Перекрестные ссылки на родственные заявки
Данная заявка испрашивает приоритет предварительной патентной заявки США №62/168309, поданной 29 мая 2015 года, содержание которой включено в данный документ посредством ссылки в полном объеме.
Заявление касательно спонсированных Федеральным правительством исследований или разработок
Данное изобретение было проведено при государственной поддержке согласно СА088868, GM060911, СА182675, СА184867 и Р30 AI045008, присужденным Национальным институтом здравоохранения. Правительство обладает определенными правами в данном изобретении.
Уровень техники
Белки являются наиболее распространенными макромолекулами клетки и имеют решающее значение практически для всех физиологических процессов. Чтобы выполнять свои биологические функции, большинство белков должны быть упакованы (свернуты) и должны сохраняться в своих нативных конформациях. Несмотря на то, что нативная конформация белка определяется его аминокислотной последовательностью, процесс сворачивания является чрезвычайно сложным и очень подвержен ошибкам, и его полезность может быть дополнительно ограничена в ситуациях генетических мутаций, биогенетических неточностей и посттрансляционных повреждений (Dobson, 2003, Nature, 426: 884-890; Goldberg, 2003, Nature, 426: 895-899). Белки, которые приняли аберрантные конформации, и образующиеся ими агрегаты представляют постоянную угрозу жизнеспособности и функционированию клеток. Неспособность устранить эти белки тесно связана с патогенезом различных изнурительных заболеваний человека (Selkoe, 2003, Nature, 426: 900-904; Taylor et al., 2002, Science, 296: 1991-1995).
Для борьбы с неправильно упакованными белками клетки используют два широких набора систем контроля качества белка (protein quality control, PQC): системы, которые помогают белкам достигать их природных конформаций, и системы, которые элиминируют неправильно упакованные белки, когда они формируются. Первая состоит главным образом из большого числа молекулярных шаперонов и их кошаперонов, которые АТФ-зависимым способом защищают белки в их ненативном состоянии и уменьшают неправильную упаковку и агрегацию. Известные примеры включают (1) белок теплового шока 70 (heat shock protein 70, Hsp70), который помогает упаковывать широкий спектр белков; (2) Hsp60/шаперонин, который формирует макромолекулярную клетку для инкапсуляции относительно небольших белков для непрерывного фолдинга (упаковки); и (3) HSP90, который чаще всего действует на белки, участвующие в клеточной передаче сигналов и транскрипции (Hartl et al., 2011, Nature, 475: 324-332).
Системы, которые удаляют неправильно упакованные белки, включают белковые дезагрегазы. Например, белки Hsp100 у прокариот или низших эукариот (например, ClpB у бактерий и Hsp104 у дрожжей) могут повторно солюбилизировать белковые агрегаты, функционирующие совместно с Hsp70 и его кошапероном Hsp40 (Glover и Lindquist, 1998, Cell, 94: 73-82). Тем не менее, учитывая, что неправильная упаковка белков является неизбежной и часто не может быть исправлена из-за мутаций, биогенетических ошибок или непоправимых повреждений, клетки в конечном итоге полагаются на системы деградации для поддержания качества белка. Тем не менее, эти системы до сих пор плохо изучены. Хотя убиквитин-протеасомальный путь, наряду с аутофагией, должен быть важной частью этих систем, неясным остается критический вопрос, как они избирательно распознают неправильно упакованные белки и направляют их на деградацию (Goldberg, 2003, Nature, 426: 895-899; Tyedmers et al, 2010, Nat Rev Mol Cell Biol, 11: 777-788).
Кроме того, по сравнению с другими клеточными компартментами, такими как эндоплазматический ретикулум (Buchberger et al., 2010, Mol Cell, 40: 238-252), системы PQC в ядре являются заметно неясными. Неправильно упакованные белки в ядре могут быть частично повреждающими для постмитотических клеток млекопитающих (например, нейронов и кардиомиоцитов), которые неспособны удалять эти белки через распад ядерной оболочки во время митоза. Важность понимания PQC в этом клеточном компартменте подчеркивается формированием нейрональных внутриядерных включений, которые ассоциированы с различными доминантно наследуемыми нейродегенеративными заболеваниями, включая болезнь Хантингтона (Huntington's disease, HD) и несколько типов спиноцеребеллярной атаксии (spinocerebellar ataxia, SCA). Эти заболевания вызваны удлинением в релевантных генах CAG-повтора, который кодирует полиQ-тракт (полиглутаминовый тракт). Они проявляются, когда полиQ-тракт превышает пороговую длину, которая является специфической для заболевания, и становятся прогрессивно более тяжелыми, когда его длина увеличивается (Orr and Zoghbi, 2007, Annu Rev Neurosci, 30: 575-621).
Таким образом, в данной области существует потребность в композициях и способах устранения неправильно упакованных белков. Данное изобретение удовлетворяет эту неудовлетворенную потребность.
Сущность изобретения
В одном из аспектов данное изобретение предусматривает композицию для лечения или профилактики заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковыми агрегатами, где указанная композиция содержит модулятор одного или более чем одного из TRIM-белков (от англ. tripartite motif family - семейство белков с трехсторонним мотивом). В одном из воплощений указанный модулятор повышает экспрессию или активность одного или более чем одного из TRIM-белков. В одном из воплощений указанный модулятор представляет собой по меньшей мере один, выбранный из группы, состоящей из химического соединения, белка, пептида, пептидомиметика, антитела, рибозима, низкомолекулярного химического соединения, нуклеиновой кислоты, вектора и антисмысловой нуклеиновой кислоты.
В одном из воплощений указанный модулятор повышает экспрессию или активность по меньшей мере одного из человеческих TRIM3, TRIM4, TRIM5, TRIM6, TRIM7, TRIM9, TRIM1, TRIM7, TRIM1, TRIM1, TRIM1, TRIM1, TRIM1, TRIM16, TRIM19 (также упоминаемого в данном документе как "PML" (англ. promyelocyte leukemia protein - белок промиелоцитарного лейкоза)), TRIM20, TRIM21, TRIM24, TRIM25, TRIM27, TRIM28, TRIM29, TRIM32, TRIM34, TRIM39, TRIM43, TRIM44, TRIM45, TRIM46, TRIM49, TRIM50, TRIM52, TRIM58, TRIM59, TRIM65, TRIM67, TRIM69, TRIM70, TRIM74 и TRIM75; и мышиного TRIM30.
В одном из воплощений указанная композиция содержит изолированный пептид, содержащий один или более чем один из TRIM-белков. В одном из воплощений изолированный пептид дополнительно содержит проникающий в клетку пептид (cell penetrating peptide, СРР), чтобы обеспечить проникновение изолированного пептида в клетку. В одном из воплощений СРР содержит домен трансдукции белка tat из ВИЧ (HIV tat).
В одном из воплощений указанная композиция содержит изолированную молекулу нуклеиновой кислоты, кодирующую один или более чем один из TRIM-белков.
В одном из воплощений указанное заболевание или нарушение представляет собой полиQ-нарушение. В одном из воплощений указанное заболевание или нарушение представляет собой нейродегенеративное заболевание или нарушение, выбранное из группы, состоящей из спиноцеребеллярной атаксии (SCA) типа 1 (SCA1), SCA2, SCA3, SCA6, SCA7, SCA17, болезни Хантингтона, дентаторубро-паллидолюисовой атрофии (dentatorubral-pallidoluysian atrophy, DRPLA), болезни Альцгеймера, болезни Паркинсона, бокового амиотрофического склероза (amyotrophic lateral sclerosis, ALS), трансмиссивной губчатой энцефалопатии (прионное заболевание), тауопатии и лобно-височной дегенерации (Frontotemporal lobar degeneration, FTLD). В одном из воплощений данное заболевание или нарушение выбрано из группы, состоящей из AL-амилоидоза, АА-амилоидоза, семейной средиземноморской лихорадки, старческого системного амилоидоза, семейной амилоидотической полинейропатии, амилоидоза, связанного с гемодиализом, ApoAI-амилоидоза, ApoAII-амилоидоза, ApoAIV-амилоидоза, финского наследственного амилоидоза, лизоцимного амилоидоза, фибриногенового амилоидоза, исландской наследственной церебральной амилоидной ангиопатии, диабета II типа, медуллярной карциномы щитовидной железы, предсердного амилоидоза, наследственных кровоизлияний в мозг с амилоидозом, пролактиномы гипофиза, локализованного амилоидоза в месте инъекции, аортального медиального амилоидоза, наследственной решетчатой дистрофии роговицы, амилоидоза роговицы, связанного с трихиазом, катаракты, кальцификации эпителиальной одонтогенной опухоли, легочного альвеолярного протеиноза, миозита с тельцами включения и узелкового амилоидоза кожи. В одном из воплощений данное заболевание или нарушение представляет собой рак, ассоциированный с мутантными агрегатами р53.
В одном из аспектов данное изобретение предусматривает способ лечения или профилактики заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковыми агрегатами, у субъекта, нуждающегося в этом, где указанный способ включает содержит субъекту композиции, содержащей модулятор одного или более чем одного из TRIM-белков. В одном из воплощений указанный модулятор повышает экспрессию или активность одного или более чем одного из TRIM-белков. В одном из воплощений указанный модулятор представляет собой по меньшей мере один, выбранный из группы, состоящей из химического соединения, белка, пептида, пептидомиметика, антитела, рибозима, низкомолекулярного химического соединения, нуклеиновой кислоты, вектора и антисмысловой нуклеиновой кислоты.
В одном из воплощений указанный модулятор повышает экспрессию или активность по меньшей мере одного из человеческих TRIM3, TRIM4, TRIM5, TRIM6, TRIM7, TRIM9, TRIM1, TRIM7, TRIM1, TRIM1, TRIM1, TRIM1, TRIM1, TRIM16, TRIM19 (также упоминаемого в данном документе как "PML"), TRIM20, TRIM21, TRIM24, TRIM25, TRIM27, TRIM28, TRIM29, TRIM32, TRIM34, TRIM39, TRIM43, TRIM44, TRIM45, TRIM46, TRIM49, TRIM50, TRIM52, TRIM58, TRIM59, TRIM65, TRIM67, TRIM69, TRIM70, TRIM74 и TRIM75; и мышиного TRIM30.
В одном из воплощений указанная композиция содержит изолированный пептид, содержащий один или более чем один из TRIM-белков. В одном из воплощений изолированный пептид дополнительно содержит проникающий в клетку пептид (СРР), чтобы обеспечить проникновение изолированного пептида в клетку. В одном из воплощений СРР содержит домен трансдукции tat-белка ВИЧ.
В одном из воплощений указанная композиция содержит изолированную молекулу нуклеиновой кислоты, кодирующую один или более чем один из TRIM-белков.
В одном из воплощений указанное заболевание или нарушение представляет собой полиQ-нарушение. В одном из воплощений указанное заболевание или нарушение представляет собой нейродегенеративное заболевание или нарушение, выбранное из группы, состоящей из спиноцеребеллярной атаксии (SCA) типа 1 (SCA1), SCA2, SCA3, SCA6, SCA7, SCA17, болезни Хантингтона, дентаторубро-паллидолюисовой атрофии (DRPLA), болезни Альцгеймера, болезни Паркинсона, бокового амиотрофического склероза (ALS), трансмиссивной губчатой энцефалопатии (прионное заболевание), тауопатии и лобно-височной дегенерации (FTLD). В одном из воплощений данное заболевание или нарушение выбрано из группы, состоящей из AL-амилоидоза, АА-амилоидоза, семейной средиземноморской лихорадки, старческого системного амилоидоза, семейной амилоидотической полинейропатии, амилоидоза, связанного с гемодиализом, ApoAI-амилоидоза, АроАII-амилоидоза, ApoAIV-амилоидоза, финского наследственного амилоидоза, лизоцимного амилоидоза, фибриногенового амилоидоза, исландской наследственной церебральной амилоидной ангиопатии, диабета II типа, медуллярной карциномы щитовидной железы, предсердного амилоидоза, наследственных кровоизлияний в мозг с амилоидозом, пролактиномы гипофиза, локализованного амилоидоза в месте инъекции, аортального медиального амилоидоза, наследственной решетчатой дистрофии роговицы, амилоидоза роговицы, связанного с трихиазом, катаракты, кальцификации эпителиальной одонтогенной опухоли, легочного альвеолярного протеиноза, миозита с тельцами включения и узелкового амилоидоза кожи. В одном из воплощений данное заболевание или нарушение представляет собой рак, ассоциированный с мутантными агрегатами р53.
В одном из воплощений указанный способ включает введение композиции по меньшей мере в одну нервную клетку субъекта.
В одном из аспектов данное изобретение предусматривает композицию для лечения или профилактики заболевания или нарушения, ассоциированного с деградацией функционального мутантного белка, где указанная композиция содержит модулятор одного или более чем одного из TRIM-белков. В одном из воплощений указанный модулятор повышает экспрессию или активность одного или более чем одного из TRIM-белков. В одном из воплощений указанный модулятор представляет собой по меньшей мере один, выбранный из группы, состоящей из химического соединения, белка, пептида, пептидомиметика, антитела, рибозима, низкомолекулярного химического соединения, нуклеиновой кислоты, вектора и антисмысловой нуклеиновой кислоты. В одном из воплощений указанное заболевание или нарушение представляет собой муковисцидоз.
В одном из аспектов данное изобретение предусматривает способ лечения или профилактики заболевания или нарушения, ассоциированного с деградацией функционального мутантного белка, у субъекта, нуждающегося в этом, где указанный способ включает введение субъекту композиции, содержащей модулятор одного или более чем одного из TRIM-белков. В одном из воплощений указанный модулятор повышает экспрессию или активность одного или более чем одного из TRIM-белков. В одном из воплощений указанный модулятор представляет собой по меньшей мере один, выбранный из группы, состоящей из химического соединения, белка, пептида, пептидомиметика, антитела, рибозима, низкомолекулярного химического соединения, нуклеиновой кислоты, вектора и антисмысловой нуклеиновой кислоты. В одном из воплощений указанное заболевание или нарушение представляет собой муковисцидоз.
В одном из аспектов данное изобретение предусматривает композицию для лечения или профилактики заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковыми агрегатами, где указанная композиция содержит модулятор одной или более чем одной из убиквитиновых лигаз, нацеленных на малый убиквитин-подобный модификатор (SUMO, от англ. Small Ubiquitin-like Modifier) (STUbl, от англ. SUMO-targeted ubiquitin ligase. В одном из воплощений указанный модулятор повышает экспрессию или активность одной или более чем одной из STUbL. В одном из воплощений указанный модулятор представляет собой по меньшей мере один, выбранный из группы, состоящей из химического соединения, белка, пептида, пептидомиметика, антитела, рибозима, низкомолекулярного химического соединения, нуклеиновой кислоты, вектора и антисмысловой нуклеиновой кислоты. В одном из воплощений указанный модулятор повышает экспрессию или активность RNF4.
В одном из аспектов данное изобретение предусматривает способ лечения или профилактики заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковыми агрегатами, у нуждающегося в этом субъекта, где указанный способ включает введение субъекту композиции, содержащей модулятор одной или более чем одной из STUbL. В одном из воплощений указанный модулятор повышает экспрессию или активность одной или более чем одной из STUbL. В одном из воплощений указанный модулятор представляет собой по меньшей мере один, выбранный из группы, состоящей из химического соединения, белка, пептида, пептидомиметика, антитела, рибозима, низкомолекулярного химического соединения, нуклеиновой кислоты, вектора и антисмысловой нуклеиновой кислоты. В одном из воплощений указанный модулятор повышает экспрессию или активность RNF4.
В одном из аспектов данное изобретение предусматривает способ получения рекомбинантного белка, где указанный способ включает введение модулятора одного или более чем одного из TRIM-белков в клетку, модифицированную для экспрессии рекомбинантного белка. В одном из воплощений указанный модулятор содержит изолированный пептид, содержащий один или более чем один из TRIM-белков. В одном из воплощений указанный модулятор содержит изолированную молекулу нуклеиновой кислоты, кодирующую один или более чем один из TRIM-белков.
Краткое описание графических материалов
Следующее далее подробное описание предпочтительных воплощений данного изобретения будет более понятным при прочтении в сочетании с прилагаемыми графическими материалами. В целях иллюстрации данного изобретения на графических материалах показаны воплощения, которые в настоящее время являются предпочтительными. Тем не менее, следует понимать, что данное изобретение не ограничивается точными механизмами и инструментами воплощений, показанными в графических материалах.
На фиг. 1, содержащей фиг. 1A-1L, показаны результаты иллюстративных экспериментов, демонстрирующие, что PML способствует деградации Atxn1 82Q и других ядерных неправильно упакованных белков. (Фиг. 1А). Клетки HeLa, трансфицированные Atxn1 82Q-GFP (GFP, от англ. green fluorescent protein -зеленый флуоресцентный белок), окрашивали антителом против PML (красный) и DAPI (синий). Показаны отдельные и объединенные изображения. Масштабная линейка, 10 мкм. (Фиг. 1В) Atxn1 82Q-GFP экспрессировали отдельно или вместе с PML в клетках HeLa. Слева, репрезентативные флуоресцентные изображения клеток. Масштабная линейка, 20 мкм. Справа, количественная оценка клеток на основе размеров включений Atxn1 82Q-GFP. (Фиг. 1С) Atxn1 82Q-GFP экспрессировали отдельно или вместе с PML в клетках HeLa (слева) или отдельно в клетках HeLa, которые ранее обрабатывали контролем (-) или киРНК (siRNA -короткие интерферирующие РНК) PML. Клеточные фракции лизата (если указано) и тотальные клеточные лизаты (whole-cell lysates, WCL) анализировали с помощью анализа задержки в фильтре (для фракции SR) или вестерн-блоттинга (western blot, WB, для остальных). Показаны стандарты молекулярной массы (в кДа) и отношения SS или SR Atxn1 к актину. (Фиг. 1D) Уровни FLAG-Atxn1 82Q или 30Q в стабильном состоянии при экспрессии отдельно или вместе с PML в клетках HeLa (слева) или при экспрессии отдельно в клетках HeLa, которые были обработаны контролем или киРНК PML (справа), проанализированные с помощью WB. (Фиг. 1Е) Влияние PML на стабильность общего белка FLAG-Atxn1 82Q, проанализированную с помощью анализа вытеснения метки и авторадиографии. Показаны относительные количества 35S-меченного Atxn1 82Q. (Фиг. 1F и фиг. 1G) Влияние сверхэкспрессии (фиг. 1F) и нокдауна (фиг. 1G) PML на стабильность Atxn1 82Q-GFP, проанализированную путем обработки циклогексимидом (СНХ) и WB. (Фиг. 1Н) Влияние PML на уровни Atxn1 82Q-GFP в отсутствие или в присутствии MG132. (Фиг. 11) Наверху, относительный процент клеток, экспрессирующих Httex1p 97QP, с цитоплазматическими (слева) и ядерными (справа) включениями, в отсутствие или в присутствии PML (среднее плюс среднеквадратическое отклонение (СО), n равен 3). Внизу, репрезентативные флуоресцентные изображения трансфицированных клеток, иммуноокрашенных антителом против Htt. Стрелки указывают на агрегаты Httex1p 97QP. (Фиг. 1J и фиг. 1К) Уровни HA-Httex1p 97QP и HA-Httex1p 97QP(KR) (фиг. 1J) и GFP-TDP-43 (фиг. 1К) в клетках со сверхэкспрессией PML и без нее. Практически все агрегаты Htt находились во фракции SR. (Фиг. 1L) Стабильность nFucDM-GFP в контрольных и PML-истощенных клетках, проанализированная путем обработки СНХ и WB.
На фиг. 2, содержащей фиг. 2А-2Е, показаны результаты иллюстративных экспериментов, демонстрирующие распознавание неправильно упакованных белков с помощью PML. (Фиг. 2А) Связывание GST-Htt 25Q и GST-Htt 103Q с иммобилизованным FLAG-PML и FLAG-GFP (отрицательный контроль), проанализированное с помощью in vitro анализа соосаждения с последующим WB (наверху и внизу) и окрашиванием Понсо (Ponceau) S (посередине). *IgG тяжелая цепь. (Фиг. 2В) Связывание GST-PML (показано справа) и контрольного GST-белка (глутатион-S-трансфераза) с нативной (N) и денатурированной мочевиной (D) люциферазой (luc), иммобилизованной на Ni-NTA-гранулах, проанализированное как в фиг. 2А. *Неспецифические белки из бактериальных лизатов BL21, которые связаны с контрольными гранулами. (Фиг. 2С) Связывание указанных GST-Htt-гибридов с FLAG-PML СС, конъюгированными на анти-Flag М2-гранулах, или с контрольными гранулами, проанализированное путем WB (наверху и посередине) и окрашивания Кумасси (внизу). (Фиг. 2D) Связывание PML F12/SRS2 (показано справа) с пептидной библиотекой, полученной из люциферазы. Показана N-концевая аминокислота первого пептида и номер последнего пептида, отмеченного в каждом ряду. (Фиг. 2Е) Появление каждой аминокислоты в PML SRS2-связывающих пептидах относительно ее появления в люциферазной пептидной матрице (принятого за 100%).
На фиг. 3, содержащей фиг. 3A-3F, представлены результаты иллюстративных экспериментов, демонстрирующие, что SUMO2/3 участвует в убиквитинировании и PML-опосредованной деградации Atxn1 82Q. (Фиг. 3А) SUMO1- и SUMO2/3-модификации Atxn1 82Q в клетках HeLa, обработанных или не обработанных MG132. Для лучшего сравнения модифицированного Atxn1 82Q продукты денатурирующей иммунопреципитации (denaturing immunoprecipitation, d-IP) с аналогичным уровнем немодифицированного Atxn1 82Q анализировали путем WB. *Неспецифические полосы. (Фиг. 3В) Локализация Atxn1 82Q (обнаруженная с помощью анти-FLAG-антитела, красный) в GFP-SUMO2- или GFP-SUMO3-экспрессирующих клетках U20S, обработанных или не обработанных MG132. Масштабная линейка, 10 мкм. (Фиг. 3С) SUMO2/3-модификация Atxn182Q и 30Q в клетках HeLa, проанализированная с помощью d-IP с последующим WB (наверху) и окрашиванием Понсо S (внизу). (Фиг. 3D) Atxn1 82Q экспрессировали отдельно или вместе с SUMO1 или HA-SUMO2 KR в клетках HeLa, которые ранее были трансфицированы указанной киРНК или оставались нетрансфицированными (-). Клетки обрабатывали или не обрабатывали MG132. Сумоилирование и убиквитинирование FLAG-Atxn1 82Q анализировали с помощью d-IP и WB. (Фиг. 3Е) Уровни Atxn1 82Q-GFP, экспрессированного отдельно или вместе с увеличенными количествами PML в клетках HeLa, предварительно обработанных указанной киРНК. (Фиг. 3F) Влияние PML на уровни Atxn1 82Q-GFP в присутствии или в отсутствие SUMO1 или SUMO2 KR.
На фиг. 4, содержащей фиг. 4A-4F, показаны результаты иллюстративных экспериментов, демонстрирующие, что PML способствует сумоилированию Atxn1 82Q. (Фиг. 4А) Сумоилирование FLAG-Atxn1 82Q в клетках HeLa в отсутствие или присутствии клеток HA-PML без обработки или с обработкой MG132. Количество ДНК Atxn1 82Q, используемое для трансфекции, корректировали для получения сравнимых уровней немодифицированного белка. (Фиг. 4В и фиг. 4С) Сумоилирование FLAG-Atxn1 82Q (фиг. 4В) и FLAG-nFlucDM-GFP (фиг. 4С) в контрольных и трансфицированных киРНК PML клетках HeLa, не обработанных или обработанных MG132. (Фиг. 4D и фиг. 4Е) Сумоилирование очищенного НА-Atxn1 82Q-FLAG проводили в присутствии рекомбинантных FLAG-PML, FLAG-PML М6 и SUMO2, как указано на фиг. 4D. Количество различных d-IP-продуктов регулировали таким образом, чтобы получить аналогичный уровень немодифицированного Atxn1 82Q (посередине). (Фиг. 4F) Уровни Atxn1 82Q-GFP в клетках HeLa в отсутствие или в присутствии увеличивающихся количеств PML или PML М6.
На фиг. 5, содержащей фиг. 5A-5I, показаны результаты иллюстративных экспериментов, демонстрирующие роль RNF4 в деградации Atxn1 82Q. (Фиг. 5А) Уровни Atxn1 82Q-GFP в клетках HeLa без и со сверхэкспрессией RNF4. (Фиг. 5В и фиг. 5С). Влияние сверхэкспрессии RNF4 на стабильность Atxn1 82Q-GFP в контрольных и PML-обедненных клетках HeLa, проанализированную путем обработки СНХ и WB. Соотношения SS Atxn1 82Q/актин показаны на фиг. 5С. (Фиг. 5D) Уровни FLAG-Atxn1 82Q в клетках HeLa, предварительно обработанных контрольной киРНК (-) или комбинацией трех киРНК RNF4. (Фиг. 5Е) Репрезентативные флуоресцентные изображения Atxn1 82Q-GFP в контрольных клетках HeLa и клетках HeLa с нокдауном RNF4. Масштабная линейка, 20 мкм. (Фиг. 5F) Локализация Atxn1 82Q-GFP и эндогенного RNF4 в клетках HeLa, обработанных носителем (диметилсульфоксидом (ДМСО)) или MG132. Масштабная линейка, 10 мкм. (Фиг. 5G и фиг. 5Н) Уровни FLAG-Atxn1 82Q и FLAG-Atxn1 30Q (фиг. 5G) или HA-Httex1p 97QP и HA-Httex1p 97QP(KR) (фиг. 5Н) в клетках HeLa без и со сверхэкспрессией RNF4. (Фиг. 5I) Стабильность nFlucDM-GFP в клетках HeLa, стабильно экспрессирующих негативный контроль - короткие РНК, образующие шпильки (shCtrl) и shRNF4 (слева) и уровни RNF4 в этих клетках (справа).
На фиг. 6, содержащей фиг. 6A-6I, показаны результаты иллюстративных экспериментов, демонстрирующие, что RNF4 способствует убквитинированию и деградации SUMO2/3-модифицированного Atxn1 82Q. (Фиг. 6А и фиг. 6В) Уровни сумоилированного FLAG-Atxn1 82Q (фиг. 6А) и FLAG-nFlucDM-GFP (фиг. 6В) в отсутствие или в присутствии RNF4 в клетках HeLa, обработанных или не обработанных MG132. Были проанализированы продукты d-IP с аналогичными уровнями немодифицированных белков, а также WCL. (Фиг. 6С) Уровни сумоилированного FLAG-Atxn1 82Q в клетках HeLa, которые были предварительно обработаны контрольной киРНК или комбинацией киРНК RNF4, проанализированные, как описано в фиг. 6А. (Фиг. 6D и фиг. 6Е) Немодифицированные и SUMO2-модифицированные белки FLAG-Atxn1 82Q, конъюгированные на М2-гранулах (+), или контрольные М2-гранулы (-) инкубировали со смесью для реакции убиквитинирования в отсутствие или в присутствии GST-RNF4. (Фиг. 6D) Схематическая диаграмма экспериментальной разработки. (Фиг. 6Е) WB-анализ FLAG-Atxn1 82Q (слева) и GST-RNF4 (справа). (Фиг. 6F и фиг. 6G) Локализация белков Atxn1 82Q-GFP и RNF4 (обнаруженных с помощью анти-FLAG-антитела) в HeLa. Масштабная линейка, 10 мкм. (Фиг. 6Н) Влияние указанных белков RNF4 на уровни Atxn1 82Q-GFP в клетках HeLa. (Фиг. 6I) Влияние сверхэкспрессии PML на уровни Atxn1 82Q-GFP в клетках HeLa, которые были предварительно обработаны контрольной киРНК или киРНК RNAF4.
На фиг. 7, содержащей фиг. 7A-7I, показаны результаты иллюстративных экспериментов, демонстрирующие, что дефицит PML усугубляет поведенческие и патологические фенотипы мышиной модели SCA1. (Фиг. 7А и фиг. 7В) Время удерживания (среднее значение плюс стандартная ошибка среднего (СОС)) в анализе на Rotarod с ускорением в возрасте 7 (фиг. 7А) и 11 (фиг. 7В) недель с указанием числа животных в скобках. (Фиг. 7С и фиг. 7D) Срезы мозжечка животных в возрасте 12 недель окрашивали гематоксилином. (Фиг. 7С) Количественная оценка толщины молекулярного слоя (среднее значение плюс/минус СОС, n равен 3 мыши/генотип). (Фиг. 7D) Репрезентативные изображения окрашивания. Масштабная линейка, 200 мкм. (Фиг. 7Е и фиг. 7F) Срезы мозжечка животных в возрасте 1 года окрашивали с помощью антитела против кальбиндина. (Е) Количественная оценка клеток Пуркинье, обозначенная как среднее число сом на 1 мм длины (среднее значение плюс/минус СОС, n равен 4 мыши/генотип). (F) Репрезентативные изображения окрашивания. Масштабная линейка, 200 мкм. (Фиг. 7G и фиг. 7Н) Срезы коры мозжечка мышей в возрасте 12-недель окрашивали антителом против убиквитина и контрастировали гематоксилином. (Фиг. 7G) Процент клеток Пуркинье с агрегатами (среднее значение плюс/минус СОС, n равен 3 мыши/генотип). (Фиг. 7Н) Репрезентативные изображения, полученные при окрашивании иммуногистохимическим способом. Стрелки указывают на положительные по убиквитину агрегаты в тельцах клеток Пуркинье. Масштабная линейка, 50 мкм. У мышей без Atxn1tg/- в клетках Пуркинье не наблюдалось никаких убиквитин-положительных агрегатов (см. фиг. 14D). (Фиг. 7I) Модель для PQC, полученная с помощью системы PML-RNF4. PML распознает неправильно упакованные белки через SRS и конъюгирует их с поли-SUMO2/3-цепью за счет его SUMO Е3-лигазной активности (a). RNF4 убиквитинирует сумоилированные неправильно упакованные белки (b) и нацеливает их на протеасомальную деградацию (с).
На фиг. 8, содержащей фиг. 8A-8G, показаны результаты иллюстративных экспериментов, демонстрирующие, что PML колокализуется с агрегатами Atxn1 82Q и уменьшает нерастворимый Atxn1 82Q. (Фиг. 8А) Atxn1 82Q-GFP экспрессировали в PML-дефицитных (PML-/-) мышиных эмбриональных фибробластах (mouse embryonic fibroblasts, MEF) вместе с каждой из указанных изоформ PML. Клетки окрашивали анти-PML-антителом (красный) и DAPI (синий). (Фиг. 8В) Уровни FLAG-Atxn1 82Q в клетках HeLa, обработанных контрольной киРНК (-), киРНК PML №4 или киРНК PML №9. Клеточные лизаты анализировали с помощью анализа вестерн-блоттинга и анализа задержки в фильтре. Показаны соотношения Atxn1 82Q во фракции SS и актина, нормированные по контролю. (Фиг. 8С) Клетки HeLa трансфицировали контрольной киРНК, киРНК PML №4 (которая нацелена на 5'UTR мРНК PML) или киРНК PML №4 с плазмидой, экспрессирующей открытую рамку считывания PML (следовательно, устойчивой к киРНК). Были проанализированы уровни Atxn1 82Q-GFP в различных фракциях. (Фиг. 8D) Клетки HeLa обрабатывали контрольной киРНК, киРНК PML №4 или киРНК PML №9, а затем трансфицировали FLAG-Atxn1 82Q. Уровни транскрипта FLAG-Atxn1 82Q определяли с помощью количественной RT-PCR, нормированной по уровням рРНК 18S. (Фиг. 8Е) Atxn1 30Q-GFP экспрессировали в клетках HeLa в отсутствие или в присутствии PML. Затем клетки обрабатывали СНХ в указанные моменты времени. (Фиг. 8F) Клетки HeLa трансфицировали nFlucDM-GFP и соответствующим белком люциферазой дикого типа (wild-type, WT). Эндогенный PML обнаруживали с помощью антитела против PML (красный), а ДНК с помощью DAPI (синий). Масштабная линейка: 10 мкм. (Фиг. 8G) Нокдаун PML приводит к накоплению нерастворимой мутантной люциферазы. Клетки HeLa трансфицировали контрольной киРНК или киРНК PML, а затем nFluc-GFP или nFlucDM-GFP. Фракция SR содержала очень небольшие количества nFlucDM-GFP.
На фиг. 9, содержащей фиг. 9А-9Е, показаны результаты иллюстративных экспериментов, демонстрирующие взаимодействие PML с патогенными белками Htt. (Фиг. 9А) PML предпочтительно взаимодействует с патогенным Htt. Лизаты клеток 293Т, экспрессирующих FLAG-GFP или FLAG-PML, инкубировали с GST-Htt 25Q или GST-Htt 103Q, иммобилизованным на глутатионовых гранулах (дорожки 1-3 и 5-7), или с контрольными глутатионовыми гранулами (дорожки 4 и 8). Входящую и соосажденную фракции анализировали с помощью вестерн-блоттинга. (Фиг. 9В) Схематическое представление изоформ IV PML дикого типа (аминокислоты 1-633) (называемого PML в данном документе) и различных делеционных фрагментов (F1-F10). Обозначены RING-домен (R), В1-мотив, В2-мотив и область суперспирали (coiled-coil region, СС). Сайты распознавания субстрата SRS1 и SRS2 обозначены линиями. Показано взаимодействие PML с патогенными белками Htt (Htt 103Q или 52Q) и денатурированной люциферазой. ND: не определено. (Фиг. 9С) Взаимодействие полноразмерных PML и делетированных мутантов PML с Htt. PML-белки получали путем связывания транскрипции/трансляции in vitro в присутствии [35S]Met и инкубировали с очищенными GST-Htt 103Q, GST-Htt 25Q или GST, иммобилизованными на глутатионовых гранулах. [35S]Met-меченные белки во входящих и соосажденных образцах анализировали с помощью авторадиографии, а GST-белки в выпадающих в осадок образцах анализировали окрашиванием Кумасси. Серию из трех соосажденных образцов анализировали одновременно и одинаковым образом, включая количество образцов и продолжительность экспозиции при авторадиографии. Входящие образцы экспонировали в течение более короткого периода времени. (Фиг. 9D) Последовательности Htt 52Q и СС-дестабилизированного (сс-) мутанта. Аминокислоты в Htt 52Q, которые были изменены на Pro в Htt 52Q сс-, показаны красным цветом. (Фиг. 9Е) Взаимодействие СС-области очищенного PML (показанной справа) с пептидами люциферазы, связанными с целлюлозой, анализировали, как показано на фиг. 2D. *TEV-протеаза.
На фиг. 10, содержащей фиг. 10А-10С, показаны результаты иллюстративных экспериментов, демонстрирующие взаимодействие PML с денатурированной люциферазой. (Фиг. 10А) Взаимодействие фрагментов PML с денатурированной люциферазой. In vitro транслированные [35S]-меченные полноразмерные FLAG-PML и делегированные мутанты FLAG-PML инкубировали с нативной или денатурированной люциферазой, иммобилизованной на гранулах, или с контрольными гранулами. Входящие и связавшиеся с гранулами белки PML анализировали с помощью авторадиографии, а люциферазу с помощью окрашивания Кумасси синим. * Неспецифические полосы. Серию из трех соосажденных образцов анализировали одновременно и одинаковым образом, включая количество образцов и продолжительность экспозиции при авторадиографии. Входящие образцы экспонировали в течение более короткого периода времени. (Фиг. 10В и Фиг. 10С) Идентификация второго сайта распознавания субстрата (SRS2) на PML. (Фиг. 10В) Делеционные мутации PML, охватывающие аминокислоты на С-конце, и краткое изложение их взаимодействия с денатурированной люциферазой. (Фиг. 10С) In vitro транслированные [35S]-меченные GST-гибриды фрагментов PML или GST анализировали на предмет взаимодействия с люциферазой, как описано в фиг. 10А.
На фиг. 11, содержащей фиг. 11A-11G, показаны результаты иллюстративных экспериментов, демонстрирующие модификацию неправильно упакованных белков с помощью SUMO2/3. (Фиг. 11А) Клетки HeLa трансфицировали FLAG-Atxn1 82Q или FLAG-Atxn1 82Q (5KR) и обрабатывали MG132 или не обрабатывали. FLAG-Atxn1 82Q и FLAG-Atxn1 82Q (5KR) выделяли путем d-IP, и их SUMO2/3-модификацию анализировали с помощью вестерн-блоттинга. (Фиг. 11В) Клетки HeLa трансфицировали GFP-TDP-43 или не трансфицировали и обрабатывали носителем (ДМСО) (-) или MG132 (+). d-IP проводили с использованием антитела против GFP или контрольного антитела. Продукты d-IP анализировали с помощью вестерн-блоттинга. (Фиг. 11С) Клетки HeLa трансфицировали nFluc-GFP, nFlucSM-GFP и nFlucSM-GFP (каждый из них был также мечен с N-конца эпитопом FLAG) и обрабатывали MG132 или не обрабатывали. Белки nFluc выделяли путем d-IP. Тотальные клеточные лизаты (WCL) и продукты IP анализировали с помощью вестерн-блоттинга. Следует отметить, что разница между SUMO2/3-модификациями люциферазы WT по сравнению с люциферазой SM/DM (наверху, дорожки 1-3) обусловлена не изменением общего конъюгата SUMO2/3 в WCL (внизу). (Фиг. 11D) Atxn1 82Q-GFP экспрессировали в клетках HeLa, предварительно обработанных контрольной киРНК (Ctrl), SUMO2/3 киРНК или SUMO1 киРНК. Клеточные лизаты анализировали путем вестерн-блоттинга. (Фиг. 11Е и фиг. 11F). Клетки HeLa обрабатывали контрольной (Ctrl) киРНК, SUMO2/3 киРНК или SUMO1 киРНК (фиг. 11Е) или обрабатывали этими киРНК, а затем трансфицировали GFP (фиг. 11F). Клеточные лизаты анализировали путем вестерн-блоттинга. (Фиг. 11G) Белки PML и PML М6, используемые для анализа in vitro сумоилирования. FLAG-PML и FLAG-PML М6 экспрессировали в клетках 293Т и очищали на гранулах с антителами против FLAG (М2). Белки анализировали путем окрашивания Кумасси наряду со стандартами BSA (слева) и вестерн-блоттингом (справа). Две дополнительные полосы (стрелки), представленные на дорожках PML и PML М6 (слева), были определены как фрагменты PML на основании как вестерн-блоттинга (справа), так и масс-спектрометрического анализа. Схематическое изображение мутанта М6 показано внизу. *: Точечные мутации описаны в другом месте.
На фиг. 12, содержащей фиг. 12A-12I, показаны результаты иллюстративных экспериментов, демонстрирующие, что RNF4 способствует деградации неправильно упакованных белков. (Фиг. 12А) Репрезентативные флуоресцентные изображения клеток HeLa, экспрессирующих Atxn1 82Q-GFP отдельно или вместе с RNF4. Масштабная линейка: 20 мкм. Изображения взяты из того же эксперимента, что и на фиг. 1В. (Фиг. 12В) Период полужизни Atxn1 82Q-GFP в клетках HeLa со сверхэкспрессией RNF4 и без нее. Образцы взяты из тех же экспериментов, что и на фиг. 1F. (Фиг. 12С) Клетки HeLa трансфицировали контрольной киРНК (-), только киРНК RnF4 или киРНК RNAF с RNF4, устойчивым к киРНК. Клеточные лизаты анализировали с помощью вестерн-блоттинга. (Фиг. 12D) FLAG-Atxn1 82Q экспрессировали в клетках HeLa, которые предварительно обрабатывали контрольной киРНК и указанной киРНК RNF4. FLAG-Atxn1 82Q выделяли путем d-IP с анти-FLAG М2-гранулами. Продукты WCL и IP анализировали путем вестерн-блоттинга с помощью указанных антител. (Фиг. 12Е) Клетки HeLa, экспрессирующие как Atxn1 82Q-GFP, так и FLAG-RNF4, обрабатывали носителем (ДМСО) или MG132. Экзогенный (Exo.) RNF4 обнаруживали с помощью анти-FLAG-антител. В контрольных клетках, обработанных ДМСО, экзогенный RNF4 показал частичную колокализацию с агрегатами Atxn1 82Q-GFP. При обработке MG132 полная колокализация экзогенного RNF4 с агрегатами Atxn1 82Q наблюдалась в 100% клеток. Масштабная линейка: 10 мкм. (Фиг. 12F) Анализ путем вестерн-блоттинг клеток HeLa, трансфицированных только GFP-TDP-43 или GFP-TDP-43 вместе с повышающимися количествами RNF4. (Фиг. 12G) GFP-TDP-43 экспрессировали в клетках, предварительно обработанных контрольной киРНК (-) или указанной киРНК RNF4. В каждом эксперименте оценивали 500 клеток. Показаны процентные доли клеток с очагами GFP-TDP-43. (Фиг. 12Н) Клетки HeLa, обработанные киРНК RNF4, трансфицировали GFP-TDP-43. Клетки окрашивали с помощью анти-RNF4-антитела (красный) и DAPI (синий). Следует отметить, что TDP-43 формировал агрегаты в клетке, в которой RNF4 был подвергнут докдану (заштрихованная стрелка), но был диффузным в контрольной клетке (незаштрихованная стрелка). (Фиг. 12I) Клетки HeLa трансфицировали GFP-TDP-43 и обрабатывали MG132. Эндогенный RNF4 подвергали иммунному окрашиванию антителом против RNF4 (красный). Следует отметить, что RNF4 также формировал ядерные очаги в клетках без TDP-43 (фиг. 12Е-12Н).
На фиг. 13, содержащей фиг. 13A-13F, изображены результаты иллюстративных экспериментов, демонстрирующие, что SUMO2/3 участвуют в RNF4-oпocpeдoвaннoй деградации Atxn1 82Q. (Фиг. 13А) Atxn1 82Q-GFP и/или RNF4 экспрессировали в клетках HeLa, предварительно обработанных контрольной киРНК, киРНК SUMO2/3 и киРНК SUMO1. Клеточные лизаты анализировали с помощью вестерн-блоттинга. (Фиг. 13В) Клетки U20S, стабильно экспрессирующие GFP-SUMO2, сначала трансфицировали указанными киРНК RNF4 или контрольной киРНК (-), а затем FLAG-Atxn1 82Q. Показаны проценты трансфицированных клеток с CFP-SUMO2-положительными агрегатами Atxn1 82Q (среднее значение плюс СО, n равен 3). В каждом эксперименте оценивали 200 клеток. Справа показаны репрезентативные изображения трансфицированных клеток. GFP-SUMO2 не формирует агрегированную структуру в клетках без экспрессии Atxn1 82Q. (Фиг. 13С) Схематическое представление белков RNF4 дикого типа и мутантов. Показаны мотивы взаимодействия с SUMO (SUMO-interaction motif, SIM) с 1 по 4, а также RING-домен. *: Точечные мутации описаны в другом месте. (Фиг. 13D и фиг. 13Е) Очищенные рекомбинантные GST-гибриды крысиного (г) RNF4 и RNF4 CS1 (фиг. 13D) или человеческого RNF4 и RNF4 SIMm (фиг. 13Е) инкубировали с убиквитином Е1, Е2 (UbcH5a) и убиквитином (Ub), как было указано, плюс Mg2+-АТР. Реакционные смеси анализировали путем вестерн-блоттинга с использованием антитела против GST. (Фиг. 13F) Экспрессия Atxn1 82Q-GFP в клетках, обработанных указанными комбинациями контрольных киРНК, киРНК PML и киРНК RNF4, как было указано. Клеточные лизаты анализировали путем вестерн-блоттинга.
На фиг. 14, содержащей фиг. 14A-14D, показаны результаты экспериментов, демонстрирующие, что дефицит PML уменьшает арборизацию дендритов клеток Пуркинье, но не приводит к формированию агрегатов в клетках Пуркинье. (Фиг. 14А) Срединно-сагиттальные срезы мозжечка 12-недельных мышей окрашивали антителом против белка кальбиндина, специфического для клеток Пуркинье. Интенсивность флуоресценции строили из прямоугольной области в предвершинной щели (n равен 2 мыши для PML+/+, и n равен 3 мыши для всех других генотипов). Мыши PML-/- демонстрировали значительную потерю дендритной арборизации по сравнению с мышами PML+/+(ANOVA, р равен 0,031). (Фиг. 14В) Репрезентативные конфокальные изображения иммунофлуоресценции кальбиндина. Масштабная линейка: 100 мкм. (Фиг. 14С) Количественная оценка плотности клеток Пуркинье у 12-недельных мышей PML+/+, PML+/- и PML-/- с и без Atxn1tg/-, построенная как среднее число сом на 1 мм длины (среднее значение плюс СОС, n равен 3 мыши/генотип). (Фиг. 14D) Иммуногистохимическое окрашивание участков коры мозжечка от 12-недельных мышей PML+/+ и PML-/- без Atxn1tg/-. Срезы окрашивали антителом против убиквитина и контрастировали гематоксилином. Масштабная линейка: 50 мкм. Следует отметить, что в этих срезах не было обнаружено агрегатов, положительных по убиквитину. Окрашенные срезы от мышей PML+/+:Atxn1tg/- и PML-/-:Atxn1tg/- показаны на фиг. 7G.
На фиг. 15, содержащей фиг. 15A-15D, показаны результаты иллюстративных экспериментов, демонстрирующие колокализацию TRIM27, TRIM32 и TRIM56 с EGFP-Atxn1 82Q и Httex1p 97QP. (Фиг. 15А) Atxn1 82Q-GFP экспрессировали в клетках HeLa вместе с указанными FLAG-меченными TRIM-белками. Клетки окрашивали анти-FLAG-антителом (красный) и DAPI (синий). Масштабная линейка: 10 мкм. (Фиг. 15В и фиг. 15С). Httex1p 97QP экспрессировали в клетках HeLa вместе с FLAG-меченными TRIM5δ, TRIM27 (фиг. 15В) и TRIM32 (фиг. 15С). Клетки подвергали иммунному окрашиванию антителами против хантингтина (зеленый) и FLAG (красный). Следует отметить, что TRIM32 колокализовался с Httex1p 97QP независимо от клеточной локализации Httex1p 97QP. (Фиг. 15D) Клетки HeLa трансфицировали с помощью Atxn1 82Q-GFP. Эндогенный TRIM27 обнаруживали с помощью aнти-TRIM27-aнтитeлa (красный). Стрелки указывают на эндогенные тельца TRIM27, которые были колокализованы с агрегатами Atxn1 82Q. Масштабная линейка: 10 мкм.
На фиг. 16, содержащей фиг. 16A-16D, показаны результаты иллюстративных экспериментов, демонстрирующие уменьшение агрегированного Atxn1 82Q под влиянием TRIM27, TRIM32 и TRIM5δ. (Фиг. 16А и фиг. 16В) Уровни Atxn1 82Q-GFP при экспрессии отдельно (-) или вместе с указанными FLAG-меченными белками TRIM в клетках HeLa. Лизаты клеток анализировали путем вестерн-блоттинга. На левой панели фиг. 16А приведены отношения Atxn1 82Q в SS-фракции к актину, и экспрессия TRIM11 может быть обнаружена после продолжительной экспозиции. (Фиг. 16С) Уровни экспрессии Atxn1 82Q в клетках HeLa, обработанных контрольной киРНК (-) или киРНК TRIM27. * Неспецифическая полоса. (Фиг. 16D) PIASy не ингибирует уровни белка Atxn1 82Q. Анализ путем вестерн-блоттинга клеток HeLa, трансфицированных Atxn1 82Q-GFP, PIASy и PML, как было указано.
На фиг. 17, содержащей фиг. 17А-17С, показаны результаты иллюстративных экспериментов, демонстрирующие, что TRIM27 и TRIM32 уменьшают агрегированный Atxn1 82Q независимо от PML. (Фиг. 17А) Частичная колокализация TRIM27 с PML. Клетки HeLa, трансфицированные FLAG-TRIM27, подвергали иммунному окрашиванию антителами против FLAG (зеленый) и против PML (красный). (Фиг. 17В). Колокализация TRIM27 с агрегатами Atxn1 82Q-GFP в PML+/+ и PML-/- MEF. FLAG-TRIM 27 окрашивали антителом против FLAG (красный). (Фиг. 17С) Atxn1 82Q-GFP экспрессировали отдельно или вместе с указанными белками TRIM в PML+/+ и PML-/-' MEF. Экстракты анализировали путем анализа задержки в фильтре. Для лучшего сравнения влияния TRIM-белков на агрегаты на правой панели приведено изображение с меньшей экспозицией.
На фиг. 18, содержащей фиг. 18A-18G, показаны результаты иллюстративных экспериментов, демонстрирующие, что TRIM-белки зависят от SUMO2/3 и протеасомы при удалении нерастворимого Atxn1 82Q. (Фиг. 18A-18F) Atxn1 82Q-GFP экспрессировали отдельно или вместе с TRIM5δ, TRIM27 и TRIM32 в клетках, обработанных или не обработанных MG132 (фиг. 18А-18С), или в контрольных клетках или клетках с нокдауном SUMO2/3 (фиг. 18D-18F). Клеточные лизаты анализировали путем вестерн-блоттинга. (Фиг. 18G) Сумоилирование очищенного HA-Atxn1 82Q-FLAG проводили в присутствии рекомбинантных FLAG-TRIM11 и SUMO2, как было указано. HA-Atxn1 82Q-FLAG выделяли с использованием денатурирующей иммунопреципитации. Реакционные смеси и образцы IP анализировали путем вестерн-блоттинга.
На фиг. 19, содержащей фиг. 19A-19F, показаны результаты иллюстративных экспериментов, демонстрирующие локализацию TRIM-белков относительно Atxn1 82Q. Atxn1 82Q-GFP (зеленый) экспрессировали в клетках HeLa вместе с указанными НА-меченными TRIM-белками. Клетки подвергали иммунному окрашиванию антителом против НА (красный). Показаны репрезентативные паттерны локализации для каждого TRIM-белка. (Фиг. 19А) Репрезентативные паттерны локализации TRIM1 - TRIM 16. (Фиг. 19В) Репрезентативные паттерны локализации TRIM17 - TRIM32. (Фиг. 19С) Репрезентативные паттерны локализации TRIM33 - TRIM41 и TRIM44 - TRIM 41. (Фиг. 19D) Репрезентативные паттерны локализации TRIM52, TRIM54-TRIM58, TRIM62-TRIM66, TRIM73-TRIM74 и TRIM76. TRIM-белки, которые продемонстрировали колокализацию с Atxn1 82Q-GFP в значительном количестве клеток, обозначены желтым цветом. Масштабная линейка: 10 мкм.
На фиг. 20, содержащей фиг. 20А и фиг. 20В, представлены результаты систематического анализа TRIM-белков на Atxn1 82Q и Httex1p 97QP. Atxn1 82Q-GFP (фиг. 20А) или Httex1p 97QP (фиг. 20В) коэкспрессировали с указанными белками TRIM в клетках HeLa. Клеточные лизаты анализировали путем вестерн-блоттинга. TRIM-белки, обозначенные красным и зеленым, представляют собой те белки, которые снижали и повышали уровни полиQ-белков, соответственно, тогда как TRIM-белки, меченные черным, не имели наблюдаемого эффекта. Следует отметить, что на эффекты TRIM-белков могут влиять их уровни экспрессии, как описано в другом месте.
На фиг. 21, содержащей фиг. 21А-21С, изображены результаты иллюстративных экспериментов, демонстрирующие, что рекомбинантный ТАТ-TRIM11 снижает уровни неправильно упакованных белков. Клетки HeLa трансфицировали Atxn1 82Q-GFP, Atxn1 30Q или Htt 97Q-GFP и затем инкубировали с рекомбинантными белками TRIM11 или SUMO2. (Фиг. 21А) Обработка клеток HeLa с помощью TRIM11 приводила к значительному снижению уровней Atxn1 82Q. (Фиг. 21В) Обработка клеток HeLa с помощью TRIM11 также приводила к значительному снижению уровней Htt 97Q. (Фиг. 21С) SUMO2 оказывал минимальное влияние на уровни Atxn1 82Q.
На фиг. 22 показана аминокислотная последовательность Tat-TRIM11, используемая в иллюстративных экспериментах.
На фиг. 23, содержащей фиг. 23A-23F, показаны результаты экспериментов, демонстрирующие окрашивание RNF4 в образцах человеческого мозга. Иммунное окрашивание тканей мозга пациентов с HD анти-RNF4-антителом (зеленый). RNF4 продемонстрировал диффузную ядерную локализацию (фиг. 23А-23С) или сформированные очаги (фиг. 23D-23F) (обозначенные стрелками). Масштабная линейка: 10 мкм.
На фиг. 24, содержащей фиг. 24А-24Н, показаны результаты экспериментов, демонстрирующие колокализацию RNF4 с нейрональными включениями у пациентов SCA1. Иммуноокрашивание тканей мозга SCA1 антителами против полиQ (1С2) и против RNF4. Масштабная линейка: 10 мкм.
На фиг. 25, содержащей фиг. 25A-25L, показаны результаты экспериментов, демонстрирующие колокализацию RNF4 с нейрональными включениями у пациентов с SCA1. На фиг. 25 показано иммунное окрашивание тканей мозга от пациентов с болезнью Хантингтона (HD) антителами против Htt, против убиквитина и двумя отдельными антителами против RNF4. Необходимо отметить, что Htt и убиквитин формируют кольцеобразные структуры (фиг. 25А-25Н) или равномерно распределенные включения (фиг. 25I-25L) с сигналом RNF4 в центре.
На фиг. 26, содержащей фиг. 26А-26Н, показаны результаты экспериментов, демонстрирующие колокализацию RNF4 с включениями в нейронах пациентов с HD. Показано иммунное Htt- и RNF4-окрашивание тканей головного мозга от пациентов с HD. Использовали два разных антитела RNF4 (№1 и №2). Масштабная линейка: 10 мкм.
На фиг. 27, содержащей фиг. 27A-27D, показаны результаты экспериментов, демонстрирующие сумоилирование Atxn1 82Q, р53 и альфа-синуклеина. На фиг. 27А показаны эксперименты, в которых сумоилирование Atxn1 82Q анализировали при коэкспрессии TRIM11 WT, TRIM11 MUT или PML. Перед лизисом добавляли 10 мкМ MG132 на 4 часа. На фиг. 27В показано in vitro сумоилирование очищенного Atxn1 82Q, инкубированного cTRIMH WT или TRIM11 MUT в присутствии Е1, Е2 и SUMO2. На фиг. 27С изображено in vitro сумоилирование очищенного Flag-p53, инкубированного с TRIM11 или PML в присутствии Е1, Е2 и SUMO2. На фиг. 27D показано in vitro сумоилирование альфа-синуклеина, инкубированного с TRIM11 WT в присутствии или в отсутствие Е1, Е2 и SUMO2.
На фиг. 28, содержащей фиг. 28A-28G, показаны результаты экспериментов, демонстрирующие, что TRIM11 привлекается в агрегаты Atxn1 82Q. На фиг. 28А показан иммунофлуоресцентный анализ клеток 293Т, трансфицированных GFP-Hsp70. На фиг. 28В показан иммунофлуоресцентный анализ трансфицированного GFP-TRIM11 в клетках 293Т. На фиг. 28С показан иммунофлуоресцентный анализ, показывающий, что Hsp70 может быть привлечен в агрегаты Atxn1 82Q. На фиг. 28D показан иммунофлуоресцентный анализ, демонстрирующий, что TRIM11 может быть привлечен в агрегаты Atxn1 82Q. На фиг. 28Е показан иммуноблоттинг-анализ растворимых и нерастворимых в детергенте фракций клеток, трансфицированных Atxn1 82Q, TRIM11 или Hsp70. Там, где указано, добавляют 10 мкМ MG132 на 3 часа. На фиг. 28F показан иммуноблоттинг-анализ растворимых и нерастворимых в детергенте фракций клеток, трансфицированных Atxn1 82Q, TRIM11 WT (дикого типа) или TRIM11 MUT (мутация). Там, где указано, добавляют 10 мкМ MG132 на 3 часа. На фиг. 28G изображен иммуноблоттинг-анализ, в котором клетки НСТ116 трансфицированы указанными плазмидами. Через 48 часов клетки лизировали и затем окрашивали 20 мкМ тиофлавином-Т (thioflavin-T, ThT).
На фиг. 29, содержащей фиг. 29А-29С, показаны результаты экспериментов, демонстрирующие связывание TRIM11 с Atxn1 82Q. На фиг. 29А показаны эксперименты, в которых очищенные Flag-Atxn1 82Q, иммобилизованный на гранулах, инкубировали с GST или GST-TRIM11. На фиг. 29В показаны эксперименты, в которых очищенный Flag-Atxn1 82Q или Flag-Atxn1 30Q, иммобилизованный на гранулах, инкубировали с GST или GST-TRIM11. На фиг. 29С показано связывание GST-TRIM11 и GST-белка с нативной (N) и денатурированной мочевиной (D) люциферазой (luciferase, luc), иммобилизованной на Ni-NTA-гранулах.
На фиг. 30, содержащий фиг. 30A-30D, показаны результаты экспериментов, демонстрирующие, что TRIM11 уменьшает клеточные агрегаты. На фиг. 30А показаны эксперименты, в которых клетки НСТ116, стабильно экспрессирующие GFP-Atxn1 82Q, лизировали и затем окрашивали 20 мкМ тиофлавином-Т (ТрТ). На фиг. 30В показан седиментационный анализ клеток GFP-Atxn1 82Q-HCT116, трансфицированных TRIM11. На фиг. 30С показаны эксперименты, в которых клетки НСТ116, стабильно экспрессирующие GFP-Atxn1 82Q, трансфицировали TRIM11 WT или TRIM11 MUT. Через 48 часов клетки лизировали и окрашивали 20 мкМ ThT. На фиг. 30D показан седиментационный анализ клеток GFP-Atxn1 82Q-НСТ116, трансфицированных TRIM11 WT или TRIM11 MUT.
На фиг. 31, содержащей фиг. 31А-31Н, показаны результаты экспериментов, демонстрирующие, что TRIM11 действует как молекулярный шаперон для предотвращения формирования агрегатов. На фиг. 31А показаны эксперименты, в которых люциферазу (10 нМ) инкубировали с 200 нМ GST, 200 нМ GST-TRIM11 или 200 нМ Hsp70 при 45°С в течение указанного времени. Нативную активность люциферазы принимали за 100%. N равен 3. На фиг. 31В показаны эксперименты, в которых GFP (0,45 мкМ) инкубировали с 200 нМ GST, 200 нМ GST-TRIM11 или 200 нМ Hsp70 при 45°С в течение указанного времени. Нативную флуоресценцию GFP принимали за 100%. N равен 3. На фиг. 31С показана активность трансфицированной люциферазы в НСТ116, измеренная без теплового шока в качестве контроля. После 30-минутного теплового шока при 45°С или после 3-часового восстановления в инкубаторе активность люциферазы оценивали относительно контроля. На фиг. 31D показана активность трансфицированной люциферазы в НСТ116, измеренная без теплового шока в качестве контроля. После 60-минутного теплового шока при 45°С или после 1,5-часового или 3-часового восстановления в инкубаторе активность люциферазы оценивали относительно контроля. На фиг. 31Е показан иммуноблоттинг-анализ клеток НСТ116, стабильно экспрессирующих контрольный вектор или Flag-TRIM11. На фиг. 31F показан ThT-анализ, демонстрирующий предотвращение формирования бета-амилоидных фибрилл под влиянием GST, TRIM 11 или Hsp70. На фиг. 31G показан седиментационный анализ, показывающий предотвращение формирования агрегатов Atxn1 82Q под влиянием лизоцима, GST или TRIM11. Результаты были продемонстрированы путем иммуноблоттинга и дот-блоттинга. На фиг. 31Н показан седиментационный анализ, показывающий предотвращение формирования агрегатов р53 под влиянием TRIM11. Там, где указано, применяли Е1, Е2, SUMO2 или АТР. Результаты были продемонстрированы путем иммуноблоттинга и дот-блоттинга.
На фиг. 32, содержащей фиг. 32A-32G, показаны результаты экспериментов, демонстрирующие что HSF1 не требуется для регуляции транскрипции TRIM11. На фиг. 32А показаны эксперименты, в которых клетки НСТ116 подвергали или не подвергали тепловому шоку (42°С) в течение 1 часа, а затем восстанавливали в течение разных периодов времени. Тотальные клеточные лизаты подвергали иммуноблоттингу с указанными антителами. На фиг. 32В показаны эксперименты, в которых клетки НСТ116, стабильно экспрессирующие Flag-TRIM11, подвергали или не подвергали тепловому шоку (42°С) в течение 1 часа и затем восстанавливали в течение разных периодов времени. Тотальные клеточные лизаты подвергали иммуноблоттингу с указанными антителами. На фиг. 32С показаны эксперименты, в которых клетки HeLa подвергали или не подвергали тепловому шоку (42°С) в течение 1 часа, а затем восстанавливали в течение разных периодов времени. Тотальные клеточные лизаты подвергали иммуноблоттингу с указанными антителами. На фиг. 32D показаны эксперименты, в которых клетки А549 обрабатывали или не обрабатывали As203 в течение 30 минут, а затем восстанавливали в течение разных периодов времени. Тотальные клеточные лизаты подвергали иммуноблоттингу с указанными антителами. На фиг. 32Е показаны эксперименты, в которых клетки А549 обрабатывали или не обрабатывали H2O2 в течение 100 минут, а затем восстанавливали в течение разных периодов времени. Тотальные клеточные лизаты подвергали иммуноблоттингу с указанными антителами. На фиг. 32F показан полуколичественный ПЦР-анализ TRIM11, HSP70, HSP90 и GAPDH в ответ на тепловой шок. На фиг. 32G показаны эксперименты, в которых клетки А549, стабильно экспрессирующие вектор или HSF1, подвергали или не подвергали тепловому шоку и восстанавливали в течение 3 часов. Анализировали путем иммуноблоттинга и полуколичественного ПЦР-анализа.
На фиг. 33, содержащей фиг. 33A-33F, показаны результаты экспериментов, демонстрирующие, что р53 является фактором, повышающим экспрессию TRIM11 в ответ на тепловой шок. На фиг. 33А изображен иммуноблоттинг клеток НСТ116 с р53 дикого типа или клеток НСТ116 без р53, подвергнутых тепловому шоку и восстановленных. На фиг. 33В показан кПЦР (дРСР)-анализ уровня мРНК TRIM11 в клетках НСТ116 с р53 дикого типа или клетках НСТ116 без р53, подвергнутых тепловому шоку и восстановленных. На фиг. 33С показан иммуноблоттинг и полуколичественный ПЦР-анализ клеток А549, стабильно экспрессирующих контроль (Ctrl) или кшРНК р53, подвергнутых или не подвергнутых тепловому шоку и восстановленных в течение 3 часов. На фиг. 33D показан иммуноблоттинг и полуколичественный ПЦР-анализ клеток НСТ116, трансфицированных Ctrl или кшРНК р53, подвергнутых или не подвергнутых тепловому шоку и восстановленных в течение 3 часов. На фиг. 33Е изображен анализ с кристаллическим фиолетовым выживших клеток НСТ116, подвергнутых тепловому шоку и восстановленных в течение 24 часов. Там, где указано, добавляли KRIBB11. На фиг. 33F показано относительное число клеток в результатах, представленных на фиг. 33Е, проанализированных при OD490.
На фиг. 34, содержащей фиг. 34A-34G, показаны результаты экспериментов, демонстрирующие, что TRIM11 действует как дезагрегаза для устранения предварительно сформированных агрегатов. На фиг. 34А показана дезагрегация и реактивация предварительно сформированных агрегатов люциферазы с использованием возрастающих концентраций лизоцима, GST или GST-TRIM11 (n равен 3). На фиг. 34В изображен седиментационный анализ, показывающий, что образующиеся при нагревании агрегаты люциферазы разрешаются под влиянием GST или GST-TRIM11. Эти результаты были продемонстрированы путем иммуноблоттинга. На фиг. 34С показана дезагрегация и реактивация предварительно сформированных агрегатов GFP с использованием повышающихся концентраций лизоцима, GST или GST-TRIM11 (n равен 3). На фиг. 34D изображен седиментационный анализ, показывающий, что образующиеся при нагревании агрегаты GFP разрешаются под влиянием GST или GST-TRIM11. Эти результаты были продемонстрированы путем иммуноблоттинга. На фиг. 34Е изображен седиментационный анализ, показывающий, что предварительно сформированные агрегаты Atxn1 82Q разрешаются под влиянием лизоцима, GST или TRIM11. Эти результаты были продемонстрированы путем иммуноблоттинга. На фиг. 34F изображен седиментационный анализ, показывающий, что предварительно сформированные агрегаты Atxn1 82Q (слева) и р53 (справа) дезагрегировались под влиянием 1 мкМ Hsp70 и 0,5 мкМ Hsp40. На фиг. 34G изображен седиментационный анализ, показывающий, что предварительно сформированные агрегаты Atxn1 82Q дезагрегировались под влиянием 0,5 мкМ GST, 0,5 мкМ TRIM11, 1 мкМ Hsp70, 0,5 мкМ Hsp40 или 1 мкМ Hsp104.
На фиг. 35, содержащей фиг. 35A-35D, показаны результаты экспериментов, демонстрирующие, что полноразмерный TRIM 11 необходим для рефолдинговой активности. На фиг. 35А показана схематическая диаграмма структуры TRIM11. На фиг. 35В показана дезагрегация и реактивация предварительно сформированных агрегатов люциферазы с использованием увеличенных концентраций указанных белков (n равен 3). На фиг. 35С изображен седиментационный анализ, показывающий, что образующиеся при нагревании агрегаты люциферазы дезагрегировались под влиянием GST, TRIM11, RBC или В30.2. На фиг. 35D показана дезагрегация и реактивация предварительно сформированных агрегатов люциферазы с использованием указанных белков (n равен 3).
На фиг. 36, содержащей фиг. 36А и фиг. 36В, показаны результаты экспериментов, демонстрирующие, что связывание TRIM11 с субстратами необходимо для дезагрегирующей функции TRIM11. На фиг. 36А изображен очищенный Flag-Atxn1 82Q, иммобилизованный на гранулах, который инкубировали с GST, GST-TRIM11, GST-RBC или GST-B30.2. На фиг. 36В изображен очищенный Flag-Atxn1 82Q, иммобилизованный на гранулах, который инкубировали с GST, GST-TRIM11 или другими фрагментами TRIM11.
На фиг. 37, содержащей фиг. 37А-37Е, показаны результаты экспериментов, демонстрирующие, что TRIM11 выполняет дезагрегацию независимо от его SUMO Е3-лигазной активности. На фиг. 37А показаны эксперименты, в которых люциферазу (10 нМ) инкубировали с 200 нМ GST, 200 нМ GST-TRIM11 WT или MUT при 45°С в течение указанного времени. Активность нативной люциферазы принимали за 100%. N равен 3. На фиг. 37В показана дезагрегация и реактивация предварительно сформированных агрегатов люциферазы под влиянием 200 нМ GST, 200 нМ GST-TRIM11 WT или MUT. На фиг. 37С изображено связывание GST, GST-TRIM11 WT или MUT с нативной (N) и денатурированной мочевиной (D) люциферазой (luc), иммобилизованной на Ni-NTA-гранулах. На фиг. 37D показан иммунофлуоресцентный анализ трансфицированного GFP-TRIM11 MUT в клетках 293Т. На фиг. 37Е изображен анализ иммунофлуоресценции, который показывает, что TRIM11 MUT может быть привлечен в агрегаты Atxn1 82Q.
На фиг. 38, содержащей фиг. 38А-38Е, показаны результаты экспериментов, демонстрирующие, что TRIM11 также может осуществлять формирование амилоидных фибрилл из альфа-синуклеина и дезагрегировать предварительно сформированные альфа-синуклеиновые волокна. На фиг. 38А показан ThT-анализ, демонстрирующий предотвращение формирования альфа-синуклеиновых фибрилл под влиянием GST, TRIM11, Hsp70, Hsp40 или Hsp104. На фиг. 38В показан ThT-анализ, демонстрирующий предотвращение формирования альфа-синуклеиновых фибрилл под влиянием TRIM 11 дозозависимым образом. На фиг. 38С приведены ЕМ-изображения формирования волокон из альфа-синуклеиновых мономеров, инкубированных с GST или GST-TRIM11. На фиг. 38D изображен седиментационный анализ, показывающий, что предварительно сформированное альфа-синуклеиновое волокно дезагрегировалось под влиянием TRIM11 и Hsp104 A503S. На фиг. 38Е показан ThT-анализ, показывающий дезагрегацию предварительно сформированных альфа-синуклеиновых фибрилл под влиянием GST, TRIM 11 или Hsp104.
На фиг. 39, содержащей фиг. 39A-39D, показаны результаты экспериментов, демонстрирующие, что TRIM21 имеет дезагрегирующие функции, аналогичные TRIM11. На фиг. 39А показано связывание GST, GST-TRIM11 WT или MUT с нативной (N) и денатурированной мочевиной (D) люциферазой (luc), иммобилизованной на Ni-NTA-гранулах. На фиг. 39В изображен седиментационный анализ, показывающий, что агрегаты люмиферазы, сформированные при нагревании, разрешаются под влиянием GST или GST-TRIM21. На фиг. 39С изображена дезагрегация и реактивация предварительно сформированных агрегатов люциферазы с использованием повышающихся концентраций GST или GST-TRIM21 (n равен 3). На фиг. 39D показан люциферазный анализ, в котором люциферазу (10 нМ) инкубировали с помощью 200 нМ GST или 200 нМ GST-TRIM21 при 45°С в течение 1 минуты. Активность нативной люциферазы принимали за 100%. N равен 3.
На фиг. 40, содержащей фиг. 40А-40Е, показаны результаты экспериментов, демонстрирующие дезагрегацию PML и Atxn1 82Q. На фиг. 40А показано окрашивание Кумасси синим очищенного Flag-PML6 из клеток 293Т. На фиг. 40В показана дезагрегация и реактивация предварительно сформованных агрегатов GFP с использованием повышающихся концентраций лизоцима или Flag-PML6 (n равен 3). На фиг. 40С показана дезагрегация и реактивация предварительно сформированных агрегатов GFP с использованием лизоцима, Flag-PML6 или GST-TRIM11 (n равен 3). На фиг. 40D изображено окрашивание Кумасси синим очищенных фрагментов Flag-PML4 из клеток 293Т. На фиг. 40Е показана дезагрегация и реактивация предварительно сформированных агрегатов GFP с использованием различных фрагментов PML4 (n равен 3).
На фиг. 41, содержащей фиг. 41А и фиг. 41В, показаны результаты экспериментов, демонстрирующие TRIM11 в первичных нейронах гиппокампа мыши. На фиг. 41А изображен МТТ-анализ, показывающий, что инкубированные с GST или TRIM11 альфа-синуклеиновые волокна вызывали гибель клеток. На фиг. 41В показан иммунофлуоресцентный анализ р-альфа-синуклеина или р62 в нервных клетках гиппокампа, обработанных альфа-синуклеиновыми волокнами.
На фиг. 42, содержащей фиг. 42А-42С, показаны результаты экспериментов, демонстрирующие, что экспрессия TRIM11 повышается в ответ на тепловой шок в кортикальных и гиппокампальных нейронах. На фиг. 42А изображен иммуноблоттинг первичных кортикальных нейронов мыши, подвергнутых тепловому шоку в течение 30 минут при 42°С и восстановленных в течение 3 часов. На фиг. 42В изображен иммуноблоттинг первичных гиппокампальных нейронов мыши, подвергнутых тепловому шоку в течение 30 минут при 42°С и восстановленных в течение 3 часов. На фиг. 42С изображен полуколичественный ПЦР-анализ TRIM11, HSP70, HSP90 и GAPDH в ответ на тепловой шок в гиппокампальных нейронах.
Подробное описание
Данное изобретение относится к выяснению роли членов семейства белков трехчастного мотива (tripartite motif, TRIM) и SUMO-зависимой убиквитинлигазы RNF4 в распознавании и деградации неправильно упакованных белков, которые играют определенную роль в патологии разнообразных нейродегенеративных нарушений.
В одном из аспектов данное изобретение предусматривает композиции и способы лечения или профилактики заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковыми агрегатами. В данном исследовании показано, что TRIM-белки играют определенные роли в нацеливании неправильно упакованных белков на протеасомальную деградацию, в качестве белка-шаперона, и в дезагрегации белковых агрегатов или включений. Таким образом, в некоторых аспектах данное изобретение может быть использовано для устранения внутриклеточных или внеклеточных неправильно упакованных белков, белковых агрегатов или белковых включений.
Например, в некоторых воплощениях данное изобретение предусматривает композиции и способы лечения или профилактики нейродегенеративного нарушения у субъекта, нуждающегося в этом. Например, в некоторых воплощениях данное изобретение предусматривает композиции и способы лечения или профилактики нейродегенеративных нарушений, которые представляют собой полиглутаминовые (полиQ) нарушения, где повторы CAG-кодона кодируют белки с полиглутаминовыми трактами, которые могут приводить к формированию агрегатов из неправильно упакованных белков. Иллюстративные полиQ-нарушения включают, но не ограничиваясь ими, спиноцеребеллярную атаксию (SCA) типа 1 (SCA1), SCA2, SCA3, SCA6, SCA7, SCA17, болезнь Хантингтона и дентаторубро-паллидолюисовую атрофию (DRPLA). В некоторых воплощениях данное изобретение предусматривает композиции и способы лечения нейродегенеративных нарушений, ассоциированных с неправильно упакованными белками или белковыми агрегатами, включая, но не ограничиваясь ими, болезнь Альцгеймера, болезнь Паркинсона, боковой амиотрофический склероз (ALS), трансмиссивную губчатую энцефалопатию (прионное заболевание), тауопатии и лобно-височную дегенерацию (FTLD). Тем не менее, данное изобретение не ограничивается лечением или профилактикой нейродегенеративных нарушений. Напротив, данное изобретение охватывает лечение или профилактику любого заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковым агрегатом. Другие такие заболевания и нарушения включают, но не ограничиваясь ими, AL-амилоидоз, АА-амилоидоз, семейную средиземноморскую лихорадку, старческий системный амилоидоз, семейную амилоидотическую полинейропатию, амилоидоз, связанный с гемодиализом, ApoAI-амилоидоз, ApoAII-амилоидоз, ApoAIV-амилоидоз, финский наследственный амилоидоз, лизоцимный амилоидоз, фибриногеновый амилоидоз, исландскую наследственную церебральную амилоидную ангиопатию, диабет II типа, медуллярную карциному щитовидной железы, предсердный амилоидоз, наследственные кровоизлияния в мозг с амилоидозом, пролактиному гипофиза, локализованный амилоидоз в месте инъекции, аортальный медиальный амилоидоз, наследственную решетчатую дистрофию роговицы, амилоидоз роговицы, связанный с трихиазом, катаракту, кальцификацию эпителиальной одонтогенной опухоли, легочный альвеолярный протеиноз, миозит с тельцами включения и узелкового амилоидоз кожи. В некоторых воплощениях данное изобретение охватывает лечение или профилактику рака, ассоциированного с р53-мутантными агрегатами, включая, но не ограничиваясь ими, карциному мочевого пузыря, астроцитому, рак глотки, лимфому и аденокарциному.
В одном из аспектов данное изобретение охватывает использование одного или более чем одного из TRIM-белков для стабилизации неправильно упакованного белка. В некоторых аспектах стабилизация функционального неправильно упакованного белка через один или более чем один из TRIM-белков, описанных в данном документе, может лечить или предотвращать заболевание или нарушение, ассоциированное с неправильно упакованным белком. Например, в одном из воплощений стабилизация мутантного регулятора трансмембранной проводимости при муковисцидозе (cystic fibrosis transmembrane conductance regulator, CFTR) через один или более чем один из TRIM-белков, описанных в данном документе, позволила бы мутантному CFTR функционировать вместо того, чтобы быть разрушенным. Предполагается, что использование TRIM-белков для стабилизации неправильно упакованных белков может быть использовано для лечения муковисцидоза и других заболеваний, ассоциированных с деградацией частично функциональных белков. Стабилизация белков посредством одного или более чем одного из TRIM-белков, описанных в данном документе, может быть использована для лечения любого заболевания или нарушения, ассоциированного с деградацией функционального мутантного белка, включая, но не ограничиваясь ими, муковисцидоз и лизосомные болезни накопления, такие как болезнь Гоше и болезнь Фабри.
В одном из аспектов данное изобретение предусматривает композиции и способы повышения экспрессии, активности, либо и экспрессии, и активности TRIM-белков. В некоторых воплощениях указанная композиция содержит молекулу нуклеиновой кислоты, экспрессионный вектор, белок, пептид, малую молекулу и т.п., которая повышает экспрессию, активность, либо и экспрессию, и активность одного или более чем одного из TRIM-белков.
В одном из аспектов данное изобретение предусматривает композиции и способы для увеличения экспрессии, активности, либо и экспрессии, и активности одной или более чем одной из убиквитинлигаз, нацеленных на SUMO (STUbL). В некоторых воплощениях указанная композиция содержит молекулу нуклеиновой кислоты, экспрессионный вектор, белок, пептид, малую молекулу и т.п., которая повышает экспрессию, активность, либо и экспрессию, и активность одной или более чем одной из STUbL.
Определения
Если не указано иное, то все технические и научные термины, используемые в данном документе, имеют то же значение, которое обычно понимается специалистом в данной области, к которой относится данное изобретение. Хотя любые способы и материалы, аналогичные или эквивалентные описанным в данном документе, могут быть использованы в осуществлении на практике или в тестировании данного изобретения, описаны предпочтительные способы и материалы.
Каждый из следующих терминов, используемых в данном документе, имеет значение, связанное с ним в этом разделе.
Понятия в единственном числе используются в данном документе для обозначения одного или более чем одного (т.е. по меньшей мере одного) грамматического объекта статьи. В качестве примера, "элемент" означает один элемент или более чем один элемент.
Понятие "примерно", используемое в данном документе касательно измеримого значения, такого как количество, временная продолжительность и т.п., предназначено для охвата вариаций плюс/минус 20%, плюс/минус 10%, плюс/минус 5%, плюс/минус 1% или плюс/минус 0,1% от указанного значения, поскольку такие вариации подходят для выполнения раскрытых способов.
Термин "аномальный" при использовании в контексте организмов, тканей, клеток или их компонентов относится к тем организмам, тканям, клеткам или их компонентам, которые отличаются по меньшей мере одной из наблюдаемых или обнаруживаемых характеристик (например, возрастом, лечением, временем дня и т.д.) от тех организмов, тканей, клеток или их компонентов, которые демонстрируют "нормальную" (ожидаемую) соответствующую характеристику. Характеристики, которые являются нормальными или ожидаемыми для одного типа клеток или тканей, могут быть аномальными для другого типа клеток или тканей.
Понятие "заболевание" означает состояние здоровья животного, при котором животное не может поддерживать гомеостаз, и при котором, если заболевание не ослабляется, то здоровье животного продолжает ухудшаться.
Напротив, понятие "нарушение" у животного означает состояние здоровья, при котором животное может поддерживать гомеостаз, но при котором состояние здоровья животного является менее благоприятным, чем в отсутствие нарушения. В отсутствие лечения нарушение не обязательно приводит к дальнейшему ухудшению состояния здоровья животного.
Заболевание или нарушение "облегчается", если уменьшается степень тяжести признака или симптома заболевания или нарушения, частота, с которой такой признак или симптом испытывается пациентом, или и то, и другое.
"Эффективное количество" или "терапевтически эффективное количество" соединения представляет собой такое количество соединения, которое является достаточным для обеспечения благоприятного эффекта у субъекта, которому вводится данное соединение. "Эффективное количество" носителя представляет собой количество, достаточное для эффективного связывания или доставки соединения.
Используемый в данном документе термин "инструктивный материал" включает публикацию, запись, диаграмму или любое другое средство выражения, которое может использоваться для сообщения о пригодности соединения, композиции, вектора или системы доставки согласно данному изобретению в наборе для эффективного облегчения различных заболеваний или нарушений, упомянутых в данном документе. Возможно, или альтернативно, инструктивный материал может описывать один или более чем один из способов облегчения заболеваний или нарушений в клетке или ткани млекопитающего. Инструктивный материал набора согласно данному изобретению может быть, например, прикреплен к контейнеру, который содержит соединение, композицию, вектор или систему доставки согласно данному изобретению, или может поставляться вместе с контейнером, который содержит указанное соединение, композицию, вектор и систему доставки. Альтернативно, инструктивный материал может поставляться отдельно от контейнера с намерением о том, чтобы инструктивный материал и соединение были использованы получателем совместно.
Термины "пациент", "субъект", "индивидуум" и т.п. используются в данном документе взаимозаменяемо и относятся к любому животному или его клеткам in vitro или in situ, применимым к способам, описанным в данном документе. В некоторых неограничивающих воплощениях указанный пациент, субъект или индивидуум является человеком.
Используемый в данном документе термин "терапевтический" означает лечение, проводимое субъекту, который демонстрирует признаки или симптомы заболевания или нарушения, с целью ослабления или удаления этих признаков или симптомов.
Используемый в данном документе термин "лечение заболевания или нарушения" означает снижение тяжести и/или частоты, с которой пациент испытывает признак или симптом указанного заболевания или нарушения.
Используемая в данном документе фраза "биологический образец" предназначена для включения любого образца, содержащего клетку, ткань или физиологическую жидкость, в которой присутствует или может быть обнаружена экспрессия нуклеиновой кислоты или полипептид. Образцы, которые являются жидкими в природе, называются в данном документе "физиологическими жидкостями". Биологические образцы могут быть получены от пациента с помощью различных методик, включая, например, соскабливание или взятие мазков из определенной области у субъекта или с помощью иглы для получения физиологических жидкостей. Способы сбора различных образцов из организма хорошо известны в данной области.
Используемый в данном документе термин "иммуноанализ" относится к любому анализу связывания, в котором используется антитело, способное специфически связываться с молекулой-мишенью, для обнаружения и количественной оценки молекулы-мишени.
Под термином "специфически связывается", используемым в данном документе в отношении антитела, понимают антитело, которое распознает специфический антиген, но по существу не распознает или не связывает другие молекулы в образце. Например, антитело, которое специфически связывается с антигеном от одного вида, также может связываться с этим антигеном от одного или более чем одного вида. Но такая перекрестная реакционная способность сама по себе не изменяет классификацию антитела как специфического. В другом примере антитело, которое специфически связывается с антигеном, также может связываться с различными аллельными формами антигена. Тем не менее, такая перекрестная реакционная способность сама по себе не изменяет классификацию антитела как специфического.
В некоторых случаях термины "специфическое связывание" или "специфически связывающийся" могут быть использованы в отношении взаимодействия антитела, белка или пептида со второй химической формой, что означает, что взаимодействие зависит от присутствия конкретной структуры (например, антигенной детерминанты или эпитопа) на химических образцах; например, антитело распознает и связывается со специфической структурой белка, а не с белками вообще. Если антитело является специфическим для эпитопа "А", то присутствие молекулы, содержащей эпитоп А (или свободного немеченого А), в реакции, содержащей меченый "А" и антитело, уменьшит количество меченого А, связанного с антителом.
"Кодирующая область" гена состоит из нуклеотидных остатков кодирующей нити гена и нуклеотидов некодирующей нити гена, которые являются гомологичными или комплементарными, соответственно, кодирующей области молекулы мРНК, которая продуцируется при транскрипции указанного гена.
"Кодирующая область" молекулы мРНК состоит из нуклеотидных остатков молекулы мРНК, которые совпадают с антикодоновой областью молекулы транспортной РНК во время трансляции молекулы мРНК, или которые кодируют стоп-кодон. Кодирующая область может, таким образом, включать нуклеотидные остатки, содержащие кодоны для аминокислотных остатков, которые не присутствуют в зрелом белке, кодируемом молекулой мРНК (например, аминокислотные остатки в сигнальной последовательности экспорта белка).
Термин "комплементарный", используемый в данном документе в отношении нуклеиновой кислоты, относится к распространенной концепции комплементарности последовательностей областей двух нитей нуклеиновой кислоты или двух областей одной и той же нуклеиновой кислоты. Известно, что адениновый остаток первой области нуклеиновой кислоты способен образовывать специфические водородные связи ("спаривание оснований") с остатком второй области нуклеиновой кислоты, которая является антипараллельной первой области, если остаток представляет собой тимин или урацил. Аналогичным образом известно, что остаток цитозина первой нити нуклеиновой кислоты способен к спариванию оснований с остатком второй нити нуклеиновой кислоты, которая является антипараллельной первой нити, если остаток представляет собой гуанин. Первая область нуклеиновой кислоты является комплементарной второй области той же или другой нуклеиновой кислоты, если в случае, когда две области расположены антипараллельно, по меньшей мере один нуклеотидный остаток первой области способен к спариванию оснований с остатком второй области. Предпочтительно, первая область содержит первую часть, а вторая область содержит вторую часть, при этом, когда первая и вторая части расположены антипараллельно, по меньшей мере примерно 50% и предпочтительно по меньшей мере примерно 75%, по меньшей мере примерно 90% или по меньшей мере примерно 95% нуклеотидных остатков первой части способны к спариванию оснований с нуклеотидными остатками во второй части. Более предпочтительно, все нуклеотидные остатки первой части способны к спариванию оснований с нуклеотидными остатками во второй части.
Понятие "изолированный" означает измененный или удаленный из природного состояния. Например, нуклеиновая кислота или пептид, в природе присутствующие в живом животном, не "изолированы", но та же нуклеиновая кислота или пептид, частично или полностью отделенные от материалов, присутствующих рядом с ними в их природном состоянии, являются "изолированными". Изолированная нуклеиновая кислота или белок могут существовать в практически очищенной форме или могут существовать в неприродной среде, такой как, например, клетка-хозяин.
Понятие "изолированная нуклеиновая кислота" относится к сегменту или фрагменту нуклеиновой кислоты, который был отделен от последовательностей, которые фланкируют его в природном состоянии, т.е. к фрагменту ДНК, который был удален из последовательностей, которые обычно являются смежными с указанным фрагментом, т.е. из последовательностей, смежных с указанным фрагментом в геноме, в котором он встречается в природе. Этот термин также относится к нуклеиновым кислотам, которые были по существу очищены от других компонентов, которые в природе сопровождают нуклеиновую кислоту, т.е. от РНК или ДНК или белков, которые в природе сопровождают их в клетке. Таким образом, данный термин включает, например, рекомбинантную ДНК, которая встроена в вектор, в автономно реплицирущуюся плазмиду или вирус, или в геномную ДНК прокариот или эукариот, или которая существует в виде отдельной молекулы (т.е. в виде кДНК или фрагмента геномной ДНК или кДНК, образованного путем ПЦР или расщепления рестрикционными ферментами) независимо от других последовательностей. Он также включает рекомбинантную ДНК, которая является частью гибридного гена, кодирующего дополнительную полипептидную последовательность.
В контексте данного изобретения используются следующие сокращения для общеизвестных нуклеиновокислотных оснований. "А" относится к аденозину, "С" относится к цитозину, "G" относится к гуанозину, "Т" относится к тимидину, a "U" относится к уридину.
Используемый в данном документе термин "полинуклеотид" определяется как цепь нуклеотидов. Кроме того, нуклеиновые кислоты представляют собой полимеры нуклеотидов. Таким образом, термины "нуклеиновые кислоты" и "полинуклеотиды", используемые в данном документе, являются взаимозаменяемыми. Специалист в данной области имеет общее представление о том, что нуклеиновые кислоты являются полинуклеотидами, которые могут быть гидролизованы до мономерных "нуклеотидов". Мономерные нуклеотиды могут быть гидролизованы до нуклеозидов. Используемые в данном документе полинуклеотиды включают, но не ограничиваясь ими, все последовательности нуклеиновых кислот, которые получены любыми способами, доступными в данной области, включая, но не ограничиваясь ими, рекомбинантные средства, т.е. клонирование последовательностей нуклеиновых кислот из рекомбинантной библиотеки или клеточного генома с использованием обычной методики клонирования и PCR™ и т.п., а также средства синтеза.
Используемые в данном документе термины "пептид", "полипептид" и "белок" используются взаимозаменяемо и относятся к соединению, состоящему из аминокислотных остатков, ковалентно связанных пептидными связями. Белок или пептид должен содержать по меньшей мере две аминокислоты, и никакое ограничение не установлено на максимальное число аминокислот, которые может содержать последовательность белка или пептида. Полипептиды включают любой пептид или белок, содержащий две или более двух аминокислот, соединенных друг с другом пептидными связями. Используемый в данном документе термин относится как к коротким цепям, которые также обычно упоминаются в данной области как пептиды, олигопептиды и олигомеры, например, так и к более длинным цепям, которые обычно упоминаются в данной области как белки, среди которых есть много типов. Например, "полипептиды" включают, помимо прочего, биологически активные фрагменты, по существу гомологичные полипептиды, олигопептиды, гомодимеры, гетеродимеры, варианты полипептидов, модифицированные полипептиды, производные, аналоги, гибридные белки. Полипептиды включают природные пептиды, рекомбинантные пептиды, синтетические пептиды или их комбинацию.
Используемый в данном документе термин "конъюгированный" относится к ковалентному присоединению одной молекулы ко второй молекуле.
"Вариант" в качестве термина, используемого в данном документе, представляет собой последовательность нуклеиновой кислоты или пептидную последовательность, которая отличается по последовательности от референсной последовательности нуклеиновой кислоты или пептида, соответственно, но сохраняет основные биологические свойства референсной молекулы. Изменения в последовательности варианта нуклеиновой кислоты могут не изменять аминокислотную последовательность пептида, кодируемого референсной нуклеиновой кислотой, либо могут приводить к аминокислотным замещениям, добавлениям, делециям, слияниям и усечениям. Изменения в последовательности пептидных вариантов, как правило, ограничены или консервативны, так что последовательности референсного пептида и варианта близки друг к другу в целом и во многих областях идентичны. Вариантный и референсный пептид могут отличаться по аминокислотной последовательности одним или более чем одним замещением, добавлением, делецией в любой комбинации. Вариант нуклеиновой кислоты или пептида может быть природным, таким как аллельный вариант, или может быть вариантом, который, как известно, не существует в природе. Неприродные варианты нуклеиновых кислот и пептидов могут быть получены с помощью методик мутагенеза или прямого синтеза.
Используемый в данном документе термин "модулятор одного или более чем одного из TRIM-белков" представляет собой соединение, которое модифицирует экспрессию, активность или биологическую функцию TRIM-белка по сравнению с экспрессией, активностью или биологической функцией TRIM-белка в отсутствие модулятора.
Используемый в данном документе термин "модулятор RNF4" представляет собой соединение, которое модифицирует экспрессию, активность или биологическую функцию RNF4 по сравнению с экспрессией, активностью или биологической функцией RNF4 в отсутствие модулятора.
Диапазоны: на всем протяжении этого документа различные аспекты данного изобретения могут быть представлены в формате диапазонов. Следует понимать, что описание в формате диапазонов дано только для удобства и краткости и не должно истолковываться как негибкое ограничение объема данного изобретения. Соответственно, описание диапазона следует рассматривать как конкретно раскрывающее все возможные поддиапазоны, а также отдельные числовые значения в этом диапазоне. Например, описание диапазона, такое как от 1 до 6, следует рассматривать как конкретно раскрывающее такие поддиапазоны как от 1 до 3, от 1 до 4, от 1 до 5, от 2 до 4, от 2 до 6, от 3 до 6 и т.д., а также отдельные значения в пределах этого диапазона, например, 1, 2, 2,7, 3, 4, 5, 5,3 и 6. Это условие применимо независимо от ширины диапазона.
Описание
В одном из аспектов данное изобретение предусматривает композиции и способы лечения или профилактики заболевания или нарушения, ассоциированного с неправильно упакованными белками или белковыми агрегатами. Например, данное изобретение предусматривает композиции и способы повышения распознавания и элиминации неправильно упакованных белков. В некоторых воплощениях данное изобретение предусматривает SUMO-опосредованное убиквитинирование и последующую деградацию неправильно упакованного белка. В некоторых воплощениях данное изобретение предусматривает дезагрегацию белковых агрегатов или включений. Таким образом, данное изобретение может быть использовано для устранения неправильно упакованных белков, белковых агрегатов или белковых включений как внутриклеточно,так и внеклеточно.
Данное изобретение относится к выяснению роли членов семейства белков трехстороннего мотива (TRIM) и SUMO-нацеленной убиквитинлигазы (STUbL), RNF4, в распознавании и деградации неправильно упакованных белков, которые играют определенную роль в патологии различных заболеваний и нарушений, включая многие нейродегенеративные заболевания и нарушения.
Представленные в данном документе данные демонстрируют, что члены семейства TRIM-белков колокализуются с неправильно упакованными белками и опосредуют деградацию неправильно упакованных белков. Кроме того, в данном документе описано, что RNF4 представляет собой убиквитинлигазу, которая опосредует убиквитинирование и деградацию неправильно упакованных белков. Таким образом, данное изобретение предусматривает композиции, которые повышают экспрессию, активность, либо и экспрессию, и активность одного или более чем одного из TRIM-белков, одной или более чем одной из STUbL или их комбинации. Например, показано, что молекулы нуклеиновых кислот, кодирующие TRIM-белок и рекомбинантные TRIM-белки, способствуют деградации неправильно упакованного белка.
В одном из воплощений указанная композиция содержит модулятор экспрессии или активности одного или более чем одного из TRIM-белков. Например, в одном из воплощений указанный модулятор повышает экспрессию или активность одного или более чем одного из TRIM-белков. Один или более чем один из TRIM-белков включает любой член семейства TRIM-белков, включая представителей млекопитающих и немлекопитающих. В некоторых воплощениях указанный модулятор повышает экспрессию или активность одного или более чем одного из человеческих TRIM3, TRIM4, TRIM5, TRIM6, TRIM7, TRIM9, TRIM11, TRIM13, TRIM14, TRIM15, TRIM16, TRIM17, TRIM19 (также упоминаемого в данном документе как "PML"), TRIM20, TRIM21, TRIM24, TRIM25, TRIM27, TRIM28, TRIM29, TRIM32, TRIM34, TRIM39, TRIM43, TRIM44, TRIM45, TRIM46, TRIM49, TRIM50, TRIM52, TRIM58, TRIM59, TRIM65, TRIM67, TRIM69, TRIM70, TRIM74 и TRIM75; и мышиного TRIM30.
В одном из воплощений указанная композиция содержит модулятор одной или более чем одной из STUbL. Например, в одном из воплощений указанный модулятор повышает экспрессию или активность одной или более чем одной из STUbL. Примеры STUbL включают, но не ограничиваясь ими, RNF4 и RNF111 (также известный как Arkadia).
В одном из воплощений указанная композиция содержит модулятор одного или более чем одного из TRIM-белков и модулятор одной или более чем одной из STUbL.
Данное изобретение предусматривает способ лечения или профилактики заболевания или нарушения, ассоциированного с неправильно упакованными белками или белковыми агрегатами, у нуждающегося в этом субъекта. В данном исследовании было обнаружено, что повышение уровня экспрессии или активности TRIM-белка или STUbL может способствовать деградации неправильно упакованного белка, тем самым вылечивая заболевание или нарушение у субъекта.
Примеры нейродегенеративных заболеваний или нарушений, которые могут быть излечены или предотвращены с помощью композиций и способов согласно данному изобретению, включают, но не ограничиваясь ими, полиQ-нарушения, такие как SCA1, SCA2, SCA3, SCA6, SCA7, SCA17, болезнь Хантингтона, дентаторубро-паллидолюисовая атрофия (DRPLA), болезнь Альцгеймера, болезнь Паркинсона, боковой амиотрофический склероз (ALS), трансмиссивная губчатая энцефалопатия (прионное заболевание), тауопатия и лобно-височная дегенерация (FTLD). Тем не менее, данное изобретение не ограничивается лечением или профилактикой нейродегенеративных нарушений. Напротив, данное изобретение охватывает лечение или профилактику любого заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковым агрегатом. Другие такие заболевания и нарушения включают, но не ограничиваясь ими, AL-амилоидоз, АА-амилоидоз, семейную средиземноморскую лихорадку, старческий системный амилоидоз, семейную амилоидотическую полинейропатию, амилоидоз, связанный с гемодиализом, ApoAI-амилоидоз, АроАII-амилоидоз, ApoAIV-амилоидоз, финский наследственный амилоидоз, лизоцимный амилоидоз, фибриногеновый амилоидоз, исландскую наследственную церебральную амилоидную ангиопатию, диабет II типа, медуллярную карциному щитовидной железы, предсердный амилоидоз, наследственные кровоизлияния в мозг с амилоидозом, пролактиному гипофиза, локализованный амилоидоз в месте инъекции, аортальный медиальный амилоидоз, наследственную решетчатую дистрофию роговицы, амилоидоз роговицы, связанный с трихиазом, катаракту, кальцификацию эпителиальной одонтогенной опухоли, легочный альвеолярный протеиноз, миозит с тельцами включения и узелкового амилоидоз кожи. В некоторых воплощениях данное изобретение охватывает лечение или профилактику рака, ассоциированного с р53-мутантными агрегатами, включая, но не ограничиваясь ими, карциному мочевого пузыря, астроцитому, рак глотки, лимфому и аденокарциному.
В одном из аспектов данное изобретение охватывает использование одного или более чем одного из TRIM-белков для стабилизации неправильно упакованного белка. В некоторых аспектах стабилизация функционального неправильно упакованного белка через один или более чем один из TRIM-белков, описанных в данном документе, может лечить или предотвращать заболевание или нарушение, ассоциированное с неправильно упакованным белком, включая, но не ограничиваясь ими, муковисцидоз и лизосомные болезни накопления, такие как болезнь Гоше и болезнь Фабри.
В одном из аспектов данное изобретение предусматривает способ диагностики заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковыми агрегатами. Например, в одном из воплощений один или более чем один из TRIM-белков или одну или более чем одну из STUbL используют в качестве диагностических маркеров.
В одном из аспектов данное изобретение предусматривает композиции и способы производства рекомбинантного белка, представляющего интерес.Например, в некоторых воплощениях один или более чем один из TRIM-белков и одна или более чем одна из STUbL могут быть использованы для дезагрегации белковых агрегатов рекомбинантного белка, представляющего интерес.
Композиции
В различных воплощениях данное изобретение включает композиции с модулятором и способы профилактики и лечения заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковыми агрегатами. В различных воплощениях указанные композиции с модулятором и способы профилактики или лечения согласно данному изобретению модулируют уровень или активность гена или продукта гена. В некоторых воплощениях композиции с модулятором согласно данному изобретению представляет собой активатор, который увеличивает уровень или активность гена или продукта гена.
Специалисту в данной области будет понятно на основе представленного в данном документе описания, что модуляция гена или продукта гена охватывает модуляцию уровня или активности гена или продукта гена, включая, но не ограничиваясь этим, модуляцию транскрипции, трансляции, сплайсинга, деградации, ферментативной активности, связывающей активности или их комбинации. Таким образом, модуляция уровня или активности гена или продукта гена включает, но не ограничиваясь ими, модуляцию транскрипции, трансляции, деградации, сплайсинга нуклеиновой кислоты или их сочетание; а также включает модуляцию любой активности полипептидного продукта гена.
В одном из воплощений указанный модулятор повышает экспрессию или активность гена или продукта гена путем увеличения продукции гена или продукта гена, например, путем модуляции транскрипции гена или трансляции продукта гена. В одном из воплощений указанный модулятор повышает экспрессию или активность гена или продукта гена путем предоставления экзогенного гена или продукта гена. Например, в некоторых воплощениях указанный модулятор содержит изолированную нуклеиновую кислоту, кодирующую один или более чем один из TRIM-белков или одну или более чем одну из STUbL. В одном из воплощений указанный модулятор содержит изолированную нуклеиновую кислоту, кодирующую один или более чем один из TRIM-белков и одну или содержит чем одну из STUbL. В некоторых воплощениях указанный модулятор содержит изолированный пептид, содержащий один или более чем один из TRIM-белков или одну или более чем одну из STUbL. В одном из воплощений указанный модулятор содержит изолированный пептид, содержащий один или более чем один из TRIM-белков и одну или более чем одну из STUbL. В одном из воплощений указанный модулятор повышает экспрессию или активность гена или продукта гена путем ингибирования деградации гена или продукта гена. Например, в одном из воплощений указанный модулятор уменьшает убиквитинирование, протеасомальную деградацию или протеолиз одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL. В одном из воплощений указанный модулятор повышает стабильность или период полужизни продукта гена.
В различных воплощениях модулированный ген или продукт гена представляет собой один или более чем один из TRIM-белков. Например, в данном документе описано, что TRIM-белки распознают неправильно упакованные белки и опосредуют деградацию неправильно упакованных белков и белковых агрегатов. В одном из воплощений указанный ген или продукт гена представляет собой одну или более чем одну из STUbL. Например, в данном документе описано, что RNF4, член семейства белков STUbl, опосредует деградацию неправильно упакованных белков и белковых агрегатов.
Модуляцию гена или продукта гена можно оценить с использованием широкого спектра способов, в том числе описанных в данном документе, а также способов, которые известны в данной области или которые будут разработаны в будущем. Т.е. специалист понял бы, основываясь на представленном в данном документе описании, что модуляцию уровня или активности гена или продукта гена можно легко оценить с использованием способов, которые оценивают уровень нуклеиновой кислоты, кодирующей генный продукт (например, мРНК), уровень полипептидного продукта гена, присутствующего в биологическом образце, активность полипептидного продукта гена, присутствующего в биологическом образце, или их комбинации.
Композиции с модулятором и способы согласно данному изобретению, которые модулируют уровень или активность гена или продукта гена, включают, но не ограничиваясь ими, химическое соединение, белок, пептид, пептидомиметик, антитело, рибозим, низкомолекулярное химическое соединение, нуклеиновую кислоту, вектор, антисмысловую молекулу нуклеиновой кислоты (например, киРНК, микроРНК и т.д.) или их комбинацию. Специалист в данной области легко поймет, основываясь на представленном в данном документе описании, что композиция с модулятором охватывает химическое соединение, которое модулирует уровень или активность гена или продукта гена. Кроме того, композиция с модулятором включает химически модифицированное соединение и его производные, как хорошо известно специалистам в области химии.
В одном из воплощений композиция с модулятором согласно данному изобретению представляет собой агонист, который повышает экспрессию, активность или биологическую функцию гена или продукта гена. Например, в некоторых воплощениях модулятор согласно данному изобретению является агонистом одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL.
Кроме того, специалист в данной области, если он обладает описанием и способами, приведенными в данном документе в качестве примера, поймет, что модуляторы включают такие модуляторы, которые будут обнаружены в будущем и могут быть определены по известным в области фармакологии критериям, таким как физиологические результаты модуляции генов и генных продуктов, как подробно описано в данном документе и/или как известно в данной области. Следовательно, данное изобретение никоим образом не ограничено какой-либо конкретной композицией модулятора, проиллюстрированной или раскрытой в данном документе; скорее, данное изобретение охватывает такие композиции с модулятором, которые, как будет понятно специалисту, могут быть использованы в данной области, и которые будут обнаружены в будущем.
Другие способы выявления и получения композиций с модулятором хорошо известны специалистам в данной области. Альтернативно, модулятор может быть синтезирован химически. Кроме того, специалист на основании изложенных в данном документе принципов сможет понять, что композиция с модулятором может быть получена из рекомбинантного организма. Композиции с химически синтезированными модуляторами и способы их получения из природных источников хорошо известны и описаны в данной области.
Специалистам в данной области будет понятно, что модулятор можно вводить в виде низкомолекулярного химического соединения, полипептида, пептида, антитела, нуклеиновокислотной конструкции, кодирующей белок, антисмысловой нуклеиновой кислоты, нуклеиновокислотной конструкции, кодирующей антисмысловую нуклеиновую кислоту, или их комбинации. Многочисленные векторы и другие композиции и способы хорошо известны для введения белка или нуклеиновокислотной конструкции, кодирующей белок, в клетки или ткани. Следовательно, данное изобретение включает пептид или нуклеиновую кислоту, кодирующую пептид, который является модулятором гена или продукта гена. Например, данное изобретение включает пептид или нуклеиновую кислоту, кодирующую пептид, который содержит один или более чем один из TRIM-белков, одну или более чем одну из STUbL или их комбинацию. (Sambrook et al., 2001, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory, New York; Ausubel et al., 1997, Current Protocols in Molecular Biology, John Wiley & Sons, New York).
Пептиды
В одном из воплощений композиция согласно данному изобретению содержит один или более чем один пептид. Например, в одном из воплощений пептид в данной композиции содержит аминокислотную последовательность одного или более чем одного из TRIM-белков. Например, в одном из воплощений указанный пептид содержит один или более чем один из TRIM56, TRIM 11, TRIM19, TRIM 21, TRIM27 и TRIM32. В некоторых воплощениях указанный пептид содержит аминокислотную последовательность одной или более чем одной из STUbL. Например, в одном из воплощений указанный пептид содержит один или более чем один из RNF4 и RNF111 (Arkadia).
Иллюстративные аминокислотные последовательности TRIM-белков и нуклеотидные последовательности кДНК, кодирующие TRIM-белки, представлены в таблице 1 ниже.


Данное изобретение также должно быть истолковано как включающее любую форму пептида, имеющего существенную гомологию с пептидами, описанными в данном документе. Предпочтительно, пептид, который является "по существу гомологичным", является примерно на 50% гомологичным, более предпочтительно примерно на 70% гомологичным, еще более предпочтительно примерно на 80% гомологичным, более предпочтительно примерно на 90% гомологичным, еще более предпочтительно примерно на 95% гомологичным и даже более предпочтительно примерно на 99% гомологичным аминокислотной последовательности пептидов, описанных в данном документе.
В одном из воплощений композиция согласно данному изобретению содержит пептид, фрагмент пептида, гомолог, вариант, производное или соль пептида, описанного в данном документе. Например, в некоторых воплощениях указанная композиция содержит пептид, содержащий один или более чем один из TRIM-белков, фрагмент одного или более чем одного из TRIM-белков, гомолог одного или более чем одного из TRIM-белков, вариант одного или более чем одного из TRIM-белков, производное одного или более чем одного из TRIM-белков, или соль одного или более чем одного из TRIM-белков. В некоторых воплощениях указанная композиция содержит пептид, содержащий одну или более чем одну из STUbL, фрагмент одной или более чем одной из STUbL, гомолог одной или более чем одной из STUbL, вариант одной или более чем одной из STUbL, производное одной или более чем одной из STUbL или соль одной или более чем одной STUbL.
В одном из воплощений указанная композиция содержит комбинацию пептидов, описанных в данном документе. Например, в некоторых воплощениях указанная композиция содержит пептид, содержащий один или более чем один из TRIM-белков, и пептид, содержащий одну или более чем одну из STUbL. В одном из воплощений указанная композиция содержит пептид, содержащий один или более чем один из TRIM-белков и одну или более чем одну из STUbL.
В некоторых воплощениях указанный пептид содержит нацеливающий домен, который нацеливает пептид в нужное место. Например, в некоторых воплощениях нацеливающий домен связывается с целевой клеткой, белком или белковым агрегатом, тем самым доставляя терапевтический пептид в нужное место. Например, в одном из воплощений нацеливающий домен нацелен на связывание с белком или белковым агрегатом, ассоциированным с заболеванием или нарушением, включая, но не ограничиваясь ими, белки и белковые агрегаты амилоида-бета, альфа-синуклеина, тау, прионов, SOD1, TDP-43, FUS, р53-мутанты и белки, ассоциированные с полиглутаминовыми трактами, такие как хантингтин, атаксины.
В некоторых воплощениях нацеливающий домен содержит пептид, нуклеиновую кислоту, малую молекулу и т.п., которая обладает способностью связываться с целевой клеткой, белком или белковым агрегатом. Например, в одном из воплощений нацеливающий домен содержит антитело или фрагмент антитела, который связывается с целевой клеткой, белком или белковым агрегатом.
Пептид согласно данному изобретению может быть получен с использованием химических способов. Например, пептиды можно синтезировать с помощью твердофазных методик (Roberge J Y et al., 1995) Science 269: 202-204), отщепить из смолы и очистить путем препаративной высокоэффективной жидкостной хроматографии. Автоматический синтез может быть проведен, например, с использованием пептидного синтезатора ABI 431 A (Perkin Elmer) в соответствии с инструкциями производителя.
Альтернативно, пептид может быть получен рекомбинантным путем или путем расщепления более длинного полипептида. Состав пептида может быть подтвержден аминокислотным анализом или секвенированием.
Варианты пептидов согласно данному изобретению могут быть (i) такими, в которых один или более чем один из аминокислотных остатков замещен консервативным или неконсервативным аминокислотным остатком (предпочтительно консервативным аминокислотным остатком), и такой замещенный аминокислотный остаток может быть или не быть таким, который закодирован генетическим кодом, (и) такими, в которых есть один или более чем один из модифицированных аминокислотных остатков, например, остатков, модифицированных присоединением групп заместителей, (iii) такими, в которых пептид представляет собой вариант альтернативного сплайсинга пептида согласно данному изобретению, (iv) фрагментами пептидов и/или (v) такими, в которых пептид слит с другим пептидом, таким как лидерная или секреторная последовательность или последовательность, которая используется для очистки (например, His-метка) или для обнаружения (например, Sv5-эпитопная метка). Указанные фрагменты включают пептиды, полученные путем протеолитического расщепления (включая многосайтовый протеолиз) исходной последовательности. Варианты могут быть посттрансляционно или химически модифицированными. Считается, что такие варианты находятся в пределах компетенции специалистов в данной области.
Пептиды согласно данному изобретению могут подвергаться посттрансляционной модификации. Например, посттрансляционные модификации, подпадающие под объем данного изобретения, включают отщепление сигнального пептида, гликозилирование, ацетилирование, изопренилирование, протеолиз, миристоилирование, фолдинг белка и протеолитическую обработку и т.д. Некоторые модификации или события процессинга требуют введения дополнительного биологического механизма. Например, такие события процессинга, как отщепление сигнального пептида и гликозилирование ядра, исследуют путем добавления собачьих микросомальных мембран или яичных экстрактов Xenopus (патент США №6103889) к стандартной реакции трансляции.
Пептиды согласно данному изобретению могут включать неприродные аминокислоты, образованные путем посттрансляционной модификации или путем введения неприродных аминокислот в ходе трансляции. Существует множество подходов к введению неприродных аминокислот в ходе трансляции белка. В качестве примера, специальные тРНК, такие как тРНК, которые обладают супрессорными свойствами, супрессорные тРНК, были использованы в процессе сайт-специфического замещения неприродной аминокислотой (site-directed non-native amino acid replacement, SNAAR). В SNAAR требуется уникальный кодон для мРНК и супрессорная тРНК, действующая для нацеливания неприродной аминокислоты в уникальный сайт во время синтеза белка (как описано в WO 90/05785). Тем не менее, супрессорную тРНК нельзя распознавать аминоацил-тРНК-синтетазами, присутствующими в системе трансляции белка. В некоторых случаях неприродная аминокислота может быть образована после того, как молекула тРНК была аминоацилирована с использованием химических реакций, которые специфически модифицируют природную аминокислоту и существенно не изменяют функциональную активность аминоацилированной тРНК. Эти реакции упоминаются как модификации типа постаминоацилирования. Например, эпсилон-аминогруппа лизина, связанная с его родственной тРНК (tRNALYS), может быть модифицирована с помощью аминоспецифической фотоаффинной метки.
Пептид или белок согласно данному изобретению может быть конъюгирован с другими молекулами, такими как белки, с образованием гибридных белков. Это может быть достигнуто, например, путем синтеза N-концевых или С-концевых гибридных белков при условии, что полученный гибридный белок сохраняет функциональность пептида согласно данному изобретению.
Циклические производные пептидов согласно данному изобретению также являются частью данного изобретения. Циклизация может позволить пептиду принимать конформацию, более благоприятную для ассоциации с другими молекулами. Циклизация может быть достигнута с помощью методик, известных в данной области. Например, могут формироваться дисульфидные связи между двумя соответствующими разделенными компонентами, имеющими свободные сульфгидрильные группы, или может быть образована амидная связь между аминогруппой одного компонента и карбоксильной группой другого компонента. Циклизация также может быть достигнута с помощью азобензолсодержащей аминокислоты, как описано в Ulysse, L., et al., J. Am. Chem. Soc. 1995, 117, 8466-8467. Компоненты, которые формируют связи, могут быть боковыми цепями аминокислот, неаминокислотными компонентами или их комбинацией. В одном из воплощений данного изобретения циклические пептиды могут содержать бета-изгиб в правую сторону. Бета-изгибы могут быть введены в пептиды согласно данному изобретению путем добавления аминокислот Pro-Gly в правой позиции.
Может быть желательным получить циклический пептид, который является более гибким, чем циклические пептиды, содержащие пептидные связи, описанные выше. Более гибкий пептид может быть получен путем введения цистеинов в правой и левой позиции пептида и формирования дисульфидного мостика между двумя цистеинами. Два цистеина располагают таким образом, чтобы не деформировать бета-складчатость и изгиб. Указанный пептид является более гибким в результате длины дисульфидной связи и меньшего числа водородных связей в бета-складчатой части. Относительная гибкость циклического пептида может быть определена путем моделирования молекулярной динамики.
Пептиды согласно данному изобретению могут быть превращены в фармацевтические соли путем взаимодействия с неорганическими кислотами, такими как хлористоводородная кислота, серная кислота, бромистоводородная кислота, фосфорная кислота и т.д., или с органическими кислотами, такими как муравьиная кислота, уксусная кислота, пропионовая кислота, гликолевая кислота, молочная кислота, пировиноградная кислота, щавелевая кислота, янтарная кислота, яблочная кислота, винная кислота, лимонная кислота, бензойная кислота, салициловая кислота, бензенсульфоновая кислота и толуолсульфоновые кислоты.
Пептиды согласно данному изобретению могут также иметь модификации. Модификации (которые обычно не изменяют первичную последовательность) включают in vivo или in vitro химическую дериватизацию полипептидов, например, ацетилирование или карбоксилирование. Также включены модификации гликозилирования, например, те, которые сделаны путем модификации паттернов гликозилирования полипептида во время его синтеза и процессинга или на последующих этапах процессинга; например, путем воздействия на полипептид ферментов, которые влияют на гликозилирование, например гликозилирующих или дегликозилирующих ферментов млекопитающих. Также охватываются последовательности, которые имеют фосфорилированные аминокислотные остатки, например фосфотирозин, фосфосерин или фосфотреонин.
Также включены пептиды, которые были модифицированы с использованием стандартных молекулярно-биологических методик, чтобы улучшить их устойчивость к протеолитической деградации или оптимизировать свойства растворимости или сделать их более подходящими в качестве терапевтического агента. Такие варианты включают те, которые содержат остатки, отличающиеся от встречающихся в природе L-аминокислот, например, D-аминокислоты или неприродные синтетические аминокислоты. Пептиды согласно данному изобретению также могут быть конъюгированы с неаминокислотными группировками, которые могут быть использованы для терапевтического применения. В частности, могут быть использованы группировки, которые повышают стабильность, биологический период полужизни, растворимость в воде и/или иммунологические характеристики пептида. Неограничивающим примером такой группировки является полиэтиленгликоль (ПЭГ, polyethylene glycol, PEG).
Ковалентное присоединение биологически активных соединений к водорастворимым полимерам является одним из способов изменения и контроля над биораспределением, фармакокинетикой и, зачастую, токсичностью этих соединений (Duncan et al., 1984, Adv. Polym. Sci. 57:53-101). Для достижения этих эффектов использовались многие водорастворимые полимеры, такие как полисиаловая кислота, декстран, поли(N-(2-гидроксипропил)метакриламид) (РНРМА), поли-N-винилпирролидон) (PVP), поливиниловый спирт (PVA), сополимер полиэтиленгликоля и полипропиленгликоля, поли(N-акрилоилморфолин) (РАсМ) и полиэтиленгликоль (PEG) (Powell, 1980, Polyethylene glycol. In R.L. Davidson (Ed.) Handbook of Water Soluble Gums and Resins. McGraw-Hill, New York, глава 18). ПЭГ обладает идеальным набором свойств: очень низкая токсичность (Pang, 1993, J. Am. Coll. Toxicol. 12: 429-456), превосходная растворимость в водном растворе (Powell, см. выше), низкая иммуногенность и антигенность (Dreborg et al., 1990, Crit. Rev. Ther. Drug Carrier Syst. 6: 315-365). ПЭГ-конъюгированные или "ПЭГилированные" белковые терапевтические средства, содержащие одну или множество цепей полиэтиленгликоля на белке, были описаны в научной литературе (Clark et al., 1996, J. Biol. Chem. 271: 21969-21977; Hershfield, 1997, Biochemistry and immunology of poly(ethylene glycol)-modified adenosine deaminase (PEG-ADA). In J. M. Harris and S. Zalipsky (Eds) Poly(ethylene glycol): Chemistry and Biological Applications. American Chemical Society, Washington, D.C., p 145-154; Olson et al., 1997, Preparation and characterization of poly(ethylene glycosylated human growth hormone antagonist. In J. M. Harris and S. Zalipsky (Eds) Poly(ethylene glycol): Chemistry and Biological Applications. American Chemical Society, Washington, D.C., p 170-181).
Пептид согласно данному изобретению может быть синтезирован с помощью стандартных методик. Например, пептиды согласно данному изобретению могут быть синтезированы путем химического синтеза с использованием твердофазного пептидного синтеза. Эти способы используют твердофазный синтез или синтез в растворе (см., например, J.М. Stewart, and J.D. Young, Solid Phase Peptide Synthesis, 2nd Ed., Pierce Chemical Co., Rockford III. (1984), и G. Barany and R. B. Merrifield, The Peptides: Analysis Synthesis, Biology editors E. Gross and J. Meienhofer Vol.2 Academic Press, New York, 1980, pp.3-254 для методик твердофазного синтеза; и М Bodansky, Principles of Peptide Synthesis, Springer-Verlag, Berlin 1984, и E. Gross and J. Meienhofer, Eds., The Peptides: Analysis, Synthesis, Biology, см. выше, том 1, для классического синтеза в растворе).
Пептиды могут быть химически синтезированы путем твердофазного пептидного синтеза по Меррифилду. Этот способ может быть выполнен стандартным образом для получения пептидов длиной до 60-70 остатков и может в некоторых случаях использоваться для получения пептидов длиной до 100 аминокислот. Более крупные пептиды могут также быть созданы синтетически путем конденсации фрагментов или нативного химического лигирования (Dawson et al., 2000, Ann. Rev. Biochem., 69: 923-960). Преимуществом использования пути синтеза пептидов является способность производить большое число пептидов, даже тех, которые редко встречаются в природе, с относительно высокой чистотой, т.е. чистотой, достаточной для исследовательских, диагностических или терапевтических целей.
Твердофазный пептидный синтез описан Stewart et al. в Solid Phase Peptide Synthesis, 2nd Edition, 1984, Pierce Chemical Company, Rockford, III.; и Bodanszky and Bodanszky в The Practice of Peptide Synthesis, 1984, Springer-Verlag, New York. Вначале подходящим образом защищенный аминокислотный остаток присоединяют через его карбоксильную группу к дериватизированной нерастворимой полимерной подложке, такой как сшитый полистирол или полиамидная смола. Понятие "подходящим образом защищенный" относится к присутствию защитных групп как на альфа-аминогруппе аминокислоты, так и на любых функциональных группах боковых цепей. Защитные группы боковых цепей, как правило, стабильны по отношению к растворителям, реагентам и реакционным условиям, используемым на протяжении всего синтеза, и могут быть удалены в условиях, которые не влияют на конечный пептидный продукт. Поэтапный синтез олигопептида проводят путем удаления N-защитной группы с исходной аминокислоты и связывания с ней карбоксильного конца следующей аминокислоты в последовательности нужного пептида. Эта аминокислота также подходящим образом защищена. Карбоксил входящей аминокислоты может быть активирован для взаимодействия с N-концом связанной с подложкой аминокислоты путем формирования реакционноспособной группы, таким как формирование карбодиимида, симметричного кислотного ангидрида или "активной эфирной" группы, такой как эфиры гидроксибензотриазола или пентафторфенила.
Примеры способов твердофазного синтеза пептидов включают способ ВОС, в котором используют трет-бутилоксикарбонил в качестве альфа-аминозащитной группы, и способ FMOC, в котором используют 9-флуоренилметилоксикарбонил для защиты альфа-амино-группы аминокислотных остатков, причем оба способа хорошо известны специалистам в данной области.
Включение N- и/или С-блокирующих групп также может быть достигнуто с использованием протоколов традиционного и твердофазного синтеза пептидов. Для введения С-концевых блокирующих групп, например, обычно проводят синтез нужного пептида с использованием в качестве твердой фазы подлежащей смолы, которая была химически модифицирована, так что отщепление от смолы приводит к получению пептида, имеющего нужную С-концевую блокирующую группу. Для получения пептидов, в которых С-конец имеет первичную амино-блокирующую группу, например, синтез осуществляют с использованием пара-метилбензгидриламиновой (p-methylbenzhydrylamine, МВНА) смолы, так что, когда пептидный синтез завершается, обработка фтористоводородной кислотой высвобождает нужный С-концевой амидированный пептид. Аналогичным образом, включение N-метиламиновой блокирующей группы на С-конце достигается с использованием N-метиламиноэтил-дериватизованной DVB, смолы, которая при обработке HF высвобождает пептид, несущий N-метиламидированный С-конец. Блокирование С-конца путем этерификации также может быть достигнуто с использованием стандартных процедур. Это влечет за собой использование комбинации смолы/блокирующей группы, которая позволяет высвобождать пептид боковой цепи из смолы, чтобы обеспечить последующую реакцию с нужным спиртом, с формирование сложноэфирной функциональной группы. Для этой цели можно использовать защитную группу FMOC в сочетании со смолой DVB, дериватизованной метоксиалкоксибензиловым спиртом или эквивалентным линкером, с отщеплением от подложки, осуществляемым с помощью трифторуксусной кислоты (TFA) в дихлорометане. Этерификацию подходящим образом активированной карбоксильной функциональной группы, например, с помощью DCC, затем можно продолжить путем добавления нужного спирта с последующим снятием защиты и выделением этерифицированного пептидного продукта.
Пептиды согласно данному изобретению могут быть получены стандартными химическими или биологическими способами синтеза пептидов. Биологические способы включают, но не ограничиваясь ими, экспрессию нуклеиновой кислоты, кодирующей пептид в клетке-хозяине или в системе трансляции in vitro.
В изобретение включены последовательности нуклеиновых кислот, которые кодируют пептид согласно данному изобретению. В одном из воплощений данное изобретение включает последовательности нуклеиновых кислот, кодирующие аминокислотную последовательность одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL. Соответственно, субклоны последовательности нуклеиновой кислоты, кодирующей пептид согласно данному изобретению, могут быть получены с использованием стандартных молекулярно-генетических манипуляций для субклонирования генных фрагментов, таких как описаны в изданиях Sambrook et al., Molecular Cloning: A Laboratory Manual, Cold Springs Laboratory, Cold Springs Harbor, New York (2012), и Ausubel et al. (ed.), Current Protocols in Molecular Biology, John Wiley & Sons (New York, NY) (1999 и предыдущие издания), каждое из которых полностью включено в данный документ посредством ссылки. Затем субклоны экспрессируют in vitro или in vivo в бактериальных клетках, получая белок меньшего размера или полипептид, который можно проанализировать на наличие конкретной активности.
В сочетании с некоторыми составами такие пептиды могут быть эффективными внутриклеточными агентами. Тем не менее, для повышения эффективности таких пептидов один или более чем один из пептидов согласно данному изобретению могут быть получены в виде гибридного пептида вместе со вторым пептидом, который способствует "трансцитозу", например, поглощению пептида клетками. Например, в одном из воплощений указанный пептид может содержать домен, проникающий в клетку, например, пептид, проникающий в клетку (cell-penetrating peptide, СРР), чтобы позволить пептиду войти в клетку. В одном из воплощений СРР получен из Tat-гена ВИЧ.
С целью иллюстрации один или более чем один из пептидов согласно данному изобретению может быть представлен как часть гибридного полипептида с целым N-концевым доменом Tat-белка ВИЧ или его фрагментом, например, остатками 1-72 Tat или меньшим фрагментом, который может способствовать трансцитозу. В одном из воплощений указанный пептид содержит домен белковой трансдукции Tat из ВИЧ (YGRKKRRQRRR (SEQ ID NO 163)). В других воплощениях один или более чем один из пептидов согласно данному изобретению может быть представлен как гибридный полипептид со целым белком антенопедии III или его частью. Другие проникающие в клетку домены, которые опосредуют поглощение пептида, известны в данной области и одинаково применимы для использования в гибридном пептиде согласно данному изобретению.
Нуклеиновые кислоты
В одном из воплощений композиция согласно данному изобретению содержит одну или более чем одну изолированную нуклеиновую кислоту. Например, в одном из воплощений одна или более чем одна изолированная нуклеиновая кислота кодирует один или более чем один из TRIM-белков. Например, в одном из воплощений одна или более чем одна изолированная нуклеиновая кислота кодирует один или более чем один из человеческих TRIM3, TRIM4, TRIM5, TRIM6, TRIM7, TRIM9, TRIM11, TRIM13, TRIM14, TRIM15, TRIM16, TRIM17, TRIM19 (также упоминаемого в данном документе как "PML"), TRIM20, TRIM21, TRIM24, TRIM25, TRIM27, TRIM28, TRIM29, TRIM32, TRIM34, TRIM39, TRIM43, TRIM44, TRIM45, TRIM46, TRIM49, TRIM50, TRIM52, TRIM58, TRIM69, TRIM70, TRIM74 и TRIM75; и мышиного TRIM30. В некоторых воплощениях одна или более чем одна изолированная нуклеиновая кислота кодирует одну или более чем одну из STUbL. Например, в одном из воплощений одна или более чем изолированная нуклеиновая кислота кодирует один или более чем один из RNF4 и RNF111 (Arkadia).
Иллюстративные нуклеотидные последовательности, кодирующие TRIM-белки, приведены в таблице 1.
В некоторых воплощениях пептид, соответствующий одному или более чем одному белку TRIM или одной или более чем одной STUbL, экспрессируют с одной или более чем одной нуклеиновой кислоты в клетке in vivo или in vitro с использованием известных методик.
Нуклеотидная последовательность изолированных нуклеиновых кислот включает как последовательность ДНК, которая транскрибируется в РНК, так и последовательность РНК, которая транслируется в полипептид. В соответствии с другими воплощениями нуклеотидные последовательности выведены из аминокислотной последовательности пептидов согласно данному изобретению. Как известно в данной области, возможно выведение несколько альтернативных нуклеотидных последовательностей из-за избыточности кодонов, при этом с сохранением биологической активности транслированных пептидов.
Кроме того, данное изобретение охватывает изолированную нуклеиновую кислоту, содержащую нуклеотидную последовательность, имеющую существенную гомологию с кодирующей нуклеотидной последовательностью, раскрытой в данном документе. Предпочтительно, нуклеотидная последовательность изолированной нуклеиновой кислоты является "по существу гомологичной", т.е. является примерно на 60% гомологичной, более предпочтительно примерно на 70% гомологичной, еще более предпочтительно примерно на 80% гомологичной, более предпочтительно примерно на 90% гомологичной, еще более предпочтительно примерно на 95% гомологичной и даже более предпочтительно примерно на 99% гомологичной нуклеотидной последовательности изолированной нуклеиновой кислоты, кодирующей пептид согласно данному изобретению.
