ala Phe Glu Lys Ser Ser Gln Ile Ala Glu Leu Gln Pro Lys Ile Glu
195 200 205
Lys Leu Tyr Lys Glu Phe Glu Ala Tyr Leu Asn Val Asn Ser Ile Ser
210 215 220
Glu Leu Phe Glu Ile Asp Tyr Phe Asn Glu Val Leu Thr Gln Lys Gly
225 230 235 240
Ile Thr Val Tyr Asn Asn Ile Ile Gly Gly Arg Thr Ala Thr Glu Gly
245 250 255
Lys Gln Lys Ile Gln Gly Leu Asn Glu Ile Ile Asn Leu Tyr Asn Gln
260 265 270
Thr Lys Pro Lys Asn Glu Arg Leu Pro Lys Leu Lys Gln Leu Tyr Lys
275 280 285
Gln Ile Leu Ser Asp Arg Ile Ser Leu Ser Phe Leu Pro Asp Ala Phe
290 295 300
Thr Glu Gly Lys Gln Val Leu Lys Ala Val Phe Glu Phe Tyr Lys Ile
305 310 315 320
Asn Leu Leu Ser Tyr Lys Gln Asp Gly Val Glu Glu Ser Gln Asn Leu
325 330 335
Leu Glu Leu Ile Gln Gln Val Val Lys Asn Leu Gly Asn Gln Asp Val
340 345 350
Asn Lys Ile Tyr Leu Lys Asn Asp Thr Ser Leu Thr Thr Ile Ala Gln
355 360 365
Gln Leu Phe Gly Asp Phe Ser Val Phe Ser Ala Ala Leu Gln Tyr Arg
370 375 380
Tyr Glu Thr Val Val Asn Pro Lys Tyr Thr Ala Glu Tyr Gln Lys Ala
385 390 395 400
Asn Glu Ala Lys Gln Glu Lys Leu Asp Lys Glu Lys Ile Lys Phe Val
405 410 415
Lys Gln Asp Tyr Phe Ser Ile Ala Phe Leu Gln Glu Val Val Ala Asp
420 425 430
Tyr Val Lys Thr Leu Asp Glu Asn Leu Asp Trp Lys Gln Lys Tyr Thr
435 440 445
Pro Ser Cys Ile Ala Asp Tyr Phe Thr Thr His Phe Ile Ala Lys Lys
450 455 460
Glu Asn Glu Ala Asp Lys Thr Phe Asn Phe Ile Ala Asn Ile Lys Ala
465 470 475 480
Lys Tyr Gln Cys Ile Gln Gly Ile Leu Glu Gln Ala Asp Asp Tyr Glu
485 490 495
Asp Glu Leu Lys Gln Asp Gln Lys Leu Ile Asp Asn Ile Lys Phe Phe
500 505 510
Leu Asp Ala Ile Leu Glu Val Val His Phe Ile Lys Pro Leu His Leu
515 520 525
Lys Ser Glu Ser Ile Thr Glu Lys Asp Asn Ala Phe Tyr Asp Val Phe
530 535 540
Glu Asn Tyr Tyr Glu Ala Leu Asn Val Val Thr Pro Leu Tyr Asn Met
545 550 555 560
Val Arg Asn Tyr Val Thr Gln Lys Pro Tyr Ser Thr Glu Lys Ile Lys
565 570 575
Leu Asn Phe Glu Asn Ala Gln Leu Leu Asn Gly Trp Asp Ala Asn Lys
580 585 590
Glu Lys Asp Tyr Leu Thr Thr Ile Leu Lys Arg Asp Gly Asn Tyr Phe
595 600 605
Leu Ala Ile Met Asp Lys Lys His Asn Lys Thr Phe Gln Gln Phe Thr
610 615 620
Glu Asp Asp Glu Asn Tyr Glu Lys Ile Val Tyr Lys Leu Leu Pro Gly
625 630 635 640
Val Asn Lys Met Leu Pro Lys Val Phe Phe Ser Asn Lys Asn Ile Ala
645 650 655
Phe Phe Asn Pro Ser Lys Glu Ile Leu Asp Asn Tyr Lys Asn Asn Thr
660 665 670
His Lys Lys Gly Ala Thr Phe Asn Leu Lys Asp Cys His Ala Leu Ile
675 680 685
Asp Phe Phe Lys Asp Ser Leu Asn Lys His Glu Asp Trp Lys Tyr Phe
690 695 700
Asp Phe Gln Phe Ser Glu Thr Lys Thr Tyr Gln Asp Leu Ser Gly Phe
705 710 715 720
Tyr Lys Glu Val Glu His Gln Gly Tyr Lys Ile Asn Phe Lys Lys Val
725 730 735
Ser Val Ser Gln Ile Asp Thr Leu Ile Glu Glu Gly Lys Met Tyr Leu
740 745 750
Phe Gln Ile Tyr Asn Lys Asp Phe Ser Pro Tyr Ala Lys Gly Lys Pro
755 760 765
Asn Met His Thr Leu Tyr Trp Lys Ala Leu Phe Glu Thr Gln Asn Leu
770 775 780
Glu Asn Val Ile Tyr Lys Leu Asn Gly Gln Ala Glu Ile Phe Phe Arg
785 790 795 800
Lys Ala Ser Ile Lys Lys Lys Asn Ile Ile Thr His Lys Ala His Gln
805 810 815
Pro Ile Ala Ala Lys Asn Pro Leu Thr Pro Thr Ala Lys Asn Thr Phe
820 825 830
Ala Tyr Asp Leu Ile Lys Asp Lys Arg Tyr Thr Val Asp Lys Phe Gln
835 840 845
Phe His Val Pro Ile Thr Met Asn Phe Lys Ala Thr Gly Asn Ser Tyr
850 855 860
Ile Asn Gln Asp Val Leu Ala Tyr Leu Lys Asp Asn Pro Glu Val Asn
865 870 875 880
Ile Ile Gly Leu Asp Arg Gly Glu Arg His Leu Val Tyr Leu Thr Leu
885 890 895
Ile Asp Gln Lys Gly Thr Ile Leu Leu Gln Glu Ser Leu Asn Val Ile
900 905 910
Gln Asp Glu Lys Thr His Thr Pro Tyr His Thr Leu Leu Asp Asn Lys
915 920 925
Glu Ile Ala Arg Asp Lys Ala Arg Lys Asn Trp Gly Ser Ile Glu Ser
930 935 940
Ile Lys Glu Leu Lys Glu Gly Tyr Ile Ser Gln Val Val His Lys Ile
945 950 955 960
Thr Lys Met Met Ile Glu His Asn Ala Ile Val Val Met Glu Asp Leu
965 970 975
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Ile Tyr
980 985 990
Gln Lys Leu Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Leu
995 1000 1005
Lys Asp Lys Gln Pro His Glu Leu Gly Gly Leu Tyr Asn Ala Leu
1010 1015 1020
Gln Leu Thr Asn Lys Phe Glu Ser Phe Gln Lys Met Gly Lys Gln
1025 1030 1035
Ser Gly Phe Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile
1040 1045 1050
Asp Pro Thr Thr Gly Phe Val Asn Tyr Phe Tyr Thr Lys Tyr Glu
1055 1060 1065
Asn Val Glu Lys Ala Lys Thr Phe Phe Ser Lys Phe Asp Ser Ile
1070 1075 1080
Leu Tyr Asn Lys Thr Lys Gly Tyr Phe Glu Phe Val Val Lys Asn
1085 1090 1095
Tyr Ser Asp Phe Asn Pro Lys Ala Ala Asp Thr Arg Gln Glu Trp
1100 1105 1110
Thr Ile Cys Thr His Gly Glu Arg Ile Glu Thr Lys Arg Gln Lys
1115 1120 1125
Glu Gln Asn Asn Asn Phe Val Ser Thr Thr Ile Gln Leu Thr Glu
1130 1135 1140
Gln Phe Val Asn Phe Phe Glu Lys Val Gly Leu Asp Leu Ser Lys
1145 1150 1155
Glu Leu Lys Thr Gln Leu Ile Ala Gln Asn Glu Lys Ser Phe Phe
1160 1165 1170
Glu Glu Leu Phe His Leu Leu Lys Leu Thr Leu Gln Met Arg Asn
1175 1180 1185
Ser Glu Ser His Thr Glu Ile Asp Tyr Leu Ile Ser Pro Val Ala
1190 1195 1200
Asn Glu Lys Gly Ile Phe Tyr Asp Ser Arg Lys Ala Thr Ala Ser
1205 1210 1215
Leu Pro Ile Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Lys
1220 1225 1230
Lys Gly Leu Trp Ile Met Glu Gln Ile Asn Lys Thr Asn Ser Glu
1235 1240 1245
Asp Asp Leu Lys Lys Val Lys Leu Ala Ile Ser Asn Arg Glu Trp
1250 1255 1260
Leu Gln Tyr Val Gln Gln Val Gln Lys Lys
1265 1270
<210> 87
<211> 1264
<212> БЕЛОК
<213> Prevotella brevis
<400> 87
Met Lys Gln Phe Thr Asn Leu Tyr Gln Leu Ser Lys Thr Leu Arg Phe
1 5 10 15
Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu His Ile Asn Ala Asn Gly
20 25 30
Phe Ile Asp Asn Asp Ala His Arg Ala Glu Ser Tyr Lys Lys Val Lys
35 40 45
Lys Leu Ile Asp Asp Tyr His Lys Asp Tyr Ile Glu Asn Val Leu Asn
50 55 60
Asn Phe Lys Leu Asn Gly Glu Tyr Leu Gln Ala Tyr Phe Asp Leu Tyr
65 70 75 80
Ser Gln Asp Thr Lys Asp Lys Gln Phe Lys Asp Ile Gln Asp Lys Leu
85 90 95
Arg Lys Ser Ile Ala Ser Ala Leu Lys Gly Asp Asp Arg Tyr Lys Thr
100 105 110
Ile Asp Lys Lys Glu Leu Ile Arg Gln Asp Met Lys Thr Phe Leu Lys
115 120 125
Lys Asp Thr Asp Lys Ala Leu Leu Asp Glu Phe Tyr Glu Phe Thr Thr
130 135 140
Tyr Phe Thr Gly Tyr His Glu Asn Arg Lys Asn Met Tyr Ser Asp Glu
145 150 155 160
Ala Lys Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Asp Asn Leu Pro
165 170 175
Lys Phe Ile Asp Asn Ile Ala Val Phe Lys Lys Ile Ala Asn Thr Ser
180 185 190
Val Ala Asp Asn Phe Ser Thr Ile Tyr Lys Asn Phe Glu Glu Tyr Leu
195 200 205
Asn Val Asn Ser Ile Asp Glu Ile Phe Ser Leu Asp Tyr Tyr Asn Ile
210 215 220
Val Leu Thr Gln Thr Gln Ile Glu Val Tyr Asn Ser Ile Ile Gly Gly
225 230 235 240
Arg Thr Leu Glu Asp Asp Thr Lys Ile Gln Gly Ile Asn Glu Phe Val
245 250 255
Asn Leu Tyr Asn Gln Gln Leu Ala Asn Lys Lys Asp Arg Leu Pro Lys
260 265 270
Leu Lys Pro Leu Phe Lys Gln Ile Leu Ser Asp Arg Val Gln Leu Ser
275 280 285
Trp Leu Gln Glu Glu Phe Asn Thr Gly Ala Asp Val Leu Asn Ala Val
290 295 300
Lys Glu Tyr Cys Thr Ser Tyr Phe Asp Asn Val Glu Glu Ser Val Lys
305 310 315 320
Val Leu Leu Thr Gly Ile Ser Asp Tyr Asp Leu Ser Lys Ile Tyr Ile
325 330 335
Thr Asn Asp Leu Ala Leu Thr Asp Val Ser Gln Arg Met Phe Gly Glu
340 345 350
Trp Ser Ile Ile Pro Asn Ala Ile Glu Gln Arg Leu Arg Ser Asp Asn
355 360 365
Pro Lys Lys Thr Asn Glu Lys Glu Glu Lys Tyr Ser Asp Arg Ile Ser
370 375 380
Lys Leu Lys Lys Leu Pro Lys Ser Tyr Ser Leu Gly Tyr Ile Asn Glu
385 390 395 400
Cys Ile Ser Glu Leu Asn Gly Ile Asp Ile Ala Asp Tyr Tyr Ala Thr
405 410 415
Leu Gly Ala Ile Asn Thr Glu Ser Lys Gln Glu Pro Ser Ile Pro Thr
420 425 430
Ser Ile Gln Val His Tyr Asn Ala Leu Lys Pro Ile Leu Asp Thr Asp
435 440 445
Tyr Pro Arg Glu Lys Asn Leu Ser Gln Asp Lys Leu Thr Val Met Gln
450 455 460
Leu Lys Asp Leu Leu Asp Asp Phe Lys Ala Leu Gln His Phe Ile Lys
465 470 475 480
Pro Leu Leu Gly Asn Gly Asp Glu Ala Glu Lys Asp Glu Lys Phe Tyr
485 490 495
Gly Glu Leu Met Gln Leu Trp Glu Val Ile Asp Ser Ile Thr Pro Leu
500 505 510
Tyr Asn Lys Val Arg Asn Tyr Cys Thr Arg Lys Pro Phe Ser Thr Glu
515 520 525
Lys Ile Lys Val Asn Phe Glu Asn Ala Gln Leu Leu Asp Gly Trp Asp
530 535 540
Glu Asn Lys Glu Ser Thr Asn Ala Ser Ile Ile Leu Arg Lys Asn Gly
545 550 555 560
Met Tyr Tyr Leu Gly Ile Met Lys Lys Glu Tyr Arg Asn Ile Leu Thr
565 570 575
Lys Pro Met Pro Ser Asp Gly Asp Cys Tyr Asp Lys Val Val Tyr Lys
580 585 590
Phe Phe Lys Asp Ile Thr Thr Met Val Pro Lys Cys Thr Thr Gln Met
595 600 605
Lys Ser Val Lys Glu His Phe Ser Asn Ser Asn Asp Asp Tyr Thr Leu
610 615 620
Phe Glu Lys Asp Lys Phe Ile Ala Pro Val Val Ile Thr Lys Glu Ile
625 630 635 640
Phe Asp Leu Asn Asn Val Leu Tyr Asn Gly Val Lys Lys Phe Gln Ile
645 650 655
Gly Tyr Leu Asn Asn Thr Gly Asp Ser Phe Gly Tyr Asn His Ala Val
660 665 670
Glu Ile Trp Lys Ser Phe Cys Leu Lys Phe Leu Lys Ala Tyr Lys Ser
675 680 685
Thr Ser Ile Tyr Asp Phe Ser Ser Ile Glu Lys Asn Ile Gly Cys Tyr
690 695 700
Asn Asp Leu Asn Ser Phe Tyr Gly Ala Val Asn Leu Leu Leu Tyr Asn
705 710 715 720
Leu Thr Tyr Arg Lys Val Ser Val Asp Tyr Ile His Gln Leu Val Asp
725 730 735
Glu Asp Lys Met Tyr Leu Phe Met Ile Tyr Asn Lys Asp Phe Ser Thr
740 745 750
Tyr Ser Lys Gly Thr Pro Asn Met His Thr Leu Tyr Trp Lys Met Leu
755 760 765
Phe Asp Glu Ser Asn Leu Asn Asp Val Val Tyr Lys Leu Asn Gly Gln
770 775 780
Ala Glu Val Phe Tyr Arg Lys Lys Ser Ile Thr Tyr Gln His Pro Thr
785 790 795 800
His Pro Ala Asn Lys Pro Ile Asp Asn Lys Asn Val Asn Asn Pro Lys
805 810 815
Lys Gln Ser Asn Phe Glu Tyr Asp Leu Ile Lys Asp Lys Arg Tyr Thr
820 825 830
Val Asp Lys Phe Met Phe His Val Pro Ile Thr Leu Asn Phe Lys Gly
835 840 845
Met Gly Asn Gly Asp Ile Asn Met Gln Val Arg Glu Tyr Ile Lys Thr
850 855 860
Thr Asp Asp Leu His Phe Ile Gly Ile Asp Arg Gly Glu Arg His Leu
865 870 875 880
Leu Tyr Ile Cys Val Ile Asn Gly Lys Gly Glu Ile Val Glu Gln Tyr
885 890 895
Ser Leu Asn Glu Ile Val Asn Asn Tyr Lys Gly Thr Glu Tyr Lys Thr
900 905 910
Asp Tyr His Thr Leu Leu Ser Glu Arg Asp Lys Lys Arg Lys Glu Glu
915 920 925
Arg Ser Ser Trp Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Ser Gly
930 935 940
Tyr Leu Ser Gln Val Ile His Lys Ile Thr Gln Leu Met Ile Lys Tyr
945 950 955 960
Asn Ala Ile Val Leu Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly
965 970 975
Arg Gln Lys Val Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Ala Leu
980 985 990
Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Asn Lys Asp Ala Asn Glu
995 1000 1005
Ile Gly Gly Leu Leu His Ala Tyr Gln Leu Thr Asn Asp Pro Lys
1010 1015 1020
Leu Pro Asn Lys Asn Ser Lys Gln Ser Gly Phe Leu Phe Tyr Val
1025 1030 1035
Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro Val Thr Gly Phe Val
1040 1045 1050
Asn Leu Leu Asp Thr Arg Tyr Glu Asn Val Ala Lys Ala Gln Ala
1055 1060 1065
Phe Phe Lys Lys Phe Asp Ser Ile Arg Tyr Asn Lys Glu Tyr Asp
1070 1075 1080
Arg Phe Glu Phe Lys Phe Asp Tyr Ser Asn Phe Thr Ala Lys Ala
1085 1090 1095
Glu Asp Thr Arg Thr Gln Trp Thr Leu Cys Thr Tyr Gly Thr Arg
1100 1105 1110
Ile Glu Thr Phe Arg Asn Ala Glu Lys Asn Ser Asn Trp Asp Ser
1115 1120 1125
Arg Glu Ile Asp Leu Thr Thr Glu Trp Lys Thr Leu Phe Thr Gln
1130 1135 1140
His Asn Ile Pro Leu Asn Ala Asn Leu Lys Glu Ala Ile Leu Leu
1145 1150 1155
Gln Ala Asn Lys Asn Phe Tyr Thr Asp Ile Leu His Leu Met Lys
1160 1165 1170
Leu Thr Leu Gln Met Arg Asn Ser Val Thr Gly Thr Asp Ile Asp
1175 1180 1185
Tyr Met Val Ser Pro Val Ala Asn Glu Cys Gly Glu Phe Phe Asp
1190 1195 1200
Ser Arg Lys Val Lys Glu Gly Leu Pro Val Asn Ala Asp Ala Asn
1205 1210 1215
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Trp Leu Ala Gln Gln
1220 1225 1230
Ile Lys Asn Ala Asn Asp Leu Ser Asp Val Lys Leu Ala Ile Thr
1235 1240 1245
Asn Lys Glu Trp Leu Gln Phe Ala Gln Lys Lys Gln Tyr Leu Lys
1250 1255 1260
Asp
<210> 88
<211> 1264
<212> БЕЛОК
<213> Moraxella caprae
<400> 88
Met Leu Phe Gln Asp Phe Thr His Leu Tyr Pro Leu Ser Lys Thr Met
1 5 10 15
Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu His Ile His Ala
20 25 30
Lys Asn Phe Leu Ser Gln Asp Glu Thr Met Ala Asp Met Tyr Gln Lys
35 40 45
Val Lys Ala Ile Leu Asp Asp Tyr His Arg Asp Phe Ile Ala Asp Met
50 55 60
Met Gly Glu Val Lys Leu Thr Lys Leu Ala Glu Phe Tyr Asp Val Tyr
65 70 75 80
Leu Lys Phe Arg Lys Asn Pro Lys Asp Asp Gly Leu Gln Lys Gln Leu
85 90 95
Lys Asp Leu Gln Ala Val Leu Arg Lys Glu Ile Val Lys Pro Ile Gly
100 105 110
Asn Gly Gly Lys Tyr Lys Ala Gly Tyr Asp Arg Leu Phe Gly Ala Lys
115 120 125
Leu Phe Lys Asp Gly Lys Glu Leu Gly Asp Leu Ala Lys Phe Val Ile
130 135 140
Ala Gln Glu Gly Glu Ser Ser Pro Lys Leu Ala His Leu Ala His Phe
145 150 155 160
Glu Lys Phe Ser Thr Tyr Phe Thr Gly Phe His Asp Asn Arg Lys Asn
165 170 175
Met Tyr Ser Asp Glu Asp Lys His Thr Ala Ile Thr Tyr Arg Leu Ile
180 185 190
His Glu Asn Leu Pro Arg Phe Ile Asp Asn Leu Gln Ile Leu Ala Thr
195 200 205
Ile Lys Gln Lys His Ser Ala Leu Tyr Asp Gln Ile Ile Asn Glu Leu
210 215 220
Thr Ala Ser Gly Leu Asp Val Ser Leu Ala Ser His Leu Asp Gly Tyr
225 230 235 240
His Lys Leu Leu Thr Gln Glu Gly Ile Thr Ala Tyr Asn Thr Leu Leu
245 250 255
Gly Gly Ile Ser Gly Glu Ala Gly Ser Arg Lys Ile Gln Gly Ile Asn
260 265 270
Glu Leu Ile Asn Ser His His Asn Gln His Cys His Lys Ser Glu Arg
275 280 285
Ile Ala Lys Leu Arg Pro Leu His Lys Gln Ile Leu Ser Asp Gly Met
290 295 300
Gly Val Ser Phe Leu Pro Ser Lys Phe Ala Asp Asp Ser Glu Met Cys
305 310 315 320
Gln Ala Val Asn Glu Phe Tyr Arg His Tyr Ala Asp Val Phe Ala Lys
325 330 335
Val Gln Ser Leu Phe Asp Gly Phe Asp Asp His Gln Lys Asp Gly Ile
340 345 350
Tyr Val Glu His Lys Asn Leu Asn Glu Leu Ser Lys Gln Ala Phe Gly
355 360 365
Asp Phe Ala Leu Leu Gly Arg Val Leu Asp Gly Tyr Tyr Val Asp Val
370 375 380
Val Asn Pro Glu Phe Asn Glu Arg Phe Ala Lys Ala Lys Thr Asp Asn
385 390 395 400
Ala Lys Ala Lys Leu Thr Lys Glu Lys Asp Lys Phe Ile Lys Gly Val
405 410 415
His Ser Leu Ala Ser Leu Glu Gln Ala Ile Glu His Tyr Thr Ala Arg
420 425 430
His Asp Asp Glu Ser Val Gln Ala Gly Lys Leu Gly Gln Tyr Phe Lys
435 440 445
His Gly Leu Ala Gly Val Asp Asn Pro Ile Gln Lys Ile His Asn Asn
450 455 460
His Ser Thr Ile Lys Gly Phe Leu Glu Arg Glu Arg Pro Ala Gly Glu
465 470 475 480
Arg Ala Leu Pro Lys Ile Lys Ser Gly Lys Asn Pro Glu Met Thr Gln
485 490 495
Leu Arg Gln Leu Lys Glu Leu Leu Asp Asn Ala Leu Asn Val Ala His
500 505 510
Phe Ala Lys Leu Leu Thr Thr Lys Thr Thr Leu Asp Asn Gln Asp Gly
515 520 525
Asn Phe Tyr Gly Glu Phe Gly Ala Leu Tyr Asp Glu Leu Ala Lys Ile
530 535 540
Pro Thr Leu Tyr Asn Lys Val Arg Asp Tyr Leu Ser Gln Lys Pro Phe
545 550 555 560
Ser Thr Glu Lys Tyr Lys Leu Asn Phe Gly Asn Pro Thr Leu Leu Asn
565 570 575
Gly Trp Asp Leu Asn Lys Glu Lys Asp Asn Phe Gly Ile Ile Leu Gln
580 585 590
Lys Asp Gly Cys Tyr Tyr Leu Ala Leu Leu Asp Lys Ala His Lys Lys
595 600 605
Val Phe Asp Asn Ala Pro Asn Thr Gly Lys Asn Val Tyr Gln Lys Met
610 615 620
Ile Tyr Lys Leu Leu Pro Gly Pro Asn Lys Met Leu Pro Lys Val Phe
625 630 635 640
Phe Ala Lys Ser Asn Leu Asp Tyr Tyr Asn Pro Ser Ala Glu Leu Leu
645 650 655
Asp Lys Tyr Ala Gln Gly Thr His Lys Lys Gly Asn Asn Phe Asn Leu
660 665 670
Lys Asp Cys His Ala Leu Ile Asp Phe Phe Lys Ala Gly Ile Asn Lys
675 680 685
His Pro Glu Trp Gln His Phe Gly Phe Lys Phe Ser Pro Thr Ser Ser
690 695 700
Tyr Gln Asp Leu Ser Asp Phe Tyr Arg Glu Val Glu Pro Gln Gly Tyr
705 710 715 720
Gln Val Lys Phe Val Asp Ile Asn Ala Asp Tyr Ile Asn Glu Leu Val
725 730 735
Glu Gln Gly Gln Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser
740 745 750
Pro Lys Ala His Gly Lys Pro Asn Leu His Thr Leu Tyr Phe Lys Ala
755 760 765
Leu Phe Ser Lys Asp Asn Leu Ala Asn Pro Ile Tyr Lys Leu Asn Gly
770 775 780
Glu Ala Gln Ile Phe Tyr Arg Lys Ala Ser Leu Asp Met Asn Glu Thr
785 790 795 800
Thr Ile His Arg Ala Gly Glu Val Leu Glu Asn Lys Asn Pro Asp Asn
805 810 815
Pro Lys Lys Arg Gln Phe Val Tyr Asp Ile Ile Lys Asp Lys Arg Tyr
820 825 830
Thr Gln Asp Lys Phe Met Leu His Val Pro Ile Thr Met Asn Phe Gly
835 840 845
Val Gln Gly Met Thr Ile Lys Glu Phe Asn Lys Lys Val Asn Gln Ser
850 855 860
Ile Gln Gln Tyr Asp Glu Val Asn Val Ile Gly Ile Asp Arg Gly Glu
865 870 875 880
Arg His Leu Leu Tyr Leu Thr Val Ile Asn Ser Lys Gly Glu Ile Leu
885 890 895
Glu Gln Arg Ser Leu Asn Asp Ile Thr Thr Ala Ser Ala Asn Gly Thr
900 905 910
Gln Met Thr Thr Pro Tyr His Lys Ile Leu Asp Lys Arg Glu Ile Glu
915 920 925
Arg Leu Asn Ala Arg Val Gly Trp Gly Glu Ile Glu Thr Ile Lys Glu
930 935 940
Leu Lys Ser Gly Tyr Leu Ser His Val Val His Gln Ile Ser Gln Leu
945 950 955 960
Met Leu Lys Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn Phe Gly
965 970 975
Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Ile Tyr Gln Asn Phe
980 985 990
Glu Asn Ala Leu Ile Lys Lys Leu Asn His Leu Val Leu Lys Asp Glu
995 1000 1005
Ala Asp Asp Glu Ile Gly Ser Tyr Lys Asn Ala Leu Gln Leu Thr
1010 1015 1020
Asn Asn Phe Thr Asp Leu Lys Ser Ile Gly Lys Gln Thr Gly Phe
1025 1030 1035
Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro Glu
1040 1045 1050
Thr Gly Phe Val Asp Leu Leu Lys Pro Arg Tyr Glu Asn Ile Ala
1055 1060 1065
Gln Ser Gln Ala Phe Phe Gly Lys Phe Asp Lys Ile Cys Tyr Asn
1070 1075 1080
Ala Asp Lys Asp Tyr Phe Glu Phe His Ile Asp Tyr Ala Lys Phe
1085 1090 1095
Thr Asp Lys Ala Lys Asn Ser Arg Gln Ile Trp Lys Ile Cys Ser
1100 1105 1110
His Gly Asp Lys Arg Tyr Val Tyr Asp Lys Thr Ala Asn Gln Asn
1115 1120 1125
Lys Gly Ala Thr Lys Gly Ile Asn Val Asn Asp Glu Leu Lys Ser
1130 1135 1140
Leu Phe Ala Arg His His Ile Asn Asp Lys Gln Pro Asn Leu Val
1145 1150 1155
Met Asp Ile Cys Gln Asn Asn Asp Lys Glu Phe His Lys Ser Leu
1160 1165 1170
Ile Tyr Leu Leu Lys Thr Leu Leu Ala Leu Arg Tyr Ser Asn Ala
1175 1180 1185
Ser Ser Asp Glu Asp Phe Ile Leu Ser Pro Val Ala Asn Asp Glu
1190 1195 1200
Gly Met Phe Phe Asn Ser Ala Leu Ala Asp Asp Thr Gln Pro Gln
1205 1210 1215
Asn Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Leu
1220 1225 1230
Trp Val Leu Glu Gln Ile Lys Asn Ser Asp Asp Leu Asn Lys Val
1235 1240 1245
Lys Leu Ala Ile Asp Asn Gln Thr Trp Leu Asn Phe Ala Gln Asn
1250 1255 1260
Arg
<210> 89
<211> 1263
<212> БЕЛОК
<213> Leptospira inadai
<400> 89
Met Glu Asp Tyr Ser Gly Phe Val Asn Ile Tyr Ser Ile Gln Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu His Ile Glu
20 25 30
Lys Lys Gly Phe Leu Lys Lys Asp Lys Ile Arg Ala Glu Asp Tyr Lys
35 40 45
Ala Val Lys Lys Ile Ile Asp Lys Tyr His Arg Ala Tyr Ile Glu Glu
50 55 60
Val Phe Asp Ser Val Leu His Gln Lys Lys Lys Lys Asp Lys Thr Arg
65 70 75 80
Phe Ser Thr Gln Phe Ile Lys Glu Ile Lys Glu Phe Ser Glu Leu Tyr
85 90 95
Tyr Lys Thr Glu Lys Asn Ile Pro Asp Lys Glu Arg Leu Glu Ala Leu
100 105 110
Ser Glu Lys Leu Arg Lys Met Leu Val Gly Ala Phe Lys Gly Glu Phe
115 120 125
Ser Glu Glu Val Ala Glu Lys Tyr Lys Asn Leu Phe Ser Lys Glu Leu
130 135 140
Ile Arg Asn Glu Ile Glu Lys Phe Cys Glu Thr Asp Glu Glu Arg Lys
145 150 155 160
Gln Val Ser Asn Phe Lys Ser Phe Thr Thr Tyr Phe Thr Gly Phe His
165 170 175
Ser Asn Arg Gln Asn Ile Tyr Ser Asp Glu Lys Lys Ser Thr Ala Ile
180 185 190
Gly Tyr Arg Ile Ile His Gln Asn Leu Pro Lys Phe Leu Asp Asn Leu
195 200 205
Lys Ile Ile Glu Ser Ile Gln Arg Arg Phe Lys Asp Phe Pro Trp Ser
210 215 220
Asp Leu Lys Lys Asn Leu Lys Lys Ile Asp Lys Asn Ile Lys Leu Thr
225 230 235 240
Glu Tyr Phe Ser Ile Asp Gly Phe Val Asn Val Leu Asn Gln Lys Gly
245 250 255
Ile Asp Ala Tyr Asn Thr Ile Leu Gly Gly Lys Ser Glu Glu Ser Gly
260 265 270
Glu Lys Ile Gln Gly Leu Asn Glu Tyr Ile Asn Leu Tyr Arg Gln Lys
275 280 285
Asn Asn Ile Asp Arg Lys Asn Leu Pro Asn Val Lys Ile Leu Phe Lys
290 295 300
Gln Ile Leu Gly Asp Arg Glu Thr Lys Ser Phe Ile Pro Glu Ala Phe
305 310 315 320
Pro Asp Asp Gln Ser Val Leu Asn Ser Ile Thr Glu Phe Ala Lys Tyr
325 330 335
Leu Lys Leu Asp Lys Lys Lys Lys Ser Ile Ile Ala Glu Leu Lys Lys
340 345 350
Phe Leu Ser Ser Phe Asn Arg Tyr Glu Leu Asp Gly Ile Tyr Leu Ala
355 360 365
Asn Asp Asn Ser Leu Ala Ser Ile Ser Thr Phe Leu Phe Asp Asp Trp
370 375 380
Ser Phe Ile Lys Lys Ser Val Ser Phe Lys Tyr Asp Glu Ser Val Gly
385 390 395 400
Asp Pro Lys Lys Lys Ile Lys Ser Pro Leu Lys Tyr Glu Lys Glu Lys
405 410 415
Glu Lys Trp Leu Lys Gln Lys Tyr Tyr Thr Ile Ser Phe Leu Asn Asp
420 425 430
Ala Ile Glu Ser Tyr Ser Lys Ser Gln Asp Glu Lys Arg Val Lys Ile
435 440 445
Arg Leu Glu Ala Tyr Phe Ala Glu Phe Lys Ser Lys Asp Asp Ala Lys
450 455 460
Lys Gln Phe Asp Leu Leu Glu Arg Ile Glu Glu Ala Tyr Ala Ile Val
465 470 475 480
Glu Pro Leu Leu Gly Ala Glu Tyr Pro Arg Asp Arg Asn Leu Lys Ala
485 490 495
Asp Lys Lys Glu Val Gly Lys Ile Lys Asp Phe Leu Asp Ser Ile Lys
500 505 510
Ser Leu Gln Phe Phe Leu Lys Pro Leu Leu Ser Ala Glu Ile Phe Asp
515 520 525
Glu Lys Asp Leu Gly Phe Tyr Asn Gln Leu Glu Gly Tyr Tyr Glu Glu
530 535 540
Ile Asp Ser Ile Gly His Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr
545 550 555 560
Gly Lys Ile Tyr Ser Lys Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser
565 570 575
Thr Leu Leu Lys Gly Trp Asp Glu Asn Arg Glu Val Ala Asn Leu Cys
580 585 590
Val Ile Phe Arg Glu Asp Gln Lys Tyr Tyr Leu Gly Val Met Asp Lys
595 600 605
Glu Asn Asn Thr Ile Leu Ser Asp Ile Pro Lys Val Lys Pro Asn Glu
610 615 620
Leu Phe Tyr Glu Lys Met Val Tyr Lys Leu Ile Pro Thr Pro His Met
625 630 635 640
Gln Leu Pro Arg Ile Ile Phe Ser Ser Asp Asn Leu Ser Ile Tyr Asn
645 650 655
Pro Ser Lys Ser Ile Leu Lys Ile Arg Glu Ala Lys Ser Phe Lys Glu
660 665 670
Gly Lys Asn Phe Lys Leu Lys Asp Cys His Lys Phe Ile Asp Phe Tyr
675 680 685
Lys Glu Ser Ile Ser Lys Asn Glu Asp Trp Ser Arg Phe Asp Phe Lys
690 695 700
Phe Ser Lys Thr Ser Ser Tyr Glu Asn Ile Ser Glu Phe Tyr Arg Glu
705 710 715 720
Val Glu Arg Gln Gly Tyr Asn Leu Asp Phe Lys Lys Val Ser Lys Phe
725 730 735
Tyr Ile Asp Ser Leu Val Glu Asp Gly Lys Leu Tyr Leu Phe Gln Ile
740 745 750
Tyr Asn Lys Asp Phe Ser Ile Phe Ser Lys Gly Lys Pro Asn Leu His
755 760 765
Thr Ile Tyr Phe Arg Ser Leu Phe Ser Lys Glu Asn Leu Lys Asp Val
770 775 780
Cys Leu Lys Leu Asn Gly Glu Ala Glu Met Phe Phe Arg Lys Lys Ser
785 790 795 800
Ile Asn Tyr Asp Glu Lys Lys Lys Arg Glu Gly His His Pro Glu Leu
805 810 815
Phe Glu Lys Leu Lys Tyr Pro Ile Leu Lys Asp Lys Arg Tyr Ser Glu
820 825 830
Asp Lys Phe Gln Phe His Leu Pro Ile Ser Leu Asn Phe Lys Ser Lys
835 840 845
Glu Arg Leu Asn Phe Asn Leu Lys Val Asn Glu Phe Leu Lys Arg Asn
850 855 860
Lys Asp Ile Asn Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Leu
865 870 875 880
Tyr Leu Val Met Ile Asn Gln Lys Gly Glu Ile Leu Lys Gln Thr Leu
885 890 895
Leu Asp Ser Met Gln Ser Gly Lys Gly Arg Pro Glu Ile Asn Tyr Lys
900 905 910
Glu Lys Leu Gln Glu Lys Glu Ile Glu Arg Asp Lys Ala Arg Lys Ser
915 920 925
Trp Gly Thr Val Glu Asn Ile Lys Glu Leu Lys Glu Gly Tyr Leu Ser
930 935 940
Ile Val Ile His Gln Ile Ser Lys Leu Met Val Glu Asn Asn Ala Ile
945 950 955 960
Val Val Leu Glu Asp Leu Asn Ile Gly Phe Lys Arg Gly Arg Gln Lys
965 970 975
Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Lys Met Leu Ile Asp Lys
980 985 990
Leu Asn Phe Leu Val Phe Lys Glu Asn Lys Pro Thr Glu Pro Gly Gly
995 1000 1005
Val Leu Lys Ala Tyr Gln Leu Thr Asp Glu Phe Gln Ser Phe Glu
1010 1015 1020
Lys Leu Ser Lys Gln Thr Gly Phe Leu Phe Tyr Val Pro Ser Trp
1025 1030 1035
Asn Thr Ser Lys Ile Asp Pro Arg Thr Gly Phe Ile Asp Phe Leu
1040 1045 1050
His Pro Ala Tyr Glu Asn Ile Glu Lys Ala Lys Gln Trp Ile Asn
1055 1060 1065
Lys Phe Asp Ser Ile Arg Phe Asn Ser Lys Met Asp Trp Phe Glu
1070 1075 1080
Phe Thr Ala Asp Thr Arg Lys Phe Ser Glu Asn Leu Met Leu Gly
1085 1090 1095
Lys Asn Arg Val Trp Val Ile Cys Thr Thr Asn Val Glu Arg Tyr
1100 1105 1110
Phe Thr Ser Lys Thr Ala Asn Ser Ser Ile Gln Tyr Asn Ser Ile
1115 1120 1125
Gln Ile Thr Glu Lys Leu Lys Glu Leu Phe Val Asp Ile Pro Phe
1130 1135 1140
Ser Asn Gly Gln Asp Leu Lys Pro Glu Ile Leu Arg Lys Asn Asp
1145 1150 1155
Ala Val Phe Phe Lys Ser Leu Leu Phe Tyr Ile Lys Thr Thr Leu
1160 1165 1170
Ser Leu Arg Gln Asn Asn Gly Lys Lys Gly Glu Glu Glu Lys Asp
1175 1180 1185
Phe Ile Leu Ser Pro Val Val Asp Ser Lys Gly Arg Phe Phe Asn
1190 1195 1200
Ser Leu Glu Ala Ser Asp Asp Glu Pro Lys Asp Ala Asp Ala Asn
1205 1210 1215
Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Met Asn Leu Leu Val
1220 1225 1230
Leu Asn Glu Thr Lys Glu Glu Asn Leu Ser Arg Pro Lys Trp Lys
1235 1240 1245
Ile Lys Asn Lys Asp Trp Leu Glu Phe Val Trp Glu Arg Asn Arg
1250 1255 1260
<210> 90
<211> 1262
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 90
Met Pro Trp Ile Asp Leu Lys Asp Phe Thr Asn Leu Tyr Pro Val Ser
1 5 10 15
Lys Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn
20 25 30
Ile Glu Lys Ala Gly Ile Leu Lys Glu Asp Glu His Arg Ala Glu Ser
35 40 45
Tyr Arg Arg Val Lys Lys Ile Ile Asp Thr Tyr His Lys Val Phe Ile
50 55 60
Asp Ser Ser Leu Glu Asn Met Ala Lys Met Gly Ile Glu Asn Glu Ile
65 70 75 80
Lys Ala Met Leu Gln Ser Phe Cys Glu Leu Tyr Lys Lys Asp His Arg
85 90 95
Thr Glu Gly Glu Asp Lys Ala Leu Asp Lys Ile Arg Ala Val Leu Arg
100 105 110
Gly Leu Ile Val Gly Ala Phe Thr Gly Val Cys Gly Arg Arg Glu Asn
115 120 125
Thr Val Gln Asn Glu Lys Tyr Glu Ser Leu Phe Lys Glu Lys Leu Ile
130 135 140
Lys Glu Ile Leu Pro Asp Phe Val Leu Ser Thr Glu Ala Glu Ser Leu
145 150 155 160
Pro Phe Ser Val Glu Glu Ala Thr Arg Ser Leu Lys Glu Phe Asp Ser
165 170 175
Phe Thr Ser Tyr Phe Ala Gly Phe Tyr Glu Asn Arg Lys Asn Ile Tyr
180 185 190
Ser Thr Lys Pro Gln Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Glu
195 200 205
Asn Leu Pro Lys Phe Ile Asp Asn Ile Leu Val Phe Gln Lys Ile Lys
210 215 220
Glu Pro Ile Ala Lys Glu Leu Glu His Ile Arg Ala Asp Phe Ser Ala
225 230 235 240
Gly Gly Tyr Ile Lys Lys Asp Glu Arg Leu Glu Asp Ile Phe Ser Leu
245 250 255
Asn Tyr Tyr Ile His Val Leu Ser Gln Ala Gly Ile Glu Lys Tyr Asn
260 265 270
Ala Leu Ile Gly Lys Ile Val Thr Glu Gly Asp Gly Glu Met Lys Gly
275 280 285
Leu Asn Glu His Ile Asn Leu Tyr Asn Gln Gln Arg Gly Arg Glu Asp
290 295 300
Arg Leu Pro Leu Phe Arg Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg
305 310 315 320
Glu Gln Leu Ser Tyr Leu Pro Glu Ser Phe Glu Lys Asp Glu Glu Leu
325 330 335
Leu Arg Ala Leu Lys Glu Phe Tyr Asp His Ile Ala Glu Asp Ile Leu
340 345 350
Gly Arg Thr Gln Gln Leu Met Thr Ser Ile Ser Glu Tyr Asp Leu Ser
355 360 365
Arg Ile Tyr Val Arg Asn Asp Ser Gln Leu Thr Asp Ile Ser Lys Lys
370 375 380
Met Leu Gly Asp Trp Asn Ala Ile Tyr Met Ala Arg Glu Arg Ala Tyr
385 390 395 400
Asp His Glu Gln Ala Pro Lys Arg Ile Thr Ala Lys Tyr Glu Arg Asp
405 410 415
Arg Ile Lys Ala Leu Lys Gly Glu Glu Ser Ile Ser Leu Ala Asn Leu
420 425 430
Asn Ser Cys Ile Ala Phe Leu Asp Asn Val Arg Asp Cys Arg Val Asp
435 440 445
Thr Tyr Leu Ser Thr Leu Gly Gln Lys Glu Gly Pro His Gly Leu Ser
450 455 460
Asn Leu Val Glu Asn Val Phe Ala Ser Tyr His Glu Ala Glu Gln Leu
465 470 475 480
Leu Ser Phe Pro Tyr Pro Glu Glu Asn Asn Leu Ile Gln Asp Lys Asp
485 490 495
Asn Val Val Leu Ile Lys Asn Leu Leu Asp Asn Ile Ser Asp Leu Gln
500 505 510
Arg Phe Leu Lys Pro Leu Trp Gly Met Gly Asp Glu Pro Asp Lys Asp
515 520 525
Glu Arg Phe Tyr Gly Glu Tyr Asn Tyr Ile Arg Gly Ala Leu Asp Gln
530 535 540
Val Ile Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Arg Lys Pro
545 550 555 560
Tyr Ser Thr Arg Lys Val Lys Leu Asn Phe Gly Asn Ser Gln Leu Leu
565 570 575
Ser Gly Trp Asp Arg Asn Lys Glu Lys Asp Asn Ser Cys Val Ile Leu
580 585 590
Arg Lys Gly Gln Asn Phe Tyr Leu Ala Ile Met Asn Asn Arg His Lys
595 600 605
Arg Ser Phe Glu Asn Lys Val Leu Pro Glu Tyr Lys Glu Gly Glu Pro
610 615 620
Tyr Phe Glu Lys Met Asp Tyr Lys Phe Leu Pro Asp Pro Asn Lys Met
625 630 635 640
Leu Pro Lys Val Phe Leu Ser Lys Lys Gly Ile Glu Ile Tyr Glu Pro
645 650 655
Ser Pro Lys Leu Leu Glu Gln Tyr Gly His Gly Thr His Lys Lys Gly
660 665 670
Asp Thr Phe Ser Met Asp Asp Leu His Glu Leu Ile Asp Phe Phe Lys
675 680 685
His Ser Ile Glu Ala His Glu Asp Trp Lys Gln Phe Gly Phe Lys Phe
690 695 700
Ser Asp Thr Ala Thr Tyr Glu Asn Val Ser Ser Phe Tyr Arg Glu Val
705 710 715 720
Glu Asp Gln Gly Tyr Lys Leu Ser Phe Arg Lys Val Ser Glu Ser Tyr
725 730 735
Val Tyr Ser Leu Ile Asp Gln Gly Lys Leu Tyr Leu Phe Gln Ile Tyr
740 745 750
Asn Lys Asp Phe Ser Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr
755 760 765
Leu Tyr Trp Arg Met Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile
770 775 780
Tyr Lys Leu Asp Gly Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu
785 790 795 800
Lys Asn Asp His Pro Thr His Pro Ala Gly Lys Pro Ile Lys Lys Lys
805 810 815
Ser Arg Gln Lys Lys Gly Glu Glu Ser Leu Phe Glu Tyr Asp Leu Val
820 825 830
Lys Asp Arg Arg Tyr Thr Met Asp Lys Phe Gln Phe His Val Pro Ile
835 840 845
Thr Met Asn Phe Lys Cys Ser Ala Gly Ser Lys Val Asn Asp Met Val
850 855 860
Asn Ala His Ile Arg Glu Ala Lys Asp Met His Val Ile Gly Ile Asp
865 870 875 880
Arg Gly Glu Arg Asn Leu Leu Tyr Ile Cys Val Ile Asp Ser Arg Gly
885 890 895
Thr Ile Leu Asp Gln Ile Ser Leu Asn Thr Ile Asn Asp Ile Asp Tyr
900 905 910
His Asp Leu Leu Glu Ser Arg Asp Lys Asp Arg Gln Gln Glu Arg Arg
915 920 925
Asn Trp Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Gln Gly Tyr Leu
930 935 940
Ser Gln Ala Val His Arg Ile Ala Glu Leu Met Val Ala Tyr Lys Ala
945 950 955 960
Val Val Ala Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly Arg Gln
965 970 975
Lys Val Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Gln Leu Ile Asp
980 985 990
Lys Leu Asn Tyr Leu Val Asp Lys Lys Lys Arg Pro Glu Asp Ile Gly
995 1000 1005
Gly Leu Leu Arg Ala Tyr Gln Phe Thr Ala Pro Phe Lys Ser Phe
1010 1015 1020
Lys Glu Met Gly Lys Gln Asn Gly Phe Leu Phe Tyr Ile Pro Ala
1025 1030 1035
Trp Asn Thr Ser Asn Ile Asp Pro Thr Thr Gly Phe Val Asn Leu
1040 1045 1050
Phe His Ala Gln Tyr Glu Asn Val Asp Lys Ala Lys Ser Phe Phe
1055 1060 1065
Gln Lys Phe Asp Ser Ile Ser Tyr Asn Pro Lys Lys Asp Trp Phe
1070 1075 1080
Glu Phe Ala Phe Asp Tyr Lys Asn Phe Thr Lys Lys Ala Glu Gly
1085 1090 1095
Ser Arg Ser Met Trp Ile Leu Cys Thr His Gly Ser Arg Ile Lys
1100 1105 1110
Asn Phe Arg Asn Ser Gln Lys Asn Gly Gln Trp Asp Ser Glu Glu
1115 1120 1125
Phe Ala Leu Thr Glu Ala Phe Lys Ser Leu Phe Val Arg Tyr Glu
1130 1135 1140
Ile Asp Tyr Thr Ala Asp Leu Lys Thr Ala Ile Val Asp Glu Lys
1145 1150 1155
Gln Lys Asp Phe Phe Val Asp Leu Leu Lys Leu Phe Lys Leu Thr
1160 1165 1170
Val Gln Met Arg Asn Ser Trp Lys Glu Lys Asp Leu Asp Tyr Leu
1175 1180 1185
Ile Ser Pro Val Ala Gly Ala Asp Gly Arg Phe Phe Asp Thr Arg
1190 1195 1200
Glu Gly Asn Lys Ser Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala
1205 1210 1215
Tyr Asn Ile Ala Leu Lys Gly Leu Trp Ala Leu Arg Gln Ile Arg
1220 1225 1230
Gln Thr Ser Glu Gly Gly Lys Leu Lys Leu Ala Ile Ser Asn Lys
1235 1240 1245
Glu Trp Leu Gln Phe Val Gln Glu Arg Ser Tyr Glu Lys Asp
1250 1255 1260
<210> 91
<211> 1262
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Bacteroidetes из ротовой полости, таксон 274
<400> 91
Met Arg Lys Phe Asn Glu Phe Val Gly Leu Tyr Pro Ile Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu His Ile Gln
20 25 30
Arg Asn Lys Leu Leu Glu His Asp Ala Val Arg Ala Asp Asp Tyr Val
35 40 45
Lys Val Lys Lys Ile Ile Asp Lys Tyr His Lys Cys Leu Ile Asp Glu
50 55 60
Ala Leu Ser Gly Phe Thr Phe Asp Thr Glu Ala Asp Gly Arg Ser Asn
65 70 75 80
Asn Ser Leu Ser Glu Tyr Tyr Leu Tyr Tyr Asn Leu Lys Lys Arg Asn
85 90 95
Glu Gln Glu Gln Lys Thr Phe Lys Thr Ile Gln Asn Asn Leu Arg Lys
100 105 110
Gln Ile Val Asn Lys Leu Thr Gln Ser Glu Lys Tyr Lys Arg Ile Asp
115 120 125
Lys Lys Glu Leu Ile Thr Thr Asp Leu Pro Asp Phe Leu Thr Asn Glu
130 135 140
Ser Glu Lys Glu Leu Val Glu Lys Phe Lys Asn Phe Thr Thr Tyr Phe
145 150 155 160
Thr Glu Phe His Lys Asn Arg Lys Asn Met Tyr Ser Lys Glu Glu Lys
165 170 175
Ser Thr Ala Ile Ala Phe Arg Leu Ile Asn Glu Asn Leu Pro Lys Phe
180 185 190
Val Asp Asn Ile Ala Ala Phe Glu Lys Val Val Ser Ser Pro Leu Ala
195 200 205
Glu Lys Ile Asn Ala Leu Tyr Glu Asp Phe Lys Glu Tyr Leu Asn Val
210 215 220
Glu Glu Ile Ser Arg Val Phe Arg Leu Asp Tyr Tyr Asp Glu Leu Leu
225 230 235 240
Thr Gln Lys Gln Ile Asp Leu Tyr Asn Ala Ile Val Gly Gly Arg Thr
245 250 255
Glu Glu Asp Asn Lys Ile Gln Ile Lys Gly Leu Asn Gln Tyr Ile Asn
260 265 270
Glu Tyr Asn Gln Gln Gln Thr Asp Arg Ser Asn Arg Leu Pro Lys Leu
275 280 285
Lys Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Ser Val Ser Trp
290 295 300
Leu Pro Pro Lys Phe Asp Ser Asp Lys Asn Leu Leu Ile Lys Ile Lys
305 310 315 320
Glu Cys Tyr Asp Ala Leu Ser Glu Lys Glu Lys Val Phe Asp Lys Leu
325 330 335
Glu Ser Ile Leu Lys Ser Leu Ser Thr Tyr Asp Leu Ser Lys Ile Tyr
340 345 350
Ile Ser Asn Asp Ser Gln Leu Ser Tyr Ile Ser Gln Lys Met Phe Gly
355 360 365
Arg Trp Asp Ile Ile Ser Lys Ala Ile Arg Glu Asp Cys Ala Lys Arg
370 375 380
Asn Pro Gln Lys Ser Arg Glu Ser Leu Glu Lys Phe Ala Glu Arg Ile
385 390 395 400
Asp Lys Lys Leu Lys Thr Ile Asp Ser Ile Ser Ile Gly Asp Val Asp
405 410 415
Glu Cys Leu Ala Gln Leu Gly Glu Thr Tyr Val Lys Arg Val Glu Asp
420 425 430
Tyr Phe Val Ala Met Gly Glu Ser Glu Ile Asp Asp Glu Gln Thr Asp
435 440 445
Thr Thr Ser Phe Lys Lys Asn Ile Glu Gly Ala Tyr Glu Ser Val Lys
450 455 460
Glu Leu Leu Asn Asn Ala Asp Asn Ile Thr Asp Asn Asn Leu Met Gln
465 470 475 480
Asp Lys Gly Asn Val Glu Lys Ile Lys Thr Leu Leu Asp Ala Ile Lys
485 490 495
Asp Leu Gln Arg Phe Ile Lys Pro Leu Leu Gly Lys Gly Asp Glu Ala
500 505 510
Asp Lys Asp Gly Val Phe Tyr Gly Glu Phe Thr Ser Leu Trp Thr Lys
515 520 525
Leu Asp Gln Val Thr Pro Leu Tyr Asn Met Val Arg Asn Tyr Leu Thr
530 535 540
Ser Lys Pro Tyr Ser Thr Lys Lys Ile Lys Leu Asn Phe Glu Asn Ser
545 550 555 560
Thr Leu Met Asp Gly Trp Asp Leu Asn Lys Glu Pro Asp Asn Thr Thr
565 570 575
Val Ile Phe Cys Lys Asp Gly Leu Tyr Tyr Leu Gly Ile Met Gly Lys
580 585 590
Lys Tyr Asn Arg Val Phe Val Asp Arg Glu Asp Leu Pro His Asp Gly
595 600 605
Glu Cys Tyr Asp Lys Met Glu Tyr Lys Leu Leu Pro Gly Ala Asn Lys
610 615 620
Met Leu Pro Lys Val Phe Phe Ser Glu Thr Gly Ile Gln Arg Phe Leu
625 630 635 640
Pro Ser Glu Glu Leu Leu Gly Lys Tyr Glu Arg Gly Thr His Lys Lys
645 650 655
Gly Ala Gly Phe Asp Leu Gly Asp Cys Arg Ala Leu Ile Asp Phe Phe
660 665 670
Lys Lys Ser Ile Glu Arg His Asp Asp Trp Lys Lys Phe Asp Phe Lys
675 680 685
Phe Ser Asp Thr Ser Thr Tyr Gln Asp Ile Ser Glu Phe Tyr Arg Glu
690 695 700
Val Glu Gln Gln Gly Tyr Lys Met Ser Phe Arg Lys Val Ser Val Asp
705 710 715 720
Tyr Ile Lys Ser Leu Val Glu Glu Gly Lys Leu Tyr Leu Phe Gln Ile
725 730 735
Tyr Asn Lys Asp Phe Ser Ala His Ser Lys Gly Thr Pro Asn Met His
740 745 750
Thr Leu Tyr Trp Lys Met Leu Phe Asp Glu Glu Asn Leu Lys Asp Val
755 760 765
Val Tyr Lys Leu Asn Gly Glu Ala Glu Val Phe Phe Arg Lys Ser Ser
770 775 780
Ile Thr Val Gln Ser Pro Thr His Pro Ala Asn Ser Pro Ile Lys Asn
785 790 795 800
Lys Asn Lys Asp Asn Gln Lys Lys Glu Ser Lys Phe Glu Tyr Asp Leu
805 810 815
Ile Lys Asp Arg Arg Tyr Thr Val Asp Lys Phe Leu Phe His Val Pro
820 825 830
Ile Thr Met Asn Phe Lys Ser Val Gly Gly Ser Asn Ile Asn Gln Leu
835 840 845
Val Lys Arg His Ile Arg Ser Ala Thr Asp Leu His Ile Ile Gly Ile
850 855 860
Asp Arg Gly Glu Arg His Leu Leu Tyr Leu Thr Val Ile Asp Ser Arg
865 870 875 880
Gly Asn Ile Lys Glu Gln Phe Ser Leu Asn Glu Ile Val Asn Glu Tyr
885 890 895
Asn Gly Asn Thr Tyr Arg Thr Asp Tyr His Glu Leu Leu Asp Thr Arg
900 905 910
Glu Gly Glu Arg Thr Glu Ala Arg Arg Asn Trp Gln Thr Ile Gln Asn
915 920 925
Ile Arg Glu Leu Lys Glu Gly Tyr Leu Ser Gln Val Ile His Lys Ile
930 935 940
Ser Glu Leu Ala Ile Lys Tyr Asn Ala Val Ile Val Leu Glu Asp Leu
945 950 955 960
Asn Phe Gly Phe Met Arg Ser Arg Gln Lys Val Glu Lys Gln Val Tyr
965 970 975
Gln Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp
980 985 990
Lys Lys Lys Pro Val Ala Glu Thr Gly Gly Leu Leu Arg Ala Tyr Gln
995 1000 1005
Leu Thr Gly Glu Phe Glu Ser Phe Lys Thr Leu Gly Lys Gln Ser
1010 1015 1020
Gly Ile Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile Asp
1025 1030 1035
Pro Val Thr Gly Phe Val Asn Leu Phe Asp Thr His Tyr Glu Asn
1040 1045 1050
Ile Glu Lys Ala Lys Val Phe Phe Asp Lys Phe Lys Ser Ile Arg
1055 1060 1065
Tyr Asn Ser Asp Lys Asp Trp Phe Glu Phe Val Val Asp Asp Tyr
1070 1075 1080
Thr Arg Phe Ser Pro Lys Ala Glu Gly Thr Arg Arg Asp Trp Thr
1085 1090 1095
Ile Cys Thr Gln Gly Lys Arg Ile Gln Ile Cys Arg Asn His Gln
1100 1105 1110
Arg Asn Asn Glu Trp Glu Gly Gln Glu Ile Asp Leu Thr Lys Ala
1115 1120 1125
Phe Lys Glu His Phe Glu Ala Tyr Gly Val Asp Ile Ser Lys Asp
1130 1135 1140
Leu Arg Glu Gln Ile Asn Thr Gln Asn Lys Lys Glu Phe Phe Glu
1145 1150 1155
Glu Leu Leu Arg Leu Leu Arg Leu Thr Leu Gln Met Arg Asn Ser
1160 1165 1170
Met Pro Ser Ser Asp Ile Asp Tyr Leu Ile Ser Pro Val Ala Asn
1175 1180 1185
Asp Thr Gly Cys Phe Phe Asp Ser Arg Lys Gln Ala Glu Leu Lys
1190 1195 1200
Glu Asn Ala Val Leu Pro Met Asn Ala Asp Ala Asn Gly Ala Tyr
1205 1210 1215
Asn Ile Ala Arg Lys Gly Leu Leu Ala Ile Arg Lys Met Lys Gln
1220 1225 1230
Glu Glu Asn Asp Ser Ala Lys Ile Ser Leu Ala Ile Ser Asn Lys
1235 1240 1245
Glu Trp Leu Lys Phe Ala Gln Thr Lys Pro Tyr Leu Glu Asp
1250 1255 1260
<210> 92
<211> 1260
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 92
Met Asp Ser Leu Lys Asp Phe Thr Asn Leu Tyr Pro Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn Ile Glu
20 25 30
Lys Ala Gly Ile Leu Lys Glu Asp Glu His Arg Ala Glu Ser Tyr Arg
35 40 45
Arg Val Lys Lys Ile Ile Asp Thr Tyr His Lys Val Phe Ile Asp Ser
50 55 60
Ser Leu Glu Asn Met Ala Lys Met Gly Ile Glu Asn Glu Ile Lys Ala
65 70 75 80
Met Leu Gln Ser Phe Cys Glu Leu Tyr Lys Lys Asp His Arg Thr Glu
85 90 95
Gly Glu Asp Lys Ala Leu Asp Lys Ile Arg Ala Val Leu Arg Gly Leu
100 105 110
Ile Val Gly Ala Phe Thr Gly Val Cys Gly Arg Arg Glu Asn Thr Val
115 120 125
Gln Asn Glu Lys Tyr Glu Ser Leu Phe Lys Glu Lys Leu Ile Lys Glu
130 135 140
Ile Leu Pro Asp Phe Val Leu Ser Thr Glu Ala Glu Ser Leu Pro Phe
145 150 155 160
Ser Val Glu Glu Ala Thr Arg Ser Leu Lys Glu Phe Asp Ser Phe Thr
165 170 175
Ser Tyr Phe Ala Gly Phe Tyr Glu Asn Arg Lys Asn Ile Tyr Ser Thr
180 185 190
Lys Pro Gln Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Glu Asn Leu
195 200 205
Pro Lys Phe Ile Asp Asn Ile Leu Val Phe Gln Lys Ile Lys Glu Pro
210 215 220
Ile Ala Lys Glu Leu Glu His Ile Arg Ala Asp Phe Ser Ala Gly Gly
225 230 235 240
Tyr Ile Lys Lys Asp Glu Arg Leu Glu Asp Ile Phe Ser Leu Asn Tyr
245 250 255
Tyr Ile His Val Leu Ser Gln Ala Gly Ile Glu Lys Tyr Asn Ala Leu
260 265 270
Ile Gly Lys Ile Val Thr Glu Gly Asp Gly Glu Met Lys Gly Leu Asn
275 280 285
Glu His Ile Asn Leu Tyr Asn Gln Gln Arg Gly Arg Glu Asp Arg Leu
290 295 300
Pro Leu Phe Arg Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Gln
305 310 315 320
Leu Ser Tyr Leu Pro Glu Ser Phe Glu Lys Asp Glu Glu Leu Leu Arg
325 330 335
Ala Leu Lys Glu Phe Tyr Asp His Ile Ala Glu Asp Ile Leu Gly Arg
340 345 350
Thr Gln Gln Leu Met Thr Ser Ile Ser Glu Tyr Asp Leu Ser Arg Ile
355 360 365
Tyr Val Arg Asn Asp Ser Gln Leu Thr Asp Ile Ser Lys Lys Met Leu
370 375 380
Gly Asp Trp Asn Ala Ile Tyr Met Ala Arg Glu Arg Ala Tyr Asp His
385 390 395 400
Glu Gln Ala Pro Lys Arg Ile Thr Ala Lys Tyr Glu Arg Asp Arg Ile
405 410 415
Lys Ala Leu Lys Gly Glu Glu Ser Ile Ser Leu Ala Asn Leu Asn Ser
420 425 430
Cys Ile Ala Phe Leu Asp Asn Val Arg Asp Cys Arg Val Asp Thr Tyr
435 440 445
Leu Ser Thr Leu Gly Gln Lys Glu Gly Pro His Gly Leu Ser Asn Leu
450 455 460
Val Glu Asn Val Phe Ala Ser Tyr His Glu Ala Glu Gln Leu Leu Ser
465 470 475 480
Phe Pro Tyr Pro Glu Glu Asn Asn Leu Ile Gln Asp Lys Asp Asn Val
485 490 495
Val Leu Ile Lys Asn Leu Leu Asp Asn Ile Ser Asp Leu Gln Arg Phe
500 505 510
Leu Lys Pro Leu Trp Gly Met Gly Asp Glu Pro Asp Lys Asp Glu Arg
515 520 525
Phe Tyr Gly Glu Tyr Asn Tyr Ile Arg Gly Ala Leu Asp Gln Val Ile
530 535 540
Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Arg Lys Pro Tyr Ser
545 550 555 560
Thr Arg Lys Val Lys Leu Asn Phe Gly Asn Ser Gln Leu Leu Ser Gly
565 570 575
Trp Asp Arg Asn Lys Glu Lys Asp Asn Ser Cys Val Ile Leu Arg Lys
580 585 590
Gly Gln Asn Phe Tyr Leu Ala Ile Met Asn Asn Arg His Lys Arg Ser
595 600 605
Phe Glu Asn Lys Met Leu Pro Glu Tyr Lys Glu Gly Glu Pro Tyr Phe
610 615 620
Glu Lys Met Asp Tyr Lys Phe Leu Pro Asp Pro Asn Lys Met Leu Pro
625 630 635 640
Lys Val Phe Leu Ser Lys Lys Gly Ile Glu Ile Tyr Lys Pro Ser Pro
645 650 655
Lys Leu Leu Glu Gln Tyr Gly His Gly Thr His Lys Lys Gly Asp Thr
660 665 670
Phe Ser Met Asp Asp Leu His Glu Leu Ile Asp Phe Phe Lys His Ser
675 680 685
Ile Glu Ala His Glu Asp Trp Lys Gln Phe Gly Phe Lys Phe Ser Asp
690 695 700
Thr Ala Thr Tyr Glu Asn Val Ser Ser Phe Tyr Arg Glu Val Glu Asp
705 710 715 720
Gln Gly Tyr Lys Leu Ser Phe Arg Lys Val Ser Glu Ser Tyr Val Tyr
725 730 735
Ser Leu Ile Asp Gln Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
740 745 750
Asp Phe Ser Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr
755 760 765
Trp Arg Met Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys
770 775 780
Leu Asp Gly Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys Asn
785 790 795 800
Asp His Pro Thr His Pro Ala Gly Lys Pro Ile Lys Lys Lys Ser Arg
805 810 815
Gln Lys Lys Gly Glu Glu Ser Leu Phe Glu Tyr Asp Leu Val Lys Asp
820 825 830
Arg Arg Tyr Thr Met Asp Lys Phe Gln Phe His Val Pro Ile Thr Met
835 840 845
Asn Phe Lys Cys Ser Ala Gly Ser Lys Val Asn Asp Met Val Asn Ala
850 855 860
His Ile Arg Glu Ala Lys Asp Met His Val Ile Gly Ile Asp Arg Gly
865 870 875 880
Glu Arg Asn Leu Leu Tyr Ile Cys Val Ile Asp Ser Arg Gly Thr Ile
885 890 895
Leu Asp Gln Ile Ser Leu Asn Thr Ile Asn Asp Ile Asp Tyr His Asp
900 905 910
Leu Leu Glu Ser Arg Asp Lys Asp Arg Gln Gln Glu His Arg Asn Trp
915 920 925
Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Gln Gly Tyr Leu Ser Gln
930 935 940
Ala Val His Arg Ile Ala Glu Leu Met Val Ala Tyr Lys Ala Val Val
945 950 955 960
Ala Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly Arg Gln Lys Val
965 970 975
Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Gln Leu Ile Asp Lys Leu
980 985 990
Asn Tyr Leu Val Asp Lys Lys Lys Arg Pro Glu Asp Ile Gly Gly Leu
995 1000 1005
Leu Arg Ala Tyr Gln Phe Thr Ala Pro Phe Lys Ser Phe Lys Glu
1010 1015 1020
Met Gly Lys Gln Asn Gly Phe Leu Phe Tyr Ile Pro Ala Trp Asn
1025 1030 1035
Thr Ser Asn Ile Asp Pro Thr Thr Gly Phe Val Asn Leu Phe His
1040 1045 1050
Val Gln Tyr Glu Asn Val Asp Lys Ala Lys Ser Phe Phe Gln Lys
1055 1060 1065
Phe Asp Ser Ile Ser Tyr Asn Pro Lys Lys Asp Trp Phe Glu Phe
1070 1075 1080
Ala Phe Asp Tyr Lys Asn Phe Thr Lys Lys Ala Glu Gly Ser Arg
1085 1090 1095
Ser Met Trp Ile Leu Cys Thr His Gly Ser Arg Ile Lys Asn Phe
1100 1105 1110
Arg Asn Ser Gln Lys Asn Gly Gln Trp Asp Ser Glu Glu Phe Ala
1115 1120 1125
Leu Thr Glu Ala Phe Lys Ser Leu Phe Val Arg Tyr Glu Ile Asp
1130 1135 1140
Tyr Thr Ala Asp Leu Lys Thr Ala Ile Val Asp Glu Lys Gln Lys
1145 1150 1155
Asp Phe Phe Val Asp Leu Leu Lys Leu Phe Lys Leu Thr Val Gln
1160 1165 1170
Met Arg Asn Ser Trp Lys Glu Lys Asp Leu Asp Tyr Leu Ile Ser
1175 1180 1185
Pro Val Ala Gly Ala Asp Gly Arg Phe Phe Asp Thr Arg Glu Gly
1190 1195 1200
Asn Lys Ser Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala Tyr Asn
1205 1210 1215
Ile Ala Leu Lys Gly Leu Trp Ala Leu Arg Gln Ile Arg Gln Thr
1220 1225 1230
Ser Glu Gly Gly Lys Leu Lys Leu Ala Ile Ser Asn Lys Glu Trp
1235 1240 1245
Leu Gln Phe Val Gln Glu Arg Ser Tyr Glu Lys Asp
1250 1255 1260
<210> 93
<211> 1260
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 93
Met Asp Ser Leu Lys Asp Phe Thr Asn Leu Tyr Pro Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn Ile Glu
20 25 30
Lys Ala Gly Ile Leu Lys Glu Asp Glu His Arg Ala Glu Ser Tyr Arg
35 40 45
Arg Val Lys Lys Ile Ile Asp Thr Tyr His Lys Val Phe Ile Asp Ser
50 55 60
Ser Leu Glu Asn Met Ala Lys Met Gly Ile Glu Asn Glu Ile Lys Ala
65 70 75 80
Met Leu Gln Ser Phe Cys Glu Leu Tyr Lys Lys Asp His Arg Thr Glu
85 90 95
Gly Glu Asp Lys Ala Leu Asp Lys Ile Arg Ala Val Leu Arg Gly Leu
100 105 110
Ile Val Gly Ala Phe Thr Gly Val Cys Gly Arg Arg Glu Asn Thr Val
115 120 125
Gln Asn Glu Lys Tyr Glu Ser Leu Phe Lys Glu Lys Leu Ile Lys Glu
130 135 140
Ile Leu Pro Asp Phe Val Leu Ser Thr Glu Ala Glu Ser Leu Pro Phe
145 150 155 160
Ser Val Glu Glu Ala Thr Arg Ser Leu Lys Glu Phe Asp Ser Phe Thr
165 170 175
Ser Tyr Phe Ala Gly Phe Tyr Glu Asn Arg Lys Asn Ile Tyr Ser Thr
180 185 190
Lys Pro Gln Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Glu Asn Leu
195 200 205
Pro Lys Phe Ile Asp Asn Ile Leu Val Phe Gln Lys Ile Lys Glu Pro
210 215 220
Ile Ala Lys Glu Leu Glu His Ile Arg Ala Asp Phe Ser Ala Gly Gly
225 230 235 240
Tyr Ile Lys Lys Asp Glu Arg Leu Glu Asp Ile Phe Ser Leu Asn Tyr
245 250 255
Tyr Ile His Val Leu Ser Gln Ala Gly Ile Glu Lys Tyr Asn Ala Leu
260 265 270
Ile Gly Lys Ile Val Thr Glu Gly Asp Gly Glu Met Lys Gly Leu Asn
275 280 285
Glu His Ile Asn Leu Tyr Asn Gln Gln Arg Gly Arg Glu Asp Arg Leu
290 295 300
Pro Leu Phe Arg Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Gln
305 310 315 320
Leu Ser Tyr Leu Pro Glu Ser Phe Glu Lys Asp Glu Glu Leu Leu Arg
325 330 335
Ala Leu Lys Glu Phe Tyr Asp His Ile Ala Glu Asp Ile Leu Gly Arg
340 345 350
Thr Gln Gln Leu Met Thr Ser Ile Ser Glu Tyr Asp Leu Ser Arg Ile
355 360 365
Tyr Val Arg Asn Asp Ser Gln Leu Thr Asp Ile Ser Lys Lys Met Leu
370 375 380
Gly Asp Trp Asn Ala Ile Tyr Met Ala Arg Glu Arg Ala Tyr Asp His
385 390 395 400
Glu Gln Ala Pro Lys Arg Ile Thr Ala Lys Tyr Glu Arg Asp Arg Ile
405 410 415
Lys Ala Leu Lys Gly Glu Glu Ser Ile Ser Leu Ala Asn Leu Asn Ser
420 425 430
Cys Ile Ala Phe Leu Asp Asn Val Arg Asp Cys Arg Val Asp Thr Tyr
435 440 445
Leu Ser Thr Leu Gly Gln Lys Glu Gly Pro His Gly Leu Ser Asn Leu
450 455 460
Val Glu Asn Val Phe Ala Ser Tyr His Glu Ala Glu Gln Leu Leu Ser
465 470 475 480
Phe Pro Tyr Pro Glu Glu Asn Asn Leu Ile Gln Asp Lys Asp Asn Val
485 490 495
Val Leu Ile Lys Asn Leu Leu Asp Asn Ile Ser Asp Leu Gln Arg Phe
500 505 510
Leu Lys Pro Leu Trp Gly Met Gly Asp Glu Pro Asp Lys Asp Glu Arg
515 520 525
Phe Tyr Gly Glu Tyr Asn Tyr Ile Arg Gly Ala Leu Asp Gln Val Ile
530 535 540
Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Arg Lys Pro Tyr Ser
545 550 555 560
Thr Arg Lys Val Lys Leu Asn Phe Gly Asn Ser Gln Leu Leu Ser Gly
565 570 575
Trp Asp Arg Asn Lys Glu Lys Asp Asn Ser Cys Val Ile Leu Arg Lys
580 585 590
Gly Gln Asn Phe Tyr Leu Ala Ile Met Asn Asn Arg His Lys Arg Ser
595 600 605
Phe Glu Asn Lys Val Leu Pro Glu Tyr Lys Glu Gly Glu Pro Tyr Phe
610 615 620
Glu Lys Met Asp Tyr Lys Phe Leu Pro Asp Pro Asn Lys Met Leu Pro
625 630 635 640
Lys Val Phe Leu Ser Lys Lys Gly Ile Glu Ile Tyr Lys Pro Ser Pro
645 650 655
Lys Leu Leu Glu Gln Tyr Gly His Gly Thr His Lys Lys Gly Asp Thr
660 665 670
Phe Ser Met Asp Asp Leu His Glu Leu Ile Asp Phe Phe Lys His Ser
675 680 685
Ile Glu Ala His Glu Asp Trp Lys Gln Phe Gly Phe Lys Phe Ser Asp
690 695 700
Thr Ala Thr Tyr Glu Asn Val Ser Ser Phe Tyr Arg Glu Val Glu Asp
705 710 715 720
Gln Gly Tyr Lys Leu Ser Phe Arg Lys Val Ser Glu Ser Tyr Val Tyr
725 730 735
Ser Leu Ile Asp Gln Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
740 745 750
Asp Phe Ser Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr
755 760 765
Trp Arg Met Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys
770 775 780
Leu Asp Gly Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys Asn
785 790 795 800
Asp His Pro Thr His Pro Ala Gly Lys Pro Ile Lys Lys Lys Ser Arg
805 810 815
Gln Lys Lys Gly Glu Glu Ser Leu Phe Glu Tyr Asp Leu Val Lys Asp
820 825 830
Arg His Tyr Thr Met Asp Lys Phe Gln Phe His Val Pro Ile Thr Met
835 840 845
Asn Phe Lys Cys Ser Ala Gly Ser Lys Val Asn Asp Met Val Asn Ala
850 855 860
His Ile Arg Glu Ala Lys Asp Met His Val Ile Gly Ile Asp Arg Gly
865 870 875 880
Glu Arg Asn Leu Leu Tyr Ile Cys Val Ile Asp Ser Arg Gly Thr Ile
885 890 895
Leu Asp Gln Ile Ser Leu Asn Thr Ile Asn Asp Ile Asp Tyr His Asp
900 905 910
Leu Leu Glu Ser Arg Asp Lys Asp Arg Gln Gln Glu Arg Arg Asn Trp
915 920 925
Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Gln Gly Tyr Leu Ser Gln
930 935 940
Ala Val His Arg Ile Ala Glu Leu Met Val Ala Tyr Lys Ala Val Val
945 950 955 960
Ala Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly Arg Gln Lys Val
965 970 975
Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Gln Leu Ile Asp Lys Leu
980 985 990
Asn Tyr Leu Val Asp Lys Lys Lys Arg Pro Glu Asp Ile Gly Gly Leu
995 1000 1005
Leu Arg Ala Tyr Gln Phe Thr Ala Pro Phe Lys Ser Phe Lys Glu
1010 1015 1020
Met Gly Lys Gln Asn Gly Phe Leu Phe Tyr Ile Pro Ala Trp Asn
1025 1030 1035
Thr Ser Asn Ile Asp Pro Thr Thr Gly Phe Val Asn Leu Phe His
1040 1045 1050
Ala Gln Tyr Glu Asn Val Asp Lys Ala Lys Ser Phe Phe Gln Lys
1055 1060 1065
Phe Asp Ser Ile Ser Tyr Asn Pro Lys Lys Asp Trp Phe Glu Phe
1070 1075 1080
Ala Phe Asp Tyr Lys Asn Phe Thr Lys Lys Ala Glu Gly Ser Arg
1085 1090 1095
Ser Met Trp Ile Leu Cys Thr His Gly Ser Arg Ile Lys Asn Phe
1100 1105 1110
Arg Asn Ser Gln Lys Asn Gly Gln Trp Asp Ser Glu Glu Phe Ala
1115 1120 1125
Leu Thr Glu Ala Phe Lys Ser Leu Phe Val Arg Tyr Glu Ile Asp
1130 1135 1140
Tyr Thr Ala Asp Leu Lys Thr Ala Ile Val Asp Glu Lys Gln Lys
1145 1150 1155
Asp Phe Phe Val Asp Leu Leu Lys Leu Phe Lys Leu Thr Val Gln
1160 1165 1170
Met Arg Asn Ser Trp Lys Glu Lys Asp Leu Asp Tyr Leu Ile Ser
1175 1180 1185
Pro Val Ala Gly Ala Asp Gly Arg Phe Phe Asp Thr Arg Glu Gly
1190 1195 1200
Asn Lys Ser Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala Tyr Asn
1205 1210 1215
Ile Ala Leu Lys Gly Leu Trp Ala Leu Arg Gln Ile Arg Gln Thr
1220 1225 1230
Ser Glu Gly Gly Lys Leu Lys Leu Ala Ile Ser Asn Lys Glu Trp
1235 1240 1245
Leu Gln Phe Val Gln Glu Arg Ser Tyr Glu Lys Asp
1250 1255 1260
<210> 94
<211> 1260
<212> БЕЛОК
<213> Porphyromonas cansulci
<400> 94
Met Asp Ser Leu Lys Asp Phe Thr Asn Leu Tyr Pro Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn Ile Glu
20 25 30
Lys Ala Gly Ile Leu Lys Glu Asp Glu His Arg Ala Glu Ser Tyr Arg
35 40 45
Arg Val Lys Lys Ile Ile Asp Thr Tyr His Lys Val Phe Ile Asp Ser
50 55 60
Ser Leu Glu Asn Met Ala Lys Met Gly Ile Glu Asn Glu Ile Lys Ala
65 70 75 80
Met Leu Gln Ser Phe Cys Glu Leu Tyr Lys Lys Asp His Arg Thr Glu
85 90 95
Gly Glu Asp Lys Ala Leu Asp Lys Ile Arg Ala Val Leu Arg Gly Leu
100 105 110
Ile Val Gly Ala Phe Thr Gly Val Cys Gly Arg Arg Glu Asn Thr Val
115 120 125
Gln Asn Glu Lys Tyr Glu Ser Leu Phe Lys Glu Lys Leu Ile Lys Glu
130 135 140
Ile Leu Pro Asp Phe Val Leu Ser Thr Glu Ala Glu Ser Leu Pro Phe
145 150 155 160
Ser Val Glu Glu Ala Thr Arg Ser Leu Lys Glu Phe Asp Ser Phe Thr
165 170 175
Ser Tyr Phe Ala Gly Phe Tyr Glu Asn Arg Lys Asn Ile Tyr Ser Thr
180 185 190
Lys Pro Gln Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Glu Asn Leu
195 200 205
Pro Lys Phe Ile Asp Asn Ile Leu Val Phe Gln Lys Ile Lys Glu Pro
210 215 220
Ile Ala Lys Glu Leu Glu His Ile Arg Ala Asp Phe Ser Ala Gly Gly
225 230 235 240
Tyr Ile Lys Lys Asp Glu Arg Leu Glu Asp Ile Phe Ser Leu Asn Tyr
245 250 255
Tyr Ile His Val Leu Ser Gln Ala Gly Ile Glu Lys Tyr Asn Ala Leu
260 265 270
Ile Gly Lys Ile Val Thr Glu Gly Asp Gly Glu Met Lys Gly Leu Asn
275 280 285
Glu His Ile Asn Leu Tyr Asn Gln Gln Arg Gly Arg Glu Asp Arg Leu
290 295 300
Pro Leu Phe Arg Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Gln
305 310 315 320
Leu Ser Tyr Leu Pro Glu Ser Phe Glu Lys Asp Glu Glu Leu Leu Arg
325 330 335
Ala Leu Lys Glu Phe Tyr Asp His Ile Ala Glu Asp Ile Leu Gly Arg
340 345 350
Thr Gln Gln Leu Met Thr Ser Ile Ser Glu Tyr Asp Leu Ser Arg Ile
355 360 365
Tyr Val Arg Asn Asp Ser Gln Leu Thr Asp Ile Ser Lys Lys Met Leu
370 375 380
Gly Asp Trp Asn Ala Ile Tyr Met Ala Arg Glu Arg Ala Tyr Asp His
385 390 395 400
Glu Gln Ala Pro Lys Arg Ile Thr Ala Lys Tyr Glu Arg Asp Arg Ile
405 410 415
Lys Ala Leu Lys Gly Glu Glu Ser Ile Ser Leu Ala Asn Leu Asn Ser
420 425 430
Cys Ile Ala Phe Leu Asp Asn Val Arg Asp Cys Arg Val Asp Thr Tyr
435 440 445
Leu Ser Thr Leu Gly Gln Lys Glu Gly Pro His Gly Leu Ser Asn Leu
450 455 460
Val Glu Asn Val Phe Ala Ser Tyr His Glu Ala Glu Gln Leu Leu Ser
465 470 475 480
Phe Pro Tyr Pro Glu Glu Asn Asn Leu Ile Gln Asp Lys Asp Asn Val
485 490 495
Val Leu Ile Lys Asn Leu Leu Asp Asn Ile Ser Asp Leu Gln Arg Phe
500 505 510
Leu Lys Pro Leu Trp Gly Met Gly Asp Glu Pro Asp Lys Asp Glu Arg
515 520 525
Phe Tyr Gly Glu Tyr Asn Tyr Ile Arg Gly Ala Leu Asp Gln Val Ile
530 535 540
Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Arg Lys Pro Tyr Ser
545 550 555 560
Thr Arg Lys Val Lys Leu Asn Phe Gly Asn Ser Gln Leu Leu Ser Gly
565 570 575
Trp Asp Arg Asn Lys Glu Lys Asp Asn Ser Cys Val Ile Leu Arg Lys
580 585 590
Gly Gln Asn Phe Tyr Leu Ala Ile Met Asn Asn Arg His Lys Arg Ser
595 600 605
Phe Glu Asn Lys Val Leu Pro Glu Tyr Lys Glu Gly Glu Pro Tyr Phe
610 615 620
Glu Lys Met Asp Tyr Lys Phe Leu Pro Asp Pro Asn Lys Met Leu Pro
625 630 635 640
Lys Val Phe Leu Ser Lys Lys Gly Ile Glu Ile Tyr Lys Pro Ser Pro
645 650 655
Lys Leu Leu Glu Gln Tyr Gly His Gly Thr His Lys Lys Gly Asp Thr
660 665 670
Phe Ser Met Asp Asp Leu His Glu Leu Ile Asp Phe Phe Lys His Ser
675 680 685
Ile Glu Ala His Glu Asp Trp Lys Gln Phe Gly Phe Lys Phe Ser Asp
690 695 700
Thr Ala Thr Tyr Glu Asn Val Ser Ser Phe Tyr Arg Glu Val Glu Asp
705 710 715 720
Gln Gly Tyr Lys Leu Ser Phe Arg Lys Val Ser Glu Ser Tyr Val Tyr
725 730 735
Ser Leu Ile Asp Gln Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
740 745 750
Asp Phe Ser Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr
755 760 765
Trp Arg Met Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys
770 775 780
Leu Asp Gly Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys Asn
785 790 795 800
Asp His Pro Thr His Pro Ala Gly Lys Pro Ile Lys Lys Lys Ser Arg
805 810 815
Gln Lys Lys Gly Glu Glu Ser Leu Phe Glu Tyr Asp Leu Val Lys Asp
820 825 830
Arg Arg Tyr Thr Met Asp Lys Phe Gln Phe His Val Pro Ile Thr Met
835 840 845
Asn Phe Lys Cys Ser Ala Gly Ser Lys Val Asn Asp Met Val Asn Ala
850 855 860
His Ile Arg Glu Ala Lys Asp Met His Val Ile Gly Ile Asp Arg Gly
865 870 875 880
Glu Arg Asn Leu Leu Tyr Ile Cys Val Ile Asp Ser Arg Gly Thr Ile
885 890 895
Leu Asp Gln Ile Ser Leu Asn Thr Ile Asn Asp Ile Asp Tyr His Asp
900 905 910
Leu Leu Glu Ser Arg Asp Lys Asp Arg Gln Gln Glu Arg Arg Asn Trp
915 920 925
Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Gln Gly Tyr Leu Ser Gln
930 935 940
Ala Val His Arg Ile Ala Glu Leu Met Val Ala Tyr Lys Ala Val Val
945 950 955 960
Ala Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly Arg Gln Lys Val
965 970 975
Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Gln Leu Ile Asp Lys Leu
980 985 990
Asn Tyr Leu Val Asp Lys Lys Lys Arg Pro Glu Asp Ile Gly Gly Leu
995 1000 1005
Leu Arg Ala Tyr Gln Phe Thr Ala Pro Phe Lys Ser Phe Lys Glu
1010 1015 1020
Met Gly Lys Gln Asn Gly Phe Leu Phe Tyr Ile Pro Ala Trp Asn
1025 1030 1035
Thr Ser Asn Ile Asp Pro Thr Thr Gly Phe Val Asn Leu Phe His
1040 1045 1050
Ala Gln Tyr Glu Asn Val Asp Lys Ala Lys Ser Phe Phe Gln Lys
1055 1060 1065
Phe Asp Ser Ile Ser Tyr Asn Pro Lys Lys Asp Trp Phe Glu Phe
1070 1075 1080
Ala Phe Asp Tyr Lys Asn Phe Thr Lys Lys Ala Glu Gly Ser Arg
1085 1090 1095
Ser Met Trp Ile Leu Cys Thr His Gly Ser Arg Ile Lys Asn Phe
1100 1105 1110
Arg Asn Ser Gln Lys Asn Gly Gln Trp Asp Ser Glu Glu Phe Ala
1115 1120 1125
Leu Thr Glu Ala Phe Lys Ser Leu Phe Val Arg Tyr Glu Ile Asp
1130 1135 1140
Tyr Thr Ala Asp Leu Lys Thr Ala Ile Val Asp Glu Lys Gln Lys
1145 1150 1155
Asp Phe Phe Val Asp Leu Leu Lys Leu Phe Lys Leu Thr Val Gln
1160 1165 1170
Met Arg Asn Ser Trp Lys Glu Lys Asp Leu Asp Tyr Leu Ile Ser
1175 1180 1185
Pro Val Ala Gly Ala Asp Gly Arg Phe Phe Asp Thr Arg Glu Gly
1190 1195 1200
Asn Lys Ser Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala Tyr Asn
1205 1210 1215
Ile Ala Leu Lys Gly Leu Trp Ala Leu Arg Gln Ile Arg Gln Thr
1220 1225 1230
Ser Glu Gly Gly Lys Leu Lys Leu Ala Ile Ser Asn Lys Glu Trp
1235 1240 1245
Leu Gln Phe Val Gln Glu Arg Ser Tyr Glu Lys Asp
1250 1255 1260
<210> 95
<211> 1259
<212> БЕЛОК
<213> Synergistes jonesii
<400> 95
Met Ala Asn Ser Leu Lys Asp Phe Thr Asn Ile Tyr Gln Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Glu Glu His Ile
20 25 30
Asn Arg Lys Leu Ile Ile Met His Asp Glu Lys Arg Gly Glu Asp Tyr
35 40 45
Lys Ser Val Thr Lys Leu Ile Asp Asp Tyr His Arg Lys Phe Ile His
50 55 60
Glu Thr Leu Asp Pro Ala His Phe Asp Trp Asn Pro Leu Ala Glu Ala
65 70 75 80
Leu Ile Gln Ser Gly Ser Lys Asn Asn Lys Ala Leu Pro Ala Glu Gln
85 90 95
Lys Glu Met Arg Glu Lys Ile Ile Ser Met Phe Thr Ser Gln Ala Val
100 105 110
Tyr Lys Lys Leu Phe Lys Lys Glu Leu Phe Ser Glu Leu Leu Pro Glu
115 120 125
Met Ile Lys Ser Glu Leu Val Ser Asp Leu Glu Lys Gln Ala Gln Leu
130 135 140
Asp Ala Val Lys Ser Phe Asp Lys Phe Ser Thr Tyr Phe Thr Gly Phe
145 150 155 160
His Glu Asn Arg Lys Asn Ile Tyr Ser Lys Lys Asp Thr Ser Thr Ser
165 170 175
Ile Ala Phe Arg Ile Val His Gln Asn Phe Pro Lys Phe Leu Ala Asn
180 185 190
Val Arg Ala Tyr Thr Leu Ile Lys Glu Arg Ala Pro Glu Val Ile Asp
195 200 205
Lys Ala Gln Lys Glu Leu Ser Gly Ile Leu Gly Gly Lys Thr Leu Asp
210 215 220
Asp Ile Phe Ser Ile Glu Ser Phe Asn Asn Val Leu Thr Gln Asp Lys
225 230 235 240
Ile Asp Tyr Tyr Asn Gln Ile Ile Gly Gly Val Ser Gly Lys Ala Gly
245 250 255
Asp Lys Lys Leu Arg Gly Val Asn Glu Phe Ser Asn Leu Tyr Arg Gln
260 265 270
Gln His Pro Glu Val Ala Ser Leu Arg Ile Lys Met Val Pro Leu Tyr
275 280 285
Lys Gln Ile Leu Ser Asp Arg Thr Thr Leu Ser Phe Val Pro Glu Ala
290 295 300
Leu Lys Asp Asp Glu Gln Ala Ile Asn Ala Val Asp Gly Leu Arg Ser
305 310 315 320
Glu Leu Glu Arg Asn Asp Ile Phe Asn Arg Ile Lys Arg Leu Phe Gly
325 330 335
Lys Asn Asn Leu Tyr Ser Leu Asp Lys Ile Trp Ile Lys Asn Ser Ser
340 345 350
Ile Ser Ala Phe Ser Asn Glu Leu Phe Lys Asn Trp Ser Phe Ile Glu
355 360 365
Asp Ala Leu Lys Glu Phe Lys Glu Asn Glu Phe Asn Gly Ala Arg Ser
370 375 380
Ala Gly Lys Lys Ala Glu Lys Trp Leu Lys Ser Lys Tyr Phe Ser Phe
385 390 395 400
Ala Asp Ile Asp Ala Ala Val Lys Ser Tyr Ser Glu Gln Val Ser Ala
405 410 415
Asp Ile Ser Ser Ala Pro Ser Ala Ser Tyr Phe Ala Lys Phe Thr Asn
420 425 430
Leu Ile Glu Thr Ala Ala Glu Asn Gly Arg Lys Phe Ser Tyr Phe Ala
435 440 445
Ala Glu Ser Lys Ala Phe Arg Gly Asp Asp Gly Lys Thr Glu Ile Ile
450 455 460
Lys Ala Tyr Leu Asp Ser Leu Asn Asp Ile Leu His Cys Leu Lys Pro
465 470 475 480
Phe Glu Thr Glu Asp Ile Ser Asp Ile Asp Thr Glu Phe Tyr Ser Ala
485 490 495
Phe Ala Glu Ile Tyr Asp Ser Val Lys Asp Val Ile Pro Val Tyr Asn
500 505 510
Ala Val Arg Asn Tyr Thr Thr Gln Lys Pro Phe Ser Thr Glu Lys Phe
515 520 525
Lys Leu Asn Phe Glu Asn Pro Ala Leu Ala Lys Gly Trp Asp Lys Asn
530 535 540
Lys Glu Gln Asn Asn Thr Ala Ile Ile Leu Met Lys Asp Gly Lys Tyr
545 550 555 560
Tyr Leu Gly Val Ile Asp Lys Asn Asn Lys Leu Arg Ala Asp Asp Leu
565 570 575
Ala Asp Asp Gly Ser Ala Tyr Gly Tyr Met Lys Met Asn Tyr Lys Phe
580 585 590
Ile Pro Thr Pro His Met Glu Leu Pro Lys Val Phe Leu Pro Lys Arg
595 600 605
Ala Pro Lys Arg Tyr Asn Pro Ser Arg Glu Ile Leu Leu Ile Lys Glu
610 615 620
Asn Lys Thr Phe Ile Lys Asp Lys Asn Phe Asn Arg Thr Asp Cys His
625 630 635 640
Lys Leu Ile Asp Phe Phe Lys Asp Ser Ile Asn Lys His Lys Asp Trp
645 650 655
Arg Thr Phe Gly Phe Asp Phe Ser Asp Thr Asp Ser Tyr Glu Asp Ile
660 665 670
Ser Asp Phe Tyr Met Glu Val Gln Asp Gln Gly Tyr Lys Leu Thr Phe
675 680 685
Thr Arg Leu Ser Ala Glu Lys Ile Asp Lys Trp Val Glu Glu Gly Arg
690 695 700
Leu Phe Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Asp Gly Ala Gln
705 710 715 720
Gly Ser Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Ile Phe Ser Glu
725 730 735
Glu Asn Leu Lys Asp Val Val Leu Lys Leu Asn Gly Glu Ala Glu Leu
740 745 750
Phe Phe Arg Arg Lys Ser Ile Asp Lys Pro Ala Val His Ala Lys Gly
755 760 765
Ser Met Lys Val Asn Arg Arg Asp Ile Asp Gly Asn Pro Ile Asp Glu
770 775 780
Gly Thr Tyr Val Glu Ile Cys Gly Tyr Ala Asn Gly Lys Arg Asp Met
785 790 795 800
Ala Ser Leu Asn Ala Gly Ala Arg Gly Leu Ile Glu Ser Gly Leu Val
805 810 815
Arg Ile Thr Glu Val Lys His Glu Leu Val Lys Asp Lys Arg Tyr Thr
820 825 830
Ile Asp Lys Tyr Phe Phe His Val Pro Phe Thr Ile Asn Phe Lys Ala
835 840 845
Gln Gly Gln Gly Asn Ile Asn Ser Asp Val Asn Leu Phe Leu Arg Asn
850 855 860
Asn Lys Asp Val Asn Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu
865 870 875 880
Val Tyr Val Ser Leu Ile Asp Arg Asp Gly His Ile Lys Leu Gln Lys
885 890 895
Asp Phe Asn Ile Ile Gly Gly Met Asp Tyr His Ala Lys Leu Asn Gln
900 905 910
Lys Glu Lys Glu Arg Asp Thr Ala Arg Lys Ser Trp Lys Thr Ile Gly
915 920 925
Thr Ile Lys Glu Leu Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu
930 935 940
Ile Val Arg Leu Ala Val Asp Asn Asn Ala Val Ile Val Met Glu Asp
945 950 955 960
Leu Asn Ile Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
965 970 975
Tyr Gln Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val
980 985 990
Phe Lys Asp Ala Gly Tyr Asp Ala Pro Cys Gly Ile Leu Lys Gly Leu
995 1000 1005
Gln Leu Thr Glu Lys Phe Glu Ser Phe Thr Lys Leu Gly Lys Gln
1010 1015 1020
Cys Gly Ile Ile Phe Tyr Ile Pro Ala Gly Tyr Thr Ser Lys Ile
1025 1030 1035
Asp Pro Thr Thr Gly Phe Val Asn Leu Phe Asn Ile Asn Asp Val
1040 1045 1050
Ser Ser Lys Glu Lys Gln Lys Asp Phe Ile Gly Lys Leu Asp Ser
1055 1060 1065
Ile Arg Phe Asp Ala Lys Arg Asp Met Phe Thr Phe Glu Phe Asp
1070 1075 1080
Tyr Asp Lys Phe Arg Thr Tyr Gln Thr Ser Tyr Arg Lys Lys Trp
1085 1090 1095
Ala Val Trp Thr Asn Gly Lys Arg Ile Val Arg Glu Lys Asp Lys
1100 1105 1110
Asp Gly Lys Phe Arg Met Asn Asp Arg Leu Leu Thr Glu Asp Met
1115 1120 1125
Lys Asn Ile Leu Asn Lys Tyr Ala Leu Ala Tyr Lys Ala Gly Glu
1130 1135 1140
Asp Ile Leu Pro Asp Val Ile Ser Arg Asp Lys Ser Leu Ala Ser
1145 1150 1155
Glu Ile Phe Tyr Val Phe Lys Asn Thr Leu Gln Met Arg Asn Ser
1160 1165 1170
Lys Arg Asp Thr Gly Glu Asp Phe Ile Ile Ser Pro Val Leu Asn
1175 1180 1185
Ala Lys Gly Arg Phe Phe Asp Ser Arg Lys Thr Asp Ala Ala Leu
1190 1195 1200
Pro Ile Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys
1205 1210 1215
Gly Ser Leu Val Leu Asp Ala Ile Asp Glu Lys Leu Lys Glu Asp
1220 1225 1230
Gly Arg Ile Asp Tyr Lys Asp Met Ala Val Ser Asn Pro Lys Trp
1235 1240 1245
Phe Glu Phe Met Gln Thr Arg Lys Phe Asp Phe
1250 1255
<210> 96
<211> 1257
<212> БЕЛОК
<213> Prevotella bryantii
<400> 96
Met Gln Ile Asn Asn Leu Lys Ile Ile Tyr Met Lys Phe Thr Asp Phe
1 5 10 15
Thr Gly Leu Tyr Ser Leu Ser Lys Thr Leu Arg Phe Glu Leu Lys Pro
20 25 30
Ile Gly Lys Thr Leu Glu Asn Ile Lys Lys Ala Gly Leu Leu Glu Gln
35 40 45
Asp Gln His Arg Ala Asp Ser Tyr Lys Lys Val Lys Lys Ile Ile Asp
50 55 60
Glu Tyr His Lys Ala Phe Ile Glu Lys Ser Leu Ser Asn Phe Glu Leu
65 70 75 80
Lys Tyr Gln Ser Glu Asp Lys Leu Asp Ser Leu Glu Glu Tyr Leu Met
85 90 95
Tyr Tyr Ser Met Lys Arg Ile Glu Lys Thr Glu Lys Asp Lys Phe Ala
100 105 110
Lys Ile Gln Asp Asn Leu Arg Lys Gln Ile Ala Asp His Leu Lys Gly
115 120 125
Asp Glu Ser Tyr Lys Thr Ile Phe Ser Lys Asp Leu Ile Arg Lys Asn
130 135 140
Leu Pro Asp Phe Val Lys Ser Asp Glu Glu Arg Thr Leu Ile Lys Glu
145 150 155 160
Phe Lys Asp Phe Thr Thr Tyr Phe Lys Gly Phe Tyr Glu Asn Arg Glu
165 170 175
Asn Met Tyr Ser Ala Glu Asp Lys Ser Thr Ala Ile Ser His Arg Ile
180 185 190
Ile His Glu Asn Leu Pro Lys Phe Val Asp Asn Ile Asn Ala Phe Ser
195 200 205
Lys Ile Ile Leu Ile Pro Glu Leu Arg Glu Lys Leu Asn Gln Ile Tyr
210 215 220
Gln Asp Phe Glu Glu Tyr Leu Asn Val Glu Ser Ile Asp Glu Ile Phe
225 230 235 240
His Leu Asp Tyr Phe Ser Met Val Met Thr Gln Lys Gln Ile Glu Val
245 250 255
Tyr Asn Ala Ile Ile Gly Gly Lys Ser Thr Asn Asp Lys Lys Ile Gln
260 265 270
Gly Leu Asn Glu Tyr Ile Asn Leu Tyr Asn Gln Lys His Lys Asp Cys
275 280 285
Lys Leu Pro Lys Leu Lys Leu Leu Phe Lys Gln Ile Leu Ser Asp Arg
290 295 300
Ile Ala Ile Ser Trp Leu Pro Asp Asn Phe Lys Asp Asp Gln Glu Ala
305 310 315 320
Leu Asp Ser Ile Asp Thr Cys Tyr Lys Asn Leu Leu Asn Asp Gly Asn
325 330 335
Val Leu Gly Glu Gly Asn Leu Lys Leu Leu Leu Glu Asn Ile Asp Thr
340 345 350
Tyr Asn Leu Lys Gly Ile Phe Ile Arg Asn Asp Leu Gln Leu Thr Asp
355 360 365
Ile Ser Gln Lys Met Tyr Ala Ser Trp Asn Val Ile Gln Asp Ala Val
370 375 380
Ile Leu Asp Leu Lys Lys Gln Val Ser Arg Lys Lys Lys Glu Ser Ala
385 390 395 400
Glu Asp Tyr Asn Asp Arg Leu Lys Lys Leu Tyr Thr Ser Gln Glu Ser
405 410 415
Phe Ser Ile Gln Tyr Leu Asn Asp Cys Leu Arg Ala Tyr Gly Lys Thr
420 425 430
Glu Asn Ile Gln Asp Tyr Phe Ala Lys Leu Gly Ala Val Asn Asn Glu
435 440 445
His Glu Gln Thr Ile Asn Leu Phe Ala Gln Val Arg Asn Ala Tyr Thr
450 455 460
Ser Val Gln Ala Ile Leu Thr Thr Pro Tyr Pro Glu Asn Ala Asn Leu
465 470 475 480
Ala Gln Asp Lys Glu Thr Val Ala Leu Ile Lys Asn Leu Leu Asp Ser
485 490 495
Leu Lys Arg Leu Gln Arg Phe Ile Lys Pro Leu Leu Gly Lys Gly Asp
500 505 510
Glu Ser Asp Lys Asp Glu Arg Phe Tyr Gly Asp Phe Thr Pro Leu Trp
515 520 525
Glu Thr Leu Asn Gln Ile Thr Pro Leu Tyr Asn Met Val Arg Asn Tyr
530 535 540
Met Thr Arg Lys Pro Tyr Ser Gln Glu Lys Ile Lys Leu Asn Phe Glu
545 550 555 560
Asn Ser Thr Leu Leu Gly Gly Trp Asp Leu Asn Lys Glu His Asp Asn
565 570 575
Thr Ala Ile Ile Leu Arg Lys Asn Gly Leu Tyr Tyr Leu Ala Ile Met
580 585 590
Lys Lys Ser Ala Asn Lys Ile Phe Asp Lys Asp Lys Leu Asp Asn Ser
595 600 605
Gly Asp Cys Tyr Glu Lys Met Val Tyr Lys Leu Leu Pro Gly Ala Asn
610 615 620
Lys Met Leu Pro Lys Val Phe Phe Ser Lys Ser Arg Ile Asp Glu Phe
625 630 635 640
Lys Pro Ser Glu Asn Ile Ile Glu Asn Tyr Lys Lys Gly Thr His Lys
645 650 655
Lys Gly Ala Asn Phe Asn Leu Ala Asp Cys His Asn Leu Ile Asp Phe
660 665 670
Phe Lys Ser Ser Ile Ser Lys His Glu Asp Trp Ser Lys Phe Asn Phe
675 680 685
His Phe Ser Asp Thr Ser Ser Tyr Glu Asp Leu Ser Asp Phe Tyr Arg
690 695 700
Glu Val Glu Gln Gln Gly Tyr Ser Ile Ser Phe Cys Asp Val Ser Val
705 710 715 720
Glu Tyr Ile Asn Lys Met Val Glu Lys Gly Asp Leu Tyr Leu Phe Gln
725 730 735
Ile Tyr Asn Lys Asp Phe Ser Glu Phe Ser Lys Gly Thr Pro Asn Met
740 745 750
His Thr Leu Tyr Trp Asn Ser Leu Phe Ser Lys Glu Asn Leu Asn Asn
755 760 765
Ile Ile Tyr Lys Leu Asn Gly Gln Ala Glu Ile Phe Phe Arg Lys Lys
770 775 780
Ser Leu Asn Tyr Lys Arg Pro Thr His Pro Ala His Gln Ala Ile Lys
785 790 795 800
Asn Lys Asn Lys Cys Asn Glu Lys Lys Glu Ser Ile Phe Asp Tyr Asp
805 810 815
Leu Val Lys Asp Lys Arg Tyr Thr Val Asp Lys Phe Gln Phe His Val
820 825 830
Pro Ile Thr Met Asn Phe Lys Ser Thr Gly Asn Thr Asn Ile Asn Gln
835 840 845
Gln Val Ile Asp Tyr Leu Arg Thr Glu Asp Asp Thr His Ile Ile Gly
850 855 860
Ile Asp Arg Gly Glu Arg His Leu Leu Tyr Leu Val Val Ile Asp Ser
865 870 875 880
His Gly Lys Ile Val Glu Gln Phe Thr Leu Asn Glu Ile Val Asn Glu
885 890 895
Tyr Gly Gly Asn Ile Tyr Arg Thr Asn Tyr His Asp Leu Leu Asp Thr
900 905 910
Arg Glu Gln Asn Arg Glu Lys Ala Arg Glu Ser Trp Gln Thr Ile Glu
915 920 925
Asn Ile Lys Glu Leu Lys Glu Gly Tyr Ile Ser Gln Val Ile His Lys
930 935 940
Ile Thr Asp Leu Met Gln Lys Tyr His Ala Val Val Val Leu Glu Asp
945 950 955 960
Leu Asn Met Gly Phe Met Arg Gly Arg Gln Lys Val Glu Lys Gln Val
965 970 975
Tyr Gln Lys Phe Glu Glu Met Leu Ile Asn Lys Leu Asn Tyr Leu Val
980 985 990
Asn Lys Lys Ala Asp Gln Asn Ser Ala Gly Gly Leu Leu His Ala Tyr
995 1000 1005
Gln Leu Thr Ser Lys Phe Glu Ser Phe Gln Lys Leu Gly Lys Gln
1010 1015 1020
Ser Gly Phe Leu Phe Tyr Ile Pro Ala Trp Asn Thr Ser Lys Ile
1025 1030 1035
Asp Pro Val Thr Gly Phe Val Asn Leu Phe Asp Thr Arg Tyr Glu
1040 1045 1050
Ser Ile Asp Lys Ala Lys Ala Phe Phe Gly Lys Phe Asp Ser Ile
1055 1060 1065
Arg Tyr Asn Ala Asp Lys Asp Trp Phe Glu Phe Ala Phe Asp Tyr
1070 1075 1080
Asn Asn Phe Thr Thr Lys Ala Glu Gly Thr Arg Thr Asn Trp Thr
1085 1090 1095
Ile Cys Thr Tyr Gly Ser Arg Ile Arg Thr Phe Arg Asn Gln Ala
1100 1105 1110
Lys Asn Ser Gln Trp Asp Asn Glu Glu Ile Asp Leu Thr Lys Ala
1115 1120 1125
Tyr Lys Ala Phe Phe Ala Lys His Gly Ile Asn Ile Tyr Asp Asn
1130 1135 1140
Ile Lys Glu Ala Ile Ala Met Glu Thr Glu Lys Ser Phe Phe Glu
1145 1150 1155
Asp Leu Leu His Leu Leu Lys Leu Thr Leu Gln Met Arg Asn Ser
1160 1165 1170
Ile Thr Gly Thr Thr Thr Asp Tyr Leu Ile Ser Pro Val His Asp
1175 1180 1185
Ser Lys Gly Asn Phe Tyr Asp Ser Arg Ile Cys Asp Asn Ser Leu
1190 1195 1200
Pro Ala Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys
1205 1210 1215
Gly Leu Met Leu Ile Gln Gln Ile Lys Asp Ser Thr Ser Ser Asn
1220 1225 1230
Arg Phe Lys Phe Ser Pro Ile Thr Asn Lys Asp Trp Leu Ile Phe
1235 1240 1245
Ala Gln Glu Lys Pro Tyr Leu Asn Asp
1250 1255
<210> 97
<211> 1253
<212> БЕЛОК
<213> Prevotella albensis
<400> 97
Met Asn Ile Lys Asn Phe Thr Gly Leu Tyr Pro Leu Ser Lys Thr Leu
1 5 10 15
Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Lys Glu Asn Ile Glu Lys
20 25 30
Asn Gly Ile Leu Thr Lys Asp Glu Gln Arg Ala Lys Asp Tyr Leu Ile
35 40 45
Val Lys Gly Phe Ile Asp Glu Tyr His Lys Gln Phe Ile Lys Asp Arg
50 55 60
Leu Trp Asp Phe Lys Leu Pro Leu Glu Ser Glu Gly Glu Lys Asn Ser
65 70 75 80
Leu Glu Glu Tyr Gln Glu Leu Tyr Glu Leu Thr Lys Arg Asn Asp Ala
85 90 95
Gln Glu Ala Asp Phe Thr Glu Ile Lys Asp Asn Leu Arg Ser Ser Ile
100 105 110
Thr Glu Gln Leu Thr Lys Ser Gly Ser Ala Tyr Asp Arg Ile Phe Lys
115 120 125
Lys Glu Phe Ile Arg Glu Asp Leu Val Asn Phe Leu Glu Asp Glu Lys
130 135 140
Asp Lys Asn Ile Val Lys Gln Phe Glu Asp Phe Thr Thr Tyr Phe Thr
145 150 155 160
Gly Phe Tyr Glu Asn Arg Lys Asn Met Tyr Ser Ser Glu Glu Lys Ser
165 170 175
Thr Ala Ile Ala Tyr Arg Leu Ile His Gln Asn Leu Pro Lys Phe Met
180 185 190
Asp Asn Met Arg Ser Phe Ala Lys Ile Ala Asn Ser Ser Val Ser Glu
195 200 205
His Phe Ser Asp Ile Tyr Glu Ser Trp Lys Glu Tyr Leu Asn Val Asn
210 215 220
Ser Ile Glu Glu Ile Phe Gln Leu Asp Tyr Phe Ser Glu Thr Leu Thr
225 230 235 240
Gln Pro His Ile Glu Val Tyr Asn Tyr Ile Ile Gly Lys Lys Val Leu
245 250 255
Glu Asp Gly Thr Glu Ile Lys Gly Ile Asn Glu Tyr Val Asn Leu Tyr
260 265 270
Asn Gln Gln Gln Lys Asp Lys Ser Lys Arg Leu Pro Phe Leu Val Pro
275 280 285
Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Lys Leu Ser Trp Ile Ala
290 295 300
Glu Glu Phe Asp Ser Asp Lys Lys Met Leu Ser Ala Ile Thr Glu Ser
305 310 315 320
Tyr Asn His Leu His Asn Val Leu Met Gly Asn Glu Asn Glu Ser Leu
325 330 335
Arg Asn Leu Leu Leu Asn Ile Lys Asp Tyr Asn Leu Glu Lys Ile Asn
340 345 350
Ile Thr Asn Asp Leu Ser Leu Thr Glu Ile Ser Gln Asn Leu Phe Gly
355 360 365
Arg Tyr Asp Val Phe Thr Asn Gly Ile Lys Asn Lys Leu Arg Val Leu
370 375 380
Thr Pro Arg Lys Lys Lys Glu Thr Asp Glu Asn Phe Glu Asp Arg Ile
385 390 395 400
Asn Lys Ile Phe Lys Thr Gln Lys Ser Phe Ser Ile Ala Phe Leu Asn
405 410 415
Lys Leu Pro Gln Pro Glu Met Glu Asp Gly Lys Pro Arg Asn Ile Glu
420 425 430
Asp Tyr Phe Ile Thr Gln Gly Ala Ile Asn Thr Lys Ser Ile Gln Lys
435 440 445
Glu Asp Ile Phe Ala Gln Ile Glu Asn Ala Tyr Glu Asp Ala Gln Val
450 455 460
Phe Leu Gln Ile Lys Asp Thr Asp Asn Lys Leu Ser Gln Asn Lys Thr
465 470 475 480
Ala Val Glu Lys Ile Lys Thr Leu Leu Asp Ala Leu Lys Glu Leu Gln
485 490 495
His Phe Ile Lys Pro Leu Leu Gly Ser Gly Glu Glu Asn Glu Lys Asp
500 505 510
Glu Leu Phe Tyr Gly Ser Phe Leu Ala Ile Trp Asp Glu Leu Asp Thr
515 520 525
Ile Thr Pro Leu Tyr Asn Lys Val Arg Asn Trp Leu Thr Arg Lys Pro
530 535 540
Tyr Ser Thr Glu Lys Ile Lys Leu Asn Phe Asp Asn Ala Gln Leu Leu
545 550 555 560
Gly Gly Trp Asp Val Asn Lys Glu His Asp Cys Ala Gly Ile Leu Leu
565 570 575
Arg Lys Asn Asp Ser Tyr Tyr Leu Gly Ile Ile Asn Lys Lys Thr Asn
580 585 590
His Ile Phe Asp Thr Asp Ile Thr Pro Ser Asp Gly Glu Cys Tyr Asp
595 600 605
Lys Ile Asp Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys
610 615 620
Val Phe Phe Ser Lys Ser Arg Ile Lys Glu Phe Glu Pro Ser Glu Ala
625 630 635 640
Ile Ile Asn Cys Tyr Lys Lys Gly Thr His Lys Lys Gly Lys Asn Phe
645 650 655
Asn Leu Thr Asp Cys His Arg Leu Ile Asn Phe Phe Lys Thr Ser Ile
660 665 670
Glu Lys His Glu Asp Trp Ser Lys Phe Gly Phe Lys Phe Ser Asp Thr
675 680 685
Glu Thr Tyr Glu Asp Ile Ser Gly Phe Tyr Arg Glu Val Glu Gln Gln
690 695 700
Gly Tyr Arg Leu Thr Ser His Pro Val Ser Ala Ser Tyr Ile His Ser
705 710 715 720
Leu Val Lys Glu Gly Lys Leu Tyr Leu Phe Gln Ile Trp Asn Lys Asp
725 730 735
Phe Ser Gln Phe Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr Trp
740 745 750
Lys Met Leu Phe Asp Lys Arg Asn Leu Ser Asp Val Val Tyr Lys Leu
755 760 765
Asn Gly Gln Ala Glu Val Phe Tyr Arg Lys Ser Ser Ile Glu His Gln
770 775 780
Asn Arg Ile Ile His Pro Ala Gln His Pro Ile Thr Asn Lys Asn Glu
785 790 795 800
Leu Asn Lys Lys His Thr Ser Thr Phe Lys Tyr Asp Ile Ile Lys Asp
805 810 815
Arg Arg Tyr Thr Val Asp Lys Phe Gln Phe His Val Pro Ile Thr Ile
820 825 830
Asn Phe Lys Ala Thr Gly Gln Asn Asn Ile Asn Pro Ile Val Gln Glu
835 840 845
Val Ile Arg Gln Asn Gly Ile Thr His Ile Ile Gly Ile Asp Arg Gly
850 855 860
Glu Arg His Leu Leu Tyr Leu Ser Leu Ile Asp Leu Lys Gly Asn Ile
865 870 875 880
Ile Lys Gln Met Thr Leu Asn Glu Ile Ile Asn Glu Tyr Lys Gly Val
885 890 895
Thr Tyr Lys Thr Asn Tyr His Asn Leu Leu Glu Lys Arg Glu Lys Glu
900 905 910
Arg Thr Glu Ala Arg His Ser Trp Ser Ser Ile Glu Ser Ile Lys Glu
915 920 925
Leu Lys Asp Gly Tyr Met Ser Gln Val Ile His Lys Ile Thr Asp Met
930 935 940
Met Val Lys Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn Gly Gly
945 950 955 960
Phe Met Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe
965 970 975
Glu Lys Lys Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Lys Leu
980 985 990
Asp Ala Asn Glu Val Gly Gly Val Leu Asn Ala Tyr Gln Leu Thr Asn
995 1000 1005
Lys Phe Glu Ser Phe Lys Lys Ile Gly Lys Gln Ser Gly Phe Leu
1010 1015 1020
Phe Tyr Ile Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro Ile Thr
1025 1030 1035
Gly Phe Val Asn Leu Phe Asn Thr Arg Tyr Glu Ser Ile Lys Glu
1040 1045 1050
Thr Lys Val Phe Trp Ser Lys Phe Asp Ile Ile Arg Tyr Asn Lys
1055 1060 1065
Glu Lys Asn Trp Phe Glu Phe Val Phe Asp Tyr Asn Thr Phe Thr
1070 1075 1080
Thr Lys Ala Glu Gly Thr Arg Thr Lys Trp Thr Leu Cys Thr His
1085 1090 1095
Gly Thr Arg Ile Gln Thr Phe Arg Asn Pro Glu Lys Asn Ala Gln
1100 1105 1110
Trp Asp Asn Lys Glu Ile Asn Leu Thr Glu Ser Phe Lys Ala Leu
1115 1120 1125
Phe Glu Lys Tyr Lys Ile Asp Ile Thr Ser Asn Leu Lys Glu Ser
1130 1135 1140
Ile Met Gln Glu Thr Glu Lys Lys Phe Phe Gln Glu Leu His Asn
1145 1150 1155
Leu Leu His Leu Thr Leu Gln Met Arg Asn Ser Val Thr Gly Thr
1160 1165 1170
Asp Ile Asp Tyr Leu Ile Ser Pro Val Ala Asp Glu Asp Gly Asn
1175 1180 1185
Phe Tyr Asp Ser Arg Ile Asn Gly Lys Asn Phe Pro Glu Asn Ala
1190 1195 1200
Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Met Leu
1205 1210 1215
Ile Arg Gln Ile Lys Gln Ala Asp Pro Gln Lys Lys Phe Lys Phe
1220 1225 1230
Glu Thr Ile Thr Asn Lys Asp Trp Leu Lys Phe Ala Gln Asp Lys
1235 1240 1245
Pro Tyr Leu Lys Asp
1250
<210> 98
<211> 1250
<212> БЕЛОК
<213> Smithella sp.
<400> 98
Met Gln Thr Leu Phe Glu Asn Phe Thr Asn Gln Tyr Pro Val Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Lys Asp Phe Ile
20 25 30
Glu Gln Lys Gly Leu Leu Lys Lys Asp Glu Asp Arg Ala Glu Lys Tyr
35 40 45
Lys Lys Val Lys Asn Ile Ile Asp Glu Tyr His Lys Asp Phe Ile Glu
50 55 60
Lys Ser Leu Asn Gly Leu Lys Leu Asp Gly Leu Glu Lys Tyr Lys Thr
65 70 75 80
Leu Tyr Leu Lys Gln Glu Lys Asp Asp Lys Asp Lys Lys Ala Phe Asp
85 90 95
Lys Glu Lys Glu Asn Leu Arg Lys Gln Ile Ala Asn Ala Phe Arg Asn
100 105 110
Asn Glu Lys Phe Lys Thr Leu Phe Ala Lys Glu Leu Ile Lys Asn Asp
115 120 125
Leu Met Ser Phe Ala Cys Glu Glu Asp Lys Lys Asn Val Lys Glu Phe
130 135 140
Glu Ala Phe Thr Thr Tyr Phe Thr Gly Phe His Gln Asn Arg Ala Asn
145 150 155 160
Met Tyr Val Ala Asp Glu Lys Arg Thr Ala Ile Ala Ser Arg Leu Ile
165 170 175
His Glu Asn Leu Pro Lys Phe Ile Asp Asn Ile Lys Ile Phe Glu Lys
180 185 190
Met Lys Lys Glu Ala Pro Glu Leu Leu Ser Pro Phe Asn Gln Thr Leu
195 200 205
Lys Asp Met Lys Asp Val Ile Lys Gly Thr Thr Leu Glu Glu Ile Phe
210 215 220
Ser Leu Asp Tyr Phe Asn Lys Thr Leu Thr Gln Ser Gly Ile Asp Ile
225 230 235 240
Tyr Asn Ser Val Ile Gly Gly Arg Thr Pro Glu Glu Gly Lys Thr Lys
245 250 255
Ile Lys Gly Leu Asn Glu Tyr Ile Asn Thr Asp Phe Asn Gln Lys Gln
260 265 270
Thr Asp Lys Lys Lys Arg Gln Pro Lys Phe Lys Gln Leu Tyr Lys Gln
275 280 285
Ile Leu Ser Asp Arg Gln Ser Leu Ser Phe Ile Ala Glu Ala Phe Lys
290 295 300
Asn Asp Thr Glu Ile Leu Glu Ala Ile Glu Lys Phe Tyr Val Asn Glu
305 310 315 320
Leu Leu His Phe Ser Asn Glu Gly Lys Ser Thr Asn Val Leu Asp Ala
325 330 335
Ile Lys Asn Ala Val Ser Asn Leu Glu Ser Phe Asn Leu Thr Lys Met
340 345 350
Tyr Phe Arg Ser Gly Ala Ser Leu Thr Asp Val Ser Arg Lys Val Phe
355 360 365
Gly Glu Trp Ser Ile Ile Asn Arg Ala Leu Asp Asn Tyr Tyr Ala Thr
370 375 380
Thr Tyr Pro Ile Lys Pro Arg Glu Lys Ser Glu Lys Tyr Glu Glu Arg
385 390 395 400
Lys Glu Lys Trp Leu Lys Gln Asp Phe Asn Val Ser Leu Ile Gln Thr
405 410 415
Ala Ile Asp Glu Tyr Asp Asn Glu Thr Val Lys Gly Lys Asn Ser Gly
420 425 430
Lys Val Ile Ala Asp Tyr Phe Ala Lys Phe Cys Asp Asp Lys Glu Thr
435 440 445
Asp Leu Ile Gln Lys Val Asn Glu Gly Tyr Ile Ala Val Lys Asp Leu
450 455 460
Leu Asn Thr Pro Cys Pro Glu Asn Glu Lys Leu Gly Ser Asn Lys Asp
465 470 475 480
Gln Val Lys Gln Ile Lys Ala Phe Met Asp Ser Ile Met Asp Ile Met
485 490 495
His Phe Val Arg Pro Leu Ser Leu Lys Asp Thr Asp Lys Glu Lys Asp
500 505 510
Glu Thr Phe Tyr Ser Leu Phe Thr Pro Leu Tyr Asp His Leu Thr Gln
515 520 525
Thr Ile Ala Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Gln Lys Pro
530 535 540
Tyr Ser Thr Glu Lys Ile Lys Leu Asn Phe Glu Asn Ser Thr Leu Leu
545 550 555 560
Gly Gly Trp Asp Leu Asn Lys Glu Thr Asp Asn Thr Ala Ile Ile Leu
565 570 575
Arg Lys Asp Asn Leu Tyr Tyr Leu Gly Ile Met Asp Lys Arg His Asn
580 585 590
Arg Ile Phe Arg Asn Val Pro Lys Ala Asp Lys Lys Asp Phe Cys Tyr
595 600 605
Glu Lys Met Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro
610 615 620
Lys Val Phe Phe Ser Gln Ser Arg Ile Gln Glu Phe Thr Pro Ser Ala
625 630 635 640
Lys Leu Leu Glu Asn Tyr Ala Asn Glu Thr His Lys Lys Gly Asp Asn
645 650 655
Phe Asn Leu Asn His Cys His Lys Leu Ile Asp Phe Phe Lys Asp Ser
660 665 670
Ile Asn Lys His Glu Asp Trp Lys Asn Phe Asp Phe Arg Phe Ser Ala
675 680 685
Thr Ser Thr Tyr Ala Asp Leu Ser Gly Phe Tyr His Glu Val Glu His
690 695 700
Gln Gly Tyr Lys Ile Ser Phe Gln Ser Val Ala Asp Ser Phe Ile Asp
705 710 715 720
Asp Leu Val Asn Glu Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
725 730 735
Asp Phe Ser Pro Phe Ser Lys Gly Lys Pro Asn Leu His Thr Leu Tyr
740 745 750
Trp Lys Met Leu Phe Asp Glu Asn Asn Leu Lys Asp Val Val Tyr Lys
755 760 765
Leu Asn Gly Glu Ala Glu Val Phe Tyr Arg Lys Lys Ser Ile Ala Glu
770 775 780
Lys Asn Thr Thr Ile His Lys Ala Asn Glu Ser Ile Ile Asn Lys Asn
785 790 795 800
Pro Asp Asn Pro Lys Ala Thr Ser Thr Phe Asn Tyr Asp Ile Val Lys
805 810 815
Asp Lys Arg Tyr Thr Ile Asp Lys Phe Gln Phe His Ile Pro Ile Thr
820 825 830
Met Asn Phe Lys Ala Glu Gly Ile Phe Asn Met Asn Gln Arg Val Asn
835 840 845
Gln Phe Leu Lys Ala Asn Pro Asp Ile Asn Ile Ile Gly Ile Asp Arg
850 855 860
Gly Glu Arg His Leu Leu Tyr Tyr Ala Leu Ile Asn Gln Lys Gly Lys
865 870 875 880
Ile Leu Lys Gln Asp Thr Leu Asn Val Ile Ala Asn Glu Lys Gln Lys
885 890 895
Val Asp Tyr His Asn Leu Leu Asp Lys Lys Glu Gly Asp Arg Ala Thr
900 905 910
Ala Arg Gln Glu Trp Gly Val Ile Glu Thr Ile Lys Glu Leu Lys Glu
915 920 925
Gly Tyr Leu Ser Gln Val Ile His Lys Leu Thr Asp Leu Met Ile Glu
930 935 940
Asn Asn Ala Ile Ile Val Met Glu Asp Leu Asn Phe Gly Phe Lys Arg
945 950 955 960
Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys Met
965 970 975
Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Asn Lys Lys Ala Asn
980 985 990
Glu Leu Gly Gly Leu Leu Asn Ala Phe Gln Leu Ala Asn Lys Phe Glu
995 1000 1005
Ser Phe Gln Lys Met Gly Lys Gln Asn Gly Phe Ile Phe Tyr Val
1010 1015 1020
Pro Ala Trp Asn Thr Ser Lys Thr Asp Pro Ala Thr Gly Phe Ile
1025 1030 1035
Asp Phe Leu Lys Pro Arg Tyr Glu Asn Leu Asn Gln Ala Lys Asp
1040 1045 1050
Phe Phe Glu Lys Phe Asp Ser Ile Arg Leu Asn Ser Lys Ala Asp
1055 1060 1065
Tyr Phe Glu Phe Ala Phe Asp Phe Lys Asn Phe Thr Glu Lys Ala
1070 1075 1080
Asp Gly Gly Arg Thr Lys Trp Thr Val Cys Thr Thr Asn Glu Asp
1085 1090 1095
Arg Tyr Ala Trp Asn Arg Ala Leu Asn Asn Asn Arg Gly Ser Gln
1100 1105 1110
Glu Lys Tyr Asp Ile Thr Ala Glu Leu Lys Ser Leu Phe Asp Gly
1115 1120 1125
Lys Val Asp Tyr Lys Ser Gly Lys Asp Leu Lys Gln Gln Ile Ala
1130 1135 1140
Ser Gln Glu Ser Ala Asp Phe Phe Lys Ala Leu Met Lys Asn Leu
1145 1150 1155
Ser Ile Thr Leu Ser Leu Arg His Asn Asn Gly Glu Lys Gly Asp
1160 1165 1170
Asn Glu Gln Asp Tyr Ile Leu Ser Pro Val Ala Asp Ser Lys Gly
1175 1180 1185
Arg Phe Phe Asp Ser Arg Lys Ala Asp Asp Asp Met Pro Lys Asn
1190 1195 1200
Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Trp
1205 1210 1215
Cys Leu Glu Gln Ile Ser Lys Thr Asp Asp Leu Lys Lys Val Lys
1220 1225 1230
Leu Ala Ile Ser Asn Lys Glu Trp Leu Glu Phe Val Gln Thr Leu
1235 1240 1245
Lys Gly
1250
<210> 99
<211> 1250
<212> БЕЛОК
<213> Smithella sp.
<400> 99
Met Gln Thr Leu Phe Glu Asn Phe Thr Asn Gln Tyr Pro Val Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Lys Asp Phe Ile
20 25 30
Glu Gln Lys Gly Leu Leu Lys Lys Asp Glu Asp Arg Ala Glu Lys Tyr
35 40 45
Lys Lys Val Lys Asn Ile Ile Asp Glu Tyr His Lys Asp Phe Ile Glu
50 55 60
Lys Ser Leu Asn Gly Leu Lys Leu Asp Gly Leu Glu Glu Tyr Lys Thr
65 70 75 80
Leu Tyr Leu Lys Gln Glu Lys Asp Asp Lys Asp Lys Lys Ala Phe Asp
85 90 95
Lys Glu Lys Glu Asn Leu Arg Lys Gln Ile Ala Asn Ala Phe Arg Asn
100 105 110
Asn Glu Lys Phe Lys Thr Leu Phe Ala Lys Glu Leu Ile Lys Asn Asp
115 120 125
Leu Met Ser Phe Ala Cys Glu Glu Asp Lys Lys Asn Val Lys Glu Phe
130 135 140
Glu Ala Phe Thr Thr Tyr Phe Thr Gly Phe His Gln Asn Arg Ala Asn
145 150 155 160
Met Tyr Val Ala Asp Glu Lys Arg Thr Ala Ile Ala Ser Arg Leu Ile
165 170 175
His Glu Asn Leu Pro Lys Phe Ile Asp Asn Ile Lys Ile Phe Glu Lys
180 185 190
Met Lys Lys Glu Ala Pro Glu Leu Leu Ser Pro Phe Asn Gln Thr Leu
195 200 205
Lys Asp Met Lys Asp Val Ile Lys Gly Thr Thr Leu Glu Glu Ile Phe
210 215 220
Ser Leu Asp Tyr Phe Asn Lys Thr Leu Thr Gln Ser Gly Ile Asp Ile
225 230 235 240
Tyr Asn Ser Val Ile Gly Gly Arg Thr Pro Glu Glu Gly Lys Thr Lys
245 250 255
Ile Lys Gly Leu Asn Glu Tyr Ile Asn Thr Asp Phe Asn Gln Lys Gln
260 265 270
Thr Asp Lys Lys Lys Arg Gln Pro Lys Phe Lys Gln Leu Tyr Lys Gln
275 280 285
Ile Leu Ser Asp Arg Gln Ser Leu Ser Phe Ile Ala Glu Ala Phe Lys
290 295 300
Asn Asp Thr Glu Ile Leu Glu Ala Ile Glu Lys Phe Tyr Val Asn Glu
305 310 315 320
Leu Leu His Phe Ser Asn Glu Gly Lys Ser Thr Asn Val Leu Asp Ala
325 330 335
Ile Lys Asn Ala Val Ser Asn Leu Glu Ser Phe Asn Leu Thr Lys Ile
340 345 350
Tyr Phe Arg Ser Gly Thr Ser Leu Thr Asp Val Ser Arg Lys Val Phe
355 360 365
Gly Glu Trp Ser Ile Ile Asn Arg Ala Leu Asp Asn Tyr Tyr Ala Thr
370 375 380
Thr Tyr Pro Ile Lys Pro Arg Glu Lys Ser Glu Lys Tyr Glu Glu Arg
385 390 395 400
Lys Glu Lys Trp Leu Lys Gln Asp Phe Asn Val Ser Leu Ile Gln Thr
405 410 415
Ala Ile Asp Glu Tyr Asp Asn Glu Thr Val Lys Gly Lys Asn Ser Gly
420 425 430
Lys Val Ile Val Asp Tyr Phe Ala Lys Phe Cys Asp Asp Lys Glu Thr
435 440 445
Asp Leu Ile Gln Lys Val Asn Glu Gly Tyr Ile Ala Val Lys Asp Leu
450 455 460
Leu Asn Thr Pro Tyr Pro Glu Asn Glu Lys Leu Gly Ser Asn Lys Asp
465 470 475 480
Gln Val Lys Gln Ile Lys Ala Phe Met Asp Ser Ile Met Asp Ile Met
485 490 495
His Phe Val Arg Pro Leu Ser Leu Lys Asp Thr Asp Lys Glu Lys Asp
500 505 510
Glu Thr Phe Tyr Ser Leu Phe Thr Pro Leu Tyr Asp His Leu Thr Gln
515 520 525
Thr Ile Ala Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Gln Lys Pro
530 535 540
Tyr Ser Thr Glu Lys Ile Lys Leu Asn Phe Glu Asn Ser Thr Leu Leu
545 550 555 560
Gly Gly Trp Asp Leu Asn Lys Glu Thr Asp Asn Thr Ala Ile Ile Leu
565 570 575
Arg Lys Glu Asn Leu Tyr Tyr Leu Gly Ile Met Asp Lys Arg His Asn
580 585 590
Arg Ile Phe Arg Asn Val Pro Lys Ala Asp Lys Lys Asp Ser Cys Tyr
595 600 605
Glu Lys Met Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro
610 615 620
Lys Val Phe Phe Ser Gln Ser Arg Ile Gln Glu Phe Thr Pro Ser Ala
625 630 635 640
Lys Leu Leu Glu Asn Tyr Glu Asn Glu Thr His Lys Lys Gly Asp Asn
645 650 655
Phe Asn Leu Asn His Cys His Gln Leu Ile Asp Phe Phe Lys Asp Ser
660 665 670
Ile Asn Lys His Glu Asp Trp Lys Asn Phe Asp Phe Arg Phe Ser Ala
675 680 685
Thr Ser Thr Tyr Ala Asp Leu Ser Gly Phe Tyr His Glu Val Glu His
690 695 700
Gln Gly Tyr Lys Ile Ser Phe Gln Ser Ile Ala Asp Ser Phe Ile Asp
705 710 715 720
Asp Leu Val Asn Glu Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
725 730 735
Asp Phe Ser Pro Phe Ser Lys Gly Lys Pro Asn Leu His Thr Leu Tyr
740 745 750
Trp Lys Met Leu Phe Asp Glu Asn Asn Leu Lys Asp Val Val Tyr Lys
755 760 765
Leu Asn Gly Glu Ala Glu Val Phe Tyr Arg Lys Lys Ser Ile Ala Glu
770 775 780
Lys Asn Thr Thr Ile His Lys Ala Asn Glu Ser Ile Ile Asn Lys Asn
785 790 795 800
Pro Asp Asn Pro Lys Ala Thr Ser Thr Phe Asn Tyr Asp Ile Val Lys
805 810 815
Asp Lys Arg Tyr Thr Ile Asp Lys Phe Gln Phe His Val Pro Ile Thr
820 825 830
Met Asn Phe Lys Ala Glu Gly Ile Phe Asn Met Asn Gln Arg Val Asn
835 840 845
Gln Phe Leu Lys Ala Asn Pro Asp Ile Asn Ile Ile Gly Ile Asp Arg
850 855 860
Gly Glu Arg His Leu Leu Tyr Tyr Thr Leu Ile Asn Gln Lys Gly Lys
865 870 875 880
Ile Leu Lys Gln Asp Thr Leu Asn Val Ile Ala Asn Glu Lys Gln Lys
885 890 895
Val Asp Tyr His Asn Leu Leu Asp Lys Lys Glu Gly Asp Arg Ala Thr
900 905 910
Ala Arg Gln Glu Trp Gly Val Ile Glu Thr Ile Lys Glu Leu Lys Glu
915 920 925
Gly Tyr Leu Ser Gln Val Ile His Lys Leu Thr Asp Leu Met Ile Glu
930 935 940
Asn Asn Ala Ile Ile Val Met Glu Asp Leu Asn Phe Gly Phe Lys Arg
945 950 955 960
Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys Met
965 970 975
Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Asn Lys Lys Ala Asn
980 985 990
Glu Leu Gly Gly Leu Leu Asn Ala Phe Gln Leu Ala Asn Lys Phe Glu
995 1000 1005
Ser Phe Gln Lys Met Gly Lys Gln Asn Gly Phe Ile Phe Tyr Val
1010 1015 1020
Pro Ala Trp Asn Thr Ser Lys Thr Asp Pro Ala Thr Gly Phe Ile
1025 1030 1035
Asp Phe Leu Lys Pro Arg Tyr Glu Asn Leu Lys Gln Ala Lys Asp
1040 1045 1050
Phe Phe Glu Lys Phe Asp Ser Ile Arg Leu Asn Ser Lys Ala Asp
1055 1060 1065
Tyr Phe Glu Phe Ala Phe Asp Phe Lys Asn Phe Thr Gly Lys Ala
1070 1075 1080
Asp Gly Gly Arg Thr Lys Trp Thr Val Cys Thr Thr Asn Glu Asp
1085 1090 1095
Arg Tyr Ala Trp Asn Arg Ala Leu Asn Asn Asn Arg Gly Ser Gln
1100 1105 1110
Glu Lys Tyr Asp Ile Thr Ala Glu Leu Lys Ser Leu Phe Asp Gly
1115 1120 1125
Lys Val Asp Tyr Lys Ser Gly Lys Asp Leu Lys Gln Gln Ile Ala
1130 1135 1140
Ser Gln Glu Leu Ala Asp Phe Phe Arg Thr Leu Met Lys Tyr Leu
1145 1150 1155
Ser Val Thr Leu Ser Leu Arg His Asn Asn Gly Glu Lys Gly Glu
1160 1165 1170
Thr Glu Gln Asp Tyr Ile Leu Ser Pro Val Ala Asp Ser Met Gly
1175 1180 1185
Lys Phe Phe Asp Ser Arg Lys Ala Gly Asp Asp Met Pro Lys Asn
1190 1195 1200
Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Trp
1205 1210 1215
Cys Leu Glu Gln Ile Ser Lys Thr Asp Asp Leu Lys Lys Val Lys
1220 1225 1230
Leu Ala Ile Ser Asn Lys Glu Trp Leu Glu Phe Met Gln Thr Leu
1235 1240 1245
Lys Gly
1250
<210> 100
<211> 1247
<212> БЕЛОК
<213> Prevotella bryantii
<400> 100
Met Lys Phe Thr Asp Phe Thr Gly Leu Tyr Ser Leu Ser Lys Thr Leu
1 5 10 15
Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu Asn Ile Lys Lys
20 25 30
Ala Gly Leu Leu Glu Gln Asp Gln His Arg Ala Asp Ser Tyr Lys Lys
35 40 45
Val Lys Lys Ile Ile Asp Glu Tyr His Lys Ala Phe Ile Glu Lys Ser
50 55 60
Leu Ser Asn Phe Glu Leu Lys Tyr Gln Ser Glu Asp Lys Leu Asp Ser
65 70 75 80
Leu Glu Glu Tyr Leu Met Tyr Tyr Ser Met Lys Arg Ile Glu Lys Thr
85 90 95
Glu Lys Asp Lys Phe Ala Lys Ile Gln Asp Asn Leu Arg Lys Gln Ile
100 105 110
Ala Asp His Leu Lys Gly Asp Glu Ser Tyr Lys Thr Ile Phe Ser Lys
115 120 125
Asp Leu Ile Arg Lys Asn Leu Pro Asp Phe Val Lys Ser Asp Glu Glu
130 135 140
Arg Thr Leu Ile Lys Glu Phe Lys Asp Phe Thr Thr Tyr Phe Lys Gly
145 150 155 160
Phe Tyr Glu Asn Arg Glu Asn Met Tyr Ser Ala Glu Asp Lys Ser Thr
165 170 175
Ala Ile Ser His Arg Ile Ile His Glu Asn Leu Pro Lys Phe Val Asp
180 185 190
Asn Ile Asn Ala Phe Ser Lys Ile Ile Leu Ile Pro Glu Leu Arg Glu
195 200 205
Lys Leu Asn Gln Ile Tyr Gln Asp Phe Glu Glu Tyr Leu Asn Val Glu
210 215 220
Ser Ile Asp Glu Ile Phe His Leu Asp Tyr Phe Ser Met Val Met Thr
225 230 235 240
Gln Lys Gln Ile Glu Val Tyr Asn Ala Ile Ile Gly Gly Lys Ser Thr
245 250 255
Asn Asp Lys Lys Ile Gln Gly Leu Asn Glu Tyr Ile Asn Leu Tyr Asn
260 265 270
Gln Lys His Lys Asp Cys Lys Leu Pro Lys Leu Lys Leu Leu Phe Lys
275 280 285
Gln Ile Leu Ser Asp Arg Ile Ala Ile Ser Trp Leu Pro Asp Asn Phe
290 295 300
Lys Asp Asp Gln Glu Ala Leu Asp Ser Ile Asp Thr Cys Tyr Lys Asn
305 310 315 320
Leu Leu Asn Asp Gly Asn Val Leu Gly Glu Gly Asn Leu Lys Leu Leu
325 330 335
Leu Glu Asn Ile Asp Thr Tyr Asn Leu Lys Gly Ile Phe Ile Arg Asn
340 345 350
Asp Leu Gln Leu Thr Asp Ile Ser Gln Lys Met Tyr Ala Ser Trp Asn
355 360 365
Val Ile Gln Asp Ala Val Ile Leu Asp Leu Lys Lys Gln Val Ser Arg
370 375 380
Lys Lys Lys Glu Ser Ala Glu Asp Tyr Asn Asp Arg Leu Lys Lys Leu
385 390 395 400
Tyr Thr Ser Gln Glu Ser Phe Ser Ile Gln Tyr Leu Asn Asp Cys Leu
405 410 415
Arg Ala Tyr Gly Lys Thr Glu Asn Ile Gln Asp Tyr Phe Ala Lys Leu
420 425 430
Gly Ala Val Asn Asn Glu His Glu Gln Thr Ile Asn Leu Phe Ala Gln
435 440 445
Val Arg Asn Ala Tyr Thr Ser Val Gln Ala Ile Leu Thr Thr Pro Tyr
450 455 460
Pro Glu Asn Ala Asn Leu Ala Gln Asp Lys Glu Thr Val Ala Leu Ile
465 470 475 480
Lys Asn Leu Leu Asp Ser Leu Lys Arg Leu Gln Arg Phe Ile Lys Pro
485 490 495
Leu Leu Gly Lys Gly Asp Glu Ser Asp Lys Asp Glu Arg Phe Tyr Gly
500 505 510
Asp Phe Thr Pro Leu Trp Glu Thr Leu Asn Gln Ile Thr Pro Leu Tyr
515 520 525
Asn Met Val Arg Asn Tyr Met Thr Arg Lys Pro Tyr Ser Gln Glu Lys
530 535 540
Ile Lys Leu Asn Phe Glu Asn Ser Thr Leu Leu Gly Gly Trp Asp Leu
545 550 555 560
Asn Lys Glu His Asp Asn Thr Ala Ile Ile Leu Arg Lys Asn Gly Leu
565 570 575
Tyr Tyr Leu Ala Ile Met Lys Lys Ser Ala Asn Lys Ile Phe Asp Lys
580 585 590
Asp Lys Leu Asp Asn Ser Gly Asp Cys Tyr Glu Lys Met Val Tyr Lys
595 600 605
Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val Phe Phe Ser Lys
610 615 620
Ser Arg Ile Asp Glu Phe Lys Pro Ser Glu Asn Ile Ile Glu Asn Tyr
625 630 635 640
Lys Lys Gly Thr His Lys Lys Gly Ala Asn Phe Asn Leu Ala Asp Cys
645 650 655
His Asn Leu Ile Asp Phe Phe Lys Ser Ser Ile Ser Lys His Glu Asp
660 665 670
Trp Ser Lys Phe Asn Phe His Phe Ser Asp Thr Ser Ser Tyr Glu Asp
675 680 685
Leu Ser Asp Phe Tyr Arg Glu Val Glu Gln Gln Gly Tyr Ser Ile Ser
690 695 700
Phe Cys Asp Val Ser Val Glu Tyr Ile Asn Lys Met Val Glu Lys Gly
705 710 715 720
Asp Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Glu Phe Ser
725 730 735
Lys Gly Thr Pro Asn Met His Thr Leu Tyr Trp Asn Ser Leu Phe Ser
740 745 750
Lys Glu Asn Leu Asn Asn Ile Ile Tyr Lys Leu Asn Gly Gln Ala Glu
755 760 765
Ile Phe Phe Arg Lys Lys Ser Leu Asn Tyr Lys Arg Pro Thr His Pro
770 775 780
Ala His Gln Ala Ile Lys Asn Lys Asn Lys Cys Asn Glu Lys Lys Glu
785 790 795 800
Ser Ile Phe Asp Tyr Asp Leu Val Lys Asp Lys Arg Tyr Thr Val Asp
805 810 815
Lys Phe Gln Phe His Val Pro Ile Thr Met Asn Phe Lys Ser Thr Gly
820 825 830
Asn Thr Asn Ile Asn Gln Gln Val Ile Asp Tyr Leu Arg Thr Glu Asp
835 840 845
Asp Thr His Ile Ile Gly Ile Asp Arg Gly Glu Arg His Leu Leu Tyr
850 855 860
Leu Val Val Ile Asp Ser His Gly Lys Ile Val Glu Gln Phe Thr Leu
865 870 875 880
Asn Glu Ile Val Asn Glu Tyr Gly Gly Asn Ile Tyr Arg Thr Asn Tyr
885 890 895
His Asp Leu Leu Asp Thr Arg Glu Gln Asn Arg Glu Lys Ala Arg Glu
900 905 910
Ser Trp Gln Thr Ile Glu Asn Ile Lys Glu Leu Lys Glu Gly Tyr Ile
915 920 925
Ser Gln Val Ile His Lys Ile Thr Asp Leu Met Gln Lys Tyr His Ala
930 935 940
Val Val Val Leu Glu Asp Leu Asn Met Gly Phe Met Arg Gly Arg Gln
945 950 955 960
Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Glu Met Leu Ile Asn
965 970 975
Lys Leu Asn Tyr Leu Val Asn Lys Lys Ala Asp Gln Asn Ser Ala Gly
980 985 990
Gly Leu Leu His Ala Tyr Gln Leu Thr Ser Lys Phe Glu Ser Phe Gln
995 1000 1005
Lys Leu Gly Lys Gln Ser Gly Phe Leu Phe Tyr Ile Pro Ala Trp
1010 1015 1020
Asn Thr Ser Lys Ile Asp Pro Val Thr Gly Phe Val Asn Leu Phe
1025 1030 1035
Asp Thr Arg Tyr Glu Ser Ile Asp Lys Ala Lys Ala Phe Phe Gly
1040 1045 1050
Lys Phe Asp Ser Ile Arg Tyr Asn Ala Asp Lys Asp Trp Phe Glu
1055 1060 1065
Phe Ala Phe Asp Tyr Asn Asn Phe Thr Thr Lys Ala Glu Gly Thr
1070 1075 1080
Arg Thr Asn Trp Thr Ile Cys Thr Tyr Gly Ser Arg Ile Arg Thr
1085 1090 1095
Phe Arg Asn Gln Ala Lys Asn Ser Gln Trp Asp Asn Glu Glu Ile
1100 1105 1110
Asp Leu Thr Lys Ala Tyr Lys Ala Phe Phe Ala Lys His Gly Ile
1115 1120 1125
Asn Ile Tyr Asp Asn Ile Lys Glu Ala Ile Ala Met Glu Thr Glu
1130 1135 1140
Lys Ser Phe Phe Glu Asp Leu Leu His Leu Leu Lys Leu Thr Leu
1145 1150 1155
Gln Met Arg Asn Ser Ile Thr Gly Thr Thr Thr Asp Tyr Leu Ile
1160 1165 1170
Ser Pro Val His Asp Ser Lys Gly Asn Phe Tyr Asp Ser Arg Ile
1175 1180 1185
Cys Asp Asn Ser Leu Pro Ala Asn Ala Asp Ala Asn Gly Ala Tyr
1190 1195 1200
Asn Ile Ala Arg Lys Gly Leu Met Leu Ile Gln Gln Ile Lys Asp
1205 1210 1215
Ser Thr Ser Ser Asn Arg Phe Lys Phe Ser Pro Ile Thr Asn Lys
1220 1225 1230
Asp Trp Leu Ile Phe Ala Gln Glu Lys Pro Tyr Leu Asn Asp
1235 1240 1245
<210> 101
<211> 1247
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность некультивируемой бактерии
<400> 101
Met Phe Lys Gly Asp Ala Phe Thr Gly Leu Tyr Glu Val Gln Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Val Pro Ile Gly Leu Thr Gln Ser Tyr Leu Glu
20 25 30
Asn Asp Trp Val Ile Gln Lys Asp Lys Glu Val Glu Glu Asn Tyr Gly
35 40 45
Lys Ile Lys Ala Tyr Phe Asp Leu Ile His Lys Glu Phe Val Arg Gln
50 55 60
Ser Leu Glu Asn Ala Trp Leu Cys Gln Leu Asp Asp Phe Tyr Glu Lys
65 70 75 80
Tyr Ile Glu Leu His Asn Ser Leu Glu Thr Arg Lys Asp Lys Asn Leu
85 90 95
Ala Lys Gln Phe Glu Lys Val Met Lys Ser Leu Lys Lys Glu Phe Val
100 105 110
Ser Phe Phe Asp Ala Lys Trp Asn Glu Trp Lys Gln Lys Phe Ser Phe
115 120 125
Leu Lys Lys Trp Trp Ile Asp Val Leu Asn Glu Lys Glu Val Leu Asp
130 135 140
Leu Met Ala Glu Phe Tyr Pro Asp Glu Lys Glu Leu Phe Asp Lys Phe
145 150 155 160
Asp Lys Phe Phe Thr Tyr Phe Ser Asn Phe Lys Glu Ser Arg Lys Asn
165 170 175
Phe Tyr Ala Asp Asp Gly Arg Ala Trp Ala Ile Ala Thr Arg Ala Ile
180 185 190
Asp Glu Asn Leu Ile Thr Phe Ile Lys Asn Ile Glu Asp Phe Lys Lys
195 200 205
Leu Asn Ser Ser Phe Arg Glu Phe Val Asn Asp Asn Phe Ser Glu Glu
210 215 220
Asp Lys Gln Ile Phe Glu Ile Asp Phe Tyr Asn Asn Cys Leu Leu Gln
225 230 235 240
Pro Trp Ile Asp Lys Tyr Asn Lys Ile Val Trp Trp Tyr Ser Leu Glu
245 250 255
Asn Trp Glu Lys Val Gln Trp Leu Asn Glu Lys Ile Asn Asn Phe Lys
260 265 270
Gln Asn Gln Asn Lys Ser Asn Ser Lys Asp Leu Lys Phe Pro Arg Met
275 280 285
Lys Leu Leu Tyr Lys Gln Ile Leu Gly Asp Lys Glu Lys Lys Val Tyr
290 295 300
Ile Asp Glu Ile Arg Asp Asp Lys Asn Leu Ile Asp Leu Ile Asp Asn
305 310 315 320
Ser Lys Arg Arg Asn Gln Ile Lys Ile Asp Asn Ala Asn Asp Ile Ile
325 330 335
Asn Asp Phe Ile Asn Asn Asn Ala Lys Phe Glu Leu Asp Lys Ile Tyr
340 345 350
Leu Thr Arg Gln Ser Ile Asn Thr Ile Ser Ser Lys Tyr Phe Ser Ser
355 360 365
Trp Asp Tyr Ile Arg Trp Tyr Phe Trp Thr Gly Glu Leu Gln Glu Phe
370 375 380
Val Ser Phe Tyr Asp Leu Lys Glu Thr Phe Trp Lys Ile Glu Tyr Glu
385 390 395 400
Thr Leu Glu Asn Ile Phe Lys Asp Cys Tyr Val Lys Gly Ile Asn Thr
405 410 415
Glu Ser Gln Asn Asn Ile Val Phe Glu Thr Gln Gly Ile Tyr Glu Asn
420 425 430
Phe Leu Asn Ile Phe Lys Phe Glu Phe Asn Gln Asn Ile Ser Gln Ile
435 440 445
Ser Leu Leu Glu Trp Glu Leu Asp Lys Ile Gln Asn Glu Asp Ile Lys
450 455 460
Lys Asn Glu Lys Gln Val Glu Val Ile Lys Asn Tyr Phe Asp Ser Val
465 470 475 480
Met Ser Val Tyr Lys Met Thr Lys Tyr Phe Ser Leu Glu Lys Trp Lys
485 490 495
Lys Arg Val Glu Leu Asp Thr Asp Asn Asn Phe Tyr Asn Asp Phe Asn
500 505 510
Glu Tyr Leu Glu Gly Phe Glu Ile Trp Lys Asp Tyr Asn Leu Val Arg
515 520 525
Asn Tyr Ile Thr Lys Lys Gln Val Asn Thr Asp Lys Ile Lys Leu Asn
530 535 540
Phe Asp Asn Ser Gln Phe Leu Thr Trp Trp Asp Lys Asp Lys Glu Asn
545 550 555 560
Glu Arg Leu Gly Ile Ile Leu Arg Arg Glu Trp Lys Tyr Tyr Leu Trp
565 570 575
Ile Leu Lys Lys Trp Asn Thr Leu Asn Phe Gly Asp Tyr Leu Gln Lys
580 585 590
Glu Trp Glu Ile Phe Tyr Glu Lys Met Asn Tyr Lys Gln Leu Asn Asn
595 600 605
Val Tyr Arg Gln Leu Pro Arg Leu Leu Phe Pro Leu Thr Lys Lys Leu
610 615 620
Asn Glu Leu Lys Trp Asp Glu Leu Lys Lys Tyr Leu Ser Lys Tyr Ile
625 630 635 640
Gln Asn Phe Trp Tyr Asn Glu Glu Ile Ala Gln Ile Lys Ile Glu Phe
645 650 655
Asp Ile Phe Gln Glu Ser Lys Glu Lys Trp Glu Lys Phe Asp Ile Asp
660 665 670
Lys Leu Arg Lys Leu Ile Glu Tyr Tyr Lys Lys Trp Val Leu Ala Leu
675 680 685
Tyr Ser Asp Leu Tyr Asp Leu Glu Phe Ile Lys Tyr Lys Asn Tyr Asp
690 695 700
Asp Leu Ser Ile Phe Tyr Ser Asp Val Glu Lys Lys Met Tyr Asn Leu
705 710 715 720
Asn Phe Thr Lys Ile Asp Lys Ser Leu Ile Asp Gly Lys Val Lys Ser
725 730 735
Trp Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Glu Ser
740 745 750
Lys Lys Glu Trp Ser Thr Glu Asn Ile His Thr Lys Tyr Phe Lys Leu
755 760 765
Leu Phe Asn Glu Lys Asn Leu Gln Asn Leu Val Val Lys Leu Ser Trp
770 775 780
Trp Ala Asp Ile Phe Phe Arg Asp Lys Thr Glu Asn Leu Lys Phe Lys
785 790 795 800
Lys Asp Lys Asn Gly Gln Glu Ile Leu Asp His Arg Arg Phe Ser Gln
805 810 815
Asp Lys Ile Met Phe His Ile Ser Ile Thr Leu Asn Ala Asn Cys Trp
820 825 830
Asp Lys Tyr Trp Phe Asn Gln Tyr Val Asn Glu Tyr Met Asn Lys Glu
835 840 845
Arg Asp Ile Lys Ile Ile Trp Ile Asp Arg Trp Glu Lys His Leu Ala
850 855 860
Tyr Tyr Cys Val Ile Asp Lys Ser Trp Lys Ile Phe Asn Asn Glu Ile
865 870 875 880
Trp Thr Leu Asn Glu Leu Asn Trp Val Asn Tyr Leu Glu Lys Leu Glu
885 890 895
Lys Ile Glu Ser Ser Arg Lys Asp Ser Arg Ile Ser Trp Trp Glu Ile
900 905 910
Glu Asn Ile Lys Glu Leu Lys Asn Gly Tyr Ile Ser Gln Val Ile Asn
915 920 925
Lys Leu Thr Glu Leu Ile Val Lys Tyr Asn Ala Ile Ile Val Phe Glu
930 935 940
Asp Leu Asn Ile Trp Phe Lys Arg Trp Arg Gln Lys Ile Glu Lys Gln
945 950 955 960
Ile Tyr Gln Lys Leu Glu Leu Ala Leu Ala Lys Lys Leu Asn Tyr Leu
965 970 975
Thr Gln Lys Asp Lys Lys Asp Asp Glu Ile Leu Trp Asn Leu Lys Ala
980 985 990
Leu Gln Leu Val Pro Lys Val Asn Asp Tyr Gln Asp Ile Trp Asn Tyr
995 1000 1005
Lys Gln Ser Trp Ile Met Phe Tyr Val Arg Ala Asn Tyr Thr Ser
1010 1015 1020
Val Thr Cys Pro Asn Cys Trp Leu Arg Lys Asn Leu Tyr Ile Ser
1025 1030 1035
Asn Ser Ala Thr Lys Glu Asn Gln Lys Lys Ser Leu Asn Ser Ile
1040 1045 1050
Ala Ile Lys Tyr Asn Asp Trp Lys Phe Ser Phe Ser Tyr Glu Ile
1055 1060 1065
Asp Asp Lys Ser Trp Lys Gln Lys Gln Ser Leu Asn Lys Lys Lys
1070 1075 1080
Phe Ile Val Tyr Ser Asp Ile Glu Arg Phe Val Tyr Ser Pro Leu
1085 1090 1095
Glu Lys Leu Thr Lys Val Ile Asp Val Asn Lys Lys Leu Leu Glu
1100 1105 1110
Leu Phe Arg Asp Phe Asn Leu Ser Leu Asp Ile Asn Lys Gln Ile
1115 1120 1125
Gln Glu Lys Asp Leu Asp Ser Val Phe Phe Lys Ser Leu Thr His
1130 1135 1140
Leu Phe Asn Leu Ile Leu Gln Leu Arg Asn Ser Asp Ser Lys Asp
1145 1150 1155
Asn Lys Asp Tyr Ile Ser Cys Pro Ser Cys Tyr Tyr His Ser Asn
1160 1165 1170
Asn Trp Leu Gln Trp Phe Glu Phe Asn Trp Asp Ala Asn Trp Ala
1175 1180 1185
Tyr Asn Ile Ala Arg Lys Gly Ile Ile Leu Leu Asp Arg Ile Arg
1190 1195 1200
Lys Asn Gln Glu Lys Pro Asp Leu Tyr Val Ser Asp Ile Asp Trp
1205 1210 1215
Asp Asn Phe Val Gln Ser Asn Gln Phe Pro Asn Thr Ile Ile Pro
1220 1225 1230
Ile Gln Asn Ile Glu Lys Gln Val Pro Leu Asn Ile Lys Ile
1235 1240 1245
<210> 102
<211> 1246
<212> БЕЛОК
<213> Porphyromonas macacae
<400> 102
Met Lys Thr Gln His Phe Phe Glu Asp Phe Thr Ser Leu Tyr Ser Leu
1 5 10 15
Ser Lys Thr Ile Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu
20 25 30
Asn Ile Lys Lys Asn Gly Leu Ile Arg Arg Asp Glu Gln Arg Leu Asp
35 40 45
Asp Tyr Glu Lys Leu Lys Lys Val Ile Asp Glu Tyr His Glu Asp Phe
50 55 60
Ile Ala Asn Ile Leu Ser Ser Phe Ser Phe Ser Glu Glu Ile Leu Gln
65 70 75 80
Ser Tyr Ile Gln Asn Leu Ser Glu Ser Glu Ala Arg Ala Lys Ile Glu
85 90 95
Lys Thr Met Arg Asp Thr Leu Ala Lys Ala Phe Ser Glu Asp Glu Arg
100 105 110
Tyr Lys Ser Ile Phe Lys Lys Glu Leu Val Lys Lys Asp Ile Pro Val
115 120 125
Trp Cys Pro Ala Tyr Lys Ser Leu Cys Lys Lys Phe Asp Asn Phe Thr
130 135 140
Thr Ser Leu Val Pro Phe His Glu Asn Arg Lys Asn Leu Tyr Thr Ser
145 150 155 160
Asn Glu Ile Thr Ala Ser Ile Pro Tyr Arg Ile Val His Val Asn Leu
165 170 175
Pro Lys Phe Ile Gln Asn Ile Glu Ala Leu Cys Glu Leu Gln Lys Lys
180 185 190
Met Gly Ala Asp Leu Tyr Leu Glu Met Met Glu Asn Leu Arg Asn Val
195 200 205
Trp Pro Ser Phe Val Lys Thr Pro Asp Asp Leu Cys Asn Leu Lys Thr
210 215 220
Tyr Asn His Leu Met Val Gln Ser Ser Ile Ser Glu Tyr Asn Arg Phe
225 230 235 240
Val Gly Gly Tyr Ser Thr Glu Asp Gly Thr Lys His Gln Gly Ile Asn
245 250 255
Glu Trp Ile Asn Ile Tyr Arg Gln Arg Asn Lys Glu Met Arg Leu Pro
260 265 270
Gly Leu Val Phe Leu His Lys Gln Ile Leu Ala Lys Val Asp Ser Ser
275 280 285
Ser Phe Ile Ser Asp Thr Leu Glu Asn Asp Asp Gln Val Phe Cys Val
290 295 300
Leu Arg Gln Phe Arg Lys Leu Phe Trp Asn Thr Val Ser Ser Lys Glu
305 310 315 320
Asp Asp Ala Ala Ser Leu Lys Asp Leu Phe Cys Gly Leu Ser Gly Tyr
325 330 335
Asp Pro Glu Ala Ile Tyr Val Ser Asp Ala His Leu Ala Thr Ile Ser
340 345 350
Lys Asn Ile Phe Asp Arg Trp Asn Tyr Ile Ser Asp Ala Ile Arg Arg
355 360 365
Lys Thr Glu Val Leu Met Pro Arg Lys Lys Glu Ser Val Glu Arg Tyr
370 375 380
Ala Glu Lys Ile Ser Lys Gln Ile Lys Lys Arg Gln Ser Tyr Ser Leu
385 390 395 400
Ala Glu Leu Asp Asp Leu Leu Ala His Tyr Ser Glu Glu Ser Leu Pro
405 410 415
Ala Gly Phe Ser Leu Leu Ser Tyr Phe Thr Ser Leu Gly Gly Gln Lys
420 425 430
Tyr Leu Val Ser Asp Gly Glu Val Ile Leu Tyr Glu Glu Gly Ser Asn
435 440 445
Ile Trp Asp Glu Val Leu Ile Ala Phe Arg Asp Leu Gln Val Ile Leu
450 455 460
Asp Lys Asp Phe Thr Glu Lys Lys Leu Gly Lys Asp Glu Glu Ala Val
465 470 475 480
Ser Val Ile Lys Lys Ala Leu Asp Ser Ala Leu Arg Leu Arg Lys Phe
485 490 495
Phe Asp Leu Leu Ser Gly Thr Gly Ala Glu Ile Arg Arg Asp Ser Ser
500 505 510
Phe Tyr Ala Leu Tyr Thr Asp Arg Met Asp Lys Leu Lys Gly Leu Leu
515 520 525
Lys Met Tyr Asp Lys Val Arg Asn Tyr Leu Thr Lys Lys Pro Tyr Ser
530 535 540
Ile Glu Lys Phe Lys Leu His Phe Asp Asn Pro Ser Leu Leu Ser Gly
545 550 555 560
Trp Asp Lys Asn Lys Glu Leu Asn Asn Leu Ser Val Ile Phe Arg Gln
565 570 575
Asn Gly Tyr Tyr Tyr Leu Gly Ile Met Thr Pro Lys Gly Lys Asn Leu
580 585 590
Phe Lys Thr Leu Pro Lys Leu Gly Ala Glu Glu Met Phe Tyr Glu Lys
595 600 605
Met Glu Tyr Lys Gln Ile Ala Glu Pro Met Leu Met Leu Pro Lys Val
610 615 620
Phe Phe Pro Lys Lys Thr Lys Pro Ala Phe Ala Pro Asp Gln Ser Val
625 630 635 640
Val Asp Ile Tyr Asn Lys Lys Thr Phe Lys Thr Gly Gln Lys Gly Phe
645 650 655
Asn Lys Lys Asp Leu Tyr Arg Leu Ile Asp Phe Tyr Lys Glu Ala Leu
660 665 670
Thr Val His Glu Trp Lys Leu Phe Asn Phe Ser Phe Ser Pro Thr Glu
675 680 685
Gln Tyr Arg Asn Ile Gly Glu Phe Phe Asp Glu Val Arg Glu Gln Ala
690 695 700
Tyr Lys Val Ser Met Val Asn Val Pro Ala Ser Tyr Ile Asp Glu Ala
705 710 715 720
Val Glu Asn Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe
725 730 735
Ser Pro Tyr Ser Lys Gly Ile Pro Asn Leu His Thr Leu Tyr Trp Lys
740 745 750
Ala Leu Phe Ser Glu Gln Asn Gln Ser Arg Val Tyr Lys Leu Cys Gly
755 760 765
Gly Gly Glu Leu Phe Tyr Arg Lys Ala Ser Leu His Met Gln Asp Thr
770 775 780
Thr Val His Pro Lys Gly Ile Ser Ile His Lys Lys Asn Leu Asn Lys
785 790 795 800
Lys Gly Glu Thr Ser Leu Phe Asn Tyr Asp Leu Val Lys Asp Lys Arg
805 810 815
Phe Thr Glu Asp Lys Phe Phe Phe His Val Pro Ile Ser Ile Asn Tyr
820 825 830
Lys Asn Lys Lys Ile Thr Asn Val Asn Gln Met Val Arg Asp Tyr Ile
835 840 845
Ala Gln Asn Asp Asp Leu Gln Ile Ile Gly Ile Asp Arg Gly Glu Arg
850 855 860
Asn Leu Leu Tyr Ile Ser Arg Ile Asp Thr Arg Gly Asn Leu Leu Glu
865 870 875 880
Gln Phe Ser Leu Asn Val Ile Glu Ser Asp Lys Gly Asp Leu Arg Thr
885 890 895
Asp Tyr Gln Lys Ile Leu Gly Asp Arg Glu Gln Glu Arg Leu Arg Arg
900 905 910
Arg Gln Glu Trp Lys Ser Ile Glu Ser Ile Lys Asp Leu Lys Asp Gly
915 920 925
Tyr Met Ser Gln Val Val His Lys Ile Cys Asn Met Val Val Glu His
930 935 940
Lys Ala Ile Val Val Leu Glu Asn Leu Asn Leu Ser Phe Met Lys Gly
945 950 955 960
Arg Lys Lys Val Glu Lys Ser Val Tyr Glu Lys Phe Glu Arg Met Leu
965 970 975
Val Asp Lys Leu Asn Tyr Leu Val Val Asp Lys Lys Asn Leu Ser Asn
980 985 990
Glu Pro Gly Gly Leu Tyr Ala Ala Tyr Gln Leu Thr Asn Pro Leu Phe
995 1000 1005
Ser Phe Glu Glu Leu His Arg Tyr Pro Gln Ser Gly Ile Leu Phe
1010 1015 1020
Phe Val Asp Pro Trp Asn Thr Ser Leu Thr Asp Pro Ser Thr Gly
1025 1030 1035
Phe Val Asn Leu Leu Gly Arg Ile Asn Tyr Thr Asn Val Gly Asp
1040 1045 1050
Ala Arg Lys Phe Phe Asp Arg Phe Asn Ala Ile Arg Tyr Asp Gly
1055 1060 1065
Lys Gly Asn Ile Leu Phe Asp Leu Asp Leu Ser Arg Phe Asp Val
1070 1075 1080
Arg Val Glu Thr Gln Arg Lys Leu Trp Thr Leu Thr Thr Phe Gly
1085 1090 1095
Ser Arg Ile Ala Lys Ser Lys Lys Ser Gly Lys Trp Met Val Glu
1100 1105 1110
Arg Ile Glu Asn Leu Ser Leu Cys Phe Leu Glu Leu Phe Glu Gln
1115 1120 1125
Phe Asn Ile Gly Tyr Arg Val Glu Lys Asp Leu Lys Lys Ala Ile
1130 1135 1140
Leu Ser Gln Asp Arg Lys Glu Phe Tyr Val Arg Leu Ile Tyr Leu
1145 1150 1155
Phe Asn Leu Met Met Gln Ile Arg Asn Ser Asp Gly Glu Glu Asp
1160 1165 1170
Tyr Ile Leu Ser Pro Ala Leu Asn Glu Lys Asn Leu Gln Phe Asp
1175 1180 1185
Ser Arg Leu Ile Glu Ala Lys Asp Leu Pro Val Asp Ala Asp Ala
1190 1195 1200
Asn Gly Ala Tyr Asn Val Ala Arg Lys Gly Leu Met Val Val Gln
1205 1210 1215
Arg Ile Lys Arg Gly Asp His Glu Ser Ile His Arg Ile Gly Arg
1220 1225 1230
Ala Gln Trp Leu Arg Tyr Val Gln Glu Gly Ile Val Glu
1235 1240 1245
<210> 103
<211> 1241
<212> БЕЛОК
<213> Butyrivibrio proteoclasticus
<400> 103
Met Leu Leu Tyr Glu Asn Tyr Thr Lys Arg Asn Gln Ile Thr Lys Ser
1 5 10 15
Leu Arg Leu Glu Leu Arg Pro Gln Gly Lys Thr Leu Arg Asn Ile Lys
20 25 30
Glu Leu Asn Leu Leu Glu Gln Asp Lys Ala Ile Tyr Ala Leu Leu Glu
35 40 45
Arg Leu Lys Pro Val Ile Asp Glu Gly Ile Lys Asp Ile Ala Arg Asp
50 55 60
Thr Leu Lys Asn Cys Glu Leu Ser Phe Glu Lys Leu Tyr Glu His Phe
65 70 75 80
Leu Ser Gly Asp Lys Lys Ala Tyr Ala Lys Glu Ser Glu Arg Leu Lys
85 90 95
Lys Glu Ile Val Lys Thr Leu Ile Lys Asn Leu Pro Glu Gly Ile Gly
100 105 110
Lys Ile Ser Glu Ile Asn Ser Ala Lys Tyr Leu Asn Gly Val Leu Tyr
115 120 125
Asp Phe Ile Asp Lys Thr His Lys Asp Ser Glu Glu Lys Gln Asn Ile
130 135 140
Leu Ser Asp Ile Leu Glu Thr Lys Gly Tyr Leu Ala Leu Phe Ser Lys
145 150 155 160
Phe Leu Thr Ser Arg Ile Thr Thr Leu Glu Gln Ser Met Pro Lys Arg
165 170 175
Val Ile Glu Asn Phe Glu Ile Tyr Ala Ala Asn Ile Pro Lys Met Gln
180 185 190
Asp Ala Leu Glu Arg Gly Ala Val Ser Phe Ala Ile Glu Tyr Glu Ser
195 200 205
Ile Cys Ser Val Asp Tyr Tyr Asn Gln Ile Leu Ser Gln Glu Asp Ile
210 215 220
Asp Ser Tyr Asn Arg Leu Ile Ser Gly Ile Met Asp Glu Asp Gly Ala
225 230 235 240
Lys Glu Lys Gly Ile Asn Gln Thr Ile Ser Glu Lys Asn Ile Lys Ile
245 250 255
Lys Ser Glu His Leu Glu Glu Lys Pro Phe Arg Ile Leu Lys Gln Leu
260 265 270
His Lys Gln Ile Leu Glu Glu Arg Glu Lys Ala Phe Thr Ile Asp His
275 280 285
Ile Asp Ser Asp Glu Glu Val Val Gln Val Thr Lys Glu Ala Phe Glu
290 295 300
Gln Thr Lys Glu Gln Trp Glu Asn Ile Lys Lys Ile Asn Gly Phe Tyr
305 310 315 320
Ala Lys Asp Pro Gly Asp Ile Thr Leu Phe Ile Val Val Gly Pro Asn
325 330 335
Gln Thr His Val Leu Ser Gln Leu Ile Tyr Gly Glu His Asp Arg Ile
340 345 350
Arg Leu Leu Leu Glu Glu Tyr Glu Lys Asn Thr Leu Glu Val Leu Pro
355 360 365
Arg Arg Thr Lys Ser Glu Lys Ala Arg Tyr Asp Lys Phe Val Asn Ala
370 375 380
Val Pro Lys Lys Val Ala Lys Glu Ser His Thr Phe Asp Gly Leu Gln
385 390 395 400
Lys Met Thr Gly Asp Asp Arg Leu Phe Ile Leu Tyr Arg Asp Glu Leu
405 410 415
Ala Arg Asn Tyr Met Arg Ile Lys Glu Ala Tyr Gly Thr Phe Glu Arg
420 425 430
Asp Ile Leu Lys Ser Arg Arg Gly Ile Lys Gly Asn Arg Asp Val Gln
435 440 445
Glu Ser Leu Val Ser Phe Tyr Asp Glu Leu Thr Lys Phe Arg Ser Ala
450 455 460
Leu Arg Ile Ile Asn Ser Gly Asn Asp Glu Lys Ala Asp Pro Ile Phe
465 470 475 480
Tyr Asn Thr Phe Asp Gly Ile Phe Glu Lys Ala Asn Arg Thr Tyr Lys
485 490 495
Ala Glu Asn Leu Cys Arg Asn Tyr Val Thr Lys Ser Pro Ala Asp Asp
500 505 510
Ala Arg Ile Met Ala Ser Cys Leu Gly Thr Pro Ala Arg Leu Arg Thr
515 520 525
His Trp Trp Asn Gly Glu Glu Asn Phe Ala Ile Asn Asp Val Ala Met
530 535 540
Ile Arg Arg Gly Asp Glu Tyr Tyr Tyr Phe Val Leu Thr Pro Asp Val
545 550 555 560
Lys Pro Val Asp Leu Lys Thr Lys Asp Glu Thr Asp Ala Gln Ile Phe
565 570 575
Val Gln Arg Lys Gly Ala Lys Ser Phe Leu Gly Leu Pro Lys Ala Leu
580 585 590
Phe Lys Cys Ile Leu Glu Pro Tyr Phe Glu Ser Pro Glu His Lys Asn
595 600 605
Asp Lys Asn Cys Val Ile Glu Glu Tyr Val Ser Lys Pro Leu Thr Ile
610 615 620
Asp Arg Arg Ala Tyr Asp Ile Phe Lys Asn Gly Thr Phe Lys Lys Thr
625 630 635 640
Asn Ile Gly Ile Asp Gly Leu Thr Glu Glu Lys Phe Lys Asp Asp Cys
645 650 655
Arg Tyr Leu Ile Asp Val Tyr Lys Glu Phe Ile Ala Val Tyr Thr Arg
660 665 670
Tyr Ser Cys Phe Asn Met Ser Gly Leu Lys Arg Ala Asp Glu Tyr Asn
675 680 685
Asp Ile Gly Glu Phe Phe Ser Asp Val Asp Thr Arg Leu Cys Thr Met
690 695 700
Glu Trp Ile Pro Val Ser Phe Glu Arg Ile Asn Asp Met Val Asp Lys
705 710 715 720
Lys Glu Gly Leu Leu Phe Leu Val Arg Ser Met Phe Leu Tyr Asn Arg
725 730 735
Pro Arg Lys Pro Tyr Glu Arg Thr Phe Ile Gln Leu Phe Ser Asp Ser
740 745 750
Asn Met Glu His Thr Ser Met Leu Leu Asn Ser Arg Ala Met Ile Gln
755 760 765
Tyr Arg Ala Ala Ser Leu Pro Arg Arg Val Thr His Lys Lys Gly Ser
770 775 780
Ile Leu Val Ala Leu Arg Asp Ser Asn Gly Glu His Ile Pro Met His
785 790 795 800
Ile Arg Glu Ala Ile Tyr Lys Met Lys Asn Asn Phe Asp Ile Ser Ser
805 810 815
Glu Asp Phe Ile Met Ala Lys Ala Tyr Leu Ala Glu His Asp Val Ala
820 825 830
Ile Lys Lys Ala Asn Glu Asp Ile Ile Arg Asn Arg Arg Tyr Thr Glu
835 840 845
Asp Lys Phe Phe Leu Ser Leu Ser Tyr Thr Lys Asn Ala Asp Ile Ser
850 855 860
Ala Arg Thr Leu Asp Tyr Ile Asn Asp Lys Val Glu Glu Asp Thr Gln
865 870 875 880
Asp Ser Arg Met Ala Val Ile Val Thr Arg Asn Leu Lys Asp Leu Thr
885 890 895
Tyr Val Ala Val Val Asp Glu Lys Asn Asn Val Leu Glu Glu Lys Ser
900 905 910
Leu Asn Glu Ile Asp Gly Val Asn Tyr Arg Glu Leu Leu Lys Glu Arg
915 920 925
Thr Lys Ile Lys Tyr His Asp Lys Thr Arg Leu Trp Gln Tyr Asp Val
930 935 940
Ser Ser Lys Gly Leu Lys Glu Ala Tyr Val Glu Leu Ala Val Thr Gln
945 950 955 960
Ile Ser Lys Leu Ala Thr Lys Tyr Asn Ala Val Val Val Val Glu Ser
965 970 975
Met Ser Ser Thr Phe Lys Asp Lys Phe Ser Phe Leu Asp Glu Gln Ile
980 985 990
Phe Lys Ala Phe Glu Ala Arg Leu Cys Ala Arg Met Ser Asp Leu Ser
995 1000 1005
Phe Asn Thr Ile Lys Glu Gly Glu Ala Gly Ser Ile Ser Asn Pro
1010 1015 1020
Ile Gln Val Ser Asn Asn Asn Gly Asn Ser Tyr Gln Asp Gly Val
1025 1030 1035
Ile Tyr Phe Leu Asn Asn Ala Tyr Thr Arg Thr Leu Cys Pro Asp
1040 1045 1050
Thr Gly Phe Val Asp Val Phe Asp Lys Thr Arg Leu Ile Thr Met
1055 1060 1065
Gln Ser Lys Arg Gln Phe Phe Ala Lys Met Lys Asp Ile Arg Ile
1070 1075 1080
Asp Asp Gly Glu Met Leu Phe Thr Phe Asn Leu Glu Glu Tyr Pro
1085 1090 1095
Thr Lys Arg Leu Leu Asp Arg Lys Glu Trp Thr Val Lys Ile Ala
1100 1105 1110
Gly Asp Gly Ser Tyr Phe Asp Lys Asp Lys Gly Glu Tyr Val Tyr
1115 1120 1125
Val Asn Asp Ile Val Arg Glu Gln Ile Ile Pro Ala Leu Leu Glu
1130 1135 1140
Asp Lys Ala Val Phe Asp Gly Asn Met Ala Glu Lys Phe Leu Asp
1145 1150 1155
Lys Thr Ala Ile Ser Gly Lys Ser Val Glu Leu Ile Tyr Lys Trp
1160 1165 1170
Phe Ala Asn Ala Leu Tyr Gly Ile Ile Thr Lys Lys Asp Gly Glu
1175 1180 1185
Lys Ile Tyr Arg Ser Pro Ile Thr Gly Thr Glu Ile Asp Val Ser
1190 1195 1200
Lys Asn Thr Thr Tyr Asn Phe Gly Lys Lys Phe Met Phe Lys Gln
1205 1210 1215
Glu Tyr Arg Gly Asp Gly Asp Phe Leu Asp Ala Phe Leu Asn Tyr
1220 1225 1230
Met Gln Ala Gln Asp Ile Ala Val
1235 1240
<210> 104
<211> 1238
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methanoplasma termitum
<400> 104
Met Asn Asn Tyr Asp Glu Phe Thr Lys Leu Tyr Pro Ile Gln Lys Thr
1 5 10 15
Ile Arg Phe Glu Leu Lys Pro Gln Gly Arg Thr Met Glu His Leu Glu
20 25 30
Thr Phe Asn Phe Phe Glu Glu Asp Arg Asp Arg Ala Glu Lys Tyr Lys
35 40 45
Ile Leu Lys Glu Ala Ile Asp Glu Tyr His Lys Lys Phe Ile Asp Glu
50 55 60
His Leu Thr Asn Met Ser Leu Asp Trp Asn Ser Leu Lys Gln Ile Ser
65 70 75 80
Glu Lys Tyr Tyr Lys Ser Arg Glu Glu Lys Asp Lys Lys Val Phe Leu
85 90 95
Ser Glu Gln Lys Arg Met Arg Gln Glu Ile Val Ser Glu Phe Lys Lys
100 105 110
Asp Asp Arg Phe Lys Asp Leu Phe Ser Lys Lys Leu Phe Ser Glu Leu
115 120 125
Leu Lys Glu Glu Ile Tyr Lys Lys Gly Asn His Gln Glu Ile Asp Ala
130 135 140
Leu Lys Ser Phe Asp Lys Phe Ser Gly Tyr Phe Ile Gly Leu His Glu
145 150 155 160
Asn Arg Lys Asn Met Tyr Ser Asp Gly Asp Glu Ile Thr Ala Ile Ser
165 170 175
Asn Arg Ile Val Asn Glu Asn Phe Pro Lys Phe Leu Asp Asn Leu Gln
180 185 190
Lys Tyr Gln Glu Ala Arg Lys Lys Tyr Pro Glu Trp Ile Ile Lys Ala
195 200 205
Glu Ser Ala Leu Val Ala His Asn Ile Lys Met Asp Glu Val Phe Ser
210 215 220
Leu Glu Tyr Phe Asn Lys Val Leu Asn Gln Glu Gly Ile Gln Arg Tyr
225 230 235 240
Asn Leu Ala Leu Gly Gly Tyr Val Thr Lys Ser Gly Glu Lys Met Met
245 250 255
Gly Leu Asn Asp Ala Leu Asn Leu Ala His Gln Ser Glu Lys Ser Ser
260 265 270
Lys Gly Arg Ile His Met Thr Pro Leu Phe Lys Gln Ile Leu Ser Glu
275 280 285
Lys Glu Ser Phe Ser Tyr Ile Pro Asp Val Phe Thr Glu Asp Ser Gln
290 295 300
Leu Leu Pro Ser Ile Gly Gly Phe Phe Ala Gln Ile Glu Asn Asp Lys
305 310 315 320
Asp Gly Asn Ile Phe Asp Arg Ala Leu Glu Leu Ile Ser Ser Tyr Ala
325 330 335
Glu Tyr Asp Thr Glu Arg Ile Tyr Ile Arg Gln Ala Asp Ile Asn Arg
340 345 350
Val Ser Asn Val Ile Phe Gly Glu Trp Gly Thr Leu Gly Gly Leu Met
355 360 365
Arg Glu Tyr Lys Ala Asp Ser Ile Asn Asp Ile Asn Leu Glu Arg Thr
370 375 380
Cys Lys Lys Val Asp Lys Trp Leu Asp Ser Lys Glu Phe Ala Leu Ser
385 390 395 400
Asp Val Leu Glu Ala Ile Lys Arg Thr Gly Asn Asn Asp Ala Phe Asn
405 410 415
Glu Tyr Ile Ser Lys Met Arg Thr Ala Arg Glu Lys Ile Asp Ala Ala
420 425 430
Arg Lys Glu Met Lys Phe Ile Ser Glu Lys Ile Ser Gly Asp Glu Glu
435 440 445
Ser Ile His Ile Ile Lys Thr Leu Leu Asp Ser Val Gln Gln Phe Leu
450 455 460
His Phe Phe Asn Leu Phe Lys Ala Arg Gln Asp Ile Pro Leu Asp Gly
465 470 475 480
Ala Phe Tyr Ala Glu Phe Asp Glu Val His Ser Lys Leu Phe Ala Ile
485 490 495
Val Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Lys Asn Asn Leu
500 505 510
Asn Thr Lys Lys Ile Lys Leu Asn Phe Lys Asn Pro Thr Leu Ala Asn
515 520 525
Gly Trp Asp Gln Asn Lys Val Tyr Asp Tyr Ala Ser Leu Ile Phe Leu
530 535 540
Arg Asp Gly Asn Tyr Tyr Leu Gly Ile Ile Asn Pro Lys Arg Lys Lys
545 550 555 560
Asn Ile Lys Phe Glu Gln Gly Ser Gly Asn Gly Pro Phe Tyr Arg Lys
565 570 575
Met Val Tyr Lys Gln Ile Pro Gly Pro Asn Lys Asn Leu Pro Arg Val
580 585 590
Phe Leu Thr Ser Thr Lys Gly Lys Lys Glu Tyr Lys Pro Ser Lys Glu
595 600 605
Ile Ile Glu Gly Tyr Glu Ala Asp Lys His Ile Arg Gly Asp Lys Phe
610 615 620
Asp Leu Asp Phe Cys His Lys Leu Ile Asp Phe Phe Lys Glu Ser Ile
625 630 635 640
Glu Lys His Lys Asp Trp Ser Lys Phe Asn Phe Tyr Phe Ser Pro Thr
645 650 655
Glu Ser Tyr Gly Asp Ile Ser Glu Phe Tyr Leu Asp Val Glu Lys Gln
660 665 670
Gly Tyr Arg Met His Phe Glu Asn Ile Ser Ala Glu Thr Ile Asp Glu
675 680 685
Tyr Val Glu Lys Gly Asp Leu Phe Leu Phe Gln Ile Tyr Asn Lys Asp
690 695 700
Phe Val Lys Ala Ala Thr Gly Lys Lys Asp Met His Thr Ile Tyr Trp
705 710 715 720
Asn Ala Ala Phe Ser Pro Glu Asn Leu Gln Asp Val Val Val Lys Leu
725 730 735
Asn Gly Glu Ala Glu Leu Phe Tyr Arg Asp Lys Ser Asp Ile Lys Glu
740 745 750
Ile Val His Arg Glu Gly Glu Ile Leu Val Asn Arg Thr Tyr Asn Gly
755 760 765
Arg Thr Pro Val Pro Asp Lys Ile His Lys Lys Leu Thr Asp Tyr His
770 775 780
Asn Gly Arg Thr Lys Asp Leu Gly Glu Ala Lys Glu Tyr Leu Asp Lys
785 790 795 800
Val Arg Tyr Phe Lys Ala His Tyr Asp Ile Thr Lys Asp Arg Arg Tyr
805 810 815
Leu Asn Asp Lys Ile Tyr Phe His Val Pro Leu Thr Leu Asn Phe Lys
820 825 830
Ala Asn Gly Lys Lys Asn Leu Asn Lys Met Val Ile Glu Lys Phe Leu
835 840 845
Ser Asp Glu Lys Ala His Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn
850 855 860
Leu Leu Tyr Tyr Ser Ile Ile Asp Arg Ser Gly Lys Ile Ile Asp Gln
865 870 875 880
Gln Ser Leu Asn Val Ile Asp Gly Phe Asp Tyr Arg Glu Lys Leu Asn
885 890 895
Gln Arg Glu Ile Glu Met Lys Asp Ala Arg Gln Ser Trp Asn Ala Ile
900 905 910
Gly Lys Ile Lys Asp Leu Lys Glu Gly Tyr Leu Ser Lys Ala Val His
915 920 925
Glu Ile Thr Lys Met Ala Ile Gln Tyr Asn Ala Ile Val Val Met Glu
930 935 940
Glu Leu Asn Tyr Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln
945 950 955 960
Ile Tyr Gln Lys Phe Glu Asn Met Leu Ile Asp Lys Met Asn Tyr Leu
965 970 975
Val Phe Lys Asp Ala Pro Asp Glu Ser Pro Gly Gly Val Leu Asn Ala
980 985 990
Tyr Gln Leu Thr Asn Pro Leu Glu Ser Phe Ala Lys Leu Gly Lys Gln
995 1000 1005
Thr Gly Ile Leu Phe Tyr Val Pro Ala Ala Tyr Thr Ser Lys Ile
1010 1015 1020
Asp Pro Thr Thr Gly Phe Val Asn Leu Phe Asn Thr Ser Ser Lys
1025 1030 1035
Thr Asn Ala Gln Glu Arg Lys Glu Phe Leu Gln Lys Phe Glu Ser
1040 1045 1050
Ile Ser Tyr Ser Ala Lys Asp Gly Gly Ile Phe Ala Phe Ala Phe
1055 1060 1065
Asp Tyr Arg Lys Phe Gly Thr Ser Lys Thr Asp His Lys Asn Val
1070 1075 1080
Trp Thr Ala Tyr Thr Asn Gly Glu Arg Met Arg Tyr Ile Lys Glu
1085 1090 1095
Lys Lys Arg Asn Glu Leu Phe Asp Pro Ser Lys Glu Ile Lys Glu
1100 1105 1110
Ala Leu Thr Ser Ser Gly Ile Lys Tyr Asp Gly Gly Gln Asn Ile
1115 1120 1125
Leu Pro Asp Ile Leu Arg Ser Asn Asn Asn Gly Leu Ile Tyr Thr
1130 1135 1140
Met Tyr Ser Ser Phe Ile Ala Ala Ile Gln Met Arg Val Tyr Asp
1145 1150 1155
Gly Lys Glu Asp Tyr Ile Ile Ser Pro Ile Lys Asn Ser Lys Gly
1160 1165 1170
Glu Phe Phe Arg Thr Asp Pro Lys Arg Arg Glu Leu Pro Ile Asp
1175 1180 1185
Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Leu Arg Gly Glu Leu
1190 1195 1200
Thr Met Arg Ala Ile Ala Glu Lys Phe Asp Pro Asp Ser Glu Lys
1205 1210 1215
Met Ala Lys Leu Glu Leu Lys His Lys Asp Trp Phe Glu Phe Met
1220 1225 1230
Gln Thr Arg Gly Asp
1235
<210> 105
<211> 1235
<212> БЕЛОК
<213> Anaerovibrio sp.
<400> 105
Met Val Ala Phe Ile Asp Glu Phe Val Gly Gln Tyr Pro Val Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Ala Arg Pro Val Pro Glu Thr Lys Lys Trp Leu
20 25 30
Glu Ser Asp Gln Cys Ser Val Leu Phe Asn Asp Gln Lys Arg Asn Glu
35 40 45
Tyr Tyr Gly Val Leu Lys Glu Leu Leu Asp Asp Tyr Tyr Arg Ala Tyr
50 55 60
Ile Glu Asp Ala Leu Thr Ser Phe Thr Leu Asp Lys Ala Leu Leu Glu
65 70 75 80
Asn Ala Tyr Asp Leu Tyr Cys Asn Arg Asp Thr Asn Ala Phe Ser Ser
85 90 95
Cys Cys Glu Lys Leu Arg Lys Asp Leu Val Lys Ala Phe Gly Asn Leu
100 105 110
Lys Asp Tyr Leu Leu Gly Ser Asp Gln Leu Lys Asp Leu Val Lys Leu
115 120 125
Lys Ala Lys Val Asp Ala Pro Ala Gly Lys Gly Lys Lys Lys Ile Glu
130 135 140
Val Asp Ser Arg Leu Ile Asn Trp Leu Asn Asn Asn Ala Lys Tyr Ser
145 150 155 160
Ala Glu Asp Arg Glu Lys Tyr Ile Lys Ala Ile Glu Ser Phe Glu Gly
165 170 175
Phe Val Thr Tyr Leu Thr Asn Tyr Lys Gln Ala Arg Glu Asn Met Phe
180 185 190
Ser Ser Glu Asp Lys Ser Thr Ala Ile Ala Phe Arg Val Ile Asp Gln
195 200 205
Asn Met Val Thr Tyr Phe Gly Asn Ile Arg Ile Tyr Glu Lys Ile Lys
210 215 220
Ala Lys Tyr Pro Glu Leu Tyr Ser Ala Leu Lys Gly Phe Glu Lys Phe
225 230 235 240
Phe Ser Pro Thr Ala Tyr Ser Glu Ile Leu Ser Gln Ser Lys Ile Asp
245 250 255
Glu Tyr Asn Tyr Gln Cys Ile Gly Arg Pro Ile Asp Asp Ala Asp Phe
260 265 270
Lys Gly Val Asn Ser Leu Ile Asn Glu Tyr Arg Gln Lys Asn Gly Ile
275 280 285
Lys Ala Arg Glu Leu Pro Val Met Ser Met Leu Tyr Lys Gln Ile Leu
290 295 300
Ser Asp Arg Asp Asn Ser Phe Met Ser Glu Val Ile Asn Arg Asn Glu
305 310 315 320
Glu Ala Ile Glu Cys Ala Lys Asn Gly Tyr Lys Val Ser Tyr Ala Leu
325 330 335
Phe Asn Glu Leu Leu Gln Leu Tyr Lys Lys Ile Phe Thr Glu Asp Asn
340 345 350
Tyr Gly Asn Ile Tyr Val Lys Thr Gln Pro Leu Thr Glu Leu Ser Gln
355 360 365
Ala Leu Phe Gly Asp Trp Ser Ile Leu Arg Asn Ala Leu Asp Asn Gly
370 375 380
Lys Tyr Asp Lys Asp Ile Ile Asn Leu Ala Glu Leu Glu Lys Tyr Phe
385 390 395 400
Ser Glu Tyr Cys Lys Val Leu Asp Ala Asp Asp Ala Ala Lys Ile Gln
405 410 415
Asp Lys Phe Asn Leu Lys Asp Tyr Phe Ile Gln Lys Asn Ala Leu Asp
420 425 430
Ala Thr Leu Pro Asp Leu Asp Lys Ile Thr Gln Tyr Lys Pro His Leu
435 440 445
Asp Ala Met Leu Gln Ala Ile Arg Lys Tyr Lys Leu Phe Ser Met Tyr
450 455 460
Asn Gly Arg Lys Lys Met Asp Val Pro Glu Asn Gly Ile Asp Phe Ser
465 470 475 480
Asn Glu Phe Asn Ala Ile Tyr Asp Lys Leu Ser Glu Phe Ser Ile Leu
485 490 495
Tyr Asp Arg Ile Arg Asn Phe Ala Thr Lys Lys Pro Tyr Ser Asp Glu
500 505 510
Lys Met Lys Leu Ser Phe Asn Met Pro Thr Met Leu Ala Gly Trp Asp
515 520 525
Tyr Asn Asn Glu Thr Ala Asn Gly Cys Phe Leu Phe Ile Lys Asp Gly
530 535 540
Lys Tyr Phe Leu Gly Val Ala Asp Ser Lys Ser Lys Asn Ile Phe Asp
545 550 555 560
Phe Lys Lys Asn Pro His Leu Leu Asp Lys Tyr Ser Ser Lys Asp Ile
565 570 575
Tyr Tyr Lys Val Lys Tyr Lys Gln Val Ser Gly Ser Ala Lys Met Leu
580 585 590
Pro Lys Val Val Phe Ala Gly Ser Asn Glu Lys Ile Phe Gly His Leu
595 600 605
Ile Ser Lys Arg Ile Leu Glu Ile Arg Glu Lys Lys Leu Tyr Thr Ala
610 615 620
Ala Ala Gly Asp Arg Lys Ala Val Ala Glu Trp Ile Asp Phe Met Lys
625 630 635 640
Ser Ala Ile Ala Ile His Pro Glu Trp Asn Glu Tyr Phe Lys Phe Lys
645 650 655
Phe Lys Asn Thr Ala Glu Tyr Asp Asn Ala Asn Lys Phe Tyr Glu Asp
660 665 670
Ile Asp Lys Gln Thr Tyr Ser Leu Glu Lys Val Glu Ile Pro Thr Glu
675 680 685
Tyr Ile Asp Glu Met Val Ser Gln His Lys Leu Tyr Leu Phe Gln Leu
690 695 700
Tyr Thr Lys Asp Phe Ser Asp Lys Lys Lys Lys Lys Gly Thr Asp Asn
705 710 715 720
Leu His Thr Met Tyr Trp His Gly Val Phe Ser Asp Glu Asn Leu Lys
725 730 735
Ala Val Thr Glu Gly Thr Gln Pro Ile Ile Lys Leu Asn Gly Glu Ala
740 745 750
Glu Met Phe Met Arg Asn Pro Ser Ile Glu Phe Gln Val Thr His Glu
755 760 765
His Asn Lys Pro Ile Ala Asn Lys Asn Pro Leu Asn Thr Lys Lys Glu
770 775 780
Ser Val Phe Asn Tyr Asp Leu Ile Lys Asp Lys Arg Tyr Thr Glu Arg
785 790 795 800
Lys Phe Tyr Phe His Cys Pro Ile Thr Leu Asn Phe Arg Ala Asp Lys
805 810 815
Pro Ile Lys Tyr Asn Glu Lys Ile Asn Arg Phe Val Glu Asn Asn Pro
820 825 830
Asp Val Cys Ile Ile Gly Ile Asp Arg Gly Glu Arg His Leu Leu Tyr
835 840 845
Tyr Thr Val Ile Asn Gln Thr Gly Asp Ile Leu Glu Gln Gly Ser Leu
850 855 860
Asn Lys Ile Ser Gly Ser Tyr Thr Asn Asp Lys Gly Glu Lys Val Asn
865 870 875 880
Lys Glu Thr Asp Tyr His Asp Leu Leu Asp Arg Lys Glu Lys Gly Lys
885 890 895
His Val Ala Gln Gln Ala Trp Glu Thr Ile Glu Asn Ile Lys Glu Leu
900 905 910
Lys Ala Gly Tyr Leu Ser Gln Val Val Tyr Lys Leu Thr Gln Leu Met
915 920 925
Leu Gln Tyr Asn Ala Val Ile Val Leu Glu Asn Leu Asn Val Gly Phe
930 935 940
Lys Arg Gly Arg Thr Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu
945 950 955 960
Lys Ala Met Ile Asp Lys Leu Asn Tyr Leu Val Phe Lys Asp Arg Gly
965 970 975
Tyr Glu Met Asn Gly Ser Tyr Ala Lys Gly Leu Gln Leu Thr Asp Lys
980 985 990
Phe Glu Ser Phe Asp Lys Ile Gly Lys Gln Thr Gly Cys Ile Tyr Tyr
995 1000 1005
Val Ile Pro Ser Tyr Thr Ser His Ile Asp Pro Lys Thr Gly Phe
1010 1015 1020
Val Asn Leu Leu Asn Ala Lys Leu Arg Tyr Glu Asn Ile Thr Lys
1025 1030 1035
Ala Gln Asp Thr Ile Arg Lys Phe Asp Ser Ile Ser Tyr Asn Ala
1040 1045 1050
Lys Ala Asp Tyr Phe Glu Phe Ala Phe Asp Tyr Arg Ser Phe Gly
1055 1060 1065
Val Asp Met Ala Arg Asn Glu Trp Val Val Cys Thr Cys Gly Asp
1070 1075 1080
Leu Arg Trp Glu Tyr Ser Ala Lys Thr Arg Glu Thr Lys Ala Tyr
1085 1090 1095
Ser Val Thr Asp Arg Leu Lys Glu Leu Phe Lys Ala His Gly Ile
1100 1105 1110
Asp Tyr Val Gly Gly Glu Asn Leu Val Ser His Ile Thr Glu Val
1115 1120 1125
Ala Asp Lys His Phe Leu Ser Thr Leu Leu Phe Tyr Leu Arg Leu
1130 1135 1140
Val Leu Lys Met Arg Tyr Thr Val Ser Gly Thr Glu Asn Glu Asn
1145 1150 1155
Asp Phe Ile Leu Ser Pro Val Glu Tyr Ala Pro Gly Lys Phe Phe
1160 1165 1170
Asp Ser Arg Glu Ala Thr Ser Thr Glu Pro Met Asn Ala Asp Ala
1175 1180 1185
Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Met Thr Ile Arg
1190 1195 1200
Gly Ile Glu Asp Gly Lys Leu His Asn Tyr Gly Lys Gly Gly Glu
1205 1210 1215
Asn Ala Ala Trp Phe Lys Phe Met Gln Asn Gln Glu Tyr Lys Asn
1220 1225 1230
Asn Gly
1235
<210> 106
<211> 1233
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 106
Met Asp Tyr Gly Asn Gly Gln Phe Glu Arg Arg Ala Pro Leu Thr Lys
1 5 10 15
Thr Ile Thr Leu Arg Leu Lys Pro Ile Gly Glu Thr Arg Glu Thr Ile
20 25 30
Arg Glu Gln Lys Leu Leu Glu Gln Asp Ala Ala Phe Arg Lys Leu Val
35 40 45
Glu Thr Val Thr Pro Ile Val Asp Asp Cys Ile Arg Lys Ile Ala Asp
50 55 60
Asn Ala Leu Cys His Phe Gly Thr Glu Tyr Asp Phe Ser Cys Leu Gly
65 70 75 80
Asn Ala Ile Ser Lys Asn Asp Ser Lys Ala Ile Lys Lys Glu Thr Glu
85 90 95
Lys Val Glu Lys Leu Leu Ala Lys Val Leu Thr Glu Asn Leu Pro Asp
100 105 110
Gly Leu Arg Lys Val Asn Asp Ile Asn Ser Ala Ala Phe Ile Gln Asp
115 120 125
Thr Leu Thr Ser Phe Val Gln Asp Asp Ala Asp Lys Arg Val Leu Ile
130 135 140
Gln Glu Leu Lys Gly Lys Thr Val Leu Met Gln Arg Phe Leu Thr Thr
145 150 155 160
Arg Ile Thr Ala Leu Thr Val Trp Leu Pro Asp Arg Val Phe Glu Asn
165 170 175
Phe Asn Ile Phe Ile Glu Asn Ala Glu Lys Met Arg Ile Leu Leu Asp
180 185 190
Ser Pro Leu Asn Glu Lys Ile Met Lys Phe Asp Pro Asp Ala Glu Gln
195 200 205
Tyr Ala Ser Leu Glu Phe Tyr Gly Gln Cys Leu Ser Gln Lys Asp Ile
210 215 220
Asp Ser Tyr Asn Leu Ile Ile Ser Gly Ile Tyr Ala Asp Asp Glu Val
225 230 235 240
Lys Asn Pro Gly Ile Asn Glu Ile Val Lys Glu Tyr Asn Gln Gln Ile
245 250 255
Arg Gly Asp Lys Asp Glu Ser Pro Leu Pro Lys Leu Lys Lys Leu His
260 265 270
Lys Gln Ile Leu Met Pro Val Glu Lys Ala Phe Phe Val Arg Val Leu
275 280 285
Ser Asn Asp Ser Asp Ala Arg Ser Ile Leu Glu Lys Ile Leu Lys Asp
290 295 300
Thr Glu Met Leu Pro Ser Lys Ile Ile Glu Ala Met Lys Glu Ala Asp
305 310 315 320
Ala Gly Asp Ile Ala Val Tyr Gly Ser Arg Leu His Glu Leu Ser His
325 330 335
Val Ile Tyr Gly Asp His Gly Lys Leu Ser Gln Ile Ile Tyr Asp Lys
340 345 350
Glu Ser Lys Arg Ile Ser Glu Leu Met Glu Thr Leu Ser Pro Lys Glu
355 360 365
Arg Lys Glu Ser Lys Lys Arg Leu Glu Gly Leu Glu Glu His Ile Arg
370 375 380
Lys Ser Thr Tyr Thr Phe Asp Glu Leu Asn Arg Tyr Ala Glu Lys Asn
385 390 395 400
Val Met Ala Ala Tyr Ile Ala Ala Val Glu Glu Ser Cys Ala Glu Ile
405 410 415
Met Arg Lys Glu Lys Asp Leu Arg Thr Leu Leu Ser Lys Glu Asp Val
420 425 430
Lys Ile Arg Gly Asn Arg His Asn Thr Leu Ile Val Lys Asn Tyr Phe
435 440 445
Asn Ala Trp Thr Val Phe Arg Asn Leu Ile Arg Ile Leu Arg Arg Lys
450 455 460
Ser Glu Ala Glu Ile Asp Ser Asp Phe Tyr Asp Val Leu Asp Asp Ser
465 470 475 480
Val Glu Val Leu Ser Leu Thr Tyr Lys Gly Glu Asn Leu Cys Arg Ser
485 490 495
Tyr Ile Thr Lys Lys Ile Gly Ser Asp Leu Lys Pro Glu Ile Ala Thr
500 505 510
Tyr Gly Ser Ala Leu Arg Pro Asn Ser Arg Trp Trp Ser Pro Gly Glu
515 520 525
Lys Phe Asn Val Lys Phe His Thr Ile Val Arg Arg Asp Gly Arg Leu
530 535 540
Tyr Tyr Phe Ile Leu Pro Lys Gly Ala Lys Pro Val Glu Leu Glu Asp
545 550 555 560
Met Asp Gly Asp Ile Glu Cys Leu Gln Met Arg Lys Ile Pro Asn Pro
565 570 575
Thr Ile Phe Leu Pro Lys Leu Val Phe Lys Asp Pro Glu Ala Phe Phe
580 585 590
Arg Asp Asn Pro Glu Ala Asp Glu Phe Val Phe Leu Ser Gly Met Lys
595 600 605
Ala Pro Val Thr Ile Thr Arg Glu Thr Tyr Glu Ala Tyr Arg Tyr Lys
610 615 620
Leu Tyr Thr Val Gly Lys Leu Arg Asp Gly Glu Val Ser Glu Glu Glu
625 630 635 640
Tyr Lys Arg Ala Leu Leu Gln Val Leu Thr Ala Tyr Lys Glu Phe Leu
645 650 655
Glu Asn Arg Met Ile Tyr Ala Asp Leu Asn Phe Gly Phe Lys Asp Leu
660 665 670
Glu Glu Tyr Lys Asp Ser Ser Glu Phe Ile Lys Gln Val Glu Thr His
675 680 685
Asn Thr Phe Met Cys Trp Ala Lys Val Ser Ser Ser Gln Leu Asp Asp
690 695 700
Leu Val Lys Ser Gly Asn Gly Leu Leu Phe Glu Ile Trp Ser Glu Arg
705 710 715 720
Leu Glu Ser Tyr Tyr Lys Tyr Gly Asn Glu Lys Val Leu Arg Gly Tyr
725 730 735
Glu Gly Val Leu Leu Ser Ile Leu Lys Asp Glu Asn Leu Val Ser Met
740 745 750
Arg Thr Leu Leu Asn Ser Arg Pro Met Leu Val Tyr Arg Pro Lys Glu
755 760 765
Ser Ser Lys Pro Met Val Val His Arg Asp Gly Ser Arg Val Val Asp
770 775 780
Arg Phe Asp Lys Asp Gly Lys Tyr Ile Pro Pro Glu Val His Asp Glu
785 790 795 800
Leu Tyr Arg Phe Phe Asn Asn Leu Leu Ile Lys Glu Lys Leu Gly Glu
805 810 815
Lys Ala Arg Lys Ile Leu Asp Asn Lys Lys Val Lys Val Lys Val Leu
820 825 830
Glu Ser Glu Arg Val Lys Trp Ser Lys Phe Tyr Asp Glu Gln Phe Ala
835 840 845
Val Thr Phe Ser Val Lys Lys Asn Ala Asp Cys Leu Asp Thr Thr Lys
850 855 860
Asp Leu Asn Ala Glu Val Met Glu Gln Tyr Ser Glu Ser Asn Arg Leu
865 870 875 880
Ile Leu Ile Arg Asn Thr Thr Asp Ile Leu Tyr Tyr Leu Val Leu Asp
885 890 895
Lys Asn Gly Lys Val Leu Lys Gln Arg Ser Leu Asn Ile Ile Asn Asp
900 905 910
Gly Ala Arg Asp Val Asp Trp Lys Glu Arg Phe Arg Gln Val Thr Lys
915 920 925
Asp Arg Asn Glu Gly Tyr Asn Glu Trp Asp Tyr Ser Arg Thr Ser Asn
930 935 940
Asp Leu Lys Glu Val Tyr Leu Asn Tyr Ala Leu Lys Glu Ile Ala Glu
945 950 955 960
Ala Val Ile Glu Tyr Asn Ala Ile Leu Ile Ile Glu Lys Met Ser Asn
965 970 975
Ala Phe Lys Asp Lys Tyr Ser Phe Leu Asp Asp Val Thr Phe Lys Gly
980 985 990
Phe Glu Thr Lys Leu Leu Ala Lys Leu Ser Asp Leu His Phe Arg Gly
995 1000 1005
Ile Lys Asp Gly Glu Pro Cys Ser Phe Thr Asn Pro Leu Gln Leu
1010 1015 1020
Cys Gln Asn Asp Ser Asn Lys Ile Leu Gln Asp Gly Val Ile Phe
1025 1030 1035
Met Val Pro Asn Ser Met Thr Arg Ser Leu Asp Pro Asp Thr Gly
1040 1045 1050
Phe Ile Phe Ala Ile Asn Asp His Asn Ile Arg Thr Lys Lys Ala
1055 1060 1065
Lys Leu Asn Phe Leu Ser Lys Phe Asp Gln Leu Lys Val Ser Ser
1070 1075 1080
Glu Gly Cys Leu Ile Met Lys Tyr Ser Gly Asp Ser Leu Pro Thr
1085 1090 1095
His Asn Thr Asp Asn Arg Val Trp Asn Cys Cys Cys Asn His Pro
1100 1105 1110
Ile Thr Asn Tyr Asp Arg Glu Thr Lys Lys Val Glu Phe Ile Glu
1115 1120 1125
Glu Pro Val Glu Glu Leu Ser Arg Val Leu Glu Glu Asn Gly Ile
1130 1135 1140
Glu Thr Asp Thr Glu Leu Asn Lys Leu Asn Glu Arg Glu Asn Val
1145 1150 1155
Pro Gly Lys Val Val Asp Ala Ile Tyr Ser Leu Val Leu Asn Tyr
1160 1165 1170
Leu Arg Gly Thr Val Ser Gly Val Ala Gly Gln Arg Ala Val Tyr
1175 1180 1185
Tyr Ser Pro Val Thr Gly Lys Lys Tyr Asp Ile Ser Phe Ile Gln
1190 1195 1200
Ala Met Asn Leu Asn Arg Lys Cys Asp Tyr Tyr Arg Ile Gly Ser
1205 1210 1215
Lys Glu Arg Gly Glu Trp Thr Asp Phe Val Ala Gln Leu Ile Asn
1220 1225 1230
<210> 107
<211> 1231
<212> БЕЛОК
<213> Butyrivibrio fibrisolvens
<400> 107
Met Tyr Tyr Glu Ser Leu Thr Lys Leu Tyr Pro Ile Lys Lys Thr Ile
1 5 10 15
Arg Asn Glu Leu Val Pro Ile Gly Lys Thr Leu Glu Asn Ile Lys Lys
20 25 30
Asn Asn Ile Leu Glu Ala Asp Glu Asp Arg Lys Ile Ala Tyr Ile Arg
35 40 45
Val Lys Ala Ile Met Asp Asp Tyr His Lys Arg Leu Ile Asn Glu Ala
50 55 60
Leu Ser Gly Phe Ala Leu Ile Asp Leu Asp Lys Ala Ala Asn Leu Tyr
65 70 75 80
Leu Ser Arg Ser Lys Ser Ala Asp Asp Ile Glu Ser Phe Ser Arg Phe
85 90 95
Gln Asp Lys Leu Arg Lys Ala Ile Ala Lys Arg Leu Arg Glu His Glu
100 105 110
Asn Phe Gly Lys Ile Gly Asn Lys Asp Ile Ile Pro Leu Leu Gln Lys
115 120 125
Leu Ser Glu Asn Glu Asp Asp Tyr Asn Ala Leu Glu Ser Phe Lys Asn
130 135 140
Phe Tyr Thr Tyr Phe Glu Ser Tyr Asn Asp Val Arg Leu Asn Leu Tyr
145 150 155 160
Ser Asp Lys Glu Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn Glu
165 170 175
Asn Leu Pro Arg Phe Leu Asp Asn Ile Arg Ala Tyr Asp Ala Val Gln
180 185 190
Lys Ala Gly Ile Thr Ser Glu Glu Leu Ser Ser Glu Ala Gln Asp Gly
195 200 205
Leu Phe Leu Val Asn Thr Phe Asn Asn Val Leu Ile Gln Asp Gly Ile
210 215 220
Asn Thr Tyr Asn Glu Asp Ile Gly Lys Leu Asn Val Ala Ile Asn Leu
225 230 235 240
Tyr Asn Gln Lys Asn Ala Ser Val Gln Gly Phe Arg Lys Val Pro Lys
245 250 255
Met Lys Val Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Glu Ser Phe
260 265 270
Ile Asp Glu Phe Glu Ser Asp Thr Glu Leu Leu Asp Ser Leu Glu Ser
275 280 285
His Tyr Ala Asn Leu Ala Lys Tyr Phe Gly Ser Asn Lys Val Gln Leu
290 295 300
Leu Phe Thr Ala Leu Arg Glu Ser Lys Gly Val Asn Val Tyr Val Lys
305 310 315 320
Asn Asp Ile Ala Lys Thr Ser Phe Ser Asn Val Val Phe Gly Ser Trp
325 330 335
Ser Arg Ile Asp Glu Leu Ile Asn Gly Glu Tyr Asp Asp Asn Asn Asn
340 345 350
Arg Lys Lys Asp Glu Lys Tyr Tyr Asp Lys Arg Gln Lys Glu Leu Lys
355 360 365
Lys Asn Lys Ser Tyr Thr Ile Glu Lys Ile Ile Thr Leu Ser Thr Glu
370 375 380
Asp Val Asp Val Ile Gly Lys Tyr Ile Glu Lys Leu Glu Ser Asp Ile
385 390 395 400
Asp Asp Ile Arg Phe Lys Gly Lys Asn Phe Tyr Glu Ala Val Leu Cys
405 410 415
Gly His Asp Arg Ser Lys Lys Leu Ser Lys Asn Lys Gly Ala Val Glu
420 425 430
Ala Ile Lys Gly Tyr Leu Asp Ser Val Lys Asp Phe Glu Arg Asp Leu
435 440 445
Lys Leu Ile Asn Gly Ser Gly Gln Glu Leu Glu Lys Asn Leu Val Val
450 455 460
Tyr Gly Glu Gln Glu Ala Val Leu Ser Glu Leu Ser Gly Ile Asp Ser
465 470 475 480
Leu Tyr Asn Met Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe Ser Thr
485 490 495
Glu Lys Ile Lys Leu Asn Phe Asn Lys Pro Thr Phe Leu Asp Gly Trp
500 505 510
Asp Tyr Gly Asn Glu Glu Ala Tyr Leu Gly Phe Phe Met Ile Lys Glu
515 520 525
Gly Asn Tyr Phe Leu Ala Val Met Asp Ala Asn Trp Asn Lys Glu Phe
530 535 540
Arg Asn Ile Pro Ser Val Asp Lys Ser Asp Cys Tyr Lys Lys Val Ile
545 550 555 560
Tyr Lys Gln Ile Ser Ser Pro Glu Lys Ser Ile Gln Asn Leu Met Val
565 570 575
Ile Asp Gly Lys Thr Val Lys Lys Asn Gly Arg Lys Glu Lys Glu Gly
580 585 590
Ile His Ser Gly Glu Asn Leu Ile Leu Glu Glu Leu Lys Asn Thr Tyr
595 600 605
Leu Pro Lys Lys Ile Asn Asp Ile Arg Lys Arg Arg Ser Tyr Leu Asn
610 615 620
Gly Asp Thr Phe Ser Lys Lys Asp Leu Thr Glu Phe Ile Gly Tyr Tyr
625 630 635 640
Lys Gln Arg Val Ile Glu Tyr Tyr Asn Gly Tyr Ser Phe Tyr Phe Lys
645 650 655
Ser Asp Asp Asp Tyr Ala Ser Phe Lys Glu Phe Gln Glu Asp Val Gly
660 665 670
Arg Gln Ala Tyr Gln Ile Ser Tyr Val Asp Val Pro Val Ser Phe Val
675 680 685
Asp Asp Leu Ile Asn Ser Gly Lys Leu Tyr Leu Phe Arg Val Tyr Asn
690 695 700
Lys Asp Phe Ser Glu Tyr Ser Lys Gly Arg Leu Asn Leu His Thr Leu
705 710 715 720
Tyr Phe Lys Met Leu Phe Asp Glu Arg Asn Leu Lys Asn Val Val Tyr
725 730 735
Lys Leu Asn Gly Gln Ala Glu Val Phe Tyr Arg Pro Ser Ser Ile Lys
740 745 750
Lys Glu Glu Leu Ile Val His Arg Ala Gly Glu Glu Ile Lys Asn Lys
755 760 765
Asn Pro Lys Arg Ala Ala Gln Lys Pro Thr Arg Arg Leu Asp Tyr Asp
770 775 780
Ile Val Lys Asp Arg Arg Tyr Ser Gln Asp Lys Phe Met Leu His Thr
785 790 795 800
Ser Ile Ile Met Asn Phe Gly Ala Glu Glu Asn Val Ser Phe Asn Asp
805 810 815
Ile Val Asn Gly Val Leu Arg Asn Glu Asp Lys Val Asn Val Ile Gly
820 825 830
Ile Asp Arg Gly Glu Arg Asn Leu Leu Tyr Val Val Val Ile Asp Pro
835 840 845
Glu Gly Lys Ile Leu Glu Gln Arg Ser Leu Asn Cys Ile Thr Asp Ser
850 855 860
Asn Leu Asp Ile Glu Thr Asp Tyr His Arg Leu Leu Asp Glu Lys Glu
865 870 875 880
Ser Asp Arg Lys Ile Ala Arg Arg Asp Trp Thr Thr Ile Glu Asn Ile
885 890 895
Lys Glu Leu Lys Ala Gly Tyr Leu Ser Gln Val Val His Ile Val Ala
900 905 910
Glu Leu Val Leu Lys Tyr Asn Ala Ile Ile Cys Leu Glu Asp Leu Asn
915 920 925
Phe Gly Phe Lys Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln
930 935 940
Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Met Asp
945 950 955 960
Lys Ser Arg Glu Gln Leu Ser Pro Glu Lys Ile Ser Gly Ala Leu Asn
965 970 975
Ala Leu Gln Leu Thr Pro Asp Phe Lys Ser Phe Lys Val Leu Gly Lys
980 985 990
Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile
995 1000 1005
Asp Pro Met Thr Gly Phe Ala Asn Leu Phe Tyr Val Lys Tyr Glu
1010 1015 1020
Asn Val Asp Lys Ala Lys Glu Phe Phe Ser Lys Phe Asp Ser Ile
1025 1030 1035
Lys Tyr Asn Lys Asp Gly Lys Asn Trp Asn Thr Lys Gly Tyr Phe
1040 1045 1050
Glu Phe Ala Phe Asp Tyr Lys Lys Phe Thr Asp Arg Ala Tyr Gly
1055 1060 1065
Arg Val Ser Glu Trp Thr Val Cys Thr Val Gly Glu Arg Ile Ile
1070 1075 1080
Lys Phe Lys Asn Lys Glu Lys Asn Asn Ser Tyr Asp Asp Lys Val
1085 1090 1095
Ile Asp Leu Thr Asn Ser Leu Lys Glu Leu Phe Asp Ser Tyr Lys
1100 1105 1110
Val Thr Tyr Glu Ser Glu Val Asp Leu Lys Asp Ala Ile Leu Ala
1115 1120 1125
Ile Asp Asp Pro Ala Phe Tyr Arg Asp Leu Thr Arg Arg Leu Gln
1130 1135 1140
Gln Thr Leu Gln Met Arg Asn Ser Ser Cys Asp Gly Ser Arg Asp
1145 1150 1155
Tyr Ile Ile Ser Pro Val Lys Asn Ser Lys Gly Glu Phe Phe Cys
1160 1165 1170
Ser Asp Asn Asn Asp Asp Thr Thr Pro Asn Asp Ala Asp Ala Asn
1175 1180 1185
Gly Ala Phe Asn Ile Ala Arg Lys Gly Leu Trp Val Leu Asn Glu
1190 1195 1200
Ile Arg Asn Ser Glu Glu Gly Ser Lys Ile Asn Leu Ala Met Ser
1205 1210 1215
Asn Ala Gln Trp Leu Glu Tyr Ala Gln Asp Asn Thr Ile
1220 1225 1230
<210> 108
<211> 1230
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 108
Met His Glu Asn Asn Gly Lys Ile Ala Asp Asn Phe Ile Gly Ile Tyr
1 5 10 15
Pro Val Ser Lys Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr
20 25 30
Gln Glu Tyr Ile Glu Lys His Gly Ile Leu Asp Glu Asp Leu Lys Arg
35 40 45
Ala Gly Asp Tyr Lys Ser Val Lys Lys Ile Ile Asp Ala Tyr His Lys
50 55 60
Tyr Phe Ile Asp Glu Ala Leu Asn Gly Ile Gln Leu Asp Gly Leu Lys
65 70 75 80
Asn Tyr Tyr Glu Leu Tyr Glu Lys Lys Arg Asp Asn Asn Glu Glu Lys
85 90 95
Glu Phe Gln Lys Ile Gln Met Ser Leu Arg Lys Gln Ile Val Lys Arg
100 105 110
Phe Ser Glu His Pro Gln Tyr Lys Tyr Leu Phe Lys Lys Glu Leu Ile
115 120 125
Lys Asn Val Leu Pro Glu Phe Thr Lys Asp Asn Ala Glu Glu Gln Thr
130 135 140
Leu Val Lys Ser Phe Gln Glu Phe Thr Thr Tyr Phe Glu Gly Phe His
145 150 155 160
Gln Asn Arg Lys Asn Met Tyr Ser Asp Glu Glu Lys Ser Thr Ala Ile
165 170 175
Ala Tyr Arg Val Val His Gln Asn Leu Pro Lys Tyr Ile Asp Asn Met
180 185 190
Arg Ile Phe Ser Met Ile Leu Asn Thr Asp Ile Arg Ser Asp Leu Thr
195 200 205
Glu Leu Phe Asn Asn Leu Lys Thr Lys Met Asp Ile Thr Ile Val Glu
210 215 220
Glu Tyr Phe Ala Ile Asp Gly Phe Asn Lys Val Val Asn Gln Lys Gly
225 230 235 240
Ile Asp Val Tyr Asn Thr Ile Leu Gly Ala Phe Ser Thr Asp Asp Asn
245 250 255
Thr Lys Ile Lys Gly Leu Asn Glu Tyr Ile Asn Leu Tyr Asn Gln Lys
260 265 270
Asn Lys Ala Lys Leu Pro Lys Leu Lys Pro Leu Phe Lys Gln Ile Leu
275 280 285
Ser Asp Arg Asp Lys Ile Ser Phe Ile Pro Glu Gln Phe Asp Ser Asp
290 295 300
Thr Glu Val Leu Glu Ala Val Asp Met Phe Tyr Asn Arg Leu Leu Gln
305 310 315 320
Phe Val Ile Glu Asn Glu Gly Gln Ile Thr Ile Ser Lys Leu Leu Thr
325 330 335
Asn Phe Ser Ala Tyr Asp Leu Asn Lys Ile Tyr Val Lys Asn Asp Thr
340 345 350
Thr Ile Ser Ala Ile Ser Asn Asp Leu Phe Asp Asp Trp Ser Tyr Ile
355 360 365
Ser Lys Ala Val Arg Glu Asn Tyr Asp Ser Glu Asn Val Asp Lys Asn
370 375 380
Lys Arg Ala Ala Ala Tyr Glu Glu Lys Lys Glu Lys Ala Leu Ser Lys
385 390 395 400
Ile Lys Met Tyr Ser Ile Glu Glu Leu Asn Phe Phe Val Lys Lys Tyr
405 410 415
Ser Cys Asn Glu Cys His Ile Glu Gly Tyr Phe Glu Arg Arg Ile Leu
420 425 430
Glu Ile Leu Asp Lys Met Arg Tyr Ala Tyr Glu Ser Cys Lys Ile Leu
435 440 445
His Asp Lys Gly Leu Ile Asn Asn Ile Ser Leu Cys Gln Asp Arg Gln
450 455 460
Ala Ile Ser Glu Leu Lys Asp Phe Leu Asp Ser Ile Lys Glu Val Gln
465 470 475 480
Trp Leu Leu Lys Pro Leu Met Ile Gly Gln Glu Gln Ala Asp Lys Glu
485 490 495
Glu Ala Phe Tyr Thr Glu Leu Leu Arg Ile Trp Glu Glu Leu Glu Pro
500 505 510
Ile Thr Leu Leu Tyr Asn Lys Val Arg Asn Tyr Val Thr Lys Lys Pro
515 520 525
Tyr Thr Leu Glu Lys Val Lys Leu Asn Phe Tyr Lys Ser Thr Leu Leu
530 535 540
Asp Gly Trp Asp Lys Asn Lys Glu Lys Asp Asn Leu Gly Ile Ile Leu
545 550 555 560
Leu Lys Asp Gly Gln Tyr Tyr Leu Gly Ile Met Asn Arg Arg Asn Asn
565 570 575
Lys Ile Ala Asp Asp Ala Pro Leu Ala Lys Thr Asp Asn Val Tyr Arg
580 585 590
Lys Met Glu Tyr Lys Leu Leu Thr Lys Val Ser Ala Asn Leu Pro Arg
595 600 605
Ile Phe Leu Lys Asp Lys Tyr Asn Pro Ser Glu Glu Met Leu Glu Lys
610 615 620
Tyr Glu Lys Gly Thr His Leu Lys Gly Glu Asn Phe Cys Ile Asp Asp
625 630 635 640
Cys Arg Glu Leu Ile Asp Phe Phe Lys Lys Gly Ile Lys Gln Tyr Glu
645 650 655
Asp Trp Gly Gln Phe Asp Phe Lys Phe Ser Asp Thr Glu Ser Tyr Asp
660 665 670
Asp Ile Ser Ala Phe Tyr Lys Glu Val Glu His Gln Gly Tyr Lys Ile
675 680 685
Thr Phe Arg Asp Ile Asp Glu Thr Tyr Ile Asp Ser Leu Val Asn Glu
690 695 700
Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Pro Tyr
705 710 715 720
Ser Lys Gly Thr Lys Asn Leu His Thr Leu Tyr Trp Glu Met Leu Phe
725 730 735
Ser Gln Gln Asn Leu Gln Asn Ile Val Tyr Lys Leu Asn Gly Asn Ala
740 745 750
Glu Ile Phe Tyr Arg Lys Ala Ser Ile Asn Gln Lys Asp Val Val Val
755 760 765
His Lys Ala Asp Leu Pro Ile Lys Asn Lys Asp Pro Gln Asn Ser Lys
770 775 780
Lys Glu Ser Met Phe Asp Tyr Asp Ile Ile Lys Asp Lys Arg Phe Thr
785 790 795 800
Cys Asp Lys Tyr Gln Phe His Val Pro Ile Thr Met Asn Phe Lys Ala
805 810 815
Leu Gly Glu Asn His Phe Asn Arg Lys Val Asn Arg Leu Ile His Asp
820 825 830
Ala Glu Asn Met His Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu
835 840 845
Ile Tyr Leu Cys Met Ile Asp Met Lys Gly Asn Ile Val Lys Gln Ile
850 855 860
Ser Leu Asn Glu Ile Ile Ser Tyr Asp Lys Asn Lys Leu Glu His Lys
865 870 875 880
Arg Asn Tyr His Gln Leu Leu Lys Thr Arg Glu Asp Glu Asn Lys Ser
885 890 895
Ala Arg Gln Ser Trp Gln Thr Ile His Thr Ile Lys Glu Leu Lys Glu
900 905 910
Gly Tyr Leu Ser Gln Val Ile His Val Ile Thr Asp Leu Met Val Glu
915 920 925
Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn Phe Gly Phe Lys Gln
930 935 940
Gly Arg Gln Lys Phe Glu Arg Gln Val Tyr Gln Lys Phe Glu Lys Met
945 950 955 960
Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Ser Lys Gly Met Asp
965 970 975
Glu Asp Gly Gly Leu Leu His Ala Tyr Gln Leu Thr Asp Glu Phe Lys
980 985 990
Ser Phe Lys Gln Leu Gly Lys Gln Ser Gly Phe Leu Tyr Tyr Ile Pro
995 1000 1005
Ala Trp Asn Thr Ser Lys Leu Asp Pro Thr Thr Gly Phe Val Asn
1010 1015 1020
Leu Phe Tyr Thr Lys Tyr Glu Ser Val Glu Lys Ser Lys Glu Phe
1025 1030 1035
Ile Asn Asn Phe Thr Ser Ile Leu Tyr Asn Gln Glu Arg Glu Tyr
1040 1045 1050
Phe Glu Phe Leu Phe Asp Tyr Ser Ala Phe Thr Ser Lys Ala Glu
1055 1060 1065
Gly Ser Arg Leu Lys Trp Thr Val Cys Ser Lys Gly Glu Arg Val
1070 1075 1080
Glu Thr Tyr Arg Asn Pro Lys Lys Asn Asn Glu Trp Asp Thr Gln
1085 1090 1095
Lys Ile Asp Leu Thr Phe Glu Leu Lys Lys Leu Phe Asn Asp Tyr
1100 1105 1110
Ser Ile Ser Leu Leu Asp Gly Asp Leu Arg Glu Gln Met Gly Lys
1115 1120 1125
Ile Asp Lys Ala Asp Phe Tyr Lys Lys Phe Met Lys Leu Phe Ala
1130 1135 1140
Leu Ile Val Gln Met Arg Asn Ser Asp Glu Arg Glu Asp Lys Leu
1145 1150 1155
Ile Ser Pro Val Leu Asn Lys Tyr Gly Ala Phe Phe Glu Thr Gly
1160 1165 1170
Lys Asn Glu Arg Met Pro Leu Asp Ala Asp Ala Asn Gly Ala Tyr
1175 1180 1185
Asn Ile Ala Arg Lys Gly Leu Trp Ile Ile Glu Lys Ile Lys Asn
1190 1195 1200
Thr Asp Val Glu Gln Leu Asp Lys Val Lys Leu Thr Ile Ser Asn
1205 1210 1215
Lys Glu Trp Leu Gln Tyr Ala Gln Glu His Ile Leu
1220 1225 1230
<210> 109
<211> 1228
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 109
Met Ser Lys Leu Glu Lys Phe Thr Asn Cys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Lys Ala Ile Pro Val Gly Lys Thr Gln Glu Asn Ile Asp
20 25 30
Asn Lys Arg Leu Leu Val Glu Asp Glu Lys Arg Ala Glu Asp Tyr Lys
35 40 45
Gly Val Lys Lys Leu Leu Asp Arg Tyr Tyr Leu Ser Phe Ile Asn Asp
50 55 60
Val Leu His Ser Ile Lys Leu Lys Asn Leu Asn Asn Tyr Ile Ser Leu
65 70 75 80
Phe Arg Lys Lys Thr Arg Thr Glu Lys Glu Asn Lys Glu Leu Glu Asn
85 90 95
Leu Glu Ile Asn Leu Arg Lys Glu Ile Ala Lys Ala Phe Lys Gly Asn
100 105 110
Glu Gly Tyr Lys Ser Leu Phe Lys Lys Asp Ile Ile Glu Thr Ile Leu
115 120 125
Pro Glu Phe Leu Asp Asp Lys Asp Glu Ile Ala Leu Val Asn Ser Phe
130 135 140
Asn Gly Phe Thr Thr Ala Phe Thr Gly Phe Phe Asp Asn Arg Glu Asn
145 150 155 160
Met Phe Ser Glu Glu Ala Lys Ser Thr Ser Ile Ala Phe Arg Cys Ile
165 170 175
Asn Glu Asn Leu Thr Arg Tyr Ile Ser Asn Met Asp Ile Phe Glu Lys
180 185 190
Val Asp Ala Ile Phe Asp Lys His Glu Val Gln Glu Ile Lys Glu Lys
195 200 205
Ile Leu Asn Ser Asp Tyr Asp Val Glu Asp Phe Phe Glu Gly Glu Phe
210 215 220
Phe Asn Phe Val Leu Thr Gln Glu Gly Ile Asp Val Tyr Asn Ala Ile
225 230 235 240
Ile Gly Gly Phe Val Thr Glu Ser Gly Glu Lys Ile Lys Gly Leu Asn
245 250 255
Glu Tyr Ile Asn Leu Tyr Asn Gln Lys Thr Lys Gln Lys Leu Pro Lys
260 265 270
Phe Lys Pro Leu Tyr Lys Gln Val Leu Ser Asp Arg Glu Ser Leu Ser
275 280 285
Phe Tyr Gly Glu Gly Tyr Thr Ser Asp Glu Glu Val Leu Glu Val Phe
290 295 300
Arg Asn Thr Leu Asn Lys Asn Ser Glu Ile Phe Ser Ser Ile Lys Lys
305 310 315 320
Leu Glu Lys Leu Phe Lys Asn Phe Asp Glu Tyr Ser Ser Ala Gly Ile
325 330 335
Phe Val Lys Asn Gly Pro Ala Ile Ser Thr Ile Ser Lys Asp Ile Phe
340 345 350
Gly Glu Trp Asn Val Ile Arg Asp Lys Trp Asn Ala Glu Tyr Asp Asp
355 360 365
Ile His Leu Lys Lys Lys Ala Val Val Thr Glu Lys Tyr Glu Asp Asp
370 375 380
Arg Arg Lys Ser Phe Lys Lys Ile Gly Ser Phe Ser Leu Glu Gln Leu
385 390 395 400
Gln Glu Tyr Ala Asp Ala Asp Leu Ser Val Val Glu Lys Leu Lys Glu
405 410 415
Ile Ile Ile Gln Lys Val Asp Glu Ile Tyr Lys Val Tyr Gly Ser Ser
420 425 430
Glu Lys Leu Phe Asp Ala Asp Phe Val Leu Glu Lys Ser Leu Lys Lys
435 440 445
Asn Asp Ala Val Val Ala Ile Met Lys Asp Leu Leu Asp Ser Val Lys
450 455 460
Ser Phe Glu Asn Tyr Ile Lys Ala Phe Phe Gly Glu Gly Lys Glu Thr
465 470 475 480
Asn Arg Asp Glu Ser Phe Tyr Gly Asp Phe Val Leu Ala Tyr Asp Ile
485 490 495
Leu Leu Lys Val Asp His Ile Tyr Asp Ala Ile Arg Asn Tyr Val Thr
500 505 510
Gln Lys Pro Tyr Ser Lys Asp Lys Phe Lys Leu Tyr Phe Gln Asn Pro
515 520 525
Gln Phe Met Gly Gly Trp Asp Lys Asp Lys Glu Thr Asp Tyr Arg Ala
530 535 540
Thr Ile Leu Arg Tyr Gly Ser Lys Tyr Tyr Leu Ala Ile Met Asp Lys
545 550 555 560
Lys Tyr Ala Lys Cys Leu Gln Lys Ile Asp Lys Asp Asp Val Asn Gly
565 570 575
Asn Tyr Glu Lys Ile Asn Tyr Lys Leu Leu Pro Gly Pro Asn Lys Met
580 585 590
Leu Pro Lys Val Phe Phe Ser Lys Lys Trp Met Ala Tyr Tyr Asn Pro
595 600 605
Ser Glu Asp Ile Gln Lys Ile Tyr Lys Asn Gly Thr Phe Lys Lys Gly
610 615 620
Asp Met Phe Asn Leu Asn Asp Cys His Lys Leu Ile Asp Phe Phe Lys
625 630 635 640
Asp Ser Ile Ser Arg Tyr Pro Lys Trp Ser Asn Ala Tyr Asp Phe Asn
645 650 655
Phe Ser Glu Thr Glu Lys Tyr Lys Asp Ile Ala Gly Phe Tyr Arg Glu
660 665 670
Val Glu Glu Gln Gly Tyr Lys Val Ser Phe Glu Ser Ala Ser Lys Lys
675 680 685
Glu Val Asp Lys Leu Val Glu Glu Gly Lys Leu Tyr Met Phe Gln Ile
690 695 700
Tyr Asn Lys Asp Phe Ser Asp Lys Ser His Gly Thr Pro Asn Leu His
705 710 715 720
Thr Met Tyr Phe Lys Leu Leu Phe Asp Glu Asn Asn His Gly Gln Ile
725 730 735
Arg Leu Ser Gly Gly Ala Glu Leu Phe Met Arg Arg Ala Ser Leu Lys
740 745 750
Lys Glu Glu Leu Val Val His Pro Ala Asn Ser Pro Ile Ala Asn Lys
755 760 765
Asn Pro Asp Asn Pro Lys Lys Thr Thr Thr Leu Ser Tyr Asp Val Tyr
770 775 780
Lys Asp Lys Arg Phe Ser Glu Asp Gln Tyr Glu Leu His Ile Pro Ile
785 790 795 800
Ala Ile Asn Lys Cys Pro Lys Asn Ile Phe Lys Ile Asn Thr Glu Val
805 810 815
Arg Val Leu Leu Lys His Asp Asp Asn Pro Tyr Val Ile Gly Ile Asp
820 825 830
Arg Gly Glu Arg Asn Leu Leu Tyr Ile Val Val Val Asp Gly Lys Gly
835 840 845
Asn Ile Val Glu Gln Tyr Ser Leu Asn Glu Ile Ile Asn Asn Phe Asn
850 855 860
Gly Ile Arg Ile Lys Thr Asp Tyr His Ser Leu Leu Asp Lys Lys Glu
865 870 875 880
Lys Glu Arg Phe Glu Ala Arg Gln Asn Trp Thr Ser Ile Glu Asn Ile
885 890 895
Lys Glu Leu Lys Ala Gly Tyr Ile Ser Gln Val Val His Lys Ile Cys
900 905 910
Glu Leu Val Glu Lys Tyr Asp Ala Val Ile Ala Leu Glu Asp Leu Asn
915 920 925
Ser Gly Phe Lys Asn Ser Arg Val Lys Val Glu Lys Gln Val Tyr Gln
930 935 940
Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Met Val Asp Lys
945 950 955 960
Lys Ser Asn Pro Cys Ala Thr Gly Gly Ala Leu Lys Gly Tyr Gln Ile
965 970 975
Thr Asn Lys Phe Glu Ser Phe Lys Ser Met Ser Thr Gln Asn Gly Phe
980 985 990
Ile Phe Tyr Ile Pro Ala Trp Leu Thr Ser Lys Ile Asp Pro Ser Thr
995 1000 1005
Gly Phe Val Asn Leu Leu Lys Thr Lys Tyr Thr Ser Ile Ala Asp
1010 1015 1020
Ser Lys Lys Phe Ile Ser Ser Phe Asp Arg Ile Met Tyr Val Pro
1025 1030 1035
Glu Glu Asp Leu Phe Glu Phe Ala Leu Asp Tyr Lys Asn Phe Ser
1040 1045 1050
Arg Thr Asp Ala Asp Tyr Ile Lys Lys Trp Lys Leu Tyr Ser Tyr
1055 1060 1065
Gly Asn Arg Ile Arg Ile Phe Arg Asn Pro Lys Lys Asn Asn Val
1070 1075 1080
Phe Asp Trp Glu Glu Val Cys Leu Thr Ser Ala Tyr Lys Glu Leu
1085 1090 1095
Phe Asn Lys Tyr Gly Ile Asn Tyr Gln Gln Gly Asp Ile Arg Ala
1100 1105 1110
Leu Leu Cys Glu Gln Ser Asp Lys Ala Phe Tyr Ser Ser Phe Met
1115 1120 1125
Ala Leu Met Ser Leu Met Leu Gln Met Arg Asn Ser Ile Thr Gly
1130 1135 1140
Arg Thr Asp Val Asp Phe Leu Ile Ser Pro Val Lys Asn Ser Asp
1145 1150 1155
Gly Ile Phe Tyr Asp Ser Arg Asn Tyr Glu Ala Gln Glu Asn Ala
1160 1165 1170
Ile Leu Pro Lys Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala
1175 1180 1185
Arg Lys Val Leu Trp Ala Ile Gly Gln Phe Lys Lys Ala Glu Asp
1190 1195 1200
Glu Lys Leu Asp Lys Val Lys Ile Ala Ile Ser Asn Lys Glu Trp
1205 1210 1215
Leu Glu Tyr Ala Gln Thr Ser Val Lys His
1220 1225
<210> 110
<211> 1227
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methanomethylophilus alvus
<400> 110
Met Asp Ala Lys Glu Phe Thr Gly Gln Tyr Pro Leu Ser Lys Thr Leu
1 5 10 15
Arg Phe Glu Leu Arg Pro Ile Gly Arg Thr Trp Asp Asn Leu Glu Ala
20 25 30
Ser Gly Tyr Leu Ala Glu Asp Arg His Arg Ala Glu Cys Tyr Pro Arg
35 40 45
Ala Lys Glu Leu Leu Asp Asp Asn His Arg Ala Phe Leu Asn Arg Val
50 55 60
Leu Pro Gln Ile Asp Met Asp Trp His Pro Ile Ala Glu Ala Phe Cys
65 70 75 80
Lys Val His Lys Asn Pro Gly Asn Lys Glu Leu Ala Gln Asp Tyr Asn
85 90 95
Leu Gln Leu Ser Lys Arg Arg Lys Glu Ile Ser Ala Tyr Leu Gln Asp
100 105 110
Ala Asp Gly Tyr Lys Gly Leu Phe Ala Lys Pro Ala Leu Asp Glu Ala
115 120 125
Met Lys Ile Ala Lys Glu Asn Gly Asn Glu Ser Asp Ile Glu Val Leu
130 135 140
Glu Ala Phe Asn Gly Phe Ser Val Tyr Phe Thr Gly Tyr His Glu Ser
145 150 155 160
Arg Glu Asn Ile Tyr Ser Asp Glu Asp Met Val Ser Val Ala Tyr Arg
165 170 175
Ile Thr Glu Asp Asn Phe Pro Arg Phe Val Ser Asn Ala Leu Ile Phe
180 185 190
Asp Lys Leu Asn Glu Ser His Pro Asp Ile Ile Ser Glu Val Ser Gly
195 200 205
Asn Leu Gly Val Asp Asp Ile Gly Lys Tyr Phe Asp Val Ser Asn Tyr
210 215 220
Asn Asn Phe Leu Ser Gln Ala Gly Ile Asp Asp Tyr Asn His Ile Ile
225 230 235 240
Gly Gly His Thr Thr Glu Asp Gly Leu Ile Gln Ala Phe Asn Val Val
245 250 255
Leu Asn Leu Arg His Gln Lys Asp Pro Gly Phe Glu Lys Ile Gln Phe
260 265 270
Lys Gln Leu Tyr Lys Gln Ile Leu Ser Val Arg Thr Ser Lys Ser Tyr
275 280 285
Ile Pro Lys Gln Phe Asp Asn Ser Lys Glu Met Val Asp Cys Ile Cys
290 295 300
Asp Tyr Val Ser Lys Ile Glu Lys Ser Glu Thr Val Glu Arg Ala Leu
305 310 315 320
Lys Leu Val Arg Asn Ile Ser Ser Phe Asp Leu Arg Gly Ile Phe Val
325 330 335
Asn Lys Lys Asn Leu Arg Ile Leu Ser Asn Lys Leu Ile Gly Asp Trp
340 345 350
Asp Ala Ile Glu Thr Ala Leu Met His Ser Ser Ser Ser Glu Asn Asp
355 360 365
Lys Lys Ser Val Tyr Asp Ser Ala Glu Ala Phe Thr Leu Asp Asp Ile
370 375 380
Phe Ser Ser Val Lys Lys Phe Ser Asp Ala Ser Ala Glu Asp Ile Gly
385 390 395 400
Asn Arg Ala Glu Asp Ile Cys Arg Val Ile Ser Glu Thr Ala Pro Phe
405 410 415
Ile Asn Asp Leu Arg Ala Val Asp Leu Asp Ser Leu Asn Asp Asp Gly
420 425 430
Tyr Glu Ala Ala Val Ser Lys Ile Arg Glu Ser Leu Glu Pro Tyr Met
435 440 445
Asp Leu Phe His Glu Leu Glu Ile Phe Ser Val Gly Asp Glu Phe Pro
450 455 460
Lys Cys Ala Ala Phe Tyr Ser Glu Leu Glu Glu Val Ser Glu Gln Leu
465 470 475 480
Ile Glu Ile Ile Pro Leu Phe Asn Lys Ala Arg Ser Phe Cys Thr Arg
485 490 495
Lys Arg Tyr Ser Thr Asp Lys Ile Lys Val Asn Leu Lys Phe Pro Thr
500 505 510
Leu Ala Asp Gly Trp Asp Leu Asn Lys Glu Arg Asp Asn Lys Ala Ala
515 520 525
Ile Leu Arg Lys Asp Gly Lys Tyr Tyr Leu Ala Ile Leu Asp Met Lys
530 535 540
Lys Asp Leu Ser Ser Ile Arg Thr Ser Asp Glu Asp Glu Ser Ser Phe
545 550 555 560
Glu Lys Met Glu Tyr Lys Leu Leu Pro Ser Pro Val Lys Met Leu Pro
565 570 575
Lys Ile Phe Val Lys Ser Lys Ala Ala Lys Glu Lys Tyr Gly Leu Thr
580 585 590
Asp Arg Met Leu Glu Cys Tyr Asp Lys Gly Met His Lys Ser Gly Ser
595 600 605
Ala Phe Asp Leu Gly Phe Cys His Glu Leu Ile Asp Tyr Tyr Lys Arg
610 615 620
Cys Ile Ala Glu Tyr Pro Gly Trp Asp Val Phe Asp Phe Lys Phe Arg
625 630 635 640
Glu Thr Ser Asp Tyr Gly Ser Met Lys Glu Phe Asn Glu Asp Val Ala
645 650 655
Gly Ala Gly Tyr Tyr Met Ser Leu Arg Lys Ile Pro Cys Ser Glu Val
660 665 670
Tyr Arg Leu Leu Asp Glu Lys Ser Ile Tyr Leu Phe Gln Ile Tyr Asn
675 680 685
Lys Asp Tyr Ser Glu Asn Ala His Gly Asn Lys Asn Met His Thr Met
690 695 700
Tyr Trp Glu Gly Leu Phe Ser Pro Gln Asn Leu Glu Ser Pro Val Phe
705 710 715 720
Lys Leu Ser Gly Gly Ala Glu Leu Phe Phe Arg Lys Ser Ser Ile Pro
725 730 735
Asn Asp Ala Lys Thr Val His Pro Lys Gly Ser Val Leu Val Pro Arg
740 745 750
Asn Asp Val Asn Gly Arg Arg Ile Pro Asp Ser Ile Tyr Arg Glu Leu
755 760 765
Thr Arg Tyr Phe Asn Arg Gly Asp Cys Arg Ile Ser Asp Glu Ala Lys
770 775 780
Ser Tyr Leu Asp Lys Val Lys Thr Lys Lys Ala Asp His Asp Ile Val
785 790 795 800
Lys Asp Arg Arg Phe Thr Val Asp Lys Met Met Phe His Val Pro Ile
805 810 815
Ala Met Asn Phe Lys Ala Ile Ser Lys Pro Asn Leu Asn Lys Lys Val
820 825 830
Ile Asp Gly Ile Ile Asp Asp Gln Asp Leu Lys Ile Ile Gly Ile Asp
835 840 845
Arg Gly Glu Arg Asn Leu Ile Tyr Val Thr Met Val Asp Arg Lys Gly
850 855 860
Asn Ile Leu Tyr Gln Asp Ser Leu Asn Ile Leu Asn Gly Tyr Asp Tyr
865 870 875 880
Arg Lys Ala Leu Asp Val Arg Glu Tyr Asp Asn Lys Glu Ala Arg Arg
885 890 895
Asn Trp Thr Lys Val Glu Gly Ile Arg Lys Met Lys Glu Gly Tyr Leu
900 905 910
Ser Leu Ala Val Ser Lys Leu Ala Asp Met Ile Ile Glu Asn Asn Ala
915 920 925
Ile Ile Val Met Glu Asp Leu Asn His Gly Phe Lys Ala Gly Arg Ser
930 935 940
Lys Ile Glu Lys Gln Val Tyr Gln Lys Phe Glu Ser Met Leu Ile Asn
945 950 955 960
Lys Leu Gly Tyr Met Val Leu Lys Asp Lys Ser Ile Asp Gln Ser Gly
965 970 975
Gly Ala Leu His Gly Tyr Gln Leu Ala Asn His Val Thr Thr Leu Ala
980 985 990
Ser Val Gly Lys Gln Cys Gly Val Ile Phe Tyr Ile Pro Ala Ala Phe
995 1000 1005
Thr Ser Lys Ile Asp Pro Thr Thr Gly Phe Ala Asp Leu Phe Ala
1010 1015 1020
Leu Ser Asn Val Lys Asn Val Ala Ser Met Arg Glu Phe Phe Ser
1025 1030 1035
Lys Met Lys Ser Val Ile Tyr Asp Lys Ala Glu Gly Lys Phe Ala
1040 1045 1050
Phe Thr Phe Asp Tyr Leu Asp Tyr Asn Val Lys Ser Glu Cys Gly
1055 1060 1065
Arg Thr Leu Trp Thr Val Tyr Thr Val Gly Glu Arg Phe Thr Tyr
1070 1075 1080
Ser Arg Val Asn Arg Glu Tyr Val Arg Lys Val Pro Thr Asp Ile
1085 1090 1095
Ile Tyr Asp Ala Leu Gln Lys Ala Gly Ile Ser Val Glu Gly Asp
1100 1105 1110
Leu Arg Asp Arg Ile Ala Glu Ser Asp Gly Asp Thr Leu Lys Ser
1115 1120 1125
Ile Phe Tyr Ala Phe Lys Tyr Ala Leu Asp Met Arg Val Glu Asn
1130 1135 1140
Arg Glu Glu Asp Tyr Ile Gln Ser Pro Val Lys Asn Ala Ser Gly
1145 1150 1155
Glu Phe Phe Cys Ser Lys Asn Ala Gly Lys Ser Leu Pro Gln Asp
1160 1165 1170
Ser Asp Ala Asn Gly Ala Tyr Asn Ile Ala Leu Lys Gly Ile Leu
1175 1180 1185
Gln Leu Arg Met Leu Ser Glu Gln Tyr Asp Pro Asn Ala Glu Ser
1190 1195 1200
Ile Arg Leu Pro Leu Ile Thr Asn Lys Ala Trp Leu Thr Phe Met
1205 1210 1215
Gln Ser Gly Met Lys Thr Trp Lys Asn
1220 1225
<210> 111
<211> 1224
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 111
Met Gly Leu Tyr Asp Gly Phe Val Asn Arg Tyr Ser Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Arg Thr Arg Glu Tyr Ile Glu
20 25 30
Thr Asn Gly Ile Leu Ser Asp Asp Glu Glu Arg Ala Lys Asp Tyr Lys
35 40 45
Thr Ile Lys Arg Leu Ile Asp Glu Tyr His Lys Asp Tyr Ile Ser Arg
50 55 60
Cys Leu Lys Asn Val Asn Ile Ser Cys Leu Glu Glu Tyr Tyr His Leu
65 70 75 80
Tyr Asn Ser Ser Asn Arg Asp Lys Arg His Glu Glu Leu Asp Ala Leu
85 90 95
Ser Asp Gln Met Arg Gly Glu Ile Ala Ser Phe Leu Thr Gly Asn Asp
100 105 110
Glu Tyr Lys Glu Gln Lys Ser Arg Asp Ile Ile Ile Asn Glu Arg Ile
115 120 125
Ile Asn Phe Ala Ser Thr Asp Glu Glu Leu Ala Ala Val Lys Arg Phe
130 135 140
Arg Lys Phe Thr Ser Tyr Phe Thr Gly Phe Phe Thr Asn Arg Glu Asn
145 150 155 160
Met Tyr Ser Ala Glu Lys Lys Ser Thr Ala Ile Ala His Arg Ile Ile
165 170 175
Asp Val Asn Leu Pro Lys Tyr Val Asp Asn Ile Lys Ala Phe Asn Thr
180 185 190
Ala Ile Glu Ala Gly Val Phe Asp Ile Ala Glu Phe Glu Ser Asn Phe
195 200 205
Lys Ala Ile Thr Asp Glu His Glu Val Ser Asp Leu Leu Asp Ile Thr
210 215 220
Lys Tyr Ser Arg Phe Ile Arg Asn Glu Asp Ile Ile Ile Tyr Asn Thr
225 230 235 240
Leu Leu Gly Gly Ile Ser Met Lys Asp Glu Lys Ile Gln Gly Leu Asn
245 250 255
Glu Leu Ile Asn Leu His Asn Gln Lys His Pro Gly Lys Lys Val Pro
260 265 270
Leu Leu Lys Val Leu Tyr Lys Gln Ile Leu Gly Asp Ser Gln Thr His
275 280 285
Ser Phe Val Asp Asp Gln Phe Glu Asp Asp Gln Gln Val Ile Asn Ala
290 295 300
Val Lys Ala Val Thr Asp Thr Phe Ser Glu Thr Leu Leu Gly Ser Leu
305 310 315 320
Lys Ile Ile Ile Asn Asn Ile Gly His Tyr Asp Leu Asp Arg Ile Tyr
325 330 335
Ile Lys Ala Gly Gln Asp Ile Thr Thr Leu Ser Lys Arg Ala Leu Asn
340 345 350
Asp Trp His Ile Ile Thr Glu Cys Leu Glu Ser Glu Tyr Asp Asp Lys
355 360 365
Phe Pro Lys Asn Lys Lys Ser Asp Thr Tyr Glu Glu Met Arg Asn Arg
370 375 380
Tyr Val Lys Ser Phe Lys Ser Phe Ser Ile Gly Arg Leu Asn Ser Leu
385 390 395 400
Val Thr Thr Tyr Thr Glu Gln Ala Cys Phe Leu Glu Asn Tyr Leu Gly
405 410 415
Ser Phe Gly Gly Asp Thr Asp Lys Asn Cys Leu Thr Asp Phe Thr Asn
420 425 430
Ser Leu Met Glu Val Glu His Leu Leu Asn Ser Glu Tyr Pro Val Thr
435 440 445
Asn Arg Leu Ile Thr Asp Tyr Glu Ser Val Arg Ile Leu Lys Arg Leu
450 455 460
Leu Asp Ser Glu Met Glu Val Ile His Phe Leu Lys Pro Leu Leu Gly
465 470 475 480
Asn Gly Asn Glu Ser Asp Lys Asp Leu Val Phe Tyr Gly Glu Phe Glu
485 490 495
Ala Glu Tyr Glu Lys Leu Leu Pro Val Ile Lys Val Tyr Asn Arg Val
500 505 510
Arg Asn Tyr Leu Thr Arg Lys Pro Phe Ser Thr Glu Lys Ile Lys Leu
515 520 525
Asn Phe Asn Ser Pro Thr Leu Leu Cys Gly Trp Ser Gln Ser Lys Glu
530 535 540
Lys Glu Tyr Met Gly Val Ile Leu Arg Lys Asp Gly Gln Tyr Tyr Leu
545 550 555 560
Gly Ile Met Thr Pro Ser Asn Lys Lys Ile Phe Ser Glu Ala Pro Lys
565 570 575
Pro Asp Glu Asp Cys Tyr Glu Lys Met Val Leu Arg Tyr Ile Pro His
580 585 590
Pro Tyr Gln Met Leu Pro Lys Val Phe Phe Ser Lys Ser Asn Ile Ala
595 600 605
Phe Phe Asn Pro Ser Asp Glu Ile Leu Arg Ile Lys Lys Gln Glu Ser
610 615 620
Phe Lys Lys Gly Lys Ser Phe Asn Arg Asp Asp Cys His Lys Phe Ile
625 630 635 640
Asp Phe Tyr Lys Asp Ser Ile Asn Arg His Glu Glu Trp Arg Lys Phe
645 650 655
Asn Phe Lys Phe Ser Asp Thr Asp Ser Tyr Glu Asp Ile Ser Arg Phe
660 665 670
Tyr Lys Glu Val Glu Asn Gln Ala Phe Ser Met Ser Phe Thr Lys Ile
675 680 685
Pro Thr Val Tyr Ile Asp Ser Leu Val Asp Glu Gly Lys Leu Tyr Leu
690 695 700
Phe Lys Leu His Asn Lys Asp Phe Ser Glu His Ser Lys Gly Lys Pro
705 710 715 720
Asn Leu His Thr Val Tyr Trp Asn Ala Leu Phe Ser Glu Tyr Asn Leu
725 730 735
Gln Asn Thr Val Tyr Gln Leu Asn Gly Ser Ala Glu Ile Phe Phe Arg
740 745 750
Lys Ala Ser Ile Pro Glu Asn Glu Arg Val Ile His Lys Lys Asn Val
755 760 765
Pro Ile Thr Arg Lys Val Ala Glu Leu Asn Gly Lys Lys Glu Val Ser
770 775 780
Val Phe Pro Tyr Asp Ile Ile Lys Asn Arg Arg Tyr Thr Val Asp Lys
785 790 795 800
Phe Gln Phe His Val Pro Leu Lys Met Asn Phe Lys Ala Asp Glu Lys
805 810 815
Lys Arg Ile Asn Asp Asp Val Ile Glu Ala Ile Arg Ser Asn Lys Gly
820 825 830
Ile His Val Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Leu Tyr Leu
835 840 845
Ser Leu Ile Asn Glu Glu Gly Arg Ile Ile Glu Gln Arg Ser Leu Asn
850 855 860
Ile Ile Asp Ser Gly Glu Gly His Thr Gln Asn Tyr Arg Asp Leu Leu
865 870 875 880
Asp Ser Arg Glu Lys Asp Arg Glu Lys Ala Arg Glu Asn Trp Gln Glu
885 890 895
Ile Gln Glu Ile Lys Asp Leu Lys Thr Gly Tyr Leu Ser Gln Ala Ile
900 905 910
His Thr Ile Thr Lys Trp Met Lys Glu Tyr Asn Ala Ile Ile Val Leu
915 920 925
Glu Asp Leu Asn Asp Arg Phe Thr Asn Gly Arg Lys Lys Val Glu Lys
930 935 940
Gln Val Tyr Gln Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr
945 950 955 960
Tyr Val Asp Lys Asp Glu Glu Phe Asp Arg Met Gly Gly Thr His Arg
965 970 975
Ala Leu Gln Leu Thr Glu Lys Phe Glu Ser Phe Gln Lys Leu Gly Arg
980 985 990
Gln Thr Gly Phe Ile Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Leu
995 1000 1005
Asp Pro Thr Thr Gly Phe Val Asp Leu Leu Tyr Pro Lys Tyr Lys
1010 1015 1020
Ser Val Asp Ala Thr Lys Asp Phe Ile Lys Lys Phe Asp Phe Ile
1025 1030 1035
Arg Phe Asn Ser Glu Lys Asn Tyr Phe Glu Phe Gly Leu His Tyr
1040 1045 1050
Ser Asn Phe Thr Glu Arg Ala Ile Gly Cys Arg Asp Glu Trp Ile
1055 1060 1065
Leu Cys Ser Tyr Gly Asn Arg Ile Val Asn Phe Arg Asn Ala Ala
1070 1075 1080
Lys Asn Asn Ser Trp Asp Tyr Lys Glu Ile Asp Ile Thr Lys Gln
1085 1090 1095
Leu Leu Asp Leu Phe Glu Lys Asn Gly Ile Asp Val Lys Gln Glu
1100 1105 1110
Asn Leu Ile Asp Ser Ile Cys Glu Met Lys Asp Lys Pro Phe Phe
1115 1120 1125
Lys Ser Leu Ile Ala Asn Ile Lys Leu Ile Leu Gln Ile Arg Asn
1130 1135 1140
Ser Ala Ser Gly Thr Asp Ile Asp Tyr Met Ile Ser Pro Ala Met
1145 1150 1155
Asn Asp Arg Gly Glu Phe Phe Asp Thr Arg Lys Gly Leu Gln Gln
1160 1165 1170
Leu Pro Leu Asp Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Lys
1175 1180 1185
Lys Gly Leu Trp Ile Val Asp Gln Ile Arg Asn Thr Thr Gly Asn
1190 1195 1200
Asn Val Lys Met Ala Met Ser Asn Arg Glu Trp Met His Phe Ala
1205 1210 1215
Gln Glu Ser Arg Leu Ala
1220
<210> 112
<211> 1214
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность бактерии кандидатного отдела WS6
<400> 112
Met Lys Asn Val Phe Gly Gly Phe Thr Asn Leu Tyr Ser Leu Thr Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Thr Ser Lys Thr Gln Lys Leu Met
20 25 30
Lys Arg Asn Asn Val Ile Gln Thr Asp Glu Glu Ile Asp Lys Leu Tyr
35 40 45
His Asp Glu Met Lys Pro Ile Leu Asp Glu Ile His Arg Arg Phe Ile
50 55 60
Asn Asp Ala Leu Ala Gln Lys Ile Phe Ile Ser Ala Ser Leu Asp Asn
65 70 75 80
Phe Leu Lys Val Val Lys Asn Tyr Lys Val Glu Ser Ala Lys Lys Asn
85 90 95
Ile Lys Gln Asn Gln Val Lys Leu Leu Gln Lys Glu Ile Thr Ile Lys
100 105 110
Thr Leu Gly Leu Arg Arg Glu Val Val Ser Gly Phe Ile Thr Val Ser
115 120 125
Lys Lys Trp Lys Asp Lys Tyr Val Gly Leu Gly Ile Lys Leu Lys Gly
130 135 140
Asp Gly Tyr Lys Val Leu Thr Glu Gln Ala Val Leu Asp Ile Leu Lys
145 150 155 160
Ile Glu Phe Pro Asn Lys Ala Lys Tyr Ile Asp Lys Phe Arg Gly Phe
165 170 175
Trp Thr Tyr Phe Ser Gly Phe Asn Glu Asn Arg Lys Asn Tyr Tyr Ser
180 185 190
Glu Glu Asp Lys Ala Thr Ser Ile Ala Asn Arg Ile Val Asn Glu Asn
195 200 205
Leu Ser Arg Tyr Ile Asp Asn Ile Ile Ala Phe Glu Glu Ile Leu Gln
210 215 220
Lys Ile Pro Asn Leu Lys Lys Phe Lys Gln Asp Leu Asp Ile Thr Ser
225 230 235 240
Tyr Asn Tyr Tyr Leu Asn Gln Ala Gly Ile Asp Lys Tyr Asn Lys Ile
245 250 255
Ile Gly Gly Tyr Ile Val Asp Lys Asp Lys Lys Ile Gln Gly Ile Asn
260 265 270
Glu Lys Val Asn Leu Tyr Thr Gln Gln Thr Lys Lys Lys Leu Pro Lys
275 280 285
Leu Lys Phe Leu Phe Lys Gln Ile Gly Ser Glu Arg Lys Gly Phe Gly
290 295 300
Ile Phe Glu Ile Lys Glu Gly Lys Glu Trp Glu Gln Leu Gly Asp Leu
305 310 315 320
Phe Lys Leu Gln Arg Thr Lys Ile Asn Ser Asn Gly Arg Glu Lys Gly
325 330 335
Leu Phe Asp Ser Leu Arg Thr Met Tyr Arg Glu Phe Phe Asp Glu Ile
340 345 350
Lys Arg Asp Ser Asn Ser Gln Ala Arg Tyr Ser Leu Asp Lys Ile Tyr
355 360 365
Phe Asn Lys Ala Ser Val Asn Thr Ile Ser Asn Ser Trp Phe Thr Asn
370 375 380
Trp Asn Lys Phe Ala Glu Leu Leu Asn Ile Lys Glu Asp Lys Lys Asn
385 390 395 400
Gly Glu Lys Lys Ile Pro Glu Gln Ile Ser Ile Glu Asp Ile Lys Asp
405 410 415
Ser Leu Ser Ile Ile Pro Lys Glu Asn Leu Glu Glu Leu Phe Lys Leu
420 425 430
Thr Asn Arg Glu Lys His Asp Arg Thr Arg Phe Phe Gly Ser Asn Ala
435 440 445
Trp Val Thr Phe Leu Asn Ile Trp Gln Asn Glu Ile Glu Glu Ser Phe
450 455 460
Asn Lys Leu Glu Glu Lys Glu Lys Asp Phe Lys Lys Asn Ala Ala Ile
465 470 475 480
Lys Phe Gln Lys Asn Asn Leu Val Gln Lys Asn Tyr Ile Lys Glu Val
485 490 495
Cys Asp Arg Met Leu Ala Ile Glu Arg Met Ala Lys Tyr His Leu Pro
500 505 510
Lys Asp Ser Asn Leu Ser Arg Glu Glu Asp Phe Tyr Trp Ile Ile Asp
515 520 525
Asn Leu Ser Glu Gln Arg Glu Ile Tyr Lys Tyr Tyr Asn Ala Phe Arg
530 535 540
Asn Tyr Ile Ser Lys Lys Pro Tyr Asn Lys Ser Lys Met Lys Leu Asn
545 550 555 560
Phe Glu Asn Gly Asn Leu Leu Gly Gly Trp Ser Asp Gly Gln Glu Arg
565 570 575
Asn Lys Ala Gly Val Ile Leu Arg Asn Gly Asn Lys Tyr Tyr Leu Gly
580 585 590
Val Leu Ile Asn Arg Gly Ile Phe Arg Thr Asp Lys Ile Asn Asn Glu
595 600 605
Ile Tyr Arg Thr Gly Ser Ser Lys Trp Glu Arg Leu Ile Leu Ser Asn
610 615 620
Leu Lys Phe Gln Thr Leu Ala Gly Lys Gly Phe Leu Gly Lys His Gly
625 630 635 640
Val Ser Tyr Gly Asn Met Asn Pro Glu Lys Ser Val Pro Ser Leu Gln
645 650 655
Lys Phe Ile Arg Glu Asn Tyr Leu Lys Lys Tyr Pro Gln Leu Thr Glu
660 665 670
Val Ser Asn Thr Lys Phe Leu Ser Lys Lys Asp Phe Asp Ala Ala Ile
675 680 685
Lys Glu Ala Leu Lys Glu Cys Phe Thr Met Asn Phe Ile Asn Ile Ala
690 695 700
Glu Asn Lys Leu Leu Glu Ala Glu Asp Lys Gly Asp Leu Tyr Leu Phe
705 710 715 720
Glu Ile Thr Asn Lys Asp Phe Ser Gly Lys Lys Ser Gly Lys Asp Asn
725 730 735
Ile His Thr Ile Tyr Trp Lys Tyr Leu Phe Ser Glu Ser Asn Cys Lys
740 745 750
Ser Pro Ile Ile Gly Leu Asn Gly Gly Ala Glu Ile Phe Phe Arg Glu
755 760 765
Gly Gln Lys Asp Lys Leu His Thr Lys Leu Asp Lys Lys Gly Lys Lys
770 775 780
Val Phe Asp Ala Lys Arg Tyr Ser Glu Asp Lys Leu Phe Phe His Val
785 790 795 800
Ser Ile Thr Ile Asn Tyr Gly Lys Pro Lys Asn Ile Lys Phe Arg Asp
805 810 815
Ile Ile Asn Gln Leu Ile Thr Ser Met Asn Val Asn Ile Ile Gly Ile
820 825 830
Asp Arg Gly Glu Lys His Leu Leu Tyr Tyr Ser Val Ile Asp Ser Asn
835 840 845
Gly Ile Ile Leu Lys Gln Gly Ser Leu Asn Lys Ile Arg Val Gly Asp
850 855 860
Lys Glu Val Asp Phe Asn Lys Lys Leu Thr Glu Arg Ala Asn Glu Met
865 870 875 880
Lys Lys Ala Arg Gln Ser Trp Glu Gln Ile Gly Asn Ile Lys Asn Phe
885 890 895
Lys Glu Gly Tyr Leu Ser Gln Ala Ile His Glu Ile Tyr Gln Leu Met
900 905 910
Ile Lys Tyr Asn Ala Ile Ile Val Leu Glu Asp Leu Asn Thr Glu Phe
915 920 925
Lys Ala Lys Arg Leu Ser Lys Val Glu Lys Ser Val Tyr Lys Lys Phe
930 935 940
Glu Leu Lys Leu Ala Arg Lys Leu Asn His Leu Ile Leu Lys Asp Arg
945 950 955 960
Asn Thr Asn Glu Ile Gly Gly Val Leu Lys Ala Tyr Gln Leu Thr Pro
965 970 975
Thr Ile Gly Gly Gly Asp Val Ser Lys Phe Glu Lys Ala Lys Gln Trp
980 985 990
Gly Met Met Phe Tyr Val Arg Ala Asn Tyr Thr Ser Thr Thr Asp Pro
995 1000 1005
Val Thr Gly Trp Arg Lys His Leu Tyr Ile Ser Asn Phe Ser Asn
1010 1015 1020
Asn Ser Val Ile Lys Ser Phe Phe Asp Pro Thr Asn Arg Asp Thr
1025 1030 1035
Gly Ile Glu Ile Phe Tyr Ser Gly Lys Tyr Arg Ser Trp Gly Phe
1040 1045 1050
Arg Tyr Val Gln Lys Glu Thr Gly Lys Lys Trp Glu Leu Phe Ala
1055 1060 1065
Thr Lys Glu Leu Glu Arg Phe Lys Tyr Asn Gln Thr Thr Lys Leu
1070 1075 1080
Cys Glu Lys Ile Asn Leu Tyr Asp Lys Phe Glu Glu Leu Phe Lys
1085 1090 1095
Gly Ile Asp Lys Ser Ala Asp Ile Tyr Ser Gln Leu Cys Asn Val
1100 1105 1110
Leu Asp Phe Arg Trp Lys Ser Leu Val Tyr Leu Trp Asn Leu Leu
1115 1120 1125
Asn Gln Ile Arg Asn Val Asp Lys Asn Ala Glu Gly Asn Lys Asn
1130 1135 1140
Asp Phe Ile Gln Ser Pro Val Tyr Pro Phe Phe Asp Ser Arg Lys
1145 1150 1155
Thr Asp Gly Lys Thr Glu Pro Ile Asn Gly Asp Ala Asn Gly Ala
1160 1165 1170
Leu Asn Ile Ala Arg Lys Gly Leu Met Leu Val Glu Arg Ile Lys
1175 1180 1185
Asn Asn Pro Glu Lys Tyr Glu Gln Leu Ile Arg Asp Thr Glu Trp
1190 1195 1200
Asp Ala Trp Ile Gln Asn Phe Asn Lys Val Asn
1205 1210
<210> 113
<211> 1200
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 113
Met Tyr Tyr Glu Ser Leu Thr Lys Gln Tyr Pro Val Ser Lys Thr Ile
1 5 10 15
Arg Asn Glu Leu Ile Pro Ile Gly Lys Thr Leu Asp Asn Ile Arg Gln
20 25 30
Asn Asn Ile Leu Glu Ser Asp Val Lys Arg Lys Gln Asn Tyr Glu His
35 40 45
Val Lys Gly Ile Leu Asp Glu Tyr His Lys Gln Leu Ile Asn Glu Ala
50 55 60
Leu Asp Asn Cys Thr Leu Pro Ser Leu Lys Ile Ala Ala Glu Ile Tyr
65 70 75 80
Leu Lys Asn Gln Lys Glu Val Ser Asp Arg Glu Asp Phe Asn Lys Thr
85 90 95
Gln Asp Leu Leu Arg Lys Glu Val Val Glu Lys Leu Lys Ala His Glu
100 105 110
Asn Phe Thr Lys Ile Gly Lys Lys Asp Ile Leu Asp Leu Leu Glu Lys
115 120 125
Leu Pro Ser Ile Ser Glu Asp Asp Tyr Asn Ala Leu Glu Ser Phe Arg
130 135 140
Asn Phe Tyr Thr Tyr Phe Thr Ser Tyr Asn Lys Val Arg Glu Asn Leu
145 150 155 160
Tyr Ser Asp Lys Glu Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn
165 170 175
Glu Asn Phe Pro Lys Phe Leu Asp Asn Val Lys Ser Tyr Arg Phe Val
180 185 190
Lys Thr Ala Gly Ile Leu Ala Asp Gly Leu Gly Glu Glu Glu Gln Asp
195 200 205
Ser Leu Phe Ile Val Glu Thr Phe Asn Lys Thr Leu Thr Gln Asp Gly
210 215 220
Ile Asp Thr Tyr Asn Ser Gln Val Gly Lys Ile Asn Ser Ser Ile Asn
225 230 235 240
Leu Tyr Asn Gln Lys Asn Gln Lys Ala Asn Gly Phe Arg Lys Ile Pro
245 250 255
Lys Met Lys Met Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Glu Ser
260 265 270
Phe Ile Asp Glu Phe Gln Ser Asp Glu Val Leu Ile Asp Asn Val Glu
275 280 285
Ser Tyr Gly Ser Val Leu Ile Glu Ser Leu Lys Ser Ser Lys Val Ser
290 295 300
Ala Phe Phe Asp Ala Leu Arg Glu Ser Lys Gly Lys Asn Val Tyr Val
305 310 315 320
Lys Asn Asp Leu Ala Lys Thr Ala Met Ser Asn Ile Val Phe Glu Asn
325 330 335
Trp Arg Thr Phe Asp Asp Leu Leu Asn Gln Glu Tyr Asp Leu Ala Asn
340 345 350
Glu Asn Lys Lys Lys Asp Asp Lys Tyr Phe Glu Lys Arg Gln Lys Glu
355 360 365
Leu Lys Lys Asn Lys Ser Tyr Ser Leu Glu His Leu Cys Asn Leu Ser
370 375 380
Glu Asp Ser Cys Asn Leu Ile Glu Asn Tyr Ile His Gln Ile Ser Asp
385 390 395 400
Asp Ile Glu Asn Ile Ile Ile Asn Asn Glu Thr Phe Leu Arg Ile Val
405 410 415
Ile Asn Glu His Asp Arg Ser Arg Lys Leu Ala Lys Asn Arg Lys Ala
420 425 430
Val Lys Ala Ile Lys Asp Phe Leu Asp Ser Ile Lys Val Leu Glu Arg
435 440 445
Glu Leu Lys Leu Ile Asn Ser Ser Gly Gln Glu Leu Glu Lys Asp Leu
450 455 460
Ile Val Tyr Ser Ala His Glu Glu Leu Leu Val Glu Leu Lys Gln Val
465 470 475 480
Asp Ser Leu Tyr Asn Met Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe
485 490 495
Ser Thr Glu Lys Val Lys Leu Asn Phe Asn Arg Ser Thr Leu Leu Asn
500 505 510
Gly Trp Asp Arg Asn Lys Glu Thr Asp Asn Leu Gly Val Leu Leu Leu
515 520 525
Lys Asp Gly Lys Tyr Tyr Leu Gly Ile Met Asn Thr Ser Ala Asn Lys
530 535 540
Ala Phe Val Asn Pro Pro Val Ala Lys Thr Glu Lys Val Phe Lys Lys
545 550 555 560
Val Asp Tyr Lys Leu Leu Pro Val Pro Asn Gln Met Leu Pro Lys Val
565 570 575
Phe Phe Ala Lys Ser Asn Ile Asp Phe Tyr Asn Pro Ser Ser Glu Ile
580 585 590
Tyr Ser Asn Tyr Lys Lys Gly Thr His Lys Lys Gly Asn Met Phe Ser
595 600 605
Leu Glu Asp Cys His Asn Leu Ile Asp Phe Phe Lys Glu Ser Ile Ser
610 615 620
Lys His Glu Asp Trp Ser Lys Phe Gly Phe Lys Phe Ser Asp Thr Ala
625 630 635 640
Ser Tyr Asn Asp Ile Ser Glu Phe Tyr Arg Glu Val Glu Lys Gln Gly
645 650 655
Tyr Lys Leu Thr Tyr Thr Asp Ile Asp Glu Thr Tyr Ile Asn Asp Leu
660 665 670
Ile Glu Arg Asn Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe
675 680 685
Ser Met Tyr Ser Lys Gly Lys Leu Asn Leu His Thr Leu Tyr Phe Met
690 695 700
Met Leu Phe Asp Gln Arg Asn Ile Asp Asp Val Val Tyr Lys Leu Asn
705 710 715 720
Gly Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Ser Glu Asp Glu
725 730 735
Leu Ile Ile His Lys Ala Gly Glu Glu Ile Lys Asn Lys Asn Pro Asn
740 745 750
Arg Ala Arg Thr Lys Glu Thr Ser Thr Phe Ser Tyr Asp Ile Val Lys
755 760 765
Asp Lys Arg Tyr Ser Lys Asp Lys Phe Thr Leu His Ile Pro Ile Thr
770 775 780
Met Asn Phe Gly Val Asp Glu Val Lys Arg Phe Asn Asp Ala Val Asn
785 790 795 800
Ser Ala Ile Arg Ile Asp Glu Asn Val Asn Val Ile Gly Ile Asp Arg
805 810 815
Gly Glu Arg Asn Leu Leu Tyr Val Val Val Ile Asp Ser Lys Gly Asn
820 825 830
Ile Leu Glu Gln Ile Ser Leu Asn Ser Ile Ile Asn Lys Glu Tyr Asp
835 840 845
Ile Glu Thr Asp Tyr His Ala Leu Leu Asp Glu Arg Glu Gly Gly Arg
850 855 860
Asp Lys Ala Arg Lys Asp Trp Asn Thr Val Glu Asn Ile Arg Asp Leu
865 870 875 880
Lys Ala Gly Tyr Leu Ser Gln Val Val Asn Val Val Ala Lys Leu Val
885 890 895
Leu Lys Tyr Asn Ala Ile Ile Cys Leu Glu Asp Leu Asn Phe Gly Phe
900 905 910
Lys Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu
915 920 925
Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Ile Asp Lys Ser Arg
930 935 940
Glu Gln Thr Ser Pro Lys Glu Leu Gly Gly Ala Leu Asn Ala Leu Gln
945 950 955 960
Leu Thr Ser Lys Phe Lys Ser Phe Lys Glu Leu Gly Lys Gln Ser Gly
965 970 975
Val Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile Asp Pro Thr
980 985 990
Thr Gly Phe Ala Asn Leu Phe Tyr Met Lys Cys Glu Asn Val Glu Lys
995 1000 1005
Ser Lys Arg Phe Phe Asp Gly Phe Asp Phe Ile Arg Phe Asn Ala
1010 1015 1020
Leu Glu Asn Val Phe Glu Phe Gly Phe Asp Tyr Arg Ser Phe Thr
1025 1030 1035
Gln Arg Ala Cys Gly Ile Asn Ser Lys Trp Thr Val Cys Thr Asn
1040 1045 1050
Gly Glu Arg Ile Ile Lys Tyr Arg Asn Pro Asp Lys Asn Asn Met
1055 1060 1065
Phe Asp Glu Lys Val Val Val Val Thr Asp Glu Met Lys Asn Leu
1070 1075 1080
Phe Glu Gln Tyr Lys Ile Pro Tyr Glu Asp Gly Arg Asn Val Lys
1085 1090 1095
Asp Met Ile Ile Ser Asn Glu Glu Ala Glu Phe Tyr Arg Arg Leu
1100 1105 1110
Tyr Arg Leu Leu Gln Gln Thr Leu Gln Met Arg Asn Ser Thr Ser
1115 1120 1125
Asp Gly Thr Arg Asp Tyr Ile Ile Ser Pro Val Lys Asn Lys Arg
1130 1135 1140
Glu Ala Tyr Phe Asn Ser Glu Leu Ser Asp Gly Ser Val Pro Lys
1145 1150 1155
Asp Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu
1160 1165 1170
Trp Val Leu Glu Gln Ile Arg Gln Lys Ser Glu Gly Glu Lys Ile
1175 1180 1185
Asn Leu Ala Met Thr Asn Ala Glu Trp Leu Glu Tyr
1190 1195 1200
<210> 114
<211> 1206
<212> БЕЛОК
<213> Butyrivibrio sp.
<400> 114
Met Tyr Tyr Gln Asn Leu Thr Lys Lys Tyr Pro Val Ser Lys Thr Ile
1 5 10 15
Arg Asn Glu Leu Ile Pro Ile Gly Lys Thr Leu Glu Asn Ile Arg Lys
20 25 30
Asn Asn Ile Leu Glu Ser Asp Val Lys Arg Lys Gln Asp Tyr Glu His
35 40 45
Val Lys Gly Ile Met Asp Glu Tyr His Lys Gln Leu Ile Asn Glu Ala
50 55 60
Leu Asp Asn Tyr Met Leu Pro Ser Leu Asn Gln Ala Ala Glu Ile Tyr
65 70 75 80
Leu Lys Lys His Val Asp Val Glu Asp Arg Glu Glu Phe Lys Lys Thr
85 90 95
Gln Asp Leu Leu Arg Arg Glu Val Thr Gly Arg Leu Lys Glu His Glu
100 105 110
Asn Tyr Thr Lys Ile Gly Lys Lys Asp Ile Leu Asp Leu Leu Glu Lys
115 120 125
Leu Pro Ser Ile Ser Glu Glu Asp Tyr Asn Ala Leu Glu Ser Phe Arg
130 135 140
Asn Phe Tyr Thr Tyr Phe Thr Ser Tyr Asn Lys Val Arg Glu Asn Leu
145 150 155 160
Tyr Ser Asp Glu Glu Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn
165 170 175
Glu Asn Leu Pro Lys Phe Leu Asp Asn Ile Lys Ser Tyr Ala Phe Val
180 185 190
Lys Ala Ala Gly Val Leu Ala Asp Cys Ile Glu Glu Glu Glu Gln Asp
195 200 205
Ala Leu Phe Met Val Glu Thr Phe Asn Met Thr Leu Thr Gln Glu Gly
210 215 220
Ile Asp Met Tyr Asn Tyr Gln Ile Gly Lys Val Asn Ser Ala Ile Asn
225 230 235 240
Leu Tyr Asn Gln Lys Asn His Lys Val Glu Glu Phe Lys Lys Ile Pro
245 250 255
Lys Met Lys Val Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Glu Val
260 265 270
Phe Ile Gly Glu Phe Lys Asp Asp Glu Thr Leu Leu Ser Ser Ile Gly
275 280 285
Ala Tyr Gly Asn Val Leu Met Thr Tyr Leu Lys Ser Glu Lys Ile Asn
290 295 300
Ile Phe Phe Asp Ala Leu Arg Glu Ser Glu Gly Lys Asn Val Tyr Val
305 310 315 320
Lys Asn Asp Leu Ser Lys Thr Thr Met Ser Asn Ile Val Phe Gly Ser
325 330 335
Trp Ser Ala Phe Asp Glu Leu Leu Asn Gln Glu Tyr Asp Leu Ala Asn
340 345 350
Glu Asn Lys Lys Lys Asp Asp Lys Tyr Phe Glu Lys Arg Gln Lys Glu
355 360 365
Leu Lys Lys Asn Lys Ser Tyr Thr Leu Glu Gln Met Ser Asn Leu Ser
370 375 380
Lys Glu Asp Ile Ser Pro Ile Glu Asn Tyr Ile Glu Arg Ile Ser Glu
385 390 395 400
Asp Ile Glu Lys Ile Cys Ile Tyr Asn Gly Glu Phe Glu Lys Ile Val
405 410 415
Val Asn Glu His Asp Ser Ser Arg Lys Leu Ser Lys Asn Ile Lys Ala
420 425 430
Val Lys Val Ile Lys Asp Tyr Leu Asp Ser Ile Lys Glu Leu Glu His
435 440 445
Asp Ile Lys Leu Ile Asn Gly Ser Gly Gln Glu Leu Glu Lys Asn Leu
450 455 460
Val Val Tyr Val Gly Gln Glu Glu Ala Leu Glu Gln Leu Arg Pro Val
465 470 475 480
Asp Ser Leu Tyr Asn Leu Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe
485 490 495
Ser Thr Glu Lys Val Lys Leu Asn Phe Asn Lys Ser Thr Leu Leu Asn
500 505 510
Gly Trp Asp Lys Asn Lys Glu Thr Asp Asn Leu Gly Ile Leu Phe Phe
515 520 525
Lys Asp Gly Lys Tyr Tyr Leu Gly Ile Met Asn Thr Thr Ala Asn Lys
530 535 540
Ala Phe Val Asn Pro Pro Ala Ala Lys Thr Glu Asn Val Phe Lys Lys
545 550 555 560
Val Asp Tyr Lys Leu Leu Pro Gly Ser Asn Lys Met Leu Pro Lys Val
565 570 575
Phe Phe Ala Lys Ser Asn Ile Gly Tyr Tyr Asn Pro Ser Thr Glu Leu
580 585 590
Tyr Ser Asn Tyr Lys Lys Gly Thr His Lys Lys Gly Pro Ser Phe Ser
595 600 605
Ile Asp Asp Cys His Asn Leu Ile Asp Phe Phe Lys Glu Ser Ile Lys
610 615 620
Lys His Glu Asp Trp Ser Lys Phe Gly Phe Glu Phe Ser Asp Thr Ala
625 630 635 640
Asp Tyr Arg Asp Ile Ser Glu Phe Tyr Arg Glu Val Glu Lys Gln Gly
645 650 655
Tyr Lys Leu Thr Phe Thr Asp Ile Asp Glu Ser Tyr Ile Asn Asp Leu
660 665 670
Ile Glu Lys Asn Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe
675 680 685
Ser Glu Tyr Ser Lys Gly Lys Leu Asn Leu His Thr Leu Tyr Phe Met
690 695 700
Met Leu Phe Asp Gln Arg Asn Leu Asp Asn Val Val Tyr Lys Leu Asn
705 710 715 720
Gly Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Ala Glu Asn Glu
725 730 735
Leu Val Ile His Lys Ala Gly Glu Gly Ile Lys Asn Lys Asn Pro Asn
740 745 750
Arg Ala Lys Val Lys Glu Thr Ser Thr Phe Ser Tyr Asp Ile Val Lys
755 760 765
Asp Lys Arg Tyr Ser Lys Tyr Lys Phe Thr Leu His Ile Pro Ile Thr
770 775 780
Met Asn Phe Gly Val Asp Glu Val Arg Arg Phe Asn Asp Val Ile Asn
785 790 795 800
Asn Ala Leu Arg Thr Asp Asp Asn Val Asn Val Ile Gly Ile Asp Arg
805 810 815
Gly Glu Arg Asn Leu Leu Tyr Val Val Val Ile Asn Ser Glu Gly Lys
820 825 830
Ile Leu Glu Gln Ile Ser Leu Asn Ser Ile Ile Asn Lys Glu Tyr Asp
835 840 845
Ile Glu Thr Asn Tyr His Ala Leu Leu Asp Glu Arg Glu Asp Asp Arg
850 855 860
Asn Lys Ala Arg Lys Asp Trp Asn Thr Ile Glu Asn Ile Lys Glu Leu
865 870 875 880
Lys Thr Gly Tyr Leu Ser Gln Val Val Asn Val Val Ala Lys Leu Val
885 890 895
Leu Lys Tyr Asn Ala Ile Ile Cys Leu Glu Asp Leu Asn Phe Gly Phe
900 905 910
Lys Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu
915 920 925
Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu Val Ile Asp Lys Ser Arg
930 935 940
Glu Gln Val Ser Pro Glu Lys Met Gly Gly Ala Leu Asn Ala Leu Gln
945 950 955 960
Leu Thr Ser Lys Phe Lys Ser Phe Ala Glu Leu Gly Lys Gln Ser Gly
965 970 975
Ile Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile Asp Pro Thr
980 985 990
Thr Gly Phe Val Asn Leu Phe Tyr Ile Lys Tyr Glu Asn Ile Glu Lys
995 1000 1005
Ala Lys Gln Phe Phe Asp Gly Phe Asp Phe Ile Arg Phe Asn Lys
1010 1015 1020
Lys Asp Asp Met Phe Glu Phe Ser Phe Asp Tyr Lys Ser Phe Thr
1025 1030 1035
Gln Lys Ala Cys Gly Ile Arg Ser Lys Trp Ile Val Tyr Thr Asn
1040 1045 1050
Gly Glu Arg Ile Ile Lys Tyr Pro Asn Pro Glu Lys Asn Asn Leu
1055 1060 1065
Phe Asp Glu Lys Val Ile Asn Val Thr Asp Glu Ile Lys Gly Leu
1070 1075 1080
Phe Lys Gln Tyr Arg Ile Pro Tyr Glu Asn Gly Glu Asp Ile Lys
1085 1090 1095
Glu Ile Ile Ile Ser Lys Ala Glu Ala Asp Phe Tyr Lys Arg Leu
1100 1105 1110
Phe Arg Leu Leu His Gln Thr Leu Gln Met Arg Asn Ser Thr Ser
1115 1120 1125
Asp Gly Thr Arg Asp Tyr Ile Ile Ser Pro Val Lys Asn Asp Arg
1130 1135 1140
Gly Glu Phe Phe Cys Ser Glu Phe Ser Glu Gly Thr Met Pro Lys
1145 1150 1155
Asp Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu
1160 1165 1170
Trp Val Leu Glu Gln Ile Arg Gln Lys Asp Glu Gly Glu Lys Val
1175 1180 1185
Asn Leu Ser Met Thr Asn Ala Glu Trp Leu Lys Tyr Ala Gln Leu
1190 1195 1200
His Leu Leu
1205
<210> 115
<211> 1206
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 115
Met Glu Asn Tyr Tyr Asp Ser Leu Thr Arg Gln Tyr Pro Val Thr Lys
1 5 10 15
Thr Ile Arg Gln Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn Ile
20 25 30
Lys Asn Ala Glu Ile Ile Glu Ala Asp Lys Gln Lys Lys Glu Ala Tyr
35 40 45
Val Lys Val Lys Glu Leu Met Asp Glu Phe His Lys Ser Ile Ile Glu
50 55 60
Lys Ser Leu Val Gly Ile Lys Leu Asp Gly Leu Ser Glu Phe Glu Lys
65 70 75 80
Leu Tyr Lys Ile Lys Thr Lys Thr Asp Glu Asp Lys Asn Arg Ile Ser
85 90 95
Glu Leu Phe Tyr Tyr Met Arg Lys Gln Ile Ala Asp Ala Leu Lys Asn
100 105 110
Ser Arg Asp Tyr Gly Tyr Val Asp Asn Lys Asp Leu Ile Glu Lys Ile
115 120 125
Leu Pro Glu Arg Val Lys Asp Glu Asn Ser Leu Asn Ala Leu Ser Cys
130 135 140
Phe Lys Gly Phe Thr Thr Tyr Phe Thr Asp Tyr Tyr Lys Asn Arg Lys
145 150 155 160
Asn Ile Tyr Ser Asp Glu Glu Lys His Ser Thr Val Gly Tyr Arg Cys
165 170 175
Ile Asn Glu Asn Leu Leu Ile Phe Met Ser Asn Ile Glu Val Tyr Gln
180 185 190
Ile Tyr Lys Lys Ala Asn Ile Lys Asn Asp Asn Tyr Asp Glu Glu Thr
195 200 205
Leu Asp Lys Thr Phe Met Ile Glu Ser Phe Asn Glu Cys Leu Thr Gln
210 215 220
Ser Gly Val Glu Ala Tyr Asn Ser Val Val Ala Ser Ile Lys Thr Ala
225 230 235 240
Thr Asn Leu Tyr Ile Gln Lys Asn Asn Lys Glu Glu Asn Phe Val Arg
245 250 255
Val Pro Lys Met Lys Val Leu Phe Lys Gln Ile Leu Ser Asp Arg Thr
260 265 270
Ser Leu Phe Asp Gly Leu Ile Ile Glu Ser Asp Asp Glu Leu Leu Asp
275 280 285
Lys Leu Cys Ser Phe Ser Ala Glu Val Asp Lys Phe Leu Pro Ile Asn
290 295 300
Ile Asp Arg Tyr Ile Lys Thr Leu Met Asp Ser Asn Asn Gly Thr Gly
305 310 315 320
Ile Tyr Val Lys Asn Asp Ser Ser Leu Thr Thr Leu Ser Asn Tyr Leu
325 330 335
Thr Asp Ser Trp Ser Ser Ile Arg Asn Ala Phe Asn Glu Asn Tyr Asp
340 345 350
Ala Lys Tyr Thr Gly Lys Val Asn Asp Lys Tyr Glu Glu Lys Arg Glu
355 360 365
Lys Ala Tyr Lys Ser Asn Asp Ser Phe Glu Leu Asn Tyr Ile Gln Asn
370 375 380
Leu Leu Gly Ile Asn Val Ile Asp Lys Tyr Ile Glu Arg Ile Asn Phe
385 390 395 400
Asp Ile Lys Glu Ile Cys Glu Ala Tyr Lys Glu Met Thr Lys Asn Cys
405 410 415
Phe Glu Asp His Asp Lys Thr Lys Lys Leu Gln Lys Asn Ile Lys Ala
420 425 430
Val Ala Ser Ile Lys Ser Tyr Leu Asp Ser Leu Lys Asn Ile Glu Arg
435 440 445
Asp Ile Lys Leu Leu Asn Gly Thr Gly Leu Glu Ser Arg Asn Glu Phe
450 455 460
Phe Tyr Gly Glu Gln Ser Thr Val Leu Glu Glu Ile Thr Lys Val Asp
465 470 475 480
Glu Leu Tyr Asn Ile Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe Ser
485 490 495
Thr Glu Lys Met Lys Leu Asn Phe Asn Asn Pro Gln Leu Leu Gly Gly
500 505 510
Trp Asp Val Asn Lys Glu Arg Asp Cys Tyr Gly Val Ile Leu Ile Lys
515 520 525
Asp Asn Asn Tyr Tyr Leu Gly Ile Met Asp Lys Ser Ala Asn Lys Ser
530 535 540
Phe Leu Asn Ile Lys Glu Ser Lys Asn Glu Asn Ala Tyr Lys Lys Val
545 550 555 560
Asn Cys Lys Leu Leu Pro Gly Pro Asn Lys Met Phe Pro Lys Val Phe
565 570 575
Phe Ala Lys Ser Asn Ile Asp Tyr Tyr Asp Pro Thr His Glu Ile Lys
580 585 590
Lys Leu Tyr Asp Lys Gly Thr Phe Lys Lys Gly Asn Ser Phe Asn Leu
595 600 605
Glu Asp Cys His Lys Leu Ile Asp Phe Tyr Lys Glu Ser Ile Lys Lys
610 615 620
Asn Asp Asp Trp Lys Asn Phe Asn Phe Asn Phe Ser Asp Thr Lys Asp
625 630 635 640
Tyr Glu Asp Ile Ser Gly Phe Phe Arg Glu Val Glu Ala Gln Asn Tyr
645 650 655
Lys Ile Thr Tyr Thr Asn Val Ser Cys Asp Phe Ile Glu Ser Leu Val
660 665 670
Asp Glu Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser
675 680 685
Glu Tyr Ala Thr Gly Asn Leu Asn Leu His Thr Leu Tyr Leu Lys Met
690 695 700
Leu Phe Asp Glu Arg Asn Leu Lys Asp Leu Cys Ile Lys Met Asn Gly
705 710 715 720
Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Leu Asp Glu Asp Lys
725 730 735
Val Val His Lys Ala Asn Gln Lys Ile Thr Asn Lys Asn Thr Asn Ser
740 745 750
Lys Lys Lys Glu Ser Ile Phe Ser Tyr Asp Ile Val Lys Asp Lys Arg
755 760 765
Tyr Thr Val Asp Lys Phe Phe Ile His Leu Pro Ile Thr Leu Asn Tyr
770 775 780
Lys Glu Gln Asn Val Ser Arg Phe Asn Asp Tyr Ile Arg Glu Ile Leu
785 790 795 800
Lys Lys Ser Lys Asn Ile Arg Val Ile Gly Ile Asp Arg Gly Glu Arg
805 810 815
Asn Leu Leu Tyr Val Val Val Cys Asp Ser Asp Gly Ser Ile Leu Tyr
820 825 830
Gln Arg Ser Ile Asn Glu Ile Val Ser Gly Ser His Lys Thr Asp Tyr
835 840 845
His Lys Leu Leu Asp Asn Lys Glu Lys Glu Arg Leu Ser Ser Arg Arg
850 855 860
Asp Trp Lys Thr Ile Glu Asn Ile Lys Asp Leu Lys Ala Gly Tyr Met
865 870 875 880
Ser Gln Val Val Asn Glu Ile Tyr Asn Leu Ile Leu Lys Tyr Asn Ala
885 890 895
Ile Val Val Leu Glu Asp Leu Asn Ile Gly Phe Lys Asn Gly Arg Lys
900 905 910
Lys Val Glu Lys Gln Val Tyr Gln Asn Phe Glu Lys Ala Leu Ile Asp
915 920 925
Lys Leu Asn Tyr Leu Cys Ile Asp Lys Thr Arg Glu Gln Leu Ser Pro
930 935 940
Ser Ser Pro Gly Gly Val Leu Asn Ala Tyr Gln Leu Thr Ala Lys Phe
945 950 955 960
Glu Ser Phe Glu Lys Ile Gly Lys Gln Thr Gly Cys Ile Phe Tyr Val
965 970 975
Pro Ala Tyr Leu Thr Ser Gln Ile Asp Pro Thr Thr Gly Phe Val Asn
980 985 990
Leu Phe Tyr Gln Lys Asp Thr Ser Lys Gln Gly Leu Gln Leu Phe Phe
995 1000 1005
Arg Lys Phe Lys Lys Ile Asn Phe Asp Lys Val Ala Ser Asn Phe
1010 1015 1020
Glu Phe Val Phe Asp Tyr Asn Asp Phe Thr Asn Lys Ala Glu Gly
1025 1030 1035
Thr Lys Thr Asn Trp Thr Ile Ser Thr Gln Gly Thr Arg Ile Ala
1040 1045 1050
Lys Tyr Arg Ser Asp Asp Ala Asn Gly Lys Trp Ile Ser Arg Thr
1055 1060 1065
Val His Pro Thr Asp Ile Ile Lys Glu Ala Leu Asn Arg Glu Lys
1070 1075 1080
Ile Asn Tyr Asn Asp Gly His Asp Leu Ile Asp Glu Ile Val Ser
1085 1090 1095
Ile Glu Lys Ser Ala Val Leu Lys Glu Ile Tyr Tyr Gly Phe Lys
1100 1105 1110
Leu Thr Leu Gln Leu Arg Asn Ser Thr Leu Ala Asn Glu Glu Glu
1115 1120 1125
Gln Glu Asp Tyr Ile Ile Ser Pro Val Lys Asn Ser Ser Gly Asn
1130 1135 1140
Tyr Phe Asp Ser Arg Ile Thr Ser Lys Glu Leu Pro Cys Asp Ala
1145 1150 1155
Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Trp Ala
1160 1165 1170
Leu Glu Gln Ile Arg Asn Ser Glu Asn Val Ser Lys Val Lys Leu
1175 1180 1185
Ala Ile Ser Asn Lys Glu Trp Phe Glu Tyr Thr Gln Asn Asn Ile
1190 1195 1200
Pro Ser Leu
1205
<210> 116
<211> 1205
<212> БЕЛОК
<213> Oribacterium sp.
<400> 116
Met Tyr Tyr Asp Gly Leu Thr Lys Gln Tyr Ala Leu Ser Lys Thr Ile
1 5 10 15
Arg Asn Glu Leu Val Pro Ile Gly Lys Thr Leu Asp Asn Ile Lys Lys
20 25 30
Asn Arg Ile Leu Glu Ala Asp Ile Lys Arg Lys Ser Asp Tyr Glu His
35 40 45
Val Lys Lys Leu Met Asp Met Tyr His Lys Lys Ile Ile Asn Glu Ala
50 55 60
Leu Asp Asn Phe Lys Leu Ser Val Leu Glu Asp Ala Ala Asp Ile Tyr
65 70 75 80
Phe Asn Lys Gln Asn Asp Glu Arg Asp Ile Asp Ala Phe Leu Lys Ile
85 90 95
Gln Asp Lys Leu Arg Lys Glu Ile Val Glu Gln Leu Lys Gly His Thr
100 105 110
Asp Tyr Ser Lys Val Gly Asn Lys Asp Phe Leu Gly Leu Leu Lys Ala
115 120 125
Ala Ser Thr Glu Glu Asp Arg Ile Leu Ile Glu Ser Phe Asp Asn Phe
130 135 140
Tyr Thr Tyr Phe Thr Ser Tyr Asn Lys Val Arg Ser Asn Leu Tyr Ser
145 150 155 160
Ala Glu Asp Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn Glu Asn
165 170 175
Leu Pro Lys Phe Phe Asp Asn Ile Lys Ala Tyr Arg Thr Val Arg Asn
180 185 190
Ala Gly Val Ile Ser Gly Asp Met Ser Ile Val Glu Gln Asp Glu Leu
195 200 205
Phe Glu Val Asp Thr Phe Asn His Thr Leu Thr Gln Tyr Gly Ile Asp
210 215 220
Thr Tyr Asn His Met Ile Gly Gln Leu Asn Ser Ala Ile Asn Leu Tyr
225 230 235 240
Asn Gln Lys Met His Gly Ala Gly Ser Phe Lys Lys Leu Pro Lys Met
245 250 255
Lys Glu Leu Tyr Lys Gln Leu Leu Thr Glu Arg Glu Glu Glu Phe Ile
260 265 270
Glu Glu Tyr Thr Asp Asp Glu Val Leu Ile Thr Ser Val His Asn Tyr
275 280 285
Val Ser Tyr Leu Ile Asp Tyr Leu Asn Ser Asp Lys Val Glu Ser Phe
290 295 300
Phe Asp Thr Leu Arg Lys Ser Asp Gly Lys Glu Val Phe Ile Lys Asn
305 310 315 320
Asp Val Ser Lys Thr Thr Met Ser Asn Ile Leu Phe Asp Asn Trp Ser
325 330 335
Thr Ile Asp Asp Leu Ile Asn His Glu Tyr Asp Ser Ala Pro Glu Asn
340 345 350
Val Lys Lys Thr Lys Asp Asp Lys Tyr Phe Glu Lys Arg Gln Lys Asp
355 360 365
Leu Lys Lys Asn Lys Ser Tyr Ser Leu Ser Lys Ile Ala Ala Leu Cys
370 375 380
Arg Asp Thr Thr Ile Leu Glu Lys Tyr Ile Arg Arg Leu Val Asp Asp
385 390 395 400
Ile Glu Lys Ile Tyr Thr Ser Asn Asn Val Phe Ser Asp Ile Val Leu
405 410 415
Ser Lys His Asp Arg Ser Lys Lys Leu Ser Lys Asn Thr Asn Ala Val
420 425 430
Gln Ala Ile Lys Asn Met Leu Asp Ser Ile Lys Asp Phe Glu His Asp
435 440 445
Val Met Leu Ile Asn Gly Ser Gly Gln Glu Ile Lys Lys Asn Leu Asn
450 455 460
Val Tyr Ser Glu Gln Glu Ala Leu Ala Gly Ile Leu Arg Gln Val Asp
465 470 475 480
His Ile Tyr Asn Leu Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe Ser
485 490 495
Thr Glu Lys Ile Lys Leu Asn Phe Asn Arg Pro Thr Phe Leu Asp Gly
500 505 510
Trp Asp Lys Asn Lys Glu Glu Ala Asn Leu Gly Ile Leu Leu Ile Lys
515 520 525
Asp Asn Arg Tyr Tyr Leu Gly Ile Met Asn Thr Ser Ser Asn Lys Ala
530 535 540
Phe Val Asn Pro Pro Lys Ala Ile Ser Asn Asp Ile Tyr Lys Lys Val
545 550 555 560
Asp Tyr Lys Leu Leu Pro Gly Pro Asn Lys Met Leu Pro Lys Val Phe
565 570 575
Phe Ala Thr Lys Asn Ile Ala Tyr Tyr Ala Pro Ser Glu Glu Leu Leu
580 585 590
Ser Lys Tyr Arg Lys Gly Thr His Lys Lys Gly Asp Ser Phe Ser Ile
595 600 605
Asp Asp Cys Arg Asn Leu Ile Asp Phe Phe Lys Ser Ser Ile Asn Lys
610 615 620
Asn Thr Asp Trp Ser Thr Phe Gly Phe Asn Phe Ser Asp Thr Asn Ser
625 630 635 640
Tyr Asn Asp Ile Ser Asp Phe Tyr Arg Glu Val Glu Lys Gln Gly Tyr
645 650 655
Lys Leu Ser Phe Thr Asp Ile Asp Ala Cys Tyr Ile Lys Asp Leu Val
660 665 670
Asp Asn Asn Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser
675 680 685
Pro Tyr Ser Lys Gly Lys Leu Asn Leu His Thr Leu Tyr Phe Lys Met
690 695 700
Leu Phe Asp Gln Arg Asn Leu Asp Asn Val Val Tyr Lys Leu Asn Gly
705 710 715 720
Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Glu Ser Asp Glu Gln
725 730 735
Ile Ile His Lys Ser Gly Gln Asn Ile Lys Asn Lys Asn Gln Lys Arg
740 745 750
Ser Asn Cys Lys Lys Thr Ser Thr Phe Asp Tyr Asp Ile Val Lys Asp
755 760 765
Arg Arg Tyr Cys Lys Asp Lys Phe Met Leu His Leu Pro Ile Thr Val
770 775 780
Asn Phe Gly Thr Asn Glu Ser Gly Lys Phe Asn Glu Leu Val Asn Asn
785 790 795 800
Ala Ile Arg Ala Asp Lys Asp Val Asn Val Ile Gly Ile Asp Arg Gly
805 810 815
Glu Arg Asn Leu Leu Tyr Val Val Val Val Asp Pro Cys Gly Lys Ile
820 825 830
Ile Glu Gln Ile Ser Leu Asn Thr Ile Val Asp Lys Glu Tyr Asp Ile
835 840 845
Glu Thr Asp Tyr His Gln Leu Leu Asp Glu Lys Glu Gly Ser Arg Asp
850 855 860
Lys Ala Arg Lys Asp Trp Asn Thr Ile Glu Asn Ile Lys Glu Leu Lys
865 870 875 880
Glu Gly Tyr Leu Ser Gln Val Val Asn Ile Ile Ala Lys Leu Val Leu
885 890 895
Lys Tyr Asp Ala Ile Ile Cys Leu Glu Asp Leu Asn Phe Gly Phe Lys
900 905 910
Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys
915 920 925
Met Leu Ile Asp Lys Met Asn Tyr Leu Val Leu Asp Lys Ser Arg Lys
930 935 940
Gln Glu Ser Pro Gln Lys Pro Gly Gly Ala Leu Asn Ala Leu Gln Leu
945 950 955 960
Thr Ser Ala Phe Lys Ser Phe Lys Glu Leu Gly Lys Gln Thr Gly Ile
965 970 975
Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile Asp Pro Thr Thr
980 985 990
Gly Phe Ala Asn Leu Phe Tyr Ile Lys Tyr Glu Ser Val Asp Lys Ala
995 1000 1005
Arg Asp Phe Phe Ser Lys Phe Asp Phe Ile Arg Tyr Asn Gln Met
1010 1015 1020
Asp Asn Tyr Phe Glu Phe Gly Phe Asp Tyr Lys Ser Phe Thr Glu
1025 1030 1035
Arg Ala Ser Gly Cys Lys Ser Lys Trp Ile Ala Cys Thr Asn Gly
1040 1045 1050
Glu Arg Ile Val Lys Tyr Arg Asn Ser Asp Lys Asn Asn Ser Phe
1055 1060 1065
Asp Asp Lys Thr Val Ile Leu Thr Asp Glu Tyr Arg Ser Leu Phe
1070 1075 1080
Asp Lys Tyr Leu Gln Asn Tyr Ile Asp Glu Asp Asp Leu Lys Asp
1085 1090 1095
Gln Ile Leu Gln Ile Asp Ser Ala Asp Phe Tyr Lys Asn Leu Ile
1100 1105 1110
Lys Leu Phe Gln Leu Thr Leu Gln Met Arg Asn Ser Ser Ser Asp
1115 1120 1125
Gly Lys Arg Asp Tyr Ile Ile Ser Pro Val Lys Asn Tyr Arg Glu
1130 1135 1140
Glu Phe Phe Cys Ser Glu Phe Ser Asp Asp Thr Phe Pro Arg Asp
1145 1150 1155
Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Trp
1160 1165 1170
Val Ile Lys Gln Ile Arg Glu Thr Lys Ser Gly Thr Lys Ile Asn
1175 1180 1185
Leu Ala Met Ser Asn Ser Glu Trp Leu Glu Tyr Ala Gln Cys Asn
1190 1195 1200
Leu Leu
1205
<210> 117
<211> 1125
<212> БЕЛОК
<213> Pseudobutyrivibrio ruminis
<400> 117
Phe Asn Leu Ser Lys Glu Lys Asn Ser Val Asp Ala Phe Ser Lys Cys
1 5 10 15
Gln Asp Lys Leu Arg Lys Glu Ile Val Ser Leu Leu Lys Asn His Glu
20 25 30
Asn Phe Pro Lys Ile Gly Asn Lys Glu Ile Ile Lys Leu Leu Gln Ser
35 40 45
Leu Tyr Asp Asn Asp Thr Asp Tyr Lys Ala Leu Asp Ser Phe Ser Asn
50 55 60
Phe Tyr Thr Tyr Phe Ser Ser Tyr Asn Glu Val Arg Lys Asn Leu Tyr
65 70 75 80
Ser Asp Glu Glu Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn Glu
85 90 95
Asn Leu Pro Lys Phe Leu Asp Asn Ile Lys Ala Tyr Ala Ile Ala Lys
100 105 110
Lys Ala Gly Val Arg Ala Glu Gly Leu Ser Glu Glu Asp Gln Asp Cys
115 120 125
Leu Phe Ile Ile Glu Thr Phe Glu Arg Thr Leu Thr Gln Asp Gly Ile
130 135 140
Asp Asn Tyr Asn Ala Ala Ile Gly Lys Leu Asn Thr Ala Ile Asn Leu
145 150 155 160
Phe Asn Gln Gln Asn Lys Lys Gln Glu Gly Phe Arg Lys Val Pro Gln
165 170 175
Met Lys Cys Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Glu Ala Phe
180 185 190
Ile Asp Glu Phe Ser Asp Asp Glu Asp Leu Ile Thr Asn Ile Glu Ser
195 200 205
Phe Ala Glu Asn Met Asn Val Phe Leu Asn Ser Glu Ile Ile Thr Asp
210 215 220
Phe Lys Ile Ala Leu Val Glu Ser Asp Gly Ser Leu Val Tyr Ile Lys
225 230 235 240
Asn Asp Val Ser Lys Thr Ser Phe Ser Asn Ile Val Phe Gly Ser Trp
245 250 255
Asn Ala Ile Asp Glu Lys Leu Ser Asp Glu Tyr Asp Leu Ala Asn Ser
260 265 270
Lys Lys Lys Lys Asp Glu Lys Tyr Tyr Glu Lys Arg Gln Lys Glu Leu
275 280 285
Lys Lys Asn Lys Ser Tyr Asp Leu Glu Thr Ile Ile Gly Leu Phe Asp
290 295 300
Asp Asn Ser Asp Val Ile Gly Lys Tyr Ile Glu Lys Leu Glu Ser Asp
305 310 315 320
Ile Thr Ala Ile Ala Glu Ala Lys Asn Asp Phe Asp Glu Ile Val Leu
325 330 335
Arg Lys His Asp Lys Asn Lys Ser Leu Arg Lys Asn Thr Asn Ala Val
340 345 350
Glu Ala Ile Lys Ser Tyr Leu Asp Thr Val Lys Asp Phe Glu Arg Asp
355 360 365
Ile Lys Leu Ile Asn Gly Ser Gly Gln Glu Val Glu Lys Asn Leu Val
370 375 380
Val Tyr Ala Glu Gln Glu Asn Ile Leu Ala Glu Ile Lys Asn Val Asp
385 390 395 400
Ser Leu Tyr Asn Met Ser Arg Asn Tyr Leu Thr Gln Lys Pro Phe Ser
405 410 415
Thr Glu Lys Phe Lys Leu Asn Phe Asn Arg Ala Thr Leu Leu Asn Gly
420 425 430
Trp Asp Lys Asn Lys Glu Thr Asp Asn Leu Gly Ile Leu Phe Glu Lys
435 440 445
Asp Gly Met Tyr Tyr Leu Gly Ile Met Asn Thr Lys Ala Asn Lys Ile
450 455 460
Phe Val Asn Ile Pro Lys Ala Thr Ser Asn Asp Val Tyr His Lys Val
465 470 475 480
Asn Tyr Lys Leu Leu Pro Gly Pro Asn Lys Met Leu Pro Lys Val Phe
485 490 495
Phe Ala Gln Ser Asn Leu Asp Tyr Tyr Lys Pro Ser Glu Glu Leu Leu
500 505 510
Ala Lys Tyr Lys Ala Gly Thr His Lys Lys Gly Asp Asn Phe Ser Leu
515 520 525
Glu Asp Cys His Ala Leu Ile Asp Phe Phe Lys Ala Ser Ile Glu Lys
530 535 540
His Pro Asp Trp Ser Ser Phe Gly Phe Glu Phe Ser Glu Thr Cys Thr
545 550 555 560
Tyr Glu Asp Leu Ser Gly Phe Tyr Arg Glu Val Glu Lys Gln Gly Tyr
565 570 575
Lys Ile Thr Tyr Thr Asp Val Asp Ala Asp Tyr Ile Thr Ser Leu Val
580 585 590
Glu Arg Asp Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser
595 600 605
Pro Tyr Ser Lys Gly Asn Leu Asn Leu His Thr Ile Tyr Leu Gln Met
610 615 620
Leu Phe Asp Gln Arg Asn Leu Asn Asn Val Val Tyr Lys Leu Asn Gly
625 630 635 640
Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Asn Asp Glu Glu Val
645 650 655
Ile Ile His Lys Ala Gly Glu Glu Ile Lys Asn Lys Asn Ser Lys Arg
660 665 670
Ala Val Asp Lys Pro Thr Ser Lys Phe Gly Tyr Asp Ile Ile Lys Asp
675 680 685
Arg Arg Tyr Ser Lys Asp Lys Phe Met Leu His Ile Pro Val Thr Met
690 695 700
Asn Phe Gly Val Asp Glu Thr Arg Arg Phe Asn Asp Val Val Asn Asp
705 710 715 720
Ala Leu Arg Asn Asp Glu Lys Val Arg Val Ile Gly Ile Asp Arg Gly
725 730 735
Glu Arg Asn Leu Leu Tyr Val Val Val Val Asp Thr Asp Gly Thr Ile
740 745 750
Leu Glu Gln Ile Ser Leu Asn Ser Ile Ile Asn Asn Glu Tyr Ser Ile
755 760 765
Glu Thr Asp Tyr His Lys Leu Leu Asp Glu Lys Glu Gly Asp Arg Asp
770 775 780
Arg Ala Arg Lys Asn Trp Thr Thr Ile Glu Asn Ile Lys Glu Leu Lys
785 790 795 800
Glu Gly Tyr Leu Ser Gln Val Val Asn Val Ile Ala Lys Leu Val Leu
805 810 815
Lys Tyr Asn Ala Ile Ile Cys Leu Glu Asp Leu Asn Phe Gly Phe Lys
820 825 830
Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys
835 840 845
Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Ile Asp Lys Ser Arg Lys
850 855 860
Gln Asp Lys Pro Glu Glu Phe Gly Gly Ala Leu Asn Ala Leu Gln Leu
865 870 875 880
Thr Ser Lys Phe Thr Ser Phe Lys Asp Met Gly Lys Gln Thr Gly Ile
885 890 895
Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile Asp Pro Thr Thr
900 905 910
Gly Phe Ala Asn Leu Phe Tyr Val Lys Tyr Glu Asn Val Glu Lys Ala
915 920 925
Lys Glu Phe Phe Ser Arg Phe Asp Ser Ile Ser Tyr Asn Asn Glu Ser
930 935 940
Gly Tyr Phe Glu Phe Ala Phe Asp Tyr Lys Lys Phe Thr Asp Arg Ala
945 950 955 960
Cys Gly Ala Arg Ser Gln Trp Thr Val Cys Thr Tyr Gly Glu Arg Ile
965 970 975
Ile Lys Phe Arg Asn Thr Glu Lys Asn Asn Ser Phe Asp Asp Lys Thr
980 985 990
Ile Val Leu Ser Glu Glu Phe Lys Glu Leu Phe Ser Ile Tyr Gly Ile
995 1000 1005
Ser Tyr Glu Asp Gly Ala Glu Leu Lys Asn Lys Ile Met Ser Val
1010 1015 1020
Asp Glu Ala Asp Phe Phe Arg Ser Leu Thr Arg Leu Phe Gln Gln
1025 1030 1035
Thr Met Gln Met Arg Asn Ser Ser Asn Asp Val Thr Arg Asp Tyr
1040 1045 1050
Ile Ile Ser Pro Ile Met Asn Asp Arg Gly Glu Phe Phe Asn Ser
1055 1060 1065
Glu Ala Cys Asp Ala Ser Lys Pro Lys Asp Ala Asp Ala Asn Gly
1070 1075 1080
Ala Phe Asn Ile Ala Arg Lys Gly Leu Trp Val Leu Glu Gln Ile
1085 1090 1095
Arg Asn Thr Pro Ser Gly Asp Lys Leu Asn Leu Ala Met Ser Asn
1100 1105 1110
Ala Glu Trp Leu Glu Tyr Ala Gln Arg Asn Gln Ile
1115 1120 1125
<210> 118
<211> 1154
<212> БЕЛОК
<213> Proteocatella sphenisci
<400> 118
Met Glu Asn Phe Lys Asn Leu Tyr Pro Ile Asn Lys Thr Leu Arg Phe
1 5 10 15
Glu Leu Arg Pro Tyr Gly Lys Thr Leu Glu Asn Phe Lys Lys Ser Gly
20 25 30
Leu Leu Glu Lys Asp Ala Phe Lys Ala Asn Ser Arg Arg Ser Met Gln
35 40 45
Ala Ile Ile Asp Glu Lys Phe Lys Glu Thr Ile Glu Glu Arg Leu Lys
50 55 60
Tyr Thr Glu Phe Ser Glu Cys Asp Leu Gly Asn Met Thr Ser Lys Asp
65 70 75 80
Lys Lys Ile Thr Asp Lys Ala Ala Thr Asn Leu Lys Lys Gln Val Ile
85 90 95
Leu Ser Phe Asp Asp Glu Ile Phe Asn Asn Tyr Leu Lys Pro Asp Lys
100 105 110
Asn Ile Asp Ala Leu Phe Lys Asn Asp Pro Ser Asn Pro Val Ile Ser
115 120 125
Thr Phe Lys Gly Phe Thr Thr Tyr Phe Val Asn Phe Phe Glu Ile Arg
130 135 140
Lys His Ile Phe Lys Gly Glu Ser Ser Gly Ser Met Ala Tyr Arg Ile
145 150 155 160
Ile Asp Glu Asn Leu Thr Thr Tyr Leu Asn Asn Ile Glu Lys Ile Lys
165 170 175
Lys Leu Pro Glu Glu Leu Lys Ser Gln Leu Glu Gly Ile Asp Gln Ile
180 185 190
Asp Lys Leu Asn Asn Tyr Asn Glu Phe Ile Thr Gln Ser Gly Ile Thr
195 200 205
His Tyr Asn Glu Ile Ile Gly Gly Ile Ser Lys Ser Glu Asn Val Lys
210 215 220
Ile Gln Gly Ile Asn Glu Gly Ile Asn Leu Tyr Cys Gln Lys Asn Lys
225 230 235 240
Val Lys Leu Pro Arg Leu Thr Pro Leu Tyr Lys Met Ile Leu Ser Asp
245 250 255
Arg Val Ser Asn Ser Phe Val Leu Asp Thr Ile Glu Asn Asp Thr Glu
260 265 270
Leu Ile Glu Met Ile Ser Asp Leu Ile Asn Lys Thr Glu Ile Ser Gln
275 280 285
Asp Val Ile Met Ser Asp Ile Gln Asn Ile Phe Ile Lys Tyr Lys Gln
290 295 300
Leu Gly Asn Leu Pro Gly Ile Ser Tyr Ser Ser Ile Val Asn Ala Ile
305 310 315 320
Cys Ser Asp Tyr Asp Asn Asn Phe Gly Asp Gly Lys Arg Lys Lys Ser
325 330 335
Tyr Glu Asn Asp Arg Lys Lys His Leu Glu Thr Asn Val Tyr Ser Ile
340 345 350
Asn Tyr Ile Ser Glu Leu Leu Thr Asp Thr Asp Val Ser Ser Asn Ile
355 360 365
Lys Met Arg Tyr Lys Glu Leu Glu Gln Asn Tyr Gln Val Cys Lys Glu
370 375 380
Asn Phe Asn Ala Thr Asn Trp Met Asn Ile Lys Asn Ile Lys Gln Ser
385 390 395 400
Glu Lys Thr Asn Leu Ile Lys Asp Leu Leu Asp Ile Leu Lys Ser Ile
405 410 415
Gln Arg Phe Tyr Asp Leu Phe Asp Ile Val Asp Glu Asp Lys Asn Pro
420 425 430
Ser Ala Glu Phe Tyr Thr Trp Leu Ser Lys Asn Ala Glu Lys Leu Asp
435 440 445
Phe Glu Phe Asn Ser Val Tyr Asn Lys Ser Arg Asn Tyr Leu Thr Arg
450 455 460
Lys Gln Tyr Ser Asp Lys Lys Ile Lys Leu Asn Phe Asp Ser Pro Thr
465 470 475 480
Leu Ala Lys Gly Trp Asp Ala Asn Lys Glu Ile Asp Asn Ser Thr Ile
485 490 495
Ile Met Arg Lys Phe Asn Asn Asp Arg Gly Asp Tyr Asp Tyr Phe Leu
500 505 510
Gly Ile Trp Asn Lys Ser Thr Pro Ala Asn Glu Lys Ile Ile Pro Leu
515 520 525
Glu Asp Asn Gly Leu Phe Glu Lys Met Gln Tyr Lys Leu Tyr Pro Asp
530 535 540
Pro Ser Lys Met Leu Pro Lys Gln Phe Leu Ser Lys Ile Trp Lys Ala
545 550 555 560
Lys His Pro Thr Thr Pro Glu Phe Asp Lys Lys Tyr Lys Glu Gly Arg
565 570 575
His Lys Lys Gly Pro Asp Phe Glu Lys Glu Phe Leu His Glu Leu Ile
580 585 590
Asp Cys Phe Lys His Gly Leu Val Asn His Asp Glu Lys Tyr Gln Asp
595 600 605
Val Phe Gly Phe Asn Leu Arg Asn Thr Glu Asp Tyr Asn Ser Tyr Thr
610 615 620
Glu Phe Leu Glu Asp Val Glu Arg Cys Asn Tyr Asn Leu Ser Phe Asn
625 630 635 640
Lys Ile Ala Asp Thr Ser Asn Leu Ile Asn Asp Gly Lys Leu Tyr Val
645 650 655
Phe Gln Ile Trp Ser Lys Asp Phe Ser Ile Asp Ser Lys Gly Thr Lys
660 665 670
Asn Leu Asn Thr Ile Tyr Phe Glu Ser Leu Phe Ser Glu Glu Asn Met
675 680 685
Ile Glu Lys Met Phe Lys Leu Ser Gly Glu Ala Glu Ile Phe Tyr Arg
690 695 700
Pro Ala Ser Leu Asn Tyr Cys Glu Asp Ile Ile Lys Lys Gly His His
705 710 715 720
His Ala Glu Leu Lys Asp Lys Phe Asp Tyr Pro Ile Ile Lys Asp Lys
725 730 735
Arg Tyr Ser Gln Asp Lys Phe Phe Phe His Val Pro Met Val Ile Asn
740 745 750
Tyr Lys Ser Glu Lys Leu Asn Ser Lys Ser Leu Asn Asn Arg Thr Asn
755 760 765
Glu Asn Leu Gly Gln Phe Thr His Ile Ile Gly Ile Asp Arg Gly Glu
770 775 780
Arg His Leu Ile Tyr Leu Thr Val Val Asp Val Ser Thr Gly Glu Ile
785 790 795 800
Val Glu Gln Lys His Leu Asp Glu Ile Ile Asn Thr Asp Thr Lys Gly
805 810 815
Val Glu His Lys Thr His Tyr Leu Asn Lys Leu Glu Glu Lys Ser Lys
820 825 830
Thr Arg Asp Asn Glu Arg Lys Ser Trp Glu Ala Ile Glu Thr Ile Lys
835 840 845
Glu Leu Lys Glu Gly Tyr Ile Ser His Val Ile Asn Glu Ile Gln Lys
850 855 860
Leu Gln Glu Lys Tyr Asn Ala Leu Ile Val Met Glu Asn Leu Asn Tyr
865 870 875 880
Gly Phe Lys Asn Ser Arg Ile Lys Val Glu Lys Gln Val Tyr Gln Lys
885 890 895
Phe Glu Thr Ala Leu Ile Lys Lys Phe Asn Tyr Ile Ile Asp Lys Lys
900 905 910
Asp Pro Glu Thr Tyr Ile His Gly Tyr Gln Leu Thr Asn Pro Ile Thr
915 920 925
Thr Leu Asp Lys Ile Gly Asn Gln Ser Gly Ile Val Leu Tyr Ile Pro
930 935 940
Ala Trp Asn Thr Ser Lys Ile Asp Pro Val Thr Gly Phe Val Asn Leu
945 950 955 960
Leu Tyr Ala Asp Asp Leu Lys Tyr Lys Asn Gln Glu Gln Ala Lys Ser
965 970 975
Phe Ile Gln Lys Ile Asp Asn Ile Tyr Phe Glu Asn Gly Glu Phe Lys
980 985 990
Phe Asp Ile Asp Phe Ser Lys Trp Asn Asn Arg Tyr Ser Ile Ser Lys
995 1000 1005
Thr Lys Trp Thr Leu Thr Ser Tyr Gly Thr Arg Ile Gln Thr Phe
1010 1015 1020
Arg Asn Pro Gln Lys Asn Asn Lys Trp Asp Ser Ala Glu Tyr Asp
1025 1030 1035
Leu Thr Glu Glu Phe Lys Leu Ile Leu Asn Ile Asp Gly Thr Leu
1040 1045 1050
Lys Ser Gln Asp Val Glu Thr Tyr Lys Lys Phe Met Ser Leu Phe
1055 1060 1065
Lys Leu Met Leu Gln Leu Arg Asn Ser Val Thr Gly Thr Asp Ile
1070 1075 1080
Asp Tyr Met Ile Ser Pro Val Thr Asp Lys Thr Gly Thr His Phe
1085 1090 1095
Asp Ser Arg Glu Asn Ile Lys Asn Leu Pro Ala Asp Ala Asp Ala
1100 1105 1110
Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Ile Met Ala Ile Glu
1115 1120 1125
Asn Ile Met Asn Gly Ile Ser Asp Pro Leu Lys Ile Ser Asn Glu
1130 1135 1140
Asp Tyr Leu Lys Tyr Ile Gln Asn Gln Gln Glu
1145 1150
<210> 119
<211> 34
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 119
ttagagaagt catttaataa ggccactgtt aaaa 34
<210> 120
<211> 34
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<223> Описание объединенной молекулы ДНК/РНК: Синтетический олигонуклеотид
<400> 120
ttcgagaagu cauuuaauaa ggccacuguu aaaa 34
<210> 121
<211> 34
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<223> Описание объединенной молекулы ДНК/РНК: Синтетический олигонуклеотид
<400> 121
ttcgagaagu cauuuaauaa ggccacuguu aaaa 34
<210> 122
<211> 34
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<223> Описание объединенной молекулы ДНК/РНК: Синтетический олигонуклеотид
<400> 122
ttcgagaagu cauuuaauaa ggccacuguu aaaa 34
<210> 123
<211> 34
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<223> Описание объединенной молекулы ДНК/РНК: Синтетический олигонуклеотид
<400> 123
ttcgagaagu cauuuaauaa ggccacuguu aaaa 34
<210> 124
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 124
ctgatggtcc atgtctgtta ctcg 24
<210> 125
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<400> 125
ctgggactca ggcgggtcac 20
<210> 126
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<400> 126
cctcacacaa cagcttcatg tcagc 25
<210> 127
<211> 3960
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 127
atggccccaa agaagaagcg gaaggtcggt atccacggag tcccagcagc cggtagtaac 60
atcaaaaact ttaccgggct ctaccccctc agcaaaactt tgcgctttga actcaagcct 120
attggcaaaa ccaaggaaaa catcgagaaa aatggcatcc tgaccaagga cgagcaacgg 180
gctaaagact acctcatagt caaaggcttt attgacgagt atcacaagca gttcatcaaa 240
gacaggcttt gggactttaa attgcctctc gaaagtgagg gggagaagaa cagtctcgaa 300
gaataccagg aactgtacga gctcactaag cgcaacgatg cccaggaggc cgacttcacc 360
gagattaaag ataaccttcg cagctctatt accgaacagc tcacgaagtc tggatctgcg 420
tacgatcgga tttttaaaaa agagttcatt agagaagacc tggtcaactt cctcgaagat 480
gaaaaagata aaaatatcgt gaaacagttc gaggacttta ctacatattt tacgggtttt 540
tatgaaaata ggaagaacat gtactctagc gaagagaagt ccacggccat cgcataccgg 600
cttatccatc agaatctgcc aaaattcatg gacaacatga gaagttttgc caaaattgca 660
aattccagtg tttccgagca ctttagcgac atctatgaaa gctggaagga atatctgaat 720
gtaaatagca tcgaggaaat cttccagctc gactatttta gcgaaacctt gactcagcca 780
catattgagg tgtataacta tattatcggg aagaaagtcc tggaagacgg aaccgagata 840
aagggcatca acgagtatgt gaacctctac aatcagcagc agaaagataa gagtaaacga 900
ctgcctttcc tggtgccact gtataagcaa attttgtctg atagggaaaa actctcctgg 960
attgctgaag agttcgacag cgacaagaag atgctgagcg ctatcaccga gtcttacaac 1020
cacctgcaca acgtgttgat gggtaacgag aacgaaagcc tgcgaaatct gctgctgaat 1080
attaaggact ataacctgga gaaaattaat atcacaaacg acttgtctct caccgaaatc 1140
tcccagaatc tttttggccg atatgatgta ttcacaaatg ggatcaaaaa caagctgaga 1200
gtgttgactc caaggaagaa aaaggagacg gacgaaaatt ttgaggaccg cattaacaaa 1260
atttttaaga cccagaagtc cttcagcatc gcttttctga acaagctgcc tcagcccgaa 1320
atggaggatg ggaagccccg gaacattgag gactatttca ttacacaggg ggcgattaac 1380
accaaatcta tacagaaaga agatatcttc gcccaaattg agaatgcata cgaggatgca 1440
caggtgttcc tgcaaattaa ggacaccgac aacaaactta gccagaacaa gacggcggtg 1500
gaaaagatca aaactttgct ggacgccttg aaggaactcc agcacttcat caaaccgctg 1560
ctgggctctg gggaggagaa cgagaaagac gaactgttct acggttcctt cctggccatc 1620
tgggacgaac tggacaccat tacaccactt tataacaaag tgagaaattg gctgacccga 1680
aaaccatatt caacagaaaa aatcaaattg aatttcgaca acgctcagct gctgggaggg 1740
tgggatgtca ataaagaaca cgactgtgca ggtatcttgt tgcggaaaaa cgatagctac 1800
tatctcggaa ttatcaataa gaaaaccaac cacatctttg atacggatat tacgccatca 1860
gatggcgagt gctatgacaa aatcgactac aagctccttc ccggggcgaa caaaatgctt 1920
ccaaaggtgt tttttagtaa gtcccgaatc aaagagttcg agccatcaga ggccataatc 1980
aattgctata agaaggggac acacaaaaaa ggaaaaaact ttaacctgac ggactgtcac 2040
cgcctgatca acttttttaa gacctcaatc gagaaacacg aggattggtc aaaattcgga 2100
ttcaagttct ccgataccga aacgtatgag gatattagcg gtttttatag agaggtcgag 2160
cagcagggat acaggctgac gagccatcca gtcagtgcca gctatataca tagtctggtc 2220
aaggaaggaa aactgtacct cttccaaatc tggaacaagg acttttctca attctccaag 2280
gggaccccta acttgcacac tctctattgg aagatgctgt ttgacaaacg gaatcttagc 2340
gatgtggttt ataagctgaa tggccaggct gaagtgttct atagaaagag ctccattgaa 2400
caccagaacc gaattatcca ccccgctcag catcccatca caaataagaa tgagcttaac 2460
aaaaagcaca ctagcacctt caaatacgat atcatcaaag atcgcagata cacggtggat 2520
aaattccagt tccatgtgcc cattactata aattttaagg cgaccgggca gaacaacatc 2580
aacccaatcg tccaagaggt gattcgccaa aacggtatca cccacatcat aggcatcgat 2640
cgaggtgaac gccatcttct gtacctctct ctcatcgatt tgaaaggcaa catcatcaag 2700
cagatgactc tcaacgaaat tattaatgag tataagggtg tgacctataa gaccaactac 2760
cataacctcc tggagaagag ggagaaggag cggaccgagg ccagacactc ctggagtagt 2820
attgaaagca taaaagaact gaaggatgga tacatgtcac aggtgattca caaaattacg 2880
gacatgatgg ttaagtacaa tgcgattgtg gtcctggagg acctcaacgg ggggtttatg 2940
cgaggccgcc agaaggtcga gaagcaggtg taccagaaat ttgaaaaaaa gttgatcgac 3000
aagctgaact atctcgttga caagaaactc gacgctaacg aggtcggcgg agtactgaat 3060
gcttatcagc tgaccaacaa gttcgagtct ttcaagaaga ttgggaaaca aagcggattt 3120
ttgttctaca tccccgcctg gaacacaagc aaaatcgatc ctataacagg gttcgttaat 3180
ctgttcaaca ccaggtacga gtctatcaag gagacaaaag ttttttggtc taagtttgat 3240
attatccgat acaataaaga gaagaattgg ttcgagttcg tcttcgatta caataccttt 3300
acgactaaag cggagggaac acgcactaag tggactctgt gcacccacgg cactcgcatc 3360
cagacattcc ggaacccaga aaagaatgcc cagtgggaca ataaagagat caatttgact 3420
gagtccttca aagctctgtt tgaaaagtac aagatcgata tcaccagtaa tctcaaggaa 3480
tccatcatgc aggaaaccga gaagaagttc ttccaggaac tgcataatct gctccacctg 3540
accctgcaga tgaggaatag cgttactgga accgacatag actatttgat cagccccgtt 3600
gccgatgagg atggaaattt ctatgatagt cgcataaatg gcaaaaattt tccggagaat 3660
gccgatgcca atggcgcgta caacatcgca cgaaagggtc tgatgcttat tcggcagatc 3720
aagcaagcag atccacagaa gaaattcaag tttgagacaa tcaccaataa agactggctg 3780
aaattcgccc aagacaagcc ctatcttaaa gatggcagcg ggaaaaggcc ggcggccacg 3840
aaaaaggccg gccaggcaaa aaagaaaaag ggatcctacc catacgatgt tccagattac 3900
gcttatccct acgacgtgcc tgattatgca tacccatacg atgtccccga ctatgcctaa 3960
<210> 128
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 128
cctcactcct gctcggtgaa ttt 23
<210> 129
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 129
ctgatggtcc atgtctgtta ctc 23
<210> 130
<211> 6
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетическая 6xHis метка
<400> 130
His His His His His His
1 5
<210> 131
<211> 31
<212> ДНК
<213> Francisella novicida
<400> 131
gagaagtcat ttaataaggc cactgttaaa a 31
<210> 132
<211> 30
<212> ДНК
<213> Francisella novicida
<400> 132
gctactattc ctgtgccttc agataattca 30
<210> 133
<211> 27
<212> ДНК
<213> Francisella novicida
<400> 133
gtctagagcc ttttgtatta gtagccg 27
<210> 134
<211> 98
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (30)..(37)
<223> a, c, t, g, неизвестное или другое
<400> 134
ggccagtgaa ttcgagctcg gtacccgggn nnnnnnngag aagtcattta ataaggccac 60
tgttaaaaag cttggcgtaa tcatggtcat agctgttt 98
<210> 135
<211> 98
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (61)..(68)
<223> a, c, t, g, неизвестное или другое
<400> 135
ggccagtgaa ttcgagctcg gtacccgggg agaagtcatt taataaggcc actgttaaaa 60
nnnnnnnnag cttggcgtaa tcatggtcat agctgttt 98
<210> 136
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 136
gctgacatga agctgttgtg tgagg 25
<210> 137
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<400> 137
ggccagtgaa ttcgagctcg g 21
<210> 138
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<400> 138
caatttcaca caggaaacag ctatgacc 28
<210> 139
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<400> 139
cggggctggc ttaactatgc g 21
<210> 140
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<400> 140
gcccaatacg caaaccgcct 20
<210> 141
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<400> 141
ccatcccctt ctgtgaatgt 20
<210> 142
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<400> 142
tctccgtgtc tccaatctcc 20
<210> 143
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<400> 143
ctgggactca ggcgggtcac 20
<210> 144
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<400> 144
gctgacatga agctgttgtg tgagg 25
<210> 145
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 145
gagaagtcat ttaataaggc cact 24
<210> 146
<211> 22
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 146
gagaagtcat ttaataaggc ca 22
<210> 147
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 147
gagaagtcat ttaataaggc 20
<210> 148
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 148
gagaagtcat ttaataag 18
<210> 149
<211> 17
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 149
gagaagtcat ttaataa 17
<210> 150
<211> 16
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 150
gagaagtcat ttaata 16
<210> 151
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 151
gataagtcat ttaataaggc cact 24
<210> 152
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 152
gagaaggcat ttaataaggc cact 24
<210> 153
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 153
gagaagtcat gtaataaggc cact 24
<210> 154
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 154
gagaagtcat ttaagaaggc cact 24
<210> 155
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 155
gagaagtcat ttaataagtc cact 24
<210> 156
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 156
gagaagtcat ttaataaggc caat 24
<210> 157
<211> 42
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 157
atttctactg ttgtagatga gaagtcattt aataaggcca ct 42
<210> 158
<211> 41
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 158
tttctactgt tgtagatgag aagtcattta ataaggccac t 41
<210> 159
<211> 40
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 159
ttctactgtt gtagatgaga agtcatttaa taaggccact 40
<210> 160
<211> 39
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 160
tctactgttg tagatgagaa gtcatttaat aaggccact 39
<210> 161
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 161
ctgttgtaga tgagaagtca tttaataagg ccact 35
<210> 162
<211> 31
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 162
tgtagatgag aagtcattta ataaggccac t 31
<210> 163
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 163
aatttctgct gttgcagat 19
<210> 164
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 164
aatttccact gttgtggat 19
<210> 165
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 165
aattcctact gttgtaggt 19
<210> 166
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 166
aatttatact gttgtagat 19
<210> 167
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 167
aatttcgact gttgtagat 19
<210> 168
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 168
aatttctagt gttgtagat 19
<210> 169
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 169
aatttctact attgtagat 19
<210> 170
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 170
aatttctact gctgtagat 19
<210> 171
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 171
aatttctact ttgtagat 18
<210> 172
<211> 17
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 172
aatttctact tgtagat 17
<210> 173
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 173
aatttctact tttgtagaa 19
<210> 174
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 174
aatttctact tttgtagac 19
<210> 175
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 175
taatttctac tgttgtagat 20
<210> 176
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 176
cctcactcct gctcggtgaa ttt 23
<210> 177
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 177
taatttctac tgttgtagat 20
<210> 178
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 178
aggagtgttc agtctccgtg aac 23
<210> 179
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 179
taatttctac tgttgtagat 20
<210> 180
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 180
ctgatggtcc atgtctgtta ctc 23
<210> 181
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 181
taatttctac tgttgtagat 20
<210> 182
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 182
tttcccttca gctaaaataa agg 23
<210> 183
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 183
taatttctac taagtgtaga t 21
<210> 184
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 184
cctcactcct gctcggtgaa ttt 23
<210> 185
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 185
taatttctac taagtgtaga t 21
<210> 186
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 186
aggagtgttc agtctccgtg aac 23
<210> 187
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 187
taatttctac taagtgtaga t 21
<210> 188
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 188
ctgatggtcc atgtctgtta ctc 23
<210> 189
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 189
taatttctac taagtgtaga t 21
<210> 190
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 190
tttcccttca gctaaaataa agg 23
<210> 191
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 191
tcactcctgc tcggtgaatt 20
<210> 192
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 192
aaccctctgg ggaccgtttg 20
<210> 193
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 193
agtacgttaa tgtttcctga 20
<210> 194
<400> 194
000
<210> 195
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 195
taatttctac tgttgtagat 20
<210> 196
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 196
agaaatgcat ggttctcatg c 21
<210> 197
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 197
aaaattacct agtaattagg t 21
<210> 198
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 198
ggatttctac ttttgtagat 20
<210> 199
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 199
aaatttctac ttttgtagat 20
<210> 200
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 200
cgcgcccacg cggggcgcga c 21
<210> 201
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 201
taatttctac tcttgtagat 20
<210> 202
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 202
gaatttctac tattgtagat 20
<210> 203
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 203
gaatctctac tctttgtaga t 21
<210> 204
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 204
taatttctac tttgtagat 19
<210> 205
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 205
aaatttctac tgtttgtaga t 21
<210> 206
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 206
gaatttctac ttttgtagat 20
<210> 207
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 207
taatttctac taagtgtaga t 21
<210> 208
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 208
taatttctac tattgtagat 20
<210> 209
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 209
taatttctac ttcggtagat 20
<210> 210
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 210
taatttctac tattgtagat 20
<210> 211
<211> 6569
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 211
catcaaggaa ttggttctaa gcttatagaa gcaatgatta aggaagccaa aaaaaataat 60
attgatgcaa tatttgtctt aggtcatcca agttattatc caaaatttgg ttttaaacca 120
gccacagaat atcagataaa atgtgaatat gatgtcccag cggatgtttt tatggtacta 180
gatttgtcag ctaaactagc tagtttaaaa ggacaaactg tctactatgc cgatgagttt 240
ggcaaaattt tttagatcta caaaattata aactaaataa agattcttat aataacttta 300
tatataatcg aaatgtagag aattttataa ggagtcttta tcatgtcaat ttatcaagaa 360
tttgttaata aatatagttt aagtaaaact ctaagatttg agttaatccc acagggtaaa 420
acacttgaaa acataaaagc aagaggtttg attttagatg atgagaaaag agctaaagac 480
tacaaaaagg ctaaacaaat aattgataaa tatcatcagt tttttataga ggagatatta 540
agttcggttt gtattagcga agatttatta caaaactatt ctgatgttta ttttaaactt 600
aaaaagagtg atgatgataa tctacaaaaa gattttaaaa gtgcaaaaga tacgataaag 660
aaacaaatat ctgaatatat aaaggactca gagaaattta agaatttgtt taatcaaaac 720
cttatcgatg ctaaaaaagg gcaagagtca gatttaattc tatggctaaa gcaatctaag 780
gataatggta tagaactatt taaagccaat agtgatatca cagatataga tgaggcgtta 840
gaaataatca aatcttttaa aggttggaca acttatttta agggttttca tgaaaataga 900
aaaaatgttt atagtagcaa tgatattcct acatctatta tttataggat agtagatgat 960
aatttgccta aatttctaga aaataaagct aagtatgaga gtttaaaaga caaagctcca 1020
gaagctataa actatgaaca aattaaaaaa gatttggcag aagagctaac ctttgatatt 1080
gactacaaaa catctgaagt taatcaaaga gttttttcac ttgatgaagt ttttgagata 1140
gcaaacttta ataattatct aaatcaaagt ggtattacta aatttaatac tattattggt 1200
ggtaaatttg taaatggtga aaatacaaag agaaaaggta taaatgaata tataaatcta 1260
tactcacagc aaataaatga taaaacactc aaaaaatata aaatgagtgt tttatttaag 1320
caaattttaa gtgatacaga atctaaatct tttgtaattg ataagttaga agatgatagt 1380
gatgtagtta caacgatgca aagtttttat gagcaaatag cagcttttaa aacagtagaa 1440
gaaaaatcta ttaaagaaac actatcttta ttatttgatg atttaaaagc tcaaaaactt 1500
gatttgagta aaatttattt taaaaatgat aaatctctta ctgatctatc acaacaagtt 1560
tttgatgatt atagtgttat tggtacagcg gtactagaat atataactca acaaatagca 1620
cctaaaaatc ttgataaccc tagtaagaaa gagcaagaat taatagccaa aaaaactgaa 1680
aaagcaaaat acttatctct agaaactata aagcttgcct tagaagaatt taataagcat 1740
agagatatag ataaacagtg taggtttgaa gaaatacttg caaactttgc ggctattccg 1800
atgatatttg atgaaatagc tcaaaacaaa gacaatttgg cacagatatc tatcaaatat 1860
caaaatcaag gtaaaaaaga cctacttcaa gctagtgcgg aagatgatgt taaagctatc 1920
aaggatcttt tagatcaaac taataatctc ttacataaac taaaaatatt tcatattagt 1980
cagtcagaag ataaggcaaa tattttagac aaggatgagc atttttatct agtatttgag 2040
gagtgctact ttgagctagc gaatatagtg cctctttata acaaaattag aaactatata 2100
actcaaaagc catatagtga tgagaaattt aagctcaatt ttgagaactc gactttggct 2160
aatggttggg ataaaaataa agagcctgac aatacggcaa ttttatttat caaagatgat 2220
aaatattatc tgggtgtgat gaataagaaa aataacaaaa tatttgatga taaagctatc 2280
aaagaaaata aaggcgaggg ttataaaaaa attgtttata aacttttacc tggcgcaaat 2340
aaaatgttac ctaaggtttt cttttctgct aaatctataa aattttataa tcctagtgaa 2400
gatatactta gaataagaaa tcattccaca catacaaaaa atggtagtcc tcaaaaagga 2460
tatgaaaaat ttgagtttaa tattgaagat tgccgaaaat ttatagattt ttataaacag 2520
tctataagta agcatccgga gtggaaagat tttggattta gattttctga tactcaaaga 2580
tataattcta tagatgaatt ttatagagaa gttgaaaatc aaggctacaa actaactttt 2640
gaaaatatat cagagagcta tattgatagc gtagttaatc agggtaaatt gtacctattc 2700
caaatctata ataaagattt ttcagcttat agcaaagggc gaccaaatct acatacttta 2760
tattggaaag cgctgtttga tgagagaaat cttcaagatg tggtttataa gctaaatggt 2820
gaggcagagc ttttttatcg taaacaatca atacctaaaa aaatcactca cccagctaaa 2880
gaggcaatag ctaataaaaa caaagataat cctaaaaaag agagtgtttt tgaatatgat 2940
ttaatcaaag ataaacgctt tactgaagat aagtttttct ttcactgtcc tattacaatc 3000
aattttaaat ctagtggagc taataagttt aatgatgaaa tcaatttatt gctaaaagaa 3060
aaagcaaatg atgttcatat attaagtata gatagaggtg aaagacattt agcttactat 3120
actttggtag atggtaaagg caatatcatc aaacaagata ctttcaacat cattggtaat 3180
gatagaatga aaacaaacta ccatgataag cttgctgcaa tagagaaaga tagggattca 3240
gctaggaaag actggaaaaa gataaataac atcaaagaga tgaaagaggg ctatctatct 3300
caggtagttc atgaaatagc taagctagtt atagagtata atgctattgt ggtttttgag 3360
gatttaaatt ttggatttaa aagagggcgt ttcaaggtag agaagcaggt ctatcaaaag 3420
ttagaaaaaa tgctaattga gaaactaaac tatctagttt tcaaagataa tgagtttgat 3480
aaaactgggg gagtgcttag agcttatcag ctaacagcac cttttgagac ttttaaaaag 3540
atgggtaaac aaacaggtat tatctactat gtaccagctg gttttacttc aaaaatttgt 3600
cctgtaactg gttttgtaaa tcagttatat cctaagtatg aaagtgtcag caaatctcaa 3660
gagttcttta gtaagtttga caagatttgt tataaccttg ataagggcta ttttgagttt 3720
agttttgatt ataaaaactt tggtgacaag gctgccaaag gcaagtggac tatagctagc 3780
tttgggagta gattgattaa ctttagaaat tcagataaaa atcataattg ggatactcga 3840
gaagtttatc caactaaaga gttggagaaa ttgctaaaag attattctat cgaatatggg 3900
catggcgaat gtatcaaagc agctatttgc ggtgagagcg acaaaaagtt ttttgctaag 3960
ctaactagtg tcctaaatac tatcttacaa atgcgtaact caaaaacagg tactgagtta 4020
gattatctaa tttcaccagt agcagatgta aatggcaatt tctttgattc gcgacaggcg 4080
ccaaaaaata tgcctcaaga tgctgatgcc aatggtgctt atcatattgg gctaaaaggt 4140
ctgatgctac taggtaggat caaaaataat caagagggca aaaaactcaa tttggttatc 4200
aaaaatgaag agtattttga gttcgtgcag aataggaata actaattcat tcaagaatat 4260
attaccctgt cagtttagcg actattacct ctttaataat ttgcagggga attattttag 4320
taatagtaat atacacaaga gttattgatt atatggaaaa ttatatttag ataacatggt 4380
taaatgattt tatattctgt ccttactcga tatatttgca taatatctat agtaatgcct 4440
cagatactac atactattca tctagccaaa caaaagggcg cgatgctcat aaaagtatcg 4500
ataaaggaat ctatagtacc aaaaaagatg acctgatcgg tatcgatgtt attaaccata 4560
aatatggttt ggttggtaaa attgatgttt ttcataaaga taagggctta cttgtggaga 4620
gaaaaaggca aatcaagact atctatgatg gctataaata tcagctttat gcgcaatatt 4680
tttgtctcca agagatgggc tatgatgtca aagccattaa attttattcg atggttgata 4740
ataaatcata cccaatagct ataccaactt cagctgagtt agaaaagttt gaaaaacata 4800
ttcaaacaat caagcaatat aatccaatgg ataactcatt taggcaaaat attgaaaagt 4860
gtaaattttg tatatatgca aacttatgtg ataaaacgga cttgtagatt atgtttagta 4920
aaaatgatat tgaatcaaag aatatagttt ttgttaatat ttttgatgga gtgaaactta 4980
gtctatcatt ggggaatata gttataaaag ataaagaaac tgatgaggtg aaaactaagc 5040
tttctgttca taaagttctt gcattgttta tcgtaggtaa tatgacgatg acctcgcaac 5100
ttttagagac ctgtaagaaa aatgctatac agctagtttt tatgaaaaat agctttagac 5160
catatctatg ttttggtgat attgctgagg ctaatttttt agctagatat aagcaatata 5220
gtgtagttga gcaagatata agtttagcaa ggatttttat aacatcaaag atacgcaatc 5280
aacataactt agtcaaaagc ctaagagata aaactccaga gcagcaagag atagtcaaaa 5340
agaataaaca gctaatagca gagttagaaa atacaacaag cctagcggag ctaatgggta 5400
tagagggcaa tgttgccaaa aatttcttca aaggattcta tggacattta gatagttggc 5460
aagggcgcaa acctagaata aaacaggatc catataatgt tgttttagac ttgggctata 5520
gtatgttgtt taattttgta gagtgttttt tgcgactttt tggctttgat ttatacaagg 5580
gcttttgtca tcagacttgg tataagcgta aatccctagt ttgtgacttt gttgagccat 5640
ttagatgtat agtggataac caagttagaa aatcatggaa tctcgggcaa ttttctgtag 5700
aggattttgg ttgcaaaaat gagcagtttt atataaaaaa agataaaaca aaagactact 5760
caaaaatact ttttgccgag attatcagct acaagctaga gatatttgaa tatgtaagag 5820
aattttatcg tgcctttatg cgaggcaaag aaattgcaga gtatccaata ttttgttatg 5880
aaactaggag ggtgtatgtt gatagtcagt tatgatttta gtaataataa agtacgtgca 5940
aagtttgcca aatttctaga aagttatggt gtacgtttac aatattcggt atttgagctc 6000
aaatatagca agagaatgtt agacttgatt ttagctgaga tagaaaataa ctatgtacca 6060
ctatttacaa atgctgatag tgttttaatc tttaatgctc cagataaaga tgtgataaaa 6120
tatggttatg cgattcatag agaacaagag gttgttttta tagactaaaa attgcaaacc 6180
ttagtcttta tgttaaaata actactaagt tcttagagat atttaaaaat atgactgttg 6240
ttatatatca aaatgctaaa aaaatcatag attttaggtc tttttttgct gatttaggca 6300
aaaacgggtc taagaacttt aaataatttc tactgttgta gatgagaagt catttaataa 6360
ggccactgtt aaaagtctaa gaactttaaa taatttctac tgttgtagat gctactattc 6420
ctgtgccttc agataattca gtctaagaac tttaaataat ttctactgtt gtagatgtct 6480
agagcctttt gtattagtag ccggtctaag aactttaaat aatttctact gttgtagatt 6540
agcgatttat gaaggtcatt tttttgtct 6569
<210> 212
<211> 4170
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 212
tttacacttt atgcttccgg ctcgtatgtt aggaggtctt tatcatgtca atttatcaag 60
aatttgttaa taaatatagt ttaagtaaaa ctctaagatt tgagttaatc ccacagggta 120
aaacacttga aaacataaaa gcaagaggtt tgattttaga tgatgagaaa agagctaaag 180
actacaaaaa ggctaaacaa ataattgata aatatcatca gttttttata gaggagatat 240
taagttcggt ttgtattagc gaagatttat tacaaaacta ttctgatgtt tattttaaac 300
ttaaaaagag tgatgatgat aatctacaaa aagattttaa aagtgcaaaa gatacgataa 360
agaaacaaat atctgaatat ataaaggact cagagaaatt taagaatttg tttaatcaaa 420
accttatcga tgctaaaaaa gggcaagagt cagatttaat tctatggcta aagcaatcta 480
aggataatgg tatagaacta tttaaagcca atagtgatat cacagatata gatgaggcgt 540
tagaaataat caaatctttt aaaggttgga caacttattt taagggtttt catgaaaata 600
gaaaaaatgt ttatagtagc aatgatattc ctacatctat tatttatagg atagtagatg 660
ataatttgcc taaatttcta gaaaataaag ctaagtatga gagtttaaaa gacaaagctc 720
cagaagctat aaactatgaa caaattaaaa aagatttggc agaagagcta acctttgata 780
ttgactacaa aacatctgaa gttaatcaaa gagttttttc acttgatgaa gtttttgaga 840
tagcaaactt taataattat ctaaatcaaa gtggtattac taaatttaat actattattg 900
gtggtaaatt tgtaaatggt gaaaatacaa agagaaaagg tataaatgaa tatataaatc 960
tatactcaca gcaaataaat gataaaacac tcaaaaaata taaaatgagt gttttattta 1020
agcaaatttt aagtgataca gaatctaaat cttttgtaat tgataagtta gaagatgata 1080
gtgatgtagt tacaacgatg caaagttttt atgagcaaat agcagctttt aaaacagtag 1140
aagaaaaatc tattaaagaa acactatctt tattatttga tgatttaaaa gctcaaaaac 1200
ttgatttgag taaaatttat tttaaaaatg ataaatctct tactgatcta tcacaacaag 1260
tttttgatga ttatagtgtt attggtacag cggtactaga atatataact caacaaatag 1320
cacctaaaaa tcttgataac cctagtaaga aagagcaaga attaatagcc aaaaaaactg 1380
aaaaagcaaa atacttatct ctagaaacta taaagcttgc cttagaagaa tttaataagc 1440
atagagatat agataaacag tgtaggtttg aagaaatact tgcaaacttt gcggctattc 1500
cgatgatatt tgatgaaata gctcaaaaca aagacaattt ggcacagata tctatcaaat 1560
atcaaaatca aggtaaaaaa gacctacttc aagctagtgc ggaagatgat gttaaagcta 1620
tcaaggatct tttagatcaa actaataatc tcttacataa actaaaaata tttcatatta 1680
gtcagtcaga agataaggca aatattttag acaaggatga gcatttttat ctagtatttg 1740
aggagtgcta ctttgagcta gcgaatatag tgcctcttta taacaaaatt agaaactata 1800
taactcaaaa gccatatagt gatgagaaat ttaagctcaa ttttgagaac tcgactttgg 1860
ctaatggttg ggataaaaat aaagagcctg acaatacggc aattttattt atcaaagatg 1920
ataaatatta tctgggtgtg atgaataaga aaaataacaa aatatttgat gataaagcta 1980
tcaaagaaaa taaaggcgag ggttataaaa aaattgttta taaactttta cctggcgcaa 2040
ataaaatgtt acctaaggtt ttcttttctg ctaaatctat aaaattttat aatcctagtg 2100
aagatatact tagaataaga aatcattcca cacatacaaa aaatggtagt cctcaaaaag 2160
gatatgaaaa atttgagttt aatattgaag attgccgaaa atttatagat ttttataaac 2220
agtctataag taagcatccg gagtggaaag attttggatt tagattttct gatactcaaa 2280
gatataattc tatagatgaa ttttatagag aagttgaaaa tcaaggctac aaactaactt 2340
ttgaaaatat atcagagagc tatattgata gcgtagttaa tcagggtaaa ttgtacctat 2400
tccaaatcta taataaagat ttttcagctt atagcaaagg gcgaccaaat ctacatactt 2460
tatattggaa agcgctgttt gatgagagaa atcttcaaga tgtggtttat aagctaaatg 2520
gtgaggcaga gcttttttat cgtaaacaat caatacctaa aaaaatcact cacccagcta 2580
aagaggcaat agctaataaa aacaaagata atcctaaaaa agagagtgtt tttgaatatg 2640
atttaatcaa agataaacgc tttactgaag ataagttttt ctttcactgt cctattacaa 2700
tcaattttaa atctagtgga gctaataagt ttaatgatga aatcaattta ttgctaaaag 2760
aaaaagcaaa tgatgttcat atattaagta tagatagagg tgaaagacat ttagcttact 2820
atactttggt agatggtaaa ggcaatatca tcaaacaaga tactttcaac atcattggta 2880
atgatagaat gaaaacaaac taccatgata agcttgctgc aatagagaaa gatagggatt 2940
cagctaggaa agactggaaa aagataaata acatcaaaga gatgaaagag ggctatctat 3000
ctcaggtagt tcatgaaata gctaagctag ttatagagta taatgctatt gtggtttttg 3060
aggatttaaa ttttggattt aaaagagggc gtttcaaggt agagaagcag gtctatcaaa 3120
agttagaaaa aatgctaatt gagaaactaa actatctagt tttcaaagat aatgagtttg 3180
ataaaactgg gggagtgctt agagcttatc agctaacagc accttttgag acttttaaaa 3240
agatgggtaa acaaacaggt attatctact atgtaccagc tggttttact tcaaaaattt 3300
gtcctgtaac tggttttgta aatcagttat atcctaagta tgaaagtgtc agcaaatctc 3360
aagagttctt tagtaagttt gacaagattt gttataacct tgataagggc tattttgagt 3420
ttagttttga ttataaaaac tttggtgaca aggctgccaa aggcaagtgg actatagcta 3480
gctttgggag tagattgatt aactttagaa attcagataa aaatcataat tgggatactc 3540
gagaagttta tccaactaaa gagttggaga aattgctaaa agattattct atcgaatatg 3600
ggcatggcga atgtatcaaa gcagctattt gcggtgagag cgacaaaaag ttttttgcta 3660
agctaactag tgtcctaaat actatcttac aaatgcgtaa ctcaaaaaca ggtactgagt 3720
tagattatct aatttcacca gtagcagatg taaatggcaa tttctttgat tcgcgacagg 3780
cgccaaaaaa tatgcctcaa gatgctgatg ccaatggtgc ttatcatatt gggctaaaag 3840
gtctgatgct actaggtagg atcaaaaata atcaagaggg caaaaaactc aatttggtta 3900
tcaaaaatga agagtatttt gagttcgtgc agaataggaa taactaattg acagctagct 3960
cagtcctagg tataatgcta gcgctgattt aggcaaaaac gggtctaaga actttaaata 4020
atttctactg ttgtagatga gaagtcattt aataaggcca ctgttaaaag tctaagaact 4080
ttaaataatt tctactgttg tagatgctac tattcctgtg ccttcagata attcagtcta 4140
agaactttaa ataatttcta ctgttgtaga 4170
<210> 213
<211> 4613
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 213
ctgtctacta tgccgatgag tttggcaaaa ttttttagat ctacaaaatt ataaactaaa 60
taaagattct tataataact ttatatataa tcgaaatgta gagaatttta taaggagtct 120
ttatcatgtc aatttatcaa gaatttgtta ataaatatag tttaagtaaa actctaagat 180
ttgagttaat cccacagggt aaaacacttg aaaacataaa agcaagaggt ttgattttag 240
atgatgagaa aagagctaaa gactacaaaa aggctaaaca aataattgat aaatatcatc 300
agttttttat agaggagata ttaagttcgg tttgtattag cgaagattta ttacaaaact 360
attctgatgt ttattttaaa cttaaaaaga gtgatgatga taatctacaa aaagatttta 420
aaagtgcaaa agatacgata aagaaacaaa tatctgaata tataaaggac tcagagaaat 480
ttaagaattt gtttaatcaa aaccttatcg atgctaaaaa agggcaagag tcagatttaa 540
ttctatggct aaagcaatct aaggataatg gtatagaact atttaaagcc aatagtgata 600
tcacagatat agatgaggcg ttagaaataa tcaaatcttt taaaggttgg acaacttatt 660
ttaagggttt tcatgaaaat agaaaaaatg tttatagtag caatgatatt cctacatcta 720
ttatttatag gatagtagat gataatttgc ctaaatttct agaaaataaa gctaagtatg 780
agagtttaaa agacaaagct ccagaagcta taaactatga acaaattaaa aaagatttgg 840
cagaagagct aacctttgat attgactaca aaacatctga agttaatcaa agagtttttt 900
cacttgatga agtttttgag atagcaaact ttaataatta tctaaatcaa agtggtatta 960
ctaaatttaa tactattatt ggtggtaaat ttgtaaatgg tgaaaataca aagagaaaag 1020
gtataaatga atatataaat ctatactcac agcaaataaa tgataaaaca ctcaaaaaat 1080
ataaaatgag tgttttattt aagcaaattt taagtgatac agaatctaaa tcttttgtaa 1140
ttgataagtt agaagatgat agtgatgtag ttacaacgat gcaaagtttt tatgagcaaa 1200
tagcagcttt taaaacagta gaagaaaaat ctattaaaga aacactatct ttattatttg 1260
atgatttaaa agctcaaaaa cttgatttga gtaaaattta ttttaaaaat gataaatctc 1320
ttactgatct atcacaacaa gtttttgatg attatagtgt tattggtaca gcggtactag 1380
aatatataac tcaacaaata gcacctaaaa atcttgataa ccctagtaag aaagagcaag 1440
aattaatagc caaaaaaact gaaaaagcaa aatacttatc tctagaaact ataaagcttg 1500
ccttagaaga atttaataag catagagata tagataaaca gtgtaggttt gaagaaatac 1560
ttgcaaactt tgcggctatt ccgatgatat ttgatgaaat agctcaaaac aaagacaatt 1620
tggcacagat atctatcaaa tatcaaaatc aaggtaaaaa agacctactt caagctagtg 1680
cggaagatga tgttaaagct atcaaggatc ttttagatca aactaataat ctcttacata 1740
aactaaaaat atttcatatt agtcagtcag aagataaggc aaatatttta gacaaggatg 1800
agcattttta tctagtattt gaggagtgct actttgagct agcgaatata gtgcctcttt 1860
ataacaaaat tagaaactat ataactcaaa agccatatag tgatgagaaa tttaagctca 1920
attttgagaa ctcgactttg gctaatggtt gggataaaaa taaagagcct gacaatacgg 1980
caattttatt tatcaaagat gataaatatt atctgggtgt gatgaataag aaaaataaca 2040
aaatatttga tgataaagct atcaaagaaa ataaaggcga gggttataaa aaaattgttt 2100
ataaactttt acctggcgca aataaaatgt tacctaaggt tttcttttct gctaaatcta 2160
taaaatttta taatcctagt gaagatatac ttagaataag aaatcattcc acacatacaa 2220
aaaatggtag tcctcaaaaa ggatatgaaa aatttgagtt taatattgaa gattgccgaa 2280
aatttataga tttttataaa cagtctataa gtaagcatcc ggagtggaaa gattttggat 2340
ttagattttc tgatactcaa agatataatt ctatagatga attttataga gaagttgaaa 2400
atcaaggcta caaactaact tttgaaaata tatcagagag ctatattgat agcgtagtta 2460
atcagggtaa attgtaccta ttccaaatct ataataaaga tttttcagct tatagcaaag 2520
ggcgaccaaa tctacatact ttatattgga aagcgctgtt tgatgagaga aatcttcaag 2580
atgtggttta taagctaaat ggtgaggcag agctttttta tcgtaaacaa tcaataccta 2640
aaaaaatcac tcacccagct aaagaggcaa tagctaataa aaacaaagat aatcctaaaa 2700
aagagagtgt ttttgaatat gatttaatca aagataaacg ctttactgaa gataagtttt 2760
tctttcactg tcctattaca atcaatttta aatctagtgg agctaataag tttaatgatg 2820
aaatcaattt attgctaaaa gaaaaagcaa atgatgttca tatattaagt atagatagag 2880
gtgaaagaca tttagcttac tatactttgg tagatggtaa aggcaatatc atcaaacaag 2940
atactttcaa catcattggt aatgatagaa tgaaaacaaa ctaccatgat aagcttgctg 3000
caatagagaa agatagggat tcagctagga aagactggaa aaagataaat aacatcaaag 3060
agatgaaaga gggctatcta tctcaggtag ttcatgaaat agctaagcta gttatagagt 3120
ataatgctat tgtggttttt gaggatttaa attttggatt taaaagaggg cgtttcaagg 3180
tagagaagca ggtctatcaa aagttagaaa aaatgctaat tgagaaacta aactatctag 3240
ttttcaaaga taatgagttt gataaaactg ggggagtgct tagagcttat cagctaacag 3300
caccttttga gacttttaaa aagatgggta aacaaacagg tattatctac tatgtaccag 3360
ctggttttac ttcaaaaatt tgtcctgtaa ctggttttgt aaatcagtta tatcctaagt 3420
atgaaagtgt cagcaaatct caagagttct ttagtaagtt tgacaagatt tgttataacc 3480
ttgataaggg ctattttgag tttagttttg attataaaaa ctttggtgac aaggctgcca 3540
aaggcaagtg gactatagct agctttggga gtagattgat taactttaga aattcagata 3600
aaaatcataa ttgggatact cgagaagttt atccaactaa agagttggag aaattgctaa 3660
aagattattc tatcgaatat gggcatggcg aatgtatcaa agcagctatt tgcggtgaga 3720
gcgacaaaaa gttttttgct aagctaacta gtgtcctaaa tactatctta caaatgcgta 3780
actcaaaaac aggtactgag ttagattatc taatttcacc agtagcagat gtaaatggca 3840
atttctttga ttcgcgacag gcgccaaaaa atatgcctca agatgctgat gccaatggtg 3900
cttatcatat tgggctaaaa ggtctgatgc tactaggtag gatcaaaaat aatcaagagg 3960
gcaaaaaact caatttggtt atcaaaaatg aagagtattt tgagttcgtg cagaatagga 4020
ataactaatt cattcaagaa tatattaccc tgtcagttta gcgactatta cctctttaat 4080
aatttgcagg ggaattattt tagtaatagt aatatacaca agagttattg attatatgga 4140
aaattatatt tagataacat ggttaaatga ttttatattc tgtccttact cgatatattt 4200
tttatagact aaaaattgca aaccttagtc tttatgttaa aataactact aagttcttag 4260
agatatttaa aaatatgact gttgttatat atcaaaatgc taaaaaaatc atagatttta 4320
ggtctttttt tgctgattta ggcaaaaacg ggtctaagaa ctttaaataa tttctactgt 4380
tgtagatgag aagtcattta ataaggccac tgttaaaagt ctaagaactt taaataattt 4440
ctactgttgt agatgctact attcctgtgc cttcagataa ttcagtctaa gaactttaaa 4500
taatttctac tgttgtagat gtctagagcc ttttgtatta gtagccggtc taagaacttt 4560
aaataatttc tactgttgta gattagcgat ttatgaaggt catttttttg tct 4613
<210> 214
<211> 4035
<212> ДНК
<213> Francisella tularensis
<400> 214
atgagcatct accaggagtt cgtcaacaag tattcactga gtaagacact gcggttcgag 60
ctgatcccac agggcaagac actggagaac atcaaggccc gaggcctgat tctggacgat 120
gagaagcggg caaaagacta taagaaagcc aagcagatca ttgataaata ccaccagttc 180
tttatcgagg aaattctgag ctccgtgtgc atcagtgagg atctgctgca gaattactca 240
gacgtgtact tcaagctgaa gaagagcgac gatgacaacc tgcagaagga cttcaagtcc 300
gccaaggaca ccatcaagaa acagattagc gagtacatca aggactccga aaagtttaaa 360
aatctgttca accagaatct gatcgatgct aagaaaggcc aggagtccga cctgatcctg 420
tggctgaaac agtctaagga caatgggatt gaactgttca aggctaactc cgatatcact 480
gatattgacg aggcactgga aatcatcaag agcttcaagg gatggaccac atactttaaa 540
ggcttccacg agaaccgcaa gaacgtgtac tccagcaacg acattcctac ctccatcatc 600
taccgaatcg tcgatgacaa tctgccaaag ttcctggaga acaaggccaa atatgaatct 660
ctgaaggaca aagctcccga ggcaattaat tacgaacaga tcaagaaaga tctggctgag 720
gaactgacat tcgatatcga ctataagact agcgaggtga accagagggt cttttccctg 780
gacgaggtgt ttgaaatcgc caatttcaac aattacctga accagtccgg cattactaaa 840
ttcaatacca tcattggcgg gaagtttgtg aacggggaga ataccaagcg caagggaatt 900
aacgaataca tcaatctgta tagccagcag atcaacgaca aaactctgaa gaaatacaag 960
atgtctgtgc tgttcaaaca gatcctgagt gataccgagt ccaagtcttt tgtcattgat 1020
aaactggaag atgactcaga cgtggtcact accatgcaga gcttttatga gcagatcgcc 1080
gctttcaaga cagtggagga aaaatctatt aaggaaactc tgagtctgct gttcgatgac 1140
ctgaaagccc agaagctgga cctgagtaag atctacttca aaaacgataa gagtctgaca 1200
gacctgtcac agcaggtgtt tgatgactat tccgtgattg ggaccgccgt cctggagtac 1260
attacacagc agatcgctcc aaagaacctg gataatccct ctaagaaaga gcaggaactg 1320
atcgctaaga aaaccgagaa ggcaaaatat ctgagtctgg aaacaattaa gctggcactg 1380
gaggagttca acaagcacag ggatattgac aaacagtgcc gctttgagga aatcctggcc 1440
aacttcgcag ccatccccat gatttttgat gagatcgccc agaacaaaga caatctggct 1500
cagatcagta ttaagtacca gaaccagggc aagaaagacc tgctgcaggc ttcagcagaa 1560
gatgacgtga aagccatcaa ggatctgctg gaccagacca acaatctgct gcacaagctg 1620
aaaatcttcc atattagtca gtcagaggat aaggctaata tcctggataa agacgaacac 1680
ttctacctgg tgttcgagga atgttacttc gagctggcaa acattgtccc cctgtataac 1740
aagattagga actacatcac acagaagcct tactctgacg agaagtttaa actgaacttc 1800
gaaaatagta ccctggccaa cgggtgggat aagaacaagg agcctgacaa cacagctatc 1860
ctgttcatca aggatgacaa gtactatctg ggagtgatga ataagaaaaa caataagatc 1920
ttcgatgaca aagccattaa ggagaacaaa ggggaaggat acaagaaaat cgtgtataag 1980
ctgctgcccg gcgcaaataa gatgctgcct aaggtgttct tcagcgccaa gagtatcaaa 2040
ttctacaacc catccgagga catcctgcgg attagaaatc actcaacaca tactaagaac 2100
gggagccccc agaagggata tgagaaattt gagttcaaca tcgaggattg caggaagttt 2160
attgacttct acaagcagag catctccaaa caccctgaat ggaaggattt tggcttccgg 2220
ttttccgaca cacagagata taactctatc gacgagttct accgcgaggt ggaaaatcag 2280
gggtataagc tgacttttga gaacatttct gaaagttaca tcgacagcgt ggtcaatcag 2340
ggaaagctgt acctgttcca gatctataac aaagattttt cagcatacag caagggcaga 2400
ccaaacctgc atacactgta ctggaaggcc ctgttcgatg agaggaatct gcaggacgtg 2460
gtctataaac tgaacggaga ggccgaactg ttttaccgga agcagtctat tcctaagaaa 2520
atcactcacc cagctaagga ggccatcgct aacaagaaca aggacaatcc taagaaagag 2580
agcgtgttcg aatacgatct gattaaggac aagcggttca ccgaagataa gttctttttc 2640
cattgtccaa tcaccattaa cttcaagtca agcggcgcta acaagttcaa cgacgagatc 2700
aatctgctgc tgaaggaaaa agcaaacgat gtgcacatcc tgagcattga ccgaggagag 2760
cggcatctgg cctactatac cctggtggat ggcaaaggga atatcattaa gcaggataca 2820
ttcaacatca ttggcaatga ccggatgaaa accaactacc acgataaact ggctgcaatc 2880
gagaaggata gagactcagc taggaaggac tggaagaaaa tcaacaacat taaggagatg 2940
aaggaaggct atctgagcca ggtggtccat gagattgcaa agctggtcat cgaatacaat 3000
gccattgtgg tgttcgagga tctgaacttc ggctttaaga gggggcgctt taaggtggaa 3060
aaacaggtct atcagaagct ggagaaaatg ctgatcgaaa agctgaatta cctggtgttt 3120
aaagataacg agttcgacaa gaccggaggc gtcctgagag cctaccagct gacagctccc 3180
tttgaaactt tcaagaaaat gggaaaacag acaggcatca tctactatgt gccagccgga 3240
ttcacttcca agatctgccc cgtgaccggc tttgtcaacc agctgtaccc taaatatgag 3300
tcagtgagca agtcccagga atttttcagc aagttcgata agatctgtta taatctggac 3360
aaggggtact tcgagttttc cttcgattac aagaacttcg gcgacaaggc cgctaagggg 3420
aaatggacca ttgcctcctt cggatctcgc ctgatcaact ttcgaaattc cgataaaaac 3480
cacaattggg acactaggga ggtgtaccca accaaggagc tggaaaagct gctgaaagac 3540
tactctatcg agtatggaca tggcgaatgc atcaaggcag ccatctgtgg cgagagtgat 3600
aagaaatttt tcgccaagct gacctcagtg ctgaatacaa tcctgcagat gcggaactca 3660
aagaccggga cagaactgga ctatctgatt agccccgtgg ctgatgtcaa cggaaacttc 3720
ttcgacagca gacaggcacc caaaaatatg cctcaggatg cagacgccaa cggggcctac 3780
cacatcgggc tgaagggact gatgctgctg ggccggatca agaacaatca ggaggggaag 3840
aagctgaacc tggtcattaa gaacgaggaa tacttcgagt ttgtccagaa tagaaataac 3900
aaaaggccgg cggccacgaa aaaggccggc caggcaaaaa agaaaaaggg atcctaccca 3960
tacgatgttc cagattacgc ttatccctac gacgtgcctg attatgcata cccatatgat 4020
gtccccgact atgcc 4035
<210> 215
<211> 3834
<212> ДНК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 215
atggattacg gcaacggcca gtttgagcgg agagcccccc tgaccaagac aatcaccctg 60
cgcctgaagc ctatcggcga gacacgggag acaatccgcg agcagaagct gctggagcag 120
gacgccgcct tcagaaagct ggtggagaca gtgaccccta tcgtggacga ttgtatcagg 180
aagatcgccg ataacgccct gtgccacttt ggcaccgagt atgacttcag ctgtctgggc 240
aacgccatct ctaagaatga cagcaaggcc atcaagaagg agacagagaa ggtggagaag 300
ctgctggcca aggtgctgac cgagaatctg ccagatggcc tgcgcaaggt gaacgacatc 360
aattccgccg cctttatcca ggatacactg acctctttcg tgcaggacga tgccgacaag 420
cgggtgctga tccaggagct gaagggcaag accgtgctga tgcagcggtt cctgaccaca 480
cggatcacag ccctgaccgt gtggctgccc gacagagtgt tcgagaactt taatatcttc 540
atcgagaacg ccgagaagat gagaatcctg ctggactccc ctctgaatga gaagatcatg 600
aagtttgacc cagatgccga gcagtacgcc tctctggagt tctatggcca gtgcctgtct 660
cagaaggaca tcgatagcta caacctgatc atctccggca tctatgccga cgatgaggtg 720
aagaaccctg gcatcaatga gatcgtgaag gagtacaatc agcagatccg gggcgacaag 780
gatgagtccc cactgcccaa gctgaagaag ctgcacaagc agatcctgat gccagtggag 840
aaggccttct ttgtgcgcgt gctgtctaac gacagcgatg cccggagcat cctggagaag 900
atcctgaagg acacagagat gctgccctcc aagatcatcg aggccatgaa ggaggcagat 960
gcaggcgaca tcgccgtgta cggcagccgg ctgcacgagc tgagccacgt gatctacggc 1020
gatcacggca agctgtccca gatcatctat gacaaggagt ccaagaggat ctctgagctg 1080
atggagacac tgtctccaaa ggagcgcaag gagagcaaga agcggctgga gggcctggag 1140
gagcacatca gaaagtctac atacaccttc gacgagctga acaggtatgc cgagaagaat 1200
gtgatggcag catacatcgc agcagtggag gagtcttgtg ccgagatcat gagaaaggag 1260
aaggatctga ggaccctgct gagcaaggag gacgtgaaga tccggggcaa cagacacaat 1320
acactgatcg tgaagaacta ctttaatgcc tggaccgtgt tccggaacct gatcagaatc 1380
ctgaggcgca agtccgaggc cgagatcgac tctgacttct acgatgtgct ggacgattcc 1440
gtggaggtgc tgtctctgac atacaagggc gagaatctgt gccgcagcta tatcaccaag 1500
aagatcggct ccgacctgaa gcccgagatc gccacatacg gcagcgccct gaggcctaac 1560
agccgctggt ggtccccagg agagaagttt aatgtgaagt tccacaccat cgtgcggaga 1620
gatggccggc tgtactattt catcctgccc aagggcgcca agcctgtgga gctggaggac 1680
atggatggcg acatcgagtg tctgcagatg agaaagatcc ctaacccaac aatctttctg 1740
cccaagctgg tgttcaagga ccctgaggcc ttctttaggg ataatccaga ggccgacgag 1800
ttcgtgtttc tgagcggcat gaaggccccc gtgacaatca ccagagagac atacgaggcc 1860
tacaggtata agctgtatac cgtgggcaag ctgcgcgatg gcgaggtgtc cgaagaggag 1920
tacaagcggg ccctgctgca ggtgctgacc gcctacaagg agtttctgga gaacagaatg 1980
atctatgccg acctgaattt cggctttaag gatctggagg agtataagga cagctccgag 2040
tttatcaagc aggtggagac acacaacacc ttcatgtgct gggccaaggt gtctagctcc 2100
cagctggacg atctggtgaa gtctggcaac ggcctgctgt tcgagatctg gagcgagcgc 2160
ctggagtcct actataagta cggcaatgag aaggtgctgc ggggctatga gggcgtgctg 2220
ctgagcatcc tgaaggatga gaacctggtg tccatgcgga ccctgctgaa cagccggccc 2280
atgctggtgt accggccaaa ggagtctagc aagcctatgg tggtgcaccg ggatggcagc 2340
agagtggtgg acaggtttga taaggacggc aagtacatcc cccctgaggt gcacgacgag 2400
ctgtatcgct tctttaacaa tctgctgatc aaggagaagc tgggcgagaa ggcccggaag 2460
atcctggaca acaagaaggt gaaggtgaag gtgctggaga gcgagagagt gaagtggtcc 2520
aagttctacg atgagcagtt tgccgtgacc ttcagcgtga agaagaacgc cgattgtctg 2580
gacaccacaa aggacctgaa tgccgaagtg atggagcagt atagcgagtc caacagactg 2640
atcctgatca ggaataccac agatatcctg tactatctgg tgctggacaa gaatggcaag 2700
gtgctgaagc agagatccct gaacatcatc aatgacggcg ccagggatgt ggactggaag 2760
gagaggttcc gccaggtgac aaaggataga aacgagggct acaatgagtg ggattattcc 2820
aggacctcta acgacctgaa ggaggtgtac ctgaattatg ccctgaagga gatcgccgag 2880
gccgtgatcg agtacaacgc catcctgatc atcgagaaga tgtctaatgc ctttaaggac 2940
aagtatagct tcctggacga cgtgaccttc aagggcttcg agacaaagct gctggccaag 3000
ctgagcgatc tgcactttag gggcatcaag gacggcgagc catgttcctt cacaaacccc 3060
ctgcagctgt gccagaacga ttctaataag atcctgcagg acggcgtgat ctttatggtg 3120
ccaaattcta tgacacggag cctggacccc gacaccggct tcatctttgc catcaacgac 3180
cacaatatca ggaccaagaa ggccaagctg aactttctga gcaagttcga tcagctgaag 3240
gtgtcctctg agggctgcct gatcatgaag tacagcggcg attccctgcc tacacacaac 3300
accgacaatc gcgtgtggaa ctgctgttgc aatcacccaa tcacaaacta tgaccgggag 3360
acaaagaagg tggagttcat cgaggagccc gtggaggagc tgtcccgcgt gctggaggag 3420
aatggcatcg agacagacac cgagctgaac aagctgaatg agcgggagaa cgtgcctggc 3480
aaggtggtgg atgccatcta ctctctggtg ctgaattatc tgcgcggcac agtgagcgga 3540
gtggcaggac agagggccgt gtactatagc cctgtgaccg gcaagaagta cgatatctcc 3600
tttatccagg ccatgaacct gaataggaag tgtgactact ataggatcgg ctccaaggag 3660
aggggagagt ggaccgattt cgtggcccag ctgatcaaca aaaggccggc ggccacgaaa 3720
aaggccggcc aggcaaaaaa gaaaaaggga tcctacccat acgatgttcc agattacgct 3780
tatccctacg acgtgcctga ttatgcatac ccatatgatg tccccgacta tgcc 3834
<210> 216
<211> 4035
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 216
atgagcatct accaggagtt cgtcaacaag tattcactga gtaagacact gcggttcgag 60
ctgatcccac agggcaagac actggagaac atcaaggccc gaggcctgat tctggacgat 120
gagaagcggg caaaagacta taagaaagcc aagcagatca ttgataaata ccaccagttc 180
tttatcgagg aaattctgag ctccgtgtgc atcagtgagg atctgctgca gaattactca 240
gacgtgtact tcaagctgaa gaagagcgac gatgacaacc tgcagaagga cttcaagtcc 300
gccaaggaca ccatcaagaa acagattagc gagtacatca aggactccga aaagtttaaa 360
aatctgttca accagaatct gatcgatgct aagaaaggcc aggagtccga cctgatcctg 420
tggctgaaac agtctaagga caatgggatt gaactgttca aggctaactc cgatatcact 480
gatattgacg aggcactgga aatcatcaag agcttcaagg gatggaccac atactttaaa 540
ggcttccacg agaaccgcaa gaacgtgtac tccagcaacg acattcctac ctccatcatc 600
taccgaatcg tcgatgacaa tctgccaaag ttcctggaga acaaggccaa atatgaatct 660
ctgaaggaca aagctcccga ggcaattaat tacgaacaga tcaagaaaga tctggctgag 720
gaactgacat tcgatatcga ctataagact agcgaggtga accagagggt cttttccctg 780
gacgaggtgt ttgaaatcgc caatttcaac aattacctga accagtccgg cattactaaa 840
ttcaatacca tcattggcgg gaagtttgtg aacggggaga ataccaagcg caagggaatt 900
aacgaataca tcaatctgta tagccagcag atcaacgaca aaactctgaa gaaatacaag 960
atgtctgtgc tgttcaaaca gatcctgagt gataccgagt ccaagtcttt tgtcattgat 1020
aaactggaag atgactcaga cgtggtcact accatgcaga gcttttatga gcagatcgcc 1080
gctttcaaga cagtggagga aaaatctatt aaggaaactc tgagtctgct gttcgatgac 1140
ctgaaagccc agaagctgga cctgagtaag atctacttca aaaacgataa gagtctgaca 1200
gacctgtcac agcaggtgtt tgatgactat tccgtgattg ggaccgccgt cctggagtac 1260
attacacagc agatcgctcc aaagaacctg gataatccct ctaagaaaga gcaggaactg 1320
atcgctaaga aaaccgagaa ggcaaaatat ctgagtctgg aaacaattaa gctggcactg 1380
gaggagttca acaagcacag ggatattgac aaacagtgcc gctttgagga aatcctggcc 1440
aacttcgcag ccatccccat gatttttgat gagatcgccc agaacaaaga caatctggct 1500
cagatcagta ttaagtacca gaaccagggc aagaaagacc tgctgcaggc ttcagcagaa 1560
gatgacgtga aagccatcaa ggatctgctg gaccagacca acaatctgct gcacaagctg 1620
aaaatcttcc atattagtca gtcagaggat aaggctaata tcctggataa agacgaacac 1680
ttctacctgg tgttcgagga atgttacttc gagctggcaa acattgtccc cctgtataac 1740
aagattagga actacatcac acagaagcct tactctgacg agaagtttaa actgaacttc 1800
gaaaatagta ccctggccaa cgggtgggat aagaacaagg agcctgacaa cacagctatc 1860
ctgttcatca aggatgacaa gtactatctg ggagtgatga ataagaaaaa caataagatc 1920
ttcgatgaca aagccattaa ggagaacaaa ggggaaggat acaagaaaat cgtgtataag 1980
ctgctgcccg gcgcaaataa gatgctgcct aaggtgttct tcagcgccaa gagtatcaaa 2040
ttctacaacc catccgagga catcctgcgg attagaaatc actcaacaca tactaagaac 2100
gggagccccc agaagggata tgagaaattt gagttcaaca tcgaggattg caggaagttt 2160
attgacttct acaagcagag catctccaaa caccctgaat ggaaggattt tggcttccgg 2220
ttttccgaca cacagagata taactctatc gacgagttct accgcgaggt ggaaaatcag 2280
gggtataagc tgacttttga gaacatttct gaaagttaca tcgacagcgt ggtcaatcag 2340
ggaaagctgt acctgttcca gatctataac aaagattttt cagcatacag caagggcaga 2400
ccaaacctgc atacactgta ctggaaggcc ctgttcgatg agaggaatct gcaggacgtg 2460
gtctataaac tgaacggaga ggccgaactg ttttaccgga agcagtctat tcctaagaaa 2520
atcactcacc cagctaagga ggccatcgct aacaagaaca aggacaatcc taagaaagag 2580
agcgtgttcg aatacgatct gattaaggac aagcggttca ccgaagataa gttctttttc 2640
cattgtccaa tcaccattaa cttcaagtca agcggcgcta acaagttcaa cgacgagatc 2700
aatctgctgc tgaaggaaaa agcaaacgat gtgcacatcc tgagcattga ccgaggagag 2760
cggcatctgg cctactatac cctggtggat ggcaaaggga atatcattaa gcaggataca 2820
ttcaacatca ttggcaatga ccggatgaaa accaactacc acgataaact ggctgcaatc 2880
gagaaggata gagactcagc taggaaggac tggaagaaaa tcaacaacat taaggagatg 2940
aaggaaggct atctgagcca ggtggtccat gagattgcaa agctggtcat cgaatacaat 3000
gccattgtgg tgttcgagga tctgaacttc ggctttaaga gggggcgctt taaggtggaa 3060
aaacaggtct atcagaagct ggagaaaatg ctgatcgaaa agctgaatta cctggtgttt 3120
aaagataacg agttcgacaa gaccggaggc gtcctgagag cctaccagct gacagctccc 3180
tttgaaactt tcaagaaaat gggaaaacag acaggcatca tctactatgt gccagccgga 3240
ttcacttcca agatctgccc cgtgaccggc tttgtcaacc agctgtaccc taaatatgag 3300
tcagtgagca agtcccagga atttttcagc aagttcgata agatctgtta taatctggac 3360
aaggggtact tcgagttttc cttcgattac aagaacttcg gcgacaaggc cgctaagggg 3420
aaatggacca ttgcctcctt cggatctcgc ctgatcaact ttcgaaattc cgataaaaac 3480
cacaattggg acactaggga ggtgtaccca accaaggagc tggaaaagct gctgaaagac 3540
tactctatcg agtatggaca tggcgaatgc atcaaggcag ccatctgtgg cgagagtgat 3600
aagaaatttt tcgccaagct gacctcagtg ctgaatacaa tcctgcagat gcggaactca 3660
aagaccggga cagaactgga ctatctgatt agccccgtgg ctgatgtcaa cggaaacttc 3720
ttcgacagca gacaggcacc caaaaatatg cctcaggatg cagacgccaa cggggcctac 3780
cacatcgggc tgaagggact gatgctgctg ggccggatca agaacaatca ggaggggaag 3840
aagctgaacc tggtcattaa gaacgaggaa tacttcgagt ttgtccagaa tagaaataac 3900
aaaaggccgg cggccacgaa aaaggccggc caggcaaaaa agaaaaaggg atcctaccca 3960
tacgatgttc cagattacgc ttatccctac gacgtgcctg attatgcata cccatatgat 4020
gtccccgact atgcc 4035
<210> 217
<211> 4575
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 217
atgtccaact tctttaagaa tttcaccaac ctgtatgagc tgtccaagac actgaggttt 60
gagctgaagc ccgtgggcga caccctgaca aacatgaagg accacctgga gtacgatgag 120
aagctgcaga ccttcctgaa ggatcagaat atcgacgatg cctatcaggc cctgaagcct 180
cagttcgacg agatccacga ggagtttatc acagattctc tggagagcaa gaaggccaag 240
gagatcgact tctccgagta cctggatctg tttcaggaga agaaggagct gaacgactct 300
gagaagaagc tgcgcaacaa gatcggcgag acattcaaca aggccggcga gaagtggaag 360
aaggagaagt accctcagta tgagtggaag aagggctcca agatcgccaa tggcgccgac 420
atcctgtctt gccaggatat gctgcagttt atcaagtata agaacccaga ggatgagaag 480
atcaagaatt acatcgacga tacactgaag ggcttcttta cctatttcgg cggctttaat 540
cagaacaggg ccaactacta tgagacaaag aaggaggcct ccaccgcagt ggcaacaagg 600
atcgtgcacg agaacctgcc aaagttctgt gacaatgtga tccagtttaa gcacatcatc 660
aagcggaaga aggatggcac cgtggagaaa accgagagaa agaccgagta cctgaacgcc 720
taccagtatc tgaagaacaa taacaagatc acacagatca aggacgccga gacagagaag 780
atgatcgagt ctacacccat cgccgagaag atcttcgacg tgtactactt cagcagctgc 840
ctgagccaga agcagatcga ggagtacaac cggatcatcg gccactataa tctgctgatc 900
aacctgtata accaggccaa gagatctgag ggcaagcacc tgagcgccaa cgagaagaag 960
tataaggacc tgcctaagtt caagaccctg tataagcaga tcggctgcgg caagaagaag 1020
gacctgtttt acacaatcaa gtgtgatacc gaggaggagg ccaataagtc ccggaacgag 1080
ggcaaggagt cccactctgt ggaggagatc atcaacaagg cccaggaggc catcaataag 1140
tacttcaagt ctaataacga ctgtgagaat atcaacaccg tgcccgactt catcaactat 1200
atcctgacaa aggagaatta cgagggcgtg tattggagca aggccgccat gaacaccatc 1260
tccgacaagt acttcgccaa ttatcacgac ctgcaggata gactgaagga ggccaaggtg 1320
tttcagaagg ccgataagaa gtccgaggac gatatcaaga tcccagaggc catcgagctg 1380
tctggcctgt tcggcgtgct ggacagcctg gccgattggc agaccacact gtttaagtct 1440
agcatcctga gcaacgagga caagctgaag atcatcacag attcccagac cccctctgag 1500
gccctgctga agatgatctt caatgacatc gagaagaaca tggagtcctt tctgaaggag 1560
acaaacgata tcatcaccct gaagaagtat aagggcaata aggagggcac cgagaagatc 1620
aagcagtggt tcgactatac actggccatc aaccggatgc tgaagtactt tctggtgaag 1680
gagaataaga tcaagggcaa ctccctggat accaatatct ctgaggccct gaaaaccctg 1740
atctacagcg acgatgccga gtggttcaag tggtacgacg ccctgagaaa ctatctgacc 1800
cagaagcctc aggatgaggc caaggagaat aagctgaagc tgaatttcga caacccatct 1860
ctggccggcg gctgggatgt gaacaaggag tgcagcaatt tttgcgtgat cctgaaggac 1920
aagaacgaga agaagtacct ggccatcatg aagaagggcg agaataccct gttccagaag 1980
gagtggacag agggccgggg caagaacctg acaaagaagt ctaatccact gttcgagatc 2040
aataactgcg agatcctgag caagatggag tatgactttt gggccgacgt gagcaagatg 2100
atccccaagt gtagcaccca gctgaaggcc gtggtgaacc acttcaagca gtccgacaat 2160
gagttcatct ttcctatcgg ctacaaggtg acaagcggcg agaagtttag ggaggagtgc 2220
aagatctcca agcaggactt cgagctgaat aacaaggtgt ttaataagaa cgagctgagc 2280
gtgaccgcca tgcgctacga tctgtcctct acacaggaga agcagtatat caaggccttc 2340
cagaaggagt actgggagct gctgtttaag caggagaagc gggacaccaa gctgacaaat 2400
aacgagatct tcaacgagtg gatcaatttt tgcaacaaga agtatagcga gctgctgtcc 2460
tgggagagaa agtacaagga tgccctgacc aattggatca acttctgtaa gtactttctg 2520
agcaagtatc ccaagaccac actgttcaac tactctttta aggagagcga gaattataac 2580
tccctggacg agttctaccg ggacgtggat atctgttctt acaagctgaa tatcaacacc 2640
acaatcaata agagcatcct ggatagactg gtggaggagg gcaagctgta cctgtttgag 2700
atcaagaatc aggacagcaa cgatggcaag tccatcggcc acaagaataa cctgcacacc 2760
atctactgga acgccatctt cgagaatttt gacaacaggc ctaagctgaa tggcgaggcc 2820
gagatcttct atcgcaaggc catctccaag gataagctgg gcatcgtgaa gggcaagaaa 2880
accaagaacg gcaccgagat catcaagaat tacagattca gcaaggagaa gtttatcctg 2940
cacgtgccaa tcaccctgaa cttctgctcc aataacgagt atgtgaatga catcgtgaac 3000
acaaagttct acaatttttc caacctgcac tttctgggca tcgatagggg cgagaagcac 3060
ctggcctact attctctggt gaataagaac ggcgagatcg tggaccaggg cacactgaac 3120
ctgcctttca ccgacaagga tggcaatcag cgcagcatca agaaggagaa gtacttttat 3180
aacaagcagg aggacaagtg ggaggccaag gaggtggatt gttggaatta taacgacctg 3240
ctggatgcca tggcctctaa ccgggacatg gccagaaaga attggcagag gatcggcacc 3300
atcaaggagg ccaagaacgg ctacgtgagc ctggtcatca ggaagatcgc cgatctggcc 3360
gtgaataacg agcgccccgc cttcatcgtg ctggaggacc tgaatacagg ctttaagcgg 3420
tccagacaga agatcgataa gagcgtgtac cagaagttcg agctggccct ggccaagaag 3480
ctgaactttc tggtggacaa gaatgccaag cgcgatgaga tcggctcccc tacaaaggcc 3540
ctgcagctga ccccccctgt gaataactac ggcgacattg agaacaagaa gcaggccggc 3600
atcatgctgt atacccgggc caattatacc tctcagacag atccagccac aggctggaga 3660
aagaccatct atctgaaggc cggccccgag gagacaacat acaagaagga cggcaagatc 3720
aagaacaaga gcgtgaagga ccagatcatc gagacattca ccgatatcgg ctttgacggc 3780
aaggattact atttcgagta cgacaagggc gagtttgtgg atgagaaaac cggcgagatc 3840
aagcccaaga agtggcggct gtactccggc gagaatggca agtccctgga caggttccgc 3900
ggagagaggg agaaggataa gtatgagtgg aagatcgaca agatcgatat cgtgaagatc 3960
ctggacgatc tgttcgtgaa ttttgacaag aacatcagcc tgctgaagca gctgaaggag 4020
ggcgtggagc tgacccggaa taacgagcac ggcacaggcg agtccctgag attcgccatc 4080
aacctgatcc agcagatccg gaataccggc aataacgaga gagacaacga tttcatcctg 4140
tccccagtga gggacgagaa tggcaagcac tttgactctc gcgagtactg ggataaggag 4200
acaaagggcg agaagatcag catgcccagc tccggcgatg ccaatggcgc cttcaacatc 4260
gcccggaagg gcatcatcat gaacgcccac atcctggcca atagcgactc caaggatctg 4320
tccctgttcg tgtctgacga ggagtgggat ctgcacctga ataacaagac cgagtggaag 4380
aagcagctga acatcttttc tagcaggaag gccatggcca agcgcaagaa gaaaaggccg 4440
gcggccacga aaaaggccgg ccaggcaaaa aagaaaaagg gatcctaccc atacgatgtt 4500
ccagattacg cttatcccta cgacgtgcct gattatgcat acccatatga tgtccccgac 4560
tatgcctaag aattc 4575
<210> 218
<211> 4200
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 218
atggagaaca tcttcgacca gtttatcggc aagtacagcc tgtccaagac cctgagattc 60
gagctgaagc ccgtgggcaa gacagaggac ttcctgaaga tcaacaaggt gtttgagaag 120
gatcagacca tcgacgatag ctacaatcag gccaagttct attttgattc cctgcaccag 180
aagtttatcg acgccgccct ggcctccgat aagacatccg agctgtcttt ccagaacttt 240
gccgacgtgc tggagaagca gaataagatc atcctggata agaagagaga gatgggcgcc 300
ctgaggaagc gcgacaagaa cgccgtgggc atcgataggc tgcagaagga gatcaatgac 360
gccgaggata tcatccagaa ggagaaggag aagatctaca aggacgtgcg caccctgttc 420
gataacgagg ccgagtcttg gaaaacctac tatcaggagc gggaggtgga cggcaagaag 480
atcaccttca gcaaggccga cctgaagcag aagggcgccg attttctgac agccgccggc 540
atcctgaagg tgctgaagta tgagttcccc gaggagaagg agaaggagtt tcaggccaag 600
aaccagccct ccctgttcgt ggaggagaag gagaatcctg gccagaagag gtacatcttc 660
gactcttttg ataagttcgc cggctatctg accaagtttc agcagacaaa gaagaatctg 720
tacgcagcag acggcaccag cacagcagtg gccacccgca tcgccgataa ctttatcatc 780
ttccaccaga ataccaaggt gttccgggac aagtacaaga acaatcacac agacctgggc 840
ttcgatgagg agaacatctt tgagatcgag aggtataaga attgcctgct gcagcgcgag 900
atcgagcaca tcaagaatga gaatagctac aacaagatca tcggccggat caataagaag 960
atcaaggagt atcgggacca gaaggccaag gataccaagc tgacaaagtc cgacttccct 1020
ttctttaaga acctggataa gcagatcctg ggcgaggtgg agaaggagaa gcagctgatc 1080
gagaaaaccc gggagaaaac cgaggaggac gtgctgatcg agcggttcaa ggagttcatc 1140
gagaacaatg aggagaggtt caccgccgcc aagaagctga tgaatgcctt ctgtaacggc 1200
gagtttgagt ccgagtacga gggcatctat ctgaagaata aggccatcaa cacaatctcc 1260
cggagatggt tcgtgtctga cagagatttt gagctgaagc tgcctcagca gaagtccaag 1320
aacaagtctg agaagaatga gccaaaggtg aagaagttca tctccatcgc cgagatcaag 1380
aacgccgtgg aggagctgga cggcgatatc tttaaggccg tgttctacga caagaagatc 1440
atcgcccagg gcggctctaa gctggagcag ttcctggtca tctggaagta cgagtttgag 1500
tatctgttcc gggacatcga gagagagaac ggcgagaagc tgctgggcta tgatagctgc 1560
ctgaagatcg ccaagcagct gggcatcttc ccacaggaga aggaggcccg cgagaaggca 1620
accgccgtga tcaagaatta cgccgacgcc ggcctgggca tcttccagat gatgaagtat 1680
ttttctctgg acgataagga tcggaagaac acccccggcc agctgagcac aaatttctac 1740
gccgagtatg acggctacta caaggatttc gagtttatca agtactacaa cgagtttagg 1800
aacttcatca ccaagaagcc tttcgacgag gataagatca agctgaactt tgagaatggc 1860
gccctgctga agggctggga cgagaacaag gagtacgatt tcatgggcgt gatcctgaag 1920
aaggagggcc gcctgtatct gggcatcatg cacaagaacc accggaagct gtttcagtcc 1980
atgggcaatg ccaagggcga caacgccaat agataccaga agatgatcta taagcagatc 2040
gccgacgcct ctaaggatgt gcccaggctg ctgctgacca gcaagaaggc catggagaag 2100
ttcaagcctt cccaggagat cctgagaatc aagaaggaga aaaccttcaa gcgggagagc 2160
aagaactttt ccctgagaga tctgcacgcc ctgatcgagt actataggaa ctgcatccct 2220
cagtacagca attggtcctt ttatgacttc cagtttcagg ataccggcaa gtaccagaat 2280
atcaaggagt tcacagacga tgtgcagaag tacggctata agatctcctt tcgcgacatc 2340
gacgatgagt atatcaatca ggccctgaac gagggcaaga tgtacctgtt cgaggtggtg 2400
aacaaggata tctataacac caagaatggc tccaagaatc tgcacacact gtactttgag 2460
cacatcctgt ctgccgagaa cctgaatgac ccagtgttca agctgtctgg catggccgag 2520
atctttcagc ggcagcccag cgtgaacgaa agagagaaga tcaccacaca gaagaatcag 2580
tgtatcctgg acaagggcga tagagcctac aagtataggc gctacaccga gaagaagatc 2640
atgttccaca tgagcctggt gctgaacaca ggcaagggcg agatcaagca ggtgcagttt 2700
aataagatca tcaaccagag gatcagctcc tctgacaacg agatgagggt gaatgtgatc 2760
ggcatcgatc gcggcgagaa gaacctgctg tactatagcg tggtgaagca gaatggcgag 2820
atcatcgagc aggcctccct gaacgagatc aatggcgtga actaccggga caagctgatc 2880
gagagggaga aggagcgcct gaagaaccgg cagagctgga agcctgtggt gaagatcaag 2940
gatctgaaga agggctacat ctcccacgtg atccacaaga tctgccagct gatcgagaag 3000
tattctgcca tcgtggtgct ggaggacctg aatatgagat tcaagcagat caggggagga 3060
atcgagcgga gcgtgtacca gcagttcgag aaggccctga tcgataagct gggctatctg 3120
gtgtttaagg acaacaggga tctgagggca ccaggaggcg tgctgaatgg ctaccagctg 3180
tctgccccct ttgtgagctt cgagaagatg cgcaagcaga ccggcatcct gttctacaca 3240
caggccgagt ataccagcaa gacagaccca atcaccggct ttcggaagaa cgtgtatatc 3300
tctaatagcg cctccctgga taagatcaag gaggccgtga agaagttcga cgccatcggc 3360
tgggatggca aggagcagtc ttacttcttt aagtacaacc cttacaacct ggccgacgag 3420
aagtataaga actctaccgt gagcaaggag tgggccatct ttgccagcgc cccaagaatc 3480
cggagacaga agggcgagga cggctactgg aagtatgata gggtgaaagt gaatgaggag 3540
ttcgagaagc tgctgaaggt ctggaatttt gtgaacccaa aggccacaga tatcaagcag 3600
gagatcatca agaaggagaa ggcaggcgac ctgcagggag agaaggagct ggatggccgg 3660
ctgagaaact tttggcactc tttcatctac ctgtttaacc tggtgctgga gctgcgcaat 3720
tctttcagcc tgcagatcaa gatcaaggca ggagaagtga tcgcagtgga cgagggcgtg 3780
gacttcatcg ccagcccagt gaagcccttc tttaccacac ccaaccctta catcccctcc 3840
aacctgtgct ggctggccgt ggagaatgca gacgcaaacg gagcctataa tatcgccagg 3900
aagggcgtga tgatcctgaa gaagatccgc gagcacgcca agaaggaccc cgagttcaag 3960
aagctgccaa acctgtttat cagcaatgca gagtgggacg aggcagcccg ggattggggc 4020
aagtacgcag gcaccacagc cctgaacctg gaccacaaaa ggccggcggc cacgaaaaag 4080
gccggccagg caaaaaagaa aaagggatcc tacccatacg atgttccaga ttacgcttat 4140
ccctacgacg tgcctgatta tgcataccca tatgatgtcc ccgactatgc ctaagaattc 4200
<210> 219
<211> 3894
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 219
atgcagaccc tgtttgagaa cttcacaaat cagtacccag tgtccaagac cctgcgcttt 60
gagctgatcc cccagggcaa gacaaaggac ttcatcgagc agaagggcct gctgaagaag 120
gatgaggacc gggccgagaa gtataagaag gtgaagaaca tcatcgatga gtaccacaag 180
gacttcatcg agaagtctct gaatggcctg aagctggacg gcctggagaa gtacaagacc 240
ctgtatctga agcaggagaa ggacgataag gataagaagg cctttgacaa ggagaaggag 300
aacctgcgca agcagatcgc caatgccttc cggaacaatg agaagtttaa gacactgttc 360
gccaaggagc tgatcaagaa cgatctgatg tctttcgcct gcgaggagga caagaagaat 420
gtgaaggagt ttgaggcctt caccacatac ttcaccggct tccaccagaa ccgcgccaat 480
atgtacgtgg ccgatgagaa gagaacagcc atcgccagca ggctgatcca cgagaacctg 540
ccaaagttta tcgacaatat caagatcttc gagaagatga agaaggaggc ccccgagctg 600
ctgtctcctt tcaaccagac cctgaaggat atgaaggacg tgatcaaggg caccacactg 660
gaggagatct ttagcctgga ttatttcaac aagaccctga cacagagcgg catcgacatc 720
tacaattccg tgatcggcgg cagaacccct gaggagggca agacaaagat caagggcctg 780
aacgagtaca tcaataccga cttcaaccag aagcagacag acaagaagaa gcggcagcca 840
aagttcaagc agctgtataa gcagatcctg agcgataggc agagcctgtc ctttatcgcc 900
gaggccttca agaacgacac cgagatcctg gaggccatcg agaagtttta cgtgaatgag 960
ctgctgcact tcagcaatga gggcaagtcc acaaacgtgc tggacgccat caagaatgcc 1020
gtgtctaacc tggagagctt taacctgacc aagatgtatt tccgctccgg cgcctctctg 1080
acagacgtga gccggaaggt gtttggcgag tggagcatca tcaatagagc cctggacaac 1140
tactatgcca ccacatatcc aatcaagccc agagagaagt ctgagaagta cgaggagagg 1200
aaggagaagt ggctgaagca ggacttcaac gtgagcctga tccagaccgc catcgatgag 1260
tacgacaacg agacagtgaa gggcaagaac agcggcaaag tgatcgccga ttattttgcc 1320
aagttctgcg acgataagga gacagacctg atccagaagg tgaacgaggg ctacatcgcc 1380
gtgaaggatc tgctgaatac accctgtcct gagaacgaga agctgggcag caataaggac 1440
caggtgaagc agatcaaggc ctttatggat tctatcatgg acatcatgca cttcgtgcgc 1500
cccctgagcc tgaaggatac cgacaaggag aaggatgaga cattctactc cctgttcaca 1560
cctctgtacg accacctgac ccagacaatc gccctgtata acaaggtgcg gaactatctg 1620
acccagaagc cttacagcac agagaagatc aagctgaact tcgagaacag caccctgctg 1680
ggcggctggg atctgaataa ggagacagac aacacagcca tcatcctgag gaaggataac 1740
ctgtactatc tgggcatcat ggacaagagg cacaatcgca tctttcggaa cgtgcccaag 1800
gccgataaga aggacttctg ctacgagaag atggtgtata agctgctgcc tggcgccaac 1860
aagatgctgc caaaggtgtt cttttctcag agcagaatcc aggagtttac cccttccgcc 1920
aagctgctgg agaactacgc caatgagaca cacaagaagg gcgataattt caacctgaat 1980
cactgtcaca agctgatcga tttctttaag gactctatca acaagcacga ggattggaag 2040
aatttcgact ttaggttcag cgccacctcc acctacgccg acctgagcgg cttttaccac 2100
gaggtggagc accagggcta caagatctct tttcagagcg tggccgattc cttcatcgac 2160
gatctggtga acgagggcaa gctgtacctg ttccagatct ataataagga cttttcccca 2220
ttctctaagg gcaagcccaa cctgcacacc ctgtactgga agatgctgtt tgatgagaac 2280
aatctgaagg acgtggtgta taagctgaat ggcgaggccg aggtgttcta ccgcaagaag 2340
agcattgccg agaagaacac cacaatccac aaggccaatg agtccatcat caacaagaat 2400
cctgataacc caaaggccac cagcaccttc aactatgata tcgtgaagga caagagatac 2460
accatcgaca agtttcagtt ccacatccca atcacaatga actttaaggc cgagggcatc 2520
ttcaacatga atcagagggt gaatcagttc ctgaaggcca atcccgatat caacatcatc 2580
ggcatcgaca gaggcgagag gcacctgctg tactatgccc tgatcaacca gaagggcaag 2640
atcctgaagc aggataccct gaatgtgatc gccaacgaga agcagaaggt ggactaccac 2700
aatctgctgg ataagaagga gggcgaccgc gcaaccgcaa ggcaggagtg gggcgtgatc 2760
gagacaatca aggagctgaa ggagggctat ctgtcccagg tcatccacaa gctgaccgat 2820
ctgatgatcg agaacaatgc catcatcgtg atggaggacc tgaactttgg cttcaagcgg 2880
ggcagacaga aggtggagaa gcaggtgtat cagaagtttg agaagatgct gatcgataag 2940
ctgaattacc tggtggacaa gaataagaag gcaaacgagc tgggaggcct gctgaacgca 3000
ttccagctgg ccaataagtt tgagtccttc cagaagatgg gcaagcagaa cggctttatc 3060
ttctacgtgc ccgcctggaa tacctctaag acagatcctg ccaccggctt tatcgacttc 3120
ctgaagcccc gctatgagaa cctgaatcag gccaaggatt tctttgagaa gtttgactct 3180
atccggctga acagcaaggc cgattacttt gagttcgcct ttgacttcaa gaatttcacc 3240
gagaaggccg atggcggcag aaccaagtgg acagtgtgca ccacaaacga ggacagatat 3300
gcctggaata gggccctgaa caataacagg ggcagccagg agaagtacga catcacagcc 3360
gagctgaagt ccctgttcga tggcaaggtg gactataagt ctggcaagga tctgaagcag 3420
cagatcgcca gccaggagtc cgccgacttc tttaaggccc tgatgaagaa cctgtccatc 3480
accctgtctc tgagacacaa taacggcgag aagggcgata atgagcagga ctacatcctg 3540
tcccctgtgg ccgattctaa gggccgcttc tttgactccc ggaaggccga cgatgacatg 3600
ccaaagaatg ccgacgccaa cggcgcctat cacatcgccc tgaagggcct gtggtgtctg 3660
gagcagatca gcaagaccga tgacctgaag aaggtgaagc tggccatctc caacaaggag 3720
tggctggagt tcgtgcagac actgaagggc aaaaggccgg cggccacgaa aaaggccggc 3780
caggcaaaaa agaaaaaggg atcctaccca tacgatgttc cagattacgc ttatccctac 3840
gacgtgcctg attatgcata cccatatgat gtccccgact atgcctaaga attc 3894
<210> 220
<211> 4065
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 220
atgacacagt tcgagggctt taccaacctg tatcaggtga gcaagacact gcggtttgag 60
ctgatcccac agggcaagac cctgaagcac atccaggagc agggcttcat cgaggaggac 120
aaggcccgca atgatcacta caaggagctg aagcccatca tcgatcggat ctacaagacc 180
tatgccgacc agtgcctgca gctggtgcag ctggattggg agaacctgag cgccgccatc 240
gactcctata gaaaggagaa aaccgaggag acaaggaacg ccctgatcga ggagcaggcc 300
acatatcgca atgccatcca cgactacttc atcggccgga cagacaacct gaccgatgcc 360
atcaataaga gacacgccga gatctacaag ggcctgttca aggccgagct gtttaatggc 420
aaggtgctga agcagctggg caccgtgacc acaaccgagc acgagaacgc cctgctgcgg 480
agcttcgaca agtttacaac ctacttctcc ggcttttatg agaacaggaa gaacgtgttc 540
agcgccgagg atatcagcac agccatccca caccgcatcg tgcaggacaa cttccccaag 600
tttaaggaga attgtcacat cttcacacgc ctgatcaccg ccgtgcccag cctgcgggag 660
cactttgaga acgtgaagaa ggccatcggc atcttcgtga gcacctccat cgaggaggtg 720
ttttccttcc ctttttataa ccagctgctg acacagaccc agatcgacct gtataaccag 780
ctgctgggag gaatctctcg ggaggcaggc accgagaaga tcaagggcct gaacgaggtg 840
ctgaatctgg ccatccagaa gaatgatgag acagcccaca tcatcgcctc cctgccacac 900
agattcatcc ccctgtttaa gcagatcctg tccgatagga acaccctgtc tttcatcctg 960
gaggagttta agagcgacga ggaagtgatc cagtccttct gcaagtacaa gacactgctg 1020
agaaacgaga acgtgctgga gacagccgag gccctgttta acgagctgaa cagcatcgac 1080
ctgacacaca tcttcatcag ccacaagaag ctggagacaa tcagcagcgc cctgtgcgac 1140
cactgggata cactgaggaa tgccctgtat gagcggagaa tctccgagct gacaggcaag 1200
atcaccaagt ctgccaagga gaaggtgcag cgcagcctga agcacgagga tatcaacctg 1260
caggagatca tctctgccgc aggcaaggag ctgagcgagg ccttcaagca gaaaaccagc 1320
gagatcctgt cccacgcaca cgccgccctg gatcagccac tgcctacaac cctgaagaag 1380
caggaggaga aggagatcct gaagtctcag ctggacagcc tgctgggcct gtaccacctg 1440
ctggactggt ttgccgtgga tgagtccaac gaggtggacc ccgagttctc tgcccggctg 1500
accggcatca agctggagat ggagccttct ctgagcttct acaacaaggc cagaaattat 1560
gccaccaaga agccctactc cgtggagaag ttcaagctga actttcagat gcctacactg 1620
gcctctggct gggacgtgaa taaggagaag aacaatggcg ccatcctgtt tgtgaagaac 1680
ggcctgtact atctgggcat catgccaaag cagaagggca ggtataaggc cctgagcttc 1740
gagcccacag agaaaaccag cgagggcttt gataagatgt actatgacta cttccctgat 1800
gccgccaaga tgatcccaaa gtgcagcacc cagctgaagg ccgtgacagc ccactttcag 1860
acccacacaa cccccatcct gctgtccaac aatttcatcg agcctctgga gatcacaaag 1920
gagatctacg acctgaacaa tcctgagaag gagccaaaga agtttcagac agcctacgcc 1980
aagaaaaccg gcgaccagaa gggctacaga gaggccctgt gcaagtggat cgacttcaca 2040
agggattttc tgtccaagta taccaagaca acctctatcg atctgtctag cctgcggcca 2100
tcctctcagt ataaggacct gggcgagtac tatgccgagc tgaatcccct gctgtaccac 2160
atcagcttcc agagaatcgc cgagaaggag atcatggatg ccgtggagac aggcaagctg 2220
tacctgttcc agatctataa caaggacttt gccaagggcc accacggcaa gcctaatctg 2280
cacacactgt attggaccgg cctgttttct ccagagaacc tggccaagac aagcatcaag 2340
ctgaatggcc aggccgagct gttctaccgc cctaagtcca ggatgaagag gatggcacac 2400
cggctgggag agaagatgct gaacaagaag ctgaaggatc agaaaacccc aatccccgac 2460
accctgtacc aggagctgta cgactatgtg aatcacagac tgtcccacga cctgtctgat 2520
gaggccaggg ccctgctgcc caacgtgatc accaaggagg tgtctcacga gatcatcaag 2580
gataggcgct ttaccagcga caagttcttt ttccacgtgc ctatcacact gaactatcag 2640
gccgccaatt ccccatctaa gttcaaccag agggtgaatg cctacctgaa ggagcacccc 2700
gagacaccta tcatcggcat cgatcggggc gagagaaacc tgatctatat cacagtgatc 2760
gactccaccg gcaagatcct ggagcagcgg agcctgaaca ccatccagca gtttgattac 2820
cagaagaagc tggacaacag ggagaaggag agggtggcag caaggcaggc ctggtctgtg 2880
gtgggcacaa tcaaggatct gaagcagggc tatctgagcc aggtcatcca cgagatcgtg 2940
gacctgatga tccactacca ggccgtggtg gtgctggaga acctgaattt cggctttaag 3000
agcaagagga ccggcatcgc cgagaaggcc gtgtaccagc agttcgagaa gatgctgatc 3060
gataagctga attgcctggt gctgaaggac tatccagcag agaaagtggg aggcgtgctg 3120
aacccatacc agctgacaga ccagttcacc tcctttgcca agatgggcac ccagtctggc 3180
ttcctgtttt acgtgcctgc cccatataca tctaagatcg atcccctgac cggcttcgtg 3240
gaccccttcg tgtggaaaac catcaagaat cacgagagcc gcaagcactt cctggagggc 3300
ttcgactttc tgcactacga cgtgaaaacc ggcgacttca tcctgcactt taagatgaac 3360
agaaatctgt ccttccagag gggcctgccc ggctttatgc ctgcatggga tatcgtgttc 3420
gagaagaacg agacacagtt tgacgccaag ggcacccctt tcatcgccgg caagagaatc 3480
gtgccagtga tcgagaatca cagattcacc ggcagatacc gggacctgta tcctgccaac 3540
gagctgatcg ccctgctgga ggagaagggc atcgtgttca gggatggctc caacatcctg 3600
ccaaagctgc tggagaatga cgattctcac gccatcgaca ccatggtggc cctgatccgc 3660
agcgtgctgc agatgcggaa ctccaatgcc gccacaggcg aggactatat caacagcccc 3720
gtgcgcgatc tgaatggcgt gtgcttcgac tcccggtttc agaacccaga gtggcccatg 3780
gacgccgatg ccaatggcgc ctaccacatc gccctgaagg gccagctgct gctgaatcac 3840
ctgaaggaga gcaaggatct gaagctgcag aacggcatct ccaatcagga ctggctggcc 3900
tacatccagg agctgcgcaa caaaaggccg gcggccacga aaaaggccgg ccaggcaaaa 3960
aagaaaaagg gatcctaccc atacgatgtt ccagattacg cttatcccta cgacgtgcct 4020
gattatgcat acccatatga tgtccccgac tatgcctaag aattc 4065
<210> 221
<211> 3762
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 221
atgtactatg agtccctgac caagcagtac cccgtgtcta agacaatccg gaatgagctg 60
atccctatcg gcaagacact ggataacatc cgccagaaca atatcctgga gagcgacgtg 120
aagcggaagc agaactacga gcacgtgaag ggcatcctgg atgagtatca caagcagctg 180
atcaacgagg ccctggacaa ttgcaccctg ccatccctga agatcgccgc cgagatctac 240
ctgaagaatc agaaggaggt gtctgacaga gaggatttca acaagacaca ggacctgctg 300
aggaaggagg tggtggagaa gctgaaggcc cacgagaact ttaccaagat cggcaagaag 360
gacatcctgg atctgctgga gaagctgcct tccatctctg aggacgatta caatgccctg 420
gagagcttcc gcaactttta cacctatttc acatcctaca acaaggtgcg ggagaatctg 480
tattctgata aggagaagag ctccacagtg gcctacagac tgatcaacga gaatttccca 540
aagtttctgg acaatgtgaa gagctatagg tttgtgaaaa ccgcaggcat cctggcagat 600
ggcctgggag aggaggagca ggactccctg ttcatcgtgg agacattcaa caagaccctg 660
acacaggacg gcatcgatac ctacaattct caagtgggca agatcaactc tagcatcaat 720
ctgtataacc agaagaatca gaaggccaat ggcttcagaa agatccccaa gatgaagatg 780
ctgtataagc agatcctgtc cgatagggag gagtctttca tcgacgagtt tcagagcgat 840
gaggtgctga tcgacaacgt ggagtcttat ggcagcgtgc tgatcgagtc tctgaagtcc 900
tctaaggtga gcgccttctt tgatgccctg agagagtcta agggcaagaa cgtgtacgtg 960
aagaatgacc tggccaagac agccatgagc aacatcgtgt tcgagaattg gaggaccttt 1020
gacgatctgc tgaaccagga gtacgacctg gccaacgaga acaagaagaa ggacgataag 1080
tatttcgaga agcgccagaa ggagctgaag aagaataaga gctactccct ggagcacctg 1140
tgcaacctgt ccgaggattc ttgtaacctg atcgagaatt atatccacca gatctccgac 1200
gatatcgaga atatcatcat caacaatgag acattcctgc gcatcgtgat caatgagcac 1260
gacaggtccc gcaagctggc caagaaccgg aaggccgtga aggccatcaa ggactttctg 1320
gattctatca aggtgctgga gcgggagctg aagctgatca acagctccgg ccaggagctg 1380
gagaaggatc tgatcgtgta ctctgcccac gaggagctgc tggtggagct gaagcaggtg 1440
gacagcctgt ataacatgac cagaaattat ctgacaaaga agcctttctc taccgagaag 1500
gtgaagctga actttaatcg cagcacactg ctgaacggct gggatcggaa taaggagaca 1560
gacaacctgg gcgtgctgct gctgaaggac ggcaagtact atctgggcat catgaacaca 1620
agcgccaata aggccttcgt gaatccccct gtggccaaga ccgagaaggt gtttaagaag 1680
gtggattaca agctgctgcc agtgcccaac cagatgctgc caaaggtgtt ctttgccaag 1740
agcaatatcg acttctataa cccctctagc gagatctact ccaattataa gaagggcacc 1800
cacaagaagg gcaatatgtt ttccctggag gattgtcaca acctgatcga cttctttaag 1860
gagtctatca gcaagcacga ggactggagc aagttcggct ttaagttcag cgatacagcc 1920
tcctacaacg acatctccga gttctatcgc gaggtggaga agcagggcta caagctgacc 1980
tatacagaca tcgatgagac atacatcaat gatctgatcg agcggaacga gctgtacctg 2040
ttccagatct ataataagga ctttagcatg tactccaagg gcaagctgaa cctgcacaca 2100
ctgtatttca tgatgctgtt tgatcagcgc aatatcgacg acgtggtgta taagctgaac 2160
ggagaggcag aggtgttcta taggccagcc tccatctctg aggacgagct gatcatccac 2220
aaggccggcg aggagatcaa gaacaagaat cctaaccggg ccagaaccaa ggagacaagc 2280
accttcagct acgacatcgt gaaggataag cggtatagca aggataagtt taccctgcac 2340
atccccatca caatgaactt cggcgtggat gaggtgaagc ggttcaacga cgccgtgaac 2400
agcgccatcc ggatcgatga gaatgtgaac gtgatcggca tcgaccgggg cgagagaaat 2460
ctgctgtacg tggtggtcat cgactctaag ggcaacatcc tggagcagat ctccctgaac 2520
tctatcatca ataaggagta cgacatcgag acagattatc acgcactgct ggatgagagg 2580
gagggcggca gagataaggc ccggaaggac tggaacaccg tggagaatat cagggacctg 2640
aaggccggct acctgagcca ggtggtgaac gtggtggcca agctggtgct gaagtataat 2700
gccatcatct gcctggagga cctgaacttt ggcttcaaga ggggccgcca gaaggtggag 2760
aagcaggtgt accagaagtt cgagaagatg ctgatcgata agctgaatta cctggtcatc 2820
gacaagagcc gcgagcagac atcccctaag gagctgggag gcgccctgaa cgcactgcag 2880
ctgacctcta agttcaagag ctttaaggag ctgggcaagc agtccggcgt gatctactat 2940
gtgcctgcct acctgacctc taagatcgat ccaaccacag gcttcgccaa tctgttttat 3000
atgaagtgtg agaacgtgga gaagtccaag agattctttg acggctttga tttcatcagg 3060
ttcaacgccc tggagaacgt gttcgagttc ggctttgact accggagctt cacccagagg 3120
gcctgcggca tcaattccaa gtggaccgtg tgcaccaacg gcgagcgcat catcaagtat 3180
cggaatccag ataagaacaa tatgttcgac gagaaggtgg tggtggtgac cgatgagatg 3240
aagaacctgt ttgagcagta caagatcccc tatgaggatg gcagaaatgt gaaggacatg 3300
atcatcagca acgaggaggc cgagttctac cggagactgt ataggctgct gcagcagacc 3360
ctgcagatga gaaacagcac ctccgacggc acaagggatt acatcatctc ccctgtgaag 3420
aataagagag aggcctactt caacagcgag ctgtccgacg gctctgtgcc aaaggacgcc 3480
gatgccaacg gcgcctacaa tatcgccaga aagggcctgt gggtgctgga gcagatcagg 3540
cagaagagcg agggcgagaa gatcaatctg gccatgacca acgccgagtg gctggagtat 3600
gcccagacac acctgctgaa aaggccggcg gccacgaaaa aggccggcca ggcaaaaaag 3660
aaaaagggat cctacccata cgatgttcca gattacgctt atccctacga cgtgcctgat 3720
tatgcatacc catatgatgt ccccgactat gcctaagaat tc 3762
<210> 222
<211> 3858
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 222
atgaacaatt acgacgagtt caccaagctg tatcctatcc agaaaaccat ccggtttgag 60
ctgaagccac agggcagaac catggagcac ctggagacat tcaacttctt tgaggaggac 120
cgggatagag ccgagaagta taagatcctg aaggaggcca tcgacgagta ccacaagaag 180
tttatcgatg agcacctgac caatatgtcc ctggattgga actctctgaa gcagatcagc 240
gagaagtact ataagagcag ggaggagaag gacaagaagg tgttcctgtc cgagcagaag 300
aggatgcgcc aggagatcgt gtctgagttt aagaaggacg atcgcttcaa ggacctgttt 360
tccaagaagc tgttctctga gctgctgaag gaggagatct acaagaaggg caaccaccag 420
gagatcgacg ccctgaagag cttcgataag ttttccggct atttcatcgg cctgcacgag 480
aataggaaga acatgtactc cgacggcgat gagatcaccg ccatctccaa tcgcatcgtg 540
aatgagaact tccccaagtt tctggataac ctgcagaagt accaggaggc caggaagaag 600
tatcctgagt ggatcatcaa ggccgagagc gccctggtgg cccacaatat caagatggac 660
gaggtgttct ccctggagta ctttaataag gtgctgaacc aggagggcat ccagcggtac 720
aacctggccc tgggcggcta tgtgaccaag agcggcgaga agatgatggg cctgaatgat 780
gccctgaacc tggcccacca gtccgagaag agctccaagg gcagaatcca catgaccccc 840
ctgttcaagc agatcctgtc cgagaaggag tccttctctt acatccccga cgtgtttaca 900
gaggattctc agctgctgcc tagcatcggc ggcttctttg cccagatcga gaatgacaag 960
gatggcaaca tcttcgaccg ggccctggag ctgatctcta gctacgccga gtatgatacc 1020
gagcggatct atatcagaca ggccgacatc aatagagtgt ccaacgtgat ctttggagag 1080
tggggcaccc tgggaggcct gatgagggag tacaaggccg actctatcaa tgatatcaac 1140
ctggagcgca catgcaagaa ggtggacaag tggctggatt ctaaggagtt tgccctgagc 1200
gatgtgctgg aggccatcaa gaggaccggc aacaatgacg ccttcaacga gtatatctcc 1260
aagatgcgga cagccagaga gaagatcgat gccgcccgca aggagatgaa gttcatcagc 1320
gagaagatct ccggcgatga ggagtctatc cacatcatca agaccctgct ggacagcgtg 1380
cagcagttcc tgcacttctt taatctgttt aaggcaaggc aggacatccc actggatgga 1440
gccttctacg ccgagtttga cgaggtgcac agcaagctgt ttgccatcgt gcccctgtat 1500
aacaaggtgc ggaactatct gaccaagaac aatctgaaca caaagaagat caagctgaat 1560
ttcaagaacc ctacactggc caatggctgg gaccagaaca aggtgtacga ttatgcctcc 1620
ctgatctttc tgcgggacgg caattactat ctgggcatca tcaatcctaa gagaaagaag 1680
aacatcaagt tcgagcaggg ctctggcaac ggccccttct accggaagat ggtgtataag 1740
cagatccccg gccctaataa gaacctgcca agagtgttcc tgacctccac aaagggcaag 1800
aaggagtata agccctctaa ggagatcatc gagggctacg aggccgacaa gcacatcagg 1860
ggcgataagt tcgacctgga tttttgtcac aagctgatcg atttctttaa ggagtccatc 1920
gagaagcaca aggactggtc taagttcaac ttctacttca gcccaaccga gagctatggc 1980
gacatctctg agttctacct ggatgtggag aagcagggct atcgcatgca ctttgagaat 2040
atcagcgccg agacaatcga cgagtatgtg gagaagggcg atctgtttct gttccagatc 2100
tacaacaagg attttgtgaa ggccgccacc ggcaagaagg acatgcacac aatctactgg 2160
aatgccgcct tcagccccga gaacctgcag gacgtggtgg tgaagctgaa cggcgaggcc 2220
gagctgtttt atagggacaa gtccgatatc aaggagatcg tgcaccgcga gggcgagatc 2280
ctggtgaata ggacctacaa cggccgcaca ccagtgcccg acaagatcca caagaagctg 2340
accgattatc acaatggccg gacaaaggac ctgggcgagg ccaaggagta cctggataag 2400
gtgagatact tcaaggccca ctatgacatc accaaggatc ggagatacct gaacgacaag 2460
atctatttcc acgtgcctct gaccctgaac ttcaaggcca acggcaagaa gaatctgaac 2520
aagatggtca tcgagaagtt cctgtccgat gagaaggccc acatcatcgg catcgacagg 2580
ggcgagcgca atctgctgta ctattccatc atcgacaggt ctggcaagat catcgatcag 2640
cagagcctga atgtgatcga cggctttgat tatcgggaga agctgaacca gagagagatc 2700
gagatgaagg atgcccgcca gtcttggaac gccatcggca agatcaagga cctgaaggag 2760
ggctacctga gcaaggccgt gcacgagatc accaagatgg ccatccagta taatgccatc 2820
gtggtcatgg aggagctgaa ctacggcttc aagcggggcc ggttcaaggt ggagaagcag 2880
atctatcaga agttcgagaa tatgctgatc gataagatga actacctggt gtttaaggac 2940
gcacctgatg agtccccagg aggcgtgctg aatgcctacc agctgacaaa cccactggag 3000
tctttcgcca agctgggcaa gcagaccggc atcctgtttt acgtgccagc cgcctataca 3060
tccaagatcg accccaccac aggcttcgtg aatctgttta acacctcctc taagacaaac 3120
gcccaggagc ggaaggagtt cctgcagaag tttgagagca tctcctattc tgccaaggat 3180
ggcggcatct ttgccttcgc ctttgactac agaaagttcg gcaccagcaa gacagatcac 3240
aagaacgtgt ggaccgccta tacaaacggc gagaggatgc gctacatcaa ggagaagaag 3300
cggaatgagc tgtttgaccc ttctaaggag atcaaggagg ccctgaccag ctccggcatc 3360
aagtacgatg gcggccagaa catcctgcca gacatcctga ggagcaacaa taacggcctg 3420
atctacacaa tgtattctag cttcatcgcc gccatccaga tgcgcgtgta cgacggcaag 3480
gaggattata tcatcagccc catcaagaac tccaagggcg agttctttag gaccgacccc 3540
aagaggcgcg agctgcctat cgacgccgat gccaatggcg cctacaacat cgccctgagg 3600
ggagagctga caatgagggc aatcgcagag aagttcgacc ctgatagcga gaagatggcc 3660
aagctggagc tgaagcacaa ggattggttc gagtttatgc agaccagagg cgacaaaagg 3720
ccggcggcca cgaaaaaggc cggccaggca aaaaagaaaa agggatccta cccatacgat 3780
gttccagatt acgcttatcc ctacgacgtg cctgattatg catacccata tgatgtcccc 3840
gactatgcct aagaattc 3858
<210> 223
<211> 3990
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 223
atgaacggca ataggtccat cgtgtaccgc gagttcgtgg gcgtgatccc cgtggccaag 60
accctgagga atgagctgcg ccctgtgggc cacacacagg agcacatcat ccagaacggc 120
ctgatccagg aggacgagct gcggcaggag aagagcaccg agctgaagaa catcatggac 180
gattactata gagagtacat cgataagtct ctgagcggcg tgaccgacct ggacttcacc 240
ctgctgttcg agctgatgaa cctggtgcag agctccccct ccaaggacaa taagaaggcc 300
ctggagaagg agcagtctaa gatgagggag cagatctgca cccacctgca gtccgactct 360
aactacaaga atatctttaa cgccaagctg ctgaaggaga tcctgcctga tttcatcaag 420
aactacaatc agtatgacgt gaaggataag gccggcaagc tggagacact ggccctgttt 480
aatggcttca gcacatactt taccgacttc tttgagaaga ggaagaacgt gttcaccaag 540
gaggccgtga gcacatccat cgcctaccgc atcgtgcacg agaactccct gatcttcctg 600
gccaatatga cctcttataa gaagatcagc gagaaggccc tggatgagat cgaagtgatc 660
gagaagaaca atcaggacaa gatgggcgat tgggagctga atcagatctt taaccctgac 720
ttctacaata tggtgctgat ccagtccggc atcgacttct acaacgagat ctgcggcgtg 780
gtgaatgccc acatgaacct gtactgtcag cagaccaaga acaattataa cctgttcaag 840
atgcggaagc tgcacaagca gatcctggcc tacaccagca ccagcttcga ggtgcccaag 900
atgttcgagg acgatatgag cgtgtataac gccgtgaacg ccttcatcga cgagacagag 960
aagggcaaca tcatcggcaa gctgaaggat atcgtgaata agtacgacga gctggatgag 1020
aagagaatct atatcagcaa ggacttttac gagacactga gctgcttcat gtccggcaac 1080
tggaatctga tcacaggctg cgtggagaac ttctacgatg agaacatcca cgccaagggc 1140
aagtccaagg aggagaaggt gaagaaggcc gtgaaggagg acaagtacaa gtctatcaat 1200
gacgtgaacg atctggtgga gaagtatatc gatgagaagg agaggaatga gttcaagaac 1260
agcaatgcca agcagtacat ccgcgagatc tccaacatca tcaccgacac agagacagcc 1320
cacctggagt atgacgatca catctctctg atcgagagcg aggagaaggc cgacgagatg 1380
aagaagcggc tggatatgta tatgaacatg taccactggg ccaaggcctt tatcgtggac 1440
gaggtgctgg acagagatga gatgttctac agcgatatcg acgatatcta taatatcctg 1500
gagaacatcg tgccactgta taatcgggtg agaaactacg tgacccagaa gccctacaac 1560
tctaagaaga tcaagctgaa tttccagagc cctacactgg ccaatggctg gtcccagtct 1620
aaggagttcg acaacaatgc catcatcctg atcagagata acaagtacta tctggccatc 1680
ttcaatgcca agaacaagcc agacaagaag atcatccagg gcaactccga taagaagaac 1740
gacaacgatt acaagaagat ggtgtataac ctgctgccag gcgccaacaa gatgctgccc 1800
aaggtgtttc tgtctaagaa gggcatcgag acattcaagc cctccgacta tatcatctct 1860
ggctacaacg cccacaagca catcaagaca agcgagaatt ttgatatctc cttctgtcgg 1920
gacctgatcg attacttcaa gaacagcatc gagaagcacg ccgagtggag aaagtatgag 1980
ttcaagtttt ccgccaccga cagctactcc gatatctctg agttctatcg ggaggtggag 2040
atgcagggct acagaatcga ctggacatat atcagcgagg ccgacatcaa caagctggat 2100
gaggagggca agatctatct gtttcagatc tacaataagg atttcgccga gaacagcacc 2160
ggcaaggaga atctgcacac aatgtacttt aagaacatct tctccgagga gaatctgaag 2220
gacatcatca tcaagctgaa cggccaggcc gagctgtttt atcggagagc ctctgtgaag 2280
aatcccgtga agcacaagaa ggatagcgtg ctggtgaaca agacctacaa gaatcagctg 2340
gacaacggcg acgtggtgag aatccccatc cctgacgata tctataacga gatctacaag 2400
atgtataatg gctacatcaa ggagtccgac ctgtctgagg ccgccaagga gtacctggat 2460
aaggtggagg tgaggaccgc ccagaaggac atcgtgaagg attaccgcta tacagtggac 2520
aagtacttca tccacacacc tatcaccatc aactataagg tgaccgcccg caacaatgtg 2580
aatgatatgg tggtgaagta catcgcccag aacgacgata tccacgtgat cggcatcgac 2640
cggggcgaga gaaacctgat ctacatctcc gtgatcgatt ctcacggcaa catcgtgaag 2700
cagaaatcct acaacatcct gaacaactac gactacaaga agaagctggt ggagaaggag 2760
aaaacccggg agtacgccag aaagaactgg aagagcatcg gcaatatcaa ggagctgaag 2820
gagggctata tctccggcgt ggtgcacgag atcgccatgc tgatcgtgga gtacaacgcc 2880
atcatcgcca tggaggacct gaattatggc tttaagaggg gccgcttcaa ggtggagcgg 2940
caggtgtacc agaagtttga gagcatgctg atcaataagc tgaactattt cgccagcaag 3000
gagaagtccg tggacgagcc aggaggcctg ctgaagggct atcagctgac ctacgtgccc 3060
gataatatca agaacctggg caagcagtgc ggcgtgatct tttacgtgcc tgccgccttc 3120
accagcaaga tcgacccatc cacaggcttt atctctgcct tcaactttaa gtctatcagc 3180
acaaatgcct ctcggaagca gttctttatg cagtttgacg agatcagata ctgtgccgag 3240
aaggatatgt tcagctttgg cttcgactac aacaacttcg atacctacaa catcacaatg 3300
ggcaagacac agtggaccgt gtatacaaac ggcgagagac tgcagtctga gttcaacaat 3360
gccaggcgca ccggcaagac aaagagcatc aatctgacag agacaatcaa gctgctgctg 3420
gaggacaatg agatcaacta cgccgacggc cacgatatca ggatcgatat ggagaagatg 3480
gacgaggata agaagagcga gttctttgcc cagctgctga gcctgtataa gctgaccgtg 3540
cagatgcgca attcctatac agaggccgag gagcaggaga acggcatctc ttacgacaag 3600
atcatcagcc ctgtgatcaa tgatgagggc gagttctttg actccgataa ctataaggag 3660
tctgacgata aggagtgcaa gatgccaaag gacgccgatg ccaacggcgc ctactgtatc 3720
gccctgaagg gcctgtatga ggtgctgaag atcaagagcg agtggaccga ggacggcttt 3780
gataggaatt gcctgaagct gccacacgca gagtggctgg acttcatcca gaacaagcgg 3840
tacgagaaaa ggccggcggc cacgaaaaag gccggccagg caaaaaagaa aaagggatcc 3900
tacccatacg atgttccaga ttacgcttat ccctacgacg tgcctgatta tgcataccca 3960
tatgatgtcc ccgactatgc ctaagaattc 3990
<210> 224
<211> 4263
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 224
atgctgttcc aggactttac ccacctgtat ccactgtcca agacagtgag atttgagctg 60
aagcccatcg ataggaccct ggagcacatc cacgccaaga acttcctgtc tcaggacgag 120
acaatggccg atatgcacca gaaggtgaaa gtgatcctgg acgattacca ccgcgacttc 180
atcgccgata tgatgggcga ggtgaagctg accaagctgg ccgagttcta tgacgtgtac 240
ctgaagtttc ggaagaaccc aaaggacgat gagctgcaga agcagctgaa ggatctgcag 300
gccgtgctga gaaaggagat cgtgaagccc atcggcaatg gcggcaagta taaggccggc 360
tacgacaggc tgttcggcgc caagctgttt aaggacggca aggagctggg cgatctggcc 420
aagttcgtga tcgcacagga gggagagagc tccccaaagc tggcccacct ggcccacttc 480
gagaagtttt ccacctattt cacaggcttt cacgataacc ggaagaatat gtattctgac 540
gaggataagc acaccgccat cgcctaccgc ctgatccacg agaacctgcc ccggtttatc 600
gacaatctgc agatcctgac cacaatcaag cagaagcact ctgccctgta cgatcagatc 660
atcaacgagc tgaccgccag cggcctggac gtgtctctgg ccagccacct ggatggctat 720
cacaagctgc tgacacagga gggcatcacc gcctacaata cactgctggg aggaatctcc 780
ggagaggcag gctctcctaa gatccagggc atcaacgagc tgatcaattc tcaccacaac 840
cagcactgcc acaagagcga gagaatcgcc aagctgaggc cactgcacaa gcagatcctg 900
tccgacggca tgagcgtgtc cttcctgccc tctaagtttg ccgacgatag cgagatgtgc 960
caggccgtga acgagttcta tcgccactac gccgacgtgt tcgccaaggt gcagagcctg 1020
ttcgacggct ttgacgatca ccagaaggat ggcatctacg tggagcacaa gaacctgaat 1080
gagctgtcca agcaggcctt cggcgacttt gcactgctgg gacgcgtgct ggacggatac 1140
tatgtggatg tggtgaatcc agagttcaac gagcggtttg ccaaggccaa gaccgacaat 1200
gccaaggcca agctgacaaa ggagaaggat aagttcatca agggcgtgca ctccctggcc 1260
tctctggagc aggccatcga gcactatacc gcaaggcacg acgatgagag cgtgcaggca 1320
ggcaagctgg gacagtactt caagcacggc ctggccggag tggacaaccc catccagaag 1380
atccacaaca atcacagcac catcaagggc tttctggaga gggagcgccc tgcaggagag 1440
agagccctgc caaagatcaa gtccggcaag aatcctgaga tgacacagct gaggcagctg 1500
aaggagctgc tggataacgc cctgaatgtg gcccacttcg ccaagctgct gaccacaaag 1560
accacactgg acaatcagga tggcaacttc tatggcgagt ttggcgtgct gtacgacgag 1620
ctggccaaga tccccaccct gtataacaag gtgagagatt acctgagcca gaagcctttc 1680
tccaccgaga agtacaagct gaactttggc aatccaacac tgctgaatgg ctgggacctg 1740
aacaaggaga aggataattt cggcgtgatc ctgcagaagg acggctgcta ctatctggcc 1800
ctgctggaca aggcccacaa gaaggtgttt gataacgccc ctaatacagg caagagcatc 1860
tatcagaaga tgatctataa gtacctggag gtgaggaagc agttccccaa ggtgttcttt 1920
tccaaggagg ccatcgccat caactaccac ccttctaagg agctggtgga gatcaaggac 1980
aagggccggc agagatccga cgatgagcgc ctgaagctgt atcggtttat cctggagtgt 2040
ctgaagatcc accctaagta cgataagaag ttcgagggcg ccatcggcga catccagctg 2100
tttaagaagg ataagaaggg cagagaggtg ccaatcagcg agaaggacct gttcgataag 2160
atcaacggca tcttttctag caagcctaag ctggagatgg aggacttctt tatcggcgag 2220
ttcaagaggt ataacccaag ccaggacctg gtggatcagt ataatatcta caagaagatc 2280
gactccaacg ataatcgcaa gaaggagaat ttctacaaca atcaccccaa gtttaagaag 2340
gatctggtgc ggtactatta cgagtctatg tgcaagcacg aggagtggga ggagagcttc 2400
gagttttcca agaagctgca ggacatcggc tgttacgtgg atgtgaacga gctgtttacc 2460
gagatcgaga cacggagact gaattataag atctccttct gcaacatcaa tgccgactac 2520
atcgatgagc tggtggagca gggccagctg tatctgttcc agatctacaa caaggacttt 2580
tccccaaagg cccacggcaa gcccaatctg cacaccctgt acttcaaggc cctgttttct 2640
gaggacaacc tggccgatcc tatctataag ctgaatggcg aggcccagat cttctacaga 2700
aaggcctccc tggacatgaa cgagacaaca atccacaggg ccggcgaggt gctggagaac 2760
aagaatcccg ataatcctaa gaagagacag ttcgtgtacg acatcatcaa ggataagagg 2820
tacacacagg acaagttcat gctgcacgtg ccaatcacca tgaactttgg cgtgcagggc 2880
atgacaatca aggagttcaa taagaaggtg aaccagtcta tccagcagta tgacgaggtg 2940
aacgtgatcg gcatcgatcg gggcgagaga cacctgctgt acctgaccgt gatcaatagc 3000
aagggcgaga tcctggagca gtgttccctg aacgacatca ccacagcctc tgccaatggc 3060
acacagatga ccacacctta ccacaagatc ctggataaga gggagatcga gcgcctgaac 3120
gcccgggtgg gatggggcga gatcgagaca atcaaggagc tgaagtctgg ctatctgagc 3180
cacgtggtgc accagatcag ccagctgatg ctgaagtaca acgccatcgt ggtgctggag 3240
gacctgaatt tcggctttaa gaggggccgc tttaaggtgg agaagcagat ctatcagaac 3300
ttcgagaatg ccctgatcaa gaagctgaac cacctggtgc tgaaggacaa ggccgacgat 3360
gagatcggct cttacaagaa tgccctgcag ctgaccaaca atttcacaga tctgaagagc 3420
atcggcaagc agaccggctt cctgttttat gtgcccgcct ggaacacctc taagatcgac 3480
cctgagacag gctttgtgga tctgctgaag ccaagatacg agaacatcgc ccagagccag 3540
gccttctttg gcaagttcga caagatctgc tataatgccg acaaggatta cttcgagttt 3600
cacatcgact acgccaagtt taccgataag gccaagaata gccgccagat ctggacaatc 3660
tgttcccacg gcgacaagcg gtacgtgtac gataagacag ccaaccagaa taagggcgcc 3720
gccaagggca tcaacgtgaa tgatgagctg aagtccctgt tcgcccgcca ccacatcaac 3780
gagaagcagc ccaacctggt catggacatc tgccagaaca atgataagga gtttcacaag 3840
tctctgatgt acctgctgaa aaccctgctg gccctgcggt acagcaacgc ctcctctgac 3900
gaggatttca tcctgtcccc cgtggcaaac gacgagggcg tgttctttaa tagcgccctg 3960
gccgacgata cacagcctca gaatgccgat gccaacggcg cctaccacat cgccctgaag 4020
ggcctgtggc tgctgaatga gctgaagaac tccgacgatc tgaacaaggt gaagctggcc 4080
atcgacaatc agacctggct gaatttcgcc cagaacagga aaaggccggc ggccacgaaa 4140
aaggccggcc aggcaaaaaa gaaaaaggga tcctacccat acgatgttcc agattacgct 4200
tatccctacg acgtgcctga ttatgcatac ccatatgatg tccccgacta tgcctaagaa 4260
ttc 4263
<210> 225
<211> 3933
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 225
atggaggact attccggctt tgtgaacatc tactctatcc agaaaaccct gaggttcgag 60
ctgaagccag tgggcaagac actggagcac atcgagaaga agggcttcct gaagaaggac 120
aagatccggg ccgaggatta caaggccgtg aagaagatca tcgataagta ccacagagcc 180
tatatcgagg aggtgtttga ttccgtgctg caccagaaga agaagaagga caagacccgc 240
ttttctacac agttcatcaa ggagatcaag gagttcagcg agctgtacta taagaccgag 300
aagaacatcc ccgacaagga gaggctggag gccctgagcg agaagctgcg caagatgctg 360
gtgggcgcct ttaagggcga gttctccgag gaggtggccg agaagtataa gaacctgttt 420
tctaaggagc tgatcaggaa tgagatcgag aagttctgcg agacagacga ggagcgcaag 480
caggtgtcta acttcaagag cttcaccaca tactttaccg gcttccactc caacaggcag 540
aatatctatt ccgacgagaa gaagtctaca gccatcggct accgcatcat ccaccagaac 600
ctgcctaagt tcctggataa tctgaagatc atcgagtcca tccagcggcg gttcaaggac 660
ttcccatggt ctgatctgaa gaagaacctg aagaagatcg ataagaatat caagctgacc 720
gagtacttca gcatcgacgg cttcgtgaac gtgctgaatc agaagggcat cgatgcctac 780
aacacaatcc tgggcggcaa gtccgaggag tctggcgaga agatccaggg cctgaacgag 840
tacatcaatc tgtatcggca gaagaacaat atcgacagaa agaacctgcc caatgtgaag 900
atcctgttta agcagatcct gggcgatagg gagacaaaga gctttatccc tgaggccttc 960
ccagacgatc agtccgtgct gaactctatc acagagttcg ccaagtacct gaagctggat 1020
aagaagaaga agagcatcat cgccgagctg aagaagtttc tgagctcctt caatcgctac 1080
gagctggacg gcatctatct ggccaacgat aatagcctgg cctctatcag caccttcctg 1140
tttgacgatt ggtcctttat caagaagtcc gtgtctttca agtatgacga gtccgtgggc 1200
gaccccaaga agaagatcaa gtctcccctg aagtacgaga aggagaagga gaagtggctg 1260
aagcagaagt actatacaat ctctttcctg aacgatgcca tcgagagcta ttccaagtct 1320
caggacgaga agagggtgaa gatccgcctg gaggcctact ttgccgagtt caagagcaag 1380
gacgatgcca agaagcagtt cgacctgctg gagaggatcg aggaggccta tgccatcgtg 1440
gagcctctgc tgggagcaga gtacccaagg gaccgcaacc tgaaggccga taagaaggaa 1500
gtgggcaaga tcaaggactt cctggatagc atcaagtccc tgcagttctt tctgaagcct 1560
ctgctgtccg ccgagatctt tgacgagaag gatctgggct tctacaatca gctggagggc 1620
tactatgagg agatcgattc tatcggccac ctgtataaca aggtgcggaa ttatctgacc 1680
ggcaagatct acagcaagga gaagtttaag ctgaacttcg agaacagcac cctgctgaag 1740
ggctgggacg agaaccggga ggtggccaat ctgtgcgtga tcttcagaga ggaccagaag 1800
tactatctgg gcgtgatgga taaggagaac aataccatcc tgtccgacat ccccaaggtg 1860
aagcctaacg agctgtttta cgagaagatg gtgtataagc tgatccccac acctcacatg 1920
cagctgcccc ggatcatctt ctctagcgac aacctgtcta tctataatcc tagcaagtcc 1980
atcctgaaga tcagagaggc caagagcttt aaggagggca agaacttcaa gctgaaggac 2040
tgtcacaagt ttatcgattt ctacaaggag tctatcagca agaatgagga ctggagcaga 2100
ttcgacttca agttcagcaa gaccagcagc tacgagaaca tcagcgagtt ttaccgggag 2160
gtggagagac agggctataa cctggacttc aagaaggtgt ctaagttcta catcgacagc 2220
ctggtggagg atggcaagct gtacctgttc cagatctata acaaggactt ttctatcttc 2280
agcaagggca agcccaatct gcacaccatc tattttcggt ccctgttctc taaggagaac 2340
ctgaaggacg tgtgcctgaa gctgaatggc gaggccgaga tgttctttcg gaagaagtcc 2400
atcaactacg atgagaagaa gaagcgggag ggccaccacc ccgagctgtt tgagaagctg 2460
aagtatccta tcctgaagga caagagatac agcgaggata agtttcagtt ccacctgccc 2520
atcagcctga acttcaagtc caaggagcgg ctgaacttta atctgaaagt gaatgagttc 2580
ctgaagagaa acaaggacat caatatcatc ggcatcgatc ggggcgagag aaacctgctg 2640
tacctggtca tgatcaatca gaagggcgag atcctgaagc agaccctgct ggacagcatg 2700
cagtccggca agggccggcc tgagatcaac tacaaggaga agctgcagga gaaggagatc 2760
gagagggata aggcccgcaa gagctggggc acagtggaga atatcaagga gctgaaggag 2820
ggctatctgt ctatcgtgat ccaccagatc agcaagctga tggtggagaa caatgccatc 2880
gtggtgctgg aggacctgaa catcggcttt aagcggggca gacagaaggt ggagcggcag 2940
gtgtaccaga agttcgagaa gatgctgatc gataagctga actttctggt gttcaaggag 3000
aataagccaa ccgagccagg aggcgtgctg aaggcctatc agctgacaga cgagtttcag 3060
tctttcgaga agctgagcaa gcagaccggc tttctgttct acgtgccaag ctggaacacc 3120
tccaagatcg accccagaac aggctttatc gatttcctgc accctgccta cgagaatatc 3180
gagaaggcca agcagtggat caacaagttt gattccatca ggttcaattc taagatggac 3240
tggtttgagt tcaccgccga tacacgcaag ttttccgaga acctgatgct gggcaagaat 3300
cgggtgtggg tcatctgcac cacaaatgtg gagcggtact tcaccagcaa gaccgccaac 3360
agctccatcc agtacaatag catccagatc accgagaagc tgaaggagct gtttgtggac 3420
atccctttca gcaacggcca ggatctgaag ccagagatcc tgaggaagaa tgacgccgtg 3480
ttctttaaga gcctgctgtt ttacatcaag accacactgt ccctgcgcca gaacaatggc 3540
aagaagggcg aggaggagaa ggacttcatc ctgagcccag tggtggattc caagggccgg 3600
ttctttaact ctctggaggc cagcgacgat gagcccaagg acgccgatgc caatggcgcc 3660
taccacatcg ccctgaaggg cctgatgaac ctgctggtgc tgaatgagac aaaggaggag 3720
aacctgagca gaccaaagtg gaagatcaag aataaggact ggctggagtt cgtgtgggag 3780
aggaaccgca aaaggccggc ggccacgaaa aaggccggcc aggcaaaaaa gaaaaaggga 3840
tcctacccat acgatgttcc agattacgct tatccctacg acgtgcctga ttatgcatac 3900
ccatatgatg tccccgacta tgcctaagaa ttc 3933
<210> 226
<211> 3828
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 226
atgagcaagc tggagaagtt tacaaactgc tactccctgt ctaagaccct gaggttcaag 60
gccatccctg tgggcaagac ccaggagaac atcgacaata agcggctgct ggtggaggac 120
gagaagagag ccgaggatta taagggcgtg aagaagctgc tggatcgcta ctatctgtct 180
tttatcaacg acgtgctgca cagcatcaag ctgaagaatc tgaacaatta catcagcctg 240
ttccggaaga aaaccagaac cgagaaggag aataaggagc tggagaacct ggagatcaat 300
ctgcggaagg agatcgccaa ggccttcaag ggcaacgagg gctacaagtc cctgtttaag 360
aaggatatca tcgagacaat cctgccagag ttcctggacg ataaggacga gatcgccctg 420
gtgaacagct tcaatggctt taccacagcc ttcaccggct tctttgataa cagagagaat 480
atgttttccg aggaggccaa gagcacatcc atcgccttca ggtgtatcaa cgagaatctg 540
acccgctaca tctctaatat ggacatcttc gagaaggtgg acgccatctt tgataagcac 600
gaggtgcagg agatcaagga gaagatcctg aacagcgact atgatgtgga ggatttcttt 660
gagggcgagt tctttaactt tgtgctgaca caggagggca tcgacgtgta taacgccatc 720
atcggcggct tcgtgaccga gagcggcgag aagatcaagg gcctgaacga gtacatcaac 780
ctgtataatc agaaaaccaa gcagaagctg cctaagttta agccactgta taagcaggtg 840
ctgagcgatc gggagtctct gagcttctac ggcgagggct atacatccga tgaggaggtg 900
ctggaggtgt ttagaaacac cctgaacaag aacagcgaga tcttcagctc catcaagaag 960
ctggagaagc tgttcaagaa ttttgacgag tactctagcg ccggcatctt tgtgaagaac 1020
ggccccgcca tcagcacaat ctccaaggat atcttcggcg agtggaacgt gatccgggac 1080
aagtggaatg ccgagtatga cgatatccac ctgaagaaga aggccgtggt gaccgagaag 1140
tacgaggacg atcggagaaa gtccttcaag aagatcggct ccttttctct ggagcagctg 1200
caggagtacg ccgacgccga tctgtctgtg gtggagaagc tgaaggagat catcatccag 1260
aaggtggatg agatctacaa ggtgtatggc tcctctgaga agctgttcga cgccgatttt 1320
gtgctggaga agagcctgaa gaagaacgac gccgtggtgg ccatcatgaa ggacctgctg 1380
gattctgtga agagcttcga gaattacatc aaggccttct ttggcgaggg caaggagaca 1440
aacagggacg agtccttcta tggcgatttt gtgctggcct acgacatcct gctgaaggtg 1500
gaccacatct acgatgccat ccgcaattat gtgacccaga agccctactc taaggataag 1560
ttcaagctgt attttcagaa ccctcagttc atgggcggct gggacaagga taaggagaca 1620
gactatcggg ccaccatcct gagatacggc tccaagtact atctggccat catggataag 1680
aagtacgcca agtgcctgca gaagatcgac aaggacgatg tgaacggcaa ttacgagaag 1740
atcaactata agctgctgcc cggccctaat aagatgctgc caaaggtgtt cttttctaag 1800
aagtggatgg cctactataa ccccagcgag gacatccaga agatctacaa gaatggcaca 1860
ttcaagaagg gcgatatgtt taacctgaat gactgtcaca agctgatcga cttctttaag 1920
gatagcatct cccggtatcc aaagtggtcc aatgcctacg atttcaactt ttctgagaca 1980
gagaagtata aggacatcgc cggcttttac agagaggtgg aggagcaggg ctataaggtg 2040
agcttcgagt ctgccagcaa gaaggaggtg gataagctgg tggaggaggg caagctgtat 2100
atgttccaga tctataacaa ggacttttcc gataagtctc acggcacacc caatctgcac 2160
accatgtact tcaagctgct gtttgacgag aacaatcacg gacagatcag gctgagcgga 2220
ggagcagagc tgttcatgag gcgcgcctcc ctgaagaagg aggagctggt ggtgcaccca 2280
gccaactccc ctatcgccaa caagaatcca gataatccca agaaaaccac aaccctgtcc 2340
tacgacgtgt ataaggataa gaggttttct gaggaccagt acgagctgca catcccaatc 2400
gccatcaata agtgccccaa gaacatcttc aagatcaata cagaggtgcg cgtgctgctg 2460
aagcacgacg ataaccccta tgtgatcggc atcgataggg gcgagcgcaa tctgctgtat 2520
atcgtggtgg tggacggcaa gggcaacatc gtggagcagt attccctgaa cgagatcatc 2580
aacaacttca acggcatcag gatcaagaca gattaccact ctctgctgga caagaaggag 2640
aaggagaggt tcgaggcccg ccagaactgg acctccatcg agaatatcaa ggagctgaag 2700
gccggctata tctctcaggt ggtgcacaag atctgcgagc tggtggagaa gtacgatgcc 2760
gtgatcgccc tggaggacct gaactctggc tttaagaata gccgcgtgaa ggtggagaag 2820
caggtgtatc agaagttcga gaagatgctg atcgataagc tgaactacat ggtggacaag 2880
aagtctaatc cttgtgcaac aggcggcgcc ctgaagggct atcagatcac caataagttc 2940
gagagcttta agtccatgtc tacccagaac ggcttcatct tttacatccc tgcctggctg 3000
acatccaaga tcgatccatc taccggcttt gtgaacctgc tgaaaaccaa gtataccagc 3060
atcgccgatt ccaagaagtt catcagctcc tttgacagga tcatgtacgt gcccgaggag 3120
gatctgttcg agtttgccct ggactataag aacttctctc gcacagacgc cgattacatc 3180
aagaagtgga agctgtactc ctacggcaac cggatcagaa tcttccggaa tcctaagaag 3240
aacaacgtgt tcgactggga ggaggtgtgc ctgaccagcg cctataagga gctgttcaac 3300
aagtacggca tcaattatca gcagggcgat atcagagccc tgctgtgcga gcagtccgac 3360
aaggccttct actctagctt tatggccctg atgagcctga tgctgcagat gcggaacagc 3420
atcacaggcc gcaccgacgt ggattttctg atcagccctg tgaagaactc cgacggcatc 3480
ttctacgata gccggaacta tgaggcccag gagaatgcca tcctgccaaa gaacgccgac 3540
gccaatggcg cctataacat cgccagaaag gtgctgtggg ccatcggcca gttcaagaag 3600
gccgaggacg agaagctgga taaggtgaag atcgccatct ctaacaagga gtggctggag 3660
tacgcccaga ccagcgtgaa gcacaaaagg ccggcggcca cgaaaaaggc cggccaggca 3720
aaaaagaaaa agggatccta cccatacgat gttccagatt acgcttatcc ctacgacgtg 3780
cctgattatg catacccata tgatgtcccc gactatgcct aagaattc 3828
<210> 227
<211> 3924
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 227
atggacagcc tgaaggattt caccaacctg taccccgtgt ccaagacact gcggtttgag 60
ctgaagcctg tgggcaagac cctggagaat atcgagaagg ccggcatcct gaaggaggat 120
gagcacagag ccgagagcta ccggagagtg aagaagatca tcgatacata tcacaaggtg 180
ttcatcgaca gctccctgga gaacatggcc aagatgggca tcgagaatga gatcaaggcc 240
atgctgcagt ccttttgcga gctgtataag aaggaccaca ggaccgaggg agaggacaag 300
gccctggata agatcagggc cgtgctgagg ggcctgatcg tgggagcctt caccggcgtg 360
tgcggccggc gggagaacac agtgcagaat gagaagtatg agagcctgtt taaggagaag 420
ctgatcaagg agatcctgcc agatttcgtg ctgtctacag aggccgagtc cctgcccttt 480
tctgtggagg aggccaccag aagcctgaag gagttcgact cctttacatc ttacttcgcc 540
ggcttttatg agaaccggaa gaatatctac tctaccaagc cccagagcac agccatcgcc 600
tatagactga tccacgagaa cctgcctaag ttcatcgata atatcctggt gtttcagaag 660
atcaaggagc caatcgccaa ggagctggag cacatcaggg cagacttcag cgccggcggc 720
tacatcaaga aggatgagcg cctggaggac atcttttccc tgaactacta tatccacgtg 780
ctgtctcagg ccggcatcga gaagtacaat gccctgatcg gcaagatcgt gaccgagggc 840
gatggcgaga tgaagggcct gaacgagcac atcaacctgt ataatcagca gaggggccgc 900
gaggaccggc tgccactgtt cagacccctg tataagcaga tcctgtctga tagggagcag 960
ctgtcctatc tgccagagtc tttcgagaag gacgaggagc tgctgagggc cctgaaggag 1020
ttttacgatc acatcgcaga ggacatcctg ggaaggaccc agcagctgat gacaagcatc 1080
tccgagtacg atctgtcccg gatctatgtg agaaacgata gccagctgac cgacatctcc 1140
aagaagatgc tgggcgattg gaatgccatc tacatggccc gggagagagc ctatgaccac 1200
gagcaggccc ccaagcgcat cacagccaag tacgagaggg accgcatcaa ggccctgaag 1260
ggcgaggagt ctatcagcct ggccaacctg aacagctgca tcgccttcct ggacaacgtg 1320
agggattgtc gcgtggacac ctatctgtct acactgggac agaaggaggg acctcacggc 1380
ctgagcaacc tggtggagaa cgtgttcgcc tcctaccacg aggccgagca gctgctgtct 1440
tttccctatc ctgaggagaa caatctgatc caggacaagg ataacgtggt gctgatcaag 1500
aacctgctgg ataatatcag cgacctgcag aggttcctga agccactgtg gggcatgggc 1560
gatgagcccg acaaggatga gaggttttac ggcgagtaca attatatcag gggcgccctg 1620
gaccaggtca tccctctgta taacaaggtg cggaattatc tgacccgcaa gccatactcc 1680
acacgcaagg tgaagctgaa cttcggcaat agccagctgc tgtccggctg ggataggaac 1740
aaggagaagg acaattcttg cgtgatcctg cgcaagggcc agaacttcta cctggccatc 1800
atgaacaatc ggcacaagcg gagcttcgag aataagatgc tgcccgagta taaggagggc 1860
gagccttact tcgagaagat ggattataag tttctgccag accccaacaa gatgctgccc 1920
aaggtgttcc tgtctaagaa gggcatcgag atctacaagc ctagcccaaa gctgctggag 1980
cagtatggcc acggcaccca caagaagggc gataccttca gcatggacga tctgcacgag 2040
ctgatcgact tctttaagca ctccatcgag gcccacgagg attggaagca gttcggcttt 2100
aagttcagcg acaccgccac atacgagaac gtgagcagct tctaccggga ggtggaggac 2160
cagggctaca agctgtcttt tagaaaggtg tccgagtctt acgtgtatag cctgatcgat 2220
cagggcaagc tgtacctgtt ccagatctat aacaaggact ttagcccttg ttccaagggc 2280
accccaaatc tgcacacact gtactggcgg atgctgttcg atgagagaaa cctggccgac 2340
gtgatctata agctggatgg caaggccgag atcttctttc gggagaagtc cctgaagaat 2400
gaccacccaa cccaccctgc aggcaagccc atcaagaaga agagccggca gaagaagggc 2460
gaggagagcc tgttcgagta cgatctggtg aaggaccgga gatataccat ggataagttt 2520
cagttccacg tgccaatcac aatgaacttt aagtgctctg ccggcagcaa ggtgaacgac 2580
atggtgaatg cccacatcag ggaggccaag gacatgcacg tgatcggcat cgataggggc 2640
gagcgcaatc tgctgtatat ctgcgtgatc gacagccgcg gcaccatcct ggatcagatc 2700
tccctgaaca caatcaatga catcgattat cacgatctgc tggagtccag ggacaaggat 2760
cgccagcagg agcacaggaa ctggcagacc atcgagggca tcaaggagct gaagcagggc 2820
tacctgtctc aggccgtgca ccgcatcgcc gagctgatgg tggcctataa ggccgtggtg 2880
gccctggagg acctgaacat gggcttcaag cggggcagac agaaggtgga gagcagcgtg 2940
taccagcagt ttgagaagca gctgatcgac aagctgaatt atctggtgga taagaagaag 3000
cggcccgagg acatcggagg cctgctgaga gcctaccagt tcaccgcccc tttcaagagc 3060
tttaaggaga tgggcaagca gaacggcttt ctgttctata tccctgcctg gaacacatcc 3120
aatatcgacc caaccacagg cttcgtgaac ctgtttcacg tgcagtacga gaatgtggat 3180
aaggccaaga gcttctttca gaagttcgac agcatctcct acaaccctaa gaaggattgg 3240
tttgagttcg cctttgacta taagaacttc accaagaagg ccgagggctc taggagcatg 3300
tggattctgt gcacccacgg ctcccggatc aagaacttca gaaattctca gaagaatggc 3360
cagtgggata gcgaggagtt tgccctgacc gaggccttca agtccctgtt tgtgcggtac 3420
gagatcgatt ataccgccga cctgaaaacc gccatcgtgg acgagaagca gaaggatttc 3480
tttgtggacc tgctgaagct gttcaagctg accgtgcaga tgagaaactc ctggaaggag 3540
aaggacctgg attacctgat ctctccagtg gccggcgccg atggcaggtt ctttgacaca 3600
cgcgagggca ataagagcct gcccaaggac gcagatgcaa acggagccta taatatcgcc 3660
ctgaagggcc tgtgggcact gaggcagatc agacagacct ccgagggcgg caagctgaag 3720
ctggccatct ctaacaagga gtggctgcag tttgtgcagg agagatccta cgagaaggac 3780
aaaaggccgg cggccacgaa aaaggccggc caggcaaaaa agaaaaaggg atcctaccca 3840
tacgatgttc cagattacgc ttatccctac gacgtgcctg attatgcata cccatatgat 3900
gtccccgact atgcctaaga attc 3924
<210> 228
<211> 4113
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 228
atggagaact atcaggagtt caccaacctg tttcagctga ataagacact gagattcgag 60
ctgaagccca tcggcaagac ctgcgagctg ctggaggagg gcaagatctt cgccagcggc 120
tcctttctgg agaaggacaa ggtgagggcc gataacgtga gctacgtgaa gaaggagatc 180
gacaagaagc acaagatctt tatcgaggag acactgagct ccttctctat cagcaacgat 240
ctgctgaagc agtactttga ctgctataat gagctgaagg ccttcaagaa ggactgtaag 300
agcgatgagg aggaggtgaa gaaaaccgcc ctgcgcaaca agtgtacctc catccagagg 360
gccatgcgcg aggccatctc tcaggccttt ctgaagagcc cccagaagaa gctgctggcc 420
atcaagaacc tgatcgagaa cgtgttcaag gccgacgaga atgtgcagca cttctccgag 480
tttaccagct atttctccgg ctttgagaca aacagagaga atttctactc tgacgaggag 540
aagtccacat ctatcgccta taggctggtg cacgataacc tgcctatctt catcaagaac 600
atctacatct tcgagaagct gaaggagcag ttcgacgcca agaccctgag cgagatcttc 660
gagaactaca agctgtatgt ggccggctct agcctggatg aggtgttctc cctggagtac 720
tttaacaata ccctgacaca gaagggcatc gacaactata atgccgtgat cggcaagatc 780
gtgaaggagg ataagcagga gatccagggc ctgaacgagc acatcaacct gtataatcag 840
aagcacaagg accggagact gcccttcttt atctccctga agaagcagat cctgtccgat 900
cgggaggccc tgtcttggct gcctgacatg ttcaagaatg attctgaagt gatcaaggcc 960
ctgaagggct tctacatcga ggacggcttt gagaacaatg tgctgacacc tctggccacc 1020
ctgctgtcct ctctggataa gtacaacctg aatggcatct ttatccgcaa caatgaggcc 1080
ctgagctccc tgtcccagaa cgtgtatcgg aatttttcta tcgacgaggc catcgatgcc 1140
aacgccgagc tgcagacctt caacaattac gagctgatcg ccaatgccct gcgcgccaag 1200
atcaagaagg agacaaagca gggccggaag tctttcgaga agtacgagga gtatatcgat 1260
aagaaggtga aggccatcga cagcctgtcc atccaggaga tcaacgagct ggtggagaat 1320
tacgtgagcg agtttaactc taatagcggc aacatgccaa gaaaggtgga ggactacttc 1380
agcctgatga ggaagggcga cttcggctcc aacgatctga tcgaaaatat caagaccaag 1440
ctgagcgccg cagagaagct gctgggcaca aagtaccagg agacagccaa ggacatcttc 1500
aagaaggatg agaactccaa gctgatcaag gagctgctgg acgccaccaa gcagttccag 1560
cactttatca agccactgct gggcacaggc gaggaggcag atcgggacct ggtgttctac 1620
ggcgattttc tgcccctgta tgagaagttt gaggagctga ccctgctgta taacaaggtg 1680
cggaatagac tgacacagaa gccctattcc aaggacaaga tccgcctgtg cttcaacaag 1740
cctaagctga tgacaggctg ggtggattcc aagaccgaga agtctgacaa cggcacacag 1800
tacggcggct atctgtttcg gaagaagaat gagatcggcg agtacgatta ttttctgggc 1860
atctctagca aggcccagct gttcagaaag aacgaggccg tgatcggcga ctacgagagg 1920
ctggattact atcagccaaa ggccaatacc atctacggct ctgcctatga gggcgagaac 1980
agctacaagg aggacaagaa gcggctgaac aaagtgatca tcgcctatat cgagcagatc 2040
aagcagacaa acatcaagaa gtctatcatc gagtccatct ctaagtatcc taatatcagc 2100
gacgatgaca aggtgacccc atcctctctg ctggagaaga tcaagaaggt gtctatcgac 2160
agctacaacg gcatcctgtc cttcaagtct tttcagagcg tgaacaagga agtgatcgat 2220
aacctgctga aaaccatcag ccccctgaag aacaaggccg agtttctgga cctgatcaat 2280
aaggattatc agatcttcac cgaggtgcag gccgtgatcg acgagatctg caagcagaaa 2340
accttcatct actttccaat ctccaacgtg gagctggaga aggagatggg cgataaggac 2400
aagcccctgt gcctgttcca gatcagcaat aaggatctgt ccttcgccaa gacctttagc 2460
gccaacctgc ggaagaagag aggcgccgag aatctgcaca caatgctgtt taaggccctg 2520
atggagggca accaggataa tctggacctg ggctctggcg ccatcttcta cagagccaag 2580
agcctggacg gcaacaagcc cacacaccct gccaatgagg ccatcaagtg taggaacgtg 2640
gccaataagg ataaggtgtc cctgttcacc tacgacatct ataagaacag gcgctacatg 2700
gagaataagt tcctgtttca cctgagcatc gtgcagaact ataaggccgc caatgactcc 2760
gcccagctga acagctccgc caccgagtat atcagaaagg ccgatgacct gcacatcatc 2820
ggcatcgata ggggcgagcg caatctgctg tactattccg tgatcgatat gaagggcaac 2880
atcgtggagc aggactctct gaatatcatc aggaacaatg acctggagac agattaccac 2940
gacctgctgg ataagaggga gaaggagcgc aaggccaacc ggcagaattg ggaggccgtg 3000
gagggcatca aggacctgaa gaagggctac ctgagccagg ccgtgcacca gatcgcccag 3060
ctgatgctga agtataacgc catcatcgcc ctggaggatc tgggccagat gtttgtgacc 3120
cgcggccaga agatcgagaa ggccgtgtac cagcagttcg agaagagcct ggtggataag 3180
ctgtcctacc tggtggacaa gaagcggcct tataatgagc tgggcggcat cctgaaggcc 3240
taccagctgg cctctagcat caccaagaac aattctgaca agcagaacgg cttcctgttt 3300
tatgtgccag cctggaatac aagcaagatc gatcccgtga ccggctttac agacctgctg 3360
cggcccaagg ccatgaccat caaggaggcc caggacttct ttggcgcctt cgataacatc 3420
tcttacaatg acaagggcta tttcgagttt gagacaaact acgacaagtt taagatcaga 3480
atgaagagcg cccagaccag gtggacaatc tgcaccttcg gcaatcggat caagagaaag 3540
aaggataaga actactggaa ttatgaggag gtggagctga ccgaggagtt caagaagctg 3600
tttaaggaca gcaacatcga ttacgagaac tgtaatctga aggaggagat ccagaacaag 3660
gacaatcgca agttctttga tgacctgatc aagctgctgc agctgacact gcagatgcgg 3720
aactccgatg acaagggcaa tgattatatc atctctcctg tggccaacgc cgagggccag 3780
ttctttgact cccgcaatgg cgataagaag ctgccactgg atgcagacgc aaacggagcc 3840
tacaatatcg cccgcaaggg cctgtggaac atccggcaga tcaagcagac caagaacgac 3900
aagaagctga atctgagcat ctcctctaca gagtggctgg atttcgtgcg ggagaagcct 3960
tacctgaaga aaaggccggc ggccacgaaa aaggccggcc aggcaaaaaa gaaaaaggga 4020
tcctacccat acgatgttcc agattacgct tatccctacg acgtgcctga ttatgcatac 4080
ccatatgatg tccccgacta tgcctaagaa ttc 4113
<210> 229
<211> 3882
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 229
atgaaaaccc agcacttctt tgaggacttc acaagcctgt actctctgag caagaccatc 60
cggtttgagc tgaagccaat cggcaagacc ctggagaaca tcaagaagaa tggcctgatc 120
cggagagatg agcagagact ggacgattac gagaagctga agaaagtgat cgacgagtat 180
cacgaggatt tcatcgccaa catcctgagc tccttttcct tctctgagga gatcctgcag 240
tcctacatcc agaatctgag cgagtccgag gccagggcca agatcgagaa aaccatgcgc 300
gacacactgg ccaaggcctt ctctgaggat gagaggtaca agagcatctt taagaaggag 360
ctggtgaaga aggacatccc cgtgtggtgc cctgcctata agagcctgtg caagaagttc 420
gataacttta ccacatctct ggtgcccttc cacgagaaca ggaagaacct gtataccagc 480
aatgagatca cagcctctat cccttatcgc atcgtgcacg tgaacctgcc aaagtttatc 540
cagaatatcg aggccctgtg cgagctgcag aagaagatgg gcgccgacct gtacctggag 600
atgatggaga acctgcgcaa cgtgtggccc agcttcgtga aaaccccaga cgacctgtgc 660
aacctgaaaa cctataatca cctgatggtg cagtctagca tcagcgagta caacaggttt 720
gtgggcggct attccaccga ggacggcaca aagcaccagg gcatcaacga gtggatcaat 780
atctacagac agaggaataa ggagatgcgc ctgcctggcc tggtgttcct gcacaagcag 840
atcctggcca aggtggactc ctctagcttc atcagcgata cactggagaa cgacgatcag 900
gtgttttgcg tgctgagaca gttcaggaag ctgttttgga ataccgtgtc ctctaaggag 960
gacgatgccg cctccctgaa ggacctgttc tgtggcctgt ctggctatga ccctgaggcc 1020
atctacgtga gcgatgccca cctggccaca atctccaaga acatctttga cagatggaat 1080
tacatctccg atgccatcag gcgcaagacc gaggtgctga tgccacggaa gaaggagagc 1140
gtggagagat atgccgagaa gatctccaag cagatcaaga agagacagtc ttacagcctg 1200
gccgagctgg acgatctgct ggcccactat agcgaggagt ccctgcccgc aggcttctct 1260
ctgctgagct actttacatc tctgggcggc cagaagtatc tggtgagcga cggcgaagtg 1320
atcctgtacg aggagggcag caacatctgg gacgaggtgc tgatcgcctt cagggatctg 1380
caggtcatcc tggacaagga cttcaccgag aagaagctgg gcaaggatga ggaggccgtg 1440
tctgtgatca agaaggccct ggacagcgcc ctgcgcctgc ggaagttctt tgatctgctg 1500
tccggcacag gcgcagagat caggagagac agctccttct atgccctgta taccgaccgg 1560
atggataagc tgaagggcct gctgaagatg tatgataagg tgagaaacta cctgaccaag 1620
aagccttatt ccatcgagaa gttcaagctg cactttgaca acccatccct gctgtctggc 1680
tgggataaga ataaggagct gaacaatctg tctgtgatct tccggcagaa cggctactat 1740
tacctgggca tcatgacacc caagggcaag aatctgttca agaccctgcc taagctgggc 1800
gccgaggaga tgttttatga gaagatggag tacaagcaga tcgccgagcc tatgctgatg 1860
ctgccaaagg tgttctttcc caagaaaacc aagccagcct tcgccccaga ccagagcgtg 1920
gtggatatct acaacaagaa aaccttcaag acaggccaga agggctttaa taagaaggac 1980
ctgtaccggc tgatcgactt ctacaaggag gccctgacag tgcacgagtg gaagctgttt 2040
aacttctcct tttctccaac cgagcagtat cggaatatcg gcgagttctt tgacgaggtg 2100
agagagcagg cctacaaggt gtccatggtg aacgtgcccg cctcttatat cgacgaggcc 2160
gtggagaacg gcaagctgta tctgttccag atctacaata aggacttcag cccctactcc 2220
aagggcatcc ctaacctgca cacactgtat tggaaggccc tgttcagcga gcagaatcag 2280
agccgggtgt ataagctgtg cggaggagga gagctgtttt atagaaaggc cagcctgcac 2340
atgcaggaca ccacagtgca ccccaagggc atctctatcc acaagaagaa cctgaataag 2400
aagggcgaga caagcctgtt caactacgac ctggtgaagg ataagaggtt taccgaggac 2460
aagttctttt tccacgtgcc tatctctatc aactacaaga ataagaagat caccaacgtg 2520
aatcagatgg tgcgcgatta tatcgcccag aacgacgatc tgcagatcat cggcatcgac 2580
cgcggcgagc ggaatctgct gtatatcagc cggatcgata caaggggcaa cctgctggag 2640
cagttcagcc tgaatgtgat cgagtccgac aagggcgatc tgagaaccga ctatcagaag 2700
atcctgggcg atcgcgagca ggagcggctg aggcgccggc aggagtggaa gtctatcgag 2760
agcatcaagg acctgaagga tggctacatg agccaggtgg tgcacaagat ctgtaacatg 2820
gtggtggagc acaaggccat cgtggtgctg gagaacctga atctgagctt catgaagggc 2880
aggaagaagg tggagaagtc cgtgtacgag aagtttgagc gcatgctggt ggacaagctg 2940
aactatctgg tggtggataa gaagaacctg tccaatgagc caggaggcct gtatgcagca 3000
taccagctga ccaatccact gttctctttt gaggagctgc acagataccc ccagagcggc 3060
atcctgtttt tcgtggaccc atggaacacc tctctgacag atcccagcac aggcttcgtg 3120
aatctgctgg gcagaatcaa ctacaccaat gtgggcgacg cccgcaagtt tttcgatcgg 3180
tttaacgcca tcagatatga cggcaagggc aatatcctgt tcgacctgga tctgtccaga 3240
tttgatgtga gggtggagac acagaggaag ctgtggacac tgaccacatt cggctctcgc 3300
atcgccaaat ccaagaagtc tggcaagtgg atggtggagc ggatcgagaa cctgagcctg 3360
tgctttctgg agctgttcga gcagtttaat atcggctaca gagtggagaa ggacctgaag 3420
aaggccatcc tgagccagga taggaaggag ttctatgtgc gcctgatcta cctgtttaac 3480
ctgatgatgc agatccggaa cagcgacggc gaggaggatt atatcctgtc tcccgccctg 3540
aacgagaaga atctgcagtt cgacagcagg ctgatcgagg ccaaggatct gcctgtggac 3600
gcagatgcaa acggagcata caatgtggcc cgcaagggcc tgatggtggt gcagagaatc 3660
aagaggggcg accacgagtc catccacagg atcggaaggg cacagtggct gagatatgtg 3720
caggagggca tcgtggagaa aaggccggcg gccacgaaaa aggccggcca ggcaaaaaag 3780
aaaaagggat cctacccata cgatgttcca gattacgctt atccctacga cgtgcctgat 3840
tatgcatacc catatgatgt ccccgactat gcctaagaat tc 3882
<210> 230
<211> 1345
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 230
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Ile Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Glu Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Asp Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Lys Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Ser Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr Lys Gln Ser Ile Ser Lys His Pro Glu Trp Lys Asp
725 730 735
Phe Gly Phe Arg Phe Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu
740 745 750
Phe Tyr Arg Glu Val Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn
755 760 765
Ile Ser Glu Ser Tyr Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr
770 775 780
Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg
785 790 795 800
Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn
805 810 815
Leu Gln Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr
820 825 830
Arg Lys Gln Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
835 840 845
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Val Phe Glu
850 855 860
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
865 870 875 880
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
885 890 895
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
900 905 910
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
915 920 925
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
930 935 940
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
945 950 955 960
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
965 970 975
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
980 985 990
Ala Lys Leu Val Ile Glu Tyr Asn Ala Ile Val Val Phe Glu Asp Leu
995 1000 1005
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
1010 1015 1020
Tyr Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu
1025 1030 1035
Val Phe Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg
1040 1045 1050
Ala Tyr Gln Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly
1055 1060 1065
Lys Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser
1070 1075 1080
Lys Ile Cys Pro Val Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys
1085 1090 1095
Tyr Glu Ser Val Ser Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp
1100 1105 1110
Lys Ile Cys Tyr Asn Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe
1115 1120 1125
Asp Tyr Lys Asn Phe Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr
1130 1135 1140
Ile Ala Ser Phe Gly Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp
1145 1150 1155
Lys Asn His Asn Trp Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu
1160 1165 1170
Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly
1175 1180 1185
Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe
1190 1195 1200
Phe Ala Lys Leu Thr Ser Val Leu Asn Thr Ile Leu Gln Met Arg
1205 1210 1215
Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val
1220 1225 1230
Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
1235 1240 1245
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly
1250 1255 1260
Leu Lys Gly Leu Met Leu Leu Gly Arg Ile Lys Asn Asn Gln Glu
1265 1270 1275
Gly Lys Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu
1280 1285 1290
Phe Val Gln Asn Arg Asn Asn Lys Arg Pro Ala Ala Thr Lys Lys
1295 1300 1305
Ala Gly Gln Ala Lys Lys Lys Lys Gly Ser Tyr Pro Tyr Asp Val
1310 1315 1320
Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro
1325 1330 1335
Tyr Asp Val Pro Asp Tyr Ala
1340 1345
<210> 231
<211> 1278
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 231
Met Asp Tyr Gly Asn Gly Gln Phe Glu Arg Arg Ala Pro Leu Thr Lys
1 5 10 15
Thr Ile Thr Leu Arg Leu Lys Pro Ile Gly Glu Thr Arg Glu Thr Ile
20 25 30
Arg Glu Gln Lys Leu Leu Glu Gln Asp Ala Ala Phe Arg Lys Leu Val
35 40 45
Glu Thr Val Thr Pro Ile Val Asp Asp Cys Ile Arg Lys Ile Ala Asp
50 55 60
Asn Ala Leu Cys His Phe Gly Thr Glu Tyr Asp Phe Ser Cys Leu Gly
65 70 75 80
Asn Ala Ile Ser Lys Asn Asp Ser Lys Ala Ile Lys Lys Glu Thr Glu
85 90 95
Lys Val Glu Lys Leu Leu Ala Lys Val Leu Thr Glu Asn Leu Pro Asp
100 105 110
Gly Leu Arg Lys Val Asn Asp Ile Asn Ser Ala Ala Phe Ile Gln Asp
115 120 125
Thr Leu Thr Ser Phe Val Gln Asp Asp Ala Asp Lys Arg Val Leu Ile
130 135 140
Gln Glu Leu Lys Gly Lys Thr Val Leu Met Gln Arg Phe Leu Thr Thr
145 150 155 160
Arg Ile Thr Ala Leu Thr Val Trp Leu Pro Asp Arg Val Phe Glu Asn
165 170 175
Phe Asn Ile Phe Ile Glu Asn Ala Glu Lys Met Arg Ile Leu Leu Asp
180 185 190
Ser Pro Leu Asn Glu Lys Ile Met Lys Phe Asp Pro Asp Ala Glu Gln
195 200 205
Tyr Ala Ser Leu Glu Phe Tyr Gly Gln Cys Leu Ser Gln Lys Asp Ile
210 215 220
Asp Ser Tyr Asn Leu Ile Ile Ser Gly Ile Tyr Ala Asp Asp Glu Val
225 230 235 240
Lys Asn Pro Gly Ile Asn Glu Ile Val Lys Glu Tyr Asn Gln Gln Ile
245 250 255
Arg Gly Asp Lys Asp Glu Ser Pro Leu Pro Lys Leu Lys Lys Leu His
260 265 270
Lys Gln Ile Leu Met Pro Val Glu Lys Ala Phe Phe Val Arg Val Leu
275 280 285
Ser Asn Asp Ser Asp Ala Arg Ser Ile Leu Glu Lys Ile Leu Lys Asp
290 295 300
Thr Glu Met Leu Pro Ser Lys Ile Ile Glu Ala Met Lys Glu Ala Asp
305 310 315 320
Ala Gly Asp Ile Ala Val Tyr Gly Ser Arg Leu His Glu Leu Ser His
325 330 335
Val Ile Tyr Gly Asp His Gly Lys Leu Ser Gln Ile Ile Tyr Asp Lys
340 345 350
Glu Ser Lys Arg Ile Ser Glu Leu Met Glu Thr Leu Ser Pro Lys Glu
355 360 365
Arg Lys Glu Ser Lys Lys Arg Leu Glu Gly Leu Glu Glu His Ile Arg
370 375 380
Lys Ser Thr Tyr Thr Phe Asp Glu Leu Asn Arg Tyr Ala Glu Lys Asn
385 390 395 400
Val Met Ala Ala Tyr Ile Ala Ala Val Glu Glu Ser Cys Ala Glu Ile
405 410 415
Met Arg Lys Glu Lys Asp Leu Arg Thr Leu Leu Ser Lys Glu Asp Val
420 425 430
Lys Ile Arg Gly Asn Arg His Asn Thr Leu Ile Val Lys Asn Tyr Phe
435 440 445
Asn Ala Trp Thr Val Phe Arg Asn Leu Ile Arg Ile Leu Arg Arg Lys
450 455 460
Ser Glu Ala Glu Ile Asp Ser Asp Phe Tyr Asp Val Leu Asp Asp Ser
465 470 475 480
Val Glu Val Leu Ser Leu Thr Tyr Lys Gly Glu Asn Leu Cys Arg Ser
485 490 495
Tyr Ile Thr Lys Lys Ile Gly Ser Asp Leu Lys Pro Glu Ile Ala Thr
500 505 510
Tyr Gly Ser Ala Leu Arg Pro Asn Ser Arg Trp Trp Ser Pro Gly Glu
515 520 525
Lys Phe Asn Val Lys Phe His Thr Ile Val Arg Arg Asp Gly Arg Leu
530 535 540
Tyr Tyr Phe Ile Leu Pro Lys Gly Ala Lys Pro Val Glu Leu Glu Asp
545 550 555 560
Met Asp Gly Asp Ile Glu Cys Leu Gln Met Arg Lys Ile Pro Asn Pro
565 570 575
Thr Ile Phe Leu Pro Lys Leu Val Phe Lys Asp Pro Glu Ala Phe Phe
580 585 590
Arg Asp Asn Pro Glu Ala Asp Glu Phe Val Phe Leu Ser Gly Met Lys
595 600 605
Ala Pro Val Thr Ile Thr Arg Glu Thr Tyr Glu Ala Tyr Arg Tyr Lys
610 615 620
Leu Tyr Thr Val Gly Lys Leu Arg Asp Gly Glu Val Ser Glu Glu Glu
625 630 635 640
Tyr Lys Arg Ala Leu Leu Gln Val Leu Thr Ala Tyr Lys Glu Phe Leu
645 650 655
Glu Asn Arg Met Ile Tyr Ala Asp Leu Asn Phe Gly Phe Lys Asp Leu
660 665 670
Glu Glu Tyr Lys Asp Ser Ser Glu Phe Ile Lys Gln Val Glu Thr His
675 680 685
Asn Thr Phe Met Cys Trp Ala Lys Val Ser Ser Ser Gln Leu Asp Asp
690 695 700
Leu Val Lys Ser Gly Asn Gly Leu Leu Phe Glu Ile Trp Ser Glu Arg
705 710 715 720
Leu Glu Ser Tyr Tyr Lys Tyr Gly Asn Glu Lys Val Leu Arg Gly Tyr
725 730 735
Glu Gly Val Leu Leu Ser Ile Leu Lys Asp Glu Asn Leu Val Ser Met
740 745 750
Arg Thr Leu Leu Asn Ser Arg Pro Met Leu Val Tyr Arg Pro Lys Glu
755 760 765
Ser Ser Lys Pro Met Val Val His Arg Asp Gly Ser Arg Val Val Asp
770 775 780
Arg Phe Asp Lys Asp Gly Lys Tyr Ile Pro Pro Glu Val His Asp Glu
785 790 795 800
Leu Tyr Arg Phe Phe Asn Asn Leu Leu Ile Lys Glu Lys Leu Gly Glu
805 810 815
Lys Ala Arg Lys Ile Leu Asp Asn Lys Lys Val Lys Val Lys Val Leu
820 825 830
Glu Ser Glu Arg Val Lys Trp Ser Lys Phe Tyr Asp Glu Gln Phe Ala
835 840 845
Val Thr Phe Ser Val Lys Lys Asn Ala Asp Cys Leu Asp Thr Thr Lys
850 855 860
Asp Leu Asn Ala Glu Val Met Glu Gln Tyr Ser Glu Ser Asn Arg Leu
865 870 875 880
Ile Leu Ile Arg Asn Thr Thr Asp Ile Leu Tyr Tyr Leu Val Leu Asp
885 890 895
Lys Asn Gly Lys Val Leu Lys Gln Arg Ser Leu Asn Ile Ile Asn Asp
900 905 910
Gly Ala Arg Asp Val Asp Trp Lys Glu Arg Phe Arg Gln Val Thr Lys
915 920 925
Asp Arg Asn Glu Gly Tyr Asn Glu Trp Asp Tyr Ser Arg Thr Ser Asn
930 935 940
Asp Leu Lys Glu Val Tyr Leu Asn Tyr Ala Leu Lys Glu Ile Ala Glu
945 950 955 960
Ala Val Ile Glu Tyr Asn Ala Ile Leu Ile Ile Glu Lys Met Ser Asn
965 970 975
Ala Phe Lys Asp Lys Tyr Ser Phe Leu Asp Asp Val Thr Phe Lys Gly
980 985 990
Phe Glu Thr Lys Leu Leu Ala Lys Leu Ser Asp Leu His Phe Arg Gly
995 1000 1005
Ile Lys Asp Gly Glu Pro Cys Ser Phe Thr Asn Pro Leu Gln Leu
1010 1015 1020
Cys Gln Asn Asp Ser Asn Lys Ile Leu Gln Asp Gly Val Ile Phe
1025 1030 1035
Met Val Pro Asn Ser Met Thr Arg Ser Leu Asp Pro Asp Thr Gly
1040 1045 1050
Phe Ile Phe Ala Ile Asn Asp His Asn Ile Arg Thr Lys Lys Ala
1055 1060 1065
Lys Leu Asn Phe Leu Ser Lys Phe Asp Gln Leu Lys Val Ser Ser
1070 1075 1080
Glu Gly Cys Leu Ile Met Lys Tyr Ser Gly Asp Ser Leu Pro Thr
1085 1090 1095
His Asn Thr Asp Asn Arg Val Trp Asn Cys Cys Cys Asn His Pro
1100 1105 1110
Ile Thr Asn Tyr Asp Arg Glu Thr Lys Lys Val Glu Phe Ile Glu
1115 1120 1125
Glu Pro Val Glu Glu Leu Ser Arg Val Leu Glu Glu Asn Gly Ile
1130 1135 1140
Glu Thr Asp Thr Glu Leu Asn Lys Leu Asn Glu Arg Glu Asn Val
1145 1150 1155
Pro Gly Lys Val Val Asp Ala Ile Tyr Ser Leu Val Leu Asn Tyr
1160 1165 1170
Leu Arg Gly Thr Val Ser Gly Val Ala Gly Gln Arg Ala Val Tyr
1175 1180 1185
Tyr Ser Pro Val Thr Gly Lys Lys Tyr Asp Ile Ser Phe Ile Gln
1190 1195 1200
Ala Met Asn Leu Asn Arg Lys Cys Asp Tyr Tyr Arg Ile Gly Ser
1205 1210 1215
Lys Glu Arg Gly Glu Trp Thr Asp Phe Val Ala Gln Leu Ile Asn
1220 1225 1230
Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys
1235 1240 1245
Lys Gly Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr
1250 1255 1260
Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1265 1270 1275
<210> 232
<211> 1286
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 232
Met Leu Leu Tyr Glu Asn Tyr Thr Lys Arg Asn Gln Ile Thr Lys Ser
1 5 10 15
Leu Arg Leu Glu Leu Arg Pro Gln Gly Lys Thr Leu Arg Asn Ile Lys
20 25 30
Glu Leu Asn Leu Leu Glu Gln Asp Lys Ala Ile Tyr Ala Leu Leu Glu
35 40 45
Arg Leu Lys Pro Val Ile Asp Glu Gly Ile Lys Asp Ile Ala Arg Asp
50 55 60
Thr Leu Lys Asn Cys Glu Leu Ser Phe Glu Lys Leu Tyr Glu His Phe
65 70 75 80
Leu Ser Gly Asp Lys Lys Ala Tyr Ala Lys Glu Ser Glu Arg Leu Lys
85 90 95
Lys Glu Ile Val Lys Thr Leu Ile Lys Asn Leu Pro Glu Gly Ile Gly
100 105 110
Lys Ile Ser Glu Ile Asn Ser Ala Lys Tyr Leu Asn Gly Val Leu Tyr
115 120 125
Asp Phe Ile Asp Lys Thr His Lys Asp Ser Glu Glu Lys Gln Asn Ile
130 135 140
Leu Ser Asp Ile Leu Glu Thr Lys Gly Tyr Leu Ala Leu Phe Ser Lys
145 150 155 160
Phe Leu Thr Ser Arg Ile Thr Thr Leu Glu Gln Ser Met Pro Lys Arg
165 170 175
Val Ile Glu Asn Phe Glu Ile Tyr Ala Ala Asn Ile Pro Lys Met Gln
180 185 190
Asp Ala Leu Glu Arg Gly Ala Val Ser Phe Ala Ile Glu Tyr Glu Ser
195 200 205
Ile Cys Ser Val Asp Tyr Tyr Asn Gln Ile Leu Ser Gln Glu Asp Ile
210 215 220
Asp Ser Tyr Asn Arg Leu Ile Ser Gly Ile Met Asp Glu Asp Gly Ala
225 230 235 240
Lys Glu Lys Gly Ile Asn Gln Thr Ile Ser Glu Lys Asn Ile Lys Ile
245 250 255
Lys Ser Glu His Leu Glu Glu Lys Pro Phe Arg Ile Leu Lys Gln Leu
260 265 270
His Lys Gln Ile Leu Glu Glu Arg Glu Lys Ala Phe Thr Ile Asp His
275 280 285
Ile Asp Ser Asp Glu Glu Val Val Gln Val Thr Lys Glu Ala Phe Glu
290 295 300
Gln Thr Lys Glu Gln Trp Glu Asn Ile Lys Lys Ile Asn Gly Phe Tyr
305 310 315 320
Ala Lys Asp Pro Gly Asp Ile Thr Leu Phe Ile Val Val Gly Pro Asn
325 330 335
Gln Thr His Val Leu Ser Gln Leu Ile Tyr Gly Glu His Asp Arg Ile
340 345 350
Arg Leu Leu Leu Glu Glu Tyr Glu Lys Asn Thr Leu Glu Val Leu Pro
355 360 365
Arg Arg Thr Lys Ser Glu Lys Ala Arg Tyr Asp Lys Phe Val Asn Ala
370 375 380
Val Pro Lys Lys Val Ala Lys Glu Ser His Thr Phe Asp Gly Leu Gln
385 390 395 400
Lys Met Thr Gly Asp Asp Arg Leu Phe Ile Leu Tyr Arg Asp Glu Leu
405 410 415
Ala Arg Asn Tyr Met Arg Ile Lys Glu Ala Tyr Gly Thr Phe Glu Arg
420 425 430
Asp Ile Leu Lys Ser Arg Arg Gly Ile Lys Gly Asn Arg Asp Val Gln
435 440 445
Glu Ser Leu Val Ser Phe Tyr Asp Glu Leu Thr Lys Phe Arg Ser Ala
450 455 460
Leu Arg Ile Ile Asn Ser Gly Asn Asp Glu Lys Ala Asp Pro Ile Phe
465 470 475 480
Tyr Asn Thr Phe Asp Gly Ile Phe Glu Lys Ala Asn Arg Thr Tyr Lys
485 490 495
Ala Glu Asn Leu Cys Arg Asn Tyr Val Thr Lys Ser Pro Ala Asp Asp
500 505 510
Ala Arg Ile Met Ala Ser Cys Leu Gly Thr Pro Ala Arg Leu Arg Thr
515 520 525
His Trp Trp Asn Gly Glu Glu Asn Phe Ala Ile Asn Asp Val Ala Met
530 535 540
Ile Arg Arg Gly Asp Glu Tyr Tyr Tyr Phe Val Leu Thr Pro Asp Val
545 550 555 560
Lys Pro Val Asp Leu Lys Thr Lys Asp Glu Thr Asp Ala Gln Ile Phe
565 570 575
Val Gln Arg Lys Gly Ala Lys Ser Phe Leu Gly Leu Pro Lys Ala Leu
580 585 590
Phe Lys Cys Ile Leu Glu Pro Tyr Phe Glu Ser Pro Glu His Lys Asn
595 600 605
Asp Lys Asn Cys Val Ile Glu Glu Tyr Val Ser Lys Pro Leu Thr Ile
610 615 620
Asp Arg Arg Ala Tyr Asp Ile Phe Lys Asn Gly Thr Phe Lys Lys Thr
625 630 635 640
Asn Ile Gly Ile Asp Gly Leu Thr Glu Glu Lys Phe Lys Asp Asp Cys
645 650 655
Arg Tyr Leu Ile Asp Val Tyr Lys Glu Phe Ile Ala Val Tyr Thr Arg
660 665 670
Tyr Ser Cys Phe Asn Met Ser Gly Leu Lys Arg Ala Asp Glu Tyr Asn
675 680 685
Asp Ile Gly Glu Phe Phe Ser Asp Val Asp Thr Arg Leu Cys Thr Met
690 695 700
Glu Trp Ile Pro Val Ser Phe Glu Arg Ile Asn Asp Met Val Asp Lys
705 710 715 720
Lys Glu Gly Leu Leu Phe Leu Val Arg Ser Met Phe Leu Tyr Asn Arg
725 730 735
Pro Arg Lys Pro Tyr Glu Arg Thr Phe Ile Gln Leu Phe Ser Asp Ser
740 745 750
Asn Met Glu His Thr Ser Met Leu Leu Asn Ser Arg Ala Met Ile Gln
755 760 765
Tyr Arg Ala Ala Ser Leu Pro Arg Arg Val Thr His Lys Lys Gly Ser
770 775 780
Ile Leu Val Ala Leu Arg Asp Ser Asn Gly Glu His Ile Pro Met His
785 790 795 800
Ile Arg Glu Ala Ile Tyr Lys Met Lys Asn Asn Phe Asp Ile Ser Ser
805 810 815
Glu Asp Phe Ile Met Ala Lys Ala Tyr Leu Ala Glu His Asp Val Ala
820 825 830
Ile Lys Lys Ala Asn Glu Asp Ile Ile Arg Asn Arg Arg Tyr Thr Glu
835 840 845
Asp Lys Phe Phe Leu Ser Leu Ser Tyr Thr Lys Asn Ala Asp Ile Ser
850 855 860
Ala Arg Thr Leu Asp Tyr Ile Asn Asp Lys Val Glu Glu Asp Thr Gln
865 870 875 880
Asp Ser Arg Met Ala Val Ile Val Thr Arg Asn Leu Lys Asp Leu Thr
885 890 895
Tyr Val Ala Val Val Asp Glu Lys Asn Asn Val Leu Glu Glu Lys Ser
900 905 910
Leu Asn Glu Ile Asp Gly Val Asn Tyr Arg Glu Leu Leu Lys Glu Arg
915 920 925
Thr Lys Ile Lys Tyr His Asp Lys Thr Arg Leu Trp Gln Tyr Asp Val
930 935 940
Ser Ser Lys Gly Leu Lys Glu Ala Tyr Val Glu Leu Ala Val Thr Gln
945 950 955 960
Ile Ser Lys Leu Ala Thr Lys Tyr Asn Ala Val Val Val Val Glu Ser
965 970 975
Met Ser Ser Thr Phe Lys Asp Lys Phe Ser Phe Leu Asp Glu Gln Ile
980 985 990
Phe Lys Ala Phe Glu Ala Arg Leu Cys Ala Arg Met Ser Asp Leu Ser
995 1000 1005
Phe Asn Thr Ile Lys Glu Gly Glu Ala Gly Ser Ile Ser Asn Pro
1010 1015 1020
Ile Gln Val Ser Asn Asn Asn Gly Asn Ser Tyr Gln Asp Gly Val
1025 1030 1035
Ile Tyr Phe Leu Asn Asn Ala Tyr Thr Arg Thr Leu Cys Pro Asp
1040 1045 1050
Thr Gly Phe Val Asp Val Phe Asp Lys Thr Arg Leu Ile Thr Met
1055 1060 1065
Gln Ser Lys Arg Gln Phe Phe Ala Lys Met Lys Asp Ile Arg Ile
1070 1075 1080
Asp Asp Gly Glu Met Leu Phe Thr Phe Asn Leu Glu Glu Tyr Pro
1085 1090 1095
Thr Lys Arg Leu Leu Asp Arg Lys Glu Trp Thr Val Lys Ile Ala
1100 1105 1110
Gly Asp Gly Ser Tyr Phe Asp Lys Asp Lys Gly Glu Tyr Val Tyr
1115 1120 1125
Val Asn Asp Ile Val Arg Glu Gln Ile Ile Pro Ala Leu Leu Glu
1130 1135 1140
Asp Lys Ala Val Phe Asp Gly Asn Met Ala Glu Lys Phe Leu Asp
1145 1150 1155
Lys Thr Ala Ile Ser Gly Lys Ser Val Glu Leu Ile Tyr Lys Trp
1160 1165 1170
Phe Ala Asn Ala Leu Tyr Gly Ile Ile Thr Lys Lys Asp Gly Glu
1175 1180 1185
Lys Ile Tyr Arg Ser Pro Ile Thr Gly Thr Glu Ile Asp Val Ser
1190 1195 1200
Lys Asn Thr Thr Tyr Asn Phe Gly Lys Lys Phe Met Phe Lys Gln
1205 1210 1215
Glu Tyr Arg Gly Asp Gly Asp Phe Leu Asp Ala Phe Leu Asn Tyr
1220 1225 1230
Met Gln Ala Gln Asp Ile Ala Val Lys Arg Pro Ala Ala Thr Lys
1235 1240 1245
Lys Ala Gly Gln Ala Lys Lys Lys Lys Gly Ser Tyr Pro Tyr Asp
1250 1255 1260
Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr
1265 1270 1275
Pro Tyr Asp Val Pro Asp Tyr Ala
1280 1285
<210> 233
<211> 1522
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 233
Met Ser Asn Phe Phe Lys Asn Phe Thr Asn Leu Tyr Glu Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Asp Thr Leu Thr Asn Met
20 25 30
Lys Asp His Leu Glu Tyr Asp Glu Lys Leu Gln Thr Phe Leu Lys Asp
35 40 45
Gln Asn Ile Asp Asp Ala Tyr Gln Ala Leu Lys Pro Gln Phe Asp Glu
50 55 60
Ile His Glu Glu Phe Ile Thr Asp Ser Leu Glu Ser Lys Lys Ala Lys
65 70 75 80
Glu Ile Asp Phe Ser Glu Tyr Leu Asp Leu Phe Gln Glu Lys Lys Glu
85 90 95
Leu Asn Asp Ser Glu Lys Lys Leu Arg Asn Lys Ile Gly Glu Thr Phe
100 105 110
Asn Lys Ala Gly Glu Lys Trp Lys Lys Glu Lys Tyr Pro Gln Tyr Glu
115 120 125
Trp Lys Lys Gly Ser Lys Ile Ala Asn Gly Ala Asp Ile Leu Ser Cys
130 135 140
Gln Asp Met Leu Gln Phe Ile Lys Tyr Lys Asn Pro Glu Asp Glu Lys
145 150 155 160
Ile Lys Asn Tyr Ile Asp Asp Thr Leu Lys Gly Phe Phe Thr Tyr Phe
165 170 175
Gly Gly Phe Asn Gln Asn Arg Ala Asn Tyr Tyr Glu Thr Lys Lys Glu
180 185 190
Ala Ser Thr Ala Val Ala Thr Arg Ile Val His Glu Asn Leu Pro Lys
195 200 205
Phe Cys Asp Asn Val Ile Gln Phe Lys His Ile Ile Lys Arg Lys Lys
210 215 220
Asp Gly Thr Val Glu Lys Thr Glu Arg Lys Thr Glu Tyr Leu Asn Ala
225 230 235 240
Tyr Gln Tyr Leu Lys Asn Asn Asn Lys Ile Thr Gln Ile Lys Asp Ala
245 250 255
Glu Thr Glu Lys Met Ile Glu Ser Thr Pro Ile Ala Glu Lys Ile Phe
260 265 270
Asp Val Tyr Tyr Phe Ser Ser Cys Leu Ser Gln Lys Gln Ile Glu Glu
275 280 285
Tyr Asn Arg Ile Ile Gly His Tyr Asn Leu Leu Ile Asn Leu Tyr Asn
290 295 300
Gln Ala Lys Arg Ser Glu Gly Lys His Leu Ser Ala Asn Glu Lys Lys
305 310 315 320
Tyr Lys Asp Leu Pro Lys Phe Lys Thr Leu Tyr Lys Gln Ile Gly Cys
325 330 335
Gly Lys Lys Lys Asp Leu Phe Tyr Thr Ile Lys Cys Asp Thr Glu Glu
340 345 350
Glu Ala Asn Lys Ser Arg Asn Glu Gly Lys Glu Ser His Ser Val Glu
355 360 365
Glu Ile Ile Asn Lys Ala Gln Glu Ala Ile Asn Lys Tyr Phe Lys Ser
370 375 380
Asn Asn Asp Cys Glu Asn Ile Asn Thr Val Pro Asp Phe Ile Asn Tyr
385 390 395 400
Ile Leu Thr Lys Glu Asn Tyr Glu Gly Val Tyr Trp Ser Lys Ala Ala
405 410 415
Met Asn Thr Ile Ser Asp Lys Tyr Phe Ala Asn Tyr His Asp Leu Gln
420 425 430
Asp Arg Leu Lys Glu Ala Lys Val Phe Gln Lys Ala Asp Lys Lys Ser
435 440 445
Glu Asp Asp Ile Lys Ile Pro Glu Ala Ile Glu Leu Ser Gly Leu Phe
450 455 460
Gly Val Leu Asp Ser Leu Ala Asp Trp Gln Thr Thr Leu Phe Lys Ser
465 470 475 480
Ser Ile Leu Ser Asn Glu Asp Lys Leu Lys Ile Ile Thr Asp Ser Gln
485 490 495
Thr Pro Ser Glu Ala Leu Leu Lys Met Ile Phe Asn Asp Ile Glu Lys
500 505 510
Asn Met Glu Ser Phe Leu Lys Glu Thr Asn Asp Ile Ile Thr Leu Lys
515 520 525
Lys Tyr Lys Gly Asn Lys Glu Gly Thr Glu Lys Ile Lys Gln Trp Phe
530 535 540
Asp Tyr Thr Leu Ala Ile Asn Arg Met Leu Lys Tyr Phe Leu Val Lys
545 550 555 560
Glu Asn Lys Ile Lys Gly Asn Ser Leu Asp Thr Asn Ile Ser Glu Ala
565 570 575
Leu Lys Thr Leu Ile Tyr Ser Asp Asp Ala Glu Trp Phe Lys Trp Tyr
580 585 590
Asp Ala Leu Arg Asn Tyr Leu Thr Gln Lys Pro Gln Asp Glu Ala Lys
595 600 605
Glu Asn Lys Leu Lys Leu Asn Phe Asp Asn Pro Ser Leu Ala Gly Gly
610 615 620
Trp Asp Val Asn Lys Glu Cys Ser Asn Phe Cys Val Ile Leu Lys Asp
625 630 635 640
Lys Asn Glu Lys Lys Tyr Leu Ala Ile Met Lys Lys Gly Glu Asn Thr
645 650 655
Leu Phe Gln Lys Glu Trp Thr Glu Gly Arg Gly Lys Asn Leu Thr Lys
660 665 670
Lys Ser Asn Pro Leu Phe Glu Ile Asn Asn Cys Glu Ile Leu Ser Lys
675 680 685
Met Glu Tyr Asp Phe Trp Ala Asp Val Ser Lys Met Ile Pro Lys Cys
690 695 700
Ser Thr Gln Leu Lys Ala Val Val Asn His Phe Lys Gln Ser Asp Asn
705 710 715 720
Glu Phe Ile Phe Pro Ile Gly Tyr Lys Val Thr Ser Gly Glu Lys Phe
725 730 735
Arg Glu Glu Cys Lys Ile Ser Lys Gln Asp Phe Glu Leu Asn Asn Lys
740 745 750
Val Phe Asn Lys Asn Glu Leu Ser Val Thr Ala Met Arg Tyr Asp Leu
755 760 765
Ser Ser Thr Gln Glu Lys Gln Tyr Ile Lys Ala Phe Gln Lys Glu Tyr
770 775 780
Trp Glu Leu Leu Phe Lys Gln Glu Lys Arg Asp Thr Lys Leu Thr Asn
785 790 795 800
Asn Glu Ile Phe Asn Glu Trp Ile Asn Phe Cys Asn Lys Lys Tyr Ser
805 810 815
Glu Leu Leu Ser Trp Glu Arg Lys Tyr Lys Asp Ala Leu Thr Asn Trp
820 825 830
Ile Asn Phe Cys Lys Tyr Phe Leu Ser Lys Tyr Pro Lys Thr Thr Leu
835 840 845
Phe Asn Tyr Ser Phe Lys Glu Ser Glu Asn Tyr Asn Ser Leu Asp Glu
850 855 860
Phe Tyr Arg Asp Val Asp Ile Cys Ser Tyr Lys Leu Asn Ile Asn Thr
865 870 875 880
Thr Ile Asn Lys Ser Ile Leu Asp Arg Leu Val Glu Glu Gly Lys Leu
885 890 895
Tyr Leu Phe Glu Ile Lys Asn Gln Asp Ser Asn Asp Gly Lys Ser Ile
900 905 910
Gly His Lys Asn Asn Leu His Thr Ile Tyr Trp Asn Ala Ile Phe Glu
915 920 925
Asn Phe Asp Asn Arg Pro Lys Leu Asn Gly Glu Ala Glu Ile Phe Tyr
930 935 940
Arg Lys Ala Ile Ser Lys Asp Lys Leu Gly Ile Val Lys Gly Lys Lys
945 950 955 960
Thr Lys Asn Gly Thr Glu Ile Ile Lys Asn Tyr Arg Phe Ser Lys Glu
965 970 975
Lys Phe Ile Leu His Val Pro Ile Thr Leu Asn Phe Cys Ser Asn Asn
980 985 990
Glu Tyr Val Asn Asp Ile Val Asn Thr Lys Phe Tyr Asn Phe Ser Asn
995 1000 1005
Leu His Phe Leu Gly Ile Asp Arg Gly Glu Lys His Leu Ala Tyr
1010 1015 1020
Tyr Ser Leu Val Asn Lys Asn Gly Glu Ile Val Asp Gln Gly Thr
1025 1030 1035
Leu Asn Leu Pro Phe Thr Asp Lys Asp Gly Asn Gln Arg Ser Ile
1040 1045 1050
Lys Lys Glu Lys Tyr Phe Tyr Asn Lys Gln Glu Asp Lys Trp Glu
1055 1060 1065
Ala Lys Glu Val Asp Cys Trp Asn Tyr Asn Asp Leu Leu Asp Ala
1070 1075 1080
Met Ala Ser Asn Arg Asp Met Ala Arg Lys Asn Trp Gln Arg Ile
1085 1090 1095
Gly Thr Ile Lys Glu Ala Lys Asn Gly Tyr Val Ser Leu Val Ile
1100 1105 1110
Arg Lys Ile Ala Asp Leu Ala Val Asn Asn Glu Arg Pro Ala Phe
1115 1120 1125
Ile Val Leu Glu Asp Leu Asn Thr Gly Phe Lys Arg Ser Arg Gln
1130 1135 1140
Lys Ile Asp Lys Ser Val Tyr Gln Lys Phe Glu Leu Ala Leu Ala
1145 1150 1155
Lys Lys Leu Asn Phe Leu Val Asp Lys Asn Ala Lys Arg Asp Glu
1160 1165 1170
Ile Gly Ser Pro Thr Lys Ala Leu Gln Leu Thr Pro Pro Val Asn
1175 1180 1185
Asn Tyr Gly Asp Ile Glu Asn Lys Lys Gln Ala Gly Ile Met Leu
1190 1195 1200
Tyr Thr Arg Ala Asn Tyr Thr Ser Gln Thr Asp Pro Ala Thr Gly
1205 1210 1215
Trp Arg Lys Thr Ile Tyr Leu Lys Ala Gly Pro Glu Glu Thr Thr
1220 1225 1230
Tyr Lys Lys Asp Gly Lys Ile Lys Asn Lys Ser Val Lys Asp Gln
1235 1240 1245
Ile Ile Glu Thr Phe Thr Asp Ile Gly Phe Asp Gly Lys Asp Tyr
1250 1255 1260
Tyr Phe Glu Tyr Asp Lys Gly Glu Phe Val Asp Glu Lys Thr Gly
1265 1270 1275
Glu Ile Lys Pro Lys Lys Trp Arg Leu Tyr Ser Gly Glu Asn Gly
1280 1285 1290
Lys Ser Leu Asp Arg Phe Arg Gly Glu Arg Glu Lys Asp Lys Tyr
1295 1300 1305
Glu Trp Lys Ile Asp Lys Ile Asp Ile Val Lys Ile Leu Asp Asp
1310 1315 1320
Leu Phe Val Asn Phe Asp Lys Asn Ile Ser Leu Leu Lys Gln Leu
1325 1330 1335
Lys Glu Gly Val Glu Leu Thr Arg Asn Asn Glu His Gly Thr Gly
1340 1345 1350
Glu Ser Leu Arg Phe Ala Ile Asn Leu Ile Gln Gln Ile Arg Asn
1355 1360 1365
Thr Gly Asn Asn Glu Arg Asp Asn Asp Phe Ile Leu Ser Pro Val
1370 1375 1380
Arg Asp Glu Asn Gly Lys His Phe Asp Ser Arg Glu Tyr Trp Asp
1385 1390 1395
Lys Glu Thr Lys Gly Glu Lys Ile Ser Met Pro Ser Ser Gly Asp
1400 1405 1410
Ala Asn Gly Ala Phe Asn Ile Ala Arg Lys Gly Ile Ile Met Asn
1415 1420 1425
Ala His Ile Leu Ala Asn Ser Asp Ser Lys Asp Leu Ser Leu Phe
1430 1435 1440
Val Ser Asp Glu Glu Trp Asp Leu His Leu Asn Asn Lys Thr Glu
1445 1450 1455
Trp Lys Lys Gln Leu Asn Ile Phe Ser Ser Arg Lys Ala Met Ala
1460 1465 1470
Lys Arg Lys Lys Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln
1475 1480 1485
Ala Lys Lys Lys Lys Gly Ser Tyr Pro Tyr Asp Val Pro Asp Tyr
1490 1495 1500
Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val
1505 1510 1515
Pro Asp Tyr Ala
1520
<210> 234
<211> 1397
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 234
Met Glu Asn Ile Phe Asp Gln Phe Ile Gly Lys Tyr Ser Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Glu Asp Phe Leu
20 25 30
Lys Ile Asn Lys Val Phe Glu Lys Asp Gln Thr Ile Asp Asp Ser Tyr
35 40 45
Asn Gln Ala Lys Phe Tyr Phe Asp Ser Leu His Gln Lys Phe Ile Asp
50 55 60
Ala Ala Leu Ala Ser Asp Lys Thr Ser Glu Leu Ser Phe Gln Asn Phe
65 70 75 80
Ala Asp Val Leu Glu Lys Gln Asn Lys Ile Ile Leu Asp Lys Lys Arg
85 90 95
Glu Met Gly Ala Leu Arg Lys Arg Asp Lys Asn Ala Val Gly Ile Asp
100 105 110
Arg Leu Gln Lys Glu Ile Asn Asp Ala Glu Asp Ile Ile Gln Lys Glu
115 120 125
Lys Glu Lys Ile Tyr Lys Asp Val Arg Thr Leu Phe Asp Asn Glu Ala
130 135 140
Glu Ser Trp Lys Thr Tyr Tyr Gln Glu Arg Glu Val Asp Gly Lys Lys
145 150 155 160
Ile Thr Phe Ser Lys Ala Asp Leu Lys Gln Lys Gly Ala Asp Phe Leu
165 170 175
Thr Ala Ala Gly Ile Leu Lys Val Leu Lys Tyr Glu Phe Pro Glu Glu
180 185 190
Lys Glu Lys Glu Phe Gln Ala Lys Asn Gln Pro Ser Leu Phe Val Glu
195 200 205
Glu Lys Glu Asn Pro Gly Gln Lys Arg Tyr Ile Phe Asp Ser Phe Asp
210 215 220
Lys Phe Ala Gly Tyr Leu Thr Lys Phe Gln Gln Thr Lys Lys Asn Leu
225 230 235 240
Tyr Ala Ala Asp Gly Thr Ser Thr Ala Val Ala Thr Arg Ile Ala Asp
245 250 255
Asn Phe Ile Ile Phe His Gln Asn Thr Lys Val Phe Arg Asp Lys Tyr
260 265 270
Lys Asn Asn His Thr Asp Leu Gly Phe Asp Glu Glu Asn Ile Phe Glu
275 280 285
Ile Glu Arg Tyr Lys Asn Cys Leu Leu Gln Arg Glu Ile Glu His Ile
290 295 300
Lys Asn Glu Asn Ser Tyr Asn Lys Ile Ile Gly Arg Ile Asn Lys Lys
305 310 315 320
Ile Lys Glu Tyr Arg Asp Gln Lys Ala Lys Asp Thr Lys Leu Thr Lys
325 330 335
Ser Asp Phe Pro Phe Phe Lys Asn Leu Asp Lys Gln Ile Leu Gly Glu
340 345 350
Val Glu Lys Glu Lys Gln Leu Ile Glu Lys Thr Arg Glu Lys Thr Glu
355 360 365
Glu Asp Val Leu Ile Glu Arg Phe Lys Glu Phe Ile Glu Asn Asn Glu
370 375 380
Glu Arg Phe Thr Ala Ala Lys Lys Leu Met Asn Ala Phe Cys Asn Gly
385 390 395 400
Glu Phe Glu Ser Glu Tyr Glu Gly Ile Tyr Leu Lys Asn Lys Ala Ile
405 410 415
Asn Thr Ile Ser Arg Arg Trp Phe Val Ser Asp Arg Asp Phe Glu Leu
420 425 430
Lys Leu Pro Gln Gln Lys Ser Lys Asn Lys Ser Glu Lys Asn Glu Pro
435 440 445
Lys Val Lys Lys Phe Ile Ser Ile Ala Glu Ile Lys Asn Ala Val Glu
450 455 460
Glu Leu Asp Gly Asp Ile Phe Lys Ala Val Phe Tyr Asp Lys Lys Ile
465 470 475 480
Ile Ala Gln Gly Gly Ser Lys Leu Glu Gln Phe Leu Val Ile Trp Lys
485 490 495
Tyr Glu Phe Glu Tyr Leu Phe Arg Asp Ile Glu Arg Glu Asn Gly Glu
500 505 510
Lys Leu Leu Gly Tyr Asp Ser Cys Leu Lys Ile Ala Lys Gln Leu Gly
515 520 525
Ile Phe Pro Gln Glu Lys Glu Ala Arg Glu Lys Ala Thr Ala Val Ile
530 535 540
Lys Asn Tyr Ala Asp Ala Gly Leu Gly Ile Phe Gln Met Met Lys Tyr
545 550 555 560
Phe Ser Leu Asp Asp Lys Asp Arg Lys Asn Thr Pro Gly Gln Leu Ser
565 570 575
Thr Asn Phe Tyr Ala Glu Tyr Asp Gly Tyr Tyr Lys Asp Phe Glu Phe
580 585 590
Ile Lys Tyr Tyr Asn Glu Phe Arg Asn Phe Ile Thr Lys Lys Pro Phe
595 600 605
Asp Glu Asp Lys Ile Lys Leu Asn Phe Glu Asn Gly Ala Leu Leu Lys
610 615 620
Gly Trp Asp Glu Asn Lys Glu Tyr Asp Phe Met Gly Val Ile Leu Lys
625 630 635 640
Lys Glu Gly Arg Leu Tyr Leu Gly Ile Met His Lys Asn His Arg Lys
645 650 655
Leu Phe Gln Ser Met Gly Asn Ala Lys Gly Asp Asn Ala Asn Arg Tyr
660 665 670
Gln Lys Met Ile Tyr Lys Gln Ile Ala Asp Ala Ser Lys Asp Val Pro
675 680 685
Arg Leu Leu Leu Thr Ser Lys Lys Ala Met Glu Lys Phe Lys Pro Ser
690 695 700
Gln Glu Ile Leu Arg Ile Lys Lys Glu Lys Thr Phe Lys Arg Glu Ser
705 710 715 720
Lys Asn Phe Ser Leu Arg Asp Leu His Ala Leu Ile Glu Tyr Tyr Arg
725 730 735
Asn Cys Ile Pro Gln Tyr Ser Asn Trp Ser Phe Tyr Asp Phe Gln Phe
740 745 750
Gln Asp Thr Gly Lys Tyr Gln Asn Ile Lys Glu Phe Thr Asp Asp Val
755 760 765
Gln Lys Tyr Gly Tyr Lys Ile Ser Phe Arg Asp Ile Asp Asp Glu Tyr
770 775 780
Ile Asn Gln Ala Leu Asn Glu Gly Lys Met Tyr Leu Phe Glu Val Val
785 790 795 800
Asn Lys Asp Ile Tyr Asn Thr Lys Asn Gly Ser Lys Asn Leu His Thr
805 810 815
Leu Tyr Phe Glu His Ile Leu Ser Ala Glu Asn Leu Asn Asp Pro Val
820 825 830
Phe Lys Leu Ser Gly Met Ala Glu Ile Phe Gln Arg Gln Pro Ser Val
835 840 845
Asn Glu Arg Glu Lys Ile Thr Thr Gln Lys Asn Gln Cys Ile Leu Asp
850 855 860
Lys Gly Asp Arg Ala Tyr Lys Tyr Arg Arg Tyr Thr Glu Lys Lys Ile
865 870 875 880
Met Phe His Met Ser Leu Val Leu Asn Thr Gly Lys Gly Glu Ile Lys
885 890 895
Gln Val Gln Phe Asn Lys Ile Ile Asn Gln Arg Ile Ser Ser Ser Asp
900 905 910
Asn Glu Met Arg Val Asn Val Ile Gly Ile Asp Arg Gly Glu Lys Asn
915 920 925
Leu Leu Tyr Tyr Ser Val Val Lys Gln Asn Gly Glu Ile Ile Glu Gln
930 935 940
Ala Ser Leu Asn Glu Ile Asn Gly Val Asn Tyr Arg Asp Lys Leu Ile
945 950 955 960
Glu Arg Glu Lys Glu Arg Leu Lys Asn Arg Gln Ser Trp Lys Pro Val
965 970 975
Val Lys Ile Lys Asp Leu Lys Lys Gly Tyr Ile Ser His Val Ile His
980 985 990
Lys Ile Cys Gln Leu Ile Glu Lys Tyr Ser Ala Ile Val Val Leu Glu
995 1000 1005
Asp Leu Asn Met Arg Phe Lys Gln Ile Arg Gly Gly Ile Glu Arg
1010 1015 1020
Ser Val Tyr Gln Gln Phe Glu Lys Ala Leu Ile Asp Lys Leu Gly
1025 1030 1035
Tyr Leu Val Phe Lys Asp Asn Arg Asp Leu Arg Ala Pro Gly Gly
1040 1045 1050
Val Leu Asn Gly Tyr Gln Leu Ser Ala Pro Phe Val Ser Phe Glu
1055 1060 1065
Lys Met Arg Lys Gln Thr Gly Ile Leu Phe Tyr Thr Gln Ala Glu
1070 1075 1080
Tyr Thr Ser Lys Thr Asp Pro Ile Thr Gly Phe Arg Lys Asn Val
1085 1090 1095
Tyr Ile Ser Asn Ser Ala Ser Leu Asp Lys Ile Lys Glu Ala Val
1100 1105 1110
Lys Lys Phe Asp Ala Ile Gly Trp Asp Gly Lys Glu Gln Ser Tyr
1115 1120 1125
Phe Phe Lys Tyr Asn Pro Tyr Asn Leu Ala Asp Glu Lys Tyr Lys
1130 1135 1140
Asn Ser Thr Val Ser Lys Glu Trp Ala Ile Phe Ala Ser Ala Pro
1145 1150 1155
Arg Ile Arg Arg Gln Lys Gly Glu Asp Gly Tyr Trp Lys Tyr Asp
1160 1165 1170
Arg Val Lys Val Asn Glu Glu Phe Glu Lys Leu Leu Lys Val Trp
1175 1180 1185
Asn Phe Val Asn Pro Lys Ala Thr Asp Ile Lys Gln Glu Ile Ile
1190 1195 1200
Lys Lys Glu Lys Ala Gly Asp Leu Gln Gly Glu Lys Glu Leu Asp
1205 1210 1215
Gly Arg Leu Arg Asn Phe Trp His Ser Phe Ile Tyr Leu Phe Asn
1220 1225 1230
Leu Val Leu Glu Leu Arg Asn Ser Phe Ser Leu Gln Ile Lys Ile
1235 1240 1245
Lys Ala Gly Glu Val Ile Ala Val Asp Glu Gly Val Asp Phe Ile
1250 1255 1260
Ala Ser Pro Val Lys Pro Phe Phe Thr Thr Pro Asn Pro Tyr Ile
1265 1270 1275
Pro Ser Asn Leu Cys Trp Leu Ala Val Glu Asn Ala Asp Ala Asn
1280 1285 1290
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Val Met Ile Leu Lys Lys
1295 1300 1305
Ile Arg Glu His Ala Lys Lys Asp Pro Glu Phe Lys Lys Leu Pro
1310 1315 1320
Asn Leu Phe Ile Ser Asn Ala Glu Trp Asp Glu Ala Ala Arg Asp
1325 1330 1335
Trp Gly Lys Tyr Ala Gly Thr Thr Ala Leu Asn Leu Asp His Lys
1340 1345 1350
Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1355 1360 1365
Gly Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp
1370 1375 1380
Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1385 1390 1395
<210> 235
<211> 1295
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 235
Met Gln Thr Leu Phe Glu Asn Phe Thr Asn Gln Tyr Pro Val Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Lys Asp Phe Ile
20 25 30
Glu Gln Lys Gly Leu Leu Lys Lys Asp Glu Asp Arg Ala Glu Lys Tyr
35 40 45
Lys Lys Val Lys Asn Ile Ile Asp Glu Tyr His Lys Asp Phe Ile Glu
50 55 60
Lys Ser Leu Asn Gly Leu Lys Leu Asp Gly Leu Glu Lys Tyr Lys Thr
65 70 75 80
Leu Tyr Leu Lys Gln Glu Lys Asp Asp Lys Asp Lys Lys Ala Phe Asp
85 90 95
Lys Glu Lys Glu Asn Leu Arg Lys Gln Ile Ala Asn Ala Phe Arg Asn
100 105 110
Asn Glu Lys Phe Lys Thr Leu Phe Ala Lys Glu Leu Ile Lys Asn Asp
115 120 125
Leu Met Ser Phe Ala Cys Glu Glu Asp Lys Lys Asn Val Lys Glu Phe
130 135 140
Glu Ala Phe Thr Thr Tyr Phe Thr Gly Phe His Gln Asn Arg Ala Asn
145 150 155 160
Met Tyr Val Ala Asp Glu Lys Arg Thr Ala Ile Ala Ser Arg Leu Ile
165 170 175
His Glu Asn Leu Pro Lys Phe Ile Asp Asn Ile Lys Ile Phe Glu Lys
180 185 190
Met Lys Lys Glu Ala Pro Glu Leu Leu Ser Pro Phe Asn Gln Thr Leu
195 200 205
Lys Asp Met Lys Asp Val Ile Lys Gly Thr Thr Leu Glu Glu Ile Phe
210 215 220
Ser Leu Asp Tyr Phe Asn Lys Thr Leu Thr Gln Ser Gly Ile Asp Ile
225 230 235 240
Tyr Asn Ser Val Ile Gly Gly Arg Thr Pro Glu Glu Gly Lys Thr Lys
245 250 255
Ile Lys Gly Leu Asn Glu Tyr Ile Asn Thr Asp Phe Asn Gln Lys Gln
260 265 270
Thr Asp Lys Lys Lys Arg Gln Pro Lys Phe Lys Gln Leu Tyr Lys Gln
275 280 285
Ile Leu Ser Asp Arg Gln Ser Leu Ser Phe Ile Ala Glu Ala Phe Lys
290 295 300
Asn Asp Thr Glu Ile Leu Glu Ala Ile Glu Lys Phe Tyr Val Asn Glu
305 310 315 320
Leu Leu His Phe Ser Asn Glu Gly Lys Ser Thr Asn Val Leu Asp Ala
325 330 335
Ile Lys Asn Ala Val Ser Asn Leu Glu Ser Phe Asn Leu Thr Lys Met
340 345 350
Tyr Phe Arg Ser Gly Ala Ser Leu Thr Asp Val Ser Arg Lys Val Phe
355 360 365
Gly Glu Trp Ser Ile Ile Asn Arg Ala Leu Asp Asn Tyr Tyr Ala Thr
370 375 380
Thr Tyr Pro Ile Lys Pro Arg Glu Lys Ser Glu Lys Tyr Glu Glu Arg
385 390 395 400
Lys Glu Lys Trp Leu Lys Gln Asp Phe Asn Val Ser Leu Ile Gln Thr
405 410 415
Ala Ile Asp Glu Tyr Asp Asn Glu Thr Val Lys Gly Lys Asn Ser Gly
420 425 430
Lys Val Ile Ala Asp Tyr Phe Ala Lys Phe Cys Asp Asp Lys Glu Thr
435 440 445
Asp Leu Ile Gln Lys Val Asn Glu Gly Tyr Ile Ala Val Lys Asp Leu
450 455 460
Leu Asn Thr Pro Cys Pro Glu Asn Glu Lys Leu Gly Ser Asn Lys Asp
465 470 475 480
Gln Val Lys Gln Ile Lys Ala Phe Met Asp Ser Ile Met Asp Ile Met
485 490 495
His Phe Val Arg Pro Leu Ser Leu Lys Asp Thr Asp Lys Glu Lys Asp
500 505 510
Glu Thr Phe Tyr Ser Leu Phe Thr Pro Leu Tyr Asp His Leu Thr Gln
515 520 525
Thr Ile Ala Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Gln Lys Pro
530 535 540
Tyr Ser Thr Glu Lys Ile Lys Leu Asn Phe Glu Asn Ser Thr Leu Leu
545 550 555 560
Gly Gly Trp Asp Leu Asn Lys Glu Thr Asp Asn Thr Ala Ile Ile Leu
565 570 575
Arg Lys Asp Asn Leu Tyr Tyr Leu Gly Ile Met Asp Lys Arg His Asn
580 585 590
Arg Ile Phe Arg Asn Val Pro Lys Ala Asp Lys Lys Asp Phe Cys Tyr
595 600 605
Glu Lys Met Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro
610 615 620
Lys Val Phe Phe Ser Gln Ser Arg Ile Gln Glu Phe Thr Pro Ser Ala
625 630 635 640
Lys Leu Leu Glu Asn Tyr Ala Asn Glu Thr His Lys Lys Gly Asp Asn
645 650 655
Phe Asn Leu Asn His Cys His Lys Leu Ile Asp Phe Phe Lys Asp Ser
660 665 670
Ile Asn Lys His Glu Asp Trp Lys Asn Phe Asp Phe Arg Phe Ser Ala
675 680 685
Thr Ser Thr Tyr Ala Asp Leu Ser Gly Phe Tyr His Glu Val Glu His
690 695 700
Gln Gly Tyr Lys Ile Ser Phe Gln Ser Val Ala Asp Ser Phe Ile Asp
705 710 715 720
Asp Leu Val Asn Glu Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
725 730 735
Asp Phe Ser Pro Phe Ser Lys Gly Lys Pro Asn Leu His Thr Leu Tyr
740 745 750
Trp Lys Met Leu Phe Asp Glu Asn Asn Leu Lys Asp Val Val Tyr Lys
755 760 765
Leu Asn Gly Glu Ala Glu Val Phe Tyr Arg Lys Lys Ser Ile Ala Glu
770 775 780
Lys Asn Thr Thr Ile His Lys Ala Asn Glu Ser Ile Ile Asn Lys Asn
785 790 795 800
Pro Asp Asn Pro Lys Ala Thr Ser Thr Phe Asn Tyr Asp Ile Val Lys
805 810 815
Asp Lys Arg Tyr Thr Ile Asp Lys Phe Gln Phe His Ile Pro Ile Thr
820 825 830
Met Asn Phe Lys Ala Glu Gly Ile Phe Asn Met Asn Gln Arg Val Asn
835 840 845
Gln Phe Leu Lys Ala Asn Pro Asp Ile Asn Ile Ile Gly Ile Asp Arg
850 855 860
Gly Glu Arg His Leu Leu Tyr Tyr Ala Leu Ile Asn Gln Lys Gly Lys
865 870 875 880
Ile Leu Lys Gln Asp Thr Leu Asn Val Ile Ala Asn Glu Lys Gln Lys
885 890 895
Val Asp Tyr His Asn Leu Leu Asp Lys Lys Glu Gly Asp Arg Ala Thr
900 905 910
Ala Arg Gln Glu Trp Gly Val Ile Glu Thr Ile Lys Glu Leu Lys Glu
915 920 925
Gly Tyr Leu Ser Gln Val Ile His Lys Leu Thr Asp Leu Met Ile Glu
930 935 940
Asn Asn Ala Ile Ile Val Met Glu Asp Leu Asn Phe Gly Phe Lys Arg
945 950 955 960
Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys Met
965 970 975
Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Asn Lys Lys Ala Asn
980 985 990
Glu Leu Gly Gly Leu Leu Asn Ala Phe Gln Leu Ala Asn Lys Phe Glu
995 1000 1005
Ser Phe Gln Lys Met Gly Lys Gln Asn Gly Phe Ile Phe Tyr Val
1010 1015 1020
Pro Ala Trp Asn Thr Ser Lys Thr Asp Pro Ala Thr Gly Phe Ile
1025 1030 1035
Asp Phe Leu Lys Pro Arg Tyr Glu Asn Leu Asn Gln Ala Lys Asp
1040 1045 1050
Phe Phe Glu Lys Phe Asp Ser Ile Arg Leu Asn Ser Lys Ala Asp
1055 1060 1065
Tyr Phe Glu Phe Ala Phe Asp Phe Lys Asn Phe Thr Glu Lys Ala
1070 1075 1080
Asp Gly Gly Arg Thr Lys Trp Thr Val Cys Thr Thr Asn Glu Asp
1085 1090 1095
Arg Tyr Ala Trp Asn Arg Ala Leu Asn Asn Asn Arg Gly Ser Gln
1100 1105 1110
Glu Lys Tyr Asp Ile Thr Ala Glu Leu Lys Ser Leu Phe Asp Gly
1115 1120 1125
Lys Val Asp Tyr Lys Ser Gly Lys Asp Leu Lys Gln Gln Ile Ala
1130 1135 1140
Ser Gln Glu Ser Ala Asp Phe Phe Lys Ala Leu Met Lys Asn Leu
1145 1150 1155
Ser Ile Thr Leu Ser Leu Arg His Asn Asn Gly Glu Lys Gly Asp
1160 1165 1170
Asn Glu Gln Asp Tyr Ile Leu Ser Pro Val Ala Asp Ser Lys Gly
1175 1180 1185
Arg Phe Phe Asp Ser Arg Lys Ala Asp Asp Asp Met Pro Lys Asn
1190 1195 1200
Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Trp
1205 1210 1215
Cys Leu Glu Gln Ile Ser Lys Thr Asp Asp Leu Lys Lys Val Lys
1220 1225 1230
Leu Ala Ile Ser Asn Lys Glu Trp Leu Glu Phe Val Gln Thr Leu
1235 1240 1245
Lys Gly Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys
1250 1255 1260
Lys Lys Lys Gly Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr
1265 1270 1275
Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp
1280 1285 1290
Tyr Ala
1295
<210> 236
<211> 1352
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 236
Met Thr Gln Phe Glu Gly Phe Thr Asn Leu Tyr Gln Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Lys His Ile Gln
20 25 30
Glu Gln Gly Phe Ile Glu Glu Asp Lys Ala Arg Asn Asp His Tyr Lys
35 40 45
Glu Leu Lys Pro Ile Ile Asp Arg Ile Tyr Lys Thr Tyr Ala Asp Gln
50 55 60
Cys Leu Gln Leu Val Gln Leu Asp Trp Glu Asn Leu Ser Ala Ala Ile
65 70 75 80
Asp Ser Tyr Arg Lys Glu Lys Thr Glu Glu Thr Arg Asn Ala Leu Ile
85 90 95
Glu Glu Gln Ala Thr Tyr Arg Asn Ala Ile His Asp Tyr Phe Ile Gly
100 105 110
Arg Thr Asp Asn Leu Thr Asp Ala Ile Asn Lys Arg His Ala Glu Ile
115 120 125
Tyr Lys Gly Leu Phe Lys Ala Glu Leu Phe Asn Gly Lys Val Leu Lys
130 135 140
Gln Leu Gly Thr Val Thr Thr Thr Glu His Glu Asn Ala Leu Leu Arg
145 150 155 160
Ser Phe Asp Lys Phe Thr Thr Tyr Phe Ser Gly Phe Tyr Glu Asn Arg
165 170 175
Lys Asn Val Phe Ser Ala Glu Asp Ile Ser Thr Ala Ile Pro His Arg
180 185 190
Ile Val Gln Asp Asn Phe Pro Lys Phe Lys Glu Asn Cys His Ile Phe
195 200 205
Thr Arg Leu Ile Thr Ala Val Pro Ser Leu Arg Glu His Phe Glu Asn
210 215 220
Val Lys Lys Ala Ile Gly Ile Phe Val Ser Thr Ser Ile Glu Glu Val
225 230 235 240
Phe Ser Phe Pro Phe Tyr Asn Gln Leu Leu Thr Gln Thr Gln Ile Asp
245 250 255
Leu Tyr Asn Gln Leu Leu Gly Gly Ile Ser Arg Glu Ala Gly Thr Glu
260 265 270
Lys Ile Lys Gly Leu Asn Glu Val Leu Asn Leu Ala Ile Gln Lys Asn
275 280 285
Asp Glu Thr Ala His Ile Ile Ala Ser Leu Pro His Arg Phe Ile Pro
290 295 300
Leu Phe Lys Gln Ile Leu Ser Asp Arg Asn Thr Leu Ser Phe Ile Leu
305 310 315 320
Glu Glu Phe Lys Ser Asp Glu Glu Val Ile Gln Ser Phe Cys Lys Tyr
325 330 335
Lys Thr Leu Leu Arg Asn Glu Asn Val Leu Glu Thr Ala Glu Ala Leu
340 345 350
Phe Asn Glu Leu Asn Ser Ile Asp Leu Thr His Ile Phe Ile Ser His
355 360 365
Lys Lys Leu Glu Thr Ile Ser Ser Ala Leu Cys Asp His Trp Asp Thr
370 375 380
Leu Arg Asn Ala Leu Tyr Glu Arg Arg Ile Ser Glu Leu Thr Gly Lys
385 390 395 400
Ile Thr Lys Ser Ala Lys Glu Lys Val Gln Arg Ser Leu Lys His Glu
405 410 415
Asp Ile Asn Leu Gln Glu Ile Ile Ser Ala Ala Gly Lys Glu Leu Ser
420 425 430
Glu Ala Phe Lys Gln Lys Thr Ser Glu Ile Leu Ser His Ala His Ala
435 440 445
Ala Leu Asp Gln Pro Leu Pro Thr Thr Leu Lys Lys Gln Glu Glu Lys
450 455 460
Glu Ile Leu Lys Ser Gln Leu Asp Ser Leu Leu Gly Leu Tyr His Leu
465 470 475 480
Leu Asp Trp Phe Ala Val Asp Glu Ser Asn Glu Val Asp Pro Glu Phe
485 490 495
Ser Ala Arg Leu Thr Gly Ile Lys Leu Glu Met Glu Pro Ser Leu Ser
500 505 510
Phe Tyr Asn Lys Ala Arg Asn Tyr Ala Thr Lys Lys Pro Tyr Ser Val
515 520 525
Glu Lys Phe Lys Leu Asn Phe Gln Met Pro Thr Leu Ala Ser Gly Trp
530 535 540
Asp Val Asn Lys Glu Lys Asn Asn Gly Ala Ile Leu Phe Val Lys Asn
545 550 555 560
Gly Leu Tyr Tyr Leu Gly Ile Met Pro Lys Gln Lys Gly Arg Tyr Lys
565 570 575
Ala Leu Ser Phe Glu Pro Thr Glu Lys Thr Ser Glu Gly Phe Asp Lys
580 585 590
Met Tyr Tyr Asp Tyr Phe Pro Asp Ala Ala Lys Met Ile Pro Lys Cys
595 600 605
Ser Thr Gln Leu Lys Ala Val Thr Ala His Phe Gln Thr His Thr Thr
610 615 620
Pro Ile Leu Leu Ser Asn Asn Phe Ile Glu Pro Leu Glu Ile Thr Lys
625 630 635 640
Glu Ile Tyr Asp Leu Asn Asn Pro Glu Lys Glu Pro Lys Lys Phe Gln
645 650 655
Thr Ala Tyr Ala Lys Lys Thr Gly Asp Gln Lys Gly Tyr Arg Glu Ala
660 665 670
Leu Cys Lys Trp Ile Asp Phe Thr Arg Asp Phe Leu Ser Lys Tyr Thr
675 680 685
Lys Thr Thr Ser Ile Asp Leu Ser Ser Leu Arg Pro Ser Ser Gln Tyr
690 695 700
Lys Asp Leu Gly Glu Tyr Tyr Ala Glu Leu Asn Pro Leu Leu Tyr His
705 710 715 720
Ile Ser Phe Gln Arg Ile Ala Glu Lys Glu Ile Met Asp Ala Val Glu
725 730 735
Thr Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Lys
740 745 750
Gly His His Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Thr Gly Leu
755 760 765
Phe Ser Pro Glu Asn Leu Ala Lys Thr Ser Ile Lys Leu Asn Gly Gln
770 775 780
Ala Glu Leu Phe Tyr Arg Pro Lys Ser Arg Met Lys Arg Met Ala His
785 790 795 800
Arg Leu Gly Glu Lys Met Leu Asn Lys Lys Leu Lys Asp Gln Lys Thr
805 810 815
Pro Ile Pro Asp Thr Leu Tyr Gln Glu Leu Tyr Asp Tyr Val Asn His
820 825 830
Arg Leu Ser His Asp Leu Ser Asp Glu Ala Arg Ala Leu Leu Pro Asn
835 840 845
Val Ile Thr Lys Glu Val Ser His Glu Ile Ile Lys Asp Arg Arg Phe
850 855 860
Thr Ser Asp Lys Phe Phe Phe His Val Pro Ile Thr Leu Asn Tyr Gln
865 870 875 880
Ala Ala Asn Ser Pro Ser Lys Phe Asn Gln Arg Val Asn Ala Tyr Leu
885 890 895
Lys Glu His Pro Glu Thr Pro Ile Ile Gly Ile Asp Arg Gly Glu Arg
900 905 910
Asn Leu Ile Tyr Ile Thr Val Ile Asp Ser Thr Gly Lys Ile Leu Glu
915 920 925
Gln Arg Ser Leu Asn Thr Ile Gln Gln Phe Asp Tyr Gln Lys Lys Leu
930 935 940
Asp Asn Arg Glu Lys Glu Arg Val Ala Ala Arg Gln Ala Trp Ser Val
945 950 955 960
Val Gly Thr Ile Lys Asp Leu Lys Gln Gly Tyr Leu Ser Gln Val Ile
965 970 975
His Glu Ile Val Asp Leu Met Ile His Tyr Gln Ala Val Val Val Leu
980 985 990
Glu Asn Leu Asn Phe Gly Phe Lys Ser Lys Arg Thr Gly Ile Ala Glu
995 1000 1005
Lys Ala Val Tyr Gln Gln Phe Glu Lys Met Leu Ile Asp Lys Leu
1010 1015 1020
Asn Cys Leu Val Leu Lys Asp Tyr Pro Ala Glu Lys Val Gly Gly
1025 1030 1035
Val Leu Asn Pro Tyr Gln Leu Thr Asp Gln Phe Thr Ser Phe Ala
1040 1045 1050
Lys Met Gly Thr Gln Ser Gly Phe Leu Phe Tyr Val Pro Ala Pro
1055 1060 1065
Tyr Thr Ser Lys Ile Asp Pro Leu Thr Gly Phe Val Asp Pro Phe
1070 1075 1080
Val Trp Lys Thr Ile Lys Asn His Glu Ser Arg Lys His Phe Leu
1085 1090 1095
Glu Gly Phe Asp Phe Leu His Tyr Asp Val Lys Thr Gly Asp Phe
1100 1105 1110
Ile Leu His Phe Lys Met Asn Arg Asn Leu Ser Phe Gln Arg Gly
1115 1120 1125
Leu Pro Gly Phe Met Pro Ala Trp Asp Ile Val Phe Glu Lys Asn
1130 1135 1140
Glu Thr Gln Phe Asp Ala Lys Gly Thr Pro Phe Ile Ala Gly Lys
1145 1150 1155
Arg Ile Val Pro Val Ile Glu Asn His Arg Phe Thr Gly Arg Tyr
1160 1165 1170
Arg Asp Leu Tyr Pro Ala Asn Glu Leu Ile Ala Leu Leu Glu Glu
1175 1180 1185
Lys Gly Ile Val Phe Arg Asp Gly Ser Asn Ile Leu Pro Lys Leu
1190 1195 1200
Leu Glu Asn Asp Asp Ser His Ala Ile Asp Thr Met Val Ala Leu
1205 1210 1215
Ile Arg Ser Val Leu Gln Met Arg Asn Ser Asn Ala Ala Thr Gly
1220 1225 1230
Glu Asp Tyr Ile Asn Ser Pro Val Arg Asp Leu Asn Gly Val Cys
1235 1240 1245
Phe Asp Ser Arg Phe Gln Asn Pro Glu Trp Pro Met Asp Ala Asp
1250 1255 1260
Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Gln Leu Leu Leu
1265 1270 1275
Asn His Leu Lys Glu Ser Lys Asp Leu Lys Leu Gln Asn Gly Ile
1280 1285 1290
Ser Asn Gln Asp Trp Leu Ala Tyr Ile Gln Glu Leu Arg Asn Lys
1295 1300 1305
Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1310 1315 1320
Gly Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp
1325 1330 1335
Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1340 1345 1350
<210> 237
<211> 1251
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 237
Met Tyr Tyr Glu Ser Leu Thr Lys Gln Tyr Pro Val Ser Lys Thr Ile
1 5 10 15
Arg Asn Glu Leu Ile Pro Ile Gly Lys Thr Leu Asp Asn Ile Arg Gln
20 25 30
Asn Asn Ile Leu Glu Ser Asp Val Lys Arg Lys Gln Asn Tyr Glu His
35 40 45
Val Lys Gly Ile Leu Asp Glu Tyr His Lys Gln Leu Ile Asn Glu Ala
50 55 60
Leu Asp Asn Cys Thr Leu Pro Ser Leu Lys Ile Ala Ala Glu Ile Tyr
65 70 75 80
Leu Lys Asn Gln Lys Glu Val Ser Asp Arg Glu Asp Phe Asn Lys Thr
85 90 95
Gln Asp Leu Leu Arg Lys Glu Val Val Glu Lys Leu Lys Ala His Glu
100 105 110
Asn Phe Thr Lys Ile Gly Lys Lys Asp Ile Leu Asp Leu Leu Glu Lys
115 120 125
Leu Pro Ser Ile Ser Glu Asp Asp Tyr Asn Ala Leu Glu Ser Phe Arg
130 135 140
Asn Phe Tyr Thr Tyr Phe Thr Ser Tyr Asn Lys Val Arg Glu Asn Leu
145 150 155 160
Tyr Ser Asp Lys Glu Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn
165 170 175
Glu Asn Phe Pro Lys Phe Leu Asp Asn Val Lys Ser Tyr Arg Phe Val
180 185 190
Lys Thr Ala Gly Ile Leu Ala Asp Gly Leu Gly Glu Glu Glu Gln Asp
195 200 205
Ser Leu Phe Ile Val Glu Thr Phe Asn Lys Thr Leu Thr Gln Asp Gly
210 215 220
Ile Asp Thr Tyr Asn Ser Gln Val Gly Lys Ile Asn Ser Ser Ile Asn
225 230 235 240
Leu Tyr Asn Gln Lys Asn Gln Lys Ala Asn Gly Phe Arg Lys Ile Pro
245 250 255
Lys Met Lys Met Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Glu Ser
260 265 270
Phe Ile Asp Glu Phe Gln Ser Asp Glu Val Leu Ile Asp Asn Val Glu
275 280 285
Ser Tyr Gly Ser Val Leu Ile Glu Ser Leu Lys Ser Ser Lys Val Ser
290 295 300
Ala Phe Phe Asp Ala Leu Arg Glu Ser Lys Gly Lys Asn Val Tyr Val
305 310 315 320
Lys Asn Asp Leu Ala Lys Thr Ala Met Ser Asn Ile Val Phe Glu Asn
325 330 335
Trp Arg Thr Phe Asp Asp Leu Leu Asn Gln Glu Tyr Asp Leu Ala Asn
340 345 350
Glu Asn Lys Lys Lys Asp Asp Lys Tyr Phe Glu Lys Arg Gln Lys Glu
355 360 365
Leu Lys Lys Asn Lys Ser Tyr Ser Leu Glu His Leu Cys Asn Leu Ser
370 375 380
Glu Asp Ser Cys Asn Leu Ile Glu Asn Tyr Ile His Gln Ile Ser Asp
385 390 395 400
Asp Ile Glu Asn Ile Ile Ile Asn Asn Glu Thr Phe Leu Arg Ile Val
405 410 415
Ile Asn Glu His Asp Arg Ser Arg Lys Leu Ala Lys Asn Arg Lys Ala
420 425 430
Val Lys Ala Ile Lys Asp Phe Leu Asp Ser Ile Lys Val Leu Glu Arg
435 440 445
Glu Leu Lys Leu Ile Asn Ser Ser Gly Gln Glu Leu Glu Lys Asp Leu
450 455 460
Ile Val Tyr Ser Ala His Glu Glu Leu Leu Val Glu Leu Lys Gln Val
465 470 475 480
Asp Ser Leu Tyr Asn Met Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe
485 490 495
Ser Thr Glu Lys Val Lys Leu Asn Phe Asn Arg Ser Thr Leu Leu Asn
500 505 510
Gly Trp Asp Arg Asn Lys Glu Thr Asp Asn Leu Gly Val Leu Leu Leu
515 520 525
Lys Asp Gly Lys Tyr Tyr Leu Gly Ile Met Asn Thr Ser Ala Asn Lys
530 535 540
Ala Phe Val Asn Pro Pro Val Ala Lys Thr Glu Lys Val Phe Lys Lys
545 550 555 560
Val Asp Tyr Lys Leu Leu Pro Val Pro Asn Gln Met Leu Pro Lys Val
565 570 575
Phe Phe Ala Lys Ser Asn Ile Asp Phe Tyr Asn Pro Ser Ser Glu Ile
580 585 590
Tyr Ser Asn Tyr Lys Lys Gly Thr His Lys Lys Gly Asn Met Phe Ser
595 600 605
Leu Glu Asp Cys His Asn Leu Ile Asp Phe Phe Lys Glu Ser Ile Ser
610 615 620
Lys His Glu Asp Trp Ser Lys Phe Gly Phe Lys Phe Ser Asp Thr Ala
625 630 635 640
Ser Tyr Asn Asp Ile Ser Glu Phe Tyr Arg Glu Val Glu Lys Gln Gly
645 650 655
Tyr Lys Leu Thr Tyr Thr Asp Ile Asp Glu Thr Tyr Ile Asn Asp Leu
660 665 670
Ile Glu Arg Asn Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe
675 680 685
Ser Met Tyr Ser Lys Gly Lys Leu Asn Leu His Thr Leu Tyr Phe Met
690 695 700
Met Leu Phe Asp Gln Arg Asn Ile Asp Asp Val Val Tyr Lys Leu Asn
705 710 715 720
Gly Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Ser Glu Asp Glu
725 730 735
Leu Ile Ile His Lys Ala Gly Glu Glu Ile Lys Asn Lys Asn Pro Asn
740 745 750
Arg Ala Arg Thr Lys Glu Thr Ser Thr Phe Ser Tyr Asp Ile Val Lys
755 760 765
Asp Lys Arg Tyr Ser Lys Asp Lys Phe Thr Leu His Ile Pro Ile Thr
770 775 780
Met Asn Phe Gly Val Asp Glu Val Lys Arg Phe Asn Asp Ala Val Asn
785 790 795 800
Ser Ala Ile Arg Ile Asp Glu Asn Val Asn Val Ile Gly Ile Asp Arg
805 810 815
Gly Glu Arg Asn Leu Leu Tyr Val Val Val Ile Asp Ser Lys Gly Asn
820 825 830
Ile Leu Glu Gln Ile Ser Leu Asn Ser Ile Ile Asn Lys Glu Tyr Asp
835 840 845
Ile Glu Thr Asp Tyr His Ala Leu Leu Asp Glu Arg Glu Gly Gly Arg
850 855 860
Asp Lys Ala Arg Lys Asp Trp Asn Thr Val Glu Asn Ile Arg Asp Leu
865 870 875 880
Lys Ala Gly Tyr Leu Ser Gln Val Val Asn Val Val Ala Lys Leu Val
885 890 895
Leu Lys Tyr Asn Ala Ile Ile Cys Leu Glu Asp Leu Asn Phe Gly Phe
900 905 910
Lys Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu
915 920 925
Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Ile Asp Lys Ser Arg
930 935 940
Glu Gln Thr Ser Pro Lys Glu Leu Gly Gly Ala Leu Asn Ala Leu Gln
945 950 955 960
Leu Thr Ser Lys Phe Lys Ser Phe Lys Glu Leu Gly Lys Gln Ser Gly
965 970 975
Val Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile Asp Pro Thr
980 985 990
Thr Gly Phe Ala Asn Leu Phe Tyr Met Lys Cys Glu Asn Val Glu Lys
995 1000 1005
Ser Lys Arg Phe Phe Asp Gly Phe Asp Phe Ile Arg Phe Asn Ala
1010 1015 1020
Leu Glu Asn Val Phe Glu Phe Gly Phe Asp Tyr Arg Ser Phe Thr
1025 1030 1035
Gln Arg Ala Cys Gly Ile Asn Ser Lys Trp Thr Val Cys Thr Asn
1040 1045 1050
Gly Glu Arg Ile Ile Lys Tyr Arg Asn Pro Asp Lys Asn Asn Met
1055 1060 1065
Phe Asp Glu Lys Val Val Val Val Thr Asp Glu Met Lys Asn Leu
1070 1075 1080
Phe Glu Gln Tyr Lys Ile Pro Tyr Glu Asp Gly Arg Asn Val Lys
1085 1090 1095
Asp Met Ile Ile Ser Asn Glu Glu Ala Glu Phe Tyr Arg Arg Leu
1100 1105 1110
Tyr Arg Leu Leu Gln Gln Thr Leu Gln Met Arg Asn Ser Thr Ser
1115 1120 1125
Asp Gly Thr Arg Asp Tyr Ile Ile Ser Pro Val Lys Asn Lys Arg
1130 1135 1140
Glu Ala Tyr Phe Asn Ser Glu Leu Ser Asp Gly Ser Val Pro Lys
1145 1150 1155
Asp Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu
1160 1165 1170
Trp Val Leu Glu Gln Ile Arg Gln Lys Ser Glu Gly Glu Lys Ile
1175 1180 1185
Asn Leu Ala Met Thr Asn Ala Glu Trp Leu Glu Tyr Ala Gln Thr
1190 1195 1200
His Leu Leu Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala
1205 1210 1215
Lys Lys Lys Lys Gly Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1220 1225 1230
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro
1235 1240 1245
Asp Tyr Ala
1250
<210> 238
<211> 1283
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 238
Met Asn Asn Tyr Asp Glu Phe Thr Lys Leu Tyr Pro Ile Gln Lys Thr
1 5 10 15
Ile Arg Phe Glu Leu Lys Pro Gln Gly Arg Thr Met Glu His Leu Glu
20 25 30
Thr Phe Asn Phe Phe Glu Glu Asp Arg Asp Arg Ala Glu Lys Tyr Lys
35 40 45
Ile Leu Lys Glu Ala Ile Asp Glu Tyr His Lys Lys Phe Ile Asp Glu
50 55 60
His Leu Thr Asn Met Ser Leu Asp Trp Asn Ser Leu Lys Gln Ile Ser
65 70 75 80
Glu Lys Tyr Tyr Lys Ser Arg Glu Glu Lys Asp Lys Lys Val Phe Leu
85 90 95
Ser Glu Gln Lys Arg Met Arg Gln Glu Ile Val Ser Glu Phe Lys Lys
100 105 110
Asp Asp Arg Phe Lys Asp Leu Phe Ser Lys Lys Leu Phe Ser Glu Leu
115 120 125
Leu Lys Glu Glu Ile Tyr Lys Lys Gly Asn His Gln Glu Ile Asp Ala
130 135 140
Leu Lys Ser Phe Asp Lys Phe Ser Gly Tyr Phe Ile Gly Leu His Glu
145 150 155 160
Asn Arg Lys Asn Met Tyr Ser Asp Gly Asp Glu Ile Thr Ala Ile Ser
165 170 175
Asn Arg Ile Val Asn Glu Asn Phe Pro Lys Phe Leu Asp Asn Leu Gln
180 185 190
Lys Tyr Gln Glu Ala Arg Lys Lys Tyr Pro Glu Trp Ile Ile Lys Ala
195 200 205
Glu Ser Ala Leu Val Ala His Asn Ile Lys Met Asp Glu Val Phe Ser
210 215 220
Leu Glu Tyr Phe Asn Lys Val Leu Asn Gln Glu Gly Ile Gln Arg Tyr
225 230 235 240
Asn Leu Ala Leu Gly Gly Tyr Val Thr Lys Ser Gly Glu Lys Met Met
245 250 255
Gly Leu Asn Asp Ala Leu Asn Leu Ala His Gln Ser Glu Lys Ser Ser
260 265 270
Lys Gly Arg Ile His Met Thr Pro Leu Phe Lys Gln Ile Leu Ser Glu
275 280 285
Lys Glu Ser Phe Ser Tyr Ile Pro Asp Val Phe Thr Glu Asp Ser Gln
290 295 300
Leu Leu Pro Ser Ile Gly Gly Phe Phe Ala Gln Ile Glu Asn Asp Lys
305 310 315 320
Asp Gly Asn Ile Phe Asp Arg Ala Leu Glu Leu Ile Ser Ser Tyr Ala
325 330 335
Glu Tyr Asp Thr Glu Arg Ile Tyr Ile Arg Gln Ala Asp Ile Asn Arg
340 345 350
Val Ser Asn Val Ile Phe Gly Glu Trp Gly Thr Leu Gly Gly Leu Met
355 360 365
Arg Glu Tyr Lys Ala Asp Ser Ile Asn Asp Ile Asn Leu Glu Arg Thr
370 375 380
Cys Lys Lys Val Asp Lys Trp Leu Asp Ser Lys Glu Phe Ala Leu Ser
385 390 395 400
Asp Val Leu Glu Ala Ile Lys Arg Thr Gly Asn Asn Asp Ala Phe Asn
405 410 415
Glu Tyr Ile Ser Lys Met Arg Thr Ala Arg Glu Lys Ile Asp Ala Ala
420 425 430
Arg Lys Glu Met Lys Phe Ile Ser Glu Lys Ile Ser Gly Asp Glu Glu
435 440 445
Ser Ile His Ile Ile Lys Thr Leu Leu Asp Ser Val Gln Gln Phe Leu
450 455 460
His Phe Phe Asn Leu Phe Lys Ala Arg Gln Asp Ile Pro Leu Asp Gly
465 470 475 480
Ala Phe Tyr Ala Glu Phe Asp Glu Val His Ser Lys Leu Phe Ala Ile
485 490 495
Val Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Lys Asn Asn Leu
500 505 510
Asn Thr Lys Lys Ile Lys Leu Asn Phe Lys Asn Pro Thr Leu Ala Asn
515 520 525
Gly Trp Asp Gln Asn Lys Val Tyr Asp Tyr Ala Ser Leu Ile Phe Leu
530 535 540
Arg Asp Gly Asn Tyr Tyr Leu Gly Ile Ile Asn Pro Lys Arg Lys Lys
545 550 555 560
Asn Ile Lys Phe Glu Gln Gly Ser Gly Asn Gly Pro Phe Tyr Arg Lys
565 570 575
Met Val Tyr Lys Gln Ile Pro Gly Pro Asn Lys Asn Leu Pro Arg Val
580 585 590
Phe Leu Thr Ser Thr Lys Gly Lys Lys Glu Tyr Lys Pro Ser Lys Glu
595 600 605
Ile Ile Glu Gly Tyr Glu Ala Asp Lys His Ile Arg Gly Asp Lys Phe
610 615 620
Asp Leu Asp Phe Cys His Lys Leu Ile Asp Phe Phe Lys Glu Ser Ile
625 630 635 640
Glu Lys His Lys Asp Trp Ser Lys Phe Asn Phe Tyr Phe Ser Pro Thr
645 650 655
Glu Ser Tyr Gly Asp Ile Ser Glu Phe Tyr Leu Asp Val Glu Lys Gln
660 665 670
Gly Tyr Arg Met His Phe Glu Asn Ile Ser Ala Glu Thr Ile Asp Glu
675 680 685
Tyr Val Glu Lys Gly Asp Leu Phe Leu Phe Gln Ile Tyr Asn Lys Asp
690 695 700
Phe Val Lys Ala Ala Thr Gly Lys Lys Asp Met His Thr Ile Tyr Trp
705 710 715 720
Asn Ala Ala Phe Ser Pro Glu Asn Leu Gln Asp Val Val Val Lys Leu
725 730 735
Asn Gly Glu Ala Glu Leu Phe Tyr Arg Asp Lys Ser Asp Ile Lys Glu
740 745 750
Ile Val His Arg Glu Gly Glu Ile Leu Val Asn Arg Thr Tyr Asn Gly
755 760 765
Arg Thr Pro Val Pro Asp Lys Ile His Lys Lys Leu Thr Asp Tyr His
770 775 780
Asn Gly Arg Thr Lys Asp Leu Gly Glu Ala Lys Glu Tyr Leu Asp Lys
785 790 795 800
Val Arg Tyr Phe Lys Ala His Tyr Asp Ile Thr Lys Asp Arg Arg Tyr
805 810 815
Leu Asn Asp Lys Ile Tyr Phe His Val Pro Leu Thr Leu Asn Phe Lys
820 825 830
Ala Asn Gly Lys Lys Asn Leu Asn Lys Met Val Ile Glu Lys Phe Leu
835 840 845
Ser Asp Glu Lys Ala His Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn
850 855 860
Leu Leu Tyr Tyr Ser Ile Ile Asp Arg Ser Gly Lys Ile Ile Asp Gln
865 870 875 880
Gln Ser Leu Asn Val Ile Asp Gly Phe Asp Tyr Arg Glu Lys Leu Asn
885 890 895
Gln Arg Glu Ile Glu Met Lys Asp Ala Arg Gln Ser Trp Asn Ala Ile
900 905 910
Gly Lys Ile Lys Asp Leu Lys Glu Gly Tyr Leu Ser Lys Ala Val His
915 920 925
Glu Ile Thr Lys Met Ala Ile Gln Tyr Asn Ala Ile Val Val Met Glu
930 935 940
Glu Leu Asn Tyr Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln
945 950 955 960
Ile Tyr Gln Lys Phe Glu Asn Met Leu Ile Asp Lys Met Asn Tyr Leu
965 970 975
Val Phe Lys Asp Ala Pro Asp Glu Ser Pro Gly Gly Val Leu Asn Ala
980 985 990
Tyr Gln Leu Thr Asn Pro Leu Glu Ser Phe Ala Lys Leu Gly Lys Gln
995 1000 1005
Thr Gly Ile Leu Phe Tyr Val Pro Ala Ala Tyr Thr Ser Lys Ile
1010 1015 1020
Asp Pro Thr Thr Gly Phe Val Asn Leu Phe Asn Thr Ser Ser Lys
1025 1030 1035
Thr Asn Ala Gln Glu Arg Lys Glu Phe Leu Gln Lys Phe Glu Ser
1040 1045 1050
Ile Ser Tyr Ser Ala Lys Asp Gly Gly Ile Phe Ala Phe Ala Phe
1055 1060 1065
Asp Tyr Arg Lys Phe Gly Thr Ser Lys Thr Asp His Lys Asn Val
1070 1075 1080
Trp Thr Ala Tyr Thr Asn Gly Glu Arg Met Arg Tyr Ile Lys Glu
1085 1090 1095
Lys Lys Arg Asn Glu Leu Phe Asp Pro Ser Lys Glu Ile Lys Glu
1100 1105 1110
Ala Leu Thr Ser Ser Gly Ile Lys Tyr Asp Gly Gly Gln Asn Ile
1115 1120 1125
Leu Pro Asp Ile Leu Arg Ser Asn Asn Asn Gly Leu Ile Tyr Thr
1130 1135 1140
Met Tyr Ser Ser Phe Ile Ala Ala Ile Gln Met Arg Val Tyr Asp
1145 1150 1155
Gly Lys Glu Asp Tyr Ile Ile Ser Pro Ile Lys Asn Ser Lys Gly
1160 1165 1170
Glu Phe Phe Arg Thr Asp Pro Lys Arg Arg Glu Leu Pro Ile Asp
1175 1180 1185
Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Leu Arg Gly Glu Leu
1190 1195 1200
Thr Met Arg Ala Ile Ala Glu Lys Phe Asp Pro Asp Ser Glu Lys
1205 1210 1215
Met Ala Lys Leu Glu Leu Lys His Lys Asp Trp Phe Glu Phe Met
1220 1225 1230
Gln Thr Arg Gly Asp Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly
1235 1240 1245
Gln Ala Lys Lys Lys Lys Gly Ser Tyr Pro Tyr Asp Val Pro Asp
1250 1255 1260
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp
1265 1270 1275
Val Pro Asp Tyr Ala
1280
<210> 239
<211> 1327
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 239
Met Asn Gly Asn Arg Ser Ile Val Tyr Arg Glu Phe Val Gly Val Ile
1 5 10 15
Pro Val Ala Lys Thr Leu Arg Asn Glu Leu Arg Pro Val Gly His Thr
20 25 30
Gln Glu His Ile Ile Gln Asn Gly Leu Ile Gln Glu Asp Glu Leu Arg
35 40 45
Gln Glu Lys Ser Thr Glu Leu Lys Asn Ile Met Asp Asp Tyr Tyr Arg
50 55 60
Glu Tyr Ile Asp Lys Ser Leu Ser Gly Val Thr Asp Leu Asp Phe Thr
65 70 75 80
Leu Leu Phe Glu Leu Met Asn Leu Val Gln Ser Ser Pro Ser Lys Asp
85 90 95
Asn Lys Lys Ala Leu Glu Lys Glu Gln Ser Lys Met Arg Glu Gln Ile
100 105 110
Cys Thr His Leu Gln Ser Asp Ser Asn Tyr Lys Asn Ile Phe Asn Ala
115 120 125
Lys Leu Leu Lys Glu Ile Leu Pro Asp Phe Ile Lys Asn Tyr Asn Gln
130 135 140
Tyr Asp Val Lys Asp Lys Ala Gly Lys Leu Glu Thr Leu Ala Leu Phe
145 150 155 160
Asn Gly Phe Ser Thr Tyr Phe Thr Asp Phe Phe Glu Lys Arg Lys Asn
165 170 175
Val Phe Thr Lys Glu Ala Val Ser Thr Ser Ile Ala Tyr Arg Ile Val
180 185 190
His Glu Asn Ser Leu Ile Phe Leu Ala Asn Met Thr Ser Tyr Lys Lys
195 200 205
Ile Ser Glu Lys Ala Leu Asp Glu Ile Glu Val Ile Glu Lys Asn Asn
210 215 220
Gln Asp Lys Met Gly Asp Trp Glu Leu Asn Gln Ile Phe Asn Pro Asp
225 230 235 240
Phe Tyr Asn Met Val Leu Ile Gln Ser Gly Ile Asp Phe Tyr Asn Glu
245 250 255
Ile Cys Gly Val Val Asn Ala His Met Asn Leu Tyr Cys Gln Gln Thr
260 265 270
Lys Asn Asn Tyr Asn Leu Phe Lys Met Arg Lys Leu His Lys Gln Ile
275 280 285
Leu Ala Tyr Thr Ser Thr Ser Phe Glu Val Pro Lys Met Phe Glu Asp
290 295 300
Asp Met Ser Val Tyr Asn Ala Val Asn Ala Phe Ile Asp Glu Thr Glu
305 310 315 320
Lys Gly Asn Ile Ile Gly Lys Leu Lys Asp Ile Val Asn Lys Tyr Asp
325 330 335
Glu Leu Asp Glu Lys Arg Ile Tyr Ile Ser Lys Asp Phe Tyr Glu Thr
340 345 350
Leu Ser Cys Phe Met Ser Gly Asn Trp Asn Leu Ile Thr Gly Cys Val
355 360 365
Glu Asn Phe Tyr Asp Glu Asn Ile His Ala Lys Gly Lys Ser Lys Glu
370 375 380
Glu Lys Val Lys Lys Ala Val Lys Glu Asp Lys Tyr Lys Ser Ile Asn
385 390 395 400
Asp Val Asn Asp Leu Val Glu Lys Tyr Ile Asp Glu Lys Glu Arg Asn
405 410 415
Glu Phe Lys Asn Ser Asn Ala Lys Gln Tyr Ile Arg Glu Ile Ser Asn
420 425 430
Ile Ile Thr Asp Thr Glu Thr Ala His Leu Glu Tyr Asp Asp His Ile
435 440 445
Ser Leu Ile Glu Ser Glu Glu Lys Ala Asp Glu Met Lys Lys Arg Leu
450 455 460
Asp Met Tyr Met Asn Met Tyr His Trp Ala Lys Ala Phe Ile Val Asp
465 470 475 480
Glu Val Leu Asp Arg Asp Glu Met Phe Tyr Ser Asp Ile Asp Asp Ile
485 490 495
Tyr Asn Ile Leu Glu Asn Ile Val Pro Leu Tyr Asn Arg Val Arg Asn
500 505 510
Tyr Val Thr Gln Lys Pro Tyr Asn Ser Lys Lys Ile Lys Leu Asn Phe
515 520 525
Gln Ser Pro Thr Leu Ala Asn Gly Trp Ser Gln Ser Lys Glu Phe Asp
530 535 540
Asn Asn Ala Ile Ile Leu Ile Arg Asp Asn Lys Tyr Tyr Leu Ala Ile
545 550 555 560
Phe Asn Ala Lys Asn Lys Pro Asp Lys Lys Ile Ile Gln Gly Asn Ser
565 570 575
Asp Lys Lys Asn Asp Asn Asp Tyr Lys Lys Met Val Tyr Asn Leu Leu
580 585 590
Pro Gly Ala Asn Lys Met Leu Pro Lys Val Phe Leu Ser Lys Lys Gly
595 600 605
Ile Glu Thr Phe Lys Pro Ser Asp Tyr Ile Ile Ser Gly Tyr Asn Ala
610 615 620
His Lys His Ile Lys Thr Ser Glu Asn Phe Asp Ile Ser Phe Cys Arg
625 630 635 640
Asp Leu Ile Asp Tyr Phe Lys Asn Ser Ile Glu Lys His Ala Glu Trp
645 650 655
Arg Lys Tyr Glu Phe Lys Phe Ser Ala Thr Asp Ser Tyr Ser Asp Ile
660 665 670
Ser Glu Phe Tyr Arg Glu Val Glu Met Gln Gly Tyr Arg Ile Asp Trp
675 680 685
Thr Tyr Ile Ser Glu Ala Asp Ile Asn Lys Leu Asp Glu Glu Gly Lys
690 695 700
Ile Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Glu Asn Ser Thr
705 710 715 720
Gly Lys Glu Asn Leu His Thr Met Tyr Phe Lys Asn Ile Phe Ser Glu
725 730 735
Glu Asn Leu Lys Asp Ile Ile Ile Lys Leu Asn Gly Gln Ala Glu Leu
740 745 750
Phe Tyr Arg Arg Ala Ser Val Lys Asn Pro Val Lys His Lys Lys Asp
755 760 765
Ser Val Leu Val Asn Lys Thr Tyr Lys Asn Gln Leu Asp Asn Gly Asp
770 775 780
Val Val Arg Ile Pro Ile Pro Asp Asp Ile Tyr Asn Glu Ile Tyr Lys
785 790 795 800
Met Tyr Asn Gly Tyr Ile Lys Glu Ser Asp Leu Ser Glu Ala Ala Lys
805 810 815
Glu Tyr Leu Asp Lys Val Glu Val Arg Thr Ala Gln Lys Asp Ile Val
820 825 830
Lys Asp Tyr Arg Tyr Thr Val Asp Lys Tyr Phe Ile His Thr Pro Ile
835 840 845
Thr Ile Asn Tyr Lys Val Thr Ala Arg Asn Asn Val Asn Asp Met Val
850 855 860
Val Lys Tyr Ile Ala Gln Asn Asp Asp Ile His Val Ile Gly Ile Asp
865 870 875 880
Arg Gly Glu Arg Asn Leu Ile Tyr Ile Ser Val Ile Asp Ser His Gly
885 890 895
Asn Ile Val Lys Gln Lys Ser Tyr Asn Ile Leu Asn Asn Tyr Asp Tyr
900 905 910
Lys Lys Lys Leu Val Glu Lys Glu Lys Thr Arg Glu Tyr Ala Arg Lys
915 920 925
Asn Trp Lys Ser Ile Gly Asn Ile Lys Glu Leu Lys Glu Gly Tyr Ile
930 935 940
Ser Gly Val Val His Glu Ile Ala Met Leu Ile Val Glu Tyr Asn Ala
945 950 955 960
Ile Ile Ala Met Glu Asp Leu Asn Tyr Gly Phe Lys Arg Gly Arg Phe
965 970 975
Lys Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Ser Met Leu Ile Asn
980 985 990
Lys Leu Asn Tyr Phe Ala Ser Lys Glu Lys Ser Val Asp Glu Pro Gly
995 1000 1005
Gly Leu Leu Lys Gly Tyr Gln Leu Thr Tyr Val Pro Asp Asn Ile
1010 1015 1020
Lys Asn Leu Gly Lys Gln Cys Gly Val Ile Phe Tyr Val Pro Ala
1025 1030 1035
Ala Phe Thr Ser Lys Ile Asp Pro Ser Thr Gly Phe Ile Ser Ala
1040 1045 1050
Phe Asn Phe Lys Ser Ile Ser Thr Asn Ala Ser Arg Lys Gln Phe
1055 1060 1065
Phe Met Gln Phe Asp Glu Ile Arg Tyr Cys Ala Glu Lys Asp Met
1070 1075 1080
Phe Ser Phe Gly Phe Asp Tyr Asn Asn Phe Asp Thr Tyr Asn Ile
1085 1090 1095
Thr Met Gly Lys Thr Gln Trp Thr Val Tyr Thr Asn Gly Glu Arg
1100 1105 1110
Leu Gln Ser Glu Phe Asn Asn Ala Arg Arg Thr Gly Lys Thr Lys
1115 1120 1125
Ser Ile Asn Leu Thr Glu Thr Ile Lys Leu Leu Leu Glu Asp Asn
1130 1135 1140
Glu Ile Asn Tyr Ala Asp Gly His Asp Ile Arg Ile Asp Met Glu
1145 1150 1155
Lys Met Asp Glu Asp Lys Lys Ser Glu Phe Phe Ala Gln Leu Leu
1160 1165 1170
Ser Leu Tyr Lys Leu Thr Val Gln Met Arg Asn Ser Tyr Thr Glu
1175 1180 1185
Ala Glu Glu Gln Glu Asn Gly Ile Ser Tyr Asp Lys Ile Ile Ser
1190 1195 1200
Pro Val Ile Asn Asp Glu Gly Glu Phe Phe Asp Ser Asp Asn Tyr
1205 1210 1215
Lys Glu Ser Asp Asp Lys Glu Cys Lys Met Pro Lys Asp Ala Asp
1220 1225 1230
Ala Asn Gly Ala Tyr Cys Ile Ala Leu Lys Gly Leu Tyr Glu Val
1235 1240 1245
Leu Lys Ile Lys Ser Glu Trp Thr Glu Asp Gly Phe Asp Arg Asn
1250 1255 1260
Cys Leu Lys Leu Pro His Ala Glu Trp Leu Asp Phe Ile Gln Asn
1265 1270 1275
Lys Arg Tyr Glu Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln
1280 1285 1290
Ala Lys Lys Lys Lys Gly Ser Tyr Pro Tyr Asp Val Pro Asp Tyr
1295 1300 1305
Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val
1310 1315 1320
Pro Asp Tyr Ala
1325
<210> 240
<211> 1418
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 240
Met Leu Phe Gln Asp Phe Thr His Leu Tyr Pro Leu Ser Lys Thr Val
1 5 10 15
Arg Phe Glu Leu Lys Pro Ile Asp Arg Thr Leu Glu His Ile His Ala
20 25 30
Lys Asn Phe Leu Ser Gln Asp Glu Thr Met Ala Asp Met His Gln Lys
35 40 45
Val Lys Val Ile Leu Asp Asp Tyr His Arg Asp Phe Ile Ala Asp Met
50 55 60
Met Gly Glu Val Lys Leu Thr Lys Leu Ala Glu Phe Tyr Asp Val Tyr
65 70 75 80
Leu Lys Phe Arg Lys Asn Pro Lys Asp Asp Glu Leu Gln Lys Gln Leu
85 90 95
Lys Asp Leu Gln Ala Val Leu Arg Lys Glu Ile Val Lys Pro Ile Gly
100 105 110
Asn Gly Gly Lys Tyr Lys Ala Gly Tyr Asp Arg Leu Phe Gly Ala Lys
115 120 125
Leu Phe Lys Asp Gly Lys Glu Leu Gly Asp Leu Ala Lys Phe Val Ile
130 135 140
Ala Gln Glu Gly Glu Ser Ser Pro Lys Leu Ala His Leu Ala His Phe
145 150 155 160
Glu Lys Phe Ser Thr Tyr Phe Thr Gly Phe His Asp Asn Arg Lys Asn
165 170 175
Met Tyr Ser Asp Glu Asp Lys His Thr Ala Ile Ala Tyr Arg Leu Ile
180 185 190
His Glu Asn Leu Pro Arg Phe Ile Asp Asn Leu Gln Ile Leu Thr Thr
195 200 205
Ile Lys Gln Lys His Ser Ala Leu Tyr Asp Gln Ile Ile Asn Glu Leu
210 215 220
Thr Ala Ser Gly Leu Asp Val Ser Leu Ala Ser His Leu Asp Gly Tyr
225 230 235 240
His Lys Leu Leu Thr Gln Glu Gly Ile Thr Ala Tyr Asn Thr Leu Leu
245 250 255
Gly Gly Ile Ser Gly Glu Ala Gly Ser Pro Lys Ile Gln Gly Ile Asn
260 265 270
Glu Leu Ile Asn Ser His His Asn Gln His Cys His Lys Ser Glu Arg
275 280 285
Ile Ala Lys Leu Arg Pro Leu His Lys Gln Ile Leu Ser Asp Gly Met
290 295 300
Ser Val Ser Phe Leu Pro Ser Lys Phe Ala Asp Asp Ser Glu Met Cys
305 310 315 320
Gln Ala Val Asn Glu Phe Tyr Arg His Tyr Ala Asp Val Phe Ala Lys
325 330 335
Val Gln Ser Leu Phe Asp Gly Phe Asp Asp His Gln Lys Asp Gly Ile
340 345 350
Tyr Val Glu His Lys Asn Leu Asn Glu Leu Ser Lys Gln Ala Phe Gly
355 360 365
Asp Phe Ala Leu Leu Gly Arg Val Leu Asp Gly Tyr Tyr Val Asp Val
370 375 380
Val Asn Pro Glu Phe Asn Glu Arg Phe Ala Lys Ala Lys Thr Asp Asn
385 390 395 400
Ala Lys Ala Lys Leu Thr Lys Glu Lys Asp Lys Phe Ile Lys Gly Val
405 410 415
His Ser Leu Ala Ser Leu Glu Gln Ala Ile Glu His Tyr Thr Ala Arg
420 425 430
His Asp Asp Glu Ser Val Gln Ala Gly Lys Leu Gly Gln Tyr Phe Lys
435 440 445
His Gly Leu Ala Gly Val Asp Asn Pro Ile Gln Lys Ile His Asn Asn
450 455 460
His Ser Thr Ile Lys Gly Phe Leu Glu Arg Glu Arg Pro Ala Gly Glu
465 470 475 480
Arg Ala Leu Pro Lys Ile Lys Ser Gly Lys Asn Pro Glu Met Thr Gln
485 490 495
Leu Arg Gln Leu Lys Glu Leu Leu Asp Asn Ala Leu Asn Val Ala His
500 505 510
Phe Ala Lys Leu Leu Thr Thr Lys Thr Thr Leu Asp Asn Gln Asp Gly
515 520 525
Asn Phe Tyr Gly Glu Phe Gly Val Leu Tyr Asp Glu Leu Ala Lys Ile
530 535 540
Pro Thr Leu Tyr Asn Lys Val Arg Asp Tyr Leu Ser Gln Lys Pro Phe
545 550 555 560
Ser Thr Glu Lys Tyr Lys Leu Asn Phe Gly Asn Pro Thr Leu Leu Asn
565 570 575
Gly Trp Asp Leu Asn Lys Glu Lys Asp Asn Phe Gly Val Ile Leu Gln
580 585 590
Lys Asp Gly Cys Tyr Tyr Leu Ala Leu Leu Asp Lys Ala His Lys Lys
595 600 605
Val Phe Asp Asn Ala Pro Asn Thr Gly Lys Ser Ile Tyr Gln Lys Met
610 615 620
Ile Tyr Lys Tyr Leu Glu Val Arg Lys Gln Phe Pro Lys Val Phe Phe
625 630 635 640
Ser Lys Glu Ala Ile Ala Ile Asn Tyr His Pro Ser Lys Glu Leu Val
645 650 655
Glu Ile Lys Asp Lys Gly Arg Gln Arg Ser Asp Asp Glu Arg Leu Lys
660 665 670
Leu Tyr Arg Phe Ile Leu Glu Cys Leu Lys Ile His Pro Lys Tyr Asp
675 680 685
Lys Lys Phe Glu Gly Ala Ile Gly Asp Ile Gln Leu Phe Lys Lys Asp
690 695 700
Lys Lys Gly Arg Glu Val Pro Ile Ser Glu Lys Asp Leu Phe Asp Lys
705 710 715 720
Ile Asn Gly Ile Phe Ser Ser Lys Pro Lys Leu Glu Met Glu Asp Phe
725 730 735
Phe Ile Gly Glu Phe Lys Arg Tyr Asn Pro Ser Gln Asp Leu Val Asp
740 745 750
Gln Tyr Asn Ile Tyr Lys Lys Ile Asp Ser Asn Asp Asn Arg Lys Lys
755 760 765
Glu Asn Phe Tyr Asn Asn His Pro Lys Phe Lys Lys Asp Leu Val Arg
770 775 780
Tyr Tyr Tyr Glu Ser Met Cys Lys His Glu Glu Trp Glu Glu Ser Phe
785 790 795 800
Glu Phe Ser Lys Lys Leu Gln Asp Ile Gly Cys Tyr Val Asp Val Asn
805 810 815
Glu Leu Phe Thr Glu Ile Glu Thr Arg Arg Leu Asn Tyr Lys Ile Ser
820 825 830
Phe Cys Asn Ile Asn Ala Asp Tyr Ile Asp Glu Leu Val Glu Gln Gly
835 840 845
Gln Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Pro Lys Ala
850 855 860
His Gly Lys Pro Asn Leu His Thr Leu Tyr Phe Lys Ala Leu Phe Ser
865 870 875 880
Glu Asp Asn Leu Ala Asp Pro Ile Tyr Lys Leu Asn Gly Glu Ala Gln
885 890 895
Ile Phe Tyr Arg Lys Ala Ser Leu Asp Met Asn Glu Thr Thr Ile His
900 905 910
Arg Ala Gly Glu Val Leu Glu Asn Lys Asn Pro Asp Asn Pro Lys Lys
915 920 925
Arg Gln Phe Val Tyr Asp Ile Ile Lys Asp Lys Arg Tyr Thr Gln Asp
930 935 940
Lys Phe Met Leu His Val Pro Ile Thr Met Asn Phe Gly Val Gln Gly
945 950 955 960
Met Thr Ile Lys Glu Phe Asn Lys Lys Val Asn Gln Ser Ile Gln Gln
965 970 975
Tyr Asp Glu Val Asn Val Ile Gly Ile Asp Arg Gly Glu Arg His Leu
980 985 990
Leu Tyr Leu Thr Val Ile Asn Ser Lys Gly Glu Ile Leu Glu Gln Cys
995 1000 1005
Ser Leu Asn Asp Ile Thr Thr Ala Ser Ala Asn Gly Thr Gln Met
1010 1015 1020
Thr Thr Pro Tyr His Lys Ile Leu Asp Lys Arg Glu Ile Glu Arg
1025 1030 1035
Leu Asn Ala Arg Val Gly Trp Gly Glu Ile Glu Thr Ile Lys Glu
1040 1045 1050
Leu Lys Ser Gly Tyr Leu Ser His Val Val His Gln Ile Ser Gln
1055 1060 1065
Leu Met Leu Lys Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn
1070 1075 1080
Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Ile Tyr
1085 1090 1095
Gln Asn Phe Glu Asn Ala Leu Ile Lys Lys Leu Asn His Leu Val
1100 1105 1110
Leu Lys Asp Lys Ala Asp Asp Glu Ile Gly Ser Tyr Lys Asn Ala
1115 1120 1125
Leu Gln Leu Thr Asn Asn Phe Thr Asp Leu Lys Ser Ile Gly Lys
1130 1135 1140
Gln Thr Gly Phe Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys
1145 1150 1155
Ile Asp Pro Glu Thr Gly Phe Val Asp Leu Leu Lys Pro Arg Tyr
1160 1165 1170
Glu Asn Ile Ala Gln Ser Gln Ala Phe Phe Gly Lys Phe Asp Lys
1175 1180 1185
Ile Cys Tyr Asn Ala Asp Lys Asp Tyr Phe Glu Phe His Ile Asp
1190 1195 1200
Tyr Ala Lys Phe Thr Asp Lys Ala Lys Asn Ser Arg Gln Ile Trp
1205 1210 1215
Thr Ile Cys Ser His Gly Asp Lys Arg Tyr Val Tyr Asp Lys Thr
1220 1225 1230
Ala Asn Gln Asn Lys Gly Ala Ala Lys Gly Ile Asn Val Asn Asp
1235 1240 1245
Glu Leu Lys Ser Leu Phe Ala Arg His His Ile Asn Glu Lys Gln
1250 1255 1260
Pro Asn Leu Val Met Asp Ile Cys Gln Asn Asn Asp Lys Glu Phe
1265 1270 1275
His Lys Ser Leu Met Tyr Leu Leu Lys Thr Leu Leu Ala Leu Arg
1280 1285 1290
Tyr Ser Asn Ala Ser Ser Asp Glu Asp Phe Ile Leu Ser Pro Val
1295 1300 1305
Ala Asn Asp Glu Gly Val Phe Phe Asn Ser Ala Leu Ala Asp Asp
1310 1315 1320
Thr Gln Pro Gln Asn Ala Asp Ala Asn Gly Ala Tyr His Ile Ala
1325 1330 1335
Leu Lys Gly Leu Trp Leu Leu Asn Glu Leu Lys Asn Ser Asp Asp
1340 1345 1350
Leu Asn Lys Val Lys Leu Ala Ile Asp Asn Gln Thr Trp Leu Asn
1355 1360 1365
Phe Ala Gln Asn Arg Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly
1370 1375 1380
Gln Ala Lys Lys Lys Lys Gly Ser Tyr Pro Tyr Asp Val Pro Asp
1385 1390 1395
Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp
1400 1405 1410
Val Pro Asp Tyr Ala
1415
<210> 241
<211> 1308
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 241
Met Glu Asp Tyr Ser Gly Phe Val Asn Ile Tyr Ser Ile Gln Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu His Ile Glu
20 25 30
Lys Lys Gly Phe Leu Lys Lys Asp Lys Ile Arg Ala Glu Asp Tyr Lys
35 40 45
Ala Val Lys Lys Ile Ile Asp Lys Tyr His Arg Ala Tyr Ile Glu Glu
50 55 60
Val Phe Asp Ser Val Leu His Gln Lys Lys Lys Lys Asp Lys Thr Arg
65 70 75 80
Phe Ser Thr Gln Phe Ile Lys Glu Ile Lys Glu Phe Ser Glu Leu Tyr
85 90 95
Tyr Lys Thr Glu Lys Asn Ile Pro Asp Lys Glu Arg Leu Glu Ala Leu
100 105 110
Ser Glu Lys Leu Arg Lys Met Leu Val Gly Ala Phe Lys Gly Glu Phe
115 120 125
Ser Glu Glu Val Ala Glu Lys Tyr Lys Asn Leu Phe Ser Lys Glu Leu
130 135 140
Ile Arg Asn Glu Ile Glu Lys Phe Cys Glu Thr Asp Glu Glu Arg Lys
145 150 155 160
Gln Val Ser Asn Phe Lys Ser Phe Thr Thr Tyr Phe Thr Gly Phe His
165 170 175
Ser Asn Arg Gln Asn Ile Tyr Ser Asp Glu Lys Lys Ser Thr Ala Ile
180 185 190
Gly Tyr Arg Ile Ile His Gln Asn Leu Pro Lys Phe Leu Asp Asn Leu
195 200 205
Lys Ile Ile Glu Ser Ile Gln Arg Arg Phe Lys Asp Phe Pro Trp Ser
210 215 220
Asp Leu Lys Lys Asn Leu Lys Lys Ile Asp Lys Asn Ile Lys Leu Thr
225 230 235 240
Glu Tyr Phe Ser Ile Asp Gly Phe Val Asn Val Leu Asn Gln Lys Gly
245 250 255
Ile Asp Ala Tyr Asn Thr Ile Leu Gly Gly Lys Ser Glu Glu Ser Gly
260 265 270
Glu Lys Ile Gln Gly Leu Asn Glu Tyr Ile Asn Leu Tyr Arg Gln Lys
275 280 285
Asn Asn Ile Asp Arg Lys Asn Leu Pro Asn Val Lys Ile Leu Phe Lys
290 295 300
Gln Ile Leu Gly Asp Arg Glu Thr Lys Ser Phe Ile Pro Glu Ala Phe
305 310 315 320
Pro Asp Asp Gln Ser Val Leu Asn Ser Ile Thr Glu Phe Ala Lys Tyr
325 330 335
Leu Lys Leu Asp Lys Lys Lys Lys Ser Ile Ile Ala Glu Leu Lys Lys
340 345 350
Phe Leu Ser Ser Phe Asn Arg Tyr Glu Leu Asp Gly Ile Tyr Leu Ala
355 360 365
Asn Asp Asn Ser Leu Ala Ser Ile Ser Thr Phe Leu Phe Asp Asp Trp
370 375 380
Ser Phe Ile Lys Lys Ser Val Ser Phe Lys Tyr Asp Glu Ser Val Gly
385 390 395 400
Asp Pro Lys Lys Lys Ile Lys Ser Pro Leu Lys Tyr Glu Lys Glu Lys
405 410 415
Glu Lys Trp Leu Lys Gln Lys Tyr Tyr Thr Ile Ser Phe Leu Asn Asp
420 425 430
Ala Ile Glu Ser Tyr Ser Lys Ser Gln Asp Glu Lys Arg Val Lys Ile
435 440 445
Arg Leu Glu Ala Tyr Phe Ala Glu Phe Lys Ser Lys Asp Asp Ala Lys
450 455 460
Lys Gln Phe Asp Leu Leu Glu Arg Ile Glu Glu Ala Tyr Ala Ile Val
465 470 475 480
Glu Pro Leu Leu Gly Ala Glu Tyr Pro Arg Asp Arg Asn Leu Lys Ala
485 490 495
Asp Lys Lys Glu Val Gly Lys Ile Lys Asp Phe Leu Asp Ser Ile Lys
500 505 510
Ser Leu Gln Phe Phe Leu Lys Pro Leu Leu Ser Ala Glu Ile Phe Asp
515 520 525
Glu Lys Asp Leu Gly Phe Tyr Asn Gln Leu Glu Gly Tyr Tyr Glu Glu
530 535 540
Ile Asp Ser Ile Gly His Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr
545 550 555 560
Gly Lys Ile Tyr Ser Lys Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser
565 570 575
Thr Leu Leu Lys Gly Trp Asp Glu Asn Arg Glu Val Ala Asn Leu Cys
580 585 590
Val Ile Phe Arg Glu Asp Gln Lys Tyr Tyr Leu Gly Val Met Asp Lys
595 600 605
Glu Asn Asn Thr Ile Leu Ser Asp Ile Pro Lys Val Lys Pro Asn Glu
610 615 620
Leu Phe Tyr Glu Lys Met Val Tyr Lys Leu Ile Pro Thr Pro His Met
625 630 635 640
Gln Leu Pro Arg Ile Ile Phe Ser Ser Asp Asn Leu Ser Ile Tyr Asn
645 650 655
Pro Ser Lys Ser Ile Leu Lys Ile Arg Glu Ala Lys Ser Phe Lys Glu
660 665 670
Gly Lys Asn Phe Lys Leu Lys Asp Cys His Lys Phe Ile Asp Phe Tyr
675 680 685
Lys Glu Ser Ile Ser Lys Asn Glu Asp Trp Ser Arg Phe Asp Phe Lys
690 695 700
Phe Ser Lys Thr Ser Ser Tyr Glu Asn Ile Ser Glu Phe Tyr Arg Glu
705 710 715 720
Val Glu Arg Gln Gly Tyr Asn Leu Asp Phe Lys Lys Val Ser Lys Phe
725 730 735
Tyr Ile Asp Ser Leu Val Glu Asp Gly Lys Leu Tyr Leu Phe Gln Ile
740 745 750
Tyr Asn Lys Asp Phe Ser Ile Phe Ser Lys Gly Lys Pro Asn Leu His
755 760 765
Thr Ile Tyr Phe Arg Ser Leu Phe Ser Lys Glu Asn Leu Lys Asp Val
770 775 780
Cys Leu Lys Leu Asn Gly Glu Ala Glu Met Phe Phe Arg Lys Lys Ser
785 790 795 800
Ile Asn Tyr Asp Glu Lys Lys Lys Arg Glu Gly His His Pro Glu Leu
805 810 815
Phe Glu Lys Leu Lys Tyr Pro Ile Leu Lys Asp Lys Arg Tyr Ser Glu
820 825 830
Asp Lys Phe Gln Phe His Leu Pro Ile Ser Leu Asn Phe Lys Ser Lys
835 840 845
Glu Arg Leu Asn Phe Asn Leu Lys Val Asn Glu Phe Leu Lys Arg Asn
850 855 860
Lys Asp Ile Asn Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Leu
865 870 875 880
Tyr Leu Val Met Ile Asn Gln Lys Gly Glu Ile Leu Lys Gln Thr Leu
885 890 895
Leu Asp Ser Met Gln Ser Gly Lys Gly Arg Pro Glu Ile Asn Tyr Lys
900 905 910
Glu Lys Leu Gln Glu Lys Glu Ile Glu Arg Asp Lys Ala Arg Lys Ser
915 920 925
Trp Gly Thr Val Glu Asn Ile Lys Glu Leu Lys Glu Gly Tyr Leu Ser
930 935 940
Ile Val Ile His Gln Ile Ser Lys Leu Met Val Glu Asn Asn Ala Ile
945 950 955 960
Val Val Leu Glu Asp Leu Asn Ile Gly Phe Lys Arg Gly Arg Gln Lys
965 970 975
Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Lys Met Leu Ile Asp Lys
980 985 990
Leu Asn Phe Leu Val Phe Lys Glu Asn Lys Pro Thr Glu Pro Gly Gly
995 1000 1005
Val Leu Lys Ala Tyr Gln Leu Thr Asp Glu Phe Gln Ser Phe Glu
1010 1015 1020
Lys Leu Ser Lys Gln Thr Gly Phe Leu Phe Tyr Val Pro Ser Trp
1025 1030 1035
Asn Thr Ser Lys Ile Asp Pro Arg Thr Gly Phe Ile Asp Phe Leu
1040 1045 1050
His Pro Ala Tyr Glu Asn Ile Glu Lys Ala Lys Gln Trp Ile Asn
1055 1060 1065
Lys Phe Asp Ser Ile Arg Phe Asn Ser Lys Met Asp Trp Phe Glu
1070 1075 1080
Phe Thr Ala Asp Thr Arg Lys Phe Ser Glu Asn Leu Met Leu Gly
1085 1090 1095
Lys Asn Arg Val Trp Val Ile Cys Thr Thr Asn Val Glu Arg Tyr
1100 1105 1110
Phe Thr Ser Lys Thr Ala Asn Ser Ser Ile Gln Tyr Asn Ser Ile
1115 1120 1125
Gln Ile Thr Glu Lys Leu Lys Glu Leu Phe Val Asp Ile Pro Phe
1130 1135 1140
Ser Asn Gly Gln Asp Leu Lys Pro Glu Ile Leu Arg Lys Asn Asp
1145 1150 1155
Ala Val Phe Phe Lys Ser Leu Leu Phe Tyr Ile Lys Thr Thr Leu
1160 1165 1170
Ser Leu Arg Gln Asn Asn Gly Lys Lys Gly Glu Glu Glu Lys Asp
1175 1180 1185
Phe Ile Leu Ser Pro Val Val Asp Ser Lys Gly Arg Phe Phe Asn
1190 1195 1200
Ser Leu Glu Ala Ser Asp Asp Glu Pro Lys Asp Ala Asp Ala Asn
1205 1210 1215
Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Met Asn Leu Leu Val
1220 1225 1230
Leu Asn Glu Thr Lys Glu Glu Asn Leu Ser Arg Pro Lys Trp Lys
1235 1240 1245
Ile Lys Asn Lys Asp Trp Leu Glu Phe Val Trp Glu Arg Asn Arg
1250 1255 1260
Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys
1265 1270 1275
Lys Gly Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr
1280 1285 1290
Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1295 1300 1305
<210> 242
<211> 1273
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 242
Met Ser Lys Leu Glu Lys Phe Thr Asn Cys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Lys Ala Ile Pro Val Gly Lys Thr Gln Glu Asn Ile Asp
20 25 30
Asn Lys Arg Leu Leu Val Glu Asp Glu Lys Arg Ala Glu Asp Tyr Lys
35 40 45
Gly Val Lys Lys Leu Leu Asp Arg Tyr Tyr Leu Ser Phe Ile Asn Asp
50 55 60
Val Leu His Ser Ile Lys Leu Lys Asn Leu Asn Asn Tyr Ile Ser Leu
65 70 75 80
Phe Arg Lys Lys Thr Arg Thr Glu Lys Glu Asn Lys Glu Leu Glu Asn
85 90 95
Leu Glu Ile Asn Leu Arg Lys Glu Ile Ala Lys Ala Phe Lys Gly Asn
100 105 110
Glu Gly Tyr Lys Ser Leu Phe Lys Lys Asp Ile Ile Glu Thr Ile Leu
115 120 125
Pro Glu Phe Leu Asp Asp Lys Asp Glu Ile Ala Leu Val Asn Ser Phe
130 135 140
Asn Gly Phe Thr Thr Ala Phe Thr Gly Phe Phe Asp Asn Arg Glu Asn
145 150 155 160
Met Phe Ser Glu Glu Ala Lys Ser Thr Ser Ile Ala Phe Arg Cys Ile
165 170 175
Asn Glu Asn Leu Thr Arg Tyr Ile Ser Asn Met Asp Ile Phe Glu Lys
180 185 190
Val Asp Ala Ile Phe Asp Lys His Glu Val Gln Glu Ile Lys Glu Lys
195 200 205
Ile Leu Asn Ser Asp Tyr Asp Val Glu Asp Phe Phe Glu Gly Glu Phe
210 215 220
Phe Asn Phe Val Leu Thr Gln Glu Gly Ile Asp Val Tyr Asn Ala Ile
225 230 235 240
Ile Gly Gly Phe Val Thr Glu Ser Gly Glu Lys Ile Lys Gly Leu Asn
245 250 255
Glu Tyr Ile Asn Leu Tyr Asn Gln Lys Thr Lys Gln Lys Leu Pro Lys
260 265 270
Phe Lys Pro Leu Tyr Lys Gln Val Leu Ser Asp Arg Glu Ser Leu Ser
275 280 285
Phe Tyr Gly Glu Gly Tyr Thr Ser Asp Glu Glu Val Leu Glu Val Phe
290 295 300
Arg Asn Thr Leu Asn Lys Asn Ser Glu Ile Phe Ser Ser Ile Lys Lys
305 310 315 320
Leu Glu Lys Leu Phe Lys Asn Phe Asp Glu Tyr Ser Ser Ala Gly Ile
325 330 335
Phe Val Lys Asn Gly Pro Ala Ile Ser Thr Ile Ser Lys Asp Ile Phe
340 345 350
Gly Glu Trp Asn Val Ile Arg Asp Lys Trp Asn Ala Glu Tyr Asp Asp
355 360 365
Ile His Leu Lys Lys Lys Ala Val Val Thr Glu Lys Tyr Glu Asp Asp
370 375 380
Arg Arg Lys Ser Phe Lys Lys Ile Gly Ser Phe Ser Leu Glu Gln Leu
385 390 395 400
Gln Glu Tyr Ala Asp Ala Asp Leu Ser Val Val Glu Lys Leu Lys Glu
405 410 415
Ile Ile Ile Gln Lys Val Asp Glu Ile Tyr Lys Val Tyr Gly Ser Ser
420 425 430
Glu Lys Leu Phe Asp Ala Asp Phe Val Leu Glu Lys Ser Leu Lys Lys
435 440 445
Asn Asp Ala Val Val Ala Ile Met Lys Asp Leu Leu Asp Ser Val Lys
450 455 460
Ser Phe Glu Asn Tyr Ile Lys Ala Phe Phe Gly Glu Gly Lys Glu Thr
465 470 475 480
Asn Arg Asp Glu Ser Phe Tyr Gly Asp Phe Val Leu Ala Tyr Asp Ile
485 490 495
Leu Leu Lys Val Asp His Ile Tyr Asp Ala Ile Arg Asn Tyr Val Thr
500 505 510
Gln Lys Pro Tyr Ser Lys Asp Lys Phe Lys Leu Tyr Phe Gln Asn Pro
515 520 525
Gln Phe Met Gly Gly Trp Asp Lys Asp Lys Glu Thr Asp Tyr Arg Ala
530 535 540
Thr Ile Leu Arg Tyr Gly Ser Lys Tyr Tyr Leu Ala Ile Met Asp Lys
545 550 555 560
Lys Tyr Ala Lys Cys Leu Gln Lys Ile Asp Lys Asp Asp Val Asn Gly
565 570 575
Asn Tyr Glu Lys Ile Asn Tyr Lys Leu Leu Pro Gly Pro Asn Lys Met
580 585 590
Leu Pro Lys Val Phe Phe Ser Lys Lys Trp Met Ala Tyr Tyr Asn Pro
595 600 605
Ser Glu Asp Ile Gln Lys Ile Tyr Lys Asn Gly Thr Phe Lys Lys Gly
610 615 620
Asp Met Phe Asn Leu Asn Asp Cys His Lys Leu Ile Asp Phe Phe Lys
625 630 635 640
Asp Ser Ile Ser Arg Tyr Pro Lys Trp Ser Asn Ala Tyr Asp Phe Asn
645 650 655
Phe Ser Glu Thr Glu Lys Tyr Lys Asp Ile Ala Gly Phe Tyr Arg Glu
660 665 670
Val Glu Glu Gln Gly Tyr Lys Val Ser Phe Glu Ser Ala Ser Lys Lys
675 680 685
Glu Val Asp Lys Leu Val Glu Glu Gly Lys Leu Tyr Met Phe Gln Ile
690 695 700
Tyr Asn Lys Asp Phe Ser Asp Lys Ser His Gly Thr Pro Asn Leu His
705 710 715 720
Thr Met Tyr Phe Lys Leu Leu Phe Asp Glu Asn Asn His Gly Gln Ile
725 730 735
Arg Leu Ser Gly Gly Ala Glu Leu Phe Met Arg Arg Ala Ser Leu Lys
740 745 750
Lys Glu Glu Leu Val Val His Pro Ala Asn Ser Pro Ile Ala Asn Lys
755 760 765
Asn Pro Asp Asn Pro Lys Lys Thr Thr Thr Leu Ser Tyr Asp Val Tyr
770 775 780
Lys Asp Lys Arg Phe Ser Glu Asp Gln Tyr Glu Leu His Ile Pro Ile
785 790 795 800
Ala Ile Asn Lys Cys Pro Lys Asn Ile Phe Lys Ile Asn Thr Glu Val
805 810 815
Arg Val Leu Leu Lys His Asp Asp Asn Pro Tyr Val Ile Gly Ile Asp
820 825 830
Arg Gly Glu Arg Asn Leu Leu Tyr Ile Val Val Val Asp Gly Lys Gly
835 840 845
Asn Ile Val Glu Gln Tyr Ser Leu Asn Glu Ile Ile Asn Asn Phe Asn
850 855 860
Gly Ile Arg Ile Lys Thr Asp Tyr His Ser Leu Leu Asp Lys Lys Glu
865 870 875 880
Lys Glu Arg Phe Glu Ala Arg Gln Asn Trp Thr Ser Ile Glu Asn Ile
885 890 895
Lys Glu Leu Lys Ala Gly Tyr Ile Ser Gln Val Val His Lys Ile Cys
900 905 910
Glu Leu Val Glu Lys Tyr Asp Ala Val Ile Ala Leu Glu Asp Leu Asn
915 920 925
Ser Gly Phe Lys Asn Ser Arg Val Lys Val Glu Lys Gln Val Tyr Gln
930 935 940
Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Met Val Asp Lys
945 950 955 960
Lys Ser Asn Pro Cys Ala Thr Gly Gly Ala Leu Lys Gly Tyr Gln Ile
965 970 975
Thr Asn Lys Phe Glu Ser Phe Lys Ser Met Ser Thr Gln Asn Gly Phe
980 985 990
Ile Phe Tyr Ile Pro Ala Trp Leu Thr Ser Lys Ile Asp Pro Ser Thr
995 1000 1005
Gly Phe Val Asn Leu Leu Lys Thr Lys Tyr Thr Ser Ile Ala Asp
1010 1015 1020
Ser Lys Lys Phe Ile Ser Ser Phe Asp Arg Ile Met Tyr Val Pro
1025 1030 1035
Glu Glu Asp Leu Phe Glu Phe Ala Leu Asp Tyr Lys Asn Phe Ser
1040 1045 1050
Arg Thr Asp Ala Asp Tyr Ile Lys Lys Trp Lys Leu Tyr Ser Tyr
1055 1060 1065
Gly Asn Arg Ile Arg Ile Phe Arg Asn Pro Lys Lys Asn Asn Val
1070 1075 1080
Phe Asp Trp Glu Glu Val Cys Leu Thr Ser Ala Tyr Lys Glu Leu
1085 1090 1095
Phe Asn Lys Tyr Gly Ile Asn Tyr Gln Gln Gly Asp Ile Arg Ala
1100 1105 1110
Leu Leu Cys Glu Gln Ser Asp Lys Ala Phe Tyr Ser Ser Phe Met
1115 1120 1125
Ala Leu Met Ser Leu Met Leu Gln Met Arg Asn Ser Ile Thr Gly
1130 1135 1140
Arg Thr Asp Val Asp Phe Leu Ile Ser Pro Val Lys Asn Ser Asp
1145 1150 1155
Gly Ile Phe Tyr Asp Ser Arg Asn Tyr Glu Ala Gln Glu Asn Ala
1160 1165 1170
Ile Leu Pro Lys Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala
1175 1180 1185
Arg Lys Val Leu Trp Ala Ile Gly Gln Phe Lys Lys Ala Glu Asp
1190 1195 1200
Glu Lys Leu Asp Lys Val Lys Ile Ala Ile Ser Asn Lys Glu Trp
1205 1210 1215
Leu Glu Tyr Ala Gln Thr Ser Val Lys His Lys Arg Pro Ala Ala
1220 1225 1230
Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys Gly Ser Tyr Pro
1235 1240 1245
Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr
1250 1255 1260
Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1265 1270
<210> 243
<211> 1305
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 243
Met Asp Ser Leu Lys Asp Phe Thr Asn Leu Tyr Pro Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn Ile Glu
20 25 30
Lys Ala Gly Ile Leu Lys Glu Asp Glu His Arg Ala Glu Ser Tyr Arg
35 40 45
Arg Val Lys Lys Ile Ile Asp Thr Tyr His Lys Val Phe Ile Asp Ser
50 55 60
Ser Leu Glu Asn Met Ala Lys Met Gly Ile Glu Asn Glu Ile Lys Ala
65 70 75 80
Met Leu Gln Ser Phe Cys Glu Leu Tyr Lys Lys Asp His Arg Thr Glu
85 90 95
Gly Glu Asp Lys Ala Leu Asp Lys Ile Arg Ala Val Leu Arg Gly Leu
100 105 110
Ile Val Gly Ala Phe Thr Gly Val Cys Gly Arg Arg Glu Asn Thr Val
115 120 125
Gln Asn Glu Lys Tyr Glu Ser Leu Phe Lys Glu Lys Leu Ile Lys Glu
130 135 140
Ile Leu Pro Asp Phe Val Leu Ser Thr Glu Ala Glu Ser Leu Pro Phe
145 150 155 160
Ser Val Glu Glu Ala Thr Arg Ser Leu Lys Glu Phe Asp Ser Phe Thr
165 170 175
Ser Tyr Phe Ala Gly Phe Tyr Glu Asn Arg Lys Asn Ile Tyr Ser Thr
180 185 190
Lys Pro Gln Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Glu Asn Leu
195 200 205
Pro Lys Phe Ile Asp Asn Ile Leu Val Phe Gln Lys Ile Lys Glu Pro
210 215 220
Ile Ala Lys Glu Leu Glu His Ile Arg Ala Asp Phe Ser Ala Gly Gly
225 230 235 240
Tyr Ile Lys Lys Asp Glu Arg Leu Glu Asp Ile Phe Ser Leu Asn Tyr
245 250 255
Tyr Ile His Val Leu Ser Gln Ala Gly Ile Glu Lys Tyr Asn Ala Leu
260 265 270
Ile Gly Lys Ile Val Thr Glu Gly Asp Gly Glu Met Lys Gly Leu Asn
275 280 285
Glu His Ile Asn Leu Tyr Asn Gln Gln Arg Gly Arg Glu Asp Arg Leu
290 295 300
Pro Leu Phe Arg Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Gln
305 310 315 320
Leu Ser Tyr Leu Pro Glu Ser Phe Glu Lys Asp Glu Glu Leu Leu Arg
325 330 335
Ala Leu Lys Glu Phe Tyr Asp His Ile Ala Glu Asp Ile Leu Gly Arg
340 345 350
Thr Gln Gln Leu Met Thr Ser Ile Ser Glu Tyr Asp Leu Ser Arg Ile
355 360 365
Tyr Val Arg Asn Asp Ser Gln Leu Thr Asp Ile Ser Lys Lys Met Leu
370 375 380
Gly Asp Trp Asn Ala Ile Tyr Met Ala Arg Glu Arg Ala Tyr Asp His
385 390 395 400
Glu Gln Ala Pro Lys Arg Ile Thr Ala Lys Tyr Glu Arg Asp Arg Ile
405 410 415
Lys Ala Leu Lys Gly Glu Glu Ser Ile Ser Leu Ala Asn Leu Asn Ser
420 425 430
Cys Ile Ala Phe Leu Asp Asn Val Arg Asp Cys Arg Val Asp Thr Tyr
435 440 445
Leu Ser Thr Leu Gly Gln Lys Glu Gly Pro His Gly Leu Ser Asn Leu
450 455 460
Val Glu Asn Val Phe Ala Ser Tyr His Glu Ala Glu Gln Leu Leu Ser
465 470 475 480