В одном из воплощений указанная композиция содержит комбинацию описанных в данном документе молекул нуклеиновых кислот. Например, в некоторых воплощениях указанная композиция содержит изолированную молекулу нуклеиновой кислоты, кодирующую один или более чем один из TRIM-белков, и изолированную молекулу нуклеиновой кислоты, кодирующую одну или более чем одну из STUbL. В одном из воплощений указанная композиция содержит изолированную молекулу нуклеиновой кислоты, кодирующую один или более чем один из TRIM-белков и одну или более чем одну из STUbL.
Таким образом, данное изобретение охватывает экспрессионные векторы и способы введения экзогенной ДНК в клетки с сопутствующей экспрессией экзогенной ДНК в клетках, как описано, например, в Sambrook et al. (2012, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory, New York), и в Ausubel et al. (1997, Current Protocols in Molecular Biology, John Wiley & Sons, New York).
Нужная нуклеиновая кислота, кодирующая один или более чем один из TRIM-белков или одну или более чем одну из STUbL, может быть клонирована в несколько типов векторов. Тем не менее, данное изобретение не должно истолковываться как ограниченное каким-либо конкретным вектором. Напротив, данное изобретение должно толковаться как охватывающее широкий спектр векторов, которые легко доступны и/или хорошо известны в данной области. Например, нужный полинуклеотид согласно данному изобретению может быть клонирован в вектор, включая, но не ограничиваясь ими, плазмиду, фагмиду, производное фага, вирус животного и космиду. Векторы, представляющие особый интерес, включают векторы для экспрессии, векторы для репликации, векторы для создания зондов и векторы для секвенирования.
В конкретных воплощениях экспрессионный вектор выбран из группы, состоящей из вирусного вектора, бактериального вектора и вектора клетки млекопитающего. Существуют многочисленные системы экспрессионных векторов, которые содержат по меньшей мере часть или все композиции, рассмотренные выше. Системы, основанные на прокариотическом и/или эукариотическом векторе, могут быть использованы для применения согласно данному изобретению для получения полинуклеотидов или их родственных полипептидов. Многие такие системы являются коммерческими и широко доступными.
Кроме того, экспрессионный вектор может быть предоставлен клетке в форме вирусного вектора. Технология вирусных векторов хорошо известна в данной области и описана, например, в Sambrook et al. (2012) и в Ausubel et al. (1997), а также в других руководствах по вирусологии и молекулярной биологии. Вирусы, которые могут быть использованы в качестве векторов, включают, но не ограничиваясь ими, ретровирусы, аденовирусы, аденоассоциированные вирусы, вирусы герпеса и лентивирусы. В целом, подходящий вектор содержит сайт начала репликации, функционирующий по меньшей мере в одном организме, промоторную последовательность, удобные рестрикционные сайты эндонуклеаз и один или более чем один из селектируемых маркеров (см., например, WO 01/96584; WO 01/29058; и патент США №6326193).
На основе вирусов был разработан ряд систем для переноса генов в клетки млекопитающих. Например, ретровирусы предоставляют удобную платформу для систем доставки генов. Выбранный ген может быть вставлен в вектор и упакован в ретровирусные частицы с использованием методик, известных в данной области. Затем рекомбинантный вирус может быть выделен и доставлен в клетки субъекта in vivo или ex vivo. В данной области известен ряд ретровирусных систем. В некоторых воплощениях используются аденовирусные векторы. В данной области известен ряд аденовирусных векторов. В одном из воплощений используются лентивирусные векторы.
Например, векторы, полученные из ретровирусов, таких как лентивирус, являются подходящими инструментами для достижения долгосрочного переноса генов, поскольку они делают возможной долговременную стабильную интеграцию трансгена и его размножение в дочерних клетках. Лентивирусные векторы обладают дополнительным преимуществом по сравнению с векторами, полученными из онкоретровирусов, таких как вирусы лейкемии мыши, которое заключается в том, что они могут трансдуцировать непролиферирующие клетки, такие как гепатоциты. Они также обладают дополнительным преимуществом низкой иммуногенности. В предпочтительном воплощении указанная композиция включает вектор, на основе аденоассоциированного вируса (AAV). Векторы на основе аденоассоциированных вирусов (AAV) стали мощными инструментами доставки генов для лечения различных нарушений. AAV-векторы обладают рядом особенностей, которые делают их идеально подходящими для генной терапии, включая отсутствие патогенности, минимальную иммуногенность и способность трансформировать постмитотические клетки стабильным и эффективным образом. Экспрессия конкретного гена, содержащегося в AAV-векторе, может быть специфически нацелена на один или более чем один тип клеток за счет выбора подходящей комбинации серотипа AAV, промотора и способа доставки.
В одном из воплощений кодирующая последовательность содержится в векторе AAV. Доступно более 30 природных серотипов AAV. Существует множество природных вариантов капсида AAV, позволяющих идентифицировать и использовать AAV со свойствами, специфически подходящими для скелетных мышц. AAV-вирусы могут быть сконструированы с использованием стандартных методик молекулярной биологии, позволяющих оптимизировать эти частицы для кпеточно-специфической доставки последовательностей нуклеиновых кислот, для минимизации иммуногенности, для увеличения стабильности и времени жизни частиц, для эффективной деградации, для точной доставки в ядро и т.д.
Таким образом, экспрессия одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL может быть достигнута путем доставки рекомбинантно разработанного AAV вектора или искусственного AAV вектора, который содержит одну или более чем одну кодирующую последовательность. Использование AAV является распространенным способом экзогенной доставки ДНК, поскольку он относительно нетоксичен, обеспечивает эффективный перенос генов и может быть легко оптимизирован для конкретных целей. Иллюстративные серотипы AAV включают, но не ограничиваясь ими, AAV1, AAV2, AAV3, AAV4, AAV5, AAV6, AAV7, AAV8 и AAV9.
Нужные фрагменты AAV для сборки в векторы включают cap-белки, включая vp1, vp2, vp3 и гипервариабельные области, rep-белки, включая rep 78, rep 68, rep 52 и rep 40, и последовательности, кодирующие эти белки. Эти фрагменты могут быть легко использованы в различных векторных системах и клетках-хозяевах. Такие фрагменты могут использоваться отдельно, в комбинации с другими последовательностями или фрагментами серотипа AAV или в комбинации с элементами из других вирусных AAV- или нe-AAV-последовательностей. Используемые в данном документе искусственные серотипы AAV включают, но не ограничиваясь ими, AAV с неприродным капсидным белком. Такой искусственный капсид может быть получен с помощью любой подходящей методики с использованием выбранной последовательности AAV (например, фрагмента капсидного белка vp1) в комбинации с гетерологичными последовательностями, которые могут быть получены из другого выбранного серотипа AAV, несмежных частей такого же серотипа AAV, из вирусного He-AAV-источника или из невирусного источника. Искусственный серотип AAV может представлять собой, но не ограничиваясь ими, химерный капсид AAV, рекомбинантный капсид AAV или "гуманизированный" капсид AAV. Таким образом, иллюстративные AAV, или искусственные AAV, подходящие для экспрессии одного или более чем одного TRIM-белка или одной или более чем одной STUbL, включают AAV2/8 (см. патент США №7282199), AAV2/5 (доступный из Национального института здоровья) AAV2/9 (международная патентная публикация №WO2005/033321), AAV2/6 (патент США №6156303) и AAVrh8 (международная патентная публикация №WO2003/042397) и другие.
Для экспрессии нужного полинуклеотида по меньшей мере один модуль в каждом промоторе функционирует как определяющий место начала синтеза РНК. Наиболее известным примером его является ТАТА-мотив, но в некоторых промоторах, у которых отсутствует ТАТА-мотив, таких как промотор гена концевой дезоксинуклеотидилтрансферазы млекопитающих и промотор генов SV40, дискретный элемент, лежащий выше места начала, помогает исправить место инициации.
Дополнительные промоторные элементы, т.е. энхансеры, регулируют частоту инициации транскрипции. Как правило, они расположены в области 30-110 п. о. выше старт-кодона, хотя недавно было показано, что ряд промоторов также содержит функциональные элементы ниже старт-кодона. Расстояние между промоторными элементами часто является гибким, так что промоторная функция сохраняется, когда элементы инвертируются или перемещаются относительно друг друга. В промоторе тимидинкиназы (thymidine kinase, tk) расстояние между промоторными элементами может быть увеличено до 50 п. о., прежде чем активность начнет снижаться. В зависимости от промотора, по-видимому, отдельные элементы могут функционировать либо совместно, либо независимо для активации транскрипции.
Промотор может быть таким, который в природе связан с геном или полинуклеотидной последовательностью, а также может быть получен путем выделения 5'-некодирующих последовательностей, расположенных выше кодирующего сегмента и/или экзона. Такой промотор можно назвать "эндогенным". Аналогичным образом, энхансер может быть естественным образом связан с полинуклеотидной последовательностью, расположенной либо ниже, либо выше этой последовательности. Альтернативно, некоторые преимущества будут достигнуты путем позиционирования кодирующего полинуклеотидного сегмента под контролем рекомбинантного или гетерологичного промотора, который относится к промотору, который обычно не ассоциирован с полинуклеотидной последовательностью в его природной среде. Рекомбинантный или гетерологичный энхансер также относится к энхансеру, который обычно не ассоциирован с полинуклеотидной последовательностью в его природной среде. Такие промоторы или энхансеры могут включать промоторы или энхансеры других генов и промоторы или энхансеры, выделенные из любой другой прокариотической клетки, вируса или эукариотической клетки, и промоторы или энхансеры не являются "природными", т.е. содержат отличающиеся элементы отличающихся регуляторных областей транскрипции и/или мутации, которые изменяют экспрессию. В дополнение к получению нуклеиновокислотных последовательностей промоторов и энхансеров синтетически, эти последовательности могут быть получены с использованием технологии рекомбинантного клонирования и/или амплификации нуклеиновой кислоты, включая PCR™, в связи с описанными в данном документе композициями (патент США 4683202, патент США 5928906). Кроме того, предполагается, что также могут использоваться контрольные последовательности, которые направляют транскрипцию и/или экспрессию последовательностей в неядерные органеллы, такие как митохондрии, хлоропласты и т.п.
Естественно, будет важно использовать промотор и/или энхансер, который эффективно направляет экспрессию сегмента ДНК в клеточный тип, органеллу и организм, выбранный для экспрессии. Специалисты в области молекулярной биологии обычно знают, как использовать промоторы, энхансеры и комбинации типов клеток для экспрессии белка, например, см. Sambrook et al. (2012). Используемые промоторы могут быть конститутивными, тканеспецифическими, индуцируемыми и/или используемыми в соответствующих условиях для прямой экспрессии на высоком уровне введенного сегмента ДНК, такого, который выгоден при крупномасштабной продукции рекомбинантных белков и/или пептидов. Промотор может быть гетерологичным или эндогенным.
В одном из воплощений промотор или энхансер специфически направляет экспрессию одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL в нервной ткани в эпителии кишечника. Например, в некоторых воплощениях промотор или энхансер специфически направляет экспрессию одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL в нейроне, астроците, олигодендроците, клетке Пуркинье, пирамидальной клетке и т.п.
Для оценки экспрессии нужного полинуклеотида экспрессионный вектор, который должен быть введен в клетку, также может содержать либо селектируемый маркерный ген, либо репортерный ген, либо оба, чтобы облегчить идентификацию и выбор экспрессирующих клеток из популяции клеток, которые были подвергнуты трансфекции или инфицированы вирусными векторами. В других воплощениях селектируемый маркер может быть перенесен на отдельный фрагмент ДНК и использован в процедуре котрансфекции. Как селектируемые маркеры, так и репортерные гены могут быть фланкированы соответствующими регуляторными последовательностями для обеспечения экспрессии в клетках-хозяевах. Селектируемые маркеры известны в данной области и включают, например, гены устойчивости к антибиотикам, такие как нео, и т.п.
Репортерные гены используются для идентификации потенциально трансфицированных клеток и для оценки функциональности регуляторных последовательностей. Репортерные гены, которые кодируют легко анализируемые белки, хорошо известны в данной области. Как правило, репортерный ген представляет собой ген, который отсутствует или не экспрессируется организмом или тканями реципиента и который кодирует белок, экспрессия которого проявляется с помощью некоего легко обнаружимого свойства, например, ферментативной активности. Экспрессию репортерного гена анализируют в подходящий момент времени после того, как ДНК была введена в клетки-реципиенты.
Подходящие репортерные гены могут включать гены, кодирующие люциферазу, бета-галактозидазу, хлорамфениколацетилтрансферазу, секретируемую щелочную фосфатазу или ген зеленого флуоресцентного белка (см., например, Ui-Tei et al., 2000 FEBS Letters 479: 79-82). Подходящие экспрессионные системы хорошо известны и могут быть получены с использованием известных методик или получены коммерчески. Как правило, конструкции с внутренней делецией могут быть образованы с помощью уникальных внутренних сайтов распознавания рестриктаз или путем частичного расщепления не уникальных сайтов распознавания рестриктаз. Затем конструкциями могут быть трансфицированы клетки, которые демонстрируют высокие уровни полинуклеотидов киРНК и/или экспрессию полипептида. Как правило, конструкция с минимальной 5'-фланкирующей областью, демонстрирующая наивысший уровень экспрессии репортерного гена, идентифицируется как промотор. Такие промоторные области могут быть связаны с репортерным геном и использованы для оценки агентов на их способность модулировать транскрипцию, упарвляемую промотором.
В контексте экспрессионного вектора указанный вектор может быть легко введен в клетку-хозяина, например, клетку млекопитающего, бактериальную, дрожжевую или клетку насекомого любым способом, известным в данной области. Например, экспрессионный вектор может быть перенесен в клетку-хозяина физическими, химическими или биологическими способами.
Физические способы введения полинуклеотида в клетку-хозяина включают осаждение фосфатом кальция, липофекцию, бомбардировку частицами, микроинъекцию, электропорацию и т.п. Способы получения клеток, содержащих векторы и/или экзогенные нуклеиновые кислоты, хорошо известны в данной области. См., например, Sambrook et al. (2012, Molecular Cloning: A Laboratory Manual, Cold Spring Harbor Laboratory, New York) и Ausubel et al. (1997, Current Protocols in Molecular Biology, John Wiley & Sons, New York).
Биологические способы введения в клетку-хозяина полинуклеотида, представляющего интерес, включают использование ДНК- и РНК-векторов. Вирусные векторы, и особенно ретровирусные векторы, стали наиболее широко используемым способом введения генов в клетки млекопитающих, например, в человеческие клетки. Другие вирусные векторы могут быть получены из лентивирусов, поксвирусов, вируса простого герпеса I, аденовирусов и аденоассоциированных вирусов и т.п. См., например, патенты США №№5350674 и 5585362.
Химические средства для введения полинуклеотида в клетку-хозяина включают коллоидные дисперсионные системы, такие как комплексы макромолекул, нанокапсулы, микросферы, гранулы и системы на основе липидов, включая эмульсии типа "масло-в-воде", мицеллы, смешанные мицеллы и липосомы. Иллюстративная коллоидная система для использования в качестве носителя для доставки in vitro и in vivo представляет собой липосому (т.е. везикулу с искусственной оболочкой). Получение и применение таких систем хорошо известно в данной области.
Независимо от способа, используемого для введения экзогенных нуклеиновых кислот в клетку-хозяина, для подтверждения наличия рекомбинантной ДНК-последовательности в клетке-хозяине может быть проведен ряд анализов. Такие анализы включают, например, "молекулярно-биологические" анализы, хорошо известные специалистам в данной области, такие как саузерн- и нозерн-блоттинг, ОТ-ПЦР и ПЦР; "биохимические" анализы, такие как обнаружение наличия или отсутствия конкретного пептида, например, иммунологическими средствами (ELISA и вестерн-блоттинг), или анализы, описанные в данном документе для идентификации агентов, входящих в объем данного изобретения.
Любой ДНК-вектор или носитель для доставки может быть использован для переноса нужного полинуклеотида в клетку in vitro или in vivo. В случае, когда используется невирусная система доставки, предпочтительным средством доставки является липосома. Упомянутые выше системы доставки и протоколы можно найти в Gene Targeting Protocols, 2ed., pp 1-35 (2002) и в Gene Transfer and Expression Protocols, Vol.7, Murray ed., pp 81-89 (1991).
"Липосома" представляет собой общий термин, охватывающий различные одно- и многослойные липидные носители, сформированные путем образования закрытых липидных бислоев или агрегатов. Липосомы можно охарактеризовать как везикулярные структуры с фосфолипидной двухслойной мембраной и внутренней водной средой. Многослойные липосомы имеют несколько липидных слоев, разделенных водной средой. Они формируются спонтанно, когда фосфолипиды суспендированы в избытке водного раствора. Липидные компоненты подвергаются самоперестраиванию перед формированием закрытых структур и захватывают воду и растворенные вещества между липидными бислоями. Тем не менее, данное изобретение также охватывает композиции, которые имеют структуры в растворе, отличающиеся от нормальной везикулярной структуры. Например, липиды могут приобретать мицеллярную структуру или просто существовать как неоднородные агрегаты липидных молекул. Также рассматриваются комплексы "липофектамин -нуклеиновая кислота".
В одном из воплощений композиция согласно данному изобретению содержит РНК, транскрибированную in vitro (in vitro transcribed, IVT), кодирующую один или более чем один компонент одного или более чем одного TRIM-белка и одной или более чем одной STUbL. В одном из воплощений IVT РНК может быть введена в клетку в форме временной трансфекции. РНК продуцируется путем транскрипции in vitro с помощью плазмидной ДНК-матрицы, образованной синтетически. Представляющая интерес ДНК из любого источника может быть напрямую преобразована путем ПЦР в матрицу для синтеза мРНК in vitro с использованием подходящих праймеров и РНК-полимеразы. Источником ДНК может служить, например, последовательность геномной ДНК, плазмидной ДНК, фаговой ДНК, кДНК, синтетической ДНК или любой другой подходящий источник ДНК. Нужной матрицей для транскрипции in vitro является один или более чем один TRIM-белок и одна или более чем одна STUbL.
В одном из воплощений ДНК, которая должна использоваться для ПЦР, содержит открытую рамку считывания. ДНК может быть природной последовательностью ДНК из генома организма. В одном из воплощений ДНК представляет собой полноразмерный ген, представляющий интерес, или часть гена. Ген может включать некоторые или все 5'- и/или 3'-нетранслируемые области (untranslated region, UTR). Ген может включать экзоны и интроны. В одном из воплощений ДНК, которая будет использоваться для ПЦР, представляет собой человеческий ген. В другом воплощении ДНК, которая будет использоваться для ПЦР, представляет собой человеческий ген, включающий 5'- и 3'-UTR. Альтернативно, ДНК может быть искусственной последовательностью ДНК, которая в природе обычно не экспрессируется в организме. Иллюстративная искусственная последовательность ДНК представляет собой последовательность, которая содержит части генов, которые лигированы вместе, формируя открытую рамку считывания, которая кодирует гибридный белок. Части ДНК, которые лигированы вместе, могут быть получены из одного организма или более чем из одного организма.
В одном из воплощений композиция согласно данному изобретению содержит модифицированную нуклеиновую кислоту, кодирующую один или более чем один из TRIM-белков или RNF4, описанных в данном документе. Например, в одном из воплощений указанная композиция содержит нуклеозид-модифицированную РНК. В одном из воплощений указанная композиция содержит нуклеозид-модифицированную мРНК. Нуклеозид-модифицированная мРНК имеет особые преимущества перед немодифицированной мРНК, включая, например, повышенную стабильность, низкую иммуногенность и улучшенную трансляцию. Нуклеозид-модифицированная мРНК, используемая в данном изобретении, также описана в патенте США №8278036, который полностью включен в данный документ посредством ссылки.
Модифицированная клетка
Данное изобретение включает композицию, содержащую клетку, которая содержит один или более чем один из TRIM-белков, одну или более чем одну из STUbL, нуклеиновую кислоту, кодирующую один или более чем один из TRIM-белков, нуклеиновую кислоту, кодирующую одну или более чем одну из STUbL, или их комбинацию. В одном из воплощений указанная клетка генетически модифицирована для экспрессии белка и/или нуклеиновой кислоты согласно данному изобретению. В некоторых воплощениях генетически модифицированная клетка является аутологичной по отношению к субъекту, которому вводят композицию согласно данному изобретению. Альтернативно, указанные клетки могут быть аллогенными, сингенными или ксеногенными по отношению к субъекту. В определенном воплощении клетка способна секретировать или высвобождать экспрессированный белок во внеклеточное пространство, чтобы доставить пептид в одну или более чем одну другую клетку.
Генетически модифицированную клетку можно модифицировать in vivo или ex vivo с использованием методик, стандартных в данной области. Генетическую модификацию клетки можно проводить с использованием экспрессионного вектора или с использованием голой изолированной нуклеиновокислотной конструкции.
В одном из воплощений указанную клетку получают и модифицируют ех vivo, используя изолированную нуклеиновую кислоту, кодирующую один или более чем один из белков, описанных в данном документе. В одном из воплощений указанную клетку получают от субъекта, генетически модифицированного для экспрессии белка и/или нуклеиновой кислоты, и повторно вводят субъекту. В некоторых воплощениях указанную клетку размножают ex vivo или in vitro для получения популяции клеток, где по меньшей мере часть указанной популяции вводят нуждающемуся в этом субъекту.
В одном из воплощений указанную клетку генетически модифицируют для стабильной экспрессии белка. В другом воплощении клетку генетически модифицируют для временной экспрессии белка.
Субстраты
Данное изобретение предусматривает матричную или субстратную композицию, содержащую белок согласно данному изобретению, изолированную нуклеиновую кислоту согласно данному изобретению, клетку, экспрессирующую белок согласно данному изобретению, или их комбинацию. Например, в одном из воплощений белок согласно данному изобретению, изолированная нуклеиновая кислота согласно данному изобретению, клетка, экспрессирующая белок согласно данному изобретению, или их комбинация встроены в матрицу. В другом воплощении белок согласно данному изобретению, изолированную нуклеиновую кислоту согласно данному изобретению, клетку, экспрессирующую белок согласно данному изобретению, или их комбинацию наносят на поверхность матрицы. Матрица согласно данному изобретению может быть любого типа, известного в данной области. Неограничивающие примеры таких матриц включают гидрогель, электроформованную матрицу, пену, сетку, лист, пластырь и губку.
Способы лечения
Данное изобретение также предусматривает способы лечения заболевания или нарушения, ассоциированного с неправильной упаковкой белка, белковыми агрегатами или их комбинацией.
В различных воплощениях заболевания и нарушения, поддающиеся лечению с помощью способов согласно данному изобретению, включают, но не ограничиваясь ими: полиQ-нарушения, такие как SCA1, SCA2, SCA3, SCA6, SCA7, SCA17, болезнь Хантингтона, дентаторубро-паллидолюисовую атрофию (DRPLA), болезнь Альцгеймера, болезнь Паркинсона, боковой амиотрофический склероз (ALS), трансмиссивную губчатую энцефалопатию (прионное заболевание), тауопатии и лобно-височную дегенерацию (FTLD), AL-амилоидоз, АА-амилоидоз, семейную средиземноморскую лихорадку, старческий системный амилоидоз, семейную амилоидотическую полинейропатию, амилоидоз, связанный с гемодиализом, ApoAI-амилоидоз, ApoAII-амилоидоз, ApoAIV-амилоидоз, финский наследственный амилоидоз, лизоцимный амилоидоз, фибриногеновый амилоидоз, исландскую наследственную церебральную амилоидную ангиопатию, диабет II типа, медуллярную карциному щитовидной железы, предсердный амилоидоз, наследственные кровоизлияния в мозг с амилоидозом, пролактиному гипофиза, локализованный амилоидоз в месте инъекции, аортальный медиальный амилоидоз, наследственную решетчатую дистрофию роговицы, амилоидоз роговицы, связанный с трихиазом, катаракту, кальцификацию эпителиальной одонтогенной опухоли, легочный альвеолярный протеиноз, миозит с тельцами включения и узелкового амилоидоз кожи. В некоторых воплощениях указанный способ включает лечение или профилактику рака, ассоциированного с р53-мутантными агрегатами, включая, но не ограничиваясь ими, карциному мочевого пузыря, астроцитому, рак глотки, лимфому и аденокарциному.
Специалисту в данной области, вооруженному данным описанием, включая способы, подробно описанные в данном документе, будет понятно, что данное изобретение не ограничивается лечением заболевания, ассоциированного с неправильной упаковкой белка или агрегатами белка, которое уже установлено. В частности, данное заболевание или нарушение не обязательно должно проявляться до момента нанесения вреда субъекту; действительно, заболевание или нарушение не обязательно должно быть обнаружено у субъекта до того, как лечение будет назначено. Т.е. значимые признаки или симптомы заболевания или нарушения не обязательно должны возникать до того, как данное изобретение может принести пользу. Таким образом, данное изобретение включает способ профилактики заболевания или нарушения, ассоциированного с неправильной упаковкой белков или белковыми агрегатами, поскольку композицию с модулятором, обсуждаемоую ранее в другом месте в данном документе, можно вводить субъекту до начала заболевания или нарушения, тем самым предотвращая заболевание или нарушение.
Специалист в данной области, вооруженный описанием в данном документе, поймет, что профилактика заболевания, ассоциированного с неправильной упаковкой белков или белковыми агрегатами, охватывает введение субъекту композиции с модулятором в качестве профилактической меры против развития или прогрессирования заболевания, ассоциированного с неправильной упаковкой белка или белковыми агрегатами. Как более подробно описано в данном документе, способы модуляции уровня или активности гена или продукта гена охватывают широкий спектр методик модуляции не только уровня и активности полипептидных продуктов генов, но также модуляции экспрессии нуклеиновой кислоты, включая транскрипцию, трансляцию или и то, и другое.
Кроме того, как описано в другом месте в данном документе, специалист в данной области, вооружившись приведенными в данном документе знаниями, поймет, что данное изобретение охватывает способы лечения или профилактики широкого спектра заболеваний, ассоциированных с неправильной упаковкой белка или белковыми агрегатами, где модуляция уровня или активности гена или генного продукта лечит или предотвращает заболевание. В данной области известны различные способы оценки того, ассоциировано ли заболевание с неправильной упаковкой белка или белковыми агрегатами. Кроме того, данное изобретение охватывает лечение или профилактику таких заболеваний, обнаруженных в будущем.
В одном из аспектов данный способ включает использование одного или более чем одного из TRIM-белков для стабилизации неправильно упакованного белка. В некоторых аспектах стабилизация функционального неправильно упакованного белка через один или более чем один из TRIM-белков, описанных в данном документе, может лечить или предотвращать заболевание или нарушение, ассоциированное с неправильно упакованным белком. Например, в одном из воплощений стабилизация мутантного регулятора трансмембранной проводимости при муковисцидозе (CFTR) через один или более чем один из TRIM-белков, описанных в данном документе, позволила бы мутантному CFTR функционировать вместо деградации. Предполагается, что использование TRIM-белков для стабилизации неправильно упакованных белков может быть использовано для лечения муковисцидоза и других заболеваний, ассоциированных с деградацией частично функциональных белков. Стабилизация белков посредством одного или более чем одного из TRIM-белков, описанных в данном документе, может быть использована для лечения любого заболевания или нарушения, ассоциированного с деградацией функционального мутантного белка, включая, но не ограничиваясь ими, муковисцидоз и лизосомные болезни накопления, такие как болезнь Гоше и болезнь Фабри.
Данное изобретение охватывает введение модулятора гена или продукта гена. При осуществлении способов согласно данному изобретению на практике квалифицированный специалист понимает на основе раскрытого в данном документе описания, как собирать в состав и вводить соответствующую композицию с модулятором субъекту. Данное изобретение не ограничено каким-либо конкретным способом введения или режимом лечения.
В одном из воплощений указанный способ включает введение нуждающемуся в этом субъекту эффективного количества композиции, которая повышает экспрессию или активность одного или более из TRIM-белков или одной или более чем одной из STUbL.
Например, в одном из воплощений указанный способ включает введение нуждающемуся в этом субъекту эффективного количества композиции, которая повышает экспрессию или активность одного или более чем одного из человеческих TRIM3, TRIM4, TRIM5, TRIM6, TRIM7, TRIM9, TRIM11, TRIM13, TRIM14, TRIM15, TRIM16, TRIM17, TRIM19 (также называемого в данном документе "PML"), TRIM20, TRIM21, TRIM24, TRIM25, TRIM27, TRIM28, TRIM29, TRIM32, TRIM34, TRIM39, TRIM43, TRIM44, TRIM45, TRIM46, TRIM49, TRIM50, TRIM52, TRIM58, TRIM59, TRIM65, TRIM67, TRIM69, TRIM70, TRIM74 и TRIM75; и мышиного TRIM30.
В одном из воплощений указанный способ включает введение нуждающемуся в этом субъекту эффективного количества композиции, которая повышает экспрессию или активность одного или более чем одного из RNF4 и RNF111 (Arkadia).
В одном из воплощений указанный способ включает введение субъекту эффективного количества композиции, которая повышает экспрессию или активность одного или более чем одного из TRIM-белков и одной или более чем одной из STUbL.
В одном из воплощений указанный способ включает повышение экспрессии или активности одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL по меньшей мере в одной нервной клетке субъекта. Например, в некоторых воплощениях указанный способ включает повышение экспрессии или активности одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL по меньшей мере в одном нейроне, астроците, олигодендроците, клетке Пуркинье, пирамидальной клетке и т.п.
В одном из воплощений указанный способ включает контактирование нервной ткани субъекта с эффективным количеством композиции, которая повышает экспрессию или активность одного или более чем одного компонента одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL. Например, в некоторых воплощениях указанный способ включает контактирование нейрона, астроцита, олигодендроцита, клетки Пуркинье, пирамидальной клетки или т.п. клетки субъекта с эффективным количеством композиции, которая повышает экспрессию или активность одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL.
Специалисту в данной области будет понятно, что модуляторы согласно данному изобретению могут вводиться отдельно или в любой комбинации. Кроме того, модуляторы согласно данному изобретению могут вводиться по отдельности или в любой комбинации во временном смысле, т.е. они могут вводиться одновременно или до и/или после друг друга. Специалисту в данной области на основе раскрытого в данном документе описания будет понятно, что композиции с модулятором согласно данному изобретению могут быть использованы для профилактики или лечения заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковым агрегатом, и что композиции с модулятором могут использоваться отдельно или в любой комбинации с другим модулятором для получения профилактического или терапевтического результата.
В различных воплощениях любой из модуляторов согласно данному изобретению, описанных в данном документе, можно вводить отдельно или в комбинации с другими модуляторами других молекул, ассоциированных с заболеванием, которое ассоциировано с неправильной упаковкой белка или белковыми агрегатами. В различных воплощениях любой из модуляторов согласно данному изобретению, описанных в данном документе, можно вводить отдельно или в комбинации с другими терапевтическими или профилактическими агентами, которые могут быть использованы для лечения или профилактики заболевания, ассоциированного с неправильно упакованным белками или белковыми агрегатами. Иллюстративные терапевтические агенты, которые могут использоваться в комбинации с модуляторами согласно данному изобретению, включают, но не ограничиваясь ими, антитела против амилоида-6 и анти-тау-антитела.
Генная терапия
Контактирование клеток у субъекта с нуклеиновокислотной композицией, которая кодирует белок, который повышает экспрессию или активность одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL, может ингибировать или замедлять наступление одного или более чем одного из симптомов заболевания или нарушения, ассоциированного с неправильной упаковкой белка или белковыми агрегатами.
В одном из воплощений указанная нуклеиновокислотная композиция согласно данному изобретению кодирует один или более чем один пептид. Например, в одном из воплощений нуклеиновокислотная композиция может кодировать пептид, который содержит аминокислотную последовательность одного или более чем одного из TRIM-белков. Например, в одном из воплощений указанная нуклеиновокислотная композиция кодирует пептид, содержащий один или более чем один из человеческих TRIM3, TRIM4, TRIM5, TRIM6, TRIM7, TRIM9, TRIM11, TRIM13, TRIM14, TRIM15, TRIM16, TRIM17, TRIM19 (также упоминаемого в данном документе как "PML"), TRIM20, TRIM21, TRIM24, TRIM25, TRIM27, TRIM28, TRIM29, TRIM32, TRIM34, TRIM39, TRIM43, TRIM44, TRIM45, TRIM46, TRIM49, TRIM50, TRIM52, TRIM58, TRIM69, TRIM70, TRIM74 и TRIM75; и мышиного TRIM30. В некоторых воплощениях нуклеиновокислотная композиция кодирует пептид, содержащий аминокислотную последовательность одной или более чем одной из STUbL. Например, в одном из воплощений указанная нуклеиновокислотная композиция кодирует пептид, содержащий один или более чем один из RNF4 и RNF111 (Arkadia).
Данное изобретение также следует толковать как включающее любую форму нуклеиновой кислоты, кодирующей пептид, имеющий существенную гомологию с описанными в данном документе пептидами. Предпочтительно, пептид, который является "по существу гомологичным", является примерно на 50% гомологичным, более предпочтительно примерно на 70% гомологичным, еще более предпочтительно примерно на 80% гомологичным, более предпочтительно примерно на 90% гомологичным, еще более предпочтительно примерно на 95% гомологичным и даже более предпочтительно примерно на 99% гомологичным аминокислотной последовательности пептидов, описанных в данном документе.
В одном из воплощений композиция согласно данному изобретению содержит нуклеиновую кислоту, кодирующую пептид, фрагмент пептида, гомолог, вариант, производное или соль пептида, описанного в данном документе. Например, в некоторых воплощениях указанная композиция содержит нуклеиновую кислоту, кодирующую пептид, включающий один или более чем один из TRIM-белков, фрагмент одного или более чем одного из TRIM-белков, гомолог одного или более чем одного из TRIM-белков, вариант одного или более чем одного из TRIM-белков, производное одного или более чем одного из TRIM-белков, или соль одного или более чем одного из TRIM-белков. В некоторых воплощениях указанная композиция содержит нуклеиновую кислоту, кодирующую пептид, содержащий одну или более чем одну из STUbL, фрагмент одной или более чем одной из STUbL, гомолог одной или более чем одной из STUbL, вариант одной или более чем одной из STUbL, производное одной или более чем одной из STUbL или соль одной или более чем одной STUbL.
Согласно данному изобретению предусмотрен способ доставки белка в клетку, которая несет нормальный или мутантный ген, ассоциированный с уменьшенной или недостаточной активностью одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL. Доставка белка в клетку с мутантным геном должна обеспечивать нормальное функционирование клеток-реципиентов. Нуклеиновую кислоту, кодирующую пептид, можно ввести в клетку в таком векторе, чтобы нуклеиновая кислота оставалась внехромосомной. В такой ситуации нуклеиновая кислота будет экспрессироваться клеткой из внехромосомной локализации. Более предпочтительной является ситуация, когда нуклеиновая кислота или ее часть вводятся в клетку таким образом, что она интегрируется в геном клетки или рекомбинирует с эндогенным мутантным геном, присутствующим в клетке. Векторы для введения генов для рекомбинации, для интеграции и для внехромосомного сохранения известны в данной области, и может использоваться любой подходящий вектор. Способы введения ДНК в клетки, такие как электропорация, копреципитация с фосфатом кальция и трансдукция вируса, известны в данной области, и выбор способа находится в компетенции врача.
Как в целом обсуждалось выше, нуклеиновая кислота, где это применимо, может быть использована в способах генной терапии для повышения уровня или активности пептидов согласно данному изобретению даже у тех лиц, у которых ген дикого типа экспрессирован на "нормальном" уровне, но продукт гена недостаточно функционален.
"Генная терапия" включает как традиционную генную терапию, где длительный эффект достигается посредством однократного лечения, так и введение генных терапевтических агентов, которое включает однократное или повторное введение терапевтически эффективной ДНК или мРНК. Олигонуклеотиды могут быть модифицированы для усиления их поглощения, например, путем замещения их отрицательно заряженных фосфодиэфирных групп незаряженными группами. Один или более чем один из TRIM-белков или одна или более чем одна из STUbL согласно данному изобретению могут быть доставлены с использованием способов генной терапии, например, локально в нервную клетку или ткань или системно (например, через векторы, которые селективно нацелены на конкретные типы тканей, например тканеспецифические адено-ассоциированные вирусные векторы). В некоторых воплощениях первичные клетки, собранные от индивидуума, могут быть трансфицированы ex vivo нуклеиновой кислотой, кодирующей любой из пептидов согласно данному изобретению, а затем трансфицированные клетки возвращены в организм индивидуума.
Способы генной терапии хорошо известны в данной области. См., например, WO 96/07321, в котором раскрывается применение способов генной терапии для получения внутриклеточных антител. Способы генной терапии были успешно продемонстрированы на людях. См., например, Baumgartner et al., Circulation 97: 12, 1114-1123 (1998), Fatham, C.G. 'A gene therapy approach to treatment of autoimmune diseases', Immun. Res. 18:15-26 (2007); и патент США №7378089, которые включены в данный документ посредством ссылки. См. также Bainbridge JWB et al. "Effect of gene therapy on visual function in Leber's congenital Amaurosis". N Engl J Med 358:2231-2239, 2008; и Maguire AM et al. "Safety and efficacy of gene transfer for Leber's Congenital Amaurosis". N Engl J Med 358:2240-8, 2008.
Существует два основных подхода для введения нуклеиновой кислоты, кодирующей пептид или белок (возможно, содержащийся в векторе), в клетки пациентов; in vivo и ex vivo. Для доставки in vivo в некоторых случаях нуклеиновую кислоту вводят непосредственно пациенту, иногда в место, где белок наиболее необходим. Для обработки ex vivo клетки пациента извлекают, нуклеиновую кислоту вводят в эти изолированные клетки, а модифицированные клетки вводят пациенту либо непосредственно, либо, например, инкапсулируют в пористые мембраны, которые имплантируют пациенту (см., например, патенты США №№4892538 и 5283187). Существует множество методик, доступных для введения нуклеиновых кислот в жизнеспособные клетки. Методики варьируют в зависимости от того, переносится ли нуклеиновая кислота in vitro в культивируемые клетки или in vivo в клетки предполагаемого хозяина. Методики, подходящие для переноса нуклеиновой кислоты в клетки млекопитающих in vitro, включают использование липосом, электропорацию, микроинъекцию, слияние клеток, DEAE-декстран, способ копреципитации с фосфатом кальция и т.д. Обычно используемые векторы для доставки гена ex vivo представляют собой ретровирусные и лентивирусные векторы.
Генная терапия может проводиться в соответствии с общепринятыми способами, например, описанными в Friedman et al., 1991, Cell 66:799-806, или в Culver, 1996, Bone Marrow Transplant 3:S6-9; Culver, 1996, Mol. Med. Today 2:234-236. В одном из воплощений клетки от пациента сначала анализируют с помощью диагностических способов, известных в данной области, для определения экспрессии или активности одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL. Получают вирус или плазмидный вектор, содержащий копию гена или его функциональный эквивалент, связанный с элементами контроля экспрессии и способный к репликации внутри клеток. Указанный вектор может быть способен к репликации внутри клеток. Альтернативно, указанный вектор может быть дефектным по репликации и реплицируется в хелперных клетках для использования в генной терапии. Подходящие векторы известны, например, описаны в патенте США №5252479 и в опубликованной заявке РСТ WO 93/07282, а также в патентах США №№5691198; 5747469; 5436146 и 5753500. Затем вектор вводят пациенту. Если трансфицированный ген не является постоянно встроенным в геном каждой из целевых клеток, то введение, возможно, придется периодически повторять.
Системы переноса генов, известные в данной области, могут быть использованы в осуществлении на практике способов генной терапии согласно данному изобретению. К ним относятся вирусные и невирусные способы переноса. Ряд вирусов был использован в качестве векторов для переноса генов или в качестве основы для восстановления векторов для переноса генов, включая паповавирусы (например, SV40, Madzak et al., 1992, J. Gen. Virol. 73:1533-1536), аденовирус (Berkner, 1992;Curr. Topics Microbiol. Immunol. 158:39-66), вирус осповакцины (Moss, 1992, Current Opin. Biotechnol. 3:518-522; Moss, 1996, PNAS 93:11341-11348), адено-ассоциированный вирус (Russell and Hirata, 1998, Mol. Genetics 18:325-330), герпесвирусы, включая HSV и EBV (Fink et al., 1996, Ann. Rev. Neurosci. 19:265-287), лентивирусы (Naldini et al., 1996, PNAS 93:11382-11388), вирус Синдбис и вирус леса Семлики (Berglund et al., 1993, Biotechnol. 11:916-920), и ретровирусы птичьего (Petropoulos et al., 1992, J. Virol. 66:3391-3397), мышиного (Miller, 1992, Hum. Gene Ther. 3:619-624) и человеческого происхождения (Shimada et al., 1991; Helseth et al., 1990; Page et al., 1990; Buchschacher and Panganiban, 1992, J. Virol. 66:2731-2739). Большинство протоколов генной терапии человека основаны на неработающих мышиных ретровирусах, хотя также используются аденовирус и аденоассоциированный вирус.
Невирусные способы переноса генов, известные в данной области, включают химические методики, такие как копреципитация с фосфатом кальция; механические методики, например микроинъекции; опосредованный слиянием мембран перенос через липосомы; и прямое поглощение ДНК и опосредованный рецептором перенос ДНК (Curiel et al., 1992, Am. J. Respir. Cell. Mol. Biol 6:247-252). Опосредованный вирусом перенос гена может быть объединен с прямым переносом гена in vitro с использованием липосомной доставки, позволяя направлять вирусные векторы к опухолевым клеткам, а не в окружающие неделящиеся клетки. Введение затем клеток-продуцентов обеспечило бы непрерывный источник векторных частиц. Эта методика была одобрена для использования у людей с неоперабельными опухолями головного мозга.
В подходе, который объединяет биологические и физические способы переноса генов, плазмидную ДНК любого размера объединяют с конъюгированным с полилизином антителом, специфическим для белка аденовируса гексона, и полученный комплекс связывают с аденовирусным вектором. Затем тримолекулярный комплекс используется для инфицирования клеток.
Аденовирусный вектор обеспечивает эффективное связывание, интернализацию и деградацию эндосомы до повреждения связанной ДНК. Другие методики доставки векторов на основе аденовирусов см. в патентах США №№5691198; 5747469; 5436146 и 5753500.
Было показано, что комплексы липосома/ДНК способны опосредовать прямой перенос гена in vivo. В то время как в стандартных липосомных препаратах процесс переноса генов является неспецифическим, локализованное in vivo поглощение и экспрессия наблюдаются в опухолевых отложениях, например, после прямого введения in situ.
Экспрессионные векторы в контексте генной терапии должны включать те конструкции, которые содержат последовательности, достаточные для экспрессии полинуклеотида, который был клонирован в них. В вирусных экспрессионных векторах конструкция содержит вирусные последовательности, достаточные для поддержки упаковки конструкции. Если полинуклеотид кодирует белок, то экспрессия будет продуцировать этот белок. Если полинуклеотид кодирует антисмысловый полинуклеотид или рибозим, то экспрессия будет давать антисмысловый полинуклеотид или рибозим. Таким образом, в этом контексте экспрессия не требует, чтобы белковый продукт был синтезирован. В дополнение к полинуклеотиду, клонированному в экспрессионный вектор, данный вектор также содержит промотор, функциональный в эукариотических клетках. Клонированная полинуклеотидная последовательность находится под контролем этого промотора. Подходящие эукариотические промоторы включают описанные выше. Экспрессионный вектор также может включать последовательности, такие как селективные маркеры и другие последовательности, описанные в данном документе.
В некоторых воплощениях указанный способ включает использование методик переноса генов, которые нацеливают изолированную нуклеиновую кислоту непосредственно в нервную ткань. Рецептор-опосредованный перенос генов, например, осуществляется путем конъюгации молекулы нуклеиновой кислоты (обычно в форме ковалентно замкнутой сверхспиральной плазмиды) с белковым лигандом через полилизин. Лиганды выбирают исходя из наличия соответствующих лигандных рецепторов на клеточной поверхности целевого типа клеток/ткани. Эти конъюгаты "лиганд - ДНК" могут быть введены непосредственно в кровь, если это необходимо, и направлены в ткань-мишень, где происходит связывание рецептора и интернализация комплекса "ДНК-белок". Чтобы преодолеть проблему внутриклеточного разрушения ДНК, может быть включено коинфицирование аденовирусом для нарушения эндосомальной функции.
Фармацевтические композиции и составы
Данное изобретение также охватывает применение фармацевтических композиций согласно данному изобретению или их солей для осуществления на практике способов согласно данному изобретению. Такая фармацевтическая композиция может состоять по меньшей мере из одной композиции с модулятором согласно данному изобретению или ее соли в форме, подходящей для введения субъекту, или фармацевтическая композиция может содержать по меньшей мере одну композицию с модулятором согласно данному изобретению или ее соль и один или более чем один из фармацевтически приемлемых носителей, один или более чем один из дополнительных ингредиентов или их комбинацию. Соединение или конъюгат согласно данному изобретению могут присутствовать в фармацевтической композиции в форме физиологически приемлемой соли, такой как в комбинации с физиологически приемлемым катионом или анионом, хорошо известным в данной области.
В одном из воплощений фармацевтические композиции, пригодные для осуществления на практике способов согласно данному изобретению, можно вводить для доставки дозы от 1 нг/кг/день до 100 мг/кг/день. В другом воплощении фармацевтические композиции, пригодные для осуществления на практике данного изобретения, можно вводить для доставки дозы от 1 нг/кг/день до 500 мг/кг/день.
Относительные количества активного ингредиента, фармацевтически приемлемого носителя и любых дополнительных ингредиентов в фармацевтической композиции согласно данному изобретению будут варьировать в зависимости от идентичности, размера и состояния субъекта, подвергаемого лечению, а также в зависимости от пути, с помощью которого композиция должна быть введена. В качестве примера данная композиция может содержать от 0,1% до 100% (по массе) активного ингредиента.
Фармацевтические композиции, которые могут быть использованы в способах согласно данному изобретению, могут быть соответствующим образом подготовлены для перорального, ректального, вагинального, парентерального, местного, легочного, интраназального, буккального, офтальмологического или другого пути введения. Композиция, которая может быть использована в способах согласно данному изобретению, может быть непосредственно введена в кожу, влагалище или любую другую ткань млекопитающего. Другие рассматриваемые составы включают липосомальные препараты, возвращенные эритроциты, содержащие активный ингредиент, и составы на основе иммунологических препаратов. Путь (пути) введения будет легко понятен специалисту в данной области и будет зависеть от ряда факторов, включая тип и тяжесть заболевания, подлежащего лечению, тип и возраст животного или человека, подлежащего лечению, и т.п.
Составы фармацевтических композиций, описанных в данном документе, могут быть получены любым способом, известным или в дальнейшем разработанным в области фармакологии. Как правило, такие способы получения включают этап привнесения активного ингредиента в ассоциацию с носителем или одним или более чем одним другим вспомогательным ингредиентом, а затем, при необходимости или по желанию, этап формования или упаковки указанного продукта в нужную однодозовую или многодозовую единицу дозирования.
Используемый в данном документе термин "единица дозирования" представляет собой дискретное количество фармацевтической композиции, содержащее заданное количество активного ингредиента. Количество активного ингредиента, как правило, равно дозировке активного ингредиента, которое вводится субъекту, или удобной фракции такой дозировки, такой как, например, половина или одна треть такой дозировки. Единичная лекарственная форма может быть предназначена для введения одной дневной дозы или одного из приемов дневной дозы, разделенной на несколько приемов (например, от 1 до 4 или более раз в день). При использовании дневной дозы, разделенной на несколько приемов, единичная дозированная форма может быть одинаковой или различной для каждой дозы.
Хотя описания фармацевтических композиций, предложенных в данном документе, в основном направлены на фармацевтические композиции, которые подходят для этичного введения людям, специалисту в данной области будет понятно, что такие композиции обычно подходят для введения животным всех видов. Модификация фармацевтических композиций, подходящих для введения людям, чтобы сделать композиции подходящими для введения различным животным, хорошо понятна, и специалист в области ветеринарной фармакологии сможет разработать и выполнить такую модификацию с помощью простых, если они нужны, экспериментов. Субъекты, к которым относится введение фармацевтических композиций согласно данному изобретению, включают, но не ограничиваясь ими, людей и приматов, млекопитающих, включая коммерчески значимых млекопитающих, таких как крупный рогатый скот, свиньи, лошади, овцы, кошки и собаки.
В одном из воплощений композиции согласно данному изобретению собраны в состав с использованием одного или более чем одного из фармацевтически приемлемых эксципиентов или носителей. В одном из воплощений фармацевтические композиции согласно данному изобретению содержат терапевтически эффективное количество соединения или конъюгата согласно данному изобретению и фармацевтически приемлемый носитель. Фармацевтически приемлемые носители, которые могут быть использованы, включают, но не ограничиваясь ими, глицерин, воду, физиологический раствор, этанол и другие фармацевтически приемлемые солевые растворы, такие как фосфаты и соли органических кислот. Примеры этих и других фармацевтически приемлемых носителей описаны в Remington's Pharmaceutical Sciences (1991, Mack Publication Co., New Jersey).
Носитель может представлять собой растворитель или дисперсионную среду, содержащую, например, воду, этанол, полиол (например, глицерин, пропиленгликоль и жидкий полиэтиленгликоль и т.п.), подходящие их смеси и растительные масла. Правильную текучесть можно поддерживать, например, путем использования покрытия, такого как лецитин, путем поддержания требуемого размера частиц в случае дисперсии и путем использования поверхностно-активных веществ. Предотвращение действия микроорганизмов может быть достигнуто различными антибактериальными и противогрибковыми агентами, например парабенами, хлорбутанолом, фенолом, аскорбиновой кислотой, тимеросалом и т.п. Во многих случаях композиция предпочтительно включает изотонические агенты, например сахара, хлорид натрия или полиспирты, такие как маннит и сорбит. Пролонгированной абсорбции инъекционных композиций можно достичь путем включения в композицию агента, который задерживает абсорбцию, например, моностеарата алюминия или желатина. В одном из воплощений фармацевтически приемлемый носитель не является только ДМСО.
Составы могут быть использованы в смесях со стандартными эксципиентами, т.е. с фармацевтически приемлемыми органическими или неорганическими веществами-носителями, подходящими для перорального, вагинального, парентерального, назального, внутривенного, подкожного, энтерального или любого другого подходящего способа введения, известного в данной области. Фармацевтические препараты могут быть стерилизованы и, если нужно, смешаны со вспомогательными агентами, например, смазывающими агентами, консервантами, стабилизаторами, смачивающими агентами, эмульгаторами, солями для буферов, влияющих на осмотическое давление, красителями, отдушками и/или ароматическими веществами и т.п.Их также можно комбинировать, если нужно, с другими активными агентами, например, с другими анальгетиками.
Используемые в данном документе "дополнительные ингредиенты" включают, но не ограничиваясь ими, один или более чем один из следующих агентов: эксципиенты; поверхностно-активные агенты; диспергирующие агенты; инертные разбавители; гранулирующие и дезинтегрирующие агенты; связывающие агенты; смазочные агенты; подсластители; ароматизаторы; красители; консерванты; физиологически разлагаемые композиции, такие как желатин; водные носители и растворители; масляные носители и растворители; суспендирующие агенты; диспергирующие или смачивающие агенты; смягчающие агенты; буферы; соли; загустители; наполнители; эмульгаторы; антиоксиданты; антибиотики; противогрибковые агенты; стабилизирующие агенты; и фармацевтически приемлемые полимерные или гидрофобные материалы. Другие "дополнительные ингредиенты", которые могут быть включены в фармацевтические композиции согласно данному изобретению, известны в данной области и описаны, например, в публикации Genaro, ed. (1985, Remington's Pharmaceutical Sciences, Mack Publishing Co., Easton, PA), которая включена в данный документ посредством ссылки.
Композиция согласно данному изобретению может содержать консервант в количестве примерно от 0,005% до 2,0% от общей массы композиции. Консервант используется для предотвращения порчи в случае воздействия загрязняющих веществ из окружающей среды. Примеры консервантов, которые могут быть использованы в соответствии с данным изобретением, включают, но не ограничиваясь ими, такие, которые выбраны из группы, состоящей из бензилового спирта, сорбиновой кислоты, парабенов, имидуреи и их комбинаций. Особенно предпочтительным консервантом является комбинация примерно от 0,5 до 2,0% бензилового спирта и от 0,05 до 0,5% сорбиновой кислоты.
Указанная композиция предпочтительно включает антиоксидант и хелатирующий агент, который ингибирует деградацию соединения. Предпочтительными антиоксидантами для некоторых соединений являются ВНТ, ВНА, альфа-токоферол и аскорбиновая кислота в предпочтительном диапазоне примерно от 0,01% до 0,3%, и более предпочтительно ВНТ в диапазоне от 0,03 до 0,1% по массе от общей массы композиции. Предпочтительно, хелатирующий агент присутствует в количестве от 0,01 до 0,5% по массе от общей массы композиции. Особенно предпочтительные хелатирующие агенты включают соли эдетата (например, динатриевый эдетат) и лимонную кислоту в диапазоне примерно от 0,01% до 0,20%, и более предпочтительно в диапазоне от 0,02% до 0,10% по массе от общей массы композиции. Хелатирующий агент используется для хелатирования в композиции ионов металлов, которые могут быть вредными для срока годности состава. Хотя ВНТ и динатриевый эдетат для некоторых соединений являются особенно предпочтительным антиоксидантом и хелатирующим агентом, соответственно, они могут быть заменены другими подходящими и эквивалентными антиоксидантами и хелатирующими агентами, которые известны специалистам в данной области.
Жидкие суспензии могут быть приготовлены обычными способами для получения суспензии активного ингидиента в водном или масляном носителе. Водные носители включают, например, воду и изотонический солевой раствор. Масляные носители включают, например, миндальное масло, масляные сложные эфиры, этиловый спирт, растительные масла, такие как арахисовое, оливковое, кунжутное или кокосовое масло, фракционированные растительные масла и минеральные масла, такие как жидкий парафин. Жидкие суспензии могут также содержать один или более чем один из дополнительных ингредиентов, включая, но не ограничиваясь ими, суспендирующие агенты, диспергирующие или смачивающие агенты, эмульгирующие агенты, смягчающие агенты, консерванты, буферы, соли, ароматизаторы, красители и подсластители. Масляные суспензии могут также содержать загуститель. Известные суспендирующие агенты включают, но не ограничиваясь ими, сироп сорбита, гидрогенированные пищевые жиры, альгинат натрия, поливинилпирролидон, трагакант камеди, аравийскую камедь и производные целлюлозы, такие как карбоксиметилцеллюлоза натрия, метилцеллюлоза, гидроксипропилметилцеллюлоза. Известные диспергирующие или смачивающие агенты включают, но не ограничиваясь ими, природные фосфатиды, такие как лецитин, продукты конденсации алкиленоксида с жирной кислотой, с длинноцепочечным алифатическим спиртом, с неполным эфиром, полученным из жирной кислоты и гекситола, или с неполным эфиром, полученным из жирной кислоты и ангидрида гекситола (например, полиоксиэтиленстеарата, гептадекаэтиленоксицетанола, моноолеата полиоксиэтиленсорбита и моноолеата полиоксиэтиленсорбитана, соответственно). Известные эмульгаторы включают, но не ограничиваясь ими, лецитин и аравийскую камедь. Известные консерванты включают, но не ограничиваясь ими, метил-, этил- или н-пропил-пара-гидроксибензоаты, аскорбиновую кислоту и сорбиновую кислоту. Известные подсластители включают, например, глицерин, пропиленгликоль, сорбит, сахарозу и сахарин. Известные загустители для масляных суспензий включают, например, пчелиный воск, твердый парафин и цетиловый спирт.
Жидкие растворы активного ингредиента в водных или масляных растворителях могут быть получены по существу таким же образом, что и жидкие суспензии, причем основное различие заключается в том, что активный ингредиент растворяют, а не суспендируют в растворителе. Используемый в данном документе термин "масляная" жидкость представляет собой жидкость, которая содержит углеродсодержащую жидкую молекулу и которая имеет менее полярный характер, чем вода. Жидкие растворы фармацевтической композиции согласно данному изобретению могут содержать каждый из компонентов, описанных в отношении жидких суспензий, при этом понятно, что суспендирующие агенты не обязательно будут способствовать растворению активного ингредиента в растворителе. Водные растворители включают, например, воду и изотонический солевой раствор. Масляные растворители включают, например, миндальное масло, масляные сложные эфиры, этиловый спирт, растительные масла, такие как арахис, оливковое, кунжутное или кокосовое масло, фракционированные растительные масла и минеральные масла, такие как жидкий парафин.
Порошкообразные и гранулированные составы фармацевтического препарата согласно данному изобретению могут быть получены известными способами. Такие составы можно вводить непосредственно субъекту, используя, например, их для формирования таблеток, для заполнения капсул или для приготовления водной или масляной суспензии или раствора путем добавления к ним водного или масляного носителя. Каждый из этих составов может дополнительно содержать один или более чем один из диспергирующего или смачивающего агента, суспендирующего агента и консерванта. В эти составы также могут быть включены дополнительные эксципиенты, такие как наполнители и подсластители, ароматизаторы или красители.
Фармацевтическую композицию согласно данному изобретению можно также приготовить, упаковать или продать в форме эмульсии "масло в воде" или в форме эмульсии "вода в масле". Масляная фаза может быть растительным маслом, таким как оливковое или арахисовое масло, минеральным маслом, таким как жидкий парафин, или их комбинацией. Такие композиции могут дополнительно содержать один или более чем один эмульгирующий агент, такой как природные камеди, такие как аравийская камедь или трагакантовая камедь, природные фосфатиды, такие как фосфатид или лецитин сои, сложные эфиры или неполные эфиры многоатомного спирта, полученные из комбинаций жирных кислот и ангидридов гекситола, таких как сорбитан моноолеат, и продукты конденсации такие как неполные эфиры с этиленоксидом, такие как полиоксиэтиленсорбитан моноолеат.Эти эмульсии могут также содержать дополнительные ингредиенты, включая, например, подсластители или ароматизаторы.
Способы пропитки или покрытия материала химической композицией известны в данной области и включают, но не ограничиваясь ими, способы нанесения или связывания химической композиции с поверхностью, способы встраивания химической композиции в структуру материала во время синтеза материала (например, с физиологически разлагаемым материалом) и способы абсорбции водного или масляного раствора или суспензии в абсорбирующий материал с последующим высушиванием или без него.
Режим введения может повлиять на то, что составляет эффективное количество. Терапевтические составы можно вводить субъекту либо до, либо после диагностирования заболевания. Кроме того, несколько разделенных дозировок, а также ступенчатые дозировки могут вводиться ежедневно или последовательно, или указанная доза может непрерывно вводиться или может быть болюсной инъекцией. Кроме того, дозировки терапевтических составов могут быть пропорционально увеличены или уменьшены, что указано в требованиях терапевтической или профилактической ситуации.
Введение композиций согласно данному изобретению субъекту, предпочтительно млекопитающему, более предпочтительно человеку, может быть осуществлено с использованием известных процедур в дозировках и в течение периодов времени, эффективных для профилактики или лечения заболеваний. Эффективное количество терапевтического соединения, необходимое для достижения терапевтического эффекта, может варьировать в зависимости от факторов, таких как активность конкретного используемого соединения; время введения; скорость экскреции соединения; продолжительность лечения; другие лекарственные препараты, соединения или материалы, используемые в комбинации с данным соединением; состояние заболевания или нарушения, возраст, пол, вес, состояние, общее состояние здоровья и анамнез заболевания субъекта, подлежащего лечащего, и подобные факторы, хорошо известные в медицине. Схемы дозировки могут быть скорректированы для обеспечения оптимального терапевтического ответа. Например, несколько разделенных доз можно вводить ежедневно, или указанная доза может быть пропорционально уменьшена, как указано, в зависимости от терапевтической ситуации. Неограничивающий пример эффективного диапазона доз терапевтического соединения согласно данному изобретению составляет от 1 до 5000 мг/кг массы тела в день. Специалист в данной области сможет изучить релевантные факторы и определить эффективное количество терапевтического соединения без чрезмерного экспериментирования.
Указанное соединение можно вводить субъекту так часто, как несколько раз в день, или его можно вводить реже, например один раз в день, один раз в неделю, один раз в две недели, один раз в месяц или даже реже, например один раз в несколько месяцев или даже один раз в год или реже. Понятно, что количество соединения, дозированное на день, можно вводить в неограничивающих примерах каждый день, через день, каждые 2 дня, каждые 3 дня, каждые 4 дня или каждые 5 дней. Например, при введении через день дозу 5 мг/день можно вводить в понедельник, затем дозу 5 мг/день в среду, вторую последующую дозу 5 мг/день в пятницу и т.д. Частота дозы будет очевидна специалисту в данной области и будет зависеть от ряда факторов, таких как, но не ограничиваясь ими, тип и тяжесть заболевания, подлежащего лечению, тип и возраст животного и т.д.
Фактические уровни дозировки активных ингредиентов в фармацевтических композициях согласно данному изобретению могут варьировать таким образом, чтобы давать количество активного ингредиента, которое эффективно для достижения нужного терапевтического ответа для конкретного субъекта, композиции и способа введения, не будучи токсичным для данного субъекта.
Специалист в медицине, например, врач или ветеринар, имеющий стандартные навыки в данной области, сможет легко определить и прописать эффективное количество требуемой фармацевтической композиции. Например, врач или ветеринар могут начинать с введения соединений согласно данному изобретению, используемых в фармацевтической композиции, в дозах на более низких уровнях, чем требуется для достижения нужного терапевтического эффекта, и постепенно увеличивать дозировку до достижения нужного эффекта.
В конкретных воплощениях особенно выгодно собирать в состав указанное соединение в единичной дозированной форме для удобства введения и единообразия дозировки. Используемое в данном документе понятие "единичная дозированная форма" относится к физически дискретным единицам, подходящим в качестве унифицированных дозировок субъектам, подлежащим лечению; при этом каждая единица содержит предопределенное количество терапевтического соединения, рассчитанное для получения нужного терапевтического эффекта в сочетании с необходимым фармацевтическим носителем. Единичные дозированные формы согласно данному изобретению диктуются и непосредственно зависят от (а) уникальных характеристик терапевтического соединения и конкретного терапевтического эффекта, который должен быть достигнут, и (b) ограничений, присущих области смешивания/сборки в состав такого терапевтического соединение для лечения заболевания у субъекта.
В одном из воплощений композиции согласно данному изобретению вводят субъекту в дозах, которые варьируют от одного до пяти раз в день или более. В другом воплощении композиции согласно данному изобретению вводят субъекту в диапазоне доз, которые включают, но не ограничиваясь этим, один раз в день, каждые два дня, каждые три дня, и до одного раза в неделю и одного раза в две недели. Специалисту в данной области будет очевидно, что частота введения различных комбинированных композиций согласно данному изобретению будет варьировать от субъекта к субъекту в зависимости от многих факторов, включая, но не ограничиваясь ими, возраст, заболевание или нарушение, подлежащие лечению, пол, общее состояние здоровья и другие факторы. Таким образом, данное изобретение не следует толковать как ограниченное каким-либо конкретным режимом дозирования, а точная дозировка и композиция, которые должны вводиться любому субъекту, будут определяться врачом, принимающим во внимание все остальные факторы, касающиеся субъекта.
Соединения согласно данному изобретению для введения могут находиться в диапазоне от примерно 1 мг до примерно 10000 мг, от примерно 20 мг до примерно 9500 мг, от примерно 40 мг до примерно 9000 мг, от примерно 75 мг до примерно 8500 мг, от примерно 150 мг до примерно 7500 мг, от примерно 200 мг до примерно 7000 мг, от примерно 3050 мг до примерно 6000 мг, от примерно 500 мг до примерно 5000 мг, от примерно 750 мг до примерно 4000 мг, от примерно 1 мг до примерно 3000 мг, от примерно 10 мг до примерно 2500 мг, от примерно 20 мг до примерно 2000 мг, от примерно 25 мг до примерно 1500 мг, от примерно 50 мг до примерно 1000 мг, от примерно 75 мг до примерно 900 мг, от примерно 100 мг до примерно 800 мг, от примерно 250 мг до примерно 750 мг, от примерно 300 мг до примерно 600 мг, от примерно 400 мг до примерно 500 мг, и любые и все целые или частичные приросты между ними.
В некоторых воплощениях доза соединения согласно данному изобретению составляет от примерно 1 мг до примерно 2500 мг. В некоторых воплощениях доза соединения согласно данному изобретению, используемого в композициях, описанных в данном документе, составляет менее примерно 10000 мг, или менее примерно 8000 мг, или менее примерно 6000 мг, или менее примерно 5000 мг, или менее примерно 3000 мг, или менее примерно 2000 мг, или менее примерно 1000 мг, или менее примерно 500 мг, или менее примерно 200 мг, или менее примерно 50 мг. Аналогичным образом, в некоторых воплощениях доза второго соединения (т.е. лекарственного препарата, используемого для лечения того же или другого заболевания, которое лечат с помощью композиции согласно данному изобретению), описанного в данном документе, составляет менее примерно 1000 мг, или менее примерно 800 мг, или менее примерно 600 мг, или менее примерно 500 мг, или менее примерно 400 мг, или менее примерно 300 мг, или менее примерно 200 мг, или менее примерно 100 мг, или менее примерно 50 мг, или менее примерно 40 мг, или менее примерно 30 мг, или менее примерно 25 мг, или менее примерно 20 мг, или менее примерно 15 мг, или менее примерно 10 мг, или менее примерно 5 мг, или менее примерно 2 мг, или менее примерно 1 мг, или менее примерно 0,5 мг, и любые и все целые или частичные приросты между ними.
В одном из воплощений данное изобретение относится к упакованной фармацевтической композиции, содержащей контейнер, содержащий терапевтически эффективное количество соединения или конъюгата согласно данному изобретению, отдельно или в сочетании со вторым фармацевтическим агентом; и инструкции по применению соединения или конъюгата для лечения, профилактики или уменьшения одного или более чем одного из симптомов заболевания у субъекта.
Термин "контейнер" включает любой сосуд для хранения фармацевтической композиции. Например, в одном из воплощений контейнер представляет собой упаковку, которая содержит фармацевтическую композицию. В других воплощениях контейнер не является упаковкой, которая содержит фармацевтическую композицию, т.е. контейнер представляет собой сосуд, такой как коробка или флакон, который содержит упакованную фармацевтическую композицию или неупакованную фармацевтическую композицию и инструкции по применению фармацевтической композиции. Кроме того, методики упаковывания хорошо известны в данной области. Следует понимать, что инструкции по применению фармацевтической композиции могут содержаться на упаковке, содержащей фармацевтическую композицию, и, таким образом, инструкции образуют повышенную функциональную связь с упакованным продуктом. Тем не менее, следует понимать, что инструкции могут содержать информацию, относящуюся к способности соединения выполнять свою предполагаемую функцию, например, лечить или предупреждать заболевание у субъекта или доставлять визуализирующий или диагностический агент субъекту.
Пути введения любой из композиций согласно данному изобретению включают пероральный, назальный, ректальный, парентеральный, подъязычный, чрескожный, чрезслизистый (например, подъязычный, лингвальный (транс)буккальный, (транс)уретральный, вагинальный (например, транс- и перивагинальный), (внутри)носовый и (транс)ректальный), внутрипузырный, внутрилегочный, внутримозговой, эпидуральный, внутрижелудочковый, интрадуоденальный, внутрижелудочный, интратекальный, подкожный, внутримышечный, внутрикожный, внутриартериальный, внутривенный, внутрибронхиальный, ингаляционный и локальный пути введения.
Подходящие композиции и лекарственные формы включают, например, таблетки, капсулы, капсулы, пилюли, гелевые колпачки, таблетки для рассасывания, дисперсии, суспензии, растворы, сиропы, гранулы, шарики, трансдермальные пластыри, порошки, пастилки, магмы, леденцы, кремы, пасты, пластыри, лосьоны, диски, суппозитории, жидкие спреи для назального или перорального введения, сухопорошковые или аэрозольные составы для ингаляции, композиции и составы для внутрипузырного введения и т.п. Следует понимать, что составы и композиции, которые могут быть использованы в данном изобретении, не ограничиваются конкретными составами и композициями, которые описаны в данном документе.
Диагностические способы
Данное изобретение предусматривает способ выявления субъекта, имеющего и подверженного риску развития заболевания или нарушения, ассоциированного с неправильной упаковкой белка или белковыми агрегатами. Например, в одном из воплощений указанный способ включает использование уровня экспрессии или активности одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL в качестве диагностических маркеров. В одном из воплощений указанный способ включает обнаружение наличия генетической мутации в нуклеиновой кислоте, кодирующей один или более чем один из TRIM-белков или одну или более чем одну из STUbL.
В одном из воплощений указанный способ используется для выявления субъекта как имеющего заболевание или нарушение, ассоциированное с неправильной упаковкой белка или белковыми агрегатами. В одном из воплощений указанный способ используется для выявления субъекта, который подвержен риску развития заболевания или нарушения, ассоциированного с неправильной упаковкой белка или белковыми агрегатами. В одном из воплощений указанный способ используется для оценки эффективности лечения нейродегенеративного заболевания или нарушения, ассоциированного с неправильной упаковкой белка или белковыми агрегатами.
В одном из воплощений указанный способ включает сбор биологического образца от субъекта. Иллюстративные образцы включают, но не ограничиваясь ими, кровь, мочу, фекалии, пот, желчь, сыворотку, плазму, биопсию ткани и т.п. Например, в одном из воплощений указанный образец содержит по меньшей мере одну клетку нервной ткани. В одном из воплощений указанный образец содержит нейрон, астроцит, олигодендроцит, клетку Пуркинье, пирамидальную клетку и т.п.
Способы обнаружения сниженной экспрессии или активности одного или более чем одного из TRIM-белков или одной или более чем одной из STUbL содержат любой способ, который исследует ген или его продукты на уровне нуклеиновой кислоты или белка. Такие способы хорошо известны в данной области и включают, но не ограничиваясь ими, методики гибридизации нуклеиновых кислот, способы обратной транскрипции нуклеиновых кислот и способы амплификации нуклеиновых кислот, вестерн-блоттинг, нозерн-блоттинг, саузерн-блоттинг, ELISA, иммунопреципитацию, иммунофлуоресценцию, проточную цитометрию, иммуноцитохимию. В конкретных воплощениях нарушенную транскрипцию гена обнаруживают на уровне белка, используя, например, антитела, направленные против конкретных белков. Эти антитела могут быть использованы в различных способах, таких как методики вестерн-блоттинга, ELISA, иммунопреципитации, проточной цитометрии или иммуноцитохимии.
Способы производства рекомбинантного белка
В некоторых воплощениях данное изобретение предусматривает способ использования одного или более чем одного из TRIM-белков, одной или более чем одной из STUbL или их комбинации в получении рекомбинантного белка, представляющего интерес. Например, один или более чем один из TRIM-белков, одну или более чем одну из STUbL или их комбинацию можно использовать для дезагрегации белковых агрегатов рекомбинантного белка, представляющего интерес, что позволяет продуцировать и собирать рекомбинантный белок, представляющий интерес.
В некоторых воплощениях указанный способ включает введение в клетку одного или более чем одного из TRIM-белков, одной или более чем одной из STUbL, молекулы нуклеиновой кислоты, кодирующей один или более чем один из TRIM-белков, молекулы нуклеиновой кислоты, кодирующей одну или более чем одну из STUbL, или их комбинации. В некоторых воплощениях клетку модифицируют для экспрессии рекомбинантного белка, представляющего интерес. Клетка может представлять собой любую экспрессионную систему, включая, но не ограничиваясь ими, систему экспрессионную систему дрожжей, экспрессионную систему бактерий, экспрессионную систему насекомых или экспрессионную систему млекопитающих.
Экспериментальные примеры
Далее данное изобретение подробно описано со ссылкой на следующие экспериментальные примеры. Эти примеры приведены только для иллюстрации и не предназначены для ограничения, если не указано иное. Таким образом, данное изобретение никоим образом не должно истолковываться как ограниченное следующими примерами, а скорее должно толковаться как охватывающее любые и все варианты, которые становятся очевидными в результате приведенного в данном документе объяснения.
Без дальнейшего описания считается, что специалист в данной области сможет с использованием предыдущего описания и последующих иллюстративных примеров сделать и использовать данное изобретение и применять заявленные способы. Поэтому следующие рабочие примеры конкретно указывают на предпочтительные воплощения данного изобретения и не должны истолковываться как ограничивающие каким-либо образом оставшуюся часть описания.
Пример 1: Клеточная система, которая вызывает деградацию неправильно упакованных белков и защищает от нейродегенерации
Неправильно упакованные белки ставят под угрозу клеточную функцию и вызывают заболевание. В настоящее время не до конца понятно, как эти белки обнаруживаются и деградируют. Представленные в данном документе эксперименты показывают, что PML (также известный как TRIM19) и SUMO-зависимая убиквитинлигаза RNF4 действуют вместе, чтобы способствовать деградации неправильно упакованных белков в ядре клетки млекопитающего. PML селективно взаимодействует с неправильно упакованными белками через различные сайты распознавания субстрата и вызывает конъюгацию этих белков с малыми убиквитин-подобными модификаторами (small ubiquitin-like modifier, SUMO) за счет SUMO-лигазной активности. Затем RNF4 распознает и подвергает убиквитированию сумоилированные неправильно упакованные белки, и затем они направляются на протеасомальную деградацию. Кроме того, в данном документе показано, что дефицит PML усугубляет полиглутаминовое (полиQ) заболевание на мышиной модели спиноцеребеллярной атаксии 1 (SCA1). Эти данные раскрывают систему млекопитающих, которая удаляет неправильно упакованные белки посредством последовательного сумоилирования и убиквитинирования, и определяют ее роль в защите от заболеваний, ассоциированных с неправильно упакованными белками.
Белок промиелоцитарной лейкемии (promyelocytic leukemia protein, PML, также известный как TRIM 19) является членом семейства белков трехчастного мотива (TRIM), которые содержат N-концевую TRIM/BRCC-область, состоящую из RING-домена, одного или двух В-мотивов и суперспирального (coiled-coil region, СС) мотива, за которым следует вариабельная С-концевая область. PML является преимущественно ядерным белком и является одноименным компонентом ядерных телец PML. Он участвует в широком спектре клеточных процессов, включая апоптоз, транскрипцию, сигналинг повреждения ДНК и противовирусные реакции (Bernardi and Pandolfi, 2007, Nat Rev Mol Cell Biol, 8: 1006-1016). Примечательно, что PML также колокализуется с агрегатами, образованными полиQ-белками, ассоциироанными с SCA (Skinner et al., 1997, Nature, 389, 971-974; Takahashi et al., 2003, Neurobiol Dis, 13: 230-237), и при сверхэкспрессии способствует деградации по меньшей мере одного из них (мутантный атаксин-7) (Janer et al., 2006, J Cell Biol, 174: 65-76). Несмотря на потенциальную важность этих наблюдений, роль PML в удалении неправильно упакованных белков не совсем понятна. В частности, неясно, играет ли PML большую роль в удалении ядерных неправильно упакованных белков. Критическая проблема молекулярных механизмов, с помощью которых PML удаляет неправильно упакованные белки, не затрагивается. Более того, физиологическая значимость влияния PML на неправильно упакованные белки неизвестна.
Далее описаны материалы и методы, используемые в этих экспериментах.
Плазмиды
Все белки имеют человеческое происхождение, если не указано иное. Плазмиды для экспрессии следующих белков в клетках млекопитающих были получены в pRK5 с помощью ПЦР, и каждый был слит с НА-, FLAG- или 6xHis-меткой или GST- или GFP-белком на NH2- или СООН-конце, как указано: мутанты FLAG-PML (изоформа IV, если не указано иное); GST-PML; Atxn1 82Q-GFP, НА-Atxn1 82Q-FLAG, FLAG-Atxn1 82Q; HA-Httex1p 97QP и HA-Httex1p 97QP(KR); FLAG-nFluc-GFP, FLAG-nFlucSM-GFP и FLAG-nFlucDM-GFP; HA-RNF4, HA-RNF4 SIMm, HA-RNF4-FLAG и HA-RNF4 SIMm-FLAG; и HA-SUMO2 KR. Плазмиды Atxn1 82Q получали на основе плазмиды FLAG-Atxn1 82Q/pcDNA, предоставленной H. Orr (Riley et al., 2005, J Biol Chem, 280: 21942-21948); Httex1p 97QP и Httex1p 97QP(KR) (в которых Кб, K9 и К15 были заменены на Arg) были получены на основе Steffan et al., 2004, Science, 304: 100-104; a nFluc-плазмиды были получены на основе Gupta et al., 2011, Nat Methods, 8: 879-884. Каждый белок nFluc сливали с сигналом ядерной локализации SV40 (PKKKRKV) (SEQ ID NO 147) на NH2-конце и с GFP на СООН-конце. В FlucDM R188 и R261 были заменены на Glu; в FlucSM R188 был заменен на Glu (Gupta et al., 2011, Nat Methods, 8: 879-884). Матрица для ПЦР-амплификации RNF4 была приобретена у Open Biosystems (номер гена: NM002938). В RNF4 SIMm в SIM были произведены следующие замены на Ala: I36, L38 и V39 (SIM1); I46, V47 и L49 (SIM2); V57, V58 и V59 (SIM3); и V67, V68, I69 и V70 (SIM4). В SUMO2 KR, внутреннем консенсусном сайте сумоидирования, Lys11 был мутирован на Arg.
Для бактериальной экспрессии GST-гибриды Htt 25Q, Htt 103Q, Htt 52Q, Htt 52Q сс-, PML CC-FLAG, RNF4 и RNF4 SIMm были сконструированы в pGEX-1ZT, производном pGEX-1AT с дополнительными сайтами клонирования. Htt 25Q, Htt 52Q и Htt 103Q содержали Htt-аминокислоты 1-17 с последующим полиQ-трактом указанной длины (Krobitsch and Lindquist, 2000, Proc Natl Acad Sci USA, 97: 1589-1594). Htt 52Q и Htt 52Q сс- кДНК собирали путем соединения синтетических олигонуклеотидов. FLAG-PML F12 (571-633)-6xHis конструировали в рЕТ28а. Все плазмиды, полученные для этого исследования, подтверждали секвенированием ДНК.
Ранее были описаны следующие плазмиды: FLAG-PML, FLAG-PML М6 (с мутациями C57S, C60S, С129А, С132А, С189Аи Н194А), 6xHis-SUMO1 и 6xHis-SUMO2 (Chu and Yang, 2011, Oncogene, 30: 1108-1116); FLAG-Atxn1 82Q и FLAG Atxn1 30Q (Riley et al., 2005, J Biol Chem, 280: 21942-21948); люцифераза-6xHis (вариант люциферазы от Photinus pyralis) (Sharma et al., 2010, Nat Chem Biol, 6: 914-920); GST-rRNF4 (где "r" обозначает крысиное происхождение, то же обозначение используется ниже), GSTrRNF4 CS1 (в котором С136 и С139 были заменены на Ser), FLAG-rRNF4 и FLAGrRNF4 CS (в котором С136, С139, С177 и С180 были заменены на Ser) (Hakli et al., 2004, FEBS Lett, 560: 56-62); и изоформы PML I, II, III, IV и VI (используемые на фиг. 8А) (Xu et al., 2005, Mol Cel, 17: 721-732).
киРНК
киРНК PML и RNF4 были приобретены у Qiagen, и последовательности смысловых нитей были следующими: PML №4, CTCCAAGATCTAAACCGAGAA (SEQ ID NO 148); PML №9, CACCCGCAAGACCAACAACAT (SEQ ID NO 149); RNF4 №5, CCCTGTTTCCTAAGAACGAAA (SEQ ID NO 150); RNF4 №6, TAGGCCGAGCTTTGCGGGAAA (SEQ ID NO 151); RNF4 №8, AAGACTGTTTCGAAACCAACA (SEQ ID NO 152). RNF4 подвергали нокдауну либо с помощью киРНК по отдельности, либо в комбинации в равном молярном отношении. киРНК SUMO1 (Thermo Scientific, siGENOME SMARTpool M-016005-03-0005) представляла собой пул из 4 специфических для мишени дуплексов киРНК. Последовательности смысловых нитей были следующими: TCAAGAAACUCAAAGAATC (SEQ ID NO 153), GACAGGGTGTTCCAATGAA (SEQ ID NO 154), GGTTTCTCTTTGAGGGTCA (SEQ ID NO 155) и GAATAAATGGGCATGCCAA (SEQ ID NO 156). киРНК SUMO2/3 (Santa Cruz sc-37167) представляли собой пул из трех различных дуплексов киРНК, а последовательности смысловых последовательностей были следующими: CCCAUUCCUUUAUUGUACA (SEQ ID NO 157), CAGAGAAUGACCACAUCAA (SEQ ID NO 158) и CAGUUAUGUUGUCGUGUAU (SEQ ID NO 159).
Культивирование и трансфекция клеток
В стандартных условиях культивирования поддерживали клетки HeLa (из АТСС) и клетки U20S, экспрессирующие GFP-SUMO2 или GFP-SUMO3 (Mukhopadhyay et al., 2006, J Cell Biol, 174: 939-949). ДНК-плазмидами трансфицировали клетки с использованием реагента Lipofectamine 2000. При котрансфекции PML и Atxn1 использовали либо FLAG-PML плюс Atxn1 82Q/30Q-GFP, либо HA-PML плюс FLAG-Atxn1 82Q/30Q. Плазмиды HA-RNF4 и HA-RNF4-FLAG использовали для анализа экспрессии и клеточной локализации белка, соответственно.
киРНК с использованием Lipofectamine 2000 или RNAiMAX (Invitrogen) в соответствии с инструкциями производителя. Для экспериментов с нокдауном в течение последовательных дней проводили два раунда трансфекции киРНК. Когда проводили трансфекцию и ДНК, и киРНК, то ДНК вводили через 4-6 часов после обработки комбинированными киРНК RNF4, и через день после обработки другими киРНК. MG132 (Sigma) добавляли через 24 часа после последней трансфекции в концентрации 7,5-10 мкМ (конечная концентрация) на 4-5 часов.
Создание стабильных клеточных линий кшРНК RNF4
кшРНК против человеческого RNF4, клонированную в pLKO.1, получали от Thermo Scientific. Антисмысловая последовательность кшРНК RNF4 представляет собой TGGCGTTTCTGGGAGTATGGG (SEQ ID NO 160) (TRCN0000017054). Для получения лентивирусов клетки 293Т трансфицировали лентивирусными векторами, Gag-хелперной плазмидой, Rev-хелперной плазмидой и VSVG-хелперной плазмидой. Содержащие вирус среды собирали через 48 часов и 72 часа и вращали в течение 5 минут со скоростью 100 g. Клетки HeLa трансдуцировали с использованием содержащего вирус супернатанта с полибреном и отбирали с помощью пуромицина. Вектор pLKO.1 использовали для создания контрольных стабильных клеток.
Фракционирование клеточного лизата, анализ задержки в Фильтре и вестерн-блоттинг
Клеточные лизаты помещали в буфер, содержащий NP-40, и путем центрифугирования фракционировали на супернатант (NS) и осадок. Обе фракции кипятили в буфере, содержащем 2% SDS, и анализировали путем вестерн-блоттинга. Часть осадка анализировали с помощью анализа задержки в фильтре для SR-образцов.
Образцы готовили согласно описанию с модификациями (Janer et al., 2006, J Cell Biol, 174: 65-76). Клетки собирали и лизировали в течение 30 минут на льду в буфере, содержащем 50 мМ Tris, рН 8,8, 100 мМ NaCl, 5 мМ MgCl2, 0,5% NP-40, 2 мМ DTT, 250 МЕ/мл бензоназы (Sigma), 1 мМ PMSF, 1х полный протеазный коктейль (Roche) и 20 мМ N-этилмалеимид (NEM, Sigma). Концентрации белка определяли с помощью анализа по Брэдфорд (Bio-Rad Labs). Тотальные клеточные лизаты центрифугировали со скоростью 13000 об/мин в течение 15 минут при 4°С. Супернатант, содержащий растворимые в NP-40 (NP-40-soluble, NS) белки, анализировали с помощью SDS-PAGE. Осадок ресуспендировали в буфере для осадка (20 мМ Tris, рН 8,0, 15 мМ MgCl2, 2 мМ DTT, 250 МЕ/мл бензоназы, 1 мМ PMSF, 1Х полный протеазный коктейль и 20 мМ NEM) и инкубировали в течение 30 минут на льду. Фракцию осадка кипятили в 2% SDS, 50 мМ DTT. Одну часть кипяченой фракции осадка подвергали SDS-PAGE, и белки, входящие в гель (SDS-растворимые, SDS-soluble, SS), обнаруживали путем вестерн-блоттинга. Другую часть наносили на мембранный фильтр с размером пор 0,2 мкм, как было описано ранее (Wanker et al., 1999, Methods Enzymol, 309: 375-386), и агрегаты, устойчивые к SDS (SDS-resistant, SR), оставшиеся на фильтре, анализировали путем иммуноблоттинга.
Для вестерн-блоттинга использовали первичные антитела против следующих белков с информацией о продуктах и в указанных разведениях: PML (кроличье, Н-238, 1:1000, и козлиное, N-19, 1:500), убиквитин (мышиное, P4D1, 1:10000) и НА (кроличье, Y-11, 1:500) (Santa Cruz Biotechnology); FLAG (мышиное, М2, 1:7500), актин (кроличье, 1:0000) и β-тубулин (мышиное, 1:5000) (Sigma); GFP (мышиное, 1:4000) (Clonetech); GST (козлиное, 1:1000, GE Healthcare Life Sciences); SUMO1 (мышиное, 1:500, Invitrogen); SUMO2/3 (кроличье, 1:250, Abgent); НА (для трансфицированного HA-RNF4) (крысиное, 3F10, конъюгированное с пероксидазой хрена, или HRP, 1:10000) (Roche); RNF4 (мышиное, 1:500, Abnova, и мышиное моноклональное антитело, разработанное Abmart с использованием антигенного пептида DLTHNDSWI (SEQ ID NO 161), 1:1000). Трансфицированный FLAG-PML обнаруживали с помощью анти-FLAG-антитела, а трансфицированные HA-PML и HA-RNF4 обнаруживали с помощью антител против НА.
Вторичные антитела были либо конъюгированы с HRP (Santa Cruz Biotechnology), либо мечены IRD Fluor 800 или IRD Fluor 680 (LI-COR, Inc.). Окрашивание в вестерн-блоттинге получали с помощью реагентов ECL и анализировали с использованием ImageJ, либо сканировали с помощью системы инфракрасной визуализации Odyssey и анализировали с использованием Image Studio Lite (LI-COR, Inc.).
Иммунофлуоресценция культивируемых клеток
Клетки, культивированные на покровных стеклах, фиксировали 4% параформальдегидом в течение 15 минут, пермеабилизовали с помощью 0,2% Triton Х-100 в течение 15 минут, блокировали 1% BSA и инкубировали с антителами, как было указано. Клетки заливали средой, содержащей DAPI (для обнаружения ДНК) (Vector Labs), и получали изображения с помощью микроскопа Nikon Eclipse Е800 или Olympus IX81. Использовали следующие первичные антитела с информацией о продуктах и в указанных концентрациях: PML (кроличье, Н-238 и мышиное, PG-M3, 1:100), RNF4 (козлиное, С-15, 1:25) (Santa Cruz Biotechnology) и FLAG (для трансфицированных FLAG-PML и HA-RNF4-FLAG) (мышиное, М2, 1:2000) (Sigma). Вторичными антителами были FITC-конъюгированные противомышиные, противокроличьи (Zymed) и противокозлиные (Invitrogen) IgG; Texas Red-конъюгированные противомышиные и противокроличьи IgG (Vector labs); и Rhodamine Red-X-конъюгированные противокозлиные (Jackson ImmunoResearch Labs).
Для количественной оценки Atxn1 82Q, Httex1p 97QP и SUMO2-положительных агрегатов Atxn1 82Q было исследовано приблизительно 400, 500 и 200 клеток, соответственно, из десяти или более случайно выбранных полей. Размеры включений Atxn1 82Q измеряли с помощью ImageJ, и клетки классифицировали на основании наибольшего включения в клетках. Р-значение для пропорций клеток с агрегатами разного размера в присутствии и в отсутствие PML рассчитывали с использованием критерия хи-квадрат. Среди клеток, трансфицированных Httex1p 97QP, примерно 30% имели либо цитоплазматические, либо ядерные агрегаты.
Анализы периода полужизни белка
Клетки подвергали импульсному мечению в среде DMEM без Met и Cys, дополненной [35S]Met и [35S]Cys, а затем культивировали в обычной DMEM. Альтернативно, клетки обрабатывали СНХ. Иммунопреципитированный [35S]Atxn1 82Q или немеченый Atxn1 82Q в клеточном лизате анализировали с помощью авторадиографии или вестерн-блоттинга.
Для анализа вытеснения метки клетки HeLa трансфицировали FLAG-Atxn1 82Q отдельно или вместе с умеренным количеством PML. Через 17 ч после трансфекции клетки культивировали в среде DMEM без Met и Cys в течение 30 минут, а затем подвергали импульсному мечению в течение 30 минут с помощью [35S]Met и [35S]Cys (100 мкКи/мл каждый). Затем клетки дважды промывали натрий-фосфатным буфером (PBS) и помещали в DMEM с 10% FBS на 0-18 часов. Клетки лизировали в IP-лизисном буфере (50 мМ HEPES, рН 7,5, 150 мМ NaCl, 0,5% NP-40 и 2 мМ DTT), содержащем 2% SDS и 50 мМ DTT и кипятили при 95°С в течение 10 минут. Тотальные клеточные лизаты центрифугировали со скоростью 13000 об/мин в течение 15 минут. Супернатанты разводили в 20 раз в IP-лизисном буфере и инкубировали с анти-FLAG М2-гранулами при 4°С в течение ночи. Гранулы последовательно промывали в IP-лизисном буфере с дополнительным 0, 0,5 М и 1 М KCl и кипятили в буфере для образцов с 2% SDS. Образцы разгоняли с помощью SDS-PAGE и анализировали путем авторадиографии. Чтобы лучше сравнить период полужизни Atxn1 82Q в разных условиях, были представлены экспозиции с одинаковой интенсивностью сигнала в момент времени 0.
Для обработки циклогексимидом (cycloheximide, СНХ) Atxn1 82Q-трансфицированных клеток150 мкг/мл СНХ добавляли в клеточную культуральную среду через 4-5 часов после трансфекции. Клетки собирали и мгновенно замораживали на сухом льду в указанные моменты времени, лизировали и фракционировали для анализа путем вестерн-блоттинга. Для обработки СНХ nFlucDM-трансфицированных клеток добавляли 50 мкг/мл СНХ в клеточную культуральную среду через 17 часов после трансфекции. Клетки собирали в указанные моменты времени и тотальные клеточные лизаты использовали для анализа путем вестерн-блоттинга.
Анализ путем количественной ОТ-ПЦР
Тотальную РНК экстрагировали с использованием TRIzol (Invitrogen). Синтез кДНК проводили путем обратной транскрипции тотальной РНК с использованием набора для синтеза первой нити First Strand cDNA Synthesis Kit (Marligen Biosciences). Для анализа кПЦР использовали анализ экспрессии гена Taqman Gene Expression Assay (Applied Biosystems) с наборами праймеров/зондов Atxn1 (Hs00165656_m1) и 18s pPHK (4333760F) человека.
Очистка белков
FLAG-PML, FLAG-PML М6 и FLAG-Atxn1 82Q-HA экспрессировали в клетках 293Т и очищали с помощью анти-FLAG М2-гранул (Sigma), как описано ранее (Tang et al., 2006, Nat Cell Biol, 8: 855-862; Tang et al., 2004, J Biol Chem, 279: 20369-20377) с модификациями. Клетки лизировали в IP-лизисном буфере (50 мМ Tris, рН 7,5, 150 мМ NaCl, 0,5% Triton Х-100, 0,5% NP-40 и 2 мМ DTT), дополненном 1 мМ PMSF и 1х полным протеазным коктейлем. Для очистки PML IP-лизисный буфер также дополняли 20 мкМ ZnCl2. Лизаты центрифугировали со скоростью 13000 об/мин в течение 15 минут. Супернатанты инкубировали с анти-FLAG М2-гранулами при 4°С в течение периода от 4 часов до ночи. М2-гранулы последовательно промывали IP-лизисными буферами, содержащими 0, 0,5 и 1 М KCl, и буфером для элюирования (50 мМ Tris, рН 7,5, 150 мМ NaCl и 2 мМ DTT). Связанные белки элюировали в буфере для элюирования, содержащем 0,1-0,3 мг/мл 3*FLAG-пептида (Sigma). Основные дополнительные полосы, наблюдаемые в препаратах FLAG-PML и FLAG-PML М6, были получены из PML на основании как вестерн-блоттинга, так и масс-спектрометрии (фиг. 11G).
GST-гибрид PML экспрессировали в клетках 293Т и очищали с использованием гранул глутатион-сефарозы glutathione-Sepharose™ 4 В (GE Healthcare Life Sciences) с аналогичными условиями лизиса и промывания, описанными выше. GST-гибриды rRNF4, rRNF4 CS1, RNF4 и RNF4 SIMm экспрессировали в Escherichia coli BL21 DE3 или Rosetta 2 (EMD Chemicals) и очищали, как описано ранее (Hakli et al., 2001, J Biol Chem, 276: 23653-23660). Бактерии выращивали при 37°C до абсорбции при 600 нм, равной 0,6-0,8, и индуцировали экспрессию белка с 0,3 мМ IPTG в течение 3 часов при 30°С. GST-меченные белки очищали на гранулах с глутатионом. GST и GST-гибриды Htt 25Q, Htt 103Q очищали аналогично за исключением того, что для индукции экспрессии белка использовали 0,1 мМ IPTG. Связанные белки элюировали в буфере для элюирования, содержащем 30 мМ глутатион (Sigma).
Люциферазу-бхЫэ экспрессировали в BL21 DE3, как было описано ранее (Sharma et al., 2010, Nat Chem Biol, 6: 914-920). Для получения иммобилизованной нативной люциферазы, Luc (N), Ni-NTA-гранулы (Qiagen) инкубировали с бактериальными лизатами и промывали в соответствии с инструкциями производителя. Денатурированную люциферазу, Luc (D), получали путем обработки иммобилизованной Luc (N) 8 М мочевиной в течение 5 минут. Анализ активности люциферазы показал, что после обработки мочевиной оставалось только 0,2% от ферментативной активности. Для контрольных гранул лизаты бактерий, экспрессирующих люциферазу, инкубировали параллельно с Ni-NTA-гранулами.
Для получения мутантов PML, используемых для сканирования пептидов люциферазы, FLAG-PML F12 (571-633)-6xHis и GST-PML CC-FLAG экспрессировали в клетках BL21 DE при комнатной температуре с индукцией 0,1 мМ IPTG в течение 3 часов и 1 часа, соответственно. Flag-PML F12 (571-633)-6xHis сначала очищали с использованием М2-гранул и элюирования FLAG-пептида и подвергали второй очистке с использованием Ni-NTA-гранул в соответствии с инструкциями производителя. Для создания домена PML СС вводили сайт расщепления протеазой TEV между GST и PML СС. Конъюгированные с GST-PML CC-FLAG глутатионовые гранулы инкубировали с TEV-протеазой (Sigma) в соответствии с инструкциями производителя для высвобождения PML CC-FLAG из группировки GST (и из гранул). PML CC-FLAG, используемый для анализа соосаждения, получали путем инкубации очищенных белков PML CC-FLAG с М2-гранулами и промывали, как было описано выше.
Анализы соосаждения
Для анализов соосаждения FLAG использовали FLAG-PML, FLAG-GFP и PML CC-FLAG, связанные с анти-FLAG М2-гранулами, как было описано выше. Очищенные GST-Htt 25Q, GST-Htt 103Q, GST-Htt 52Q или GST-Htt 52Q сс-центрифугировали со скоростью 13000 об/мин в течение 15 минут для удаления любых агрегированных белков. FLAG-PML (2,5 мкг) или FLAG-GFP (1,1 мкг) в сопоставимой молярности инкубировали с GST-Htt 25Q или GST-Htt 103Q (по 2,5 мкг каждый) в отсутствие или в присутствии Hsp70 (2,5 мкг) и Hsp40 (1,4 мкг) (Enzo Life Sciences) в конечном объеме 200 мкл аналитического буфера (50 мМ Tris, рН 7,5, 150 мМ NaCl и 2 мМ DTT, 0,5% NP-40) в течение 2 часов при 4°С. Гранулы трижды промывали IP-лизисным буфером в колонках Compact Reaction Columns (Affymetrix/USB) и кипятили в 2% буфере для образцов SDS. Образцы анализировали с помощью вестерн-блоттинга. Анализ соосаждения PML СС проводили аналогичным образом за исключением М2-гранул, содержащих 1,6 мкг PML CC-FLAG, или контрольных М2-гранул, которые инкубировали с 5 мкг GST или GST-Htt белков.
Чтобы провести анализ соосаждения GST, 2 мкг каждого из белков GST, GST-Htt 25Q и GST-Htt 103Q, которые связаны с гранулами из глутатион-сефарозы™ 4 В, инкубировали с 400 мкг лизатов от клеток 293Т, экспрессирующих белок FLAG-PML, при 4°С в течение 4 часов. Гранулы трижды промывали IP-лизисным буфером в колонках Compact Reaction Columns и кипятили в буфере для образцов с 2% SDS. Образцы анализировали путем вестерн-блоттинга. Для обнаружения взаимодействия между мутантами PML и Htt [35S]Met-меченный полноразмерный и мутантный PML-белки получали с использованием системы SP6 Coupled Transcription/Translation System (Promega) и инкубировали с GST, GST-25Q и GST-Htt 103Q, которые были связаны с гранулами, в 150 мкл IP-лизисного буфера при 4°С в течение ночи. Гранулы промывали и кипятили, как описано выше. Входящие и выпадающие в осадок образцы анализировали путем авторадиографии и окрашивания Кумасси синим. При авторадиографии выпадающие в осадок образцы из одних и тех же экспериментов, которые разгоняли в разных гелях, подвергали одинаковому времени воздействия.
Для анализа соосаждения люциферазы 3 мкг связанных с Luc (N) или Luc (D) Ni-NTA-гранул или контрольных гранул, полученных из равного количества бактериального лизата, инкубировали с очищенным GST (1 мкг), GST-PML (3 мкг) в отсутствие или в присутствии Hsp70 (3 мкг) и Hsp40 (1,7 мкг), либо [35S]Met-меченных полноразмерных и мутантных PML-белков в 200 мкл PBS, содержащего 15 мМ имидазол, 1 мМ DTT, 0,5% Triton Х-100 и 0,5% NP-40, при 4°С в течение 4 часов. Гранулы трижды промывали PBS, содержащим 20 мМ имидазол, 1 мМ DTT, 0,5% Triton Х-100 и 0,5% NP-40, и кипятили. Входящие и выпадающие в осадок образцы анализировали, как описано выше.
Скрининг пептидов, связанных с целлюлозой, на способность связываться с доменами PML
Библиотеку пептидов (13-меры, перекрывающиеся на десять аминокислот) люциферазы Photinus pyralis получали путем автоматического синтеза пятен (JPT peptide Technologies). Матричную пептидную мембрану метили очищенными фрагментами PML SRS1 и SRS2. Матричную пептидную мембрану блокировали блокирующим буфером Odyssey Blocking buffer (LI-COR, Inc) и инкубировали с FLAG-PML F12 (571-633)-HisX6 или PML F4/CC-FLAG (150 нМ каждый) в TBS-T (50 мМ TRIS, рН 8,0, 137 мМ NaCl, 2,7 мМ KCl, 0,05% Tween и 1 мМ DTT) при 4°С в течение 2 часов. Мембрану промывали и метили мышиными анти-Flag-антителами и противомышиными HRP-антителами в соответствии с инструкциями производителя. Окрашивание развивали с помощью реагентов ECL. Фоновый сигнал на блотах с анти-Flag-антителами и противомышиными HRP-антителами был минимальным даже при длительном воздействии. Матричную пептидную мембрану подвергали регенерации в соответствии с протоколом производителя.
Анализ сумоилирования и убиквитинирования
Клетки или реакционные смеси in vitro кипятили в буфере, содержащем 2% SDS, а затем разводили в буфере без SDS или пропускали через хроматографическую колонку Bio-Spin для уменьшения концентрации SDS. Белки подвергали иммунопреципитации (денатурируя IP или d-IP) и анализировали путем вестерн-блоттинга.
Анализ сумоилирования и убиквитинирования in vivo
Клетки трансфицировали FLAG-Atxn1, FLAG-nFluc-GFP и другими экспрессионными плазмидами, как было указано. Для экспериментов, показанных на фиг. 4А, также использовалась SUMO2-экспрессионная плазмида. Через 24 часа после трансфекции клетки обрабатывали 7,5 мкМ MG132 или ДМСО в течение 5 часов или оставляли необработанными, и собирали в IP-лизисный буфер с добавлением 2% SDS и 50 мМ DTT. Для денатурирующей иммунопреципитации (denaturing immunoprecipitation, d-IP) клеточные лизаты кипятили при 95°С в течение 10 минут. Одну аликвоту сохраняли для анализа путем вестерн-блоттинга. Остальные лизаты либо разводили в 20 раз в IP-лизисном буфере, либо пропускали через хроматографическую колонку Bio-Spin (Bio-Rad), уравновешенную IP-лизисным буфером, чтобы уменьшить концентрацию SDS. Затем лизаты инкубировали с гранулами против FLAG (М2) при 4°С в течение 4 часов или в течение ночи. Гранулы промывали, как описано для FLAG-меченной очистки белка, и кипятили в 2% SDS-буфере для образцов. Белки из гранул анализировали с помощью вестерн-блоттинга с анти-FLAG, -SUMO2/3, -SUMO1, -убиквитином и другими антителами, как было указано. Для лучшего сравнения уровней убиквитинированных или сумоилированных видов продукты d-IP, содержащие одинаковые уровни немодифицированных белков, часто использовались для анализа путем вестерн-блоттинга.
Анализы сумоилирования in vitro
Компоненты для реакций убиквитинирования и сумоилирования in vitro приобретали у Boston Biochem. Анализ сумоилирования in vitro проводили при 37°С в течение 1,5 часов в 30 мкл реакционного буфера (50 мМ Tris, рН 7,5, 5,0 мМ Mg2+-АТР и 2,5 мМ DTT), содержащего очищенный HA-Atxn1 82Q-FLAG (600 нг/200 нМ), FLAG-PML (фиг. 4D, 50 и 200 нг или 22 и 90 нМ; фиг. 4Е, 100 нг или 45 нМ) или FLAG-PML М6 (100 нг или 45 нМ), SAE1/SAE2 (125 нМ), Ubc9 (1 мкМ), His-SUMO2 (25 мкМ), Hsp70 (420 нг/200 нМ), Hsp40 (240 нг/200 нМ) и BSA (0,1 мкг/мл). Реакционные смеси подвергали денатурации путем добавления 30 мкл IP-лизисного буфера, содержащего 2% SDS и 50 мМ DTT, и нагревания при 95°С в течение 10 минут. Одну аликвоту нагретых реакционных смесей сохраняли для анализа путем вестерн-блоттинга, а остальные разводили в 20 раз в IP-лизисном буфере без SDS. HA-Atxn1-FLAG подвергали иммунопреципитации с помощью гранул против НА (Roche) и анализировали на модификацию SUMO2/3 с использованием антител против SUMO2/3.
Анализы убиквитинирования in vitro
Анализы in vitro на самоубиквитинирование RNF4 проводили при 37°С в течение 1 часа в 10 мкл реакционного буфера (50 мМ Tris, рН 7,5 и 2,5 мМ DTT), содержащего очищенный белок GST-RNF4 (250 нг/530 нМ), UBE1 (125 nM), UbcH5a (625 нМ), убиквитин (2,5 мкг/30 мкМ) и Mg2+-АТР (2,5 мМ). Реакционные смеси нагревали при 95°С в течение 10 минут и анализировали с помощью вестерн-блоттинга.
Для убиквитинирования in vitro сумоилированного Atxn1 82Q смесь сумоилированного и немодифицированного белков Atxn1 82Q готовили в качестве субстрата для реакции убиквитинирования. М2-гранулы, конъюгированные с FLAG-Atxn1 82Q-HA (1,5 мкг/300 нМ), и контрольные М2-гранулы смешивали с 0,75 мкМ SAE1/SAE2, 12,5 мкМ Ubc9, 125 мкМ His-SUMO2 и 2,5 мМ DTT в общем объеме 50 мкл раствора Mg2+-ATP-Energy Regeneration Solution, содержащего 5 мМ АТФ (Boston Biochem). Для достижения достаточного сумоилирования Atxn1 82Q реакцию проводили при 37°С в течение 24 часов и реакционный буфер заменяли через 12 часов. Затем гранулы промывали последовательно IP-лизисным буфером, дополненным 0, 0,5 и 1 М KCl, и буфером для реакции убиквитинирования (50 мМ Tris, рН 7,5 и 150 мМ NaCl) (Tang et al., 2006, Nat Cell Biol, 8: 855-862).
Затем гранулы Atxn1 82Q и контрольные гранулы инкубировали при 37°С в течение 1 часа с реакционными смесями для убиквитинирования в объеме 20 мкл, содержащем GST-rRNF4 (0, 40, 160 и 500 нг или 0, 43, 170 и 530 нМ) UBE1 (100 нМ), UbcH5a (500 нМ), убиквИтин (5 мкг/30 мкМ) и Mg2+-АТР (2,5 мМ) в реакционном буфере (50 мМ Tris-HCl, рН 7,5, 150 мМ NaCl и 2,5 мМ DTT). Затем гранулы отделяли от супернатанта и промывали IP-лизисным буфером. Atxn1 82Q денатурировали и высвобождали из гранул путем добавления 1Р-лизисного буфера, содержащего 2% SDS и 50 мМ DTT, и нагревали при 95°С в течение 10 минут. После разведения Atxn1 82Q подвергали иммунопреципитации с М2-гранулами. Продукты IP и супернатант от реакции анализировали с помощью вестерн-блоттинга.
Ведение мышей и генотипирование
Были получены гетерозиготные В05 трансгенные мыши (Atxn1tg/-), которые несут человеческую SCA1-кодирующую область с 82 CAG-повторами, управляемую промоторным элементом, специфическим для клеток Пуркинье (Burright et al., 1995, Cell, 82: 937-948). Получали мышей PML-/- (Wang et al., 1998, Science, 279: 1547-1551). Мышей Atxn1tg/- (на основе FVB) скрещивали с PML-/- (на основе 129Sv). Мышей PML+/-:Atxn1t9/- из поколения F1 скрещивали с PML-/- или PML+/+ для создания мышей, используемых для анализа на Rotarod и анализа патологии. Схема скрещивания не влияла на характеристики в анализах на Rotarod, формирование агрегатов, толщину молекулярного слоя или дендритную арборизацию у поколения F2 мышей PML+ или PML+/-:Atxn1tg/-. Мышиный генотип определяли с помощью ПЦР либо как было описано (Burright et al., 1995, Cell, 82: 937-948) (для Atxn1), либо в соответствии с предложениями NCl Mouse Repository (для PML).
Анализ на Rotarod с ускорением
Аппарат Rotarod с ускорением (47600, Ugo Basile, Италия) использовали для измерения координации движений и баланса. Использовали только наивных животных. С каждым животным проводили по три испытания в день в течение четырех последовательных дней с 1-часовым перерывом между испытаниями. Для каждого испытания мышей помещали на Rotarod с возрастающей скоростью, от 4 до 80 об/мин, в течение 10 минут. Записывали латентность до момента падения с Rotarod (в секундах).
Иммуноокрашивание и патологический анализ мышиного мозжечка
Залитые в парафин срединно-сагиттальные срезы мозжечков окрашивали с помощью указанных антител и визуализировали с использованием лазерного сканирующего конфокального микроскопа Leica SP5 II или окрашивали гематоксилином и визуализировали с использованием микроскопа Olympus ВХ51.
Иммуногистохимию и иммунофлуоресценцию выполняли, как был описано ранее, с модификациями (Duda et al., 2000, J Neuropathol Exp Neurol, 59: 830-841; Emmer et al., 2011, J Biol Chem 286: 35104-35118). Залитые в парафин мозжечки нарезали на 10-миллиметровые срезы. Для измерения молекулярного слоя анализировали три окрашенных гематоксилином срединно-сагиттальных среза с интервалами 100 мкм на каждую мышь. Усредняли двадцать измерений в первичной щели для каждого среза.
Для количественной оценки дендритной арборизации клеток Пуркинье срединно-сагиттальные срезы мозжечка окрашивали антителом против белка кальбиндина, специфического для клеток Пуркинье (мышиное, СВ-955, 1:250, Sigma). Двадцать оптических срезов толщиной 0,5 мкм накапливали с помощью лазерного сканирующего конфокального микроскопа Leica SP5 II. Самые яркие последовательные 12 срезов (6 мкм) отражали максимальную интенсивность. Профиль интенсивности флуоресценции из одной и той же области предвершинной щели изображали с помощью ImageJ.
Для количественной оценки клеток Пуркинье срединно-сагиттальные срезы окрашивали антителом против кальбиндина и сравниваемые области использовали для подсчета клеток. Длину слоя клеток Пуркинье измеряли, рисуя пунктирную линию вдоль центра сомы клетки Пуркинье с использованием ImageJ. Для каждой мыши измеряли примерно 350-900 нейронов на 30 мм. Плотность клеток Пуркинье определяли путем деления числа клеток на длину слоя клеток Пуркинье.
Чтобы определить число клеток Пуркинье с агрегатами, срединные срезы окрашивали антителом против убиквитина (мышиное, Ubi-1, МАВ1510, 1:2000, Millipore). 300 или более клеток подсчитывали из одной и той же области мозга у каждой мыши. Изображения делали с использованием микроскопа Olympus ВХ51, оснащенного цифровой камерой DP71 Olympus.
По четыре мыши на каждый генотип использовали для подсчета клеток Пуркинье у мышей в возрасте 1 года, по две мыши PML+/+ на генотип для количественной оценки дендритной арборизации и по три мыши на генотип для остальных исследований.
Статистический анализ
Число клеток с агрегатами анализировали с помощью критерия хи-квадрат и t-критерия Стьюдента, когда это было подходящим. Поведенческие оценки и мозжечковую патологию анализировали с помощью двухстороннего ANOVA с повторными измерениями и t-критерием Стьюдента. Все данные анализировали с использованием программного обеспечения Prism5 или Microsoft Excel 2008.
Результаты экспериментов описаны далее.
PML способствует протеасомальной деградации патогенного белка атаксина-1
SCA1 является фатальным неврологическим нарушением, характеризующимся прогрессирующей атаксией и потерей нейронов, особенно клеток Пуркинье мозжечка. Оно связано с удлинением полиQ-тракта в продукте гена SCA1, атаксине-1 (Atxn1) (Orr and Zoghbi, 2007, Annu Rev Neurosci, 30: 575-621). Чтобы исследовать роль PML в устранении ядерных неправильно упакованных белков, была создана модель клеточной культуры, в которой патогенный белок Atxn1 с 82 смежными глутаминами, который был слит с С-конца с усиленным зеленым флуоресцентным белком, Atxn1 82Q-GFP, экспрессировали в клетках HeLa. Подобно патогенным белкам Atxn1 у людей с SCA1 и трансгенных мышиных моделей SCA1 (Skinner et al., 1997, Nature, 389: 971-974), Atxn1 82Q-GFP локализовался в ядре, демонстрируя диффузный характер локализации с заметно более высокой концентрацией в микроскопически видимых включениях (фиг. 1А и фиг. 1В). Atxn1 82Q-GFP также давал как NP-40-растворимые (растворимые, или NS), так и NP-40-нерастворимые (агрегированные) виды в клеточных лизатах. Последние можно разделить на SDS-растворимые (SS) и SDS-устойчивые (SR) виды (фиг. 1С).
В согласии с предыдущими сообщениями (Skinner et al., 1997, Nature, 389: 971-974) эндогенный PML колокализовался с включениями Atxn1 82Q-GFP, накапливаясь в тельцах, прилегающих к ним, а также распределяясь внутри (фиг. 1А). PML экспрессировался в виде нескольких изоформ (Nisole et al., 2013, Front Oncol, 3: 125). Были проверены пять основных изоформ PML (I, II, III, IV и VI), и было обнаружено, что все пять колокализировались с включениями Atxn1 -GFP (фиг. 8А). Для последующих анализов была выбрана широко используемая изоформа IV (далее называемая PML, если не указано иначе).
При коэкспрессии с Atxn1 82Q PML значительно уменьшал размер ядерных включений Atxn1 82Q-GFP (фиг. 1В). Он также уменьшал уровни белка Atxn1 82Q-GFP в стабильном состоянии, особенно агрегированных видов SS и SR (фиг. 1С, слева). Чтобы оценить влияние эндогенных PML (все изоформы), его подвергали нокауту с использованием двух независимых коротких интерферирующих РНК (киРНК). Это заметно повышало уровни Atxn1 82Q-GFP, особенно агрегированных видов (фиг. 1С, справа). Молчание PML также повышало уровни FLAG-меченного белка Atxn1 82Q в стабильном состоянии (фиг. 8В). Влияние киРНК PIM на Atxn1 82Q могло быть отменено киРНК-резистентной формой PML (фиг. 8С), что исключает влияния киРНК мимо мишени.
Чтобы оценить, действительно ли PML уменьшает патогенные белки Atxn1, использовали непатогенный белок атаксин-1, Atxn1 30Q. Принудительная экспрессия PML не уменьшала обилие Atxn1 30Q-GFP, в то время как нокдаун PML значительно не увеличивал его (фиг. 1D), подчеркивая селективное влияние PML на патогенные белки Atxn1.
PML не ингибировал транскрипцию гена Atxn1 82Q (фиг. 8D). Чтобы определить, способствует ли PML деградации белка Atxn1 82Q, был проведен анализ вытеснения метки. В отсутствие котрансфицированного PML общий [35S]-меченный белок Atxn1 82Q был довольно стабильным, и его уровни снизились лишь примерно на 20% за 18 часов. Напротив, в присутствии PML общий [35S]-меченный белок Atxn1 82Q был дестабилизирован, и его уровни снизились примерно на 80% за тот же период времени (фиг. 1Е).
Эксперименты проводили с использованием циклогексимида (СНХ) для блокирования синтеза белка и для исследования деградации ранее существовавшего белка Atxn1 82Q. Принудительная экспрессия PML ускорила деградацию агрегированного Atxn1 82Q, уменьшив период полужизни от примерно 8 часов до примерно 2 часов, минимально влияя на растворимый Atxn1 82Q (фиг. 1F). И наоборот, молчание PML продлевало период полужизни агрегированного Atxn1 82Q и, в меньшей степени, период полужизни растворимого Atxn1 82Q (фиг. 1G). Способность PML удалять агрегированный Atxn1 82Q заметно уменьшалась под влиянием протеасомального ингибитора MG132 (фиг. 1H). Напротив, PML не изменял период полужизни Atxn1 30Q (фиг. 8Е). В совокупности эти результаты показывают, что PML нацеливает патогенный, но не нормальный, белок Atxn1 на протеасомальную деградацию.
Общая роль PML в деградации ядерных неправильно упакованных белков
Чтобы оценить, играет ли PML большую роль в деградации неправильно упакованных белков в ядре, были проверены два дополнительных белка, связанных с нейродегенерацией: (1) патогенный фрагмент хантингтина (huntingtin, Htt), кодируемый первым экзоном гена HD, Httex1p 97QP (Steffan et al., 2004, Science, 304: 100-104); и (2) TAR ДНК-связывающий белок 43 (TDP-43), который ассоциирован как с амиотрофическим боковым склерозом (ALS, также известным как болезнь Лу Герига), так и с лобно-височной дегенерацией с убиквитинированными включениями (FTLD-U) (Chen-Plotkin et al., 2010, Nat Rev Neurosci, 6: 211-220). Httex1p 97QP формировал микроскопически видимые включения как в ядре, так и в цитоплазме (фиг. 11), тогда как TDP-43 формировал включения в основном в ядре. PML уменьшал ядерные, но не цитоплазматические включения Httex1p 97QP (фиг. 11), и уменьшал количество агрегированного Httex1p 97QP (фиг. 1J, линии 1 и 2). PML также уменьшал количество агрегированного, но не растворимого TDP-43 (фиг. 1К).
Чтобы расширить эти анализы, был использован структурно дестабилизированный мутант модельного субстрата шаперона люциферазы светлячка (FlucDM), который был разработан как зонд для определения возможностей клеточных систем PQC (Gupta et al., 2011, Nat Methods, 8: 879-884). Эндогенный PML частично колокализовался с ядерной формой FlucDM (nFlucDM-GFP), которая формировала включения, но не с аналогами дикого типа (nFlucWT-GFP), которые демонстрировали диффузную локализацию (фиг. 8F). Молчание PML заметно повышало уровни агрегированного nFlucDM-GFP (фиг. 8G) и увеличивало период полужизни тотального белка nFlucDM-GFP (фиг. 1L). В совокупности эти результаты показывают, что PML облегчает удаление множественных неправильно упакованных белков в ядре клетки млекопитающего.
Распознавание неправильно упакованных белков отдельными сайтами на PML
Чтобы исследовать механизм, с помощью которого PML вызывает деградацию неправильно упакованных белков, сначала было исследовано, способен ли PML напрямую распознавать эти белки. Для этих экспериментов использовали патогенный (103Q) и непатогенный (25Q) фрагмент Htt, каждый из которых был слит с глутатион-S-трансферазой (glutathione S-transferase, GST). В анализе in vitro с очищенными рекомбинантными белками иммобилизованный FLAG-PML, но не контрольный белок FLAG-GFP, вызывал осаждение GST-Htt 103Q (фиг. 2А), что указывает на специфическое и прямое взаимодействие между PML и Htt 103Q. FLAG-PML также вызывал осаждение GST-Htt 25Q. Тем не менее, это взаимодействие было существенно слабее, чем взаимодействие PML-Htt 103Q (фиг. 2А). В обратном эксперименте иммобилизованные белки GST-Htt 103Q также более интенсивно взаимодействовали с FLAG-PML, чем иммобилизованный GST-Htt 25Q (фиг. 9А). Hsp70 и Hsp40, которые распознают широкий спектр неправильно упакованных белков, не усиливали взаимодействие PML-Htt 103Q (фиг. 2А). Эти результаты подтверждают, что PML может напрямую ассоциировать с полиQ-белками и преимущественно с патогенной формой.
Было также проверено, селективно ли PML связывается с денатурированной люциферазой. бхЫэ-меченную люциферазу, которая была иммобилизована на Ni-NTA-гранулах, либо подвергали денатурации мочевиной, либо сохраняли в нативной форме. Денатурированная, но не нативная люцифераза специфически взаимодействовала с GST-PML, а система Hsp707Hsp40 не усиливала это взаимодействие (фиг. 2В). Таким образом, PML может непосредственно распознавать неправильно упакованную, но не нативную люциферазу.
Чтобы понять молекулярную основу взаимодействия PML с неправильно упакованными белками, было предложено идентифицировать сайты распознавания субстрата (substrate recognition site, SRS) PML, а также структурные особенности на субстратах, которые распознают эти SRS. Ранее было показано, что в зависимости от их длины полиQ. и фланкирующие области формируют СС-структуры, которые облегчают сборку полиQ-белков в олигомерном или агрегированном состоянии, а также опосредуют взаимодействие полиQ-белков с СС-содержащими белками (Fiumara et al., 2010, Cell, 143: 1121-1135). Таким образом, было высказано предположение, что PML через свою СС-область в мотиве TRIM/RBCC взаимодействует с патогенными полиQ-белками. Была построена панель фрагментов PML (F1-F5), где каждый фрагмент содержал или не содержал СС-область (фиг. 9В). Фрагмент, содержащий СС-область (F1), взаимодействовал с Htt 103Q, тогда как два фрагмента, лишенные этой области (F2 и F3), не взаимодействовали (фиг. 9В и фиг. 9С). Кроме того, только СС-область (F4), связанная с Htt 103Q, при удалении этой области из целого белка PML (F5 или ЛСС) значительно уменьшала это связывание. Таким образом, PML распознает Htt 103Q почти исключительно через СС-область. Подобно полноразмерному PML, PML СС продемонстрировал четкое предпочтение связывания патогенного Htt 103Q непатогенному Htt 25Q (фиг. 2С). PML СС также сильно взаимодействовал с другой патогенной конструкцией Htt, Htt 52Q (фиг. 2С). Таким образом, PML СС, по-видимому, представляет собой SRS (называемый SRS1).
Чтобы проверить, распознает ли PML СС гомологичную СС-структуру в белках Htt, остатки в Htt 52Q, которые, как было предсказано, участвуют в формировании СС, подвергали мутированию, получая Htt 52Q сс- (фиг. 9D). Ранее было показано, что аналогичная мутация уменьшает формирование СС-структуры BHtt72Q (Fiumara et al., 2010, Cell, 143: 1121-1135). Действительно, по сравнению с Htt 52Q, Htt 52Q сс- демонстрирует заметно сниженную склонность к формированию агрегатов и существенно более слабое взаимодействие с PML СС (фиг. 2С). Таким образом, PML CC/SRS1, по-видимому, взаимодействует с СС-структурой на патогенных Htt-белках.
Учитывая, что PML также способствует деградации не-полиQ.-белков, таких как люцифераза и TDP-43 (фиг. 1 и фиг. 8), было высказано предположение, что PML может содержать по меньшей мере другой SRS, который мог бы различить структурные не-СС-особенности на неправильно упакованных белках. Чтобы проверить эту возможность, панель фрагментов PML исследовали на взаимодействие с денатурированной люциферазой. Хотя только СС-область могла взаимодействовать с денатурированной люциферазой, значительные уровни взаимодействия наблюдались также у двух фрагментов (F2 и F5), которые не обладали этой областью, но содержали С-конец (аминокислоты 361-633) (фиг. 9В и фиг. 10А). Используя дополнительные конструкции с делециями на С-конце (F6-F18, фиг. 9В и фиг. 10В), обнаружили, что для связывания с денатурированной люциферазой было достаточно фрагмента в 63 аминокислоты (аминокислоты 571-633). Либо NH2-, либо СООН-концевые делеции этого фрагмента отменяют связывание (фиг. 10). Таким образом, последние 63 аминокислоты PML, по-видимому, представляют собой другой SRS (называемый SRS2).
Чтобы исследовать линейные последовательности в люциферазе, которые могут быть распознаны PML SRS2, очищенный PML SRS2 использовали для скрининга библиотеки пептидов, связанных с целлюлозой, которая представляла полную последовательность люциферазы. Библиотека состояла из 180 пептидов, каждый из которых содержал 13 аминокислотных остатков, которые перекрывали соседние пептиды на десять аминокислотных остатков. Подобно шаперонам, таким как Hsp70 и ClpB (Rudiger et al., 1997, EMBO J, 16: 1501-1507; Schlieker et al., 2004, Nat Struct Mol Biol, 11: 607-615), PML SRS2 связывался только с подгруппой этих пептидов (фиг. 2D), что указывает на его способность различать пептиды с различными аминокислотными составами. Анализ присутствия всех 20 аминокислот в PML 8Р32-взаимодействующих пептидах относительно всех пептидов в библиотеке показал, что в PML SRS2 сильное предпочтение отдается ароматическим (Phe, Trp и Tyr) и положительно заряженным (Arg и Lys) остаткам и не отдается отрицательно заряженным остаткам (Asp и Glu) (фиг. 2Е). Это аминокислотное предпочтение было аналогично предпочтению в ClpB за исключением того, что в SRS2 дополнительное предпочтение отдавалось Leu и His, которым не отдавалось в ClpB (Schlieker et al., 2004, Nat Struct Mol Biol, 11: 607-615).
Для сравнения было проверено связывание PML CC/SRS1 с этой библиотекой пептидов. Учитывая, что эта область распознает структуры более высокого порядка вместо линейных последовательностей, PML CC/SRS1 слабо связывался только с несколькими пептидами (фиг. 9Е). Исходя из этих результатов, был сделан вывод о том, что PML содержит по меньшей мере две области, которые могут распознавать неправильно упакованные белки: СС-область в мотиве TRIM/RBCC (SRS1) и фрагмент длиной 63 аминокислоты на С-конце (SRS2), который может различать СС-структуры и экспонированные пептиды, обогащенные как ароматическими, так и основными аминокислотами, соответственно.
Вовлечение сумоилирования в деградацию Atxn1 82Q
Эксперименты проводили для исследования того, как PML способствует деградации неправильно упакованных белков при распознавании. Неправильно упакованные белки, ассоциированные с нейродегенерацией, часто модифицируются путем SUMO, хотя роль этой модификации остается неясной (Martin et al., 2007, Nat Rev Neurosci, 8: 948-959). Клетки млекопитающих экспрессируют три основных SUMO-белка, SUMO1-SUMO3. SUMO2 и SUMO3 почти идентичны друг другу по своей последовательности (вместе они называются SUMO2/3) и примерно на 50% идентичны SUMO1 (Wilkinson and Henley, 2010, Biochem J, 428: 133-145). Была исследована модификация Atxn1 82Q этими белками SUMO и их участие в деградации Atxn1 82Q.
Atxn1 82Q модифицировали как экзогенным (Riley et al., 2005, J Biol Chem, 280: 21942-21948), так и эндогенным (фиг. 3А, слева) SUMO1, и эта модификация была слабее, чем Atxn1 30Q (Riley et al., 2005, J Biol Chem, 280: 21942-21948). Atxn1 82Q также модифицировали эндогенным SUMO2/3 (фиг. 3А, справа), и он колокализовался с GFP-SUMO2/3 в ядре (фиг. 3В). Сайты в Atxn1 82Q, которые были конъюгированы с SUMO1 и SUMO2/3, могут быть разными, поскольку мутантный Atxn1 82Q с нарушенной конъюгацией SUMO1, Atxn1 82Q (5KR) (Riley et al., 2005, J Biol Chem, 280: 21942-21948), не обнаружил дефекта в конъюгации SUMO2/3 (фиг. 11А).
Следует отметить, что Atxn1 82Q был более сильно модифицирован эндогенным SUMO2/3 по сравнению с Atxn1 30Q (фиг. 3С), что коррелировало с различными ответами этих белков Atxn1 на PML-опосредованную деградацию (фиг. 1 и фиг. 8). Аналогично, TDP-43 был модифицирован эндогенным SUMO2/3 (фиг. 11В). SUMO 2/3 также модифицировал FlucDM, а также другой структурно дестабилизированный мутант люциферазы, FlucSM (Gupta et al., 2011, Nat Methods, 8: 879-884). Модификация SUMO2/3 этих мутантов люциферазы была также сильнее, чем у люциферазы дикого типа (фиг. 11С).
Более того, протеасомальное ингибирование усиливало колокализацию Atxn1 82Q с GFP-SUMO2/3 (фиг. 3В). Оно также повышало SUMO2/3-модифицированный Atxn1 82Q одновременно с убиквитинированным Atxn1 82Q, но не SUMOI-модифицированный Atxn1 82Q (фиг. 3А и фиг. 3D, дорожки 2 и 3). Аналогично, протеасомальное ингибирование увеличивало SUMO2/3-модифицированный TDP-43 и мутанты люциферазы (фиг. 11В и фиг. 11С).
Чтобы оценить роль SUMO-белков в убиквитинировании и протеасомальной деградации Atxn1 82Q, SUMO2/3 и SUMO1 по отдельности выключали с помощью киРНК. Молчание SUMO2/3, но не SUMO1, эффективно уменьшало убиквитинирование Atxn1 82Q (фиг. 3D, дорожки 4-7). Молчание SUMO2/3 также повышало уровни Atxn1 82Q, особенно агрегированной формы, но не уровни контрольного белка GFP (фиг. 11D-11F), и уменьшало способность PML удалять агрегированный Atxn1 82Q (фиг. 3Е).