Phe Pro Tyr Pro Glu Glu Asn Asn Leu Ile Gln Asp Lys Asp Asn Val
485 490 495
Val Leu Ile Lys Asn Leu Leu Asp Asn Ile Ser Asp Leu Gln Arg Phe
500 505 510
Leu Lys Pro Leu Trp Gly Met Gly Asp Glu Pro Asp Lys Asp Glu Arg
515 520 525
Phe Tyr Gly Glu Tyr Asn Tyr Ile Arg Gly Ala Leu Asp Gln Val Ile
530 535 540
Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Arg Lys Pro Tyr Ser
545 550 555 560
Thr Arg Lys Val Lys Leu Asn Phe Gly Asn Ser Gln Leu Leu Ser Gly
565 570 575
Trp Asp Arg Asn Lys Glu Lys Asp Asn Ser Cys Val Ile Leu Arg Lys
580 585 590
Gly Gln Asn Phe Tyr Leu Ala Ile Met Asn Asn Arg His Lys Arg Ser
595 600 605
Phe Glu Asn Lys Met Leu Pro Glu Tyr Lys Glu Gly Glu Pro Tyr Phe
610 615 620
Glu Lys Met Asp Tyr Lys Phe Leu Pro Asp Pro Asn Lys Met Leu Pro
625 630 635 640
Lys Val Phe Leu Ser Lys Lys Gly Ile Glu Ile Tyr Lys Pro Ser Pro
645 650 655
Lys Leu Leu Glu Gln Tyr Gly His Gly Thr His Lys Lys Gly Asp Thr
660 665 670
Phe Ser Met Asp Asp Leu His Glu Leu Ile Asp Phe Phe Lys His Ser
675 680 685
Ile Glu Ala His Glu Asp Trp Lys Gln Phe Gly Phe Lys Phe Ser Asp
690 695 700
Thr Ala Thr Tyr Glu Asn Val Ser Ser Phe Tyr Arg Glu Val Glu Asp
705 710 715 720
Gln Gly Tyr Lys Leu Ser Phe Arg Lys Val Ser Glu Ser Tyr Val Tyr
725 730 735
Ser Leu Ile Asp Gln Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
740 745 750
Asp Phe Ser Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr
755 760 765
Trp Arg Met Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys
770 775 780
Leu Asp Gly Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys Asn
785 790 795 800
Asp His Pro Thr His Pro Ala Gly Lys Pro Ile Lys Lys Lys Ser Arg
805 810 815
Gln Lys Lys Gly Glu Glu Ser Leu Phe Glu Tyr Asp Leu Val Lys Asp
820 825 830
Arg Arg Tyr Thr Met Asp Lys Phe Gln Phe His Val Pro Ile Thr Met
835 840 845
Asn Phe Lys Cys Ser Ala Gly Ser Lys Val Asn Asp Met Val Asn Ala
850 855 860
His Ile Arg Glu Ala Lys Asp Met His Val Ile Gly Ile Asp Arg Gly
865 870 875 880
Glu Arg Asn Leu Leu Tyr Ile Cys Val Ile Asp Ser Arg Gly Thr Ile
885 890 895
Leu Asp Gln Ile Ser Leu Asn Thr Ile Asn Asp Ile Asp Tyr His Asp
900 905 910
Leu Leu Glu Ser Arg Asp Lys Asp Arg Gln Gln Glu His Arg Asn Trp
915 920 925
Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Gln Gly Tyr Leu Ser Gln
930 935 940
Ala Val His Arg Ile Ala Glu Leu Met Val Ala Tyr Lys Ala Val Val
945 950 955 960
Ala Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly Arg Gln Lys Val
965 970 975
Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Gln Leu Ile Asp Lys Leu
980 985 990
Asn Tyr Leu Val Asp Lys Lys Lys Arg Pro Glu Asp Ile Gly Gly Leu
995 1000 1005
Leu Arg Ala Tyr Gln Phe Thr Ala Pro Phe Lys Ser Phe Lys Glu
1010 1015 1020
Met Gly Lys Gln Asn Gly Phe Leu Phe Tyr Ile Pro Ala Trp Asn
1025 1030 1035
Thr Ser Asn Ile Asp Pro Thr Thr Gly Phe Val Asn Leu Phe His
1040 1045 1050
Val Gln Tyr Glu Asn Val Asp Lys Ala Lys Ser Phe Phe Gln Lys
1055 1060 1065
Phe Asp Ser Ile Ser Tyr Asn Pro Lys Lys Asp Trp Phe Glu Phe
1070 1075 1080
Ala Phe Asp Tyr Lys Asn Phe Thr Lys Lys Ala Glu Gly Ser Arg
1085 1090 1095
Ser Met Trp Ile Leu Cys Thr His Gly Ser Arg Ile Lys Asn Phe
1100 1105 1110
Arg Asn Ser Gln Lys Asn Gly Gln Trp Asp Ser Glu Glu Phe Ala
1115 1120 1125
Leu Thr Glu Ala Phe Lys Ser Leu Phe Val Arg Tyr Glu Ile Asp
1130 1135 1140
Tyr Thr Ala Asp Leu Lys Thr Ala Ile Val Asp Glu Lys Gln Lys
1145 1150 1155
Asp Phe Phe Val Asp Leu Leu Lys Leu Phe Lys Leu Thr Val Gln
1160 1165 1170
Met Arg Asn Ser Trp Lys Glu Lys Asp Leu Asp Tyr Leu Ile Ser
1175 1180 1185
Pro Val Ala Gly Ala Asp Gly Arg Phe Phe Asp Thr Arg Glu Gly
1190 1195 1200
Asn Lys Ser Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala Tyr Asn
1205 1210 1215
Ile Ala Leu Lys Gly Leu Trp Ala Leu Arg Gln Ile Arg Gln Thr
1220 1225 1230
Ser Glu Gly Gly Lys Leu Lys Leu Ala Ile Ser Asn Lys Glu Trp
1235 1240 1245
Leu Gln Phe Val Gln Glu Arg Ser Tyr Glu Lys Asp Lys Arg Pro
1250 1255 1260
Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys Gly Ser
1265 1270 1275
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro
1280 1285 1290
Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1295 1300 1305
<210> 244
<211> 1368
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 244
Met Glu Asn Tyr Gln Glu Phe Thr Asn Leu Phe Gln Leu Asn Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Cys Glu Leu Leu Glu
20 25 30
Glu Gly Lys Ile Phe Ala Ser Gly Ser Phe Leu Glu Lys Asp Lys Val
35 40 45
Arg Ala Asp Asn Val Ser Tyr Val Lys Lys Glu Ile Asp Lys Lys His
50 55 60
Lys Ile Phe Ile Glu Glu Thr Leu Ser Ser Phe Ser Ile Ser Asn Asp
65 70 75 80
Leu Leu Lys Gln Tyr Phe Asp Cys Tyr Asn Glu Leu Lys Ala Phe Lys
85 90 95
Lys Asp Cys Lys Ser Asp Glu Glu Glu Val Lys Lys Thr Ala Leu Arg
100 105 110
Asn Lys Cys Thr Ser Ile Gln Arg Ala Met Arg Glu Ala Ile Ser Gln
115 120 125
Ala Phe Leu Lys Ser Pro Gln Lys Lys Leu Leu Ala Ile Lys Asn Leu
130 135 140
Ile Glu Asn Val Phe Lys Ala Asp Glu Asn Val Gln His Phe Ser Glu
145 150 155 160
Phe Thr Ser Tyr Phe Ser Gly Phe Glu Thr Asn Arg Glu Asn Phe Tyr
165 170 175
Ser Asp Glu Glu Lys Ser Thr Ser Ile Ala Tyr Arg Leu Val His Asp
180 185 190
Asn Leu Pro Ile Phe Ile Lys Asn Ile Tyr Ile Phe Glu Lys Leu Lys
195 200 205
Glu Gln Phe Asp Ala Lys Thr Leu Ser Glu Ile Phe Glu Asn Tyr Lys
210 215 220
Leu Tyr Val Ala Gly Ser Ser Leu Asp Glu Val Phe Ser Leu Glu Tyr
225 230 235 240
Phe Asn Asn Thr Leu Thr Gln Lys Gly Ile Asp Asn Tyr Asn Ala Val
245 250 255
Ile Gly Lys Ile Val Lys Glu Asp Lys Gln Glu Ile Gln Gly Leu Asn
260 265 270
Glu His Ile Asn Leu Tyr Asn Gln Lys His Lys Asp Arg Arg Leu Pro
275 280 285
Phe Phe Ile Ser Leu Lys Lys Gln Ile Leu Ser Asp Arg Glu Ala Leu
290 295 300
Ser Trp Leu Pro Asp Met Phe Lys Asn Asp Ser Glu Val Ile Lys Ala
305 310 315 320
Leu Lys Gly Phe Tyr Ile Glu Asp Gly Phe Glu Asn Asn Val Leu Thr
325 330 335
Pro Leu Ala Thr Leu Leu Ser Ser Leu Asp Lys Tyr Asn Leu Asn Gly
340 345 350
Ile Phe Ile Arg Asn Asn Glu Ala Leu Ser Ser Leu Ser Gln Asn Val
355 360 365
Tyr Arg Asn Phe Ser Ile Asp Glu Ala Ile Asp Ala Asn Ala Glu Leu
370 375 380
Gln Thr Phe Asn Asn Tyr Glu Leu Ile Ala Asn Ala Leu Arg Ala Lys
385 390 395 400
Ile Lys Lys Glu Thr Lys Gln Gly Arg Lys Ser Phe Glu Lys Tyr Glu
405 410 415
Glu Tyr Ile Asp Lys Lys Val Lys Ala Ile Asp Ser Leu Ser Ile Gln
420 425 430
Glu Ile Asn Glu Leu Val Glu Asn Tyr Val Ser Glu Phe Asn Ser Asn
435 440 445
Ser Gly Asn Met Pro Arg Lys Val Glu Asp Tyr Phe Ser Leu Met Arg
450 455 460
Lys Gly Asp Phe Gly Ser Asn Asp Leu Ile Glu Asn Ile Lys Thr Lys
465 470 475 480
Leu Ser Ala Ala Glu Lys Leu Leu Gly Thr Lys Tyr Gln Glu Thr Ala
485 490 495
Lys Asp Ile Phe Lys Lys Asp Glu Asn Ser Lys Leu Ile Lys Glu Leu
500 505 510
Leu Asp Ala Thr Lys Gln Phe Gln His Phe Ile Lys Pro Leu Leu Gly
515 520 525
Thr Gly Glu Glu Ala Asp Arg Asp Leu Val Phe Tyr Gly Asp Phe Leu
530 535 540
Pro Leu Tyr Glu Lys Phe Glu Glu Leu Thr Leu Leu Tyr Asn Lys Val
545 550 555 560
Arg Asn Arg Leu Thr Gln Lys Pro Tyr Ser Lys Asp Lys Ile Arg Leu
565 570 575
Cys Phe Asn Lys Pro Lys Leu Met Thr Gly Trp Val Asp Ser Lys Thr
580 585 590
Glu Lys Ser Asp Asn Gly Thr Gln Tyr Gly Gly Tyr Leu Phe Arg Lys
595 600 605
Lys Asn Glu Ile Gly Glu Tyr Asp Tyr Phe Leu Gly Ile Ser Ser Lys
610 615 620
Ala Gln Leu Phe Arg Lys Asn Glu Ala Val Ile Gly Asp Tyr Glu Arg
625 630 635 640
Leu Asp Tyr Tyr Gln Pro Lys Ala Asn Thr Ile Tyr Gly Ser Ala Tyr
645 650 655
Glu Gly Glu Asn Ser Tyr Lys Glu Asp Lys Lys Arg Leu Asn Lys Val
660 665 670
Ile Ile Ala Tyr Ile Glu Gln Ile Lys Gln Thr Asn Ile Lys Lys Ser
675 680 685
Ile Ile Glu Ser Ile Ser Lys Tyr Pro Asn Ile Ser Asp Asp Asp Lys
690 695 700
Val Thr Pro Ser Ser Leu Leu Glu Lys Ile Lys Lys Val Ser Ile Asp
705 710 715 720
Ser Tyr Asn Gly Ile Leu Ser Phe Lys Ser Phe Gln Ser Val Asn Lys
725 730 735
Glu Val Ile Asp Asn Leu Leu Lys Thr Ile Ser Pro Leu Lys Asn Lys
740 745 750
Ala Glu Phe Leu Asp Leu Ile Asn Lys Asp Tyr Gln Ile Phe Thr Glu
755 760 765
Val Gln Ala Val Ile Asp Glu Ile Cys Lys Gln Lys Thr Phe Ile Tyr
770 775 780
Phe Pro Ile Ser Asn Val Glu Leu Glu Lys Glu Met Gly Asp Lys Asp
785 790 795 800
Lys Pro Leu Cys Leu Phe Gln Ile Ser Asn Lys Asp Leu Ser Phe Ala
805 810 815
Lys Thr Phe Ser Ala Asn Leu Arg Lys Lys Arg Gly Ala Glu Asn Leu
820 825 830
His Thr Met Leu Phe Lys Ala Leu Met Glu Gly Asn Gln Asp Asn Leu
835 840 845
Asp Leu Gly Ser Gly Ala Ile Phe Tyr Arg Ala Lys Ser Leu Asp Gly
850 855 860
Asn Lys Pro Thr His Pro Ala Asn Glu Ala Ile Lys Cys Arg Asn Val
865 870 875 880
Ala Asn Lys Asp Lys Val Ser Leu Phe Thr Tyr Asp Ile Tyr Lys Asn
885 890 895
Arg Arg Tyr Met Glu Asn Lys Phe Leu Phe His Leu Ser Ile Val Gln
900 905 910
Asn Tyr Lys Ala Ala Asn Asp Ser Ala Gln Leu Asn Ser Ser Ala Thr
915 920 925
Glu Tyr Ile Arg Lys Ala Asp Asp Leu His Ile Ile Gly Ile Asp Arg
930 935 940
Gly Glu Arg Asn Leu Leu Tyr Tyr Ser Val Ile Asp Met Lys Gly Asn
945 950 955 960
Ile Val Glu Gln Asp Ser Leu Asn Ile Ile Arg Asn Asn Asp Leu Glu
965 970 975
Thr Asp Tyr His Asp Leu Leu Asp Lys Arg Glu Lys Glu Arg Lys Ala
980 985 990
Asn Arg Gln Asn Trp Glu Ala Val Glu Gly Ile Lys Asp Leu Lys Lys
995 1000 1005
Gly Tyr Leu Ser Gln Ala Val His Gln Ile Ala Gln Leu Met Leu
1010 1015 1020
Lys Tyr Asn Ala Ile Ile Ala Leu Glu Asp Leu Gly Gln Met Phe
1025 1030 1035
Val Thr Arg Gly Gln Lys Ile Glu Lys Ala Val Tyr Gln Gln Phe
1040 1045 1050
Glu Lys Ser Leu Val Asp Lys Leu Ser Tyr Leu Val Asp Lys Lys
1055 1060 1065
Arg Pro Tyr Asn Glu Leu Gly Gly Ile Leu Lys Ala Tyr Gln Leu
1070 1075 1080
Ala Ser Ser Ile Thr Lys Asn Asn Ser Asp Lys Gln Asn Gly Phe
1085 1090 1095
Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro Val
1100 1105 1110
Thr Gly Phe Thr Asp Leu Leu Arg Pro Lys Ala Met Thr Ile Lys
1115 1120 1125
Glu Ala Gln Asp Phe Phe Gly Ala Phe Asp Asn Ile Ser Tyr Asn
1130 1135 1140
Asp Lys Gly Tyr Phe Glu Phe Glu Thr Asn Tyr Asp Lys Phe Lys
1145 1150 1155
Ile Arg Met Lys Ser Ala Gln Thr Arg Trp Thr Ile Cys Thr Phe
1160 1165 1170
Gly Asn Arg Ile Lys Arg Lys Lys Asp Lys Asn Tyr Trp Asn Tyr
1175 1180 1185
Glu Glu Val Glu Leu Thr Glu Glu Phe Lys Lys Leu Phe Lys Asp
1190 1195 1200
Ser Asn Ile Asp Tyr Glu Asn Cys Asn Leu Lys Glu Glu Ile Gln
1205 1210 1215
Asn Lys Asp Asn Arg Lys Phe Phe Asp Asp Leu Ile Lys Leu Leu
1220 1225 1230
Gln Leu Thr Leu Gln Met Arg Asn Ser Asp Asp Lys Gly Asn Asp
1235 1240 1245
Tyr Ile Ile Ser Pro Val Ala Asn Ala Glu Gly Gln Phe Phe Asp
1250 1255 1260
Ser Arg Asn Gly Asp Lys Lys Leu Pro Leu Asp Ala Asp Ala Asn
1265 1270 1275
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Trp Asn Ile Arg Gln
1280 1285 1290
Ile Lys Gln Thr Lys Asn Asp Lys Lys Leu Asn Leu Ser Ile Ser
1295 1300 1305
Ser Thr Glu Trp Leu Asp Phe Val Arg Glu Lys Pro Tyr Leu Lys
1310 1315 1320
Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys
1325 1330 1335
Lys Gly Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr
1340 1345 1350
Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1355 1360 1365
<210> 245
<211> 1291
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 245
Met Lys Thr Gln His Phe Phe Glu Asp Phe Thr Ser Leu Tyr Ser Leu
1 5 10 15
Ser Lys Thr Ile Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu
20 25 30
Asn Ile Lys Lys Asn Gly Leu Ile Arg Arg Asp Glu Gln Arg Leu Asp
35 40 45
Asp Tyr Glu Lys Leu Lys Lys Val Ile Asp Glu Tyr His Glu Asp Phe
50 55 60
Ile Ala Asn Ile Leu Ser Ser Phe Ser Phe Ser Glu Glu Ile Leu Gln
65 70 75 80
Ser Tyr Ile Gln Asn Leu Ser Glu Ser Glu Ala Arg Ala Lys Ile Glu
85 90 95
Lys Thr Met Arg Asp Thr Leu Ala Lys Ala Phe Ser Glu Asp Glu Arg
100 105 110
Tyr Lys Ser Ile Phe Lys Lys Glu Leu Val Lys Lys Asp Ile Pro Val
115 120 125
Trp Cys Pro Ala Tyr Lys Ser Leu Cys Lys Lys Phe Asp Asn Phe Thr
130 135 140
Thr Ser Leu Val Pro Phe His Glu Asn Arg Lys Asn Leu Tyr Thr Ser
145 150 155 160
Asn Glu Ile Thr Ala Ser Ile Pro Tyr Arg Ile Val His Val Asn Leu
165 170 175
Pro Lys Phe Ile Gln Asn Ile Glu Ala Leu Cys Glu Leu Gln Lys Lys
180 185 190
Met Gly Ala Asp Leu Tyr Leu Glu Met Met Glu Asn Leu Arg Asn Val
195 200 205
Trp Pro Ser Phe Val Lys Thr Pro Asp Asp Leu Cys Asn Leu Lys Thr
210 215 220
Tyr Asn His Leu Met Val Gln Ser Ser Ile Ser Glu Tyr Asn Arg Phe
225 230 235 240
Val Gly Gly Tyr Ser Thr Glu Asp Gly Thr Lys His Gln Gly Ile Asn
245 250 255
Glu Trp Ile Asn Ile Tyr Arg Gln Arg Asn Lys Glu Met Arg Leu Pro
260 265 270
Gly Leu Val Phe Leu His Lys Gln Ile Leu Ala Lys Val Asp Ser Ser
275 280 285
Ser Phe Ile Ser Asp Thr Leu Glu Asn Asp Asp Gln Val Phe Cys Val
290 295 300
Leu Arg Gln Phe Arg Lys Leu Phe Trp Asn Thr Val Ser Ser Lys Glu
305 310 315 320
Asp Asp Ala Ala Ser Leu Lys Asp Leu Phe Cys Gly Leu Ser Gly Tyr
325 330 335
Asp Pro Glu Ala Ile Tyr Val Ser Asp Ala His Leu Ala Thr Ile Ser
340 345 350
Lys Asn Ile Phe Asp Arg Trp Asn Tyr Ile Ser Asp Ala Ile Arg Arg
355 360 365
Lys Thr Glu Val Leu Met Pro Arg Lys Lys Glu Ser Val Glu Arg Tyr
370 375 380
Ala Glu Lys Ile Ser Lys Gln Ile Lys Lys Arg Gln Ser Tyr Ser Leu
385 390 395 400
Ala Glu Leu Asp Asp Leu Leu Ala His Tyr Ser Glu Glu Ser Leu Pro
405 410 415
Ala Gly Phe Ser Leu Leu Ser Tyr Phe Thr Ser Leu Gly Gly Gln Lys
420 425 430
Tyr Leu Val Ser Asp Gly Glu Val Ile Leu Tyr Glu Glu Gly Ser Asn
435 440 445
Ile Trp Asp Glu Val Leu Ile Ala Phe Arg Asp Leu Gln Val Ile Leu
450 455 460
Asp Lys Asp Phe Thr Glu Lys Lys Leu Gly Lys Asp Glu Glu Ala Val
465 470 475 480
Ser Val Ile Lys Lys Ala Leu Asp Ser Ala Leu Arg Leu Arg Lys Phe
485 490 495
Phe Asp Leu Leu Ser Gly Thr Gly Ala Glu Ile Arg Arg Asp Ser Ser
500 505 510
Phe Tyr Ala Leu Tyr Thr Asp Arg Met Asp Lys Leu Lys Gly Leu Leu
515 520 525
Lys Met Tyr Asp Lys Val Arg Asn Tyr Leu Thr Lys Lys Pro Tyr Ser
530 535 540
Ile Glu Lys Phe Lys Leu His Phe Asp Asn Pro Ser Leu Leu Ser Gly
545 550 555 560
Trp Asp Lys Asn Lys Glu Leu Asn Asn Leu Ser Val Ile Phe Arg Gln
565 570 575
Asn Gly Tyr Tyr Tyr Leu Gly Ile Met Thr Pro Lys Gly Lys Asn Leu
580 585 590
Phe Lys Thr Leu Pro Lys Leu Gly Ala Glu Glu Met Phe Tyr Glu Lys
595 600 605
Met Glu Tyr Lys Gln Ile Ala Glu Pro Met Leu Met Leu Pro Lys Val
610 615 620
Phe Phe Pro Lys Lys Thr Lys Pro Ala Phe Ala Pro Asp Gln Ser Val
625 630 635 640
Val Asp Ile Tyr Asn Lys Lys Thr Phe Lys Thr Gly Gln Lys Gly Phe
645 650 655
Asn Lys Lys Asp Leu Tyr Arg Leu Ile Asp Phe Tyr Lys Glu Ala Leu
660 665 670
Thr Val His Glu Trp Lys Leu Phe Asn Phe Ser Phe Ser Pro Thr Glu
675 680 685
Gln Tyr Arg Asn Ile Gly Glu Phe Phe Asp Glu Val Arg Glu Gln Ala
690 695 700
Tyr Lys Val Ser Met Val Asn Val Pro Ala Ser Tyr Ile Asp Glu Ala
705 710 715 720
Val Glu Asn Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe
725 730 735
Ser Pro Tyr Ser Lys Gly Ile Pro Asn Leu His Thr Leu Tyr Trp Lys
740 745 750
Ala Leu Phe Ser Glu Gln Asn Gln Ser Arg Val Tyr Lys Leu Cys Gly
755 760 765
Gly Gly Glu Leu Phe Tyr Arg Lys Ala Ser Leu His Met Gln Asp Thr
770 775 780
Thr Val His Pro Lys Gly Ile Ser Ile His Lys Lys Asn Leu Asn Lys
785 790 795 800
Lys Gly Glu Thr Ser Leu Phe Asn Tyr Asp Leu Val Lys Asp Lys Arg
805 810 815
Phe Thr Glu Asp Lys Phe Phe Phe His Val Pro Ile Ser Ile Asn Tyr
820 825 830
Lys Asn Lys Lys Ile Thr Asn Val Asn Gln Met Val Arg Asp Tyr Ile
835 840 845
Ala Gln Asn Asp Asp Leu Gln Ile Ile Gly Ile Asp Arg Gly Glu Arg
850 855 860
Asn Leu Leu Tyr Ile Ser Arg Ile Asp Thr Arg Gly Asn Leu Leu Glu
865 870 875 880
Gln Phe Ser Leu Asn Val Ile Glu Ser Asp Lys Gly Asp Leu Arg Thr
885 890 895
Asp Tyr Gln Lys Ile Leu Gly Asp Arg Glu Gln Glu Arg Leu Arg Arg
900 905 910
Arg Gln Glu Trp Lys Ser Ile Glu Ser Ile Lys Asp Leu Lys Asp Gly
915 920 925
Tyr Met Ser Gln Val Val His Lys Ile Cys Asn Met Val Val Glu His
930 935 940
Lys Ala Ile Val Val Leu Glu Asn Leu Asn Leu Ser Phe Met Lys Gly
945 950 955 960
Arg Lys Lys Val Glu Lys Ser Val Tyr Glu Lys Phe Glu Arg Met Leu
965 970 975
Val Asp Lys Leu Asn Tyr Leu Val Val Asp Lys Lys Asn Leu Ser Asn
980 985 990
Glu Pro Gly Gly Leu Tyr Ala Ala Tyr Gln Leu Thr Asn Pro Leu Phe
995 1000 1005
Ser Phe Glu Glu Leu His Arg Tyr Pro Gln Ser Gly Ile Leu Phe
1010 1015 1020
Phe Val Asp Pro Trp Asn Thr Ser Leu Thr Asp Pro Ser Thr Gly
1025 1030 1035
Phe Val Asn Leu Leu Gly Arg Ile Asn Tyr Thr Asn Val Gly Asp
1040 1045 1050
Ala Arg Lys Phe Phe Asp Arg Phe Asn Ala Ile Arg Tyr Asp Gly
1055 1060 1065
Lys Gly Asn Ile Leu Phe Asp Leu Asp Leu Ser Arg Phe Asp Val
1070 1075 1080
Arg Val Glu Thr Gln Arg Lys Leu Trp Thr Leu Thr Thr Phe Gly
1085 1090 1095
Ser Arg Ile Ala Lys Ser Lys Lys Ser Gly Lys Trp Met Val Glu
1100 1105 1110
Arg Ile Glu Asn Leu Ser Leu Cys Phe Leu Glu Leu Phe Glu Gln
1115 1120 1125
Phe Asn Ile Gly Tyr Arg Val Glu Lys Asp Leu Lys Lys Ala Ile
1130 1135 1140
Leu Ser Gln Asp Arg Lys Glu Phe Tyr Val Arg Leu Ile Tyr Leu
1145 1150 1155
Phe Asn Leu Met Met Gln Ile Arg Asn Ser Asp Gly Glu Glu Asp
1160 1165 1170
Tyr Ile Leu Ser Pro Ala Leu Asn Glu Lys Asn Leu Gln Phe Asp
1175 1180 1185
Ser Arg Leu Ile Glu Ala Lys Asp Leu Pro Val Asp Ala Asp Ala
1190 1195 1200
Asn Gly Ala Tyr Asn Val Ala Arg Lys Gly Leu Met Val Val Gln
1205 1210 1215
Arg Ile Lys Arg Gly Asp His Glu Ser Ile His Arg Ile Gly Arg
1220 1225 1230
Ala Gln Trp Leu Arg Tyr Val Gln Glu Gly Ile Val Glu Lys Arg
1235 1240 1245
Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys Gly
1250 1255 1260
Ser Tyr Pro Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val
1265 1270 1275
Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1280 1285 1290
<210> 246
<211> 18
<212> БЕЛОК
<213> Alicyclobacillus acidoterrestris
<400> 246
Leu Arg Val Met Ser Val Asp Leu Gly Leu Arg Thr Ser Ala Ser Ile
1 5 10 15
Ser Val
<210> 247
<211> 22
<212> БЕЛОК
<213> Alicyclobacillus acidoterrestris
<400> 247
Gln Arg Thr Leu Arg Gln Leu Arg Thr Gln Leu Ala Tyr Leu Arg Leu
1 5 10 15
Leu Val Arg Cys Gly Ser
20
<210> 248
<211> 12
<212> БЕЛОК
<213> Alicyclobacillus acidoterrestris
<400> 248
Cys Gln Leu Ile Leu Leu Glu Glu Leu Ser Glu Tyr
1 5 10
<210> 249
<211> 16
<212> БЕЛОК
<213> Alicyclobacillus acidoterrestris
<400> 249
His Gln Ile His Ala Asp Leu Asn Ala Ala Gln Asn Leu Gln Gln Arg
1 5 10 15
<210> 250
<211> 18
<212> БЕЛОК
<213> Alicyclobacillus contaminans
<400> 250
Val Arg Val Met Ser Val Asp Leu Gly Val Arg Tyr Gly Ala Ala Ile
1 5 10 15
Ser Val
<210> 251
<211> 22
<212> БЕЛОК
<213> Alicyclobacillus contaminans
<400> 251
Lys Gln Ala Leu Ala Ala Ile Arg Ala Glu Met Ser Ile Leu Arg Lys
1 5 10 15
Trp Leu Arg Val Ser Gln
20
<210> 252
<211> 12
<212> БЕЛОК
<213> Alicyclobacillus contaminans
<400> 252
Cys Asp Leu Ile Leu Phe Glu Asp Leu Ser Arg Tyr
1 5 10
<210> 253
<211> 16
<212> БЕЛОК
<213> Alicyclobacillus contaminans
<400> 253
Lys Cys Val His Ala Asp Ile Asn Ala Ala His Asn Leu Gln Arg Arg
1 5 10 15
<210> 254
<211> 18
<212> БЕЛОК
<213> Desulfovibrio inopinatus
<400> 254
Leu Arg Val Leu Ser Val Asp Leu Gly Met Arg Thr Phe Ala Ser Cys
1 5 10 15
Ser Val
<210> 255
<211> 22
<212> БЕЛОК
<213> Desulfovibrio inopinatus
<400> 255
Arg Ala Glu Ile Tyr Ala Leu Lys Arg Asp Ile Gln Arg Leu Lys Ser
1 5 10 15
Leu Leu Arg Leu Gly Glu
20
<210> 256
<211> 12
<212> БЕЛОК
<213> Desulfovibrio inopinatus
<400> 256
Cys Gln Leu Ile Leu Phe Glu Asp Leu Ala Arg Tyr
1 5 10
<210> 257
<211> 16
<212> БЕЛОК
<213> Desulfovibrio inopinatus
<400> 257
Cys Val Ile His Ala Asp Met Asn Ala Ala Gln Asn Leu Gln Arg Arg
1 5 10 15
<210> 258
<211> 18
<212> БЕЛОК
<213> Desulfonatronum thiodismutans
<400> 258
Leu Arg Val Leu Ser Val Asp Leu Gly Val Arg Ser Phe Ala Ala Cys
1 5 10 15
Ser Val
<210> 259
<211> 22
<212> БЕЛОК
<213> Desulfonatronum thiodismutans
<400> 259
Met Glu Glu Leu Arg Ser Leu Asn Gly Asp Ile Arg Arg Leu Lys Ala
1 5 10 15
Ile Leu Arg Leu Ser Val
20
<210> 260
<211> 12
<212> БЕЛОК
<213> Desulfonatronum thiodismutans
<400> 260
Cys Arg Leu Ile Leu Phe Glu Asp Leu Ala Arg Tyr
1 5 10
<210> 261
<211> 16
<212> БЕЛОК
<213> Desulfonatronum thiodismutans
<400> 261
His Val Ile His Ala Asp Ile Asn Ala Ala Gln Asn Leu Gln Arg Arg
1 5 10 15
<210> 262
<211> 18
<212> БЕЛОК
<213> Tuberibacillus calidus
<400> 262
Leu Arg Val Met Ser Val Asp Leu Gly Gln Arg Gln Ala Ala Ala Ile
1 5 10 15
Ser Ile
<210> 263
<211> 22
<212> БЕЛОК
<213> Tuberibacillus calidus
<400> 263
Asp Gln Ala Ile Arg Asp Leu Ser Arg Lys Leu Lys Phe Leu Lys Asn
1 5 10 15
Val Leu Asn Met Gln Lys
20
<210> 264
<211> 12
<212> БЕЛОК
<213> Tuberibacillus calidus
<400> 264
Cys Gln Leu Val Leu Phe Glu Asp Leu Ser Arg Tyr
1 5 10
<210> 265
<211> 16
<212> БЕЛОК
<213> Tuberibacillus calidus
<400> 265
Val Ile Thr His Ala Asp Ile Asn Ala Ala Gln Asn Leu Gln Lys Arg
1 5 10 15
<210> 266
<211> 18
<212> БЕЛОК
<213> Bacillus thermoamylovorans
<400> 266
Leu Arg Val Met Ser Ile Asp Leu Gly Gln Arg Gln Ala Ala Ala Ala
1 5 10 15
Ser Ile
<210> 267
<211> 22
<212> БЕЛОК
<213> Bacillus thermoamylovorans
<400> 267
Glu Asp Asn Leu Lys Leu Met Asn Gln Lys Leu Asn Phe Leu Arg Asn
1 5 10 15
Val Leu His Phe Gln Gln
20
<210> 268
<211> 12
<212> БЕЛОК
<213> Bacillus thermoamylovorans
<400> 268
Cys Gln Ile Ile Leu Phe Glu Asp Leu Ser Asn Tyr
1 5 10
<210> 269
<211> 16
<212> БЕЛОК
<213> Bacillus thermoamylovorans
<400> 269
Val Thr Thr His Ala Asp Ile Asn Ala Ala Gln Asn Leu Gln Lys Arg
1 5 10 15
<210> 270
<211> 18
<212> БЕЛОК
<213> Bacillus sp.
<400> 270
Phe Arg Val Met Ser Ile Asp Leu Gly Leu Arg Ala Ala Ala Ala Thr
1 5 10 15
Ser Ile
<210> 271
<211> 22
<212> БЕЛОК
<213> Bacillus sp.
<400> 271
Phe Gln Leu His Gln Arg Val Lys Phe Gln Ile Arg Val Leu Ala Gln
1 5 10 15
Ile Met Arg Met Ala Asn
20
<210> 272
<211> 12
<212> БЕЛОК
<213> Bacillus sp.
<400> 272
Cys Gln Val Ile Leu Phe Glu Asn Leu Ser Gln Tyr
1 5 10
<210> 273
<211> 16
<212> БЕЛОК
<213> Bacillus sp.
<400> 273
Val Phe Leu Gln Ala Asp Ile Asn Ala Ala His Asn Leu Gln Lys Arg
1 5 10 15
<210> 274
<211> 18
<212> БЕЛОК
<213> Methylobacterium nodulans
<400> 274
Leu Arg Val Leu Ser Ile Asp Leu Gly Val Arg Ser Phe Ala Thr Cys
1 5 10 15
Ser Val
<210> 275
<211> 22
<212> БЕЛОК
<213> Methylobacterium nodulans
<400> 275
Asp Ala Glu Leu Arg Gln Leu Arg Gly Gly Leu Asn Arg His Arg Gln
1 5 10 15
Leu Leu Arg Ala Ala Thr
20
<210> 276
<211> 12
<212> БЕЛОК
<213> Methylobacterium nodulans
<400> 276
Cys His Val Ile Leu Phe Glu Asp Leu Ser Arg Tyr
1 5 10
<210> 277
<211> 16
<212> БЕЛОК
<213> Methylobacterium nodulans
<400> 277
Ser Arg Ile His Ala Asp Ile Asn Ala Ala Gln Asn Leu Gln Arg Arg
1 5 10 15
<210> 278
<211> 18
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methanomethylophilus alvus
<400> 278
Leu Lys Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Ile Tyr Val
1 5 10 15
Thr Met
<210> 279
<211> 22
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methanomethylophilus alvus
<400> 279
Arg Lys Ala Leu Asp Val Arg Glu Tyr Asp Asn Lys Glu Ala Arg Arg
1 5 10 15
Asn Trp Thr Lys Val Glu
20
<210> 280
<211> 13
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methanomethylophilus alvus
<400> 280
Asn Ala Ile Ile Val Met Glu Asp Leu Asn His Gly Phe
1 5 10
<210> 281
<211> 16
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methanomethylophilus alvus
<400> 281
Leu Pro Gln Asp Ser Asp Ala Asn Gly Ala Tyr Asn Ile Ala Leu Lys
1 5 10 15
<210> 282
<211> 18
<212> БЕЛОК
<213> Synergistes jonesii
<400> 282
Val Asn Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Val Tyr Val
1 5 10 15
Ser Leu
<210> 283
<211> 22
<212> БЕЛОК
<213> Synergistes jonesii
<400> 283
His Ala Lys Leu Asn Gln Lys Glu Lys Glu Arg Asp Thr Ala Arg Lys
1 5 10 15
Ser Trp Lys Thr Ile Gly
20
<210> 284
<211> 13
<212> БЕЛОК
<213> Synergistes jonesii
<400> 284
Asn Ala Val Ile Val Met Glu Asp Leu Asn Ile Gly Phe
1 5 10
<210> 285
<211> 16
<212> БЕЛОК
<213> Synergistes jonesii
<400> 285
Leu Pro Ile Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys
1 5 10 15
<210> 286
<211> 18
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 286
Pro Tyr Val Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Leu Tyr Ile
1 5 10 15
Val Val
<210> 287
<211> 22
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 287
His Ser Leu Leu Asp Lys Lys Glu Lys Glu Arg Phe Glu Ala Arg Gln
1 5 10 15
Asn Trp Thr Ser Ile Glu
20
<210> 288
<211> 13
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 288
Asp Ala Val Ile Ala Leu Glu Asp Leu Asn Ser Gly Phe
1 5 10
<210> 289
<211> 16
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 289
Leu Pro Lys Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys
1 5 10 15
<210> 290
<211> 18
<212> БЕЛОК
<213> Francisella tularensis
<400> 290
Val His Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr
1 5 10 15
Thr Leu
<210> 291
<211> 22
<212> БЕЛОК
<213> Francisella tularensis
<400> 291
His Asp Lys Leu Ala Ala Ile Glu Lys Asp Arg Asp Ser Ala Arg Lys
1 5 10 15
Asp Trp Lys Lys Ile Asn
20
<210> 292
<211> 13
<212> БЕЛОК
<213> Francisella tularensis
<400> 292
Asn Ala Ile Val Val Phe Glu Asp Leu Asn Phe Gly Phe
1 5 10
<210> 293
<211> 16
<212> БЕЛОК
<213> Francisella tularensis
<400> 293
Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly Leu Lys
1 5 10 15
<210> 294
<211> 18
<212> БЕЛОК
<213> Moraxella caprae
<400> 294
Val Asn Val Ile Gly Ile Asp Arg Gly Glu Arg His Leu Leu Tyr Leu
1 5 10 15
Thr Val
<210> 295
<211> 22
<212> БЕЛОК
<213> Moraxella caprae
<400> 295
His Lys Ile Leu Asp Lys Arg Glu Ile Glu Arg Leu Asn Ala Arg Val
1 5 10 15
Gly Trp Gly Glu Ile Glu
20
<210> 296
<211> 13
<212> БЕЛОК
<213> Moraxella caprae
<400> 296
Asn Ala Ile Val Val Leu Glu Asp Leu Asn Phe Gly Phe
1 5 10
<210> 297
<211> 16
<212> БЕЛОК
<213> Moraxella caprae
<400> 297
Gln Pro Gln Asn Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys
1 5 10 15
<210> 298
<211> 18
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 298
Met His Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Ile Tyr Leu
1 5 10 15
Cys Met
<210> 299
<211> 22
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 299
His Gln Leu Leu Lys Thr Arg Glu Asp Glu Asn Lys Ser Ala Arg Gln
1 5 10 15
Ser Trp Gln Thr Ile His
20
<210> 300
<211> 13
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 300
Asn Ala Ile Val Val Leu Glu Asp Leu Asn Phe Gly Phe
1 5 10
<210> 301
<211> 16
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 301
Met Pro Leu Asp Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys
1 5 10 15
<210> 302
<211> 18
<212> БЕЛОК
<213> Prevotella albensis
<400> 302
Thr His Ile Ile Gly Ile Asp Arg Gly Glu Arg His Leu Leu Tyr Leu
1 5 10 15
Ser Leu
<210> 303
<211> 22
<212> БЕЛОК
<213> Prevotella albensis
<400> 303
His Asn Leu Leu Glu Lys Arg Glu Lys Glu Arg Thr Glu Ala Arg His
1 5 10 15
Ser Trp Ser Ser Ile Glu
20
<210> 304
<211> 13
<212> БЕЛОК
<213> Prevotella albensis
<400> 304
Asn Ala Ile Val Val Leu Glu Asp Leu Asn Gly Gly Phe
1 5 10
<210> 305
<211> 16
<212> БЕЛОК
<213> Prevotella albensis
<400> 305
Phe Pro Glu Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys
1 5 10 15
<210> 306
<211> 18
<212> БЕЛОК
<213> Smithella sp.
<400> 306
Ile Asn Ile Ile Gly Ile Asp Arg Gly Glu Arg His Leu Leu Tyr Tyr
1 5 10 15
Ala Leu
<210> 307
<211> 22
<212> БЕЛОК
<213> Smithella sp.
<400> 307
His Asn Leu Leu Asp Lys Lys Glu Gly Asp Arg Ala Thr Ala Arg Gln
1 5 10 15
Glu Trp Gly Val Ile Glu
20
<210> 308
<211> 13
<212> БЕЛОК
<213> Smithella sp.
<400> 308
Asn Ala Ile Ile Val Met Glu Asp Leu Asn Phe Gly Phe
1 5 10
<210> 309
<211> 16
<212> БЕЛОК
<213> Smithella sp.
<400> 309
Met Pro Lys Asn Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys
1 5 10 15
<210> 310
<211> 18
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 310
Met His Val Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Leu Tyr Ile
1 5 10 15
Cys Val
<210> 311
<211> 22
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 311
His Asp Leu Leu Glu Ser Arg Asp Lys Asp Arg Gln Gln Glu Arg Arg
1 5 10 15
Asn Trp Gln Thr Ile Glu
20
<210> 312
<211> 13
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 312
Lys Ala Val Val Ala Leu Glu Asp Leu Asn Met Gly Phe
1 5 10
<210> 313
<211> 16
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 313
Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Leu Lys
1 5 10 15
<210> 314
<211> 18
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 314
Gly Lys Val Val Ala Ile Asp Val Gly Val Glu Lys Leu Leu Ile Thr
1 5 10 15
Ser Asp
<210> 315
<211> 23
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 315
Val Lys His Ile His Arg Glu Leu Ser Arg Lys Lys Phe Leu Ser Asn
1 5 10 15
Asn Trp Phe Lys Ala Lys Val
20
<210> 316
<211> 13
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 316
Tyr Asp Val Val Val Met Glu Gly Ile His Ala Lys Gln
1 5 10
<210> 317
<211> 16
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 317
Trp Ile Ala Asp Arg Asp Tyr Asn Ala Ser Leu Asn Ile Leu Arg Gly
1 5 10 15
<210> 318
<211> 18
<212> БЕЛОК
<213> Nostoc sp.
<400> 318
Leu Lys Thr Ile Gly Leu Asp Val Gly Leu Asn His Phe Leu Thr Asp
1 5 10 15
Ser Glu
<210> 319
<211> 23
<212> БЕЛОК
<213> Nostoc sp.
<400> 319
Leu Lys Arg Leu Gln Arg Arg Leu Ser Lys Thr Lys Lys Gly Ser Asn
1 5 10 15
Asn Arg Val Lys Ala Arg Asn
20
<210> 320
<211> 13
<212> БЕЛОК
<213> Nostoc sp.
<400> 320
Ser Asp Leu Val Ala Tyr Glu Asp Leu Gln Val Arg Asn
1 5 10
<210> 321
<211> 16
<212> БЕЛОК
<213> Nostoc sp.
<400> 321
His Ile Gln Asp Arg Asp Trp Asn Ala Ala Arg Asn Ile Leu Glu Leu
1 5 10 15
<210> 322
<211> 18
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Nitrososphaera gargensis
<400> 322
Ala Lys Pro Val Gly Ile Asp Val Gly Ile Ala Lys Phe Cys His His
1 5 10 15
Ser Asp
<210> 323
<211> 23
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Nitrososphaera gargensis
<400> 323
Leu Arg Arg Ala His Arg Arg Val Ser Arg Arg Gln Ile Gly Ser Asn
1 5 10 15
Asn Arg Lys Lys Ala Lys Arg
20
<210> 324
<211> 13
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Nitrososphaera gargensis
<400> 324
Tyr Asp Leu Ile Phe Leu Glu Arg Leu Arg Val Met Asn
1 5 10
<210> 325
<211> 16
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Nitrososphaera gargensis
<400> 325
Ala Ile Leu Asp Arg Asp Tyr Asn Ser Ala Ile Asn Ile Leu Lys Arg
1 5 10 15
<210> 326
<211> 18
<212> БЕЛОК
<213> Helicobacter pylori
<400> 326
Lys Lys Ala Val Gly Leu Asp Met Gly Leu Arg Thr Leu Ile Val Thr
1 5 10 15
Ser Asp
<210> 327
<211> 23
<212> БЕЛОК
<213> Helicobacter pylori
<400> 327
Leu Thr Lys Ala Gln Arg Arg Leu Ser Lys Lys Val Lys Asp Ser Asn
1 5 10 15
Asn Arg Lys Lys Gln Ala Lys
20
<210> 328
<211> 13
<212> БЕЛОК
<213> Helicobacter pylori
<400> 328
Tyr Asp Leu Ile Gly Val Glu Thr Leu Asn Val Lys Ala
1 5 10
<210> 329
<211> 16
<212> БЕЛОК
<213> Helicobacter pylori
<400> 329
Thr Thr His His Arg Asp Tyr Asn Ala Ser Val Asn Ile Arg Asn Tyr
1 5 10 15
<210> 330
<211> 18
<212> БЕЛОК
<213> Flexibacter litoralis
<400> 330
Asn Gln Ala Val Gly Ile Asp Met Gly Ile Thr Phe Phe Cys Ile Asp
1 5 10 15
Ser Asn
<210> 331
<211> 23
<212> БЕЛОК
<213> Flexibacter litoralis
<400> 331
Leu Arg Ile Ala Asn Arg Ser Leu Ser Arg Lys Lys Lys Phe Ser Asn
1 5 10 15
Gly Trp Tyr Lys Lys Lys Val
20
<210> 332
<211> 13
<212> БЕЛОК
<213> Flexibacter litoralis
<400> 332
Asn Ser Leu Val Val Val Glu Asp Leu Lys Val Lys Asn
1 5 10
<210> 333
<211> 16
<212> БЕЛОК
<213> Flexibacter litoralis
<400> 333
His Glu Thr Asn Ala Asp Glu Asn Ala Ser Lys Asn Ile Leu Ser Glu
1 5 10 15
<210> 334
<211> 18
<212> БЕЛОК
<213> Escherichia coli
<400> 334
Ala Ser Met Val Gly Leu Asp Ala Gly Val Ala Lys Leu Ala Thr Leu
1 5 10 15
Ser Asp
<210> 335
<211> 23
<212> БЕЛОК
<213> Escherichia coli
<400> 335
Leu Ala Arg Leu Gln Arg Gln Leu Ser Arg Lys Val Lys Phe Ser Asn
1 5 10 15
Asn Trp Gln Lys Gln Lys Arg
20
<210> 336
<211> 13
<212> БЕЛОК
<213> Escherichia coli
<400> 336
His Ala Met Ile Val Ile Glu Asp Leu Lys Val Ser Asn
1 5 10
<210> 337
<211> 16
<212> БЕЛОК
<213> Escherichia coli
<400> 337
Tyr Thr Ala Asn Ala Asp Val Asn Gly Ala Arg Asn Ile Leu Ala Ala
1 5 10 15
<210> 338
<211> 18
<212> БЕЛОК
<213> Clostridium botulinum
<400> 338
Asn Lys Lys Val Gly Ile Asp Val Gly Leu Lys Glu Phe Ala Thr Thr
1 5 10 15
Ser Asp
<210> 339
<211> 23
<212> БЕЛОК
<213> Clostridium botulinum
<400> 339
Leu Ala Lys Leu Gln Lys Asp Leu Ser Arg Lys Lys Lys Asn Ser Asn
1 5 10 15
Asn Arg Lys Lys Ala Arg Leu
20
<210> 340
<211> 13
<212> БЕЛОК
<213> Clostridium botulinum
<400> 340
Asn Gln Ala Ile Val Ile Glu Asn Leu Lys Val Ser Asn
1 5 10
<210> 341
<211> 16
<212> БЕЛОК
<213> Clostridium botulinum
<400> 341
Met Ile Met Asp Arg Asp Leu Asn Ala Ser Lys Asn Leu Leu Asn Leu
1 5 10 15
<210> 342
<211> 18
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 342
Met Tyr Tyr Leu Gly Leu Asp Ile Gly Thr Asn Ser Val Gly Tyr Ala
1 5 10 15
Val Thr
<210> 343
<211> 22
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 343
Ala Glu Arg Arg Ser Phe Arg Thr Ser Arg Arg Arg Leu Asp Arg Arg
1 5 10 15
Gln Gln Arg Val Lys Leu
20
<210> 344
<211> 13
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 344
Pro Lys Arg Ile Phe Ile Glu Met Ala Arg Asp Gly Glu
1 5 10
<210> 345
<211> 16
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 345
Leu His His Ala Lys Asp Ala Phe Leu Ala Ile Val Thr Gly Asn Val
1 5 10 15
<210> 346
<211> 18
<212> БЕЛОК
<213> Coprococcus catus
<400> 346
Glu Tyr Phe Leu Gly Leu Asp Met Gly Thr Gly Ser Leu Gly Trp Ala
1 5 10 15
Val Thr
<210> 347
<211> 22
<212> БЕЛОК
<213> Coprococcus catus
<400> 347
Glu Glu Arg Arg Met Phe Arg Thr Ala Arg Arg Arg Leu Asp Arg Arg
1 5 10 15
Asn Trp Arg Ile Gln Val
20
<210> 348
<211> 13
<212> БЕЛОК
<213> Coprococcus catus
<400> 348
Pro Lys Arg Val Phe Val Glu Met Ala Arg Glu Lys Gln
1 5 10
<210> 349
<211> 16
<212> БЕЛОК
<213> Coprococcus catus
<400> 349
Leu His His Ala Lys Asp Ala Tyr Leu Asn Ile Val Val Gly Asn Ala
1 5 10 15
<210> 350
<211> 18
<212> БЕЛОК
<213> Treponema denticola
<400> 350
Asp Tyr Phe Leu Gly Leu Asp Val Gly Thr Gly Ser Val Gly Trp Ala
1 5 10 15
Val Thr
<210> 351
<211> 22
<212> БЕЛОК
<213> Treponema denticola
<400> 351
Glu Val Arg Arg Leu His Arg Gly Ala Arg Arg Arg Ile Glu Arg Arg
1 5 10 15
Lys Lys Arg Ile Lys Leu
20
<210> 352
<211> 13
<212> БЕЛОК
<213> Treponema denticola
<400> 352
Pro Lys Lys Ile Phe Ile Glu Met Ala Lys Gly Ala Glu
1 5 10
<210> 353
<211> 16
<212> БЕЛОК
<213> Treponema denticola
<400> 353
Phe His His Ala His Asp Ala Tyr Leu Asn Ile Val Val Gly Asn Val
1 5 10 15
<210> 354
<211> 18
<212> БЕЛОК
<213> Mycoplasma mobile
<400> 354
Lys Val Val Leu Gly Leu Asp Leu Gly Ile Ala Ser Val Gly Trp Cys
1 5 10 15
Leu Thr
<210> 355
<211> 22
<212> БЕЛОК
<213> Mycoplasma mobile
<400> 355
Glu Thr Arg Arg Lys Lys Arg Gly Gln Arg Arg Arg Asn Arg Arg Leu
1 5 10 15
Phe Thr Arg Lys Arg Asp
20
<210> 356
<211> 13
<212> БЕЛОК
<213> Mycoplasma mobile
<400> 356
Ile Glu Lys Ile Val Val Glu Val Thr Arg Ser Ser Asn
1 5 10
<210> 357
<211> 16
<212> БЕЛОК
<213> Mycoplasma mobile
<400> 357
Gly His His Ala Glu Asp Ala Tyr Phe Ile Thr Ile Ile Ser Gln Tyr
1 5 10 15
<210> 358
<211> 18
<212> БЕЛОК
<213> Streptococcus thermophilus
<400> 358
Asp Leu Val Leu Gly Leu Asp Ile Gly Ile Gly Ser Val Gly Val Gly
1 5 10 15
Ile Leu
<210> 359
<211> 22
<212> БЕЛОК
<213> Streptococcus thermophilus
<400> 359
Leu Val Arg Arg Thr Asn Arg Gln Gly Arg Arg Leu Thr Arg Arg Lys
1 5 10 15
Lys His Arg Ile Val Arg
20
<210> 360
<211> 13
<212> БЕЛОК
<213> Streptococcus thermophilus
<400> 360
Phe Asp Asn Ile Val Ile Glu Met Ala Arg Glu Thr Asn
1 5 10
<210> 361
<211> 16
<212> БЕЛОК
<213> Streptococcus thermophilus
<400> 361
His His His Ala Val Asp Ala Leu Ile Ile Ala Ala Ser Ser Gln Leu
1 5 10 15
<210> 362
<211> 18
<212> БЕЛОК
<213> Campylobacter jejuni
<400> 362
Ala Arg Ile Leu Ala Phe Asp Ile Gly Ile Ser Ser Ile Gly Trp Ala
1 5 10 15
Phe Ser
<210> 363
<211> 22
<212> БЕЛОК
<213> Campylobacter jejuni
<400> 363
Leu Pro Arg Arg Leu Ala Arg Ser Ala Arg Lys Arg Leu Ala Arg Arg
1 5 10 15
Lys Ala Arg Leu Asn His
20
<210> 364
<211> 13
<212> БЕЛОК
<213> Campylobacter jejuni
<400> 364
Val His Lys Ile Asn Ile Glu Leu Ala Arg Glu Val Gly
1 5 10
<210> 365
<211> 16
<212> БЕЛОК
<213> Campylobacter jejuni
<400> 365
Leu His His Ala Ile Asp Ala Val Ile Ile Ala Tyr Ala Asn Asn Ser
1 5 10 15
<210> 366
<211> 18
<212> БЕЛОК
<213> Clostridium perfringens
<400> 366
Asn Tyr Ala Leu Gly Leu Asp Ile Gly Ile Thr Ser Val Gly Trp Ala
1 5 10 15
Val Ile
<210> 367
<211> 22
<212> БЕЛОК
<213> Clostridium perfringens
<400> 367
Leu Pro Arg Arg Leu Ala Arg Gly Arg Arg Arg Leu Leu Arg Arg Lys
1 5 10 15
Ala Tyr Arg Val Glu Arg
20
<210> 368
<211> 13
<212> БЕЛОК
<213> Clostridium perfringens
<400> 368
Pro Val Arg Ile Asn Ile Glu Leu Ala Arg Asp Leu Ala
1 5 10
<210> 369
<211> 16
<212> БЕЛОК
<213> Clostridium perfringens
<400> 369
Lys His His Ala Leu Asp Ala Ala Val Val Gly Val Thr Thr Gln Gly
1 5 10 15
<210> 370
<211> 18
<212> БЕЛОК
<213> Akkermansia muciniphila
<400> 370
Ser Leu Thr Phe Ser Phe Asp Ile Gly Tyr Ala Ser Ile Gly Trp Ala
1 5 10 15
Val Ile
<210> 371
<211> 22
<212> БЕЛОК
<213> Akkermansia muciniphila
<400> 371
Phe Lys Arg Arg Glu Tyr Arg Arg Leu Arg Arg Asn Ile Arg Ser Arg
1 5 10 15
Arg Val Arg Ile Glu Arg
20
<210> 372
<211> 13
<212> БЕЛОК
<213> Akkermansia muciniphila
<400> 372
Ile Ser Arg Val Cys Val Glu Val Gly Lys Glu Leu Thr
1 5 10
<210> 373
<211> 16
<212> БЕЛОК
<213> Akkermansia muciniphila
<400> 373
Leu His His Ala Leu Asp Ala Cys Val Leu Gly Leu Ile Pro Tyr Ile
1 5 10 15
<210> 374
<211> 18
<212> БЕЛОК
<213> Bifidobacterium longum
<400> 374
Arg Tyr Arg Ile Gly Ile Asp Val Gly Leu Asn Ser Val Gly Leu Ala
1 5 10 15
Ala Val
<210> 375
<211> 22
<212> БЕЛОК
<213> Bifidobacterium longum
<400> 375
Asn Met Ser Gly Val Ala Arg Arg Thr Arg Arg Met Arg Arg Arg Lys
1 5 10 15
Arg Glu Arg Leu His Lys
20
<210> 376
<211> 13
<212> БЕЛОК
<213> Bifidobacterium longum
<400> 376
Pro Val Ser Val Asn Ile Glu His Val Arg Ser Ser Phe
1 5 10
<210> 377
<211> 16
<212> БЕЛОК
<213> Bifidobacterium longum
<400> 377
Arg His His Ala Val Asp Ala Ser Val Ile Ala Met Met Asn Thr Ala
1 5 10 15
<210> 378
<211> 18
<212> БЕЛОК
<213> Wolinella succinogenes
<400> 378
Val Ser Pro Ile Ser Val Asp Leu Gly Gly Lys Asn Thr Gly Phe Phe
1 5 10 15
Ser Phe
<210> 379
<211> 22
<212> БЕЛОК
<213> Wolinella succinogenes
<400> 379
Val Gly Arg Arg Ser Lys Arg His Ser Lys Arg Asn Asn Leu Arg Asn
1 5 10 15
Lys Leu Val Lys Arg Leu
20
<210> 380
<211> 13
<212> БЕЛОК
<213> Wolinella succinogenes
<400> 380
Lys Val Pro Ile Ile Leu Glu Gln Asn Ala Phe Glu Tyr
1 5 10
<210> 381
<211> 16
<212> БЕЛОК
<213> Wolinella succinogenes
<400> 381
Ser Ser His Ala Ile Asp Ala Val Met Ala Phe Val Ala Arg Tyr Gln
1 5 10 15
<210> 382
<211> 18
<212> БЕЛОК
<213> Legionella pneumophila
<400> 382
Leu Ser Pro Ile Gly Ile Asp Leu Gly Gly Lys Phe Thr Gly Val Cys
1 5 10 15
Leu Ser
<210> 383
<211> 22
<212> БЕЛОК
<213> Legionella pneumophila
<400> 383
Ala Gln Arg Arg Ala Thr Arg His Arg Val Arg Asn Lys Lys Arg Asn
1 5 10 15
Gln Phe Val Lys Arg Val
20
<210> 384
<211> 13
<212> БЕЛОК
<213> Legionella pneumophila
<400> 384
Leu Ile Pro Ile Tyr Leu Glu Gln Asn Arg Phe Glu Phe
1 5 10
<210> 385
<211> 15
<212> БЕЛОК
<213> Legionella pneumophila
<400> 385
Pro Ser His Ala Ile Asp Ala Thr Leu Thr Met Ser Ile Gly Leu
1 5 10 15
<210> 386
<211> 18
<212> БЕЛОК
<213> Francisella tularensis
<400> 386
Ile Leu Pro Ile Ala Ile Asp Leu Gly Val Lys Asn Thr Gly Val Phe
1 5 10 15
Ser Ala
<210> 387
<211> 22
<212> БЕЛОК
<213> Francisella tularensis
<400> 387
Asn Asn Arg Thr Ala Arg Arg His Gln Arg Arg Gly Ile Asp Arg Lys
1 5 10 15
Gln Leu Val Lys Arg Leu
20
<210> 388
<211> 13
<212> БЕЛОК
<213> Francisella tularensis
<400> 388
His Ile Pro Ile Ile Thr Glu Ser Asn Ala Phe Glu Phe
1 5 10
<210> 389
<211> 16
<212> БЕЛОК
<213> Francisella tularensis
<400> 389
Tyr Ser His Leu Ile Asp Ala Met Leu Ala Phe Cys Ile Ala Ala Asp
1 5 10 15
<210> 390
<211> 18
<212> БЕЛОК
<213> Streptococcus pyogenes
<400> 390
Lys Tyr Ser Ile Gly Leu Asp Ile Gly Thr Asn Ser Val Gly Trp Ala
1 5 10 15
Val Ile
<210> 391
<211> 22
<212> БЕЛОК
<213> Streptococcus pyogenes
<400> 391
Glu Ala Thr Arg Leu Lys Arg Thr Ala Arg Arg Arg Tyr Thr Arg Arg
1 5 10 15
Lys Asn Arg Ile Cys Tyr
20
<210> 392
<211> 13
<212> БЕЛОК
<213> Streptococcus pyogenes
<400> 392
Pro Glu Asn Ile Val Ile Glu Met Ala Arg Glu Asn Gln
1 5 10
<210> 393
<211> 16
<212> БЕЛОК
<213> Streptococcus pyogenes
<400> 393
Tyr His His Ala His Asp Ala Tyr Leu Asn Ala Val Val Gly Thr Ala
1 5 10 15
<210> 394
<211> 18
<212> БЕЛОК
<213> Lactobacillus delbrueckii
<400> 394
Lys Val Ser Leu Gly Val Asp Thr Gly Gln Arg His Ile Gly Phe Ala
1 5 10 15
Ile Val
<210> 395
<211> 23
<212> БЕЛОК
<213> Lactobacillus delbrueckii
<400> 395
Tyr Thr Arg Lys Ile Tyr Arg Arg Ser Lys Arg Asn Arg Lys Thr Arg
1 5 10 15
Tyr Arg Gln Ala Arg Phe Leu
20
<210> 396
<211> 13
<212> БЕЛОК
<213> Lactobacillus delbrueckii
<400> 396
Asn Pro Asp Leu His Ile Glu Val Gly Lys Phe Asp Met
1 5 10
<210> 397
<211> 15
<212> БЕЛОК
<213> Lactobacillus delbrueckii
<400> 397
Lys Gly His Phe Met Asp Ala Ile Ala Ile Ser Gly Ile Lys Pro
1 5 10 15
<210> 398
<211> 18
<212> БЕЛОК
<213> Methanohalobium evestigatum
<400> 398
Pro Val Val Ala Gly Met Asp Ser Gly Ser Lys His Ile Gly Cys Ala
1 5 10 15
Ala Val
<210> 399
<211> 23
<212> БЕЛОК
<213> Methanohalobium evestigatum
<400> 399
Lys Asp Arg Ala Asp Tyr Arg Arg Asn Arg Arg Ser Arg Lys Thr Arg
1 5 10 15
Tyr Arg Lys Pro Arg Phe Asp
20
<210> 400
<211> 13
<212> БЕЛОК
<213> Methanohalobium evestigatum
<400> 400
Val Lys Lys Trp Ile Val Glu Thr Ala Ser Phe Asp Ile
1 5 10
<210> 401
<211> 15
<212> БЕЛОК
<213> Methanohalobium evestigatum
<400> 401
Lys Thr His Tyr Asn Asp Ala Val Ala Ile Cys Cys Asp Glu Asn
1 5 10 15
<210> 402
<211> 18
<212> БЕЛОК
<213> Clostridium botulinum
<400> 402
Pro Ile Thr Leu Gly Ile Asp Ser Gly Tyr Leu Asn Ile Gly Phe Ser
1 5 10 15
Ala Ile
<210> 403
<211> 22
<212> БЕЛОК
<213> Clostridium botulinum
<400> 403
Lys Glu Lys Ala Met Tyr Arg Arg Gln Arg Arg Ser Arg Leu Arg Tyr
1 5 10 15
Arg Lys Pro Arg Phe Asn
20
<210> 404
<211> 13
<212> БЕЛОК
<213> Clostridium botulinum
<400> 404
Ile Thr Asn Ile Ile Ile Glu Val Ala Asn Phe Asp Thr
1 5 10
<210> 405
<211> 15
<212> БЕЛОК
<213> Clostridium botulinum
<400> 405
Lys Thr His Tyr Asn Asp Ala Phe Cys Ile Ala Gly Ser Ser Asn
1 5 10 15
<210> 406
<211> 18
<212> БЕЛОК
<213> Geobacillus thermoleovorans
<400> 406
Pro Val Ser Leu Gly Val Asp Met Gly Thr Arg His Val Gly Ile Ser
1 5 10 15
Ala Thr
<210> 407
<211> 23
<212> БЕЛОК
<213> Geobacillus thermoleovorans
<400> 407
Ala Ile Arg Arg Gln Phe Arg Arg Ser Arg Arg Asn Arg Lys Thr Arg
1 5 10 15
Tyr Arg Glu Ala Arg Phe Leu
20
<210> 408
<211> 13
<212> БЕЛОК
<213> Geobacillus thermoleovorans
<400> 408
Val Thr Ser Val Thr Ile Glu Val Ala Ala Phe Asp Thr
1 5 10
<210> 409
<211> 15
<212> БЕЛОК
<213> Geobacillus thermoleovorans
<400> 409
Lys Ser His Met Val Asp Ala Arg Cys Ile Ser Gly Asn Pro Leu
1 5 10 15
<210> 410
<211> 18
<212> БЕЛОК
<213> Ammonifex degensii
<400> 410
Ser Leu Arg Ala Lys Val Asp Asp Gly Ser Arg Tyr Val Gly Ile Ala
1 5 10 15
Leu Val
<210> 411
<211> 23
<212> БЕЛОК
<213> Ammonifex degensii
<400> 411
Thr Leu Arg Arg Glu Tyr Arg Arg Gly Arg Arg Tyr Arg Ile Val Arg
1 5 10 15
His Arg Pro Cys Arg Asn Arg
20
<210> 412
<211> 13
<212> БЕЛОК
<213> Ammonifex degensii
<400> 412
Ile Ser Gly Val Asp Val Glu Leu Val Ser Ser Gly Val
1 5 10
<210> 413
<211> 15
<212> БЕЛОК
<213> Ammonifex degensii
<400> 413
Lys Ser His Thr Asn Asp Ala Leu Ser Leu Phe Leu Pro Gly Gly
1 5 10 15
<210> 414
<211> 18
<212> БЕЛОК
<213> Polaromonas sp.
<400> 414
Pro Leu Arg Ile Lys Leu Asp Pro Gly Ser Lys Thr Thr Gly Val Ala
1 5 10 15
Leu Val
<210> 415
<211> 22
<212> БЕЛОК
<213> Polaromonas sp.
<400> 415
Thr Ala Arg Arg Gln Met Arg Arg Arg Arg Arg Ser Asn Leu Arg Cys
1 5 10 15
Arg Ala Pro Arg Phe Leu
20
<210> 416
<211> 13
<212> БЕЛОК
<213> Polaromonas sp.
<400> 416
Val Arg Ala Ile Ser Ser Glu Leu Val Arg Phe Asp Met
1 5 10
<210> 417
<211> 15
<212> БЕЛОК
<213> Polaromonas sp.
<400> 417
Lys Thr His Ala Leu Asp Ala Ala Cys Val Gly Gln Val Arg Phe
1 5 10 15
<210> 418
<211> 18
<212> БЕЛОК
<213> Anabaena variabilis
<400> 418
Asp Leu Arg Ile Lys Leu Asp Pro Gly Ala Lys Ile Thr Gly Ile Ala
1 5 10 15
Leu Val
<210> 419
<211> 23
<212> БЕЛОК
<213> Anabaena variabilis
<400> 419
Ile Ser Arg Arg Gln Leu Arg Arg Thr Arg Arg Asn Arg Lys Thr Arg
1 5 10 15
Tyr Arg Lys Pro Arg Phe Leu
20
<210> 420
<211> 13
<212> БЕЛОК
<213> Anabaena variabilis
<400> 420
Ile Thr Ala Ile Ser Thr Glu Leu Val Lys Phe Asp Met
1 5 10
<210> 421
<211> 15
<212> БЕЛОК
<213> Anabaena variabilis
<400> 421
Lys Thr His Trp Leu Asp Ala Ala Cys Val Gly Gln Ser Thr Pro
1 5 10 15
<210> 422
<211> 18
<212> БЕЛОК
<213> Nostoc sp.
<400> 422
Pro Leu Arg Leu Lys Phe Asp Pro Gly Ala Lys Tyr Thr Gly Ile Ala
1 5 10 15
Leu Val
<210> 423
<211> 23
<212> БЕЛОК
<213> Nostoc sp.
<400> 423
Thr Ser Arg Arg Gln Leu Arg Arg Ser Arg Arg Ser Arg Lys Thr Arg
1 5 10 15
Tyr Arg Gln Pro Arg Phe Phe
20
<210> 424
<211> 13
<212> БЕЛОК
<213> Nostoc sp.
<400> 424
Ile Thr Ala Ile Ser Gln Glu Leu Val Lys Phe Asp Thr
1 5 10
<210> 425
<211> 15
<212> БЕЛОК
<213> Nostoc sp.
<400> 425
Lys Ser His Trp Leu Asp Ala Cys Cys Val Gly Ala Ser Thr Pro
1 5 10 15
<210> 426
<211> 18
<212> БЕЛОК
<213> Thermus thermophilus
<400> 426
Met Val Val Ala Gly Ile Asp Pro Gly Ile Thr His Leu Gly Leu Gly
1 5 10 15
Val Val
<210> 427
<211> 13
<212> БЕЛОК
<213> Thermus thermophilus
<400> 427
Pro Glu Ala Val Ala Val Glu Glu Gln Phe Phe Tyr Arg
1 5 10
<210> 428
<211> 15
<212> БЕЛОК
<213> Thermus thermophilus
<400> 428
Pro Ser His Leu Ala Asp Ala Leu Ala Ile Ala Leu Thr His Ala
1 5 10 15
<210> 429
<211> 10
<212> БЕЛОК
<213> Lactococcus lactis
<400> 429
Phe Leu Val Asn His Asn Tyr Tyr Ser Phe
1 5 10
<210> 430
<211> 16
<212> БЕЛОК
<213> Lactococcus lactis
<400> 430
Leu Gln Lys Phe Thr Gly Asp Ile Glu Asn Leu Val Lys Ala Ser Leu
1 5 10 15
<210> 431
<211> 9
<212> БЕЛОК
<213> Lactococcus lactis
<400> 431
Val Ile Val Pro Glu Leu Thr Phe Gly
1 5
<210> 432
<211> 15
<212> БЕЛОК
<213> Lactococcus lactis
<400> 432
Trp Ile Arg Ala Gly Trp Phe Ile Arg Asn Arg Ser Ala His Tyr
1 5 10 15
<210> 433
<211> 13
<212> БЕЛОК
<213> Lactococcus lactis
<400> 433
Asn Lys Asp Leu Phe Ala Phe Met Leu Ser Ile Lys Gln
1 5 10
<210> 434
<211> 10
<212> БЕЛОК
<213> Lactococcus lactis
<400> 434
Phe Leu His Lys Asn Ser Tyr Phe Arg Phe
1 5 10
<210> 435
<211> 16
<212> БЕЛОК
<213> Lactococcus lactis
<400> 435
Leu Phe Ile Phe Ser Thr Arg Leu Glu Ile Phe Trp Lys Lys Lys Ile
1 5 10 15
<210> 436
<211> 9
<212> БЕЛОК
<213> Lactococcus lactis
<400> 436
Ala Leu Val Glu Glu Leu Thr Phe Gly
1 5
<210> 437
<211> 15
<212> БЕЛОК
<213> Lactococcus lactis
<400> 437
Trp Met Asn Val Val Arg Leu Tyr Arg Asn Lys Ser Ala His Gly
1 5 10 15
<210> 438
<211> 13
<212> БЕЛОК
<213> Lactococcus lactis
<400> 438
Lys Ser Tyr Leu Tyr Gly Ala Leu Tyr Val Phe Lys His
1 5 10
<210> 439
<211> 10
<212> БЕЛОК
<213> Corynebacterium diphtheriae
<400> 439
Leu Leu Ala Gln Leu Asn Tyr Tyr Arg Leu
1 5 10
<210> 440
<211> 16
<212> БЕЛОК
<213> Corynebacterium diphtheriae
<400> 440
Val Phe Ile Glu Leu Asp Arg Val Glu Leu Ala Ile Gln Thr Arg Leu
1 5 10 15
<210> 441
<211> 9
<212> БЕЛОК
<213> Corynebacterium diphtheriae
<400> 441
Ala Ala Val Glu Val Met Asp Trp Gly
1 5
<210> 442
<211> 15
<212> БЕЛОК
<213> Corynebacterium diphtheriae
<400> 442
Trp Leu Lys Ser Leu Asn Ile Leu Arg Asn Tyr Ala Ala His His
1 5 10 15
<210> 443
<211> 13
<212> БЕЛОК
<213> Corynebacterium diphtheriae
<400> 443
Gly Gln Leu Ser Met Ile Gln Tyr Leu His His Gln Leu
1 5 10
<210> 444
<211> 12
<212> БЕЛОК
<213> Shewanella baltica
<400> 444
Met Leu Ile Glu Asn Asp Leu Asp Gly Ile Glu Asn
1 5 10
<210> 445
<211> 16
<212> БЕЛОК
<213> Shewanella baltica
<400> 445
Asn Tyr Gln Leu Phe Tyr Phe Leu Glu Lys Thr Ile Arg Asn Gln Ile
1 5 10 15
<210> 446
<211> 15
<212> БЕЛОК
<213> Shewanella baltica
<400> 446
Val Met Phe Asn Leu Asn Thr Leu Arg Asn Pro Ile Ala His Cys
1 5 10 15
<210> 447
<211> 13
<212> БЕЛОК
<213> Shewanella baltica
<400> 447
Asp Glu Lys Leu Arg Leu Glu Ile Ser Leu Arg Asp Trp
1 5 10
<210> 448
<211> 12
<212> БЕЛОК
<213> Lactococcus lactis
<400> 448
Leu Arg Glu Ile Asn Ile Lys Ala Ser Lys Ser Arg
1 5 10
<210> 449
<211> 16
<212> БЕЛОК
<213> Lactococcus lactis
<400> 449
Leu Leu Pro Leu Leu His Lys Tyr Glu Trp Ser Leu Arg Lys Leu Ile
1 5 10 15
<210> 450
<211> 9
<212> БЕЛОК
<213> Lactococcus lactis
<400> 450
Tyr Asp Phe Glu Glu Tyr Leu Phe Gly
1 5
<210> 451
<211> 15
<212> БЕЛОК
<213> Lactococcus lactis
<400> 451
Asp Met Arg Leu Ile Arg Asp Gly Arg Asn Ile Val Gly His Asn
1 5 10 15
<210> 452
<211> 13
<212> БЕЛОК
<213> Lactococcus lactis
<400> 452
Leu Ser Lys Gly Leu Lys Lys Tyr Ile Lys Lys Leu Asp
1 5 10
<210> 453
<211> 12
<212> БЕЛОК
<213> Geobacter bemidjiensis
<400> 453
Arg Leu Pro Leu Thr Ser His Ile Gln Lys Gln Asp
1 5 10
<210> 454
<211> 16
<212> БЕЛОК
<213> Geobacter bemidjiensis
<400> 454
Ile Tyr Pro Lys Leu Asn Arg Ile Glu Asn Arg Leu Arg His Tyr Leu
1 5 10 15
<210> 455
<211> 9
<212> БЕЛОК
<213> Geobacter bemidjiensis
<400> 455
Phe Glu Leu Gly Lys Ile Val Tyr Ala
1 5
<210> 456
<211> 15
<212> БЕЛОК
<213> Geobacter bemidjiensis
<400> 456
Lys Trp Ile Arg Leu Glu Glu Ile Arg His Lys Val Ala His Asn
1 5 10 15
<210> 457
<211> 13
<212> БЕЛОК
<213> Geobacter bemidjiensis
<400> 457
Ala Asn Glu Tyr Ile Asp Ser Leu Gln Ser Ile Ile Asp
1 5 10
<210> 458
<211> 12
<212> БЕЛОК
<213> Salmonella enterica
<400> 458
Phe Val Thr Ser Leu Glu His Leu Arg Gln Gln Gln
1 5 10
<210> 459
<211> 16
<212> БЕЛОК
<213> Salmonella enterica
<400> 459
Ala Gln Arg Gln Leu Arg Ala Ile Glu Leu Thr Leu Lys Ala Leu Ile
1 5 10 15
<210> 460
<211> 9
<212> БЕЛОК
<213> Salmonella enterica
<400> 460
Asn His Tyr Leu Lys Gln His Phe Gly
1 5
<210> 461
<211> 15
<212> БЕЛОК
<213> Salmonella enterica
<400> 461
Phe Leu Asp Asp Cys Arg Leu Ala Arg Asn Glu Val Ile Ala Arg
1 5 10 15
<210> 462
<211> 13
<212> БЕЛОК
<213> Salmonella enterica
<400> 462
Leu Met Leu Leu Asn Val Gln Tyr Gln Gln Ile Val Arg
1 5 10
<210> 463
<211> 12
<212> БЕЛОК
<213> Shigella flexneri
<400> 463
Phe Leu Trp Gln Leu Glu Tyr Leu Arg Glu Lys Gln
1 5 10
<210> 464
<211> 16
<212> БЕЛОК
<213> Shigella flexneri
<400> 464
Ser Leu Gln Gln Val Arg Ala Leu Glu Leu Thr Ile Arg Ser Leu Ile
1 5 10 15
<210> 465
<211> 9
<212> БЕЛОК
<213> Shigella flexneri
<400> 465
Leu Glu His Leu Asn Lys Leu Phe Gly
1 5
<210> 466
<211> 15
<212> БЕЛОК
<213> Shigella flexneri
<400> 466
Phe Leu Asp Asp Ile Arg Val Ile Arg Asn Arg Leu Ala His His
1 5 10 15
<210> 467
<211> 13
<212> БЕЛОК
<213> Shigella flexneri
<400> 467
Thr Thr Leu Val Asn Tyr Tyr Tyr Arg Glu Ile Thr Glu
1 5 10
<210> 468
<211> 16
<212> БЕЛОК
<213> Streptomyces avermitilis
<400> 468
Ala Tyr Ile Trp Leu Asn Leu Val Glu Gln Arg Leu Arg Ala Val Val
1 5 10 15
<210> 469
<211> 9
<212> БЕЛОК
<213> Streptomyces avermitilis
<400> 469
Asn Val Leu Ser Phe Leu Thr Leu Pro
1 5
<210> 470
<211> 11
<212> БЕЛОК
<213> Streptomyces avermitilis
<400> 470
Leu Glu Val Thr Arg Asn Val Val Ser Arg Asn
1 5 10
<210> 471
<211> 13
<212> БЕЛОК
<213> Streptomyces avermitilis
<400> 471
Arg Tyr Gly Asp Val Val Gly Val His Pro Asp Arg Val
1 5 10
<210> 472
<211> 10
<212> БЕЛОК
<213> Helicobacter pylori
<400> 472
Ser Ile Ser Val Leu His Tyr Asp Tyr Leu
1 5 10
<210> 473
<211> 16
<212> БЕЛОК
<213> Helicobacter pylori
<400> 473
Leu Phe Leu Trp Ile His Phe Phe Glu Thr Ala Leu Arg Ser Lys Met
1 5 10 15
<210> 474
<211> 9
<212> БЕЛОК
<213> Helicobacter pylori
<400> 474
Gln Ile Leu Asn Leu Phe Thr Leu Gly
1 5
<210> 475
<211> 15
<212> БЕЛОК
<213> Helicobacter pylori
<400> 475
Thr Phe Ser Leu Ile Arg Lys Ala Arg Asn Asp Leu Phe His Asn
1 5 10 15
<210> 476
<211> 13
<212> БЕЛОК
<213> Helicobacter pylori
<400> 476
Thr Leu Lys Leu Glu Arg Ala Ile Phe Phe Lys Thr Ile
1 5 10
<210> 477
<211> 11
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methylomirabilis oxyfera
<400> 477
Gly Pro Pro Glu Tyr Tyr Tyr Arg Leu Cys Arg
1 5 10
<210> 478
<211> 16
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methylomirabilis oxyfera
<400> 478
Ala Asp Ser Lys Leu Lys Asp Thr Val Ser Glu Met Arg Lys Phe Ile
1 5 10 15
<210> 479
<211> 15
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methylomirabilis oxyfera
<400> 479
Trp Met Asn Arg Ile Asn Glu Leu Arg Arg Ile Pro Ala His Pro
1 5 10 15
<210> 480
<211> 13
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methylomirabilis oxyfera
<400> 480
Asp Phe Glu Tyr Ile Asp Phe Ile Tyr Asp Glu Leu Met
1 5 10
<210> 481
<211> 12
<212> БЕЛОК
<213> Novosphingobium aromaticivorans
<400> 481
Thr Ala Val Lys Gln Gln Ser Phe Gly Met Glu Ala
1 5 10
<210> 482
<211> 16
<212> БЕЛОК
<213> Novosphingobium aromaticivorans
<400> 482
Ala Ala Ala Lys Val Thr Gln Ile His Lys Lys Leu Phe Asn Tyr Val
1 5 10 15
<210> 483
<211> 15
<212> БЕЛОК
<213> Novosphingobium aromaticivorans
<400> 483
Trp Ile Lys Val Leu Asn Asp Ile Arg Gln Tyr Thr Ala His Pro
1 5 10 15
<210> 484
<211> 13
<212> БЕЛОК
<213> Novosphingobium aromaticivorans
<400> 484
Gln Val Ser Phe Val Asn Glu Val Tyr Glu Lys Val Glu
1 5 10
<210> 485
<211> 11
<212> БЕЛОК
<213> Elizabethkingia anophelis
<400> 485
Gly Glu Ile Lys Tyr Trp Arg Thr Phe Gln Lys
1 5 10
<210> 486
<211> 16
<212> БЕЛОК
<213> Elizabethkingia anophelis
<400> 486
Ala Ile Ala Tyr Ile Arg Asp Ile Glu Thr Glu Phe Lys Ser Asp Phe
1 5 10 15
<210> 487
<211> 15
<212> БЕЛОК
<213> Elizabethkingia anophelis
<400> 487
Trp Met Val Lys Leu Glu Arg Ile Arg Asn Gln Asn Phe His Ser
1 5 10 15
<210> 488
<211> 13
<212> БЕЛОК
<213> Elizabethkingia anophelis
<400> 488
Glu Leu Ser Phe Leu Glu Glu Leu His Asp Trp Ile Tyr
1 5 10
<210> 489
<211> 12
<212> БЕЛОК
<213> Escherichia coli
<400> 489
Phe Ser Ala Leu Pro Arg Ile Ile Glu Tyr Ala Tyr
1 5 10
<210> 490
<211> 16
<212> БЕЛОК
<213> Escherichia coli
<400> 490
Pro Phe Leu Leu Leu Ser Glu Ile Glu Asn His Ile Arg Lys Leu Ile
1 5 10 15
<210> 491
<211> 9
<212> БЕЛОК
<213> Escherichia coli
<400> 491
Glu Ser Val Ala Asp Leu Thr Phe Gly
1 5
<210> 492
<211> 15
<212> БЕЛОК
<213> Escherichia coli
<400> 492
Glu Leu Asp Lys Val Arg Ile Ile Arg Asn Asp Val Met His Phe
1 5 10 15
<210> 493
<211> 13
<212> БЕЛОК
<213> Escherichia coli
<400> 493
Asn His Glu Leu Leu His Asn Phe Val Arg Phe Ile His
1 5 10
<210> 494
<211> 12
<212> БЕЛОК
<213> Haloarcula marismortui
<400> 494
Phe Glu Leu Phe Asp Thr Leu Ala Glu Asp Asp Tyr
1 5 10
<210> 495
<211> 16
<212> БЕЛОК
<213> Haloarcula marismortui
<400> 495
Pro Phe Leu Gln Ile Gly Glu Ile Glu Glu Ser Leu Arg His Leu Phe
1 5 10 15
<210> 496
<211> 9
<212> БЕЛОК
<213> Haloarcula marismortui
<400> 496
Asp Arg Pro Glu Asp Phe Ser Phe Asp
1 5
<210> 497
<211> 15
<212> БЕЛОК
<213> Haloarcula marismortui
<400> 497
Leu Leu Glu Asp Ile Arg Glu Thr Arg Asn Ala Leu Leu His Phe
1 5 10 15
<210> 498
<211> 13
<212> БЕЛОК
<213> Haloarcula marismortui
<400> 498
Asp Arg Asp Gln Leu Asp Met Ala His Gly Tyr Phe Thr
1 5 10
<210> 499
<211> 12
<212> БЕЛОК
<213> Nostoc sp.
<400> 499
Met Lys Leu Leu Pro Ile Leu Gln Gln Asn Pro Arg
1 5 10
<210> 500
<211> 15
<212> БЕЛОК
<213> Nostoc sp.
<400> 500
Phe Gly Leu Val Thr Leu Leu Glu Met Asn Leu Leu Arg Leu Val
1 5 10 15
<210> 501
<211> 9
<212> БЕЛОК
<213> Nostoc sp.
<400> 501
Asp Leu Leu Asp Tyr Leu Gln Phe Cys
1 5
<210> 502
<211> 15
<212> БЕЛОК
<213> Nostoc sp.
<400> 502
Phe Leu Lys Ser Ala Glu Gln Leu Arg Asn Arg Leu Ala His Ala
1 5 10 15
<210> 503
<211> 13
<212> БЕЛОК
<213> Nostoc sp.
<400> 503
Ser Trp Asn Asp Leu Ile Ser Leu Ala Glu Ala Met Glu
1 5 10
<210> 504
<211> 10
<212> БЕЛОК
<213> Xanthobacter autotrophicus
<400> 504
Val Phe Glu Gly Met Glu Leu Leu Pro Ala
1 5 10
<210> 505
<211> 14
<212> БЕЛОК
<213> Xanthobacter autotrophicus
<400> 505
Ala Leu Ile Pro Phe Val Glu Lys Arg Leu Glu Thr Ser Leu
1 5 10
<210> 506
<211> 8
<212> БЕЛОК
<213> Xanthobacter autotrophicus
<400> 506
Glu Ala Phe Lys Ala Val Leu Gly
1 5
<210> 507
<211> 15
<212> БЕЛОК
<213> Xanthobacter autotrophicus
<400> 507
Leu Val Asn Glu Leu Gly Asp Val Arg Asn Lys Leu Ser His Asn
1 5 10 15
<210> 508
<211> 13
<212> БЕЛОК
<213> Xanthobacter autotrophicus
<400> 508
Tyr Asp Asp Ala Glu Arg Ala Leu Asp Thr Met Arg Arg
1 5 10
<210> 509
<211> 10
<212> БЕЛОК
<213> Methanospirillum hungatei
<400> 509
Val Gly Arg Ala Met Asp Gln Leu Lys Thr
1 5 10
<210> 510
<211> 14
<212> БЕЛОК
<213> Methanospirillum hungatei
<400> 510
Gly Leu Met Arg Phe Val Glu Arg Glu Met Lys Ser Ala Tyr
1 5 10
<210> 511
<211> 8
<212> БЕЛОК
<213> Methanospirillum hungatei
<400> 511
Lys Val Phe Ser Gln Ile Leu Gly
1 5
<210> 512
<211> 15
<212> БЕЛОК
<213> Methanospirillum hungatei
<400> 512
Leu Val Ser Glu Leu Arg Glu Thr Arg Asn Gln Trp Ala His Gln
1 5 10 15
<210> 513
<211> 13
<212> БЕЛОК
<213> Methanospirillum hungatei
<400> 513
Thr Asn Asp Thr Leu Arg Ala Leu Asp Ser Thr Ala Arg
1 5 10
<210> 514
<211> 10
<212> БЕЛОК
<213> Roseiflexus sp.
<400> 514
Ile Gly Lys Ala Leu Asp Leu Leu Arg Gln
1 5 10
<210> 515
<211> 14
<212> БЕЛОК
<213> Roseiflexus sp.
<400> 515
Gly Leu Gln Pro Phe Ile Glu Arg Glu Leu Gln Asn His Tyr
1 5 10
<210> 516
<211> 8
<212> БЕЛОК
<213> Roseiflexus sp.
<400> 516
Asp Val Phe Arg Lys Thr Leu Gly
1 5
<210> 517
<211> 15
<212> БЕЛОК
<213> Roseiflexus sp.
<400> 517
Leu Val Ser Glu Leu Arg Glu Trp Arg Asn Lys Trp Ala His Gln
1 5 10 15
<210> 518
<211> 13
<212> БЕЛОК
<213> Roseiflexus sp.
<400> 518
Thr Asp Asp Thr Tyr Arg Val Leu Asp Ser Ala Ala Arg
1 5 10
<210> 519
<211> 10
<212> БЕЛОК
<213> Plasmodium yoelii
<400> 519
Ile Leu Asn Ile Phe His Ile Leu Ser Ala
1 5 10
<210> 520
<211> 14
<212> БЕЛОК
<213> Plasmodium yoelii
<400> 520
His Leu Ser Pro Ile Ile Glu Gln Ile Met Glu Met Glu Tyr
1 5 10
<210> 521
<211> 7
<212> БЕЛОК
<213> Plasmodium yoelii
<400> 521
Asp Ile Phe Glu Asn Arg Ile
1 5
<210> 522
<211> 15
<212> БЕЛОК
<213> Plasmodium yoelii
<400> 522
Ile Leu Glu Asn Leu Gln Lys Ala Ser Ile Phe Trp Ala Asn Gln
1 5 10 15
<210> 523
<211> 13
<212> БЕЛОК
<213> Plasmodium yoelii
<400> 523
Glu Phe Phe Leu Ser Asn Leu Val Ser Ser Tyr Phe Phe
1 5 10
<210> 524
<211> 10
<212> БЕЛОК
<213> Theileria parva
<400> 524
Val Val Met Ile Phe Gln Cys Val Cys Asp
1 5 10
<210> 525
<211> 14
<212> БЕЛОК
<213> Theileria parva
<400> 525
Ala Phe Gln Pro Phe Ile Ser Lys Cys Met Leu Lys Lys Phe
1 5 10
<210> 526
<211> 7
<212> БЕЛОК
<213> Theileria parva
<400> 526
Asp Ile Phe Glu Gln Val Leu
1 5
<210> 527
<211> 15
<212> БЕЛОК
<213> Theileria parva
<400> 527
His Leu Asn Thr Ile Gln Thr Ala Ser Ile Tyr Trp Ala Asn Gln
1 5 10 15
<210> 528
<211> 8
<212> БЕЛОК
<213> Theileria parva
<400> 528
Asn Tyr Gly Lys Cys Arg Lys Ile
1 5
<210> 529
<211> 10
<212> БЕЛОК
<213> Daphnia pulex
<400> 529
Ser Ser Lys Glu Ser Ala Ala Ile Ala Ile
1 5 10
<210> 530
<211> 14
<212> БЕЛОК
<213> Daphnia pulex
<400> 530
Gly His Ile Val Phe Asp Thr Phe Leu Glu Asp Val Ala Pro
1 5 10
<210> 531
<211> 8
<212> БЕЛОК
<213> Daphnia pulex
<400> 531
Asp Cys Phe Ile Ile Pro Pro Gly
1 5
<210> 532
<211> 15
<212> БЕЛОК
<213> Daphnia pulex
<400> 532
Ile Leu Glu Arg Ala Met Asp Gly Arg His Ala Val Ser His His
1 5 10 15
<210> 533
<211> 13
<212> БЕЛОК
<213> Daphnia pulex
<400> 533
Trp Glu Gln His Leu Lys Asp Tyr Val Tyr Ile Leu Thr
1 5 10
<210> 534
<211> 10
<212> БЕЛОК
<213> Homo sapiens
<400> 534
Ala Gly His Cys Leu Leu Leu Leu Arg Ser
1 5 10
<210> 535
<211> 16
<212> БЕЛОК
<213> Homo sapiens
<400> 535
Cys Leu Gln Gly Phe Val Gly Arg Glu Val Leu Ser Phe His Arg Gly
1 5 10 15
<210> 536
<211> 15
<212> БЕЛОК
<213> Homo sapiens
<400> 536
Lys Val Thr Glu Val Ile Lys Cys Arg Asn Glu Ile Met His Ser
1 5 10 15
<210> 537
<211> 13
<212> БЕЛОК
<213> Homo sapiens
<400> 537
Ser Ser Thr Trp Leu Arg Asp Phe Gln Met Lys Ile Gln
1 5 10
<210> 538
<211> 10
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 538
Val Gly Ile Ala Leu Leu Thr Thr Arg Asp
1 5 10
<210> 539
<211> 16
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 539
Gly Leu Thr Asn Val Thr Glu Gln Ala Ala Lys Glu Leu Gln Ala Glu
1 5 10 15
<210> 540
<211> 15
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 540
Pro Leu Lys Asn Val Ile Glu Val Arg Asn Lys Thr Met His Ser
1 5 10 15
<210> 541
<211> 13
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 541
Asp Arg Gln Thr Phe Asn Glu Tyr Met Asp Lys Met Glu
1 5 10
<210> 542
<211> 10
<212> БЕЛОК
<213> Homo sapiens
<400> 542
Val Ser Asp Leu Glu Lys Ser Leu Gly Thr
1 5 10
<210> 543
<211> 14
<212> БЕЛОК
<213> Homo sapiens
<400> 543
Gly Leu Ser Ser Ile Leu Glu Thr Glu Met Lys Ile Ala Phe
1 5 10
<210> 544
<211> 8
<212> БЕЛОК
<213> Homo sapiens
<400> 544
Lys His Trp Leu Ala Val Phe Gly
1 5
<210> 545
<211> 16
<212> БЕЛОК
<213> Homo sapiens
<400> 545
Thr Ile Glu Ser Leu Tyr Lys Asn Leu Arg Lys Ala Asn Lys Ala Val
1 5 10 15
<210> 546
<211> 13
<212> БЕЛОК
<213> Homo sapiens
<400> 546
Ser Arg Ser Leu Leu His Ala Phe Ser Thr Arg Ser Asn
1 5 10
<210> 547
<211> 10
<212> БЕЛОК
<213> Ostreococcus lucimarinus
<400> 547
Met Glu Arg Leu Met Met Val Leu Asp His
1 5 10
<210> 548
<211> 14
<212> БЕЛОК
<213> Ostreococcus lucimarinus
<400> 548
Val Leu Ala Ile Val Leu Glu Gly Gly Leu Arg Ala Glu Phe
1 5 10
<210> 549
<211> 8
<212> БЕЛОК
<213> Ostreococcus lucimarinus
<400> 549
Ala Asn Trp Gly Ser Leu Phe Ser
1 5
<210> 550
<211> 14
<212> БЕЛОК
<213> Ostreococcus lucimarinus
<400> 550
Glu Ile Glu Val Leu Leu Asp Ala Ala Ile Arg Gln Arg Lys
1 5 10
<210> 551
<211> 13
<212> БЕЛОК
<213> Ostreococcus lucimarinus
<400> 551
Ala Arg Asp Val Ser Ser Ala Ala Val Ala Leu Leu Asn
1 5 10
<210> 552
<211> 10
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 552
Leu Cys Gly Met Lys Thr Leu Leu Lys Ala
1 5 10
<210> 553
<211> 14
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 553
Val Leu Ala Val Val Leu Glu Thr Glu Met Lys Ala Val Phe
1 5 10
<210> 554
<211> 8
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 554
Lys His Trp Ile Ala Val Phe Gly
1 5
<210> 555
<211> 17
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 555
His Leu Asp Ser Leu Val Lys His Phe Thr Arg Gly Arg Ser Tyr Gly
1 5 10 15
Val
<210> 556
<211> 13
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 556
Ala Leu Gln Leu Val Arg Gln Leu His Asn His Ser Thr
1 5 10
<210> 557
<211> 10
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 557
Leu Asn Trp Leu Asp Gln Leu His Asp Asp
1 5 10
<210> 558
<211> 16
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 558
Leu Ile Glu Leu Cys Gly Trp Ile Glu Glu Thr Met Asp Asp Ile Val
1 5 10 15
<210> 559
<211> 9
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 559
Phe Arg Lys Met Leu Met Met Val Ile
1 5
<210> 560
<211> 15
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 560
Tyr Leu Gly Asn Leu Lys Asp Ser Arg Asn Arg Ala Ala His Thr
1 5 10 15
<210> 561
<211> 13
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 561
Phe Asp Lys Ile Tyr Gly Leu Leu Lys Glu Leu Asp Ala
1 5 10
<210> 562
<211> 12
<212> БЕЛОК
<213> Lactococcus lactis
<400> 562
Leu Ser Glu Leu His Glu Phe Ile Lys Lys Leu Asn
1 5 10
<210> 563
<211> 16
<212> БЕЛОК
<213> Lactococcus lactis
<400> 563
Val Ile Arg Ser Cys Gly Ile Ile Glu Gln Leu Thr Lys Thr Leu Ile
1 5 10 15
<210> 564
<211> 9
<212> БЕЛОК
<213> Lactococcus lactis
<400> 564
Ile Asn Gly Leu Ile Asp Thr Phe Asp
1 5
<210> 565
<211> 15
<212> БЕЛОК
<213> Lactococcus lactis
<400> 565
His Ile Asp Ser Leu Arg Gln Leu Arg Asn Ser Ile Ala His Gly
1 5 10 15
<210> 566
<211> 13
<212> БЕЛОК
<213> Lactococcus lactis
<400> 566
Met Gly Tyr Phe Asp Ser Cys Ile Ile Leu Met Phe Arg
1 5 10
<210> 567
<211> 12
<212> БЕЛОК
<213> Frankia sp.
<400> 567
Leu Ser Glu Leu Ala Ala Leu Val Gln Asp Gln Ala
1 5 10
<210> 568
<211> 16
<212> БЕЛОК
<213> Frankia sp.
<400> 568
Val Ile Arg Ser Cys Gly Tyr Leu Glu Gln Thr Val Ala Gly Thr Phe
1 5 10 15
<210> 569
<211> 9
<212> БЕЛОК
<213> Frankia sp.
<400> 569
Leu Glu Thr Leu Ala Gly Arg Phe Asp
1 5
<210> 570
<211> 15
<212> БЕЛОК
<213> Frankia sp.
<400> 570
Glu Leu Ala Thr Leu Val Asp Arg Arg Asn Arg Ile Ala His Gly
1 5 10 15
<210> 571
<211> 13
<212> БЕЛОК
<213> Frankia sp.
<400> 571
Leu Glu Leu His Arg Val Ala Cys Glu Ala Ala Asp Trp
1 5 10
<210> 572
<211> 10
<212> БЕЛОК
<213> Neisseria meningitidis
<400> 572
Cys Cys Ser Ile Phe Ser Asp Phe Arg Met
1 5 10
<210> 573
<211> 16
<212> БЕЛОК
<213> Neisseria meningitidis
<400> 573
Leu Phe His Val Val Ser Ile Phe Glu Ile Val Leu Arg Asn Lys Ile
1 5 10 15
<210> 574
<211> 9
<212> БЕЛОК
<213> Neisseria meningitidis
<400> 574
Gln Leu Val Ala Gly Leu Gly Phe Gly
1 5
<210> 575
<211> 15
<212> БЕЛОК
<213> Neisseria meningitidis
<400> 575
Glu Leu Ser Asn Ile Asn Lys Phe Arg Asn Arg Leu Ala His His
1 5 10 15
<210> 576
<211> 13
<212> БЕЛОК
<213> Neisseria meningitidis
<400> 576
Asp Val Asp Thr Ala Ser Val Phe Ser His Phe Ser Asp
1 5 10
<210> 577
<211> 10
<212> БЕЛОК
<213> Pseudomonas syringae
<400> 577
Leu Glu Lys His Phe Ser Ser Ala Arg Leu
1 5 10
<210> 578
<211> 16
<212> БЕЛОК
<213> Pseudomonas syringae
<400> 578
Met Met Pro Met Leu Ser Val Leu Glu Ile Ala Leu Lys Asn Gly Ile
1 5 10 15
<210> 579
<211> 9
<212> БЕЛОК
<213> Pseudomonas syringae
<400> 579
Lys Ile Val Ala Glu Leu Ala Phe Gly
1 5
<210> 580
<211> 15
<212> БЕЛОК
<213> Pseudomonas syringae
<400> 580
Ala Leu Asn Leu Ile Arg Asn Leu Arg Asn Arg Val Phe His His
1 5 10 15
<210> 581
<211> 13
<212> БЕЛОК
<213> Pseudomonas syringae
<400> 581
Asp Pro Gln Leu Val Pro Trp Leu Ala Gln Tyr Asp Arg
1 5 10
<210> 582
<211> 10
<212> БЕЛОК
<213> Geobacter uraniireducens
<400> 582
Leu Arg Arg Ala Ile Ser His Glu Arg Leu
1 5 10
<210> 583
<211> 16
<212> БЕЛОК
<213> Geobacter uraniireducens
<400> 583
Leu Tyr Thr Pro Leu Gln Cys Leu Glu Val Cys Leu Arg Asn Ser Ile
1 5 10 15
<210> 584
<211> 9
<212> БЕЛОК
<213> Geobacter uraniireducens
<400> 584
Arg Ile Ile Pro Glu Leu Thr Phe Gly
1 5
<210> 585
<211> 15
<212> БЕЛОК
<213> Geobacter uraniireducens
<400> 585
Arg Phe Asn His Ile Arg Thr Leu Arg Asn Arg Ile Phe His His
1 5 10 15
<210> 586
<211> 13
<212> БЕЛОК
<213> Geobacter uraniireducens
<400> 586
Asn Pro Ala Met Met Thr Phe Val Glu Pro Phe Asp Ser
1 5 10
<210> 587
<211> 16
<212> БЕЛОК
<213> Sulfuricurvum kujiense
<400> 587
Glu Glu Lys Ser Glu Phe Ile Arg Glu Phe Phe Lys Arg Thr Leu His
1 5 10 15
<210> 588
<211> 9
<212> БЕЛОК
<213> Sulfuricurvum kujiense
<400> 588
Thr Gln Thr Ile Asn Ser Phe Leu Gly
1 5
<210> 589
<211> 14
<212> БЕЛОК
<213> Sulfuricurvum kujiense
<400> 589
Phe Arg Asn Tyr Leu Lys Arg Leu Arg Asn Ala Val Ser His
1 5 10
<210> 590
<211> 13
<212> БЕЛОК
<213> Sulfuricurvum kujiense
<400> 590
Val Asn Leu Leu Ile Thr Leu Leu Ser Arg Asn Ile Leu
1 5 10
<210> 591
<211> 13
<212> БЕЛОК
<213> Dethiobacter alkaliphilus
<400> 591
Gln Val Val Glu Lys Asp Phe Val Ala Arg Thr Met His
1 5 10
<210> 592
<211> 9
<212> БЕЛОК
<213> Dethiobacter alkaliphilus
<400> 592
Thr Leu Leu Ile Asn Cys Leu Leu Gly
1 5
<210> 593
<211> 14
<212> БЕЛОК
<213> Dethiobacter alkaliphilus
<400> 593
Ala Ser Arg Phe Leu Gln Cys Met Arg Asn Ser Val Ala His
1 5 10
<210> 594
<211> 10
<212> БЕЛОК
<213> Dethiobacter alkaliphilus
<400> 594
Leu Ala Thr Lys Leu Ala Gln Tyr Val Gln
1 5 10
<210> 595
<211> 13
<212> БЕЛОК
<213> Klebsiella pneumoniae
<400> 595
Ser Asp Phe Glu Thr Asp Phe Val Gln Arg Thr Leu Ala
1 5 10
<210> 596
<211> 9
<212> БЕЛОК
<213> Klebsiella pneumoniae
<400> 596
Thr Leu Thr Leu Asn Cys Leu Leu Gly
1 5
<210> 597
<211> 14
<212> БЕЛОК
<213> Klebsiella pneumoniae
<400> 597
Leu Arg Gln Leu Ile His Lys Met Arg Asn Ser Val Ala His
1 5 10
<210> 598
<211> 13
<212> БЕЛОК
<213> Klebsiella pneumoniae
<400> 598
Leu Leu Pro Phe Leu Lys Tyr Tyr Ala Thr Leu Leu Leu
1 5 10
<210> 599
<211> 10
<212> БЕЛОК
<213> Lactobacillus casei
<400> 599
Lys Ile Asp Arg Glu Met Phe Trp Arg Arg
1 5 10
<210> 600
<211> 16
<212> БЕЛОК
<213> Lactobacillus casei
<400> 600
Tyr Leu Leu Leu Tyr Ser Ser Trp Glu Gly Phe Ile Arg Ser Ile Ala
1 5 10 15
<210> 601
<211> 9
<212> БЕЛОК
<213> Lactobacillus casei
<400> 601
Leu Ala Arg Ile Val Ser Val Leu Asp
1 5
<210> 602
<211> 14
<212> БЕЛОК
<213> Lactobacillus casei
<400> 602
Asp Arg Asp Leu Leu Lys Val Arg Asn Glu Ile Ala His Gly
1 5 10
<210> 603
<211> 13
<212> БЕЛОК
<213> Lactobacillus casei
<400> 603
Thr Val Ser His Val Leu Glu Met Met Asp Leu Phe Ser
1 5 10
<210> 604
<211> 10
<212> БЕЛОК
<213> Caulobacter sp.
<400> 604
Asp Leu Asp Ala Ala Arg Leu Arg Arg Ala
1 5 10
<210> 605
<211> 16
<212> БЕЛОК
<213> Caulobacter sp.
<400> 605
Ile Val Leu Ala Tyr Ser His Trp Glu Gly Phe Tyr Asn Glu Cys Ile
1 5 10 15
<210> 606
<211> 9
<212> БЕЛОК
<213> Caulobacter sp.
<400> 606
Leu Lys Glu Asn Phe Arg Ile Leu Gly
1 5
<210> 607
<211> 14
<212> БЕЛОК
<213> Caulobacter sp.
<400> 607
Asn Lys Glu Leu Val Gly Trp Arg His Ser Ile Ala His Gly
1 5 10
<210> 608
<211> 13
<212> БЕЛОК
<213> Caulobacter sp.
<400> 608
His Ile Ile Leu Thr Asn Ser Leu Leu Leu Thr Leu Ser
1 5 10
<210> 609
<211> 10
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 609
Asn Leu Asp Glu Asp Met Ala Trp Arg Ile
1 5 10
<210> 610
<211> 16
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 610
Ile Thr Thr Leu Tyr Ala His Trp Glu Gly Phe Ile Lys Tyr Ala Ala
1 5 10 15
<210> 611
<211> 9
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 611
Phe Thr Asp Ile Cys Thr Ile Leu Gly
1 5
<210> 612
<211> 14
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 612
Asp Glu Gln Leu Leu Thr Gln Arg Asn Lys Ile Ala His Gly
1 5 10
<210> 613
<211> 13
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 613
Thr Tyr Asn Leu Val Ile Lys Leu Ile Arg Asp Phe Lys
1 5 10
<210> 614
<211> 11
<212> БЕЛОК
<213> Arabidopsis thaliana
<400> 614
Pro Trp Leu Ser Trp Glu Glu Trp Asp Ser Val
1 5 10
<210> 615
<211> 15
<212> БЕЛОК
<213> Arabidopsis thaliana
<400> 615
Gly Ser Leu Pro Ala Pro Val Asp Val Thr Cys Ser Leu Ile Glu
1 5 10 15
<210> 616
<211> 9
<212> БЕЛОК
<213> Arabidopsis thaliana
<400> 616
Ile Ala Asp Ala Ala Arg Ala Ile Gly
1 5
<210> 617
<211> 15
<212> БЕЛОК
<213> Arabidopsis thaliana
<400> 617
Ile Pro Arg Lys Leu Ile Asp Leu Arg His Glu Gly Ser His Arg
1 5 10 15
<210> 618
<211> 13
<212> БЕЛОК
<213> Arabidopsis thaliana
<400> 618
Ala Ala Asp Glu Ala Leu Glu Trp Leu Lys Ser Tyr Tyr
1 5 10
<210> 619
<211> 11
<212> БЕЛОК
<213> Homo sapiens
<400> 619
Ala Trp Leu Ser Arg Ala Glu Trp Asp Gln Val
1 5 10
<210> 620
<211> 16
<212> БЕЛОК
<213> Homo sapiens
<400> 620
Gly Asn Glu Leu Pro Leu Ala Val Ala Ser Thr Ala Asp Leu Ile Arg
1 5 10 15
<210> 621
<211> 9
<212> БЕЛОК
<213> Homo sapiens
<400> 621
Leu Lys Cys Leu Ala Gln Glu Val Asn
1 5
<210> 622
<211> 15
<212> БЕЛОК
<213> Homo sapiens
<400> 622
Ile Pro Asp Trp Ile Val Asp Leu Arg His Glu Leu Thr His Lys
1 5 10 15
<210> 623
<211> 13
<212> БЕЛОК
<213> Homo sapiens
<400> 623
Gly Cys Tyr Phe Val Leu Asp Trp Leu Gln Lys Thr Tyr
1 5 10
<210> 624
<211> 11
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<400> 624
Pro Trp Arg Asp Phe Ala Glu Leu Glu Glu Leu
1 5 10
<210> 625
<211> 16
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<400> 625
Ser Gln Tyr Leu Pro His Val Val Asp Ser Thr Ala Gln Ile Thr Cys
1 5 10 15
<210> 626
<211> 9
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<400> 626
Leu His Thr Leu Ala Ala Lys Ile Gly
1 5
<210> 627
<211> 15
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<400> 627
Leu Pro Ser Trp Phe Val Asp Leu Arg His Trp Gly Thr His Glu
1 5 10 15
<210> 628
<211> 13
<212> БЕЛОК
<213> Saccharomyces cerevisiae
<400> 628
Ala Ala Asn Glu Ala Leu Ser Trp Leu Tyr Asp His Tyr
1 5 10
<210> 629
<211> 11
<212> БЕЛОК
<213> Streptococcus pneumoniae
<400> 629
Ser Lys Pro Cys Ile Glu Ala Glu Asn Met Ile
1 5 10
<210> 630
<211> 16
<212> БЕЛОК
<213> Streptococcus pneumoniae
<400> 630
Ala Phe Met Ala Arg Arg Ala Leu Glu Gln Ala Val His Trp Ile Tyr
1 5 10 15
<210> 631
<211> 8
<212> БЕЛОК
<213> Streptococcus pneumoniae
<400> 631
Ser Ser Leu Val Trp Asp Asp Asp
1 5
<210> 632
<211> 15
<212> БЕЛОК
<213> Streptococcus pneumoniae
<400> 632
Gln Ile Val Leu Leu Ile Arg Trp Gly Asn His Ala Ala His Gly
1 5 10 15
<210> 633
<211> 13
<212> БЕЛОК
<213> Streptococcus pneumoniae
<400> 633
Ala Leu His His Leu Tyr Gln Phe Val Asn Phe Ile Asp
1 5 10
<210> 634
<211> 11
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 634
Tyr Asp His Ala Ser Gln Ala Glu Gly Leu Val
1 5 10
<210> 635
<211> 16
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 635
Cys Phe Tyr Thr Arg Phe Val Leu Glu Gln Met Val Cys Trp Leu Tyr
1 5 10 15
<210> 636
<211> 8
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 636
Gly Ala Leu Ile His Glu Gln Thr
1 5
<210> 637
<211> 15
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 637
Lys Ile Arg Thr Ile His Lys Val Gly Asn Asn Ala Ala His Asp
1 5 10 15
<210> 638
<211> 13
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 638
Leu Ile Glu Glu Leu Phe His Leu Thr Tyr Trp Leu Val
1 5 10
<210> 639
<211> 11
<212> БЕЛОК
<213> Escherichia coli
<400> 639
Tyr Ala Ile Ala Cys Ala Ala Glu Asn Asn Tyr
1 5 10
<210> 640
<211> 16
<212> БЕЛОК
<213> Escherichia coli
<400> 640
Leu Ile Lys Met Arg Met Phe Gly Glu Ala Thr Ala Lys His Leu Gly
1 5 10 15
<210> 641
<211> 8
<212> БЕЛОК
<213> Escherichia coli
<400> 641
His Asp Leu Leu Arg Glu Leu Gly
1 5
<210> 642
<211> 15
<212> БЕЛОК
<213> Escherichia coli
<400> 642
Val Phe His Lys Leu Arg Arg Ile Gly Asn Gln Ala Val His Glu
1 5 10 15
<210> 643
<211> 13
<212> БЕЛОК
<213> Escherichia coli
<400> 643
Cys Leu Arg Leu Gly Phe Arg Leu Ala Val Trp Tyr Tyr
1 5 10
<210> 644
<211> 11
<212> БЕЛОК
<213> Bradyrhizobium japonicum
<400> 644
Val Gln Lys Leu Ile Lys Ala Ser Gln Leu Ala
1 5 10
<210> 645
<211> 16
<212> БЕЛОК
<213> Bradyrhizobium japonicum
<400> 645
Leu Thr Glu Val Arg Arg Ala Met Lys Ala Ala Ala Asp Leu Phe Trp
1 5 10 15
<210> 646
<211> 10
<212> БЕЛОК
<213> Bradyrhizobium japonicum
<400> 646
Leu Asn Arg Leu Gln Glu Phe Ala Arg Val
1 5 10
<210> 647
<211> 13
<212> БЕЛОК
<213> Bradyrhizobium japonicum
<400> 647
Arg Arg Leu Asn Asp Leu Ala Ser Lys Gly Val His Ala
1 5 10
<210> 648
<211> 13
<212> БЕЛОК
<213> Bradyrhizobium japonicum
<400> 648
Ala Glu Ala Arg Gln Gly Leu Val Gly Leu Tyr Phe Phe
1 5 10
<210> 649
<211> 11
<212> БЕЛОК
<213> Leptospira meyeri
<400> 649
Leu Pro Lys Phe Ser Ala Ile Tyr Ser Asn Leu
1 5 10
<210> 650
<211> 16
<212> БЕЛОК
<213> Leptospira meyeri
<400> 650
Val His Ser Cys Arg Arg Leu Leu Gln Ser Val Ala Asp Lys Leu Met
1 5 10 15
<210> 651
<211> 10
<212> БЕЛОК
<213> Leptospira meyeri
<400> 651
Ile Asn Arg Leu Ile Tyr Tyr Ile Glu Thr
1 5 10
<210> 652
<211> 13
<212> БЕЛОК
<213> Leptospira meyeri
<400> 652
Asp Ser Val Phe Gln Ala Ser Gln Lys Gly Ser His Ser
1 5 10
<210> 653
<211> 13
<212> БЕЛОК
<213> Leptospira meyeri
<400> 653
Gln Glu Ala Asp Arg Tyr Val Ile His Thr Phe Leu Leu
1 5 10
<210> 654
<211> 11
<212> БЕЛОК
<213> Bacteroides coprosuis
<400> 654
Val Val Asp Asp Arg Asp Phe Ser Leu Leu Ala
1 5 10
<210> 655
<211> 16
<212> БЕЛОК
<213> Bacteroides coprosuis
<400> 655
Leu Asp Arg Leu His Thr Tyr Val Ile Lys Phe Ile Arg Gln Leu Cys
1 5 10 15
<210> 656
<211> 9
<212> БЕЛОК
<213> Bacteroides coprosuis
<400> 656
Phe Gly Lys Tyr Val Lys Phe Ile Val
1 5
<210> 657
<211> 16
<212> БЕЛОК
<213> Bacteroides coprosuis
<400> 657
Ile Glu Ala Phe Asn Asp Ile Arg Asn Asn Lys Ser Phe Ala His Asp
1 5 10 15
<210> 658
<211> 13
<212> БЕЛОК
<213> Bacteroides coprosuis
<400> 658
Tyr Ala Glu Ser Val Leu Ile Phe Asn Asn Val Thr Asn
1 5 10
<210> 659
<211> 10
<212> БЕЛОК
<213> Escherichia coli
<400> 659
Asn Val Asn Glu Asn Ile Tyr Gln Ala Leu
1 5 10
<210> 660
<211> 16
<212> БЕЛОК
<213> Escherichia coli
<400> 660
Tyr Asp Arg Val His Thr Ala Leu His Ala Ser Leu Arg Gln Met Cys
1 5 10 15
<210> 661
<211> 9
<212> БЕЛОК
<213> Escherichia coli
<400> 661
Leu Ser Leu Ile Thr Ala His Leu Lys
1 5
<210> 662
<211> 16
<212> БЕЛОК
<213> Escherichia coli
<400> 662
Leu His Gly Ile Asn Asn Leu Arg Asn Asn Tyr Ser Met Ala His Pro
1 5 10 15
<210> 663
<211> 13
<212> БЕЛОК
<213> Escherichia coli
<400> 663
Glu Ala Asp Ala Arg Phe Ala Ile Asn Leu Val Arg Ser
1 5 10
<210> 664
<211> 11
<212> БЕЛОК
<213> Lactococcus lactis
<400> 664
Ile Met Asn Ile Gly Tyr Val Glu Lys Ile Leu
1 5 10
<210> 665
<211> 16
<212> БЕЛОК
<213> Lactococcus lactis
<400> 665
Val Thr Lys Ser Arg Thr Ile Ile Glu Thr Val Phe Ile Ala Ile Leu
1 5 10 15
<210> 666
<211> 9
<212> БЕЛОК
<213> Lactococcus lactis
<400> 666
Arg Ser Leu Val Asn Lys Thr Leu Gly
1 5
<210> 667
<211> 16
<212> БЕЛОК
<213> Lactococcus lactis
<400> 667
Val Asp Ser Ile Thr Thr Met Arg Asn Ile Asn Ser Asp Ser His Gly
1 5 10 15
<210> 668
<211> 13
<212> БЕЛОК
<213> Lactococcus lactis
<400> 668
Glu Ala Glu Ala Glu Leu Ile Leu Asn Ser Ala Val Asn
1 5 10
<210> 669
<211> 11
<212> БЕЛОК
<213> Peptoniphilus indolicus
<400> 669
Phe Leu Tyr Leu Lys Thr Leu Lys Asn Lys Glu
1 5 10
<210> 670
<211> 16
<212> БЕЛОК
<213> Peptoniphilus indolicus
<400> 670
Arg Gly Ile Thr Pro Leu Val Thr Glu Leu Phe Ile Leu Ile Ile Asp
1 5 10 15
<210> 671
<211> 9
<212> БЕЛОК
<213> Peptoniphilus indolicus
<400> 671
Leu Ile Glu Ile Ile Lys Asn Glu Arg
1 5
<210> 672
<211> 15
<212> БЕЛОК
<213> Peptoniphilus indolicus
<400> 672
Ile Arg Asp Val Glu Gly Lys Leu Arg Asn Arg Ala Ala His Glu
1 5 10 15
<210> 673
<211> 13
<212> БЕЛОК
<213> Peptoniphilus indolicus
<400> 673
Gly Asn Asn His Tyr Asp Ser Tyr Asp Leu Met Asn Lys
1 5 10
<210> 674
<211> 11
<212> БЕЛОК
<213> Mycobacterium tuberculosis
<400> 674
Ile Ser Ala Leu Ala Leu Leu Ala Lys Arg Glu
1 5 10
<210> 675
<211> 16
<212> БЕЛОК
<213> Mycobacterium tuberculosis
<400> 675
Arg Ser Ala Thr Pro Ala Ile Thr Ile Val Leu Arg Ala Ala Val Ala
1 5 10 15
<210> 676
<211> 9
<212> БЕЛОК
<213> Mycobacterium tuberculosis
<400> 676
Trp Leu Ala Leu Leu Arg Gln Phe Ala
1 5
<210> 677
<211> 15
<212> БЕЛОК
<213> Mycobacterium tuberculosis
<400> 677
Leu Gly Arg Phe Glu Ser Arg Val Arg Asn Thr Ala Ala His Glu
1 5 10 15
<210> 678
<211> 11
<212> БЕЛОК
<213> Mycobacterium tuberculosis
<400> 678
Ala Asp Leu Thr Leu Tyr Asp Arg Leu Asn Asp
1 5 10
<210> 679
<211> 12
<212> БЕЛОК
<213> Streptococcus thermophilus
<400> 679
Tyr Leu Met Ile Asp Val Leu Lys Glu Arg Glu His
1 5 10
<210> 680
<211> 16
<212> БЕЛОК
<213> Streptococcus thermophilus
<400> 680
Ile Glu Glu Ile Ile Lys Lys Asp His Glu Gly Leu Ile Val Phe Asp
1 5 10 15
<210> 681
<211> 9
<212> БЕЛОК
<213> Streptococcus thermophilus
<400> 681
Tyr Leu Asn Ile Leu Glu Phe Tyr Glu
1 5
<210> 682
<211> 14
<212> БЕЛОК
<213> Streptococcus thermophilus
<400> 682
Ile Leu Ser Leu Asn Gly Glu Arg Asn Lys Val Ala His Gly
1 5 10
<210> 683
<211> 13
<212> БЕЛОК
<213> Streptococcus thermophilus
<400> 683
Asp Ser Ser Tyr Phe Asn Tyr Tyr Asp Lys Gln Asn Lys
1 5 10
<210> 684
<211> 10
<212> БЕЛОК
<213> Synechocystis sp.
<400> 684
Leu Ile Ser Val Val Ala Phe Arg Leu Gly
1 5 10
<210> 685
<211> 16
<212> БЕЛОК
<213> Synechocystis sp.
<400> 685
Ile Leu Asp His Arg Lys Gln Ile Asn Phe Ala Leu Asn Asn Gly Gly
1 5 10 15
<210> 686
<211> 10
<212> БЕЛОК
<213> Synechocystis sp.
<400> 686
Thr Glu Ile Arg Asn Asp Leu Ala His Cys
1 5 10
<210> 687
<211> 12
<212> БЕЛОК
<213> Synechocystis sp.
<400> 687
Asn Lys Ile Phe Pro Gln Leu Glu Glu Ile Ala Asn
1 5 10
<210> 688
<211> 5
<212> БЕЛОК
<213> Methanocaldococcus jannaschii
<400> 688
Lys Asn Thr Leu Phe
1 5
<210> 689
<211> 14
<212> БЕЛОК
<213> Methanocaldococcus jannaschii
<400> 689
Lys Glu Asn Pro Asn Ser Gln Tyr Ile Lys Asn Glu Ile Ser
1 5 10
<210> 690
<211> 15
<212> БЕЛОК
<213> Methanocaldococcus jannaschii
<400> 690
Glu Asn Ile Asp Lys Phe Lys Ile Arg Asn Phe Leu Ala His Ala
1 5 10 15
<210> 691
<211> 13
<212> БЕЛОК
<213> Methanocaldococcus jannaschii
<400> 691
Ser Glu Lys Thr Ser Leu Arg Tyr Asn Lys Asn Tyr Ile
1 5 10
<210> 692
<211> 11
<212> БЕЛОК
<213> Pyrococcus furiosus
<400> 692
Ser Lys Ile Phe Glu Ser Leu Pro Arg Ile Gly
1 5 10
<210> 693
<211> 15
<212> БЕЛОК
<213> Pyrococcus furiosus
<400> 693
Arg Gln Val Glu Trp Leu Arg Asn Leu Val Tyr Gly Arg Leu Trp
1 5 10 15
<210> 694
<211> 15
<212> БЕЛОК
<213> Pyrococcus furiosus
<400> 694
Thr Ile Glu Ser Pro Asn Val Val Arg Asn Phe Ile Ala His Ser
1 5 10 15
<210> 695
<211> 13
<212> БЕЛОК
<213> Pyrococcus furiosus
<400> 695
Asp Lys Glu Lys Ala Ala Asn Leu Ala Tyr Glu Ala Leu
1 5 10
<210> 696
<211> 5
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 696
Ala Glu Thr Tyr Ala
1 5
<210> 697
<211> 13
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 697
Asp Lys Val Thr Arg Ala Ile Ile Glu Asn Glu Val Asp
1 5 10
<210> 698
<211> 13
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 698
Gly Lys Gly Phe Asp Lys Arg Ile Leu Tyr Ala His Gly
1 5 10
<210> 699
<211> 10
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 699
Asp Lys Ile Asp Glu Ile Glu Arg Gln Ile
1 5 10
<210> 700
<211> 12
<212> БЕЛОК
<213> Desulfococcus oleovorans
<400> 700
Phe Ala Asn Ala Glu Arg Arg Phe Asp Glu Gly Lys
1 5 10
<210> 701
<211> 16
<212> БЕЛОК
<213> Desulfococcus oleovorans
<400> 701
Val Leu Arg Leu Tyr Arg Ile Val Glu Met Ala Gly Gln Gln Arg Leu
1 5 10 15
<210> 702
<211> 9
<212> БЕЛОК
<213> Desulfococcus oleovorans
<400> 702
Gly Tyr Ser Leu Leu Lys Glu Met Gly
1 5
<210> 703
<211> 17
<212> БЕЛОК
<213> Desulfococcus oleovorans
<400> 703
Ser Phe Leu Lys Ile Gln Asp Ser Arg Asn His Ser Phe Leu Ala His
1 5 10 15
Gly
<210> 704
<211> 13
<212> БЕЛОК
<213> Desulfococcus oleovorans
<400> 704
Tyr Met Ser Leu Arg Asp Phe Ile Val Ser Leu Asn Ile
1 5 10
<210> 705
<211> 12
<212> БЕЛОК
<213> Oscillochloris trichoides
<400> 705
Leu Arg Asn Ala Glu Arg Arg Ala Ala Arg Ala Arg
1 5 10
<210> 706
<211> 16
<212> БЕЛОК
<213> Oscillochloris trichoides
<400> 706
Val Ala Arg Leu Tyr Arg Ala Thr Glu Leu Phe Ala Gln Ile Arg Leu
1 5 10 15
<210> 707
<211> 9
<212> БЕЛОК
<213> Oscillochloris trichoides
<400> 707
Ser Tyr Ala Leu Leu Gly Lys Leu Asp
1 5
<210> 708
<211> 17
<212> БЕЛОК
<213> Oscillochloris trichoides
<400> 708
Pro Leu Asn Asn Ala Leu Thr Arg Arg Asn Gln Ser Ile Leu Ala His
1 5 10 15
Gly
<210> 709
<211> 13
<212> БЕЛОК
<213> Oscillochloris trichoides
<400> 709
Tyr His Asp Leu Ala Ser His Leu Tyr Thr Leu Ile Asn
1 5 10
<210> 710
<211> 12
<212> БЕЛОК
<213> Homo sapiens
<400> 710
Phe Pro Glu Ile Phe Asp Ala Leu Glu Ser Leu Gln
1 5 10
<210> 711
<211> 14
<212> БЕЛОК
<213> Homo sapiens
<400> 711
Lys Leu Thr Ser Cys Leu Glu Arg Ala Leu Gly Asp Val Phe
1 5 10
<210> 712
<211> 9
<212> БЕЛОК
<213> Homo sapiens
<400> 712
Ser Glu Glu Leu Ala Gln Val Phe Ser
1 5
<210> 713
<211> 15
<212> БЕЛОК
<213> Homo sapiens
<400> 713
Gly Ser Pro Cys Gly Leu Asn Leu Arg Asn Val Leu Trp His Gly
1 5 10 15
<210> 714
<211> 13
<212> БЕЛОК
<213> Homo sapiens
<400> 714
Tyr Cys Ser Met Met Ile Leu Leu Thr Ala Gly Leu Gly
1 5 10
<210> 715
<211> 12
<212> БЕЛОК
<213> Entamoeba histolytica
<400> 715
Trp Phe Glu Ser Phe Gln Glu Ile Ile Gln Thr Pro
1 5 10
<210> 716
<211> 14
<212> БЕЛОК
<213> Entamoeba histolytica
<400> 716
Leu Leu Ser Val Gln Phe Asn Val His Leu Lys Asp Asn Ile
1 5 10
<210> 717
<211> 9
<212> БЕЛОК
<213> Entamoeba histolytica
<400> 717
Lys Met Tyr Glu Glu His Thr Val Pro
1 5
<210> 718
<211> 15
<212> БЕЛОК
<213> Entamoeba histolytica
<400> 718
Gly Pro Pro Thr Gly Leu Asn Leu Arg Asn Leu Leu Trp His Gly
1 5 10 15
<210> 719
<211> 13
<212> БЕЛОК
<213> Entamoeba histolytica
<400> 719
His Ile Cys Leu Leu Ile Ile Leu Tyr Gln Thr Ile Gln
1 5 10
<210> 720
<211> 12
<212> БЕЛОК
<213> Staphylococcus aureus
<400> 720
Ile Glu His Gly Ile Ser Arg Phe Leu Glu Lys Asp
1 5 10
<210> 721
<211> 14
<212> БЕЛОК
<213> Staphylococcus aureus
<400> 721
Ile Leu Val Pro Gln Phe Glu Ser Thr Val Arg Arg Met Phe
1 5 10
<210> 722
<211> 9
<212> БЕЛОК
<213> Staphylococcus aureus
<400> 722
Arg Asp Asp Val Lys Ser Thr Leu Gly
1 5
<210> 723
<211> 15
<212> БЕЛОК
<213> Staphylococcus aureus
<400> 723
Val Glu Gln Ser Gly Leu Asn Leu Arg Asn Glu Ile Ala His Gly
1 5 10 15
<210> 724
<211> 12
<212> БЕЛОК
<213> Staphylococcus aureus
<400> 724
Lys Cys Ile Leu Val Ile Tyr Leu Phe Leu Ile Leu
1 5 10
<210> 725
<211> 12
<212> БЕЛОК
<213> Cyanothece sp.
<400> 725
Leu Leu Lys Gly Ile Gln Ala Tyr Leu Glu Glu Asp
1 5 10
<210> 726
<211> 14
<212> БЕЛОК
<213> Cyanothece sp.
<400> 726
Leu Leu Ile Pro Gln Ile Glu Ala Ala Ile Arg Asn Leu Val
1 5 10
<210> 727
<211> 9
<212> БЕЛОК
<213> Cyanothece sp.
<400> 727
Ser Glu Gln Val Lys Gln Ser Leu Gly
1 5
<210> 728
<211> 15
<212> БЕЛОК
<213> Cyanothece sp.
<400> 728
Thr Asp Gln Arg Gly Trp Asn Val Arg Asn Asn Val Cys His Gly
1 5 10 15
<210> 729
<211> 12
<212> БЕЛОК
<213> Cyanothece sp.
<400> 729
Leu Thr Glu Arg Leu Ile His Ile Leu Leu Ile Leu
1 5 10
<210> 730
<211> 9
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 730
Ile Ser Thr Ser Ala Glu Val Tyr Tyr
1 5
<210> 731
<211> 16
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 731
Cys Glu Lys Tyr Tyr Lys Ala Ala Glu Glu Ala Ile Lys Leu Leu Val
1 5 10 15
<210> 732
<211> 8
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 732
Lys Leu Leu Arg Ser Asn Asn Thr
1 5
<210> 733
<211> 15
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 733
Leu Trp Lys Ser Ala Trp Thr Leu His Val Glu Gly Phe His Glu
1 5 10 15
<210> 734
<211> 13
<212> БЕЛОК
<213> Sulfolobus solfataricus
<400> 734
Leu Lys Glu Asp Val Arg Lys Leu Val Ile Phe Ala Val
1 5 10
<210> 735
<211> 9
<212> БЕЛОК
<213> Pyrobaculum aerophilum
<400> 735
Tyr Ala Glu Ala Ala Arg Glu Leu Leu
1 5
<210> 736
<211> 16
<212> БЕЛОК
<213> Pyrobaculum aerophilum
<400> 736
Ser Glu Lys Ala Trp Gly Ala Ala Ala Leu Ala Val Lys Ala Tyr Ala
1 5 10 15
<210> 737
<211> 7
<212> БЕЛОК
<213> Pyrobaculum aerophilum
<400> 737
Lys Ile Ala Gly Glu Leu Gly
1 5
<210> 738
<211> 14
<212> БЕЛОК
<213> Pyrobaculum aerophilum
<400> 738
Ala Trp Ala Gln Ala Asn Ala Met His Ile Asn Phe Tyr Glu
1 5 10
<210> 739
<211> 13
<212> БЕЛОК
<213> Pyrobaculum aerophilum
<400> 739
Ala Leu Lys Lys Val Ser Arg Leu Val Glu Glu Leu Thr
1 5 10
<210> 740
<211> 11
<212> БЕЛОК
<213> Homo sapiens
<400> 740
Arg Arg Trp Leu Arg Gln Ala Arg Ala Asn Phe
1 5 10
<210> 741
<211> 16
<212> БЕЛОК
<213> Homo sapiens
<400> 741
Asn Glu Trp Val Cys Phe Lys Cys Tyr Leu Ser Thr Lys Leu Ala Leu
1 5 10 15
<210> 742
<211> 8
<212> БЕЛОК
<213> Homo sapiens
<400> 742
Ala Gln Lys Ile Glu Glu Tyr Ser
1 5
<210> 743
<211> 15
<212> БЕЛОК
<213> Homo sapiens
<400> 743
Val His Thr Leu Glu Ala Tyr Gly Val Asp Ser Leu Lys Thr Arg
1 5 10 15
<210> 744
<211> 13
<212> БЕЛОК
<213> Homo sapiens
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (2)..(2)
<223> Любая аминокислота
<400> 744
Val Xaa Glu Cys Thr Ala Cys Ile Ile Ile Lys Leu Glu
1 5 10
<210> 745
<211> 11
<212> БЕЛОК
<213> Haemophilus influenzae
<400> 745
Lys Leu Asn Leu Asn Val Leu Asp Ala Ala Phe
1 5 10
<210> 746
<211> 16
<212> БЕЛОК
<213> Haemophilus influenzae
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (14)..(15)
<223> Любая аминокислота
<400> 746
Ile Gln Lys Phe Glu Phe Val Tyr Glu Leu Ser Leu Lys Xaa Xaa Lys
1 5 10 15
<210> 747
<211> 8
<212> БЕЛОК
<213> Haemophilus influenzae
<400> 747
Leu Arg Glu Ala Leu Arg Phe Gly
1 5
<210> 748
<211> 15
<212> БЕЛОК
<213> Haemophilus influenzae
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (8)..(8)
<223> Любая аминокислота
<400> 748
Lys Trp Val Ala Tyr Arg Asp Xaa Arg Asn Ile Thr Ser His Thr
1 5 10 15
<210> 749
<211> 13
<212> БЕЛОК
<213> Haemophilus influenzae
<400> 749
Asp Phe Leu Ile Glu Ser Ser Phe Leu Leu Glu Gln Leu
1 5 10
<210> 750
<211> 6
<212> БЕЛОК
<213> Thermus thermophilus
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (1)..(1)
<223> Любая аминокислота
<400> 750
Xaa Ala Glu Lys Ala Leu
1 5
<210> 751
<211> 16
<212> БЕЛОК
<213> Thermus thermophilus
<400> 751
Ile Gln Arg Phe Glu Tyr Thr Phe Glu Ala Phe Trp Lys Ala Leu Gln
1 5 10 15
<210> 752
<211> 8
<212> БЕЛОК
<213> Thermus thermophilus
<400> 752
Ile Arg Leu Ala Arg Glu Val Gly
1 5
<210> 753
<211> 15
<212> БЕЛОК
<213> Thermus thermophilus
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (5)..(5)
<223> Любая аминокислота
<400> 753
Leu Ala Leu Gly Xaa Val Asp Asp Arg Ser Leu Thr Val His Thr
1 5 10 15
<210> 754
<211> 13
<212> БЕЛОК
<213> Thermus thermophilus
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (12)..(12)
<223> Любая аминокислота
<400> 754
Ile Phe Arg Arg Leu Pro Asp Tyr Ala Arg Leu Xaa Glu
1 5 10
<210> 755
<211> 11
<212> БЕЛОК
<213> Rhodococcus equi
<400> 755
Val Asn Leu Leu Arg Arg Ala Asp Gly Leu Leu
1 5 10
<210> 756
<211> 16
<212> БЕЛОК
<213> Rhodococcus equi
<400> 756
Phe Cys Ala Ala Tyr Val Gly Ala Leu Arg Gly Ala Ala Ala Val Leu
1 5 10 15
<210> 757
<211> 8
<212> БЕЛОК
<213> Rhodococcus equi
<400> 757
Trp Val Leu Met Ala Arg Ala Glu
1 5
<210> 758
<211> 15
<212> БЕЛОК
<213> Rhodococcus equi
<400> 758
Tyr Phe Ala Gly Tyr Ser Gly Leu Arg Ala Asp Leu Glu Ala Gly
1 5 10 15
<210> 759
<211> 13
<212> БЕЛОК
<213> Rhodococcus equi
<400> 759
Asp Ala Glu Glu Val Asp Gly Phe Tyr Ala Glu Val Gly
1 5 10
<210> 760
<211> 11
<212> БЕЛОК
<213> Streptomyces avermitilis
<400> 760
Leu Asp Leu Leu Ala Gln Ala Arg Ala Gly Leu
1 5 10
<210> 761
<211> 16
<212> БЕЛОК
<213> Streptomyces avermitilis
<400> 761
Tyr Ala Thr Ala His Leu Ala Ala Leu Arg Thr Ala Ala Ala Val Leu
1 5 10 15
<210> 762
<211> 8
<212> БЕЛОК
<213> Streptomyces avermitilis
<400> 762
Trp Glu Val Leu Pro Glu Ile Ala
1 5
<210> 763
<211> 15
<212> БЕЛОК
<213> Streptomyces avermitilis
<400> 763
Leu Phe Ala Ser Gly Ala Gly Arg Arg Ala Arg Ala Glu Ala Gly
1 5 10 15
<210> 764
<211> 13
<212> БЕЛОК
<213> Streptomyces avermitilis
<400> 764
Ser Asn Arg Asp Ala Asp Asp Leu Ile Arg Asp Val Ala
1 5 10
<210> 765
<211> 11
<212> БЕЛОК
<213> Staphylococcus aureus
<400> 765
Ala Leu Ile Val Glu Glu Leu Phe Glu Tyr Ala
1 5 10
<210> 766
<211> 16
<212> БЕЛОК
<213> Staphylococcus aureus
<400> 766
Pro Ser Leu Thr Val Gln Val Ala Met Ala Gly Ala Met Leu Ile Gly
1 5 10 15
<210> 767
<211> 8
<212> БЕЛОК
<213> Staphylococcus aureus
<400> 767
Thr Glu Ala Val Lys Gln Ser Asp
1 5
<210> 768
<211> 10
<212> БЕЛОК
<213> Staphylococcus aureus
<400> 768
His Leu Cys Gln Phe Val Met Ser Gly Gln
1 5 10
<210> 769
<211> 13
<212> БЕЛОК
<213> Staphylococcus aureus
<400> 769
Ser Glu Lys Leu Leu Glu Ser Leu Glu Asn Phe Trp Asn
1 5 10
<210> 770
<211> 11
<212> БЕЛОК
<213> Enterococcus faecium
<400> 770
Asn Phe Leu Leu Cys Asn Phe Ser Asn Leu Trp
1 5 10
<210> 771
<211> 16
<212> БЕЛОК
<213> Enterococcus faecium
<400> 771
Leu Glu Leu Leu Ser Gln Leu Gln Lys Asn Thr Leu Gln Leu Ile Arg
1 5 10 15
<210> 772
<211> 10
<212> БЕЛОК
<213> Enterococcus faecium
<400> 772
Lys Lys Phe Ala Lys Thr Thr Ala Arg Leu
1 5 10
<210> 773
<211> 13
<212> БЕЛОК
<213> Enterococcus faecium
<400> 773
Lys Val Glu Leu Phe Glu Ala Tyr Lys Asn Ser Leu Leu
1 5 10
<210> 774
<211> 9
<212> БЕЛОК
<213> Escherichia coli
<400> 774
Gly Val Tyr Ala Asn Glu Leu Arg Ala
1 5
<210> 775
<211> 16
<212> БЕЛОК
<213> Escherichia coli
<400> 775
Gly Gly Ile Arg Glu Ile Glu Phe Ile Val Gln Val Phe Gln Leu Ile
1 5 10 15
<210> 776
<211> 8
<212> БЕЛОК
<213> Escherichia coli
<400> 776
Thr Leu Ser Ala Ile Ala Glu Leu
1 5
<210> 777
<211> 15
<212> БЕЛОК
<213> Escherichia coli
<400> 777
Glu Gln Leu Arg Val Ala Tyr Leu Phe Leu Arg Arg Leu Glu Asn
1 5 10 15
<210> 778
<211> 13
<212> БЕЛОК
<213> Escherichia coli
<400> 778
Leu Thr Gly His Met Thr Asn Val Arg Arg Val Phe Asn
1 5 10
<210> 779
<211> 11
<212> БЕЛОК
<213> Sebaldella termitidis
<400> 779
Ser Arg Cys Met Lys Ile Ala Gln Ser Gly Gln
1 5 10
<210> 780
<211> 16
<212> БЕЛОК
<213> Sebaldella termitidis
<400> 780
Ile Ala Glu Ala Glu Phe Ile Asn Glu Ser Ile Tyr Met Ile Tyr Leu
1 5 10 15
<210> 781
<211> 8
<212> БЕЛОК
<213> Sebaldella termitidis
<400> 781
Lys Asp Met Gln Phe Leu Pro Ile
1 5
<210> 782
<211> 14
<212> БЕЛОК
<213> Sebaldella termitidis
<400> 782
Asn Leu Leu Asn Asn Leu Ile Ser Ile Gln Asn Ser Glu Lys
1 5 10
<210> 783
<211> 13
<212> БЕЛОК
<213> Sebaldella termitidis
<400> 783
Ala Glu Lys Ile Cys Gly Leu Ile Ile Asn Glu Leu Lys
1 5 10
<210> 784
<211> 10
<212> БЕЛОК
<213> Streptomyces coelicolor
<400> 784
Ala Arg Leu Asp Ala Tyr Ala Asn Ser His
1 5 10
<210> 785
<211> 16
<212> БЕЛОК
<213> Streptomyces coelicolor
<400> 785
Leu Asp Ala Ala Asp Ser Ile Gly Phe Leu Leu Glu Leu Leu Phe Ala
1 5 10 15
<210> 786
<211> 8
<212> БЕЛОК
<213> Streptomyces coelicolor
<400> 786
Trp Glu Leu Asp Arg Phe Pro Leu
1 5
<210> 787
<211> 14
<212> БЕЛОК
<213> Streptomyces coelicolor
<400> 787
Glu Leu Leu Ala Thr Leu Gly Arg Ile Thr Gly Ala Gly Gly
1 5 10
<210> 788
<211> 13
<212> БЕЛОК
<213> Streptomyces coelicolor
<400> 788
Gln Arg Glu Leu Phe Gly Arg Val Glu Ala Ala Ala Arg
1 5 10
<210> 789
<211> 11
<212> БЕЛОК
<213> Flavobacterium psychrophilum
<400> 789
Tyr Ser Ile Tyr Lys Asn Ala Arg Gln Leu Arg
1 5 10
<210> 790
<211> 16
<212> БЕЛОК
<213> Flavobacterium psychrophilum
<400> 790
Thr Ser Leu Leu Ile Leu Ser Ser Glu Glu Val Ile Lys Ser Ile Leu
1 5 10 15
<210> 791
<211> 8
<212> БЕЛОК
<213> Flavobacterium psychrophilum
<400> 791
Gln Leu Ile Glu Leu Ser Ile Gly
1 5
<210> 792
<211> 15
<212> БЕЛОК
<213> Flavobacterium psychrophilum
<400> 792
Lys Leu Thr Glu Phe Asp Asp Lys Lys Asn Gln Gly Phe Tyr Val
1 5 10 15
<210> 793
<211> 13
<212> БЕЛОК
<213> Flavobacterium psychrophilum
<400> 793
Lys Thr Glu Phe Thr Glu Thr Lys Val Val Val Asp Arg
1 5 10
<210> 794
<211> 10
<212> БЕЛОК
<213> Lactococcus lactis
<400> 794
Lys Cys Ile Asp His Ile Ser Val Leu Ile
1 5 10
<210> 795
<211> 16
<212> БЕЛОК
<213> Lactococcus lactis
<400> 795
Thr Phe Ile Ser Ile Thr Ile Ile Glu Glu Val Gly Lys Thr His Ile
1 5 10 15
<210> 796
<211> 8
<212> БЕЛОК
<213> Lactococcus lactis
<400> 796
Ser Leu Pro Thr Ile Lys Met Gly
1 5
<210> 797
<211> 14
<212> БЕЛОК
<213> Lactococcus lactis
<400> 797
Thr Gly Glu Leu Ile Ser Ile Arg Glu Ser Ser Leu Tyr Ala
1 5 10
<210> 798
<211> 13
<212> БЕЛОК
<213> Lactococcus lactis
<400> 798
Lys Glu Gln Ser Arg Ala Leu Leu Leu Tyr Ala Ile Glu
1 5 10
<210> 799
<211> 11
<212> БЕЛОК
<213> Pseudomonas putida
<400> 799
Asp Ala Leu Leu Thr Asn Ala Ala Ser Leu Ile
1 5 10
<210> 800
<211> 16
<212> БЕЛОК
<213> Pseudomonas putida
<400> 800
Phe Ala Leu Ala His Leu Ala Arg Glu Glu Ile Ala Lys Thr Leu Met
1 5 10 15
<210> 801
<211> 8
<212> БЕЛОК
<213> Pseudomonas putida
<400> 801
Thr Ile Asn Ser Ile Val Phe Cys
1 5
<210> 802
<211> 12
<212> БЕЛОК
<213> Pseudomonas putida
<400> 802
Phe Arg Asn Asp Leu Lys Asn Asn Ser Leu Tyr Val
1 5 10
<210> 803
<211> 13
<212> БЕЛОК
<213> Pseudomonas putida
<400> 803
Ala Glu Arg Ala Leu Arg Thr Ile Thr Leu Ala Trp Asp
1 5 10
<210> 804
<211> 11
<212> БЕЛОК
<213> Selenomonas sputigena
<400> 804
Gln Ile Ala Tyr Tyr Leu Tyr Phe Met Tyr Leu
1 5 10
<210> 805
<211> 16
<212> БЕЛОК
<213> Selenomonas sputigena
<400> 805
Met Thr Ser Phe Ala Tyr Tyr Lys Ser Tyr Phe Asp Arg Val Thr Ala
1 5 10 15
<210> 806
<211> 10
<212> БЕЛОК
<213> Selenomonas sputigena
<400> 806
Arg Leu Cys Glu Phe Tyr Glu Glu Phe Asp
1 5 10
<210> 807
<211> 17
<212> БЕЛОК
<213> Selenomonas sputigena
<400> 807
Ile Ile Asp Lys Ala Gln Ala Leu Arg Tyr Ala Asn Pro Leu Thr His
1 5 10 15
Ser
<210> 808
<211> 13
<212> БЕЛОК
<213> Selenomonas sputigena
<400> 808
Ile Arg Glu Leu Ser Thr Leu Leu Asp Arg Tyr Ile Ala
1 5 10
<210> 809
<211> 11
<212> БЕЛОК
<213> Lactobacillus helveticus
<400> 809
Trp Ile Ser Tyr Tyr Leu Tyr Phe Glu Ser Ile
1 5 10
<210> 810
<211> 16
<212> БЕЛОК
<213> Lactobacillus helveticus
<400> 810
Leu Thr Ser Tyr Ala Phe Phe Lys Asn Tyr Phe Asp Arg Thr Thr Ala
1 5 10 15
<210> 811
<211> 10
<212> БЕЛОК
<213> Lactobacillus helveticus
<400> 811
Gln Leu Gln Lys Val Tyr Arg Ile Leu Asn
1 5 10
<210> 812
<211> 17
<212> БЕЛОК
<213> Lactobacillus helveticus
<400> 812
Ile Ile Ser Lys Ala Asn Asp Leu Arg Asn Asn Asn Pro Leu Ser His
1 5 10 15
Ala
<210> 813
<211> 13
<212> БЕЛОК
<213> Lactobacillus helveticus
<400> 813
Ile Ala Thr Met Arg Ser Leu Phe Lys Leu Leu Val Glu
1 5 10
<210> 814
<211> 11
<212> БЕЛОК
<213> Lactococcus lactis
<400> 814
Lys Ile Leu Asn Phe Ile Tyr Phe Arg Ala Lys
1 5 10
<210> 815
<211> 16
<212> БЕЛОК
<213> Lactococcus lactis
<400> 815
Leu Glu Ser Phe Ala Tyr Tyr Lys Asn Tyr Phe Asp Arg Phe Val Ala
1 5 10 15
<210> 816
<211> 10
<212> БЕЛОК
<213> Lactococcus lactis
<400> 816
Lys Leu Ile Asp Gly Leu Lys Gln Leu Asn
1 5 10
<210> 817
<211> 17
<212> БЕЛОК
<213> Lactococcus lactis
<400> 817
Ile Ile Asn Glu Ala His Lys Ile Arg Asn Ser Asn Pro Val Ser His
1 5 10 15
Ser
<210> 818
<211> 13
<212> БЕЛОК
<213> Lactococcus lactis
<400> 818
Leu Asn Asp Leu Lys Ile Ile Ile Glu Gln Leu Ser Thr
1 5 10
<210> 819
<211> 11
<212> БЕЛОК
<213> Pseudomonas sp.
<400> 819
Lys Trp Leu Phe Ile Asp Gln Met Val Asp Leu
1 5 10
<210> 820
<211> 12
<212> БЕЛОК
<213> Pseudomonas sp.
<400> 820
Phe Lys Phe Arg Glu Ile Arg Ile Glu Tyr Ser Gln
1 5 10
<210> 821
<211> 9
<212> БЕЛОК
<213> Pseudomonas sp.
<400> 821
Tyr Glu Tyr Ala Gln Glu Ile Arg Ser
1 5
<210> 822
<211> 14
<212> БЕЛОК
<213> Pseudomonas sp.
<400> 822
Arg Lys Ile Pro Asp Phe Arg Gly Lys Tyr Ala Ala His Ile
1 5 10
<210> 823
<211> 13
<212> БЕЛОК
<213> Pseudomonas sp.
<400> 823
Lys Ala Leu Glu Phe Tyr Asn Trp Ile His Ser Asn Glu
1 5 10
<210> 824
<211> 11
<212> БЕЛОК
<213> Vibrio paracholerae
<400> 824
Glu Glu Ile Leu Ser Gly Leu Ile Gly Asp Leu
1 5 10
<210> 825
<211> 12
<212> БЕЛОК
<213> Vibrio paracholerae
<400> 825
Arg Lys Tyr Val Glu Leu Asn Gln Lys Tyr Gly Lys
1 5 10
<210> 826
<211> 10
<212> БЕЛОК
<213> Vibrio paracholerae
<400> 826
Gly Val Tyr Asn Asn Glu Ile Asn Lys Asn
1 5 10
<210> 827
<211> 14
<212> БЕЛОК
<213> Vibrio paracholerae
<400> 827
Thr Ala Ile Lys Lys Leu Arg Asn His Cys Val Ala His Val
1 5 10
<210> 828
<211> 13
<212> БЕЛОК
<213> Vibrio paracholerae
<400> 828
Phe Ala Asp Glu Phe Leu Asp Trp Ile Cys Pro Asp Asn
1 5 10
<210> 829
<211> 11
<212> БЕЛОК
<213> Escherichia coli
<400> 829
Thr Met Ala Asp His Met Val Asn Glu Ala Trp
1 5 10
<210> 830
<211> 16
<212> БЕЛОК
<213> Escherichia coli
<400> 830
Phe Asn Leu Ile Leu Gln Ser Ile Glu Phe Arg Leu Lys Gly Leu Ile
1 5 10 15
<210> 831
<211> 10
<212> БЕЛОК
<213> Escherichia coli
<400> 831
Lys Val Tyr Asn Thr Phe Ala Ser Lys Ser
1 5 10
<210> 832
<211> 14
<212> БЕЛОК
<213> Escherichia coli
<400> 832
Trp Phe Asn Ser Met Arg Ile Leu Arg Asn Arg Phe Met His
1 5 10
<210> 833
<211> 13
<212> БЕЛОК
<213> Escherichia coli
<400> 833
Asp Ile Met Pro Glu Leu Ile Phe Thr Ser Val Val Arg
1 5 10
<210> 834
<211> 11
<212> БЕЛОК
<213> Geobacter sulfurreducens
<400> 834
Leu Asn Tyr Glu Ala Leu Tyr Val Lys Ser Lys
1 5 10
<210> 835
<211> 16
<212> БЕЛОК
<213> Geobacter sulfurreducens
<400> 835
Gln Leu Trp Ala Ser Met Ala Leu Glu Leu Leu Ala Lys Ser Ser Leu
1 5 10 15
<210> 836
<211> 9
<212> БЕЛОК
<213> Geobacter sulfurreducens
<400> 836
Gln Arg Leu Gly His Ile Ser Lys Leu
1 5
<210> 837
<211> 15
<212> БЕЛОК
<213> Geobacter sulfurreducens
<400> 837
Phe Cys Glu Gln Leu Ser Leu Arg Arg Asn Ser Glu Ile His Ser
1 5 10 15
<210> 838
<211> 13
<212> БЕЛОК
<213> Geobacter sulfurreducens
<400> 838
Asp Ala Trp Glu Val Lys Tyr Trp Tyr Ala Ile Glu Val
1 5 10
<210> 839
<211> 11
<212> БЕЛОК
<213> Streptomyces coelicolor
<400> 839
Asp Val Ser Tyr Thr Pro Val Ser Asn Gly Met
1 5 10
<210> 840
<211> 16
<212> БЕЛОК
<213> Streptomyces coelicolor
<400> 840
Val Leu His Leu Gln Ala Ala Thr Glu Val Leu Leu Lys Ala Arg Leu
1 5 10 15
<210> 841
<211> 10
<212> БЕЛОК
<213> Streptomyces coelicolor
<400> 841
Asp Arg Leu Arg Asp Ile Ala Arg Leu Asp
1 5 10
<210> 842
<211> 15
<212> БЕЛОК
<213> Streptomyces coelicolor
<400> 842
Arg Ile Lys Glu Pro Gly Glu Ser Arg Asn Ala Leu Gln His Tyr
1 5 10 15
<210> 843
<211> 13
<212> БЕЛОК
<213> Streptomyces coelicolor
<400> 843
Tyr Ala Ile Glu Ser Arg Ala Ala Arg Val Leu Asp Phe
1 5 10
<210> 844
<211> 10
<212> БЕЛОК
<213> Leptospira interrogans
<400> 844
Cys Thr Arg Leu Tyr Asn Gln Ile Leu Glu
1 5 10
<210> 845
<211> 16
<212> БЕЛОК
<213> Leptospira interrogans
<400> 845
Tyr Thr Lys Leu Phe Asn Ile Leu Asp Lys Val Ala Ala Ile Val Tyr
1 5 10 15
<210> 846
<211> 6
<212> БЕЛОК
<213> Leptospira interrogans
<400> 846
Phe Pro Ser Thr Phe Gly
1 5
<210> 847
<211> 13
<212> БЕЛОК
<213> Leptospira interrogans
<400> 847
His His Leu Arg Val Arg Arg Asn Asn Ile Val His Trp
1 5 10
<210> 848
<211> 13
<212> БЕЛОК
<213> Leptospira interrogans
<400> 848
Glu Glu Asp Val Gln Arg Leu Phe Leu Ile Ser Lys Ala
1 5 10
<210> 849
<211> 10
<212> БЕЛОК
<213> Shigella boydii
<400> 849
Met Glu Met Val Leu Asn Arg Leu Lys Ser
1 5 10
<210> 850
<211> 16
<212> БЕЛОК
<213> Shigella boydii
<400> 850
Phe Arg Leu Cys Phe Gly Ile Leu Asp Lys Ile Ala Val Ala Ile Cys
1 5 10 15
<210> 851
<211> 8
<212> БЕЛОК
<213> Shigella boydii
<400> 851
Pro Gln Lys Asn Ile Tyr Phe Gln
1 5
<210> 852
<211> 15
<212> БЕЛОК
<213> Shigella boydii
<400> 852
Glu Leu Ala Phe Tyr Lys Glu Trp Arg Asn Gly Leu Glu His Lys
1 5 10 15
<210> 853
<211> 13
<212> БЕЛОК
<213> Shigella boydii
<400> 853
Ile His His Phe Glu His Leu Leu Gln Ile Thr Arg Ser
1 5 10
<210> 854
<211> 10
<212> БЕЛОК
<213> Enterococcus faecalis
<400> 854
Phe Tyr Ser Leu Phe Asn Gln Ile Lys Gln
1 5 10
<210> 855
<211> 16
<212> БЕЛОК
<213> Enterococcus faecalis
<400> 855
Tyr Arg Ser Val Tyr Ser Ile Phe Asp Lys Ile Ala Tyr Phe Leu Asn
1 5 10 15
<210> 856
<211> 8
<212> БЕЛОК
<213> Enterococcus faecalis
<400> 856
Pro Lys Asn Leu Ile Thr Phe His
1 5
<210> 857
<211> 15
<212> БЕЛОК
<213> Enterococcus faecalis
<400> 857
Asn Leu Glu Lys Ile Ala Glu Ile Arg Asn Ala Met Glu His Lys
1 5 10 15
<210> 858
<211> 13
<212> БЕЛОК
<213> Enterococcus faecalis
<400> 858
Glu Lys Ile Thr Leu Glu Leu Phe Lys Leu Thr Arg Glu
1 5 10
<210> 859
<211> 10
<212> БЕЛОК
<213> Ruminiclostridium thermocellum
<400> 859
Phe Asn Asn Arg Ala Phe Asp Leu Ile Val
1 5 10
<210> 860
<211> 16
<212> БЕЛОК
<213> Ruminiclostridium thermocellum
<400> 860
Tyr Thr Arg Phe Glu Gly Leu Ile Asp Thr Ile Tyr His Ile Ile Asn
1 5 10 15
<210> 861
<211> 7
<212> БЕЛОК
<213> Ruminiclostridium thermocellum
<400> 861
Lys Pro Ser Ser Glu Phe Arg
1 5
<210> 862
<211> 15
<212> БЕЛОК
<213> Ruminiclostridium thermocellum
<400> 862
Val Tyr Lys Lys Ile Asn Lys Phe Arg Asn Asn Ile Val His Asn
1 5 10 15
<210> 863
<211> 13
<212> БЕЛОК
<213> Ruminiclostridium thermocellum
<400> 863
Tyr Thr Thr Ser Thr Glu Phe Leu Asn Asn Ile Lys Asp
1 5 10
<210> 864
<211> 10
<212> БЕЛОК
<213> Bacillus cereus
<400> 864
Leu Asn Asn Arg Ile Phe Gln Leu Asp Leu
1 5 10
<210> 865
<211> 16
<212> БЕЛОК
<213> Bacillus cereus
<400> 865
Phe Pro Lys Ala Phe Thr Ala Leu Asp Leu Leu Ala His Leu Leu Phe
1 5 10 15
<210> 866
<211> 7
<212> БЕЛОК
<213> Bacillus cereus
<400> 866
Lys Thr Glu Lys Lys Ile Lys
1 5
<210> 867
<211> 15
<212> БЕЛОК
<213> Bacillus cereus
<400> 867
Glu Phe Gln Lys Ala Ser Lys Val Arg Asn Asp Ile Ile His Asn
1 5 10 15
<210> 868
<211> 13
<212> БЕЛОК
<213> Bacillus cereus
<400> 868
Tyr Thr Pro Ser Lys Glu Ile Leu Asn Ile Ala Arg Gly
1 5 10
<210> 869
<211> 10
<212> БЕЛОК
<213> Pseudomonas syringae
<400> 869
Glu Tyr Leu Arg Cys Lys Asp Ala Phe Glu
1 5 10
<210> 870
<211> 16
<212> БЕЛОК
<213> Pseudomonas syringae
<400> 870
Ser Ser Phe Ile His His Leu Tyr Glu Leu Tyr Met Ala Leu Phe Ala
1 5 10 15
<210> 871
<211> 8
<212> БЕЛОК
<213> Pseudomonas syringae
<400> 871
Ser Ile Asp Arg Gly Ala Val Ser
1 5
<210> 872
<211> 16
<212> БЕЛОК
<213> Pseudomonas syringae
<400> 872
Phe Gly Pro Ala Phe Arg Ser Met Arg Asn Lys Ile Ala Gly His Val
1 5 10 15
<210> 873
<211> 13
<212> БЕЛОК
<213> Pseudomonas syringae
<400> 873
Val Lys Leu Thr Glu Phe Phe Gln Lys Tyr His Pro Tyr
1 5 10
<210> 874
<211> 10
<212> БЕЛОК
<213> Burkholderia xenovorans
<400> 874
Glu Tyr Leu Arg Cys Asp Asp Ala Leu His
1 5 10
<210> 875
<211> 16
<212> БЕЛОК
<213> Burkholderia xenovorans
<400> 875
Ala Arg Phe Ile His His Leu Tyr Glu Phe Asn Ile Ala Cys Ala Gln
1 5 10 15
<210> 876
<211> 8
<212> БЕЛОК
<213> Burkholderia xenovorans
<400> 876
Arg Val Arg Arg Gln Ala Tyr Asn
1 5
<210> 877
<211> 16
<212> БЕЛОК
<213> Burkholderia xenovorans
<400> 877
Phe Ala Lys Ala Phe Arg Thr Ala Arg Asn Thr Thr Asn Gly His Ala
1 5 10 15
<210> 878
<211> 13
<212> БЕЛОК
<213> Burkholderia xenovorans
<400> 878
Leu Asn Leu Ser Asp Phe Phe Thr Arg Tyr His Arg Phe
1 5 10
<210> 879
<211> 10
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 879
Glu His Leu Asp Cys Glu Leu Trp Glu Arg
1 5 10
<210> 880
<211> 16
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 880
Ile Arg Asn Ala Thr Val Ile Leu Glu Asp Arg Met Arg Lys Leu Gly
1 5 10 15
<210> 881
<211> 8
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 881
Gly Ile Val Asn Leu Ile Phe Gly
1 5
<210> 882
<211> 15
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 882
Tyr Ser Gly Thr Met Lys Ile Phe Arg Asn Arg Tyr Ala His Arg
1 5 10 15
<210> 883
<211> 13
<212> БЕЛОК
<213> Microcystis aeruginosa
<400> 883
Ile Ile Val Phe Ile Asp Leu Leu Leu Lys Met Leu Asp
1 5 10
<210> 884
<211> 11
<212> БЕЛОК
<213> Vibrio parahaemolyticus
<400> 884
Ser Arg Asn Val His Pro Asp Val Leu Lys Tyr
1 5 10
<210> 885
<211> 16
<212> БЕЛОК
<213> Vibrio parahaemolyticus
<400> 885
Val Phe Glu Ala Thr Lys Ser Val Ala Asp Lys Ile Arg Asn Lys Thr
1 5 10 15
<210> 886
<211> 8
<212> БЕЛОК
<213> Vibrio parahaemolyticus
<400> 886
Val Leu Val Asp Glu Ala Phe Ser
1 5
<210> 887
<211> 15
<212> БЕЛОК
<213> Vibrio parahaemolyticus
<400> 887
Leu Lys Gly Leu Phe Gly Thr Phe Arg Asn Thr Thr Ala His Ala
1 5 10 15
<210> 888
<211> 13
<212> БЕЛОК
<213> Vibrio parahaemolyticus
<400> 888
Ile Leu Ser Met Val Ser Leu Val His Arg Arg Leu Asp
1 5 10
<210> 889
<211> 11
<212> БЕЛОК
<213> Lactococcus lactis
<400> 889
Ala Leu Glu Leu His Ser Glu Val Thr Lys Tyr
1 5 10
<210> 890
<211> 16
<212> БЕЛОК
<213> Lactococcus lactis
<400> 890
Val Phe Glu Ser Cys Lys Gly Leu Phe Asp Arg Ile Arg Leu Ile Ser
1 5 10 15
<210> 891
<211> 8
<212> БЕЛОК
<213> Lactococcus lactis
<400> 891
Thr Leu Ile Asn Gln Ala Phe Asn
1 5
<210> 892
<211> 15
<212> БЕЛОК
<213> Lactococcus lactis
<400> 892
Ile Lys Thr Cys Leu Tyr Leu Tyr Arg Asn His Gln Ala His Val
1 5 10 15
<210> 893
<211> 13
<212> БЕЛОК
<213> Lactococcus lactis
<400> 893
Gly Leu Met Ser Ile Ser Leu Ala His Glu Leu Leu Asp
1 5 10
<210> 894
<211> 11
<212> БЕЛОК
<213> Nematostella vectensis
<400> 894
Ser Thr Thr Leu Thr Thr Phe Leu Asn Leu His
1 5 10
<210> 895
<211> 16
<212> БЕЛОК
<213> Nematostella vectensis
<400> 895
Glu Asp Tyr Asp Ile Thr Leu Leu Thr Cys Leu Leu Arg Asn Ile Cys
1 5 10 15
<210> 896
<211> 8
<212> БЕЛОК
<213> Nematostella vectensis
<400> 896
Asp Lys Leu Pro Pro Ala Tyr Asp
1 5
<210> 897
<211> 15
<212> БЕЛОК
<213> Nematostella vectensis
<400> 897
Val Val Arg Leu Arg His Tyr Arg Asn Asp Leu Tyr Ala His Ile
1 5 10 15
<210> 898
<211> 13
<212> БЕЛОК
<213> Nematostella vectensis
<400> 898
Trp Ala Asp Ile Ser Ala Ala Leu Leu Ser Leu Gly Gly
1 5 10
<210> 899
<211> 11
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 899
Pro Pro Ser Leu Pro Ala Gln Leu Lys Lys His
1 5 10
<210> 900
<211> 16
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 900
Glu Glu Phe Asp Ile Ser Leu Leu Leu Leu Leu Leu Lys Glu Leu Val
1 5 10 15
<210> 901
<211> 8
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 901
Gly Arg Asp Ala Pro Tyr Ser Asp
1 5
<210> 902
<211> 13
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 902
Lys Leu Gly Gln Phe Arg Asn Lys Asn Tyr Gly His Ile
1 5 10
<210> 903
<211> 13
<212> БЕЛОК
<213> Branchiostoma floridae
<400> 903
Trp Asp Glu Leu Thr Glu Ile Leu Val Asp Leu Gly Gly
1 5 10
<210> 904
<211> 11
<212> БЕЛОК
<213> Homo sapiens
<400> 904
Pro Pro Leu Leu Lys Lys Glu Leu Leu Ile His
1 5 10
<210> 905
<211> 16
<212> БЕЛОК
<213> Homo sapiens
<400> 905
Lys Gln Phe Asp Leu Cys Leu Leu Leu Ala Leu Ile Lys His Leu Asn
1 5 10 15
<210> 906
<211> 8
<212> БЕЛОК
<213> Homo sapiens
<400> 906
Asn Met Glu Pro Pro Ser Ser Asp
1 5
<210> 907
<211> 15
<212> БЕЛОК
<213> Homo sapiens
<400> 907
Ile Leu Arg Leu Cys Lys Tyr Arg Asp Ile Leu Leu Ser Glu Ile
1 5 10 15
<210> 908
<211> 13
<212> БЕЛОК
<213> Homo sapiens
<400> 908
Trp Lys Lys Val Ser Asp Ile Leu Leu Arg Leu Gly Met
1 5 10
<210> 909
<211> 11
<212> БЕЛОК
<213> Escherichia coli
<400> 909
Val Thr Ala Glu Lys Leu Leu Val Ser Gly Leu
1 5 10
<210> 910
<211> 16
<212> БЕЛОК
<213> Escherichia coli
<400> 910
Leu Tyr Pro Glu Leu Arg Thr Ile Glu Gly Val Leu Lys Ser Lys Met
1 5 10 15
<210> 911
<211> 8
<212> БЕЛОК
<213> Escherichia coli
<400> 911
Tyr Ile Leu Lys Pro Gln Phe Ala
1 5
<210> 912
<211> 14
<212> БЕЛОК
<213> Escherichia coli
<400> 912
Ala Tyr Thr Phe Phe Asn Val Glu Arg His Ser Leu Phe His
1 5 10
<210> 913
<211> 13
<212> БЕЛОК
<213> Escherichia coli
<400> 913
Met Ile Ser Asp Met Ala Arg Leu Met Gly Lys Ala Thr
1 5 10
<210> 914
<211> 11
<212> БЕЛОК
<213> Photobacterium profundum
<400> 914
Asp Thr Tyr Arg Ser Leu Leu Ser Ser Ser Tyr
1 5 10
<210> 915
<211> 16
<212> БЕЛОК
<213> Photobacterium profundum
<400> 915
Ile Tyr Pro Asp Leu Arg Val Leu Glu Gly Val Ile Lys Glu Ala Met
1 5 10 15
<210> 916
<211> 8
<212> БЕЛОК
<213> Photobacterium profundum
<400> 916
Thr Glu Leu Lys Thr Glu Tyr Asn
1 5
<210> 917
<211> 14
<212> БЕЛОК
<213> Photobacterium profundum
<400> 917
Cys Tyr Ala Tyr Phe Lys Ala His Arg His Ser Leu Phe His
1 5 10
<210> 918
<211> 13
<212> БЕЛОК
<213> Photobacterium profundum
<400> 918
Thr Thr Asp Thr Ile Gly Glu Val Met Gln Met Ser Glu
1 5 10
<210> 919
<211> 11
<212> БЕЛОК
<213> Geobacillus thermoglucosidasius
<400> 919
Leu Tyr Asp Arg Asp Arg Ile Glu Ala Ser Glu
1 5 10
<210> 920
<211> 16
<212> БЕЛОК
<213> Geobacillus thermoglucosidasius
<400> 920
Val Ser Gly Thr Leu Arg Ala Phe Glu Gly Phe Phe Lys Lys Leu Leu
1 5 10 15
<210> 921
<211> 8
<212> БЕЛОК
<213> Geobacillus thermoglucosidasius
<400> 921
Asp Ile Ser Glu Lys Val Phe Asn
1 5
<210> 922
<211> 14
<212> БЕЛОК
<213> Geobacillus thermoglucosidasius
<400> 922
Met Leu Asn His Met Ser Gln Asp Arg Asn Pro Tyr Ser His
1 5 10
<210> 923
<211> 13
<212> БЕЛОК
<213> Geobacillus thermoglucosidasius
<400> 923
Pro Leu Arg Thr Leu Asn Gln Ala Ile Ser Leu His Asn
1 5 10
<210> 924
<211> 12
<212> БЕЛОК
<213> Teredinibacter turnerae
<400> 924
Cys Arg Ser Ile Arg Lys Leu Leu Asn Met Asn Ala
1 5 10
<210> 925
<211> 16
<212> БЕЛОК
<213> Teredinibacter turnerae
<400> 925
Ser Tyr Pro Leu Ile Tyr Glu Ile Glu Asn Leu Val Arg Lys Leu Ile
1 5 10 15
<210> 926
<211> 9
<212> БЕЛОК
<213> Teredinibacter turnerae
<400> 926
Ile Gln Leu Ser Asn Phe Leu Phe Asp
1 5
<210> 927
<211> 15
<212> БЕЛОК
<213> Teredinibacter turnerae
<400> 927
Arg Trp Gly Lys Leu Tyr Lys Leu Arg Cys Lys Ile Ala His Asn
1 5 10 15
<210> 928
<211> 13
<212> БЕЛОК
<213> Teredinibacter turnerae
<400> 928
Thr Thr Lys Leu Val Glu Glu Val Lys Leu Lys Ile Leu
1 5 10
<210> 929
<211> 5
<212> БЕЛОК
<213> Methanococcus maripaludis
<400> 929
Phe Arg Leu Met Tyr
1 5
<210> 930
<211> 16
<212> БЕЛОК
<213> Methanococcus maripaludis
<400> 930
Phe Leu Asp Ser Val Leu Ala Leu Glu Ile Tyr His Thr Leu Lys Phe
1 5 10 15
<210> 931
<211> 10
<212> БЕЛОК
<213> Methanococcus maripaludis
<400> 931
Phe Ile Asn Lys Met Lys Asp Val Phe Asn
1 5 10
<210> 932
<211> 15
<212> БЕЛОК
<213> Methanococcus maripaludis
<400> 932
Ile Cys Arg Ile Ile Arg Asp Thr Arg Asn Lys Leu Val His Asp
1 5 10 15
<210> 933
<211> 13
<212> БЕЛОК
<213> Methanococcus maripaludis
<400> 933
Pro Tyr Phe Leu Ile Glu Leu Leu Lys Asn Ile Phe Lys
1 5 10
<210> 934
<211> 11
<212> БЕЛОК
<213> Novosphingobium pentaromativorans
<400> 934
Val His Arg Ala Leu Ser Trp Leu Arg Arg Ala
1 5 10
<210> 935
<211> 14
<212> БЕЛОК
<213> Novosphingobium pentaromativorans
<400> 935
Phe Ile Leu Leu Trp Ile Gly Phe Asn Ala Ala Tyr Ala Gly
1 5 10
<210> 936
<211> 10
<212> БЕЛОК
<213> Novosphingobium pentaromativorans
<400> 936
Glu Arg Ser Arg Thr Ala Ile Asn Tyr Ala
1 5 10
<210> 937
<211> 15
<212> БЕЛОК
<213> Novosphingobium pentaromativorans
<400> 937
Leu Phe Asp Arg Leu Tyr Val Leu Arg Asn Gln Leu Val His Gly
1 5 10 15
<210> 938
<211> 13
<212> БЕЛОК
<213> Novosphingobium pentaromativorans
<400> 938
Arg Asp Gln Val Arg Asp Gly Ala Ser Leu Leu Gly Cys
1 5 10
<210> 939
<211> 12
<212> БЕЛОК
<213> Chlorobium chlorochromatii
<400> 939
Ile Met Glu Gln Arg Lys Ala Ile Leu Glu Pro Leu
1 5 10
<210> 940
<211> 16
<212> БЕЛОК
<213> Chlorobium chlorochromatii
<400> 940
Ala Val Ala Tyr Asn His Phe Val Pro Leu Leu Ala Gln Asp Leu Ile
1 5 10 15
<210> 941
<211> 6
<212> БЕЛОК
<213> Chlorobium chlorochromatii
<400> 941
Lys Ile Ser Asn Lys Lys
1 5
<210> 942
<211> 15
<212> БЕЛОК
<213> Chlorobium chlorochromatii
<400> 942
Ser Glu Lys Leu Lys Thr Phe Arg Asp Lys Tyr Tyr Ala His Leu
1 5 10 15
<210> 943
<211> 13
<212> БЕЛОК
<213> Chlorobium chlorochromatii
<400> 943
Phe Leu Gly Ile His Arg Lys Ser Ala Asn Glu Met Trp
1 5 10
<210> 944
<211> 12
<212> БЕЛОК
<213> Lactococcus lactis
<400> 944
Asp Ala Tyr Asn Lys Leu Ile Leu Leu Lys Gln Tyr
1 5 10
<210> 945
<211> 15
<212> БЕЛОК
<213> Lactococcus lactis
<400> 945
Phe Phe Tyr Asn Asn Leu Leu Asp Ser Leu Val Ile Ala Ile Phe
1 5 10 15
<210> 946
<211> 6
<212> БЕЛОК
<213> Lactococcus lactis
<400> 946
Asn Tyr Thr Asn Phe Pro
1 5
<210> 947
<211> 15
<212> БЕЛОК
<213> Lactococcus lactis
<400> 947
Leu Glu Tyr Leu Tyr Ala Gln Arg Asn Lys Ile Tyr Val His Asn
1 5 10 15
<210> 948
<211> 13
<212> БЕЛОК
<213> Lactococcus lactis
<400> 948
Asn Tyr Ala Trp Glu Pro Thr Asn Ile Asn Asp Trp Glu
1 5 10
<210> 949
<211> 16
<212> БЕЛОК
<213> Escherichia coli
<400> 949
Glu Ser Val Ile Ala His Met Asn Glu Leu Leu Ile Ala Leu Ser Asp
1 5 10 15
<210> 950
<211> 15
<212> БЕЛОК
<213> Escherichia coli
<400> 950
Arg Tyr Thr Gln Gln Gln Arg Leu Arg Thr Ala Ile Ala His His
1 5 10 15
<210> 951
<211> 12
<212> БЕЛОК
<213> Escherichia coli
<400> 951
Glu Ala Arg His Glu Gln Leu Thr Lys Gly Gly Thr
1 5 10
<210> 952
<211> 16
<212> БЕЛОК
<213> Cronobacter sakazakii
<400> 952
Gln His Val Ile Ala Pro Met Asn Glu Leu Leu Ile Ala Leu Ser Asp
1 5 10 15
<210> 953
<211> 15
<212> БЕЛОК
<213> Cronobacter sakazakii
<400> 953
Arg Tyr Asp Leu Gln Gln Gln Leu Arg Thr Ala Ile Ala His His
1 5 10 15
<210> 954
<211> 13
<212> БЕЛОК
<213> Cronobacter sakazakii
<400> 954
Ala Ala Glu Arg Leu Ala Glu Leu Thr Arg Gly Gly Thr
1 5 10
<210> 955
<211> 16
<212> БЕЛОК
<213> Homo sapiens
<400> 955
Glu Ser Arg Tyr Arg Thr Leu Arg Asn Val Gly Asn Glu Ser Asp Ile
1 5 10 15
<210> 956
<211> 10
<212> БЕЛОК
<213> Homo sapiens
<400> 956
Leu Gln Pro Gly Pro Ser Glu His Ser Lys
1 5 10
<210> 957
<211> 14
<212> БЕЛОК
<213> Homo sapiens
<400> 957
Val Gly Asp Leu Leu Lys Phe Ile Arg Asn Leu Gly Glu His
1 5 10
<210> 958
<211> 13
<212> БЕЛОК
<213> Homo sapiens
<400> 958
Ile Gly Asp Pro Ser Leu Tyr Phe Gln Lys Thr Phe Pro
1 5 10
<210> 959
<211> 16
<212> БЕЛОК
<213> Arabidopsis thaliana
<400> 959
Glu Met Arg Leu Ser Phe Leu Arg Asp Ala Ser Asp Arg Val Glu Leu
1 5 10 15
<210> 960
<211> 10
<212> БЕЛОК
<213> Arabidopsis thaliana
<400> 960
Met Glu Ser Thr Ala Pro Val Ala Ile Gly
1 5 10
<210> 961
<211> 15
<212> БЕЛОК
<213> Arabidopsis thaliana
<400> 961
Ile Arg Asp Leu Leu Arg Val Ile Arg Asn Lys Leu Asn His His
1 5 10 15
<210> 962
<211> 13
<212> БЕЛОК
<213> Arabidopsis thaliana
<400> 962
Pro Glu Gly Phe Asp Glu Tyr Phe Ala Val Arg Phe Pro
1 5 10
<210> 963
<211> 12
<212> БЕЛОК
<213> Helicobacter pylori
<400> 963
Tyr Glu Leu Leu Trp Gln Glu Val Ile Arg Ala Lys
1 5 10
<210> 964
<211> 15
<212> БЕЛОК
<213> Helicobacter pylori
<400> 964
Trp Val Ser Leu Gln Asn Val Met Arg Arg Ile Ile Glu Tyr Tyr
1 5 10 15
<210> 965
<211> 5
<212> БЕЛОК
<213> Helicobacter pylori
<400> 965
Phe Arg Ile Leu Gly
1 5
<210> 966
<211> 17
<212> БЕЛОК
<213> Helicobacter pylori
<400> 966
Lys Gln Val Phe Ser Ser Phe Ile Ser Trp Phe Asn Asp Gly Ser His
1 5 10 15
Gly
<210> 967
<211> 13
<212> БЕЛОК
<213> Helicobacter pylori
<400> 967
Ile Glu Thr Tyr Leu Lys Val Phe Glu Asn Ile Phe Lys
1 5 10
<210> 968
<211> 12
<212> БЕЛОК
<213> Streptococcus mutans
<400> 968
His Leu Met Leu Val Asp Glu Leu Lys Lys Ala Ile
1 5 10
<210> 969
<211> 15
<212> БЕЛОК
<213> Streptococcus mutans
<400> 969
Glu Lys Tyr His Phe Asn Leu Leu Arg Asn Leu Leu Glu Lys Thr
1 5 10 15
<210> 970
<211> 5
<212> БЕЛОК
<213> Streptococcus mutans
<400> 970
Ala Thr Phe Leu Gly
1 5
<210> 971
<211> 14
<212> БЕЛОК
<213> Streptococcus mutans
<400> 971
Pro Ala Pro Tyr Ile Arg Arg Ile Asn Leu His Ser His Ser
1 5 10
<210> 972
<211> 13
<212> БЕЛОК
<213> Streptococcus mutans
<400> 972
Lys Lys Val Leu Glu Arg Val Phe Asn Gln Phe Leu Gln
1 5 10
<210> 973
<211> 12
<212> БЕЛОК
<213> Escherichia coli
<400> 973
His Leu His Leu Lys Gln Thr Ile Glu Gln Ala Ile
1 5 10
<210> 974
<211> 15
<212> БЕЛОК
<213> Escherichia coli
<400> 974
Glu Arg Tyr His Phe Thr Leu Leu Arg Asn Leu Tyr Glu Lys Thr
1 5 10 15
<210> 975
<211> 5
<212> БЕЛОК
<213> Escherichia coli
<400> 975
Ala Ser Phe Leu Gly
1 5
<210> 976
<211> 13
<212> БЕЛОК
<213> Escherichia coli
<400> 976
Leu Tyr Leu Ser Arg Ile Ile Asn Phe Thr Ser His Ser
1 5 10
<210> 977
<211> 13
<212> БЕЛОК
<213> Escherichia coli
<400> 977
Lys Ala Thr Val Lys Leu Leu Leu Asp His Leu Lys Asn
1 5 10
<210> 978
<211> 12
<212> БЕЛОК
<213> Bacteroides fragilis
<400> 978
Lys Glu Ile Glu Glu Glu Arg Thr Val Gln Asn Ile
1 5 10
<210> 979
<211> 16
<212> БЕЛОК
<213> Bacteroides fragilis
<400> 979
Thr Ser Phe Gly Glu Val Thr Glu Glu Tyr His Asp Glu Leu Tyr Ser
1 5 10 15
<210> 980
<211> 8
<212> БЕЛОК
<213> Bacteroides fragilis
<400> 980
Tyr Ile Lys Glu Leu Ser Asn Gly
1 5
<210> 981
<211> 15
<212> БЕЛОК
<213> Bacteroides fragilis
<400> 981
Gln Lys Thr Leu Thr Glu Lys Ile Arg His Gln Ile His His Pro
1 5 10 15
<210> 982
<211> 13
<212> БЕЛОК
<213> Bacteroides fragilis
<400> 982
Glu Thr Glu Ile Arg Gln Ser Ile Glu Asp Met Arg Ala
1 5 10
<210> 983
<211> 12
<212> БЕЛОК
<213> Methylobacillus flagellatus
<400> 983
Ser Asn Gln Ile Pro Thr Arg Val Ser Pro Val Leu
1 5 10
<210> 984
<211> 16
<212> БЕЛОК
<213> Methylobacillus flagellatus
<400> 984
Ser Ala Phe Gly Glu Ala Ser Tyr Glu Tyr His Asn Glu Leu Tyr Gly
1 5 10 15
<210> 985
<211> 8
<212> БЕЛОК
<213> Methylobacillus flagellatus
<400> 985
Tyr Asn Arg Leu Arg Arg Asp Gly
1 5
<210> 986
<211> 15
<212> БЕЛОК
<213> Methylobacillus flagellatus
<400> 986
Gln Val Ile Leu Thr Glu Tyr Ile Arg His Gln Ile His His Pro
1 5 10 15
<210> 987
<211> 13
<212> БЕЛОК
<213> Methylobacillus flagellatus
<400> 987
Thr Ala Glu Leu Thr Glu Ser Ile Glu Thr Met Arg Leu
1 5 10
<210> 988
<211> 12
<212> БЕЛОК
<213> Campylobacter hominis
<400> 988
Lys Asp Gly Glu Gln Lys Lys Glu Val Lys Asn Val
1 5 10
<210> 989
<211> 16
<212> БЕЛОК
<213> Campylobacter hominis
<400> 989
Met Ala Phe Gly Glu Ile Thr Glu Glu Tyr His Asn Glu Leu Tyr Gly
1 5 10 15
<210> 990
<211> 8
<212> БЕЛОК
<213> Campylobacter hominis
<400> 990
Tyr Lys Lys Leu Lys Lys Asp Gly
1 5
<210> 991
<211> 15
<212> БЕЛОК
<213> Campylobacter hominis
<400> 991
Lys Leu Thr Leu Thr Glu Tyr Ile Arg His Gln Ile His His Pro
1 5 10 15
<210> 992
<211> 13
<212> БЕЛОК
<213> Campylobacter hominis
<400> 992
Leu Ser Glu Leu Lys Asp Ser Ile Glu Met Met Arg Asn
1 5 10
<210> 993
<211> 15
<212> БЕЛОК
<213> Homo sapiens
<400> 993
Ile Pro Asp Trp Ile Val Asp Leu Arg His Glu Leu Thr His Lys
1 5 10 15
<210> 994
<211> 15
<212> БЕЛОК
<213> Mycobacterium tuberculosis
<400> 994
Leu Gly Arg Phe Glu Ser Arg Val Arg Asn Thr Ala Ala His Glu
1 5 10 15
<210> 995
<211> 15
<212> БЕЛОК
<213> Lactococcus lactis
<400> 995
Trp Ile Arg Ala Gly Trp Phe Ile Arg Asn Arg Ser Ala His Tyr
1 5 10 15
<210> 996
<211> 15
<212> БЕЛОК
<213> Thermus thermophilus
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (5)..(5)
<223> Любая аминокислота
<400> 996
Leu Ala Leu Gly Xaa Val Asp Asp Arg Ser Leu Thr Val His Thr
1 5 10 15
<210> 997
<211> 22
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 997
Leu Lys Ser Met Leu Tyr Ser Met Arg Asn Ser Ser Phe His Phe Ser
1 5 10 15
Thr Glu Asn Val Asp Asn
20
<210> 998
<211> 22
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 998
Leu Lys Asp Val Ile Tyr Ser Met Arg Asn Asp Ser Phe His Tyr Ala
1 5 10 15
Thr Glu Asn His Asn Asn
20
<210> 999
<211> 22
<212> БЕЛОК
<213> Clostridium aminophilum
<400> 999
Leu Arg Lys Ala Ile Tyr Ser Leu Arg Asn Glu Thr Phe His Phe Thr
1 5 10 15
Thr Leu Asn Lys Gly Ser
20
<210> 1000
<211> 22
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1000
Ile Ile Gln Ile Ile Tyr Ser Leu Arg Asn Lys Ser Phe His Phe Lys
1 5 10 15
Thr Tyr Asp His Gly Asp
20
<210> 1001
<211> 22
<212> БЕЛОК
<213> Carnobacterium gallinarum
<400> 1001
Leu Arg Gly Ser Val Gln Gln Ile Arg Asn Glu Ile Phe His Ser Phe
1 5 10 15
Asp Lys Asn Gln Lys Phe
20
<210> 1002
<211> 21
<212> БЕЛОК
<213> Carnobacterium gallinarum
<400> 1002
Ile Arg Gly Ala Val Gln Arg Val Arg Asn Gln Ile Phe His Gln Gln
1 5 10 15
Ile Asn Lys Arg His
20
<210> 1003
<211> 20
<212> БЕЛОК
<213> Paludibacter propionicigenes
<400> 1003
Ile Arg Gly Ala Val Gln Gln Ile Arg Asn Asn Val Asn His Tyr Lys
1 5 10 15
Lys Asp Ala Leu
20
<210> 1004
<211> 20
<212> БЕЛОК
<213> Listeria seeligeri
<400> 1004
Leu Arg Gly Ala Ile Ala Pro Ile Arg Asn Glu Ile Ile His Leu Lys
1 5 10 15
Lys His Ser Trp
20
<210> 1005
<211> 20
<212> БЕЛОК
<213> Listeria weihenstephanensis
<400> 1005
Ile Arg Gly Ser Ile Gln Gln Ile Arg Asn Glu Val Tyr His Cys Lys
1 5 10 15
Lys His Ser Trp
20
<210> 1006
<211> 20
<212> БЕЛОК
<213> Listeria newyorkensis
<400> 1006
Ile Arg Gly Ser Ile Gln Gln Ile Arg Asn Glu Val Tyr His Cys Lys
1 5 10 15
Lys His Ser Trp
20
<210> 1007
<211> 21
<212> БЕЛОК
<213> Leptotrichia wadei
<400> 1007
Ile Ser Tyr Ser Ile Tyr Asn Val Arg Asn Gly Val Gly His Phe Asn
1 5 10 15
Lys Leu Ile Leu Gly
20
<210> 1008
<211> 21
<212> БЕЛОК
<213> Leptotrichia wadei
<400> 1008
Met Leu Asn Ala Ile Thr Ser Ile Arg His Arg Val Val His Tyr Asn
1 5 10 15
Met Asn Thr Asn Ser
20
<210> 1009
<211> 21
<212> БЕЛОК
<213> Leptotrichia wadei
<400> 1009
Ile Asp Glu Ala Ile Ser Ser Ile Arg His Gly Ile Val His Phe Asn
1 5 10 15
Leu Glu Leu Glu Gly
20
<210> 1010
<211> 22
<212> БЕЛОК
<213> Rhodobacter capsulatus
<400> 1010
Leu Leu Arg Tyr Leu Arg Gly Cys Arg Asn Gln Thr Phe His Leu Gly
1 5 10 15
Ala Arg Ala Gly Phe Leu
20
<210> 1011
<211> 21
<212> БЕЛОК
<213> Leptotrichia buccalis
<400> 1011
Ile Asp Glu Ala Ile Ser Ser Ile Arg His Gly Ile Val His Phe Asn
1 5 10 15
Leu Glu Leu Glu Gly
20
<210> 1012
<211> 21
<212> БЕЛОК
<213> Leptotrichia sp.
<400> 1012
Ile Asp Glu Ala Ile Ser Ser Ile Arg His Gly Ile Val His Phe Asn
1 5 10 15
Leu Glu Leu Glu Gly
20
<210> 1013
<211> 16
<212> БЕЛОК
<213> Leptotrichia sp.
<400> 1013
Phe Gln Lys Glu Gly Tyr Leu Leu Arg Asn Lys Ile Leu His Asn Ser
1 5 10 15
<210> 1014
<211> 15
<212> БЕЛОК
<213> Leptotrichia shahii
<400> 1014
Phe Thr Lys Ile Gly Thr Asn Glu Arg Asn Arg Ile Leu His Ala
1 5 10 15
<210> 1015
<211> 14
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1015
Phe Arg Asn Glu Ile Asp His Phe His Tyr Phe Tyr Asp Arg
1 5 10
<210> 1016
<211> 14
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1016
Leu Arg Asn Tyr Ile Glu His Phe Arg Tyr Tyr Ser Ser Phe
1 5 10
<210> 1017
<211> 14
<212> БЕЛОК
<213> Clostridium aminophilum
<400> 1017
Val Arg Lys Tyr Val Asp His Phe Lys Tyr Tyr Ala Thr Ser
1 5 10
<210> 1018
<211> 14
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1018
Leu Arg Lys Tyr Val Asp His Phe Lys Tyr Tyr Ala Tyr Gly
1 5 10
<210> 1019
<211> 14
<212> БЕЛОК
<213> Carnobacterium gallinarum
<400> 1019
Ile Arg Asn Gln Thr Ala His Leu Ser Val Leu Gln Leu Glu
1 5 10
<210> 1020
<211> 14
<212> БЕЛОК
<213> Carnobacterium gallinarum
<400> 1020
Ile Arg Asn Asn Ile Ala His Leu His Val Leu Arg Asn Asp
1 5 10
<210> 1021
<211> 14
<212> БЕЛОК
<213> Paludibacter propionicigenes
<400> 1021
Ile Arg Asn His Ile Ala His Phe Asn Tyr Leu Thr Lys Asp
1 5 10
<210> 1022
<211> 14
<212> БЕЛОК
<213> Listeria seeligeri
<400> 1022
Lys Arg Asn Asn Ile Ser His Phe Asn Tyr Leu Asn Gly Gln
1 5 10
<210> 1023
<211> 14
<212> БЕЛОК
<213> Listeria weihenstephanensis
<400> 1023
Ala Arg Asn His Ile Ala His Leu Asn Tyr Leu Ser Leu Lys
1 5 10
<210> 1024
<211> 14
<212> БЕЛОК
<213> Listeria newyorkensis
<400> 1024
Ala Arg Asn His Ile Ala His Leu Asn Tyr Leu Ser Leu Lys
1 5 10
<210> 1025
<211> 14
<212> БЕЛОК
<213> Leptotrichia wadei
<400> 1025
Phe Arg Asn Tyr Ile Ala His Phe Leu His Leu His Thr Lys
1 5 10
<210> 1026
<211> 14
<212> БЕЛОК
<213> Leptotrichia wadei
<400> 1026
Ile Arg Asn Tyr Ile Ala His Phe Asn Tyr Ile Pro Asp Ala
1 5 10
<210> 1027
<211> 14
<212> БЕЛОК
<213> Leptotrichia wadei
<400> 1027
Ile Arg Asn Tyr Ile Ala His Phe Asn Tyr Ile Pro His Ala
1 5 10
<210> 1028
<211> 14
<212> БЕЛОК
<213> Rhodobacter capsulatus
<400> 1028
Thr Arg Lys Asp Leu Ala His Phe Asn Val Leu Asp Arg Ala
1 5 10
<210> 1029
<211> 14
<212> БЕЛОК
<213> Leptotrichia buccalis
<400> 1029
Ile Arg Asn Tyr Ile Ala His Phe Asn Tyr Ile Pro His Ala
1 5 10
<210> 1030
<211> 14
<212> БЕЛОК
<213> Leptotrichia sp.
<400> 1030
Ile Arg Asn Tyr Ile Ala His Phe Asn Tyr Ile Pro Asn Ala
1 5 10
<210> 1031
<211> 14
<212> БЕЛОК
<213> Leptotrichia sp.
<400> 1031
Ile Arg Asn Tyr Ile Ser His Phe Tyr Ile Val Arg Asn Pro
1 5 10
<210> 1032
<211> 14
<212> БЕЛОК
<213> Leptotrichia shahii
<400> 1032
Ile Arg Asn Tyr Ile Ser His Phe Tyr Ile Val Arg Asn Pro
1 5 10
<210> 1033
<211> 1200
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетическая консенсусная последовательность
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (7)..(7)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (11)..(13)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (18)..(18)
<223> Ile или Leu
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (20)..(21)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (39)..(39)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (75)..(75)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (93)..(93)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (100)..(100)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (145)..(145)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (149)..(149)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (154)..(154)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (216)..(216)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (236)..(236)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (278)..(278)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (315)..(315)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (317)..(317)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (319)..(319)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (370)..(370)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (407)..(407)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (419)..(419)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (428)..(428)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (445)..(445)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (455)..(455)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (563)..(563)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (717)..(717)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (795)..(796)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (800)..(800)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (942)..(942)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (971)..(971)
<223> Ile или Leu
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (1045)..(1045)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (1050)..(1050)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (1063)..(1064)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (1117)..(1118)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (1132)..(1132)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (1138)..(1138)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (1194)..(1194)
<223> Любая аминокислота
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (1196)..(1196)
<223> Любая аминокислота
<400> 1033
Met Leu Phe Phe Met Ser Xaa Asp Ile Thr Xaa Xaa Xaa Asn Met Met
1 5 10 15
Met Xaa Tyr Xaa Xaa Phe Thr Asn Leu Tyr Pro Leu Ser Lys Thr Leu
20 25 30
Arg Phe Glu Leu Lys Pro Xaa Gly Lys Thr Leu Glu Asn Ile Glu Lys
35 40 45
Asn Gly Leu Leu Glu Lys Asp Glu Lys Arg Ala Glu Asp Tyr Lys Lys
50 55 60
Val Lys Lys Ile Ile Asp Glu Tyr His Lys Xaa Phe Ile Glu Glu Ala
65 70 75 80
Leu Ser Ser Val Lys Leu Ser Glu Leu Glu Glu Tyr Xaa Asp Leu Tyr
85 90 95
Leu Lys Lys Xaa Lys Asp Asp Lys Asp Lys Lys Ala Leu Lys Lys Glu
100 105 110
Gln Asp Lys Leu Arg Lys Glu Ile Val Lys Ala Phe Lys Ala Asp Glu
115 120 125
Lys Tyr Lys Lys Leu Phe Lys Lys Glu Leu Ile Leu Lys Asp Leu Pro
130 135 140
Xaa Phe Val Lys Xaa Glu Glu Asp Lys Xaa Leu Leu Lys Ser Phe Lys
145 150 155 160
Gly Phe Thr Thr Tyr Phe Thr Gly Phe His Glu Asn Arg Lys Asn Met
165 170 175
Tyr Ser Asp Glu Asp Lys Ser Thr Ala Ile Ala Tyr Arg Ile Ile His
180 185 190
Glu Asn Leu Pro Lys Phe Ile Asp Asn Ile Lys Ile Phe Glu Lys Ile
195 200 205
Lys Glu Lys Ala Glu Leu Leu Xaa Glx Ile Glu Leu Glu Glu Ile Phe
210 215 220
Ser Leu Asp Tyr Tyr Asn Asn Val Leu Thr Gln Xaa Gly Ile Asp Lys
225 230 235 240
Tyr Asn Ala Ile Ile Gly Gly Ile Ser Thr Glu Asp Gly Lys Ile Lys
245 250 255
Gly Leu Asn Glu Tyr Ile Asn Leu Tyr Asn Gln Gln Asn Lys Asp Lys
260 265 270
Lys Lys Leu Pro Lys Xaa Lys Pro Leu Tyr Lys Gln Ile Leu Ser Asp
275 280 285
Arg Glu Ser Leu Ser Phe Leu Pro Glu Lys Phe Glu Asp Asp Glu Glu
290 295 300
Val Leu Asp Ala Ile Lys Glu Phe Tyr Asp Xaa Ile Xaa Glu Xaa Ile
305 310 315 320
Leu Glu Lys Leu Lys Leu Leu Phe Asp Asn Leu Ser Glu Tyr Asp Leu
325 330 335
Ser Lys Ile Tyr Ile Lys Asn Asp Ala Leu Thr Thr Ile Ser Gln Lys
340 345 350
Val Phe Gly Asp Trp Ser Val Ile Gly Asp Ala Leu Glu Glu Tyr Tyr
355 360 365
Asp Xaa Pro Lys Lys Lys Lys Glu Lys Tyr Glu Glu Lys Arg Lys Lys
370 375 380
Lys Leu Lys Lys Lys Lys Ser Phe Ser Leu Glu Glu Leu Asn Glu Leu
385 390 395 400
Leu Glu Glu Arg Ile Glu Xaa Tyr Phe Ala Thr Leu Gly Asp Leu Ile
405 410 415
Glu Asn Xaa Tyr Leu Ala Ala Glu Lys Leu Leu Xaa Thr Glu Tyr Pro
420 425 430
Glu Glu Lys Asn Leu Lys Lys Asp Lys Glu Ala Val Xaa Ala Ile Lys
435 440 445
Asp Leu Leu Asp Ser Ile Xaa Asx Leu Gln His Phe Leu Lys Pro Leu
450 455 460
Leu Gly Lys Gly Asp Glu Leu Asp Lys Asp Glu Asn Phe Tyr Gly Glu
465 470 475 480
Phe Glu Glu Leu Tyr Glu Glu Leu Asp Glu Ile Ile Pro Leu Tyr Asn
485 490 495
Lys Val Arg Asn Tyr Leu Thr Gln Lys Pro Tyr Ser Thr Glu Lys Ile
500 505 510
Lys Leu Asn Phe Glu Asn Pro Thr Leu Leu Asn Gly Trp Asp Lys Asn
515 520 525
Lys Glu Lys Asp Asn Leu Ala Ile Ile Leu Arg Lys Asp Gly Lys Tyr
530 535 540
Tyr Leu Gly Ile Met Asn Lys Lys His Asn Lys Ile Phe Asp Asn Lys
545 550 555 560
Pro Lys Xaa Cys Tyr Glu Lys Met Val Tyr Lys Leu Leu Pro Gly Pro
565 570 575
Asn Lys Met Leu Pro Lys Val Phe Phe Ser Lys Lys Asn Ile Lys Glu
580 585 590
Tyr Asn Pro Ser Glu Glu Ile Leu Glu Ile Tyr Lys Lys Gly Thr His
595 600 605
Lys Lys Gly Asp Asn Phe Ser Leu Lys Asp Cys His Lys Leu Ile Asp
610 615 620
Phe Phe Lys Glu Ser Ile Glu Lys His Glu Asp Trp Lys Lys Phe Gly
625 630 635 640
Phe Lys Phe Ser Asp Thr Glu Ser Tyr Asn Asp Ile Ser Glu Phe Tyr
645 650 655
Arg Glu Val Glu Lys Gln Gly Tyr Lys Leu Ser Phe Thr Lys Ile Ser
660 665 670
Glu Ser Tyr Ile Asp Ser Leu Val Glu Glu Gly Lys Leu Tyr Leu Phe
675 680 685
Gln Ile Tyr Asn Lys Asp Phe Ser Pro Tyr Ser Lys Gly Lys Pro Asn
690 695 700
Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Ser Glu Xaa Asn Leu Lys
705 710 715 720
Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Ile Phe Tyr Arg Lys
725 730 735
Ala Ser Ile Lys Lys Lys Lys Ile Thr His Lys Ala Gly Glu Pro Ile
740 745 750
Lys Asn Lys Asn Asn Pro Lys Lys Glu Ser Lys Phe Glu Tyr Asp Ile
755 760 765
Ile Lys Asp Lys Arg Tyr Thr Glu Asp Lys Phe Phe Phe His Val Pro
770 775 780
Ile Thr Met Asn Phe Lys Ala Ser Gly Asn Xaa Xaa Phe Asn Asp Xaa
785 790 795 800
Val Asn Glu Tyr Ile Arg Glu Asn Asp Asp Val His Ile Ile Gly Ile
805 810 815
Asp Arg Gly Glu Arg Asn Leu Leu Tyr Tyr Ser Val Ile Asp Ser Lys
820 825 830
Gly Asn Ile Leu Glu Gln Asp Ser Leu Asn Ile Ile Asn Asn Lys Thr
835 840 845
Asp Tyr His Asp Leu Leu Asp Glu Arg Glu Lys Glu Arg Asp Lys Ala
850 855 860
Arg Lys Asn Trp Gln Thr Ile Glu Asn Ile Lys Glu Leu Lys Glu Gly
865 870 875 880
Tyr Leu Ser Gln Val Val His Lys Ile Ala Lys Leu Met Ile Lys Tyr
885 890 895
Asn Ala Ile Val Val Leu Glu Asp Leu Asn Phe Gly Phe Lys Arg Gly
900 905 910
Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys Met Leu
915 920 925
Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Asp Lys Glu Xaa Asp Glu
930 935 940
Ile Gly Gly Leu Leu Asn Ala Tyr Gln Leu Thr Asn Pro Phe Glu Ser
945 950 955 960
Phe Lys Lys Leu Gly Lys Gln Thr Gly Phe Xaa Phe Tyr Val Pro Ala
965 970 975
Trp Asn Thr Ser Lys Ile Asp Pro Thr Thr Gly Phe Val Asn Leu Phe
980 985 990
Tyr Pro Lys Tyr Glu Asn Val Asp Lys Ala Lys Glu Phe Phe Ser Lys
995 1000 1005
Phe Asp Ser Ile Arg Tyr Asn Asp Lys Asp Tyr Phe Glu Phe Ala
1010 1015 1020
Phe Asp Tyr Lys Asn Phe Thr Lys Lys Ala Glu Gly Ser Arg Thr
1025 1030 1035
Lys Trp Thr Ile Cys Thr Xaa Gly Glu Arg Ile Xaa Asn Phe Arg
1040 1045 1050
Asn Ser Asp Lys Asn Asn Lys Trp Asp Xaa Xaa Glu Ile Asp Leu
1055 1060 1065
Thr Glu Glu Leu Lys Glu Leu Phe Lys Asp Tyr Gly Ile Asn Tyr
1070 1075 1080
Gly Glu Asp Leu Lys Glu Ala Ile Cys Ser Glu Asp Asp Lys Asp
1085 1090 1095
Phe Phe Lys Ser Leu Leu Tyr Leu Leu Lys Leu Thr Leu Gln Met
1100 1105 1110
Arg Asn Ser Xaa Xaa Asp Asp Tyr Ile Ile Ser Pro Val Ala Asn
1115 1120 1125
Asp Asn Gly Xaa Phe Phe Asp Ser Arg Xaa Ala Lys Leu Pro Lys
1130 1135 1140
Asp Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu
1145 1150 1155
Trp Leu Leu Glu Gln Ile Lys Asn Thr Asp Glu Gly Lys Lys Ala
1160 1165 1170
Leu Ile Ser Asn Lys Glu Trp Leu Glu Phe Ala Gln Asn Arg Pro
1175 1180 1185
Tyr Leu Lys Asp Ala Xaa Ala Xaa Asn Lys Lys His
1190 1195 1200
<210> 1034
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1034
gugccacuuc ucagaucgcu cgcucaguga uccgac 36
<210> 1035
<211> 105
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1035
gucagaacac ugagcgagcg uucuuuuuga gaagcucaac gggcuuugcc accuggaaag 60
uggccauugg cacacccguu gaaaaaauuc uguccucuag acaga 105
<210> 1036
<211> 105
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1036
gucagaacac ugagcgagcg uucuuuuuga gaagcucaac gggcuuugcc accuggaaag 60
uggccauugg cacacccguu gaaaaaauuc uguccucuag acaga 105
<210> 1037
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1037
gugccacuuc ucagaucgcu cgcucaguga uccgac 36
<210> 1038
<211> 37
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1038
gugccaauca cccaacacug accaagcuug ccgagac 37
<210> 1039
<211> 64
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1039
cuuggggaaa gcuaggcaag uuuuggauga uaagaaauaa ucaugucaca aggagggagu 60
uuuu 64
<210> 1040
<211> 64
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1040
cuuggggaaa gcuaggcaag uuuuggauga uaagaaauaa ucaugucaca aggagggagu 60
uuuu 64
<210> 1041
<211> 37
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1041
gugccaauca cccaacacug accaagcuug ccgagac 37
<210> 1042
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1042
gccgcagcga augccguuuc acgaaucguc aggcgg 36
<210> 1043
<211> 75
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1043
gcuggagacg uuuuuugaaa cggcgagugc ugcggauagc gaguuucucu uggggaggcg 60
cucgcggcca cuuuu 75
<210> 1044
<211> 75
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1044
gcuggagacg uuuuuugaaa cggcgagugc ugcggauagc gaguuucucu uggggaggcg 60
cucgcggcca cuuuu 75
<210> 1045
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1045
gccgcagcga augccguuuc acgaaucguc aggcgg 36
<210> 1046
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1046
guccaagaaa aaagaaauga uacgaggcau uagcac 36
<210> 1047
<211> 107
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1047
cuggacgaug ucucuuuuau uucuuuuuuc uuggaucuga guacgagcac ccacauugga 60
cauuucgcau ggugggugcu cguacuauag guaaaacaaa ccuuuuu 107
<210> 1048
<211> 107
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1048
cuggacgaug ucucuuuuau uucuuuuuuc uuggaucuga guacgagcac ccacauugga 60
cauuucgcau ggugggugcu cguacuauag guaaaacaaa ccuuuuu 107
<210> 1049
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1049
guccaagaaa aaagaaauga uacgaggcau uagcac 36
<210> 1050
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1050
guucgaaagc uuaguggaaa gcuucguccu uagcac 36
<210> 1051
<211> 69
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1051
cacggauaau cacgacuuuc cacuaagcuu ucgaauuuua ugaugcgagc auccucucag 60
gucaaaaaa 69
<210> 1052
<211> 69
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1052
cacggauaau cacgacuuuc cacuaagcuu ucgaauuuua ugaugcgagc auccucucag 60
gucaaaaaa 69
<210> 1053
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1053
guucgaaagc uuaguggaaa gcuucguggu uagcac 36
<210> 1054
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1054
guauugagaa aagccagaua uaguuggcaa uagac 35
<210> 1055
<211> 62
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1055
auauuuugau ucccauuuau gguuauuuac cauaaauggg aaucaacuaa aaaauauuuu 60
uu 62
<210> 1056
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1056
guauugagaa aagccagaua uaguuggcaa uagac 35
<210> 1057
<211> 62
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1057
auauuuugau ucccauuuau gguuauuuac cauaaauggg aaucaacuaa aaaauauuuu 60
uu 62
<210> 1058
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1058
guugaugaga agagcccaag auagagggca auaac 35
<210> 1059
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1059
gcuggagaag auagcccaag aaagagggca auaac 35
<210> 1060
<211> 78
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1060
auuauuacca uuuugguugg aaugcuauua uaaaggauca uucgauuauu accucuaccu 60
cccuucccac gauuucuu 78
<210> 1061
<211> 78
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1061
attattacca ttttggttgg aatgctatta taaaggatca ttcgattatt acctctacct 60
cccttcccac gatttctt 78
<210> 1062
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1062
guugaugaga agagcccaag auagagggca auaac 35
<210> 1063
<211> 78
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1063
attattacca ttttggttgg aatgctatta taaaggatca ttcgattatt acctctacct 60
cccttcccac gatttctt 78
<210> 1064
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1064
gcuggagaag auagcccaag aaagagggca auaac 35
<210> 1065
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1065
guuuggagaa cagcccgaua uagagggcaa uagac 35
<210> 1066
<211> 81
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1066
gucuuacgac cucaguauua ggaagauuuc aaccaagaaa acuuaguuuc aggcuuaaug 60
aucgagucau gcagccaaag u 81
<210> 1067
<211> 81
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1067
gucuuacgac cucaguauua ggaagauuuc aaccaagaaa acuuaguuuc aggcuuaaug 60
aucgagucau gcagccaaag u 81
<210> 1068
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1068
guuuggagaa cagcccgaua uagagggcaa uagac 35
<210> 1069
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1069
guuuugagaa uagcccgaca uagagggcaa uagac 35
<210> 1070
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1070
guuaugaaaa cagcccgaca uagagggcaa uagaca 36
<210> 1071
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1071
guuauagucc ucuuacauuu agagguaguc uuuaau 36
<210> 1072
<211> 98
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1072
ucuuaagaac uucucuaccu gaaguuggau uauaaaugac ucuugcucuc auagauaucc 60
uccuuugaaa auauacacug ccgauuaauu accguuuu 98
<210> 1073
<211> 98
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1073
ucuuaagaac uucucuaccu gaaguuggau uauaaaugac ucuugcucuc auagauaucc 60
uccuuugaaa auauacacug ccgauuaauu accguuuu 98
<210> 1074
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1074
guuauagucc ucuuacauuu agagguaguc uuuaau 36
<210> 1075
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1075
guuauagucc ucuuacauuu agagguaguu uauauu 36
<210> 1076
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1076
guuauagucc ccuuacauuu agggguaguc uuuaau 36
<210> 1077
<211> 102
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1077
aauauaaauu cucccuaaau auaagagaau aauaacucaa ucucuucauu cguauuuugu 60
cuaguuaaga uaaguaccac caaauacaau caauccaaaa aa 102
<210> 1078
<211> 102
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1078
aauauaaauu cucccuaaau auaagagaau aauaacucaa ucucuucauu cguauuuugu 60
cuaguuaaga uaaguaccac caaauacaau caauccaaaa aa 102
<210> 1079
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1079
guuauagucc ucuuacauuu agagguaguu uauauu 36
<210> 1080
<211> 102
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1080
aauauaaauu cucccuaaau auaagagaau aauaacucaa ucucuucauu cguauuuugu 60
cuaguuaaga uaaguaccac caaauacaau caauccaaaa aa 102
<210> 1081
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1081
guuauagucc ccuuacauuu agggguaguc uuuaau 36
<210> 1082
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1082
guuguaguuc ccuucaauuu ugggauaauc cacaag 36
<210> 1083
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1083
guuuuagucc ucuuucauau agagguaguc ucuuac 36
<210> 1084
<211> 99
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1084
augaaaagag gacuaaaacu gaaagaggac uaaaacacca gauguggaua acuauauuag 60
uggcuauuaa aaauucgucg auauuagaga ggaaacuuu 99
<210> 1085
<211> 99
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1085
augaaaagag gacuaaaacu gaaagaggac uaaaacacca gauguggaua acuauauuag 60
uggcuauuaa aaauucgucg auauuagaga ggaaacuuu 99
<210> 1086
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1086
guuuuagucc ucuuucauau agagguaguc ucuuac 36
<210> 1087
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1087
guuuuagacc ucuucuauuu ugagguacuc uaaauc 36
<210> 1088
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1088
guuuuagucc ucuuuuguuu ugagguacuc uaaauc 36
<210> 1089
<211> 147
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1089
aagucagcgc acaacaaaga agaugacgaa caaaaucucu cgccaucuuc uuaaaauuau 60
uugccacaca gccaacauua uaagcguuaa aaccagcacc augaguacau uucacccaac 120
aaucagaauc cccguuucuc cguuuuu 147
<210> 1090
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1090
guuuuagucc ucuuuuguuu ugagguacuc uaaauc 36
<210> 1091
<211> 147
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1091
aagucagcgc acaacaaaga agaugacgaa caaaaucucu cgccaucuuc uuaaaauuau 60
uugccacaca gccaacauua uaagcguuaa aaccagcacc augaguacau uucacccaac 120
aaucagaauc cccguuucuc cguuuuu 147
<210> 1092
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1092
guuuuagauc ccuucguuuu ugggguuauc uauauc 36
<210> 1093
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1093
guuuuagucc ccuucguuuu ugggguaguc uaaauc 36
<210> 1094
<211> 113
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1094
gauuuagagc accccaaaag uaaugaaaau uugcaauuaa auaaggaaua uuaaaaaaau 60
gugauuuuaa aaaaauugaa gaaauuaaau gaaaaauugu ccaaguaaaa aaa 113
<210> 1095
<211> 70
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1095
auuuagauua ccccuuuaau uuauuuuacc auauuuuucu cauaaugcaa acuaauauuc 60
caaaauuuuu 70
<210> 1096
<211> 113
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1096
gauuuagagc accccaaaag uaaugaaaau uugcaauuaa auaaggaaua uuaaaaaaau 60
gugauuuuaa aaaaauugaa gaaauuaaau gaaaaauugu ccaaguaaaa aaa 113
<210> 1097
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1097
guuuuagucc ccuucguuuu ugggguaguc uaaauc 36
<210> 1098
<211> 70
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1098
auuuagauua ccccuuuaau uuauuuuacc auauuuuucu cauaaugcaa acuaauauuc 60
caaaauuuuu 70
<210> 1099
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1099
guuuuagucc ccuucguuuu ugggguaguc uaaauc 36
<210> 1100
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1100
guuuuagucc ccuucgauau uggggugguc uauauc 36
<210> 1101
<211> 95
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1101
auugaugugg uauacuaaaa auggaaaauu guauuuuuga uuagaaagau guaaaauuga 60
uuuaauuuaa aaauauuuua uuagauuaaa guaga 95
<210> 1102
<211> 95
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1102
auugaugugg uauacuaaaa auggaaaauu guauuuuuga uuagaaagau guaaaauuga 60
uuuaauuuaa aaauauuuua uuagauuaaa guaga 95
<210> 1103
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1103
guuuuagucc ccuucgauau uggggugguc uauauc 36
<210> 1104
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1104
guucaguccg ccgucgucuu ggcggugaug ugaggc 36
<210> 1105
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1105
guucaguccg ccgucauuuu ggcggugaug ugcucc 36
<210> 1106
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1106
guucaguccg ccgucgucuu ggcggugaug ugaggc 36
<210> 1107
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1107
guucaguccg ccgucauuuu ggcggugaug ugcucc 36
<210> 1108
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1108
guucaguccg ccgucgucuu ggcggugaug ugaggc 36
<210> 1109
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1109
guucaguccg ccgucauuuu ggcggugaug ugcucc 36
<210> 1110
<211> 1300
<212> БЕЛОК
<213> Francisella tularensis
<400> 1110
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Ile Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Glu Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Asp Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Lys Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Ser Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr Lys Gln Ser Ile Ser Lys His Pro Glu Trp Lys Asp
725 730 735
Phe Gly Phe Arg Phe Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu
740 745 750
Phe Tyr Arg Glu Val Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn
755 760 765
Ile Ser Glu Ser Tyr Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr
770 775 780
Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg
785 790 795 800
Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn
805 810 815
Leu Gln Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr
820 825 830
Arg Lys Gln Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
835 840 845
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Val Phe Glu
850 855 860
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
865 870 875 880
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
885 890 895
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
900 905 910
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
915 920 925
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
930 935 940
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
945 950 955 960
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
965 970 975
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
980 985 990
Ala Lys Leu Val Ile Glu Tyr Asn Ala Ile Val Val Phe Glu Asp Leu
995 1000 1005
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
1010 1015 1020
Tyr Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu
1025 1030 1035
Val Phe Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg
1040 1045 1050
Ala Tyr Gln Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly
1055 1060 1065
Lys Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser
1070 1075 1080
Lys Ile Cys Pro Val Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys
1085 1090 1095
Tyr Glu Ser Val Ser Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp
1100 1105 1110
Lys Ile Cys Tyr Asn Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe
1115 1120 1125
Asp Tyr Lys Asn Phe Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr
1130 1135 1140
Ile Ala Ser Phe Gly Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp
1145 1150 1155
Lys Asn His Asn Trp Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu
1160 1165 1170
Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly
1175 1180 1185
Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe
1190 1195 1200
Phe Ala Lys Leu Thr Ser Val Leu Asn Thr Ile Leu Gln Met Arg
1205 1210 1215
Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val
1220 1225 1230
Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
1235 1240 1245
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly
1250 1255 1260
Leu Lys Gly Leu Met Leu Leu Gly Arg Ile Lys Asn Asn Gln Glu
1265 1270 1275
Gly Lys Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu
1280 1285 1290
Phe Val Gln Asn Arg Asn Asn
1295 1300
<210> 1111
<211> 1477
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Peregrinibacteria bacterium
<400> 1111
Met Ser Asn Phe Phe Lys Asn Phe Thr Asn Leu Tyr Glu Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Asp Thr Leu Thr Asn Met
20 25 30
Lys Asp His Leu Glu Tyr Asp Glu Lys Leu Gln Thr Phe Leu Lys Asp
35 40 45
Gln Asn Ile Asp Asp Ala Tyr Gln Ala Leu Lys Pro Gln Phe Asp Glu
50 55 60
Ile His Glu Glu Phe Ile Thr Asp Ser Leu Glu Ser Lys Lys Ala Lys
65 70 75 80
Glu Ile Asp Phe Ser Glu Tyr Leu Asp Leu Phe Gln Glu Lys Lys Glu
85 90 95
Leu Asn Asp Ser Glu Lys Lys Leu Arg Asn Lys Ile Gly Glu Thr Phe
100 105 110
Asn Lys Ala Gly Glu Lys Trp Lys Lys Glu Lys Tyr Pro Gln Tyr Glu
115 120 125
Trp Lys Lys Gly Ser Lys Ile Ala Asn Gly Ala Asp Ile Leu Ser Cys
130 135 140
Gln Asp Met Leu Gln Phe Ile Lys Tyr Lys Asn Pro Glu Asp Glu Lys
145 150 155 160
Ile Lys Asn Tyr Ile Asp Asp Thr Leu Lys Gly Phe Phe Thr Tyr Phe
165 170 175
Gly Gly Phe Asn Gln Asn Arg Ala Asn Tyr Tyr Glu Thr Lys Lys Glu
180 185 190
Ala Ser Thr Ala Val Ala Thr Arg Ile Val His Glu Asn Leu Pro Lys
195 200 205
Phe Cys Asp Asn Val Ile Gln Phe Lys His Ile Ile Lys Arg Lys Lys
210 215 220
Asp Gly Thr Val Glu Lys Thr Glu Arg Lys Thr Glu Tyr Leu Asn Ala
225 230 235 240
Tyr Gln Tyr Leu Lys Asn Asn Asn Lys Ile Thr Gln Ile Lys Asp Ala
245 250 255
Glu Thr Glu Lys Met Ile Glu Ser Thr Pro Ile Ala Glu Lys Ile Phe
260 265 270
Asp Val Tyr Tyr Phe Ser Ser Cys Leu Ser Gln Lys Gln Ile Glu Glu
275 280 285
Tyr Asn Arg Ile Ile Gly His Tyr Asn Leu Leu Ile Asn Leu Tyr Asn
290 295 300
Gln Ala Lys Arg Ser Glu Gly Lys His Leu Ser Ala Asn Glu Lys Lys
305 310 315 320
Tyr Lys Asp Leu Pro Lys Phe Lys Thr Leu Tyr Lys Gln Ile Gly Cys
325 330 335
Gly Lys Lys Lys Asp Leu Phe Tyr Thr Ile Lys Cys Asp Thr Glu Glu
340 345 350
Glu Ala Asn Lys Ser Arg Asn Glu Gly Lys Glu Ser His Ser Val Glu
355 360 365
Glu Ile Ile Asn Lys Ala Gln Glu Ala Ile Asn Lys Tyr Phe Lys Ser
370 375 380
Asn Asn Asp Cys Glu Asn Ile Asn Thr Val Pro Asp Phe Ile Asn Tyr
385 390 395 400
Ile Leu Thr Lys Glu Asn Tyr Glu Gly Val Tyr Trp Ser Lys Ala Ala
405 410 415
Met Asn Thr Ile Ser Asp Lys Tyr Phe Ala Asn Tyr His Asp Leu Gln
420 425 430
Asp Arg Leu Lys Glu Ala Lys Val Phe Gln Lys Ala Asp Lys Lys Ser
435 440 445
Glu Asp Asp Ile Lys Ile Pro Glu Ala Ile Glu Leu Ser Gly Leu Phe
450 455 460
Gly Val Leu Asp Ser Leu Ala Asp Trp Gln Thr Thr Leu Phe Lys Ser
465 470 475 480
Ser Ile Leu Ser Asn Glu Asp Lys Leu Lys Ile Ile Thr Asp Ser Gln
485 490 495
Thr Pro Ser Glu Ala Leu Leu Lys Met Ile Phe Asn Asp Ile Glu Lys
500 505 510
Asn Met Glu Ser Phe Leu Lys Glu Thr Asn Asp Ile Ile Thr Leu Lys
515 520 525
Lys Tyr Lys Gly Asn Lys Glu Gly Thr Glu Lys Ile Lys Gln Trp Phe
530 535 540
Asp Tyr Thr Leu Ala Ile Asn Arg Met Leu Lys Tyr Phe Leu Val Lys
545 550 555 560
Glu Asn Lys Ile Lys Gly Asn Ser Leu Asp Thr Asn Ile Ser Glu Ala
565 570 575
Leu Lys Thr Leu Ile Tyr Ser Asp Asp Ala Glu Trp Phe Lys Trp Tyr
580 585 590
Asp Ala Leu Arg Asn Tyr Leu Thr Gln Lys Pro Gln Asp Glu Ala Lys
595 600 605
Glu Asn Lys Leu Lys Leu Asn Phe Asp Asn Pro Ser Leu Ala Gly Gly
610 615 620
Trp Asp Val Asn Lys Glu Cys Ser Asn Phe Cys Val Ile Leu Lys Asp
625 630 635 640
Lys Asn Glu Lys Lys Tyr Leu Ala Ile Met Lys Lys Gly Glu Asn Thr
645 650 655
Leu Phe Gln Lys Glu Trp Thr Glu Gly Arg Gly Lys Asn Leu Thr Lys
660 665 670
Lys Ser Asn Pro Leu Phe Glu Ile Asn Asn Cys Glu Ile Leu Ser Lys
675 680 685
Met Glu Tyr Asp Phe Trp Ala Asp Val Ser Lys Met Ile Pro Lys Cys
690 695 700
Ser Thr Gln Leu Lys Ala Val Val Asn His Phe Lys Gln Ser Asp Asn
705 710 715 720
Glu Phe Ile Phe Pro Ile Gly Tyr Lys Val Thr Ser Gly Glu Lys Phe
725 730 735
Arg Glu Glu Cys Lys Ile Ser Lys Gln Asp Phe Glu Leu Asn Asn Lys
740 745 750
Val Phe Asn Lys Asn Glu Leu Ser Val Thr Ala Met Arg Tyr Asp Leu
755 760 765
Ser Ser Thr Gln Glu Lys Gln Tyr Ile Lys Ala Phe Gln Lys Glu Tyr
770 775 780
Trp Glu Leu Leu Phe Lys Gln Glu Lys Arg Asp Thr Lys Leu Thr Asn
785 790 795 800
Asn Glu Ile Phe Asn Glu Trp Ile Asn Phe Cys Asn Lys Lys Tyr Ser
805 810 815
Glu Leu Leu Ser Trp Glu Arg Lys Tyr Lys Asp Ala Leu Thr Asn Trp
820 825 830
Ile Asn Phe Cys Lys Tyr Phe Leu Ser Lys Tyr Pro Lys Thr Thr Leu
835 840 845
Phe Asn Tyr Ser Phe Lys Glu Ser Glu Asn Tyr Asn Ser Leu Asp Glu
850 855 860
Phe Tyr Arg Asp Val Asp Ile Cys Ser Tyr Lys Leu Asn Ile Asn Thr
865 870 875 880
Thr Ile Asn Lys Ser Ile Leu Asp Arg Leu Val Glu Glu Gly Lys Leu
885 890 895
Tyr Leu Phe Glu Ile Lys Asn Gln Asp Ser Asn Asp Gly Lys Ser Ile
900 905 910
Gly His Lys Asn Asn Leu His Thr Ile Tyr Trp Asn Ala Ile Phe Glu
915 920 925
Asn Phe Asp Asn Arg Pro Lys Leu Asn Gly Glu Ala Glu Ile Phe Tyr
930 935 940
Arg Lys Ala Ile Ser Lys Asp Lys Leu Gly Ile Val Lys Gly Lys Lys
945 950 955 960
Thr Lys Asn Gly Thr Glu Ile Ile Lys Asn Tyr Arg Phe Ser Lys Glu
965 970 975
Lys Phe Ile Leu His Val Pro Ile Thr Leu Asn Phe Cys Ser Asn Asn
980 985 990
Glu Tyr Val Asn Asp Ile Val Asn Thr Lys Phe Tyr Asn Phe Ser Asn
995 1000 1005
Leu His Phe Leu Gly Ile Asp Arg Gly Glu Lys His Leu Ala Tyr
1010 1015 1020
Tyr Ser Leu Val Asn Lys Asn Gly Glu Ile Val Asp Gln Gly Thr
1025 1030 1035
Leu Asn Leu Pro Phe Thr Asp Lys Asp Gly Asn Gln Arg Ser Ile
1040 1045 1050
Lys Lys Glu Lys Tyr Phe Tyr Asn Lys Gln Glu Asp Lys Trp Glu
1055 1060 1065
Ala Lys Glu Val Asp Cys Trp Asn Tyr Asn Asp Leu Leu Asp Ala
1070 1075 1080
Met Ala Ser Asn Arg Asp Met Ala Arg Lys Asn Trp Gln Arg Ile
1085 1090 1095
Gly Thr Ile Lys Glu Ala Lys Asn Gly Tyr Val Ser Leu Val Ile
1100 1105 1110
Arg Lys Ile Ala Asp Leu Ala Val Asn Asn Glu Arg Pro Ala Phe
1115 1120 1125
Ile Val Leu Glu Asp Leu Asn Thr Gly Phe Lys Arg Ser Arg Gln
1130 1135 1140
Lys Ile Asp Lys Ser Val Tyr Gln Lys Phe Glu Leu Ala Leu Ala
1145 1150 1155
Lys Lys Leu Asn Phe Leu Val Asp Lys Asn Ala Lys Arg Asp Glu
1160 1165 1170
Ile Gly Ser Pro Thr Lys Ala Leu Gln Leu Thr Pro Pro Val Asn
1175 1180 1185
Asn Tyr Gly Asp Ile Glu Asn Lys Lys Gln Ala Gly Ile Met Leu
1190 1195 1200
Tyr Thr Arg Ala Asn Tyr Thr Ser Gln Thr Asp Pro Ala Thr Gly
1205 1210 1215
Trp Arg Lys Thr Ile Tyr Leu Lys Ala Gly Pro Glu Glu Thr Thr
1220 1225 1230
Tyr Lys Lys Asp Gly Lys Ile Lys Asn Lys Ser Val Lys Asp Gln
1235 1240 1245
Ile Ile Glu Thr Phe Thr Asp Ile Gly Phe Asp Gly Lys Asp Tyr
1250 1255 1260
Tyr Phe Glu Tyr Asp Lys Gly Glu Phe Val Asp Glu Lys Thr Gly
1265 1270 1275
Glu Ile Lys Pro Lys Lys Trp Arg Leu Tyr Ser Gly Glu Asn Gly
1280 1285 1290
Lys Ser Leu Asp Arg Phe Arg Gly Glu Arg Glu Lys Asp Lys Tyr
1295 1300 1305
Glu Trp Lys Ile Asp Lys Ile Asp Ile Val Lys Ile Leu Asp Asp
1310 1315 1320
Leu Phe Val Asn Phe Asp Lys Asn Ile Ser Leu Leu Lys Gln Leu
1325 1330 1335
Lys Glu Gly Val Glu Leu Thr Arg Asn Asn Glu His Gly Thr Gly
1340 1345 1350
Glu Ser Leu Arg Phe Ala Ile Asn Leu Ile Gln Gln Ile Arg Asn
1355 1360 1365
Thr Gly Asn Asn Glu Arg Asp Asn Asp Phe Ile Leu Ser Pro Val
1370 1375 1380
Arg Asp Glu Asn Gly Lys His Phe Asp Ser Arg Glu Tyr Trp Asp
1385 1390 1395
Lys Glu Thr Lys Gly Glu Lys Ile Ser Met Pro Ser Ser Gly Asp
1400 1405 1410
Ala Asn Gly Ala Phe Asn Ile Ala Arg Lys Gly Ile Ile Met Asn
1415 1420 1425
Ala His Ile Leu Ala Asn Ser Asp Ser Lys Asp Leu Ser Leu Phe
1430 1435 1440
Val Ser Asp Glu Glu Trp Asp Leu His Leu Asn Asn Lys Thr Glu
1445 1450 1455
Trp Lys Lys Gln Leu Asn Ile Phe Ser Ser Arg Lys Ala Met Ala
1460 1465 1470
Lys Arg Lys Lys
1475
<210> 1112
<211> 1477
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Peregrinibacteria bacterium
<400> 1112
Met Ser Asn Phe Phe Lys Asn Phe Thr Asn Leu Tyr Glu Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Asp Thr Leu Thr Asn Met
20 25 30
Lys Asp His Leu Glu Tyr Asp Glu Lys Leu Gln Thr Phe Leu Lys Asp
35 40 45
Gln Asn Ile Asp Asp Ala Tyr Gln Ala Leu Lys Pro Gln Phe Asp Glu
50 55 60
Ile His Glu Glu Phe Ile Thr Asp Ser Leu Glu Ser Lys Lys Ala Lys
65 70 75 80
Glu Ile Asp Phe Ser Glu Tyr Leu Asp Leu Phe Gln Glu Lys Lys Glu
85 90 95
Leu Asn Asp Ser Glu Lys Lys Leu Arg Asn Lys Ile Gly Glu Thr Phe
100 105 110
Asn Lys Ala Gly Glu Lys Trp Lys Lys Glu Lys Tyr Pro Gln Tyr Glu
115 120 125
Trp Lys Lys Gly Ser Lys Ile Ala Asn Gly Ala Asp Ile Leu Ser Cys
130 135 140
Gln Asp Met Leu Gln Phe Ile Lys Tyr Lys Asn Pro Glu Asp Glu Lys
145 150 155 160
Ile Lys Asn Tyr Ile Asp Asp Thr Leu Lys Gly Phe Phe Thr Tyr Phe
165 170 175
Gly Gly Phe Asn Gln Asn Arg Ala Asn Tyr Tyr Glu Thr Lys Lys Glu
180 185 190
Ala Ser Thr Ala Val Ala Thr Arg Ile Val His Glu Asn Leu Pro Lys
195 200 205
Phe Cys Asp Asn Val Ile Gln Phe Lys His Ile Ile Lys Arg Lys Lys
210 215 220
Asp Gly Thr Val Glu Lys Thr Glu Arg Lys Thr Glu Tyr Leu Asn Ala
225 230 235 240
Tyr Gln Tyr Leu Lys Asn Asn Asn Lys Ile Thr Gln Ile Lys Asp Ala
245 250 255
Glu Thr Glu Lys Met Ile Glu Ser Thr Pro Ile Ala Glu Lys Ile Phe
260 265 270
Asp Val Tyr Tyr Phe Ser Ser Cys Leu Ser Gln Lys Gln Ile Glu Glu
275 280 285
Tyr Asn Arg Ile Ile Gly His Tyr Asn Leu Leu Ile Asn Leu Tyr Asn
290 295 300
Gln Ala Lys Arg Ser Glu Gly Lys His Leu Ser Ala Asn Glu Lys Lys
305 310 315 320
Tyr Lys Asp Leu Pro Lys Phe Lys Thr Leu Tyr Lys Gln Ile Gly Cys
325 330 335
Gly Lys Lys Lys Asp Leu Phe Tyr Thr Ile Lys Cys Asp Thr Glu Glu
340 345 350
Glu Ala Asn Lys Ser Arg Asn Glu Gly Lys Glu Ser His Ser Val Glu
355 360 365
Glu Ile Ile Asn Lys Ala Gln Glu Ala Ile Asn Lys Tyr Phe Lys Ser
370 375 380
Asn Asn Asp Cys Glu Asn Ile Asn Thr Val Pro Asp Phe Ile Asn Tyr
385 390 395 400
Ile Leu Thr Lys Glu Asn Tyr Glu Gly Val Tyr Trp Ser Lys Ala Ala
405 410 415
Met Asn Thr Ile Ser Asp Lys Tyr Phe Ala Asn Tyr His Asp Leu Gln
420 425 430
Asp Arg Leu Lys Glu Ala Lys Val Phe Gln Lys Ala Asp Lys Lys Ser
435 440 445
Glu Asp Asp Ile Lys Ile Pro Glu Ala Ile Glu Leu Ser Gly Leu Phe
450 455 460
Gly Val Leu Asp Ser Leu Ala Asp Trp Gln Thr Thr Leu Phe Lys Ser
465 470 475 480
Ser Ile Leu Ser Asn Glu Asp Lys Leu Lys Ile Ile Thr Asp Ser Gln
485 490 495
Thr Pro Ser Glu Ala Leu Leu Lys Met Ile Phe Asn Asp Ile Glu Lys
500 505 510
Asn Met Glu Ser Phe Leu Lys Glu Thr Asn Asp Ile Ile Thr Leu Lys
515 520 525
Lys Tyr Lys Gly Asn Lys Glu Gly Thr Glu Lys Ile Lys Gln Trp Phe
530 535 540
Asp Tyr Thr Leu Ala Ile Asn Arg Met Leu Lys Tyr Phe Leu Val Lys
545 550 555 560
Glu Asn Lys Ile Lys Gly Asn Ser Leu Asp Thr Asn Ile Ser Glu Ala
565 570 575
Leu Lys Thr Leu Ile Tyr Ser Asp Asp Ala Glu Trp Phe Lys Trp Tyr
580 585 590
Asp Ala Leu Arg Asn Tyr Leu Thr Gln Lys Pro Gln Asp Glu Ala Lys
595 600 605
Glu Asn Lys Leu Lys Leu Asn Phe Asp Asn Pro Ser Leu Ala Gly Gly
610 615 620
Trp Asp Val Asn Lys Glu Cys Ser Asn Phe Cys Val Ile Leu Lys Asp
625 630 635 640
Lys Asn Glu Lys Lys Tyr Leu Ala Ile Met Lys Lys Gly Glu Asn Thr
645 650 655
Leu Phe Gln Lys Glu Trp Thr Glu Gly Arg Gly Lys Asn Leu Thr Lys
660 665 670
Lys Ser Asn Pro Leu Phe Glu Ile Asn Asn Cys Glu Ile Leu Ser Lys
675 680 685
Met Glu Tyr Asp Phe Trp Ala Asp Val Ser Lys Met Ile Pro Lys Cys
690 695 700
Ser Thr Gln Leu Lys Ala Val Val Asn His Phe Lys Gln Ser Asp Asn
705 710 715 720
Glu Phe Ile Phe Pro Ile Gly Tyr Lys Val Thr Ser Gly Glu Lys Phe
725 730 735
Arg Glu Glu Cys Lys Ile Ser Lys Gln Asp Phe Glu Leu Asn Asn Lys
740 745 750
Val Phe Asn Lys Asn Glu Leu Ser Val Thr Ala Met Arg Tyr Asp Leu
755 760 765
Ser Ser Thr Gln Glu Lys Gln Tyr Ile Lys Ala Phe Gln Lys Glu Tyr
770 775 780
Trp Glu Leu Leu Phe Lys Gln Glu Lys Arg Asp Thr Lys Leu Thr Asn
785 790 795 800
Asn Glu Ile Phe Asn Glu Trp Ile Asn Phe Cys Asn Lys Lys Tyr Ser
805 810 815
Glu Leu Leu Ser Trp Glu Arg Lys Tyr Lys Asp Ala Leu Thr Asn Trp
820 825 830
Ile Asn Phe Cys Lys Tyr Phe Leu Ser Lys Tyr Pro Lys Thr Thr Leu
835 840 845
Phe Asn Tyr Ser Phe Lys Glu Ser Glu Asn Tyr Asn Ser Leu Asp Glu
850 855 860
Phe Tyr Arg Asp Val Asp Ile Cys Ser Tyr Lys Leu Asn Ile Asn Thr
865 870 875 880
Thr Ile Asn Lys Ser Ile Leu Asp Arg Leu Val Glu Glu Gly Lys Leu
885 890 895
Tyr Leu Phe Glu Ile Lys Asn Gln Asp Ser Asn Asp Gly Lys Ser Ile
900 905 910
Gly His Lys Asn Asn Leu His Thr Ile Tyr Trp Asn Ala Ile Phe Glu
915 920 925
Asn Phe Asp Asn Arg Pro Lys Leu Asn Gly Glu Ala Glu Ile Phe Tyr
930 935 940
Arg Lys Ala Ile Ser Lys Asp Lys Leu Gly Ile Val Lys Gly Lys Lys
945 950 955 960
Thr Lys Asn Gly Thr Glu Ile Ile Lys Asn Tyr Arg Phe Ser Lys Glu
965 970 975
Lys Phe Ile Leu His Val Pro Ile Thr Leu Asn Phe Cys Ser Asn Asn
980 985 990
Glu Tyr Val Asn Asp Ile Val Asn Thr Lys Phe Tyr Asn Phe Ser Asn
995 1000 1005
Leu His Phe Leu Gly Ile Asp Arg Gly Glu Lys His Leu Ala Tyr
1010 1015 1020
Tyr Ser Leu Val Asn Lys Asn Gly Glu Ile Val Asp Gln Gly Thr
1025 1030 1035
Leu Asn Leu Pro Phe Thr Asp Lys Asp Gly Asn Gln Arg Ser Ile
1040 1045 1050
Lys Lys Glu Lys Tyr Phe Tyr Asn Lys Gln Glu Asp Lys Trp Glu
1055 1060 1065
Ala Lys Glu Val Asp Cys Trp Asn Tyr Asn Asp Leu Leu Asp Ala
1070 1075 1080
Met Ala Ser Asn Arg Asp Met Ala Arg Lys Asn Trp Gln Arg Ile
1085 1090 1095
Gly Thr Ile Lys Glu Ala Lys Asn Gly Tyr Val Ser Leu Val Ile
1100 1105 1110
Arg Lys Ile Ala Asp Leu Ala Val Asn Asn Glu Arg Pro Ala Phe
1115 1120 1125
Ile Val Leu Glu Asp Leu Asn Thr Gly Phe Lys Arg Ser Arg Gln
1130 1135 1140
Lys Ile Asp Lys Ser Val Tyr Gln Lys Phe Glu Leu Ala Leu Ala
1145 1150 1155
Lys Lys Leu Asn Phe Leu Val Asp Lys Asn Ala Lys Arg Asp Glu
1160 1165 1170
Ile Gly Ser Pro Thr Lys Ala Leu Gln Leu Thr Pro Pro Val Asn
1175 1180 1185
Asn Tyr Gly Asp Ile Glu Asn Lys Lys Gln Ala Gly Ile Met Leu
1190 1195 1200
Tyr Thr Arg Ala Asn Tyr Thr Ser Gln Thr Asp Pro Ala Thr Gly
1205 1210 1215
Trp Arg Lys Thr Ile Tyr Leu Lys Ala Gly Pro Glu Glu Thr Thr
1220 1225 1230
Tyr Lys Lys Asp Gly Lys Ile Lys Asn Lys Ser Val Lys Asp Gln
1235 1240 1245
Ile Ile Glu Thr Phe Thr Asp Ile Gly Phe Asp Gly Lys Asp Tyr
1250 1255 1260
Tyr Phe Glu Tyr Asp Lys Gly Glu Phe Val Asp Glu Lys Thr Gly
1265 1270 1275
Glu Ile Lys Pro Lys Lys Trp Arg Leu Tyr Ser Gly Glu Asn Gly
1280 1285 1290
Lys Ser Leu Asp Arg Phe Arg Gly Glu Arg Glu Lys Asp Lys Tyr
1295 1300 1305
Glu Trp Lys Ile Asp Lys Ile Asp Ile Val Lys Ile Leu Asp Asp
1310 1315 1320
Leu Phe Val Asn Phe Asp Lys Asn Ile Ser Leu Leu Lys Gln Leu
1325 1330 1335
Lys Glu Gly Val Glu Leu Thr Arg Asn Asn Glu His Gly Thr Gly
1340 1345 1350
Glu Ser Leu Arg Phe Ala Ile Asn Leu Ile Gln Gln Ile Arg Asn
1355 1360 1365
Thr Gly Asn Asn Glu Arg Asp Asn Asp Phe Ile Leu Ser Pro Val
1370 1375 1380
Arg Asp Glu Asn Gly Lys His Phe Asp Ser Arg Glu Tyr Trp Asp
1385 1390 1395
Lys Glu Thr Lys Gly Glu Lys Ile Ser Met Pro Ser Ser Gly Asp
1400 1405 1410
Ala Asn Gly Ala Phe Asn Ile Ala Arg Lys Gly Ile Ile Met Asn
1415 1420 1425
Ala His Ile Leu Ala Asn Ser Asp Ser Lys Asp Leu Ser Leu Phe
1430 1435 1440
Val Ser Asp Glu Glu Trp Asp Leu His Leu Asn Asn Lys Thr Glu
1445 1450 1455
Trp Lys Lys Gln Leu Asn Ile Phe Ser Ser Arg Lys Ala Met Ala
1460 1465 1470
Lys Arg Lys Lys
1475
<210> 1113
<211> 1477
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Peregrinibacteria bacterium
<400> 1113
Met Ser Asn Phe Phe Lys Asn Phe Thr Asn Leu Tyr Glu Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Asp Thr Leu Thr Asn Met
20 25 30
Lys Asp His Leu Glu Tyr Asp Glu Lys Leu Gln Thr Phe Leu Lys Asp
35 40 45
Gln Asn Ile Asp Asp Ala Tyr Gln Ala Leu Lys Pro Gln Phe Asp Glu
50 55 60
Ile His Glu Glu Phe Ile Thr Asp Ser Leu Glu Ser Lys Lys Ala Lys
65 70 75 80
Glu Ile Asp Phe Ser Glu Tyr Leu Asp Leu Phe Gln Glu Lys Lys Glu
85 90 95
Leu Asn Asp Ser Glu Lys Lys Leu Arg Asn Lys Ile Gly Glu Thr Phe
100 105 110
Asn Lys Ala Gly Glu Lys Trp Lys Lys Glu Lys Tyr Pro Gln Tyr Glu
115 120 125
Trp Lys Lys Gly Ser Lys Ile Ala Asn Gly Ala Asp Ile Leu Ser Cys
130 135 140
Gln Asp Met Leu Gln Phe Ile Lys Tyr Lys Asn Pro Glu Asp Glu Lys
145 150 155 160
Ile Lys Asn Tyr Ile Asp Asp Thr Leu Lys Gly Phe Phe Thr Tyr Phe
165 170 175
Gly Gly Phe Asn Gln Asn Arg Ala Asn Tyr Tyr Glu Thr Lys Lys Glu
180 185 190
Ala Ser Thr Ala Val Ala Thr Arg Ile Val His Glu Asn Leu Pro Lys
195 200 205
Phe Cys Asp Asn Val Ile Gln Phe Lys His Ile Ile Lys Arg Lys Lys
210 215 220
Asp Gly Thr Val Glu Lys Thr Glu Arg Lys Thr Glu Tyr Leu Asn Ala
225 230 235 240
Tyr Gln Tyr Leu Lys Asn Asn Asn Lys Ile Thr Gln Ile Lys Asp Ala
245 250 255
Glu Thr Glu Lys Met Ile Glu Ser Thr Pro Ile Ala Glu Lys Ile Phe
260 265 270
Asp Val Tyr Tyr Phe Ser Ser Cys Leu Ser Gln Lys Gln Ile Glu Glu
275 280 285
Tyr Asn Arg Ile Ile Gly His Tyr Asn Leu Leu Ile Asn Leu Tyr Asn
290 295 300
Gln Ala Lys Arg Ser Glu Gly Lys His Leu Ser Ala Asn Glu Lys Lys
305 310 315 320
Tyr Lys Asp Leu Pro Lys Phe Lys Thr Leu Tyr Lys Gln Ile Gly Cys
325 330 335
Gly Lys Lys Lys Asp Leu Phe Tyr Thr Ile Lys Cys Asp Thr Glu Glu
340 345 350
Glu Ala Asn Lys Ser Arg Asn Glu Gly Lys Glu Ser His Ser Val Glu
355 360 365
Glu Ile Ile Asn Lys Ala Gln Glu Ala Ile Asn Lys Tyr Phe Lys Ser
370 375 380
Asn Asn Asp Cys Glu Asn Ile Asn Thr Val Pro Asp Phe Ile Asn Tyr
385 390 395 400
Ile Leu Thr Lys Glu Asn Tyr Glu Gly Val Tyr Trp Ser Lys Ala Ala
405 410 415
Met Asn Thr Ile Ser Asp Lys Tyr Phe Ala Asn Tyr His Asp Leu Gln
420 425 430
Asp Arg Leu Lys Glu Ala Lys Val Phe Gln Lys Ala Asp Lys Lys Ser
435 440 445
Glu Asp Asp Ile Lys Ile Pro Glu Ala Ile Glu Leu Ser Gly Leu Phe
450 455 460
Gly Val Leu Asp Ser Leu Ala Asp Trp Gln Thr Thr Leu Phe Lys Ser
465 470 475 480
Ser Ile Leu Ser Asn Glu Asp Lys Leu Lys Ile Ile Thr Asp Ser Gln
485 490 495
Thr Pro Ser Glu Ala Leu Leu Lys Met Ile Phe Asn Asp Ile Glu Lys
500 505 510
Asn Met Glu Ser Phe Leu Lys Glu Thr Asn Asp Ile Ile Thr Leu Lys
515 520 525
Lys Tyr Lys Gly Asn Lys Glu Gly Thr Glu Lys Ile Lys Gln Trp Phe
530 535 540
Asp Tyr Thr Leu Ala Ile Asn Arg Met Leu Lys Tyr Phe Leu Val Lys
545 550 555 560
Glu Asn Lys Ile Lys Gly Asn Ser Leu Asp Thr Asn Ile Ser Glu Ala
565 570 575
Leu Lys Thr Leu Ile Tyr Ser Asp Asp Ala Glu Trp Phe Lys Trp Tyr
580 585 590
Asp Ala Leu Arg Asn Tyr Leu Thr Gln Lys Pro Gln Asp Glu Ala Lys
595 600 605
Glu Asn Lys Leu Lys Leu Asn Phe Asp Asn Pro Ser Leu Ala Gly Gly
610 615 620
Trp Asp Val Asn Lys Glu Cys Ser Asn Phe Cys Val Ile Leu Lys Asp
625 630 635 640
Lys Asn Glu Lys Lys Tyr Leu Ala Ile Met Lys Lys Gly Glu Asn Thr
645 650 655
Leu Phe Gln Lys Glu Trp Thr Glu Gly Arg Gly Lys Asn Leu Thr Lys
660 665 670
Lys Ser Asn Pro Leu Phe Glu Ile Asn Asn Cys Glu Ile Leu Ser Lys
675 680 685
Met Glu Tyr Asp Phe Trp Ala Asp Val Ser Lys Met Ile Pro Lys Cys
690 695 700
Ser Thr Gln Leu Lys Ala Val Val Asn His Phe Lys Gln Ser Asp Asn
705 710 715 720
Glu Phe Ile Phe Pro Ile Gly Tyr Lys Val Thr Ser Gly Glu Lys Phe
725 730 735
Arg Glu Glu Cys Lys Ile Ser Lys Gln Asp Phe Glu Leu Asn Asn Lys
740 745 750
Val Phe Asn Lys Asn Glu Leu Ser Val Thr Ala Met Arg Tyr Asp Leu
755 760 765
Ser Ser Thr Gln Glu Lys Gln Tyr Ile Lys Ala Phe Gln Lys Glu Tyr
770 775 780
Trp Glu Leu Leu Phe Lys Gln Glu Lys Arg Asp Thr Lys Leu Thr Asn
785 790 795 800
Asn Glu Ile Phe Asn Glu Trp Ile Asn Phe Cys Asn Lys Lys Tyr Ser
805 810 815
Glu Leu Leu Ser Trp Glu Arg Lys Tyr Lys Asp Ala Leu Thr Asn Trp
820 825 830
Ile Asn Phe Cys Lys Tyr Phe Leu Ser Lys Tyr Pro Lys Thr Thr Leu
835 840 845
Phe Asn Tyr Ser Phe Lys Glu Ser Glu Asn Tyr Asn Ser Leu Asp Glu
850 855 860
Phe Tyr Arg Asp Val Asp Ile Cys Ser Tyr Lys Leu Asn Ile Asn Thr
865 870 875 880
Thr Ile Asn Lys Ser Ile Leu Asp Arg Leu Val Glu Glu Gly Lys Leu
885 890 895
Tyr Leu Phe Glu Ile Lys Asn Gln Asp Ser Asn Asp Gly Lys Ser Ile
900 905 910
Gly His Lys Asn Asn Leu His Thr Ile Tyr Trp Asn Ala Ile Phe Glu
915 920 925
Asn Phe Asp Asn Arg Pro Lys Leu Asn Gly Glu Ala Glu Ile Phe Tyr
930 935 940
Arg Lys Ala Ile Ser Lys Asp Lys Leu Gly Ile Val Lys Gly Lys Lys
945 950 955 960
Thr Lys Asn Gly Thr Glu Ile Ile Lys Asn Tyr Arg Phe Ser Lys Glu
965 970 975
Lys Phe Ile Leu His Val Pro Ile Thr Leu Asn Phe Cys Ser Asn Asn
980 985 990
Glu Tyr Val Asn Asp Ile Val Asn Thr Lys Phe Tyr Asn Phe Ser Asn
995 1000 1005
Leu His Phe Leu Gly Ile Asp Arg Gly Glu Lys His Leu Ala Tyr
1010 1015 1020
Tyr Ser Leu Val Asn Lys Asn Gly Glu Ile Val Asp Gln Gly Thr
1025 1030 1035
Leu Asn Leu Pro Phe Thr Asp Lys Asp Gly Asn Gln Arg Ser Ile
1040 1045 1050
Lys Lys Glu Lys Tyr Phe Tyr Asn Lys Gln Glu Asp Lys Trp Glu
1055 1060 1065
Ala Lys Glu Val Asp Cys Trp Asn Tyr Asn Asp Leu Leu Asp Ala
1070 1075 1080
Met Ala Ser Asn Arg Asp Met Ala Arg Lys Asn Trp Gln Arg Ile
1085 1090 1095
Gly Thr Ile Lys Glu Ala Lys Asn Gly Tyr Val Ser Leu Val Ile
1100 1105 1110
Arg Lys Ile Ala Asp Leu Ala Val Asn Asn Glu Arg Pro Ala Phe
1115 1120 1125
Ile Val Leu Glu Asp Leu Asn Thr Gly Phe Lys Arg Ser Arg Gln
1130 1135 1140
Lys Ile Asp Lys Ser Val Tyr Gln Lys Phe Glu Leu Ala Leu Ala
1145 1150 1155
Lys Lys Leu Asn Phe Leu Val Asp Lys Asn Ala Lys Arg Asp Glu
1160 1165 1170
Ile Gly Ser Pro Thr Lys Ala Leu Gln Leu Thr Pro Pro Val Asn
1175 1180 1185
Asn Tyr Gly Asp Ile Glu Asn Lys Lys Gln Ala Gly Ile Met Leu
1190 1195 1200
Tyr Thr Arg Ala Asn Tyr Thr Ser Gln Thr Asp Pro Ala Thr Gly
1205 1210 1215
Trp Arg Lys Thr Ile Tyr Leu Lys Ala Gly Pro Glu Glu Thr Thr
1220 1225 1230
Tyr Lys Lys Asp Gly Lys Ile Lys Asn Lys Ser Val Lys Asp Gln
1235 1240 1245
Ile Ile Glu Thr Phe Thr Asp Ile Gly Phe Asp Gly Lys Asp Tyr
1250 1255 1260
Tyr Phe Glu Tyr Asp Lys Gly Glu Phe Val Asp Glu Lys Thr Gly
1265 1270 1275
Glu Ile Lys Pro Lys Lys Trp Arg Leu Tyr Ser Gly Glu Asn Gly
1280 1285 1290
Lys Ser Leu Asp Arg Phe Arg Gly Glu Arg Glu Lys Asp Lys Tyr
1295 1300 1305
Glu Trp Lys Ile Asp Lys Ile Asp Ile Val Lys Ile Leu Asp Asp
1310 1315 1320
Leu Phe Val Asn Phe Asp Lys Asn Ile Ser Leu Leu Lys Gln Leu
1325 1330 1335
Lys Glu Gly Val Glu Leu Thr Arg Asn Asn Glu His Gly Thr Gly
1340 1345 1350
Glu Ser Leu Arg Phe Ala Ile Asn Leu Ile Gln Gln Ile Arg Asn
1355 1360 1365
Thr Gly Asn Asn Glu Arg Asp Asn Asp Phe Ile Leu Ser Pro Val
1370 1375 1380
Arg Asp Glu Asn Gly Lys His Phe Asp Ser Arg Glu Tyr Trp Asp
1385 1390 1395
Lys Glu Thr Lys Gly Glu Lys Ile Ser Met Pro Ser Ser Gly Asp
1400 1405 1410
Ala Asn Gly Ala Phe Asn Ile Ala Arg Lys Gly Ile Ile Met Asn
1415 1420 1425
Ala His Ile Leu Ala Asn Ser Asp Ser Lys Asp Leu Ser Leu Phe
1430 1435 1440
Val Ser Asp Glu Glu Trp Asp Leu His Leu Asn Asn Lys Thr Glu
1445 1450 1455
Trp Lys Lys Gln Leu Asn Ile Phe Ser Ser Arg Lys Ala Met Ala
1460 1465 1470
Lys Arg Lys Lys
1475
<210> 1114
<211> 1403
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Falkowbacteria bacterium
<400> 1114
Met Leu Phe Phe Met Ser Thr Asp Ile Thr Asn Lys Pro Arg Glu Lys
1 5 10 15
Gly Val Phe Asp Asn Phe Thr Asn Leu Tyr Glu Phe Ser Lys Thr Leu
20 25 30
Thr Phe Gly Leu Ile Pro Leu Lys Trp Asp Asp Asn Lys Lys Met Ile
35 40 45
Val Glu Asp Glu Asp Phe Ser Val Leu Arg Lys Tyr Gly Val Ile Glu
50 55 60
Glu Asp Lys Arg Ile Ala Glu Ser Ile Lys Ile Ala Lys Phe Tyr Leu
65 70 75 80
Asn Ile Leu His Arg Glu Leu Ile Gly Lys Val Leu Gly Ser Leu Lys
85 90 95
Phe Glu Lys Lys Asn Leu Glu Asn Tyr Asp Arg Leu Leu Gly Glu Ile
100 105 110
Glu Lys Asn Asn Lys Asn Glu Asn Ile Ser Glu Asp Lys Lys Lys Glu
115 120 125
Ile Arg Lys Asn Phe Lys Lys Glu Leu Ser Ile Ala Gln Asp Ile Leu
130 135 140
Leu Lys Lys Val Gly Glu Val Phe Glu Ser Asn Gly Ser Gly Ile Leu
145 150 155 160
Ser Ser Lys Asn Cys Leu Asp Glu Leu Thr Lys Arg Phe Thr Arg Gln
165 170 175
Glu Val Asp Lys Leu Arg Arg Glu Asn Lys Asp Ile Gly Val Glu Tyr
180 185 190
Pro Asp Val Ala Tyr Arg Glu Lys Asp Gly Lys Glu Glu Thr Lys Ser
195 200 205
Phe Phe Ala Met Asp Val Gly Tyr Leu Asp Asp Phe His Lys Asn Arg
210 215 220
Lys Gln Leu Tyr Ser Val Lys Gly Lys Lys Asn Ser Leu Gly Arg Arg
225 230 235 240
Ile Leu Asp Asn Phe Glu Ile Phe Cys Lys Asn Lys Lys Leu Tyr Glu
245 250 255
Lys Tyr Lys Asn Leu Asp Ile Asp Phe Ser Glu Ile Glu Arg Asn Phe
260 265 270
Asn Leu Thr Leu Glu Lys Val Phe Asp Phe Asp Asn Tyr Asn Glu Arg
275 280 285
Leu Thr Gln Glu Gly Leu Asp Glu Tyr Ala Lys Ile Leu Gly Gly Glu
290 295 300
Ser Asn Lys Gln Glu Arg Thr Ala Asn Ile His Gly Leu Asn Gln Ile
305 310 315 320
Ile Asn Leu Tyr Ile Gln Lys Lys Gln Ser Glu Gln Lys Ala Glu Gln
325 330 335
Lys Glu Thr Gly Lys Lys Lys Ile Lys Phe Asn Lys Lys Asp Tyr Pro
340 345 350
Thr Phe Thr Cys Leu Gln Lys Gln Ile Leu Ser Gln Val Phe Arg Lys
355 360 365
Glu Ile Ile Ile Glu Ser Asp Arg Asp Leu Ile Arg Glu Leu Lys Phe
370 375 380
Phe Val Glu Glu Ser Lys Glu Lys Val Asp Lys Ala Arg Gly Ile Ile
385 390 395 400
Glu Phe Leu Leu Asn His Glu Glu Asn Asp Ile Asp Leu Ala Met Val
405 410 415
Tyr Leu Pro Lys Ser Lys Ile Asn Ser Phe Val Tyr Lys Val Phe Lys
420 425 430
Glu Pro Gln Asp Phe Leu Ser Val Phe Gln Asp Gly Ala Ser Asn Leu
435 440 445
Asp Phe Val Ser Phe Asp Lys Ile Lys Thr His Leu Glu Asn Asn Lys
450 455 460
Leu Thr Tyr Lys Ile Phe Phe Lys Thr Leu Ile Lys Glu Asn His Asp
465 470 475 480
Phe Glu Ser Phe Leu Ile Leu Leu Gln Gln Glu Ile Asp Leu Leu Ile
485 490 495
Asp Gly Gly Glu Thr Val Thr Leu Gly Gly Lys Lys Glu Ser Ile Thr
500 505 510
Ser Leu Asp Glu Lys Lys Asn Arg Leu Lys Glu Lys Leu Gly Trp Phe
515 520 525
Glu Gly Lys Val Arg Glu Asn Glu Lys Met Lys Asp Glu Glu Glu Gly
530 535 540
Glu Phe Cys Ser Thr Val Leu Ala Tyr Ser Gln Ala Val Leu Asn Ile
545 550 555 560
Thr Lys Arg Ala Glu Ile Phe Trp Leu Asn Glu Lys Gln Asp Ala Lys
565 570 575
Val Gly Glu Asp Asn Lys Asp Met Ile Phe Tyr Lys Lys Phe Asp Glu
580 585 590
Phe Ala Asp Asp Gly Phe Ala Pro Phe Phe Tyr Phe Asp Lys Phe Gly
595 600 605
Asn Tyr Leu Lys Arg Arg Ser Arg Asn Thr Thr Lys Glu Ile Lys Leu
610 615 620
His Phe Gly Asn Asp Asp Leu Leu Glu Gly Trp Asp Met Asn Lys Glu
625 630 635 640
Pro Glu Tyr Trp Ser Phe Ile Leu Arg Asp Arg Asn Gln Tyr Tyr Leu
645 650 655
Gly Ile Gly Lys Lys Asp Gly Glu Ile Phe His Lys Lys Leu Gly Asn
660 665 670
Ser Val Glu Ala Val Lys Glu Ala Tyr Glu Leu Glu Asn Glu Ala Asp
675 680 685
Phe Tyr Glu Lys Ile Asp Tyr Lys Gln Leu Asn Ile Asp Arg Phe Glu
690 695 700
Gly Ile Ala Phe Pro Lys Lys Thr Lys Thr Glu Glu Ala Phe Arg Gln
705 710 715 720
Val Cys Lys Lys Arg Ala Asp Glu Phe Leu Gly Gly Asp Thr Tyr Glu
725 730 735
Phe Lys Ile Leu Leu Ala Ile Lys Lys Glu Tyr Asp Asp Phe Lys Ala
740 745 750
Arg Arg Gln Lys Glu Lys Asp Trp Asp Ser Lys Phe Ser Lys Glu Lys
755 760 765
Met Ser Lys Leu Ile Glu Tyr Tyr Ile Thr Cys Leu Gly Lys Arg Asp
770 775 780
Asp Trp Lys Arg Phe Asn Leu Asn Phe Arg Gln Pro Lys Glu Tyr Glu
785 790 795 800
Asp Arg Ser Asp Phe Val Arg His Ile Gln Arg Gln Ala Tyr Trp Ile
805 810 815
Asp Pro Arg Lys Val Ser Lys Asp Tyr Val Asp Lys Lys Val Ala Glu
820 825 830
Gly Glu Met Phe Leu Phe Lys Val His Asn Lys Asp Phe Tyr Asp Phe
835 840 845
Glu Arg Lys Ser Glu Asp Lys Lys Asn His Thr Ala Asn Leu Phe Thr
850 855 860
Gln Tyr Leu Leu Glu Leu Phe Ser Cys Glu Asn Ile Lys Asn Ile Lys
865 870 875 880
Ser Lys Asp Leu Ile Glu Ser Ile Phe Glu Leu Asp Gly Lys Ala Glu
885 890 895
Ile Arg Phe Arg Pro Lys Thr Asp Asp Val Lys Leu Lys Ile Tyr Gln
900 905 910
Lys Lys Gly Lys Asp Val Thr Tyr Ala Asp Lys Arg Asp Gly Asn Lys
915 920 925
Glu Lys Glu Val Ile Gln His Arg Arg Phe Ala Lys Asp Ala Leu Thr
930 935 940
Leu His Leu Lys Ile Arg Leu Asn Phe Gly Lys His Val Asn Leu Phe
945 950 955 960
Asp Phe Asn Lys Leu Val Asn Thr Glu Leu Phe Ala Lys Val Pro Val
965 970 975
Lys Ile Leu Gly Met Asp Arg Gly Glu Asn Asn Leu Ile Tyr Tyr Cys
980 985 990
Phe Leu Asp Glu His Gly Glu Ile Glu Asn Gly Lys Cys Gly Ser Leu
995 1000 1005
Asn Arg Val Gly Glu Gln Ile Ile Thr Leu Glu Asp Asp Lys Lys
1010 1015 1020
Val Lys Glu Pro Val Asp Tyr Phe Gln Leu Leu Val Asp Arg Glu
1025 1030 1035
Gly Gln Arg Asp Trp Glu Gln Lys Asn Trp Gln Lys Met Thr Arg
1040 1045 1050
Ile Lys Asp Leu Lys Lys Ala Tyr Leu Gly Asn Val Val Ser Trp
1055 1060 1065
Ile Ser Lys Glu Met Leu Ser Gly Ile Lys Glu Gly Val Val Thr
1070 1075 1080
Ile Gly Val Leu Glu Asp Leu Asn Ser Asn Phe Lys Arg Thr Arg
1085 1090 1095
Phe Phe Arg Glu Arg Gln Val Tyr Gln Gly Phe Glu Lys Ala Leu
1100 1105 1110
Val Asn Lys Leu Gly Tyr Leu Val Asp Lys Lys Tyr Asp Asn Tyr
1115 1120 1125
Arg Asn Val Tyr Gln Phe Ala Pro Ile Val Asp Ser Val Glu Glu
1130 1135 1140
Met Glu Lys Asn Lys Gln Ile Gly Thr Leu Val Tyr Val Pro Ala
1145 1150 1155
Ser Tyr Thr Ser Lys Ile Cys Pro His Pro Lys Cys Gly Trp Arg
1160 1165 1170
Glu Arg Leu Tyr Met Lys Asn Ser Ala Ser Lys Glu Lys Ile Val
1175 1180 1185
Gly Leu Leu Lys Ser Asp Gly Ile Lys Ile Ser Tyr Asp Gln Lys
1190 1195 1200
Asn Asp Arg Phe Tyr Phe Glu Tyr Gln Trp Glu Gln Glu His Lys
1205 1210 1215
Ser Asp Gly Lys Lys Lys Lys Tyr Ser Gly Val Asp Lys Val Phe
1220 1225 1230
Ser Asn Val Ser Arg Met Arg Trp Asp Val Glu Gln Lys Lys Ser
1235 1240 1245
Ile Asp Phe Val Asp Gly Thr Asp Gly Ser Ile Thr Asn Lys Leu
1250 1255 1260
Lys Ser Leu Leu Lys Gly Lys Gly Ile Glu Leu Asp Asn Ile Asn
1265 1270 1275
Gln Gln Ile Val Asn Gln Gln Lys Glu Leu Gly Val Glu Phe Phe
1280 1285 1290
Gln Ser Ile Ile Phe Tyr Phe Asn Leu Ile Met Gln Ile Arg Asn
1295 1300 1305
Tyr Asp Lys Glu Lys Ser Gly Ser Glu Ala Asp Tyr Ile Gln Cys
1310 1315 1320
Pro Ser Cys Leu Phe Asp Ser Arg Lys Pro Glu Met Asn Gly Lys
1325 1330 1335
Leu Ser Ala Ile Thr Asn Gly Asp Ala Asn Gly Ala Tyr Asn Ile
1340 1345 1350
Ala Arg Lys Gly Phe Met Gln Leu Cys Arg Ile Arg Glu Asn Pro
1355 1360 1365
Gln Glu Pro Met Lys Leu Ile Thr Asn Arg Glu Trp Asp Glu Ala
1370 1375 1380
Val Arg Glu Trp Asp Ile Tyr Ser Ala Ala Gln Lys Ile Pro Val
1385 1390 1395
Leu Ser Glu Glu Asn
1400
<210> 1115
<211> 1403
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Falkowbacteria bacterium
<400> 1115
Met Leu Phe Phe Met Ser Thr Asp Ile Thr Asn Lys Pro Arg Glu Lys
1 5 10 15
Gly Val Phe Asp Asn Phe Thr Asn Leu Tyr Glu Phe Ser Lys Thr Leu
20 25 30
Thr Phe Gly Leu Ile Pro Leu Lys Trp Asp Asp Asn Lys Lys Met Ile
35 40 45
Val Glu Asp Glu Asp Phe Ser Val Leu Arg Lys Tyr Gly Val Ile Glu
50 55 60
Glu Asp Lys Arg Ile Ala Glu Ser Ile Lys Ile Ala Lys Phe Tyr Leu
65 70 75 80
Asn Ile Leu His Arg Glu Leu Ile Gly Lys Val Leu Gly Ser Leu Lys
85 90 95
Phe Glu Lys Lys Asn Leu Glu Asn Tyr Asp Arg Leu Leu Gly Glu Ile
100 105 110
Glu Lys Asn Asn Lys Asn Glu Asn Ile Ser Glu Asp Lys Lys Lys Glu
115 120 125
Ile Arg Lys Asn Phe Lys Lys Glu Leu Ser Ile Ala Gln Asp Ile Leu
130 135 140
Leu Lys Lys Val Gly Glu Val Phe Glu Ser Asn Gly Ser Gly Ile Leu
145 150 155 160
Ser Ser Lys Asn Cys Leu Asp Glu Leu Thr Lys Arg Phe Thr Arg Gln
165 170 175
Glu Val Asp Lys Leu Arg Arg Glu Asn Lys Asp Ile Gly Val Glu Tyr
180 185 190
Pro Asp Val Ala Tyr Arg Glu Lys Asp Gly Lys Glu Glu Thr Lys Ser
195 200 205
Phe Phe Ala Met Asp Val Gly Tyr Leu Asp Asp Phe His Lys Asn Arg
210 215 220
Lys Gln Leu Tyr Ser Val Lys Gly Lys Lys Asn Ser Leu Gly Arg Arg
225 230 235 240
Ile Leu Asp Asn Phe Glu Ile Phe Cys Lys Asn Lys Lys Leu Tyr Glu
245 250 255
Lys Tyr Lys Asn Leu Asp Ile Asp Phe Ser Glu Ile Glu Arg Asn Phe
260 265 270
Asn Leu Thr Leu Glu Lys Val Phe Asp Phe Asp Asn Tyr Asn Glu Arg
275 280 285
Leu Thr Gln Glu Gly Leu Asp Glu Tyr Ala Lys Ile Leu Gly Gly Glu
290 295 300
Ser Asn Lys Gln Glu Arg Thr Ala Asn Ile His Gly Leu Asn Gln Ile
305 310 315 320
Ile Asn Leu Tyr Ile Gln Lys Lys Gln Ser Glu Gln Lys Ala Glu Gln
325 330 335
Lys Glu Thr Gly Lys Lys Lys Ile Lys Phe Asn Lys Lys Asp Tyr Pro
340 345 350
Thr Phe Thr Cys Leu Gln Lys Gln Ile Leu Ser Gln Val Phe Arg Lys
355 360 365
Glu Ile Ile Ile Glu Ser Asp Arg Asp Leu Ile Arg Glu Leu Lys Phe
370 375 380
Phe Val Glu Glu Ser Lys Glu Lys Val Asp Lys Ala Arg Gly Ile Ile
385 390 395 400
Glu Phe Leu Leu Asn His Glu Glu Asn Asp Ile Asp Leu Ala Met Val
405 410 415
Tyr Leu Pro Lys Ser Lys Ile Asn Ser Phe Val Tyr Lys Val Phe Lys
420 425 430
Glu Pro Gln Asp Phe Leu Ser Val Phe Gln Asp Gly Ala Ser Asn Leu
435 440 445
Asp Phe Val Ser Phe Asp Lys Ile Lys Thr His Leu Glu Asn Asn Lys
450 455 460
Leu Thr Tyr Lys Ile Phe Phe Lys Thr Leu Ile Lys Glu Asn His Asp
465 470 475 480
Phe Glu Ser Phe Leu Ile Leu Leu Gln Gln Glu Ile Asp Leu Leu Ile
485 490 495
Asp Gly Gly Glu Thr Val Thr Leu Gly Gly Lys Lys Glu Ser Ile Thr
500 505 510
Ser Leu Asp Glu Lys Lys Asn Arg Leu Lys Glu Lys Leu Gly Trp Phe
515 520 525
Glu Gly Lys Val Arg Glu Asn Glu Lys Met Lys Asp Glu Glu Glu Gly
530 535 540
Glu Phe Cys Ser Thr Val Leu Ala Tyr Ser Gln Ala Val Leu Asn Ile
545 550 555 560
Thr Lys Arg Ala Glu Ile Phe Trp Leu Asn Glu Lys Gln Asp Ala Lys
565 570 575
Val Gly Glu Asp Asn Lys Asp Met Ile Phe Tyr Lys Lys Phe Asp Glu
580 585 590
Phe Ala Asp Asp Gly Phe Ala Pro Phe Phe Tyr Phe Asp Lys Phe Gly
595 600 605
Asn Tyr Leu Lys Arg Arg Ser Arg Asn Thr Thr Lys Glu Ile Lys Leu
610 615 620
His Phe Gly Asn Asp Asp Leu Leu Glu Gly Trp Asp Met Asn Lys Glu
625 630 635 640
Pro Glu Tyr Trp Ser Phe Ile Leu Arg Asp Arg Asn Gln Tyr Tyr Leu
645 650 655
Gly Ile Gly Lys Lys Asp Gly Glu Ile Phe His Lys Lys Leu Gly Asn
660 665 670
Ser Val Glu Ala Val Lys Glu Ala Tyr Glu Leu Glu Asn Glu Ala Asp
675 680 685
Phe Tyr Glu Lys Ile Asp Tyr Lys Gln Leu Asn Ile Asp Arg Phe Glu
690 695 700
Gly Ile Ala Phe Pro Lys Lys Thr Lys Thr Glu Glu Ala Phe Arg Gln
705 710 715 720
Val Cys Lys Lys Arg Ala Asp Glu Phe Leu Gly Gly Asp Thr Tyr Glu
725 730 735
Phe Lys Ile Leu Leu Ala Ile Lys Lys Glu Tyr Asp Asp Phe Lys Ala
740 745 750
Arg Arg Gln Lys Glu Lys Asp Trp Asp Ser Lys Phe Ser Lys Glu Lys
755 760 765
Met Ser Lys Leu Ile Glu Tyr Tyr Ile Thr Cys Leu Gly Lys Arg Asp
770 775 780
Asp Trp Lys Arg Phe Asn Leu Asn Phe Arg Gln Pro Lys Glu Tyr Glu
785 790 795 800
Asp Arg Ser Asp Phe Val Arg His Ile Gln Arg Gln Ala Tyr Trp Ile
805 810 815
Asp Pro Arg Lys Val Ser Lys Asp Tyr Val Asp Lys Lys Val Ala Glu
820 825 830
Gly Glu Met Phe Leu Phe Lys Val His Asn Lys Asp Phe Tyr Asp Phe
835 840 845
Glu Arg Lys Ser Glu Asp Lys Lys Asn His Thr Ala Asn Leu Phe Thr
850 855 860
Gln Tyr Leu Leu Glu Leu Phe Ser Cys Glu Asn Ile Lys Asn Ile Lys
865 870 875 880
Ser Lys Asp Leu Ile Glu Ser Ile Phe Glu Leu Asp Gly Lys Ala Glu
885 890 895
Ile Arg Phe Arg Pro Lys Thr Asp Asp Val Lys Leu Lys Ile Tyr Gln
900 905 910
Lys Lys Gly Lys Asp Val Thr Tyr Ala Asp Lys Arg Asp Gly Asn Lys
915 920 925
Glu Lys Glu Val Ile Gln His Arg Arg Phe Ala Lys Asp Ala Leu Thr
930 935 940
Leu His Leu Lys Ile Arg Leu Asn Phe Gly Lys His Val Asn Leu Phe
945 950 955 960
Asp Phe Asn Lys Leu Val Asn Thr Glu Leu Phe Ala Lys Val Pro Val
965 970 975
Lys Ile Leu Gly Met Asp Arg Gly Glu Asn Asn Leu Ile Tyr Tyr Cys
980 985 990
Phe Leu Asp Glu His Gly Glu Ile Glu Asn Gly Lys Cys Gly Ser Leu
995 1000 1005
Asn Arg Val Gly Glu Gln Ile Ile Thr Leu Glu Asp Asp Lys Lys
1010 1015 1020
Val Lys Glu Pro Val Asp Tyr Phe Gln Leu Leu Val Asp Arg Glu
1025 1030 1035
Gly Gln Arg Asp Trp Glu Gln Lys Asn Trp Gln Lys Met Thr Arg
1040 1045 1050
Ile Lys Asp Leu Lys Lys Ala Tyr Leu Gly Asn Val Val Ser Trp
1055 1060 1065
Ile Ser Lys Glu Met Leu Ser Gly Ile Lys Glu Gly Val Val Thr
1070 1075 1080
Ile Gly Val Leu Glu Asp Leu Asn Ser Asn Phe Lys Arg Thr Arg
1085 1090 1095
Phe Phe Arg Glu Arg Gln Val Tyr Gln Gly Phe Glu Lys Ala Leu
1100 1105 1110
Val Asn Lys Leu Gly Tyr Leu Val Asp Lys Lys Tyr Asp Asn Tyr
1115 1120 1125
Arg Asn Val Tyr Gln Phe Ala Pro Ile Val Asp Ser Val Glu Glu
1130 1135 1140
Met Glu Lys Asn Lys Gln Ile Gly Thr Leu Val Tyr Val Pro Ala
1145 1150 1155
Ser Tyr Thr Ser Lys Ile Cys Pro His Pro Lys Cys Gly Trp Arg
1160 1165 1170
Glu Arg Leu Tyr Met Lys Asn Ser Ala Ser Lys Glu Lys Ile Val
1175 1180 1185
Gly Leu Leu Lys Ser Asp Gly Ile Lys Ile Ser Tyr Asp Gln Lys
1190 1195 1200
Asn Asp Arg Phe Tyr Phe Glu Tyr Gln Trp Glu Gln Glu His Lys
1205 1210 1215
Ser Asp Gly Lys Lys Lys Lys Tyr Ser Gly Val Asp Lys Val Phe
1220 1225 1230
Ser Asn Val Ser Arg Met Arg Trp Asp Val Glu Gln Lys Lys Ser
1235 1240 1245
Ile Asp Phe Val Asp Gly Thr Asp Gly Ser Ile Thr Asn Lys Leu
1250 1255 1260
Lys Ser Leu Leu Lys Gly Lys Gly Ile Glu Leu Asp Asn Ile Asn
1265 1270 1275
Gln Gln Ile Val Asn Gln Gln Lys Glu Leu Gly Val Glu Phe Phe
1280 1285 1290
Gln Ser Ile Ile Phe Tyr Phe Asn Leu Ile Met Gln Ile Arg Asn
1295 1300 1305
Tyr Asp Lys Glu Lys Ser Gly Ser Glu Ala Asp Tyr Ile Gln Cys
1310 1315 1320
Pro Ser Cys Leu Phe Asp Ser Arg Lys Pro Glu Met Asn Gly Lys
1325 1330 1335
Leu Ser Ala Ile Thr Asn Gly Asp Ala Asn Gly Ala Tyr Asn Ile
1340 1345 1350
Ala Arg Lys Gly Phe Met Gln Leu Cys Arg Ile Arg Glu Asn Pro
1355 1360 1365
Gln Glu Pro Met Lys Leu Ile Thr Asn Arg Glu Trp Asp Glu Ala
1370 1375 1380
Val Arg Glu Trp Asp Ile Tyr Ser Ala Ala Gln Lys Ile Pro Val
1385 1390 1395
Leu Ser Glu Glu Asn
1400
<210> 1116
<211> 1352
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность бактерии группы Parcubacteria
<400> 1116
Met Glu Asn Ile Phe Asp Gln Phe Ile Gly Lys Tyr Ser Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Glu Asp Phe Leu
20 25 30
Lys Ile Asn Lys Val Phe Glu Lys Asp Gln Thr Ile Asp Asp Ser Tyr
35 40 45
Asn Gln Ala Lys Phe Tyr Phe Asp Ser Leu His Gln Lys Phe Ile Asp
50 55 60
Ala Ala Leu Ala Ser Asp Lys Thr Ser Glu Leu Ser Phe Gln Asn Phe
65 70 75 80
Ala Asp Val Leu Glu Lys Gln Asn Lys Ile Ile Leu Asp Lys Lys Arg
85 90 95
Glu Met Gly Ala Leu Arg Lys Arg Asp Lys Asn Ala Val Gly Ile Asp
100 105 110
Arg Leu Gln Lys Glu Ile Asn Asp Ala Glu Asp Ile Ile Gln Lys Glu
115 120 125
Lys Glu Lys Ile Tyr Lys Asp Val Arg Thr Leu Phe Asp Asn Glu Ala
130 135 140
Glu Ser Trp Lys Thr Tyr Tyr Gln Glu Arg Glu Val Asp Gly Lys Lys
145 150 155 160
Ile Thr Phe Ser Lys Ala Asp Leu Lys Gln Lys Gly Ala Asp Phe Leu
165 170 175
Thr Ala Ala Gly Ile Leu Lys Val Leu Lys Tyr Glu Phe Pro Glu Glu
180 185 190
Lys Glu Lys Glu Phe Gln Ala Lys Asn Gln Pro Ser Leu Phe Val Glu
195 200 205
Glu Lys Glu Asn Pro Gly Gln Lys Arg Tyr Ile Phe Asp Ser Phe Asp
210 215 220
Lys Phe Ala Gly Tyr Leu Thr Lys Phe Gln Gln Thr Lys Lys Asn Leu
225 230 235 240
Tyr Ala Ala Asp Gly Thr Ser Thr Ala Val Ala Thr Arg Ile Ala Asp
245 250 255
Asn Phe Ile Ile Phe His Gln Asn Thr Lys Val Phe Arg Asp Lys Tyr
260 265 270
Lys Asn Asn His Thr Asp Leu Gly Phe Asp Glu Glu Asn Ile Phe Glu
275 280 285
Ile Glu Arg Tyr Lys Asn Cys Leu Leu Gln Arg Glu Ile Glu His Ile
290 295 300
Lys Asn Glu Asn Ser Tyr Asn Lys Ile Ile Gly Arg Ile Asn Lys Lys
305 310 315 320
Ile Lys Glu Tyr Arg Asp Gln Lys Ala Lys Asp Thr Lys Leu Thr Lys
325 330 335
Ser Asp Phe Pro Phe Phe Lys Asn Leu Asp Lys Gln Ile Leu Gly Glu
340 345 350
Val Glu Lys Glu Lys Gln Leu Ile Glu Lys Thr Arg Glu Lys Thr Glu
355 360 365
Glu Asp Val Leu Ile Glu Arg Phe Lys Glu Phe Ile Glu Asn Asn Glu
370 375 380
Glu Arg Phe Thr Ala Ala Lys Lys Leu Met Asn Ala Phe Cys Asn Gly
385 390 395 400
Glu Phe Glu Ser Glu Tyr Glu Gly Ile Tyr Leu Lys Asn Lys Ala Ile
405 410 415
Asn Thr Ile Ser Arg Arg Trp Phe Val Ser Asp Arg Asp Phe Glu Leu
420 425 430
Lys Leu Pro Gln Gln Lys Ser Lys Asn Lys Ser Glu Lys Asn Glu Pro
435 440 445
Lys Val Lys Lys Phe Ile Ser Ile Ala Glu Ile Lys Asn Ala Val Glu
450 455 460
Glu Leu Asp Gly Asp Ile Phe Lys Ala Val Phe Tyr Asp Lys Lys Ile
465 470 475 480
Ile Ala Gln Gly Gly Ser Lys Leu Glu Gln Phe Leu Val Ile Trp Lys
485 490 495
Tyr Glu Phe Glu Tyr Leu Phe Arg Asp Ile Glu Arg Glu Asn Gly Glu
500 505 510
Lys Leu Leu Gly Tyr Asp Ser Cys Leu Lys Ile Ala Lys Gln Leu Gly
515 520 525
Ile Phe Pro Gln Glu Lys Glu Ala Arg Glu Lys Ala Thr Ala Val Ile
530 535 540
Lys Asn Tyr Ala Asp Ala Gly Leu Gly Ile Phe Gln Met Met Lys Tyr
545 550 555 560
Phe Ser Leu Asp Asp Lys Asp Arg Lys Asn Thr Pro Gly Gln Leu Ser
565 570 575
Thr Asn Phe Tyr Ala Glu Tyr Asp Gly Tyr Tyr Lys Asp Phe Glu Phe
580 585 590
Ile Lys Tyr Tyr Asn Glu Phe Arg Asn Phe Ile Thr Lys Lys Pro Phe
595 600 605
Asp Glu Asp Lys Ile Lys Leu Asn Phe Glu Asn Gly Ala Leu Leu Lys
610 615 620
Gly Trp Asp Glu Asn Lys Glu Tyr Asp Phe Met Gly Val Ile Leu Lys
625 630 635 640
Lys Glu Gly Arg Leu Tyr Leu Gly Ile Met His Lys Asn His Arg Lys
645 650 655
Leu Phe Gln Ser Met Gly Asn Ala Lys Gly Asp Asn Ala Asn Arg Tyr
660 665 670
Gln Lys Met Ile Tyr Lys Gln Ile Ala Asp Ala Ser Lys Asp Val Pro
675 680 685
Arg Leu Leu Leu Thr Ser Lys Lys Ala Met Glu Lys Phe Lys Pro Ser
690 695 700
Gln Glu Ile Leu Arg Ile Lys Lys Glu Lys Thr Phe Lys Arg Glu Ser
705 710 715 720
Lys Asn Phe Ser Leu Arg Asp Leu His Ala Leu Ile Glu Tyr Tyr Arg
725 730 735
Asn Cys Ile Pro Gln Tyr Ser Asn Trp Ser Phe Tyr Asp Phe Gln Phe
740 745 750
Gln Asp Thr Gly Lys Tyr Gln Asn Ile Lys Glu Phe Thr Asp Asp Val
755 760 765
Gln Lys Tyr Gly Tyr Lys Ile Ser Phe Arg Asp Ile Asp Asp Glu Tyr
770 775 780
Ile Asn Gln Ala Leu Asn Glu Gly Lys Met Tyr Leu Phe Glu Val Val
785 790 795 800
Asn Lys Asp Ile Tyr Asn Thr Lys Asn Gly Ser Lys Asn Leu His Thr
805 810 815
Leu Tyr Phe Glu His Ile Leu Ser Ala Glu Asn Leu Asn Asp Pro Val
820 825 830
Phe Lys Leu Ser Gly Met Ala Glu Ile Phe Gln Arg Gln Pro Ser Val
835 840 845
Asn Glu Arg Glu Lys Ile Thr Thr Gln Lys Asn Gln Cys Ile Leu Asp
850 855 860
Lys Gly Asp Arg Ala Tyr Lys Tyr Arg Arg Tyr Thr Glu Lys Lys Ile
865 870 875 880
Met Phe His Met Ser Leu Val Leu Asn Thr Gly Lys Gly Glu Ile Lys
885 890 895
Gln Val Gln Phe Asn Lys Ile Ile Asn Gln Arg Ile Ser Ser Ser Asp
900 905 910
Asn Glu Met Arg Val Asn Val Ile Gly Ile Asp Arg Gly Glu Lys Asn
915 920 925
Leu Leu Tyr Tyr Ser Val Val Lys Gln Asn Gly Glu Ile Ile Glu Gln
930 935 940
Ala Ser Leu Asn Glu Ile Asn Gly Val Asn Tyr Arg Asp Lys Leu Ile
945 950 955 960
Glu Arg Glu Lys Glu Arg Leu Lys Asn Arg Gln Ser Trp Lys Pro Val
965 970 975
Val Lys Ile Lys Asp Leu Lys Lys Gly Tyr Ile Ser His Val Ile His
980 985 990
Lys Ile Cys Gln Leu Ile Glu Lys Tyr Ser Ala Ile Val Val Leu Glu
995 1000 1005
Asp Leu Asn Met Arg Phe Lys Gln Ile Arg Gly Gly Ile Glu Arg
1010 1015 1020
Ser Val Tyr Gln Gln Phe Glu Lys Ala Leu Ile Asp Lys Leu Gly
1025 1030 1035
Tyr Leu Val Phe Lys Asp Asn Arg Asp Leu Arg Ala Pro Gly Gly
1040 1045 1050
Val Leu Asn Gly Tyr Gln Leu Ser Ala Pro Phe Val Ser Phe Glu
1055 1060 1065
Lys Met Arg Lys Gln Thr Gly Ile Leu Phe Tyr Thr Gln Ala Glu
1070 1075 1080
Tyr Thr Ser Lys Thr Asp Pro Ile Thr Gly Phe Arg Lys Asn Val
1085 1090 1095
Tyr Ile Ser Asn Ser Ala Ser Leu Asp Lys Ile Lys Glu Ala Val
1100 1105 1110
Lys Lys Phe Asp Ala Ile Gly Trp Asp Gly Lys Glu Gln Ser Tyr
1115 1120 1125
Phe Phe Lys Tyr Asn Pro Tyr Asn Leu Ala Asp Glu Lys Tyr Lys
1130 1135 1140
Asn Ser Thr Val Ser Lys Glu Trp Ala Ile Phe Ala Ser Ala Pro
1145 1150 1155
Arg Ile Arg Arg Gln Lys Gly Glu Asp Gly Tyr Trp Lys Tyr Asp
1160 1165 1170
Arg Val Lys Val Asn Glu Glu Phe Glu Lys Leu Leu Lys Val Trp
1175 1180 1185
Asn Phe Val Asn Pro Lys Ala Thr Asp Ile Lys Gln Glu Ile Ile
1190 1195 1200
Lys Lys Glu Lys Ala Gly Asp Leu Gln Gly Glu Lys Glu Leu Asp
1205 1210 1215
Gly Arg Leu Arg Asn Phe Trp His Ser Phe Ile Tyr Leu Phe Asn
1220 1225 1230
Leu Val Leu Glu Leu Arg Asn Ser Phe Ser Leu Gln Ile Lys Ile
1235 1240 1245
Lys Ala Gly Glu Val Ile Ala Val Asp Glu Gly Val Asp Phe Ile
1250 1255 1260
Ala Ser Pro Val Lys Pro Phe Phe Thr Thr Pro Asn Pro Tyr Ile
1265 1270 1275
Pro Ser Asn Leu Cys Trp Leu Ala Val Glu Asn Ala Asp Ala Asn
1280 1285 1290
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Val Met Ile Leu Lys Lys
1295 1300 1305
Ile Arg Glu His Ala Lys Lys Asp Pro Glu Phe Lys Lys Leu Pro
1310 1315 1320
Asn Leu Phe Ile Ser Asn Ala Glu Trp Asp Glu Ala Ala Arg Asp
1325 1330 1335
Trp Gly Lys Tyr Ala Gly Thr Thr Ala Leu Asn Leu Asp His
1340 1345 1350
<210> 1117
<211> 1331
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность бактерии группы Parcubacteria
<400> 1117
Met Lys Pro Val Gly Lys Thr Glu Asp Phe Leu Lys Ile Asn Lys Val
1 5 10 15
Phe Glu Lys Asp Gln Thr Ile Asp Asp Ser Tyr Asn Gln Ala Lys Phe
20 25 30
Tyr Phe Asp Ser Leu His Gln Lys Phe Ile Asp Ala Ala Leu Ala Ser
35 40 45
Asp Lys Thr Ser Glu Leu Ser Phe Gln Asn Phe Ala Asp Val Leu Glu
50 55 60
Lys Gln Asn Lys Ile Ile Leu Asp Lys Lys Arg Glu Met Gly Ala Leu
65 70 75 80
Arg Lys Arg Asp Lys Asn Ala Val Gly Ile Asp Arg Leu Gln Lys Glu
85 90 95
Ile Asn Asp Ala Glu Asp Ile Ile Gln Lys Glu Lys Glu Lys Ile Tyr
100 105 110
Lys Asp Val Arg Thr Leu Phe Asp Asn Glu Ala Glu Ser Trp Lys Thr
115 120 125
Tyr Tyr Gln Glu Arg Glu Val Asp Gly Lys Lys Ile Thr Phe Ser Lys
130 135 140
Ala Asp Leu Lys Gln Lys Gly Ala Asp Phe Leu Thr Ala Ala Gly Ile
145 150 155 160
Leu Lys Val Leu Lys Tyr Glu Phe Pro Glu Glu Lys Glu Lys Glu Phe
165 170 175
Gln Ala Lys Asn Gln Pro Ser Leu Phe Val Glu Glu Lys Glu Asn Pro
180 185 190
Gly Gln Lys Arg Tyr Ile Phe Asp Ser Phe Asp Lys Phe Ala Gly Tyr
195 200 205
Leu Thr Lys Phe Gln Gln Thr Lys Lys Asn Leu Tyr Ala Ala Asp Gly
210 215 220
Thr Ser Thr Ala Val Ala Thr Arg Ile Ala Asp Asn Phe Ile Ile Phe
225 230 235 240
His Gln Asn Thr Lys Val Phe Arg Asp Lys Tyr Lys Asn Asn His Thr
245 250 255
Asp Leu Gly Phe Asp Glu Glu Asn Ile Phe Glu Ile Glu Arg Tyr Lys
260 265 270
Asn Cys Leu Leu Gln Arg Glu Ile Glu His Ile Lys Asn Glu Asn Ser
275 280 285
Tyr Asn Lys Ile Ile Gly Arg Ile Asn Lys Lys Ile Lys Glu Tyr Arg
290 295 300
Asp Gln Lys Ala Lys Asp Thr Lys Leu Thr Lys Ser Asp Phe Pro Phe
305 310 315 320
Phe Lys Asn Leu Asp Lys Gln Ile Leu Gly Glu Val Glu Lys Glu Lys
325 330 335
Gln Leu Ile Glu Lys Thr Arg Glu Lys Thr Glu Glu Asp Val Leu Ile
340 345 350
Glu Arg Phe Lys Glu Phe Ile Glu Asn Asn Glu Glu Arg Phe Thr Ala
355 360 365
Ala Lys Lys Leu Met Asn Ala Phe Cys Asn Gly Glu Phe Glu Ser Glu
370 375 380
Tyr Glu Gly Ile Tyr Leu Lys Asn Lys Ala Ile Asn Thr Ile Ser Arg
385 390 395 400
Arg Trp Phe Val Ser Asp Arg Asp Phe Glu Leu Lys Leu Pro Gln Gln
405 410 415
Lys Ser Lys Asn Lys Ser Glu Lys Asn Glu Pro Lys Val Lys Lys Phe
420 425 430
Ile Ser Ile Ala Glu Ile Lys Asn Ala Val Glu Glu Leu Asp Gly Asp
435 440 445
Ile Phe Lys Ala Val Phe Tyr Asp Lys Lys Ile Ile Ala Gln Gly Gly
450 455 460
Ser Lys Leu Glu Gln Phe Leu Val Ile Trp Lys Tyr Glu Phe Glu Tyr
465 470 475 480
Leu Phe Arg Asp Ile Glu Arg Glu Asn Gly Glu Lys Leu Leu Gly Tyr
485 490 495
Asp Ser Cys Leu Lys Ile Ala Lys Gln Leu Gly Ile Phe Pro Gln Glu
500 505 510
Lys Glu Ala Arg Glu Lys Ala Thr Ala Val Ile Lys Asn Tyr Ala Asp
515 520 525
Ala Gly Leu Gly Ile Phe Gln Met Met Lys Tyr Phe Ser Leu Asp Asp
530 535 540
Lys Asp Arg Lys Asn Thr Pro Gly Gln Leu Ser Thr Asn Phe Tyr Ala
545 550 555 560
Glu Tyr Asp Gly Tyr Tyr Lys Asp Phe Glu Phe Ile Lys Tyr Tyr Asn
565 570 575
Glu Phe Arg Asn Phe Ile Thr Lys Lys Pro Phe Asp Glu Asp Lys Ile
580 585 590
Lys Leu Asn Phe Glu Asn Gly Ala Leu Leu Lys Gly Trp Asp Glu Asn
595 600 605
Lys Glu Tyr Asp Phe Met Gly Val Ile Leu Lys Lys Glu Gly Arg Leu
610 615 620
Tyr Leu Gly Ile Met His Lys Asn His Arg Lys Leu Phe Gln Ser Met
625 630 635 640
Gly Asn Ala Lys Gly Asp Asn Ala Asn Arg Tyr Gln Lys Met Ile Tyr
645 650 655
Lys Gln Ile Ala Asp Ala Ser Lys Asp Val Pro Arg Leu Leu Leu Thr
660 665 670
Ser Lys Lys Ala Met Glu Lys Phe Lys Pro Ser Gln Glu Ile Leu Arg
675 680 685
Ile Lys Lys Glu Lys Thr Phe Lys Arg Glu Ser Lys Asn Phe Ser Leu
690 695 700
Arg Asp Leu His Ala Leu Ile Glu Tyr Tyr Arg Asn Cys Ile Pro Gln
705 710 715 720
Tyr Ser Asn Trp Ser Phe Tyr Asp Phe Gln Phe Gln Asp Thr Gly Lys
725 730 735
Tyr Gln Asn Ile Lys Glu Phe Thr Asp Asp Val Gln Lys Tyr Gly Tyr
740 745 750
Lys Ile Ser Phe Arg Asp Ile Asp Asp Glu Tyr Ile Asn Gln Ala Leu
755 760 765
Asn Glu Gly Lys Met Tyr Leu Phe Glu Val Val Asn Lys Asp Ile Tyr
770 775 780
Asn Thr Lys Asn Gly Ser Lys Asn Leu His Thr Leu Tyr Phe Glu His
785 790 795 800
Ile Leu Ser Ala Glu Asn Leu Asn Asp Pro Val Phe Lys Leu Ser Gly
805 810 815
Met Ala Glu Ile Phe Gln Arg Gln Pro Ser Val Asn Glu Arg Glu Lys
820 825 830
Ile Thr Thr Gln Lys Asn Gln Cys Ile Leu Asp Lys Gly Asp Arg Ala
835 840 845
Tyr Lys Tyr Arg Arg Tyr Thr Glu Lys Lys Ile Met Phe His Met Ser
850 855 860
Leu Val Leu Asn Thr Gly Lys Gly Glu Ile Lys Gln Val Gln Phe Asn
865 870 875 880
Lys Ile Ile Asn Gln Arg Ile Ser Ser Ser Asp Asn Glu Met Arg Val
885 890 895
Asn Val Ile Gly Ile Asp Arg Gly Glu Lys Asn Leu Leu Tyr Tyr Ser
900 905 910
Val Val Lys Gln Asn Gly Glu Ile Ile Glu Gln Ala Ser Leu Asn Glu
915 920 925
Ile Asn Gly Val Asn Tyr Arg Asp Lys Leu Ile Glu Arg Glu Lys Glu
930 935 940
Arg Leu Lys Asn Arg Gln Ser Trp Lys Pro Val Val Lys Ile Lys Asp
945 950 955 960
Leu Lys Lys Gly Tyr Ile Ser His Val Ile His Lys Ile Cys Gln Leu
965 970 975
Ile Glu Lys Tyr Ser Ala Ile Val Val Leu Glu Asp Leu Asn Met Arg
980 985 990
Phe Lys Gln Ile Arg Gly Gly Ile Glu Arg Ser Val Tyr Gln Gln Phe
995 1000 1005
Glu Lys Ala Leu Ile Asp Lys Leu Gly Tyr Leu Val Phe Lys Asp
1010 1015 1020
Asn Arg Asp Leu Arg Ala Pro Gly Gly Val Leu Asn Gly Tyr Gln
1025 1030 1035
Leu Ser Ala Pro Phe Val Ser Phe Glu Lys Met Arg Lys Gln Thr
1040 1045 1050
Gly Ile Leu Phe Tyr Thr Gln Ala Glu Tyr Thr Ser Lys Thr Asp
1055 1060 1065
Pro Ile Thr Gly Phe Arg Lys Asn Val Tyr Ile Ser Asn Ser Ala
1070 1075 1080
Ser Leu Asp Lys Ile Lys Glu Ala Val Lys Lys Phe Asp Ala Ile
1085 1090 1095
Gly Trp Asp Gly Lys Glu Gln Ser Tyr Phe Phe Lys Tyr Asn Pro
1100 1105 1110
Tyr Asn Leu Ala Asp Glu Lys Tyr Lys Asn Ser Thr Val Ser Lys
1115 1120 1125
Glu Trp Ala Ile Phe Ala Ser Ala Pro Arg Ile Arg Arg Gln Lys
1130 1135 1140
Gly Glu Asp Gly Tyr Trp Lys Tyr Asp Arg Val Lys Val Asn Glu
1145 1150 1155
Glu Phe Glu Lys Leu Leu Lys Val Trp Asn Phe Val Asn Pro Lys
1160 1165 1170
Ala Thr Asp Ile Lys Gln Glu Ile Ile Lys Lys Glu Lys Ala Gly
1175 1180 1185
Asp Leu Gln Gly Glu Lys Glu Leu Asp Gly Arg Leu Arg Asn Phe
1190 1195 1200
Trp His Ser Phe Ile Tyr Leu Phe Asn Leu Val Leu Glu Leu Arg
1205 1210 1215
Asn Ser Phe Ser Leu Gln Ile Lys Ile Lys Ala Gly Glu Val Ile
1220 1225 1230
Ala Val Asp Glu Gly Val Asp Phe Ile Ala Ser Pro Val Lys Pro
1235 1240 1245
Phe Phe Thr Thr Pro Asn Pro Tyr Ile Pro Ser Asn Leu Cys Trp
1250 1255 1260
Leu Ala Val Glu Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala
1265 1270 1275
Arg Lys Gly Val Met Ile Leu Lys Lys Ile Arg Glu His Ala Lys
1280 1285 1290
Lys Asp Pro Glu Phe Lys Lys Leu Pro Asn Leu Phe Ile Ser Asn
1295 1300 1305
Ala Glu Trp Asp Glu Ala Ala Arg Asp Trp Gly Lys Tyr Ala Gly
1310 1315 1320
Thr Thr Ala Leu Asn Leu Asp His
1325 1330
<210> 1118
<211> 1285
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Roizmanbacteria bacterium
<400> 1118
Met Lys Ser Phe Asp Ser Phe Thr Asn Leu Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Lys Phe Glu Met Arg Pro Val Gly Asn Thr Gln Lys Met Leu Asp
20 25 30
Asn Ala Gly Val Phe Glu Lys Asp Lys Leu Ile Gln Lys Lys Tyr Gly
35 40 45
Lys Thr Lys Pro Tyr Phe Asp Arg Leu His Arg Glu Phe Ile Glu Glu
50 55 60
Ala Leu Thr Gly Val Glu Leu Ile Gly Leu Asp Glu Asn Phe Arg Thr
65 70 75 80
Leu Val Asp Trp Gln Lys Asp Lys Lys Asn Asn Val Ala Met Lys Ala
85 90 95
Tyr Glu Asn Ser Leu Gln Arg Leu Arg Thr Glu Ile Gly Lys Ile Phe
100 105 110
Asn Leu Lys Ala Glu Asp Trp Val Lys Asn Lys Tyr Pro Ile Leu Gly
115 120 125
Leu Lys Asn Lys Asn Thr Asp Ile Leu Phe Glu Glu Ala Val Phe Gly
130 135 140
Ile Leu Lys Ala Arg Tyr Gly Glu Glu Lys Asp Thr Phe Ile Glu Val
145 150 155 160
Glu Glu Ile Asp Lys Thr Gly Lys Ser Lys Ile Asn Gln Ile Ser Ile
165 170 175
Phe Asp Ser Trp Lys Gly Phe Thr Gly Tyr Phe Lys Lys Phe Phe Glu
180 185 190
Thr Arg Lys Asn Phe Tyr Lys Asn Asp Gly Thr Ser Thr Ala Ile Ala
195 200 205
Thr Arg Ile Ile Asp Gln Asn Leu Lys Arg Phe Ile Asp Asn Leu Ser
210 215 220
Ile Val Glu Ser Val Arg Gln Lys Val Asp Leu Ala Glu Thr Glu Lys
225 230 235 240
Ser Phe Ser Ile Ser Leu Ser Gln Phe Phe Ser Ile Asp Phe Tyr Asn
245 250 255
Lys Cys Leu Leu Gln Asp Gly Ile Asp Tyr Tyr Asn Lys Ile Ile Gly
260 265 270
Gly Glu Thr Leu Lys Asn Gly Glu Lys Leu Ile Gly Leu Asn Glu Leu
275 280 285
Ile Asn Gln Tyr Arg Gln Asn Asn Lys Asp Gln Lys Ile Pro Phe Phe
290 295 300
Lys Leu Leu Asp Lys Gln Ile Leu Ser Glu Lys Ile Leu Phe Leu Asp
305 310 315 320
Glu Ile Lys Asn Asp Thr Glu Leu Ile Glu Ala Leu Ser Gln Phe Ala
325 330 335
Lys Thr Ala Glu Glu Lys Thr Lys Ile Val Lys Lys Leu Phe Ala Asp
340 345 350
Phe Val Glu Asn Asn Ser Lys Tyr Asp Leu Ala Gln Ile Tyr Ile Ser
355 360 365
Gln Glu Ala Phe Asn Thr Ile Ser Asn Lys Trp Thr Ser Glu Thr Glu
370 375 380
Thr Phe Ala Lys Tyr Leu Phe Glu Ala Met Lys Ser Gly Lys Leu Ala
385 390 395 400
Lys Tyr Glu Lys Lys Asp Asn Ser Tyr Lys Phe Pro Asp Phe Ile Ala
405 410 415
Leu Ser Gln Met Lys Ser Ala Leu Leu Ser Ile Ser Leu Glu Gly His
420 425 430
Phe Trp Lys Glu Lys Tyr Tyr Lys Ile Ser Lys Phe Gln Glu Lys Thr
435 440 445
Asn Trp Glu Gln Phe Leu Ala Ile Phe Leu Tyr Glu Phe Asn Ser Leu
450 455 460
Phe Ser Asp Lys Ile Asn Thr Lys Asp Gly Glu Thr Lys Gln Val Gly
465 470 475 480
Tyr Tyr Leu Phe Ala Lys Asp Leu His Asn Leu Ile Leu Ser Glu Gln
485 490 495
Ile Asp Ile Pro Lys Asp Ser Lys Val Thr Ile Lys Asp Phe Ala Asp
500 505 510
Ser Val Leu Thr Ile Tyr Gln Met Ala Lys Tyr Phe Ala Val Glu Lys