SUMO2 и SUMO3 содержат внутренний консенсусный сайт сумоилирования, который делает возможным формирование полицепей. SUMO1 не содержит этого сайта, и когда он конъюгирован с цепью SUMO2/3, он может прекратить удлинение цепи (Wilkinson and Henley, 2010, Biochem J, 428: 133-145). Поэтому для ингибирования модификации Atxn1 82Q путем SUMO2/3 использовали две дополнительные стратегии. Во-первых, сверхэкспрессировали SUMO1. Это сильно уменьшало конъюгацию Atxn1 82Q с SUMO2/3 и в то же время нарушало конъюгацию Atxn1 82Q с убиквитином (фиг. 3D, дорожки 8 и 9) и его деградацию под влиянием PML (фиг. 3F, слева). Во-вторых, использовали мутант SUMO2, который был дефицитным в формировании цепи, SUMO2 KR. Сверхэкспрессия SUMO2 KR эффективно уменьшала количество SUMO2/3-модифицированных видов Atxn1 82Q, особенно высокомолекулярных. Она также уменьшала виды Atxn1 82Q, модифицированные убиквитином (фиг. 3D, дорожки 12 и 13) и притупляла способность PML вызывать деградацию Atxn1 82Q (фиг. 3F, справа). Кроме того, использовали мутант Htt с дефектным сумоилированием, Htttexlp 97QP (KR) (Steffan et al., 2004, Science, 304: 100-104), и было установлено, что он устойчив к PML-опосредованной деградации (фиг. 1J). В совокупности эти результаты показывают, что убиквитинирование и деградация Atxn1 82Q и, по-видимому, других неправильно упакованных белков зависят от их модификации SUMO2/3.
PML в качестве SUMO Е3-лигазы Atxn1 82Q
Ранее было продемонстрировано, что PML обладает активностью SUMO Е3-лигазы, которая повышает эффективность и специфичность сумоилирования (Chu and Yang, 2011, Oncogene, 30: 1108-1116). Следовательно, было исследовано, способствует ли PML сумоилированию Atxn1 82Q. При коэкспрессии с Atxn1 82Q в клетках PML сильно увеличивал SUMO2/3-модификацию Atxn1 82Q как в отсутствие, так и в присутствии протеасомального ингибитора MG132 (фиг. 4А). И наоборот, молчание PML заметно уменьшало SUMO2/3-модифицированный Atxn1 82Q в этих условиях (фиг. 4В). Аналогичным образом, молчание PML уменьшало SUMO2/3-модификацию nFlucDM (фиг. 4С).
Чтобы подтвердить SUMO Е3-активность PML в отношении Atxn1 82Q, проводили in vitro анализы сумоилирования с очищенными рекомбинантными белками. В отсутствие PML Atxn1 82Q слабо модифицировали SUMO2 (фиг. 4D и фиг. 4Е) в соответствии с предыдущими наблюдениями, что сумоилирование может протекать in vitro без SUMO Е3-лигазы (Wilkinson and Henley, 2010, Biochem J, 428: 133-145). Следует отметить, что PML увеличивал сумоилирование Atxn1 82Q дозозависимым образом (фиг. 4D и фиг. 4Е). Напротив, SUMO Е3-дефектный мутант, PML М6 (Chu and Yang, 2011, Oncogene, 30: 1108-1116), не мог этого сделать (фиг. 4Е и фиг. 11G); PML М6 также был неэффективен в уменьшении агрегированного Atxn1 82Q (фиг. 4F). Эти результаты показывают, что PML представляет собой SUMO Е3-лигазу Atxn1 82Q, и что эта активность участвует в деградации Atxn1 82Q.
Роль RNF4 в деградации неправильно упакованных белков
Белки, конъюгированные с поли-SUМO2/3-цепью, могут быть распознаны и убиквитированы RNF4, убиквитинлигазой с RING-доменом с четырьмя тандемными SUMO-взаимодействующими мотивами (SUMO-interacting motif, SIM) (Sun et al., 2007, EMBO J, 26: 4102-4112). Тем не менее, роль RNF4 в деградации неправильно упакованных белков остается неопределенной. Было обнаружено, что принудительная экспрессия RNF4 сильно уменьшала уровни агрегированного Atxn1 82Q в стабильном состоянии в клеточных лизатах (фиг. 5А), а также количество включений Atxn1 82Q в ядре (фиг. 12А). RNF4 также сократил период полужизни агрегированного, но не растворимого Atxn1 82Q (фиг. 5В, дорожки 1-12, фиг. 5С и фиг. 12В). Напротив, нокдаун эндогенного RNF4 тремя киРНК, по отдельности или в комбинации, увеличивал тотальный и агрегированный белок Atxn1 82Q в клеточных лизатах (фиг. 5D, фиг. 12С и фиг. 12D), а также включения Atxn1 82Q в ядре (фиг. 5Е). КиРНК-резистентная форма RNF4 может обратить эффект нокдауна RNF4 (фиг. 12С), что указывает на специфичность киРНК.
Более того, как эндогенные, так и экзогенные белки RNF4 обычно демонстрируют диффузный характер распределения в ядре с минимальной или умеренной колокализацией с включениями Atxn1 82Q. Тем не менее, при протеасомальном блокировании RNF4 сильно обогащался включениями Atxn1 82Q (фиг. 5F и фиг. 12Е), что, по-видимому, отражает задержанную попытку RNF4 вывести Atxn1 82Q. В отличие от его влияния на Atxn1 82Q, RNF4 не уменьшал уровни Atxn1 30Q (фиг. 5G). В совокупности эти результаты демонстрируют роль RNF4 в устранении патогенных белков Atxn1.
Чтобы оценить общее влияние RNF4 на неправильно упакованные белки, его анализировали на Httex1p 97QP, TDP-43 и nFlucDM. Принудительная экспрессия RNF4 заметно уменьшала Httex1p 97QP, особенно агрегированную форму, но оказывала гораздо более слабое влияние на Httex1p 97QP (KR) (фиг. 5Н). Аналогичным образом, принудительная экспрессия RNF4 уменьшала уровни TDP-43 (фиг. 12F), тогда как молчание RNF4 увеличивало процент TDP-43-экспрессирующих клеток с ядерными включениями (фиг. 12G и фиг. 12Н). При протеасомальном ингибировании эндогенный RNF4 сильно обогащался включениями TDP-43 (фиг. 12I) подобно его накоплению во включениях Atxn1 82Q в тех же условиях (фиг. 5F). Более того, молчание RNF4 продлевало период полужизни nFlucDM (фиг. 51). В совокупности эти наблюдения подтверждают, что RNF4 играет критическую роль в деградации разнообразных неправильно упакованных белков.
RNF4 опосредует убиквитинирование и деградацию SUMO2/3-модифицированного Atxn1 82Q
Подобно PML, способность RNF4 устранять неправильно упакованные белки зависела от SUMO2/3, так как эта способность была скомпрометирована в клетках, лишенных SUMO2/3, но не в клетках, лишенных SUMO1 (фиг. 13А). Следует отметить, что принудительная экспрессия RNF4 преимущественно уменьшала SUMO2/3-модифицированные Atxn1 82Q и nFlucDM по сравнению с немодифицированными белками (фиг. 6А и фиг. 6В). И наоборот, молчание RNF4 увеличивало SUMO2/3-модифицированный Atxn1 82Q (фиг. 6С) и усиливало локализацию GFP-SUMO2 с включениями Atxn1 82Q (фиг. 13В). Эти результаты показывают, что RNF4 направляет SUMO2/3-модифицированные неправильно упакованные белки на деградацию.
Для подтверждения того, что RNF4 убиквитинирует SUMO2/3-конъюгированные неправильно упакованные белки, проводили анализ убиквитинирования in vitro с использованием смеси немодифицированных и SUMO2-модифицированных белков Atxn1 82Q (фиг. 6D). В присутствии возрастающих доз RNF4 SUMO2-модифицированные белки Atxn1 82Q, которые имели относительно низкую молекулярную массу (фиг. 6Е, дорожки 1, 6 и 9), постепенно превращались в высокомолекулярные частицы, которые также были модифицированы убиквитином (дорожки 2-4, 7-9 и 12-14). Напротив, немодифицированный белок Atxn1 82Q не был убиквитинирован (дорожки 1-4). Следовательно, RNF4 представляет собой убиквитинлигазу для SUMO2/3-модифицированного, но не для немодифицированного белка Atxn1 82Q.
RNF4 обладает как убиквитинлигазной, так и SUMO-связывающей активностью (Sun et al., 2007, EMBO J, 26: 4102-4112). Для выяснения участия этих активностей в деградации Atxn1 82Q были получены мутанты RNF4, дефектные по их убиквитинлигазной (CS и CS1) или SUMO-связывающей (SIMm) активности (фиг. 13С). CS и CS1, хотя и теряли свою убиквитин-Е3-активность (фиг. 13D), но все еще были способны колокализоваться с включениями Atxn1 82Q (фиг. 6F). С другой стороны, SIMm сохранил существенный уровень убиквитинлигазной активности (фиг. 13Е), но не смог колокализоваться с включениями Atxn1 82Q (фиг. 6G). Ни один из классов RNF4-мутанта не смог удалить агрегированный Atxn1 82Q (фиг. 6Н). В совокупности эти результаты показывают, что RNF4 связывается с SUMO2/3-модифицированными неправильно упакованными белками через его SIM-область и убиквитинирует эти белки посредством его лигазной активности.
Хотя принудительная экспрессия PML привела к эффективному выведению агрегированного Atxn1 82Q в контрольных клетках, эта способность значительно уменьшалась в RNF4-обедненных клетках (фиг. 61). Напротив, принудительная экспрессия RNF4, хотя и очень эффективная в ускорении деградации Atxn1 82Q в контрольных клетках, не смогла этого добиться в PML-обедненных клетках (фиг. 5В, дорожки 19-24 по сравнению с дорожками 7-12; и фиг. 5С). Более того, в PML-обедненных клетках, которые демонстрировали высокие уровни Atxn1 82Q, молчание RNF4 не повышало далее уровни Atxn1 82Q (фиг. 13F). Эти результаты указывают на взаимную зависимость PML и RNF4 в деградации Atxn1 82Q.
Дефицит PML усугубляет поведенческие и патологические Фенотипы в мышиной модели SCA1
Результаты, описанные выше, раскрыли систему PQC, которая вызывает деградацию Atxn1 82Q и, по-видимому, других ядерных неправильно упакованных белков за счет последовательного PML-опосредованного сумоилирования и RNF4-опосредованного убиквитинирования. Для исследования физиологической роли этой системы была использована мышиная модель SCA1 (В05), которая экспрессирует трансген Atxn1 82Q (Atxn1tg/-) в клетках Пуркинье мозжечка. Подобно людям с SCA1, у мышей В05 с возрастом развивается атаксия и неврологические аномалии (Burright et al., 1995, Cell, 82: 937-948). Потеря RNF4 у мышей приводит к эмбриональной летальности (Hu et al., 2010, Proc Natl Acad Sci, 107: 15087-15092), что исключает анализ ее влияния на мышей В05. Тем не менее, PML-нокаутные (PML-/-) мыши являются жизнеспособными и, по-видимому, развиваются нормально (Wang et al., 1998, Science, 279: 1547-1551). Мышей B05 скрещивали с мышами PML-/- и PML дикого типа (PML+/+), и особей из одного помета со всеми генотипами - PML+/+, РМС+-/ и PML-/-, PML+/+:Atxn1tg/-, PML+/-:Atxn1tg/- и PML-/-:Atxn1tg/- - сравнивали с точки зрения как двигательной активности, так и с невропатологии.
Двигательную активность, включая баланс, координацию и выносливость, оценивали с помощью устройства Rotarod с возрастающей скоростью. Чтобы определить, были ли какие-либо потенциальные поведенческие дефекты обусловлены постепенно уменьшающейся емкостью, а не нарушением развития, исследовали мышей в разном возрасте. Чтобы исключить влияние долговременной двигательной памяти, использовали только наивных животных, каждое из которых подвергали тестированию в течение 4 последовательных дней.
В возрасте 7 недель все мыши выполняли аналогичные операции на Rotarod (фиг. 7А). Хотя некоторые различия наблюдались среди мышей с разными генотипами, они не были статистически значимыми (ANOVA р равен 0,53), подтверждая, что у мышей PML-/- не было ранее существовавших нарушений двигательных функциях. В возрасте 11 недель все мыши, у которых отсутствовал трансген Atxn1 82Q (PML+/+, PML+/- и PML-/-), по-прежнему не демонстрировали статистической разницы в их характеристиках (ANOVA р равен 0,33) (фиг. 7В), и PML+/+ и PML+/+:Atxn1tg/- также выполняли тест аналогично. Эти наблюдения свидетельствуют о том, что ни дефицит PML, ни экспрессия трансгена Atxn1 82Q сами по себе недостаточны, чтобы вызвать двигательные дефекты в этом возрасте. Интересно отметить, что PML-/-:Atxn1tg/- продемонстрировали серьезные нарушения в выполнении теста на Rotarod по сравнению с мышами PML+/+:Atxn1tg/- или PML-/-. Хотя эти три группы животных были сопоставимы в начале 4-х последовательных дней тестирования, в отличие от двух других групп мыши PML-/-:Atxn1tg/- со временем демонстрировали минимальное улучшение. Отсутствие улучшения у мышей PML-/-:Atxn1tg/- на Rotarod напоминало мышей Atxn1tg/- на поздних стадиях (Clark et al., 1997, J Neurosci, 17: 7385-7395). Гетерозиготные аналоги PML (мыши PML+/-:Atxn1tg/-) демонстрировали промежуточное ухудшение на Rotarod (ANOVA р равен 00004 для трех групп Atxn1tg/-) (фиг. 7В). Таким образом, дефицит PML усугубляет двигательные дефекты у мышей Atxn1tg/-.
Основным невропатологическим фенотипом мышей Atxn1tg/- является дегенерация клеток Пуркинье, составляющих верхний слой (молекулярный слой) коры мозжечка. Эта дегенерация проявляется первоначально в истончении молекулярного слоя и атрофии дендритов клеток Пуркинье, а затем в потере телец клеток Пуркинье (Burright et al., 1995, Cell, 82: 937-948; Clark et al., 1997, J Neurosci, 17: 7385-7395). В возрасте 12 недель мыши PML+/- и PML-/- демонстрировали лишь незначительное и статистически незначимое истончение молекулярного слоя, тогда как мыши PML+/+:Atxn1tg/- демонстрировали заметное истончение по сравнению с мышами PML+/+ (фиг. 7С и фиг. 7D). Поскольку мыши PML+/+:Atxn1tg/- тест на Rotarod выполняли аналогично мышам PML+/+ (фиг. 7В), нейродегенерация у мышей PML+/+:Atxn1tg/-, возможно, не достигала критического порога. Эта нелинейная корреляция между поведенческими и патологическими фенотипами трансгенной модели SCA1 наблюдалась ранее (Gehrking et al., 2011, Hum Mol Genet, 20: 2204-2212). Важно отметить, что по сравнению с мышами PML+/+:Atxn1tg/- мыши PML+/-:Atxn1tg/- и PML-/-:Atxn1tg/- демонстрировали умеренное и сильное дальнейшее уменьшение, соответственно, толщины молекулярного слоя (фиг. 7С и фиг. 7D). Это коррелировало с ухудшением характеристик этих животных в тесте на Rotarod (фиг. 7 В). Таким образом, дефицит PML усугубляет истончение молекулярного слоя у мышей Atxn1tg/-.
Дендритную арборизацию клеток Пуркинье также анализировали с помощью иммунофлуоресцентного окрашивания антителом против белка кальбиндина, специфического для клеток Пуркинье. В возрасте 12 недель интенсивность флуоресценции дендритов клеток Пуркинье во всех группах, содержащих трансген Atxn1 82Q, была снижена до очень низких уровней, что исключало точное сравнение (фиг. 14А и фиг. 14В). Следует отметить, что по сравнению с животными того же помета PML+/+ мыши PML-/- уже демонстрировали сильное снижение дендритной арборизации клеток Пуркинье, в то время как мыши PML+/+ демонстрировали промежуточное снижение (фиг. 14А и фиг. 14В). Эти результаты показывают, что сам PML играет роль в защите от нейродегенерации.
Несмотря на истончение молекулярного слоя и потерю дендритов клеток Пуркинье, что было ассоциировано с дефицитом PML, у 12-недельных животных с разными генотипами не наблюдалось значительной разницы в популяции клеток Пуркинье (фиг. 14С). В возрасте 1 года мыши PML-/- демонстрировали только умеренное (11,0%) и статистически незначимое (р равен 0,107) снижение числа клеток Пуркинье по сравнению с мышами PML+/+, тогда как мыши PML+/+:Atxn1tg/- демонстрировали заметное уменьшение (фиг. 7Е и фиг. 7F). Следует отметить, что мыши PML-/-:Atxn1tg/- демонстрировали значительное дальнейшее снижение плотности клеток Пуркинье по сравнению с мышами PML+/+:Atxn1tg/- (примерно 24%, р равен 0,0023), и мыши PML+/-:Atxn1tg/- демонстрировали промежуточную потерю клеток (фиг. 7Е и фиг. 7F). Опять же, эти результаты показывают, что дефицит PML ухудшает невропатологические дефекты, вызванные трансгеном Atxn1 82Q.
Нейродегенерация мышей В05 сопровождается формированием убиквитин-положительных включений Atxn1 82Q в клетках Пуркинье (Clark et al., 1997, J Neurosci, 17: 7385-7395). Чтобы определить влияние PML на ядерные включения Atxn1 82Q, клетки Пуркинье с этими включениями количественно оценивали у мышей в возрасте 12 недель. Дефицит PML не приводил к формированию агрегатов (фиг. 14D), но значительно увеличивал число содержащих агрегаты клеток Пуркинье у трансгенных мышей Atxn1 82Q (фиг. 7G и фиг. 7Н). В совокупности эти результаты свидетельствуют о том, что эндогенный PML играет роль в предотвращении накопления неправильно упакованных белков у животных с SCA1 и в подавлении прогрессирования этого нейродегенеративного заболевания.
PQC-система. которая вызывает деградацию неправильно упакованных белков
В данном документе представлено подтверждение системы PQC, которая вызывает деградацию неправильно упакованных белков в ядрах клеток млекопитающих. Эта система содержит распознающую ветвь, PML, которая избирательно связывается с неправильно упакованными белками и метит эти белки поли-SUMO2/3-цепями, а также эффекторную ветвь, RNF4, которая убиквитирует сумоилированные неправильно упакованные белки и направляет их на протеасомальную деградацию. Эта передающая система, по-видимому, обеспечивает критическую связь между неправильно упакованными белками и протеасомой в клетках млекопитающих и может играть важную роль в защите от нейродегенерации и других протеопатий (фиг. 71).
Селективное распознавание PML неправильно упакованных белков
Превосходная селективность этой системы находится в PML, который содержит по меньшей мере два SRS. SRS1, состоящий из СС-области в мотиве TRIM/RBCC, благоприятствует СС-структурам на патогенных полиQ-белках и, возможно, на других неправильно упакованных белках. SRS2, состоящий из С-концевых 63 аминокислот, распознает короткие пептиды, обогащенные как ароматическими (Phe, Trp и Tyr), так и положительно заряженными (Arg и Lys) аминокислотами. SRS2 подобен бактериальному Hsp100 ClpB (Schlieker et al., 2004, Nat Struct Mol Biol, 11: 607-615) за исключением того, что SRS2 также благоприятствует пептидам, содержащим Leu, остаток, который часто экспонируется в неправильно упакованных белках и подвергается воздействию Hsp70 (Rudiger et al., 1997, EMBO J, 16: 1501-1507). Таким образом, SRS2 демонстрирует гибридную субстратную специфичность ClpB и Hsp70. Эти наблюдения указывают на то, что PML может распознавать структуры или области, которые обычно встречаются в неправильно упакованных белках.
Роль сумоилирования в деградации неправильно упакованных белков
Конъюгация с SUMO является значительной посттрансляционной модификацией, происходящей на многих белках, и жизненно важной для жизни эукариот.Тем не менее, помимо обобщения, что он изменяет белок-белковые взаимодействия, физиологическая функция сумоилирования остается неизвестной (Wilkinson and Henley, 2010, Biochem J, 428: 133-145). Важной особенностью системы PML-RNF4 является участие SUMO2/3-модификации в убиквитинировании (фиг. 3, фиг. 4 и фиг. 11). Ранее отмечалось, что конъюгация SUMO2/3 с клеточными белками заметно усиливается под влиянием воздействий, денатурирующих белки (Saitoh and Hinchey, 2000, J Biol Chem, 275: 6252-6258). Данные, представленные в настоящем исследовании, дают объяснение этому наблюдению и подтверждают, что основная физиологическая функция SUMO2/3-модификации, по-видимому, заключается в облегчении деградации неправильно упакованных белков за счет действия совместно с убиквитинированием.
Конъюгация с SUMO повышает растворимость белка (Panavas et al., 2009, Methods Mol Biol, 497: 303-317). Поскольку агрегированные белки не могут быть эффективно деградированы протеасомой (Verhoef et al., 2002, Hum Mol Genet, 11: 2689-2700), повышение растворимости белка может быть полезным эффектом, получаемым за счет PML до убиквитинирования. Более того, степень сумоилирования может обеспечивать "решение о сортировке" относительно того, выбран ли данный неправильно упакованный белок для рефолдинга или деградации. В соответствии с этим понятием, конъюгация с одним SUMO, по-видимому, является достаточной для повышения растворимости белка (Panavas et al., 2009, Methods Mol Biol, 497: 303-317) и, таким образом, может способствовать рефолдингу. Напротив, конъюгация с цепями SUMO2/3 необходима для эффективного распознавания четырьмя тандемными SIM на RNF4 для убиквитинирования и деградации (Tatham et al., 2008, Nat Cell Biol, 10: 538-546). Такие цепи могут формироваться после неудачных попыток рефолдинга.
Сообщалось, что сумоилирование неправильно упакованных белков усиливает или ингибирует нейродегенеративные заболевания (Martin et al., 2007, Nat Rev Neurosci, 8: 948-959). Эти, казалось бы, противоречивые наблюдения могут согласоваться за счет различных функций SUMO1 и SUMO2/3 в удалении неправильно упакованных белков (фиг. 3) и дихотомии между функциями сумоилирования: повышением растворимости аномального белка (что может повысить его токсичность) и усилением его деградации. Таким образом, результат повышенного сумоилирования, по-видимому, зависит от того, может ли он соответствовать клеточной способности деградировать.
Потенциальная основная система PQC
Белки в ядре могут нести мутации или поддерживать острое и хроническое повреждение, как и белки в других местах. Сильно заполненная среда ядра, по-видимому, делает особенно сложным поддержание качества белка. Ожидается, что путь "убиквитин - протеасома" будет основной системой деградации в ядре, где неизвестно, чтобы работала аутофагия. Предыдущие исследования показали участие нескольких убиквитинлигаз, таких как дрожжевые убиквитинлигазы San1 и Doa10 и убиквитинлигазы млекопитающих UHRF-2 и Е6-АР, в деградации ядерных неправильно упакованных белков (Cummings et al., 1999, Neuron, 24: 879-892; Deng and Hochstrasser, 2006, Nature, 443: 827-831; Gardner et al., 2005, Cell, 120: 803-815; Iwata et al., 2009, J Biol Chem, 284: 9796-9803). Тем не менее, преимущественно ядерная локализация PML наряду с мощным влиянием PML и RNF4 на различные неправильно упакованные ядерные белки предполагает, что система PML-RNF4, по-видимому, является основной системой PQC в ядрах клеток млекопитающих.
Семейство TRIM-белков является общим среди метазоанов, от примерно 20 у членов С. elegans до более 70 у мышей и людей (Ozato et al., 2008, Nat Rev Immunol, 8: 849-860). Ранее было продемонстрировано, что по меньшей мере несколько других TRIM-белков также обладают активностью SUMO Е3 (Chu and Yang, 2011, Oncogene, 30: 1108-116). Учитывая их локализацию в цитоплазме в дополнение к ядру (Ozato et al., 2008, Nat Rev Immunol, 8: 849-860), предполагается, что TRIM-белки также участвуют в PQC в цитоплазме. Быстрое увеличение числа TRIM-белков в ходе эволюции может отчасти быть ответом на возрастающую сложность управления качеством белка в клетках дольше живущих животных.
RNF4 сохраняется среди позвоночных (Sun et al., 2007, EMBO J, 26: 4102-4112). SUMO-зависимые убиквитинлигазы также присутствуют у низших эукариотических видов (Sun et al., 2007, EMBO J, 26: 4102-4112) и участвуют в деградации по меньшей мере одного мутантного дрожжевого транскрипционного фактора (Sun et al., 2007, EMBO J, 26: 4102-4112). Таким образом, также возможно, что системы, аналогичные системе PML-RNF4, могут играть роль в поддержании качества белка в этих организмах.
Система PML-RNF4 и нейродегенерация
Мыши PML-/- были широко охарактеризованы по различным фенотипам, включая опухолегенез (Wang et al., 1998, Science, 279: 1547-1551). Данное исследование указывает на роль PML в защите от нейродегенерации (фиг. 7 и фиг. 14). Нейродегенеративные нарушения, включая SCA и HD, как правило, являются заболеваниями с поздним началом Накопление данных свидетельствует о прогрессирующем ухудшении PQC во время старения (Balch et al., 2008, Science, 319: 916-919). Сильное влияние PML-RNF4 на патогенные белки, ассоциированные с SCA1, HD и ALS, а также дефицита PML на прогрессирование мышиной модели SCA1, наряду с накоплением PML в нейрональных включениях у пациентов с различными нейродегенеративными заболеваниями (Skinner et al., 1997, Nature, 389, 971-974; Takahashi et al., 2003, Neurobiol Dis, 13: 230-237), подтверждает, что недостаточность или дисфункция системы PML-RNF4 может играть определенную роль в развитии этих заболеваний. Таким образом, система PML-RNF4 и аналогичные системы были бы ценными мишенями в их лечении.
Пример 2: TRIM-белки могут распознавать неправильно упакованные белки и способствовать их деградации
Семейство, содержащее трехчастный мотив (TRIM), состоит из большого числа белков в клетках метазоанов, в пределах от примерно 20 у С.elegans до более семидесяти у мышей и людей. Эти белки имеют на своих N-концах общий характерный TRIM- или RBCC-мотив, который состоит из RING-домена, одного или двух В-мотивов (которые, подобно RING-домену, координируются ионами цинка) и области суперспирали. За ними следует С-концевая область, которая намного более вариабельна среди TRIM-белков и содержит различные мотивы (Hatakeyama, 2011, Nat Rev Cancer, 11: 792-804; Ozato et al., 2008, Nat Rev Immunol, 8: 849-860). TRIM-белки модулируют ряд клеточных процессов, включая те, которые защищают от рака и вирусной инфекции. Биохимически ряд TRIM-белков проявляет убиквитин-Е3-лигазную активность, которая приписывается RING-домену в области TRIM/RBCC. Кроме того, по меньшей мере несколько TRIM-белков обладают свойствами Е3-лигаз для конъюгации белка с SUMO (малым убиквитин-подобным модификатором). Тем не менее, остается нерешенным вопрос о субстратах TRIM-семейства SUMO Е3.
Как описано выше, было продемонстрировано, что PML (белок промиелоцитарной лейкемии, также известный как TRIM19) играет критически важную роль в элиминации неправильно упакованных белков. Первоначально PML был идентифицирован как продукт гена, участвующего в хромосомной транслокации t(15;17), которая связана с большинством случаев острой промиелоцитарной лейкемииа. Это основной структурный и названный так же компонент ядерных телец PML. Было показано, что PML способен специфически связываться и усиливать деградацию ряда неправильно упакованных белков. Через отдаленные области PML может различать общие особенности, обнаруженные в неправильно упакованных белках, включая пептиды, обогащенные ароматическими аминокислотными остатками и суперспиральными структурами. Затем PML метит неправильно упакованные белки поли-SUMO2/3-цепями за счет своей SUMO Е3-активности. Это позволяет модифицированным неправильно упакованным белкам быть распознанными SUMO-нацеленной убиквитинлигазой (STUbL) RNF4, которая убиквитинирует неправильно упакованные белки и направляет их на последующую деградацию в протеасоме. Роль PML в контроле качества белка важна для защиты от нейродегенеративных заболеваний, поскольку дефицит PML усугубляет поведенческие и невропатологические фенотипы мышиной модели спиноцеребеллярной атаксии типа 1 (SCA1), прогрессирующего и летального заболевания, вызванного удлинением полиглутаминого (полиQ) тракта в атаксине-1. Учитывая существование большого числа TRIM-белков, результаты, полученные с использованием PML, поднимают важный вопрос о том, способны ли другие TRIM-белки, такие как PML, распознавать и вызывать деградацию неправильно упакованных белков. В экспериментах, представленных в данном документе, анализируется панель TRIM-белков и отмечается, что способность распознавать и вызывать деградацию неправильно упакованных белков распространена среди TRIM-белков, указывая на критически важную роль этого семейства в контроле качества белка в клетках метазоанов.
Далее описаны материалы и методы, используемые в данных экспериментах.
Плазмиды
FLAG-TRIM27, FLAG-TRIM32 и FLAG-TRIM56 были сделаны в pRK5 посредством ПЦР. Матрицы для ПЦР-амплификации были приобретены у Open Biosystems, а соответствующие регистрационные номера генов были ВС013580, BG0Q3T54 и CV029096, соответственно. Все три гена имеют человеческое происхождение. Ранее были описаны следующие плазмиды: FLAG-PML (изоформа IV) (Chu and Yang, 2011, Oncogene, 30: 1108-116); Atxn1 82Q-GFP, FLAG-Atxn1 82Q и HA-Httex1p 97QP (Guo et al., 2014, Mol Cell, 55(1): 15-30); FLAG-TRIM 11 (Ishikawa et al., 2006, FEBS Lett, 580: 4784-4792); FLAG-TRIM22 (длинная форма) (Barr et al., 2008); HA-TRIM39 (Lee et al., 2009, Exp Cell Res, 315: 1313-1325); НА-меченные TRIM1, 2, 3, 4, 5, 6, 8, 9, 10, 11, 12, 13, 14, 18, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 и 32 (Reymond et al., 2001, EMBO J, 20: 2140-2151; Uchil et al., 2008, 2008, PLoS Pathog, 4: e16); и остальные TRIM-экспрессионные плазмиды, экспрессирующие белки с N-концевой НА-меткой или С-концевой V5-меткой (Versteeg et al., 2013, Immunity, 38: 384-398). Для анализа влияния TRIM-белков на уровни Atxn1 82Q и Httex1p 97QP были сконструированы Trim11 (NM_145214.2), Trim15 (NM_033229.2), Trim28 (NM_005762.2), Trim34 (NM_021616.5), Trim39 (NM_021253.3), Trim42 (NM_152616.4), Trim43 (NM_138800.1), Trim65 (NM_173547.3), Trim67 (NM_001004342.3), Trim70 (NM_001037330.1), Trim71 (NM_001039111.2) и Trim75 (NM_001033429.2) в векторе pcDNA 3.1(-), содержащем 5'-НА-метку. Все остальные Trim-плазмиды были получены (Versteeg et al., 2013, Immunity, 38: 384-398).
киРНК
киРНК SUMO2/3 (Santa Cruz sc-37167) представляли собой пул трех различных дуплексов киРНК с последовательностями смысловой нити 5'-CCCAUUCCUUUAUUGUACA-3' (SEQ ID NO: 157), 5'-CAGAGAAUGACCACAUCAA-3' (SEQ ID NO 158) и 5'-CAGUUAUGUUGUCGUGUAU-3' (SEQ ID NO 159).
киРНК TRIM27 была приобретена у Qiagen, причем последовательность смысловой нити представляла собой 5'-AACTCTTAGGCCTAACCCAGA-3' (SEQ ID NO 162).
Клеточная культура и трансфекция
Клетки HeLa получали из АТСС. Клетки MEF PML+/+ и PML-/- получали из эмбрионов мышей с соответствующими генотипами. Клетки поддерживали в стандартных условиях культивирования. Клетки трансфицировали ДНК-плазмидами с использованием реагента Lipofectamine 2000, а также клетки трансфицировали киРНК в двух раундах в течение последовательных дней, используя реагент Lipofectamine 2000 или RNAiMAX (Invitrogen) в соответствии с инструкциями производителя. Когда трансфекция и ДНК, и киРНК произошла, ДНК использовали для трансфекции через день после второго раунда трансфекции киРНК. MG132 (Sigma) добавляли через 24 часа после последней трансфекции в концентрации 7,5-10 мкМ (конечная концентрация) в течение 4-5 часов.
Иммунофлуоресценция
Клетки, культивированные на покровных стеклах, фиксировали 4% параформальдегидом в течение 15 минут, пермеабилизовали 0,2% Triton Х-100 в течение 15 минут и инкубировали последовательно с первичными и вторичными антителами. Первичными антителами были анти-НА, анти-FLAG (мышиное МКА М2, 1:2000) (Sigma) и анти-ТРх1М27. Вторичными антителами были FITC-конъюгированные противомышиные, противокроличные (Zymed) и противокозлиные (Invitrogen) IgG; Texas Red-конъюгированные противомышиные и противокроличные IgG (Vector labs); и Rhodamine Red-X-конъюгированные противокозлиные (Jackson ImmunoResearch Labs). Затем клетки помещали в среду, содержащую DAPI (Vector Labs), и получали изображения с помощью микроскопа Nikon Eclipse Е800 или Olympus 1X81.
Фракционирование клеточного лизата. вестерн-блоттинг и анализа задержки в Фильтре
Образцы готовили, как было описано (Guo et al., 2014, Mol Cell, 55 (1): 15-30). Вкратце, клетки лизировали на льду в лизисном буфере NP-40 (50 мМ Tris, рН 8,8, 100 мМ NaCl, 5 мМ MgCl2, 0,5% NP-40, 2 мМ DTT), дополненном 250 МЕ/мл бензоназы (Sigma), 1 мМ PMSF, 1х полным протеазным коктейлем (Roche) и 20 мМ N-этилмалеимидом (NEM; Sigma). Клеточные лизаты центрифугировали со скоростью 13000 об/мин в течение 15 минут при 4°С. Супернатант, содержащий NP-40-растворимые (NS) белки, анализировали путем SDS-PAGE и вестерн-блоттинга. Осадок ресуспендировали в буфере для гранул (20 мМ Tris, рН 8,0, 15 мМ MgCl2, 2 мМ DTT), дополненном 250 МЕ/мл бензоназы, 1 мМ PMSF, 1Х полным протеазным коктейлем и 20 мМ NEM. Фракцию гранул кипятили в 2% SDS плюс 50 мМ DTT и растворяли для SDS-PAGE. Белки, входящие в гель (SDS-растворимые, SS), обнаруживали путем вестерн-блоттинга. Для анализа задержки в фильтре (дот-блот) часть кипятившихся гранул наносили на мембранный фильтр с размером пор 0,2 мкм, и агрегаты, устойчивые к SDS (SR), которые оставались на фильтре, анализировали путем иммуноблоттинга. Первичные антитела представляли собой: против НА (кроличье, Y-11, 1:500) (Santa Cruz Biotechnology); против FLAG (мышиное, М2, 1:7500) и против актина (кроличье, 1:10000) (Sigma); против GFP (мышиное, 1:4000) (Clonetech); и SUMO2/3 (кроличье, 1:250, Abgent). Вторичные антитела были либо конъюгированы с HRP (Santa Cruz Biotechnology), либо помечены IRD Fluor 800 или IRD Fluor 680 (LI-COR, Inc.). Окрашивание в вестерн-блоттинге получали с использованием реагентов ECL и анализировали с использованием ImageJ или сканировали с помощью инфракрасной системы визуализации Odyssey и анализировали с использованием Image Studio Lite (LI-COR, Inc.).
Очистка белков и анализы сумоилирования in vitro
FLAG-TRIM27 и HA-Atxn1 82Q-FLAG экспрессировали в клетках 293Т и очищали с помощью анти-FLAG М2-гранул (Sigma), как описано ранее (Tang et al., 2006, Nat Cell Biol, 8: 855-862; Tang et al., 2004, J Biol Chem, 279: 20369-20377) с модификациями. Клетки лизировали в IP-лизисном буфере (50 мМ Tris, рН 7,5, 150 мМ NaCl, 0,5% Triton Х-100, 0,5% NP-40 и 2 мМ DTT), дополненном 1 мМ PMSF и 1х полным протеазным коктейлем. Для очистки TRIM27 IP-лизисный буфер также дополняли 20 мкМ ZnCl2. Лизаты инкубировали с анти-FLAG М2-гранулами при 4°С в течение периода от 4 часов до ночи. М2-гранулы промывали IP-лизисными буферами, содержащими 0, 0,5 и 1 М KCl, и буфером для элюирования (50 мМ Tris, рН 7,5, 150 мМ NaCl и 2 мМ DTT). Связанные белки элюировали в буфере для элюирования, содержащем 0,1-0,3 мг/мл 3×FLAG-пептида (Sigma).
Другие компоненты реакций сумоилирования in vitro были приобретены в Boston Biochem. Анализ сумоилирования in vitro проводили при 37°С в течение 1,5 часов в 30 мкл реакционного буфера (50 мМ Tris, рН 7,5, 5,0 мМ Mg2+-АТР и 2,5 мМ DTT), содержащего очищенный HA-Atxn1 82Q-FLAG (600 нг/200 нМ), FLAG-TRIM27, SAE1/SAE2 (125 нМ), Ubc9 (1 мкМ), His-SUMO2 (25 мкМ) и BSA (0,1 мкг/мл). Реакционные смеси подвергали денатурации путем добавления 30 мкл IP-лизисного буфера, содержащего 2% SDS и 50 мМ DTT, и нагревания при 95°С в течение 10 минут. Одну аликвоту нагретых реакционных смесей сохраняли для анализа путем вестерн-блоттинга, а остальные разводили в 20 раз в IP-лизисном буфере без SDS. HA-Atxn1 82Q-FLAG подвергали иммунопреципитации с использованием анти-НА-гранул (Roche) и анализировали на модификацию SUMO2/3 с использованием антитела против SUMO2/3.
Далее описаны результаты экспериментов.
Колокализация TRIM27, TRIM32 и TRIM56 с патогенными белками атаксином-1 и хантингтином
Ранее было показано, что PML/TRIM19 может распознавать и усиливать деградацию различных ядерных неправильно упакованных белков, включая Atxn1 82Q, патогенный белок атаксин 1 с трактом из восьмидесяти двух глутаминов, который ассоциирован со спиноцеребеллярной атаксией типа 1 (SCA1) (Guo et al., 2014, Mol Cell, 55 (1): 15-30). Семейство TRIM-белков у людей и мышей состоит из более чем семидесяти членов, которые можно отличить на основании структурных особенностей области, расположенной с С-конца от консервативного мотива TRIM/RBCC (Ozato et al., 2008, Nat Rev Immunol, 8: 849-860). Большинство TRIM-белков содержат в этой области один или более чем один консервативный домен, наиболее распространенные из которых включают домен PRY-SPRY (присутствующий примерно в 40 белках TRIM) и несколько доменов NHL (присутствующих в 4 TRIM-белках). Кроме того, несколько TRIM-белков не содержат распознаваемый мотив в С-концевой области. Чтобы проверить, способны ли другие человеческие TRIM-белки, такие как PML, распознавать неправильно упакованные белки, сначала были выбраны TRIM27 (с доменом PRY-SPRY), TRIM32 (с несколькими доменами NHL) и TRIM56 (короткий вариант сплайсинга TRIM5, не содержащий известных доменов). Когда они экспрессировались в клетках HeLa, эти три TRIM-белка демонстрировали перекрывающиеся, но различные паттерны клеточной локализации: TRIM27 и TRIM32 были локализованы как в цитоплазме, так и в ядре, тогда как TRIM56 локализовался только в цитоплазме. Тем не менее, все три белка сконцентрированы в гранулярных структурах (спеклах) в их соответствующих компартментах (фиг. 15А).
Проводили эксперименты для изучения колокализации TRIM27, TRIM32 и TRIM56 с Atxn1 82Q, а также с фрагментом белка хантингтина (Htt), содержащего тракт из девяноста семи глутаминов (Httex1p 97Q), который ассоциирован с HD. Atxn1 82Q, который был экспрессирован как гибрид с усиленным зеленым флуоресцентным белком (GFP), формировал включения только в ядре, тогда как НА-меченый Httex1p 97QP формировал включения как в ядре, так и в цитоплазме (Guo et al., 2014, Mol Cell, 55(1): 15-30) (фиг. 15A и фиг. 15В). Экзогенные TRIM27 и TRIM32 колокализовались с включениями Atxn1 82Q-GFP в ядре (фиг. 15А) и с включениями HA-Httex1p 97QP как в ядре, так и в цитоплазме (фиг. 15В и фиг. 15С). Более того, эндогенный TRIM27 также колокализовался с включениями Atxn1 82QGFP (фиг. 15D). Экзогенный TRIM55 колокализовался только с цитоплазматическими включениями HA-Httex1p 97QP (фиг. 15В и фиг. 15С). Таким образом, несмотря на различия в их С-концевой последовательности, TRIM27, TRIM32 и TRIM56 способны распознавать неправильно упакованный белок, сформированный в их соответствующих клеточных компартментах.
TRIM27, TRIM32 и TRIM56 снижают уровни как нерастворимых, так и растворимых белков Atxn1 82Q
Чтобы проверить, способны ли эти TRIM-белки снижать уровни неправильно упакованных белков, каждый из них экспрессировали с FLAG-меченным Atxn1 82Q в клетках HeLa. Анализировали уровни FLAG-Atxn1 82Q в клеточных лизатах, которые были NP40-растворимыми (растворимыми, или NS) и NP-40-нерастворимыми, но SDS-растворимыми (агрегированными, или SS). Следует отметить, что каждый TRIM-белок был способен снижать уровни растворимого и агрегированного белка Atxn1 82Q (фиг. 16А и фиг. 16В). TRIM27 и TRIM32 также снижали уровни белков Atxn1 82Q, которые были устойчивы как к NB-40, так и к SDS (SR), которые были обнаружены с помощью анализа запаздывания фильтра и, по-видимому, представляли собой 3-амилоидную структуру (см. ниже).
При экспрессии на одинаковых уровнях все три TRIM-белка, особенно TRIM32, демонстрировали более высокую активность, чем PML, в снижении уровней растворимого Atxn1 82Q (фиг. 16А). Более того, хотя активность TRIM27 и TRIM56 была несколько слабее, активность TRIM32 в уменьшении агрегированного Atxn1 82Q была сопоставима с активностью PML (фиг. 16А и фиг. 16В). TRIM27 был выбран для дальнейшего анализа. Экспрессию эндогенного TRIM27 подвергали нокауту с использованием киРНК, что приводило к значительному повышению уровней как растворимых, так и агрегированных белков Atnxl 82Q (фиг. 16С). Вместе эти результаты показывают, что, аналогично PML, TRIM27, TRIM32 и TRIM56 способны удалять неправильно упакованные белки. В отличие от этих TRIM-белков, PIASy, член PIAS-семейства SUMO Е3, не мог снижать уровни растворимого или агрегированного Atxn1 82Q (фиг. 16D).
Влияние TRIM27 и TRIM32 на Atxn1 82Q не зависит от PML
TRIM27 частично колокализуется в ядерных тельцах PML (Cao et al., 1998, J Cell Sci, 111(Pt 10): 1319-1329) (фиг. 17A). Чтобы исследовать, зависел ли TRIM27 и другой локализованный в ядре TRIM-белок, TRIM32, от PML в деградации неправильно упакованного белка, использовали мышиные эмбриональные фибробласты (mouse embryonic fibroblast, MEF) с PML дикого типа (PML+/+) и PML-дефицитные (PML-/-) MEF, Несмотря на колокализацию TRIM27 с ядерными тельцами PML, TRIM27 присутствовал в агрегатах Atxn1 82Q даже в отсутствие PML (фиг. 17В). Уровни SDS-нерастворимых агрегатов Atxn1 82Q были значительно выше в PML-/- MEF по сравнению с PML+/+ MEF (фиг. 17С), что согласуется с ролью PML в удалении Atxn1 82Q (Guo et al., 2014, Mol Cell, 55(1): 15-30). Повторное введение PML снижало уровни агрегата Atxn1 82Q. Следует отметить, что TRIM27 и TRIM32 были столь же эффективны, как и PML, в снижении агрегированного Atxn1 82Q как в клетках PML+/+, так и в клетках PML-/- (фиг. 17С). Вместе эти результаты показывают, что TRIM27 и TRIM32 могут элиминировать Atxn1 82Q независимо от PML.
TRIM27, TRIM32 и TRIM5δ нацеливают Atxn1 82Q на протеасомальную деградацию 5ЦМ02/3-зависимым образом
Ранее было обнаружено, что PML способствует протеасомальной деградации неправильно упакованных белков посредством его SUMO Е3-активности (Guo et al., 2014, Mol Cell, 55 (1): 15-30). Когда клетки обрабатывали протеасомальным ингибитором MG132, способность TRIM27, TRIM32 и TRIM56 снижать количество растворимого и особенно нерастворимого белка Atxn1 82Q значительно нарушалась, что указывает на то, что эти три TRIM-белка также направляют Atxn1 82Q на протеасомальную деградацию (фиг. 18А-18С). Кроме того, когда эндогенный SUMO2/3 подвергали нокауту с помощью киРНК, TRIM27, TRIM32 и TRIM5δ больше не могли эффективно снижать уровни Atxn1 82Q (фиг. 18D-18F). Следовательно, эти TRIM-белки также зависят от SUMO2/3 в деградации Atxn1 82Q.
Используя TRIM27 в качестве примера, в дальнейшем было рассмотрено, могут ли TRIM-белки, отличающиеся от PML, выступать в качестве SUMO Е3-лигаз для Atxn1 82Q. При инкубации с компонентами реакции сумоилирования, включая SUMO Е1 (SAE1/SAE2), Е2 (Ubc9), SUMO2 и ATP, Atxn1 82Q был минимально конъюгирован с SUMO2. Тем не менее, конъюгация Atxn1 82Q с SUMO2 усиливалась ТР1М27-дозозависимым образом (фиг. 18G), подтверждая, что TRIM27 представляет собой SUMO Е3 для Atxn1 82Q.
Колокализация с неправильно упакованными белками является преобладающим свойством TRIM-белков
В соответствии с этими наблюдениями остальные TRIM-белки анализировали на их способность распознавать Atxn1 82Q. За исключением двух (TRIM 12 и TRIM30), которые присутствуют у мышей, но не у людей, все другие TRIM-белки имеют человеческое происхождение. Каждый TRIM-белок метили НА-, Flag- или V5-эпитопом и коэкспрессировали с Atxn1 82Q-EGFP в клетках HeLa.
Предыдущее исследование подгруппы TRIM-белков показало, что эти белки идентифицируются в компартментах как в цитоплазме, так и в ядре (Reymond et al., 2001, EMBO J, 20: 2140-2151). Среди TRIM-белков, проанализрованных в данном документе, одиннадцать (TRIM42, 43, 53, 59-61, 67, 70-72 и 75) не удалось обнаружить с помощью иммунофлуоресценции. Среди оставшихся шестидесяти трех TRIM-белков пять (TRIM22, 28, 33, 65 и 66) локализовались исключительно в ядре, имея паттерн локализации, подобный PML. Тем не менее, нельзя исключить возможность того, что некоторые изоформы этих TRIM-белков, которые не были проанализированы в данном исследовании, могут присутствовать в цитоплазме. Например, такие цитоплазматические изоформы были показаны для PML. Двадцать три TRIM-белка (TRIM1-5, 7, 9, 10, 13, 18, 20, 24, 25, 29, 34, 36, 37, 39, 45-47, 50, 54, 63, 69 и 76) были локализованы главным образом или исключительно в цитоплазме. Двадцать три TRIM-белка (TRIM6, 8, 11, 12, 16, 21, 23, 27, 30-32, 35, 38, 40, 44, 48, 49, 51, 52, 55, 56, 58, 62, 64, 68, 73 и 74) присутствовали в существенном количестве в ядре и цитоплазме. Ряд TRIM-белков образовывали либо гранулярные, либо нитчатые структуры в ядре или цитоплазме, другие локализовались диффузно, а некоторые из них демонстрировали перинуклеарную локализацию. Часто TRIM-белок демонстрировал комбинацию этих паттернов локализации либо в одних и тех же, либо в различных клетках (фиг. 19 и таблица 2).
Четырнадцать TRIM-белков (TRIM6, 8, 11, 19, 21, 22, 27, 28, 30, 32, 33, 35, 38 и 51), включая PML/TRIM19, колокализовались с ядерными включениями Atxn1 82Q в значительном числе клеток (фиг. 19 и таблица 2), представляя почти 43% из тридцати двух TRIM-белков, которые присутствовали либо частично, либо исключительно в ядре. Эти TRIM-белки представляют собой различные подгруппы с различными С-концевыми последовательностями. Шесть белков (TRIM6, 11, 21, 22, 35 и 38), как и TRIM27, являются членами подгруппы IV, содержащими мотив SPRY, которому часто предшествует мотив PRY. TRIM8, как и PML, является членом группы V, не содержащим известных доменов. TRIM28 и TRIM33 являются членами группы VI, содержащими мотив PHD-BR. TRIM32 относится к подгруппе VII с пятью NHL-повторами. TRIM51 считается TRIM-подобным белком, не содержащим двух В-мотивов, но содержащим RING-домен и суперспиральную область; он также содержит домен SPRY, как и члены подгруппы IV. Вместе эти результаты показывают, что значительное число TRIM-белков, несмотря на расхождение в их С-конце, обладают способностью распознавать неправильно упакованные белки.
Деградация неправильно упакованных белков, опосредуемая другими TRIM-белками
Чтобы исследовать роль TRIM-белков в контроле качества белка, все человеческие TRIM-белки, за исключением TRIM53 (псевдоген) и TRIM57 (такой же, как TRIM59), а также TRIM12 и TRIM30 (мышиного происхождения), были проанализированы на способность вызывать деградацию Atxn1 82Q. Тридцать пять человеческих TRIM-белков (TRIM3, 4, 5, 6, 7, 9, 11, 13-17, 19, 20, 21, 24, 25, 28, 29, 34, 39, 43-46, 49, 50, 52, 58, 59, 75) и мышиный TRIM30 были способны снижать уровни NS- и/или SS-фракций Atxn1 82Q в различной степени (фиг. 20А и таблица 2). Несколько TRIM-белков демонстрировали высокую активность, включая TRIM4, 5, 9, 11, 16, 17, 20, 30, 39, 43, 65, 70, 75 (фиг. 20А и таблица 2), а один с наибольшей активностью, по-видимому, представлял собой TRIM11 (Фиг. 16А, Фиг. 20А и Таблица 2). Следует отметить, что TRIM27 и TRIM32, которые, как было показано выше, могли снижать Atxn1 82Q, не демонстрировали какого-либо эффекта в этом анализе. Это различие, по-видимому, связано с уровнями экспрессии. В экспериментах, описанных выше, TRIM27 и TRIM32 были клонированы в плазмиду pRK5. Но в экспериментах, описанных в этом разделе, TRIM27 и TRIM32 были клонированы в pcDNA. Из плазмид pRK5 неизменно наблюдали более сильную экспрессию по сравнению с экспрессией из плазмиды pcDNA. Таким образом, даже те белкт, которые не демонстрировали активность в деградации Atxn1 82Q, могли это делать при повышении уровней их экспрессии. Поэтому делается вывод о том, что способность стимулировать деградацию Atxn1 82Q преобладает среди TRIM-белков.
Следует отметить, что несколько TRIM-белков, включая TRIM26, 33, 42, 47, 48, 66, 69 и 76, усиливали, а не ингибировали экспрессию Atxn1 82Q. Это говорит о разнообразном влиянии различных TRIM-белков на Atxn1 82Q.
Параллельно изучалось влияние TRIM-белков на Httex1p 97QP (фиг. 20В). Только несколько TRIM-белков могли снижать уровни Httex1p 97QP в NS- и/или SS-фракциях, включая TRIM3, 11, 30, 68, 74 и 75. Большинство TRIM-белков могли повышать уровни Httex1p 97QP, включая TRIM1, 4, 6-10, 12-15, 21, 23-28, 32-39, 41-47, 49-51, 54-56, 58, 60-67, 69-73, 76 и 77. В отличие от Atxn1 82Q только небольшая часть клеток, экспрессирующих Httex1p 97QP, содержала включение. Неизменно часть белка Httex1p 97QP в SS-фракции была очень низкой по сравнению с частью Atxn1 82Q в той же фракции. Кроме того, в предыдущем исследовании PML (клонированный в плазмиду pRK5) мог снижать уровни Httex1p 97QP, тогда как PML (клонированный в pcDNA) не мог. Таким образом, влияние TRIM-белков на Httex1p 97QP, как и их влияние на Atxn1 82Q, также может зависеть от их уровней экспрессии. Эти результаты подтверждают различные влияния TRIM-белков на различные неправильно упакованные белки, на которые, помимо прочего, влияют их уровни экспрессии.
TRIM-белки
Ранее было показано, что PML способен элиминировать ряд неправильно упакованных белков, присутствующих в ядрах клеток млекопитающих. Представленные в данном документе эксперименты систематически проанализировали почти все TRIM-белки и обнаружили, что беспрецедентно большое их число может распознавать неправильно упакованные белки. Тем не менее, это число, по-видимому, недооценено, потому что в основном использовался один неправильно упакованный белок, Atxn1 82Q. В PML было идентифицировано по меньшей мере два сайта распознавания субстрата (SRS), суперспиральная область в мотиве RBCC и область, содержащая последние шестьдесят аминокислот. Эти SRS могут различать суперспиральные структуры и пептиды, обогащенные ароматическими аминокислотными остатками (Phe, Trp и Tyr), соответственно, которые обнаружены в некоторых денатурированных белках. TRIM-белки наиболее сильно расходятся в С-концевой области (Hatakeyama, 2011, Nat Rev Cancer, 11: 792-804; Ozato et al., 2008, Nat Rev Immunol, 8: 849-860). Вполне вероятно, что другие TRIM-белки могут обладать специфической способностью распознавать неправильно упакованные белки с различными структурными особенностями. Кроме того, вполне вероятно, что многие TRIM-белки могут распознавать неправильно упакованные белки в цитоплазме. Следовательно, данные наблюдения подчеркивают критическую важность этого большого семейства в контроле качества белка.
Следует отметить, что TRIM56 был способен усиливать деградацию Atxn1 82Q несмотря на его цитоплазматическую локализацию. Возможно, что TRIM56 может распознавать растворимый неправильно упакованный Atxn1 82Q в цитоплазме до того, как он будет импортирован в ядро. Кроме того, TRIM27 и TRIM32 демонстрируют высокую способность вызывать деградацию растворимого Atxn1 82Q, тогда как PML демонстрирует меньшую активность. Это может быть связано с тем, что в отличие от PML TRIM27 и TRIM32 частично локализованы в цитоплазме, где образуется белок Atxn1 82Q (и практически все остальные белки). Следовательно, распознавая неправильно упакованные белки, предназначенные для ядра, цитоплазматические TRIM-белки могут играть важную роль в контроле качества белка в ядре.
PML вызывает деградацию неправильно упакованных белков способом, который зависит от его SUMO Е3-активности (Guo et al., 2014, Mol Cell, 55 (1): 15-30). Аналогично, TRIM55, TRIM27 и TRIM32 полагаются на SUMO для удаления Atxn1 82Q. Анализ in vitro также подтверждает SUMO Е3-активность TRIM27 в отношении Atxn1 82Q. Следовательно, TRIM-белки могут использовать аналогичный механизм избавления клеток от неправильно упакованных белков. Наиболее релевантными SUMO-белками для деградации неправильно упакованных белков являются SUMO2/3. Полицепи, образованные SUMO2/3, облегчают распознавание несколькими SIM на RNF4 (Tatham et al., 2008, Nat Cell Biol, 10: 538-546). В соответствии с ролью в контроле качества белка SUMO2/3 в клетках, не подвергающихся стрессу, находятся в основном в неконъюгированных формах, но становятся конъюгированными с белками-мишенями после воздействия, разрушающего белок (Golebiowski et al., 2009, Sci Signal, 2: ra24; Saitoh and Hinchey, 2000, J Biol Chem, 275: 6252-6258). Тем не менее, учитывая разнообразие среди TRIM-белков и убиквитин-Е3-лигазную активность, ассоциированную с некоторыми (Meroni и Diez-Roux, 2005, Bioessays, 27: 1147-1157), все же возможно, что некоторые TRIM-белки могут в основном функционировать как убиквитин-Е3 для неправильно упакованных белков.
В настоящее время неясно, почему некоторые TRIM-белки могут вызывать деградацию неправильно упакованных белков, таких как Atxn1 82Q, в то время как другие не могут. Кроме того, среди проанализированных TRIM-белков TRIM11 обладает удивительно мощной активностью в уменьшении Atxn1 82Q. Остается определить, как можно объяснить его активность. Некоторые TRIM-белки могут усиливать уровни экспрессии Atxn1 82Q и особенно Httex1p 97QP. Это еще раз подчеркивает функциональное разнообразие этих белков. TRIM-белки могут функционировать в качестве шаперонов для предотвращения неправильной упаковки белка и в качестве дезагрегазы для растворения ранее сформированных белковых агрегатов. Эти активности могут частично объяснять влияние TRIM-белков на стабилизацию Atxn1 82Q и особенно Httex1p 97QP. Это подтверждает другое важное использование TRIM-белков в терапии заболеваний, ассоциированных с неправильно упакованными белками. Ряд заболеваний человека тесно связаны с деградацией мутантных белков, которые являются частично функциональными. Примечательным примером является муковисцидоз (CF), который вызван мутациями в гене регулятора трансмембранной проводимости при муковисцидозе (CFTR). Эти мутации вызывают деградацию в цитоплазме. Разрабатываются терапевтические подходы для стабилизации мутантного CFTR, позволяющие мутантному CFTR достигать способности выполнять его функции. Предполагается, что использование TRIM-белков может достичь такой цели в отношении CF и других заболеваний, ассоциированных с деградацией частично функциональных белков.

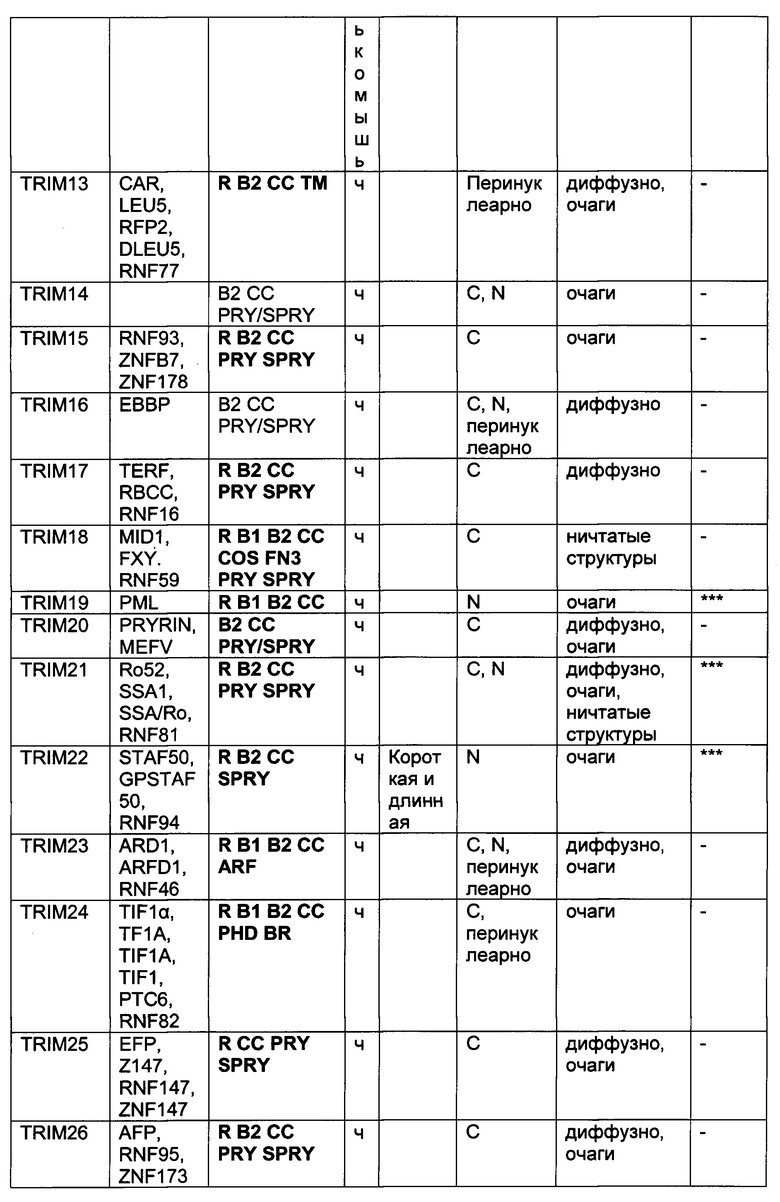
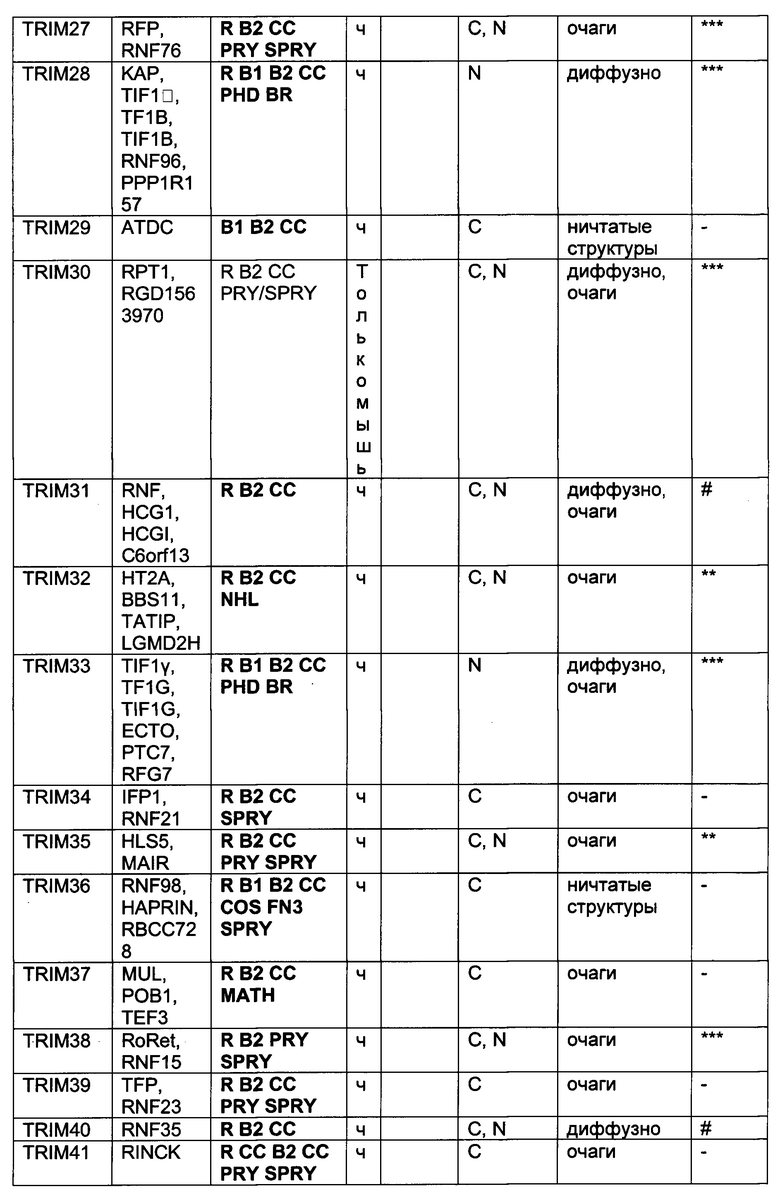

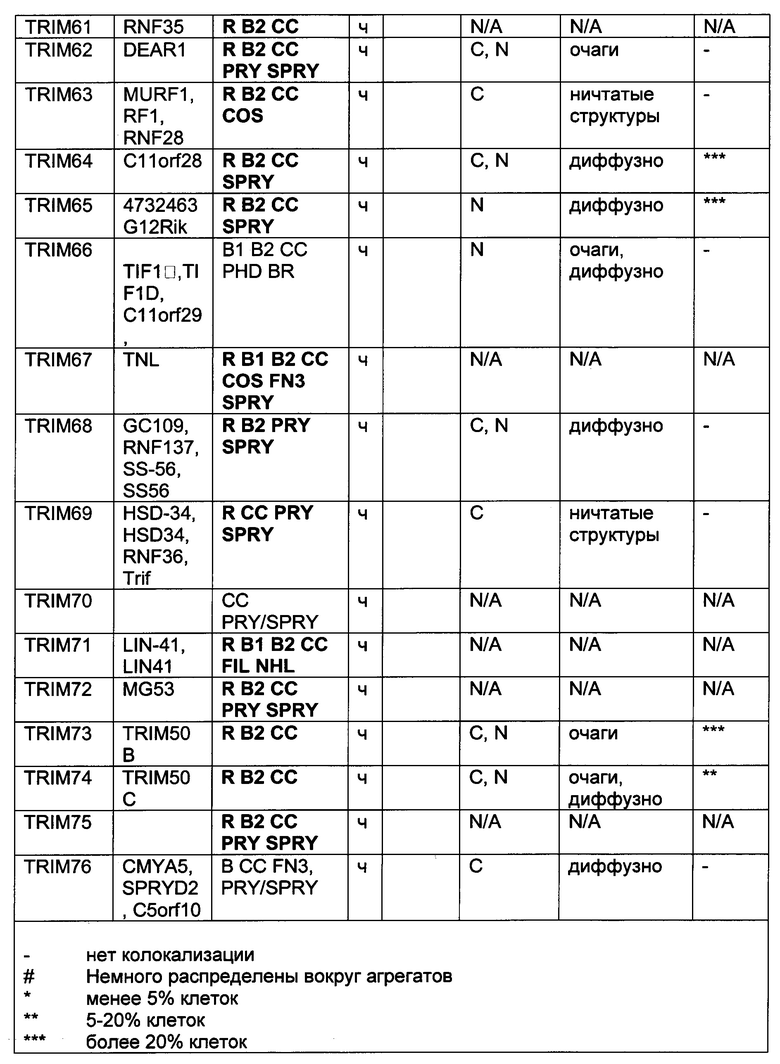


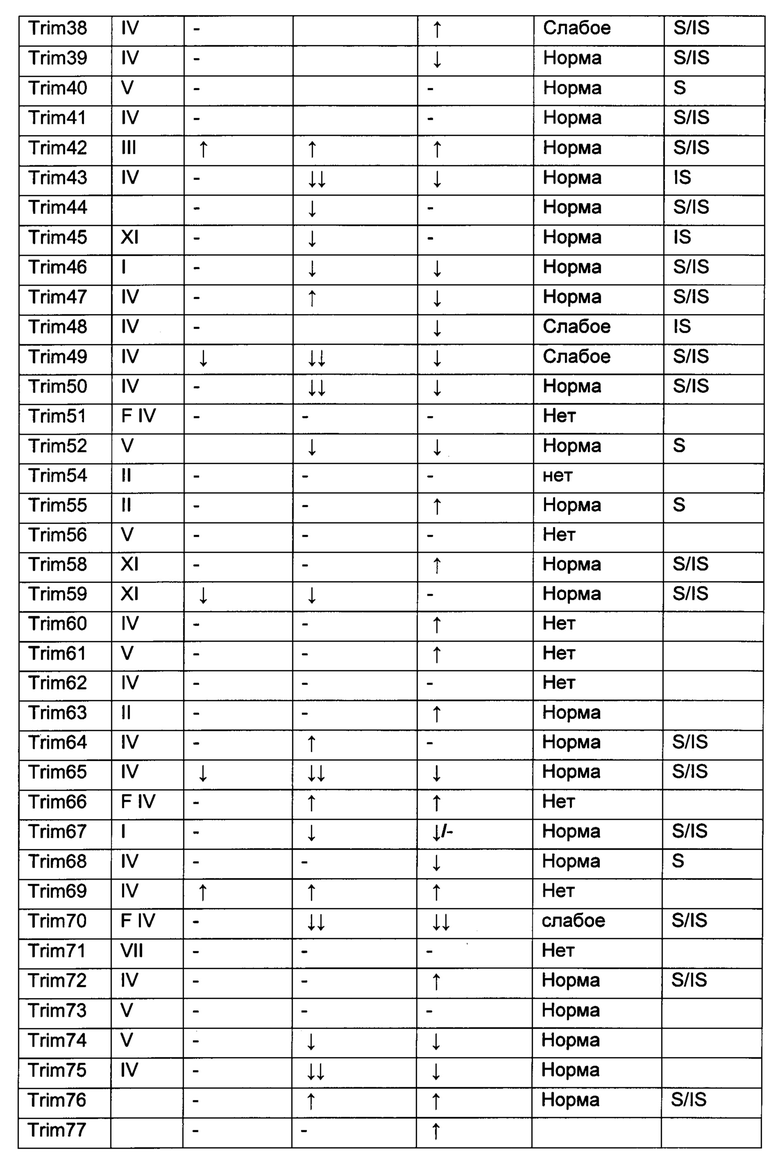

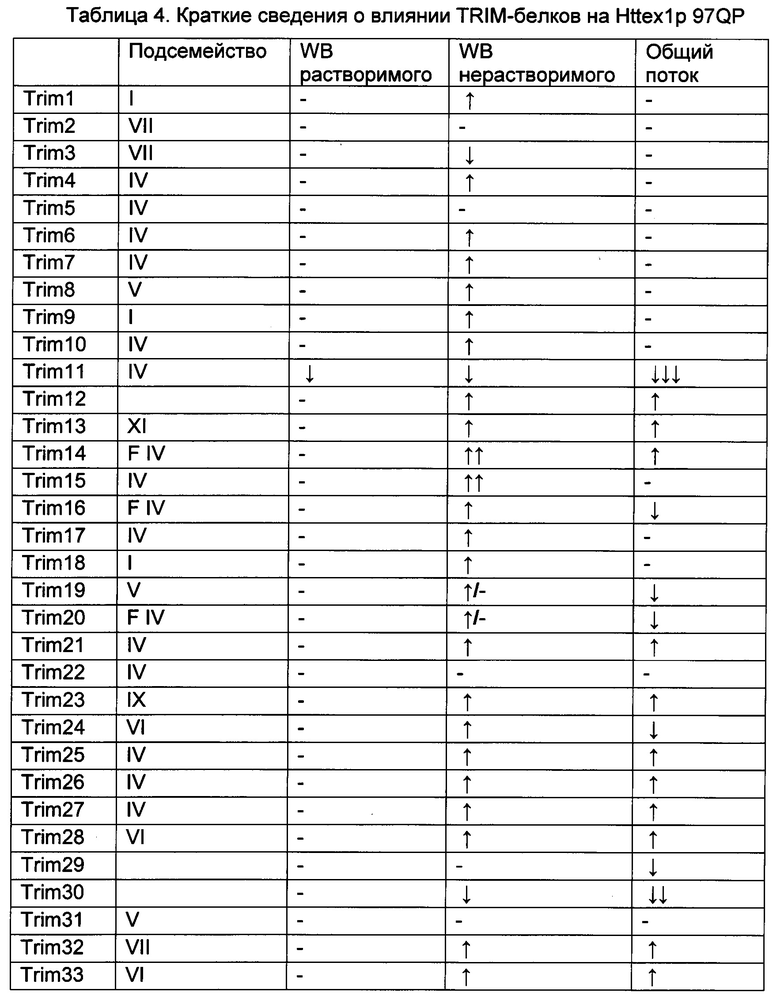
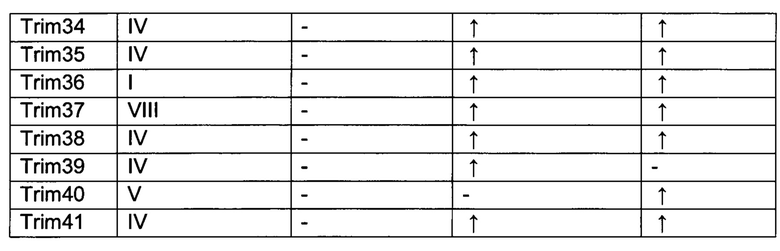
Пример 3: Доставка рекомбинантного TRIM11 в клетки млекопитающих способствует деградации неправильно упакованных белков
Как описано выше, было продемонстрировано, что члены семейства белков, содержащих трехчастные мотивы (TRIM), играют важную роль в распознавании и деградации неправильно упакованных белков. Первоначально с использованием PML/TRIM19 в качестве примера было показано, что PML может специфически связываться с неправильно упакованными белками через отдельные области, которые распознают структурные особенности, обычно встречающиеся в неправильно упакованных белках. Затем PML использует свою SUMO Е3-активность для мечения неправильно упакованных белков поли-SUMO2/3-цепями. Это позволяет неправильно упакованным белкам быть распознанными убиквитинлигазой RNF4, нацеленной на сумоилирование (STUbL), с последующим убиквитированием и протеасомальной деградацией неправильно упакованных белков. Также было показано, что эта PML-RNF4-опосредованная последовательная система сумоилирования и убиквитинирования играет важную роль в защите от нейродегенеративных заболеваний.
Впоследствии было исследовано подавляющее большинство всех известных человеческих TRIM-белков, и было обнаружено, что существенное их число может локализоваться с включением, образованным неправильно упакованными белками, такими как патогенный атаксин 1 (Atxn1 82Q) и хантингтин (Htt 97Q). При анализе репрезентативных TRIM-белков было показано, что многие TRIM-белки также способны вызывать деградацию неправильно упакованных белков SUMO-зависимым образом. Следует отметить, что среди TRIM-белков, которые были проанализированы, один TRIM-белок, TRIM11, демонстрирует особенно высокую активность в уменьшении неправильно упакованных белков.
В экспериментах, представленных в данном документе, предполагалось разработать рекомбинантный TRIM11 в качестве агента для деградации внутриклеточных неправильно упакованных белков, ассоциированных с нейродегенерацией. Для этого использовали пептид, полученный из Tat-белка вируса иммунодефицита человека (ВИЧ), который способен доставлять белки в клетки млекопитающих (фиг. 22). TRIM11 сливали с пептидом, полученным из Tat-белка, гибридный белок экспрессировали в бактериях, и белок очищали до гомогенности с использованием аффинной смолы, а затем гель-фильтрационной колонки. Для сравнения также параллельно очищали слитый с Tat-пептидом SUMO2-белок.
Клетки HeLa трансфицировали Atxn1 82Q-GFP, Atxn1 30Q или Htt 97Q-GFP и затем инкубировали с рекомбинантными белками TRIM 11 или SUMO2. Как показано на фиг. 21А, обработка клеток HeLa с помощью TRIM11 приводила к значительному снижению уровней Atxn1 82Q. Также она приводила к значительному снижению уровней Htt 97Q (фиг. 21В). Напротив, SUMO2 оказывал минимальное влияние на уровни Atxn1 82Q (фиг. 21С). Эти данные свидетельствуют о том, что доставка TRIM11 в клетки млекопитающих снижает уровень неправильно упакованных белков, обеспечивая доказательство или подтверждение концепции нацеливания системы TRIM-RNF4 для лечения нейродегенеративных и других заболеваний, ассоциированных с неправильно упакованными белками.
Пример 4: Локализация RNF4 с нейрональными включениями у пациентов с SCA1 и HD
Дефицит RNF4 у мышей приводит к эмбриональной летальности (Ни et al, 2010, PNAS 107: 15087-92), что исключает анализ этого дефицита на мышиных моделях нейродегенерации. Предыдущие исследования показали, что PML наряду с SUMO и убиквитином колокализуется с нейрональными включениями у пациентов с полиглутаминовыми заболеваниями (Dorval and Fraser; 2006, J Biol Chem 281:9919-24; Martin et al., 2007, Nat Rev Neurosci 8:948-59; Skinner et al., 1997, Nature 389:971-4; Takahasi et al., 2003, Neurobiol Dis 13:230-70), подтверждая участие PML в развитии этих заболеваний. Представленные в данном документе данные анализируют локализацию RNF4 в посмертных тканях мозга людей с SCA1 и HD.
Далее описаны материалы и методы, используемые в этих экспериментах.
Ткани от пациентов с HD (globus pallidus, бледный шар) были предоставлены Ресурсным центром тканей мозга Гарварда: AN06564, AN12127 и AN12029 (наблюдались агрегаты) и AN09048, AN19685, AN14942, AN13612 и AN17467 (агрегаты не наблюдались); ткани от пациентов с SCA1 (базальные точки) были получены из Национальной ассоциации атаксии. Иммуногистохимическое и иммунофлуоресцентное исследование выполняли так, как было описано ранее, с модификациями (Duda et al., 2000, J Neuropathol Exp Neurol 59:830-41; Emmer et al., 2011, J Biol Chem 286:35104-18). Ткани мозга от пациентов с HD и SCA1 заливали в парафин и делали срезы толщиной 6 мкм. Срезы окрашивали антителом против RNF4 (№1: кроличье, 11-25, 1:300, Sigma, №2: козлиное, С15, 1:25, Santa Cruz), против хантингтина (мышиное, МАВ5374, 1:500; Millipore), против убиквитина (мышиное, Ubi-1, МАВ1510, 1:2000, Millipore) и против полиQ. (мышиное МАВ1574, 1С2, 1:1000, Millipore), как было указано. Контрольные кроличьи антитела использовали для подтверждения специфичности анти-RNF4-окрашивания.
Далее описаны результаты экспериментов.
При обнаружении в нейронах пациентов без включений RNF4 имел тенденцию распространяться диффузно по всему ядру или формировать ядерные очаги (фиг. 23). В двух случаях SCA1, которые были исследованы, присутствовали ядерные включения, реактивных в отношении анти-полиQ-антитела (1С2). RNF4 был обнаружен в пяти из шестнадцати и в четырех из семнадцати 1С2-реактивных ядерных включений, соответственно (фиг. 24).
Среди пациентов с HD цитоплазматические включения, реактивные в отношении либо антитела против хантингтина, либо антитела против убиквитина, присутствовали в области бледного ядра в трех из восьми рассмотренных образцов от пациентов. Это согласуется с предыдущими наблюдениями о том, что ядерные включения были редкими в случаях HD с началом во взрослом возрасте (DiFiglia et al., 1997, Science 277:1990-3). Тем не менее, RNF4 колокализовался примерно с 20% включений в области бледного ядра на основании результатов с двумя отдельными анти-RNF4-антителами (фиг. 25 и фиг. 26). Включения, содержащие RNF4, как правило, демонстрируют RNF4-иммунореактивность, окруженную кольцом сигналов в отношении хантингтина или убиквитина (фиг. 25 и фиг. 26). Частичная колокализация RNF4 с полиQ-агрегатами у пациентов с SCA1 и HD напоминает частичную колокализацию PML с полиQ-агрегатами (Skinner et al., 1997, Nature 389:971-4; Takahashi et al., 2003, Neurobiol Dis 13:230-7), и это может отражать блокирование системы PML/TRIM-RNF4 в пораженных заболеванием нейронах.
Пример 5. Активности TRIM-белков в качестве молекулярного шаперона и белковой дезагрегазы
Данные, представленные в данном документе, демонстрируют, что TRIM11 может функционировать в качестве молекулярного шаперона и дезагрегазы. В одном из аспектов TRIM11 может предотвращать формирование агрегатов. С другой стороны, TRIM11 способен не только обеспечивать рефолдинг неамилоидных агрегатов, индуцированных стрессом (агрегаты люциферазы и GFP), но также дезагрегировать амилоидные агрегаты (агрегаты Atxn1 82Q и фибриллы альфа-синуклеина). Кроме того, в данном документе также показано, что TRIM11 также представляет собой SUMO Е3-лигазу, которая может сумоилировать Atxn1 82Q и вызывать последующую деградацию. Следовательно, TRIM11 может служить связующим звеном между дезагрегацией и деградацией белка.
Далее описаны материалы и методы, используемые в этих экспериментах.
Трансфекция киРНК
Мышиная киРНК TRIM11 (sc-76735) была приобретена у Santa Cruz. В первый день клетки нейронов гиппокампа (15000 клеток/лунка) высевали в 96-луночные планшеты на среду для чашек Петри. На второй день (примерно через 18 часов после посева) полностью меняли среду для чашек Петри на среду для нейронов. На третий день клетки трансфицировали киРНК (1 пмоль) с помощью реагента Lipofectamine RNAiMAX. Трансфекцию проводили в соответствии с инструкциями производителя.
Культура клеток
Клетки НСТ16 культивировали в среде McCoy 5А. Клетки А549 культивировали в среде RPMI1640. Клетки HeLa и НЕК293Т культивировали в среде DMEM.
Все эти культуральные среды содержат 10% фетальной бычьей сыворотки (fetal bovine serum, FBS). Получали первичные нервные клетки. Нервные клетки культивировали в соответствии с ранее описанными способами. Вкратце, клетки сначала засевали на среду для чашек Петри (Combine Neurobasal medium, В27, GlutaMAX, пенициллин/стрептомицин и 10% FBS с указанными коэффициентами разведения). Через 18-24 ч полностью меняли среду для чашек Петри на среду для нейронов (Combine Neurobasal medium, В27, GlutaMAX и пенициллин/стрептомицин с указанными коэффициентами разведения). За исключением отдельных указаний, все клетки содержали при 37°С в увлажненной атмосфере с 5% CO2.
Иммунофлуоресиениия
Клетки, помещенные на покровные стекла, фиксировали 4% параформальдегидом в течение 10 минут при комнатной температуре. Далее клетки пермеабилизировали метанолом в течение 10 минут при 20°С. Клетки промывали PBS и затем блокировали 2% бычьим сывороточным альбумином (BSA) в течение 30 минут при комнатной температуре. Клетки инкубировали с первичным антителом в течение ночи при 4°С с последующей инкубацией с флуоресцентно меченным вторичным антителом в течение 1 часа при комнатной температуре. Наконец, покровные стекла помещали на стекла со средой для заливки, содержащей 4',6-диамидино-2-фенилиндол (DAPI) (Vector Laboratories; Н-1200). Применяли следующие разведения антител: анти-НА (1:100), анти-p-a-Syn (1:100) и анти-р62 (1:200).
Антитела
Анти-TRIM11-антител о (АВС926) было приобретено у Millipore. Моноклональное анти-Plag-антитело, кроличье Flag-антитело и анти-Flag-агарозные гранулы были приобретены у Sigma. Матрица с аффинностью против НА (клон 3F10, 11815016001) была приобретена у Roche. Анти-HSFI-антитело (sc-9144) было приобретено у Santa Cruz. Анти-альфа-синукпеин-фосфо(Ser129)-антитело (825701) было приобретено у Biolegend. Анти-Hsp70-антитело (ADI-SPA-810-D) было приобретено у Enzo. Анти-альфа-синуклеин-антитело (2642) и анти-Hsp90-антитело (4874) были приобретены у Cell signaling technology.
Фракционирование белка, анализ задержки в Фильтре и иммуноблоттинг Клетки лизировали с помощью лизирующего буфера (50 мМ Tris, рН 8,8, 100 мМ NaCl, 5 мМ MgCl2, 0,5% IGEPAL СА-630, 1 мМ DTT, 250 МЕ/мл бензоназы (Sigma), 1 мМ PMSF и 1х полный протеазный коктейль (Roche)) в течение 30 минут на льду. Супернатант получали центрифугированием со скоростью 13000 об/мин в течение 15-20 минут при 4°С. Далее осадок ресуспендировали в буфере для осадка (20 мМ Tris, рН 8,0, 15 мМ MgCl2, 1 мМ DTT, 250 МЕ/мл бензоназы, 1 мМ PMSF и 1х полный протеазный коктейль) в течение 30 минут на льду с последующим прямым кипячением в буфере с 2% SDS. Концентрацию белка измеряли с помощью анализа Брэдфорда (Bio-Rad Labs). Все образцы белка подвергали иммуноблоттингу с помощью SDS-PAGE. Супернатант рассматривали как растворимую фракцию. Осадок рассматривали как нерастворимую фракцию (SDS-растворимую). Другую часть подвергали анализу задержки в фильтре. Вкратце, образцы осадка фильтровали через мембрану с размером пор 0,2 мкм, так что устойчивые к SDS агрегаты, которые удерживались на мембране, анализировали путем иммуноблоттинга.
Очистка белков
Клетки 293Т трансфицировали Flag-Atxn1-82Q-HA и очищали с помощью анти-Flag М2-гранул. Для получения высокоочищенных белков гранулы интенсивно промывали возрастающими концентрациями NaCl.
His-люциферазу экспрессировали в очищенных клетках BL21 DE3. Для получения иммобилизованной нативной или денатурированной люциферазы нативную люциферазу, во-первых, очищали из лизатов бактериальных клеток в соответствии с инструкциями производителя. Во-вторых, денатурированную люциферазу получали путем инкубации нативной люциферазы с 8 М мочевиной в течение 5 минут.
Анализы сумоилирования in vivo и in vitro
Для анализов сумоилирования in vivo клетки трансфицировали указанными плазмидами. Через 48 часов клетки лизировали в лизисном буфере (50 мМ Tris-Cl, рН 7,4, 150 мМ NaCl, 0,5% Trition, 1 мМ DTT, 1 мМ PMSF и 1х полный протеазный коктейль), дополненном 2% SDS и 50 мМ DTT. Далее клеточные лизаты кипятили при 95°С в течение 10 минут. Одну аликвоту сохраняли для анализа входящего образца. Остальные клеточные лизаты разводили в 10 раз в лизисном буфере и затем инкубировали с гранулами против НА при 4°С в течение ночи. Гранулы интенсивно промывали и анализировали путем иммуноблоттинга с указанными антителами. Для анализов сумоилирования in vitro His-SUMO-2 (UL-753), UbcH9 (E2-465) и SUMO E1 (E-315) получали из Boston Biochem.
Плазмиды
Flag-TRIM11 был сконструирован путем вставки кДНК Kpnl/Xbal TRIM11 в расщепленный по Kpnl/Xbal вектор pcDNA3.1-Flag. Мутацию в Flag-TRIM11 (замена 12/13ЕЕ на 12/13АА) получали путем сайт-направленного мутагенеза. GST-TRIM11 был сконструирован путем вставки «ДНК BgIII/SaII TRIM11 в расщепленный по BamHI/SaII вектор pGEX-1AT. GFP-Hsp70 и GFP-TRIM11 были сконструированы путем вставки кДНК Hsp70 и TRIM11 в вектор pEGFP-C1. Все конструкции были проверены секвенированием ДНК.
Анализ реактивации люциферазы
Для получения агрегатов люциферазу светлячков (100 нМ) в буфере для рефолдинга люциферазы (luciferase refolding buffer, LRB; 25 мМ HEPES-KOH [рН 7,4], 150 мМ КАОс, 10 мМ MgAOc, 10 мМ DTT) нагревали при 45°С в течение 8-10 минут. Агрегированную люциферазу (10 нМ) инкубировали с указанными концентрациями TRIM11 или другими белками при 25°С в течение 90 минут. Для двухшапероновой системы Hsp104/Hsp70-Hsp40 требовалось 5 мМ АТФ и система восстановления АТФ (1 мМ креатинфосфат, 0,5 мкМ креатинкиназа). Для анализа рефолдинга люциферазы in vivo клетки в 96-луночном планшете временно трансфицировали люциферазой дикого типа. Через 24 часа клетки нагревали при 42°С или 45°С в течение 1 часа или 30 минут, соответственно. Перед тепловым шоком в культуральную среду добавляли 20 мкг/мл циклогексимида. После теплового шока клетки переносили в инкубатор с 37°С еще на 1,5 или 3 часа. Активность люциферазы измеряли с помощью системы Promega Luciferase.
Анализ дезагрегации GFP
Для получения агрегатов GFP (4,5 мкМ) в буфере А (20 мМ Tris-HCl, рН 7,5, 100 мМ KCl, 20 мМ MgCl2, 5 мМ DTT, 0,1 мМ EDTA, 10% (объем/объем) глицерин) инкубировали в течение 15 минут при 85°С. GFP-агрегаты (0,45 мкМ) инкубировали с указанными белками с различными количествами при 25°С в течение 60 минут. Дезагрегацию агрегатов GFP определяли путем измерения флуоресценции при 510 нм с возбуждением при 395 нм (Infinite М200 pro).
Реагенты
Люцифераза (L9506), Mg-ATP (А9187), фосфокреатин (Р1937) и креатинкиназа (С3755) были приобретены у Sigma. KRIBB11 (385570) был приобретен у Millipore. Бета-амилоид (1-42) (RP10017) был приобретен у GenScript.
Далее описаны результаты экспериментов.
PML (TRIM19) сумоилировал неправильно упакованный белок, который может быть распознан RNF4 для деградации через протеасому. Тем не менее, неизвестно, является ли TRIM11 также SUMO Е3-лигазой. Согласно структурному анализу TRIM, для его убиквитин-Е3-лигазной активности требуются два высоко консервативных глутамата (Glu9 и Glu 10) TRIM25. Поэтому были получены мутантные TRIM11 (замена Glu12/Glu13 на Ala12/Ala13), которые не обладали Е3-лигазной активностью (фиг. 27А и фиг. 27В). Анализ сумоилирования in vivo показал, что Atxn1 82Q эффективно сумоилировался под влиянием TRIM11 дикого типа, а также PML (фиг. 27А). Для дальнейшего подтверждения этого проводили анализ сумоилирования in vitro, который показал, что очищенный Atxn1 82Q мог быть значительно сумоилирован под влиянием TRIM11. Поэтому TRIM11 также был SUMO Е3-лигазой для Atxn1 82Q. В клетках TRIM 11-подобный Hsp70 был в основном локализован в цитоплазме (фиг. 28А и фиг. 28В). Интригующе, что TRIM11 или Hsp70 могут быть привлечены в агрегаты Atxn1 82Q (фиг. 28С и фиг. 28D), подтверждая, что между TRIM11 и Atxn1 82Q может быть взаимодействие. Чтобы проверить это, проводили анализ соосаждения, который показал, что TRIM11 селективно связывался с Atxn1 82Q (фиг. 29А). Важно отметить, что TRIM11 преимущественно взаимодействовал с патологической формой Atxn1 82Q, а не с Atxn1 30Q (фиг. 29В). Поэтому было выдвинуто предположение, что TRIM11 имеет потенциал для селективного связывания с неправильно упакованными белками. Чтобы исследовать это предположение, далее получали гранулы с нативной или денатурированной люциферазой, а затем проводили анализ соосаждения. Как показано на фиг. 29С, в отличие от контрольных GST-белков TRIM11 специфически связывался с денатурированной люциферазой, указывая на то, что TRIM11 способен связывать неправильно упакованные белки.
Было продемонстрировано, что Hsp70, молекулярный шаперон, может подавлять экспрессию ассоциированного с патологией Atxn1 82Q у мышей SCA1. Кроме того, Hsp70 уменьшал во фракции, нерастворимой в детергенте, уровень белка Atxn1 82Q, что соответствовало результатам, представленным в данном документе (фиг. 28Е). Далее исследовали, существует ли сходство между TRIM 11 и Hsp70 в формировании агрегатов. Чтобы изучить это, анализировали способность Atxn1 82Q к солюбилизации путем фракционирования с детергентом. Как показано на фиг. 28Е, TRIM11, как и Hsp70, уменьшал нерастворимую в детергенте фракцию Atxn1 82Q, подтверждая, что TRIM11 может контролировать агрегацию белка. Кроме того, обработка MG132 умеренно увеличивала нерастворимую фракцию Atxn1 82Q (фиг. 28Е), что согласуется с предыдущим сообщением о том, что для контроля формирования агрегатов Atxn1 82Q необходима протеасома. Интересно, что когда Atxn1 82Q коэкспрессировался с TRIM11 дикого типа или мутантным TRIM11, мутантный TRIM11 имел более низкую способность уменьшать нерастворимую в детергенте фракцию Atxn1 82Q по сравнению с TRIM11 дикого типа (фиг. 28F), подтверждая, что Е3-лигазная активность TRIM11 требуется для уменьшения агрегатов Atxn1 82Q. Чтобы дополнительно проверить, влиял ли TRIM11 на амилоидоподобные агрегаты в клетках, клетки трансфицировали TRIM11 дикого типа или мутантным TRIM11, и окрашивание ThT показало, что TRIM11 дикого типа и мутантный TRIM11 могут снижать уровень амилоидоподобных агрегатов (фиг. 28G). Стабильная сверхэкспрессия Atxn1 82Q умеренно усиливала окрашивание ThT (фиг. 30А). Аналогичным образом, TRIM11 может также уменьшать нерастворимые в детергенте фракции Atxn1 82Q в стабильных клетках (фиг. 30В). Важно отметить, что TRIM11 дикого типа обладает более высокой способностью, чем мутантный TRIM11, в уменьшении клеточных агрегатов (фиг. 30С и 30D).
Из-за сходства Hsp70 и TRIM11 было высказано предположение, что TRIM11 может функционировать в качестве молекулярного шаперона для контроля агрегации белка. Как правило, шапероны обладают способностью предотвращать склонность к агрегации неправильно упакованных белков. Это самый первый и наиболее эффективный способ борьбы с агрегацией белка. Поэтому была исследована способность TRIM11 предотвращать формирование агрегата. Активность люциферазы быстро снижалась без шаперона в ответ на тепловой шок (фиг. 31А). Тем не менее, инкубация TRIM11, а также Hsp70 могла эффективно защитить люциферазу от инактивации нагреванием (фиг. 31А). Аналогично, TRIM11 также защищает белки GFP от нагревания (фиг. 31С). Эти результаты подтвердили, что TRIM 11 может функционировать как молекулярный шаперон, такой как Hsp70. В клетках стабильная сверхэкспрессия TRIM11 способна умеренно защитить люциферазу от теплового шока (фиг. 31С и фиг. 31D). Более того, TRIM11 может также очевидно восстанавливать инактивированную нагреванием люциферазу (фиг. 31С и фиг. 31D), что также подтвердило шапероноподобную функцию TRIM11. Важно отметить, что сверхэкспрессия TRIM11 не меняла уровень белка Hsp70 (фиг. 31Е). Затем в качестве субстрата для исследования профилактической функции TRIM11 использовали бета-амилоид, ассоциированный с болезнью Альцгеймера (1-42). Как показано на фиг. 31F, TRIM11 мог ингибировать формирование амилоидного волокна в ThT-анализе. Кроме того, Atxn1 82Q очищали для анализа процесса формирования агрегатов. Контрольный белок GST не мог предотвратить формирование агрегатов Atxn1, тогда как TRIM11 эффективно блокировал формирование агрегатов (фиг. 31G). Кроме того, TRIM11 мог также предотвратить амилоидоподобные агрегаты Atxn1 82Q (фиг. 31G). Известно, что р53 склонен формировать агрегаты in vitro. Как показано на фиг. 31Н, TRIM11 значительно предотвращал денатурацию р53. Интригующе, что р53 мог быть сумоилирован под влиянием TRIM11 in vitro (фиг. 27С), и сумоилирование р53 могло блокировать амилоидоподобные агрегаты, но способствовало формированию олигомеров. Подводя итог, TRIM11 может функционировать в качестве молекулярного шаперона для предотвращения формирования агрегатов.
Чтобы определить, может ли экспрессия TRIM11 повышаться в ответ на тепловой шок, были использованы клетки НСТ116, стабильно экспрессирующие вектор или TRIM11. В контрольных стабильных клетках экспрессия TRIM11 повышалась во время восстановления после теплового шока (фиг. 32А). Тем не менее, в TRIMH-экспрессирующих клетках экспрессия экзогенного белка TRIM-11 не могла повышаться (фиг. 32В), что означает, что повышение экспрессии TRIM11, вызванное нагреванием, не было обусловлено изменением стабильности белка. Повышение экспрессии TRIM11 также, индуцированное нагреванием, было подтверждено в клетках HeLa (фиг. 32С). Поскольку многие воздействия могут индуцировать неправильную упаковку белка, было проведено исследование, может ли TRIM11 быть индуцирован другим воздействием. Как показано на фиг. 30D и 30Е, уровень белка TRIM11 повышался в ответ на обработку As2O3 и H2O2. Уровень мРНК TRIM11 мог быть индуцирован в ответ на тепловой шок (фиг. 32F), который аналогичен Hsp70. Чтобы исследовать механизмы, с помощью которых TRIM11 был индуцирован тепловым шоком, были созданы клетки А549, которые стабильно экспрессируют HSF1, ключевой транскрипционный фактор для контроля белков, чувствительных к нагреванию. Неожиданно, что сверхэкспрессия HSF1 снижала уровень белка TRIM 11 при воздействии теплового шока или без него (фиг. 32G), подтверждая, что HSF1, возможно, не требуется для регуляции транскрипции TRIM11.
Другой ключевой транскрипционный фактор, р53, может быть активирован в ответ на тепловой шок. р53 также способен напрямую увеличивать транскрипцию TRIM, например, TRIM21 и TRIM24. Поэтому было исследовано, может ли TRIM11 контролироваться р53 в ответ на тепловой шок. Как показано на фиг. 33А, экспрессия TRIM11 повышалась в ответ на тепловой шок в клетках НСТ116 с р53 дикого типа, но не повышалась в клетках без р53. Соответственно, уровень мРНК TRIM11 повышался только в клетках НСТ116 с р53 дикого типа (фиг. 33В), подтверждая, что р53 способствовал транскрипции TRIM11. Еще раз подтверждая важность р53, уровень белка и мРНК TRIM11 не мог повышаться в клетках А549, стабильно экспрессирующих кшРНК р53 (фиг. 33С). Подобное явление снова подтвердилось в клетках НСТ116 с нокдауном р53 (фиг. 33D). Вместе эти результаты убедительно подразумевают, что р53 может быть ключевым фактором повышения экспрессии TRIM11 в ответ на тепловой шок. HSF1 считается защитой выживаемости клеток после воздействия нагреванием. KRIBB11, химический ингибитор, может быть использован для ингибирования активности HSF1. Как показано на фиг. 33Е и фиг. 33F, при обработке KRIBB11 клетки без р53 были более чувствительны к тепловому шоку, что подразумевало, что р53 также способствовал выживаемости клеток в ответ на воздействие нагреванием.
Hsp70 может способствовать растворению некоторых видов белковых агрегатов. Далее было исследовано, может ли TRIM11 вызывать дезагрегацию белковых агрегатов. Как и ожидалось, TRIM 11 вызывал ресолюбилизацию инактивированной нагреванием люциферазы из нерастворимых агрегатов (фиг. 34А) и восстанавливал активность люциферазы дозозависимым образом (фиг. 34В). Кроме того, солюбилизирующая способность TRIM11 была дополнительно подтверждена с использованием предварительно сформированных агрегатов GFP в качестве субстратов (фиг. 34С и фиг. 34D). Эти результаты подтвердили, что TRIM11 может вызывать дезагрегацию неупорядоченных агрегатов. Затем проводили анализы с использованием агрегатов Atxn1 82Q в качестве субстратов. Как показано на фиг. 34Е, TRIM11 может эффективно ресолюбилизировать агрегаты Atxn1 82Q. Примечательно, что двойной шаперон Hsp707Hsp40 дезагрегировал только амилоидоподобную структуру Atxn1 82Q в осадке (фиг. 34F), подтверждая, что TRIM 11 может действовать различными путями. Как и ожидалось, TRIM11, а также Hsp104, значительно восстанавливали амилоидоподобную структуру в супернатант (фиг. 34G).
Чтобы определить, какой функциональный домен TRIM11 необходим для дезагрегационной активности TRIM11, в качестве субстратов использовали агрегаты люциферазы, образованные при нагревании. Как показано на фиг. 35В, TRIM 11 мог эффективно восстанавливать активность люциферазы, инактивированной нагреванием, но RBC- или В30.2-фрагменты TRIM11 обладали более слабой реакционной способностью. В последствии, в анализе седиментации, TRIM11 обладал более сильной активностью, чем два его фрагмента, в отношении ресолюбилизации предварительно сформированных агрегатов люциферазы (фиг. 35С). Кроме того, каждый отдельный домен почти полностью терял способность к рефолдингу по сравнению с полноразмерным TRIM11 (фиг. 35D). Кроме того, полноразмерный TRIM11 очень сильно взаимодействовал с Atxn1 82Q, но RBC или В30.2 не связывались с Atxn1 82Q (фиг. 36А). Аналогично, отдельный домен TRIM11 не связывался с Atxn1 82Q (фиг. 36В). Эти результаты убедительно показали, что для дезагрегационной функции TRIM11 может потребоваться связывание с субстратами.
Затем проводили исследование того, необходима ли SUMO Е3-лигазная активность для дезагрегации белка. В данном документе мутантный TRIM11 использовался для анализа его дезагрегационной активности. Как показано на фиг. 37А, мутантный TRIM11 сохранял способность предотвращать инактивацию люциферазы при нагревании, как и TRIM11 дикого типа. Более того, мутантный TRIM11 также имел сходный потенциал с TRIM11 дикого типа в восстановлении активности денатурированной люциферазы (фиг. 37В). Мутантный TRIM11 все еще был способен селективно связываться с денатурированной люциферазой (фиг. 37С). Все эти результаты показали, что in vitro TRIM11 выполнял свою дезагрегационную функцию независимо от его Е3-активности. Примечательно, что мутантный TRIM11 был в значительной степени локализован в ядре (фиг. 37D), что отличалось от TRIM11 дикого типа. Кроме того, мутант TRIM11 также мог быть колокализован с Atxn1 82Q.
Предыдущие исследования показали, что Hsp110, Hsp70 и Hsp40, система дезагрегации белков метазоанов, не может эффективно вызывать дезагрегацию амилоида. Поэтому было исследовано, может ли TRIM11 вызывать дезагрегацию амилоидного волокна. В данном случае в качестве объекта применялся альфа-синуклеин. Во-первых, было определено, может ли TRIM11 предотвращать формирование альфа-синуклеиновых волокон. Как показано на фиг. 38А, TRIM11, а также Hsp70 и Hsp104, эффективно ингибируют формирование альфа-синуклеиновых амилоидных волокон (фиг. 38А). Кроме того, ингибирование было дозозависимым (фиг. 38В). Действительно, электронная микроскопия (electron microscopy, ЕМ) показала, что альфа-синуклеиновые волокна демонстрировались контрольным белком GST, тогда как с TRIM 11 волокон не наблюдалось (фиг. 38С). Затем альфа-синуклеиновые волокна использовали для изучения дезагрегации TRIM11. Как показано на фиг. 38D, при обработке TRIM11 или мутантным Hsp104 солюбилизация альфа-синуклеиновых волокон увеличивалась дозозависимым образом. Соответственно, разрешение волокон было очевидным при обработке TRIM11 или Hsp104 при анализе флуоресценции ThT (фиг. 38Е).
Есть более 70 членов семейства TRIM с общим N-концом и различными С-концами. Поэтому в дальнейшем было исследовано, обладали ли другие TRIM-белки аналогичной функцией, такой как обладал TRIM11. Таким образом, был выбран TRIM21, поскольку он имеет такие же домены, как TRIM11. Анализ соосаждения in vitro показал, что TRIM21 также предпочтительно связывался с денатурированной люциферазой (фиг. 39А). Аналогичным образом, TRIM21 мог вызывать умеренную солюбилизацию агрегатов люциферазы, образованных при нагревании (фиг. 39В) и восстанавливать активность люциферазы, инактивированной нагреванием (фиг. 39С). TRIM21 также был способен защищать люциферазу от инактивации нагреванием (фиг. 39D). PML мог вызывать деградацию агрегатов Atxn1 82Q через протеасому. Таким образом, чтобы выяснить, связаны ли дезагрегация и деградация агрегатов Atxn1 с PML, PML очищали из клеток 293Т (фиг. 40А). Как показано на фиг. 40В, PML мог восстанавливать инактивированную нагреванием флуоресценцию GFP дозозависимым образом. Тем не менее, способность к восстановлению была слабее, чем у TRIM11 (фиг. 40С). Несколько фрагментов PML также очищали из клеток 293Т (фиг. 40D). Интересно, что один фрагмент (361-633) PML может быть необходим для реактивации агрегатов GFP, образованных при нагревании (фиг. 40Е).
Чтобы лучше понять роль TRIM11 в контроле формирования альфа-синуклеиновых агрегатов, в качестве модели использовали первичные нейроны гиппокампа мыши. Альфа-синуклеиновые волокна (PEF) были получены с помощью GST или TRIM11 in vitro (GST-PEF и TRIM11-PEF). Через две недели после добавления PEF примерно 30% нейронов умирали под влиянием агрегатов PEF (фиг. 41А). Тем не менее, TRIM11-PEF имеют более низкий уровень токсичности для нейронов (фиг. 41А). Действительно, иммунофлуоресценция показала, что имели место значительные альфа-синуклеиновые агрегаты, которые повторяли особенности телец Леви в мозге от пациентов с болезнью Паркинсона, тогда как после добавления TRIM 11 больших агрегатов PEF не наблюдалось (фиг. 41В), что также показало, что TRIM11 имел профилактическую функцию в формировании альфа-синуклеиновых волокон. Примечательно, что в двух видах нейронов (кортикальных и гиппокампальных нейронах) TRIM11 мог иметь повышенную экспрессию в ответ на тепловой шок (фиг. 42А и фиг. 42В). Более того, уровень мРНК TRIM11 также повышался в гиппокампальных нейронах (фиг. 42С). Интересно, что TRIM11, по-видимому, участвовал в контроле над нейродегенеративным заболеванием.
Раскрытие информации о каждом патенте, заявке на патент и публикации, цитируемой в данном документе, настоящим включено сюда посредством ссылки во всей их полноте. Хотя данное изобретение раскрыто со ссылкой на конкретные воплощения, очевидно, что другие воплощения и варианты этого изобретения могут быть разработаны специалистами в данной области без отхода от истинной сущности и объема данного изобретения. Приложенная формула изобретения должна быть истолкована как включающая все такие воплощения и эквивалентные варианты.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> The Trustees Of The University Of Pennsylvania
Yang, Xiaolu
Guo, Lili
<120> Compositions and Methods for Degradation of Misfolded Proteins
<130> 046483-6149-00-WO.605285
<150> US 62/168,309
<151> 2015-05-29
<160> 169
<170> PatentIn version 3.5
<210> 1
<211> 2208
<212> DNA
<213> Homo sapiens
<400> 1
atgggtgaaa gcccagcctc cgtggttctt aatgcctcag gaggactatt ttcactaaag 60
atggaaacac tggagtctga attgacctgt ccaatctgcc tagagttgtt tgaagacccc 120
cttctgctcc cttgtgctca cagcctctgc ttcagctgtg cccatcgcat tttggtatca 180
agctgcagct ctggtgaatc cattgaaccc attactgctt tccagtgtcc tacctgcagg 240
tatgttatct cgctgaacca ccggggcctg gatggcctca agaggaatgt gactctgcag 300
aacattattg atcgcttcca gaaggcttca gtcagtgggc ccaattcccc tagtgagagc 360
cgccgggaaa ggacttacag gcccaccact gccatgtcta gcgagcgaat tgcttgccaa 420
ttctgtgagc aggacccgcc aagggatgca gtaaaaacat gcatcacctg tgaggtctcc 480
tactgtgacc gttgcctgcg ggccacgcac cccaacaaga aacctttcac cagccaccgc 540
ctggtggaac cagtgccaga cacacatctt cgagggatca cctgcctgga ccatgagaat 600
gagaaagtga acatgtactg tgtatctgat gaccaattga tctgtgcctt atgcaaactg 660
gtgggtcgtc accgagacca tcaggtcgca tccctgaatg atcgatttga gaaactcaag 720
caaactctgg agatgaacct caccaacctg gttaagcgca acagcgaact agaaaatcaa 780
atggccaaac taatacagat ctgccagcag gttgaggtga atactgctat gcatgaggca 840
aaacttatgg aagaatgtga cgagttggta gagatcatcc agcagaggaa gcaaatgatc 900
gctgtcaaaa tcaaagagac aaaggttatg aaactgagaa agttggcaca gcaggttgct 960
aattgccgcc agtgtcttga acggtcaaca gtcctcatca accaagctga gcatatcctg 1020
aaagaaaatg accaggcacg gtttctacag tctgcaaaaa atattgctga gagggtcgct 1080
atggcaactg catcttctca agttctgatt ccagacatca attttaatga tgcctttgaa 1140
aactttgctt tagatttttc cagagaaaag aaactgctag aggggttaga ttatttaaca 1200
gccccaaacc caccatctat ccgagaagaa ctctgtactg cctcccatga caccattaca 1260
gtccactgga tctcggatga tgagttcagc atcagctcct atgagcttca gtacaccata 1320
ttcactggcc aggctaactt catcagtaag tcatggtgta gttggggcct gtggccagag 1380
ataaggaaat gtaaggaagc agtaagctgc tcaagattgg ccggggcgcc acgaggcctg 1440
tataattcag tagacagctg gatgattgtt cccaacatta aacagaacca ttacacagtg 1500
catggactcc agagcgggac tcgctacatc ttcatcgtta aagccataaa ccaagccggc 1560
agccggaaca gtgaacctac ccgactaaaa acaaacagcc aaccctttaa attggatccc 1620
aaaatgactc acaagaagtt gaagatctcc aatgatggat tgcagatgga gaaggatgaa 1680
agctctctaa agaagagcca caccccagag aggtttagtg gcacagggtg ctatggggca 1740
gcaggaaata tattcattga cagtggctgc cactattggg aggtggtcat gggttcctca 1800
acatggtatg caattggcat tgcctacaaa tcagctccaa agaatgaatg gattggcaag 1860
aatgcctcct catgggtctt ctctcgctgc aatagtaact tcgtggtgag acacaacaac 1920
aaggaaatgc tggtggatgt gcccccacac ctgaagcgtc tgggtgtcct cctggattat 1980
gacaacaata tgctgtcttt ctatgaccca gctaactctc tccatcttca tacttttgat 2040
gtgaccttca ttcttccagt ttgtccaaca tttacaatct ggaacaaatc cctaatgatc 2100
ctgtctggct tgcctgcccc agattttatt gattaccctg agcggcagga atgcaactgc 2160
aggcctcaag aatcccctta tgtttctggg atgaaaacct gtcattaa 2208
<210> 2
<211> 735
<212> PRT
<213> Homo sapiens
<400> 2
Met Gly Glu Ser Pro Ala Ser Val Val Leu Asn Ala Ser Gly Gly Leu
1 5 10 15
Phe Ser Leu Lys Met Glu Thr Leu Glu Ser Glu Leu Thr Cys Pro Ile
20 25 30
Cys Leu Glu Leu Phe Glu Asp Pro Leu Leu Leu Pro Cys Ala His Ser
35 40 45
Leu Cys Phe Ser Cys Ala His Arg Ile Leu Val Ser Ser Cys Ser Ser
50 55 60
Gly Glu Ser Ile Glu Pro Ile Thr Ala Phe Gln Cys Pro Thr Cys Arg
65 70 75 80
Tyr Val Ile Ser Leu Asn His Arg Gly Leu Asp Gly Leu Lys Arg Asn
85 90 95
Val Thr Leu Gln Asn Ile Ile Asp Arg Phe Gln Lys Ala Ser Val Ser
100 105 110
Gly Pro Asn Ser Pro Ser Glu Ser Arg Arg Glu Arg Thr Tyr Arg Pro
115 120 125
Thr Thr Ala Met Ser Ser Glu Arg Ile Ala Cys Gln Phe Cys Glu Gln
130 135 140
Asp Pro Pro Arg Asp Ala Val Lys Thr Cys Ile Thr Cys Glu Val Ser
145 150 155 160
Tyr Cys Asp Arg Cys Leu Arg Ala Thr His Pro Asn Lys Lys Pro Phe
165 170 175
Thr Ser His Arg Leu Val Glu Pro Val Pro Asp Thr His Leu Arg Gly
180 185 190
Ile Thr Cys Leu Asp His Glu Asn Glu Lys Val Asn Met Tyr Cys Val
195 200 205
Ser Asp Asp Gln Leu Ile Cys Ala Leu Cys Lys Leu Val Gly Arg His
210 215 220
Arg Asp His Gln Val Ala Ser Leu Asn Asp Arg Phe Glu Lys Leu Lys
225 230 235 240
Gln Thr Leu Glu Met Asn Leu Thr Asn Leu Val Lys Arg Asn Ser Glu
245 250 255
Leu Glu Asn Gln Met Ala Lys Leu Ile Gln Ile Cys Gln Gln Val Glu
260 265 270
Val Asn Thr Ala Met His Glu Ala Lys Leu Met Glu Glu Cys Asp Glu
275 280 285
Leu Val Glu Ile Ile Gln Gln Arg Lys Gln Met Ile Ala Val Lys Ile
290 295 300
Lys Glu Thr Lys Val Met Lys Leu Arg Lys Leu Ala Gln Gln Val Ala
305 310 315 320
Asn Cys Arg Gln Cys Leu Glu Arg Ser Thr Val Leu Ile Asn Gln Ala
325 330 335
Glu His Ile Leu Lys Glu Asn Asp Gln Ala Arg Phe Leu Gln Ser Ala
340 345 350
Lys Asn Ile Ala Glu Arg Val Ala Met Ala Thr Ala Ser Ser Gln Val
355 360 365
Leu Ile Pro Asp Ile Asn Phe Asn Asp Ala Phe Glu Asn Phe Ala Leu
370 375 380
Asp Phe Ser Arg Glu Lys Lys Leu Leu Glu Gly Leu Asp Tyr Leu Thr
385 390 395 400
Ala Pro Asn Pro Pro Ser Ile Arg Glu Glu Leu Cys Thr Ala Ser His
405 410 415
Asp Thr Ile Thr Val His Trp Ile Ser Asp Asp Glu Phe Ser Ile Ser
420 425 430
Ser Tyr Glu Leu Gln Tyr Thr Ile Phe Thr Gly Gln Ala Asn Phe Ile
435 440 445
Ser Lys Ser Trp Cys Ser Trp Gly Leu Trp Pro Glu Ile Arg Lys Cys
450 455 460
Lys Glu Ala Val Ser Cys Ser Arg Leu Ala Gly Ala Pro Arg Gly Leu
465 470 475 480
Tyr Asn Ser Val Asp Ser Trp Met Ile Val Pro Asn Ile Lys Gln Asn
485 490 495
His Tyr Thr Val His Gly Leu Gln Ser Gly Thr Arg Tyr Ile Phe Ile
500 505 510
Val Lys Ala Ile Asn Gln Ala Gly Ser Arg Asn Ser Glu Pro Thr Arg
515 520 525
Leu Lys Thr Asn Ser Gln Pro Phe Lys Leu Asp Pro Lys Met Thr His
530 535 540
Lys Lys Leu Lys Ile Ser Asn Asp Gly Leu Gln Met Glu Lys Asp Glu
545 550 555 560
Ser Ser Leu Lys Lys Ser His Thr Pro Glu Arg Phe Ser Gly Thr Gly
565 570 575
Cys Tyr Gly Ala Ala Gly Asn Ile Phe Ile Asp Ser Gly Cys His Tyr
580 585 590
Trp Glu Val Val Met Gly Ser Ser Thr Trp Tyr Ala Ile Gly Ile Ala
595 600 605
Tyr Lys Ser Ala Pro Lys Asn Glu Trp Ile Gly Lys Asn Ala Ser Ser
610 615 620
Trp Val Phe Ser Arg Cys Asn Ser Asn Phe Val Val Arg His Asn Asn
625 630 635 640
Lys Glu Met Leu Val Asp Val Pro Pro His Leu Lys Arg Leu Gly Val
645 650 655
Leu Leu Asp Tyr Asp Asn Asn Met Leu Ser Phe Tyr Asp Pro Ala Asn
660 665 670
Ser Leu His Leu His Thr Phe Asp Val Thr Phe Ile Leu Pro Val Cys
675 680 685
Pro Thr Phe Thr Ile Trp Asn Lys Ser Leu Met Ile Leu Ser Gly Leu
690 695 700
Pro Ala Pro Asp Phe Ile Asp Tyr Pro Glu Arg Gln Glu Cys Asn Cys
705 710 715 720
Arg Pro Gln Glu Ser Pro Tyr Val Ser Gly Met Lys Thr Cys His
725 730 735
<210> 3
<211> 2316
<212> DNA
<213> Homo sapiens
<400> 3
atgcacagga gtggccgtta tggaacgcag cagcagcgtg cagggtcaaa gacagccggc 60
cccccatgtc agtggtctag gatggccagt gaaggcacca acatcccaag tcctgtggtg 120
cgccagattg acaagcagtt tctgatttgc agtatatgcc tggaacggta caagaatccc 180
aaggttctcc cctgtctgca cactttctgc gagaggtgcc tgcagaacta cattcctgcc 240
cacagtttaa ccctctcctg cccagtgtgc cgccagacct ccatcctgcc cgagaaaggg 300
gtggccgcgc tccagaacaa tttcttcatc acaaacctga tggacgtgct gcagcgaact 360
ccaggcagca acgctgagga gtcttccatc ctggagacag tcactgctgt ggctgcggga 420
aagcctctct cttgcccaaa ccacgatggg aatgtgatgg aattttactg ccagtcctgt 480
gagactgcca tgtgtcggga gtgcacggag ggggagcacg cagagcaccc cacagttcca 540
ctcaaggatg tggtggaaca gcacaaggcc tcgctccagg tccagctgga tgctgtcaac 600
aaaaggctcc cagaaataga ttctgctctt cagttcatct ctgaaatcat tcatcagtta 660
accaaccaaa aggccagcat cgtggatgac attcattcca cctttgatga gctccagaag 720
actttaaatg tgcgcaagag tgtgctgctt atggaattgg aggtcaacta tggcctcaaa 780
cacaaagtcc tccagtcgca gctggatact ctgctccagg ggcaggagag cattaagagc 840
tgcagcaact tcacagcgca ggccctcaac catggcacgg agaccgaggt cctactggtg 900
aagaagcaga tgagcgagaa gctgaacgag ctggccgacc aggacttccc cttgcacccg 960
cgggagaacg accagctgga tttcatcgtg gaaaccgagg ggctgaagaa gtccatccac 1020
aacctcggga cgatcttaac caccaacgcc gttgcctcag agacagtggc cacgggcgag 1080
gggctgcggc agaccatcat cgggcagccc atgtccgtca ccatcaccac caaggacaaa 1140
gacggtgagc tgtgcaaaac cggcaacgcc tacctcaccg ccgaactgag cacccccgac 1200
gggagcgtgg cagacgggga gatcctggac aacaagaacg gcacctatga gtttttgtac 1260
actgtccaga aggaagggga ctttaccctg tctctgagac tctatgacca gcacatccga 1320
ggcagcccgt ttaagctgaa agtgatccga tccgctgatg tgtctcccac cacagaaggc 1380
gtgaagaggc gcgttaagtc cccggggagc ggccacgtca agcagaaagc tgtgaaaaga 1440
cccgcaagca tgtacagcac tggaaaacga aaagagaatc ccatcgaaga cgatttgatc 1500
tttcgagtgg gtaccaaagg aagaaataaa ggagagttta caaatcttca gggggtagct 1560
gcatctacaa atggaaagat attaattgca gacagtaaca accaatgtgt gcagatattt 1620
tccaatgatg gccagttcaa aagtcgtttt ggcatacggg gacgctctcc ggggcagctg 1680
cagcggccca caggagtggc tgtacatccc agtggggaca taatcattgc cgattatgat 1740
aataaatggg tcagcatttt ctcctccgat gggaaattta agacaaaaat tggatcagga 1800
aagctgatgg gacccaaagg agtttctgtg gaccgcaatg ggcacattat tgttgtggac 1860
aacaaggcgt gctgcgtgtt tatcttccag ccaaacggga aaatagtcac caggtttggt 1920
agccgaggaa atggggacag gcagtttgca ggtccccatt ttgcagctgt aaatagcaat 1980
aatgagatta ttattacaga tttccataat cattctgtca aggtgtttaa tcaggaagga 2040
gaattcatgt tgaagtttgg ctcaaatgga gaaggaaatg ggcagtttaa tgctccaaca 2100
ggtgtagcag tggattcaaa tggaaacatc attgtggccg actggggaaa cagcaggatc 2160
caggtttttg atgggagtgg atcatttttg tcctacatta acacatctgc tgacccactc 2220
tatggccccc aaggcctggc cctaacttca gatggtcatg ttgtggttgc agactctgga 2280
aatcactgtt tcaaagtcta tcgatactta cagtaa 2316
<210> 4
<211> 771
<212> PRT
<213> Homo sapiens
<400> 4
Met His Arg Ser Gly Arg Tyr Gly Thr Gln Gln Gln Arg Ala Gly Ser
1 5 10 15
Lys Thr Ala Gly Pro Pro Cys Gln Trp Ser Arg Met Ala Ser Glu Gly
20 25 30
Thr Asn Ile Pro Ser Pro Val Val Arg Gln Ile Asp Lys Gln Phe Leu
35 40 45
Ile Cys Ser Ile Cys Leu Glu Arg Tyr Lys Asn Pro Lys Val Leu Pro
50 55 60
Cys Leu His Thr Phe Cys Glu Arg Cys Leu Gln Asn Tyr Ile Pro Ala
65 70 75 80
His Ser Leu Thr Leu Ser Cys Pro Val Cys Arg Gln Thr Ser Ile Leu
85 90 95
Pro Glu Lys Gly Val Ala Ala Leu Gln Asn Asn Phe Phe Ile Thr Asn
100 105 110
Leu Met Asp Val Leu Gln Arg Thr Pro Gly Ser Asn Ala Glu Glu Ser
115 120 125
Ser Ile Leu Glu Thr Val Thr Ala Val Ala Ala Gly Lys Pro Leu Ser
130 135 140
Cys Pro Asn His Asp Gly Asn Val Met Glu Phe Tyr Cys Gln Ser Cys
145 150 155 160
Glu Thr Ala Met Cys Arg Glu Cys Thr Glu Gly Glu His Ala Glu His
165 170 175
Pro Thr Val Pro Leu Lys Asp Val Val Glu Gln His Lys Ala Ser Leu
180 185 190
Gln Val Gln Leu Asp Ala Val Asn Lys Arg Leu Pro Glu Ile Asp Ser
195 200 205
Ala Leu Gln Phe Ile Ser Glu Ile Ile His Gln Leu Thr Asn Gln Lys
210 215 220
Ala Ser Ile Val Asp Asp Ile His Ser Thr Phe Asp Glu Leu Gln Lys
225 230 235 240
Thr Leu Asn Val Arg Lys Ser Val Leu Leu Met Glu Leu Glu Val Asn
245 250 255
Tyr Gly Leu Lys His Lys Val Leu Gln Ser Gln Leu Asp Thr Leu Leu
260 265 270
Gln Gly Gln Glu Ser Ile Lys Ser Cys Ser Asn Phe Thr Ala Gln Ala
275 280 285
Leu Asn His Gly Thr Glu Thr Glu Val Leu Leu Val Lys Lys Gln Met
290 295 300
Ser Glu Lys Leu Asn Glu Leu Ala Asp Gln Asp Phe Pro Leu His Pro
305 310 315 320
Arg Glu Asn Asp Gln Leu Asp Phe Ile Val Glu Thr Glu Gly Leu Lys
325 330 335
Lys Ser Ile His Asn Leu Gly Thr Ile Leu Thr Thr Asn Ala Val Ala
340 345 350
Ser Glu Thr Val Ala Thr Gly Glu Gly Leu Arg Gln Thr Ile Ile Gly
355 360 365
Gln Pro Met Ser Val Thr Ile Thr Thr Lys Asp Lys Asp Gly Glu Leu
370 375 380
Cys Lys Thr Gly Asn Ala Tyr Leu Thr Ala Glu Leu Ser Thr Pro Asp
385 390 395 400
Gly Ser Val Ala Asp Gly Glu Ile Leu Asp Asn Lys Asn Gly Thr Tyr
405 410 415
Glu Phe Leu Tyr Thr Val Gln Lys Glu Gly Asp Phe Thr Leu Ser Leu
420 425 430
Arg Leu Tyr Asp Gln His Ile Arg Gly Ser Pro Phe Lys Leu Lys Val
435 440 445
Ile Arg Ser Ala Asp Val Ser Pro Thr Thr Glu Gly Val Lys Arg Arg
450 455 460
Val Lys Ser Pro Gly Ser Gly His Val Lys Gln Lys Ala Val Lys Arg
465 470 475 480
Pro Ala Ser Met Tyr Ser Thr Gly Lys Arg Lys Glu Asn Pro Ile Glu
485 490 495
Asp Asp Leu Ile Phe Arg Val Gly Thr Lys Gly Arg Asn Lys Gly Glu
500 505 510
Phe Thr Asn Leu Gln Gly Val Ala Ala Ser Thr Asn Gly Lys Ile Leu
515 520 525
Ile Ala Asp Ser Asn Asn Gln Cys Val Gln Ile Phe Ser Asn Asp Gly
530 535 540
Gln Phe Lys Ser Arg Phe Gly Ile Arg Gly Arg Ser Pro Gly Gln Leu
545 550 555 560
Gln Arg Pro Thr Gly Val Ala Val His Pro Ser Gly Asp Ile Ile Ile
565 570 575
Ala Asp Tyr Asp Asn Lys Trp Val Ser Ile Phe Ser Ser Asp Gly Lys
580 585 590
Phe Lys Thr Lys Ile Gly Ser Gly Lys Leu Met Gly Pro Lys Gly Val
595 600 605
Ser Val Asp Arg Asn Gly His Ile Ile Val Val Asp Asn Lys Ala Cys
610 615 620
Cys Val Phe Ile Phe Gln Pro Asn Gly Lys Ile Val Thr Arg Phe Gly
625 630 635 640
Ser Arg Gly Asn Gly Asp Arg Gln Phe Ala Gly Pro His Phe Ala Ala
645 650 655
Val Asn Ser Asn Asn Glu Ile Ile Ile Thr Asp Phe His Asn His Ser
660 665 670
Val Lys Val Phe Asn Gln Glu Gly Glu Phe Met Leu Lys Phe Gly Ser
675 680 685
Asn Gly Glu Gly Asn Gly Gln Phe Asn Ala Pro Thr Gly Val Ala Val
690 695 700
Asp Ser Asn Gly Asn Ile Ile Val Ala Asp Trp Gly Asn Ser Arg Ile
705 710 715 720
Gln Val Phe Asp Gly Ser Gly Ser Phe Leu Ser Tyr Ile Asn Thr Ser
725 730 735
Ala Asp Pro Leu Tyr Gly Pro Gln Gly Leu Ala Leu Thr Ser Asp Gly
740 745 750
His Val Val Val Ala Asp Ser Gly Asn His Cys Phe Lys Val Tyr Arg
755 760 765
Tyr Leu Gln
770
<210> 5
<211> 2235
<212> DNA
<213> Homo sapiens
<400> 5
atggcaaaga gggaggacag ccctggccca gaggtccagc caatggacaa gcagttcctg 60
gtatgcagca tctgcctgga tcggtaccag tgccccaagg ttcttccttg cctgcacacc 120
ttctgtgaga gatgtctcca aaactatatc cctgcccaga gcctgacgct atcctgtcca 180
gtatgccggc agacgtccat cctcccagag cagggcgtct cggcactgca gaacaacttc 240
ttcatcagca gcctcatgga ggcaatgcag caggcacctg atggggccca cgacccggag 300
gacccccacc ccctcagtgt agtggctggc cgccctctct cctgccccaa ccatgaaggc 360
aagacgatgg agttttactg tgaggcctgt gagacggcca tgtgtggtga gtgccgcgcc 420
ggggagcatc gtgagcatgg cacagtgctg ctgagggatg tggtggagca gcacaaggcg 480
gccctgcagc gccagctcga ggctgtgcgt ggccgattgc cacagctgtc cgcagcaatt 540
gccttagtcg ggggcatcag ccagcagctg caggagcgca aggcagaggc cctggcccag 600
atcagtgcag cgttcgagga cctggagcaa gcactgcagc agcgcaagca ggctctggtc 660
agcgacctgg agaccatttg tggggccaaa cagaaggtgt tgcaaagcca gctggacaca 720
ctgcgccagg gtcaggaaca catcggcagt agctgcagct ttgcagagca ggcactgcgc 780
ctgggctcgg ccccggaggt gttgctggtg cgcaagcaca tgcgagagcg gctggctgca 840
ttggcggcac aggccttccc ggagcggcca catgagaatg cacagctgga actggtcctt 900
gaggtggacg gtctgcggcg atcggtgctc aatctgggcg cactgctcac cacgagcgcc 960
actgcacacg aaacggtggc cacgggagag ggcctgcgcc aggcgctagt gggccagcct 1020
gcctcgctca ctgtcactac caaagacaag gacgggcggt tggtgcgcac aggcagcgct 1080
gagctgcgtg cagagatcac cggcccggac ggcacgcgcc ttccggtgcc agtggtggac 1140
cacaagaatg gcacatatga gctagtgtac acagcgcgca cggaaggcga gctgctcctc 1200
tcggtgctgc tctacggaca gccagtgcgc ggcagcccct tccgcgtgcg tgccctgcgt 1260
ccgggggacc tgccaccttc cccggacgat gtgaagcgcc gtgtcaagtc ccctggcggc 1320
cccggcagcc atgtgcgcca gaaggcagtg cgtaggccca gctccatgta cagcacaggc 1380
ggcaaacgaa aggacaaccc aattgaggat gagctcgtct tccgtgttgg cagtcgtgga 1440
agggagaaag gtgaattcac caatttacaa ggtgtgtccg cagccagcag cggccgcatc 1500
gtggtagcag acagcaacaa ccagtgtatt caggttttct ccaatgaggg ccagttcaag 1560
ttccgttttg gggtccgagg acgctcacct gggcagctgc agcgccccac aggtgtggca 1620
gtggacacca atggagacat aattgtggca gactatgaca accgttgggt cagcatcttc 1680
tcccctgagg gcaagttcaa gaccaagatt ggagctggcc gcctcatggg ccccaaggga 1740
gtggccgtag accggaatgg acatatcatt gtggtcgaca acaagtcttg ctgcgtcttt 1800
accttccagc ccaatggcaa actggttggc cgttttgggg gccgtggggc cactgaccgc 1860
cactttgcag ggccccattt tgtggctgtg aacaacaaga atgaaattgt agtaacggac 1920
ttccataacc attcagtgaa ggtgtacagt gccgatggag agttcctctt caagtttggc 1980
tcccatggcg agggcaatgg gcagttcaat gcccccacag gagtagctgt ggactccaat 2040
ggaaacatca ttgtggctga ctggggcaac agccgcatcc aggtattcga cagctctggc 2100
tccttcctgt cctatatcaa cacatctgca gaaccactgt atggtccaca gggcctggca 2160
ctgacctcgg atggccatgt ggtggtggct gatgctggca accactgctt taaagcctat 2220
cgctacctcc agtag 2235
<210> 6
<211> 744
<212> PRT
<213> Homo sapiens
<400> 6
Met Ala Lys Arg Glu Asp Ser Pro Gly Pro Glu Val Gln Pro Met Asp
1 5 10 15
Lys Gln Phe Leu Val Cys Ser Ile Cys Leu Asp Arg Tyr Gln Cys Pro
20 25 30
Lys Val Leu Pro Cys Leu His Thr Phe Cys Glu Arg Cys Leu Gln Asn
35 40 45
Tyr Ile Pro Ala Gln Ser Leu Thr Leu Ser Cys Pro Val Cys Arg Gln
50 55 60
Thr Ser Ile Leu Pro Glu Gln Gly Val Ser Ala Leu Gln Asn Asn Phe
65 70 75 80
Phe Ile Ser Ser Leu Met Glu Ala Met Gln Gln Ala Pro Asp Gly Ala
85 90 95
His Asp Pro Glu Asp Pro His Pro Leu Ser Val Val Ala Gly Arg Pro
100 105 110
Leu Ser Cys Pro Asn His Glu Gly Lys Thr Met Glu Phe Tyr Cys Glu
115 120 125
Ala Cys Glu Thr Ala Met Cys Gly Glu Cys Arg Ala Gly Glu His Arg
130 135 140
Glu His Gly Thr Val Leu Leu Arg Asp Val Val Glu Gln His Lys Ala
145 150 155 160
Ala Leu Gln Arg Gln Leu Glu Ala Val Arg Gly Arg Leu Pro Gln Leu
165 170 175
Ser Ala Ala Ile Ala Leu Val Gly Gly Ile Ser Gln Gln Leu Gln Glu
180 185 190
Arg Lys Ala Glu Ala Leu Ala Gln Ile Ser Ala Ala Phe Glu Asp Leu
195 200 205
Glu Gln Ala Leu Gln Gln Arg Lys Gln Ala Leu Val Ser Asp Leu Glu
210 215 220
Thr Ile Cys Gly Ala Lys Gln Lys Val Leu Gln Ser Gln Leu Asp Thr
225 230 235 240
Leu Arg Gln Gly Gln Glu His Ile Gly Ser Ser Cys Ser Phe Ala Glu
245 250 255
Gln Ala Leu Arg Leu Gly Ser Ala Pro Glu Val Leu Leu Val Arg Lys
260 265 270
His Met Arg Glu Arg Leu Ala Ala Leu Ala Ala Gln Ala Phe Pro Glu
275 280 285
Arg Pro His Glu Asn Ala Gln Leu Glu Leu Val Leu Glu Val Asp Gly
290 295 300
Leu Arg Arg Ser Val Leu Asn Leu Gly Ala Leu Leu Thr Thr Ser Ala
305 310 315 320
Thr Ala His Glu Thr Val Ala Thr Gly Glu Gly Leu Arg Gln Ala Leu
325 330 335
Val Gly Gln Pro Ala Ser Leu Thr Val Thr Thr Lys Asp Lys Asp Gly
340 345 350
Arg Leu Val Arg Thr Gly Ser Ala Glu Leu Arg Ala Glu Ile Thr Gly
355 360 365
Pro Asp Gly Thr Arg Leu Pro Val Pro Val Val Asp His Lys Asn Gly
370 375 380
Thr Tyr Glu Leu Val Tyr Thr Ala Arg Thr Glu Gly Glu Leu Leu Leu
385 390 395 400
Ser Val Leu Leu Tyr Gly Gln Pro Val Arg Gly Ser Pro Phe Arg Val
405 410 415
Arg Ala Leu Arg Pro Gly Asp Leu Pro Pro Ser Pro Asp Asp Val Lys
420 425 430
Arg Arg Val Lys Ser Pro Gly Gly Pro Gly Ser His Val Arg Gln Lys
435 440 445
Ala Val Arg Arg Pro Ser Ser Met Tyr Ser Thr Gly Gly Lys Arg Lys
450 455 460
Asp Asn Pro Ile Glu Asp Glu Leu Val Phe Arg Val Gly Ser Arg Gly
465 470 475 480
Arg Glu Lys Gly Glu Phe Thr Asn Leu Gln Gly Val Ser Ala Ala Ser
485 490 495
Ser Gly Arg Ile Val Val Ala Asp Ser Asn Asn Gln Cys Ile Gln Val
500 505 510
Phe Ser Asn Glu Gly Gln Phe Lys Phe Arg Phe Gly Val Arg Gly Arg
515 520 525
Ser Pro Gly Gln Leu Gln Arg Pro Thr Gly Val Ala Val Asp Thr Asn
530 535 540
Gly Asp Ile Ile Val Ala Asp Tyr Asp Asn Arg Trp Val Ser Ile Phe
545 550 555 560
Ser Pro Glu Gly Lys Phe Lys Thr Lys Ile Gly Ala Gly Arg Leu Met
565 570 575
Gly Pro Lys Gly Val Ala Val Asp Arg Asn Gly His Ile Ile Val Val
580 585 590
Asp Asn Lys Ser Cys Cys Val Phe Thr Phe Gln Pro Asn Gly Lys Leu
595 600 605
Val Gly Arg Phe Gly Gly Arg Gly Ala Thr Asp Arg His Phe Ala Gly
610 615 620
Pro His Phe Val Ala Val Asn Asn Lys Asn Glu Ile Val Val Thr Asp
625 630 635 640
Phe His Asn His Ser Val Lys Val Tyr Ser Ala Asp Gly Glu Phe Leu
645 650 655
Phe Lys Phe Gly Ser His Gly Glu Gly Asn Gly Gln Phe Asn Ala Pro
660 665 670
Thr Gly Val Ala Val Asp Ser Asn Gly Asn Ile Ile Val Ala Asp Trp
675 680 685
Gly Asn Ser Arg Ile Gln Val Phe Asp Ser Ser Gly Ser Phe Leu Ser
690 695 700
Tyr Ile Asn Thr Ser Ala Glu Pro Leu Tyr Gly Pro Gln Gly Leu Ala
705 710 715 720
Leu Thr Ser Asp Gly His Val Val Val Ala Asp Ala Gly Asn His Cys
725 730 735
Phe Lys Ala Tyr Arg Tyr Leu Gln
740
<210> 7
<211> 1503
<212> DNA
<213> Homo sapiens
<400> 7
atggaagctg aggacatcca ggaggagttg acctgcccca tctgcctgga ctatttccag 60
gacccggtgt ccatcgagtg cggccacaac ttctgccgcg gctgcctgca ccgcaactgg 120
gcgccgggcg gcggcccgtt cccctgcccc gaatgtcggc acccatcggc gcccgccgcg 180
ctgcgaccca actgggccct ggccaggctg actgagaaga cgcagcgccg gcgcctgggc 240
cccgtgcccc cgggcctgtg cggccgccac tgggagccgc tgcggctctt ctgcgaggac 300
gaccagcggc cagtgtgcct ggtgtgcagg gagtcccagg agcaccagac tcacgccatg 360
gcacccatcg acgaggcctt cgagagctac cggacaggta actttgacat ccacgtggat 420
gaatggaaga gaagactaat taggctgctc ttgtaccatt ttaagcagga ggagaaactt 480
cttaagtctc agcgtaatct cgtggccaag atgaagaaag tcatgcattt acaggatgta 540
gaagtgaaga acgccacaca gtggaaggat aagataaaga gtcagcgaat gagaatcagc 600
acggagtttt caaagctgca caacttcctg gttgaagaag aggacctgtt tcttcagaga 660
ttgaacaaag aagaagaaga gacgaagaag aagctgaatg agaacacgtt aaaactcaat 720
caaactatcg cttcattgaa gaagctcatc ttagaggtgg gggagaagag ccaggctccc 780
accctggagc tgcttcagaa tccaaaagaa gtgttgacca ggagtgagat ccaggatgtg 840
aactattctc ttgaagctgt aaaggtgaag acagtgtgcc agataccatt gatgaaggaa 900
atgctaaagc gattccaagt ggctgtaaac ctagctgaag acacagctca tcccaaactc 960
gtcttctccc aggaagggag atacgtgaaa aatacagcat cagccagttc ttggccagtg 1020
ttttcttcag catggaacta ctttgctgga tggaggaatc ctcagaagac tgcttttgta 1080
gagagatttc agcacttacc ctgtgttctg ggaaaaaacg ttttcacctc agggaaacat 1140
tactgggaag ttgagagtag agatagtctg gaggttgctg ttggggtgtg tcgggaggac 1200
gtcatgggaa ttactgatcg ttcaaaaatg tccccagatg tgggcatctg ggcgatttat 1260
tggagtgctg ctggctattg gcccttgata ggcttccctg gaactcccac ccagcaagag 1320
ccagctctcc accgagtggg ggtttacctg gatcgtggga ctgggaatgt ctccttctac 1380
agcgctgtgg acggagtgca cctgcacacc ttttcttgtt cttctgtctc acgcctccgg 1440
ccattttttt ggttgagtcc attagcatct ttagtcattc caccagtgac tgataggaaa 1500
tga 1503
<210> 8
<211> 500
<212> PRT
<213> Homo sapiens
<400> 8
Met Glu Ala Glu Asp Ile Gln Glu Glu Leu Thr Cys Pro Ile Cys Leu
1 5 10 15
Asp Tyr Phe Gln Asp Pro Val Ser Ile Glu Cys Gly His Asn Phe Cys
20 25 30
Arg Gly Cys Leu His Arg Asn Trp Ala Pro Gly Gly Gly Pro Phe Pro
35 40 45
Cys Pro Glu Cys Arg His Pro Ser Ala Pro Ala Ala Leu Arg Pro Asn
50 55 60
Trp Ala Leu Ala Arg Leu Thr Glu Lys Thr Gln Arg Arg Arg Leu Gly
65 70 75 80
Pro Val Pro Pro Gly Leu Cys Gly Arg His Trp Glu Pro Leu Arg Leu
85 90 95
Phe Cys Glu Asp Asp Gln Arg Pro Val Cys Leu Val Cys Arg Glu Ser
100 105 110
Gln Glu His Gln Thr His Ala Met Ala Pro Ile Asp Glu Ala Phe Glu
115 120 125
Ser Tyr Arg Thr Gly Asn Phe Asp Ile His Val Asp Glu Trp Lys Arg
130 135 140
Arg Leu Ile Arg Leu Leu Leu Tyr His Phe Lys Gln Glu Glu Lys Leu
145 150 155 160
Leu Lys Ser Gln Arg Asn Leu Val Ala Lys Met Lys Lys Val Met His
165 170 175
Leu Gln Asp Val Glu Val Lys Asn Ala Thr Gln Trp Lys Asp Lys Ile
180 185 190
Lys Ser Gln Arg Met Arg Ile Ser Thr Glu Phe Ser Lys Leu His Asn
195 200 205
Phe Leu Val Glu Glu Glu Asp Leu Phe Leu Gln Arg Leu Asn Lys Glu
210 215 220
Glu Glu Glu Thr Lys Lys Lys Leu Asn Glu Asn Thr Leu Lys Leu Asn
225 230 235 240
Gln Thr Ile Ala Ser Leu Lys Lys Leu Ile Leu Glu Val Gly Glu Lys
245 250 255
Ser Gln Ala Pro Thr Leu Glu Leu Leu Gln Asn Pro Lys Glu Val Leu
260 265 270
Thr Arg Ser Glu Ile Gln Asp Val Asn Tyr Ser Leu Glu Ala Val Lys
275 280 285
Val Lys Thr Val Cys Gln Ile Pro Leu Met Lys Glu Met Leu Lys Arg
290 295 300
Phe Gln Val Ala Val Asn Leu Ala Glu Asp Thr Ala His Pro Lys Leu
305 310 315 320
Val Phe Ser Gln Glu Gly Arg Tyr Val Lys Asn Thr Ala Ser Ala Ser
325 330 335
Ser Trp Pro Val Phe Ser Ser Ala Trp Asn Tyr Phe Ala Gly Trp Arg
340 345 350
Asn Pro Gln Lys Thr Ala Phe Val Glu Arg Phe Gln His Leu Pro Cys
355 360 365
Val Leu Gly Lys Asn Val Phe Thr Ser Gly Lys His Tyr Trp Glu Val
370 375 380
Glu Ser Arg Asp Ser Leu Glu Val Ala Val Gly Val Cys Arg Glu Asp
385 390 395 400
Val Met Gly Ile Thr Asp Arg Ser Lys Met Ser Pro Asp Val Gly Ile
405 410 415
Trp Ala Ile Tyr Trp Ser Ala Ala Gly Tyr Trp Pro Leu Ile Gly Phe
420 425 430
Pro Gly Thr Pro Thr Gln Gln Glu Pro Ala Leu His Arg Val Gly Val
435 440 445
Tyr Leu Asp Arg Gly Thr Gly Asn Val Ser Phe Tyr Ser Ala Val Asp
450 455 460
Gly Val His Leu His Thr Phe Ser Cys Ser Ser Val Ser Arg Leu Arg
465 470 475 480
Pro Phe Phe Trp Leu Ser Pro Leu Ala Ser Leu Val Ile Pro Pro Val
485 490 495
Thr Asp Arg Lys
500
<210> 9
<211> 1482
<212> DNA
<213> Homo sapiens
<400> 9
atggcttctg gaatcctggt taatgtaaag gaggaggtga cctgccccat ctgcctggaa 60
ctcctgacac aacccctgag cctggactgc ggccacagct tctgccaagc atgcctcact 120
gcaaaccaca agaagtccat gctagacaaa ggagagagta gctgccctgt gtgccggatc 180
agttaccagc ctgagaacat acggcctaat cggcatgtag ccaacatagt ggagaagctc 240
agggaggtca agttgagccc agaggggcag aaagttgatc attgtgcacg ccatggagag 300
aaacttctac tcttctgtca ggaggacggg aaggtcattt gctggctttg tgagcggtct 360
caggagcacc gtggtcacca cacgttcctc acagaggagg ttgcccggga gtaccaagtg 420
aagctccagg cagctctgga gatgctgagg cagaagcagc aggaagctga agagttagaa 480
gctgacatca gagaagagaa agcttcctgg aagactcaaa tacagtatga caaaaccaac 540
gtcttggcag attttgagca actgagagac atcctggact gggaggagag caatgagctg 600
caaaacctgg agaaggagga ggaagacatt ctgaaaagcc ttacgaactc tgaaactgag 660
atggtgcagc agacccagtc cctgagagag ctcatctcag atctggagca tcggctgcag 720
gggtcagtga tggagctgct tcagggtgtg gatggcgtca taaaaaggac ggagaacgtg 780
accttgaaga agccagaaac ttttccaaaa aatcaaagga gagtgtttcg agctcctgat 840
ctgaaaggaa tgctagaagt gtttagagag ctgacagatg tccgacgcta ctgggttgat 900
gtgacagtgg ctccaaacaa catttcatgt gctgtcattt ctgaagataa gagacaagtg 960
agctctccga aaccacagat aatatatggg gcacgaggga caagatacca gacatttgtg 1020
aatttcaatt attgtactgg catcctgggc tctcaaagta tcacatcagg gaaacattac 1080
tgggaggtag acgtgtccaa gaaaactgct tggatcctgg gggtatgtgc tggcttccaa 1140
cctgatgcaa tgtgtaatat tgaaaaaaat gaaaattatc aacctaaata cggctactgg 1200
gttatagggt tagaggaagg agttaaatgt agtgctttcc aggatagttc cttccatact 1260
ccttctgttc ctttcattgt gcccctctct gtgattattt gtcctgatcg tgttggagtt 1320
ttcctagact atgaggcttg cactgtctca ttcttcaata tcacaaacca tggatttctc 1380
atctataagt tttctcactg ttctttttct cagcctgtat ttccatattt aaatcctaga 1440
aaatgtggag tccccatgac tctgtgctca ccaagctctt ga 1482
<210> 10
<211> 493
<212> PRT
<213> Homo sapiens
<400> 10
Met Ala Ser Gly Ile Leu Val Asn Val Lys Glu Glu Val Thr Cys Pro
1 5 10 15
Ile Cys Leu Glu Leu Leu Thr Gln Pro Leu Ser Leu Asp Cys Gly His
20 25 30
Ser Phe Cys Gln Ala Cys Leu Thr Ala Asn His Lys Lys Ser Met Leu
35 40 45
Asp Lys Gly Glu Ser Ser Cys Pro Val Cys Arg Ile Ser Tyr Gln Pro
50 55 60
Glu Asn Ile Arg Pro Asn Arg His Val Ala Asn Ile Val Glu Lys Leu
65 70 75 80
Arg Glu Val Lys Leu Ser Pro Glu Gly Gln Lys Val Asp His Cys Ala
85 90 95
Arg His Gly Glu Lys Leu Leu Leu Phe Cys Gln Glu Asp Gly Lys Val
100 105 110
Ile Cys Trp Leu Cys Glu Arg Ser Gln Glu His Arg Gly His His Thr
115 120 125
Phe Leu Thr Glu Glu Val Ala Arg Glu Tyr Gln Val Lys Leu Gln Ala
130 135 140
Ala Leu Glu Met Leu Arg Gln Lys Gln Gln Glu Ala Glu Glu Leu Glu
145 150 155 160
Ala Asp Ile Arg Glu Glu Lys Ala Ser Trp Lys Thr Gln Ile Gln Tyr
165 170 175
Asp Lys Thr Asn Val Leu Ala Asp Phe Glu Gln Leu Arg Asp Ile Leu
180 185 190
Asp Trp Glu Glu Ser Asn Glu Leu Gln Asn Leu Glu Lys Glu Glu Glu
195 200 205
Asp Ile Leu Lys Ser Leu Thr Asn Ser Glu Thr Glu Met Val Gln Gln
210 215 220
Thr Gln Ser Leu Arg Glu Leu Ile Ser Asp Leu Glu His Arg Leu Gln
225 230 235 240
Gly Ser Val Met Glu Leu Leu Gln Gly Val Asp Gly Val Ile Lys Arg
245 250 255
Thr Glu Asn Val Thr Leu Lys Lys Pro Glu Thr Phe Pro Lys Asn Gln
260 265 270
Arg Arg Val Phe Arg Ala Pro Asp Leu Lys Gly Met Leu Glu Val Phe
275 280 285
Arg Glu Leu Thr Asp Val Arg Arg Tyr Trp Val Asp Val Thr Val Ala
290 295 300
Pro Asn Asn Ile Ser Cys Ala Val Ile Ser Glu Asp Lys Arg Gln Val
305 310 315 320
Ser Ser Pro Lys Pro Gln Ile Ile Tyr Gly Ala Arg Gly Thr Arg Tyr
325 330 335
Gln Thr Phe Val Asn Phe Asn Tyr Cys Thr Gly Ile Leu Gly Ser Gln
340 345 350
Ser Ile Thr Ser Gly Lys His Tyr Trp Glu Val Asp Val Ser Lys Lys
355 360 365
Thr Ala Trp Ile Leu Gly Val Cys Ala Gly Phe Gln Pro Asp Ala Met
370 375 380
Cys Asn Ile Glu Lys Asn Glu Asn Tyr Gln Pro Lys Tyr Gly Tyr Trp
385 390 395 400
Val Ile Gly Leu Glu Glu Gly Val Lys Cys Ser Ala Phe Gln Asp Ser
405 410 415
Ser Phe His Thr Pro Ser Val Pro Phe Ile Val Pro Leu Ser Val Ile
420 425 430
Ile Cys Pro Asp Arg Val Gly Val Phe Leu Asp Tyr Glu Ala Cys Thr
435 440 445
Val Ser Phe Phe Asn Ile Thr Asn His Gly Phe Leu Ile Tyr Lys Phe
450 455 460
Ser His Cys Ser Phe Ser Gln Pro Val Phe Pro Tyr Leu Asn Pro Arg
465 470 475 480
Lys Cys Gly Val Pro Met Thr Leu Cys Ser Pro Ser Ser
485 490
<210> 11
<211> 1551
<212> DNA
<213> Homo sapiens
<400> 11
atgtgcgggt cagagaggat tctacaggca ggaaacatct tagaaatcag ggttgggcag 60
gcaggagcca ggagagtagc tacaatgact tcaccagtac tggtggacat acgagaagag 120
gtgacctgcc ctatctgcct ggagctccta acagaacccc tgagcataga ctgtggccac 180
agcttctgcc aagcctgcat cacaccaaat ggcagggaat cagtgattgg tcaagaaggg 240
gaaagaagct gccctgtgtg ccagaccagc taccagccag ggaacctgcg gcctaatcgg 300
catctggcca acatagtgag gcggctcaga gaggtagtgt tgggccctgg gaagcagctg 360
aaagcagttc tttgtgcaga ccatggagaa aaactgcagc tcttctgtca ggaggatggg 420
aaggtcattt gctggctttg tgagcggtct caggagcacc gtggtcacca cacgttcctc 480
gtggaggagg ttgcccagga gtaccaggag aagtttcagg agtctctaaa gaagctgaag 540
aacgaggagc aggaagctga gaagctaaca gcttttatca gagagaagaa aacatcctgg 600
aagaatcaga tggagcctga gagatgcagg atccagacag agtttaatca gctgcgaaat 660
atcctagaca gagtggagca acgggagctg aaaaagctgg aacaggaaga gaagaagggg 720
ctacgaatta tagaagaggc tgagaatgat ctggtccacc agacccagtc gctgcgagag 780
ctcatctcgg atctggagcg tcgatgtcag gggtcaacaa tggagctgct gcaggatgtg 840
agtgatgtca cagaaaggag tgagttctgg accctgagga agccagaagc tctccctaca 900
aagctgagaa gtatgttccg agccccagat ctgaaaagga tgctgcgagt gtgtagagag 960
ctgacagatg tccaaagcta ctgggttgac gtgaccctga atccacacac agctaattta 1020
aatcttgtcc tggctaaaaa ccggagacaa gtgaggtttg tgggagctaa agtatctgga 1080
ccttcctgtc tggaaaagca ttatgactgt agtgtcctgg gctcccagca cttctcctct 1140
ggtaagcatt actgggaggt agatgtggcc aagaagactg cctggatcct gggggtatgc 1200
agcaattcac tgggacctac attctctttc aaccattttg ctcaaaatca cagtgcttac 1260
tccaggtatc agcctcagag tggatactgg gtgattgggt tacagcataa ccatgaatat 1320
agggcctatg aggattcttc cccttccctg cttctctcca tgacagtgcc ccctcgccgt 1380
gttggggttt tcttagatta tgaggctggt actgtctcct tttataatgt cacaaaccat 1440
ggcttcccca tctacacttt ctctaaatat tactttccca ctactctttg tccatatttt 1500
aatccttgca actgtgtaat tcctatgacc ctgcgtcgtc caagctcttg a 1551
<210> 12
<211> 516
<212> PRT
<213> Homo sapiens
<400> 12
Met Cys Gly Ser Glu Arg Ile Leu Gln Ala Gly Asn Ile Leu Glu Ile
1 5 10 15
Arg Val Gly Gln Ala Gly Ala Arg Arg Val Ala Thr Met Thr Ser Pro
20 25 30
Val Leu Val Asp Ile Arg Glu Glu Val Thr Cys Pro Ile Cys Leu Glu
35 40 45
Leu Leu Thr Glu Pro Leu Ser Ile Asp Cys Gly His Ser Phe Cys Gln
50 55 60
Ala Cys Ile Thr Pro Asn Gly Arg Glu Ser Val Ile Gly Gln Glu Gly
65 70 75 80
Glu Arg Ser Cys Pro Val Cys Gln Thr Ser Tyr Gln Pro Gly Asn Leu
85 90 95
Arg Pro Asn Arg His Leu Ala Asn Ile Val Arg Arg Leu Arg Glu Val
100 105 110
Val Leu Gly Pro Gly Lys Gln Leu Lys Ala Val Leu Cys Ala Asp His
115 120 125
Gly Glu Lys Leu Gln Leu Phe Cys Gln Glu Asp Gly Lys Val Ile Cys
130 135 140
Trp Leu Cys Glu Arg Ser Gln Glu His Arg Gly His His Thr Phe Leu
145 150 155 160
Val Glu Glu Val Ala Gln Glu Tyr Gln Glu Lys Phe Gln Glu Ser Leu
165 170 175
Lys Lys Leu Lys Asn Glu Glu Gln Glu Ala Glu Lys Leu Thr Ala Phe
180 185 190
Ile Arg Glu Lys Lys Thr Ser Trp Lys Asn Gln Met Glu Pro Glu Arg
195 200 205
Cys Arg Ile Gln Thr Glu Phe Asn Gln Leu Arg Asn Ile Leu Asp Arg
210 215 220
Val Glu Gln Arg Glu Leu Lys Lys Leu Glu Gln Glu Glu Lys Lys Gly
225 230 235 240
Leu Arg Ile Ile Glu Glu Ala Glu Asn Asp Leu Val His Gln Thr Gln
245 250 255
Ser Leu Arg Glu Leu Ile Ser Asp Leu Glu Arg Arg Cys Gln Gly Ser
260 265 270
Thr Met Glu Leu Leu Gln Asp Val Ser Asp Val Thr Glu Arg Ser Glu
275 280 285
Phe Trp Thr Leu Arg Lys Pro Glu Ala Leu Pro Thr Lys Leu Arg Ser
290 295 300
Met Phe Arg Ala Pro Asp Leu Lys Arg Met Leu Arg Val Cys Arg Glu
305 310 315 320
Leu Thr Asp Val Gln Ser Tyr Trp Val Asp Val Thr Leu Asn Pro His
325 330 335
Thr Ala Asn Leu Asn Leu Val Leu Ala Lys Asn Arg Arg Gln Val Arg
340 345 350
Phe Val Gly Ala Lys Val Ser Gly Pro Ser Cys Leu Glu Lys His Tyr
355 360 365
Asp Cys Ser Val Leu Gly Ser Gln His Phe Ser Ser Gly Lys His Tyr
370 375 380
Trp Glu Val Asp Val Ala Lys Lys Thr Ala Trp Ile Leu Gly Val Cys
385 390 395 400
Ser Asn Ser Leu Gly Pro Thr Phe Ser Phe Asn His Phe Ala Gln Asn
405 410 415
His Ser Ala Tyr Ser Arg Tyr Gln Pro Gln Ser Gly Tyr Trp Val Ile
420 425 430
Gly Leu Gln His Asn His Glu Tyr Arg Ala Tyr Glu Asp Ser Ser Pro
435 440 445
Ser Leu Leu Leu Ser Met Thr Val Pro Pro Arg Arg Val Gly Val Phe
450 455 460
Leu Asp Tyr Glu Ala Gly Thr Val Ser Phe Tyr Asn Val Thr Asn His
465 470 475 480
Gly Phe Pro Ile Tyr Thr Phe Ser Lys Tyr Tyr Phe Pro Thr Thr Leu
485 490 495
Cys Pro Tyr Phe Asn Pro Cys Asn Cys Val Ile Pro Met Thr Leu Arg
500 505 510
Arg Pro Ser Ser
515
<210> 13
<211> 666
<212> DNA
<213> Homo sapiens
<400> 13
atggcggctg tgggaccgcg gaccggcccc ggaaccggcg ccgaggctct agcgctggcg 60
gcagagctgc agggcgaggc gacgtgctcc atctgcctag agctctttcg tgagccggtg 120
tccgtcgagt gcggccacag cttctgccgc gcctgcatag ggcgctgctg ggagcgcccg 180
ggcgcggggt ctgttggggc cgccacccgc gcgcccccct tcccactgcc ctgtccgcag 240
tgccgcgagc ccgcgcgccc cagtcagctg cggcccaacc ggcagctggc ggcagtggcc 300
acgctcctgc ggcgcttcag cctgcccgcg gctgccccgg gagagcacgg gtctcaggcg 360
gccgcggccc gggcagcggc tgcccgctgc gggcagcatg gcgaaccctt caagctctac 420
tgccaggacg acggacgcgc catctgcgtg gtgtgcgacc gcgcccgcga gcaccgcgag 480
cacgccgtgc tgccgctgga cgaggcggtg caggaggcca aggagctctt ggagtccagg 540
ctgagggtct tgaagaagga actggaggac tgtgaggtgt tccggtccac ggaaaagaag 600
gagagcaagg agctgctggt gagccaggca cccgcaggcc ccccgtggga cattacagag 660
gcctga 666
<210> 14
<211> 221
<212> PRT
<213> Homo sapiens
<400> 14
Met Ala Ala Val Gly Pro Arg Thr Gly Pro Gly Thr Gly Ala Glu Ala
1 5 10 15
Leu Ala Leu Ala Ala Glu Leu Gln Gly Glu Ala Thr Cys Ser Ile Cys
20 25 30
Leu Glu Leu Phe Arg Glu Pro Val Ser Val Glu Cys Gly His Ser Phe
35 40 45
Cys Arg Ala Cys Ile Gly Arg Cys Trp Glu Arg Pro Gly Ala Gly Ser
50 55 60
Val Gly Ala Ala Thr Arg Ala Pro Pro Phe Pro Leu Pro Cys Pro Gln
65 70 75 80
Cys Arg Glu Pro Ala Arg Pro Ser Gln Leu Arg Pro Asn Arg Gln Leu
85 90 95
Ala Ala Val Ala Thr Leu Leu Arg Arg Phe Ser Leu Pro Ala Ala Ala
100 105 110
Pro Gly Glu His Gly Ser Gln Ala Ala Ala Ala Arg Ala Ala Ala Ala
115 120 125
Arg Cys Gly Gln His Gly Glu Pro Phe Lys Leu Tyr Cys Gln Asp Asp
130 135 140
Gly Arg Ala Ile Cys Val Val Cys Asp Arg Ala Arg Glu His Arg Glu
145 150 155 160
His Ala Val Leu Pro Leu Asp Glu Ala Val Gln Glu Ala Lys Glu Leu
165 170 175
Leu Glu Ser Arg Leu Arg Val Leu Lys Lys Glu Leu Glu Asp Cys Glu
180 185 190
Val Phe Arg Ser Thr Glu Lys Lys Glu Ser Lys Glu Leu Leu Val Ser
195 200 205
Gln Ala Pro Ala Gly Pro Pro Trp Asp Ile Thr Glu Ala
210 215 220
<210> 15
<211> 1656
<212> DNA
<213> Homo sapiens
<400> 15
atggcggaga attggaagaa ctgcttcgag gaggagctca tctgccctat ctgcctgcac 60
gttttcgtgg agccagtgca gctgccgtgc aaacacaact tctgccgggg ctgcatcggc 120
gaggcgtggg ccaaggacag cggcctcgta cgctgcccag agtgcaacca ggcctacaac 180
cagaagccgg gcctggagaa gaacctgaag ctcaccaaca tcgtggagaa gttcaatgcc 240
ctgcacgtgg agaagccgcc ggcggcgctg cactgcgtgt tctgccgccg cggccccccg 300
ctgcccgcgc agaaggtctg cctgcgctgc gaggcgccct gctgccagtc ccacgtgcag 360
acgcacctgc agcagccctc caccgcccgc gggcacctcc tggtggaggc ggacgacgtg 420
cgggcctgga gctgcccgca gcacaacgcc taccgcctct accactgcga ggccgagcag 480
gtggccgtgt gccagtactg ctgctactac agcggcgcgc atcagggaca ctcggtgtgc 540
gacgtggaga tccgaaggaa tgaaatccgg aagatgctca tgaagcagca ggaccggctg 600
gaggagcgag agcaggacat tgaggaccag ctgtacaaac tcgagtcaga caagcgcctg 660
gtggaggaga aagtgaacca actgaaggag gaagttcggc tgcagtacga gaagctgcac 720
cagctgctgg acgaggacct gcggcagaca gtggaggtcc tagacaaggc ccaggccaag 780
ttctgcagcg agaacgcagc gcaggcgctg cacctcgggg agcgcatgca ggaggccaag 840
aagctgctgg gctccctgca gctgctcttt gataagacgg aggatgtcag cttcatgaag 900
aacaccaagt ctgtgaaaat cctgatggac aggacccaga cctgcacgag cagcagcctt 960
tcccccacta agatcggcca cctgaactcc aagctcttcc tgaacgaagt ggccaagaag 1020
gagaagcagc tgcggaaaat gctagaaggc cccttcagca cgccggtgcc cttcctgcag 1080
agtgtccccc tgtacccttg cggcgtgagc agctctgggg cggaaaagcg caagcactca 1140
acggccttcc cagaggccag tttcctagag acgtcgtcgg gccctgtggg cggccagtac 1200
ggggcggcgg gcacagccag cggtgagggc cagtctgggc agcccctggg gccctgcagc 1260
tccacgcagc acttggtggc cctgccgggc ggcgcccaac cagtgcactc aagccccgtg 1320
ttccccccat cgcagtatcc caatggctcc gccgcccagc agcccatgct cccccagtat 1380
ggcggccgca agattctcgt ctgttctgtg gacaactgtt actgttcttc cgtggccaac 1440
catggcggcc accagcccta cccccgctcc ggccactttc cctggacagt gccctcgcag 1500
gagtactcac acccgctccc gcccacaccc tccgtccccc agtcccttcc cagcctggcg 1560
gtcagagact ggcttgacgc ctcccagcag cccggccacc aggatttcta cagggtgtat 1620
gggcagccgt ccaccaaaca ctacgtgacg agctaa 1656
<210> 16
<211> 551
<212> PRT
<213> Homo sapiens
<400> 16
Met Ala Glu Asn Trp Lys Asn Cys Phe Glu Glu Glu Leu Ile Cys Pro
1 5 10 15
Ile Cys Leu His Val Phe Val Glu Pro Val Gln Leu Pro Cys Lys His
20 25 30
Asn Phe Cys Arg Gly Cys Ile Gly Glu Ala Trp Ala Lys Asp Ser Gly
35 40 45
Leu Val Arg Cys Pro Glu Cys Asn Gln Ala Tyr Asn Gln Lys Pro Gly
50 55 60
Leu Glu Lys Asn Leu Lys Leu Thr Asn Ile Val Glu Lys Phe Asn Ala
65 70 75 80
Leu His Val Glu Lys Pro Pro Ala Ala Leu His Cys Val Phe Cys Arg
85 90 95
Arg Gly Pro Pro Leu Pro Ala Gln Lys Val Cys Leu Arg Cys Glu Ala
100 105 110
Pro Cys Cys Gln Ser His Val Gln Thr His Leu Gln Gln Pro Ser Thr
115 120 125
Ala Arg Gly His Leu Leu Val Glu Ala Asp Asp Val Arg Ala Trp Ser
130 135 140
Cys Pro Gln His Asn Ala Tyr Arg Leu Tyr His Cys Glu Ala Glu Gln
145 150 155 160
Val Ala Val Cys Gln Tyr Cys Cys Tyr Tyr Ser Gly Ala His Gln Gly
165 170 175
His Ser Val Cys Asp Val Glu Ile Arg Arg Asn Glu Ile Arg Lys Met
180 185 190
Leu Met Lys Gln Gln Asp Arg Leu Glu Glu Arg Glu Gln Asp Ile Glu
195 200 205
Asp Gln Leu Tyr Lys Leu Glu Ser Asp Lys Arg Leu Val Glu Glu Lys
210 215 220
Val Asn Gln Leu Lys Glu Glu Val Arg Leu Gln Tyr Glu Lys Leu His
225 230 235 240
Gln Leu Leu Asp Glu Asp Leu Arg Gln Thr Val Glu Val Leu Asp Lys
245 250 255
Ala Gln Ala Lys Phe Cys Ser Glu Asn Ala Ala Gln Ala Leu His Leu
260 265 270
Gly Glu Arg Met Gln Glu Ala Lys Lys Leu Leu Gly Ser Leu Gln Leu
275 280 285
Leu Phe Asp Lys Thr Glu Asp Val Ser Phe Met Lys Asn Thr Lys Ser
290 295 300
Val Lys Ile Leu Met Asp Arg Thr Gln Thr Cys Thr Ser Ser Ser Leu
305 310 315 320
Ser Pro Thr Lys Ile Gly His Leu Asn Ser Lys Leu Phe Leu Asn Glu
325 330 335
Val Ala Lys Lys Glu Lys Gln Leu Arg Lys Met Leu Glu Gly Pro Phe
340 345 350
Ser Thr Pro Val Pro Phe Leu Gln Ser Val Pro Leu Tyr Pro Cys Gly
355 360 365
Val Ser Ser Ser Gly Ala Glu Lys Arg Lys His Ser Thr Ala Phe Pro
370 375 380
Glu Ala Ser Phe Leu Glu Thr Ser Ser Gly Pro Val Gly Gly Gln Tyr
385 390 395 400
Gly Ala Ala Gly Thr Ala Ser Gly Glu Gly Gln Ser Gly Gln Pro Leu
405 410 415
Gly Pro Cys Ser Ser Thr Gln His Leu Val Ala Leu Pro Gly Gly Ala
420 425 430
Gln Pro Val His Ser Ser Pro Val Phe Pro Pro Ser Gln Tyr Pro Asn
435 440 445
Gly Ser Ala Ala Gln Gln Pro Met Leu Pro Gln Tyr Gly Gly Arg Lys
450 455 460
Ile Leu Val Cys Ser Val Asp Asn Cys Tyr Cys Ser Ser Val Ala Asn
465 470 475 480
His Gly Gly His Gln Pro Tyr Pro Arg Ser Gly His Phe Pro Trp Thr
485 490 495
Val Pro Ser Gln Glu Tyr Ser His Pro Leu Pro Pro Thr Pro Ser Val
500 505 510
Pro Gln Ser Leu Pro Ser Leu Ala Val Arg Asp Trp Leu Asp Ala Ser
515 520 525
Gln Gln Pro Gly His Gln Asp Phe Tyr Arg Val Tyr Gly Gln Pro Ser
530 535 540
Thr Lys His Tyr Val Thr Ser
545 550
<210> 17
<211> 2133
<212> DNA
<213> Homo sapiens
<400> 17
atggaggaga tggaagagga gttgaaatgc cccgtgtgcg gctccttcta tcgggagccc 60
atcatcctgc cctgctctca caatttgtgt caggcgtgcg cccgcaacat cctggtgcag 120
accccagagt ctgaatcccc ccagagccat cgggccgcgg gctccggggt ctccgactat 180
gactatctgg acctggacaa gatgagccta tacagcgagg cggacagcgg ctatggctcc 240
tacggggggt tcgccagcgc ccccactacc ccgtgccaga agtcccccaa cggcgtccgc 300
gtgtttcccc cggctatgcc gccaccggcc acccacttgt caccggccct ggccccggtg 360
ccccgcaact cctgtatcac ctgcccccag tgtcaccgca gcctcatcct ggatgaccgg 420
gggctccgcg gcttccccaa gaatcgcgta ctggaagggg taattgaccg ctaccagcag 480
agcaaagccg cggccctcaa gtgccagctc tgcgagaagg cgcccaagga agccaccgtc 540
atgtgcgaac agtgcgatgt cttctactgc gatccgtgcc gcctgcgctg ccacccgccc 600
cgggggcccc tagccaagca ccgcctggtg cccccggccc agggtcgtgt gagccggagg 660
ctgagcccac gcaaggtctc cacctgcaca gaccacgagc tggagaacca cagcatgtac 720
tgcgtgcaat gcaagatgcc cgtgtgctac cagtgcttgg aggagggcaa acactccagc 780
cacgaagtca aggctctggg ggccatgtgg aaactacata agagccagct ctcccaggcg 840
ctgaacggac tgtcagacag ggccaaagaa gccaaggagt ttctggtaca gctgcgcaac 900
atggtccagc agatccagga gaacagtgtg gagtttgaag cctgtctggt ggcccaatgt 960
gatgccctca tcgatgccct caacagaaga aaagcccagc tgctggcccg cgtcaacaag 1020
gagcatgagc acaagctgaa ggtggttcga gatcagatct ctcactgcac agtgaaattg 1080
cgccagacca caggtctcat ggagtactgc ttggaggtga ttaaggaaaa tgatcctagt 1140
ggttttttgc agatttctga cgccctcata agaagagtgc acctgactga ggatcagtgg 1200
ggtaaaggca cactcactcc aaggatgacc acggactttg acttgagtct ggacaacagc 1260
cctctgctgc aatccatcca ccagctggat ttcgtgcaag tgaaagcttc ctctccagtc 1320
ccagcaaccc ctatcctaca gctggaggaa tgttgtaccc acaacaacag cgctacgttg 1380
tcctggaaac agccacctct gtccacggtg cccgccgatg gatacattct ggagctggat 1440
gatggcaacg gtggtcaatt ccgggaggtg tatgtgggga aggagacaat gtgcactgtg 1500
gatggtcttc acttcaacag cacatacaac gctcgggtca aggccttcaa caaaacagga 1560
gtcagcccgt acagcaagac cctggtcctc caaacgtctg aggtggcctg gtttgctttc 1620
gaccctggct cggcgcactc ggacatcatc ctctccaatg acaacctgac agtgacctgt 1680
agtagctatg atgaccgggt ggtgctaggg aagactggct tctccaaggg catccactac 1740
tgggagctca cggtagatcg ctatgacaac caccctgatc ctgcctttgg tgtggctcgc 1800
atggacgtga tgaaggatgt gatgttagga aaagacgaca aagcttgggc aatgtatgtg 1860
gacaataacc ggagctggtt catgcacaac aactcgcaca ccaacagaac tgagggaggg 1920
atcacaaaag gggccacaat tggggtcctc ctcgacttaa atagaaaaaa cttgacattt 1980
tttatcaacg atgaacaaca aggtcccata gcatttgata acgtggaggg cctcttcttc 2040
cctgcggtca gcctgaacag gaacgtgcag gtcacgctgc acaccgggct cccagtcccc 2100
gacttctact ccagcagagc atcaatagcc taa 2133
<210> 18
<211> 710
<212> PRT
<213> Homo sapiens
<400> 18
Met Glu Glu Met Glu Glu Glu Leu Lys Cys Pro Val Cys Gly Ser Phe
1 5 10 15
Tyr Arg Glu Pro Ile Ile Leu Pro Cys Ser His Asn Leu Cys Gln Ala
20 25 30
Cys Ala Arg Asn Ile Leu Val Gln Thr Pro Glu Ser Glu Ser Pro Gln
35 40 45
Ser His Arg Ala Ala Gly Ser Gly Val Ser Asp Tyr Asp Tyr Leu Asp
50 55 60
Leu Asp Lys Met Ser Leu Tyr Ser Glu Ala Asp Ser Gly Tyr Gly Ser
65 70 75 80
Tyr Gly Gly Phe Ala Ser Ala Pro Thr Thr Pro Cys Gln Lys Ser Pro
85 90 95
Asn Gly Val Arg Val Phe Pro Pro Ala Met Pro Pro Pro Ala Thr His
100 105 110
Leu Ser Pro Ala Leu Ala Pro Val Pro Arg Asn Ser Cys Ile Thr Cys
115 120 125
Pro Gln Cys His Arg Ser Leu Ile Leu Asp Asp Arg Gly Leu Arg Gly
130 135 140
Phe Pro Lys Asn Arg Val Leu Glu Gly Val Ile Asp Arg Tyr Gln Gln
145 150 155 160
Ser Lys Ala Ala Ala Leu Lys Cys Gln Leu Cys Glu Lys Ala Pro Lys
165 170 175
Glu Ala Thr Val Met Cys Glu Gln Cys Asp Val Phe Tyr Cys Asp Pro
180 185 190
Cys Arg Leu Arg Cys His Pro Pro Arg Gly Pro Leu Ala Lys His Arg
195 200 205
Leu Val Pro Pro Ala Gln Gly Arg Val Ser Arg Arg Leu Ser Pro Arg
210 215 220
Lys Val Ser Thr Cys Thr Asp His Glu Leu Glu Asn His Ser Met Tyr
225 230 235 240
Cys Val Gln Cys Lys Met Pro Val Cys Tyr Gln Cys Leu Glu Glu Gly
245 250 255
Lys His Ser Ser His Glu Val Lys Ala Leu Gly Ala Met Trp Lys Leu
260 265 270
His Lys Ser Gln Leu Ser Gln Ala Leu Asn Gly Leu Ser Asp Arg Ala
275 280 285
Lys Glu Ala Lys Glu Phe Leu Val Gln Leu Arg Asn Met Val Gln Gln
290 295 300
Ile Gln Glu Asn Ser Val Glu Phe Glu Ala Cys Leu Val Ala Gln Cys
305 310 315 320
Asp Ala Leu Ile Asp Ala Leu Asn Arg Arg Lys Ala Gln Leu Leu Ala
325 330 335
Arg Val Asn Lys Glu His Glu His Lys Leu Lys Val Val Arg Asp Gln
340 345 350
Ile Ser His Cys Thr Val Lys Leu Arg Gln Thr Thr Gly Leu Met Glu
355 360 365
Tyr Cys Leu Glu Val Ile Lys Glu Asn Asp Pro Ser Gly Phe Leu Gln
370 375 380
Ile Ser Asp Ala Leu Ile Arg Arg Val His Leu Thr Glu Asp Gln Trp
385 390 395 400
Gly Lys Gly Thr Leu Thr Pro Arg Met Thr Thr Asp Phe Asp Leu Ser
405 410 415
Leu Asp Asn Ser Pro Leu Leu Gln Ser Ile His Gln Leu Asp Phe Val
420 425 430
Gln Val Lys Ala Ser Ser Pro Val Pro Ala Thr Pro Ile Leu Gln Leu
435 440 445
Glu Glu Cys Cys Thr His Asn Asn Ser Ala Thr Leu Ser Trp Lys Gln
450 455 460
Pro Pro Leu Ser Thr Val Pro Ala Asp Gly Tyr Ile Leu Glu Leu Asp
465 470 475 480
Asp Gly Asn Gly Gly Gln Phe Arg Glu Val Tyr Val Gly Lys Glu Thr
485 490 495
Met Cys Thr Val Asp Gly Leu His Phe Asn Ser Thr Tyr Asn Ala Arg
500 505 510
Val Lys Ala Phe Asn Lys Thr Gly Val Ser Pro Tyr Ser Lys Thr Leu
515 520 525
Val Leu Gln Thr Ser Glu Val Ala Trp Phe Ala Phe Asp Pro Gly Ser
530 535 540
Ala His Ser Asp Ile Ile Leu Ser Asn Asp Asn Leu Thr Val Thr Cys
545 550 555 560
Ser Ser Tyr Asp Asp Arg Val Val Leu Gly Lys Thr Gly Phe Ser Lys
565 570 575
Gly Ile His Tyr Trp Glu Leu Thr Val Asp Arg Tyr Asp Asn His Pro
580 585 590
Asp Pro Ala Phe Gly Val Ala Arg Met Asp Val Met Lys Asp Val Met
595 600 605
Leu Gly Lys Asp Asp Lys Ala Trp Ala Met Tyr Val Asp Asn Asn Arg
610 615 620
Ser Trp Phe Met His Asn Asn Ser His Thr Asn Arg Thr Glu Gly Gly
625 630 635 640
Ile Thr Lys Gly Ala Thr Ile Gly Val Leu Leu Asp Leu Asn Arg Lys
645 650 655
Asn Leu Thr Phe Phe Ile Asn Asp Glu Gln Gln Gly Pro Ile Ala Phe
660 665 670
Asp Asn Val Glu Gly Leu Phe Phe Pro Ala Val Ser Leu Asn Arg Asn
675 680 685
Val Gln Val Thr Leu His Thr Gly Leu Pro Val Pro Asp Phe Tyr Ser
690 695 700
Ser Arg Ala Ser Ile Ala
705 710
<210> 19
<211> 1446
<212> DNA
<213> Homo sapiens
<400> 19
atggcctctg ctgcctctgt gaccagcctg gcagatgaag tcaactgccc catctgtcag 60
ggtaccctga gggagccggt cactatcgac tgcggccaca acttctgccg ggcctgcctt 120
acccgctact gtgagatacc aggcccagac ctggaggagt cccctacttg cccactctgc 180
aaagaaccct tccgtcctgg gagcttccgg cccaactggc agctggctaa cgtggtggag 240
aacattgagc gcctccagct ggtgtccaca ctgggtttgg gagaggagga tgtctgccaa 300
gagcacggag agaagatcta cttcttctgt gaggatgatg agatgcagtt gtgcgtggtg 360
tgccgggagg ctggggagca cgctacccac accatgcgct tcctggagga tgcagcggct 420
ccctataggg aacaaatcca taagtgtctt aaatgtctaa gaaaagagag agaggagatt 480
caagaaatcc agtcaagaga aaataaaagg atgcaagtcc tcctgactca ggtgtccacc 540
aagagacaac aggtgatttc tgagttcgca cacctgagga agtttctaga ggaacagcag 600
agcatcctct tagcacaatt ggagagccag gatggggaca tcttgaggca acgggatgaa 660
tttgatttgc tggttgctgg ggagatctgc cggtttagtg ctcttattga agaactggag 720
gagaagaatg agaggccagc aagggagctc ctgacggaca tcagaagcac tctaataaga 780
tgtgaaacca gaaagtgccg gaaaccggtg gctgtgtcgc cagagctggg ccagaggatt 840
cgggactttc cccagcaggc cctcccgctg cagagggaga tgaagatgtt tctggaaaaa 900
ctatgctttg agttggacta tgagccagct cacatttctc tagaccctca gacttcccac 960
cccaagctcc tcttgtccga ggaccaccag cgagctcagt tctcctacaa atggcagaac 1020
tcaccagaca acccccaacg ttttgaccgg gccacctgtg ttctggccca cactggcatc 1080
acagggggga gacacacgtg ggtggtgagt atagacctgg cccatggggg cagctgcacc 1140
gtgggcgtgg tgagcgagga tgtgcagcgg aagggggagc ttcggctgcg gccagaggag 1200
ggggtgtggg ctgtgaggct ggcttggggc ttcgtctcgg ctctgggctc cttccccaca 1260
cggctgaccc tgaaggagca gccccggcag gtgagggtgt ctcttgacta tgaggtgggc 1320
tgggtgacct tcaccaacgc tgtcacccga gagcccatct acaccttcac tgcctccttc 1380
actaggaagg tcattccctt ctttgggctc tggggccgag ggtccagttt ctccctgagc 1440
tcctga 1446
<210> 20
<211> 481
<212> PRT
<213> Homo sapiens
<400> 20
Met Ala Ser Ala Ala Ser Val Thr Ser Leu Ala Asp Glu Val Asn Cys
1 5 10 15
Pro Ile Cys Gln Gly Thr Leu Arg Glu Pro Val Thr Ile Asp Cys Gly
20 25 30
His Asn Phe Cys Arg Ala Cys Leu Thr Arg Tyr Cys Glu Ile Pro Gly
35 40 45
Pro Asp Leu Glu Glu Ser Pro Thr Cys Pro Leu Cys Lys Glu Pro Phe
50 55 60
Arg Pro Gly Ser Phe Arg Pro Asn Trp Gln Leu Ala Asn Val Val Glu
65 70 75 80
Asn Ile Glu Arg Leu Gln Leu Val Ser Thr Leu Gly Leu Gly Glu Glu
85 90 95
Asp Val Cys Gln Glu His Gly Glu Lys Ile Tyr Phe Phe Cys Glu Asp
100 105 110
Asp Glu Met Gln Leu Cys Val Val Cys Arg Glu Ala Gly Glu His Ala
115 120 125
Thr His Thr Met Arg Phe Leu Glu Asp Ala Ala Ala Pro Tyr Arg Glu
130 135 140
Gln Ile His Lys Cys Leu Lys Cys Leu Arg Lys Glu Arg Glu Glu Ile
145 150 155 160
Gln Glu Ile Gln Ser Arg Glu Asn Lys Arg Met Gln Val Leu Leu Thr
165 170 175
Gln Val Ser Thr Lys Arg Gln Gln Val Ile Ser Glu Phe Ala His Leu
180 185 190
Arg Lys Phe Leu Glu Glu Gln Gln Ser Ile Leu Leu Ala Gln Leu Glu
195 200 205
Ser Gln Asp Gly Asp Ile Leu Arg Gln Arg Asp Glu Phe Asp Leu Leu
210 215 220
Val Ala Gly Glu Ile Cys Arg Phe Ser Ala Leu Ile Glu Glu Leu Glu
225 230 235 240
Glu Lys Asn Glu Arg Pro Ala Arg Glu Leu Leu Thr Asp Ile Arg Ser
245 250 255
Thr Leu Ile Arg Cys Glu Thr Arg Lys Cys Arg Lys Pro Val Ala Val
260 265 270
Ser Pro Glu Leu Gly Gln Arg Ile Arg Asp Phe Pro Gln Gln Ala Leu
275 280 285
Pro Leu Gln Arg Glu Met Lys Met Phe Leu Glu Lys Leu Cys Phe Glu
290 295 300
Leu Asp Tyr Glu Pro Ala His Ile Ser Leu Asp Pro Gln Thr Ser His
305 310 315 320
Pro Lys Leu Leu Leu Ser Glu Asp His Gln Arg Ala Gln Phe Ser Tyr
325 330 335
Lys Trp Gln Asn Ser Pro Asp Asn Pro Gln Arg Phe Asp Arg Ala Thr
340 345 350
Cys Val Leu Ala His Thr Gly Ile Thr Gly Gly Arg His Thr Trp Val
355 360 365
Val Ser Ile Asp Leu Ala His Gly Gly Ser Cys Thr Val Gly Val Val
370 375 380
Ser Glu Asp Val Gln Arg Lys Gly Glu Leu Arg Leu Arg Pro Glu Glu
385 390 395 400
Gly Val Trp Ala Val Arg Leu Ala Trp Gly Phe Val Ser Ala Leu Gly
405 410 415
Ser Phe Pro Thr Arg Leu Thr Leu Lys Glu Gln Pro Arg Gln Val Arg
420 425 430
Val Ser Leu Asp Tyr Glu Val Gly Trp Val Thr Phe Thr Asn Ala Val
435 440 445
Thr Arg Glu Pro Ile Tyr Thr Phe Thr Ala Ser Phe Thr Arg Lys Val
450 455 460
Ile Pro Phe Phe Gly Leu Trp Gly Arg Gly Ser Ser Phe Ser Leu Ser
465 470 475 480
Ser
<210> 21
<211> 1407
<212> DNA
<213> Homo sapiens
<400> 21
atggccgccc ccgacctgtc caccaacctc caggaggagg ccacctgcgc catctgcctc 60
gactacttca cggatccggt gatgaccgac tgcggccaca acttctgccg cgagtgcatc 120
cggcgctgct ggggccagcc cgagggcccg tacgcgtgcc ccgagtgccg cgagctgtcc 180
ccgcagagga acctgcggcc caaccgcccg cttgctaaga tggccgagat ggcgcggcgc 240
ctgcacccgc cgtcgccggt cccgcagggc gtgtgccccg cgcaccgcga gccactggcc 300
gccttctgtg gcgacgagct gcgcctcctg tgtgcggcct gcgagcgctc tggggagcac 360
tgggcgcacc gcgtgcggcc gctgcaggac gcggccgaag acctcaaggc gaagctggag 420
aagtcactgg agcatctccg gaagcagatg caggatgcgt tgctgttcca agcccaggcg 480
gatgagacct gcgtcttgtg gcagaagatg gtggagagcc agcggcagaa cgtgctgggt 540
gagttcgagc gtcttcgccg tttgctggca gaggaggagc agcagctgct gcagaggctg 600
gaggaggagg agctggaggt gctgccccgg ctgcgggagg gcgcagccca cctaggccag 660
cagagcgccc acctagctga gctcatcgcc gagctcgagg gccgctgcca gctgcctgct 720
ctggggctgc tgcaggacat caaggacgcc ctgcgcaggg tccaggatgt gaagctgcag 780
cccccagaag ttgtgcctat ggagctgagg accgtgtgca gggtcccggg actggtagag 840
acactgcgga ggtttcgagg ggacgtgacc ttggacccgg acaccgccaa ccctgagctg 900
atcctgtctg aagacaggcg gagcgtgcag cggggggacc tacggcaggc cctgccggac 960
agcccagagc gctttgaccc cggcccctgc gtgctgggcc aggagcgctt cacctcaggc 1020
cgccactact gggaggtgga ggttggggac cgcaccagct gggccctggg ggtgtgcagg 1080
gagaacgtga acaggaagga gaagggcgag ctgtccgcgg gcaacggctt ctggatcctg 1140
gtcttcctgg ggagctatta caattcctcg gaacgggcct tggctccact ccgggaccca 1200
cccaggcgcg tggggatctt tctggactac gaggctggac atctctcttt ctacagtgcc 1260
accgatgggt cactgctatt catctttccc gagatcccct tctcggggac gctgcggccc 1320
ctcttctcac ccctgtccag cagcccgacc ccgatgacta tctgccggcc gaaaggtggg 1380
tccggggaca ccctggctcc ccagtga 1407
<210> 22
<211> 468
<212> PRT
<213> Homo sapiens
<400> 22
Met Ala Ala Pro Asp Leu Ser Thr Asn Leu Gln Glu Glu Ala Thr Cys
1 5 10 15
Ala Ile Cys Leu Asp Tyr Phe Thr Asp Pro Val Met Thr Asp Cys Gly
20 25 30
His Asn Phe Cys Arg Glu Cys Ile Arg Arg Cys Trp Gly Gln Pro Glu
35 40 45
Gly Pro Tyr Ala Cys Pro Glu Cys Arg Glu Leu Ser Pro Gln Arg Asn
50 55 60
Leu Arg Pro Asn Arg Pro Leu Ala Lys Met Ala Glu Met Ala Arg Arg
65 70 75 80
Leu His Pro Pro Ser Pro Val Pro Gln Gly Val Cys Pro Ala His Arg
85 90 95
Glu Pro Leu Ala Ala Phe Cys Gly Asp Glu Leu Arg Leu Leu Cys Ala
100 105 110
Ala Cys Glu Arg Ser Gly Glu His Trp Ala His Arg Val Arg Pro Leu
115 120 125
Gln Asp Ala Ala Glu Asp Leu Lys Ala Lys Leu Glu Lys Ser Leu Glu
130 135 140
His Leu Arg Lys Gln Met Gln Asp Ala Leu Leu Phe Gln Ala Gln Ala
145 150 155 160
Asp Glu Thr Cys Val Leu Trp Gln Lys Met Val Glu Ser Gln Arg Gln
165 170 175
Asn Val Leu Gly Glu Phe Glu Arg Leu Arg Arg Leu Leu Ala Glu Glu
180 185 190
Glu Gln Gln Leu Leu Gln Arg Leu Glu Glu Glu Glu Leu Glu Val Leu
195 200 205
Pro Arg Leu Arg Glu Gly Ala Ala His Leu Gly Gln Gln Ser Ala His
210 215 220
Leu Ala Glu Leu Ile Ala Glu Leu Glu Gly Arg Cys Gln Leu Pro Ala
225 230 235 240
Leu Gly Leu Leu Gln Asp Ile Lys Asp Ala Leu Arg Arg Val Gln Asp
245 250 255
Val Lys Leu Gln Pro Pro Glu Val Val Pro Met Glu Leu Arg Thr Val
260 265 270
Cys Arg Val Pro Gly Leu Val Glu Thr Leu Arg Arg Phe Arg Gly Asp
275 280 285
Val Thr Leu Asp Pro Asp Thr Ala Asn Pro Glu Leu Ile Leu Ser Glu
290 295 300
Asp Arg Arg Ser Val Gln Arg Gly Asp Leu Arg Gln Ala Leu Pro Asp
305 310 315 320
Ser Pro Glu Arg Phe Asp Pro Gly Pro Cys Val Leu Gly Gln Glu Arg
325 330 335
Phe Thr Ser Gly Arg His Tyr Trp Glu Val Glu Val Gly Asp Arg Thr
340 345 350
Ser Trp Ala Leu Gly Val Cys Arg Glu Asn Val Asn Arg Lys Glu Lys
355 360 365
Gly Glu Leu Ser Ala Gly Asn Gly Phe Trp Ile Leu Val Phe Leu Gly
370 375 380
Ser Tyr Tyr Asn Ser Ser Glu Arg Ala Leu Ala Pro Leu Arg Asp Pro
385 390 395 400
Pro Arg Arg Val Gly Ile Phe Leu Asp Tyr Glu Ala Gly His Leu Ser
405 410 415
Phe Tyr Ser Ala Thr Asp Gly Ser Leu Leu Phe Ile Phe Pro Glu Ile
420 425 430
Pro Phe Ser Gly Thr Leu Arg Pro Leu Phe Ser Pro Leu Ser Ser Ser
435 440 445
Pro Thr Pro Met Thr Ile Cys Arg Pro Lys Gly Gly Ser Gly Asp Thr
450 455 460
Leu Ala Pro Gln
465
<210> 23
<211> 894
<212> DNA
<213> Mus musculus
<400> 23
atggcttcac aattcatgaa gaatttaaag gaggaggtga cctgtcctgt ctgtctgaac 60
ctgatggtga aacctgtgag tgcagattgt ggtcacacct tctgccaagg ctgcatcacg 120
ttgtactttg aatccatcaa atgcgataag aaagtgttca tttgccctgt gtgccgaatt 180
agttaccagt ttagcaatct gaggcctaat cgaaatgtgg ccaacatagt agagaggctc 240
aaaatgttca agcccagccc agaagaggag cagaaagtgt ttaactgtgc aagacatgga 300
aagaaactcc agctcttctg taggaaggac atgatggcca tctgctggct ttgtgagcga 360
tctcaggagc accgtggtca caaaacagct ctcattgaag aggtggccca ggagtacaag 420
gagcagctgc aggtagttct gcaaaggctg atggcagata agaaaaaatt tgaaaactgg 480
aaagatgacc ttcagaagga tagaacttac tgggagaatc aaatacagaa agatgtgcag 540
aatgttcggt cagagtttaa acgaatgagg gatatcatgg actctgagga gaagaaggaa 600
ttgcagaagc tgaggcaaga gaaggaagac attctcaaca acctggcaga gtctgaaagt 660
gagcatgctc agcagagcaa gttgctagaa gacttcatct cagatgtgga acatcagtta 720
cagtgctcag acatagaaat actgcagggt gtggagaaca tcatagaacg gagtcatact 780
ttttcgatga agaagcccaa agccatcgcc agggaacaaa gaaagttccg agcccctgac 840
ctgcaaggca tgctgcaagt gctgcaagag gtcacagagg ctcatcgcta ctag 894
<210> 24
<211> 297
<212> PRT
<213> Mus musculus
<400> 24
Met Ala Ser Gln Phe Met Lys Asn Leu Lys Glu Glu Val Thr Cys Pro
1 5 10 15
Val Cys Leu Asn Leu Met Val Lys Pro Val Ser Ala Asp Cys Gly His
20 25 30
Thr Phe Cys Gln Gly Cys Ile Thr Leu Tyr Phe Glu Ser Ile Lys Cys
35 40 45
Asp Lys Lys Val Phe Ile Cys Pro Val Cys Arg Ile Ser Tyr Gln Phe
50 55 60
Ser Asn Leu Arg Pro Asn Arg Asn Val Ala Asn Ile Val Glu Arg Leu
65 70 75 80
Lys Met Phe Lys Pro Ser Pro Glu Glu Glu Gln Lys Val Phe Asn Cys
85 90 95
Ala Arg His Gly Lys Lys Leu Gln Leu Phe Cys Arg Lys Asp Met Met
100 105 110
Ala Ile Cys Trp Leu Cys Glu Arg Ser Gln Glu His Arg Gly His Lys
115 120 125
Thr Ala Leu Ile Glu Glu Val Ala Gln Glu Tyr Lys Glu Gln Leu Gln
130 135 140
Val Val Leu Gln Arg Leu Met Ala Asp Lys Lys Lys Phe Glu Asn Trp
145 150 155 160
Lys Asp Asp Leu Gln Lys Asp Arg Thr Tyr Trp Glu Asn Gln Ile Gln
165 170 175
Lys Asp Val Gln Asn Val Arg Ser Glu Phe Lys Arg Met Arg Asp Ile
180 185 190
Met Asp Ser Glu Glu Lys Lys Glu Leu Gln Lys Leu Arg Gln Glu Lys
195 200 205
Glu Asp Ile Leu Asn Asn Leu Ala Glu Ser Glu Ser Glu His Ala Gln
210 215 220
Gln Ser Lys Leu Leu Glu Asp Phe Ile Ser Asp Val Glu His Gln Leu
225 230 235 240
Gln Cys Ser Asp Ile Glu Ile Leu Gln Gly Val Glu Asn Ile Ile Glu
245 250 255
Arg Ser His Thr Phe Ser Met Lys Lys Pro Lys Ala Ile Ala Arg Glu
260 265 270
Gln Arg Lys Phe Arg Ala Pro Asp Leu Gln Gly Met Leu Gln Val Leu
275 280 285
Gln Glu Val Thr Glu Ala His Arg Tyr
290 295
<210> 25
<211> 1224
<212> DNA
<213> Homo sapiens
<400> 25
atggagctgc ttgaagaaga tctcacatgc cctatttgtt gtagtctgtt tgatgatcca 60
cgggttttgc cttgctccca caacttctgc aaaaaatgct tagaaggtat cttagaaggg 120
agtgtgcgga attccttgtg gagaccagct ccattcaagt gtcctacatg ccgtaaggaa 180
acttcagcta ctggaattaa tagcctgcag gttaattact ccctgaaggg tattgtggaa 240
aagtataaca agatcaagat ctctcccaaa atgccagtat gcaaaggaca cttggggcag 300
cctctcaaca ttttctgcct gactgatatg cagctgattt gtgggatctg tgctactcgt 360
ggggagcaca ccaaacatgt cttctgttct attgaagatg cctatgctca ggaaagggat 420
gcctttgagt ccctcttcca gagctttgag acctggcgtc ggggagatgc tctttctcgc 480
ttggatacct tggaaactag taagaggaaa tccctacagt tactgactaa agattcagat 540
aaagtgaagg aattttttga gaagttacaa cacacactgg atcaaaagaa gaatgaaatt 600
ctgtctgact ttgagaccat gaaacttgct gttatgcaag catatgaccc agagatcaac 660
aaactcaaca ccatcttgca ggagcaacgg atggccttta acattgctga ggctttcaaa 720
gatgtgtcag aacccattgt atttctgcaa cagatgcagg agtttagaga gaaaatcaaa 780
gtaatcaagg aaactccttt acctccctct aatttgcctg caagcccttt aatgaagaac 840
tttgatacca gtcagtggga agacataaaa ctagtcgatg tggataaact ttctttgcct 900
caagacactg gcacattcat tagcaagatt ccctggagct tttataagtt atttttgcta 960
atccttctgc ttggccttgt cattgtcttt ggtcctacca tgttcctaga atggtcatta 1020
tttgatgacc tggcaacttg gaaaggctgt ctttcaaact tcagttccta tctgactaaa 1080
acagccgatt tcatagaaca atcagttttt tactgggaac aggtgacaga tgggtttttc 1140
attttcaatg aaagattcaa gaattttact ttggtggtac tgaacaatgt ggcagaattt 1200
gtgtgcaaat ataaactatt ataa 1224
<210> 26
<211> 407
<212> PRT
<213> Homo sapiens
<400> 26
Met Glu Leu Leu Glu Glu Asp Leu Thr Cys Pro Ile Cys Cys Ser Leu
1 5 10 15
Phe Asp Asp Pro Arg Val Leu Pro Cys Ser His Asn Phe Cys Lys Lys
20 25 30
Cys Leu Glu Gly Ile Leu Glu Gly Ser Val Arg Asn Ser Leu Trp Arg
35 40 45
Pro Ala Pro Phe Lys Cys Pro Thr Cys Arg Lys Glu Thr Ser Ala Thr
50 55 60
Gly Ile Asn Ser Leu Gln Val Asn Tyr Ser Leu Lys Gly Ile Val Glu
65 70 75 80
Lys Tyr Asn Lys Ile Lys Ile Ser Pro Lys Met Pro Val Cys Lys Gly
85 90 95
His Leu Gly Gln Pro Leu Asn Ile Phe Cys Leu Thr Asp Met Gln Leu
100 105 110
Ile Cys Gly Ile Cys Ala Thr Arg Gly Glu His Thr Lys His Val Phe
115 120 125
Cys Ser Ile Glu Asp Ala Tyr Ala Gln Glu Arg Asp Ala Phe Glu Ser
130 135 140
Leu Phe Gln Ser Phe Glu Thr Trp Arg Arg Gly Asp Ala Leu Ser Arg
145 150 155 160
Leu Asp Thr Leu Glu Thr Ser Lys Arg Lys Ser Leu Gln Leu Leu Thr
165 170 175
Lys Asp Ser Asp Lys Val Lys Glu Phe Phe Glu Lys Leu Gln His Thr
180 185 190
Leu Asp Gln Lys Lys Asn Glu Ile Leu Ser Asp Phe Glu Thr Met Lys
195 200 205
Leu Ala Val Met Gln Ala Tyr Asp Pro Glu Ile Asn Lys Leu Asn Thr
210 215 220
Ile Leu Gln Glu Gln Arg Met Ala Phe Asn Ile Ala Glu Ala Phe Lys
225 230 235 240
Asp Val Ser Glu Pro Ile Val Phe Leu Gln Gln Met Gln Glu Phe Arg
245 250 255
Glu Lys Ile Lys Val Ile Lys Glu Thr Pro Leu Pro Pro Ser Asn Leu
260 265 270
Pro Ala Ser Pro Leu Met Lys Asn Phe Asp Thr Ser Gln Trp Glu Asp
275 280 285
Ile Lys Leu Val Asp Val Asp Lys Leu Ser Leu Pro Gln Asp Thr Gly
290 295 300
Thr Phe Ile Ser Lys Ile Pro Trp Ser Phe Tyr Lys Leu Phe Leu Leu
305 310 315 320
Ile Leu Leu Leu Gly Leu Val Ile Val Phe Gly Pro Thr Met Phe Leu
325 330 335
Glu Trp Ser Leu Phe Asp Asp Leu Ala Thr Trp Lys Gly Cys Leu Ser
340 345 350
Asn Phe Ser Ser Tyr Leu Thr Lys Thr Ala Asp Phe Ile Glu Gln Ser
355 360 365
Val Phe Tyr Trp Glu Gln Val Thr Asp Gly Phe Phe Ile Phe Asn Glu
370 375 380
Arg Phe Lys Asn Phe Thr Leu Val Val Leu Asn Asn Val Ala Glu Phe
385 390 395 400
Val Cys Lys Tyr Lys Leu Leu
405
<210> 27
<211> 1329
<212> DNA
<213> Homo sapiens
<400> 27
atggcgggcg cggcgaccgg gagccggacc cctgggaggt cggagcttgt cgagggatgc 60
ggctggcgct gcccggagca tggcgaccgc gtggctgagc tcttctgtcg ccgctgccgc 120
cgctgcgtgt gcgcgctttg cccggtgctg ggcgcgcacc gtggccaccc tgtgggcctg 180
gcgctggagg cagcggtgca cgtgcagaaa ctcagccaag aatgtttaaa gcagctggca 240
atcaagaagc agcagcacat tgacaacata acccagatag aagatgccac cgagaagctc 300
aaggctaatg cagagtcaag taaaacctgg ctgaagggga aattcactga actcagatta 360
ctacttgacg aagaggaagc gctggccaag aaattcattg ataaaaacac gcagcttacc 420
ctccaggtgt acagggaaca agctgactct tgcagagagc aacttgacat catgaatgat 480
ctctccaaca gggtctggag tatcagccag gagcccgatc ctgtccagag gcttcaggca 540
tacacggcca ccgagcagga gatgcagcag cagatgagcc tcggggagct gtgccatccc 600
gtgcccctct cctttgagcc cgtcaagagc ttctttaagg gcctcgtgga agccgtggag 660
agtacattac agacgccatt ggacattcgc cttaaggaaa gcataaactg ccagctctca 720
gacccttcca gcaccaagcc aggtaccttg ttgaaaacca gcccctcacc agagcgatcg 780
ctattgctga aatacgcgcg cacgcccacg ctggatcctg acacgatgca cgcgcgcctg 840
cgcctgtccg ccgatcgcct gacggtgcgc tgcggcctgc tgggcagcct ggggcccgtg 900
cccgtgctgc ggttcgacgc gctctggcaa gtgctggctc gtgactgctt cgccaccggc 960
cgccactact gggaggttga cgtgcaggag gcgggcgccg gctggtgggt gggcgcggcc 1020
tacgcctccc ttcggcgccg cggggcctcg gccgccgccc gcctgggctg caaccgccag 1080
tcctggtgcc tcaagcgcta cgaccttgag tactgggcct tccacgacgg ccagcgcagc 1140
cgcctgcggc cccgcgacga cctcgaccgg ctcggcgtct tcctggacta cgaggccggc 1200
gtcctcgcct tctacgacgt gacgggcggc atgagccacc tgcatacctt ccgcgccacg 1260
ttccaggagc cgctctaccc ggccctgcgg ctctgggagg gggccatcag catcccccgg 1320
ctgccctag 1329
<210> 28
<211> 442
<212> PRT
<213> Homo sapiens
<400> 28
Met Ala Gly Ala Ala Thr Gly Ser Arg Thr Pro Gly Arg Ser Glu Leu
1 5 10 15
Val Glu Gly Cys Gly Trp Arg Cys Pro Glu His Gly Asp Arg Val Ala
20 25 30
Glu Leu Phe Cys Arg Arg Cys Arg Arg Cys Val Cys Ala Leu Cys Pro
35 40 45
Val Leu Gly Ala His Arg Gly His Pro Val Gly Leu Ala Leu Glu Ala
50 55 60
Ala Val His Val Gln Lys Leu Ser Gln Glu Cys Leu Lys Gln Leu Ala
65 70 75 80
Ile Lys Lys Gln Gln His Ile Asp Asn Ile Thr Gln Ile Glu Asp Ala
85 90 95
Thr Glu Lys Leu Lys Ala Asn Ala Glu Ser Ser Lys Thr Trp Leu Lys
100 105 110
Gly Lys Phe Thr Glu Leu Arg Leu Leu Leu Asp Glu Glu Glu Ala Leu
115 120 125
Ala Lys Lys Phe Ile Asp Lys Asn Thr Gln Leu Thr Leu Gln Val Tyr
130 135 140
Arg Glu Gln Ala Asp Ser Cys Arg Glu Gln Leu Asp Ile Met Asn Asp
145 150 155 160
Leu Ser Asn Arg Val Trp Ser Ile Ser Gln Glu Pro Asp Pro Val Gln
165 170 175
Arg Leu Gln Ala Tyr Thr Ala Thr Glu Gln Glu Met Gln Gln Gln Met
180 185 190
Ser Leu Gly Glu Leu Cys His Pro Val Pro Leu Ser Phe Glu Pro Val
195 200 205
Lys Ser Phe Phe Lys Gly Leu Val Glu Ala Val Glu Ser Thr Leu Gln
210 215 220
Thr Pro Leu Asp Ile Arg Leu Lys Glu Ser Ile Asn Cys Gln Leu Ser
225 230 235 240
Asp Pro Ser Ser Thr Lys Pro Gly Thr Leu Leu Lys Thr Ser Pro Ser
245 250 255
Pro Glu Arg Ser Leu Leu Leu Lys Tyr Ala Arg Thr Pro Thr Leu Asp
260 265 270
Pro Asp Thr Met His Ala Arg Leu Arg Leu Ser Ala Asp Arg Leu Thr
275 280 285
Val Arg Cys Gly Leu Leu Gly Ser Leu Gly Pro Val Pro Val Leu Arg
290 295 300
Phe Asp Ala Leu Trp Gln Val Leu Ala Arg Asp Cys Phe Ala Thr Gly
305 310 315 320
Arg His Tyr Trp Glu Val Asp Val Gln Glu Ala Gly Ala Gly Trp Trp
325 330 335
Val Gly Ala Ala Tyr Ala Ser Leu Arg Arg Arg Gly Ala Ser Ala Ala
340 345 350
Ala Arg Leu Gly Cys Asn Arg Gln Ser Trp Cys Leu Lys Arg Tyr Asp
355 360 365
Leu Glu Tyr Trp Ala Phe His Asp Gly Gln Arg Ser Arg Leu Arg Pro
370 375 380
Arg Asp Asp Leu Asp Arg Leu Gly Val Phe Leu Asp Tyr Glu Ala Gly
385 390 395 400
Val Leu Ala Phe Tyr Asp Val Thr Gly Gly Met Ser His Leu His Thr
405 410 415
Phe Arg Ala Thr Phe Gln Glu Pro Leu Tyr Pro Ala Leu Arg Leu Trp
420 425 430
Glu Gly Ala Ile Ser Ile Pro Arg Leu Pro
435 440
<210> 29
<211> 1398
<212> DNA
<213> Homo sapiens
<400> 29
atgcccgcaa ccccgtccct gaaggtggtc catgagctgc ctgcctgtac cctctgtgcg 60
gggccgctgg aggatgcggt gaccattccc tgtggacaca ccttctgccg gctctgcctc 120
cccgcgctct cccagatggg ggcccaatcc tcgggcaaga tcctgctctg cccgctctgc 180
caagaggagg agcaggcaga gactcccatg gcccctgtgc ccctgggccc gctgggagaa 240
acttactgcg aggagcacgg cgagaagatc tacttcttct gcgagaacga tgccgagttc 300
ctctgtgtgt tctgcaggga gggtcccacg caccaggcgc acaccgtggg gttcctggac 360
gaggccattc agccctaccg ggatcgtctc aggagtcgac tggaagctct gagcacggag 420
agagatgaga ttgaggatgt aaagtgtcaa gaagaccaga agcttcaagt gctgctgact 480
cagatcgaaa gcaagaagca tcaggtggaa acagcttttg agaggctgca gcaggagctg 540
gagcagcagc gatgtctcct gctggccagg ctgagggagc tggagcagca gatttggaag 600
gagagggatg aatatatcac aaaggtctct gaggaagtca cccggcttgg agcccaggtc 660
aaggagctgg aggagaagtg tcagcagcca gcaagtgagc ttctacaaga tgtcagagtc 720
aaccagagca ggtgtgagat gaagactttt gtgagtcctg aggccatttc tcctgacctt 780
gtcaagaaga tccgtgattt ccacaggaaa atactcaccc tcccagagat gatgaggatg 840
ttctcagaaa acttggcgca tcatctggaa atagattcag gggtcatcac tctggaccct 900
cagaccgcca gccggagcct ggttctctcg gaagacagga agtcagtgag gtacacccgg 960
cagaagaaga gcctgccaga cagccccctg cgcttcgacg gcctcccggc ggttctgggc 1020
ttcccgggct tctcctccgg gcgccaccgc tggcaggttg acctgcagct gggcgacggc 1080
ggcggctgca cggtgggggt ggccggggag ggggtgagga ggaagggaga gatgggactc 1140
agcgccgagg acggcgtctg ggccgtgatc atctcgcacc agcagtgctg ggccagcacc 1200
tccccgggca ccgacctgcc gctgagcgag atcccgcgcg gcgtgagagt cgccctggac 1260
tacgaggcgg ggcaggtgac cctccacaac gcccagaccc aggagcccat cttcaccttc 1320
actgcctctt tctccggcaa agtcttccct ttctttgccg tctggaaaaa aggttcctgc 1380
cttacgctga aaggctga 1398
<210> 30
<211> 465
<212> PRT
<213> Homo sapiens
<400> 30
Met Pro Ala Thr Pro Ser Leu Lys Val Val His Glu Leu Pro Ala Cys
1 5 10 15
Thr Leu Cys Ala Gly Pro Leu Glu Asp Ala Val Thr Ile Pro Cys Gly
20 25 30
His Thr Phe Cys Arg Leu Cys Leu Pro Ala Leu Ser Gln Met Gly Ala
35 40 45
Gln Ser Ser Gly Lys Ile Leu Leu Cys Pro Leu Cys Gln Glu Glu Glu
50 55 60
Gln Ala Glu Thr Pro Met Ala Pro Val Pro Leu Gly Pro Leu Gly Glu
65 70 75 80
Thr Tyr Cys Glu Glu His Gly Glu Lys Ile Tyr Phe Phe Cys Glu Asn
85 90 95
Asp Ala Glu Phe Leu Cys Val Phe Cys Arg Glu Gly Pro Thr His Gln
100 105 110
Ala His Thr Val Gly Phe Leu Asp Glu Ala Ile Gln Pro Tyr Arg Asp
115 120 125
Arg Leu Arg Ser Arg Leu Glu Ala Leu Ser Thr Glu Arg Asp Glu Ile
130 135 140
Glu Asp Val Lys Cys Gln Glu Asp Gln Lys Leu Gln Val Leu Leu Thr
145 150 155 160
Gln Ile Glu Ser Lys Lys His Gln Val Glu Thr Ala Phe Glu Arg Leu
165 170 175
Gln Gln Glu Leu Glu Gln Gln Arg Cys Leu Leu Leu Ala Arg Leu Arg
180 185 190
Glu Leu Glu Gln Gln Ile Trp Lys Glu Arg Asp Glu Tyr Ile Thr Lys
195 200 205
Val Ser Glu Glu Val Thr Arg Leu Gly Ala Gln Val Lys Glu Leu Glu
210 215 220
Glu Lys Cys Gln Gln Pro Ala Ser Glu Leu Leu Gln Asp Val Arg Val
225 230 235 240
Asn Gln Ser Arg Cys Glu Met Lys Thr Phe Val Ser Pro Glu Ala Ile
245 250 255
Ser Pro Asp Leu Val Lys Lys Ile Arg Asp Phe His Arg Lys Ile Leu
260 265 270
Thr Leu Pro Glu Met Met Arg Met Phe Ser Glu Asn Leu Ala His His
275 280 285
Leu Glu Ile Asp Ser Gly Val Ile Thr Leu Asp Pro Gln Thr Ala Ser
290 295 300
Arg Ser Leu Val Leu Ser Glu Asp Arg Lys Ser Val Arg Tyr Thr Arg
305 310 315 320
Gln Lys Lys Ser Leu Pro Asp Ser Pro Leu Arg Phe Asp Gly Leu Pro
325 330 335
Ala Val Leu Gly Phe Pro Gly Phe Ser Ser Gly Arg His Arg Trp Gln
340 345 350
Val Asp Leu Gln Leu Gly Asp Gly Gly Gly Cys Thr Val Gly Val Ala
355 360 365
Gly Glu Gly Val Arg Arg Lys Gly Glu Met Gly Leu Ser Ala Glu Asp
370 375 380
Gly Val Trp Ala Val Ile Ile Ser His Gln Gln Cys Trp Ala Ser Thr
385 390 395 400
Ser Pro Gly Thr Asp Leu Pro Leu Ser Glu Ile Pro Arg Gly Val Arg
405 410 415
Val Ala Leu Asp Tyr Glu Ala Gly Gln Val Thr Leu His Asn Ala Gln
420 425 430
Thr Gln Glu Pro Ile Phe Thr Phe Thr Ala Ser Phe Ser Gly Lys Val
435 440 445
Phe Pro Phe Phe Ala Val Trp Lys Lys Gly Ser Cys Leu Thr Leu Lys
450 455 460
Gly
465
<210> 31
<211> 1695
<212> DNA
<213> Homo sapiens
<400> 31
atggctgagt tggatctaat ggctccaggg ccactgccca gggccactgc tcagccccca 60
gcccctctca gcccagactc tgggtcaccc agcccagatt ctgggtcagc cagcccagtg 120
gaagaagagg acgtgggctc ctcggagaag cttggcaggg agacggagga acaggacagc 180
gactctgcag agcaggggga tcctgctggt gaggggaaag aggtcctgtg tgacttctgc 240
cttgatgaca ccagaagagt gaaggcagtg aagtcctgtc taacctgcat ggtgaattac 300
tgtgaagagc acttgcagcc gcatcaggtg aacatcaaac tgcaaagcca cctgctgacc 360
gagccagtga aggaccacaa ctggcgatac tgccctgccc accacagccc actgtctgcc 420
ttctgctgcc ctgatcagca gtgcatctgc caggactgtt gccaggagca cagtggccac 480
accatagtct ccctggatgc agcccgcagg gacaaggagg ctgaactcca gtgcacccag 540
ttagacttgg agcggaaact caagttgaat gaaaatgcca tctccaggct ccaggctaac 600
caaaagtctg ttctggtgtc ggtgtcagag gtcaaagcgg tggctgaaat gcagtttggg 660
gaactccttg ctgctgtgag gaaggcccag gccaatgtga tgctcttctt agaggagaag 720
gagcaagctg cgctgagcca ggccaacggt atcaaggccc acctggagta caggagtgcc 780
gagatggaga agagcaagca ggagctggag aggatggcgg ccatcagcaa cactgtccag 840
ttcttggagg agtactgcaa gtttaagaac actgaagaca tcaccttccc tagtgtttac 900
gtagggctga aggataaact ctcgggcatc cgcaaagtta tcacggaatc cactgtacac 960
ttaatccagt tgctggagaa ctataagaaa aagctccagg agttttccaa ggaagaggag 1020
tatgacatca gaactcaagt gtctgccgtt gttcagcgca aatattggac ttccaaacct 1080
gagcccagca ccagggaaca gttcctccaa tatgcgtatg acatcacgtt tgacccggac 1140
acagcacaca agtatctccg gctgcaggag gagaaccgca aggtcaccaa caccacgccc 1200
tgggagcatc cctacccgga cctccccagc aggttcctgc actggcggca ggtgctgtcc 1260
cagcagagtc tgtacctgca caggtactat tttgaggtgg agatcttcgg ggcaggcacc 1320
tatgttggcc tgacctgcaa aggcatcgac cggaaagggg aggagcgcaa cagttgcatt 1380
tccggaaaca acttctcctg gagcctccaa tggaacggga aggagttcac ggcctggtac 1440
agtgacatgg agaccccact caaagctggc cctttccgga ggctcggggt ctatatcgac 1500
ttcccgggag ggatcctttc cttctatggc gtagagtatg ataccatgac tctggttcac 1560
aagtttgcct gcaaattttc agaaccagtc tatgctgcct tctggctttc caagaaggaa 1620
aacgccatcc ggattgtaga tctgggagag gaacccgaga agccagcacc gtccttggtg 1680
gggactgctc cctag 1695
<210> 32
<211> 564
<212> PRT
<213> Homo sapiens
<400> 32
Met Ala Glu Leu Asp Leu Met Ala Pro Gly Pro Leu Pro Arg Ala Thr
1 5 10 15
Ala Gln Pro Pro Ala Pro Leu Ser Pro Asp Ser Gly Ser Pro Ser Pro
20 25 30
Asp Ser Gly Ser Ala Ser Pro Val Glu Glu Glu Asp Val Gly Ser Ser
35 40 45
Glu Lys Leu Gly Arg Glu Thr Glu Glu Gln Asp Ser Asp Ser Ala Glu
50 55 60
Gln Gly Asp Pro Ala Gly Glu Gly Lys Glu Val Leu Cys Asp Phe Cys
65 70 75 80
Leu Asp Asp Thr Arg Arg Val Lys Ala Val Lys Ser Cys Leu Thr Cys
85 90 95
Met Val Asn Tyr Cys Glu Glu His Leu Gln Pro His Gln Val Asn Ile
100 105 110
Lys Leu Gln Ser His Leu Leu Thr Glu Pro Val Lys Asp His Asn Trp
115 120 125
Arg Tyr Cys Pro Ala His His Ser Pro Leu Ser Ala Phe Cys Cys Pro
130 135 140
Asp Gln Gln Cys Ile Cys Gln Asp Cys Cys Gln Glu His Ser Gly His
145 150 155 160
Thr Ile Val Ser Leu Asp Ala Ala Arg Arg Asp Lys Glu Ala Glu Leu
165 170 175
Gln Cys Thr Gln Leu Asp Leu Glu Arg Lys Leu Lys Leu Asn Glu Asn
180 185 190
Ala Ile Ser Arg Leu Gln Ala Asn Gln Lys Ser Val Leu Val Ser Val
195 200 205
Ser Glu Val Lys Ala Val Ala Glu Met Gln Phe Gly Glu Leu Leu Ala
210 215 220
Ala Val Arg Lys Ala Gln Ala Asn Val Met Leu Phe Leu Glu Glu Lys
225 230 235 240
Glu Gln Ala Ala Leu Ser Gln Ala Asn Gly Ile Lys Ala His Leu Glu
245 250 255
Tyr Arg Ser Ala Glu Met Glu Lys Ser Lys Gln Glu Leu Glu Arg Met
260 265 270
Ala Ala Ile Ser Asn Thr Val Gln Phe Leu Glu Glu Tyr Cys Lys Phe
275 280 285
Lys Asn Thr Glu Asp Ile Thr Phe Pro Ser Val Tyr Val Gly Leu Lys
290 295 300
Asp Lys Leu Ser Gly Ile Arg Lys Val Ile Thr Glu Ser Thr Val His
305 310 315 320
Leu Ile Gln Leu Leu Glu Asn Tyr Lys Lys Lys Leu Gln Glu Phe Ser
325 330 335
Lys Glu Glu Glu Tyr Asp Ile Arg Thr Gln Val Ser Ala Val Val Gln
340 345 350
Arg Lys Tyr Trp Thr Ser Lys Pro Glu Pro Ser Thr Arg Glu Gln Phe
355 360 365
Leu Gln Tyr Ala Tyr Asp Ile Thr Phe Asp Pro Asp Thr Ala His Lys
370 375 380
Tyr Leu Arg Leu Gln Glu Glu Asn Arg Lys Val Thr Asn Thr Thr Pro
385 390 395 400
Trp Glu His Pro Tyr Pro Asp Leu Pro Ser Arg Phe Leu His Trp Arg
405 410 415
Gln Val Leu Ser Gln Gln Ser Leu Tyr Leu His Arg Tyr Tyr Phe Glu
420 425 430
Val Glu Ile Phe Gly Ala Gly Thr Tyr Val Gly Leu Thr Cys Lys Gly
435 440 445
Ile Asp Arg Lys Gly Glu Glu Arg Asn Ser Cys Ile Ser Gly Asn Asn
450 455 460
Phe Ser Trp Ser Leu Gln Trp Asn Gly Lys Glu Phe Thr Ala Trp Tyr
465 470 475 480
Ser Asp Met Glu Thr Pro Leu Lys Ala Gly Pro Phe Arg Arg Leu Gly
485 490 495
Val Tyr Ile Asp Phe Pro Gly Gly Ile Leu Ser Phe Tyr Gly Val Glu
500 505 510
Tyr Asp Thr Met Thr Leu Val His Lys Phe Ala Cys Lys Phe Ser Glu
515 520 525
Pro Val Tyr Ala Ala Phe Trp Leu Ser Lys Lys Glu Asn Ala Ile Arg
530 535 540
Ile Val Asp Leu Gly Glu Glu Pro Glu Lys Pro Ala Pro Ser Leu Val
545 550 555 560
Gly Thr Ala Pro
<210> 33
<211> 1434
<212> DNA
<213> Homo sapiens
<400> 33
atggaggctg tggaactcgc cagaaaactg caggaggaag ctacgtgctc catctgtctg 60
gattacttca cagaccctgt gatgaccacc tgtggccaca acttctgccg agcctgcatc 120
cagctgagct gggaaaaggc gaggggcaag aaggggaggc ggaagcggaa gggctccttc 180
ccctgccccg agtgcagaga gatgtccccg cagaggaacc tgctgcccaa ccggctgctg 240
accaaggtgg ccgagatggc gcagcagcat cctggtctgc agaagcaaga cctgtgccag 300
gagcaccacg agcccctcaa gcttttctgc cagaaggacc agagccccat ctgtgtggtg 360
tgcagggagt cccgggagca ccggctgcac agggtgctgc ccgccgagga ggcagtgcag 420
gggtacaagt tgaagctgga ggaggacatg gagtaccttc gggagcagat caccaggaca 480
gggaatctgc aggccaggga ggagcagagc ttagccgagt ggcagggcaa ggtgaaggag 540
cggagagaac gcattgtgct ggagtttgag aagatgaacc tctacctggt ggaagaagag 600
cagaggctcc tccaggctct ggagacggaa gaagaggaga ctgccagcag gctccgggag 660
agcgtggcct gcctggaccg gcagggtcac tctctggagc tgctgctgct gcagctggag 720
gagcggagca cacaggggcc cctccagatg ctgcaggaca tgaaggaacc cctgagcagg 780
aagaacaacg tgagtgtgca gtgcccagag gttgcccccc caaccagacc caggactgtg 840
tgcagagttc ccggacagat tgaagtgcta agaggctttc tagaggatgt ggtgcctgat 900
gccacctccg cgtaccccta cctcctcctg tatgagagcc gccagaggcg ctacctcggc 960
tcttcgccgg agggcagtgg gttctgcagc aaggaccgat ttgtggctta cccctgtgct 1020
gtgggccaga cggccttctc ctctgggagg cactactggg aggtgggcat gaacatcacc 1080
ggggacgcgt tgtgggccct gggtgtgtgc agggacaacg tgagccggaa agacagggtc 1140
cccaagtgcc ccgaaaacgg cttctgggtg gtgcagctgt ccaaggggac caagtactta 1200
tccaccttct ctgccctaac cccggtcatg ctgatggagc ctcccagcca catgggcatc 1260
ttcctggact tcgaagccgg ggaagtgtcc ttctacagtg taagcgatgg gtcccacctg 1320
cacacctact cccaggccac cttcccaggc cccctgcagc ctttcttctg cctgggggct 1380
ccgaagtctg gtcagatggt catctccaca gtgaccatgt gggtgaaagg atag 1434
<210> 34
<211> 477
<212> PRT
<213> Homo sapiens
<400> 34
Met Glu Ala Val Glu Leu Ala Arg Lys Leu Gln Glu Glu Ala Thr Cys
1 5 10 15
Ser Ile Cys Leu Asp Tyr Phe Thr Asp Pro Val Met Thr Thr Cys Gly
20 25 30
His Asn Phe Cys Arg Ala Cys Ile Gln Leu Ser Trp Glu Lys Ala Arg
35 40 45
Gly Lys Lys Gly Arg Arg Lys Arg Lys Gly Ser Phe Pro Cys Pro Glu
50 55 60
Cys Arg Glu Met Ser Pro Gln Arg Asn Leu Leu Pro Asn Arg Leu Leu
65 70 75 80
Thr Lys Val Ala Glu Met Ala Gln Gln His Pro Gly Leu Gln Lys Gln
85 90 95
Asp Leu Cys Gln Glu His His Glu Pro Leu Lys Leu Phe Cys Gln Lys
100 105 110
Asp Gln Ser Pro Ile Cys Val Val Cys Arg Glu Ser Arg Glu His Arg
115 120 125
Leu His Arg Val Leu Pro Ala Glu Glu Ala Val Gln Gly Tyr Lys Leu
130 135 140
Lys Leu Glu Glu Asp Met Glu Tyr Leu Arg Glu Gln Ile Thr Arg Thr
145 150 155 160
Gly Asn Leu Gln Ala Arg Glu Glu Gln Ser Leu Ala Glu Trp Gln Gly
165 170 175
Lys Val Lys Glu Arg Arg Glu Arg Ile Val Leu Glu Phe Glu Lys Met
180 185 190
Asn Leu Tyr Leu Val Glu Glu Glu Gln Arg Leu Leu Gln Ala Leu Glu
195 200 205
Thr Glu Glu Glu Glu Thr Ala Ser Arg Leu Arg Glu Ser Val Ala Cys
210 215 220
Leu Asp Arg Gln Gly His Ser Leu Glu Leu Leu Leu Leu Gln Leu Glu
225 230 235 240
Glu Arg Ser Thr Gln Gly Pro Leu Gln Met Leu Gln Asp Met Lys Glu
245 250 255
Pro Leu Ser Arg Lys Asn Asn Val Ser Val Gln Cys Pro Glu Val Ala
260 265 270
Pro Pro Thr Arg Pro Arg Thr Val Cys Arg Val Pro Gly Gln Ile Glu
275 280 285
Val Leu Arg Gly Phe Leu Glu Asp Val Val Pro Asp Ala Thr Ser Ala
290 295 300
Tyr Pro Tyr Leu Leu Leu Tyr Glu Ser Arg Gln Arg Arg Tyr Leu Gly
305 310 315 320
Ser Ser Pro Glu Gly Ser Gly Phe Cys Ser Lys Asp Arg Phe Val Ala
325 330 335
Tyr Pro Cys Ala Val Gly Gln Thr Ala Phe Ser Ser Gly Arg His Tyr
340 345 350
Trp Glu Val Gly Met Asn Ile Thr Gly Asp Ala Leu Trp Ala Leu Gly
355 360 365
Val Cys Arg Asp Asn Val Ser Arg Lys Asp Arg Val Pro Lys Cys Pro
370 375 380
Glu Asn Gly Phe Trp Val Val Gln Leu Ser Lys Gly Thr Lys Tyr Leu
385 390 395 400
Ser Thr Phe Ser Ala Leu Thr Pro Val Met Leu Met Glu Pro Pro Ser
405 410 415
His Met Gly Ile Phe Leu Asp Phe Glu Ala Gly Glu Val Ser Phe Tyr
420 425 430
Ser Val Ser Asp Gly Ser His Leu His Thr Tyr Ser Gln Ala Thr Phe
435 440 445
Pro Gly Pro Leu Gln Pro Phe Phe Cys Leu Gly Ala Pro Lys Ser Gly
450 455 460
Gln Met Val Ile Ser Thr Val Thr Met Trp Val Lys Gly
465 470 475
<210> 35
<211> 1945
<212> DNA
<213> Homo sapiens
<400> 35
atggaaacac tggagtcaga actgacctgc cctatttgtc tggagctctt tgaggaccct 60
cttctactgc cctgcgcaca cagcctctgc ttcaactgcg cccaccgcat cctagtatca 120
cactgtgcca ccaacgagtc tgtggagtcc atcaccgcct tccagtgccc cacctgccgg 180
catgtcatca ccctcagcca gcgaggtcta gacgggctca agcgcaacgt caccctacag 240
aacatcatcg acaggttcca gaaagcatca gtgagcgggc ccaactctcc cagcgagacc 300
cgtcgggagc gggcctttga cgccaacacc atgacctccg ccgagaaggt cctctgccag 360
ttttgtgacc aggatcctgc ccaggacgct gtgaagacct gtgtcacttg tgaagtatcc 420
tactgtgacg agtgcctgaa agccactcac ccgaataaga agccctttac aggccatcgt 480
ctgattgagc caattccgga ctctcacatc cgggggctga tgtgcttgga gcatgaggat 540
gagaaggtga atatgtactg tgtgaccgat gaccagttaa tctgtgcctt gtgtaaactg 600
gttgggcggc accgcgatca tcaggtggca gctttgagtg agcgctatga caaattgaag 660
caaaacttag agagtaacct caccaacctt attaagagga acacagaact ggagaccctt 720
ttggctaaac tcatccaaac ctgtcaacat gttgaagtca atgcatcacg tcaagaagcc 780
aaattgacag aggagtgtga tcttctcatt gagatcattc agcaaagacg acagattatt 840
ggaaccaaga tcaaagaagg gaaggtgatg aggcttcgca aactggctca gcagattgca 900
aactgcaaac agtgcattga gcggtcagca tcactcatct cccaagcgga acactctctg 960
aaggagaatg atcatgcgcg tttcctacag actgctaaga atatcaccga gagagtctcc 1020
atggcaactg catcctccca ggttctaatt cctgaaatca acctcaatga cacatttgac 1080
acctttgcct tagatttttc ccgagagaag aaactgctag aatgtctgga ttaccttaca 1140