515 520 525
Lys Arg Ala Trp Leu Ala Glu Tyr Glu Leu Asp Ser Phe Tyr Thr Gln
530 535 540
Pro Asp Thr Gly Tyr Leu Gln Phe Tyr Asp Asn Ala Tyr Glu Asp Ile
545 550 555 560
Val Gln Val Tyr Asn Lys Leu Arg Asn Tyr Leu Thr Lys Lys Pro Tyr
565 570 575
Ser Glu Glu Lys Trp Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn
580 585 590
Gly Trp Asp Lys Asn Lys Glu Ser Asp Asn Ser Ala Val Ile Leu Gln
595 600 605
Lys Gly Gly Lys Tyr Tyr Leu Gly Leu Ile Thr Lys Gly His Asn Lys
610 615 620
Ile Phe Asp Asp Arg Phe Gln Glu Lys Phe Ile Val Gly Ile Glu Gly
625 630 635 640
Gly Lys Tyr Glu Lys Ile Val Tyr Lys Phe Phe Pro Asp Gln Ala Lys
645 650 655
Met Phe Pro Lys Val Cys Phe Ser Ala Lys Gly Leu Glu Phe Phe Arg
660 665 670
Pro Ser Glu Glu Ile Leu Arg Ile Tyr Asn Asn Ala Glu Phe Lys Lys
675 680 685
Gly Glu Thr Tyr Ser Ile Asp Ser Met Gln Lys Leu Ile Asp Phe Tyr
690 695 700
Lys Asp Cys Leu Thr Lys Tyr Glu Gly Trp Ala Cys Tyr Thr Phe Arg
705 710 715 720
His Leu Lys Pro Thr Glu Glu Tyr Gln Asn Asn Ile Gly Glu Phe Phe
725 730 735
Arg Asp Val Ala Glu Asp Gly Tyr Arg Ile Asp Phe Gln Gly Ile Ser
740 745 750
Asp Gln Tyr Ile His Glu Lys Asn Glu Lys Gly Glu Leu His Leu Phe
755 760 765
Glu Ile His Asn Lys Asp Trp Asn Leu Asp Lys Ala Arg Asp Gly Lys
770 775 780
Ser Lys Thr Thr Gln Lys Asn Leu His Thr Leu Tyr Phe Glu Ser Leu
785 790 795 800
Phe Ser Asn Asp Asn Val Val Gln Asn Phe Pro Ile Lys Leu Asn Gly
805 810 815
Gln Ala Glu Ile Phe Tyr Arg Pro Lys Thr Glu Lys Asp Lys Leu Glu
820 825 830
Ser Lys Lys Asp Lys Lys Gly Asn Lys Val Ile Asp His Lys Arg Tyr
835 840 845
Ser Glu Asn Lys Ile Phe Phe His Val Pro Leu Thr Leu Asn Arg Thr
850 855 860
Lys Asn Asp Ser Tyr Arg Phe Asn Ala Gln Ile Asn Asn Phe Leu Ala
865 870 875 880
Asn Asn Lys Asp Ile Asn Ile Ile Gly Val Asp Arg Gly Glu Lys His
885 890 895
Leu Val Tyr Tyr Ser Val Ile Thr Gln Ala Ser Asp Ile Leu Glu Ser
900 905 910
Gly Ser Leu Asn Glu Leu Asn Gly Val Asn Tyr Ala Glu Lys Leu Gly
915 920 925
Lys Lys Ala Glu Asn Arg Glu Gln Ala Arg Arg Asp Trp Gln Asp Val
930 935 940
Gln Gly Ile Lys Asp Leu Lys Lys Gly Tyr Ile Ser Gln Val Val Arg
945 950 955 960
Lys Leu Ala Asp Leu Ala Ile Lys His Asn Ala Ile Ile Ile Leu Glu
965 970 975
Asp Leu Asn Met Arg Phe Lys Gln Val Arg Gly Gly Ile Glu Lys Ser
980 985 990
Ile Tyr Gln Gln Leu Glu Lys Ala Leu Ile Asp Lys Leu Ser Phe Leu
995 1000 1005
Val Asp Lys Gly Glu Lys Asn Pro Glu Gln Ala Gly His Leu Leu
1010 1015 1020
Lys Ala Tyr Gln Leu Ser Ala Pro Phe Glu Thr Phe Gln Lys Met
1025 1030 1035
Gly Lys Gln Thr Gly Ile Ile Phe Tyr Thr Gln Ala Ser Tyr Thr
1040 1045 1050
Ser Lys Ser Asp Pro Val Thr Gly Trp Arg Pro His Leu Tyr Leu
1055 1060 1065
Lys Tyr Phe Ser Ala Lys Lys Ala Lys Asp Asp Ile Ala Lys Phe
1070 1075 1080
Thr Lys Ile Glu Phe Val Asn Asp Arg Phe Glu Leu Thr Tyr Asp
1085 1090 1095
Ile Lys Asp Phe Gln Gln Ala Lys Glu Tyr Pro Asn Lys Thr Val
1100 1105 1110
Trp Lys Val Cys Ser Asn Val Glu Arg Phe Arg Trp Asp Lys Asn
1115 1120 1125
Leu Asn Gln Asn Lys Gly Gly Tyr Thr His Tyr Thr Asn Ile Thr
1130 1135 1140
Glu Asn Ile Gln Glu Leu Phe Thr Lys Tyr Gly Ile Asp Ile Thr
1145 1150 1155
Lys Asp Leu Leu Thr Gln Ile Ser Thr Ile Asp Glu Lys Gln Asn
1160 1165 1170
Thr Ser Phe Phe Arg Asp Phe Ile Phe Tyr Phe Asn Leu Ile Cys
1175 1180 1185
Gln Ile Arg Asn Thr Asp Asp Ser Glu Ile Ala Lys Lys Asn Gly
1190 1195 1200
Lys Asp Asp Phe Ile Leu Ser Pro Val Glu Pro Phe Phe Asp Ser
1205 1210 1215
Arg Lys Asp Asn Gly Asn Lys Leu Pro Glu Asn Gly Asp Asp Asn
1220 1225 1230
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Ile Val Ile Leu Asn Lys
1235 1240 1245
Ile Ser Gln Tyr Ser Glu Lys Asn Glu Asn Cys Glu Lys Met Lys
1250 1255 1260
Trp Gly Asp Leu Tyr Val Ser Asn Ile Asp Trp Asp Asn Phe Val
1265 1270 1275
Thr Gln Ala Asn Ala Arg His
1280 1285
<210> 1119
<211> 1247
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность некультивируемой бактерии
<400> 1119
Met Phe Lys Gly Asp Ala Phe Thr Gly Leu Tyr Glu Val Gln Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Val Pro Ile Gly Leu Thr Gln Ser Tyr Leu Glu
20 25 30
Asn Asp Trp Val Ile Gln Lys Asp Lys Glu Val Glu Glu Asn Tyr Gly
35 40 45
Lys Ile Lys Ala Tyr Phe Asp Leu Ile His Lys Glu Phe Val Arg Gln
50 55 60
Ser Leu Glu Asn Ala Trp Leu Cys Gln Leu Asp Asp Phe Tyr Glu Lys
65 70 75 80
Tyr Ile Glu Leu His Asn Ser Leu Glu Thr Arg Lys Asp Lys Asn Leu
85 90 95
Ala Lys Gln Phe Glu Lys Val Met Lys Ser Leu Lys Lys Glu Phe Val
100 105 110
Ser Phe Phe Asp Ala Lys Trp Asn Glu Trp Lys Gln Lys Phe Ser Phe
115 120 125
Leu Lys Lys Trp Trp Ile Asp Val Leu Asn Glu Lys Glu Val Leu Asp
130 135 140
Leu Met Ala Glu Phe Tyr Pro Asp Glu Lys Glu Leu Phe Asp Lys Phe
145 150 155 160
Asp Lys Phe Phe Thr Tyr Phe Ser Asn Phe Lys Glu Ser Arg Lys Asn
165 170 175
Phe Tyr Ala Asp Asp Gly Arg Ala Trp Ala Ile Ala Thr Arg Ala Ile
180 185 190
Asp Glu Asn Leu Ile Thr Phe Ile Lys Asn Ile Glu Asp Phe Lys Lys
195 200 205
Leu Asn Ser Ser Phe Arg Glu Phe Val Asn Asp Asn Phe Ser Glu Glu
210 215 220
Asp Lys Gln Ile Phe Glu Ile Asp Phe Tyr Asn Asn Cys Leu Leu Gln
225 230 235 240
Pro Trp Ile Asp Lys Tyr Asn Lys Ile Val Trp Trp Tyr Ser Leu Glu
245 250 255
Asn Trp Glu Lys Val Gln Trp Leu Asn Glu Lys Ile Asn Asn Phe Lys
260 265 270
Gln Asn Gln Asn Lys Ser Asn Ser Lys Asp Leu Lys Phe Pro Arg Met
275 280 285
Lys Leu Leu Tyr Lys Gln Ile Leu Gly Asp Lys Glu Lys Lys Val Tyr
290 295 300
Ile Asp Glu Ile Arg Asp Asp Lys Asn Leu Ile Asp Leu Ile Asp Asn
305 310 315 320
Ser Lys Arg Arg Asn Gln Ile Lys Ile Asp Asn Ala Asn Asp Ile Ile
325 330 335
Asn Asp Phe Ile Asn Asn Asn Ala Lys Phe Glu Leu Asp Lys Ile Tyr
340 345 350
Leu Thr Arg Gln Ser Ile Asn Thr Ile Ser Ser Lys Tyr Phe Ser Ser
355 360 365
Trp Asp Tyr Ile Arg Trp Tyr Phe Trp Thr Gly Glu Leu Gln Glu Phe
370 375 380
Val Ser Phe Tyr Asp Leu Lys Glu Thr Phe Trp Lys Ile Glu Tyr Glu
385 390 395 400
Thr Leu Glu Asn Ile Phe Lys Asp Cys Tyr Val Lys Gly Ile Asn Thr
405 410 415
Glu Ser Gln Asn Asn Ile Val Phe Glu Thr Gln Gly Ile Tyr Glu Asn
420 425 430
Phe Leu Asn Ile Phe Lys Phe Glu Phe Asn Gln Asn Ile Ser Gln Ile
435 440 445
Ser Leu Leu Glu Trp Glu Leu Asp Lys Ile Gln Asn Glu Asp Ile Lys
450 455 460
Lys Asn Glu Lys Gln Val Glu Val Ile Lys Asn Tyr Phe Asp Ser Val
465 470 475 480
Met Ser Val Tyr Lys Met Thr Lys Tyr Phe Ser Leu Glu Lys Trp Lys
485 490 495
Lys Arg Val Glu Leu Asp Thr Asp Asn Asn Phe Tyr Asn Asp Phe Asn
500 505 510
Glu Tyr Leu Glu Gly Phe Glu Ile Trp Lys Asp Tyr Asn Leu Val Arg
515 520 525
Asn Tyr Ile Thr Lys Lys Gln Val Asn Thr Asp Lys Ile Lys Leu Asn
530 535 540
Phe Asp Asn Ser Gln Phe Leu Thr Trp Trp Asp Lys Asp Lys Glu Asn
545 550 555 560
Glu Arg Leu Gly Ile Ile Leu Arg Arg Glu Trp Lys Tyr Tyr Leu Trp
565 570 575
Ile Leu Lys Lys Trp Asn Thr Leu Asn Phe Gly Asp Tyr Leu Gln Lys
580 585 590
Glu Trp Glu Ile Phe Tyr Glu Lys Met Asn Tyr Lys Gln Leu Asn Asn
595 600 605
Val Tyr Arg Gln Leu Pro Arg Leu Leu Phe Pro Leu Thr Lys Lys Leu
610 615 620
Asn Glu Leu Lys Trp Asp Glu Leu Lys Lys Tyr Leu Ser Lys Tyr Ile
625 630 635 640
Gln Asn Phe Trp Tyr Asn Glu Glu Ile Ala Gln Ile Lys Ile Glu Phe
645 650 655
Asp Ile Phe Gln Glu Ser Lys Glu Lys Trp Glu Lys Phe Asp Ile Asp
660 665 670
Lys Leu Arg Lys Leu Ile Glu Tyr Tyr Lys Lys Trp Val Leu Ala Leu
675 680 685
Tyr Ser Asp Leu Tyr Asp Leu Glu Phe Ile Lys Tyr Lys Asn Tyr Asp
690 695 700
Asp Leu Ser Ile Phe Tyr Ser Asp Val Glu Lys Lys Met Tyr Asn Leu
705 710 715 720
Asn Phe Thr Lys Ile Asp Lys Ser Leu Ile Asp Gly Lys Val Lys Ser
725 730 735
Trp Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Glu Ser
740 745 750
Lys Lys Glu Trp Ser Thr Glu Asn Ile His Thr Lys Tyr Phe Lys Leu
755 760 765
Leu Phe Asn Glu Lys Asn Leu Gln Asn Leu Val Val Lys Leu Ser Trp
770 775 780
Trp Ala Asp Ile Phe Phe Arg Asp Lys Thr Glu Asn Leu Lys Phe Lys
785 790 795 800
Lys Asp Lys Asn Gly Gln Glu Ile Leu Asp His Arg Arg Phe Ser Gln
805 810 815
Asp Lys Ile Met Phe His Ile Ser Ile Thr Leu Asn Ala Asn Cys Trp
820 825 830
Asp Lys Tyr Trp Phe Asn Gln Tyr Val Asn Glu Tyr Met Asn Lys Glu
835 840 845
Arg Asp Ile Lys Ile Ile Trp Ile Asp Arg Trp Glu Lys His Leu Ala
850 855 860
Tyr Tyr Cys Val Ile Asp Lys Ser Trp Lys Ile Phe Asn Asn Glu Ile
865 870 875 880
Trp Thr Leu Asn Glu Leu Asn Trp Val Asn Tyr Leu Glu Lys Leu Glu
885 890 895
Lys Ile Glu Ser Ser Arg Lys Asp Ser Arg Ile Ser Trp Trp Glu Ile
900 905 910
Glu Asn Ile Lys Glu Leu Lys Asn Gly Tyr Ile Ser Gln Val Ile Asn
915 920 925
Lys Leu Thr Glu Leu Ile Val Lys Tyr Asn Ala Ile Ile Val Phe Glu
930 935 940
Asp Leu Asn Ile Trp Phe Lys Arg Trp Arg Gln Lys Ile Glu Lys Gln
945 950 955 960
Ile Tyr Gln Lys Leu Glu Leu Ala Leu Ala Lys Lys Leu Asn Tyr Leu
965 970 975
Thr Gln Lys Asp Lys Lys Asp Asp Glu Ile Leu Trp Asn Leu Lys Ala
980 985 990
Leu Gln Leu Val Pro Lys Val Asn Asp Tyr Gln Asp Ile Trp Asn Tyr
995 1000 1005
Lys Gln Ser Trp Ile Met Phe Tyr Val Arg Ala Asn Tyr Thr Ser
1010 1015 1020
Val Thr Cys Pro Asn Cys Trp Leu Arg Lys Asn Leu Tyr Ile Ser
1025 1030 1035
Asn Ser Ala Thr Lys Glu Asn Gln Lys Lys Ser Leu Asn Ser Ile
1040 1045 1050
Ala Ile Lys Tyr Asn Asp Trp Lys Phe Ser Phe Ser Tyr Glu Ile
1055 1060 1065
Asp Asp Lys Ser Trp Lys Gln Lys Gln Ser Leu Asn Lys Lys Lys
1070 1075 1080
Phe Ile Val Tyr Ser Asp Ile Glu Arg Phe Val Tyr Ser Pro Leu
1085 1090 1095
Glu Lys Leu Thr Lys Val Ile Asp Val Asn Lys Lys Leu Leu Glu
1100 1105 1110
Leu Phe Arg Asp Phe Asn Leu Ser Leu Asp Ile Asn Lys Gln Ile
1115 1120 1125
Gln Glu Lys Asp Leu Asp Ser Val Phe Phe Lys Ser Leu Thr His
1130 1135 1140
Leu Phe Asn Leu Ile Leu Gln Leu Arg Asn Ser Asp Ser Lys Asp
1145 1150 1155
Asn Lys Asp Tyr Ile Ser Cys Pro Ser Cys Tyr Tyr His Ser Asn
1160 1165 1170
Asn Trp Leu Gln Trp Phe Glu Phe Asn Trp Asp Ala Asn Trp Ala
1175 1180 1185
Tyr Asn Ile Ala Arg Lys Gly Ile Ile Leu Leu Asp Arg Ile Arg
1190 1195 1200
Lys Asn Gln Glu Lys Pro Asp Leu Tyr Val Ser Asp Ile Asp Trp
1205 1210 1215
Asp Asn Phe Val Gln Ser Asn Gln Phe Pro Asn Thr Ile Ile Pro
1220 1225 1230
Ile Gln Asn Ile Glu Lys Gln Val Pro Leu Asn Ile Lys Ile
1235 1240 1245
<210> 1120
<211> 1219
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность бактерии кандидатного отдела WS6
<400> 1120
Met Lys Asn Val Phe Gly Gly Phe Thr Asn Leu Tyr Ser Leu Thr Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Thr Ser Lys Thr Gln Lys Leu Met
20 25 30
Lys Arg Asn Asn Val Ile Gln Thr Asp Glu Glu Ile Asp Lys Leu Tyr
35 40 45
His Asp Glu Met Lys Pro Ile Leu Asp Glu Ile His Arg Arg Phe Ile
50 55 60
Asn Asp Ala Leu Ala Gln Lys Ile Phe Ile Ser Ala Ser Leu Asp Asn
65 70 75 80
Phe Leu Lys Val Val Lys Asn Tyr Lys Val Glu Ser Ala Lys Lys Asn
85 90 95
Ile Lys Gln Asn Gln Val Lys Leu Leu Gln Lys Glu Ile Thr Ile Lys
100 105 110
Thr Leu Gly Leu Arg Arg Glu Val Val Ser Gly Phe Ile Thr Val Ser
115 120 125
Lys Lys Trp Lys Asp Lys Tyr Val Gly Leu Gly Ile Lys Leu Lys Gly
130 135 140
Asp Gly Tyr Lys Val Leu Thr Glu Gln Ala Val Leu Asp Ile Leu Lys
145 150 155 160
Ile Glu Phe Pro Asn Lys Ala Lys Tyr Ile Asp Lys Phe Arg Gly Phe
165 170 175
Trp Thr Tyr Phe Ser Gly Phe Asn Glu Asn Arg Lys Asn Tyr Tyr Ser
180 185 190
Glu Glu Asp Lys Ala Thr Ser Ile Ala Asn Arg Ile Val Asn Glu Asn
195 200 205
Leu Ser Arg Tyr Ile Asp Asn Ile Ile Ala Phe Glu Glu Ile Leu Gln
210 215 220
Lys Ile Pro Asn Leu Lys Lys Phe Lys Gln Asp Leu Asp Ile Thr Ser
225 230 235 240
Tyr Asn Tyr Tyr Leu Asn Gln Ala Gly Ile Asp Lys Tyr Asn Lys Ile
245 250 255
Ile Gly Gly Tyr Ile Val Asp Lys Asp Lys Lys Ile Gln Gly Ile Asn
260 265 270
Glu Lys Val Asn Leu Tyr Thr Gln Gln Thr Lys Lys Lys Leu Pro Lys
275 280 285
Leu Lys Phe Leu Phe Lys Gln Ile Gly Ser Glu Arg Lys Gly Phe Gly
290 295 300
Ile Phe Glu Ile Lys Glu Gly Lys Glu Trp Glu Gln Leu Gly Asp Leu
305 310 315 320
Phe Lys Leu Gln Arg Thr Lys Ile Asn Ser Asn Gly Arg Glu Lys Gly
325 330 335
Leu Phe Asp Ser Leu Arg Thr Met Tyr Arg Glu Phe Phe Asp Glu Ile
340 345 350
Lys Arg Asp Ser Asn Ser Gln Ala Arg Tyr Ser Leu Asp Lys Ile Tyr
355 360 365
Phe Asn Lys Ala Ser Val Asn Thr Ile Ser Asn Ser Trp Phe Thr Asn
370 375 380
Trp Asn Lys Phe Ala Glu Leu Leu Asn Ile Lys Glu Asp Lys Lys Asn
385 390 395 400
Gly Glu Lys Lys Ile Pro Glu Gln Ile Ser Ile Glu Asp Ile Lys Asp
405 410 415
Ser Leu Ser Ile Ile Pro Lys Glu Asn Leu Glu Glu Leu Phe Lys Leu
420 425 430
Thr Asn Arg Glu Lys His Asp Arg Thr Arg Phe Phe Gly Ser Asn Ala
435 440 445
Trp Val Thr Phe Leu Asn Ile Trp Gln Asn Glu Ile Glu Glu Ser Phe
450 455 460
Asn Lys Leu Glu Glu Lys Glu Lys Asp Phe Lys Lys Asn Ala Ala Ile
465 470 475 480
Lys Phe Gln Lys Asn Asn Leu Val Gln Lys Asn Tyr Ile Lys Glu Val
485 490 495
Cys Asp Arg Met Leu Ala Ile Glu Arg Met Ala Lys Tyr His Leu Pro
500 505 510
Lys Asp Ser Asn Leu Ser Arg Glu Glu Asp Phe Tyr Trp Ile Ile Asp
515 520 525
Asn Leu Ser Glu Gln Arg Glu Ile Tyr Lys Tyr Tyr Asn Ala Phe Arg
530 535 540
Asn Tyr Ile Ser Lys Lys Pro Tyr Asn Lys Ser Lys Met Lys Leu Asn
545 550 555 560
Phe Glu Asn Gly Asn Leu Leu Gly Gly Trp Ser Asp Gly Gln Glu Arg
565 570 575
Asn Lys Ala Gly Val Ile Leu Arg Asn Gly Asn Lys Tyr Tyr Leu Gly
580 585 590
Val Leu Ile Asn Arg Gly Ile Phe Arg Thr Asp Lys Ile Asn Asn Glu
595 600 605
Ile Tyr Arg Thr Gly Ser Ser Lys Trp Glu Arg Leu Ile Leu Ser Asn
610 615 620
Leu Lys Phe Gln Thr Leu Ala Gly Lys Gly Phe Leu Gly Lys His Gly
625 630 635 640
Val Ser Tyr Gly Asn Met Asn Pro Glu Lys Ser Val Pro Ser Leu Gln
645 650 655
Lys Phe Ile Arg Glu Asn Tyr Leu Lys Lys Tyr Pro Gln Leu Thr Glu
660 665 670
Val Ser Asn Thr Lys Phe Leu Ser Lys Lys Asp Phe Asp Ala Ala Ile
675 680 685
Lys Glu Ala Leu Lys Glu Cys Phe Thr Met Asn Phe Ile Asn Ile Ala
690 695 700
Glu Asn Lys Leu Leu Glu Ala Glu Asp Lys Gly Asp Leu Tyr Leu Phe
705 710 715 720
Glu Ile Thr Asn Lys Asp Phe Ser Gly Lys Lys Ser Lys Gly Tyr Glu
725 730 735
Lys Gly Lys Asp Asn Ile His Thr Ile Tyr Trp Lys Tyr Leu Phe Ser
740 745 750
Glu Ser Asn Cys Lys Ser Pro Ile Ile Gly Leu Asn Gly Gly Ala Glu
755 760 765
Ile Phe Phe Arg Glu Gly Gln Lys Asp Lys Leu His Thr Lys Leu Asp
770 775 780
Lys Lys Gly Lys Lys Val Phe Asp Ala Lys Arg Tyr Ser Glu Asp Lys
785 790 795 800
Leu Phe Phe His Val Ser Ile Thr Ile Asn Tyr Gly Lys Pro Lys Asn
805 810 815
Ile Lys Phe Arg Asp Ile Ile Asn Gln Leu Ile Thr Ser Met Asn Val
820 825 830
Asn Ile Ile Gly Ile Asp Arg Gly Glu Lys His Leu Leu Tyr Tyr Ser
835 840 845
Val Ile Asp Ser Asn Gly Ile Ile Leu Lys Gln Gly Ser Leu Asn Lys
850 855 860
Ile Arg Val Gly Asp Lys Glu Val Asp Phe Asn Lys Lys Leu Thr Glu
865 870 875 880
Arg Ala Asn Glu Met Lys Lys Ala Arg Gln Ser Trp Glu Gln Ile Gly
885 890 895
Asn Ile Lys Asn Phe Lys Glu Gly Tyr Leu Ser Gln Ala Ile His Glu
900 905 910
Ile Tyr Gln Leu Met Ile Lys Tyr Asn Ala Ile Ile Val Leu Glu Asp
915 920 925
Leu Asn Thr Glu Phe Lys Ala Lys Arg Leu Ser Lys Val Glu Lys Ser
930 935 940
Val Tyr Lys Lys Phe Glu Leu Lys Leu Ala Arg Lys Leu Asn His Leu
945 950 955 960
Ile Leu Lys Asp Arg Asn Thr Asn Glu Ile Gly Gly Val Leu Lys Ala
965 970 975
Tyr Gln Leu Thr Pro Thr Ile Gly Gly Gly Asp Val Ser Lys Phe Glu
980 985 990
Lys Ala Lys Gln Trp Gly Met Met Phe Tyr Val Arg Ala Asn Tyr Thr
995 1000 1005
Ser Thr Thr Asp Pro Val Thr Gly Trp Arg Lys His Leu Tyr Ile
1010 1015 1020
Ser Asn Phe Ser Asn Asn Ser Val Ile Lys Ser Phe Phe Asp Pro
1025 1030 1035
Thr Asn Arg Asp Thr Gly Ile Glu Ile Phe Tyr Ser Gly Lys Tyr
1040 1045 1050
Arg Ser Trp Gly Phe Arg Tyr Val Gln Lys Glu Thr Gly Lys Lys
1055 1060 1065
Trp Glu Leu Phe Ala Thr Lys Glu Leu Glu Arg Phe Lys Tyr Asn
1070 1075 1080
Gln Thr Thr Lys Leu Cys Glu Lys Ile Asn Leu Tyr Asp Lys Phe
1085 1090 1095
Glu Glu Leu Phe Lys Gly Ile Asp Lys Ser Ala Asp Ile Tyr Ser
1100 1105 1110
Gln Leu Cys Asn Val Leu Asp Phe Arg Trp Lys Ser Leu Val Tyr
1115 1120 1125
Leu Trp Asn Leu Leu Asn Gln Ile Arg Asn Val Asp Lys Asn Ala
1130 1135 1140
Glu Gly Asn Lys Asn Asp Phe Ile Gln Ser Pro Val Tyr Pro Phe
1145 1150 1155
Phe Asp Ser Arg Lys Thr Asp Gly Lys Thr Glu Pro Ile Asn Gly
1160 1165 1170
Asp Ala Asn Gly Ala Leu Asn Ile Ala Arg Lys Gly Leu Met Leu
1175 1180 1185
Val Glu Arg Ile Lys Asn Asn Pro Glu Lys Tyr Glu Gln Leu Ile
1190 1195 1200
Arg Asp Thr Glu Trp Asp Ala Trp Ile Gln Asn Phe Asn Lys Val
1205 1210 1215
Asn
<210> 1121
<211> 1295
<212> БЕЛОК
<213> Francisella tularensis
<400> 1121
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Val Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Asp Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Asp Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Arg Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Asn Pro Gln
690 695 700
Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe Ile Asp Phe Tyr Lys
705 710 715 720
Glu Ser Ile Ser Lys His Pro Glu Trp Lys Asp Phe Gly Phe Arg Phe
725 730 735
Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu Phe Tyr Arg Glu Val
740 745 750
Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn Ile Ser Glu Ser Tyr
755 760 765
Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr Leu Phe Gln Ile Tyr
770 775 780
Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg Pro Asn Leu His Thr
785 790 795 800
Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn Leu Gln Asp Val Val
805 810 815
Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr Arg Lys Lys Ser Ile
820 825 830
Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala Ile Ala Asn Lys Asn
835 840 845
Lys Asp Asn Pro Lys Lys Glu Ser Phe Phe Glu Tyr Asp Leu Ile Lys
850 855 860
Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe His Cys Pro Ile Thr
865 870 875 880
Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe Asn Asp Glu Ile Asn
885 890 895
Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His Ile Leu Ser Ile Asp
900 905 910
Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu Val Asp Gly Lys Gly
915 920 925
Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile Gly Asn Asp Arg Met
930 935 940
Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile Glu Lys Asp Arg Asp
945 950 955 960
Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn Ile Lys Glu Met Lys
965 970 975
Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile Ala Lys Leu Val Ile
980 985 990
Glu His Asn Ala Ile Val Val Phe Glu Asp Leu Asn Phe Gly Phe Lys
995 1000 1005
Arg Gly Arg Phe Lys Val Glu Lys Gln Val Tyr Gln Lys Leu Glu
1010 1015 1020
Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu Val Phe Lys Asp Asn
1025 1030 1035
Glu Phe Asp Lys Thr Gly Gly Val Leu Arg Ala Tyr Gln Leu Thr
1040 1045 1050
Ala Pro Phe Glu Thr Phe Lys Lys Met Gly Lys Gln Thr Gly Ile
1055 1060 1065
Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser Lys Ile Cys Pro Val
1070 1075 1080
Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys Tyr Glu Ser Val Ser
1085 1090 1095
Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp Lys Ile Cys Tyr Asn
1100 1105 1110
Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe Asp Tyr Lys Asn Phe
1115 1120 1125
Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr Ile Ala Ser Phe Gly
1130 1135 1140
Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp Lys Asn His Asn Trp
1145 1150 1155
Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu Leu Glu Lys Leu Leu
1160 1165 1170
Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly Glu Cys Ile Lys Ala
1175 1180 1185
Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe Phe Ala Lys Leu Thr
1190 1195 1200
Ser Ile Leu Asn Thr Ile Leu Gln Met Arg Asn Ser Lys Thr Gly
1205 1210 1215
Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val Ala Asp Val Asn Gly
1220 1225 1230
Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys Asn Met Pro Gln Asp
1235 1240 1245
Ala Asp Ala Asn Gly Ala Tyr His Ile Gly Leu Lys Gly Leu Met
1250 1255 1260
Leu Leu Asp Arg Ile Lys Asn Asn Gln Glu Gly Lys Lys Leu Asn
1265 1270 1275
Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu Phe Val Gln Asn Arg
1280 1285 1290
Asn Asn
1295
<210> 1122
<211> 1300
<212> БЕЛОК
<213> Francisella tularensis
<400> 1122
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asp Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Val Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Asp Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Leu Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Glu Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Arg Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Asn Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr Lys Glu Ser Ile Ser Lys His Pro Glu Trp Lys Asp
725 730 735
Phe Gly Phe Arg Phe Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu
740 745 750
Phe Tyr Arg Glu Val Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn
755 760 765
Ile Ser Glu Ser Tyr Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr
770 775 780
Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg
785 790 795 800
Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn
805 810 815
Leu Gln Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr
820 825 830
Arg Lys Gln Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
835 840 845
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Val Phe Glu
850 855 860
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
865 870 875 880
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
885 890 895
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
900 905 910
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
915 920 925
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
930 935 940
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
945 950 955 960
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
965 970 975
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
980 985 990
Ala Lys Leu Val Ile Glu His Asn Ala Ile Val Val Phe Glu Asp Leu
995 1000 1005
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
1010 1015 1020
Tyr Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu
1025 1030 1035
Val Phe Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg
1040 1045 1050
Ala Tyr Gln Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly
1055 1060 1065
Lys Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser
1070 1075 1080
Lys Ile Cys Pro Val Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys
1085 1090 1095
Tyr Glu Ser Val Ser Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp
1100 1105 1110
Lys Ile Cys Tyr Asn Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe
1115 1120 1125
Asp Tyr Lys Asn Phe Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr
1130 1135 1140
Ile Ala Ser Phe Gly Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp
1145 1150 1155
Lys Asn His Asn Trp Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu
1160 1165 1170
Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly
1175 1180 1185
Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe
1190 1195 1200
Phe Ala Lys Leu Thr Ser Val Leu Asn Thr Ile Leu Gln Met Arg
1205 1210 1215
Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val
1220 1225 1230
Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
1235 1240 1245
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly
1250 1255 1260
Leu Lys Gly Leu Met Leu Leu Asp Arg Ile Lys Asn Asn Gln Glu
1265 1270 1275
Gly Lys Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu
1280 1285 1290
Phe Val Gln Asn Arg Asn Asn
1295 1300
<210> 1123
<211> 1300
<212> БЕЛОК
<213> Francisella tularensis
<400> 1123
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Ile Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Glu Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Asp Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Lys Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Ser Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr Lys Gln Ser Ile Ser Lys His Pro Glu Trp Lys Asp
725 730 735
Phe Gly Phe Arg Phe Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu
740 745 750
Phe Tyr Arg Glu Val Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn
755 760 765
Ile Ser Glu Ser Tyr Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr
770 775 780
Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg
785 790 795 800
Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn
805 810 815
Leu Gln Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr
820 825 830
Arg Lys Gln Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
835 840 845
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Val Phe Glu
850 855 860
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
865 870 875 880
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
885 890 895
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
900 905 910
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
915 920 925
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
930 935 940
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
945 950 955 960
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
965 970 975
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
980 985 990
Ala Lys Leu Val Ile Glu Tyr Asn Ala Ile Val Val Phe Glu Asp Leu
995 1000 1005
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
1010 1015 1020
Tyr Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu
1025 1030 1035
Val Phe Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg
1040 1045 1050
Ala Tyr Gln Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly
1055 1060 1065
Lys Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser
1070 1075 1080
Lys Ile Cys Pro Val Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys
1085 1090 1095
Tyr Glu Ser Val Ser Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp
1100 1105 1110
Lys Ile Cys Tyr Asn Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe
1115 1120 1125
Asp Tyr Lys Asn Phe Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr
1130 1135 1140
Ile Ala Ser Phe Gly Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp
1145 1150 1155
Lys Asn His Asn Trp Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu
1160 1165 1170
Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly
1175 1180 1185
Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe
1190 1195 1200
Phe Ala Lys Leu Thr Ser Val Leu Asn Thr Ile Leu Gln Met Arg
1205 1210 1215
Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val
1220 1225 1230
Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
1235 1240 1245
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly
1250 1255 1260
Leu Lys Gly Leu Met Leu Leu Gly Arg Ile Lys Asn Asn Gln Glu
1265 1270 1275
Gly Lys Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu
1280 1285 1290
Phe Val Gln Asn Arg Asn Asn
1295 1300
<210> 1124
<211> 1307
<212> БЕЛОК
<213> Francisella tularensis
<400> 1124
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Lys Tyr
100 105 110
Ile Asn Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Val Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Asp Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ser
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Glu Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Arg Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Ser Gly
595 600 605
Trp Asp Lys Asn Lys Glu Ser Ala Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Ile Met Asp Lys Lys His Asn Lys Ile
625 630 635 640
Phe Ser Asp Lys Ala Ile Glu Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Gln Ile Ala Asp Ala Ser Lys Asp Ile Gln Asn Leu
660 665 670
Met Ile Ile Asp Gly Lys Thr Val Cys Lys Lys Gly Arg Lys Asp Arg
675 680 685
Asn Gly Val Asn Arg Gln Leu Leu Ser Leu Lys Arg Lys His Leu Pro
690 695 700
Glu Asn Ile Tyr Arg Ile Lys Glu Thr Lys Ser Tyr Leu Lys Asn Glu
705 710 715 720
Ala Arg Phe Ser Arg Lys Asp Leu Tyr Asp Phe Ile Asp Tyr Tyr Lys
725 730 735
Asp Arg Leu Asp Tyr Tyr Asp Phe Glu Phe Glu Leu Lys Pro Ser Asn
740 745 750
Glu Tyr Ser Asp Phe Asn Asp Phe Thr Asn His Ile Gly Ser Gln Gly
755 760 765
Tyr Lys Leu Thr Phe Glu Asn Ile Ser Gln Asp Tyr Ile Asn Ser Leu
770 775 780
Val Asn Glu Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Ser Lys Asp Phe
785 790 795 800
Ser Ala Tyr Ser Lys Gly Arg Pro Asn Leu His Thr Leu Tyr Trp Lys
805 810 815
Ala Leu Phe Asp Glu Arg Asn Leu Gln Asp Val Val Tyr Lys Leu Asn
820 825 830
Gly Glu Ala Glu Leu Phe Tyr Arg Lys Gln Ser Ile Pro Lys Lys Ile
835 840 845
Thr His Pro Ala Lys Glu Thr Ile Ala Asn Lys Asn Lys Asp Asn Pro
850 855 860
Lys Lys Glu Ser Val Phe Glu Tyr Asp Leu Ile Lys Asp Lys Arg Phe
865 870 875 880
Thr Glu Asp Lys Phe Phe Phe His Cys Pro Ile Thr Ile Asn Phe Lys
885 890 895
Ser Ser Gly Ala Asn Lys Phe Asn Asp Glu Ile Asn Leu Leu Leu Lys
900 905 910
Glu Lys Ala Asn Asp Val His Ile Leu Ser Ile Asp Arg Gly Glu Arg
915 920 925
His Leu Ala Tyr Tyr Thr Leu Val Asp Gly Lys Gly Asn Ile Ile Lys
930 935 940
Gln Asp Asn Phe Asn Ile Ile Gly Asn Asp Arg Met Lys Thr Asn Tyr
945 950 955 960
His Asp Lys Leu Ala Ala Ile Glu Lys Asp Arg Asp Ser Ala Arg Lys
965 970 975
Asp Trp Lys Lys Ile Asn Asn Ile Lys Glu Met Lys Glu Gly Tyr Leu
980 985 990
Ser Gln Val Val His Glu Ile Ala Lys Leu Val Ile Glu Tyr Asn Ala
995 1000 1005
Ile Val Val Phe Glu Asp Leu Asn Phe Gly Phe Lys Arg Gly Arg
1010 1015 1020
Phe Lys Val Glu Lys Gln Val Tyr Gln Lys Leu Glu Lys Met Leu
1025 1030 1035
Ile Glu Lys Leu Asn Tyr Leu Val Phe Lys Asp Asn Glu Phe Asp
1040 1045 1050
Lys Thr Gly Gly Val Leu Arg Ala Tyr Gln Leu Thr Ala Pro Phe
1055 1060 1065
Glu Thr Phe Lys Lys Met Gly Lys Gln Thr Gly Ile Ile Tyr Tyr
1070 1075 1080
Val Pro Ala Gly Phe Thr Ser Lys Ile Cys Pro Val Thr Gly Phe
1085 1090 1095
Val Asn Gln Leu Tyr Pro Lys Tyr Glu Ser Val Ser Lys Ser Gln
1100 1105 1110
Glu Phe Phe Ser Lys Phe Asp Lys Ile Cys Tyr Asn Leu Asp Lys
1115 1120 1125
Gly Tyr Phe Glu Phe Ser Phe Asp Tyr Lys Asn Phe Gly Asp Lys
1130 1135 1140
Ala Ala Lys Gly Lys Trp Thr Ile Ala Ser Phe Gly Ser Arg Leu
1145 1150 1155
Ile Asn Phe Arg Asn Ser Asp Lys Asn His Asn Trp Asp Thr Arg
1160 1165 1170
Glu Val Tyr Pro Thr Lys Glu Leu Glu Lys Leu Leu Lys Asp Tyr
1175 1180 1185
Ser Ile Glu Tyr Gly His Gly Glu Cys Ile Lys Ala Ala Ile Cys
1190 1195 1200
Gly Glu Ser Asp Lys Lys Phe Phe Ala Lys Leu Thr Ser Val Leu
1205 1210 1215
Asn Thr Ile Leu Gln Met Arg Asn Ser Lys Thr Gly Thr Glu Leu
1220 1225 1230
Asp Tyr Leu Ile Ser Pro Val Ala Asp Val Asn Gly Asn Phe Phe
1235 1240 1245
Asp Ser Arg Gln Ala Pro Lys Asn Met Pro Gln Asp Ala Asp Ala
1250 1255 1260
Asn Gly Ala Tyr His Ile Gly Leu Lys Gly Leu Met Leu Leu Asp
1265 1270 1275
Arg Ile Lys Asn Asn Gln Glu Gly Lys Lys Leu Asn Leu Val Ile
1280 1285 1290
Lys Asn Glu Glu Tyr Phe Glu Phe Val Gln Asn Arg Asn Asn
1295 1300 1305
<210> 1125
<211> 1323
<212> БЕЛОК
<213> Prevotella disiens
<400> 1125
Met Glu Asn Tyr Gln Glu Phe Thr Asn Leu Phe Gln Leu Asn Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Cys Glu Leu Leu Glu
20 25 30
Glu Gly Lys Ile Phe Ala Ser Gly Ser Phe Leu Glu Lys Asp Lys Val
35 40 45
Arg Ala Asp Asn Val Ser Tyr Val Lys Lys Glu Ile Asp Lys Lys His
50 55 60
Lys Ile Phe Ile Glu Glu Thr Leu Ser Ser Phe Ser Ile Ser Asn Asp
65 70 75 80
Leu Leu Lys Gln Tyr Phe Asp Cys Tyr Asn Glu Leu Lys Ala Phe Lys
85 90 95
Lys Asp Cys Lys Ser Asp Glu Glu Glu Val Lys Lys Thr Ala Leu Arg
100 105 110
Asn Lys Cys Thr Ser Ile Gln Arg Ala Met Arg Glu Ala Ile Ser Gln
115 120 125
Ala Phe Leu Lys Ser Pro Gln Lys Lys Leu Leu Ala Ile Lys Asn Leu
130 135 140
Ile Glu Asn Val Phe Lys Ala Asp Glu Asn Val Gln His Phe Ser Glu
145 150 155 160
Phe Thr Ser Tyr Phe Ser Gly Phe Glu Thr Asn Arg Glu Asn Phe Tyr
165 170 175
Ser Asp Glu Glu Lys Ser Thr Ser Ile Ala Tyr Arg Leu Val His Asp
180 185 190
Asn Leu Pro Ile Phe Ile Lys Asn Ile Tyr Ile Phe Glu Lys Leu Lys
195 200 205
Glu Gln Phe Asp Ala Lys Thr Leu Ser Glu Ile Phe Glu Asn Tyr Lys
210 215 220
Leu Tyr Val Ala Gly Ser Ser Leu Asp Glu Val Phe Ser Leu Glu Tyr
225 230 235 240
Phe Asn Asn Thr Leu Thr Gln Lys Gly Ile Asp Asn Tyr Asn Ala Val
245 250 255
Ile Gly Lys Ile Val Lys Glu Asp Lys Gln Glu Ile Gln Gly Leu Asn
260 265 270
Glu His Ile Asn Leu Tyr Asn Gln Lys His Lys Asp Arg Arg Leu Pro
275 280 285
Phe Phe Ile Ser Leu Lys Lys Gln Ile Leu Ser Asp Arg Glu Ala Leu
290 295 300
Ser Trp Leu Pro Asp Met Phe Lys Asn Asp Ser Glu Val Ile Lys Ala
305 310 315 320
Leu Lys Gly Phe Tyr Ile Glu Asp Gly Phe Glu Asn Asn Val Leu Thr
325 330 335
Pro Leu Ala Thr Leu Leu Ser Ser Leu Asp Lys Tyr Asn Leu Asn Gly
340 345 350
Ile Phe Ile Arg Asn Asn Glu Ala Leu Ser Ser Leu Ser Gln Asn Val
355 360 365
Tyr Arg Asn Phe Ser Ile Asp Glu Ala Ile Asp Ala Asn Ala Glu Leu
370 375 380
Gln Thr Phe Asn Asn Tyr Glu Leu Ile Ala Asn Ala Leu Arg Ala Lys
385 390 395 400
Ile Lys Lys Glu Thr Lys Gln Gly Arg Lys Ser Phe Glu Lys Tyr Glu
405 410 415
Glu Tyr Ile Asp Lys Lys Val Lys Ala Ile Asp Ser Leu Ser Ile Gln
420 425 430
Glu Ile Asn Glu Leu Val Glu Asn Tyr Val Ser Glu Phe Asn Ser Asn
435 440 445
Ser Gly Asn Met Pro Arg Lys Val Glu Asp Tyr Phe Ser Leu Met Arg
450 455 460
Lys Gly Asp Phe Gly Ser Asn Asp Leu Ile Glu Asn Ile Lys Thr Lys
465 470 475 480
Leu Ser Ala Ala Glu Lys Leu Leu Gly Thr Lys Tyr Gln Glu Thr Ala
485 490 495
Lys Asp Ile Phe Lys Lys Asp Glu Asn Ser Lys Leu Ile Lys Glu Leu
500 505 510
Leu Asp Ala Thr Lys Gln Phe Gln His Phe Ile Lys Pro Leu Leu Gly
515 520 525
Thr Gly Glu Glu Ala Asp Arg Asp Leu Val Phe Tyr Gly Asp Phe Leu
530 535 540
Pro Leu Tyr Glu Lys Phe Glu Glu Leu Thr Leu Leu Tyr Asn Lys Val
545 550 555 560
Arg Asn Arg Leu Thr Gln Lys Pro Tyr Ser Lys Asp Lys Ile Arg Leu
565 570 575
Cys Phe Asn Lys Pro Lys Leu Met Thr Gly Trp Val Asp Ser Lys Thr
580 585 590
Glu Lys Ser Asp Asn Gly Thr Gln Tyr Gly Gly Tyr Leu Phe Arg Lys
595 600 605
Lys Asn Glu Ile Gly Glu Tyr Asp Tyr Phe Leu Gly Ile Ser Ser Lys
610 615 620
Ala Gln Leu Phe Arg Lys Asn Glu Ala Val Ile Gly Asp Tyr Glu Arg
625 630 635 640
Leu Asp Tyr Tyr Gln Pro Lys Ala Asn Thr Ile Tyr Gly Ser Ala Tyr
645 650 655
Glu Gly Glu Asn Ser Tyr Lys Glu Asp Lys Lys Arg Leu Asn Lys Val
660 665 670
Ile Ile Ala Tyr Ile Glu Gln Ile Lys Gln Thr Asn Ile Lys Lys Ser
675 680 685
Ile Ile Glu Ser Ile Ser Lys Tyr Pro Asn Ile Ser Asp Asp Asp Lys
690 695 700
Val Thr Pro Ser Ser Leu Leu Glu Lys Ile Lys Lys Val Ser Ile Asp
705 710 715 720
Ser Tyr Asn Gly Ile Leu Ser Phe Lys Ser Phe Gln Ser Val Asn Lys
725 730 735
Glu Val Ile Asp Asn Leu Leu Lys Thr Ile Ser Pro Leu Lys Asn Lys
740 745 750
Ala Glu Phe Leu Asp Leu Ile Asn Lys Asp Tyr Gln Ile Phe Thr Glu
755 760 765
Val Gln Ala Val Ile Asp Glu Ile Cys Lys Gln Lys Thr Phe Ile Tyr
770 775 780
Phe Pro Ile Ser Asn Val Glu Leu Glu Lys Glu Met Gly Asp Lys Asp
785 790 795 800
Lys Pro Leu Cys Leu Phe Gln Ile Ser Asn Lys Asp Leu Ser Phe Ala
805 810 815
Lys Thr Phe Ser Ala Asn Leu Arg Lys Lys Arg Gly Ala Glu Asn Leu
820 825 830
His Thr Met Leu Phe Lys Ala Leu Met Glu Gly Asn Gln Asp Asn Leu
835 840 845
Asp Leu Gly Ser Gly Ala Ile Phe Tyr Arg Ala Lys Ser Leu Asp Gly
850 855 860
Asn Lys Pro Thr His Pro Ala Asn Glu Ala Ile Lys Cys Arg Asn Val
865 870 875 880
Ala Asn Lys Asp Lys Val Ser Leu Phe Thr Tyr Asp Ile Tyr Lys Asn
885 890 895
Arg Arg Tyr Met Glu Asn Lys Phe Leu Phe His Leu Ser Ile Val Gln
900 905 910
Asn Tyr Lys Ala Ala Asn Asp Ser Ala Gln Leu Asn Ser Ser Ala Thr
915 920 925
Glu Tyr Ile Arg Lys Ala Asp Asp Leu His Ile Ile Gly Ile Asp Arg
930 935 940
Gly Glu Arg Asn Leu Leu Tyr Tyr Ser Val Ile Asp Met Lys Gly Asn
945 950 955 960
Ile Val Glu Gln Asp Ser Leu Asn Ile Ile Arg Asn Asn Asp Leu Glu
965 970 975
Thr Asp Tyr His Asp Leu Leu Asp Lys Arg Glu Lys Glu Arg Lys Ala
980 985 990
Asn Arg Gln Asn Trp Glu Ala Val Glu Gly Ile Lys Asp Leu Lys Lys
995 1000 1005
Gly Tyr Leu Ser Gln Ala Val His Gln Ile Ala Gln Leu Met Leu
1010 1015 1020
Lys Tyr Asn Ala Ile Ile Ala Leu Glu Asp Leu Gly Gln Met Phe
1025 1030 1035
Val Thr Arg Gly Gln Lys Ile Glu Lys Ala Val Tyr Gln Gln Phe
1040 1045 1050
Glu Lys Ser Leu Val Asp Lys Leu Ser Tyr Leu Val Asp Lys Lys
1055 1060 1065
Arg Pro Tyr Asn Glu Leu Gly Gly Ile Leu Lys Ala Tyr Gln Leu
1070 1075 1080
Ala Ser Ser Ile Thr Lys Asn Asn Ser Asp Lys Gln Asn Gly Phe
1085 1090 1095
Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro Val
1100 1105 1110
Thr Gly Phe Thr Asp Leu Leu Arg Pro Lys Ala Met Thr Ile Lys
1115 1120 1125
Glu Ala Gln Asp Phe Phe Gly Ala Phe Asp Asn Ile Ser Tyr Asn
1130 1135 1140
Asp Lys Gly Tyr Phe Glu Phe Glu Thr Asn Tyr Asp Lys Phe Lys
1145 1150 1155
Ile Arg Met Lys Ser Ala Gln Thr Arg Trp Thr Ile Cys Thr Phe
1160 1165 1170
Gly Asn Arg Ile Lys Arg Lys Lys Asp Lys Asn Tyr Trp Asn Tyr
1175 1180 1185
Glu Glu Val Glu Leu Thr Glu Glu Phe Lys Lys Leu Phe Lys Asp
1190 1195 1200
Ser Asn Ile Asp Tyr Glu Asn Cys Asn Leu Lys Glu Glu Ile Gln
1205 1210 1215
Asn Lys Asp Asn Arg Lys Phe Phe Asp Asp Leu Ile Lys Leu Leu
1220 1225 1230
Gln Leu Thr Leu Gln Met Arg Asn Ser Asp Asp Lys Gly Asn Asp
1235 1240 1245
Tyr Ile Ile Ser Pro Val Ala Asn Ala Glu Gly Gln Phe Phe Asp
1250 1255 1260
Ser Arg Asn Gly Asp Lys Lys Leu Pro Leu Asp Ala Asp Ala Asn
1265 1270 1275
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Trp Asn Ile Arg Gln
1280 1285 1290
Ile Lys Gln Thr Lys Asn Asp Lys Lys Leu Asn Leu Ser Ile Ser
1295 1300 1305
Ser Thr Glu Trp Leu Asp Phe Val Arg Glu Lys Pro Tyr Leu Lys
1310 1315 1320
<210> 1126
<211> 1323
<212> БЕЛОК
<213> Prevotella disiens
<400> 1126
Met Glu Asn Tyr Gln Glu Phe Thr Asn Leu Phe Gln Leu Asn Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Cys Glu Leu Leu Glu
20 25 30
Glu Gly Lys Ile Phe Ala Ser Gly Ser Phe Leu Glu Lys Asp Lys Val
35 40 45
Arg Ala Asp Asn Val Ser Tyr Val Lys Lys Glu Ile Asp Lys Lys His
50 55 60
Lys Ile Phe Ile Glu Glu Thr Leu Ser Ser Phe Ser Ile Ser Asn Asp
65 70 75 80
Leu Leu Lys Gln Tyr Phe Asp Cys Tyr Asn Glu Leu Lys Ala Phe Lys
85 90 95
Lys Asp Cys Lys Ser Asp Glu Glu Glu Val Lys Lys Thr Ala Leu Arg
100 105 110
Asn Lys Cys Thr Ser Ile Gln Arg Ala Met Arg Glu Ala Ile Ser Gln
115 120 125
Ala Phe Leu Lys Ser Pro Gln Lys Lys Leu Leu Ala Ile Lys Asn Leu
130 135 140
Ile Glu Asn Val Phe Lys Ala Asp Glu Asn Val Gln His Phe Ser Glu
145 150 155 160
Phe Thr Ser Tyr Phe Ser Gly Phe Glu Thr Asn Arg Glu Asn Phe Tyr
165 170 175
Ser Asp Glu Glu Lys Ser Thr Ser Ile Ala Tyr Arg Leu Val His Asp
180 185 190
Asn Leu Pro Ile Phe Ile Lys Asn Ile Tyr Ile Phe Glu Lys Leu Lys
195 200 205
Glu Gln Phe Asp Ala Lys Thr Leu Ser Glu Ile Phe Glu Asn Tyr Lys
210 215 220
Leu Tyr Val Ala Gly Ser Ser Leu Asp Glu Val Phe Ser Leu Glu Tyr
225 230 235 240
Phe Asn Asn Thr Leu Thr Gln Lys Gly Ile Asp Asn Tyr Asn Ala Val
245 250 255
Ile Gly Lys Ile Val Lys Glu Asp Lys Gln Glu Ile Gln Gly Leu Asn
260 265 270
Glu His Ile Asn Leu Tyr Asn Gln Lys His Lys Asp Arg Arg Leu Pro
275 280 285
Phe Phe Ile Ser Leu Lys Lys Gln Ile Leu Ser Asp Arg Glu Ala Leu
290 295 300
Ser Trp Leu Pro Asp Met Phe Lys Asn Asp Ser Glu Val Ile Lys Ala
305 310 315 320
Leu Lys Gly Phe Tyr Ile Glu Asp Gly Phe Glu Asn Asn Val Leu Thr
325 330 335
Pro Leu Ala Thr Leu Leu Ser Ser Leu Asp Lys Tyr Asn Leu Asn Gly
340 345 350
Ile Phe Ile Arg Asn Asn Glu Ala Leu Ser Ser Leu Ser Gln Asn Val
355 360 365
Tyr Arg Asn Phe Ser Ile Asp Glu Ala Ile Asp Ala Asn Ala Glu Leu
370 375 380
Gln Thr Phe Asn Asn Tyr Glu Leu Ile Ala Asn Ala Leu Arg Ala Lys
385 390 395 400
Ile Lys Lys Glu Thr Lys Gln Gly Arg Lys Ser Phe Glu Lys Tyr Glu
405 410 415
Glu Tyr Ile Asp Lys Lys Val Lys Ala Ile Asp Ser Leu Ser Ile Gln
420 425 430
Glu Ile Asn Glu Leu Val Glu Asn Tyr Val Ser Glu Phe Asn Ser Asn
435 440 445
Ser Gly Asn Met Pro Arg Lys Val Glu Asp Tyr Phe Ser Leu Met Arg
450 455 460
Lys Gly Asp Phe Gly Ser Asn Asp Leu Ile Glu Asn Ile Lys Thr Lys
465 470 475 480
Leu Ser Ala Ala Glu Lys Leu Leu Gly Thr Lys Tyr Gln Glu Thr Ala
485 490 495
Lys Asp Ile Phe Lys Lys Asp Glu Asn Ser Lys Leu Ile Lys Glu Leu
500 505 510
Leu Asp Ala Thr Lys Gln Phe Gln His Phe Ile Lys Pro Leu Leu Gly
515 520 525
Thr Gly Glu Glu Ala Asp Arg Asp Leu Val Phe Tyr Gly Asp Phe Leu
530 535 540
Pro Leu Tyr Glu Lys Phe Glu Glu Leu Thr Leu Leu Tyr Asn Lys Val
545 550 555 560
Arg Asn Arg Leu Thr Gln Lys Pro Tyr Ser Lys Asp Lys Ile Arg Leu
565 570 575
Cys Phe Asn Lys Pro Lys Leu Met Thr Gly Trp Val Asp Ser Lys Thr
580 585 590
Glu Lys Ser Asp Asn Gly Thr Gln Tyr Gly Gly Tyr Leu Phe Arg Lys
595 600 605
Lys Asn Glu Ile Gly Glu Tyr Asp Tyr Phe Leu Gly Ile Ser Ser Lys
610 615 620
Ala Gln Leu Phe Arg Lys Asn Glu Ala Val Ile Gly Asp Tyr Glu Arg
625 630 635 640
Leu Asp Tyr Tyr Gln Pro Lys Ala Asn Thr Ile Tyr Gly Ser Ala Tyr
645 650 655
Glu Gly Glu Asn Ser Tyr Lys Glu Asp Lys Lys Arg Leu Asn Lys Val
660 665 670
Ile Ile Ala Tyr Ile Glu Gln Ile Lys Gln Thr Asn Ile Lys Lys Ser
675 680 685
Ile Ile Glu Ser Ile Ser Lys Tyr Pro Asn Ile Ser Asp Asp Asp Lys
690 695 700
Val Thr Pro Ser Ser Leu Leu Glu Lys Ile Lys Lys Val Ser Ile Asp
705 710 715 720
Ser Tyr Asn Gly Ile Leu Ser Phe Lys Ser Phe Gln Ser Val Asn Lys
725 730 735
Glu Val Ile Asp Asn Leu Leu Lys Thr Ile Ser Pro Leu Lys Asn Lys
740 745 750
Ala Glu Phe Leu Asp Leu Ile Asn Lys Asp Tyr Gln Ile Phe Thr Glu
755 760 765
Val Gln Ala Val Ile Asp Glu Ile Cys Lys Gln Lys Thr Phe Ile Tyr
770 775 780
Phe Pro Ile Ser Asn Val Glu Leu Glu Lys Glu Met Gly Asp Lys Asp
785 790 795 800
Lys Pro Leu Cys Leu Phe Gln Ile Ser Asn Lys Asp Leu Ser Phe Ala
805 810 815
Lys Thr Phe Ser Ala Asn Leu Arg Lys Lys Arg Gly Ala Glu Asn Leu
820 825 830
His Thr Met Leu Phe Lys Ala Leu Met Glu Gly Asn Gln Asp Asn Leu
835 840 845
Asp Leu Gly Ser Gly Ala Ile Phe Tyr Arg Ala Lys Ser Leu Asp Gly
850 855 860
Asn Lys Pro Thr His Pro Ala Asn Glu Ala Ile Lys Cys Arg Asn Val
865 870 875 880
Ala Asn Lys Asp Lys Val Ser Leu Phe Thr Tyr Asp Ile Tyr Lys Asn
885 890 895
Arg Arg Tyr Met Glu Asn Lys Phe Leu Phe His Leu Ser Ile Val Gln
900 905 910
Asn Tyr Lys Ala Ala Asn Asp Ser Ala Gln Leu Asn Ser Ser Ala Thr
915 920 925
Glu Tyr Ile Arg Lys Ala Asp Asp Leu His Ile Ile Gly Ile Asp Arg
930 935 940
Gly Glu Arg Asn Leu Leu Tyr Tyr Ser Val Ile Asp Met Lys Gly Asn
945 950 955 960
Ile Val Glu Gln Asp Ser Leu Asn Ile Ile Arg Asn Asn Asp Leu Glu
965 970 975
Thr Asp Tyr His Asp Leu Leu Asp Lys Arg Glu Lys Glu Arg Lys Ala
980 985 990
Asn Arg Gln Asn Trp Glu Ala Val Glu Gly Ile Lys Asp Leu Lys Lys
995 1000 1005
Gly Tyr Leu Ser Gln Ala Val His Gln Ile Ala Gln Leu Met Leu
1010 1015 1020
Lys Tyr Asn Ala Ile Ile Ala Leu Glu Asp Leu Gly Gln Met Phe
1025 1030 1035
Val Thr Arg Gly Gln Lys Ile Glu Lys Ala Val Tyr Gln Gln Phe
1040 1045 1050
Glu Lys Ser Leu Val Asp Lys Leu Ser Tyr Leu Val Asp Lys Lys
1055 1060 1065
Arg Pro Tyr Asn Glu Leu Gly Gly Ile Leu Lys Ala Tyr Gln Leu
1070 1075 1080
Ala Ser Ser Ile Thr Lys Asn Asn Ser Asp Lys Gln Asn Gly Phe
1085 1090 1095
Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro Val
1100 1105 1110
Thr Gly Phe Thr Asp Leu Leu Arg Pro Lys Ala Met Thr Ile Lys
1115 1120 1125
Glu Ala Gln Asp Phe Phe Gly Ala Phe Asp Asn Ile Ser Tyr Asn
1130 1135 1140
Asp Lys Gly Tyr Phe Glu Phe Glu Thr Asn Tyr Asp Lys Phe Lys
1145 1150 1155
Ile Arg Met Lys Ser Ala Gln Thr Arg Trp Thr Ile Cys Thr Phe
1160 1165 1170
Gly Asn Arg Ile Lys Arg Lys Lys Asp Lys Asn Tyr Trp Asn Tyr
1175 1180 1185
Glu Glu Val Glu Leu Thr Glu Glu Phe Lys Lys Leu Phe Lys Asp
1190 1195 1200
Ser Asn Ile Asp Tyr Glu Asn Cys Asn Leu Lys Glu Glu Ile Gln
1205 1210 1215
Asn Lys Asp Asn Arg Lys Phe Phe Asp Asp Leu Ile Lys Leu Leu
1220 1225 1230
Gln Leu Thr Leu Gln Met Arg Asn Ser Asp Asp Lys Gly Asn Asp
1235 1240 1245
Tyr Ile Ile Ser Pro Val Ala Asn Ala Glu Gly Gln Phe Phe Asp
1250 1255 1260
Ser Arg Asn Gly Asp Lys Lys Leu Pro Leu Asp Ala Asp Ala Asn
1265 1270 1275
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Trp Asn Ile Arg Gln
1280 1285 1290
Ile Lys Gln Thr Lys Asn Asp Lys Lys Leu Asn Leu Ser Ile Ser
1295 1300 1305
Ser Thr Glu Trp Leu Asp Phe Val Arg Glu Lys Pro Tyr Leu Lys
1310 1315 1320
<210> 1127
<211> 1246
<212> БЕЛОК
<213> Porphyromonas macacae
<400> 1127
Met Lys Thr Gln His Phe Phe Glu Asp Phe Thr Ser Leu Tyr Ser Leu
1 5 10 15
Ser Lys Thr Ile Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu
20 25 30
Asn Ile Lys Lys Asn Gly Leu Ile Arg Arg Asp Glu Gln Arg Leu Asp
35 40 45
Asp Tyr Glu Lys Leu Lys Lys Val Ile Asp Glu Tyr His Glu Asp Phe
50 55 60
Ile Ala Asn Ile Leu Ser Ser Phe Ser Phe Ser Glu Glu Ile Leu Gln
65 70 75 80
Ser Tyr Ile Gln Asn Leu Ser Glu Ser Glu Ala Arg Ala Lys Ile Glu
85 90 95
Lys Thr Met Arg Asp Thr Leu Ala Lys Ala Phe Ser Glu Asp Glu Arg
100 105 110
Tyr Lys Ser Ile Phe Lys Lys Glu Leu Val Lys Lys Asp Ile Pro Val
115 120 125
Trp Cys Pro Ala Tyr Lys Ser Leu Cys Lys Lys Phe Asp Asn Phe Thr
130 135 140
Thr Ser Leu Val Pro Phe His Glu Asn Arg Lys Asn Leu Tyr Thr Ser
145 150 155 160
Asn Glu Ile Thr Ala Ser Ile Pro Tyr Arg Ile Val His Val Asn Leu
165 170 175
Pro Lys Phe Ile Gln Asn Ile Glu Ala Leu Cys Glu Leu Gln Lys Lys
180 185 190
Met Gly Ala Asp Leu Tyr Leu Glu Met Met Glu Asn Leu Arg Asn Val
195 200 205
Trp Pro Ser Phe Val Lys Thr Pro Asp Asp Leu Cys Asn Leu Lys Thr
210 215 220
Tyr Asn His Leu Met Val Gln Ser Ser Ile Ser Glu Tyr Asn Arg Phe
225 230 235 240
Val Gly Gly Tyr Ser Thr Glu Asp Gly Thr Lys His Gln Gly Ile Asn
245 250 255
Glu Trp Ile Asn Ile Tyr Arg Gln Arg Asn Lys Glu Met Arg Leu Pro
260 265 270
Gly Leu Val Phe Leu His Lys Gln Ile Leu Ala Lys Val Asp Ser Ser
275 280 285
Ser Phe Ile Ser Asp Thr Leu Glu Asn Asp Asp Gln Val Phe Cys Val
290 295 300
Leu Arg Gln Phe Arg Lys Leu Phe Trp Asn Thr Val Ser Ser Lys Glu
305 310 315 320
Asp Asp Ala Ala Ser Leu Lys Asp Leu Phe Cys Gly Leu Ser Gly Tyr
325 330 335
Asp Pro Glu Ala Ile Tyr Val Ser Asp Ala His Leu Ala Thr Ile Ser
340 345 350
Lys Asn Ile Phe Asp Arg Trp Asn Tyr Ile Ser Asp Ala Ile Arg Arg
355 360 365
Lys Thr Glu Val Leu Met Pro Arg Lys Lys Glu Ser Val Glu Arg Tyr
370 375 380
Ala Glu Lys Ile Ser Lys Gln Ile Lys Lys Arg Gln Ser Tyr Ser Leu
385 390 395 400
Ala Glu Leu Asp Asp Leu Leu Ala His Tyr Ser Glu Glu Ser Leu Pro
405 410 415
Ala Gly Phe Ser Leu Leu Ser Tyr Phe Thr Ser Leu Gly Gly Gln Lys
420 425 430
Tyr Leu Val Ser Asp Gly Glu Val Ile Leu Tyr Glu Glu Gly Ser Asn
435 440 445
Ile Trp Asp Glu Val Leu Ile Ala Phe Arg Asp Leu Gln Val Ile Leu
450 455 460
Asp Lys Asp Phe Thr Glu Lys Lys Leu Gly Lys Asp Glu Glu Ala Val
465 470 475 480
Ser Val Ile Lys Lys Ala Leu Asp Ser Ala Leu Arg Leu Arg Lys Phe
485 490 495
Phe Asp Leu Leu Ser Gly Thr Gly Ala Glu Ile Arg Arg Asp Ser Ser
500 505 510
Phe Tyr Ala Leu Tyr Thr Asp Arg Met Asp Lys Leu Lys Gly Leu Leu
515 520 525
Lys Met Tyr Asp Lys Val Arg Asn Tyr Leu Thr Lys Lys Pro Tyr Ser
530 535 540
Ile Glu Lys Phe Lys Leu His Phe Asp Asn Pro Ser Leu Leu Ser Gly
545 550 555 560
Trp Asp Lys Asn Lys Glu Leu Asn Asn Leu Ser Val Ile Phe Arg Gln
565 570 575
Asn Gly Tyr Tyr Tyr Leu Gly Ile Met Thr Pro Lys Gly Lys Asn Leu
580 585 590
Phe Lys Thr Leu Pro Lys Leu Gly Ala Glu Glu Met Phe Tyr Glu Lys
595 600 605
Met Glu Tyr Lys Gln Ile Ala Glu Pro Met Leu Met Leu Pro Lys Val
610 615 620
Phe Phe Pro Lys Lys Thr Lys Pro Ala Phe Ala Pro Asp Gln Ser Val
625 630 635 640
Val Asp Ile Tyr Asn Lys Lys Thr Phe Lys Thr Gly Gln Lys Gly Phe
645 650 655
Asn Lys Lys Asp Leu Tyr Arg Leu Ile Asp Phe Tyr Lys Glu Ala Leu
660 665 670
Thr Val His Glu Trp Lys Leu Phe Asn Phe Ser Phe Ser Pro Thr Glu
675 680 685
Gln Tyr Arg Asn Ile Gly Glu Phe Phe Asp Glu Val Arg Glu Gln Ala
690 695 700
Tyr Lys Val Ser Met Val Asn Val Pro Ala Ser Tyr Ile Asp Glu Ala
705 710 715 720
Val Glu Asn Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe
725 730 735
Ser Pro Tyr Ser Lys Gly Ile Pro Asn Leu His Thr Leu Tyr Trp Lys
740 745 750
Ala Leu Phe Ser Glu Gln Asn Gln Ser Arg Val Tyr Lys Leu Cys Gly
755 760 765
Gly Gly Glu Leu Phe Tyr Arg Lys Ala Ser Leu His Met Gln Asp Thr
770 775 780
Thr Val His Pro Lys Gly Ile Ser Ile His Lys Lys Asn Leu Asn Lys
785 790 795 800
Lys Gly Glu Thr Ser Leu Phe Asn Tyr Asp Leu Val Lys Asp Lys Arg
805 810 815
Phe Thr Glu Asp Lys Phe Phe Phe His Val Pro Ile Ser Ile Asn Tyr
820 825 830
Lys Asn Lys Lys Ile Thr Asn Val Asn Gln Met Val Arg Asp Tyr Ile
835 840 845
Ala Gln Asn Asp Asp Leu Gln Ile Ile Gly Ile Asp Arg Gly Glu Arg
850 855 860
Asn Leu Leu Tyr Ile Ser Arg Ile Asp Thr Arg Gly Asn Leu Leu Glu
865 870 875 880
Gln Phe Ser Leu Asn Val Ile Glu Ser Asp Lys Gly Asp Leu Arg Thr
885 890 895
Asp Tyr Gln Lys Ile Leu Gly Asp Arg Glu Gln Glu Arg Leu Arg Arg
900 905 910
Arg Gln Glu Trp Lys Ser Ile Glu Ser Ile Lys Asp Leu Lys Asp Gly
915 920 925
Tyr Met Ser Gln Val Val His Lys Ile Cys Asn Met Val Val Glu His
930 935 940
Lys Ala Ile Val Val Leu Glu Asn Leu Asn Leu Ser Phe Met Lys Gly
945 950 955 960
Arg Lys Lys Val Glu Lys Ser Val Tyr Glu Lys Phe Glu Arg Met Leu
965 970 975
Val Asp Lys Leu Asn Tyr Leu Val Val Asp Lys Lys Asn Leu Ser Asn
980 985 990
Glu Pro Gly Gly Leu Tyr Ala Ala Tyr Gln Leu Thr Asn Pro Leu Phe
995 1000 1005
Ser Phe Glu Glu Leu His Arg Tyr Pro Gln Ser Gly Ile Leu Phe
1010 1015 1020
Phe Val Asp Pro Trp Asn Thr Ser Leu Thr Asp Pro Ser Thr Gly
1025 1030 1035
Phe Val Asn Leu Leu Gly Arg Ile Asn Tyr Thr Asn Val Gly Asp
1040 1045 1050
Ala Arg Lys Phe Phe Asp Arg Phe Asn Ala Ile Arg Tyr Asp Gly
1055 1060 1065
Lys Gly Asn Ile Leu Phe Asp Leu Asp Leu Ser Arg Phe Asp Val
1070 1075 1080
Arg Val Glu Thr Gln Arg Lys Leu Trp Thr Leu Thr Thr Phe Gly
1085 1090 1095
Ser Arg Ile Ala Lys Ser Lys Lys Ser Gly Lys Trp Met Val Glu
1100 1105 1110
Arg Ile Glu Asn Leu Ser Leu Cys Phe Leu Glu Leu Phe Glu Gln
1115 1120 1125
Phe Asn Ile Gly Tyr Arg Val Glu Lys Asp Leu Lys Lys Ala Ile
1130 1135 1140
Leu Ser Gln Asp Arg Lys Glu Phe Tyr Val Arg Leu Ile Tyr Leu
1145 1150 1155
Phe Asn Leu Met Met Gln Ile Arg Asn Ser Asp Gly Glu Glu Asp
1160 1165 1170
Tyr Ile Leu Ser Pro Ala Leu Asn Glu Lys Asn Leu Gln Phe Asp
1175 1180 1185
Ser Arg Leu Ile Glu Ala Lys Asp Leu Pro Val Asp Ala Asp Ala
1190 1195 1200
Asn Gly Ala Tyr Asn Val Ala Arg Lys Gly Leu Met Val Val Gln
1205 1210 1215
Arg Ile Lys Arg Gly Asp His Glu Ser Ile His Arg Ile Gly Arg
1220 1225 1230
Ala Gln Trp Leu Arg Tyr Val Gln Glu Gly Ile Val Glu
1235 1240 1245
<210> 1128
<211> 1257
<212> БЕЛОК
<213> Prevotella bryantii
<400> 1128
Met Gln Ile Asn Asn Leu Lys Ile Ile Tyr Met Lys Phe Thr Asp Phe
1 5 10 15
Thr Gly Leu Tyr Ser Leu Ser Lys Thr Leu Arg Phe Glu Leu Lys Pro
20 25 30
Ile Gly Lys Thr Leu Glu Asn Ile Lys Lys Ala Gly Leu Leu Glu Gln
35 40 45
Asp Gln His Arg Ala Asp Ser Tyr Lys Lys Val Lys Lys Ile Ile Asp
50 55 60
Glu Tyr His Lys Ala Phe Ile Glu Lys Ser Leu Ser Asn Phe Glu Leu
65 70 75 80
Lys Tyr Gln Ser Glu Asp Lys Leu Asp Ser Leu Glu Glu Tyr Leu Met
85 90 95
Tyr Tyr Ser Met Lys Arg Ile Glu Lys Thr Glu Lys Asp Lys Phe Ala
100 105 110
Lys Ile Gln Asp Asn Leu Arg Lys Gln Ile Ala Asp His Leu Lys Gly
115 120 125
Asp Glu Ser Tyr Lys Thr Ile Phe Ser Lys Asp Leu Ile Arg Lys Asn
130 135 140
Leu Pro Asp Phe Val Lys Ser Asp Glu Glu Arg Thr Leu Ile Lys Glu
145 150 155 160
Phe Lys Asp Phe Thr Thr Tyr Phe Lys Gly Phe Tyr Glu Asn Arg Glu
165 170 175
Asn Met Tyr Ser Ala Glu Asp Lys Ser Thr Ala Ile Ser His Arg Ile
180 185 190
Ile His Glu Asn Leu Pro Lys Phe Val Asp Asn Ile Asn Ala Phe Ser
195 200 205
Lys Ile Ile Leu Ile Pro Glu Leu Arg Glu Lys Leu Asn Gln Ile Tyr
210 215 220
Gln Asp Phe Glu Glu Tyr Leu Asn Val Glu Ser Ile Asp Glu Ile Phe
225 230 235 240
His Leu Asp Tyr Phe Ser Met Val Met Thr Gln Lys Gln Ile Glu Val
245 250 255
Tyr Asn Ala Ile Ile Gly Gly Lys Ser Thr Asn Asp Lys Lys Ile Gln
260 265 270
Gly Leu Asn Glu Tyr Ile Asn Leu Tyr Asn Gln Lys His Lys Asp Cys
275 280 285
Lys Leu Pro Lys Leu Lys Leu Leu Phe Lys Gln Ile Leu Ser Asp Arg
290 295 300
Ile Ala Ile Ser Trp Leu Pro Asp Asn Phe Lys Asp Asp Gln Glu Ala
305 310 315 320
Leu Asp Ser Ile Asp Thr Cys Tyr Lys Asn Leu Leu Asn Asp Gly Asn
325 330 335
Val Leu Gly Glu Gly Asn Leu Lys Leu Leu Leu Glu Asn Ile Asp Thr
340 345 350
Tyr Asn Leu Lys Gly Ile Phe Ile Arg Asn Asp Leu Gln Leu Thr Asp
355 360 365
Ile Ser Gln Lys Met Tyr Ala Ser Trp Asn Val Ile Gln Asp Ala Val
370 375 380
Ile Leu Asp Leu Lys Lys Gln Val Ser Arg Lys Lys Lys Glu Ser Ala
385 390 395 400
Glu Asp Tyr Asn Asp Arg Leu Lys Lys Leu Tyr Thr Ser Gln Glu Ser
405 410 415
Phe Ser Ile Gln Tyr Leu Asn Asp Cys Leu Arg Ala Tyr Gly Lys Thr
420 425 430
Glu Asn Ile Gln Asp Tyr Phe Ala Lys Leu Gly Ala Val Asn Asn Glu
435 440 445
His Glu Gln Thr Ile Asn Leu Phe Ala Gln Val Arg Asn Ala Tyr Thr
450 455 460
Ser Val Gln Ala Ile Leu Thr Thr Pro Tyr Pro Glu Asn Ala Asn Leu
465 470 475 480
Ala Gln Asp Lys Glu Thr Val Ala Leu Ile Lys Asn Leu Leu Asp Ser
485 490 495
Leu Lys Arg Leu Gln Arg Phe Ile Lys Pro Leu Leu Gly Lys Gly Asp
500 505 510
Glu Ser Asp Lys Asp Glu Arg Phe Tyr Gly Asp Phe Thr Pro Leu Trp
515 520 525
Glu Thr Leu Asn Gln Ile Thr Pro Leu Tyr Asn Met Val Arg Asn Tyr
530 535 540
Met Thr Arg Lys Pro Tyr Ser Gln Glu Lys Ile Lys Leu Asn Phe Glu
545 550 555 560
Asn Ser Thr Leu Leu Gly Gly Trp Asp Leu Asn Lys Glu His Asp Asn
565 570 575
Thr Ala Ile Ile Leu Arg Lys Asn Gly Leu Tyr Tyr Leu Ala Ile Met
580 585 590
Lys Lys Ser Ala Asn Lys Ile Phe Asp Lys Asp Lys Leu Asp Asn Ser
595 600 605
Gly Asp Cys Tyr Glu Lys Met Val Tyr Lys Leu Leu Pro Gly Ala Asn
610 615 620
Lys Met Leu Pro Lys Val Phe Phe Ser Lys Ser Arg Ile Asp Glu Phe
625 630 635 640
Lys Pro Ser Glu Asn Ile Ile Glu Asn Tyr Lys Lys Gly Thr His Lys
645 650 655
Lys Gly Ala Asn Phe Asn Leu Ala Asp Cys His Asn Leu Ile Asp Phe
660 665 670
Phe Lys Ser Ser Ile Ser Lys His Glu Asp Trp Ser Lys Phe Asn Phe
675 680 685
His Phe Ser Asp Thr Ser Ser Tyr Glu Asp Leu Ser Asp Phe Tyr Arg
690 695 700
Glu Val Glu Gln Gln Gly Tyr Ser Ile Ser Phe Cys Asp Val Ser Val
705 710 715 720
Glu Tyr Ile Asn Lys Met Val Glu Lys Gly Asp Leu Tyr Leu Phe Gln
725 730 735
Ile Tyr Asn Lys Asp Phe Ser Glu Phe Ser Lys Gly Thr Pro Asn Met
740 745 750
His Thr Leu Tyr Trp Asn Ser Leu Phe Ser Lys Glu Asn Leu Asn Asn
755 760 765
Ile Ile Tyr Lys Leu Asn Gly Gln Ala Glu Ile Phe Phe Arg Lys Lys
770 775 780
Ser Leu Asn Tyr Lys Arg Pro Thr His Pro Ala His Gln Ala Ile Lys
785 790 795 800
Asn Lys Asn Lys Cys Asn Glu Lys Lys Glu Ser Ile Phe Asp Tyr Asp
805 810 815
Leu Val Lys Asp Lys Arg Tyr Thr Val Asp Lys Phe Gln Phe His Val
820 825 830
Pro Ile Thr Met Asn Phe Lys Ser Thr Gly Asn Thr Asn Ile Asn Gln
835 840 845
Gln Val Ile Asp Tyr Leu Arg Thr Glu Asp Asp Thr His Ile Ile Gly
850 855 860
Ile Asp Arg Gly Glu Arg His Leu Leu Tyr Leu Val Val Ile Asp Ser
865 870 875 880
His Gly Lys Ile Val Glu Gln Phe Thr Leu Asn Glu Ile Val Asn Glu
885 890 895
Tyr Gly Gly Asn Ile Tyr Arg Thr Asn Tyr His Asp Leu Leu Asp Thr
900 905 910
Arg Glu Gln Asn Arg Glu Lys Ala Arg Glu Ser Trp Gln Thr Ile Glu
915 920 925
Asn Ile Lys Glu Leu Lys Glu Gly Tyr Ile Ser Gln Val Ile His Lys
930 935 940
Ile Thr Asp Leu Met Gln Lys Tyr His Ala Val Val Val Leu Glu Asp
945 950 955 960
Leu Asn Met Gly Phe Met Arg Gly Arg Gln Lys Val Glu Lys Gln Val
965 970 975
Tyr Gln Lys Phe Glu Glu Met Leu Ile Asn Lys Leu Asn Tyr Leu Val
980 985 990
Asn Lys Lys Ala Asp Gln Asn Ser Ala Gly Gly Leu Leu His Ala Tyr
995 1000 1005
Gln Leu Thr Ser Lys Phe Glu Ser Phe Gln Lys Leu Gly Lys Gln
1010 1015 1020
Ser Gly Phe Leu Phe Tyr Ile Pro Ala Trp Asn Thr Ser Lys Ile
1025 1030 1035
Asp Pro Val Thr Gly Phe Val Asn Leu Phe Asp Thr Arg Tyr Glu
1040 1045 1050
Ser Ile Asp Lys Ala Lys Ala Phe Phe Gly Lys Phe Asp Ser Ile
1055 1060 1065
Arg Tyr Asn Ala Asp Lys Asp Trp Phe Glu Phe Ala Phe Asp Tyr
1070 1075 1080
Asn Asn Phe Thr Thr Lys Ala Glu Gly Thr Arg Thr Asn Trp Thr
1085 1090 1095
Ile Cys Thr Tyr Gly Ser Arg Ile Arg Thr Phe Arg Asn Gln Ala
1100 1105 1110
Lys Asn Ser Gln Trp Asp Asn Glu Glu Ile Asp Leu Thr Lys Ala
1115 1120 1125
Tyr Lys Ala Phe Phe Ala Lys His Gly Ile Asn Ile Tyr Asp Asn
1130 1135 1140
Ile Lys Glu Ala Ile Ala Met Glu Thr Glu Lys Ser Phe Phe Glu
1145 1150 1155
Asp Leu Leu His Leu Leu Lys Leu Thr Leu Gln Met Arg Asn Ser
1160 1165 1170
Ile Thr Gly Thr Thr Thr Asp Tyr Leu Ile Ser Pro Val His Asp
1175 1180 1185
Ser Lys Gly Asn Phe Tyr Asp Ser Arg Ile Cys Asp Asn Ser Leu
1190 1195 1200
Pro Ala Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys
1205 1210 1215
Gly Leu Met Leu Ile Gln Gln Ile Lys Asp Ser Thr Ser Ser Asn
1220 1225 1230
Arg Phe Lys Phe Ser Pro Ile Thr Asn Lys Asp Trp Leu Ile Phe
1235 1240 1245
Ala Gln Glu Lys Pro Tyr Leu Asn Asp
1250 1255
<210> 1129
<211> 1247
<212> БЕЛОК
<213> Prevotella bryantii
<400> 1129
Met Lys Phe Thr Asp Phe Thr Gly Leu Tyr Ser Leu Ser Lys Thr Leu
1 5 10 15
Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu Asn Ile Lys Lys
20 25 30
Ala Gly Leu Leu Glu Gln Asp Gln His Arg Ala Asp Ser Tyr Lys Lys
35 40 45
Val Lys Lys Ile Ile Asp Glu Tyr His Lys Ala Phe Ile Glu Lys Ser
50 55 60
Leu Ser Asn Phe Glu Leu Lys Tyr Gln Ser Glu Asp Lys Leu Asp Ser
65 70 75 80
Leu Glu Glu Tyr Leu Met Tyr Tyr Ser Met Lys Arg Ile Glu Lys Thr
85 90 95
Glu Lys Asp Lys Phe Ala Lys Ile Gln Asp Asn Leu Arg Lys Gln Ile
100 105 110
Ala Asp His Leu Lys Gly Asp Glu Ser Tyr Lys Thr Ile Phe Ser Lys
115 120 125
Asp Leu Ile Arg Lys Asn Leu Pro Asp Phe Val Lys Ser Asp Glu Glu
130 135 140
Arg Thr Leu Ile Lys Glu Phe Lys Asp Phe Thr Thr Tyr Phe Lys Gly
145 150 155 160
Phe Tyr Glu Asn Arg Glu Asn Met Tyr Ser Ala Glu Asp Lys Ser Thr
165 170 175
Ala Ile Ser His Arg Ile Ile His Glu Asn Leu Pro Lys Phe Val Asp
180 185 190
Asn Ile Asn Ala Phe Ser Lys Ile Ile Leu Ile Pro Glu Leu Arg Glu
195 200 205
Lys Leu Asn Gln Ile Tyr Gln Asp Phe Glu Glu Tyr Leu Asn Val Glu
210 215 220
Ser Ile Asp Glu Ile Phe His Leu Asp Tyr Phe Ser Met Val Met Thr
225 230 235 240
Gln Lys Gln Ile Glu Val Tyr Asn Ala Ile Ile Gly Gly Lys Ser Thr
245 250 255
Asn Asp Lys Lys Ile Gln Gly Leu Asn Glu Tyr Ile Asn Leu Tyr Asn
260 265 270
Gln Lys His Lys Asp Cys Lys Leu Pro Lys Leu Lys Leu Leu Phe Lys
275 280 285
Gln Ile Leu Ser Asp Arg Ile Ala Ile Ser Trp Leu Pro Asp Asn Phe
290 295 300
Lys Asp Asp Gln Glu Ala Leu Asp Ser Ile Asp Thr Cys Tyr Lys Asn
305 310 315 320
Leu Leu Asn Asp Gly Asn Val Leu Gly Glu Gly Asn Leu Lys Leu Leu
325 330 335
Leu Glu Asn Ile Asp Thr Tyr Asn Leu Lys Gly Ile Phe Ile Arg Asn
340 345 350
Asp Leu Gln Leu Thr Asp Ile Ser Gln Lys Met Tyr Ala Ser Trp Asn
355 360 365
Val Ile Gln Asp Ala Val Ile Leu Asp Leu Lys Lys Gln Val Ser Arg
370 375 380
Lys Lys Lys Glu Ser Ala Glu Asp Tyr Asn Asp Arg Leu Lys Lys Leu
385 390 395 400
Tyr Thr Ser Gln Glu Ser Phe Ser Ile Gln Tyr Leu Asn Asp Cys Leu
405 410 415
Arg Ala Tyr Gly Lys Thr Glu Asn Ile Gln Asp Tyr Phe Ala Lys Leu
420 425 430
Gly Ala Val Asn Asn Glu His Glu Gln Thr Ile Asn Leu Phe Ala Gln
435 440 445
Val Arg Asn Ala Tyr Thr Ser Val Gln Ala Ile Leu Thr Thr Pro Tyr
450 455 460
Pro Glu Asn Ala Asn Leu Ala Gln Asp Lys Glu Thr Val Ala Leu Ile
465 470 475 480
Lys Asn Leu Leu Asp Ser Leu Lys Arg Leu Gln Arg Phe Ile Lys Pro
485 490 495
Leu Leu Gly Lys Gly Asp Glu Ser Asp Lys Asp Glu Arg Phe Tyr Gly
500 505 510
Asp Phe Thr Pro Leu Trp Glu Thr Leu Asn Gln Ile Thr Pro Leu Tyr
515 520 525
Asn Met Val Arg Asn Tyr Met Thr Arg Lys Pro Tyr Ser Gln Glu Lys
530 535 540
Ile Lys Leu Asn Phe Glu Asn Ser Thr Leu Leu Gly Gly Trp Asp Leu
545 550 555 560
Asn Lys Glu His Asp Asn Thr Ala Ile Ile Leu Arg Lys Asn Gly Leu
565 570 575
Tyr Tyr Leu Ala Ile Met Lys Lys Ser Ala Asn Lys Ile Phe Asp Lys
580 585 590
Asp Lys Leu Asp Asn Ser Gly Asp Cys Tyr Glu Lys Met Val Tyr Lys
595 600 605
Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val Phe Phe Ser Lys
610 615 620
Ser Arg Ile Asp Glu Phe Lys Pro Ser Glu Asn Ile Ile Glu Asn Tyr
625 630 635 640
Lys Lys Gly Thr His Lys Lys Gly Ala Asn Phe Asn Leu Ala Asp Cys
645 650 655
His Asn Leu Ile Asp Phe Phe Lys Ser Ser Ile Ser Lys His Glu Asp
660 665 670
Trp Ser Lys Phe Asn Phe His Phe Ser Asp Thr Ser Ser Tyr Glu Asp
675 680 685
Leu Ser Asp Phe Tyr Arg Glu Val Glu Gln Gln Gly Tyr Ser Ile Ser
690 695 700
Phe Cys Asp Val Ser Val Glu Tyr Ile Asn Lys Met Val Glu Lys Gly
705 710 715 720
Asp Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Glu Phe Ser
725 730 735
Lys Gly Thr Pro Asn Met His Thr Leu Tyr Trp Asn Ser Leu Phe Ser
740 745 750
Lys Glu Asn Leu Asn Asn Ile Ile Tyr Lys Leu Asn Gly Gln Ala Glu
755 760 765
Ile Phe Phe Arg Lys Lys Ser Leu Asn Tyr Lys Arg Pro Thr His Pro
770 775 780
Ala His Gln Ala Ile Lys Asn Lys Asn Lys Cys Asn Glu Lys Lys Glu
785 790 795 800
Ser Ile Phe Asp Tyr Asp Leu Val Lys Asp Lys Arg Tyr Thr Val Asp
805 810 815
Lys Phe Gln Phe His Val Pro Ile Thr Met Asn Phe Lys Ser Thr Gly
820 825 830
Asn Thr Asn Ile Asn Gln Gln Val Ile Asp Tyr Leu Arg Thr Glu Asp
835 840 845
Asp Thr His Ile Ile Gly Ile Asp Arg Gly Glu Arg His Leu Leu Tyr
850 855 860
Leu Val Val Ile Asp Ser His Gly Lys Ile Val Glu Gln Phe Thr Leu
865 870 875 880
Asn Glu Ile Val Asn Glu Tyr Gly Gly Asn Ile Tyr Arg Thr Asn Tyr
885 890 895
His Asp Leu Leu Asp Thr Arg Glu Gln Asn Arg Glu Lys Ala Arg Glu
900 905 910
Ser Trp Gln Thr Ile Glu Asn Ile Lys Glu Leu Lys Glu Gly Tyr Ile
915 920 925
Ser Gln Val Ile His Lys Ile Thr Asp Leu Met Gln Lys Tyr His Ala
930 935 940
Val Val Val Leu Glu Asp Leu Asn Met Gly Phe Met Arg Gly Arg Gln
945 950 955 960
Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Glu Met Leu Ile Asn
965 970 975
Lys Leu Asn Tyr Leu Val Asn Lys Lys Ala Asp Gln Asn Ser Ala Gly
980 985 990
Gly Leu Leu His Ala Tyr Gln Leu Thr Ser Lys Phe Glu Ser Phe Gln
995 1000 1005
Lys Leu Gly Lys Gln Ser Gly Phe Leu Phe Tyr Ile Pro Ala Trp
1010 1015 1020
Asn Thr Ser Lys Ile Asp Pro Val Thr Gly Phe Val Asn Leu Phe
1025 1030 1035
Asp Thr Arg Tyr Glu Ser Ile Asp Lys Ala Lys Ala Phe Phe Gly
1040 1045 1050
Lys Phe Asp Ser Ile Arg Tyr Asn Ala Asp Lys Asp Trp Phe Glu
1055 1060 1065
Phe Ala Phe Asp Tyr Asn Asn Phe Thr Thr Lys Ala Glu Gly Thr
1070 1075 1080
Arg Thr Asn Trp Thr Ile Cys Thr Tyr Gly Ser Arg Ile Arg Thr
1085 1090 1095
Phe Arg Asn Gln Ala Lys Asn Ser Gln Trp Asp Asn Glu Glu Ile
1100 1105 1110
Asp Leu Thr Lys Ala Tyr Lys Ala Phe Phe Ala Lys His Gly Ile
1115 1120 1125
Asn Ile Tyr Asp Asn Ile Lys Glu Ala Ile Ala Met Glu Thr Glu
1130 1135 1140
Lys Ser Phe Phe Glu Asp Leu Leu His Leu Leu Lys Leu Thr Leu
1145 1150 1155
Gln Met Arg Asn Ser Ile Thr Gly Thr Thr Thr Asp Tyr Leu Ile
1160 1165 1170
Ser Pro Val His Asp Ser Lys Gly Asn Phe Tyr Asp Ser Arg Ile
1175 1180 1185
Cys Asp Asn Ser Leu Pro Ala Asn Ala Asp Ala Asn Gly Ala Tyr
1190 1195 1200
Asn Ile Ala Arg Lys Gly Leu Met Leu Ile Gln Gln Ile Lys Asp
1205 1210 1215
Ser Thr Ser Ser Asn Arg Phe Lys Phe Ser Pro Ile Thr Asn Lys
1220 1225 1230
Asp Trp Leu Ile Phe Ala Gln Glu Lys Pro Tyr Leu Asn Asp
1235 1240 1245
<210> 1130
<211> 1253
<212> БЕЛОК
<213> Prevotella albensis
<400> 1130
Met Asn Ile Lys Asn Phe Thr Gly Leu Tyr Pro Leu Ser Lys Thr Leu
1 5 10 15
Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Lys Glu Asn Ile Glu Lys
20 25 30
Asn Gly Ile Leu Thr Lys Asp Glu Gln Arg Ala Lys Asp Tyr Leu Ile
35 40 45
Val Lys Gly Phe Ile Asp Glu Tyr His Lys Gln Phe Ile Lys Asp Arg
50 55 60
Leu Trp Asp Phe Lys Leu Pro Leu Glu Ser Glu Gly Glu Lys Asn Ser
65 70 75 80
Leu Glu Glu Tyr Gln Glu Leu Tyr Glu Leu Thr Lys Arg Asn Asp Ala
85 90 95
Gln Glu Ala Asp Phe Thr Glu Ile Lys Asp Asn Leu Arg Ser Ser Ile
100 105 110
Thr Glu Gln Leu Thr Lys Ser Gly Ser Ala Tyr Asp Arg Ile Phe Lys
115 120 125
Lys Glu Phe Ile Arg Glu Asp Leu Val Asn Phe Leu Glu Asp Glu Lys
130 135 140
Asp Lys Asn Ile Val Lys Gln Phe Glu Asp Phe Thr Thr Tyr Phe Thr
145 150 155 160
Gly Phe Tyr Glu Asn Arg Lys Asn Met Tyr Ser Ser Glu Glu Lys Ser
165 170 175
Thr Ala Ile Ala Tyr Arg Leu Ile His Gln Asn Leu Pro Lys Phe Met
180 185 190
Asp Asn Met Arg Ser Phe Ala Lys Ile Ala Asn Ser Ser Val Ser Glu
195 200 205
His Phe Ser Asp Ile Tyr Glu Ser Trp Lys Glu Tyr Leu Asn Val Asn
210 215 220
Ser Ile Glu Glu Ile Phe Gln Leu Asp Tyr Phe Ser Glu Thr Leu Thr
225 230 235 240
Gln Pro His Ile Glu Val Tyr Asn Tyr Ile Ile Gly Lys Lys Val Leu
245 250 255
Glu Asp Gly Thr Glu Ile Lys Gly Ile Asn Glu Tyr Val Asn Leu Tyr
260 265 270
Asn Gln Gln Gln Lys Asp Lys Ser Lys Arg Leu Pro Phe Leu Val Pro
275 280 285
Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Lys Leu Ser Trp Ile Ala
290 295 300
Glu Glu Phe Asp Ser Asp Lys Lys Met Leu Ser Ala Ile Thr Glu Ser
305 310 315 320
Tyr Asn His Leu His Asn Val Leu Met Gly Asn Glu Asn Glu Ser Leu
325 330 335
Arg Asn Leu Leu Leu Asn Ile Lys Asp Tyr Asn Leu Glu Lys Ile Asn
340 345 350
Ile Thr Asn Asp Leu Ser Leu Thr Glu Ile Ser Gln Asn Leu Phe Gly
355 360 365
Arg Tyr Asp Val Phe Thr Asn Gly Ile Lys Asn Lys Leu Arg Val Leu
370 375 380
Thr Pro Arg Lys Lys Lys Glu Thr Asp Glu Asn Phe Glu Asp Arg Ile
385 390 395 400
Asn Lys Ile Phe Lys Thr Gln Lys Ser Phe Ser Ile Ala Phe Leu Asn
405 410 415
Lys Leu Pro Gln Pro Glu Met Glu Asp Gly Lys Pro Arg Asn Ile Glu
420 425 430
Asp Tyr Phe Ile Thr Gln Gly Ala Ile Asn Thr Lys Ser Ile Gln Lys
435 440 445
Glu Asp Ile Phe Ala Gln Ile Glu Asn Ala Tyr Glu Asp Ala Gln Val
450 455 460
Phe Leu Gln Ile Lys Asp Thr Asp Asn Lys Leu Ser Gln Asn Lys Thr
465 470 475 480
Ala Val Glu Lys Ile Lys Thr Leu Leu Asp Ala Leu Lys Glu Leu Gln
485 490 495
His Phe Ile Lys Pro Leu Leu Gly Ser Gly Glu Glu Asn Glu Lys Asp
500 505 510
Glu Leu Phe Tyr Gly Ser Phe Leu Ala Ile Trp Asp Glu Leu Asp Thr
515 520 525
Ile Thr Pro Leu Tyr Asn Lys Val Arg Asn Trp Leu Thr Arg Lys Pro
530 535 540
Tyr Ser Thr Glu Lys Ile Lys Leu Asn Phe Asp Asn Ala Gln Leu Leu
545 550 555 560
Gly Gly Trp Asp Val Asn Lys Glu His Asp Cys Ala Gly Ile Leu Leu
565 570 575
Arg Lys Asn Asp Ser Tyr Tyr Leu Gly Ile Ile Asn Lys Lys Thr Asn
580 585 590
His Ile Phe Asp Thr Asp Ile Thr Pro Ser Asp Gly Glu Cys Tyr Asp
595 600 605
Lys Ile Asp Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys
610 615 620
Val Phe Phe Ser Lys Ser Arg Ile Lys Glu Phe Glu Pro Ser Glu Ala
625 630 635 640
Ile Ile Asn Cys Tyr Lys Lys Gly Thr His Lys Lys Gly Lys Asn Phe
645 650 655
Asn Leu Thr Asp Cys His Arg Leu Ile Asn Phe Phe Lys Thr Ser Ile
660 665 670
Glu Lys His Glu Asp Trp Ser Lys Phe Gly Phe Lys Phe Ser Asp Thr
675 680 685
Glu Thr Tyr Glu Asp Ile Ser Gly Phe Tyr Arg Glu Val Glu Gln Gln
690 695 700
Gly Tyr Arg Leu Thr Ser His Pro Val Ser Ala Ser Tyr Ile His Ser
705 710 715 720
Leu Val Lys Glu Gly Lys Leu Tyr Leu Phe Gln Ile Trp Asn Lys Asp
725 730 735
Phe Ser Gln Phe Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr Trp
740 745 750
Lys Met Leu Phe Asp Lys Arg Asn Leu Ser Asp Val Val Tyr Lys Leu
755 760 765
Asn Gly Gln Ala Glu Val Phe Tyr Arg Lys Ser Ser Ile Glu His Gln
770 775 780
Asn Arg Ile Ile His Pro Ala Gln His Pro Ile Thr Asn Lys Asn Glu
785 790 795 800
Leu Asn Lys Lys His Thr Ser Thr Phe Lys Tyr Asp Ile Ile Lys Asp
805 810 815
Arg Arg Tyr Thr Val Asp Lys Phe Gln Phe His Val Pro Ile Thr Ile
820 825 830
Asn Phe Lys Ala Thr Gly Gln Asn Asn Ile Asn Pro Ile Val Gln Glu
835 840 845
Val Ile Arg Gln Asn Gly Ile Thr His Ile Ile Gly Ile Asp Arg Gly
850 855 860
Glu Arg His Leu Leu Tyr Leu Ser Leu Ile Asp Leu Lys Gly Asn Ile
865 870 875 880
Ile Lys Gln Met Thr Leu Asn Glu Ile Ile Asn Glu Tyr Lys Gly Val
885 890 895
Thr Tyr Lys Thr Asn Tyr His Asn Leu Leu Glu Lys Arg Glu Lys Glu
900 905 910
Arg Thr Glu Ala Arg His Ser Trp Ser Ser Ile Glu Ser Ile Lys Glu
915 920 925
Leu Lys Asp Gly Tyr Met Ser Gln Val Ile His Lys Ile Thr Asp Met
930 935 940
Met Val Lys Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn Gly Gly
945 950 955 960
Phe Met Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe
965 970 975
Glu Lys Lys Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Lys Leu
980 985 990
Asp Ala Asn Glu Val Gly Gly Val Leu Asn Ala Tyr Gln Leu Thr Asn
995 1000 1005
Lys Phe Glu Ser Phe Lys Lys Ile Gly Lys Gln Ser Gly Phe Leu
1010 1015 1020
Phe Tyr Ile Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro Ile Thr
1025 1030 1035
Gly Phe Val Asn Leu Phe Asn Thr Arg Tyr Glu Ser Ile Lys Glu
1040 1045 1050
Thr Lys Val Phe Trp Ser Lys Phe Asp Ile Ile Arg Tyr Asn Lys
1055 1060 1065
Glu Lys Asn Trp Phe Glu Phe Val Phe Asp Tyr Asn Thr Phe Thr
1070 1075 1080
Thr Lys Ala Glu Gly Thr Arg Thr Lys Trp Thr Leu Cys Thr His
1085 1090 1095
Gly Thr Arg Ile Gln Thr Phe Arg Asn Pro Glu Lys Asn Ala Gln
1100 1105 1110
Trp Asp Asn Lys Glu Ile Asn Leu Thr Glu Ser Phe Lys Ala Leu
1115 1120 1125
Phe Glu Lys Tyr Lys Ile Asp Ile Thr Ser Asn Leu Lys Glu Ser
1130 1135 1140
Ile Met Gln Glu Thr Glu Lys Lys Phe Phe Gln Glu Leu His Asn
1145 1150 1155
Leu Leu His Leu Thr Leu Gln Met Arg Asn Ser Val Thr Gly Thr
1160 1165 1170
Asp Ile Asp Tyr Leu Ile Ser Pro Val Ala Asp Glu Asp Gly Asn
1175 1180 1185
Phe Tyr Asp Ser Arg Ile Asn Gly Lys Asn Phe Pro Glu Asn Ala
1190 1195 1200
Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Met Leu
1205 1210 1215
Ile Arg Gln Ile Lys Gln Ala Asp Pro Gln Lys Lys Phe Lys Phe
1220 1225 1230
Glu Thr Ile Thr Asn Lys Asp Trp Leu Lys Phe Ala Gln Asp Lys
1235 1240 1245
Pro Tyr Leu Lys Asp
1250
<210> 1131
<211> 1262
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Bacteroidetes из ротовой полости, таксон 274
<400> 1131
Met Arg Lys Phe Asn Glu Phe Val Gly Leu Tyr Pro Ile Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu His Ile Gln
20 25 30
Arg Asn Lys Leu Leu Glu His Asp Ala Val Arg Ala Asp Asp Tyr Val
35 40 45
Lys Val Lys Lys Ile Ile Asp Lys Tyr His Lys Cys Leu Ile Asp Glu
50 55 60
Ala Leu Ser Gly Phe Thr Phe Asp Thr Glu Ala Asp Gly Arg Ser Asn
65 70 75 80
Asn Ser Leu Ser Glu Tyr Tyr Leu Tyr Tyr Asn Leu Lys Lys Arg Asn
85 90 95
Glu Gln Glu Gln Lys Thr Phe Lys Thr Ile Gln Asn Asn Leu Arg Lys
100 105 110
Gln Ile Val Asn Lys Leu Thr Gln Ser Glu Lys Tyr Lys Arg Ile Asp
115 120 125
Lys Lys Glu Leu Ile Thr Thr Asp Leu Pro Asp Phe Leu Thr Asn Glu
130 135 140
Ser Glu Lys Glu Leu Val Glu Lys Phe Lys Asn Phe Thr Thr Tyr Phe
145 150 155 160
Thr Glu Phe His Lys Asn Arg Lys Asn Met Tyr Ser Lys Glu Glu Lys
165 170 175
Ser Thr Ala Ile Ala Phe Arg Leu Ile Asn Glu Asn Leu Pro Lys Phe
180 185 190
Val Asp Asn Ile Ala Ala Phe Glu Lys Val Val Ser Ser Pro Leu Ala
195 200 205
Glu Lys Ile Asn Ala Leu Tyr Glu Asp Phe Lys Glu Tyr Leu Asn Val
210 215 220
Glu Glu Ile Ser Arg Val Phe Arg Leu Asp Tyr Tyr Asp Glu Leu Leu
225 230 235 240
Thr Gln Lys Gln Ile Asp Leu Tyr Asn Ala Ile Val Gly Gly Arg Thr
245 250 255
Glu Glu Asp Asn Lys Ile Gln Ile Lys Gly Leu Asn Gln Tyr Ile Asn
260 265 270
Glu Tyr Asn Gln Gln Gln Thr Asp Arg Ser Asn Arg Leu Pro Lys Leu
275 280 285
Lys Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Ser Val Ser Trp
290 295 300
Leu Pro Pro Lys Phe Asp Ser Asp Lys Asn Leu Leu Ile Lys Ile Lys
305 310 315 320
Glu Cys Tyr Asp Ala Leu Ser Glu Lys Glu Lys Val Phe Asp Lys Leu
325 330 335
Glu Ser Ile Leu Lys Ser Leu Ser Thr Tyr Asp Leu Ser Lys Ile Tyr
340 345 350
Ile Ser Asn Asp Ser Gln Leu Ser Tyr Ile Ser Gln Lys Met Phe Gly
355 360 365
Arg Trp Asp Ile Ile Ser Lys Ala Ile Arg Glu Asp Cys Ala Lys Arg
370 375 380
Asn Pro Gln Lys Ser Arg Glu Ser Leu Glu Lys Phe Ala Glu Arg Ile
385 390 395 400
Asp Lys Lys Leu Lys Thr Ile Asp Ser Ile Ser Ile Gly Asp Val Asp
405 410 415
Glu Cys Leu Ala Gln Leu Gly Glu Thr Tyr Val Lys Arg Val Glu Asp
420 425 430
Tyr Phe Val Ala Met Gly Glu Ser Glu Ile Asp Asp Glu Gln Thr Asp
435 440 445
Thr Thr Ser Phe Lys Lys Asn Ile Glu Gly Ala Tyr Glu Ser Val Lys
450 455 460
Glu Leu Leu Asn Asn Ala Asp Asn Ile Thr Asp Asn Asn Leu Met Gln
465 470 475 480
Asp Lys Gly Asn Val Glu Lys Ile Lys Thr Leu Leu Asp Ala Ile Lys
485 490 495
Asp Leu Gln Arg Phe Ile Lys Pro Leu Leu Gly Lys Gly Asp Glu Ala
500 505 510
Asp Lys Asp Gly Val Phe Tyr Gly Glu Phe Thr Ser Leu Trp Thr Lys
515 520 525
Leu Asp Gln Val Thr Pro Leu Tyr Asn Met Val Arg Asn Tyr Leu Thr
530 535 540
Ser Lys Pro Tyr Ser Thr Lys Lys Ile Lys Leu Asn Phe Glu Asn Ser
545 550 555 560
Thr Leu Met Asp Gly Trp Asp Leu Asn Lys Glu Pro Asp Asn Thr Thr
565 570 575
Val Ile Phe Cys Lys Asp Gly Leu Tyr Tyr Leu Gly Ile Met Gly Lys
580 585 590
Lys Tyr Asn Arg Val Phe Val Asp Arg Glu Asp Leu Pro His Asp Gly
595 600 605
Glu Cys Tyr Asp Lys Met Glu Tyr Lys Leu Leu Pro Gly Ala Asn Lys
610 615 620
Met Leu Pro Lys Val Phe Phe Ser Glu Thr Gly Ile Gln Arg Phe Leu
625 630 635 640
Pro Ser Glu Glu Leu Leu Gly Lys Tyr Glu Arg Gly Thr His Lys Lys
645 650 655
Gly Ala Gly Phe Asp Leu Gly Asp Cys Arg Ala Leu Ile Asp Phe Phe
660 665 670
Lys Lys Ser Ile Glu Arg His Asp Asp Trp Lys Lys Phe Asp Phe Lys
675 680 685
Phe Ser Asp Thr Ser Thr Tyr Gln Asp Ile Ser Glu Phe Tyr Arg Glu
690 695 700
Val Glu Gln Gln Gly Tyr Lys Met Ser Phe Arg Lys Val Ser Val Asp
705 710 715 720
Tyr Ile Lys Ser Leu Val Glu Glu Gly Lys Leu Tyr Leu Phe Gln Ile
725 730 735
Tyr Asn Lys Asp Phe Ser Ala His Ser Lys Gly Thr Pro Asn Met His
740 745 750
Thr Leu Tyr Trp Lys Met Leu Phe Asp Glu Glu Asn Leu Lys Asp Val
755 760 765
Val Tyr Lys Leu Asn Gly Glu Ala Glu Val Phe Phe Arg Lys Ser Ser
770 775 780
Ile Thr Val Gln Ser Pro Thr His Pro Ala Asn Ser Pro Ile Lys Asn
785 790 795 800
Lys Asn Lys Asp Asn Gln Lys Lys Glu Ser Lys Phe Glu Tyr Asp Leu
805 810 815
Ile Lys Asp Arg Arg Tyr Thr Val Asp Lys Phe Leu Phe His Val Pro
820 825 830
Ile Thr Met Asn Phe Lys Ser Val Gly Gly Ser Asn Ile Asn Gln Leu
835 840 845
Val Lys Arg His Ile Arg Ser Ala Thr Asp Leu His Ile Ile Gly Ile
850 855 860
Asp Arg Gly Glu Arg His Leu Leu Tyr Leu Thr Val Ile Asp Ser Arg
865 870 875 880
Gly Asn Ile Lys Glu Gln Phe Ser Leu Asn Glu Ile Val Asn Glu Tyr
885 890 895
Asn Gly Asn Thr Tyr Arg Thr Asp Tyr His Glu Leu Leu Asp Thr Arg
900 905 910
Glu Gly Glu Arg Thr Glu Ala Arg Arg Asn Trp Gln Thr Ile Gln Asn
915 920 925
Ile Arg Glu Leu Lys Glu Gly Tyr Leu Ser Gln Val Ile His Lys Ile
930 935 940
Ser Glu Leu Ala Ile Lys Tyr Asn Ala Val Ile Val Leu Glu Asp Leu
945 950 955 960
Asn Phe Gly Phe Met Arg Ser Arg Gln Lys Val Glu Lys Gln Val Tyr
965 970 975
Gln Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp
980 985 990
Lys Lys Lys Pro Val Ala Glu Thr Gly Gly Leu Leu Arg Ala Tyr Gln
995 1000 1005
Leu Thr Gly Glu Phe Glu Ser Phe Lys Thr Leu Gly Lys Gln Ser
1010 1015 1020
Gly Ile Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile Asp
1025 1030 1035
Pro Val Thr Gly Phe Val Asn Leu Phe Asp Thr His Tyr Glu Asn
1040 1045 1050
Ile Glu Lys Ala Lys Val Phe Phe Asp Lys Phe Lys Ser Ile Arg
1055 1060 1065
Tyr Asn Ser Asp Lys Asp Trp Phe Glu Phe Val Val Asp Asp Tyr
1070 1075 1080
Thr Arg Phe Ser Pro Lys Ala Glu Gly Thr Arg Arg Asp Trp Thr
1085 1090 1095
Ile Cys Thr Gln Gly Lys Arg Ile Gln Ile Cys Arg Asn His Gln
1100 1105 1110
Arg Asn Asn Glu Trp Glu Gly Gln Glu Ile Asp Leu Thr Lys Ala
1115 1120 1125
Phe Lys Glu His Phe Glu Ala Tyr Gly Val Asp Ile Ser Lys Asp
1130 1135 1140
Leu Arg Glu Gln Ile Asn Thr Gln Asn Lys Lys Glu Phe Phe Glu
1145 1150 1155
Glu Leu Leu Arg Leu Leu Arg Leu Thr Leu Gln Met Arg Asn Ser
1160 1165 1170
Met Pro Ser Ser Asp Ile Asp Tyr Leu Ile Ser Pro Val Ala Asn
1175 1180 1185
Asp Thr Gly Cys Phe Phe Asp Ser Arg Lys Gln Ala Glu Leu Lys
1190 1195 1200
Glu Asn Ala Val Leu Pro Met Asn Ala Asp Ala Asn Gly Ala Tyr
1205 1210 1215
Asn Ile Ala Arg Lys Gly Leu Leu Ala Ile Arg Lys Met Lys Gln
1220 1225 1230
Glu Glu Asn Asp Ser Ala Lys Ile Ser Leu Ala Ile Ser Asn Lys
1235 1240 1245
Glu Trp Leu Lys Phe Ala Gln Thr Lys Pro Tyr Leu Glu Asp
1250 1255 1260
<210> 1132
<211> 1264
<212> БЕЛОК
<213> Prevotella brevis
<400> 1132
Met Lys Gln Phe Thr Asn Leu Tyr Gln Leu Ser Lys Thr Leu Arg Phe
1 5 10 15
Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu His Ile Asn Ala Asn Gly
20 25 30
Phe Ile Asp Asn Asp Ala His Arg Ala Glu Ser Tyr Lys Lys Val Lys
35 40 45
Lys Leu Ile Asp Asp Tyr His Lys Asp Tyr Ile Glu Asn Val Leu Asn
50 55 60
Asn Phe Lys Leu Asn Gly Glu Tyr Leu Gln Ala Tyr Phe Asp Leu Tyr
65 70 75 80
Ser Gln Asp Thr Lys Asp Lys Gln Phe Lys Asp Ile Gln Asp Lys Leu
85 90 95
Arg Lys Ser Ile Ala Ser Ala Leu Lys Gly Asp Asp Arg Tyr Lys Thr
100 105 110
Ile Asp Lys Lys Glu Leu Ile Arg Gln Asp Met Lys Thr Phe Leu Lys
115 120 125
Lys Asp Thr Asp Lys Ala Leu Leu Asp Glu Phe Tyr Glu Phe Thr Thr
130 135 140
Tyr Phe Thr Gly Tyr His Glu Asn Arg Lys Asn Met Tyr Ser Asp Glu
145 150 155 160
Ala Lys Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Asp Asn Leu Pro
165 170 175
Lys Phe Ile Asp Asn Ile Ala Val Phe Lys Lys Ile Ala Asn Thr Ser
180 185 190
Val Ala Asp Asn Phe Ser Thr Ile Tyr Lys Asn Phe Glu Glu Tyr Leu
195 200 205
Asn Val Asn Ser Ile Asp Glu Ile Phe Ser Leu Asp Tyr Tyr Asn Ile
210 215 220
Val Leu Thr Gln Thr Gln Ile Glu Val Tyr Asn Ser Ile Ile Gly Gly
225 230 235 240
Arg Thr Leu Glu Asp Asp Thr Lys Ile Gln Gly Ile Asn Glu Phe Val
245 250 255
Asn Leu Tyr Asn Gln Gln Leu Ala Asn Lys Lys Asp Arg Leu Pro Lys
260 265 270
Leu Lys Pro Leu Phe Lys Gln Ile Leu Ser Asp Arg Val Gln Leu Ser
275 280 285
Trp Leu Gln Glu Glu Phe Asn Thr Gly Ala Asp Val Leu Asn Ala Val
290 295 300
Lys Glu Tyr Cys Thr Ser Tyr Phe Asp Asn Val Glu Glu Ser Val Lys
305 310 315 320
Val Leu Leu Thr Gly Ile Ser Asp Tyr Asp Leu Ser Lys Ile Tyr Ile
325 330 335
Thr Asn Asp Leu Ala Leu Thr Asp Val Ser Gln Arg Met Phe Gly Glu
340 345 350
Trp Ser Ile Ile Pro Asn Ala Ile Glu Gln Arg Leu Arg Ser Asp Asn
355 360 365
Pro Lys Lys Thr Asn Glu Lys Glu Glu Lys Tyr Ser Asp Arg Ile Ser
370 375 380
Lys Leu Lys Lys Leu Pro Lys Ser Tyr Ser Leu Gly Tyr Ile Asn Glu
385 390 395 400
Cys Ile Ser Glu Leu Asn Gly Ile Asp Ile Ala Asp Tyr Tyr Ala Thr
405 410 415
Leu Gly Ala Ile Asn Thr Glu Ser Lys Gln Glu Pro Ser Ile Pro Thr
420 425 430
Ser Ile Gln Val His Tyr Asn Ala Leu Lys Pro Ile Leu Asp Thr Asp
435 440 445
Tyr Pro Arg Glu Lys Asn Leu Ser Gln Asp Lys Leu Thr Val Met Gln
450 455 460
Leu Lys Asp Leu Leu Asp Asp Phe Lys Ala Leu Gln His Phe Ile Lys
465 470 475 480
Pro Leu Leu Gly Asn Gly Asp Glu Ala Glu Lys Asp Glu Lys Phe Tyr
485 490 495
Gly Glu Leu Met Gln Leu Trp Glu Val Ile Asp Ser Ile Thr Pro Leu
500 505 510
Tyr Asn Lys Val Arg Asn Tyr Cys Thr Arg Lys Pro Phe Ser Thr Glu
515 520 525
Lys Ile Lys Val Asn Phe Glu Asn Ala Gln Leu Leu Asp Gly Trp Asp
530 535 540
Glu Asn Lys Glu Ser Thr Asn Ala Ser Ile Ile Leu Arg Lys Asn Gly
545 550 555 560
Met Tyr Tyr Leu Gly Ile Met Lys Lys Glu Tyr Arg Asn Ile Leu Thr
565 570 575
Lys Pro Met Pro Ser Asp Gly Asp Cys Tyr Asp Lys Val Val Tyr Lys
580 585 590
Phe Phe Lys Asp Ile Thr Thr Met Val Pro Lys Cys Thr Thr Gln Met
595 600 605
Lys Ser Val Lys Glu His Phe Ser Asn Ser Asn Asp Asp Tyr Thr Leu
610 615 620
Phe Glu Lys Asp Lys Phe Ile Ala Pro Val Val Ile Thr Lys Glu Ile
625 630 635 640
Phe Asp Leu Asn Asn Val Leu Tyr Asn Gly Val Lys Lys Phe Gln Ile
645 650 655
Gly Tyr Leu Asn Asn Thr Gly Asp Ser Phe Gly Tyr Asn His Ala Val
660 665 670
Glu Ile Trp Lys Ser Phe Cys Leu Lys Phe Leu Lys Ala Tyr Lys Ser
675 680 685
Thr Ser Ile Tyr Asp Phe Ser Ser Ile Glu Lys Asn Ile Gly Cys Tyr
690 695 700
Asn Asp Leu Asn Ser Phe Tyr Gly Ala Val Asn Leu Leu Leu Tyr Asn
705 710 715 720
Leu Thr Tyr Arg Lys Val Ser Val Asp Tyr Ile His Gln Leu Val Asp
725 730 735
Glu Asp Lys Met Tyr Leu Phe Met Ile Tyr Asn Lys Asp Phe Ser Thr
740 745 750
Tyr Ser Lys Gly Thr Pro Asn Met His Thr Leu Tyr Trp Lys Met Leu
755 760 765
Phe Asp Glu Ser Asn Leu Asn Asp Val Val Tyr Lys Leu Asn Gly Gln
770 775 780
Ala Glu Val Phe Tyr Arg Lys Lys Ser Ile Thr Tyr Gln His Pro Thr
785 790 795 800
His Pro Ala Asn Lys Pro Ile Asp Asn Lys Asn Val Asn Asn Pro Lys
805 810 815
Lys Gln Ser Asn Phe Glu Tyr Asp Leu Ile Lys Asp Lys Arg Tyr Thr
820 825 830
Val Asp Lys Phe Met Phe His Val Pro Ile Thr Leu Asn Phe Lys Gly
835 840 845
Met Gly Asn Gly Asp Ile Asn Met Gln Val Arg Glu Tyr Ile Lys Thr
850 855 860
Thr Asp Asp Leu His Phe Ile Gly Ile Asp Arg Gly Glu Arg His Leu
865 870 875 880
Leu Tyr Ile Cys Val Ile Asn Gly Lys Gly Glu Ile Val Glu Gln Tyr
885 890 895
Ser Leu Asn Glu Ile Val Asn Asn Tyr Lys Gly Thr Glu Tyr Lys Thr
900 905 910
Asp Tyr His Thr Leu Leu Ser Glu Arg Asp Lys Lys Arg Lys Glu Glu
915 920 925
Arg Ser Ser Trp Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Ser Gly
930 935 940
Tyr Leu Ser Gln Val Ile His Lys Ile Thr Gln Leu Met Ile Lys Tyr
945 950 955 960
Asn Ala Ile Val Leu Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly
965 970 975
Arg Gln Lys Val Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Ala Leu
980 985 990
Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Asn Lys Asp Ala Asn Glu
995 1000 1005
Ile Gly Gly Leu Leu His Ala Tyr Gln Leu Thr Asn Asp Pro Lys
1010 1015 1020
Leu Pro Asn Lys Asn Ser Lys Gln Ser Gly Phe Leu Phe Tyr Val
1025 1030 1035
Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro Val Thr Gly Phe Val
1040 1045 1050
Asn Leu Leu Asp Thr Arg Tyr Glu Asn Val Ala Lys Ala Gln Ala
1055 1060 1065
Phe Phe Lys Lys Phe Asp Ser Ile Arg Tyr Asn Lys Glu Tyr Asp
1070 1075 1080
Arg Phe Glu Phe Lys Phe Asp Tyr Ser Asn Phe Thr Ala Lys Ala
1085 1090 1095
Glu Asp Thr Arg Thr Gln Trp Thr Leu Cys Thr Tyr Gly Thr Arg
1100 1105 1110
Ile Glu Thr Phe Arg Asn Ala Glu Lys Asn Ser Asn Trp Asp Ser
1115 1120 1125
Arg Glu Ile Asp Leu Thr Thr Glu Trp Lys Thr Leu Phe Thr Gln
1130 1135 1140
His Asn Ile Pro Leu Asn Ala Asn Leu Lys Glu Ala Ile Leu Leu
1145 1150 1155
Gln Ala Asn Lys Asn Phe Tyr Thr Asp Ile Leu His Leu Met Lys
1160 1165 1170
Leu Thr Leu Gln Met Arg Asn Ser Val Thr Gly Thr Asp Ile Asp
1175 1180 1185
Tyr Met Val Ser Pro Val Ala Asn Glu Cys Gly Glu Phe Phe Asp
1190 1195 1200
Ser Arg Lys Val Lys Glu Gly Leu Pro Val Asn Ala Asp Ala Asn
1205 1210 1215
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Trp Leu Ala Gln Gln
1220 1225 1230
Ile Lys Asn Ala Asn Asp Leu Ser Asp Val Lys Leu Ala Ile Thr
1235 1240 1245
Asn Lys Glu Trp Leu Gln Phe Ala Gln Lys Lys Gln Tyr Leu Lys
1250 1255 1260
Asp
<210> 1133
<211> 1260
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 1133
Met Asp Ser Leu Lys Asp Phe Thr Asn Leu Tyr Pro Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn Ile Glu
20 25 30
Lys Ala Gly Ile Leu Lys Glu Asp Glu His Arg Ala Glu Ser Tyr Arg
35 40 45
Arg Val Lys Lys Ile Ile Asp Thr Tyr His Lys Val Phe Ile Asp Ser
50 55 60
Ser Leu Glu Asn Met Ala Lys Met Gly Ile Glu Asn Glu Ile Lys Ala
65 70 75 80
Met Leu Gln Ser Phe Cys Glu Leu Tyr Lys Lys Asp His Arg Thr Glu
85 90 95
Gly Glu Asp Lys Ala Leu Asp Lys Ile Arg Ala Val Leu Arg Gly Leu
100 105 110
Ile Val Gly Ala Phe Thr Gly Val Cys Gly Arg Arg Glu Asn Thr Val
115 120 125
Gln Asn Glu Lys Tyr Glu Ser Leu Phe Lys Glu Lys Leu Ile Lys Glu
130 135 140
Ile Leu Pro Asp Phe Val Leu Ser Thr Glu Ala Glu Ser Leu Pro Phe
145 150 155 160
Ser Val Glu Glu Ala Thr Arg Ser Leu Lys Glu Phe Asp Ser Phe Thr
165 170 175
Ser Tyr Phe Ala Gly Phe Tyr Glu Asn Arg Lys Asn Ile Tyr Ser Thr
180 185 190
Lys Pro Gln Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Glu Asn Leu
195 200 205
Pro Lys Phe Ile Asp Asn Ile Leu Val Phe Gln Lys Ile Lys Glu Pro
210 215 220
Ile Ala Lys Glu Leu Glu His Ile Arg Ala Asp Phe Ser Ala Gly Gly
225 230 235 240
Tyr Ile Lys Lys Asp Glu Arg Leu Glu Asp Ile Phe Ser Leu Asn Tyr
245 250 255
Tyr Ile His Val Leu Ser Gln Ala Gly Ile Glu Lys Tyr Asn Ala Leu
260 265 270
Ile Gly Lys Ile Val Thr Glu Gly Asp Gly Glu Met Lys Gly Leu Asn
275 280 285
Glu His Ile Asn Leu Tyr Asn Gln Gln Arg Gly Arg Glu Asp Arg Leu
290 295 300
Pro Leu Phe Arg Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Gln
305 310 315 320
Leu Ser Tyr Leu Pro Glu Ser Phe Glu Lys Asp Glu Glu Leu Leu Arg
325 330 335
Ala Leu Lys Glu Phe Tyr Asp His Ile Ala Glu Asp Ile Leu Gly Arg
340 345 350
Thr Gln Gln Leu Met Thr Ser Ile Ser Glu Tyr Asp Leu Ser Arg Ile
355 360 365
Tyr Val Arg Asn Asp Ser Gln Leu Thr Asp Ile Ser Lys Lys Met Leu
370 375 380
Gly Asp Trp Asn Ala Ile Tyr Met Ala Arg Glu Arg Ala Tyr Asp His
385 390 395 400
Glu Gln Ala Pro Lys Arg Ile Thr Ala Lys Tyr Glu Arg Asp Arg Ile
405 410 415
Lys Ala Leu Lys Gly Glu Glu Ser Ile Ser Leu Ala Asn Leu Asn Ser
420 425 430
Cys Ile Ala Phe Leu Asp Asn Val Arg Asp Cys Arg Val Asp Thr Tyr
435 440 445
Leu Ser Thr Leu Gly Gln Lys Glu Gly Pro His Gly Leu Ser Asn Leu
450 455 460
Val Glu Asn Val Phe Ala Ser Tyr His Glu Ala Glu Gln Leu Leu Ser
465 470 475 480
Phe Pro Tyr Pro Glu Glu Asn Asn Leu Ile Gln Asp Lys Asp Asn Val
485 490 495
Val Leu Ile Lys Asn Leu Leu Asp Asn Ile Ser Asp Leu Gln Arg Phe
500 505 510
Leu Lys Pro Leu Trp Gly Met Gly Asp Glu Pro Asp Lys Asp Glu Arg
515 520 525
Phe Tyr Gly Glu Tyr Asn Tyr Ile Arg Gly Ala Leu Asp Gln Val Ile
530 535 540
Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Arg Lys Pro Tyr Ser
545 550 555 560
Thr Arg Lys Val Lys Leu Asn Phe Gly Asn Ser Gln Leu Leu Ser Gly
565 570 575
Trp Asp Arg Asn Lys Glu Lys Asp Asn Ser Cys Val Ile Leu Arg Lys
580 585 590
Gly Gln Asn Phe Tyr Leu Ala Ile Met Asn Asn Arg His Lys Arg Ser
595 600 605
Phe Glu Asn Lys Val Leu Pro Glu Tyr Lys Glu Gly Glu Pro Tyr Phe
610 615 620
Glu Lys Met Asp Tyr Lys Phe Leu Pro Asp Pro Asn Lys Met Leu Pro
625 630 635 640
Lys Val Phe Leu Ser Lys Lys Gly Ile Glu Ile Tyr Lys Pro Ser Pro
645 650 655
Lys Leu Leu Glu Gln Tyr Gly His Gly Thr His Lys Lys Gly Asp Thr
660 665 670
Phe Ser Met Asp Asp Leu His Glu Leu Ile Asp Phe Phe Lys His Ser
675 680 685
Ile Glu Ala His Glu Asp Trp Lys Gln Phe Gly Phe Lys Phe Ser Asp
690 695 700
Thr Ala Thr Tyr Glu Asn Val Ser Ser Phe Tyr Arg Glu Val Glu Asp
705 710 715 720
Gln Gly Tyr Lys Leu Ser Phe Arg Lys Val Ser Glu Ser Tyr Val Tyr
725 730 735
Ser Leu Ile Asp Gln Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
740 745 750
Asp Phe Ser Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr
755 760 765
Trp Arg Met Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys
770 775 780
Leu Asp Gly Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys Asn
785 790 795 800
Asp His Pro Thr His Pro Ala Gly Lys Pro Ile Lys Lys Lys Ser Arg
805 810 815
Gln Lys Lys Gly Glu Glu Ser Leu Phe Glu Tyr Asp Leu Val Lys Asp
820 825 830
Arg His Tyr Thr Met Asp Lys Phe Gln Phe His Val Pro Ile Thr Met
835 840 845
Asn Phe Lys Cys Ser Ala Gly Ser Lys Val Asn Asp Met Val Asn Ala
850 855 860
His Ile Arg Glu Ala Lys Asp Met His Val Ile Gly Ile Asp Arg Gly
865 870 875 880
Glu Arg Asn Leu Leu Tyr Ile Cys Val Ile Asp Ser Arg Gly Thr Ile
885 890 895
Leu Asp Gln Ile Ser Leu Asn Thr Ile Asn Asp Ile Asp Tyr His Asp
900 905 910
Leu Leu Glu Ser Arg Asp Lys Asp Arg Gln Gln Glu Arg Arg Asn Trp
915 920 925
Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Gln Gly Tyr Leu Ser Gln
930 935 940
Ala Val His Arg Ile Ala Glu Leu Met Val Ala Tyr Lys Ala Val Val
945 950 955 960
Ala Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly Arg Gln Lys Val
965 970 975
Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Gln Leu Ile Asp Lys Leu
980 985 990
Asn Tyr Leu Val Asp Lys Lys Lys Arg Pro Glu Asp Ile Gly Gly Leu
995 1000 1005
Leu Arg Ala Tyr Gln Phe Thr Ala Pro Phe Lys Ser Phe Lys Glu
1010 1015 1020
Met Gly Lys Gln Asn Gly Phe Leu Phe Tyr Ile Pro Ala Trp Asn
1025 1030 1035
Thr Ser Asn Ile Asp Pro Thr Thr Gly Phe Val Asn Leu Phe His
1040 1045 1050
Ala Gln Tyr Glu Asn Val Asp Lys Ala Lys Ser Phe Phe Gln Lys
1055 1060 1065
Phe Asp Ser Ile Ser Tyr Asn Pro Lys Lys Asp Trp Phe Glu Phe
1070 1075 1080
Ala Phe Asp Tyr Lys Asn Phe Thr Lys Lys Ala Glu Gly Ser Arg
1085 1090 1095
Ser Met Trp Ile Leu Cys Thr His Gly Ser Arg Ile Lys Asn Phe
1100 1105 1110
Arg Asn Ser Gln Lys Asn Gly Gln Trp Asp Ser Glu Glu Phe Ala
1115 1120 1125
Leu Thr Glu Ala Phe Lys Ser Leu Phe Val Arg Tyr Glu Ile Asp
1130 1135 1140
Tyr Thr Ala Asp Leu Lys Thr Ala Ile Val Asp Glu Lys Gln Lys
1145 1150 1155
Asp Phe Phe Val Asp Leu Leu Lys Leu Phe Lys Leu Thr Val Gln
1160 1165 1170
Met Arg Asn Ser Trp Lys Glu Lys Asp Leu Asp Tyr Leu Ile Ser
1175 1180 1185
Pro Val Ala Gly Ala Asp Gly Arg Phe Phe Asp Thr Arg Glu Gly
1190 1195 1200
Asn Lys Ser Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala Tyr Asn
1205 1210 1215
Ile Ala Leu Lys Gly Leu Trp Ala Leu Arg Gln Ile Arg Gln Thr
1220 1225 1230
Ser Glu Gly Gly Lys Leu Lys Leu Ala Ile Ser Asn Lys Glu Trp
1235 1240 1245
Leu Gln Phe Val Gln Glu Arg Ser Tyr Glu Lys Asp
1250 1255 1260
<210> 1134
<211> 1260
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 1134
Met Asp Ser Leu Lys Asp Phe Thr Asn Leu Tyr Pro Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn Ile Glu
20 25 30
Lys Ala Gly Ile Leu Lys Glu Asp Glu His Arg Ala Glu Ser Tyr Arg
35 40 45
Arg Val Lys Lys Ile Ile Asp Thr Tyr His Lys Val Phe Ile Asp Ser
50 55 60
Ser Leu Glu Asn Met Ala Lys Met Gly Ile Glu Asn Glu Ile Lys Ala
65 70 75 80
Met Leu Gln Ser Phe Cys Glu Leu Tyr Lys Lys Asp His Arg Thr Glu
85 90 95
Gly Glu Asp Lys Ala Leu Asp Lys Ile Arg Ala Val Leu Arg Gly Leu
100 105 110
Ile Val Gly Ala Phe Thr Gly Val Cys Gly Arg Arg Glu Asn Thr Val
115 120 125
Gln Asn Glu Lys Tyr Glu Ser Leu Phe Lys Glu Lys Leu Ile Lys Glu
130 135 140
Ile Leu Pro Asp Phe Val Leu Ser Thr Glu Ala Glu Ser Leu Pro Phe
145 150 155 160
Ser Val Glu Glu Ala Thr Arg Ser Leu Lys Glu Phe Asp Ser Phe Thr
165 170 175
Ser Tyr Phe Ala Gly Phe Tyr Glu Asn Arg Lys Asn Ile Tyr Ser Thr
180 185 190
Lys Pro Gln Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Glu Asn Leu
195 200 205
Pro Lys Phe Ile Asp Asn Ile Leu Val Phe Gln Lys Ile Lys Glu Pro
210 215 220
Ile Ala Lys Glu Leu Glu His Ile Arg Ala Asp Phe Ser Ala Gly Gly
225 230 235 240
Tyr Ile Lys Lys Asp Glu Arg Leu Glu Asp Ile Phe Ser Leu Asn Tyr
245 250 255
Tyr Ile His Val Leu Ser Gln Ala Gly Ile Glu Lys Tyr Asn Ala Leu
260 265 270
Ile Gly Lys Ile Val Thr Glu Gly Asp Gly Glu Met Lys Gly Leu Asn
275 280 285
Glu His Ile Asn Leu Tyr Asn Gln Gln Arg Gly Arg Glu Asp Arg Leu
290 295 300
Pro Leu Phe Arg Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Gln
305 310 315 320
Leu Ser Tyr Leu Pro Glu Ser Phe Glu Lys Asp Glu Glu Leu Leu Arg
325 330 335
Ala Leu Lys Glu Phe Tyr Asp His Ile Ala Glu Asp Ile Leu Gly Arg
340 345 350
Thr Gln Gln Leu Met Thr Ser Ile Ser Glu Tyr Asp Leu Ser Arg Ile
355 360 365
Tyr Val Arg Asn Asp Ser Gln Leu Thr Asp Ile Ser Lys Lys Met Leu
370 375 380
Gly Asp Trp Asn Ala Ile Tyr Met Ala Arg Glu Arg Ala Tyr Asp His
385 390 395 400
Glu Gln Ala Pro Lys Arg Ile Thr Ala Lys Tyr Glu Arg Asp Arg Ile
405 410 415
Lys Ala Leu Lys Gly Glu Glu Ser Ile Ser Leu Ala Asn Leu Asn Ser
420 425 430
Cys Ile Ala Phe Leu Asp Asn Val Arg Asp Cys Arg Val Asp Thr Tyr
435 440 445
Leu Ser Thr Leu Gly Gln Lys Glu Gly Pro His Gly Leu Ser Asn Leu
450 455 460
Val Glu Asn Val Phe Ala Ser Tyr His Glu Ala Glu Gln Leu Leu Ser
465 470 475 480
Phe Pro Tyr Pro Glu Glu Asn Asn Leu Ile Gln Asp Lys Asp Asn Val
485 490 495
Val Leu Ile Lys Asn Leu Leu Asp Asn Ile Ser Asp Leu Gln Arg Phe
500 505 510
Leu Lys Pro Leu Trp Gly Met Gly Asp Glu Pro Asp Lys Asp Glu Arg
515 520 525
Phe Tyr Gly Glu Tyr Asn Tyr Ile Arg Gly Ala Leu Asp Gln Val Ile
530 535 540
Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Arg Lys Pro Tyr Ser
545 550 555 560
Thr Arg Lys Val Lys Leu Asn Phe Gly Asn Ser Gln Leu Leu Ser Gly
565 570 575
Trp Asp Arg Asn Lys Glu Lys Asp Asn Ser Cys Val Ile Leu Arg Lys
580 585 590
Gly Gln Asn Phe Tyr Leu Ala Ile Met Asn Asn Arg His Lys Arg Ser
595 600 605
Phe Glu Asn Lys Val Leu Pro Glu Tyr Lys Glu Gly Glu Pro Tyr Phe
610 615 620
Glu Lys Met Asp Tyr Lys Phe Leu Pro Asp Pro Asn Lys Met Leu Pro
625 630 635 640
Lys Val Phe Leu Ser Lys Lys Gly Ile Glu Ile Tyr Lys Pro Ser Pro
645 650 655
Lys Leu Leu Glu Gln Tyr Gly His Gly Thr His Lys Lys Gly Asp Thr
660 665 670
Phe Ser Met Asp Asp Leu His Glu Leu Ile Asp Phe Phe Lys His Ser
675 680 685
Ile Glu Ala His Glu Asp Trp Lys Gln Phe Gly Phe Lys Phe Ser Asp
690 695 700
Thr Ala Thr Tyr Glu Asn Val Ser Ser Phe Tyr Arg Glu Val Glu Asp
705 710 715 720
Gln Gly Tyr Lys Leu Ser Phe Arg Lys Val Ser Glu Ser Tyr Val Tyr
725 730 735
Ser Leu Ile Asp Gln Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
740 745 750
Asp Phe Ser Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr
755 760 765
Trp Arg Met Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys
770 775 780
Leu Asp Gly Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys Asn
785 790 795 800
Asp His Pro Thr His Pro Ala Gly Lys Pro Ile Lys Lys Lys Ser Arg
805 810 815
Gln Lys Lys Gly Glu Glu Ser Leu Phe Glu Tyr Asp Leu Val Lys Asp
820 825 830
Arg Arg Tyr Thr Met Asp Lys Phe Gln Phe His Val Pro Ile Thr Met
835 840 845
Asn Phe Lys Cys Ser Ala Gly Ser Lys Val Asn Asp Met Val Asn Ala
850 855 860
His Ile Arg Glu Ala Lys Asp Met His Val Ile Gly Ile Asp Arg Gly
865 870 875 880
Glu Arg Asn Leu Leu Tyr Ile Cys Val Ile Asp Ser Arg Gly Thr Ile
885 890 895
Leu Asp Gln Ile Ser Leu Asn Thr Ile Asn Asp Ile Asp Tyr His Asp
900 905 910
Leu Leu Glu Ser Arg Asp Lys Asp Arg Gln Gln Glu Arg Arg Asn Trp
915 920 925
Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Gln Gly Tyr Leu Ser Gln
930 935 940
Ala Val His Arg Ile Ala Glu Leu Met Val Ala Tyr Lys Ala Val Val
945 950 955 960
Ala Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly Arg Gln Lys Val
965 970 975
Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Gln Leu Ile Asp Lys Leu
980 985 990
Asn Tyr Leu Val Asp Lys Lys Lys Arg Pro Glu Asp Ile Gly Gly Leu
995 1000 1005
Leu Arg Ala Tyr Gln Phe Thr Ala Pro Phe Lys Ser Phe Lys Glu
1010 1015 1020
Met Gly Lys Gln Asn Gly Phe Leu Phe Tyr Ile Pro Ala Trp Asn
1025 1030 1035
Thr Ser Asn Ile Asp Pro Thr Thr Gly Phe Val Asn Leu Phe His
1040 1045 1050
Ala Gln Tyr Glu Asn Val Asp Lys Ala Lys Ser Phe Phe Gln Lys
1055 1060 1065
Phe Asp Ser Ile Ser Tyr Asn Pro Lys Lys Asp Trp Phe Glu Phe
1070 1075 1080
Ala Phe Asp Tyr Lys Asn Phe Thr Lys Lys Ala Glu Gly Ser Arg
1085 1090 1095
Ser Met Trp Ile Leu Cys Thr His Gly Ser Arg Ile Lys Asn Phe
1100 1105 1110
Arg Asn Ser Gln Lys Asn Gly Gln Trp Asp Ser Glu Glu Phe Ala
1115 1120 1125
Leu Thr Glu Ala Phe Lys Ser Leu Phe Val Arg Tyr Glu Ile Asp
1130 1135 1140
Tyr Thr Ala Asp Leu Lys Thr Ala Ile Val Asp Glu Lys Gln Lys
1145 1150 1155
Asp Phe Phe Val Asp Leu Leu Lys Leu Phe Lys Leu Thr Val Gln
1160 1165 1170
Met Arg Asn Ser Trp Lys Glu Lys Asp Leu Asp Tyr Leu Ile Ser
1175 1180 1185
Pro Val Ala Gly Ala Asp Gly Arg Phe Phe Asp Thr Arg Glu Gly
1190 1195 1200
Asn Lys Ser Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala Tyr Asn
1205 1210 1215
Ile Ala Leu Lys Gly Leu Trp Ala Leu Arg Gln Ile Arg Gln Thr
1220 1225 1230
Ser Glu Gly Gly Lys Leu Lys Leu Ala Ile Ser Asn Lys Glu Trp
1235 1240 1245
Leu Gln Phe Val Gln Glu Arg Ser Tyr Glu Lys Asp
1250 1255 1260
<210> 1135
<211> 1260
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 1135
Met Asp Ser Leu Lys Asp Phe Thr Asn Leu Tyr Pro Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn Ile Glu
20 25 30
Lys Ala Gly Ile Leu Lys Glu Asp Glu His Arg Ala Glu Ser Tyr Arg
35 40 45
Arg Val Lys Lys Ile Ile Asp Thr Tyr His Lys Val Phe Ile Asp Ser
50 55 60
Ser Leu Glu Asn Met Ala Lys Met Gly Ile Glu Asn Glu Ile Lys Ala
65 70 75 80
Met Leu Gln Ser Phe Cys Glu Leu Tyr Lys Lys Asp His Arg Thr Glu
85 90 95
Gly Glu Asp Lys Ala Leu Asp Lys Ile Arg Ala Val Leu Arg Gly Leu
100 105 110
Ile Val Gly Ala Phe Thr Gly Val Cys Gly Arg Arg Glu Asn Thr Val
115 120 125
Gln Asn Glu Lys Tyr Glu Ser Leu Phe Lys Glu Lys Leu Ile Lys Glu
130 135 140
Ile Leu Pro Asp Phe Val Leu Ser Thr Glu Ala Glu Ser Leu Pro Phe
145 150 155 160
Ser Val Glu Glu Ala Thr Arg Ser Leu Lys Glu Phe Asp Ser Phe Thr
165 170 175
Ser Tyr Phe Ala Gly Phe Tyr Glu Asn Arg Lys Asn Ile Tyr Ser Thr
180 185 190
Lys Pro Gln Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Glu Asn Leu
195 200 205
Pro Lys Phe Ile Asp Asn Ile Leu Val Phe Gln Lys Ile Lys Glu Pro
210 215 220
Ile Ala Lys Glu Leu Glu His Ile Arg Ala Asp Phe Ser Ala Gly Gly
225 230 235 240
Tyr Ile Lys Lys Asp Glu Arg Leu Glu Asp Ile Phe Ser Leu Asn Tyr
245 250 255
Tyr Ile His Val Leu Ser Gln Ala Gly Ile Glu Lys Tyr Asn Ala Leu
260 265 270
Ile Gly Lys Ile Val Thr Glu Gly Asp Gly Glu Met Lys Gly Leu Asn
275 280 285
Glu His Ile Asn Leu Tyr Asn Gln Gln Arg Gly Arg Glu Asp Arg Leu
290 295 300
Pro Leu Phe Arg Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Gln
305 310 315 320
Leu Ser Tyr Leu Pro Glu Ser Phe Glu Lys Asp Glu Glu Leu Leu Arg
325 330 335
Ala Leu Lys Glu Phe Tyr Asp His Ile Ala Glu Asp Ile Leu Gly Arg
340 345 350
Thr Gln Gln Leu Met Thr Ser Ile Ser Glu Tyr Asp Leu Ser Arg Ile
355 360 365
Tyr Val Arg Asn Asp Ser Gln Leu Thr Asp Ile Ser Lys Lys Met Leu
370 375 380
Gly Asp Trp Asn Ala Ile Tyr Met Ala Arg Glu Arg Ala Tyr Asp His
385 390 395 400
Glu Gln Ala Pro Lys Arg Ile Thr Ala Lys Tyr Glu Arg Asp Arg Ile
405 410 415
Lys Ala Leu Lys Gly Glu Glu Ser Ile Ser Leu Ala Asn Leu Asn Ser
420 425 430
Cys Ile Ala Phe Leu Asp Asn Val Arg Asp Cys Arg Val Asp Thr Tyr
435 440 445
Leu Ser Thr Leu Gly Gln Lys Glu Gly Pro His Gly Leu Ser Asn Leu
450 455 460
Val Glu Asn Val Phe Ala Ser Tyr His Glu Ala Glu Gln Leu Leu Ser
465 470 475 480
Phe Pro Tyr Pro Glu Glu Asn Asn Leu Ile Gln Asp Lys Asp Asn Val
485 490 495
Val Leu Ile Lys Asn Leu Leu Asp Asn Ile Ser Asp Leu Gln Arg Phe
500 505 510
Leu Lys Pro Leu Trp Gly Met Gly Asp Glu Pro Asp Lys Asp Glu Arg
515 520 525
Phe Tyr Gly Glu Tyr Asn Tyr Ile Arg Gly Ala Leu Asp Gln Val Ile
530 535 540
Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Arg Lys Pro Tyr Ser
545 550 555 560
Thr Arg Lys Val Lys Leu Asn Phe Gly Asn Ser Gln Leu Leu Ser Gly
565 570 575
Trp Asp Arg Asn Lys Glu Lys Asp Asn Ser Cys Val Ile Leu Arg Lys
580 585 590
Gly Gln Asn Phe Tyr Leu Ala Ile Met Asn Asn Arg His Lys Arg Ser
595 600 605
Phe Glu Asn Lys Met Leu Pro Glu Tyr Lys Glu Gly Glu Pro Tyr Phe
610 615 620
Glu Lys Met Asp Tyr Lys Phe Leu Pro Asp Pro Asn Lys Met Leu Pro
625 630 635 640
Lys Val Phe Leu Ser Lys Lys Gly Ile Glu Ile Tyr Lys Pro Ser Pro
645 650 655
Lys Leu Leu Glu Gln Tyr Gly His Gly Thr His Lys Lys Gly Asp Thr
660 665 670
Phe Ser Met Asp Asp Leu His Glu Leu Ile Asp Phe Phe Lys His Ser
675 680 685
Ile Glu Ala His Glu Asp Trp Lys Gln Phe Gly Phe Lys Phe Ser Asp
690 695 700
Thr Ala Thr Tyr Glu Asn Val Ser Ser Phe Tyr Arg Glu Val Glu Asp
705 710 715 720
Gln Gly Tyr Lys Leu Ser Phe Arg Lys Val Ser Glu Ser Tyr Val Tyr
725 730 735
Ser Leu Ile Asp Gln Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
740 745 750
Asp Phe Ser Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr
755 760 765
Trp Arg Met Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys
770 775 780
Leu Asp Gly Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys Asn
785 790 795 800
Asp His Pro Thr His Pro Ala Gly Lys Pro Ile Lys Lys Lys Ser Arg
805 810 815
Gln Lys Lys Gly Glu Glu Ser Leu Phe Glu Tyr Asp Leu Val Lys Asp
820 825 830
Arg Arg Tyr Thr Met Asp Lys Phe Gln Phe His Val Pro Ile Thr Met
835 840 845
Asn Phe Lys Cys Ser Ala Gly Ser Lys Val Asn Asp Met Val Asn Ala
850 855 860
His Ile Arg Glu Ala Lys Asp Met His Val Ile Gly Ile Asp Arg Gly
865 870 875 880
Glu Arg Asn Leu Leu Tyr Ile Cys Val Ile Asp Ser Arg Gly Thr Ile
885 890 895
Leu Asp Gln Ile Ser Leu Asn Thr Ile Asn Asp Ile Asp Tyr His Asp
900 905 910
Leu Leu Glu Ser Arg Asp Lys Asp Arg Gln Gln Glu His Arg Asn Trp
915 920 925
Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Gln Gly Tyr Leu Ser Gln
930 935 940
Ala Val His Arg Ile Ala Glu Leu Met Val Ala Tyr Lys Ala Val Val
945 950 955 960
Ala Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly Arg Gln Lys Val
965 970 975
Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Gln Leu Ile Asp Lys Leu
980 985 990
Asn Tyr Leu Val Asp Lys Lys Lys Arg Pro Glu Asp Ile Gly Gly Leu
995 1000 1005
Leu Arg Ala Tyr Gln Phe Thr Ala Pro Phe Lys Ser Phe Lys Glu
1010 1015 1020
Met Gly Lys Gln Asn Gly Phe Leu Phe Tyr Ile Pro Ala Trp Asn
1025 1030 1035
Thr Ser Asn Ile Asp Pro Thr Thr Gly Phe Val Asn Leu Phe His
1040 1045 1050
Val Gln Tyr Glu Asn Val Asp Lys Ala Lys Ser Phe Phe Gln Lys
1055 1060 1065
Phe Asp Ser Ile Ser Tyr Asn Pro Lys Lys Asp Trp Phe Glu Phe
1070 1075 1080
Ala Phe Asp Tyr Lys Asn Phe Thr Lys Lys Ala Glu Gly Ser Arg
1085 1090 1095
Ser Met Trp Ile Leu Cys Thr His Gly Ser Arg Ile Lys Asn Phe
1100 1105 1110
Arg Asn Ser Gln Lys Asn Gly Gln Trp Asp Ser Glu Glu Phe Ala
1115 1120 1125
Leu Thr Glu Ala Phe Lys Ser Leu Phe Val Arg Tyr Glu Ile Asp
1130 1135 1140
Tyr Thr Ala Asp Leu Lys Thr Ala Ile Val Asp Glu Lys Gln Lys
1145 1150 1155
Asp Phe Phe Val Asp Leu Leu Lys Leu Phe Lys Leu Thr Val Gln
1160 1165 1170
Met Arg Asn Ser Trp Lys Glu Lys Asp Leu Asp Tyr Leu Ile Ser
1175 1180 1185
Pro Val Ala Gly Ala Asp Gly Arg Phe Phe Asp Thr Arg Glu Gly
1190 1195 1200
Asn Lys Ser Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala Tyr Asn
1205 1210 1215
Ile Ala Leu Lys Gly Leu Trp Ala Leu Arg Gln Ile Arg Gln Thr
1220 1225 1230
Ser Glu Gly Gly Lys Leu Lys Leu Ala Ile Ser Asn Lys Glu Trp
1235 1240 1245
Leu Gln Phe Val Gln Glu Arg Ser Tyr Glu Lys Asp
1250 1255 1260
<210> 1136
<211> 1262
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 1136
Met Pro Trp Ile Asp Leu Lys Asp Phe Thr Asn Leu Tyr Pro Val Ser
1 5 10 15
Lys Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn
20 25 30
Ile Glu Lys Ala Gly Ile Leu Lys Glu Asp Glu His Arg Ala Glu Ser
35 40 45
Tyr Arg Arg Val Lys Lys Ile Ile Asp Thr Tyr His Lys Val Phe Ile
50 55 60
Asp Ser Ser Leu Glu Asn Met Ala Lys Met Gly Ile Glu Asn Glu Ile
65 70 75 80
Lys Ala Met Leu Gln Ser Phe Cys Glu Leu Tyr Lys Lys Asp His Arg
85 90 95
Thr Glu Gly Glu Asp Lys Ala Leu Asp Lys Ile Arg Ala Val Leu Arg
100 105 110
Gly Leu Ile Val Gly Ala Phe Thr Gly Val Cys Gly Arg Arg Glu Asn
115 120 125
Thr Val Gln Asn Glu Lys Tyr Glu Ser Leu Phe Lys Glu Lys Leu Ile
130 135 140
Lys Glu Ile Leu Pro Asp Phe Val Leu Ser Thr Glu Ala Glu Ser Leu
145 150 155 160
Pro Phe Ser Val Glu Glu Ala Thr Arg Ser Leu Lys Glu Phe Asp Ser
165 170 175
Phe Thr Ser Tyr Phe Ala Gly Phe Tyr Glu Asn Arg Lys Asn Ile Tyr
180 185 190
Ser Thr Lys Pro Gln Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Glu
195 200 205
Asn Leu Pro Lys Phe Ile Asp Asn Ile Leu Val Phe Gln Lys Ile Lys
210 215 220
Glu Pro Ile Ala Lys Glu Leu Glu His Ile Arg Ala Asp Phe Ser Ala
225 230 235 240
Gly Gly Tyr Ile Lys Lys Asp Glu Arg Leu Glu Asp Ile Phe Ser Leu
245 250 255
Asn Tyr Tyr Ile His Val Leu Ser Gln Ala Gly Ile Glu Lys Tyr Asn
260 265 270
Ala Leu Ile Gly Lys Ile Val Thr Glu Gly Asp Gly Glu Met Lys Gly
275 280 285
Leu Asn Glu His Ile Asn Leu Tyr Asn Gln Gln Arg Gly Arg Glu Asp
290 295 300
Arg Leu Pro Leu Phe Arg Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg
305 310 315 320
Glu Gln Leu Ser Tyr Leu Pro Glu Ser Phe Glu Lys Asp Glu Glu Leu
325 330 335
Leu Arg Ala Leu Lys Glu Phe Tyr Asp His Ile Ala Glu Asp Ile Leu
340 345 350
Gly Arg Thr Gln Gln Leu Met Thr Ser Ile Ser Glu Tyr Asp Leu Ser
355 360 365
Arg Ile Tyr Val Arg Asn Asp Ser Gln Leu Thr Asp Ile Ser Lys Lys
370 375 380
Met Leu Gly Asp Trp Asn Ala Ile Tyr Met Ala Arg Glu Arg Ala Tyr
385 390 395 400
Asp His Glu Gln Ala Pro Lys Arg Ile Thr Ala Lys Tyr Glu Arg Asp
405 410 415
Arg Ile Lys Ala Leu Lys Gly Glu Glu Ser Ile Ser Leu Ala Asn Leu
420 425 430
Asn Ser Cys Ile Ala Phe Leu Asp Asn Val Arg Asp Cys Arg Val Asp
435 440 445
Thr Tyr Leu Ser Thr Leu Gly Gln Lys Glu Gly Pro His Gly Leu Ser
450 455 460
Asn Leu Val Glu Asn Val Phe Ala Ser Tyr His Glu Ala Glu Gln Leu
465 470 475 480
Leu Ser Phe Pro Tyr Pro Glu Glu Asn Asn Leu Ile Gln Asp Lys Asp
485 490 495
Asn Val Val Leu Ile Lys Asn Leu Leu Asp Asn Ile Ser Asp Leu Gln
500 505 510
Arg Phe Leu Lys Pro Leu Trp Gly Met Gly Asp Glu Pro Asp Lys Asp
515 520 525
Glu Arg Phe Tyr Gly Glu Tyr Asn Tyr Ile Arg Gly Ala Leu Asp Gln
530 535 540
Val Ile Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Arg Lys Pro
545 550 555 560
Tyr Ser Thr Arg Lys Val Lys Leu Asn Phe Gly Asn Ser Gln Leu Leu
565 570 575
Ser Gly Trp Asp Arg Asn Lys Glu Lys Asp Asn Ser Cys Val Ile Leu
580 585 590
Arg Lys Gly Gln Asn Phe Tyr Leu Ala Ile Met Asn Asn Arg His Lys
595 600 605
Arg Ser Phe Glu Asn Lys Val Leu Pro Glu Tyr Lys Glu Gly Glu Pro
610 615 620
Tyr Phe Glu Lys Met Asp Tyr Lys Phe Leu Pro Asp Pro Asn Lys Met
625 630 635 640
Leu Pro Lys Val Phe Leu Ser Lys Lys Gly Ile Glu Ile Tyr Glu Pro
645 650 655
Ser Pro Lys Leu Leu Glu Gln Tyr Gly His Gly Thr His Lys Lys Gly
660 665 670
Asp Thr Phe Ser Met Asp Asp Leu His Glu Leu Ile Asp Phe Phe Lys
675 680 685
His Ser Ile Glu Ala His Glu Asp Trp Lys Gln Phe Gly Phe Lys Phe
690 695 700
Ser Asp Thr Ala Thr Tyr Glu Asn Val Ser Ser Phe Tyr Arg Glu Val
705 710 715 720
Glu Asp Gln Gly Tyr Lys Leu Ser Phe Arg Lys Val Ser Glu Ser Tyr
725 730 735
Val Tyr Ser Leu Ile Asp Gln Gly Lys Leu Tyr Leu Phe Gln Ile Tyr
740 745 750
Asn Lys Asp Phe Ser Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr
755 760 765
Leu Tyr Trp Arg Met Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile
770 775 780
Tyr Lys Leu Asp Gly Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu
785 790 795 800
Lys Asn Asp His Pro Thr His Pro Ala Gly Lys Pro Ile Lys Lys Lys
805 810 815
Ser Arg Gln Lys Lys Gly Glu Glu Ser Leu Phe Glu Tyr Asp Leu Val
820 825 830
Lys Asp Arg Arg Tyr Thr Met Asp Lys Phe Gln Phe His Val Pro Ile
835 840 845
Thr Met Asn Phe Lys Cys Ser Ala Gly Ser Lys Val Asn Asp Met Val
850 855 860
Asn Ala His Ile Arg Glu Ala Lys Asp Met His Val Ile Gly Ile Asp
865 870 875 880
Arg Gly Glu Arg Asn Leu Leu Tyr Ile Cys Val Ile Asp Ser Arg Gly
885 890 895
Thr Ile Leu Asp Gln Ile Ser Leu Asn Thr Ile Asn Asp Ile Asp Tyr
900 905 910
His Asp Leu Leu Glu Ser Arg Asp Lys Asp Arg Gln Gln Glu Arg Arg
915 920 925
Asn Trp Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Gln Gly Tyr Leu
930 935 940
Ser Gln Ala Val His Arg Ile Ala Glu Leu Met Val Ala Tyr Lys Ala
945 950 955 960
Val Val Ala Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly Arg Gln
965 970 975
Lys Val Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Gln Leu Ile Asp
980 985 990
Lys Leu Asn Tyr Leu Val Asp Lys Lys Lys Arg Pro Glu Asp Ile Gly
995 1000 1005
Gly Leu Leu Arg Ala Tyr Gln Phe Thr Ala Pro Phe Lys Ser Phe
1010 1015 1020
Lys Glu Met Gly Lys Gln Asn Gly Phe Leu Phe Tyr Ile Pro Ala
1025 1030 1035
Trp Asn Thr Ser Asn Ile Asp Pro Thr Thr Gly Phe Val Asn Leu
1040 1045 1050
Phe His Ala Gln Tyr Glu Asn Val Asp Lys Ala Lys Ser Phe Phe
1055 1060 1065
Gln Lys Phe Asp Ser Ile Ser Tyr Asn Pro Lys Lys Asp Trp Phe
1070 1075 1080
Glu Phe Ala Phe Asp Tyr Lys Asn Phe Thr Lys Lys Ala Glu Gly
1085 1090 1095
Ser Arg Ser Met Trp Ile Leu Cys Thr His Gly Ser Arg Ile Lys
1100 1105 1110
Asn Phe Arg Asn Ser Gln Lys Asn Gly Gln Trp Asp Ser Glu Glu
1115 1120 1125
Phe Ala Leu Thr Glu Ala Phe Lys Ser Leu Phe Val Arg Tyr Glu
1130 1135 1140
Ile Asp Tyr Thr Ala Asp Leu Lys Thr Ala Ile Val Asp Glu Lys
1145 1150 1155
Gln Lys Asp Phe Phe Val Asp Leu Leu Lys Leu Phe Lys Leu Thr
1160 1165 1170
Val Gln Met Arg Asn Ser Trp Lys Glu Lys Asp Leu Asp Tyr Leu
1175 1180 1185
Ile Ser Pro Val Ala Gly Ala Asp Gly Arg Phe Phe Asp Thr Arg
1190 1195 1200
Glu Gly Asn Lys Ser Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala
1205 1210 1215
Tyr Asn Ile Ala Leu Lys Gly Leu Trp Ala Leu Arg Gln Ile Arg
1220 1225 1230
Gln Thr Ser Glu Gly Gly Lys Leu Lys Leu Ala Ile Ser Asn Lys
1235 1240 1245
Glu Trp Leu Gln Phe Val Gln Glu Arg Ser Tyr Glu Lys Asp
1250 1255 1260
<210> 1137
<211> 1224
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1137
Met Gly Leu Tyr Asp Gly Phe Val Asn Arg Tyr Ser Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Arg Thr Arg Glu Tyr Ile Glu
20 25 30
Thr Asn Gly Ile Leu Ser Asp Asp Glu Glu Arg Ala Lys Asp Tyr Lys
35 40 45
Thr Ile Lys Arg Leu Ile Asp Glu Tyr His Lys Asp Tyr Ile Ser Arg
50 55 60
Cys Leu Lys Asn Val Asn Ile Ser Cys Leu Glu Glu Tyr Tyr His Leu
65 70 75 80
Tyr Asn Ser Ser Asn Arg Asp Lys Arg His Glu Glu Leu Asp Ala Leu
85 90 95
Ser Asp Gln Met Arg Gly Glu Ile Ala Ser Phe Leu Thr Gly Asn Asp
100 105 110
Glu Tyr Lys Glu Gln Lys Ser Arg Asp Ile Ile Ile Asn Glu Arg Ile
115 120 125
Ile Asn Phe Ala Ser Thr Asp Glu Glu Leu Ala Ala Val Lys Arg Phe
130 135 140
Arg Lys Phe Thr Ser Tyr Phe Thr Gly Phe Phe Thr Asn Arg Glu Asn
145 150 155 160
Met Tyr Ser Ala Glu Lys Lys Ser Thr Ala Ile Ala His Arg Ile Ile
165 170 175
Asp Val Asn Leu Pro Lys Tyr Val Asp Asn Ile Lys Ala Phe Asn Thr
180 185 190
Ala Ile Glu Ala Gly Val Phe Asp Ile Ala Glu Phe Glu Ser Asn Phe
195 200 205
Lys Ala Ile Thr Asp Glu His Glu Val Ser Asp Leu Leu Asp Ile Thr
210 215 220
Lys Tyr Ser Arg Phe Ile Arg Asn Glu Asp Ile Ile Ile Tyr Asn Thr
225 230 235 240
Leu Leu Gly Gly Ile Ser Met Lys Asp Glu Lys Ile Gln Gly Leu Asn
245 250 255
Glu Leu Ile Asn Leu His Asn Gln Lys His Pro Gly Lys Lys Val Pro
260 265 270
Leu Leu Lys Val Leu Tyr Lys Gln Ile Leu Gly Asp Ser Gln Thr His
275 280 285
Ser Phe Val Asp Asp Gln Phe Glu Asp Asp Gln Gln Val Ile Asn Ala
290 295 300
Val Lys Ala Val Thr Asp Thr Phe Ser Glu Thr Leu Leu Gly Ser Leu
305 310 315 320
Lys Ile Ile Ile Asn Asn Ile Gly His Tyr Asp Leu Asp Arg Ile Tyr
325 330 335
Ile Lys Ala Gly Gln Asp Ile Thr Thr Leu Ser Lys Arg Ala Leu Asn
340 345 350
Asp Trp His Ile Ile Thr Glu Cys Leu Glu Ser Glu Tyr Asp Asp Lys
355 360 365
Phe Pro Lys Asn Lys Lys Ser Asp Thr Tyr Glu Glu Met Arg Asn Arg
370 375 380
Tyr Val Lys Ser Phe Lys Ser Phe Ser Ile Gly Arg Leu Asn Ser Leu
385 390 395 400
Val Thr Thr Tyr Thr Glu Gln Ala Cys Phe Leu Glu Asn Tyr Leu Gly
405 410 415
Ser Phe Gly Gly Asp Thr Asp Lys Asn Cys Leu Thr Asp Phe Thr Asn
420 425 430
Ser Leu Met Glu Val Glu His Leu Leu Asn Ser Glu Tyr Pro Val Thr
435 440 445
Asn Arg Leu Ile Thr Asp Tyr Glu Ser Val Arg Ile Leu Lys Arg Leu
450 455 460
Leu Asp Ser Glu Met Glu Val Ile His Phe Leu Lys Pro Leu Leu Gly
465 470 475 480
Asn Gly Asn Glu Ser Asp Lys Asp Leu Val Phe Tyr Gly Glu Phe Glu
485 490 495
Ala Glu Tyr Glu Lys Leu Leu Pro Val Ile Lys Val Tyr Asn Arg Val
500 505 510
Arg Asn Tyr Leu Thr Arg Lys Pro Phe Ser Thr Glu Lys Ile Lys Leu
515 520 525
Asn Phe Asn Ser Pro Thr Leu Leu Cys Gly Trp Ser Gln Ser Lys Glu
530 535 540
Lys Glu Tyr Met Gly Val Ile Leu Arg Lys Asp Gly Gln Tyr Tyr Leu
545 550 555 560
Gly Ile Met Thr Pro Ser Asn Lys Lys Ile Phe Ser Glu Ala Pro Lys
565 570 575
Pro Asp Glu Asp Cys Tyr Glu Lys Met Val Leu Arg Tyr Ile Pro His
580 585 590
Pro Tyr Gln Met Leu Pro Lys Val Phe Phe Ser Lys Ser Asn Ile Ala
595 600 605
Phe Phe Asn Pro Ser Asp Glu Ile Leu Arg Ile Lys Lys Gln Glu Ser
610 615 620
Phe Lys Lys Gly Lys Ser Phe Asn Arg Asp Asp Cys His Lys Phe Ile
625 630 635 640
Asp Phe Tyr Lys Asp Ser Ile Asn Arg His Glu Glu Trp Arg Lys Phe
645 650 655
Asn Phe Lys Phe Ser Asp Thr Asp Ser Tyr Glu Asp Ile Ser Arg Phe
660 665 670
Tyr Lys Glu Val Glu Asn Gln Ala Phe Ser Met Ser Phe Thr Lys Ile
675 680 685
Pro Thr Val Tyr Ile Asp Ser Leu Val Asp Glu Gly Lys Leu Tyr Leu
690 695 700
Phe Lys Leu His Asn Lys Asp Phe Ser Glu His Ser Lys Gly Lys Pro
705 710 715 720
Asn Leu His Thr Val Tyr Trp Asn Ala Leu Phe Ser Glu Tyr Asn Leu
725 730 735
Gln Asn Thr Val Tyr Gln Leu Asn Gly Ser Ala Glu Ile Phe Phe Arg
740 745 750
Lys Ala Ser Ile Pro Glu Asn Glu Arg Val Ile His Lys Lys Asn Val
755 760 765
Pro Ile Thr Arg Lys Val Ala Glu Leu Asn Gly Lys Lys Glu Val Ser
770 775 780
Val Phe Pro Tyr Asp Ile Ile Lys Asn Arg Arg Tyr Thr Val Asp Lys
785 790 795 800
Phe Gln Phe His Val Pro Leu Lys Met Asn Phe Lys Ala Asp Glu Lys
805 810 815
Lys Arg Ile Asn Asp Asp Val Ile Glu Ala Ile Arg Ser Asn Lys Gly
820 825 830
Ile His Val Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Leu Tyr Leu
835 840 845
Ser Leu Ile Asn Glu Glu Gly Arg Ile Ile Glu Gln Arg Ser Leu Asn
850 855 860
Ile Ile Asp Ser Gly Glu Gly His Thr Gln Asn Tyr Arg Asp Leu Leu
865 870 875 880
Asp Ser Arg Glu Lys Asp Arg Glu Lys Ala Arg Glu Asn Trp Gln Glu
885 890 895
Ile Gln Glu Ile Lys Asp Leu Lys Thr Gly Tyr Leu Ser Gln Ala Ile
900 905 910
His Thr Ile Thr Lys Trp Met Lys Glu Tyr Asn Ala Ile Ile Val Leu
915 920 925
Glu Asp Leu Asn Asp Arg Phe Thr Asn Gly Arg Lys Lys Val Glu Lys
930 935 940
Gln Val Tyr Gln Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr
945 950 955 960
Tyr Val Asp Lys Asp Glu Glu Phe Asp Arg Met Gly Gly Thr His Arg
965 970 975
Ala Leu Gln Leu Thr Glu Lys Phe Glu Ser Phe Gln Lys Leu Gly Arg
980 985 990
Gln Thr Gly Phe Ile Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Leu
995 1000 1005
Asp Pro Thr Thr Gly Phe Val Asp Leu Leu Tyr Pro Lys Tyr Lys
1010 1015 1020
Ser Val Asp Ala Thr Lys Asp Phe Ile Lys Lys Phe Asp Phe Ile
1025 1030 1035
Arg Phe Asn Ser Glu Lys Asn Tyr Phe Glu Phe Gly Leu His Tyr
1040 1045 1050
Ser Asn Phe Thr Glu Arg Ala Ile Gly Cys Arg Asp Glu Trp Ile
1055 1060 1065
Leu Cys Ser Tyr Gly Asn Arg Ile Val Asn Phe Arg Asn Ala Ala
1070 1075 1080
Lys Asn Asn Ser Trp Asp Tyr Lys Glu Ile Asp Ile Thr Lys Gln
1085 1090 1095
Leu Leu Asp Leu Phe Glu Lys Asn Gly Ile Asp Val Lys Gln Glu
1100 1105 1110
Asn Leu Ile Asp Ser Ile Cys Glu Met Lys Asp Lys Pro Phe Phe
1115 1120 1125
Lys Ser Leu Ile Ala Asn Ile Lys Leu Ile Leu Gln Ile Arg Asn
1130 1135 1140
Ser Ala Ser Gly Thr Asp Ile Asp Tyr Met Ile Ser Pro Ala Met
1145 1150 1155
Asn Asp Arg Gly Glu Phe Phe Asp Thr Arg Lys Gly Leu Gln Gln
1160 1165 1170
Leu Pro Leu Asp Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Lys
1175 1180 1185
Lys Gly Leu Trp Ile Val Asp Gln Ile Arg Asn Thr Thr Gly Asn
1190 1195 1200
Asn Val Lys Met Ala Met Ser Asn Arg Glu Trp Met His Phe Ala
1205 1210 1215
Gln Glu Ser Arg Leu Ala
1220
<210> 1138
<211> 1318
<212> БЕЛОК
<213> Flavobacterium branchiophilum
<400> 1138
Met Thr Asn Lys Phe Thr Asn Gln Tyr Ser Leu Ser Lys Thr Leu Arg
1 5 10 15
Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Phe Ile Gln Glu Lys
20 25 30
Gly Leu Leu Ser Gln Asp Lys Gln Arg Ala Glu Ser Tyr Gln Glu Met
35 40 45
Lys Lys Thr Ile Asp Lys Phe His Lys Tyr Phe Ile Asp Leu Ala Leu
50 55 60
Ser Asn Ala Lys Leu Thr His Leu Glu Thr Tyr Leu Glu Leu Tyr Asn
65 70 75 80
Lys Ser Ala Glu Thr Lys Lys Glu Gln Lys Phe Lys Asp Asp Leu Lys
85 90 95
Lys Val Gln Asp Asn Leu Arg Lys Glu Ile Val Lys Ser Phe Ser Asp
100 105 110
Gly Asp Ala Lys Ser Ile Phe Ala Ile Leu Asp Lys Lys Glu Leu Ile
115 120 125
Thr Val Glu Leu Glu Lys Trp Phe Glu Asn Asn Glu Gln Lys Asp Ile
130 135 140
Tyr Phe Asp Glu Lys Phe Lys Thr Phe Thr Thr Tyr Phe Thr Gly Phe
145 150 155 160
His Gln Asn Arg Lys Asn Met Tyr Ser Val Glu Pro Asn Ser Thr Ala
165 170 175
Ile Ala Tyr Arg Leu Ile His Glu Asn Leu Pro Lys Phe Leu Glu Asn
180 185 190
Ala Lys Ala Phe Glu Lys Ile Lys Gln Val Glu Ser Leu Gln Val Asn
195 200 205
Phe Arg Glu Leu Met Gly Glu Phe Gly Asp Glu Gly Leu Ile Phe Val
210 215 220
Asn Glu Leu Glu Glu Met Phe Gln Ile Asn Tyr Tyr Asn Asp Val Leu
225 230 235 240
Ser Gln Asn Gly Ile Thr Ile Tyr Asn Ser Ile Ile Ser Gly Phe Thr
245 250 255
Lys Asn Asp Ile Lys Tyr Lys Gly Leu Asn Glu Tyr Ile Asn Asn Tyr
260 265 270
Asn Gln Thr Lys Asp Lys Lys Asp Arg Leu Pro Lys Leu Lys Gln Leu
275 280 285
Tyr Lys Gln Ile Leu Ser Asp Arg Ile Ser Leu Ser Phe Leu Pro Asp
290 295 300
Ala Phe Thr Asp Gly Lys Gln Val Leu Lys Ala Ile Phe Asp Phe Tyr
305 310 315 320
Lys Ile Asn Leu Leu Ser Tyr Thr Ile Glu Gly Gln Glu Glu Ser Gln
325 330 335
Asn Leu Leu Leu Leu Ile Arg Gln Thr Ile Glu Asn Leu Ser Ser Phe
340 345 350
Asp Thr Gln Lys Ile Tyr Leu Lys Asn Asp Thr His Leu Thr Thr Ile
355 360 365
Ser Gln Gln Val Phe Gly Asp Phe Ser Val Phe Ser Thr Ala Leu Asn
370 375 380
Tyr Trp Tyr Glu Thr Lys Val Asn Pro Lys Phe Glu Thr Glu Tyr Ser
385 390 395 400
Lys Ala Asn Glu Lys Lys Arg Glu Ile Leu Asp Lys Ala Lys Ala Val
405 410 415
Phe Thr Lys Gln Asp Tyr Phe Ser Ile Ala Phe Leu Gln Glu Val Leu
420 425 430
Ser Glu Tyr Ile Leu Thr Leu Asp His Thr Ser Asp Ile Val Lys Lys
435 440 445
His Ser Ser Asn Cys Ile Ala Asp Tyr Phe Lys Asn His Phe Val Ala
450 455 460
Lys Lys Glu Asn Glu Thr Asp Lys Thr Phe Asp Phe Ile Ala Asn Ile
465 470 475 480
Thr Ala Lys Tyr Gln Cys Ile Gln Gly Ile Leu Glu Asn Ala Asp Gln
485 490 495
Tyr Glu Asp Glu Leu Lys Gln Asp Gln Lys Leu Ile Asp Asn Leu Lys
500 505 510
Phe Phe Leu Asp Ala Ile Leu Glu Leu Leu His Phe Ile Lys Pro Leu
515 520 525
His Leu Lys Ser Glu Ser Ile Thr Glu Lys Asp Thr Ala Phe Tyr Asp
530 535 540
Val Phe Glu Asn Tyr Tyr Glu Ala Leu Ser Leu Leu Thr Pro Leu Tyr
545 550 555 560
Asn Met Val Arg Asn Tyr Val Thr Gln Lys Pro Tyr Ser Thr Glu Lys
565 570 575
Ile Lys Leu Asn Phe Glu Asn Ala Gln Leu Leu Asn Gly Trp Asp Ala
580 585 590
Asn Lys Glu Gly Asp Tyr Leu Thr Thr Ile Leu Lys Lys Asp Gly Asn
595 600 605
Tyr Phe Leu Ala Ile Met Asp Lys Lys His Asn Lys Ala Phe Gln Lys
610 615 620
Phe Pro Glu Gly Lys Glu Asn Tyr Glu Lys Met Val Tyr Lys Leu Leu
625 630 635 640
Pro Gly Val Asn Lys Met Leu Pro Lys Val Phe Phe Ser Asn Lys Asn
645 650 655
Ile Ala Tyr Phe Asn Pro Ser Lys Glu Leu Leu Glu Asn Tyr Lys Lys
660 665 670
Glu Thr His Lys Lys Gly Asp Thr Phe Asn Leu Glu His Cys His Thr
675 680 685
Leu Ile Asp Phe Phe Lys Asp Ser Leu Asn Lys His Glu Asp Trp Lys
690 695 700
Tyr Phe Asp Phe Gln Phe Ser Glu Thr Lys Ser Tyr Gln Asp Leu Ser
705 710 715 720
Gly Phe Tyr Arg Glu Val Glu His Gln Gly Tyr Lys Ile Asn Phe Lys
725 730 735
Asn Ile Asp Ser Glu Tyr Ile Asp Gly Leu Val Asn Glu Gly Lys Leu
740 745 750
Phe Leu Phe Gln Ile Tyr Ser Lys Asp Phe Ser Pro Phe Ser Lys Gly
755 760 765
Lys Pro Asn Met His Thr Leu Tyr Trp Lys Ala Leu Phe Glu Glu Gln
770 775 780
Asn Leu Gln Asn Val Ile Tyr Lys Leu Asn Gly Gln Ala Glu Ile Phe
785 790 795 800
Phe Arg Lys Ala Ser Ile Lys Pro Lys Asn Ile Ile Leu His Lys Lys
805 810 815
Lys Ile Lys Ile Ala Lys Lys His Phe Ile Asp Lys Lys Thr Lys Thr
820 825 830
Ser Glu Ile Val Pro Val Gln Thr Ile Lys Asn Leu Asn Met Tyr Tyr
835 840 845
Gln Gly Lys Ile Ser Glu Lys Glu Leu Thr Gln Asp Asp Leu Arg Tyr
850 855 860
Ile Asp Asn Phe Ser Ile Phe Asn Glu Lys Asn Lys Thr Ile Asp Ile
865 870 875 880
Ile Lys Asp Lys Arg Phe Thr Val Asp Lys Phe Gln Phe His Val Pro
885 890 895
Ile Thr Met Asn Phe Lys Ala Thr Gly Gly Ser Tyr Ile Asn Gln Thr
900 905 910
Val Leu Glu Tyr Leu Gln Asn Asn Pro Glu Val Lys Ile Ile Gly Leu
915 920 925
Asp Arg Gly Glu Arg His Leu Val Tyr Leu Thr Leu Ile Asp Gln Gln
930 935 940
Gly Asn Ile Leu Lys Gln Glu Ser Leu Asn Thr Ile Thr Asp Ser Lys
945 950 955 960
Ile Ser Thr Pro Tyr His Lys Leu Leu Asp Asn Lys Glu Asn Glu Arg
965 970 975
Asp Leu Ala Arg Lys Asn Trp Gly Thr Val Glu Asn Ile Lys Glu Leu
980 985 990
Lys Glu Gly Tyr Ile Ser Gln Val Val His Lys Ile Ala Thr Leu Met
995 1000 1005
Leu Glu Glu Asn Ala Ile Val Val Met Glu Asp Leu Asn Phe Gly
1010 1015 1020
Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Ile Tyr Gln Lys
1025 1030 1035
Leu Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Leu Lys
1040 1045 1050
Asp Lys Gln Pro Gln Glu Leu Gly Gly Leu Tyr Asn Ala Leu Gln
1055 1060 1065
Leu Thr Asn Lys Phe Glu Ser Phe Gln Lys Met Gly Lys Gln Ser
1070 1075 1080
Gly Phe Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile Asp
1085 1090 1095
Pro Thr Thr Gly Phe Val Asn Tyr Phe Tyr Thr Lys Tyr Glu Asn
1100 1105 1110
Val Asp Lys Ala Lys Ala Phe Phe Glu Lys Phe Glu Ala Ile Arg
1115 1120 1125
Phe Asn Ala Glu Lys Lys Tyr Phe Glu Phe Glu Val Lys Lys Tyr
1130 1135 1140
Ser Asp Phe Asn Pro Lys Ala Glu Gly Thr Gln Gln Ala Trp Thr
1145 1150 1155
Ile Cys Thr Tyr Gly Glu Arg Ile Glu Thr Lys Arg Gln Lys Asp
1160 1165 1170
Gln Asn Asn Lys Phe Val Ser Thr Pro Ile Asn Leu Thr Glu Lys
1175 1180 1185
Ile Glu Asp Phe Leu Gly Lys Asn Gln Ile Val Tyr Gly Asp Gly
1190 1195 1200
Asn Cys Ile Lys Ser Gln Ile Ala Ser Lys Asp Asp Lys Ala Phe
1205 1210 1215
Phe Glu Thr Leu Leu Tyr Trp Phe Lys Met Thr Leu Gln Met Arg
1220 1225 1230
Asn Ser Glu Thr Arg Thr Asp Ile Asp Tyr Leu Ile Ser Pro Val
1235 1240 1245
Met Asn Asp Asn Gly Thr Phe Tyr Asn Ser Arg Asp Tyr Glu Lys
1250 1255 1260
Leu Glu Asn Pro Thr Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala
1265 1270 1275
Tyr His Ile Ala Lys Lys Gly Leu Met Leu Leu Asn Lys Ile Asp
1280 1285 1290
Gln Ala Asp Leu Thr Lys Lys Val Asp Leu Ser Ile Ser Asn Arg
1295 1300 1305
Asp Trp Leu Gln Phe Val Gln Lys Asn Lys
1310 1315
<210> 1139
<211> 1273
<212> БЕЛОК
<213> Flavobacterium sp.
<400> 1139
Met Lys Asn Phe Ser Asn Leu Tyr Gln Val Ser Lys Thr Val Arg Phe
1 5 10 15
Glu Leu Lys Pro Ile Gly Asn Thr Leu Glu Asn Ile Lys Asn Lys Ser
20 25 30
Leu Leu Lys Asn Asp Ser Ile Arg Ala Glu Ser Tyr Gln Lys Met Lys
35 40 45
Lys Thr Ile Asp Glu Phe His Lys Tyr Phe Ile Asp Leu Ala Leu Asn
50 55 60
Asn Lys Lys Leu Ser Tyr Leu Asn Glu Tyr Ile Ala Leu Tyr Thr Gln
65 70 75 80
Ser Ala Glu Ala Lys Lys Glu Asp Lys Phe Lys Ala Asp Phe Lys Lys
85 90 95
Val Gln Asp Asn Leu Arg Lys Glu Ile Val Ser Ser Phe Thr Glu Gly
100 105 110
Glu Ala Lys Ala Ile Phe Ser Val Leu Asp Lys Lys Glu Leu Ile Thr
115 120 125
Ile Glu Leu Glu Lys Trp Lys Asn Glu Asn Asn Leu Ala Val Tyr Leu
130 135 140
Asp Glu Ser Phe Lys Ser Phe Thr Thr Tyr Phe Thr Gly Phe His Gln
145 150 155 160
Asn Arg Lys Asn Met Tyr Ser Ala Glu Ala Asn Ser Thr Ala Ile Ala
165 170 175
Tyr Arg Leu Ile His Glu Asn Leu Pro Lys Phe Ile Glu Asn Ser Lys
180 185 190
Ala Phe Glu Lys Ser Ser Gln Ile Ala Glu Leu Gln Pro Lys Ile Glu
195 200 205
Lys Leu Tyr Lys Glu Phe Glu Ala Tyr Leu Asn Val Asn Ser Ile Ser
210 215 220
Glu Leu Phe Glu Ile Asp Tyr Phe Asn Glu Val Leu Thr Gln Lys Gly
225 230 235 240
Ile Thr Val Tyr Asn Asn Ile Ile Gly Gly Arg Thr Ala Thr Glu Gly
245 250 255
Lys Gln Lys Ile Gln Gly Leu Asn Glu Ile Ile Asn Leu Tyr Asn Gln
260 265 270
Thr Lys Pro Lys Asn Glu Arg Leu Pro Lys Leu Lys Gln Leu Tyr Lys
275 280 285
Gln Ile Leu Ser Asp Arg Ile Ser Leu Ser Phe Leu Pro Asp Ala Phe
290 295 300
Thr Glu Gly Lys Gln Val Leu Lys Ala Val Phe Glu Phe Tyr Lys Ile
305 310 315 320
Asn Leu Leu Ser Tyr Lys Gln Asp Gly Val Glu Glu Ser Gln Asn Leu
325 330 335
Leu Glu Leu Ile Gln Gln Val Val Lys Asn Leu Gly Asn Gln Asp Val
340 345 350
Asn Lys Ile Tyr Leu Lys Asn Asp Thr Ser Leu Thr Thr Ile Ala Gln
355 360 365
Gln Leu Phe Gly Asp Phe Ser Val Phe Ser Ala Ala Leu Gln Tyr Arg
370 375 380
Tyr Glu Thr Val Val Asn Pro Lys Tyr Thr Ala Glu Tyr Gln Lys Ala
385 390 395 400
Asn Glu Ala Lys Gln Glu Lys Leu Asp Lys Glu Lys Ile Lys Phe Val
405 410 415
Lys Gln Asp Tyr Phe Ser Ile Ala Phe Leu Gln Glu Val Val Ala Asp
420 425 430
Tyr Val Lys Thr Leu Asp Glu Asn Leu Asp Trp Lys Gln Lys Tyr Thr
435 440 445
Pro Ser Cys Ile Ala Asp Tyr Phe Thr Thr His Phe Ile Ala Lys Lys
450 455 460
Glu Asn Glu Ala Asp Lys Thr Phe Asn Phe Ile Ala Asn Ile Lys Ala
465 470 475 480
Lys Tyr Gln Cys Ile Gln Gly Ile Leu Glu Gln Ala Asp Asp Tyr Glu
485 490 495
Asp Glu Leu Lys Gln Asp Gln Lys Leu Ile Asp Asn Ile Lys Phe Phe
500 505 510
Leu Asp Ala Ile Leu Glu Val Val His Phe Ile Lys Pro Leu His Leu
515 520 525
Lys Ser Glu Ser Ile Thr Glu Lys Asp Asn Ala Phe Tyr Asp Val Phe
530 535 540
Glu Asn Tyr Tyr Glu Ala Leu Asn Val Val Thr Pro Leu Tyr Asn Met
545 550 555 560
Val Arg Asn Tyr Val Thr Gln Lys Pro Tyr Ser Thr Glu Lys Ile Lys
565 570 575
Leu Asn Phe Glu Asn Ala Gln Leu Leu Asn Gly Trp Asp Ala Asn Lys
580 585 590
Glu Lys Asp Tyr Leu Thr Thr Ile Leu Lys Arg Asp Gly Asn Tyr Phe
595 600 605
Leu Ala Ile Met Asp Lys Lys His Asn Lys Thr Phe Gln Gln Phe Thr
610 615 620
Glu Asp Asp Glu Asn Tyr Glu Lys Ile Val Tyr Lys Leu Leu Pro Gly
625 630 635 640
Val Asn Lys Met Leu Pro Lys Val Phe Phe Ser Asn Lys Asn Ile Ala
645 650 655
Phe Phe Asn Pro Ser Lys Glu Ile Leu Asp Asn Tyr Lys Asn Asn Thr
660 665 670
His Lys Lys Gly Ala Thr Phe Asn Leu Lys Asp Cys His Ala Leu Ile
675 680 685
Asp Phe Phe Lys Asp Ser Leu Asn Lys His Glu Asp Trp Lys Tyr Phe
690 695 700
Asp Phe Gln Phe Ser Glu Thr Lys Thr Tyr Gln Asp Leu Ser Gly Phe
705 710 715 720
Tyr Lys Glu Val Glu His Gln Gly Tyr Lys Ile Asn Phe Lys Lys Val
725 730 735
Ser Val Ser Gln Ile Asp Thr Leu Ile Glu Glu Gly Lys Met Tyr Leu
740 745 750
Phe Gln Ile Tyr Asn Lys Asp Phe Ser Pro Tyr Ala Lys Gly Lys Pro
755 760 765
Asn Met His Thr Leu Tyr Trp Lys Ala Leu Phe Glu Thr Gln Asn Leu
770 775 780
Glu Asn Val Ile Tyr Lys Leu Asn Gly Gln Ala Glu Ile Phe Phe Arg
785 790 795 800
Lys Ala Ser Ile Lys Lys Lys Asn Ile Ile Thr His Lys Ala His Gln
805 810 815
Pro Ile Ala Ala Lys Asn Pro Leu Thr Pro Thr Ala Lys Asn Thr Phe
820 825 830
Ala Tyr Asp Leu Ile Lys Asp Lys Arg Tyr Thr Val Asp Lys Phe Gln
835 840 845
Phe His Val Pro Ile Thr Met Asn Phe Lys Ala Thr Gly Asn Ser Tyr
850 855 860
Ile Asn Gln Asp Val Leu Ala Tyr Leu Lys Asp Asn Pro Glu Val Asn
865 870 875 880
Ile Ile Gly Leu Asp Arg Gly Glu Arg His Leu Val Tyr Leu Thr Leu
885 890 895
Ile Asp Gln Lys Gly Thr Ile Leu Leu Gln Glu Ser Leu Asn Val Ile
900 905 910
Gln Asp Glu Lys Thr His Thr Pro Tyr His Thr Leu Leu Asp Asn Lys
915 920 925
Glu Ile Ala Arg Asp Lys Ala Arg Lys Asn Trp Gly Ser Ile Glu Ser
930 935 940
Ile Lys Glu Leu Lys Glu Gly Tyr Ile Ser Gln Val Val His Lys Ile
945 950 955 960
Thr Lys Met Met Ile Glu His Asn Ala Ile Val Val Met Glu Asp Leu
965 970 975
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Ile Tyr
980 985 990
Gln Lys Leu Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Leu
995 1000 1005
Lys Asp Lys Gln Pro His Glu Leu Gly Gly Leu Tyr Asn Ala Leu
1010 1015 1020
Gln Leu Thr Asn Lys Phe Glu Ser Phe Gln Lys Met Gly Lys Gln
1025 1030 1035
Ser Gly Phe Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile
1040 1045 1050
Asp Pro Thr Thr Gly Phe Val Asn Tyr Phe Tyr Thr Lys Tyr Glu
1055 1060 1065
Asn Val Glu Lys Ala Lys Thr Phe Phe Ser Lys Phe Asp Ser Ile
1070 1075 1080
Leu Tyr Asn Lys Thr Lys Gly Tyr Phe Glu Phe Val Val Lys Asn
1085 1090 1095
Tyr Ser Asp Phe Asn Pro Lys Ala Ala Asp Thr Arg Gln Glu Trp
1100 1105 1110
Thr Ile Cys Thr His Gly Glu Arg Ile Glu Thr Lys Arg Gln Lys
1115 1120 1125
Glu Gln Asn Asn Asn Phe Val Ser Thr Thr Ile Gln Leu Thr Glu
1130 1135 1140
Gln Phe Val Asn Phe Phe Glu Lys Val Gly Leu Asp Leu Ser Lys
1145 1150 1155
Glu Leu Lys Thr Gln Leu Ile Ala Gln Asn Glu Lys Ser Phe Phe
1160 1165 1170
Glu Glu Leu Phe His Leu Leu Lys Leu Thr Leu Gln Met Arg Asn
1175 1180 1185
Ser Glu Ser His Thr Glu Ile Asp Tyr Leu Ile Ser Pro Val Ala
1190 1195 1200
Asn Glu Lys Gly Ile Phe Tyr Asp Ser Arg Lys Ala Thr Ala Ser
1205 1210 1215
Leu Pro Ile Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Lys
1220 1225 1230
Lys Gly Leu Trp Ile Met Glu Gln Ile Asn Lys Thr Asn Ser Glu
1235 1240 1245
Asp Asp Leu Lys Lys Val Lys Leu Ala Ile Ser Asn Arg Glu Trp
1250 1255 1260
Leu Gln Tyr Val Gln Gln Val Gln Lys Lys
1265 1270
<210> 1140
<211> 1264
<212> БЕЛОК
<213> Smithella sp.
<400> 1140
Met Gln Thr Leu Phe Glu Asn Phe Thr Asn Gln Tyr Pro Val Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Lys Asp Phe Ile
20 25 30
Glu Gln Lys Gly Leu Leu Lys Lys Asp Glu Asp Arg Ala Glu Lys Tyr
35 40 45
Lys Lys Val Lys Asn Ile Ile Asp Glu Tyr His Lys Asp Phe Ile Glu
50 55 60
Lys Ser Leu Asn Gly Leu Lys Leu Asp Gly Leu Glu Lys Tyr Lys Thr
65 70 75 80
Leu Tyr Leu Lys Gln Glu Lys Asp Asp Lys Asp Lys Lys Ala Phe Asp
85 90 95
Lys Glu Lys Glu Asn Leu Arg Lys Gln Ile Ala Asn Ala Phe Arg Asn
100 105 110
Asn Glu Lys Phe Lys Thr Leu Phe Ala Lys Glu Leu Ile Lys Asn Asp
115 120 125
Leu Met Ser Phe Ala Cys Glu Glu Asp Lys Lys Asn Val Lys Glu Phe
130 135 140
Glu Ala Phe Thr Thr Tyr Phe Thr Gly Phe His Gln Asn Arg Ala Asn
145 150 155 160
Met Tyr Val Ala Asp Glu Lys Arg Thr Ala Ile Ala Ser Arg Leu Ile
165 170 175
His Glu Asn Leu Pro Lys Phe Ile Asp Asn Ile Lys Ile Phe Glu Lys
180 185 190
Met Lys Lys Glu Ala Pro Glu Leu Leu Ser Pro Phe Asn Gln Thr Leu
195 200 205
Lys Asp Met Lys Asp Val Ile Lys Gly Thr Thr Leu Glu Glu Ile Phe
210 215 220
Ser Leu Asp Tyr Phe Asn Lys Thr Leu Thr Gln Ser Gly Ile Asp Ile
225 230 235 240
Tyr Asn Ser Val Ile Gly Gly Arg Thr Pro Glu Glu Gly Lys Thr Lys
245 250 255
Ile Lys Gly Leu Asn Glu Tyr Ile Asn Thr Tyr Phe Thr Gly Phe His
260 265 270
Gln Asn Arg Ala Asn Met Tyr Val Asp Phe Asn Gln Lys Gln Thr Asp
275 280 285
Lys Lys Lys Arg Gln Pro Lys Phe Lys Gln Leu Tyr Lys Gln Ile Leu
290 295 300
Ser Asp Arg Gln Ser Leu Ser Phe Ile Ala Glu Ala Phe Lys Asn Asp
305 310 315 320
Thr Glu Ile Leu Glu Ala Ile Glu Lys Phe Tyr Val Asn Glu Leu Leu
325 330 335
His Phe Ser Asn Glu Gly Lys Ser Thr Asn Val Leu Asp Ala Ile Lys
340 345 350
Asn Ala Val Ser Asn Leu Glu Ser Phe Asn Leu Thr Lys Met Tyr Phe
355 360 365
Arg Ser Gly Ala Ser Leu Thr Asp Val Ser Arg Lys Val Phe Gly Glu
370 375 380
Trp Ser Ile Ile Asn Arg Ala Leu Asp Asn Tyr Tyr Ala Thr Thr Tyr
385 390 395 400
Pro Ile Lys Pro Arg Glu Lys Ser Glu Lys Tyr Glu Glu Arg Lys Glu
405 410 415
Lys Trp Leu Lys Gln Asp Phe Asn Val Ser Leu Ile Gln Thr Ala Ile
420 425 430
Asp Glu Tyr Asp Asn Glu Thr Val Lys Gly Lys Asn Ser Gly Lys Val
435 440 445
Ile Ala Asp Tyr Phe Ala Lys Phe Cys Asp Asp Lys Glu Thr Asp Leu
450 455 460
Ile Gln Lys Val Asn Glu Gly Tyr Ile Ala Val Lys Asp Leu Leu Asn
465 470 475 480
Thr Pro Cys Pro Glu Asn Glu Lys Leu Gly Ser Asn Lys Asp Gln Val
485 490 495
Lys Gln Ile Lys Ala Phe Met Asp Ser Ile Met Asp Ile Met His Phe
500 505 510
Val Arg Pro Leu Ser Leu Lys Asp Thr Asp Lys Glu Lys Asp Glu Thr
515 520 525
Phe Tyr Ser Leu Phe Thr Pro Leu Tyr Asp His Leu Thr Gln Thr Ile
530 535 540
Ala Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Gln Lys Pro Tyr Ser
545 550 555 560
Thr Glu Lys Ile Lys Leu Asn Phe Glu Asn Ser Thr Leu Leu Gly Gly
565 570 575
Trp Asp Leu Asn Lys Glu Thr Asp Asn Thr Ala Ile Ile Leu Arg Lys
580 585 590
Asp Asn Leu Tyr Tyr Leu Gly Ile Met Asp Lys Arg His Asn Arg Ile
595 600 605
Phe Arg Asn Val Pro Lys Ala Asp Lys Lys Asp Phe Cys Tyr Glu Lys
610 615 620
Met Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
625 630 635 640
Phe Phe Ser Gln Ser Arg Ile Gln Glu Phe Thr Pro Ser Ala Lys Leu
645 650 655
Leu Glu Asn Tyr Ala Asn Glu Thr His Lys Lys Gly Asp Asn Phe Asn
660 665 670
Leu Asn His Cys His Lys Leu Ile Asp Phe Phe Lys Asp Ser Ile Asn
675 680 685
Lys His Glu Asp Trp Lys Asn Phe Asp Phe Arg Phe Ser Ala Thr Ser
690 695 700
Thr Tyr Ala Asp Leu Ser Gly Phe Tyr His Glu Val Glu His Gln Gly
705 710 715 720
Tyr Lys Ile Ser Phe Gln Ser Val Ala Asp Ser Phe Ile Asp Asp Leu
725 730 735
Val Asn Glu Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe
740 745 750
Ser Pro Phe Ser Lys Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Lys
755 760 765
Met Leu Phe Asp Glu Asn Asn Leu Lys Asp Val Val Tyr Lys Leu Asn
770 775 780
Gly Glu Ala Glu Val Phe Tyr Arg Lys Lys Ser Ile Ala Glu Lys Asn
785 790 795 800
Thr Thr Ile His Lys Ala Asn Glu Ser Ile Ile Asn Lys Asn Pro Asp
805 810 815
Asn Pro Lys Ala Thr Ser Thr Phe Asn Tyr Asp Ile Val Lys Asp Lys
820 825 830
Arg Tyr Thr Ile Asp Lys Phe Gln Phe His Ile Pro Ile Thr Met Asn
835 840 845
Phe Lys Ala Glu Gly Ile Phe Asn Met Asn Gln Arg Val Asn Gln Phe
850 855 860
Leu Lys Ala Asn Pro Asp Ile Asn Ile Ile Gly Ile Asp Arg Gly Glu
865 870 875 880
Arg His Leu Leu Tyr Tyr Ala Leu Ile Asn Gln Lys Gly Lys Ile Leu
885 890 895
Lys Gln Asp Thr Leu Asn Val Ile Ala Asn Glu Lys Gln Lys Val Asp
900 905 910
Tyr His Asn Leu Leu Asp Lys Lys Glu Gly Asp Arg Ala Thr Ala Arg
915 920 925
Gln Glu Trp Gly Val Ile Glu Thr Ile Lys Glu Leu Lys Glu Gly Tyr
930 935 940
Leu Ser Gln Val Ile His Lys Leu Thr Asp Leu Met Ile Glu Asn Asn
945 950 955 960
Ala Ile Ile Val Met Glu Asp Leu Asn Phe Gly Phe Lys Arg Gly Arg
965 970 975
Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys Met Leu Ile
980 985 990
Asp Lys Leu Asn Tyr Leu Val Asp Lys Asn Lys Lys Ala Asn Glu Leu
995 1000 1005
Gly Gly Leu Leu Asn Ala Phe Gln Leu Ala Asn Lys Phe Glu Ser
1010 1015 1020
Phe Gln Lys Met Gly Lys Gln Asn Gly Phe Ile Phe Tyr Val Pro
1025 1030 1035
Ala Trp Asn Thr Ser Lys Thr Asp Pro Ala Thr Gly Phe Ile Asp
1040 1045 1050
Phe Leu Lys Pro Arg Tyr Glu Asn Leu Asn Gln Ala Lys Asp Phe
1055 1060 1065
Phe Glu Lys Phe Asp Ser Ile Arg Leu Asn Ser Lys Ala Asp Tyr
1070 1075 1080
Phe Glu Phe Ala Phe Asp Phe Lys Asn Phe Thr Glu Lys Ala Asp
1085 1090 1095
Gly Gly Arg Thr Lys Trp Thr Val Cys Thr Thr Asn Glu Asp Arg
1100 1105 1110
Tyr Ala Trp Asn Arg Ala Leu Asn Asn Asn Arg Gly Ser Gln Glu
1115 1120 1125
Lys Tyr Asp Ile Thr Ala Glu Leu Lys Ser Leu Phe Asp Gly Lys
1130 1135 1140
Val Asp Tyr Lys Ser Gly Lys Asp Leu Lys Gln Gln Ile Ala Ser
1145 1150 1155
Gln Glu Ser Ala Asp Phe Phe Lys Ala Leu Met Lys Asn Leu Ser
1160 1165 1170
Ile Thr Leu Ser Leu Arg His Asn Asn Gly Glu Lys Gly Asp Asn
1175 1180 1185
Glu Gln Asp Tyr Ile Leu Ser Pro Val Ala Asp Ser Lys Gly Arg
1190 1195 1200
Phe Phe Asp Ser Arg Lys Ala Asp Asp Asp Met Pro Lys Asn Ala
1205 1210 1215
Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Trp Cys
1220 1225 1230
Leu Glu Gln Ile Ser Lys Thr Asp Asp Leu Lys Lys Val Lys Leu
1235 1240 1245
Ala Ile Ser Asn Lys Glu Trp Leu Glu Phe Val Gln Thr Leu Lys
1250 1255 1260
Gly
<210> 1141
<211> 1250
<212> БЕЛОК
<213> Smithella sp.
<400> 1141
Met Gln Thr Leu Phe Glu Asn Phe Thr Asn Gln Tyr Pro Val Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Lys Asp Phe Ile
20 25 30
Glu Gln Lys Gly Leu Leu Lys Lys Asp Glu Asp Arg Ala Glu Lys Tyr
35 40 45
Lys Lys Val Lys Asn Ile Ile Asp Glu Tyr His Lys Asp Phe Ile Glu
50 55 60
Lys Ser Leu Asn Gly Leu Lys Leu Asp Gly Leu Glu Glu Tyr Lys Thr
65 70 75 80
Leu Tyr Leu Lys Gln Glu Lys Asp Asp Lys Asp Lys Lys Ala Phe Asp
85 90 95
Lys Glu Lys Glu Asn Leu Arg Lys Gln Ile Ala Asn Ala Phe Arg Asn
100 105 110
Asn Glu Lys Phe Lys Thr Leu Phe Ala Lys Glu Leu Ile Lys Asn Asp
115 120 125
Leu Met Ser Phe Ala Cys Glu Glu Asp Lys Lys Asn Val Lys Glu Phe
130 135 140
Glu Ala Phe Thr Thr Ala Asp Glu Lys Arg Thr Ala Ile Ala Ser Arg
145 150 155 160
Leu Ile His Glu Asn Leu Pro Lys Phe Ile Asp Asn Ile Lys Ile Phe
165 170 175
Glu Lys Met Lys Lys Glu Ala Pro Glu Leu Leu Ser Pro Phe Asn Gln
180 185 190
Thr Leu Lys Asp Met Lys Asp Val Ile Lys Gly Thr Thr Leu Glu Glu
195 200 205
Ile Phe Ser Leu Asp Tyr Phe Asn Lys Thr Leu Thr Gln Ser Gly Ile
210 215 220
Asp Ile Tyr Asn Ser Val Ile Gly Gly Arg Thr Pro Glu Glu Gly Lys
225 230 235 240
Thr Lys Ile Lys Gly Leu Asn Glu Tyr Ile Asn Thr Tyr Phe Thr Gly
245 250 255
Phe His Ser Asn Arg Gln Asn Ile Tyr Ser Asp Phe Asn Gln Lys Gln
260 265 270
Thr Asp Lys Lys Lys Arg Gln Pro Lys Phe Lys Gln Leu Tyr Lys Gln
275 280 285
Ile Leu Ser Asp Arg Gln Ser Leu Ser Phe Ile Ala Glu Ala Phe Lys
290 295 300
Asn Asp Thr Glu Ile Leu Glu Ala Ile Glu Lys Phe Tyr Val Asn Glu
305 310 315 320
Leu Leu His Phe Ser Asn Glu Gly Lys Ser Thr Asn Val Leu Asp Ala
325 330 335
Ile Lys Asn Ala Val Ser Asn Leu Glu Ser Phe Asn Leu Thr Lys Ile
340 345 350
Tyr Phe Arg Ser Gly Thr Ser Leu Thr Asp Val Ser Arg Lys Val Phe
355 360 365
Gly Glu Trp Ser Ile Ile Asn Arg Ala Leu Asp Asn Tyr Tyr Ala Thr
370 375 380
Thr Tyr Pro Ile Lys Pro Arg Glu Lys Ser Glu Lys Tyr Glu Glu Arg
385 390 395 400
Lys Glu Lys Trp Leu Lys Gln Asp Phe Asn Val Ser Leu Ile Gln Thr
405 410 415
Ala Ile Asp Glu Tyr Asp Asn Glu Thr Val Lys Gly Lys Asn Ser Gly
420 425 430
Lys Val Ile Val Asp Tyr Phe Ala Lys Phe Cys Asp Asp Lys Glu Thr
435 440 445
Asp Leu Ile Gln Lys Val Asn Glu Gly Tyr Ile Ala Val Lys Asp Leu
450 455 460
Leu Asn Thr Pro Tyr Pro Glu Asn Glu Lys Leu Gly Ser Asn Lys Asp
465 470 475 480
Gln Val Lys Gln Ile Lys Ala Phe Met Asp Ser Ile Met Asp Ile Met
485 490 495
His Phe Val Arg Pro Leu Ser Leu Lys Asp Thr Asp Lys Glu Lys Asp
500 505 510
Glu Thr Phe Tyr Ser Leu Phe Thr Pro Leu Tyr Asp His Leu Thr Gln
515 520 525
Thr Ile Ala Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Gln Lys Pro
530 535 540
Tyr Ser Thr Glu Lys Ile Lys Leu Asn Phe Glu Asn Ser Thr Leu Leu
545 550 555 560
Gly Gly Trp Asp Leu Asn Lys Glu Thr Asp Asn Thr Ala Ile Ile Leu
565 570 575
Arg Lys Glu Asn Leu Tyr Tyr Leu Gly Ile Met Asp Lys Arg His Asn
580 585 590
Arg Ile Phe Arg Asn Val Pro Lys Ala Asp Lys Lys Asp Ser Cys Tyr
595 600 605
Glu Lys Met Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro
610 615 620
Lys Val Phe Phe Ser Gln Ser Arg Ile Gln Glu Phe Thr Pro Ser Ala
625 630 635 640
Lys Leu Leu Glu Asn Tyr Glu Asn Glu Thr His Lys Lys Gly Asp Asn
645 650 655
Phe Asn Leu Asn His Cys His Gln Leu Ile Asp Phe Phe Lys Asp Ser
660 665 670
Ile Asn Lys His Glu Asp Trp Lys Asn Phe Asp Phe Arg Phe Ser Ala
675 680 685
Thr Ser Thr Tyr Ala Asp Leu Ser Gly Phe Tyr His Glu Val Glu His
690 695 700
Gln Gly Tyr Lys Ile Ser Phe Gln Ser Ile Ala Asp Ser Phe Ile Asp
705 710 715 720
Asp Leu Val Asn Glu Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
725 730 735
Asp Phe Ser Pro Phe Ser Lys Gly Lys Pro Asn Leu His Thr Leu Tyr
740 745 750
Trp Lys Met Leu Phe Asp Glu Asn Asn Leu Lys Asp Val Val Tyr Lys
755 760 765
Leu Asn Gly Glu Ala Glu Val Phe Tyr Arg Lys Lys Ser Ile Ala Glu
770 775 780
Lys Asn Thr Thr Ile His Lys Ala Asn Glu Ser Ile Ile Asn Lys Asn
785 790 795 800
Pro Asp Asn Pro Lys Ala Thr Ser Thr Phe Asn Tyr Asp Ile Val Lys
805 810 815
Asp Lys Arg Tyr Thr Ile Asp Lys Phe Gln Phe His Val Pro Ile Thr
820 825 830
Met Asn Phe Lys Ala Glu Gly Ile Phe Asn Met Asn Gln Arg Val Asn
835 840 845
Gln Phe Leu Lys Ala Asn Pro Asp Ile Asn Ile Ile Gly Ile Asp Arg
850 855 860
Gly Glu Arg His Leu Leu Tyr Tyr Thr Leu Ile Asn Gln Lys Gly Lys
865 870 875 880
Ile Leu Lys Gln Asp Thr Leu Asn Val Ile Ala Asn Glu Lys Gln Lys
885 890 895
Val Asp Tyr His Asn Leu Leu Asp Lys Lys Glu Gly Asp Arg Ala Thr
900 905 910
Ala Arg Gln Glu Trp Gly Val Ile Glu Thr Ile Lys Glu Leu Lys Glu
915 920 925
Gly Tyr Leu Ser Gln Val Ile His Lys Leu Thr Asp Leu Met Ile Glu
930 935 940
Asn Asn Ala Ile Ile Val Met Glu Asp Leu Asn Phe Gly Phe Lys Arg
945 950 955 960
Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys Met
965 970 975
Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Asn Lys Lys Ala Asn
980 985 990
Glu Leu Gly Gly Leu Leu Asn Ala Phe Gln Leu Ala Asn Lys Phe Glu
995 1000 1005
Ser Phe Gln Lys Met Gly Lys Gln Asn Gly Phe Ile Phe Tyr Val
1010 1015 1020
Pro Ala Trp Asn Thr Ser Lys Thr Asp Pro Ala Thr Gly Phe Ile
1025 1030 1035
Asp Phe Leu Lys Pro Arg Tyr Glu Asn Leu Lys Gln Ala Lys Asp
1040 1045 1050
Phe Phe Glu Lys Phe Asp Ser Ile Arg Leu Asn Ser Lys Ala Asp
1055 1060 1065
Tyr Phe Glu Phe Ala Phe Asp Phe Lys Asn Phe Thr Gly Lys Ala
1070 1075 1080
Asp Gly Gly Arg Thr Lys Trp Thr Val Cys Thr Thr Asn Glu Asp
1085 1090 1095
Arg Tyr Ala Trp Asn Arg Ala Leu Asn Asn Asn Arg Gly Ser Gln
1100 1105 1110
Glu Lys Tyr Asp Ile Thr Ala Glu Leu Lys Ser Leu Phe Asp Gly
1115 1120 1125
Lys Val Asp Tyr Lys Ser Gly Lys Asp Leu Lys Gln Gln Ile Ala
1130 1135 1140
Ser Gln Glu Leu Ala Asp Phe Phe Arg Thr Leu Met Lys Tyr Leu
1145 1150 1155
Ser Val Thr Leu Ser Leu Arg His Asn Asn Gly Glu Lys Gly Glu
1160 1165 1170
Thr Glu Gln Asp Tyr Ile Leu Ser Pro Val Ala Asp Ser Met Gly
1175 1180 1185
Lys Phe Phe Asp Ser Arg Lys Ala Gly Asp Asp Met Pro Lys Asn
1190 1195 1200
Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Trp
1205 1210 1215
Cys Leu Glu Gln Ile Ser Lys Thr Asp Asp Leu Lys Lys Val Lys
1220 1225 1230
Leu Ala Ile Ser Asn Lys Glu Trp Leu Glu Phe Met Gln Thr Leu
1235 1240 1245
Lys Gly
1250
<210> 1142
<211> 1249
<212> БЕЛОК
<213> Leptospira inadai
<400> 1142
Met Glu Asp Tyr Ser Gly Phe Val Asn Ile Tyr Ser Ile Gln Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu His Ile Glu
20 25 30
Lys Lys Gly Phe Leu Lys Lys Asp Lys Ile Arg Ala Glu Asp Tyr Lys
35 40 45
Ala Val Lys Lys Ile Ile Asp Lys Tyr His Arg Ala Tyr Ile Glu Glu
50 55 60
Val Phe Asp Ser Val Leu His Gln Lys Lys Lys Lys Asp Lys Thr Arg
65 70 75 80
Phe Ser Thr Gln Phe Ile Lys Glu Ile Lys Glu Phe Ser Glu Leu Tyr
85 90 95
Tyr Lys Thr Glu Lys Asn Ile Pro Asp Lys Glu Arg Leu Glu Ala Leu
100 105 110
Ser Glu Lys Leu Arg Lys Met Leu Val Gly Ala Phe Lys Gly Glu Phe
115 120 125
Ser Glu Glu Val Ala Glu Lys Tyr Lys Asn Leu Phe Ser Lys Glu Leu
130 135 140
Ile Arg Asn Glu Ile Glu Lys Phe Cys Glu Thr Asp Glu Glu Arg Lys
145 150 155 160
Gln Val Ser Asn Phe Lys Ser Phe Thr Thr Asp Glu Lys Lys Ser Thr
165 170 175
Ala Ile Gly Tyr Arg Ile Ile His Gln Asn Leu Pro Lys Phe Leu Asp
180 185 190
Asn Leu Lys Ile Ile Glu Ser Ile Gln Arg Arg Phe Lys Asp Phe Pro
195 200 205
Trp Ser Asp Leu Lys Lys Asn Leu Lys Lys Ile Asp Lys Asn Ile Lys
210 215 220
Leu Thr Glu Tyr Phe Ser Ile Asp Gly Phe Val Asn Val Leu Asn Gln
225 230 235 240
Lys Gly Ile Asp Ala Tyr Asn Thr Ile Leu Gly Gly Lys Ser Glu Glu
245 250 255
Ser Gly Glu Lys Ile Gln Gly Leu Asn Glu Tyr Ile Asn Leu Tyr Arg
260 265 270
Gln Lys Asn Asn Ile Asp Arg Lys Asn Leu Pro Asn Val Lys Ile Leu
275 280 285
Phe Lys Gln Ile Leu Gly Asp Arg Glu Thr Lys Ser Phe Ile Pro Glu
290 295 300
Ala Phe Pro Asp Asp Gln Ser Val Leu Asn Ser Ile Thr Glu Phe Ala
305 310 315 320
Lys Tyr Leu Lys Leu Asp Lys Lys Lys Lys Ser Ile Ile Ala Glu Leu
325 330 335
Lys Lys Phe Leu Ser Ser Phe Asn Arg Tyr Glu Leu Asp Gly Ile Tyr
340 345 350
Leu Ala Asn Asp Asn Ser Leu Ala Ser Ile Ser Thr Phe Leu Phe Asp
355 360 365
Asp Trp Ser Phe Ile Lys Lys Ser Val Ser Phe Lys Tyr Asp Glu Ser
370 375 380
Val Gly Asp Pro Lys Lys Lys Ile Lys Ser Pro Leu Lys Tyr Glu Lys
385 390 395 400
Glu Lys Glu Lys Trp Leu Lys Gln Lys Tyr Tyr Thr Ile Ser Phe Leu
405 410 415
Asn Asp Ala Ile Glu Ser Tyr Ser Lys Ser Gln Asp Glu Lys Arg Val
420 425 430
Lys Ile Arg Leu Glu Ala Tyr Phe Ala Glu Phe Lys Ser Lys Asp Asp
435 440 445
Ala Lys Lys Gln Phe Asp Leu Leu Glu Arg Ile Glu Glu Ala Tyr Ala
450 455 460
Ile Val Glu Pro Leu Leu Gly Ala Glu Tyr Pro Arg Asp Arg Asn Leu
465 470 475 480
Lys Ala Asp Lys Lys Glu Val Gly Lys Ile Lys Asp Phe Leu Asp Ser
485 490 495
Ile Lys Ser Leu Gln Phe Phe Leu Lys Pro Leu Leu Ser Ala Glu Ile
500 505 510
Phe Asp Glu Lys Asp Leu Gly Phe Tyr Asn Gln Leu Glu Gly Tyr Tyr
515 520 525
Glu Glu Ile Asp Ser Ile Gly His Leu Tyr Asn Lys Val Arg Asn Tyr
530 535 540
Leu Thr Gly Lys Ile Tyr Ser Lys Glu Lys Phe Lys Leu Asn Phe Glu
545 550 555 560
Asn Ser Thr Leu Leu Lys Gly Trp Asp Glu Asn Arg Glu Val Ala Asn
565 570 575
Leu Cys Val Ile Phe Arg Glu Asp Gln Lys Tyr Tyr Leu Gly Val Met
580 585 590
Asp Lys Glu Asn Asn Thr Ile Leu Ser Asp Ile Pro Lys Val Lys Pro
595 600 605
Asn Glu Leu Phe Tyr Glu Lys Met Val Tyr Lys Leu Ile Pro Thr Pro
610 615 620
His Met Gln Leu Pro Arg Ile Ile Phe Ser Ser Asp Asn Leu Ser Ile
625 630 635 640
Tyr Asn Pro Ser Lys Ser Ile Leu Lys Ile Arg Glu Ala Lys Ser Phe
645 650 655
Lys Glu Gly Lys Asn Phe Lys Leu Lys Asp Cys His Lys Phe Ile Asp
660 665 670
Phe Tyr Lys Glu Ser Ile Ser Lys Asn Glu Asp Trp Ser Arg Phe Asp
675 680 685
Phe Lys Phe Ser Lys Thr Ser Ser Tyr Glu Asn Ile Ser Glu Phe Tyr
690 695 700
Arg Glu Val Glu Arg Gln Gly Tyr Asn Leu Asp Phe Lys Lys Val Ser
705 710 715 720
Lys Phe Tyr Ile Asp Ser Leu Val Glu Asp Gly Lys Leu Tyr Leu Phe
725 730 735
Gln Ile Tyr Asn Lys Asp Phe Ser Ile Phe Ser Lys Gly Lys Pro Asn
740 745 750
Leu His Thr Ile Tyr Phe Arg Ser Leu Phe Ser Lys Glu Asn Leu Lys
755 760 765
Asp Val Cys Leu Lys Leu Asn Gly Glu Ala Glu Met Phe Phe Arg Lys
770 775 780
Lys Ser Ile Asn Tyr Asp Glu Lys Lys Lys Arg Glu Gly His His Pro
785 790 795 800
Glu Leu Phe Glu Lys Leu Lys Tyr Pro Ile Leu Lys Asp Lys Arg Tyr
805 810 815
Ser Glu Asp Lys Phe Gln Phe His Leu Pro Ile Ser Leu Asn Phe Lys
820 825 830
Ser Lys Glu Arg Leu Asn Phe Asn Leu Lys Val Asn Glu Phe Leu Lys
835 840 845
Arg Asn Lys Asp Ile Asn Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn
850 855 860
Leu Leu Tyr Leu Val Met Ile Asn Gln Lys Gly Glu Ile Leu Lys Gln
865 870 875 880
Thr Leu Leu Asp Ser Met Gln Ser Gly Lys Gly Arg Pro Glu Ile Asn
885 890 895
Tyr Lys Glu Lys Leu Gln Glu Lys Glu Ile Glu Arg Asp Lys Ala Arg
900 905 910
Lys Ser Trp Gly Thr Val Glu Asn Ile Lys Glu Leu Lys Glu Gly Tyr
915 920 925
Leu Ser Ile Val Ile His Gln Ile Ser Lys Leu Met Val Glu Asn Asn
930 935 940
Ala Ile Val Val Leu Glu Asp Leu Asn Ile Gly Phe Lys Arg Gly Arg
945 950 955 960
Gln Lys Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Lys Met Leu Ile
965 970 975
Asp Lys Leu Asn Phe Leu Val Phe Lys Glu Asn Lys Pro Thr Glu Pro
980 985 990
Gly Gly Val Leu Lys Ala Tyr Gln Leu Thr Asp Glu Phe Gln Ser Phe
995 1000 1005
Glu Lys Leu Ser Lys Gln Thr Gly Phe Leu Phe Tyr Val Pro Ser
1010 1015 1020
Trp Asn Thr Ser Lys Ile Asp Pro Arg Thr Gly Phe Ile Asp Phe
1025 1030 1035
Leu His Pro Ala Tyr Glu Asn Ile Glu Lys Ala Lys Gln Trp Ile
1040 1045 1050
Asn Lys Phe Asp Ser Ile Arg Phe Asn Ser Lys Met Asp Trp Phe
1055 1060 1065
Glu Phe Thr Ala Asp Thr Arg Lys Phe Ser Glu Asn Leu Met Leu
1070 1075 1080
Gly Lys Asn Arg Val Trp Val Ile Cys Thr Thr Asn Val Glu Arg
1085 1090 1095
Tyr Phe Thr Ser Lys Thr Ala Asn Ser Ser Ile Gln Tyr Asn Ser
1100 1105 1110
Ile Gln Ile Thr Glu Lys Leu Lys Glu Leu Phe Val Asp Ile Pro
1115 1120 1125
Phe Ser Asn Gly Gln Asp Leu Lys Pro Glu Ile Leu Arg Lys Asn
1130 1135 1140
Asp Ala Val Phe Phe Lys Ser Leu Leu Phe Tyr Ile Lys Thr Thr
1145 1150 1155
Leu Ser Leu Arg Gln Asn Asn Gly Lys Lys Gly Glu Glu Glu Lys
1160 1165 1170
Asp Phe Ile Leu Ser Pro Val Val Asp Ser Lys Gly Arg Phe Phe
1175 1180 1185
Asn Ser Leu Glu Ala Ser Asp Asp Glu Pro Lys Asp Ala Asp Ala
1190 1195 1200
Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Met Asn Leu Leu
1205 1210 1215
Val Leu Asn Glu Thr Lys Glu Glu Asn Leu Ser Arg Pro Lys Trp
1220 1225 1230
Lys Ile Lys Asn Lys Asp Trp Leu Glu Phe Val Trp Glu Arg Asn
1235 1240 1245
Arg
<210> 1143
<211> 1230
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1143
Met His Glu Asn Asn Gly Lys Ile Ala Asp Asn Phe Ile Gly Ile Tyr
1 5 10 15
Pro Val Ser Lys Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr
20 25 30
Gln Glu Tyr Ile Glu Lys His Gly Ile Leu Asp Glu Asp Leu Lys Arg
35 40 45
Ala Gly Asp Tyr Lys Ser Val Lys Lys Ile Ile Asp Ala Tyr His Lys
50 55 60
Tyr Phe Ile Asp Glu Ala Leu Asn Gly Ile Gln Leu Asp Gly Leu Lys
65 70 75 80
Asn Tyr Tyr Glu Leu Tyr Glu Lys Lys Arg Asp Asn Asn Glu Glu Lys
85 90 95
Glu Phe Gln Lys Ile Gln Met Ser Leu Arg Lys Gln Ile Val Lys Arg
100 105 110
Phe Ser Glu His Pro Gln Tyr Lys Tyr Leu Phe Lys Lys Glu Leu Ile
115 120 125
Lys Asn Val Leu Pro Glu Phe Thr Lys Asp Asn Ala Glu Glu Gln Thr
130 135 140
Leu Val Lys Ser Phe Gln Glu Phe Thr Thr Tyr Phe Glu Gly Phe His
145 150 155 160
Gln Asn Arg Lys Asn Met Tyr Ser Asp Glu Glu Lys Ser Thr Ala Ile
165 170 175
Ala Tyr Arg Val Val His Gln Asn Leu Pro Lys Tyr Ile Asp Asn Met
180 185 190
Arg Ile Phe Ser Met Ile Leu Asn Thr Asp Ile Arg Ser Asp Leu Thr
195 200 205
Glu Leu Phe Asn Asn Leu Lys Thr Lys Met Asp Ile Thr Ile Val Glu
210 215 220
Glu Tyr Phe Ala Ile Asp Gly Phe Asn Lys Val Val Asn Gln Lys Gly
225 230 235 240
Ile Asp Val Tyr Asn Thr Ile Leu Gly Ala Phe Ser Thr Asp Asp Asn
245 250 255
Thr Lys Ile Lys Gly Leu Asn Glu Tyr Ile Asn Leu Tyr Asn Gln Lys
260 265 270
Asn Lys Ala Lys Leu Pro Lys Leu Lys Pro Leu Phe Lys Gln Ile Leu
275 280 285
Ser Asp Arg Asp Lys Ile Ser Phe Ile Pro Glu Gln Phe Asp Ser Asp
290 295 300
Thr Glu Val Leu Glu Ala Val Asp Met Phe Tyr Asn Arg Leu Leu Gln
305 310 315 320
Phe Val Ile Glu Asn Glu Gly Gln Ile Thr Ile Ser Lys Leu Leu Thr
325 330 335
Asn Phe Ser Ala Tyr Asp Leu Asn Lys Ile Tyr Val Lys Asn Asp Thr
340 345 350
Thr Ile Ser Ala Ile Ser Asn Asp Leu Phe Asp Asp Trp Ser Tyr Ile
355 360 365
Ser Lys Ala Val Arg Glu Asn Tyr Asp Ser Glu Asn Val Asp Lys Asn
370 375 380
Lys Arg Ala Ala Ala Tyr Glu Glu Lys Lys Glu Lys Ala Leu Ser Lys
385 390 395 400
Ile Lys Met Tyr Ser Ile Glu Glu Leu Asn Phe Phe Val Lys Lys Tyr
405 410 415
Ser Cys Asn Glu Cys His Ile Glu Gly Tyr Phe Glu Arg Arg Ile Leu
420 425 430
Glu Ile Leu Asp Lys Met Arg Tyr Ala Tyr Glu Ser Cys Lys Ile Leu
435 440 445
His Asp Lys Gly Leu Ile Asn Asn Ile Ser Leu Cys Gln Asp Arg Gln
450 455 460
Ala Ile Ser Glu Leu Lys Asp Phe Leu Asp Ser Ile Lys Glu Val Gln
465 470 475 480
Trp Leu Leu Lys Pro Leu Met Ile Gly Gln Glu Gln Ala Asp Lys Glu
485 490 495
Glu Ala Phe Tyr Thr Glu Leu Leu Arg Ile Trp Glu Glu Leu Glu Pro
500 505 510
Ile Thr Leu Leu Tyr Asn Lys Val Arg Asn Tyr Val Thr Lys Lys Pro
515 520 525
Tyr Thr Leu Glu Lys Val Lys Leu Asn Phe Tyr Lys Ser Thr Leu Leu
530 535 540
Asp Gly Trp Asp Lys Asn Lys Glu Lys Asp Asn Leu Gly Ile Ile Leu
545 550 555 560
Leu Lys Asp Gly Gln Tyr Tyr Leu Gly Ile Met Asn Arg Arg Asn Asn
565 570 575
Lys Ile Ala Asp Asp Ala Pro Leu Ala Lys Thr Asp Asn Val Tyr Arg
580 585 590
Lys Met Glu Tyr Lys Leu Leu Thr Lys Val Ser Ala Asn Leu Pro Arg
595 600 605
Ile Phe Leu Lys Asp Lys Tyr Asn Pro Ser Glu Glu Met Leu Glu Lys
610 615 620
Tyr Glu Lys Gly Thr His Leu Lys Gly Glu Asn Phe Cys Ile Asp Asp
625 630 635 640
Cys Arg Glu Leu Ile Asp Phe Phe Lys Lys Gly Ile Lys Gln Tyr Glu
645 650 655
Asp Trp Gly Gln Phe Asp Phe Lys Phe Ser Asp Thr Glu Ser Tyr Asp
660 665 670
Asp Ile Ser Ala Phe Tyr Lys Glu Val Glu His Gln Gly Tyr Lys Ile
675 680 685
Thr Phe Arg Asp Ile Asp Glu Thr Tyr Ile Asp Ser Leu Val Asn Glu
690 695 700
Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Pro Tyr
705 710 715 720
Ser Lys Gly Thr Lys Asn Leu His Thr Leu Tyr Trp Glu Met Leu Phe
725 730 735
Ser Gln Gln Asn Leu Gln Asn Ile Val Tyr Lys Leu Asn Gly Asn Ala
740 745 750
Glu Ile Phe Tyr Arg Lys Ala Ser Ile Asn Gln Lys Asp Val Val Val
755 760 765
His Lys Ala Asp Leu Pro Ile Lys Asn Lys Asp Pro Gln Asn Ser Lys
770 775 780
Lys Glu Ser Met Phe Asp Tyr Asp Ile Ile Lys Asp Lys Arg Phe Thr
785 790 795 800
Cys Asp Lys Tyr Gln Phe His Val Pro Ile Thr Met Asn Phe Lys Ala
805 810 815
Leu Gly Glu Asn His Phe Asn Arg Lys Val Asn Arg Leu Ile His Asp
820 825 830
Ala Glu Asn Met His Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu
835 840 845
Ile Tyr Leu Cys Met Ile Asp Met Lys Gly Asn Ile Val Lys Gln Ile
850 855 860
Ser Leu Asn Glu Ile Ile Ser Tyr Asp Lys Asn Lys Leu Glu His Lys
865 870 875 880
Arg Asn Tyr His Gln Leu Leu Lys Thr Arg Glu Asp Glu Asn Lys Ser
885 890 895
Ala Arg Gln Ser Trp Gln Thr Ile His Thr Ile Lys Glu Leu Lys Glu
900 905 910
Gly Tyr Leu Ser Gln Val Ile His Val Ile Thr Asp Leu Met Val Glu
915 920 925
Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn Phe Gly Phe Lys Gln
930 935 940
Gly Arg Gln Lys Phe Glu Arg Gln Val Tyr Gln Lys Phe Glu Lys Met
945 950 955 960
Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Ser Lys Gly Met Asp
965 970 975
Glu Asp Gly Gly Leu Leu His Ala Tyr Gln Leu Thr Asp Glu Phe Lys
980 985 990
Ser Phe Lys Gln Leu Gly Lys Gln Ser Gly Phe Leu Tyr Tyr Ile Pro
995 1000 1005
Ala Trp Asn Thr Ser Lys Leu Asp Pro Thr Thr Gly Phe Val Asn
1010 1015 1020
Leu Phe Tyr Thr Lys Tyr Glu Ser Val Glu Lys Ser Lys Glu Phe
1025 1030 1035
Ile Asn Asn Phe Thr Ser Ile Leu Tyr Asn Gln Glu Arg Glu Tyr
1040 1045 1050
Phe Glu Phe Leu Phe Asp Tyr Ser Ala Phe Thr Ser Lys Ala Glu
1055 1060 1065
Gly Ser Arg Leu Lys Trp Thr Val Cys Ser Lys Gly Glu Arg Val
1070 1075 1080
Glu Thr Tyr Arg Asn Pro Lys Lys Asn Asn Glu Trp Asp Thr Gln
1085 1090 1095
Lys Ile Asp Leu Thr Phe Glu Leu Lys Lys Leu Phe Asn Asp Tyr
1100 1105 1110
Ser Ile Ser Leu Leu Asp Gly Asp Leu Arg Glu Gln Met Gly Lys
1115 1120 1125
Ile Asp Lys Ala Asp Phe Tyr Lys Lys Phe Met Lys Leu Phe Ala
1130 1135 1140
Leu Ile Val Gln Met Arg Asn Ser Asp Glu Arg Glu Asp Lys Leu
1145 1150 1155
Ile Ser Pro Val Leu Asn Lys Tyr Gly Ala Phe Phe Glu Thr Gly
1160 1165 1170
Lys Asn Glu Arg Met Pro Leu Asp Ala Asp Ala Asn Gly Ala Tyr
1175 1180 1185
Asn Ile Ala Arg Lys Gly Leu Trp Ile Ile Glu Lys Ile Lys Asn
1190 1195 1200
Thr Asp Val Glu Gln Leu Asp Lys Val Lys Leu Thr Ile Ser Asn
1205 1210 1215
Lys Glu Trp Leu Gln Tyr Ala Gln Glu His Ile Leu
1220 1225 1230
<210> 1144
<211> 1206
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1144
Met Tyr Tyr Glu Ser Leu Thr Lys Gln Tyr Pro Val Ser Lys Thr Ile
1 5 10 15
Arg Asn Glu Leu Ile Pro Ile Gly Lys Thr Leu Asp Asn Ile Arg Gln
20 25 30
Asn Asn Ile Leu Glu Ser Asp Val Lys Arg Lys Gln Asn Tyr Glu His
35 40 45
Val Lys Gly Ile Leu Asp Glu Tyr His Lys Gln Leu Ile Asn Glu Ala
50 55 60
Leu Asp Asn Cys Thr Leu Pro Ser Leu Lys Ile Ala Ala Glu Ile Tyr
65 70 75 80
Leu Lys Asn Gln Lys Glu Val Ser Asp Arg Glu Asp Phe Asn Lys Thr
85 90 95
Gln Asp Leu Leu Arg Lys Glu Val Val Glu Lys Leu Lys Ala His Glu
100 105 110
Asn Phe Thr Lys Ile Gly Lys Lys Asp Ile Leu Asp Leu Leu Glu Lys
115 120 125
Leu Pro Ser Ile Ser Glu Asp Asp Tyr Asn Ala Leu Glu Ser Phe Arg
130 135 140
Asn Phe Tyr Thr Tyr Phe Thr Ser Tyr Asn Lys Val Arg Glu Asn Leu
145 150 155 160
Tyr Ser Asp Lys Glu Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn
165 170 175
Glu Asn Phe Pro Lys Phe Leu Asp Asn Val Lys Ser Tyr Arg Phe Val
180 185 190
Lys Thr Ala Gly Ile Leu Ala Asp Gly Leu Gly Glu Glu Glu Gln Asp
195 200 205
Ser Leu Phe Ile Val Glu Thr Phe Asn Lys Thr Leu Thr Gln Asp Gly
210 215 220
Ile Asp Thr Tyr Asn Ser Gln Val Gly Lys Ile Asn Ser Ser Ile Asn
225 230 235 240
Leu Tyr Asn Gln Lys Asn Gln Lys Ala Asn Gly Phe Arg Lys Ile Pro
245 250 255
Lys Met Lys Met Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Glu Ser
260 265 270
Phe Ile Asp Glu Phe Gln Ser Asp Glu Val Leu Ile Asp Asn Val Glu
275 280 285
Ser Tyr Gly Ser Val Leu Ile Glu Ser Leu Lys Ser Ser Lys Val Ser
290 295 300
Ala Phe Phe Asp Ala Leu Arg Glu Ser Lys Gly Lys Asn Val Tyr Val
305 310 315 320
Lys Asn Asp Leu Ala Lys Thr Ala Met Ser Asn Ile Val Phe Glu Asn
325 330 335
Trp Arg Thr Phe Asp Asp Leu Leu Asn Gln Glu Tyr Asp Leu Ala Asn
340 345 350
Glu Asn Lys Lys Lys Asp Asp Lys Tyr Phe Glu Lys Arg Gln Lys Glu
355 360 365
Leu Lys Lys Asn Lys Ser Tyr Ser Leu Glu His Leu Cys Asn Leu Ser
370 375 380
Glu Asp Ser Cys Asn Leu Ile Glu Asn Tyr Ile His Gln Ile Ser Asp
385 390 395 400
Asp Ile Glu Asn Ile Ile Ile Asn Asn Glu Thr Phe Leu Arg Ile Val
405 410 415
Ile Asn Glu His Asp Arg Ser Arg Lys Leu Ala Lys Asn Arg Lys Ala
420 425 430
Val Lys Ala Ile Lys Asp Phe Leu Asp Ser Ile Lys Val Leu Glu Arg
435 440 445
Glu Leu Lys Leu Ile Asn Ser Ser Gly Gln Glu Leu Glu Lys Asp Leu
450 455 460
Ile Val Tyr Ser Ala His Glu Glu Leu Leu Val Glu Leu Lys Gln Val
465 470 475 480
Asp Ser Leu Tyr Asn Met Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe
485 490 495
Ser Thr Glu Lys Val Lys Leu Asn Phe Asn Arg Ser Thr Leu Leu Asn
500 505 510
Gly Trp Asp Arg Asn Lys Glu Thr Asp Asn Leu Gly Val Leu Leu Leu
515 520 525
Lys Asp Gly Lys Tyr Tyr Leu Gly Ile Met Asn Thr Ser Ala Asn Lys
530 535 540
Ala Phe Val Asn Pro Pro Val Ala Lys Thr Glu Lys Val Phe Lys Lys
545 550 555 560
Val Asp Tyr Lys Leu Leu Pro Val Pro Asn Gln Met Leu Pro Lys Val
565 570 575
Phe Phe Ala Lys Ser Asn Ile Asp Phe Tyr Asn Pro Ser Ser Glu Ile
580 585 590
Tyr Ser Asn Tyr Lys Lys Gly Thr His Lys Lys Gly Asn Met Phe Ser
595 600 605
Leu Glu Asp Cys His Asn Leu Ile Asp Phe Phe Lys Glu Ser Ile Ser
610 615 620
Lys His Glu Asp Trp Ser Lys Phe Gly Phe Lys Phe Ser Asp Thr Ala
625 630 635 640
Ser Tyr Asn Asp Ile Ser Glu Phe Tyr Arg Glu Val Glu Lys Gln Gly
645 650 655
Tyr Lys Leu Thr Tyr Thr Asp Ile Asp Glu Thr Tyr Ile Asn Asp Leu
660 665 670
Ile Glu Arg Asn Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe
675 680 685
Ser Met Tyr Ser Lys Gly Lys Leu Asn Leu His Thr Leu Tyr Phe Met
690 695 700
Met Leu Phe Asp Gln Arg Asn Ile Asp Asp Val Val Tyr Lys Leu Asn
705 710 715 720
Gly Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Ser Glu Asp Glu
725 730 735
Leu Ile Ile His Lys Ala Gly Glu Glu Ile Lys Asn Lys Asn Pro Asn
740 745 750
Arg Ala Arg Thr Lys Glu Thr Ser Thr Phe Ser Tyr Asp Ile Val Lys
755 760 765
Asp Lys Arg Tyr Ser Lys Asp Lys Phe Thr Leu His Ile Pro Ile Thr
770 775 780
Met Asn Phe Gly Val Asp Glu Val Lys Arg Phe Asn Asp Ala Val Asn
785 790 795 800
Ser Ala Ile Arg Ile Asp Glu Asn Val Asn Val Ile Gly Ile Asp Arg
805 810 815
Gly Glu Arg Asn Leu Leu Tyr Val Val Val Ile Asp Ser Lys Gly Asn
820 825 830
Ile Leu Glu Gln Ile Ser Leu Asn Ser Ile Ile Asn Lys Glu Tyr Asp
835 840 845
Ile Glu Thr Asp Tyr His Ala Leu Leu Asp Glu Arg Glu Gly Gly Arg
850 855 860
Asp Lys Ala Arg Lys Asp Trp Asn Thr Val Glu Asn Ile Arg Asp Leu
865 870 875 880
Lys Ala Gly Tyr Leu Ser Gln Val Val Asn Val Val Ala Lys Leu Val
885 890 895
Leu Lys Tyr Asn Ala Ile Ile Cys Leu Glu Asp Leu Asn Phe Gly Phe
900 905 910
Lys Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu
915 920 925
Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Ile Asp Lys Ser Arg
930 935 940
Glu Gln Thr Ser Pro Lys Glu Leu Gly Gly Ala Leu Asn Ala Leu Gln
945 950 955 960
Leu Thr Ser Lys Phe Lys Ser Phe Lys Glu Leu Gly Lys Gln Ser Gly
965 970 975
Val Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile Asp Pro Thr
980 985 990
Thr Gly Phe Ala Asn Leu Phe Tyr Met Lys Cys Glu Asn Val Glu Lys
995 1000 1005
Ser Lys Arg Phe Phe Asp Gly Phe Asp Phe Ile Arg Phe Asn Ala
1010 1015 1020
Leu Glu Asn Val Phe Glu Phe Gly Phe Asp Tyr Arg Ser Phe Thr
1025 1030 1035
Gln Arg Ala Cys Gly Ile Asn Ser Lys Trp Thr Val Cys Thr Asn
1040 1045 1050
Gly Glu Arg Ile Ile Lys Tyr Arg Asn Pro Asp Lys Asn Asn Met
1055 1060 1065
Phe Asp Glu Lys Val Val Val Val Thr Asp Glu Met Lys Asn Leu
1070 1075 1080
Phe Glu Gln Tyr Lys Ile Pro Tyr Glu Asp Gly Arg Asn Val Lys
1085 1090 1095
Asp Met Ile Ile Ser Asn Glu Glu Ala Glu Phe Tyr Arg Arg Leu
1100 1105 1110
Tyr Arg Leu Leu Gln Gln Thr Leu Gln Met Arg Asn Ser Thr Ser
1115 1120 1125
Asp Gly Thr Arg Asp Tyr Ile Ile Ser Pro Val Lys Asn Lys Arg
1130 1135 1140
Glu Ala Tyr Phe Asn Ser Glu Leu Ser Asp Gly Ser Val Pro Lys
1145 1150 1155
Asp Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu
1160 1165 1170
Trp Val Leu Glu Gln Ile Arg Gln Lys Ser Glu Gly Glu Lys Ile
1175 1180 1185
Asn Leu Ala Met Thr Asn Ala Glu Trp Leu Glu Tyr Ala Gln Thr
1190 1195 1200
His Leu Leu
1205
<210> 1145
<211> 1206
<212> БЕЛОК
<213> Butyrivibrio sp.
<400> 1145
Met Tyr Tyr Gln Asn Leu Thr Lys Lys Tyr Pro Val Ser Lys Thr Ile
1 5 10 15
Arg Asn Glu Leu Ile Pro Ile Gly Lys Thr Leu Glu Asn Ile Arg Lys
20 25 30
Asn Asn Ile Leu Glu Ser Asp Val Lys Arg Lys Gln Asp Tyr Glu His
35 40 45
Val Lys Gly Ile Met Asp Glu Tyr His Lys Gln Leu Ile Asn Glu Ala
50 55 60
Leu Asp Asn Tyr Met Leu Pro Ser Leu Asn Gln Ala Ala Glu Ile Tyr
65 70 75 80
Leu Lys Lys His Val Asp Val Glu Asp Arg Glu Glu Phe Lys Lys Thr
85 90 95
Gln Asp Leu Leu Arg Arg Glu Val Thr Gly Arg Leu Lys Glu His Glu
100 105 110
Asn Tyr Thr Lys Ile Gly Lys Lys Asp Ile Leu Asp Leu Leu Glu Lys
115 120 125
Leu Pro Ser Ile Ser Glu Glu Asp Tyr Asn Ala Leu Glu Ser Phe Arg
130 135 140
Asn Phe Tyr Thr Tyr Phe Thr Ser Tyr Asn Lys Val Arg Glu Asn Leu
145 150 155 160
Tyr Ser Asp Glu Glu Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn
165 170 175
Glu Asn Leu Pro Lys Phe Leu Asp Asn Ile Lys Ser Tyr Ala Phe Val
180 185 190
Lys Ala Ala Gly Val Leu Ala Asp Cys Ile Glu Glu Glu Glu Gln Asp
195 200 205
Ala Leu Phe Met Val Glu Thr Phe Asn Met Thr Leu Thr Gln Glu Gly
210 215 220
Ile Asp Met Tyr Asn Tyr Gln Ile Gly Lys Val Asn Ser Ala Ile Asn
225 230 235 240
Leu Tyr Asn Gln Lys Asn His Lys Val Glu Glu Phe Lys Lys Ile Pro
245 250 255
Lys Met Lys Val Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Glu Val
260 265 270
Phe Ile Gly Glu Phe Lys Asp Asp Glu Thr Leu Leu Ser Ser Ile Gly
275 280 285
Ala Tyr Gly Asn Val Leu Met Thr Tyr Leu Lys Ser Glu Lys Ile Asn
290 295 300
Ile Phe Phe Asp Ala Leu Arg Glu Ser Glu Gly Lys Asn Val Tyr Val
305 310 315 320
Lys Asn Asp Leu Ser Lys Thr Thr Met Ser Asn Ile Val Phe Gly Ser
325 330 335
Trp Ser Ala Phe Asp Glu Leu Leu Asn Gln Glu Tyr Asp Leu Ala Asn
340 345 350
Glu Asn Lys Lys Lys Asp Asp Lys Tyr Phe Glu Lys Arg Gln Lys Glu
355 360 365
Leu Lys Lys Asn Lys Ser Tyr Thr Leu Glu Gln Met Ser Asn Leu Ser
370 375 380
Lys Glu Asp Ile Ser Pro Ile Glu Asn Tyr Ile Glu Arg Ile Ser Glu
385 390 395 400
Asp Ile Glu Lys Ile Cys Ile Tyr Asn Gly Glu Phe Glu Lys Ile Val
405 410 415
Val Asn Glu His Asp Ser Ser Arg Lys Leu Ser Lys Asn Ile Lys Ala
420 425 430
Val Lys Val Ile Lys Asp Tyr Leu Asp Ser Ile Lys Glu Leu Glu His
435 440 445
Asp Ile Lys Leu Ile Asn Gly Ser Gly Gln Glu Leu Glu Lys Asn Leu
450 455 460
Val Val Tyr Val Gly Gln Glu Glu Ala Leu Glu Gln Leu Arg Pro Val
465 470 475 480
Asp Ser Leu Tyr Asn Leu Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe
485 490 495
Ser Thr Glu Lys Val Lys Leu Asn Phe Asn Lys Ser Thr Leu Leu Asn
500 505 510
Gly Trp Asp Lys Asn Lys Glu Thr Asp Asn Leu Gly Ile Leu Phe Phe
515 520 525
Lys Asp Gly Lys Tyr Tyr Leu Gly Ile Met Asn Thr Thr Ala Asn Lys
530 535 540
Ala Phe Val Asn Pro Pro Ala Ala Lys Thr Glu Asn Val Phe Lys Lys
545 550 555 560
Val Asp Tyr Lys Leu Leu Pro Gly Ser Asn Lys Met Leu Pro Lys Val
565 570 575
Phe Phe Ala Lys Ser Asn Ile Gly Tyr Tyr Asn Pro Ser Thr Glu Leu
580 585 590
Tyr Ser Asn Tyr Lys Lys Gly Thr His Lys Lys Gly Pro Ser Phe Ser
595 600 605
Ile Asp Asp Cys His Asn Leu Ile Asp Phe Phe Lys Glu Ser Ile Lys
610 615 620
Lys His Glu Asp Trp Ser Lys Phe Gly Phe Glu Phe Ser Asp Thr Ala
625 630 635 640
Asp Tyr Arg Asp Ile Ser Glu Phe Tyr Arg Glu Val Glu Lys Gln Gly
645 650 655
Tyr Lys Leu Thr Phe Thr Asp Ile Asp Glu Ser Tyr Ile Asn Asp Leu
660 665 670
Ile Glu Lys Asn Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe
675 680 685
Ser Glu Tyr Ser Lys Gly Lys Leu Asn Leu His Thr Leu Tyr Phe Met
690 695 700
Met Leu Phe Asp Gln Arg Asn Leu Asp Asn Val Val Tyr Lys Leu Asn
705 710 715 720
Gly Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Ala Glu Asn Glu
725 730 735
Leu Val Ile His Lys Ala Gly Glu Gly Ile Lys Asn Lys Asn Pro Asn
740 745 750
Arg Ala Lys Val Lys Glu Thr Ser Thr Phe Ser Tyr Asp Ile Val Lys
755 760 765
Asp Lys Arg Tyr Ser Lys Tyr Lys Phe Thr Leu His Ile Pro Ile Thr
770 775 780
Met Asn Phe Gly Val Asp Glu Val Arg Arg Phe Asn Asp Val Ile Asn
785 790 795 800
Asn Ala Leu Arg Thr Asp Asp Asn Val Asn Val Ile Gly Ile Asp Arg
805 810 815
Gly Glu Arg Asn Leu Leu Tyr Val Val Val Ile Asn Ser Glu Gly Lys
820 825 830
Ile Leu Glu Gln Ile Ser Leu Asn Ser Ile Ile Asn Lys Glu Tyr Asp
835 840 845
Ile Glu Thr Asn Tyr His Ala Leu Leu Asp Glu Arg Glu Asp Asp Arg
850 855 860
Asn Lys Ala Arg Lys Asp Trp Asn Thr Ile Glu Asn Ile Lys Glu Leu
865 870 875 880
Lys Thr Gly Tyr Leu Ser Gln Val Val Asn Val Val Ala Lys Leu Val
885 890 895
Leu Lys Tyr Asn Ala Ile Ile Cys Leu Glu Asp Leu Asn Phe Gly Phe
900 905 910
Lys Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu
915 920 925
Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu Val Ile Asp Lys Ser Arg
930 935 940
Glu Gln Val Ser Pro Glu Lys Met Gly Gly Ala Leu Asn Ala Leu Gln
945 950 955 960
Leu Thr Ser Lys Phe Lys Ser Phe Ala Glu Leu Gly Lys Gln Ser Gly
965 970 975
Ile Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile Asp Pro Thr
980 985 990
Thr Gly Phe Val Asn Leu Phe Tyr Ile Lys Tyr Glu Asn Ile Glu Lys
995 1000 1005
Ala Lys Gln Phe Phe Asp Gly Phe Asp Phe Ile Arg Phe Asn Lys
1010 1015 1020
Lys Asp Asp Met Phe Glu Phe Ser Phe Asp Tyr Lys Ser Phe Thr
1025 1030 1035
Gln Lys Ala Cys Gly Ile Arg Ser Lys Trp Ile Val Tyr Thr Asn
1040 1045 1050
Gly Glu Arg Ile Ile Lys Tyr Pro Asn Pro Glu Lys Asn Asn Leu
1055 1060 1065
Phe Asp Glu Lys Val Ile Asn Val Thr Asp Glu Ile Lys Gly Leu
1070 1075 1080
Phe Lys Gln Tyr Arg Ile Pro Tyr Glu Asn Gly Glu Asp Ile Lys
1085 1090 1095
Glu Ile Ile Ile Ser Lys Ala Glu Ala Asp Phe Tyr Lys Arg Leu
1100 1105 1110
Phe Arg Leu Leu His Gln Thr Leu Gln Met Arg Asn Ser Thr Ser
1115 1120 1125
Asp Gly Thr Arg Asp Tyr Ile Ile Ser Pro Val Lys Asn Asp Arg
1130 1135 1140
Gly Glu Phe Phe Cys Ser Glu Phe Ser Glu Gly Thr Met Pro Lys
1145 1150 1155
Asp Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu
1160 1165 1170
Trp Val Leu Glu Gln Ile Arg Gln Lys Asp Glu Gly Glu Lys Val
1175 1180 1185
Asn Leu Ser Met Thr Asn Ala Glu Trp Leu Lys Tyr Ala Gln Leu
1190 1195 1200
His Leu Leu
1205
<210> 1146
<211> 1205
<212> БЕЛОК
<213> Oribacterium sp.
<400> 1146
Met Tyr Tyr Asp Gly Leu Thr Lys Gln Tyr Ala Leu Ser Lys Thr Ile
1 5 10 15
Arg Asn Glu Leu Val Pro Ile Gly Lys Thr Leu Asp Asn Ile Lys Lys
20 25 30
Asn Arg Ile Leu Glu Ala Asp Ile Lys Arg Lys Ser Asp Tyr Glu His
35 40 45
Val Lys Lys Leu Met Asp Met Tyr His Lys Lys Ile Ile Asn Glu Ala
50 55 60
Leu Asp Asn Phe Lys Leu Ser Val Leu Glu Asp Ala Ala Asp Ile Tyr
65 70 75 80
Phe Asn Lys Gln Asn Asp Glu Arg Asp Ile Asp Ala Phe Leu Lys Ile
85 90 95
Gln Asp Lys Leu Arg Lys Glu Ile Val Glu Gln Leu Lys Gly His Thr
100 105 110
Asp Tyr Ser Lys Val Gly Asn Lys Asp Phe Leu Gly Leu Leu Lys Ala
115 120 125
Ala Ser Thr Glu Glu Asp Arg Ile Leu Ile Glu Ser Phe Asp Asn Phe
130 135 140
Tyr Thr Tyr Phe Thr Ser Tyr Asn Lys Val Arg Ser Asn Leu Tyr Ser
145 150 155 160
Ala Glu Asp Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn Glu Asn
165 170 175
Leu Pro Lys Phe Phe Asp Asn Ile Lys Ala Tyr Arg Thr Val Arg Asn
180 185 190
Ala Gly Val Ile Ser Gly Asp Met Ser Ile Val Glu Gln Asp Glu Leu
195 200 205
Phe Glu Val Asp Thr Phe Asn His Thr Leu Thr Gln Tyr Gly Ile Asp
210 215 220
Thr Tyr Asn His Met Ile Gly Gln Leu Asn Ser Ala Ile Asn Leu Tyr
225 230 235 240
Asn Gln Lys Met His Gly Ala Gly Ser Phe Lys Lys Leu Pro Lys Met
245 250 255
Lys Glu Leu Tyr Lys Gln Leu Leu Thr Glu Arg Glu Glu Glu Phe Ile
260 265 270
Glu Glu Tyr Thr Asp Asp Glu Val Leu Ile Thr Ser Val His Asn Tyr
275 280 285
Val Ser Tyr Leu Ile Asp Tyr Leu Asn Ser Asp Lys Val Glu Ser Phe
290 295 300
Phe Asp Thr Leu Arg Lys Ser Asp Gly Lys Glu Val Phe Ile Lys Asn
305 310 315 320
Asp Val Ser Lys Thr Thr Met Ser Asn Ile Leu Phe Asp Asn Trp Ser
325 330 335
Thr Ile Asp Asp Leu Ile Asn His Glu Tyr Asp Ser Ala Pro Glu Asn
340 345 350
Val Lys Lys Thr Lys Asp Asp Lys Tyr Phe Glu Lys Arg Gln Lys Asp
355 360 365
Leu Lys Lys Asn Lys Ser Tyr Ser Leu Ser Lys Ile Ala Ala Leu Cys
370 375 380
Arg Asp Thr Thr Ile Leu Glu Lys Tyr Ile Arg Arg Leu Val Asp Asp
385 390 395 400
Ile Glu Lys Ile Tyr Thr Ser Asn Asn Val Phe Ser Asp Ile Val Leu
405 410 415
Ser Lys His Asp Arg Ser Lys Lys Leu Ser Lys Asn Thr Asn Ala Val
420 425 430
Gln Ala Ile Lys Asn Met Leu Asp Ser Ile Lys Asp Phe Glu His Asp
435 440 445
Val Met Leu Ile Asn Gly Ser Gly Gln Glu Ile Lys Lys Asn Leu Asn
450 455 460
Val Tyr Ser Glu Gln Glu Ala Leu Ala Gly Ile Leu Arg Gln Val Asp
465 470 475 480
His Ile Tyr Asn Leu Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe Ser
485 490 495
Thr Glu Lys Ile Lys Leu Asn Phe Asn Arg Pro Thr Phe Leu Asp Gly
500 505 510
Trp Asp Lys Asn Lys Glu Glu Ala Asn Leu Gly Ile Leu Leu Ile Lys
515 520 525
Asp Asn Arg Tyr Tyr Leu Gly Ile Met Asn Thr Ser Ser Asn Lys Ala
530 535 540
Phe Val Asn Pro Pro Lys Ala Ile Ser Asn Asp Ile Tyr Lys Lys Val
545 550 555 560
Asp Tyr Lys Leu Leu Pro Gly Pro Asn Lys Met Leu Pro Lys Val Phe
565 570 575
Phe Ala Thr Lys Asn Ile Ala Tyr Tyr Ala Pro Ser Glu Glu Leu Leu
580 585 590
Ser Lys Tyr Arg Lys Gly Thr His Lys Lys Gly Asp Ser Phe Ser Ile
595 600 605
Asp Asp Cys Arg Asn Leu Ile Asp Phe Phe Lys Ser Ser Ile Asn Lys
610 615 620
Asn Thr Asp Trp Ser Thr Phe Gly Phe Asn Phe Ser Asp Thr Asn Ser
625 630 635 640
Tyr Asn Asp Ile Ser Asp Phe Tyr Arg Glu Val Glu Lys Gln Gly Tyr
645 650 655
Lys Leu Ser Phe Thr Asp Ile Asp Ala Cys Tyr Ile Lys Asp Leu Val
660 665 670
Asp Asn Asn Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser
675 680 685
Pro Tyr Ser Lys Gly Lys Leu Asn Leu His Thr Leu Tyr Phe Lys Met
690 695 700
Leu Phe Asp Gln Arg Asn Leu Asp Asn Val Val Tyr Lys Leu Asn Gly
705 710 715 720
Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Glu Ser Asp Glu Gln
725 730 735
Ile Ile His Lys Ser Gly Gln Asn Ile Lys Asn Lys Asn Gln Lys Arg
740 745 750
Ser Asn Cys Lys Lys Thr Ser Thr Phe Asp Tyr Asp Ile Val Lys Asp
755 760 765
Arg Arg Tyr Cys Lys Asp Lys Phe Met Leu His Leu Pro Ile Thr Val
770 775 780
Asn Phe Gly Thr Asn Glu Ser Gly Lys Phe Asn Glu Leu Val Asn Asn
785 790 795 800
Ala Ile Arg Ala Asp Lys Asp Val Asn Val Ile Gly Ile Asp Arg Gly
805 810 815
Glu Arg Asn Leu Leu Tyr Val Val Val Val Asp Pro Cys Gly Lys Ile
820 825 830
Ile Glu Gln Ile Ser Leu Asn Thr Ile Val Asp Lys Glu Tyr Asp Ile
835 840 845
Glu Thr Asp Tyr His Gln Leu Leu Asp Glu Lys Glu Gly Ser Arg Asp
850 855 860
Lys Ala Arg Lys Asp Trp Asn Thr Ile Glu Asn Ile Lys Glu Leu Lys
865 870 875 880
Glu Gly Tyr Leu Ser Gln Val Val Asn Ile Ile Ala Lys Leu Val Leu
885 890 895
Lys Tyr Asp Ala Ile Ile Cys Leu Glu Asp Leu Asn Phe Gly Phe Lys
900 905 910
Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys
915 920 925
Met Leu Ile Asp Lys Met Asn Tyr Leu Val Leu Asp Lys Ser Arg Lys
930 935 940
Gln Glu Ser Pro Gln Lys Pro Gly Gly Ala Leu Asn Ala Leu Gln Leu
945 950 955 960
Thr Ser Ala Phe Lys Ser Phe Lys Glu Leu Gly Lys Gln Thr Gly Ile
965 970 975
Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile Asp Pro Thr Thr
980 985 990
Gly Phe Ala Asn Leu Phe Tyr Ile Lys Tyr Glu Ser Val Asp Lys Ala
995 1000 1005
Arg Asp Phe Phe Ser Lys Phe Asp Phe Ile Arg Tyr Asn Gln Met
1010 1015 1020
Asp Asn Tyr Phe Glu Phe Gly Phe Asp Tyr Lys Ser Phe Thr Glu
1025 1030 1035
Arg Ala Ser Gly Cys Lys Ser Lys Trp Ile Ala Cys Thr Asn Gly
1040 1045 1050
Glu Arg Ile Val Lys Tyr Arg Asn Ser Asp Lys Asn Asn Ser Phe
1055 1060 1065
Asp Asp Lys Thr Val Ile Leu Thr Asp Glu Tyr Arg Ser Leu Phe
1070 1075 1080
Asp Lys Tyr Leu Gln Asn Tyr Ile Asp Glu Asp Asp Leu Lys Asp
1085 1090 1095
Gln Ile Leu Gln Ile Asp Ser Ala Asp Phe Tyr Lys Asn Leu Ile
1100 1105 1110
Lys Leu Phe Gln Leu Thr Leu Gln Met Arg Asn Ser Ser Ser Asp
1115 1120 1125
Gly Lys Arg Asp Tyr Ile Ile Ser Pro Val Lys Asn Tyr Arg Glu
1130 1135 1140
Glu Phe Phe Cys Ser Glu Phe Ser Asp Asp Thr Phe Pro Arg Asp
1145 1150 1155
Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Trp
1160 1165 1170
Val Ile Lys Gln Ile Arg Glu Thr Lys Ser Gly Thr Lys Ile Asn
1175 1180 1185
Leu Ala Met Ser Asn Ser Glu Trp Leu Glu Tyr Ala Gln Cys Asn
1190 1195 1200
Leu Leu
1205
<210> 1147
<211> 1205
<212> БЕЛОК
<213> Pseudobutyrivibrio ruminis
<400> 1147
Met Tyr Tyr Gln Asn Leu Thr Lys Met Tyr Pro Ile Ser Lys Thr Leu
1 5 10 15
Arg Asn Glu Leu Ile Pro Val Gly Lys Thr Leu Glu Asn Ile Arg Lys
20 25 30
Asn Gly Ile Leu Glu Ala Asp Ile Gln Arg Lys Ala Asp Tyr Glu His
35 40 45
Val Lys Lys Leu Met Asp Asn Tyr His Lys Gln Leu Ile Asn Glu Ala
50 55 60
Leu Gln Gly Val His Leu Ser Asp Leu Ser Asp Ala Tyr Asp Leu Tyr
65 70 75 80
Phe Asn Leu Ser Lys Glu Lys Asn Ser Val Asp Ala Phe Ser Lys Cys
85 90 95
Gln Asp Lys Leu Arg Lys Glu Ile Val Ser Leu Leu Lys Asn His Glu
100 105 110
Asn Phe Pro Lys Ile Gly Asn Lys Glu Ile Ile Lys Leu Leu Gln Ser
115 120 125
Leu Tyr Asp Asn Asp Thr Asp Tyr Lys Ala Leu Asp Ser Phe Ser Asn
130 135 140
Phe Tyr Thr Tyr Phe Ser Ser Tyr Asn Glu Val Arg Lys Asn Leu Tyr
145 150 155 160
Ser Asp Glu Glu Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn Glu
165 170 175
Asn Leu Pro Lys Phe Leu Asp Asn Ile Lys Ala Tyr Ala Ile Ala Lys
180 185 190
Lys Ala Gly Val Arg Ala Glu Gly Leu Ser Glu Glu Asp Gln Asp Cys
195 200 205
Leu Phe Ile Ile Glu Thr Phe Glu Arg Thr Leu Thr Gln Asp Gly Ile
210 215 220
Asp Asn Tyr Asn Ala Ala Ile Gly Lys Leu Asn Thr Ala Ile Asn Leu
225 230 235 240
Phe Asn Gln Gln Asn Lys Lys Gln Glu Gly Phe Arg Lys Val Pro Gln
245 250 255
Met Lys Cys Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Glu Ala Phe
260 265 270
Ile Asp Glu Phe Ser Asp Asp Glu Asp Leu Ile Thr Asn Ile Glu Ser
275 280 285
Phe Ala Glu Asn Met Asn Val Phe Leu Asn Ser Glu Ile Ile Thr Asp
290 295 300
Phe Lys Ile Ala Leu Val Glu Ser Asp Gly Ser Leu Val Tyr Ile Lys
305 310 315 320
Asn Asp Val Ser Lys Thr Ser Phe Ser Asn Ile Val Phe Gly Ser Trp
325 330 335
Asn Ala Ile Asp Glu Lys Leu Ser Asp Glu Tyr Asp Leu Ala Asn Ser
340 345 350
Lys Lys Lys Lys Asp Glu Lys Tyr Tyr Glu Lys Arg Gln Lys Glu Leu
355 360 365
Lys Lys Asn Lys Ser Tyr Asp Leu Glu Thr Ile Ile Gly Leu Phe Asp
370 375 380
Asp Asn Ser Asp Val Ile Gly Lys Tyr Ile Glu Lys Leu Glu Ser Asp
385 390 395 400
Ile Thr Ala Ile Ala Glu Ala Lys Asn Asp Phe Asp Glu Ile Val Leu
405 410 415
Arg Lys His Asp Lys Asn Lys Ser Leu Arg Lys Asn Thr Asn Ala Val
420 425 430
Glu Ala Ile Lys Ser Tyr Leu Asp Thr Val Lys Asp Phe Glu Arg Asp
435 440 445
Ile Lys Leu Ile Asn Gly Ser Gly Gln Glu Val Glu Lys Asn Leu Val
450 455 460
Val Tyr Ala Glu Gln Glu Asn Ile Leu Ala Glu Ile Lys Asn Val Asp
465 470 475 480
Ser Leu Tyr Asn Met Ser Arg Asn Tyr Leu Thr Gln Lys Pro Phe Ser
485 490 495
Thr Glu Lys Phe Lys Leu Asn Phe Asn Arg Ala Thr Leu Leu Asn Gly
500 505 510
Trp Asp Lys Asn Lys Glu Thr Asp Asn Leu Gly Ile Leu Phe Glu Lys
515 520 525
Asp Gly Met Tyr Tyr Leu Gly Ile Met Asn Thr Lys Ala Asn Lys Ile
530 535 540
Phe Val Asn Ile Pro Lys Ala Thr Ser Asn Asp Val Tyr His Lys Val
545 550 555 560
Asn Tyr Lys Leu Leu Pro Gly Pro Asn Lys Met Leu Pro Lys Val Phe
565 570 575
Phe Ala Gln Ser Asn Leu Asp Tyr Tyr Lys Pro Ser Glu Glu Leu Leu
580 585 590
Ala Lys Tyr Lys Ala Gly Thr His Lys Lys Gly Asp Asn Phe Ser Leu
595 600 605
Glu Asp Cys His Ala Leu Ile Asp Phe Phe Lys Ala Ser Ile Glu Lys
610 615 620
His Pro Asp Trp Ser Ser Phe Gly Phe Glu Phe Ser Glu Thr Cys Thr
625 630 635 640
Tyr Glu Asp Leu Ser Gly Phe Tyr Arg Glu Val Glu Lys Gln Gly Tyr
645 650 655
Lys Ile Thr Tyr Thr Asp Val Asp Ala Asp Tyr Ile Thr Ser Leu Val
660 665 670
Glu Arg Asp Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser
675 680 685
Pro Tyr Ser Lys Gly Asn Leu Asn Leu His Thr Ile Tyr Leu Gln Met
690 695 700
Leu Phe Asp Gln Arg Asn Leu Asn Asn Val Val Tyr Lys Leu Asn Gly
705 710 715 720
Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Asn Asp Glu Glu Val
725 730 735
Ile Ile His Lys Ala Gly Glu Glu Ile Lys Asn Lys Asn Ser Lys Arg
740 745 750
Ala Val Asp Lys Pro Thr Ser Lys Phe Gly Tyr Asp Ile Ile Lys Asp
755 760 765
Arg Arg Tyr Ser Lys Asp Lys Phe Met Leu His Ile Pro Val Thr Met
770 775 780
Asn Phe Gly Val Asp Glu Thr Arg Arg Phe Asn Asp Val Val Asn Asp
785 790 795 800
Ala Leu Arg Asn Asp Glu Lys Val Arg Val Ile Gly Ile Asp Arg Gly
805 810 815
Glu Arg Asn Leu Leu Tyr Val Val Val Val Asp Thr Asp Gly Thr Ile
820 825 830
Leu Glu Gln Ile Ser Leu Asn Ser Ile Ile Asn Asn Glu Tyr Ser Ile
835 840 845
Glu Thr Asp Tyr His Lys Leu Leu Asp Glu Lys Glu Gly Asp Arg Asp
850 855 860
Arg Ala Arg Lys Asn Trp Thr Thr Ile Glu Asn Ile Lys Glu Leu Lys
865 870 875 880
Glu Gly Tyr Leu Ser Gln Val Val Asn Val Ile Ala Lys Leu Val Leu
885 890 895
Lys Tyr Asn Ala Ile Ile Cys Leu Glu Asp Leu Asn Phe Gly Phe Lys
900 905 910
Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys
915 920 925
Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Ile Asp Lys Ser Arg Lys
930 935 940
Gln Asp Lys Pro Glu Glu Phe Gly Gly Ala Leu Asn Ala Leu Gln Leu
945 950 955 960
Thr Ser Lys Phe Thr Ser Phe Lys Asp Met Gly Lys Gln Thr Gly Ile
965 970 975
Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile Asp Pro Thr Thr
980 985 990
Gly Phe Ala Asn Leu Phe Tyr Val Lys Tyr Glu Asn Val Glu Lys Ala
995 1000 1005
Lys Glu Phe Phe Ser Arg Phe Asp Ser Ile Ser Tyr Asn Asn Glu
1010 1015 1020
Ser Gly Tyr Phe Glu Phe Ala Phe Asp Tyr Lys Lys Phe Thr Asp
1025 1030 1035
Arg Ala Cys Gly Ala Arg Ser Gln Trp Thr Val Cys Thr Tyr Gly
1040 1045 1050
Glu Arg Ile Ile Lys Phe Arg Asn Thr Glu Lys Asn Asn Ser Phe
1055 1060 1065
Asp Asp Lys Thr Ile Val Leu Ser Glu Glu Phe Lys Glu Leu Phe
1070 1075 1080
Ser Ile Tyr Gly Ile Ser Tyr Glu Asp Gly Ala Glu Leu Lys Asn
1085 1090 1095
Lys Ile Met Ser Val Asp Glu Ala Asp Phe Phe Arg Ser Leu Thr
1100 1105 1110
Arg Leu Phe Gln Gln Thr Met Gln Met Arg Asn Ser Ser Asn Asp
1115 1120 1125
Val Thr Arg Asp Tyr Ile Ile Ser Pro Ile Met Asn Asp Arg Gly
1130 1135 1140
Glu Phe Phe Asn Ser Glu Ala Cys Asp Ala Ser Lys Pro Lys Asp
1145 1150 1155
Ala Asp Ala Asn Gly Ala Phe Asn Ile Ala Arg Lys Gly Leu Trp
1160 1165 1170
Val Leu Glu Gln Ile Arg Asn Thr Pro Ser Gly Asp Lys Leu Asn
1175 1180 1185
Leu Ala Met Ser Asn Ala Glu Trp Leu Glu Tyr Ala Gln Arg Asn
1190 1195 1200
Gln Ile
1205
<210> 1148
<211> 1231
<212> БЕЛОК
<213> Butyrivibrio fibrisolvens
<400> 1148
Met Tyr Tyr Glu Ser Leu Thr Lys Leu Tyr Pro Ile Lys Lys Thr Ile
1 5 10 15
Arg Asn Glu Leu Val Pro Ile Gly Lys Thr Leu Glu Asn Ile Lys Lys
20 25 30
Asn Asn Ile Leu Glu Ala Asp Glu Asp Arg Lys Ile Ala Tyr Ile Arg
35 40 45
Val Lys Ala Ile Met Asp Asp Tyr His Lys Arg Leu Ile Asn Glu Ala
50 55 60
Leu Ser Gly Phe Ala Leu Ile Asp Leu Asp Lys Ala Ala Asn Leu Tyr
65 70 75 80
Leu Ser Arg Ser Lys Ser Ala Asp Asp Ile Glu Ser Phe Ser Arg Phe
85 90 95
Gln Asp Lys Leu Arg Lys Ala Ile Ala Lys Arg Leu Arg Glu His Glu
100 105 110
Asn Phe Gly Lys Ile Gly Asn Lys Asp Ile Ile Pro Leu Leu Gln Lys
115 120 125
Leu Ser Glu Asn Glu Asp Asp Tyr Asn Ala Leu Glu Ser Phe Lys Asn
130 135 140
Phe Tyr Thr Tyr Phe Glu Ser Tyr Asn Asp Val Arg Leu Asn Leu Tyr
145 150 155 160
Ser Asp Lys Glu Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn Glu
165 170 175
Asn Leu Pro Arg Phe Leu Asp Asn Ile Arg Ala Tyr Asp Ala Val Gln
180 185 190
Lys Ala Gly Ile Thr Ser Glu Glu Leu Ser Ser Glu Ala Gln Asp Gly
195 200 205
Leu Phe Leu Val Asn Thr Phe Asn Asn Val Leu Ile Gln Asp Gly Ile
210 215 220
Asn Thr Tyr Asn Glu Asp Ile Gly Lys Leu Asn Val Ala Ile Asn Leu
225 230 235 240
Tyr Asn Gln Lys Asn Ala Ser Val Gln Gly Phe Arg Lys Val Pro Lys
245 250 255
Met Lys Val Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Glu Ser Phe
260 265 270
Ile Asp Glu Phe Glu Ser Asp Thr Glu Leu Leu Asp Ser Leu Glu Ser
275 280 285
His Tyr Ala Asn Leu Ala Lys Tyr Phe Gly Ser Asn Lys Val Gln Leu
290 295 300
Leu Phe Thr Ala Leu Arg Glu Ser Lys Gly Val Asn Val Tyr Val Lys
305 310 315 320
Asn Asp Ile Ala Lys Thr Ser Phe Ser Asn Val Val Phe Gly Ser Trp
325 330 335
Ser Arg Ile Asp Glu Leu Ile Asn Gly Glu Tyr Asp Asp Asn Asn Asn
340 345 350
Arg Lys Lys Asp Glu Lys Tyr Tyr Asp Lys Arg Gln Lys Glu Leu Lys
355 360 365
Lys Asn Lys Ser Tyr Thr Ile Glu Lys Ile Ile Thr Leu Ser Thr Glu
370 375 380
Asp Val Asp Val Ile Gly Lys Tyr Ile Glu Lys Leu Glu Ser Asp Ile
385 390 395 400
Asp Asp Ile Arg Phe Lys Gly Lys Asn Phe Tyr Glu Ala Val Leu Cys
405 410 415
Gly His Asp Arg Ser Lys Lys Leu Ser Lys Asn Lys Gly Ala Val Glu
420 425 430
Ala Ile Lys Gly Tyr Leu Asp Ser Val Lys Asp Phe Glu Arg Asp Leu
435 440 445
Lys Leu Ile Asn Gly Ser Gly Gln Glu Leu Glu Lys Asn Leu Val Val
450 455 460
Tyr Gly Glu Gln Glu Ala Val Leu Ser Glu Leu Ser Gly Ile Asp Ser
465 470 475 480
Leu Tyr Asn Met Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe Ser Thr
485 490 495
Glu Lys Ile Lys Leu Asn Phe Asn Lys Pro Thr Phe Leu Asp Gly Trp
500 505 510
Asp Tyr Gly Asn Glu Glu Ala Tyr Leu Gly Phe Phe Met Ile Lys Glu
515 520 525
Gly Asn Tyr Phe Leu Ala Val Met Asp Ala Asn Trp Asn Lys Glu Phe
530 535 540
Arg Asn Ile Pro Ser Val Asp Lys Ser Asp Cys Tyr Lys Lys Val Ile
545 550 555 560
Tyr Lys Gln Ile Ser Ser Pro Glu Lys Ser Ile Gln Asn Leu Met Val
565 570 575
Ile Asp Gly Lys Thr Val Lys Lys Asn Gly Arg Lys Glu Lys Glu Gly
580 585 590
Ile His Ser Gly Glu Asn Leu Ile Leu Glu Glu Leu Lys Asn Thr Tyr
595 600 605
Leu Pro Lys Lys Ile Asn Asp Ile Arg Lys Arg Arg Ser Tyr Leu Asn
610 615 620
Gly Asp Thr Phe Ser Lys Lys Asp Leu Thr Glu Phe Ile Gly Tyr Tyr
625 630 635 640
Lys Gln Arg Val Ile Glu Tyr Tyr Asn Gly Tyr Ser Phe Tyr Phe Lys
645 650 655
Ser Asp Asp Asp Tyr Ala Ser Phe Lys Glu Phe Gln Glu Asp Val Gly
660 665 670
Arg Gln Ala Tyr Gln Ile Ser Tyr Val Asp Val Pro Val Ser Phe Val
675 680 685
Asp Asp Leu Ile Asn Ser Gly Lys Leu Tyr Leu Phe Arg Val Tyr Asn
690 695 700
Lys Asp Phe Ser Glu Tyr Ser Lys Gly Arg Leu Asn Leu His Thr Leu
705 710 715 720
Tyr Phe Lys Met Leu Phe Asp Glu Arg Asn Leu Lys Asn Val Val Tyr
725 730 735
Lys Leu Asn Gly Gln Ala Glu Val Phe Tyr Arg Pro Ser Ser Ile Lys
740 745 750
Lys Glu Glu Leu Ile Val His Arg Ala Gly Glu Glu Ile Lys Asn Lys
755 760 765
Asn Pro Lys Arg Ala Ala Gln Lys Pro Thr Arg Arg Leu Asp Tyr Asp
770 775 780
Ile Val Lys Asp Arg Arg Tyr Ser Gln Asp Lys Phe Met Leu His Thr
785 790 795 800
Ser Ile Ile Met Asn Phe Gly Ala Glu Glu Asn Val Ser Phe Asn Asp
805 810 815
Ile Val Asn Gly Val Leu Arg Asn Glu Asp Lys Val Asn Val Ile Gly
820 825 830
Ile Asp Arg Gly Glu Arg Asn Leu Leu Tyr Val Val Val Ile Asp Pro
835 840 845
Glu Gly Lys Ile Leu Glu Gln Arg Ser Leu Asn Cys Ile Thr Asp Ser
850 855 860
Asn Leu Asp Ile Glu Thr Asp Tyr His Arg Leu Leu Asp Glu Lys Glu
865 870 875 880
Ser Asp Arg Lys Ile Ala Arg Arg Asp Trp Thr Thr Ile Glu Asn Ile
885 890 895
Lys Glu Leu Lys Ala Gly Tyr Leu Ser Gln Val Val His Ile Val Ala
900 905 910
Glu Leu Val Leu Lys Tyr Asn Ala Ile Ile Cys Leu Glu Asp Leu Asn
915 920 925
Phe Gly Phe Lys Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln
930 935 940
Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Met Asp
945 950 955 960
Lys Ser Arg Glu Gln Leu Ser Pro Glu Lys Ile Ser Gly Ala Leu Asn
965 970 975
Ala Leu Gln Leu Thr Pro Asp Phe Lys Ser Phe Lys Val Leu Gly Lys
980 985 990
Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile
995 1000 1005
Asp Pro Met Thr Gly Phe Ala Asn Leu Phe Tyr Val Lys Tyr Glu
1010 1015 1020
Asn Val Asp Lys Ala Lys Glu Phe Phe Ser Lys Phe Asp Ser Ile
1025 1030 1035
Lys Tyr Asn Lys Asp Gly Lys Asn Trp Asn Thr Lys Gly Tyr Phe
1040 1045 1050
Glu Phe Ala Phe Asp Tyr Lys Lys Phe Thr Asp Arg Ala Tyr Gly
1055 1060 1065
Arg Val Ser Glu Trp Thr Val Cys Thr Val Gly Glu Arg Ile Ile
1070 1075 1080
Lys Phe Lys Asn Lys Glu Lys Asn Asn Ser Tyr Asp Asp Lys Val
1085 1090 1095
Ile Asp Leu Thr Asn Ser Leu Lys Glu Leu Phe Asp Ser Tyr Lys
1100 1105 1110
Val Thr Tyr Glu Ser Glu Val Asp Leu Lys Asp Ala Ile Leu Ala
1115 1120 1125
Ile Asp Asp Pro Ala Phe Tyr Arg Asp Leu Thr Arg Arg Leu Gln
1130 1135 1140
Gln Thr Leu Gln Met Arg Asn Ser Ser Cys Asp Gly Ser Arg Asp
1145 1150 1155
Tyr Ile Ile Ser Pro Val Lys Asn Ser Lys Gly Glu Phe Phe Cys
1160 1165 1170
Ser Asp Asn Asn Asp Asp Thr Thr Pro Asn Asp Ala Asp Ala Asn
1175 1180 1185
Gly Ala Phe Asn Ile Ala Arg Lys Gly Leu Trp Val Leu Asn Glu
1190 1195 1200
Ile Arg Asn Ser Glu Glu Gly Ser Lys Ile Asn Leu Ala Met Ser
1205 1210 1215
Asn Ala Gln Trp Leu Glu Tyr Ala Gln Asp Asn Thr Ile
1220 1225 1230
<210> 1149
<211> 1206
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1149
Met Glu Asn Tyr Tyr Asp Ser Leu Thr Arg Gln Tyr Pro Val Thr Lys
1 5 10 15
Thr Ile Arg Gln Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn Ile
20 25 30
Lys Asn Ala Glu Ile Ile Glu Ala Asp Lys Gln Lys Lys Glu Ala Tyr
35 40 45
Val Lys Val Lys Glu Leu Met Asp Glu Phe His Lys Ser Ile Ile Glu
50 55 60
Lys Ser Leu Val Gly Ile Lys Leu Asp Gly Leu Ser Glu Phe Glu Lys
65 70 75 80
Leu Tyr Lys Ile Lys Thr Lys Thr Asp Glu Asp Lys Asn Arg Ile Ser
85 90 95
Glu Leu Phe Tyr Tyr Met Arg Lys Gln Ile Ala Asp Ala Leu Lys Asn
100 105 110
Ser Arg Asp Tyr Gly Tyr Val Asp Asn Lys Asp Leu Ile Glu Lys Ile
115 120 125
Leu Pro Glu Arg Val Lys Asp Glu Asn Ser Leu Asn Ala Leu Ser Cys
130 135 140
Phe Lys Gly Phe Thr Thr Tyr Phe Thr Asp Tyr Tyr Lys Asn Arg Lys
145 150 155 160
Asn Ile Tyr Ser Asp Glu Glu Lys His Ser Thr Val Gly Tyr Arg Cys
165 170 175
Ile Asn Glu Asn Leu Leu Ile Phe Met Ser Asn Ile Glu Val Tyr Gln
180 185 190
Ile Tyr Lys Lys Ala Asn Ile Lys Asn Asp Asn Tyr Asp Glu Glu Thr
195 200 205
Leu Asp Lys Thr Phe Met Ile Glu Ser Phe Asn Glu Cys Leu Thr Gln
210 215 220
Ser Gly Val Glu Ala Tyr Asn Ser Val Val Ala Ser Ile Lys Thr Ala
225 230 235 240
Thr Asn Leu Tyr Ile Gln Lys Asn Asn Lys Glu Glu Asn Phe Val Arg
245 250 255
Val Pro Lys Met Lys Val Leu Phe Lys Gln Ile Leu Ser Asp Arg Thr
260 265 270
Ser Leu Phe Asp Gly Leu Ile Ile Glu Ser Asp Asp Glu Leu Leu Asp
275 280 285
Lys Leu Cys Ser Phe Ser Ala Glu Val Asp Lys Phe Leu Pro Ile Asn
290 295 300
Ile Asp Arg Tyr Ile Lys Thr Leu Met Asp Ser Asn Asn Gly Thr Gly
305 310 315 320
Ile Tyr Val Lys Asn Asp Ser Ser Leu Thr Thr Leu Ser Asn Tyr Leu
325 330 335
Thr Asp Ser Trp Ser Ser Ile Arg Asn Ala Phe Asn Glu Asn Tyr Asp
340 345 350
Ala Lys Tyr Thr Gly Lys Val Asn Asp Lys Tyr Glu Glu Lys Arg Glu
355 360 365
Lys Ala Tyr Lys Ser Asn Asp Ser Phe Glu Leu Asn Tyr Ile Gln Asn
370 375 380
Leu Leu Gly Ile Asn Val Ile Asp Lys Tyr Ile Glu Arg Ile Asn Phe
385 390 395 400
Asp Ile Lys Glu Ile Cys Glu Ala Tyr Lys Glu Met Thr Lys Asn Cys
405 410 415
Phe Glu Asp His Asp Lys Thr Lys Lys Leu Gln Lys Asn Ile Lys Ala
420 425 430
Val Ala Ser Ile Lys Ser Tyr Leu Asp Ser Leu Lys Asn Ile Glu Arg
435 440 445
Asp Ile Lys Leu Leu Asn Gly Thr Gly Leu Glu Ser Arg Asn Glu Phe
450 455 460
Phe Tyr Gly Glu Gln Ser Thr Val Leu Glu Glu Ile Thr Lys Val Asp
465 470 475 480
Glu Leu Tyr Asn Ile Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe Ser
485 490 495
Thr Glu Lys Met Lys Leu Asn Phe Asn Asn Pro Gln Leu Leu Gly Gly
500 505 510
Trp Asp Val Asn Lys Glu Arg Asp Cys Tyr Gly Val Ile Leu Ile Lys
515 520 525
Asp Asn Asn Tyr Tyr Leu Gly Ile Met Asp Lys Ser Ala Asn Lys Ser
530 535 540
Phe Leu Asn Ile Lys Glu Ser Lys Asn Glu Asn Ala Tyr Lys Lys Val
545 550 555 560
Asn Cys Lys Leu Leu Pro Gly Pro Asn Lys Met Phe Pro Lys Val Phe
565 570 575
Phe Ala Lys Ser Asn Ile Asp Tyr Tyr Asp Pro Thr His Glu Ile Lys
580 585 590
Lys Leu Tyr Asp Lys Gly Thr Phe Lys Lys Gly Asn Ser Phe Asn Leu
595 600 605
Glu Asp Cys His Lys Leu Ile Asp Phe Tyr Lys Glu Ser Ile Lys Lys
610 615 620
Asn Asp Asp Trp Lys Asn Phe Asn Phe Asn Phe Ser Asp Thr Lys Asp
625 630 635 640
Tyr Glu Asp Ile Ser Gly Phe Phe Arg Glu Val Glu Ala Gln Asn Tyr
645 650 655
Lys Ile Thr Tyr Thr Asn Val Ser Cys Asp Phe Ile Glu Ser Leu Val
660 665 670
Asp Glu Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser
675 680 685
Glu Tyr Ala Thr Gly Asn Leu Asn Leu His Thr Leu Tyr Leu Lys Met
690 695 700
Leu Phe Asp Glu Arg Asn Leu Lys Asp Leu Cys Ile Lys Met Asn Gly
705 710 715 720
Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Leu Asp Glu Asp Lys
725 730 735
Val Val His Lys Ala Asn Gln Lys Ile Thr Asn Lys Asn Thr Asn Ser
740 745 750
Lys Lys Lys Glu Ser Ile Phe Ser Tyr Asp Ile Val Lys Asp Lys Arg
755 760 765
Tyr Thr Val Asp Lys Phe Phe Ile His Leu Pro Ile Thr Leu Asn Tyr
770 775 780
Lys Glu Gln Asn Val Ser Arg Phe Asn Asp Tyr Ile Arg Glu Ile Leu
785 790 795 800
Lys Lys Ser Lys Asn Ile Arg Val Ile Gly Ile Asp Arg Gly Glu Arg
805 810 815
Asn Leu Leu Tyr Val Val Val Cys Asp Ser Asp Gly Ser Ile Leu Tyr
820 825 830
Gln Arg Ser Ile Asn Glu Ile Val Ser Gly Ser His Lys Thr Asp Tyr
835 840 845
His Lys Leu Leu Asp Asn Lys Glu Lys Glu Arg Leu Ser Ser Arg Arg
850 855 860
Asp Trp Lys Thr Ile Glu Asn Ile Lys Asp Leu Lys Ala Gly Tyr Met
865 870 875 880
Ser Gln Val Val Asn Glu Ile Tyr Asn Leu Ile Leu Lys Tyr Asn Ala
885 890 895
Ile Val Val Leu Glu Asp Leu Asn Ile Gly Phe Lys Asn Gly Arg Lys
900 905 910
Lys Val Glu Lys Gln Val Tyr Gln Asn Phe Glu Lys Ala Leu Ile Asp
915 920 925
Lys Leu Asn Tyr Leu Cys Ile Asp Lys Thr Arg Glu Gln Leu Ser Pro
930 935 940
Ser Ser Pro Gly Gly Val Leu Asn Ala Tyr Gln Leu Thr Ala Lys Phe
945 950 955 960
Glu Ser Phe Glu Lys Ile Gly Lys Gln Thr Gly Cys Ile Phe Tyr Val
965 970 975
Pro Ala Tyr Leu Thr Ser Gln Ile Asp Pro Thr Thr Gly Phe Val Asn
980 985 990
Leu Phe Tyr Gln Lys Asp Thr Ser Lys Gln Gly Leu Gln Leu Phe Phe
995 1000 1005
Arg Lys Phe Lys Lys Ile Asn Phe Asp Lys Val Ala Ser Asn Phe
1010 1015 1020
Glu Phe Val Phe Asp Tyr Asn Asp Phe Thr Asn Lys Ala Glu Gly
1025 1030 1035
Thr Lys Thr Asn Trp Thr Ile Ser Thr Gln Gly Thr Arg Ile Ala
1040 1045 1050
Lys Tyr Arg Ser Asp Asp Ala Asn Gly Lys Trp Ile Ser Arg Thr
1055 1060 1065
Val His Pro Thr Asp Ile Ile Lys Glu Ala Leu Asn Arg Glu Lys
1070 1075 1080
Ile Asn Tyr Asn Asp Gly His Asp Leu Ile Asp Glu Ile Val Ser
1085 1090 1095
Ile Glu Lys Ser Ala Val Leu Lys Glu Ile Tyr Tyr Gly Phe Lys
1100 1105 1110
Leu Thr Leu Gln Leu Arg Asn Ser Thr Leu Ala Asn Glu Glu Glu
1115 1120 1125
Gln Glu Asp Tyr Ile Ile Ser Pro Val Lys Asn Ser Ser Gly Asn
1130 1135 1140
Tyr Phe Asp Ser Arg Ile Thr Ser Lys Glu Leu Pro Cys Asp Ala
1145 1150 1155
Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Trp Ala
1160 1165 1170
Leu Glu Gln Ile Arg Asn Ser Glu Asn Val Ser Lys Val Lys Leu
1175 1180 1185
Ala Ile Ser Asn Lys Glu Trp Phe Glu Tyr Thr Gln Asn Asn Ile
1190 1195 1200
Pro Ser Leu
1205
<210> 1150
<211> 1228
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1150
Met Ser Lys Leu Glu Lys Phe Thr Asn Cys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Lys Ala Ile Pro Val Gly Lys Thr Gln Glu Asn Ile Asp
20 25 30
Asn Lys Arg Leu Leu Val Glu Asp Glu Lys Arg Ala Glu Asp Tyr Lys
35 40 45
Gly Val Lys Lys Leu Leu Asp Arg Tyr Tyr Leu Ser Phe Ile Asn Asp
50 55 60
Val Leu His Ser Ile Lys Leu Lys Asn Leu Asn Asn Tyr Ile Ser Leu
65 70 75 80
Phe Arg Lys Lys Thr Arg Thr Glu Lys Glu Asn Lys Glu Leu Glu Asn
85 90 95
Leu Glu Ile Asn Leu Arg Lys Glu Ile Ala Lys Ala Phe Lys Gly Asn
100 105 110
Glu Gly Tyr Lys Ser Leu Phe Lys Lys Asp Ile Ile Glu Thr Ile Leu
115 120 125
Pro Glu Phe Leu Asp Asp Lys Asp Glu Ile Ala Leu Val Asn Ser Phe
130 135 140
Asn Gly Phe Thr Thr Ala Phe Thr Gly Phe Phe Asp Asn Arg Glu Asn
145 150 155 160
Met Phe Ser Glu Glu Ala Lys Ser Thr Ser Ile Ala Phe Arg Cys Ile
165 170 175
Asn Glu Asn Leu Thr Arg Tyr Ile Ser Asn Met Asp Ile Phe Glu Lys
180 185 190
Val Asp Ala Ile Phe Asp Lys His Glu Val Gln Glu Ile Lys Glu Lys
195 200 205
Ile Leu Asn Ser Asp Tyr Asp Val Glu Asp Phe Phe Glu Gly Glu Phe
210 215 220
Phe Asn Phe Val Leu Thr Gln Glu Gly Ile Asp Val Tyr Asn Ala Ile
225 230 235 240
Ile Gly Gly Phe Val Thr Glu Ser Gly Glu Lys Ile Lys Gly Leu Asn
245 250 255
Glu Tyr Ile Asn Leu Tyr Asn Gln Lys Thr Lys Gln Lys Leu Pro Lys
260 265 270
Phe Lys Pro Leu Tyr Lys Gln Val Leu Ser Asp Arg Glu Ser Leu Ser
275 280 285
Phe Tyr Gly Glu Gly Tyr Thr Ser Asp Glu Glu Val Leu Glu Val Phe
290 295 300
Arg Asn Thr Leu Asn Lys Asn Ser Glu Ile Phe Ser Ser Ile Lys Lys
305 310 315 320
Leu Glu Lys Leu Phe Lys Asn Phe Asp Glu Tyr Ser Ser Ala Gly Ile
325 330 335
Phe Val Lys Asn Gly Pro Ala Ile Ser Thr Ile Ser Lys Asp Ile Phe
340 345 350
Gly Glu Trp Asn Val Ile Arg Asp Lys Trp Asn Ala Glu Tyr Asp Asp
355 360 365
Ile His Leu Lys Lys Lys Ala Val Val Thr Glu Lys Tyr Glu Asp Asp
370 375 380
Arg Arg Lys Ser Phe Lys Lys Ile Gly Ser Phe Ser Leu Glu Gln Leu
385 390 395 400
Gln Glu Tyr Ala Asp Ala Asp Leu Ser Val Val Glu Lys Leu Lys Glu
405 410 415
Ile Ile Ile Gln Lys Val Asp Glu Ile Tyr Lys Val Tyr Gly Ser Ser
420 425 430
Glu Lys Leu Phe Asp Ala Asp Phe Val Leu Glu Lys Ser Leu Lys Lys
435 440 445
Asn Asp Ala Val Val Ala Ile Met Lys Asp Leu Leu Asp Ser Val Lys
450 455 460
Ser Phe Glu Asn Tyr Ile Lys Ala Phe Phe Gly Glu Gly Lys Glu Thr
465 470 475 480
Asn Arg Asp Glu Ser Phe Tyr Gly Asp Phe Val Leu Ala Tyr Asp Ile
485 490 495
Leu Leu Lys Val Asp His Ile Tyr Asp Ala Ile Arg Asn Tyr Val Thr
500 505 510
Gln Lys Pro Tyr Ser Lys Asp Lys Phe Lys Leu Tyr Phe Gln Asn Pro
515 520 525
Gln Phe Met Gly Gly Trp Asp Lys Asp Lys Glu Thr Asp Tyr Arg Ala
530 535 540
Thr Ile Leu Arg Tyr Gly Ser Lys Tyr Tyr Leu Ala Ile Met Asp Lys
545 550 555 560
Lys Tyr Ala Lys Cys Leu Gln Lys Ile Asp Lys Asp Asp Val Asn Gly
565 570 575
Asn Tyr Glu Lys Ile Asn Tyr Lys Leu Leu Pro Gly Pro Asn Lys Met
580 585 590
Leu Pro Lys Val Phe Phe Ser Lys Lys Trp Met Ala Tyr Tyr Asn Pro
595 600 605
Ser Glu Asp Ile Gln Lys Ile Tyr Lys Asn Gly Thr Phe Lys Lys Gly
610 615 620
Asp Met Phe Asn Leu Asn Asp Cys His Lys Leu Ile Asp Phe Phe Lys
625 630 635 640
Asp Ser Ile Ser Arg Tyr Pro Lys Trp Ser Asn Ala Tyr Asp Phe Asn
645 650 655
Phe Ser Glu Thr Glu Lys Tyr Lys Asp Ile Ala Gly Phe Tyr Arg Glu
660 665 670
Val Glu Glu Gln Gly Tyr Lys Val Ser Phe Glu Ser Ala Ser Lys Lys
675 680 685
Glu Val Asp Lys Leu Val Glu Glu Gly Lys Leu Tyr Met Phe Gln Ile
690 695 700
Tyr Asn Lys Asp Phe Ser Asp Lys Ser His Gly Thr Pro Asn Leu His
705 710 715 720
Thr Met Tyr Phe Lys Leu Leu Phe Asp Glu Asn Asn His Gly Gln Ile
725 730 735
Arg Leu Ser Gly Gly Ala Glu Leu Phe Met Arg Arg Ala Ser Leu Lys
740 745 750
Lys Glu Glu Leu Val Val His Pro Ala Asn Ser Pro Ile Ala Asn Lys
755 760 765
Asn Pro Asp Asn Pro Lys Lys Thr Thr Thr Leu Ser Tyr Asp Val Tyr
770 775 780
Lys Asp Lys Arg Phe Ser Glu Asp Gln Tyr Glu Leu His Ile Pro Ile
785 790 795 800
Ala Ile Asn Lys Cys Pro Lys Asn Ile Phe Lys Ile Asn Thr Glu Val
805 810 815
Arg Val Leu Leu Lys His Asp Asp Asn Pro Tyr Val Ile Gly Ile Asp
820 825 830
Arg Gly Glu Arg Asn Leu Leu Tyr Ile Val Val Val Asp Gly Lys Gly
835 840 845
Asn Ile Val Glu Gln Tyr Ser Leu Asn Glu Ile Ile Asn Asn Phe Asn
850 855 860
Gly Ile Arg Ile Lys Thr Asp Tyr His Ser Leu Leu Asp Lys Lys Glu
865 870 875 880
Lys Glu Arg Phe Glu Ala Arg Gln Asn Trp Thr Ser Ile Glu Asn Ile
885 890 895
Lys Glu Leu Lys Ala Gly Tyr Ile Ser Gln Val Val His Lys Ile Cys
900 905 910
Glu Leu Val Glu Lys Tyr Asp Ala Val Ile Ala Leu Glu Asp Leu Asn
915 920 925
Ser Gly Phe Lys Asn Ser Arg Val Lys Val Glu Lys Gln Val Tyr Gln
930 935 940
Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Met Val Asp Lys
945 950 955 960
Lys Ser Asn Pro Cys Ala Thr Gly Gly Ala Leu Lys Gly Tyr Gln Ile
965 970 975
Thr Asn Lys Phe Glu Ser Phe Lys Ser Met Ser Thr Gln Asn Gly Phe
980 985 990
Ile Phe Tyr Ile Pro Ala Trp Leu Thr Ser Lys Ile Asp Pro Ser Thr
995 1000 1005
Gly Phe Val Asn Leu Leu Lys Thr Lys Tyr Thr Ser Ile Ala Asp
1010 1015 1020
Ser Lys Lys Phe Ile Ser Ser Phe Asp Arg Ile Met Tyr Val Pro
1025 1030 1035
Glu Glu Asp Leu Phe Glu Phe Ala Leu Asp Tyr Lys Asn Phe Ser
1040 1045 1050
Arg Thr Asp Ala Asp Tyr Ile Lys Lys Trp Lys Leu Tyr Ser Tyr
1055 1060 1065
Gly Asn Arg Ile Arg Ile Phe Arg Asn Pro Lys Lys Asn Asn Val
1070 1075 1080
Phe Asp Trp Glu Glu Val Cys Leu Thr Ser Ala Tyr Lys Glu Leu
1085 1090 1095
Phe Asn Lys Tyr Gly Ile Asn Tyr Gln Gln Gly Asp Ile Arg Ala
1100 1105 1110
Leu Leu Cys Glu Gln Ser Asp Lys Ala Phe Tyr Ser Ser Phe Met
1115 1120 1125
Ala Leu Met Ser Leu Met Leu Gln Met Arg Asn Ser Ile Thr Gly
1130 1135 1140
Arg Thr Asp Val Asp Phe Leu Ile Ser Pro Val Lys Asn Ser Asp
1145 1150 1155
Gly Ile Phe Tyr Asp Ser Arg Asn Tyr Glu Ala Gln Glu Asn Ala
1160 1165 1170
Ile Leu Pro Lys Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala
1175 1180 1185
Arg Lys Val Leu Trp Ala Ile Gly Gln Phe Lys Lys Ala Glu Asp
1190 1195 1200
Glu Lys Leu Asp Lys Val Lys Ile Ala Ile Ser Asn Lys Glu Trp
1205 1210 1215
Leu Glu Tyr Ala Gln Thr Ser Val Lys His
1220 1225
<210> 1151
<211> 1373
<212> БЕЛОК
<213> Moraxella bovoculi
<400> 1151
Met Leu Phe Gln Asp Phe Thr His Leu Tyr Pro Leu Ser Lys Thr Val
1 5 10 15
Arg Phe Glu Leu Lys Pro Ile Asp Arg Thr Leu Glu His Ile His Ala
20 25 30
Lys Asn Phe Leu Ser Gln Asp Glu Thr Met Ala Asp Met His Gln Lys
35 40 45
Val Lys Val Ile Leu Asp Asp Tyr His Arg Asp Phe Ile Ala Asp Met
50 55 60
Met Gly Glu Val Lys Leu Thr Lys Leu Ala Glu Phe Tyr Asp Val Tyr
65 70 75 80
Leu Lys Phe Arg Lys Asn Pro Lys Asp Asp Glu Leu Gln Lys Gln Leu
85 90 95
Lys Asp Leu Gln Ala Val Leu Arg Lys Glu Ile Val Lys Pro Ile Gly
100 105 110
Asn Gly Gly Lys Tyr Lys Ala Gly Tyr Asp Arg Leu Phe Gly Ala Lys
115 120 125
Leu Phe Lys Asp Gly Lys Glu Leu Gly Asp Leu Ala Lys Phe Val Ile
130 135 140
Ala Gln Glu Gly Glu Ser Ser Pro Lys Leu Ala His Leu Ala His Phe
145 150 155 160
Glu Lys Phe Ser Thr Tyr Phe Thr Gly Phe His Asp Asn Arg Lys Asn
165 170 175
Met Tyr Ser Asp Glu Asp Lys His Thr Ala Ile Ala Tyr Arg Leu Ile
180 185 190
His Glu Asn Leu Pro Arg Phe Ile Asp Asn Leu Gln Ile Leu Thr Thr
195 200 205
Ile Lys Gln Lys His Ser Ala Leu Tyr Asp Gln Ile Ile Asn Glu Leu
210 215 220
Thr Ala Ser Gly Leu Asp Val Ser Leu Ala Ser His Leu Asp Gly Tyr
225 230 235 240
His Lys Leu Leu Thr Gln Glu Gly Ile Thr Ala Tyr Asn Thr Leu Leu
245 250 255
Gly Gly Ile Ser Gly Glu Ala Gly Ser Pro Lys Ile Gln Gly Ile Asn
260 265 270
Glu Leu Ile Asn Ser His His Asn Gln His Cys His Lys Ser Glu Arg
275 280 285
Ile Ala Lys Leu Arg Pro Leu His Lys Gln Ile Leu Ser Asp Gly Met
290 295 300
Ser Val Ser Phe Leu Pro Ser Lys Phe Ala Asp Asp Ser Glu Met Cys
305 310 315 320
Gln Ala Val Asn Glu Phe Tyr Arg His Tyr Ala Asp Val Phe Ala Lys
325 330 335
Val Gln Ser Leu Phe Asp Gly Phe Asp Asp His Gln Lys Asp Gly Ile
340 345 350
Tyr Val Glu His Lys Asn Leu Asn Glu Leu Ser Lys Gln Ala Phe Gly
355 360 365
Asp Phe Ala Leu Leu Gly Arg Val Leu Asp Gly Tyr Tyr Val Asp Val
370 375 380
Val Asn Pro Glu Phe Asn Glu Arg Phe Ala Lys Ala Lys Thr Asp Asn
385 390 395 400
Ala Lys Ala Lys Leu Thr Lys Glu Lys Asp Lys Phe Ile Lys Gly Val
405 410 415
His Ser Leu Ala Ser Leu Glu Gln Ala Ile Glu His Tyr Thr Ala Arg
420 425 430
His Asp Asp Glu Ser Val Gln Ala Gly Lys Leu Gly Gln Tyr Phe Lys
435 440 445
His Gly Leu Ala Gly Val Asp Asn Pro Ile Gln Lys Ile His Asn Asn
450 455 460
His Ser Thr Ile Lys Gly Phe Leu Glu Arg Glu Arg Pro Ala Gly Glu
465 470 475 480
Arg Ala Leu Pro Lys Ile Lys Ser Gly Lys Asn Pro Glu Met Thr Gln
485 490 495
Leu Arg Gln Leu Lys Glu Leu Leu Asp Asn Ala Leu Asn Val Ala His
500 505 510
Phe Ala Lys Leu Leu Thr Thr Lys Thr Thr Leu Asp Asn Gln Asp Gly
515 520 525
Asn Phe Tyr Gly Glu Phe Gly Val Leu Tyr Asp Glu Leu Ala Lys Ile
530 535 540
Pro Thr Leu Tyr Asn Lys Val Arg Asp Tyr Leu Ser Gln Lys Pro Phe
545 550 555 560
Ser Thr Glu Lys Tyr Lys Leu Asn Phe Gly Asn Pro Thr Leu Leu Asn
565 570 575
Gly Trp Asp Leu Asn Lys Glu Lys Asp Asn Phe Gly Val Ile Leu Gln
580 585 590
Lys Asp Gly Cys Tyr Tyr Leu Ala Leu Leu Asp Lys Ala His Lys Lys
595 600 605
Val Phe Asp Asn Ala Pro Asn Thr Gly Lys Ser Ile Tyr Gln Lys Met
610 615 620
Ile Tyr Lys Tyr Leu Glu Val Arg Lys Gln Phe Pro Lys Val Phe Phe
625 630 635 640
Ser Lys Glu Ala Ile Ala Ile Asn Tyr His Pro Ser Lys Glu Leu Val
645 650 655
Glu Ile Lys Asp Lys Gly Arg Gln Arg Ser Asp Asp Glu Arg Leu Lys
660 665 670
Leu Tyr Arg Phe Ile Leu Glu Cys Leu Lys Ile His Pro Lys Tyr Asp
675 680 685
Lys Lys Phe Glu Gly Ala Ile Gly Asp Ile Gln Leu Phe Lys Lys Asp
690 695 700
Lys Lys Gly Arg Glu Val Pro Ile Ser Glu Lys Asp Leu Phe Asp Lys
705 710 715 720
Ile Asn Gly Ile Phe Ser Ser Lys Pro Lys Leu Glu Met Glu Asp Phe
725 730 735
Phe Ile Gly Glu Phe Lys Arg Tyr Asn Pro Ser Gln Asp Leu Val Asp
740 745 750
Gln Tyr Asn Ile Tyr Lys Lys Ile Asp Ser Asn Asp Asn Arg Lys Lys
755 760 765
Glu Asn Phe Tyr Asn Asn His Pro Lys Phe Lys Lys Asp Leu Val Arg
770 775 780
Tyr Tyr Tyr Glu Ser Met Cys Lys His Glu Glu Trp Glu Glu Ser Phe
785 790 795 800
Glu Phe Ser Lys Lys Leu Gln Asp Ile Gly Cys Tyr Val Asp Val Asn
805 810 815
Glu Leu Phe Thr Glu Ile Glu Thr Arg Arg Leu Asn Tyr Lys Ile Ser
820 825 830
Phe Cys Asn Ile Asn Ala Asp Tyr Ile Asp Glu Leu Val Glu Gln Gly
835 840 845
Gln Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Pro Lys Ala
850 855 860
His Gly Lys Pro Asn Leu His Thr Leu Tyr Phe Lys Ala Leu Phe Ser
865 870 875 880
Glu Asp Asn Leu Ala Asp Pro Ile Tyr Lys Leu Asn Gly Glu Ala Gln
885 890 895
Ile Phe Tyr Arg Lys Ala Ser Leu Asp Met Asn Glu Thr Thr Ile His
900 905 910
Arg Ala Gly Glu Val Leu Glu Asn Lys Asn Pro Asp Asn Pro Lys Lys
915 920 925
Arg Gln Phe Val Tyr Asp Ile Ile Lys Asp Lys Arg Tyr Thr Gln Asp
930 935 940
Lys Phe Met Leu His Val Pro Ile Thr Met Asn Phe Gly Val Gln Gly
945 950 955 960
Met Thr Ile Lys Glu Phe Asn Lys Lys Val Asn Gln Ser Ile Gln Gln
965 970 975
Tyr Asp Glu Val Asn Val Ile Gly Ile Asp Arg Gly Glu Arg His Leu
980 985 990
Leu Tyr Leu Thr Val Ile Asn Ser Lys Gly Glu Ile Leu Glu Gln Cys
995 1000 1005
Ser Leu Asn Asp Ile Thr Thr Ala Ser Ala Asn Gly Thr Gln Met
1010 1015 1020
Thr Thr Pro Tyr His Lys Ile Leu Asp Lys Arg Glu Ile Glu Arg
1025 1030 1035
Leu Asn Ala Arg Val Gly Trp Gly Glu Ile Glu Thr Ile Lys Glu
1040 1045 1050
Leu Lys Ser Gly Tyr Leu Ser His Val Val His Gln Ile Ser Gln
1055 1060 1065
Leu Met Leu Lys Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn
1070 1075 1080
Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Ile Tyr
1085 1090 1095
Gln Asn Phe Glu Asn Ala Leu Ile Lys Lys Leu Asn His Leu Val
1100 1105 1110
Leu Lys Asp Lys Ala Asp Asp Glu Ile Gly Ser Tyr Lys Asn Ala
1115 1120 1125
Leu Gln Leu Thr Asn Asn Phe Thr Asp Leu Lys Ser Ile Gly Lys
1130 1135 1140
Gln Thr Gly Phe Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys
1145 1150 1155
Ile Asp Pro Glu Thr Gly Phe Val Asp Leu Leu Lys Pro Arg Tyr
1160 1165 1170
Glu Asn Ile Ala Gln Ser Gln Ala Phe Phe Gly Lys Phe Asp Lys
1175 1180 1185
Ile Cys Tyr Asn Ala Asp Lys Asp Tyr Phe Glu Phe His Ile Asp
1190 1195 1200
Tyr Ala Lys Phe Thr Asp Lys Ala Lys Asn Ser Arg Gln Ile Trp
1205 1210 1215
Thr Ile Cys Ser His Gly Asp Lys Arg Tyr Val Tyr Asp Lys Thr
1220 1225 1230
Ala Asn Gln Asn Lys Gly Ala Ala Lys Gly Ile Asn Val Asn Asp
1235 1240 1245
Glu Leu Lys Ser Leu Phe Ala Arg His His Ile Asn Glu Lys Gln
1250 1255 1260
Pro Asn Leu Val Met Asp Ile Cys Gln Asn Asn Asp Lys Glu Phe
1265 1270 1275
His Lys Ser Leu Met Tyr Leu Leu Lys Thr Leu Leu Ala Leu Arg
1280 1285 1290
Tyr Ser Asn Ala Ser Ser Asp Glu Asp Phe Ile Leu Ser Pro Val
1295 1300 1305
Ala Asn Asp Glu Gly Val Phe Phe Asn Ser Ala Leu Ala Asp Asp
1310 1315 1320
Thr Gln Pro Gln Asn Ala Asp Ala Asn Gly Ala Tyr His Ile Ala
1325 1330 1335
Leu Lys Gly Leu Trp Leu Leu Asn Glu Leu Lys Asn Ser Asp Asp
1340 1345 1350
Leu Asn Lys Val Lys Leu Ala Ile Asp Asn Gln Thr Trp Leu Asn
1355 1360 1365
Phe Ala Gln Asn Arg
1370
<210> 1152
<211> 1373
<212> БЕЛОК
<213> Moraxella bovoculi
<400> 1152
Met Leu Phe Gln Asp Phe Thr His Leu Tyr Pro Leu Ser Lys Thr Val
1 5 10 15
Arg Phe Glu Leu Lys Pro Ile Asp Arg Thr Leu Glu His Ile His Ala
20 25 30
Lys Asn Phe Leu Ser Gln Asp Glu Thr Met Ala Asp Met His Gln Lys
35 40 45
Val Lys Val Ile Leu Asp Asp Tyr His Arg Asp Phe Ile Ala Asp Met
50 55 60
Met Gly Glu Val Lys Leu Thr Lys Leu Ala Glu Phe Tyr Asp Val Tyr
65 70 75 80
Leu Lys Phe Arg Lys Asn Pro Lys Asp Asp Glu Leu Gln Lys Gln Leu
85 90 95
Lys Asp Leu Gln Ala Val Leu Arg Lys Glu Ile Val Lys Pro Ile Gly
100 105 110
Asn Gly Gly Lys Tyr Lys Ala Gly Tyr Asp Arg Leu Phe Gly Ala Lys
115 120 125
Leu Phe Lys Asp Gly Lys Glu Leu Gly Asp Leu Ala Lys Phe Val Ile
130 135 140
Ala Gln Glu Gly Glu Ser Ser Pro Lys Leu Ala His Leu Ala His Phe
145 150 155 160
Glu Lys Phe Ser Thr Tyr Phe Thr Gly Phe His Asp Asn Arg Lys Asn
165 170 175
Met Tyr Ser Asp Glu Asp Lys His Thr Ala Ile Ala Tyr Arg Leu Ile
180 185 190
His Glu Asn Leu Pro Arg Phe Ile Asp Asn Leu Gln Ile Leu Thr Thr
195 200 205
Ile Lys Gln Lys His Ser Ala Leu Tyr Asp Gln Ile Ile Asn Glu Leu
210 215 220
Thr Ala Ser Gly Leu Asp Val Ser Leu Ala Ser His Leu Asp Gly Tyr
225 230 235 240
His Lys Leu Leu Thr Gln Glu Gly Ile Thr Ala Tyr Asn Thr Leu Leu
245 250 255
Gly Gly Ile Ser Gly Glu Ala Gly Ser Pro Lys Ile Gln Gly Ile Asn
260 265 270
Glu Leu Ile Asn Ser His His Asn Gln His Cys His Lys Ser Glu Arg
275 280 285
Ile Ala Lys Leu Arg Pro Leu His Lys Gln Ile Leu Ser Asp Gly Met
290 295 300
Ser Val Ser Phe Leu Pro Ser Lys Phe Ala Asp Asp Ser Glu Met Cys
305 310 315 320
Gln Ala Val Asn Glu Phe Tyr Arg His Tyr Ala Asp Val Phe Ala Lys
325 330 335
Val Gln Ser Leu Phe Asp Gly Phe Asp Asp His Gln Lys Asp Gly Ile
340 345 350
Tyr Val Glu His Lys Asn Leu Asn Glu Leu Ser Lys Gln Ala Phe Gly
355 360 365
Asp Phe Ala Leu Leu Gly Arg Val Leu Asp Gly Tyr Tyr Val Asp Val
370 375 380
Val Asn Pro Glu Phe Asn Glu Arg Phe Ala Lys Ala Lys Thr Asp Asn
385 390 395 400
Ala Lys Ala Lys Leu Thr Lys Glu Lys Asp Lys Phe Ile Lys Gly Val
405 410 415
His Ser Leu Ala Ser Leu Glu Gln Ala Ile Glu His Tyr Thr Ala Arg
420 425 430
His Asp Asp Glu Ser Val Gln Ala Gly Lys Leu Gly Gln Tyr Phe Lys
435 440 445
His Gly Leu Ala Gly Val Asp Asn Pro Ile Gln Lys Ile His Asn Asn
450 455 460
His Ser Thr Ile Lys Gly Phe Leu Glu Arg Glu Arg Pro Ala Gly Glu
465 470 475 480
Arg Ala Leu Pro Lys Ile Lys Ser Gly Lys Asn Pro Glu Met Thr Gln
485 490 495
Leu Arg Gln Leu Lys Glu Leu Leu Asp Asn Ala Leu Asn Val Ala His
500 505 510
Phe Ala Lys Leu Leu Thr Thr Lys Thr Thr Leu Asp Asn Gln Asp Gly
515 520 525
Asn Phe Tyr Gly Glu Phe Gly Val Leu Tyr Asp Glu Leu Ala Lys Ile
530 535 540
Pro Thr Leu Tyr Asn Lys Val Arg Asp Tyr Leu Ser Gln Lys Pro Phe
545 550 555 560
Ser Thr Glu Lys Tyr Lys Leu Asn Phe Gly Asn Pro Thr Leu Leu Asn
565 570 575
Gly Trp Asp Leu Asn Lys Glu Lys Asp Asn Phe Gly Val Ile Leu Gln
580 585 590
Lys Asp Gly Cys Tyr Tyr Leu Ala Leu Leu Asp Lys Ala His Lys Lys
595 600 605
Val Phe Asp Asn Ala Pro Asn Thr Gly Lys Ser Ile Tyr Gln Lys Met
610 615 620
Ile Tyr Lys Tyr Leu Glu Val Arg Lys Gln Phe Pro Lys Val Phe Phe
625 630 635 640
Ser Lys Glu Ala Ile Ala Ile Asn Tyr His Pro Ser Lys Glu Leu Val
645 650 655
Glu Ile Lys Asp Lys Gly Arg Gln Arg Ser Asp Asp Glu Arg Leu Lys
660 665 670
Leu Tyr Arg Phe Ile Leu Glu Cys Leu Lys Ile His Pro Lys Tyr Asp
675 680 685
Lys Lys Phe Glu Gly Ala Ile Gly Asp Ile Gln Leu Phe Lys Lys Asp
690 695 700
Lys Lys Gly Arg Glu Val Pro Ile Ser Glu Lys Asp Leu Phe Asp Lys
705 710 715 720
Ile Asn Gly Ile Phe Ser Ser Lys Pro Lys Leu Glu Met Glu Asp Phe
725 730 735
Phe Ile Gly Glu Phe Lys Arg Tyr Asn Pro Ser Gln Asp Leu Val Asp
740 745 750
Gln Tyr Asn Ile Tyr Lys Lys Ile Asp Ser Asn Asp Asn Arg Lys Lys
755 760 765
Glu Asn Phe Tyr Asn Asn His Pro Lys Phe Lys Lys Asp Leu Val Arg
770 775 780
Tyr Tyr Tyr Glu Ser Met Cys Lys His Glu Glu Trp Glu Glu Ser Phe
785 790 795 800
Glu Phe Ser Lys Lys Leu Gln Asp Ile Gly Cys Tyr Val Asp Val Asn
805 810 815
Glu Leu Phe Thr Glu Ile Glu Thr Arg Arg Leu Asn Tyr Lys Ile Ser
820 825 830
Phe Cys Asn Ile Asn Ala Asp Tyr Ile Asp Glu Leu Val Glu Gln Gly
835 840 845
Gln Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Pro Lys Ala
850 855 860
His Gly Lys Pro Asn Leu His Thr Leu Tyr Phe Lys Ala Leu Phe Ser
865 870 875 880
Glu Asp Asn Leu Ala Asp Pro Ile Tyr Lys Leu Asn Gly Glu Ala Gln
885 890 895
Ile Phe Tyr Arg Lys Ala Ser Leu Asp Met Asn Glu Thr Thr Ile His
900 905 910
Arg Ala Gly Glu Val Leu Glu Asn Lys Asn Pro Asp Asn Pro Lys Lys
915 920 925
Arg Gln Phe Val Tyr Asp Ile Ile Lys Asp Lys Arg Tyr Thr Gln Asp
930 935 940
Lys Phe Met Leu His Val Pro Ile Thr Met Asn Phe Gly Val Gln Gly
945 950 955 960
Met Thr Ile Lys Glu Phe Asn Lys Lys Val Asn Gln Ser Ile Gln Gln
965 970 975
Tyr Asp Glu Val Asn Val Ile Gly Ile Asp Arg Gly Glu Arg His Leu
980 985 990
Leu Tyr Leu Thr Val Ile Asn Ser Lys Gly Glu Ile Leu Glu Gln Cys
995 1000 1005
Ser Leu Asn Asp Ile Thr Thr Ala Ser Ala Asn Gly Thr Gln Met
1010 1015 1020
Thr Thr Pro Tyr His Lys Ile Leu Asp Lys Arg Glu Ile Glu Arg
1025 1030 1035
Leu Asn Ala Arg Val Gly Trp Gly Glu Ile Glu Thr Ile Lys Glu
1040 1045 1050
Leu Lys Ser Gly Tyr Leu Ser His Val Val His Gln Ile Ser Gln
1055 1060 1065
Leu Met Leu Lys Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn
1070 1075 1080
Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Ile Tyr
1085 1090 1095
Gln Asn Phe Glu Asn Ala Leu Ile Lys Lys Leu Asn His Leu Val
1100 1105 1110
Leu Lys Asp Lys Ala Asp Asp Glu Ile Gly Ser Tyr Lys Asn Ala
1115 1120 1125
Leu Gln Leu Thr Asn Asn Phe Thr Asp Leu Lys Ser Ile Gly Lys
1130 1135 1140
Gln Thr Gly Phe Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys
1145 1150 1155
Ile Asp Pro Glu Thr Gly Phe Val Asp Leu Leu Lys Pro Arg Tyr
1160 1165 1170
Glu Asn Ile Ala Gln Ser Gln Ala Phe Phe Gly Lys Phe Asp Lys
1175 1180 1185
Ile Cys Tyr Asn Ala Asp Lys Asp Tyr Phe Glu Phe His Ile Asp
1190 1195 1200
Tyr Ala Lys Phe Thr Asp Lys Ala Lys Asn Ser Arg Gln Ile Trp
1205 1210 1215
Thr Ile Cys Ser His Gly Asp Lys Arg Tyr Val Tyr Asp Lys Thr
1220 1225 1230
Ala Asn Gln Asn Lys Gly Ala Ala Lys Gly Ile Asn Val Asn Asp
1235 1240 1245
Glu Leu Lys Ser Leu Phe Ala Arg His His Ile Asn Glu Lys Gln
1250 1255 1260
Pro Asn Leu Val Met Asp Ile Cys Gln Asn Asn Asp Lys Glu Phe
1265 1270 1275
His Lys Ser Leu Met Tyr Leu Leu Lys Thr Leu Leu Ala Leu Arg
1280 1285 1290
Tyr Ser Asn Ala Ser Ser Asp Glu Asp Phe Ile Leu Ser Pro Val
1295 1300 1305
Ala Asn Asp Glu Gly Val Phe Phe Asn Ser Ala Leu Ala Asp Asp
1310 1315 1320
Thr Gln Pro Gln Asn Ala Asp Ala Asn Gly Ala Tyr His Ile Ala
1325 1330 1335
Leu Lys Gly Leu Trp Leu Leu Asn Glu Leu Lys Asn Ser Asp Asp
1340 1345 1350
Leu Asn Lys Val Lys Leu Ala Ile Asp Asn Gln Thr Trp Leu Asn
1355 1360 1365
Phe Ala Gln Asn Arg
1370
<210> 1153
<211> 1264
<212> БЕЛОК
<213> Moraxella caprae
<400> 1153
Met Leu Phe Gln Asp Phe Thr His Leu Tyr Pro Leu Ser Lys Thr Met
1 5 10 15
Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu His Ile His Ala
20 25 30
Lys Asn Phe Leu Ser Gln Asp Glu Thr Met Ala Asp Met Tyr Gln Lys
35 40 45
Val Lys Ala Ile Leu Asp Asp Tyr His Arg Asp Phe Ile Ala Asp Met
50 55 60
Met Gly Glu Val Lys Leu Thr Lys Leu Ala Glu Phe Tyr Asp Val Tyr
65 70 75 80
Leu Lys Phe Arg Lys Asn Pro Lys Asp Asp Gly Leu Gln Lys Gln Leu
85 90 95
Lys Asp Leu Gln Ala Val Leu Arg Lys Glu Ile Val Lys Pro Ile Gly
100 105 110
Asn Gly Gly Lys Tyr Lys Ala Gly Tyr Asp Arg Leu Phe Gly Ala Lys
115 120 125
Leu Phe Lys Asp Gly Lys Glu Leu Gly Asp Leu Ala Lys Phe Val Ile
130 135 140
Ala Gln Glu Gly Glu Ser Ser Pro Lys Leu Ala His Leu Ala His Phe
145 150 155 160
Glu Lys Phe Ser Thr Tyr Phe Thr Gly Phe His Asp Asn Arg Lys Asn
165 170 175
Met Tyr Ser Asp Glu Asp Lys His Thr Ala Ile Thr Tyr Arg Leu Ile
180 185 190
His Glu Asn Leu Pro Arg Phe Ile Asp Asn Leu Gln Ile Leu Ala Thr
195 200 205
Ile Lys Gln Lys His Ser Ala Leu Tyr Asp Gln Ile Ile Asn Glu Leu
210 215 220
Thr Ala Ser Gly Leu Asp Val Ser Leu Ala Ser His Leu Asp Gly Tyr
225 230 235 240
His Lys Leu Leu Thr Gln Glu Gly Ile Thr Ala Tyr Asn Thr Leu Leu
245 250 255
Gly Gly Ile Ser Gly Glu Ala Gly Ser Arg Lys Ile Gln Gly Ile Asn
260 265 270
Glu Leu Ile Asn Ser His His Asn Gln His Cys His Lys Ser Glu Arg
275 280 285
Ile Ala Lys Leu Arg Pro Leu His Lys Gln Ile Leu Ser Asp Gly Met
290 295 300
Gly Val Ser Phe Leu Pro Ser Lys Phe Ala Asp Asp Ser Glu Met Cys
305 310 315 320
Gln Ala Val Asn Glu Phe Tyr Arg His Tyr Ala Asp Val Phe Ala Lys
325 330 335
Val Gln Ser Leu Phe Asp Gly Phe Asp Asp His Gln Lys Asp Gly Ile
340 345 350
Tyr Val Glu His Lys Asn Leu Asn Glu Leu Ser Lys Gln Ala Phe Gly
355 360 365
Asp Phe Ala Leu Leu Gly Arg Val Leu Asp Gly Tyr Tyr Val Asp Val
370 375 380
Val Asn Pro Glu Phe Asn Glu Arg Phe Ala Lys Ala Lys Thr Asp Asn
385 390 395 400
Ala Lys Ala Lys Leu Thr Lys Glu Lys Asp Lys Phe Ile Lys Gly Val
405 410 415
His Ser Leu Ala Ser Leu Glu Gln Ala Ile Glu His Tyr Thr Ala Arg
420 425 430
His Asp Asp Glu Ser Val Gln Ala Gly Lys Leu Gly Gln Tyr Phe Lys
435 440 445
His Gly Leu Ala Gly Val Asp Asn Pro Ile Gln Lys Ile His Asn Asn
450 455 460
His Ser Thr Ile Lys Gly Phe Leu Glu Arg Glu Arg Pro Ala Gly Glu
465 470 475 480
Arg Ala Leu Pro Lys Ile Lys Ser Gly Lys Asn Pro Glu Met Thr Gln
485 490 495
Leu Arg Gln Leu Lys Glu Leu Leu Asp Asn Ala Leu Asn Val Ala His
500 505 510
Phe Ala Lys Leu Leu Thr Thr Lys Thr Thr Leu Asp Asn Gln Asp Gly
515 520 525
Asn Phe Tyr Gly Glu Phe Gly Ala Leu Tyr Asp Glu Leu Ala Lys Ile
530 535 540
Pro Thr Leu Tyr Asn Lys Val Arg Asp Tyr Leu Ser Gln Lys Pro Phe
545 550 555 560
Ser Thr Glu Lys Tyr Lys Leu Asn Phe Gly Asn Pro Thr Leu Leu Asn
565 570 575
Gly Trp Asp Leu Asn Lys Glu Lys Asp Asn Phe Gly Ile Ile Leu Gln
580 585 590
Lys Asp Gly Cys Tyr Tyr Leu Ala Leu Leu Asp Lys Ala His Lys Lys
595 600 605
Val Phe Asp Asn Ala Pro Asn Thr Gly Lys Asn Val Tyr Gln Lys Met
610 615 620
Ile Tyr Lys Leu Leu Pro Gly Pro Asn Lys Met Leu Pro Lys Val Phe
625 630 635 640
Phe Ala Lys Ser Asn Leu Asp Tyr Tyr Asn Pro Ser Ala Glu Leu Leu
645 650 655
Asp Lys Tyr Ala Gln Gly Thr His Lys Lys Gly Asn Asn Phe Asn Leu
660 665 670
Lys Asp Cys His Ala Leu Ile Asp Phe Phe Lys Ala Gly Ile Asn Lys
675 680 685
His Pro Glu Trp Gln His Phe Gly Phe Lys Phe Ser Pro Thr Ser Ser
690 695 700
Tyr Gln Asp Leu Ser Asp Phe Tyr Arg Glu Val Glu Pro Gln Gly Tyr
705 710 715 720
Gln Val Lys Phe Val Asp Ile Asn Ala Asp Tyr Ile Asn Glu Leu Val
725 730 735
Glu Gln Gly Gln Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser
740 745 750
Pro Lys Ala His Gly Lys Pro Asn Leu His Thr Leu Tyr Phe Lys Ala
755 760 765
Leu Phe Ser Lys Asp Asn Leu Ala Asn Pro Ile Tyr Lys Leu Asn Gly
770 775 780
Glu Ala Gln Ile Phe Tyr Arg Lys Ala Ser Leu Asp Met Asn Glu Thr
785 790 795 800
Thr Ile His Arg Ala Gly Glu Val Leu Glu Asn Lys Asn Pro Asp Asn
805 810 815
Pro Lys Lys Arg Gln Phe Val Tyr Asp Ile Ile Lys Asp Lys Arg Tyr
820 825 830
Thr Gln Asp Lys Phe Met Leu His Val Pro Ile Thr Met Asn Phe Gly
835 840 845
Val Gln Gly Met Thr Ile Lys Glu Phe Asn Lys Lys Val Asn Gln Ser
850 855 860
Ile Gln Gln Tyr Asp Glu Val Asn Val Ile Gly Ile Asp Arg Gly Glu
865 870 875 880
Arg His Leu Leu Tyr Leu Thr Val Ile Asn Ser Lys Gly Glu Ile Leu
885 890 895
Glu Gln Arg Ser Leu Asn Asp Ile Thr Thr Ala Ser Ala Asn Gly Thr
900 905 910
Gln Met Thr Thr Pro Tyr His Lys Ile Leu Asp Lys Arg Glu Ile Glu
915 920 925
Arg Leu Asn Ala Arg Val Gly Trp Gly Glu Ile Glu Thr Ile Lys Glu
930 935 940
Leu Lys Ser Gly Tyr Leu Ser His Val Val His Gln Ile Ser Gln Leu
945 950 955 960
Met Leu Lys Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn Phe Gly
965 970 975
Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Ile Tyr Gln Asn Phe
980 985 990
Glu Asn Ala Leu Ile Lys Lys Leu Asn His Leu Val Leu Lys Asp Glu
995 1000 1005
Ala Asp Asp Glu Ile Gly Ser Tyr Lys Asn Ala Leu Gln Leu Thr
1010 1015 1020
Asn Asn Phe Thr Asp Leu Lys Ser Ile Gly Lys Gln Thr Gly Phe
1025 1030 1035
Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro Glu
1040 1045 1050
Thr Gly Phe Val Asp Leu Leu Lys Pro Arg Tyr Glu Asn Ile Ala
1055 1060 1065
Gln Ser Gln Ala Phe Phe Gly Lys Phe Asp Lys Ile Cys Tyr Asn
1070 1075 1080
Ala Asp Lys Asp Tyr Phe Glu Phe His Ile Asp Tyr Ala Lys Phe
1085 1090 1095
Thr Asp Lys Ala Lys Asn Ser Arg Gln Ile Trp Lys Ile Cys Ser
1100 1105 1110
His Gly Asp Lys Arg Tyr Val Tyr Asp Lys Thr Ala Asn Gln Asn
1115 1120 1125
Lys Gly Ala Thr Lys Gly Ile Asn Val Asn Asp Glu Leu Lys Ser
1130 1135 1140
Leu Phe Ala Arg His His Ile Asn Asp Lys Gln Pro Asn Leu Val
1145 1150 1155
Met Asp Ile Cys Gln Asn Asn Asp Lys Glu Phe His Lys Ser Leu
1160 1165 1170
Ile Tyr Leu Leu Lys Thr Leu Leu Ala Leu Arg Tyr Ser Asn Ala
1175 1180 1185
Ser Ser Asp Glu Asp Phe Ile Leu Ser Pro Val Ala Asn Asp Glu
1190 1195 1200
Gly Met Phe Phe Asn Ser Ala Leu Ala Asp Asp Thr Gln Pro Gln
1205 1210 1215
Asn Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Leu
1220 1225 1230
Trp Val Leu Glu Gln Ile Lys Asn Ser Asp Asp Leu Asn Lys Val
1235 1240 1245
Lys Leu Ala Ile Asp Asn Gln Thr Trp Leu Asn Phe Ala Gln Asn
1250 1255 1260
Arg
<210> 1154
<211> 1235
<212> БЕЛОК
<213> Anaerovibrio sp.
<400> 1154
Met Val Ala Phe Ile Asp Glu Phe Val Gly Gln Tyr Pro Val Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Ala Arg Pro Val Pro Glu Thr Lys Lys Trp Leu
20 25 30
Glu Ser Asp Gln Cys Ser Val Leu Phe Asn Asp Gln Lys Arg Asn Glu
35 40 45
Tyr Tyr Gly Val Leu Lys Glu Leu Leu Asp Asp Tyr Tyr Arg Ala Tyr
50 55 60
Ile Glu Asp Ala Leu Thr Ser Phe Thr Leu Asp Lys Ala Leu Leu Glu
65 70 75 80
Asn Ala Tyr Asp Leu Tyr Cys Asn Arg Asp Thr Asn Ala Phe Ser Ser
85 90 95
Cys Cys Glu Lys Leu Arg Lys Asp Leu Val Lys Ala Phe Gly Asn Leu
100 105 110
Lys Asp Tyr Leu Leu Gly Ser Asp Gln Leu Lys Asp Leu Val Lys Leu
115 120 125
Lys Ala Lys Val Asp Ala Pro Ala Gly Lys Gly Lys Lys Lys Ile Glu
130 135 140
Val Asp Ser Arg Leu Ile Asn Trp Leu Asn Asn Asn Ala Lys Tyr Ser
145 150 155 160
Ala Glu Asp Arg Glu Lys Tyr Ile Lys Ala Ile Glu Ser Phe Glu Gly
165 170 175
Phe Val Thr Tyr Leu Thr Asn Tyr Lys Gln Ala Arg Glu Asn Met Phe
180 185 190
Ser Ser Glu Asp Lys Ser Thr Ala Ile Ala Phe Arg Val Ile Asp Gln
195 200 205
Asn Met Val Thr Tyr Phe Gly Asn Ile Arg Ile Tyr Glu Lys Ile Lys
210 215 220
Ala Lys Tyr Pro Glu Leu Tyr Ser Ala Leu Lys Gly Phe Glu Lys Phe
225 230 235 240
Phe Ser Pro Thr Ala Tyr Ser Glu Ile Leu Ser Gln Ser Lys Ile Asp
245 250 255
Glu Tyr Asn Tyr Gln Cys Ile Gly Arg Pro Ile Asp Asp Ala Asp Phe
260 265 270
Lys Gly Val Asn Ser Leu Ile Asn Glu Tyr Arg Gln Lys Asn Gly Ile
275 280 285
Lys Ala Arg Glu Leu Pro Val Met Ser Met Leu Tyr Lys Gln Ile Leu
290 295 300
Ser Asp Arg Asp Asn Ser Phe Met Ser Glu Val Ile Asn Arg Asn Glu
305 310 315 320
Glu Ala Ile Glu Cys Ala Lys Asn Gly Tyr Lys Val Ser Tyr Ala Leu
325 330 335
Phe Asn Glu Leu Leu Gln Leu Tyr Lys Lys Ile Phe Thr Glu Asp Asn
340 345 350
Tyr Gly Asn Ile Tyr Val Lys Thr Gln Pro Leu Thr Glu Leu Ser Gln
355 360 365
Ala Leu Phe Gly Asp Trp Ser Ile Leu Arg Asn Ala Leu Asp Asn Gly
370 375 380
Lys Tyr Asp Lys Asp Ile Ile Asn Leu Ala Glu Leu Glu Lys Tyr Phe
385 390 395 400
Ser Glu Tyr Cys Lys Val Leu Asp Ala Asp Asp Ala Ala Lys Ile Gln
405 410 415
Asp Lys Phe Asn Leu Lys Asp Tyr Phe Ile Gln Lys Asn Ala Leu Asp
420 425 430
Ala Thr Leu Pro Asp Leu Asp Lys Ile Thr Gln Tyr Lys Pro His Leu
435 440 445
Asp Ala Met Leu Gln Ala Ile Arg Lys Tyr Lys Leu Phe Ser Met Tyr
450 455 460
Asn Gly Arg Lys Lys Met Asp Val Pro Glu Asn Gly Ile Asp Phe Ser
465 470 475 480
Asn Glu Phe Asn Ala Ile Tyr Asp Lys Leu Ser Glu Phe Ser Ile Leu
485 490 495
Tyr Asp Arg Ile Arg Asn Phe Ala Thr Lys Lys Pro Tyr Ser Asp Glu
500 505 510
Lys Met Lys Leu Ser Phe Asn Met Pro Thr Met Leu Ala Gly Trp Asp
515 520 525
Tyr Asn Asn Glu Thr Ala Asn Gly Cys Phe Leu Phe Ile Lys Asp Gly
530 535 540
Lys Tyr Phe Leu Gly Val Ala Asp Ser Lys Ser Lys Asn Ile Phe Asp
545 550 555 560
Phe Lys Lys Asn Pro His Leu Leu Asp Lys Tyr Ser Ser Lys Asp Ile
565 570 575
Tyr Tyr Lys Val Lys Tyr Lys Gln Val Ser Gly Ser Ala Lys Met Leu
580 585 590
Pro Lys Val Val Phe Ala Gly Ser Asn Glu Lys Ile Phe Gly His Leu
595 600 605
Ile Ser Lys Arg Ile Leu Glu Ile Arg Glu Lys Lys Leu Tyr Thr Ala
610 615 620
Ala Ala Gly Asp Arg Lys Ala Val Ala Glu Trp Ile Asp Phe Met Lys
625 630 635 640
Ser Ala Ile Ala Ile His Pro Glu Trp Asn Glu Tyr Phe Lys Phe Lys
645 650 655
Phe Lys Asn Thr Ala Glu Tyr Asp Asn Ala Asn Lys Phe Tyr Glu Asp
660 665 670
Ile Asp Lys Gln Thr Tyr Ser Leu Glu Lys Val Glu Ile Pro Thr Glu
675 680 685
Tyr Ile Asp Glu Met Val Ser Gln His Lys Leu Tyr Leu Phe Gln Leu
690 695 700
Tyr Thr Lys Asp Phe Ser Asp Lys Lys Lys Lys Lys Gly Thr Asp Asn
705 710 715 720
Leu His Thr Met Tyr Trp His Gly Val Phe Ser Asp Glu Asn Leu Lys
725 730 735
Ala Val Thr Glu Gly Thr Gln Pro Ile Ile Lys Leu Asn Gly Glu Ala
740 745 750
Glu Met Phe Met Arg Asn Pro Ser Ile Glu Phe Gln Val Thr His Glu
755 760 765
His Asn Lys Pro Ile Ala Asn Lys Asn Pro Leu Asn Thr Lys Lys Glu
770 775 780
Ser Val Phe Asn Tyr Asp Leu Ile Lys Asp Lys Arg Tyr Thr Glu Arg
785 790 795 800
Lys Phe Tyr Phe His Cys Pro Ile Thr Leu Asn Phe Arg Ala Asp Lys
805 810 815
Pro Ile Lys Tyr Asn Glu Lys Ile Asn Arg Phe Val Glu Asn Asn Pro
820 825 830
Asp Val Cys Ile Ile Gly Ile Asp Arg Gly Glu Arg His Leu Leu Tyr
835 840 845
Tyr Thr Val Ile Asn Gln Thr Gly Asp Ile Leu Glu Gln Gly Ser Leu
850 855 860
Asn Lys Ile Ser Gly Ser Tyr Thr Asn Asp Lys Gly Glu Lys Val Asn
865 870 875 880
Lys Glu Thr Asp Tyr His Asp Leu Leu Asp Arg Lys Glu Lys Gly Lys
885 890 895
His Val Ala Gln Gln Ala Trp Glu Thr Ile Glu Asn Ile Lys Glu Leu
900 905 910
Lys Ala Gly Tyr Leu Ser Gln Val Val Tyr Lys Leu Thr Gln Leu Met
915 920 925
Leu Gln Tyr Asn Ala Val Ile Val Leu Glu Asn Leu Asn Val Gly Phe
930 935 940
Lys Arg Gly Arg Thr Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu
945 950 955 960
Lys Ala Met Ile Asp Lys Leu Asn Tyr Leu Val Phe Lys Asp Arg Gly
965 970 975
Tyr Glu Met Asn Gly Ser Tyr Ala Lys Gly Leu Gln Leu Thr Asp Lys
980 985 990
Phe Glu Ser Phe Asp Lys Ile Gly Lys Gln Thr Gly Cys Ile Tyr Tyr
995 1000 1005
Val Ile Pro Ser Tyr Thr Ser His Ile Asp Pro Lys Thr Gly Phe
1010 1015 1020
Val Asn Leu Leu Asn Ala Lys Leu Arg Tyr Glu Asn Ile Thr Lys
1025 1030 1035
Ala Gln Asp Thr Ile Arg Lys Phe Asp Ser Ile Ser Tyr Asn Ala
1040 1045 1050
Lys Ala Asp Tyr Phe Glu Phe Ala Phe Asp Tyr Arg Ser Phe Gly
1055 1060 1065
Val Asp Met Ala Arg Asn Glu Trp Val Val Cys Thr Cys Gly Asp
1070 1075 1080
Leu Arg Trp Glu Tyr Ser Ala Lys Thr Arg Glu Thr Lys Ala Tyr
1085 1090 1095
Ser Val Thr Asp Arg Leu Lys Glu Leu Phe Lys Ala His Gly Ile
1100 1105 1110
Asp Tyr Val Gly Gly Glu Asn Leu Val Ser His Ile Thr Glu Val
1115 1120 1125
Ala Asp Lys His Phe Leu Ser Thr Leu Leu Phe Tyr Leu Arg Leu
1130 1135 1140
Val Leu Lys Met Arg Tyr Thr Val Ser Gly Thr Glu Asn Glu Asn
1145 1150 1155
Asp Phe Ile Leu Ser Pro Val Glu Tyr Ala Pro Gly Lys Phe Phe
1160 1165 1170
Asp Ser Arg Glu Ala Thr Ser Thr Glu Pro Met Asn Ala Asp Ala
1175 1180 1185
Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Met Thr Ile Arg
1190 1195 1200
Gly Ile Glu Asp Gly Lys Leu His Asn Tyr Gly Lys Gly Gly Glu
1205 1210 1215
Asn Ala Ala Trp Phe Lys Phe Met Gln Asn Gln Glu Tyr Lys Asn
1220 1225 1230
Asn Gly
1235
<210> 1155
<211> 1154
<212> БЕЛОК
<213> Proteocatella sphenisci
<400> 1155
Met Glu Asn Phe Lys Asn Leu Tyr Pro Ile Asn Lys Thr Leu Arg Phe
1 5 10 15
Glu Leu Arg Pro Tyr Gly Lys Thr Leu Glu Asn Phe Lys Lys Ser Gly
20 25 30
Leu Leu Glu Lys Asp Ala Phe Lys Ala Asn Ser Arg Arg Ser Met Gln
35 40 45
Ala Ile Ile Asp Glu Lys Phe Lys Glu Thr Ile Glu Glu Arg Leu Lys
50 55 60
Tyr Thr Glu Phe Ser Glu Cys Asp Leu Gly Asn Met Thr Ser Lys Asp
65 70 75 80
Lys Lys Ile Thr Asp Lys Ala Ala Thr Asn Leu Lys Lys Gln Val Ile
85 90 95
Leu Ser Phe Asp Asp Glu Ile Phe Asn Asn Tyr Leu Lys Pro Asp Lys
100 105 110
Asn Ile Asp Ala Leu Phe Lys Asn Asp Pro Ser Asn Pro Val Ile Ser
115 120 125
Thr Phe Lys Gly Phe Thr Thr Tyr Phe Val Asn Phe Phe Glu Ile Arg
130 135 140
Lys His Ile Phe Lys Gly Glu Ser Ser Gly Ser Met Ala Tyr Arg Ile
145 150 155 160
Ile Asp Glu Asn Leu Thr Thr Tyr Leu Asn Asn Ile Glu Lys Ile Lys
165 170 175
Lys Leu Pro Glu Glu Leu Lys Ser Gln Leu Glu Gly Ile Asp Gln Ile
180 185 190
Asp Lys Leu Asn Asn Tyr Asn Glu Phe Ile Thr Gln Ser Gly Ile Thr
195 200 205
His Tyr Asn Glu Ile Ile Gly Gly Ile Ser Lys Ser Glu Asn Val Lys
210 215 220
Ile Gln Gly Ile Asn Glu Gly Ile Asn Leu Tyr Cys Gln Lys Asn Lys
225 230 235 240
Val Lys Leu Pro Arg Leu Thr Pro Leu Tyr Lys Met Ile Leu Ser Asp
245 250 255
Arg Val Ser Asn Ser Phe Val Leu Asp Thr Ile Glu Asn Asp Thr Glu
260 265 270
Leu Ile Glu Met Ile Ser Asp Leu Ile Asn Lys Thr Glu Ile Ser Gln
275 280 285
Asp Val Ile Met Ser Asp Ile Gln Asn Ile Phe Ile Lys Tyr Lys Gln
290 295 300
Leu Gly Asn Leu Pro Gly Ile Ser Tyr Ser Ser Ile Val Asn Ala Ile
305 310 315 320
Cys Ser Asp Tyr Asp Asn Asn Phe Gly Asp Gly Lys Arg Lys Lys Ser
325 330 335
Tyr Glu Asn Asp Arg Lys Lys His Leu Glu Thr Asn Val Tyr Ser Ile
340 345 350
Asn Tyr Ile Ser Glu Leu Leu Thr Asp Thr Asp Val Ser Ser Asn Ile
355 360 365
Lys Met Arg Tyr Lys Glu Leu Glu Gln Asn Tyr Gln Val Cys Lys Glu
370 375 380
Asn Phe Asn Ala Thr Asn Trp Met Asn Ile Lys Asn Ile Lys Gln Ser
385 390 395 400
Glu Lys Thr Asn Leu Ile Lys Asp Leu Leu Asp Ile Leu Lys Ser Ile
405 410 415
Gln Arg Phe Tyr Asp Leu Phe Asp Ile Val Asp Glu Asp Lys Asn Pro
420 425 430
Ser Ala Glu Phe Tyr Thr Trp Leu Ser Lys Asn Ala Glu Lys Leu Asp
435 440 445
Phe Glu Phe Asn Ser Val Tyr Asn Lys Ser Arg Asn Tyr Leu Thr Arg
450 455 460
Lys Gln Tyr Ser Asp Lys Lys Ile Lys Leu Asn Phe Asp Ser Pro Thr
465 470 475 480
Leu Ala Lys Gly Trp Asp Ala Asn Lys Glu Ile Asp Asn Ser Thr Ile
485 490 495
Ile Met Arg Lys Phe Asn Asn Asp Arg Gly Asp Tyr Asp Tyr Phe Leu
500 505 510
Gly Ile Trp Asn Lys Ser Thr Pro Ala Asn Glu Lys Ile Ile Pro Leu
515 520 525
Glu Asp Asn Gly Leu Phe Glu Lys Met Gln Tyr Lys Leu Tyr Pro Asp
530 535 540
Pro Ser Lys Met Leu Pro Lys Gln Phe Leu Ser Lys Ile Trp Lys Ala
545 550 555 560
Lys His Pro Thr Thr Pro Glu Phe Asp Lys Lys Tyr Lys Glu Gly Arg
565 570 575
His Lys Lys Gly Pro Asp Phe Glu Lys Glu Phe Leu His Glu Leu Ile
580 585 590
Asp Cys Phe Lys His Gly Leu Val Asn His Asp Glu Lys Tyr Gln Asp
595 600 605
Val Phe Gly Phe Asn Leu Arg Asn Thr Glu Asp Tyr Asn Ser Tyr Thr
610 615 620
Glu Phe Leu Glu Asp Val Glu Arg Cys Asn Tyr Asn Leu Ser Phe Asn
625 630 635 640
Lys Ile Ala Asp Thr Ser Asn Leu Ile Asn Asp Gly Lys Leu Tyr Val
645 650 655
Phe Gln Ile Trp Ser Lys Asp Phe Ser Ile Asp Ser Lys Gly Thr Lys
660 665 670
Asn Leu Asn Thr Ile Tyr Phe Glu Ser Leu Phe Ser Glu Glu Asn Met
675 680 685
Ile Glu Lys Met Phe Lys Leu Ser Gly Glu Ala Glu Ile Phe Tyr Arg
690 695 700
Pro Ala Ser Leu Asn Tyr Cys Glu Asp Ile Ile Lys Lys Gly His His
705 710 715 720
His Ala Glu Leu Lys Asp Lys Phe Asp Tyr Pro Ile Ile Lys Asp Lys
725 730 735
Arg Tyr Ser Gln Asp Lys Phe Phe Phe His Val Pro Met Val Ile Asn
740 745 750
Tyr Lys Ser Glu Lys Leu Asn Ser Lys Ser Leu Asn Asn Arg Thr Asn
755 760 765
Glu Asn Leu Gly Gln Phe Thr His Ile Ile Gly Ile Asp Arg Gly Glu
770 775 780
Arg His Leu Ile Tyr Leu Thr Val Val Asp Val Ser Thr Gly Glu Ile
785 790 795 800
Val Glu Gln Lys His Leu Asp Glu Ile Ile Asn Thr Asp Thr Lys Gly
805 810 815
Val Glu His Lys Thr His Tyr Leu Asn Lys Leu Glu Glu Lys Ser Lys
820 825 830
Thr Arg Asp Asn Glu Arg Lys Ser Trp Glu Ala Ile Glu Thr Ile Lys
835 840 845
Glu Leu Lys Glu Gly Tyr Ile Ser His Val Ile Asn Glu Ile Gln Lys
850 855 860
Leu Gln Glu Lys Tyr Asn Ala Leu Ile Val Met Glu Asn Leu Asn Tyr
865 870 875 880
Gly Phe Lys Asn Ser Arg Ile Lys Val Glu Lys Gln Val Tyr Gln Lys
885 890 895
Phe Glu Thr Ala Leu Ile Lys Lys Phe Asn Tyr Ile Ile Asp Lys Lys
900 905 910
Asp Pro Glu Thr Tyr Ile His Gly Tyr Gln Leu Thr Asn Pro Ile Thr
915 920 925
Thr Leu Asp Lys Ile Gly Asn Gln Ser Gly Ile Val Leu Tyr Ile Pro
930 935 940
Ala Trp Asn Thr Ser Lys Ile Asp Pro Val Thr Gly Phe Val Asn Leu
945 950 955 960
Leu Tyr Ala Asp Asp Leu Lys Tyr Lys Asn Gln Glu Gln Ala Lys Ser
965 970 975
Phe Ile Gln Lys Ile Asp Asn Ile Tyr Phe Glu Asn Gly Glu Phe Lys
980 985 990
Phe Asp Ile Asp Phe Ser Lys Trp Asn Asn Arg Tyr Ser Ile Ser Lys
995 1000 1005
Thr Lys Trp Thr Leu Thr Ser Tyr Gly Thr Arg Ile Gln Thr Phe
1010 1015 1020
Arg Asn Pro Gln Lys Asn Asn Lys Trp Asp Ser Ala Glu Tyr Asp
1025 1030 1035
Leu Thr Glu Glu Phe Lys Leu Ile Leu Asn Ile Asp Gly Thr Leu
1040 1045 1050
Lys Ser Gln Asp Val Glu Thr Tyr Lys Lys Phe Met Ser Leu Phe
1055 1060 1065
Lys Leu Met Leu Gln Leu Arg Asn Ser Val Thr Gly Thr Asp Ile
1070 1075 1080
Asp Tyr Met Ile Ser Pro Val Thr Asp Lys Thr Gly Thr His Phe
1085 1090 1095
Asp Ser Arg Glu Asn Ile Lys Asn Leu Pro Ala Asp Ala Asp Ala
1100 1105 1110
Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Ile Met Ala Ile Glu
1115 1120 1125
Asn Ile Met Asn Gly Ile Ser Asp Pro Leu Lys Ile Ser Asn Glu
1130 1135 1140
Asp Tyr Leu Lys Tyr Ile Gln Asn Gln Gln Glu
1145 1150
<210> 1156
<211> 1282
<212> БЕЛОК
<213> Eubacterium eligens
<400> 1156
Met Asn Gly Asn Arg Ser Ile Val Tyr Arg Glu Phe Val Gly Val Thr
1 5 10 15
Pro Val Ala Lys Thr Leu Arg Asn Glu Leu Arg Pro Val Gly His Thr
20 25 30
Gln Glu His Ile Ile Gln Asn Gly Leu Ile Gln Glu Asp Glu Leu Arg
35 40 45
Gln Glu Lys Ser Thr Glu Leu Lys Asn Ile Met Asp Asp Tyr Tyr Arg
50 55 60
Glu Tyr Ile Asp Lys Ser Leu Ser Gly Leu Thr Asp Leu Asp Phe Thr
65 70 75 80
Leu Leu Phe Glu Leu Met Asn Ser Val Gln Ser Ser Leu Ser Lys Asp
85 90 95
Asn Lys Lys Ala Leu Glu Lys Glu His Asn Lys Met Arg Glu Gln Ile
100 105 110
Cys Thr His Leu Gln Ser Asp Ser Asp Tyr Lys Asn Met Phe Asn Ala
115 120 125
Lys Leu Phe Lys Glu Ile Leu Pro Asp Phe Ile Lys Asn Tyr Asn Gln
130 135 140
Tyr Asp Val Lys Asp Lys Ala Gly Lys Leu Glu Thr Leu Ala Leu Phe
145 150 155 160
Asn Gly Phe Ser Thr Tyr Phe Thr Asp Phe Phe Glu Lys Arg Lys Asn
165 170 175
Val Phe Thr Lys Glu Ala Val Ser Thr Ser Ile Ala Tyr Arg Ile Val
180 185 190
His Glu Asn Ser Leu Ile Phe Leu Ala Asn Met Thr Ser Tyr Lys Lys
195 200 205
Ile Ser Glu Lys Ala Leu Asp Glu Ile Glu Val Ile Glu Lys Asn Asn
210 215 220
Gln Asp Lys Met Gly Asp Trp Glu Leu Asn Gln Ile Phe Asn Pro Asp
225 230 235 240
Phe Tyr Asn Met Val Leu Ile Gln Ser Gly Ile Asp Phe Tyr Asn Glu
245 250 255
Ile Cys Gly Val Val Asn Ala His Met Asn Leu Tyr Cys Gln Gln Thr
260 265 270
Lys Asn Asn Tyr Asn Leu Phe Lys Met Arg Lys Leu His Lys Gln Ile
275 280 285
Leu Ala Tyr Thr Ser Thr Ser Phe Glu Val Pro Lys Met Phe Glu Asp
290 295 300
Asp Met Ser Val Tyr Asn Ala Val Asn Ala Phe Ile Asp Glu Thr Glu
305 310 315 320
Lys Gly Asn Ile Ile Gly Lys Leu Lys Asp Ile Val Asn Lys Tyr Asp
325 330 335
Glu Leu Asp Glu Lys Arg Ile Tyr Ile Ser Lys Asp Phe Tyr Glu Thr
340 345 350
Leu Ser Cys Phe Met Ser Gly Asn Trp Asn Leu Ile Thr Gly Cys Val
355 360 365
Glu Asn Phe Tyr Asp Glu Asn Ile His Ala Lys Gly Lys Ser Lys Glu
370 375 380
Glu Lys Val Lys Lys Ala Val Lys Glu Asp Lys Tyr Lys Ser Ile Asn
385 390 395 400
Asp Val Asn Asp Leu Val Glu Lys Tyr Ile Asp Glu Lys Glu Arg Asn
405 410 415
Glu Phe Lys Asn Ser Asn Ala Lys Gln Tyr Ile Arg Glu Ile Ser Asn
420 425 430
Ile Ile Thr Asp Thr Glu Thr Ala His Leu Glu Tyr Asp Glu His Ile
435 440 445
Ser Leu Ile Glu Ser Glu Glu Lys Ala Asp Glu Ile Lys Lys Arg Leu
450 455 460
Asp Met Tyr Met Asn Met Tyr His Trp Val Lys Ala Phe Ile Val Asp
465 470 475 480
Glu Val Leu Asp Arg Asp Glu Met Phe Tyr Ser Asp Ile Asp Asp Ile
485 490 495
Tyr Asn Ile Leu Glu Asn Ile Val Pro Leu Tyr Asn Arg Val Arg Asn
500 505 510
Tyr Val Thr Gln Lys Pro Tyr Thr Ser Lys Lys Ile Lys Leu Asn Phe
515 520 525
Gln Ser Pro Thr Leu Ala Asn Gly Trp Ser Gln Ser Lys Glu Phe Asp
530 535 540
Asn Asn Ala Ile Ile Leu Ile Arg Asp Asn Lys Tyr Tyr Leu Ala Ile
545 550 555 560
Phe Asn Ala Lys Asn Lys Pro Asp Lys Lys Ile Ile Gln Gly Asn Ser
565 570 575
Asp Lys Lys Asn Asp Asn Asp Tyr Lys Lys Met Val Tyr Asn Leu Leu
580 585 590
Pro Gly Ala Asn Lys Met Leu Pro Lys Val Phe Leu Ser Lys Lys Gly
595 600 605
Ile Glu Thr Phe Lys Pro Ser Asp Tyr Ile Ile Ser Gly Tyr Asn Ala
610 615 620
His Lys His Ile Lys Thr Ser Glu Asn Phe Asp Ile Ser Phe Cys Arg
625 630 635 640
Asp Leu Ile Asp Tyr Phe Lys Asn Ser Ile Glu Lys His Ala Glu Trp
645 650 655
Arg Lys Tyr Glu Phe Lys Phe Ser Ala Thr Asp Ser Tyr Asn Asp Ile
660 665 670
Ser Glu Phe Tyr Arg Glu Val Glu Met Gln Gly Tyr Arg Ile Asp Trp
675 680 685
Thr Tyr Ile Ser Glu Ala Asp Ile Asn Lys Leu Asp Glu Glu Gly Lys
690 695 700
Ile Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Glu Asn Ser Thr
705 710 715 720
Gly Lys Glu Asn Leu His Thr Met Tyr Phe Lys Asn Ile Phe Ser Glu
725 730 735
Glu Asn Leu Lys Asn Ile Val Ile Lys Leu Asn Gly Gln Ala Glu Leu
740 745 750
Phe Tyr Arg Lys Ala Ser Val Lys Asn Pro Val Lys His Lys Lys Asp
755 760 765
Ser Val Leu Val Asn Lys Thr Tyr Lys Asn Gln Leu Asp Asn Gly Asp
770 775 780
Val Val Arg Ile Pro Ile Pro Asp Asp Ile Tyr Asn Glu Ile Tyr Lys
785 790 795 800
Met Tyr Asn Gly Tyr Ile Lys Glu Ser Asp Leu Ser Glu Ala Ala Lys
805 810 815
Glu Tyr Leu Asp Lys Val Glu Val Arg Thr Ala Gln Lys Asp Ile Val
820 825 830
Lys Asp Tyr Arg Tyr Thr Val Asp Lys Tyr Phe Ile His Thr Pro Ile
835 840 845
Thr Ile Asn Tyr Lys Val Thr Ala Arg Asn Asn Val Asn Asp Met Ala
850 855 860
Val Lys Tyr Ile Ala Gln Asn Asp Asp Ile His Val Ile Gly Ile Asp
865 870 875 880
Arg Gly Glu Arg Asn Leu Ile Tyr Ile Ser Val Ile Asp Ser His Gly
885 890 895
Asn Ile Val Lys Gln Lys Ser Tyr Asn Ile Leu Asn Asn Tyr Asp Tyr
900 905 910
Lys Lys Lys Leu Val Glu Lys Glu Lys Thr Arg Glu Tyr Ala Arg Lys
915 920 925
Asn Trp Lys Ser Ile Gly Asn Ile Lys Glu Leu Lys Glu Gly Tyr Ile
930 935 940
Ser Gly Val Val His Glu Ile Ala Met Leu Met Val Glu Tyr Asn Ala
945 950 955 960
Ile Ile Ala Met Glu Asp Leu Asn Tyr Gly Phe Lys Arg Gly Arg Phe
965 970 975
Lys Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Ser Met Leu Ile Asn
980 985 990
Lys Leu Asn Tyr Phe Ala Ser Lys Gly Lys Ser Val Asp Glu Pro Gly
995 1000 1005
Gly Leu Leu Lys Gly Tyr Gln Leu Thr Tyr Val Pro Asp Asn Ile
1010 1015 1020
Lys Asn Leu Gly Lys Gln Cys Gly Val Ile Phe Tyr Val Pro Ala
1025 1030 1035
Ala Phe Thr Ser Lys Ile Asp Pro Ser Thr Gly Phe Ile Ser Ala
1040 1045 1050
Phe Asn Phe Lys Ser Ile Ser Thr Asn Ala Ser Arg Lys Gln Phe
1055 1060 1065
Phe Met Gln Phe Asp Glu Ile Arg Tyr Cys Ala Glu Lys Asp Met
1070 1075 1080
Phe Ser Phe Gly Phe Asp Tyr Asn Asn Phe Asp Thr Tyr Asn Ile
1085 1090 1095
Thr Met Gly Lys Thr Gln Trp Thr Val Tyr Thr Asn Gly Glu Arg
1100 1105 1110
Leu Gln Ser Glu Phe Asn Asn Ala Arg Arg Thr Gly Lys Thr Lys
1115 1120 1125
Ser Ile Asn Leu Thr Glu Thr Ile Lys Leu Leu Leu Glu Asp Asn
1130 1135 1140
Glu Ile Asn Tyr Ala Asp Gly His Asp Val Arg Ile Asp Met Glu
1145 1150 1155
Lys Met Tyr Glu Asp Lys Asn Ser Glu Phe Phe Ala Gln Leu Leu
1160 1165 1170
Ser Leu Tyr Lys Leu Thr Val Gln Met Arg Asn Ser Tyr Thr Glu
1175 1180 1185
Ala Glu Glu Gln Glu Lys Gly Ile Ser Tyr Asp Lys Ile Ile Ser
1190 1195 1200
Pro Val Ile Asn Asp Glu Gly Glu Phe Phe Asp Ser Asp Asn Tyr
1205 1210 1215
Lys Glu Ser Asp Asp Lys Glu Cys Lys Met Pro Lys Asp Ala Asp
1220 1225 1230
Ala Asn Gly Ala Tyr Cys Ile Ala Leu Lys Gly Leu Tyr Glu Val
1235 1240 1245
Leu Lys Ile Lys Ser Glu Trp Thr Glu Asp Gly Phe Asp Arg Asn
1250 1255 1260
Cys Leu Lys Leu Pro His Ala Glu Trp Leu Asp Phe Ile Gln Asn
1265 1270 1275
Lys Arg Tyr Glu
1280
<210> 1157
<211> 1282
<212> БЕЛОК
<213> Eubacterium eligens
<400> 1157
Met Asn Gly Asn Arg Ser Ile Val Tyr Arg Glu Phe Val Gly Val Ile
1 5 10 15
Pro Val Ala Lys Thr Leu Arg Asn Glu Leu Arg Pro Val Gly His Thr
20 25 30
Gln Glu His Ile Ile Gln Asn Gly Leu Ile Gln Glu Asp Glu Leu Arg
35 40 45
Gln Glu Lys Ser Thr Glu Leu Lys Asn Ile Met Asp Asp Tyr Tyr Arg
50 55 60
Glu Tyr Ile Asp Lys Ser Leu Ser Gly Val Thr Asp Leu Asp Phe Thr
65 70 75 80
Leu Leu Phe Glu Leu Met Asn Leu Val Gln Ser Ser Pro Ser Lys Asp
85 90 95
Asn Lys Lys Ala Leu Glu Lys Glu Gln Ser Lys Met Arg Glu Gln Ile
100 105 110
Cys Thr His Leu Gln Ser Asp Ser Asn Tyr Lys Asn Ile Phe Asn Ala
115 120 125
Lys Leu Leu Lys Glu Ile Leu Pro Asp Phe Ile Lys Asn Tyr Asn Gln
130 135 140
Tyr Asp Val Lys Asp Lys Ala Gly Lys Leu Glu Thr Leu Ala Leu Phe
145 150 155 160
Asn Gly Phe Ser Thr Tyr Phe Thr Asp Phe Phe Glu Lys Arg Lys Asn
165 170 175
Val Phe Thr Lys Glu Ala Val Ser Thr Ser Ile Ala Tyr Arg Ile Val
180 185 190
His Glu Asn Ser Leu Ile Phe Leu Ala Asn Met Thr Ser Tyr Lys Lys
195 200 205
Ile Ser Glu Lys Ala Leu Asp Glu Ile Glu Val Ile Glu Lys Asn Asn
210 215 220
Gln Asp Lys Met Gly Asp Trp Glu Leu Asn Gln Ile Phe Asn Pro Asp
225 230 235 240
Phe Tyr Asn Met Val Leu Ile Gln Ser Gly Ile Asp Phe Tyr Asn Glu
245 250 255
Ile Cys Gly Val Val Asn Ala His Met Asn Leu Tyr Cys Gln Gln Thr
260 265 270
Lys Asn Asn Tyr Asn Leu Phe Lys Met Arg Lys Leu His Lys Gln Ile
275 280 285
Leu Ala Tyr Thr Ser Thr Ser Phe Glu Val Pro Lys Met Phe Glu Asp
290 295 300
Asp Met Ser Val Tyr Asn Ala Val Asn Ala Phe Ile Asp Glu Thr Glu
305 310 315 320
Lys Gly Asn Ile Ile Gly Lys Leu Lys Asp Ile Val Asn Lys Tyr Asp
325 330 335
Glu Leu Asp Glu Lys Arg Ile Tyr Ile Ser Lys Asp Phe Tyr Glu Thr
340 345 350
Leu Ser Cys Phe Met Ser Gly Asn Trp Asn Leu Ile Thr Gly Cys Val
355 360 365
Glu Asn Phe Tyr Asp Glu Asn Ile His Ala Lys Gly Lys Ser Lys Glu
370 375 380
Glu Lys Val Lys Lys Ala Val Lys Glu Asp Lys Tyr Lys Ser Ile Asn
385 390 395 400
Asp Val Asn Asp Leu Val Glu Lys Tyr Ile Asp Glu Lys Glu Arg Asn
405 410 415
Glu Phe Lys Asn Ser Asn Ala Lys Gln Tyr Ile Arg Glu Ile Ser Asn
420 425 430
Ile Ile Thr Asp Thr Glu Thr Ala His Leu Glu Tyr Asp Asp His Ile
435 440 445
Ser Leu Ile Glu Ser Glu Glu Lys Ala Asp Glu Met Lys Lys Arg Leu
450 455 460
Asp Met Tyr Met Asn Met Tyr His Trp Ala Lys Ala Phe Ile Val Asp
465 470 475 480
Glu Val Leu Asp Arg Asp Glu Met Phe Tyr Ser Asp Ile Asp Asp Ile
485 490 495
Tyr Asn Ile Leu Glu Asn Ile Val Pro Leu Tyr Asn Arg Val Arg Asn
500 505 510
Tyr Val Thr Gln Lys Pro Tyr Asn Ser Lys Lys Ile Lys Leu Asn Phe
515 520 525
Gln Ser Pro Thr Leu Ala Asn Gly Trp Ser Gln Ser Lys Glu Phe Asp
530 535 540
Asn Asn Ala Ile Ile Leu Ile Arg Asp Asn Lys Tyr Tyr Leu Ala Ile
545 550 555 560
Phe Asn Ala Lys Asn Lys Pro Asp Lys Lys Ile Ile Gln Gly Asn Ser
565 570 575
Asp Lys Lys Asn Asp Asn Asp Tyr Lys Lys Met Val Tyr Asn Leu Leu
580 585 590
Pro Gly Ala Asn Lys Met Leu Pro Lys Val Phe Leu Ser Lys Lys Gly
595 600 605
Ile Glu Thr Phe Lys Pro Ser Asp Tyr Ile Ile Ser Gly Tyr Asn Ala
610 615 620
His Lys His Ile Lys Thr Ser Glu Asn Phe Asp Ile Ser Phe Cys Arg
625 630 635 640
Asp Leu Ile Asp Tyr Phe Lys Asn Ser Ile Glu Lys His Ala Glu Trp
645 650 655
Arg Lys Tyr Glu Phe Lys Phe Ser Ala Thr Asp Ser Tyr Ser Asp Ile
660 665 670
Ser Glu Phe Tyr Arg Glu Val Glu Met Gln Gly Tyr Arg Ile Asp Trp
675 680 685
Thr Tyr Ile Ser Glu Ala Asp Ile Asn Lys Leu Asp Glu Glu Gly Lys
690 695 700
Ile Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Glu Asn Ser Thr
705 710 715 720
Gly Lys Glu Asn Leu His Thr Met Tyr Phe Lys Asn Ile Phe Ser Glu
725 730 735
Glu Asn Leu Lys Asp Ile Ile Ile Lys Leu Asn Gly Gln Ala Glu Leu
740 745 750
Phe Tyr Arg Arg Ala Ser Val Lys Asn Pro Val Lys His Lys Lys Asp
755 760 765
Ser Val Leu Val Asn Lys Thr Tyr Lys Asn Gln Leu Asp Asn Gly Asp
770 775 780
Val Val Arg Ile Pro Ile Pro Asp Asp Ile Tyr Asn Glu Ile Tyr Lys
785 790 795 800
Met Tyr Asn Gly Tyr Ile Lys Glu Ser Asp Leu Ser Glu Ala Ala Lys
805 810 815
Glu Tyr Leu Asp Lys Val Glu Val Arg Thr Ala Gln Lys Asp Ile Val
820 825 830
Lys Asp Tyr Arg Tyr Thr Val Asp Lys Tyr Phe Ile His Thr Pro Ile
835 840 845
Thr Ile Asn Tyr Lys Val Thr Ala Arg Asn Asn Val Asn Asp Met Val
850 855 860
Val Lys Tyr Ile Ala Gln Asn Asp Asp Ile His Val Ile Gly Ile Asp
865 870 875 880
Arg Gly Glu Arg Asn Leu Ile Tyr Ile Ser Val Ile Asp Ser His Gly
885 890 895
Asn Ile Val Lys Gln Lys Ser Tyr Asn Ile Leu Asn Asn Tyr Asp Tyr
900 905 910
Lys Lys Lys Leu Val Glu Lys Glu Lys Thr Arg Glu Tyr Ala Arg Lys
915 920 925
Asn Trp Lys Ser Ile Gly Asn Ile Lys Glu Leu Lys Glu Gly Tyr Ile
930 935 940
Ser Gly Val Val His Glu Ile Ala Met Leu Ile Val Glu Tyr Asn Ala
945 950 955 960
Ile Ile Ala Met Glu Asp Leu Asn Tyr Gly Phe Lys Arg Gly Arg Phe
965 970 975
Lys Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Ser Met Leu Ile Asn
980 985 990
Lys Leu Asn Tyr Phe Ala Ser Lys Glu Lys Ser Val Asp Glu Pro Gly
995 1000 1005
Gly Leu Leu Lys Gly Tyr Gln Leu Thr Tyr Val Pro Asp Asn Ile
1010 1015 1020
Lys Asn Leu Gly Lys Gln Cys Gly Val Ile Phe Tyr Val Pro Ala
1025 1030 1035
Ala Phe Thr Ser Lys Ile Asp Pro Ser Thr Gly Phe Ile Ser Ala
1040 1045 1050
Phe Asn Phe Lys Ser Ile Ser Thr Asn Ala Ser Arg Lys Gln Phe
1055 1060 1065
Phe Met Gln Phe Asp Glu Ile Arg Tyr Cys Ala Glu Lys Asp Met
1070 1075 1080
Phe Ser Phe Gly Phe Asp Tyr Asn Asn Phe Asp Thr Tyr Asn Ile
1085 1090 1095
Thr Met Gly Lys Thr Gln Trp Thr Val Tyr Thr Asn Gly Glu Arg
1100 1105 1110
Leu Gln Ser Glu Phe Asn Asn Ala Arg Arg Thr Gly Lys Thr Lys
1115 1120 1125
Ser Ile Asn Leu Thr Glu Thr Ile Lys Leu Leu Leu Glu Asp Asn
1130 1135 1140
Glu Ile Asn Tyr Ala Asp Gly His Asp Ile Arg Ile Asp Met Glu
1145 1150 1155
Lys Met Asp Glu Asp Lys Lys Ser Glu Phe Phe Ala Gln Leu Leu
1160 1165 1170
Ser Leu Tyr Lys Leu Thr Val Gln Met Arg Asn Ser Tyr Thr Glu
1175 1180 1185
Ala Glu Glu Gln Glu Asn Gly Ile Ser Tyr Asp Lys Ile Ile Ser
1190 1195 1200
Pro Val Ile Asn Asp Glu Gly Glu Phe Phe Asp Ser Asp Asn Tyr
1205 1210 1215
Lys Glu Ser Asp Asp Lys Glu Cys Lys Met Pro Lys Asp Ala Asp
1220 1225 1230
Ala Asn Gly Ala Tyr Cys Ile Ala Leu Lys Gly Leu Tyr Glu Val
1235 1240 1245
Leu Lys Ile Lys Ser Glu Trp Thr Glu Asp Gly Phe Asp Arg Asn
1250 1255 1260
Cys Leu Lys Leu Pro His Ala Glu Trp Leu Asp Phe Ile Gln Asn
1265 1270 1275
Lys Arg Tyr Glu
1280
<210> 1158
<211> 1305
<212> БЕЛОК
<213> Eubacterium sp.
<400> 1158
Met Asn Lys Ala Ala Asp Asn Tyr Thr Gly Gly Asn Tyr Asp Glu Phe
1 5 10 15
Ile Ala Leu Ser Lys Val Gln Lys Thr Leu Arg Asn Glu Leu Lys Pro
20 25 30
Thr Pro Phe Thr Ala Glu His Ile Lys Gln Arg Gly Ile Ile Ser Glu
35 40 45
Asp Glu Tyr Arg Ala Gln Gln Ser Leu Glu Leu Lys Lys Ile Ala Asp
50 55 60
Glu Tyr Tyr Arg Asn Tyr Ile Thr His Lys Leu Asn Asp Ile Asn Asn
65 70 75 80
Leu Asp Phe Tyr Asn Leu Phe Asp Ala Ile Glu Glu Lys Tyr Lys Lys
85 90 95
Asn Asp Lys Asp Asn Arg Asp Lys Leu Asp Leu Val Glu Lys Ser Lys
100 105 110
Arg Gly Glu Ile Ala Lys Met Leu Ser Ala Asp Asp Asn Phe Lys Ser
115 120 125
Met Phe Glu Ala Lys Leu Ile Thr Lys Leu Leu Pro Asp Tyr Val Glu
130 135 140
Arg Asn Tyr Thr Gly Glu Asp Lys Glu Lys Ala Leu Glu Thr Leu Ala
145 150 155 160
Leu Phe Lys Gly Phe Thr Thr Tyr Phe Lys Gly Tyr Phe Lys Thr Arg
165 170 175
Lys Asn Met Phe Ser Gly Glu Gly Gly Ala Ser Ser Ile Cys His Arg
180 185 190
Ile Val Asn Val Asn Ala Ser Ile Phe Tyr Asp Asn Leu Lys Thr Phe
195 200 205
Met Arg Ile Gln Glu Lys Ala Gly Asp Glu Ile Ala Leu Ile Glu Glu
210 215 220
Glu Leu Thr Glu Lys Leu Asp Gly Trp Arg Leu Glu His Ile Phe Ser
225 230 235 240
Arg Asp Tyr Tyr Asn Glu Val Leu Ala Gln Lys Gly Ile Asp Tyr Tyr
245 250 255
Asn Gln Ile Cys Gly Asp Ile Asn Lys His Met Asn Leu Tyr Cys Gln
260 265 270
Gln Asn Lys Phe Lys Ala Asn Ile Phe Lys Met Met Lys Ile Gln Lys
275 280 285
Gln Ile Met Gly Ile Ser Glu Lys Ala Phe Glu Ile Pro Pro Met Tyr
290 295 300
Gln Asn Asp Glu Glu Val Tyr Ala Ser Phe Asn Glu Phe Ile Ser Arg
305 310 315 320
Leu Glu Glu Val Lys Leu Thr Asp Arg Leu Ile Asn Ile Leu Gln Asn
325 330 335
Ile Asn Ile Tyr Asn Thr Ala Lys Ile Tyr Ile Asn Ala Arg Tyr Tyr
340 345 350
Thr Asn Val Ser Ser Tyr Val Tyr Gly Gly Trp Gly Val Ile Asp Ser
355 360 365
Ala Ile Glu Arg Tyr Leu Tyr Asn Thr Ile Ala Gly Lys Gly Gln Ser
370 375 380
Lys Val Lys Lys Ile Glu Asn Ala Lys Lys Asp Asn Lys Phe Met Ser
385 390 395 400
Val Lys Glu Leu Asp Ser Ile Val Ala Glu Tyr Glu Pro Asp Tyr Phe
405 410 415
Asn Ala Pro Tyr Ile Asp Asp Asp Asp Asn Ala Val Lys Ala Phe Gly
420 425 430
Gly Gln Gly Val Leu Gly Tyr Phe Asn Lys Met Ser Glu Leu Leu Ala
435 440 445
Asp Val Ser Leu Tyr Thr Ile Asp Tyr Asn Ser Asp Asp Ser Leu Ile
450 455 460
Glu Asn Lys Glu Ser Ala Leu Arg Ile Lys Lys Gln Leu Asp Asp Ile
465 470 475 480
Met Ser Leu Tyr His Trp Leu Gln Thr Phe Ile Ile Asp Glu Val Val
485 490 495
Glu Lys Asp Asn Ala Phe Tyr Ala Glu Leu Glu Asp Ile Cys Cys Glu
500 505 510
Leu Glu Asn Val Val Thr Leu Tyr Asp Arg Ile Arg Asn Tyr Val Thr
515 520 525
Lys Lys Pro Tyr Ser Thr Gln Lys Phe Lys Leu Asn Phe Ala Ser Pro
530 535 540
Thr Leu Ala Ala Gly Trp Ser Arg Ser Lys Glu Phe Asp Asn Asn Ala
545 550 555 560
Ile Ile Leu Leu Arg Asn Asn Lys Tyr Tyr Ile Ala Ile Phe Asn Val
565 570 575
Asn Asn Lys Pro Asp Lys Gln Ile Ile Lys Gly Ser Glu Glu Gln Arg
580 585 590
Leu Ser Thr Asp Tyr Lys Lys Met Val Tyr Asn Leu Leu Pro Gly Pro
595 600 605
Asn Lys Met Leu Pro Lys Val Phe Ile Lys Ser Asp Thr Gly Lys Arg
610 615 620
Asp Tyr Asn Pro Ser Ser Tyr Ile Leu Glu Gly Tyr Glu Lys Asn Arg
625 630 635 640
His Ile Lys Ser Ser Gly Asn Phe Asp Ile Asn Tyr Cys His Asp Leu
645 650 655
Ile Asp Tyr Tyr Lys Ala Cys Ile Asn Lys His Pro Glu Trp Lys Asn
660 665 670
Tyr Gly Phe Lys Phe Lys Glu Thr Asn Gln Tyr Asn Asp Ile Gly Gln
675 680 685
Phe Tyr Lys Asp Val Glu Lys Gln Gly Tyr Ser Ile Ser Trp Ala Tyr
690 695 700
Ile Ser Glu Glu Asp Ile Asn Lys Leu Asp Glu Glu Gly Lys Ile Tyr
705 710 715 720
Leu Phe Glu Ile Tyr Asn Lys Asp Leu Ser Ala His Ser Thr Gly Arg
725 730 735
Asp Asn Leu His Thr Met Tyr Leu Lys Asn Ile Phe Ser Glu Asp Asn
740 745 750
Leu Lys Asn Ile Cys Ile Glu Leu Asn Gly Glu Ala Glu Leu Phe Tyr
755 760 765
Arg Lys Ser Ser Met Lys Ser Asn Ile Thr His Lys Lys Asp Thr Ile
770 775 780
Leu Val Asn Lys Thr Tyr Ile Asn Glu Thr Gly Val Arg Val Ser Leu
785 790 795 800
Ser Asp Glu Asp Tyr Met Lys Val Tyr Asn Tyr Tyr Asn Asn Asn Tyr
805 810 815
Val Ile Asp Thr Glu Asn Asp Lys Asn Leu Ile Asp Ile Ile Glu Lys
820 825 830
Ile Gly His Arg Lys Ser Lys Ile Asp Ile Val Lys Asp Lys Arg Tyr
835 840 845
Thr Glu Asp Lys Tyr Phe Leu Tyr Leu Pro Ile Thr Ile Asn Tyr Gly
850 855 860
Ile Glu Asp Glu Asn Val Asn Ser Lys Ile Ile Glu Tyr Ile Ala Lys
865 870 875 880
Gln Asp Asn Met Asn Val Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu
885 890 895
Ile Tyr Ile Ser Val Ile Asp Asn Lys Gly Asn Ile Ile Glu Gln Lys
900 905 910
Ser Phe Asn Leu Val Asn Asn Tyr Asp Tyr Lys Asn Lys Leu Lys Asn
915 920 925
Met Glu Lys Thr Arg Asp Asn Ala Arg Lys Asn Trp Gln Glu Ile Gly
930 935 940
Lys Ile Lys Asp Val Lys Ser Gly Tyr Leu Ser Gly Val Ile Ser Lys
945 950 955 960
Ile Ala Arg Met Val Ile Asp Tyr Asn Ala Ile Ile Val Met Glu Asp
965 970 975
Leu Asn Lys Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Arg Gln Val
980 985 990
Tyr Gln Lys Phe Glu Asn Met Leu Ile Ser Lys Leu Asn Tyr Leu Val
995 1000 1005
Phe Lys Glu Arg Lys Ala Asp Glu Asn Gly Gly Ile Leu Arg Gly
1010 1015 1020
Tyr Gln Leu Thr Tyr Ile Pro Lys Ser Ile Lys Asn Val Gly Lys
1025 1030 1035
Gln Cys Gly Cys Ile Phe Tyr Val Pro Ala Ala Tyr Thr Ser Lys
1040 1045 1050
Ile Asp Pro Ala Thr Gly Phe Ile Asn Ile Phe Asp Phe Lys Lys
1055 1060 1065
Tyr Ser Gly Ser Gly Ile Asn Ala Lys Val Lys Asp Lys Lys Glu
1070 1075 1080
Phe Leu Met Ser Met Asn Ser Ile Arg Tyr Ile Asn Glu Cys Ser
1085 1090 1095
Glu Glu Tyr Glu Lys Ile Gly His Arg Glu Leu Phe Ala Phe Ser
1100 1105 1110
Phe Asp Tyr Asn Asn Phe Lys Thr Tyr Asn Val Ser Ser Pro Val
1115 1120 1125
Asn Glu Trp Thr Ala Tyr Thr Tyr Gly Glu Arg Ile Lys Lys Leu
1130 1135 1140
Tyr Lys Asp Gly Arg Trp Leu Arg Ser Glu Val Leu Asn Leu Thr
1145 1150 1155
Glu Asn Leu Ile Lys Leu Met Glu Gln Tyr Asn Ile Glu Tyr Lys
1160 1165 1170
Asp Gly His Asp Ile Arg Glu Asp Ile Ser His Met Asp Glu Thr
1175 1180 1185
Arg Asn Ala Asp Phe Ile Cys Ser Leu Phe Glu Glu Leu Lys Tyr
1190 1195 1200
Thr Val Gln Leu Arg Asn Ser Lys Ser Glu Ala Glu Asp Glu Asn
1205 1210 1215
Tyr Asp Arg Leu Val Ser Pro Ile Leu Asn Ser Ser Asn Gly Phe
1220 1225 1230
Tyr Asp Ser Ser Asp Tyr Met Glu Asn Glu Asn Asn Thr Thr His
1235 1240 1245
Thr Met Pro Lys Asp Ala Asp Ala Asn Gly Ala Tyr Cys Ile Ala
1250 1255 1260
Leu Lys Gly Leu Tyr Glu Ile Asn Lys Ile Lys Gln Asn Trp Ser
1265 1270 1275
Asp Asp Lys Lys Phe Lys Glu Asn Glu Leu Tyr Ile Asn Val Thr
1280 1285 1290
Glu Trp Leu Asp Tyr Ile Gln Asn Arg Arg Phe Glu
1295 1300 1305
<210> 1159
<211> 1259
<212> БЕЛОК
<213> Synergistes jonesii
<400> 1159
Met Ala Asn Ser Leu Lys Asp Phe Thr Asn Ile Tyr Gln Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Glu Glu His Ile
20 25 30
Asn Arg Lys Leu Ile Ile Met His Asp Glu Lys Arg Gly Glu Asp Tyr
35 40 45
Lys Ser Val Thr Lys Leu Ile Asp Asp Tyr His Arg Lys Phe Ile His
50 55 60
Glu Thr Leu Asp Pro Ala His Phe Asp Trp Asn Pro Leu Ala Glu Ala
65 70 75 80
Leu Ile Gln Ser Gly Ser Lys Asn Asn Lys Ala Leu Pro Ala Glu Gln
85 90 95
Lys Glu Met Arg Glu Lys Ile Ile Ser Met Phe Thr Ser Gln Ala Val
100 105 110
Tyr Lys Lys Leu Phe Lys Lys Glu Leu Phe Ser Glu Leu Leu Pro Glu
115 120 125
Met Ile Lys Ser Glu Leu Val Ser Asp Leu Glu Lys Gln Ala Gln Leu
130 135 140
Asp Ala Val Lys Ser Phe Asp Lys Phe Ser Thr Tyr Phe Thr Gly Phe
145 150 155 160
His Glu Asn Arg Lys Asn Ile Tyr Ser Lys Lys Asp Thr Ser Thr Ser
165 170 175
Ile Ala Phe Arg Ile Val His Gln Asn Phe Pro Lys Phe Leu Ala Asn
180 185 190
Val Arg Ala Tyr Thr Leu Ile Lys Glu Arg Ala Pro Glu Val Ile Asp
195 200 205
Lys Ala Gln Lys Glu Leu Ser Gly Ile Leu Gly Gly Lys Thr Leu Asp
210 215 220
Asp Ile Phe Ser Ile Glu Ser Phe Asn Asn Val Leu Thr Gln Asp Lys
225 230 235 240
Ile Asp Tyr Tyr Asn Gln Ile Ile Gly Gly Val Ser Gly Lys Ala Gly
245 250 255
Asp Lys Lys Leu Arg Gly Val Asn Glu Phe Ser Asn Leu Tyr Arg Gln
260 265 270
Gln His Pro Glu Val Ala Ser Leu Arg Ile Lys Met Val Pro Leu Tyr
275 280 285
Lys Gln Ile Leu Ser Asp Arg Thr Thr Leu Ser Phe Val Pro Glu Ala
290 295 300
Leu Lys Asp Asp Glu Gln Ala Ile Asn Ala Val Asp Gly Leu Arg Ser
305 310 315 320
Glu Leu Glu Arg Asn Asp Ile Phe Asn Arg Ile Lys Arg Leu Phe Gly
325 330 335
Lys Asn Asn Leu Tyr Ser Leu Asp Lys Ile Trp Ile Lys Asn Ser Ser
340 345 350
Ile Ser Ala Phe Ser Asn Glu Leu Phe Lys Asn Trp Ser Phe Ile Glu
355 360 365
Asp Ala Leu Lys Glu Phe Lys Glu Asn Glu Phe Asn Gly Ala Arg Ser
370 375 380
Ala Gly Lys Lys Ala Glu Lys Trp Leu Lys Ser Lys Tyr Phe Ser Phe
385 390 395 400
Ala Asp Ile Asp Ala Ala Val Lys Ser Tyr Ser Glu Gln Val Ser Ala
405 410 415
Asp Ile Ser Ser Ala Pro Ser Ala Ser Tyr Phe Ala Lys Phe Thr Asn
420 425 430
Leu Ile Glu Thr Ala Ala Glu Asn Gly Arg Lys Phe Ser Tyr Phe Ala
435 440 445
Ala Glu Ser Lys Ala Phe Arg Gly Asp Asp Gly Lys Thr Glu Ile Ile
450 455 460
Lys Ala Tyr Leu Asp Ser Leu Asn Asp Ile Leu His Cys Leu Lys Pro
465 470 475 480
Phe Glu Thr Glu Asp Ile Ser Asp Ile Asp Thr Glu Phe Tyr Ser Ala
485 490 495
Phe Ala Glu Ile Tyr Asp Ser Val Lys Asp Val Ile Pro Val Tyr Asn
500 505 510
Ala Val Arg Asn Tyr Thr Thr Gln Lys Pro Phe Ser Thr Glu Lys Phe
515 520 525
Lys Leu Asn Phe Glu Asn Pro Ala Leu Ala Lys Gly Trp Asp Lys Asn
530 535 540
Lys Glu Gln Asn Asn Thr Ala Ile Ile Leu Met Lys Asp Gly Lys Tyr
545 550 555 560
Tyr Leu Gly Val Ile Asp Lys Asn Asn Lys Leu Arg Ala Asp Asp Leu
565 570 575
Ala Asp Asp Gly Ser Ala Tyr Gly Tyr Met Lys Met Asn Tyr Lys Phe
580 585 590
Ile Pro Thr Pro His Met Glu Leu Pro Lys Val Phe Leu Pro Lys Arg
595 600 605
Ala Pro Lys Arg Tyr Asn Pro Ser Arg Glu Ile Leu Leu Ile Lys Glu
610 615 620
Asn Lys Thr Phe Ile Lys Asp Lys Asn Phe Asn Arg Thr Asp Cys His
625 630 635 640
Lys Leu Ile Asp Phe Phe Lys Asp Ser Ile Asn Lys His Lys Asp Trp
645 650 655
Arg Thr Phe Gly Phe Asp Phe Ser Asp Thr Asp Ser Tyr Glu Asp Ile
660 665 670
Ser Asp Phe Tyr Met Glu Val Gln Asp Gln Gly Tyr Lys Leu Thr Phe
675 680 685
Thr Arg Leu Ser Ala Glu Lys Ile Asp Lys Trp Val Glu Glu Gly Arg
690 695 700
Leu Phe Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Asp Gly Ala Gln
705 710 715 720
Gly Ser Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Ile Phe Ser Glu
725 730 735
Glu Asn Leu Lys Asp Val Val Leu Lys Leu Asn Gly Glu Ala Glu Leu
740 745 750
Phe Phe Arg Arg Lys Ser Ile Asp Lys Pro Ala Val His Ala Lys Gly
755 760 765
Ser Met Lys Val Asn Arg Arg Asp Ile Asp Gly Asn Pro Ile Asp Glu
770 775 780
Gly Thr Tyr Val Glu Ile Cys Gly Tyr Ala Asn Gly Lys Arg Asp Met
785 790 795 800
Ala Ser Leu Asn Ala Gly Ala Arg Gly Leu Ile Glu Ser Gly Leu Val
805 810 815
Arg Ile Thr Glu Val Lys His Glu Leu Val Lys Asp Lys Arg Tyr Thr
820 825 830
Ile Asp Lys Tyr Phe Phe His Val Pro Phe Thr Ile Asn Phe Lys Ala
835 840 845
Gln Gly Gln Gly Asn Ile Asn Ser Asp Val Asn Leu Phe Leu Arg Asn
850 855 860
Asn Lys Asp Val Asn Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu
865 870 875 880
Val Tyr Val Ser Leu Ile Asp Arg Asp Gly His Ile Lys Leu Gln Lys
885 890 895
Asp Phe Asn Ile Ile Gly Gly Met Asp Tyr His Ala Lys Leu Asn Gln
900 905 910
Lys Glu Lys Glu Arg Asp Thr Ala Arg Lys Ser Trp Lys Thr Ile Gly
915 920 925
Thr Ile Lys Glu Leu Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu
930 935 940
Ile Val Arg Leu Ala Val Asp Asn Asn Ala Val Ile Val Met Glu Asp
945 950 955 960
Leu Asn Ile Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
965 970 975
Tyr Gln Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val
980 985 990
Phe Lys Asp Ala Gly Tyr Asp Ala Pro Cys Gly Ile Leu Lys Gly Leu
995 1000 1005
Gln Leu Thr Glu Lys Phe Glu Ser Phe Thr Lys Leu Gly Lys Gln
1010 1015 1020
Cys Gly Ile Ile Phe Tyr Ile Pro Ala Gly Tyr Thr Ser Lys Ile
1025 1030 1035
Asp Pro Thr Thr Gly Phe Val Asn Leu Phe Asn Ile Asn Asp Val
1040 1045 1050
Ser Ser Lys Glu Lys Gln Lys Asp Phe Ile Gly Lys Leu Asp Ser
1055 1060 1065
Ile Arg Phe Asp Ala Lys Arg Asp Met Phe Thr Phe Glu Phe Asp
1070 1075 1080
Tyr Asp Lys Phe Arg Thr Tyr Gln Thr Ser Tyr Arg Lys Lys Trp
1085 1090 1095
Ala Val Trp Thr Asn Gly Lys Arg Ile Val Arg Glu Lys Asp Lys
1100 1105 1110
Asp Gly Lys Phe Arg Met Asn Asp Arg Leu Leu Thr Glu Asp Met
1115 1120 1125
Lys Asn Ile Leu Asn Lys Tyr Ala Leu Ala Tyr Lys Ala Gly Glu
1130 1135 1140
Asp Ile Leu Pro Asp Val Ile Ser Arg Asp Lys Ser Leu Ala Ser
1145 1150 1155
Glu Ile Phe Tyr Val Phe Lys Asn Thr Leu Gln Met Arg Asn Ser
1160 1165 1170
Lys Arg Asp Thr Gly Glu Asp Phe Ile Ile Ser Pro Val Leu Asn
1175 1180 1185
Ala Lys Gly Arg Phe Phe Asp Ser Arg Lys Thr Asp Ala Ala Leu
1190 1195 1200
Pro Ile Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys
1205 1210 1215
Gly Ser Leu Val Leu Asp Ala Ile Asp Glu Lys Leu Lys Glu Asp
1220 1225 1230
Gly Arg Ile Asp Tyr Lys Asp Met Ala Val Ser Asn Pro Lys Trp
1235 1240 1245
Phe Glu Phe Met Gln Thr Arg Lys Phe Asp Phe
1250 1255
<210> 1160
<211> 1238
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methanoplasma termitum
<400> 1160
Met Asn Asn Tyr Asp Glu Phe Thr Lys Leu Tyr Pro Ile Gln Lys Thr
1 5 10 15
Ile Arg Phe Glu Leu Lys Pro Gln Gly Arg Thr Met Glu His Leu Glu
20 25 30
Thr Phe Asn Phe Phe Glu Glu Asp Arg Asp Arg Ala Glu Lys Tyr Lys
35 40 45
Ile Leu Lys Glu Ala Ile Asp Glu Tyr His Lys Lys Phe Ile Asp Glu
50 55 60
His Leu Thr Asn Met Ser Leu Asp Trp Asn Ser Leu Lys Gln Ile Ser
65 70 75 80
Glu Lys Tyr Tyr Lys Ser Arg Glu Glu Lys Asp Lys Lys Val Phe Leu
85 90 95
Ser Glu Gln Lys Arg Met Arg Gln Glu Ile Val Ser Glu Phe Lys Lys
100 105 110
Asp Asp Arg Phe Lys Asp Leu Phe Ser Lys Lys Leu Phe Ser Glu Leu
115 120 125
Leu Lys Glu Glu Ile Tyr Lys Lys Gly Asn His Gln Glu Ile Asp Ala
130 135 140
Leu Lys Ser Phe Asp Lys Phe Ser Gly Tyr Phe Ile Gly Leu His Glu
145 150 155 160
Asn Arg Lys Asn Met Tyr Ser Asp Gly Asp Glu Ile Thr Ala Ile Ser
165 170 175
Asn Arg Ile Val Asn Glu Asn Phe Pro Lys Phe Leu Asp Asn Leu Gln
180 185 190
Lys Tyr Gln Glu Ala Arg Lys Lys Tyr Pro Glu Trp Ile Ile Lys Ala
195 200 205
Glu Ser Ala Leu Val Ala His Asn Ile Lys Met Asp Glu Val Phe Ser
210 215 220
Leu Glu Tyr Phe Asn Lys Val Leu Asn Gln Glu Gly Ile Gln Arg Tyr
225 230 235 240
Asn Leu Ala Leu Gly Gly Tyr Val Thr Lys Ser Gly Glu Lys Met Met
245 250 255
Gly Leu Asn Asp Ala Leu Asn Leu Ala His Gln Ser Glu Lys Ser Ser
260 265 270
Lys Gly Arg Ile His Met Thr Pro Leu Phe Lys Gln Ile Leu Ser Glu
275 280 285
Lys Glu Ser Phe Ser Tyr Ile Pro Asp Val Phe Thr Glu Asp Ser Gln
290 295 300
Leu Leu Pro Ser Ile Gly Gly Phe Phe Ala Gln Ile Glu Asn Asp Lys
305 310 315 320
Asp Gly Asn Ile Phe Asp Arg Ala Leu Glu Leu Ile Ser Ser Tyr Ala
325 330 335
Glu Tyr Asp Thr Glu Arg Ile Tyr Ile Arg Gln Ala Asp Ile Asn Arg
340 345 350
Val Ser Asn Val Ile Phe Gly Glu Trp Gly Thr Leu Gly Gly Leu Met
355 360 365
Arg Glu Tyr Lys Ala Asp Ser Ile Asn Asp Ile Asn Leu Glu Arg Thr
370 375 380
Cys Lys Lys Val Asp Lys Trp Leu Asp Ser Lys Glu Phe Ala Leu Ser
385 390 395 400
Asp Val Leu Glu Ala Ile Lys Arg Thr Gly Asn Asn Asp Ala Phe Asn
405 410 415
Glu Tyr Ile Ser Lys Met Arg Thr Ala Arg Glu Lys Ile Asp Ala Ala
420 425 430
Arg Lys Glu Met Lys Phe Ile Ser Glu Lys Ile Ser Gly Asp Glu Glu
435 440 445
Ser Ile His Ile Ile Lys Thr Leu Leu Asp Ser Val Gln Gln Phe Leu
450 455 460
His Phe Phe Asn Leu Phe Lys Ala Arg Gln Asp Ile Pro Leu Asp Gly
465 470 475 480
Ala Phe Tyr Ala Glu Phe Asp Glu Val His Ser Lys Leu Phe Ala Ile
485 490 495
Val Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Lys Asn Asn Leu
500 505 510
Asn Thr Lys Lys Ile Lys Leu Asn Phe Lys Asn Pro Thr Leu Ala Asn
515 520 525
Gly Trp Asp Gln Asn Lys Val Tyr Asp Tyr Ala Ser Leu Ile Phe Leu
530 535 540
Arg Asp Gly Asn Tyr Tyr Leu Gly Ile Ile Asn Pro Lys Arg Lys Lys
545 550 555 560
Asn Ile Lys Phe Glu Gln Gly Ser Gly Asn Gly Pro Phe Tyr Arg Lys
565 570 575
Met Val Tyr Lys Gln Ile Pro Gly Pro Asn Lys Asn Leu Pro Arg Val
580 585 590
Phe Leu Thr Ser Thr Lys Gly Lys Lys Glu Tyr Lys Pro Ser Lys Glu
595 600 605
Ile Ile Glu Gly Tyr Glu Ala Asp Lys His Ile Arg Gly Asp Lys Phe
610 615 620
Asp Leu Asp Phe Cys His Lys Leu Ile Asp Phe Phe Lys Glu Ser Ile
625 630 635 640
Glu Lys His Lys Asp Trp Ser Lys Phe Asn Phe Tyr Phe Ser Pro Thr
645 650 655
Glu Ser Tyr Gly Asp Ile Ser Glu Phe Tyr Leu Asp Val Glu Lys Gln
660 665 670
Gly Tyr Arg Met His Phe Glu Asn Ile Ser Ala Glu Thr Ile Asp Glu
675 680 685
Tyr Val Glu Lys Gly Asp Leu Phe Leu Phe Gln Ile Tyr Asn Lys Asp
690 695 700
Phe Val Lys Ala Ala Thr Gly Lys Lys Asp Met His Thr Ile Tyr Trp
705 710 715 720
Asn Ala Ala Phe Ser Pro Glu Asn Leu Gln Asp Val Val Val Lys Leu
725 730 735
Asn Gly Glu Ala Glu Leu Phe Tyr Arg Asp Lys Ser Asp Ile Lys Glu
740 745 750
Ile Val His Arg Glu Gly Glu Ile Leu Val Asn Arg Thr Tyr Asn Gly
755 760 765
Arg Thr Pro Val Pro Asp Lys Ile His Lys Lys Leu Thr Asp Tyr His
770 775 780
Asn Gly Arg Thr Lys Asp Leu Gly Glu Ala Lys Glu Tyr Leu Asp Lys
785 790 795 800
Val Arg Tyr Phe Lys Ala His Tyr Asp Ile Thr Lys Asp Arg Arg Tyr
805 810 815
Leu Asn Asp Lys Ile Tyr Phe His Val Pro Leu Thr Leu Asn Phe Lys
820 825 830
Ala Asn Gly Lys Lys Asn Leu Asn Lys Met Val Ile Glu Lys Phe Leu
835 840 845
Ser Asp Glu Lys Ala His Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn
850 855 860
Leu Leu Tyr Tyr Ser Ile Ile Asp Arg Ser Gly Lys Ile Ile Asp Gln
865 870 875 880
Gln Ser Leu Asn Val Ile Asp Gly Phe Asp Tyr Arg Glu Lys Leu Asn
885 890 895
Gln Arg Glu Ile Glu Met Lys Asp Ala Arg Gln Ser Trp Asn Ala Ile
900 905 910
Gly Lys Ile Lys Asp Leu Lys Glu Gly Tyr Leu Ser Lys Ala Val His
915 920 925
Glu Ile Thr Lys Met Ala Ile Gln Tyr Asn Ala Ile Val Val Met Glu
930 935 940
Glu Leu Asn Tyr Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln
945 950 955 960
Ile Tyr Gln Lys Phe Glu Asn Met Leu Ile Asp Lys Met Asn Tyr Leu
965 970 975
Val Phe Lys Asp Ala Pro Asp Glu Ser Pro Gly Gly Val Leu Asn Ala
980 985 990
Tyr Gln Leu Thr Asn Pro Leu Glu Ser Phe Ala Lys Leu Gly Lys Gln
995 1000 1005
Thr Gly Ile Leu Phe Tyr Val Pro Ala Ala Tyr Thr Ser Lys Ile
1010 1015 1020
Asp Pro Thr Thr Gly Phe Val Asn Leu Phe Asn Thr Ser Ser Lys
1025 1030 1035
Thr Asn Ala Gln Glu Arg Lys Glu Phe Leu Gln Lys Phe Glu Ser
1040 1045 1050
Ile Ser Tyr Ser Ala Lys Asp Gly Gly Ile Phe Ala Phe Ala Phe
1055 1060 1065
Asp Tyr Arg Lys Phe Gly Thr Ser Lys Thr Asp His Lys Asn Val
1070 1075 1080
Trp Thr Ala Tyr Thr Asn Gly Glu Arg Met Arg Tyr Ile Lys Glu
1085 1090 1095
Lys Lys Arg Asn Glu Leu Phe Asp Pro Ser Lys Glu Ile Lys Glu
1100 1105 1110
Ala Leu Thr Ser Ser Gly Ile Lys Tyr Asp Gly Gly Gln Asn Ile
1115 1120 1125
Leu Pro Asp Ile Leu Arg Ser Asn Asn Asn Gly Leu Ile Tyr Thr
1130 1135 1140
Met Tyr Ser Ser Phe Ile Ala Ala Ile Gln Met Arg Val Tyr Asp
1145 1150 1155
Gly Lys Glu Asp Tyr Ile Ile Ser Pro Ile Lys Asn Ser Lys Gly
1160 1165 1170
Glu Phe Phe Arg Thr Asp Pro Lys Arg Arg Glu Leu Pro Ile Asp
1175 1180 1185
Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Leu Arg Gly Glu Leu
1190 1195 1200
Thr Met Arg Ala Ile Ala Glu Lys Phe Asp Pro Asp Ser Glu Lys
1205 1210 1215
Met Ala Lys Leu Glu Leu Lys His Lys Asp Trp Phe Glu Phe Met
1220 1225 1230
Gln Thr Arg Gly Asp
1235
<210> 1161
<211> 1227
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methanomethylophilus alvus
<400> 1161
Met Asp Ala Lys Glu Phe Thr Gly Gln Tyr Pro Leu Ser Lys Thr Leu
1 5 10 15
Arg Phe Glu Leu Arg Pro Ile Gly Arg Thr Trp Asp Asn Leu Glu Ala
20 25 30
Ser Gly Tyr Leu Ala Glu Asp Arg His Arg Ala Glu Cys Tyr Pro Arg
35 40 45
Ala Lys Glu Leu Leu Asp Asp Asn His Arg Ala Phe Leu Asn Arg Val
50 55 60
Leu Pro Gln Ile Asp Met Asp Trp His Pro Ile Ala Glu Ala Phe Cys
65 70 75 80
Lys Val His Lys Asn Pro Gly Asn Lys Glu Leu Ala Gln Asp Tyr Asn
85 90 95
Leu Gln Leu Ser Lys Arg Arg Lys Glu Ile Ser Ala Tyr Leu Gln Asp
100 105 110
Ala Asp Gly Tyr Lys Gly Leu Phe Ala Lys Pro Ala Leu Asp Glu Ala
115 120 125
Met Lys Ile Ala Lys Glu Asn Gly Asn Glu Ser Asp Ile Glu Val Leu
130 135 140
Glu Ala Phe Asn Gly Phe Ser Val Tyr Phe Thr Gly Tyr His Glu Ser
145 150 155 160
Arg Glu Asn Ile Tyr Ser Asp Glu Asp Met Val Ser Val Ala Tyr Arg
165 170 175
Ile Thr Glu Asp Asn Phe Pro Arg Phe Val Ser Asn Ala Leu Ile Phe
180 185 190
Asp Lys Leu Asn Glu Ser His Pro Asp Ile Ile Ser Glu Val Ser Gly
195 200 205
Asn Leu Gly Val Asp Asp Ile Gly Lys Tyr Phe Asp Val Ser Asn Tyr
210 215 220
Asn Asn Phe Leu Ser Gln Ala Gly Ile Asp Asp Tyr Asn His Ile Ile
225 230 235 240
Gly Gly His Thr Thr Glu Asp Gly Leu Ile Gln Ala Phe Asn Val Val
245 250 255
Leu Asn Leu Arg His Gln Lys Asp Pro Gly Phe Glu Lys Ile Gln Phe
260 265 270
Lys Gln Leu Tyr Lys Gln Ile Leu Ser Val Arg Thr Ser Lys Ser Tyr
275 280 285
Ile Pro Lys Gln Phe Asp Asn Ser Lys Glu Met Val Asp Cys Ile Cys
290 295 300
Asp Tyr Val Ser Lys Ile Glu Lys Ser Glu Thr Val Glu Arg Ala Leu
305 310 315 320
Lys Leu Val Arg Asn Ile Ser Ser Phe Asp Leu Arg Gly Ile Phe Val
325 330 335
Asn Lys Lys Asn Leu Arg Ile Leu Ser Asn Lys Leu Ile Gly Asp Trp
340 345 350
Asp Ala Ile Glu Thr Ala Leu Met His Ser Ser Ser Ser Glu Asn Asp
355 360 365
Lys Lys Ser Val Tyr Asp Ser Ala Glu Ala Phe Thr Leu Asp Asp Ile
370 375 380
Phe Ser Ser Val Lys Lys Phe Ser Asp Ala Ser Ala Glu Asp Ile Gly
385 390 395 400
Asn Arg Ala Glu Asp Ile Cys Arg Val Ile Ser Glu Thr Ala Pro Phe
405 410 415
Ile Asn Asp Leu Arg Ala Val Asp Leu Asp Ser Leu Asn Asp Asp Gly
420 425 430
Tyr Glu Ala Ala Val Ser Lys Ile Arg Glu Ser Leu Glu Pro Tyr Met
435 440 445
Asp Leu Phe His Glu Leu Glu Ile Phe Ser Val Gly Asp Glu Phe Pro
450 455 460
Lys Cys Ala Ala Phe Tyr Ser Glu Leu Glu Glu Val Ser Glu Gln Leu
465 470 475 480
Ile Glu Ile Ile Pro Leu Phe Asn Lys Ala Arg Ser Phe Cys Thr Arg
485 490 495
Lys Arg Tyr Ser Thr Asp Lys Ile Lys Val Asn Leu Lys Phe Pro Thr
500 505 510
Leu Ala Asp Gly Trp Asp Leu Asn Lys Glu Arg Asp Asn Lys Ala Ala
515 520 525
Ile Leu Arg Lys Asp Gly Lys Tyr Tyr Leu Ala Ile Leu Asp Met Lys
530 535 540
Lys Asp Leu Ser Ser Ile Arg Thr Ser Asp Glu Asp Glu Ser Ser Phe
545 550 555 560
Glu Lys Met Glu Tyr Lys Leu Leu Pro Ser Pro Val Lys Met Leu Pro
565 570 575
Lys Ile Phe Val Lys Ser Lys Ala Ala Lys Glu Lys Tyr Gly Leu Thr
580 585 590
Asp Arg Met Leu Glu Cys Tyr Asp Lys Gly Met His Lys Ser Gly Ser
595 600 605
Ala Phe Asp Leu Gly Phe Cys His Glu Leu Ile Asp Tyr Tyr Lys Arg
610 615 620
Cys Ile Ala Glu Tyr Pro Gly Trp Asp Val Phe Asp Phe Lys Phe Arg
625 630 635 640
Glu Thr Ser Asp Tyr Gly Ser Met Lys Glu Phe Asn Glu Asp Val Ala
645 650 655
Gly Ala Gly Tyr Tyr Met Ser Leu Arg Lys Ile Pro Cys Ser Glu Val
660 665 670
Tyr Arg Leu Leu Asp Glu Lys Ser Ile Tyr Leu Phe Gln Ile Tyr Asn
675 680 685
Lys Asp Tyr Ser Glu Asn Ala His Gly Asn Lys Asn Met His Thr Met
690 695 700
Tyr Trp Glu Gly Leu Phe Ser Pro Gln Asn Leu Glu Ser Pro Val Phe
705 710 715 720
Lys Leu Ser Gly Gly Ala Glu Leu Phe Phe Arg Lys Ser Ser Ile Pro
725 730 735
Asn Asp Ala Lys Thr Val His Pro Lys Gly Ser Val Leu Val Pro Arg
740 745 750
Asn Asp Val Asn Gly Arg Arg Ile Pro Asp Ser Ile Tyr Arg Glu Leu
755 760 765
Thr Arg Tyr Phe Asn Arg Gly Asp Cys Arg Ile Ser Asp Glu Ala Lys
770 775 780
Ser Tyr Leu Asp Lys Val Lys Thr Lys Lys Ala Asp His Asp Ile Val
785 790 795 800
Lys Asp Arg Arg Phe Thr Val Asp Lys Met Met Phe His Val Pro Ile
805 810 815
Ala Met Asn Phe Lys Ala Ile Ser Lys Pro Asn Leu Asn Lys Lys Val
820 825 830
Ile Asp Gly Ile Ile Asp Asp Gln Asp Leu Lys Ile Ile Gly Ile Asp
835 840 845
Arg Gly Glu Arg Asn Leu Ile Tyr Val Thr Met Val Asp Arg Lys Gly
850 855 860
Asn Ile Leu Tyr Gln Asp Ser Leu Asn Ile Leu Asn Gly Tyr Asp Tyr
865 870 875 880
Arg Lys Ala Leu Asp Val Arg Glu Tyr Asp Asn Lys Glu Ala Arg Arg
885 890 895
Asn Trp Thr Lys Val Glu Gly Ile Arg Lys Met Lys Glu Gly Tyr Leu
900 905 910
Ser Leu Ala Val Ser Lys Leu Ala Asp Met Ile Ile Glu Asn Asn Ala
915 920 925
Ile Ile Val Met Glu Asp Leu Asn His Gly Phe Lys Ala Gly Arg Ser
930 935 940
Lys Ile Glu Lys Gln Val Tyr Gln Lys Phe Glu Ser Met Leu Ile Asn
945 950 955 960
Lys Leu Gly Tyr Met Val Leu Lys Asp Lys Ser Ile Asp Gln Ser Gly
965 970 975
Gly Ala Leu His Gly Tyr Gln Leu Ala Asn His Val Thr Thr Leu Ala
980 985 990
Ser Val Gly Lys Gln Cys Gly Val Ile Phe Tyr Ile Pro Ala Ala Phe
995 1000 1005
Thr Ser Lys Ile Asp Pro Thr Thr Gly Phe Ala Asp Leu Phe Ala
1010 1015 1020
Leu Ser Asn Val Lys Asn Val Ala Ser Met Arg Glu Phe Phe Ser
1025 1030 1035
Lys Met Lys Ser Val Ile Tyr Asp Lys Ala Glu Gly Lys Phe Ala
1040 1045 1050
Phe Thr Phe Asp Tyr Leu Asp Tyr Asn Val Lys Ser Glu Cys Gly
1055 1060 1065
Arg Thr Leu Trp Thr Val Tyr Thr Val Gly Glu Arg Phe Thr Tyr
1070 1075 1080
Ser Arg Val Asn Arg Glu Tyr Val Arg Lys Val Pro Thr Asp Ile
1085 1090 1095
Ile Tyr Asp Ala Leu Gln Lys Ala Gly Ile Ser Val Glu Gly Asp
1100 1105 1110
Leu Arg Asp Arg Ile Ala Glu Ser Asp Gly Asp Thr Leu Lys Ser
1115 1120 1125
Ile Phe Tyr Ala Phe Lys Tyr Ala Leu Asp Met Arg Val Glu Asn
1130 1135 1140
Arg Glu Glu Asp Tyr Ile Gln Ser Pro Val Lys Asn Ala Ser Gly
1145 1150 1155
Glu Phe Phe Cys Ser Lys Asn Ala Gly Lys Ser Leu Pro Gln Asp
1160 1165 1170
Ser Asp Ala Asn Gly Ala Tyr Asn Ile Ala Leu Lys Gly Ile Leu
1175 1180 1185
Gln Leu Arg Met Leu Ser Glu Gln Tyr Asp Pro Asn Ala Glu Ser
1190 1195 1200
Ile Arg Leu Pro Leu Ile Thr Asn Lys Ala Trp Leu Thr Phe Met
1205 1210 1215
Gln Ser Gly Met Lys Thr Trp Lys Asn
1220 1225
<210> 1162
<211> 1334
<212> БЕЛОК
<213> Succinivibrio dextrinosolvens
<400> 1162
Met Ser Ser Leu Thr Lys Phe Thr Asn Lys Tyr Ser Lys Gln Leu Thr
1 5 10 15
Ile Lys Asn Glu Leu Ile Pro Val Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Glu Asn Gly Leu Ile Asp Gly Asp Glu Gln Leu Asn Glu Asn Tyr Gln
35 40 45
Lys Ala Lys Ile Ile Val Asp Asp Phe Leu Arg Asp Phe Ile Asn Lys
50 55 60
Ala Leu Asn Asn Thr Gln Ile Gly Asn Trp Arg Glu Leu Ala Asp Ala
65 70 75 80
Leu Asn Lys Glu Asp Glu Asp Asn Ile Glu Lys Leu Gln Asp Lys Ile
85 90 95
Arg Gly Ile Ile Val Ser Lys Phe Glu Thr Phe Asp Leu Phe Ser Ser
100 105 110
Tyr Ser Ile Lys Lys Asp Glu Lys Ile Ile Asp Asp Asp Asn Asp Val
115 120 125
Glu Glu Glu Glu Leu Asp Leu Gly Lys Lys Thr Ser Ser Phe Lys Tyr
130 135 140
Ile Phe Lys Lys Asn Leu Phe Lys Leu Val Leu Pro Ser Tyr Leu Lys
145 150 155 160
Thr Thr Asn Gln Asp Lys Leu Lys Ile Ile Ser Ser Phe Asp Asn Phe
165 170 175
Ser Thr Tyr Phe Arg Gly Phe Phe Glu Asn Arg Lys Asn Ile Phe Thr
180 185 190
Lys Lys Pro Ile Ser Thr Ser Ile Ala Tyr Arg Ile Val His Asp Asn
195 200 205
Phe Pro Lys Phe Leu Asp Asn Ile Arg Cys Phe Asn Val Trp Gln Thr
210 215 220
Glu Cys Pro Gln Leu Ile Val Lys Ala Asp Asn Tyr Leu Lys Ser Lys
225 230 235 240
Asn Val Ile Ala Lys Asp Lys Ser Leu Ala Asn Tyr Phe Thr Val Gly
245 250 255
Ala Tyr Asp Tyr Phe Leu Ser Gln Asn Gly Ile Asp Phe Tyr Asn Asn
260 265 270
Ile Ile Gly Gly Leu Pro Ala Phe Ala Gly His Glu Lys Ile Gln Gly
275 280 285
Leu Asn Glu Phe Ile Asn Gln Glu Cys Gln Lys Asp Ser Glu Leu Lys
290 295 300
Ser Lys Leu Lys Asn Arg His Ala Phe Lys Met Ala Val Leu Phe Lys
305 310 315 320
Gln Ile Leu Ser Asp Arg Glu Lys Ser Phe Val Ile Asp Glu Phe Glu
325 330 335
Ser Asp Ala Gln Val Ile Asp Ala Val Lys Asn Phe Tyr Ala Glu Gln
340 345 350
Cys Lys Asp Asn Asn Val Ile Phe Asn Leu Leu Asn Leu Ile Lys Asn
355 360 365
Ile Ala Phe Leu Ser Asp Asp Glu Leu Asp Gly Ile Phe Ile Glu Gly
370 375 380
Lys Tyr Leu Ser Ser Val Ser Gln Lys Leu Tyr Ser Asp Trp Ser Lys
385 390 395 400
Leu Arg Asn Asp Ile Glu Asp Ser Ala Asn Ser Lys Gln Gly Asn Lys
405 410 415
Glu Leu Ala Lys Lys Ile Lys Thr Asn Lys Gly Asp Val Glu Lys Ala
420 425 430
Ile Ser Lys Tyr Glu Phe Ser Leu Ser Glu Leu Asn Ser Ile Val His
435 440 445
Asp Asn Thr Lys Phe Ser Asp Leu Leu Ser Cys Thr Leu His Lys Val
450 455 460
Ala Ser Glu Lys Leu Val Lys Val Asn Glu Gly Asp Trp Pro Lys His
465 470 475 480
Leu Lys Asn Asn Glu Glu Lys Gln Lys Ile Lys Glu Pro Leu Asp Ala
485 490 495
Leu Leu Glu Ile Tyr Asn Thr Leu Leu Ile Phe Asn Cys Lys Ser Phe
500 505 510
Asn Lys Asn Gly Asn Phe Tyr Val Asp Tyr Asp Arg Cys Ile Asn Glu
515 520 525
Leu Ser Ser Val Val Tyr Leu Tyr Asn Lys Thr Arg Asn Tyr Cys Thr
530 535 540
Lys Lys Pro Tyr Asn Thr Asp Lys Phe Lys Leu Asn Phe Asn Ser Pro
545 550 555 560
Gln Leu Gly Glu Gly Phe Ser Lys Ser Lys Glu Asn Asp Cys Leu Thr
565 570 575
Leu Leu Phe Lys Lys Asp Asp Asn Tyr Tyr Val Gly Ile Ile Arg Lys
580 585 590
Gly Ala Lys Ile Asn Phe Asp Asp Thr Gln Ala Ile Ala Asp Asn Thr
595 600 605
Asp Asn Cys Ile Phe Lys Met Asn Tyr Phe Leu Leu Lys Asp Ala Lys
610 615 620
Lys Phe Ile Pro Lys Cys Ser Ile Gln Leu Lys Glu Val Lys Ala His
625 630 635 640
Phe Lys Lys Ser Glu Asp Asp Tyr Ile Leu Ser Asp Lys Glu Lys Phe
645 650 655
Ala Ser Pro Leu Val Ile Lys Lys Ser Thr Phe Leu Leu Ala Thr Ala
660 665 670
His Val Lys Gly Lys Lys Gly Asn Ile Lys Lys Phe Gln Lys Glu Tyr
675 680 685
Ser Lys Glu Asn Pro Thr Glu Tyr Arg Asn Ser Leu Asn Glu Trp Ile
690 695 700
Ala Phe Cys Lys Glu Phe Leu Lys Thr Tyr Lys Ala Ala Thr Ile Phe
705 710 715 720
Asp Ile Thr Thr Leu Lys Lys Ala Glu Glu Tyr Ala Asp Ile Val Glu
725 730 735
Phe Tyr Lys Asp Val Asp Asn Leu Cys Tyr Lys Leu Glu Phe Cys Pro
740 745 750
Ile Lys Thr Ser Phe Ile Glu Asn Leu Ile Asp Asn Gly Asp Leu Tyr
755 760 765
Leu Phe Arg Ile Asn Asn Lys Asp Phe Ser Ser Lys Ser Thr Gly Thr
770 775 780
Lys Asn Leu His Thr Leu Tyr Leu Gln Ala Ile Phe Asp Glu Arg Asn
785 790 795 800
Leu Asn Asn Pro Thr Ile Met Leu Asn Gly Gly Ala Glu Leu Phe Tyr
805 810 815
Arg Lys Glu Ser Ile Glu Gln Lys Asn Arg Ile Thr His Lys Ala Gly
820 825 830
Ser Ile Leu Val Asn Lys Val Cys Lys Asp Gly Thr Ser Leu Asp Asp
835 840 845
Lys Ile Arg Asn Glu Ile Tyr Gln Tyr Glu Asn Lys Phe Ile Asp Thr
850 855 860
Leu Ser Asp Glu Ala Lys Lys Val Leu Pro Asn Val Ile Lys Lys Glu
865 870 875 880
Ala Thr His Asp Ile Thr Lys Asp Lys Arg Phe Thr Ser Asp Lys Phe
885 890 895
Phe Phe His Cys Pro Leu Thr Ile Asn Tyr Lys Glu Gly Asp Thr Lys
900 905 910
Gln Phe Asn Asn Glu Val Leu Ser Phe Leu Arg Gly Asn Pro Asp Ile
915 920 925
Asn Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Ile Tyr Val Thr
930 935 940
Val Ile Asn Gln Lys Gly Glu Ile Leu Asp Ser Val Ser Phe Asn Thr
945 950 955 960
Val Thr Asn Lys Ser Ser Lys Ile Glu Gln Thr Val Asp Tyr Glu Glu
965 970 975
Lys Leu Ala Val Arg Glu Lys Glu Arg Ile Glu Ala Lys Arg Ser Trp
980 985 990
Asp Ser Ile Ser Lys Ile Ala Thr Leu Lys Glu Gly Tyr Leu Ser Ala
995 1000 1005
Ile Val His Glu Ile Cys Leu Leu Met Ile Lys His Asn Ala Ile
1010 1015 1020
Val Val Leu Glu Asn Leu Asn Ala Gly Phe Lys Arg Ile Arg Gly
1025 1030 1035
Gly Leu Ser Glu Lys Ser Val Tyr Gln Lys Phe Glu Lys Met Leu
1040 1045 1050
Ile Asn Lys Leu Asn Tyr Phe Val Ser Lys Lys Glu Ser Asp Trp
1055 1060 1065
Asn Lys Pro Ser Gly Leu Leu Asn Gly Leu Gln Leu Ser Asp Gln
1070 1075 1080
Phe Glu Ser Phe Glu Lys Leu Gly Ile Gln Ser Gly Phe Ile Phe
1085 1090 1095
Tyr Val Pro Ala Ala Tyr Thr Ser Lys Ile Asp Pro Thr Thr Gly
1100 1105 1110
Phe Ala Asn Val Leu Asn Leu Ser Lys Val Arg Asn Val Asp Ala
1115 1120 1125
Ile Lys Ser Phe Phe Ser Asn Phe Asn Glu Ile Ser Tyr Ser Lys
1130 1135 1140
Lys Glu Ala Leu Phe Lys Phe Ser Phe Asp Leu Asp Ser Leu Ser
1145 1150 1155
Lys Lys Gly Phe Ser Ser Phe Val Lys Phe Ser Lys Ser Lys Trp
1160 1165 1170
Asn Val Tyr Thr Phe Gly Glu Arg Ile Ile Lys Pro Lys Asn Lys
1175 1180 1185
Gln Gly Tyr Arg Glu Asp Lys Arg Ile Asn Leu Thr Phe Glu Met
1190 1195 1200
Lys Lys Leu Leu Asn Glu Tyr Lys Val Ser Phe Asp Leu Glu Asn
1205 1210 1215
Asn Leu Ile Pro Asn Leu Thr Ser Ala Asn Leu Lys Asp Thr Phe
1220 1225 1230
Trp Lys Glu Leu Phe Phe Ile Phe Lys Thr Thr Leu Gln Leu Arg
1235 1240 1245
Asn Ser Val Thr Asn Gly Lys Glu Asp Val Leu Ile Ser Pro Val
1250 1255 1260
Lys Asn Ala Lys Gly Glu Phe Phe Val Ser Gly Thr His Asn Lys
1265 1270 1275
Thr Leu Pro Gln Asp Cys Asp Ala Asn Gly Ala Tyr His Ile Ala
1280 1285 1290
Leu Lys Gly Leu Met Ile Leu Glu Arg Asn Asn Leu Val Arg Glu
1295 1300 1305
Glu Lys Asp Thr Lys Lys Ile Met Ala Ile Ser Asn Val Asp Trp
1310 1315 1320
Phe Glu Tyr Val Gln Lys Arg Arg Gly Val Leu
1325 1330
<210> 1163
<211> 1307
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 1163
Met Thr Gln Phe Glu Gly Phe Thr Asn Leu Tyr Gln Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Lys His Ile Gln
20 25 30
Glu Gln Gly Phe Ile Glu Glu Asp Lys Ala Arg Asn Asp His Tyr Lys
35 40 45
Glu Leu Lys Pro Ile Ile Asp Arg Ile Tyr Lys Thr Tyr Ala Asp Gln
50 55 60
Cys Leu Gln Leu Val Gln Leu Asp Trp Glu Asn Leu Ser Ala Ala Ile
65 70 75 80
Asp Ser Tyr Arg Lys Glu Lys Thr Glu Glu Thr Arg Asn Ala Leu Ile
85 90 95
Glu Glu Gln Ala Thr Tyr Arg Asn Ala Ile His Asp Tyr Phe Ile Gly
100 105 110
Arg Thr Asp Asn Leu Thr Asp Ala Ile Asn Lys Arg His Ala Glu Ile
115 120 125
Tyr Lys Gly Leu Phe Lys Ala Glu Leu Phe Asn Gly Lys Val Leu Lys
130 135 140
Gln Leu Gly Thr Val Thr Thr Thr Glu His Glu Asn Ala Leu Leu Arg
145 150 155 160
Ser Phe Asp Lys Phe Thr Thr Tyr Phe Ser Gly Phe Tyr Glu Asn Arg
165 170 175
Lys Asn Val Phe Ser Ala Glu Asp Ile Ser Thr Ala Ile Pro His Arg
180 185 190
Ile Val Gln Asp Asn Phe Pro Lys Phe Lys Glu Asn Cys His Ile Phe
195 200 205
Thr Arg Leu Ile Thr Ala Val Pro Ser Leu Arg Glu His Phe Glu Asn
210 215 220
Val Lys Lys Ala Ile Gly Ile Phe Val Ser Thr Ser Ile Glu Glu Val
225 230 235 240
Phe Ser Phe Pro Phe Tyr Asn Gln Leu Leu Thr Gln Thr Gln Ile Asp
245 250 255
Leu Tyr Asn Gln Leu Leu Gly Gly Ile Ser Arg Glu Ala Gly Thr Glu
260 265 270
Lys Ile Lys Gly Leu Asn Glu Val Leu Asn Leu Ala Ile Gln Lys Asn
275 280 285
Asp Glu Thr Ala His Ile Ile Ala Ser Leu Pro His Arg Phe Ile Pro
290 295 300
Leu Phe Lys Gln Ile Leu Ser Asp Arg Asn Thr Leu Ser Phe Ile Leu
305 310 315 320
Glu Glu Phe Lys Ser Asp Glu Glu Val Ile Gln Ser Phe Cys Lys Tyr
325 330 335
Lys Thr Leu Leu Arg Asn Glu Asn Val Leu Glu Thr Ala Glu Ala Leu
340 345 350
Phe Asn Glu Leu Asn Ser Ile Asp Leu Thr His Ile Phe Ile Ser His
355 360 365
Lys Lys Leu Glu Thr Ile Ser Ser Ala Leu Cys Asp His Trp Asp Thr
370 375 380
Leu Arg Asn Ala Leu Tyr Glu Arg Arg Ile Ser Glu Leu Thr Gly Lys
385 390 395 400
Ile Thr Lys Ser Ala Lys Glu Lys Val Gln Arg Ser Leu Lys His Glu
405 410 415
Asp Ile Asn Leu Gln Glu Ile Ile Ser Ala Ala Gly Lys Glu Leu Ser
420 425 430
Glu Ala Phe Lys Gln Lys Thr Ser Glu Ile Leu Ser His Ala His Ala
435 440 445
Ala Leu Asp Gln Pro Leu Pro Thr Thr Leu Lys Lys Gln Glu Glu Lys
450 455 460
Glu Ile Leu Lys Ser Gln Leu Asp Ser Leu Leu Gly Leu Tyr His Leu
465 470 475 480
Leu Asp Trp Phe Ala Val Asp Glu Ser Asn Glu Val Asp Pro Glu Phe
485 490 495
Ser Ala Arg Leu Thr Gly Ile Lys Leu Glu Met Glu Pro Ser Leu Ser
500 505 510
Phe Tyr Asn Lys Ala Arg Asn Tyr Ala Thr Lys Lys Pro Tyr Ser Val
515 520 525
Glu Lys Phe Lys Leu Asn Phe Gln Met Pro Thr Leu Ala Ser Gly Trp
530 535 540
Asp Val Asn Lys Glu Lys Asn Asn Gly Ala Ile Leu Phe Val Lys Asn
545 550 555 560
Gly Leu Tyr Tyr Leu Gly Ile Met Pro Lys Gln Lys Gly Arg Tyr Lys
565 570 575
Ala Leu Ser Phe Glu Pro Thr Glu Lys Thr Ser Glu Gly Phe Asp Lys
580 585 590
Met Tyr Tyr Asp Tyr Phe Pro Asp Ala Ala Lys Met Ile Pro Lys Cys
595 600 605
Ser Thr Gln Leu Lys Ala Val Thr Ala His Phe Gln Thr His Thr Thr
610 615 620
Pro Ile Leu Leu Ser Asn Asn Phe Ile Glu Pro Leu Glu Ile Thr Lys
625 630 635 640
Glu Ile Tyr Asp Leu Asn Asn Pro Glu Lys Glu Pro Lys Lys Phe Gln
645 650 655
Thr Ala Tyr Ala Lys Lys Thr Gly Asp Gln Lys Gly Tyr Arg Glu Ala
660 665 670
Leu Cys Lys Trp Ile Asp Phe Thr Arg Asp Phe Leu Ser Lys Tyr Thr
675 680 685
Lys Thr Thr Ser Ile Asp Leu Ser Ser Leu Arg Pro Ser Ser Gln Tyr
690 695 700
Lys Asp Leu Gly Glu Tyr Tyr Ala Glu Leu Asn Pro Leu Leu Tyr His
705 710 715 720
Ile Ser Phe Gln Arg Ile Ala Glu Lys Glu Ile Met Asp Ala Val Glu
725 730 735
Thr Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Lys
740 745 750
Gly His His Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Thr Gly Leu
755 760 765
Phe Ser Pro Glu Asn Leu Ala Lys Thr Ser Ile Lys Leu Asn Gly Gln
770 775 780
Ala Glu Leu Phe Tyr Arg Pro Lys Ser Arg Met Lys Arg Met Ala His
785 790 795 800
Arg Leu Gly Glu Lys Met Leu Asn Lys Lys Leu Lys Asp Gln Lys Thr
805 810 815
Pro Ile Pro Asp Thr Leu Tyr Gln Glu Leu Tyr Asp Tyr Val Asn His
820 825 830
Arg Leu Ser His Asp Leu Ser Asp Glu Ala Arg Ala Leu Leu Pro Asn
835 840 845
Val Ile Thr Lys Glu Val Ser His Glu Ile Ile Lys Asp Arg Arg Phe
850 855 860
Thr Ser Asp Lys Phe Phe Phe His Val Pro Ile Thr Leu Asn Tyr Gln
865 870 875 880
Ala Ala Asn Ser Pro Ser Lys Phe Asn Gln Arg Val Asn Ala Tyr Leu
885 890 895
Lys Glu His Pro Glu Thr Pro Ile Ile Gly Ile Asp Arg Gly Glu Arg
900 905 910
Asn Leu Ile Tyr Ile Thr Val Ile Asp Ser Thr Gly Lys Ile Leu Glu
915 920 925
Gln Arg Ser Leu Asn Thr Ile Gln Gln Phe Asp Tyr Gln Lys Lys Leu
930 935 940
Asp Asn Arg Glu Lys Glu Arg Val Ala Ala Arg Gln Ala Trp Ser Val
945 950 955 960
Val Gly Thr Ile Lys Asp Leu Lys Gln Gly Tyr Leu Ser Gln Val Ile
965 970 975
His Glu Ile Val Asp Leu Met Ile His Tyr Gln Ala Val Val Val Leu
980 985 990
Glu Asn Leu Asn Phe Gly Phe Lys Ser Lys Arg Thr Gly Ile Ala Glu
995 1000 1005
Lys Ala Val Tyr Gln Gln Phe Glu Lys Met Leu Ile Asp Lys Leu
1010 1015 1020
Asn Cys Leu Val Leu Lys Asp Tyr Pro Ala Glu Lys Val Gly Gly
1025 1030 1035
Val Leu Asn Pro Tyr Gln Leu Thr Asp Gln Phe Thr Ser Phe Ala
1040 1045 1050
Lys Met Gly Thr Gln Ser Gly Phe Leu Phe Tyr Val Pro Ala Pro
1055 1060 1065
Tyr Thr Ser Lys Ile Asp Pro Leu Thr Gly Phe Val Asp Pro Phe
1070 1075 1080
Val Trp Lys Thr Ile Lys Asn His Glu Ser Arg Lys His Phe Leu
1085 1090 1095
Glu Gly Phe Asp Phe Leu His Tyr Asp Val Lys Thr Gly Asp Phe
1100 1105 1110
Ile Leu His Phe Lys Met Asn Arg Asn Leu Ser Phe Gln Arg Gly
1115 1120 1125
Leu Pro Gly Phe Met Pro Ala Trp Asp Ile Val Phe Glu Lys Asn
1130 1135 1140
Glu Thr Gln Phe Asp Ala Lys Gly Thr Pro Phe Ile Ala Gly Lys
1145 1150 1155
Arg Ile Val Pro Val Ile Glu Asn His Arg Phe Thr Gly Arg Tyr
1160 1165 1170
Arg Asp Leu Tyr Pro Ala Asn Glu Leu Ile Ala Leu Leu Glu Glu
1175 1180 1185
Lys Gly Ile Val Phe Arg Asp Gly Ser Asn Ile Leu Pro Lys Leu
1190 1195 1200
Leu Glu Asn Asp Asp Ser His Ala Ile Asp Thr Met Val Ala Leu
1205 1210 1215
Ile Arg Ser Val Leu Gln Met Arg Asn Ser Asn Ala Ala Thr Gly
1220 1225 1230
Glu Asp Tyr Ile Asn Ser Pro Val Arg Asp Leu Asn Gly Val Cys
1235 1240 1245
Phe Asp Ser Arg Phe Gln Asn Pro Glu Trp Pro Met Asp Ala Asp
1250 1255 1260
Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Gln Leu Leu Leu
1265 1270 1275
Asn His Leu Lys Glu Ser Lys Asp Leu Lys Leu Gln Asn Gly Ile
1280 1285 1290
Ser Asn Gln Asp Trp Leu Ala Tyr Ile Gln Glu Leu Arg Asn
1295 1300 1305
<210> 1164
<211> 1310
<212> БЕЛОК
<213> Helcococcus kunzii
<400> 1164
Met Phe Glu Lys Leu Ser Asn Ile Val Ser Ile Ser Lys Thr Ile Arg
1 5 10 15
Phe Lys Leu Ile Pro Val Gly Lys Thr Leu Glu Asn Ile Glu Lys Leu
20 25 30
Gly Lys Leu Glu Lys Asp Phe Glu Arg Ser Asp Phe Tyr Pro Ile Leu
35 40 45
Lys Asn Ile Ser Asp Asp Tyr Tyr Arg Gln Tyr Ile Lys Glu Lys Leu
50 55 60
Ser Asp Leu Asn Leu Asp Trp Gln Lys Leu Tyr Asp Ala His Glu Leu
65 70 75 80
Leu Asp Ser Ser Lys Lys Glu Ser Gln Lys Asn Leu Glu Met Ile Gln
85 90 95
Ala Gln Tyr Arg Lys Val Leu Phe Asn Ile Leu Ser Gly Glu Leu Asp
100 105 110
Lys Ser Gly Glu Lys Asn Ser Lys Asp Leu Ile Lys Asn Asn Lys Ala
115 120 125
Leu Tyr Gly Lys Leu Phe Lys Lys Gln Phe Ile Leu Glu Val Leu Pro
130 135 140
Asp Phe Val Asn Asn Asn Asp Ser Tyr Ser Glu Glu Asp Leu Glu Gly
145 150 155 160
Leu Asn Leu Tyr Ser Lys Phe Thr Thr Arg Leu Lys Asn Phe Trp Glu
165 170 175
Thr Arg Lys Asn Val Phe Thr Asp Lys Asp Ile Val Thr Ala Ile Pro
180 185 190
Phe Arg Ala Val Asn Glu Asn Phe Gly Phe Tyr Tyr Asp Asn Ile Lys
195 200 205
Ile Phe Asn Lys Asn Ile Glu Tyr Leu Glu Asn Lys Ile Pro Asn Leu
210 215 220
Glu Asn Glu Leu Lys Glu Ala Asp Ile Leu Asp Asp Asn Arg Ser Val
225 230 235 240
Lys Asp Tyr Phe Thr Pro Asn Gly Phe Asn Tyr Val Ile Thr Gln Asp
245 250 255
Gly Ile Asp Val Tyr Gln Ala Ile Arg Gly Gly Phe Thr Lys Glu Asn
260 265 270
Gly Glu Lys Val Gln Gly Ile Asn Glu Ile Leu Asn Leu Thr Gln Gln
275 280 285
Gln Leu Arg Arg Lys Pro Glu Thr Lys Asn Val Lys Leu Gly Val Leu
290 295 300
Thr Lys Leu Arg Lys Gln Ile Leu Glu Tyr Ser Glu Ser Thr Ser Phe
305 310 315 320
Leu Ile Asp Gln Ile Glu Asp Asp Asn Asp Leu Val Asp Arg Ile Asn
325 330 335
Lys Phe Asn Val Ser Phe Phe Glu Ser Thr Glu Val Ser Pro Ser Leu
340 345 350
Phe Glu Gln Ile Glu Arg Leu Tyr Asn Ala Leu Lys Ser Ile Lys Lys
355 360 365
Glu Glu Val Tyr Ile Asp Ala Arg Asn Thr Gln Lys Phe Ser Gln Met
370 375 380
Leu Phe Gly Gln Trp Asp Val Ile Arg Arg Gly Tyr Thr Val Lys Ile
385 390 395 400
Thr Glu Gly Ser Lys Glu Glu Lys Lys Lys Tyr Lys Glu Tyr Leu Glu
405 410 415
Leu Asp Glu Thr Ser Lys Ala Lys Arg Tyr Leu Asn Ile Arg Glu Ile
420 425 430
Glu Glu Leu Val Asn Leu Val Glu Gly Phe Glu Glu Val Asp Val Phe
435 440 445
Ser Val Leu Leu Glu Lys Phe Lys Met Asn Asn Ile Glu Arg Ser Glu
450 455 460
Phe Glu Ala Pro Ile Tyr Gly Ser Pro Ile Lys Leu Glu Ala Ile Lys
465 470 475 480
Glu Tyr Leu Glu Lys His Leu Glu Glu Tyr His Lys Trp Lys Leu Leu
485 490 495
Leu Ile Gly Asn Asp Asp Leu Asp Thr Asp Glu Thr Phe Tyr Pro Leu
500 505 510
Leu Asn Glu Val Ile Ser Asp Tyr Tyr Ile Ile Pro Leu Tyr Asn Leu
515 520 525
Thr Arg Asn Tyr Leu Thr Arg Lys His Ser Asp Lys Asp Lys Ile Lys
530 535 540
Val Asn Phe Asp Phe Pro Thr Leu Ala Asp Gly Trp Ser Glu Ser Lys
545 550 555 560
Ile Ser Asp Asn Arg Ser Ile Ile Leu Arg Lys Gly Gly Tyr Tyr Tyr
565 570 575
Leu Gly Ile Leu Ile Asp Asn Lys Leu Leu Ile Asn Lys Lys Asn Lys
580 585 590
Ser Lys Lys Ile Tyr Glu Ile Leu Ile Tyr Asn Gln Ile Pro Glu Phe
595 600 605
Ser Lys Ser Ile Pro Asn Tyr Pro Phe Thr Lys Lys Val Lys Glu His
610 615 620
Phe Lys Asn Asn Val Ser Asp Phe Gln Leu Ile Asp Gly Tyr Val Ser
625 630 635 640
Pro Leu Ile Ile Thr Lys Glu Ile Tyr Asp Ile Lys Lys Glu Lys Lys
645 650 655
Tyr Lys Lys Asp Phe Tyr Lys Asp Asn Asn Thr Asn Lys Asn Tyr Leu
660 665 670
Tyr Thr Ile Tyr Lys Trp Ile Glu Phe Cys Lys Gln Phe Leu Tyr Lys
675 680 685
Tyr Lys Gly Pro Asn Lys Glu Ser Tyr Lys Glu Met Tyr Asp Phe Ser
690 695 700
Thr Leu Lys Asp Thr Ser Leu Tyr Val Asn Leu Asn Asp Phe Tyr Ala
705 710 715 720
Asp Val Asn Ser Cys Ala Tyr Arg Val Leu Phe Asn Lys Ile Asp Glu
725 730 735
Asn Thr Ile Asp Asn Ala Val Glu Asp Gly Lys Leu Leu Leu Phe Gln
740 745 750
Ile Tyr Asn Lys Asp Phe Ser Pro Glu Ser Lys Gly Lys Lys Asn Leu
755 760 765
His Thr Leu Tyr Trp Leu Ser Met Phe Ser Glu Glu Asn Leu Arg Thr
770 775 780
Arg Lys Leu Lys Leu Asn Gly Gln Ala Glu Ile Phe Tyr Arg Lys Lys
785 790 795 800
Leu Glu Lys Lys Pro Ile Ile His Lys Glu Gly Ser Ile Leu Leu Asn
805 810 815
Lys Ile Asp Lys Glu Gly Asn Thr Ile Pro Glu Asn Ile Tyr His Glu
820 825 830
Cys Tyr Arg Tyr Leu Asn Lys Lys Ile Gly Arg Glu Asp Leu Ser Asp
835 840 845
Glu Ala Ile Ala Leu Phe Asn Lys Asp Val Leu Lys Tyr Lys Glu Ala
850 855 860
Arg Phe Asp Ile Ile Lys Asp Arg Arg Tyr Ser Glu Ser Gln Phe Phe
865 870 875 880
Phe His Val Pro Ile Thr Phe Asn Trp Asp Ile Lys Thr Asn Lys Asn
885 890 895
Val Asn Gln Ile Val Gln Gly Met Ile Lys Asp Gly Glu Ile Lys His
900 905 910
Ile Ile Gly Ile Asp Arg Gly Glu Arg His Leu Leu Tyr Tyr Ser Val
915 920 925
Ile Asp Leu Glu Gly Asn Ile Val Glu Gln Gly Ser Leu Asn Thr Leu
930 935 940
Glu Gln Asn Arg Phe Asp Asn Ser Thr Val Lys Val Asp Tyr Gln Asn
945 950 955 960
Lys Leu Arg Thr Arg Glu Glu Asp Arg Asp Arg Ala Arg Lys Asn Trp
965 970 975
Thr Asn Ile Asn Lys Ile Lys Glu Leu Lys Asp Gly Tyr Leu Ser His
980 985 990
Val Val His Lys Leu Ser Arg Leu Ile Ile Lys Tyr Glu Ala Ile Val
995 1000 1005
Ile Met Glu Asn Leu Asn Gln Gly Phe Lys Arg Gly Arg Phe Lys
1010 1015 1020
Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Leu Ala Leu Met Asn
1025 1030 1035
Lys Leu Ser Ala Leu Ser Phe Lys Glu Lys Tyr Asp Glu Arg Lys
1040 1045 1050
Asn Leu Glu Pro Ser Gly Ile Leu Asn Pro Ile Gln Ala Cys Tyr
1055 1060 1065
Pro Val Asp Ala Tyr Gln Glu Leu Gln Gly Gln Asn Gly Ile Val
1070 1075 1080
Phe Tyr Leu Pro Ala Ala Tyr Thr Ser Val Ile Asp Pro Val Thr
1085 1090 1095
Gly Phe Thr Asn Leu Phe Arg Leu Lys Ser Ile Asn Ser Ser Lys
1100 1105 1110
Tyr Glu Glu Phe Ile Lys Lys Phe Lys Asn Ile Tyr Phe Asp Asn
1115 1120 1125
Glu Glu Glu Asp Phe Lys Phe Ile Phe Asn Tyr Lys Asp Phe Ala
1130 1135 1140
Lys Ala Asn Leu Val Ile Leu Asn Asn Ile Lys Ser Lys Asp Trp
1145 1150 1155
Lys Ile Ser Thr Arg Gly Glu Arg Ile Ser Tyr Asn Ser Lys Lys
1160 1165 1170
Lys Glu Tyr Phe Tyr Val Gln Pro Thr Glu Phe Leu Ile Asn Lys
1175 1180 1185
Leu Lys Glu Leu Asn Ile Asp Tyr Glu Asn Ile Asp Ile Ile Pro
1190 1195 1200
Leu Ile Asp Asn Leu Glu Glu Lys Ala Lys Arg Lys Ile Leu Lys
1205 1210 1215
Ala Leu Phe Asp Thr Phe Lys Tyr Ser Val Gln Leu Arg Asn Tyr
1220 1225 1230
Asp Phe Glu Asn Asp Tyr Ile Ile Ser Pro Thr Ala Asp Asp Asn
1235 1240 1245
Gly Asn Tyr Tyr Asn Ser Asn Glu Ile Asp Ile Asp Lys Thr Asn
1250 1255 1260
Leu Pro Asn Asn Gly Asp Ala Asn Gly Ala Phe Asn Ile Ala Arg
1265 1270 1275
Lys Gly Leu Leu Leu Lys Asp Arg Ile Val Asn Ser Asn Glu Ser
1280 1285 1290
Lys Val Asp Leu Lys Ile Lys Asn Glu Asp Trp Ile Asn Phe Ile
1295 1300 1305
Ile Ser
1310
<210> 1165
<211> 1255
<212> БЕЛОК
<213> Butyrivibrio proteoclasticus
<400> 1165
Met Leu Leu Tyr Glu Asn Tyr Thr Lys Arg Asn Gln Ile Thr Lys Ser
1 5 10 15
Leu Arg Leu Glu Leu Arg Pro Gln Gly Lys Thr Leu Arg Asn Ile Lys
20 25 30
Glu Leu Asn Leu Leu Glu Gln Asp Lys Ala Ile Tyr Ala Leu Leu Glu
35 40 45
Arg Leu Lys Pro Val Ile Asp Glu Gly Ile Lys Asp Ile Ala Arg Asp
50 55 60
Thr Leu Lys Asn Cys Glu Leu Ser Phe Glu Lys Leu Tyr Glu His Phe
65 70 75 80
Leu Ser Gly Asp Lys Lys Ala Tyr Ala Lys Glu Ser Glu Arg Leu Lys
85 90 95
Lys Glu Ile Val Lys Thr Leu Ile Lys Asn Leu Pro Glu Gly Ile Gly
100 105 110
Lys Ile Ser Glu Ile Asn Ser Ala Lys Tyr Leu Asn Gly Val Leu Tyr
115 120 125
Asp Phe Ile Asp Lys Thr His Lys Asp Ser Glu Glu Lys Gln Asn Ile
130 135 140
Leu Ser Asp Ile Leu Glu Thr Lys Gly Tyr Leu Ala Leu Phe Ser Lys
145 150 155 160
Phe Leu Thr Ser Arg Ile Thr Thr Leu Glu Gln Ser Met Pro Lys Arg
165 170 175
Val Ile Glu Asn Phe Glu Ile Tyr Ala Ala Asn Ile Pro Lys Met Gln
180 185 190
Asp Ala Leu Glu Arg Gly Ala Val Ser Phe Ala Ile Glu Tyr Glu Ser
195 200 205
Ile Cys Ser Val Asp Tyr Tyr Asn Gln Ile Leu Ser Gln Glu Asp Ile
210 215 220
Asp Ser Tyr Asn Arg Leu Ile Ser Gly Ile Met Asp Glu Asp Gly Ala
225 230 235 240
Lys Glu Lys Gly Ile Asn Gln Thr Ile Ser Glu Leu Met Gln Arg Phe
245 250 255
Leu Thr Thr Arg Ile Thr Ala Leu Thr Lys Asn Ile Lys Ile Lys Ser
260 265 270
Glu His Leu Glu Glu Lys Pro Phe Arg Ile Leu Lys Gln Leu His Lys
275 280 285
Gln Ile Leu Glu Glu Arg Glu Lys Ala Phe Thr Ile Asp His Ile Asp
290 295 300
Ser Asp Glu Glu Val Val Gln Val Thr Lys Glu Ala Phe Glu Gln Thr
305 310 315 320
Lys Glu Gln Trp Glu Asn Ile Lys Lys Ile Asn Gly Phe Tyr Ala Lys
325 330 335
Asp Pro Gly Asp Ile Thr Leu Phe Ile Val Val Gly Pro Asn Gln Thr
340 345 350
His Val Leu Ser Gln Leu Ile Tyr Gly Glu His Asp Arg Ile Arg Leu
355 360 365
Leu Leu Glu Glu Tyr Glu Lys Asn Thr Leu Glu Val Leu Pro Arg Arg
370 375 380
Thr Lys Ser Glu Lys Ala Arg Tyr Asp Lys Phe Val Asn Ala Val Pro
385 390 395 400
Lys Lys Val Ala Lys Glu Ser His Thr Phe Asp Gly Leu Gln Lys Met
405 410 415
Thr Gly Asp Asp Arg Leu Phe Ile Leu Tyr Arg Asp Glu Leu Ala Arg
420 425 430
Asn Tyr Met Arg Ile Lys Glu Ala Tyr Gly Thr Phe Glu Arg Asp Ile
435 440 445
Leu Lys Ser Arg Arg Gly Ile Lys Gly Asn Arg Asp Val Gln Glu Ser
450 455 460
Leu Val Ser Phe Tyr Asp Glu Leu Thr Lys Phe Arg Ser Ala Leu Arg
465 470 475 480
Ile Ile Asn Ser Gly Asn Asp Glu Lys Ala Asp Pro Ile Phe Tyr Asn
485 490 495
Thr Phe Asp Gly Ile Phe Glu Lys Ala Asn Arg Thr Tyr Lys Ala Glu
500 505 510
Asn Leu Cys Arg Asn Tyr Val Thr Lys Ser Pro Ala Asp Asp Ala Arg
515 520 525
Ile Met Ala Ser Cys Leu Gly Thr Pro Ala Arg Leu Arg Thr His Trp
530 535 540
Trp Asn Gly Glu Glu Asn Phe Ala Ile Asn Asp Val Ala Met Ile Arg
545 550 555 560
Arg Gly Asp Glu Tyr Tyr Tyr Phe Val Leu Thr Pro Asp Val Lys Pro
565 570 575
Val Asp Leu Lys Thr Lys Asp Glu Thr Asp Ala Gln Ile Phe Val Gln
580 585 590
Arg Lys Gly Ala Lys Ser Phe Leu Gly Leu Pro Lys Ala Leu Phe Lys
595 600 605
Cys Ile Leu Glu Pro Tyr Phe Glu Ser Pro Glu His Lys Asn Asp Lys
610 615 620
Asn Cys Val Ile Glu Glu Tyr Val Ser Lys Pro Leu Thr Ile Asp Arg
625 630 635 640
Arg Ala Tyr Asp Ile Phe Lys Asn Gly Thr Phe Lys Lys Thr Asn Ile
645 650 655
Gly Ile Asp Gly Leu Thr Glu Glu Lys Phe Lys Asp Asp Cys Arg Tyr
660 665 670
Leu Ile Asp Val Tyr Lys Glu Phe Ile Ala Val Tyr Thr Arg Tyr Ser
675 680 685
Cys Phe Asn Met Ser Gly Leu Lys Arg Ala Asp Glu Tyr Asn Asp Ile
690 695 700
Gly Glu Phe Phe Ser Asp Val Asp Thr Arg Leu Cys Thr Met Glu Trp
705 710 715 720
Ile Pro Val Ser Phe Glu Arg Ile Asn Asp Met Val Asp Lys Lys Glu
725 730 735
Gly Leu Leu Phe Leu Val Arg Ser Met Phe Leu Tyr Asn Arg Pro Arg
740 745 750
Lys Pro Tyr Glu Arg Thr Phe Ile Gln Leu Phe Ser Asp Ser Asn Met
755 760 765
Glu His Thr Ser Met Leu Leu Asn Ser Arg Ala Met Ile Gln Tyr Arg
770 775 780
Ala Ala Ser Leu Pro Arg Arg Val Thr His Lys Lys Gly Ser Ile Leu
785 790 795 800
Val Ala Leu Arg Asp Ser Asn Gly Glu His Ile Pro Met His Ile Arg
805 810 815
Glu Ala Ile Tyr Lys Met Lys Asn Asn Phe Asp Ile Ser Ser Glu Asp
820 825 830
Phe Ile Met Ala Lys Ala Tyr Leu Ala Glu His Asp Val Ala Ile Lys
835 840 845
Lys Ala Asn Glu Asp Ile Ile Arg Asn Arg Arg Tyr Thr Glu Asp Lys
850 855 860
Phe Phe Leu Ser Leu Ser Tyr Thr Lys Asn Ala Asp Ile Ser Ala Arg
865 870 875 880
Thr Leu Asp Tyr Ile Asn Asp Lys Val Glu Glu Asp Thr Gln Asp Ser
885 890 895
Arg Met Ala Val Ile Val Thr Arg Asn Leu Lys Asp Leu Thr Tyr Val
900 905 910
Ala Val Val Asp Glu Lys Asn Asn Val Leu Glu Glu Lys Ser Leu Asn
915 920 925
Glu Ile Asp Gly Val Asn Tyr Arg Glu Leu Leu Lys Glu Arg Thr Lys
930 935 940
Ile Lys Tyr His Asp Lys Thr Arg Leu Trp Gln Tyr Asp Val Ser Ser
945 950 955 960
Lys Gly Leu Lys Glu Ala Tyr Val Glu Leu Ala Val Thr Gln Ile Ser
965 970 975
Lys Leu Ala Thr Lys Tyr Asn Ala Val Val Val Val Glu Ser Met Ser
980 985 990
Ser Thr Phe Lys Asp Lys Phe Ser Phe Leu Asp Glu Gln Ile Phe Lys
995 1000 1005
Ala Phe Glu Ala Arg Leu Cys Ala Arg Met Ser Asp Leu Ser Phe
1010 1015 1020
Asn Thr Ile Lys Glu Gly Glu Ala Gly Ser Ile Ser Asn Pro Ile
1025 1030 1035
Gln Val Ser Asn Asn Asn Gly Asn Ser Tyr Gln Asp Gly Val Ile
1040 1045 1050
Tyr Phe Leu Asn Asn Ala Tyr Thr Arg Thr Leu Cys Pro Asp Thr
1055 1060 1065
Gly Phe Val Asp Val Phe Asp Lys Thr Arg Leu Ile Thr Met Gln
1070 1075 1080
Ser Lys Arg Gln Phe Phe Ala Lys Met Lys Asp Ile Arg Ile Asp
1085 1090 1095
Asp Gly Glu Met Leu Phe Thr Phe Asn Leu Glu Glu Tyr Pro Thr
1100 1105 1110
Lys Arg Leu Leu Asp Arg Lys Glu Trp Thr Val Lys Ile Ala Gly
1115 1120 1125
Asp Gly Ser Tyr Phe Asp Lys Asp Lys Gly Glu Tyr Val Tyr Val
1130 1135 1140
Asn Asp Ile Val Arg Glu Gln Ile Ile Pro Ala Leu Leu Glu Asp
1145 1150 1155
Lys Ala Val Phe Asp Gly Asn Met Ala Glu Lys Phe Leu Asp Lys
1160 1165 1170
Thr Ala Ile Ser Gly Lys Ser Val Glu Leu Ile Tyr Lys Trp Phe
1175 1180 1185
Ala Asn Ala Leu Tyr Gly Ile Ile Thr Lys Lys Asp Gly Glu Lys
1190 1195 1200
Ile Tyr Arg Ser Pro Ile Thr Gly Thr Glu Ile Asp Val Ser Lys
1205 1210 1215
Asn Thr Thr Tyr Asn Phe Gly Lys Lys Phe Met Phe Lys Gln Glu
1220 1225 1230
Tyr Arg Gly Asp Gly Asp Phe Leu Asp Ala Phe Leu Asn Tyr Met
1235 1240 1245
Gln Ala Gln Asp Ile Ala Val
1250 1255
<210> 1166
<211> 1219
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1166
Met Asp Tyr Gly Asn Gly Gln Phe Glu Arg Arg Ala Pro Leu Thr Lys
1 5 10 15
Thr Ile Thr Leu Arg Leu Lys Pro Ile Gly Glu Thr Arg Glu Thr Ile
20 25 30
Arg Glu Gln Lys Leu Leu Glu Gln Asp Ala Ala Phe Arg Lys Leu Val
35 40 45
Glu Thr Val Thr Pro Ile Val Asp Asp Cys Ile Arg Lys Ile Ala Asp
50 55 60
Asn Ala Leu Cys His Phe Gly Thr Glu Tyr Asp Phe Ser Cys Leu Gly
65 70 75 80
Asn Ala Ile Ser Lys Asn Asp Ser Lys Ala Ile Lys Lys Glu Thr Glu
85 90 95
Lys Val Glu Lys Leu Leu Ala Lys Val Leu Thr Glu Asn Leu Pro Asp
100 105 110
Gly Leu Arg Lys Val Asn Asp Ile Asn Ser Ala Ala Phe Ile Gln Asp
115 120 125
Thr Leu Thr Ser Phe Val Gln Asp Asp Ala Asp Lys Arg Val Leu Ile
130 135 140
Gln Glu Leu Lys Gly Lys Thr Val Val Trp Leu Pro Asp Arg Val Phe
145 150 155 160
Glu Asn Phe Asn Ile Phe Ile Glu Asn Ala Glu Lys Met Arg Ile Leu
165 170 175
Leu Asp Ser Pro Leu Asn Glu Lys Ile Met Lys Phe Asp Pro Asp Ala
180 185 190
Glu Gln Tyr Ala Ser Leu Glu Phe Tyr Gly Gln Cys Leu Ser Gln Lys
195 200 205
Asp Ile Asp Ser Tyr Asn Leu Ile Ile Ser Gly Ile Tyr Ala Asp Asp
210 215 220
Glu Val Lys Asn Pro Gly Ile Asn Glu Ile Val Lys Glu Tyr Asn Gln
225 230 235 240
Gln Ile Arg Gly Asp Lys Asp Glu Ser Pro Leu Pro Lys Leu Lys Lys
245 250 255
Leu His Lys Gln Ile Leu Met Pro Val Glu Lys Ala Phe Phe Val Arg
260 265 270
Val Leu Ser Asn Asp Ser Asp Ala Arg Ser Ile Leu Glu Lys Ile Leu
275 280 285
Lys Asp Thr Glu Met Leu Pro Ser Lys Ile Ile Glu Ala Met Lys Glu
290 295 300
Ala Asp Ala Gly Asp Ile Ala Val Tyr Gly Ser Arg Leu His Glu Leu
305 310 315 320
Ser His Val Ile Tyr Gly Asp His Gly Lys Leu Ser Gln Ile Ile Tyr
325 330 335
Asp Lys Glu Ser Lys Arg Ile Ser Glu Leu Met Glu Thr Leu Ser Pro
340 345 350
Lys Glu Arg Lys Glu Ser Lys Lys Arg Leu Glu Gly Leu Glu Glu His
355 360 365
Ile Arg Lys Ser Thr Tyr Thr Phe Asp Glu Leu Asn Arg Tyr Ala Glu
370 375 380
Lys Asn Val Met Ala Ala Tyr Ile Ala Ala Val Glu Glu Ser Cys Ala
385 390 395 400
Glu Ile Met Arg Lys Glu Lys Asp Leu Arg Thr Leu Leu Ser Lys Glu
405 410 415
Asp Val Lys Ile Arg Gly Asn Arg His Asn Thr Leu Ile Val Lys Asn
420 425 430
Tyr Phe Asn Ala Trp Thr Val Phe Arg Asn Leu Ile Arg Ile Leu Arg
435 440 445
Arg Lys Ser Glu Ala Glu Ile Asp Ser Asp Phe Tyr Asp Val Leu Asp
450 455 460
Asp Ser Val Glu Val Leu Ser Leu Thr Tyr Lys Gly Glu Asn Leu Cys
465 470 475 480
Arg Ser Tyr Ile Thr Lys Lys Ile Gly Ser Asp Leu Lys Pro Glu Ile
485 490 495
Ala Thr Tyr Gly Ser Ala Leu Arg Pro Asn Ser Arg Trp Trp Ser Pro
500 505 510
Gly Glu Lys Phe Asn Val Lys Phe His Thr Ile Val Arg Arg Asp Gly
515 520 525
Arg Leu Tyr Tyr Phe Ile Leu Pro Lys Gly Ala Lys Pro Val Glu Leu
530 535 540
Glu Asp Met Asp Gly Asp Ile Glu Cys Leu Gln Met Arg Lys Ile Pro
545 550 555 560
Asn Pro Thr Ile Phe Leu Pro Lys Leu Val Phe Lys Asp Pro Glu Ala
565 570 575
Phe Phe Arg Asp Asn Pro Glu Ala Asp Glu Phe Val Phe Leu Ser Gly
580 585 590
Met Lys Ala Pro Val Thr Ile Thr Arg Glu Thr Tyr Glu Ala Tyr Arg
595 600 605
Tyr Lys Leu Tyr Thr Val Gly Lys Leu Arg Asp Gly Glu Val Ser Glu
610 615 620
Glu Glu Tyr Lys Arg Ala Leu Leu Gln Val Leu Thr Ala Tyr Lys Glu
625 630 635 640
Phe Leu Glu Asn Arg Met Ile Tyr Ala Asp Leu Asn Phe Gly Phe Lys
645 650 655
Asp Leu Glu Glu Tyr Lys Asp Ser Ser Glu Phe Ile Lys Gln Val Glu
660 665 670
Thr His Asn Thr Phe Met Cys Trp Ala Lys Val Ser Ser Ser Gln Leu
675 680 685
Asp Asp Leu Val Lys Ser Gly Asn Gly Leu Leu Phe Glu Ile Trp Ser
690 695 700
Glu Arg Leu Glu Ser Tyr Tyr Lys Tyr Gly Asn Glu Lys Val Leu Arg
705 710 715 720
Gly Tyr Glu Gly Val Leu Leu Ser Ile Leu Lys Asp Glu Asn Leu Val
725 730 735
Ser Met Arg Thr Leu Leu Asn Ser Arg Pro Met Leu Val Tyr Arg Pro
740 745 750
Lys Glu Ser Ser Lys Pro Met Val Val His Arg Asp Gly Ser Arg Val
755 760 765
Val Asp Arg Phe Asp Lys Asp Gly Lys Tyr Ile Pro Pro Glu Val His
770 775 780
Asp Glu Leu Tyr Arg Phe Phe Asn Asn Leu Leu Ile Lys Glu Lys Leu
785 790 795 800
Gly Glu Lys Ala Arg Lys Ile Leu Asp Asn Lys Lys Val Lys Val Lys
805 810 815
Val Leu Glu Ser Glu Arg Val Lys Trp Ser Lys Phe Tyr Asp Glu Gln
820 825 830
Phe Ala Val Thr Phe Ser Val Lys Lys Asn Ala Asp Cys Leu Asp Thr
835 840 845
Thr Lys Asp Leu Asn Ala Glu Val Met Glu Gln Tyr Ser Glu Ser Asn
850 855 860
Arg Leu Ile Leu Ile Arg Asn Thr Thr Asp Ile Leu Tyr Tyr Leu Val
865 870 875 880
Leu Asp Lys Asn Gly Lys Val Leu Lys Gln Arg Ser Leu Asn Ile Ile
885 890 895
Asn Asp Gly Ala Arg Asp Val Asp Trp Lys Glu Arg Phe Arg Gln Val
900 905 910
Thr Lys Asp Arg Asn Glu Gly Tyr Asn Glu Trp Asp Tyr Ser Arg Thr
915 920 925
Ser Asn Asp Leu Lys Glu Val Tyr Leu Asn Tyr Ala Leu Lys Glu Ile
930 935 940
Ala Glu Ala Val Ile Glu Tyr Asn Ala Ile Leu Ile Ile Glu Lys Met
945 950 955 960
Ser Asn Ala Phe Lys Asp Lys Tyr Ser Phe Leu Asp Asp Val Thr Phe
965 970 975
Lys Gly Phe Glu Thr Lys Leu Leu Ala Lys Leu Ser Asp Leu His Phe
980 985 990
Arg Gly Ile Lys Asp Gly Glu Pro Cys Ser Phe Thr Asn Pro Leu Gln
995 1000 1005
Leu Cys Gln Asn Asp Ser Asn Lys Ile Leu Gln Asp Gly Val Ile
1010 1015 1020
Phe Met Val Pro Asn Ser Met Thr Arg Ser Leu Asp Pro Asp Thr
1025 1030 1035
Gly Phe Ile Phe Ala Ile Asn Asp His Asn Ile Arg Thr Lys Lys
1040 1045 1050
Ala Lys Leu Asn Phe Leu Ser Lys Phe Asp Gln Leu Lys Val Ser
1055 1060 1065
Ser Glu Gly Cys Leu Ile Met Lys Tyr Ser Gly Asp Ser Leu Pro
1070 1075 1080
Thr His Asn Thr Asp Asn Arg Val Trp Asn Cys Cys Cys Asn His
1085 1090 1095
Pro Ile Thr Asn Tyr Asp Arg Glu Thr Lys Lys Val Glu Phe Ile
1100 1105 1110
Glu Glu Pro Val Glu Glu Leu Ser Arg Val Leu Glu Glu Asn Gly
1115 1120 1125
Ile Glu Thr Asp Thr Glu Leu Asn Lys Leu Asn Glu Arg Glu Asn
1130 1135 1140
Val Pro Gly Lys Val Val Asp Ala Ile Tyr Ser Leu Val Leu Asn
1145 1150 1155
Tyr Leu Arg Gly Thr Val Ser Gly Val Ala Gly Gln Arg Ala Val
1160 1165 1170
Tyr Tyr Ser Pro Val Thr Gly Lys Lys Tyr Asp Ile Ser Phe Ile
1175 1180 1185
Gln Ala Met Asn Leu Asn Arg Lys Cys Asp Tyr Tyr Arg Ile Gly
1190 1195 1200
Ser Lys Glu Arg Gly Glu Trp Thr Asp Phe Val Ala Gln Leu Ile
1205 1210 1215
Asn
<210> 1167
<211> 10715
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1167
gaattccgga tgagcattca tcaggcgggc aagaatgtga ataaaggccg gataaaactt 60
gtgcttattt ttctttacgg tctttaaaaa ggccgtaata tccagctgaa cggtctggtt 120
ataggtacat tgagcaactg actgaaatgc ctcaaaatgt tctttacgat gccattggga 180
tatatcaacg gtggtatatc cagtgatttt tttctccatt ttagcttcct tagctcctga 240
aaatctcgat aactcaaaaa atacgcccgg tagtgatctt atttcattat ggtgaaagtt 300
ggaacctctt acgtgccgat caacgtctca ttttcgccaa aagttggccc agggcttccc 360
ggtatcaaca gggacaccag gatttattta ttctgcgaag tgatcttccg tcacaggtat 420
ttattcggcg caaagtgcgt cgggtgatgc tgccaactta ctgatttagt gtatgatggt 480
gtttttgagg tgctccagtg gcttctgttt ctatcagctg tccctcctgt tcagctactg 540
acggggtggt gcgtaacggc aaaagcaccg ccggacatca gcgctagcgg agtgtatact 600
ggcttactat gttggcactg atgagggtgt cagtgaagtg cttcatgtgg caggagaaaa 660
aaggctgcac cggtgcgtca gcagaatatg tgatacagga tatattccgc ttcctcgctc 720
actgactcgc tacgctcggt cgttcgactg cggcgagcgg aaatggctta cgaacggggc 780
ggagatttcc tggaagatgc caggaagata cttaacaggg aagtgagagg gccgcggcaa 840
agccgttttt ccataggctc cgcccccctg acaagcatca cgaaatctga cgctcaaatc 900
agtggtggcg aaacccgaca ggactataaa gataccaggc gtttccccct ggcggctccc 960
tcgtgcgctc tcctgttcct gcctttcggt ttaccggtgt cattccgctg ttatggccgc 1020
gtttgtctca ttccacgcct gacactcagt tccgggtagg cagttcgctc caagctggac 1080
tgtatgcacg aaccccccgt tcagtccgac cgctgcgcct tatccggtaa ctatcgtctt 1140
gagtccaacc cggaaagaca tgcaaaagca ccactggcag cagccactgg taattgattt 1200
agaggagtta gtcttgaagt catgcgccgg ttaaggctaa actgaaagga caagttttgg 1260
tgactgcgct cctccaagcc agttacctcg gttcaaagag ttggtagctc agagaacctt 1320
cgaaaaaccg ccctgcaagg cggttttttc gttttcagag caagagatta cgcgcagacc 1380
aaaacgatct caagaagatc atcttattaa tcagataaaa tatttcatca aggaattggt 1440
tctaagctta tagaagcaat gattaaggaa gccaaaaaaa ataatattga tgcaatattt 1500
gtcttaggtc atccaagtta ttatccaaaa tttggtttta aaccagccac agaatatcag 1560
ataaaatgtg aatatgatgt cccagcggat gtttttatgg tactagattt gtcagctaaa 1620
ctagctagtt taaaaggaca aactgtctac tatgccgatg agtttggcaa aattttttag 1680
atctacaaaa ttataaacta aataaagatt cttataataa ctttatatat aatcgaaatg 1740
tagagaattt tataaggagt ctttatcatg tcaatttatc aagaatttgt taataaatat 1800
agtttaagta aaactctaag atttgagtta atcccacagg gtaaaacact tgaaaacata 1860
aaagcaagag gtttgatttt agatgatgag aaaagagcta aagactacaa aaaggctaaa 1920
caaataattg ataaatatca tcagtttttt atagaggaga tattaagttc ggtttgtatt 1980
agcgaagatt tattacaaaa ctattctgat gtttatttta aacttaaaaa gagtgatgat 2040
gataatctac aaaaagattt taaaagtgca aaagatacga taaagaaaca aatatctgaa 2100
tatataaagg actcagagaa atttaagaat ttgtttaatc aaaaccttat cgatgctaaa 2160
aaagggcaag agtcagattt aattctatgg ctaaagcaat ctaaggataa tggtatagaa 2220
ctatttaaag ccaatagtga tatcacagat atagatgagg cgttagaaat aatcaaatct 2280
tttaaaggtt ggacaactta ttttaagggt tttcatgaaa atagaaaaaa tgtttatagt 2340
agcaatgata ttcctacatc tattatttat aggatagtag atgataattt gcctaaattt 2400
ctagaaaata aagctaagta tgagagttta aaagacaaag ctccagaagc tataaactat 2460
gaacaaatta aaaaagattt ggcagaagag ctaacctttg atattgacta caaaacatct 2520
gaagttaatc aaagagtttt ttcacttgat gaagtttttg agatagcaaa ctttaataat 2580
tatctaaatc aaagtggtat tactaaattt aatactatta ttggtggtaa atttgtaaat 2640
ggtgaaaata caaagagaaa aggtataaat gaatatataa atctatactc acagcaaata 2700
aatgataaaa cactcaaaaa atataaaatg agtgttttat ttaagcaaat tttaagtgat 2760
acagaatcta aatcttttgt aattgataag ttagaagatg atagtgatgt agttacaacg 2820
atgcaaagtt tttatgagca aatagcagct tttaaaacag tagaagaaaa atctattaaa 2880
gaaacactat ctttattatt tgatgattta aaagctcaaa aacttgattt gagtaaaatt 2940
tattttaaaa atgataaatc tcttactgat ctatcacaac aagtttttga tgattatagt 3000
gttattggta cagcggtact agaatatata actcaacaaa tagcacctaa aaatcttgat 3060
aaccctagta agaaagagca agaattaata gccaaaaaaa ctgaaaaagc aaaatactta 3120
tctctagaaa ctataaagct tgccttagaa gaatttaata agcatagaga tatagataaa 3180
cagtgtaggt ttgaagaaat acttgcaaac tttgcggcta ttccgatgat atttgatgaa 3240
atagctcaaa acaaagacaa tttggcacag atatctatca aatatcaaaa tcaaggtaaa 3300
aaagacctac ttcaagctag tgcggaagat gatgttaaag ctatcaagga tcttttagat 3360
caaactaata atctcttaca taaactaaaa atatttcata ttagtcagtc agaagataag 3420
gcaaatattt tagacaagga tgagcatttt tatctagtat ttgaggagtg ctactttgag 3480
ctagcgaata tagtgcctct ttataacaaa attagaaact atataactca aaagccatat 3540
agtgatgaga aatttaagct caattttgag aactcgactt tggctaatgg ttgggataaa 3600
aataaagagc ctgacaatac ggcaatttta tttatcaaag atgataaata ttatctgggt 3660
gtgatgaata agaaaaataa caaaatattt gatgataaag ctatcaaaga aaataaaggc 3720
gagggttata aaaaaattgt ttataaactt ttacctggcg caaataaaat gttacctaag 3780
gttttctttt ctgctaaatc tataaaattt tataatccta gtgaagatat acttagaata 3840
agaaatcatt ccacacatac aaaaaatggt agtcctcaaa aaggatatga aaaatttgag 3900
tttaatattg aagattgccg aaaatttata gatttttata aacagtctat aagtaagcat 3960
ccggagtgga aagattttgg atttagattt tctgatactc aaagatataa ttctatagat 4020
gaattttata gagaagttga aaatcaaggc tacaaactaa cttttgaaaa tatatcagag 4080
agctatattg atagcgtagt taatcagggt aaattgtacc tattccaaat ctataataaa 4140
gatttttcag cttatagcaa agggcgacca aatctacata ctttatattg gaaagcgctg 4200
tttgatgaga gaaatcttca agatgtggtt tataagctaa atggtgaggc agagcttttt 4260
tatcgtaaac aatcaatacc taaaaaaatc actcacccag ctaaagaggc aatagctaat 4320
aaaaacaaag ataatcctaa aaaagagagt gtttttgaat atgatttaat caaagataaa 4380
cgctttactg aagataagtt tttctttcac tgtcctatta caatcaattt taaatctagt 4440
ggagctaata agtttaatga tgaaatcaat ttattgctaa aagaaaaagc aaatgatgtt 4500
catatattaa gtatagatag aggtgaaaga catttagctt actatacttt ggtagatggt 4560
aaaggcaata tcatcaaaca agatactttc aacatcattg gtaatgatag aatgaaaaca 4620
aactaccatg ataagcttgc tgcaatagag aaagataggg attcagctag gaaagactgg 4680
aaaaagataa ataacatcaa agagatgaaa gagggctatc tatctcaggt agttcatgaa 4740
atagctaagc tagttataga gtataatgct attgtggttt ttgaggattt aaattttgga 4800
tttaaaagag ggcgtttcaa ggtagagaag caggtctatc aaaagttaga aaaaatgcta 4860
attgagaaac taaactatct agttttcaaa gataatgagt ttgataaaac tgggggagtg 4920
cttagagctt atcagctaac agcacctttt gagactttta aaaagatggg taaacaaaca 4980
ggtattatct actatgtacc agctggtttt acttcaaaaa tttgtcctgt aactggtttt 5040
gtaaatcagt tatatcctaa gtatgaaagt gtcagcaaat ctcaagagtt ctttagtaag 5100
tttgacaaga tttgttataa ccttgataag ggctattttg agtttagttt tgattataaa 5160
aactttggtg acaaggctgc caaaggcaag tggactatag ctagctttgg gagtagattg 5220
attaacttta gaaattcaga taaaaatcat aattgggata ctcgagaagt ttatccaact 5280
aaagagttgg agaaattgct aaaagattat tctatcgaat atgggcatgg cgaatgtatc 5340
aaagcagcta tttgcggtga gagcgacaaa aagttttttg ctaagctaac tagtgtccta 5400
aatactatct tacaaatgcg taactcaaaa acaggtactg agttagatta tctaatttca 5460
ccagtagcag atgtaaatgg caatttcttt gattcgcgac aggcgccaaa aaatatgcct 5520
caagatgctg atgccaatgg tgcttatcat attgggctaa aaggtctgat gctactaggt 5580
aggatcaaaa ataatcaaga gggcaaaaaa ctcaatttgg ttatcaaaaa tgaagagtat 5640
tttgagttcg tgcagaatag gaataactaa ttcattcaag aatatattac cctgtcagtt 5700
tagcgactat tacctcttta ataatttgca ggggaattat tttagtaata gtaatataca 5760
caagagttat tgattatatg gaaaattata tttagataac atggttaaat gattttatat 5820
tctgtcctta ctcgatatat ttgcataata tctatagtaa tgcctcagat actacatact 5880
attcatctag ccaaacaaaa gggcgcgatg ctcataaaag tatcgataaa ggaatctata 5940
gtaccaaaaa agatgacctg atcggtatcg atgttattaa ccataaatat ggtttggttg 6000
gtaaaattga tgtttttcat aaagataagg gcttacttgt ggagagaaaa aggcaaatca 6060
agactatcta tgatggctat aaatatcagc tttatgcgca atatttttgt ctccaagaga 6120
tgggctatga tgtcaaagcc attaaatttt attcgatggt tgataataaa tcatacccaa 6180
tagctatacc aacttcagct gagttagaaa agtttgaaaa acatattcaa acaatcaagc 6240
aatataatcc aatggataac tcatttaggc aaaatattga aaagtgtaaa ttttgtatat 6300
atgcaaactt atgtgataaa acggacttgt agattatgtt tagtaaaaat gatattgaat 6360
caaagaatat agtttttgtt aatatttttg atggagtgaa acttagtcta tcattgggga 6420
atatagttat aaaagataaa gaaactgatg aggtgaaaac taagctttct gttcataaag 6480
ttcttgcatt gtttatcgta ggtaatatga cgatgacctc gcaactttta gagacctgta 6540
agaaaaatgc tatacagcta gtttttatga aaaatagctt tagaccatat ctatgttttg 6600
gtgatattgc tgaggctaat tttttagcta gatataagca atatagtgta gttgagcaag 6660
atataagttt agcaaggatt tttataacat caaagatacg caatcaacat aacttagtca 6720
aaagcctaag agataaaact ccagagcagc aagagatagt caaaaagaat aaacagctaa 6780
tagcagagtt agaaaataca acaagcctag cggagctaat gggtatagag ggcaatgttg 6840
ccaaaaattt cttcaaagga ttctatggac atttagatag ttggcaaggg cgcaaaccta 6900
gaataaaaca ggatccatat aatgttgttt tagacttggg ctatagtatg ttgtttaatt 6960
ttgtagagtg ttttttgcga ctttttggct ttgatttata caagggcttt tgtcatcaga 7020
cttggtataa gcgtaaatcc ctagtttgtg actttgttga gccatttaga tgtatagtgg 7080
ataaccaagt tagaaaatca tggaatctcg ggcaattttc tgtagaggat tttggttgca 7140
aaaatgagca gttttatata aaaaaagata aaacaaaaga ctactcaaaa atactttttg 7200
ccgagattat cagctacaag ctagagatat ttgaatatgt aagagaattt tatcgtgcct 7260
ttatgcgagg caaagaaatt gcagagtatc caatattttg ttatgaaact aggagggtgt 7320
atgttgatag tcagttatga ttttagtaat aataaagtac gtgcaaagtt tgccaaattt 7380
ctagaaagtt atggtgtacg tttacaatat tcggtatttg agctcaaata tagcaagaga 7440
atgttagact tgattttagc tgagatagaa aataactatg taccactatt tacaaatgct 7500
gatagtgttt taatctttaa tgctccagat aaagatgtga taaaatatgg ttatgcgatt 7560
catagagaac aagaggttgt ttttatagac taaaaattgc aaaccttagt ctttatgtta 7620
aaataactac taagttctta gagatattta aaaatatgac tgttgttata tatcaaaatg 7680
ctaaaaaaat catagatttt aggtcttttt ttgctgattt aggcaaaaac gggtctaaga 7740
actttaaata atttctactg ttgtagatga gaagtcattt aataaggcca ctgttaaaag 7800
tctaagaact ttaaataatt tctactgttg tagatgctac tattcctgtg ccttcagata 7860
attcagtcta agaactttaa ataatttcta ctgttgtaga tgtctagagc cttttgtatt 7920
agtagccggt ctaagaactt taaataattt ctactgttgt agattagcga tttatgaagg 7980
tcattttttt gtctagcttt aatgcggtag tttatcacag ttaaattgct aacgcagtca 8040
ggcaccgtgt atgaaatcta acaatgcgct catcgtcatc ctcggcaccg tcaccctgga 8100
tgctgtaggc ataggcttgg ttatgccggt actgccgggc ctcttgcggg atatcgtcca 8160
ttccgacagc atcgccagtc actatggcgt gctgctagcg ctatatgcgt tgatgcaatt 8220
tctatgcgca cccgttctcg gagcactgtc cgaccgcttt ggccgccgcc cagtcctgct 8280
cgcttcgcta cttggagcca ctatcgacta cgcgatcatg gcgaccacac ccgtcctgtg 8340
gatcctctac gccggacgca tcgtggccgg catcaccggc gccacaggtg cggttgctgg 8400
cgcctatatc gccgacatca ccgatgggga agatcgggct cgccacttcg ggctcatgag 8460
cgcttgtttc ggcgtgggta tggtggcagg ccccgtggcc gggggactgt tgggcgccat 8520
ctccttgcat gcaccattcc ttgcggcggc ggtgctcaac ggcctcaacc tactactggg 8580
ctgcttccta atgcaggagt cgcataaggg agagcgtcga ccgatgccct tgagagcctt 8640
caacccagtc agctccttcc ggtgggcgcg gggcatgact atcgtcgccg cacttatgac 8700
tgtcttcttt atcatgcaac tcgtaggaca ggtgccggca gcgctctggg tcattttcgg 8760
cgaggaccgc tttcgctgga gcgcgacgat gatcggcctg tcgcttgcgg tattcggaat 8820
cttgcacgcc ctcgctcaag ccttcgtcac tggtcccgcc accaaacgtt tcggcgagaa 8880
gcaggccatt atcgccggca tggcggccga cgcgctgggc tacgtcttgc tggcgttcgc 8940
gacgcgaggc tggatggcct tccccattat gattcttctc gcttccggcg gcatcgggat 9000
gcccgcgttg caggccatgc tgtccaggca ggtagatgac gaccatcagg gacagcttca 9060
aggatcgctc gcggctctta ccagcctaac ttcgatcatt ggaccgctga tcgtcacggc 9120
gatttatgcc gcctcggcga gcacatggaa cgggttggca tggattgtag gcgccgccct 9180
ataccttgtc tgcctccccg cgttgcgtcg cggtgcatgg agccgggcca cctcgacctg 9240
aatggaagcc ggcggcacct cgctaacgga ttcaccactc caagaattgg agccaatcaa 9300
ttcttgcgga gaactgtgaa tgcgcaaacc aacccttggc agaacatatc catcgcgtcc 9360
gccatctcca gcagccgcac gcggcgcatc tcgggcagcg ttgggtcctg gccacgggtg 9420
cgcatgatcg tgctcctgtc gttgaggacc cggctaggct ggcggggttg ccttactggt 9480
tagcagaatg aatcaccgat acgcgagcga acgtgaagcg actgctgctg caaaacgtct 9540
gcgacctgag caacaacatg aatggtcttc ggtttccgtg tttcgtaaag tctggaaacg 9600
cggaagtccc ctacgtgctg ctgaagttgc ccgcaacaga gagtggaacc aaccggtgat 9660
accacgatac tatgactgag agtcaacgcc atgagcggcc tcatttctta ttctgagtta 9720
caacagtccg caccgctgtc cggtagctcc ttccggtggg cgcggggcat gactatcgtc 9780
gccgcactta tgactgtctt ctttatcatg caactcgtag gacaggtgcc ggcagcgccc 9840
aacagtcccc cggccacggg gcctgccacc atacccacgc cgaaacaagc gccctgcacc 9900
attatgttcc ggatctgcat cgcaggatgc tgctggctac cctgtggaac acctacatct 9960
gtattaacga agcgctaacc gtttttatca ggctctggga ggcagaataa atgatcatat 10020
cgtcaattat tacctccacg gggagagcct gagcaaactg gcctcaggca tttgagaagc 10080
acacggtcac actgcttccg gtagtcaata aaccggtaaa ccagcaatag acataagcgg 10140
ctatttaacg accctgccct gaaccgacga ccgggtcgaa tttgctttcg aatttctgcc 10200
attcatccgc ttattatcac ttattcaggc gtagcaccag gcgtttaagg gcaccaataa 10260
ctgccttaaa aaaattacgc cccgccctgc cactcatcgc agtactgttg taattcatta 10320
agcattctgc cgacatggaa gccatcacag acggcatgat gaacctgaat cgccagcggc 10380
atcagcacct tgtcgccttg cgtataatat ttgcccatgg tgaaaacggg ggcgaagaag 10440
ttgtccatat tggccacgtt taaatcaaaa ctggtgaaac tcacccaggg attggctgag 10500
acgaaaaaca tattctcaat aaacccttta gggaaatagg ccaggttttc accgtaacac 10560
gccacatctt gcgaatatat gtgtagaaac tgccggaaat cgtcgtggta ttcactccag 10620
agcgatgaaa acgtttcagt ttgctcatgg aaaacggtgt aacaagggtg aacactatcc 10680
catatcacca gctcaccgtc tttcattgcc atacg 10715
<210> 1168
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1168
gccctgcaag gcggtttttt 20
<210> 1169
<211> 32
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1169
catcaaggaa ttgagcttat agaagccata gc 32
<210> 1170
<211> 29
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1170
tgatgctcca agtgatgcaa tcatccaag 29
<210> 1171
<211> 29
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1171
aaccatgtga accagccaca taaaatgtg 29
<210> 1172
<211> 48
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1172
atgtcaattt atcaagaata aatatagttt aagtaaaatg tcagtaaa 48
<210> 1173
<211> 33
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1173
aggagatatt aagttcggtt tgtattagcg aag 33
<210> 1174
<211> 31
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1174
tcgctaatac aaaccgaact taatatctcc t 31
<210> 1175
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1175
taatactatt attggtggta aatttgtaaa tggtg 35
<210> 1176
<211> 26
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1176
tgaggagtgc tactttgagc tagcga 26
<210> 1177
<211> 44
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1177
gattataaaa accttaggat tataaaattt aaagaaaacc ttag 44
<210> 1178
<211> 41
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1178
tatgttcata tgtgtggaat gattttctaa gtatatcttc a 41
<210> 1179
<211> 40
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1179
tgaagatata cttagaaatc attccacaca tatgaacata 40
<210> 1180
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1180
ggtaaaggtg aggcagtatc gtaaa 25
<210> 1181
<211> 26
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1181
ctgggggagt gcttagagct tatcag 26
<210> 1182
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1182
tgccaatggt tcatattggg tggg 24
<210> 1183
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1183
ttagttattc actcaaaata cttagttaaa aatac 35
<210> 1184
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1184
atttttgtct ccaagagatg ggctatga 28
<210> 1185
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1185
taaaaacaga ggttctctac ccgatact 28
<210> 1186
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1186
ggcaagggca cctagaag 18
<210> 1187
<211> 29
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1187
ggttatgcga ttcatagaga acaagaggt 29
<210> 1188
<211> 29
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1188
agacaaaaaa atgaccttca taaatcgct 29
<210> 1189
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1189
tcatacacgg ttgactgcgt t 21
<210> 1190
<211> 3912
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<220>
<221> CDS
<222> (1)..(3909)
<400> 1190
gcc acc atg aac atc aaa aac ttt acc ggg ctc tac ccc ctc agc aaa 48
Ala Thr Met Asn Ile Lys Asn Phe Thr Gly Leu Tyr Pro Leu Ser Lys
1 5 10 15
act ttg cgc ttt gaa ctc aag cct att ggc aaa acc aag gaa aac atc 96
Thr Leu Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Lys Glu Asn Ile
20 25 30
gag aaa aat ggc atc ctg acc aag gac gag caa cgg gct aaa gac tac 144
Glu Lys Asn Gly Ile Leu Thr Lys Asp Glu Gln Arg Ala Lys Asp Tyr
35 40 45
ctc ata gtc aaa ggc ttt att gac gag tat cac aag cag ttc atc aaa 192
Leu Ile Val Lys Gly Phe Ile Asp Glu Tyr His Lys Gln Phe Ile Lys
50 55 60
gac agg ctt tgg gac ttt aaa ttg cct ctc gaa agt gag ggg gag aag 240
Asp Arg Leu Trp Asp Phe Lys Leu Pro Leu Glu Ser Glu Gly Glu Lys
65 70 75 80
aac agt ctc gaa gaa tac cag gaa ctg tac gag ctc act aag cgc aac 288
Asn Ser Leu Glu Glu Tyr Gln Glu Leu Tyr Glu Leu Thr Lys Arg Asn
85 90 95
gat gcc cag gag gcc gac ttc acc gag att aaa gat aac ctt cgc agc 336
Asp Ala Gln Glu Ala Asp Phe Thr Glu Ile Lys Asp Asn Leu Arg Ser
100 105 110
tct att acc gaa cag ctc acg aag tct gga tct gcg tac gat cgg att 384
Ser Ile Thr Glu Gln Leu Thr Lys Ser Gly Ser Ala Tyr Asp Arg Ile
115 120 125
ttt aaa aaa gag ttc att aga gaa gac ctg gtc aac ttc ctc gaa gat 432
Phe Lys Lys Glu Phe Ile Arg Glu Asp Leu Val Asn Phe Leu Glu Asp
130 135 140
gaa aaa gat aaa aat atc gtg aaa cag ttc gag gac ttt act aca tat 480
Glu Lys Asp Lys Asn Ile Val Lys Gln Phe Glu Asp Phe Thr Thr Tyr
145 150 155 160
ttt acg ggt ttt tat gaa aat agg aag aac atg tac tct agc gaa gag 528
Phe Thr Gly Phe Tyr Glu Asn Arg Lys Asn Met Tyr Ser Ser Glu Glu
165 170 175
aag tcc acg gcc atc gca tac cgg ctt atc cat cag aat ctg cca aaa 576
Lys Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Gln Asn Leu Pro Lys
180 185 190
ttc atg gac aac atg aga agt ttt gcc aaa att gca aat tcc agt gtt 624
Phe Met Asp Asn Met Arg Ser Phe Ala Lys Ile Ala Asn Ser Ser Val
195 200 205
tcc gag cac ttt agc gac atc tat gaa agc tgg aag gaa tat ctg aat 672
Ser Glu His Phe Ser Asp Ile Tyr Glu Ser Trp Lys Glu Tyr Leu Asn
210 215 220
gta aat agc atc gag gaa atc ttc cag ctc gac tat ttt agc gaa acc 720
Val Asn Ser Ile Glu Glu Ile Phe Gln Leu Asp Tyr Phe Ser Glu Thr
225 230 235 240
ttg act cag cca cat att gag gtg tat aac tat att atc ggg aag aaa 768
Leu Thr Gln Pro His Ile Glu Val Tyr Asn Tyr Ile Ile Gly Lys Lys
245 250 255
gtc ctg gaa gac gga acc gag ata aag ggc atc aac gag tat gtg aac 816
Val Leu Glu Asp Gly Thr Glu Ile Lys Gly Ile Asn Glu Tyr Val Asn
260 265 270
ctc tac aat cag cag cag aaa gat aag agt aaa cga ctg cct ttc ctg 864
Leu Tyr Asn Gln Gln Gln Lys Asp Lys Ser Lys Arg Leu Pro Phe Leu
275 280 285
gtg cca ctg tat aag caa att ttg tct gat agg gaa aaa ctc tcc tgg 912
Val Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Lys Leu Ser Trp
290 295 300
att gct gaa gag ttc gac agc gac aag aag atg ctg agc gct atc acc 960
Ile Ala Glu Glu Phe Asp Ser Asp Lys Lys Met Leu Ser Ala Ile Thr
305 310 315 320
gag tct tac aac cac ctg cac aac gtg ttg atg ggt aac gag aac gaa 1008
Glu Ser Tyr Asn His Leu His Asn Val Leu Met Gly Asn Glu Asn Glu
325 330 335
agc ctg cga aat ctg ctg ctg aat att aag gac tat aac ctg gag aaa 1056
Ser Leu Arg Asn Leu Leu Leu Asn Ile Lys Asp Tyr Asn Leu Glu Lys
340 345 350
att aat atc aca aac gac ttg tct ctc acc gaa atc tcc cag aat ctt 1104
Ile Asn Ile Thr Asn Asp Leu Ser Leu Thr Glu Ile Ser Gln Asn Leu
355 360 365
ttt ggc cga tat gat gta ttc aca aat ggg atc aaa aac aag ctg aga 1152
Phe Gly Arg Tyr Asp Val Phe Thr Asn Gly Ile Lys Asn Lys Leu Arg
370 375 380
gtg ttg act cca agg aag aaa aag gag acg gac gaa aat ttt gag gac 1200
Val Leu Thr Pro Arg Lys Lys Lys Glu Thr Asp Glu Asn Phe Glu Asp
385 390 395 400
cgc att aac aaa att ttt aag acc cag aag tcc ttc agc atc gct ttt 1248
Arg Ile Asn Lys Ile Phe Lys Thr Gln Lys Ser Phe Ser Ile Ala Phe
405 410 415
ctg aac aag ctg cct cag ccc gaa atg gag gat ggg aag ccc cgg aac 1296
Leu Asn Lys Leu Pro Gln Pro Glu Met Glu Asp Gly Lys Pro Arg Asn
420 425 430
att gag gac tat ttc att aca cag ggg gcg att aac acc aaa tct ata 1344
Ile Glu Asp Tyr Phe Ile Thr Gln Gly Ala Ile Asn Thr Lys Ser Ile
435 440 445
cag aaa gaa gat atc ttc gcc caa att gag aat gca tac gag gat gca 1392
Gln Lys Glu Asp Ile Phe Ala Gln Ile Glu Asn Ala Tyr Glu Asp Ala
450 455 460
cag gtg ttc ctg caa att aag gac acc gac aac aaa ctt agc cag aac 1440
Gln Val Phe Leu Gln Ile Lys Asp Thr Asp Asn Lys Leu Ser Gln Asn
465 470 475 480
aag acg gcg gtg gaa aag atc aaa act ttg ctg gac gcc ttg aag gaa 1488
Lys Thr Ala Val Glu Lys Ile Lys Thr Leu Leu Asp Ala Leu Lys Glu
485 490 495
ctc cag cac ttc atc aaa ccg ctg ctg ggc tct ggg gag gag aac gag 1536
Leu Gln His Phe Ile Lys Pro Leu Leu Gly Ser Gly Glu Glu Asn Glu
500 505 510
aaa gac gaa ctg ttc tac ggt tcc ttc ctg gcc atc tgg gac gaa ctg 1584
Lys Asp Glu Leu Phe Tyr Gly Ser Phe Leu Ala Ile Trp Asp Glu Leu
515 520 525
gac acc att aca cca ctt tat aac aaa gtg aga aat tgg ctg acc cga 1632
Asp Thr Ile Thr Pro Leu Tyr Asn Lys Val Arg Asn Trp Leu Thr Arg
530 535 540
aaa cca tat tca aca gaa aaa atc aaa ttg aat ttc gac aac gct cag 1680
Lys Pro Tyr Ser Thr Glu Lys Ile Lys Leu Asn Phe Asp Asn Ala Gln
545 550 555 560
ctg ctg gga ggg tgg gat gtc aat aaa gaa cac gac tgt gca ggt atc 1728
Leu Leu Gly Gly Trp Asp Val Asn Lys Glu His Asp Cys Ala Gly Ile
565 570 575
ttg ttg cgg aaa aac gat agc tac tat ctc gga att atc aat aag aaa 1776
Leu Leu Arg Lys Asn Asp Ser Tyr Tyr Leu Gly Ile Ile Asn Lys Lys
580 585 590
acc aac cac atc ttt gat acg gat att acg cca tca gat ggc gag tgc 1824
Thr Asn His Ile Phe Asp Thr Asp Ile Thr Pro Ser Asp Gly Glu Cys
595 600 605
tat gac aaa atc gac tac aag ctc ctt ccc ggg gcg aac aaa atg ctt 1872
Tyr Asp Lys Ile Asp Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu
610 615 620
cca aag gtg ttt ttt agt aag tcc cga atc aaa gag ttc gag cca tca 1920
Pro Lys Val Phe Phe Ser Lys Ser Arg Ile Lys Glu Phe Glu Pro Ser
625 630 635 640
gag gcc ata atc aat tgc tat aag aag ggg aca cac aaa aaa gga aaa 1968
Glu Ala Ile Ile Asn Cys Tyr Lys Lys Gly Thr His Lys Lys Gly Lys
645 650 655
aac ttt aac ctg acg gac tgt cac cgc ctg atc aac ttt ttt aag acc 2016
Asn Phe Asn Leu Thr Asp Cys His Arg Leu Ile Asn Phe Phe Lys Thr
660 665 670
tca atc gag aaa cac gag gat tgg tca aaa ttc gga ttc aag ttc tcc 2064
Ser Ile Glu Lys His Glu Asp Trp Ser Lys Phe Gly Phe Lys Phe Ser
675 680 685
gat acc gaa acg tat gag gat att agc ggt ttt tat aga gag gtc gag 2112
Asp Thr Glu Thr Tyr Glu Asp Ile Ser Gly Phe Tyr Arg Glu Val Glu
690 695 700
cag cag gga tac agg ctg acg agc cat cca gtc agt gcc agc tat ata 2160
Gln Gln Gly Tyr Arg Leu Thr Ser His Pro Val Ser Ala Ser Tyr Ile
705 710 715 720
cat agt ctg gtc aag gaa gga aaa ctg tac ctc ttc caa atc tgg aac 2208
His Ser Leu Val Lys Glu Gly Lys Leu Tyr Leu Phe Gln Ile Trp Asn
725 730 735
aag gac ttt tct caa ttc tcc aag ggg acc cct aac ttg cac act ctc 2256
Lys Asp Phe Ser Gln Phe Ser Lys Gly Thr Pro Asn Leu His Thr Leu
740 745 750
tat tgg aag atg ctg ttt gac aaa cgg aat ctt agc gat gtg gtt tat 2304
Tyr Trp Lys Met Leu Phe Asp Lys Arg Asn Leu Ser Asp Val Val Tyr
755 760 765
aag ctg aat ggc cag gct gaa gtg ttc tat aga aag agc tcc att gaa 2352
Lys Leu Asn Gly Gln Ala Glu Val Phe Tyr Arg Lys Ser Ser Ile Glu
770 775 780
cac cag aac cga att atc cac ccc gct cag cat ccc atc aca aat aag 2400
His Gln Asn Arg Ile Ile His Pro Ala Gln His Pro Ile Thr Asn Lys
785 790 795 800
aat gag ctt aac aaa aag cac act agc acc ttc aaa tac gat atc atc 2448
Asn Glu Leu Asn Lys Lys His Thr Ser Thr Phe Lys Tyr Asp Ile Ile
805 810 815
aaa gat cgc aga tac acg gtg gat aaa ttc cag ttc cat gtg ccc att 2496
Lys Asp Arg Arg Tyr Thr Val Asp Lys Phe Gln Phe His Val Pro Ile
820 825 830
act ata aat ttt aag gcg acc ggg cag aac aac atc aac cca atc gtc 2544
Thr Ile Asn Phe Lys Ala Thr Gly Gln Asn Asn Ile Asn Pro Ile Val
835 840 845
caa gag gtg att cgc caa aac ggt atc acc cac atc ata ggc atc gat 2592
Gln Glu Val Ile Arg Gln Asn Gly Ile Thr His Ile Ile Gly Ile Asp
850 855 860
cga ggt gaa cgc cat ctt ctg tac ctc tct ctc atc gat ttg aaa ggc 2640
Arg Gly Glu Arg His Leu Leu Tyr Leu Ser Leu Ile Asp Leu Lys Gly
865 870 875 880
aac atc atc aag cag atg act ctc aac gaa att att aat gag tat aag 2688
Asn Ile Ile Lys Gln Met Thr Leu Asn Glu Ile Ile Asn Glu Tyr Lys
885 890 895
ggt gtg acc tat aag acc aac tac cat aac ctc ctg gag aag agg gag 2736
Gly Val Thr Tyr Lys Thr Asn Tyr His Asn Leu Leu Glu Lys Arg Glu
900 905 910
aag gag cgg acc gag gcc aga cac tcc tgg agt agt att gaa agc ata 2784
Lys Glu Arg Thr Glu Ala Arg His Ser Trp Ser Ser Ile Glu Ser Ile
915 920 925
aaa gaa ctg aag gat gga tac atg tca cag gtg att cac aaa att acg 2832
Lys Glu Leu Lys Asp Gly Tyr Met Ser Gln Val Ile His Lys Ile Thr
930 935 940
gac atg atg gtt aag tac aat gcg att gtg gtc ctg gag gac ctc aac 2880
Asp Met Met Val Lys Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn
945 950 955 960
ggg ggg ttt atg cga ggc cgc cag aag gtc gag aag cag gtg tac cag 2928
Gly Gly Phe Met Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln
965 970 975
aaa ttt gaa aaa aag ttg atc gac aag ctg aac tat ctc gtt gac aag 2976
Lys Phe Glu Lys Lys Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys
980 985 990
aaa ctc gac gct aac gag gtc ggc gga gta ctg aat gct tat cag ctg 3024
Lys Leu Asp Ala Asn Glu Val Gly Gly Val Leu Asn Ala Tyr Gln Leu
995 1000 1005
acc aac aag ttc gag tct ttc aag aag att ggg aaa caa agc gga 3069
Thr Asn Lys Phe Glu Ser Phe Lys Lys Ile Gly Lys Gln Ser Gly
1010 1015 1020
ttt ttg ttc tac atc ccc gcc tgg aac aca agc aaa atc gat cct 3114
Phe Leu Phe Tyr Ile Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro
1025 1030 1035
ata aca ggg ttc gtt aat ctg ttc aac acc agg tac gag tct atc 3159
Ile Thr Gly Phe Val Asn Leu Phe Asn Thr Arg Tyr Glu Ser Ile
1040 1045 1050
aag gag aca aaa gtt ttt tgg tct aag ttt gat att atc cga tac 3204
Lys Glu Thr Lys Val Phe Trp Ser Lys Phe Asp Ile Ile Arg Tyr
1055 1060 1065
aat aaa gag aag aat tgg ttc gag ttc gtc ttc gat tac aat acc 3249
Asn Lys Glu Lys Asn Trp Phe Glu Phe Val Phe Asp Tyr Asn Thr
1070 1075 1080
ttt acg act aaa gcg gag gga aca cgc act aag tgg act ctg tgc 3294
Phe Thr Thr Lys Ala Glu Gly Thr Arg Thr Lys Trp Thr Leu Cys
1085 1090 1095
acc cac ggc act cgc atc cag aca ttc cgg aac cca gaa aag aat 3339
Thr His Gly Thr Arg Ile Gln Thr Phe Arg Asn Pro Glu Lys Asn
1100 1105 1110
gcc cag tgg gac aat aaa gag atc aat ttg act gag tcc ttc aaa 3384
Ala Gln Trp Asp Asn Lys Glu Ile Asn Leu Thr Glu Ser Phe Lys
1115 1120 1125
gct ctg ttt gaa aag tac aag atc gat atc acc agt aat ctc aag 3429
Ala Leu Phe Glu Lys Tyr Lys Ile Asp Ile Thr Ser Asn Leu Lys
1130 1135 1140
gaa tcc atc atg cag gaa acc gag aag aag ttc ttc cag gaa ctg 3474
Glu Ser Ile Met Gln Glu Thr Glu Lys Lys Phe Phe Gln Glu Leu
1145 1150 1155
cat aat ctg ctc cac ctg acc ctg cag atg agg aat agc gtt act 3519
His Asn Leu Leu His Leu Thr Leu Gln Met Arg Asn Ser Val Thr
1160 1165 1170
gga acc gac ata gac tat ttg atc agc ccc gtt gcc gat gag gat 3564
Gly Thr Asp Ile Asp Tyr Leu Ile Ser Pro Val Ala Asp Glu Asp
1175 1180 1185
gga aat ttc tat gat agt cgc ata aat ggc aaa aat ttt ccg gag 3609
Gly Asn Phe Tyr Asp Ser Arg Ile Asn Gly Lys Asn Phe Pro Glu
1190 1195 1200
aat gcc gat gcc aat ggc gcg tac aac atc gca cga aag ggt ctg 3654
Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu
1205 1210 1215
atg ctt att cgg cag atc aag caa gca gat cca cag aag aaa ttc 3699
Met Leu Ile Arg Gln Ile Lys Gln Ala Asp Pro Gln Lys Lys Phe
1220 1225 1230
aag ttt gag aca atc acc aat aaa gac tgg ctg aaa ttc gcc caa 3744
Lys Phe Glu Thr Ile Thr Asn Lys Asp Trp Leu Lys Phe Ala Gln
1235 1240 1245
gac aag ccc tat ctt aaa gat ggc agc ggg aaa agg ccg gcg gcc 3789
Asp Lys Pro Tyr Leu Lys Asp Gly Ser Gly Lys Arg Pro Ala Ala
1250 1255 1260
acg aaa aag gcc ggc cag gca aaa aag aaa aag gga tcc tac cca 3834
Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys Gly Ser Tyr Pro
1265 1270 1275
tac gat gtt cca gat tac gct tat ccc tac gac gtg cct gat tat 3879
Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr
1280 1285 1290
gca tac cca tac gat gtc ccc gac tat gcc taa 3912
Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1295 1300
<210> 1191
<211> 1303
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1191
Ala Thr Met Asn Ile Lys Asn Phe Thr Gly Leu Tyr Pro Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Lys Glu Asn Ile
20 25 30
Glu Lys Asn Gly Ile Leu Thr Lys Asp Glu Gln Arg Ala Lys Asp Tyr
35 40 45
Leu Ile Val Lys Gly Phe Ile Asp Glu Tyr His Lys Gln Phe Ile Lys
50 55 60
Asp Arg Leu Trp Asp Phe Lys Leu Pro Leu Glu Ser Glu Gly Glu Lys
65 70 75 80
Asn Ser Leu Glu Glu Tyr Gln Glu Leu Tyr Glu Leu Thr Lys Arg Asn
85 90 95
Asp Ala Gln Glu Ala Asp Phe Thr Glu Ile Lys Asp Asn Leu Arg Ser
100 105 110
Ser Ile Thr Glu Gln Leu Thr Lys Ser Gly Ser Ala Tyr Asp Arg Ile
115 120 125
Phe Lys Lys Glu Phe Ile Arg Glu Asp Leu Val Asn Phe Leu Glu Asp
130 135 140
Glu Lys Asp Lys Asn Ile Val Lys Gln Phe Glu Asp Phe Thr Thr Tyr
145 150 155 160
Phe Thr Gly Phe Tyr Glu Asn Arg Lys Asn Met Tyr Ser Ser Glu Glu
165 170 175
Lys Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Gln Asn Leu Pro Lys
180 185 190
Phe Met Asp Asn Met Arg Ser Phe Ala Lys Ile Ala Asn Ser Ser Val
195 200 205
Ser Glu His Phe Ser Asp Ile Tyr Glu Ser Trp Lys Glu Tyr Leu Asn
210 215 220
Val Asn Ser Ile Glu Glu Ile Phe Gln Leu Asp Tyr Phe Ser Glu Thr
225 230 235 240
Leu Thr Gln Pro His Ile Glu Val Tyr Asn Tyr Ile Ile Gly Lys Lys
245 250 255
Val Leu Glu Asp Gly Thr Glu Ile Lys Gly Ile Asn Glu Tyr Val Asn
260 265 270
Leu Tyr Asn Gln Gln Gln Lys Asp Lys Ser Lys Arg Leu Pro Phe Leu
275 280 285
Val Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Lys Leu Ser Trp
290 295 300
Ile Ala Glu Glu Phe Asp Ser Asp Lys Lys Met Leu Ser Ala Ile Thr
305 310 315 320
Glu Ser Tyr Asn His Leu His Asn Val Leu Met Gly Asn Glu Asn Glu
325 330 335
Ser Leu Arg Asn Leu Leu Leu Asn Ile Lys Asp Tyr Asn Leu Glu Lys
340 345 350
Ile Asn Ile Thr Asn Asp Leu Ser Leu Thr Glu Ile Ser Gln Asn Leu
355 360 365
Phe Gly Arg Tyr Asp Val Phe Thr Asn Gly Ile Lys Asn Lys Leu Arg
370 375 380
Val Leu Thr Pro Arg Lys Lys Lys Glu Thr Asp Glu Asn Phe Glu Asp
385 390 395 400
Arg Ile Asn Lys Ile Phe Lys Thr Gln Lys Ser Phe Ser Ile Ala Phe
405 410 415
Leu Asn Lys Leu Pro Gln Pro Glu Met Glu Asp Gly Lys Pro Arg Asn
420 425 430
Ile Glu Asp Tyr Phe Ile Thr Gln Gly Ala Ile Asn Thr Lys Ser Ile
435 440 445
Gln Lys Glu Asp Ile Phe Ala Gln Ile Glu Asn Ala Tyr Glu Asp Ala
450 455 460
Gln Val Phe Leu Gln Ile Lys Asp Thr Asp Asn Lys Leu Ser Gln Asn
465 470 475 480
Lys Thr Ala Val Glu Lys Ile Lys Thr Leu Leu Asp Ala Leu Lys Glu
485 490 495
Leu Gln His Phe Ile Lys Pro Leu Leu Gly Ser Gly Glu Glu Asn Glu
500 505 510
Lys Asp Glu Leu Phe Tyr Gly Ser Phe Leu Ala Ile Trp Asp Glu Leu
515 520 525
Asp Thr Ile Thr Pro Leu Tyr Asn Lys Val Arg Asn Trp Leu Thr Arg
530 535 540
Lys Pro Tyr Ser Thr Glu Lys Ile Lys Leu Asn Phe Asp Asn Ala Gln
545 550 555 560
Leu Leu Gly Gly Trp Asp Val Asn Lys Glu His Asp Cys Ala Gly Ile
565 570 575
Leu Leu Arg Lys Asn Asp Ser Tyr Tyr Leu Gly Ile Ile Asn Lys Lys
580 585 590
Thr Asn His Ile Phe Asp Thr Asp Ile Thr Pro Ser Asp Gly Glu Cys
595 600 605
Tyr Asp Lys Ile Asp Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu
610 615 620
Pro Lys Val Phe Phe Ser Lys Ser Arg Ile Lys Glu Phe Glu Pro Ser
625 630 635 640
Glu Ala Ile Ile Asn Cys Tyr Lys Lys Gly Thr His Lys Lys Gly Lys
645 650 655
Asn Phe Asn Leu Thr Asp Cys His Arg Leu Ile Asn Phe Phe Lys Thr
660 665 670
Ser Ile Glu Lys His Glu Asp Trp Ser Lys Phe Gly Phe Lys Phe Ser
675 680 685
Asp Thr Glu Thr Tyr Glu Asp Ile Ser Gly Phe Tyr Arg Glu Val Glu
690 695 700
Gln Gln Gly Tyr Arg Leu Thr Ser His Pro Val Ser Ala Ser Tyr Ile
705 710 715 720
His Ser Leu Val Lys Glu Gly Lys Leu Tyr Leu Phe Gln Ile Trp Asn
725 730 735
Lys Asp Phe Ser Gln Phe Ser Lys Gly Thr Pro Asn Leu His Thr Leu
740 745 750
Tyr Trp Lys Met Leu Phe Asp Lys Arg Asn Leu Ser Asp Val Val Tyr
755 760 765
Lys Leu Asn Gly Gln Ala Glu Val Phe Tyr Arg Lys Ser Ser Ile Glu
770 775 780
His Gln Asn Arg Ile Ile His Pro Ala Gln His Pro Ile Thr Asn Lys
785 790 795 800
Asn Glu Leu Asn Lys Lys His Thr Ser Thr Phe Lys Tyr Asp Ile Ile
805 810 815
Lys Asp Arg Arg Tyr Thr Val Asp Lys Phe Gln Phe His Val Pro Ile
820 825 830
Thr Ile Asn Phe Lys Ala Thr Gly Gln Asn Asn Ile Asn Pro Ile Val
835 840 845
Gln Glu Val Ile Arg Gln Asn Gly Ile Thr His Ile Ile Gly Ile Asp
850 855 860
Arg Gly Glu Arg His Leu Leu Tyr Leu Ser Leu Ile Asp Leu Lys Gly
865 870 875 880
Asn Ile Ile Lys Gln Met Thr Leu Asn Glu Ile Ile Asn Glu Tyr Lys
885 890 895
Gly Val Thr Tyr Lys Thr Asn Tyr His Asn Leu Leu Glu Lys Arg Glu
900 905 910
Lys Glu Arg Thr Glu Ala Arg His Ser Trp Ser Ser Ile Glu Ser Ile
915 920 925
Lys Glu Leu Lys Asp Gly Tyr Met Ser Gln Val Ile His Lys Ile Thr
930 935 940
Asp Met Met Val Lys Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn
945 950 955 960
Gly Gly Phe Met Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln
965 970 975
Lys Phe Glu Lys Lys Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys
980 985 990
Lys Leu Asp Ala Asn Glu Val Gly Gly Val Leu Asn Ala Tyr Gln Leu
995 1000 1005
Thr Asn Lys Phe Glu Ser Phe Lys Lys Ile Gly Lys Gln Ser Gly
1010 1015 1020
Phe Leu Phe Tyr Ile Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro
1025 1030 1035
Ile Thr Gly Phe Val Asn Leu Phe Asn Thr Arg Tyr Glu Ser Ile
1040 1045 1050
Lys Glu Thr Lys Val Phe Trp Ser Lys Phe Asp Ile Ile Arg Tyr
1055 1060 1065
Asn Lys Glu Lys Asn Trp Phe Glu Phe Val Phe Asp Tyr Asn Thr
1070 1075 1080
Phe Thr Thr Lys Ala Glu Gly Thr Arg Thr Lys Trp Thr Leu Cys
1085 1090 1095
Thr His Gly Thr Arg Ile Gln Thr Phe Arg Asn Pro Glu Lys Asn
1100 1105 1110
Ala Gln Trp Asp Asn Lys Glu Ile Asn Leu Thr Glu Ser Phe Lys
1115 1120 1125
Ala Leu Phe Glu Lys Tyr Lys Ile Asp Ile Thr Ser Asn Leu Lys
1130 1135 1140
Glu Ser Ile Met Gln Glu Thr Glu Lys Lys Phe Phe Gln Glu Leu
1145 1150 1155
His Asn Leu Leu His Leu Thr Leu Gln Met Arg Asn Ser Val Thr
1160 1165 1170
Gly Thr Asp Ile Asp Tyr Leu Ile Ser Pro Val Ala Asp Glu Asp
1175 1180 1185
Gly Asn Phe Tyr Asp Ser Arg Ile Asn Gly Lys Asn Phe Pro Glu
1190 1195 1200
Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu
1205 1210 1215
Met Leu Ile Arg Gln Ile Lys Gln Ala Asp Pro Gln Lys Lys Phe
1220 1225 1230
Lys Phe Glu Thr Ile Thr Asn Lys Asp Trp Leu Lys Phe Ala Gln
1235 1240 1245
Asp Lys Pro Tyr Leu Lys Asp Gly Ser Gly Lys Arg Pro Ala Ala
1250 1255 1260
Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys Gly Ser Tyr Pro
1265 1270 1275
Tyr Asp Val Pro Asp Tyr Ala Tyr Pro Tyr Asp Val Pro Asp Tyr
1280 1285 1290
Ala Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1295 1300
<210> 1192
<211> 112
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<220>
<221> модифицированное_основание
<222> (30)..(37)
<223> a, c, t, g, неизвестное или другое
<400> 1192
ggccagtgaa ttcgagctcg gtacccgggn nnnnnnngag aagtcattta ataaggccac 60
tgttaaaaag cttggcgtaa tcatggtcat agctgtttcc tgtgtgaaat tg 112
<210> 1193
<211> 112
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<220>
<221> модифицированное_основание
<222> (61)..(68)
<223> a, c, t, g, неизвестное или другое
<400> 1193
ggccagtgaa ttcgagctcg gtacccgggg agaagtcatt taataaggcc actgttaaaa 60
nnnnnnnnag cttggcgtaa tcatggtcat agctgtttcc tgtgtgaaat tg 112
<210> 1194
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1194
ggccagtgaa ttcgagctcg g 21
<210> 1195
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1195
caatttcaca caggaaacag ctatgacc 28
<210> 1196
<211> 81
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1196
aaguucuuag agauauuuaa aaauaugacu guuguuauau aucaaaaugc uaaaaaaauc 60
auagauuuua ggucuuuuuu u 81
<210> 1197
<211> 111
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1197
aattttttag atctacaaaa ttataaacta aataaagatt cttataataa ctttatatat 60
aatcgaaatg tagagaattt tataaggagt ctttatcatg tcaatttatc a 111
<210> 1198
<211> 77
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1198
aaaattataa actaaataaa gattcttata ataactttat atataatcga aatgtagaga 60
attttataag gagtctt 77
<210> 1199
<211> 77
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1199
aaaattataa actaaataaa gattcttata ataactttat atataatcga aatgtagaga 60
attttataag gagtctt 77
<210> 1200
<211> 77
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1200
aaaattataa actaaataaa gattcttata ataactttat atataatcga aatgtagaga 60
attttataag gagtctt 77
<210> 1201
<211> 77
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1201
aaattataaa ctaaataaag attcttataa taactttata tataatcgaa atgtagagaa 60
ttttataagg agtcttt 77
<210> 1202
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1202
aattttttag atct 14
<210> 1203
<211> 77
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1203
aaaauuauaa acuaaauaaa gauucuuaua auaacuuuau auauaaucga auguagagaa 60
auuuuauaag gagucuu 77
<210> 1204
<211> 44
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<220>
<221> МОДИФИЦИРОВАННЫЙ_ОСТАТОК
<222> (16)..(16)
<223> Любая аминокислота
<400> 1204
Pro Tyr Ser Lys Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Lys Xaa
1 5 10 15
Leu Phe Ser Glu Arg Asn Leu Lys Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Ile Phe Tyr Arg Lys Lys Ser Ile Lys
35 40
<210> 1205
<211> 77
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1205
actttaaata atttctactg ttgtagatga gaagtcattt aataaggcca ctgttaaaag 60
tctaagaact ttaaata 77
<210> 1206
<211> 77
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1206
ctactattcc tgtgccttca gataattcag tctaagaact ttaaataatt tctactgttg 60
tagatgtcta gagcctt 77
<210> 1207
<211> 103
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1207
gtctaagaac tttaaataat ttctactgtt gtagatgaga agtcatttaa taaggccact 60
gttaaaagtc taagaacttt aaataatttc tactgttgta gat 103
<210> 1208
<211> 149
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1208
ctgatttagg caaaaacggg tctaagaact ttaaataatt tctactgttg tagatgagaa 60
gtcatttaat aaggccactg ttaaaagtct aagaacttta aataatttct actgttgtag 120
atgctactat tcctgtgcct tcagataat 149
<210> 1209
<211> 34
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1209
ttagagaagt catttaataa ggccactgtt aaaa 34
<210> 1210
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1210
acuuuaaaua auuucuacug uuguagau 28
<210> 1211
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1211
gagaagucau uuaauaaggc cacuguuaaa aagcu 35
<210> 1212
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1212
gucuaagaac uuuaaau 17
<210> 1213
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1213
acuuuaaaua auuucuacug uuguagau 28
<210> 1214
<211> 31
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1214
gagaagucau uuaauaaggc cacuguuaaa a 31
<210> 1215
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1215
gucuaagaac uuuaaau 17
<210> 1216
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1216
acuuuaaaua auuucuacug uuguagau 28
<210> 1217
<211> 30
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1217
gagaagucau uuaauaaggc cacuguuaaa 30
<210> 1218
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1218
gucuaagaac uuuaaau 17
<210> 1219
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1219
acuuuaaaua auuucuacug uuguagau 28
<210> 1220
<211> 27
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1220
gagaagucau uuaauaaggc cacuguu 27
<210> 1221
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1221
gucuaagaac uuuaaau 17
<210> 1222
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1222
acuuuaaaua auuucuacug uuguagau 28
<210> 1223
<211> 24
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1223
gagaagucau uuaauaaggc cacu 24
<210> 1224
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1224
gucuaagaac uuuaaau 17
<210> 1225
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1225
acuuuaaaua auuucuacug uuguagau 28
<210> 1226
<211> 20
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1226
gagaagucau uuaauaaggc 20
<210> 1227
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1227
gucuaagaac uuuaaau 17
<210> 1228
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1228
acuuuaaaua auuucuacug uuguagau 28
<210> 1229
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1229
gagaagucau uuaauaa 17
<210> 1230
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1230
gucuaagaac uuuaaau 17
<210> 1231
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1231
acuuuaaaua auuucuacug uuguagau 28
<210> 1232
<211> 14
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1232
gagaagucau uuaa 14
<210> 1233
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1233
gucuaagaac uuuaaau 17
<210> 1234
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1234
acuuuaaaua auuucuacug uuguagau 28
<210> 1235
<211> 27
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1235
agucauuuaa uaaggccacu guuaaaa 27
<210> 1236
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1236
gucuaagaac uuuaaau 17
<210> 1237
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1237
acuuuaaaua auuucuacug uuguagau 28
<210> 1238
<211> 24
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1238
cauuuaauaa ggccacuguu aaaa 24
<210> 1239
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1239
gucuaagaac uuuaaau 17
<210> 1240
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1240
acuuuaaaua auuucuacug uuguagau 28
<210> 1241
<211> 20
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1241
uaauaaggcc acuguuaaaa 20
<210> 1242
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1242
gucuaagaac uuuaaau 17
<210> 1243
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1243
acuuuaaaua auuucuacug uuguagau 28
<210> 1244
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1244
uaaggccacu guuaaaa 17
<210> 1245
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1245
gucuaagaac uuuaaau 17
<210> 1246
<211> 28
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1246
acuuuaaaua auuucuacug uuguagau 28
<210> 1247
<211> 14
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1247
ggccacuguu aaaa 14
<210> 1248
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1248
gucuaagaac uuuaaau 17
<210> 1249
<211> 103
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1249
gtctaagaac tttaaataat ttctactgtt gtagatgaga agtcatttaa taaggccact 60
gttaaaagtc taagaacttt aaataatttc tactgttgta gat 103
<210> 1250
<211> 3849
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1250
ggtaccatgg attacggcaa cggccagttt gagcggagag cccccctgac caagacaatc 60
accctgcgcc tgaagcctat cggcgagaca cgggagacaa tccgcgagca gaagctgctg 120
gagcaggacg ccgccttcag aaagctggtg gagacagtga cccctatcgt ggacgattgt 180
atcaggaaga tcgccgataa cgccctgtgc cactttggca ccgagtatga cttcagctgt 240
ctgggcaacg ccatctctaa gaatgacagc aaggccatca agaaggagac agagaaggtg 300
gagaagctgc tggccaaggt gctgaccgag aatctgccag atggcctgcg caaggtgaac 360
gacatcaatt ccgccgcctt tatccaggat acactgacct ctttcgtgca ggacgatgcc 420
gacaagcggg tgctgatcca ggagctgaag ggcaagaccg tgctgatgca gcggttcctg 480
accacacgga tcacagccct gaccgtgtgg ctgcccgaca gagtgttcga gaactttaat 540
atcttcatcg agaacgccga gaagatgaga atcctgctgg actcccctct gaatgagaag 600
atcatgaagt ttgacccaga tgccgagcag tacgcctctc tggagttcta tggccagtgc 660
ctgtctcaga aggacatcga tagctacaac ctgatcatct ccggcatcta tgccgacgat 720
gaggtgaaga accctggcat caatgagatc gtgaaggagt acaatcagca gatccggggc 780
gacaaggatg agtccccact gcccaagctg aagaagctgc acaagcagat cctgatgcca 840
gtggagaagg ccttctttgt gcgcgtgctg tctaacgaca gcgatgcccg gagcatcctg 900
gagaagatcc tgaaggacac agagatgctg ccctccaaga tcatcgaggc catgaaggag 960
gcagatgcag gcgacatcgc cgtgtacggc agccggctgc acgagctgag ccacgtgatc 1020
tacggcgatc acggcaagct gtcccagatc atctatgaca aggagtccaa gaggatctct 1080
gagctgatgg agacactgtc tccaaaggag cgcaaggaga gcaagaagcg gctggagggc 1140
ctggaggagc acatcagaaa gtctacatac accttcgacg agctgaacag gtatgccgag 1200
aagaatgtga tggcagcata catcgcagca gtggaggagt cttgtgccga gatcatgaga 1260
aaggagaagg atctgaggac cctgctgagc aaggaggacg tgaagatccg gggcaacaga 1320
cacaatacac tgatcgtgaa gaactacttt aatgcctgga ccgtgttccg gaacctgatc 1380
agaatcctga ggcgcaagtc cgaggccgag atcgactctg acttctacga tgtgctggac 1440
gattccgtgg aggtgctgtc tctgacatac aagggcgaga atctgtgccg cagctatatc 1500
accaagaaga tcggctccga cctgaagccc gagatcgcca catacggcag cgccctgagg 1560
cctaacagcc gctggtggtc cccaggagag aagtttaatg tgaagttcca caccatcgtg 1620
cggagagatg gccggctgta ctatttcatc ctgcccaagg gcgccaagcc tgtggagctg 1680
gaggacatgg atggcgacat cgagtgtctg cagatgagaa agatccctaa cccaacaatc 1740
tttctgccca agctggtgtt caaggaccct gaggccttct ttagggataa tccagaggcc 1800
gacgagttcg tgtttctgag cggcatgaag gcccccgtga caatcaccag agagacatac 1860
gaggcctaca ggtataagct gtataccgtg ggcaagctgc gcgatggcga ggtgtccgaa 1920
gaggagtaca agcgggccct gctgcaggtg ctgaccgcct acaaggagtt tctggagaac 1980
agaatgatct atgccgacct gaatttcggc tttaaggatc tggaggagta taaggacagc 2040
tccgagttta tcaagcaggt ggagacacac aacaccttca tgtgctgggc caaggtgtct 2100
agctcccagc tggacgatct ggtgaagtct ggcaacggcc tgctgttcga gatctggagc 2160
gagcgcctgg agtcctacta taagtacggc aatgagaagg tgctgcgggg ctatgagggc 2220
gtgctgctga gcatcctgaa ggatgagaac ctggtgtcca tgcggaccct gctgaacagc 2280
cggcccatgc tggtgtaccg gccaaaggag tctagcaagc ctatggtggt gcaccgggat 2340
ggcagcagag tggtggacag gtttgataag gacggcaagt acatcccccc tgaggtgcac 2400
gacgagctgt atcgcttctt taacaatctg ctgatcaagg agaagctggg cgagaaggcc 2460
cggaagatcc tggacaacaa gaaggtgaag gtgaaggtgc tggagagcga gagagtgaag 2520
tggtccaagt tctacgatga gcagtttgcc gtgaccttca gcgtgaagaa gaacgccgat 2580
tgtctggaca ccacaaagga cctgaatgcc gaagtgatgg agcagtatag cgagtccaac 2640
agactgatcc tgatcaggaa taccacagat atcctgtact atctggtgct ggacaagaat 2700
ggcaaggtgc tgaagcagag atccctgaac atcatcaatg acggcgccag ggatgtggac 2760
tggaaggaga ggttccgcca ggtgacaaag gatagaaacg agggctacaa tgagtgggat 2820
tattccagga cctctaacga cctgaaggag gtgtacctga attatgccct gaaggagatc 2880
gccgaggccg tgatcgagta caacgccatc ctgatcatcg agaagatgtc taatgccttt 2940
aaggacaagt atagcttcct ggacgacgtg accttcaagg gcttcgagac aaagctgctg 3000
gccaagctga gcgatctgca ctttaggggc atcaaggacg gcgagccatg ttccttcaca 3060
aaccccctgc agctgtgcca gaacgattct aataagatcc tgcaggacgg cgtgatcttt 3120
atggtgccaa attctatgac acggagcctg gaccccgaca ccggcttcat ctttgccatc 3180
aacgaccaca atatcaggac caagaaggcc aagctgaact ttctgagcaa gttcgatcag 3240
ctgaaggtgt cctctgaggg ctgcctgatc atgaagtaca gcggcgattc cctgcctaca 3300
cacaacaccg acaatcgcgt gtggaactgc tgttgcaatc acccaatcac aaactatgac 3360
cgggagacaa agaaggtgga gttcatcgag gagcccgtgg aggagctgtc ccgcgtgctg 3420
gaggagaatg gcatcgagac agacaccgag ctgaacaagc tgaatgagcg ggagaacgtg 3480
cctggcaagg tggtggatgc catctactct ctggtgctga attatctgcg cggcacagtg 3540
agcggagtgg caggacagag ggccgtgtac tatagccctg tgaccggcaa gaagtacgat 3600
atctccttta tccaggccat gaacctgaat aggaagtgtg actactatag gatcggctcc 3660
aaggagaggg gagagtggac cgatttcgtg gcccagctga tcaacaaaag gccggcggcc 3720
acgaaaaagg ccggccaggc aaaaaagaaa aagggatcct acccatacga tgttccagat 3780
tacgcttatc cctacgacgt gcctgattat gcatacccat atgatgtccc cgactatgcc 3840
taagaattc 3849
<210> 1251
<211> 1233
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1251
Met Asp Tyr Gly Asn Gly Gln Phe Glu Arg Arg Ala Pro Leu Thr Lys
1 5 10 15
Thr Ile Thr Leu Arg Leu Lys Pro Ile Gly Glu Thr Arg Glu Thr Ile
20 25 30
Arg Glu Gln Lys Leu Leu Glu Gln Asp Ala Ala Phe Arg Lys Leu Val
35 40 45
Glu Thr Val Thr Pro Ile Val Asp Asp Cys Ile Arg Lys Ile Ala Asp
50 55 60
Asn Ala Leu Cys His Phe Gly Thr Glu Tyr Asp Phe Ser Cys Leu Gly
65 70 75 80
Asn Ala Ile Ser Lys Asn Asp Ser Lys Ala Ile Lys Lys Glu Thr Glu
85 90 95
Lys Val Glu Lys Leu Leu Ala Lys Val Leu Thr Glu Asn Leu Pro Asp
100 105 110
Gly Leu Arg Lys Val Asn Asp Ile Asn Ser Ala Ala Phe Ile Gln Asp
115 120 125
Thr Leu Thr Ser Phe Val Gln Asp Asp Ala Asp Lys Arg Val Leu Ile
130 135 140
Gln Glu Leu Lys Gly Lys Thr Val Leu Met Gln Arg Phe Leu Thr Thr
145 150 155 160
Arg Ile Thr Ala Leu Thr Val Trp Leu Pro Asp Arg Val Phe Glu Asn
165 170 175
Phe Asn Ile Phe Ile Glu Asn Ala Glu Lys Met Arg Ile Leu Leu Asp
180 185 190
Ser Pro Leu Asn Glu Lys Ile Met Lys Phe Asp Pro Asp Ala Glu Gln
195 200 205
Tyr Ala Ser Leu Glu Phe Tyr Gly Gln Cys Leu Ser Gln Lys Asp Ile
210 215 220
Asp Ser Tyr Asn Leu Ile Ile Ser Gly Ile Tyr Ala Asp Asp Glu Val
225 230 235 240
Lys Asn Pro Gly Ile Asn Glu Ile Val Lys Glu Tyr Asn Gln Gln Ile
245 250 255
Arg Gly Asp Lys Asp Glu Ser Pro Leu Pro Lys Leu Lys Lys Leu His
260 265 270
Lys Gln Ile Leu Met Pro Val Glu Lys Ala Phe Phe Val Arg Val Leu
275 280 285
Ser Asn Asp Ser Asp Ala Arg Ser Ile Leu Glu Lys Ile Leu Lys Asp
290 295 300
Thr Glu Met Leu Pro Ser Lys Ile Ile Glu Ala Met Lys Glu Ala Asp
305 310 315 320
Ala Gly Asp Ile Ala Val Tyr Gly Ser Arg Leu His Glu Leu Ser His
325 330 335
Val Ile Tyr Gly Asp His Gly Lys Leu Ser Gln Ile Ile Tyr Asp Lys
340 345 350
Glu Ser Lys Arg Ile Ser Glu Leu Met Glu Thr Leu Ser Pro Lys Glu
355 360 365
Arg Lys Glu Ser Lys Lys Arg Leu Glu Gly Leu Glu Glu His Ile Arg
370 375 380
Lys Ser Thr Tyr Thr Phe Asp Glu Leu Asn Arg Tyr Ala Glu Lys Asn
385 390 395 400
Val Met Ala Ala Tyr Ile Ala Ala Val Glu Glu Ser Cys Ala Glu Ile
405 410 415
Met Arg Lys Glu Lys Asp Leu Arg Thr Leu Leu Ser Lys Glu Asp Val
420 425 430
Lys Ile Arg Gly Asn Arg His Asn Thr Leu Ile Val Lys Asn Tyr Phe
435 440 445
Asn Ala Trp Thr Val Phe Arg Asn Leu Ile Arg Ile Leu Arg Arg Lys
450 455 460
Ser Glu Ala Glu Ile Asp Ser Asp Phe Tyr Asp Val Leu Asp Asp Ser
465 470 475 480
Val Glu Val Leu Ser Leu Thr Tyr Lys Gly Glu Asn Leu Cys Arg Ser
485 490 495
Tyr Ile Thr Lys Lys Ile Gly Ser Asp Leu Lys Pro Glu Ile Ala Thr
500 505 510
Tyr Gly Ser Ala Leu Arg Pro Asn Ser Arg Trp Trp Ser Pro Gly Glu
515 520 525
Lys Phe Asn Val Lys Phe His Thr Ile Val Arg Arg Asp Gly Arg Leu
530 535 540
Tyr Tyr Phe Ile Leu Pro Lys Gly Ala Lys Pro Val Glu Leu Glu Asp
545 550 555 560
Met Asp Gly Asp Ile Glu Cys Leu Gln Met Arg Lys Ile Pro Asn Pro
565 570 575
Thr Ile Phe Leu Pro Lys Leu Val Phe Lys Asp Pro Glu Ala Phe Phe
580 585 590
Arg Asp Asn Pro Glu Ala Asp Glu Phe Val Phe Leu Ser Gly Met Lys
595 600 605
Ala Pro Val Thr Ile Thr Arg Glu Thr Tyr Glu Ala Tyr Arg Tyr Lys
610 615 620
Leu Tyr Thr Val Gly Lys Leu Arg Asp Gly Glu Val Ser Glu Glu Glu
625 630 635 640
Tyr Lys Arg Ala Leu Leu Gln Val Leu Thr Ala Tyr Lys Glu Phe Leu
645 650 655
Glu Asn Arg Met Ile Tyr Ala Asp Leu Asn Phe Gly Phe Lys Asp Leu
660 665 670
Glu Glu Tyr Lys Asp Ser Ser Glu Phe Ile Lys Gln Val Glu Thr His
675 680 685
Asn Thr Phe Met Cys Trp Ala Lys Val Ser Ser Ser Gln Leu Asp Asp
690 695 700
Leu Val Lys Ser Gly Asn Gly Leu Leu Phe Glu Ile Trp Ser Glu Arg
705 710 715 720
Leu Glu Ser Tyr Tyr Lys Tyr Gly Asn Glu Lys Val Leu Arg Gly Tyr
725 730 735
Glu Gly Val Leu Leu Ser Ile Leu Lys Asp Glu Asn Leu Val Ser Met
740 745 750
Arg Thr Leu Leu Asn Ser Arg Pro Met Leu Val Tyr Arg Pro Lys Glu
755 760 765
Ser Ser Lys Pro Met Val Val His Arg Asp Gly Ser Arg Val Val Asp
770 775 780
Arg Phe Asp Lys Asp Gly Lys Tyr Ile Pro Pro Glu Val His Asp Glu
785 790 795 800
Leu Tyr Arg Phe Phe Asn Asn Leu Leu Ile Lys Glu Lys Leu Gly Glu
805 810 815
Lys Ala Arg Lys Ile Leu Asp Asn Lys Lys Val Lys Val Lys Val Leu
820 825 830
Glu Ser Glu Arg Val Lys Trp Ser Lys Phe Tyr Asp Glu Gln Phe Ala
835 840 845
Val Thr Phe Ser Val Lys Lys Asn Ala Asp Cys Leu Asp Thr Thr Lys
850 855 860
Asp Leu Asn Ala Glu Val Met Glu Gln Tyr Ser Glu Ser Asn Arg Leu
865 870 875 880
Ile Leu Ile Arg Asn Thr Thr Asp Ile Leu Tyr Tyr Leu Val Leu Asp
885 890 895
Lys Asn Gly Lys Val Leu Lys Gln Arg Ser Leu Asn Ile Ile Asn Asp
900 905 910
Gly Ala Arg Asp Val Asp Trp Lys Glu Arg Phe Arg Gln Val Thr Lys
915 920 925
Asp Arg Asn Glu Gly Tyr Asn Glu Trp Asp Tyr Ser Arg Thr Ser Asn
930 935 940
Asp Leu Lys Glu Val Tyr Leu Asn Tyr Ala Leu Lys Glu Ile Ala Glu
945 950 955 960
Ala Val Ile Glu Tyr Asn Ala Ile Leu Ile Ile Glu Lys Met Ser Asn
965 970 975
Ala Phe Lys Asp Lys Tyr Ser Phe Leu Asp Asp Val Thr Phe Lys Gly
980 985 990
Phe Glu Thr Lys Leu Leu Ala Lys Leu Ser Asp Leu His Phe Arg Gly
995 1000 1005
Ile Lys Asp Gly Glu Pro Cys Ser Phe Thr Asn Pro Leu Gln Leu
1010 1015 1020
Cys Gln Asn Asp Ser Asn Lys Ile Leu Gln Asp Gly Val Ile Phe
1025 1030 1035
Met Val Pro Asn Ser Met Thr Arg Ser Leu Asp Pro Asp Thr Gly
1040 1045 1050
Phe Ile Phe Ala Ile Asn Asp His Asn Ile Arg Thr Lys Lys Ala
1055 1060 1065
Lys Leu Asn Phe Leu Ser Lys Phe Asp Gln Leu Lys Val Ser Ser
1070 1075 1080
Glu Gly Cys Leu Ile Met Lys Tyr Ser Gly Asp Ser Leu Pro Thr
1085 1090 1095
His Asn Thr Asp Asn Arg Val Trp Asn Cys Cys Cys Asn His Pro
1100 1105 1110
Ile Thr Asn Tyr Asp Arg Glu Thr Lys Lys Val Glu Phe Ile Glu
1115 1120 1125
Glu Pro Val Glu Glu Leu Ser Arg Val Leu Glu Glu Asn Gly Ile
1130 1135 1140
Glu Thr Asp Thr Glu Leu Asn Lys Leu Asn Glu Arg Glu Asn Val
1145 1150 1155
Pro Gly Lys Val Val Asp Ala Ile Tyr Ser Leu Val Leu Asn Tyr
1160 1165 1170
Leu Arg Gly Thr Val Ser Gly Val Ala Gly Gln Arg Ala Val Tyr
1175 1180 1185
Tyr Ser Pro Val Thr Gly Lys Lys Tyr Asp Ile Ser Phe Ile Gln
1190 1195 1200
Ala Met Asn Leu Asn Arg Lys Cys Asp Tyr Tyr Arg Ile Gly Ser
1205 1210 1215
Lys Glu Arg Gly Glu Trp Thr Asp Phe Val Ala Gln Leu Ile Asn
1220 1225 1230
<210> 1252
<211> 3873
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1252
ggtaccatgc tgctgtatga gaactacacc aagcggaatc agatcacaaa gagcctgagg 60
ctggagctgc gccctcaggg caagaccctg agaaacatca aggagctgaa tctgctggag 120
caggacaagg ccatctacgc cctgctggag cggctgaagc cagtgatcga tgagggcatc 180
aaggacatcg ccagagatac cctgaagaac tgcgagctgt cttttgagaa gctgtacgag 240
cacttcctga gcggcgacaa gaaggcctat gccaaggagt ccgagcggct gaagaaggag 300
atcgtgaaaa ccctgatcaa gaacctgccc gagggcatcg gcaagatctc tgagatcaac 360
agcgccaagt atctgaatgg cgtgctgtac gacttcatcg ataagacaca caaggactct 420
gaggagaagc agaatatcct gagcgatatc ctggagacaa agggctacct ggccctgttc 480
tccaagtttc tgacatctcg gatcaccaca ctggagcagt ccatgcctaa gagagtgatc 540
gagaacttcg agatctatgc cgccaatatc ccaaagatgc aggacgccct ggagagggga 600
gccgtgtctt ttgccatcga gtacgagagc atctgttccg tggattacta taaccagatc 660
ctgtcccagg aggacatcga ttcttataat cgcctgatca gcggcatcat ggacgaggat 720
ggcgccaagg agaagggcat caaccagacc atctccgaga agaatatcaa gatcaagtct 780
gagcacctgg aggagaagcc cttcagaatc ctgaagcagc tgcacaagca gatcctggag 840
gagcgcgaga aggcctttac aatcgaccac atcgacagcg atgaggaggt ggtgcaggtg 900
accaaggagg ccttcgagca gacaaaggag cagtgggaga acatcaagaa gatcaatggc 960
ttctacgcca aggaccccgg cgatatcacc ctgtttatcg tggtgggccc taaccagaca 1020
cacgtgctgt cccagctgat ctacggcgag cacgaccgga tcagactgct gctggaggag 1080
tatgagaaga acaccctgga ggtgctgccc cggagaacaa agtctgagaa ggccagatac 1140
gataagttcg tgaatgccgt gcctaagaag gtggccaagg agagccacac cttcgacggc 1200
ctgcagaaga tgacaggcga cgatcggctg tttatcctgt atagagatga gctggcccgg 1260
aactacatga gaatcaagga ggcctatggc acctttgagc gggacatcct gaagagcagg 1320
cgcggcatca agggcaatcg ggacgtgcag gagtctctgg tgagctttta cgatgagctg 1380
acaaagttca ggagcgccct gcgcatcatc aattccggca acgacgagaa ggccgatcca 1440
atcttctata acacctttga tggcatcttc gagaaggcca ataggacata caaggccgag 1500
aatctgtgcc gcaactatgt gaccaagtct ccagccgacg atgccaggat catggccagc 1560
tgtctgggca ccccagcaag gctgcgcaca cactggtgga atggcgagga gaacttcgcc 1620
atcaatgacg tggccatgat ccggagaggc gatgagtact attactttgt gctgacccca 1680
gacgtgaagc ccgtggacct gaaaaccaag gacgagacag atgcccagat cttcgtgcag 1740
cgcaagggcg ccaagtcctt tctgggcctg ccaaaggccc tgttcaagtg catcctggag 1800
ccttactttg agtccccaga gcacaagaat gacaagaact gcgtgatcga ggagtacgtg 1860
tctaagcccc tgaccatcga caggcgcgcc tatgatatct ttaagaacgg caccttcaag 1920
aaaaccaata tcggcatcga cggcctgacc gaggagaagt tcaaggacga ttgccgctat 1980
ctgatcgacg tgtataagga gttcatcgcc gtgtatacaa ggtacagctg ttttaacatg 2040
tccggcctga agcgcgccga cgagtacaat gatatcggcg agttcttttc tgacgtggat 2100
accaggctgt gcacaatgga gtggattccc gtgagcttcg agcgcatcaa cgacatggtg 2160
gataagaagg agggcctgct gtttctggtg aggagcatgt tcctgtataa ccggcccaga 2220
aagccttatg agcgcacctt tatccagctg ttcagcgact ccaacatgga gcacacatct 2280
atgctgctga atagcagggc catgatccag tacagggcag cctccctgcc acggagagtg 2340
acccacaaga agggcagcat cctggtggcc ctgcgggatt ccaacggcga gcacatcccc 2400
atgcacatca gagaggccat ctacaagatg aagaacaatt ttgacatcag ctccgaggat 2460
ttcatcatgg ccaaggccta tctggccgag cacgacgtgg ccatcaagaa ggccaacgag 2520
gatatcatca ggaataggcg ctacaccgag gacaagttct ttctgtctct gagctatacc 2580
aagaacgccg atatcagcgc ccgcacactg gactacatca atgataaggt ggaggaggac 2640
acacaggatt ccaggatggc cgtgatcgtg acccgcaacc tgaaggacct gacatacgtg 2700
gccgtggtgg atgagaagaa caatgtgctg gaggagaaga gcctgaacga gatcgacggc 2760
gtgaattatc gggagctgct gaaggagaga accaagatca agtaccacga caagacacgg 2820
ctgtggcagt atgacgtgag cagcaagggc ctgaaggagg cctacgtgga gctggccgtg 2880
acccagatct ccaagctggc cacaaagtat aacgccgtgg tggtggtgga gtccatgtcc 2940
tctaccttca aggacaagtt ctcttttctg gatgagcaga tcttcaaggc ctttgaggcc 3000
cggctgtgcg ccagaatgtc cgacctgtct tttaatacaa tcaaggaggg cgaggccggc 3060
tccatctcta accccatcca ggtgtccaac aataacggca attcttatca ggacggcgtg 3120
atctacttcc tgaataacgc ctatacccgg accctgtgcc ctgataccgg ctttgtggac 3180
gtgttcgata agacccggct gatcacaatg cagtctaaga gacagttctt tgccaagatg 3240
aaggacatca gaatcgacga tggcgagatg ctgttcacct ttaacctgga ggagtaccct 3300
acaaagaggc tgctggaccg caaggagtgg accgtgaaga tcgccggcga tggctcctat 3360
ttcgacaagg ataagggcga gtacgtgtac gtgaacgaca tcgtgagaga gcagatcatc 3420
ccagccctgc tggaggacaa ggccgtgttc gatggcaata tggccgagaa gtttctggat 3480
aagaccgcca tcagcggcaa gtccgtggag ctgatctaca agtggttcgc caacgccctg 3540
tatggcatca tcacaaagaa ggacggcgag aagatctacc ggagccccat caccggcaca 3600
gagatcgacg tgagcaagaa caccacatac aacttcggca agaagttcat gttcaagcag 3660
gagtatagag gcgacggcga ttttctggac gccttcctga attacatgca ggcccaggat 3720
atcgccgtga aaaggccggc ggccacgaaa aaggccggcc aggcaaaaaa gaaaaaggga 3780
tcctacccat acgatgttcc agattacgct tatccctacg acgtgcctga ttatgcatac 3840
ccatatgatg tccccgacta tgcctaagaa ttc 3873
<210> 1253
<211> 1241
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1253
Met Leu Leu Tyr Glu Asn Tyr Thr Lys Arg Asn Gln Ile Thr Lys Ser
1 5 10 15
Leu Arg Leu Glu Leu Arg Pro Gln Gly Lys Thr Leu Arg Asn Ile Lys
20 25 30
Glu Leu Asn Leu Leu Glu Gln Asp Lys Ala Ile Tyr Ala Leu Leu Glu
35 40 45
Arg Leu Lys Pro Val Ile Asp Glu Gly Ile Lys Asp Ile Ala Arg Asp
50 55 60
Thr Leu Lys Asn Cys Glu Leu Ser Phe Glu Lys Leu Tyr Glu His Phe
65 70 75 80
Leu Ser Gly Asp Lys Lys Ala Tyr Ala Lys Glu Ser Glu Arg Leu Lys
85 90 95
Lys Glu Ile Val Lys Thr Leu Ile Lys Asn Leu Pro Glu Gly Ile Gly
100 105 110
Lys Ile Ser Glu Ile Asn Ser Ala Lys Tyr Leu Asn Gly Val Leu Tyr
115 120 125
Asp Phe Ile Asp Lys Thr His Lys Asp Ser Glu Glu Lys Gln Asn Ile
130 135 140
Leu Ser Asp Ile Leu Glu Thr Lys Gly Tyr Leu Ala Leu Phe Ser Lys
145 150 155 160
Phe Leu Thr Ser Arg Ile Thr Thr Leu Glu Gln Ser Met Pro Lys Arg
165 170 175
Val Ile Glu Asn Phe Glu Ile Tyr Ala Ala Asn Ile Pro Lys Met Gln
180 185 190
Asp Ala Leu Glu Arg Gly Ala Val Ser Phe Ala Ile Glu Tyr Glu Ser
195 200 205
Ile Cys Ser Val Asp Tyr Tyr Asn Gln Ile Leu Ser Gln Glu Asp Ile
210 215 220
Asp Ser Tyr Asn Arg Leu Ile Ser Gly Ile Met Asp Glu Asp Gly Ala
225 230 235 240
Lys Glu Lys Gly Ile Asn Gln Thr Ile Ser Glu Lys Asn Ile Lys Ile
245 250 255
Lys Ser Glu His Leu Glu Glu Lys Pro Phe Arg Ile Leu Lys Gln Leu
260 265 270
His Lys Gln Ile Leu Glu Glu Arg Glu Lys Ala Phe Thr Ile Asp His
275 280 285
Ile Asp Ser Asp Glu Glu Val Val Gln Val Thr Lys Glu Ala Phe Glu
290 295 300
Gln Thr Lys Glu Gln Trp Glu Asn Ile Lys Lys Ile Asn Gly Phe Tyr
305 310 315 320
Ala Lys Asp Pro Gly Asp Ile Thr Leu Phe Ile Val Val Gly Pro Asn
325 330 335
Gln Thr His Val Leu Ser Gln Leu Ile Tyr Gly Glu His Asp Arg Ile
340 345 350
Arg Leu Leu Leu Glu Glu Tyr Glu Lys Asn Thr Leu Glu Val Leu Pro
355 360 365
Arg Arg Thr Lys Ser Glu Lys Ala Arg Tyr Asp Lys Phe Val Asn Ala
370 375 380
Val Pro Lys Lys Val Ala Lys Glu Ser His Thr Phe Asp Gly Leu Gln
385 390 395 400
Lys Met Thr Gly Asp Asp Arg Leu Phe Ile Leu Tyr Arg Asp Glu Leu
405 410 415
Ala Arg Asn Tyr Met Arg Ile Lys Glu Ala Tyr Gly Thr Phe Glu Arg
420 425 430
Asp Ile Leu Lys Ser Arg Arg Gly Ile Lys Gly Asn Arg Asp Val Gln
435 440 445
Glu Ser Leu Val Ser Phe Tyr Asp Glu Leu Thr Lys Phe Arg Ser Ala
450 455 460
Leu Arg Ile Ile Asn Ser Gly Asn Asp Glu Lys Ala Asp Pro Ile Phe
465 470 475 480
Tyr Asn Thr Phe Asp Gly Ile Phe Glu Lys Ala Asn Arg Thr Tyr Lys
485 490 495
Ala Glu Asn Leu Cys Arg Asn Tyr Val Thr Lys Ser Pro Ala Asp Asp
500 505 510
Ala Arg Ile Met Ala Ser Cys Leu Gly Thr Pro Ala Arg Leu Arg Thr
515 520 525
His Trp Trp Asn Gly Glu Glu Asn Phe Ala Ile Asn Asp Val Ala Met
530 535 540
Ile Arg Arg Gly Asp Glu Tyr Tyr Tyr Phe Val Leu Thr Pro Asp Val
545 550 555 560
Lys Pro Val Asp Leu Lys Thr Lys Asp Glu Thr Asp Ala Gln Ile Phe
565 570 575
Val Gln Arg Lys Gly Ala Lys Ser Phe Leu Gly Leu Pro Lys Ala Leu
580 585 590
Phe Lys Cys Ile Leu Glu Pro Tyr Phe Glu Ser Pro Glu His Lys Asn
595 600 605
Asp Lys Asn Cys Val Ile Glu Glu Tyr Val Ser Lys Pro Leu Thr Ile
610 615 620
Asp Arg Arg Ala Tyr Asp Ile Phe Lys Asn Gly Thr Phe Lys Lys Thr
625 630 635 640
Asn Ile Gly Ile Asp Gly Leu Thr Glu Glu Lys Phe Lys Asp Asp Cys
645 650 655
Arg Tyr Leu Ile Asp Val Tyr Lys Glu Phe Ile Ala Val Tyr Thr Arg
660 665 670
Tyr Ser Cys Phe Asn Met Ser Gly Leu Lys Arg Ala Asp Glu Tyr Asn
675 680 685
Asp Ile Gly Glu Phe Phe Ser Asp Val Asp Thr Arg Leu Cys Thr Met
690 695 700
Glu Trp Ile Pro Val Ser Phe Glu Arg Ile Asn Asp Met Val Asp Lys
705 710 715 720
Lys Glu Gly Leu Leu Phe Leu Val Arg Ser Met Phe Leu Tyr Asn Arg
725 730 735
Pro Arg Lys Pro Tyr Glu Arg Thr Phe Ile Gln Leu Phe Ser Asp Ser
740 745 750
Asn Met Glu His Thr Ser Met Leu Leu Asn Ser Arg Ala Met Ile Gln
755 760 765
Tyr Arg Ala Ala Ser Leu Pro Arg Arg Val Thr His Lys Lys Gly Ser
770 775 780
Ile Leu Val Ala Leu Arg Asp Ser Asn Gly Glu His Ile Pro Met His
785 790 795 800
Ile Arg Glu Ala Ile Tyr Lys Met Lys Asn Asn Phe Asp Ile Ser Ser
805 810 815
Glu Asp Phe Ile Met Ala Lys Ala Tyr Leu Ala Glu His Asp Val Ala
820 825 830
Ile Lys Lys Ala Asn Glu Asp Ile Ile Arg Asn Arg Arg Tyr Thr Glu
835 840 845
Asp Lys Phe Phe Leu Ser Leu Ser Tyr Thr Lys Asn Ala Asp Ile Ser
850 855 860
Ala Arg Thr Leu Asp Tyr Ile Asn Asp Lys Val Glu Glu Asp Thr Gln
865 870 875 880
Asp Ser Arg Met Ala Val Ile Val Thr Arg Asn Leu Lys Asp Leu Thr
885 890 895
Tyr Val Ala Val Val Asp Glu Lys Asn Asn Val Leu Glu Glu Lys Ser
900 905 910
Leu Asn Glu Ile Asp Gly Val Asn Tyr Arg Glu Leu Leu Lys Glu Arg
915 920 925
Thr Lys Ile Lys Tyr His Asp Lys Thr Arg Leu Trp Gln Tyr Asp Val
930 935 940
Ser Ser Lys Gly Leu Lys Glu Ala Tyr Val Glu Leu Ala Val Thr Gln
945 950 955 960
Ile Ser Lys Leu Ala Thr Lys Tyr Asn Ala Val Val Val Val Glu Ser
965 970 975
Met Ser Ser Thr Phe Lys Asp Lys Phe Ser Phe Leu Asp Glu Gln Ile
980 985 990
Phe Lys Ala Phe Glu Ala Arg Leu Cys Ala Arg Met Ser Asp Leu Ser
995 1000 1005
Phe Asn Thr Ile Lys Glu Gly Glu Ala Gly Ser Ile Ser Asn Pro
1010 1015 1020
Ile Gln Val Ser Asn Asn Asn Gly Asn Ser Tyr Gln Asp Gly Val
1025 1030 1035
Ile Tyr Phe Leu Asn Asn Ala Tyr Thr Arg Thr Leu Cys Pro Asp
1040 1045 1050
Thr Gly Phe Val Asp Val Phe Asp Lys Thr Arg Leu Ile Thr Met
1055 1060 1065
Gln Ser Lys Arg Gln Phe Phe Ala Lys Met Lys Asp Ile Arg Ile
1070 1075 1080
Asp Asp Gly Glu Met Leu Phe Thr Phe Asn Leu Glu Glu Tyr Pro
1085 1090 1095
Thr Lys Arg Leu Leu Asp Arg Lys Glu Trp Thr Val Lys Ile Ala
1100 1105 1110
Gly Asp Gly Ser Tyr Phe Asp Lys Asp Lys Gly Glu Tyr Val Tyr
1115 1120 1125
Val Asn Asp Ile Val Arg Glu Gln Ile Ile Pro Ala Leu Leu Glu
1130 1135 1140
Asp Lys Ala Val Phe Asp Gly Asn Met Ala Glu Lys Phe Leu Asp
1145 1150 1155
Lys Thr Ala Ile Ser Gly Lys Ser Val Glu Leu Ile Tyr Lys Trp
1160 1165 1170
Phe Ala Asn Ala Leu Tyr Gly Ile Ile Thr Lys Lys Asp Gly Glu
1175 1180 1185
Lys Ile Tyr Arg Ser Pro Ile Thr Gly Thr Glu Ile Asp Val Ser
1190 1195 1200
Lys Asn Thr Thr Tyr Asn Phe Gly Lys Lys Phe Met Phe Lys Gln
1205 1210 1215
Glu Tyr Arg Gly Asp Gly Asp Phe Leu Asp Ala Phe Leu Asn Tyr
1220 1225 1230
Met Gln Ala Gln Asp Ile Ala Val
1235 1240
<210> 1254
<211> 4581
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1254
ggtaccatgt ccaacttctt taagaatttc accaacctgt atgagctgtc caagacactg 60
aggtttgagc tgaagcccgt gggcgacacc ctgacaaaca tgaaggacca cctggagtac 120
gatgagaagc tgcagacctt cctgaaggat cagaatatcg acgatgccta tcaggccctg 180
aagcctcagt tcgacgagat ccacgaggag tttatcacag attctctgga gagcaagaag 240
gccaaggaga tcgacttctc cgagtacctg gatctgtttc aggagaagaa ggagctgaac 300
gactctgaga agaagctgcg caacaagatc ggcgagacat tcaacaaggc cggcgagaag 360
tggaagaagg agaagtaccc tcagtatgag tggaagaagg gctccaagat cgccaatggc 420
gccgacatcc tgtcttgcca ggatatgctg cagtttatca agtataagaa cccagaggat 480
gagaagatca agaattacat cgacgataca ctgaagggct tctttaccta tttcggcggc 540
tttaatcaga acagggccaa ctactatgag acaaagaagg aggcctccac cgcagtggca 600
acaaggatcg tgcacgagaa cctgccaaag ttctgtgaca atgtgatcca gtttaagcac 660
atcatcaagc ggaagaagga tggcaccgtg gagaaaaccg agagaaagac cgagtacctg 720
aacgcctacc agtatctgaa gaacaataac aagatcacac agatcaagga cgccgagaca 780
gagaagatga tcgagtctac acccatcgcc gagaagatct tcgacgtgta ctacttcagc 840
agctgcctga gccagaagca gatcgaggag tacaaccgga tcatcggcca ctataatctg 900
ctgatcaacc tgtataacca ggccaagaga tctgagggca agcacctgag cgccaacgag 960
aagaagtata aggacctgcc taagttcaag accctgtata agcagatcgg ctgcggcaag 1020
aagaaggacc tgttttacac aatcaagtgt gataccgagg aggaggccaa taagtcccgg 1080
aacgagggca aggagtccca ctctgtggag gagatcatca acaaggccca ggaggccatc 1140
aataagtact tcaagtctaa taacgactgt gagaatatca acaccgtgcc cgacttcatc 1200
aactatatcc tgacaaagga gaattacgag ggcgtgtatt ggagcaaggc cgccatgaac 1260
accatctccg acaagtactt cgccaattat cacgacctgc aggatagact gaaggaggcc 1320
aaggtgtttc agaaggccga taagaagtcc gaggacgata tcaagatccc agaggccatc 1380
gagctgtctg gcctgttcgg cgtgctggac agcctggccg attggcagac cacactgttt 1440
aagtctagca tcctgagcaa cgaggacaag ctgaagatca tcacagattc ccagaccccc 1500
tctgaggccc tgctgaagat gatcttcaat gacatcgaga agaacatgga gtcctttctg 1560
aaggagacaa acgatatcat caccctgaag aagtataagg gcaataagga gggcaccgag 1620
aagatcaagc agtggttcga ctatacactg gccatcaacc ggatgctgaa gtactttctg 1680
gtgaaggaga ataagatcaa gggcaactcc ctggatacca atatctctga ggccctgaaa 1740
accctgatct acagcgacga tgccgagtgg ttcaagtggt acgacgccct gagaaactat 1800
ctgacccaga agcctcagga tgaggccaag gagaataagc tgaagctgaa tttcgacaac 1860
ccatctctgg ccggcggctg ggatgtgaac aaggagtgca gcaatttttg cgtgatcctg 1920
aaggacaaga acgagaagaa gtacctggcc atcatgaaga agggcgagaa taccctgttc 1980
cagaaggagt ggacagaggg ccggggcaag aacctgacaa agaagtctaa tccactgttc 2040
gagatcaata actgcgagat cctgagcaag atggagtatg acttttgggc cgacgtgagc 2100
aagatgatcc ccaagtgtag cacccagctg aaggccgtgg tgaaccactt caagcagtcc 2160
gacaatgagt tcatctttcc tatcggctac aaggtgacaa gcggcgagaa gtttagggag 2220
gagtgcaaga tctccaagca ggacttcgag ctgaataaca aggtgtttaa taagaacgag 2280
ctgagcgtga ccgccatgcg ctacgatctg tcctctacac aggagaagca gtatatcaag 2340
gccttccaga aggagtactg ggagctgctg tttaagcagg agaagcggga caccaagctg 2400
acaaataacg agatcttcaa cgagtggatc aatttttgca acaagaagta tagcgagctg 2460
ctgtcctggg agagaaagta caaggatgcc ctgaccaatt ggatcaactt ctgtaagtac 2520
tttctgagca agtatcccaa gaccacactg ttcaactact cttttaagga gagcgagaat 2580
tataactccc tggacgagtt ctaccgggac gtggatatct gttcttacaa gctgaatatc 2640
aacaccacaa tcaataagag catcctggat agactggtgg aggagggcaa gctgtacctg 2700
tttgagatca agaatcagga cagcaacgat ggcaagtcca tcggccacaa gaataacctg 2760
cacaccatct actggaacgc catcttcgag aattttgaca acaggcctaa gctgaatggc 2820
gaggccgaga tcttctatcg caaggccatc tccaaggata agctgggcat cgtgaagggc 2880
aagaaaacca agaacggcac cgagatcatc aagaattaca gattcagcaa ggagaagttt 2940
atcctgcacg tgccaatcac cctgaacttc tgctccaata acgagtatgt gaatgacatc 3000
gtgaacacaa agttctacaa tttttccaac ctgcactttc tgggcatcga taggggcgag 3060
aagcacctgg cctactattc tctggtgaat aagaacggcg agatcgtgga ccagggcaca 3120
ctgaacctgc ctttcaccga caaggatggc aatcagcgca gcatcaagaa ggagaagtac 3180
ttttataaca agcaggagga caagtgggag gccaaggagg tggattgttg gaattataac 3240
gacctgctgg atgccatggc ctctaaccgg gacatggcca gaaagaattg gcagaggatc 3300
ggcaccatca aggaggccaa gaacggctac gtgagcctgg tcatcaggaa gatcgccgat 3360
ctggccgtga ataacgagcg ccccgccttc atcgtgctgg aggacctgaa tacaggcttt 3420
aagcggtcca gacagaagat cgataagagc gtgtaccaga agttcgagct ggccctggcc 3480
aagaagctga actttctggt ggacaagaat gccaagcgcg atgagatcgg ctcccctaca 3540
aaggccctgc agctgacccc ccctgtgaat aactacggcg acattgagaa caagaagcag 3600
gccggcatca tgctgtatac ccgggccaat tatacctctc agacagatcc agccacaggc 3660
tggagaaaga ccatctatct gaaggccggc cccgaggaga caacatacaa gaaggacggc 3720
aagatcaaga acaagagcgt gaaggaccag atcatcgaga cattcaccga tatcggcttt 3780
gacggcaagg attactattt cgagtacgac aagggcgagt ttgtggatga gaaaaccggc 3840
gagatcaagc ccaagaagtg gcggctgtac tccggcgaga atggcaagtc cctggacagg 3900
ttccgcggag agagggagaa ggataagtat gagtggaaga tcgacaagat cgatatcgtg 3960
aagatcctgg acgatctgtt cgtgaatttt gacaagaaca tcagcctgct gaagcagctg 4020
aaggagggcg tggagctgac ccggaataac gagcacggca caggcgagtc cctgagattc 4080
gccatcaacc tgatccagca gatccggaat accggcaata acgagagaga caacgatttc 4140
atcctgtccc cagtgaggga cgagaatggc aagcactttg actctcgcga gtactgggat 4200
aaggagacaa agggcgagaa gatcagcatg cccagctccg gcgatgccaa tggcgccttc 4260
aacatcgccc ggaagggcat catcatgaac gcccacatcc tggccaatag cgactccaag 4320
gatctgtccc tgttcgtgtc tgacgaggag tgggatctgc acctgaataa caagaccgag 4380
tggaagaagc agctgaacat cttttctagc aggaaggcca tggccaagcg caagaagaaa 4440
aggccggcgg ccacgaaaaa ggccggccag gcaaaaaaga aaaagggatc ctacccatac 4500
gatgttccag attacgctta tccctacgac gtgcctgatt atgcataccc atatgatgtc 4560
cccgactatg cctaagaatt c 4581
<210> 1255
<211> 1477
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1255
Met Ser Asn Phe Phe Lys Asn Phe Thr Asn Leu Tyr Glu Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Asp Thr Leu Thr Asn Met
20 25 30
Lys Asp His Leu Glu Tyr Asp Glu Lys Leu Gln Thr Phe Leu Lys Asp
35 40 45
Gln Asn Ile Asp Asp Ala Tyr Gln Ala Leu Lys Pro Gln Phe Asp Glu
50 55 60
Ile His Glu Glu Phe Ile Thr Asp Ser Leu Glu Ser Lys Lys Ala Lys
65 70 75 80
Glu Ile Asp Phe Ser Glu Tyr Leu Asp Leu Phe Gln Glu Lys Lys Glu
85 90 95
Leu Asn Asp Ser Glu Lys Lys Leu Arg Asn Lys Ile Gly Glu Thr Phe
100 105 110
Asn Lys Ala Gly Glu Lys Trp Lys Lys Glu Lys Tyr Pro Gln Tyr Glu
115 120 125
Trp Lys Lys Gly Ser Lys Ile Ala Asn Gly Ala Asp Ile Leu Ser Cys
130 135 140
Gln Asp Met Leu Gln Phe Ile Lys Tyr Lys Asn Pro Glu Asp Glu Lys
145 150 155 160
Ile Lys Asn Tyr Ile Asp Asp Thr Leu Lys Gly Phe Phe Thr Tyr Phe
165 170 175
Gly Gly Phe Asn Gln Asn Arg Ala Asn Tyr Tyr Glu Thr Lys Lys Glu
180 185 190
Ala Ser Thr Ala Val Ala Thr Arg Ile Val His Glu Asn Leu Pro Lys
195 200 205
Phe Cys Asp Asn Val Ile Gln Phe Lys His Ile Ile Lys Arg Lys Lys
210 215 220
Asp Gly Thr Val Glu Lys Thr Glu Arg Lys Thr Glu Tyr Leu Asn Ala
225 230 235 240
Tyr Gln Tyr Leu Lys Asn Asn Asn Lys Ile Thr Gln Ile Lys Asp Ala
245 250 255
Glu Thr Glu Lys Met Ile Glu Ser Thr Pro Ile Ala Glu Lys Ile Phe
260 265 270
Asp Val Tyr Tyr Phe Ser Ser Cys Leu Ser Gln Lys Gln Ile Glu Glu
275 280 285
Tyr Asn Arg Ile Ile Gly His Tyr Asn Leu Leu Ile Asn Leu Tyr Asn
290 295 300
Gln Ala Lys Arg Ser Glu Gly Lys His Leu Ser Ala Asn Glu Lys Lys
305 310 315 320
Tyr Lys Asp Leu Pro Lys Phe Lys Thr Leu Tyr Lys Gln Ile Gly Cys
325 330 335
Gly Lys Lys Lys Asp Leu Phe Tyr Thr Ile Lys Cys Asp Thr Glu Glu
340 345 350
Glu Ala Asn Lys Ser Arg Asn Glu Gly Lys Glu Ser His Ser Val Glu
355 360 365
Glu Ile Ile Asn Lys Ala Gln Glu Ala Ile Asn Lys Tyr Phe Lys Ser
370 375 380
Asn Asn Asp Cys Glu Asn Ile Asn Thr Val Pro Asp Phe Ile Asn Tyr
385 390 395 400
Ile Leu Thr Lys Glu Asn Tyr Glu Gly Val Tyr Trp Ser Lys Ala Ala
405 410 415
Met Asn Thr Ile Ser Asp Lys Tyr Phe Ala Asn Tyr His Asp Leu Gln
420 425 430
Asp Arg Leu Lys Glu Ala Lys Val Phe Gln Lys Ala Asp Lys Lys Ser
435 440 445
Glu Asp Asp Ile Lys Ile Pro Glu Ala Ile Glu Leu Ser Gly Leu Phe
450 455 460
Gly Val Leu Asp Ser Leu Ala Asp Trp Gln Thr Thr Leu Phe Lys Ser
465 470 475 480
Ser Ile Leu Ser Asn Glu Asp Lys Leu Lys Ile Ile Thr Asp Ser Gln
485 490 495
Thr Pro Ser Glu Ala Leu Leu Lys Met Ile Phe Asn Asp Ile Glu Lys
500 505 510
Asn Met Glu Ser Phe Leu Lys Glu Thr Asn Asp Ile Ile Thr Leu Lys
515 520 525
Lys Tyr Lys Gly Asn Lys Glu Gly Thr Glu Lys Ile Lys Gln Trp Phe
530 535 540
Asp Tyr Thr Leu Ala Ile Asn Arg Met Leu Lys Tyr Phe Leu Val Lys
545 550 555 560
Glu Asn Lys Ile Lys Gly Asn Ser Leu Asp Thr Asn Ile Ser Glu Ala
565 570 575
Leu Lys Thr Leu Ile Tyr Ser Asp Asp Ala Glu Trp Phe Lys Trp Tyr
580 585 590
Asp Ala Leu Arg Asn Tyr Leu Thr Gln Lys Pro Gln Asp Glu Ala Lys
595 600 605
Glu Asn Lys Leu Lys Leu Asn Phe Asp Asn Pro Ser Leu Ala Gly Gly
610 615 620
Trp Asp Val Asn Lys Glu Cys Ser Asn Phe Cys Val Ile Leu Lys Asp
625 630 635 640
Lys Asn Glu Lys Lys Tyr Leu Ala Ile Met Lys Lys Gly Glu Asn Thr
645 650 655
Leu Phe Gln Lys Glu Trp Thr Glu Gly Arg Gly Lys Asn Leu Thr Lys
660 665 670
Lys Ser Asn Pro Leu Phe Glu Ile Asn Asn Cys Glu Ile Leu Ser Lys
675 680 685
Met Glu Tyr Asp Phe Trp Ala Asp Val Ser Lys Met Ile Pro Lys Cys
690 695 700
Ser Thr Gln Leu Lys Ala Val Val Asn His Phe Lys Gln Ser Asp Asn
705 710 715 720
Glu Phe Ile Phe Pro Ile Gly Tyr Lys Val Thr Ser Gly Glu Lys Phe
725 730 735
Arg Glu Glu Cys Lys Ile Ser Lys Gln Asp Phe Glu Leu Asn Asn Lys
740 745 750
Val Phe Asn Lys Asn Glu Leu Ser Val Thr Ala Met Arg Tyr Asp Leu
755 760 765
Ser Ser Thr Gln Glu Lys Gln Tyr Ile Lys Ala Phe Gln Lys Glu Tyr
770 775 780
Trp Glu Leu Leu Phe Lys Gln Glu Lys Arg Asp Thr Lys Leu Thr Asn
785 790 795 800
Asn Glu Ile Phe Asn Glu Trp Ile Asn Phe Cys Asn Lys Lys Tyr Ser
805 810 815
Glu Leu Leu Ser Trp Glu Arg Lys Tyr Lys Asp Ala Leu Thr Asn Trp
820 825 830
Ile Asn Phe Cys Lys Tyr Phe Leu Ser Lys Tyr Pro Lys Thr Thr Leu
835 840 845
Phe Asn Tyr Ser Phe Lys Glu Ser Glu Asn Tyr Asn Ser Leu Asp Glu
850 855 860
Phe Tyr Arg Asp Val Asp Ile Cys Ser Tyr Lys Leu Asn Ile Asn Thr
865 870 875 880
Thr Ile Asn Lys Ser Ile Leu Asp Arg Leu Val Glu Glu Gly Lys Leu
885 890 895
Tyr Leu Phe Glu Ile Lys Asn Gln Asp Ser Asn Asp Gly Lys Ser Ile
900 905 910
Gly His Lys Asn Asn Leu His Thr Ile Tyr Trp Asn Ala Ile Phe Glu
915 920 925
Asn Phe Asp Asn Arg Pro Lys Leu Asn Gly Glu Ala Glu Ile Phe Tyr
930 935 940
Arg Lys Ala Ile Ser Lys Asp Lys Leu Gly Ile Val Lys Gly Lys Lys
945 950 955 960
Thr Lys Asn Gly Thr Glu Ile Ile Lys Asn Tyr Arg Phe Ser Lys Glu
965 970 975
Lys Phe Ile Leu His Val Pro Ile Thr Leu Asn Phe Cys Ser Asn Asn
980 985 990
Glu Tyr Val Asn Asp Ile Val Asn Thr Lys Phe Tyr Asn Phe Ser Asn
995 1000 1005
Leu His Phe Leu Gly Ile Asp Arg Gly Glu Lys His Leu Ala Tyr
1010 1015 1020
Tyr Ser Leu Val Asn Lys Asn Gly Glu Ile Val Asp Gln Gly Thr
1025 1030 1035
Leu Asn Leu Pro Phe Thr Asp Lys Asp Gly Asn Gln Arg Ser Ile
1040 1045 1050
Lys Lys Glu Lys Tyr Phe Tyr Asn Lys Gln Glu Asp Lys Trp Glu
1055 1060 1065
Ala Lys Glu Val Asp Cys Trp Asn Tyr Asn Asp Leu Leu Asp Ala
1070 1075 1080
Met Ala Ser Asn Arg Asp Met Ala Arg Lys Asn Trp Gln Arg Ile
1085 1090 1095
Gly Thr Ile Lys Glu Ala Lys Asn Gly Tyr Val Ser Leu Val Ile
1100 1105 1110
Arg Lys Ile Ala Asp Leu Ala Val Asn Asn Glu Arg Pro Ala Phe
1115 1120 1125
Ile Val Leu Glu Asp Leu Asn Thr Gly Phe Lys Arg Ser Arg Gln
1130 1135 1140
Lys Ile Asp Lys Ser Val Tyr Gln Lys Phe Glu Leu Ala Leu Ala
1145 1150 1155
Lys Lys Leu Asn Phe Leu Val Asp Lys Asn Ala Lys Arg Asp Glu
1160 1165 1170
Ile Gly Ser Pro Thr Lys Ala Leu Gln Leu Thr Pro Pro Val Asn
1175 1180 1185
Asn Tyr Gly Asp Ile Glu Asn Lys Lys Gln Ala Gly Ile Met Leu
1190 1195 1200
Tyr Thr Arg Ala Asn Tyr Thr Ser Gln Thr Asp Pro Ala Thr Gly
1205 1210 1215
Trp Arg Lys Thr Ile Tyr Leu Lys Ala Gly Pro Glu Glu Thr Thr
1220 1225 1230
Tyr Lys Lys Asp Gly Lys Ile Lys Asn Lys Ser Val Lys Asp Gln
1235 1240 1245
Ile Ile Glu Thr Phe Thr Asp Ile Gly Phe Asp Gly Lys Asp Tyr
1250 1255 1260
Tyr Phe Glu Tyr Asp Lys Gly Glu Phe Val Asp Glu Lys Thr Gly
1265 1270 1275
Glu Ile Lys Pro Lys Lys Trp Arg Leu Tyr Ser Gly Glu Asn Gly
1280 1285 1290
Lys Ser Leu Asp Arg Phe Arg Gly Glu Arg Glu Lys Asp Lys Tyr
1295 1300 1305
Glu Trp Lys Ile Asp Lys Ile Asp Ile Val Lys Ile Leu Asp Asp
1310 1315 1320
Leu Phe Val Asn Phe Asp Lys Asn Ile Ser Leu Leu Lys Gln Leu
1325 1330 1335
Lys Glu Gly Val Glu Leu Thr Arg Asn Asn Glu His Gly Thr Gly
1340 1345 1350
Glu Ser Leu Arg Phe Ala Ile Asn Leu Ile Gln Gln Ile Arg Asn
1355 1360 1365
Thr Gly Asn Asn Glu Arg Asp Asn Asp Phe Ile Leu Ser Pro Val
1370 1375 1380
Arg Asp Glu Asn Gly Lys His Phe Asp Ser Arg Glu Tyr Trp Asp
1385 1390 1395
Lys Glu Thr Lys Gly Glu Lys Ile Ser Met Pro Ser Ser Gly Asp
1400 1405 1410
Ala Asn Gly Ala Phe Asn Ile Ala Arg Lys Gly Ile Ile Met Asn
1415 1420 1425
Ala His Ile Leu Ala Asn Ser Asp Ser Lys Asp Leu Ser Leu Phe
1430 1435 1440
Val Ser Asp Glu Glu Trp Asp Leu His Leu Asn Asn Lys Thr Glu
1445 1450 1455
Trp Lys Lys Gln Leu Asn Ile Phe Ser Ser Arg Lys Ala Met Ala
1460 1465 1470
Lys Arg Lys Lys
1475
<210> 1256
<211> 4206
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1256
ggtaccatgg agaacatctt cgaccagttt atcggcaagt acagcctgtc caagaccctg 60
agattcgagc tgaagcccgt gggcaagaca gaggacttcc tgaagatcaa caaggtgttt 120
gagaaggatc agaccatcga cgatagctac aatcaggcca agttctattt tgattccctg 180
caccagaagt ttatcgacgc cgccctggcc tccgataaga catccgagct gtctttccag 240
aactttgccg acgtgctgga gaagcagaat aagatcatcc tggataagaa gagagagatg 300
ggcgccctga ggaagcgcga caagaacgcc gtgggcatcg ataggctgca gaaggagatc 360
aatgacgccg aggatatcat ccagaaggag aaggagaaga tctacaagga cgtgcgcacc 420
ctgttcgata acgaggccga gtcttggaaa acctactatc aggagcggga ggtggacggc 480
aagaagatca ccttcagcaa ggccgacctg aagcagaagg gcgccgattt tctgacagcc 540
gccggcatcc tgaaggtgct gaagtatgag ttccccgagg agaaggagaa ggagtttcag 600
gccaagaacc agccctccct gttcgtggag gagaaggaga atcctggcca gaagaggtac 660
atcttcgact cttttgataa gttcgccggc tatctgacca agtttcagca gacaaagaag 720
aatctgtacg cagcagacgg caccagcaca gcagtggcca cccgcatcgc cgataacttt 780
atcatcttcc accagaatac caaggtgttc cgggacaagt acaagaacaa tcacacagac 840
ctgggcttcg atgaggagaa catctttgag atcgagaggt ataagaattg cctgctgcag 900
cgcgagatcg agcacatcaa gaatgagaat agctacaaca agatcatcgg ccggatcaat 960
aagaagatca aggagtatcg ggaccagaag gccaaggata ccaagctgac aaagtccgac 1020
ttccctttct ttaagaacct ggataagcag atcctgggcg aggtggagaa ggagaagcag 1080
ctgatcgaga aaacccggga gaaaaccgag gaggacgtgc tgatcgagcg gttcaaggag 1140
ttcatcgaga acaatgagga gaggttcacc gccgccaaga agctgatgaa tgccttctgt 1200
aacggcgagt ttgagtccga gtacgagggc atctatctga agaataaggc catcaacaca 1260
atctcccgga gatggttcgt gtctgacaga gattttgagc tgaagctgcc tcagcagaag 1320
tccaagaaca agtctgagaa gaatgagcca aaggtgaaga agttcatctc catcgccgag 1380
atcaagaacg ccgtggagga gctggacggc gatatcttta aggccgtgtt ctacgacaag 1440
aagatcatcg cccagggcgg ctctaagctg gagcagttcc tggtcatctg gaagtacgag 1500
tttgagtatc tgttccggga catcgagaga gagaacggcg agaagctgct gggctatgat 1560
agctgcctga agatcgccaa gcagctgggc atcttcccac aggagaagga ggcccgcgag 1620
aaggcaaccg ccgtgatcaa gaattacgcc gacgccggcc tgggcatctt ccagatgatg 1680
aagtattttt ctctggacga taaggatcgg aagaacaccc ccggccagct gagcacaaat 1740
ttctacgccg agtatgacgg ctactacaag gatttcgagt ttatcaagta ctacaacgag 1800
tttaggaact tcatcaccaa gaagcctttc gacgaggata agatcaagct gaactttgag 1860
aatggcgccc tgctgaaggg ctgggacgag aacaaggagt acgatttcat gggcgtgatc 1920
ctgaagaagg agggccgcct gtatctgggc atcatgcaca agaaccaccg gaagctgttt 1980
cagtccatgg gcaatgccaa gggcgacaac gccaatagat accagaagat gatctataag 2040
cagatcgccg acgcctctaa ggatgtgccc aggctgctgc tgaccagcaa gaaggccatg 2100
gagaagttca agccttccca ggagatcctg agaatcaaga aggagaaaac cttcaagcgg 2160
gagagcaaga acttttccct gagagatctg cacgccctga tcgagtacta taggaactgc 2220
atccctcagt acagcaattg gtccttttat gacttccagt ttcaggatac cggcaagtac 2280
cagaatatca aggagttcac agacgatgtg cagaagtacg gctataagat ctcctttcgc 2340
gacatcgacg atgagtatat caatcaggcc ctgaacgagg gcaagatgta cctgttcgag 2400
gtggtgaaca aggatatcta taacaccaag aatggctcca agaatctgca cacactgtac 2460
tttgagcaca tcctgtctgc cgagaacctg aatgacccag tgttcaagct gtctggcatg 2520
gccgagatct ttcagcggca gcccagcgtg aacgaaagag agaagatcac cacacagaag 2580
aatcagtgta tcctggacaa gggcgataga gcctacaagt ataggcgcta caccgagaag 2640
aagatcatgt tccacatgag cctggtgctg aacacaggca agggcgagat caagcaggtg 2700
cagtttaata agatcatcaa ccagaggatc agctcctctg acaacgagat gagggtgaat 2760
gtgatcggca tcgatcgcgg cgagaagaac ctgctgtact atagcgtggt gaagcagaat 2820
ggcgagatca tcgagcaggc ctccctgaac gagatcaatg gcgtgaacta ccgggacaag 2880
ctgatcgaga gggagaagga gcgcctgaag aaccggcaga gctggaagcc tgtggtgaag 2940
atcaaggatc tgaagaaggg ctacatctcc cacgtgatcc acaagatctg ccagctgatc 3000
gagaagtatt ctgccatcgt ggtgctggag gacctgaata tgagattcaa gcagatcagg 3060
ggaggaatcg agcggagcgt gtaccagcag ttcgagaagg ccctgatcga taagctgggc 3120
tatctggtgt ttaaggacaa cagggatctg agggcaccag gaggcgtgct gaatggctac 3180
cagctgtctg ccccctttgt gagcttcgag aagatgcgca agcagaccgg catcctgttc 3240
tacacacagg ccgagtatac cagcaagaca gacccaatca ccggctttcg gaagaacgtg 3300
tatatctcta atagcgcctc cctggataag atcaaggagg ccgtgaagaa gttcgacgcc 3360
atcggctggg atggcaagga gcagtcttac ttctttaagt acaaccctta caacctggcc 3420
gacgagaagt ataagaactc taccgtgagc aaggagtggg ccatctttgc cagcgcccca 3480
agaatccgga gacagaaggg cgaggacggc tactggaagt atgatagggt gaaagtgaat 3540
gaggagttcg agaagctgct gaaggtctgg aattttgtga acccaaaggc cacagatatc 3600
aagcaggaga tcatcaagaa ggagaaggca ggcgacctgc agggagagaa ggagctggat 3660
ggccggctga gaaacttttg gcactctttc atctacctgt ttaacctggt gctggagctg 3720
cgcaattctt tcagcctgca gatcaagatc aaggcaggag aagtgatcgc agtggacgag 3780
ggcgtggact tcatcgccag cccagtgaag cccttcttta ccacacccaa cccttacatc 3840
ccctccaacc tgtgctggct ggccgtggag aatgcagacg caaacggagc ctataatatc 3900
gccaggaagg gcgtgatgat cctgaagaag atccgcgagc acgccaagaa ggaccccgag 3960
ttcaagaagc tgccaaacct gtttatcagc aatgcagagt gggacgaggc agcccgggat 4020
tggggcaagt acgcaggcac cacagccctg aacctggacc acaaaaggcc ggcggccacg 4080
aaaaaggccg gccaggcaaa aaagaaaaag ggatcctacc catacgatgt tccagattac 4140
gcttatccct acgacgtgcc tgattatgca tacccatatg atgtccccga ctatgcctaa 4200
gaattc 4206
<210> 1257
<211> 1352
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1257
Met Glu Asn Ile Phe Asp Gln Phe Ile Gly Lys Tyr Ser Leu Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Glu Asp Phe Leu
20 25 30
Lys Ile Asn Lys Val Phe Glu Lys Asp Gln Thr Ile Asp Asp Ser Tyr
35 40 45
Asn Gln Ala Lys Phe Tyr Phe Asp Ser Leu His Gln Lys Phe Ile Asp
50 55 60
Ala Ala Leu Ala Ser Asp Lys Thr Ser Glu Leu Ser Phe Gln Asn Phe
65 70 75 80
Ala Asp Val Leu Glu Lys Gln Asn Lys Ile Ile Leu Asp Lys Lys Arg
85 90 95
Glu Met Gly Ala Leu Arg Lys Arg Asp Lys Asn Ala Val Gly Ile Asp
100 105 110
Arg Leu Gln Lys Glu Ile Asn Asp Ala Glu Asp Ile Ile Gln Lys Glu
115 120 125
Lys Glu Lys Ile Tyr Lys Asp Val Arg Thr Leu Phe Asp Asn Glu Ala
130 135 140
Glu Ser Trp Lys Thr Tyr Tyr Gln Glu Arg Glu Val Asp Gly Lys Lys
145 150 155 160
Ile Thr Phe Ser Lys Ala Asp Leu Lys Gln Lys Gly Ala Asp Phe Leu
165 170 175
Thr Ala Ala Gly Ile Leu Lys Val Leu Lys Tyr Glu Phe Pro Glu Glu
180 185 190
Lys Glu Lys Glu Phe Gln Ala Lys Asn Gln Pro Ser Leu Phe Val Glu
195 200 205
Glu Lys Glu Asn Pro Gly Gln Lys Arg Tyr Ile Phe Asp Ser Phe Asp
210 215 220
Lys Phe Ala Gly Tyr Leu Thr Lys Phe Gln Gln Thr Lys Lys Asn Leu
225 230 235 240
Tyr Ala Ala Asp Gly Thr Ser Thr Ala Val Ala Thr Arg Ile Ala Asp
245 250 255
Asn Phe Ile Ile Phe His Gln Asn Thr Lys Val Phe Arg Asp Lys Tyr
260 265 270
Lys Asn Asn His Thr Asp Leu Gly Phe Asp Glu Glu Asn Ile Phe Glu
275 280 285
Ile Glu Arg Tyr Lys Asn Cys Leu Leu Gln Arg Glu Ile Glu His Ile
290 295 300
Lys Asn Glu Asn Ser Tyr Asn Lys Ile Ile Gly Arg Ile Asn Lys Lys
305 310 315 320
Ile Lys Glu Tyr Arg Asp Gln Lys Ala Lys Asp Thr Lys Leu Thr Lys
325 330 335
Ser Asp Phe Pro Phe Phe Lys Asn Leu Asp Lys Gln Ile Leu Gly Glu
340 345 350
Val Glu Lys Glu Lys Gln Leu Ile Glu Lys Thr Arg Glu Lys Thr Glu
355 360 365
Glu Asp Val Leu Ile Glu Arg Phe Lys Glu Phe Ile Glu Asn Asn Glu
370 375 380
Glu Arg Phe Thr Ala Ala Lys Lys Leu Met Asn Ala Phe Cys Asn Gly
385 390 395 400
Glu Phe Glu Ser Glu Tyr Glu Gly Ile Tyr Leu Lys Asn Lys Ala Ile
405 410 415
Asn Thr Ile Ser Arg Arg Trp Phe Val Ser Asp Arg Asp Phe Glu Leu
420 425 430
Lys Leu Pro Gln Gln Lys Ser Lys Asn Lys Ser Glu Lys Asn Glu Pro
435 440 445
Lys Val Lys Lys Phe Ile Ser Ile Ala Glu Ile Lys Asn Ala Val Glu
450 455 460
Glu Leu Asp Gly Asp Ile Phe Lys Ala Val Phe Tyr Asp Lys Lys Ile
465 470 475 480
Ile Ala Gln Gly Gly Ser Lys Leu Glu Gln Phe Leu Val Ile Trp Lys
485 490 495
Tyr Glu Phe Glu Tyr Leu Phe Arg Asp Ile Glu Arg Glu Asn Gly Glu
500 505 510
Lys Leu Leu Gly Tyr Asp Ser Cys Leu Lys Ile Ala Lys Gln Leu Gly
515 520 525
Ile Phe Pro Gln Glu Lys Glu Ala Arg Glu Lys Ala Thr Ala Val Ile
530 535 540
Lys Asn Tyr Ala Asp Ala Gly Leu Gly Ile Phe Gln Met Met Lys Tyr
545 550 555 560
Phe Ser Leu Asp Asp Lys Asp Arg Lys Asn Thr Pro Gly Gln Leu Ser
565 570 575
Thr Asn Phe Tyr Ala Glu Tyr Asp Gly Tyr Tyr Lys Asp Phe Glu Phe
580 585 590
Ile Lys Tyr Tyr Asn Glu Phe Arg Asn Phe Ile Thr Lys Lys Pro Phe
595 600 605
Asp Glu Asp Lys Ile Lys Leu Asn Phe Glu Asn Gly Ala Leu Leu Lys
610 615 620
Gly Trp Asp Glu Asn Lys Glu Tyr Asp Phe Met Gly Val Ile Leu Lys
625 630 635 640
Lys Glu Gly Arg Leu Tyr Leu Gly Ile Met His Lys Asn His Arg Lys
645 650 655
Leu Phe Gln Ser Met Gly Asn Ala Lys Gly Asp Asn Ala Asn Arg Tyr
660 665 670
Gln Lys Met Ile Tyr Lys Gln Ile Ala Asp Ala Ser Lys Asp Val Pro
675 680 685
Arg Leu Leu Leu Thr Ser Lys Lys Ala Met Glu Lys Phe Lys Pro Ser
690 695 700
Gln Glu Ile Leu Arg Ile Lys Lys Glu Lys Thr Phe Lys Arg Glu Ser
705 710 715 720
Lys Asn Phe Ser Leu Arg Asp Leu His Ala Leu Ile Glu Tyr Tyr Arg
725 730 735
Asn Cys Ile Pro Gln Tyr Ser Asn Trp Ser Phe Tyr Asp Phe Gln Phe
740 745 750
Gln Asp Thr Gly Lys Tyr Gln Asn Ile Lys Glu Phe Thr Asp Asp Val
755 760 765
Gln Lys Tyr Gly Tyr Lys Ile Ser Phe Arg Asp Ile Asp Asp Glu Tyr
770 775 780
Ile Asn Gln Ala Leu Asn Glu Gly Lys Met Tyr Leu Phe Glu Val Val
785 790 795 800
Asn Lys Asp Ile Tyr Asn Thr Lys Asn Gly Ser Lys Asn Leu His Thr
805 810 815
Leu Tyr Phe Glu His Ile Leu Ser Ala Glu Asn Leu Asn Asp Pro Val
820 825 830
Phe Lys Leu Ser Gly Met Ala Glu Ile Phe Gln Arg Gln Pro Ser Val
835 840 845
Asn Glu Arg Glu Lys Ile Thr Thr Gln Lys Asn Gln Cys Ile Leu Asp
850 855 860
Lys Gly Asp Arg Ala Tyr Lys Tyr Arg Arg Tyr Thr Glu Lys Lys Ile
865 870 875 880
Met Phe His Met Ser Leu Val Leu Asn Thr Gly Lys Gly Glu Ile Lys
885 890 895
Gln Val Gln Phe Asn Lys Ile Ile Asn Gln Arg Ile Ser Ser Ser Asp
900 905 910
Asn Glu Met Arg Val Asn Val Ile Gly Ile Asp Arg Gly Glu Lys Asn
915 920 925
Leu Leu Tyr Tyr Ser Val Val Lys Gln Asn Gly Glu Ile Ile Glu Gln
930 935 940
Ala Ser Leu Asn Glu Ile Asn Gly Val Asn Tyr Arg Asp Lys Leu Ile
945 950 955 960
Glu Arg Glu Lys Glu Arg Leu Lys Asn Arg Gln Ser Trp Lys Pro Val
965 970 975
Val Lys Ile Lys Asp Leu Lys Lys Gly Tyr Ile Ser His Val Ile His
980 985 990
Lys Ile Cys Gln Leu Ile Glu Lys Tyr Ser Ala Ile Val Val Leu Glu
995 1000 1005
Asp Leu Asn Met Arg Phe Lys Gln Ile Arg Gly Gly Ile Glu Arg
1010 1015 1020
Ser Val Tyr Gln Gln Phe Glu Lys Ala Leu Ile Asp Lys Leu Gly
1025 1030 1035
Tyr Leu Val Phe Lys Asp Asn Arg Asp Leu Arg Ala Pro Gly Gly
1040 1045 1050
Val Leu Asn Gly Tyr Gln Leu Ser Ala Pro Phe Val Ser Phe Glu
1055 1060 1065
Lys Met Arg Lys Gln Thr Gly Ile Leu Phe Tyr Thr Gln Ala Glu
1070 1075 1080
Tyr Thr Ser Lys Thr Asp Pro Ile Thr Gly Phe Arg Lys Asn Val
1085 1090 1095
Tyr Ile Ser Asn Ser Ala Ser Leu Asp Lys Ile Lys Glu Ala Val
1100 1105 1110
Lys Lys Phe Asp Ala Ile Gly Trp Asp Gly Lys Glu Gln Ser Tyr
1115 1120 1125
Phe Phe Lys Tyr Asn Pro Tyr Asn Leu Ala Asp Glu Lys Tyr Lys
1130 1135 1140
Asn Ser Thr Val Ser Lys Glu Trp Ala Ile Phe Ala Ser Ala Pro
1145 1150 1155
Arg Ile Arg Arg Gln Lys Gly Glu Asp Gly Tyr Trp Lys Tyr Asp
1160 1165 1170
Arg Val Lys Val Asn Glu Glu Phe Glu Lys Leu Leu Lys Val Trp
1175 1180 1185
Asn Phe Val Asn Pro Lys Ala Thr Asp Ile Lys Gln Glu Ile Ile
1190 1195 1200
Lys Lys Glu Lys Ala Gly Asp Leu Gln Gly Glu Lys Glu Leu Asp
1205 1210 1215
Gly Arg Leu Arg Asn Phe Trp His Ser Phe Ile Tyr Leu Phe Asn
1220 1225 1230
Leu Val Leu Glu Leu Arg Asn Ser Phe Ser Leu Gln Ile Lys Ile
1235 1240 1245
Lys Ala Gly Glu Val Ile Ala Val Asp Glu Gly Val Asp Phe Ile
1250 1255 1260
Ala Ser Pro Val Lys Pro Phe Phe Thr Thr Pro Asn Pro Tyr Ile
1265 1270 1275
Pro Ser Asn Leu Cys Trp Leu Ala Val Glu Asn Ala Asp Ala Asn
1280 1285 1290
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Val Met Ile Leu Lys Lys
1295 1300 1305
Ile Arg Glu His Ala Lys Lys Asp Pro Glu Phe Lys Lys Leu Pro
1310 1315 1320
Asn Leu Phe Ile Ser Asn Ala Glu Trp Asp Glu Ala Ala Arg Asp
1325 1330 1335
Trp Gly Lys Tyr Ala Gly Thr Thr Ala Leu Asn Leu Asp His
1340 1345 1350
<210> 1258
<211> 3900
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1258
ggtaccatgc agaccctgtt tgagaacttc acaaatcagt acccagtgtc caagaccctg 60
cgctttgagc tgatccccca gggcaagaca aaggacttca tcgagcagaa gggcctgctg 120
aagaaggatg aggaccgggc cgagaagtat aagaaggtga agaacatcat cgatgagtac 180
cacaaggact tcatcgagaa gtctctgaat ggcctgaagc tggacggcct ggagaagtac 240
aagaccctgt atctgaagca ggagaaggac gataaggata agaaggcctt tgacaaggag 300
aaggagaacc tgcgcaagca gatcgccaat gccttccgga acaatgagaa gtttaagaca 360
ctgttcgcca aggagctgat caagaacgat ctgatgtctt tcgcctgcga ggaggacaag 420
aagaatgtga aggagtttga ggccttcacc acatacttca ccggcttcca ccagaaccgc 480
gccaatatgt acgtggccga tgagaagaga acagccatcg ccagcaggct gatccacgag 540
aacctgccaa agtttatcga caatatcaag atcttcgaga agatgaagaa ggaggccccc 600
gagctgctgt ctcctttcaa ccagaccctg aaggatatga aggacgtgat caagggcacc 660
acactggagg agatctttag cctggattat ttcaacaaga ccctgacaca gagcggcatc 720
gacatctaca attccgtgat cggcggcaga acccctgagg agggcaagac aaagatcaag 780
ggcctgaacg agtacatcaa taccgacttc aaccagaagc agacagacaa gaagaagcgg 840
cagccaaagt tcaagcagct gtataagcag atcctgagcg ataggcagag cctgtccttt 900
atcgccgagg ccttcaagaa cgacaccgag atcctggagg ccatcgagaa gttttacgtg 960
aatgagctgc tgcacttcag caatgagggc aagtccacaa acgtgctgga cgccatcaag 1020
aatgccgtgt ctaacctgga gagctttaac ctgaccaaga tgtatttccg ctccggcgcc 1080
tctctgacag acgtgagccg gaaggtgttt ggcgagtgga gcatcatcaa tagagccctg 1140
gacaactact atgccaccac atatccaatc aagcccagag agaagtctga gaagtacgag 1200
gagaggaagg agaagtggct gaagcaggac ttcaacgtga gcctgatcca gaccgccatc 1260
gatgagtacg acaacgagac agtgaagggc aagaacagcg gcaaagtgat cgccgattat 1320
tttgccaagt tctgcgacga taaggagaca gacctgatcc agaaggtgaa cgagggctac 1380
atcgccgtga aggatctgct gaatacaccc tgtcctgaga acgagaagct gggcagcaat 1440
aaggaccagg tgaagcagat caaggccttt atggattcta tcatggacat catgcacttc 1500
gtgcgccccc tgagcctgaa ggataccgac aaggagaagg atgagacatt ctactccctg 1560
ttcacacctc tgtacgacca cctgacccag acaatcgccc tgtataacaa ggtgcggaac 1620
tatctgaccc agaagcctta cagcacagag aagatcaagc tgaacttcga gaacagcacc 1680
ctgctgggcg gctgggatct gaataaggag acagacaaca cagccatcat cctgaggaag 1740
gataacctgt actatctggg catcatggac aagaggcaca atcgcatctt tcggaacgtg 1800
cccaaggccg ataagaagga cttctgctac gagaagatgg tgtataagct gctgcctggc 1860
gccaacaaga tgctgccaaa ggtgttcttt tctcagagca gaatccagga gtttacccct 1920
tccgccaagc tgctggagaa ctacgccaat gagacacaca agaagggcga taatttcaac 1980
ctgaatcact gtcacaagct gatcgatttc tttaaggact ctatcaacaa gcacgaggat 2040
tggaagaatt tcgactttag gttcagcgcc acctccacct acgccgacct gagcggcttt 2100
taccacgagg tggagcacca gggctacaag atctcttttc agagcgtggc cgattccttc 2160
atcgacgatc tggtgaacga gggcaagctg tacctgttcc agatctataa taaggacttt 2220
tccccattct ctaagggcaa gcccaacctg cacaccctgt actggaagat gctgtttgat 2280
gagaacaatc tgaaggacgt ggtgtataag ctgaatggcg aggccgaggt gttctaccgc 2340
aagaagagca ttgccgagaa gaacaccaca atccacaagg ccaatgagtc catcatcaac 2400
aagaatcctg ataacccaaa ggccaccagc accttcaact atgatatcgt gaaggacaag 2460
agatacacca tcgacaagtt tcagttccac atcccaatca caatgaactt taaggccgag 2520
ggcatcttca acatgaatca gagggtgaat cagttcctga aggccaatcc cgatatcaac 2580
atcatcggca tcgacagagg cgagaggcac ctgctgtact atgccctgat caaccagaag 2640
ggcaagatcc tgaagcagga taccctgaat gtgatcgcca acgagaagca gaaggtggac 2700
taccacaatc tgctggataa gaaggagggc gaccgcgcaa ccgcaaggca ggagtggggc 2760
gtgatcgaga caatcaagga gctgaaggag ggctatctgt cccaggtcat ccacaagctg 2820
accgatctga tgatcgagaa caatgccatc atcgtgatgg aggacctgaa ctttggcttc 2880
aagcggggca gacagaaggt ggagaagcag gtgtatcaga agtttgagaa gatgctgatc 2940
gataagctga attacctggt ggacaagaat aagaaggcaa acgagctggg aggcctgctg 3000
aacgcattcc agctggccaa taagtttgag tccttccaga agatgggcaa gcagaacggc 3060
tttatcttct acgtgcccgc ctggaatacc tctaagacag atcctgccac cggctttatc 3120
gacttcctga agccccgcta tgagaacctg aatcaggcca aggatttctt tgagaagttt 3180
gactctatcc ggctgaacag caaggccgat tactttgagt tcgcctttga cttcaagaat 3240
ttcaccgaga aggccgatgg cggcagaacc aagtggacag tgtgcaccac aaacgaggac 3300
agatatgcct ggaatagggc cctgaacaat aacaggggca gccaggagaa gtacgacatc 3360
acagccgagc tgaagtccct gttcgatggc aaggtggact ataagtctgg caaggatctg 3420
aagcagcaga tcgccagcca ggagtccgcc gacttcttta aggccctgat gaagaacctg 3480
tccatcaccc tgtctctgag acacaataac ggcgagaagg gcgataatga gcaggactac 3540
atcctgtccc ctgtggccga ttctaagggc cgcttctttg actcccggaa ggccgacgat 3600
gacatgccaa agaatgccga cgccaacggc gcctatcaca tcgccctgaa gggcctgtgg 3660
tgtctggagc agatcagcaa gaccgatgac ctgaagaagg tgaagctggc catctccaac 3720
aaggagtggc tggagttcgt gcagacactg aagggcaaaa ggccggcggc cacgaaaaag 3780
gccggccagg caaaaaagaa aaagggatcc tacccatacg atgttccaga ttacgcttat 3840
ccctacgacg tgcctgatta tgcataccca tatgatgtcc ccgactatgc ctaagaattc 3900
<210> 1259
<211> 1250
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1259
Met Gln Thr Leu Phe Glu Asn Phe Thr Asn Gln Tyr Pro Val Ser Lys
1 5 10 15
Thr Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Lys Asp Phe Ile
20 25 30
Glu Gln Lys Gly Leu Leu Lys Lys Asp Glu Asp Arg Ala Glu Lys Tyr
35 40 45
Lys Lys Val Lys Asn Ile Ile Asp Glu Tyr His Lys Asp Phe Ile Glu
50 55 60
Lys Ser Leu Asn Gly Leu Lys Leu Asp Gly Leu Glu Lys Tyr Lys Thr
65 70 75 80
Leu Tyr Leu Lys Gln Glu Lys Asp Asp Lys Asp Lys Lys Ala Phe Asp
85 90 95
Lys Glu Lys Glu Asn Leu Arg Lys Gln Ile Ala Asn Ala Phe Arg Asn
100 105 110
Asn Glu Lys Phe Lys Thr Leu Phe Ala Lys Glu Leu Ile Lys Asn Asp
115 120 125
Leu Met Ser Phe Ala Cys Glu Glu Asp Lys Lys Asn Val Lys Glu Phe
130 135 140
Glu Ala Phe Thr Thr Tyr Phe Thr Gly Phe His Gln Asn Arg Ala Asn
145 150 155 160
Met Tyr Val Ala Asp Glu Lys Arg Thr Ala Ile Ala Ser Arg Leu Ile
165 170 175
His Glu Asn Leu Pro Lys Phe Ile Asp Asn Ile Lys Ile Phe Glu Lys
180 185 190
Met Lys Lys Glu Ala Pro Glu Leu Leu Ser Pro Phe Asn Gln Thr Leu
195 200 205
Lys Asp Met Lys Asp Val Ile Lys Gly Thr Thr Leu Glu Glu Ile Phe
210 215 220
Ser Leu Asp Tyr Phe Asn Lys Thr Leu Thr Gln Ser Gly Ile Asp Ile
225 230 235 240
Tyr Asn Ser Val Ile Gly Gly Arg Thr Pro Glu Glu Gly Lys Thr Lys
245 250 255
Ile Lys Gly Leu Asn Glu Tyr Ile Asn Thr Asp Phe Asn Gln Lys Gln
260 265 270
Thr Asp Lys Lys Lys Arg Gln Pro Lys Phe Lys Gln Leu Tyr Lys Gln
275 280 285
Ile Leu Ser Asp Arg Gln Ser Leu Ser Phe Ile Ala Glu Ala Phe Lys
290 295 300
Asn Asp Thr Glu Ile Leu Glu Ala Ile Glu Lys Phe Tyr Val Asn Glu
305 310 315 320
Leu Leu His Phe Ser Asn Glu Gly Lys Ser Thr Asn Val Leu Asp Ala
325 330 335
Ile Lys Asn Ala Val Ser Asn Leu Glu Ser Phe Asn Leu Thr Lys Met
340 345 350
Tyr Phe Arg Ser Gly Ala Ser Leu Thr Asp Val Ser Arg Lys Val Phe
355 360 365
Gly Glu Trp Ser Ile Ile Asn Arg Ala Leu Asp Asn Tyr Tyr Ala Thr
370 375 380
Thr Tyr Pro Ile Lys Pro Arg Glu Lys Ser Glu Lys Tyr Glu Glu Arg
385 390 395 400
Lys Glu Lys Trp Leu Lys Gln Asp Phe Asn Val Ser Leu Ile Gln Thr
405 410 415
Ala Ile Asp Glu Tyr Asp Asn Glu Thr Val Lys Gly Lys Asn Ser Gly
420 425 430
Lys Val Ile Ala Asp Tyr Phe Ala Lys Phe Cys Asp Asp Lys Glu Thr
435 440 445
Asp Leu Ile Gln Lys Val Asn Glu Gly Tyr Ile Ala Val Lys Asp Leu
450 455 460
Leu Asn Thr Pro Cys Pro Glu Asn Glu Lys Leu Gly Ser Asn Lys Asp
465 470 475 480
Gln Val Lys Gln Ile Lys Ala Phe Met Asp Ser Ile Met Asp Ile Met
485 490 495
His Phe Val Arg Pro Leu Ser Leu Lys Asp Thr Asp Lys Glu Lys Asp
500 505 510
Glu Thr Phe Tyr Ser Leu Phe Thr Pro Leu Tyr Asp His Leu Thr Gln
515 520 525
Thr Ile Ala Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Gln Lys Pro
530 535 540
Tyr Ser Thr Glu Lys Ile Lys Leu Asn Phe Glu Asn Ser Thr Leu Leu
545 550 555 560
Gly Gly Trp Asp Leu Asn Lys Glu Thr Asp Asn Thr Ala Ile Ile Leu
565 570 575
Arg Lys Asp Asn Leu Tyr Tyr Leu Gly Ile Met Asp Lys Arg His Asn
580 585 590
Arg Ile Phe Arg Asn Val Pro Lys Ala Asp Lys Lys Asp Phe Cys Tyr
595 600 605
Glu Lys Met Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro
610 615 620
Lys Val Phe Phe Ser Gln Ser Arg Ile Gln Glu Phe Thr Pro Ser Ala
625 630 635 640
Lys Leu Leu Glu Asn Tyr Ala Asn Glu Thr His Lys Lys Gly Asp Asn
645 650 655
Phe Asn Leu Asn His Cys His Lys Leu Ile Asp Phe Phe Lys Asp Ser
660 665 670
Ile Asn Lys His Glu Asp Trp Lys Asn Phe Asp Phe Arg Phe Ser Ala
675 680 685
Thr Ser Thr Tyr Ala Asp Leu Ser Gly Phe Tyr His Glu Val Glu His
690 695 700
Gln Gly Tyr Lys Ile Ser Phe Gln Ser Val Ala Asp Ser Phe Ile Asp
705 710 715 720
Asp Leu Val Asn Glu Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
725 730 735
Asp Phe Ser Pro Phe Ser Lys Gly Lys Pro Asn Leu His Thr Leu Tyr
740 745 750
Trp Lys Met Leu Phe Asp Glu Asn Asn Leu Lys Asp Val Val Tyr Lys
755 760 765
Leu Asn Gly Glu Ala Glu Val Phe Tyr Arg Lys Lys Ser Ile Ala Glu
770 775 780
Lys Asn Thr Thr Ile His Lys Ala Asn Glu Ser Ile Ile Asn Lys Asn
785 790 795 800
Pro Asp Asn Pro Lys Ala Thr Ser Thr Phe Asn Tyr Asp Ile Val Lys
805 810 815
Asp Lys Arg Tyr Thr Ile Asp Lys Phe Gln Phe His Ile Pro Ile Thr
820 825 830
Met Asn Phe Lys Ala Glu Gly Ile Phe Asn Met Asn Gln Arg Val Asn
835 840 845
Gln Phe Leu Lys Ala Asn Pro Asp Ile Asn Ile Ile Gly Ile Asp Arg
850 855 860
Gly Glu Arg His Leu Leu Tyr Tyr Ala Leu Ile Asn Gln Lys Gly Lys
865 870 875 880
Ile Leu Lys Gln Asp Thr Leu Asn Val Ile Ala Asn Glu Lys Gln Lys
885 890 895
Val Asp Tyr His Asn Leu Leu Asp Lys Lys Glu Gly Asp Arg Ala Thr
900 905 910
Ala Arg Gln Glu Trp Gly Val Ile Glu Thr Ile Lys Glu Leu Lys Glu
915 920 925
Gly Tyr Leu Ser Gln Val Ile His Lys Leu Thr Asp Leu Met Ile Glu
930 935 940
Asn Asn Ala Ile Ile Val Met Glu Asp Leu Asn Phe Gly Phe Lys Arg
945 950 955 960
Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys Met
965 970 975
Leu Ile Asp Lys Leu Asn Tyr Leu Val Asp Lys Asn Lys Lys Ala Asn
980 985 990
Glu Leu Gly Gly Leu Leu Asn Ala Phe Gln Leu Ala Asn Lys Phe Glu
995 1000 1005
Ser Phe Gln Lys Met Gly Lys Gln Asn Gly Phe Ile Phe Tyr Val
1010 1015 1020
Pro Ala Trp Asn Thr Ser Lys Thr Asp Pro Ala Thr Gly Phe Ile
1025 1030 1035
Asp Phe Leu Lys Pro Arg Tyr Glu Asn Leu Asn Gln Ala Lys Asp
1040 1045 1050
Phe Phe Glu Lys Phe Asp Ser Ile Arg Leu Asn Ser Lys Ala Asp
1055 1060 1065
Tyr Phe Glu Phe Ala Phe Asp Phe Lys Asn Phe Thr Glu Lys Ala
1070 1075 1080
Asp Gly Gly Arg Thr Lys Trp Thr Val Cys Thr Thr Asn Glu Asp
1085 1090 1095
Arg Tyr Ala Trp Asn Arg Ala Leu Asn Asn Asn Arg Gly Ser Gln
1100 1105 1110
Glu Lys Tyr Asp Ile Thr Ala Glu Leu Lys Ser Leu Phe Asp Gly
1115 1120 1125
Lys Val Asp Tyr Lys Ser Gly Lys Asp Leu Lys Gln Gln Ile Ala
1130 1135 1140
Ser Gln Glu Ser Ala Asp Phe Phe Lys Ala Leu Met Lys Asn Leu
1145 1150 1155
Ser Ile Thr Leu Ser Leu Arg His Asn Asn Gly Glu Lys Gly Asp
1160 1165 1170
Asn Glu Gln Asp Tyr Ile Leu Ser Pro Val Ala Asp Ser Lys Gly
1175 1180 1185
Arg Phe Phe Asp Ser Arg Lys Ala Asp Asp Asp Met Pro Lys Asn
1190 1195 1200
Ala Asp Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Trp
1205 1210 1215
Cys Leu Glu Gln Ile Ser Lys Thr Asp Asp Leu Lys Lys Val Lys
1220 1225 1230
Leu Ala Ile Ser Asn Lys Glu Trp Leu Glu Phe Val Gln Thr Leu
1235 1240 1245
Lys Gly
1250
<210> 1260
<211> 4071
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1260
ggtaccatga cacagttcga gggctttacc aacctgtatc aggtgagcaa gacactgcgg 60
tttgagctga tcccacaggg caagaccctg aagcacatcc aggagcaggg cttcatcgag 120
gaggacaagg cccgcaatga tcactacaag gagctgaagc ccatcatcga tcggatctac 180
aagacctatg ccgaccagtg cctgcagctg gtgcagctgg attgggagaa cctgagcgcc 240
gccatcgact cctatagaaa ggagaaaacc gaggagacaa ggaacgccct gatcgaggag 300
caggccacat atcgcaatgc catccacgac tacttcatcg gccggacaga caacctgacc 360
gatgccatca ataagagaca cgccgagatc tacaagggcc tgttcaaggc cgagctgttt 420
aatggcaagg tgctgaagca gctgggcacc gtgaccacaa ccgagcacga gaacgccctg 480
ctgcggagct tcgacaagtt tacaacctac ttctccggct tttatgagaa caggaagaac 540
gtgttcagcg ccgaggatat cagcacagcc atcccacacc gcatcgtgca ggacaacttc 600
cccaagttta aggagaattg tcacatcttc acacgcctga tcaccgccgt gcccagcctg 660
cgggagcact ttgagaacgt gaagaaggcc atcggcatct tcgtgagcac ctccatcgag 720
gaggtgtttt ccttcccttt ttataaccag ctgctgacac agacccagat cgacctgtat 780
aaccagctgc tgggaggaat ctctcgggag gcaggcaccg agaagatcaa gggcctgaac 840
gaggtgctga atctggccat ccagaagaat gatgagacag cccacatcat cgcctccctg 900
ccacacagat tcatccccct gtttaagcag atcctgtccg ataggaacac cctgtctttc 960
atcctggagg agtttaagag cgacgaggaa gtgatccagt ccttctgcaa gtacaagaca 1020
ctgctgagaa acgagaacgt gctggagaca gccgaggccc tgtttaacga gctgaacagc 1080
atcgacctga cacacatctt catcagccac aagaagctgg agacaatcag cagcgccctg 1140
tgcgaccact gggatacact gaggaatgcc ctgtatgagc ggagaatctc cgagctgaca 1200
ggcaagatca ccaagtctgc caaggagaag gtgcagcgca gcctgaagca cgaggatatc 1260
aacctgcagg agatcatctc tgccgcaggc aaggagctga gcgaggcctt caagcagaaa 1320
accagcgaga tcctgtccca cgcacacgcc gccctggatc agccactgcc tacaaccctg 1380
aagaagcagg aggagaagga gatcctgaag tctcagctgg acagcctgct gggcctgtac 1440
cacctgctgg actggtttgc cgtggatgag tccaacgagg tggaccccga gttctctgcc 1500
cggctgaccg gcatcaagct ggagatggag ccttctctga gcttctacaa caaggccaga 1560
aattatgcca ccaagaagcc ctactccgtg gagaagttca agctgaactt tcagatgcct 1620
acactggcct ctggctggga cgtgaataag gagaagaaca atggcgccat cctgtttgtg 1680
aagaacggcc tgtactatct gggcatcatg ccaaagcaga agggcaggta taaggccctg 1740
agcttcgagc ccacagagaa aaccagcgag ggctttgata agatgtacta tgactacttc 1800
cctgatgccg ccaagatgat cccaaagtgc agcacccagc tgaaggccgt gacagcccac 1860
tttcagaccc acacaacccc catcctgctg tccaacaatt tcatcgagcc tctggagatc 1920
acaaaggaga tctacgacct gaacaatcct gagaaggagc caaagaagtt tcagacagcc 1980
tacgccaaga aaaccggcga ccagaagggc tacagagagg ccctgtgcaa gtggatcgac 2040
ttcacaaggg attttctgtc caagtatacc aagacaacct ctatcgatct gtctagcctg 2100
cggccatcct ctcagtataa ggacctgggc gagtactatg ccgagctgaa tcccctgctg 2160
taccacatca gcttccagag aatcgccgag aaggagatca tggatgccgt ggagacaggc 2220
aagctgtacc tgttccagat ctataacaag gactttgcca agggccacca cggcaagcct 2280
aatctgcaca cactgtattg gaccggcctg ttttctccag agaacctggc caagacaagc 2340
atcaagctga atggccaggc cgagctgttc taccgcccta agtccaggat gaagaggatg 2400
gcacaccggc tgggagagaa gatgctgaac aagaagctga aggatcagaa aaccccaatc 2460
cccgacaccc tgtaccagga gctgtacgac tatgtgaatc acagactgtc ccacgacctg 2520
tctgatgagg ccagggccct gctgcccaac gtgatcacca aggaggtgtc tcacgagatc 2580
atcaaggata ggcgctttac cagcgacaag ttctttttcc acgtgcctat cacactgaac 2640
tatcaggccg ccaattcccc atctaagttc aaccagaggg tgaatgccta cctgaaggag 2700
caccccgaga cacctatcat cggcatcgat cggggcgaga gaaacctgat ctatatcaca 2760
gtgatcgact ccaccggcaa gatcctggag cagcggagcc tgaacaccat ccagcagttt 2820
gattaccaga agaagctgga caacagggag aaggagaggg tggcagcaag gcaggcctgg 2880
tctgtggtgg gcacaatcaa ggatctgaag cagggctatc tgagccaggt catccacgag 2940
atcgtggacc tgatgatcca ctaccaggcc gtggtggtgc tggagaacct gaatttcggc 3000
tttaagagca agaggaccgg catcgccgag aaggccgtgt accagcagtt cgagaagatg 3060
ctgatcgata agctgaattg cctggtgctg aaggactatc cagcagagaa agtgggaggc 3120
gtgctgaacc cataccagct gacagaccag ttcacctcct ttgccaagat gggcacccag 3180
tctggcttcc tgttttacgt gcctgcccca tatacatcta agatcgatcc cctgaccggc 3240
ttcgtggacc ccttcgtgtg gaaaaccatc aagaatcacg agagccgcaa gcacttcctg 3300
gagggcttcg actttctgca ctacgacgtg aaaaccggcg acttcatcct gcactttaag 3360
atgaacagaa atctgtcctt ccagaggggc ctgcccggct ttatgcctgc atgggatatc 3420
gtgttcgaga agaacgagac acagtttgac gccaagggca cccctttcat cgccggcaag 3480
agaatcgtgc cagtgatcga gaatcacaga ttcaccggca gataccggga cctgtatcct 3540
gccaacgagc tgatcgccct gctggaggag aagggcatcg tgttcaggga tggctccaac 3600
atcctgccaa agctgctgga gaatgacgat tctcacgcca tcgacaccat ggtggccctg 3660
atccgcagcg tgctgcagat gcggaactcc aatgccgcca caggcgagga ctatatcaac 3720
agccccgtgc gcgatctgaa tggcgtgtgc ttcgactccc ggtttcagaa cccagagtgg 3780
cccatggacg ccgatgccaa tggcgcctac cacatcgccc tgaagggcca gctgctgctg 3840
aatcacctga aggagagcaa ggatctgaag ctgcagaacg gcatctccaa tcaggactgg 3900
ctggcctaca tccaggagct gcgcaacaaa aggccggcgg ccacgaaaaa ggccggccag 3960
gcaaaaaaga aaaagggatc ctacccatac gatgttccag attacgctta tccctacgac 4020
gtgcctgatt atgcataccc atatgatgtc cccgactatg cctaagaatt c 4071
<210> 1261
<211> 1307
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1261
Met Thr Gln Phe Glu Gly Phe Thr Asn Leu Tyr Gln Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Lys His Ile Gln
20 25 30
Glu Gln Gly Phe Ile Glu Glu Asp Lys Ala Arg Asn Asp His Tyr Lys
35 40 45
Glu Leu Lys Pro Ile Ile Asp Arg Ile Tyr Lys Thr Tyr Ala Asp Gln
50 55 60
Cys Leu Gln Leu Val Gln Leu Asp Trp Glu Asn Leu Ser Ala Ala Ile
65 70 75 80
Asp Ser Tyr Arg Lys Glu Lys Thr Glu Glu Thr Arg Asn Ala Leu Ile
85 90 95
Glu Glu Gln Ala Thr Tyr Arg Asn Ala Ile His Asp Tyr Phe Ile Gly
100 105 110
Arg Thr Asp Asn Leu Thr Asp Ala Ile Asn Lys Arg His Ala Glu Ile
115 120 125