gctcccaacc ctcccacaat tagagaagag ctctgcacag cttcatatga caccatcact 1200
gtgcattgga cctccgatga tgagttcagc gtggtctcct acgagctcca gtacaccata 1260
ttcaccggac aagccaacgt cgttagtctg tgtaattcgg ctgatagctg gatgatagta 1320
cccaacatca agcagaacca ctacacggtg cacggtctgc agagcggcac caagtacatc 1380
ttcatggtca aggccatcaa ccaggcgggc agccgcagca gtgagcctgg gaagttgaag 1440
acaaacagcc aaccatttaa actggatccc aaatctgctc atcgaaaact gaaggtgtcc 1500
catgataact tgacagtaga acgtgatgag tcatcatcca agaagagtca cacacctgaa 1560
cgcttcacca gccaggggag ctatggagta gctggaaatg tgtttattga tagtggccgg 1620
cattattggg aagtggtcat aagtggaagc acatggtatg ccattggtct tgcttacaaa 1680
tcagccccga agcatgaatg gattgggaag aactctgctt cctgggcgct ctgccgctgc 1740
aacaataact gggtggtgag acacaatagc aaggaaatcc ccattgagcc tgccccccac 1800
ctccggcgcg tgggcatcct gctggactat gataacggct ctatcgcctt ttatgatgct 1860
ttgaactcca tccacctcta caccttcgac gtcgcatttg cgcagcctgt ttgccccacc 1920
ttcaccgtgt ggaacaagtg tctga 1945
<210> 36
<211> 667
<212> PRT
<213> Homo sapiens
<400> 36
Met Glu Thr Leu Glu Ser Glu Leu Thr Cys Pro Ile Cys Leu Glu Leu
1 5 10 15
Phe Glu Asp Pro Leu Leu Leu Pro Cys Ala His Ser Leu Cys Phe Asn
20 25 30
Cys Ala His Arg Ile Leu Val Ser His Cys Ala Thr Asn Glu Ser Val
35 40 45
Glu Ser Ile Thr Ala Phe Gln Cys Pro Thr Cys Arg His Val Ile Thr
50 55 60
Leu Ser Gln Arg Gly Leu Asp Gly Leu Lys Arg Asn Val Thr Leu Gln
65 70 75 80
Asn Ile Ile Asp Arg Phe Gln Lys Ala Ser Val Ser Gly Pro Asn Ser
85 90 95
Pro Ser Glu Thr Arg Arg Glu Arg Ala Phe Asp Ala Asn Thr Met Thr
100 105 110
Ser Ala Glu Lys Val Leu Cys Gln Phe Cys Asp Gln Asp Pro Ala Gln
115 120 125
Asp Ala Val Lys Thr Cys Val Thr Cys Glu Val Ser Tyr Cys Asp Glu
130 135 140
Cys Leu Lys Ala Thr His Pro Asn Lys Lys Pro Phe Thr Gly His Arg
145 150 155 160
Leu Ile Glu Pro Ile Pro Asp Ser His Ile Arg Gly Leu Met Cys Leu
165 170 175
Glu His Glu Asp Glu Lys Val Asn Met Tyr Cys Val Thr Asp Asp Gln
180 185 190
Leu Ile Cys Ala Leu Cys Lys Leu Val Gly Arg His Arg Asp His Gln
195 200 205
Val Ala Ala Leu Ser Glu Arg Tyr Asp Lys Leu Lys Gln Asn Leu Glu
210 215 220
Ser Asn Leu Thr Asn Leu Ile Lys Arg Asn Thr Glu Leu Glu Thr Leu
225 230 235 240
Leu Ala Lys Leu Ile Gln Thr Cys Gln His Val Glu Val Asn Ala Ser
245 250 255
Arg Gln Glu Ala Lys Leu Thr Glu Glu Cys Asp Leu Leu Ile Glu Ile
260 265 270
Ile Gln Gln Arg Arg Gln Ile Ile Gly Thr Lys Ile Lys Glu Gly Lys
275 280 285
Val Met Arg Leu Arg Lys Leu Ala Gln Gln Ile Ala Asn Cys Lys Gln
290 295 300
Cys Ile Glu Arg Ser Ala Ser Leu Ile Ser Gln Ala Glu His Ser Leu
305 310 315 320
Lys Glu Asn Asp His Ala Arg Phe Leu Gln Thr Ala Lys Asn Ile Thr
325 330 335
Glu Arg Val Ser Met Ala Thr Ala Ser Ser Gln Val Leu Ile Pro Glu
340 345 350
Ile Asn Leu Asn Asp Thr Phe Asp Thr Phe Ala Leu Asp Phe Ser Arg
355 360 365
Glu Lys Lys Leu Leu Glu Cys Leu Asp Tyr Leu Thr Ala Pro Asn Pro
370 375 380
Pro Thr Ile Arg Glu Glu Leu Cys Thr Ala Ser Tyr Asp Thr Ile Thr
385 390 395 400
Val His Trp Thr Ser Asp Asp Glu Phe Ser Val Val Ser Tyr Glu Leu
405 410 415
Gln Tyr Thr Ile Phe Thr Gly Gln Ala Asn Val Val Ser Leu Cys Asn
420 425 430
Ser Ala Asp Ser Trp Met Ile Val Pro Asn Ile Lys Gln Asn His Tyr
435 440 445
Thr Val His Gly Leu Gln Ser Gly Thr Lys Tyr Ile Phe Met Val Lys
450 455 460
Ala Ile Asn Gln Ala Gly Ser Arg Ser Ser Glu Pro Gly Lys Leu Lys
465 470 475 480
Thr Asn Ser Gln Pro Phe Lys Leu Asp Pro Lys Ser Ala His Arg Lys
485 490 495
Leu Lys Val Ser His Asp Asn Leu Thr Val Glu Arg Asp Glu Ser Ser
500 505 510
Ser Lys Lys Ser His Thr Pro Glu Arg Phe Thr Ser Gln Gly Ser Tyr
515 520 525
Gly Val Ala Gly Asn Val Phe Ile Asp Ser Gly Arg His Tyr Trp Glu
530 535 540
Val Val Ile Ser Gly Ser Thr Trp Tyr Ala Ile Gly Leu Ala Tyr Lys
545 550 555 560
Ser Ala Pro Lys His Glu Trp Ile Gly Lys Asn Ser Ala Ser Trp Ala
565 570 575
Leu Cys Arg Cys Asn Asn Asn Trp Val Val Arg His Asn Ser Lys Glu
580 585 590
Ile Pro Ile Glu Pro Ala Pro His Leu Arg Arg Val Gly Ile Leu Leu
595 600 605
Asp Tyr Asp Asn Gly Ser Ile Ala Phe Tyr Asp Ala Leu Asn Ser Ile
610 615 620
His Leu Tyr Thr Phe Asp Val Ala Phe Ala Gln Pro Val Cys Pro Thr
625 630 635 640
Phe Thr Val Trp Asn Lys Cys Leu Thr Ile Ile Thr Gly Leu Pro Ile
645 650 655
Pro Asp His Leu Asp Cys Thr Glu Gln Leu Pro
660 665
<210> 37
<211> 2649
<212> DNA
<213> Homo sapiens
<400> 37
atggagcctg cacccgcccg atctccgagg ccccagcagg accccgcccg gccccaggag 60
cccaccatgc ctccccccga gaccccctct gaaggccgcc agcccagccc cagccccagc 120
cctacagagc gagcccccgc ttcggaggag gagttccagt ttctgcgctg ccagcaatgc 180
caggcggaag ccaagtgccc gaagctgctg ccttgtctgc acacgctgtg ctcaggatgc 240
ctggaggcgt cgggcatgca gtgccccatc tgccaggcgc cctggcccct aggtgcagac 300
acacccgccc tggataacgt ctttttcgag agtctgcagc ggcgcctgtc ggtgtaccgg 360
cagattgtgg atgcgcaggc tgtgtgcacc cgctgcaaag agtcggccga cttctggtgc 420
tttgagtgcg agcagctcct ctgcgccaag tgcttcgagg cacaccagtg gttcctcaag 480
cacgaggccc ggcccctagc agagctgcgc aaccagtcgg tgcgtgagtt cctggacggc 540
acccgcaaga ccaacaacat cttctgctcc aaccccaacc accgcacccc tacgctgacc 600
agcatctact gccgaggatg ttccaagccg ctgtgctgct cgtgcgcgct ccttgacagc 660
agccacagtg agctcaagtg cgacatcagc gcagagatcc agcagcgaca ggaggagctg 720
gacgccatga cgcaggcgct gcaggagcag gatagtgcct ttggcgcggt tcacgcgcag 780
atgcacgcgg ccgtcggcca gctgggccgc gcgcgtgccg agaccgagga gctgatccgc 840
gagcgcgtgc gccaggtggt agctcacgtg cgggctcagg agcgcgagct gctggaggct 900
gtggacgcgc ggtaccagcg cgactacgag gagatggcca gtcggctggg ccgcctggat 960
gctgtgctgc agcgcatccg cacgggcagc gcgctggtgc agaggatgaa gtgctacgcc 1020
tcggaccagg aggtgctgga catgcacggt ttcctgcgcc aggcgctctg ccgcctgcgc 1080
caggaggagc cccagagcct gcaagctgcc gtgcgcaccg atggcttcga cgagttcaag 1140
gtgcgcctgc aggacctcag ctcttgcatc acccagggga aagatgcagc tgtatccaag 1200
aaagccagcc cagaggctgc cagcactccc agggacccta ttgacgttga cctgcccgag 1260
gaggcagaga gagtgaaggc ccaggttcag gccctggggc tggctgaagc ccagcctatg 1320
gctgtggtac agtcagtgcc cggggcacac cccgtgccag tgtacgcctt ctccatcaaa 1380
ggcccttcct atggagagga tgtctccaat acaacgacag cccagaagag gaagtgcagc 1440
cagacccagt gccccaggaa ggtcatcaag atggagtctg aggaggggaa ggaggcaagg 1500
ttggctcgga gctccccgga gcagcccagg cccagcacct ccaaggcagt ctcaccaccc 1560
cacctggatg gaccgcctag ccccaggagc cccgtcatag gaagtgaggt cttcctgccc 1620
aacagcaacc acgtggccag tggcgccggg gaggcagagg aacgcgttgt ggtgatcagc 1680
agctcggaag actcagatgc cgaaaactcg tcctcccgag agctggatga cagcagcagt 1740
gagtccagtg acctccagct ggaaggcccc agcaccctca gggtcctgga cgagaacctt 1800
gctgaccccc aagcagaaga cagacctctg gttttctttg acctcaagat tgacaatgaa 1860
acccagaaga ttagccagct ggctgcggtg aaccgggaaa gcaagttccg cgtggtcatc 1920
cagcctgaag ccttcttcag catctactcc aaggccgtgt ccctggaggt ggggctgcag 1980
cacttcctca gctttctgag ctccatgcgc cgccctatct tggcctgcta caagctgtgg 2040
gggcctggcc tcccaaactt cttccgggcc ctggaggaca ttaacaggct gtgggaattc 2100
caggaggcca tctcgggctt cctggctgcc ctgcctctca tccgggagcg tgtgcccggg 2160
gccagcagct tcaaactcaa gaacctggcc cagacctacc tggcgagaaa catgagcgag 2220
cgcagcgcca tggctgccgt gctggccatg cgtgacctgt gccgcctcct cgaggtctcc 2280
ccgggccccc agctggccca gcatgtctac cccttcagta gcctgcagtg ctttgcctcc 2340
ctgcagcccc tggtgcaggc agctgtgctg ccccgggctg aggcccgcct cctggcccta 2400
cacaacgtga gcttcatgga gctgctgagt gcacaccgcc gtgaccggca ggggggcctg 2460
aagaagtaca gccgctatct aagcctgcag accaccacgt tgccccctgc ccagcctgct 2520
ttcaacctgc aggctctggg cacctacttt gaaggcctgt tggagggtcc ggcgctggca 2580
cgggcagaag gagtctccac cccacttgct ggccgtggct tggcagagag ggcctcccag 2640
cagagctga 2649
<210> 38
<211> 882
<212> PRT
<213> Homo sapiens
<400> 38
Met Glu Pro Ala Pro Ala Arg Ser Pro Arg Pro Gln Gln Asp Pro Ala
1 5 10 15
Arg Pro Gln Glu Pro Thr Met Pro Pro Pro Glu Thr Pro Ser Glu Gly
20 25 30
Arg Gln Pro Ser Pro Ser Pro Ser Pro Thr Glu Arg Ala Pro Ala Ser
35 40 45
Glu Glu Glu Phe Gln Phe Leu Arg Cys Gln Gln Cys Gln Ala Glu Ala
50 55 60
Lys Cys Pro Lys Leu Leu Pro Cys Leu His Thr Leu Cys Ser Gly Cys
65 70 75 80
Leu Glu Ala Ser Gly Met Gln Cys Pro Ile Cys Gln Ala Pro Trp Pro
85 90 95
Leu Gly Ala Asp Thr Pro Ala Leu Asp Asn Val Phe Phe Glu Ser Leu
100 105 110
Gln Arg Arg Leu Ser Val Tyr Arg Gln Ile Val Asp Ala Gln Ala Val
115 120 125
Cys Thr Arg Cys Lys Glu Ser Ala Asp Phe Trp Cys Phe Glu Cys Glu
130 135 140
Gln Leu Leu Cys Ala Lys Cys Phe Glu Ala His Gln Trp Phe Leu Lys
145 150 155 160
His Glu Ala Arg Pro Leu Ala Glu Leu Arg Asn Gln Ser Val Arg Glu
165 170 175
Phe Leu Asp Gly Thr Arg Lys Thr Asn Asn Ile Phe Cys Ser Asn Pro
180 185 190
Asn His Arg Thr Pro Thr Leu Thr Ser Ile Tyr Cys Arg Gly Cys Ser
195 200 205
Lys Pro Leu Cys Cys Ser Cys Ala Leu Leu Asp Ser Ser His Ser Glu
210 215 220
Leu Lys Cys Asp Ile Ser Ala Glu Ile Gln Gln Arg Gln Glu Glu Leu
225 230 235 240
Asp Ala Met Thr Gln Ala Leu Gln Glu Gln Asp Ser Ala Phe Gly Ala
245 250 255
Val His Ala Gln Met His Ala Ala Val Gly Gln Leu Gly Arg Ala Arg
260 265 270
Ala Glu Thr Glu Glu Leu Ile Arg Glu Arg Val Arg Gln Val Val Ala
275 280 285
His Val Arg Ala Gln Glu Arg Glu Leu Leu Glu Ala Val Asp Ala Arg
290 295 300
Tyr Gln Arg Asp Tyr Glu Glu Met Ala Ser Arg Leu Gly Arg Leu Asp
305 310 315 320
Ala Val Leu Gln Arg Ile Arg Thr Gly Ser Ala Leu Val Gln Arg Met
325 330 335
Lys Cys Tyr Ala Ser Asp Gln Glu Val Leu Asp Met His Gly Phe Leu
340 345 350
Arg Gln Ala Leu Cys Arg Leu Arg Gln Glu Glu Pro Gln Ser Leu Gln
355 360 365
Ala Ala Val Arg Thr Asp Gly Phe Asp Glu Phe Lys Val Arg Leu Gln
370 375 380
Asp Leu Ser Ser Cys Ile Thr Gln Gly Lys Asp Ala Ala Val Ser Lys
385 390 395 400
Lys Ala Ser Pro Glu Ala Ala Ser Thr Pro Arg Asp Pro Ile Asp Val
405 410 415
Asp Leu Pro Glu Glu Ala Glu Arg Val Lys Ala Gln Val Gln Ala Leu
420 425 430
Gly Leu Ala Glu Ala Gln Pro Met Ala Val Val Gln Ser Val Pro Gly
435 440 445
Ala His Pro Val Pro Val Tyr Ala Phe Ser Ile Lys Gly Pro Ser Tyr
450 455 460
Gly Glu Asp Val Ser Asn Thr Thr Thr Ala Gln Lys Arg Lys Cys Ser
465 470 475 480
Gln Thr Gln Cys Pro Arg Lys Val Ile Lys Met Glu Ser Glu Glu Gly
485 490 495
Lys Glu Ala Arg Leu Ala Arg Ser Ser Pro Glu Gln Pro Arg Pro Ser
500 505 510
Thr Ser Lys Ala Val Ser Pro Pro His Leu Asp Gly Pro Pro Ser Pro
515 520 525
Arg Ser Pro Val Ile Gly Ser Glu Val Phe Leu Pro Asn Ser Asn His
530 535 540
Val Ala Ser Gly Ala Gly Glu Ala Glu Glu Arg Val Val Val Ile Ser
545 550 555 560
Ser Ser Glu Asp Ser Asp Ala Glu Asn Ser Ser Ser Arg Glu Leu Asp
565 570 575
Asp Ser Ser Ser Glu Ser Ser Asp Leu Gln Leu Glu Gly Pro Ser Thr
580 585 590
Leu Arg Val Leu Asp Glu Asn Leu Ala Asp Pro Gln Ala Glu Asp Arg
595 600 605
Pro Leu Val Phe Phe Asp Leu Lys Ile Asp Asn Glu Thr Gln Lys Ile
610 615 620
Ser Gln Leu Ala Ala Val Asn Arg Glu Ser Lys Phe Arg Val Val Ile
625 630 635 640
Gln Pro Glu Ala Phe Phe Ser Ile Tyr Ser Lys Ala Val Ser Leu Glu
645 650 655
Val Gly Leu Gln His Phe Leu Ser Phe Leu Ser Ser Met Arg Arg Pro
660 665 670
Ile Leu Ala Cys Tyr Lys Leu Trp Gly Pro Gly Leu Pro Asn Phe Phe
675 680 685
Arg Ala Leu Glu Asp Ile Asn Arg Leu Trp Glu Phe Gln Glu Ala Ile
690 695 700
Ser Gly Phe Leu Ala Ala Leu Pro Leu Ile Arg Glu Arg Val Pro Gly
705 710 715 720
Ala Ser Ser Phe Lys Leu Lys Asn Leu Ala Gln Thr Tyr Leu Ala Arg
725 730 735
Asn Met Ser Glu Arg Ser Ala Met Ala Ala Val Leu Ala Met Arg Asp
740 745 750
Leu Cys Arg Leu Leu Glu Val Ser Pro Gly Pro Gln Leu Ala Gln His
755 760 765
Val Tyr Pro Phe Ser Ser Leu Gln Cys Phe Ala Ser Leu Gln Pro Leu
770 775 780
Val Gln Ala Ala Val Leu Pro Arg Ala Glu Ala Arg Leu Leu Ala Leu
785 790 795 800
His Asn Val Ser Phe Met Glu Leu Leu Ser Ala His Arg Arg Asp Arg
805 810 815
Gln Gly Gly Leu Lys Lys Tyr Ser Arg Tyr Leu Ser Leu Gln Thr Thr
820 825 830
Thr Leu Pro Pro Ala Gln Pro Ala Phe Asn Leu Gln Ala Leu Gly Thr
835 840 845
Tyr Phe Glu Gly Leu Leu Glu Gly Pro Ala Leu Ala Arg Ala Glu Gly
850 855 860
Val Ser Thr Pro Leu Ala Gly Arg Gly Leu Ala Glu Arg Ala Ser Gln
865 870 875 880
Gln Ser
<210> 39
<211> 2346
<212> DNA
<213> Homo sapiens
<400> 39
atggctaaga cccctagtga ccatctgctg tccaccctgg aggagctggt gccctatgac 60
ttcgagaagt tcaagttcaa gctgcagaac accagtgtgc agaaggagca ctccaggatc 120
ccccggagcc agatccagag agccaggccg gtgaagatgg ccactctgct ggtcacctac 180
tatggggaag agtacgccgt gcagctcacc ctgcaggtcc tgcgggccat caaccagcgc 240
ctgctggccg aggagctcca cagggcagcc attcaggaat attccacaca agaaaacggc 300
acagatgatt ccgcagcgtc cagctccctg ggggagaaca agcccaggag cctgaagact 360
ccagaccacc ccgaggggaa cgaggggaac ggccctcggc cgtacggggg cggagctgcc 420
agcctgcggt gcagccagcc cgaggccggg agggggctgt cgaggaagcc cctgagcaaa 480
cgcagagaga aggcctcgga gggcctggac gcgcagggca agcctcggac ccggagcccg 540
gccctgccgg gcgggagaag ccccggcccc tgcagggcgc tagagggggg ccaggccgag 600
gtccggctgc gcagaaacgc cagctccgcg gggaggctgc aggggctggc ggggggcgcc 660
ccggggcaga aggagtgcag gcccttcgaa gtgtacctgc cctcgggaaa gatgcgacct 720
agaagccttg aggtcaccat ttctacaggg gagaaggcgc ccgcaaatcc agaaattctc 780
ctgactctag aggaaaagac agctgcgaat ctggactcgg caacagaacc ccgggcaagg 840
cccactccgg atggaggggc atctgcggac ctgaaggaag gccctggaaa tccagaacat 900
tcggtcaccg gaaggccacc agacacggct gcgagtcccc gctgccacgc ccaggaagga 960
gacccagttg acggtacctg tgtgcgtgat tcctgcagct tccccgaggc agtttctggg 1020
cacccccagg cctcaggcag ccgctcacct ggctgccccc ggtgccagga ctcccatgaa 1080
aggaagagcc cgggaagcct aagcccccag cccctgccac agtgtaagcg ccacctgaag 1140
caggtccagc tgctcttctg tgaggatcac gatgagccca tctgcctcat ctgcagtctg 1200
agtcaggagc accaaggcca ccgggtgcgc cccattgagg aggtcgccct ggaacacaag 1260
aagaaaattc agaagcagct ggagcatctg aagaagctga gaaaatcagg ggaggagcag 1320
cgatcctatg gggaggagaa ggcagtgagc tttctgaaac aaactgaagc gctgaagcag 1380
cgggtgcaga ggaagctgga gcaggtgtac tacttcctgg agcagcaaga gcatttcttt 1440
gtggcctcac tggaggacgt gggccagatg gttgggcaga tcaggaaggc atatgacacc 1500
cgcgtatccc aggacatcgc cctgctcgat gcgctgattg gggaactgga ggccaaggag 1560
tgccagtcag aatgggaact tctgcaggac attggagaca tcttgcacag ggctaagaca 1620
gtgcctgtcc ctgaaaagtg gaccactcct caagagataa aacaaaagat ccaactcctc 1680
caccagaagt cagagtttgt ggagaagagc acaaagtact tctcagaaac cctgcgttca 1740
gaaatggaaa tgttcaatgt tccagagctg attggcgctc aggcacatgc tgttaatgtg 1800
attctggatg cagaaaccgc ttaccccaac ctcatcttct ctgatgatct gaagagtgtt 1860
agacttggaa acaagtggga gaggctgcct gatggcccgc aaagatttga cagctgtatc 1920
attgttctgg gctctccgag tttcctctct ggccgccgtt actgggaggt ggaggttgga 1980
gacaagacag catggatcct gggagcctgc aagacatcca taagcaggaa agggaacatg 2040
actctgtcgc cagagaatgg ctactgggtg gtgataatga tgaaggaaaa tgagtaccag 2100
gcgtccagcg ttcccccgac ccgcctgcta ataaaggagc ctcccaagcg tgtgggcatc 2160
ttcgtggact acagagttgg aagcatctcc ttttacaatg tgacagccag atcccacatc 2220
tatacattcg ccagctgctc tttctctggg ccccttcaac ctatcttcag ccctgggaca 2280
cgtgatggag ggaagaacac agctcctctg actatctgtc cagtgggtgg tcaggggcct 2340
gactga 2346
<210> 40
<211> 781
<212> PRT
<213> Homo sapiens
<400> 40
Met Ala Lys Thr Pro Ser Asp His Leu Leu Ser Thr Leu Glu Glu Leu
1 5 10 15
Val Pro Tyr Asp Phe Glu Lys Phe Lys Phe Lys Leu Gln Asn Thr Ser
20 25 30
Val Gln Lys Glu His Ser Arg Ile Pro Arg Ser Gln Ile Gln Arg Ala
35 40 45
Arg Pro Val Lys Met Ala Thr Leu Leu Val Thr Tyr Tyr Gly Glu Glu
50 55 60
Tyr Ala Val Gln Leu Thr Leu Gln Val Leu Arg Ala Ile Asn Gln Arg
65 70 75 80
Leu Leu Ala Glu Glu Leu His Arg Ala Ala Ile Gln Glu Tyr Ser Thr
85 90 95
Gln Glu Asn Gly Thr Asp Asp Ser Ala Ala Ser Ser Ser Leu Gly Glu
100 105 110
Asn Lys Pro Arg Ser Leu Lys Thr Pro Asp His Pro Glu Gly Asn Glu
115 120 125
Gly Asn Gly Pro Arg Pro Tyr Gly Gly Gly Ala Ala Ser Leu Arg Cys
130 135 140
Ser Gln Pro Glu Ala Gly Arg Gly Leu Ser Arg Lys Pro Leu Ser Lys
145 150 155 160
Arg Arg Glu Lys Ala Ser Glu Gly Leu Asp Ala Gln Gly Lys Pro Arg
165 170 175
Thr Arg Ser Pro Ala Leu Pro Gly Gly Arg Ser Pro Gly Pro Cys Arg
180 185 190
Ala Leu Glu Gly Gly Gln Ala Glu Val Arg Leu Arg Arg Asn Ala Ser
195 200 205
Ser Ala Gly Arg Leu Gln Gly Leu Ala Gly Gly Ala Pro Gly Gln Lys
210 215 220
Glu Cys Arg Pro Phe Glu Val Tyr Leu Pro Ser Gly Lys Met Arg Pro
225 230 235 240
Arg Ser Leu Glu Val Thr Ile Ser Thr Gly Glu Lys Ala Pro Ala Asn
245 250 255
Pro Glu Ile Leu Leu Thr Leu Glu Glu Lys Thr Ala Ala Asn Leu Asp
260 265 270
Ser Ala Thr Glu Pro Arg Ala Arg Pro Thr Pro Asp Gly Gly Ala Ser
275 280 285
Ala Asp Leu Lys Glu Gly Pro Gly Asn Pro Glu His Ser Val Thr Gly
290 295 300
Arg Pro Pro Asp Thr Ala Ala Ser Pro Arg Cys His Ala Gln Glu Gly
305 310 315 320
Asp Pro Val Asp Gly Thr Cys Val Arg Asp Ser Cys Ser Phe Pro Glu
325 330 335
Ala Val Ser Gly His Pro Gln Ala Ser Gly Ser Arg Ser Pro Gly Cys
340 345 350
Pro Arg Cys Gln Asp Ser His Glu Arg Lys Ser Pro Gly Ser Leu Ser
355 360 365
Pro Gln Pro Leu Pro Gln Cys Lys Arg His Leu Lys Gln Val Gln Leu
370 375 380
Leu Phe Cys Glu Asp His Asp Glu Pro Ile Cys Leu Ile Cys Ser Leu
385 390 395 400
Ser Gln Glu His Gln Gly His Arg Val Arg Pro Ile Glu Glu Val Ala
405 410 415
Leu Glu His Lys Lys Lys Ile Gln Lys Gln Leu Glu His Leu Lys Lys
420 425 430
Leu Arg Lys Ser Gly Glu Glu Gln Arg Ser Tyr Gly Glu Glu Lys Ala
435 440 445
Val Ser Phe Leu Lys Gln Thr Glu Ala Leu Lys Gln Arg Val Gln Arg
450 455 460
Lys Leu Glu Gln Val Tyr Tyr Phe Leu Glu Gln Gln Glu His Phe Phe
465 470 475 480
Val Ala Ser Leu Glu Asp Val Gly Gln Met Val Gly Gln Ile Arg Lys
485 490 495
Ala Tyr Asp Thr Arg Val Ser Gln Asp Ile Ala Leu Leu Asp Ala Leu
500 505 510
Ile Gly Glu Leu Glu Ala Lys Glu Cys Gln Ser Glu Trp Glu Leu Leu
515 520 525
Gln Asp Ile Gly Asp Ile Leu His Arg Ala Lys Thr Val Pro Val Pro
530 535 540
Glu Lys Trp Thr Thr Pro Gln Glu Ile Lys Gln Lys Ile Gln Leu Leu
545 550 555 560
His Gln Lys Ser Glu Phe Val Glu Lys Ser Thr Lys Tyr Phe Ser Glu
565 570 575
Thr Leu Arg Ser Glu Met Glu Met Phe Asn Val Pro Glu Leu Ile Gly
580 585 590
Ala Gln Ala His Ala Val Asn Val Ile Leu Asp Ala Glu Thr Ala Tyr
595 600 605
Pro Asn Leu Ile Phe Ser Asp Asp Leu Lys Ser Val Arg Leu Gly Asn
610 615 620
Lys Trp Glu Arg Leu Pro Asp Gly Pro Gln Arg Phe Asp Ser Cys Ile
625 630 635 640
Ile Val Leu Gly Ser Pro Ser Phe Leu Ser Gly Arg Arg Tyr Trp Glu
645 650 655
Val Glu Val Gly Asp Lys Thr Ala Trp Ile Leu Gly Ala Cys Lys Thr
660 665 670
Ser Ile Ser Arg Lys Gly Asn Met Thr Leu Ser Pro Glu Asn Gly Tyr
675 680 685
Trp Val Val Ile Met Met Lys Glu Asn Glu Tyr Gln Ala Ser Ser Val
690 695 700
Pro Pro Thr Arg Leu Leu Ile Lys Glu Pro Pro Lys Arg Val Gly Ile
705 710 715 720
Phe Val Asp Tyr Arg Val Gly Ser Ile Ser Phe Tyr Asn Val Thr Ala
725 730 735
Arg Ser His Ile Tyr Thr Phe Ala Ser Cys Ser Phe Ser Gly Pro Leu
740 745 750
Gln Pro Ile Phe Ser Pro Gly Thr Arg Asp Gly Gly Lys Asn Thr Ala
755 760 765
Pro Leu Thr Ile Cys Pro Val Gly Gly Gln Gly Pro Asp
770 775 780
<210> 41
<211> 1428
<212> DNA
<213> Homo sapiens
<400> 41
atggcttcag cagcacgctt gacaatgatg tgggaggagg tcacatgccc tatctgcctg 60
gaccccttcg tggagcctgt gagcatcgag tgtggccaca gcttctgcca ggaatgcatc 120
tctcaggttg ggaaaggtgg gggcagcgtc tgtcctgtgt gccggcagcg ctttctgctc 180
aagaatctcc ggcccaatcg acagctagcc aacatggtga acaaccttaa agaaatcagc 240
caggaggcca gagagggcac acagggggaa cggtgtgcag tgcatggaga gagacttcac 300
ctgttctgtg agaaagatgg gaaggccctt tgctgggtat gtgcccagtc tcggaaacac 360
cgtgaccacg ccatggtccc tcttgaggag gctgcacagg agtaccagga gaagctccag 420
gtggcattag gggaactgag aagaaagcag gagttggctg agaagttgga agtggaaatt 480
gcaataaaga gagcagactg gaagaaaaca gtggaaacac agaaatctag gattcacgca 540
gagtttgtgc agcaaaaaaa cttcctggtt gaagaagaac agaggcagct gcaggagctg 600
gagaaggatg agagggagca gctgagaatc ctgggggaga aagaggccaa gctggcccag 660
cagagccagg ccctacagga gctcatctca gagctagatc gaaggtgcca cagctcagca 720
ctggaactgc tgcaggaggt gataattgtc ctggaaagga gtgagtcctg gaacctgaag 780
gacctggata ttacctctcc agaactcagg agtgtgtgcc atgtgccagg gctgaagaag 840
atgctgagga catgtgcagt ccacatcact ctggatccag acacagccaa tccgtggctg 900
atactttcag aagatcggag acaagtgagg cttggagaca cccagcagag catacctgga 960
aatgaagaga gatttgatag ttatcctatg gtcctgggtg cccagcactt tcactctgga 1020
aaacattact gggaggtaga tgtgacagga aaggaggcct gggacctggg tgtctgcaga 1080
gactctgtgc gcaggaaggg gcactttttg cttagttcca agagtggctt ctggacaatt 1140
tggttgtgga acaaacaaaa atatgaggct ggcacctacc cccagactcc cctccacctt 1200
caggtgcctc catgccaagt tgggattttc ctggactatg aggctggcat ggtctccttc 1260
tacaacatca ctgaccatgg ctccctcatc tactccttct ctgaatgtgc ctttacagga 1320
cctctgcggc ccttcttcag tcctggtttc aatgatggag gaaaaaacac agcccctcta 1380
accctctgtc cactgaatat tggatcacaa ggatccactg actattga 1428
<210> 42
<211> 475
<212> PRT
<213> Homo sapiens
<400> 42
Met Ala Ser Ala Ala Arg Leu Thr Met Met Trp Glu Glu Val Thr Cys
1 5 10 15
Pro Ile Cys Leu Asp Pro Phe Val Glu Pro Val Ser Ile Glu Cys Gly
20 25 30
His Ser Phe Cys Gln Glu Cys Ile Ser Gln Val Gly Lys Gly Gly Gly
35 40 45
Ser Val Cys Pro Val Cys Arg Gln Arg Phe Leu Leu Lys Asn Leu Arg
50 55 60
Pro Asn Arg Gln Leu Ala Asn Met Val Asn Asn Leu Lys Glu Ile Ser
65 70 75 80
Gln Glu Ala Arg Glu Gly Thr Gln Gly Glu Arg Cys Ala Val His Gly
85 90 95
Glu Arg Leu His Leu Phe Cys Glu Lys Asp Gly Lys Ala Leu Cys Trp
100 105 110
Val Cys Ala Gln Ser Arg Lys His Arg Asp His Ala Met Val Pro Leu
115 120 125
Glu Glu Ala Ala Gln Glu Tyr Gln Glu Lys Leu Gln Val Ala Leu Gly
130 135 140
Glu Leu Arg Arg Lys Gln Glu Leu Ala Glu Lys Leu Glu Val Glu Ile
145 150 155 160
Ala Ile Lys Arg Ala Asp Trp Lys Lys Thr Val Glu Thr Gln Lys Ser
165 170 175
Arg Ile His Ala Glu Phe Val Gln Gln Lys Asn Phe Leu Val Glu Glu
180 185 190
Glu Gln Arg Gln Leu Gln Glu Leu Glu Lys Asp Glu Arg Glu Gln Leu
195 200 205
Arg Ile Leu Gly Glu Lys Glu Ala Lys Leu Ala Gln Gln Ser Gln Ala
210 215 220
Leu Gln Glu Leu Ile Ser Glu Leu Asp Arg Arg Cys His Ser Ser Ala
225 230 235 240
Leu Glu Leu Leu Gln Glu Val Ile Ile Val Leu Glu Arg Ser Glu Ser
245 250 255
Trp Asn Leu Lys Asp Leu Asp Ile Thr Ser Pro Glu Leu Arg Ser Val
260 265 270
Cys His Val Pro Gly Leu Lys Lys Met Leu Arg Thr Cys Ala Val His
275 280 285
Ile Thr Leu Asp Pro Asp Thr Ala Asn Pro Trp Leu Ile Leu Ser Glu
290 295 300
Asp Arg Arg Gln Val Arg Leu Gly Asp Thr Gln Gln Ser Ile Pro Gly
305 310 315 320
Asn Glu Glu Arg Phe Asp Ser Tyr Pro Met Val Leu Gly Ala Gln His
325 330 335
Phe His Ser Gly Lys His Tyr Trp Glu Val Asp Val Thr Gly Lys Glu
340 345 350
Ala Trp Asp Leu Gly Val Cys Arg Asp Ser Val Arg Arg Lys Gly His
355 360 365
Phe Leu Leu Ser Ser Lys Ser Gly Phe Trp Thr Ile Trp Leu Trp Asn
370 375 380
Lys Gln Lys Tyr Glu Ala Gly Thr Tyr Pro Gln Thr Pro Leu His Leu
385 390 395 400
Gln Val Pro Pro Cys Gln Val Gly Ile Phe Leu Asp Tyr Glu Ala Gly
405 410 415
Met Val Ser Phe Tyr Asn Ile Thr Asp His Gly Ser Leu Ile Tyr Ser
420 425 430
Phe Ser Glu Cys Ala Phe Thr Gly Pro Leu Arg Pro Phe Phe Ser Pro
435 440 445
Gly Phe Asn Asp Gly Gly Lys Asn Thr Ala Pro Leu Thr Leu Cys Pro
450 455 460
Leu Asn Ile Gly Ser Gln Gly Ser Thr Asp Tyr
465 470 475
<210> 43
<211> 1497
<212> DNA
<213> Homo sapiens
<400> 43
atggatttct cagtaaaggt agacatagag aaggaggtga cctgccccat ctgcctggag 60
ctcctgacag aacctctgag cctagattgt ggccacagct tctgccaagc ctgcatcact 120
gcaaagatca aggagtcagt gatcatctca agaggggaaa gcagctgtcc tgtgtgtcag 180
accagattcc agcctgggaa cctccgacct aatcggcatc tggccaacat agttgagaga 240
gtcaaagagg tcaagatgag cccacaggag gggcagaaga gagatgtctg tgagcaccat 300
ggaaaaaaac tccagatctt ctgtaaggag gatggaaaag tcatttgctg ggtttgtgaa 360
ctgtctcagg aacaccaagg tcaccaaaca ttccgcataa acgaggtggt caaggaatgt 420
caggaaaagc tgcaggtagc cctgcagagg ctgataaagg aggatcaaga ggctgagaag 480
ctggaagatg acatcagaca agagagaacc gcctggaaga attatatcca gatcgagaga 540
cagaagattc tgaaagggtt caatgaaatg agagtcatct tggacaatga ggagcagaga 600
gagctgcaaa agctggagga aggtgaggtg aatgtgctgg ataacctggc agcagctaca 660
gaccagctgg tccagcagag gcaggatgcc agcacgctca tctcagatct ccagcggagg 720
ttgaggggat cgtcagtaga gatgctgcag gatgtgattg acgtcatgaa aaggagtgaa 780
agctggacat tgaagaagcc aaaatctgtt tccaagaaac taaagagtgt attccgagta 840
ccagatctga gtgggatgct gcaagttctt aaagagctga cagatgtcca gtactactgg 900
gtggacgtga tgctgaatcc aggcagtgcc acttcgaatg ttgctatttc tgtggatcag 960
agacaagtga aaactgtacg cacctgcaca tttaagaatt caaatccatg tgatttttct 1020
gcttttggtg tcttcggctg ccaatatttc tcttcgggga aatattactg ggaagtagat 1080
gtgtctggaa agattgcctg gatcctgggc gtacacagta aaataagtag tctgaataaa 1140
aggaagagct ctgggtttgc ttttgatcca agtgtaaatt attcaaaagt ttactccaga 1200
tatagacctc aatatggcta ctgggttata ggattacaga atacatgtga atataatgct 1260
tttgaggact cctcctcttc tgatcccaag gttttgactc tctttatggc tgtgcctccc 1320
tgtcgtattg gggttttcct agactatgag gcaggcattg tctcattttt caatgtcaca 1380
aaccacggag cactcatcta caagttctct ggatgtcgct tttctcgacc tgcttatccg 1440
tatttcaatc cttggaactg cctagtcccc atgactgtgt gcccaccgag ctcctga 1497
<210> 44
<211> 498
<212> PRT
<213> Homo sapiens
<400> 44
Met Asp Phe Ser Val Lys Val Asp Ile Glu Lys Glu Val Thr Cys Pro
1 5 10 15
Ile Cys Leu Glu Leu Leu Thr Glu Pro Leu Ser Leu Asp Cys Gly His
20 25 30
Ser Phe Cys Gln Ala Cys Ile Thr Ala Lys Ile Lys Glu Ser Val Ile
35 40 45
Ile Ser Arg Gly Glu Ser Ser Cys Pro Val Cys Gln Thr Arg Phe Gln
50 55 60
Pro Gly Asn Leu Arg Pro Asn Arg His Leu Ala Asn Ile Val Glu Arg
65 70 75 80
Val Lys Glu Val Lys Met Ser Pro Gln Glu Gly Gln Lys Arg Asp Val
85 90 95
Cys Glu His His Gly Lys Lys Leu Gln Ile Phe Cys Lys Glu Asp Gly
100 105 110
Lys Val Ile Cys Trp Val Cys Glu Leu Ser Gln Glu His Gln Gly His
115 120 125
Gln Thr Phe Arg Ile Asn Glu Val Val Lys Glu Cys Gln Glu Lys Leu
130 135 140
Gln Val Ala Leu Gln Arg Leu Ile Lys Glu Asp Gln Glu Ala Glu Lys
145 150 155 160
Leu Glu Asp Asp Ile Arg Gln Glu Arg Thr Ala Trp Lys Asn Tyr Ile
165 170 175
Gln Ile Glu Arg Gln Lys Ile Leu Lys Gly Phe Asn Glu Met Arg Val
180 185 190
Ile Leu Asp Asn Glu Glu Gln Arg Glu Leu Gln Lys Leu Glu Glu Gly
195 200 205
Glu Val Asn Val Leu Asp Asn Leu Ala Ala Ala Thr Asp Gln Leu Val
210 215 220
Gln Gln Arg Gln Asp Ala Ser Thr Leu Ile Ser Asp Leu Gln Arg Arg
225 230 235 240
Leu Arg Gly Ser Ser Val Glu Met Leu Gln Asp Val Ile Asp Val Met
245 250 255
Lys Arg Ser Glu Ser Trp Thr Leu Lys Lys Pro Lys Ser Val Ser Lys
260 265 270
Lys Leu Lys Ser Val Phe Arg Val Pro Asp Leu Ser Gly Met Leu Gln
275 280 285
Val Leu Lys Glu Leu Thr Asp Val Gln Tyr Tyr Trp Val Asp Val Met
290 295 300
Leu Asn Pro Gly Ser Ala Thr Ser Asn Val Ala Ile Ser Val Asp Gln
305 310 315 320
Arg Gln Val Lys Thr Val Arg Thr Cys Thr Phe Lys Asn Ser Asn Pro
325 330 335
Cys Asp Phe Ser Ala Phe Gly Val Phe Gly Cys Gln Tyr Phe Ser Ser
340 345 350
Gly Lys Tyr Tyr Trp Glu Val Asp Val Ser Gly Lys Ile Ala Trp Ile
355 360 365
Leu Gly Val His Ser Lys Ile Ser Ser Leu Asn Lys Arg Lys Ser Ser
370 375 380
Gly Phe Ala Phe Asp Pro Ser Val Asn Tyr Ser Lys Val Tyr Ser Arg
385 390 395 400
Tyr Arg Pro Gln Tyr Gly Tyr Trp Val Ile Gly Leu Gln Asn Thr Cys
405 410 415
Glu Tyr Asn Ala Phe Glu Asp Ser Ser Ser Ser Asp Pro Lys Val Leu
420 425 430
Thr Leu Phe Met Ala Val Pro Pro Cys Arg Ile Gly Val Phe Leu Asp
435 440 445
Tyr Glu Ala Gly Ile Val Ser Phe Phe Asn Val Thr Asn His Gly Ala
450 455 460
Leu Ile Tyr Lys Phe Ser Gly Cys Arg Phe Ser Arg Pro Ala Tyr Pro
465 470 475 480
Tyr Phe Asn Pro Trp Asn Cys Leu Val Pro Met Thr Val Cys Pro Pro
485 490 495
Ser Ser
<210> 45
<211> 1725
<212> DNA
<213> Homo sapiens
<400> 45
atggctaccc tggttgtaaa caagctcgga gcgggagtag acagtggccg gcagggcagc 60
cgggggacag ctgtagtgaa ggtgctagag tgtggagttt gtgaagatgt cttttctttg 120
caaggagaca aagttccccg tcttttgctt tgtggccata ccgtctgtca tgactgtctc 180
actcgcctac ctcttcatgg aagagcaatc cgttgcccat ttgatcgaca agtaacagac 240
ctaggtgatt caggtgtctg gggattgaaa aaaaattttg ctttattgga gcttttggaa 300
cgactgcaga atgggcctat tggtcagtat ggagctgcag aagaatccat tgggatatct 360
ggagagagca tcattcgttg tgatgaagat gaagctcacc ttgcctctgt atattgcact 420
gtgtgtgcaa ctcatttgtg ctctgagtgt tctcaagtta ctcattctac aaagacatta 480
gcaaagcaca ggcgagttcc tctagctgat aaacctcatg agaaaactat gtgctctcag 540
caccaggtgc atgccattga gtttgtttgc ttggaagaag gttgtcaaac tagcccactc 600
atgtgctgtg tctgcaaaga atatggaaaa caccagggtc acaagcattc agtattggaa 660
ccagaagcta atcagatccg agcatcaatt ttagatatgg ctcactgcat acggaccttc 720
acagaggaaa tctcagatta ttccagaaaa ttagttggaa ttgtgcagca cattgaagga 780
ggagaacaaa tcgtggaaga tggaattgga atggctcaca cagaacatgt accagggact 840
gcagagaatg cccggtcatg tattcgagct tatttttatg atctacatga aactctgtgt 900
cgtcaagaag aaatggctct aagtgttgtt gatgctcatg ttcgtgaaaa attgatttgg 960
ctcaggcagc aacaagaaga tatgactatt ttgttgtcag aggtttctgc agcctgcctc 1020
cactgtgaaa agactttgca gcaggatgat tgtagagttg tcttggcaaa acaggaaatt 1080
acaaggttac tggaaacatt gcagaaacag cagcagcagt ttacagaagt tgcagatcac 1140
attcagttgg atgccagcat ccctgtcact tttacaaagg ataatcgagt tcacattgga 1200
ccaaaaatgg aaattcgggt cgttacgtta ggattggatg gtgctggaaa aactactatc 1260
ttgtttaagt taaaacagga tgaattcatg cagcccattc caacaattgg ttttaacgtg 1320
gaaactgtag aatataaaaa tctaaaattc actatttggg atgtaggtgg aaaacacaaa 1380
ttaagaccat tgtggaaaca ttattacctc aatactcaag ctgttgtgtt tgttgtagat 1440
agcagtcata gagacagaat tagtgaagca cacagcgaac ttgcaaagtt gttaacggaa 1500
aaagaactcc gagatgctct gctcctgatt tttgctaaca aacaggatgt tgctggagca 1560
ctgtcagtag aagaaatcac tgaactactc agtctccata aattatgctg tggccgtagc 1620
tggtatattc agggctgtga tgctcgaagt ggtatgggac tgtatgaagg gttggactgg 1680
ctctcacggc aacttgtagc tgctggagta ttggatgttg cttga 1725
<210> 46
<211> 574
<212> PRT
<213> Homo sapiens
<400> 46
Met Ala Thr Leu Val Val Asn Lys Leu Gly Ala Gly Val Asp Ser Gly
1 5 10 15
Arg Gln Gly Ser Arg Gly Thr Ala Val Val Lys Val Leu Glu Cys Gly
20 25 30
Val Cys Glu Asp Val Phe Ser Leu Gln Gly Asp Lys Val Pro Arg Leu
35 40 45
Leu Leu Cys Gly His Thr Val Cys His Asp Cys Leu Thr Arg Leu Pro
50 55 60
Leu His Gly Arg Ala Ile Arg Cys Pro Phe Asp Arg Gln Val Thr Asp
65 70 75 80
Leu Gly Asp Ser Gly Val Trp Gly Leu Lys Lys Asn Phe Ala Leu Leu
85 90 95
Glu Leu Leu Glu Arg Leu Gln Asn Gly Pro Ile Gly Gln Tyr Gly Ala
100 105 110
Ala Glu Glu Ser Ile Gly Ile Ser Gly Glu Ser Ile Ile Arg Cys Asp
115 120 125
Glu Asp Glu Ala His Leu Ala Ser Val Tyr Cys Thr Val Cys Ala Thr
130 135 140
His Leu Cys Ser Glu Cys Ser Gln Val Thr His Ser Thr Lys Thr Leu
145 150 155 160
Ala Lys His Arg Arg Val Pro Leu Ala Asp Lys Pro His Glu Lys Thr
165 170 175
Met Cys Ser Gln His Gln Val His Ala Ile Glu Phe Val Cys Leu Glu
180 185 190
Glu Gly Cys Gln Thr Ser Pro Leu Met Cys Cys Val Cys Lys Glu Tyr
195 200 205
Gly Lys His Gln Gly His Lys His Ser Val Leu Glu Pro Glu Ala Asn
210 215 220
Gln Ile Arg Ala Ser Ile Leu Asp Met Ala His Cys Ile Arg Thr Phe
225 230 235 240
Thr Glu Glu Ile Ser Asp Tyr Ser Arg Lys Leu Val Gly Ile Val Gln
245 250 255
His Ile Glu Gly Gly Glu Gln Ile Val Glu Asp Gly Ile Gly Met Ala
260 265 270
His Thr Glu His Val Pro Gly Thr Ala Glu Asn Ala Arg Ser Cys Ile
275 280 285
Arg Ala Tyr Phe Tyr Asp Leu His Glu Thr Leu Cys Arg Gln Glu Glu
290 295 300
Met Ala Leu Ser Val Val Asp Ala His Val Arg Glu Lys Leu Ile Trp
305 310 315 320
Leu Arg Gln Gln Gln Glu Asp Met Thr Ile Leu Leu Ser Glu Val Ser
325 330 335
Ala Ala Cys Leu His Cys Glu Lys Thr Leu Gln Gln Asp Asp Cys Arg
340 345 350
Val Val Leu Ala Lys Gln Glu Ile Thr Arg Leu Leu Glu Thr Leu Gln
355 360 365
Lys Gln Gln Gln Gln Phe Thr Glu Val Ala Asp His Ile Gln Leu Asp
370 375 380
Ala Ser Ile Pro Val Thr Phe Thr Lys Asp Asn Arg Val His Ile Gly
385 390 395 400
Pro Lys Met Glu Ile Arg Val Val Thr Leu Gly Leu Asp Gly Ala Gly
405 410 415
Lys Thr Thr Ile Leu Phe Lys Leu Lys Gln Asp Glu Phe Met Gln Pro
420 425 430
Ile Pro Thr Ile Gly Phe Asn Val Glu Thr Val Glu Tyr Lys Asn Leu
435 440 445
Lys Phe Thr Ile Trp Asp Val Gly Gly Lys His Lys Leu Arg Pro Leu
450 455 460
Trp Lys His Tyr Tyr Leu Asn Thr Gln Ala Val Val Phe Val Val Asp
465 470 475 480
Ser Ser His Arg Asp Arg Ile Ser Glu Ala His Ser Glu Leu Ala Lys
485 490 495
Leu Leu Thr Glu Lys Glu Leu Arg Asp Ala Leu Leu Leu Ile Phe Ala
500 505 510
Asn Lys Gln Asp Val Ala Gly Ala Leu Ser Val Glu Glu Ile Thr Glu
515 520 525
Leu Leu Ser Leu His Lys Leu Cys Cys Gly Arg Ser Trp Tyr Ile Gln
530 535 540
Gly Cys Asp Ala Arg Ser Gly Met Gly Leu Tyr Glu Gly Leu Asp Trp
545 550 555 560
Leu Ser Arg Gln Leu Val Ala Ala Gly Val Leu Asp Val Ala
565 570
<210> 47
<211> 3153
<212> DNA
<213> Homo sapiens
<400> 47
atggaggtgg cggtggagaa ggcggtggcg gcggcggcag cggcctcggc tgcggcctcc 60
ggggggccct cggcggcgcc gagcggggag aacgaggccg agagtcggca gggcccggac 120
tcggagcgcg gcggcgaggc ggcccggctc aacctgttgg acacttgcgc cgtgtgccac 180
cagaacatcc agagccgggc gcccaagctg ctgccctgcc tgcactcttt ctgccagcgc 240
tgcctgcccg cgccccagcg ctacctcatg ctgcccgcgc ccatgctggg ctcggccgag 300
accccgccac ccgtccctgc ccccggctcg ccggtcagcg gctcgtcgcc gttcgccacc 360
caagttggag tcattcgttg cccagtttgc agccaagaat gtgcagagag acacatcata 420
gataactttt ttgtgaagga cactactgag gttcccagca gtacagtaga aaagtcaaat 480
caggtatgta caagctgtga ggacaacgca gaagccaatg ggttttgtgt agagtgtgtt 540
gaatggctct gcaagacgtg tatcagagct catcagaggg taaagttcac aaaagaccac 600
actgtcagac agaaagagga agtatctcca gaggcagttg gtgtcaccag ccagcgacca 660
gtgttttgtc cttttcataa aaaggagcag ctgaagctgt actgtgagac atgtgacaaa 720
ctgacatgtc gagactgtca gttgttagaa cataaagagc atagatacca atttatagaa 780
gaagcttttc agaatcagaa agtgatcata gatacactaa tcaccaaact gatggaaaaa 840
acaaaataca taaaattcac aggaaatcag atccaaaaca gaattattga agtaaatcaa 900
aatcaaaagc aggtggaaca ggatattaaa gttgctatat ttacactgat ggtagaaata 960
aataaaaaag gaaaagctct actgcatcag ttagagagcc ttgcaaagga ccatcgcatg 1020
aaacttatgc aacaacaaca ggaagtggct ggactctcta aacaattgga gcatgtcatg 1080
catttttcta aatgggcagt ttccagtggc agcagtacag cattacttta tagcaaacga 1140
ctgattacat accggttacg gcacctcctt cgtgcaaggt gtgatgcatc cccagtgacc 1200
aacaacacca tccaatttca ctgtgatcct agtttctggg ctcaaaatat catcaactta 1260
ggttctttag taatcgagga taaagagagc cagccacaaa tgcctaagca gaatcctgtc 1320
gtggaacaga attcacagcc accaagtggt ttatcatcaa accagttatc caagttccca 1380
acacagatca gcctagctca attacggctc cagcatatgc agcaacaggt aatggctcag 1440
aggcaacagg tgcaacggag gccagcacct gtgggtttac caaaccctag aatgcagggg 1500
cccatccagc aaccttccat ctctcatcag caaccgcctc cacgtttgat aaactttcag 1560
aatcacagcc ccaaacccaa tggaccagtt cttcctcctc atcctcaaca actgagatat 1620
ccaccaaacc agaacatacc acgacaagca ataaagccaa accccctaca gatggctttc 1680
ttggctcaac aagccataaa acagtggcag atcagcagtg gacagggaac cccatcaact 1740
accaacagca catcctctac tccttccagc cccacgatta ctagtgcagc aggatatgat 1800
ggaaaggctt ttggttcacc tatgatcgat ttgagctcac cagtgggagg gtcttataat 1860
cttccctctc ttccggatat tgactgttca agtactatta tgctggacaa tattgtgagg 1920
aaagatacta atatagatca tggccagcca agaccaccct caaacagaac ggtccagtca 1980
ccaaattcat cagtgccatc tccaggcctt gcaggacctg ttactatgac tagtgtacac 2040
cccccaatac gttcacctag tgcctccagc gttggaagcc gaggaagctc tggctcttcc 2100
agcaaaccag caggagctga ctctacacac aaagtcccag tggtcatgct ggagccaatt 2160
cgaataaaac aagaaaacag tggaccaccg gaaaattatg atttccctgt tgttatagtg 2220
aagcaagaat cagatgaaga atctaggcct caaaatgcca attatccaag aagcatactc 2280
acctccctgc tcttaaatag cagtcagagc tctacttctg aggagactgt gctaagatca 2340
gatgcccctg atagtacagg agatcaacct ggacttcacc aggacaattc ctcaaatgga 2400
aagtctgaat ggttggatcc ttcccagaag tcacctcttc atgttggaga gacaaggaaa 2460
gaggatgacc ccaatgagga ctggtgtgca gtttgtcaaa acggagggga actcctctgc 2520
tgtgaaaagt gccccaaagt attccatctt tcttgtcatg tgcccacatt gacaaatttt 2580
ccaagtggag agtggatttg cactttctgc cgagacttat ctaaaccaga agttgaatat 2640
gattgtgatg ctcccagtca caactcagaa aaaaagaaaa ctgaaggcct tgttaagtta 2700
acacctatag ataaaaggaa gtgtgagcgc ctacttttat ttctttactg ccatgaaatg 2760
agcctggctt ttcaagaccc tgttcctcta actgtgcctg attattacaa aataattaaa 2820
aatccaatgg atttgtcaac catcaagaaa agactacaag aagattattc catgtactca 2880
aaacctgaag attttgtagc tgattttaga ttgatctttc aaaactgtgc tgaattcaat 2940
gagcctgatt cagaagtagc caatgctggt ataaaacttg aaaattattt tgaagaactt 3000
ctaaagaacc tctatccaga aaaaaggttt cccaaaccag aattcaggaa tgaatcagaa 3060
gataataaat ttagtgatga ttcagatgat gactttgtac agccccggaa gaaacgcctc 3120
aaaagcattg aagaacgcca gttgcttaaa taa 3153
<210> 48
<211> 1050
<212> PRT
<213> Homo sapiens
<400> 48
Met Glu Val Ala Val Glu Lys Ala Val Ala Ala Ala Ala Ala Ala Ser
1 5 10 15
Ala Ala Ala Ser Gly Gly Pro Ser Ala Ala Pro Ser Gly Glu Asn Glu
20 25 30
Ala Glu Ser Arg Gln Gly Pro Asp Ser Glu Arg Gly Gly Glu Ala Ala
35 40 45
Arg Leu Asn Leu Leu Asp Thr Cys Ala Val Cys His Gln Asn Ile Gln
50 55 60
Ser Arg Ala Pro Lys Leu Leu Pro Cys Leu His Ser Phe Cys Gln Arg
65 70 75 80
Cys Leu Pro Ala Pro Gln Arg Tyr Leu Met Leu Pro Ala Pro Met Leu
85 90 95
Gly Ser Ala Glu Thr Pro Pro Pro Val Pro Ala Pro Gly Ser Pro Val
100 105 110
Ser Gly Ser Ser Pro Phe Ala Thr Gln Val Gly Val Ile Arg Cys Pro
115 120 125
Val Cys Ser Gln Glu Cys Ala Glu Arg His Ile Ile Asp Asn Phe Phe
130 135 140
Val Lys Asp Thr Thr Glu Val Pro Ser Ser Thr Val Glu Lys Ser Asn
145 150 155 160
Gln Val Cys Thr Ser Cys Glu Asp Asn Ala Glu Ala Asn Gly Phe Cys
165 170 175
Val Glu Cys Val Glu Trp Leu Cys Lys Thr Cys Ile Arg Ala His Gln
180 185 190
Arg Val Lys Phe Thr Lys Asp His Thr Val Arg Gln Lys Glu Glu Val
195 200 205
Ser Pro Glu Ala Val Gly Val Thr Ser Gln Arg Pro Val Phe Cys Pro
210 215 220
Phe His Lys Lys Glu Gln Leu Lys Leu Tyr Cys Glu Thr Cys Asp Lys
225 230 235 240
Leu Thr Cys Arg Asp Cys Gln Leu Leu Glu His Lys Glu His Arg Tyr
245 250 255
Gln Phe Ile Glu Glu Ala Phe Gln Asn Gln Lys Val Ile Ile Asp Thr
260 265 270
Leu Ile Thr Lys Leu Met Glu Lys Thr Lys Tyr Ile Lys Phe Thr Gly
275 280 285
Asn Gln Ile Gln Asn Arg Ile Ile Glu Val Asn Gln Asn Gln Lys Gln
290 295 300
Val Glu Gln Asp Ile Lys Val Ala Ile Phe Thr Leu Met Val Glu Ile
305 310 315 320
Asn Lys Lys Gly Lys Ala Leu Leu His Gln Leu Glu Ser Leu Ala Lys
325 330 335
Asp His Arg Met Lys Leu Met Gln Gln Gln Gln Glu Val Ala Gly Leu
340 345 350
Ser Lys Gln Leu Glu His Val Met His Phe Ser Lys Trp Ala Val Ser
355 360 365
Ser Gly Ser Ser Thr Ala Leu Leu Tyr Ser Lys Arg Leu Ile Thr Tyr
370 375 380
Arg Leu Arg His Leu Leu Arg Ala Arg Cys Asp Ala Ser Pro Val Thr
385 390 395 400
Asn Asn Thr Ile Gln Phe His Cys Asp Pro Ser Phe Trp Ala Gln Asn
405 410 415
Ile Ile Asn Leu Gly Ser Leu Val Ile Glu Asp Lys Glu Ser Gln Pro
420 425 430
Gln Met Pro Lys Gln Asn Pro Val Val Glu Gln Asn Ser Gln Pro Pro
435 440 445
Ser Gly Leu Ser Ser Asn Gln Leu Ser Lys Phe Pro Thr Gln Ile Ser
450 455 460
Leu Ala Gln Leu Arg Leu Gln His Met Gln Gln Gln Val Met Ala Gln
465 470 475 480
Arg Gln Gln Val Gln Arg Arg Pro Ala Pro Val Gly Leu Pro Asn Pro
485 490 495
Arg Met Gln Gly Pro Ile Gln Gln Pro Ser Ile Ser His Gln Gln Pro
500 505 510
Pro Pro Arg Leu Ile Asn Phe Gln Asn His Ser Pro Lys Pro Asn Gly
515 520 525
Pro Val Leu Pro Pro His Pro Gln Gln Leu Arg Tyr Pro Pro Asn Gln
530 535 540
Asn Ile Pro Arg Gln Ala Ile Lys Pro Asn Pro Leu Gln Met Ala Phe
545 550 555 560
Leu Ala Gln Gln Ala Ile Lys Gln Trp Gln Ile Ser Ser Gly Gln Gly
565 570 575
Thr Pro Ser Thr Thr Asn Ser Thr Ser Ser Thr Pro Ser Ser Pro Thr
580 585 590
Ile Thr Ser Ala Ala Gly Tyr Asp Gly Lys Ala Phe Gly Ser Pro Met
595 600 605
Ile Asp Leu Ser Ser Pro Val Gly Gly Ser Tyr Asn Leu Pro Ser Leu
610 615 620
Pro Asp Ile Asp Cys Ser Ser Thr Ile Met Leu Asp Asn Ile Val Arg
625 630 635 640
Lys Asp Thr Asn Ile Asp His Gly Gln Pro Arg Pro Pro Ser Asn Arg
645 650 655
Thr Val Gln Ser Pro Asn Ser Ser Val Pro Ser Pro Gly Leu Ala Gly
660 665 670
Pro Val Thr Met Thr Ser Val His Pro Pro Ile Arg Ser Pro Ser Ala
675 680 685
Ser Ser Val Gly Ser Arg Gly Ser Ser Gly Ser Ser Ser Lys Pro Ala
690 695 700
Gly Ala Asp Ser Thr His Lys Val Pro Val Val Met Leu Glu Pro Ile
705 710 715 720
Arg Ile Lys Gln Glu Asn Ser Gly Pro Pro Glu Asn Tyr Asp Phe Pro
725 730 735
Val Val Ile Val Lys Gln Glu Ser Asp Glu Glu Ser Arg Pro Gln Asn
740 745 750
Ala Asn Tyr Pro Arg Ser Ile Leu Thr Ser Leu Leu Leu Asn Ser Ser
755 760 765
Gln Ser Ser Thr Ser Glu Glu Thr Val Leu Arg Ser Asp Ala Pro Asp
770 775 780
Ser Thr Gly Asp Gln Pro Gly Leu His Gln Asp Asn Ser Ser Asn Gly
785 790 795 800
Lys Ser Glu Trp Leu Asp Pro Ser Gln Lys Ser Pro Leu His Val Gly
805 810 815
Glu Thr Arg Lys Glu Asp Asp Pro Asn Glu Asp Trp Cys Ala Val Cys
820 825 830
Gln Asn Gly Gly Glu Leu Leu Cys Cys Glu Lys Cys Pro Lys Val Phe
835 840 845
His Leu Ser Cys His Val Pro Thr Leu Thr Asn Phe Pro Ser Gly Glu
850 855 860
Trp Ile Cys Thr Phe Cys Arg Asp Leu Ser Lys Pro Glu Val Glu Tyr
865 870 875 880
Asp Cys Asp Ala Pro Ser His Asn Ser Glu Lys Lys Lys Thr Glu Gly
885 890 895
Leu Val Lys Leu Thr Pro Ile Asp Lys Arg Lys Cys Glu Arg Leu Leu
900 905 910
Leu Phe Leu Tyr Cys His Glu Met Ser Leu Ala Phe Gln Asp Pro Val
915 920 925
Pro Leu Thr Val Pro Asp Tyr Tyr Lys Ile Ile Lys Asn Pro Met Asp
930 935 940
Leu Ser Thr Ile Lys Lys Arg Leu Gln Glu Asp Tyr Ser Met Tyr Ser
945 950 955 960
Lys Pro Glu Asp Phe Val Ala Asp Phe Arg Leu Ile Phe Gln Asn Cys
965 970 975
Ala Glu Phe Asn Glu Pro Asp Ser Glu Val Ala Asn Ala Gly Ile Lys
980 985 990
Leu Glu Asn Tyr Phe Glu Glu Leu Leu Lys Asn Leu Tyr Pro Glu Lys
995 1000 1005
Arg Phe Pro Lys Pro Glu Phe Arg Asn Glu Ser Glu Asp Asn Lys
1010 1015 1020
Phe Ser Asp Asp Ser Asp Asp Asp Phe Val Gln Pro Arg Lys Lys
1025 1030 1035
Arg Leu Lys Ser Ile Glu Glu Arg Gln Leu Leu Lys
1040 1045 1050
<210> 49
<211> 1893
<212> DNA
<213> Homo sapiens
<400> 49
atggcagagc tgtgccccct ggccgaggag ctgtcgtgct ccatctgcct ggagcccttc 60
aaggagccgg tcaccactcc gtgcggccac aacttctgcg ggtcgtgcct gaatgagacg 120
tgggcagtcc agggctcgcc atacctgtgc ccgcagtgcc gcgccgtcta ccaggcgcga 180
ccgcagctgc acaagaacac ggtgctgtgc aacgtggtgg agcagttcct gcaggccgac 240
ctggcccggg agccacccgc cgacgtctgg acgccgcccg cccgcgcctc tgcacccagc 300
ccgaatgccc aggtggcctg cgaccactgc ctgaaggagg ccgccgtgaa gacgtgcttg 360
gtgtgcatgg cctccttctg tcaggagcac ctgcagccgc acttcgacag ccccgccttc 420
caggaccacc cgctgcagcc gcccgttcgc gacctgttgc gccgcaaatg ttcccagcac 480
aatcggctgc gggaattttt ctgccccgag cacagcgagt gcatctgcca catctgcctg 540
gtggagcata agacctgctc tcccgcgtcc ctgagccagg ccagcgccga cctggaggcc 600
accctgaggc acaaactaac tgtcatgtac agtcagatca acggggcgtc gagagcactg 660
gatgatgtga gaaacaggca gcaggatgtg cggatgactg caaacagaaa ggtggagcag 720
ctacaacaag aatacacgga aatgaaggct ctcttggacg cctcagagac cacctcgaca 780
aggaagataa aggaagagga gaagagggtc aacagcaagt ttgacaccat ttatcagatt 840
ctcctcaaga agaagagtga gatccagacc ttgaaggagg agattgaaca gagcctgacc 900
aagagggatg agttcgagtt tctggagaaa gcatcaaaac tgcgaggaat ctcaacaaag 960
ccagtctaca tccccgaggt ggaactgaac cacaagctga taaaaggcat ccaccagagc 1020
accatagacc tcaaaaacga gctgaagcag tgcatcgggc ggctccagga gcccaccccc 1080
agttcaggtg accctggaga gcatgaccca gcgtccacac acaaatccac acgccctgtg 1140
aagaaggtct ccaaagagga aaagaaatcc aagaaacctc cccctgtccc tgccttaccc 1200
agcaagcttc ccacgtttgg agccccggaa cagttagtgg atttaaaaca agctggcttg 1260
gaggctgcag ccaaagccac cagctcacat ccgaactcaa catctctcaa ggccaaggtg 1320
ctggagacct tcctggccaa gtccagacct gagctcctgg agtattacat taaagtcatc 1380
ctggactaca acaccgccca caacaaagtg gctctgtcag agtgctatac agtagcttct 1440
gtggctgaga tgcctcagaa ctaccggccg catccccaga ggttcacata ctgctctcag 1500
gtgctgggcc tgcactgcta caagaagggg atccactact gggaggtgga gctgcagaag 1560
aacaacttct gtggggtagg catctgctac ggaagcatga accggcaggg cccagaaagc 1620
aggctcggcc gcaacagcgc ctcctggtgc gtggagtggt tcaacaccaa gatctctgcc 1680
tggcacaata acgtggagaa aaccctgccc tccaccaagg ccacgcgggt gggcgtgctt 1740
ctcaactgtg accacggctt tgtcatcttc ttcgctgttg ccgacaaggt ccacctgatg 1800
tataagttca gggtggactt tactgaggct ttgtacccgg ctttctgggt attttctgct 1860
ggtgccacac tctccatctg ctcccccaag tag 1893
<210> 50
<211> 630
<212> PRT
<213> Homo sapiens
<400> 50
Met Ala Glu Leu Cys Pro Leu Ala Glu Glu Leu Ser Cys Ser Ile Cys
1 5 10 15
Leu Glu Pro Phe Lys Glu Pro Val Thr Thr Pro Cys Gly His Asn Phe
20 25 30
Cys Gly Ser Cys Leu Asn Glu Thr Trp Ala Val Gln Gly Ser Pro Tyr
35 40 45
Leu Cys Pro Gln Cys Arg Ala Val Tyr Gln Ala Arg Pro Gln Leu His
50 55 60
Lys Asn Thr Val Leu Cys Asn Val Val Glu Gln Phe Leu Gln Ala Asp
65 70 75 80
Leu Ala Arg Glu Pro Pro Ala Asp Val Trp Thr Pro Pro Ala Arg Ala
85 90 95
Ser Ala Pro Ser Pro Asn Ala Gln Val Ala Cys Asp His Cys Leu Lys
100 105 110
Glu Ala Ala Val Lys Thr Cys Leu Val Cys Met Ala Ser Phe Cys Gln
115 120 125
Glu His Leu Gln Pro His Phe Asp Ser Pro Ala Phe Gln Asp His Pro
130 135 140
Leu Gln Pro Pro Val Arg Asp Leu Leu Arg Arg Lys Cys Ser Gln His
145 150 155 160
Asn Arg Leu Arg Glu Phe Phe Cys Pro Glu His Ser Glu Cys Ile Cys
165 170 175
His Ile Cys Leu Val Glu His Lys Thr Cys Ser Pro Ala Ser Leu Ser
180 185 190
Gln Ala Ser Ala Asp Leu Glu Ala Thr Leu Arg His Lys Leu Thr Val
195 200 205
Met Tyr Ser Gln Ile Asn Gly Ala Ser Arg Ala Leu Asp Asp Val Arg
210 215 220
Asn Arg Gln Gln Asp Val Arg Met Thr Ala Asn Arg Lys Val Glu Gln
225 230 235 240
Leu Gln Gln Glu Tyr Thr Glu Met Lys Ala Leu Leu Asp Ala Ser Glu
245 250 255
Thr Thr Ser Thr Arg Lys Ile Lys Glu Glu Glu Lys Arg Val Asn Ser
260 265 270
Lys Phe Asp Thr Ile Tyr Gln Ile Leu Leu Lys Lys Lys Ser Glu Ile
275 280 285
Gln Thr Leu Lys Glu Glu Ile Glu Gln Ser Leu Thr Lys Arg Asp Glu
290 295 300
Phe Glu Phe Leu Glu Lys Ala Ser Lys Leu Arg Gly Ile Ser Thr Lys
305 310 315 320
Pro Val Tyr Ile Pro Glu Val Glu Leu Asn His Lys Leu Ile Lys Gly
325 330 335
Ile His Gln Ser Thr Ile Asp Leu Lys Asn Glu Leu Lys Gln Cys Ile
340 345 350
Gly Arg Leu Gln Glu Pro Thr Pro Ser Ser Gly Asp Pro Gly Glu His
355 360 365
Asp Pro Ala Ser Thr His Lys Ser Thr Arg Pro Val Lys Lys Val Ser
370 375 380
Lys Glu Glu Lys Lys Ser Lys Lys Pro Pro Pro Val Pro Ala Leu Pro
385 390 395 400
Ser Lys Leu Pro Thr Phe Gly Ala Pro Glu Gln Leu Val Asp Leu Lys
405 410 415
Gln Ala Gly Leu Glu Ala Ala Ala Lys Ala Thr Ser Ser His Pro Asn
420 425 430
Ser Thr Ser Leu Lys Ala Lys Val Leu Glu Thr Phe Leu Ala Lys Ser
435 440 445
Arg Pro Glu Leu Leu Glu Tyr Tyr Ile Lys Val Ile Leu Asp Tyr Asn
450 455 460
Thr Ala His Asn Lys Val Ala Leu Ser Glu Cys Tyr Thr Val Ala Ser
465 470 475 480
Val Ala Glu Met Pro Gln Asn Tyr Arg Pro His Pro Gln Arg Phe Thr
485 490 495
Tyr Cys Ser Gln Val Leu Gly Leu His Cys Tyr Lys Lys Gly Ile His
500 505 510
Tyr Trp Glu Val Glu Leu Gln Lys Asn Asn Phe Cys Gly Val Gly Ile
515 520 525
Cys Tyr Gly Ser Met Asn Arg Gln Gly Pro Glu Ser Arg Leu Gly Arg
530 535 540
Asn Ser Ala Ser Trp Cys Val Glu Trp Phe Asn Thr Lys Ile Ser Ala
545 550 555 560
Trp His Asn Asn Val Glu Lys Thr Leu Pro Ser Thr Lys Ala Thr Arg
565 570 575
Val Gly Val Leu Leu Asn Cys Asp His Gly Phe Val Ile Phe Phe Ala
580 585 590
Val Ala Asp Lys Val His Leu Met Tyr Lys Phe Arg Val Asp Phe Thr
595 600 605
Glu Ala Leu Tyr Pro Ala Phe Trp Val Phe Ser Ala Gly Ala Thr Leu
610 615 620
Ser Ile Cys Ser Pro Lys
625 630
<210> 51
<211> 1620
<212> DNA
<213> Homo sapiens
<400> 51
atggccacgt cagccccact acggagcctg gaagaggagg tgacctgctc catctgtctt 60
gattacctgc gggaccctgt gaccattgac tgtggccacg tcttctgccg cagctgcacc 120
acagacgtcc gccccatctc agggagccgc cccgtctgcc cactctgcaa gaagcctttt 180
aagaaggaga acatccgacc cgtgtggcaa ctggccagcc tggtggagaa cattgagcgg 240
ctgaaggtgg acaagggcag gcagccggga gaggtgaccc gggagcagca ggatgcaaag 300
ttgtgcgagc gacaccgaga gaagctgcac tactactgtg aggacgacgg gaagctgctg 360
tgcgtgatgt gccgggagtc ccgggagcac aggccccaca cggccgtcct catggagaag 420
gccgcccagc cccacaggga aaaaatcctg aaccacctga gtaccctaag gagggacaga 480
gacaaaattc agggcttcca ggcaaaggga gaagctgata tcctggccgc gctgaagaag 540
ctccaggacc agaggcagta cattgtggct gagtttgagc agggtcatca gttcctgagg 600
gagcgggagg aacacctgct ggaacagctg gcgaagctgg agcaggagct cacggagggc 660
agggagaagt tcaagagccg gggcgtcggg gagcttgccc ggctggccct ggtcatctcc 720
gaactggagg gcaaggcgca gcagccagct gcagagctca tgcaggacac gagagacttc 780
ctaaacaggt atccacggaa gaagttctgg gttgggaaac ccattgctcg agtggttaaa 840
aaaaagaccg gagaattctc agataaactc ctctctctgc aacgaggcct gagggaattc 900
caggggaagc tgctgagaga cttggaatat aagacagtga gcgtcaccct ggacccacag 960
tcggccagtg ggtacctgca gctgtcagag gactggaagt gcgtgaccta caccagcctg 1020
tacaagagtg cctacctgca cccccagcag tttgactgtg agcctggggt gctaggcagc 1080
aagggcttca cctggggcaa ggtctactgg gaagtggaag tggagaggga gggctggtct 1140
gaggatgaag aagaggggga tgaggaggaa gagggagaag aggaggagga ggaagaggag 1200
gccggctatg gggatggata tgacgactgg gaaacggacg aagatgagga atcgttgggc 1260
gatgaagagg aagaagagga ggaggaagag gaggaagttc tggaaagctg catggtgggg 1320
gtggctagag actctgtgaa gaggaaggga gacctctccc tgcggccaga ggatggcgtg 1380
tgggcgctgc gcctctcctc ctccggcatc tgggccaaca ccagccccga ggctgagctt 1440
ttcccagcac tgcggccccg gagagtgggc atcgccctgg attatgaagg gggcaccgtg 1500
actttcacca acgcagagtc acaggaactc atctacacct tcactgccac cttcacccgg 1560
cgcctggtcc ccttcctgtg gctcaagtgg ccaggaacac gcctcctgct aagaccctga 1620
<210> 52
<211> 539
<212> PRT
<213> Homo sapiens
<400> 52
Met Ala Thr Ser Ala Pro Leu Arg Ser Leu Glu Glu Glu Val Thr Cys
1 5 10 15
Ser Ile Cys Leu Asp Tyr Leu Arg Asp Pro Val Thr Ile Asp Cys Gly
20 25 30
His Val Phe Cys Arg Ser Cys Thr Thr Asp Val Arg Pro Ile Ser Gly
35 40 45
Ser Arg Pro Val Cys Pro Leu Cys Lys Lys Pro Phe Lys Lys Glu Asn
50 55 60
Ile Arg Pro Val Trp Gln Leu Ala Ser Leu Val Glu Asn Ile Glu Arg
65 70 75 80
Leu Lys Val Asp Lys Gly Arg Gln Pro Gly Glu Val Thr Arg Glu Gln
85 90 95
Gln Asp Ala Lys Leu Cys Glu Arg His Arg Glu Lys Leu His Tyr Tyr
100 105 110
Cys Glu Asp Asp Gly Lys Leu Leu Cys Val Met Cys Arg Glu Ser Arg
115 120 125
Glu His Arg Pro His Thr Ala Val Leu Met Glu Lys Ala Ala Gln Pro
130 135 140
His Arg Glu Lys Ile Leu Asn His Leu Ser Thr Leu Arg Arg Asp Arg
145 150 155 160
Asp Lys Ile Gln Gly Phe Gln Ala Lys Gly Glu Ala Asp Ile Leu Ala
165 170 175
Ala Leu Lys Lys Leu Gln Asp Gln Arg Gln Tyr Ile Val Ala Glu Phe
180 185 190
Glu Gln Gly His Gln Phe Leu Arg Glu Arg Glu Glu His Leu Leu Glu
195 200 205
Gln Leu Ala Lys Leu Glu Gln Glu Leu Thr Glu Gly Arg Glu Lys Phe
210 215 220
Lys Ser Arg Gly Val Gly Glu Leu Ala Arg Leu Ala Leu Val Ile Ser
225 230 235 240
Glu Leu Glu Gly Lys Ala Gln Gln Pro Ala Ala Glu Leu Met Gln Asp
245 250 255
Thr Arg Asp Phe Leu Asn Arg Tyr Pro Arg Lys Lys Phe Trp Val Gly
260 265 270
Lys Pro Ile Ala Arg Val Val Lys Lys Lys Thr Gly Glu Phe Ser Asp
275 280 285
Lys Leu Leu Ser Leu Gln Arg Gly Leu Arg Glu Phe Gln Gly Lys Leu
290 295 300
Leu Arg Asp Leu Glu Tyr Lys Thr Val Ser Val Thr Leu Asp Pro Gln
305 310 315 320
Ser Ala Ser Gly Tyr Leu Gln Leu Ser Glu Asp Trp Lys Cys Val Thr
325 330 335
Tyr Thr Ser Leu Tyr Lys Ser Ala Tyr Leu His Pro Gln Gln Phe Asp
340 345 350
Cys Glu Pro Gly Val Leu Gly Ser Lys Gly Phe Thr Trp Gly Lys Val
355 360 365
Tyr Trp Glu Val Glu Val Glu Arg Glu Gly Trp Ser Glu Asp Glu Glu
370 375 380
Glu Gly Asp Glu Glu Glu Glu Gly Glu Glu Glu Glu Glu Glu Glu Glu
385 390 395 400
Ala Gly Tyr Gly Asp Gly Tyr Asp Asp Trp Glu Thr Asp Glu Asp Glu
405 410 415
Glu Ser Leu Gly Asp Glu Glu Glu Glu Glu Glu Glu Glu Glu Glu Glu
420 425 430
Val Leu Glu Ser Cys Met Val Gly Val Ala Arg Asp Ser Val Lys Arg
435 440 445
Lys Gly Asp Leu Ser Leu Arg Pro Glu Asp Gly Val Trp Ala Leu Arg
450 455 460
Leu Ser Ser Ser Gly Ile Trp Ala Asn Thr Ser Pro Glu Ala Glu Leu
465 470 475 480
Phe Pro Ala Leu Arg Pro Arg Arg Val Gly Ile Ala Leu Asp Tyr Glu
485 490 495
Gly Gly Thr Val Thr Phe Thr Asn Ala Glu Ser Gln Glu Leu Ile Tyr
500 505 510
Thr Phe Thr Ala Thr Phe Thr Arg Arg Leu Val Pro Phe Leu Trp Leu
515 520 525
Lys Trp Pro Gly Thr Arg Leu Leu Leu Arg Pro
530 535
<210> 53
<211> 1542
<212> DNA
<213> Homo sapiens
<400> 53
atggcctccg ggagtgtggc cgagtgcctg cagcaggaga ccacctgccc cgtgtgcctg 60
cagtacttcg cagagcccat gatgctcgac tgcggccata acatctgttg cgcgtgcctc 120
gcccgctgct ggggcacggc agagactaac gtgtcgtgcc cgcagtgccg ggagaccttc 180
ccgcagaggc acatgcggcc caaccggcac ctggccaacg tgacccaact ggtaaagcag 240
ctgcgcaccg agcggccgtc ggggcccggc ggcgagatgg gcgtgtgcga gaagcaccgc 300
gagcccctga agctgtactg cgaggaggac cagatgccca tctgcgtggt gtgcgaccgc 360
tcccgcgagc accgcggcca cagcgtgctg ccgctcgagg aggcggtgga gggcttcaag 420
gagcaaatcc agaaccagct cgaccattta aaaagagtga aagatttaaa gaagagacgt 480
cgggcccagg gggaacaggc acgagctgaa ctcttgagcc taacccagat ggagagggag 540
aagattgttt gggagtttga gcagctgtat cactccttaa aggagcatga gtatcgcctc 600
ctggcccgcc ttgaggagct agacttggcc atctacaata gcatcaatgg tgccatcacc 660
cagttctctt gcaacatctc ccacctcagc agcctgatcg ctcagctaga agagaagcag 720
cagcagccca ccagggagct cctgcaggac attggggaca cattgagcag ggctgaaaga 780
atcaggattc ctgaaccttg gatcacacct ccagatttgc aagagaaaat ccacattttt 840
gcccaaaaat gtctattctt gacggagagt ctaaagcagt tcacagaaaa aatgcagtca 900
gatatggaga aaatccaaga attaagagag gctcagttat actcagtgga cgtgactctg 960
gacccagaca cggcctaccc cagcctgatc ctctctgata atctgcggca agtgcggtac 1020
agttacctcc aacaggacct gcctgacaac cccgagaggt tcaatctgtt tccctgtgtc 1080
ttgggctctc catgcttcat cgccgggaga cattattggg aggtagaggt gggagataaa 1140
gccaagtgga ccataggtgt ctgtgaagac tcagtgtgca gaaaaggtgg agtaacctca 1200
gccccccaga atggattctg ggcagtgtct ttgtggtatg ggaaagaata ttgggctctt 1260
acctccccaa tgactgccct acccctgcgg accccgctcc agcgggtggg gattttcttg 1320
gactatgatg ctggtgaggt ctccttctac aacgtgacag agaggtgtca caccttcact 1380
ttctctcatg ctaccttttg tgggcctgtc cggccctact tcagtctgag ttactcggga 1440
gggaaaagtg cagctcctct gatcatctgc cccatgagtg ggatagatgg gttttctggc 1500
catgttggga atcatggtca ttccatggag acctcccctt ga 1542
<210> 54
<211> 513
<212> PRT
<213> Homo sapiens
<400> 54
Met Ala Ser Gly Ser Val Ala Glu Cys Leu Gln Gln Glu Thr Thr Cys
1 5 10 15
Pro Val Cys Leu Gln Tyr Phe Ala Glu Pro Met Met Leu Asp Cys Gly
20 25 30
His Asn Ile Cys Cys Ala Cys Leu Ala Arg Cys Trp Gly Thr Ala Glu
35 40 45
Thr Asn Val Ser Cys Pro Gln Cys Arg Glu Thr Phe Pro Gln Arg His
50 55 60
Met Arg Pro Asn Arg His Leu Ala Asn Val Thr Gln Leu Val Lys Gln
65 70 75 80
Leu Arg Thr Glu Arg Pro Ser Gly Pro Gly Gly Glu Met Gly Val Cys
85 90 95
Glu Lys His Arg Glu Pro Leu Lys Leu Tyr Cys Glu Glu Asp Gln Met
100 105 110
Pro Ile Cys Val Val Cys Asp Arg Ser Arg Glu His Arg Gly His Ser
115 120 125
Val Leu Pro Leu Glu Glu Ala Val Glu Gly Phe Lys Glu Gln Ile Gln
130 135 140
Asn Gln Leu Asp His Leu Lys Arg Val Lys Asp Leu Lys Lys Arg Arg
145 150 155 160
Arg Ala Gln Gly Glu Gln Ala Arg Ala Glu Leu Leu Ser Leu Thr Gln
165 170 175
Met Glu Arg Glu Lys Ile Val Trp Glu Phe Glu Gln Leu Tyr His Ser
180 185 190
Leu Lys Glu His Glu Tyr Arg Leu Leu Ala Arg Leu Glu Glu Leu Asp
195 200 205
Leu Ala Ile Tyr Asn Ser Ile Asn Gly Ala Ile Thr Gln Phe Ser Cys
210 215 220
Asn Ile Ser His Leu Ser Ser Leu Ile Ala Gln Leu Glu Glu Lys Gln
225 230 235 240
Gln Gln Pro Thr Arg Glu Leu Leu Gln Asp Ile Gly Asp Thr Leu Ser
245 250 255
Arg Ala Glu Arg Ile Arg Ile Pro Glu Pro Trp Ile Thr Pro Pro Asp
260 265 270
Leu Gln Glu Lys Ile His Ile Phe Ala Gln Lys Cys Leu Phe Leu Thr
275 280 285
Glu Ser Leu Lys Gln Phe Thr Glu Lys Met Gln Ser Asp Met Glu Lys
290 295 300
Ile Gln Glu Leu Arg Glu Ala Gln Leu Tyr Ser Val Asp Val Thr Leu
305 310 315 320
Asp Pro Asp Thr Ala Tyr Pro Ser Leu Ile Leu Ser Asp Asn Leu Arg
325 330 335
Gln Val Arg Tyr Ser Tyr Leu Gln Gln Asp Leu Pro Asp Asn Pro Glu
340 345 350
Arg Phe Asn Leu Phe Pro Cys Val Leu Gly Ser Pro Cys Phe Ile Ala
355 360 365
Gly Arg His Tyr Trp Glu Val Glu Val Gly Asp Lys Ala Lys Trp Thr
370 375 380
Ile Gly Val Cys Glu Asp Ser Val Cys Arg Lys Gly Gly Val Thr Ser
385 390 395 400
Ala Pro Gln Asn Gly Phe Trp Ala Val Ser Leu Trp Tyr Gly Lys Glu
405 410 415
Tyr Trp Ala Leu Thr Ser Pro Met Thr Ala Leu Pro Leu Arg Thr Pro
420 425 430
Leu Gln Arg Val Gly Ile Phe Leu Asp Tyr Asp Ala Gly Glu Val Ser
435 440 445
Phe Tyr Asn Val Thr Glu Arg Cys His Thr Phe Thr Phe Ser His Ala
450 455 460
Thr Phe Cys Gly Pro Val Arg Pro Tyr Phe Ser Leu Ser Tyr Ser Gly
465 470 475 480
Gly Lys Ser Ala Ala Pro Leu Ile Ile Cys Pro Met Ser Gly Ile Asp
485 490 495
Gly Phe Ser Gly His Val Gly Asn His Gly His Ser Met Glu Thr Ser
500 505 510
Pro
<210> 55
<211> 2508
<212> DNA
<213> Homo sapiens
<400> 55
atggcggcct ccgcggcggc agcctcggca gcagcggcct cggccgcctc tggcagcccg 60
ggcccgggcg agggctccgc tggcggcgaa aagcgctcca ccgccccttc ggccgcagcc 120
tcggcctctg cctcagccgc ggcgtcgtcg cccgcggggg gcggcgccga ggcgctggag 180
ctgctggagc actgcggcgt gtgcagagag cgcctgcgac ccgagaggga gccccgcctg 240
ctgccctgtt tgcactcggc ctgtagtgcc tgcttagggc ccgcggcccc cgccgccgcc 300
aacagctcgg gggacggcgg ggcggcgggc gacggcaccg tggtggactg tcccgtgtgc 360
aagcaacagt gcttctccaa agacatcgtg gagaattatt tcatgcgtga tagtggcagc 420
aaggctgcca ccgacgccca ggatgcgaac cagtgctgca ctagctgtga ggataatgcc 480
ccagccacca gctactgtgt ggagtgctcg gagcctctgt gtgagacctg tgtagaggcg 540
caccagcggg tgaagtacac caaggaccat actgtgcgct ctactgggcc agccaagtct 600
cgggatggtg aacgtactgt ctattgcaac gtacacaagc atgaacccct tgtgctgttt 660
tgtgagagct gtgatactct cacctgccga gactgccagc tcaatgccca caaggaccac 720
cagtaccagt tcttagagga tgcagtgagg aaccagcgca agctcctggc ctcactggtg 780
aagcgccttg gggacaaaca tgcaacattg cagaagagca ccaaggaggt tcgcagctca 840
atccgccagg tgtctgacgt acagaagcgt gtgcaagtgg atgtcaagat ggccatcctg 900
cagatcatga aggagctgaa taagcggggc cgtgtgctgg tcaatgatgc ccagaaggtg 960
actgaggggc agcaggagcg cctggagcgg cagcactgga ccatgaccaa gatccagaag 1020
caccaggagc acattctgcg ctttgcctct tgggctctgg agagtgacaa caacacagcc 1080
cttttgcttt ctaagaagtt gatctacttc cagctgcacc gggccctcaa gatgattgtg 1140
gatcccgtgg agccacatgg cgagatgaag tttcagtggg acctcaatgc ctggaccaag 1200
agtgccgagg cctttggcaa gattgtggca gagcgtcctg gcactaactc aacaggccct 1260
gcacccatgg cccctccaag agccccaggg cccctgagca agcagggctc tggcagcagc 1320
cagcccatgg aggtgcagga aggctatggc tttgggtcag gagatgatcc ctactcaagt 1380
gcagagcccc atgtgtcagg tgtgaaacgg tcccgctcag gtgagggcga ggtgagcggc 1440
cttatgcgca aggtgccacg agtgagcctt gaacgcctgg acctggacct cacagctgac 1500
agccagccac ccgtcttcaa ggtcttccca ggcagtacca ctgaggacta caaccttatt 1560
gttattgaac gtggcgctgc cgctgcagct accggccagc cagggactgc gcctgcagga 1620
acccctggtg ccccacccct ggctggcatg gccattgtca aggaggagga gacggaggct 1680
gccattggag cccctcctac tgccactgag ggccctgaga ccaaacctgt gcttatggct 1740
cttgcggagg gtcctggtgc tgagggtccc cgcctggcct cacctagtgg cagcaccagc 1800
tcagggctgg aggtggtggc tcctgagggt acctcagccc caggtggtgg cccgggaacc 1860
ctggatgaca gtgccaccat ttgccgtgtc tgccagaagc caggcgatct ggttatgtgc 1920
aaccagtgtg agttttgttt ccacctggac tgtcacctgc cggccctgca ggatgtacca 1980
ggggaggagt ggagctgctc actctgccat gtgctccctg acctgaagga ggaggatggc 2040
agcctcagcc tggatggtgc agacagcact ggcgtggtgg ccaagctctc accagccaac 2100
cagcggaaat gtgagcgtgt actgctggcc ctattctgtc acgaaccctg ccgccccctg 2160
catcagctgg ctaccgactc caccttctcc ctggaccagc ccggtggcac cctggatctg 2220
accctgatcc gtgcccgcct ccaggagaag ttgtcacctc cctacagctc cccacaggag 2280
tttgcccagg atgtgggccg catgttcaag caattcaaca agttaactga ggacaaggca 2340
gacgtgcagt ccatcatcgg cctgcagcgc ttcttcgaga cgcgcatgaa cgaggccttc 2400
ggtgacacca agttctctgc tgtgctggtg gagcccccgc cgatgagcct gcctggtgct 2460
ggcctgagtt cccaggagct gtctggtggc cctggtgatg gcccctga 2508
<210> 56
<211> 835
<212> PRT
<213> Homo sapiens
<400> 56
Met Ala Ala Ser Ala Ala Ala Ala Ser Ala Ala Ala Ala Ser Ala Ala
1 5 10 15
Ser Gly Ser Pro Gly Pro Gly Glu Gly Ser Ala Gly Gly Glu Lys Arg
20 25 30
Ser Thr Ala Pro Ser Ala Ala Ala Ser Ala Ser Ala Ser Ala Ala Ala
35 40 45
Ser Ser Pro Ala Gly Gly Gly Ala Glu Ala Leu Glu Leu Leu Glu His
50 55 60
Cys Gly Val Cys Arg Glu Arg Leu Arg Pro Glu Arg Glu Pro Arg Leu
65 70 75 80
Leu Pro Cys Leu His Ser Ala Cys Ser Ala Cys Leu Gly Pro Ala Ala
85 90 95
Pro Ala Ala Ala Asn Ser Ser Gly Asp Gly Gly Ala Ala Gly Asp Gly
100 105 110
Thr Val Val Asp Cys Pro Val Cys Lys Gln Gln Cys Phe Ser Lys Asp
115 120 125
Ile Val Glu Asn Tyr Phe Met Arg Asp Ser Gly Ser Lys Ala Ala Thr
130 135 140
Asp Ala Gln Asp Ala Asn Gln Cys Cys Thr Ser Cys Glu Asp Asn Ala
145 150 155 160
Pro Ala Thr Ser Tyr Cys Val Glu Cys Ser Glu Pro Leu Cys Glu Thr
165 170 175
Cys Val Glu Ala His Gln Arg Val Lys Tyr Thr Lys Asp His Thr Val
180 185 190
Arg Ser Thr Gly Pro Ala Lys Ser Arg Asp Gly Glu Arg Thr Val Tyr
195 200 205
Cys Asn Val His Lys His Glu Pro Leu Val Leu Phe Cys Glu Ser Cys
210 215 220
Asp Thr Leu Thr Cys Arg Asp Cys Gln Leu Asn Ala His Lys Asp His
225 230 235 240
Gln Tyr Gln Phe Leu Glu Asp Ala Val Arg Asn Gln Arg Lys Leu Leu
245 250 255
Ala Ser Leu Val Lys Arg Leu Gly Asp Lys His Ala Thr Leu Gln Lys
260 265 270
Ser Thr Lys Glu Val Arg Ser Ser Ile Arg Gln Val Ser Asp Val Gln
275 280 285
Lys Arg Val Gln Val Asp Val Lys Met Ala Ile Leu Gln Ile Met Lys
290 295 300
Glu Leu Asn Lys Arg Gly Arg Val Leu Val Asn Asp Ala Gln Lys Val
305 310 315 320
Thr Glu Gly Gln Gln Glu Arg Leu Glu Arg Gln His Trp Thr Met Thr
325 330 335
Lys Ile Gln Lys His Gln Glu His Ile Leu Arg Phe Ala Ser Trp Ala
340 345 350
Leu Glu Ser Asp Asn Asn Thr Ala Leu Leu Leu Ser Lys Lys Leu Ile
355 360 365
Tyr Phe Gln Leu His Arg Ala Leu Lys Met Ile Val Asp Pro Val Glu
370 375 380
Pro His Gly Glu Met Lys Phe Gln Trp Asp Leu Asn Ala Trp Thr Lys
385 390 395 400
Ser Ala Glu Ala Phe Gly Lys Ile Val Ala Glu Arg Pro Gly Thr Asn
405 410 415
Ser Thr Gly Pro Ala Pro Met Ala Pro Pro Arg Ala Pro Gly Pro Leu
420 425 430
Ser Lys Gln Gly Ser Gly Ser Ser Gln Pro Met Glu Val Gln Glu Gly
435 440 445
Tyr Gly Phe Gly Ser Gly Asp Asp Pro Tyr Ser Ser Ala Glu Pro His
450 455 460
Val Ser Gly Val Lys Arg Ser Arg Ser Gly Glu Gly Glu Val Ser Gly
465 470 475 480
Leu Met Arg Lys Val Pro Arg Val Ser Leu Glu Arg Leu Asp Leu Asp
485 490 495
Leu Thr Ala Asp Ser Gln Pro Pro Val Phe Lys Val Phe Pro Gly Ser
500 505 510
Thr Thr Glu Asp Tyr Asn Leu Ile Val Ile Glu Arg Gly Ala Ala Ala
515 520 525
Ala Ala Thr Gly Gln Pro Gly Thr Ala Pro Ala Gly Thr Pro Gly Ala
530 535 540
Pro Pro Leu Ala Gly Met Ala Ile Val Lys Glu Glu Glu Thr Glu Ala
545 550 555 560
Ala Ile Gly Ala Pro Pro Thr Ala Thr Glu Gly Pro Glu Thr Lys Pro
565 570 575
Val Leu Met Ala Leu Ala Glu Gly Pro Gly Ala Glu Gly Pro Arg Leu
580 585 590
Ala Ser Pro Ser Gly Ser Thr Ser Ser Gly Leu Glu Val Val Ala Pro
595 600 605
Glu Gly Thr Ser Ala Pro Gly Gly Gly Pro Gly Thr Leu Asp Asp Ser
610 615 620
Ala Thr Ile Cys Arg Val Cys Gln Lys Pro Gly Asp Leu Val Met Cys
625 630 635 640
Asn Gln Cys Glu Phe Cys Phe His Leu Asp Cys His Leu Pro Ala Leu
645 650 655
Gln Asp Val Pro Gly Glu Glu Trp Ser Cys Ser Leu Cys His Val Leu
660 665 670
Pro Asp Leu Lys Glu Glu Asp Gly Ser Leu Ser Leu Asp Gly Ala Asp
675 680 685
Ser Thr Gly Val Val Ala Lys Leu Ser Pro Ala Asn Gln Arg Lys Cys
690 695 700
Glu Arg Val Leu Leu Ala Leu Phe Cys His Glu Pro Cys Arg Pro Leu
705 710 715 720
His Gln Leu Ala Thr Asp Ser Thr Phe Ser Leu Asp Gln Pro Gly Gly
725 730 735
Thr Leu Asp Leu Thr Leu Ile Arg Ala Arg Leu Gln Glu Lys Leu Ser
740 745 750
Pro Pro Tyr Ser Ser Pro Gln Glu Phe Ala Gln Asp Val Gly Arg Met
755 760 765
Phe Lys Gln Phe Asn Lys Leu Thr Glu Asp Lys Ala Asp Val Gln Ser
770 775 780
Ile Ile Gly Leu Gln Arg Phe Phe Glu Thr Arg Met Asn Glu Ala Phe
785 790 795 800
Gly Asp Thr Lys Phe Ser Ala Val Leu Val Glu Pro Pro Pro Met Ser
805 810 815
Leu Pro Gly Ala Gly Leu Ser Ser Gln Glu Leu Ser Gly Gly Pro Gly
820 825 830
Asp Gly Pro
835
<210> 57
<211> 1767
<212> DNA
<213> Homo sapiens
<400> 57
atggaagctg cagatgcctc caggagcaac gggtcgagcc cagaagccag ggatgcccgg 60
agcccgtcgg gccccagtgg cagcctggag aatggcacca aggctgacgg caaggatgcc 120
aagaccacca acgggcacgg cggggaggca gctgagggca agagcctggg cagcgccctg 180
aagccagggg aaggtaggag cgccctgttc gcgggcaatg agtggcggcg acccatcatc 240
cagtttgtcg agtccgggga cgacaagaac tccaactact tcagcatgga ctctatggaa 300
ggcaagaggt cgccgtacgc agggctccag ctgggggctg ccaagaagcc acccgttacc 360
tttgccgaaa agggcgagct gcgcaagtcc attttctcgg agtcccggaa gcccacggtg 420
tccatcatgg agcccgggga gacccggcgg aacagctacc cccgggccga cacgggcctt 480
ttttcacggt ccaagtccgg ctccgaggag gtgctgtgcg actcctgcat cggcaacaag 540
cagaaggcgg tcaagtcctg cctggtgtgc caggcctcct tctgcgagct gcatctcaag 600
ccccacctgg agggcgccgc cttccgagac caccagctgc tcgagcccat ccgggacttt 660
gaggcccgca agtgtcccgt gcatggcaag acgatggagc tcttctgcca gaccgaccag 720
acctgcatct gctacctttg catgttccag gagcacaaga atcatagcac cgtgacagtg 780
gaggaggcca aggccgagaa ggagacggag ctgtcattgc aaaaggagca gctgcagctc 840
aagatcattg agattgagga tgaagctgag aagtggcaga aggagaagga ccgcatcaag 900
agcttcacca ccaatgagaa ggccatcctg gagcagaact tccgggacct ggtgcgggac 960
ctggagaagc aaaaggagga agtgagggct gcgctggagc agcgggagca ggatgctgtg 1020
gaccaagtga aggtgatcat ggatgctctg gatgagagag ccaaggtgct gcatgaggac 1080
aagcagaccc gggagcagct gcatagcatc agcgactctg tgttgtttct gcaggaattt 1140
ggtgcattga tgagcaatta ctctctcccc ccacccctgc ccacctatca tgtcctgctg 1200
gagggggagg gcctgggaca gtcactaggc aacttcaagg acgacctgct caatgtatgc 1260
atgcgccacg ttgagaagat gtgcaaggcg gacctgagcc gtaacttcat tgagaggaac 1320
cacatggaga acggtggtga ccatcgctat gtgaacaact acacgaacag cttcgggggt 1380
gagtggagtg caccggacac catgaagaga tactccatgt acctgacacc caaaggtggg 1440
gtccggacat cataccagcc ctcgtctcct ggccgcttca ccaaggagac cacccagaag 1500
aatttcaaca atctctatgg caccaaaggt aactacacct cccgggtctg ggagtactcc 1560
tccagcattc agaactctga caatgacctg cccgtcgtcc aaggcagctc ctccttctcc 1620
ctgaaaggct atccctccct catgcggagc caaagcccca aggcccagcc ccagacttgg 1680
aaatctggca agcagactat gctgtctcac taccggccat tctacgtcaa caaaggcaac 1740
gggattgggt ccaacgaagc cccatga 1767
<210> 58
<211> 588
<212> PRT
<213> Homo sapiens
<400> 58
Met Glu Ala Ala Asp Ala Ser Arg Ser Asn Gly Ser Ser Pro Glu Ala
1 5 10 15
Arg Asp Ala Arg Ser Pro Ser Gly Pro Ser Gly Ser Leu Glu Asn Gly
20 25 30
Thr Lys Ala Asp Gly Lys Asp Ala Lys Thr Thr Asn Gly His Gly Gly
35 40 45
Glu Ala Ala Glu Gly Lys Ser Leu Gly Ser Ala Leu Lys Pro Gly Glu
50 55 60
Gly Arg Ser Ala Leu Phe Ala Gly Asn Glu Trp Arg Arg Pro Ile Ile
65 70 75 80
Gln Phe Val Glu Ser Gly Asp Asp Lys Asn Ser Asn Tyr Phe Ser Met
85 90 95
Asp Ser Met Glu Gly Lys Arg Ser Pro Tyr Ala Gly Leu Gln Leu Gly
100 105 110
Ala Ala Lys Lys Pro Pro Val Thr Phe Ala Glu Lys Gly Glu Leu Arg
115 120 125
Lys Ser Ile Phe Ser Glu Ser Arg Lys Pro Thr Val Ser Ile Met Glu
130 135 140
Pro Gly Glu Thr Arg Arg Asn Ser Tyr Pro Arg Ala Asp Thr Gly Leu
145 150 155 160
Phe Ser Arg Ser Lys Ser Gly Ser Glu Glu Val Leu Cys Asp Ser Cys
165 170 175
Ile Gly Asn Lys Gln Lys Ala Val Lys Ser Cys Leu Val Cys Gln Ala
180 185 190
Ser Phe Cys Glu Leu His Leu Lys Pro His Leu Glu Gly Ala Ala Phe
195 200 205
Arg Asp His Gln Leu Leu Glu Pro Ile Arg Asp Phe Glu Ala Arg Lys
210 215 220
Cys Pro Val His Gly Lys Thr Met Glu Leu Phe Cys Gln Thr Asp Gln
225 230 235 240
Thr Cys Ile Cys Tyr Leu Cys Met Phe Gln Glu His Lys Asn His Ser
245 250 255
Thr Val Thr Val Glu Glu Ala Lys Ala Glu Lys Glu Thr Glu Leu Ser
260 265 270
Leu Gln Lys Glu Gln Leu Gln Leu Lys Ile Ile Glu Ile Glu Asp Glu
275 280 285
Ala Glu Lys Trp Gln Lys Glu Lys Asp Arg Ile Lys Ser Phe Thr Thr
290 295 300
Asn Glu Lys Ala Ile Leu Glu Gln Asn Phe Arg Asp Leu Val Arg Asp
305 310 315 320
Leu Glu Lys Gln Lys Glu Glu Val Arg Ala Ala Leu Glu Gln Arg Glu
325 330 335
Gln Asp Ala Val Asp Gln Val Lys Val Ile Met Asp Ala Leu Asp Glu
340 345 350
Arg Ala Lys Val Leu His Glu Asp Lys Gln Thr Arg Glu Gln Leu His
355 360 365
Ser Ile Ser Asp Ser Val Leu Phe Leu Gln Glu Phe Gly Ala Leu Met
370 375 380
Ser Asn Tyr Ser Leu Pro Pro Pro Leu Pro Thr Tyr His Val Leu Leu
385 390 395 400
Glu Gly Glu Gly Leu Gly Gln Ser Leu Gly Asn Phe Lys Asp Asp Leu
405 410 415
Leu Asn Val Cys Met Arg His Val Glu Lys Met Cys Lys Ala Asp Leu
420 425 430
Ser Arg Asn Phe Ile Glu Arg Asn His Met Glu Asn Gly Gly Asp His
435 440 445
Arg Tyr Val Asn Asn Tyr Thr Asn Ser Phe Gly Gly Glu Trp Ser Ala
450 455 460
Pro Asp Thr Met Lys Arg Tyr Ser Met Tyr Leu Thr Pro Lys Gly Gly
465 470 475 480
Val Arg Thr Ser Tyr Gln Pro Ser Ser Pro Gly Arg Phe Thr Lys Glu
485 490 495
Thr Thr Gln Lys Asn Phe Asn Asn Leu Tyr Gly Thr Lys Gly Asn Tyr
500 505 510
Thr Ser Arg Val Trp Glu Tyr Ser Ser Ser Ile Gln Asn Ser Asp Asn
515 520 525
Asp Leu Pro Val Val Gln Gly Ser Ser Ser Phe Ser Leu Lys Gly Tyr
530 535 540
Pro Ser Leu Met Arg Ser Gln Ser Pro Lys Ala Gln Pro Gln Thr Trp
545 550 555 560
Lys Ser Gly Lys Gln Thr Met Leu Ser His Tyr Arg Pro Phe Tyr Val
565 570 575
Asn Lys Gly Asn Gly Ile Gly Ser Asn Glu Ala Pro
580 585
<210> 59
<211> 1491
<212> DNA
<213> Mus musculus
<400> 59
atggcctcat cagtcctgga gatgataaag gaggaagtaa cctgtcctat ctgtttggag 60
ctcctgaagg aacctgtgag tgctgattgt aaccacagct tctgcagagc ctgcatcaca 120
ctgaattatg agtccaacag aaacacagac gggaagggca actgccctgt atgccgagtt 180
ccttacccat ttgggaatct gaggcctaat ctacatgtgg ccaacatagt agagaggctc 240
aagggattca agtccattcc agaggaggag cagaaggtga atatctgtgc acaacatgga 300
gagaaactcc ggctcttctg taggaaggac atgatggtca tctgctggct ttgtgagcga 360
tctcaggagc accgtggtca ccaaacagct ctcattgaag aggttgacca agaatacaag 420
gagaagctgc agggagctct gtggaagctg atgaaaaagg caaaaatatg tgatgaatgg 480
caggatgacc ttcaactgca gagagttgac tgggagaacc aaatacagat caatgtagaa 540
aatgttcaga gacagtttaa aggactaaga gacctcctgg actccaagga gaatgaggag 600
ctgcagaagc tgaagaaaga gaagaaagag gttatggaaa agctggaaga gtctgaaaat 660
gagctggagg atcagacaga gttggtgaga gacctcatct cagatgtgga acatcatttg 720
gagctctcaa ccttagaaat gctgcagggt gcaaattgtg tcctgagaag gagtcagtcc 780
ttaagcctgc aacagcccca aactgtcccc caaaagagaa aaagaacatt ccaagctcca 840
gatctgaaag gcatgctgca agtgtatcaa ggactcatgg atatccagca atactgggtt 900
catatgactc tacatgcaag gaacaatgca gtcattgcca ttaacaaaga aaaaagacaa 960
atacagtata gaagttacaa tacggttcca gtttctgaga tctaccattt gggtgtcctg 1020
ggatatccag ctctttcctc agggaagcat tactgggaag tagacatatc tagaagtgat 1080
gcctggctcc tcggattaaa tgacggaaag tgtgctcaac cccaacttca ctcaaaggaa 1140
gaaatgggca tcaaaaaaaa ccttcattct cagatcaaac aaaatgtatt gtttcagcct 1200
aaatgtggct actgggttat agggatgaag aatccgtctg tatacaaggc ctttgatgag 1260
tgttctatca cccacaattc cagtatcctg gtcatctctc tgcctgatcg tcccagtcgt 1320
gtcggagttt tcctggatcg gaaagctggc actctctcat tttatgatgt ttctaactgc 1380
ggtgctctca tctataggtt ctatgaccct gccttccctg ttgaagtcta tccatatttt 1440
aatcctatga aatgttcaga gccaatgact atatgcgggc caccctccta a 1491
<210> 60
<211> 496
<212> PRT
<213> Mus musculus
<400> 60
Met Ala Ser Ser Val Leu Glu Met Ile Lys Glu Glu Val Thr Cys Pro
1 5 10 15
Ile Cys Leu Glu Leu Leu Lys Glu Pro Val Ser Ala Asp Cys Asn His
20 25 30
Ser Phe Cys Arg Ala Cys Ile Thr Leu Asn Tyr Glu Ser Asn Arg Asn
35 40 45
Thr Asp Gly Lys Gly Asn Cys Pro Val Cys Arg Val Pro Tyr Pro Phe
50 55 60
Gly Asn Leu Arg Pro Asn Leu His Val Ala Asn Ile Val Glu Arg Leu
65 70 75 80
Lys Gly Phe Lys Ser Ile Pro Glu Glu Glu Gln Lys Val Asn Ile Cys
85 90 95
Ala Gln His Gly Glu Lys Leu Arg Leu Phe Cys Arg Lys Asp Met Met
100 105 110
Val Ile Cys Trp Leu Cys Glu Arg Ser Gln Glu His Arg Gly His Gln
115 120 125
Thr Ala Leu Ile Glu Glu Val Asp Gln Glu Tyr Lys Glu Lys Leu Gln
130 135 140
Gly Ala Leu Trp Lys Leu Met Lys Lys Ala Lys Ile Cys Asp Glu Trp
145 150 155 160
Gln Asp Asp Leu Gln Leu Gln Arg Val Asp Trp Glu Asn Gln Ile Gln
165 170 175
Ile Asn Val Glu Asn Val Gln Arg Gln Phe Lys Gly Leu Arg Asp Leu
180 185 190
Leu Asp Ser Lys Glu Asn Glu Glu Leu Gln Lys Leu Lys Lys Glu Lys
195 200 205
Lys Glu Val Met Glu Lys Leu Glu Glu Ser Glu Asn Glu Leu Glu Asp
210 215 220
Gln Thr Glu Leu Val Arg Asp Leu Ile Ser Asp Val Glu His His Leu
225 230 235 240
Glu Leu Ser Thr Leu Glu Met Leu Gln Gly Ala Asn Cys Val Leu Arg
245 250 255
Arg Ser Gln Ser Leu Ser Leu Gln Gln Pro Gln Thr Val Pro Gln Lys
260 265 270
Arg Lys Arg Thr Phe Gln Ala Pro Asp Leu Lys Gly Met Leu Gln Val
275 280 285
Tyr Gln Gly Leu Met Asp Ile Gln Gln Tyr Trp Val His Met Thr Leu
290 295 300
His Ala Arg Asn Asn Ala Val Ile Ala Ile Asn Lys Glu Lys Arg Gln
305 310 315 320
Ile Gln Tyr Arg Ser Tyr Asn Thr Val Pro Val Ser Glu Ile Tyr His
325 330 335
Leu Gly Val Leu Gly Tyr Pro Ala Leu Ser Ser Gly Lys His Tyr Trp
340 345 350
Glu Val Asp Ile Ser Arg Ser Asp Ala Trp Leu Leu Gly Leu Asn Asp
355 360 365
Gly Lys Cys Ala Gln Pro Gln Leu His Ser Lys Glu Glu Met Gly Ile
370 375 380
Lys Lys Asn Leu His Ser Gln Ile Lys Gln Asn Val Leu Phe Gln Pro
385 390 395 400
Lys Cys Gly Tyr Trp Val Ile Gly Met Lys Asn Pro Ser Val Tyr Lys
405 410 415
Ala Phe Asp Glu Cys Ser Ile Thr His Asn Ser Ser Ile Leu Val Ile
420 425 430
Ser Leu Pro Asp Arg Pro Ser Arg Val Gly Val Phe Leu Asp Arg Lys
435 440 445
Ala Gly Thr Leu Ser Phe Tyr Asp Val Ser Asn Cys Gly Ala Leu Ile
450 455 460
Tyr Arg Phe Tyr Asp Pro Ala Phe Pro Val Glu Val Tyr Pro Tyr Phe
465 470 475 480
Asn Pro Met Lys Cys Ser Glu Pro Met Thr Ile Cys Gly Pro Pro Ser
485 490 495
<210> 61
<211> 1278
<212> DNA
<213> Homo sapiens
<400> 61
atggccagtg ggcagtttgt gaacaaactg caagaggaag tgatctgccc catctgcctg 60
gacattctgc agaaacctgt caccatcgac tgtgggcaca atttctgcct caaatgcatc 120
actcagattg gggaaacatc atgtggattt ttcaaatgtc ccctctgcaa aacttccgta 180
aggaagaacg caatcaggtt caactcgctg ttgcggaatc tggtggagaa aatccaagct 240
ctacaagcct ctgaggtgca gtccaaaagg aaagaggcta catgcccgag gcaccaggag 300
atgttccact atttctgcga ggatgatggg aagttcctct gttttgtgtg tcgtgaatcc 360
aaggaccaca aatcccataa tgtcagcttg atcgaagaag ctgcccagaa ttatcagggg 420
cagattcaag agcagatcca agtcttgcag caaaaggaga aggagacagt acaagtgaag 480
gcacaaggtg tacacagggt cgatgtcttc acggaccagg tagaacatga gaagcaaagg 540
atcctcacag aatttgaact cctgcatcaa gtcctagagg aggagaagaa tttcctgcta 600
tcacggattt actggctggg tcatgaggga acggaagcgg ggaaacacta tgttgcctcc 660
actgagccac agttgaacga tctcaagaag ctcgttgatt ccctgaagac caagcagaac 720
atgccaccca ggcagctgct ggaggatatc aaagtcgtct tgtgcagaag tgaagagttt 780
cagtttctca acccaacccc tgttcctctg gaactggaga aaaaactcag tgaagcaaaa 840
tcaagacatg actccatcac agggagccta aaaaaattca aagaccaact ccaggctgat 900
aggaaaaaag atgaaaacag attcttcaaa agcatgaata aaaatgacat gaagagctgg 960
ggcttgttac agaaaaataa tcataaaatg aacaaaacct cagagcccgg gtcatcttct 1020
gcaggcggca gaactacatc ggggccacca aatcaccact cttcagcccc atcccactcc 1080
ctgtttcggg cctcgtctgc tgggaaagtc acttttccag tatgtctcct ggcctcttat 1140
gatgagattt ctggtcaagg agcgagctct caggatacga agacatttga cgttgcgctg 1200
tccgaggagc tccatgcggc actgagtgag tggctgacag cgatccgggc ttggttttgt 1260
gaggttcctt caagctaa 1278
<210> 62
<211> 425
<212> PRT
<213> Homo sapiens
<400> 62
Met Ala Ser Gly Gln Phe Val Asn Lys Leu Gln Glu Glu Val Ile Cys
1 5 10 15
Pro Ile Cys Leu Asp Ile Leu Gln Lys Pro Val Thr Ile Asp Cys Gly
20 25 30
His Asn Phe Cys Leu Lys Cys Ile Thr Gln Ile Gly Glu Thr Ser Cys
35 40 45
Gly Phe Phe Lys Cys Pro Leu Cys Lys Thr Ser Val Arg Lys Asn Ala
50 55 60
Ile Arg Phe Asn Ser Leu Leu Arg Asn Leu Val Glu Lys Ile Gln Ala
65 70 75 80
Leu Gln Ala Ser Glu Val Gln Ser Lys Arg Lys Glu Ala Thr Cys Pro
85 90 95
Arg His Gln Glu Met Phe His Tyr Phe Cys Glu Asp Asp Gly Lys Phe
100 105 110
Leu Cys Phe Val Cys Arg Glu Ser Lys Asp His Lys Ser His Asn Val
115 120 125
Ser Leu Ile Glu Glu Ala Ala Gln Asn Tyr Gln Gly Gln Ile Gln Glu
130 135 140
Gln Ile Gln Val Leu Gln Gln Lys Glu Lys Glu Thr Val Gln Val Lys
145 150 155 160
Ala Gln Gly Val His Arg Val Asp Val Phe Thr Asp Gln Val Glu His
165 170 175
Glu Lys Gln Arg Ile Leu Thr Glu Phe Glu Leu Leu His Gln Val Leu
180 185 190
Glu Glu Glu Lys Asn Phe Leu Leu Ser Arg Ile Tyr Trp Leu Gly His
195 200 205
Glu Gly Thr Glu Ala Gly Lys His Tyr Val Ala Ser Thr Glu Pro Gln
210 215 220
Leu Asn Asp Leu Lys Lys Leu Val Asp Ser Leu Lys Thr Lys Gln Asn
225 230 235 240
Met Pro Pro Arg Gln Leu Leu Glu Asp Ile Lys Val Val Leu Cys Arg
245 250 255
Ser Glu Glu Phe Gln Phe Leu Asn Pro Thr Pro Val Pro Leu Glu Leu
260 265 270
Glu Lys Lys Leu Ser Glu Ala Lys Ser Arg His Asp Ser Ile Thr Gly
275 280 285
Ser Leu Lys Lys Phe Lys Asp Gln Leu Gln Ala Asp Arg Lys Lys Asp
290 295 300
Glu Asn Arg Phe Phe Lys Ser Met Asn Lys Asn Asp Met Lys Ser Trp
305 310 315 320
Gly Leu Leu Gln Lys Asn Asn His Lys Met Asn Lys Thr Ser Glu Pro
325 330 335
Gly Ser Ser Ser Ala Gly Gly Arg Thr Thr Ser Gly Pro Pro Asn His
340 345 350
His Ser Ser Ala Pro Ser His Ser Leu Phe Arg Ala Ser Ser Ala Gly
355 360 365
Lys Val Thr Phe Pro Val Cys Leu Leu Ala Ser Tyr Asp Glu Ile Ser
370 375 380
Gly Gln Gly Ala Ser Ser Gln Asp Thr Lys Thr Phe Asp Val Ala Leu
385 390 395 400
Ser Glu Glu Leu His Ala Ala Leu Ser Glu Trp Leu Thr Ala Ile Arg
405 410 415
Ala Trp Phe Cys Glu Val Pro Ser Ser
420 425
<210> 63
<211> 1962
<212> DNA
<213> Homo sapiens
<400> 63
atggctgcag cagcagcttc tcacctgaac ctggatgccc tccgggaagt gctagaatgc 60
cccatctgca tggagtcctt cacagaagag cagctgcgtc ccaagcttct gcactgtggc 120
cataccatct gccgccagtg cctggagaag ctattggcca gtagcatcaa tggtgtccgc 180
tgtccctttt gcagcaagat tacccgcata accagcttga cccagctgac agacaatctg 240
acagtgctaa agatcattga tacagctggg ctcagcgagg ctgtggggct gctcatgtgt 300
cggtcctgtg ggcggcgtct gccccggcaa ttctgccgga gctgtggttt ggtgttatgt 360
gagccctgcc gggaggcaga ccatcagcct cctggccact gtacactccc tgtcaaagaa 420
gcagctgagg agcggcgtcg ggactttgga gagaagttaa ctcgtctgcg ggaacttatg 480
ggggagctgc agcggcggaa ggcagccttg gaaggtgtct ccaaggacct tcaggcaagg 540
tataaagcag ttctccagga gtatgggcat gaggagcgca gggtccagga tgagctggct 600
cgctctcgga agttcttcac aggctctttg gctgaagttg agaagtccaa tagtcaagtg 660
gtagaggagc agagttacct gcttaacatt gcagaggtgc aggctgtgtc tcgctgtgac 720
tacttcctgg ccaagatcaa gcaggcagat gtagcactac tggaggagac agctgatgag 780
gaggagccag agctcactgc cagcttgcct cgggagctca ccctgcaaga tgtggagctc 840
cttaaggtag gtcatgttgg ccccctccaa attggacaag ctgttaagaa gccccggaca 900
gttaacgtgg aagattcctg ggccatggag gccacagcgt ctgctgcctc tacctctgtt 960
acttttagag agatggacat gagcccggag gaagtggttg ccagccctag ggcctcacct 1020
gctaaacagc ggggtcctga ggcagcctcc aatatccagc agtgcctctt tctcaagaag 1080
atgggggcca aaggcagcac tccaggaatg ttcaatcttc cagtcagtct ctacgtgacc 1140
agtcaaggtg aagtactagt cgctgaccgt ggtaactatc gtatacaagt ctttacccgc 1200
aaaggctttt tgaaggaaat ccgccgcagc cccagtggca ttgatagctt tgtgctaagc 1260
ttccttgggg cagatctacc caacctcact cctctctcag tggcaatgaa ctgccagggg 1320
ctgattggtg tgactgacag ctatgataac tccctcaagg tatatacctt ggatggccac 1380
tgcgtggcct gtcacaggag ccagctgagc aaaccatggg gtatcacagc cttgccatct 1440
ggccagtttg tagtaaccga tgtggaaggt ggaaagcttt ggtgtttcac agttgatcga 1500
ggatcagggg tggtcaaata cagctgccta tgtagtgctg tgcggcccaa atttgtcacc 1560
tgtgatgctg agggcaccgt ctacttcacc cagggcttag gcctcaatct ggagaatcgg 1620
cagaatgagc accacctgga gggtggcttt tccattggct ctgtaggccc tgatgggcag 1680
ctgggtcgcc agattagcca cttcttctcg gagaatgagg atttccgctg cattgctggc 1740
atgtgtgtgg atgctcgtgg tgatctcatc gtggctgaca gtagtcgcaa ggaaattctc 1800
cattttccta agggtggggg ctatagtgtc cttattcgag agggacttac ctgtccggtg 1860
ggcatagccc taactcctaa ggggcagctg ctggtcttgg actgttggga tcattgcatc 1920
aagatctaca gctaccatct gagaagatat tccaccccat ag 1962
<210> 64
<211> 653
<212> PRT
<213> Homo sapiens
<400> 64
Met Ala Ala Ala Ala Ala Ser His Leu Asn Leu Asp Ala Leu Arg Glu
1 5 10 15
Val Leu Glu Cys Pro Ile Cys Met Glu Ser Phe Thr Glu Glu Gln Leu
20 25 30
Arg Pro Lys Leu Leu His Cys Gly His Thr Ile Cys Arg Gln Cys Leu
35 40 45
Glu Lys Leu Leu Ala Ser Ser Ile Asn Gly Val Arg Cys Pro Phe Cys
50 55 60
Ser Lys Ile Thr Arg Ile Thr Ser Leu Thr Gln Leu Thr Asp Asn Leu
65 70 75 80
Thr Val Leu Lys Ile Ile Asp Thr Ala Gly Leu Ser Glu Ala Val Gly
85 90 95
Leu Leu Met Cys Arg Ser Cys Gly Arg Arg Leu Pro Arg Gln Phe Cys