Tyr Lys Gly Leu Phe Lys Ala Glu Leu Phe Asn Gly Lys Val Leu Lys
130 135 140
Gln Leu Gly Thr Val Thr Thr Thr Glu His Glu Asn Ala Leu Leu Arg
145 150 155 160
Ser Phe Asp Lys Phe Thr Thr Tyr Phe Ser Gly Phe Tyr Glu Asn Arg
165 170 175
Lys Asn Val Phe Ser Ala Glu Asp Ile Ser Thr Ala Ile Pro His Arg
180 185 190
Ile Val Gln Asp Asn Phe Pro Lys Phe Lys Glu Asn Cys His Ile Phe
195 200 205
Thr Arg Leu Ile Thr Ala Val Pro Ser Leu Arg Glu His Phe Glu Asn
210 215 220
Val Lys Lys Ala Ile Gly Ile Phe Val Ser Thr Ser Ile Glu Glu Val
225 230 235 240
Phe Ser Phe Pro Phe Tyr Asn Gln Leu Leu Thr Gln Thr Gln Ile Asp
245 250 255
Leu Tyr Asn Gln Leu Leu Gly Gly Ile Ser Arg Glu Ala Gly Thr Glu
260 265 270
Lys Ile Lys Gly Leu Asn Glu Val Leu Asn Leu Ala Ile Gln Lys Asn
275 280 285
Asp Glu Thr Ala His Ile Ile Ala Ser Leu Pro His Arg Phe Ile Pro
290 295 300
Leu Phe Lys Gln Ile Leu Ser Asp Arg Asn Thr Leu Ser Phe Ile Leu
305 310 315 320
Glu Glu Phe Lys Ser Asp Glu Glu Val Ile Gln Ser Phe Cys Lys Tyr
325 330 335
Lys Thr Leu Leu Arg Asn Glu Asn Val Leu Glu Thr Ala Glu Ala Leu
340 345 350
Phe Asn Glu Leu Asn Ser Ile Asp Leu Thr His Ile Phe Ile Ser His
355 360 365
Lys Lys Leu Glu Thr Ile Ser Ser Ala Leu Cys Asp His Trp Asp Thr
370 375 380
Leu Arg Asn Ala Leu Tyr Glu Arg Arg Ile Ser Glu Leu Thr Gly Lys
385 390 395 400
Ile Thr Lys Ser Ala Lys Glu Lys Val Gln Arg Ser Leu Lys His Glu
405 410 415
Asp Ile Asn Leu Gln Glu Ile Ile Ser Ala Ala Gly Lys Glu Leu Ser
420 425 430
Glu Ala Phe Lys Gln Lys Thr Ser Glu Ile Leu Ser His Ala His Ala
435 440 445
Ala Leu Asp Gln Pro Leu Pro Thr Thr Leu Lys Lys Gln Glu Glu Lys
450 455 460
Glu Ile Leu Lys Ser Gln Leu Asp Ser Leu Leu Gly Leu Tyr His Leu
465 470 475 480
Leu Asp Trp Phe Ala Val Asp Glu Ser Asn Glu Val Asp Pro Glu Phe
485 490 495
Ser Ala Arg Leu Thr Gly Ile Lys Leu Glu Met Glu Pro Ser Leu Ser
500 505 510
Phe Tyr Asn Lys Ala Arg Asn Tyr Ala Thr Lys Lys Pro Tyr Ser Val
515 520 525
Glu Lys Phe Lys Leu Asn Phe Gln Met Pro Thr Leu Ala Ser Gly Trp
530 535 540
Asp Val Asn Lys Glu Lys Asn Asn Gly Ala Ile Leu Phe Val Lys Asn
545 550 555 560
Gly Leu Tyr Tyr Leu Gly Ile Met Pro Lys Gln Lys Gly Arg Tyr Lys
565 570 575
Ala Leu Ser Phe Glu Pro Thr Glu Lys Thr Ser Glu Gly Phe Asp Lys
580 585 590
Met Tyr Tyr Asp Tyr Phe Pro Asp Ala Ala Lys Met Ile Pro Lys Cys
595 600 605
Ser Thr Gln Leu Lys Ala Val Thr Ala His Phe Gln Thr His Thr Thr
610 615 620
Pro Ile Leu Leu Ser Asn Asn Phe Ile Glu Pro Leu Glu Ile Thr Lys
625 630 635 640
Glu Ile Tyr Asp Leu Asn Asn Pro Glu Lys Glu Pro Lys Lys Phe Gln
645 650 655
Thr Ala Tyr Ala Lys Lys Thr Gly Asp Gln Lys Gly Tyr Arg Glu Ala
660 665 670
Leu Cys Lys Trp Ile Asp Phe Thr Arg Asp Phe Leu Ser Lys Tyr Thr
675 680 685
Lys Thr Thr Ser Ile Asp Leu Ser Ser Leu Arg Pro Ser Ser Gln Tyr
690 695 700
Lys Asp Leu Gly Glu Tyr Tyr Ala Glu Leu Asn Pro Leu Leu Tyr His
705 710 715 720
Ile Ser Phe Gln Arg Ile Ala Glu Lys Glu Ile Met Asp Ala Val Glu
725 730 735
Thr Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Lys
740 745 750
Gly His His Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Thr Gly Leu
755 760 765
Phe Ser Pro Glu Asn Leu Ala Lys Thr Ser Ile Lys Leu Asn Gly Gln
770 775 780
Ala Glu Leu Phe Tyr Arg Pro Lys Ser Arg Met Lys Arg Met Ala His
785 790 795 800
Arg Leu Gly Glu Lys Met Leu Asn Lys Lys Leu Lys Asp Gln Lys Thr
805 810 815
Pro Ile Pro Asp Thr Leu Tyr Gln Glu Leu Tyr Asp Tyr Val Asn His
820 825 830
Arg Leu Ser His Asp Leu Ser Asp Glu Ala Arg Ala Leu Leu Pro Asn
835 840 845
Val Ile Thr Lys Glu Val Ser His Glu Ile Ile Lys Asp Arg Arg Phe
850 855 860
Thr Ser Asp Lys Phe Phe Phe His Val Pro Ile Thr Leu Asn Tyr Gln
865 870 875 880
Ala Ala Asn Ser Pro Ser Lys Phe Asn Gln Arg Val Asn Ala Tyr Leu
885 890 895
Lys Glu His Pro Glu Thr Pro Ile Ile Gly Ile Asp Arg Gly Glu Arg
900 905 910
Asn Leu Ile Tyr Ile Thr Val Ile Asp Ser Thr Gly Lys Ile Leu Glu
915 920 925
Gln Arg Ser Leu Asn Thr Ile Gln Gln Phe Asp Tyr Gln Lys Lys Leu
930 935 940
Asp Asn Arg Glu Lys Glu Arg Val Ala Ala Arg Gln Ala Trp Ser Val
945 950 955 960
Val Gly Thr Ile Lys Asp Leu Lys Gln Gly Tyr Leu Ser Gln Val Ile
965 970 975
His Glu Ile Val Asp Leu Met Ile His Tyr Gln Ala Val Val Val Leu
980 985 990
Glu Asn Leu Asn Phe Gly Phe Lys Ser Lys Arg Thr Gly Ile Ala Glu
995 1000 1005
Lys Ala Val Tyr Gln Gln Phe Glu Lys Met Leu Ile Asp Lys Leu
1010 1015 1020
Asn Cys Leu Val Leu Lys Asp Tyr Pro Ala Glu Lys Val Gly Gly
1025 1030 1035
Val Leu Asn Pro Tyr Gln Leu Thr Asp Gln Phe Thr Ser Phe Ala
1040 1045 1050
Lys Met Gly Thr Gln Ser Gly Phe Leu Phe Tyr Val Pro Ala Pro
1055 1060 1065
Tyr Thr Ser Lys Ile Asp Pro Leu Thr Gly Phe Val Asp Pro Phe
1070 1075 1080
Val Trp Lys Thr Ile Lys Asn His Glu Ser Arg Lys His Phe Leu
1085 1090 1095
Glu Gly Phe Asp Phe Leu His Tyr Asp Val Lys Thr Gly Asp Phe
1100 1105 1110
Ile Leu His Phe Lys Met Asn Arg Asn Leu Ser Phe Gln Arg Gly
1115 1120 1125
Leu Pro Gly Phe Met Pro Ala Trp Asp Ile Val Phe Glu Lys Asn
1130 1135 1140
Glu Thr Gln Phe Asp Ala Lys Gly Thr Pro Phe Ile Ala Gly Lys
1145 1150 1155
Arg Ile Val Pro Val Ile Glu Asn His Arg Phe Thr Gly Arg Tyr
1160 1165 1170
Arg Asp Leu Tyr Pro Ala Asn Glu Leu Ile Ala Leu Leu Glu Glu
1175 1180 1185
Lys Gly Ile Val Phe Arg Asp Gly Ser Asn Ile Leu Pro Lys Leu
1190 1195 1200
Leu Glu Asn Asp Asp Ser His Ala Ile Asp Thr Met Val Ala Leu
1205 1210 1215
Ile Arg Ser Val Leu Gln Met Arg Asn Ser Asn Ala Ala Thr Gly
1220 1225 1230
Glu Asp Tyr Ile Asn Ser Pro Val Arg Asp Leu Asn Gly Val Cys
1235 1240 1245
Phe Asp Ser Arg Phe Gln Asn Pro Glu Trp Pro Met Asp Ala Asp
1250 1255 1260
Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Gln Leu Leu Leu
1265 1270 1275
Asn His Leu Lys Glu Ser Lys Asp Leu Lys Leu Gln Asn Gly Ile
1280 1285 1290
Ser Asn Gln Asp Trp Leu Ala Tyr Ile Gln Glu Leu Arg Asn
1295 1300 1305
<210> 1262
<211> 3768
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1262
ggtaccatgt actatgagtc cctgaccaag cagtaccccg tgtctaagac aatccggaat 60
gagctgatcc ctatcggcaa gacactggat aacatccgcc agaacaatat cctggagagc 120
gacgtgaagc ggaagcagaa ctacgagcac gtgaagggca tcctggatga gtatcacaag 180
cagctgatca acgaggccct ggacaattgc accctgccat ccctgaagat cgccgccgag 240
atctacctga agaatcagaa ggaggtgtct gacagagagg atttcaacaa gacacaggac 300
ctgctgagga aggaggtggt ggagaagctg aaggcccacg agaactttac caagatcggc 360
aagaaggaca tcctggatct gctggagaag ctgccttcca tctctgagga cgattacaat 420
gccctggaga gcttccgcaa cttttacacc tatttcacat cctacaacaa ggtgcgggag 480
aatctgtatt ctgataagga gaagagctcc acagtggcct acagactgat caacgagaat 540
ttcccaaagt ttctggacaa tgtgaagagc tataggtttg tgaaaaccgc aggcatcctg 600
gcagatggcc tgggagagga ggagcaggac tccctgttca tcgtggagac attcaacaag 660
accctgacac aggacggcat cgatacctac aattctcaag tgggcaagat caactctagc 720
atcaatctgt ataaccagaa gaatcagaag gccaatggct tcagaaagat ccccaagatg 780
aagatgctgt ataagcagat cctgtccgat agggaggagt ctttcatcga cgagtttcag 840
agcgatgagg tgctgatcga caacgtggag tcttatggca gcgtgctgat cgagtctctg 900
aagtcctcta aggtgagcgc cttctttgat gccctgagag agtctaaggg caagaacgtg 960
tacgtgaaga atgacctggc caagacagcc atgagcaaca tcgtgttcga gaattggagg 1020
acctttgacg atctgctgaa ccaggagtac gacctggcca acgagaacaa gaagaaggac 1080
gataagtatt tcgagaagcg ccagaaggag ctgaagaaga ataagagcta ctccctggag 1140
cacctgtgca acctgtccga ggattcttgt aacctgatcg agaattatat ccaccagatc 1200
tccgacgata tcgagaatat catcatcaac aatgagacat tcctgcgcat cgtgatcaat 1260
gagcacgaca ggtcccgcaa gctggccaag aaccggaagg ccgtgaaggc catcaaggac 1320
tttctggatt ctatcaaggt gctggagcgg gagctgaagc tgatcaacag ctccggccag 1380
gagctggaga aggatctgat cgtgtactct gcccacgagg agctgctggt ggagctgaag 1440
caggtggaca gcctgtataa catgaccaga aattatctga caaagaagcc tttctctacc 1500
gagaaggtga agctgaactt taatcgcagc acactgctga acggctggga tcggaataag 1560
gagacagaca acctgggcgt gctgctgctg aaggacggca agtactatct gggcatcatg 1620
aacacaagcg ccaataaggc cttcgtgaat ccccctgtgg ccaagaccga gaaggtgttt 1680
aagaaggtgg attacaagct gctgccagtg cccaaccaga tgctgccaaa ggtgttcttt 1740
gccaagagca atatcgactt ctataacccc tctagcgaga tctactccaa ttataagaag 1800
ggcacccaca agaagggcaa tatgttttcc ctggaggatt gtcacaacct gatcgacttc 1860
tttaaggagt ctatcagcaa gcacgaggac tggagcaagt tcggctttaa gttcagcgat 1920
acagcctcct acaacgacat ctccgagttc tatcgcgagg tggagaagca gggctacaag 1980
ctgacctata cagacatcga tgagacatac atcaatgatc tgatcgagcg gaacgagctg 2040
tacctgttcc agatctataa taaggacttt agcatgtact ccaagggcaa gctgaacctg 2100
cacacactgt atttcatgat gctgtttgat cagcgcaata tcgacgacgt ggtgtataag 2160
ctgaacggag aggcagaggt gttctatagg ccagcctcca tctctgagga cgagctgatc 2220
atccacaagg ccggcgagga gatcaagaac aagaatccta accgggccag aaccaaggag 2280
acaagcacct tcagctacga catcgtgaag gataagcggt atagcaagga taagtttacc 2340
ctgcacatcc ccatcacaat gaacttcggc gtggatgagg tgaagcggtt caacgacgcc 2400
gtgaacagcg ccatccggat cgatgagaat gtgaacgtga tcggcatcga ccggggcgag 2460
agaaatctgc tgtacgtggt ggtcatcgac tctaagggca acatcctgga gcagatctcc 2520
ctgaactcta tcatcaataa ggagtacgac atcgagacag attatcacgc actgctggat 2580
gagagggagg gcggcagaga taaggcccgg aaggactgga acaccgtgga gaatatcagg 2640
gacctgaagg ccggctacct gagccaggtg gtgaacgtgg tggccaagct ggtgctgaag 2700
tataatgcca tcatctgcct ggaggacctg aactttggct tcaagagggg ccgccagaag 2760
gtggagaagc aggtgtacca gaagttcgag aagatgctga tcgataagct gaattacctg 2820
gtcatcgaca agagccgcga gcagacatcc cctaaggagc tgggaggcgc cctgaacgca 2880
ctgcagctga cctctaagtt caagagcttt aaggagctgg gcaagcagtc cggcgtgatc 2940
tactatgtgc ctgcctacct gacctctaag atcgatccaa ccacaggctt cgccaatctg 3000
ttttatatga agtgtgagaa cgtggagaag tccaagagat tctttgacgg ctttgatttc 3060
atcaggttca acgccctgga gaacgtgttc gagttcggct ttgactaccg gagcttcacc 3120
cagagggcct gcggcatcaa ttccaagtgg accgtgtgca ccaacggcga gcgcatcatc 3180
aagtatcgga atccagataa gaacaatatg ttcgacgaga aggtggtggt ggtgaccgat 3240
gagatgaaga acctgtttga gcagtacaag atcccctatg aggatggcag aaatgtgaag 3300
gacatgatca tcagcaacga ggaggccgag ttctaccgga gactgtatag gctgctgcag 3360
cagaccctgc agatgagaaa cagcacctcc gacggcacaa gggattacat catctcccct 3420
gtgaagaata agagagaggc ctacttcaac agcgagctgt ccgacggctc tgtgccaaag 3480
gacgccgatg ccaacggcgc ctacaatatc gccagaaagg gcctgtgggt gctggagcag 3540
atcaggcaga agagcgaggg cgagaagatc aatctggcca tgaccaacgc cgagtggctg 3600
gagtatgccc agacacacct gctgaaaagg ccggcggcca cgaaaaaggc cggccaggca 3660
aaaaagaaaa agggatccta cccatacgat gttccagatt acgcttatcc ctacgacgtg 3720
cctgattatg catacccata tgatgtcccc gactatgcct aagaattc 3768
<210> 1263
<211> 1206
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1263
Met Tyr Tyr Glu Ser Leu Thr Lys Gln Tyr Pro Val Ser Lys Thr Ile
1 5 10 15
Arg Asn Glu Leu Ile Pro Ile Gly Lys Thr Leu Asp Asn Ile Arg Gln
20 25 30
Asn Asn Ile Leu Glu Ser Asp Val Lys Arg Lys Gln Asn Tyr Glu His
35 40 45
Val Lys Gly Ile Leu Asp Glu Tyr His Lys Gln Leu Ile Asn Glu Ala
50 55 60
Leu Asp Asn Cys Thr Leu Pro Ser Leu Lys Ile Ala Ala Glu Ile Tyr
65 70 75 80
Leu Lys Asn Gln Lys Glu Val Ser Asp Arg Glu Asp Phe Asn Lys Thr
85 90 95
Gln Asp Leu Leu Arg Lys Glu Val Val Glu Lys Leu Lys Ala His Glu
100 105 110
Asn Phe Thr Lys Ile Gly Lys Lys Asp Ile Leu Asp Leu Leu Glu Lys
115 120 125
Leu Pro Ser Ile Ser Glu Asp Asp Tyr Asn Ala Leu Glu Ser Phe Arg
130 135 140
Asn Phe Tyr Thr Tyr Phe Thr Ser Tyr Asn Lys Val Arg Glu Asn Leu
145 150 155 160
Tyr Ser Asp Lys Glu Lys Ser Ser Thr Val Ala Tyr Arg Leu Ile Asn
165 170 175
Glu Asn Phe Pro Lys Phe Leu Asp Asn Val Lys Ser Tyr Arg Phe Val
180 185 190
Lys Thr Ala Gly Ile Leu Ala Asp Gly Leu Gly Glu Glu Glu Gln Asp
195 200 205
Ser Leu Phe Ile Val Glu Thr Phe Asn Lys Thr Leu Thr Gln Asp Gly
210 215 220
Ile Asp Thr Tyr Asn Ser Gln Val Gly Lys Ile Asn Ser Ser Ile Asn
225 230 235 240
Leu Tyr Asn Gln Lys Asn Gln Lys Ala Asn Gly Phe Arg Lys Ile Pro
245 250 255
Lys Met Lys Met Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Glu Ser
260 265 270
Phe Ile Asp Glu Phe Gln Ser Asp Glu Val Leu Ile Asp Asn Val Glu
275 280 285
Ser Tyr Gly Ser Val Leu Ile Glu Ser Leu Lys Ser Ser Lys Val Ser
290 295 300
Ala Phe Phe Asp Ala Leu Arg Glu Ser Lys Gly Lys Asn Val Tyr Val
305 310 315 320
Lys Asn Asp Leu Ala Lys Thr Ala Met Ser Asn Ile Val Phe Glu Asn
325 330 335
Trp Arg Thr Phe Asp Asp Leu Leu Asn Gln Glu Tyr Asp Leu Ala Asn
340 345 350
Glu Asn Lys Lys Lys Asp Asp Lys Tyr Phe Glu Lys Arg Gln Lys Glu
355 360 365
Leu Lys Lys Asn Lys Ser Tyr Ser Leu Glu His Leu Cys Asn Leu Ser
370 375 380
Glu Asp Ser Cys Asn Leu Ile Glu Asn Tyr Ile His Gln Ile Ser Asp
385 390 395 400
Asp Ile Glu Asn Ile Ile Ile Asn Asn Glu Thr Phe Leu Arg Ile Val
405 410 415
Ile Asn Glu His Asp Arg Ser Arg Lys Leu Ala Lys Asn Arg Lys Ala
420 425 430
Val Lys Ala Ile Lys Asp Phe Leu Asp Ser Ile Lys Val Leu Glu Arg
435 440 445
Glu Leu Lys Leu Ile Asn Ser Ser Gly Gln Glu Leu Glu Lys Asp Leu
450 455 460
Ile Val Tyr Ser Ala His Glu Glu Leu Leu Val Glu Leu Lys Gln Val
465 470 475 480
Asp Ser Leu Tyr Asn Met Thr Arg Asn Tyr Leu Thr Lys Lys Pro Phe
485 490 495
Ser Thr Glu Lys Val Lys Leu Asn Phe Asn Arg Ser Thr Leu Leu Asn
500 505 510
Gly Trp Asp Arg Asn Lys Glu Thr Asp Asn Leu Gly Val Leu Leu Leu
515 520 525
Lys Asp Gly Lys Tyr Tyr Leu Gly Ile Met Asn Thr Ser Ala Asn Lys
530 535 540
Ala Phe Val Asn Pro Pro Val Ala Lys Thr Glu Lys Val Phe Lys Lys
545 550 555 560
Val Asp Tyr Lys Leu Leu Pro Val Pro Asn Gln Met Leu Pro Lys Val
565 570 575
Phe Phe Ala Lys Ser Asn Ile Asp Phe Tyr Asn Pro Ser Ser Glu Ile
580 585 590
Tyr Ser Asn Tyr Lys Lys Gly Thr His Lys Lys Gly Asn Met Phe Ser
595 600 605
Leu Glu Asp Cys His Asn Leu Ile Asp Phe Phe Lys Glu Ser Ile Ser
610 615 620
Lys His Glu Asp Trp Ser Lys Phe Gly Phe Lys Phe Ser Asp Thr Ala
625 630 635 640
Ser Tyr Asn Asp Ile Ser Glu Phe Tyr Arg Glu Val Glu Lys Gln Gly
645 650 655
Tyr Lys Leu Thr Tyr Thr Asp Ile Asp Glu Thr Tyr Ile Asn Asp Leu
660 665 670
Ile Glu Arg Asn Glu Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe
675 680 685
Ser Met Tyr Ser Lys Gly Lys Leu Asn Leu His Thr Leu Tyr Phe Met
690 695 700
Met Leu Phe Asp Gln Arg Asn Ile Asp Asp Val Val Tyr Lys Leu Asn
705 710 715 720
Gly Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Ser Glu Asp Glu
725 730 735
Leu Ile Ile His Lys Ala Gly Glu Glu Ile Lys Asn Lys Asn Pro Asn
740 745 750
Arg Ala Arg Thr Lys Glu Thr Ser Thr Phe Ser Tyr Asp Ile Val Lys
755 760 765
Asp Lys Arg Tyr Ser Lys Asp Lys Phe Thr Leu His Ile Pro Ile Thr
770 775 780
Met Asn Phe Gly Val Asp Glu Val Lys Arg Phe Asn Asp Ala Val Asn
785 790 795 800
Ser Ala Ile Arg Ile Asp Glu Asn Val Asn Val Ile Gly Ile Asp Arg
805 810 815
Gly Glu Arg Asn Leu Leu Tyr Val Val Val Ile Asp Ser Lys Gly Asn
820 825 830
Ile Leu Glu Gln Ile Ser Leu Asn Ser Ile Ile Asn Lys Glu Tyr Asp
835 840 845
Ile Glu Thr Asp Tyr His Ala Leu Leu Asp Glu Arg Glu Gly Gly Arg
850 855 860
Asp Lys Ala Arg Lys Asp Trp Asn Thr Val Glu Asn Ile Arg Asp Leu
865 870 875 880
Lys Ala Gly Tyr Leu Ser Gln Val Val Asn Val Val Ala Lys Leu Val
885 890 895
Leu Lys Tyr Asn Ala Ile Ile Cys Leu Glu Asp Leu Asn Phe Gly Phe
900 905 910
Lys Arg Gly Arg Gln Lys Val Glu Lys Gln Val Tyr Gln Lys Phe Glu
915 920 925
Lys Met Leu Ile Asp Lys Leu Asn Tyr Leu Val Ile Asp Lys Ser Arg
930 935 940
Glu Gln Thr Ser Pro Lys Glu Leu Gly Gly Ala Leu Asn Ala Leu Gln
945 950 955 960
Leu Thr Ser Lys Phe Lys Ser Phe Lys Glu Leu Gly Lys Gln Ser Gly
965 970 975
Val Ile Tyr Tyr Val Pro Ala Tyr Leu Thr Ser Lys Ile Asp Pro Thr
980 985 990
Thr Gly Phe Ala Asn Leu Phe Tyr Met Lys Cys Glu Asn Val Glu Lys
995 1000 1005
Ser Lys Arg Phe Phe Asp Gly Phe Asp Phe Ile Arg Phe Asn Ala
1010 1015 1020
Leu Glu Asn Val Phe Glu Phe Gly Phe Asp Tyr Arg Ser Phe Thr
1025 1030 1035
Gln Arg Ala Cys Gly Ile Asn Ser Lys Trp Thr Val Cys Thr Asn
1040 1045 1050
Gly Glu Arg Ile Ile Lys Tyr Arg Asn Pro Asp Lys Asn Asn Met
1055 1060 1065
Phe Asp Glu Lys Val Val Val Val Thr Asp Glu Met Lys Asn Leu
1070 1075 1080
Phe Glu Gln Tyr Lys Ile Pro Tyr Glu Asp Gly Arg Asn Val Lys
1085 1090 1095
Asp Met Ile Ile Ser Asn Glu Glu Ala Glu Phe Tyr Arg Arg Leu
1100 1105 1110
Tyr Arg Leu Leu Gln Gln Thr Leu Gln Met Arg Asn Ser Thr Ser
1115 1120 1125
Asp Gly Thr Arg Asp Tyr Ile Ile Ser Pro Val Lys Asn Lys Arg
1130 1135 1140
Glu Ala Tyr Phe Asn Ser Glu Leu Ser Asp Gly Ser Val Pro Lys
1145 1150 1155
Asp Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu
1160 1165 1170
Trp Val Leu Glu Gln Ile Arg Gln Lys Ser Glu Gly Glu Lys Ile
1175 1180 1185
Asn Leu Ala Met Thr Asn Ala Glu Trp Leu Glu Tyr Ala Gln Thr
1190 1195 1200
His Leu Leu
1205
<210> 1264
<211> 3864
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1264
ggtaccatga acaattacga cgagttcacc aagctgtatc ctatccagaa aaccatccgg 60
tttgagctga agccacaggg cagaaccatg gagcacctgg agacattcaa cttctttgag 120
gaggaccggg atagagccga gaagtataag atcctgaagg aggccatcga cgagtaccac 180
aagaagttta tcgatgagca cctgaccaat atgtccctgg attggaactc tctgaagcag 240
atcagcgaga agtactataa gagcagggag gagaaggaca agaaggtgtt cctgtccgag 300
cagaagagga tgcgccagga gatcgtgtct gagtttaaga aggacgatcg cttcaaggac 360
ctgttttcca agaagctgtt ctctgagctg ctgaaggagg agatctacaa gaagggcaac 420
caccaggaga tcgacgccct gaagagcttc gataagtttt ccggctattt catcggcctg 480
cacgagaata ggaagaacat gtactccgac ggcgatgaga tcaccgccat ctccaatcgc 540
atcgtgaatg agaacttccc caagtttctg gataacctgc agaagtacca ggaggccagg 600
aagaagtatc ctgagtggat catcaaggcc gagagcgccc tggtggccca caatatcaag 660
atggacgagg tgttctccct ggagtacttt aataaggtgc tgaaccagga gggcatccag 720
cggtacaacc tggccctggg cggctatgtg accaagagcg gcgagaagat gatgggcctg 780
aatgatgccc tgaacctggc ccaccagtcc gagaagagct ccaagggcag aatccacatg 840
acccccctgt tcaagcagat cctgtccgag aaggagtcct tctcttacat ccccgacgtg 900
tttacagagg attctcagct gctgcctagc atcggcggct tctttgccca gatcgagaat 960
gacaaggatg gcaacatctt cgaccgggcc ctggagctga tctctagcta cgccgagtat 1020
gataccgagc ggatctatat cagacaggcc gacatcaata gagtgtccaa cgtgatcttt 1080
ggagagtggg gcaccctggg aggcctgatg agggagtaca aggccgactc tatcaatgat 1140
atcaacctgg agcgcacatg caagaaggtg gacaagtggc tggattctaa ggagtttgcc 1200
ctgagcgatg tgctggaggc catcaagagg accggcaaca atgacgcctt caacgagtat 1260
atctccaaga tgcggacagc cagagagaag atcgatgccg cccgcaagga gatgaagttc 1320
atcagcgaga agatctccgg cgatgaggag tctatccaca tcatcaagac cctgctggac 1380
agcgtgcagc agttcctgca cttctttaat ctgtttaagg caaggcagga catcccactg 1440
gatggagcct tctacgccga gtttgacgag gtgcacagca agctgtttgc catcgtgccc 1500
ctgtataaca aggtgcggaa ctatctgacc aagaacaatc tgaacacaaa gaagatcaag 1560
ctgaatttca agaaccctac actggccaat ggctgggacc agaacaaggt gtacgattat 1620
gcctccctga tctttctgcg ggacggcaat tactatctgg gcatcatcaa tcctaagaga 1680
aagaagaaca tcaagttcga gcagggctct ggcaacggcc ccttctaccg gaagatggtg 1740
tataagcaga tccccggccc taataagaac ctgccaagag tgttcctgac ctccacaaag 1800
ggcaagaagg agtataagcc ctctaaggag atcatcgagg gctacgaggc cgacaagcac 1860
atcaggggcg ataagttcga cctggatttt tgtcacaagc tgatcgattt ctttaaggag 1920
tccatcgaga agcacaagga ctggtctaag ttcaacttct acttcagccc aaccgagagc 1980
tatggcgaca tctctgagtt ctacctggat gtggagaagc agggctatcg catgcacttt 2040
gagaatatca gcgccgagac aatcgacgag tatgtggaga agggcgatct gtttctgttc 2100
cagatctaca acaaggattt tgtgaaggcc gccaccggca agaaggacat gcacacaatc 2160
tactggaatg ccgccttcag ccccgagaac ctgcaggacg tggtggtgaa gctgaacggc 2220
gaggccgagc tgttttatag ggacaagtcc gatatcaagg agatcgtgca ccgcgagggc 2280
gagatcctgg tgaataggac ctacaacggc cgcacaccag tgcccgacaa gatccacaag 2340
aagctgaccg attatcacaa tggccggaca aaggacctgg gcgaggccaa ggagtacctg 2400
gataaggtga gatacttcaa ggcccactat gacatcacca aggatcggag atacctgaac 2460
gacaagatct atttccacgt gcctctgacc ctgaacttca aggccaacgg caagaagaat 2520
ctgaacaaga tggtcatcga gaagttcctg tccgatgaga aggcccacat catcggcatc 2580
gacaggggcg agcgcaatct gctgtactat tccatcatcg acaggtctgg caagatcatc 2640
gatcagcaga gcctgaatgt gatcgacggc tttgattatc gggagaagct gaaccagaga 2700
gagatcgaga tgaaggatgc ccgccagtct tggaacgcca tcggcaagat caaggacctg 2760
aaggagggct acctgagcaa ggccgtgcac gagatcacca agatggccat ccagtataat 2820
gccatcgtgg tcatggagga gctgaactac ggcttcaagc ggggccggtt caaggtggag 2880
aagcagatct atcagaagtt cgagaatatg ctgatcgata agatgaacta cctggtgttt 2940
aaggacgcac ctgatgagtc cccaggaggc gtgctgaatg cctaccagct gacaaaccca 3000
ctggagtctt tcgccaagct gggcaagcag accggcatcc tgttttacgt gccagccgcc 3060
tatacatcca agatcgaccc caccacaggc ttcgtgaatc tgtttaacac ctcctctaag 3120
acaaacgccc aggagcggaa ggagttcctg cagaagtttg agagcatctc ctattctgcc 3180
aaggatggcg gcatctttgc cttcgccttt gactacagaa agttcggcac cagcaagaca 3240
gatcacaaga acgtgtggac cgcctataca aacggcgaga ggatgcgcta catcaaggag 3300
aagaagcgga atgagctgtt tgacccttct aaggagatca aggaggccct gaccagctcc 3360
ggcatcaagt acgatggcgg ccagaacatc ctgccagaca tcctgaggag caacaataac 3420
ggcctgatct acacaatgta ttctagcttc atcgccgcca tccagatgcg cgtgtacgac 3480
ggcaaggagg attatatcat cagccccatc aagaactcca agggcgagtt ctttaggacc 3540
gaccccaaga ggcgcgagct gcctatcgac gccgatgcca atggcgccta caacatcgcc 3600
ctgaggggag agctgacaat gagggcaatc gcagagaagt tcgaccctga tagcgagaag 3660
atggccaagc tggagctgaa gcacaaggat tggttcgagt ttatgcagac cagaggcgac 3720
aaaaggccgg cggccacgaa aaaggccggc caggcaaaaa agaaaaaggg atcctaccca 3780
tacgatgttc cagattacgc ttatccctac gacgtgcctg attatgcata cccatatgat 3840
gtccccgact atgcctaaga attc 3864
<210> 1265
<211> 1238
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1265
Met Asn Asn Tyr Asp Glu Phe Thr Lys Leu Tyr Pro Ile Gln Lys Thr
1 5 10 15
Ile Arg Phe Glu Leu Lys Pro Gln Gly Arg Thr Met Glu His Leu Glu
20 25 30
Thr Phe Asn Phe Phe Glu Glu Asp Arg Asp Arg Ala Glu Lys Tyr Lys
35 40 45
Ile Leu Lys Glu Ala Ile Asp Glu Tyr His Lys Lys Phe Ile Asp Glu
50 55 60
His Leu Thr Asn Met Ser Leu Asp Trp Asn Ser Leu Lys Gln Ile Ser
65 70 75 80
Glu Lys Tyr Tyr Lys Ser Arg Glu Glu Lys Asp Lys Lys Val Phe Leu
85 90 95
Ser Glu Gln Lys Arg Met Arg Gln Glu Ile Val Ser Glu Phe Lys Lys
100 105 110
Asp Asp Arg Phe Lys Asp Leu Phe Ser Lys Lys Leu Phe Ser Glu Leu
115 120 125
Leu Lys Glu Glu Ile Tyr Lys Lys Gly Asn His Gln Glu Ile Asp Ala
130 135 140
Leu Lys Ser Phe Asp Lys Phe Ser Gly Tyr Phe Ile Gly Leu His Glu
145 150 155 160
Asn Arg Lys Asn Met Tyr Ser Asp Gly Asp Glu Ile Thr Ala Ile Ser
165 170 175
Asn Arg Ile Val Asn Glu Asn Phe Pro Lys Phe Leu Asp Asn Leu Gln
180 185 190
Lys Tyr Gln Glu Ala Arg Lys Lys Tyr Pro Glu Trp Ile Ile Lys Ala
195 200 205
Glu Ser Ala Leu Val Ala His Asn Ile Lys Met Asp Glu Val Phe Ser
210 215 220
Leu Glu Tyr Phe Asn Lys Val Leu Asn Gln Glu Gly Ile Gln Arg Tyr
225 230 235 240
Asn Leu Ala Leu Gly Gly Tyr Val Thr Lys Ser Gly Glu Lys Met Met
245 250 255
Gly Leu Asn Asp Ala Leu Asn Leu Ala His Gln Ser Glu Lys Ser Ser
260 265 270
Lys Gly Arg Ile His Met Thr Pro Leu Phe Lys Gln Ile Leu Ser Glu
275 280 285
Lys Glu Ser Phe Ser Tyr Ile Pro Asp Val Phe Thr Glu Asp Ser Gln
290 295 300
Leu Leu Pro Ser Ile Gly Gly Phe Phe Ala Gln Ile Glu Asn Asp Lys
305 310 315 320
Asp Gly Asn Ile Phe Asp Arg Ala Leu Glu Leu Ile Ser Ser Tyr Ala
325 330 335
Glu Tyr Asp Thr Glu Arg Ile Tyr Ile Arg Gln Ala Asp Ile Asn Arg
340 345 350
Val Ser Asn Val Ile Phe Gly Glu Trp Gly Thr Leu Gly Gly Leu Met
355 360 365
Arg Glu Tyr Lys Ala Asp Ser Ile Asn Asp Ile Asn Leu Glu Arg Thr
370 375 380
Cys Lys Lys Val Asp Lys Trp Leu Asp Ser Lys Glu Phe Ala Leu Ser
385 390 395 400
Asp Val Leu Glu Ala Ile Lys Arg Thr Gly Asn Asn Asp Ala Phe Asn
405 410 415
Glu Tyr Ile Ser Lys Met Arg Thr Ala Arg Glu Lys Ile Asp Ala Ala
420 425 430
Arg Lys Glu Met Lys Phe Ile Ser Glu Lys Ile Ser Gly Asp Glu Glu
435 440 445
Ser Ile His Ile Ile Lys Thr Leu Leu Asp Ser Val Gln Gln Phe Leu
450 455 460
His Phe Phe Asn Leu Phe Lys Ala Arg Gln Asp Ile Pro Leu Asp Gly
465 470 475 480
Ala Phe Tyr Ala Glu Phe Asp Glu Val His Ser Lys Leu Phe Ala Ile
485 490 495
Val Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Lys Asn Asn Leu
500 505 510
Asn Thr Lys Lys Ile Lys Leu Asn Phe Lys Asn Pro Thr Leu Ala Asn
515 520 525
Gly Trp Asp Gln Asn Lys Val Tyr Asp Tyr Ala Ser Leu Ile Phe Leu
530 535 540
Arg Asp Gly Asn Tyr Tyr Leu Gly Ile Ile Asn Pro Lys Arg Lys Lys
545 550 555 560
Asn Ile Lys Phe Glu Gln Gly Ser Gly Asn Gly Pro Phe Tyr Arg Lys
565 570 575
Met Val Tyr Lys Gln Ile Pro Gly Pro Asn Lys Asn Leu Pro Arg Val
580 585 590
Phe Leu Thr Ser Thr Lys Gly Lys Lys Glu Tyr Lys Pro Ser Lys Glu
595 600 605
Ile Ile Glu Gly Tyr Glu Ala Asp Lys His Ile Arg Gly Asp Lys Phe
610 615 620
Asp Leu Asp Phe Cys His Lys Leu Ile Asp Phe Phe Lys Glu Ser Ile
625 630 635 640
Glu Lys His Lys Asp Trp Ser Lys Phe Asn Phe Tyr Phe Ser Pro Thr
645 650 655
Glu Ser Tyr Gly Asp Ile Ser Glu Phe Tyr Leu Asp Val Glu Lys Gln
660 665 670
Gly Tyr Arg Met His Phe Glu Asn Ile Ser Ala Glu Thr Ile Asp Glu
675 680 685
Tyr Val Glu Lys Gly Asp Leu Phe Leu Phe Gln Ile Tyr Asn Lys Asp
690 695 700
Phe Val Lys Ala Ala Thr Gly Lys Lys Asp Met His Thr Ile Tyr Trp
705 710 715 720
Asn Ala Ala Phe Ser Pro Glu Asn Leu Gln Asp Val Val Val Lys Leu
725 730 735
Asn Gly Glu Ala Glu Leu Phe Tyr Arg Asp Lys Ser Asp Ile Lys Glu
740 745 750
Ile Val His Arg Glu Gly Glu Ile Leu Val Asn Arg Thr Tyr Asn Gly
755 760 765
Arg Thr Pro Val Pro Asp Lys Ile His Lys Lys Leu Thr Asp Tyr His
770 775 780
Asn Gly Arg Thr Lys Asp Leu Gly Glu Ala Lys Glu Tyr Leu Asp Lys
785 790 795 800
Val Arg Tyr Phe Lys Ala His Tyr Asp Ile Thr Lys Asp Arg Arg Tyr
805 810 815
Leu Asn Asp Lys Ile Tyr Phe His Val Pro Leu Thr Leu Asn Phe Lys
820 825 830
Ala Asn Gly Lys Lys Asn Leu Asn Lys Met Val Ile Glu Lys Phe Leu
835 840 845
Ser Asp Glu Lys Ala His Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn
850 855 860
Leu Leu Tyr Tyr Ser Ile Ile Asp Arg Ser Gly Lys Ile Ile Asp Gln
865 870 875 880
Gln Ser Leu Asn Val Ile Asp Gly Phe Asp Tyr Arg Glu Lys Leu Asn
885 890 895
Gln Arg Glu Ile Glu Met Lys Asp Ala Arg Gln Ser Trp Asn Ala Ile
900 905 910
Gly Lys Ile Lys Asp Leu Lys Glu Gly Tyr Leu Ser Lys Ala Val His
915 920 925
Glu Ile Thr Lys Met Ala Ile Gln Tyr Asn Ala Ile Val Val Met Glu
930 935 940
Glu Leu Asn Tyr Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln
945 950 955 960
Ile Tyr Gln Lys Phe Glu Asn Met Leu Ile Asp Lys Met Asn Tyr Leu
965 970 975
Val Phe Lys Asp Ala Pro Asp Glu Ser Pro Gly Gly Val Leu Asn Ala
980 985 990
Tyr Gln Leu Thr Asn Pro Leu Glu Ser Phe Ala Lys Leu Gly Lys Gln
995 1000 1005
Thr Gly Ile Leu Phe Tyr Val Pro Ala Ala Tyr Thr Ser Lys Ile
1010 1015 1020
Asp Pro Thr Thr Gly Phe Val Asn Leu Phe Asn Thr Ser Ser Lys
1025 1030 1035
Thr Asn Ala Gln Glu Arg Lys Glu Phe Leu Gln Lys Phe Glu Ser
1040 1045 1050
Ile Ser Tyr Ser Ala Lys Asp Gly Gly Ile Phe Ala Phe Ala Phe
1055 1060 1065
Asp Tyr Arg Lys Phe Gly Thr Ser Lys Thr Asp His Lys Asn Val
1070 1075 1080
Trp Thr Ala Tyr Thr Asn Gly Glu Arg Met Arg Tyr Ile Lys Glu
1085 1090 1095
Lys Lys Arg Asn Glu Leu Phe Asp Pro Ser Lys Glu Ile Lys Glu
1100 1105 1110
Ala Leu Thr Ser Ser Gly Ile Lys Tyr Asp Gly Gly Gln Asn Ile
1115 1120 1125
Leu Pro Asp Ile Leu Arg Ser Asn Asn Asn Gly Leu Ile Tyr Thr
1130 1135 1140
Met Tyr Ser Ser Phe Ile Ala Ala Ile Gln Met Arg Val Tyr Asp
1145 1150 1155
Gly Lys Glu Asp Tyr Ile Ile Ser Pro Ile Lys Asn Ser Lys Gly
1160 1165 1170
Glu Phe Phe Arg Thr Asp Pro Lys Arg Arg Glu Leu Pro Ile Asp
1175 1180 1185
Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Leu Arg Gly Glu Leu
1190 1195 1200
Thr Met Arg Ala Ile Ala Glu Lys Phe Asp Pro Asp Ser Glu Lys
1205 1210 1215
Met Ala Lys Leu Glu Leu Lys His Lys Asp Trp Phe Glu Phe Met
1220 1225 1230
Gln Thr Arg Gly Asp
1235
<210> 1266
<211> 3996
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1266
ggtaccatga acggcaatag gtccatcgtg taccgcgagt tcgtgggcgt gatccccgtg 60
gccaagaccc tgaggaatga gctgcgccct gtgggccaca cacaggagca catcatccag 120
aacggcctga tccaggagga cgagctgcgg caggagaaga gcaccgagct gaagaacatc 180
atggacgatt actatagaga gtacatcgat aagtctctga gcggcgtgac cgacctggac 240
ttcaccctgc tgttcgagct gatgaacctg gtgcagagct ccccctccaa ggacaataag 300
aaggccctgg agaaggagca gtctaagatg agggagcaga tctgcaccca cctgcagtcc 360
gactctaact acaagaatat ctttaacgcc aagctgctga aggagatcct gcctgatttc 420
atcaagaact acaatcagta tgacgtgaag gataaggccg gcaagctgga gacactggcc 480
ctgtttaatg gcttcagcac atactttacc gacttctttg agaagaggaa gaacgtgttc 540
accaaggagg ccgtgagcac atccatcgcc taccgcatcg tgcacgagaa ctccctgatc 600
ttcctggcca atatgacctc ttataagaag atcagcgaga aggccctgga tgagatcgaa 660
gtgatcgaga agaacaatca ggacaagatg ggcgattggg agctgaatca gatctttaac 720
cctgacttct acaatatggt gctgatccag tccggcatcg acttctacaa cgagatctgc 780
ggcgtggtga atgcccacat gaacctgtac tgtcagcaga ccaagaacaa ttataacctg 840
ttcaagatgc ggaagctgca caagcagatc ctggcctaca ccagcaccag cttcgaggtg 900
cccaagatgt tcgaggacga tatgagcgtg tataacgccg tgaacgcctt catcgacgag 960
acagagaagg gcaacatcat cggcaagctg aaggatatcg tgaataagta cgacgagctg 1020
gatgagaaga gaatctatat cagcaaggac ttttacgaga cactgagctg cttcatgtcc 1080
ggcaactgga atctgatcac aggctgcgtg gagaacttct acgatgagaa catccacgcc 1140
aagggcaagt ccaaggagga gaaggtgaag aaggccgtga aggaggacaa gtacaagtct 1200
atcaatgacg tgaacgatct ggtggagaag tatatcgatg agaaggagag gaatgagttc 1260
aagaacagca atgccaagca gtacatccgc gagatctcca acatcatcac cgacacagag 1320
acagcccacc tggagtatga cgatcacatc tctctgatcg agagcgagga gaaggccgac 1380
gagatgaaga agcggctgga tatgtatatg aacatgtacc actgggccaa ggcctttatc 1440
gtggacgagg tgctggacag agatgagatg ttctacagcg atatcgacga tatctataat 1500
atcctggaga acatcgtgcc actgtataat cgggtgagaa actacgtgac ccagaagccc 1560
tacaactcta agaagatcaa gctgaatttc cagagcccta cactggccaa tggctggtcc 1620
cagtctaagg agttcgacaa caatgccatc atcctgatca gagataacaa gtactatctg 1680
gccatcttca atgccaagaa caagccagac aagaagatca tccagggcaa ctccgataag 1740
aagaacgaca acgattacaa gaagatggtg tataacctgc tgccaggcgc caacaagatg 1800
ctgcccaagg tgtttctgtc taagaagggc atcgagacat tcaagccctc cgactatatc 1860
atctctggct acaacgccca caagcacatc aagacaagcg agaattttga tatctccttc 1920
tgtcgggacc tgatcgatta cttcaagaac agcatcgaga agcacgccga gtggagaaag 1980
tatgagttca agttttccgc caccgacagc tactccgata tctctgagtt ctatcgggag 2040
gtggagatgc agggctacag aatcgactgg acatatatca gcgaggccga catcaacaag 2100
ctggatgagg agggcaagat ctatctgttt cagatctaca ataaggattt cgccgagaac 2160
agcaccggca aggagaatct gcacacaatg tactttaaga acatcttctc cgaggagaat 2220
ctgaaggaca tcatcatcaa gctgaacggc caggccgagc tgttttatcg gagagcctct 2280
gtgaagaatc ccgtgaagca caagaaggat agcgtgctgg tgaacaagac ctacaagaat 2340
cagctggaca acggcgacgt ggtgagaatc cccatccctg acgatatcta taacgagatc 2400
tacaagatgt ataatggcta catcaaggag tccgacctgt ctgaggccgc caaggagtac 2460
ctggataagg tggaggtgag gaccgcccag aaggacatcg tgaaggatta ccgctataca 2520
gtggacaagt acttcatcca cacacctatc accatcaact ataaggtgac cgcccgcaac 2580
aatgtgaatg atatggtggt gaagtacatc gcccagaacg acgatatcca cgtgatcggc 2640
atcgaccggg gcgagagaaa cctgatctac atctccgtga tcgattctca cggcaacatc 2700
gtgaagcaga aatcctacaa catcctgaac aactacgact acaagaagaa gctggtggag 2760
aaggagaaaa cccgggagta cgccagaaag aactggaaga gcatcggcaa tatcaaggag 2820
ctgaaggagg gctatatctc cggcgtggtg cacgagatcg ccatgctgat cgtggagtac 2880
aacgccatca tcgccatgga ggacctgaat tatggcttta agaggggccg cttcaaggtg 2940
gagcggcagg tgtaccagaa gtttgagagc atgctgatca ataagctgaa ctatttcgcc 3000
agcaaggaga agtccgtgga cgagccagga ggcctgctga agggctatca gctgacctac 3060
gtgcccgata atatcaagaa cctgggcaag cagtgcggcg tgatctttta cgtgcctgcc 3120
gccttcacca gcaagatcga cccatccaca ggctttatct ctgccttcaa ctttaagtct 3180
atcagcacaa atgcctctcg gaagcagttc tttatgcagt ttgacgagat cagatactgt 3240
gccgagaagg atatgttcag ctttggcttc gactacaaca acttcgatac ctacaacatc 3300
acaatgggca agacacagtg gaccgtgtat acaaacggcg agagactgca gtctgagttc 3360
aacaatgcca ggcgcaccgg caagacaaag agcatcaatc tgacagagac aatcaagctg 3420
ctgctggagg acaatgagat caactacgcc gacggccacg atatcaggat cgatatggag 3480
aagatggacg aggataagaa gagcgagttc tttgcccagc tgctgagcct gtataagctg 3540
accgtgcaga tgcgcaattc ctatacagag gccgaggagc aggagaacgg catctcttac 3600
gacaagatca tcagccctgt gatcaatgat gagggcgagt tctttgactc cgataactat 3660
aaggagtctg acgataagga gtgcaagatg ccaaaggacg ccgatgccaa cggcgcctac 3720
tgtatcgccc tgaagggcct gtatgaggtg ctgaagatca agagcgagtg gaccgaggac 3780
ggctttgata ggaattgcct gaagctgcca cacgcagagt ggctggactt catccagaac 3840
aagcggtacg agaaaaggcc ggcggccacg aaaaaggccg gccaggcaaa aaagaaaaag 3900
ggatcctacc catacgatgt tccagattac gcttatccct acgacgtgcc tgattatgca 3960
tacccatatg atgtccccga ctatgcctaa gaattc 3996
<210> 1267
<211> 1282
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1267
Met Asn Gly Asn Arg Ser Ile Val Tyr Arg Glu Phe Val Gly Val Ile
1 5 10 15
Pro Val Ala Lys Thr Leu Arg Asn Glu Leu Arg Pro Val Gly His Thr
20 25 30
Gln Glu His Ile Ile Gln Asn Gly Leu Ile Gln Glu Asp Glu Leu Arg
35 40 45
Gln Glu Lys Ser Thr Glu Leu Lys Asn Ile Met Asp Asp Tyr Tyr Arg
50 55 60
Glu Tyr Ile Asp Lys Ser Leu Ser Gly Val Thr Asp Leu Asp Phe Thr
65 70 75 80
Leu Leu Phe Glu Leu Met Asn Leu Val Gln Ser Ser Pro Ser Lys Asp
85 90 95
Asn Lys Lys Ala Leu Glu Lys Glu Gln Ser Lys Met Arg Glu Gln Ile
100 105 110
Cys Thr His Leu Gln Ser Asp Ser Asn Tyr Lys Asn Ile Phe Asn Ala
115 120 125
Lys Leu Leu Lys Glu Ile Leu Pro Asp Phe Ile Lys Asn Tyr Asn Gln
130 135 140
Tyr Asp Val Lys Asp Lys Ala Gly Lys Leu Glu Thr Leu Ala Leu Phe
145 150 155 160
Asn Gly Phe Ser Thr Tyr Phe Thr Asp Phe Phe Glu Lys Arg Lys Asn
165 170 175
Val Phe Thr Lys Glu Ala Val Ser Thr Ser Ile Ala Tyr Arg Ile Val
180 185 190
His Glu Asn Ser Leu Ile Phe Leu Ala Asn Met Thr Ser Tyr Lys Lys
195 200 205
Ile Ser Glu Lys Ala Leu Asp Glu Ile Glu Val Ile Glu Lys Asn Asn
210 215 220
Gln Asp Lys Met Gly Asp Trp Glu Leu Asn Gln Ile Phe Asn Pro Asp
225 230 235 240
Phe Tyr Asn Met Val Leu Ile Gln Ser Gly Ile Asp Phe Tyr Asn Glu
245 250 255
Ile Cys Gly Val Val Asn Ala His Met Asn Leu Tyr Cys Gln Gln Thr
260 265 270
Lys Asn Asn Tyr Asn Leu Phe Lys Met Arg Lys Leu His Lys Gln Ile
275 280 285
Leu Ala Tyr Thr Ser Thr Ser Phe Glu Val Pro Lys Met Phe Glu Asp
290 295 300
Asp Met Ser Val Tyr Asn Ala Val Asn Ala Phe Ile Asp Glu Thr Glu
305 310 315 320
Lys Gly Asn Ile Ile Gly Lys Leu Lys Asp Ile Val Asn Lys Tyr Asp
325 330 335
Glu Leu Asp Glu Lys Arg Ile Tyr Ile Ser Lys Asp Phe Tyr Glu Thr
340 345 350
Leu Ser Cys Phe Met Ser Gly Asn Trp Asn Leu Ile Thr Gly Cys Val
355 360 365
Glu Asn Phe Tyr Asp Glu Asn Ile His Ala Lys Gly Lys Ser Lys Glu
370 375 380
Glu Lys Val Lys Lys Ala Val Lys Glu Asp Lys Tyr Lys Ser Ile Asn
385 390 395 400
Asp Val Asn Asp Leu Val Glu Lys Tyr Ile Asp Glu Lys Glu Arg Asn
405 410 415
Glu Phe Lys Asn Ser Asn Ala Lys Gln Tyr Ile Arg Glu Ile Ser Asn
420 425 430
Ile Ile Thr Asp Thr Glu Thr Ala His Leu Glu Tyr Asp Asp His Ile
435 440 445
Ser Leu Ile Glu Ser Glu Glu Lys Ala Asp Glu Met Lys Lys Arg Leu
450 455 460
Asp Met Tyr Met Asn Met Tyr His Trp Ala Lys Ala Phe Ile Val Asp
465 470 475 480
Glu Val Leu Asp Arg Asp Glu Met Phe Tyr Ser Asp Ile Asp Asp Ile
485 490 495
Tyr Asn Ile Leu Glu Asn Ile Val Pro Leu Tyr Asn Arg Val Arg Asn
500 505 510
Tyr Val Thr Gln Lys Pro Tyr Asn Ser Lys Lys Ile Lys Leu Asn Phe
515 520 525
Gln Ser Pro Thr Leu Ala Asn Gly Trp Ser Gln Ser Lys Glu Phe Asp
530 535 540
Asn Asn Ala Ile Ile Leu Ile Arg Asp Asn Lys Tyr Tyr Leu Ala Ile
545 550 555 560
Phe Asn Ala Lys Asn Lys Pro Asp Lys Lys Ile Ile Gln Gly Asn Ser
565 570 575
Asp Lys Lys Asn Asp Asn Asp Tyr Lys Lys Met Val Tyr Asn Leu Leu
580 585 590
Pro Gly Ala Asn Lys Met Leu Pro Lys Val Phe Leu Ser Lys Lys Gly
595 600 605
Ile Glu Thr Phe Lys Pro Ser Asp Tyr Ile Ile Ser Gly Tyr Asn Ala
610 615 620
His Lys His Ile Lys Thr Ser Glu Asn Phe Asp Ile Ser Phe Cys Arg
625 630 635 640
Asp Leu Ile Asp Tyr Phe Lys Asn Ser Ile Glu Lys His Ala Glu Trp
645 650 655
Arg Lys Tyr Glu Phe Lys Phe Ser Ala Thr Asp Ser Tyr Ser Asp Ile
660 665 670
Ser Glu Phe Tyr Arg Glu Val Glu Met Gln Gly Tyr Arg Ile Asp Trp
675 680 685
Thr Tyr Ile Ser Glu Ala Asp Ile Asn Lys Leu Asp Glu Glu Gly Lys
690 695 700
Ile Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Glu Asn Ser Thr
705 710 715 720
Gly Lys Glu Asn Leu His Thr Met Tyr Phe Lys Asn Ile Phe Ser Glu
725 730 735
Glu Asn Leu Lys Asp Ile Ile Ile Lys Leu Asn Gly Gln Ala Glu Leu
740 745 750
Phe Tyr Arg Arg Ala Ser Val Lys Asn Pro Val Lys His Lys Lys Asp
755 760 765
Ser Val Leu Val Asn Lys Thr Tyr Lys Asn Gln Leu Asp Asn Gly Asp
770 775 780
Val Val Arg Ile Pro Ile Pro Asp Asp Ile Tyr Asn Glu Ile Tyr Lys
785 790 795 800
Met Tyr Asn Gly Tyr Ile Lys Glu Ser Asp Leu Ser Glu Ala Ala Lys
805 810 815
Glu Tyr Leu Asp Lys Val Glu Val Arg Thr Ala Gln Lys Asp Ile Val
820 825 830
Lys Asp Tyr Arg Tyr Thr Val Asp Lys Tyr Phe Ile His Thr Pro Ile
835 840 845
Thr Ile Asn Tyr Lys Val Thr Ala Arg Asn Asn Val Asn Asp Met Val
850 855 860
Val Lys Tyr Ile Ala Gln Asn Asp Asp Ile His Val Ile Gly Ile Asp
865 870 875 880
Arg Gly Glu Arg Asn Leu Ile Tyr Ile Ser Val Ile Asp Ser His Gly
885 890 895
Asn Ile Val Lys Gln Lys Ser Tyr Asn Ile Leu Asn Asn Tyr Asp Tyr
900 905 910
Lys Lys Lys Leu Val Glu Lys Glu Lys Thr Arg Glu Tyr Ala Arg Lys
915 920 925
Asn Trp Lys Ser Ile Gly Asn Ile Lys Glu Leu Lys Glu Gly Tyr Ile
930 935 940
Ser Gly Val Val His Glu Ile Ala Met Leu Ile Val Glu Tyr Asn Ala
945 950 955 960
Ile Ile Ala Met Glu Asp Leu Asn Tyr Gly Phe Lys Arg Gly Arg Phe
965 970 975
Lys Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Ser Met Leu Ile Asn
980 985 990
Lys Leu Asn Tyr Phe Ala Ser Lys Glu Lys Ser Val Asp Glu Pro Gly
995 1000 1005
Gly Leu Leu Lys Gly Tyr Gln Leu Thr Tyr Val Pro Asp Asn Ile
1010 1015 1020
Lys Asn Leu Gly Lys Gln Cys Gly Val Ile Phe Tyr Val Pro Ala
1025 1030 1035
Ala Phe Thr Ser Lys Ile Asp Pro Ser Thr Gly Phe Ile Ser Ala
1040 1045 1050
Phe Asn Phe Lys Ser Ile Ser Thr Asn Ala Ser Arg Lys Gln Phe
1055 1060 1065
Phe Met Gln Phe Asp Glu Ile Arg Tyr Cys Ala Glu Lys Asp Met
1070 1075 1080
Phe Ser Phe Gly Phe Asp Tyr Asn Asn Phe Asp Thr Tyr Asn Ile
1085 1090 1095
Thr Met Gly Lys Thr Gln Trp Thr Val Tyr Thr Asn Gly Glu Arg
1100 1105 1110
Leu Gln Ser Glu Phe Asn Asn Ala Arg Arg Thr Gly Lys Thr Lys
1115 1120 1125
Ser Ile Asn Leu Thr Glu Thr Ile Lys Leu Leu Leu Glu Asp Asn
1130 1135 1140
Glu Ile Asn Tyr Ala Asp Gly His Asp Ile Arg Ile Asp Met Glu
1145 1150 1155
Lys Met Asp Glu Asp Lys Lys Ser Glu Phe Phe Ala Gln Leu Leu
1160 1165 1170
Ser Leu Tyr Lys Leu Thr Val Gln Met Arg Asn Ser Tyr Thr Glu
1175 1180 1185
Ala Glu Glu Gln Glu Asn Gly Ile Ser Tyr Asp Lys Ile Ile Ser
1190 1195 1200
Pro Val Ile Asn Asp Glu Gly Glu Phe Phe Asp Ser Asp Asn Tyr
1205 1210 1215
Lys Glu Ser Asp Asp Lys Glu Cys Lys Met Pro Lys Asp Ala Asp
1220 1225 1230
Ala Asn Gly Ala Tyr Cys Ile Ala Leu Lys Gly Leu Tyr Glu Val
1235 1240 1245
Leu Lys Ile Lys Ser Glu Trp Thr Glu Asp Gly Phe Asp Arg Asn
1250 1255 1260
Cys Leu Lys Leu Pro His Ala Glu Trp Leu Asp Phe Ile Gln Asn
1265 1270 1275
Lys Arg Tyr Glu
1280
<210> 1268
<211> 4269
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1268
ggtaccatgc tgttccagga ctttacccac ctgtatccac tgtccaagac agtgagattt 60
gagctgaagc ccatcgatag gaccctggag cacatccacg ccaagaactt cctgtctcag 120
gacgagacaa tggccgatat gcaccagaag gtgaaagtga tcctggacga ttaccaccgc 180
gacttcatcg ccgatatgat gggcgaggtg aagctgacca agctggccga gttctatgac 240
gtgtacctga agtttcggaa gaacccaaag gacgatgagc tgcagaagca gctgaaggat 300
ctgcaggccg tgctgagaaa ggagatcgtg aagcccatcg gcaatggcgg caagtataag 360
gccggctacg acaggctgtt cggcgccaag ctgtttaagg acggcaagga gctgggcgat 420
ctggccaagt tcgtgatcgc acaggaggga gagagctccc caaagctggc ccacctggcc 480
cacttcgaga agttttccac ctatttcaca ggctttcacg ataaccggaa gaatatgtat 540
tctgacgagg ataagcacac cgccatcgcc taccgcctga tccacgagaa cctgccccgg 600
tttatcgaca atctgcagat cctgaccaca atcaagcaga agcactctgc cctgtacgat 660
cagatcatca acgagctgac cgccagcggc ctggacgtgt ctctggccag ccacctggat 720
ggctatcaca agctgctgac acaggagggc atcaccgcct acaatacact gctgggagga 780
atctccggag aggcaggctc tcctaagatc cagggcatca acgagctgat caattctcac 840
cacaaccagc actgccacaa gagcgagaga atcgccaagc tgaggccact gcacaagcag 900
atcctgtccg acggcatgag cgtgtccttc ctgccctcta agtttgccga cgatagcgag 960
atgtgccagg ccgtgaacga gttctatcgc cactacgccg acgtgttcgc caaggtgcag 1020
agcctgttcg acggctttga cgatcaccag aaggatggca tctacgtgga gcacaagaac 1080
ctgaatgagc tgtccaagca ggccttcggc gactttgcac tgctgggacg cgtgctggac 1140
ggatactatg tggatgtggt gaatccagag ttcaacgagc ggtttgccaa ggccaagacc 1200
gacaatgcca aggccaagct gacaaaggag aaggataagt tcatcaaggg cgtgcactcc 1260
ctggcctctc tggagcaggc catcgagcac tataccgcaa ggcacgacga tgagagcgtg 1320
caggcaggca agctgggaca gtacttcaag cacggcctgg ccggagtgga caaccccatc 1380
cagaagatcc acaacaatca cagcaccatc aagggctttc tggagaggga gcgccctgca 1440
ggagagagag ccctgccaaa gatcaagtcc ggcaagaatc ctgagatgac acagctgagg 1500
cagctgaagg agctgctgga taacgccctg aatgtggccc acttcgccaa gctgctgacc 1560
acaaagacca cactggacaa tcaggatggc aacttctatg gcgagtttgg cgtgctgtac 1620
gacgagctgg ccaagatccc caccctgtat aacaaggtga gagattacct gagccagaag 1680
cctttctcca ccgagaagta caagctgaac tttggcaatc caacactgct gaatggctgg 1740
gacctgaaca aggagaagga taatttcggc gtgatcctgc agaaggacgg ctgctactat 1800
ctggccctgc tggacaaggc ccacaagaag gtgtttgata acgcccctaa tacaggcaag 1860
agcatctatc agaagatgat ctataagtac ctggaggtga ggaagcagtt ccccaaggtg 1920
ttcttttcca aggaggccat cgccatcaac taccaccctt ctaaggagct ggtggagatc 1980
aaggacaagg gccggcagag atccgacgat gagcgcctga agctgtatcg gtttatcctg 2040
gagtgtctga agatccaccc taagtacgat aagaagttcg agggcgccat cggcgacatc 2100
cagctgttta agaaggataa gaagggcaga gaggtgccaa tcagcgagaa ggacctgttc 2160
gataagatca acggcatctt ttctagcaag cctaagctgg agatggagga cttctttatc 2220
ggcgagttca agaggtataa cccaagccag gacctggtgg atcagtataa tatctacaag 2280
aagatcgact ccaacgataa tcgcaagaag gagaatttct acaacaatca ccccaagttt 2340
aagaaggatc tggtgcggta ctattacgag tctatgtgca agcacgagga gtgggaggag 2400
agcttcgagt tttccaagaa gctgcaggac atcggctgtt acgtggatgt gaacgagctg 2460
tttaccgaga tcgagacacg gagactgaat tataagatct ccttctgcaa catcaatgcc 2520
gactacatcg atgagctggt ggagcagggc cagctgtatc tgttccagat ctacaacaag 2580
gacttttccc caaaggccca cggcaagccc aatctgcaca ccctgtactt caaggccctg 2640
ttttctgagg acaacctggc cgatcctatc tataagctga atggcgaggc ccagatcttc 2700
tacagaaagg cctccctgga catgaacgag acaacaatcc acagggccgg cgaggtgctg 2760
gagaacaaga atcccgataa tcctaagaag agacagttcg tgtacgacat catcaaggat 2820
aagaggtaca cacaggacaa gttcatgctg cacgtgccaa tcaccatgaa ctttggcgtg 2880
cagggcatga caatcaagga gttcaataag aaggtgaacc agtctatcca gcagtatgac 2940
gaggtgaacg tgatcggcat cgatcggggc gagagacacc tgctgtacct gaccgtgatc 3000
aatagcaagg gcgagatcct ggagcagtgt tccctgaacg acatcaccac agcctctgcc 3060
aatggcacac agatgaccac accttaccac aagatcctgg ataagaggga gatcgagcgc 3120
ctgaacgccc gggtgggatg gggcgagatc gagacaatca aggagctgaa gtctggctat 3180
ctgagccacg tggtgcacca gatcagccag ctgatgctga agtacaacgc catcgtggtg 3240
ctggaggacc tgaatttcgg ctttaagagg ggccgcttta aggtggagaa gcagatctat 3300
cagaacttcg agaatgccct gatcaagaag ctgaaccacc tggtgctgaa ggacaaggcc 3360
gacgatgaga tcggctctta caagaatgcc ctgcagctga ccaacaattt cacagatctg 3420
aagagcatcg gcaagcagac cggcttcctg ttttatgtgc ccgcctggaa cacctctaag 3480
atcgaccctg agacaggctt tgtggatctg ctgaagccaa gatacgagaa catcgcccag 3540
agccaggcct tctttggcaa gttcgacaag atctgctata atgccgacaa ggattacttc 3600
gagtttcaca tcgactacgc caagtttacc gataaggcca agaatagccg ccagatctgg 3660
acaatctgtt cccacggcga caagcggtac gtgtacgata agacagccaa ccagaataag 3720
ggcgccgcca agggcatcaa cgtgaatgat gagctgaagt ccctgttcgc ccgccaccac 3780
atcaacgaga agcagcccaa cctggtcatg gacatctgcc agaacaatga taaggagttt 3840
cacaagtctc tgatgtacct gctgaaaacc ctgctggccc tgcggtacag caacgcctcc 3900
tctgacgagg atttcatcct gtcccccgtg gcaaacgacg agggcgtgtt ctttaatagc 3960
gccctggccg acgatacaca gcctcagaat gccgatgcca acggcgccta ccacatcgcc 4020
ctgaagggcc tgtggctgct gaatgagctg aagaactccg acgatctgaa caaggtgaag 4080
ctggccatcg acaatcagac ctggctgaat ttcgcccaga acaggaaaag gccggcggcc 4140
acgaaaaagg ccggccaggc aaaaaagaaa aagggatcct acccatacga tgttccagat 4200
tacgcttatc cctacgacgt gcctgattat gcatacccat atgatgtccc cgactatgcc 4260
taagaattc 4269
<210> 1269
<211> 1373
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1269
Met Leu Phe Gln Asp Phe Thr His Leu Tyr Pro Leu Ser Lys Thr Val
1 5 10 15
Arg Phe Glu Leu Lys Pro Ile Asp Arg Thr Leu Glu His Ile His Ala
20 25 30
Lys Asn Phe Leu Ser Gln Asp Glu Thr Met Ala Asp Met His Gln Lys
35 40 45
Val Lys Val Ile Leu Asp Asp Tyr His Arg Asp Phe Ile Ala Asp Met
50 55 60
Met Gly Glu Val Lys Leu Thr Lys Leu Ala Glu Phe Tyr Asp Val Tyr
65 70 75 80
Leu Lys Phe Arg Lys Asn Pro Lys Asp Asp Glu Leu Gln Lys Gln Leu
85 90 95
Lys Asp Leu Gln Ala Val Leu Arg Lys Glu Ile Val Lys Pro Ile Gly
100 105 110
Asn Gly Gly Lys Tyr Lys Ala Gly Tyr Asp Arg Leu Phe Gly Ala Lys
115 120 125
Leu Phe Lys Asp Gly Lys Glu Leu Gly Asp Leu Ala Lys Phe Val Ile
130 135 140
Ala Gln Glu Gly Glu Ser Ser Pro Lys Leu Ala His Leu Ala His Phe
145 150 155 160
Glu Lys Phe Ser Thr Tyr Phe Thr Gly Phe His Asp Asn Arg Lys Asn
165 170 175
Met Tyr Ser Asp Glu Asp Lys His Thr Ala Ile Ala Tyr Arg Leu Ile
180 185 190
His Glu Asn Leu Pro Arg Phe Ile Asp Asn Leu Gln Ile Leu Thr Thr
195 200 205
Ile Lys Gln Lys His Ser Ala Leu Tyr Asp Gln Ile Ile Asn Glu Leu
210 215 220
Thr Ala Ser Gly Leu Asp Val Ser Leu Ala Ser His Leu Asp Gly Tyr
225 230 235 240
His Lys Leu Leu Thr Gln Glu Gly Ile Thr Ala Tyr Asn Thr Leu Leu
245 250 255
Gly Gly Ile Ser Gly Glu Ala Gly Ser Pro Lys Ile Gln Gly Ile Asn
260 265 270
Glu Leu Ile Asn Ser His His Asn Gln His Cys His Lys Ser Glu Arg
275 280 285
Ile Ala Lys Leu Arg Pro Leu His Lys Gln Ile Leu Ser Asp Gly Met
290 295 300
Ser Val Ser Phe Leu Pro Ser Lys Phe Ala Asp Asp Ser Glu Met Cys
305 310 315 320
Gln Ala Val Asn Glu Phe Tyr Arg His Tyr Ala Asp Val Phe Ala Lys
325 330 335
Val Gln Ser Leu Phe Asp Gly Phe Asp Asp His Gln Lys Asp Gly Ile
340 345 350
Tyr Val Glu His Lys Asn Leu Asn Glu Leu Ser Lys Gln Ala Phe Gly
355 360 365
Asp Phe Ala Leu Leu Gly Arg Val Leu Asp Gly Tyr Tyr Val Asp Val
370 375 380
Val Asn Pro Glu Phe Asn Glu Arg Phe Ala Lys Ala Lys Thr Asp Asn
385 390 395 400
Ala Lys Ala Lys Leu Thr Lys Glu Lys Asp Lys Phe Ile Lys Gly Val
405 410 415
His Ser Leu Ala Ser Leu Glu Gln Ala Ile Glu His Tyr Thr Ala Arg
420 425 430
His Asp Asp Glu Ser Val Gln Ala Gly Lys Leu Gly Gln Tyr Phe Lys
435 440 445
His Gly Leu Ala Gly Val Asp Asn Pro Ile Gln Lys Ile His Asn Asn
450 455 460
His Ser Thr Ile Lys Gly Phe Leu Glu Arg Glu Arg Pro Ala Gly Glu
465 470 475 480
Arg Ala Leu Pro Lys Ile Lys Ser Gly Lys Asn Pro Glu Met Thr Gln
485 490 495
Leu Arg Gln Leu Lys Glu Leu Leu Asp Asn Ala Leu Asn Val Ala His
500 505 510
Phe Ala Lys Leu Leu Thr Thr Lys Thr Thr Leu Asp Asn Gln Asp Gly
515 520 525
Asn Phe Tyr Gly Glu Phe Gly Val Leu Tyr Asp Glu Leu Ala Lys Ile
530 535 540
Pro Thr Leu Tyr Asn Lys Val Arg Asp Tyr Leu Ser Gln Lys Pro Phe
545 550 555 560
Ser Thr Glu Lys Tyr Lys Leu Asn Phe Gly Asn Pro Thr Leu Leu Asn
565 570 575
Gly Trp Asp Leu Asn Lys Glu Lys Asp Asn Phe Gly Val Ile Leu Gln
580 585 590
Lys Asp Gly Cys Tyr Tyr Leu Ala Leu Leu Asp Lys Ala His Lys Lys
595 600 605
Val Phe Asp Asn Ala Pro Asn Thr Gly Lys Ser Ile Tyr Gln Lys Met
610 615 620
Ile Tyr Lys Tyr Leu Glu Val Arg Lys Gln Phe Pro Lys Val Phe Phe
625 630 635 640
Ser Lys Glu Ala Ile Ala Ile Asn Tyr His Pro Ser Lys Glu Leu Val
645 650 655
Glu Ile Lys Asp Lys Gly Arg Gln Arg Ser Asp Asp Glu Arg Leu Lys
660 665 670
Leu Tyr Arg Phe Ile Leu Glu Cys Leu Lys Ile His Pro Lys Tyr Asp
675 680 685
Lys Lys Phe Glu Gly Ala Ile Gly Asp Ile Gln Leu Phe Lys Lys Asp
690 695 700
Lys Lys Gly Arg Glu Val Pro Ile Ser Glu Lys Asp Leu Phe Asp Lys
705 710 715 720
Ile Asn Gly Ile Phe Ser Ser Lys Pro Lys Leu Glu Met Glu Asp Phe
725 730 735
Phe Ile Gly Glu Phe Lys Arg Tyr Asn Pro Ser Gln Asp Leu Val Asp
740 745 750
Gln Tyr Asn Ile Tyr Lys Lys Ile Asp Ser Asn Asp Asn Arg Lys Lys
755 760 765
Glu Asn Phe Tyr Asn Asn His Pro Lys Phe Lys Lys Asp Leu Val Arg
770 775 780
Tyr Tyr Tyr Glu Ser Met Cys Lys His Glu Glu Trp Glu Glu Ser Phe
785 790 795 800
Glu Phe Ser Lys Lys Leu Gln Asp Ile Gly Cys Tyr Val Asp Val Asn
805 810 815
Glu Leu Phe Thr Glu Ile Glu Thr Arg Arg Leu Asn Tyr Lys Ile Ser
820 825 830
Phe Cys Asn Ile Asn Ala Asp Tyr Ile Asp Glu Leu Val Glu Gln Gly
835 840 845
Gln Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Pro Lys Ala
850 855 860
His Gly Lys Pro Asn Leu His Thr Leu Tyr Phe Lys Ala Leu Phe Ser
865 870 875 880
Glu Asp Asn Leu Ala Asp Pro Ile Tyr Lys Leu Asn Gly Glu Ala Gln
885 890 895
Ile Phe Tyr Arg Lys Ala Ser Leu Asp Met Asn Glu Thr Thr Ile His
900 905 910
Arg Ala Gly Glu Val Leu Glu Asn Lys Asn Pro Asp Asn Pro Lys Lys
915 920 925
Arg Gln Phe Val Tyr Asp Ile Ile Lys Asp Lys Arg Tyr Thr Gln Asp
930 935 940
Lys Phe Met Leu His Val Pro Ile Thr Met Asn Phe Gly Val Gln Gly
945 950 955 960
Met Thr Ile Lys Glu Phe Asn Lys Lys Val Asn Gln Ser Ile Gln Gln
965 970 975
Tyr Asp Glu Val Asn Val Ile Gly Ile Asp Arg Gly Glu Arg His Leu
980 985 990
Leu Tyr Leu Thr Val Ile Asn Ser Lys Gly Glu Ile Leu Glu Gln Cys
995 1000 1005
Ser Leu Asn Asp Ile Thr Thr Ala Ser Ala Asn Gly Thr Gln Met
1010 1015 1020
Thr Thr Pro Tyr His Lys Ile Leu Asp Lys Arg Glu Ile Glu Arg
1025 1030 1035
Leu Asn Ala Arg Val Gly Trp Gly Glu Ile Glu Thr Ile Lys Glu
1040 1045 1050
Leu Lys Ser Gly Tyr Leu Ser His Val Val His Gln Ile Ser Gln
1055 1060 1065
Leu Met Leu Lys Tyr Asn Ala Ile Val Val Leu Glu Asp Leu Asn
1070 1075 1080
Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Ile Tyr
1085 1090 1095
Gln Asn Phe Glu Asn Ala Leu Ile Lys Lys Leu Asn His Leu Val
1100 1105 1110
Leu Lys Asp Lys Ala Asp Asp Glu Ile Gly Ser Tyr Lys Asn Ala
1115 1120 1125
Leu Gln Leu Thr Asn Asn Phe Thr Asp Leu Lys Ser Ile Gly Lys
1130 1135 1140
Gln Thr Gly Phe Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys
1145 1150 1155
Ile Asp Pro Glu Thr Gly Phe Val Asp Leu Leu Lys Pro Arg Tyr
1160 1165 1170
Glu Asn Ile Ala Gln Ser Gln Ala Phe Phe Gly Lys Phe Asp Lys
1175 1180 1185
Ile Cys Tyr Asn Ala Asp Lys Asp Tyr Phe Glu Phe His Ile Asp
1190 1195 1200
Tyr Ala Lys Phe Thr Asp Lys Ala Lys Asn Ser Arg Gln Ile Trp
1205 1210 1215
Thr Ile Cys Ser His Gly Asp Lys Arg Tyr Val Tyr Asp Lys Thr
1220 1225 1230
Ala Asn Gln Asn Lys Gly Ala Ala Lys Gly Ile Asn Val Asn Asp
1235 1240 1245
Glu Leu Lys Ser Leu Phe Ala Arg His His Ile Asn Glu Lys Gln
1250 1255 1260
Pro Asn Leu Val Met Asp Ile Cys Gln Asn Asn Asp Lys Glu Phe
1265 1270 1275
His Lys Ser Leu Met Tyr Leu Leu Lys Thr Leu Leu Ala Leu Arg
1280 1285 1290
Tyr Ser Asn Ala Ser Ser Asp Glu Asp Phe Ile Leu Ser Pro Val
1295 1300 1305
Ala Asn Asp Glu Gly Val Phe Phe Asn Ser Ala Leu Ala Asp Asp
1310 1315 1320
Thr Gln Pro Gln Asn Ala Asp Ala Asn Gly Ala Tyr His Ile Ala
1325 1330 1335
Leu Lys Gly Leu Trp Leu Leu Asn Glu Leu Lys Asn Ser Asp Asp
1340 1345 1350
Leu Asn Lys Val Lys Leu Ala Ile Asp Asn Gln Thr Trp Leu Asn
1355 1360 1365
Phe Ala Gln Asn Arg
1370
<210> 1270
<211> 3939
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1270
ggtaccatgg aggactattc cggctttgtg aacatctact ctatccagaa aaccctgagg 60
ttcgagctga agccagtggg caagacactg gagcacatcg agaagaaggg cttcctgaag 120
aaggacaaga tccgggccga ggattacaag gccgtgaaga agatcatcga taagtaccac 180
agagcctata tcgaggaggt gtttgattcc gtgctgcacc agaagaagaa gaaggacaag 240
acccgctttt ctacacagtt catcaaggag atcaaggagt tcagcgagct gtactataag 300
accgagaaga acatccccga caaggagagg ctggaggccc tgagcgagaa gctgcgcaag 360
atgctggtgg gcgcctttaa gggcgagttc tccgaggagg tggccgagaa gtataagaac 420
ctgttttcta aggagctgat caggaatgag atcgagaagt tctgcgagac agacgaggag 480
cgcaagcagg tgtctaactt caagagcttc accacatact ttaccggctt ccactccaac 540
aggcagaata tctattccga cgagaagaag tctacagcca tcggctaccg catcatccac 600
cagaacctgc ctaagttcct ggataatctg aagatcatcg agtccatcca gcggcggttc 660
aaggacttcc catggtctga tctgaagaag aacctgaaga agatcgataa gaatatcaag 720
ctgaccgagt acttcagcat cgacggcttc gtgaacgtgc tgaatcagaa gggcatcgat 780
gcctacaaca caatcctggg cggcaagtcc gaggagtctg gcgagaagat ccagggcctg 840
aacgagtaca tcaatctgta tcggcagaag aacaatatcg acagaaagaa cctgcccaat 900
gtgaagatcc tgtttaagca gatcctgggc gatagggaga caaagagctt tatccctgag 960
gccttcccag acgatcagtc cgtgctgaac tctatcacag agttcgccaa gtacctgaag 1020
ctggataaga agaagaagag catcatcgcc gagctgaaga agtttctgag ctccttcaat 1080
cgctacgagc tggacggcat ctatctggcc aacgataata gcctggcctc tatcagcacc 1140
ttcctgtttg acgattggtc ctttatcaag aagtccgtgt ctttcaagta tgacgagtcc 1200
gtgggcgacc ccaagaagaa gatcaagtct cccctgaagt acgagaagga gaaggagaag 1260
tggctgaagc agaagtacta tacaatctct ttcctgaacg atgccatcga gagctattcc 1320
aagtctcagg acgagaagag ggtgaagatc cgcctggagg cctactttgc cgagttcaag 1380
agcaaggacg atgccaagaa gcagttcgac ctgctggaga ggatcgagga ggcctatgcc 1440
atcgtggagc ctctgctggg agcagagtac ccaagggacc gcaacctgaa ggccgataag 1500
aaggaagtgg gcaagatcaa ggacttcctg gatagcatca agtccctgca gttctttctg 1560
aagcctctgc tgtccgccga gatctttgac gagaaggatc tgggcttcta caatcagctg 1620
gagggctact atgaggagat cgattctatc ggccacctgt ataacaaggt gcggaattat 1680
ctgaccggca agatctacag caaggagaag tttaagctga acttcgagaa cagcaccctg 1740
ctgaagggct gggacgagaa ccgggaggtg gccaatctgt gcgtgatctt cagagaggac 1800
cagaagtact atctgggcgt gatggataag gagaacaata ccatcctgtc cgacatcccc 1860
aaggtgaagc ctaacgagct gttttacgag aagatggtgt ataagctgat ccccacacct 1920
cacatgcagc tgccccggat catcttctct agcgacaacc tgtctatcta taatcctagc 1980
aagtccatcc tgaagatcag agaggccaag agctttaagg agggcaagaa cttcaagctg 2040
aaggactgtc acaagtttat cgatttctac aaggagtcta tcagcaagaa tgaggactgg 2100
agcagattcg acttcaagtt cagcaagacc agcagctacg agaacatcag cgagttttac 2160
cgggaggtgg agagacaggg ctataacctg gacttcaaga aggtgtctaa gttctacatc 2220
gacagcctgg tggaggatgg caagctgtac ctgttccaga tctataacaa ggacttttct 2280
atcttcagca agggcaagcc caatctgcac accatctatt ttcggtccct gttctctaag 2340
gagaacctga aggacgtgtg cctgaagctg aatggcgagg ccgagatgtt ctttcggaag 2400
aagtccatca actacgatga gaagaagaag cgggagggcc accaccccga gctgtttgag 2460
aagctgaagt atcctatcct gaaggacaag agatacagcg aggataagtt tcagttccac 2520
ctgcccatca gcctgaactt caagtccaag gagcggctga actttaatct gaaagtgaat 2580
gagttcctga agagaaacaa ggacatcaat atcatcggca tcgatcgggg cgagagaaac 2640
ctgctgtacc tggtcatgat caatcagaag ggcgagatcc tgaagcagac cctgctggac 2700
agcatgcagt ccggcaaggg ccggcctgag atcaactaca aggagaagct gcaggagaag 2760
gagatcgaga gggataaggc ccgcaagagc tggggcacag tggagaatat caaggagctg 2820
aaggagggct atctgtctat cgtgatccac cagatcagca agctgatggt ggagaacaat 2880
gccatcgtgg tgctggagga cctgaacatc ggctttaagc ggggcagaca gaaggtggag 2940
cggcaggtgt accagaagtt cgagaagatg ctgatcgata agctgaactt tctggtgttc 3000
aaggagaata agccaaccga gccaggaggc gtgctgaagg cctatcagct gacagacgag 3060
tttcagtctt tcgagaagct gagcaagcag accggctttc tgttctacgt gccaagctgg 3120
aacacctcca agatcgaccc cagaacaggc tttatcgatt tcctgcaccc tgcctacgag 3180
aatatcgaga aggccaagca gtggatcaac aagtttgatt ccatcaggtt caattctaag 3240
atggactggt ttgagttcac cgccgataca cgcaagtttt ccgagaacct gatgctgggc 3300
aagaatcggg tgtgggtcat ctgcaccaca aatgtggagc ggtacttcac cagcaagacc 3360
gccaacagct ccatccagta caatagcatc cagatcaccg agaagctgaa ggagctgttt 3420
gtggacatcc ctttcagcaa cggccaggat ctgaagccag agatcctgag gaagaatgac 3480
gccgtgttct ttaagagcct gctgttttac atcaagacca cactgtccct gcgccagaac 3540
aatggcaaga agggcgagga ggagaaggac ttcatcctga gcccagtggt ggattccaag 3600
ggccggttct ttaactctct ggaggccagc gacgatgagc ccaaggacgc cgatgccaat 3660
ggcgcctacc acatcgccct gaagggcctg atgaacctgc tggtgctgaa tgagacaaag 3720
gaggagaacc tgagcagacc aaagtggaag atcaagaata aggactggct ggagttcgtg 3780
tgggagagga accgcaaaag gccggcggcc acgaaaaagg ccggccaggc aaaaaagaaa 3840
aagggatcct acccatacga tgttccagat tacgcttatc cctacgacgt gcctgattat 3900
gcatacccat atgatgtccc cgactatgcc taagaattc 3939
<210> 1271
<211> 1263
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1271
Met Glu Asp Tyr Ser Gly Phe Val Asn Ile Tyr Ser Ile Gln Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu His Ile Glu
20 25 30
Lys Lys Gly Phe Leu Lys Lys Asp Lys Ile Arg Ala Glu Asp Tyr Lys
35 40 45
Ala Val Lys Lys Ile Ile Asp Lys Tyr His Arg Ala Tyr Ile Glu Glu
50 55 60
Val Phe Asp Ser Val Leu His Gln Lys Lys Lys Lys Asp Lys Thr Arg
65 70 75 80
Phe Ser Thr Gln Phe Ile Lys Glu Ile Lys Glu Phe Ser Glu Leu Tyr
85 90 95
Tyr Lys Thr Glu Lys Asn Ile Pro Asp Lys Glu Arg Leu Glu Ala Leu
100 105 110
Ser Glu Lys Leu Arg Lys Met Leu Val Gly Ala Phe Lys Gly Glu Phe
115 120 125
Ser Glu Glu Val Ala Glu Lys Tyr Lys Asn Leu Phe Ser Lys Glu Leu
130 135 140
Ile Arg Asn Glu Ile Glu Lys Phe Cys Glu Thr Asp Glu Glu Arg Lys
145 150 155 160
Gln Val Ser Asn Phe Lys Ser Phe Thr Thr Tyr Phe Thr Gly Phe His
165 170 175
Ser Asn Arg Gln Asn Ile Tyr Ser Asp Glu Lys Lys Ser Thr Ala Ile
180 185 190
Gly Tyr Arg Ile Ile His Gln Asn Leu Pro Lys Phe Leu Asp Asn Leu
195 200 205
Lys Ile Ile Glu Ser Ile Gln Arg Arg Phe Lys Asp Phe Pro Trp Ser
210 215 220
Asp Leu Lys Lys Asn Leu Lys Lys Ile Asp Lys Asn Ile Lys Leu Thr
225 230 235 240
Glu Tyr Phe Ser Ile Asp Gly Phe Val Asn Val Leu Asn Gln Lys Gly
245 250 255
Ile Asp Ala Tyr Asn Thr Ile Leu Gly Gly Lys Ser Glu Glu Ser Gly
260 265 270
Glu Lys Ile Gln Gly Leu Asn Glu Tyr Ile Asn Leu Tyr Arg Gln Lys
275 280 285
Asn Asn Ile Asp Arg Lys Asn Leu Pro Asn Val Lys Ile Leu Phe Lys
290 295 300
Gln Ile Leu Gly Asp Arg Glu Thr Lys Ser Phe Ile Pro Glu Ala Phe
305 310 315 320
Pro Asp Asp Gln Ser Val Leu Asn Ser Ile Thr Glu Phe Ala Lys Tyr
325 330 335
Leu Lys Leu Asp Lys Lys Lys Lys Ser Ile Ile Ala Glu Leu Lys Lys
340 345 350
Phe Leu Ser Ser Phe Asn Arg Tyr Glu Leu Asp Gly Ile Tyr Leu Ala
355 360 365
Asn Asp Asn Ser Leu Ala Ser Ile Ser Thr Phe Leu Phe Asp Asp Trp
370 375 380
Ser Phe Ile Lys Lys Ser Val Ser Phe Lys Tyr Asp Glu Ser Val Gly
385 390 395 400
Asp Pro Lys Lys Lys Ile Lys Ser Pro Leu Lys Tyr Glu Lys Glu Lys
405 410 415
Glu Lys Trp Leu Lys Gln Lys Tyr Tyr Thr Ile Ser Phe Leu Asn Asp
420 425 430
Ala Ile Glu Ser Tyr Ser Lys Ser Gln Asp Glu Lys Arg Val Lys Ile
435 440 445
Arg Leu Glu Ala Tyr Phe Ala Glu Phe Lys Ser Lys Asp Asp Ala Lys
450 455 460
Lys Gln Phe Asp Leu Leu Glu Arg Ile Glu Glu Ala Tyr Ala Ile Val
465 470 475 480
Glu Pro Leu Leu Gly Ala Glu Tyr Pro Arg Asp Arg Asn Leu Lys Ala
485 490 495
Asp Lys Lys Glu Val Gly Lys Ile Lys Asp Phe Leu Asp Ser Ile Lys
500 505 510
Ser Leu Gln Phe Phe Leu Lys Pro Leu Leu Ser Ala Glu Ile Phe Asp
515 520 525
Glu Lys Asp Leu Gly Phe Tyr Asn Gln Leu Glu Gly Tyr Tyr Glu Glu
530 535 540
Ile Asp Ser Ile Gly His Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr
545 550 555 560
Gly Lys Ile Tyr Ser Lys Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser
565 570 575
Thr Leu Leu Lys Gly Trp Asp Glu Asn Arg Glu Val Ala Asn Leu Cys
580 585 590
Val Ile Phe Arg Glu Asp Gln Lys Tyr Tyr Leu Gly Val Met Asp Lys
595 600 605
Glu Asn Asn Thr Ile Leu Ser Asp Ile Pro Lys Val Lys Pro Asn Glu
610 615 620
Leu Phe Tyr Glu Lys Met Val Tyr Lys Leu Ile Pro Thr Pro His Met
625 630 635 640
Gln Leu Pro Arg Ile Ile Phe Ser Ser Asp Asn Leu Ser Ile Tyr Asn
645 650 655
Pro Ser Lys Ser Ile Leu Lys Ile Arg Glu Ala Lys Ser Phe Lys Glu
660 665 670
Gly Lys Asn Phe Lys Leu Lys Asp Cys His Lys Phe Ile Asp Phe Tyr
675 680 685
Lys Glu Ser Ile Ser Lys Asn Glu Asp Trp Ser Arg Phe Asp Phe Lys
690 695 700
Phe Ser Lys Thr Ser Ser Tyr Glu Asn Ile Ser Glu Phe Tyr Arg Glu
705 710 715 720
Val Glu Arg Gln Gly Tyr Asn Leu Asp Phe Lys Lys Val Ser Lys Phe
725 730 735
Tyr Ile Asp Ser Leu Val Glu Asp Gly Lys Leu Tyr Leu Phe Gln Ile
740 745 750
Tyr Asn Lys Asp Phe Ser Ile Phe Ser Lys Gly Lys Pro Asn Leu His
755 760 765
Thr Ile Tyr Phe Arg Ser Leu Phe Ser Lys Glu Asn Leu Lys Asp Val
770 775 780
Cys Leu Lys Leu Asn Gly Glu Ala Glu Met Phe Phe Arg Lys Lys Ser
785 790 795 800
Ile Asn Tyr Asp Glu Lys Lys Lys Arg Glu Gly His His Pro Glu Leu
805 810 815
Phe Glu Lys Leu Lys Tyr Pro Ile Leu Lys Asp Lys Arg Tyr Ser Glu
820 825 830
Asp Lys Phe Gln Phe His Leu Pro Ile Ser Leu Asn Phe Lys Ser Lys
835 840 845
Glu Arg Leu Asn Phe Asn Leu Lys Val Asn Glu Phe Leu Lys Arg Asn
850 855 860
Lys Asp Ile Asn Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Leu
865 870 875 880
Tyr Leu Val Met Ile Asn Gln Lys Gly Glu Ile Leu Lys Gln Thr Leu
885 890 895
Leu Asp Ser Met Gln Ser Gly Lys Gly Arg Pro Glu Ile Asn Tyr Lys
900 905 910
Glu Lys Leu Gln Glu Lys Glu Ile Glu Arg Asp Lys Ala Arg Lys Ser
915 920 925
Trp Gly Thr Val Glu Asn Ile Lys Glu Leu Lys Glu Gly Tyr Leu Ser
930 935 940
Ile Val Ile His Gln Ile Ser Lys Leu Met Val Glu Asn Asn Ala Ile
945 950 955 960
Val Val Leu Glu Asp Leu Asn Ile Gly Phe Lys Arg Gly Arg Gln Lys
965 970 975
Val Glu Arg Gln Val Tyr Gln Lys Phe Glu Lys Met Leu Ile Asp Lys
980 985 990
Leu Asn Phe Leu Val Phe Lys Glu Asn Lys Pro Thr Glu Pro Gly Gly
995 1000 1005
Val Leu Lys Ala Tyr Gln Leu Thr Asp Glu Phe Gln Ser Phe Glu
1010 1015 1020
Lys Leu Ser Lys Gln Thr Gly Phe Leu Phe Tyr Val Pro Ser Trp
1025 1030 1035
Asn Thr Ser Lys Ile Asp Pro Arg Thr Gly Phe Ile Asp Phe Leu
1040 1045 1050
His Pro Ala Tyr Glu Asn Ile Glu Lys Ala Lys Gln Trp Ile Asn
1055 1060 1065
Lys Phe Asp Ser Ile Arg Phe Asn Ser Lys Met Asp Trp Phe Glu
1070 1075 1080
Phe Thr Ala Asp Thr Arg Lys Phe Ser Glu Asn Leu Met Leu Gly
1085 1090 1095
Lys Asn Arg Val Trp Val Ile Cys Thr Thr Asn Val Glu Arg Tyr
1100 1105 1110
Phe Thr Ser Lys Thr Ala Asn Ser Ser Ile Gln Tyr Asn Ser Ile
1115 1120 1125
Gln Ile Thr Glu Lys Leu Lys Glu Leu Phe Val Asp Ile Pro Phe
1130 1135 1140
Ser Asn Gly Gln Asp Leu Lys Pro Glu Ile Leu Arg Lys Asn Asp
1145 1150 1155
Ala Val Phe Phe Lys Ser Leu Leu Phe Tyr Ile Lys Thr Thr Leu
1160 1165 1170
Ser Leu Arg Gln Asn Asn Gly Lys Lys Gly Glu Glu Glu Lys Asp
1175 1180 1185
Phe Ile Leu Ser Pro Val Val Asp Ser Lys Gly Arg Phe Phe Asn
1190 1195 1200
Ser Leu Glu Ala Ser Asp Asp Glu Pro Lys Asp Ala Asp Ala Asn
1205 1210 1215
Gly Ala Tyr His Ile Ala Leu Lys Gly Leu Met Asn Leu Leu Val
1220 1225 1230
Leu Asn Glu Thr Lys Glu Glu Asn Leu Ser Arg Pro Lys Trp Lys
1235 1240 1245
Ile Lys Asn Lys Asp Trp Leu Glu Phe Val Trp Glu Arg Asn Arg
1250 1255 1260
<210> 1272
<211> 3834
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1272
ggtaccatga gcaagctgga gaagtttaca aactgctact ccctgtctaa gaccctgagg 60
ttcaaggcca tccctgtggg caagacccag gagaacatcg acaataagcg gctgctggtg 120
gaggacgaga agagagccga ggattataag ggcgtgaaga agctgctgga tcgctactat 180
ctgtctttta tcaacgacgt gctgcacagc atcaagctga agaatctgaa caattacatc 240
agcctgttcc ggaagaaaac cagaaccgag aaggagaata aggagctgga gaacctggag 300
atcaatctgc ggaaggagat cgccaaggcc ttcaagggca acgagggcta caagtccctg 360
tttaagaagg atatcatcga gacaatcctg ccagagttcc tggacgataa ggacgagatc 420
gccctggtga acagcttcaa tggctttacc acagccttca ccggcttctt tgataacaga 480
gagaatatgt tttccgagga ggccaagagc acatccatcg ccttcaggtg tatcaacgag 540
aatctgaccc gctacatctc taatatggac atcttcgaga aggtggacgc catctttgat 600
aagcacgagg tgcaggagat caaggagaag atcctgaaca gcgactatga tgtggaggat 660
ttctttgagg gcgagttctt taactttgtg ctgacacagg agggcatcga cgtgtataac 720
gccatcatcg gcggcttcgt gaccgagagc ggcgagaaga tcaagggcct gaacgagtac 780
atcaacctgt ataatcagaa aaccaagcag aagctgccta agtttaagcc actgtataag 840
caggtgctga gcgatcggga gtctctgagc ttctacggcg agggctatac atccgatgag 900
gaggtgctgg aggtgtttag aaacaccctg aacaagaaca gcgagatctt cagctccatc 960
aagaagctgg agaagctgtt caagaatttt gacgagtact ctagcgccgg catctttgtg 1020
aagaacggcc ccgccatcag cacaatctcc aaggatatct tcggcgagtg gaacgtgatc 1080
cgggacaagt ggaatgccga gtatgacgat atccacctga agaagaaggc cgtggtgacc 1140
gagaagtacg aggacgatcg gagaaagtcc ttcaagaaga tcggctcctt ttctctggag 1200
cagctgcagg agtacgccga cgccgatctg tctgtggtgg agaagctgaa ggagatcatc 1260
atccagaagg tggatgagat ctacaaggtg tatggctcct ctgagaagct gttcgacgcc 1320
gattttgtgc tggagaagag cctgaagaag aacgacgccg tggtggccat catgaaggac 1380
ctgctggatt ctgtgaagag cttcgagaat tacatcaagg ccttctttgg cgagggcaag 1440
gagacaaaca gggacgagtc cttctatggc gattttgtgc tggcctacga catcctgctg 1500
aaggtggacc acatctacga tgccatccgc aattatgtga cccagaagcc ctactctaag 1560
gataagttca agctgtattt tcagaaccct cagttcatgg gcggctggga caaggataag 1620
gagacagact atcgggccac catcctgaga tacggctcca agtactatct ggccatcatg 1680
gataagaagt acgccaagtg cctgcagaag atcgacaagg acgatgtgaa cggcaattac 1740
gagaagatca actataagct gctgcccggc cctaataaga tgctgccaaa ggtgttcttt 1800
tctaagaagt ggatggccta ctataacccc agcgaggaca tccagaagat ctacaagaat 1860
ggcacattca agaagggcga tatgtttaac ctgaatgact gtcacaagct gatcgacttc 1920
tttaaggata gcatctcccg gtatccaaag tggtccaatg cctacgattt caacttttct 1980
gagacagaga agtataagga catcgccggc ttttacagag aggtggagga gcagggctat 2040
aaggtgagct tcgagtctgc cagcaagaag gaggtggata agctggtgga ggagggcaag 2100
ctgtatatgt tccagatcta taacaaggac ttttccgata agtctcacgg cacacccaat 2160
ctgcacacca tgtacttcaa gctgctgttt gacgagaaca atcacggaca gatcaggctg 2220
agcggaggag cagagctgtt catgaggcgc gcctccctga agaaggagga gctggtggtg 2280
cacccagcca actcccctat cgccaacaag aatccagata atcccaagaa aaccacaacc 2340
ctgtcctacg acgtgtataa ggataagagg ttttctgagg accagtacga gctgcacatc 2400
ccaatcgcca tcaataagtg ccccaagaac atcttcaaga tcaatacaga ggtgcgcgtg 2460
ctgctgaagc acgacgataa cccctatgtg atcggcatcg ataggggcga gcgcaatctg 2520
ctgtatatcg tggtggtgga cggcaagggc aacatcgtgg agcagtattc cctgaacgag 2580
atcatcaaca acttcaacgg catcaggatc aagacagatt accactctct gctggacaag 2640
aaggagaagg agaggttcga ggcccgccag aactggacct ccatcgagaa tatcaaggag 2700
ctgaaggccg gctatatctc tcaggtggtg cacaagatct gcgagctggt ggagaagtac 2760
gatgccgtga tcgccctgga ggacctgaac tctggcttta agaatagccg cgtgaaggtg 2820
gagaagcagg tgtatcagaa gttcgagaag atgctgatcg ataagctgaa ctacatggtg 2880
gacaagaagt ctaatccttg tgcaacaggc ggcgccctga agggctatca gatcaccaat 2940
aagttcgaga gctttaagtc catgtctacc cagaacggct tcatctttta catccctgcc 3000
tggctgacat ccaagatcga tccatctacc ggctttgtga acctgctgaa aaccaagtat 3060
accagcatcg ccgattccaa gaagttcatc agctcctttg acaggatcat gtacgtgccc 3120
gaggaggatc tgttcgagtt tgccctggac tataagaact tctctcgcac agacgccgat 3180
tacatcaaga agtggaagct gtactcctac ggcaaccgga tcagaatctt ccggaatcct 3240
aagaagaaca acgtgttcga ctgggaggag gtgtgcctga ccagcgccta taaggagctg 3300
ttcaacaagt acggcatcaa ttatcagcag ggcgatatca gagccctgct gtgcgagcag 3360
tccgacaagg ccttctactc tagctttatg gccctgatga gcctgatgct gcagatgcgg 3420
aacagcatca caggccgcac cgacgtggat tttctgatca gccctgtgaa gaactccgac 3480
ggcatcttct acgatagccg gaactatgag gcccaggaga atgccatcct gccaaagaac 3540
gccgacgcca atggcgccta taacatcgcc agaaaggtgc tgtgggccat cggccagttc 3600
aagaaggccg aggacgagaa gctggataag gtgaagatcg ccatctctaa caaggagtgg 3660
ctggagtacg cccagaccag cgtgaagcac aaaaggccgg cggccacgaa aaaggccggc 3720
caggcaaaaa agaaaaaggg atcctaccca tacgatgttc cagattacgc ttatccctac 3780
gacgtgcctg attatgcata cccatatgat gtccccgact atgcctaaga attc 3834
<210> 1273
<211> 1228
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1273
Met Ser Lys Leu Glu Lys Phe Thr Asn Cys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Lys Ala Ile Pro Val Gly Lys Thr Gln Glu Asn Ile Asp
20 25 30
Asn Lys Arg Leu Leu Val Glu Asp Glu Lys Arg Ala Glu Asp Tyr Lys
35 40 45
Gly Val Lys Lys Leu Leu Asp Arg Tyr Tyr Leu Ser Phe Ile Asn Asp
50 55 60
Val Leu His Ser Ile Lys Leu Lys Asn Leu Asn Asn Tyr Ile Ser Leu
65 70 75 80
Phe Arg Lys Lys Thr Arg Thr Glu Lys Glu Asn Lys Glu Leu Glu Asn
85 90 95
Leu Glu Ile Asn Leu Arg Lys Glu Ile Ala Lys Ala Phe Lys Gly Asn
100 105 110
Glu Gly Tyr Lys Ser Leu Phe Lys Lys Asp Ile Ile Glu Thr Ile Leu
115 120 125
Pro Glu Phe Leu Asp Asp Lys Asp Glu Ile Ala Leu Val Asn Ser Phe
130 135 140
Asn Gly Phe Thr Thr Ala Phe Thr Gly Phe Phe Asp Asn Arg Glu Asn
145 150 155 160
Met Phe Ser Glu Glu Ala Lys Ser Thr Ser Ile Ala Phe Arg Cys Ile
165 170 175
Asn Glu Asn Leu Thr Arg Tyr Ile Ser Asn Met Asp Ile Phe Glu Lys
180 185 190
Val Asp Ala Ile Phe Asp Lys His Glu Val Gln Glu Ile Lys Glu Lys
195 200 205
Ile Leu Asn Ser Asp Tyr Asp Val Glu Asp Phe Phe Glu Gly Glu Phe
210 215 220
Phe Asn Phe Val Leu Thr Gln Glu Gly Ile Asp Val Tyr Asn Ala Ile
225 230 235 240
Ile Gly Gly Phe Val Thr Glu Ser Gly Glu Lys Ile Lys Gly Leu Asn
245 250 255
Glu Tyr Ile Asn Leu Tyr Asn Gln Lys Thr Lys Gln Lys Leu Pro Lys
260 265 270
Phe Lys Pro Leu Tyr Lys Gln Val Leu Ser Asp Arg Glu Ser Leu Ser
275 280 285
Phe Tyr Gly Glu Gly Tyr Thr Ser Asp Glu Glu Val Leu Glu Val Phe
290 295 300
Arg Asn Thr Leu Asn Lys Asn Ser Glu Ile Phe Ser Ser Ile Lys Lys
305 310 315 320
Leu Glu Lys Leu Phe Lys Asn Phe Asp Glu Tyr Ser Ser Ala Gly Ile
325 330 335
Phe Val Lys Asn Gly Pro Ala Ile Ser Thr Ile Ser Lys Asp Ile Phe
340 345 350
Gly Glu Trp Asn Val Ile Arg Asp Lys Trp Asn Ala Glu Tyr Asp Asp
355 360 365
Ile His Leu Lys Lys Lys Ala Val Val Thr Glu Lys Tyr Glu Asp Asp
370 375 380
Arg Arg Lys Ser Phe Lys Lys Ile Gly Ser Phe Ser Leu Glu Gln Leu
385 390 395 400
Gln Glu Tyr Ala Asp Ala Asp Leu Ser Val Val Glu Lys Leu Lys Glu
405 410 415
Ile Ile Ile Gln Lys Val Asp Glu Ile Tyr Lys Val Tyr Gly Ser Ser
420 425 430
Glu Lys Leu Phe Asp Ala Asp Phe Val Leu Glu Lys Ser Leu Lys Lys
435 440 445
Asn Asp Ala Val Val Ala Ile Met Lys Asp Leu Leu Asp Ser Val Lys
450 455 460
Ser Phe Glu Asn Tyr Ile Lys Ala Phe Phe Gly Glu Gly Lys Glu Thr
465 470 475 480
Asn Arg Asp Glu Ser Phe Tyr Gly Asp Phe Val Leu Ala Tyr Asp Ile
485 490 495
Leu Leu Lys Val Asp His Ile Tyr Asp Ala Ile Arg Asn Tyr Val Thr
500 505 510
Gln Lys Pro Tyr Ser Lys Asp Lys Phe Lys Leu Tyr Phe Gln Asn Pro
515 520 525
Gln Phe Met Gly Gly Trp Asp Lys Asp Lys Glu Thr Asp Tyr Arg Ala
530 535 540
Thr Ile Leu Arg Tyr Gly Ser Lys Tyr Tyr Leu Ala Ile Met Asp Lys
545 550 555 560
Lys Tyr Ala Lys Cys Leu Gln Lys Ile Asp Lys Asp Asp Val Asn Gly
565 570 575
Asn Tyr Glu Lys Ile Asn Tyr Lys Leu Leu Pro Gly Pro Asn Lys Met
580 585 590
Leu Pro Lys Val Phe Phe Ser Lys Lys Trp Met Ala Tyr Tyr Asn Pro
595 600 605
Ser Glu Asp Ile Gln Lys Ile Tyr Lys Asn Gly Thr Phe Lys Lys Gly
610 615 620
Asp Met Phe Asn Leu Asn Asp Cys His Lys Leu Ile Asp Phe Phe Lys
625 630 635 640
Asp Ser Ile Ser Arg Tyr Pro Lys Trp Ser Asn Ala Tyr Asp Phe Asn
645 650 655
Phe Ser Glu Thr Glu Lys Tyr Lys Asp Ile Ala Gly Phe Tyr Arg Glu
660 665 670
Val Glu Glu Gln Gly Tyr Lys Val Ser Phe Glu Ser Ala Ser Lys Lys
675 680 685
Glu Val Asp Lys Leu Val Glu Glu Gly Lys Leu Tyr Met Phe Gln Ile
690 695 700
Tyr Asn Lys Asp Phe Ser Asp Lys Ser His Gly Thr Pro Asn Leu His
705 710 715 720
Thr Met Tyr Phe Lys Leu Leu Phe Asp Glu Asn Asn His Gly Gln Ile
725 730 735
Arg Leu Ser Gly Gly Ala Glu Leu Phe Met Arg Arg Ala Ser Leu Lys
740 745 750
Lys Glu Glu Leu Val Val His Pro Ala Asn Ser Pro Ile Ala Asn Lys
755 760 765
Asn Pro Asp Asn Pro Lys Lys Thr Thr Thr Leu Ser Tyr Asp Val Tyr
770 775 780
Lys Asp Lys Arg Phe Ser Glu Asp Gln Tyr Glu Leu His Ile Pro Ile
785 790 795 800
Ala Ile Asn Lys Cys Pro Lys Asn Ile Phe Lys Ile Asn Thr Glu Val
805 810 815
Arg Val Leu Leu Lys His Asp Asp Asn Pro Tyr Val Ile Gly Ile Asp
820 825 830
Arg Gly Glu Arg Asn Leu Leu Tyr Ile Val Val Val Asp Gly Lys Gly
835 840 845
Asn Ile Val Glu Gln Tyr Ser Leu Asn Glu Ile Ile Asn Asn Phe Asn
850 855 860
Gly Ile Arg Ile Lys Thr Asp Tyr His Ser Leu Leu Asp Lys Lys Glu
865 870 875 880
Lys Glu Arg Phe Glu Ala Arg Gln Asn Trp Thr Ser Ile Glu Asn Ile
885 890 895
Lys Glu Leu Lys Ala Gly Tyr Ile Ser Gln Val Val His Lys Ile Cys
900 905 910
Glu Leu Val Glu Lys Tyr Asp Ala Val Ile Ala Leu Glu Asp Leu Asn
915 920 925
Ser Gly Phe Lys Asn Ser Arg Val Lys Val Glu Lys Gln Val Tyr Gln
930 935 940
Lys Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Tyr Met Val Asp Lys
945 950 955 960
Lys Ser Asn Pro Cys Ala Thr Gly Gly Ala Leu Lys Gly Tyr Gln Ile
965 970 975
Thr Asn Lys Phe Glu Ser Phe Lys Ser Met Ser Thr Gln Asn Gly Phe
980 985 990
Ile Phe Tyr Ile Pro Ala Trp Leu Thr Ser Lys Ile Asp Pro Ser Thr
995 1000 1005
Gly Phe Val Asn Leu Leu Lys Thr Lys Tyr Thr Ser Ile Ala Asp
1010 1015 1020
Ser Lys Lys Phe Ile Ser Ser Phe Asp Arg Ile Met Tyr Val Pro
1025 1030 1035
Glu Glu Asp Leu Phe Glu Phe Ala Leu Asp Tyr Lys Asn Phe Ser
1040 1045 1050
Arg Thr Asp Ala Asp Tyr Ile Lys Lys Trp Lys Leu Tyr Ser Tyr
1055 1060 1065
Gly Asn Arg Ile Arg Ile Phe Arg Asn Pro Lys Lys Asn Asn Val
1070 1075 1080
Phe Asp Trp Glu Glu Val Cys Leu Thr Ser Ala Tyr Lys Glu Leu
1085 1090 1095
Phe Asn Lys Tyr Gly Ile Asn Tyr Gln Gln Gly Asp Ile Arg Ala
1100 1105 1110
Leu Leu Cys Glu Gln Ser Asp Lys Ala Phe Tyr Ser Ser Phe Met
1115 1120 1125
Ala Leu Met Ser Leu Met Leu Gln Met Arg Asn Ser Ile Thr Gly
1130 1135 1140
Arg Thr Asp Val Asp Phe Leu Ile Ser Pro Val Lys Asn Ser Asp
1145 1150 1155
Gly Ile Phe Tyr Asp Ser Arg Asn Tyr Glu Ala Gln Glu Asn Ala
1160 1165 1170
Ile Leu Pro Lys Asn Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala
1175 1180 1185
Arg Lys Val Leu Trp Ala Ile Gly Gln Phe Lys Lys Ala Glu Asp
1190 1195 1200
Glu Lys Leu Asp Lys Val Lys Ile Ala Ile Ser Asn Lys Glu Trp
1205 1210 1215
Leu Glu Tyr Ala Gln Thr Ser Val Lys His
1220 1225
<210> 1274
<211> 3930
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1274
ggtaccatgg acagcctgaa ggatttcacc aacctgtacc ccgtgtccaa gacactgcgg 60
tttgagctga agcctgtggg caagaccctg gagaatatcg agaaggccgg catcctgaag 120
gaggatgagc acagagccga gagctaccgg agagtgaaga agatcatcga tacatatcac 180
aaggtgttca tcgacagctc cctggagaac atggccaaga tgggcatcga gaatgagatc 240
aaggccatgc tgcagtcctt ttgcgagctg tataagaagg accacaggac cgagggagag 300
gacaaggccc tggataagat cagggccgtg ctgaggggcc tgatcgtggg agccttcacc 360
ggcgtgtgcg gccggcggga gaacacagtg cagaatgaga agtatgagag cctgtttaag 420
gagaagctga tcaaggagat cctgccagat ttcgtgctgt ctacagaggc cgagtccctg 480
cccttttctg tggaggaggc caccagaagc ctgaaggagt tcgactcctt tacatcttac 540
ttcgccggct tttatgagaa ccggaagaat atctactcta ccaagcccca gagcacagcc 600
atcgcctata gactgatcca cgagaacctg cctaagttca tcgataatat cctggtgttt 660
cagaagatca aggagccaat cgccaaggag ctggagcaca tcagggcaga cttcagcgcc 720
ggcggctaca tcaagaagga tgagcgcctg gaggacatct tttccctgaa ctactatatc 780
cacgtgctgt ctcaggccgg catcgagaag tacaatgccc tgatcggcaa gatcgtgacc 840
gagggcgatg gcgagatgaa gggcctgaac gagcacatca acctgtataa tcagcagagg 900
ggccgcgagg accggctgcc actgttcaga cccctgtata agcagatcct gtctgatagg 960
gagcagctgt cctatctgcc agagtctttc gagaaggacg aggagctgct gagggccctg 1020
aaggagtttt acgatcacat cgcagaggac atcctgggaa ggacccagca gctgatgaca 1080
agcatctccg agtacgatct gtcccggatc tatgtgagaa acgatagcca gctgaccgac 1140
atctccaaga agatgctggg cgattggaat gccatctaca tggcccggga gagagcctat 1200
gaccacgagc aggcccccaa gcgcatcaca gccaagtacg agagggaccg catcaaggcc 1260
ctgaagggcg aggagtctat cagcctggcc aacctgaaca gctgcatcgc cttcctggac 1320
aacgtgaggg attgtcgcgt ggacacctat ctgtctacac tgggacagaa ggagggacct 1380
cacggcctga gcaacctggt ggagaacgtg ttcgcctcct accacgaggc cgagcagctg 1440
ctgtcttttc cctatcctga ggagaacaat ctgatccagg acaaggataa cgtggtgctg 1500
atcaagaacc tgctggataa tatcagcgac ctgcagaggt tcctgaagcc actgtggggc 1560
atgggcgatg agcccgacaa ggatgagagg ttttacggcg agtacaatta tatcaggggc 1620
gccctggacc aggtcatccc tctgtataac aaggtgcgga attatctgac ccgcaagcca 1680
tactccacac gcaaggtgaa gctgaacttc ggcaatagcc agctgctgtc cggctgggat 1740
aggaacaagg agaaggacaa ttcttgcgtg atcctgcgca agggccagaa cttctacctg 1800
gccatcatga acaatcggca caagcggagc ttcgagaata agatgctgcc cgagtataag 1860
gagggcgagc cttacttcga gaagatggat tataagtttc tgccagaccc caacaagatg 1920
ctgcccaagg tgttcctgtc taagaagggc atcgagatct acaagcctag cccaaagctg 1980
ctggagcagt atggccacgg cacccacaag aagggcgata ccttcagcat ggacgatctg 2040
cacgagctga tcgacttctt taagcactcc atcgaggccc acgaggattg gaagcagttc 2100
ggctttaagt tcagcgacac cgccacatac gagaacgtga gcagcttcta ccgggaggtg 2160
gaggaccagg gctacaagct gtcttttaga aaggtgtccg agtcttacgt gtatagcctg 2220
atcgatcagg gcaagctgta cctgttccag atctataaca aggactttag cccttgttcc 2280
aagggcaccc caaatctgca cacactgtac tggcggatgc tgttcgatga gagaaacctg 2340
gccgacgtga tctataagct ggatggcaag gccgagatct tctttcggga gaagtccctg 2400
aagaatgacc acccaaccca ccctgcaggc aagcccatca agaagaagag ccggcagaag 2460
aagggcgagg agagcctgtt cgagtacgat ctggtgaagg accggagata taccatggat 2520
aagtttcagt tccacgtgcc aatcacaatg aactttaagt gctctgccgg cagcaaggtg 2580
aacgacatgg tgaatgccca catcagggag gccaaggaca tgcacgtgat cggcatcgat 2640
aggggcgagc gcaatctgct gtatatctgc gtgatcgaca gccgcggcac catcctggat 2700
cagatctccc tgaacacaat caatgacatc gattatcacg atctgctgga gtccagggac 2760
aaggatcgcc agcaggagca caggaactgg cagaccatcg agggcatcaa ggagctgaag 2820
cagggctacc tgtctcaggc cgtgcaccgc atcgccgagc tgatggtggc ctataaggcc 2880
gtggtggccc tggaggacct gaacatgggc ttcaagcggg gcagacagaa ggtggagagc 2940
agcgtgtacc agcagtttga gaagcagctg atcgacaagc tgaattatct ggtggataag 3000
aagaagcggc ccgaggacat cggaggcctg ctgagagcct accagttcac cgcccctttc 3060
aagagcttta aggagatggg caagcagaac ggctttctgt tctatatccc tgcctggaac 3120
acatccaata tcgacccaac cacaggcttc gtgaacctgt ttcacgtgca gtacgagaat 3180
gtggataagg ccaagagctt ctttcagaag ttcgacagca tctcctacaa ccctaagaag 3240
gattggtttg agttcgcctt tgactataag aacttcacca agaaggccga gggctctagg 3300
agcatgtgga ttctgtgcac ccacggctcc cggatcaaga acttcagaaa ttctcagaag 3360
aatggccagt gggatagcga ggagtttgcc ctgaccgagg ccttcaagtc cctgtttgtg 3420
cggtacgaga tcgattatac cgccgacctg aaaaccgcca tcgtggacga gaagcagaag 3480
gatttctttg tggacctgct gaagctgttc aagctgaccg tgcagatgag aaactcctgg 3540
aaggagaagg acctggatta cctgatctct ccagtggccg gcgccgatgg caggttcttt 3600
gacacacgcg agggcaataa gagcctgccc aaggacgcag atgcaaacgg agcctataat 3660
atcgccctga agggcctgtg ggcactgagg cagatcagac agacctccga gggcggcaag 3720
ctgaagctgg ccatctctaa caaggagtgg ctgcagtttg tgcaggagag atcctacgag 3780
aaggacaaaa ggccggcggc cacgaaaaag gccggccagg caaaaaagaa aaagggatcc 3840
tacccatacg atgttccaga ttacgcttat ccctacgacg tgcctgatta tgcataccca 3900
tatgatgtcc ccgactatgc ctaagaattc 3930
<210> 1275
<211> 1260
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1275
Met Asp Ser Leu Lys Asp Phe Thr Asn Leu Tyr Pro Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Val Gly Lys Thr Leu Glu Asn Ile Glu
20 25 30
Lys Ala Gly Ile Leu Lys Glu Asp Glu His Arg Ala Glu Ser Tyr Arg
35 40 45
Arg Val Lys Lys Ile Ile Asp Thr Tyr His Lys Val Phe Ile Asp Ser
50 55 60
Ser Leu Glu Asn Met Ala Lys Met Gly Ile Glu Asn Glu Ile Lys Ala
65 70 75 80
Met Leu Gln Ser Phe Cys Glu Leu Tyr Lys Lys Asp His Arg Thr Glu
85 90 95
Gly Glu Asp Lys Ala Leu Asp Lys Ile Arg Ala Val Leu Arg Gly Leu
100 105 110
Ile Val Gly Ala Phe Thr Gly Val Cys Gly Arg Arg Glu Asn Thr Val
115 120 125
Gln Asn Glu Lys Tyr Glu Ser Leu Phe Lys Glu Lys Leu Ile Lys Glu
130 135 140
Ile Leu Pro Asp Phe Val Leu Ser Thr Glu Ala Glu Ser Leu Pro Phe
145 150 155 160
Ser Val Glu Glu Ala Thr Arg Ser Leu Lys Glu Phe Asp Ser Phe Thr
165 170 175
Ser Tyr Phe Ala Gly Phe Tyr Glu Asn Arg Lys Asn Ile Tyr Ser Thr
180 185 190
Lys Pro Gln Ser Thr Ala Ile Ala Tyr Arg Leu Ile His Glu Asn Leu
195 200 205
Pro Lys Phe Ile Asp Asn Ile Leu Val Phe Gln Lys Ile Lys Glu Pro
210 215 220
Ile Ala Lys Glu Leu Glu His Ile Arg Ala Asp Phe Ser Ala Gly Gly
225 230 235 240
Tyr Ile Lys Lys Asp Glu Arg Leu Glu Asp Ile Phe Ser Leu Asn Tyr
245 250 255
Tyr Ile His Val Leu Ser Gln Ala Gly Ile Glu Lys Tyr Asn Ala Leu
260 265 270
Ile Gly Lys Ile Val Thr Glu Gly Asp Gly Glu Met Lys Gly Leu Asn
275 280 285
Glu His Ile Asn Leu Tyr Asn Gln Gln Arg Gly Arg Glu Asp Arg Leu
290 295 300
Pro Leu Phe Arg Pro Leu Tyr Lys Gln Ile Leu Ser Asp Arg Glu Gln
305 310 315 320
Leu Ser Tyr Leu Pro Glu Ser Phe Glu Lys Asp Glu Glu Leu Leu Arg
325 330 335
Ala Leu Lys Glu Phe Tyr Asp His Ile Ala Glu Asp Ile Leu Gly Arg
340 345 350
Thr Gln Gln Leu Met Thr Ser Ile Ser Glu Tyr Asp Leu Ser Arg Ile
355 360 365
Tyr Val Arg Asn Asp Ser Gln Leu Thr Asp Ile Ser Lys Lys Met Leu
370 375 380
Gly Asp Trp Asn Ala Ile Tyr Met Ala Arg Glu Arg Ala Tyr Asp His
385 390 395 400
Glu Gln Ala Pro Lys Arg Ile Thr Ala Lys Tyr Glu Arg Asp Arg Ile
405 410 415
Lys Ala Leu Lys Gly Glu Glu Ser Ile Ser Leu Ala Asn Leu Asn Ser
420 425 430
Cys Ile Ala Phe Leu Asp Asn Val Arg Asp Cys Arg Val Asp Thr Tyr
435 440 445
Leu Ser Thr Leu Gly Gln Lys Glu Gly Pro His Gly Leu Ser Asn Leu
450 455 460
Val Glu Asn Val Phe Ala Ser Tyr His Glu Ala Glu Gln Leu Leu Ser
465 470 475 480
Phe Pro Tyr Pro Glu Glu Asn Asn Leu Ile Gln Asp Lys Asp Asn Val
485 490 495
Val Leu Ile Lys Asn Leu Leu Asp Asn Ile Ser Asp Leu Gln Arg Phe
500 505 510
Leu Lys Pro Leu Trp Gly Met Gly Asp Glu Pro Asp Lys Asp Glu Arg
515 520 525
Phe Tyr Gly Glu Tyr Asn Tyr Ile Arg Gly Ala Leu Asp Gln Val Ile
530 535 540
Pro Leu Tyr Asn Lys Val Arg Asn Tyr Leu Thr Arg Lys Pro Tyr Ser
545 550 555 560
Thr Arg Lys Val Lys Leu Asn Phe Gly Asn Ser Gln Leu Leu Ser Gly
565 570 575
Trp Asp Arg Asn Lys Glu Lys Asp Asn Ser Cys Val Ile Leu Arg Lys
580 585 590
Gly Gln Asn Phe Tyr Leu Ala Ile Met Asn Asn Arg His Lys Arg Ser
595 600 605
Phe Glu Asn Lys Met Leu Pro Glu Tyr Lys Glu Gly Glu Pro Tyr Phe
610 615 620
Glu Lys Met Asp Tyr Lys Phe Leu Pro Asp Pro Asn Lys Met Leu Pro
625 630 635 640
Lys Val Phe Leu Ser Lys Lys Gly Ile Glu Ile Tyr Lys Pro Ser Pro
645 650 655
Lys Leu Leu Glu Gln Tyr Gly His Gly Thr His Lys Lys Gly Asp Thr
660 665 670
Phe Ser Met Asp Asp Leu His Glu Leu Ile Asp Phe Phe Lys His Ser
675 680 685
Ile Glu Ala His Glu Asp Trp Lys Gln Phe Gly Phe Lys Phe Ser Asp
690 695 700
Thr Ala Thr Tyr Glu Asn Val Ser Ser Phe Tyr Arg Glu Val Glu Asp
705 710 715 720
Gln Gly Tyr Lys Leu Ser Phe Arg Lys Val Ser Glu Ser Tyr Val Tyr
725 730 735
Ser Leu Ile Asp Gln Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys
740 745 750
Asp Phe Ser Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr
755 760 765
Trp Arg Met Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys
770 775 780
Leu Asp Gly Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys Asn
785 790 795 800
Asp His Pro Thr His Pro Ala Gly Lys Pro Ile Lys Lys Lys Ser Arg
805 810 815
Gln Lys Lys Gly Glu Glu Ser Leu Phe Glu Tyr Asp Leu Val Lys Asp
820 825 830
Arg Arg Tyr Thr Met Asp Lys Phe Gln Phe His Val Pro Ile Thr Met
835 840 845
Asn Phe Lys Cys Ser Ala Gly Ser Lys Val Asn Asp Met Val Asn Ala
850 855 860
His Ile Arg Glu Ala Lys Asp Met His Val Ile Gly Ile Asp Arg Gly
865 870 875 880
Glu Arg Asn Leu Leu Tyr Ile Cys Val Ile Asp Ser Arg Gly Thr Ile
885 890 895
Leu Asp Gln Ile Ser Leu Asn Thr Ile Asn Asp Ile Asp Tyr His Asp
900 905 910
Leu Leu Glu Ser Arg Asp Lys Asp Arg Gln Gln Glu His Arg Asn Trp
915 920 925
Gln Thr Ile Glu Gly Ile Lys Glu Leu Lys Gln Gly Tyr Leu Ser Gln
930 935 940
Ala Val His Arg Ile Ala Glu Leu Met Val Ala Tyr Lys Ala Val Val
945 950 955 960
Ala Leu Glu Asp Leu Asn Met Gly Phe Lys Arg Gly Arg Gln Lys Val
965 970 975
Glu Ser Ser Val Tyr Gln Gln Phe Glu Lys Gln Leu Ile Asp Lys Leu
980 985 990
Asn Tyr Leu Val Asp Lys Lys Lys Arg Pro Glu Asp Ile Gly Gly Leu
995 1000 1005
Leu Arg Ala Tyr Gln Phe Thr Ala Pro Phe Lys Ser Phe Lys Glu
1010 1015 1020
Met Gly Lys Gln Asn Gly Phe Leu Phe Tyr Ile Pro Ala Trp Asn
1025 1030 1035
Thr Ser Asn Ile Asp Pro Thr Thr Gly Phe Val Asn Leu Phe His
1040 1045 1050
Val Gln Tyr Glu Asn Val Asp Lys Ala Lys Ser Phe Phe Gln Lys
1055 1060 1065
Phe Asp Ser Ile Ser Tyr Asn Pro Lys Lys Asp Trp Phe Glu Phe
1070 1075 1080
Ala Phe Asp Tyr Lys Asn Phe Thr Lys Lys Ala Glu Gly Ser Arg
1085 1090 1095
Ser Met Trp Ile Leu Cys Thr His Gly Ser Arg Ile Lys Asn Phe
1100 1105 1110
Arg Asn Ser Gln Lys Asn Gly Gln Trp Asp Ser Glu Glu Phe Ala
1115 1120 1125
Leu Thr Glu Ala Phe Lys Ser Leu Phe Val Arg Tyr Glu Ile Asp
1130 1135 1140
Tyr Thr Ala Asp Leu Lys Thr Ala Ile Val Asp Glu Lys Gln Lys
1145 1150 1155
Asp Phe Phe Val Asp Leu Leu Lys Leu Phe Lys Leu Thr Val Gln
1160 1165 1170
Met Arg Asn Ser Trp Lys Glu Lys Asp Leu Asp Tyr Leu Ile Ser
1175 1180 1185
Pro Val Ala Gly Ala Asp Gly Arg Phe Phe Asp Thr Arg Glu Gly
1190 1195 1200
Asn Lys Ser Leu Pro Lys Asp Ala Asp Ala Asn Gly Ala Tyr Asn
1205 1210 1215
Ile Ala Leu Lys Gly Leu Trp Ala Leu Arg Gln Ile Arg Gln Thr
1220 1225 1230
Ser Glu Gly Gly Lys Leu Lys Leu Ala Ile Ser Asn Lys Glu Trp
1235 1240 1245
Leu Gln Phe Val Gln Glu Arg Ser Tyr Glu Lys Asp
1250 1255 1260
<210> 1276
<211> 4119
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1276
ggtaccatgg agaactatca ggagttcacc aacctgtttc agctgaataa gacactgaga 60
ttcgagctga agcccatcgg caagacctgc gagctgctgg aggagggcaa gatcttcgcc 120
agcggctcct ttctggagaa ggacaaggtg agggccgata acgtgagcta cgtgaagaag 180
gagatcgaca agaagcacaa gatctttatc gaggagacac tgagctcctt ctctatcagc 240
aacgatctgc tgaagcagta ctttgactgc tataatgagc tgaaggcctt caagaaggac 300
tgtaagagcg atgaggagga ggtgaagaaa accgccctgc gcaacaagtg tacctccatc 360
cagagggcca tgcgcgaggc catctctcag gcctttctga agagccccca gaagaagctg 420
ctggccatca agaacctgat cgagaacgtg ttcaaggccg acgagaatgt gcagcacttc 480
tccgagttta ccagctattt ctccggcttt gagacaaaca gagagaattt ctactctgac 540
gaggagaagt ccacatctat cgcctatagg ctggtgcacg ataacctgcc tatcttcatc 600
aagaacatct acatcttcga gaagctgaag gagcagttcg acgccaagac cctgagcgag 660
atcttcgaga actacaagct gtatgtggcc ggctctagcc tggatgaggt gttctccctg 720
gagtacttta acaataccct gacacagaag ggcatcgaca actataatgc cgtgatcggc 780
aagatcgtga aggaggataa gcaggagatc cagggcctga acgagcacat caacctgtat 840
aatcagaagc acaaggaccg gagactgccc ttctttatct ccctgaagaa gcagatcctg 900
tccgatcggg aggccctgtc ttggctgcct gacatgttca agaatgattc tgaagtgatc 960
aaggccctga agggcttcta catcgaggac ggctttgaga acaatgtgct gacacctctg 1020
gccaccctgc tgtcctctct ggataagtac aacctgaatg gcatctttat ccgcaacaat 1080
gaggccctga gctccctgtc ccagaacgtg tatcggaatt tttctatcga cgaggccatc 1140
gatgccaacg ccgagctgca gaccttcaac aattacgagc tgatcgccaa tgccctgcgc 1200
gccaagatca agaaggagac aaagcagggc cggaagtctt tcgagaagta cgaggagtat 1260
atcgataaga aggtgaaggc catcgacagc ctgtccatcc aggagatcaa cgagctggtg 1320
gagaattacg tgagcgagtt taactctaat agcggcaaca tgccaagaaa ggtggaggac 1380
tacttcagcc tgatgaggaa gggcgacttc ggctccaacg atctgatcga aaatatcaag 1440
accaagctga gcgccgcaga gaagctgctg ggcacaaagt accaggagac agccaaggac 1500
atcttcaaga aggatgagaa ctccaagctg atcaaggagc tgctggacgc caccaagcag 1560
ttccagcact ttatcaagcc actgctgggc acaggcgagg aggcagatcg ggacctggtg 1620
ttctacggcg attttctgcc cctgtatgag aagtttgagg agctgaccct gctgtataac 1680
aaggtgcgga atagactgac acagaagccc tattccaagg acaagatccg cctgtgcttc 1740
aacaagccta agctgatgac aggctgggtg gattccaaga ccgagaagtc tgacaacggc 1800
acacagtacg gcggctatct gtttcggaag aagaatgaga tcggcgagta cgattatttt 1860
ctgggcatct ctagcaaggc ccagctgttc agaaagaacg aggccgtgat cggcgactac 1920
gagaggctgg attactatca gccaaaggcc aataccatct acggctctgc ctatgagggc 1980
gagaacagct acaaggagga caagaagcgg ctgaacaaag tgatcatcgc ctatatcgag 2040
cagatcaagc agacaaacat caagaagtct atcatcgagt ccatctctaa gtatcctaat 2100
atcagcgacg atgacaaggt gaccccatcc tctctgctgg agaagatcaa gaaggtgtct 2160
atcgacagct acaacggcat cctgtccttc aagtcttttc agagcgtgaa caaggaagtg 2220
atcgataacc tgctgaaaac catcagcccc ctgaagaaca aggccgagtt tctggacctg 2280
atcaataagg attatcagat cttcaccgag gtgcaggccg tgatcgacga gatctgcaag 2340
cagaaaacct tcatctactt tccaatctcc aacgtggagc tggagaagga gatgggcgat 2400
aaggacaagc ccctgtgcct gttccagatc agcaataagg atctgtcctt cgccaagacc 2460
tttagcgcca acctgcggaa gaagagaggc gccgagaatc tgcacacaat gctgtttaag 2520
gccctgatgg agggcaacca ggataatctg gacctgggct ctggcgccat cttctacaga 2580
gccaagagcc tggacggcaa caagcccaca caccctgcca atgaggccat caagtgtagg 2640
aacgtggcca ataaggataa ggtgtccctg ttcacctacg acatctataa gaacaggcgc 2700
tacatggaga ataagttcct gtttcacctg agcatcgtgc agaactataa ggccgccaat 2760
gactccgccc agctgaacag ctccgccacc gagtatatca gaaaggccga tgacctgcac 2820
atcatcggca tcgatagggg cgagcgcaat ctgctgtact attccgtgat cgatatgaag 2880
ggcaacatcg tggagcagga ctctctgaat atcatcagga acaatgacct ggagacagat 2940
taccacgacc tgctggataa gagggagaag gagcgcaagg ccaaccggca gaattgggag 3000
gccgtggagg gcatcaagga cctgaagaag ggctacctga gccaggccgt gcaccagatc 3060
gcccagctga tgctgaagta taacgccatc atcgccctgg aggatctggg ccagatgttt 3120
gtgacccgcg gccagaagat cgagaaggcc gtgtaccagc agttcgagaa gagcctggtg 3180
gataagctgt cctacctggt ggacaagaag cggccttata atgagctggg cggcatcctg 3240
aaggcctacc agctggcctc tagcatcacc aagaacaatt ctgacaagca gaacggcttc 3300
ctgttttatg tgccagcctg gaatacaagc aagatcgatc ccgtgaccgg ctttacagac 3360
ctgctgcggc ccaaggccat gaccatcaag gaggcccagg acttctttgg cgccttcgat 3420
aacatctctt acaatgacaa gggctatttc gagtttgaga caaactacga caagtttaag 3480
atcagaatga agagcgccca gaccaggtgg acaatctgca ccttcggcaa tcggatcaag 3540
agaaagaagg ataagaacta ctggaattat gaggaggtgg agctgaccga ggagttcaag 3600
aagctgttta aggacagcaa catcgattac gagaactgta atctgaagga ggagatccag 3660
aacaaggaca atcgcaagtt ctttgatgac ctgatcaagc tgctgcagct gacactgcag 3720
atgcggaact ccgatgacaa gggcaatgat tatatcatct ctcctgtggc caacgccgag 3780
ggccagttct ttgactcccg caatggcgat aagaagctgc cactggatgc agacgcaaac 3840
ggagcctaca atatcgcccg caagggcctg tggaacatcc ggcagatcaa gcagaccaag 3900
aacgacaaga agctgaatct gagcatctcc tctacagagt ggctggattt cgtgcgggag 3960
aagccttacc tgaagaaaag gccggcggcc acgaaaaagg ccggccaggc aaaaaagaaa 4020
aagggatcct acccatacga tgttccagat tacgcttatc cctacgacgt gcctgattat 4080
gcatacccat atgatgtccc cgactatgcc taagaattc 4119
<210> 1277
<211> 1323
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1277
Met Glu Asn Tyr Gln Glu Phe Thr Asn Leu Phe Gln Leu Asn Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Cys Glu Leu Leu Glu
20 25 30
Glu Gly Lys Ile Phe Ala Ser Gly Ser Phe Leu Glu Lys Asp Lys Val
35 40 45
Arg Ala Asp Asn Val Ser Tyr Val Lys Lys Glu Ile Asp Lys Lys His
50 55 60
Lys Ile Phe Ile Glu Glu Thr Leu Ser Ser Phe Ser Ile Ser Asn Asp
65 70 75 80
Leu Leu Lys Gln Tyr Phe Asp Cys Tyr Asn Glu Leu Lys Ala Phe Lys
85 90 95
Lys Asp Cys Lys Ser Asp Glu Glu Glu Val Lys Lys Thr Ala Leu Arg
100 105 110
Asn Lys Cys Thr Ser Ile Gln Arg Ala Met Arg Glu Ala Ile Ser Gln
115 120 125
Ala Phe Leu Lys Ser Pro Gln Lys Lys Leu Leu Ala Ile Lys Asn Leu
130 135 140
Ile Glu Asn Val Phe Lys Ala Asp Glu Asn Val Gln His Phe Ser Glu
145 150 155 160
Phe Thr Ser Tyr Phe Ser Gly Phe Glu Thr Asn Arg Glu Asn Phe Tyr
165 170 175
Ser Asp Glu Glu Lys Ser Thr Ser Ile Ala Tyr Arg Leu Val His Asp
180 185 190
Asn Leu Pro Ile Phe Ile Lys Asn Ile Tyr Ile Phe Glu Lys Leu Lys
195 200 205
Glu Gln Phe Asp Ala Lys Thr Leu Ser Glu Ile Phe Glu Asn Tyr Lys
210 215 220
Leu Tyr Val Ala Gly Ser Ser Leu Asp Glu Val Phe Ser Leu Glu Tyr
225 230 235 240
Phe Asn Asn Thr Leu Thr Gln Lys Gly Ile Asp Asn Tyr Asn Ala Val
245 250 255
Ile Gly Lys Ile Val Lys Glu Asp Lys Gln Glu Ile Gln Gly Leu Asn
260 265 270
Glu His Ile Asn Leu Tyr Asn Gln Lys His Lys Asp Arg Arg Leu Pro
275 280 285
Phe Phe Ile Ser Leu Lys Lys Gln Ile Leu Ser Asp Arg Glu Ala Leu
290 295 300
Ser Trp Leu Pro Asp Met Phe Lys Asn Asp Ser Glu Val Ile Lys Ala
305 310 315 320
Leu Lys Gly Phe Tyr Ile Glu Asp Gly Phe Glu Asn Asn Val Leu Thr
325 330 335
Pro Leu Ala Thr Leu Leu Ser Ser Leu Asp Lys Tyr Asn Leu Asn Gly
340 345 350
Ile Phe Ile Arg Asn Asn Glu Ala Leu Ser Ser Leu Ser Gln Asn Val
355 360 365
Tyr Arg Asn Phe Ser Ile Asp Glu Ala Ile Asp Ala Asn Ala Glu Leu
370 375 380
Gln Thr Phe Asn Asn Tyr Glu Leu Ile Ala Asn Ala Leu Arg Ala Lys
385 390 395 400
Ile Lys Lys Glu Thr Lys Gln Gly Arg Lys Ser Phe Glu Lys Tyr Glu
405 410 415
Glu Tyr Ile Asp Lys Lys Val Lys Ala Ile Asp Ser Leu Ser Ile Gln
420 425 430
Glu Ile Asn Glu Leu Val Glu Asn Tyr Val Ser Glu Phe Asn Ser Asn
435 440 445
Ser Gly Asn Met Pro Arg Lys Val Glu Asp Tyr Phe Ser Leu Met Arg
450 455 460
Lys Gly Asp Phe Gly Ser Asn Asp Leu Ile Glu Asn Ile Lys Thr Lys
465 470 475 480
Leu Ser Ala Ala Glu Lys Leu Leu Gly Thr Lys Tyr Gln Glu Thr Ala
485 490 495
Lys Asp Ile Phe Lys Lys Asp Glu Asn Ser Lys Leu Ile Lys Glu Leu
500 505 510
Leu Asp Ala Thr Lys Gln Phe Gln His Phe Ile Lys Pro Leu Leu Gly
515 520 525
Thr Gly Glu Glu Ala Asp Arg Asp Leu Val Phe Tyr Gly Asp Phe Leu
530 535 540
Pro Leu Tyr Glu Lys Phe Glu Glu Leu Thr Leu Leu Tyr Asn Lys Val
545 550 555 560
Arg Asn Arg Leu Thr Gln Lys Pro Tyr Ser Lys Asp Lys Ile Arg Leu
565 570 575
Cys Phe Asn Lys Pro Lys Leu Met Thr Gly Trp Val Asp Ser Lys Thr
580 585 590
Glu Lys Ser Asp Asn Gly Thr Gln Tyr Gly Gly Tyr Leu Phe Arg Lys
595 600 605
Lys Asn Glu Ile Gly Glu Tyr Asp Tyr Phe Leu Gly Ile Ser Ser Lys
610 615 620
Ala Gln Leu Phe Arg Lys Asn Glu Ala Val Ile Gly Asp Tyr Glu Arg
625 630 635 640
Leu Asp Tyr Tyr Gln Pro Lys Ala Asn Thr Ile Tyr Gly Ser Ala Tyr
645 650 655
Glu Gly Glu Asn Ser Tyr Lys Glu Asp Lys Lys Arg Leu Asn Lys Val
660 665 670
Ile Ile Ala Tyr Ile Glu Gln Ile Lys Gln Thr Asn Ile Lys Lys Ser
675 680 685
Ile Ile Glu Ser Ile Ser Lys Tyr Pro Asn Ile Ser Asp Asp Asp Lys
690 695 700
Val Thr Pro Ser Ser Leu Leu Glu Lys Ile Lys Lys Val Ser Ile Asp
705 710 715 720
Ser Tyr Asn Gly Ile Leu Ser Phe Lys Ser Phe Gln Ser Val Asn Lys
725 730 735
Glu Val Ile Asp Asn Leu Leu Lys Thr Ile Ser Pro Leu Lys Asn Lys
740 745 750
Ala Glu Phe Leu Asp Leu Ile Asn Lys Asp Tyr Gln Ile Phe Thr Glu
755 760 765
Val Gln Ala Val Ile Asp Glu Ile Cys Lys Gln Lys Thr Phe Ile Tyr
770 775 780
Phe Pro Ile Ser Asn Val Glu Leu Glu Lys Glu Met Gly Asp Lys Asp
785 790 795 800
Lys Pro Leu Cys Leu Phe Gln Ile Ser Asn Lys Asp Leu Ser Phe Ala
805 810 815
Lys Thr Phe Ser Ala Asn Leu Arg Lys Lys Arg Gly Ala Glu Asn Leu
820 825 830
His Thr Met Leu Phe Lys Ala Leu Met Glu Gly Asn Gln Asp Asn Leu
835 840 845
Asp Leu Gly Ser Gly Ala Ile Phe Tyr Arg Ala Lys Ser Leu Asp Gly
850 855 860
Asn Lys Pro Thr His Pro Ala Asn Glu Ala Ile Lys Cys Arg Asn Val
865 870 875 880
Ala Asn Lys Asp Lys Val Ser Leu Phe Thr Tyr Asp Ile Tyr Lys Asn
885 890 895
Arg Arg Tyr Met Glu Asn Lys Phe Leu Phe His Leu Ser Ile Val Gln
900 905 910
Asn Tyr Lys Ala Ala Asn Asp Ser Ala Gln Leu Asn Ser Ser Ala Thr
915 920 925
Glu Tyr Ile Arg Lys Ala Asp Asp Leu His Ile Ile Gly Ile Asp Arg
930 935 940
Gly Glu Arg Asn Leu Leu Tyr Tyr Ser Val Ile Asp Met Lys Gly Asn
945 950 955 960
Ile Val Glu Gln Asp Ser Leu Asn Ile Ile Arg Asn Asn Asp Leu Glu
965 970 975
Thr Asp Tyr His Asp Leu Leu Asp Lys Arg Glu Lys Glu Arg Lys Ala
980 985 990
Asn Arg Gln Asn Trp Glu Ala Val Glu Gly Ile Lys Asp Leu Lys Lys
995 1000 1005
Gly Tyr Leu Ser Gln Ala Val His Gln Ile Ala Gln Leu Met Leu
1010 1015 1020
Lys Tyr Asn Ala Ile Ile Ala Leu Glu Asp Leu Gly Gln Met Phe
1025 1030 1035
Val Thr Arg Gly Gln Lys Ile Glu Lys Ala Val Tyr Gln Gln Phe
1040 1045 1050
Glu Lys Ser Leu Val Asp Lys Leu Ser Tyr Leu Val Asp Lys Lys
1055 1060 1065
Arg Pro Tyr Asn Glu Leu Gly Gly Ile Leu Lys Ala Tyr Gln Leu
1070 1075 1080
Ala Ser Ser Ile Thr Lys Asn Asn Ser Asp Lys Gln Asn Gly Phe
1085 1090 1095
Leu Phe Tyr Val Pro Ala Trp Asn Thr Ser Lys Ile Asp Pro Val
1100 1105 1110
Thr Gly Phe Thr Asp Leu Leu Arg Pro Lys Ala Met Thr Ile Lys
1115 1120 1125
Glu Ala Gln Asp Phe Phe Gly Ala Phe Asp Asn Ile Ser Tyr Asn
1130 1135 1140
Asp Lys Gly Tyr Phe Glu Phe Glu Thr Asn Tyr Asp Lys Phe Lys
1145 1150 1155
Ile Arg Met Lys Ser Ala Gln Thr Arg Trp Thr Ile Cys Thr Phe
1160 1165 1170
Gly Asn Arg Ile Lys Arg Lys Lys Asp Lys Asn Tyr Trp Asn Tyr
1175 1180 1185
Glu Glu Val Glu Leu Thr Glu Glu Phe Lys Lys Leu Phe Lys Asp
1190 1195 1200
Ser Asn Ile Asp Tyr Glu Asn Cys Asn Leu Lys Glu Glu Ile Gln
1205 1210 1215
Asn Lys Asp Asn Arg Lys Phe Phe Asp Asp Leu Ile Lys Leu Leu
1220 1225 1230
Gln Leu Thr Leu Gln Met Arg Asn Ser Asp Asp Lys Gly Asn Asp
1235 1240 1245
Tyr Ile Ile Ser Pro Val Ala Asn Ala Glu Gly Gln Phe Phe Asp
1250 1255 1260
Ser Arg Asn Gly Asp Lys Lys Leu Pro Leu Asp Ala Asp Ala Asn
1265 1270 1275
Gly Ala Tyr Asn Ile Ala Arg Lys Gly Leu Trp Asn Ile Arg Gln
1280 1285 1290
Ile Lys Gln Thr Lys Asn Asp Lys Lys Leu Asn Leu Ser Ile Ser
1295 1300 1305
Ser Thr Glu Trp Leu Asp Phe Val Arg Glu Lys Pro Tyr Leu Lys
1310 1315 1320
<210> 1278
<211> 3888
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1278
ggtaccatga aaacccagca cttctttgag gacttcacaa gcctgtactc tctgagcaag 60
accatccggt ttgagctgaa gccaatcggc aagaccctgg agaacatcaa gaagaatggc 120
ctgatccgga gagatgagca gagactggac gattacgaga agctgaagaa agtgatcgac 180
gagtatcacg aggatttcat cgccaacatc ctgagctcct tttccttctc tgaggagatc 240
ctgcagtcct acatccagaa tctgagcgag tccgaggcca gggccaagat cgagaaaacc 300
atgcgcgaca cactggccaa ggccttctct gaggatgaga ggtacaagag catctttaag 360
aaggagctgg tgaagaagga catccccgtg tggtgccctg cctataagag cctgtgcaag 420
aagttcgata actttaccac atctctggtg cccttccacg agaacaggaa gaacctgtat 480
accagcaatg agatcacagc ctctatccct tatcgcatcg tgcacgtgaa cctgccaaag 540
tttatccaga atatcgaggc cctgtgcgag ctgcagaaga agatgggcgc cgacctgtac 600
ctggagatga tggagaacct gcgcaacgtg tggcccagct tcgtgaaaac cccagacgac 660
ctgtgcaacc tgaaaaccta taatcacctg atggtgcagt ctagcatcag cgagtacaac 720
aggtttgtgg gcggctattc caccgaggac ggcacaaagc accagggcat caacgagtgg 780
atcaatatct acagacagag gaataaggag atgcgcctgc ctggcctggt gttcctgcac 840
aagcagatcc tggccaaggt ggactcctct agcttcatca gcgatacact ggagaacgac 900
gatcaggtgt tttgcgtgct gagacagttc aggaagctgt tttggaatac cgtgtcctct 960
aaggaggacg atgccgcctc cctgaaggac ctgttctgtg gcctgtctgg ctatgaccct 1020
gaggccatct acgtgagcga tgcccacctg gccacaatct ccaagaacat ctttgacaga 1080
tggaattaca tctccgatgc catcaggcgc aagaccgagg tgctgatgcc acggaagaag 1140
gagagcgtgg agagatatgc cgagaagatc tccaagcaga tcaagaagag acagtcttac 1200
agcctggccg agctggacga tctgctggcc cactatagcg aggagtccct gcccgcaggc 1260
ttctctctgc tgagctactt tacatctctg ggcggccaga agtatctggt gagcgacggc 1320
gaagtgatcc tgtacgagga gggcagcaac atctgggacg aggtgctgat cgccttcagg 1380
gatctgcagg tcatcctgga caaggacttc accgagaaga agctgggcaa ggatgaggag 1440
gccgtgtctg tgatcaagaa ggccctggac agcgccctgc gcctgcggaa gttctttgat 1500
ctgctgtccg gcacaggcgc agagatcagg agagacagct ccttctatgc cctgtatacc 1560
gaccggatgg ataagctgaa gggcctgctg aagatgtatg ataaggtgag aaactacctg 1620
accaagaagc cttattccat cgagaagttc aagctgcact ttgacaaccc atccctgctg 1680
tctggctggg ataagaataa ggagctgaac aatctgtctg tgatcttccg gcagaacggc 1740
tactattacc tgggcatcat gacacccaag ggcaagaatc tgttcaagac cctgcctaag 1800
ctgggcgccg aggagatgtt ttatgagaag atggagtaca agcagatcgc cgagcctatg 1860
ctgatgctgc caaaggtgtt ctttcccaag aaaaccaagc cagccttcgc cccagaccag 1920
agcgtggtgg atatctacaa caagaaaacc ttcaagacag gccagaaggg ctttaataag 1980
aaggacctgt accggctgat cgacttctac aaggaggccc tgacagtgca cgagtggaag 2040
ctgtttaact tctccttttc tccaaccgag cagtatcgga atatcggcga gttctttgac 2100
gaggtgagag agcaggccta caaggtgtcc atggtgaacg tgcccgcctc ttatatcgac 2160
gaggccgtgg agaacggcaa gctgtatctg ttccagatct acaataagga cttcagcccc 2220
tactccaagg gcatccctaa cctgcacaca ctgtattgga aggccctgtt cagcgagcag 2280
aatcagagcc gggtgtataa gctgtgcgga ggaggagagc tgttttatag aaaggccagc 2340
ctgcacatgc aggacaccac agtgcacccc aagggcatct ctatccacaa gaagaacctg 2400
aataagaagg gcgagacaag cctgttcaac tacgacctgg tgaaggataa gaggtttacc 2460
gaggacaagt tctttttcca cgtgcctatc tctatcaact acaagaataa gaagatcacc 2520
aacgtgaatc agatggtgcg cgattatatc gcccagaacg acgatctgca gatcatcggc 2580
atcgaccgcg gcgagcggaa tctgctgtat atcagccgga tcgatacaag gggcaacctg 2640
ctggagcagt tcagcctgaa tgtgatcgag tccgacaagg gcgatctgag aaccgactat 2700
cagaagatcc tgggcgatcg cgagcaggag cggctgaggc gccggcagga gtggaagtct 2760
atcgagagca tcaaggacct gaaggatggc tacatgagcc aggtggtgca caagatctgt 2820
aacatggtgg tggagcacaa ggccatcgtg gtgctggaga acctgaatct gagcttcatg 2880
aagggcagga agaaggtgga gaagtccgtg tacgagaagt ttgagcgcat gctggtggac 2940
aagctgaact atctggtggt ggataagaag aacctgtcca atgagccagg aggcctgtat 3000
gcagcatacc agctgaccaa tccactgttc tcttttgagg agctgcacag atacccccag 3060
agcggcatcc tgtttttcgt ggacccatgg aacacctctc tgacagatcc cagcacaggc 3120
ttcgtgaatc tgctgggcag aatcaactac accaatgtgg gcgacgcccg caagtttttc 3180
gatcggttta acgccatcag atatgacggc aagggcaata tcctgttcga cctggatctg 3240
tccagatttg atgtgagggt ggagacacag aggaagctgt ggacactgac cacattcggc 3300
tctcgcatcg ccaaatccaa gaagtctggc aagtggatgg tggagcggat cgagaacctg 3360
agcctgtgct ttctggagct gttcgagcag tttaatatcg gctacagagt ggagaaggac 3420
ctgaagaagg ccatcctgag ccaggatagg aaggagttct atgtgcgcct gatctacctg 3480
tttaacctga tgatgcagat ccggaacagc gacggcgagg aggattatat cctgtctccc 3540
gccctgaacg agaagaatct gcagttcgac agcaggctga tcgaggccaa ggatctgcct 3600
gtggacgcag atgcaaacgg agcatacaat gtggcccgca agggcctgat ggtggtgcag 3660
agaatcaaga ggggcgacca cgagtccatc cacaggatcg gaagggcaca gtggctgaga 3720
tatgtgcagg agggcatcgt ggagaaaagg ccggcggcca cgaaaaaggc cggccaggca 3780
aaaaagaaaa agggatccta cccatacgat gttccagatt acgcttatcc ctacgacgtg 3840
cctgattatg catacccata tgatgtcccc gactatgcct aagaattc 3888
<210> 1279
<211> 1246
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1279
Met Lys Thr Gln His Phe Phe Glu Asp Phe Thr Ser Leu Tyr Ser Leu
1 5 10 15
Ser Lys Thr Ile Arg Phe Glu Leu Lys Pro Ile Gly Lys Thr Leu Glu
20 25 30
Asn Ile Lys Lys Asn Gly Leu Ile Arg Arg Asp Glu Gln Arg Leu Asp
35 40 45
Asp Tyr Glu Lys Leu Lys Lys Val Ile Asp Glu Tyr His Glu Asp Phe
50 55 60
Ile Ala Asn Ile Leu Ser Ser Phe Ser Phe Ser Glu Glu Ile Leu Gln
65 70 75 80
Ser Tyr Ile Gln Asn Leu Ser Glu Ser Glu Ala Arg Ala Lys Ile Glu
85 90 95
Lys Thr Met Arg Asp Thr Leu Ala Lys Ala Phe Ser Glu Asp Glu Arg
100 105 110
Tyr Lys Ser Ile Phe Lys Lys Glu Leu Val Lys Lys Asp Ile Pro Val
115 120 125
Trp Cys Pro Ala Tyr Lys Ser Leu Cys Lys Lys Phe Asp Asn Phe Thr
130 135 140
Thr Ser Leu Val Pro Phe His Glu Asn Arg Lys Asn Leu Tyr Thr Ser
145 150 155 160
Asn Glu Ile Thr Ala Ser Ile Pro Tyr Arg Ile Val His Val Asn Leu
165 170 175
Pro Lys Phe Ile Gln Asn Ile Glu Ala Leu Cys Glu Leu Gln Lys Lys
180 185 190
Met Gly Ala Asp Leu Tyr Leu Glu Met Met Glu Asn Leu Arg Asn Val
195 200 205
Trp Pro Ser Phe Val Lys Thr Pro Asp Asp Leu Cys Asn Leu Lys Thr
210 215 220
Tyr Asn His Leu Met Val Gln Ser Ser Ile Ser Glu Tyr Asn Arg Phe
225 230 235 240
Val Gly Gly Tyr Ser Thr Glu Asp Gly Thr Lys His Gln Gly Ile Asn
245 250 255
Glu Trp Ile Asn Ile Tyr Arg Gln Arg Asn Lys Glu Met Arg Leu Pro
260 265 270
Gly Leu Val Phe Leu His Lys Gln Ile Leu Ala Lys Val Asp Ser Ser
275 280 285
Ser Phe Ile Ser Asp Thr Leu Glu Asn Asp Asp Gln Val Phe Cys Val
290 295 300
Leu Arg Gln Phe Arg Lys Leu Phe Trp Asn Thr Val Ser Ser Lys Glu
305 310 315 320
Asp Asp Ala Ala Ser Leu Lys Asp Leu Phe Cys Gly Leu Ser Gly Tyr
325 330 335
Asp Pro Glu Ala Ile Tyr Val Ser Asp Ala His Leu Ala Thr Ile Ser
340 345 350
Lys Asn Ile Phe Asp Arg Trp Asn Tyr Ile Ser Asp Ala Ile Arg Arg
355 360 365
Lys Thr Glu Val Leu Met Pro Arg Lys Lys Glu Ser Val Glu Arg Tyr
370 375 380
Ala Glu Lys Ile Ser Lys Gln Ile Lys Lys Arg Gln Ser Tyr Ser Leu
385 390 395 400
Ala Glu Leu Asp Asp Leu Leu Ala His Tyr Ser Glu Glu Ser Leu Pro
405 410 415
Ala Gly Phe Ser Leu Leu Ser Tyr Phe Thr Ser Leu Gly Gly Gln Lys
420 425 430
Tyr Leu Val Ser Asp Gly Glu Val Ile Leu Tyr Glu Glu Gly Ser Asn
435 440 445
Ile Trp Asp Glu Val Leu Ile Ala Phe Arg Asp Leu Gln Val Ile Leu
450 455 460
Asp Lys Asp Phe Thr Glu Lys Lys Leu Gly Lys Asp Glu Glu Ala Val
465 470 475 480
Ser Val Ile Lys Lys Ala Leu Asp Ser Ala Leu Arg Leu Arg Lys Phe
485 490 495
Phe Asp Leu Leu Ser Gly Thr Gly Ala Glu Ile Arg Arg Asp Ser Ser
500 505 510
Phe Tyr Ala Leu Tyr Thr Asp Arg Met Asp Lys Leu Lys Gly Leu Leu
515 520 525
Lys Met Tyr Asp Lys Val Arg Asn Tyr Leu Thr Lys Lys Pro Tyr Ser
530 535 540
Ile Glu Lys Phe Lys Leu His Phe Asp Asn Pro Ser Leu Leu Ser Gly
545 550 555 560
Trp Asp Lys Asn Lys Glu Leu Asn Asn Leu Ser Val Ile Phe Arg Gln
565 570 575
Asn Gly Tyr Tyr Tyr Leu Gly Ile Met Thr Pro Lys Gly Lys Asn Leu
580 585 590
Phe Lys Thr Leu Pro Lys Leu Gly Ala Glu Glu Met Phe Tyr Glu Lys
595 600 605
Met Glu Tyr Lys Gln Ile Ala Glu Pro Met Leu Met Leu Pro Lys Val
610 615 620
Phe Phe Pro Lys Lys Thr Lys Pro Ala Phe Ala Pro Asp Gln Ser Val
625 630 635 640
Val Asp Ile Tyr Asn Lys Lys Thr Phe Lys Thr Gly Gln Lys Gly Phe
645 650 655
Asn Lys Lys Asp Leu Tyr Arg Leu Ile Asp Phe Tyr Lys Glu Ala Leu
660 665 670
Thr Val His Glu Trp Lys Leu Phe Asn Phe Ser Phe Ser Pro Thr Glu
675 680 685
Gln Tyr Arg Asn Ile Gly Glu Phe Phe Asp Glu Val Arg Glu Gln Ala
690 695 700
Tyr Lys Val Ser Met Val Asn Val Pro Ala Ser Tyr Ile Asp Glu Ala
705 710 715 720
Val Glu Asn Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe
725 730 735
Ser Pro Tyr Ser Lys Gly Ile Pro Asn Leu His Thr Leu Tyr Trp Lys
740 745 750
Ala Leu Phe Ser Glu Gln Asn Gln Ser Arg Val Tyr Lys Leu Cys Gly
755 760 765
Gly Gly Glu Leu Phe Tyr Arg Lys Ala Ser Leu His Met Gln Asp Thr
770 775 780
Thr Val His Pro Lys Gly Ile Ser Ile His Lys Lys Asn Leu Asn Lys
785 790 795 800
Lys Gly Glu Thr Ser Leu Phe Asn Tyr Asp Leu Val Lys Asp Lys Arg
805 810 815
Phe Thr Glu Asp Lys Phe Phe Phe His Val Pro Ile Ser Ile Asn Tyr
820 825 830
Lys Asn Lys Lys Ile Thr Asn Val Asn Gln Met Val Arg Asp Tyr Ile
835 840 845
Ala Gln Asn Asp Asp Leu Gln Ile Ile Gly Ile Asp Arg Gly Glu Arg
850 855 860
Asn Leu Leu Tyr Ile Ser Arg Ile Asp Thr Arg Gly Asn Leu Leu Glu
865 870 875 880
Gln Phe Ser Leu Asn Val Ile Glu Ser Asp Lys Gly Asp Leu Arg Thr
885 890 895
Asp Tyr Gln Lys Ile Leu Gly Asp Arg Glu Gln Glu Arg Leu Arg Arg
900 905 910
Arg Gln Glu Trp Lys Ser Ile Glu Ser Ile Lys Asp Leu Lys Asp Gly
915 920 925
Tyr Met Ser Gln Val Val His Lys Ile Cys Asn Met Val Val Glu His
930 935 940
Lys Ala Ile Val Val Leu Glu Asn Leu Asn Leu Ser Phe Met Lys Gly
945 950 955 960
Arg Lys Lys Val Glu Lys Ser Val Tyr Glu Lys Phe Glu Arg Met Leu
965 970 975
Val Asp Lys Leu Asn Tyr Leu Val Val Asp Lys Lys Asn Leu Ser Asn
980 985 990
Glu Pro Gly Gly Leu Tyr Ala Ala Tyr Gln Leu Thr Asn Pro Leu Phe
995 1000 1005
Ser Phe Glu Glu Leu His Arg Tyr Pro Gln Ser Gly Ile Leu Phe
1010 1015 1020
Phe Val Asp Pro Trp Asn Thr Ser Leu Thr Asp Pro Ser Thr Gly
1025 1030 1035
Phe Val Asn Leu Leu Gly Arg Ile Asn Tyr Thr Asn Val Gly Asp
1040 1045 1050
Ala Arg Lys Phe Phe Asp Arg Phe Asn Ala Ile Arg Tyr Asp Gly
1055 1060 1065
Lys Gly Asn Ile Leu Phe Asp Leu Asp Leu Ser Arg Phe Asp Val
1070 1075 1080
Arg Val Glu Thr Gln Arg Lys Leu Trp Thr Leu Thr Thr Phe Gly
1085 1090 1095
Ser Arg Ile Ala Lys Ser Lys Lys Ser Gly Lys Trp Met Val Glu
1100 1105 1110
Arg Ile Glu Asn Leu Ser Leu Cys Phe Leu Glu Leu Phe Glu Gln
1115 1120 1125
Phe Asn Ile Gly Tyr Arg Val Glu Lys Asp Leu Lys Lys Ala Ile
1130 1135 1140
Leu Ser Gln Asp Arg Lys Glu Phe Tyr Val Arg Leu Ile Tyr Leu
1145 1150 1155
Phe Asn Leu Met Met Gln Ile Arg Asn Ser Asp Gly Glu Glu Asp
1160 1165 1170
Tyr Ile Leu Ser Pro Ala Leu Asn Glu Lys Asn Leu Gln Phe Asp
1175 1180 1185
Ser Arg Leu Ile Glu Ala Lys Asp Leu Pro Val Asp Ala Asp Ala
1190 1195 1200
Asn Gly Ala Tyr Asn Val Ala Arg Lys Gly Leu Met Val Val Gln
1205 1210 1215
Arg Ile Lys Arg Gly Asp His Glu Ser Ile His Arg Ile Gly Arg
1220 1225 1230
Ala Gln Trp Leu Arg Tyr Val Gln Glu Gly Ile Val Glu
1235 1240 1245
<210> 1280
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1280
gucuaagaac uuuaaauaau uucuacuguu guagau 36
<210> 1281
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1281
gucuaagaac uuuaaauaau uucuacuguu guagau 36
<210> 1282
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1282
gcuauaaugc cuauauaauu ucuacuauug uagau 35
<210> 1283
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1283
gcuauaaugc cuauauaauu ucuacuauug uagau 35
<210> 1284
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1284
gccuauaagg cuuuaguaau uucuacuauu guagau 36
<210> 1285
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1285
guuuuggagu accuuagaaa ugcaugguuc ucaugc 36
<210> 1286
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1286
gucaauaaga cucauuuaau uucuacuucg guagau 36
<210> 1287
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1287
guuuuagaac cuuaaaaauu accuaguaau uaggu 35
<210> 1288
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1288
gucuagguac ucucuuuaau uucuacuauu guagau 36
<210> 1289
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1289
guuuaaaagu ccuauuggau uucuacuuuu guagau 36
<210> 1290
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1290
guuucaaaga uuaaauaauu ucuacuaagu guagau 36
<210> 1291
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1291
gccaaauacc ucuauaaaau uucuacuuuu guagau 36
<210> 1292
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1292
cucuaaagag aggaaagaau uucuacuuuu guagau 36
<210> 1293
<211> 32
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1293
guuucaaucc acgcgcccac gcggggcgcg ac 32
<210> 1294
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1294
gucuaacgac cuuuuaaauu ucuacuguuu guagau 36
<210> 1295
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1295
gucaaaagac cuuuuuaauu ucuacucuug uagau 35
<210> 1296
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1296
guuugaauaa ccuuaaauaa uuucuacuuu guagau 36
<210> 1297
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1297
gcuuagaaca uuuaaagaau uucuacuauu guagau 36
<210> 1298
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1298
cucaaaacuc auucgaaucu cuacucuuug uagau 35
<210> 1299
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1299
cucaaaacuc auucgaaucu cuacucuuug uagau 35
<210> 1300
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1300
gcuuagaaca uuuaaagaau uucuacuauu guagau 36
<210> 1301
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1301
guuugaauaa ccuuaaauaa uuucuacuuu guagau 36
<210> 1302
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1302
gucaaaagac cuuuuuaauu ucuacucuug uagau 35
<210> 1303
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1303
gucuaacgac cuuuuaaauu ucuacuguuu guagau 36
<210> 1304
<211> 32
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1304
guuucaaucc acgcgcccac gcggggcgcg ac 32
<210> 1305
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1305
cucuaaagag aggaaagaau uucuacuuuu guagau 36
<210> 1306
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1306
gccaaauacc ucuauaaaau uucuacuuuu guagau 36
<210> 1307
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1307
guuucaaaga uuaaauaauu ucuacuaagu guagau 36
<210> 1308
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1308
guuuaaaagu ccuauuggau uucuacuuuu guagau 36
<210> 1309
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1309
gucuagguac ucucuuuaau uucuacuauu guagau 36
<210> 1310
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1310
guuuuagaac cuuaaaaauu accuaguaau uaggu 35
<210> 1311
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1311
gucaauaaga cucauuuaau uucuacuucg guagau 36
<210> 1312
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1312
guuuuggagu accuuagaaa ugcaugguuc ucaugc 36
<210> 1313
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1313
gccuauaagg cuuuaguaau uucuacuauu guagau 36
<210> 1314
<211> 77
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1314
gggacuuuaa auaauuucua cuguuguaga uaggccccag uggcugcucu gggggccucc 60
gucuaagaac uuuaaau 77
<210> 1315
<211> 77
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1315
gggacuuuaa auaauuucua cuguuguaga uucaucugug ccccucccuc ccuggcccag 60
gucuaagaac uuuaaau 77
<210> 1316
<211> 77
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1316
gggacuuuaa auaauuucua cuguuguaga ugugguugcc cacccuaguc auuggaggug 60
gucuaagaac uuuaaau 77
<210> 1317
<211> 77
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1317
gggacuuuaa auaauuucua cuguuguaga uggggcccca ggccgggguc cccucugacc 60
gucuaagaac uuuaaau 77
<210> 1318
<211> 639
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1318
ccatcccctt ctgtgaatgt tagacccatg ggagcagctg gtcagagggg accccggcct 60
ggggccccta accctatgta gcctcagtct tcccatcagg ctctcagctc agcctgagtg 120
ttgaggcccc agtggctgct ctgggggcct cctgagtttc tcatctgtgc ccctccctcc 180
ctggcccagg tgaaggtgtg gttccagaac cggaggacaa agtacaaacg gcagaagctg 240
gaggaggaag ggcctgagtc cgagcagaag aagaagggct cccatcacat caaccggtgg 300
cgcattgcca cgaagcaggc caatggggag gacatcgatg tcacctccaa tgactagggt 360
gggcaaccac aaacccacga gggcagagtg ctgcttgctg ctggccaggc ccctgcgtgg 420
gcccaagctg gactctggcc actccctggc caggctttgg ggaggcctgg agtcatggcc 480
ccacagggct tgaagcccgg ggccgccatt gacagaggga caagcaatgg gctggctgag 540
gcctgggacc acttggcctt ctcctcggag agcctgcctg cctgggcggg cccgcccgcc 600
accgcagcct cccagctgct ctccgtgtct ccaatctcc 639
<210> 1319
<211> 106
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1319
ggggucuaag aacuuuaaau aauuucuacu guuguagaug agaagucauu uaauaaggcc 60
acuguuaaaa gucuaagaac uuuaaauaau uucuacuguu guagau 106
<210> 1320
<211> 100
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1320
ggggaacuuu aaauaauuuc uacuguugua gaugagaagu cauuuaauaa ggccacuguu 60
aaaagucuaa gaacuuuaaa uaauuucuac uguuguagau 100
<210> 1321
<211> 94
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1321
ggguaaauaa uuucuacugu uguagaugag aagucauuua auaaggccac uguuaaaagu 60
cuaagaacuu uaaauaauuu cuacuguugu agau 94
<210> 1322
<211> 88
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1322
gggauuucua cuguuguaga ugagaaguca uuuaauaagg ccacuguuaa aagucuaaga 60
acuuuaaaua auuucuacug uuguagau 88
<210> 1323
<211> 82
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1323
gggacuguug uagaugagaa gucauuuaau aaggccacug uuaaaagucu aagaacuuua 60
aauaauuucu acuguuguag au 82
<210> 1324
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1324
gucuaagaac uuuaaauaau uucuacuguu guagau 36
<210> 1325
<211> 79
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1325
gggactttaa ataatttcta ctgttgtaga ttagaagtca tttaataagg ccactgttaa 60
aagtctaaga actttaaat 79
<210> 1326
<211> 79
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1326
gggactttaa ataatttcta ctgttgtaga tgaggagtca tttaataagg ccactgttaa 60
aagtctaaga actttaaat 79
<210> 1327
<211> 79
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1327
gggactttaa ataatttcta ctgttgtaga tgagaagcca tttaataagg ccactgttaa 60
aagtctaaga actttaaat 79
<210> 1328
<211> 79
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1328
gggactttaa ataatttcta ctgttgtaga tgagaagtca attaataagg ccactgttaa 60
aagtctaaga actttaaat 79
<210> 1329
<211> 79
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1329
gggactttaa ataatttcta ctgttgtaga tgagaagtca ttttataagg ccactgttaa 60
aagtctaaga actttaaat 79
<210> 1330
<211> 79
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1330
gggactttaa ataatttcta ctgttgtaga tgagaagtca tttaatgagg ccactgttaa 60
aagtctaaga actttaaat 79
<210> 1331
<211> 79
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1331
gggactttaa ataatttcta ctgttgtaga tgagaagtca tttaataagc ccactgttaa 60
aagtctaaga actttaaat 79
<210> 1332
<211> 79
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1332
gggactttaa ataatttcta ctgttgtaga tgagaagtca tttaataagg cctctgttaa 60
aagtctaaga actttaaat 79
<210> 1333
<211> 79
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1333
gggactttaa ataatttcta ctgttgtaga tgagaagtca tttaataagg ccactattaa 60
aagtctaaga actttaaat 79
<210> 1334
<211> 79
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1334
gggactttaa ataatttcta ctgttgtaga tgagaagtca tttaataagg ccactgttta 60
aagtctaaga actttaaat 79
<210> 1335
<211> 79
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1335
gggactttaa ataatttcta ctgttgtaga tgagaagtca tttaataagg ccactgttaa 60
aggtctaaga actttaaat 79
<210> 1336
<211> 76
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1336
acuuuaaaua auuucuacug uuguagauga gaagucauuu aauaaggcca cuguuaaaag 60
ucuaagaacu uuaaau 76
<210> 1337
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1337
gucuaagaac uuuaaauaau uucuacuguu guagau 36
<210> 1338
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1338
gcuauaaugc cuauauaauu ucuacuauug uagau 35
<210> 1339
<211> 43
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (20)..(43)
<223> a, c, u, g, неизвестное или другое
<220>
<221> другой_признак
<222> (40)..(43)
<223> Может присутствовать или может не присутствовать
<400> 1339
aauuucuacu guuguagaun nnnnnnnnnn nnnnnnnnnn nnn 43
<210> 1340
<211> 43
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (20)..(43)
<223> a, c, u, g, неизвестное или другое
<400> 1340
aauuucuacu guuguagaun nnnnnnnnnn nnnnnnnnnn nnn 43
<210> 1341
<211> 43
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (20)..(43)
<223> a, c, u, g, неизвестное или другое
<220>
<221> другой_признак
<222> (40)..(43)
<223> Может присутствовать или может не присутствовать
<400> 1341
aauuucuacu auuguagaun nnnnnnnnnn nnnnnnnnnn nnn 43
<210> 1342
<211> 43
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (20)..(43)
<223> a, c, u, g, неизвестное или другое
<400> 1342
aauuucuacu auuguagaun nnnnnnnnnn nnnnnnnnnn nnn 43
<210> 1343
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1343
ttaataaggc cactgttaaa a 21
<210> 1344
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (14)..(14)
<223> a, c, t, g, неизвестное или другое
<400> 1344
ttaataaggc cacn 14
<210> 1345
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1345
gccactgtta aaa 13
<210> 1346
<211> 43
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1346
aauuucuacu uguguagaug agaagucauu uaauaaggcc acu 43
<210> 1347
<211> 22
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1347
gagaagucau uuaauaaggc ca 22
<210> 1348
<211> 20
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1348
gagaagucau uuaauaaggc 20
<210> 1349
<211> 18
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1349
gagaagucau uuaauaag 18
<210> 1350
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1350
gagaagucau uuaauaa 17
<210> 1351
<211> 16
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1351
gagaagucau uuaaua 16
<210> 1352
<211> 15
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1352
gagaagucau uuaau 15
<210> 1353
<211> 68
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1353
gaattatctg aaggcacagg aatagtagca tctacaacag tagaaattat ttaaagttct 60
tagacttt 68
<210> 1354
<211> 36
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1354
atctacaaca gtagaaatta tttaaagttc ttagac 36
<210> 1355
<211> 42
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1355
tctgaaggca caggaatagt agcatctaca acagtagaaa tt 42
<210> 1356
<211> 42
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1356
tctgaaggca caggaatagt agcatctaca acagtagaaa tt 42
<210> 1357
<211> 42
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1357
tctgaaggca caggaatagt agcatctaca acagtagaaa tt 42
<210> 1358
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1358
atctacaaca gta 13
<210> 1359
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1359
atctacaaca gta 13
<210> 1360
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1360
atctacaaca gta 13
<210> 1361
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1361
atctacaaca gta 13
<210> 1362
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1362
atctacaaca gta 13
<210> 1363
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1363
atctacaaca gta 13
<210> 1364
<211> 77
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1364
agacttttaa cagtggcctt attaaatgac ttctcatcta caacagtaga aattatttaa 60
agttcttaga cccgttt 77
<210> 1365
<211> 36
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1365
atctacaaca gtagaaatta tttaaagttc ttagac 36
<210> 1366
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1366
agacttttaa cagt 14
<210> 1367
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1367
aatgacttct catctaca 18
<210> 1368
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1368
atttaaagtt cttagaccc 19
<210> 1369
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1369
agacttttaa cagt 14
<210> 1370
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1370
aatgacttct catctacaac agta 24
<210> 1371
<211> 17
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1371
agttcttaga cccgttt 17
<210> 1372
<211> 26
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1372
gacttttaac agtggcctta ttaaat 26
<210> 1373
<211> 40
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1373
ctacaacagt agaaattatt taaagttctt agacccgttt 40
<210> 1374
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1374
agacttttaa cagtggcct 19
<210> 1375
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1375
cttctcatct acaacagt 18
<210> 1376
<211> 17
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1376
agttcttaga cccgttt 17
<210> 1377
<211> 16
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1377
cttattaaat gacttc 16
<210> 1378
<211> 32
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1378
gtagaaatta tttaaagttc ttagacccgt tt 32
<210> 1379
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1379
agacttttaa cagtggcctt attaaatgac ttctc 35
<210> 1380
<211> 31
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1380
tagaaattat ttaaagttct tagacccgtt t 31
<210> 1381
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1381
agacttttaa cag 13
<210> 1382
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1382
aaatgacttc tgatctacaa cagt 24
<210> 1383
<211> 16
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1383
gttcttagac ccgttt 16
<210> 1384
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1384
agacttttaa cagtggcctt a 21
<210> 1385
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1385
tctcatctac aacagtag 18
<210> 1386
<211> 16
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1386
gttcttagac ccgttt 16
<210> 1387
<211> 10
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1387
agacttttaa 10
<210> 1388
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1388
attaaatgac ttctcatcta caac 24
<210> 1389
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1389
ttaaagttct tagacccgtt t 21
<210> 1390
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1390
agacttttaa cagt 14
<210> 1391
<211> 25
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1391
aatgacttct catctacaac agtag 25
<210> 1392
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1392
tcttagaccc gttt 14
<210> 1393
<211> 40
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1393
agacttttaa cagtggcctt attaaatgac ttctcatcta 40
<210> 1394
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1394
aattatttaa agttcttaga cccgttt 27
<210> 1395
<211> 16
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1395
agacttttaa cagtgg 16
<210> 1396
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1396
tgacttctca tctacaac 18
<210> 1397
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1397
ttaaagttct tagacccgtt t 21
<210> 1398
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1398
agacttttaa cag 13
<210> 1399
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1399
aaatgacttc tcatctacaa cagt 24
<210> 1400
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1400
tcttagaccc gttt 14
<210> 1401
<211> 32
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1401
atctacaaca gtagaaatta tttaaagttc tt 32
<210> 1402
<211> 65
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1402
ggtacccggg gatcctttag agaagtcatt taataaggcc actgttaaaa agcttggcgt 60
aatca 65
<210> 1403
<211> 43
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1403
aauuucuacu guuguagaug agaagucauu uaauaaggcc acu 43
<210> 1404
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1404
ttaataaggc cactgttaaa a 21
<210> 1405
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<220>
<221> модифицированное_основание
<222> (1)..(1)
<223> a, c, t, g, неизвестное или другое
<400> 1405
ngccactgtt aaaa 14
<210> 1406
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<220>
<221> модифицированное_основание
<222> (14)..(14)
<223> a, c, t, g, неизвестное или другое
<400> 1406
ttaataaggc cacn 14
<210> 1407
<211> 43
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1407
aauuucuacu guuguagaug agaagucauu uaauaaggcc acu 43
<210> 1408
<211> 22
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1408
gagaagucau uuaauaaggc ca 22
<210> 1409
<211> 20
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1409
gagaagucau uuaauaaggc 20
<210> 1410
<211> 18
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1410
gagaagucau uuaauaag 18
<210> 1411
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1411
gagaagucau uuaauaa 17
<210> 1412
<211> 16
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1412
gagaagucau uuaaua 16
<210> 1413
<211> 15
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1413
gagaagucau uuaau 15
<210> 1414
<211> 43
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1414
aauuucuacu guuguagaug agaagucauu uaauaaggcc acu 43
<210> 1415
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<223> Описание объединенной молекулы ДНК/РНК: Синтетический олигонуклеотид
<400> 1415
gataagucau uuaauaaggc cacu 24
<210> 1416
<211> 24
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1416
gagaaggcau uuaauaaggc cacu 24
<210> 1417
<211> 24
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1417
gagaagucau guaauaaggc cacu 24
<210> 1418
<211> 24
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1418
gagaagucau uuaagaaggc cacu 24
<210> 1419
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<223> Описание объединенной молекулы ДНК/РНК: Синтетический олигонуклеотид
<400> 1419
gagaagucau uuaauaagtc cacu 24
<210> 1420
<211> 24
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1420
gagaagucau uuaauaaggc caau 24
<210> 1421
<211> 43
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1421
aauuucuacu guuguagaug agaagucauu uaauaaggcc acu 43
<210> 1422
<211> 19
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1422
aauuucugcu guugcagau 19
<210> 1423
<211> 19
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1423
aauuuccacu guuguggau 19
<210> 1424
<211> 19
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1424
aauuccuacu guuguaggu 19
<210> 1425
<211> 19
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1425
aauuuauacu guuguagau 19
<210> 1426
<211> 19
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1426
aauuucgacu guuguagau 19
<210> 1427
<211> 19
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1427
aauuucuagu guuguagau 19
<210> 1428
<211> 19
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1428
aauuucaucu auuguagau 19
<210> 1429
<211> 19
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1429
aauuucaucu gcuguagau 19
<210> 1430
<211> 18
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1430
aauuucaucu uuguagau 18
<210> 1431
<211> 17
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1431
aauuucaucu uguagau 17
<210> 1432
<211> 19
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1432
aauuucuacu uuuguagaa 19
<210> 1433
<211> 19
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1433
aauuucuacu uuuguagac 19
<210> 1434
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1434
gucuaagaac uuuaaauaau uucuacuguu guagau 36
<210> 1435
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1435
guuuuggagu accuuagaaa ugcaugguuc ucaugc 36
<210> 1436
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1436
guuuuagaac cuuaaaaauu accuaguaau uaggu 35
<210> 1437
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1437
guuuaaaagu ccuauuggau uucuacuuuu guagau 36
<210> 1438
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1438
gccaaauacc ucuauaaaau uucuacuuuu guagau 36
<210> 1439
<211> 32
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1439
guuucaaucc acgcgcccac gcggggcgcg ac 32
<210> 1440
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1440
gucaaaagac cuuuuuaauu ucuacucuug uagau 35
<210> 1441
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1441
gcuuagaaca uuuaaagaau uucuacuauu guagau 36
<210> 1442
<211> 35
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1442
cucaaaacuc auucgaaucu cuacucuuug uagau 35
<210> 1443
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1443
guuugaauaa ccuuaaauaa uuucuacuuu guagau 36
<210> 1444
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1444
gucuaacgac cuuuuaaauu ucuacuguuu guagau 36
<210> 1445
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1445
cucuaaagag aggaaagaau uucuacuuuu guagau 36
<210> 1446
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1446
guuucaaaga uuaaauaauu ucuacuaagu guagau 36
<210> 1447
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1447
gucuagguac ucucuuuaau uucuacuauu guagau 36
<210> 1448
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1448
gucaauaaga cucauuuaau uucuacuucg guagau 36
<210> 1449
<211> 36
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1449
gccuauaagg cuuuaguaau uucuacuauu guagau 36
<210> 1450
<211> 20
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1450
uaauuucuac uguuguagau 20
<210> 1451
<211> 20
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1451
gaaaugcaug guucucaugc 20
<210> 1452
<211> 20
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1452
aaauuaccua guaauuaggu 20
<210> 1453
<211> 32
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1453
guuucaaucc acgcgcccac gcggggcgcg ac 32
<210> 1454
<211> 36
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1454
aatgtttcct gatggtccat gtctgttact cgcctg 36
<210> 1455
<211> 23
<212> РНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1455
cugauggucc augucuguua cuc 23
<210> 1456
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1456
aatgtttcct gactcgcctg 20
<210> 1457
<211> 12
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1457
aatgtttcct ga 12
<210> 1458
<211> 32
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1458
aatgtttcct gatggtccat gtctgtcgcc tg 32
<210> 1459
<211> 32
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1459
aatgtttcct gatggtccat gtctgtcgcc tg 32
<210> 1460
<211> 30
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1460
aatgtttcct gatggtccat gttgtgcctg 30
<210> 1461
<211> 31
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1461
aatgtttcct gatggtccat gtactcgcct g 31
<210> 1462
<211> 32
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1462
aatgtttcct gatggtccat gtctgtcgcc tg 32
<210> 1463
<211> 32
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1463
aatgtttcct gatggtccat gttactcgcc tg 32
<210> 1464
<211> 33
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1464
aatgtttcct gatggtccat gtctgttcgc ctg 33
<210> 1465
<211> 34
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1465
aatgtttcct gatggtccat gtcttactcg cctg 34
<210> 1466
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1466
tttccctcac tcctgctcgg tgaattt 27
<210> 1467
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1467
tttgaggagt gttcagtctc cgtgaac 27
<210> 1468
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1468
tttcctgatg gtccatgtct gttactc 27
<210> 1469
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1469
tttatttccc ttcagctaaa ataaagg 27
<210> 1470
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1470
tcactcctgc tcggtgaatt tgg 23
<210> 1471
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1471
aaccctctgg ggaccgtttg agg 23
<210> 1472
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1472
agtacgttaa tgtttcctga tgg 23
<210> 1473
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1473
tttcccttca gctaaaataa agg 23
<210> 1474
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1474
tttggagaag tcatttaata aggccactgt taaaa 35
<210> 1475
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1475
tttagagaag tcatttaata aggccactgt taaaa 35
<210> 1476
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (1)..(1)
<223> a, c, t, g, неизвестное или другое
<400> 1476
ngccactgtt aaaa 14
<210> 1477
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (1)..(1)
<223> a, c, t, g, неизвестное или другое
<400> 1477
ngccactgtt aaaa 14
<210> 1478
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (28)..(28)
<223> a, c, t, g, неизвестное или другое
<400> 1478
tttggagaag tcatttaata aggccacn 28
<210> 1479
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (28)..(28)
<223> a, c, t, g, неизвестное или другое
<400> 1479
tttagagaag tcatttaata aggccacn 28
<210> 1480
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1480
tttcgagaag tcatttaata aggccactgt taaaa 35
<210> 1481
<211> 14
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (1)..(1)
<223> a, c, t, g, неизвестное или другое
<400> 1481
ngccactgtt aaaa 14
<210> 1482
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (28)..(28)
<223> a, c, t, g, неизвестное или другое
<400> 1482
tttcgagaag tcatttaata aggccacn 28
<210> 1483
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1483
tttggctact attcctgtgc cttcagataa ttcaa 35
<210> 1484
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1484
ttttgctact attcctgtgc cttcagataa ttcaa 35
<210> 1485
<211> 15
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (1)..(1)
<223> a, c, t, g, неизвестное или другое
<400> 1485
nttcagataa ttcaa 15
<210> 1486
<211> 15
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (1)..(1)
<223> a, c, t, g, неизвестное или другое
<400> 1486
nttcagataa ttcaa 15
<210> 1487
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (28)..(28)
<223> a, c, t, g, неизвестное или другое
<400> 1487
tttggctact attcctgtgc cttcagan 28
<210> 1488
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1488
ttttgctact attcctgtgc cttcaga 27
<210> 1489
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1489
tttcgtctag agccttttgt attagtagcc gagct 35
<210> 1490
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1490
tttggtctag agccttttgt attagtagcc gagct 35
<210> 1491
<211> 15
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (1)..(1)
<223> a, c, t, g, неизвестное или другое
<400> 1491
nttagtagcc gagct 15
<210> 1492
<211> 15
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (1)..(1)
<223> a, c, t, g, неизвестное или другое
<400> 1492
nttagtagcc gagct 15
<210> 1493
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (28)..(28)
<223> a, c, t, g, неизвестное или другое
<400> 1493
tttcgtctag agccttttgt attagtan 28
<210> 1494
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<220>
<221> модифицированное_основание
<222> (28)..(28)
<223> a, c, t, g, неизвестное или другое
<400> 1494
tttggtctag agccttttgt attagtan 28
<210> 1495
<211> 724
<212> БЕЛОК
<213> Francisella tularensis
<400> 1495
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Ile Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Glu Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Asp Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Lys Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Ser Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr
<210> 1496
<211> 680
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 1496
Met Thr Gln Phe Glu Gly Phe Thr Asn Leu Tyr Gln Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Lys His Ile Gln
20 25 30
Glu Gln Gly Phe Ile Glu Glu Asp Lys Ala Arg Asn Asp His Tyr Lys
35 40 45
Glu Leu Lys Pro Ile Ile Asp Arg Ile Tyr Lys Thr Tyr Ala Asp Gln
50 55 60
Cys Leu Gln Leu Val Gln Leu Asp Trp Glu Asn Leu Ser Ala Ala Ile
65 70 75 80
Asp Ser Tyr Arg Lys Glu Lys Thr Glu Glu Thr Arg Asn Ala Leu Ile
85 90 95
Glu Glu Gln Ala Thr Tyr Arg Asn Ala Ile His Asp Tyr Phe Ile Gly
100 105 110
Arg Thr Asp Asn Leu Thr Asp Ala Ile Asn Lys Arg His Ala Glu Ile
115 120 125
Tyr Lys Gly Leu Phe Lys Ala Glu Leu Phe Asn Gly Lys Val Leu Lys
130 135 140
Gln Leu Gly Thr Val Thr Thr Thr Glu His Glu Asn Ala Leu Leu Arg
145 150 155 160
Ser Phe Asp Lys Phe Thr Thr Tyr Phe Ser Gly Phe Tyr Glu Asn Arg
165 170 175
Lys Asn Val Phe Ser Ala Glu Asp Ile Ser Thr Ala Ile Pro His Arg
180 185 190
Ile Val Gln Asp Asn Phe Pro Lys Phe Lys Glu Asn Cys His Ile Phe
195 200 205
Thr Arg Leu Ile Thr Ala Val Pro Ser Leu Arg Glu His Phe Glu Asn
210 215 220
Val Lys Lys Ala Ile Gly Ile Phe Val Ser Thr Ser Ile Glu Glu Val
225 230 235 240
Phe Ser Phe Pro Phe Tyr Asn Gln Leu Leu Thr Gln Thr Gln Ile Asp
245 250 255
Leu Tyr Asn Gln Leu Leu Gly Gly Ile Ser Arg Glu Ala Gly Thr Glu
260 265 270
Lys Ile Lys Gly Leu Asn Glu Val Leu Asn Leu Ala Ile Gln Lys Asn
275 280 285
Asp Glu Thr Ala His Ile Ile Ala Ser Leu Pro His Arg Phe Ile Pro
290 295 300
Leu Phe Lys Gln Ile Leu Ser Asp Arg Asn Thr Leu Ser Phe Ile Leu
305 310 315 320
Glu Glu Phe Lys Ser Asp Glu Glu Val Ile Gln Ser Phe Cys Lys Tyr
325 330 335
Lys Thr Leu Leu Arg Asn Glu Asn Val Leu Glu Thr Ala Glu Ala Leu
340 345 350
Phe Asn Glu Leu Asn Ser Ile Asp Leu Thr His Ile Phe Ile Ser His
355 360 365
Lys Lys Leu Glu Thr Ile Ser Ser Ala Leu Cys Asp His Trp Asp Thr
370 375 380
Leu Arg Asn Ala Leu Tyr Glu Arg Arg Ile Ser Glu Leu Thr Gly Lys
385 390 395 400
Ile Thr Lys Ser Ala Lys Glu Lys Val Gln Arg Ser Leu Lys His Glu
405 410 415
Asp Ile Asn Leu Gln Glu Ile Ile Ser Ala Ala Gly Lys Glu Leu Ser
420 425 430
Glu Ala Phe Lys Gln Lys Thr Ser Glu Ile Leu Ser His Ala His Ala
435 440 445
Ala Leu Asp Gln Pro Leu Pro Thr Thr Leu Lys Lys Gln Glu Glu Lys
450 455 460
Glu Ile Leu Lys Ser Gln Leu Asp Ser Leu Leu Gly Leu Tyr His Leu
465 470 475 480
Leu Asp Trp Phe Ala Val Asp Glu Ser Asn Glu Val Asp Pro Glu Phe
485 490 495
Ser Ala Arg Leu Thr Gly Ile Lys Leu Glu Met Glu Pro Ser Leu Ser
500 505 510
Phe Tyr Asn Lys Ala Arg Asn Tyr Ala Thr Lys Lys Pro Tyr Ser Val
515 520 525
Glu Lys Phe Lys Leu Asn Phe Gln Met Pro Thr Leu Ala Ser Gly Trp
530 535 540
Asp Val Asn Lys Glu Lys Asn Asn Gly Ala Ile Leu Phe Val Lys Asn
545 550 555 560
Gly Leu Tyr Tyr Leu Gly Ile Met Pro Lys Gln Lys Gly Arg Tyr Lys
565 570 575
Ala Leu Ser Phe Glu Pro Thr Glu Lys Thr Ser Glu Gly Phe Asp Lys
580 585 590
Met Tyr Tyr Asp Tyr Phe Pro Asp Ala Ala Lys Met Ile Pro Lys Cys
595 600 605
Ser Thr Gln Leu Lys Ala Val Thr Ala His Phe Gln Thr His Thr Thr
610 615 620
Pro Ile Leu Leu Ser Asn Asn Phe Ile Glu Pro Leu Glu Ile Thr Lys
625 630 635 640
Glu Ile Tyr Asp Leu Asn Asn Pro Glu Lys Glu Pro Lys Lys Phe Gln
645 650 655
Thr Ala Tyr Ala Lys Lys Thr Gly Asp Gln Lys Gly Tyr Arg Glu Ala
660 665 670
Leu Cys Lys Trp Ile Asp Phe Thr
675 680
<210> 1497
<211> 639
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1497
Met Ser Lys Leu Glu Lys Phe Thr Asn Cys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Lys Ala Ile Pro Val Gly Lys Thr Gln Glu Asn Ile Asp
20 25 30
Asn Lys Arg Leu Leu Val Glu Asp Glu Lys Arg Ala Glu Asp Tyr Lys
35 40 45
Gly Val Lys Lys Leu Leu Asp Arg Tyr Tyr Leu Ser Phe Ile Asn Asp
50 55 60
Val Leu His Ser Ile Lys Leu Lys Asn Leu Asn Asn Tyr Ile Ser Leu
65 70 75 80
Phe Arg Lys Lys Thr Arg Thr Glu Lys Glu Asn Lys Glu Leu Glu Asn
85 90 95
Leu Glu Ile Asn Leu Arg Lys Glu Ile Ala Lys Ala Phe Lys Gly Asn
100 105 110
Glu Gly Tyr Lys Ser Leu Phe Lys Lys Asp Ile Ile Glu Thr Ile Leu
115 120 125
Pro Glu Phe Leu Asp Asp Lys Asp Glu Ile Ala Leu Val Asn Ser Phe
130 135 140
Asn Gly Phe Thr Thr Ala Phe Thr Gly Phe Phe Asp Asn Arg Glu Asn
145 150 155 160
Met Phe Ser Glu Glu Ala Lys Ser Thr Ser Ile Ala Phe Arg Cys Ile
165 170 175
Asn Glu Asn Leu Thr Arg Tyr Ile Ser Asn Met Asp Ile Phe Glu Lys
180 185 190
Val Asp Ala Ile Phe Asp Lys His Glu Val Gln Glu Ile Lys Glu Lys
195 200 205
Ile Leu Asn Ser Asp Tyr Asp Val Glu Asp Phe Phe Glu Gly Glu Phe
210 215 220
Phe Asn Phe Val Leu Thr Gln Glu Gly Ile Asp Val Tyr Asn Ala Ile
225 230 235 240
Ile Gly Gly Phe Val Thr Glu Ser Gly Glu Lys Ile Lys Gly Leu Asn
245 250 255
Glu Tyr Ile Asn Leu Tyr Asn Gln Lys Thr Lys Gln Lys Leu Pro Lys
260 265 270
Phe Lys Pro Leu Tyr Lys Gln Val Leu Ser Asp Arg Glu Ser Leu Ser
275 280 285
Phe Tyr Gly Glu Gly Tyr Thr Ser Asp Glu Glu Val Leu Glu Val Phe
290 295 300
Arg Asn Thr Leu Asn Lys Asn Ser Glu Ile Phe Ser Ser Ile Lys Lys
305 310 315 320
Leu Glu Lys Leu Phe Lys Asn Phe Asp Glu Tyr Ser Ser Ala Gly Ile
325 330 335
Phe Val Lys Asn Gly Pro Ala Ile Ser Thr Ile Ser Lys Asp Ile Phe
340 345 350
Gly Glu Trp Asn Val Ile Arg Asp Lys Trp Asn Ala Glu Tyr Asp Asp
355 360 365
Ile His Leu Lys Lys Lys Ala Val Val Thr Glu Lys Tyr Glu Asp Asp
370 375 380
Arg Arg Lys Ser Phe Lys Lys Ile Gly Ser Phe Ser Leu Glu Gln Leu
385 390 395 400
Gln Glu Tyr Ala Asp Ala Asp Leu Ser Val Val Glu Lys Leu Lys Glu
405 410 415
Ile Ile Ile Gln Lys Val Asp Glu Ile Tyr Lys Val Tyr Gly Ser Ser
420 425 430
Glu Lys Leu Phe Asp Ala Asp Phe Val Leu Glu Lys Ser Leu Lys Lys
435 440 445
Asn Asp Ala Val Val Ala Ile Met Lys Asp Leu Leu Asp Ser Val Lys
450 455 460
Ser Phe Glu Asn Tyr Ile Lys Ala Phe Phe Gly Glu Gly Lys Glu Thr
465 470 475 480
Asn Arg Asp Glu Ser Phe Tyr Gly Asp Phe Val Leu Ala Tyr Asp Ile
485 490 495
Leu Leu Lys Val Asp His Ile Tyr Asp Ala Ile Arg Asn Tyr Val Thr
500 505 510
Gln Lys Pro Tyr Ser Lys Asp Lys Phe Lys Leu Tyr Phe Gln Asn Pro
515 520 525
Gln Phe Met Gly Gly Trp Asp Lys Asp Lys Glu Thr Asp Tyr Arg Ala
530 535 540
Thr Ile Leu Arg Tyr Gly Ser Lys Tyr Tyr Leu Ala Ile Met Asp Lys
545 550 555 560
Lys Tyr Ala Lys Cys Leu Gln Lys Ile Asp Lys Asp Asp Val Asn Gly
565 570 575
Asn Tyr Glu Lys Ile Asn Tyr Lys Leu Leu Pro Gly Pro Asn Lys Met
580 585 590
Leu Pro Lys Val Phe Phe Ser Lys Lys Trp Met Ala Tyr Tyr Asn Pro
595 600 605
Ser Glu Asp Ile Gln Lys Ile Tyr Lys Asn Gly Thr Phe Lys Lys Gly
610 615 620
Asp Met Phe Asn Leu Asn Asp Cys His Lys Leu Ile Asp Phe Phe
625 630 635
<210> 1498
<211> 44
<212> РНК
<213> Francisella tularensis
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1498
uaauuucuac uguuguagau nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1499
<211> 44
<212> РНК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1499
gaaaugcaug guucucaugc nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1500
<211> 44
<212> РНК
<213> Butyrivibrio proteoclasticus
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1500
aaauuaccua guaauuaggu nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1501
<211> 44
<212> РНК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Peregrinibacteria bacterium
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1501
ggauuucuac uuuuguagau nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1502
<211> 44
<212> РНК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Peregrinibacteria bacterium
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1502
aaauuucuac uuuuguagau nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1503
<211> 44
<212> РНК
<213> Smithella sp.
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1503
gcgcccacgc ggggcgcgac nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1504
<211> 44
<212> РНК
<213> Acidaminococcus sp.
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1504
uaauuucuac ucuuguagau nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1505
<211> 44
<212> РНК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1505
gaauuucuac uauuguagau nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1506
<211> 45
<212> РНК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methanoplasma termitum
<220>
<221> модифицированное_основание
<222> (22)..(45)
<223> a, c, u, g, неизвестное или другое
<400> 1506
gaaucucuac ucuuuguaga unnnnnnnnn nnnnnnnnnn nnnnn 45
<210> 1507
<211> 43
<212> РНК
<213> Eubacterium eligens
<220>
<221> модифицированное_основание
<222> (20)..(43)
<223> a, c, u, g, неизвестное или другое
<400> 1507
uaauuucuac uuuguagaun nnnnnnnnnn nnnnnnnnnn nnn 43
<210> 1508
<211> 44
<212> РНК
<213> Moraxella bovoculi
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1508
aauuucuacu guuuguagau nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1509
<211> 44
<212> РНК
<213> Leptospira inadai
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1509
gaauuucuac uuuuguagau nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1510
<211> 44
<212> РНК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1510
aauuucuacu aaguguagau nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1511
<211> 44
<212> РНК
<213> Porphyromonas crevioricanis
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1511
uaauuucuac uauuguagau nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1512
<211> 44
<212> РНК
<213> Prevotella disiens
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1512
uaauuucuac uucgguagau nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1513
<211> 44
<212> РНК
<213> Porphyromonas macacae
<220>
<221> модифицированное_основание
<222> (21)..(44)
<223> a, c, u, g, неизвестное или другое
<400> 1513
uaauuucuac uauuguagau nnnnnnnnnn nnnnnnnnnn nnnn 44
<210> 1514
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1514
ttttgagaag tcatttaata aggccactgt taaaa 35
<210> 1515
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<220>
<221> модифицированное_основание
<222> (1)..(1)
<223> a, c, t, g, неизвестное или другое
<400> 1515
nccactgtta aaa 13
<210> 1516
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<220>
<221> модифицированное_основание
<222> (28)..(28)
<223> a, c, t, g, неизвестное или другое
<400> 1516
ttttgagaag tcatttaata aggccacn 28
<210> 1517
<211> 35
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1517
ttttgagaag tcatttaata aggccactgt taaaa 35
<210> 1518
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<220>
<221> модифицированное_основание
<222> (1)..(1)
<223> a, c, t, g, неизвестное или другое
<400> 1518
nccactgtta aaa 13
<210> 1519
<211> 28
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический праймер
<220>
<221> модифицированное_основание
<222> (28)..(28)
<223> a, c, t, g, неизвестное или другое
<400> 1519
ttttgagaag tcatttaata aggccacn 28
<210> 1520
<211> 1307
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 1520
Met Thr Gln Phe Glu Gly Phe Thr Asn Leu Tyr Gln Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Lys His Ile Gln
20 25 30
Glu Gln Gly Phe Ile Glu Glu Asp Lys Ala Arg Asn Asp His Tyr Lys
35 40 45
Glu Leu Lys Pro Ile Ile Asp Arg Ile Tyr Lys Thr Tyr Ala Asp Gln
50 55 60
Cys Leu Gln Leu Val Gln Leu Asp Trp Glu Asn Leu Ser Ala Ala Ile
65 70 75 80
Asp Ser Tyr Arg Lys Glu Lys Thr Glu Glu Thr Arg Asn Ala Leu Ile
85 90 95
Glu Glu Gln Ala Thr Tyr Arg Asn Ala Ile His Asp Tyr Phe Ile Gly
100 105 110
Arg Thr Asp Asn Leu Thr Asp Ala Ile Asn Lys Arg His Ala Glu Ile
115 120 125
Tyr Lys Gly Leu Phe Lys Ala Glu Leu Phe Asn Gly Lys Val Leu Lys
130 135 140
Gln Leu Gly Thr Val Thr Thr Thr Glu His Glu Asn Ala Leu Leu Arg
145 150 155 160
Ser Phe Asp Lys Phe Thr Thr Tyr Phe Ser Gly Phe Tyr Glu Asn Arg
165 170 175
Lys Asn Val Phe Ser Ala Glu Asp Ile Ser Thr Ala Ile Pro His Arg
180 185 190
Ile Val Gln Asp Asn Phe Pro Lys Phe Lys Glu Asn Cys His Ile Phe
195 200 205
Thr Arg Leu Ile Thr Ala Val Pro Ser Leu Arg Glu His Phe Glu Asn
210 215 220
Val Lys Lys Ala Ile Gly Ile Phe Val Ser Thr Ser Ile Glu Glu Val
225 230 235 240
Phe Ser Phe Pro Phe Tyr Asn Gln Leu Leu Thr Gln Thr Gln Ile Asp
245 250 255
Leu Tyr Asn Gln Leu Leu Gly Gly Ile Ser Arg Glu Ala Gly Thr Glu
260 265 270
Lys Ile Lys Gly Leu Asn Glu Val Leu Asn Leu Ala Ile Gln Lys Asn
275 280 285
Asp Glu Thr Ala His Ile Ile Ala Ser Leu Pro His Arg Phe Ile Pro
290 295 300
Leu Phe Lys Gln Ile Leu Ser Asp Arg Asn Thr Leu Ser Phe Ile Leu
305 310 315 320
Glu Glu Phe Lys Ser Asp Glu Glu Val Ile Gln Ser Phe Cys Lys Tyr
325 330 335
Lys Thr Leu Leu Arg Asn Glu Asn Val Leu Glu Thr Ala Glu Ala Leu
340 345 350
Phe Asn Glu Leu Asn Ser Ile Asp Leu Thr His Ile Phe Ile Ser His
355 360 365
Lys Lys Leu Glu Thr Ile Ser Ser Ala Leu Cys Asp His Trp Asp Thr
370 375 380
Leu Arg Asn Ala Leu Tyr Glu Arg Arg Ile Ser Glu Leu Thr Gly Lys
385 390 395 400
Ile Thr Lys Ser Ala Lys Glu Lys Val Gln Arg Ser Leu Lys His Glu
405 410 415
Asp Ile Asn Leu Gln Glu Ile Ile Ser Ala Ala Gly Lys Glu Leu Ser
420 425 430
Glu Ala Phe Lys Gln Lys Thr Ser Glu Ile Leu Ser His Ala His Ala
435 440 445
Ala Leu Asp Gln Pro Leu Pro Thr Thr Leu Lys Lys Gln Glu Glu Lys
450 455 460
Glu Ile Leu Lys Ser Gln Leu Asp Ser Leu Leu Gly Leu Tyr His Leu
465 470 475 480
Leu Asp Trp Phe Ala Val Asp Glu Ser Asn Glu Val Asp Pro Glu Phe
485 490 495
Ser Ala Arg Leu Thr Gly Ile Lys Leu Glu Met Glu Pro Ser Leu Ser
500 505 510
Phe Tyr Asn Lys Ala Arg Asn Tyr Ala Thr Lys Lys Pro Tyr Ser Val
515 520 525
Glu Lys Phe Lys Leu Asn Phe Gln Met Pro Thr Leu Ala Ser Gly Trp
530 535 540
Asp Val Asn Lys Glu Lys Asn Asn Gly Ala Ile Leu Phe Val Lys Asn
545 550 555 560
Gly Leu Tyr Tyr Leu Gly Ile Met Pro Lys Gln Lys Gly Arg Tyr Lys
565 570 575
Ala Leu Ser Phe Glu Pro Thr Glu Lys Thr Ser Glu Gly Phe Asp Lys
580 585 590
Met Tyr Tyr Asp Tyr Phe Pro Asp Ala Ala Lys Met Ile Pro Lys Cys
595 600 605
Ser Thr Gln Leu Lys Ala Val Thr Ala His Phe Gln Thr His Thr Thr
610 615 620
Pro Ile Leu Leu Ser Asn Asn Phe Ile Glu Pro Leu Glu Ile Thr Lys
625 630 635 640
Glu Ile Tyr Asp Leu Asn Asn Pro Glu Lys Glu Pro Lys Lys Phe Gln
645 650 655
Thr Ala Tyr Ala Lys Lys Thr Gly Asp Gln Lys Gly Tyr Arg Glu Ala
660 665 670
Leu Cys Lys Trp Ile Asp Phe Thr Arg Asp Phe Leu Ser Lys Tyr Thr
675 680 685
Lys Thr Thr Ser Ile Asp Leu Ser Ser Leu Arg Pro Ser Ser Gln Tyr
690 695 700
Lys Asp Leu Gly Glu Tyr Tyr Ala Glu Leu Asn Pro Leu Leu Tyr His
705 710 715 720
Ile Ser Phe Gln Arg Ile Ala Glu Lys Glu Ile Met Asp Ala Val Glu
725 730 735
Thr Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Lys
740 745 750
Gly His His Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Thr Gly Leu
755 760 765
Phe Ser Pro Glu Asn Leu Ala Lys Thr Ser Ile Lys Leu Asn Gly Gln
770 775 780
Ala Glu Leu Phe Tyr Arg Pro Lys Ser Arg Met Lys Arg Met Ala His
785 790 795 800
Arg Leu Gly Glu Lys Met Leu Asn Lys Lys Leu Lys Asp Gln Lys Thr
805 810 815
Pro Ile Pro Asp Thr Leu Tyr Gln Glu Leu Tyr Asp Tyr Val Asn His
820 825 830
Arg Leu Ser His Asp Leu Ser Asp Glu Ala Arg Ala Leu Leu Pro Asn
835 840 845
Val Ile Thr Lys Glu Val Ser His Glu Ile Ile Lys Asp Arg Arg Phe
850 855 860
Thr Ser Asp Lys Phe Phe Phe His Val Pro Ile Thr Leu Asn Tyr Gln
865 870 875 880
Ala Ala Asn Ser Pro Ser Lys Phe Asn Gln Arg Val Asn Ala Tyr Leu
885 890 895
Lys Glu His Pro Glu Thr Pro Ile Ile Gly Ile Asp Arg Gly Glu Arg
900 905 910
Asn Leu Ile Tyr Ile Thr Val Ile Asp Ser Thr Gly Lys Ile Leu Glu
915 920 925
Gln Arg Ser Leu Asn Thr Ile Gln Gln Phe Asp Tyr Gln Lys Lys Leu
930 935 940
Asp Asn Arg Glu Lys Glu Arg Val Ala Ala Arg Gln Ala Trp Ser Val
945 950 955 960
Val Gly Thr Ile Lys Asp Leu Lys Gln Gly Tyr Leu Ser Gln Val Ile
965 970 975
His Glu Ile Val Asp Leu Met Ile His Tyr Gln Ala Val Val Val Leu
980 985 990
Glu Asn Leu Asn Phe Gly Phe Lys Ser Lys Arg Thr Gly Ile Ala Glu
995 1000 1005
Lys Ala Val Tyr Gln Gln Phe Glu Lys Met Leu Ile Asp Lys Leu
1010 1015 1020
Asn Cys Leu Val Leu Lys Asp Tyr Pro Ala Glu Lys Val Gly Gly
1025 1030 1035
Val Leu Asn Pro Tyr Gln Leu Thr Asp Gln Phe Thr Ser Phe Ala
1040 1045 1050
Lys Met Gly Thr Gln Ser Gly Phe Leu Phe Tyr Val Pro Ala Pro
1055 1060 1065
Tyr Thr Ser Lys Ile Asp Pro Leu Thr Gly Phe Val Asp Pro Phe
1070 1075 1080
Val Trp Lys Thr Ile Lys Asn His Glu Ser Arg Lys His Phe Leu
1085 1090 1095
Glu Gly Phe Asp Phe Leu His Tyr Asp Val Lys Thr Gly Asp Phe
1100 1105 1110
Ile Leu His Phe Lys Met Asn Arg Asn Leu Ser Phe Gln Arg Gly
1115 1120 1125
Leu Pro Gly Phe Met Pro Ala Trp Asp Ile Val Phe Glu Lys Asn
1130 1135 1140
Glu Thr Gln Phe Asp Ala Lys Gly Thr Pro Phe Ile Ala Gly Lys
1145 1150 1155
Arg Ile Val Pro Val Ile Glu Asn His Arg Phe Thr Gly Arg Tyr
1160 1165 1170
Arg Asp Leu Tyr Pro Ala Asn Glu Leu Ile Ala Leu Leu Glu Glu
1175 1180 1185
Lys Gly Ile Val Phe Arg Asp Gly Ser Asn Ile Leu Pro Lys Leu
1190 1195 1200
Leu Glu Asn Asp Asp Ser His Ala Ile Asp Thr Met Val Ala Leu
1205 1210 1215
Ile Arg Ser Val Leu Gln Met Arg Asn Ser Asn Ala Ala Thr Gly
1220 1225 1230
Glu Asp Tyr Ile Asn Ser Pro Val Arg Asp Leu Asn Gly Val Cys
1235 1240 1245
Phe Asp Ser Arg Phe Gln Asn Pro Glu Trp Pro Met Asp Ala Asp
1250 1255 1260
Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Gln Leu Leu Leu
1265 1270 1275
Asn His Leu Lys Glu Ser Lys Asp Leu Lys Leu Gln Asn Gly Ile
1280 1285 1290
Ser Asn Gln Asp Trp Leu Ala Tyr Ile Gln Glu Leu Arg Asn
1295 1300 1305
<210> 1521
<211> 365
<212> БЕЛОК
<213> Thermotoga maritima
<400> 1521
Met Arg Pro Glu Arg Leu Thr Val Arg Asn Phe Leu Gly Leu Lys Asn
1 5 10 15
Val Asp Ile Glu Phe Gln Ser Gly Ile Thr Val Val Glu Gly Pro Asn
20 25 30
Gly Ala Gly Lys Ser Ser Leu Phe Glu Ala Ile Ser Phe Ala Leu Phe
35 40 45
Gly Asn Gly Ile Arg Tyr Pro Asn Ser Tyr Asp Tyr Val Asn Arg Asn
50 55 60
Ala Val Asp Gly Thr Ala Arg Leu Val Phe Gln Phe Glu Arg Gly Gly
65 70 75 80
Lys Arg Tyr Glu Ile Ile Arg Glu Ile Asn Ala Leu Gln Arg Lys His
85 90 95
Asn Ala Lys Leu Ser Glu Ile Leu Glu Asn Gly Lys Lys Ala Ala Ile
100 105 110
Ala Ala Lys Pro Thr Ser Val Lys Gln Glu Val Glu Lys Ile Leu Gly
115 120 125
Ile Glu His Arg Thr Phe Ile Arg Thr Val Phe Leu Pro Gln Gly Glu
130 135 140
Ile Asp Lys Leu Leu Ile Ser Pro Pro Ser Glu Ile Thr Glu Ile Ile
145 150 155 160
Ser Asp Val Phe Gln Ser Lys Glu Thr Leu Glu Lys Leu Glu Lys Leu
165 170 175
Leu Lys Glu Lys Met Lys Lys Leu Glu Asn Glu Ile Ser Ser Gly Gly
180 185 190
Ala Gly Gly Ala Gly Gly Ser Leu Glu Lys Lys Leu Lys Glu Met Ser
195 200 205
Asp Glu Tyr Asn Asn Leu Asp Leu Leu Arg Lys Tyr Leu Phe Asp Lys
210 215 220
Ser Asn Phe Ser Arg Tyr Phe Thr Gly Arg Val Leu Glu Ala Val Leu
225 230 235 240
Lys Arg Thr Lys Ala Tyr Leu Asp Ile Leu Thr Asn Gly Arg Phe Asp
245 250 255
Ile Asp Phe Asp Asp Glu Lys Gly Gly Phe Ile Ile Lys Asp Trp Gly
260 265 270
Ile Glu Arg Pro Ala Arg Gly Leu Ser Gly Gly Glu Arg Ala Leu Ile
275 280 285
Ser Ile Ser Leu Ala Met Ser Leu Ala Glu Val Ala Ser Gly Arg Leu
290 295 300
Asp Ala Phe Phe Ile Asp Glu Gly Phe Ser Ser Leu Asp Thr Glu Asn
305 310 315 320
Lys Glu Lys Ile Ala Ser Val Leu Lys Glu Leu Glu Arg Leu Asn Lys
325 330 335
Val Ile Val Phe Ile Thr His Asp Arg Glu Phe Ser Glu Ala Phe Asp
340 345 350
Arg Lys Leu Arg Ile Thr Gly Gly Val Val Val Asn Glu
355 360 365
<210> 1522
<211> 1307
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 1522
Met Thr Gln Phe Glu Gly Phe Thr Asn Leu Tyr Gln Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Lys His Ile Gln
20 25 30
Glu Gln Gly Phe Ile Glu Glu Asp Lys Ala Arg Asn Asp His Tyr Lys
35 40 45
Glu Leu Lys Pro Ile Ile Asp Arg Ile Tyr Lys Thr Tyr Ala Asp Gln
50 55 60
Cys Leu Gln Leu Val Gln Leu Asp Trp Glu Asn Leu Ser Ala Ala Ile
65 70 75 80
Asp Ser Tyr Arg Lys Glu Lys Thr Glu Glu Thr Arg Asn Ala Leu Ile
85 90 95
Glu Glu Gln Ala Thr Tyr Arg Asn Ala Ile His Asp Tyr Phe Ile Gly
100 105 110
Arg Thr Asp Asn Leu Thr Asp Ala Ile Asn Lys Arg His Ala Glu Ile
115 120 125
Tyr Lys Gly Leu Phe Lys Ala Glu Leu Phe Asn Gly Lys Val Leu Lys
130 135 140
Gln Leu Gly Thr Val Thr Thr Thr Glu His Glu Asn Ala Leu Leu Arg
145 150 155 160
Ser Phe Asp Lys Phe Thr Thr Tyr Phe Ser Gly Phe Tyr Glu Asn Arg
165 170 175
Lys Asn Val Phe Ser Ala Glu Asp Ile Ser Thr Ala Ile Pro His Arg
180 185 190
Ile Val Gln Asp Asn Phe Pro Lys Phe Lys Glu Asn Cys His Ile Phe
195 200 205
Thr Arg Leu Ile Thr Ala Val Pro Ser Leu Arg Glu His Phe Glu Asn
210 215 220
Val Lys Lys Ala Ile Gly Ile Phe Val Ser Thr Ser Ile Glu Glu Val
225 230 235 240
Phe Ser Phe Pro Phe Tyr Asn Gln Leu Leu Thr Gln Thr Gln Ile Asp
245 250 255
Leu Tyr Asn Gln Leu Leu Gly Gly Ile Ser Arg Glu Ala Gly Thr Glu
260 265 270
Lys Ile Lys Gly Leu Asn Glu Val Leu Asn Leu Ala Ile Gln Lys Asn
275 280 285
Asp Glu Thr Ala His Ile Ile Ala Ser Leu Pro His Arg Phe Ile Pro
290 295 300
Leu Phe Lys Gln Ile Leu Ser Asp Arg Asn Thr Leu Ser Phe Ile Leu
305 310 315 320
Glu Glu Phe Lys Ser Asp Glu Glu Val Ile Gln Ser Phe Cys Lys Tyr
325 330 335
Lys Thr Leu Leu Arg Asn Glu Asn Val Leu Glu Thr Ala Glu Ala Leu
340 345 350
Phe Asn Glu Leu Asn Ser Ile Asp Leu Thr His Ile Phe Ile Ser His
355 360 365
Lys Lys Leu Glu Thr Ile Ser Ser Ala Leu Cys Asp His Trp Asp Thr
370 375 380
Leu Arg Asn Ala Leu Tyr Glu Arg Arg Ile Ser Glu Leu Thr Gly Lys
385 390 395 400
Ile Thr Lys Ser Ala Lys Glu Lys Val Gln Arg Ser Leu Lys His Glu
405 410 415
Asp Ile Asn Leu Gln Glu Ile Ile Ser Ala Ala Gly Lys Glu Leu Ser
420 425 430
Glu Ala Phe Lys Gln Lys Thr Ser Glu Ile Leu Ser His Ala His Ala
435 440 445
Ala Leu Asp Gln Pro Leu Pro Thr Thr Leu Lys Lys Gln Glu Glu Lys
450 455 460
Glu Ile Leu Lys Ser Gln Leu Asp Ser Leu Leu Gly Leu Tyr His Leu
465 470 475 480
Leu Asp Trp Phe Ala Val Asp Glu Ser Asn Glu Val Asp Pro Glu Phe
485 490 495
Ser Ala Arg Leu Thr Gly Ile Lys Leu Glu Met Glu Pro Ser Leu Ser
500 505 510
Phe Tyr Asn Lys Ala Arg Asn Tyr Ala Thr Lys Lys Pro Tyr Ser Val
515 520 525
Glu Lys Phe Lys Leu Asn Phe Gln Met Pro Thr Leu Ala Ser Gly Trp
530 535 540
Asp Val Asn Lys Glu Lys Asn Asn Gly Ala Ile Leu Phe Val Lys Asn
545 550 555 560
Gly Leu Tyr Tyr Leu Gly Ile Met Pro Lys Gln Lys Gly Arg Tyr Lys
565 570 575
Ala Leu Ser Phe Glu Pro Thr Glu Lys Thr Ser Glu Gly Phe Asp Lys
580 585 590
Met Tyr Tyr Asp Tyr Phe Pro Asp Ala Ala Lys Met Ile Pro Lys Cys
595 600 605
Ser Thr Gln Leu Lys Ala Val Thr Ala His Phe Gln Thr His Thr Thr
610 615 620
Pro Ile Leu Leu Ser Asn Asn Phe Ile Glu Pro Leu Glu Ile Thr Lys
625 630 635 640
Glu Ile Tyr Asp Leu Asn Asn Pro Glu Lys Glu Pro Lys Lys Phe Gln
645 650 655
Thr Ala Tyr Ala Lys Lys Thr Gly Asp Gln Lys Gly Tyr Arg Glu Ala
660 665 670
Leu Cys Lys Trp Ile Asp Phe Thr Arg Asp Phe Leu Ser Lys Tyr Thr
675 680 685
Lys Thr Thr Ser Ile Asp Leu Ser Ser Leu Arg Pro Ser Ser Gln Tyr
690 695 700
Lys Asp Leu Gly Glu Tyr Tyr Ala Glu Leu Asn Pro Leu Leu Tyr His
705 710 715 720
Ile Ser Phe Gln Arg Ile Ala Glu Lys Glu Ile Met Asp Ala Val Glu
725 730 735
Thr Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Lys
740 745 750
Gly His His Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Thr Gly Leu
755 760 765
Phe Ser Pro Glu Asn Leu Ala Lys Thr Ser Ile Lys Leu Asn Gly Gln
770 775 780
Ala Glu Leu Phe Tyr Arg Pro Lys Ser Arg Met Lys Arg Met Ala His
785 790 795 800
Arg Leu Gly Glu Lys Met Leu Asn Lys Lys Leu Lys Asp Gln Lys Thr
805 810 815
Pro Ile Pro Asp Thr Leu Tyr Gln Glu Leu Tyr Asp Tyr Val Asn His
820 825 830
Arg Leu Ser His Asp Leu Ser Asp Glu Ala Arg Ala Leu Leu Pro Asn
835 840 845
Val Ile Thr Lys Glu Val Ser His Glu Ile Ile Lys Asp Arg Arg Phe
850 855 860
Thr Ser Asp Lys Phe Phe Phe His Val Pro Ile Thr Leu Asn Tyr Gln
865 870 875 880
Ala Ala Asn Ser Pro Ser Lys Phe Asn Gln Arg Val Asn Ala Tyr Leu
885 890 895
Lys Glu His Pro Glu Thr Pro Ile Ile Gly Ile Asp Arg Gly Glu Arg
900 905 910
Asn Leu Ile Tyr Ile Thr Val Ile Asp Ser Thr Gly Lys Ile Leu Glu
915 920 925
Gln Arg Ser Leu Asn Thr Ile Gln Gln Phe Asp Tyr Gln Lys Lys Leu
930 935 940
Asp Asn Arg Glu Lys Glu Arg Val Ala Ala Arg Gln Ala Trp Ser Val
945 950 955 960
Val Gly Thr Ile Lys Asp Leu Lys Gln Gly Tyr Leu Ser Gln Val Ile
965 970 975
His Glu Ile Val Asp Leu Met Ile His Tyr Gln Ala Val Val Val Leu
980 985 990
Glu Asn Leu Asn Phe Gly Phe Lys Ser Lys Arg Thr Gly Ile Ala Glu
995 1000 1005
Lys Ala Val Tyr Gln Gln Phe Glu Lys Met Leu Ile Asp Lys Leu
1010 1015 1020
Asn Cys Leu Val Leu Lys Asp Tyr Pro Ala Glu Lys Val Gly Gly
1025 1030 1035
Val Leu Asn Pro Tyr Gln Leu Thr Asp Gln Phe Thr Ser Phe Ala
1040 1045 1050
Lys Met Gly Thr Gln Ser Gly Phe Leu Phe Tyr Val Pro Ala Pro
1055 1060 1065
Tyr Thr Ser Lys Ile Asp Pro Leu Thr Gly Phe Val Asp Pro Phe
1070 1075 1080
Val Trp Lys Thr Ile Lys Asn His Glu Ser Arg Lys His Phe Leu
1085 1090 1095
Glu Gly Phe Asp Phe Leu His Tyr Asp Val Lys Thr Gly Asp Phe
1100 1105 1110
Ile Leu His Phe Lys Met Asn Arg Asn Leu Ser Phe Gln Arg Gly
1115 1120 1125
Leu Pro Gly Phe Met Pro Ala Trp Asp Ile Val Phe Glu Lys Asn
1130 1135 1140
Glu Thr Gln Phe Asp Ala Lys Gly Thr Pro Phe Ile Ala Gly Lys
1145 1150 1155
Arg Ile Val Pro Val Ile Glu Asn His Arg Phe Thr Gly Arg Tyr
1160 1165 1170
Arg Asp Leu Tyr Pro Ala Asn Glu Leu Ile Ala Leu Leu Glu Glu
1175 1180 1185
Lys Gly Ile Val Phe Arg Asp Gly Ser Asn Ile Leu Pro Lys Leu
1190 1195 1200
Leu Glu Asn Asp Asp Ser His Ala Ile Asp Thr Met Val Ala Leu
1205 1210 1215
Ile Arg Ser Val Leu Gln Met Arg Asn Ser Asn Ala Ala Thr Gly
1220 1225 1230
Glu Asp Tyr Ile Asn Ser Pro Val Arg Asp Leu Asn Gly Val Cys
1235 1240 1245
Phe Asp Ser Arg Phe Gln Asn Pro Glu Trp Pro Met Asp Ala Asp
1250 1255 1260
Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Gln Leu Leu Leu
1265 1270 1275
Asn His Leu Lys Glu Ser Lys Asp Leu Lys Leu Gln Asn Gly Ile
1280 1285 1290
Ser Asn Gln Asp Trp Leu Ala Tyr Ile Gln Glu Leu Arg Asn
1295 1300 1305
<210> 1523
<211> 169
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1523
Gly Pro His Met Val Val Ala Gly Ile Asp Pro Gly Ile Thr His Leu
1 5 10 15
Gly Leu Gly Val Val Ala Val Glu Gly Lys Gly Ala Leu Lys Ala Arg
20 25 30
Leu Leu His Gly Glu Val Val Lys Thr Ser Pro Gln Glu Pro Ala Lys
35 40 45
Glu Arg Val Gly Arg Ile His Ala Arg Val Leu Glu Val Leu His Arg
50 55 60
Phe Arg Pro Glu Ala Val Ala Val Gln Glu Gln Phe Phe Tyr Arg Gln
65 70 75 80
Asn Glu Leu Ala Tyr Lys Val Gly Trp Ala Leu Gly Ala Val Leu Val
85 90 95
Ala Ala Phe Glu Ala Gly Val Pro Val Tyr Ala Tyr Gly Pro Met Gln
100 105 110
Val Lys Gln Ala Leu Ala Gly His Gly His Ala Ala Lys Glu Glu Val
115 120 125
Ala Leu Met Val Arg Gly Ile Leu Gly Leu Lys Glu Ala Pro Arg Pro
130 135 140
Ser His Leu Ala Asp Ala Leu Ala Ile Ala Leu Thr His Ala Phe Tyr
145 150 155 160
Ala Arg Met Gly Thr Ala Lys Pro Leu
165
<210> 1524
<211> 1307
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 1524
Met Thr Gln Phe Glu Gly Phe Thr Asn Leu Tyr Gln Val Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Lys His Ile Gln
20 25 30
Glu Gln Gly Phe Ile Glu Glu Asp Lys Ala Arg Asn Asp His Tyr Lys
35 40 45
Glu Leu Lys Pro Ile Ile Asp Arg Ile Tyr Lys Thr Tyr Ala Asp Gln
50 55 60
Cys Leu Gln Leu Val Gln Leu Asp Trp Glu Asn Leu Ser Ala Ala Ile
65 70 75 80
Asp Ser Tyr Arg Lys Glu Lys Thr Glu Glu Thr Arg Asn Ala Leu Ile
85 90 95
Glu Glu Gln Ala Thr Tyr Arg Asn Ala Ile His Asp Tyr Phe Ile Gly
100 105 110
Arg Thr Asp Asn Leu Thr Asp Ala Ile Asn Lys Arg His Ala Glu Ile
115 120 125
Tyr Lys Gly Leu Phe Lys Ala Glu Leu Phe Asn Gly Lys Val Leu Lys
130 135 140
Gln Leu Gly Thr Val Thr Thr Thr Glu His Glu Asn Ala Leu Leu Arg
145 150 155 160
Ser Phe Asp Lys Phe Thr Thr Tyr Phe Ser Gly Phe Tyr Glu Asn Arg
165 170 175
Lys Asn Val Phe Ser Ala Glu Asp Ile Ser Thr Ala Ile Pro His Arg
180 185 190
Ile Val Gln Asp Asn Phe Pro Lys Phe Lys Glu Asn Cys His Ile Phe
195 200 205
Thr Arg Leu Ile Thr Ala Val Pro Ser Leu Arg Glu His Phe Glu Asn
210 215 220
Val Lys Lys Ala Ile Gly Ile Phe Val Ser Thr Ser Ile Glu Glu Val
225 230 235 240
Phe Ser Phe Pro Phe Tyr Asn Gln Leu Leu Thr Gln Thr Gln Ile Asp
245 250 255
Leu Tyr Asn Gln Leu Leu Gly Gly Ile Ser Arg Glu Ala Gly Thr Glu
260 265 270
Lys Ile Lys Gly Leu Asn Glu Val Leu Asn Leu Ala Ile Gln Lys Asn
275 280 285
Asp Glu Thr Ala His Ile Ile Ala Ser Leu Pro His Arg Phe Ile Pro
290 295 300
Leu Phe Lys Gln Ile Leu Ser Asp Arg Asn Thr Leu Ser Phe Ile Leu
305 310 315 320
Glu Glu Phe Lys Ser Asp Glu Glu Val Ile Gln Ser Phe Cys Lys Tyr
325 330 335
Lys Thr Leu Leu Arg Asn Glu Asn Val Leu Glu Thr Ala Glu Ala Leu
340 345 350
Phe Asn Glu Leu Asn Ser Ile Asp Leu Thr His Ile Phe Ile Ser His
355 360 365
Lys Lys Leu Glu Thr Ile Ser Ser Ala Leu Cys Asp His Trp Asp Thr
370 375 380
Leu Arg Asn Ala Leu Tyr Glu Arg Arg Ile Ser Glu Leu Thr Gly Lys
385 390 395 400
Ile Thr Lys Ser Ala Lys Glu Lys Val Gln Arg Ser Leu Lys His Glu
405 410 415
Asp Ile Asn Leu Gln Glu Ile Ile Ser Ala Ala Gly Lys Glu Leu Ser
420 425 430
Glu Ala Phe Lys Gln Lys Thr Ser Glu Ile Leu Ser His Ala His Ala
435 440 445
Ala Leu Asp Gln Pro Leu Pro Thr Thr Leu Lys Lys Gln Glu Glu Lys
450 455 460
Glu Ile Leu Lys Ser Gln Leu Asp Ser Leu Leu Gly Leu Tyr His Leu
465 470 475 480
Leu Asp Trp Phe Ala Val Asp Glu Ser Asn Glu Val Asp Pro Glu Phe
485 490 495
Ser Ala Arg Leu Thr Gly Ile Lys Leu Glu Met Glu Pro Ser Leu Ser
500 505 510
Phe Tyr Asn Lys Ala Arg Asn Tyr Ala Thr Lys Lys Pro Tyr Ser Val
515 520 525
Glu Lys Phe Lys Leu Asn Phe Gln Met Pro Thr Leu Ala Ser Gly Trp
530 535 540
Asp Val Asn Lys Glu Lys Asn Asn Gly Ala Ile Leu Phe Val Lys Asn
545 550 555 560
Gly Leu Tyr Tyr Leu Gly Ile Met Pro Lys Gln Lys Gly Arg Tyr Lys
565 570 575
Ala Leu Ser Phe Glu Pro Thr Glu Lys Thr Ser Glu Gly Phe Asp Lys
580 585 590
Met Tyr Tyr Asp Tyr Phe Pro Asp Ala Ala Lys Met Ile Pro Lys Cys
595 600 605
Ser Thr Gln Leu Lys Ala Val Thr Ala His Phe Gln Thr His Thr Thr
610 615 620
Pro Ile Leu Leu Ser Asn Asn Phe Ile Glu Pro Leu Glu Ile Thr Lys
625 630 635 640
Glu Ile Tyr Asp Leu Asn Asn Pro Glu Lys Glu Pro Lys Lys Phe Gln
645 650 655
Thr Ala Tyr Ala Lys Lys Thr Gly Asp Gln Lys Gly Tyr Arg Glu Ala
660 665 670
Leu Cys Lys Trp Ile Asp Phe Thr Arg Asp Phe Leu Ser Lys Tyr Thr
675 680 685
Lys Thr Thr Ser Ile Asp Leu Ser Ser Leu Arg Pro Ser Ser Gln Tyr
690 695 700
Lys Asp Leu Gly Glu Tyr Tyr Ala Glu Leu Asn Pro Leu Leu Tyr His
705 710 715 720
Ile Ser Phe Gln Arg Ile Ala Glu Lys Glu Ile Met Asp Ala Val Glu
725 730 735
Thr Gly Lys Leu Tyr Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ala Lys
740 745 750
Gly His His Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Thr Gly Leu
755 760 765
Phe Ser Pro Glu Asn Leu Ala Lys Thr Ser Ile Lys Leu Asn Gly Gln
770 775 780
Ala Glu Leu Phe Tyr Arg Pro Lys Ser Arg Met Lys Arg Met Ala His
785 790 795 800
Arg Leu Gly Glu Lys Met Leu Asn Lys Lys Leu Lys Asp Gln Lys Thr
805 810 815
Pro Ile Pro Asp Thr Leu Tyr Gln Glu Leu Tyr Asp Tyr Val Asn His
820 825 830
Arg Leu Ser His Asp Leu Ser Asp Glu Ala Arg Ala Leu Leu Pro Asn
835 840 845
Val Ile Thr Lys Glu Val Ser His Glu Ile Ile Lys Asp Arg Arg Phe
850 855 860
Thr Ser Asp Lys Phe Phe Phe His Val Pro Ile Thr Leu Asn Tyr Gln
865 870 875 880
Ala Ala Asn Ser Pro Ser Lys Phe Asn Gln Arg Val Asn Ala Tyr Leu
885 890 895
Lys Glu His Pro Glu Thr Pro Ile Ile Gly Ile Asp Arg Gly Glu Arg
900 905 910
Asn Leu Ile Tyr Ile Thr Val Ile Asp Ser Thr Gly Lys Ile Leu Glu
915 920 925
Gln Arg Ser Leu Asn Thr Ile Gln Gln Phe Asp Tyr Gln Lys Lys Leu
930 935 940
Asp Asn Arg Glu Lys Glu Arg Val Ala Ala Arg Gln Ala Trp Ser Val
945 950 955 960
Val Gly Thr Ile Lys Asp Leu Lys Gln Gly Tyr Leu Ser Gln Val Ile
965 970 975
His Glu Ile Val Asp Leu Met Ile His Tyr Gln Ala Val Val Val Leu
980 985 990
Glu Asn Leu Asn Phe Gly Phe Lys Ser Lys Arg Thr Gly Ile Ala Glu
995 1000 1005
Lys Ala Val Tyr Gln Gln Phe Glu Lys Met Leu Ile Asp Lys Leu
1010 1015 1020
Asn Cys Leu Val Leu Lys Asp Tyr Pro Ala Glu Lys Val Gly Gly
1025 1030 1035
Val Leu Asn Pro Tyr Gln Leu Thr Asp Gln Phe Thr Ser Phe Ala
1040 1045 1050
Lys Met Gly Thr Gln Ser Gly Phe Leu Phe Tyr Val Pro Ala Pro
1055 1060 1065
Tyr Thr Ser Lys Ile Asp Pro Leu Thr Gly Phe Val Asp Pro Phe
1070 1075 1080
Val Trp Lys Thr Ile Lys Asn His Glu Ser Arg Lys His Phe Leu
1085 1090 1095
Glu Gly Phe Asp Phe Leu His Tyr Asp Val Lys Thr Gly Asp Phe
1100 1105 1110
Ile Leu His Phe Lys Met Asn Arg Asn Leu Ser Phe Gln Arg Gly
1115 1120 1125
Leu Pro Gly Phe Met Pro Ala Trp Asp Ile Val Phe Glu Lys Asn
1130 1135 1140
Glu Thr Gln Phe Asp Ala Lys Gly Thr Pro Phe Ile Ala Gly Lys
1145 1150 1155
Arg Ile Val Pro Val Ile Glu Asn His Arg Phe Thr Gly Arg Tyr
1160 1165 1170
Arg Asp Leu Tyr Pro Ala Asn Glu Leu Ile Ala Leu Leu Glu Glu
1175 1180 1185
Lys Gly Ile Val Phe Arg Asp Gly Ser Asn Ile Leu Pro Lys Leu
1190 1195 1200
Leu Glu Asn Asp Asp Ser His Ala Ile Asp Thr Met Val Ala Leu
1205 1210 1215
Ile Arg Ser Val Leu Gln Met Arg Asn Ser Asn Ala Ala Thr Gly
1220 1225 1230
Glu Asp Tyr Ile Asn Ser Pro Val Arg Asp Leu Asn Gly Val Cys
1235 1240 1245
Phe Asp Ser Arg Phe Gln Asn Pro Glu Trp Pro Met Asp Ala Asp
1250 1255 1260
Ala Asn Gly Ala Tyr His Ile Ala Leu Lys Gly Gln Leu Leu Leu
1265 1270 1275
Asn His Leu Lys Glu Ser Lys Asp Leu Lys Leu Gln Asn Gly Ile
1280 1285 1290
Ser Asn Gln Asp Trp Leu Ala Tyr Ile Gln Glu Leu Arg Asn
1295 1300 1305
<210> 1525
<211> 1300
<212> БЕЛОК
<213> Francisella tularensis
<400> 1525
Met Ser Ile Tyr Gln Glu Phe Val Asn Lys Tyr Ser Leu Ser Lys Thr
1 5 10 15
Leu Arg Phe Glu Leu Ile Pro Gln Gly Lys Thr Leu Glu Asn Ile Lys
20 25 30
Ala Arg Gly Leu Ile Leu Asp Asp Glu Lys Arg Ala Lys Asp Tyr Lys
35 40 45
Lys Ala Lys Gln Ile Ile Asp Lys Tyr His Gln Phe Phe Ile Glu Glu
50 55 60
Ile Leu Ser Ser Val Cys Ile Ser Glu Asp Leu Leu Gln Asn Tyr Ser
65 70 75 80
Asp Val Tyr Phe Lys Leu Lys Lys Ser Asp Asp Asp Asn Leu Gln Lys
85 90 95
Asp Phe Lys Ser Ala Lys Asp Thr Ile Lys Lys Gln Ile Ser Glu Tyr
100 105 110
Ile Lys Asp Ser Glu Lys Phe Lys Asn Leu Phe Asn Gln Asn Leu Ile
115 120 125
Asp Ala Lys Lys Gly Gln Glu Ser Asp Leu Ile Leu Trp Leu Lys Gln
130 135 140
Ser Lys Asp Asn Gly Ile Glu Leu Phe Lys Ala Asn Ser Asp Ile Thr
145 150 155 160
Asp Ile Asp Glu Ala Leu Glu Ile Ile Lys Ser Phe Lys Gly Trp Thr
165 170 175
Thr Tyr Phe Lys Gly Phe His Glu Asn Arg Lys Asn Val Tyr Ser Ser
180 185 190
Asn Asp Ile Pro Thr Ser Ile Ile Tyr Arg Ile Val Asp Asp Asn Leu
195 200 205
Pro Lys Phe Leu Glu Asn Lys Ala Lys Tyr Glu Ser Leu Lys Asp Lys
210 215 220
Ala Pro Glu Ala Ile Asn Tyr Glu Gln Ile Lys Lys Asp Leu Ala Glu
225 230 235 240
Glu Leu Thr Phe Asp Ile Asp Tyr Lys Thr Ser Glu Val Asn Gln Arg
245 250 255
Val Phe Ser Leu Asp Glu Val Phe Glu Ile Ala Asn Phe Asn Asn Tyr
260 265 270
Leu Asn Gln Ser Gly Ile Thr Lys Phe Asn Thr Ile Ile Gly Gly Lys
275 280 285
Phe Val Asn Gly Glu Asn Thr Lys Arg Lys Gly Ile Asn Glu Tyr Ile
290 295 300
Asn Leu Tyr Ser Gln Gln Ile Asn Asp Lys Thr Leu Lys Lys Tyr Lys
305 310 315 320
Met Ser Val Leu Phe Lys Gln Ile Leu Ser Asp Thr Glu Ser Lys Ser
325 330 335
Phe Val Ile Asp Lys Leu Glu Asp Asp Ser Asp Val Val Thr Thr Met
340 345 350
Gln Ser Phe Tyr Glu Gln Ile Ala Ala Phe Lys Thr Val Glu Glu Lys
355 360 365
Ser Ile Lys Glu Thr Leu Ser Leu Leu Phe Asp Asp Leu Lys Ala Gln
370 375 380
Lys Leu Asp Leu Ser Lys Ile Tyr Phe Lys Asn Asp Lys Ser Leu Thr
385 390 395 400
Asp Leu Ser Gln Gln Val Phe Asp Asp Tyr Ser Val Ile Gly Thr Ala
405 410 415
Val Leu Glu Tyr Ile Thr Gln Gln Ile Ala Pro Lys Asn Leu Asp Asn
420 425 430
Pro Ser Lys Lys Glu Gln Glu Leu Ile Ala Lys Lys Thr Glu Lys Ala
435 440 445
Lys Tyr Leu Ser Leu Glu Thr Ile Lys Leu Ala Leu Glu Glu Phe Asn
450 455 460
Lys His Arg Asp Ile Asp Lys Gln Cys Arg Phe Glu Glu Ile Leu Ala
465 470 475 480
Asn Phe Ala Ala Ile Pro Met Ile Phe Asp Glu Ile Ala Gln Asn Lys
485 490 495
Asp Asn Leu Ala Gln Ile Ser Ile Lys Tyr Gln Asn Gln Gly Lys Lys
500 505 510
Asp Leu Leu Gln Ala Ser Ala Glu Asp Asp Val Lys Ala Ile Lys Asp
515 520 525
Leu Leu Asp Gln Thr Asn Asn Leu Leu His Lys Leu Lys Ile Phe His
530 535 540
Ile Ser Gln Ser Glu Asp Lys Ala Asn Ile Leu Asp Lys Asp Glu His
545 550 555 560
Phe Tyr Leu Val Phe Glu Glu Cys Tyr Phe Glu Leu Ala Asn Ile Val
565 570 575
Pro Leu Tyr Asn Lys Ile Arg Asn Tyr Ile Thr Gln Lys Pro Tyr Ser
580 585 590
Asp Glu Lys Phe Lys Leu Asn Phe Glu Asn Ser Thr Leu Ala Asn Gly
595 600 605
Trp Asp Lys Asn Lys Glu Pro Asp Asn Thr Ala Ile Leu Phe Ile Lys
610 615 620
Asp Asp Lys Tyr Tyr Leu Gly Val Met Asn Lys Lys Asn Asn Lys Ile
625 630 635 640
Phe Asp Asp Lys Ala Ile Lys Glu Asn Lys Gly Glu Gly Tyr Lys Lys
645 650 655
Ile Val Tyr Lys Leu Leu Pro Gly Ala Asn Lys Met Leu Pro Lys Val
660 665 670
Phe Phe Ser Ala Lys Ser Ile Lys Phe Tyr Asn Pro Ser Glu Asp Ile
675 680 685
Leu Arg Ile Arg Asn His Ser Thr His Thr Lys Asn Gly Ser Pro Gln
690 695 700
Lys Gly Tyr Glu Lys Phe Glu Phe Asn Ile Glu Asp Cys Arg Lys Phe
705 710 715 720
Ile Asp Phe Tyr Lys Gln Ser Ile Ser Lys His Pro Glu Trp Lys Asp
725 730 735
Phe Gly Phe Arg Phe Ser Asp Thr Gln Arg Tyr Asn Ser Ile Asp Glu
740 745 750
Phe Tyr Arg Glu Val Glu Asn Gln Gly Tyr Lys Leu Thr Phe Glu Asn
755 760 765
Ile Ser Glu Ser Tyr Ile Asp Ser Val Val Asn Gln Gly Lys Leu Tyr
770 775 780
Leu Phe Gln Ile Tyr Asn Lys Asp Phe Ser Ala Tyr Ser Lys Gly Arg
785 790 795 800
Pro Asn Leu His Thr Leu Tyr Trp Lys Ala Leu Phe Asp Glu Arg Asn
805 810 815
Leu Gln Asp Val Val Tyr Lys Leu Asn Gly Glu Ala Glu Leu Phe Tyr
820 825 830
Arg Lys Gln Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
835 840 845
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Val Phe Glu
850 855 860
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
865 870 875 880
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
885 890 895
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
900 905 910
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
915 920 925
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
930 935 940
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
945 950 955 960
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
965 970 975
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
980 985 990
Ala Lys Leu Val Ile Glu Tyr Asn Ala Ile Val Val Phe Glu Asp Leu
995 1000 1005
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val
1010 1015 1020
Tyr Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu
1025 1030 1035
Val Phe Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg
1040 1045 1050
Ala Tyr Gln Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly
1055 1060 1065
Lys Gln Thr Gly Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser
1070 1075 1080
Lys Ile Cys Pro Val Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys
1085 1090 1095
Tyr Glu Ser Val Ser Lys Ser Gln Glu Phe Phe Ser Lys Phe Asp
1100 1105 1110
Lys Ile Cys Tyr Asn Leu Asp Lys Gly Tyr Phe Glu Phe Ser Phe
1115 1120 1125
Asp Tyr Lys Asn Phe Gly Asp Lys Ala Ala Lys Gly Lys Trp Thr
1130 1135 1140
Ile Ala Ser Phe Gly Ser Arg Leu Ile Asn Phe Arg Asn Ser Asp
1145 1150 1155
Lys Asn His Asn Trp Asp Thr Arg Glu Val Tyr Pro Thr Lys Glu
1160 1165 1170
Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu Tyr Gly His Gly
1175 1180 1185
Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp Lys Lys Phe
1190 1195 1200
Phe Ala Lys Leu Thr Ser Val Leu Asn Thr Ile Leu Gln Met Arg
1205 1210 1215
Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro Val
1220 1225 1230
Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
1235 1240 1245
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly
1250 1255 1260
Leu Lys Gly Leu Met Leu Leu Gly Arg Ile Lys Asn Asn Gln Glu
1265 1270 1275
Gly Lys Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu
1280 1285 1290
Phe Val Gln Asn Arg Asn Asn
1295 1300
<210> 1526
<211> 119
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1526
Phe Ala Lys Gly His His Gly Lys Pro Asn Leu His Thr Leu Tyr Trp
1 5 10 15
Thr Gly Leu Phe Ser Pro Glu Asn Leu Ala Lys Thr Ser Ile Lys Leu
20 25 30
Asn Gly Gln Ala Glu Leu Phe Tyr Arg Pro Lys Ser Arg Met Lys Arg
35 40 45
Met Ala His Arg Leu Gly Glu Lys Met Leu Asn Lys Lys Leu Lys Asp
50 55 60
Gln Lys Thr Pro Ile Pro Asp Thr Leu Tyr Gln Glu Leu Tyr Asp Tyr
65 70 75 80
Val Asn His Arg Leu Ser His Asp Leu Ser Asp Glu Ala Arg Ala Leu
85 90 95
Leu Pro Asn Val Ile Thr Lys Glu Val Ser His Glu Ile Ile Lys Asp
100 105 110
Arg Arg Phe Thr Ser Asp Lys
115
<210> 1527
<211> 118
<212> БЕЛОК
<213> Roseburia intestinalis
<400> 1527
Phe Arg Glu Gly Val Lys Asp Lys Pro Leu Ser Tyr Ile Cys Phe Glu
1 5 10 15
Val Leu Tyr Trp Thr Gly Met Arg Glu Gly Glu Leu Leu Ala Leu Ser
20 25 30
Pro Ala Asp Ile Asp Ile Asp Asn Lys Leu Ile Ser Ile Asn Arg Thr
35 40 45
Tyr Gln Arg Ile Gly Gly Lys Asp Val Phe Thr Ser Pro Lys Thr Arg
50 55 60
Lys Ser Lys Arg Thr Ile Pro Ile Pro Asp Phe Leu Cys Gln Glu Leu
65 70 75 80
Ser Asp Tyr Ile Gln Ser Arg Tyr Met Leu Asp Ala Asp Glu Arg Leu
85 90 95
Phe Pro Val Thr Lys Ser Tyr Leu Ser His Glu Met Ile Arg Gly Cys
100 105 110
Lys Ile Thr Gly Ala Lys
115
<210> 1528
<211> 44
<212> БЕЛОК
<213> Francisella tularensis
<400> 1528
Ala Tyr Ser Lys Gly Arg Pro Asn Leu His Thr Leu Tyr Trp Lys Ala
1 5 10 15
Leu Phe Asp Glu Arg Asn Leu Gln Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Leu Phe Tyr Arg Lys Gln Ser Ile Pro
35 40
<210> 1529
<211> 48
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1529
Ser Tyr Tyr Lys Tyr Gly Asn Glu Lys Val Leu Arg Gly Tyr Glu Gly
1 5 10 15
Val Leu Leu Ser Ile Leu Lys Asp Glu Asn Leu Val Ser Met Arg Thr
20 25 30
Leu Leu Asn Ser Arg Pro Met Leu Val Tyr Arg Pro Lys Glu Ser Ser
35 40 45
<210> 1530
<211> 36
<212> БЕЛОК
<213> Butyrivibrio proteoclasticus
<400> 1530
Pro Tyr Glu Arg Thr Phe Ile Gln Leu Phe Ser Asp Ser Asn Met Glu
1 5 10 15
His Thr Ser Met Leu Leu Asn Ser Arg Ala Met Ile Gln Tyr Arg Ala
20 25 30
Ala Ser Leu Pro
35
<210> 1531
<211> 59
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Falkowbacteria bacterium
<400> 1531
Asp Phe Glu Arg Lys Ser Glu Asp Lys Lys Asn His Thr Ala Asn Leu
1 5 10 15
Phe Thr Gln Tyr Leu Leu Glu Leu Phe Ser Cys Glu Asn Ile Lys Asn
20 25 30
Ile Lys Ser Lys Asp Leu Ile Glu Ser Ile Phe Glu Leu Asp Gly Lys
35 40 45
Ala Glu Ile Arg Phe Arg Pro Lys Thr Asp Asp
50 55
<210> 1532
<211> 43
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Peregrinibacteria bacterium
<400> 1532
Asp Gly Lys Ser Ile Gly His Lys Asn Asn Leu His Thr Ile Tyr Trp
1 5 10 15
Asn Ala Ile Phe Glu Asn Phe Asp Asn Arg Pro Lys Leu Asn Gly Glu
20 25 30
Ala Glu Ile Phe Tyr Arg Lys Ala Ile Ser Lys
35 40
<210> 1533
<211> 44
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность бактерии кандидатного отдела WS6
<400> 1533
Gly Lys Lys Ser Gly Lys Asp Asn Ile His Thr Ile Tyr Trp Lys Tyr
1 5 10 15
Leu Phe Ser Glu Ser Asn Cys Lys Ser Pro Ile Ile Gly Leu Asn Gly
20 25 30
Gly Ala Glu Ile Phe Phe Arg Glu Gly Gln Lys Asp
35 40
<210> 1534
<211> 46
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность некультивируемой бактерии
<400> 1534
Glu Ser Lys Lys Glu Trp Ser Thr Glu Asn Ile His Thr Lys Tyr Phe
1 5 10 15
Lys Leu Leu Phe Asn Glu Lys Asn Leu Gln Asn Leu Val Val Lys Leu
20 25 30
Ser Trp Trp Ala Asp Ile Phe Phe Arg Asp Lys Thr Glu Asn
35 40 45
<210> 1535
<211> 52
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность бактерии группы Parcubacteria
<400> 1535
Leu Asp Lys Ala Arg Asp Gly Lys Ser Lys Thr Thr Gln Lys Asn Leu
1 5 10 15
His Thr Leu Tyr Phe Glu Ser Leu Phe Ser Asn Asp Asn Val Val Gln
20 25 30
Asn Phe Pro Ile Lys Leu Asn Gly Gln Ala Glu Ile Phe Tyr Arg Pro
35 40 45
Lys Thr Glu Lys
50
<210> 1536
<211> 44
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность бактерии группы Parcubacteria
<400> 1536
Asn Thr Lys Asn Gly Ser Lys Asn Leu His Thr Leu Tyr Phe Glu His
1 5 10 15
Ile Leu Ser Ala Glu Asn Leu Asn Asp Pro Val Phe Lys Leu Ser Gly
20 25 30
Met Ala Glu Ile Phe Gln Arg Gln Pro Ser Val Asn
35 40
<210> 1537
<211> 44
<212> БЕЛОК
<213> Helcococcus kunzii
<400> 1537
Asn Thr Lys Asn Gly Ser Lys Asn Leu His Thr Leu Tyr Phe Glu His
1 5 10 15
Ile Leu Ser Ala Glu Asn Leu Asn Asp Pro Val Phe Lys Leu Ser Gly
20 25 30
Met Ala Glu Ile Phe Gln Arg Gln Pro Ser Val Asn
35 40
<210> 1538
<211> 44
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methanomethylophilus alvus
<400> 1538
Pro Glu Ser Lys Gly Lys Lys Asn Leu His Thr Leu Tyr Trp Leu Ser
1 5 10 15
Met Phe Ser Glu Glu Asn Leu Arg Thr Arg Lys Leu Lys Leu Asn Gly
20 25 30
Gln Ala Glu Ile Phe Tyr Arg Lys Lys Leu Glu Lys
35 40
<210> 1539
<211> 44
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 1539
Glu Asn Ala His Gly Asn Lys Asn Met His Thr Met Tyr Trp Glu Gly
1 5 10 15
Leu Phe Ser Pro Gln Asn Leu Glu Ser Pro Val Phe Lys Leu Ser Gly
20 25 30
Gly Ala Glu Leu Phe Phe Arg Lys Ser Ser Ile Pro
35 40
<210> 1540
<211> 44
<212> БЕЛОК
<213> Succinivibrio dextrinosolvens
<400> 1540
Lys Gly His His Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Thr Gly
1 5 10 15
Leu Phe Ser Pro Glu Asn Leu Ala Lys Thr Ser Ile Lys Leu Asn Gly
20 25 30
Gln Ala Glu Leu Phe Tyr Arg Pro Lys Ser Arg Met
35 40
<210> 1541
<211> 44
<212> БЕЛОК
<213> Eubacterium sp.
<400> 1541
Ser Lys Ser Thr Gly Thr Lys Asn Leu His Thr Leu Tyr Leu Gln Ala
1 5 10 15
Ile Phe Asp Glu Arg Asn Leu Asn Asn Pro Thr Ile Met Leu Asn Gly
20 25 30
Gly Ala Glu Leu Phe Tyr Arg Lys Glu Ser Ile Glu
35 40
<210> 1542
<211> 44
<212> БЕЛОК
<213> Eubacterium eligens
<400> 1542
Ala His Ser Thr Gly Arg Asp Asn Leu His Thr Met Tyr Leu Lys Asn
1 5 10 15
Ile Phe Ser Glu Asp Asn Leu Lys Asn Ile Cys Ile Glu Leu Asn Gly
20 25 30
Glu Ala Glu Leu Phe Tyr Arg Lys Ser Ser Met Lys
35 40
<210> 1543
<211> 44
<212> БЕЛОК
<213> Eubacterium eligens
<400> 1543
Glu Asn Ser Thr Gly Lys Glu Asn Leu His Thr Met Tyr Phe Lys Asn
1 5 10 15
Ile Phe Ser Glu Glu Asn Leu Lys Asn Ile Val Ile Lys Leu Asn Gly
20 25 30
Gln Ala Glu Leu Phe Tyr Arg Lys Ala Ser Val Lys
35 40
<210> 1544
<211> 44
<212> БЕЛОК
<213> Proteocatella sphenisci
<400> 1544
Glu Asn Ser Thr Gly Lys Glu Asn Leu His Thr Met Tyr Phe Lys Asn
1 5 10 15
Ile Phe Ser Glu Glu Asn Leu Lys Asp Ile Ile Ile Lys Leu Asn Gly
20 25 30
Gln Ala Glu Leu Phe Tyr Arg Arg Ala Ser Val Lys
35 40
<210> 1545
<211> 44
<212> БЕЛОК
<213> Anaerovibrio sp.
<400> 1545
Ile Asp Ser Lys Gly Thr Lys Asn Leu Asn Thr Ile Tyr Phe Glu Ser
1 5 10 15
Leu Phe Ser Glu Glu Asn Met Ile Glu Lys Met Phe Lys Leu Ser Gly
20 25 30
Glu Ala Glu Ile Phe Tyr Arg Pro Ala Ser Leu Asn
35 40
<210> 1546
<211> 52
<212> БЕЛОК
<213> Prevotella disiens
<400> 1546
Asp Lys Lys Lys Lys Lys Gly Thr Asp Asn Leu His Thr Met Tyr Trp
1 5 10 15
His Gly Val Phe Ser Asp Glu Asn Leu Lys Ala Val Thr Glu Gly Thr
20 25 30
Gln Pro Ile Ile Lys Leu Asn Gly Glu Ala Glu Met Phe Met Arg Asn
35 40 45
Pro Ser Ile Glu
50
<210> 1547
<211> 47
<212> БЕЛОК
<213> Porphyromonas macacae
<400> 1547
Lys Thr Phe Ser Ala Asn Leu Arg Lys Lys Arg Gly Ala Glu Asn Leu
1 5 10 15
His Thr Met Leu Phe Lys Ala Leu Met Glu Gly Asn Gln Asp Asn Leu
20 25 30
Asp Leu Gly Ser Gly Ala Ile Phe Tyr Arg Ala Lys Ser Leu Asp
35 40 45
<210> 1548
<211> 43
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Candidatus Methanoplasma termitum
<400> 1548
Pro Tyr Ser Lys Gly Ile Pro Asn Leu His Thr Leu Tyr Trp Lys Ala
1 5 10 15
Leu Phe Ser Glu Gln Asn Gln Ser Arg Val Tyr Lys Leu Cys Gly Gly
20 25 30
Gly Glu Leu Phe Tyr Arg Lys Ala Ser Leu His
35 40
<210> 1549
<211> 44
<212> БЕЛОК
<213> Synergistes jonesii
<400> 1549
Lys Ala Ala Thr Gly Lys Lys Asp Met His Thr Ile Tyr Trp Asn Ala
1 5 10 15
Ala Phe Ser Pro Glu Asn Leu Gln Asp Val Val Val Lys Leu Asn Gly
20 25 30
Glu Ala Glu Leu Phe Tyr Arg Asp Lys Ser Asp Ile
35 40
<210> 1550
<211> 44
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1550
Asp Gly Ala Gln Gly Ser Pro Asn Leu His Thr Leu Tyr Trp Lys Ala
1 5 10 15
Ile Phe Ser Glu Glu Asn Leu Lys Asp Val Val Leu Lys Leu Asn Gly
20 25 30
Glu Ala Glu Leu Phe Phe Arg Arg Lys Ser Ile Asp
35 40
<210> 1551
<211> 42
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1551
Asp Lys Ser His Gly Thr Pro Asn Leu His Thr Met Tyr Phe Lys Leu
1 5 10 15
Leu Phe Asp Glu Asn Asn His Gly Gln Ile Arg Leu Ser Gly Gly Ala
20 25 30
Glu Leu Phe Met Arg Arg Ala Ser Leu Lys
35 40
<210> 1552
<211> 44
<212> БЕЛОК
<213> Francisella tularensis
<400> 1552
Glu His Ser Lys Gly Lys Pro Asn Leu His Thr Val Tyr Trp Asn Ala
1 5 10 15
Leu Phe Ser Glu Tyr Asn Leu Gln Asn Thr Val Tyr Gln Leu Asn Gly
20 25 30
Ser Ala Glu Ile Phe Phe Arg Lys Ala Ser Ile Pro
35 40
<210> 1553
<211> 44
<212> БЕЛОК
<213> Francisella tularensis
<400> 1553
Ala Tyr Ser Lys Gly Arg Pro Asn Leu His Thr Leu Tyr Trp Lys Ala
1 5 10 15
Leu Phe Asp Glu Arg Asn Leu Gln Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Leu Phe Tyr Arg Lys Gln Ser Ile Pro
35 40
<210> 1554
<211> 44
<212> БЕЛОК
<213> Francisella tularensis
<400> 1554
Ala Tyr Ser Lys Gly Arg Pro Asn Leu His Thr Leu Tyr Trp Lys Ala
1 5 10 15
Leu Phe Asp Glu Arg Asn Leu Gln Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Leu Phe Tyr Arg Lys Lys Ser Ile Pro
35 40
<210> 1555
<211> 44
<212> БЕЛОК
<213> Francisella tularensis
<400> 1555
Ala Tyr Ser Lys Gly Arg Pro Asn Leu His Thr Leu Tyr Trp Lys Ala
1 5 10 15
Leu Phe Asp Glu Arg Asn Leu Gln Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Leu Phe Tyr Arg Lys Gln Ser Ile Pro
35 40
<210> 1556
<211> 44
<212> БЕЛОК
<213> Francisella tularensis
<400> 1556
Ala Tyr Ser Lys Gly Arg Pro Asn Leu His Thr Leu Tyr Trp Lys Ala
1 5 10 15
Leu Phe Asp Glu Arg Asn Leu Gln Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Leu Phe Tyr Arg Lys Gln Ser Ile Pro
35 40
<210> 1557
<211> 44
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1557
Glu Tyr Ala Thr Gly Asn Leu Asn Leu His Thr Leu Tyr Leu Lys Met
1 5 10 15
Leu Phe Asp Glu Arg Asn Leu Lys Asp Leu Cys Ile Lys Met Asn Gly
20 25 30
Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Leu
35 40
<210> 1558
<211> 44
<212> БЕЛОК
<213> Butyrivibrio fibrisolvens
<400> 1558
Glu Tyr Ser Lys Gly Arg Leu Asn Leu His Thr Leu Tyr Phe Lys Met
1 5 10 15
Leu Phe Asp Glu Arg Asn Leu Lys Asn Val Val Tyr Lys Leu Asn Gly
20 25 30
Gln Ala Glu Val Phe Tyr Arg Pro Ser Ser Ile Lys
35 40
<210> 1559
<211> 44
<212> БЕЛОК
<213> Pseudobutyrivibrio ruminis
<400> 1559
Pro Tyr Ser Lys Gly Asn Leu Asn Leu His Thr Ile Tyr Leu Gln Met
1 5 10 15
Leu Phe Asp Gln Arg Asn Leu Asn Asn Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Asn
35 40
<210> 1560
<211> 44
<212> БЕЛОК
<213> Oribacterium sp.
<400> 1560
Pro Tyr Ser Lys Gly Lys Leu Asn Leu His Thr Leu Tyr Phe Lys Met
1 5 10 15
Leu Phe Asp Gln Arg Asn Leu Asp Asn Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Glu
35 40
<210> 1561
<211> 44
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1561
Met Tyr Ser Lys Gly Lys Leu Asn Leu His Thr Leu Tyr Phe Met Met
1 5 10 15
Leu Phe Asp Gln Arg Asn Ile Asp Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Ser
35 40
<210> 1562
<211> 44
<212> БЕЛОК
<213> Butyrivibrio sp.
<400> 1562
Glu Tyr Ser Lys Gly Lys Leu Asn Leu His Thr Leu Tyr Phe Met Met
1 5 10 15
Leu Phe Asp Gln Arg Asn Leu Asp Asn Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Val Phe Tyr Arg Pro Ala Ser Ile Ala
35 40
<210> 1563
<211> 44
<212> БЕЛОК
<213> Moraxella caprae
<400> 1563
Pro Lys Ala His Gly Lys Pro Asn Leu His Thr Leu Tyr Phe Lys Ala
1 5 10 15
Leu Phe Ser Lys Asp Asn Leu Ala Asn Pro Ile Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Gln Ile Phe Tyr Arg Lys Ala Ser Leu Asp
35 40
<210> 1564
<211> 44
<212> БЕЛОК
<213> Moraxella bovoculi
<400> 1564
Pro Lys Ala His Gly Lys Pro Asn Leu His Thr Leu Tyr Phe Lys Ala
1 5 10 15
Leu Phe Ser Glu Asp Asn Leu Ala Asp Pro Ile Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Gln Ile Phe Tyr Arg Lys Ala Ser Leu Asp
35 40
<210> 1565
<211> 44
<212> БЕЛОК
<213> Leptospira inadai
<400> 1565
Ile Phe Ser Lys Gly Lys Pro Asn Leu His Thr Ile Tyr Phe Arg Ser
1 5 10 15
Leu Phe Ser Lys Glu Asn Leu Lys Asp Val Cys Leu Lys Leu Asn Gly
20 25 30
Glu Ala Glu Met Phe Phe Arg Lys Lys Ser Ile Asn
35 40
<210> 1566
<211> 44
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1566
Pro Tyr Ser Lys Gly Thr Lys Asn Leu His Thr Leu Tyr Trp Glu Met
1 5 10 15
Leu Phe Ser Gln Gln Asn Leu Gln Asn Ile Val Tyr Lys Leu Asn Gly
20 25 30
Asn Ala Glu Ile Phe Tyr Arg Lys Ala Ser Ile Asn
35 40
<210> 1567
<211> 44
<212> БЕЛОК
<213> Smithella sp.
<400> 1567
Pro Phe Ser Lys Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Lys Met
1 5 10 15
Leu Phe Asp Glu Asn Asn Leu Lys Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Val Phe Tyr Arg Lys Lys Ser Ile Ala
35 40
<210> 1568
<211> 44
<212> БЕЛОК
<213> Smithella sp.
<400> 1568
Pro Phe Ser Lys Gly Lys Pro Asn Leu His Thr Leu Tyr Trp Lys Met
1 5 10 15
Leu Phe Asp Glu Asn Asn Leu Lys Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Val Phe Tyr Arg Lys Lys Ser Ile Ala
35 40
<210> 1569
<211> 44
<212> БЕЛОК
<213> Flavobacterium sp.
<400> 1569
Pro Tyr Ala Lys Gly Lys Pro Asn Met His Thr Leu Tyr Trp Lys Ala
1 5 10 15
Leu Phe Glu Thr Gln Asn Leu Glu Asn Val Ile Tyr Lys Leu Asn Gly
20 25 30
Gln Ala Glu Ile Phe Phe Arg Lys Ala Ser Ile Lys
35 40
<210> 1570
<211> 44
<212> БЕЛОК
<213> Flavobacterium branchiophilum
<400> 1570
Pro Phe Ser Lys Gly Lys Pro Asn Met His Thr Leu Tyr Trp Lys Ala
1 5 10 15
Leu Phe Glu Glu Gln Asn Leu Gln Asn Val Ile Tyr Lys Leu Asn Gly
20 25 30
Gln Ala Glu Ile Phe Phe Arg Lys Ala Ser Ile Lys
35 40
<210> 1571
<211> 44
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 1571
Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr Trp Arg Met
1 5 10 15
Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys Leu Asp Gly
20 25 30
Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys
35 40
<210> 1572
<211> 44
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 1572
Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr Trp Arg Met
1 5 10 15
Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys Leu Asp Gly
20 25 30
Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys
35 40
<210> 1573
<211> 44
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 1573
Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr Trp Arg Met
1 5 10 15
Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys Leu Asp Gly
20 25 30
Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys
35 40
<210> 1574
<211> 44
<212> БЕЛОК
<213> Porphyromonas crevioricanis
<400> 1574
Pro Cys Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr Trp Arg Met
1 5 10 15
Leu Phe Asp Glu Arg Asn Leu Ala Asp Val Ile Tyr Lys Leu Asp Gly
20 25 30
Lys Ala Glu Ile Phe Phe Arg Glu Lys Ser Leu Lys
35 40
<210> 1575
<211> 44
<212> БЕЛОК
<213> Prevotella brevis
<400> 1575
Thr Tyr Ser Lys Gly Thr Pro Asn Met His Thr Leu Tyr Trp Lys Met
1 5 10 15
Leu Phe Asp Glu Ser Asn Leu Asn Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Gln Ala Glu Val Phe Tyr Arg Lys Lys Ser Ile Thr
35 40
<210> 1576
<211> 44
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Bacteroidetes из ротовой полости, таксон 274
<400> 1576
Ala His Ser Lys Gly Thr Pro Asn Met His Thr Leu Tyr Trp Lys Met
1 5 10 15
Leu Phe Asp Glu Glu Asn Leu Lys Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Glu Ala Glu Val Phe Phe Arg Lys Ser Ser Ile Thr
35 40
<210> 1577
<211> 44
<212> БЕЛОК
<213> Prevotella albensis
<400> 1577
Gln Phe Ser Lys Gly Thr Pro Asn Leu His Thr Leu Tyr Trp Lys Met
1 5 10 15
Leu Phe Asp Lys Arg Asn Leu Ser Asp Val Val Tyr Lys Leu Asn Gly
20 25 30
Gln Ala Glu Val Phe Tyr Arg Lys Ser Ser Ile Glu
35 40
<210> 1578
<211> 44
<212> БЕЛОК
<213> Prevotella bryantii
<400> 1578
Glu Phe Ser Lys Gly Thr Pro Asn Met His Thr Leu Tyr Trp Asn Ser
1 5 10 15
Leu Phe Ser Lys Glu Asn Leu Asn Asn Ile Ile Tyr Lys Leu Asn Gly
20 25 30
Gln Ala Glu Ile Phe Phe Arg Lys Lys Ser Leu Asn
35 40
<210> 1579
<211> 44
<212> БЕЛОК
<213> Prevotella bryantii
<400> 1579
Glu Phe Ser Lys Gly Thr Pro Asn Met His Thr Leu Tyr Trp Asn Ser
1 5 10 15
Leu Phe Ser Lys Glu Asn Leu Asn Asn Ile Ile Tyr Lys Leu Asn Gly
20 25 30
Gln Ala Glu Ile Phe Phe Arg Lys Lys Ser Leu Asn
35 40
<210> 1580
<211> 43
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический олигонуклеотид
<400> 1580
aatttctact gttgtagatg agaagtcatt taataaggcc act 43
<210> 1581
<211> 468
<212> БЕЛОК
<213> Francisella tularensis
<400> 1581
Arg Lys Gln Ser Ile Pro Lys Lys Ile Thr His Pro Ala Lys Glu Ala
1 5 10 15
Ile Ala Asn Lys Asn Lys Asp Asn Pro Lys Lys Glu Ser Val Phe Glu
20 25 30
Tyr Asp Leu Ile Lys Asp Lys Arg Phe Thr Glu Asp Lys Phe Phe Phe
35 40 45
His Cys Pro Ile Thr Ile Asn Phe Lys Ser Ser Gly Ala Asn Lys Phe
50 55 60
Asn Asp Glu Ile Asn Leu Leu Leu Lys Glu Lys Ala Asn Asp Val His
65 70 75 80
Ile Leu Ser Ile Asp Arg Gly Glu Arg His Leu Ala Tyr Tyr Thr Leu
85 90 95
Val Asp Gly Lys Gly Asn Ile Ile Lys Gln Asp Thr Phe Asn Ile Ile
100 105 110
Gly Asn Asp Arg Met Lys Thr Asn Tyr His Asp Lys Leu Ala Ala Ile
115 120 125
Glu Lys Asp Arg Asp Ser Ala Arg Lys Asp Trp Lys Lys Ile Asn Asn
130 135 140
Ile Lys Glu Met Lys Glu Gly Tyr Leu Ser Gln Val Val His Glu Ile
145 150 155 160
Ala Lys Leu Val Ile Glu Tyr Asn Ala Ile Val Val Phe Glu Asp Leu
165 170 175
Asn Phe Gly Phe Lys Arg Gly Arg Phe Lys Val Glu Lys Gln Val Tyr
180 185 190
Gln Lys Leu Glu Lys Met Leu Ile Glu Lys Leu Asn Tyr Leu Val Phe
195 200 205
Lys Asp Asn Glu Phe Asp Lys Thr Gly Gly Val Leu Arg Ala Tyr Gln
210 215 220
Leu Thr Ala Pro Phe Glu Thr Phe Lys Lys Met Gly Lys Gln Thr Gly
225 230 235 240
Ile Ile Tyr Tyr Val Pro Ala Gly Phe Thr Ser Lys Ile Cys Pro Val
245 250 255
Thr Gly Phe Val Asn Gln Leu Tyr Pro Lys Tyr Glu Ser Val Ser Lys
260 265 270
Ser Gln Glu Phe Phe Ser Lys Phe Asp Lys Ile Cys Tyr Asn Leu Asp
275 280 285
Lys Gly Tyr Phe Glu Phe Ser Phe Asp Tyr Lys Asn Phe Gly Asp Lys
290 295 300
Ala Ala Lys Gly Lys Trp Thr Ile Ala Ser Phe Gly Ser Arg Leu Ile
305 310 315 320
Asn Phe Arg Asn Ser Asp Lys Asn His Asn Trp Asp Thr Arg Glu Val
325 330 335
Tyr Pro Thr Lys Glu Leu Glu Lys Leu Leu Lys Asp Tyr Ser Ile Glu
340 345 350
Tyr Gly His Gly Glu Cys Ile Lys Ala Ala Ile Cys Gly Glu Ser Asp
355 360 365
Lys Lys Phe Phe Ala Lys Leu Thr Ser Val Leu Asn Thr Ile Leu Gln
370 375 380
Met Arg Asn Ser Lys Thr Gly Thr Glu Leu Asp Tyr Leu Ile Ser Pro
385 390 395 400
Val Ala Asp Val Asn Gly Asn Phe Phe Asp Ser Arg Gln Ala Pro Lys
405 410 415
Asn Met Pro Gln Asp Ala Asp Ala Asn Gly Ala Tyr His Ile Gly Leu
420 425 430
Lys Gly Leu Met Leu Leu Gly Arg Ile Lys Asn Asn Gln Glu Gly Lys
435 440 445
Lys Leu Asn Leu Val Ile Lys Asn Glu Glu Tyr Phe Glu Phe Val Gln
450 455 460
Asn Arg Asn Asn
465
<210> 1582
<211> 518
<212> БЕЛОК
<213> Acidaminococcus sp.
<400> 1582
Arg Pro Lys Ser Arg Met Lys Arg Met Ala His Arg Leu Gly Glu Lys
1 5 10 15
Met Leu Asn Lys Lys Leu Lys Asp Gln Lys Thr Pro Ile Pro Asp Thr
20 25 30
Leu Tyr Gln Glu Leu Tyr Asp Tyr Val Asn His Arg Leu Ser His Asp
35 40 45
Leu Ser Asp Glu Ala Arg Ala Leu Leu Pro Asn Val Ile Thr Lys Glu
50 55 60
Val Ser His Glu Ile Ile Lys Asp Arg Arg Phe Thr Ser Asp Lys Phe
65 70 75 80
Phe Phe His Val Pro Ile Thr Leu Asn Tyr Gln Ala Ala Asn Ser Pro
85 90 95
Ser Lys Phe Asn Gln Arg Val Asn Ala Tyr Leu Lys Glu His Pro Glu
100 105 110
Thr Pro Ile Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Ile Tyr Ile
115 120 125
Thr Val Ile Asp Ser Thr Gly Lys Ile Leu Glu Gln Arg Ser Leu Asn
130 135 140
Thr Ile Gln Gln Phe Asp Tyr Gln Lys Lys Leu Asp Asn Arg Glu Lys
145 150 155 160
Glu Arg Val Ala Ala Arg Gln Ala Trp Ser Val Val Gly Thr Ile Lys
165 170 175
Asp Leu Lys Gln Gly Tyr Leu Ser Gln Val Ile His Glu Ile Val Asp
180 185 190
Leu Met Ile His Tyr Gln Ala Val Val Val Leu Glu Asn Leu Asn Phe
195 200 205
Gly Phe Lys Ser Lys Arg Thr Gly Ile Ala Glu Lys Ala Val Tyr Gln
210 215 220
Gln Phe Glu Lys Met Leu Ile Asp Lys Leu Asn Cys Leu Val Leu Lys
225 230 235 240
Asp Tyr Pro Ala Glu Lys Val Gly Gly Val Leu Asn Pro Tyr Gln Leu
245 250 255
Thr Asp Gln Phe Thr Ser Phe Ala Lys Met Gly Thr Gln Ser Gly Phe
260 265 270
Leu Phe Tyr Val Pro Ala Pro Tyr Thr Ser Lys Ile Asp Pro Leu Thr
275 280 285
Gly Phe Val Asp Pro Phe Val Trp Lys Thr Ile Lys Asn His Glu Ser
290 295 300
Arg Lys His Phe Leu Glu Gly Phe Asp Phe Leu His Tyr Asp Val Lys
305 310 315 320
Thr Gly Asp Phe Ile Leu His Phe Lys Met Asn Arg Asn Leu Ser Phe
325 330 335
Gln Arg Gly Leu Pro Gly Phe Met Pro Ala Trp Asp Ile Val Phe Glu
340 345 350
Lys Asn Glu Thr Gln Phe Asp Ala Lys Gly Thr Pro Phe Ile Ala Gly
355 360 365
Lys Arg Ile Val Pro Val Ile Glu Asn His Arg Phe Thr Gly Arg Tyr
370 375 380
Arg Asp Leu Tyr Pro Ala Asn Glu Leu Ile Ala Leu Leu Glu Glu Lys
385 390 395 400
Gly Ile Val Phe Arg Asp Gly Ser Asn Ile Leu Pro Lys Leu Leu Glu
405 410 415
Asn Asp Asp Ser His Ala Ile Asp Thr Met Val Ala Leu Ile Arg Ser
420 425 430
Val Leu Gln Met Arg Asn Ser Asn Ala Ala Thr Gly Glu Asp Tyr Ile
435 440 445
Asn Ser Pro Val Arg Asp Leu Asn Gly Val Cys Phe Asp Ser Arg Phe
450 455 460
Gln Asn Pro Glu Trp Pro Met Asp Ala Asp Ala Asn Gly Ala Tyr His
465 470 475 480
Ile Ala Leu Lys Gly Gln Leu Leu Leu Asn His Leu Lys Glu Ser Lys
485 490 495
Asp Leu Lys Leu Gln Asn Gly Ile Ser Asn Gln Asp Trp Leu Ala Tyr
500 505 510
Ile Gln Glu Leu Arg Asn
515
<210> 1583
<211> 482
<212> БЕЛОК
<213> Неустановленное
<220>
<223> Описание неизвестного: Последовательность Lachnospiraceae bacterium
<400> 1583
Arg Arg Ala Ser Leu Lys Lys Glu Glu Leu Val Val His Pro Ala Asn
1 5 10 15
Ser Pro Ile Ala Asn Lys Asn Pro Asp Asn Pro Lys Lys Thr Thr Thr
20 25 30
Leu Ser Tyr Asp Val Tyr Lys Asp Lys Arg Phe Ser Glu Asp Gln Tyr
35 40 45
Glu Leu His Ile Pro Ile Ala Ile Asn Lys Cys Pro Lys Asn Ile Phe
50 55 60
Lys Ile Asn Thr Glu Val Arg Val Leu Leu Lys His Asp Asp Asn Pro
65 70 75 80
Tyr Val Ile Gly Ile Asp Arg Gly Glu Arg Asn Leu Leu Tyr Ile Val
85 90 95
Val Val Asp Gly Lys Gly Asn Ile Val Glu Gln Tyr Ser Leu Asn Glu
100 105 110
Ile Ile Asn Asn Phe Asn Gly Ile Arg Ile Lys Thr Asp Tyr His Ser
115 120 125
Leu Leu Asp Lys Lys Glu Lys Glu Arg Phe Glu Ala Arg Gln Asn Trp
130 135 140
Thr Ser Ile Glu Asn Ile Lys Glu Leu Lys Ala Gly Tyr Ile Ser Gln
145 150 155 160
Val Val His Lys Ile Cys Glu Leu Val Glu Lys Tyr Asp Ala Val Ile
165 170 175
Ala Leu Glu Asp Leu Asn Ser Gly Phe Lys Asn Ser Arg Val Lys Val
180 185 190
Glu Lys Gln Val Tyr Gln Lys Phe Glu Lys Met Leu Ile Asp Lys Leu
195 200 205
Asn Tyr Met Val Asp Lys Lys Ser Asn Pro Cys Ala Thr Gly Gly Ala
210 215 220
Leu Lys Gly Tyr Gln Ile Thr Asn Lys Phe Glu Ser Phe Lys Ser Met
225 230 235 240
Ser Thr Gln Asn Gly Phe Ile Phe Tyr Ile Pro Ala Trp Leu Thr Ser
245 250 255
Lys Ile Asp Pro Ser Thr Gly Phe Val Asn Leu Leu Lys Thr Lys Tyr
260 265 270
Thr Ser Ile Ala Asp Ser Lys Lys Phe Ile Ser Ser Phe Asp Arg Ile
275 280 285
Met Tyr Val Pro Glu Glu Asp Leu Phe Glu Phe Ala Leu Asp Tyr Lys
290 295 300
Asn Phe Ser Arg Thr Asp Ala Asp Tyr Ile Lys Lys Trp Lys Leu Tyr
305 310 315 320
Ser Tyr Gly Asn Arg Ile Arg Ile Phe Arg Asn Pro Lys Lys Asn Asn
325 330 335
Val Phe Asp Trp Glu Glu Val Cys Leu Thr Ser Ala Tyr Lys Glu Leu
340 345 350
Phe Asn Lys Tyr Gly Ile Asn Tyr Gln Gln Gly Asp Ile Arg Ala Leu
355 360 365
Leu Cys Glu Gln Ser Asp Lys Ala Phe Tyr Ser Ser Phe Met Ala Leu
370 375 380
Met Ser Leu Met Leu Gln Met Arg Asn Ser Ile Thr Gly Arg Thr Asp
385 390 395 400
Val Asp Phe Leu Ile Ser Pro Val Lys Asn Ser Asp Gly Ile Phe Tyr
405 410 415
Asp Ser Arg Asn Tyr Glu Ala Gln Glu Asn Ala Ile Leu Pro Lys Asn
420 425 430
Ala Asp Ala Asn Gly Ala Tyr Asn Ile Ala Arg Lys Val Leu Trp Ala
435 440 445
Ile Gly Gln Phe Lys Lys Ala Glu Asp Glu Lys Leu Asp Lys Val Lys
450 455 460
Ile Ala Ile Ser Asn Lys Glu Trp Leu Glu Tyr Ala Gln Thr Ser Val
465 470 475 480
Lys His
<210> 1584
<211> 5
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический пептид
<400> 1584
Gly Gly Gly Gly Ser
1 5
<210> 1585
<211> 10
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический пептид
<400> 1585
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10
<210> 1586
<211> 20
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический пептид
<400> 1586
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser
20
<210> 1587
<211> 25
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический пептид
<400> 1587
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25
<210> 1588
<211> 35
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1588
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser
35
<210> 1589
<211> 40
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1589
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser
35 40
<210> 1590
<211> 50
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1590
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser
50
<210> 1591
<211> 55
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полипептид
<400> 1591
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser
50 55
<210> 1592
<211> 120
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический полинуклеотид
<400> 1592
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 60
aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa aaaaaaaaaa 120
<210> 1593
<211> 4
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический пептид
<400> 1593
Gly Gly Gly Ser
1
<210> 1594
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический пептид
<400> 1594
Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser
1 5 10
<210> 1595
<211> 7
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности: Синтетический пептид
<400> 1595
Ala Glu Ala Ala Ala Lys Ala
1 5
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| НОВЫЕ ФЕРМЕНТЫ И СИСТЕМЫ CRISPR | 2023 |
|
RU2832308C2 |
| НОВЫЕ ФЕРМЕНТЫ И СИСТЕМЫ CRISPR | 2016 |
|
RU2777988C2 |
| НОВЫЕ ФЕРМЕНТЫ CRISPR И СИСТЕМЫ | 2016 |
|
RU2771826C2 |
| КОМПОЗИЦИИ И СПОСОБЫ РЕДАКТИРОВАНИЯ ГЕНОВ | 2019 |
|
RU2804665C2 |
| КОНСТРУИРОВАНИЕ СИСТЕМ, СПОСОБЫ И ОПТИМИЗИРОВАННЫЕ НАПРАВЛЯЮЩИЕ КОМПОЗИЦИИ ДЛЯ МАНИПУЛЯЦИИ С ПОСЛЕДОВАТЕЛЬНОСТЯМИ | 2013 |
|
RU2796017C2 |
| ШТАММ ESCHERICHIA COLI BL21(DE3)PLYSS/PET15B-HISCPF1 - ПРОДУЦЕНТ РНК-НАПРАВЛЯЕМОЙ ЭНДОНУКЛЕАЗЫ CRISPR/CPF1 | 2021 |
|
RU2774120C1 |
| КОМПОЗИЦИИ И СПОСОБЫ ДЛЯ ИЗБИРАТЕЛЬНОЙ ЭКСПРЕССИИ БЕЛКА | 2017 |
|
RU2795467C2 |
| НЕВИРУСНЫЙ ИММУНОТАРГЕТИНГ | 2020 |
|
RU2833379C2 |
| T-КЛЕТОЧНЫЕ РЕЦЕПТОРЫ, РАСПОЗНАЮЩИЕ МУТАЦИЮ R175H ИЛИ Y220C В P53 | 2020 |
|
RU2830061C2 |
| КОМПОЗИЦИИ И СПОСОБЫ ДЕГРАДАЦИИ НЕПРАВИЛЬНО УПАКОВАННЫХ БЕЛКОВ | 2016 |
|
RU2761564C2 |
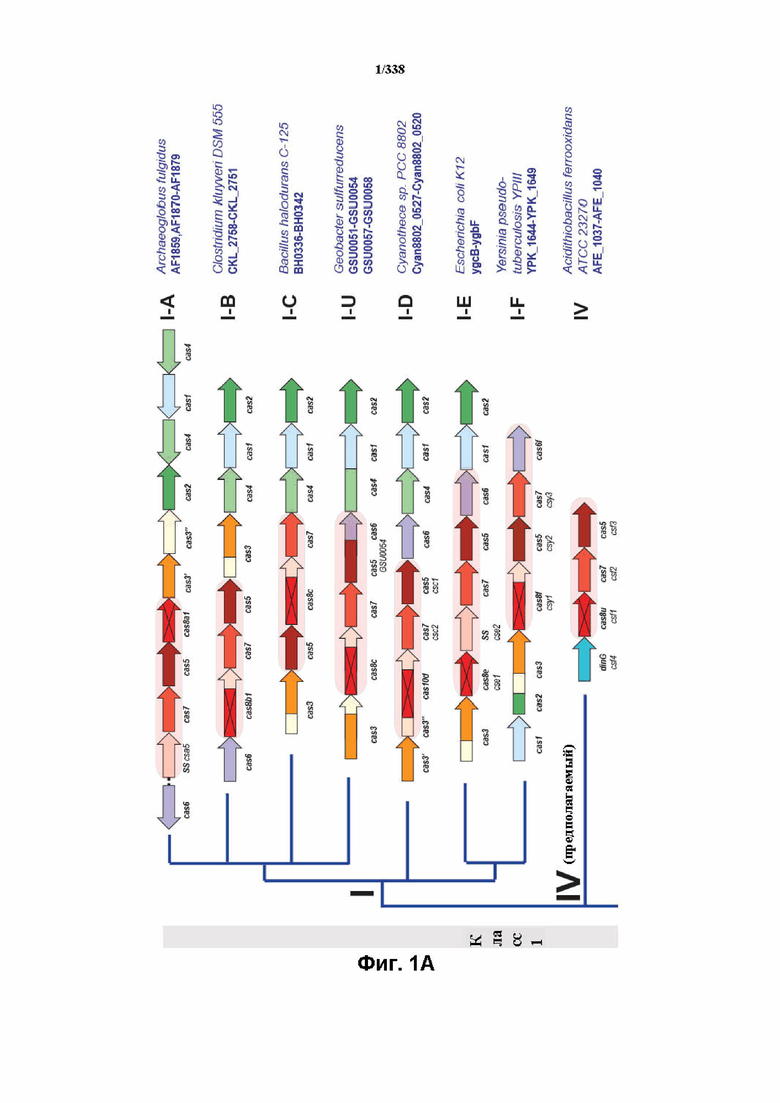
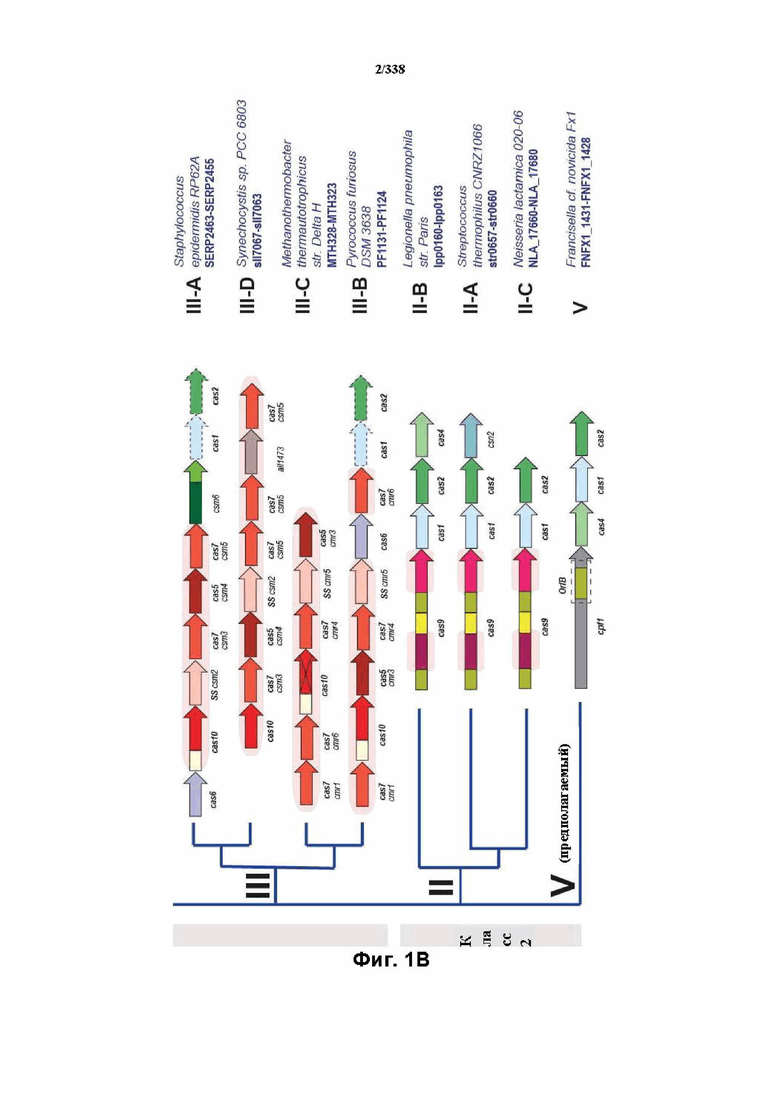