100 105 110
Arg Ser Cys Gly Leu Val Leu Cys Glu Pro Cys Arg Glu Ala Asp His
115 120 125
Gln Pro Pro Gly His Cys Thr Leu Pro Val Lys Glu Ala Ala Glu Glu
130 135 140
Arg Arg Arg Asp Phe Gly Glu Lys Leu Thr Arg Leu Arg Glu Leu Met
145 150 155 160
Gly Glu Leu Gln Arg Arg Lys Ala Ala Leu Glu Gly Val Ser Lys Asp
165 170 175
Leu Gln Ala Arg Tyr Lys Ala Val Leu Gln Glu Tyr Gly His Glu Glu
180 185 190
Arg Arg Val Gln Asp Glu Leu Ala Arg Ser Arg Lys Phe Phe Thr Gly
195 200 205
Ser Leu Ala Glu Val Glu Lys Ser Asn Ser Gln Val Val Glu Glu Gln
210 215 220
Ser Tyr Leu Leu Asn Ile Ala Glu Val Gln Ala Val Ser Arg Cys Asp
225 230 235 240
Tyr Phe Leu Ala Lys Ile Lys Gln Ala Asp Val Ala Leu Leu Glu Glu
245 250 255
Thr Ala Asp Glu Glu Glu Pro Glu Leu Thr Ala Ser Leu Pro Arg Glu
260 265 270
Leu Thr Leu Gln Asp Val Glu Leu Leu Lys Val Gly His Val Gly Pro
275 280 285
Leu Gln Ile Gly Gln Ala Val Lys Lys Pro Arg Thr Val Asn Val Glu
290 295 300
Asp Ser Trp Ala Met Glu Ala Thr Ala Ser Ala Ala Ser Thr Ser Val
305 310 315 320
Thr Phe Arg Glu Met Asp Met Ser Pro Glu Glu Val Val Ala Ser Pro
325 330 335
Arg Ala Ser Pro Ala Lys Gln Arg Gly Pro Glu Ala Ala Ser Asn Ile
340 345 350
Gln Gln Cys Leu Phe Leu Lys Lys Met Gly Ala Lys Gly Ser Thr Pro
355 360 365
Gly Met Phe Asn Leu Pro Val Ser Leu Tyr Val Thr Ser Gln Gly Glu
370 375 380
Val Leu Val Ala Asp Arg Gly Asn Tyr Arg Ile Gln Val Phe Thr Arg
385 390 395 400
Lys Gly Phe Leu Lys Glu Ile Arg Arg Ser Pro Ser Gly Ile Asp Ser
405 410 415
Phe Val Leu Ser Phe Leu Gly Ala Asp Leu Pro Asn Leu Thr Pro Leu
420 425 430
Ser Val Ala Met Asn Cys Gln Gly Leu Ile Gly Val Thr Asp Ser Tyr
435 440 445
Asp Asn Ser Leu Lys Val Tyr Thr Leu Asp Gly His Cys Val Ala Cys
450 455 460
His Arg Ser Gln Leu Ser Lys Pro Trp Gly Ile Thr Ala Leu Pro Ser
465 470 475 480
Gly Gln Phe Val Val Thr Asp Val Glu Gly Gly Lys Leu Trp Cys Phe
485 490 495
Thr Val Asp Arg Gly Ser Gly Val Val Lys Tyr Ser Cys Leu Cys Ser
500 505 510
Ala Val Arg Pro Lys Phe Val Thr Cys Asp Ala Glu Gly Thr Val Tyr
515 520 525
Phe Thr Gln Gly Leu Gly Leu Asn Leu Glu Asn Arg Gln Asn Glu His
530 535 540
His Leu Glu Gly Gly Phe Ser Ile Gly Ser Val Gly Pro Asp Gly Gln
545 550 555 560
Leu Gly Arg Gln Ile Ser His Phe Phe Ser Glu Asn Glu Asp Phe Arg
565 570 575
Cys Ile Ala Gly Met Cys Val Asp Ala Arg Gly Asp Leu Ile Val Ala
580 585 590
Asp Ser Ser Arg Lys Glu Ile Leu His Phe Pro Lys Gly Gly Gly Tyr
595 600 605
Ser Val Leu Ile Arg Glu Gly Leu Thr Cys Pro Val Gly Ile Ala Leu
610 615 620
Thr Pro Lys Gly Gln Leu Leu Val Leu Asp Cys Trp Asp His Cys Ile
625 630 635 640
Lys Ile Tyr Ser Tyr His Leu Arg Arg Tyr Ser Thr Pro
645 650
<210> 65
<211> 3384
<212> DNA
<213> Homo sapiens
<400> 65
atggcggaaa acaaaggcgg cggcgaggct gagagcggcg gcgggggcag cggcagcgcg 60
ccggtaactg ccggggccgc cgggcccgcc gcgcaggagg cggagccgcc tctcaccgcg 120
gtgctggtgg aggaggagga ggaggaaggc ggcagggccg gcgctgaggg cggcgcggcc 180
gggcccgacg acgggggggt ggccgcggcc tcctcgggct cggcccaggc tgcttcatct 240
cctgcggcct cagtgggcac tggagttgcc gggggcgcag tatcgacgcc ggctccagct 300
ccagcctcgg ctcccgctcc gggtccctcg gcagggccgc ctcctggacc gccagcctcg 360
ctcctggaca cctgcgccgt gtgtcagcag agcttgcaga gccggcgtga ggcggagccc 420
aagctgctgc cctgtcttca ctccttctgc ctgcgctgcc tgcccgagcc ggagcgccag 480
ctcagcgtgc ccatcccggg gggcagcaac ggcgacatcc agcaagttgg tgtaatacgg 540
tgcccagtat gccgccaaga atgcagacag atagaccttg tggataatta ttttgtgaaa 600
gacacatctg aagctcctag cagttctgat gaaaaatcag aacaggtatg tactagttgt 660
gaagacaatg caagtgcagt tggcttttgt gtagaatgtg gagagtggct atgtaagaca 720
tgtatcgaag cacatcaaag agtaaaattt actaaagatc acttgatcag gaagaaagaa 780
gatgtctcag agtctgttgg agcatctggt caacgccctg ttttctgccc tgtacacaaa 840
caagaacagt tgaaactttt ctgtgaaaca tgtgatagat tgacatgtag agactgtcag 900
ctattggaac acaaagaaca taggtatcag tttttggaag aagcttttca aaatcagaag 960
ggtgcaattg agaatctact ggcgaaactt cttgagaaga agaattatgt tcattttgca 1020
gctactcagg tgcagaatag gataaaagaa gtaaatgaga ctaacaaacg agtagaacag 1080
gaaattaaag tggccatttt cacccttatc aatgaaatta ataagaaagg aaaatctctc 1140
ttacaacagc tagagaatgt tacaaaggaa agacagatga agttactaca gcagcagaat 1200
gacatcacag gcctttcccg gcaggtgaag catgttatga acttcacaaa ttgggcaatt 1260
gcaagtggca gcagcacagc actactatac agcaagcgac tgattacttt ccagttgcgt 1320
catattttga aagcacggtg tgatcctgtc cctgctgcta atggagcaat acgtttccat 1380
tgtgatccca ccttctgggc aaagaatgta gtcaatttag gtaatctagt aatagagagt 1440
aaaccagctc ctggttatac tcctaatgtt gtagttgggc aagttcctcc agggacaaac 1500
cacattagta aaacccctgg acagattaac ttagcacagc ttcgactcca gcacatgcaa 1560
caacaagtat atgcacagaa acatcagcag ttgcaacaga tgaggatgca gcaaccacca 1620
gcacctgtac caactacaac aacaacaaca caacagcatc ctagacaagc agcccctcag 1680
atgttacaac aacagcctcc tcgattgatc agtgtgcaaa caatgcaaag aggcaacatg 1740
aactgtggag cttttcaagc ccatcagatg agactggctc agaatgctgc cagaatacca 1800
gggataccca ggcacagcgg ccctcaatat tccatgatgc agccacacct ccaaagacaa 1860
cactcaaacc cagggcatgc tggacccttt cccgtagtat cggtacacaa caccacaatc 1920
aacccaacga gccctactac agcaactatg gcaaatgcaa accgaggtcc caccagccca 1980
tctgttacag caatagagct aatcccctca gttaccaatc cagaaaacct tccatcgctg 2040
ccagatattc cacccataca gttggaagat gctggctcaa gtagtttaga taatctacta 2100
agtagataca tctcaggcag tcacctaccc ccacagccta caagcaccat gaatccttct 2160
ccaggtccct ctgccctttc tccgggatca tcaggtttat ccaattctca cacacctgtg 2220
agacccccaa gtacttctag tactggcagt cgaggcagct gtgggtcatc aggaagaact 2280
gctgagaaga caagtcttag tttcaaatct gatcaggtga aggtcaagca agaacctggg 2340
actgaagatg aaatatgtag cttttcagga ggtgtaaaac aagaaaaaac agaggatggc 2400
aggaggagtg cttgcatgtt gagcagtcct gagagtagct tgacaccacc tctctcaacc 2460
aacctgcatc tagaaagtga attggatgca ttggcaagcc tggaaaacca tgtgaaaatt 2520
gaacctgcag atatgaatga aagctgcaaa cagtcagggc tcagcagcct tgttaatgga 2580
aagtccccaa ttcgaagcct catgcacagg tcggcaagga ttggaggaga tggcaacaat 2640
aaagatgatg acccaaatga agactggtgt gctgtctgcc aaaacggagg agatctcttg 2700
tgctgcgaaa aatgtccaaa ggtctttcat ctaacttgtc atgttccaac actacttagc 2760
tttccaagtg gggactggat atgcacattt tgtagagata ttggaaagcc agaagttgaa 2820
tatgattgtg ataatttgca acatagtaag aaggggaaaa ctgcgcaggg gttaagcccc 2880
gtggaccaaa ggaaatgtga acgtcttctg ctttacctct attgccatga attaagtatt 2940
gaattccagg agcctgttcc tgcttcgata ccaaactact ataaaattat aaagaaacca 3000
atggatttat ccaccgtgaa aaagaagctt cagaaaaaac attcccaaca ctaccaaatc 3060
ccggatgact ttgtggccga tgtccgtttg atcttcaaga actgtgaaag gtttaatgaa 3120
atgatgaaag ttgttcaagt ttatgcagac acacaagaga ttaatttgaa ggctgattca 3180
gaagtagctc aggcagggaa agcagttgca ttgtactttg aagataaact cacagagatc 3240
tactcagaca ggaccttcgc acctttgcca gagtttgagc aggaagagga tgatggtgag 3300
gtaactgagg actctgatga agactttata cagccccgca gaaaacgcct aaagtcagat 3360
gagagaccag tacatataaa gtaa 3384
<210> 66
<211> 1127
<212> PRT
<213> Homo sapiens
<400> 66
Met Ala Glu Asn Lys Gly Gly Gly Glu Ala Glu Ser Gly Gly Gly Gly
1 5 10 15
Ser Gly Ser Ala Pro Val Thr Ala Gly Ala Ala Gly Pro Ala Ala Gln
20 25 30
Glu Ala Glu Pro Pro Leu Thr Ala Val Leu Val Glu Glu Glu Glu Glu
35 40 45
Glu Gly Gly Arg Ala Gly Ala Glu Gly Gly Ala Ala Gly Pro Asp Asp
50 55 60
Gly Gly Val Ala Ala Ala Ser Ser Gly Ser Ala Gln Ala Ala Ser Ser
65 70 75 80
Pro Ala Ala Ser Val Gly Thr Gly Val Ala Gly Gly Ala Val Ser Thr
85 90 95
Pro Ala Pro Ala Pro Ala Ser Ala Pro Ala Pro Gly Pro Ser Ala Gly
100 105 110
Pro Pro Pro Gly Pro Pro Ala Ser Leu Leu Asp Thr Cys Ala Val Cys
115 120 125
Gln Gln Ser Leu Gln Ser Arg Arg Glu Ala Glu Pro Lys Leu Leu Pro
130 135 140
Cys Leu His Ser Phe Cys Leu Arg Cys Leu Pro Glu Pro Glu Arg Gln
145 150 155 160
Leu Ser Val Pro Ile Pro Gly Gly Ser Asn Gly Asp Ile Gln Gln Val
165 170 175
Gly Val Ile Arg Cys Pro Val Cys Arg Gln Glu Cys Arg Gln Ile Asp
180 185 190
Leu Val Asp Asn Tyr Phe Val Lys Asp Thr Ser Glu Ala Pro Ser Ser
195 200 205
Ser Asp Glu Lys Ser Glu Gln Val Cys Thr Ser Cys Glu Asp Asn Ala
210 215 220
Ser Ala Val Gly Phe Cys Val Glu Cys Gly Glu Trp Leu Cys Lys Thr
225 230 235 240
Cys Ile Glu Ala His Gln Arg Val Lys Phe Thr Lys Asp His Leu Ile
245 250 255
Arg Lys Lys Glu Asp Val Ser Glu Ser Val Gly Ala Ser Gly Gln Arg
260 265 270
Pro Val Phe Cys Pro Val His Lys Gln Glu Gln Leu Lys Leu Phe Cys
275 280 285
Glu Thr Cys Asp Arg Leu Thr Cys Arg Asp Cys Gln Leu Leu Glu His
290 295 300
Lys Glu His Arg Tyr Gln Phe Leu Glu Glu Ala Phe Gln Asn Gln Lys
305 310 315 320
Gly Ala Ile Glu Asn Leu Leu Ala Lys Leu Leu Glu Lys Lys Asn Tyr
325 330 335
Val His Phe Ala Ala Thr Gln Val Gln Asn Arg Ile Lys Glu Val Asn
340 345 350
Glu Thr Asn Lys Arg Val Glu Gln Glu Ile Lys Val Ala Ile Phe Thr
355 360 365
Leu Ile Asn Glu Ile Asn Lys Lys Gly Lys Ser Leu Leu Gln Gln Leu
370 375 380
Glu Asn Val Thr Lys Glu Arg Gln Met Lys Leu Leu Gln Gln Gln Asn
385 390 395 400
Asp Ile Thr Gly Leu Ser Arg Gln Val Lys His Val Met Asn Phe Thr
405 410 415
Asn Trp Ala Ile Ala Ser Gly Ser Ser Thr Ala Leu Leu Tyr Ser Lys
420 425 430
Arg Leu Ile Thr Phe Gln Leu Arg His Ile Leu Lys Ala Arg Cys Asp
435 440 445
Pro Val Pro Ala Ala Asn Gly Ala Ile Arg Phe His Cys Asp Pro Thr
450 455 460
Phe Trp Ala Lys Asn Val Val Asn Leu Gly Asn Leu Val Ile Glu Ser
465 470 475 480
Lys Pro Ala Pro Gly Tyr Thr Pro Asn Val Val Val Gly Gln Val Pro
485 490 495
Pro Gly Thr Asn His Ile Ser Lys Thr Pro Gly Gln Ile Asn Leu Ala
500 505 510
Gln Leu Arg Leu Gln His Met Gln Gln Gln Val Tyr Ala Gln Lys His
515 520 525
Gln Gln Leu Gln Gln Met Arg Met Gln Gln Pro Pro Ala Pro Val Pro
530 535 540
Thr Thr Thr Thr Thr Thr Gln Gln His Pro Arg Gln Ala Ala Pro Gln
545 550 555 560
Met Leu Gln Gln Gln Pro Pro Arg Leu Ile Ser Val Gln Thr Met Gln
565 570 575
Arg Gly Asn Met Asn Cys Gly Ala Phe Gln Ala His Gln Met Arg Leu
580 585 590
Ala Gln Asn Ala Ala Arg Ile Pro Gly Ile Pro Arg His Ser Gly Pro
595 600 605
Gln Tyr Ser Met Met Gln Pro His Leu Gln Arg Gln His Ser Asn Pro
610 615 620
Gly His Ala Gly Pro Phe Pro Val Val Ser Val His Asn Thr Thr Ile
625 630 635 640
Asn Pro Thr Ser Pro Thr Thr Ala Thr Met Ala Asn Ala Asn Arg Gly
645 650 655
Pro Thr Ser Pro Ser Val Thr Ala Ile Glu Leu Ile Pro Ser Val Thr
660 665 670
Asn Pro Glu Asn Leu Pro Ser Leu Pro Asp Ile Pro Pro Ile Gln Leu
675 680 685
Glu Asp Ala Gly Ser Ser Ser Leu Asp Asn Leu Leu Ser Arg Tyr Ile
690 695 700
Ser Gly Ser His Leu Pro Pro Gln Pro Thr Ser Thr Met Asn Pro Ser
705 710 715 720
Pro Gly Pro Ser Ala Leu Ser Pro Gly Ser Ser Gly Leu Ser Asn Ser
725 730 735
His Thr Pro Val Arg Pro Pro Ser Thr Ser Ser Thr Gly Ser Arg Gly
740 745 750
Ser Cys Gly Ser Ser Gly Arg Thr Ala Glu Lys Thr Ser Leu Ser Phe
755 760 765
Lys Ser Asp Gln Val Lys Val Lys Gln Glu Pro Gly Thr Glu Asp Glu
770 775 780
Ile Cys Ser Phe Ser Gly Gly Val Lys Gln Glu Lys Thr Glu Asp Gly
785 790 795 800
Arg Arg Ser Ala Cys Met Leu Ser Ser Pro Glu Ser Ser Leu Thr Pro
805 810 815
Pro Leu Ser Thr Asn Leu His Leu Glu Ser Glu Leu Asp Ala Leu Ala
820 825 830
Ser Leu Glu Asn His Val Lys Ile Glu Pro Ala Asp Met Asn Glu Ser
835 840 845
Cys Lys Gln Ser Gly Leu Ser Ser Leu Val Asn Gly Lys Ser Pro Ile
850 855 860
Arg Ser Leu Met His Arg Ser Ala Arg Ile Gly Gly Asp Gly Asn Asn
865 870 875 880
Lys Asp Asp Asp Pro Asn Glu Asp Trp Cys Ala Val Cys Gln Asn Gly
885 890 895
Gly Asp Leu Leu Cys Cys Glu Lys Cys Pro Lys Val Phe His Leu Thr
900 905 910
Cys His Val Pro Thr Leu Leu Ser Phe Pro Ser Gly Asp Trp Ile Cys
915 920 925
Thr Phe Cys Arg Asp Ile Gly Lys Pro Glu Val Glu Tyr Asp Cys Asp
930 935 940
Asn Leu Gln His Ser Lys Lys Gly Lys Thr Ala Gln Gly Leu Ser Pro
945 950 955 960
Val Asp Gln Arg Lys Cys Glu Arg Leu Leu Leu Tyr Leu Tyr Cys His
965 970 975
Glu Leu Ser Ile Glu Phe Gln Glu Pro Val Pro Ala Ser Ile Pro Asn
980 985 990
Tyr Tyr Lys Ile Ile Lys Lys Pro Met Asp Leu Ser Thr Val Lys Lys
995 1000 1005
Lys Leu Gln Lys Lys His Ser Gln His Tyr Gln Ile Pro Asp Asp
1010 1015 1020
Phe Val Ala Asp Val Arg Leu Ile Phe Lys Asn Cys Glu Arg Phe
1025 1030 1035
Asn Glu Met Met Lys Val Val Gln Val Tyr Ala Asp Thr Gln Glu
1040 1045 1050
Ile Asn Leu Lys Ala Asp Ser Glu Val Ala Gln Ala Gly Lys Ala
1055 1060 1065
Val Ala Leu Tyr Phe Glu Asp Lys Leu Thr Glu Ile Tyr Ser Asp
1070 1075 1080
Arg Thr Phe Ala Pro Leu Pro Glu Phe Glu Gln Glu Glu Asp Asp
1085 1090 1095
Gly Glu Val Thr Glu Asp Ser Asp Glu Asp Phe Ile Gln Pro Arg
1100 1105 1110
Arg Lys Arg Leu Lys Ser Asp Glu Arg Pro Val His Ile Lys
1115 1120 1125
<210> 67
<211> 1467
<212> DNA
<213> Homo sapiens
<400> 67
atggcttcaa aaatcttgct taacgtacaa gaggaggtga cctgtcccat ctgcctggag 60
ctgttgacag aacccttgag tctagactgt ggccacagcc tctgccgagc ctgcatcact 120
gtgagcaaca aggaggcagt gaccagcatg ggaggaaaaa gcagctgtcc tgtgtgtggt 180
atcagttact catttgaaca tctacaggct aatcagcatc tggccaacat agtggagaga 240
ctcaaggagg tcaagttgag cccagacaat gggaagaaga gagatctctg tgatcatcat 300
ggagagaaac tcctactctt ctgtaaggag gataggaaag tcatttgctg gctttgtgag 360
cggtctcagg agcaccgtgg tcaccacaca gtcctcacgg aggaagtatt caaggaatgt 420
caggagaaac tccaggcagt cctcaagagg ctgaagaagg aagaggagga agctgagaag 480
ctggaagctg acatcagaga agagaaaact tcctggaagt atcaggtaca aactgagaga 540
caaaggatac aaacagaatt tgatcagctt agaagcatcc taaataatga ggagcagaga 600
gagctgcaaa gattggaaga agaagaaaag aagacgctgg ataagtttgc agaggctgag 660
gatgagctag ttcagcagaa gcagttggtg agagagctca tctcagatgt ggagtgtcgg 720
agtcagtggt caacaatgga gctgctgcag gacatgagtg gaatcatgaa atggagtgag 780
atctggaggc tgaaaaagcc aaaaatggtt tccaagaaac tgaagactgt attccatgct 840
ccagatctga gtaggatgct gcaaatgttt agagaactga cagctgtccg gtgctactgg 900
gtggatgtca cactgaattc agtcaaccta aatttgaatc ttgtcctttc agaagatcag 960
agacaagtga tatctgtgcc aatttggcct tttcagtgtt ataattatgg tgtcttggga 1020
tcccaatatt tctcctctgg gaaacattac tgggaagtgg acgtgtccaa gaaaactgcc 1080
tggatcctgg gggtatactg tagaacatat tcccgccata tgaagtatgt tgttagaaga 1140
tgtgcaaatc gtcaaaatct ttacaccaaa tacagacctc tatttggcta ctgggttata 1200
gggttacaga ataaatgtaa gtatggtgtc tttgaagagt ctttgtcctc tgatcccgag 1260
gttttgactc tctccatggc tgtgcctccc tgccgtgttg gggttttcct cgactatgaa 1320
gcaggcattg tctcattttt caatgtcaca agccatggct ccctcattta caagttctct 1380
aaatgttgct tttctcagcc tgtttatcca tatttcaatc cttggaactg tccagctccc 1440
atgactctat gcccaccaag ctcttga 1467
<210> 68
<211> 488
<212> PRT
<213> Homo sapiens
<400> 68
Met Ala Ser Lys Ile Leu Leu Asn Val Gln Glu Glu Val Thr Cys Pro
1 5 10 15
Ile Cys Leu Glu Leu Leu Thr Glu Pro Leu Ser Leu Asp Cys Gly His
20 25 30
Ser Leu Cys Arg Ala Cys Ile Thr Val Ser Asn Lys Glu Ala Val Thr
35 40 45
Ser Met Gly Gly Lys Ser Ser Cys Pro Val Cys Gly Ile Ser Tyr Ser
50 55 60
Phe Glu His Leu Gln Ala Asn Gln His Leu Ala Asn Ile Val Glu Arg
65 70 75 80
Leu Lys Glu Val Lys Leu Ser Pro Asp Asn Gly Lys Lys Arg Asp Leu
85 90 95
Cys Asp His His Gly Glu Lys Leu Leu Leu Phe Cys Lys Glu Asp Arg
100 105 110
Lys Val Ile Cys Trp Leu Cys Glu Arg Ser Gln Glu His Arg Gly His
115 120 125
His Thr Val Leu Thr Glu Glu Val Phe Lys Glu Cys Gln Glu Lys Leu
130 135 140
Gln Ala Val Leu Lys Arg Leu Lys Lys Glu Glu Glu Glu Ala Glu Lys
145 150 155 160
Leu Glu Ala Asp Ile Arg Glu Glu Lys Thr Ser Trp Lys Tyr Gln Val
165 170 175
Gln Thr Glu Arg Gln Arg Ile Gln Thr Glu Phe Asp Gln Leu Arg Ser
180 185 190
Ile Leu Asn Asn Glu Glu Gln Arg Glu Leu Gln Arg Leu Glu Glu Glu
195 200 205
Glu Lys Lys Thr Leu Asp Lys Phe Ala Glu Ala Glu Asp Glu Leu Val
210 215 220
Gln Gln Lys Gln Leu Val Arg Glu Leu Ile Ser Asp Val Glu Cys Arg
225 230 235 240
Ser Gln Trp Ser Thr Met Glu Leu Leu Gln Asp Met Ser Gly Ile Met
245 250 255
Lys Trp Ser Glu Ile Trp Arg Leu Lys Lys Pro Lys Met Val Ser Lys
260 265 270
Lys Leu Lys Thr Val Phe His Ala Pro Asp Leu Ser Arg Met Leu Gln
275 280 285
Met Phe Arg Glu Leu Thr Ala Val Arg Cys Tyr Trp Val Asp Val Thr
290 295 300
Leu Asn Ser Val Asn Leu Asn Leu Asn Leu Val Leu Ser Glu Asp Gln
305 310 315 320
Arg Gln Val Ile Ser Val Pro Ile Trp Pro Phe Gln Cys Tyr Asn Tyr
325 330 335
Gly Val Leu Gly Ser Gln Tyr Phe Ser Ser Gly Lys His Tyr Trp Glu
340 345 350
Val Asp Val Ser Lys Lys Thr Ala Trp Ile Leu Gly Val Tyr Cys Arg
355 360 365
Thr Tyr Ser Arg His Met Lys Tyr Val Val Arg Arg Cys Ala Asn Arg
370 375 380
Gln Asn Leu Tyr Thr Lys Tyr Arg Pro Leu Phe Gly Tyr Trp Val Ile
385 390 395 400
Gly Leu Gln Asn Lys Cys Lys Tyr Gly Val Phe Glu Glu Ser Leu Ser
405 410 415
Ser Asp Pro Glu Val Leu Thr Leu Ser Met Ala Val Pro Pro Cys Arg
420 425 430
Val Gly Val Phe Leu Asp Tyr Glu Ala Gly Ile Val Ser Phe Phe Asn
435 440 445
Val Thr Ser His Gly Ser Leu Ile Tyr Lys Phe Ser Lys Cys Cys Phe
450 455 460
Ser Gln Pro Val Tyr Pro Tyr Phe Asn Pro Trp Asn Cys Pro Ala Pro
465 470 475 480
Met Thr Leu Cys Pro Pro Ser Ser
485
<210> 69
<211> 1482
<212> DNA
<213> Homo sapiens
<400> 69
atggagcgga gtcccgacgt gtcccccggg ccttcccgct ccttcaagga ggagttgctc 60
tgcgccgtct gctacgaccc cttccgcgac gcagtcactc tgcgctgcgg ccacaacttc 120
tgccgcgggt gcgtgagccg ctgctgggag gtgcaggtgt cgcccacctg cccagtgtgc 180
aaagaccgcg cgtcacccgc cgacctgcgc accaaccaca ccctcaacaa cctggtggag 240
aagctgctgc gcgaggaggc cgagggcgcg cgctggacca gctaccgctt ctcgcgtgtc 300
tgccgcctgc accgcggaca gctcagcctc ttctgcctcg aggacaagga gctgctgtgc 360
tgctcctgcc aggccgaccc ccgacaccag gggcaccgcg tgcagccggt gaaggacact 420
gcccacgact ttcgggccaa gtgcaggaac atggagcatg cactgcggga gaaggccaag 480
gccttctggg ccatgcggcg ctcctatgag gccatcgcca agcacaatca ggtggaggct 540
gcatggctgg aaggccggat ccggcaggag tttgataagc ttcgcgagtt cttgagagtg 600
gaggagcagg ccattctgga tgccatggcc gaggagacaa ggcagaagca acttctggcc 660
gacgagaaga tgaagcagct cacagaggag acggaggtgc tggcacatga gatcgagcgg 720
ctgcagatgg agatgaagga ggacgacgtt tcttttctca tgaaacacaa gagccgaaaa 780
cgccgactct tctgcaccat ggagccagag ccagtccagc ccggcatgct tatcgatgtc 840
tgcaagtacc tgggctccct gcagtaccgc gtctggaaga agatgcttgc atctgtggaa 900
tctgtaccct tcagctttga ccccaacacc gcagctggct ggctctccgt gtctgacgac 960
ctcaccagcg tcaccaacca tggctaccgc gtgcaggtgg agaacccgga acgcttctcc 1020
tcggcgccct gcctgctggg ctcccgtgtc ttctcacagg gctcgcacgc ctgggaggtg 1080
gcccttgggg ggctgcagag ctggagggtg ggcgtggtac gtgtgcgcca ggactcgggc 1140
gctgagggcc actcacacag ctgctaccac gacacacgct cgggcttctg gtatgtctgc 1200
cgcacgcagg gcgtggaggg ggaccactgc gtgacctcgg acccagccac gtcgcccctg 1260
gtcctggcca tcccacgccg cctgcgtgtg gagctggagt gtgaggaggg cgagctgtct 1320
ttctatgacg cggagcgcca ctgccacctg tacaccttcc acgcccgctt tggggaggtt 1380
cgcccctact tctacctggg gggtgcacgg ggcgccgggc ctccagagcc tttgcgcatc 1440
tgccccttgc acatcagtgt caaggaagaa ctggatggct ga 1482
<210> 70
<211> 493
<212> PRT
<213> Homo sapiens
<400> 70
Met Glu Arg Ser Pro Asp Val Ser Pro Gly Pro Ser Arg Ser Phe Lys
1 5 10 15
Glu Glu Leu Leu Cys Ala Val Cys Tyr Asp Pro Phe Arg Asp Ala Val
20 25 30
Thr Leu Arg Cys Gly His Asn Phe Cys Arg Gly Cys Val Ser Arg Cys
35 40 45
Trp Glu Val Gln Val Ser Pro Thr Cys Pro Val Cys Lys Asp Arg Ala
50 55 60
Ser Pro Ala Asp Leu Arg Thr Asn His Thr Leu Asn Asn Leu Val Glu
65 70 75 80
Lys Leu Leu Arg Glu Glu Ala Glu Gly Ala Arg Trp Thr Ser Tyr Arg
85 90 95
Phe Ser Arg Val Cys Arg Leu His Arg Gly Gln Leu Ser Leu Phe Cys
100 105 110
Leu Glu Asp Lys Glu Leu Leu Cys Cys Ser Cys Gln Ala Asp Pro Arg
115 120 125
His Gln Gly His Arg Val Gln Pro Val Lys Asp Thr Ala His Asp Phe
130 135 140
Arg Ala Lys Cys Arg Asn Met Glu His Ala Leu Arg Glu Lys Ala Lys
145 150 155 160
Ala Phe Trp Ala Met Arg Arg Ser Tyr Glu Ala Ile Ala Lys His Asn
165 170 175
Gln Val Glu Ala Ala Trp Leu Glu Gly Arg Ile Arg Gln Glu Phe Asp
180 185 190
Lys Leu Arg Glu Phe Leu Arg Val Glu Glu Gln Ala Ile Leu Asp Ala
195 200 205
Met Ala Glu Glu Thr Arg Gln Lys Gln Leu Leu Ala Asp Glu Lys Met
210 215 220
Lys Gln Leu Thr Glu Glu Thr Glu Val Leu Ala His Glu Ile Glu Arg
225 230 235 240
Leu Gln Met Glu Met Lys Glu Asp Asp Val Ser Phe Leu Met Lys His
245 250 255
Lys Ser Arg Lys Arg Arg Leu Phe Cys Thr Met Glu Pro Glu Pro Val
260 265 270
Gln Pro Gly Met Leu Ile Asp Val Cys Lys Tyr Leu Gly Ser Leu Gln
275 280 285
Tyr Arg Val Trp Lys Lys Met Leu Ala Ser Val Glu Ser Val Pro Phe
290 295 300
Ser Phe Asp Pro Asn Thr Ala Ala Gly Trp Leu Ser Val Ser Asp Asp
305 310 315 320
Leu Thr Ser Val Thr Asn His Gly Tyr Arg Val Gln Val Glu Asn Pro
325 330 335
Glu Arg Phe Ser Ser Ala Pro Cys Leu Leu Gly Ser Arg Val Phe Ser
340 345 350
Gln Gly Ser His Ala Trp Glu Val Ala Leu Gly Gly Leu Gln Ser Trp
355 360 365
Arg Val Gly Val Val Arg Val Arg Gln Asp Ser Gly Ala Glu Gly His
370 375 380
Ser His Ser Cys Tyr His Asp Thr Arg Ser Gly Phe Trp Tyr Val Cys
385 390 395 400
Arg Thr Gln Gly Val Glu Gly Asp His Cys Val Thr Ser Asp Pro Ala
405 410 415
Thr Ser Pro Leu Val Leu Ala Ile Pro Arg Arg Leu Arg Val Glu Leu
420 425 430
Glu Cys Glu Glu Gly Glu Leu Ser Phe Tyr Asp Ala Glu Arg His Cys
435 440 445
His Leu Tyr Thr Phe His Ala Arg Phe Gly Glu Val Arg Pro Tyr Phe
450 455 460
Tyr Leu Gly Gly Ala Arg Gly Ala Gly Pro Pro Glu Pro Leu Arg Ile
465 470 475 480
Cys Pro Leu His Ile Ser Val Lys Glu Glu Leu Asp Gly
485 490
<210> 71
<211> 2187
<212> DNA
<213> Homo sapiens
<400> 71
atgtcggagt ctggggagat gagtgaattt ggctacatca tggaattgat agctaaaggc 60
aaggttacca ttaagaatat cgaaagggag ctcatttgcc cagcatgcaa ggagctgttt 120
acccacccat tgattctccc ttgccaacat agtatctgtc ataaatgtgt aaaagaactc 180
ctgctgactc tcgatgattc attcaacgat gtgggatcag acaactccaa tcaaagcagt 240
cctcgacttc ggctcccctc ccctagtatg gataaaattg accgaattaa cagaccaggc 300
tggaagcgca attcattgac cccgaggaca actgttttcc cttgccctgg ctgtgagcat 360
gatgtggatc ttggagaacg aggaatcaat ggtctgtttc gaaacttcac tttggaaact 420
attgtggaaa gatatcgtca agcagctagg gcagccacag ccattatgtg tgacctttgt 480
aaaccaccac ctcaagaatc cacaaaaagc tgcatggact gtagtgcaag ttactgcaat 540
gaatgcttca aaattcatca cccttggggt actataaaag ctcaacatga gtatgttggt 600
ccaactacta acttcagacc caagatttta atgtgcccag aacatgaaac agagagaata 660
aacatgtact gtgaattatg taggaggcca gtttgccatc tgtgtaagtt gggtggtaat 720
catgccaacc accgtgtaac cactatgagc agtgcctaca aaaccttaaa ggaaaagctt 780
tcaaaggata ttgattacct tattggtaag gaaagccagg tgaagagtca aatatctgaa 840
ctaaacttgt taatgaaaga aacagagtgt aatggagaga gggctaaaga agaagcaatt 900
acacattttg aaaagctctt tgaagttctg gaagagagga aatcatctgt tttgaaagca 960
attgactcct ctaagaaact aagattagac aaatttcaga ctcaaatgga agagtaccag 1020
ggacttctag agaacaatgg acttgtggga tatgctcaag aagtgctaaa ggagacagat 1080
cagtcttgct ttgtgcagac agcaaagcag ctccacctca gaatacagaa agccacagaa 1140
tctttgaaga gctttagacc tgcagctcag acttcttttg aagactatgt tgttaatacc 1200
tctaaacaaa cagaacttct tggagaatta tcctttttct ctagtggcat agacgtgcca 1260
gagatcaatg aggaacagag caaagtttat aacaatgcct tgataaattg gcaccatcca 1320
gaaaaggata aagctgatag ctatgttctt gaatatcgga aaatcaatag agatgatgaa 1380
atgtcatgga atgagataga agtgtgtgga acaagtaaaa taattcaaga cttggaaaac 1440
agtagtacct atgctttcag agtaagagct tacaagggtt caatctgtag tccttgcagc 1500
agagaattga ttcttcatac tcctccagct ccagttttca gcttcctctt tgatgaaaaa 1560
tgtggctata ataatgaaca cctcctgctg aacttgaaga gagaccgtgt agagagtaga 1620
gctggattta atcttctgct tgctgcagaa cgcatccaag tgggttatta cacaagctta 1680
gactacatca ttggagatac tggcattaca aaaggaaaac acttctgggc cttccgtgtg 1740
gaaccatatt catacctggt aaaagtggga gttgcttcta gcgataaact acaagaatgg 1800
ctccgttctc cccgggatgc agttagtcca agatatgagc aagacagtgg gcatgacagt 1860
ggaagtgagg atgcctgttt tgattcttca caaccattta ccttagttac tataggcatg 1920
cagaaatttt ttatacccaa gtcacctact tcttctaatg aacctgaaaa tagagttctc 1980
cctatgccaa caagtattgg gattttcctt gactgtgata aaggcaaagt agatttctat 2040
gatatggatc agatgaaatg cctttatgaa cgccaagtgg actgttcaca tacactgtat 2100
ccagcatttg cattaatggg cagtggagga attcagcttg aagaacccat cacagcaaaa 2160
tatctggaat accaagagga catgtag 2187
<210> 72
<211> 728
<212> PRT
<213> Homo sapiens
<400> 72
Met Ser Glu Ser Gly Glu Met Ser Glu Phe Gly Tyr Ile Met Glu Leu
1 5 10 15
Ile Ala Lys Gly Lys Val Thr Ile Lys Asn Ile Glu Arg Glu Leu Ile
20 25 30
Cys Pro Ala Cys Lys Glu Leu Phe Thr His Pro Leu Ile Leu Pro Cys
35 40 45
Gln His Ser Ile Cys His Lys Cys Val Lys Glu Leu Leu Leu Thr Leu
50 55 60
Asp Asp Ser Phe Asn Asp Val Gly Ser Asp Asn Ser Asn Gln Ser Ser
65 70 75 80
Pro Arg Leu Arg Leu Pro Ser Pro Ser Met Asp Lys Ile Asp Arg Ile
85 90 95
Asn Arg Pro Gly Trp Lys Arg Asn Ser Leu Thr Pro Arg Thr Thr Val
100 105 110
Phe Pro Cys Pro Gly Cys Glu His Asp Val Asp Leu Gly Glu Arg Gly
115 120 125
Ile Asn Gly Leu Phe Arg Asn Phe Thr Leu Glu Thr Ile Val Glu Arg
130 135 140
Tyr Arg Gln Ala Ala Arg Ala Ala Thr Ala Ile Met Cys Asp Leu Cys
145 150 155 160
Lys Pro Pro Pro Gln Glu Ser Thr Lys Ser Cys Met Asp Cys Ser Ala
165 170 175
Ser Tyr Cys Asn Glu Cys Phe Lys Ile His His Pro Trp Gly Thr Ile
180 185 190
Lys Ala Gln His Glu Tyr Val Gly Pro Thr Thr Asn Phe Arg Pro Lys
195 200 205
Ile Leu Met Cys Pro Glu His Glu Thr Glu Arg Ile Asn Met Tyr Cys
210 215 220
Glu Leu Cys Arg Arg Pro Val Cys His Leu Cys Lys Leu Gly Gly Asn
225 230 235 240
His Ala Asn His Arg Val Thr Thr Met Ser Ser Ala Tyr Lys Thr Leu
245 250 255
Lys Glu Lys Leu Ser Lys Asp Ile Asp Tyr Leu Ile Gly Lys Glu Ser
260 265 270
Gln Val Lys Ser Gln Ile Ser Glu Leu Asn Leu Leu Met Lys Glu Thr
275 280 285
Glu Cys Asn Gly Glu Arg Ala Lys Glu Glu Ala Ile Thr His Phe Glu
290 295 300
Lys Leu Phe Glu Val Leu Glu Glu Arg Lys Ser Ser Val Leu Lys Ala
305 310 315 320
Ile Asp Ser Ser Lys Lys Leu Arg Leu Asp Lys Phe Gln Thr Gln Met
325 330 335
Glu Glu Tyr Gln Gly Leu Leu Glu Asn Asn Gly Leu Val Gly Tyr Ala
340 345 350
Gln Glu Val Leu Lys Glu Thr Asp Gln Ser Cys Phe Val Gln Thr Ala
355 360 365
Lys Gln Leu His Leu Arg Ile Gln Lys Ala Thr Glu Ser Leu Lys Ser
370 375 380
Phe Arg Pro Ala Ala Gln Thr Ser Phe Glu Asp Tyr Val Val Asn Thr
385 390 395 400
Ser Lys Gln Thr Glu Leu Leu Gly Glu Leu Ser Phe Phe Ser Ser Gly
405 410 415
Ile Asp Val Pro Glu Ile Asn Glu Glu Gln Ser Lys Val Tyr Asn Asn
420 425 430
Ala Leu Ile Asn Trp His His Pro Glu Lys Asp Lys Ala Asp Ser Tyr
435 440 445
Val Leu Glu Tyr Arg Lys Ile Asn Arg Asp Asp Glu Met Ser Trp Asn
450 455 460
Glu Ile Glu Val Cys Gly Thr Ser Lys Ile Ile Gln Asp Leu Glu Asn
465 470 475 480
Ser Ser Thr Tyr Ala Phe Arg Val Arg Ala Tyr Lys Gly Ser Ile Cys
485 490 495
Ser Pro Cys Ser Arg Glu Leu Ile Leu His Thr Pro Pro Ala Pro Val
500 505 510
Phe Ser Phe Leu Phe Asp Glu Lys Cys Gly Tyr Asn Asn Glu His Leu
515 520 525
Leu Leu Asn Leu Lys Arg Asp Arg Val Glu Ser Arg Ala Gly Phe Asn
530 535 540
Leu Leu Leu Ala Ala Glu Arg Ile Gln Val Gly Tyr Tyr Thr Ser Leu
545 550 555 560
Asp Tyr Ile Ile Gly Asp Thr Gly Ile Thr Lys Gly Lys His Phe Trp
565 570 575
Ala Phe Arg Val Glu Pro Tyr Ser Tyr Leu Val Lys Val Gly Val Ala
580 585 590
Ser Ser Asp Lys Leu Gln Glu Trp Leu Arg Ser Pro Arg Asp Ala Val
595 600 605
Ser Pro Arg Tyr Glu Gln Asp Ser Gly His Asp Ser Gly Ser Glu Asp
610 615 620
Ala Cys Phe Asp Ser Ser Gln Pro Phe Thr Leu Val Thr Ile Gly Met
625 630 635 640
Gln Lys Phe Phe Ile Pro Lys Ser Pro Thr Ser Ser Asn Glu Pro Glu
645 650 655
Asn Arg Val Leu Pro Met Pro Thr Ser Ile Gly Ile Phe Leu Asp Cys
660 665 670
Asp Lys Gly Lys Val Asp Phe Tyr Asp Met Asp Gln Met Lys Cys Leu
675 680 685
Tyr Glu Arg Gln Val Asp Cys Ser His Thr Leu Tyr Pro Ala Phe Ala
690 695 700
Leu Met Gly Ser Gly Gly Ile Gln Leu Glu Glu Pro Ile Thr Ala Lys
705 710 715 720
Tyr Leu Glu Tyr Gln Glu Asp Met
725
<210> 73
<211> 2895
<212> DNA
<213> Homo sapiens
<400> 73
atggatgaac agagcgtgga gagcattgct gaggttttcc gatgtttcat ttgtatggag 60
aaattgcggg atgcacgcct gtgtcctcat tgctccaaac tgtgttgttt cagctgtatt 120
aggcgctggc tgacagagca gagagctcaa tgtcctcatt gccgtgctcc actccagcta 180
cgagaactag taaattgtcg ttgggcagaa gaagtaacac aacagcttga tactcttcaa 240
ctctgcagtc tcaccaaaca tgaagaaaat gaaaaggaca aatgtgaaaa tcaccatgaa 300
aaacttagtg tattttgctg gacttgtaag aagtgtatct gccatcagtg tgcactttgg 360
ggaggaatgc atggcggaca tacctttaaa cctttggcag aaatttatga gcaacacgtc 420
actaaagtga atgaagaggt agccaaactt cgtcggcgtc tcatggaact gatcagctta 480
gttcaagaag tggaaaggaa tgtagaagct gtaagaaatg caaaagatga gcgtgttcgg 540
gaaattagga atgcagtgga gatgatgatt gcacggttag acacacagct gaagaataag 600
cttataacac tgatgggtca gaagacatct ctaacccaag aaacagagct tttggaatcc 660
ttacttcagg aggtggagca ccagttgcgg tcttgtagta agagtgagtt gatatctaag 720
agctcagaga tccttatgat gtttcagcaa gttcatcgga agcccatggc atcttttgtt 780
accactcctg ttccaccaga ctttaccagt gaattagtgc catcttacga ttcagctact 840
tttgttttag agaatttcag cactttgcgt cagagagcag atcctgttta cagtccacct 900
cttcaagttt caggactttg ctggaggtta aaagtttacc cagatggaaa tggagttgtg 960
cgaggttact acttatctgt gtttctggag ctctcagctg gcttgcctga aacttctaaa 1020
tatgaatatc gtgtagagat ggttcaccag tcctgtaatg atcctacaaa aaatatcatt 1080
cgagaatttg catctgactt tgaagttgga gaatgctggg gctataatag atttttccgt 1140
ttggacttac tcgcaaatga aggatacttg aatccacaaa atgatacagt gattttaagg 1200
tttcaggtac gttcaccaac tttctttcaa aaatcccggg accagcattg gtacattact 1260
cagttggaag ctgcacagac tagttatatc caacaaataa acaaccttaa agagagactt 1320
actattgagc tgtctcgaac tcagaagtca agagatttgt caccaccaga taaccatctt 1380
agcccccaaa atgatgatgc tctggagaca cgagctaaga agtctgcatg ctctgacatg 1440
cttctcgaag gtggtcctac tacagcttct gtaagagagg ccaaagagga tgaagaagat 1500
gaggagaaga ttcagaatga agattatcat cacgagcttt cagatggaga tctggatctg 1560
gatcttgttt atgaggatga agtaaatcag ctcgatggca gcagttcctc tgctagttcc 1620
acagcaacaa gtaatacaga agaaaatgat attgatgaag aaactatgtc tggagaaaat 1680
gatgtggaat ataacaacat ggaattagaa gagggagaac tcatggaaga tgcagctgct 1740
gcaggacccg caggtagtag ccatggttat gtgggttcca gtagtagaat atcaagaaga 1800
acacatttat gctccgctgc taccagtagt ttactagaca ttgatccatt aattttaata 1860
catttgttgg accttaagga ccggagcagt atagaaaatt tgtggggctt acagcctcgc 1920
ccacctgctt cacttctgca gcccacagca tcatattctc gaaaagataa agaccaaagg 1980
aagcaacagg caatgtggcg agtgccctct gatttaaaga tgctaaaaag actcaaaact 2040
caaatggccg aagttcgatg tatgaaaact gatgtaaaga atacactttc agaaataaaa 2100
agcagcagtg ctgcttctgg agacatgcag acaagccttt tttctgctga ccaggcagct 2160
ctggctgcat gtggaactga aaactctggc agattgcagg atttgggaat ggaactcctg 2220
gcaaagtcat cagttgccaa ttgttacata cgaaactcca caaataagaa gagtaattcg 2280
cccaagccag ctcgatccag tgtagcaggt agtctatcac ttcgaagagc agtggaccct 2340
ggagaaaata gtcgttcaaa gggagactgt cagactctgt ctgaaggctc cccaggaagc 2400
tctcagtctg ggagcaggca cagttctccc cgagccttga tacatggcag tatcggtgat 2460
attctgccaa aaactgaaga ccggcagtgt aaagctttgg attcagatgc tgttgtggtt 2520
gcagttttca gtggcttgcc tgcggttgag aaaaggagga aaatggtcac cttgggggct 2580
aatgctaaag gaggtcatct ggaaggactg cagatgactg atttggaaaa taattctgaa 2640
actggagagt tacagcctgt actacctgaa ggagcttcag ctgcccctga agaaggaatg 2700
agtagcgaca gtgacattga atgtgacact gagaatgagg agcaggaaga gcataccagt 2760
gtgggcgggt ttcacgactc cttcatggtc atgacacagc ccccggatga agatacacat 2820
tccagttttc ctgatggtga acaaataggc cctgaagatc tcagcttcaa tacagatgaa 2880
aatagtggaa ggtaa 2895
<210> 74
<211> 964
<212> PRT
<213> Homo sapiens
<400> 74
Met Asp Glu Gln Ser Val Glu Ser Ile Ala Glu Val Phe Arg Cys Phe
1 5 10 15
Ile Cys Met Glu Lys Leu Arg Asp Ala Arg Leu Cys Pro His Cys Ser
20 25 30
Lys Leu Cys Cys Phe Ser Cys Ile Arg Arg Trp Leu Thr Glu Gln Arg
35 40 45
Ala Gln Cys Pro His Cys Arg Ala Pro Leu Gln Leu Arg Glu Leu Val
50 55 60
Asn Cys Arg Trp Ala Glu Glu Val Thr Gln Gln Leu Asp Thr Leu Gln
65 70 75 80
Leu Cys Ser Leu Thr Lys His Glu Glu Asn Glu Lys Asp Lys Cys Glu
85 90 95
Asn His His Glu Lys Leu Ser Val Phe Cys Trp Thr Cys Lys Lys Cys
100 105 110
Ile Cys His Gln Cys Ala Leu Trp Gly Gly Met His Gly Gly His Thr
115 120 125
Phe Lys Pro Leu Ala Glu Ile Tyr Glu Gln His Val Thr Lys Val Asn
130 135 140
Glu Glu Val Ala Lys Leu Arg Arg Arg Leu Met Glu Leu Ile Ser Leu
145 150 155 160
Val Gln Glu Val Glu Arg Asn Val Glu Ala Val Arg Asn Ala Lys Asp
165 170 175
Glu Arg Val Arg Glu Ile Arg Asn Ala Val Glu Met Met Ile Ala Arg
180 185 190
Leu Asp Thr Gln Leu Lys Asn Lys Leu Ile Thr Leu Met Gly Gln Lys
195 200 205
Thr Ser Leu Thr Gln Glu Thr Glu Leu Leu Glu Ser Leu Leu Gln Glu
210 215 220
Val Glu His Gln Leu Arg Ser Cys Ser Lys Ser Glu Leu Ile Ser Lys
225 230 235 240
Ser Ser Glu Ile Leu Met Met Phe Gln Gln Val His Arg Lys Pro Met
245 250 255
Ala Ser Phe Val Thr Thr Pro Val Pro Pro Asp Phe Thr Ser Glu Leu
260 265 270
Val Pro Ser Tyr Asp Ser Ala Thr Phe Val Leu Glu Asn Phe Ser Thr
275 280 285
Leu Arg Gln Arg Ala Asp Pro Val Tyr Ser Pro Pro Leu Gln Val Ser
290 295 300
Gly Leu Cys Trp Arg Leu Lys Val Tyr Pro Asp Gly Asn Gly Val Val
305 310 315 320
Arg Gly Tyr Tyr Leu Ser Val Phe Leu Glu Leu Ser Ala Gly Leu Pro
325 330 335
Glu Thr Ser Lys Tyr Glu Tyr Arg Val Glu Met Val His Gln Ser Cys
340 345 350
Asn Asp Pro Thr Lys Asn Ile Ile Arg Glu Phe Ala Ser Asp Phe Glu
355 360 365
Val Gly Glu Cys Trp Gly Tyr Asn Arg Phe Phe Arg Leu Asp Leu Leu
370 375 380
Ala Asn Glu Gly Tyr Leu Asn Pro Gln Asn Asp Thr Val Ile Leu Arg
385 390 395 400
Phe Gln Val Arg Ser Pro Thr Phe Phe Gln Lys Ser Arg Asp Gln His
405 410 415
Trp Tyr Ile Thr Gln Leu Glu Ala Ala Gln Thr Ser Tyr Ile Gln Gln
420 425 430
Ile Asn Asn Leu Lys Glu Arg Leu Thr Ile Glu Leu Ser Arg Thr Gln
435 440 445
Lys Ser Arg Asp Leu Ser Pro Pro Asp Asn His Leu Ser Pro Gln Asn
450 455 460
Asp Asp Ala Leu Glu Thr Arg Ala Lys Lys Ser Ala Cys Ser Asp Met
465 470 475 480
Leu Leu Glu Gly Gly Pro Thr Thr Ala Ser Val Arg Glu Ala Lys Glu
485 490 495
Asp Glu Glu Asp Glu Glu Lys Ile Gln Asn Glu Asp Tyr His His Glu
500 505 510
Leu Ser Asp Gly Asp Leu Asp Leu Asp Leu Val Tyr Glu Asp Glu Val
515 520 525
Asn Gln Leu Asp Gly Ser Ser Ser Ser Ala Ser Ser Thr Ala Thr Ser
530 535 540
Asn Thr Glu Glu Asn Asp Ile Asp Glu Glu Thr Met Ser Gly Glu Asn
545 550 555 560
Asp Val Glu Tyr Asn Asn Met Glu Leu Glu Glu Gly Glu Leu Met Glu
565 570 575
Asp Ala Ala Ala Ala Gly Pro Ala Gly Ser Ser His Gly Tyr Val Gly
580 585 590
Ser Ser Ser Arg Ile Ser Arg Arg Thr His Leu Cys Ser Ala Ala Thr
595 600 605
Ser Ser Leu Leu Asp Ile Asp Pro Leu Ile Leu Ile His Leu Leu Asp
610 615 620
Leu Lys Asp Arg Ser Ser Ile Glu Asn Leu Trp Gly Leu Gln Pro Arg
625 630 635 640
Pro Pro Ala Ser Leu Leu Gln Pro Thr Ala Ser Tyr Ser Arg Lys Asp
645 650 655
Lys Asp Gln Arg Lys Gln Gln Ala Met Trp Arg Val Pro Ser Asp Leu
660 665 670
Lys Met Leu Lys Arg Leu Lys Thr Gln Met Ala Glu Val Arg Cys Met
675 680 685
Lys Thr Asp Val Lys Asn Thr Leu Ser Glu Ile Lys Ser Ser Ser Ala
690 695 700
Ala Ser Gly Asp Met Gln Thr Ser Leu Phe Ser Ala Asp Gln Ala Ala
705 710 715 720
Leu Ala Ala Cys Gly Thr Glu Asn Ser Gly Arg Leu Gln Asp Leu Gly
725 730 735
Met Glu Leu Leu Ala Lys Ser Ser Val Ala Asn Cys Tyr Ile Arg Asn
740 745 750
Ser Thr Asn Lys Lys Ser Asn Ser Pro Lys Pro Ala Arg Ser Ser Val
755 760 765
Ala Gly Ser Leu Ser Leu Arg Arg Ala Val Asp Pro Gly Glu Asn Ser
770 775 780
Arg Ser Lys Gly Asp Cys Gln Thr Leu Ser Glu Gly Ser Pro Gly Ser
785 790 795 800
Ser Gln Ser Gly Ser Arg His Ser Ser Pro Arg Ala Leu Ile His Gly
805 810 815
Ser Ile Gly Asp Ile Leu Pro Lys Thr Glu Asp Arg Gln Cys Lys Ala
820 825 830
Leu Asp Ser Asp Ala Val Val Val Ala Val Phe Ser Gly Leu Pro Ala
835 840 845
Val Glu Lys Arg Arg Lys Met Val Thr Leu Gly Ala Asn Ala Lys Gly
850 855 860
Gly His Leu Glu Gly Leu Gln Met Thr Asp Leu Glu Asn Asn Ser Glu
865 870 875 880
Thr Gly Glu Leu Gln Pro Val Leu Pro Glu Gly Ala Ser Ala Ala Pro
885 890 895
Glu Glu Gly Met Ser Ser Asp Ser Asp Ile Glu Cys Asp Thr Glu Asn
900 905 910
Glu Glu Gln Glu Glu His Thr Ser Val Gly Gly Phe His Asp Ser Phe
915 920 925
Met Val Met Thr Gln Pro Pro Asp Glu Asp Thr His Ser Ser Phe Pro
930 935 940
Asp Gly Glu Gln Ile Gly Pro Glu Asp Leu Ser Phe Asn Thr Asp Glu
945 950 955 960
Asn Ser Gly Arg
<210> 75
<211> 1398
<212> DNA
<213> Homo sapiens
<400> 75
atggcctcaa ccaccagcac caagaagatg atggaggaag ccacctgctc catctgcctg 60
agcctgatga cgaacccagt aagcatcaac tgtggacaca gctactgcca cttgtgtata 120
acagacttct ttaaaaaccc aagccaaaag caactgaggc aggagacatt ctgctgtccc 180
cagtgtcggg ctccatttca tatggatagc ctccgaccca acaagcagct gggaagcctc 240
attgaagccc tcaaagagac ggatcaagaa atgtcatgtg aggaacacgg agagcagttc 300
cacctgttct gcgaagacga ggggcagctc atctgctggc gctgtgagcg ggcaccacag 360
cacaaagggc acaccacagc tcttgttgaa gacgtatgcc agggctacaa ggaaaagctc 420
cagaaagctg tgacaaaact gaagcaactt gaagacagat gtacggagca gaagctgtcc 480
acagcaatgc gaataactaa atggaaagag aaggtacaga ttcagagaca aaaaatccgg 540
tctgacttta agaatctcca gtgtttccta catgaggaag agaagtctta tctctggagg 600
ctggagaaag aagaacaaca gactctgagt agactgaggg actatgaggc tggtctgggg 660
ctgaagagca atgaactcaa gagccacatc ctggaactgg aggaaaaatg tcagggctca 720
gcccagaaat tgctgcagaa tgtgaatgac actttgagca ggagttgggc tgtgaagctg 780
gaaacatcag aggctgtctc cttggaactt catactatgt gcaatgtttc caagctttac 840
ttcgatgtga agaaaatgtt aaggagtcat caagttagtg tgactctgga tccagataca 900
gctcatcacg aactaattct ctctgaggat cggagacaag tgactcgtgg atacacccag 960
gagaatcagg acacatcttc caggagattt actgccttcc cctgtgtctt gggttgtgaa 1020
ggcttcacct caggaagacg ttactttgaa gtggatgttg gcgaaggaac cggatgggat 1080
ttaggagttt gtatggaaaa tgtgcagagg ggcactggca tgaagcaaga gcctcagtct 1140
ggattctgga ccctcaggct gtgcaaaaag aaaggctatg tagcacttac ttctccccca 1200
acttcccttc atctgcatga gcagcccctg cttgtgggaa tttttctgga ctatgaggcc 1260
ggagttgtat ccttttataa cgggaatact ggctgccaca tctttacttt cccgaaggct 1320
tccttctctg atactctccg gccctatttc caggtttatc aatattctcc tttgtttctg 1380
cctcccccag gtgactaa 1398
<210> 76
<211> 465
<212> PRT
<213> Homo sapiens
<400> 76
Met Ala Ser Thr Thr Ser Thr Lys Lys Met Met Glu Glu Ala Thr Cys
1 5 10 15
Ser Ile Cys Leu Ser Leu Met Thr Asn Pro Val Ser Ile Asn Cys Gly
20 25 30
His Ser Tyr Cys His Leu Cys Ile Thr Asp Phe Phe Lys Asn Pro Ser
35 40 45
Gln Lys Gln Leu Arg Gln Glu Thr Phe Cys Cys Pro Gln Cys Arg Ala
50 55 60
Pro Phe His Met Asp Ser Leu Arg Pro Asn Lys Gln Leu Gly Ser Leu
65 70 75 80
Ile Glu Ala Leu Lys Glu Thr Asp Gln Glu Met Ser Cys Glu Glu His
85 90 95
Gly Glu Gln Phe His Leu Phe Cys Glu Asp Glu Gly Gln Leu Ile Cys
100 105 110
Trp Arg Cys Glu Arg Ala Pro Gln His Lys Gly His Thr Thr Ala Leu
115 120 125
Val Glu Asp Val Cys Gln Gly Tyr Lys Glu Lys Leu Gln Lys Ala Val
130 135 140
Thr Lys Leu Lys Gln Leu Glu Asp Arg Cys Thr Glu Gln Lys Leu Ser
145 150 155 160
Thr Ala Met Arg Ile Thr Lys Trp Lys Glu Lys Val Gln Ile Gln Arg
165 170 175
Gln Lys Ile Arg Ser Asp Phe Lys Asn Leu Gln Cys Phe Leu His Glu
180 185 190
Glu Glu Lys Ser Tyr Leu Trp Arg Leu Glu Lys Glu Glu Gln Gln Thr
195 200 205
Leu Ser Arg Leu Arg Asp Tyr Glu Ala Gly Leu Gly Leu Lys Ser Asn
210 215 220
Glu Leu Lys Ser His Ile Leu Glu Leu Glu Glu Lys Cys Gln Gly Ser
225 230 235 240
Ala Gln Lys Leu Leu Gln Asn Val Asn Asp Thr Leu Ser Arg Ser Trp
245 250 255
Ala Val Lys Leu Glu Thr Ser Glu Ala Val Ser Leu Glu Leu His Thr
260 265 270
Met Cys Asn Val Ser Lys Leu Tyr Phe Asp Val Lys Lys Met Leu Arg
275 280 285
Ser His Gln Val Ser Val Thr Leu Asp Pro Asp Thr Ala His His Glu
290 295 300
Leu Ile Leu Ser Glu Asp Arg Arg Gln Val Thr Arg Gly Tyr Thr Gln
305 310 315 320
Glu Asn Gln Asp Thr Ser Ser Arg Arg Phe Thr Ala Phe Pro Cys Val
325 330 335
Leu Gly Cys Glu Gly Phe Thr Ser Gly Arg Arg Tyr Phe Glu Val Asp
340 345 350
Val Gly Glu Gly Thr Gly Trp Asp Leu Gly Val Cys Met Glu Asn Val
355 360 365
Gln Arg Gly Thr Gly Met Lys Gln Glu Pro Gln Ser Gly Phe Trp Thr
370 375 380
Leu Arg Leu Cys Lys Lys Lys Gly Tyr Val Ala Leu Thr Ser Pro Pro
385 390 395 400
Thr Ser Leu His Leu His Glu Gln Pro Leu Leu Val Gly Ile Phe Leu
405 410 415
Asp Tyr Glu Ala Gly Val Val Ser Phe Tyr Asn Gly Asn Thr Gly Cys
420 425 430
His Ile Phe Thr Phe Pro Lys Ala Ser Phe Ser Asp Thr Leu Arg Pro
435 440 445
Tyr Phe Gln Val Tyr Gln Tyr Ser Pro Leu Phe Leu Pro Pro Pro Gly
450 455 460
Asp
465
<210> 77
<211> 1557
<212> DNA
<213> Homo sapiens
<400> 77
atggcagaga caagtctgtt agaggctggg gcctctgcag cctctacagc tgcggctttg 60
gagaacttac aggtggaggc gagctgctct gtgtgcctgg agtatctgaa ggaacctgtc 120
atcattgagt gtgggcacaa cttctgcaaa gcttgcatca cccgctggtg ggaggaccta 180
gagagggact tcccttgtcc tgtctgtcga aagacatccc gctaccgcag tctccgacct 240
aatcggcaac taggcagtat ggtggaaatt gccaagcagc tccaggccgt caagcggaag 300
atccgggatg agagcctctg cccccaacac catgaggccc tcagcctttt ctgttatgag 360
gaccaggagg ctgtatgctt gatatgtgca atttcccaca cccaccgggc ccacaccgtt 420
gtgccactgg acgatgctac acaggagtac aaggaaaaac tgcagaagtg tctggagccc 480
ctggaacaga agctgcagga gatcactcgc tgcaagtcct ctgaggagaa gaagcctggt 540
gagctcaaga gactagtgga aagtcgccga cagcagatct tgagggagtt tgaagagctt 600
cataggcggc tggatgaaga gcagcaggtg ttgctttcac gactggaaga agaggaacag 660
gacattctgc agcgactccg agaaaatgct gctcaccttg gggacaagcg ccgggacctg 720
gcccacttgg ctgccgaggt ggagggcaag tgcttacagt caggcttcga gatgcttaag 780
gatgtcaaaa gtaccctgga aaagaatatt cctagaaagt tcggaggctc actctcaacg 840
atctgtccac gggatcataa ggctctcctt ggattagtaa aagaaatcaa cagatgtgaa 900
aaggtgaaga ccatggaggt gacttcagta tccatagagc tggaaaagaa cttcagcaat 960
tttccccgac agtactttgc cctaaggaaa atccttaaac agctaattgc ggatgtgacc 1020
ctggaccctg agacagctca tcctaaccta gtcctgtcag aggatcgtaa gagcgtcaag 1080
ttcgtggaga caagactccg ggatctccct gacacaccaa ggcgtttcac cttctaccct 1140
tgcgtcctgg ctactgaggg tttcacctca ggtcgacact actgggaggt ggaggtgggc 1200
gacaagaccc actgggcagt gggtgtatgc cgggactccg tgagccgaaa gggcgagttg 1260
actccactcc ctgagactgg ctactggcgg gtgcggctat ggaatgggga caaatatgca 1320
gccaccacca caccttttac ccctttgcac atcaaggtga aacccaagcg ggtaggcata 1380
ttcctagact atgaggccgg cacactgtct ttctacaatg tcacagaccg ctctcatatc 1440
tacaccttca ctgatacttt tactgagaaa ctttggcccc tcttctaccc aggcatccgg 1500
gctggacgga agaatgctgc accacttacc atcaggcccc caacagattg ggagtga 1557
<210> 78
<211> 518
<212> PRT
<213> Homo sapiens
<400> 78
Met Ala Glu Thr Ser Leu Leu Glu Ala Gly Ala Ser Ala Ala Ser Thr
1 5 10 15
Ala Ala Ala Leu Glu Asn Leu Gln Val Glu Ala Ser Cys Ser Val Cys
20 25 30
Leu Glu Tyr Leu Lys Glu Pro Val Ile Ile Glu Cys Gly His Asn Phe
35 40 45
Cys Lys Ala Cys Ile Thr Arg Trp Trp Glu Asp Leu Glu Arg Asp Phe
50 55 60
Pro Cys Pro Val Cys Arg Lys Thr Ser Arg Tyr Arg Ser Leu Arg Pro
65 70 75 80
Asn Arg Gln Leu Gly Ser Met Val Glu Ile Ala Lys Gln Leu Gln Ala
85 90 95
Val Lys Arg Lys Ile Arg Asp Glu Ser Leu Cys Pro Gln His His Glu
100 105 110
Ala Leu Ser Leu Phe Cys Tyr Glu Asp Gln Glu Ala Val Cys Leu Ile
115 120 125
Cys Ala Ile Ser His Thr His Arg Ala His Thr Val Val Pro Leu Asp
130 135 140
Asp Ala Thr Gln Glu Tyr Lys Glu Lys Leu Gln Lys Cys Leu Glu Pro
145 150 155 160
Leu Glu Gln Lys Leu Gln Glu Ile Thr Arg Cys Lys Ser Ser Glu Glu
165 170 175
Lys Lys Pro Gly Glu Leu Lys Arg Leu Val Glu Ser Arg Arg Gln Gln
180 185 190
Ile Leu Arg Glu Phe Glu Glu Leu His Arg Arg Leu Asp Glu Glu Gln
195 200 205
Gln Val Leu Leu Ser Arg Leu Glu Glu Glu Glu Gln Asp Ile Leu Gln
210 215 220
Arg Leu Arg Glu Asn Ala Ala His Leu Gly Asp Lys Arg Arg Asp Leu
225 230 235 240
Ala His Leu Ala Ala Glu Val Glu Gly Lys Cys Leu Gln Ser Gly Phe
245 250 255
Glu Met Leu Lys Asp Val Lys Ser Thr Leu Glu Lys Asn Ile Pro Arg
260 265 270
Lys Phe Gly Gly Ser Leu Ser Thr Ile Cys Pro Arg Asp His Lys Ala
275 280 285
Leu Leu Gly Leu Val Lys Glu Ile Asn Arg Cys Glu Lys Val Lys Thr
290 295 300
Met Glu Val Thr Ser Val Ser Ile Glu Leu Glu Lys Asn Phe Ser Asn
305 310 315 320
Phe Pro Arg Gln Tyr Phe Ala Leu Arg Lys Ile Leu Lys Gln Leu Ile
325 330 335
Ala Asp Val Thr Leu Asp Pro Glu Thr Ala His Pro Asn Leu Val Leu
340 345 350
Ser Glu Asp Arg Lys Ser Val Lys Phe Val Glu Thr Arg Leu Arg Asp
355 360 365
Leu Pro Asp Thr Pro Arg Arg Phe Thr Phe Tyr Pro Cys Val Leu Ala
370 375 380
Thr Glu Gly Phe Thr Ser Gly Arg His Tyr Trp Glu Val Glu Val Gly
385 390 395 400
Asp Lys Thr His Trp Ala Val Gly Val Cys Arg Asp Ser Val Ser Arg
405 410 415
Lys Gly Glu Leu Thr Pro Leu Pro Glu Thr Gly Tyr Trp Arg Val Arg
420 425 430
Leu Trp Asn Gly Asp Lys Tyr Ala Ala Thr Thr Thr Pro Phe Thr Pro
435 440 445
Leu His Ile Lys Val Lys Pro Lys Arg Val Gly Ile Phe Leu Asp Tyr
450 455 460
Glu Ala Gly Thr Leu Ser Phe Tyr Asn Val Thr Asp Arg Ser His Ile
465 470 475 480
Tyr Thr Phe Thr Asp Thr Phe Thr Glu Lys Leu Trp Pro Leu Phe Tyr
485 490 495
Pro Gly Ile Arg Ala Gly Arg Lys Asn Ala Ala Pro Leu Thr Ile Arg
500 505 510
Pro Pro Thr Asp Trp Glu
515
<210> 79
<211> 777
<212> DNA
<213> Homo sapiens
<400> 79
atgatccctt tgcagaagga caaccaggag gagggtgtct gccccatctg ccaggagagc 60
ctgaaggagg ccgtgagcac caactgcgga catctcttct gtcgagtgtg cctgacacag 120
catgtggaga aggcctcagc ctctggggtc ttctgctgcc ccctctgccg gaagccctgt 180
tctgaggagg tgctagggac aggctatatc tgccccaacc accagaagag ggtgtgcagg 240
ttctgtgagg agagcagact tcttctatgt gtggaatgcc tggtgtcccc tgaacacatg 300
tctcatcatg aactgaccat tgaaaatgcc ctcagccact acaaggaacg actcaatcgc 360
cggagcagga agctcagaaa ggacattgca gaacttcagc ggctcaaggc tcagcaggag 420
aagaaactgc aggctctgca gtttcaggta gaccacggga accacaggct ggaggctggg 480
ccggagagcc agcaccaaac cagggaacag ctgggtgccc tccctcagca gtggctgggc 540
cagctggagc acatgccagc agaagcggcc agaatccttg acatctccag ggcagtaaca 600
cagctcagaa gcctggtcat tgatctggaa aggacggcca aggaattaga caccaacaca 660
ctgaagaatg ctggtgactt actgaacagg agtgctccac agaaattaga ggttatttat 720
ccccagttgg agaaaggagt cagtgaattg cttcttcagc cccctcagaa gctctga 777
<210> 80
<211> 258
<212> PRT
<213> Homo sapiens
<400> 80
Met Ile Pro Leu Gln Lys Asp Asn Gln Glu Glu Gly Val Cys Pro Ile
1 5 10 15
Cys Gln Glu Ser Leu Lys Glu Ala Val Ser Thr Asn Cys Gly His Leu
20 25 30
Phe Cys Arg Val Cys Leu Thr Gln His Val Glu Lys Ala Ser Ala Ser
35 40 45
Gly Val Phe Cys Cys Pro Leu Cys Arg Lys Pro Cys Ser Glu Glu Val
50 55 60
Leu Gly Thr Gly Tyr Ile Cys Pro Asn His Gln Lys Arg Val Cys Arg
65 70 75 80
Phe Cys Glu Glu Ser Arg Leu Leu Leu Cys Val Glu Cys Leu Val Ser
85 90 95
Pro Glu His Met Ser His His Glu Leu Thr Ile Glu Asn Ala Leu Ser
100 105 110
His Tyr Lys Glu Arg Leu Asn Arg Arg Ser Arg Lys Leu Arg Lys Asp
115 120 125
Ile Ala Glu Leu Gln Arg Leu Lys Ala Gln Gln Glu Lys Lys Leu Gln
130 135 140
Ala Leu Gln Phe Gln Val Asp His Gly Asn His Arg Leu Glu Ala Gly
145 150 155 160
Pro Glu Ser Gln His Gln Thr Arg Glu Gln Leu Gly Ala Leu Pro Gln
165 170 175
Gln Trp Leu Gly Gln Leu Glu His Met Pro Ala Glu Ala Ala Arg Ile
180 185 190
Leu Asp Ile Ser Arg Ala Val Thr Gln Leu Arg Ser Leu Val Ile Asp
195 200 205
Leu Glu Arg Thr Ala Lys Glu Leu Asp Thr Asn Thr Leu Lys Asn Ala
210 215 220
Gly Asp Leu Leu Asn Arg Ser Ala Pro Gln Lys Leu Glu Val Ile Tyr
225 230 235 240
Pro Gln Leu Glu Lys Gly Val Ser Glu Leu Leu Leu Gln Pro Pro Gln
245 250 255
Lys Leu
<210> 81
<211> 1893
<212> DNA
<213> Homo sapiens
<400> 81
atggctgccg ttgccatgac acccaaccct gtgcagaccc ttcaggagga ggcggtgtgc 60
gccatctgcc tcgattactt cacggacccc gtgtccatcg gctgcgggca caacttctgc 120
cgagtttgtg taacccagtt gtggggtggg gaggatgagg aggacagaga tgagttagat 180
cgggaggagg aggaggagga cggagaggag gaggaagtgg aggctgtggg ggctggcgcg 240
gggtgggaca cccccatgcg ggatgaagac tacgagggtg acatggagga ggaggtcgag 300
gaggaagaag agggtgtgtt ctggaccagt ggcatgagca ggtccagctg ggacaacatg 360
gactatgtgt gggaggagga ggacgaggag gaagacctgg actactactt gggggacatg 420
gaggaggagg acctgagggg ggaggatgag gaggacgagg aggaagtgct ggaggaggtt 480
gaggaagagg atctagaccc cgtcacccca ctgcccccgc ctccagcccc tcggaggtgc 540
ttcacatgcc ctcagtgccg aaagagcttt cctcggcgga gcttccgccc caacctgcag 600
ctggccaata tggtccaggt gattcggcag atgcacccaa cccctggtcg agggagccgc 660
gtgaccgatc agggcatctg tcccaaacac caagaagccc tgaagctctt ctgcgaggta 720
gacgaagagg ccatctgtgt ggtgtgccga gaatccagga gccacaaaca gcacagcgtg 780
gtgccattgg aggaggtggt gcaggagtac aaggccaaac tgcaggggca cgtggaacca 840
ctgaggaagc acctggaggc agtgcagaag atgaaagcca aggaggagag gcgagtgaca 900
gaactgaaga gccagatgaa gtcagagctg gcagcggtgg cctcggagtt tgggcgactg 960
acacggtttc tggctgaaga gcaggcaggg ctggaacggc gtctcagaga gatgcatgaa 1020
gcccagctgg ggcgtgcggg agccgcggct agtcgccttg cagaacaggc cgcccagctc 1080
agccgcctgc tggcagaggc ccaggagcgg agccagcagg ggggtctccg gctgctccag 1140
gacatcaagg agactttcaa taggtgtgaa gaggtacagc tgcagccccc agaggtctgg 1200
tcccctgacc cgtgccaacc ccatagccat gacttcctga cagatgccat cgtgaggaaa 1260
atgagccgga tgttctgtca ggctgcgaga gtggacctga cgctggaccc tgacacggct 1320
cacccggccc tgatgctgtc ccctgaccgc cggggggtcc gcctggcaga gcggcggcag 1380
gaggttgctg accatcccaa gcgcttctcg gccgactgct gcgtactggg ggcccagggc 1440
ttccgctccg gccggcacta ctgggaggta gaggtgggcg ggcggcgggg ctgggcggtg 1500
ggtgctgccc gtgaatcaac ccatcataag gaaaaggtgg gccctggggg ttcctccgtg 1560
ggcagcgggg atgccagctc ctcgcgccat caccatcgcc gccgccggct ccacctgccc 1620
cagcagcccc tgctccagcg ggaagtgtgg tgcgtgggca ccaacggcaa acgctatcag 1680
gcccagagct ccacagaaca gacgctgctg agccccagtg agaaaccaag gcgctttggt 1740
gtgtacctgg actatgaagc tgggcgcctg ggcttctaca acgcagagac tctagcccac 1800
gtgcacacct tctcggctgc cttcctgggc gagcgtgtct ttcctttctt ccgggtgctc 1860
tccaagggca cccgcatcaa gctctgccct tga 1893
<210> 82
<211> 630
<212> PRT
<213> Homo sapiens
<400> 82
Met Ala Ala Val Ala Met Thr Pro Asn Pro Val Gln Thr Leu Gln Glu
1 5 10 15
Glu Ala Val Cys Ala Ile Cys Leu Asp Tyr Phe Thr Asp Pro Val Ser
20 25 30
Ile Gly Cys Gly His Asn Phe Cys Arg Val Cys Val Thr Gln Leu Trp
35 40 45
Gly Gly Glu Asp Glu Glu Asp Arg Asp Glu Leu Asp Arg Glu Glu Glu
50 55 60
Glu Glu Asp Gly Glu Glu Glu Glu Val Glu Ala Val Gly Ala Gly Ala
65 70 75 80
Gly Trp Asp Thr Pro Met Arg Asp Glu Asp Tyr Glu Gly Asp Met Glu
85 90 95
Glu Glu Val Glu Glu Glu Glu Glu Gly Val Phe Trp Thr Ser Gly Met
100 105 110
Ser Arg Ser Ser Trp Asp Asn Met Asp Tyr Val Trp Glu Glu Glu Asp
115 120 125
Glu Glu Glu Asp Leu Asp Tyr Tyr Leu Gly Asp Met Glu Glu Glu Asp
130 135 140
Leu Arg Gly Glu Asp Glu Glu Asp Glu Glu Glu Val Leu Glu Glu Val
145 150 155 160
Glu Glu Glu Asp Leu Asp Pro Val Thr Pro Leu Pro Pro Pro Pro Ala
165 170 175
Pro Arg Arg Cys Phe Thr Cys Pro Gln Cys Arg Lys Ser Phe Pro Arg
180 185 190
Arg Ser Phe Arg Pro Asn Leu Gln Leu Ala Asn Met Val Gln Val Ile
195 200 205
Arg Gln Met His Pro Thr Pro Gly Arg Gly Ser Arg Val Thr Asp Gln
210 215 220
Gly Ile Cys Pro Lys His Gln Glu Ala Leu Lys Leu Phe Cys Glu Val
225 230 235 240
Asp Glu Glu Ala Ile Cys Val Val Cys Arg Glu Ser Arg Ser His Lys
245 250 255
Gln His Ser Val Val Pro Leu Glu Glu Val Val Gln Glu Tyr Lys Ala
260 265 270
Lys Leu Gln Gly His Val Glu Pro Leu Arg Lys His Leu Glu Ala Val
275 280 285
Gln Lys Met Lys Ala Lys Glu Glu Arg Arg Val Thr Glu Leu Lys Ser
290 295 300
Gln Met Lys Ser Glu Leu Ala Ala Val Ala Ser Glu Phe Gly Arg Leu
305 310 315 320
Thr Arg Phe Leu Ala Glu Glu Gln Ala Gly Leu Glu Arg Arg Leu Arg
325 330 335
Glu Met His Glu Ala Gln Leu Gly Arg Ala Gly Ala Ala Ala Ser Arg
340 345 350
Leu Ala Glu Gln Ala Ala Gln Leu Ser Arg Leu Leu Ala Glu Ala Gln
355 360 365
Glu Arg Ser Gln Gln Gly Gly Leu Arg Leu Leu Gln Asp Ile Lys Glu
370 375 380
Thr Phe Asn Arg Cys Glu Glu Val Gln Leu Gln Pro Pro Glu Val Trp
385 390 395 400
Ser Pro Asp Pro Cys Gln Pro His Ser His Asp Phe Leu Thr Asp Ala
405 410 415
Ile Val Arg Lys Met Ser Arg Met Phe Cys Gln Ala Ala Arg Val Asp
420 425 430
Leu Thr Leu Asp Pro Asp Thr Ala His Pro Ala Leu Met Leu Ser Pro
435 440 445
Asp Arg Arg Gly Val Arg Leu Ala Glu Arg Arg Gln Glu Val Ala Asp
450 455 460
His Pro Lys Arg Phe Ser Ala Asp Cys Cys Val Leu Gly Ala Gln Gly
465 470 475 480
Phe Arg Ser Gly Arg His Tyr Trp Glu Val Glu Val Gly Gly Arg Arg
485 490 495
Gly Trp Ala Val Gly Ala Ala Arg Glu Ser Thr His His Lys Glu Lys
500 505 510
Val Gly Pro Gly Gly Ser Ser Val Gly Ser Gly Asp Ala Ser Ser Ser
515 520 525
Arg His His His Arg Arg Arg Arg Leu His Leu Pro Gln Gln Pro Leu
530 535 540
Leu Gln Arg Glu Val Trp Cys Val Gly Thr Asn Gly Lys Arg Tyr Gln
545 550 555 560
Ala Gln Ser Ser Thr Glu Gln Thr Leu Leu Ser Pro Ser Glu Lys Pro
565 570 575
Arg Arg Phe Gly Val Tyr Leu Asp Tyr Glu Ala Gly Arg Leu Gly Phe
580 585 590
Tyr Asn Ala Glu Thr Leu Ala His Val His Thr Phe Ser Ala Ala Phe
595 600 605
Leu Gly Glu Arg Val Phe Pro Phe Phe Arg Val Leu Ser Lys Gly Thr
610 615 620
Arg Ile Lys Leu Cys Pro
625 630
<210> 83
<211> 2172
<212> DNA
<213> Homo sapiens
<400> 83
atggaaactg ctatgtgcgt ttgctgtcca tgttgtacat ggcagagatg ttgtcctcag 60
ttatgctcct gtctgtgctg caagttcatc ttcacctcag agcggaactg cacctgcttc 120
ccctgccctt acaaagatga gcggaactgc cagttctgcc actgcacctg ttctgagagc 180
cccaactgcc attggtgttg ctgctcttgg gccaatgatc ccaactgtaa gtgctgctgc 240
acagccagca gcaatctcaa ctgctactac tatgagagcc gctgctgccg caataccatc 300
atcactttcc acaagggccg cctcaggagc atccatacct cctccaagac tgccctgcgc 360
actgggagca gcgataccca ggtggatgaa gtaaagtcaa taccagccaa cagtcacctg 420
gtgaaccacc tcaattgccc catgtgcagc cggctgcgcc tgcactcatt catgctgccc 480
tgcaaccaca gcctgtgcga gaagtgcctg cggcagctgc agaagcacgc cgaggtcacc 540
gagaacttct tcatcctcat ctgcccagtg tgcgaccgct cgcactgcat gccctacagc 600
aacaagatgc agctgcccga gaactacctg cacgggcgtc tcaccaagcg ctacatgcag 660
gagcacggct acctcaagtg gcgctttgac cgctcctccg ggcccatcct ctgccaggtc 720
tgccgcaaca agcgcatcgc ttacaagcgc tgcatcacct gccgcctcaa cctgtgcaac 780
gactgcctca aggccttcca ctcggatgtg gccatgcaag accacgtctt tgtggacacc 840
agcgccgagg aacaggacga gaagatctgc atccaccacc catccagccg catcatcgag 900
tactgccgca atgacaacaa attgctctgc accttctgca agttctcttt ccacaatggc 960
cacgacacca ttagcctcat cgacgcctgc tccgagaggg ccgcctcact cttcagcgcc 1020
atcgccaagt tcaaagcagt ccgatatgaa attgataatg acctaatgga attcaacatc 1080
ttaaaaaaca gctttaaagc tgacaaggag gcaaagcgaa aagagatcag aaatggcttt 1140
ctcaagttgc gcagcattct tcaggagaaa gagaagatca tcatggagca gatagagaat 1200
ctagaagtgt ccaggcagaa ggaaattgaa aaatatgtgt atgttacaac catgaaagtg 1260
aacgagatgg atggtctgat cgcctactcc aaggaagccc tgaaggagac tggccaggtg 1320
gcattcctgc agtcagccaa gatcctggtg gaccagatcg aggacggcat ccagaccacc 1380
tacaggcctg acccacagct ccggctgcac tcaataaact acgtgccctt ggactttgtt 1440
gagctttcca gtgccatcca tgagctcttc cccacagggc ccaagaaggt acgctcctca 1500
ggggactccc tgccctcccc ctaccccgtg cactcagaaa caatgattgc caggaaggtc 1560
actttcagca cccacagcct cggcaaccag cacatatacc agcgaagctc ctccatgttg 1620
tccttcagca acactgacaa gaaggccaag gtgggtctgg aggcctgtgg gagagcccag 1680
tcagccaccc ccgccaaacc cacagacggc ctctacacct actggagtgc tggagcagac 1740
agccagtctg tacagaacag cagcagcttc cacaactggt actcattcaa cgatggctct 1800
gtgaagaccc caggcccaat tgttatctac cagactctgg tgtacccaag agctgccaag 1860
gtttactgga catgtccagc agaagacgtg gactcttttg agatggaatt ctatgaagtc 1920
attacttctc ctcctaacaa cgtacaaatg gagctctgtg gacaaattcg ggacataatg 1980
cagcaaaatc tggagctgca caacctgacc cccaacacag aatacgtgtt taaagttaga 2040
gccatcaatg ataatggtcc tgggcaatgg agtgatatct gcaaggtggt aacaccagat 2100
ggacatggga agaaccgagc taagtggggc ctgctgaaga atatccagtc tgccctccag 2160
aagcacttct ga 2172
<210> 84
<211> 723
<212> PRT
<213> Homo sapiens
<400> 84
Met Glu Thr Ala Met Cys Val Cys Cys Pro Cys Cys Thr Trp Gln Arg
1 5 10 15
Cys Cys Pro Gln Leu Cys Ser Cys Leu Cys Cys Lys Phe Ile Phe Thr
20 25 30
Ser Glu Arg Asn Cys Thr Cys Phe Pro Cys Pro Tyr Lys Asp Glu Arg
35 40 45
Asn Cys Gln Phe Cys His Cys Thr Cys Ser Glu Ser Pro Asn Cys His
50 55 60
Trp Cys Cys Cys Ser Trp Ala Asn Asp Pro Asn Cys Lys Cys Cys Cys
65 70 75 80
Thr Ala Ser Ser Asn Leu Asn Cys Tyr Tyr Tyr Glu Ser Arg Cys Cys
85 90 95
Arg Asn Thr Ile Ile Thr Phe His Lys Gly Arg Leu Arg Ser Ile His
100 105 110
Thr Ser Ser Lys Thr Ala Leu Arg Thr Gly Ser Ser Asp Thr Gln Val
115 120 125
Asp Glu Val Lys Ser Ile Pro Ala Asn Ser His Leu Val Asn His Leu
130 135 140
Asn Cys Pro Met Cys Ser Arg Leu Arg Leu His Ser Phe Met Leu Pro
145 150 155 160
Cys Asn His Ser Leu Cys Glu Lys Cys Leu Arg Gln Leu Gln Lys His
165 170 175
Ala Glu Val Thr Glu Asn Phe Phe Ile Leu Ile Cys Pro Val Cys Asp
180 185 190
Arg Ser His Cys Met Pro Tyr Ser Asn Lys Met Gln Leu Pro Glu Asn
195 200 205
Tyr Leu His Gly Arg Leu Thr Lys Arg Tyr Met Gln Glu His Gly Tyr
210 215 220
Leu Lys Trp Arg Phe Asp Arg Ser Ser Gly Pro Ile Leu Cys Gln Val
225 230 235 240
Cys Arg Asn Lys Arg Ile Ala Tyr Lys Arg Cys Ile Thr Cys Arg Leu
245 250 255
Asn Leu Cys Asn Asp Cys Leu Lys Ala Phe His Ser Asp Val Ala Met
260 265 270
Gln Asp His Val Phe Val Asp Thr Ser Ala Glu Glu Gln Asp Glu Lys
275 280 285
Ile Cys Ile His His Pro Ser Ser Arg Ile Ile Glu Tyr Cys Arg Asn
290 295 300
Asp Asn Lys Leu Leu Cys Thr Phe Cys Lys Phe Ser Phe His Asn Gly
305 310 315 320
His Asp Thr Ile Ser Leu Ile Asp Ala Cys Ser Glu Arg Ala Ala Ser
325 330 335
Leu Phe Ser Ala Ile Ala Lys Phe Lys Ala Val Arg Tyr Glu Ile Asp
340 345 350
Asn Asp Leu Met Glu Phe Asn Ile Leu Lys Asn Ser Phe Lys Ala Asp
355 360 365
Lys Glu Ala Lys Arg Lys Glu Ile Arg Asn Gly Phe Leu Lys Leu Arg
370 375 380
Ser Ile Leu Gln Glu Lys Glu Lys Ile Ile Met Glu Gln Ile Glu Asn
385 390 395 400
Leu Glu Val Ser Arg Gln Lys Glu Ile Glu Lys Tyr Val Tyr Val Thr
405 410 415
Thr Met Lys Val Asn Glu Met Asp Gly Leu Ile Ala Tyr Ser Lys Glu
420 425 430
Ala Leu Lys Glu Thr Gly Gln Val Ala Phe Leu Gln Ser Ala Lys Ile
435 440 445
Leu Val Asp Gln Ile Glu Asp Gly Ile Gln Thr Thr Tyr Arg Pro Asp
450 455 460
Pro Gln Leu Arg Leu His Ser Ile Asn Tyr Val Pro Leu Asp Phe Val
465 470 475 480
Glu Leu Ser Ser Ala Ile His Glu Leu Phe Pro Thr Gly Pro Lys Lys
485 490 495
Val Arg Ser Ser Gly Asp Ser Leu Pro Ser Pro Tyr Pro Val His Ser
500 505 510
Glu Thr Met Ile Ala Arg Lys Val Thr Phe Ser Thr His Ser Leu Gly
515 520 525
Asn Gln His Ile Tyr Gln Arg Ser Ser Ser Met Leu Ser Phe Ser Asn
530 535 540
Thr Asp Lys Lys Ala Lys Val Gly Leu Glu Ala Cys Gly Arg Ala Gln
545 550 555 560
Ser Ala Thr Pro Ala Lys Pro Thr Asp Gly Leu Tyr Thr Tyr Trp Ser
565 570 575
Ala Gly Ala Asp Ser Gln Ser Val Gln Asn Ser Ser Ser Phe His Asn
580 585 590
Trp Tyr Ser Phe Asn Asp Gly Ser Val Lys Thr Pro Gly Pro Ile Val
595 600 605
Ile Tyr Gln Thr Leu Val Tyr Pro Arg Ala Ala Lys Val Tyr Trp Thr
610 615 620
Cys Pro Ala Glu Asp Val Asp Ser Phe Glu Met Glu Phe Tyr Glu Val
625 630 635 640
Ile Thr Ser Pro Pro Asn Asn Val Gln Met Glu Leu Cys Gly Gln Ile
645 650 655
Arg Asp Ile Met Gln Gln Asn Leu Glu Leu His Asn Leu Thr Pro Asn
660 665 670
Thr Glu Tyr Val Phe Lys Val Arg Ala Ile Asn Asp Asn Gly Pro Gly
675 680 685
Gln Trp Ser Asp Ile Cys Lys Val Val Thr Pro Asp Gly His Gly Lys
690 695 700
Asn Arg Ala Lys Trp Gly Leu Leu Lys Asn Ile Gln Ser Ala Leu Gln
705 710 715 720
Lys His Phe
<210> 85
<211> 1341
<212> DNA
<213> Homo sapiens
<400> 85
atggactcag acttctcaca tgccttccag aaggaactca cctgcgtcat ctgtttgaac 60
tacctggtag accctgtcac catctgctgt gggcacagct tctgtaggcc ctgtctctgc 120
ctttcgtggg aggaagccca aagtcctgca aactgccctg catgcaggga accatcaccg 180
aaaatggact tcaaaaccaa tattcttctg aagaatttag tgaccattgc cagaaaagcc 240
agtctctggc aattcctgag ctctgagaaa caaatatgtg ggacccatag gcaaacaaag 300
aagatgttct gtgacatgga caagagtctc ctctgcttgc tgtgctccaa ctctcaggag 360
cacggggctc acaaacacca tcccatcgaa gaggcagctg aggaacaccg ggagaaactc 420
ttaaagcaaa tgaggatttt atggaaaaag attcaagaaa atcagagaaa tctatatgag 480
gagggaagaa cagccttcct ctggaggggc aatgtggttt tacgggcaca gatgatcagg 540
aatgagtata ggaagctgca tccggttctc cataaggaag aaaaacaaca tttagagaga 600
ctgaacaagg aataccaaga gatttttcag caactccaga gaagttgggt caaaatggat 660
caaaagagta aacacttgaa agaaatgtat caggaactaa tggaaatgtg tcataaacca 720
gatgtggagc tgctccagga tttgggagac atcgtggcaa ggagtgagtc cgtgctgctg 780
cacatgcccc agcctgtgaa tccagagctc actgcaggac ccatcactgg actggtgtac 840
aggctcaacc gcttccgagt ggaaatttcc ttccattttg aagtaaccaa tcacaatatc 900
aggctctttg aggatgtgag aagttggatg tttagacgtg gacctttgaa ttctgacaga 960
tctgactatt ttgctgcatg gggagccagg gtcttctcct ttgggaaaca ctactgggag 1020
ctggatgtgg acaactcttg tgactgggct ctgggagtct gtaacaactc ctggataagg 1080
aagaatagca caatggttaa ctctgaggac atatttcttc ttttgtgtct gaaggtggat 1140
aatcatttca atctcttgac cacctcccca gtgtttcctc actacataga gaaacctctg 1200
ggccgggttg gtgtgtttct tgattttgaa agtggaagtg tgagtttttt gaatgtcacc 1260
aagagttccc tcatatggag ttacccagct ggctccttaa cttttcctgt caggcctttc 1320
ttttacactg gccacagatg a 1341
<210> 86
<211> 446
<212> PRT
<213> Homo sapiens
<400> 86
Met Asp Ser Asp Phe Ser His Ala Phe Gln Lys Glu Leu Thr Cys Val
1 5 10 15
Ile Cys Leu Asn Tyr Leu Val Asp Pro Val Thr Ile Cys Cys Gly His
20 25 30
Ser Phe Cys Arg Pro Cys Leu Cys Leu Ser Trp Glu Glu Ala Gln Ser
35 40 45
Pro Ala Asn Cys Pro Ala Cys Arg Glu Pro Ser Pro Lys Met Asp Phe
50 55 60
Lys Thr Asn Ile Leu Leu Lys Asn Leu Val Thr Ile Ala Arg Lys Ala
65 70 75 80
Ser Leu Trp Gln Phe Leu Ser Ser Glu Lys Gln Ile Cys Gly Thr His
85 90 95
Arg Gln Thr Lys Lys Met Phe Cys Asp Met Asp Lys Ser Leu Leu Cys
100 105 110
Leu Leu Cys Ser Asn Ser Gln Glu His Gly Ala His Lys His His Pro
115 120 125
Ile Glu Glu Ala Ala Glu Glu His Arg Glu Lys Leu Leu Lys Gln Met
130 135 140
Arg Ile Leu Trp Lys Lys Ile Gln Glu Asn Gln Arg Asn Leu Tyr Glu
145 150 155 160
Glu Gly Arg Thr Ala Phe Leu Trp Arg Gly Asn Val Val Leu Arg Ala
165 170 175
Gln Met Ile Arg Asn Glu Tyr Arg Lys Leu His Pro Val Leu His Lys
180 185 190
Glu Glu Lys Gln His Leu Glu Arg Leu Asn Lys Glu Tyr Gln Glu Ile
195 200 205
Phe Gln Gln Leu Gln Arg Ser Trp Val Lys Met Asp Gln Lys Ser Lys
210 215 220
His Leu Lys Glu Met Tyr Gln Glu Leu Met Glu Met Cys His Lys Pro
225 230 235 240
Asp Val Glu Leu Leu Gln Asp Leu Gly Asp Ile Val Ala Arg Ser Glu
245 250 255
Ser Val Leu Leu His Met Pro Gln Pro Val Asn Pro Glu Leu Thr Ala
260 265 270
Gly Pro Ile Thr Gly Leu Val Tyr Arg Leu Asn Arg Phe Arg Val Glu
275 280 285
Ile Ser Phe His Phe Glu Val Thr Asn His Asn Ile Arg Leu Phe Glu
290 295 300
Asp Val Arg Ser Trp Met Phe Arg Arg Gly Pro Leu Asn Ser Asp Arg
305 310 315 320
Ser Asp Tyr Phe Ala Ala Trp Gly Ala Arg Val Phe Ser Phe Gly Lys
325 330 335
His Tyr Trp Glu Leu Asp Val Asp Asn Ser Cys Asp Trp Ala Leu Gly
340 345 350
Val Cys Asn Asn Ser Trp Ile Arg Lys Asn Ser Thr Met Val Asn Ser
355 360 365
Glu Asp Ile Phe Leu Leu Leu Cys Leu Lys Val Asp Asn His Phe Asn
370 375 380
Leu Leu Thr Thr Ser Pro Val Phe Pro His Tyr Ile Glu Lys Pro Leu
385 390 395 400
Gly Arg Val Gly Val Phe Leu Asp Phe Glu Ser Gly Ser Val Ser Phe
405 410 415
Leu Asn Val Thr Lys Ser Ser Leu Ile Trp Ser Tyr Pro Ala Gly Ser
420 425 430
Leu Thr Phe Pro Val Arg Pro Phe Phe Tyr Thr Gly His Arg
435 440 445
<210> 87
<211> 1035
<212> DNA
<213> Homo sapiens
<400> 87
atggcctctg gagtgggcgc ggccttcgag gaactgcctc acgacggcac gtgtgacgag 60
tgcgagcccg acgaggctcc gggggccgag gaagtgtgcc gagaatgcgg cttctgctac 120
tgccgccgcc atgccgaggc gcacaggcag aagttcctca gtcaccatct ggccgaatac 180
gtccacggct cccaggcctg gaccccgcca gctgacggag agggggcggg gaaggaagaa 240
gcggaggtca aggtggagca ggagagggag atagaaagcg aggcagggga agagagtgag 300
tcggaggaag agagcgagtc agaggaagag agcgagacag aggaagagag tgaggatgag 360
agcgatgagg agagtgaaga agacagcgag gaagaaatgg aggatgagca agaaagcgag 420
gccgaagaag acaaccaaga agaaggggaa tccgaggcgg agggagaaac tgaggcagaa 480
agtgaatttg acccagaaat agaaatggaa gcagagagag tggccaagag gaagtgtccg 540
gaccatgggc ttgatttgag tacctattgc caggaagata ggcagctcat ctgtgtcctg 600
tgtccagtca ttggggctca ccagggccac caactctcca ccctagacga agcctttgaa 660
gaattaagaa gcaaagactc aggtggactg aaggccgcta tgatcgaatt ggtggaaagg 720
ttgaagttca agagctcaga ccctaaagta actcgggacc aaatgaagat gtttatacag 780
caggaattta agaaagttca gaaagtgatt gctgatgagg agcagaaggc ccttcatcta 840
gtggacatcc aagaggcaat ggccacagct catgtgactg agatactggc agacatccaa 900
tcccacatgg ataggttgat gactcagatg gcccaagcca aggaacaact tgatacctct 960
aatgaatcag ctgagccaaa ggcagagggc gatgaggaag gacccagtgg tgccagtgaa 1020
gaagaggaca catga 1035
<210> 88
<211> 344
<212> PRT
<213> Homo sapiens
<400> 88
Met Ala Ser Gly Val Gly Ala Ala Phe Glu Glu Leu Pro His Asp Gly
1 5 10 15
Thr Cys Asp Glu Cys Glu Pro Asp Glu Ala Pro Gly Ala Glu Glu Val
20 25 30
Cys Arg Glu Cys Gly Phe Cys Tyr Cys Arg Arg His Ala Glu Ala His
35 40 45
Arg Gln Lys Phe Leu Ser His His Leu Ala Glu Tyr Val His Gly Ser
50 55 60
Gln Ala Trp Thr Pro Pro Ala Asp Gly Glu Gly Ala Gly Lys Glu Glu
65 70 75 80
Ala Glu Val Lys Val Glu Gln Glu Arg Glu Ile Glu Ser Glu Ala Gly
85 90 95
Glu Glu Ser Glu Ser Glu Glu Glu Ser Glu Ser Glu Glu Glu Ser Glu
100 105 110
Thr Glu Glu Glu Ser Glu Asp Glu Ser Asp Glu Glu Ser Glu Glu Asp
115 120 125
Ser Glu Glu Glu Met Glu Asp Glu Gln Glu Ser Glu Ala Glu Glu Asp
130 135 140
Asn Gln Glu Glu Gly Glu Ser Glu Ala Glu Gly Glu Thr Glu Ala Glu
145 150 155 160
Ser Glu Phe Asp Pro Glu Ile Glu Met Glu Ala Glu Arg Val Ala Lys
165 170 175
Arg Lys Cys Pro Asp His Gly Leu Asp Leu Ser Thr Tyr Cys Gln Glu
180 185 190
Asp Arg Gln Leu Ile Cys Val Leu Cys Pro Val Ile Gly Ala His Gln
195 200 205
Gly His Gln Leu Ser Thr Leu Asp Glu Ala Phe Glu Glu Leu Arg Ser
210 215 220
Lys Asp Ser Gly Gly Leu Lys Ala Ala Met Ile Glu Leu Val Glu Arg
225 230 235 240
Leu Lys Phe Lys Ser Ser Asp Pro Lys Val Thr Arg Asp Gln Met Lys
245 250 255
Met Phe Ile Gln Gln Glu Phe Lys Lys Val Gln Lys Val Ile Ala Asp
260 265 270
Glu Glu Gln Lys Ala Leu His Leu Val Asp Ile Gln Glu Ala Met Ala
275 280 285
Thr Ala His Val Thr Glu Ile Leu Ala Asp Ile Gln Ser His Met Asp
290 295 300
Arg Leu Met Thr Gln Met Ala Gln Ala Lys Glu Gln Leu Asp Thr Ser
305 310 315 320
Asn Glu Ser Ala Glu Pro Lys Ala Glu Gly Asp Glu Glu Gly Pro Ser
325 330 335
Gly Ala Ser Glu Glu Glu Asp Thr
340
<210> 89
<211> 1743
<212> DNA
<213> Homo sapiens
<400> 89
atgtcagaaa acagaaaacc gctgctgggc tttgtaagca aactcactag tgggactgca 60
cttgggaact caggcaagac tcactgcccc ctgtgcttgg ggcttttcaa agcccccagg 120
ctcttgcctt gtttgcatac agtttgcacc acgtgtctgg agcagctgga gcccttctca 180
gtagtggaca tccgaggggg agactctgac acaagctctg aggggtcaat attccaggaa 240
ctcaagccac gaagtctgca gtcgcagatc ggcatccttt gtcctgtatg tgatgctcag 300
gtggacctgc ccatgggtgg agtgaaggct ttaaccatag accacctggc cgtgaatgat 360
gtgatgctgg agagcctacg tggggaaggc cagggcctgg tgtgtgacct gtgcaacgac 420
agggaagtag agaagaggtg tcagacctgc aaagccaacc tctgccactt ctgctgccag 480
gctcataggc ggcagaagaa aacgacttac cacaccatgg tggacctaaa agacttgaaa 540
ggctacagcc ggattgggaa gcccatcctg tgtcctgttc accctgcaga ggaactgagg 600
ctgttctgtg agttctgtga ccggcccgtg tgccaggatt gtgtggtggg ggagcatcgg 660
gaacacccct gtgacttcac cagcaatgtc atccacaagc atggggactc tgtgtgggag 720
ctcctcaaag gtactcagcc ccacgtggag gccctggagg aagccctggc tcagatccac 780
ataataaaca gtgccctcca gaagcgagtg gaggcagtgg cagctgatgt ccggacattc 840
tcggagggct acattaaggc cattgaggag catcgggaca agctgctgaa gcagctggaa 900
gacatacggg cccagaagga aaattccctg cagctgcaga aggcccagct ggaacagtta 960
ctggcagaca tgcggactgg agtggagttc accgagcact tgctgaccag cggctcagac 1020
ttggagatcc tcatcaccaa gagggtggtg gtagaacggc tcaggaagct gaacaaagtt 1080
caatatagca cccgtcctgg agtaaatgat aagatacgct tctgtcctca ggagaaagca 1140
ggccagtgcc gtggctatga aatttatggt acgattaata ccaaagaggt tgatccagcc 1200
aaatgtgtcc tacaaggaga agacctccac agagcccggg agaaacagac ggcctctttc 1260
accctgcttt gtaaggatgc cgcaggagaa atcatgggca ggggaggaga caacgttcaa 1320
gttgccgttg tccctaaaga taagaaagac agcccagtca gaacaatggt ccaggataac 1380
aaggatggga catactacat ttcctacacc cccaaggaac ctggcgtcta tactgtgtgg 1440
gtctgcatca aagaacagca tgtgcagggc tcgccattca ctgtgatggt gaggagaaag 1500
caccgcccac actcaggcgt gtttcactgc tgcaccttct gctccagcgg gggccagaaa 1560
accgctcgct gcgcctgtgg aggcaccatg ccaggtgggt acctaggctg tggccatgga 1620
cacaaaggcc acccaggtca tccccactgg tcatgctgtg gaaaatttaa tgagaaatct 1680
gaatgcacat ggacaggtgg gcagagcgca ccgaggagtc tacttaggac tgtggctctc 1740
tga 1743
<210> 90
<211> 580
<212> PRT
<213> Homo sapiens
<400> 90
Met Ser Glu Asn Arg Lys Pro Leu Leu Gly Phe Val Ser Lys Leu Thr
1 5 10 15
Ser Gly Thr Ala Leu Gly Asn Ser Gly Lys Thr His Cys Pro Leu Cys
20 25 30
Leu Gly Leu Phe Lys Ala Pro Arg Leu Leu Pro Cys Leu His Thr Val
35 40 45
Cys Thr Thr Cys Leu Glu Gln Leu Glu Pro Phe Ser Val Val Asp Ile
50 55 60
Arg Gly Gly Asp Ser Asp Thr Ser Ser Glu Gly Ser Ile Phe Gln Glu
65 70 75 80
Leu Lys Pro Arg Ser Leu Gln Ser Gln Ile Gly Ile Leu Cys Pro Val
85 90 95
Cys Asp Ala Gln Val Asp Leu Pro Met Gly Gly Val Lys Ala Leu Thr
100 105 110
Ile Asp His Leu Ala Val Asn Asp Val Met Leu Glu Ser Leu Arg Gly
115 120 125
Glu Gly Gln Gly Leu Val Cys Asp Leu Cys Asn Asp Arg Glu Val Glu
130 135 140
Lys Arg Cys Gln Thr Cys Lys Ala Asn Leu Cys His Phe Cys Cys Gln
145 150 155 160
Ala His Arg Arg Gln Lys Lys Thr Thr Tyr His Thr Met Val Asp Leu
165 170 175
Lys Asp Leu Lys Gly Tyr Ser Arg Ile Gly Lys Pro Ile Leu Cys Pro
180 185 190
Val His Pro Ala Glu Glu Leu Arg Leu Phe Cys Glu Phe Cys Asp Arg
195 200 205
Pro Val Cys Gln Asp Cys Val Val Gly Glu His Arg Glu His Pro Cys
210 215 220
Asp Phe Thr Ser Asn Val Ile His Lys His Gly Asp Ser Val Trp Glu
225 230 235 240
Leu Leu Lys Gly Thr Gln Pro His Val Glu Ala Leu Glu Glu Ala Leu
245 250 255
Ala Gln Ile His Ile Ile Asn Ser Ala Leu Gln Lys Arg Val Glu Ala
260 265 270
Val Ala Ala Asp Val Arg Thr Phe Ser Glu Gly Tyr Ile Lys Ala Ile
275 280 285
Glu Glu His Arg Asp Lys Leu Leu Lys Gln Leu Glu Asp Ile Arg Ala
290 295 300
Gln Lys Glu Asn Ser Leu Gln Leu Gln Lys Ala Gln Leu Glu Gln Leu
305 310 315 320
Leu Ala Asp Met Arg Thr Gly Val Glu Phe Thr Glu His Leu Leu Thr
325 330 335
Ser Gly Ser Asp Leu Glu Ile Leu Ile Thr Lys Arg Val Val Val Glu
340 345 350
Arg Leu Arg Lys Leu Asn Lys Val Gln Tyr Ser Thr Arg Pro Gly Val
355 360 365
Asn Asp Lys Ile Arg Phe Cys Pro Gln Glu Lys Ala Gly Gln Cys Arg
370 375 380
Gly Tyr Glu Ile Tyr Gly Thr Ile Asn Thr Lys Glu Val Asp Pro Ala
385 390 395 400
Lys Cys Val Leu Gln Gly Glu Asp Leu His Arg Ala Arg Glu Lys Gln
405 410 415
Thr Ala Ser Phe Thr Leu Leu Cys Lys Asp Ala Ala Gly Glu Ile Met
420 425 430
Gly Arg Gly Gly Asp Asn Val Gln Val Ala Val Val Pro Lys Asp Lys
435 440 445
Lys Asp Ser Pro Val Arg Thr Met Val Gln Asp Asn Lys Asp Gly Thr
450 455 460
Tyr Tyr Ile Ser Tyr Thr Pro Lys Glu Pro Gly Val Tyr Thr Val Trp
465 470 475 480
Val Cys Ile Lys Glu Gln His Val Gln Gly Ser Pro Phe Thr Val Met
485 490 495
Val Arg Arg Lys His Arg Pro His Ser Gly Val Phe His Cys Cys Thr
500 505 510
Phe Cys Ser Ser Gly Gly Gln Lys Thr Ala Arg Cys Ala Cys Gly Gly
515 520 525
Thr Met Pro Gly Gly Tyr Leu Gly Cys Gly His Gly His Lys Gly His
530 535 540
Pro Gly His Pro His Trp Ser Cys Cys Gly Lys Phe Asn Glu Lys Ser
545 550 555 560
Glu Cys Thr Trp Thr Gly Gly Gln Ser Ala Pro Arg Ser Leu Leu Arg
565 570 575
Thr Val Ala Leu
580
<210> 91
<211> 2280
<212> DNA
<213> Homo sapiens
<400> 91
atggcagagg gtgaggatat gcagaccttc acttccatca tggacgcact ggtccgcatc 60
agtaccagca tgaagaacat ggagaaggaa ctgctgtgcc cagtgtgtca agagatgtac 120
aagcagccac tggtgctgcc ctgtacccac aacgtgtgcc aggcctgtgc ccgagaggtc 180
ttgggccagc agggctacat aggacatggt ggggacccca gctccgagcc cacctctcct 240
gcctccaccc cttccacccg cagcccccgc ctctcccgca gaactctccc caagccagac 300
cgcctggacc ggctgcttaa gtcaggcttt gggacatacc ctgggaggaa gcgaggtgct 360
ttgcaccccc aagtgatcat gttcccgtgc ccagcctgcc aaggtgatgt ggagcttggg 420
gagcggggtc tggcagggct tttccggaac ctgaccctgg agcgtgtggt ggagcggtac 480
cgccagagtg tgagtgtggg aggtgccatc ctgtgccagt tgtgcaagcc cccaccacta 540
gaggccacca agggctgcac agagtgccgc gccaccttct gcaatgagtg cttcaagctc 600
ttccacccct ggggcaccca gaaggcccag catgagccca ccctgcctac cctctccttc 660
cgacccaagg gccttatgtg cccagaccac aaggaagagg tgacccacta ctgcaagaca 720
tgccaacgcc tggtatgtca actctgccgg gtgcggcgca cccacagcgg gcacaagatc 780
acaccagtgc tcagtgccta ccaggccctc aaggacaagc tgacaaagag cctgacatac 840
atcctgggaa accaggacac ggtacagacc cagatctgtg agctggagga ggccgtgagg 900
cacaccgagg tgagtggtca gcaggccaag gaggaggtgt cgcagctggt gcgggggctg 960
ggggctgtgc tggaggagaa gcgggcatca ctgcttcagg ccattgaaga atgccagcag 1020
gagcggctgg cccgtctcag cgcccagatc caggagcacc ggagcctgct ggatggctca 1080
ggtctggtgg gctatgccca ggaagtactt aaggaaacag accagccttg ctttgtgcaa 1140
gccgccaagc agctgcacaa caggattgcc cgagccactg aagccctcca gacattccgg 1200
ccagctgcca gctcctcctt ccgccattgc cagctcgacg tgggacgtga gatgaagctg 1260
ctgacagagc ttaacttcct gcgagtgcct gaggcccccg tcattgacac ccagcgcacc 1320
tttgcctatg atcagatctt cctgtgctgg cggctgcccc cccattcacc acctgcctgg 1380
cactataccg ttgagttccg gcgcacggat gtgcctgctc agccaggccc cacccgctgg 1440
cagcggcggg aggaggtgag gggcaccagt gccctgcttg agaaccccga cacgggctct 1500
gtgtatgtgc tgcgtgtccg cggctgcaac aaggccggct acggcgaata cagtgaagat 1560
gtgcacctgc acacgccccc ggcacctgtc ctgcacttct tcctcgatag ccgctggggc 1620
gcaagccgag agcggctggc tatcagcaag gaccagcgag cagtacggag tgttccaggg 1680
ctgcccctgc tgctggctgc tgaccggctg ctgaccggct gccacctgag tgtggatgtg 1740
gtcctgggcg acgtggctgt gacccagggc cgcagctact gggcctgcgc cgtagaccca 1800
gcctcctact tggtcaaggt gggcgtcggg ctggagagca agcttcaaga aagtttccag 1860
ggtgcccccg atgtgatcag ccccaggtac gacccggaca gcgggcacga cagcggtgcc 1920
gaggatgcca cagtggaggc gtcgccaccc ttcgctttcc taaccattgg catgggcaag 1980
atcctgctgg ggtcgggggc aagctcaaac gcagggctga cagggaggga tggccccaca 2040
gccggctgca cagtgcccct gccaccccgc ctgggcatct gcctggacta tgagcggggc 2100
cgggtttcct tcctggatgc tgtttccttc cgtgggctct tggagtgccc cctggactgc 2160
tcagggcctg tgtgccctgc cttttgcttc atcgggggtg gcgcagtaca gctccaggag 2220
ccagtgggca ctaagcctga gaggaaagtc accattgggg gcttcgccaa gctggactga 2280
<210> 92
<211> 759
<212> PRT
<213> Homo sapiens
<400> 92
Met Ala Glu Gly Glu Asp Met Gln Thr Phe Thr Ser Ile Met Asp Ala
1 5 10 15
Leu Val Arg Ile Ser Thr Ser Met Lys Asn Met Glu Lys Glu Leu Leu
20 25 30
Cys Pro Val Cys Gln Glu Met Tyr Lys Gln Pro Leu Val Leu Pro Cys
35 40 45
Thr His Asn Val Cys Gln Ala Cys Ala Arg Glu Val Leu Gly Gln Gln
50 55 60
Gly Tyr Ile Gly His Gly Gly Asp Pro Ser Ser Glu Pro Thr Ser Pro
65 70 75 80
Ala Ser Thr Pro Ser Thr Arg Ser Pro Arg Leu Ser Arg Arg Thr Leu
85 90 95
Pro Lys Pro Asp Arg Leu Asp Arg Leu Leu Lys Ser Gly Phe Gly Thr
100 105 110
Tyr Pro Gly Arg Lys Arg Gly Ala Leu His Pro Gln Val Ile Met Phe
115 120 125
Pro Cys Pro Ala Cys Gln Gly Asp Val Glu Leu Gly Glu Arg Gly Leu
130 135 140
Ala Gly Leu Phe Arg Asn Leu Thr Leu Glu Arg Val Val Glu Arg Tyr
145 150 155 160
Arg Gln Ser Val Ser Val Gly Gly Ala Ile Leu Cys Gln Leu Cys Lys
165 170 175
Pro Pro Pro Leu Glu Ala Thr Lys Gly Cys Thr Glu Cys Arg Ala Thr
180 185 190
Phe Cys Asn Glu Cys Phe Lys Leu Phe His Pro Trp Gly Thr Gln Lys
195 200 205
Ala Gln His Glu Pro Thr Leu Pro Thr Leu Ser Phe Arg Pro Lys Gly
210 215 220
Leu Met Cys Pro Asp His Lys Glu Glu Val Thr His Tyr Cys Lys Thr
225 230 235 240
Cys Gln Arg Leu Val Cys Gln Leu Cys Arg Val Arg Arg Thr His Ser
245 250 255
Gly His Lys Ile Thr Pro Val Leu Ser Ala Tyr Gln Ala Leu Lys Asp
260 265 270
Lys Leu Thr Lys Ser Leu Thr Tyr Ile Leu Gly Asn Gln Asp Thr Val
275 280 285
Gln Thr Gln Ile Cys Glu Leu Glu Glu Ala Val Arg His Thr Glu Val
290 295 300
Ser Gly Gln Gln Ala Lys Glu Glu Val Ser Gln Leu Val Arg Gly Leu
305 310 315 320
Gly Ala Val Leu Glu Glu Lys Arg Ala Ser Leu Leu Gln Ala Ile Glu
325 330 335
Glu Cys Gln Gln Glu Arg Leu Ala Arg Leu Ser Ala Gln Ile Gln Glu
340 345 350
His Arg Ser Leu Leu Asp Gly Ser Gly Leu Val Gly Tyr Ala Gln Glu
355 360 365
Val Leu Lys Glu Thr Asp Gln Pro Cys Phe Val Gln Ala Ala Lys Gln
370 375 380
Leu His Asn Arg Ile Ala Arg Ala Thr Glu Ala Leu Gln Thr Phe Arg
385 390 395 400
Pro Ala Ala Ser Ser Ser Phe Arg His Cys Gln Leu Asp Val Gly Arg
405 410 415
Glu Met Lys Leu Leu Thr Glu Leu Asn Phe Leu Arg Val Pro Glu Ala
420 425 430
Pro Val Ile Asp Thr Gln Arg Thr Phe Ala Tyr Asp Gln Ile Phe Leu
435 440 445
Cys Trp Arg Leu Pro Pro His Ser Pro Pro Ala Trp His Tyr Thr Val
450 455 460
Glu Phe Arg Arg Thr Asp Val Pro Ala Gln Pro Gly Pro Thr Arg Trp
465 470 475 480
Gln Arg Arg Glu Glu Val Arg Gly Thr Ser Ala Leu Leu Glu Asn Pro
485 490 495
Asp Thr Gly Ser Val Tyr Val Leu Arg Val Arg Gly Cys Asn Lys Ala
500 505 510
Gly Tyr Gly Glu Tyr Ser Glu Asp Val His Leu His Thr Pro Pro Ala
515 520 525
Pro Val Leu His Phe Phe Leu Asp Ser Arg Trp Gly Ala Ser Arg Glu
530 535 540
Arg Leu Ala Ile Ser Lys Asp Gln Arg Ala Val Arg Ser Val Pro Gly
545 550 555 560
Leu Pro Leu Leu Leu Ala Ala Asp Arg Leu Leu Thr Gly Cys His Leu
565 570 575
Ser Val Asp Val Val Leu Gly Asp Val Ala Val Thr Gln Gly Arg Ser
580 585 590
Tyr Trp Ala Cys Ala Val Asp Pro Ala Ser Tyr Leu Val Lys Val Gly
595 600 605
Val Gly Leu Glu Ser Lys Leu Gln Glu Ser Phe Gln Gly Ala Pro Asp
610 615 620
Val Ile Ser Pro Arg Tyr Asp Pro Asp Ser Gly His Asp Ser Gly Ala
625 630 635 640
Glu Asp Ala Thr Val Glu Ala Ser Pro Pro Phe Ala Phe Leu Thr Ile
645 650 655
Gly Met Gly Lys Ile Leu Leu Gly Ser Gly Ala Ser Ser Asn Ala Gly
660 665 670
Leu Thr Gly Arg Asp Gly Pro Thr Ala Gly Cys Thr Val Pro Leu Pro
675 680 685
Pro Arg Leu Gly Ile Cys Leu Asp Tyr Glu Arg Gly Arg Val Ser Phe
690 695 700
Leu Asp Ala Val Ser Phe Arg Gly Leu Leu Glu Cys Pro Leu Asp Cys
705 710 715 720
Ser Gly Pro Val Cys Pro Ala Phe Cys Phe Ile Gly Gly Gly Ala Val
725 730 735
Gln Leu Gln Glu Pro Val Gly Thr Lys Pro Glu Arg Lys Val Thr Ile
740 745 750
Gly Gly Phe Ala Lys Leu Asp
755
<210> 93
<211> 1917
<212> DNA
<213> Homo sapiens
<400> 93
atggacggca gtggaccctt cagctgcccc atctgcctag agccactccg ggagccggtg 60
acgctgccct gcggccacaa cttctgtctc gcctgcctgg gcgcgctctg gccgcatcgt 120
ggcgcgagtg gagccggcgg acccggaggc gcggcccgct gcccgctgtg ccaggagccc 180
ttccccgacg gccttcagct ccgcaagaac cacacgctgt ccgagctgct gcagctccgc 240
cagggctcgg gccccgggtc cggccccggc ccggcccctg ccctggcccc ggagccctcg 300
gcacccagcg cgctgcccag tgtcccggag ccgtcggccc cctgcgctcc cgagccgtgg 360
cccgcgggcg aagagccagt gcgctgcgac gcgtgccccg agggcgcggc cctgcccgcc 420
gcgctgtcct gcctctcctg cctcgcctcc ttttgccccg cgcacctggg cccgcacgag 480
cgcagccccg ccctccgcgg acaccgcctg gtgccgccgc tgcgccggct agaggagagc 540
ctgtgcccgc gccacctacg gccgctcgag cgctactgcc gcgcggagcg cgtgtgtctg 600
tgcgaggcct gcgccgcaca ggagcaccgc ggccacgagc tggtgccgct ggagcaggag 660
cgcgcgcttc aggaggctga gcagtccaaa gtcctgagcg ccgtggagga ccgcatggac 720
gagctgggtg ctggcattgc acagtccagg cgcacagtgg ccctcatcaa gagtgcagcc 780
gtagcagagc gggagagggt gagccggctg tttgcagatg ctgcggccgc cctgcagggc 840
ttccagaccc aggtgctggg cttcatcgag gagggggaag ctgccatgct aggccgctcc 900
cagggtgacc tgcggcgaca ggaggaacag cgcagccgcc tgagccgagc ccgccagaat 960
ctcagccagg tccctgaagc tgactcagtc agcttcctgc aggagctgct ggcactaagg 1020
ctggccctgg aggatgggtg tggccctggg cctggacccc cgagggagct cagcttcacc 1080
aaatcatccc aagctgtccg tgcagtgaga gacatgctgg ccgtggcctg cgtcaaccag 1140
tgggagcagc tgagggggcc gggtggcaac gaggatgggc cacagaagct ggactcggaa 1200
gctgatgctg agccccaaga cctcgagagt acgaacctct tggagagtga agctcccagg 1260
gactatttcc tcaagtttgc ctatattgtg gatttggaca gcgacacagc agacaagttc 1320
ctgcagctgt ttggaaccaa aggtgtcaag agggtgctgt gtcctatcaa ctaccccttg 1380
tcgcccaccc gcttcaccca ttgtgagcag gtgctgggcg agggtgccct ggaccgaggc 1440
acctactact gggaggtgga gattatcgag ggctgggtca gcatgggggt catggccgaa 1500
gacttctccc cacaagagcc ctacgaccgc ggccggctgg gccgcaacgc ccactcctgc 1560
tgcctgcagt ggaatggacg cagcttctcc gtctggtttc atgggctgga ggctcccctg 1620
ccccacccct tctcgcccac ggttggggtc tgcctggaat acgctgaccg tgccttggcc 1680
ttctatgctg tacgggacgg caagatgagc ctcctgcgga ggctgaaggc ctcccggccc 1740
cgccggggtg gcatcccggc ctcccccatt gaccccttcc agagccgcct ggacagtcac 1800
tttgcggggc tcttcaccca cagactcaag cctgccttct tcctggagag tgtggacgcc 1860
cacttgcaga tcgggcccct caagaagtcc tgcatatccg tgctgaagag gaggtga 1917
<210> 94
<211> 638
<212> PRT
<213> Homo sapiens
<400> 94
Met Asp Gly Ser Gly Pro Phe Ser Cys Pro Ile Cys Leu Glu Pro Leu
1 5 10 15