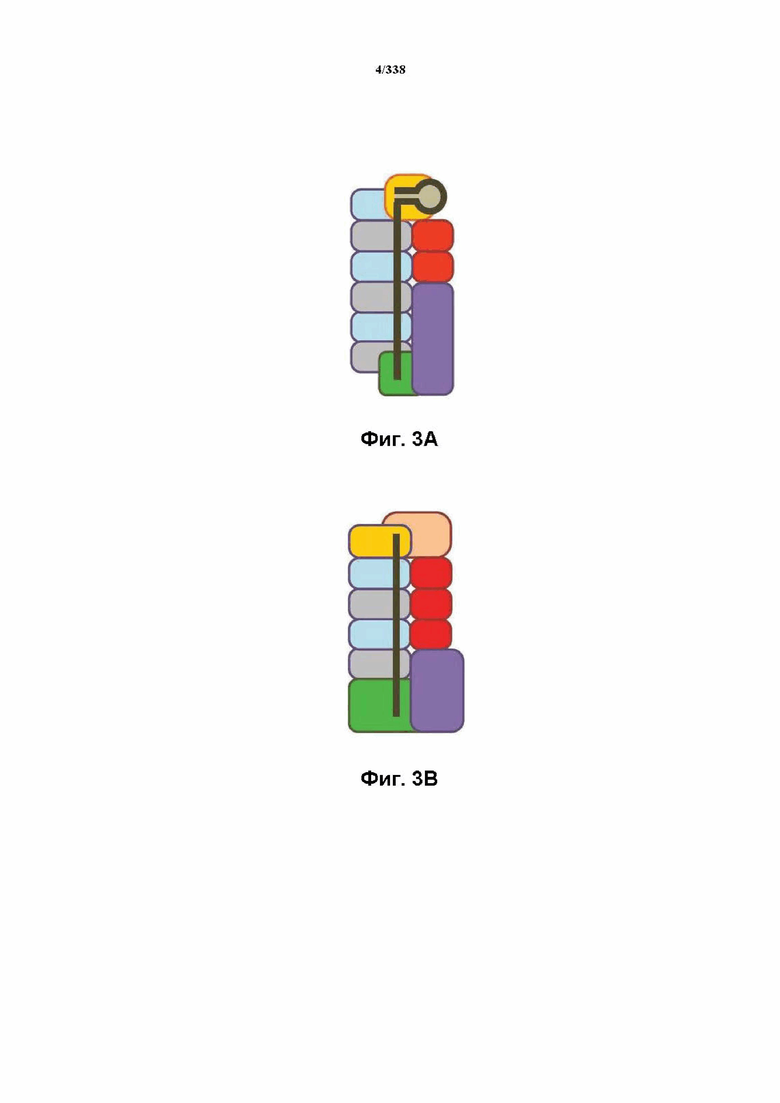

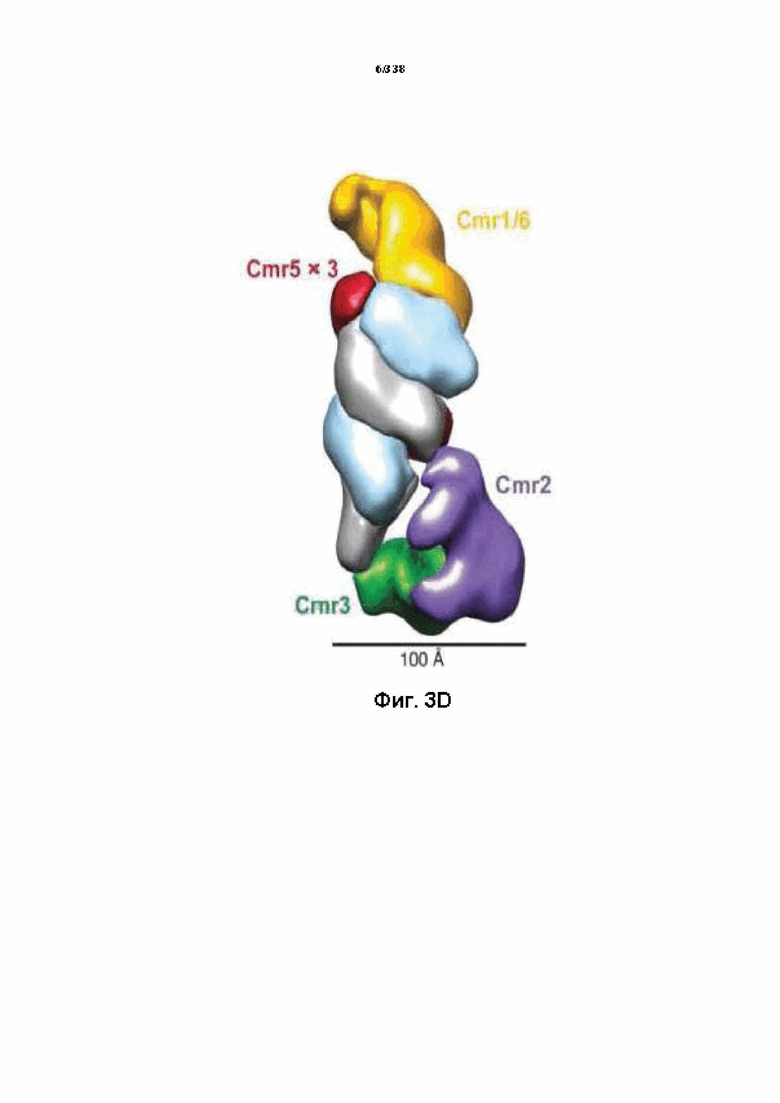
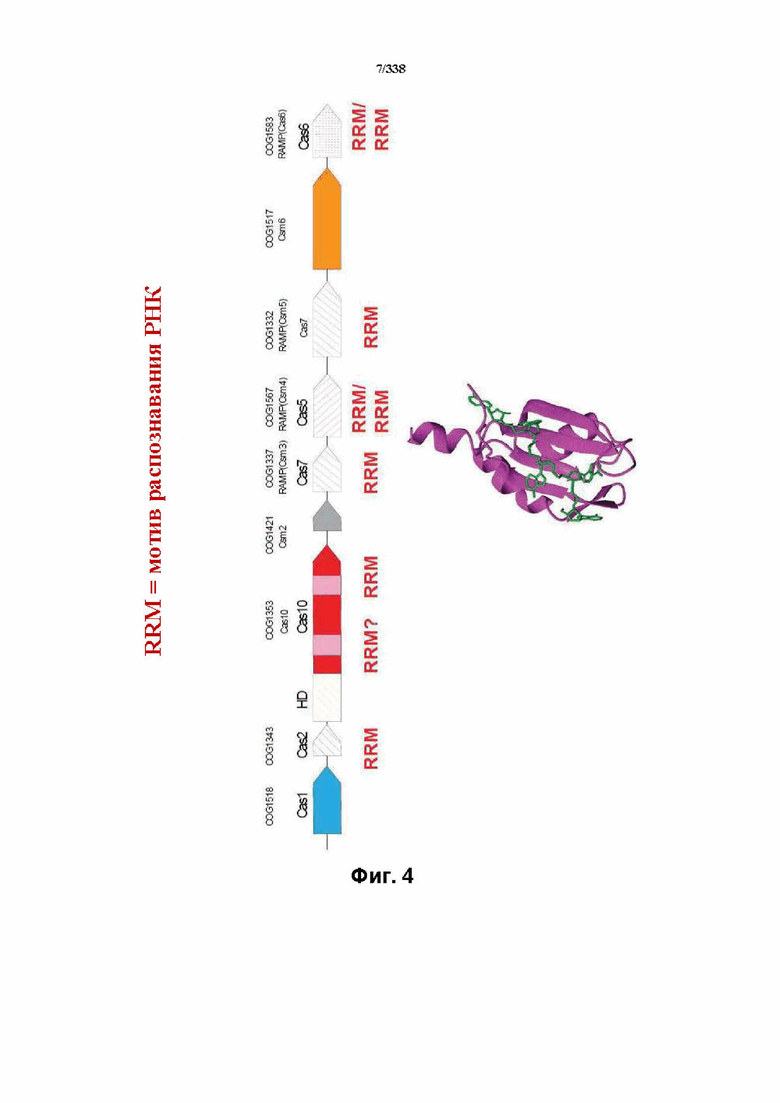
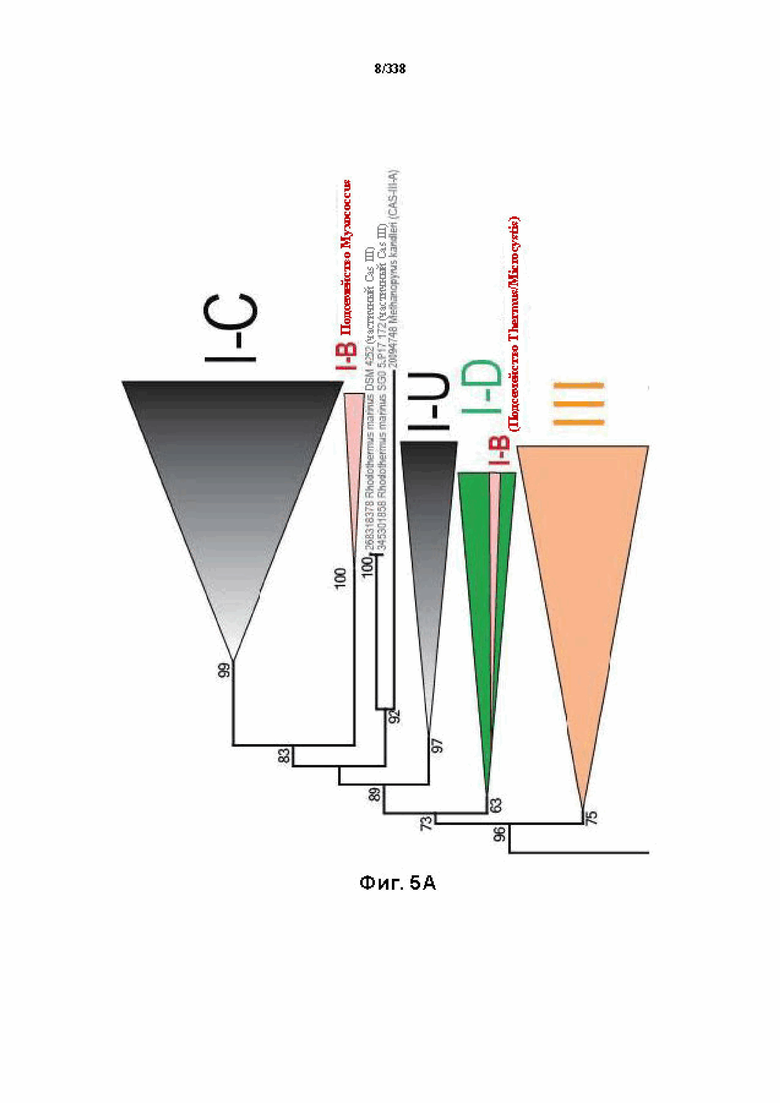
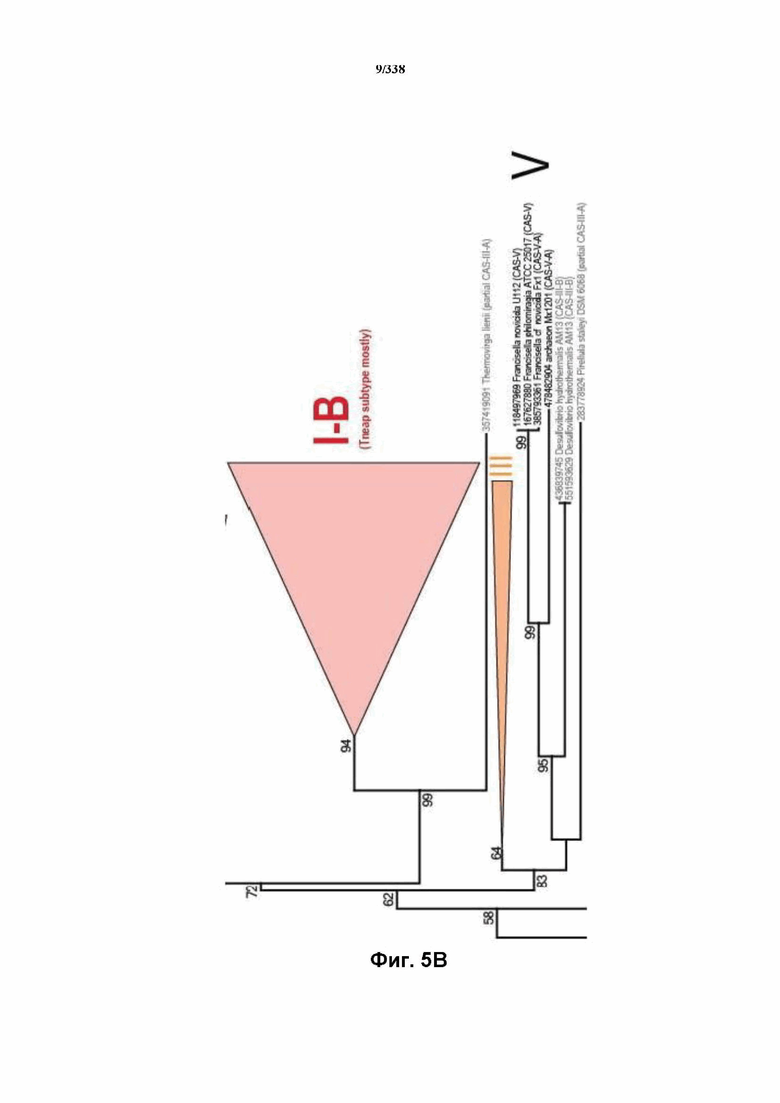

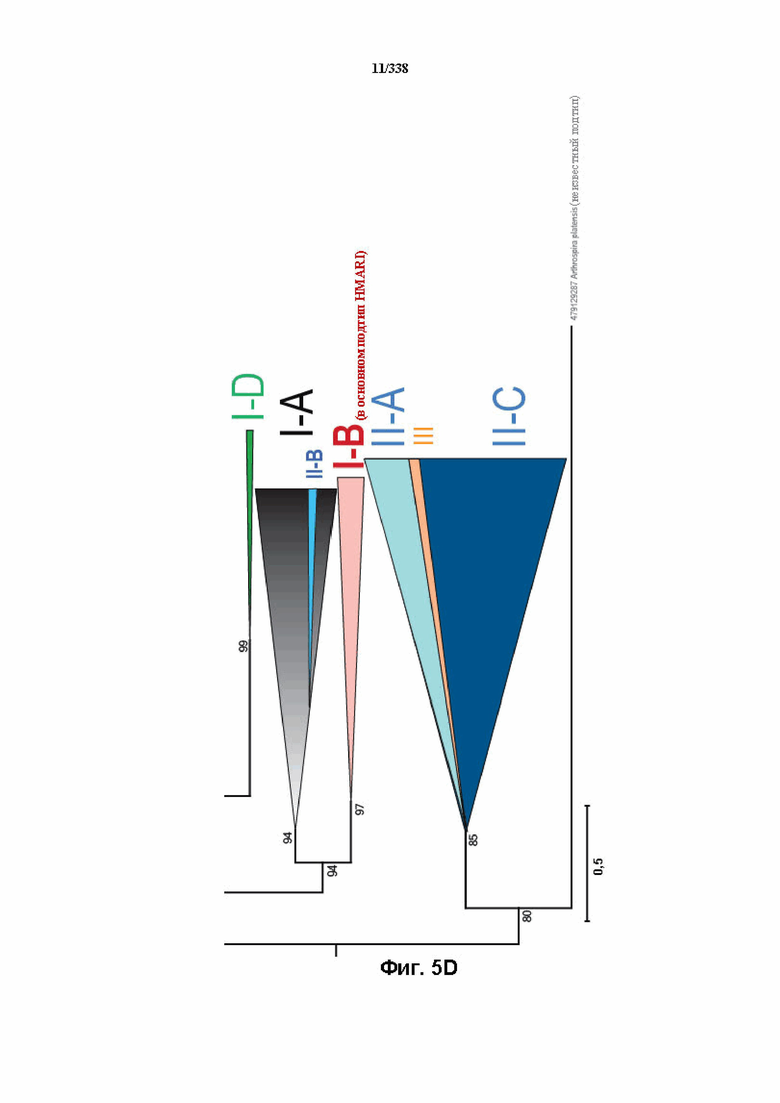
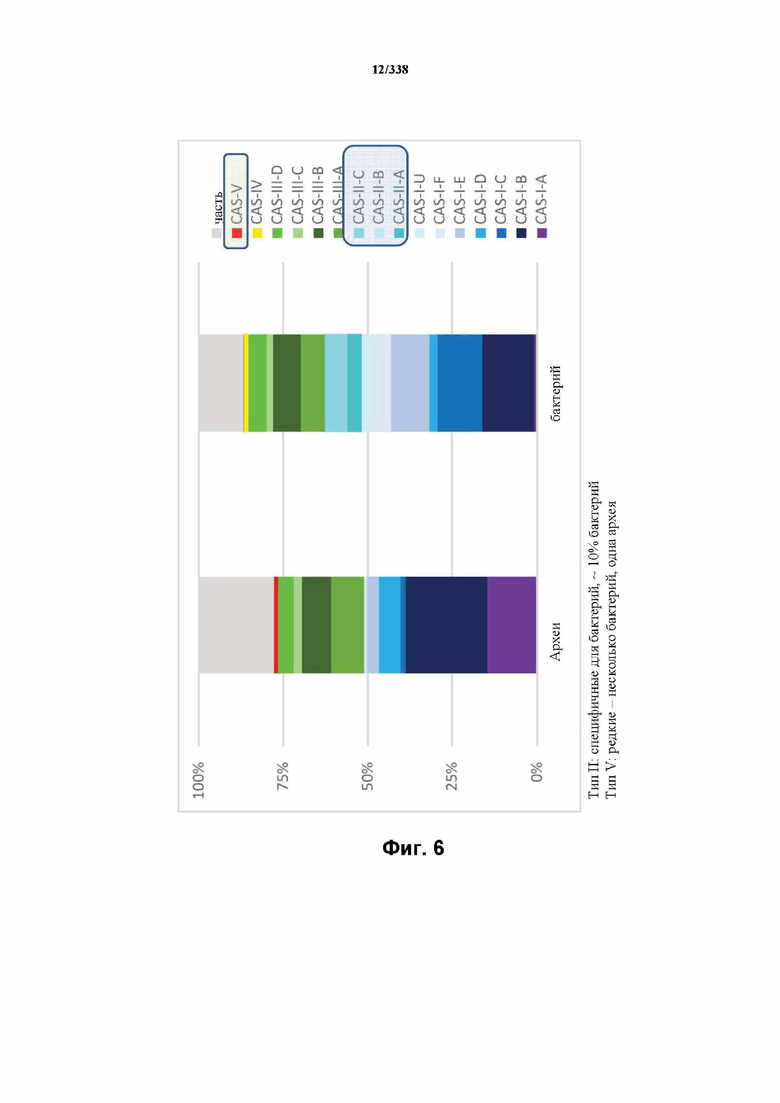



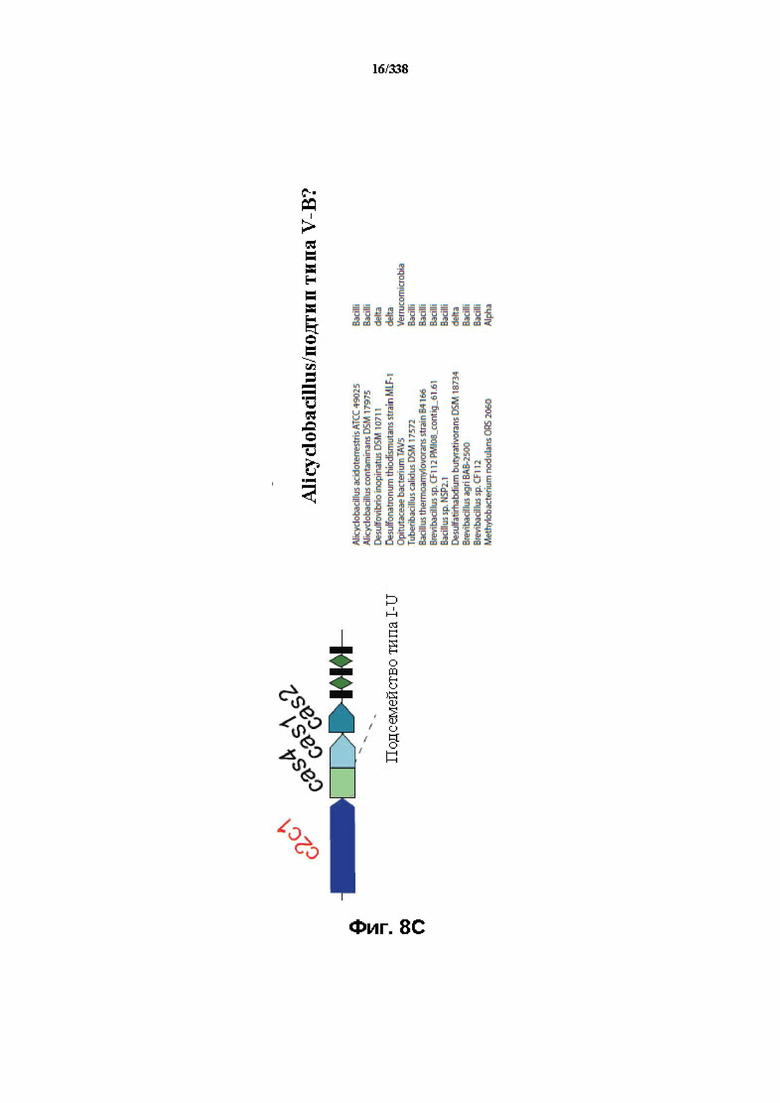
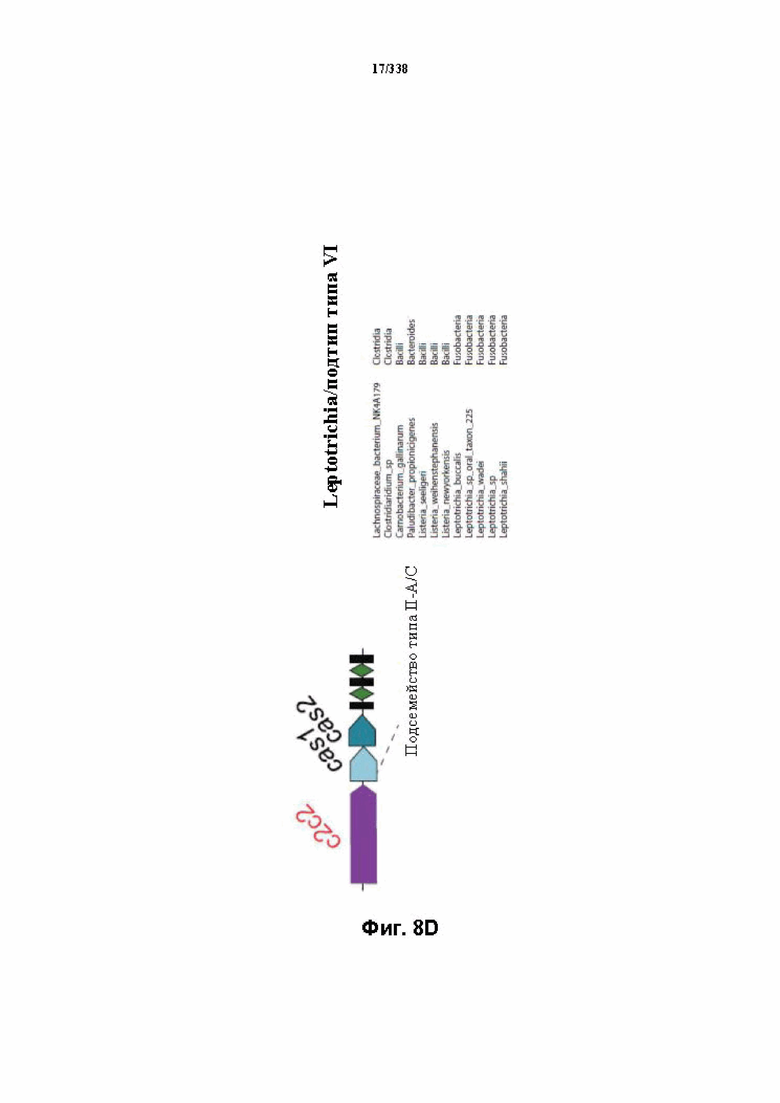
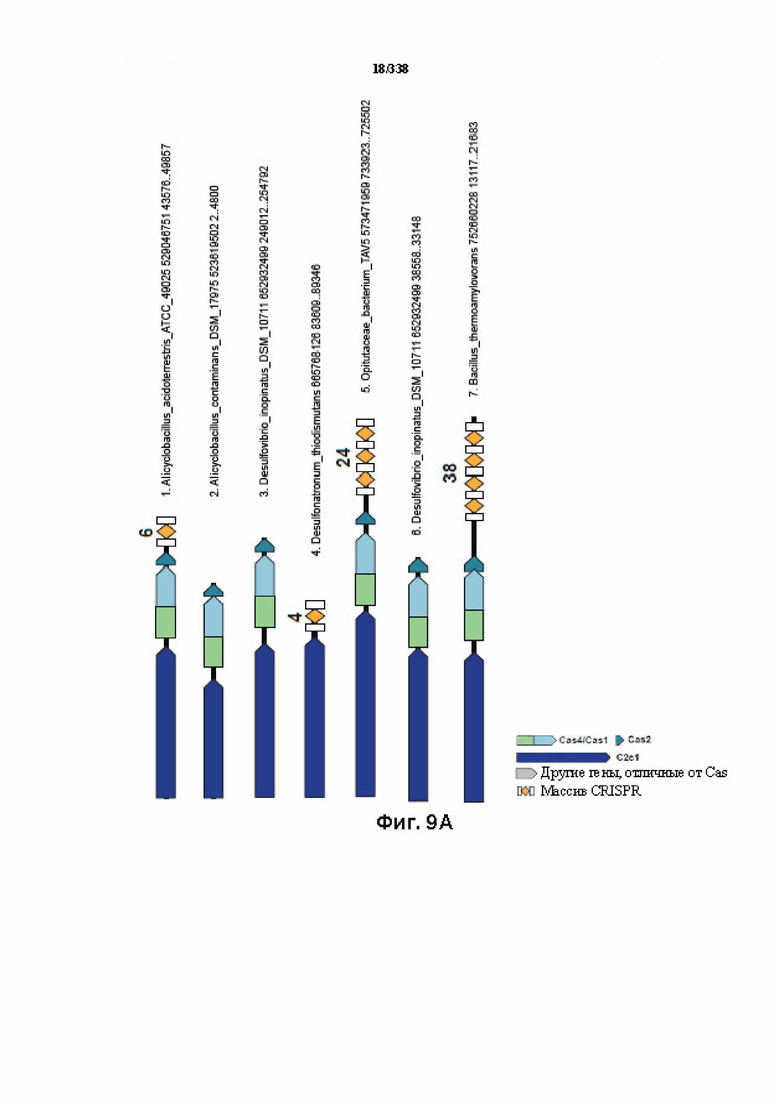
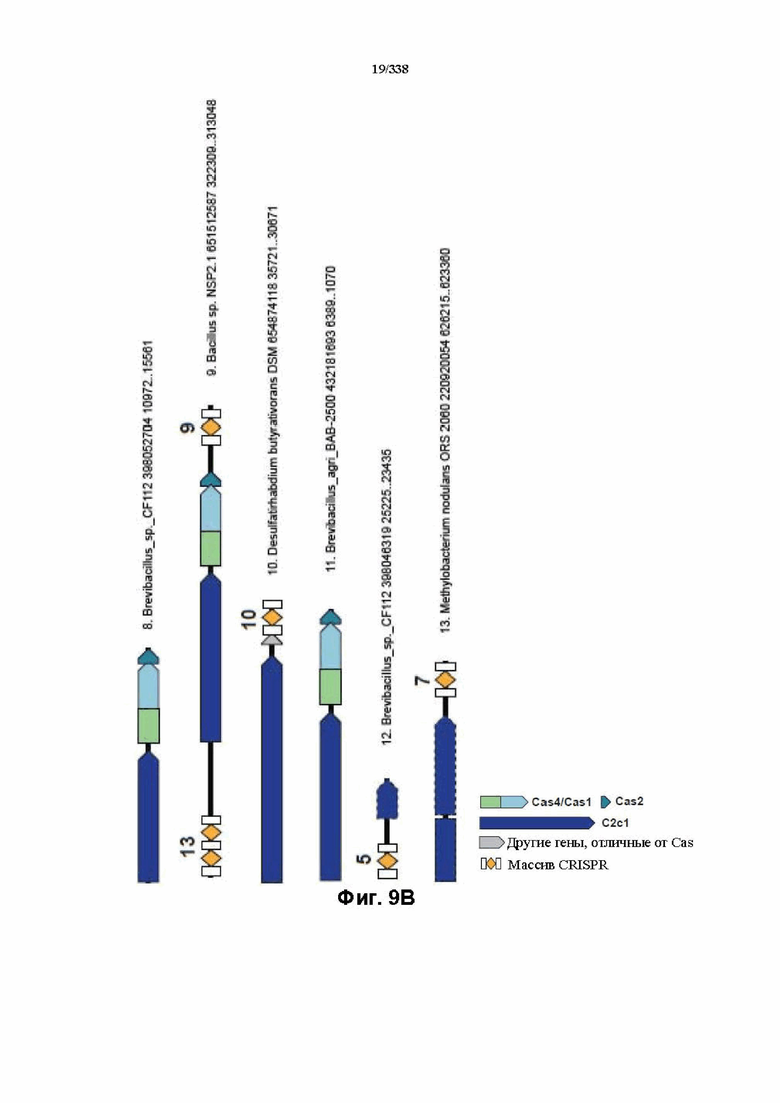

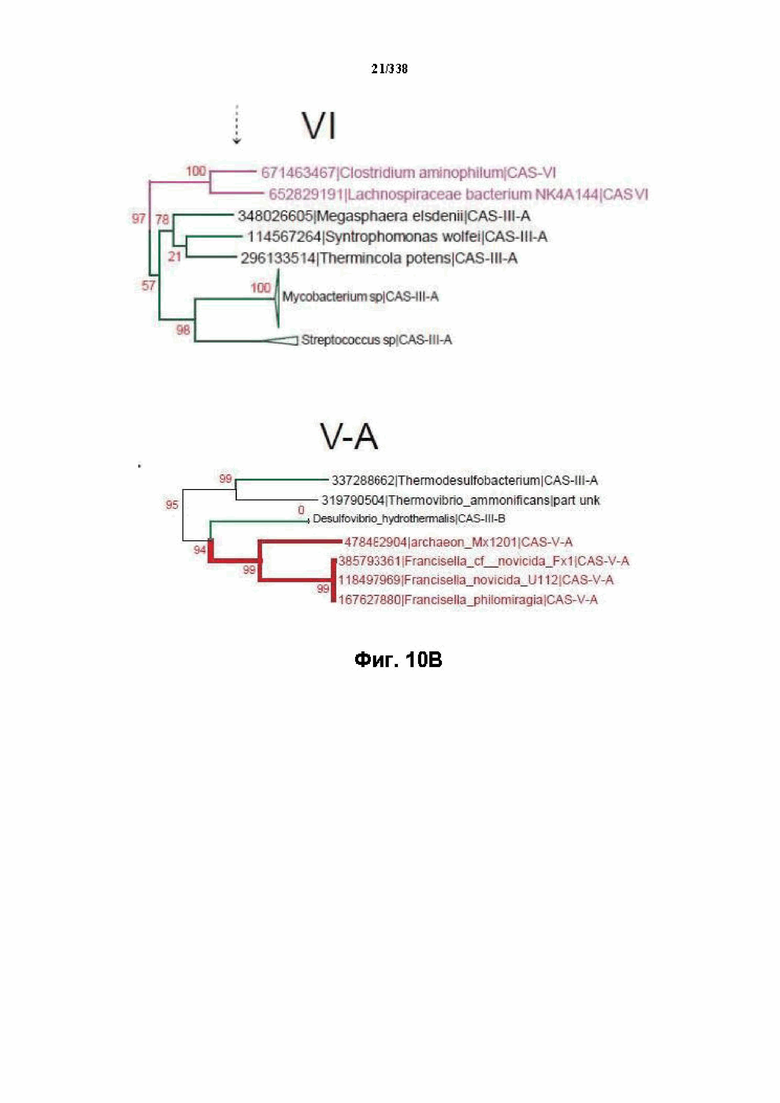
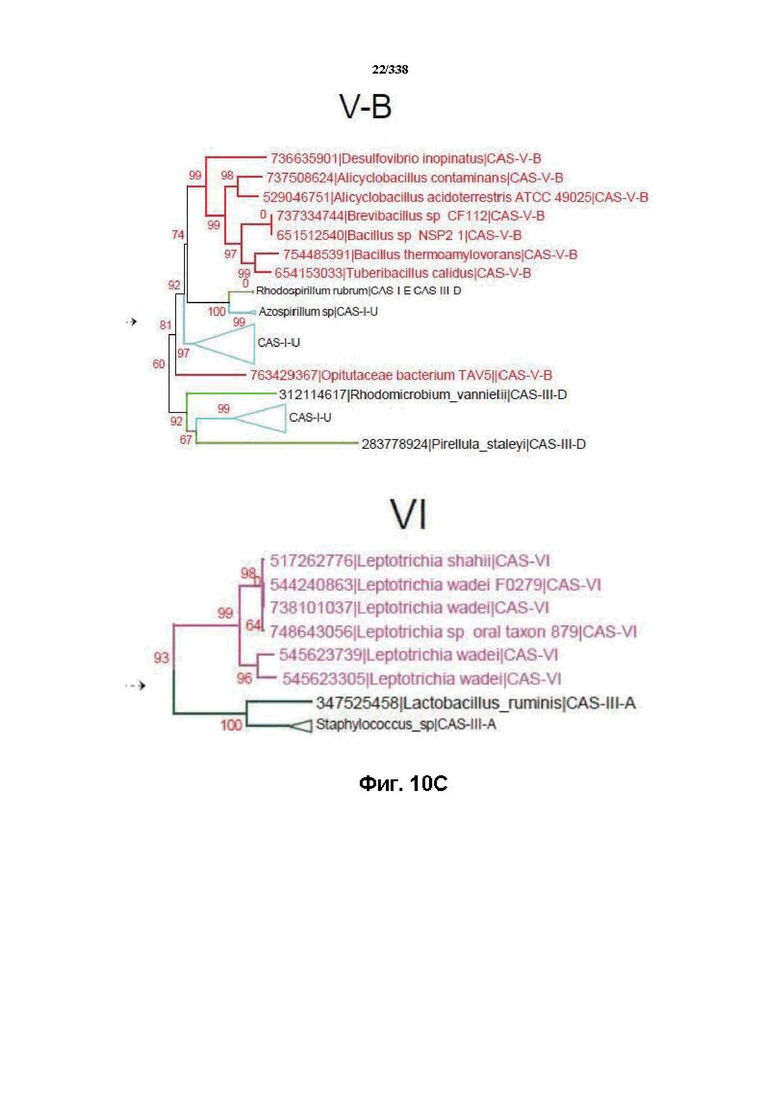
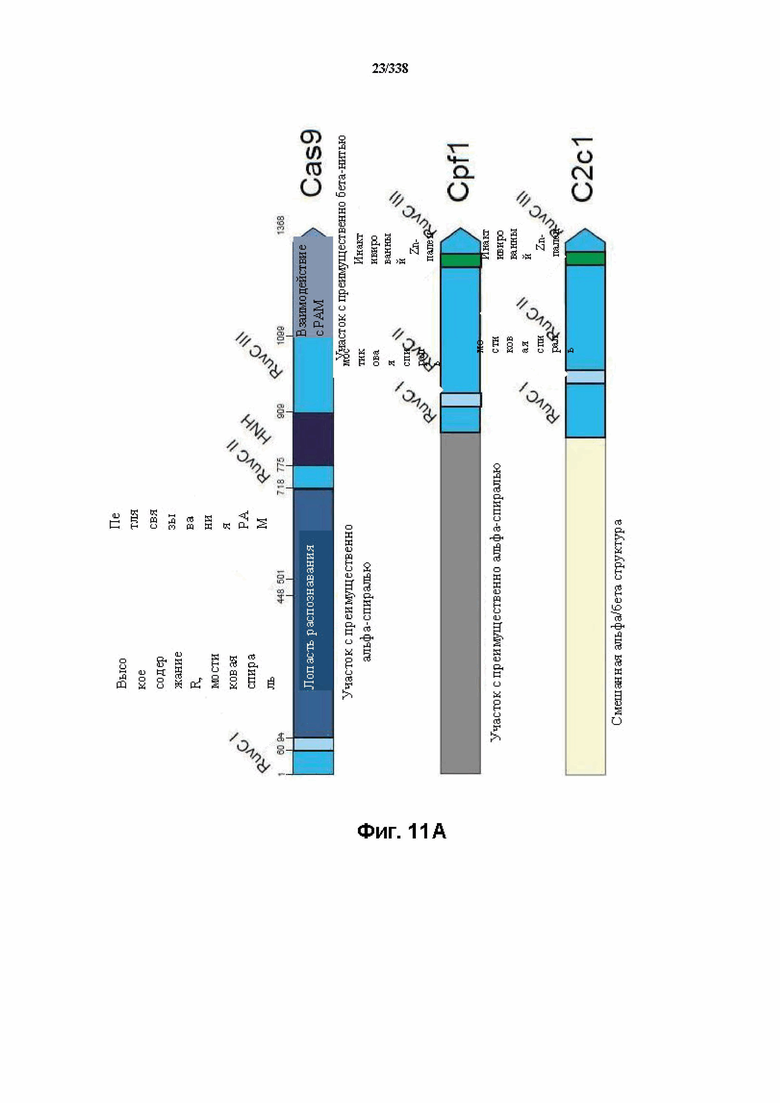
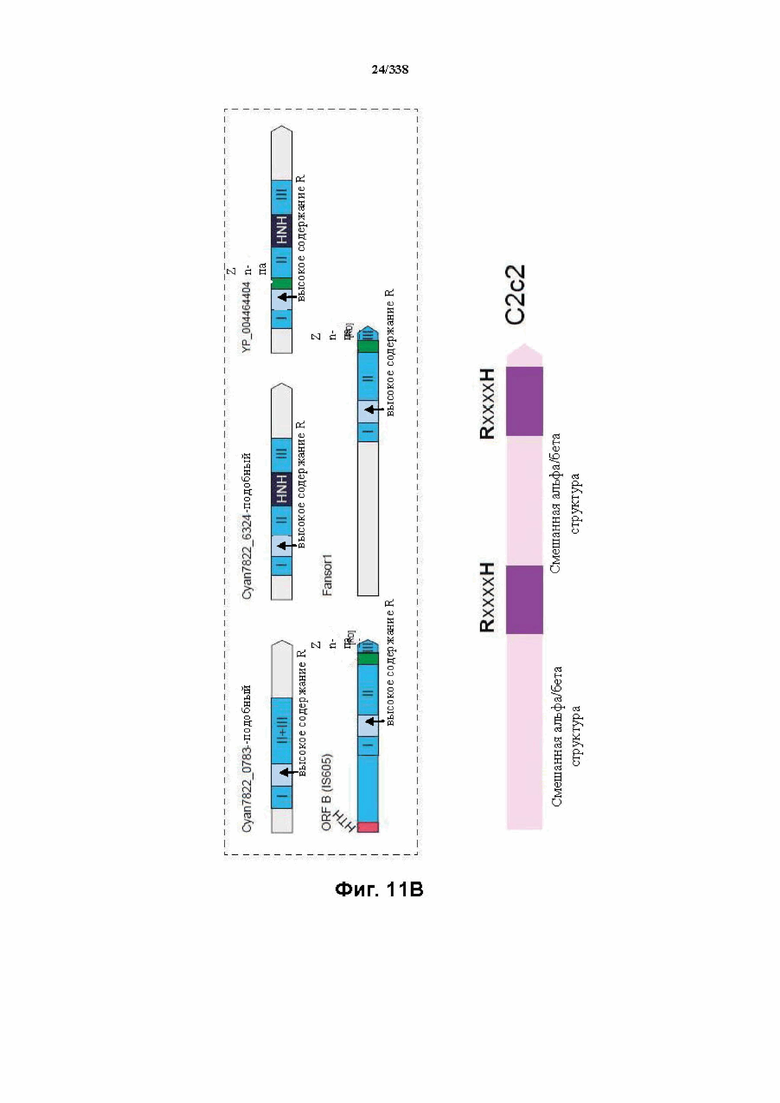


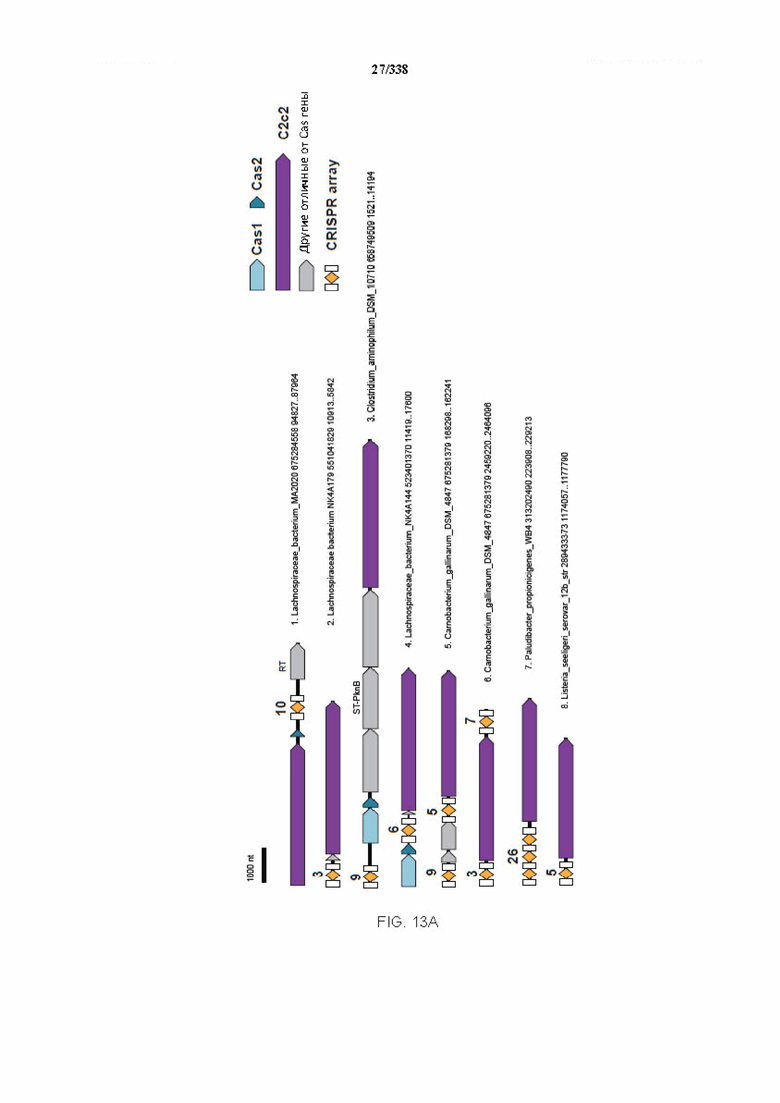

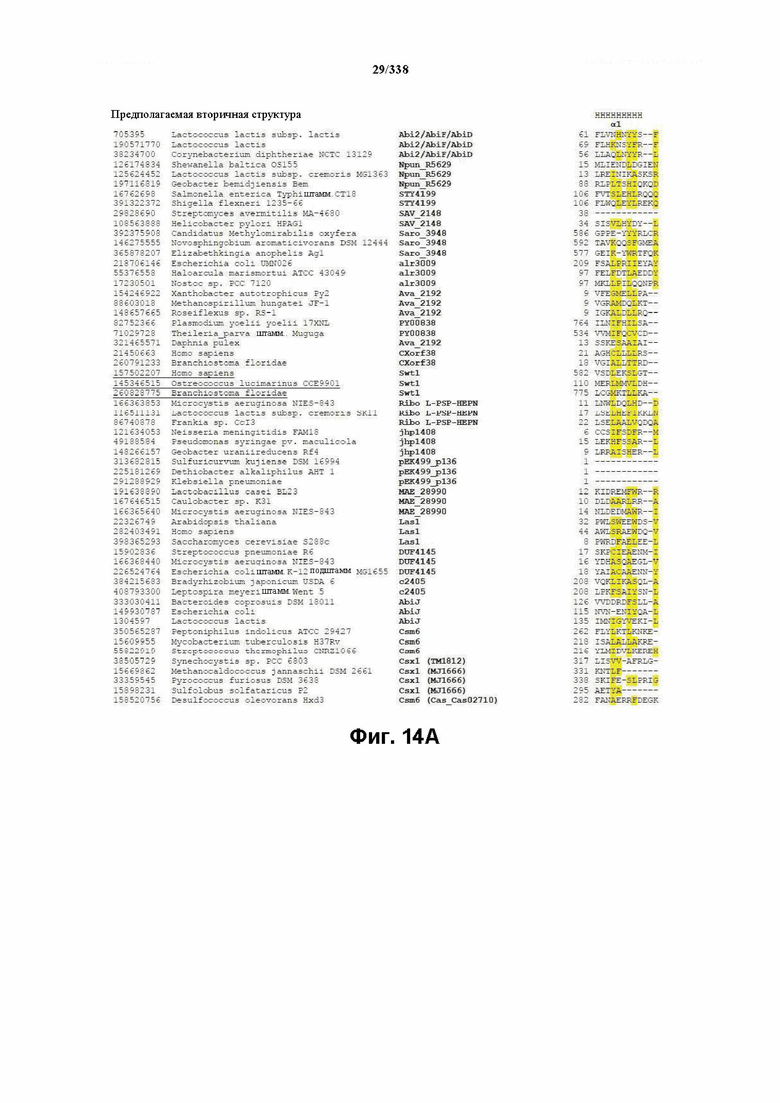







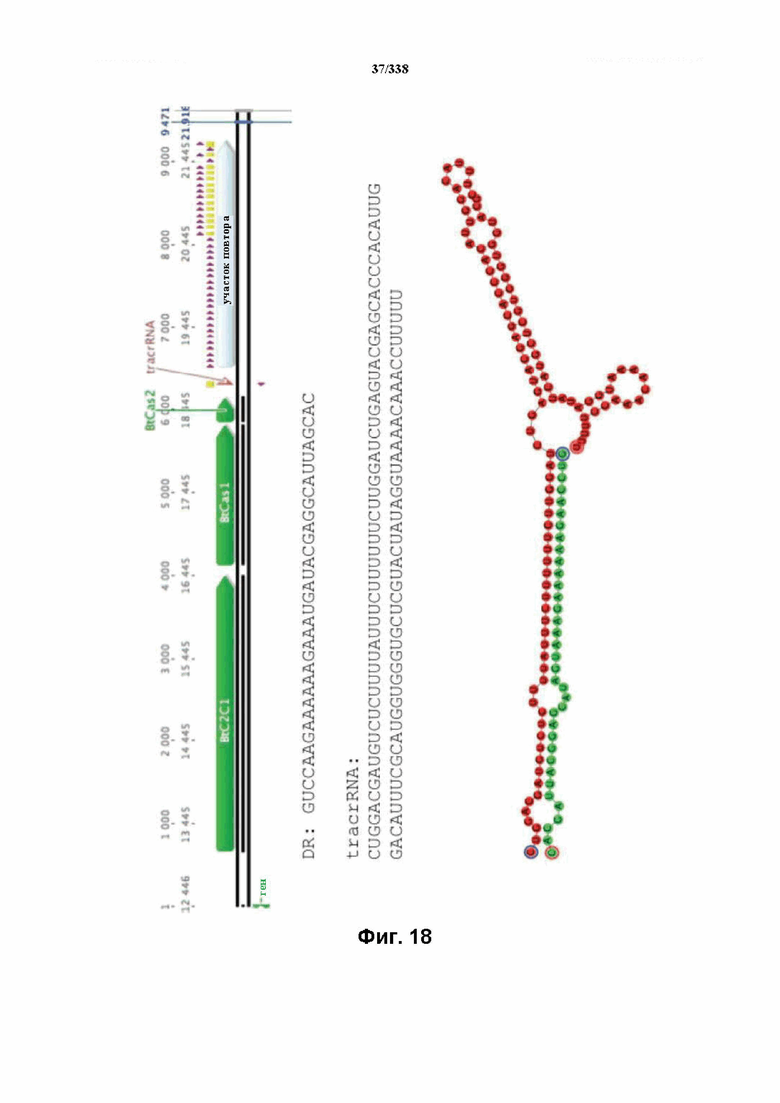

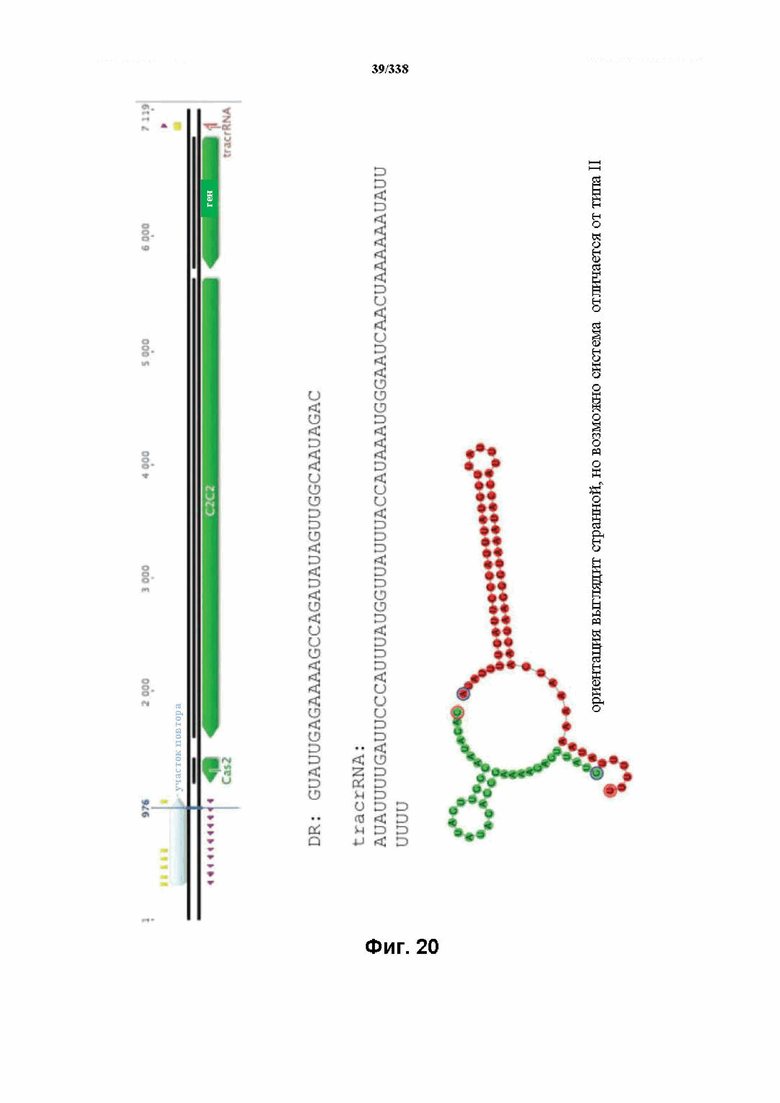
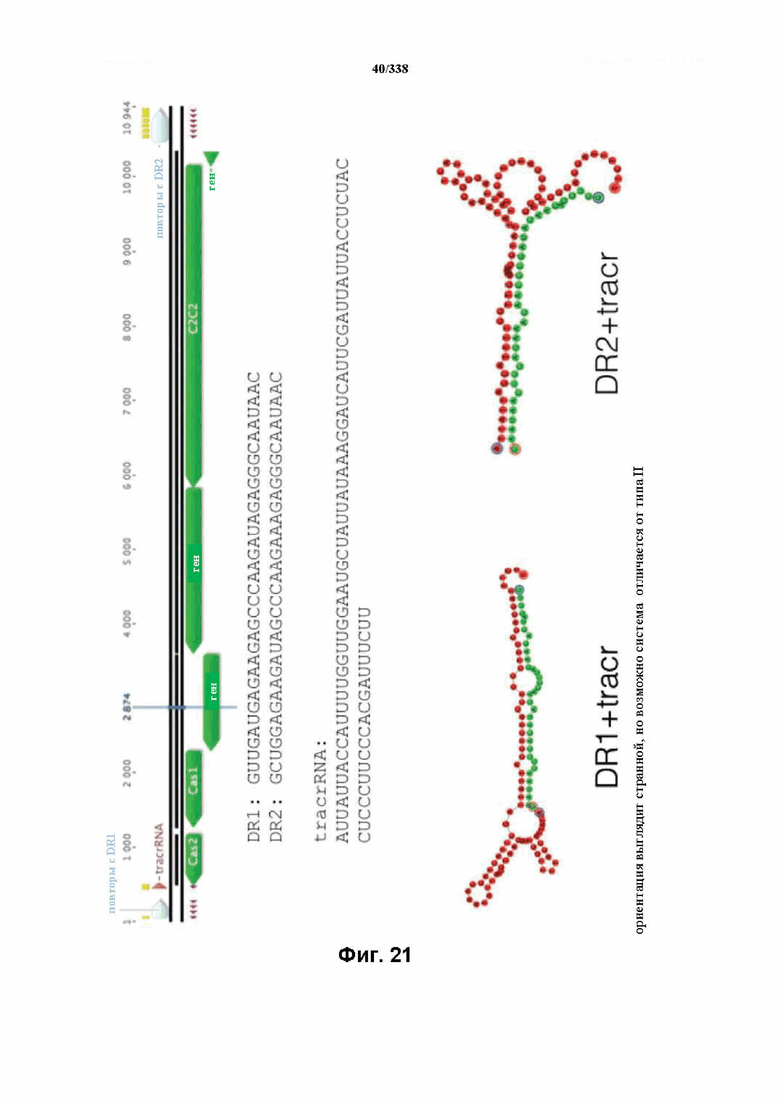


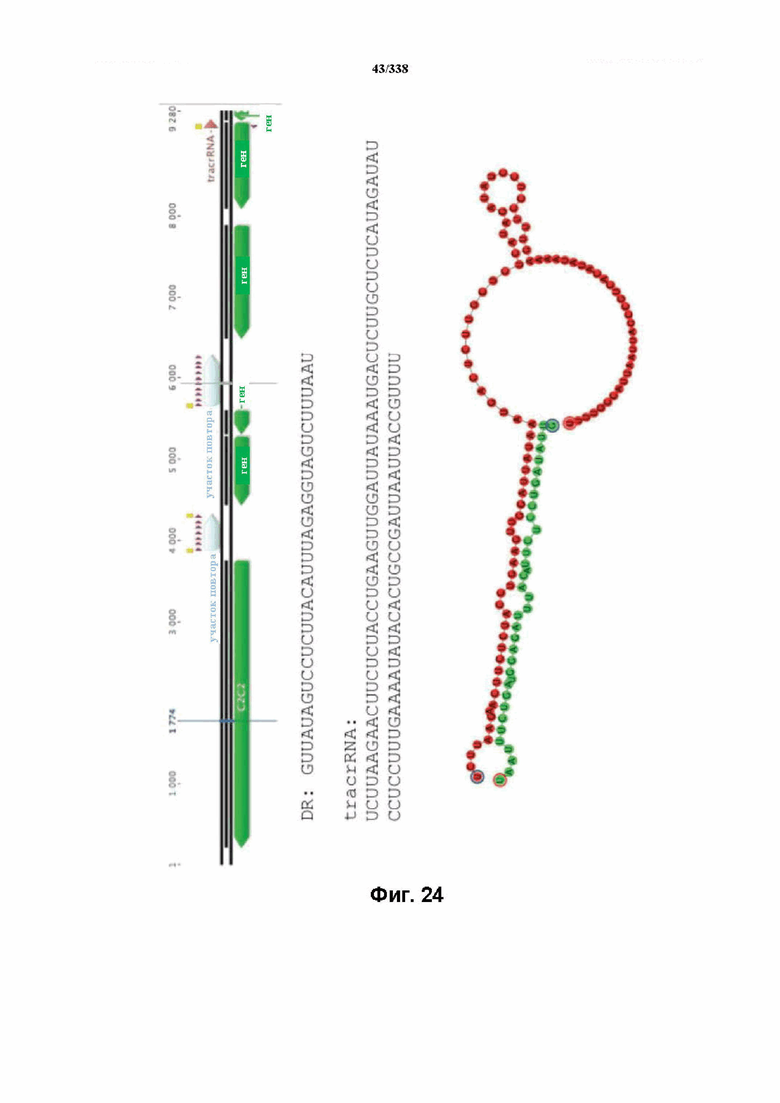
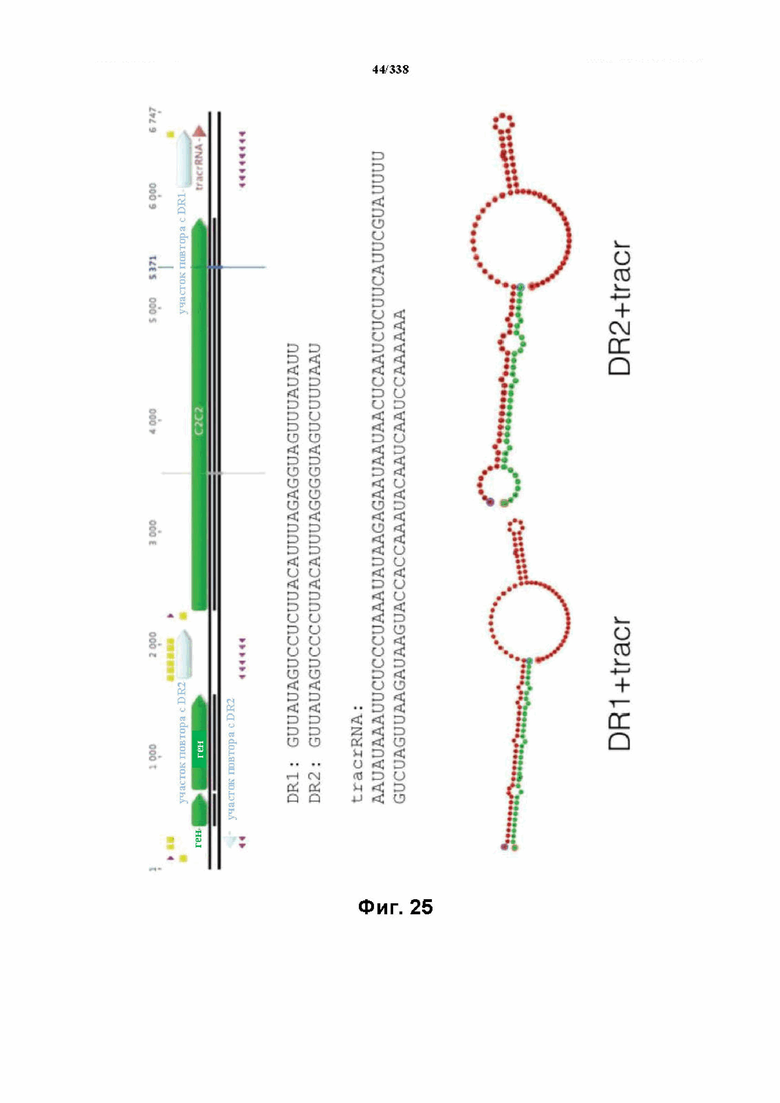
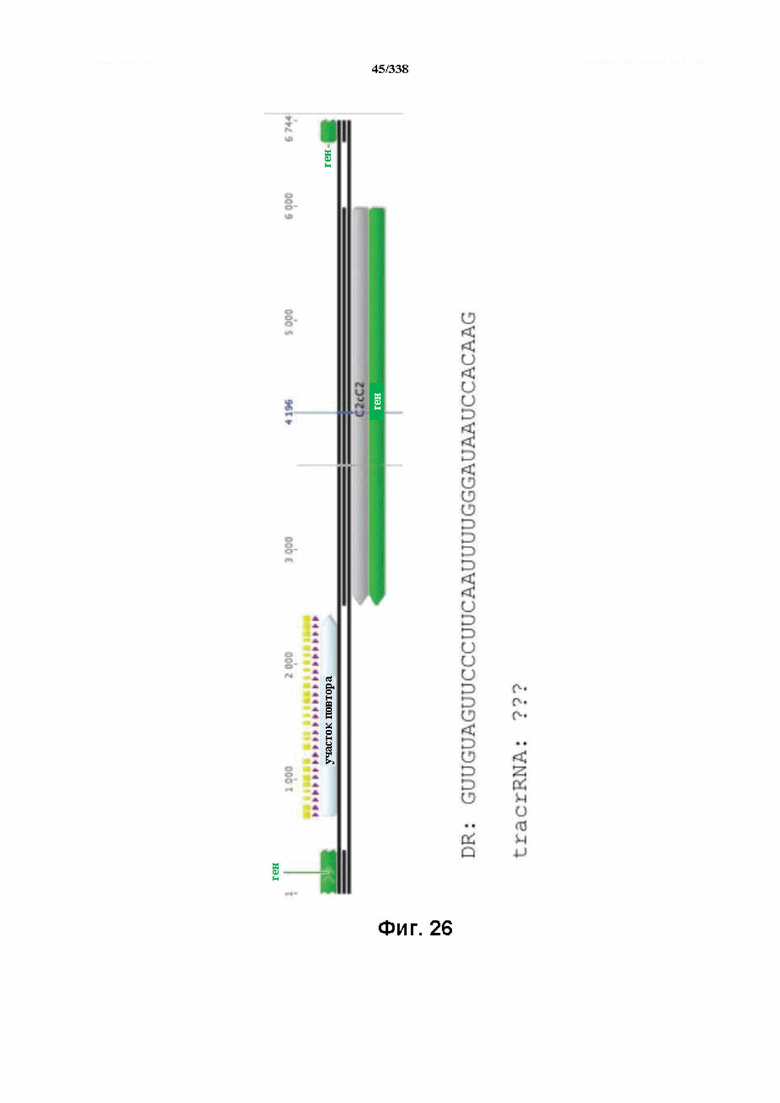
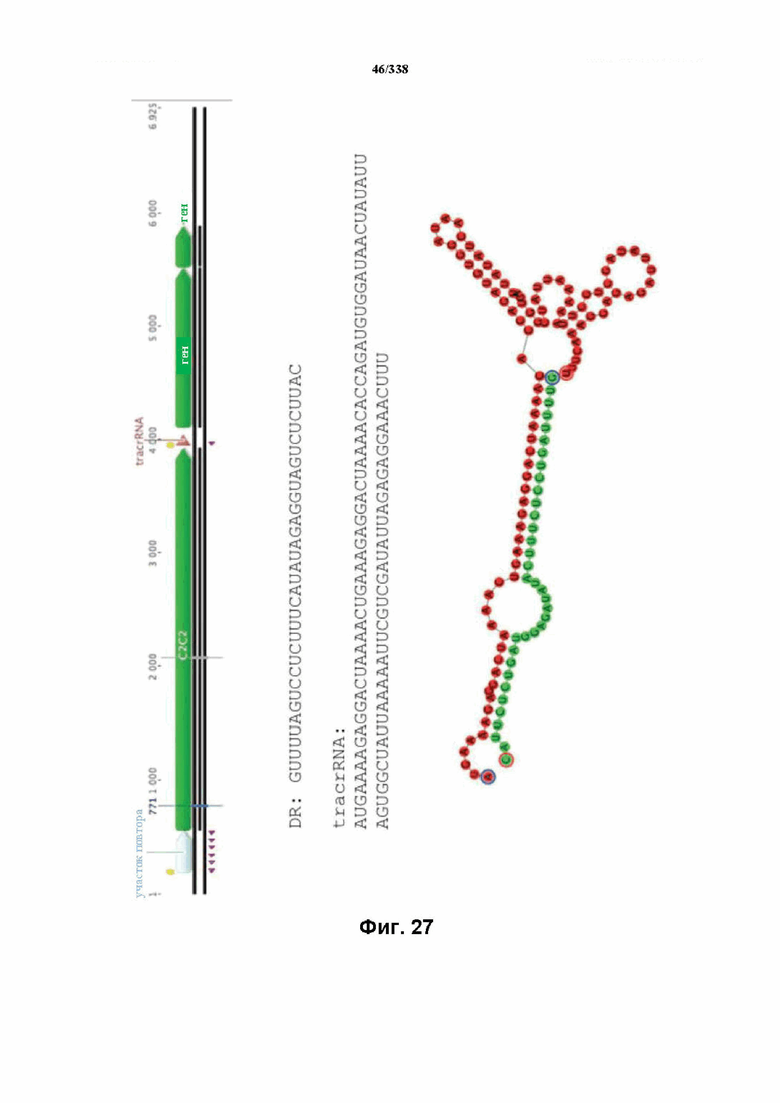


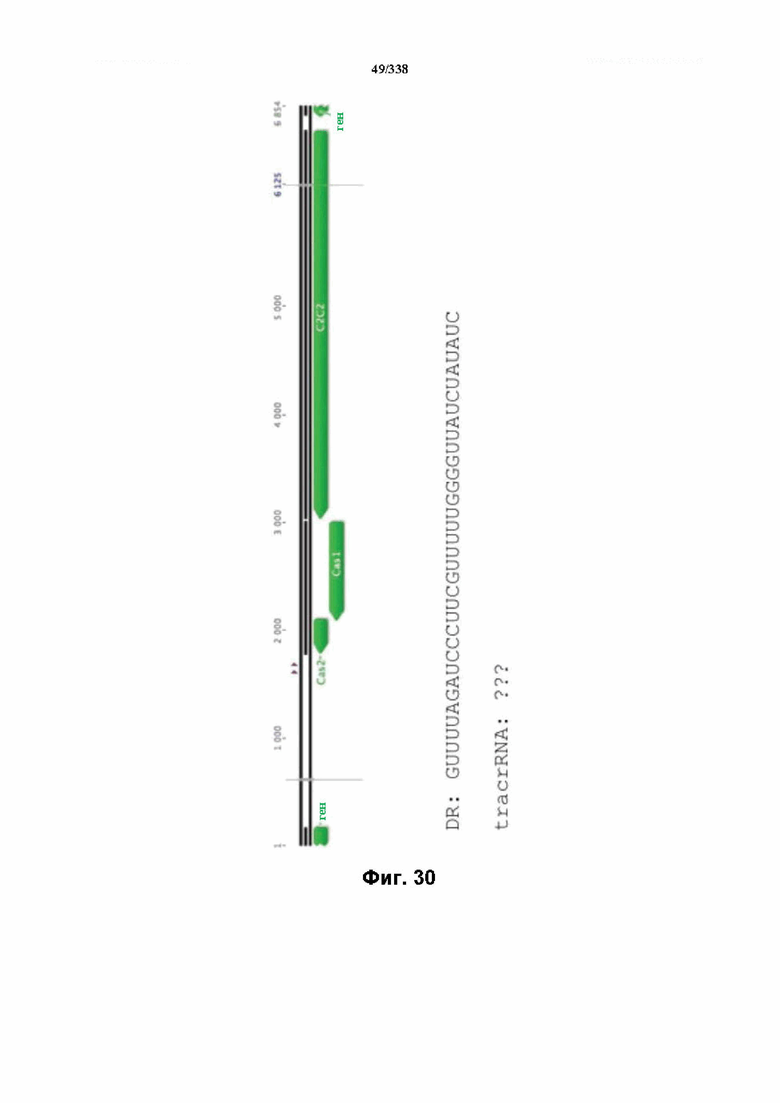
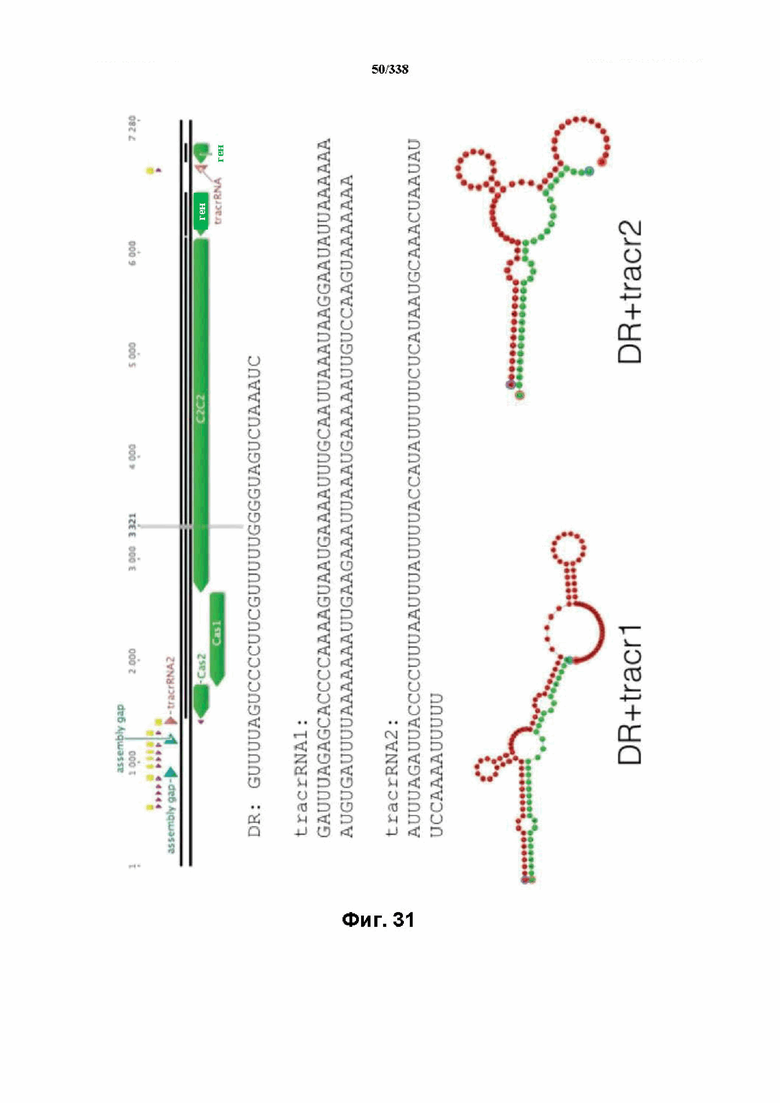
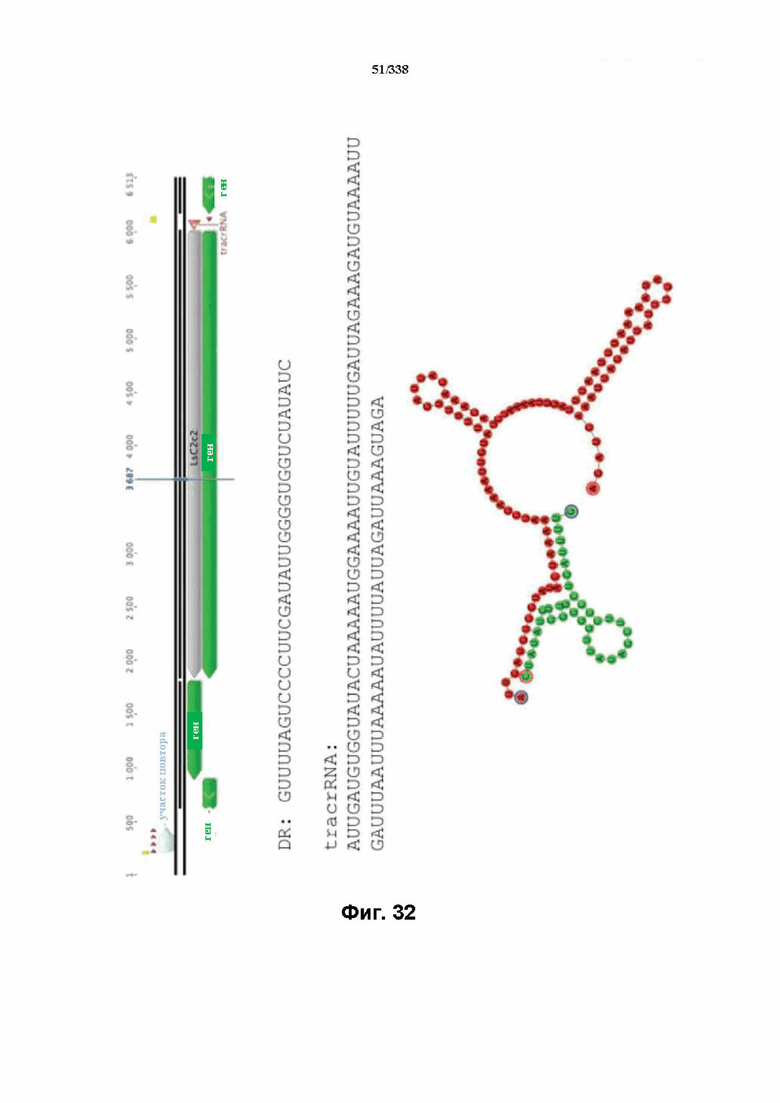

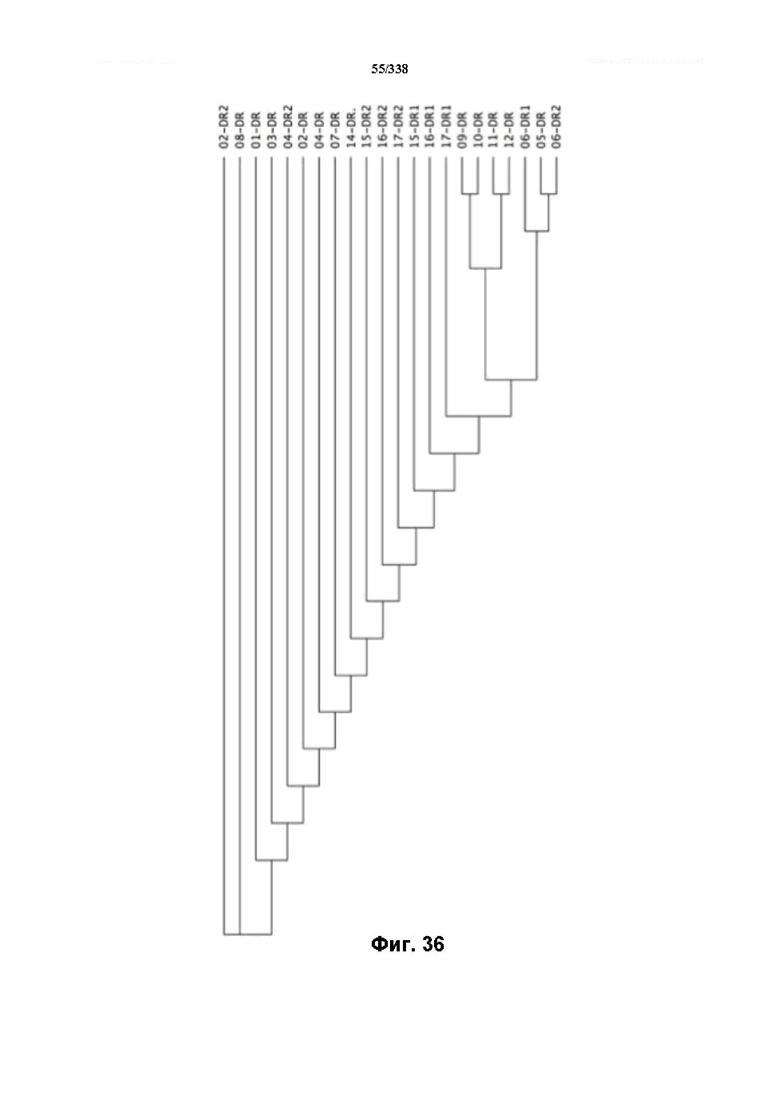
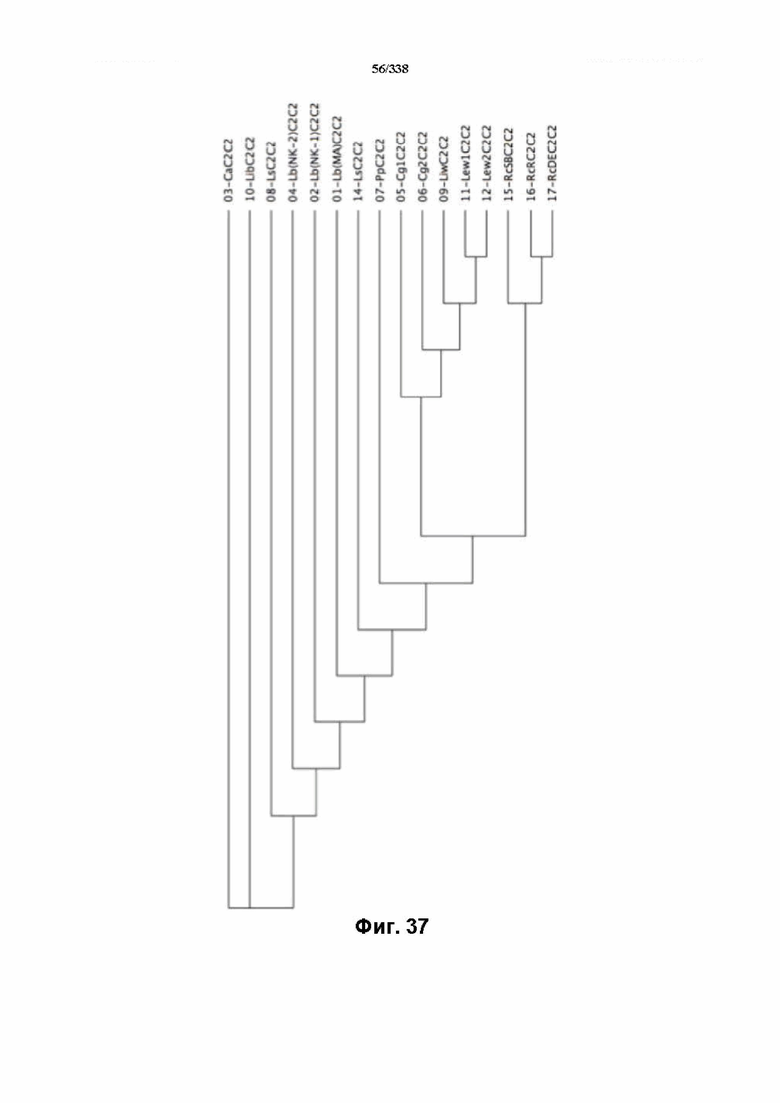















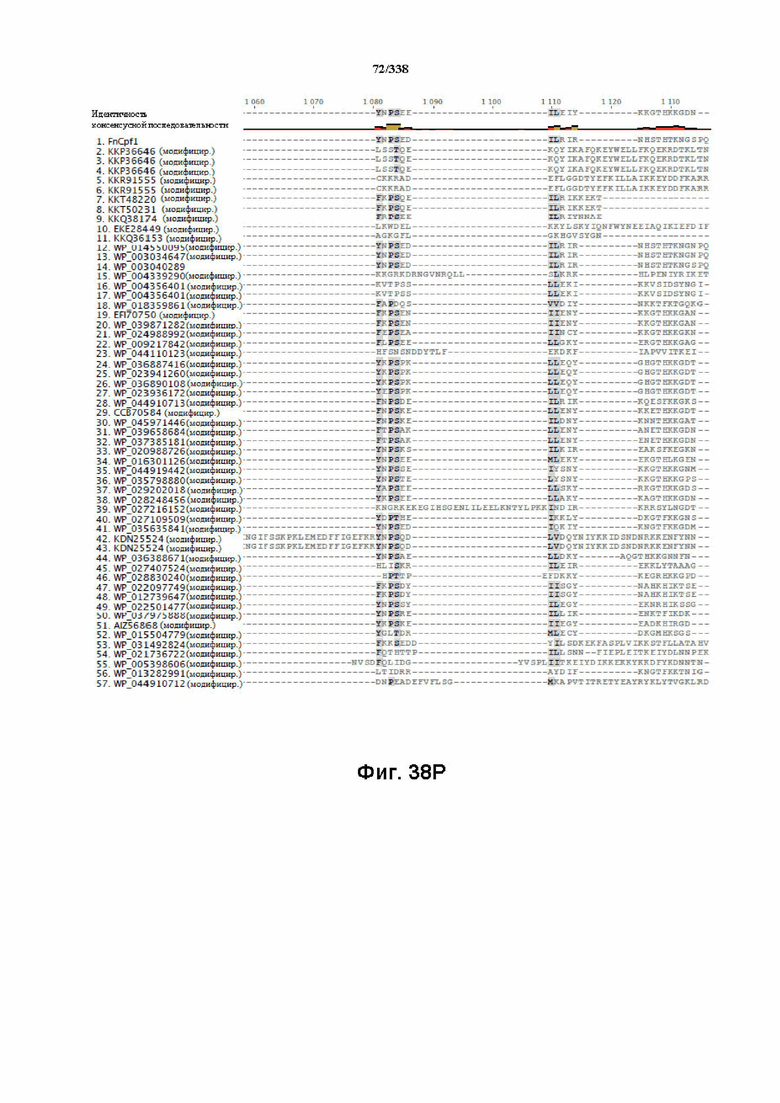
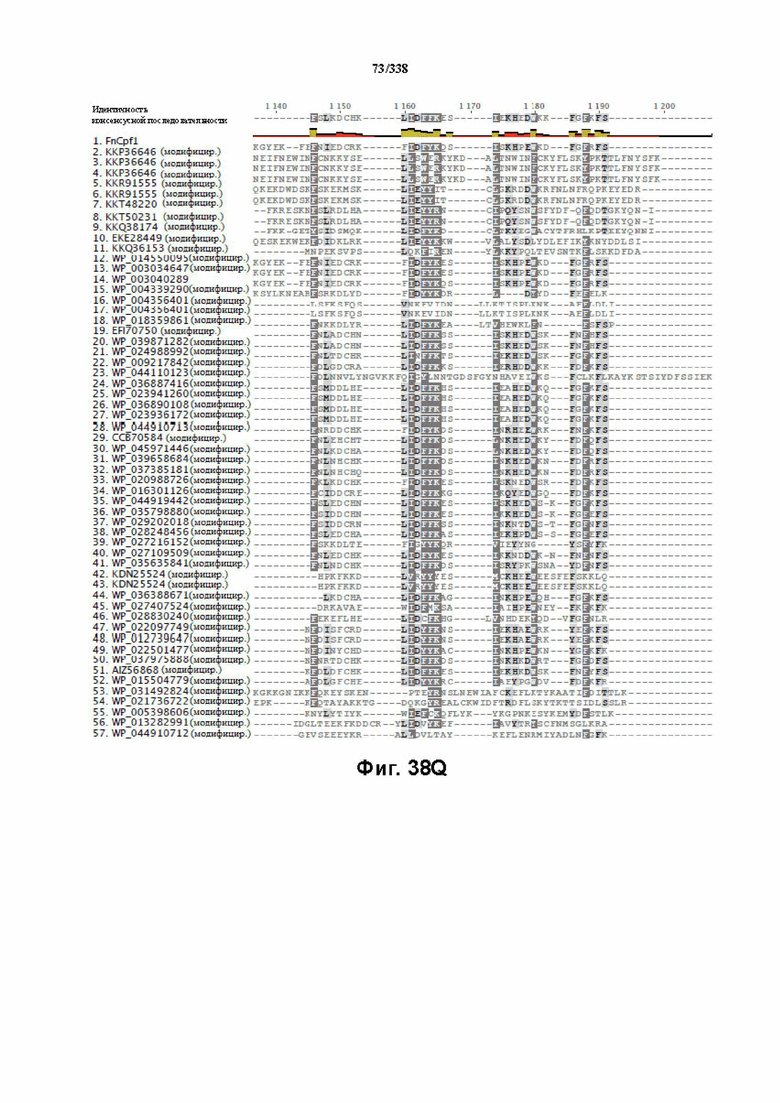








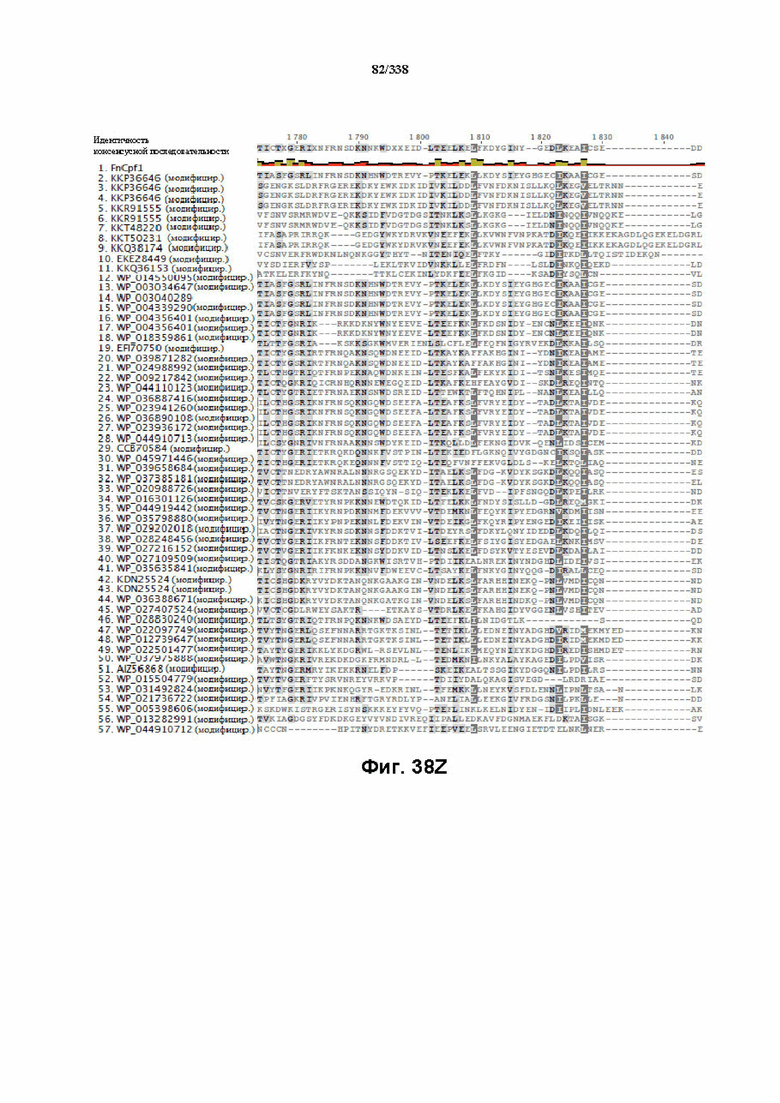
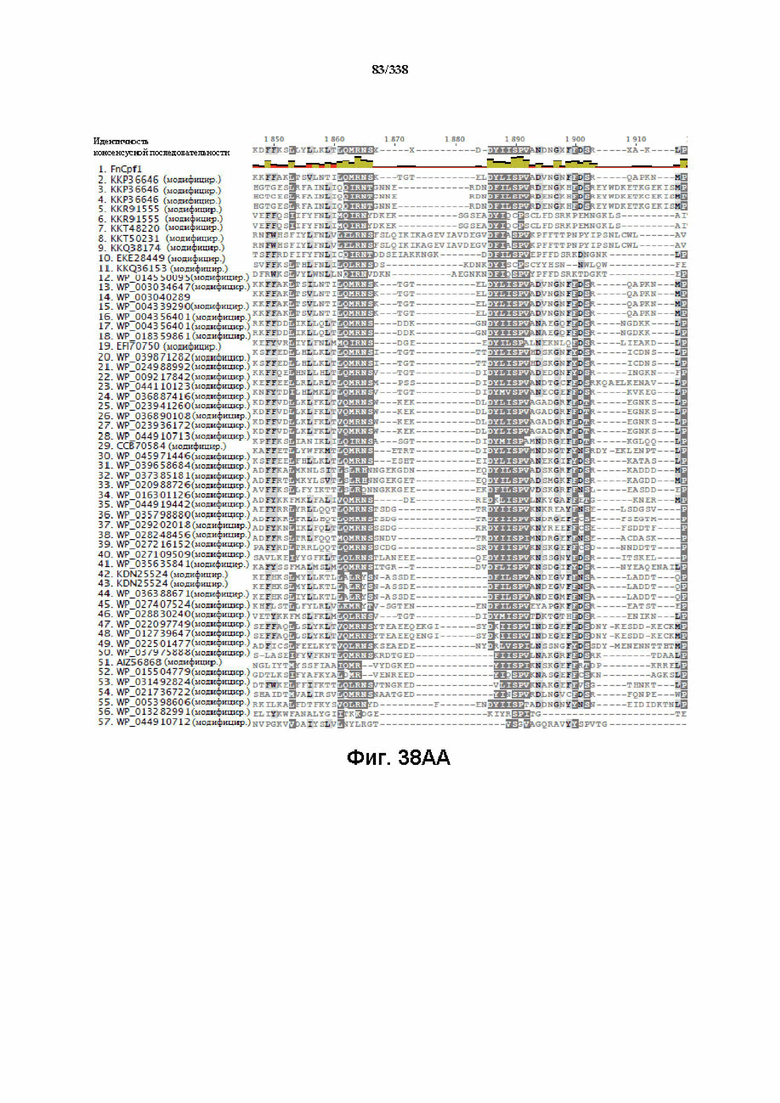


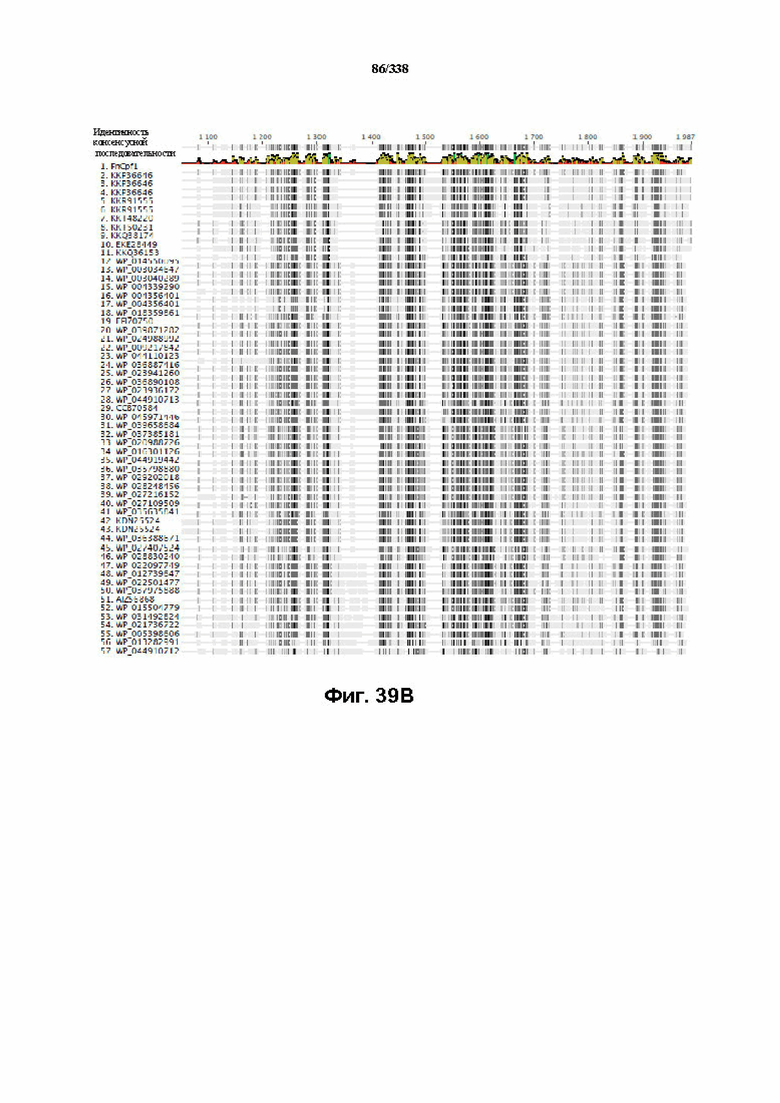



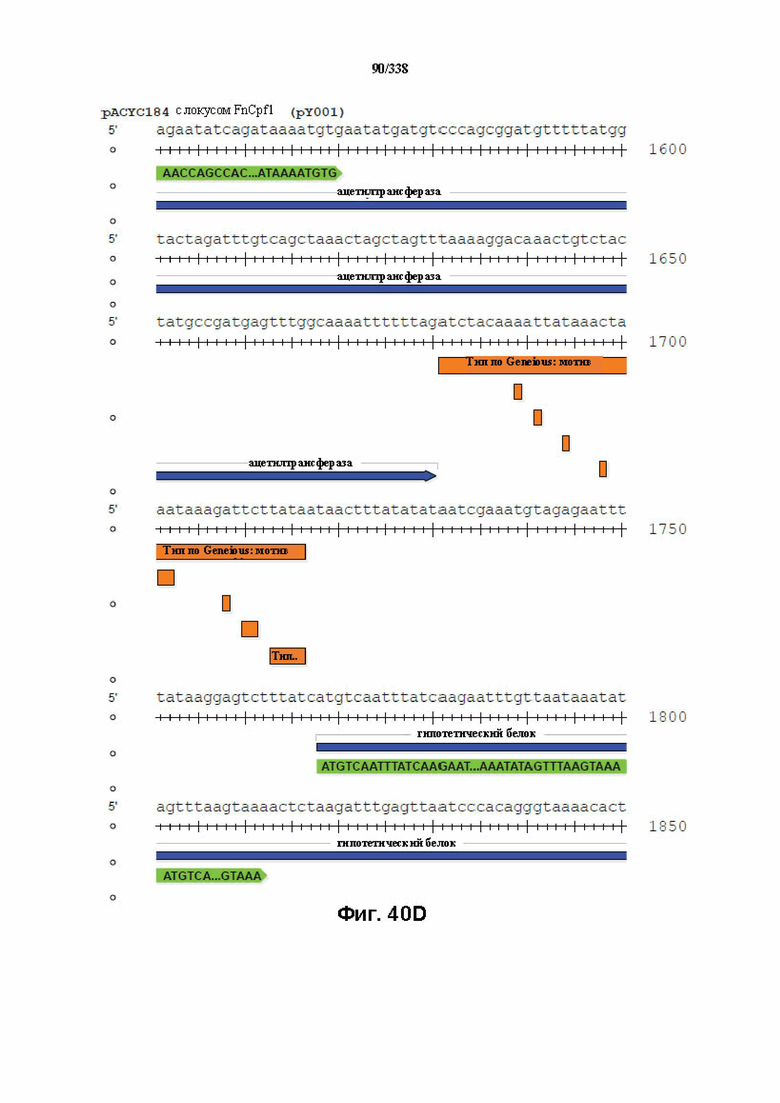
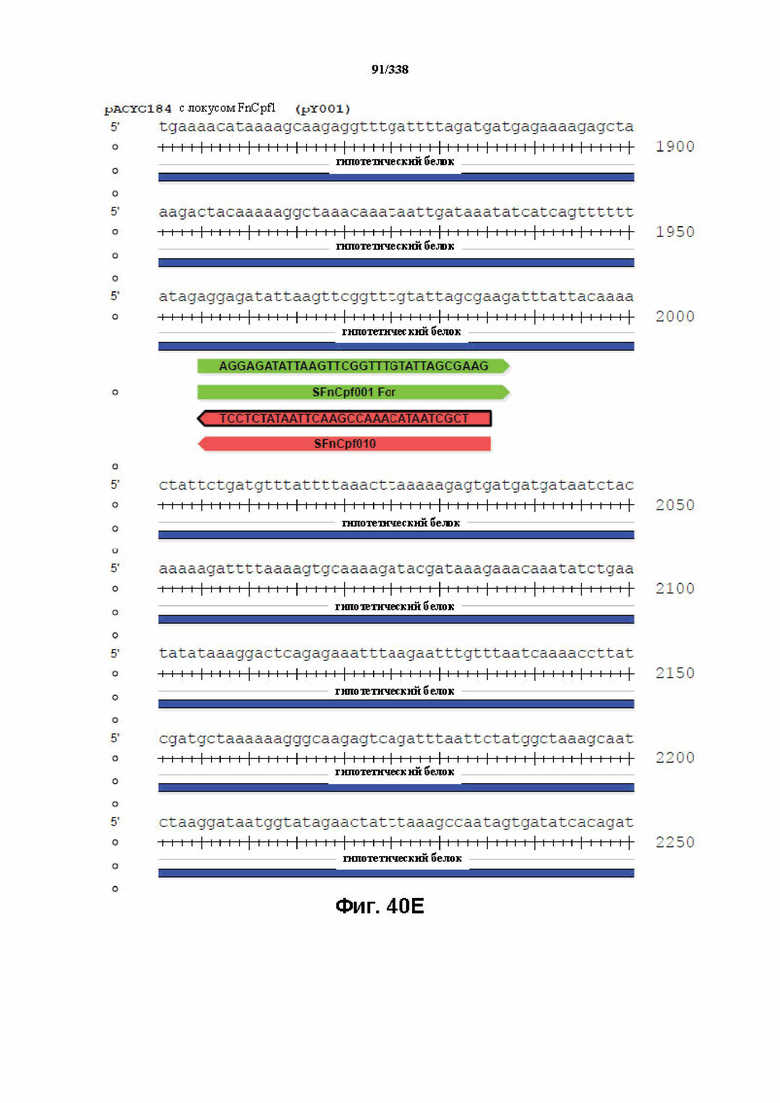















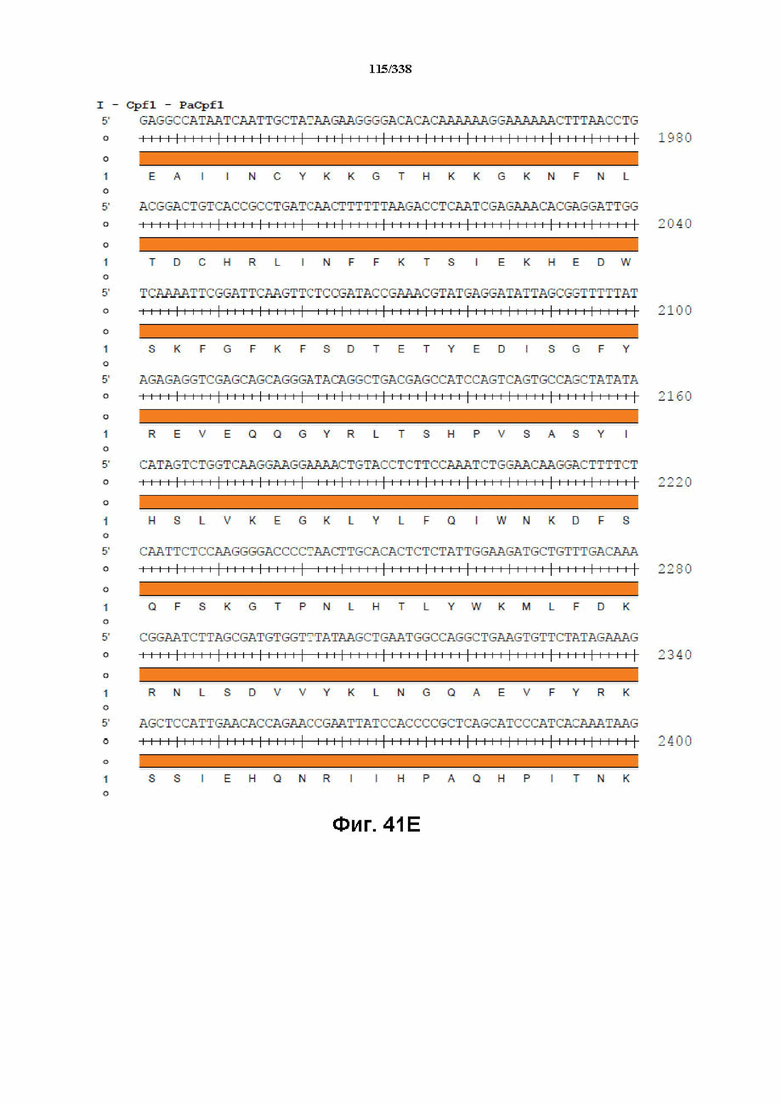
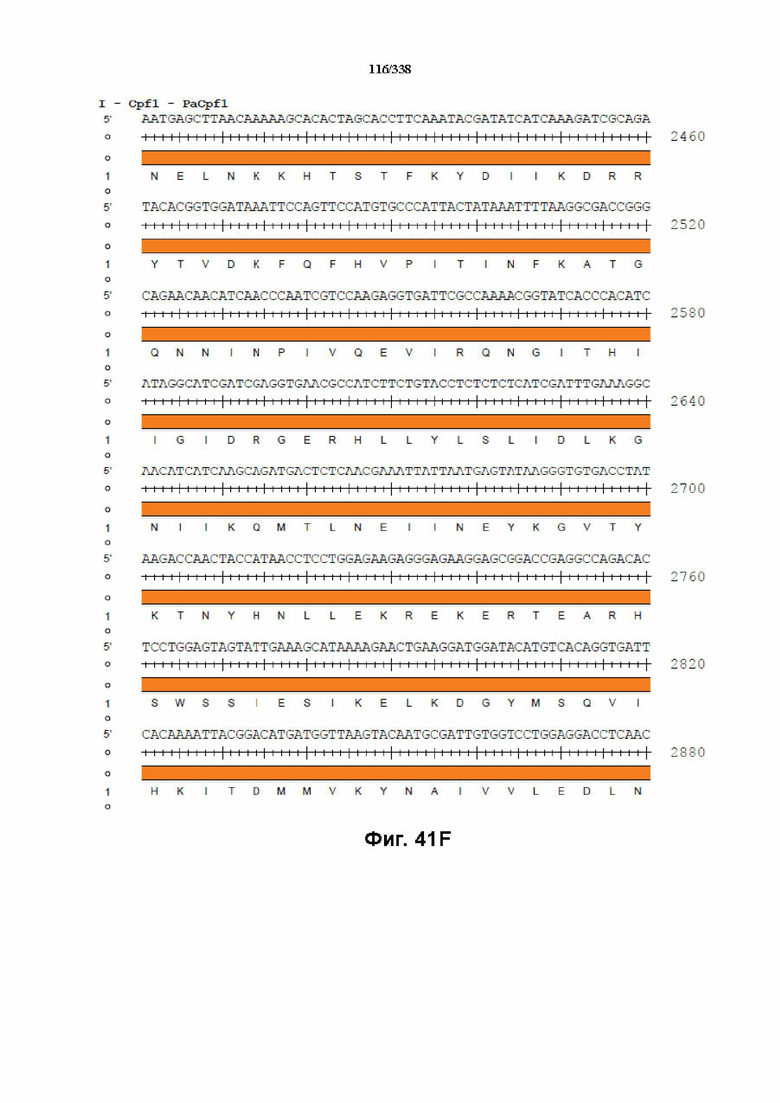

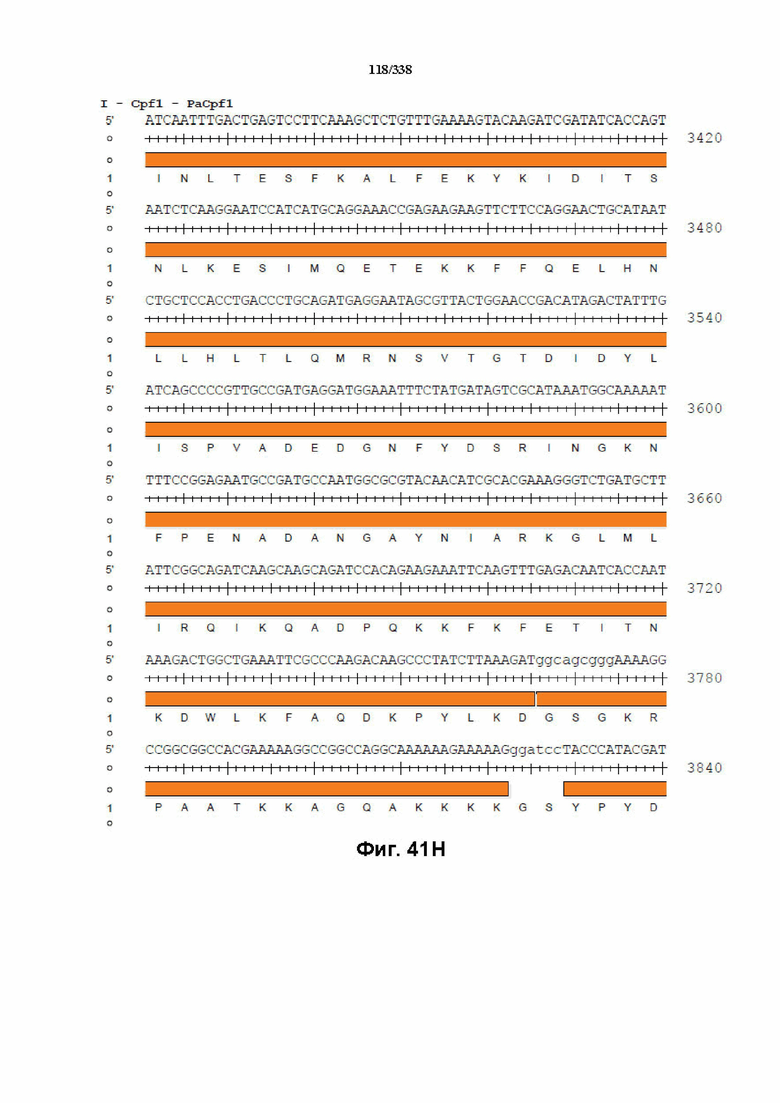

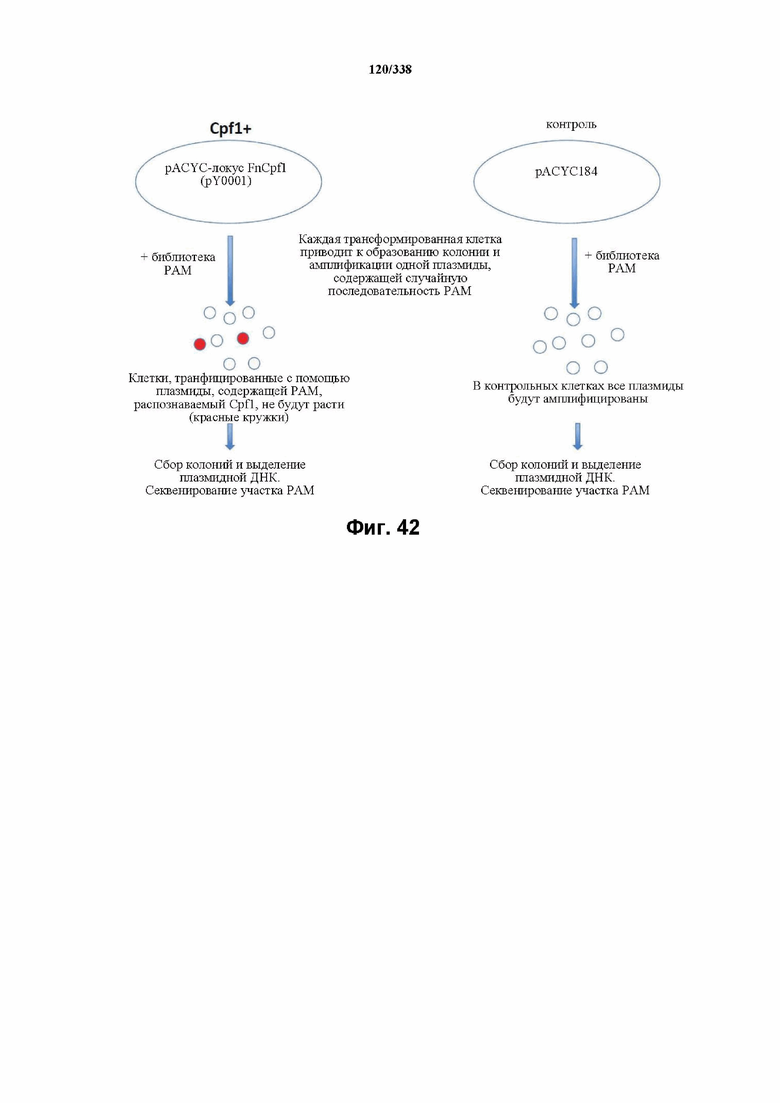



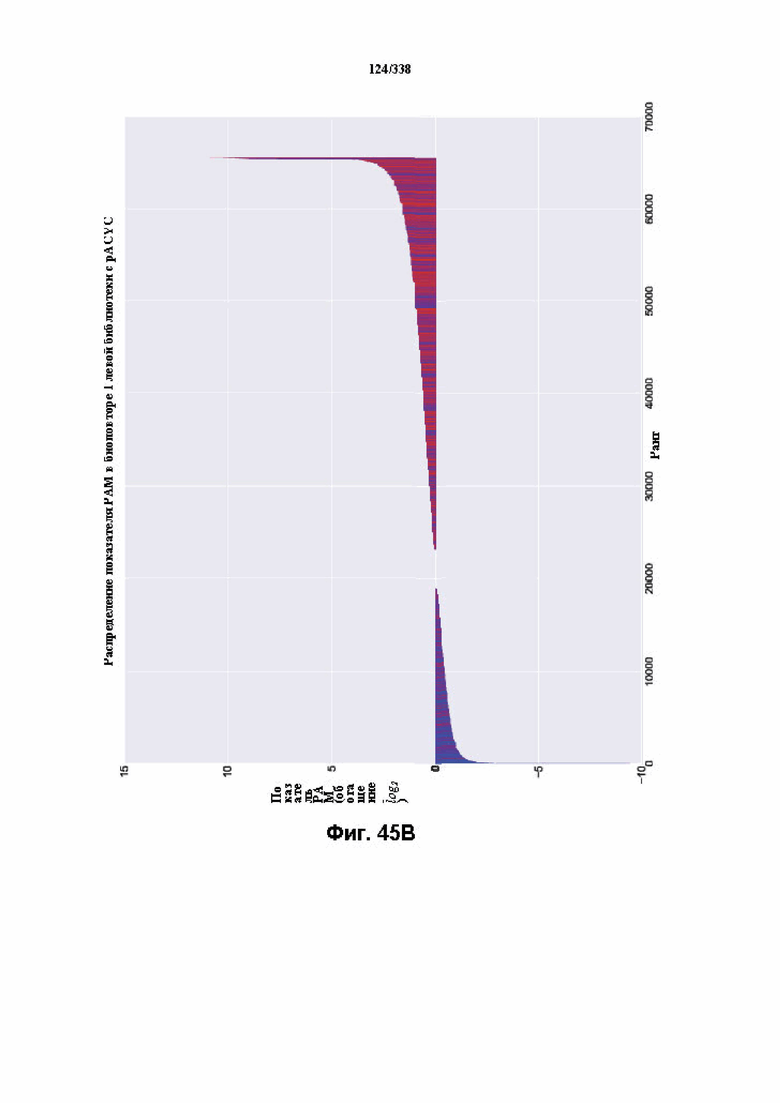
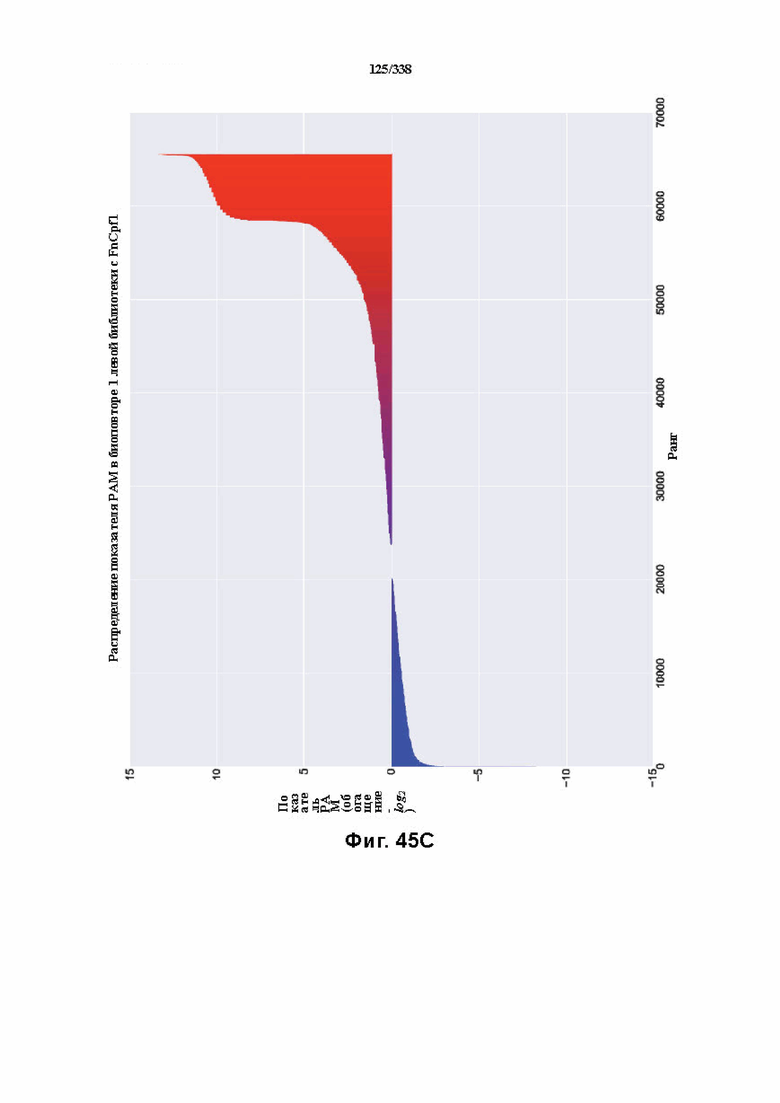
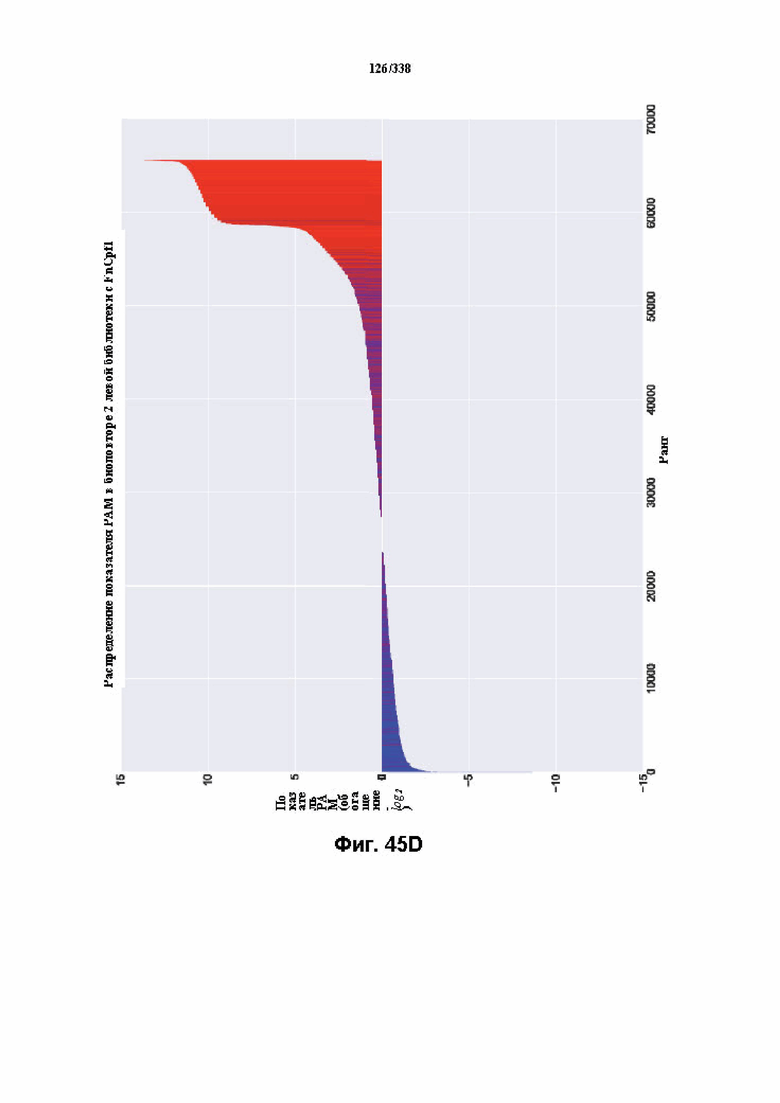
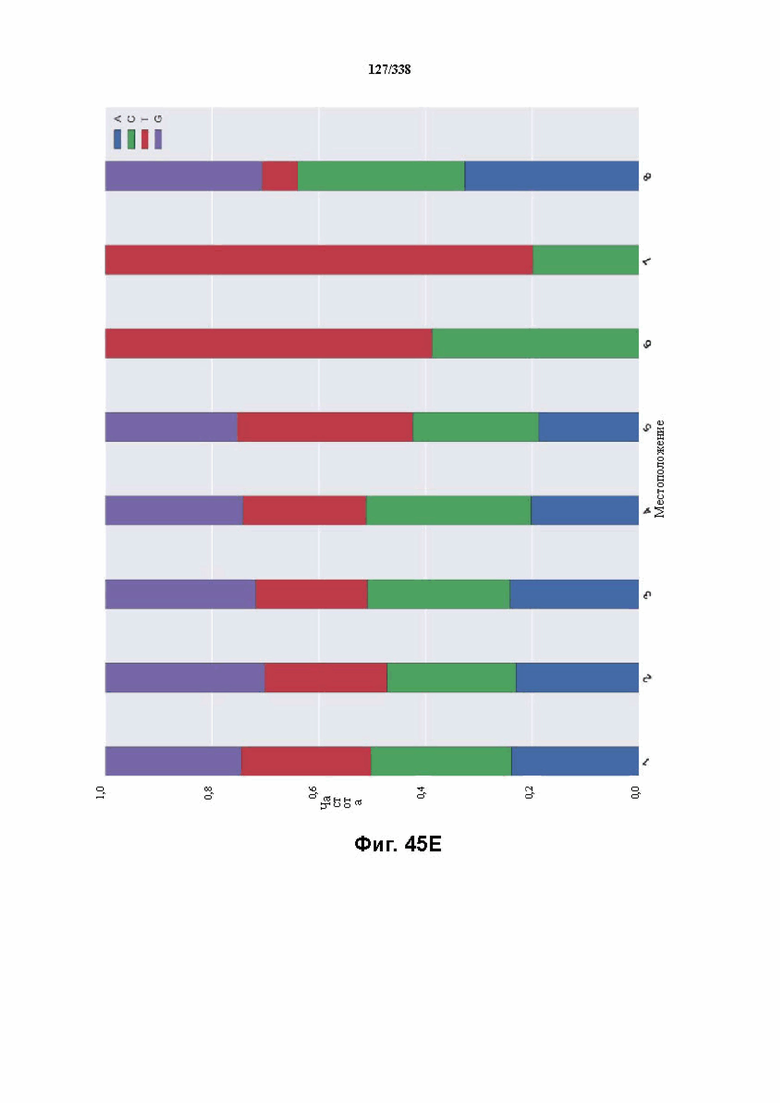
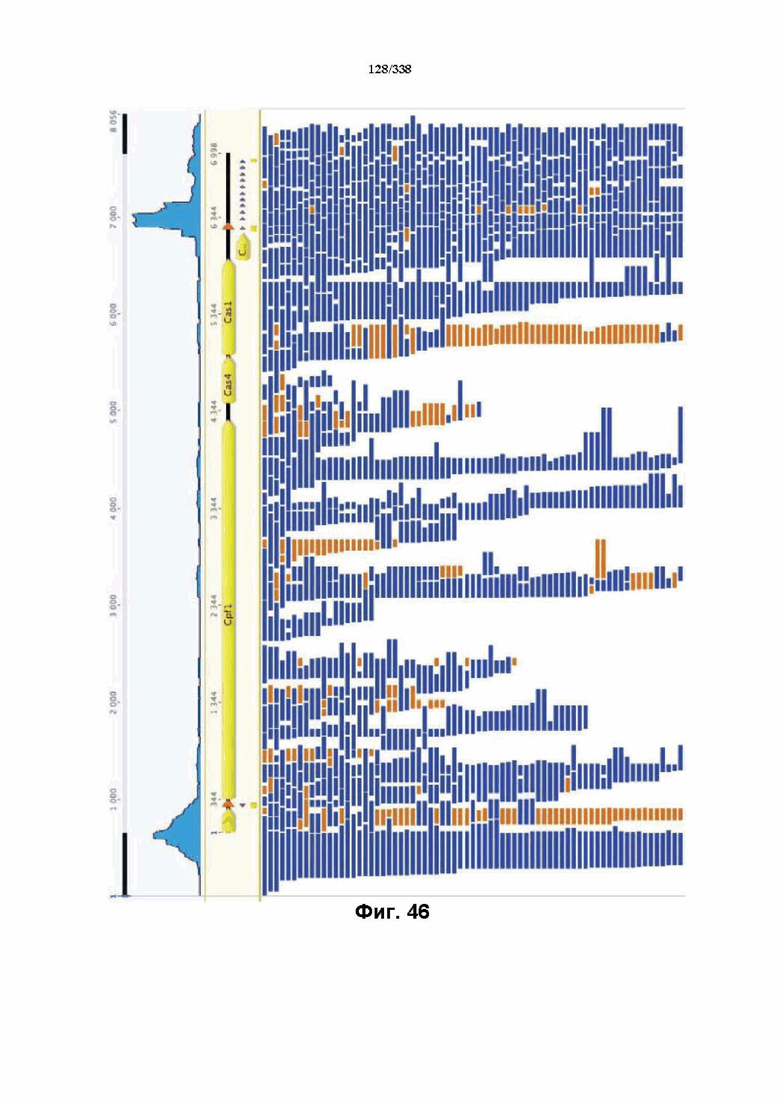
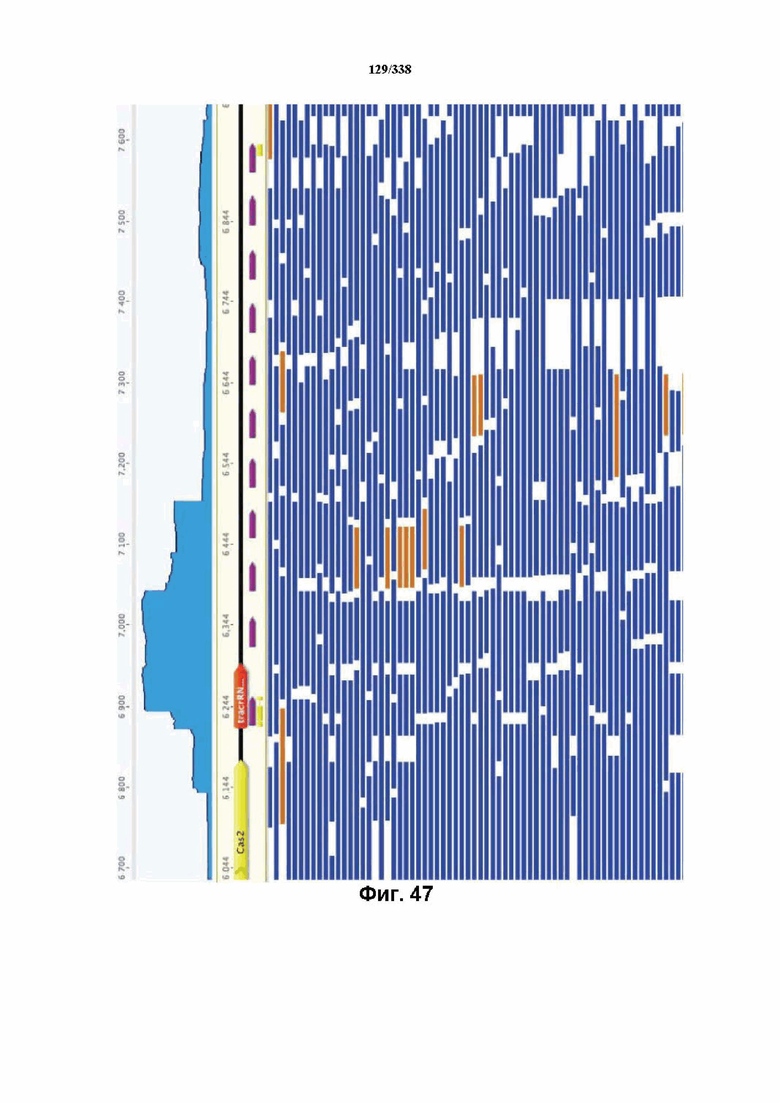
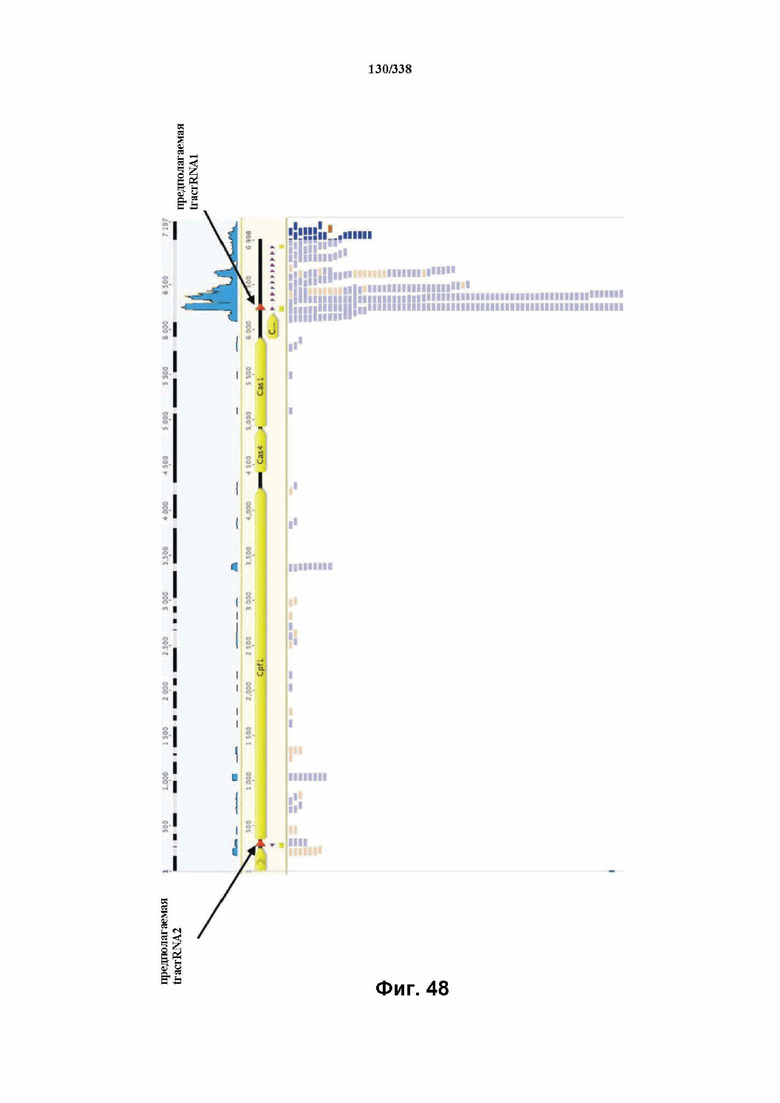
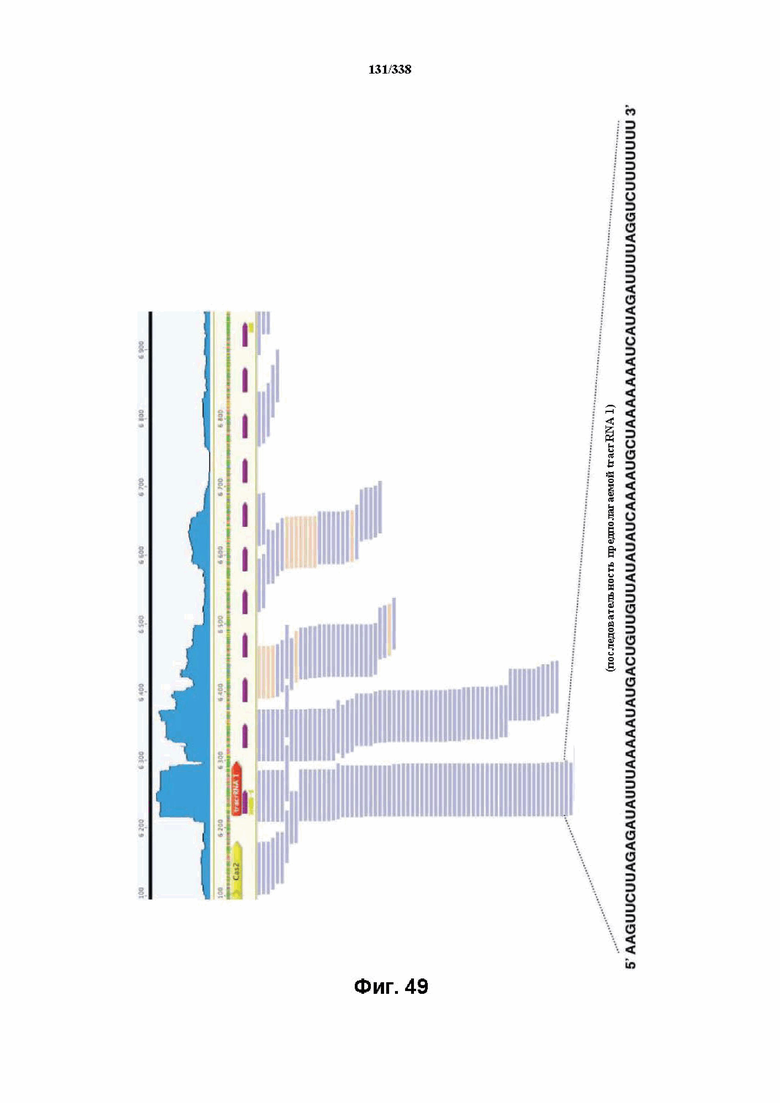

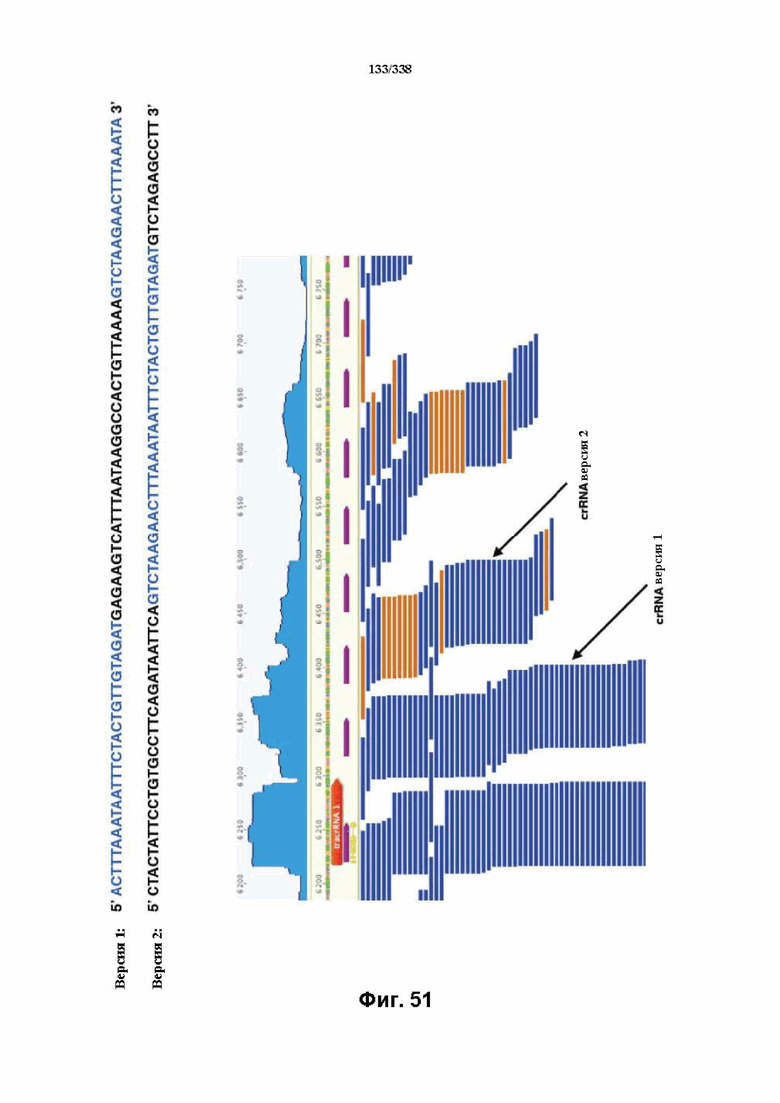
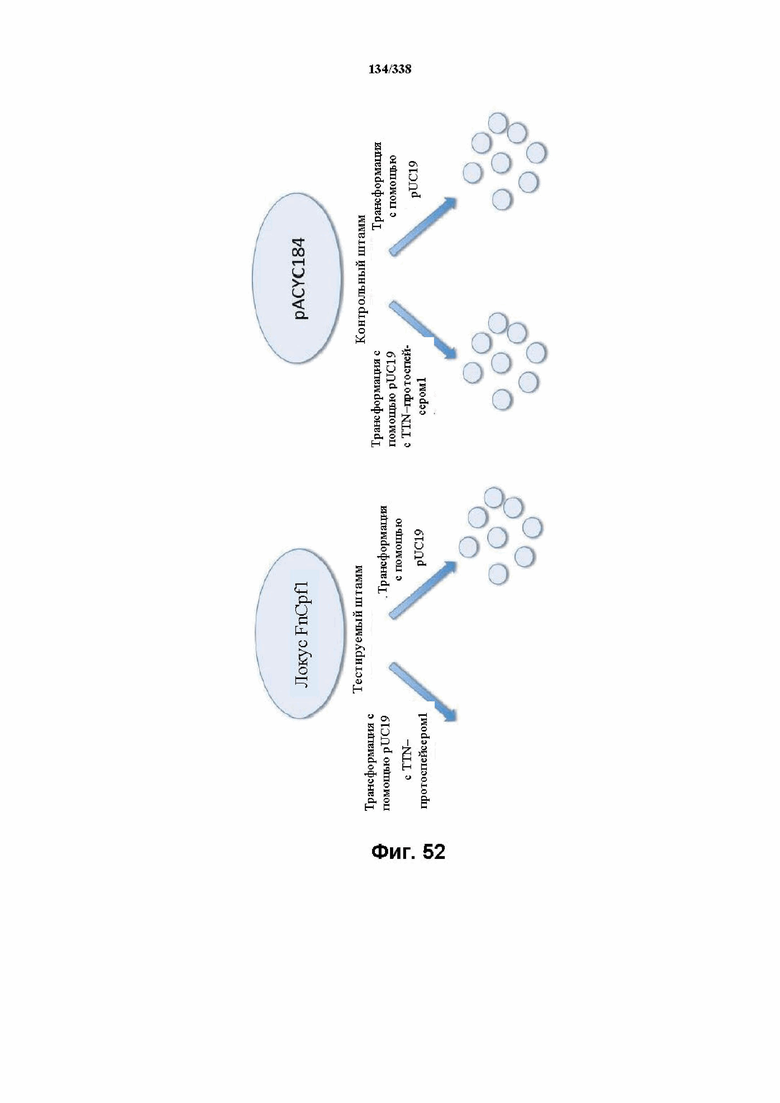

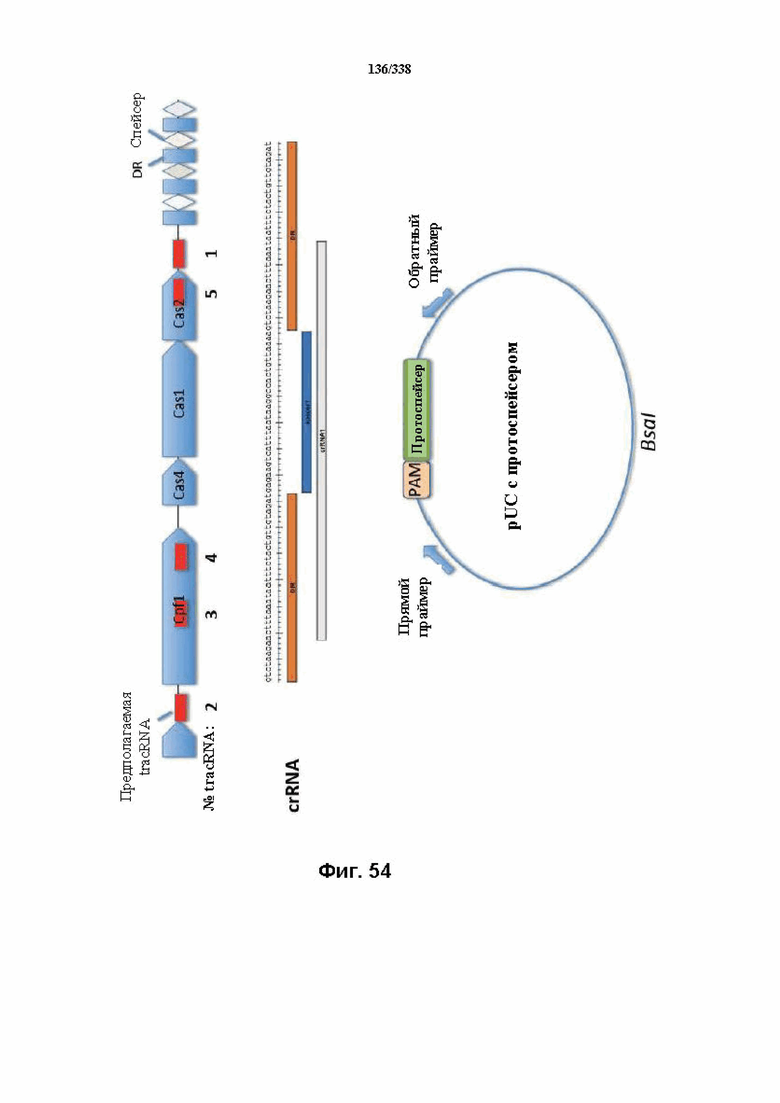
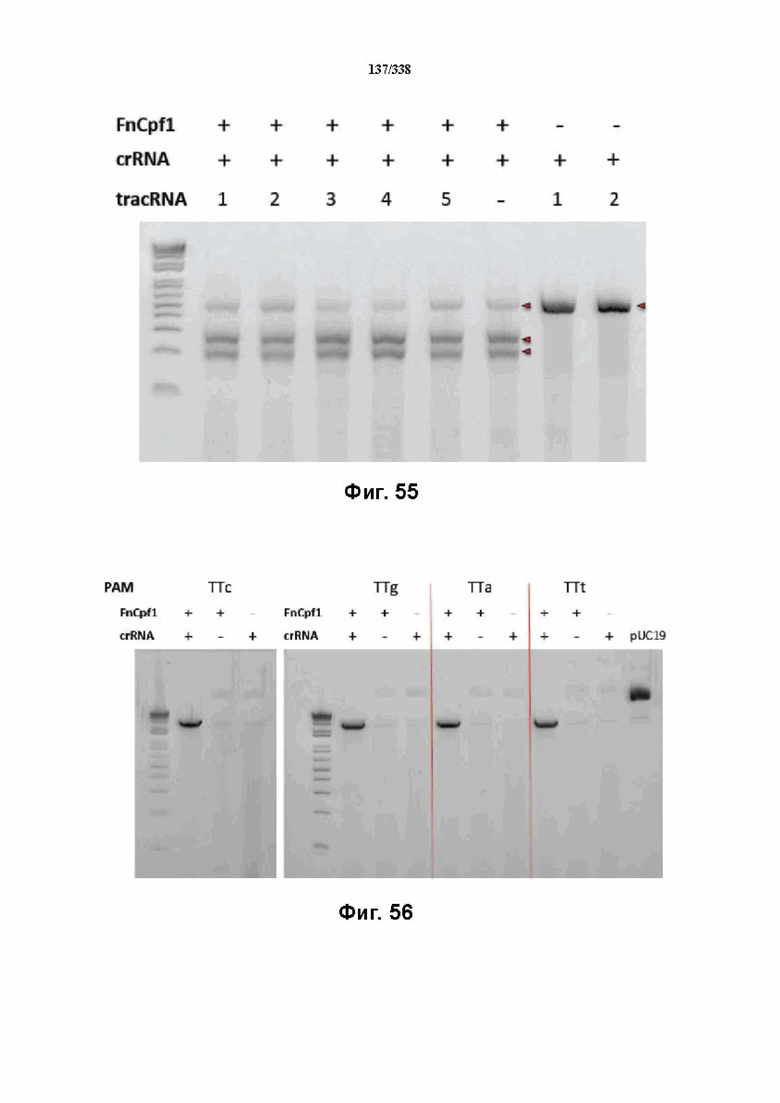