Arg Glu Pro Val Thr Leu Pro Cys Gly His Asn Phe Cys Leu Ala Cys
20 25 30
Leu Gly Ala Leu Trp Pro His Arg Gly Ala Ser Gly Ala Gly Gly Pro
35 40 45
Gly Gly Ala Ala Arg Cys Pro Leu Cys Gln Glu Pro Phe Pro Asp Gly
50 55 60
Leu Gln Leu Arg Lys Asn His Thr Leu Ser Glu Leu Leu Gln Leu Arg
65 70 75 80
Gln Gly Ser Gly Pro Gly Ser Gly Pro Gly Pro Ala Pro Ala Leu Ala
85 90 95
Pro Glu Pro Ser Ala Pro Ser Ala Leu Pro Ser Val Pro Glu Pro Ser
100 105 110
Ala Pro Cys Ala Pro Glu Pro Trp Pro Ala Gly Glu Glu Pro Val Arg
115 120 125
Cys Asp Ala Cys Pro Glu Gly Ala Ala Leu Pro Ala Ala Leu Ser Cys
130 135 140
Leu Ser Cys Leu Ala Ser Phe Cys Pro Ala His Leu Gly Pro His Glu
145 150 155 160
Arg Ser Pro Ala Leu Arg Gly His Arg Leu Val Pro Pro Leu Arg Arg
165 170 175
Leu Glu Glu Ser Leu Cys Pro Arg His Leu Arg Pro Leu Glu Arg Tyr
180 185 190
Cys Arg Ala Glu Arg Val Cys Leu Cys Glu Ala Cys Ala Ala Gln Glu
195 200 205
His Arg Gly His Glu Leu Val Pro Leu Glu Gln Glu Arg Ala Leu Gln
210 215 220
Glu Ala Glu Gln Ser Lys Val Leu Ser Ala Val Glu Asp Arg Met Asp
225 230 235 240
Glu Leu Gly Ala Gly Ile Ala Gln Ser Arg Arg Thr Val Ala Leu Ile
245 250 255
Lys Ser Ala Ala Val Ala Glu Arg Glu Arg Val Ser Arg Leu Phe Ala
260 265 270
Asp Ala Ala Ala Ala Leu Gln Gly Phe Gln Thr Gln Val Leu Gly Phe
275 280 285
Ile Glu Glu Gly Glu Ala Ala Met Leu Gly Arg Ser Gln Gly Asp Leu
290 295 300
Arg Arg Gln Glu Glu Gln Arg Ser Arg Leu Ser Arg Ala Arg Gln Asn
305 310 315 320
Leu Ser Gln Val Pro Glu Ala Asp Ser Val Ser Phe Leu Gln Glu Leu
325 330 335
Leu Ala Leu Arg Leu Ala Leu Glu Asp Gly Cys Gly Pro Gly Pro Gly
340 345 350
Pro Pro Arg Glu Leu Ser Phe Thr Lys Ser Ser Gln Ala Val Arg Ala
355 360 365
Val Arg Asp Met Leu Ala Val Ala Cys Val Asn Gln Trp Glu Gln Leu
370 375 380
Arg Gly Pro Gly Gly Asn Glu Asp Gly Pro Gln Lys Leu Asp Ser Glu
385 390 395 400
Ala Asp Ala Glu Pro Gln Asp Leu Glu Ser Thr Asn Leu Leu Glu Ser
405 410 415
Glu Ala Pro Arg Asp Tyr Phe Leu Lys Phe Ala Tyr Ile Val Asp Leu
420 425 430
Asp Ser Asp Thr Ala Asp Lys Phe Leu Gln Leu Phe Gly Thr Lys Gly
435 440 445
Val Lys Arg Val Leu Cys Pro Ile Asn Tyr Pro Leu Ser Pro Thr Arg
450 455 460
Phe Thr His Cys Glu Gln Val Leu Gly Glu Gly Ala Leu Asp Arg Gly
465 470 475 480
Thr Tyr Tyr Trp Glu Val Glu Ile Ile Glu Gly Trp Val Ser Met Gly
485 490 495
Val Met Ala Glu Asp Phe Ser Pro Gln Glu Pro Tyr Asp Arg Gly Arg
500 505 510
Leu Gly Arg Asn Ala His Ser Cys Cys Leu Gln Trp Asn Gly Arg Ser
515 520 525
Phe Ser Val Trp Phe His Gly Leu Glu Ala Pro Leu Pro His Pro Phe
530 535 540
Ser Pro Thr Val Gly Val Cys Leu Glu Tyr Ala Asp Arg Ala Leu Ala
545 550 555 560
Phe Tyr Ala Val Arg Asp Gly Lys Met Ser Leu Leu Arg Arg Leu Lys
565 570 575
Ala Ser Arg Pro Arg Arg Gly Gly Ile Pro Ala Ser Pro Ile Asp Pro
580 585 590
Phe Gln Ser Arg Leu Asp Ser His Phe Ala Gly Leu Phe Thr His Arg
595 600 605
Leu Lys Pro Ala Phe Phe Leu Glu Ser Val Asp Ala His Leu Gln Ile
610 615 620
Gly Pro Leu Lys Lys Ser Cys Ile Ser Val Leu Lys Arg Arg
625 630 635
<210> 95
<211> 675
<212> DNA
<213> Homo sapiens
<400> 95
atgtctcgaa gaatcattgt gggaaccctt caaagaaccc agcgaaacat gaattctgga 60
atctcgcaag tcttccagag ggaactcacc tgccccatct gcatgaacta cttcatagac 120
ccggtcacca tagactgtgg gcacagcttt tgcaggccct gtttctacct caactggcaa 180
gacatcccaa ttcttactca gtgctttgaa tgcataaaga caatacagca gagaaacctc 240
aaaactaaca ttcgattgaa gaagatggct tcccttgcca gaaaagccag tctctggcta 300
ttcctgagct ctgaggagca aatgtgtggc attcacaggg agacaaagaa gatgttctgt 360
gaagtggaca ggagcctgct ctgtttgctg tgctccagct ctcaggagca ccggtatcac 420
agacactgtc ccgctgagtg ggctgctgag gaacactggg agaagctttt aaagaaaatg 480
cagtctttat gggaaaaagc ttgtgaaaat cagagaaacc tgaatgtgga aaccaccaga 540
atcagccact ggaaggcttt tggagacata ttatacagga gtgagtccgt gctgctgcac 600
atgccccagc ctctgaatct agcgctcagg gcagggccca tcactggact gagggacagg 660
ctcaaccaat tctga 675
<210> 96
<211> 224
<212> PRT
<213> Homo sapiens
<400> 96
Met Ser Arg Arg Ile Ile Val Gly Thr Leu Gln Arg Thr Gln Arg Asn
1 5 10 15
Met Asn Ser Gly Ile Ser Gln Val Phe Gln Arg Glu Leu Thr Cys Pro
20 25 30
Ile Cys Met Asn Tyr Phe Ile Asp Pro Val Thr Ile Asp Cys Gly His
35 40 45
Ser Phe Cys Arg Pro Cys Phe Tyr Leu Asn Trp Gln Asp Ile Pro Ile
50 55 60
Leu Thr Gln Cys Phe Glu Cys Ile Lys Thr Ile Gln Gln Arg Asn Leu
65 70 75 80
Lys Thr Asn Ile Arg Leu Lys Lys Met Ala Ser Leu Ala Arg Lys Ala
85 90 95
Ser Leu Trp Leu Phe Leu Ser Ser Glu Glu Gln Met Cys Gly Ile His
100 105 110
Arg Glu Thr Lys Lys Met Phe Cys Glu Val Asp Arg Ser Leu Leu Cys
115 120 125
Leu Leu Cys Ser Ser Ser Gln Glu His Arg Tyr His Arg His Cys Pro
130 135 140
Ala Glu Trp Ala Ala Glu Glu His Trp Glu Lys Leu Leu Lys Lys Met
145 150 155 160
Gln Ser Leu Trp Glu Lys Ala Cys Glu Asn Gln Arg Asn Leu Asn Val
165 170 175
Glu Thr Thr Arg Ile Ser His Trp Lys Ala Phe Gly Asp Ile Leu Tyr
180 185 190
Arg Ser Glu Ser Val Leu Leu His Met Pro Gln Pro Leu Asn Leu Ala
195 200 205
Leu Arg Ala Gly Pro Ile Thr Gly Leu Arg Asp Arg Leu Asn Gln Phe
210 215 220
<210> 97
<211> 1359
<212> DNA
<213> Homo sapiens
<400> 97
atgaattctg gaatcttaca ggtctttcag ggggaactca tctgccccct gtgcatgaac 60
tacttcatag acccggtcac catagactgt gggcacagct tttgcaggcc ttgtttctac 120
ctcaactggc aagacatccc atttcttgtc cagtgctctg aatgcacaaa gtcaaccgag 180
cagataaacc tcaaaaccaa cattcatttg aagaagatgg cttctcttgc cagaaaagtc 240
agtctctggc tattcctgag ctctgaggag caaatgtgtg gcactcacag ggagacaaag 300
aagatattct gtgaagtgga caggagcctg ctctgtttgc tgtgctccag ctctcaggag 360
caccggtatc acagacaccg tcccattgag tgggctgctg aggaacaccg ggagaagctt 420
ttacagaaaa tgcagtcttt gtgggaaaaa gcttgtgaaa atcacagaaa cctgaatgtg 480
gaaaccacca gaaccagatg ctggaaggat tatgtgaatt taaggctaga agcaattaga 540
gctgagtatc agaagatgcc tgcatttcat catgaagaag aaaaacataa tttggagatg 600
ctgaaaaaga aggggaaaga aatttttcat cgacttcatt taagtaaagc caaaatggct 660
cataggatgg agattttaag aggaatgtat gaggagctga acgaaatgtg ccataaacca 720
gatgtggagc tacttcaggc ttttggagac atattacaca ggagtgagtc cgtgctgctg 780
cacatgcccc agcctctgaa tccagagctc agtgcagggc ccatcactgg actgagggac 840
aggctcaacc aattccgagt gcatattact ctgcatcatg aagaagccaa caatgatatc 900
tttctgtatg aaattttgag aagcatgtgt attggatgtg accatcaaga tgtaccctat 960
ttcactgcaa cacctagaag ttttcttgca tggggtgttc agactttcac ctcgggcaaa 1020
tattactggg aggtccatgt aggggactcc tggaattggg cttttggtgt ctgtaatatg 1080
tatcggaaag agaagaatca gaatgagaag atagatggaa aggcgggact ctttcttctt 1140
gggtgtgtta agaatgacat tcaatgcagt ctctttacca cctccccact tatgctgcaa 1200
tatatcccaa aacctaccag ccgagtagga ttattcctgg attgtgaggc taagactgtg 1260
agctttgttg atgttaatca aagctcccta atatacacca tccctaattg ctctttctca 1320
cctcctctca ggcctatctt ttgctgtatt cacttctga 1359
<210> 98
<211> 452
<212> PRT
<213> Homo sapiens
<400> 98
Met Asn Ser Gly Ile Leu Gln Val Phe Gln Gly Glu Leu Ile Cys Pro
1 5 10 15
Leu Cys Met Asn Tyr Phe Ile Asp Pro Val Thr Ile Asp Cys Gly His
20 25 30
Ser Phe Cys Arg Pro Cys Phe Tyr Leu Asn Trp Gln Asp Ile Pro Phe
35 40 45
Leu Val Gln Cys Ser Glu Cys Thr Lys Ser Thr Glu Gln Ile Asn Leu
50 55 60
Lys Thr Asn Ile His Leu Lys Lys Met Ala Ser Leu Ala Arg Lys Val
65 70 75 80
Ser Leu Trp Leu Phe Leu Ser Ser Glu Glu Gln Met Cys Gly Thr His
85 90 95
Arg Glu Thr Lys Lys Ile Phe Cys Glu Val Asp Arg Ser Leu Leu Cys
100 105 110
Leu Leu Cys Ser Ser Ser Gln Glu His Arg Tyr His Arg His Arg Pro
115 120 125
Ile Glu Trp Ala Ala Glu Glu His Arg Glu Lys Leu Leu Gln Lys Met
130 135 140
Gln Ser Leu Trp Glu Lys Ala Cys Glu Asn His Arg Asn Leu Asn Val
145 150 155 160
Glu Thr Thr Arg Thr Arg Cys Trp Lys Asp Tyr Val Asn Leu Arg Leu
165 170 175
Glu Ala Ile Arg Ala Glu Tyr Gln Lys Met Pro Ala Phe His His Glu
180 185 190
Glu Glu Lys His Asn Leu Glu Met Leu Lys Lys Lys Gly Lys Glu Ile
195 200 205
Phe His Arg Leu His Leu Ser Lys Ala Lys Met Ala His Arg Met Glu
210 215 220
Ile Leu Arg Gly Met Tyr Glu Glu Leu Asn Glu Met Cys His Lys Pro
225 230 235 240
Asp Val Glu Leu Leu Gln Ala Phe Gly Asp Ile Leu His Arg Ser Glu
245 250 255
Ser Val Leu Leu His Met Pro Gln Pro Leu Asn Pro Glu Leu Ser Ala
260 265 270
Gly Pro Ile Thr Gly Leu Arg Asp Arg Leu Asn Gln Phe Arg Val His
275 280 285
Ile Thr Leu His His Glu Glu Ala Asn Asn Asp Ile Phe Leu Tyr Glu
290 295 300
Ile Leu Arg Ser Met Cys Ile Gly Cys Asp His Gln Asp Val Pro Tyr
305 310 315 320
Phe Thr Ala Thr Pro Arg Ser Phe Leu Ala Trp Gly Val Gln Thr Phe
325 330 335
Thr Ser Gly Lys Tyr Tyr Trp Glu Val His Val Gly Asp Ser Trp Asn
340 345 350
Trp Ala Phe Gly Val Cys Asn Met Tyr Arg Lys Glu Lys Asn Gln Asn
355 360 365
Glu Lys Ile Asp Gly Lys Ala Gly Leu Phe Leu Leu Gly Cys Val Lys
370 375 380
Asn Asp Ile Gln Cys Ser Leu Phe Thr Thr Ser Pro Leu Met Leu Gln
385 390 395 400
Tyr Ile Pro Lys Pro Thr Ser Arg Val Gly Leu Phe Leu Asp Cys Glu
405 410 415
Ala Lys Thr Val Ser Phe Val Asp Val Asn Gln Ser Ser Leu Ile Tyr
420 425 430
Thr Ile Pro Asn Cys Ser Phe Ser Pro Pro Leu Arg Pro Ile Phe Cys
435 440 445
Cys Ile His Phe
450
<210> 99
<211> 1464
<212> DNA
<213> Homo sapiens
<400> 99
atggcttggc aggtgagcct gccagagctg gaggaccggc ttcagtgtcc catctgcctg 60
gaggtcttca aggagcccct gatgctgcag tgtggccact cttactgcaa gggctgcctg 120
gtttccctgt cctgccacct ggatgccgag ctgcgctgcc ccgtgtgccg gcaggcggtg 180
gacggcagca gctccctgcc caacgtctcc ctggccaggg tgatcgaagc cctgaggctc 240
cctggggacc cggagcccaa ggtctgcgtg caccaccgga acccgctcag ccttttctgc 300
gagaaggacc aggagctcat ctgtggcctc tgcggtctgc tgggctccca ccaacaccac 360
ccggtcacgc ccgtctccac cgtctacagc cgcatgaagg aggagctcgc agccctcatc 420
tctgagctga agcaggagca gaaaaaggtg gatgagctca tcgccaaact ggtgaacaac 480
cggacccgaa tcgtcaatga gtcggatgtc ttcagctggg tgatccgccg cgagttccag 540
gagctgcacc acctggtgga tgaggagaag gcccgctgcc tggaggggat agggggtcac 600
acccgtggcc tggtggcctc cctggacatg cagctggagc aggcccaggg aacccgggag 660
cggctggccc aagccgagtg tgtgctggaa cagttcggca atgaggacca ccacaagttc 720
atccggaagt tccactccat ggcctccaga gcagagatgc cgcaggcccg gcccttagaa 780
ggcgcattca gccccatctc cttcaagcca ggcctccacc aggctgacat caagctgacc 840
gtgtggaaaa ggctcttccg gaaagttttg ccagccccgg agcctctcaa gttggaccct 900
gccactgccc acccactcct ggagctctcc aagggcaaca cggtggtgca gtgcgggctt 960
ctggcccagc ggcgagccag ccagcctgag cgcttcgact acagcacctg cgtcctggcc 1020
agccgcggct tctcctgcgg ccgccactac tgggaggtgg tggtgggcag caagagcgac 1080
tggcgcctgg gggtcatcaa gggcacagcc agccgtaagg gcaagctgaa caggtccccc 1140
gagcacggcg tgtggctgat cggcctgaag gagggccggg tgtacgaagc ctttgcctgc 1200
ccccgggtac ccctgcccgt ggccggccac ccccaccgca tcgggctcta cctgcactat 1260
gagcagggcg aactcacctt cttcgatgcc gaccgccccg atgacctgcg gccgctctac 1320
accttccagg ccgacttcca gggcaagctc taccccatcc tggacacctg ctggcacgag 1380
aggggcagca actcgctgcc catggtgctg cccccgccca gcgggcctgg ccccctcagc 1440
cccgagcagc ccaccaagct gtag 1464
<210> 100
<211> 487
<212> PRT
<213> Homo sapiens
<400> 100
Met Ala Trp Gln Val Ser Leu Pro Glu Leu Glu Asp Arg Leu Gln Cys
1 5 10 15
Pro Ile Cys Leu Glu Val Phe Lys Glu Pro Leu Met Leu Gln Cys Gly
20 25 30
His Ser Tyr Cys Lys Gly Cys Leu Val Ser Leu Ser Cys His Leu Asp
35 40 45
Ala Glu Leu Arg Cys Pro Val Cys Arg Gln Ala Val Asp Gly Ser Ser
50 55 60
Ser Leu Pro Asn Val Ser Leu Ala Arg Val Ile Glu Ala Leu Arg Leu
65 70 75 80
Pro Gly Asp Pro Glu Pro Lys Val Cys Val His His Arg Asn Pro Leu
85 90 95
Ser Leu Phe Cys Glu Lys Asp Gln Glu Leu Ile Cys Gly Leu Cys Gly
100 105 110
Leu Leu Gly Ser His Gln His His Pro Val Thr Pro Val Ser Thr Val
115 120 125
Tyr Ser Arg Met Lys Glu Glu Leu Ala Ala Leu Ile Ser Glu Leu Lys
130 135 140
Gln Glu Gln Lys Lys Val Asp Glu Leu Ile Ala Lys Leu Val Asn Asn
145 150 155 160
Arg Thr Arg Ile Val Asn Glu Ser Asp Val Phe Ser Trp Val Ile Arg
165 170 175
Arg Glu Phe Gln Glu Leu His His Leu Val Asp Glu Glu Lys Ala Arg
180 185 190
Cys Leu Glu Gly Ile Gly Gly His Thr Arg Gly Leu Val Ala Ser Leu
195 200 205
Asp Met Gln Leu Glu Gln Ala Gln Gly Thr Arg Glu Arg Leu Ala Gln
210 215 220
Ala Glu Cys Val Leu Glu Gln Phe Gly Asn Glu Asp His His Lys Phe
225 230 235 240
Ile Arg Lys Phe His Ser Met Ala Ser Arg Ala Glu Met Pro Gln Ala
245 250 255
Arg Pro Leu Glu Gly Ala Phe Ser Pro Ile Ser Phe Lys Pro Gly Leu
260 265 270
His Gln Ala Asp Ile Lys Leu Thr Val Trp Lys Arg Leu Phe Arg Lys
275 280 285
Val Leu Pro Ala Pro Glu Pro Leu Lys Leu Asp Pro Ala Thr Ala His
290 295 300
Pro Leu Leu Glu Leu Ser Lys Gly Asn Thr Val Val Gln Cys Gly Leu
305 310 315 320
Leu Ala Gln Arg Arg Ala Ser Gln Pro Glu Arg Phe Asp Tyr Ser Thr
325 330 335
Cys Val Leu Ala Ser Arg Gly Phe Ser Cys Gly Arg His Tyr Trp Glu
340 345 350
Val Val Val Gly Ser Lys Ser Asp Trp Arg Leu Gly Val Ile Lys Gly
355 360 365
Thr Ala Ser Arg Lys Gly Lys Leu Asn Arg Ser Pro Glu His Gly Val
370 375 380
Trp Leu Ile Gly Leu Lys Glu Gly Arg Val Tyr Glu Ala Phe Ala Cys
385 390 395 400
Pro Arg Val Pro Leu Pro Val Ala Gly His Pro His Arg Ile Gly Leu
405 410 415
Tyr Leu His Tyr Glu Gln Gly Glu Leu Thr Phe Phe Asp Ala Asp Arg
420 425 430
Pro Asp Asp Leu Arg Pro Leu Tyr Thr Phe Gln Ala Asp Phe Gln Gly
435 440 445
Lys Leu Tyr Pro Ile Leu Asp Thr Cys Trp His Glu Arg Gly Ser Asn
450 455 460
Ser Leu Pro Met Val Leu Pro Pro Pro Ser Gly Pro Gly Pro Leu Ser
465 470 475 480
Pro Glu Gln Pro Thr Lys Leu
485
<210> 101
<211> 1359
<212> DNA
<213> Homo sapiens
<400> 101
atgaattctg gaatcttgca agtcttccag agggcactca cctgtcccat ctgcatgaac 60
tacttcctag acccagtcac catagactgt gggcacagct tttgccggcc ctgtttgtac 120
ctcaactggc aagacacggc agttcttgct cagtgctctg aatgcaagaa gacaacgcgg 180
cagagaaacc tcaacactga catttgtttg aagaacatgg ctttcattgc cagaaaagcc 240
agcctccggc aattccttag ctctgaggag caaatatgtg ggatgcacag agagacaaag 300
aagatgttct gtgaagtgga caagagcctg ctctgtttgc cgtgctccaa ctctcaggag 360
caccggaatc acatacactg tcccattgag tgggctgctg aggaacgccg ggaggagctc 420
ctaaaaaaaa tgcagtcttt atgggaaaaa gcttgtgaaa atctcagaaa tctgaacatg 480
gaaaccacaa gaaccagatg ctggaaggat tatgtgagtt taaggataga agcaatcaga 540
gctgaatatc agaagatgcc tgcatttctc catgaagaag agcaacatca cttggaaagg 600
ctgcgaaagg agggcgagga catttttcag caactcaatg aaagcaaagc cagaatggaa 660
cattccaggg agcttttaag aggaatgtat gaggatctga agcaaatgtg ccataaagca 720
gatgtggagc tactccaggc ttttggagac atattacaca ggtatgagtc tctgctgctg 780
caagtgtctg agcctgtgaa tccagagctc agtgcagggc ccatcactgg actgctggac 840
agcctcagtg gattcagagt tgattttact ctgcagcctg aaagagccaa tagtcatatc 900
ttcctgtgtg gagatttgag aagcatgaat gttggatgtg accctcaaga tgatcccgat 960
atcactggaa aatctgaatg ttttcttgta tggggggctc aggctttcac atctggcaaa 1020
tattattggg aggttcatat gggggactct tggaattggg cttttggtgt ctgtaacaat 1080
tattggaaag agaagagaca gaatgacaag atagatggag aggagggact ctttcttctt 1140
ggatgtgtta aggaggacac tcactgcagt ctctttacca cctccccact tgtggtgcaa 1200
tatgttccaa gacctaccag cacagtagga ttattcctgg attgtgaagg tagaaccgtg 1260
agctttgttg atgttgatca aagttccctg atatacacca tccccaattg ctccttctca 1320
cctcctctca ggcctatctt ttgctgtagt cacttctga 1359
<210> 102
<211> 452
<212> PRT
<213> Homo sapiens
<400> 102
Met Asn Ser Gly Ile Leu Gln Val Phe Gln Arg Ala Leu Thr Cys Pro
1 5 10 15
Ile Cys Met Asn Tyr Phe Leu Asp Pro Val Thr Ile Asp Cys Gly His
20 25 30
Ser Phe Cys Arg Pro Cys Leu Tyr Leu Asn Trp Gln Asp Thr Ala Val
35 40 45
Leu Ala Gln Cys Ser Glu Cys Lys Lys Thr Thr Arg Gln Arg Asn Leu
50 55 60
Asn Thr Asp Ile Cys Leu Lys Asn Met Ala Phe Ile Ala Arg Lys Ala
65 70 75 80
Ser Leu Arg Gln Phe Leu Ser Ser Glu Glu Gln Ile Cys Gly Met His
85 90 95
Arg Glu Thr Lys Lys Met Phe Cys Glu Val Asp Lys Ser Leu Leu Cys
100 105 110
Leu Pro Cys Ser Asn Ser Gln Glu His Arg Asn His Ile His Cys Pro
115 120 125
Ile Glu Trp Ala Ala Glu Glu Arg Arg Glu Glu Leu Leu Lys Lys Met
130 135 140
Gln Ser Leu Trp Glu Lys Ala Cys Glu Asn Leu Arg Asn Leu Asn Met
145 150 155 160
Glu Thr Thr Arg Thr Arg Cys Trp Lys Asp Tyr Val Ser Leu Arg Ile
165 170 175
Glu Ala Ile Arg Ala Glu Tyr Gln Lys Met Pro Ala Phe Leu His Glu
180 185 190
Glu Glu Gln His His Leu Glu Arg Leu Arg Lys Glu Gly Glu Asp Ile
195 200 205
Phe Gln Gln Leu Asn Glu Ser Lys Ala Arg Met Glu His Ser Arg Glu
210 215 220
Leu Leu Arg Gly Met Tyr Glu Asp Leu Lys Gln Met Cys His Lys Ala
225 230 235 240
Asp Val Glu Leu Leu Gln Ala Phe Gly Asp Ile Leu His Arg Tyr Glu
245 250 255
Ser Leu Leu Leu Gln Val Ser Glu Pro Val Asn Pro Glu Leu Ser Ala
260 265 270
Gly Pro Ile Thr Gly Leu Leu Asp Ser Leu Ser Gly Phe Arg Val Asp
275 280 285
Phe Thr Leu Gln Pro Glu Arg Ala Asn Ser His Ile Phe Leu Cys Gly
290 295 300
Asp Leu Arg Ser Met Asn Val Gly Cys Asp Pro Gln Asp Asp Pro Asp
305 310 315 320
Ile Thr Gly Lys Ser Glu Cys Phe Leu Val Trp Gly Ala Gln Ala Phe
325 330 335
Thr Ser Gly Lys Tyr Tyr Trp Glu Val His Met Gly Asp Ser Trp Asn
340 345 350
Trp Ala Phe Gly Val Cys Asn Asn Tyr Trp Lys Glu Lys Arg Gln Asn
355 360 365
Asp Lys Ile Asp Gly Glu Glu Gly Leu Phe Leu Leu Gly Cys Val Lys
370 375 380
Glu Asp Thr His Cys Ser Leu Phe Thr Thr Ser Pro Leu Val Val Gln
385 390 395 400
Tyr Val Pro Arg Pro Thr Ser Thr Val Gly Leu Phe Leu Asp Cys Glu
405 410 415
Gly Arg Thr Val Ser Phe Val Asp Val Asp Gln Ser Ser Leu Ile Tyr
420 425 430
Thr Ile Pro Asn Cys Ser Phe Ser Pro Pro Leu Arg Pro Ile Phe Cys
435 440 445
Cys Ser His Phe
450
<210> 103
<211> 894
<212> DNA
<213> Homo sapiens
<400> 103
atggctggtt atgccactac tcccagcccc atgcagaccc ttcaggagga agcggtgtgt 60
gccatctgct tggattactt caaggacccc gtgtccatca gctgtgggca caacttctgc 120
cgagggtgtg tgacccagct gtggagtaag gaggacgagg aggaccagaa cgaggaggaa 180
gatgaatggg aggaggagga ggacgaggaa gcggtggggg ccatggatgg atgggacggc 240
tccattcgag aggtgttgta tcgggggaat gctgacgaag agttgttcca agaccaagat 300
gacgatgaac tctggctcgg tgacagtggt ataactaatt gggacaacgt agactatatg 360
tgggacgagg aggaagaaga agaagaggaa gatcaggact attacctagg aggcttgaga 420
cctgacctga gaattgatgt ctaccgagaa gaagaaatac tggaagcata cgatgaggac 480
gaagatgaag agctgtatcc tgacatccac ccgcctcctt ccttgcccct tccagggcag 540
ttcacctgcc cccagtgccg aaagagcttt acacgtcgca gctttcgtcc caacttgcag 600
ctggccaaca tggtccagat aattcgccag atgtgcccca ctccttatcg gggaaaccgg 660
agtaatgatc agggcatgtg ctttaaacac caggaagccc tgaaactctt ctgtgaggtg 720
gacaaagagg ccatctgtgt ggtgtgccga gaatccagga gccacaaaca gcacagcgtg 780
ctgcctttgg aggaggtggt gcaggagtac caggaaataa agttggaaac aactctggtg 840
ggaatacttc agatagagca agaaagcatt cacagcaagg cctataatca gtaa 894
<210> 104
<211> 297
<212> PRT
<213> Homo sapiens
<400> 104
Met Ala Gly Tyr Ala Thr Thr Pro Ser Pro Met Gln Thr Leu Gln Glu
1 5 10 15
Glu Ala Val Cys Ala Ile Cys Leu Asp Tyr Phe Lys Asp Pro Val Ser
20 25 30
Ile Ser Cys Gly His Asn Phe Cys Arg Gly Cys Val Thr Gln Leu Trp
35 40 45
Ser Lys Glu Asp Glu Glu Asp Gln Asn Glu Glu Glu Asp Glu Trp Glu
50 55 60
Glu Glu Glu Asp Glu Glu Ala Val Gly Ala Met Asp Gly Trp Asp Gly
65 70 75 80
Ser Ile Arg Glu Val Leu Tyr Arg Gly Asn Ala Asp Glu Glu Leu Phe
85 90 95
Gln Asp Gln Asp Asp Asp Glu Leu Trp Leu Gly Asp Ser Gly Ile Thr
100 105 110
Asn Trp Asp Asn Val Asp Tyr Met Trp Asp Glu Glu Glu Glu Glu Glu
115 120 125
Glu Glu Asp Gln Asp Tyr Tyr Leu Gly Gly Leu Arg Pro Asp Leu Arg
130 135 140
Ile Asp Val Tyr Arg Glu Glu Glu Ile Leu Glu Ala Tyr Asp Glu Asp
145 150 155 160
Glu Asp Glu Glu Leu Tyr Pro Asp Ile His Pro Pro Pro Ser Leu Pro
165 170 175
Leu Pro Gly Gln Phe Thr Cys Pro Gln Cys Arg Lys Ser Phe Thr Arg
180 185 190
Arg Ser Phe Arg Pro Asn Leu Gln Leu Ala Asn Met Val Gln Ile Ile
195 200 205
Arg Gln Met Cys Pro Thr Pro Tyr Arg Gly Asn Arg Ser Asn Asp Gln
210 215 220
Gly Met Cys Phe Lys His Gln Glu Ala Leu Lys Leu Phe Cys Glu Val
225 230 235 240
Asp Lys Glu Ala Ile Cys Val Val Cys Arg Glu Ser Arg Ser His Lys
245 250 255
Gln His Ser Val Leu Pro Leu Glu Glu Val Val Gln Glu Tyr Gln Glu
260 265 270
Ile Lys Leu Glu Thr Thr Leu Val Gly Ile Leu Gln Ile Glu Gln Glu
275 280 285
Ser Ile His Ser Lys Ala Tyr Asn Gln
290 295
<210> 105
<211> 1203
<212> DNA
<213> Homo sapiens
<400> 105
atgaacttca cagtgggttt caagccgctg ctaggggatg cacacagcat ggacaacctg 60
gagaagcagc tcatctgccc catctgcctg gagatgttct ccaaaccagt ggtgatcctg 120
ccctgccaac acaacctgtg ccgcaaatgt gccaacgacg tcttccaggc ctcgaatcct 180
ctatggcagt cccggggctc caccactgtg tcttcaggag gccgtttccg ctgcccatcg 240
tgcaggcatg aggttgtcct ggacagacac ggtgtctacg gcctgcagcg aaacctgcta 300
gtggagaaca ttatcgacat ttacaagcag gagtcatcca ggccgctgca ctccaaggct 360
gagcagcacc tcatgtgcga ggagcatgaa gaagagaaga tcaatattta ctgcctgagc 420
tgtgaggtgc ccacctgctc tctctgcaag gtcttcggtg cccacaagga ctgtgaggtg 480
gccccactgc ccaccattta caaacgccag aagaaacagg atctcactct gttgcccagg 540
ctggagtgca gtggcacaaa cacaacttac tgcagccttg atctcccgag ctcaagtgat 600
cctcccatct tagcctcgca gaacactaag attatagata gtgagctcag cgatggcatc 660
gcgatgctgg tggcaggcaa tgaccgcgtg caagcagtga tcacacagat ggaggaggtg 720
tgccagacta tcgaggacaa tagccggagg cagaagcagt tgttaaacca gaggtttgag 780
agcctgtgcg cagtgctgga ggagcgcaag ggtgagctgc tgcaggcgct ggcccgggag 840
caagaggaga agctgcagcg cgtccgcggc ctcatccgtc agtatggcga ccacctggag 900
gcctcctcta agctggtgga gtctgccatc cagtccatgg aagagccaca aatggcgctg 960
tatctccagc aggccaagga gctgatcaat aaggtcgggg ccatgtcgaa ggtggagctg 1020
gcagggcggc cggagccagg ctatgagagc atggagcaat tcaccgtaag ggtggagcac 1080
gtggccgaaa tgctgcggac catcgacttc cagccaggcg cttccgggga ggaagaggag 1140
gtggccccag acggagagga gggcagcgcg gggccggagg aagagcggcc ggatgggcct 1200
taa 1203
<210> 106
<211> 400
<212> PRT
<213> Homo sapiens
<400> 106
Met Asn Phe Thr Val Gly Phe Lys Pro Leu Leu Gly Asp Ala His Ser
1 5 10 15
Met Asp Asn Leu Glu Lys Gln Leu Ile Cys Pro Ile Cys Leu Glu Met
20 25 30
Phe Ser Lys Pro Val Val Ile Leu Pro Cys Gln His Asn Leu Cys Arg
35 40 45
Lys Cys Ala Asn Asp Val Phe Gln Ala Ser Asn Pro Leu Trp Gln Ser
50 55 60
Arg Gly Ser Thr Thr Val Ser Ser Gly Gly Arg Phe Arg Cys Pro Ser
65 70 75 80
Cys Arg His Glu Val Val Leu Asp Arg His Gly Val Tyr Gly Leu Gln
85 90 95
Arg Asn Leu Leu Val Glu Asn Ile Ile Asp Ile Tyr Lys Gln Glu Ser
100 105 110
Ser Arg Pro Leu His Ser Lys Ala Glu Gln His Leu Met Cys Glu Glu
115 120 125
His Glu Glu Glu Lys Ile Asn Ile Tyr Cys Leu Ser Cys Glu Val Pro
130 135 140
Thr Cys Ser Leu Cys Lys Val Phe Gly Ala His Lys Asp Cys Glu Val
145 150 155 160
Ala Pro Leu Pro Thr Ile Tyr Lys Arg Gln Lys Lys Gln Asp Leu Thr
165 170 175
Leu Leu Pro Arg Leu Glu Cys Ser Gly Thr Asn Thr Thr Tyr Cys Ser
180 185 190
Leu Asp Leu Pro Ser Ser Ser Asp Pro Pro Ile Leu Ala Ser Gln Asn
195 200 205
Thr Lys Ile Ile Asp Ser Glu Leu Ser Asp Gly Ile Ala Met Leu Val
210 215 220
Ala Gly Asn Asp Arg Val Gln Ala Val Ile Thr Gln Met Glu Glu Val
225 230 235 240
Cys Gln Thr Ile Glu Asp Asn Ser Arg Arg Gln Lys Gln Leu Leu Asn
245 250 255
Gln Arg Phe Glu Ser Leu Cys Ala Val Leu Glu Glu Arg Lys Gly Glu
260 265 270
Leu Leu Gln Ala Leu Ala Arg Glu Gln Glu Glu Lys Leu Gln Arg Val
275 280 285
Arg Gly Leu Ile Arg Gln Tyr Gly Asp His Leu Glu Ala Ser Ser Lys
290 295 300
Leu Val Glu Ser Ala Ile Gln Ser Met Glu Glu Pro Gln Met Ala Leu
305 310 315 320
Tyr Leu Gln Gln Ala Lys Glu Leu Ile Asn Lys Val Gly Ala Met Ser
325 330 335
Lys Val Glu Leu Ala Gly Arg Pro Glu Pro Gly Tyr Glu Ser Met Glu
340 345 350
Gln Phe Thr Val Arg Val Glu His Val Ala Glu Met Leu Arg Thr Ile
355 360 365
Asp Phe Gln Pro Gly Ala Ser Gly Glu Glu Glu Glu Val Ala Pro Asp
370 375 380
Gly Glu Glu Gly Ser Ala Gly Pro Glu Glu Glu Arg Pro Asp Gly Pro
385 390 395 400
<210> 107
<211> 1647
<212> DNA
<213> Homo sapiens
<400> 107
atgagcgcat ctctgaatta caaatctttt tccaaagagc agcagaccat ggataactta 60
gagaagcaac tcatctgtcc catctgctta gagatgttca cgaaacctgt ggtgattctc 120
ccttgtcagc acaacctgtg taggaaatgt gccagtgata ttttccaggc ctctaacccg 180
tatttgccca caagaggagg taccaccatg gcatcagggg gccgattccg ctgcccatcc 240
tgtagacatg aagtggtttt ggatagacat ggggtatatg gacttcagag gaacctgctg 300
gtggaaaata tcattgacat ctacaagcag gagtccacca ggccagaaaa gaaatccgac 360
cagcccatgt gcgaggaaca tgaagaggag cgcatcaaca tctactgtct gaactgcgaa 420
gtacccacct gctctctgtg caaggtgttt ggtgcacaca aagactgcca ggtggctccc 480
ctcactcatg tgttccagag acagaagtct gagctcagtg atggcatcgc catcctcgtg 540
ggcagcaacg atcgagtcca gggagtgatc agccagctgg aagacacctg caaaactatc 600
gaggaatgtt gcagaaaaca gaaacaagag ctttgtgaga agtttgatta cctgtatggc 660
attttggagg agaggaagaa tgaaatgacc caagtcatta cccgaaccca agaggagaaa 720
ctggaacatg tccgtgctct gatcaaaaag tattctgatc atttggagaa cgtctcaaag 780
ttggttgagt caggaattca gtttatggat gagccagaaa tggcagtgtt tctgcagaat 840
gccaaaaccc tgctaaaaaa aatctcggaa gcatcaaagg catttcagat ggagaaaata 900
gaacatggct atgagaacat gaaccacttc acagtcaacc tcaatagaga agaaaagata 960
atacgtgaaa ttgactttta cagagaagat gaagatgaag aagaagaaga aggcggagaa 1020
ggagaaaaag aaggagaagg agaagtggga ggagaagcag tagaagtgga agaggtagaa 1080
aatgttcaaa cagagtttcc aggagaagat gaaaacccag aaaaagcttc agagctctct 1140
caggtggagc tgcaggctgc ccctggggca cttccagttt cctctccaga gccacctcca 1200
gccctgccac ctgctgcgga tgcccctgtg acacaggggg aggttgtacc cactggctct 1260
gagcagacca cagagtctga aactccagtc cctgcagcag cagaaactgc ggatcccttg 1320
ttttacccta gttggtataa aggccaaacc cggaaagcca ccaccaaccc accttgcacc 1380
ccagggagcg aaggtctggg gcaaataggg cctccaggtt ctgaggattc gaatgtacgg 1440
aaggcagaag tggcagcagc cgcagcgagt gagagggcag ctgtgagtgg taaggaaact 1500
agtgcacctg cagctacttc tcagattgga tttgaggctc ctcccctcca gggacaggct 1560
gcagctccag cgagtggcag tggagctgat tctgagccag ctcgccatat cttctccttt 1620
tcctggttga actccctaaa tgaatga 1647
<210> 108
<211> 548
<212> PRT
<213> Homo sapiens
<400> 108
Met Ser Ala Ser Leu Asn Tyr Lys Ser Phe Ser Lys Glu Gln Gln Thr
1 5 10 15
Met Asp Asn Leu Glu Lys Gln Leu Ile Cys Pro Ile Cys Leu Glu Met
20 25 30
Phe Thr Lys Pro Val Val Ile Leu Pro Cys Gln His Asn Leu Cys Arg
35 40 45
Lys Cys Ala Ser Asp Ile Phe Gln Ala Ser Asn Pro Tyr Leu Pro Thr
50 55 60
Arg Gly Gly Thr Thr Met Ala Ser Gly Gly Arg Phe Arg Cys Pro Ser
65 70 75 80
Cys Arg His Glu Val Val Leu Asp Arg His Gly Val Tyr Gly Leu Gln
85 90 95
Arg Asn Leu Leu Val Glu Asn Ile Ile Asp Ile Tyr Lys Gln Glu Ser
100 105 110
Thr Arg Pro Glu Lys Lys Ser Asp Gln Pro Met Cys Glu Glu His Glu
115 120 125
Glu Glu Arg Ile Asn Ile Tyr Cys Leu Asn Cys Glu Val Pro Thr Cys
130 135 140
Ser Leu Cys Lys Val Phe Gly Ala His Lys Asp Cys Gln Val Ala Pro
145 150 155 160
Leu Thr His Val Phe Gln Arg Gln Lys Ser Glu Leu Ser Asp Gly Ile
165 170 175
Ala Ile Leu Val Gly Ser Asn Asp Arg Val Gln Gly Val Ile Ser Gln
180 185 190
Leu Glu Asp Thr Cys Lys Thr Ile Glu Glu Cys Cys Arg Lys Gln Lys
195 200 205
Gln Glu Leu Cys Glu Lys Phe Asp Tyr Leu Tyr Gly Ile Leu Glu Glu
210 215 220
Arg Lys Asn Glu Met Thr Gln Val Ile Thr Arg Thr Gln Glu Glu Lys
225 230 235 240
Leu Glu His Val Arg Ala Leu Ile Lys Lys Tyr Ser Asp His Leu Glu
245 250 255
Asn Val Ser Lys Leu Val Glu Ser Gly Ile Gln Phe Met Asp Glu Pro
260 265 270
Glu Met Ala Val Phe Leu Gln Asn Ala Lys Thr Leu Leu Lys Lys Ile
275 280 285
Ser Glu Ala Ser Lys Ala Phe Gln Met Glu Lys Ile Glu His Gly Tyr
290 295 300
Glu Asn Met Asn His Phe Thr Val Asn Leu Asn Arg Glu Glu Lys Ile
305 310 315 320
Ile Arg Glu Ile Asp Phe Tyr Arg Glu Asp Glu Asp Glu Glu Glu Glu
325 330 335
Glu Gly Gly Glu Gly Glu Lys Glu Gly Glu Gly Glu Val Gly Gly Glu
340 345 350
Ala Val Glu Val Glu Glu Val Glu Asn Val Gln Thr Glu Phe Pro Gly
355 360 365
Glu Asp Glu Asn Pro Glu Lys Ala Ser Glu Leu Ser Gln Val Glu Leu
370 375 380
Gln Ala Ala Pro Gly Ala Leu Pro Val Ser Ser Pro Glu Pro Pro Pro
385 390 395 400
Ala Leu Pro Pro Ala Ala Asp Ala Pro Val Thr Gln Gly Glu Val Val
405 410 415
Pro Thr Gly Ser Glu Gln Thr Thr Glu Ser Glu Thr Pro Val Pro Ala
420 425 430
Ala Ala Glu Thr Ala Asp Pro Leu Phe Tyr Pro Ser Trp Tyr Lys Gly
435 440 445
Gln Thr Arg Lys Ala Thr Thr Asn Pro Pro Cys Thr Pro Gly Ser Glu
450 455 460
Gly Leu Gly Gln Ile Gly Pro Pro Gly Ser Glu Asp Ser Asn Val Arg
465 470 475 480
Lys Ala Glu Val Ala Ala Ala Ala Ala Ser Glu Arg Ala Ala Val Ser
485 490 495
Gly Lys Glu Thr Ser Ala Pro Ala Ala Thr Ser Gln Ile Gly Phe Glu
500 505 510
Ala Pro Pro Leu Gln Gly Gln Ala Ala Ala Pro Ala Ser Gly Ser Gly
515 520 525
Ala Asp Ser Glu Pro Ala Arg His Ile Phe Ser Phe Ser Trp Leu Asn
530 535 540
Ser Leu Asn Glu
545
<210> 109
<211> 2225
<212> DNA
<213> Homo sapiens
<400> 109
atggtttccc acgggtcctc gccctccctc ctggaggccc tgagcagcga cttcctggcc 60
tgtaaaatct gcctggagca gctgcgggca cccaagacac tgccctgcct gcatacctac 120
tgccaagact gcctggcaca gctggcggat ggcggccgcg tccgctgccc cgagtgccgc 180
gagacagtgc ctgtgccgcc cgagggtgtg gcctccttca agaccaactt cttcgtcaat 240
gggctgctgg acctggtgaa ggcccgggcc tgtggagacc tgcgtgccgg gaagccagcc 300
tgtgccctgt gtcccctggt gggtggcacc agcaccgggg ggccggccac ggcccggtgc 360
ctggactgtg ccgatgactt gtgccaggcc tgtgccgacg ggcaccgctg cacccgccag 420
acccacaccc accgcgtggt ggacctggtg ggctacaggg ccgggtggta tgatgaggag 480
gcccgggagc gccaagcggc ccagtgtccc cagcaccccg gggaggcact gcgcttcctg 540
tgccagccct gctcacagtt gctgtgcaga gagtgccgcc tagaccccca cctggaccac 600
ccctgcctgc ctctggctga agctgtgcgt gcccggaggc cgggcctgga gggactgctg 660
gccggtgtgg acaataacct ggtggagctg gaggcagcgc ggagggtgga gaaggaggcg 720
ctagcccggc tgcgggagca ggcggcccgg gtggggactc aggtggagga ggcggctgag 780
ggcgtcctcc gggccctgct ggcccagaag caggaggtgc tggggcagct acgagcccac 840
gtggaggctg ccgaagaagc tgctcgggag aggctggcgg agcttgaggg ccgggagcag 900
gtggccaggg ccgcagccgc cttcgcccgc cgggtactca gcctggggcg agaggccgag 960
atcctctccc tggaaggggc gatcgcacag cggctcaggc agctgcaggg ctgcccctgg 1020
gcaccaggcc cggccccctg cctgctccca cagctggagc tccatcctgg gctcctggac 1080
aagaactgcc accttcttcg gctgtccttt gaggagcagc agccccagaa ggatggtggg 1140
aaagacggag ctggtaccca gggaggtgag gagagccaga gccggaggga ggatgagccg 1200
aagactgaga gacagggtgg agtccagccc caggctggag atggagccca gaccccaaaa 1260
gaggaaaaag cccagacaac ccgagaagag ggagcccaga ccttggagga ggacagggcc 1320
cagacacccc acgaggatgg aggaccccag ccccacaggg gtggcagacc caacaagaag 1380
aaaaagttca aaggcaggct caagtcaatt tcccgggagc ccagcccagc cctggggccg 1440
aatctggacg gctctggcct cctccccaga cccatctttt actgcagttt ccccacgcgg 1500
atgcctggag acaagcggtc cccccggatc accgggctct gtcccttcgg tccccgggag 1560
atcctggtgg cggatgagca gaaccgggca ctgaaacgct tctccctcaa cggcgactac 1620
aagggcaccg tgccggtccc tgagggctgc tccccttgca gcgtggccgc cctgcagagc 1680
gcggtggcct tctccgctag cgcacggctc tatctcatca accccaacgg cgaagtgcag 1740
tggcgcaggg ccctgagcct ctcccaggcc agccacgcgg tggcggcact gcctagcggg 1800
gaccgcgtgg ctgtcagcgt ggcgggccac gtggaggtgt acaatatgga aggcagcctg 1860
gccacccggt tcattcctgg aggcaaggcc agccggggcc tgcgggcgct ggtgtttctg 1920
accaccagcc cccaggggca tttcgtgggg tcggactggc agcagaatag tgtggtaatc 1980
tgtgatgggc tgggccaggt ggttggggag tacaaggggc caggcctgca tggctgccag 2040
ccgggctccg tgtctgtgga taagaagggc tacatctttc tgacccttcg agaagtcaac 2100
aaggtggtga tcctggaccc gaaggggtcc ctccttggag acttcctgac agcctaccac 2160
ggcctggaaa agccccgggt taccaccatg gtggatggca ggtacctggt cgtgtccctc 2220
agtaa 2225
<210> 110
<211> 755
<212> PRT
<213> Homo sapiens
<400> 110
Met Val Ser His Gly Ser Ser Pro Ser Leu Leu Glu Ala Leu Ser Ser
1 5 10 15
Asp Phe Leu Ala Cys Lys Ile Cys Leu Glu Gln Leu Arg Ala Pro Lys
20 25 30
Thr Leu Pro Cys Leu His Thr Tyr Cys Gln Asp Cys Leu Ala Gln Leu
35 40 45
Ala Asp Gly Gly Arg Val Arg Cys Pro Glu Cys Arg Glu Thr Val Pro
50 55 60
Val Pro Pro Glu Gly Val Ala Ser Phe Lys Thr Asn Phe Phe Val Asn
65 70 75 80
Gly Leu Leu Asp Leu Val Lys Ala Arg Ala Cys Gly Asp Leu Arg Ala
85 90 95
Gly Lys Pro Ala Cys Ala Leu Cys Pro Leu Val Gly Gly Thr Ser Thr
100 105 110
Gly Gly Pro Ala Thr Ala Arg Cys Leu Asp Cys Ala Asp Asp Leu Cys
115 120 125
Gln Ala Cys Ala Asp Gly His Arg Cys Thr Arg Gln Thr His Thr His
130 135 140
Arg Val Val Asp Leu Val Gly Tyr Arg Ala Gly Trp Tyr Asp Glu Glu
145 150 155 160
Ala Arg Glu Arg Gln Ala Ala Gln Cys Pro Gln His Pro Gly Glu Ala
165 170 175
Leu Arg Phe Leu Cys Gln Pro Cys Ser Gln Leu Leu Cys Arg Glu Cys
180 185 190
Arg Leu Asp Pro His Leu Asp His Pro Cys Leu Pro Leu Ala Glu Ala
195 200 205
Val Arg Ala Arg Arg Pro Gly Leu Glu Gly Leu Leu Ala Gly Val Asp
210 215 220
Asn Asn Leu Val Glu Leu Glu Ala Ala Arg Arg Val Glu Lys Glu Ala
225 230 235 240
Leu Ala Arg Leu Arg Glu Gln Ala Ala Arg Val Gly Thr Gln Val Glu
245 250 255
Glu Ala Ala Glu Gly Val Leu Arg Ala Leu Leu Ala Gln Lys Gln Glu
260 265 270
Val Leu Gly Gln Leu Arg Ala His Val Glu Ala Ala Glu Glu Ala Ala
275 280 285
Arg Glu Arg Leu Ala Glu Leu Glu Gly Arg Glu Gln Val Ala Arg Ala
290 295 300
Ala Ala Ala Phe Ala Arg Arg Val Leu Ser Leu Gly Arg Glu Ala Glu
305 310 315 320
Ile Leu Ser Leu Glu Gly Ala Ile Ala Gln Arg Leu Arg Gln Leu Gln
325 330 335
Gly Cys Pro Trp Ala Pro Gly Pro Ala Pro Cys Leu Leu Pro Gln Leu
340 345 350
Glu Leu His Pro Gly Leu Leu Asp Lys Asn Cys His Leu Leu Arg Leu
355 360 365
Ser Phe Glu Glu Gln Gln Pro Gln Lys Asp Gly Gly Lys Asp Gly Ala
370 375 380
Gly Thr Gln Gly Gly Glu Glu Ser Gln Ser Arg Arg Glu Asp Glu Pro
385 390 395 400
Lys Thr Glu Arg Gln Gly Gly Val Gln Pro Gln Ala Gly Asp Gly Ala
405 410 415
Gln Thr Pro Lys Glu Glu Lys Ala Gln Thr Thr Arg Glu Glu Gly Ala
420 425 430
Gln Thr Leu Glu Glu Asp Arg Ala Gln Thr Pro His Glu Asp Gly Gly
435 440 445
Pro Gln Pro His Arg Gly Gly Arg Pro Asn Lys Lys Lys Lys Phe Lys
450 455 460
Gly Arg Leu Lys Ser Ile Ser Arg Glu Pro Ser Pro Ala Leu Gly Pro
465 470 475 480
Asn Leu Asp Gly Ser Gly Leu Leu Pro Arg Pro Ile Phe Tyr Cys Ser
485 490 495
Phe Pro Thr Arg Met Pro Gly Asp Lys Arg Ser Pro Arg Ile Thr Gly
500 505 510
Leu Cys Pro Phe Gly Pro Arg Glu Ile Leu Val Ala Asp Glu Gln Asn
515 520 525
Arg Ala Leu Lys Arg Phe Ser Leu Asn Gly Asp Tyr Lys Gly Thr Val
530 535 540
Pro Val Pro Glu Gly Cys Ser Pro Cys Ser Val Ala Ala Leu Gln Ser
545 550 555 560
Ala Val Ala Phe Ser Ala Ser Ala Arg Leu Tyr Leu Ile Asn Pro Asn
565 570 575
Gly Glu Val Gln Trp Arg Arg Ala Leu Ser Leu Ser Gln Ala Ser His
580 585 590
Ala Val Ala Ala Leu Pro Ser Gly Asp Arg Val Ala Val Ser Val Ala
595 600 605
Gly His Val Glu Val Tyr Asn Met Glu Gly Ser Leu Ala Thr Arg Phe
610 615 620
Ile Pro Gly Gly Lys Ala Ser Arg Gly Leu Arg Ala Leu Val Phe Leu
625 630 635 640
Thr Thr Ser Pro Gln Gly His Phe Val Gly Ser Asp Trp Gln Gln Asn
645 650 655
Ser Val Val Ile Cys Asp Gly Leu Gly Gln Val Val Gly Glu Tyr Lys
660 665 670
Gly Pro Gly Leu His Gly Cys Gln Pro Gly Ser Val Ser Val Asp Lys
675 680 685
Lys Gly Tyr Ile Phe Leu Thr Leu Arg Glu Val Asn Lys Val Val Ile
690 695 700
Leu Asp Pro Lys Gly Ser Leu Leu Gly Asp Phe Leu Thr Ala Tyr His
705 710 715 720
Gly Leu Glu Lys Pro Arg Val Thr Thr Met Val Asp Gly Arg Tyr Leu
725 730 735
Val Val Ser Leu Ser Asn Gly Thr Ile His Ile Phe Arg Val Arg Ser
740 745 750
Pro Asp Ser
755
<210> 111
<211> 1461
<212> DNA
<213> Homo sapiens
<400> 111
atggcctggg cgccgcccgg ggagcggctg cgcgaggatg cgcggtgccc ggtgtgcctg 60
gatttcctgc aggagccggt cagcgtggac tgcggccaca gcttctgcct caggtgcatc 120
tccgagttct gcgagaagtc ggacggcgcg cagggcggcg tctacgcctg tccgcagtgc 180
cggggcccct tccggccctc gggctttcgc cccaaccggc agctggcggg cctggtggag 240
agcgtgcggc ggctggggtt gggcgcgggg cccggggcgc ggcgatgcgc gcggcacggc 300
gaggacctga gccgcttctg cgaggaggac gaggcggcgc tgtgctgggt gtgcgacgcc 360
ggccccgagc acaggacgca ccgcacggcg ccgctgcagg aggccgccgg cagctaccag 420
gtaaagctcc agatggctct ggaacttatg aggaaagagt tggaggacgc cttgactcag 480
gaggccaacg tggggaaaaa gactgtcatt tggaaggaga aagtggaaat gcagaggcag 540
cgcttcagat tggagtttga gaagcatcgt ggctttctgg cccaggagga gcaacggcag 600
ctgaggcggc tggaggcgga ggagcgagcg acgctgcaga gactgcggga gagcaagagc 660
cggctggtcc agcagagcaa ggccctgaag gagctggcgg atgagctgca ggagaggtgc 720
cagcgcccgg ccctgggtct gctggagggt gtgagaggag tcctgagcag aagtaaggct 780
gtcacaaggc tggaagcaga gaacatcccc atggaactga agacagcatg ctgcatccct 840
gggaggaggg agctcttaag gaagttccaa gtggatgtaa agctggatcc cgccacggcg 900
cacccgagtc tgctcttgac cgccgacctg cgcagtgtgc aggatggaga accatggagg 960
gatgtcccca acaaccctga gcgatttgac acatggccct gcatcctggg tttgcagagc 1020
ttctcatcag ggaggcatta ctgggaggtt ctggtgggag aaggagcaga gtggggttta 1080
ggggtctgtc aagacacact gccaagaaag ggggaaacca cgccatctcc tgagaatggg 1140
gtctgggccc tgtggctgct gaaagggaat gagtacatgg tccttgcctc cccatcagtg 1200
cctcttctcc aactggaaag tcctcgctgc attgggattt tcttggacta tgaagccggt 1260
gaaatttcat tctacaatgt cacagatgga tcttatatct acacattcaa ccaactcttc 1320
tctggtcttc ttcggcctta ctttttcatc tgtgatgcaa ctcctcttat cttgccaccc 1380
acaacaatag cagggtcagg aaattgggca tccagggatc atttagatcc tgcttctgat 1440
gtaagagatg atcatctcta a 1461
<210> 112
<211> 486
<212> PRT
<213> Homo sapiens
<400> 112
Met Ala Trp Ala Pro Pro Gly Glu Arg Leu Arg Glu Asp Ala Arg Cys
1 5 10 15
Pro Val Cys Leu Asp Phe Leu Gln Glu Pro Val Ser Val Asp Cys Gly
20 25 30
His Ser Phe Cys Leu Arg Cys Ile Ser Glu Phe Cys Glu Lys Ser Asp
35 40 45
Gly Ala Gln Gly Gly Val Tyr Ala Cys Pro Gln Cys Arg Gly Pro Phe
50 55 60
Arg Pro Ser Gly Phe Arg Pro Asn Arg Gln Leu Ala Gly Leu Val Glu
65 70 75 80
Ser Val Arg Arg Leu Gly Leu Gly Ala Gly Pro Gly Ala Arg Arg Cys
85 90 95
Ala Arg His Gly Glu Asp Leu Ser Arg Phe Cys Glu Glu Asp Glu Ala
100 105 110
Ala Leu Cys Trp Val Cys Asp Ala Gly Pro Glu His Arg Thr His Arg
115 120 125
Thr Ala Pro Leu Gln Glu Ala Ala Gly Ser Tyr Gln Val Lys Leu Gln
130 135 140
Met Ala Leu Glu Leu Met Arg Lys Glu Leu Glu Asp Ala Leu Thr Gln
145 150 155 160
Glu Ala Asn Val Gly Lys Lys Thr Val Ile Trp Lys Glu Lys Val Glu
165 170 175
Met Gln Arg Gln Arg Phe Arg Leu Glu Phe Glu Lys His Arg Gly Phe
180 185 190
Leu Ala Gln Glu Glu Gln Arg Gln Leu Arg Arg Leu Glu Ala Glu Glu
195 200 205
Arg Ala Thr Leu Gln Arg Leu Arg Glu Ser Lys Ser Arg Leu Val Gln
210 215 220
Gln Ser Lys Ala Leu Lys Glu Leu Ala Asp Glu Leu Gln Glu Arg Cys
225 230 235 240
Gln Arg Pro Ala Leu Gly Leu Leu Glu Gly Val Arg Gly Val Leu Ser
245 250 255
Arg Ser Lys Ala Val Thr Arg Leu Glu Ala Glu Asn Ile Pro Met Glu
260 265 270
Leu Lys Thr Ala Cys Cys Ile Pro Gly Arg Arg Glu Leu Leu Arg Lys
275 280 285
Phe Gln Val Asp Val Lys Leu Asp Pro Ala Thr Ala His Pro Ser Leu
290 295 300
Leu Leu Thr Ala Asp Leu Arg Ser Val Gln Asp Gly Glu Pro Trp Arg
305 310 315 320
Asp Val Pro Asn Asn Pro Glu Arg Phe Asp Thr Trp Pro Cys Ile Leu
325 330 335
Gly Leu Gln Ser Phe Ser Ser Gly Arg His Tyr Trp Glu Val Leu Val
340 345 350
Gly Glu Gly Ala Glu Trp Gly Leu Gly Val Cys Gln Asp Thr Leu Pro
355 360 365
Arg Lys Gly Glu Thr Thr Pro Ser Pro Glu Asn Gly Val Trp Ala Leu
370 375 380
Trp Leu Leu Lys Gly Asn Glu Tyr Met Val Leu Ala Ser Pro Ser Val
385 390 395 400
Pro Leu Leu Gln Leu Glu Ser Pro Arg Cys Ile Gly Ile Phe Leu Asp
405 410 415
Tyr Glu Ala Gly Glu Ile Ser Phe Tyr Asn Val Thr Asp Gly Ser Tyr
420 425 430
Ile Tyr Thr Phe Asn Gln Leu Phe Ser Gly Leu Leu Arg Pro Tyr Phe
435 440 445
Phe Ile Cys Asp Ala Thr Pro Leu Ile Leu Pro Pro Thr Thr Ile Ala
450 455 460
Gly Ser Gly Asn Trp Ala Ser Arg Asp His Leu Asp Pro Ala Ser Asp
465 470 475 480
Val Arg Asp Asp His Leu
485
<210> 113
<211> 1212
<212> DNA
<213> Homo sapiens
<400> 113
atgcacaatt ttgaggaaga gttaacttgt cccatatgtt atagtatttt tgaagatcct 60
cgtgtactgc catgctctca tacattttgt agaaattgtt tggaaaacat tcttcaggca 120
tctggtaact tttatatatg gagaccttta cgaattccac tcaagtgccc taattgcaga 180
agtattactg aaattgctcc aactggcatt gaatctttac ctgttaattt tgcactaagg 240
gctattattg aaaagtacca gcaagaagac catccagata ttgtcacctg ccctgaacat 300
tacaggcaac cattaaatgt ttactgtcta ttagataaaa aattagtttg tggtcattgc 360
cttaccatag gtcaacatca tggtcatcct atagatgacc ttcaaagtgc ctatttgaaa 420
gaaaaggaca ctcctcaaaa actgcttgaa cagttgactg acacacactg gacagatctt 480
acccatctta ttgaaaagct gaaagaacaa aaatctcatt ctgagaaaat gatccaaggc 540
gataaggaag ctgttctcca gtattttaag gagcttaatg atacattaga acagaaaaaa 600
aaaagtttcc taacggctct ctgtgatgtt ggcaatctaa ttaatcaaga atatactcca 660
caaattgaaa gaatgaagga aatacgagag cagcagcttg aattaatggc actgacaata 720
tctttacaag aagagtctcc acttaaattt cttgaaaaag ttgatgatgt acgccagcat 780
gtacagatct tgaaacaaag accacttcct gaggttcaac ccgttgaaat ttatcctcga 840
gtaagcaaaa tattgaaaga agaatggagc agaacagaaa ttggacaaat taagaacgtt 900
ctcattccca aaatgaaaat ttctccaaaa aggatgtcat gttcctggcc tggtaaggat 960
gaaaaggaag ttgaattttt aaaaatttta aacattgttg tagttacatt aatttcagta 1020
atactgatgt cgatactctt tttcaaccaa cacatcataa cctttttaag tgaaatcact 1080
ttaatatggt tttctgaagc ctctctatct gtttaccaaa gtttatctaa cagtctgcat 1140
aaggtaaaga atatactgtg tcacattttc tatttgttga aggaatttgt gtggaaaata 1200
gtttcccatt ga 1212
<210> 114
<211> 403
<212> PRT
<213> Homo sapiens
<400> 114
Met His Asn Phe Glu Glu Glu Leu Thr Cys Pro Ile Cys Tyr Ser Ile
1 5 10 15
Phe Glu Asp Pro Arg Val Leu Pro Cys Ser His Thr Phe Cys Arg Asn
20 25 30
Cys Leu Glu Asn Ile Leu Gln Ala Ser Gly Asn Phe Tyr Ile Trp Arg
35 40 45
Pro Leu Arg Ile Pro Leu Lys Cys Pro Asn Cys Arg Ser Ile Thr Glu
50 55 60
Ile Ala Pro Thr Gly Ile Glu Ser Leu Pro Val Asn Phe Ala Leu Arg
65 70 75 80
Ala Ile Ile Glu Lys Tyr Gln Gln Glu Asp His Pro Asp Ile Val Thr
85 90 95
Cys Pro Glu His Tyr Arg Gln Pro Leu Asn Val Tyr Cys Leu Leu Asp
100 105 110
Lys Lys Leu Val Cys Gly His Cys Leu Thr Ile Gly Gln His His Gly
115 120 125
His Pro Ile Asp Asp Leu Gln Ser Ala Tyr Leu Lys Glu Lys Asp Thr
130 135 140
Pro Gln Lys Leu Leu Glu Gln Leu Thr Asp Thr His Trp Thr Asp Leu
145 150 155 160
Thr His Leu Ile Glu Lys Leu Lys Glu Gln Lys Ser His Ser Glu Lys
165 170 175
Met Ile Gln Gly Asp Lys Glu Ala Val Leu Gln Tyr Phe Lys Glu Leu
180 185 190
Asn Asp Thr Leu Glu Gln Lys Lys Lys Ser Phe Leu Thr Ala Leu Cys
195 200 205
Asp Val Gly Asn Leu Ile Asn Gln Glu Tyr Thr Pro Gln Ile Glu Arg
210 215 220
Met Lys Glu Ile Arg Glu Gln Gln Leu Glu Leu Met Ala Leu Thr Ile
225 230 235 240
Ser Leu Gln Glu Glu Ser Pro Leu Lys Phe Leu Glu Lys Val Asp Asp
245 250 255
Val Arg Gln His Val Gln Ile Leu Lys Gln Arg Pro Leu Pro Glu Val
260 265 270
Gln Pro Val Glu Ile Tyr Pro Arg Val Ser Lys Ile Leu Lys Glu Glu
275 280 285
Trp Ser Arg Thr Glu Ile Gly Gln Ile Lys Asn Val Leu Ile Pro Lys
290 295 300
Met Lys Ile Ser Pro Lys Arg Met Ser Cys Ser Trp Pro Gly Lys Asp
305 310 315 320
Glu Lys Glu Val Glu Phe Leu Lys Ile Leu Asn Ile Val Val Val Thr
325 330 335
Leu Ile Ser Val Ile Leu Met Ser Ile Leu Phe Phe Asn Gln His Ile
340 345 350
Ile Thr Phe Leu Ser Glu Ile Thr Leu Ile Trp Phe Ser Glu Ala Ser
355 360 365
Leu Ser Val Tyr Gln Ser Leu Ser Asn Ser Leu His Lys Val Lys Asn
370 375 380
Ile Leu Cys His Ile Phe Tyr Leu Leu Lys Glu Phe Val Trp Lys Ile
385 390 395 400
Val Ser His
<210> 115
<211> 1416
<212> DNA
<213> Homo sapiens
<400> 115
atggagtttg tgacagccct ggtgaacctc caagaggagt ctagctgtcc catctgtctg 60
gagtacttga aagacccagt gaccatcaac tgtgggcaca acttctgtcg ctcctgcctc 120
agtgtatcct ggaaggatct agatgatacc tttccctgtc ctgtctgccg tttttgcttt 180
ccatacaaga gcttcaggag gaacccccag ctccgtaatt tgactgaaat tgctaaacaa 240
ctccagatta ggaggagcaa gagaaagagg cagaaagaga atgccatgtg tgaaaaacac 300
aaccagtttc tgaccctctt ctgtgttaaa gatctagaga tcttatgtac acagtgcagt 360
ttctccacta aacaccagaa gcactacatt tgccctatta agaaagctgc ctcttatcac 420
agagaaattc tagaaggtag ccttgagccc ttgaggaata atatagaacg agttgaaaaa 480
gtgataattc tgcaaggcag caaatcagtg gagctgaaaa agaaggtaga atataagagg 540
gaagaaataa attctgagtt tgagcaaata agattgtttt tacagaatga acaagagatg 600
attcttaggc agatacaaga tgaagagatg aacattttag caaaactaaa tgaaaacctt 660
gtagaacttt cagattatgt ttccacatta aaacatctac tgagggaggt agagggcaag 720
tctgtgcagt caaacctgga attactgaca caagctaaga gtatgcacca caagtatcaa 780
aacctaaaat gccctgaact cttttcattt agattaacaa aatatggttt cagtcttcct 840
cctcaatatt ctggcttgga cagaattatc aagccatttc aagtagatgt gattctagat 900
ctcaacacag cacatcctca acttcttgtc tctgaggata gaaaagctgt gcgatatgaa 960
agaaaaaaac gaaacatttg ttatgaccca aggagatttt atgtctgccc tgctgtccta 1020
ggctctcaga gatttagttc tggccgacat tactgggaag tagaagtggg aaacaaacct 1080
aaatggatat tgggtgtgtg tcaagactgt cttcttagga actggcagga tcagccatca 1140
gttctgggcg gattctgggc aattgggcga tacatgaaga gtggttatgt tgcgtcaggt 1200
cctaagacaa cccagcttct gccagtagta aaacccagta aaattggtat ttttctggac 1260
tatgaattgg gtgatctttc cttttataat atgaatgata ggtctattct ctatactttt 1320
aacgattgtt tcacagaagc cgtttggcct tatttctata ctggaacaga ttccgaacct 1380
cttaaaatct gctcagtatc agattctgaa agataa 1416
<210> 116
<211> 471
<212> PRT
<213> Homo sapiens
<400> 116
Met Glu Phe Val Thr Ala Leu Val Asn Leu Gln Glu Glu Ser Ser Cys
1 5 10 15
Pro Ile Cys Leu Glu Tyr Leu Lys Asp Pro Val Thr Ile Asn Cys Gly
20 25 30
His Asn Phe Cys Arg Ser Cys Leu Ser Val Ser Trp Lys Asp Leu Asp
35 40 45
Asp Thr Phe Pro Cys Pro Val Cys Arg Phe Cys Phe Pro Tyr Lys Ser
50 55 60
Phe Arg Arg Asn Pro Gln Leu Arg Asn Leu Thr Glu Ile Ala Lys Gln
65 70 75 80
Leu Gln Ile Arg Arg Ser Lys Arg Lys Arg Gln Lys Glu Asn Ala Met
85 90 95
Cys Glu Lys His Asn Gln Phe Leu Thr Leu Phe Cys Val Lys Asp Leu
100 105 110
Glu Ile Leu Cys Thr Gln Cys Ser Phe Ser Thr Lys His Gln Lys His
115 120 125
Tyr Ile Cys Pro Ile Lys Lys Ala Ala Ser Tyr His Arg Glu Ile Leu
130 135 140
Glu Gly Ser Leu Glu Pro Leu Arg Asn Asn Ile Glu Arg Val Glu Lys
145 150 155 160
Val Ile Ile Leu Gln Gly Ser Lys Ser Val Glu Leu Lys Lys Lys Val
165 170 175
Glu Tyr Lys Arg Glu Glu Ile Asn Ser Glu Phe Glu Gln Ile Arg Leu
180 185 190
Phe Leu Gln Asn Glu Gln Glu Met Ile Leu Arg Gln Ile Gln Asp Glu
195 200 205
Glu Met Asn Ile Leu Ala Lys Leu Asn Glu Asn Leu Val Glu Leu Ser
210 215 220
Asp Tyr Val Ser Thr Leu Lys His Leu Leu Arg Glu Val Glu Gly Lys
225 230 235 240
Ser Val Gln Ser Asn Leu Glu Leu Leu Thr Gln Ala Lys Ser Met His
245 250 255
His Lys Tyr Gln Asn Leu Lys Cys Pro Glu Leu Phe Ser Phe Arg Leu
260 265 270
Thr Lys Tyr Gly Phe Ser Leu Pro Pro Gln Tyr Ser Gly Leu Asp Arg
275 280 285
Ile Ile Lys Pro Phe Gln Val Asp Val Ile Leu Asp Leu Asn Thr Ala
290 295 300
His Pro Gln Leu Leu Val Ser Glu Asp Arg Lys Ala Val Arg Tyr Glu
305 310 315 320
Arg Lys Lys Arg Asn Ile Cys Tyr Asp Pro Arg Arg Phe Tyr Val Cys
325 330 335
Pro Ala Val Leu Gly Ser Gln Arg Phe Ser Ser Gly Arg His Tyr Trp
340 345 350
Glu Val Glu Val Gly Asn Lys Pro Lys Trp Ile Leu Gly Val Cys Gln
355 360 365
Asp Cys Leu Leu Arg Asn Trp Gln Asp Gln Pro Ser Val Leu Gly Gly
370 375 380
Phe Trp Ala Ile Gly Arg Tyr Met Lys Ser Gly Tyr Val Ala Ser Gly
385 390 395 400
Pro Lys Thr Thr Gln Leu Leu Pro Val Val Lys Pro Ser Lys Ile Gly
405 410 415
Ile Phe Leu Asp Tyr Glu Leu Gly Asp Leu Ser Phe Tyr Asn Met Asn
420 425 430
Asp Arg Ser Ile Leu Tyr Thr Phe Asn Asp Cys Phe Thr Glu Ala Val
435 440 445
Trp Pro Tyr Phe Tyr Thr Gly Thr Asp Ser Glu Pro Leu Lys Ile Cys
450 455 460
Ser Val Ser Asp Ser Glu Arg
465 470
<210> 117
<211> 630
<212> DNA
<213> Homo sapiens
<400> 117
atggaatttg ttacggccct ggctgacctc cgagcagagg ctagctgtcc catctgtctg 60
gactacttga aagacccagt gaccatcagc tgtgggcata acttctgtct ctcctgcatc 120
attatgtcct ggaaggatct acatgatagt ttcccctgcc ccttttgcca cttttgctgt 180
ccagaaagga aatttataag caatccccag ctgggtagtt tgactgaaat tgctaagcaa 240
ctccagataa gaagcaagaa gaggaagagg caggaagaga agcatgtgtg taagaagcat 300
aatcaggttt tgactttctt ctgtcagaaa gacctagagc ttttatgtcc aaggtgcagt 360
ttgtccactg atcaccagca tcactgtgtt tggcccataa agaaggctgc ctcctatcat 420
aggaaaaaac tggaggaata caatgcaccg tggaaggaga gagtggaact aattgaaaaa 480
gtcataacta tgcaaaccag gaaatcactg gaactgaaga aaaagatgga gtctccttct 540
gtcaccaggc tggagtgcag ttgcacgatc tcggctcact tcaacctccg cctcccggga 600
tcaagcgatt cttctgcctc tggctcctga 630
<210> 118
<211> 209
<212> PRT
<213> Homo sapiens
<400> 118
Met Glu Phe Val Thr Ala Leu Ala Asp Leu Arg Ala Glu Ala Ser Cys
1 5 10 15
Pro Ile Cys Leu Asp Tyr Leu Lys Asp Pro Val Thr Ile Ser Cys Gly
20 25 30
His Asn Phe Cys Leu Ser Cys Ile Ile Met Ser Trp Lys Asp Leu His
35 40 45
Asp Ser Phe Pro Cys Pro Phe Cys His Phe Cys Cys Pro Glu Arg Lys
50 55 60
Phe Ile Ser Asn Pro Gln Leu Gly Ser Leu Thr Glu Ile Ala Lys Gln
65 70 75 80
Leu Gln Ile Arg Ser Lys Lys Arg Lys Arg Gln Glu Glu Lys His Val
85 90 95
Cys Lys Lys His Asn Gln Val Leu Thr Phe Phe Cys Gln Lys Asp Leu
100 105 110
Glu Leu Leu Cys Pro Arg Cys Ser Leu Ser Thr Asp His Gln His His
115 120 125
Cys Val Trp Pro Ile Lys Lys Ala Ala Ser Tyr His Arg Lys Lys Leu
130 135 140
Glu Glu Tyr Asn Ala Pro Trp Lys Glu Arg Val Glu Leu Ile Glu Lys
145 150 155 160
Val Ile Thr Met Gln Thr Arg Lys Ser Leu Glu Leu Lys Lys Lys Met
165 170 175
Glu Ser Pro Ser Val Thr Arg Leu Glu Cys Ser Cys Thr Ile Ser Ala
180 185 190
His Phe Asn Leu Arg Leu Pro Gly Ser Ser Asp Ser Ser Ala Ser Gly
195 200 205
Ser
<210> 119
<211> 1428
<212> DNA
<213> Homo sapiens
<400> 119
atggcgtgca gcctcaagga cgagctgctg tgctccatct gcctgagcat ctaccaggac 60
ccggtgagcc tgggctgcga gcattacttc tgccgccgct gcatcacgga gcactgggtg 120
cggcaggagg cgcagggcgc ccgcgactgc cccgagtgcc ggcgcacgtt cgccgagccc 180
gcgctggcgc ccagcctcaa gctggccaac atcgtggagc gctacagctc cttcccgctg 240
gacgccatcc tcaacgcgcg ccgcgccgcg cgaccctgcc aggcgcacga caaggtcaag 300
ctcttctgcc tcacggaccg cgcgcttctc tgcttcttct gcgacgagcc tgcactgcac 360
gagcagcatc aggtcaccgg catcgacgac gccttcgacg agctgcagag ggagctgaag 420
gaccaacttc aggcccttca agacagcgag cgggaacaca ccgaagcgct gcagctgctc 480
aagcgacaac tggcggagac caagtcttcc accaagagcc tgcggaccac tatcggcgag 540
gccttcgagc ggctgcaccg gctgctgcgt gaacgccaga aggccatgct agaggagctg 600
gaggcggaca cggcccgcac gctgaccgac atcgagcaga aagtccagcg ctacagccag 660
cagctgcgca aggtccagga gggagcccag atcctgcagg agcggctggc tgaaaccgac 720
cggcacacct tcctggctgg ggtggcctca ctgtccgagc ggctcaaggg aaaaatccat 780
gagaccaacc tcacatatga agacttcccg acctccaagt acacaggccc cctgcagtac 840
accatctgga agtccctgtt ccaggacatc cacccagtgc cagccgccct aaccctggac 900
ccgggcacag cccaccagcg cctgatcctg tcggacgact gcaccattgt ggcttacggc 960
aacttgcacc cacagccact gcaggactcg ccaaagcgct tcgatgtgga ggtgtcggtg 1020
ctgggttctg aagccttcag tagtggcgtc cactactggg aggtggtggt ggcggagaag 1080
acccagtggg tgatcgggct ggcacacgaa gccgcaagcc gcaagggcag catccagatc 1140
cagcccagcc gcggcttcta ctgcatcgtg atgcacgatg gcaaccagta cagcgcctgc 1200
acggagccct ggacgcggct taacgtccgg gacaagcttg acaaggtggg tgtcttcctg 1260
gactatgacc aaggcttgct catcttctac aatgctgatg acatgtcctg gctctacacc 1320
ttccgcgaga agttccctgg caagctctgc tcttacttca gccctggcca gagccacgcc 1380
aatggcaaga acgttcagcc gctgcggatc aacaccgtcc gcatctag 1428
<210> 120
<211> 475
<212> PRT
<213> Homo sapiens
<400> 120
Met Ala Cys Ser Leu Lys Asp Glu Leu Leu Cys Ser Ile Cys Leu Ser
1 5 10 15
Ile Tyr Gln Asp Pro Val Ser Leu Gly Cys Glu His Tyr Phe Cys Arg
20 25 30
Arg Cys Ile Thr Glu His Trp Val Arg Gln Glu Ala Gln Gly Ala Arg
35 40 45
Asp Cys Pro Glu Cys Arg Arg Thr Phe Ala Glu Pro Ala Leu Ala Pro
50 55 60
Ser Leu Lys Leu Ala Asn Ile Val Glu Arg Tyr Ser Ser Phe Pro Leu
65 70 75 80
Asp Ala Ile Leu Asn Ala Arg Arg Ala Ala Arg Pro Cys Gln Ala His
85 90 95
Asp Lys Val Lys Leu Phe Cys Leu Thr Asp Arg Ala Leu Leu Cys Phe
100 105 110
Phe Cys Asp Glu Pro Ala Leu His Glu Gln His Gln Val Thr Gly Ile
115 120 125
Asp Asp Ala Phe Asp Glu Leu Gln Arg Glu Leu Lys Asp Gln Leu Gln
130 135 140
Ala Leu Gln Asp Ser Glu Arg Glu His Thr Glu Ala Leu Gln Leu Leu
145 150 155 160
Lys Arg Gln Leu Ala Glu Thr Lys Ser Ser Thr Lys Ser Leu Arg Thr
165 170 175
Thr Ile Gly Glu Ala Phe Glu Arg Leu His Arg Leu Leu Arg Glu Arg
180 185 190
Gln Lys Ala Met Leu Glu Glu Leu Glu Ala Asp Thr Ala Arg Thr Leu
195 200 205
Thr Asp Ile Glu Gln Lys Val Gln Arg Tyr Ser Gln Gln Leu Arg Lys
210 215 220
Val Gln Glu Gly Ala Gln Ile Leu Gln Glu Arg Leu Ala Glu Thr Asp
225 230 235 240
Arg His Thr Phe Leu Ala Gly Val Ala Ser Leu Ser Glu Arg Leu Lys
245 250 255
Gly Lys Ile His Glu Thr Asn Leu Thr Tyr Glu Asp Phe Pro Thr Ser
260 265 270
Lys Tyr Thr Gly Pro Leu Gln Tyr Thr Ile Trp Lys Ser Leu Phe Gln
275 280 285
Asp Ile His Pro Val Pro Ala Ala Leu Thr Leu Asp Pro Gly Thr Ala
290 295 300
His Gln Arg Leu Ile Leu Ser Asp Asp Cys Thr Ile Val Ala Tyr Gly
305 310 315 320
Asn Leu His Pro Gln Pro Leu Gln Asp Ser Pro Lys Arg Phe Asp Val
325 330 335
Glu Val Ser Val Leu Gly Ser Glu Ala Phe Ser Ser Gly Val His Tyr
340 345 350
Trp Glu Val Val Val Ala Glu Lys Thr Gln Trp Val Ile Gly Leu Ala
355 360 365
His Glu Ala Ala Ser Arg Lys Gly Ser Ile Gln Ile Gln Pro Ser Arg
370 375 380
Gly Phe Tyr Cys Ile Val Met His Asp Gly Asn Gln Tyr Ser Ala Cys
385 390 395 400
Thr Glu Pro Trp Thr Arg Leu Asn Val Arg Asp Lys Leu Asp Lys Val
405 410 415
Gly Val Phe Leu Asp Tyr Asp Gln Gly Leu Leu Ile Phe Tyr Asn Ala
420 425 430
Asp Asp Met Ser Trp Leu Tyr Thr Phe Arg Glu Lys Phe Pro Gly Lys
435 440 445
Leu Cys Ser Tyr Phe Ser Pro Gly Gln Ser His Ala Asn Gly Lys Asn
450 455 460
Val Gln Pro Leu Arg Ile Asn Thr Val Arg Ile
465 470 475
<210> 121
<211> 1062
<212> DNA
<213> Homo sapiens
<400> 121
atggattata agtcgagcct gatccaggat gggaatccca tggagaactt ggagaagcag 60
ctgatctgcc ctatctgcct ggagatgttt accaagccag tggtcatctt gccgtgccag 120
cacaacctgt gccggaagtg tgccaatgac atcttccagg ctgcaaatcc ctactggacc 180
agccggggca gctcagtgtc catgtctgga ggccgtttcc gctgccccac ctgccgccac 240
gaggtgatca tggatcgtca cggagtgtac ggcctgcaga ggaacctgct ggtggagaac 300
atcatcgaca tctacaaaca ggagtgctcc agtcggccgc tgcagaaggg cagtcacccc 360
atgtgcaagg agcacgaaga tgagaaaatc aacatctact gtctcacgtg tgaggtgccc 420
acctgctcca tgtgcaaggt gtttgggatc cacaaggcct gcgaggtggc cccattgcag 480
agtgtcttcc agggacaaaa gactgaactg aataactgta tctccatgct ggtggcgggg 540
aatgaccgtg tgcagaccat catcactcag ctggaggatt cccgtcgagt gaccaaggag 600
aacagtcacc aggtaaagga agagctgagc cagaagtttg acacgttgta tgccatcctg 660
gatgagaaga aaagtgagtt gctgcagcgg atcacgcagg agcaggagaa aaagcttagc 720
ttcatcgagg ccctcatcca gcagtaccag gagcagctgg acaagtccac aaagctggtg 780
gaaactgcca tccagtccct ggacgagcct gggggagcca ccttcctctt gactgccaag 840
caactcatca aaagcattgt ggaagcttcc aagggctgcc agctggggaa gacagagcag 900
ggctttgaga acatggactt ctttactttg gatttagagc acatagcaga cgccctgaga 960
gccattgact ttgggacaga tgaggaagag gaagaattca ttgaagaaga agatcaggaa 1020
gaggaagagt ccacagaagg gaaggaagaa ggacaccagt aa 1062
<210> 122
<211> 353
<212> PRT
<213> Homo sapiens
<400> 122
Met Asp Tyr Lys Ser Ser Leu Ile Gln Asp Gly Asn Pro Met Glu Asn
1 5 10 15
Leu Glu Lys Gln Leu Ile Cys Pro Ile Cys Leu Glu Met Phe Thr Lys
20 25 30
Pro Val Val Ile Leu Pro Cys Gln His Asn Leu Cys Arg Lys Cys Ala
35 40 45
Asn Asp Ile Phe Gln Ala Ala Asn Pro Tyr Trp Thr Ser Arg Gly Ser
50 55 60
Ser Val Ser Met Ser Gly Gly Arg Phe Arg Cys Pro Thr Cys Arg His
65 70 75 80
Glu Val Ile Met Asp Arg His Gly Val Tyr Gly Leu Gln Arg Asn Leu
85 90 95
Leu Val Glu Asn Ile Ile Asp Ile Tyr Lys Gln Glu Cys Ser Ser Arg
100 105 110
Pro Leu Gln Lys Gly Ser His Pro Met Cys Lys Glu His Glu Asp Glu
115 120 125
Lys Ile Asn Ile Tyr Cys Leu Thr Cys Glu Val Pro Thr Cys Ser Met
130 135 140
Cys Lys Val Phe Gly Ile His Lys Ala Cys Glu Val Ala Pro Leu Gln
145 150 155 160
Ser Val Phe Gln Gly Gln Lys Thr Glu Leu Asn Asn Cys Ile Ser Met
165 170 175
Leu Val Ala Gly Asn Asp Arg Val Gln Thr Ile Ile Thr Gln Leu Glu
180 185 190
Asp Ser Arg Arg Val Thr Lys Glu Asn Ser His Gln Val Lys Glu Glu
195 200 205
Leu Ser Gln Lys Phe Asp Thr Leu Tyr Ala Ile Leu Asp Glu Lys Lys
210 215 220
Ser Glu Leu Leu Gln Arg Ile Thr Gln Glu Gln Glu Lys Lys Leu Ser
225 230 235 240
Phe Ile Glu Ala Leu Ile Gln Gln Tyr Gln Glu Gln Leu Asp Lys Ser
245 250 255
Thr Lys Leu Val Glu Thr Ala Ile Gln Ser Leu Asp Glu Pro Gly Gly
260 265 270
Ala Thr Phe Leu Leu Thr Ala Lys Gln Leu Ile Lys Ser Ile Val Glu
275 280 285
Ala Ser Lys Gly Cys Gln Leu Gly Lys Thr Glu Gln Gly Phe Glu Asn
290 295 300
Met Asp Phe Phe Thr Leu Asp Leu Glu His Ile Ala Asp Ala Leu Arg
305 310 315 320
Ala Ile Asp Phe Gly Thr Asp Glu Glu Glu Glu Glu Phe Ile Glu Glu
325 330 335
Glu Asp Gln Glu Glu Glu Glu Ser Thr Glu Gly Lys Glu Glu Gly His
340 345 350
Gln
<210> 123
<211> 1350
<212> DNA
<213> Homo sapiens
<400> 123
atggattcag acgacctgca agtcttccag aatgagctca tttgctgcat ttgcgtgaac 60
tacttcatag atccggtcac cattgactgt gggcacagct tttgcaggcc ctgcctctgc 120
ctctgctcag aagaaggcag agcaccaatg cgctgccctt cgtgcagaaa aatctcagag 180
aagcccaact tcaacaccaa tgtggtactc aaaaagctgt cttccctagc cagacagacc 240
agacctcaga acatcaacag ctcagacaat atctgtgtgc tccatgagga gactaaggag 300
ctcttctgtg aggctgacaa gagattgctc tgtgggccct gctctgagtc accagagcac 360
atggctcaca gccacagccc aataggatgg gctgctgagg aatgcaggga gaaacttata 420
aaggaaatgg actatttatg ggaaatcaat caagagacaa gaaacaatct aaatcaggaa 480
actagaacat ttcattcgtt aaaggactat gtgtcagtaa ggaagaggat aatcactatt 540
caatatcaaa agatgcctat atttctcgat gaggaggagc aacggcatct gcaggcactg 600
gaaagagaag cagaagagct tttccaacaa ctacaagaca gtcaagtgag aatgacccaa 660
catttagaaa ggatgaaaga catgtacaga gagctgtggg agacatgcca cgtgcctgac 720
gtggagctgc tccaggatgt gagaaatgta tcagcaagga ctgatttggc acagatgcaa 780
aagccccagc cagtgaaccc agagctcact tcatggtgca taactggagt cctagacatg 840
ctcaacaact tcagagtgga tagtgctctg agcacggaaa tgattccttg ctatataagc 900
ctttctgagg atgtgagata tgtgatattt ggagatgacc atctcagtgc tcccacggat 960
ccccagggag tggacagctt tgctgtgtgg ggagcgcaag cattcacctc cggcaagcat 1020
tactgggagg tggatgtgac cctctcctcc aactggattc tgggagtctg tcaagattcc 1080
aggactgcag atgccaattt cgttattgat tctgatgaaa gatttttttt aatttcctca 1140
aagaggagca atcactatag tctctccacc aactctccac ctttaattca gtatgtgcaa 1200
aggcctctgg gtcaagttgg ggtgtttctg gattatgata atggatctgt gagttttttt 1260
gatgtttcta aaggttctct tatctatggt tttcctcctt cctccttctc ttcccctctg 1320
aggcctttct tttgctttgg ttgtacatga 1350
<210> 124
<211> 449
<212> PRT
<213> Homo sapiens
<400> 124
Met Asp Ser Asp Asp Leu Gln Val Phe Gln Asn Glu Leu Ile Cys Cys
1 5 10 15
Ile Cys Val Asn Tyr Phe Ile Asp Pro Val Thr Ile Asp Cys Gly His
20 25 30
Ser Phe Cys Arg Pro Cys Leu Cys Leu Cys Ser Glu Glu Gly Arg Ala
35 40 45
Pro Met Arg Cys Pro Ser Cys Arg Lys Ile Ser Glu Lys Pro Asn Phe
50 55 60
Asn Thr Asn Val Val Leu Lys Lys Leu Ser Ser Leu Ala Arg Gln Thr
65 70 75 80
Arg Pro Gln Asn Ile Asn Ser Ser Asp Asn Ile Cys Val Leu His Glu
85 90 95
Glu Thr Lys Glu Leu Phe Cys Glu Ala Asp Lys Arg Leu Leu Cys Gly
100 105 110
Pro Cys Ser Glu Ser Pro Glu His Met Ala His Ser His Ser Pro Ile
115 120 125
Gly Trp Ala Ala Glu Glu Cys Arg Glu Lys Leu Ile Lys Glu Met Asp
130 135 140
Tyr Leu Trp Glu Ile Asn Gln Glu Thr Arg Asn Asn Leu Asn Gln Glu
145 150 155 160
Thr Arg Thr Phe His Ser Leu Lys Asp Tyr Val Ser Val Arg Lys Arg
165 170 175
Ile Ile Thr Ile Gln Tyr Gln Lys Met Pro Ile Phe Leu Asp Glu Glu
180 185 190
Glu Gln Arg His Leu Gln Ala Leu Glu Arg Glu Ala Glu Glu Leu Phe
195 200 205
Gln Gln Leu Gln Asp Ser Gln Val Arg Met Thr Gln His Leu Glu Arg
210 215 220
Met Lys Asp Met Tyr Arg Glu Leu Trp Glu Thr Cys His Val Pro Asp
225 230 235 240
Val Glu Leu Leu Gln Asp Val Arg Asn Val Ser Ala Arg Thr Asp Leu
245 250 255
Ala Gln Met Gln Lys Pro Gln Pro Val Asn Pro Glu Leu Thr Ser Trp
260 265 270
Cys Ile Thr Gly Val Leu Asp Met Leu Asn Asn Phe Arg Val Asp Ser
275 280 285
Ala Leu Ser Thr Glu Met Ile Pro Cys Tyr Ile Ser Leu Ser Glu Asp
290 295 300
Val Arg Tyr Val Ile Phe Gly Asp Asp His Leu Ser Ala Pro Thr Asp
305 310 315 320
Pro Gln Gly Val Asp Ser Phe Ala Val Trp Gly Ala Gln Ala Phe Thr
325 330 335
Ser Gly Lys His Tyr Trp Glu Val Asp Val Thr Leu Ser Ser Asn Trp
340 345 350
Ile Leu Gly Val Cys Gln Asp Ser Arg Thr Ala Asp Ala Asn Phe Val
355 360 365
Ile Asp Ser Asp Glu Arg Phe Phe Leu Ile Ser Ser Lys Arg Ser Asn
370 375 380
His Tyr Ser Leu Ser Thr Asn Ser Pro Pro Leu Ile Gln Tyr Val Gln
385 390 395 400
Arg Pro Leu Gly Gln Val Gly Val Phe Leu Asp Tyr Asp Asn Gly Ser
405 410 415
Val Ser Phe Phe Asp Val Ser Lys Gly Ser Leu Ile Tyr Gly Phe Pro
420 425 430
Pro Ser Ser Phe Ser Ser Pro Leu Arg Pro Phe Phe Cys Phe Gly Cys
435 440 445
Thr
<210> 125
<211> 1554
<212> DNA
<213> Homo sapiens
<400> 125
atggccgcgc agctgctgga ggagaagctg acctgcgcca tctgcctggg gctctaccag 60
gacccagtga cgctgccctg cggccacaac ttctgcgggg cctgcatccg ggactggtgg 120
gaccgctgcg gaaaggcgtg ccccgagtgc cgggagccct ttcccgacgg cgccgagctg 180
cgccgcaacg tggccctcag cggcgtgctg gaggtggtgc gcgccgggcc cgcccgggat 240
cccggccccg atcccggccc cggccccgac cctgccgcgc gctgcccccg ccacgggcgg 300
ccgctggagc tcttctgccg gaccgagggc cgctgtgtgt gcagcgtgtg caccgtgcgc 360
gagtgtcgcc tccacgagcg ggcgctgctg gatgccgagc gcctcaagcg cgaggcccag 420
ctgagagcca gcctggaggt tacccagcag caggccaccc aggccgaagg ccagctacta 480
gagctgcgca agcaaagcag ccagatccag aactcggcct gcatcttggc ctcctgggtc 540
tccggcaagt tcagcagcct gctacaggcc ctggaaatac agcacacgac agcactgagg 600
agcatcgagg tggccaagac gcaggcgctg gcacaggctc gagacgagga gcagcggctg 660
cgggtccatt tggaggctgt ggctcgccat ggctgcagga tccgggagct cctggagcag 720
gtggatgagc agaccttcct gcaggaatcg cagctcctcc agcccccagg gcctcttggg 780
ccactgaccc ctctgcagtg ggatgaagac caacagctgg gtgacctgaa gcagttgcta 840
agccggctgt gtggcctcct cttggaagag gggagccacc ctggggcacc agccaagcct 900
gtggacttag cccccgtgga ggccccaggt cccctggcac cggtcccaag cacagtttgt 960
ccactgagga ggaaactctg gcagaattat cgcaatctga cctttgatcc agtcagcgcc 1020
aaccgtcact tctatctgtc gcgccaggac cagcaggtga agcactgtcg tcagtcccgg 1080
ggcccaggcg ggcccggcag ctttgagctc tggcaggtgc aatgtgccca gagcttccag 1140
gccgggcacc actactggga ggtgcgcgcg tcagaccact cggtgacact gggcgtctcc 1200
tacccgcaac tgccacggtg caggctgggg ccccacacag acaacattgg ccggggaccc 1260
tgctcctggg ggctctgcgt ccaggaggac agcctccagg cctggcacaa cggggaagcc 1320
cagcgcctcc caggggtgtc agggcggctc ctgggcatgg atttggacct ggcctcaggc 1380
tgcctcacct tctacagcct ggagccccag acccagcccc tgtacacctt ccatgccctc 1440
ttcaaccagc ccctcacccc cgtcttctgg ctcctcgagg gtaggaccct gaccctgtgc 1500
catcagccag gggctgtgtt ccctctgggg ccccaggaag aggtgctcag ctga 1554
<210> 126
<211> 517
<212> PRT
<213> Homo sapiens
<400> 126
Met Ala Ala Gln Leu Leu Glu Glu Lys Leu Thr Cys Ala Ile Cys Leu
1 5 10 15
Gly Leu Tyr Gln Asp Pro Val Thr Leu Pro Cys Gly His Asn Phe Cys
20 25 30
Gly Ala Cys Ile Arg Asp Trp Trp Asp Arg Cys Gly Lys Ala Cys Pro
35 40 45
Glu Cys Arg Glu Pro Phe Pro Asp Gly Ala Glu Leu Arg Arg Asn Val
50 55 60
Ala Leu Ser Gly Val Leu Glu Val Val Arg Ala Gly Pro Ala Arg Asp
65 70 75 80
Pro Gly Pro Asp Pro Gly Pro Gly Pro Asp Pro Ala Ala Arg Cys Pro
85 90 95
Arg His Gly Arg Pro Leu Glu Leu Phe Cys Arg Thr Glu Gly Arg Cys
100 105 110
Val Cys Ser Val Cys Thr Val Arg Glu Cys Arg Leu His Glu Arg Ala
115 120 125
Leu Leu Asp Ala Glu Arg Leu Lys Arg Glu Ala Gln Leu Arg Ala Ser
130 135 140
Leu Glu Val Thr Gln Gln Gln Ala Thr Gln Ala Glu Gly Gln Leu Leu
145 150 155 160
Glu Leu Arg Lys Gln Ser Ser Gln Ile Gln Asn Ser Ala Cys Ile Leu
165 170 175
Ala Ser Trp Val Ser Gly Lys Phe Ser Ser Leu Leu Gln Ala Leu Glu
180 185 190
Ile Gln His Thr Thr Ala Leu Arg Ser Ile Glu Val Ala Lys Thr Gln
195 200 205
Ala Leu Ala Gln Ala Arg Asp Glu Glu Gln Arg Leu Arg Val His Leu
210 215 220
Glu Ala Val Ala Arg His Gly Cys Arg Ile Arg Glu Leu Leu Glu Gln
225 230 235 240
Val Asp Glu Gln Thr Phe Leu Gln Glu Ser Gln Leu Leu Gln Pro Pro
245 250 255
Gly Pro Leu Gly Pro Leu Thr Pro Leu Gln Trp Asp Glu Asp Gln Gln
260 265 270
Leu Gly Asp Leu Lys Gln Leu Leu Ser Arg Leu Cys Gly Leu Leu Leu
275 280 285
Glu Glu Gly Ser His Pro Gly Ala Pro Ala Lys Pro Val Asp Leu Ala
290 295 300
Pro Val Glu Ala Pro Gly Pro Leu Ala Pro Val Pro Ser Thr Val Cys
305 310 315 320
Pro Leu Arg Arg Lys Leu Trp Gln Asn Tyr Arg Asn Leu Thr Phe Asp
325 330 335
Pro Val Ser Ala Asn Arg His Phe Tyr Leu Ser Arg Gln Asp Gln Gln
340 345 350
Val Lys His Cys Arg Gln Ser Arg Gly Pro Gly Gly Pro Gly Ser Phe
355 360 365
Glu Leu Trp Gln Val Gln Cys Ala Gln Ser Phe Gln Ala Gly His His
370 375 380
Tyr Trp Glu Val Arg Ala Ser Asp His Ser Val Thr Leu Gly Val Ser
385 390 395 400
Tyr Pro Gln Leu Pro Arg Cys Arg Leu Gly Pro His Thr Asp Asn Ile
405 410 415
Gly Arg Gly Pro Cys Ser Trp Gly Leu Cys Val Gln Glu Asp Ser Leu
420 425 430
Gln Ala Trp His Asn Gly Glu Ala Gln Arg Leu Pro Gly Val Ser Gly
435 440 445
Arg Leu Leu Gly Met Asp Leu Asp Leu Ala Ser Gly Cys Leu Thr Phe
450 455 460
Tyr Ser Leu Glu Pro Gln Thr Gln Pro Leu Tyr Thr Phe His Ala Leu
465 470 475 480
Phe Asn Gln Pro Leu Thr Pro Val Phe Trp Leu Leu Glu Gly Arg Thr
485 490 495
Leu Thr Leu Cys His Gln Pro Gly Ala Val Phe Pro Leu Gly Pro Gln
500 505 510
Glu Glu Val Leu Ser
515
<210> 127
<211> 3651
<212> DNA
<213> Homo sapiens
<400> 127
atggccagga actgctctga gtgcaaggag aagagggcag cacatatcct ctgcacctac 60
tgcaatcgct ggctgtgcag ctcttgcaca gaggaacacc gacacagccc tgtccccggg 120
ggcccattct ttcctcgggc ccagaaggga tctccaggag tgaatggtgg tcccggagac 180
ttcaccttgt attgtcctct acacacacag gaagtactca agctattctg tgagacatgt 240
gatatgctca cttgccatag ctgcctagtg gtggaacaca aagaacacag gtgcagacat 300
gttgaagaag ttttgcaaaa ccagaggatg cttctggaag gtgtgactac acaggtggca 360
cataagaaat ccagtctaca gacatctgca aagcaaattg aggacaggat ttttgaagtg 420
aagcatcagc ataggaaggt ggaaaaccag atcaaaatgg ccaagatggt tctgatgaat 480
gagctgaaca aacaggccaa tgggctaata gaggaattag aggggattac taatgagaga 540
aagcggaagc tggaacagca gttacagagc atcatggttc tcaaccgtca gtttgagcat 600
gtgcagaatt tcatcaactg ggctgtctgc agcaaaacca gtgtcccttt tcttttcagc 660
aaagagctga ttgtgtttca gatgcagcga ttgctggaga caagttgtaa cacagatcct 720
ggctcccctt ggagtatcag attcacctgg gagcctaact tctggaccaa gcagctagct 780
tctcttggct gcataactac tgaaggtgga caaatgtcca gggcagatgc tcctgcttat 840
ggaggcttac aggggtcatc acccttttat caaagccacc agtctccagt ggctcagcaa 900
gaggctctta gccacccctc acacaagttc cagtctccag cagtgtgctc ctcatctgtg 960
tgctgctccc actgctcccc agtctcgcct tccctcaaag gccaggtccc cccacccagc 1020
atacacccag cccacagctt caggcagccc cctgagatgg tgccccagca gctggggtct 1080
ctgcagtgct ctgccctgct gcccagggag aaagagctgg cctgcagccc tcatccacca 1140
aagctgctgc agccctggct ggaaacccag ccccccgtgg agcaggagag cacatcccag 1200
cggctggggc agcagctgac ttcccagccc gtgtgcattg tccccccaca ggatgttcag 1260
caaggagccc atgcccagcc caccttacag acaccctcta tccaagtcca gtttggccac 1320
caccagaagc tgaagctcag tcactttcag cagcagccac agcagcagct accacctcca 1380
ccaccacccc tcccccatcc cccacctccc cttccccctc ccccacagca gccacaccca 1440
cctcttcctc catcccagca tctggcttct agtcagcacg agagccctcc tggccctgcc 1500
tgttctcaga acatggacat aatgcatcac aagtttgagc tggaggaaat gcagaaggac 1560
ttggagcttc ttctccaggc tcaacagccc agcctgcaac tgagtcagac caaatctcct 1620
cagcatcttc agcaaaccat tgtggggcag atcaactaca tcgtgaggca gccagcacct 1680
gtccagtccc agagccagga ggagaccctg caggctacag atgagccccc agcatctcag 1740
ggctcaaagc cggctctccc tcttgacaag aatactgctg ctgccttgcc ccaggcgtct 1800
ggggaagaaa cccctctcag tgtcccccca gtggacagca ccatccagca ctcctctcca 1860
aatgtggtga gaaagcactc cacctcgctg agcatcatgg gcttttccaa cactctggag 1920
atggagttgt catctaccag gttggagagg cccctagagc cacagatcca gagtgtgagc 1980
aacctgacag ctggtgcccc ccaggcagta ccaagcctgc tgagtgctcc ccccaaaatg 2040
gtgtccagcc tgacaagtgt tcaaaaccag gccatgccca gcctgacaac cagtcaccta 2100
cagactgtgc ccagccttgt gcatagcaca ttccagtcca tgcccaacct gataagtgac 2160
tcccctcagg ctatggcaag cctggcaagt gatcaccctc aggctgggcc cagcctaatg 2220
tctggtcaca cccaggctgt gccgagtctg gcaacttgtc ctctgcagag catccctcca 2280
gtttctgaca tgcagccaga aactgggtcc agctccagtt ctggccgaac ttcagggagc 2340
ctgtgtccca gagatggggc tgatccctcc ctggagaatg ctctgtgtaa ggtaaaactg 2400
gaggagccaa ttaacctctc tgtgaagaaa cctccactgg cgccagtggt cagcacgtct 2460
acagctctgc agcagtacca gaacccaaaa gagtgtgaga attttgaaca aggagcccta 2520
gagctggatg caaaagagaa ccagagcatc agagccttca atagtgagca taagattccc 2580
tatgtgcgac tggagcgact caagatctgt gctgcctcct caggagagat gcctgtgttc 2640
aaactgaagc cacagaagaa tgatcaggat gggagcttcc tgctgatcat cgagtgtggc 2700
actgagtcct ccagcatgtc cattaaggtc agccaggaca gactgtctga ggccacccag 2760
gccccaggtc tggagggaag aaaggtcact gtcacttctt tggctgggca gcggccacca 2820
gaagtggagg gcacatctcc tgaagaacac agactcattc ctcgaacccc aggagccaag 2880
aagggccccc cagccccaat agagaatgag gacttctgtg ctgtttgcct caatggcgga 2940
gagttactgt gctgtgaccg ctgccccaaa gtgttccacc tctcctgcca tgtgccagcc 3000
ttgctcagct tcccaggggg agagtgggtg tgtaccttgt gccgcagcct gacccagccc 3060
gagatggagt acgactgtga gaatgcctgc tataaccagc ctggaatgcg ggcatctcct 3120
ggcctaagca tgtatgacca gaagaagtgt gagaagctgg tattgtcctt gtgctgcaat 3180
aacctcagcc tgcccttcca tgaacctgtc agccccctgg cccggcatta ttaccagatt 3240
atcaagaggc ccatggacct gtcaatcatc cggaggaagc tgcaaaagaa ggacccagct 3300
cactatacca ccccagagga ggtggtatca gatgtgcgcc tcatgttctg gaactgtgct 3360
aagttcaatt atcctgactc cgaggttgca gaggctggcc gctgcctgga agtgttcttt 3420
gagggctggt tgaaggagat ctacccggag aaacggtttg cccagccaag gcaggaggac 3480
tcagactccg aggaggtgtc tagtgagagt ggatgttcca ctccccaggg cttcccgtgg 3540
cctccctaca tgcaggaggg catccaaccc aagaggcggc gacgacatat ggagaatgaa 3600
agagcaaaaa gaatgtcatt tcgcctggcc aacagcatct ctcaggtgtg a 3651
<210> 128
<211> 1216
<212> PRT
<213> Homo sapiens
<400> 128
Met Ala Arg Asn Cys Ser Glu Cys Lys Glu Lys Arg Ala Ala His Ile
1 5 10 15
Leu Cys Thr Tyr Cys Asn Arg Trp Leu Cys Ser Ser Cys Thr Glu Glu
20 25 30
His Arg His Ser Pro Val Pro Gly Gly Pro Phe Phe Pro Arg Ala Gln
35 40 45
Lys Gly Ser Pro Gly Val Asn Gly Gly Pro Gly Asp Phe Thr Leu Tyr
50 55 60
Cys Pro Leu His Thr Gln Glu Val Leu Lys Leu Phe Cys Glu Thr Cys
65 70 75 80
Asp Met Leu Thr Cys His Ser Cys Leu Val Val Glu His Lys Glu His
85 90 95
Arg Cys Arg His Val Glu Glu Val Leu Gln Asn Gln Arg Met Leu Leu
100 105 110
Glu Gly Val Thr Thr Gln Val Ala His Lys Lys Ser Ser Leu Gln Thr
115 120 125
Ser Ala Lys Gln Ile Glu Asp Arg Ile Phe Glu Val Lys His Gln His
130 135 140
Arg Lys Val Glu Asn Gln Ile Lys Met Ala Lys Met Val Leu Met Asn
145 150 155 160
Glu Leu Asn Lys Gln Ala Asn Gly Leu Ile Glu Glu Leu Glu Gly Ile
165 170 175
Thr Asn Glu Arg Lys Arg Lys Leu Glu Gln Gln Leu Gln Ser Ile Met
180 185 190
Val Leu Asn Arg Gln Phe Glu His Val Gln Asn Phe Ile Asn Trp Ala
195 200 205
Val Cys Ser Lys Thr Ser Val Pro Phe Leu Phe Ser Lys Glu Leu Ile
210 215 220
Val Phe Gln Met Gln Arg Leu Leu Glu Thr Ser Cys Asn Thr Asp Pro
225 230 235 240
Gly Ser Pro Trp Ser Ile Arg Phe Thr Trp Glu Pro Asn Phe Trp Thr
245 250 255
Lys Gln Leu Ala Ser Leu Gly Cys Ile Thr Thr Glu Gly Gly Gln Met
260 265 270
Ser Arg Ala Asp Ala Pro Ala Tyr Gly Gly Leu Gln Gly Ser Ser Pro
275 280 285
Phe Tyr Gln Ser His Gln Ser Pro Val Ala Gln Gln Glu Ala Leu Ser
290 295 300
His Pro Ser His Lys Phe Gln Ser Pro Ala Val Cys Ser Ser Ser Val
305 310 315 320
Cys Cys Ser His Cys Ser Pro Val Ser Pro Ser Leu Lys Gly Gln Val
325 330 335
Pro Pro Pro Ser Ile His Pro Ala His Ser Phe Arg Gln Pro Pro Glu
340 345 350
Met Val Pro Gln Gln Leu Gly Ser Leu Gln Cys Ser Ala Leu Leu Pro
355 360 365
Arg Glu Lys Glu Leu Ala Cys Ser Pro His Pro Pro Lys Leu Leu Gln
370 375 380
Pro Trp Leu Glu Thr Gln Pro Pro Val Glu Gln Glu Ser Thr Ser Gln
385 390 395 400
Arg Leu Gly Gln Gln Leu Thr Ser Gln Pro Val Cys Ile Val Pro Pro
405 410 415
Gln Asp Val Gln Gln Gly Ala His Ala Gln Pro Thr Leu Gln Thr Pro
420 425 430
Ser Ile Gln Val Gln Phe Gly His His Gln Lys Leu Lys Leu Ser His
435 440 445
Phe Gln Gln Gln Pro Gln Gln Gln Leu Pro Pro Pro Pro Pro Pro Leu
450 455 460
Pro His Pro Pro Pro Pro Leu Pro Pro Pro Pro Gln Gln Pro His Pro
465 470 475 480
Pro Leu Pro Pro Ser Gln His Leu Ala Ser Ser Gln His Glu Ser Pro
485 490 495
Pro Gly Pro Ala Cys Ser Gln Asn Met Asp Ile Met His His Lys Phe
500 505 510
Glu Leu Glu Glu Met Gln Lys Asp Leu Glu Leu Leu Leu Gln Ala Gln
515 520 525
Gln Pro Ser Leu Gln Leu Ser Gln Thr Lys Ser Pro Gln His Leu Gln
530 535 540
Gln Thr Ile Val Gly Gln Ile Asn Tyr Ile Val Arg Gln Pro Ala Pro
545 550 555 560
Val Gln Ser Gln Ser Gln Glu Glu Thr Leu Gln Ala Thr Asp Glu Pro
565 570 575
Pro Ala Ser Gln Gly Ser Lys Pro Ala Leu Pro Leu Asp Lys Asn Thr
580 585 590
Ala Ala Ala Leu Pro Gln Ala Ser Gly Glu Glu Thr Pro Leu Ser Val
595 600 605
Pro Pro Val Asp Ser Thr Ile Gln His Ser Ser Pro Asn Val Val Arg
610 615 620
Lys His Ser Thr Ser Leu Ser Ile Met Gly Phe Ser Asn Thr Leu Glu
625 630 635 640
Met Glu Leu Ser Ser Thr Arg Leu Glu Arg Pro Leu Glu Pro Gln Ile
645 650 655
Gln Ser Val Ser Asn Leu Thr Ala Gly Ala Pro Gln Ala Val Pro Ser
660 665 670
Leu Leu Ser Ala Pro Pro Lys Met Val Ser Ser Leu Thr Ser Val Gln
675 680 685
Asn Gln Ala Met Pro Ser Leu Thr Thr Ser His Leu Gln Thr Val Pro
690 695 700
Ser Leu Val His Ser Thr Phe Gln Ser Met Pro Asn Leu Ile Ser Asp
705 710 715 720
Ser Pro Gln Ala Met Ala Ser Leu Ala Ser Asp His Pro Gln Ala Gly
725 730 735
Pro Ser Leu Met Ser Gly His Thr Gln Ala Val Pro Ser Leu Ala Thr
740 745 750
Cys Pro Leu Gln Ser Ile Pro Pro Val Ser Asp Met Gln Pro Glu Thr
755 760 765
Gly Ser Ser Ser Ser Ser Gly Arg Thr Ser Gly Ser Leu Cys Pro Arg
770 775 780
Asp Gly Ala Asp Pro Ser Leu Glu Asn Ala Leu Cys Lys Val Lys Leu
785 790 795 800
Glu Glu Pro Ile Asn Leu Ser Val Lys Lys Pro Pro Leu Ala Pro Val
805 810 815
Val Ser Thr Ser Thr Ala Leu Gln Gln Tyr Gln Asn Pro Lys Glu Cys
820 825 830
Glu Asn Phe Glu Gln Gly Ala Leu Glu Leu Asp Ala Lys Glu Asn Gln
835 840 845
Ser Ile Arg Ala Phe Asn Ser Glu His Lys Ile Pro Tyr Val Arg Leu
850 855 860
Glu Arg Leu Lys Ile Cys Ala Ala Ser Ser Gly Glu Met Pro Val Phe
865 870 875 880
Lys Leu Lys Pro Gln Lys Asn Asp Gln Asp Gly Ser Phe Leu Leu Ile
885 890 895
Ile Glu Cys Gly Thr Glu Ser Ser Ser Met Ser Ile Lys Val Ser Gln
900 905 910
Asp Arg Leu Ser Glu Ala Thr Gln Ala Pro Gly Leu Glu Gly Arg Lys
915 920 925
Val Thr Val Thr Ser Leu Ala Gly Gln Arg Pro Pro Glu Val Glu Gly
930 935 940
Thr Ser Pro Glu Glu His Arg Leu Ile Pro Arg Thr Pro Gly Ala Lys
945 950 955 960
Lys Gly Pro Pro Ala Pro Ile Glu Asn Glu Asp Phe Cys Ala Val Cys
965 970 975
Leu Asn Gly Gly Glu Leu Leu Cys Cys Asp Arg Cys Pro Lys Val Phe
980 985 990
His Leu Ser Cys His Val Pro Ala Leu Leu Ser Phe Pro Gly Gly Glu
995 1000 1005
Trp Val Cys Thr Leu Cys Arg Ser Leu Thr Gln Pro Glu Met Glu
1010 1015 1020
Tyr Asp Cys Glu Asn Ala Cys Tyr Asn Gln Pro Gly Met Arg Ala
1025 1030 1035
Ser Pro Gly Leu Ser Met Tyr Asp Gln Lys Lys Cys Glu Lys Leu
1040 1045 1050
Val Leu Ser Leu Cys Cys Asn Asn Leu Ser Leu Pro Phe His Glu
1055 1060 1065
Pro Val Ser Pro Leu Ala Arg His Tyr Tyr Gln Ile Ile Lys Arg
1070 1075 1080
Pro Met Asp Leu Ser Ile Ile Arg Arg Lys Leu Gln Lys Lys Asp
1085 1090 1095
Pro Ala His Tyr Thr Thr Pro Glu Glu Val Val Ser Asp Val Arg
1100 1105 1110
Leu Met Phe Trp Asn Cys Ala Lys Phe Asn Tyr Pro Asp Ser Glu
1115 1120 1125
Val Ala Glu Ala Gly Arg Cys Leu Glu Val Phe Phe Glu Gly Trp
1130 1135 1140
Leu Lys Glu Ile Tyr Pro Glu Lys Arg Phe Ala Gln Pro Arg Gln
1145 1150 1155
Glu Asp Ser Asp Ser Glu Glu Val Ser Ser Glu Ser Gly Cys Ser
1160 1165 1170
Thr Pro Gln Gly Phe Pro Trp Pro Pro Tyr Met Gln Glu Gly Ile
1175 1180 1185
Gln Pro Lys Arg Arg Arg Arg His Met Glu Asn Glu Arg Ala Lys
1190 1195 1200
Arg Met Ser Phe Arg Leu Ala Asn Ser Ile Ser Gln Val
1205 1210 1215
<210> 129
<211> 2352
<212> DNA
<213> Homo sapiens
<400> 129
atggaggaag agctgaagtg tcccgtgtgc ggctctctgt ttcgggagcc tatcatcctg 60
ccctgttccc acaatgtctg cctgccttgc gctcgcacca tcgcggtgca gaccccggac 120
ggtgagcagc acctgcccca gccgctcctg ctttcccggg gatcggggct gcaggcgggc 180
gccgccgccg ctgcctctct ggagcacgac gctgcggctg gcccggcctg cggcggtgca 240
ggcgggagtg cagctggcgg cctcggcggc ggtgcgggag gtggcggaga ccacgcggac 300
aagctcagct tgtacagcga gacagacagc ggctacgggt cctacacccc gagcctcaag 360
tcccccaacg gggttcgcgt gctgcccatg gtgcccgcac cacccggctc ctcggctgcg 420
gcggctcggg gtgccgcctg ctcctcgctg tcctcgtctt cgagctccat cacgtgcccg 480
cagtgccacc gcagcgcatc cctggaccac cgcggcctgc gcggcttcca gcgcaaccgg 540
ctgctcgagg ccatcgtgca gcggtaccag cagggccgcg gggccgtgcc ggggacgtct 600
gcagccgcgg cggtggccat ctgccagctg tgcgaccgca ccccgccaga gccagcagcc 660
acgctctgcg agcagtgcga cgtcctctac tgctctgcct gccagctcaa gtgccatcca 720
tcccggggac ccttcgccaa gcatcgcctg gtgcagccgc cgccgccgcc gccgccgccc 780
gccgaggcag cctccgggcc cactggcacc gcccagggcg cccccagcgg aggcggcggc 840
tgcaagagcc cgggaggcgc gggggcgggg gcgactgggg gcagcacggc ccgcaagttc 900
cccacgtgtc ccgagcatga aatggagaac tacagcatgt actgcgtgag ctgtcgaacc 960
ccggtgtgtt atctgtgcct ggaggagggc cggcacgcca agcacgaggt gaagccgctg 1020
ggggccatgt ggaagcagca caaggcacaa ctatctcagg ccttaaatgg agtttcagat 1080
aaggcaaagg aagcaaagga gtttctggtt cagctaaaga acatattgca gcagatccag 1140
gaaaacggac tggactacga agcctgcctc gttgctcagt gtgatgccct tgtggatgct 1200
ttaactcgtc agaaagccaa gctgctcacc aaggtgacta aagagaggga acacaagttg 1260
aagatggttt gggaccagat caatcactgc acattgaagc tgcgtcagtc caccggactg 1320
atggagtact gcctggaggt gatcaaggag aacgacccct ccgggttctt acagatctca 1380
gatgctctga tcaagcgcgt ccaggtgtct caggagcagt gggtcaaagg cgccctggag 1440
ccgaaagtgt ctgcggagtt tgatctgact ttggacagcg agccgctgct gcaggccatc 1500
caccagctgg acttcattca gatgaaatgt agggtgccac ccgtccccct actgcagctg 1560
gagaaatgct gcacccgtaa caacagcgtc acgctggcct ggaggatgcc acccttcacc 1620
cacagccccg tggacggcta catcctggag ctggacgacg gtgccggggg acagttccgg 1680
gaagtgtacg tcggtaagga gactttgtgt accatcgacg gtcttcactt caacagcacc 1740
tacaacgccc gagtcaaagc tttcaactct tctggtgtcg ggccttacag taaaactgtc 1800
gtcctgcaga catccgatgt ggcctggttc acatttgacc ccaactctgg gcatcgggac 1860
atcattttat ccaatgacaa ccagacagcc acctgcagca gctatgacga ccgggtggtg 1920
ctgggcacag ctgcgttctc caagggcgtg cactactggg agctgcacgt ggaccggtac 1980
gacaaccacc cagaccccgc cttcggggtg gccagggcca gcgtggtcaa ggacatgatg 2040
ctgggcaagg atgacaaggc ctgggccatg tatgtggaca acaaccgcag ctggttcatg 2100
cactgcaact cccacaccaa caggacggaa ggtggcgtgt gcaagggggc caccgtgggc 2160
gtgctgctgg acctgaataa gcacactctc accttcttca tcaacgggca gcagcagggc 2220
cccacagcct tcagccacgt ggacggggtc ttcatgccag ccctcagcct caaccgcaac 2280
gtgcaggtca ccctgcacac aggattggaa gtgccgacta acctggggcg gccaaagctg 2340
tcaggcaatt ag 2352
<210> 130
<211> 783
<212> PRT
<213> Homo sapiens
<400> 130
Met Glu Glu Glu Leu Lys Cys Pro Val Cys Gly Ser Leu Phe Arg Glu
1 5 10 15
Pro Ile Ile Leu Pro Cys Ser His Asn Val Cys Leu Pro Cys Ala Arg
20 25 30
Thr Ile Ala Val Gln Thr Pro Asp Gly Glu Gln His Leu Pro Gln Pro
35 40 45
Leu Leu Leu Ser Arg Gly Ser Gly Leu Gln Ala Gly Ala Ala Ala Ala
50 55 60
Ala Ser Leu Glu His Asp Ala Ala Ala Gly Pro Ala Cys Gly Gly Ala
65 70 75 80
Gly Gly Ser Ala Ala Gly Gly Leu Gly Gly Gly Ala Gly Gly Gly Gly
85 90 95
Asp His Ala Asp Lys Leu Ser Leu Tyr Ser Glu Thr Asp Ser Gly Tyr
100 105 110
Gly Ser Tyr Thr Pro Ser Leu Lys Ser Pro Asn Gly Val Arg Val Leu
115 120 125
Pro Met Val Pro Ala Pro Pro Gly Ser Ser Ala Ala Ala Ala Arg Gly
130 135 140
Ala Ala Cys Ser Ser Leu Ser Ser Ser Ser Ser Ser Ile Thr Cys Pro
145 150 155 160
Gln Cys His Arg Ser Ala Ser Leu Asp His Arg Gly Leu Arg Gly Phe
165 170 175
Gln Arg Asn Arg Leu Leu Glu Ala Ile Val Gln Arg Tyr Gln Gln Gly
180 185 190
Arg Gly Ala Val Pro Gly Thr Ser Ala Ala Ala Ala Val Ala Ile Cys
195 200 205
Gln Leu Cys Asp Arg Thr Pro Pro Glu Pro Ala Ala Thr Leu Cys Glu
210 215 220
Gln Cys Asp Val Leu Tyr Cys Ser Ala Cys Gln Leu Lys Cys His Pro
225 230 235 240
Ser Arg Gly Pro Phe Ala Lys His Arg Leu Val Gln Pro Pro Pro Pro
245 250 255
Pro Pro Pro Pro Ala Glu Ala Ala Ser Gly Pro Thr Gly Thr Ala Gln
260 265 270
Gly Ala Pro Ser Gly Gly Gly Gly Cys Lys Ser Pro Gly Gly Ala Gly
275 280 285
Ala Gly Ala Thr Gly Gly Ser Thr Ala Arg Lys Phe Pro Thr Cys Pro
290 295 300
Glu His Glu Met Glu Asn Tyr Ser Met Tyr Cys Val Ser Cys Arg Thr
305 310 315 320
Pro Val Cys Tyr Leu Cys Leu Glu Glu Gly Arg His Ala Lys His Glu
325 330 335
Val Lys Pro Leu Gly Ala Met Trp Lys Gln His Lys Ala Gln Leu Ser
340 345 350