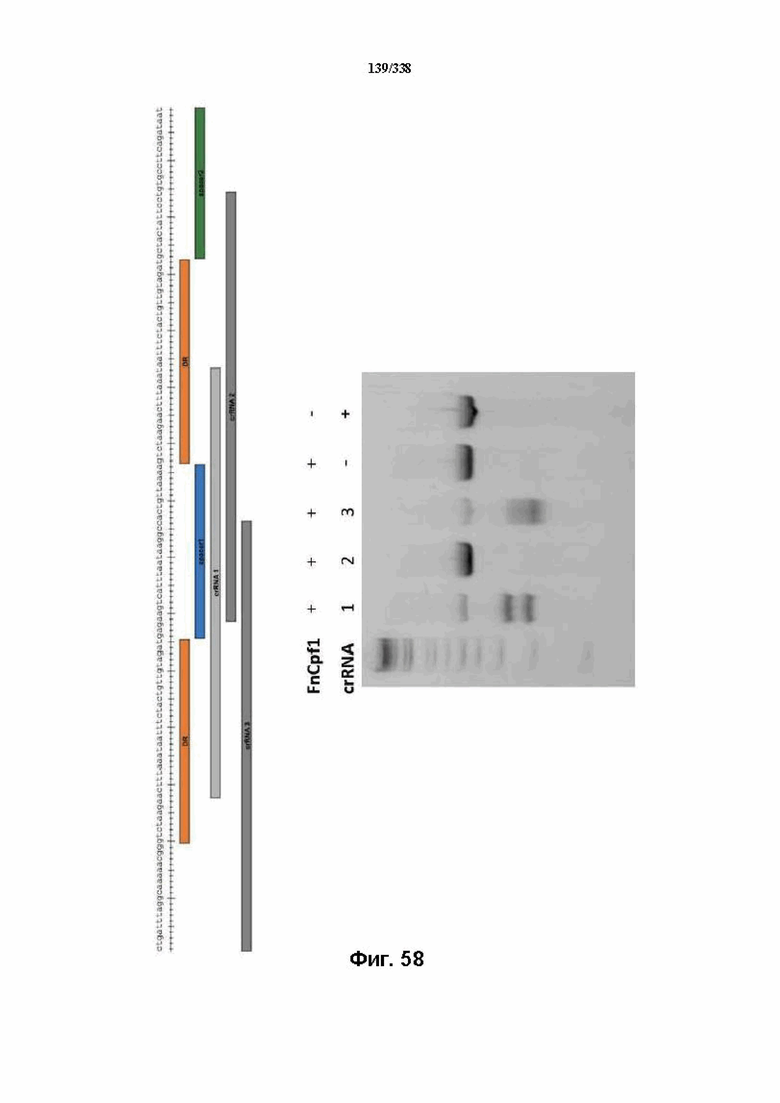

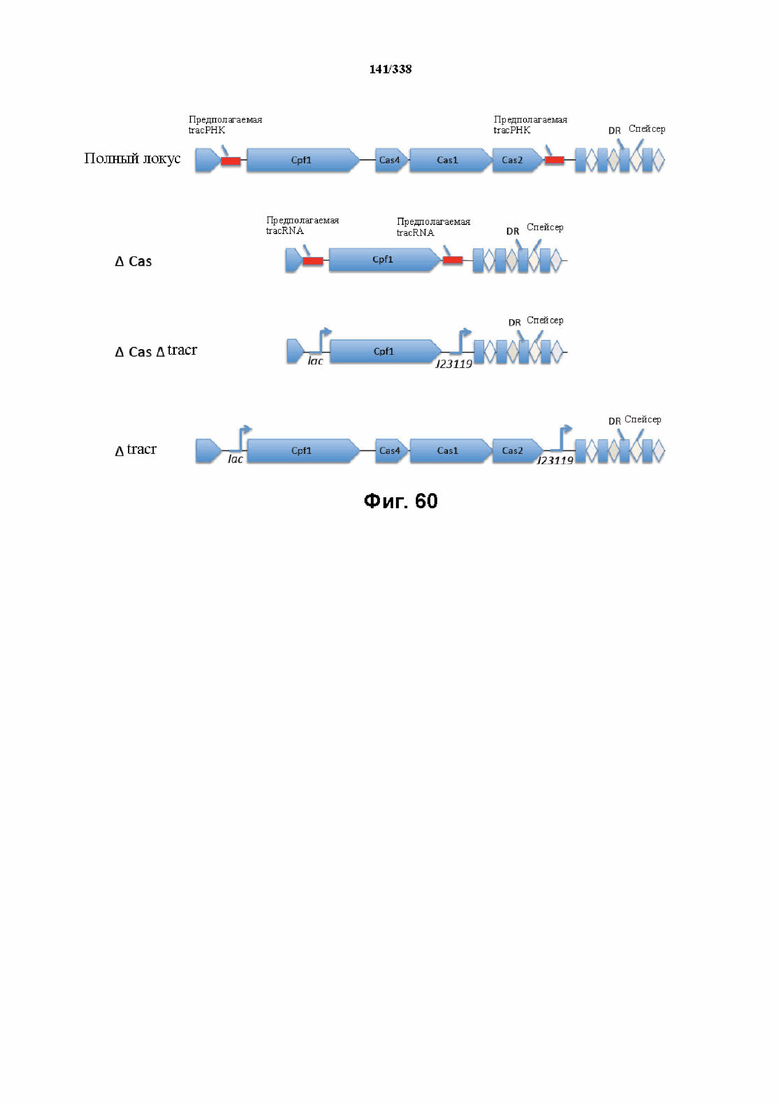
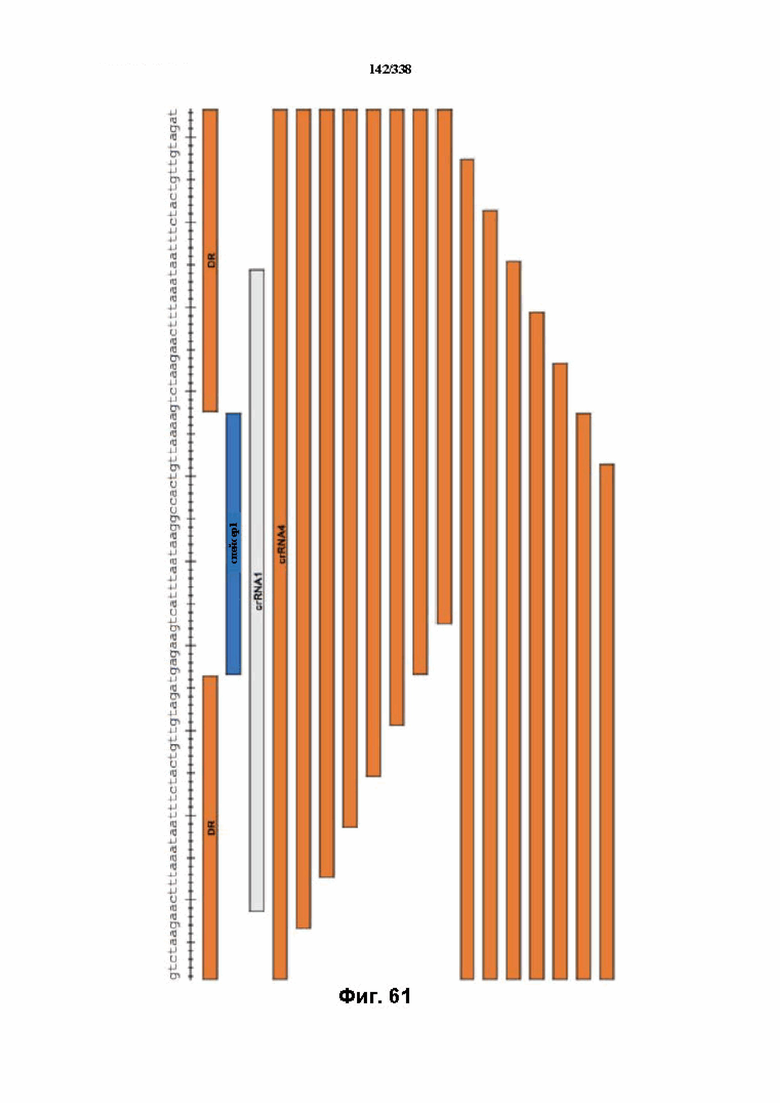
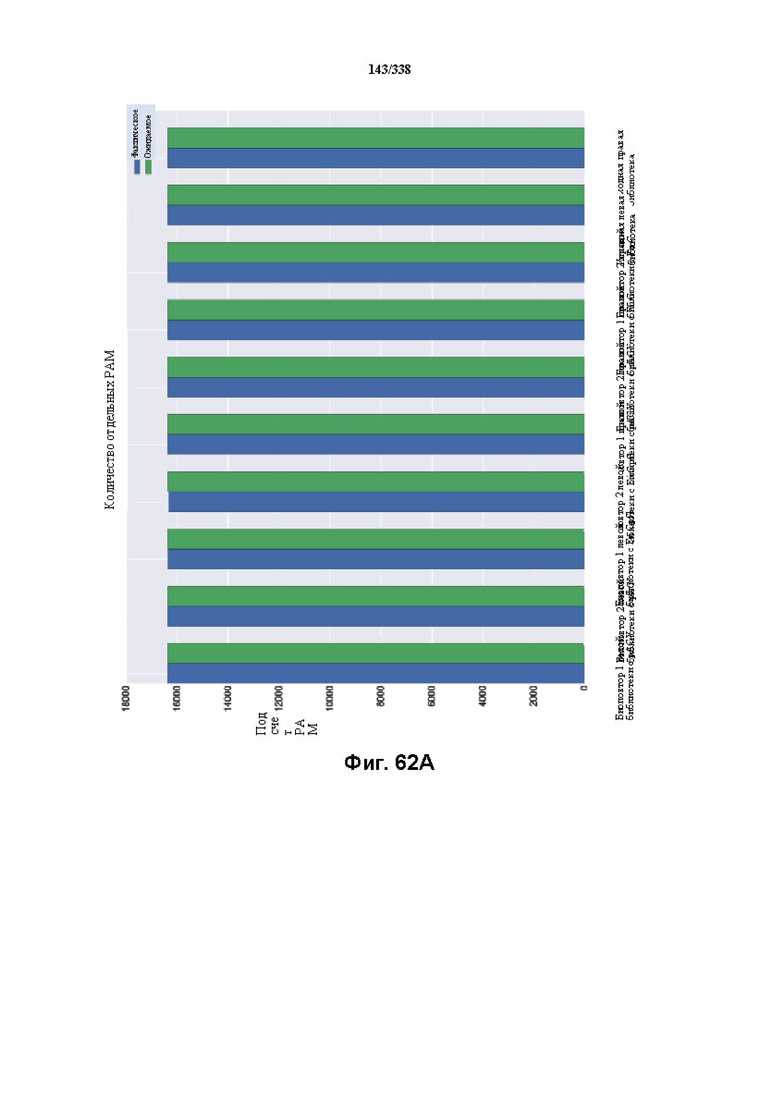
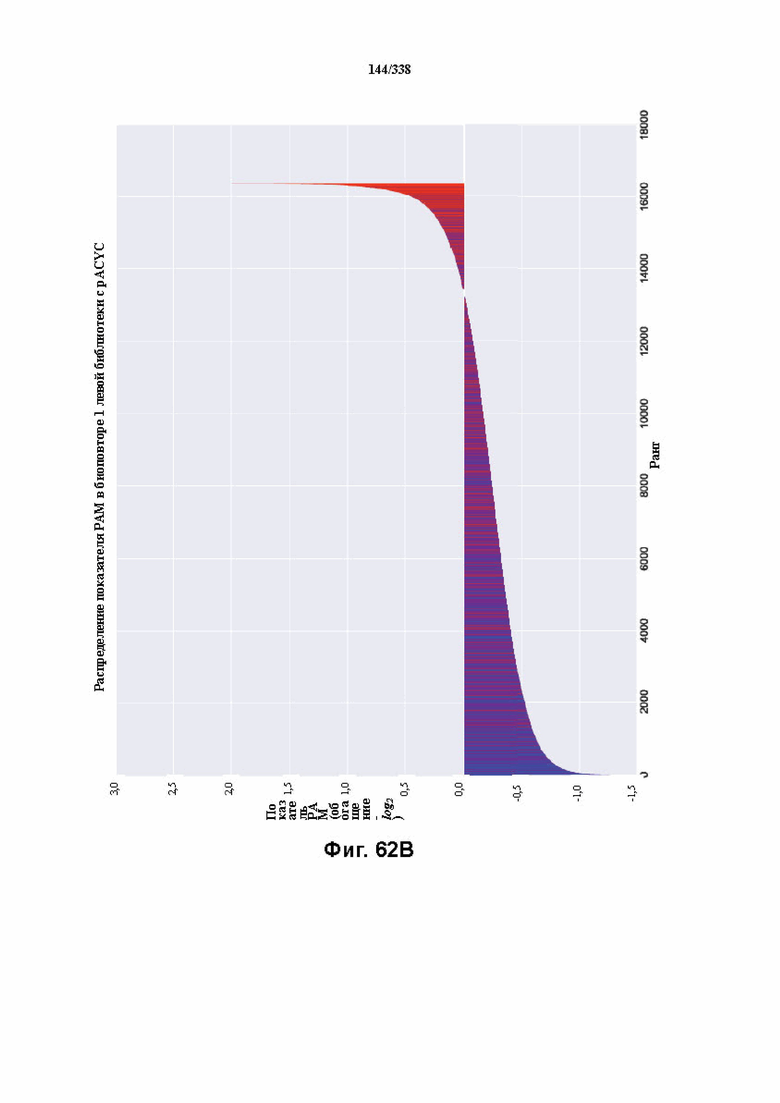
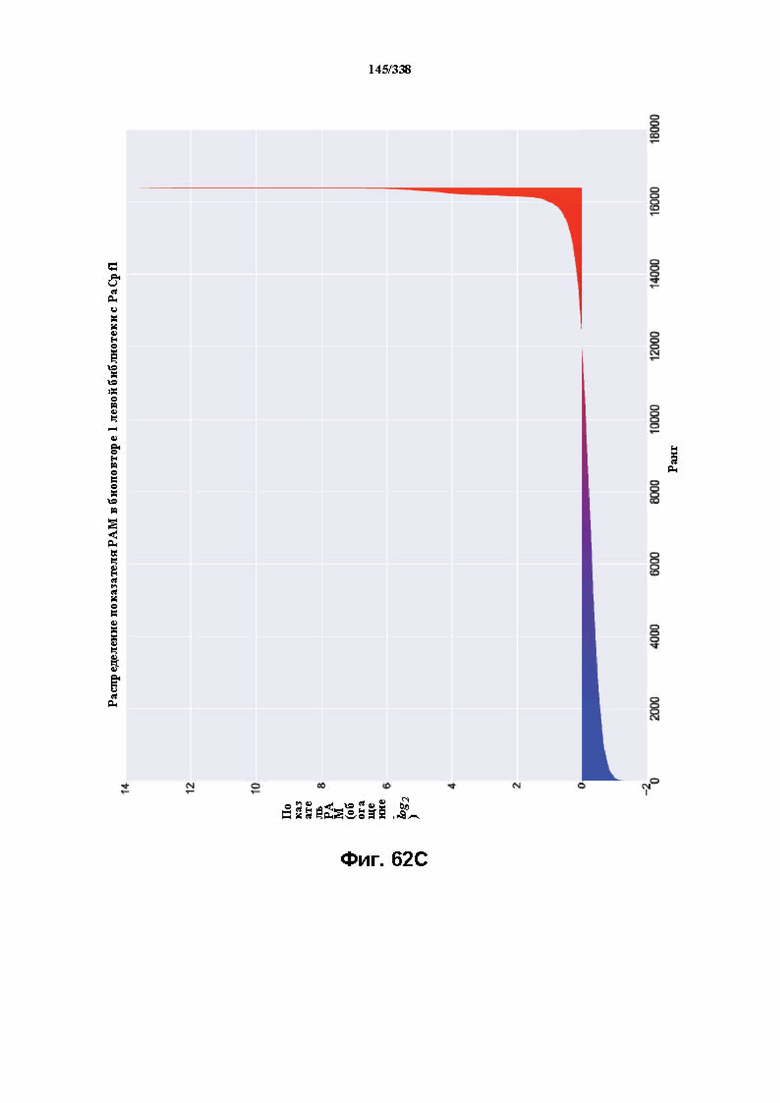
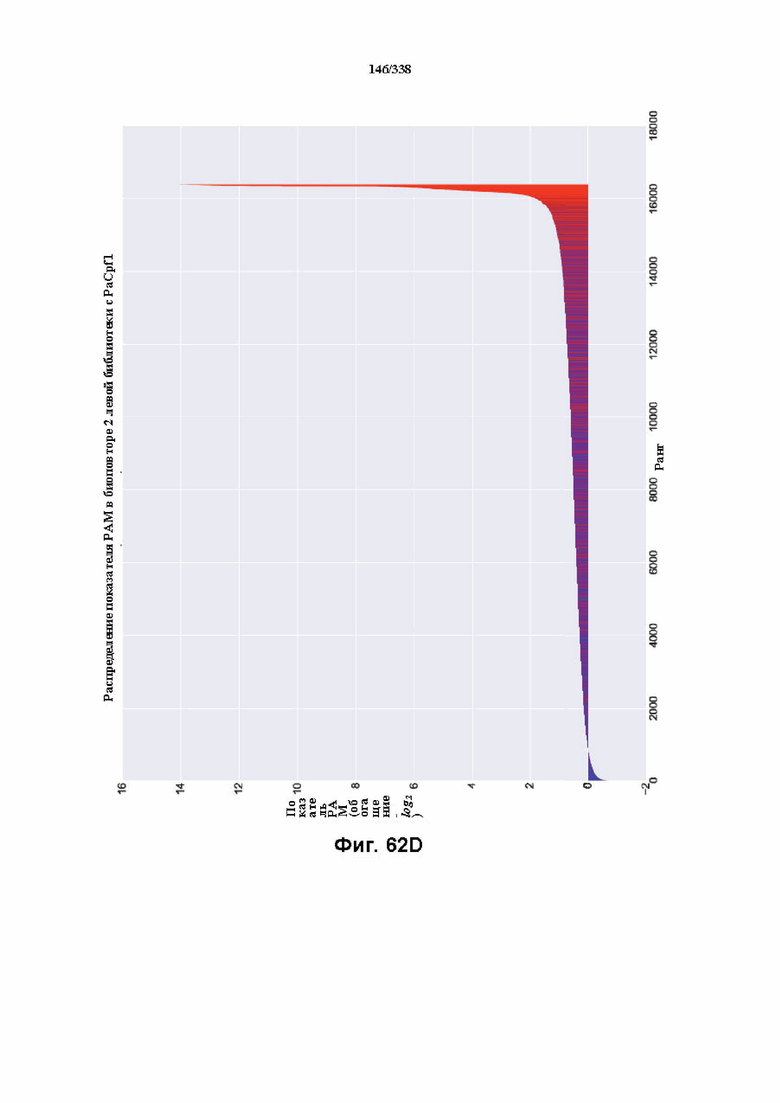

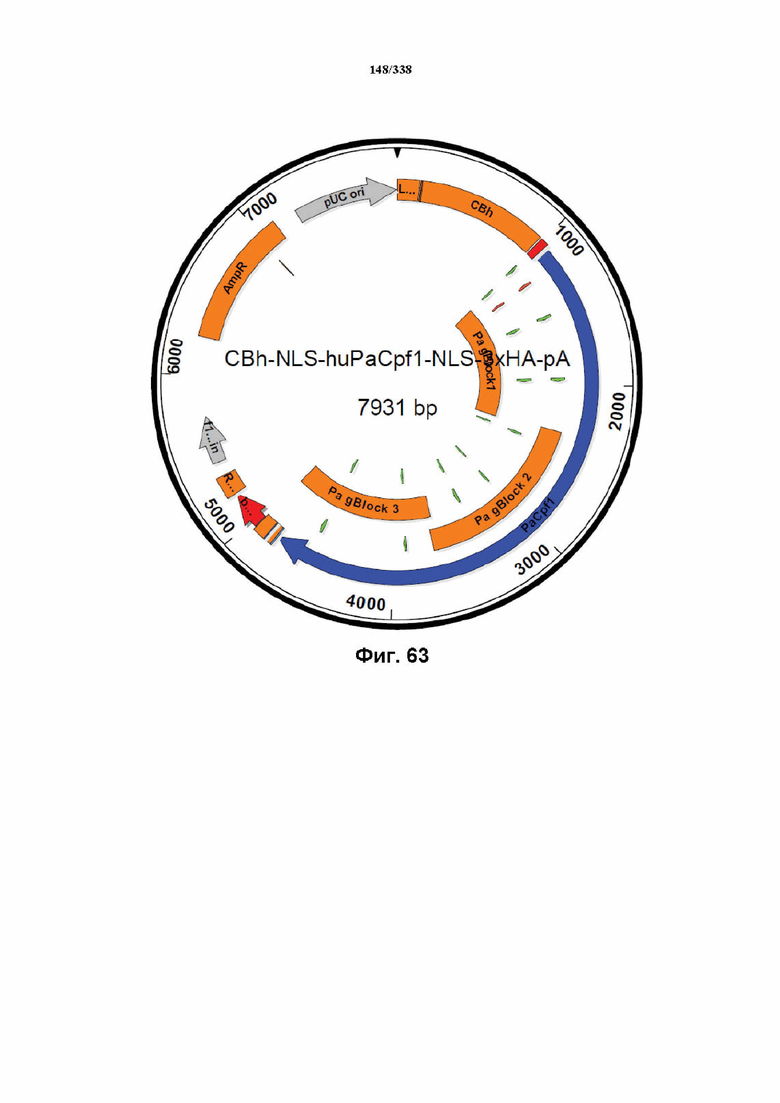
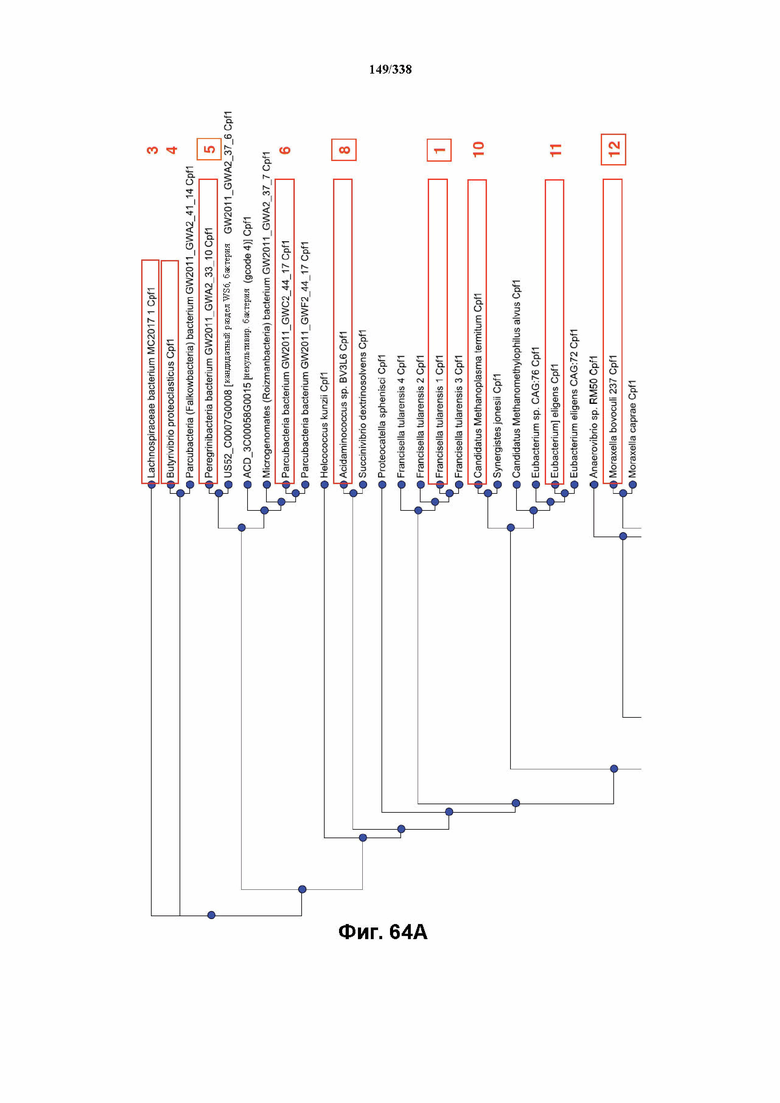
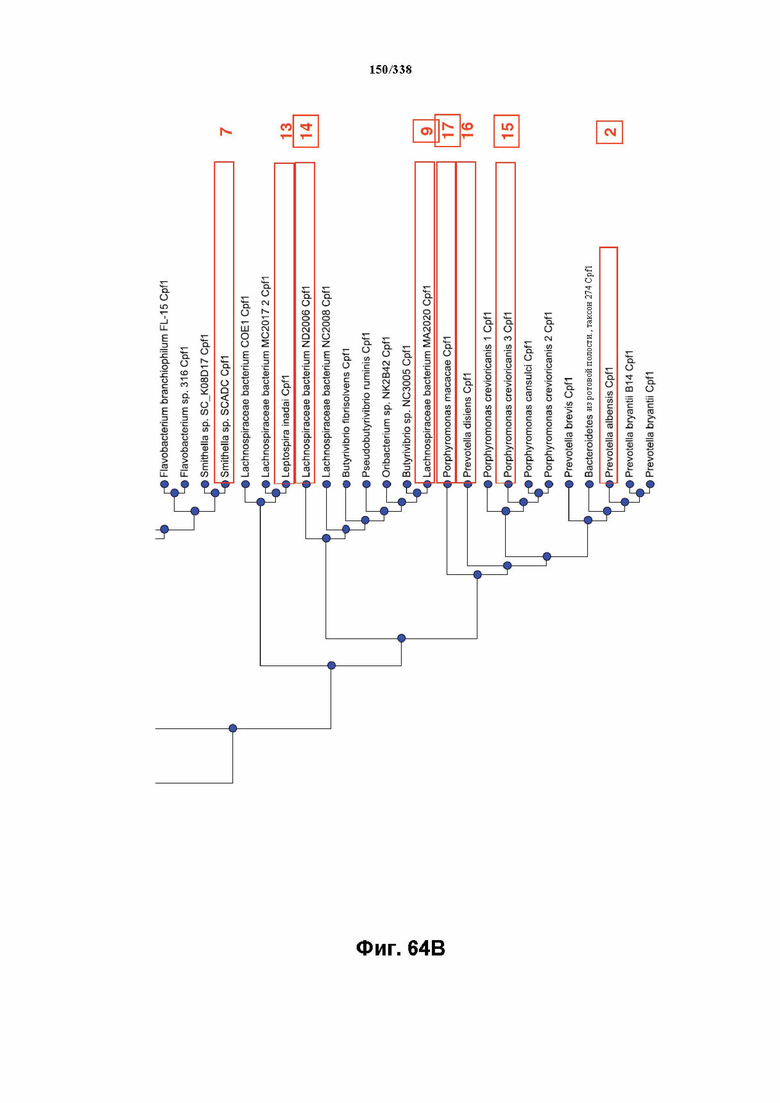
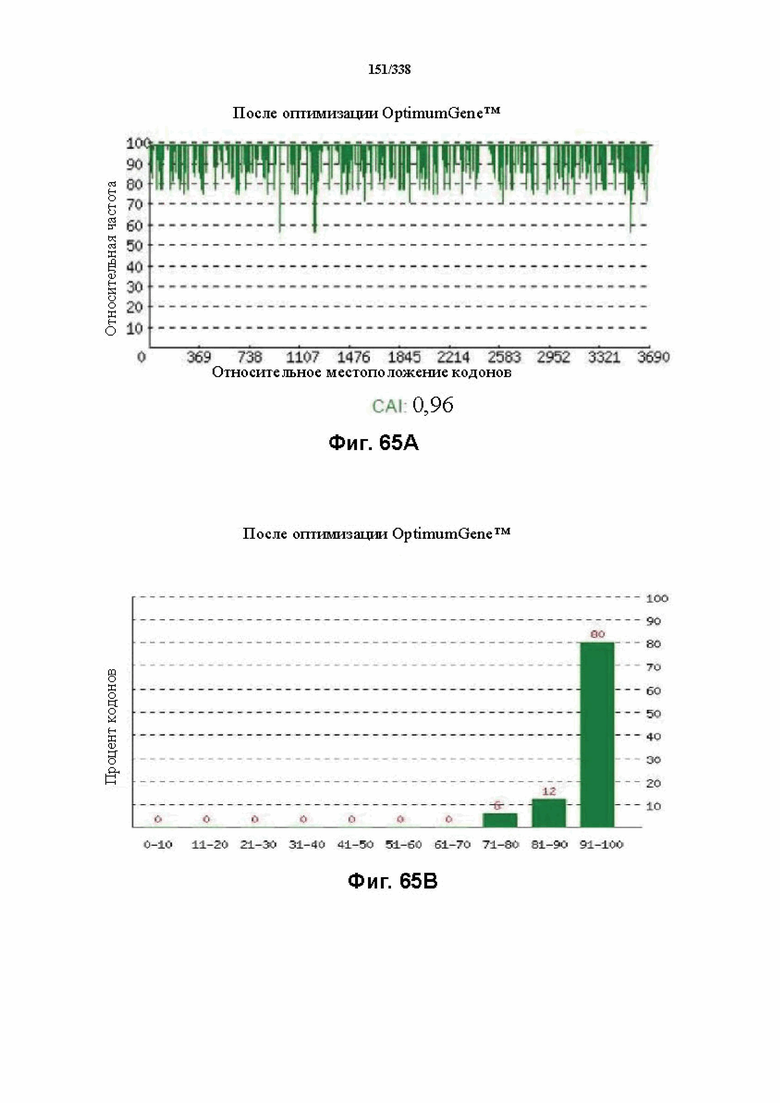
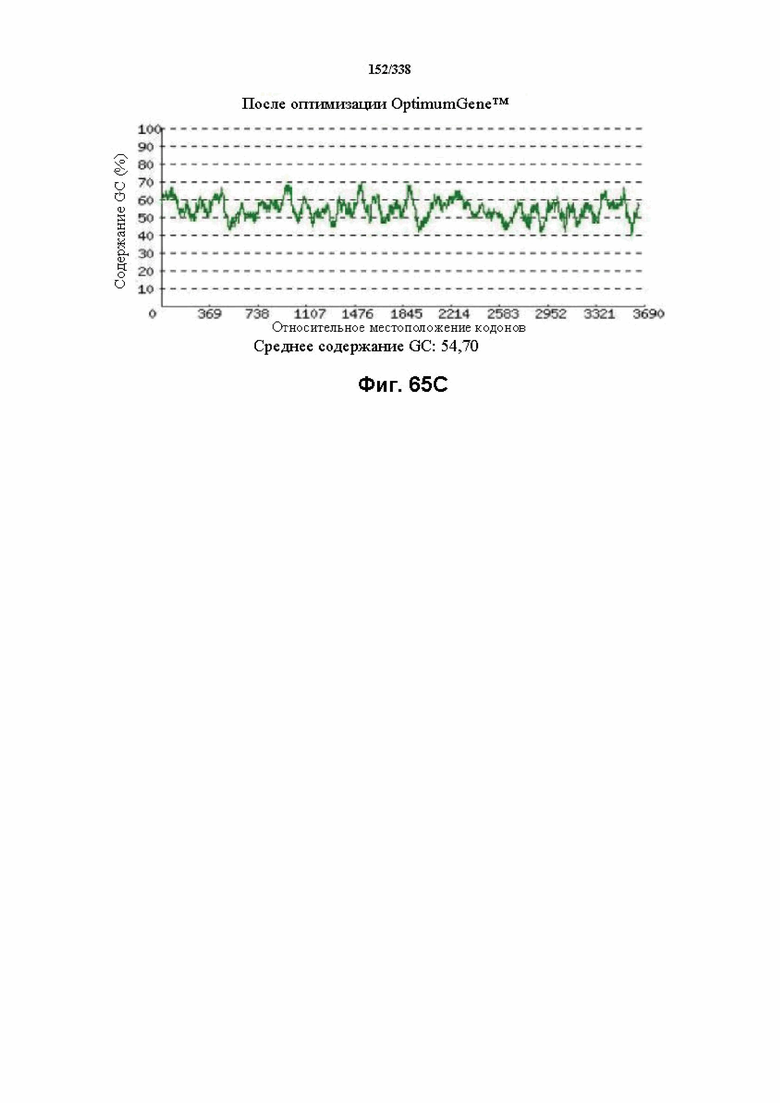




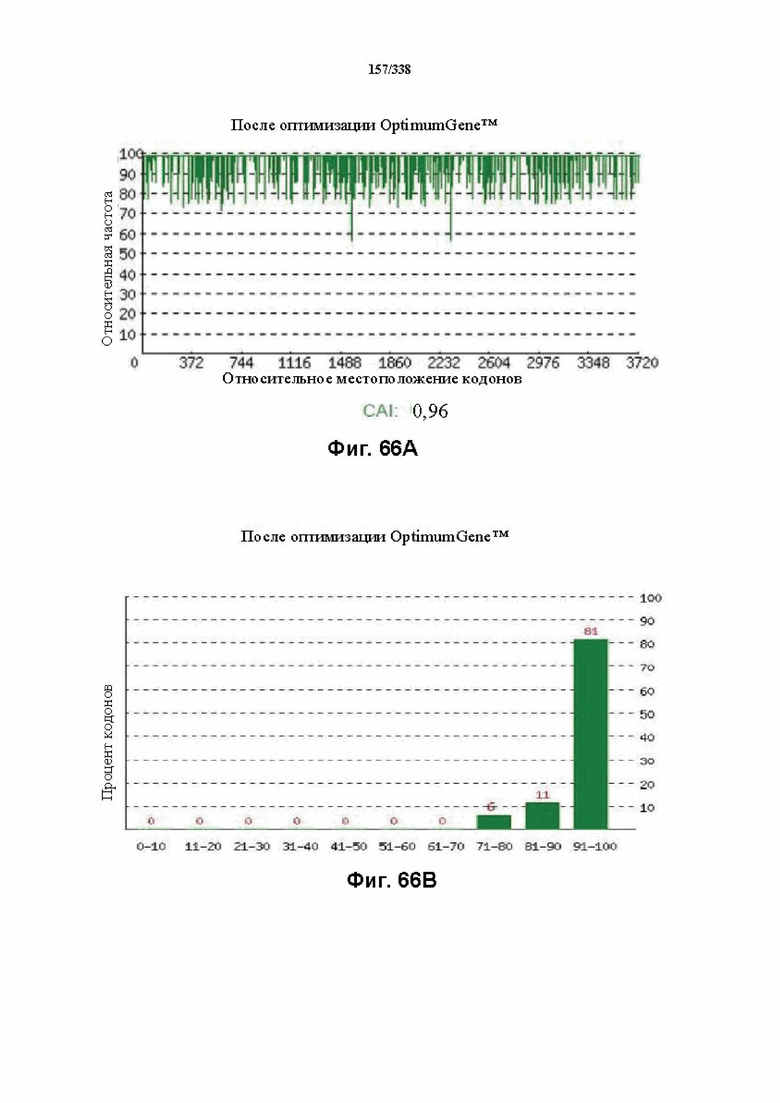
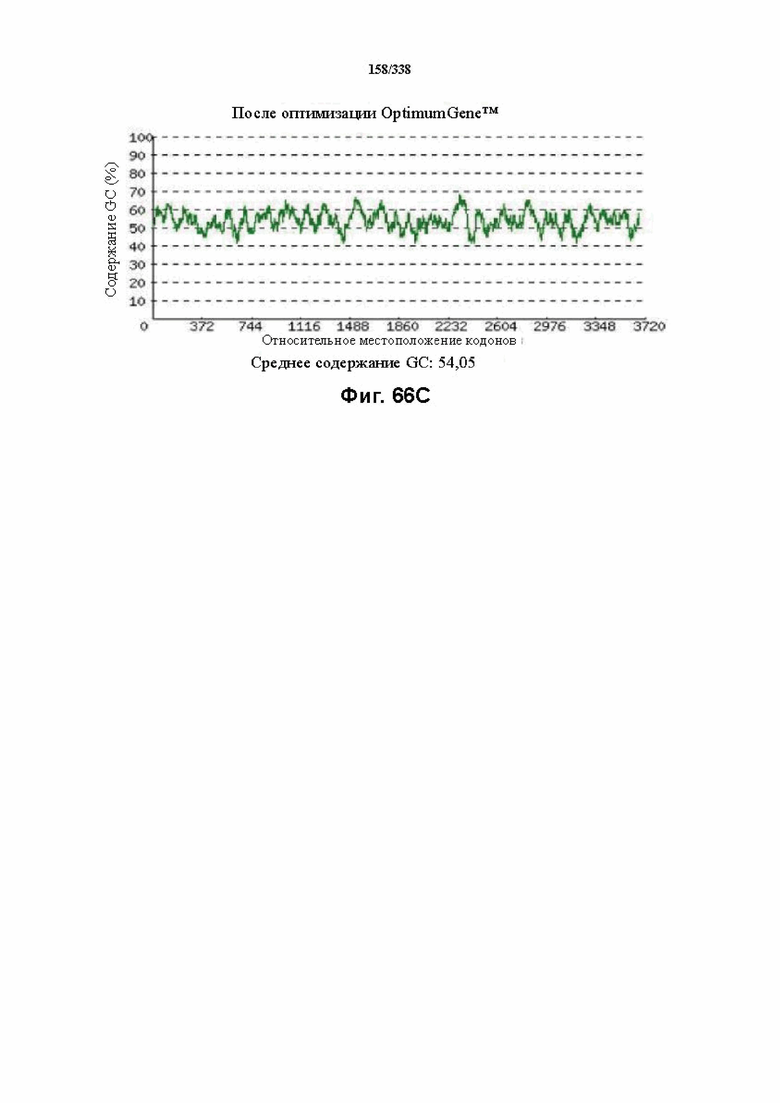




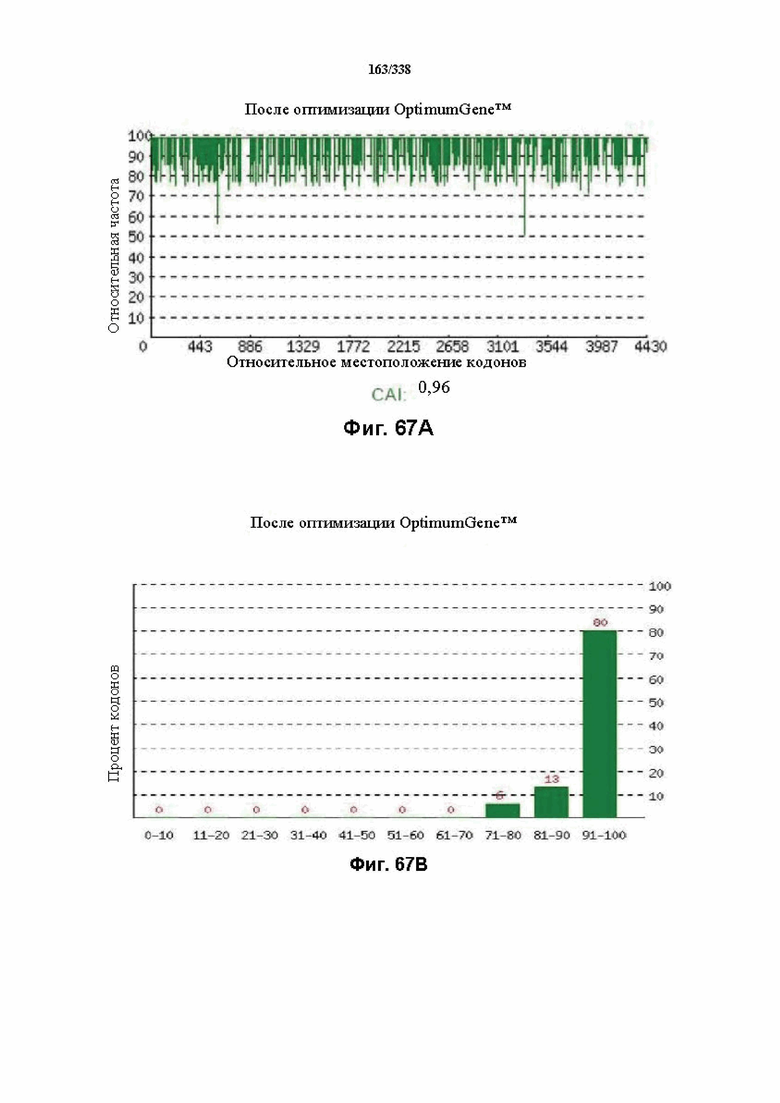
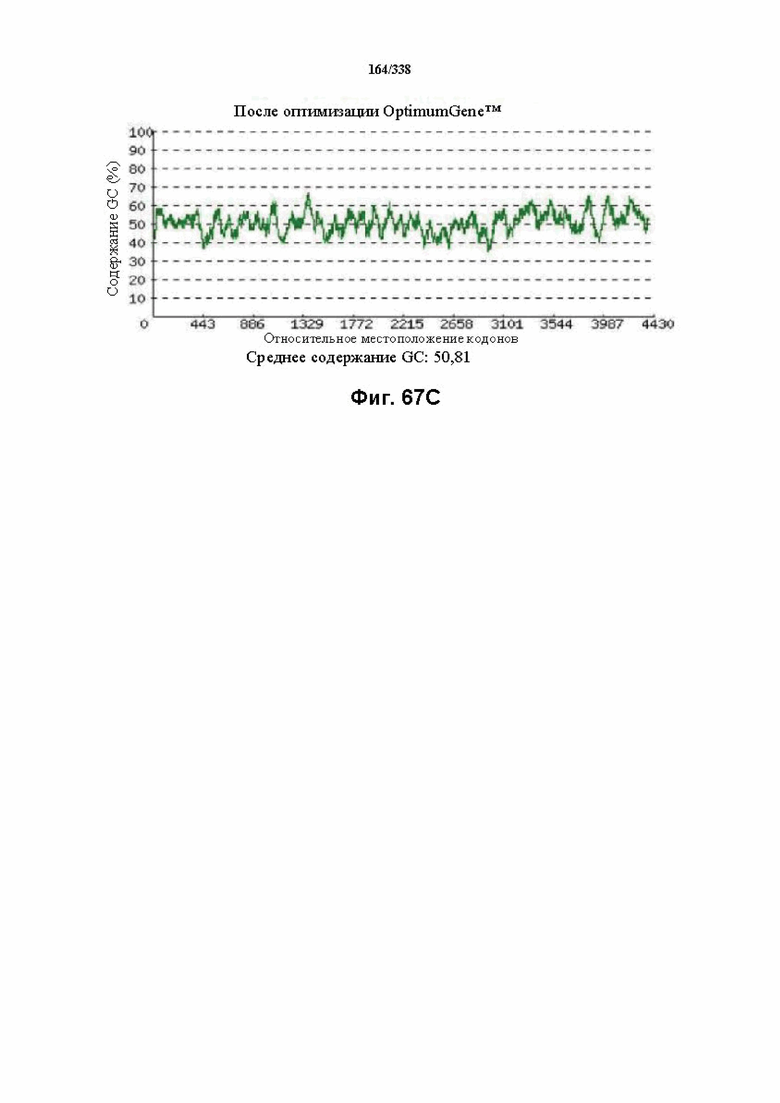




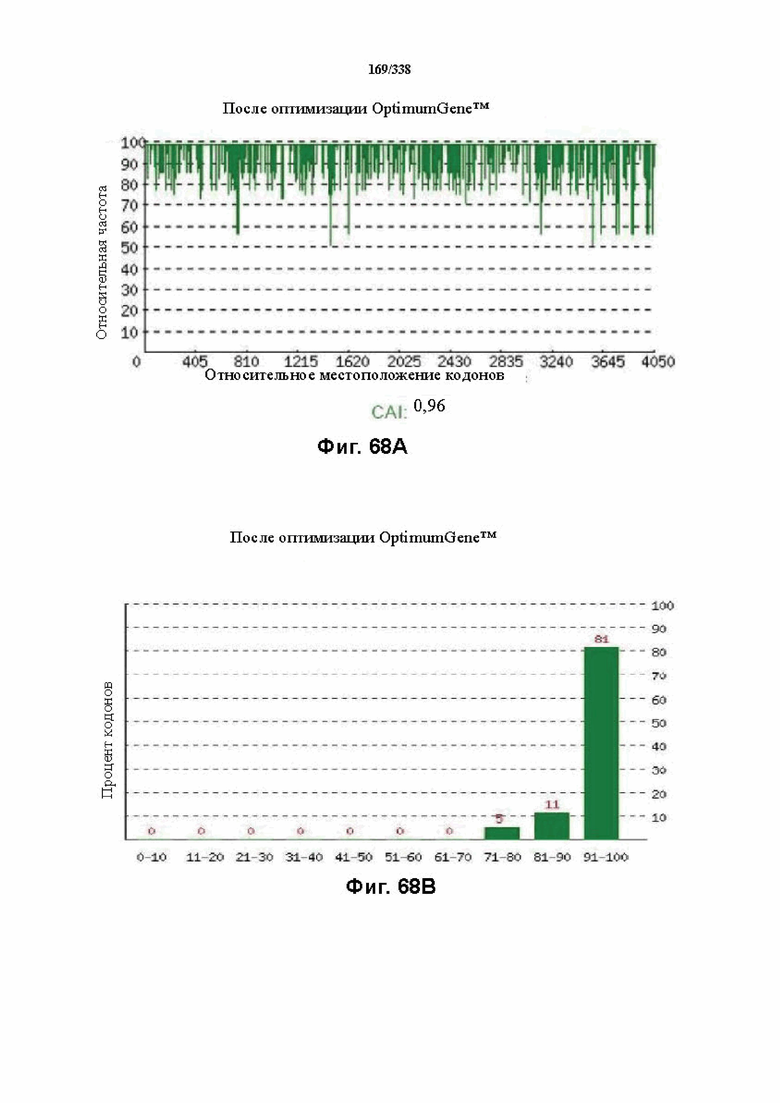
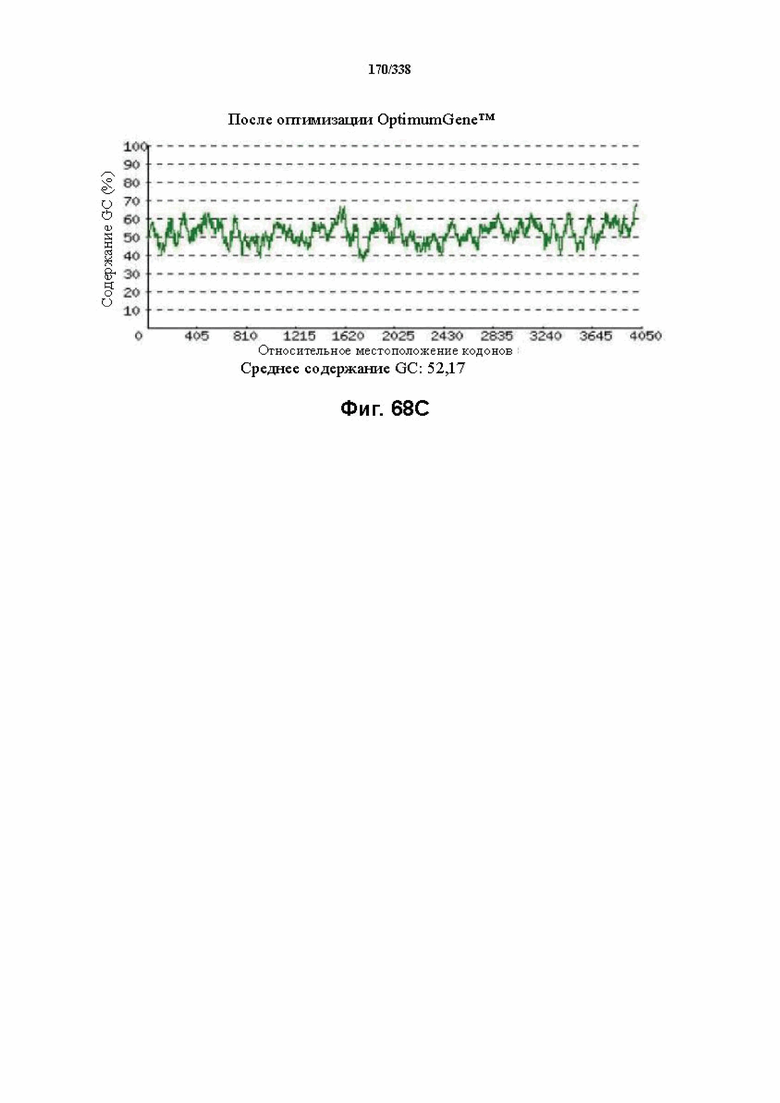




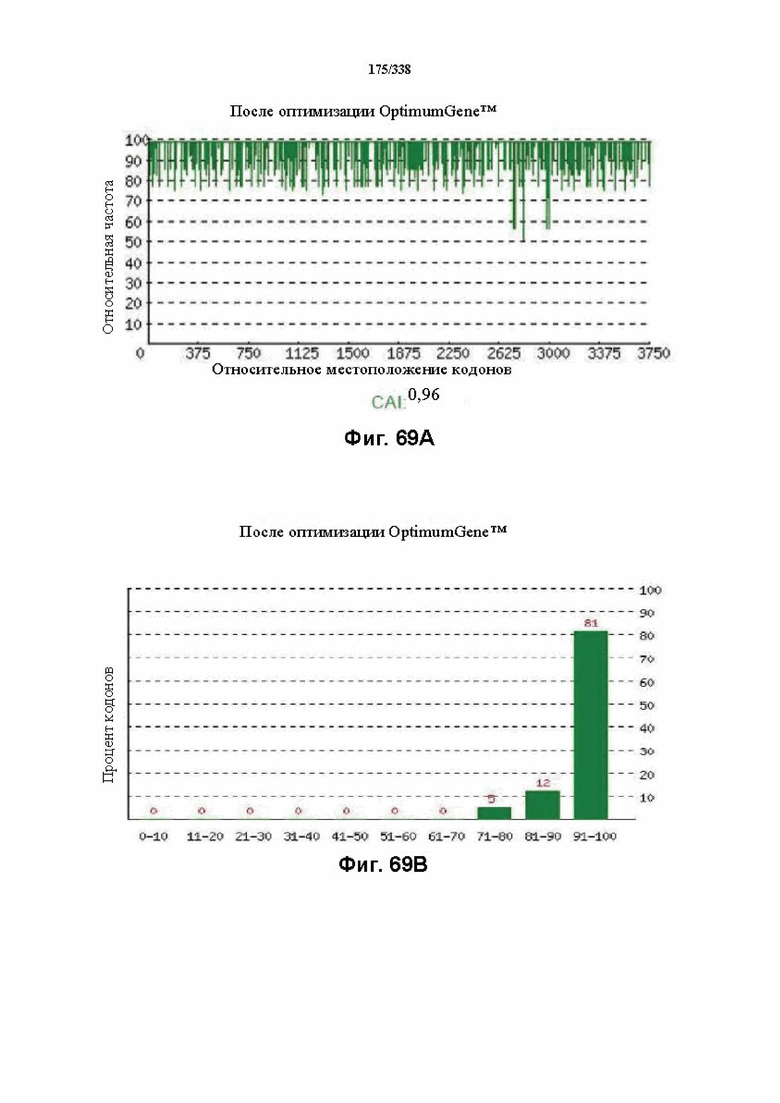






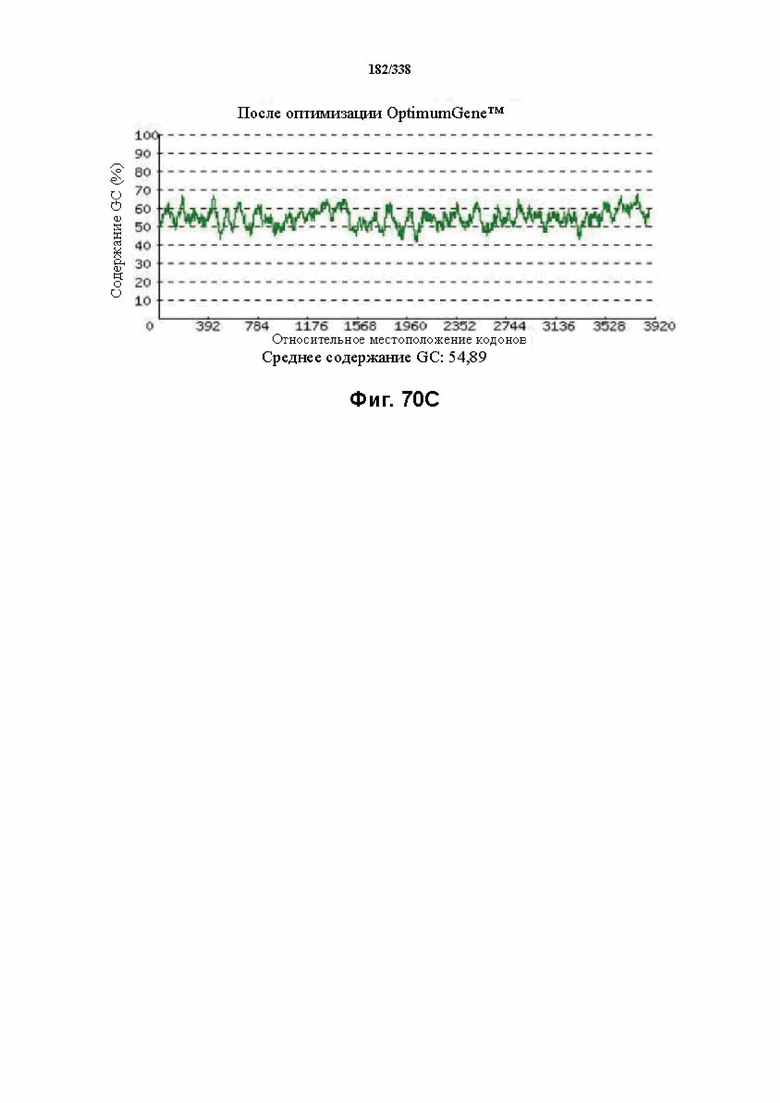




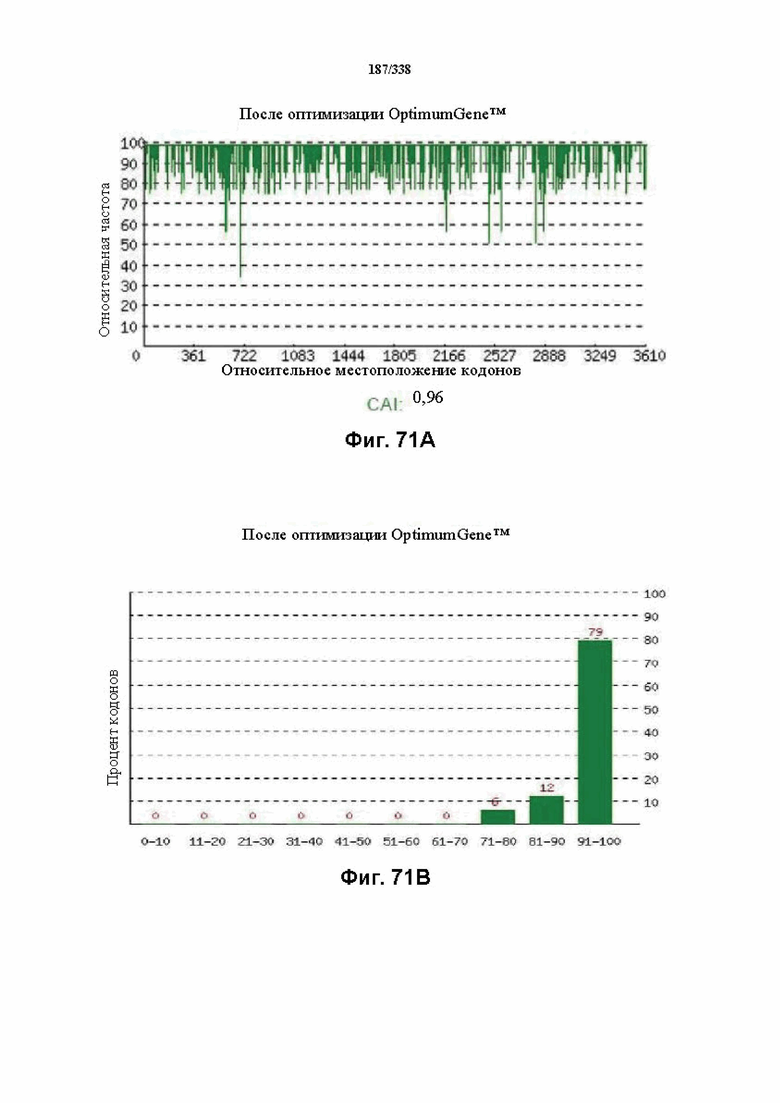
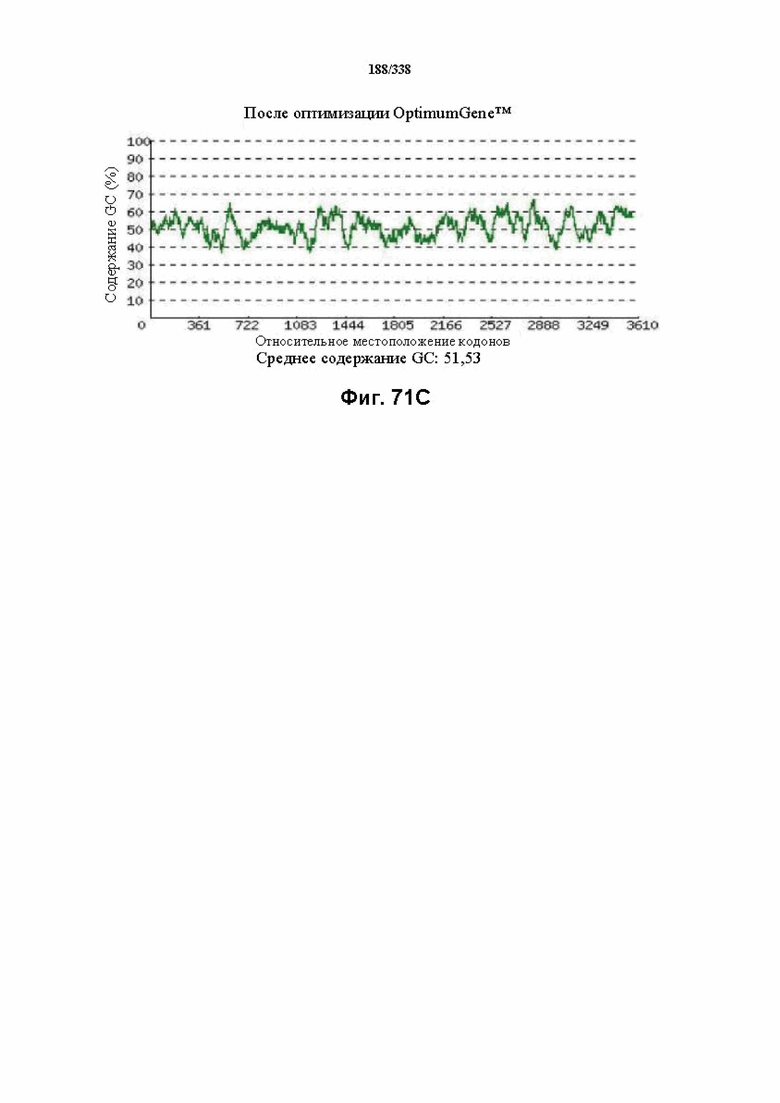




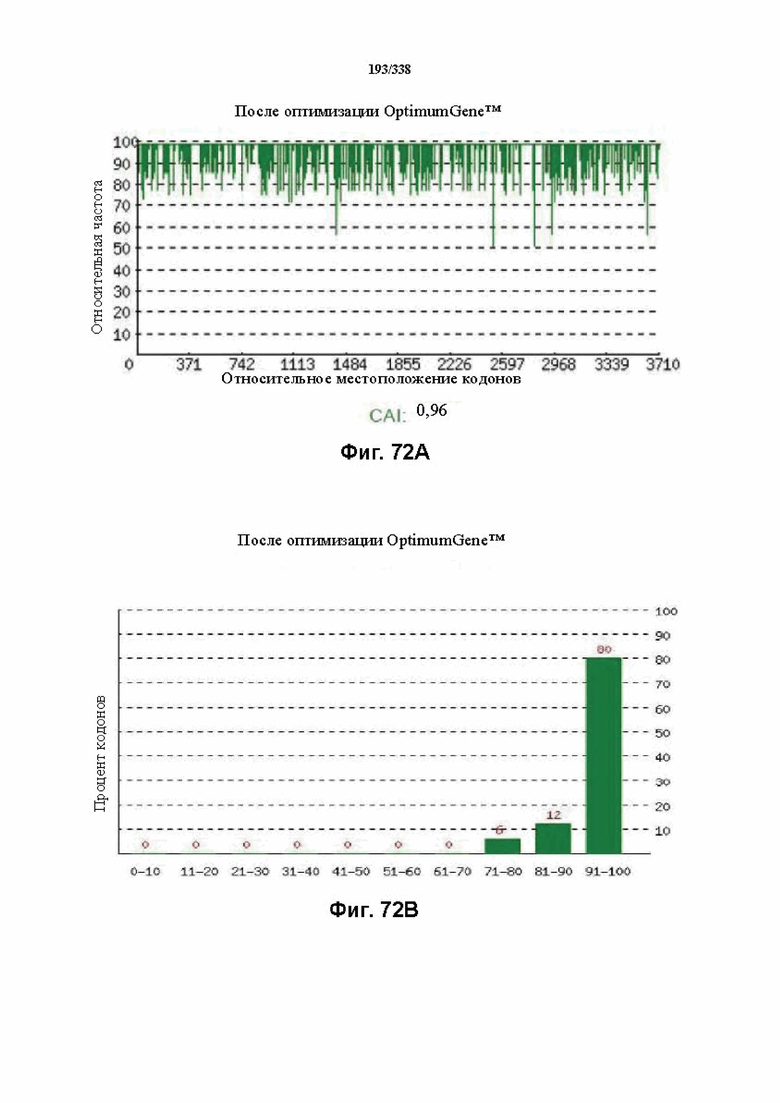
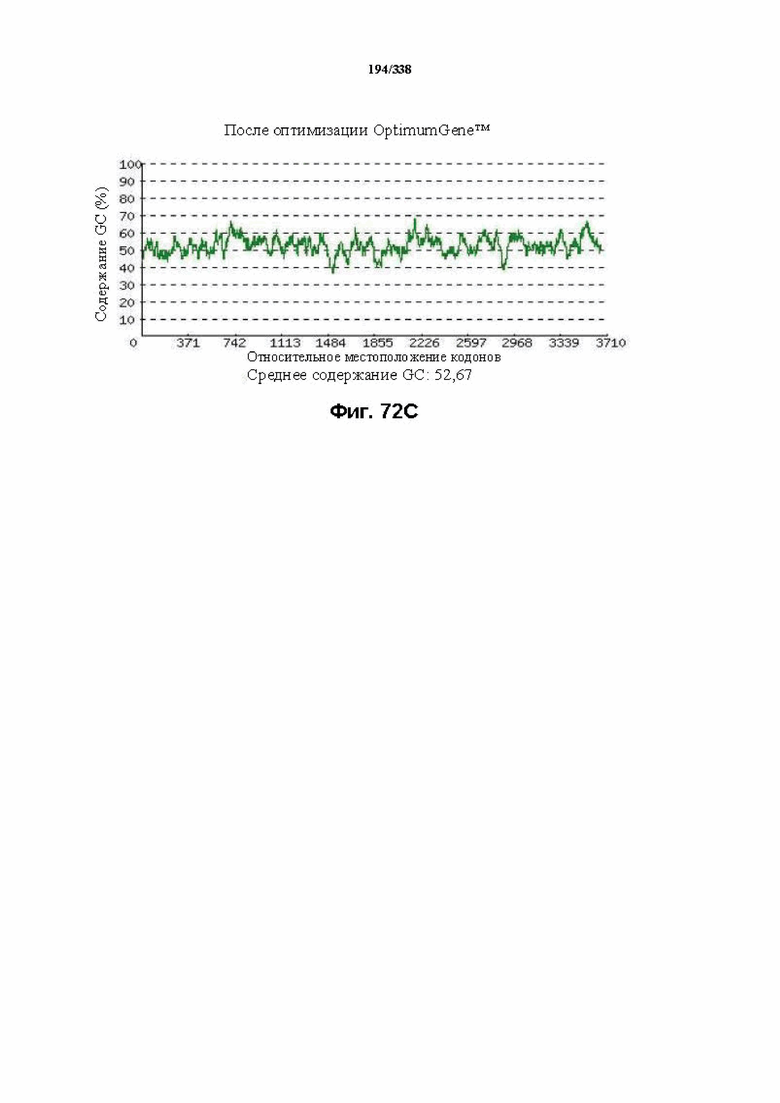




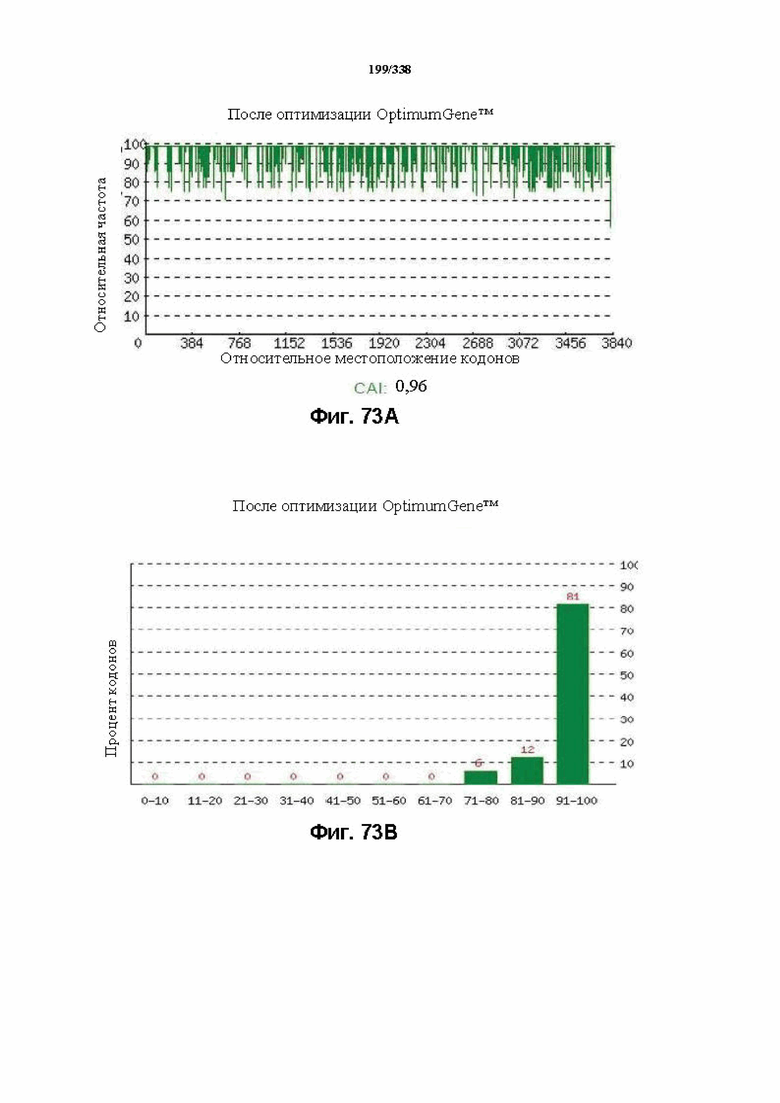
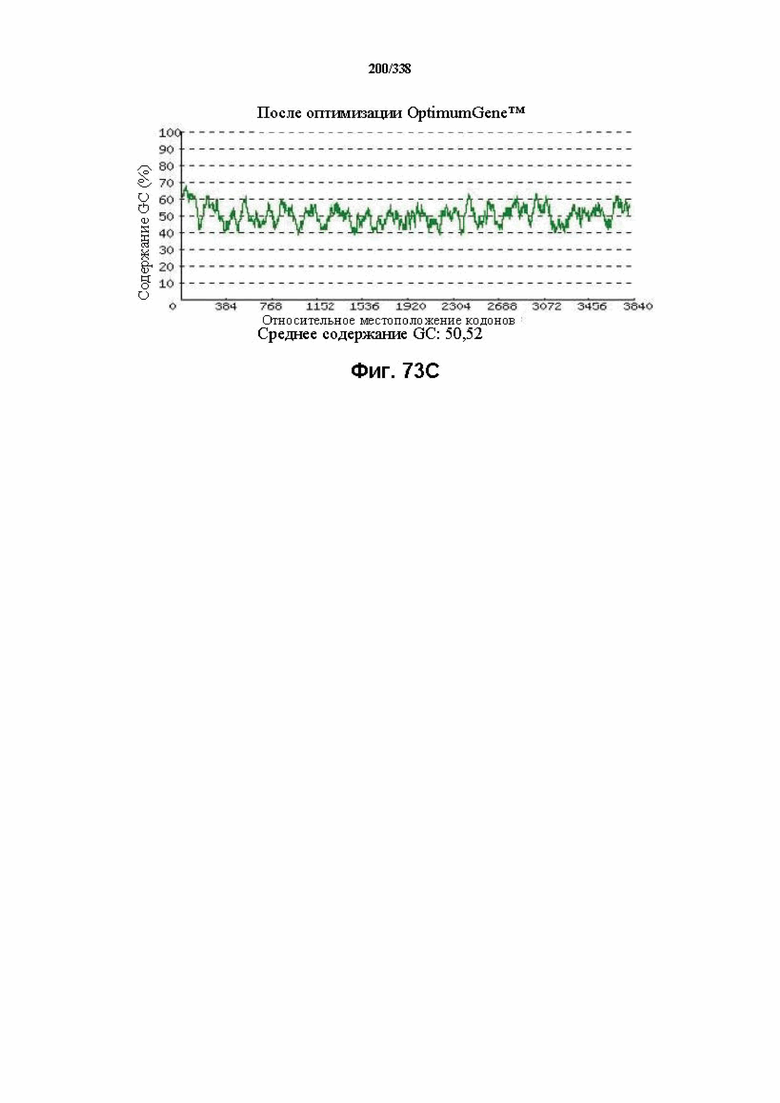










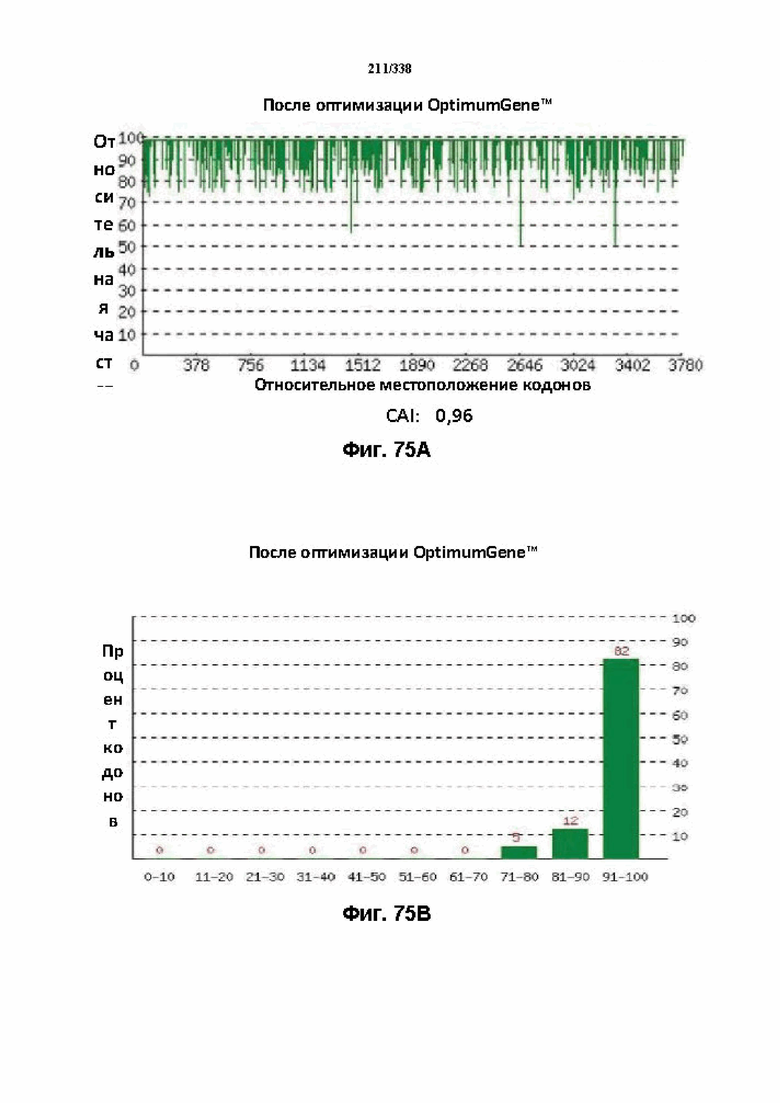
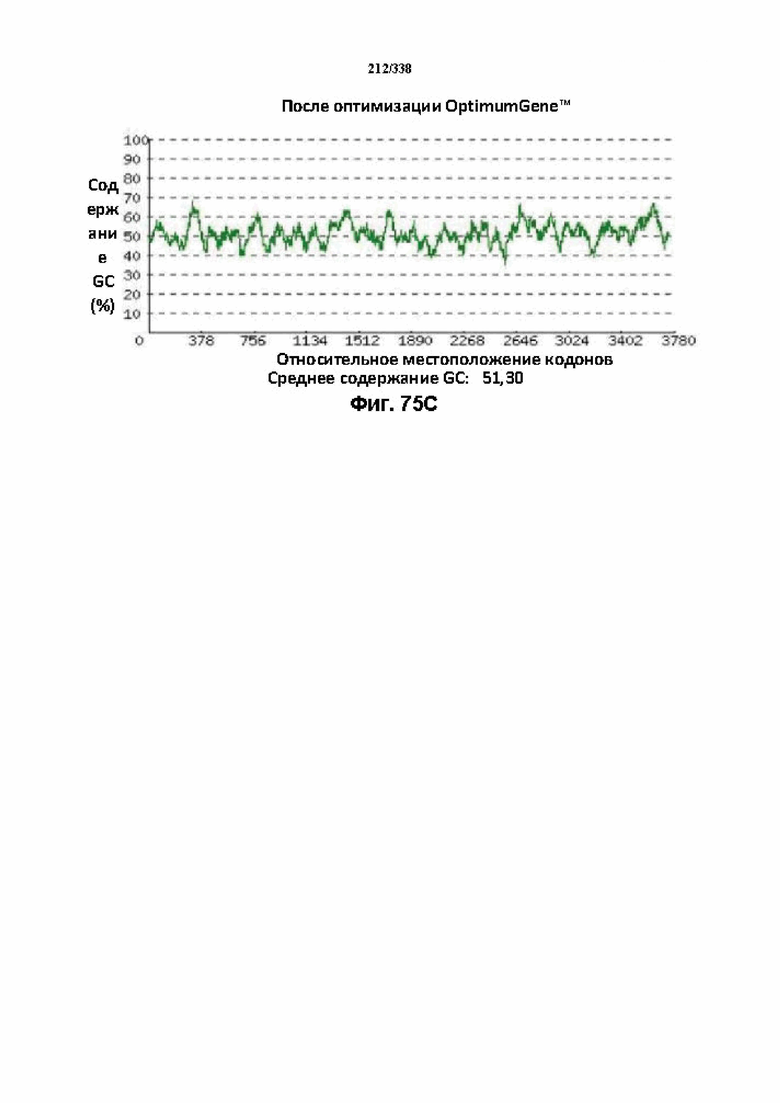




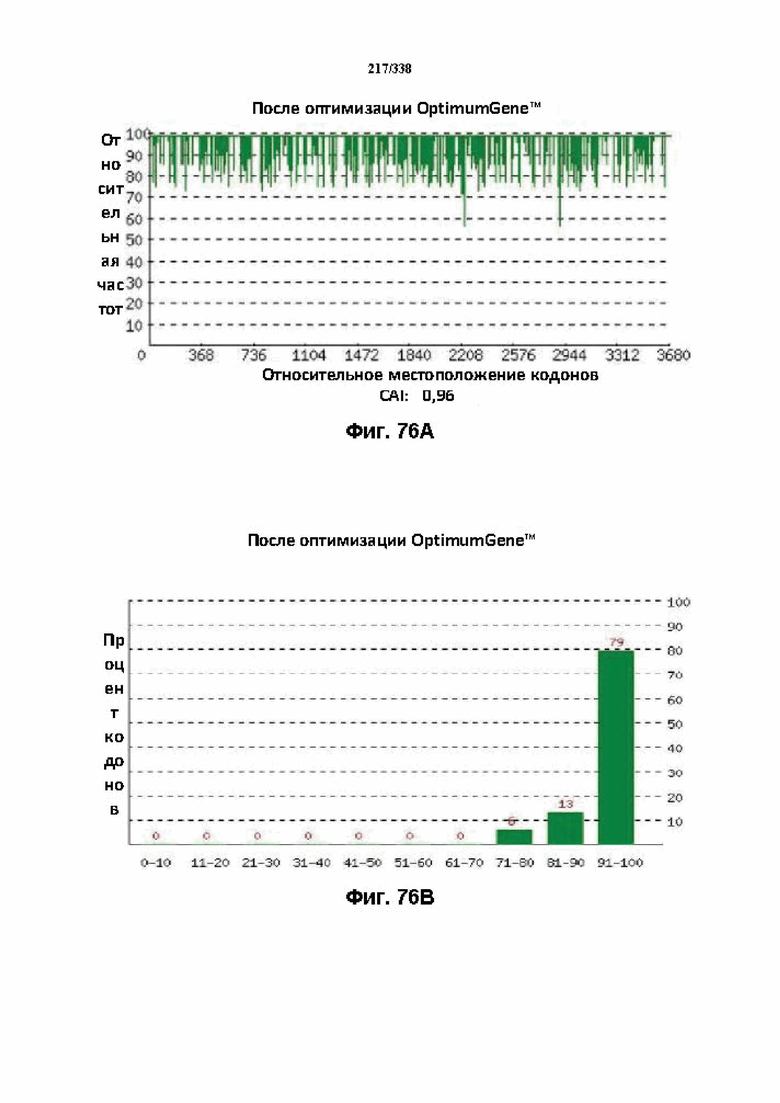
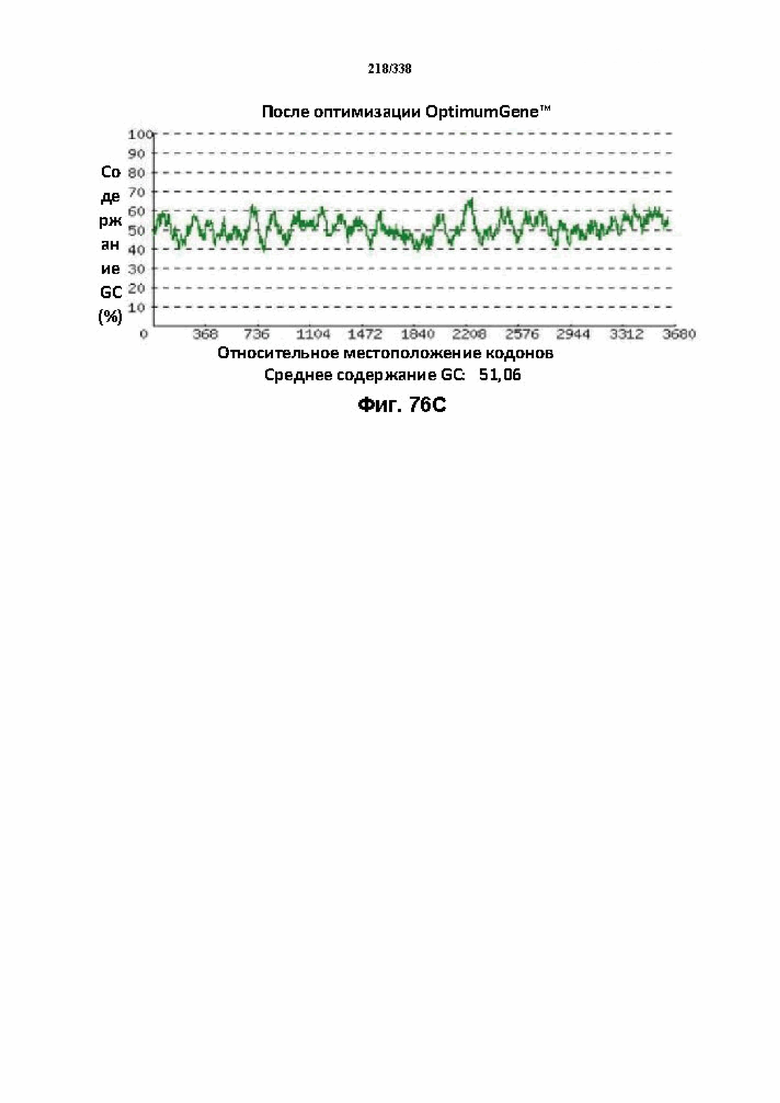




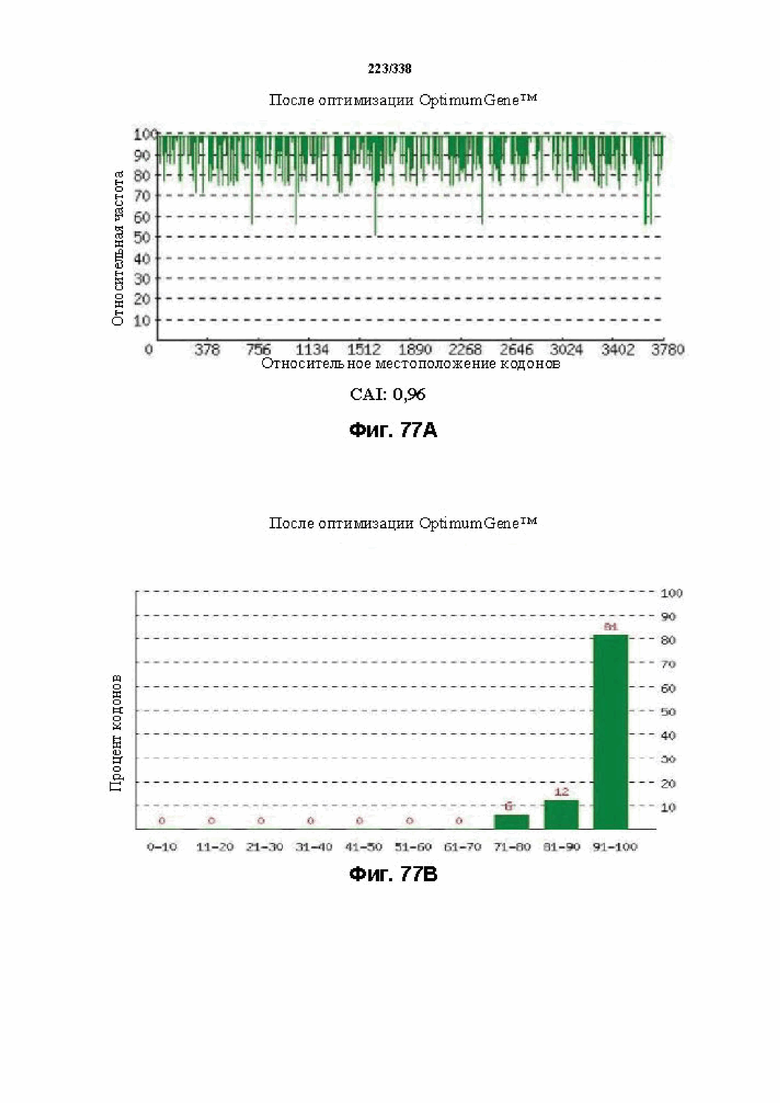
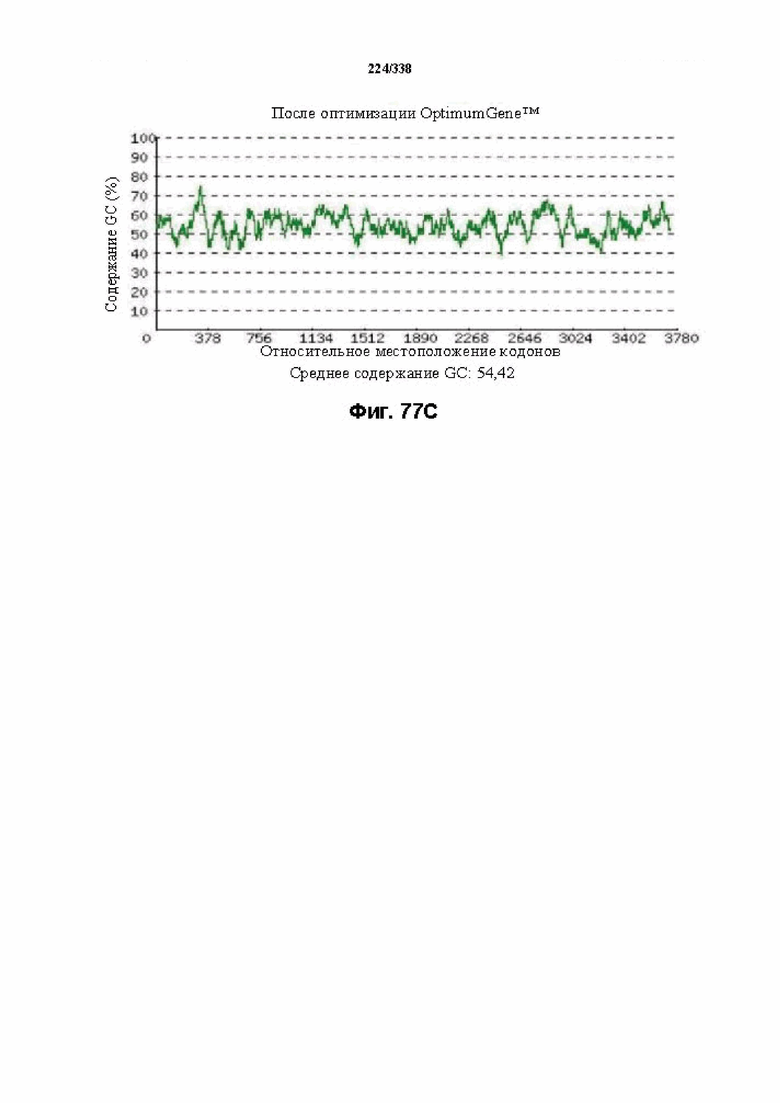




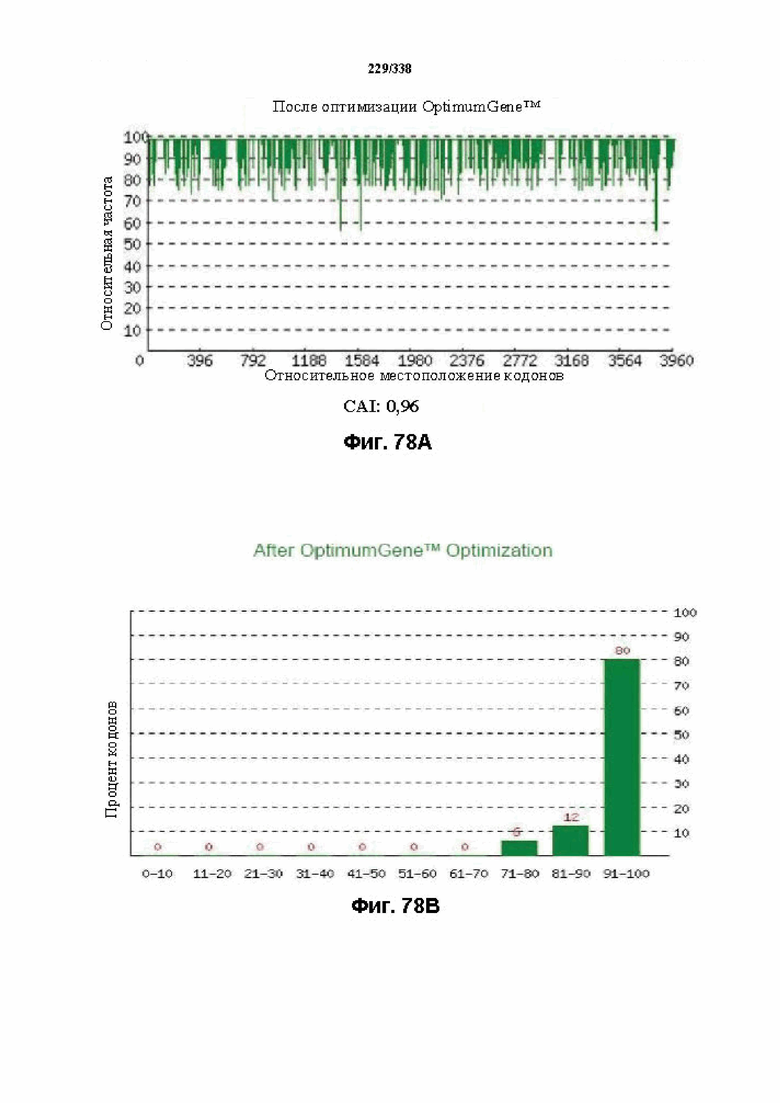
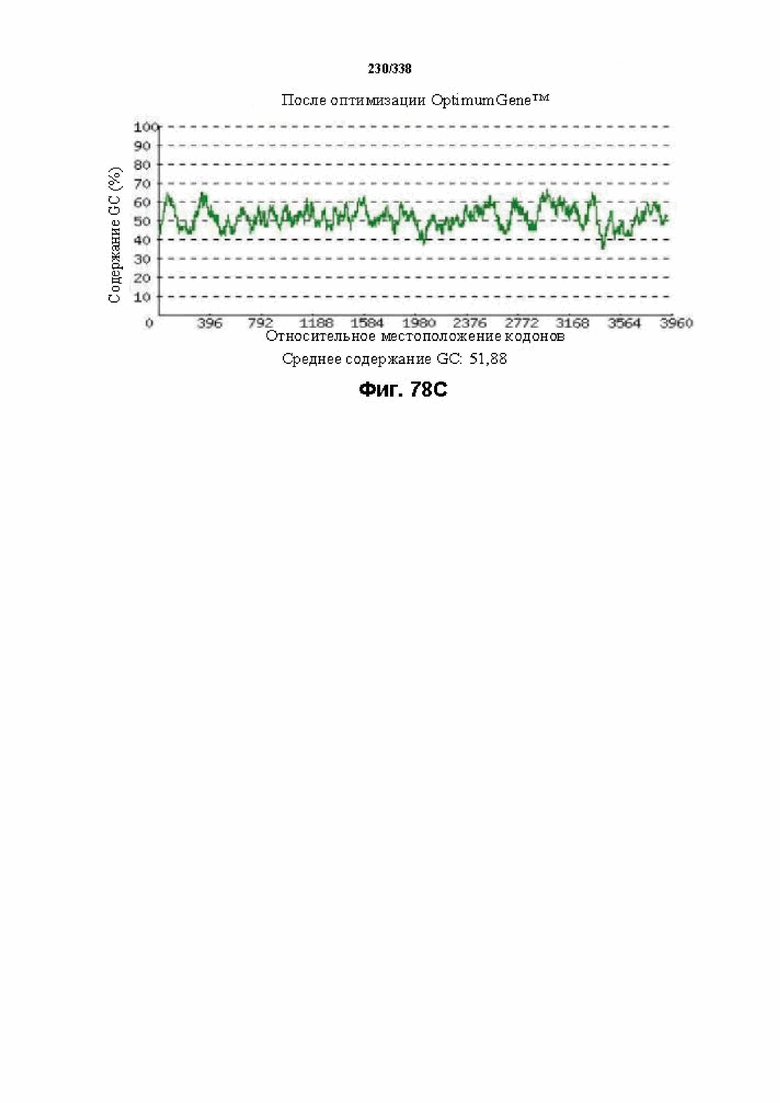




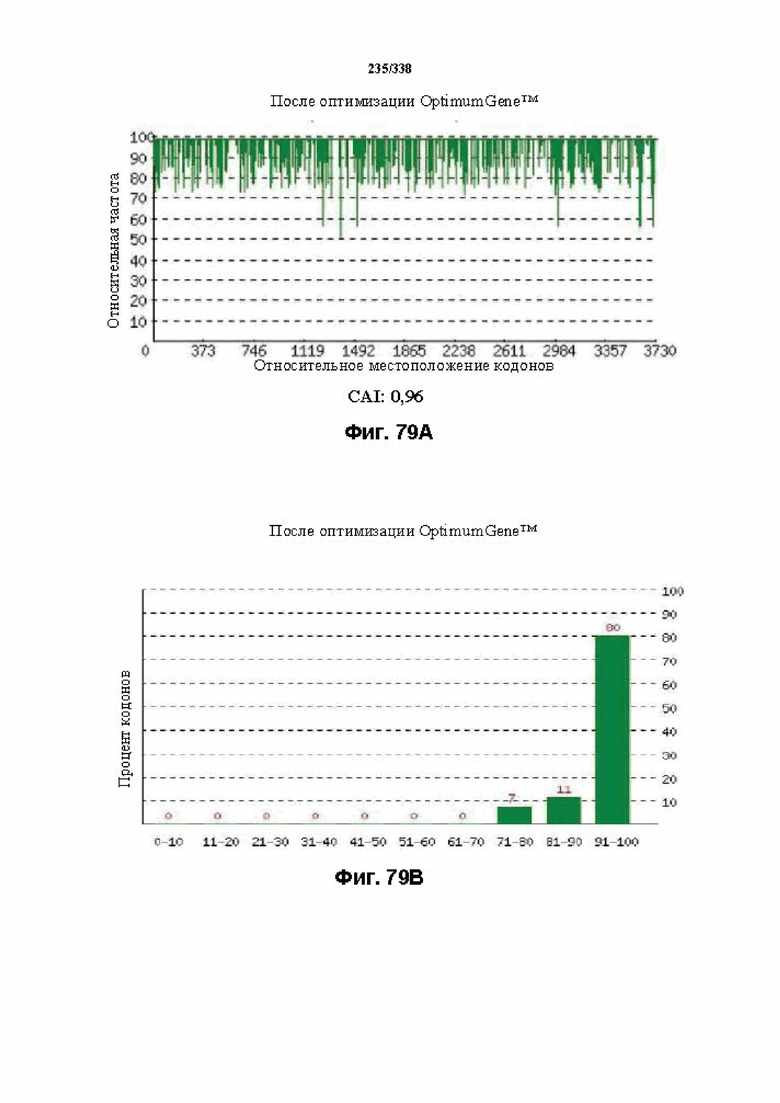
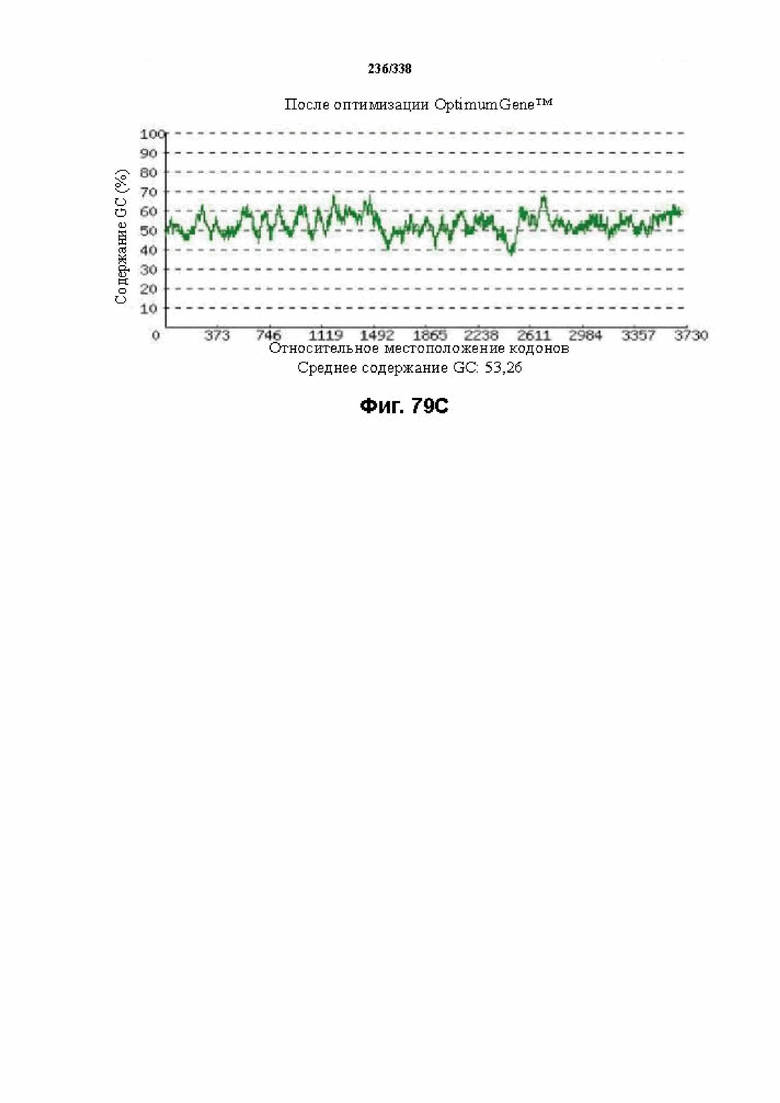




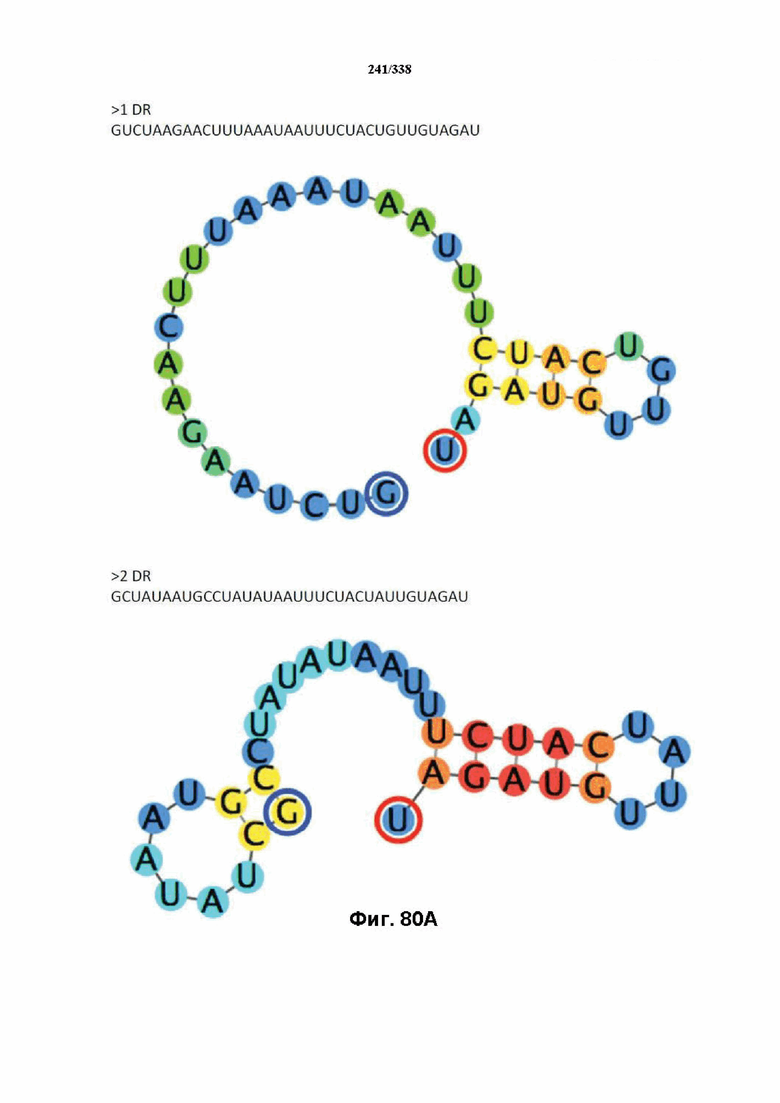
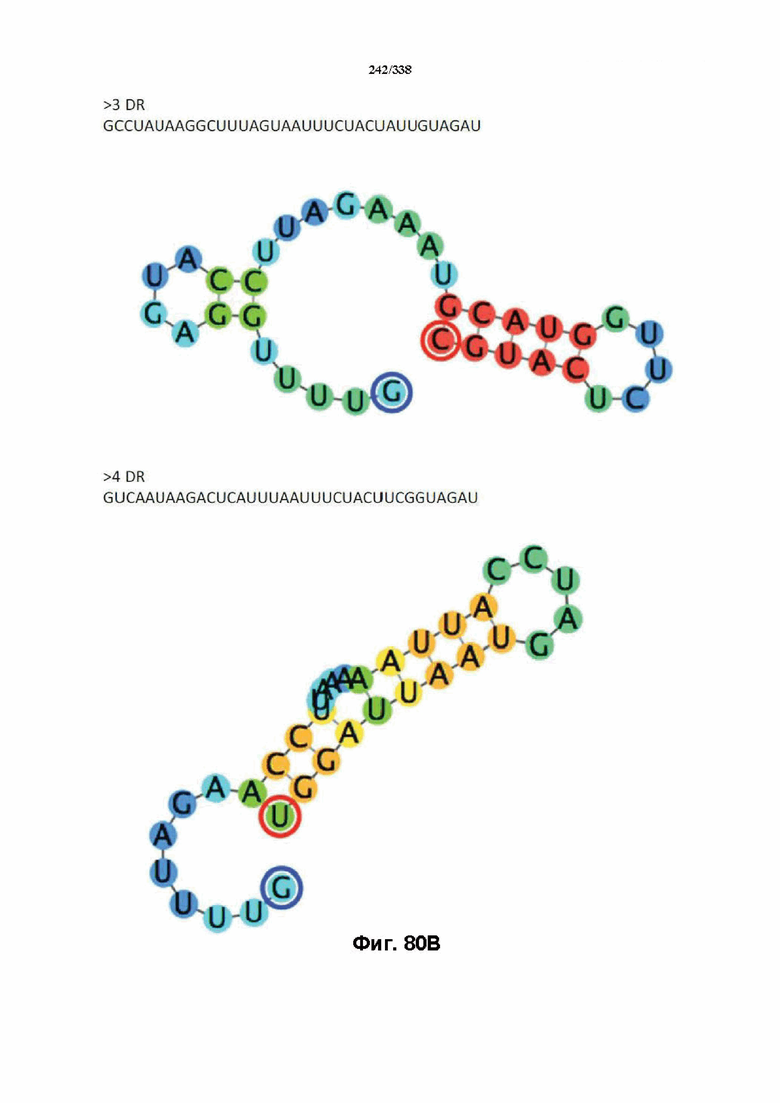
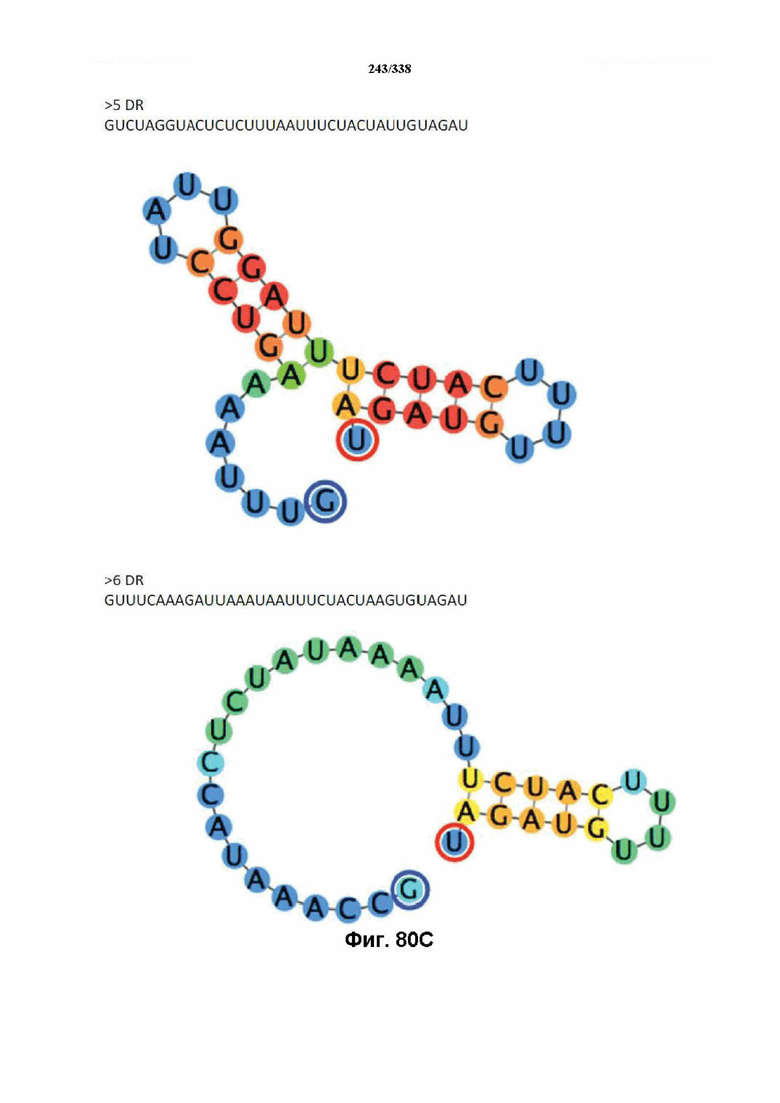
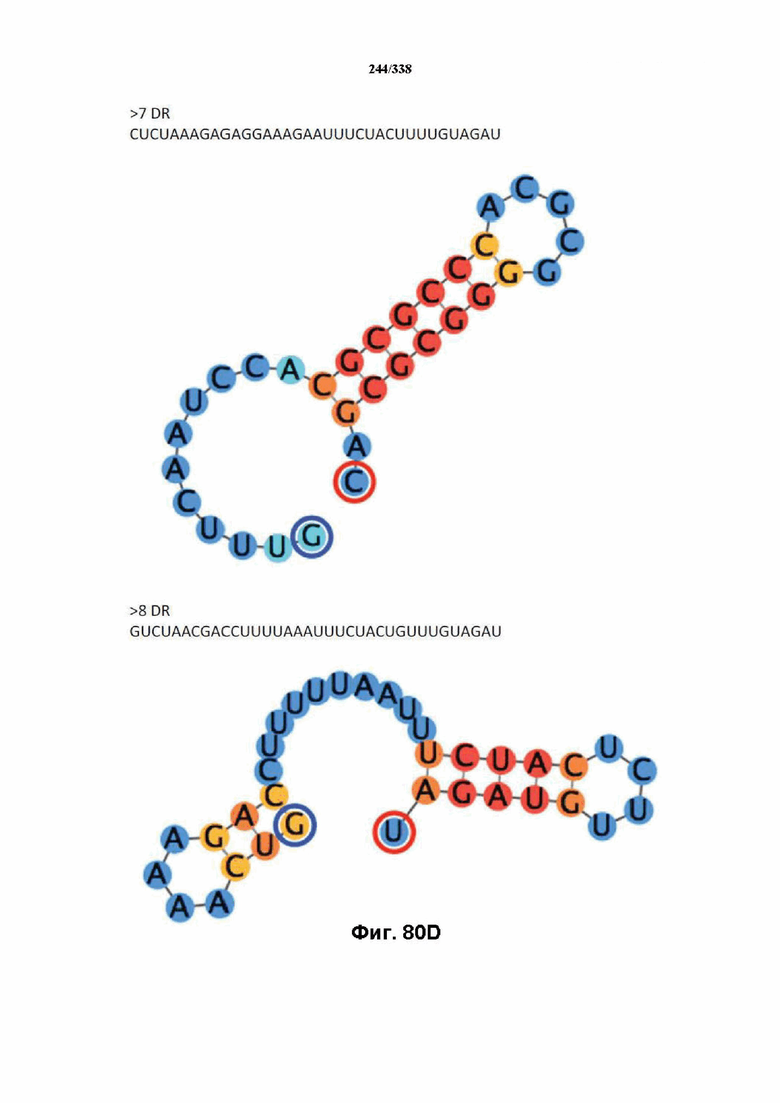
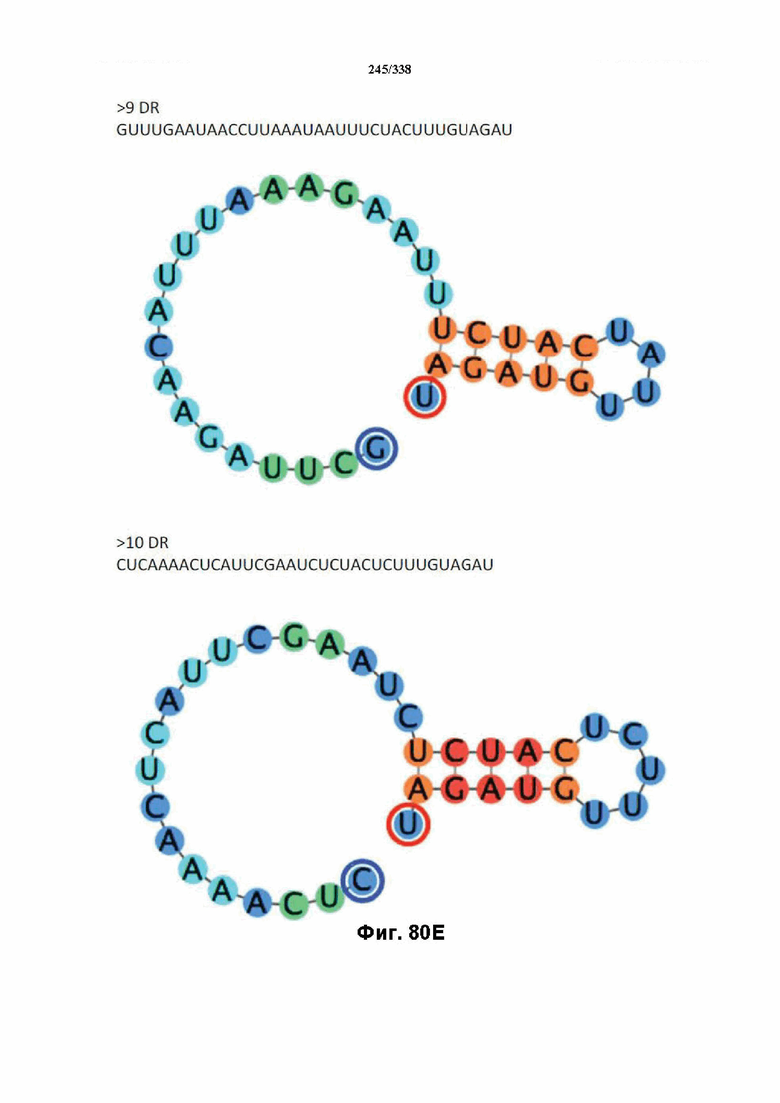
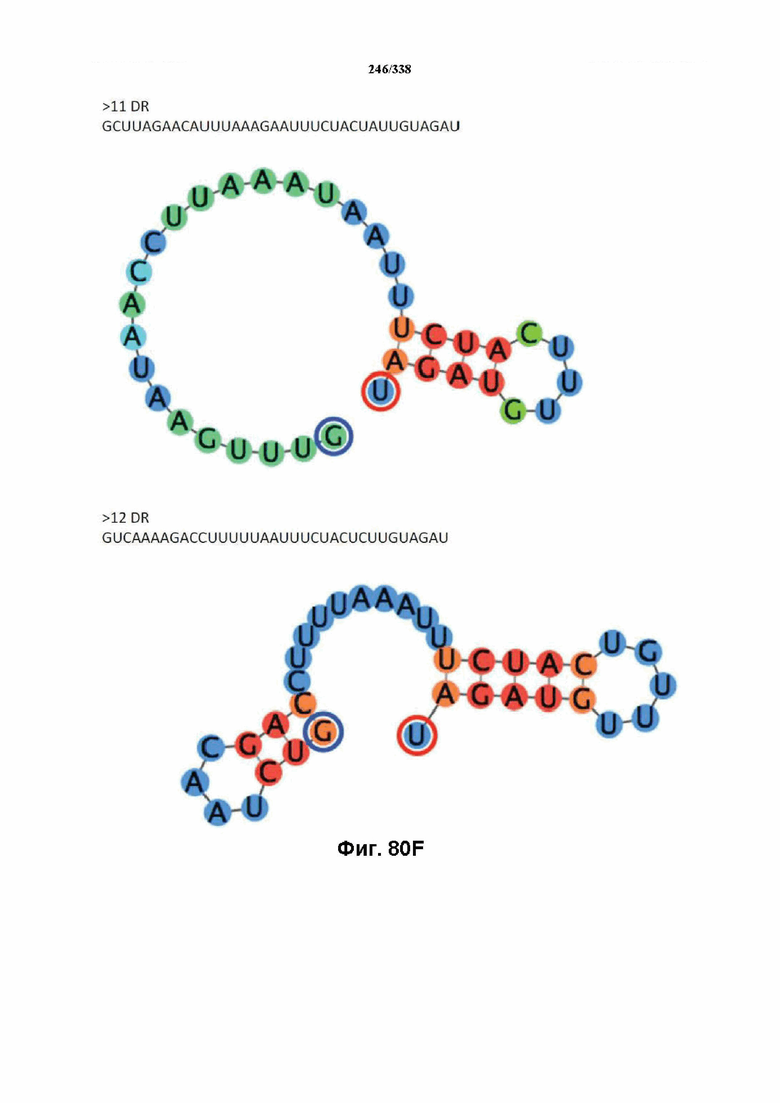

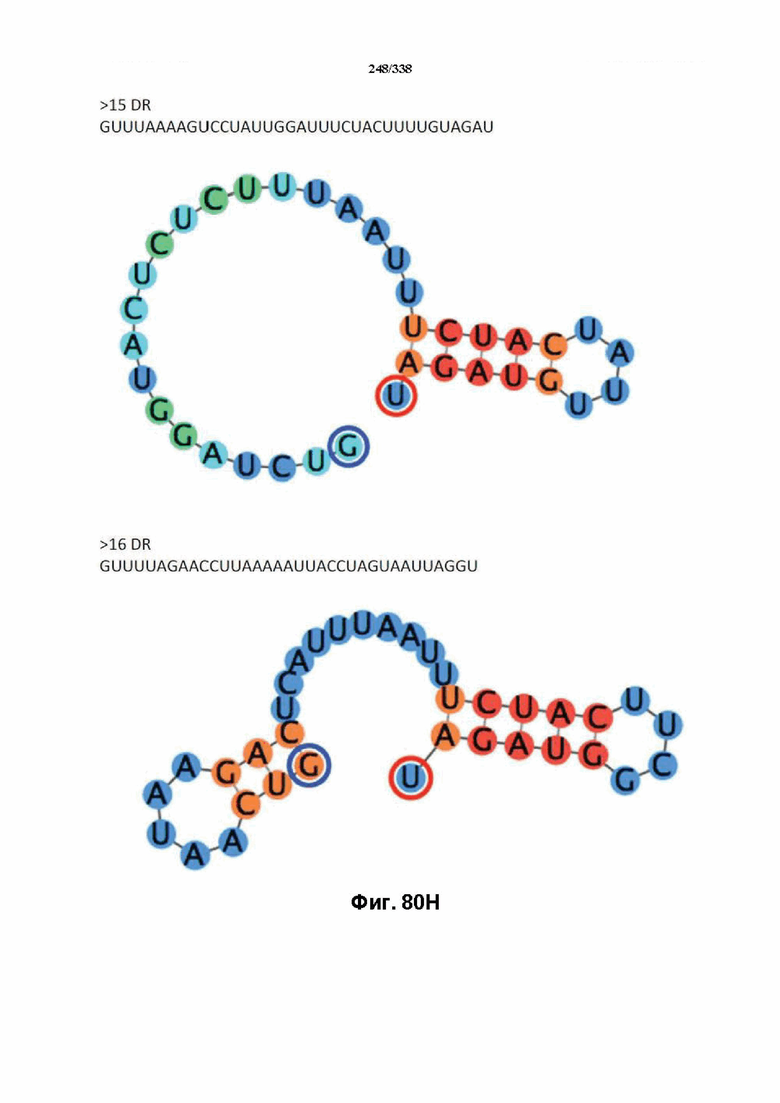
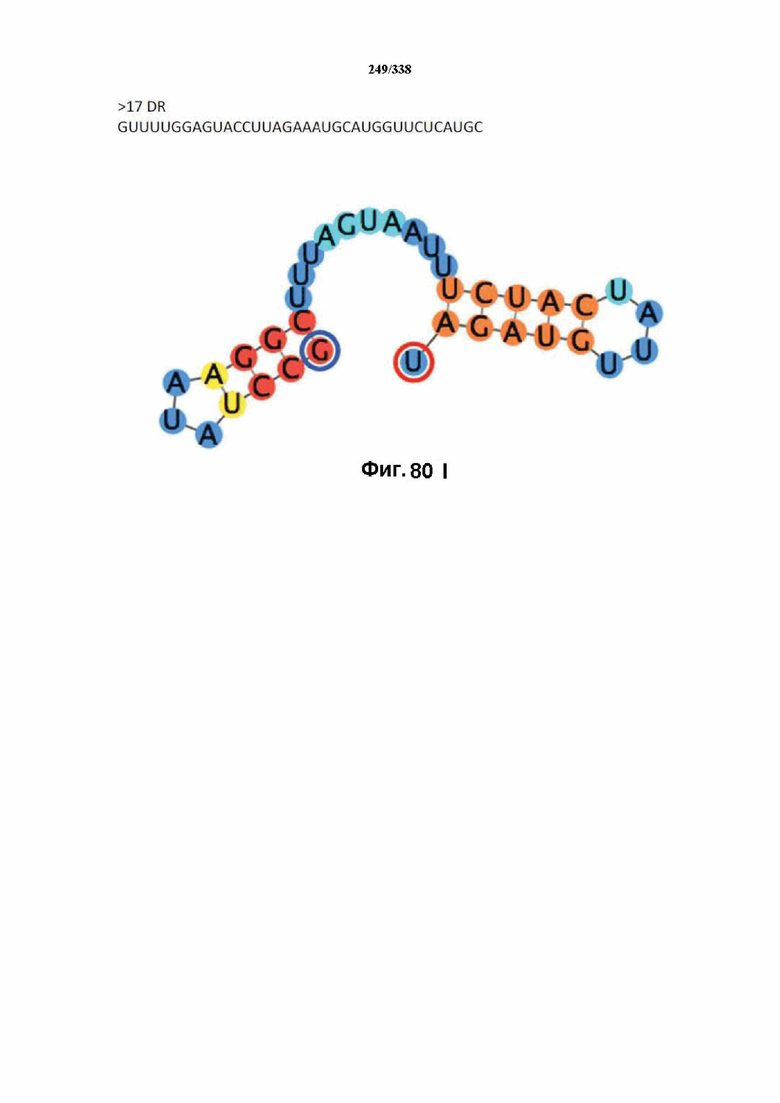

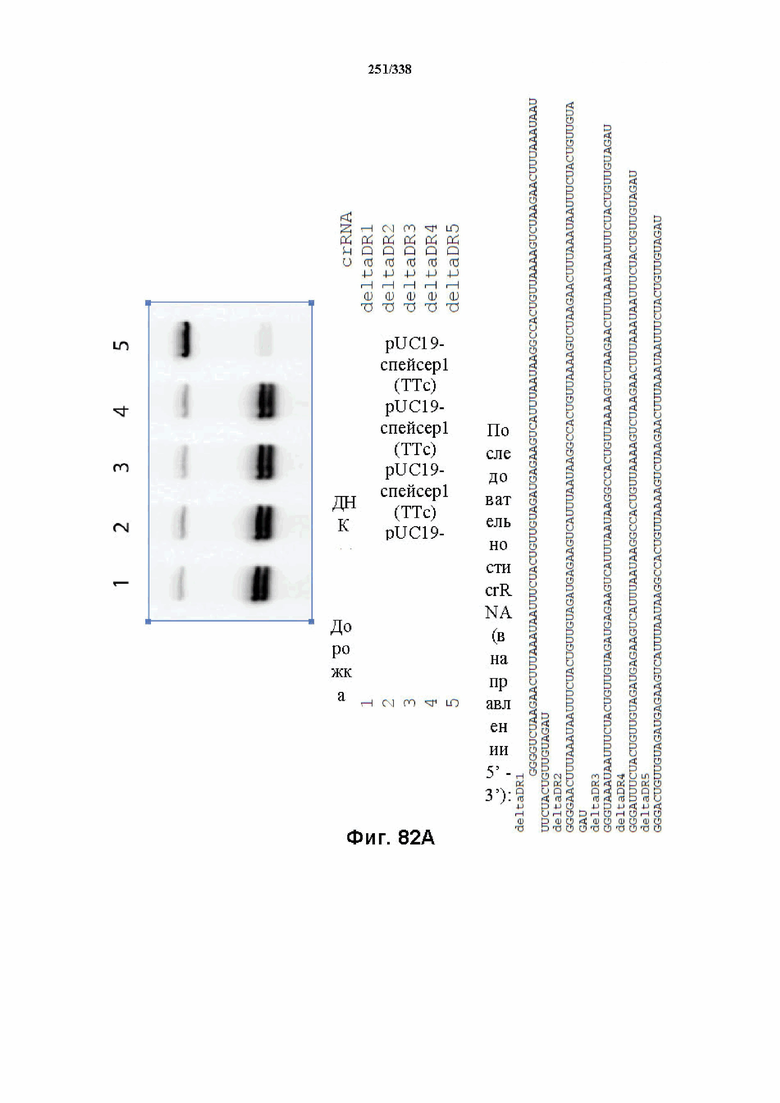
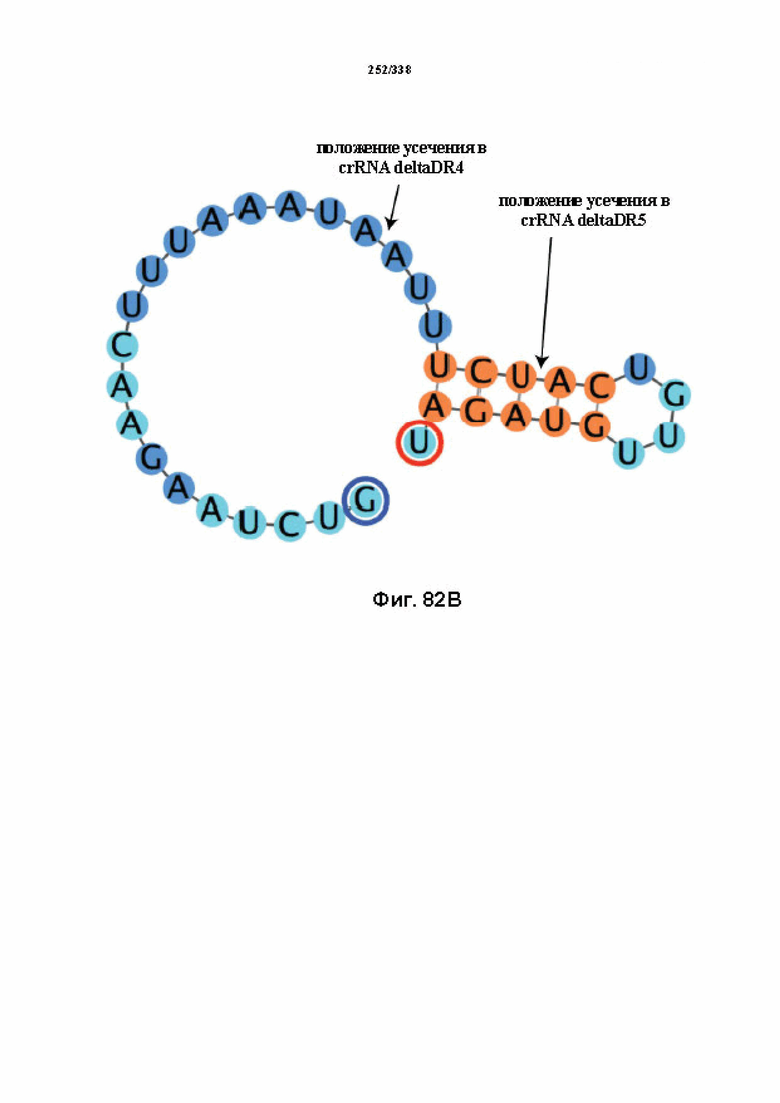
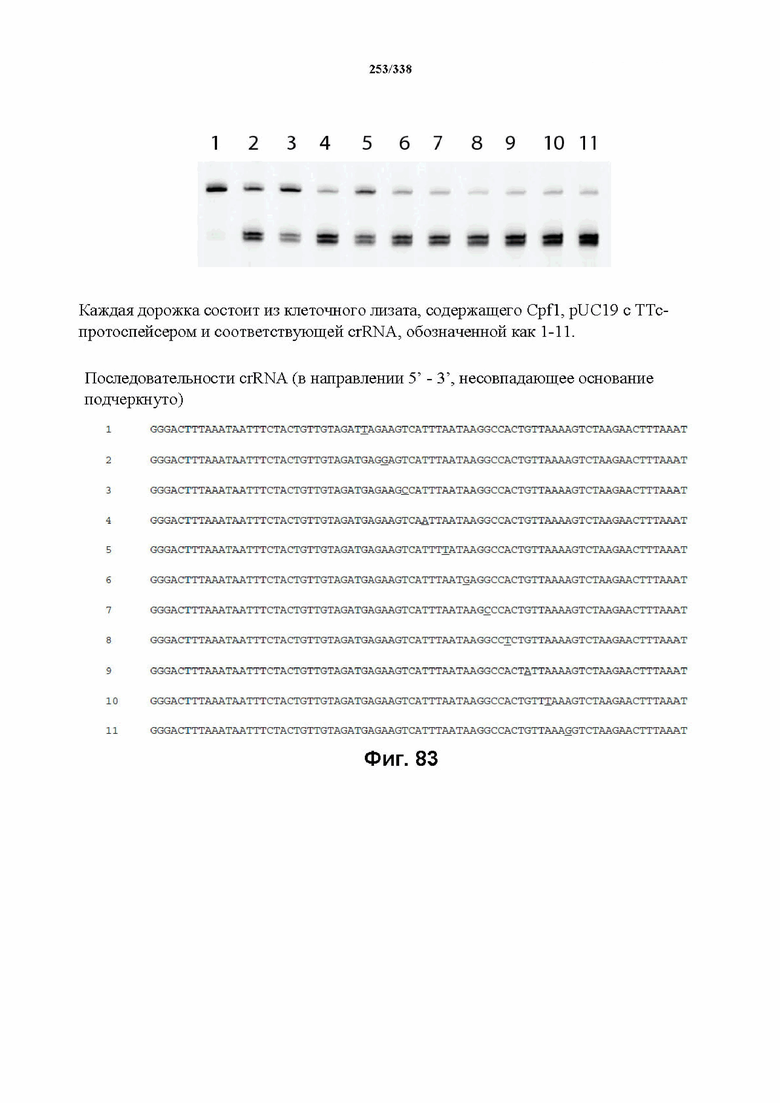

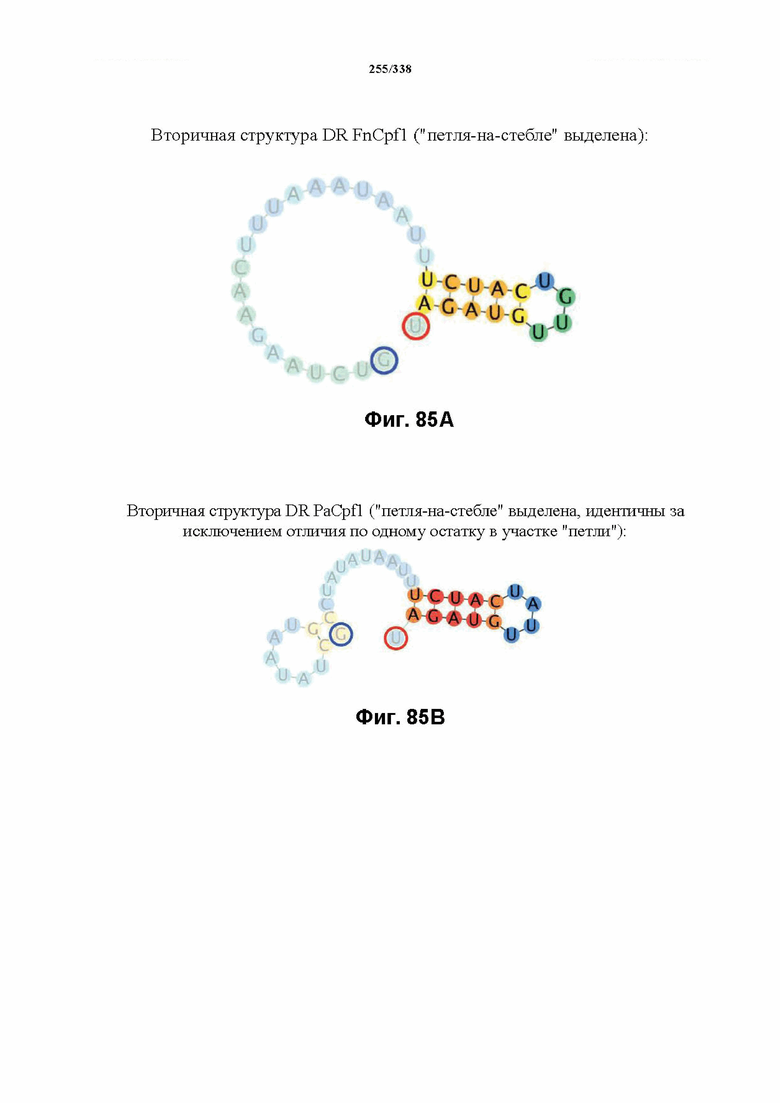
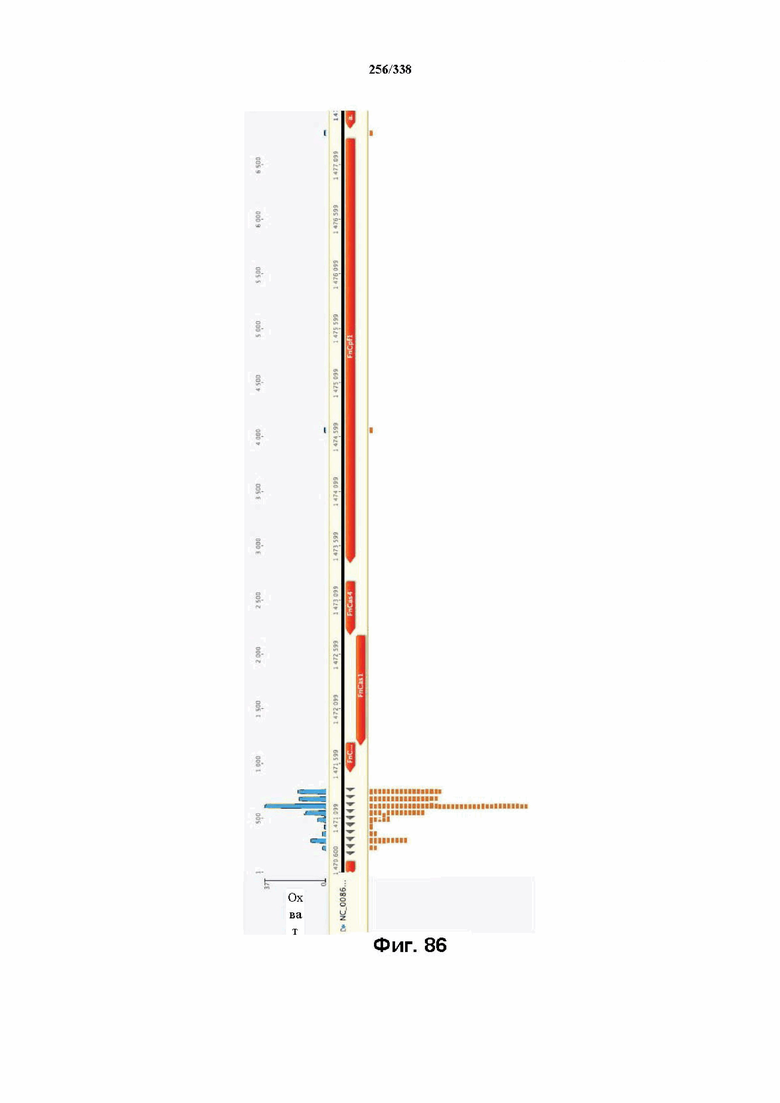
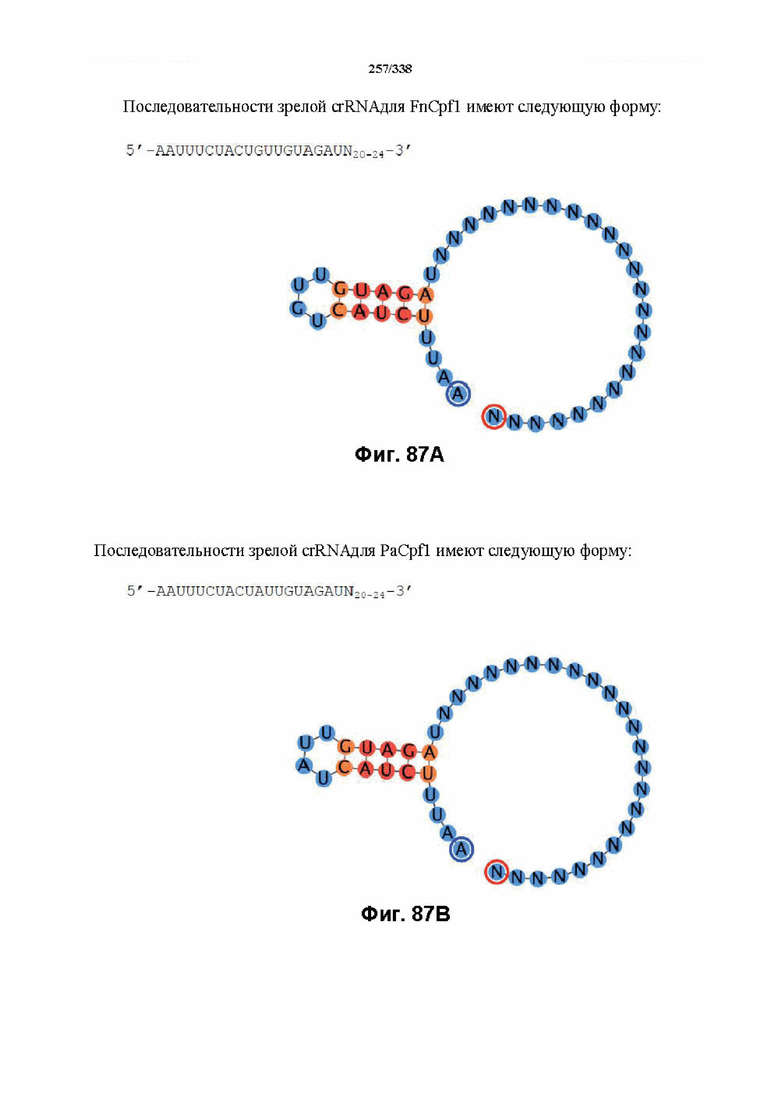



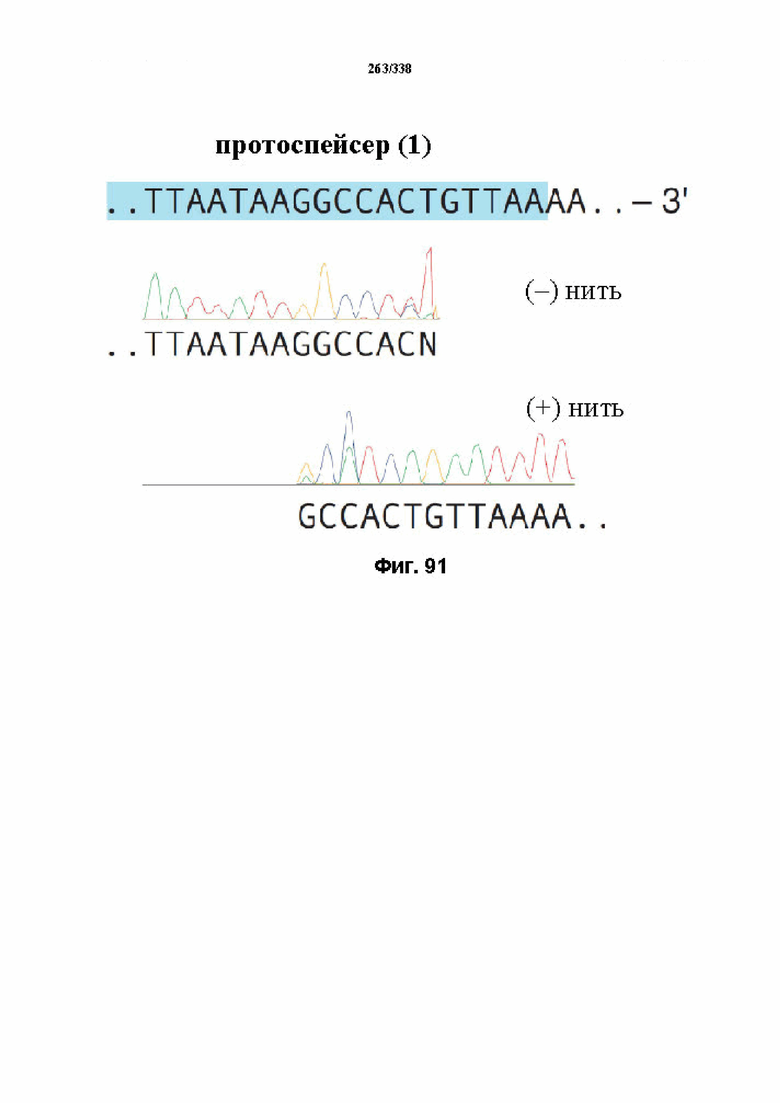
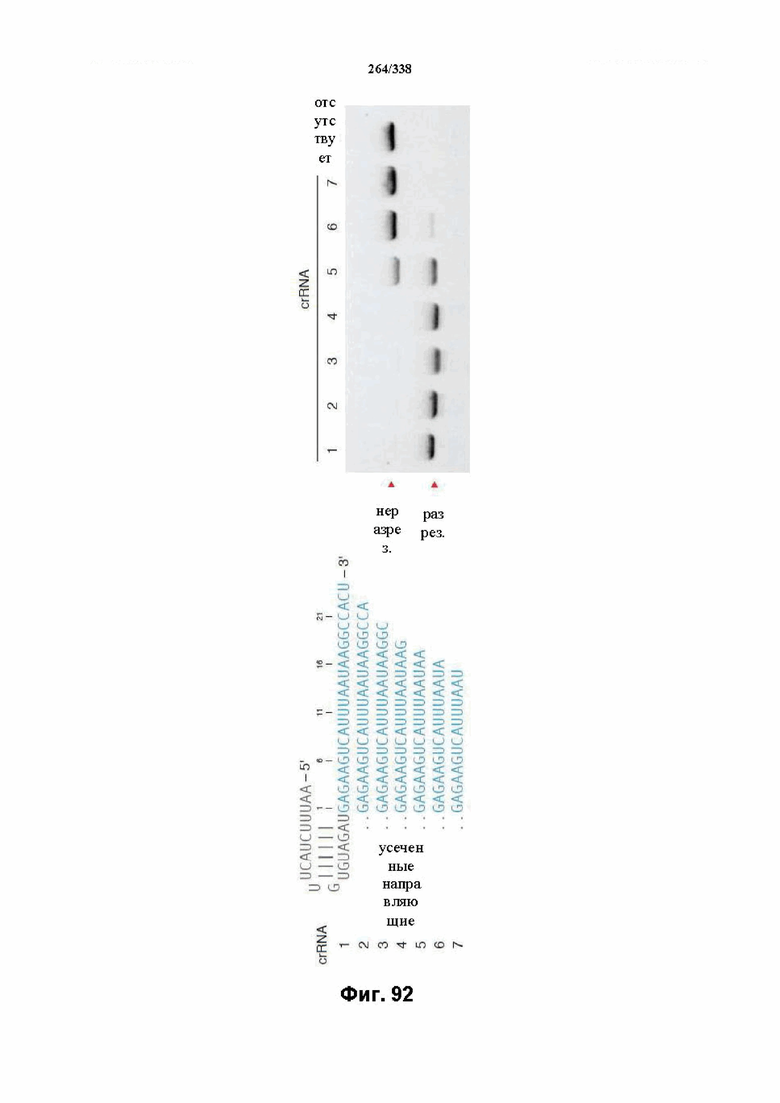
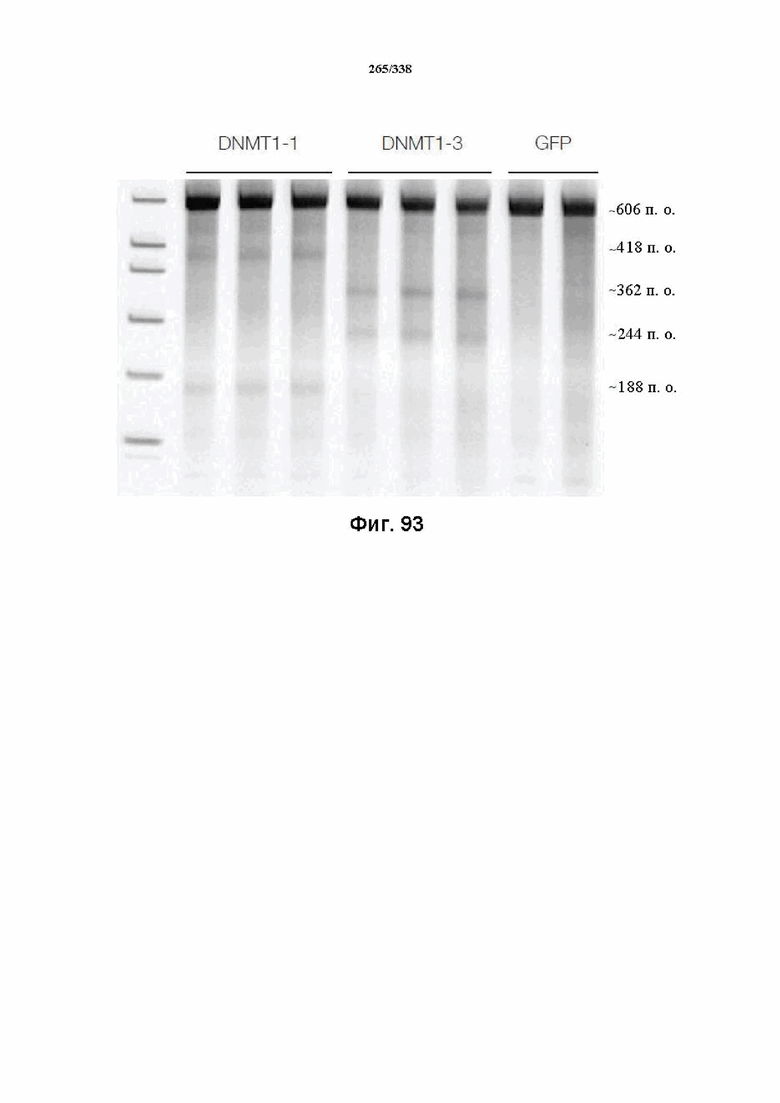

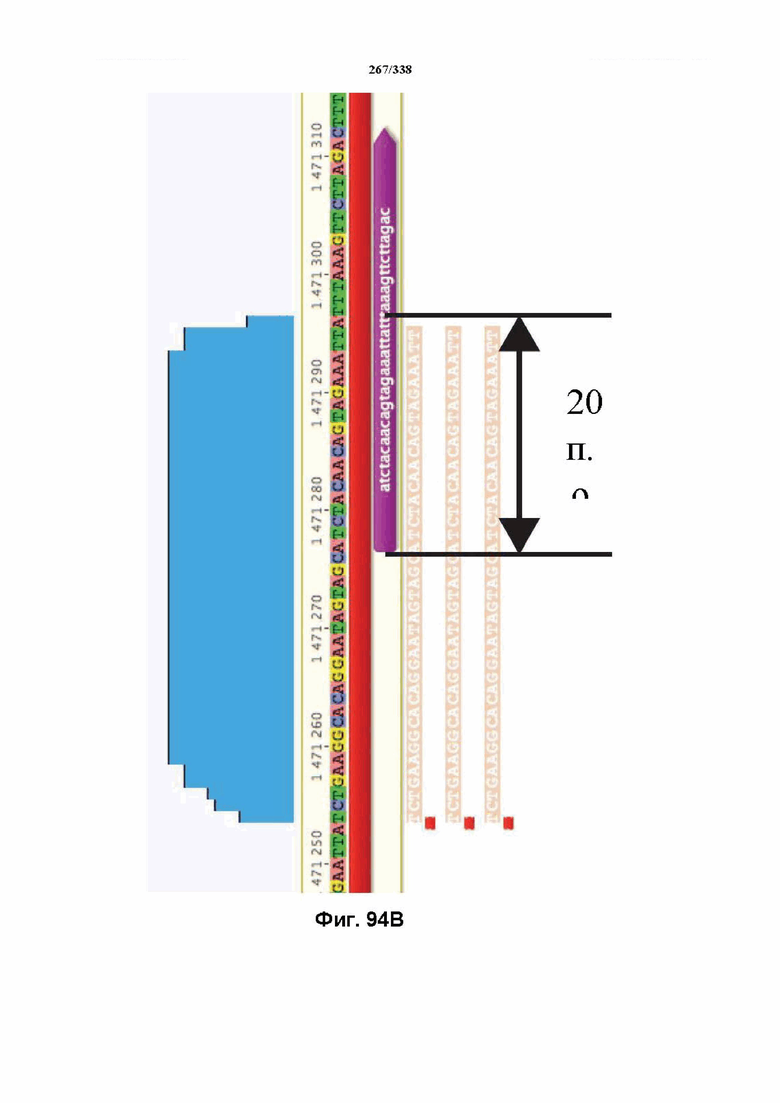

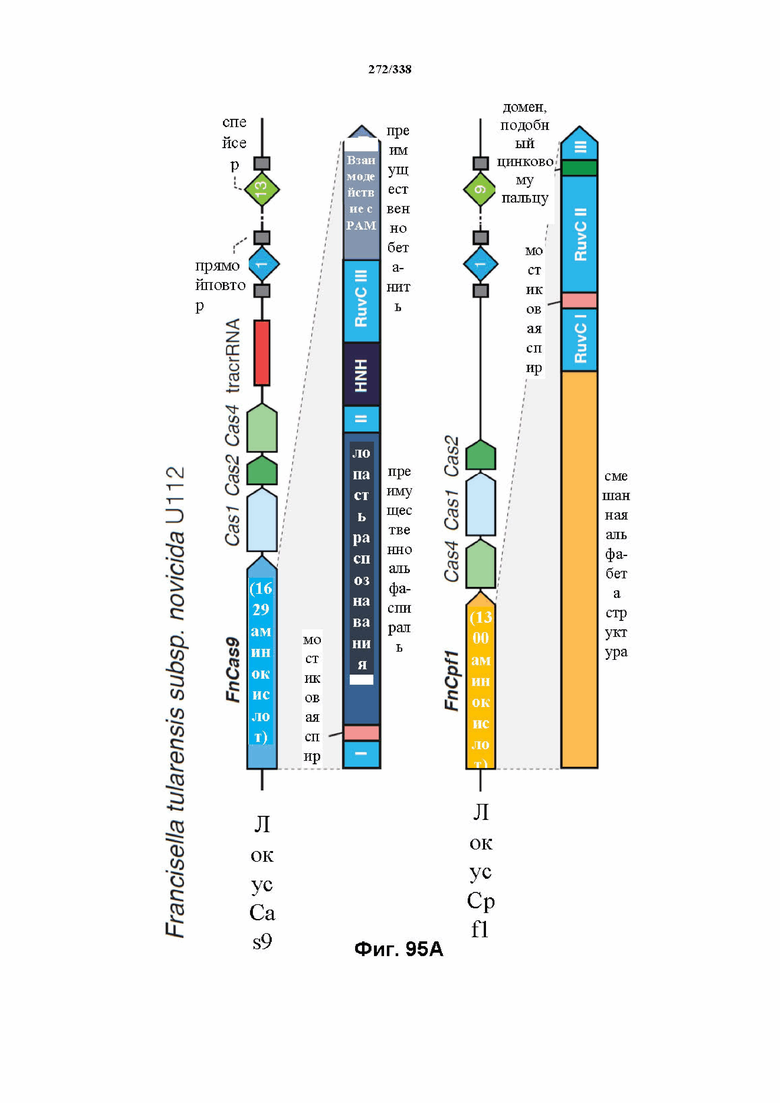
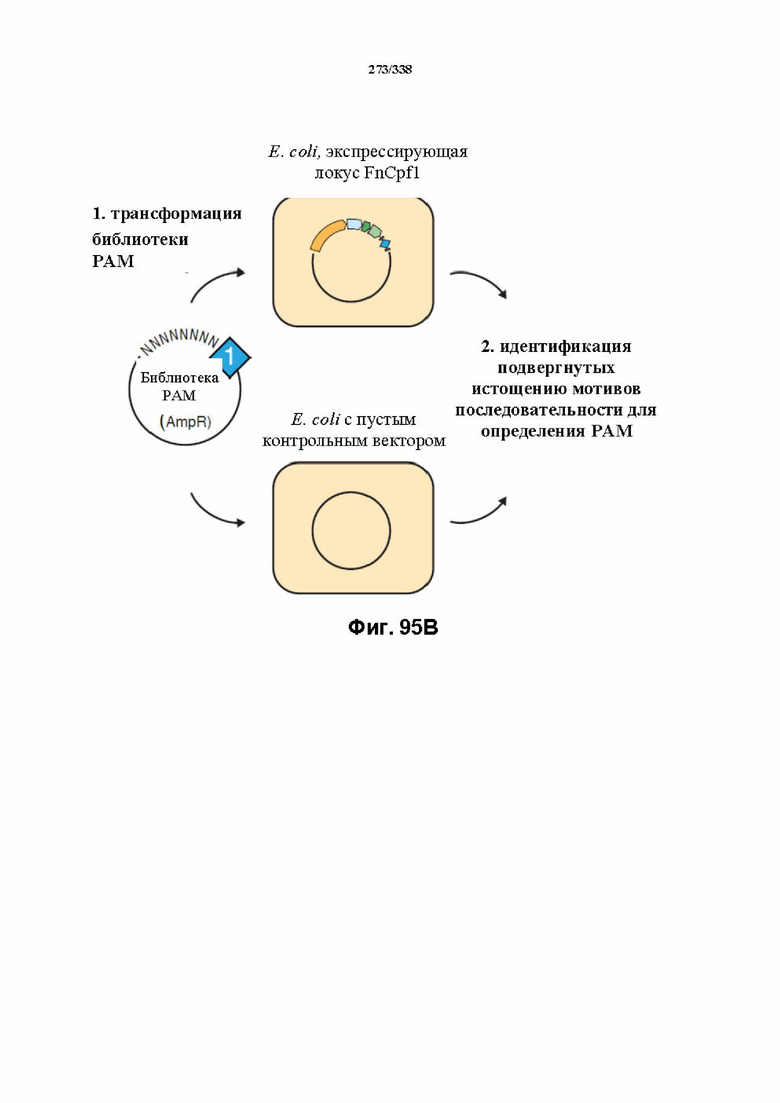
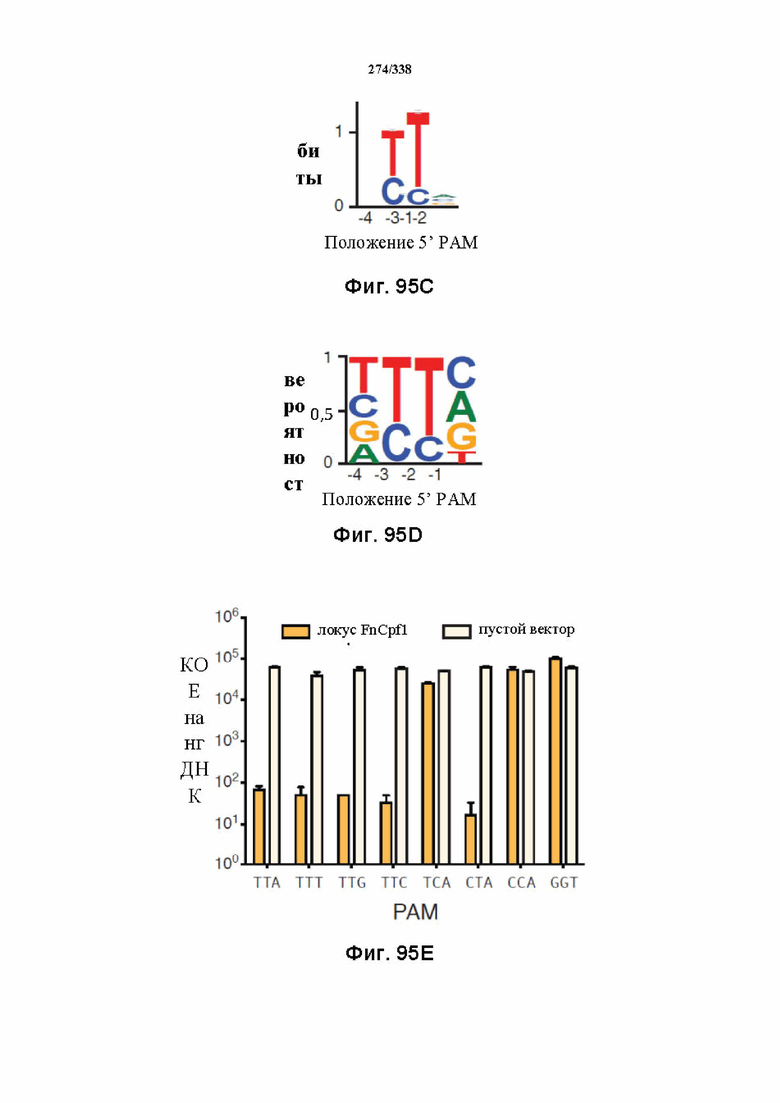
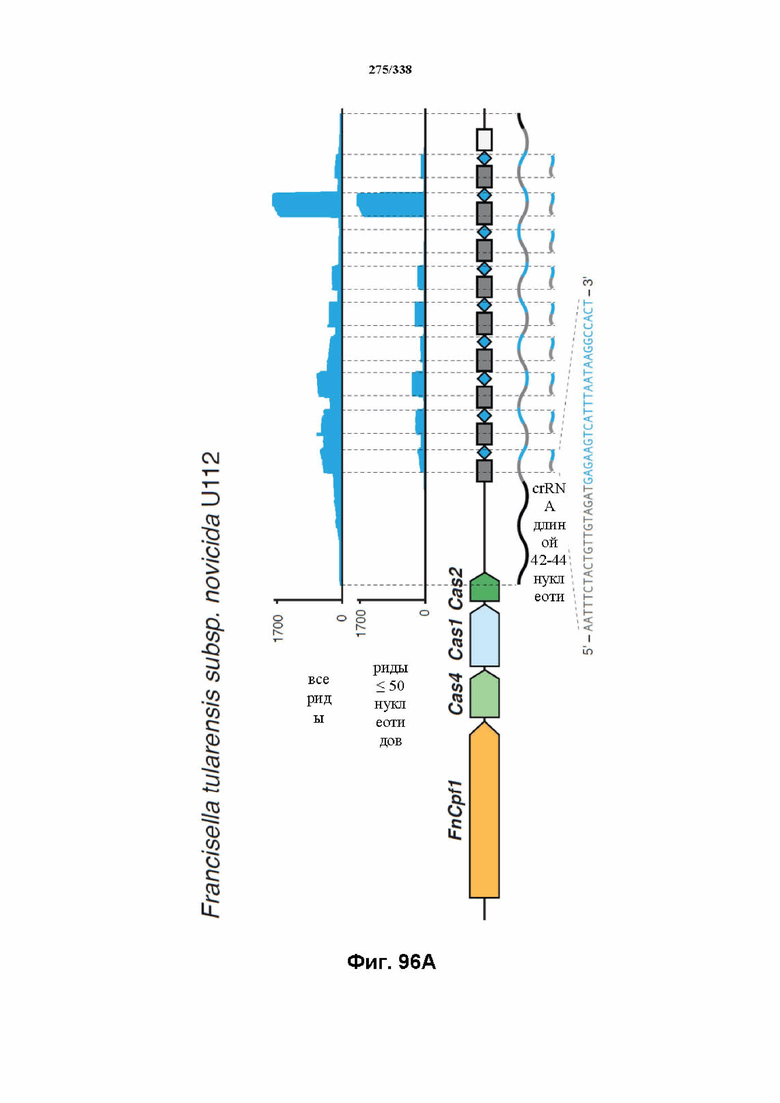
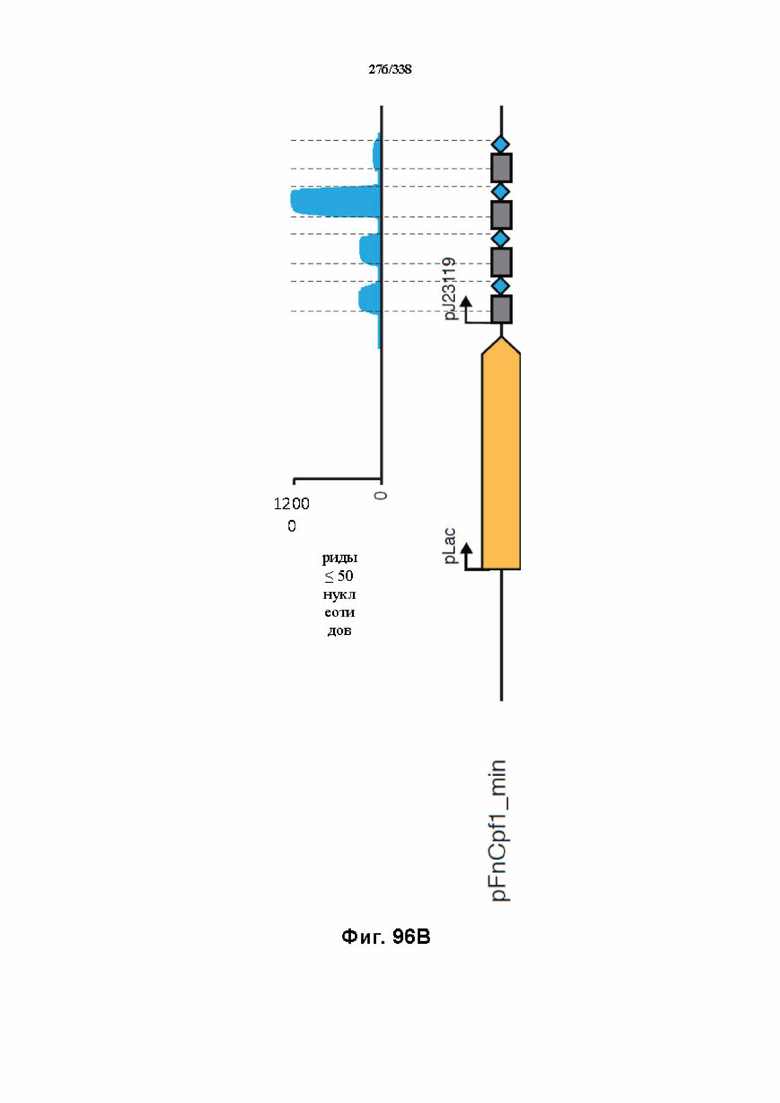
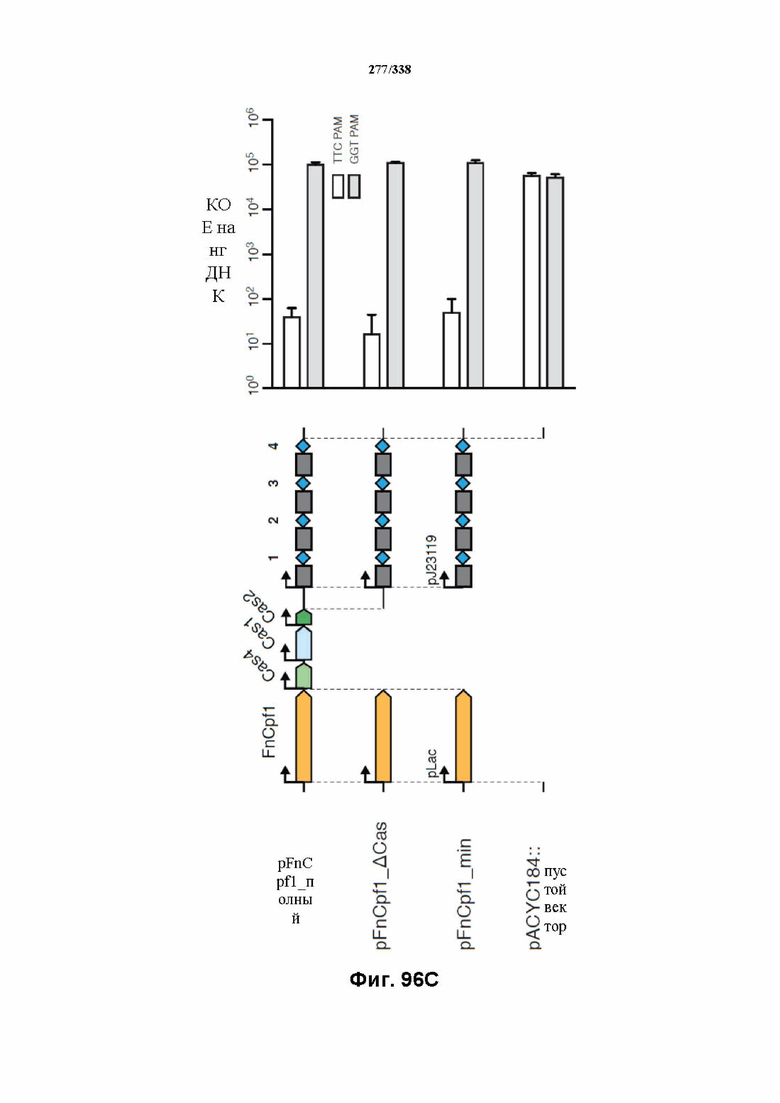

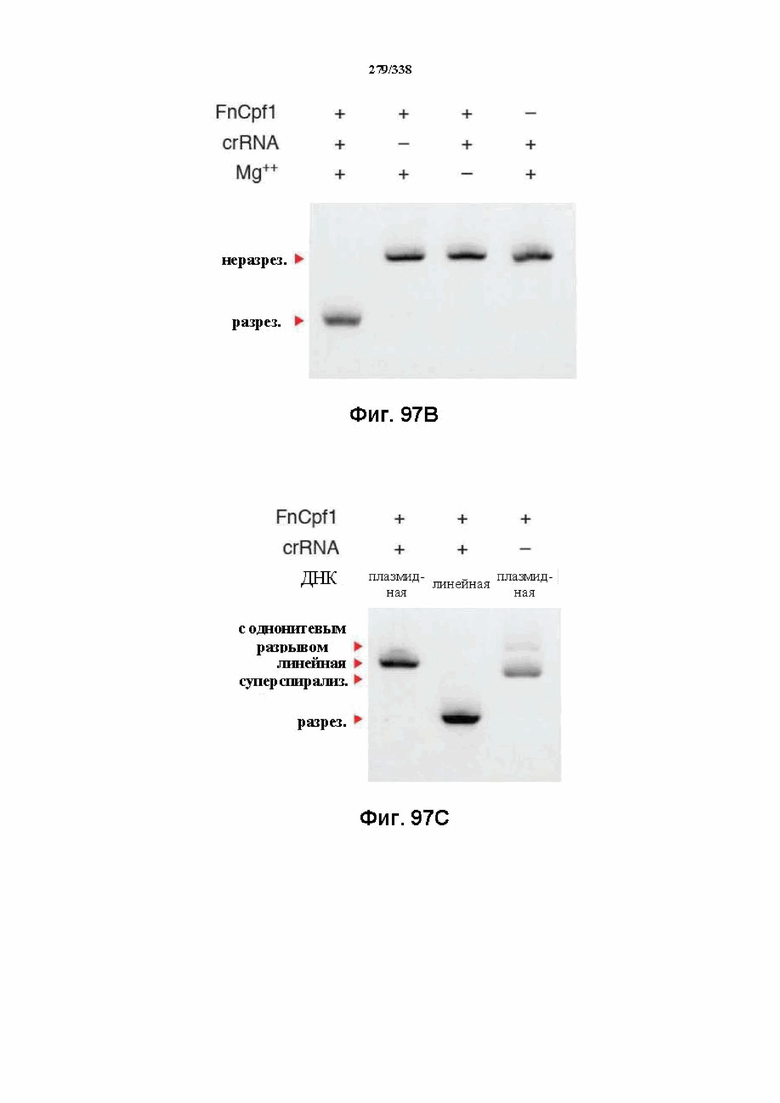
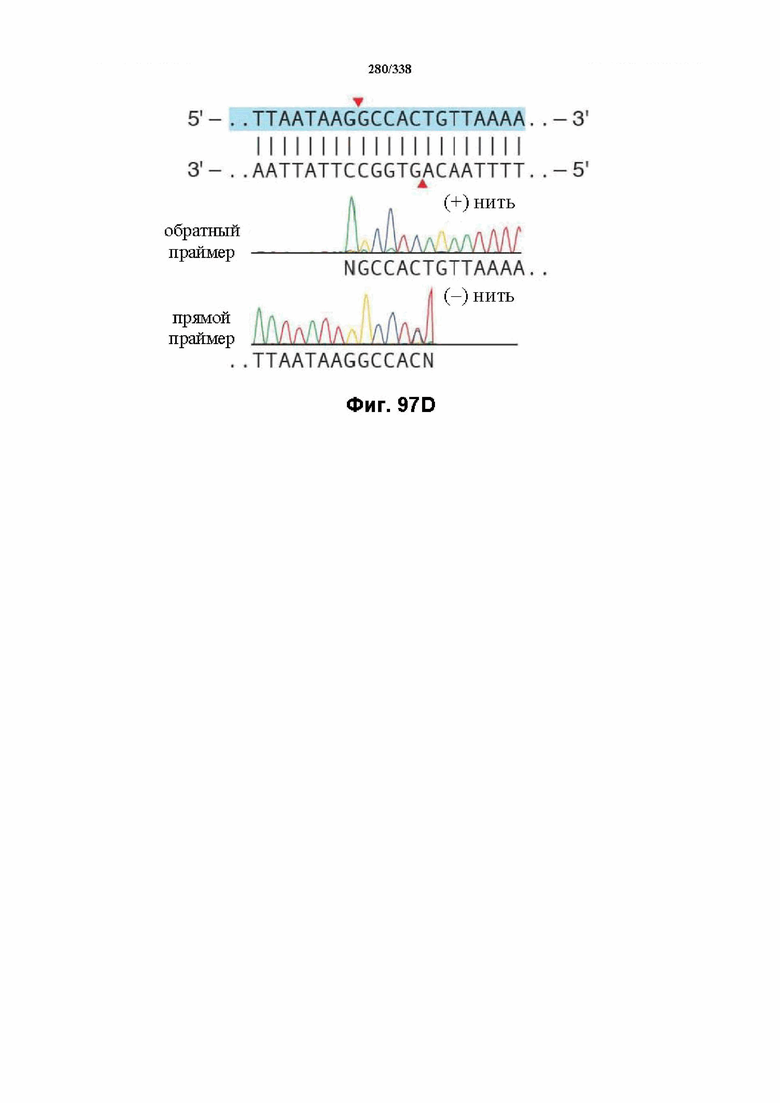
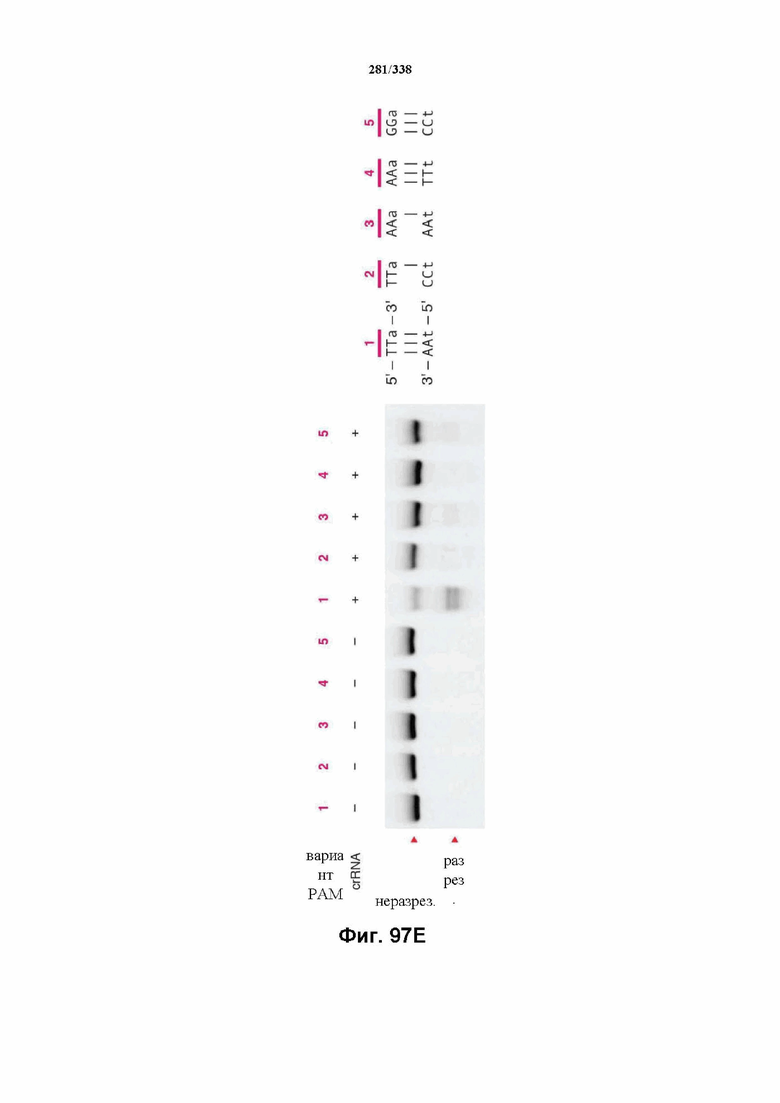

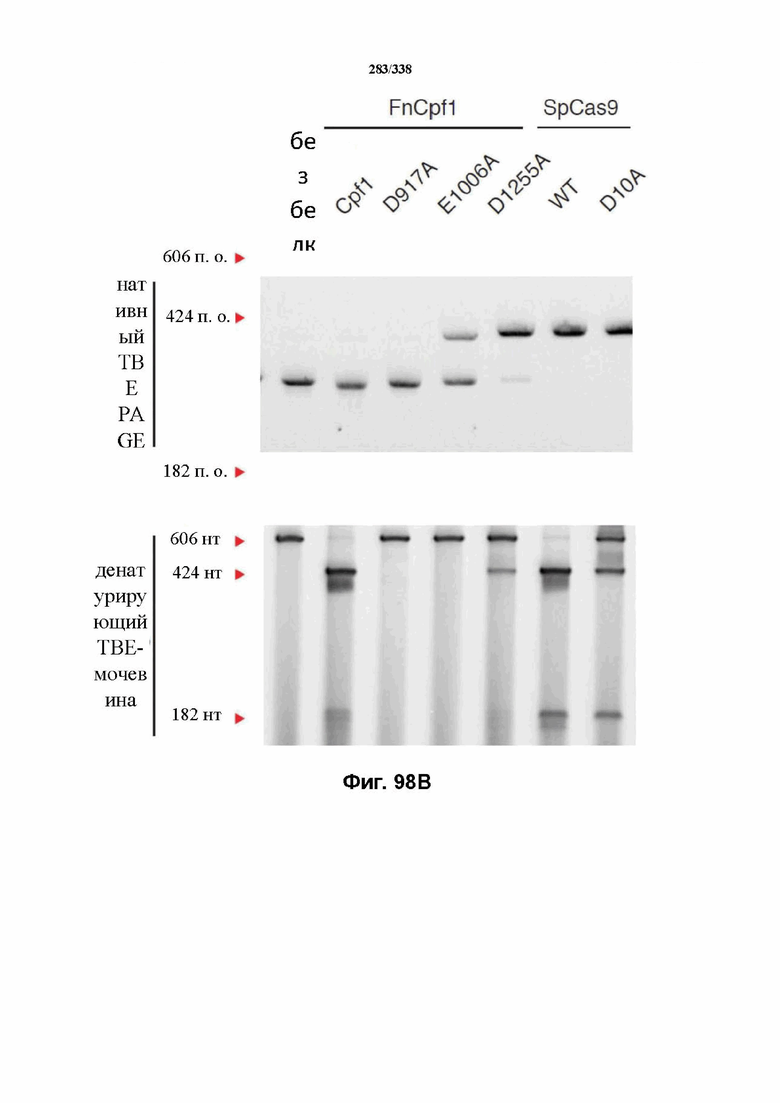
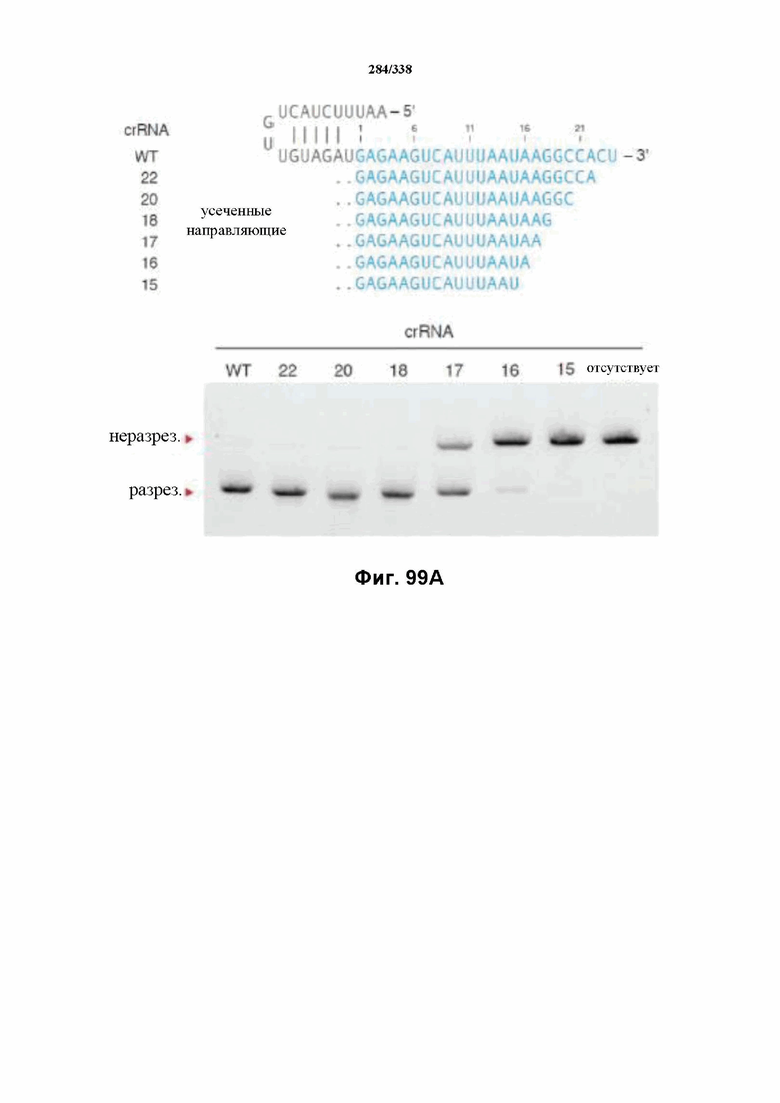
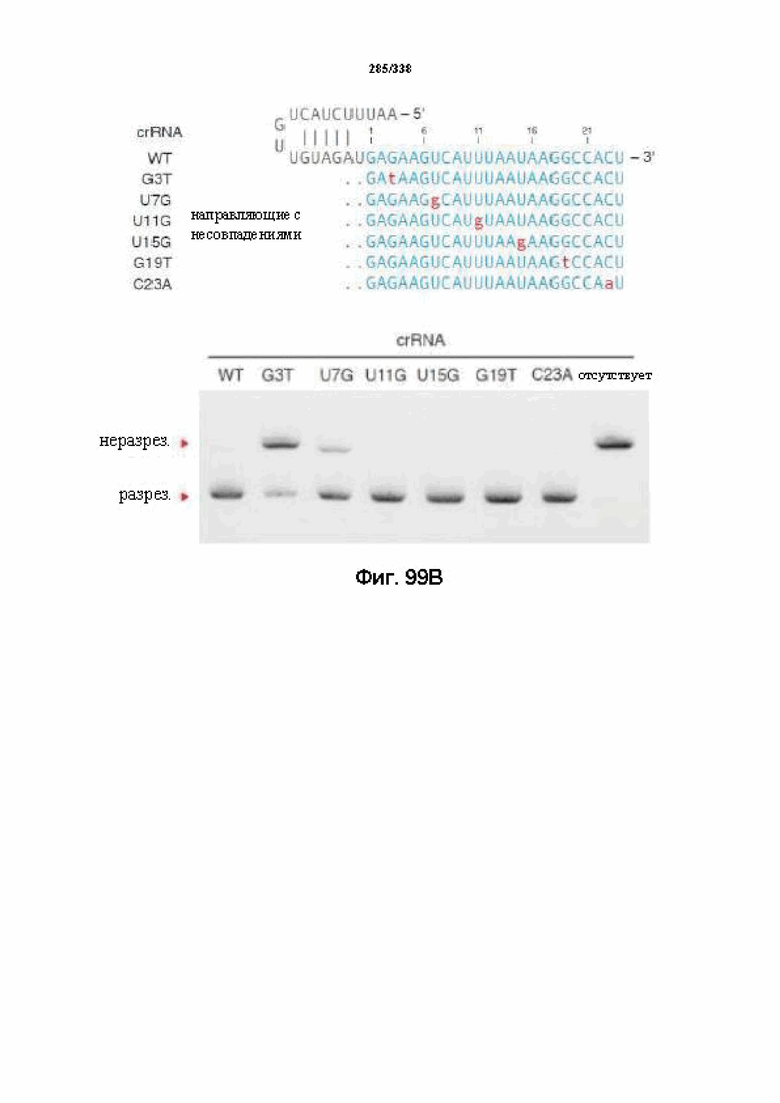
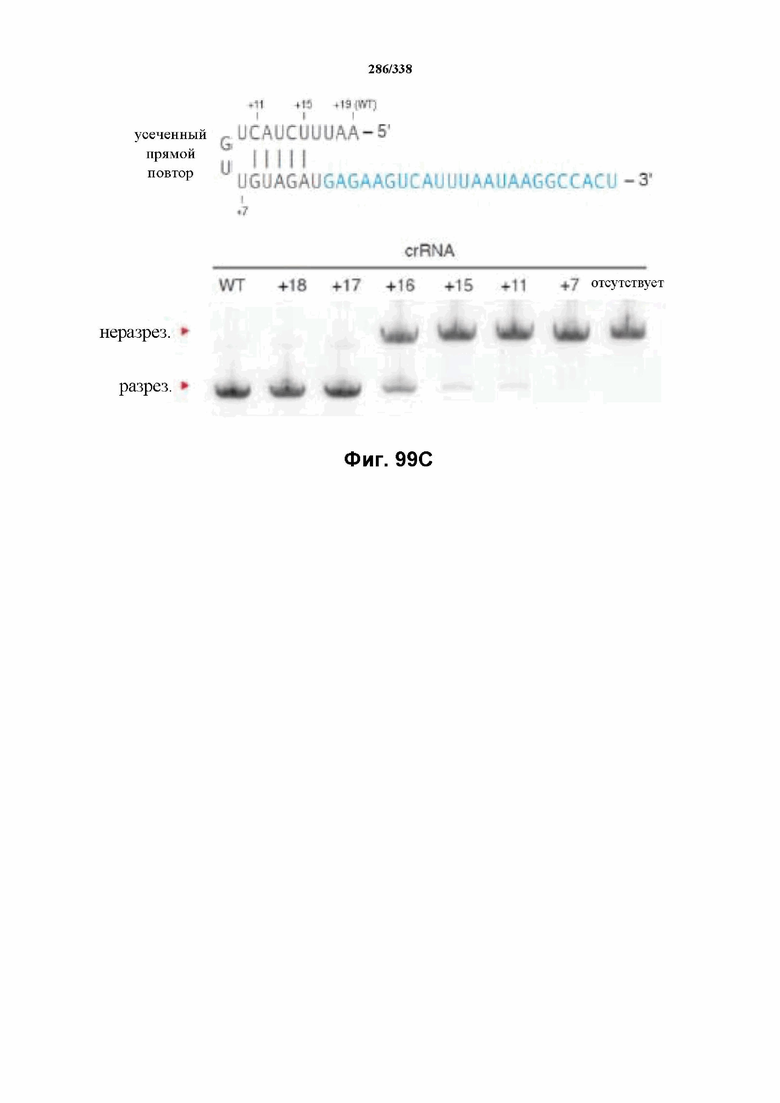
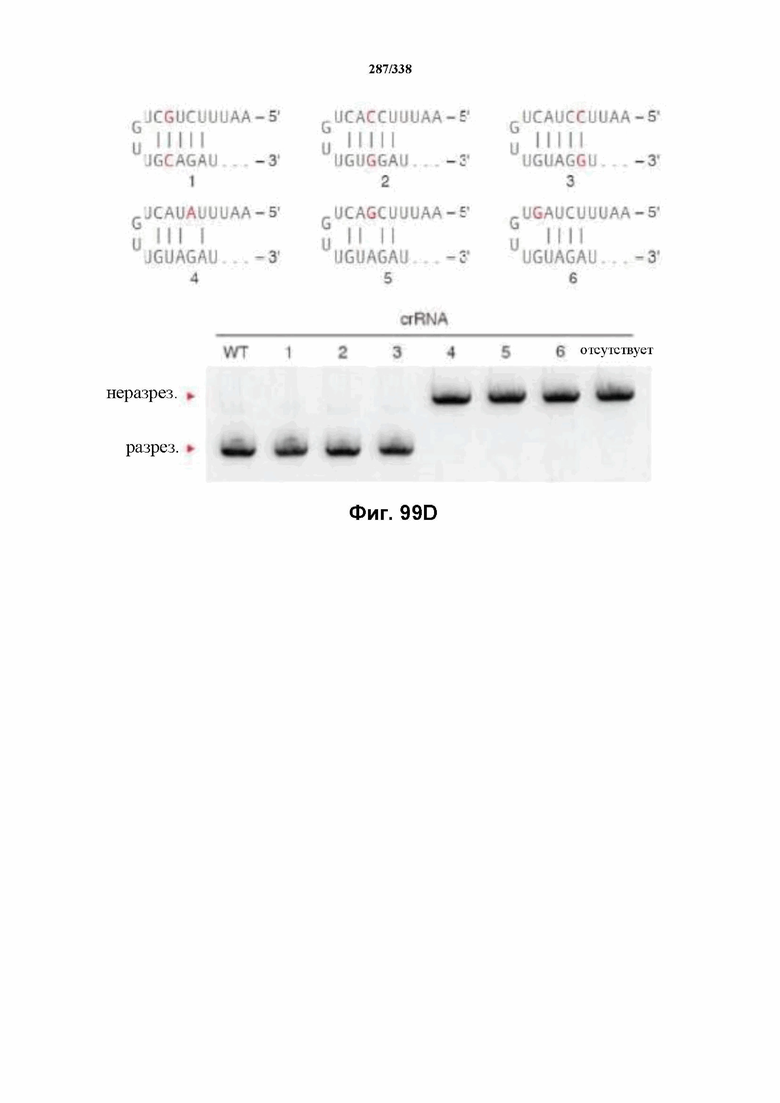



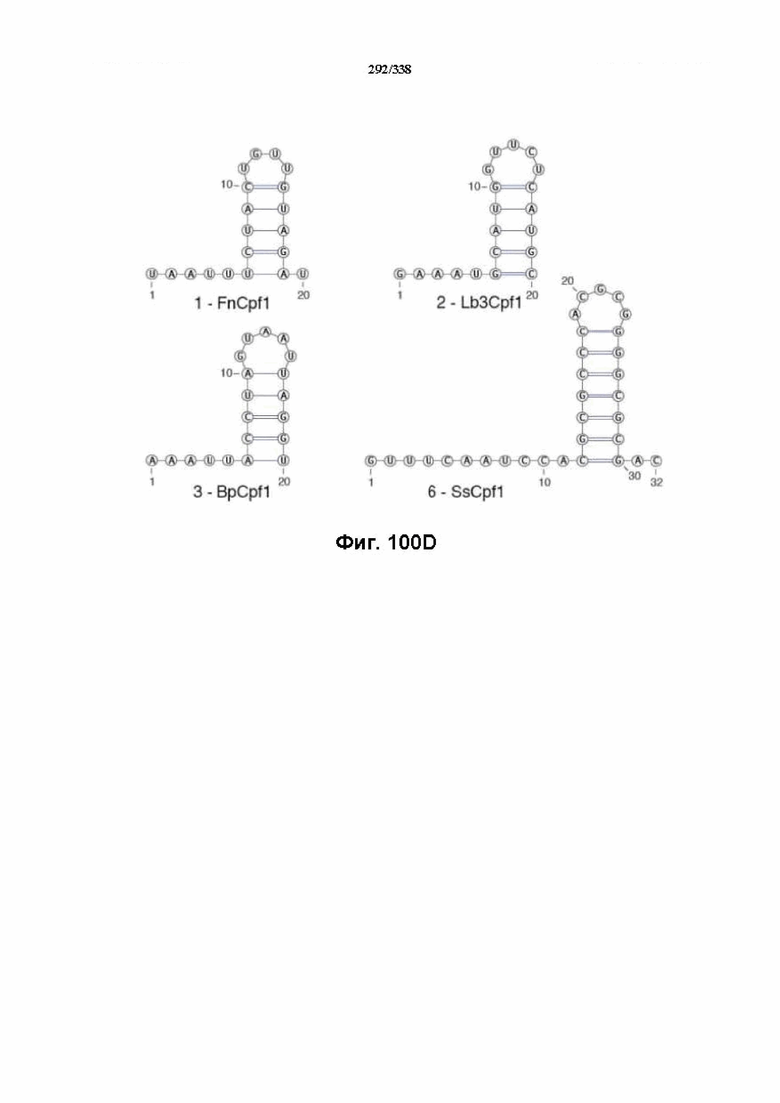

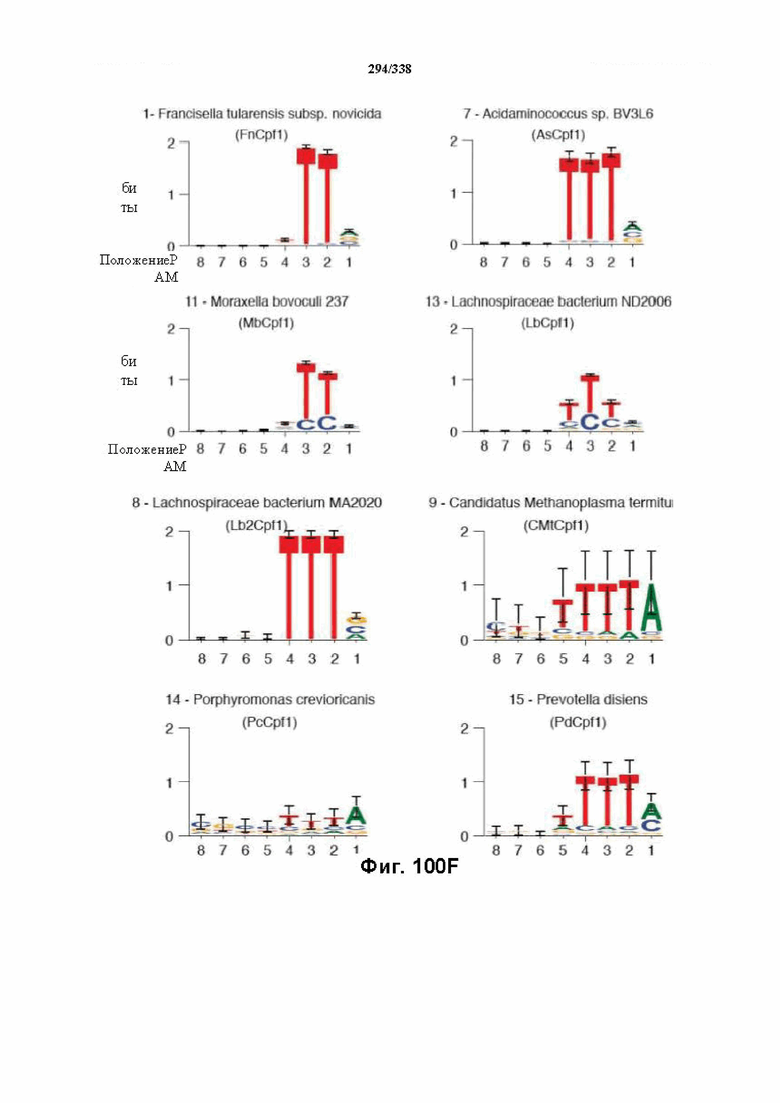
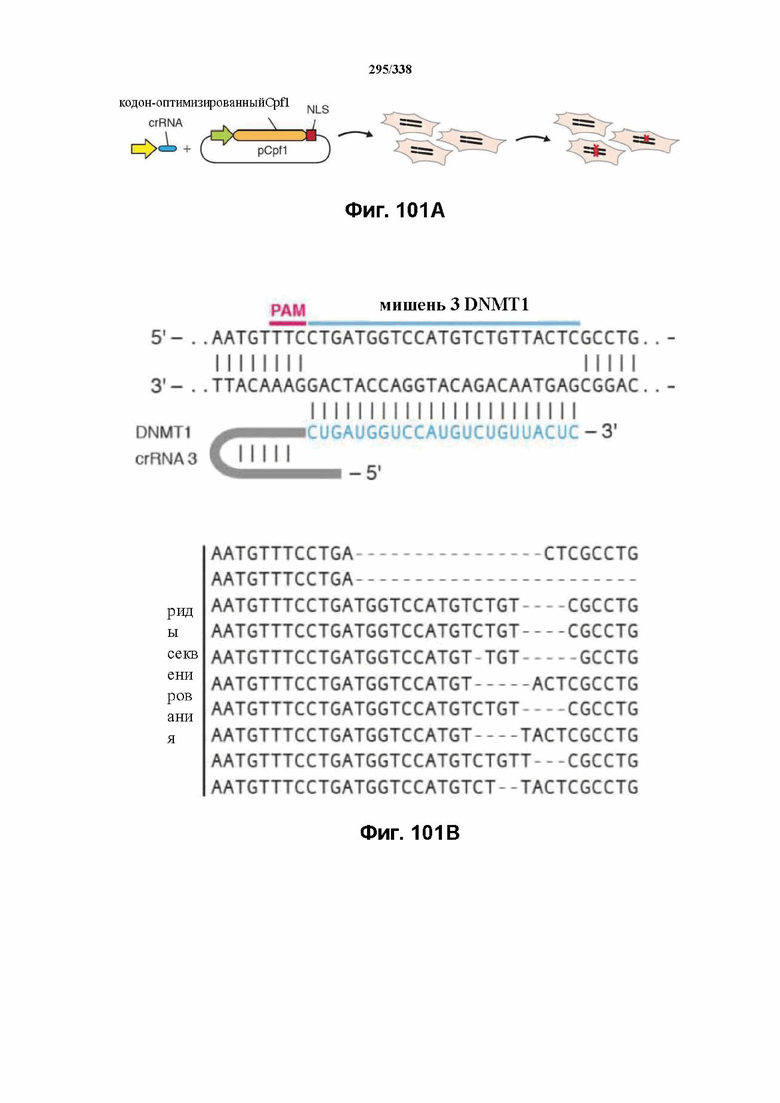

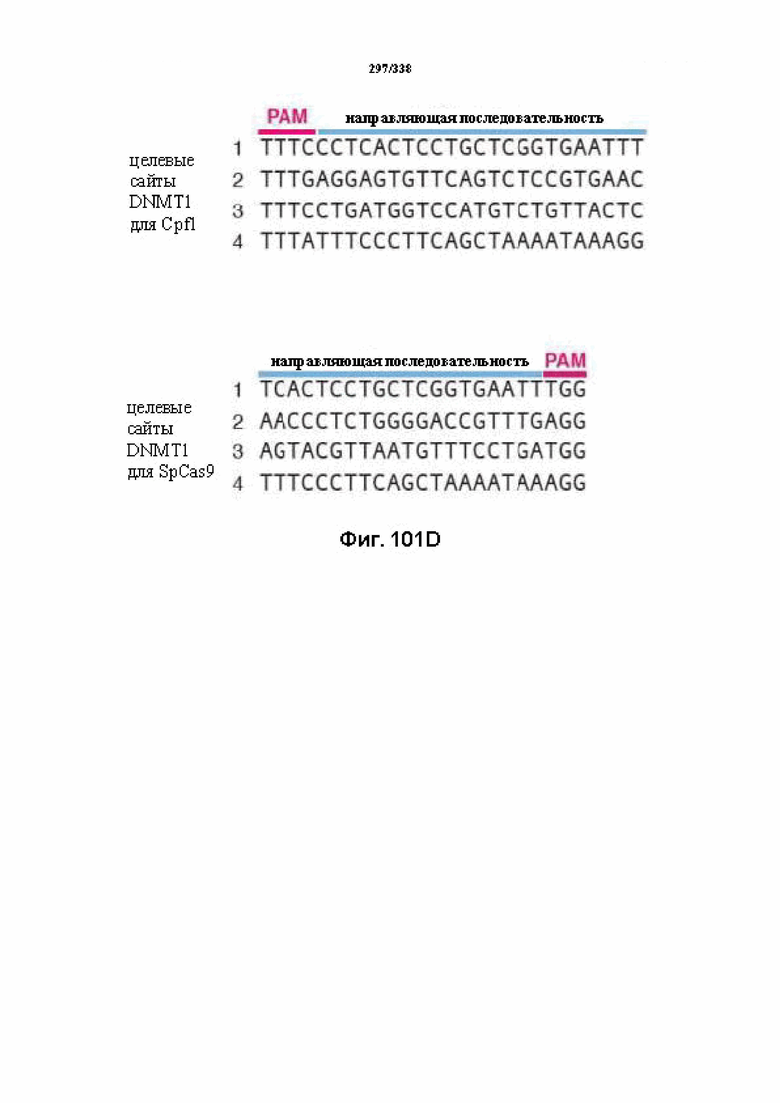

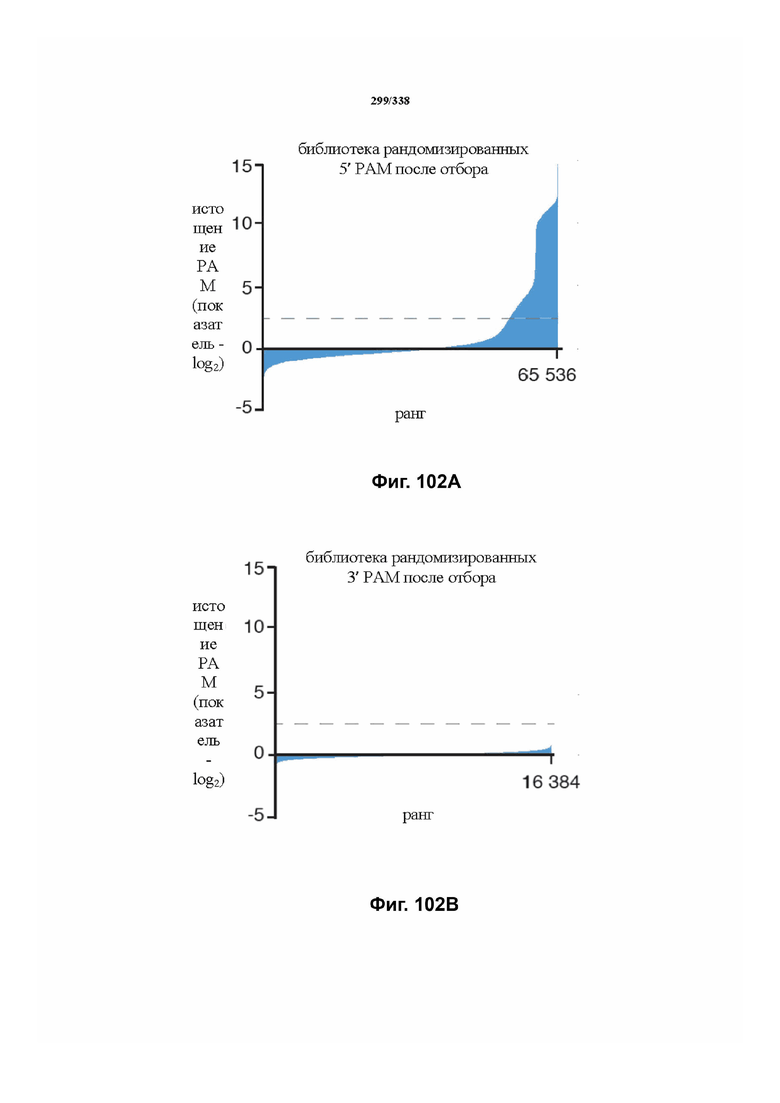
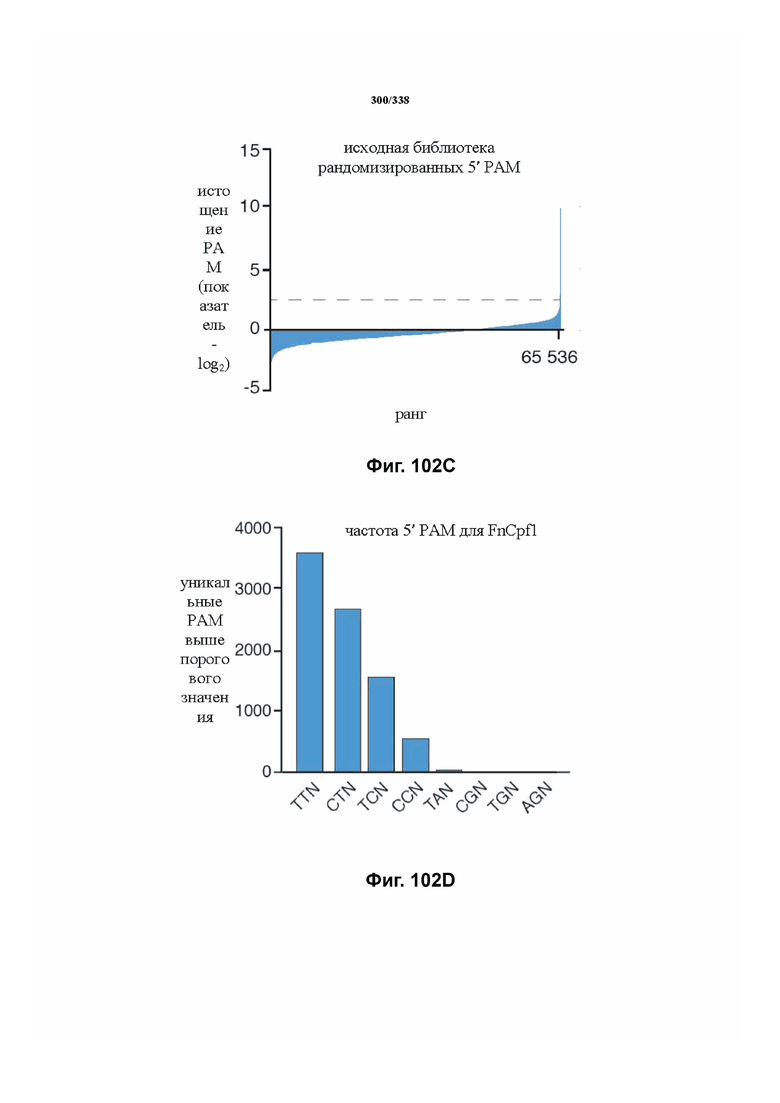
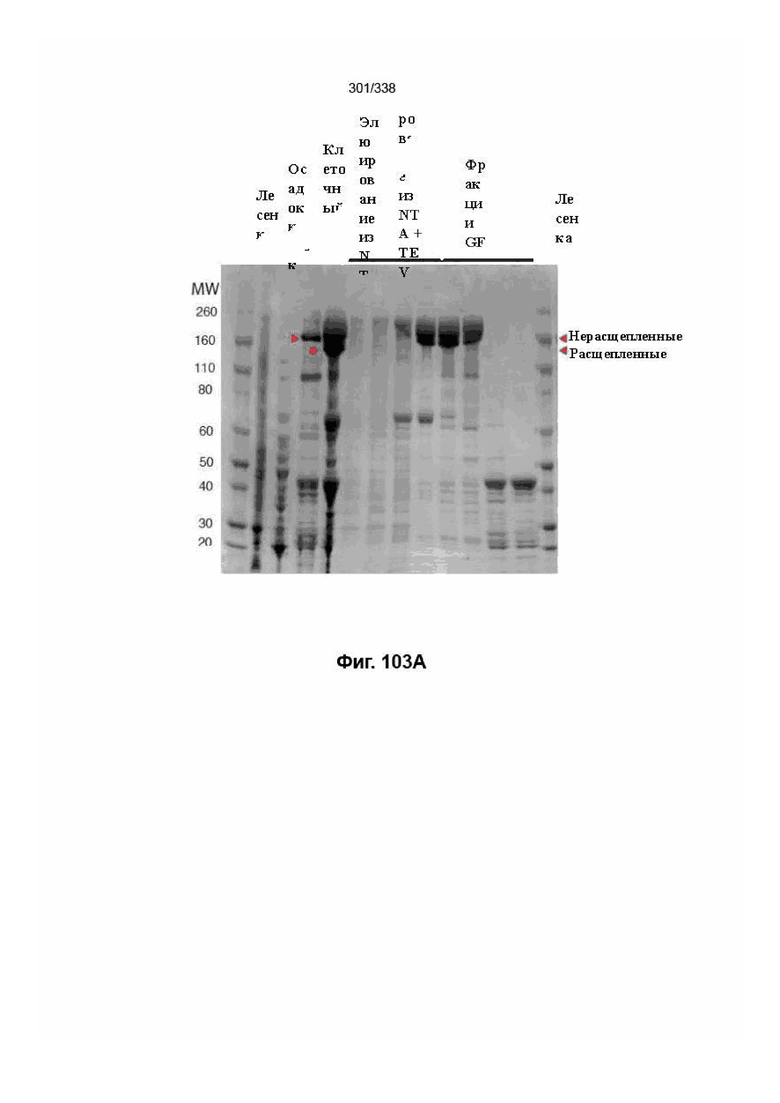
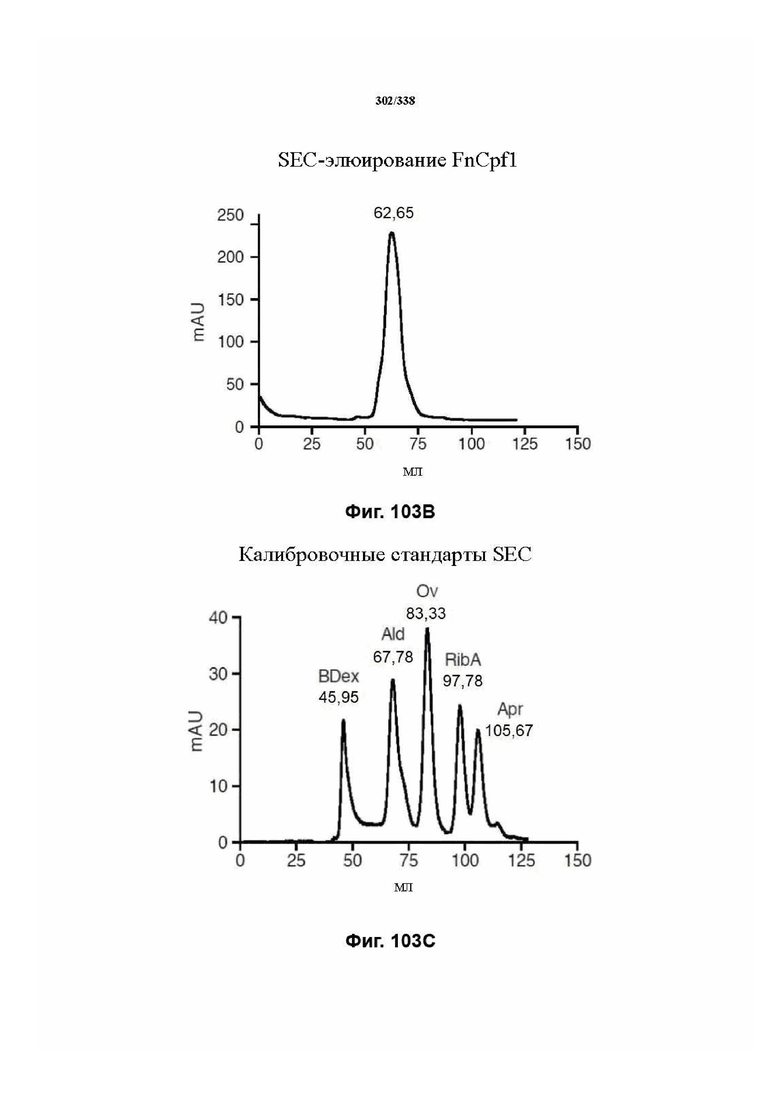
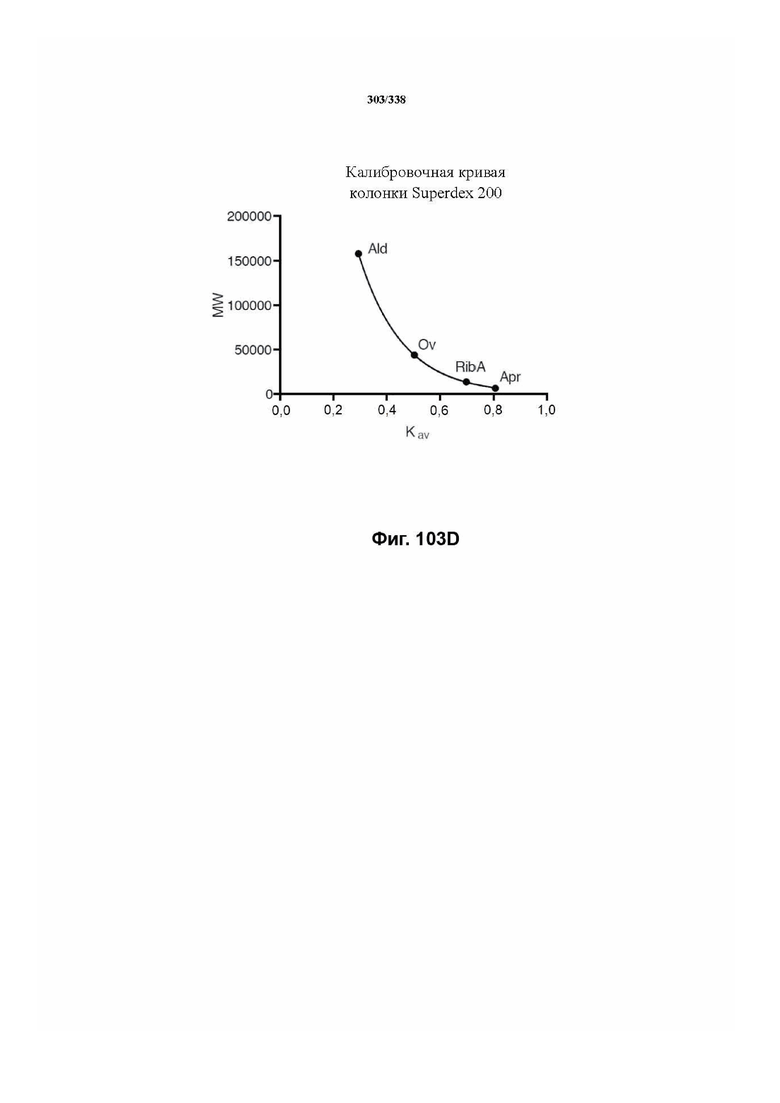
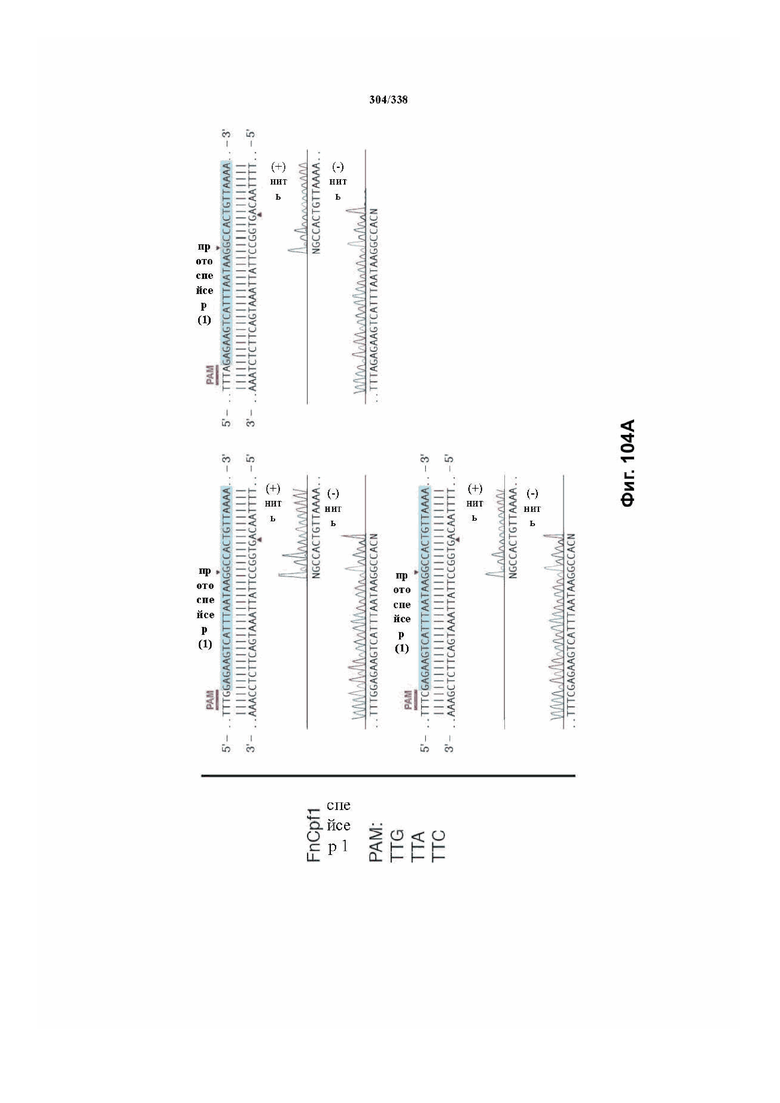
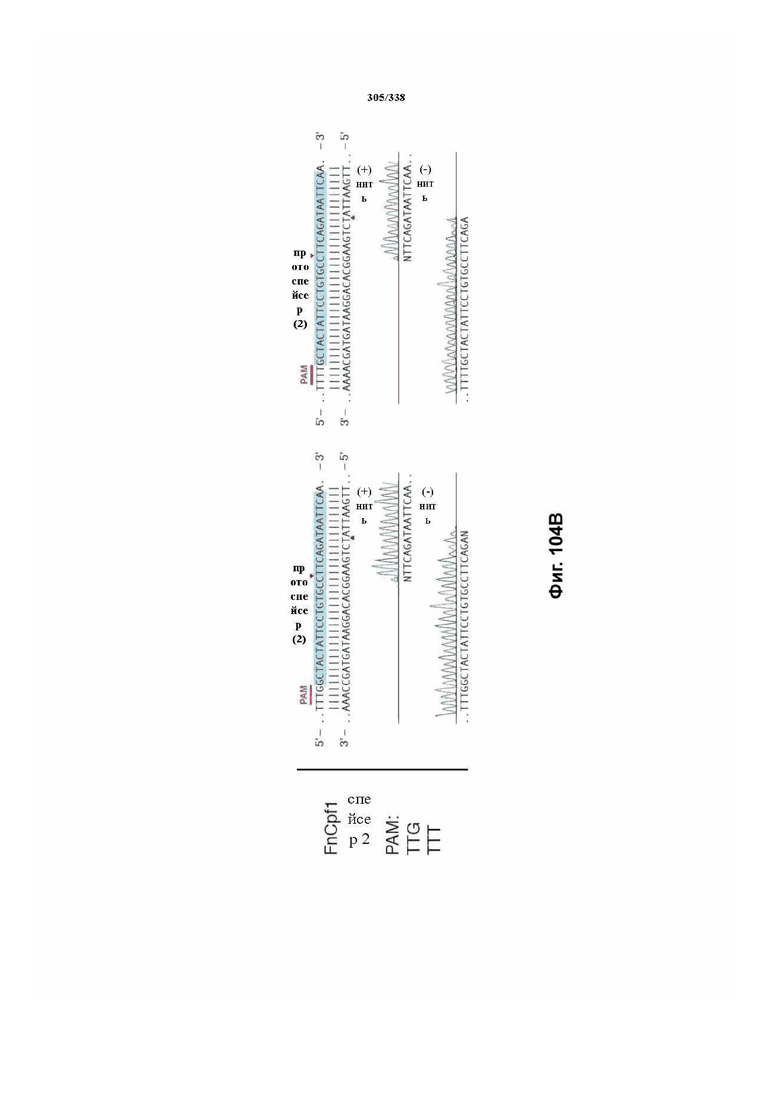
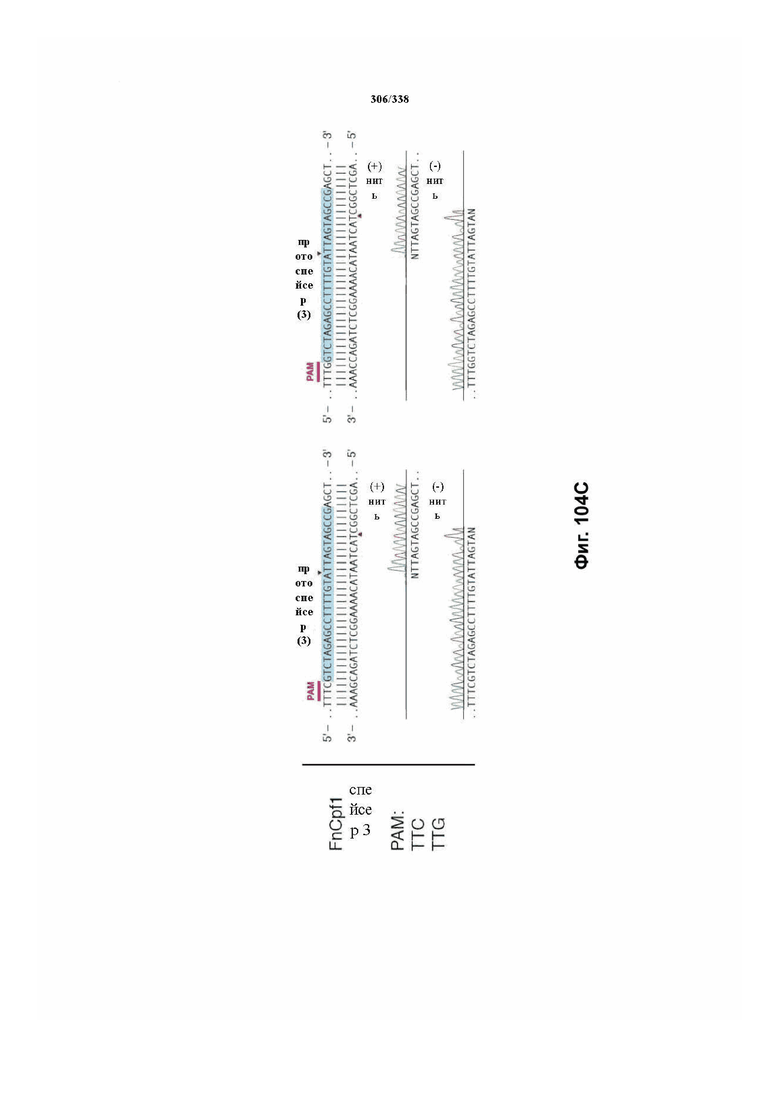
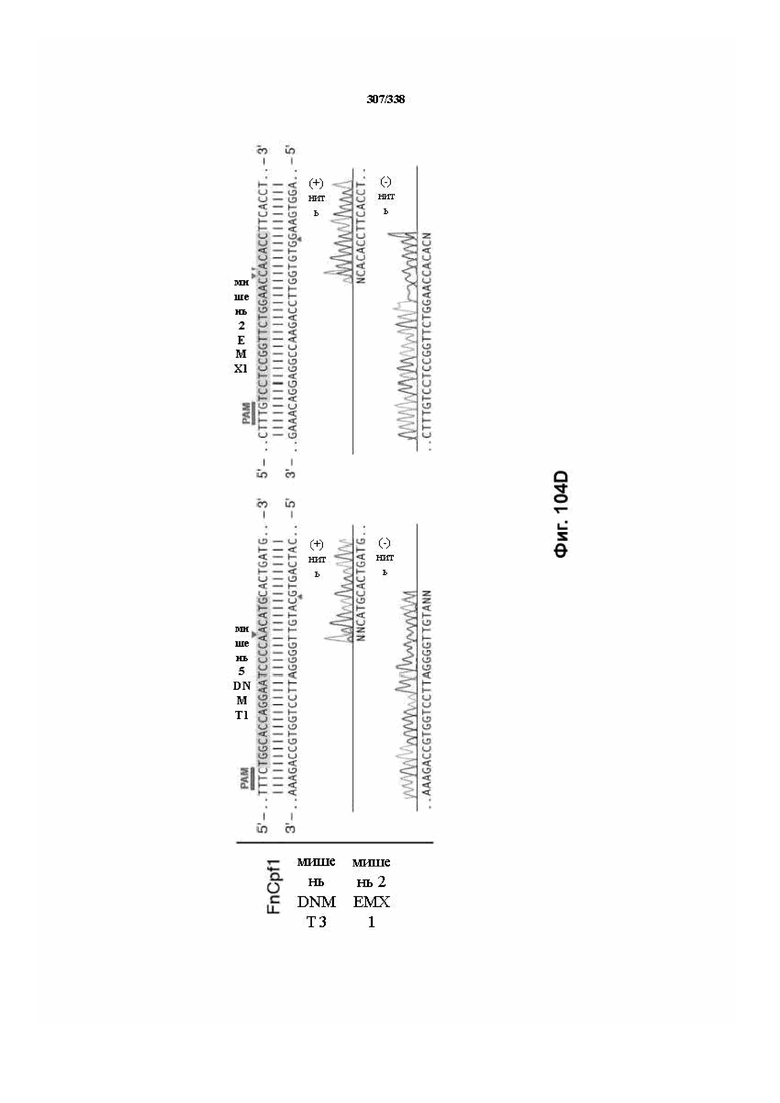
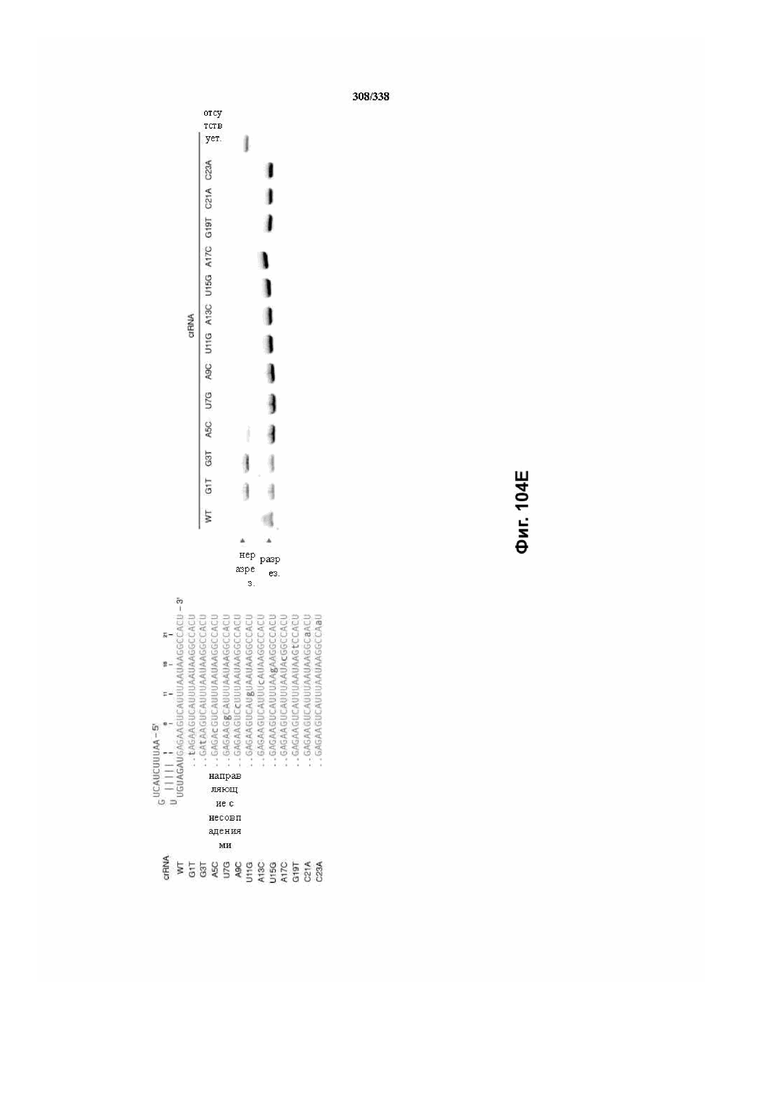
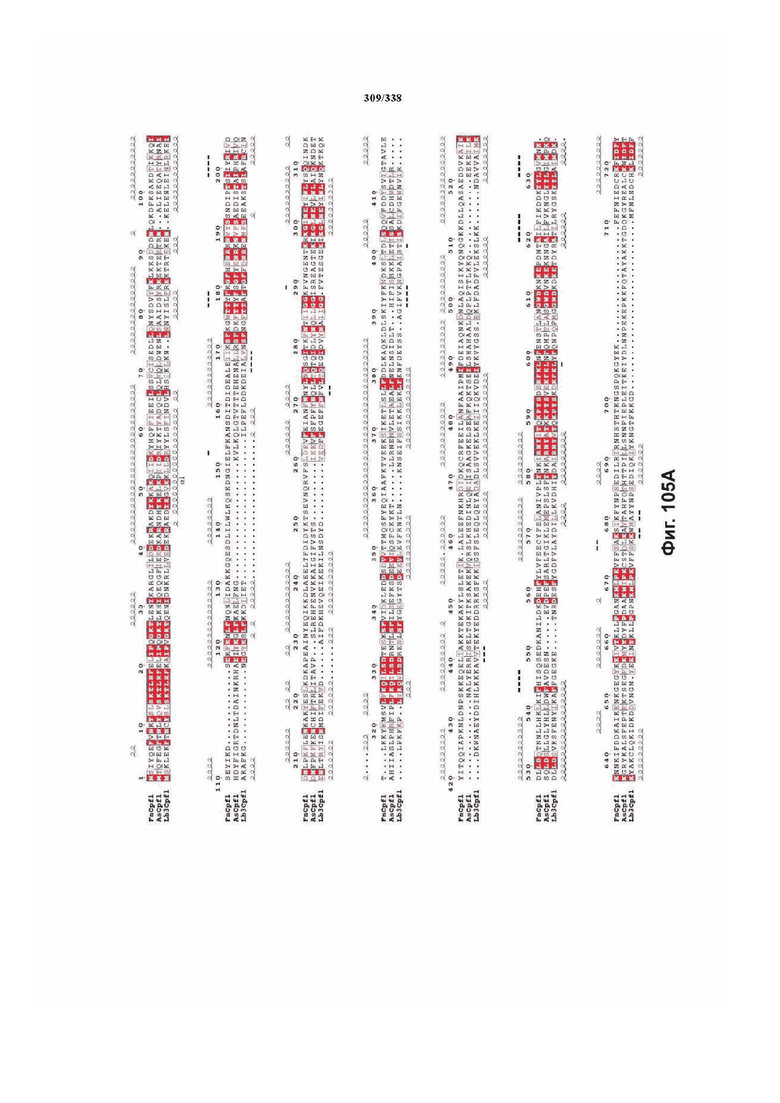
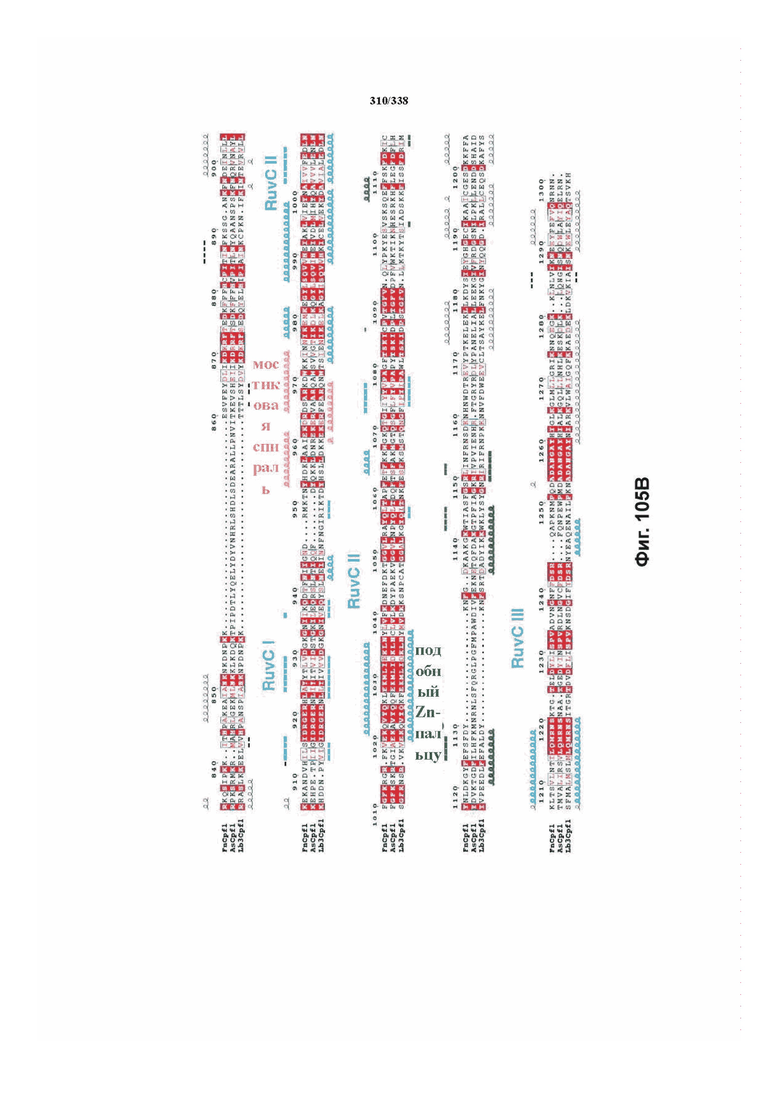
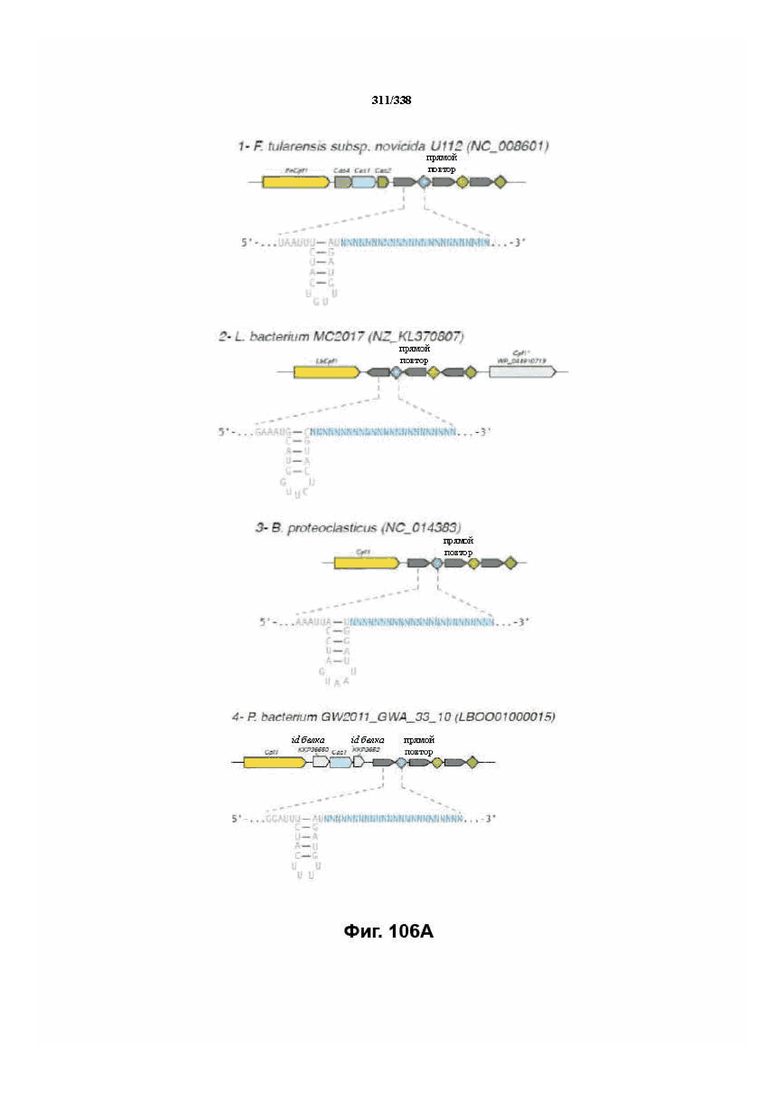
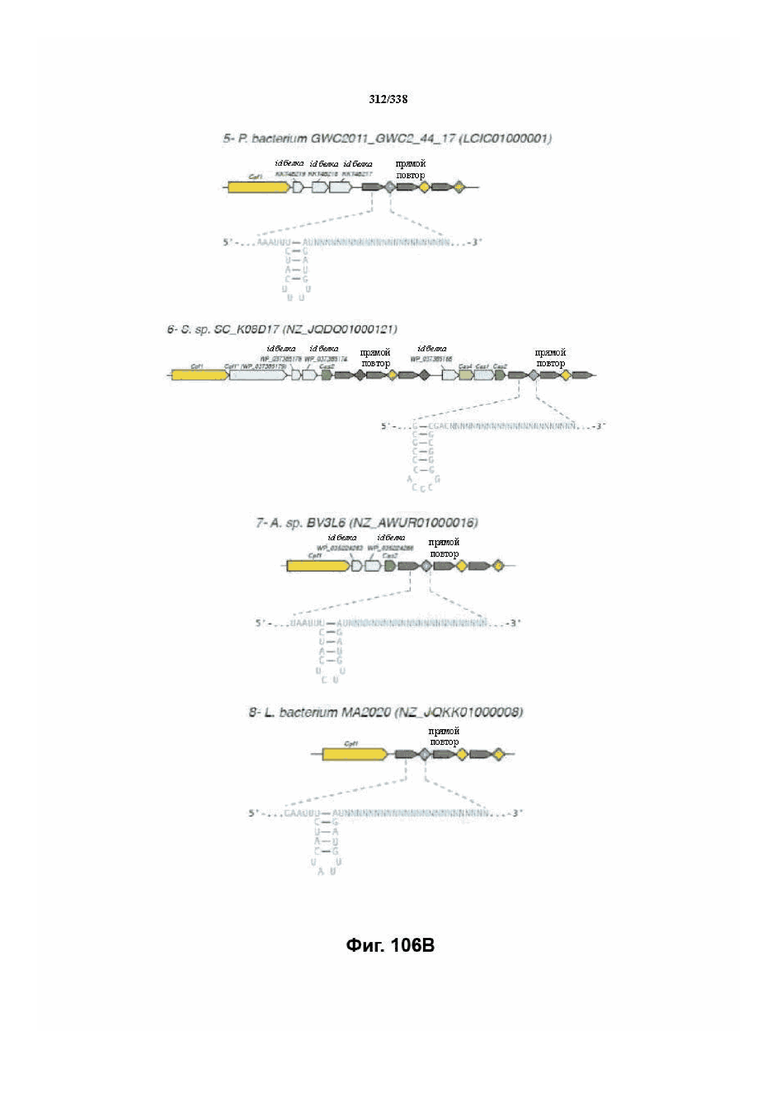
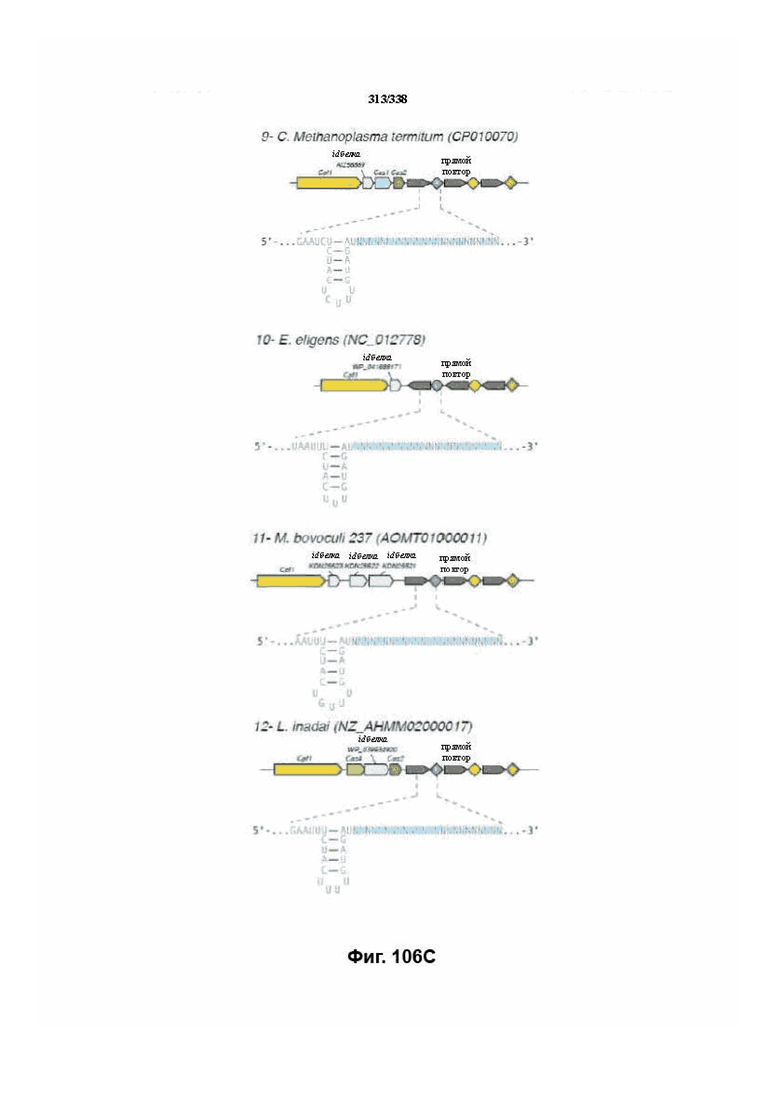

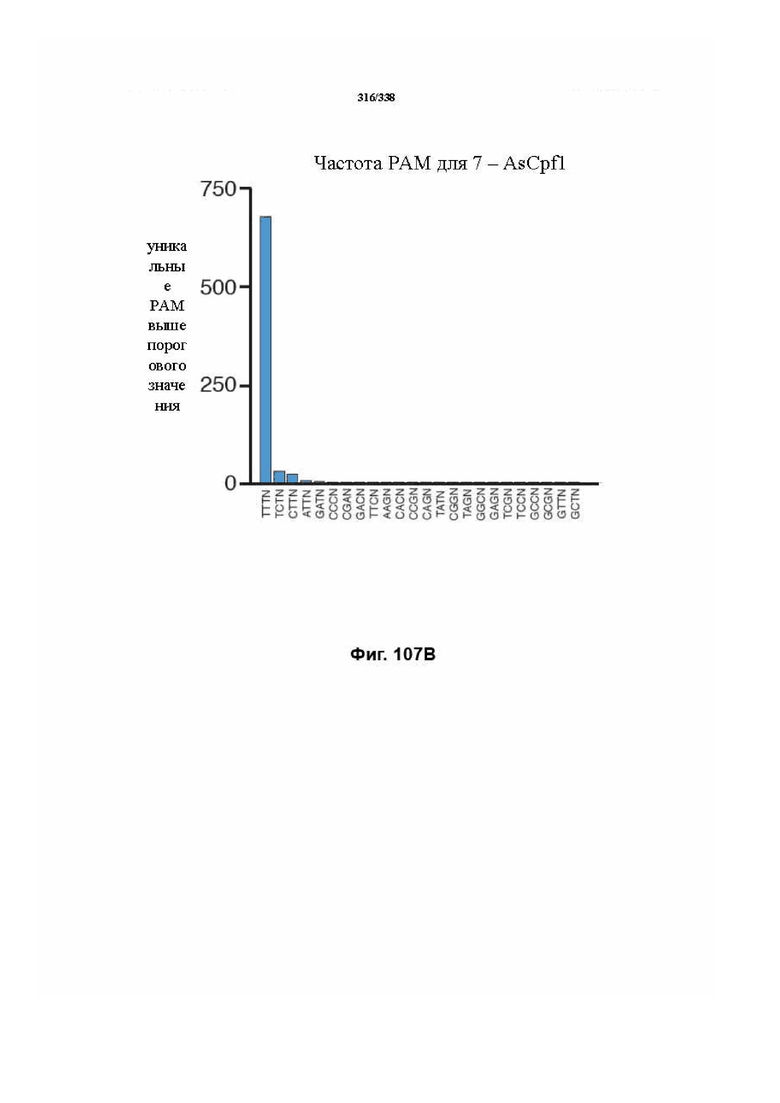
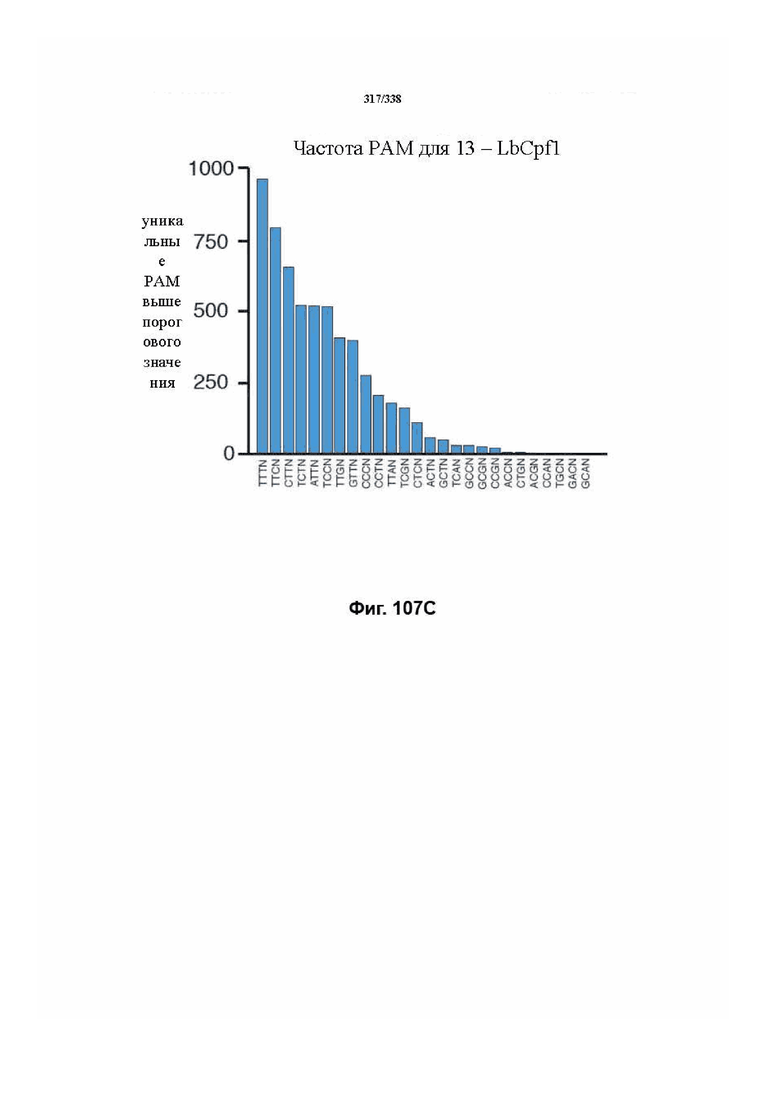


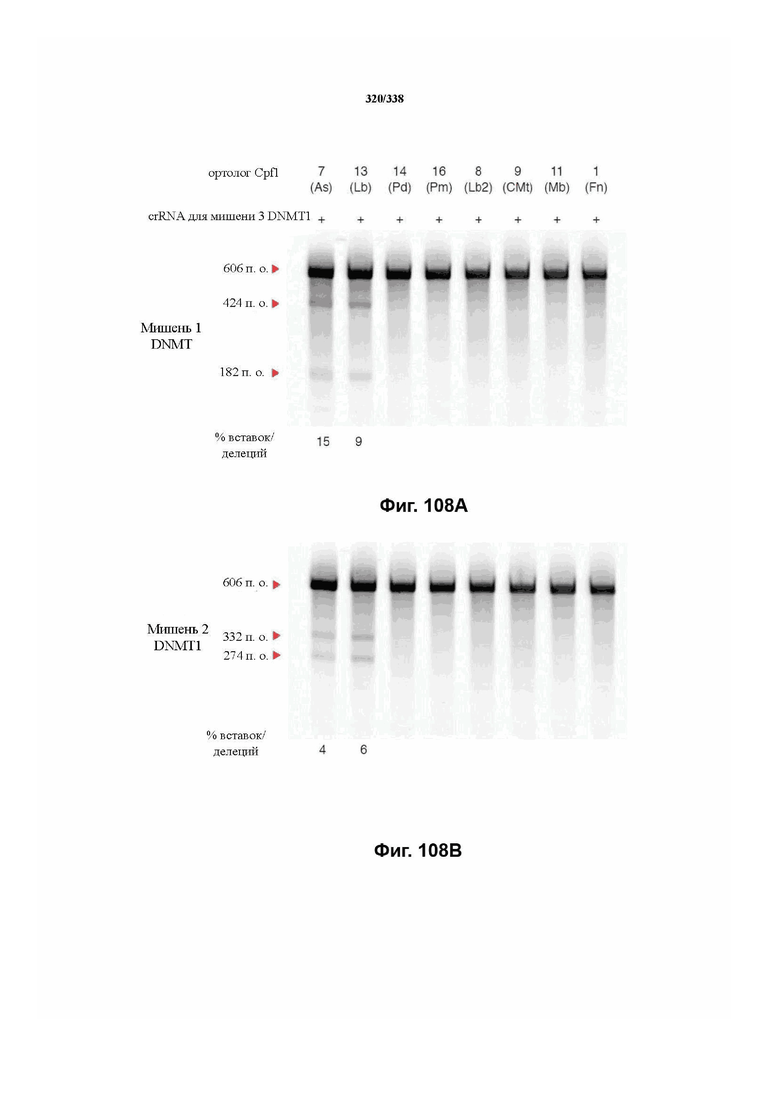
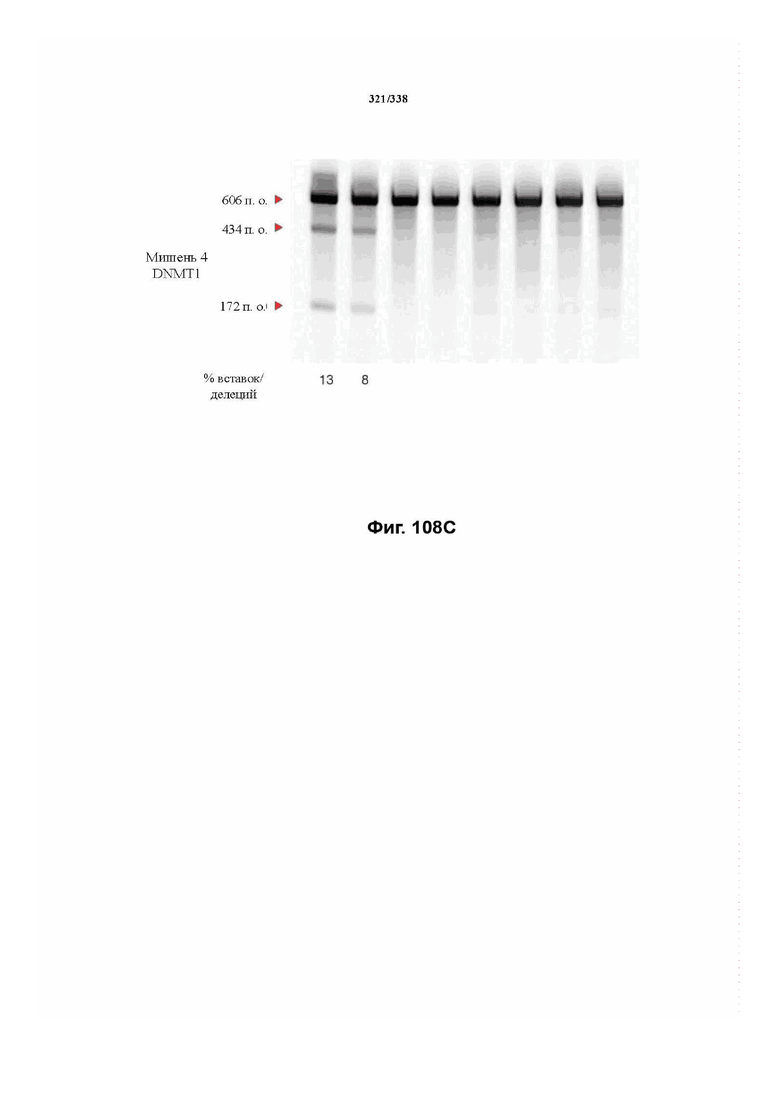
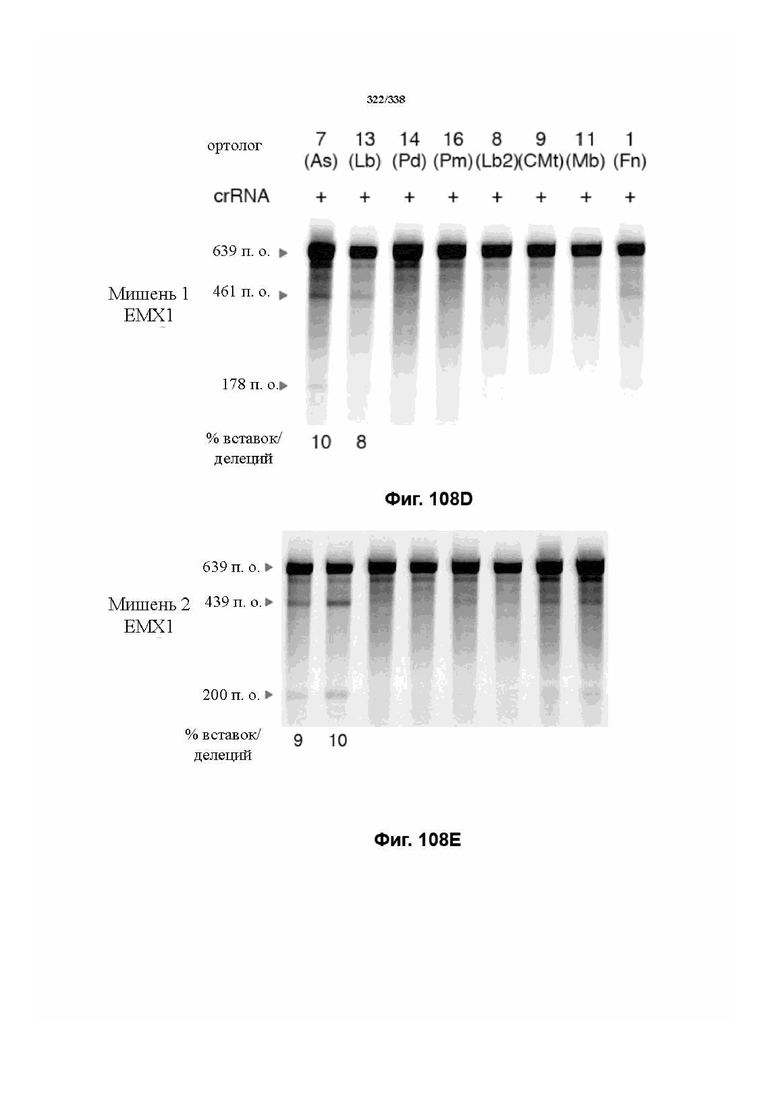


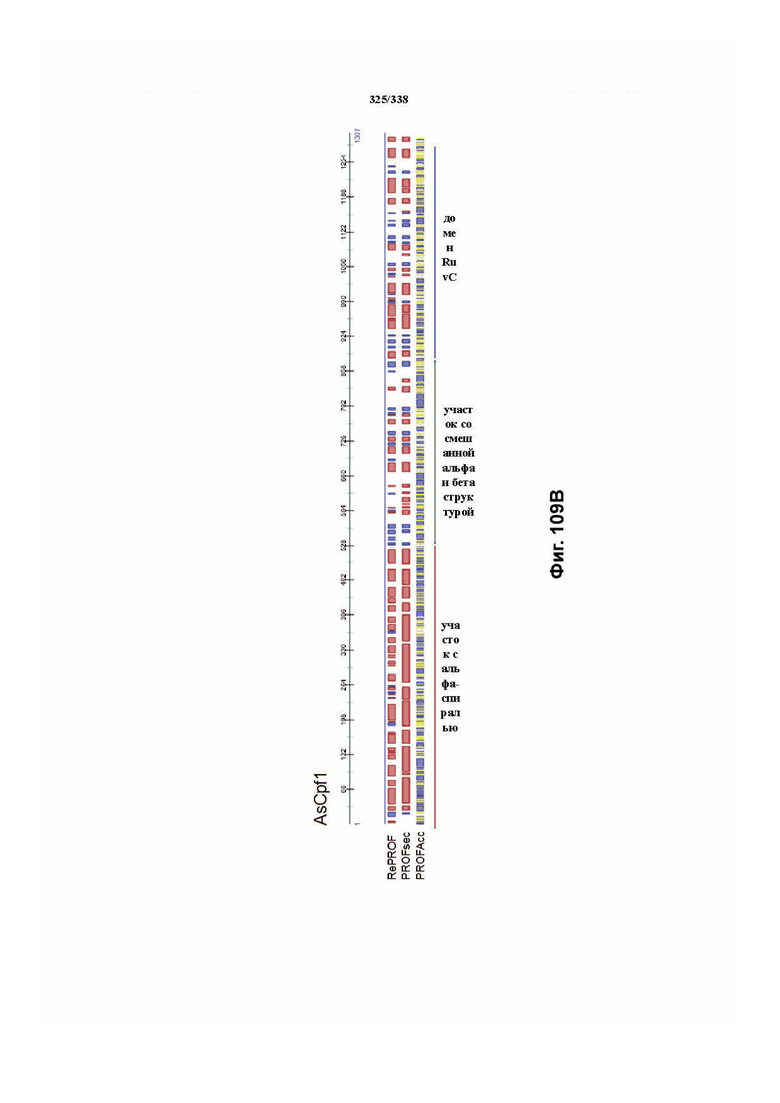

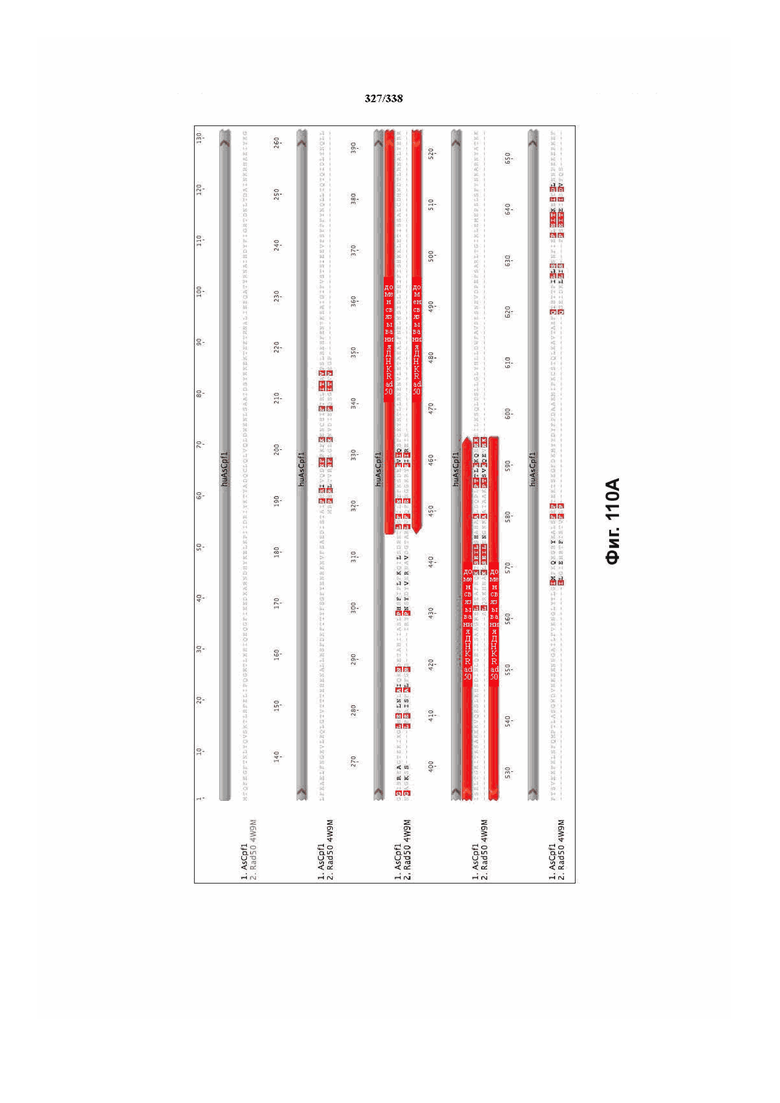


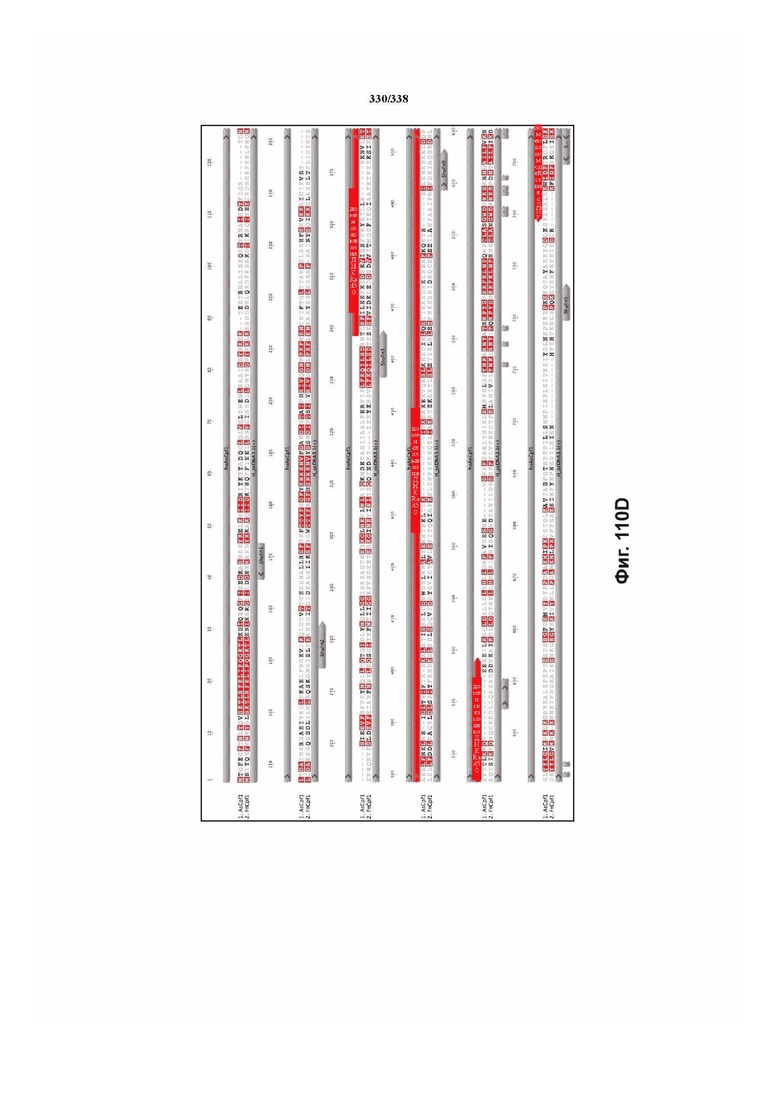
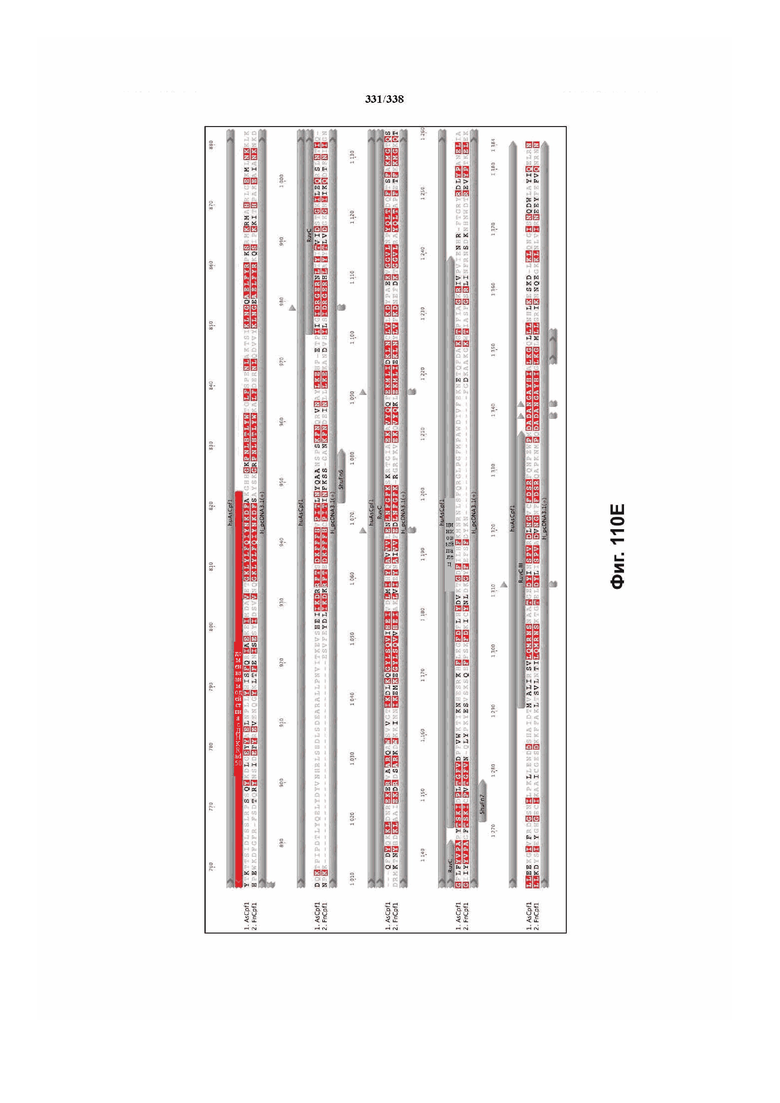

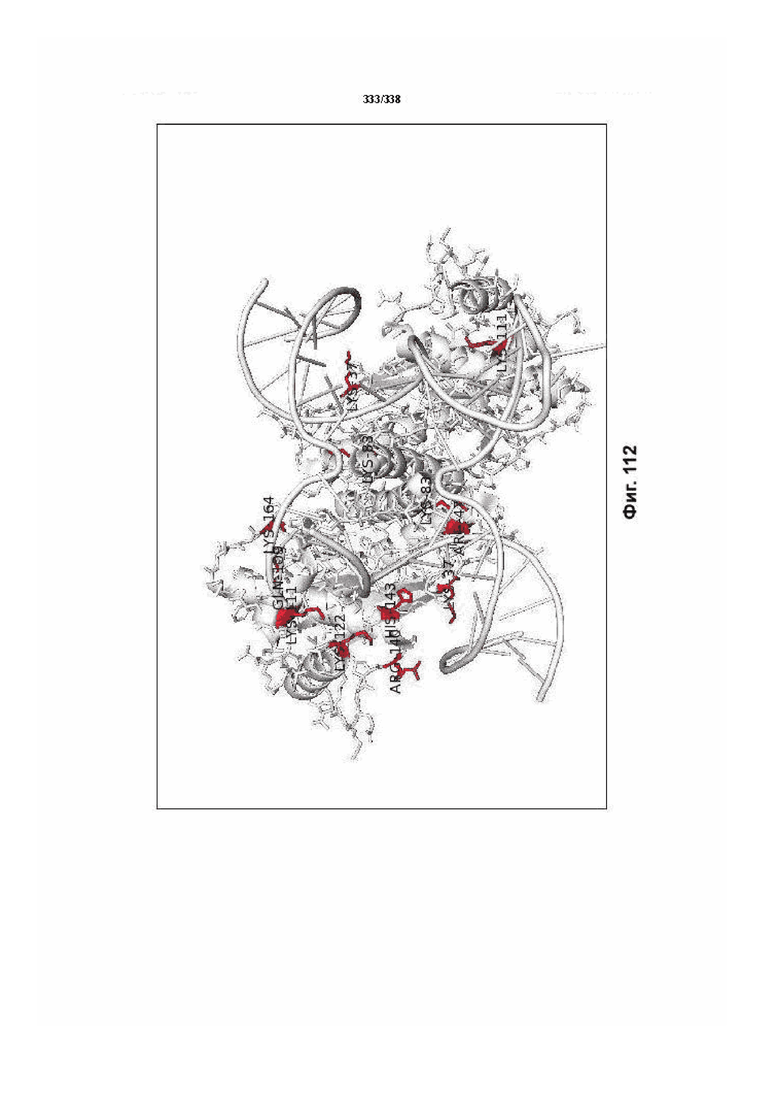


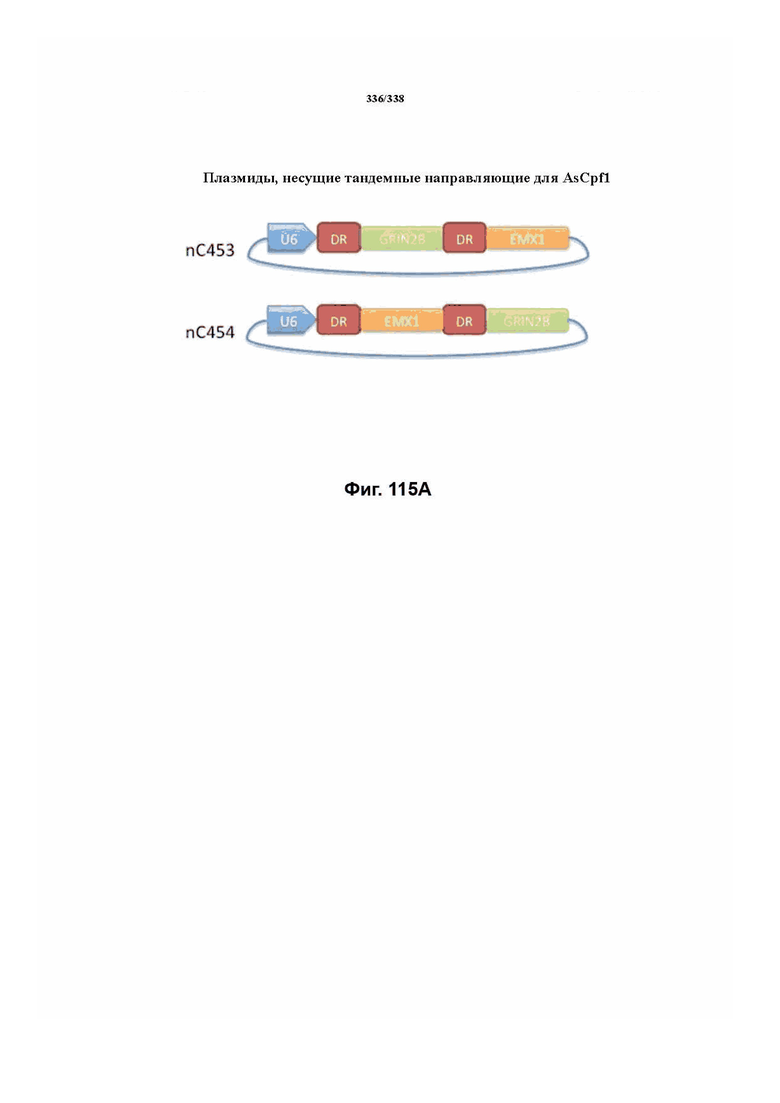
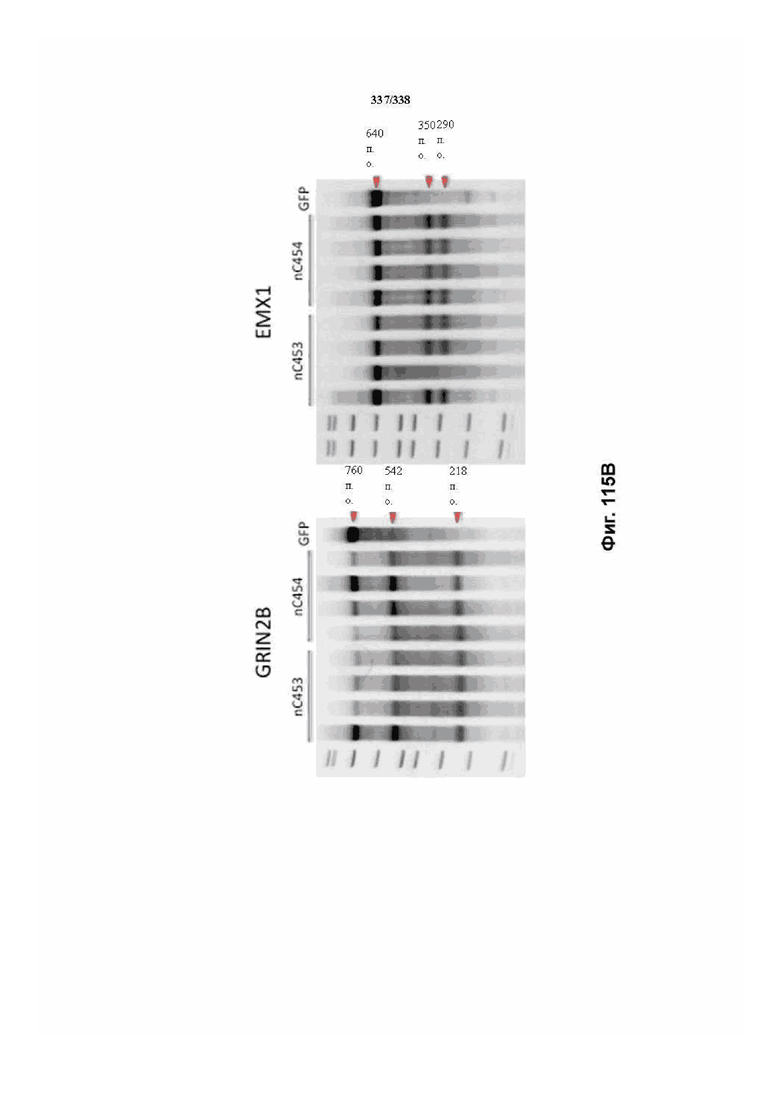
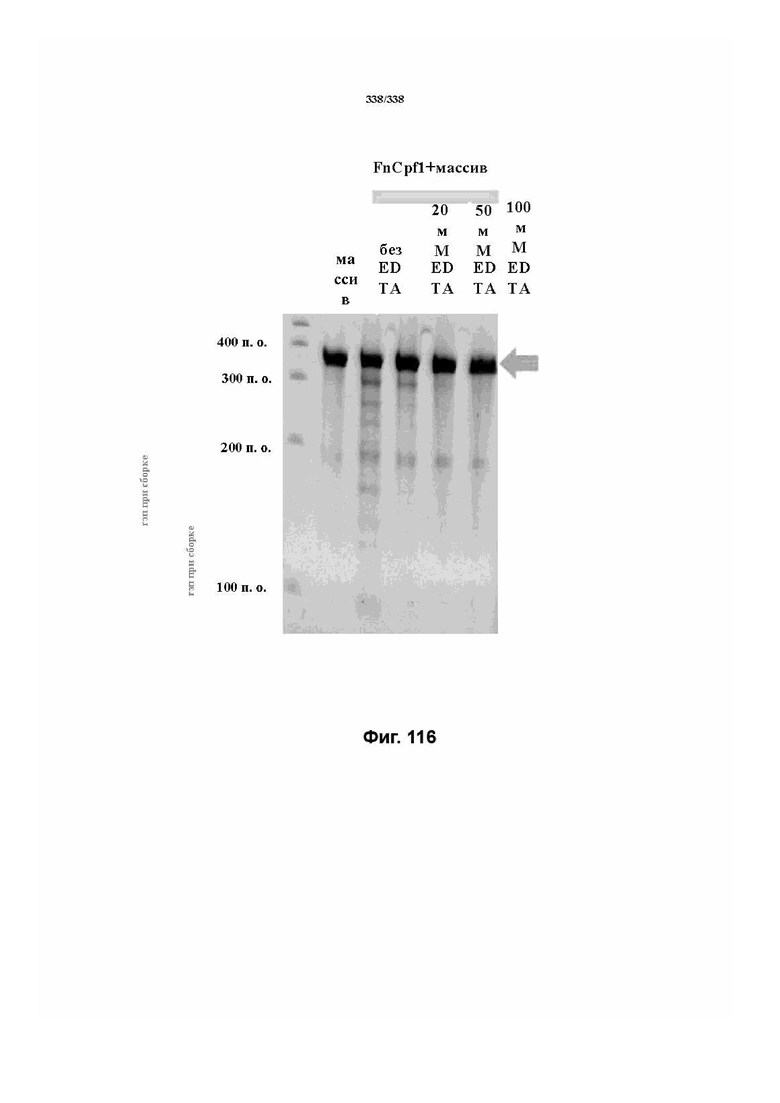
Изобретение относится к области биохимии, в частности к сконструированной, не встречающейся в природе системе на основе коротких палиндромных повторов, регулярно расположенных группами (CRISPR)-CRISPR-ассоциированного фермента (Cas) (CRISPR-Cas), для модификации представляющего интерес целевого локуса. Также раскрыты способы модифицирования, способ получения модифицированного растения, способ идентификации, с помощью указанной системы. Раскрыта клетка-хозяин, содержащая указанную систему. Изобретение позволяет эффективно получать модифицированное растение. 7 н. и 45 з.п. ф-лы, 116 ил., 10 табл., 19 пр.
1. Сконструированная, не встречающаяся в природе система на основе коротких палиндромных повторов, регулярно расположенных группами (CRISPR)-CRISPR-ассоциированного фермента (Cas) (CRISPR-Cas), для модификации представляющего интерес целевого локуса, содержащая
a) направляющую РНК, которая содержит направляющую последовательность, связанную с последовательностью прямого повтора, где направляющая последовательность способна гибридизоваться с целевой последовательностью, которая находится в направлении 3' от мотива, смежного с протоспейсером, (PAM) или нуклеотидную последовательность, кодирующую эту направляющую РНК, и
b) эффекторный белок Cpf1 или нуклеотидную последовательность, кодирующую этот эффекторный белок Cpf1;
где указанная направляющая РНК способна образовывать комплекс с этим эффекторным белком Cpf1.
2. Сконструированная, не встречающаяся в природе векторная система на основе коротких палиндромных повторов, регулярно расположенных группами (CRISPR)-CRISPR-ассоциированного фермента (Cas) (CRISPR-Cas), для модификации представляющего интерес целевого локуса, содержащая один или несколько векторов, содержащих
a) первый промотор, функционально связанный с нуклеотидной последовательностью, кодирующей направляющую РНК, которая содержит направляющую последовательность, связанную с последовательностью прямого повтора, где направляющая последовательность способна гибридизироваться с целевой последовательностью, которая находится в направлении 3' от мотива, смежного с протоспейсером (PAM),
b) второй промотор, функционально связанный с нуклеотидной последовательностью, кодирующей эффекторный белок Cpf1;
где компоненты (a) и (b) находятся в одном и том же или в разных векторах системы,
где указанная направляющая РНК способна образовывать комплекс с эффекторным белком Cpf1.
3. Система по п. 1 или 2, где целевая последовательность находится в клетке.
4. Система по п. 3, где клетка является эукариотической клеткой.
5. Система по п. 1 или 2, где, будучи транскрибированной, направляющая последовательность гибридизуется с целевой последовательностью, и при этом направляющая РНК образует комплекс c эффекторным белком Cpf1, который вызывает расщепление отдаленно от целевой последовательности.
6. Система по п. 5, где указанное расщепление приводит к образованию ступенчатого двухнитевого разрыва с "липким" 5'-концом длиной 4 или 5 нуклеотидов.
7. Система по п. 1 или 2, где PAM содержит 5'-мотив с высоким содержанием T.
8. Система по п. 1 или 2, где эффекторный белок представляет собой эффекторный белок Cpf1, происходящий из одного из видов бактерий, приведенных на фигуре 64.
9. Система по п. 8, где эффекторный белок Cpf1 происходит из вида бактерий, выбранного из группы, состоящей из Francisella tularensis 1, Francisella tularensis subsp. novicida, Prevotella albensis, Lachnospiraceae bacterium MC2017 1, Butyrivibrio proteoclasticus, Peregrinibacteria bacterium GW2011_GWA2_33_10, Parcubacteria bacterium GW2011_GWC2_44_17, Smithella sp. SCADC, Acidaminococcus sp. BV3L6, Lachnospiraceae bacterium MA2020, Candidatus Methanoplasma termitum, Eubacterium eligens, Moraxella bovoculi 237, Leptospira inadai, Lachnospiraceae bacterium ND2006, Porphyromonas crevioricanis 3, Prevotella disiens и Porphyromonas macacae.
10. Система по п. 9, где последовательность PAM представляет собой TTN, где N представляет собой A/C/G или T, а эффекторный белок представляет собой FnCpf1, или где последовательность PAM представляет собой TTTV, где V представляет собой A/C или G, а эффекторный белок представляет собой PaCpf1p, LbCpf1 или AsCpf1.
11. Система по п. 1 или 2, где эффекторный белок Cpf1 содержит один или несколько сигналов ядерной локализации.
12. Система по п. 1 или 2, где последовательность нуклеиновой кислоты, кодирующая эффекторный белок Cpf1, является кодон-оптимизированной для экспрессии в эукариотической клетке.
13. Система по п. 1 или 2, где компоненты (a) и (b) или нуклеотидная последовательность находятся в одном векторе.
14. Способ модифицирования представляющего интерес целевого локуса, включающий доставку системы по п. 1 или 2 в указанный локус или клетку, содержащую локус.
15. Способ модифицирования представляющего интерес целевого локуса, причем способ включает доставку в указанный локус не встречающейся в природе или сконструированной композиции, содержащей эффекторный белок Cpf1 и по меньшей мере одну направляющую РНК, где эффекторный белок Cpf1 образует комплекс с этой направляющей РНК, и после связывания указанного комплекса с представляющим интерес целевым локусом, который находится в направлении 3' от мотива, смежного с протоспейсером (PAM), эффекторный белок индуцирует модификацию представляющего интерес целевого локуса.
16. Способ по п. 15, где представляющий интерес целевой локус находится в клетке.
17. Способ по п. 16, где клетка является эукариотической клеткой.
18. Способ по п. 16, где клетка является клеткой животного или человека.
19. Способ по п. 16, где клетка является растительной клеткой.
20. Способ по п. 15, где представляющий интерес целевой локус содержится в
молекуле ДНК in vitro.
21. Способ по п. 15, где указанную, не встречающуюся в природе или сконструированную композицию, содержащую эффекторный белок Cpf1 и направляющую РНК, доставляют в клетку в виде одной или нескольких полинуклеотидных молекул.
22. Способ по п. 15, где представляющий интерес целевой локус содержит ДНК.
23. Способ по п. 22, где ДНК является релаксированной или свехспиральной.
24. Способ по п. 15, где композиция содержит множество направляющих РНК.
25. Способ по п. 15, где направляющая РНК содержит направляющую последовательность, связанную с последовательностью прямого повтора.
26. Способ по п. 15, где модификация представляющего интерес целевого локуса представляет собой разрыв нити.
27. Способ по п. 26, где разрыв нити предусматривает ступенчатый двухнитевой разрыв ДНК с "липким" 5'-концом длиной 4 или 5 нуклеотидов.
28. Способ по п. 26, где представляющий интерес целевой локус является модифицированным посредством интеграции ДНК-вставки в ступенчатый двухнитевой разрыв ДНК.
29. Способ по п. 15, где эффекторный белок Cpf1 содержит один или несколько сигналов ядерной локализации (NLS).
30. Способ по п. 21, где одна или несколько полинуклеотидных молекул содержатся в одном или нескольких векторах.
31. Способ по п. 21, где одна или несколько полинуклеотидных молекул содержат один или несколько промоторов, функционально сконфигурированных для обеспечения экспрессии эффекторного белка Cpf1 и/или направляющей РНК, где один или несколько промоторов необязательно являются индуцируемыми промоторами.
32. Способ по п. 21, где одна или несколько полинуклеотидных молекул или один или несколько векторов содержатся в системе доставки.
33. Способ по п. 21, где одну или несколько полинуклеотидных молекул доставляют посредством частиц, везикул или одного или нескольких вирусных векторов.
34. Способ по п. 33, где частицы содержат липид, сахар, металл или белок.
35. Способ по п. 33, где везикулы являются экзосомами или липосомами.
36. Способ по п. 33, где один или несколько вирусных векторов являются одним или несколькими, выбранными из аденовируса, одного или нескольких лентивирусов или одного или нескольких аденоассоциированных вирусов.
37. Способ по п. 15, который представляет собой способ модифицирования клетки или организма путем манипуляции с одной или несколькими целевыми последовательностями в представляющих интерес локусах генома.
38. In vitro, ex vivo или in vivo модифицированная в представляющем интерес целевом локусе клетка-хозяин, содержащая систему по п. 1 или 2 для модификации представляющего интерес целевого локуса в этой клетке-хозяине.
39. Клетка-хозяин по п. 38, где клетка является эукариотической клеткой.
40. Клетка-хозяин по п. 39, где клетка является клеткой животного.
41. Клетка-хозяин по п. 39, где клетка является клеткой человека.
42. Клетка-хозяин по п. 39, где клетка является стволовой клеткой.
43. Клетка-хозяин по п. 39, где клетка является растительной клеткой.
44. Способ получения растения с модифицированным, представляющим интерес признаком, кодируемым представляющим интерес геном, причем указанный способ включает приведение растительной клетки в контакт с системой по п. 1 или 2 или осуществление в отношении растительной клетки способа по п. 15, за счет чего обеспечивается либо модифицирование, либо введение указанного, представляющего интерес гена, и регенерацию растения из указанной растительной клетки.
45. Способ идентификации представляющего интерес признака у растения, причем указанный представляющий интерес признак кодируется представляющим интерес геном, причем указанный способ включает приведение растительной клетки в контакт с системой по п. 1 или 2 или осуществление в отношении растительной клетки способа по п. 15, за счет чего обеспечивается идентификация указанного представляющего интерес гена.
46. Способ по п. 45, дополнительно включающий введение идентифицированного, представляющего интерес гена в растительную клетку или растительную зародышевую плазму и получение из них растения, в результате чего растение содержит представляющий интерес ген.
47. Способ по п. 46, где у растения проявляется представляющий интерес признак.
48. Система по п. 1, где комплекс, направляющая РНК или белок конъюгированы по меньшей мере с одним сахарным фрагментом, необязательно N-ацетилгалактозамином (GalNAc), в частности с трехразветвленным GalNAc.
49. Система по п. 1, где система содержит Mg2+ в концентрации от приблизительно 1 мМ до приблизительно 15 мМ.
50. Система по п. 1, в которой комплекс не содержит tracr-последовательность.
51. Система по п. 2, в которой комплекс не содержит tracr-последовательность.
52. Способ по п. 15, в котором комплекс не содержит tracr-последовательность.
| ШТАММ LACTOBACILLUS PARACASEI SUBSPECIES PARACASEI, ОБЛАДАЮЩИЙ АНТИМИКРОБНЫМИ И ИММУНОМОДУЛИРУЮЩИМИ СВОЙСТВАМИ, И ПИЩЕВОЙ ПРОДУКТ НА ЕГО ОСНОВЕ | 2009 |
|
RU2501850C2 |
| CN 103261213 A, 21.08.2013 | |||
| US 8361725 B2, 29.01.2013 | |||
| US 8697359 B1, 15.04.2014. | |||