Gln Ala Leu Asn Gly Val Ser Asp Lys Ala Lys Glu Ala Lys Glu Phe
355 360 365
Leu Val Gln Leu Lys Asn Ile Leu Gln Gln Ile Gln Glu Asn Gly Leu
370 375 380
Asp Tyr Glu Ala Cys Leu Val Ala Gln Cys Asp Ala Leu Val Asp Ala
385 390 395 400
Leu Thr Arg Gln Lys Ala Lys Leu Leu Thr Lys Val Thr Lys Glu Arg
405 410 415
Glu His Lys Leu Lys Met Val Trp Asp Gln Ile Asn His Cys Thr Leu
420 425 430
Lys Leu Arg Gln Ser Thr Gly Leu Met Glu Tyr Cys Leu Glu Val Ile
435 440 445
Lys Glu Asn Asp Pro Ser Gly Phe Leu Gln Ile Ser Asp Ala Leu Ile
450 455 460
Lys Arg Val Gln Val Ser Gln Glu Gln Trp Val Lys Gly Ala Leu Glu
465 470 475 480
Pro Lys Val Ser Ala Glu Phe Asp Leu Thr Leu Asp Ser Glu Pro Leu
485 490 495
Leu Gln Ala Ile His Gln Leu Asp Phe Ile Gln Met Lys Cys Arg Val
500 505 510
Pro Pro Val Pro Leu Leu Gln Leu Glu Lys Cys Cys Thr Arg Asn Asn
515 520 525
Ser Val Thr Leu Ala Trp Arg Met Pro Pro Phe Thr His Ser Pro Val
530 535 540
Asp Gly Tyr Ile Leu Glu Leu Asp Asp Gly Ala Gly Gly Gln Phe Arg
545 550 555 560
Glu Val Tyr Val Gly Lys Glu Thr Leu Cys Thr Ile Asp Gly Leu His
565 570 575
Phe Asn Ser Thr Tyr Asn Ala Arg Val Lys Ala Phe Asn Ser Ser Gly
580 585 590
Val Gly Pro Tyr Ser Lys Thr Val Val Leu Gln Thr Ser Asp Val Ala
595 600 605
Trp Phe Thr Phe Asp Pro Asn Ser Gly His Arg Asp Ile Ile Leu Ser
610 615 620
Asn Asp Asn Gln Thr Ala Thr Cys Ser Ser Tyr Asp Asp Arg Val Val
625 630 635 640
Leu Gly Thr Ala Ala Phe Ser Lys Gly Val His Tyr Trp Glu Leu His
645 650 655
Val Asp Arg Tyr Asp Asn His Pro Asp Pro Ala Phe Gly Val Ala Arg
660 665 670
Ala Ser Val Val Lys Asp Met Met Leu Gly Lys Asp Asp Lys Ala Trp
675 680 685
Ala Met Tyr Val Asp Asn Asn Arg Ser Trp Phe Met His Cys Asn Ser
690 695 700
His Thr Asn Arg Thr Glu Gly Gly Val Cys Lys Gly Ala Thr Val Gly
705 710 715 720
Val Leu Leu Asp Leu Asn Lys His Thr Leu Thr Phe Phe Ile Asn Gly
725 730 735
Gln Gln Gln Gly Pro Thr Ala Phe Ser His Val Asp Gly Val Phe Met
740 745 750
Pro Ala Leu Ser Leu Asn Arg Asn Val Gln Val Thr Leu His Thr Gly
755 760 765
Leu Glu Val Pro Thr Asn Leu Gly Arg Pro Lys Leu Ser Gly Asn
770 775 780
<210> 131
<211> 1458
<212> DNA
<213> Homo sapiens
<400> 131
atggatccca cagccttggt ggaagccatt gtggaagaag tggcctgtcc catctgtatg 60
accttcctga gggagcccat gagcattgac tgtggccaca gcttctgcca cagctgtctc 120
tctggactct gggagatccc aggagaatcc cagaactggg gttacacctg tcccctctgt 180
cgagctcctg tccagccaag gaacctgcgg cctaattggc agctggccaa tgttgtagaa 240
aaagtccgtc tgctaaggct acatccagga atggggctga agggtgacct gtgtgagcgc 300
catggggaaa agctgaagat gttctgcaaa gaggatgtct tgataatgtg tgaggcctgc 360
agccagtccc cagagcatga ggcccacagt gttgtgccaa tggaggatgt tgcctgggag 420
tacaagtggg aacttcatga ggccctcgaa catctgaaga aagagcaaga agaggcctgg 480
aagcttgaag ttggtgaaag gaaacgaact gccacctgga agatacaggt ggaaacccga 540
aaacagagta ttgtatggga gtttgaaaaa taccagcgat tactagagaa aaagcagcca 600
ccacatcggc agctgggggc agaggtagca gcagctctgg ccagcctaca gcgggaggca 660
gcggagacca tgcagaaact ggagttgaac catagcgagc tcatccagca gagccaggtc 720
ctgtggagga tgattgcaga gttgaaagag aggtcgcaga ggcctgtccg ctggatgttg 780
caggatattc aggaagtgtt aaacaggagc aaatcttgga gcttgcagca gccagaacca 840
atctccctgg agttgaagac agattgccgt gtgctggggc taagagagat cctgaagact 900
tatgcagctg atgtgcgctt ggatccagat actgcttact cccgtctcat cgtgtctgag 960
gacagaaaac gtgtgcacta tggagacacc aaccagaaac tgccagacaa tcctgagaga 1020
ttttaccgct ataatatcgt cctgggaagc cagtgcatct cctcaggccg gcactactgg 1080
gaggtggagg tgggagacag gtctgagtgg ggcctgggag tatgtaagca aaatgtagac 1140
cggaaggagg tggtctactt atccccccac tatggattct gggtgataag gctgaggaag 1200
ggaaatgagt accgagcagg caccgatgag tacccaatcc tgtccttgcc ggtccctcct 1260
cgccgggtgg gaatcttcgt ggattatgag gcccatgaca tttctttcta caatgtgact 1320
gactgtggct cccacatctt cactttcccc cgctatccct tccctgggcg cctcctgccc 1380
tattttagtc cttgctacag cattggaacc aacaacactg ctcctctggc catctgctcc 1440
ctggatgggg aggactaa 1458
<210> 132
<211> 485
<212> PRT
<213> Homo sapiens
<400> 132
Met Asp Pro Thr Ala Leu Val Glu Ala Ile Val Glu Glu Val Ala Cys
1 5 10 15
Pro Ile Cys Met Thr Phe Leu Arg Glu Pro Met Ser Ile Asp Cys Gly
20 25 30
His Ser Phe Cys His Ser Cys Leu Ser Gly Leu Trp Glu Ile Pro Gly
35 40 45
Glu Ser Gln Asn Trp Gly Tyr Thr Cys Pro Leu Cys Arg Ala Pro Val
50 55 60
Gln Pro Arg Asn Leu Arg Pro Asn Trp Gln Leu Ala Asn Val Val Glu
65 70 75 80
Lys Val Arg Leu Leu Arg Leu His Pro Gly Met Gly Leu Lys Gly Asp
85 90 95
Leu Cys Glu Arg His Gly Glu Lys Leu Lys Met Phe Cys Lys Glu Asp
100 105 110
Val Leu Ile Met Cys Glu Ala Cys Ser Gln Ser Pro Glu His Glu Ala
115 120 125
His Ser Val Val Pro Met Glu Asp Val Ala Trp Glu Tyr Lys Trp Glu
130 135 140
Leu His Glu Ala Leu Glu His Leu Lys Lys Glu Gln Glu Glu Ala Trp
145 150 155 160
Lys Leu Glu Val Gly Glu Arg Lys Arg Thr Ala Thr Trp Lys Ile Gln
165 170 175
Val Glu Thr Arg Lys Gln Ser Ile Val Trp Glu Phe Glu Lys Tyr Gln
180 185 190
Arg Leu Leu Glu Lys Lys Gln Pro Pro His Arg Gln Leu Gly Ala Glu
195 200 205
Val Ala Ala Ala Leu Ala Ser Leu Gln Arg Glu Ala Ala Glu Thr Met
210 215 220
Gln Lys Leu Glu Leu Asn His Ser Glu Leu Ile Gln Gln Ser Gln Val
225 230 235 240
Leu Trp Arg Met Ile Ala Glu Leu Lys Glu Arg Ser Gln Arg Pro Val
245 250 255
Arg Trp Met Leu Gln Asp Ile Gln Glu Val Leu Asn Arg Ser Lys Ser
260 265 270
Trp Ser Leu Gln Gln Pro Glu Pro Ile Ser Leu Glu Leu Lys Thr Asp
275 280 285
Cys Arg Val Leu Gly Leu Arg Glu Ile Leu Lys Thr Tyr Ala Ala Asp
290 295 300
Val Arg Leu Asp Pro Asp Thr Ala Tyr Ser Arg Leu Ile Val Ser Glu
305 310 315 320
Asp Arg Lys Arg Val His Tyr Gly Asp Thr Asn Gln Lys Leu Pro Asp
325 330 335
Asn Pro Glu Arg Phe Tyr Arg Tyr Asn Ile Val Leu Gly Ser Gln Cys
340 345 350
Ile Ser Ser Gly Arg His Tyr Trp Glu Val Glu Val Gly Asp Arg Ser
355 360 365
Glu Trp Gly Leu Gly Val Cys Lys Gln Asn Val Asp Arg Lys Glu Val
370 375 380
Val Tyr Leu Ser Pro His Tyr Gly Phe Trp Val Ile Arg Leu Arg Lys
385 390 395 400
Gly Asn Glu Tyr Arg Ala Gly Thr Asp Glu Tyr Pro Ile Leu Ser Leu
405 410 415
Pro Val Pro Pro Arg Arg Val Gly Ile Phe Val Asp Tyr Glu Ala His
420 425 430
Asp Ile Ser Phe Tyr Asn Val Thr Asp Cys Gly Ser His Ile Phe Thr
435 440 445
Phe Pro Arg Tyr Pro Phe Pro Gly Arg Leu Leu Pro Tyr Phe Ser Pro
450 455 460
Cys Tyr Ser Ile Gly Thr Asn Asn Thr Ala Pro Leu Ala Ile Cys Ser
465 470 475 480
Leu Asp Gly Glu Asp
485
<210> 133
<211> 1026
<212> DNA
<213> Homo sapiens
<400> 133
atggaggagg agcttgccat ccaacagggt caactggaga caactctgaa ggagcttcag 60
accctgagga acatgcagaa ggaagctatt gctgctcaca aggaaaacaa gctacatctg 120
cagcaacatg tgtccatgga gtttctaaag ctgcatcagt tcctgcacag caaagaaaag 180
gacattttaa ctgagctccg ggaagagggg aaagccttga atgaggagat ggagttgaat 240
ctgagccagc ttcaggagca atgtctctta gccaaggata tgttggtgag cattcaggca 300
aagacggaac aacagaactc cttcgacttt ctcaaagaca tcacaactct cttacatagc 360
ttggagcaag gaatgaaggt gctggcaacc agagagctta tttccagaaa gctgaacctg 420
ggccagtaca aaggtcctat ccagtacatg gtatggaggg aaatgcagga cactctctgc 480
ccaggcctgt ctccactaac tctggaccct aaaacagctc acccaaatct ggtgctctcc 540
aaaagccaaa ccagcgtctg gcatggtgac attaagaaga taatgcctga tgatcctgag 600
aggtttgact caagtgtggc tgtactgggc tcaagaggct tcacctctgg aaagtggtac 660
tgggaagtag aagtagcaaa gaagacaaaa tggacagttg gagttgtcag agaatccatc 720
attcggaagg gcagctgtcc tctaactcct gagcaaggat tctggctttt aagactaagg 780
aaccaaactg atctaaaggc tctggatttg ccttctttca gtctgacact gactaacaac 840
ctcgacaagg tgggcatata cctggattat gaaggaggac agttgtcctt ctacaatgct 900
aaaaccatga ctcacattta caccttcagt aacactttca tggagaaact ttatccctac 960
ttctgcccct gccttaatga tggtggagag aataaagaac cattgcacat cttacatcca 1020
cagtaa 1026
<210> 134
<211> 341
<212> PRT
<213> Homo sapiens
<400> 134
Met Glu Glu Glu Leu Ala Ile Gln Gln Gly Gln Leu Glu Thr Thr Leu
1 5 10 15
Lys Glu Leu Gln Thr Leu Arg Asn Met Gln Lys Glu Ala Ile Ala Ala
20 25 30
His Lys Glu Asn Lys Leu His Leu Gln Gln His Val Ser Met Glu Phe
35 40 45
Leu Lys Leu His Gln Phe Leu His Ser Lys Glu Lys Asp Ile Leu Thr
50 55 60
Glu Leu Arg Glu Glu Gly Lys Ala Leu Asn Glu Glu Met Glu Leu Asn
65 70 75 80
Leu Ser Gln Leu Gln Glu Gln Cys Leu Leu Ala Lys Asp Met Leu Val
85 90 95
Ser Ile Gln Ala Lys Thr Glu Gln Gln Asn Ser Phe Asp Phe Leu Lys
100 105 110
Asp Ile Thr Thr Leu Leu His Ser Leu Glu Gln Gly Met Lys Val Leu
115 120 125
Ala Thr Arg Glu Leu Ile Ser Arg Lys Leu Asn Leu Gly Gln Tyr Lys
130 135 140
Gly Pro Ile Gln Tyr Met Val Trp Arg Glu Met Gln Asp Thr Leu Cys
145 150 155 160
Pro Gly Leu Ser Pro Leu Thr Leu Asp Pro Lys Thr Ala His Pro Asn
165 170 175
Leu Val Leu Ser Lys Ser Gln Thr Ser Val Trp His Gly Asp Ile Lys
180 185 190
Lys Ile Met Pro Asp Asp Pro Glu Arg Phe Asp Ser Ser Val Ala Val
195 200 205
Leu Gly Ser Arg Gly Phe Thr Ser Gly Lys Trp Tyr Trp Glu Val Glu
210 215 220
Val Ala Lys Lys Thr Lys Trp Thr Val Gly Val Val Arg Glu Ser Ile
225 230 235 240
Ile Arg Lys Gly Ser Cys Pro Leu Thr Pro Glu Gln Gly Phe Trp Leu
245 250 255
Leu Arg Leu Arg Asn Gln Thr Asp Leu Lys Ala Leu Asp Leu Pro Ser
260 265 270
Phe Ser Leu Thr Leu Thr Asn Asn Leu Asp Lys Val Gly Ile Tyr Leu
275 280 285
Asp Tyr Glu Gly Gly Gln Leu Ser Phe Tyr Asn Ala Lys Thr Met Thr
290 295 300
His Ile Tyr Thr Phe Ser Asn Thr Phe Met Glu Lys Leu Tyr Pro Tyr
305 310 315 320
Phe Cys Pro Cys Leu Asn Asp Gly Gly Glu Asn Lys Glu Pro Leu His
325 330 335
Ile Leu His Pro Gln
340
<210> 135
<211> 1047
<212> DNA
<213> Homo sapiens
<400> 135
atgcagtttg gggaactcct tgctgctgtg aggaaggccc aggccaatgt gatgctcttc 60
ttagaggaga aggagcaagc tgcgctgagc caggccaacg gtatcaaggc ccacctggag 120
tacaggagtg ccgagatgga gaagagtaag caggagctgg agacgatggc ggccatcagc 180
aacactgtcc agttcttgga ggagtactgc aagtttaaga acactgaaga catcaccttc 240
cctagtgttt acatagggct gaaggataaa ctctcgggca tccgcaaagt tatcacggaa 300
tccactgtac acttaatcca gttgctggag aactataaga aaaagctcca ggagttttcc 360
aaggaagagg agtatgacat cagaactcaa gtgtctgcca ttgttcagcg caaatattgg 420
acttccaaac ctgagcccag caccagggaa cagttcctcc aatatgtgca tgacatcacg 480
ttcgacccgg acacagcaca caagtatctc cggctgcagg aggagaaccg caaggtcacc 540
aacaccacgc cctgggagca tccctacccg gacctcccca gcaggttcct gcactggcgg 600
caggtgctgt cccagcagag tctgtacctg cacaggtact attttgaggt ggagatcttc 660
ggggcaggca cctatgttgg cctgacctgc aaaggcatcg accagaaagg ggaggagcgc 720
agcagttgca tttccggaaa caacttctcc tggagcctcc aatggaacgg gaaggagttc 780
acggcctggt acagtgacat ggagacccca ctcaaagctg gccctttctg gaggctcggg 840
gtctatattg acttcccagg agggatcctt tccttctatg gcgtagagta tgattccatg 900
actctggttc acaagtttgc ctgcaagttt tcagaaccag tctatgctgc cttctggctt 960
tccaagaagg aaaacgccat ccggattgta gatctgggag aggaacccga gaagccagca 1020
ccgtccttgg tggggactgc tccctag 1047
<210> 136
<211> 348
<212> PRT
<213> Homo sapiens
<400> 136
Met Gln Phe Gly Glu Leu Leu Ala Ala Val Arg Lys Ala Gln Ala Asn
1 5 10 15
Val Met Leu Phe Leu Glu Glu Lys Glu Gln Ala Ala Leu Ser Gln Ala
20 25 30
Asn Gly Ile Lys Ala His Leu Glu Tyr Arg Ser Ala Glu Met Glu Lys
35 40 45
Ser Lys Gln Glu Leu Glu Thr Met Ala Ala Ile Ser Asn Thr Val Gln
50 55 60
Phe Leu Glu Glu Tyr Cys Lys Phe Lys Asn Thr Glu Asp Ile Thr Phe
65 70 75 80
Pro Ser Val Tyr Ile Gly Leu Lys Asp Lys Leu Ser Gly Ile Arg Lys
85 90 95
Val Ile Thr Glu Ser Thr Val His Leu Ile Gln Leu Leu Glu Asn Tyr
100 105 110
Lys Lys Lys Leu Gln Glu Phe Ser Lys Glu Glu Glu Tyr Asp Ile Arg
115 120 125
Thr Gln Val Ser Ala Ile Val Gln Arg Lys Tyr Trp Thr Ser Lys Pro
130 135 140
Glu Pro Ser Thr Arg Glu Gln Phe Leu Gln Tyr Val His Asp Ile Thr
145 150 155 160
Phe Asp Pro Asp Thr Ala His Lys Tyr Leu Arg Leu Gln Glu Glu Asn
165 170 175
Arg Lys Val Thr Asn Thr Thr Pro Trp Glu His Pro Tyr Pro Asp Leu
180 185 190
Pro Ser Arg Phe Leu His Trp Arg Gln Val Leu Ser Gln Gln Ser Leu
195 200 205
Tyr Leu His Arg Tyr Tyr Phe Glu Val Glu Ile Phe Gly Ala Gly Thr
210 215 220
Tyr Val Gly Leu Thr Cys Lys Gly Ile Asp Gln Lys Gly Glu Glu Arg
225 230 235 240
Ser Ser Cys Ile Ser Gly Asn Asn Phe Ser Trp Ser Leu Gln Trp Asn
245 250 255
Gly Lys Glu Phe Thr Ala Trp Tyr Ser Asp Met Glu Thr Pro Leu Lys
260 265 270
Ala Gly Pro Phe Trp Arg Leu Gly Val Tyr Ile Asp Phe Pro Gly Gly
275 280 285
Ile Leu Ser Phe Tyr Gly Val Glu Tyr Asp Ser Met Thr Leu Val His
290 295 300
Lys Phe Ala Cys Lys Phe Ser Glu Pro Val Tyr Ala Ala Phe Trp Leu
305 310 315 320
Ser Lys Lys Glu Asn Ala Ile Arg Ile Val Asp Leu Gly Glu Glu Pro
325 330 335
Glu Lys Pro Ala Pro Ser Leu Val Gly Thr Ala Pro
340 345
<210> 137
<211> 2607
<212> DNA
<213> Homo sapiens
<400> 137
atggcttcgt tccccgagac cgatttccag atctgcttgc tgtgcaagga gatgtgcggc 60
tcgccggcgc cgctctcctc caactcgtcc gcgtcgtcgt cctcctcgca gacgtccacg 120
tcgtcggggg gcggcggcgg gggccctggg gcggcggcgc gccgcctaca cgtcctgccc 180
tgcctgcacg ccttctgccg cccctgcctc gaggcgcacc ggctgccggc ggcgggcggc 240
ggcgcggcgg gagagccgct caagctgcgc tgccccgtgt gcgaccagaa agtagtgcta 300
gccgaggcgg cgggtatgga cgcgctgcct tcgtccgcct tcctgcttag caacctgctc 360
gacgcggtgg tggccactgc cgacgagccg ccgcccaaga acgggcgcgc cggcgctccg 420
gcgggagcgg gcggccacag caaccaccgg caccacgctc accacgcgca cccgcgcgcg 480
tccgcctccg cgccgccact cccgcaggcg ccgcagccgc ccgcgccttc ccgctcggca 540
cccggcggcc ctgccgcttc cccgtcggcg ctgctgctcc gccgtcctca cggctgcagc 600
tcgtgcgatg agggcaacgc agcttcttcg cgctgcctcg actgccagga gcacctgtgc 660
gacaactgcg tccgagcgca ccagcgcgtg cgcctcacca aggaccacta catcgagcgc 720
ggcccgccgg gtcccggtgc cgcagcagcg gcgcagcagc tcgggctcgg gccgcccttt 780
cccggcccgc ccttctccat cctctcagtg tttcccgagc gcctcggctt ctgccagcac 840
cacgacgacg aggtgctgca cctgtactgt gacacttgct ctgtacccat ctgtcgtgag 900
tgcacaatgg gccggcatgg gggccacagc ttcatctacc tccaggaggc actgcaggac 960
tcacgggcac tcaccatcca gctgctggca gatgcccagc agggacgaca ggcaatccag 1020
ctgagcatcg agcaggccca gacggtggcg gaacaggtgg agatgaaggc gaaggttgtg 1080
cagtcggagg tcaaagccgt gacggcgagg cataagaaag ccctggagga acgcgagtgt 1140
gagctgctgt ggaaggtaga aaagatccgc caggtgaaag ccaagtctct gtacctgcag 1200
gtggagaagc tgcggcaaaa cctcaacaag cttgagagca ccatcagtgc cgtgcagcag 1260
gtcctggagg agggtagagc gctagacatc ctactggccc gagaccggat gctggcccag 1320
gtgcaggagc tgaagaccgt gcggagcctc ctgcagcccc aggaagacga ccgagtcatg 1380
ttcacacccc ccgatcaggc actgtacctt gccatcaagt cttttggctt tgttagcagc 1440
ggggcctttg ccccactcac caaggccaca ggcgatggcc tcaagcgtgc cctccagggt 1500
aaggtggcct ccttcacagt cattggttat gaccacgatg gtgagccccg cctctcagga 1560
ggcgacctga tgtcggctgt ggtcctgggc cctgatggca acctgtttgg tgcagaggtg 1620
agtgatcagc agaatgggac atacgtggtg agttaccgac cccagctgga gggtgagcac 1680
ctggtatctg tgacactgtg caaccagcac attgagaaca gccctttcaa ggtggtggtc 1740
aagtcaggcc gcagctacgt gggcattggg ctcccgggcc tgagcttcgg cagtgagggt 1800
gacagcgatg gcaagctctg ccgcccttgg ggtgtgagtg tagacaagga gggctacatc 1860
attgtcgccg accgcagcaa caaccgcatc caggtgttca agccctgcgg cgccttccac 1920
cacaaattcg gcaccctggg ctcccggcct gggcagttcg accgaccagc cggcgtggcc 1980
tgtgacgcct cacgcaggat cgtggtggct gacaaggaca atcatcgcat ccagatcttc 2040
acgttcgagg gccagttcct cctcaagttt ggtgagaaag gaaccaagaa tgggcagttc 2100
aactaccctt gggatgtggc ggtgaattct gagggcaaga tcctggtctc agacacgagg 2160
aaccaccgga tccagctgtt tgggcctgat ggtgtcttcc taaacaagta tggcttcgag 2220
ggggctctct ggaagcactt tgactcccca cggggtgtgg ccttcaacca tgagggccac 2280
ttggtggtca ctgacttcaa caaccaccgg ctcctggtta ttcaccccga ctgccagtcg 2340
gcacgctttc tgggctcgga gggcacaggc aatgggcagt tcctgcgccc acaaggggta 2400
gctgtggacc aggaagggcg catcattgtg gcggattcca ggaaccatcg ggtacagatg 2460
tttgaatcca acggcagctt cctgtgcaag tttggtgctc aaggcagcgg ctttgggcag 2520
atggaccgcc cttccggcat cgccatcacc cccgacggaa tgatcgttgt ggtggacttt 2580
ggcaacaatc gaatcctcgt cttctaa 2607
<210> 138
<211> 868
<212> PRT
<213> Homo sapiens
<400> 138
Met Ala Ser Phe Pro Glu Thr Asp Phe Gln Ile Cys Leu Leu Cys Lys
1 5 10 15
Glu Met Cys Gly Ser Pro Ala Pro Leu Ser Ser Asn Ser Ser Ala Ser
20 25 30
Ser Ser Ser Ser Gln Thr Ser Thr Ser Ser Gly Gly Gly Gly Gly Gly
35 40 45
Pro Gly Ala Ala Ala Arg Arg Leu His Val Leu Pro Cys Leu His Ala
50 55 60
Phe Cys Arg Pro Cys Leu Glu Ala His Arg Leu Pro Ala Ala Gly Gly
65 70 75 80
Gly Ala Ala Gly Glu Pro Leu Lys Leu Arg Cys Pro Val Cys Asp Gln
85 90 95
Lys Val Val Leu Ala Glu Ala Ala Gly Met Asp Ala Leu Pro Ser Ser
100 105 110
Ala Phe Leu Leu Ser Asn Leu Leu Asp Ala Val Val Ala Thr Ala Asp
115 120 125
Glu Pro Pro Pro Lys Asn Gly Arg Ala Gly Ala Pro Ala Gly Ala Gly
130 135 140
Gly His Ser Asn His Arg His His Ala His His Ala His Pro Arg Ala
145 150 155 160
Ser Ala Ser Ala Pro Pro Leu Pro Gln Ala Pro Gln Pro Pro Ala Pro
165 170 175
Ser Arg Ser Ala Pro Gly Gly Pro Ala Ala Ser Pro Ser Ala Leu Leu
180 185 190
Leu Arg Arg Pro His Gly Cys Ser Ser Cys Asp Glu Gly Asn Ala Ala
195 200 205
Ser Ser Arg Cys Leu Asp Cys Gln Glu His Leu Cys Asp Asn Cys Val
210 215 220
Arg Ala His Gln Arg Val Arg Leu Thr Lys Asp His Tyr Ile Glu Arg
225 230 235 240
Gly Pro Pro Gly Pro Gly Ala Ala Ala Ala Ala Gln Gln Leu Gly Leu
245 250 255
Gly Pro Pro Phe Pro Gly Pro Pro Phe Ser Ile Leu Ser Val Phe Pro
260 265 270
Glu Arg Leu Gly Phe Cys Gln His His Asp Asp Glu Val Leu His Leu
275 280 285
Tyr Cys Asp Thr Cys Ser Val Pro Ile Cys Arg Glu Cys Thr Met Gly
290 295 300
Arg His Gly Gly His Ser Phe Ile Tyr Leu Gln Glu Ala Leu Gln Asp
305 310 315 320
Ser Arg Ala Leu Thr Ile Gln Leu Leu Ala Asp Ala Gln Gln Gly Arg
325 330 335
Gln Ala Ile Gln Leu Ser Ile Glu Gln Ala Gln Thr Val Ala Glu Gln
340 345 350
Val Glu Met Lys Ala Lys Val Val Gln Ser Glu Val Lys Ala Val Thr
355 360 365
Ala Arg His Lys Lys Ala Leu Glu Glu Arg Glu Cys Glu Leu Leu Trp
370 375 380
Lys Val Glu Lys Ile Arg Gln Val Lys Ala Lys Ser Leu Tyr Leu Gln
385 390 395 400
Val Glu Lys Leu Arg Gln Asn Leu Asn Lys Leu Glu Ser Thr Ile Ser
405 410 415
Ala Val Gln Gln Val Leu Glu Glu Gly Arg Ala Leu Asp Ile Leu Leu
420 425 430
Ala Arg Asp Arg Met Leu Ala Gln Val Gln Glu Leu Lys Thr Val Arg
435 440 445
Ser Leu Leu Gln Pro Gln Glu Asp Asp Arg Val Met Phe Thr Pro Pro
450 455 460
Asp Gln Ala Leu Tyr Leu Ala Ile Lys Ser Phe Gly Phe Val Ser Ser
465 470 475 480
Gly Ala Phe Ala Pro Leu Thr Lys Ala Thr Gly Asp Gly Leu Lys Arg
485 490 495
Ala Leu Gln Gly Lys Val Ala Ser Phe Thr Val Ile Gly Tyr Asp His
500 505 510
Asp Gly Glu Pro Arg Leu Ser Gly Gly Asp Leu Met Ser Ala Val Val
515 520 525
Leu Gly Pro Asp Gly Asn Leu Phe Gly Ala Glu Val Ser Asp Gln Gln
530 535 540
Asn Gly Thr Tyr Val Val Ser Tyr Arg Pro Gln Leu Glu Gly Glu His
545 550 555 560
Leu Val Ser Val Thr Leu Cys Asn Gln His Ile Glu Asn Ser Pro Phe
565 570 575
Lys Val Val Val Lys Ser Gly Arg Ser Tyr Val Gly Ile Gly Leu Pro
580 585 590
Gly Leu Ser Phe Gly Ser Glu Gly Asp Ser Asp Gly Lys Leu Cys Arg
595 600 605
Pro Trp Gly Val Ser Val Asp Lys Glu Gly Tyr Ile Ile Val Ala Asp
610 615 620
Arg Ser Asn Asn Arg Ile Gln Val Phe Lys Pro Cys Gly Ala Phe His
625 630 635 640
His Lys Phe Gly Thr Leu Gly Ser Arg Pro Gly Gln Phe Asp Arg Pro
645 650 655
Ala Gly Val Ala Cys Asp Ala Ser Arg Arg Ile Val Val Ala Asp Lys
660 665 670
Asp Asn His Arg Ile Gln Ile Phe Thr Phe Glu Gly Gln Phe Leu Leu
675 680 685
Lys Phe Gly Glu Lys Gly Thr Lys Asn Gly Gln Phe Asn Tyr Pro Trp
690 695 700
Asp Val Ala Val Asn Ser Glu Gly Lys Ile Leu Val Ser Asp Thr Arg
705 710 715 720
Asn His Arg Ile Gln Leu Phe Gly Pro Asp Gly Val Phe Leu Asn Lys
725 730 735
Tyr Gly Phe Glu Gly Ala Leu Trp Lys His Phe Asp Ser Pro Arg Gly
740 745 750
Val Ala Phe Asn His Glu Gly His Leu Val Val Thr Asp Phe Asn Asn
755 760 765
His Arg Leu Leu Val Ile His Pro Asp Cys Gln Ser Ala Arg Phe Leu
770 775 780
Gly Ser Glu Gly Thr Gly Asn Gly Gln Phe Leu Arg Pro Gln Gly Val
785 790 795 800
Ala Val Asp Gln Glu Gly Arg Ile Ile Val Ala Asp Ser Arg Asn His
805 810 815
Arg Val Gln Met Phe Glu Ser Asn Gly Ser Phe Leu Cys Lys Phe Gly
820 825 830
Ala Gln Gly Ser Gly Phe Gly Gln Met Asp Arg Pro Ser Gly Ile Ala
835 840 845
Ile Thr Pro Asp Gly Met Ile Val Val Val Asp Phe Gly Asn Asn Arg
850 855 860
Ile Leu Val Phe
865
<210> 139
<211> 1434
<212> DNA
<213> Homo sapiens
<400> 139
atgtcggctg cgcccggcct cctgcaccag gagctgtcct gcccgctgtg cctgcagctg 60
ttcgacgcgc ccgtgacagc cgagtgcggc cacagtttct gccgcgcctg cctaggccgc 120
gtggccgggg agccggcggc ggatggcacc gttctctgcc cctgctgcca ggcccccacg 180
cggccgcagg cactcagcac caacctgcag ctggcgcgcc tggtggaggg gctggcccag 240
gtgccgcagg gccactgcga ggagcacctg gacccgctga gcatctactg cgagcaggac 300
cgcgcgctgg tgtgcggagt gtgcgcctca ctcggctcgc accgcggtca tcgcctcctg 360
cctgccgccg aggcccacgc acgcctcaag acacagctgc cacagcagaa actgcagctg 420
caggaggcat gcatgcgcaa ggagaagagt gtggctgtgc tggagcatca gctggtggag 480
gtggaggaga cagtgcgtca gttccggggg gccgtggggg agcagctggg caagatgcgg 540
gtgttcctgg ctgcactgga gggctccttg gaccgcgagg cagagcgtgt acggggtgag 600
gcaggggtcg ccttgcgccg ggagctgggg agcctgaact cttacctgga gcagctgcgg 660
cagatggaga aggtcctgga ggaggtggcg gacaagccgc agactgagtt cctcatgaaa 720
tactgcctgg tgaccagcag gctgcagaag atcctggcag agtctccccc acccgcccgt 780
ctggacatcc agctgccaat tatctcagat gacttcaaat tccaggtgtg gaggaagatg 840
ttccgggctc tgatgccagc gctggaggag ctgacctttg acccgagctc tgcgcacccg 900
agcctggtgg tgtcttcctc tggccgccgc gtggagtgct cggagcagaa ggcgccgccg 960
gccggggagg acccgcgcca gttcgacaag gcggtggcgg tggtggcgca ccagcagctc 1020
tccgagggcg agcactactg ggaggtggat gttggcgaca agccgcgctg ggcgctgggc 1080
gtgatcgcgg ccgaggcccc ccgccgcggg cgcctgcacg cggtgccctc gcagggcctg 1140
tggctgctgg ggctgcgcga gggcaagatc ctggaggcac acgtggaggc caaggagccg 1200
cgcgctctgc gcagccccga gaggcggccc acgcgcattg gcctttacct gagcttcggc 1260
gacggcgtcc tctccttcta cgatgccagc gacgccgacg cgctcgtgcc gctttttgcc 1320
ttccacgagc gcctgcccag gcccgtgtac cccttcttcg acgtgtgctg gcacgacaag 1380
ggcaagaatg cccagccgct gctgctcgtg ggtcccgaag gcgccgaggc ctga 1434
<210> 140
<211> 477
<212> PRT
<213> Homo sapiens
<400> 140
Met Ser Ala Ala Pro Gly Leu Leu His Gln Glu Leu Ser Cys Pro Leu
1 5 10 15
Cys Leu Gln Leu Phe Asp Ala Pro Val Thr Ala Glu Cys Gly His Ser
20 25 30
Phe Cys Arg Ala Cys Leu Gly Arg Val Ala Gly Glu Pro Ala Ala Asp
35 40 45
Gly Thr Val Leu Cys Pro Cys Cys Gln Ala Pro Thr Arg Pro Gln Ala
50 55 60
Leu Ser Thr Asn Leu Gln Leu Ala Arg Leu Val Glu Gly Leu Ala Gln
65 70 75 80
Val Pro Gln Gly His Cys Glu Glu His Leu Asp Pro Leu Ser Ile Tyr
85 90 95
Cys Glu Gln Asp Arg Ala Leu Val Cys Gly Val Cys Ala Ser Leu Gly
100 105 110
Ser His Arg Gly His Arg Leu Leu Pro Ala Ala Glu Ala His Ala Arg
115 120 125
Leu Lys Thr Gln Leu Pro Gln Gln Lys Leu Gln Leu Gln Glu Ala Cys
130 135 140
Met Arg Lys Glu Lys Ser Val Ala Val Leu Glu His Gln Leu Val Glu
145 150 155 160
Val Glu Glu Thr Val Arg Gln Phe Arg Gly Ala Val Gly Glu Gln Leu
165 170 175
Gly Lys Met Arg Val Phe Leu Ala Ala Leu Glu Gly Ser Leu Asp Arg
180 185 190
Glu Ala Glu Arg Val Arg Gly Glu Ala Gly Val Ala Leu Arg Arg Glu
195 200 205
Leu Gly Ser Leu Asn Ser Tyr Leu Glu Gln Leu Arg Gln Met Glu Lys
210 215 220
Val Leu Glu Glu Val Ala Asp Lys Pro Gln Thr Glu Phe Leu Met Lys
225 230 235 240
Tyr Cys Leu Val Thr Ser Arg Leu Gln Lys Ile Leu Ala Glu Ser Pro
245 250 255
Pro Pro Ala Arg Leu Asp Ile Gln Leu Pro Ile Ile Ser Asp Asp Phe
260 265 270
Lys Phe Gln Val Trp Arg Lys Met Phe Arg Ala Leu Met Pro Ala Leu
275 280 285
Glu Glu Leu Thr Phe Asp Pro Ser Ser Ala His Pro Ser Leu Val Val
290 295 300
Ser Ser Ser Gly Arg Arg Val Glu Cys Ser Glu Gln Lys Ala Pro Pro
305 310 315 320
Ala Gly Glu Asp Pro Arg Gln Phe Asp Lys Ala Val Ala Val Val Ala
325 330 335
His Gln Gln Leu Ser Glu Gly Glu His Tyr Trp Glu Val Asp Val Gly
340 345 350
Asp Lys Pro Arg Trp Ala Leu Gly Val Ile Ala Ala Glu Ala Pro Arg
355 360 365
Arg Gly Arg Leu His Ala Val Pro Ser Gln Gly Leu Trp Leu Leu Gly
370 375 380
Leu Arg Glu Gly Lys Ile Leu Glu Ala His Val Glu Ala Lys Glu Pro
385 390 395 400
Arg Ala Leu Arg Ser Pro Glu Arg Arg Pro Thr Arg Ile Gly Leu Tyr
405 410 415
Leu Ser Phe Gly Asp Gly Val Leu Ser Phe Tyr Asp Ala Ser Asp Ala
420 425 430
Asp Ala Leu Val Pro Leu Phe Ala Phe His Glu Arg Leu Pro Arg Pro
435 440 445
Val Tyr Pro Phe Phe Asp Val Cys Trp His Asp Lys Gly Lys Asn Ala
450 455 460
Gln Pro Leu Leu Leu Val Gly Pro Glu Gly Ala Glu Ala
465 470 475
<210> 141
<211> 753
<212> DNA
<213> Homo sapiens
<400> 141
atggcttggc aggtgagcct gctggagctg gaggaccggc ttcagtgtcc catctgcctg 60
gaggtcttca aggagtccct aatgctacag tgcggccact cctactgcaa gggctgcctg 120
gtttccctgt cctaccacct ggacaccaag gtgcgctgcc ccatgtgctg gcaggtggtg 180
gacggcagca gctccttgcc caacgtctcc ctggcctggg tgatcgaagc cctgaggctc 240
cctggggacc cggagcccaa ggtctgcgtg caccaccgga acccgctcag ccttttctgc 300
gagaaggacc aggagctcat ctgtggcctc tgcggtctgc tgggctccca ccaacaccac 360
ccggtcacgc ccgtctccac cgtctgcagc cgcatgaagg aggagctcgc agccctcttc 420
tctgagctga agcaggagca gaagaaggtg gatgagctca tcgccaaact ggtgaaaaac 480
cggacccgaa tcgtcaatga gtcggatgtc ttcagctggg tgatccgccg cgagttccag 540
gagctgcgcc acccggtgga cgaggagaag gcccgctgcc tggaggggat agggggtcac 600
acccgtggcc tggtggcctc cctggacatg cagctggagc aggcccaggg aacccgggag 660
cggctggccc aagccgagtg tgtgctggaa cagttcggca atgaggacca ccatgagttc 720
atctggaagt tccactccat ggcctccagg taa 753
<210> 142
<211> 250
<212> PRT
<213> Homo sapiens
<400> 142
Met Ala Trp Gln Val Ser Leu Leu Glu Leu Glu Asp Arg Leu Gln Cys
1 5 10 15
Pro Ile Cys Leu Glu Val Phe Lys Glu Ser Leu Met Leu Gln Cys Gly
20 25 30
His Ser Tyr Cys Lys Gly Cys Leu Val Ser Leu Ser Tyr His Leu Asp
35 40 45
Thr Lys Val Arg Cys Pro Met Cys Trp Gln Val Val Asp Gly Ser Ser
50 55 60
Ser Leu Pro Asn Val Ser Leu Ala Trp Val Ile Glu Ala Leu Arg Leu
65 70 75 80
Pro Gly Asp Pro Glu Pro Lys Val Cys Val His His Arg Asn Pro Leu
85 90 95
Ser Leu Phe Cys Glu Lys Asp Gln Glu Leu Ile Cys Gly Leu Cys Gly
100 105 110
Leu Leu Gly Ser His Gln His His Pro Val Thr Pro Val Ser Thr Val
115 120 125
Cys Ser Arg Met Lys Glu Glu Leu Ala Ala Leu Phe Ser Glu Leu Lys
130 135 140
Gln Glu Gln Lys Lys Val Asp Glu Leu Ile Ala Lys Leu Val Lys Asn
145 150 155 160
Arg Thr Arg Ile Val Asn Glu Ser Asp Val Phe Ser Trp Val Ile Arg
165 170 175
Arg Glu Phe Gln Glu Leu Arg His Pro Val Asp Glu Glu Lys Ala Arg
180 185 190
Cys Leu Glu Gly Ile Gly Gly His Thr Arg Gly Leu Val Ala Ser Leu
195 200 205
Asp Met Gln Leu Glu Gln Ala Gln Gly Thr Arg Glu Arg Leu Ala Gln
210 215 220
Ala Glu Cys Val Leu Glu Gln Phe Gly Asn Glu Asp His His Glu Phe
225 230 235 240
Ile Trp Lys Phe His Ser Met Ala Ser Arg
245 250
<210> 143
<211> 753
<212> DNA
<213> Homo sapiens
<400> 143
atggcttggc aggtgagcct gctggagctg gaggactggc ttcagtgtcc catctgcctg 60
gaggtcttca aggagtccct aatgctacag tgcggccact cctactgcaa gggctgcctg 120
gtttccctgt cctaccacct ggacaccaag gtgcgctgcc ccatgtgctg gcaggtggtg 180
gacggcagca gctccttgcc caacgtctcc ctggcctggg tgatcgaagc cctgaggctc 240
cctggggacc cggagcccaa ggtctgcgtg caccaccgga acccgctcag ccttttctgc 300
gagaaggacc aggagctcat ctgtggcctc tgcggtctgc tgggctccca ccaacaccac 360
ccggtcacgc ccgtctccac cgtctgcagc cgcatgaagg aggagctcgc agccctcttc 420
tctgagctga agcaggagca gaagaaggtg gatgagctca tcgccaaact ggtgaaaaac 480
cggacccgaa tcgtcaatga gtcggatgtc ttcagctggg tgatccgccg cgagttccag 540
gagctgcgcc acccggtgga cgaggagaag gcccgctgcc tggaggggat agggggtcac 600
acccgtggcc tggtggcctc cctggacatg cagctggagc aggcccaggg aacccgggag 660
cggctggccc aagccgagtg tgtgctggaa cagttcggaa atgaggacca ccatgagttc 720
atctggaagt tccactccat ggcctccagg taa 753
<210> 144
<211> 250
<212> PRT
<213> Homo sapiens
<400> 144
Met Ala Trp Gln Val Ser Leu Leu Glu Leu Glu Asp Trp Leu Gln Cys
1 5 10 15
Pro Ile Cys Leu Glu Val Phe Lys Glu Ser Leu Met Leu Gln Cys Gly
20 25 30
His Ser Tyr Cys Lys Gly Cys Leu Val Ser Leu Ser Tyr His Leu Asp
35 40 45
Thr Lys Val Arg Cys Pro Met Cys Trp Gln Val Val Asp Gly Ser Ser
50 55 60
Ser Leu Pro Asn Val Ser Leu Ala Trp Val Ile Glu Ala Leu Arg Leu
65 70 75 80
Pro Gly Asp Pro Glu Pro Lys Val Cys Val His His Arg Asn Pro Leu
85 90 95
Ser Leu Phe Cys Glu Lys Asp Gln Glu Leu Ile Cys Gly Leu Cys Gly
100 105 110
Leu Leu Gly Ser His Gln His His Pro Val Thr Pro Val Ser Thr Val
115 120 125
Cys Ser Arg Met Lys Glu Glu Leu Ala Ala Leu Phe Ser Glu Leu Lys
130 135 140
Gln Glu Gln Lys Lys Val Asp Glu Leu Ile Ala Lys Leu Val Lys Asn
145 150 155 160
Arg Thr Arg Ile Val Asn Glu Ser Asp Val Phe Ser Trp Val Ile Arg
165 170 175
Arg Glu Phe Gln Glu Leu Arg His Pro Val Asp Glu Glu Lys Ala Arg
180 185 190
Cys Leu Glu Gly Ile Gly Gly His Thr Arg Gly Leu Val Ala Ser Leu
195 200 205
Asp Met Gln Leu Glu Gln Ala Gln Gly Thr Arg Glu Arg Leu Ala Gln
210 215 220
Ala Glu Cys Val Leu Glu Gln Phe Gly Asn Glu Asp His His Glu Phe
225 230 235 240
Ile Trp Lys Phe His Ser Met Ala Ser Arg
245 250
<210> 145
<211> 1404
<212> DNA
<213> Homo sapiens
<400> 145
atggcacatg tcgaggtctt ggccagactc cagaaagaga ccaagtgccc catctgtttg 60
gacgatctga cagatcccgt caccgtcgag tgcggacaca acttctgtcg ttcctgcatc 120
aaagacttct gggcagggca gcaagccacg tcctcctgtc ctgtctgccg acaccagtgc 180
caacacagga acctcagaag caatgcccag ctgggaaaca tgattgaaac tgcccagctg 240
ctccaaggca tggagaacaa gaggcacgag agcagcacca gttgcgagag gcacaaccag 300
gccctgaccc tcttctgtga ggatgacctg cagttgctct gtgaccagtg cgtggagcct 360
gagagccacg ggcgccacca ggtgctgtcc attacagagg ctgcctctct ccacaggaaa 420
caccttcagg actatagcaa gctcctgaag tgggaagtga aagagattca agggctaatg 480
agcgcactaa acaaaagaac cgtgaccctg agggagcaag cagaggcaca gaggtcacag 540
ctaacctctg agtgtgagaa gctcatgcgg tttctagacc aggaagagcg ggcagctttc 600
tccaggttag aagacgagga gatgaggctc gagaagagac tgcttgataa catagcagca 660
ttagaacacc acggttccag cctcagagac ctcctgagac acttgatgct gaccggagag 720
ctctccgaag ccaagatgtt gtccacggtc aaggattttt acctgaattg taggcgtcag 780
ctcatcagcc caagcatttt cccagttcag ttgagaagag tggagtacag ctttcctctc 840
cagtattcgg ccctacagaa agttatacag cattttacag acaacgtcac tctagacctg 900
aagacagccc atccaaacct gctcatttct aaggatagaa cctgcgtaac atttacaaag 960
aaaagacaac gtattcctgg ttcttcaagt tttaccaaga gccctgttgt gttggggatt 1020
ccacatttta attctgggag acacttctgg gaggtgcagg taggaaagaa gccaaagtgg 1080
gctattggca tttgcaaagc tgattcctct atcggggaaa ggcagtcccc taacccctgg 1140
gggtactgga ggattgtttg gcagggggac agcttcaacg tctcaggagc tgatccagac 1200
tctcggctga aggccgcaag agctacaagc attggtgttt tcctggacta tgaactggga 1260
gaggtttctt tctatggcat gcctgagaaa tgtcacctct atactttcag ggacactttt 1320
tctggtcctg tctgccctta tttctacata gggcctcagt cagaacctct tagactctgt 1380
tctgccactg attcagaatg ctaa 1404
<210> 146
<211> 467
<212> PRT
<213> Homo sapiens
<400> 146
Met Ala His Val Glu Val Leu Ala Arg Leu Gln Lys Glu Thr Lys Cys
1 5 10 15
Pro Ile Cys Leu Asp Asp Leu Thr Asp Pro Val Thr Val Glu Cys Gly
20 25 30
His Asn Phe Cys Arg Ser Cys Ile Lys Asp Phe Trp Ala Gly Gln Gln
35 40 45
Ala Thr Ser Ser Cys Pro Val Cys Arg His Gln Cys Gln His Arg Asn
50 55 60
Leu Arg Ser Asn Ala Gln Leu Gly Asn Met Ile Glu Thr Ala Gln Leu
65 70 75 80
Leu Gln Gly Met Glu Asn Lys Arg His Glu Ser Ser Thr Ser Cys Glu
85 90 95
Arg His Asn Gln Ala Leu Thr Leu Phe Cys Glu Asp Asp Leu Gln Leu
100 105 110
Leu Cys Asp Gln Cys Val Glu Pro Glu Ser His Gly Arg His Gln Val
115 120 125
Leu Ser Ile Thr Glu Ala Ala Ser Leu His Arg Lys His Leu Gln Asp
130 135 140
Tyr Ser Lys Leu Leu Lys Trp Glu Val Lys Glu Ile Gln Gly Leu Met
145 150 155 160
Ser Ala Leu Asn Lys Arg Thr Val Thr Leu Arg Glu Gln Ala Glu Ala
165 170 175
Gln Arg Ser Gln Leu Thr Ser Glu Cys Glu Lys Leu Met Arg Phe Leu
180 185 190
Asp Gln Glu Glu Arg Ala Ala Phe Ser Arg Leu Glu Asp Glu Glu Met
195 200 205
Arg Leu Glu Lys Arg Leu Leu Asp Asn Ile Ala Ala Leu Glu His His
210 215 220
Gly Ser Ser Leu Arg Asp Leu Leu Arg His Leu Met Leu Thr Gly Glu
225 230 235 240
Leu Ser Glu Ala Lys Met Leu Ser Thr Val Lys Asp Phe Tyr Leu Asn
245 250 255
Cys Arg Arg Gln Leu Ile Ser Pro Ser Ile Phe Pro Val Gln Leu Arg
260 265 270
Arg Val Glu Tyr Ser Phe Pro Leu Gln Tyr Ser Ala Leu Gln Lys Val
275 280 285
Ile Gln His Phe Thr Asp Asn Val Thr Leu Asp Leu Lys Thr Ala His
290 295 300
Pro Asn Leu Leu Ile Ser Lys Asp Arg Thr Cys Val Thr Phe Thr Lys
305 310 315 320
Lys Arg Gln Arg Ile Pro Gly Ser Ser Ser Phe Thr Lys Ser Pro Val
325 330 335
Val Leu Gly Ile Pro His Phe Asn Ser Gly Arg His Phe Trp Glu Val
340 345 350
Gln Val Gly Lys Lys Pro Lys Trp Ala Ile Gly Ile Cys Lys Ala Asp
355 360 365
Ser Ser Ile Gly Glu Arg Gln Ser Pro Asn Pro Trp Gly Tyr Trp Arg
370 375 380
Ile Val Trp Gln Gly Asp Ser Phe Asn Val Ser Gly Ala Asp Pro Asp
385 390 395 400
Ser Arg Leu Lys Ala Ala Arg Ala Thr Ser Ile Gly Val Phe Leu Asp
405 410 415
Tyr Glu Leu Gly Glu Val Ser Phe Tyr Gly Met Pro Glu Lys Cys His
420 425 430
Leu Tyr Thr Phe Arg Asp Thr Phe Ser Gly Pro Val Cys Pro Tyr Phe
435 440 445
Tyr Ile Gly Pro Gln Ser Glu Pro Leu Arg Leu Cys Ser Ala Thr Asp
450 455 460
Ser Glu Cys
465
<210> 147
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> SV40 nuclear localization signal
<400> 147
Pro Lys Lys Lys Arg Lys Val
1 5
<210> 148
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> PML#4
<400> 148
ctccaagatc taaaccgaga a 21
<210> 149
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> PML#9
<400> 149
cacccgcaag accaacaaca t 21
<210> 150
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> RNF4#5
<400> 150
ccctgtttcc taagaacgaa a 21
<210> 151
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> RNF4#6
<400> 151
taggccgagc tttgcgggaa a 21
<210> 152
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> RNF4#8
<400> 152
aagactgttt cgaaaccaac a 21
<210> 153
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> SUMO1 siRNA pooled sense strand 1
<400> 153
tcaagaaacu caaagaatc 19
<210> 154
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> SUMO1 siRNA pooled sense strand 2
<400> 154
gacagggtgt tccaatgaa 19
<210> 155
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> SUMO1 siRNA pooled sense strand 3
<400> 155
ggtttctctt tgagggtca 19
<210> 156
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> SUMO1 siRNA pooled sense strand 4
<400> 156
gaataaatgg gcatgccaa 19
<210> 157
<211> 19
<212> RNA
<213> Artificial Sequence
<220>
<223> SUMO2/3 siRNA pooled sense strand 1
<400> 157
cccauuccuu uauuguaca 19
<210> 158
<211> 19
<212> RNA
<213> Artificial Sequence
<220>
<223> SUMO2/3 siRNA pooled sense strand 2
<400> 158
cagagaauga ccacaucaa 19
<210> 159
<211> 19
<212> RNA
<213> Artificial Sequence
<220>
<223> SUMO2/3 siRNA pooled sense strand 3
<400> 159
caguuauguu gucguguau 19
<210> 160
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> antisense sequence of shRNF4
<400> 160
tggcgtttct gggagtatgg g 21
<210> 161
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> antigen peptide
<400> 161
Asp Leu Thr His Asn Asp Ser Val Val Ile
1 5 10
<210> 162
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> TRIM27 siRNA sense strand
<400> 162
aactcttagg cctaacccag a 21
<210> 163
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> protein transduction domain of HIV Tat
<400> 163
Tyr Gly Arg Lys Lys Arg Arg Gln Arg Arg Arg
1 5 10
<210> 164
<211> 12207
<212> DNA
<213> Homo sapiens
<400> 164
atggcgagcc gcgatagcaa ccacgctggc gagagctttc tcggctccga cggggacgag 60
gaggcgaccc gggagctgga gaccgaggag gagtcggagg gcgaggagga cgagacggcg 120
gcggagtcgg aggaggagcc ggactccagg ttatcagacc aggatgaaga gggaaagatc 180
aagcaggagt atatcatatc tgacccctcc ttttccatgg tgacagtcca aagggaagat 240
agtgggataa cctgggaaac caattcaagt agatcttcta ctccttgggc ttcagaagaa 300
agtcagactt ctggtgtgtg tagtcgggaa gggtcaactg tgaattctcc tcctggaaat 360
gtttccttta ttgtggatga agtgaaaaag gttcggaaaa ggactcataa gtcaaagcat 420
ggttcaccat cattacgccg gaaaggcaac agaaaaagaa attcttttga atcccaagat 480
gttccaacaa acaaaaaagg cagtccttta acttcagcaa gccaggtact aaccacggag 540
aaagagaagt catatactgg catttatgat aaagcaagaa aaaagaagac cacttcaaat 600
acacctccga ttactggggc aatatacaaa gaacacaagc cattagtgtt aagaccagtc 660
tacataggaa cagtacaata taaaattaag atgtttaatt cggttaaaga agaattaatt 720
cctctacaat tttatggaac attgccaaag ggttatgtaa ttaaagaaat acattatagg 780
aaagggaaag atgcatccat tagtctagag ccagatttgg acaatagtgg ttctaataca 840
gtgtccaaaa cacgcaaatt agtagcccaa agcatagagg ataaagtaaa agaggttttt 900
ccaccctgga gaggcgcact ctccaaagga tcagagtccc taaccttaat gttcagtcat 960
gaagatcaaa agaaaattta tgctgattct cccctaaatg ccacatctgc attggagcac 1020
acagttccct cttattcaag tagtggcaga gcagaacaag gaatacagct caggcattca 1080
cagtcagtgc cacaacagcc agaagatgaa gcaaaaccac atgaagtgga acctccatct 1140
gtgacacccg acacacctgc aactatgttc ctgagaacaa caaaggaaga atgtgagctt 1200
gcttcaccag gaactgcagc ttcagagaat gactcttcag tctcaccatc atttgctaat 1260
gaggtaaaga aggaagatgt gtattctgct caccattcca tttctctgga ggcagcgtca 1320
ccaggtctgg cagcatctac ccaggatggt ttggacccag accaagaaca gccggacctg 1380
acttcaatag aaagggcaga accagtctcc gcaaaactga cccctaccca tcccagtgtc 1440
aaaggagaga aggaggaaaa catgcttgag ccatccattt ctctttctga acctctaatg 1500
ttagaagaac cagagaaaga agaaatagaa acttccctac ccatagctat tacccctgaa 1560
cctgaagatt ctaatttagt agaagaagag atcgtagaac ttgattaccc agaaagccca 1620
ttggtttccg agaagccctt cccaccacat atgtcccctg aagtggagca caaagaagaa 1680
gagcttattc taccattatt ggcagcatca tctcctgaac atgttgcttt gtctgaggaa 1740
gaaagagagg aaattgcatc tgtttctact ggttctgctt ttgtatcaga gtattcagta 1800
ccacaggatt tgaaccatga attacaggag caagaaggtg agccagttcc cccatccaat 1860
gtagaagcta tagctgaaca tgcagttttg tcagaagaag agaatgagga atttgaggct 1920
tattccccag ctgcagcccc tacatctgag agctctctct caccatccac aactgagaag 1980
acttcagaga accagtctcc actgttttca acagttacac cagaatacat ggtcctatca 2040
ggagacgagg cctcagaaag tgggtgttac acaccagact ccacatctgc ttctgaatat 2100
tcagttccat cactggcaac aaaagagtca ctgaagaaaa caattgaccg taagtccccg 2160
ttaatattga aaggtgtttc tgagtacatg attccatcag aagagaagga agacactgga 2220
tcgtttactc cagctgtggc ccctgcttct gagccctctc tctcaccatc cacaaccgaa 2280
aagacttctg aatgccagtc accactgcct tctactgcca catcagaaca cgtggtccca 2340
tcagaaggag aggacctagg aagtgaacgt ttcacaccgg attcaaagtt gatctccaaa 2400
tatgcagccc cactcaatgc aacacaggaa tctcaaaaga aaataatcaa tgaggcatcc 2460
caattcaaac caaaaggtat ttctgagcac acagttctgt cagtagacgg caaggaggtc 2520
attggaccat cttccccaga tttggttgtt gcatctgaac actctttccc accacacaca 2580
accgagatga cttctgaatg ccaggcccca ccactttcag ccaccccatc tgaatatgtt 2640
gttctatcag acgaagaggc agtcgagttg gaacgataca caccctcttc tacatctgct 2700
tctgaatttt cagtaccacc atatgcaaca ccggaggcac aggaggaaga aattgtccat 2760
agatctctaa atctaaaagg tgcatcctca cccatgaatt tatcagaaga agatcaagaa 2820
gacattggac ctttttctcc agattctgca tttgtgtcag aattctcatt tccaccgtat 2880
gcaacccagg aagcagagaa aagagaattt gagtgcgatt ctccaatatg tttaacatca 2940
ccatctgagc acactatttt gtcagatgaa gacactgaag aagcggaact gttctctcca 3000
gactcagcat cacaagtttc aatccctccc tttagaatct cagaaacaga gaaaaatgaa 3060
cttgagcctg attcactatt aactgcagtg tctgcttcag gttattcctg cttttcagaa 3120
gcagatgagg aagacattgg atccacagct gctacacctg tatctgagca gttcagttca 3180
tcacagaagc aaaaagctga aactttccct ttgatgtctc cgcttgaaga cttaagtctg 3240
ccgccttcaa cagataaatc agagaaagca gaaattaagc cagagattcc aacaacctca 3300
acatctgtat ctgaatatct cattttggca cagaagcaga aaactcaagc atatttagag 3360
cctgagtctg aagacttgat tccttcacat ttaaccagtg aagtggagaa gggagaaagg 3420
gaggcaagtt catcagtagc tgcaatacct gctgctttac ctgcacaatc atctatagta 3480
aaggaagaaa ccaaacctgc atctccacat tcagttttac ctgattcagt ccctgcaatc 3540
aagaaagaac aggaacccac agcagcactc actctaaaag ctgcagatga acagatggct 3600
ttgtcaaaag tcagaaagga agaaattgtg cctgattctc aagaagctac agcacatgta 3660
tcacaggatc aaaaaatgga gcctcagcct ccaaatgttc cagagtctga gatgaaatat 3720
tcagttttgc ctgacatggt agatgagcca aagaagggtg tcaagcccaa attagttcta 3780
aatgtgactt ctgaactaga acagagaaag ttgtccaaga atgagcctga agtaataaaa 3840
ccatattcac ctctaaagga aacatcttta tctggacctg aggctttatc agcagtgaaa 3900
atggagatga aacatgattc caaaataaca actacaccta tagtgcttca ttcagcttcc 3960
tcaggagtgg aaaagcaagt tgaacatggt ccacctgcac tagcattttc agctttgtca 4020
gaagaaatta aaaaagaaat tgaacccagt tcctcaacaa ctacagcatc tgtaactaag 4080
cttgattcaa acttaaccag agcagtaaaa gaagaaatcc caacagattc atctcttatc 4140
actcctgtag atcgtccagt cttaacaaaa gtaggaaagg gtgaattagg aagtggtttg 4200
ccaccactgg taacatctgc agatgaacat tcagttcttg cagaagaaga caaggtggca 4260
attaaaggtg cttctcccat tgaaacttca tccaaacatt tagcttggtc agaagcagag 4320
aaggaaatta aatttgattc acttccaagt gtctcctcta tagcagagca ttctgttttg 4380
tcagaagtag aagccaaaga agttaaagct gggttgccag taatcaaaac atcatcttct 4440
cagcattcag ataaatctga ggaagcaagg gtagaagaca aacaagatct tttattttct 4500
acagtctgtg actctgaacg tttggtttca tcacagaaga agagcttgat gtctacctca 4560
gaggtgttag agcctgaaca tgagcttcca ctcagcctat ggggtgagat aaagaagaaa 4620
gaaactgaac ttccttcatc acaaaatgtg tcacctgcat ccaaacatat aatcccaaaa 4680
ggcaaagatg aggaaacagc aagttcatct cctgagttgg aaaatttagc atcaggttta 4740
gccccaacat tactgctcct cagtgatgat aagaacaaac cggcagtgga ggtatcttct 4800
acagctcagg gagacttccc atcagaaaaa caagatgttg ctttggcaga gctgtctttg 4860
gaacctgaga agaaagacaa gccacaccaa ccgttggaat taccaaatgc tgggtcagaa 4920
ttttctagtg atttaggtag acaaagtgga tccataggta caaaacaagc aaagtctccc 4980
ataactgaaa cagaggattc tgttttagaa aaaggcccag ctgagcttag gagcagagaa 5040
ggaaaagaag aaaatagaga gctttgtgca tcttctacga tgcctgcaat ttcagagctt 5100
tcatcattgc ttagggagga atctcagaat gaagaaatta aacctttctc tcccaagatc 5160
atcagcctag agtcgaaaga accacctgcc tctgtagctg aaggaggcaa cccagaagaa 5220
tttcagccat ttactttttc tttaaaagga ttatcagagg aggttagcca tccagccgac 5280
tttaaaaagg gaggaaatca agaaataggc ccattaccac caactggaaa tttgaaggca 5340
caagtcatgg gagatatttt agataagcta agtgaagaaa caggccaccc aaattcatcc 5400
caggtactcc agagtataac agaaccatca aagattgctc cttctgacct ccttgtagaa 5460
caaaaaaaga cagaaaaagc acttcattca gatcaaactg ttaaattacc tgatgtaagc 5520
acctcttctg aagataaaca agatctgggt attaagcagt tttcacttat gagagagaat 5580
ttgcctttgg aacaatcaaa atcatttatg acaaccaagc ctgcggatgt caaagaaaca 5640
aaaatggaag aattctttat ttctccaaag gatgaaaact ggatgttggg aaagccagaa 5700
aatgtggcta gtcaacacga acagagaata gcaggatctg tgcagctgga ttcctctagc 5760
agcaatgagc tgaggccagg gcagctcaag gctgctgtgt ccagtaagga ccatacatgt 5820
gaagtgagaa agcaggtcct gccgcattct gctgaagaat ctcatttgtc atcacaagaa 5880
gcagtatctg ctcttgatac ttccagtggt aatacagaga ccttatcaag taaaagttac 5940
tcttctgaag aagtaaagct ggctgaagaa ccaaagtctt tagtcctagc tggaaatgta 6000
gagagaaaca tagcagaggg gaaggagatt cattctttga tggagagtga aagtttgcta 6060
ttggagaaag caaacacaga gctttcctgg ccttccaaag aagatagcca ggaaaaaatt 6120
aaactacctc ctgaaagatt cttccagaaa ccagtgtctg gcctatcagt ggaacaggtg 6180
aagtcagaaa caatctcctc ttctgtcaaa acagcccatt tcccggcaga aggtgtggaa 6240
cctgcattgg gcaatgaaaa agaagcacac aggagcacac ctccttttcc tgaagagaag 6300
ccattggaag aatcaaaaat ggttcagtca aaggttattg atgatgctga tgagggaaag 6360
aaaccatcac ctgaagtaaa aatacccaca caaagaaaac ccatctcctc aatccatgca 6420
agagagcctc aatccccaga gtcacctgag gtgacacaaa atccacctac acaaccaaag 6480
gtggctaagc cggaccttcc tgaggaaaag ggaaagaaag gaatttcatc tttcaaatcg 6540
tggatgtcca gcttgttttt tggatcgagc actccagata acaaagttgc tgaacaagaa 6600
gacttagaaa cacagccaag tccatccgta gaaaaagcag tgactgtgat agatcctgaa 6660
ggtacaattc ccaccaattt taatgtagct gagaaaccag ctgatcattc attatcagag 6720
gtaaaactta aaactgctga tgaacccaga ggtactttag taaaatctgg tgacggtcaa 6780
aacgttaaag aaaaatccat gattttatca aatgtagaag atttacaaca gccaaaattc 6840
atttctgagg tgtctaggga agattatgga aaaaaagaaa tctcaggcga ttcagaggaa 6900
atgaacataa actcagtagt tacttctgct gatggtgaga accttgaaat tcaatcttat 6960
tcactaatcg gtgagaaatt ggttatggaa gaagccaaaa ctattgttcc tcctcatgtt 7020
actgatagta aaagagtcca gaagccagca atcgctcctc catctaaatg gaatatttct 7080
atttttaagg aagagccaag aagtgatcaa aaacaaaaat cactcctttc atttgatgta 7140
gtagataagg tgccacaaca gccaaaatca gcttcctcca actttgcaag taaaaatatc 7200
acaaaggaat cagagaaacc agagtcaatt attttgccag tagaagaatc aaaaggcagt 7260
ttaattgatt tcagtgaaga cagactcaag aaagaaatgc aaaatcctac ttccttgaaa 7320
atttctgaag aggaaacaaa actcaggtct gttagtccaa ctgagaagaa agataatttg 7380
gaaaacagat catatacctt ggcagaaaag aaggtgctgg cagaaaaaca aaactctgtg 7440
gccccattag agcttagaga tagtaatgaa atagggaaga cacaaattac acttggatct 7500
agatctactg aactgaaaga atcaaaagcc gatgctatgc cacagcactt ctatcaaaat 7560
gaagactaca atgaaagacc caaaatcatt gttggttctg aaaaggagaa aggtgaagaa 7620
aaagaaaatc aggtatatgt gctttcagaa ggaaagaagc agcaggaaca tcagccttat 7680
tctgtgaatg tagccgagtc tatgagtaga gaatcagata tctctttagg tcattctttg 7740
ggtgaaactc aatcattttc attagttaaa gctacatcag ttactgaaaa atcagaagcc 7800
atgctcgcag aggctcaccc agaaatcaga gaagcaaagg cagtaggaac ccaaccacat 7860
cctttagaag aaagtaaagt tttggtggag aaaaccaaga ctttcctgcc ggtggctctt 7920
tcttgtcgtg atgaaataga gaaccactct ttatctcagg aaggaaatct agtattagaa 7980
aagtcaagca gagatatgcc agatcacagt gaagaaaaag aacagttcag agagtcagag 8040
ctatcgaaag gcggttcagt agatatcaca aaagaaactg tgaaacaagg atttcaagaa 8100
aaggcagtag gaacccaacc acgtccttta gaagaaagta aagttttggt ggagaaaact 8160
aagactttcc tgccagtggt tctttcttgt catgatgaaa tagagaacca ctctttgtct 8220
caggaaggaa atctagtgtt agaaaagtca agcagagata tgccagatca cagtgaagaa 8280
aaagaacagt tcaaagagtc agagctatgg aaaggtggtt cagtagatat cacaaaagaa 8340
agtatgaaag aaggatttcc atctaaagaa tccgaaagga ctttagctcg tccttttgat 8400
gaaactaaga gctcagaaac accgccatat ttgctgtcac ctgtaaaacc acaaactctt 8460
gcttcaggag cttctccaga aattaacgca gtgaagaaaa aagaaatgcc acgatcagaa 8520
ttgactccag aaaggcatac agttcatact attcagacat ctaaagatga cacatccgat 8580
gtgcctaaac aatctgttct tgtttcaaag caccacttgg aggctgcgga agatacccgt 8640
gtaaaggaac cactgtcttc agcaaaaagc aactatgctc aatttatatc taatacatca 8700
gcaagcaatg ctgataaaat ggtttctaat aaagaaatgc ccaaggaacc tgaagacaca 8760
tatgcaaaag gtgaagactt tacagtgact agtaagccag ccggactttc agaagatcag 8820
aagactgcct ttagtatcat ttctgaaggc tgtgagatat tgaatattca tgctccggcc 8880
tttatttctt caatcgatca ggaagaaagt gaacaaatgc aagataaatt agaatatttg 8940
gaagagaaag cctcatttaa aaccatacca ctccctgatg atagtgaaac agttgcttgt 9000
cataaaacat taaagagcag gttagaagat gaaaaagtta ccccattgaa agaaaataaa 9060
caaaaggaaa ctcataagac aaaagaagag atatccacag attcagaaac tgatttatca 9120
tttattcagc ccacaattcc cagtgaagag gattattttg aaaaatatac tttgattgat 9180
tataacatct ccccagaccc agaaaaacag aaagctccac agaaattaaa tgttgaagag 9240
aaactctcaa aggaagttac agaagaaact atctctttcc cagtaagttc agtggaaagt 9300
gcactagaac atgaatatga cttggtgaaa ttagatgaaa gtttttatgg accagaaaag 9360
ggccacaaca tattatctca tccagagacc caaagccaaa actcagctga caggaatgtt 9420
tcaaaggaca caaagagaga tgtggactca aagtcaccgg ggatgccttt atttgaagca 9480
gaggaaggag ttctatcacg aacccagata tttcctacca ctattaaagt cattgatcca 9540
gaatttctgg aggagccacc tgcacttgca tttttatata aggatctgta tgaagaagca 9600
gttggagaga aaaagaagga agaggagaca gcttctgaag gtgacagtgt gaattctgag 9660
gcatcatttc ccagcagaaa ttctgacact gatgatggaa caggaatata ttttgagaag 9720
tacatactca aagatgacat tctccatgac acatctctaa ctcaaaagga ccagggccaa 9780
ggtctggaag aaaaacgagt tggtaaggat gattcatacc aaccgatagc tgcagaaggg 9840
gaaatttggg gaaagtttgg aactatttgc agggagaaga gtctggaaga acagaaaggt 9900
gtttatgggg aaggagaatc agtagaccat gtggagaccg ttggtaacgt agcgatgcag 9960
aagaaagctc ccatcacaga ggacgtcaga gtggctaccc agaaaataag ttatgcggtt 10020
ccatttgaag acacccatca tgttctggag cgtgcagatg aagcaggcag tcacggtaat 10080
gaagtcggaa atgcaagtcc agaggtcaat ctgaatgtcc cagtacaagt gtccttcccg 10140
gaggaagaat ttgcatctgg tgcaactcat gttcaagaaa catcactaga agaacctaaa 10200
atcctggtcc cacctgagcc aagtgaagag aggctccgta atagccctgt tcaggatgag 10260
tatgaattta cagaatccct gcataatgaa gtggttcctc aagacatatt atcagaagaa 10320
ctgtcttcag aatccacacc tgaagatgtc ttatctcaag gaaaggaatc ctttgagcac 10380
atcagtgaaa atgaatttgc gagtgaggca gaacaaagta cacctgctga acaaaaagag 10440
ttgggcagcg agaggaaaga agaagaccaa ttatcatctg aggtagtaac tgaaaaggca 10500
caaaaagagc tgaaaaagtc ccagattgac acatactgtt acacctgcaa atgtccaatt 10560
tctgccactg acaaggtgtt tggcacccac aaagaccatg aagtttcaac gcttgacaca 10620
gctataagtg ctgtaaaggt tcaattagca gaatttctag aaaatttaca agaaaagtcc 10680
ttgaggattg aagcctttgt tagtgagata gaatcctttt ttaataccat tgaggaaaac 10740
tgtagtaaaa atgagaaaag gctagaagaa cagaatgagg aaatgatgaa gaaggtttta 10800
gcacagtatg atgagaaagc ccagagcttt gaggaagtga agaagaagaa gatggagttc 10860
ctgcatgagc agatggtcca ctttctgcag agcatggaca ctgccaaaga caccctggag 10920
accatcgtga gagaagcaga ggagcttgat gaggccgtct tcctgacttc gtttgaggaa 10980
atcaatgaaa ggttgctttc tgcaatggag agcactgctt ctttagagaa aatgcctgct 11040
gcgttttccc ttttcgaaca ttatgatgac agctcggcaa gaagtgacca gatgttaaaa 11100
caagtggctg ttccacagcc tcctagatta gaacctcagg aaccaaattc tgccaccagc 11160
acaacaattg cagtttactg gagcatgaac aaggaagatg tcattgattc atttcaggtt 11220
tactgcatgg aggagccaca agatgatcaa gaagtaaatg agttggtaga agaatacaga 11280
ctgacagtga aagaaagcta ctgcattttt gaagatctgg aacctgaccg atgctatcaa 11340
gtgtgggtga tggctgtgaa cttcactgga tgtagcctgc ccagtgaaag ggccatcttt 11400
aggacagcac cctccacccc tgtgatccgc gctgaggact gtactgtgtg ttggaacaca 11460
gccactatcc gatggcggcc caccacccca gaggccacgg agacctacac tctggagtac 11520
tgcagacagc actctcctga gggagagggc ctcagatctt tctctggaat caaaggactc 11580
cagctgaaag ttaacctcca acccaatgat aactactttt tctatgtgag ggccatcaat 11640
gcatttggga caagtgaaca gagtgaagct gctctcatct ccaccagagg aaccagattt 11700
ctcttgttga gagaaacagc tcatcctgct ctacacattt cctcaagtgg gacagtgatc 11760
agctttggtg agaggagacg gctgacggaa atcccgtcag tgctgggtga ggagctgcct 11820
tcctgtggcc agcattactg ggaaaccaca gtcacagact gcccagcata tcgactcggc 11880
atctgctcca gctcggctgt gcaggcaggt gccctaggac aaggggagac ctcatggtac 11940
atgcactgct ctgagccaca gagatacaca tttttctaca gtggtattgt gagtgatgtt 12000
catgtgactg agcgtccagc cagagtgggc atcctgctgg actacaacaa ccagagactt 12060
atcttcatca acgcagagag cgagcagttg ctcttcatca tcaggcacag gtttaatgag 12120
ggtgtccacc ctgcctttgc cctggagaaa cctggaaaat gtactttgca cctggggata 12180
gagcccccgg attctgtaag gcacaag 12207
<210> 165
<211> 4069
<212> PRT
<213> Homo sapiens
<400> 165
Met Ala Ser Arg Asp Ser Asn His Ala Gly Glu Ser Phe Leu Gly Ser
1 5 10 15
Asp Gly Asp Glu Glu Ala Thr Arg Glu Leu Glu Thr Glu Glu Glu Ser
20 25 30
Glu Gly Glu Glu Asp Glu Thr Ala Ala Glu Ser Glu Glu Glu Pro Asp
35 40 45
Ser Arg Leu Ser Asp Gln Asp Glu Glu Gly Lys Ile Lys Gln Glu Tyr
50 55 60
Ile Ile Ser Asp Pro Ser Phe Ser Met Val Thr Val Gln Arg Glu Asp
65 70 75 80
Ser Gly Ile Thr Trp Glu Thr Asn Ser Ser Arg Ser Ser Thr Pro Trp
85 90 95
Ala Ser Glu Glu Ser Gln Thr Ser Gly Val Cys Ser Arg Glu Gly Ser
100 105 110
Thr Val Asn Ser Pro Pro Gly Asn Val Ser Phe Ile Val Asp Glu Val
115 120 125
Lys Lys Val Arg Lys Arg Thr His Lys Ser Lys His Gly Ser Pro Ser
130 135 140
Leu Arg Arg Lys Gly Asn Arg Lys Arg Asn Ser Phe Glu Ser Gln Asp
145 150 155 160
Val Pro Thr Asn Lys Lys Gly Ser Pro Leu Thr Ser Ala Ser Gln Val
165 170 175
Leu Thr Thr Glu Lys Glu Lys Ser Tyr Thr Gly Ile Tyr Asp Lys Ala
180 185 190
Arg Lys Lys Lys Thr Thr Ser Asn Thr Pro Pro Ile Thr Gly Ala Ile
195 200 205
Tyr Lys Glu His Lys Pro Leu Val Leu Arg Pro Val Tyr Ile Gly Thr
210 215 220
Val Gln Tyr Lys Ile Lys Met Phe Asn Ser Val Lys Glu Glu Leu Ile
225 230 235 240
Pro Leu Gln Phe Tyr Gly Thr Leu Pro Lys Gly Tyr Val Ile Lys Glu
245 250 255
Ile His Tyr Arg Lys Gly Lys Asp Ala Ser Ile Ser Leu Glu Pro Asp
260 265 270
Leu Asp Asn Ser Gly Ser Asn Thr Val Ser Lys Thr Arg Lys Leu Val
275 280 285
Ala Gln Ser Ile Glu Asp Lys Val Lys Glu Val Phe Pro Pro Trp Arg
290 295 300
Gly Ala Leu Ser Lys Gly Ser Glu Ser Leu Thr Leu Met Phe Ser His
305 310 315 320
Glu Asp Gln Lys Lys Ile Tyr Ala Asp Ser Pro Leu Asn Ala Thr Ser
325 330 335
Ala Leu Glu His Thr Val Pro Ser Tyr Ser Ser Ser Gly Arg Ala Glu
340 345 350
Gln Gly Ile Gln Leu Arg His Ser Gln Ser Val Pro Gln Gln Pro Glu
355 360 365
Asp Glu Ala Lys Pro His Glu Val Glu Pro Pro Ser Val Thr Pro Asp
370 375 380
Thr Pro Ala Thr Met Phe Leu Arg Thr Thr Lys Glu Glu Cys Glu Leu
385 390 395 400
Ala Ser Pro Gly Thr Ala Ala Ser Glu Asn Asp Ser Ser Val Ser Pro
405 410 415
Ser Phe Ala Asn Glu Val Lys Lys Glu Asp Val Tyr Ser Ala His His
420 425 430
Ser Ile Ser Leu Glu Ala Ala Ser Pro Gly Leu Ala Ala Ser Thr Gln
435 440 445
Asp Gly Leu Asp Pro Asp Gln Glu Gln Pro Asp Leu Thr Ser Ile Glu
450 455 460
Arg Ala Glu Pro Val Ser Ala Lys Leu Thr Pro Thr His Pro Ser Val
465 470 475 480
Lys Gly Glu Lys Glu Glu Asn Met Leu Glu Pro Ser Ile Ser Leu Ser
485 490 495
Glu Pro Leu Met Leu Glu Glu Pro Glu Lys Glu Glu Ile Glu Thr Ser
500 505 510
Leu Pro Ile Ala Ile Thr Pro Glu Pro Glu Asp Ser Asn Leu Val Glu
515 520 525
Glu Glu Ile Val Glu Leu Asp Tyr Pro Glu Ser Pro Leu Val Ser Glu
530 535 540
Lys Pro Phe Pro Pro His Met Ser Pro Glu Val Glu His Lys Glu Glu
545 550 555 560
Glu Leu Ile Leu Pro Leu Leu Ala Ala Ser Ser Pro Glu His Val Ala
565 570 575
Leu Ser Glu Glu Glu Arg Glu Glu Ile Ala Ser Val Ser Thr Gly Ser
580 585 590
Ala Phe Val Ser Glu Tyr Ser Val Pro Gln Asp Leu Asn His Glu Leu
595 600 605
Gln Glu Gln Glu Gly Glu Pro Val Pro Pro Ser Asn Val Glu Ala Ile
610 615 620
Ala Glu His Ala Val Leu Ser Glu Glu Glu Asn Glu Glu Phe Glu Ala
625 630 635 640
Tyr Ser Pro Ala Ala Ala Pro Thr Ser Glu Ser Ser Leu Ser Pro Ser
645 650 655
Thr Thr Glu Lys Thr Ser Glu Asn Gln Ser Pro Leu Phe Ser Thr Val
660 665 670
Thr Pro Glu Tyr Met Val Leu Ser Gly Asp Glu Ala Ser Glu Ser Gly
675 680 685
Cys Tyr Thr Pro Asp Ser Thr Ser Ala Ser Glu Tyr Ser Val Pro Ser
690 695 700
Leu Ala Thr Lys Glu Ser Leu Lys Lys Thr Ile Asp Arg Lys Ser Pro
705 710 715 720
Leu Ile Leu Lys Gly Val Ser Glu Tyr Met Ile Pro Ser Glu Glu Lys
725 730 735
Glu Asp Thr Gly Ser Phe Thr Pro Ala Val Ala Pro Ala Ser Glu Pro
740 745 750
Ser Leu Ser Pro Ser Thr Thr Glu Lys Thr Ser Glu Cys Gln Ser Pro
755 760 765
Leu Pro Ser Thr Ala Thr Ser Glu His Val Val Pro Ser Glu Gly Glu
770 775 780
Asp Leu Gly Ser Glu Arg Phe Thr Pro Asp Ser Lys Leu Ile Ser Lys
785 790 795 800
Tyr Ala Ala Pro Leu Asn Ala Thr Gln Glu Ser Gln Lys Lys Ile Ile
805 810 815
Asn Glu Ala Ser Gln Phe Lys Pro Lys Gly Ile Ser Glu His Thr Val
820 825 830
Leu Ser Val Asp Gly Lys Glu Val Ile Gly Pro Ser Ser Pro Asp Leu
835 840 845
Val Val Ala Ser Glu His Ser Phe Pro Pro His Thr Thr Glu Met Thr
850 855 860
Ser Glu Cys Gln Ala Pro Pro Leu Ser Ala Thr Pro Ser Glu Tyr Val
865 870 875 880
Val Leu Ser Asp Glu Glu Ala Val Glu Leu Glu Arg Tyr Thr Pro Ser
885 890 895
Ser Thr Ser Ala Ser Glu Phe Ser Val Pro Pro Tyr Ala Thr Pro Glu
900 905 910
Ala Gln Glu Glu Glu Ile Val His Arg Ser Leu Asn Leu Lys Gly Ala
915 920 925
Ser Ser Pro Met Asn Leu Ser Glu Glu Asp Gln Glu Asp Ile Gly Pro
930 935 940
Phe Ser Pro Asp Ser Ala Phe Val Ser Glu Phe Ser Phe Pro Pro Tyr
945 950 955 960
Ala Thr Gln Glu Ala Glu Lys Arg Glu Phe Glu Cys Asp Ser Pro Ile
965 970 975
Cys Leu Thr Ser Pro Ser Glu His Thr Ile Leu Ser Asp Glu Asp Thr
980 985 990
Glu Glu Ala Glu Leu Phe Ser Pro Asp Ser Ala Ser Gln Val Ser Ile
995 1000 1005
Pro Pro Phe Arg Ile Ser Glu Thr Glu Lys Asn Glu Leu Glu Pro
1010 1015 1020
Asp Ser Leu Leu Thr Ala Val Ser Ala Ser Gly Tyr Ser Cys Phe
1025 1030 1035
Ser Glu Ala Asp Glu Glu Asp Ile Gly Ser Thr Ala Ala Thr Pro
1040 1045 1050
Val Ser Glu Gln Phe Ser Ser Ser Gln Lys Gln Lys Ala Glu Thr
1055 1060 1065
Phe Pro Leu Met Ser Pro Leu Glu Asp Leu Ser Leu Pro Pro Ser
1070 1075 1080
Thr Asp Lys Ser Glu Lys Ala Glu Ile Lys Pro Glu Ile Pro Thr
1085 1090 1095
Thr Ser Thr Ser Val Ser Glu Tyr Leu Ile Leu Ala Gln Lys Gln
1100 1105 1110
Lys Thr Gln Ala Tyr Leu Glu Pro Glu Ser Glu Asp Leu Ile Pro
1115 1120 1125
Ser His Leu Thr Ser Glu Val Glu Lys Gly Glu Arg Glu Ala Ser
1130 1135 1140
Ser Ser Val Ala Ala Ile Pro Ala Ala Leu Pro Ala Gln Ser Ser
1145 1150 1155
Ile Val Lys Glu Glu Thr Lys Pro Ala Ser Pro His Ser Val Leu
1160 1165 1170
Pro Asp Ser Val Pro Ala Ile Lys Lys Glu Gln Glu Pro Thr Ala
1175 1180 1185
Ala Leu Thr Leu Lys Ala Ala Asp Glu Gln Met Ala Leu Ser Lys
1190 1195 1200
Val Arg Lys Glu Glu Ile Val Pro Asp Ser Gln Glu Ala Thr Ala
1205 1210 1215
His Val Ser Gln Asp Gln Lys Met Glu Pro Gln Pro Pro Asn Val
1220 1225 1230
Pro Glu Ser Glu Met Lys Tyr Ser Val Leu Pro Asp Met Val Asp
1235 1240 1245
Glu Pro Lys Lys Gly Val Lys Pro Lys Leu Val Leu Asn Val Thr
1250 1255 1260
Ser Glu Leu Glu Gln Arg Lys Leu Ser Lys Asn Glu Pro Glu Val
1265 1270 1275
Ile Lys Pro Tyr Ser Pro Leu Lys Glu Thr Ser Leu Ser Gly Pro
1280 1285 1290
Glu Ala Leu Ser Ala Val Lys Met Glu Met Lys His Asp Ser Lys
1295 1300 1305
Ile Thr Thr Thr Pro Ile Val Leu His Ser Ala Ser Ser Gly Val
1310 1315 1320
Glu Lys Gln Val Glu His Gly Pro Pro Ala Leu Ala Phe Ser Ala
1325 1330 1335
Leu Ser Glu Glu Ile Lys Lys Glu Ile Glu Pro Ser Ser Ser Thr
1340 1345 1350
Thr Thr Ala Ser Val Thr Lys Leu Asp Ser Asn Leu Thr Arg Ala
1355 1360 1365
Val Lys Glu Glu Ile Pro Thr Asp Ser Ser Leu Ile Thr Pro Val
1370 1375 1380
Asp Arg Pro Val Leu Thr Lys Val Gly Lys Gly Glu Leu Gly Ser
1385 1390 1395
Gly Leu Pro Pro Leu Val Thr Ser Ala Asp Glu His Ser Val Leu
1400 1405 1410
Ala Glu Glu Asp Lys Val Ala Ile Lys Gly Ala Ser Pro Ile Glu
1415 1420 1425
Thr Ser Ser Lys His Leu Ala Trp Ser Glu Ala Glu Lys Glu Ile
1430 1435 1440
Lys Phe Asp Ser Leu Pro Ser Val Ser Ser Ile Ala Glu His Ser
1445 1450 1455
Val Leu Ser Glu Val Glu Ala Lys Glu Val Lys Ala Gly Leu Pro
1460 1465 1470
Val Ile Lys Thr Ser Ser Ser Gln His Ser Asp Lys Ser Glu Glu
1475 1480 1485
Ala Arg Val Glu Asp Lys Gln Asp Leu Leu Phe Ser Thr Val Cys
1490 1495 1500
Asp Ser Glu Arg Leu Val Ser Ser Gln Lys Lys Ser Leu Met Ser
1505 1510 1515
Thr Ser Glu Val Leu Glu Pro Glu His Glu Leu Pro Leu Ser Leu
1520 1525 1530
Trp Gly Glu Ile Lys Lys Lys Glu Thr Glu Leu Pro Ser Ser Gln
1535 1540 1545
Asn Val Ser Pro Ala Ser Lys His Ile Ile Pro Lys Gly Lys Asp
1550 1555 1560
Glu Glu Thr Ala Ser Ser Ser Pro Glu Leu Glu Asn Leu Ala Ser
1565 1570 1575
Gly Leu Ala Pro Thr Leu Leu Leu Leu Ser Asp Asp Lys Asn Lys
1580 1585 1590
Pro Ala Val Glu Val Ser Ser Thr Ala Gln Gly Asp Phe Pro Ser
1595 1600 1605
Glu Lys Gln Asp Val Ala Leu Ala Glu Leu Ser Leu Glu Pro Glu
1610 1615 1620
Lys Lys Asp Lys Pro His Gln Pro Leu Glu Leu Pro Asn Ala Gly
1625 1630 1635
Ser Glu Phe Ser Ser Asp Leu Gly Arg Gln Ser Gly Ser Ile Gly
1640 1645 1650
Thr Lys Gln Ala Lys Ser Pro Ile Thr Glu Thr Glu Asp Ser Val
1655 1660 1665
Leu Glu Lys Gly Pro Ala Glu Leu Arg Ser Arg Glu Gly Lys Glu
1670 1675 1680
Glu Asn Arg Glu Leu Cys Ala Ser Ser Thr Met Pro Ala Ile Ser
1685 1690 1695
Glu Leu Ser Ser Leu Leu Arg Glu Glu Ser Gln Asn Glu Glu Ile
1700 1705 1710
Lys Pro Phe Ser Pro Lys Ile Ile Ser Leu Glu Ser Lys Glu Pro
1715 1720 1725
Pro Ala Ser Val Ala Glu Gly Gly Asn Pro Glu Glu Phe Gln Pro
1730 1735 1740
Phe Thr Phe Ser Leu Lys Gly Leu Ser Glu Glu Val Ser His Pro
1745 1750 1755
Ala Asp Phe Lys Lys Gly Gly Asn Gln Glu Ile Gly Pro Leu Pro
1760 1765 1770
Pro Thr Gly Asn Leu Lys Ala Gln Val Met Gly Asp Ile Leu Asp
1775 1780 1785
Lys Leu Ser Glu Glu Thr Gly His Pro Asn Ser Ser Gln Val Leu
1790 1795 1800
Gln Ser Ile Thr Glu Pro Ser Lys Ile Ala Pro Ser Asp Leu Leu
1805 1810 1815
Val Glu Gln Lys Lys Thr Glu Lys Ala Leu His Ser Asp Gln Thr
1820 1825 1830
Val Lys Leu Pro Asp Val Ser Thr Ser Ser Glu Asp Lys Gln Asp
1835 1840 1845
Leu Gly Ile Lys Gln Phe Ser Leu Met Arg Glu Asn Leu Pro Leu
1850 1855 1860
Glu Gln Ser Lys Ser Phe Met Thr Thr Lys Pro Ala Asp Val Lys
1865 1870 1875
Glu Thr Lys Met Glu Glu Phe Phe Ile Ser Pro Lys Asp Glu Asn
1880 1885 1890
Trp Met Leu Gly Lys Pro Glu Asn Val Ala Ser Gln His Glu Gln
1895 1900 1905
Arg Ile Ala Gly Ser Val Gln Leu Asp Ser Ser Ser Ser Asn Glu
1910 1915 1920
Leu Arg Pro Gly Gln Leu Lys Ala Ala Val Ser Ser Lys Asp His
1925 1930 1935
Thr Cys Glu Val Arg Lys Gln Val Leu Pro His Ser Ala Glu Glu
1940 1945 1950
Ser His Leu Ser Ser Gln Glu Ala Val Ser Ala Leu Asp Thr Ser
1955 1960 1965
Ser Gly Asn Thr Glu Thr Leu Ser Ser Lys Ser Tyr Ser Ser Glu
1970 1975 1980
Glu Val Lys Leu Ala Glu Glu Pro Lys Ser Leu Val Leu Ala Gly
1985 1990 1995
Asn Val Glu Arg Asn Ile Ala Glu Gly Lys Glu Ile His Ser Leu
2000 2005 2010
Met Glu Ser Glu Ser Leu Leu Leu Glu Lys Ala Asn Thr Glu Leu
2015 2020 2025
Ser Trp Pro Ser Lys Glu Asp Ser Gln Glu Lys Ile Lys Leu Pro
2030 2035 2040
Pro Glu Arg Phe Phe Gln Lys Pro Val Ser Gly Leu Ser Val Glu
2045 2050 2055
Gln Val Lys Ser Glu Thr Ile Ser Ser Ser Val Lys Thr Ala His
2060 2065 2070
Phe Pro Ala Glu Gly Val Glu Pro Ala Leu Gly Asn Glu Lys Glu
2075 2080 2085
Ala His Arg Ser Thr Pro Pro Phe Pro Glu Glu Lys Pro Leu Glu
2090 2095 2100
Glu Ser Lys Met Val Gln Ser Lys Val Ile Asp Asp Ala Asp Glu
2105 2110 2115
Gly Lys Lys Pro Ser Pro Glu Val Lys Ile Pro Thr Gln Arg Lys
2120 2125 2130
Pro Ile Ser Ser Ile His Ala Arg Glu Pro Gln Ser Pro Glu Ser
2135 2140 2145
Pro Glu Val Thr Gln Asn Pro Pro Thr Gln Pro Lys Val Ala Lys
2150 2155 2160
Pro Asp Leu Pro Glu Glu Lys Gly Lys Lys Gly Ile Ser Ser Phe
2165 2170 2175
Lys Ser Trp Met Ser Ser Leu Phe Phe Gly Ser Ser Thr Pro Asp
2180 2185 2190
Asn Lys Val Ala Glu Gln Glu Asp Leu Glu Thr Gln Pro Ser Pro
2195 2200 2205
Ser Val Glu Lys Ala Val Thr Val Ile Asp Pro Glu Gly Thr Ile
2210 2215 2220
Pro Thr Asn Phe Asn Val Ala Glu Lys Pro Ala Asp His Ser Leu
2225 2230 2235
Ser Glu Val Lys Leu Lys Thr Ala Asp Glu Pro Arg Gly Thr Leu
2240 2245 2250
Val Lys Ser Gly Asp Gly Gln Asn Val Lys Glu Lys Ser Met Ile
2255 2260 2265
Leu Ser Asn Val Glu Asp Leu Gln Gln Pro Lys Phe Ile Ser Glu
2270 2275 2280
Val Ser Arg Glu Asp Tyr Gly Lys Lys Glu Ile Ser Gly Asp Ser
2285 2290 2295
Glu Glu Met Asn Ile Asn Ser Val Val Thr Ser Ala Asp Gly Glu
2300 2305 2310
Asn Leu Glu Ile Gln Ser Tyr Ser Leu Ile Gly Glu Lys Leu Val
2315 2320 2325
Met Glu Glu Ala Lys Thr Ile Val Pro Pro His Val Thr Asp Ser
2330 2335 2340
Lys Arg Val Gln Lys Pro Ala Ile Ala Pro Pro Ser Lys Trp Asn
2345 2350 2355
Ile Ser Ile Phe Lys Glu Glu Pro Arg Ser Asp Gln Lys Gln Lys
2360 2365 2370
Ser Leu Leu Ser Phe Asp Val Val Asp Lys Val Pro Gln Gln Pro
2375 2380 2385
Lys Ser Ala Ser Ser Asn Phe Ala Ser Lys Asn Ile Thr Lys Glu
2390 2395 2400
Ser Glu Lys Pro Glu Ser Ile Ile Leu Pro Val Glu Glu Ser Lys
2405 2410 2415
Gly Ser Leu Ile Asp Phe Ser Glu Asp Arg Leu Lys Lys Glu Met
2420 2425 2430
Gln Asn Pro Thr Ser Leu Lys Ile Ser Glu Glu Glu Thr Lys Leu
2435 2440 2445
Arg Ser Val Ser Pro Thr Glu Lys Lys Asp Asn Leu Glu Asn Arg
2450 2455 2460
Ser Tyr Thr Leu Ala Glu Lys Lys Val Leu Ala Glu Lys Gln Asn
2465 2470 2475
Ser Val Ala Pro Leu Glu Leu Arg Asp Ser Asn Glu Ile Gly Lys
2480 2485 2490
Thr Gln Ile Thr Leu Gly Ser Arg Ser Thr Glu Leu Lys Glu Ser
2495 2500 2505
Lys Ala Asp Ala Met Pro Gln His Phe Tyr Gln Asn Glu Asp Tyr
2510 2515 2520
Asn Glu Arg Pro Lys Ile Ile Val Gly Ser Glu Lys Glu Lys Gly
2525 2530 2535
Glu Glu Lys Glu Asn Gln Val Tyr Val Leu Ser Glu Gly Lys Lys
2540 2545 2550
Gln Gln Glu His Gln Pro Tyr Ser Val Asn Val Ala Glu Ser Met
2555 2560 2565
Ser Arg Glu Ser Asp Ile Ser Leu Gly His Ser Leu Gly Glu Thr
2570 2575 2580
Gln Ser Phe Ser Leu Val Lys Ala Thr Ser Val Thr Glu Lys Ser
2585 2590 2595
Glu Ala Met Leu Ala Glu Ala His Pro Glu Ile Arg Glu Ala Lys
2600 2605 2610
Ala Val Gly Thr Gln Pro His Pro Leu Glu Glu Ser Lys Val Leu
2615 2620 2625
Val Glu Lys Thr Lys Thr Phe Leu Pro Val Ala Leu Ser Cys Arg
2630 2635 2640
Asp Glu Ile Glu Asn His Ser Leu Ser Gln Glu Gly Asn Leu Val
2645 2650 2655
Leu Glu Lys Ser Ser Arg Asp Met Pro Asp His Ser Glu Glu Lys
2660 2665 2670
Glu Gln Phe Arg Glu Ser Glu Leu Ser Lys Gly Gly Ser Val Asp
2675 2680 2685
Ile Thr Lys Glu Thr Val Lys Gln Gly Phe Gln Glu Lys Ala Val
2690 2695 2700
Gly Thr Gln Pro Arg Pro Leu Glu Glu Ser Lys Val Leu Val Glu
2705 2710 2715
Lys Thr Lys Thr Phe Leu Pro Val Val Leu Ser Cys His Asp Glu
2720 2725 2730
Ile Glu Asn His Ser Leu Ser Gln Glu Gly Asn Leu Val Leu Glu
2735 2740 2745
Lys Ser Ser Arg Asp Met Pro Asp His Ser Glu Glu Lys Glu Gln
2750 2755 2760
Phe Lys Glu Ser Glu Leu Trp Lys Gly Gly Ser Val Asp Ile Thr
2765 2770 2775
Lys Glu Ser Met Lys Glu Gly Phe Pro Ser Lys Glu Ser Glu Arg
2780 2785 2790
Thr Leu Ala Arg Pro Phe Asp Glu Thr Lys Ser Ser Glu Thr Pro
2795 2800 2805
Pro Tyr Leu Leu Ser Pro Val Lys Pro Gln Thr Leu Ala Ser Gly
2810 2815 2820
Ala Ser Pro Glu Ile Asn Ala Val Lys Lys Lys Glu Met Pro Arg
2825 2830 2835
Ser Glu Leu Thr Pro Glu Arg His Thr Val His Thr Ile Gln Thr
2840 2845 2850
Ser Lys Asp Asp Thr Ser Asp Val Pro Lys Gln Ser Val Leu Val
2855 2860 2865
Ser Lys His His Leu Glu Ala Ala Glu Asp Thr Arg Val Lys Glu
2870 2875 2880
Pro Leu Ser Ser Ala Lys Ser Asn Tyr Ala Gln Phe Ile Ser Asn
2885 2890 2895
Thr Ser Ala Ser Asn Ala Asp Lys Met Val Ser Asn Lys Glu Met
2900 2905 2910
Pro Lys Glu Pro Glu Asp Thr Tyr Ala Lys Gly Glu Asp Phe Thr
2915 2920 2925
Val Thr Ser Lys Pro Ala Gly Leu Ser Glu Asp Gln Lys Thr Ala
2930 2935 2940
Phe Ser Ile Ile Ser Glu Gly Cys Glu Ile Leu Asn Ile His Ala
2945 2950 2955
Pro Ala Phe Ile Ser Ser Ile Asp Gln Glu Glu Ser Glu Gln Met
2960 2965 2970
Gln Asp Lys Leu Glu Tyr Leu Glu Glu Lys Ala Ser Phe Lys Thr
2975 2980 2985
Ile Pro Leu Pro Asp Asp Ser Glu Thr Val Ala Cys His Lys Thr
2990 2995 3000
Leu Lys Ser Arg Leu Glu Asp Glu Lys Val Thr Pro Leu Lys Glu
3005 3010 3015
Asn Lys Gln Lys Glu Thr His Lys Thr Lys Glu Glu Ile Ser Thr
3020 3025 3030
Asp Ser Glu Thr Asp Leu Ser Phe Ile Gln Pro Thr Ile Pro Ser
3035 3040 3045
Glu Glu Asp Tyr Phe Glu Lys Tyr Thr Leu Ile Asp Tyr Asn Ile
3050 3055 3060
Ser Pro Asp Pro Glu Lys Gln Lys Ala Pro Gln Lys Leu Asn Val
3065 3070 3075
Glu Glu Lys Leu Ser Lys Glu Val Thr Glu Glu Thr Ile Ser Phe
3080 3085 3090
Pro Val Ser Ser Val Glu Ser Ala Leu Glu His Glu Tyr Asp Leu
3095 3100 3105
Val Lys Leu Asp Glu Ser Phe Tyr Gly Pro Glu Lys Gly His Asn
3110 3115 3120
Ile Leu Ser His Pro Glu Thr Gln Ser Gln Asn Ser Ala Asp Arg
3125 3130 3135
Asn Val Ser Lys Asp Thr Lys Arg Asp Val Asp Ser Lys Ser Pro
3140 3145 3150
Gly Met Pro Leu Phe Glu Ala Glu Glu Gly Val Leu Ser Arg Thr
3155 3160 3165
Gln Ile Phe Pro Thr Thr Ile Lys Val Ile Asp Pro Glu Phe Leu
3170 3175 3180
Glu Glu Pro Pro Ala Leu Ala Phe Leu Tyr Lys Asp Leu Tyr Glu
3185 3190 3195
Glu Ala Val Gly Glu Lys Lys Lys Glu Glu Glu Thr Ala Ser Glu
3200 3205 3210
Gly Asp Ser Val Asn Ser Glu Ala Ser Phe Pro Ser Arg Asn Ser
3215 3220 3225
Asp Thr Asp Asp Gly Thr Gly Ile Tyr Phe Glu Lys Tyr Ile Leu
3230 3235 3240
Lys Asp Asp Ile Leu His Asp Thr Ser Leu Thr Gln Lys Asp Gln
3245 3250 3255
Gly Gln Gly Leu Glu Glu Lys Arg Val Gly Lys Asp Asp Ser Tyr
3260 3265 3270
Gln Pro Ile Ala Ala Glu Gly Glu Ile Trp Gly Lys Phe Gly Thr
3275 3280 3285
Ile Cys Arg Glu Lys Ser Leu Glu Glu Gln Lys Gly Val Tyr Gly
3290 3295 3300
Glu Gly Glu Ser Val Asp His Val Glu Thr Val Gly Asn Val Ala
3305 3310 3315
Met Gln Lys Lys Ala Pro Ile Thr Glu Asp Val Arg Val Ala Thr
3320 3325 3330
Gln Lys Ile Ser Tyr Ala Val Pro Phe Glu Asp Thr His His Val
3335 3340 3345
Leu Glu Arg Ala Asp Glu Ala Gly Ser His Gly Asn Glu Val Gly
3350 3355 3360
Asn Ala Ser Pro Glu Val Asn Leu Asn Val Pro Val Gln Val Ser
3365 3370 3375
Phe Pro Glu Glu Glu Phe Ala Ser Gly Ala Thr His Val Gln Glu
3380 3385 3390
Thr Ser Leu Glu Glu Pro Lys Ile Leu Val Pro Pro Glu Pro Ser
3395 3400 3405
Glu Glu Arg Leu Arg Asn Ser Pro Val Gln Asp Glu Tyr Glu Phe
3410 3415 3420
Thr Glu Ser Leu His Asn Glu Val Val Pro Gln Asp Ile Leu Ser
3425 3430 3435
Glu Glu Leu Ser Ser Glu Ser Thr Pro Glu Asp Val Leu Ser Gln
3440 3445 3450
Gly Lys Glu Ser Phe Glu His Ile Ser Glu Asn Glu Phe Ala Ser
3455 3460 3465
Glu Ala Glu Gln Ser Thr Pro Ala Glu Gln Lys Glu Leu Gly Ser
3470 3475 3480
Glu Arg Lys Glu Glu Asp Gln Leu Ser Ser Glu Val Val Thr Glu
3485 3490 3495
Lys Ala Gln Lys Glu Leu Lys Lys Ser Gln Ile Asp Thr Tyr Cys
3500 3505 3510
Tyr Thr Cys Lys Cys Pro Ile Ser Ala Thr Asp Lys Val Phe Gly
3515 3520 3525
Thr His Lys Asp His Glu Val Ser Thr Leu Asp Thr Ala Ile Ser
3530 3535 3540
Ala Val Lys Val Gln Leu Ala Glu Phe Leu Glu Asn Leu Gln Glu
3545 3550 3555
Lys Ser Leu Arg Ile Glu Ala Phe Val Ser Glu Ile Glu Ser Phe
3560 3565 3570
Phe Asn Thr Ile Glu Glu Asn Cys Ser Lys Asn Glu Lys Arg Leu
3575 3580 3585
Glu Glu Gln Asn Glu Glu Met Met Lys Lys Val Leu Ala Gln Tyr
3590 3595 3600
Asp Glu Lys Ala Gln Ser Phe Glu Glu Val Lys Lys Lys Lys Met
3605 3610 3615
Glu Phe Leu His Glu Gln Met Val His Phe Leu Gln Ser Met Asp
3620 3625 3630
Thr Ala Lys Asp Thr Leu Glu Thr Ile Val Arg Glu Ala Glu Glu
3635 3640 3645
Leu Asp Glu Ala Val Phe Leu Thr Ser Phe Glu Glu Ile Asn Glu
3650 3655 3660
Arg Leu Leu Ser Ala Met Glu Ser Thr Ala Ser Leu Glu Lys Met
3665 3670 3675
Pro Ala Ala Phe Ser Leu Phe Glu His Tyr Asp Asp Ser Ser Ala
3680 3685 3690
Arg Ser Asp Gln Met Leu Lys Gln Val Ala Val Pro Gln Pro Pro
3695 3700 3705
Arg Leu Glu Pro Gln Glu Pro Asn Ser Ala Thr Ser Thr Thr Ile
3710 3715 3720
Ala Val Tyr Trp Ser Met Asn Lys Glu Asp Val Ile Asp Ser Phe
3725 3730 3735
Gln Val Tyr Cys Met Glu Glu Pro Gln Asp Asp Gln Glu Val Asn
3740 3745 3750
Glu Leu Val Glu Glu Tyr Arg Leu Thr Val Lys Glu Ser Tyr Cys
3755 3760 3765
Ile Phe Glu Asp Leu Glu Pro Asp Arg Cys Tyr Gln Val Trp Val
3770 3775 3780
Met Ala Val Asn Phe Thr Gly Cys Ser Leu Pro Ser Glu Arg Ala
3785 3790 3795
Ile Phe Arg Thr Ala Pro Ser Thr Pro Val Ile Arg Ala Glu Asp
3800 3805 3810
Cys Thr Val Cys Trp Asn Thr Ala Thr Ile Arg Trp Arg Pro Thr
3815 3820 3825
Thr Pro Glu Ala Thr Glu Thr Tyr Thr Leu Glu Tyr Cys Arg Gln
3830 3835 3840
His Ser Pro Glu Gly Glu Gly Leu Arg Ser Phe Ser Gly Ile Lys
3845 3850 3855
Gly Leu Gln Leu Lys Val Asn Leu Gln Pro Asn Asp Asn Tyr Phe
3860 3865 3870
Phe Tyr Val Arg Ala Ile Asn Ala Phe Gly Thr Ser Glu Gln Ser
3875 3880 3885
Glu Ala Ala Leu Ile Ser Thr Arg Gly Thr Arg Phe Leu Leu Leu
3890 3895 3900
Arg Glu Thr Ala His Pro Ala Leu His Ile Ser Ser Ser Gly Thr
3905 3910 3915
Val Ile Ser Phe Gly Glu Arg Arg Arg Leu Thr Glu Ile Pro Ser
3920 3925 3930
Val Leu Gly Glu Glu Leu Pro Ser Cys Gly Gln His Tyr Trp Glu
3935 3940 3945
Thr Thr Val Thr Asp Cys Pro Ala Tyr Arg Leu Gly Ile Cys Ser
3950 3955 3960
Ser Ser Ala Val Gln Ala Gly Ala Leu Gly Gln Gly Glu Thr Ser
3965 3970 3975
Trp Tyr Met His Cys Ser Glu Pro Gln Arg Tyr Thr Phe Phe Tyr
3980 3985 3990
Ser Gly Ile Val Ser Asp Val His Val Thr Glu Arg Pro Ala Arg
3995 4000 4005
Val Gly Ile Leu Leu Asp Tyr Asn Asn Gln Arg Leu Ile Phe Ile
4010 4015 4020
Asn Ala Glu Ser Glu Gln Leu Leu Phe Ile Ile Arg His Arg Phe
4025 4030 4035
Asn Glu Gly Val His Pro Ala Phe Ala Leu Glu Lys Pro Gly Lys
4040 4045 4050
Cys Thr Leu His Leu Gly Ile Glu Pro Pro Asp Ser Val Arg His
4055 4060 4065
Lys
<210> 166
<211> 1350
<212> DNA
<213> Homo sapiens
<400> 166
atggcttctg ctatcacgca gtgttctacc agtgagctca cctgctcgat ctgcacagac 60
tatttgacag accctgtcac catttgttgt gggcacagat tttgtagtcc ctgtctctgc 120
ctcttgtggg aagatacact aactcctaat tgctgccctg tgtgcaggga aatatcacag 180
caaatgtact tcaaacgcat tatttttgct gagaaacaag ttattcctac aagagaatca 240
gtcccctgcc agttatcaag ctctgccatg ctgatctgta ggagacacca ggaaatcaag 300
aacctcatct gtgaaactga taggagcctg ctgtgttttc tatgctctca atccccaagg 360
catgctactc acaaacacta tatgacaagg gaggctgatg aatactatag gaagaaactc 420
ctgattcaaa tgaagtccat ctggaaaaaa aaacagaaaa atcaaagaaa tctaaacaga 480
gagaccaaca taatcggaac atgggaagtt tttataaatt tgcggagcat gatgatcagt 540
gctgaatatc ctaaggtgtg tcaatacctc cgtgaagaag agcaaaagca cgtagagagc 600
ctggcaagag aaggcaggat aatttttcag caactcaaga gaagtcaaac tagaatggct 660
aagatgggta tactcctgag agaaatgtat gagaaactga aggaaatgag ctgtaaagca 720
gatgtgaacc tgcctcagga tttgggagac gtaatgaaaa ggaatgagtt tctgaggctg 780
gccatgcctc agcctgtgaa cccacagctc agtgcatgga ccatcactgg ggtgtcagaa 840
aggcttaact tcttcagagt gtatatcacc ttggatcgta agatatgcag taatcacaag 900
cttctgttcg aagacctaag gcatttgcag tgcagccttg atgatacaga catgtcctgt 960
aatccaacaa gtacacagta tacttcttca tggggagctc agatcctcag ctctggcaaa 1020
cattactggg aggtggatgt gaaagactct tgtaattggg ttataggact ttgcagagaa 1080
gcctggacaa agaggaatga catgcgactt gactctgagg gtatctttct actcctgtgt 1140
ctcaaagtgg atgaccattt cagtctcttc tctacctccc cactgttacc tcactatatt 1200
ccaaggcccc aaggctggct aggggtgttc ctggattatg aatgtgggat agtgagcttt 1260
gttaatgttg cccaaagttc cctcatttgt agtttcctct cacgcatctt ctattttcct 1320
ctcagacctt tcatttgcca cggatctaaa 1350
<210> 167
<211> 450
<212> PRT
<213> Homo sapiens
<400> 167
Met Ala Ser Ala Ile Thr Gln Cys Ser Thr Ser Glu Leu Thr Cys Ser
1 5 10 15
Ile Cys Thr Asp Tyr Leu Thr Asp Pro Val Thr Ile Cys Cys Gly His
20 25 30
Arg Phe Cys Ser Pro Cys Leu Cys Leu Leu Trp Glu Asp Thr Leu Thr
35 40 45
Pro Asn Cys Cys Pro Val Cys Arg Glu Ile Ser Gln Gln Met Tyr Phe
50 55 60
Lys Arg Ile Ile Phe Ala Glu Lys Gln Val Ile Pro Thr Arg Glu Ser
65 70 75 80
Val Pro Cys Gln Leu Ser Ser Ser Ala Met Leu Ile Cys Arg Arg His
85 90 95
Gln Glu Ile Lys Asn Leu Ile Cys Glu Thr Asp Arg Ser Leu Leu Cys
100 105 110
Phe Leu Cys Ser Gln Ser Pro Arg His Ala Thr His Lys His Tyr Met
115 120 125
Thr Arg Glu Ala Asp Glu Tyr Tyr Arg Lys Lys Leu Leu Ile Gln Met
130 135 140
Lys Ser Ile Trp Lys Lys Lys Gln Lys Asn Gln Arg Asn Leu Asn Arg
145 150 155 160
Glu Thr Asn Ile Ile Gly Thr Trp Glu Val Phe Ile Asn Leu Arg Ser
165 170 175
Met Met Ile Ser Ala Glu Tyr Pro Lys Val Cys Gln Tyr Leu Arg Glu
180 185 190
Glu Glu Gln Lys His Val Glu Ser Leu Ala Arg Glu Gly Arg Ile Ile
195 200 205
Phe Gln Gln Leu Lys Arg Ser Gln Thr Arg Met Ala Lys Met Gly Ile
210 215 220
Leu Leu Arg Glu Met Tyr Glu Lys Leu Lys Glu Met Ser Cys Lys Ala
225 230 235 240
Asp Val Asn Leu Pro Gln Asp Leu Gly Asp Val Met Lys Arg Asn Glu
245 250 255
Phe Leu Arg Leu Ala Met Pro Gln Pro Val Asn Pro Gln Leu Ser Ala
260 265 270
Trp Thr Ile Thr Gly Val Ser Glu Arg Leu Asn Phe Phe Arg Val Tyr
275 280 285
Ile Thr Leu Asp Arg Lys Ile Cys Ser Asn His Lys Leu Leu Phe Glu
290 295 300
Asp Leu Arg His Leu Gln Cys Ser Leu Asp Asp Thr Asp Met Ser Cys
305 310 315 320
Asn Pro Thr Ser Thr Gln Tyr Thr Ser Ser Trp Gly Ala Gln Ile Leu
325 330 335
Ser Ser Gly Lys His Tyr Trp Glu Val Asp Val Lys Asp Ser Cys Asn
340 345 350
Trp Val Ile Gly Leu Cys Arg Glu Ala Trp Thr Lys Arg Asn Asp Met
355 360 365
Arg Leu Asp Ser Glu Gly Ile Phe Leu Leu Leu Cys Leu Lys Val Asp
370 375 380
Asp His Phe Ser Leu Phe Ser Thr Ser Pro Leu Leu Pro His Tyr Ile
385 390 395 400
Pro Arg Pro Gln Gly Trp Leu Gly Val Phe Leu Asp Tyr Glu Cys Gly
405 410 415
Ile Val Ser Phe Val Asn Val Ala Gln Ser Ser Leu Ile Cys Ser Phe
420 425 430
Leu Ser Arg Ile Phe Tyr Phe Pro Leu Arg Pro Phe Ile Cys His Gly
435 440 445
Ser Lys
450
<210> 168
<211> 68
<212> PRT
<213> Artificial Sequence
<220>
<223> Leader Sequence
<220>
<221> MISC_FEATURE
<222> (5)..(11)
<223> 6His Tag
<220>
<221> MISC_FEATURE
<222> (40)..(51)
<223> TAT peptide
<220>
<221> MISC_FEATURE
<222> (58)..(67)
<223> HA tag
<400> 168
Met Arg Gly Ser His His His His His His Gly Met Ala Ser Met Thr
1 5 10 15
Gly Gly Gln Gln Met Gly Arg Asp Leu Tyr Asp Asp Asp Asp Lys Asp
20 25 30
Arg Trp Gly Ser Lys Leu Gly Tyr Gly Arg Lys Lys Arg Arg Gln Arg
35 40 45
Arg Arg Gly Gly Ser Thr Met Ser Gly Tyr Pro Tyr Asp Val Pro Asp
50 55 60
Tyr Ala Gly Ser
65
<210> 169
<211> 536
<212> PRT
<213> Artificial Sequence
<220>
<223> Leader sequence and TRIM11
<400> 169
Met Arg Gly Ser His His His His His His Gly Met Ala Ser Met Thr
1 5 10 15
Gly Gly Gln Gln Met Gly Arg Asp Leu Tyr Asp Asp Asp Asp Lys Asp
20 25 30
Arg Trp Gly Ser Lys Leu Gly Tyr Gly Arg Lys Lys Arg Arg Gln Arg
35 40 45
Arg Arg Gly Gly Ser Thr Met Ser Gly Tyr Pro Tyr Asp Val Pro Asp
50 55 60
Tyr Ala Gly Ser Met Ala Ala Pro Asp Leu Ser Thr Asn Leu Gln Glu
65 70 75 80
Glu Ala Thr Cys Ala Ile Cys Leu Asp Tyr Phe Thr Asp Pro Val Met
85 90 95
Thr Asp Cys Gly His Asn Phe Cys Arg Glu Cys Ile Arg Arg Cys Trp
100 105 110
Gly Gln Pro Glu Gly Pro Tyr Ala Cys Pro Glu Cys Arg Glu Leu Ser
115 120 125
Pro Gln Arg Asn Leu Arg Pro Asn Arg Pro Leu Ala Lys Met Ala Glu
130 135 140
Met Ala Arg Arg Leu His Pro Pro Ser Pro Val Pro Gln Gly Val Cys
145 150 155 160
Pro Ala His Arg Glu Pro Leu Ala Ala Phe Cys Gly Asp Glu Leu Arg
165 170 175
Leu Leu Cys Ala Ala Cys Glu Arg Ser Gly Glu His Trp Ala His Arg
180 185 190
Val Arg Pro Leu Gln Asp Ala Ala Glu Asp Leu Lys Ala Lys Leu Glu
195 200 205
Lys Ser Leu Glu His Leu Arg Lys Gln Met Gln Asp Ala Leu Leu Phe
210 215 220
Gln Ala Gln Ala Asp Glu Thr Cys Val Leu Trp Gln Lys Met Val Glu
225 230 235 240
Ser Gln Arg Gln Asn Val Leu Gly Glu Phe Glu Arg Leu Arg Arg Leu
245 250 255
Leu Ala Glu Glu Glu Gln Gln Leu Leu Gln Arg Leu Glu Glu Glu Glu
260 265 270
Leu Glu Val Leu Pro Arg Leu Arg Glu Gly Ala Ala His Leu Gly Gln
275 280 285
Gln Ser Ala His Leu Ala Glu Leu Ile Ala Glu Leu Glu Gly Arg Cys
290 295 300
Gln Leu Pro Ala Leu Gly Leu Leu Gln Asp Ile Lys Asp Ala Leu Arg
305 310 315 320
Arg Val Gln Asp Val Lys Leu Gln Pro Pro Glu Val Val Pro Met Glu
325 330 335
Leu Arg Thr Val Cys Arg Val Pro Gly Leu Val Glu Thr Leu Arg Arg
340 345 350
Phe Arg Gly Asp Val Thr Leu Asp Pro Asp Thr Ala Asn Pro Glu Leu
355 360 365
Ile Leu Ser Glu Asp Arg Arg Ser Val Gln Arg Gly Asp Leu Arg Gln
370 375 380
Ala Leu Pro Asp Ser Pro Glu Arg Phe Asp Pro Gly Pro Cys Val Leu
385 390 395 400
Gly Gln Glu Arg Phe Thr Ser Gly Arg His Tyr Trp Glu Val Glu Val
405 410 415
Gly Asp Arg Thr Ser Trp Ala Leu Gly Val Cys Arg Glu Asn Val Asn
420 425 430
Arg Lys Glu Lys Gly Glu Leu Ser Ala Gly Asn Gly Phe Trp Ile Leu
435 440 445
Val Phe Leu Gly Ser Tyr Tyr Asn Ser Ser Glu Arg Ala Leu Ala Pro
450 455 460
Leu Arg Asp Pro Pro Arg Arg Val Gly Ile Phe Leu Asp Tyr Glu Ala
465 470 475 480
Gly His Leu Ser Phe Tyr Ser Ala Thr Asp Gly Ser Leu Leu Phe Ile
485 490 495
Phe Pro Glu Ile Pro Phe Ser Gly Thr Leu Arg Pro Leu Phe Ser Pro
500 505 510
Leu Ser Ser Ser Pro Thr Pro Met Thr Ile Cys Arg Pro Lys Gly Gly
515 520 525
Ser Gly Asp Thr Leu Ala Pro Gln
530 535
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| КОМПОЗИЦИИ И СПОСОБЫ РЕДАКТИРОВАНИЯ ГЕНОВ | 2019 |
|
RU2804665C2 |
| КОМПОЗИЦИИ И СПОСОБЫ ДЛЯ ИЗБИРАТЕЛЬНОЙ ЭКСПРЕССИИ БЕЛКА | 2017 |
|
RU2795467C2 |
| КОНСТРУКЦИИ ДНК-АНТИТЕЛ ДЛЯ ПРИМЕНЕНИЯ ПРОТИВ БОЛЕЗНИ ЛАЙМА | 2017 |
|
RU2813829C2 |
| МОДИФИЦИРОВАННЫЕ НЕПРИРОДНЫЕ ЛИГАНДЫ NKG2D, КОТОРЫЕ ИЗБИРАТЕЛЬНО ДОСТАВЛЯЮТ ПРИСОЕДИНЕННЫЕ ГЕТЕРОЛОГИЧНЫЕ МОЛЕКУЛЫ К НЕПРИРОДНЫМ РЕЦЕПТОРАМ NKG2D НА CAR-КЛЕТКАХ | 2020 |
|
RU2823728C2 |
| ВЕКТОРЫ AAV, НАЦЕЛЕННЫЕ НА ЦЕНТРАЛЬНУЮ НЕРВНУЮ СИСТЕМУ | 2015 |
|
RU2727015C2 |
| ГЛИКАНЗАВИСИМЫЕ ИММУНОТЕРАПЕВТИЧЕСКИЕ МОЛЕКУЛЫ | 2016 |
|
RU2754661C2 |
| ЛЕЧЕНИЕ РАКА С ИСПОЛЬЗОВАНИЕМ ХИМЕРНОГО АНТИГЕНСПЕЦИФИЧЕСКОГО РЕЦЕПТОРА НА ОСНОВЕ ГУМАНИЗИРОВАННОГО АНТИТЕЛА ПРОТИВ EGFRvIII | 2014 |
|
RU2831418C2 |
| ВИРУС ГРИППА, СПОСОБНЫЙ ИНФИЦИРОВАТЬ СОБАЧЬИХ, И ЕГО ПРИМЕНЕНИЕ | 2020 |
|
RU2802222C2 |
| T-КЛЕТОЧНЫЕ РЕЦЕПТОРЫ, РАСПОЗНАЮЩИЕ МУТАЦИЮ R175H ИЛИ Y220C В P53 | 2020 |
|
RU2830061C2 |
| ВАКЦИНА И СПОСОБЫ ОБНАРУЖЕНИЯ И ПРОФИЛАКТИКИ ФИЛЯРИОЗА | 2021 |
|
RU2832185C1 |

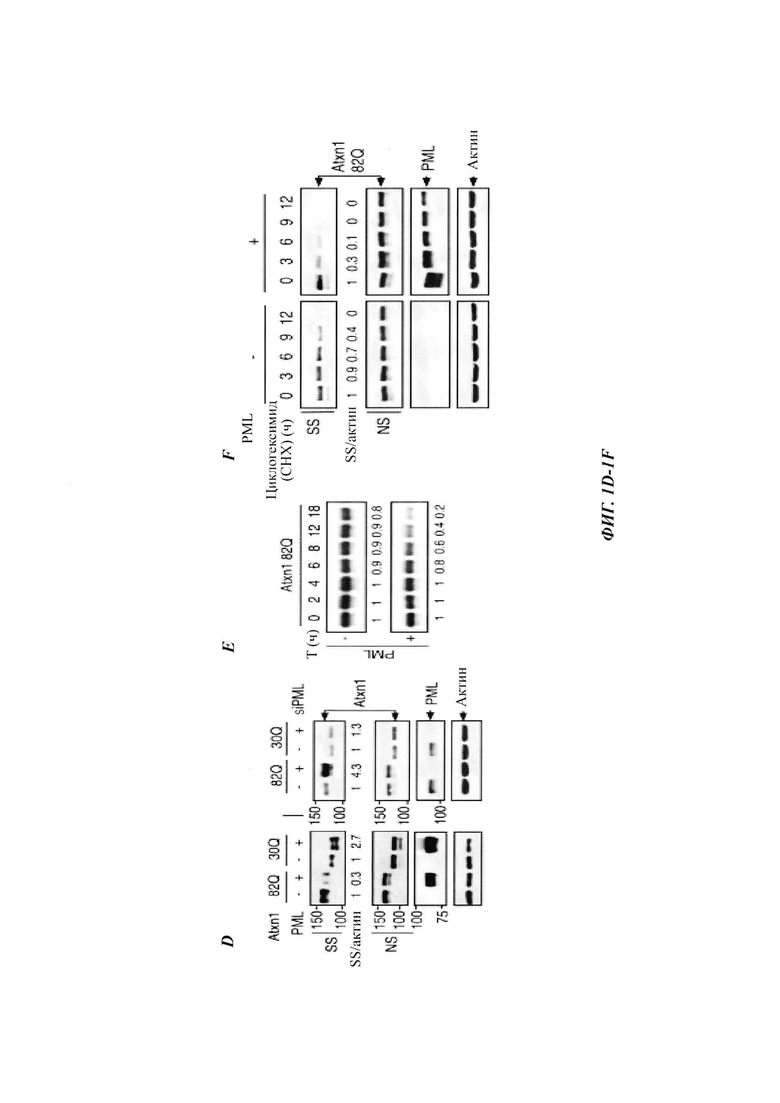

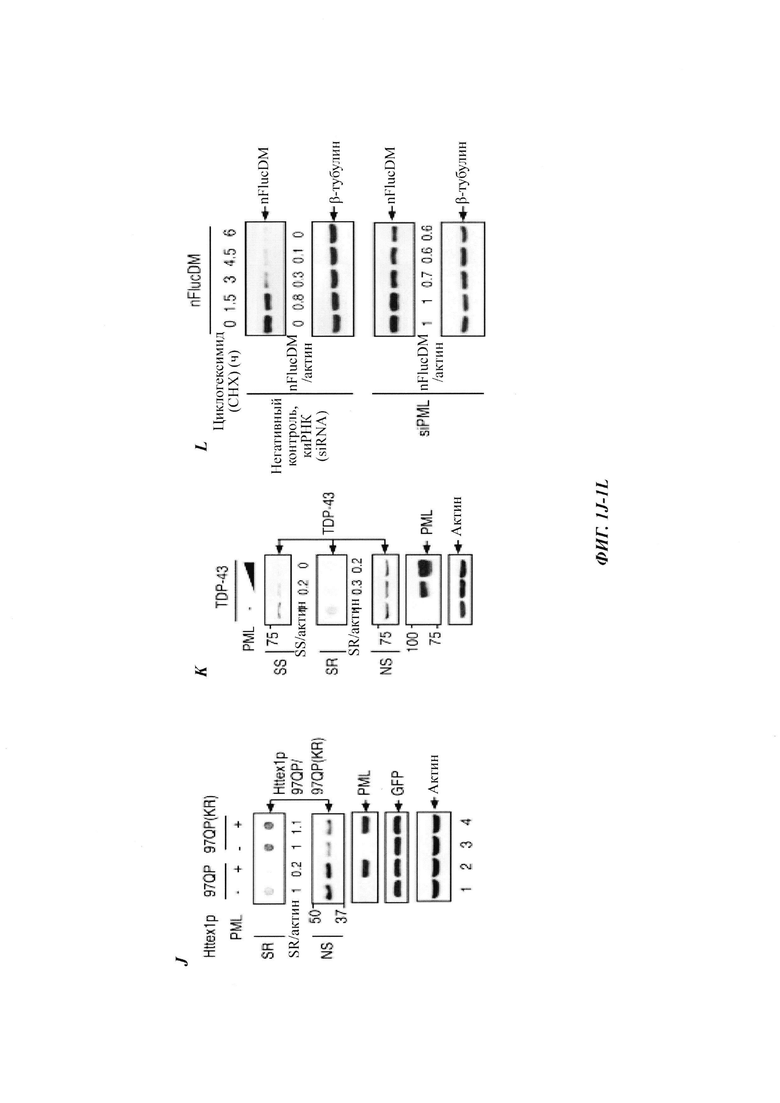

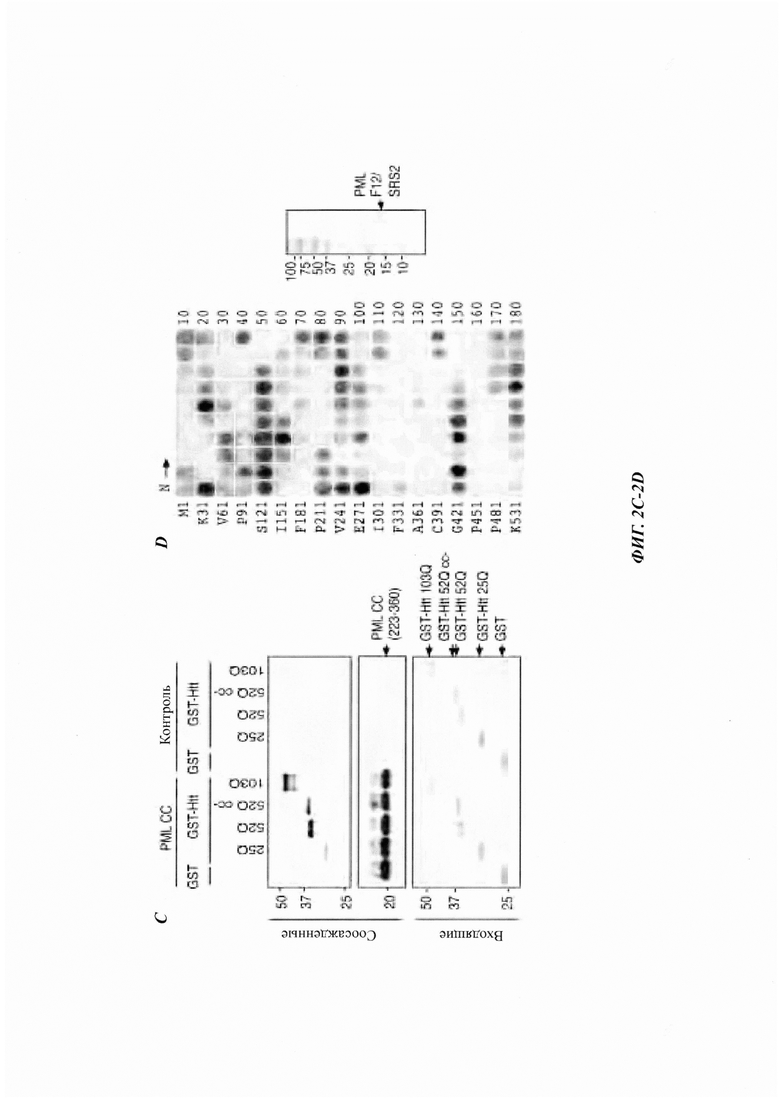
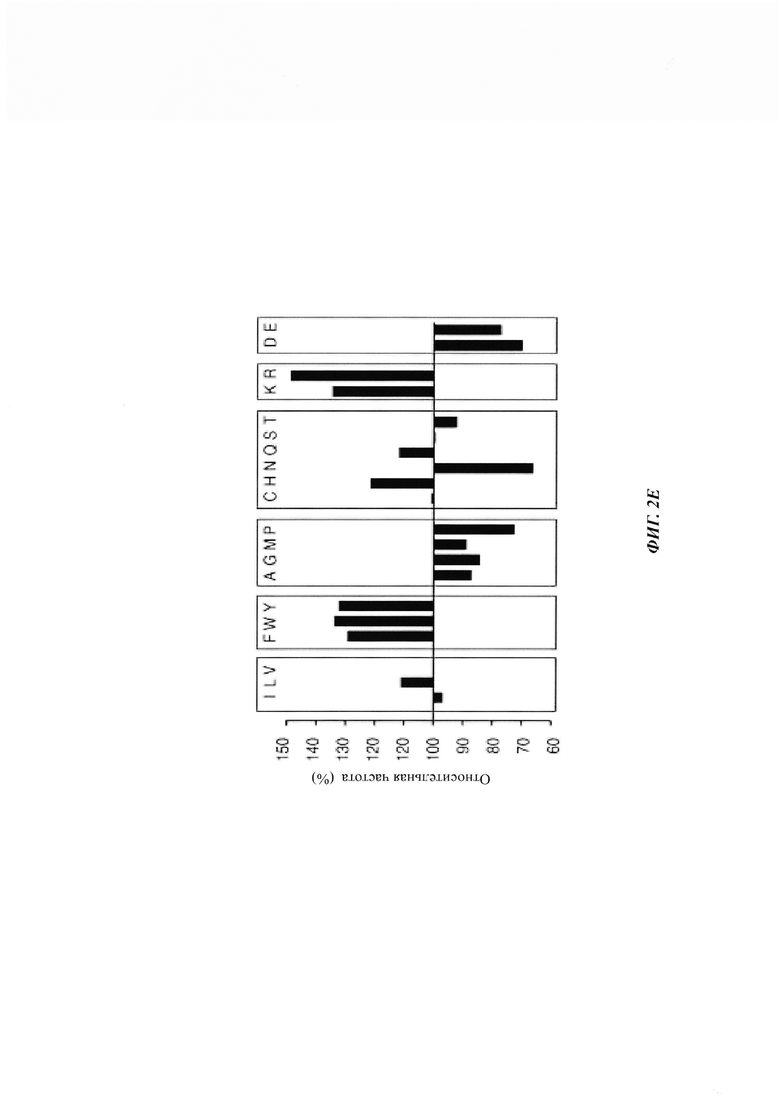

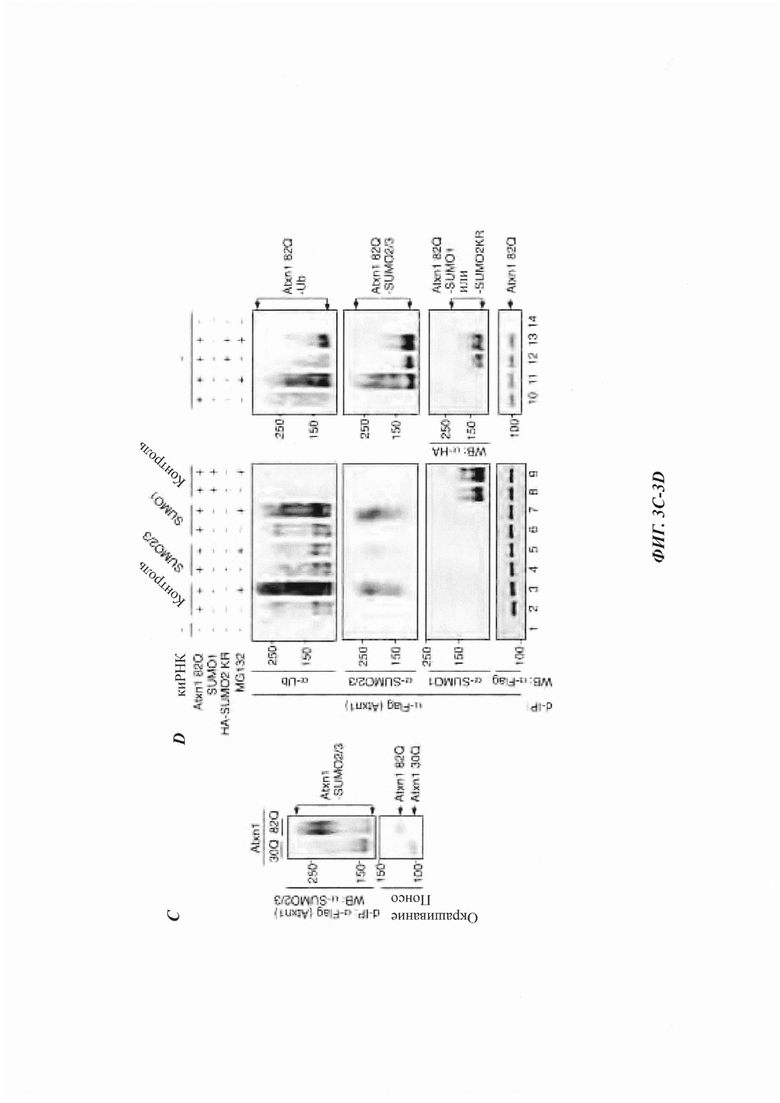

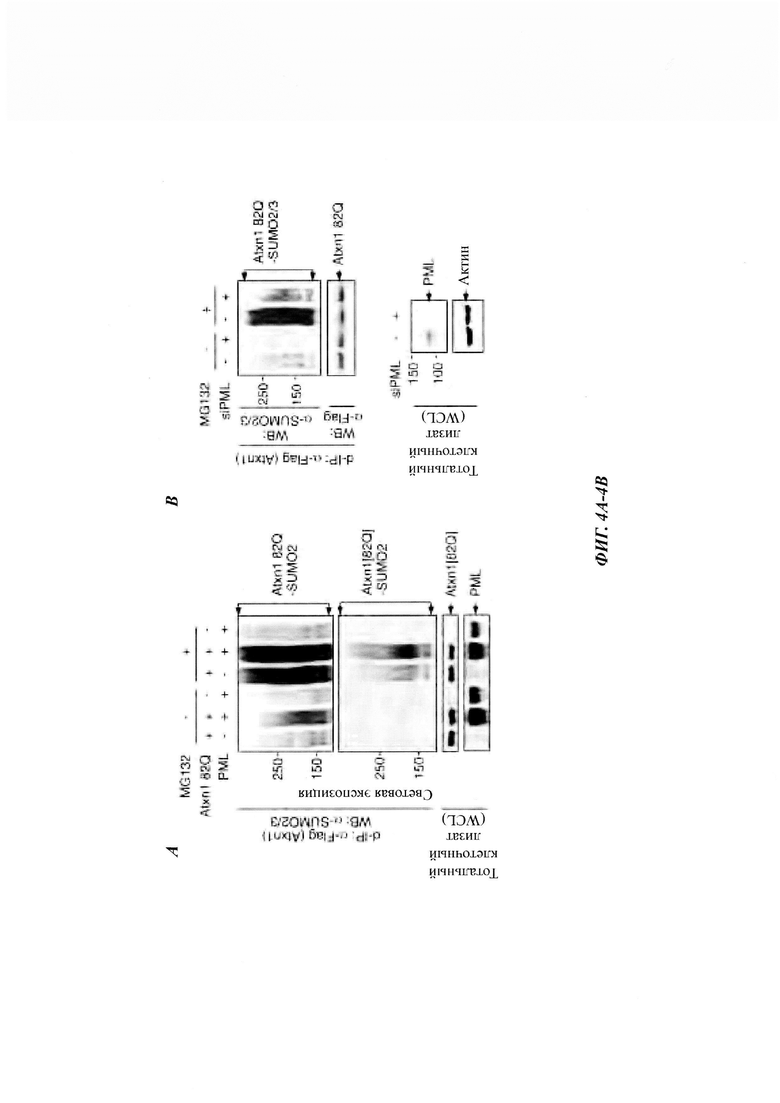

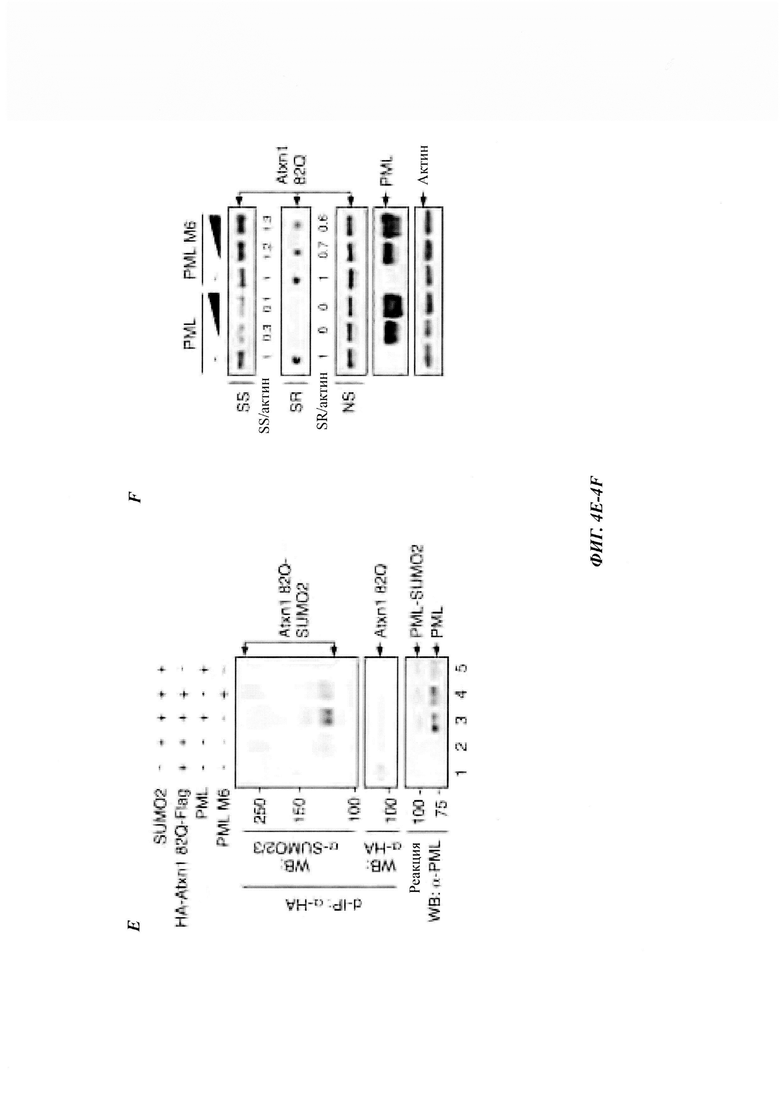
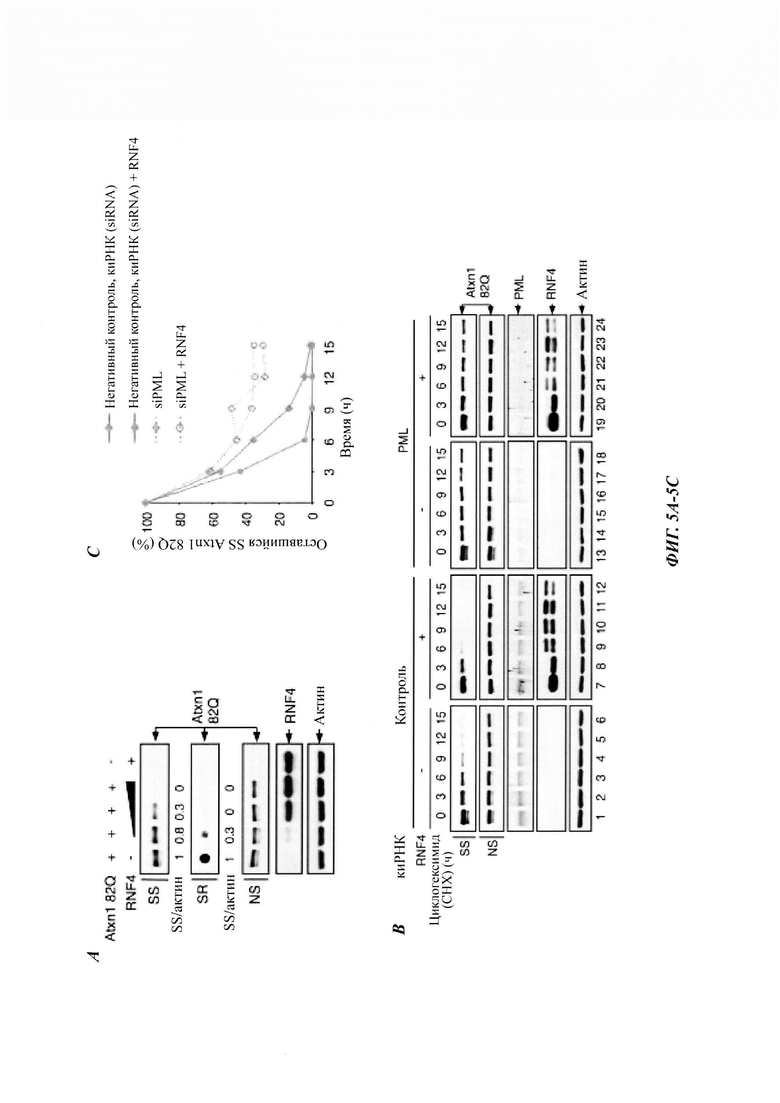
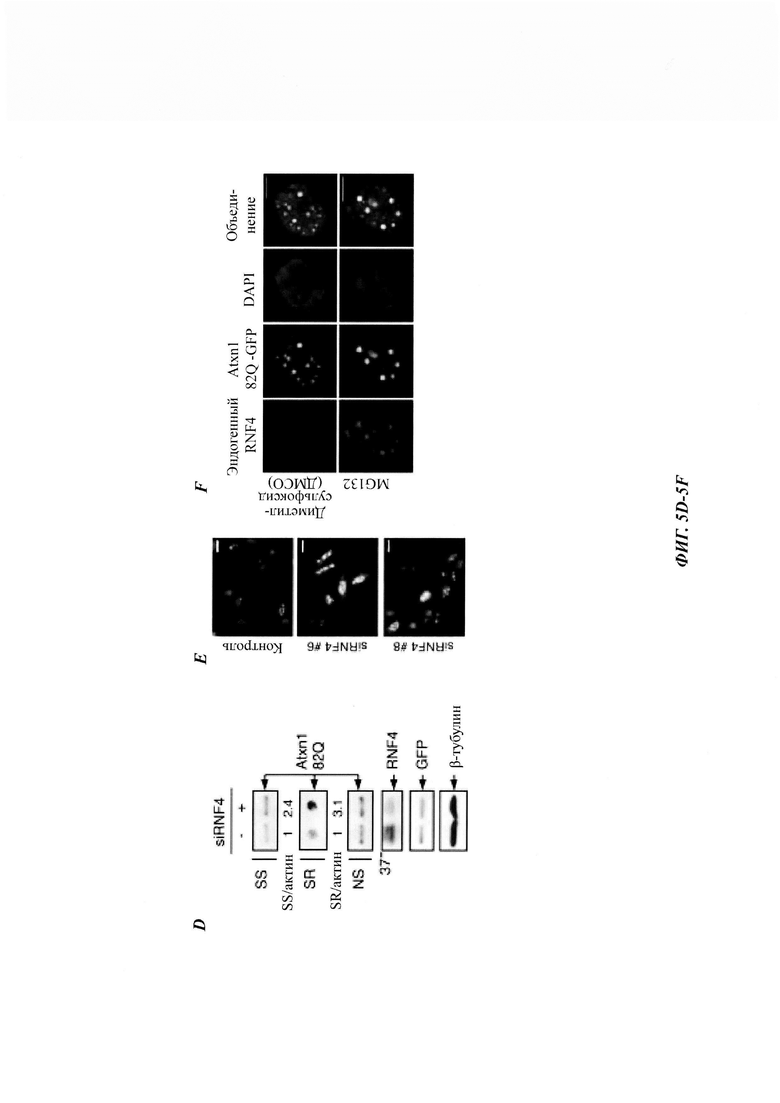
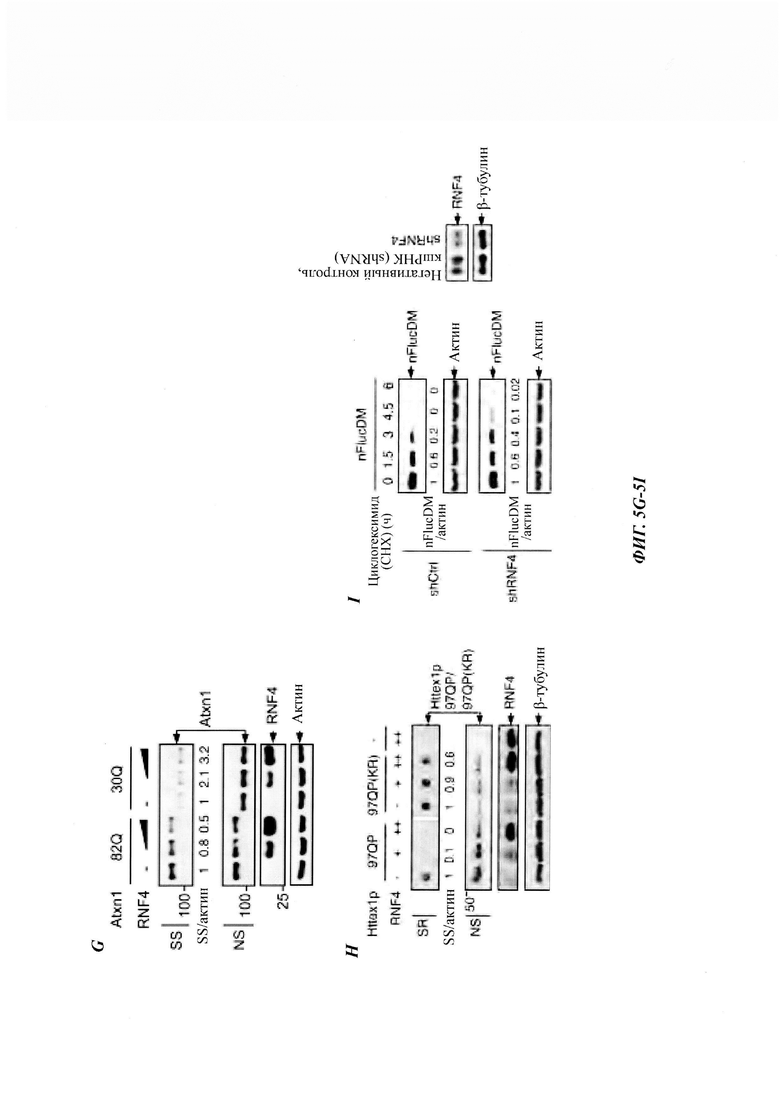


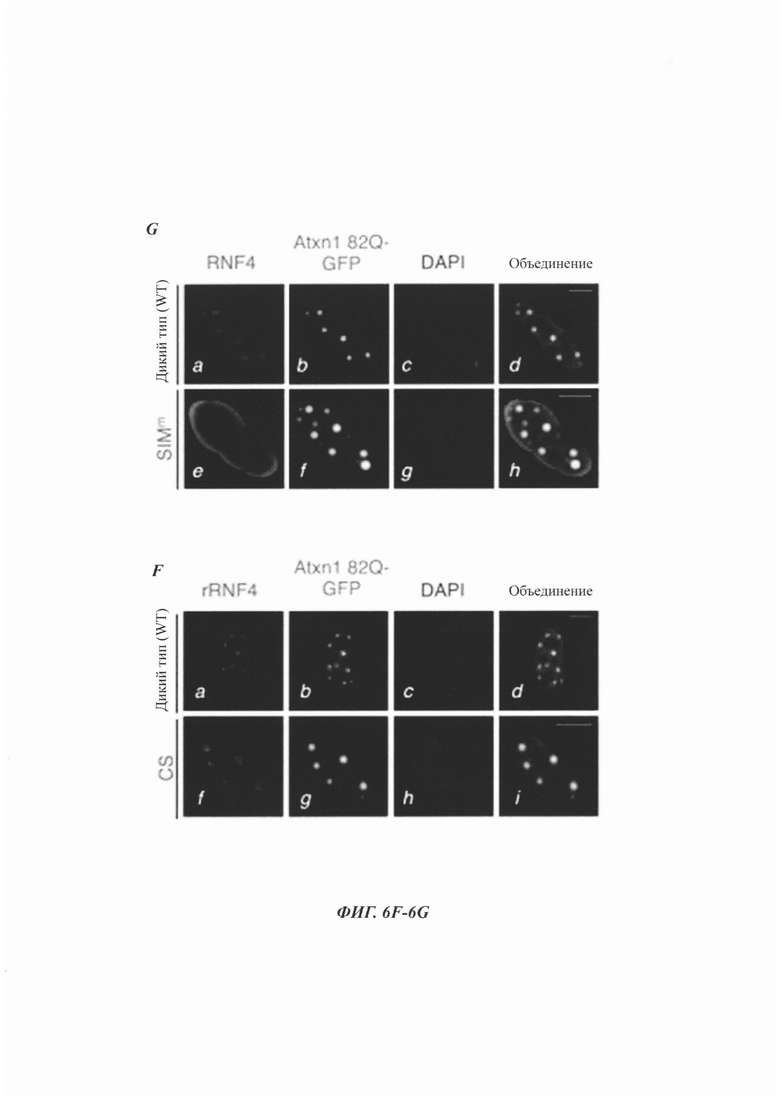
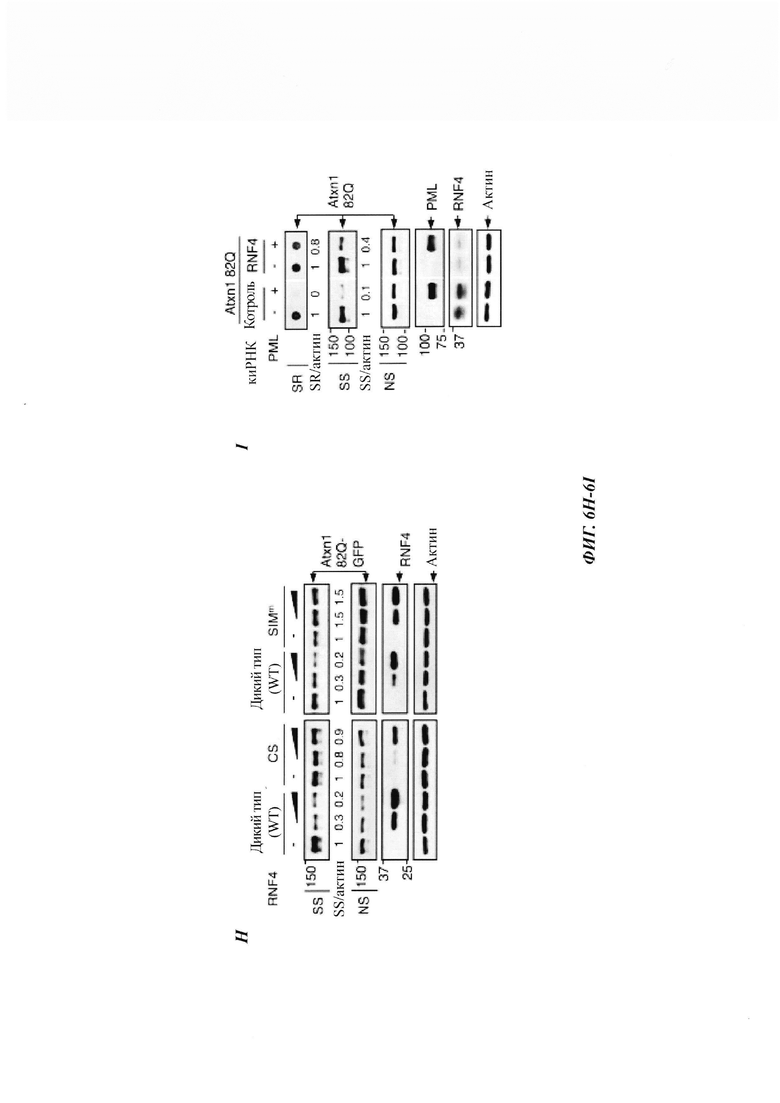
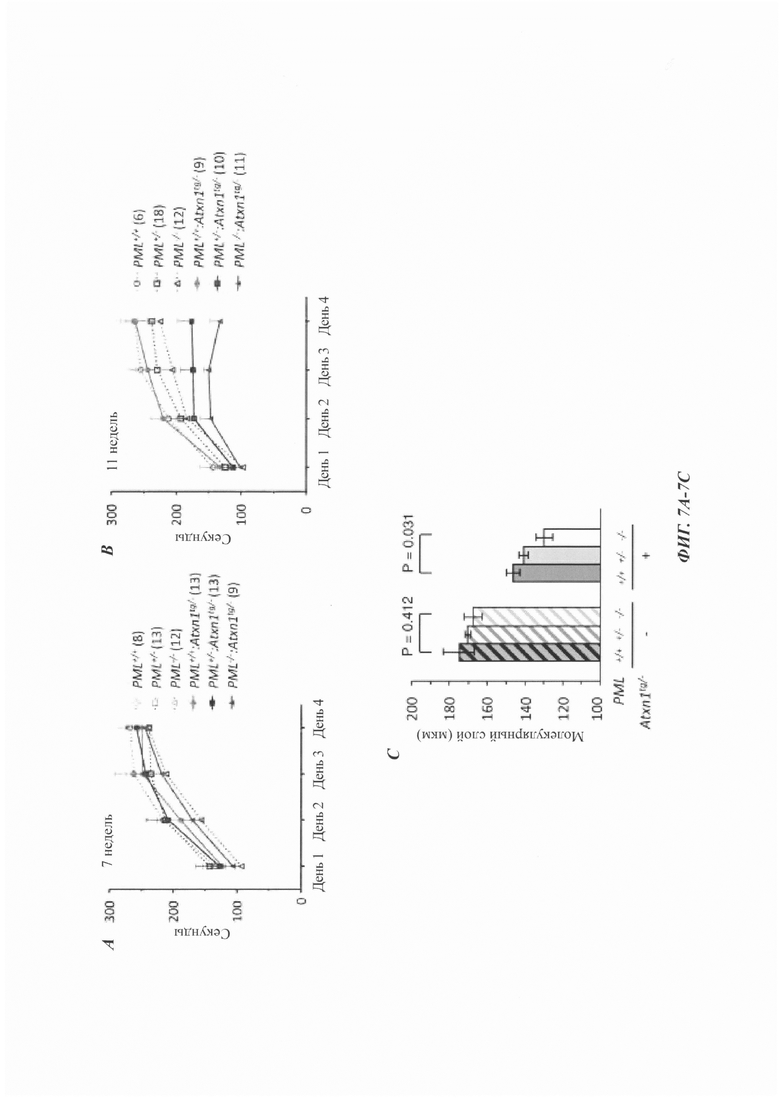
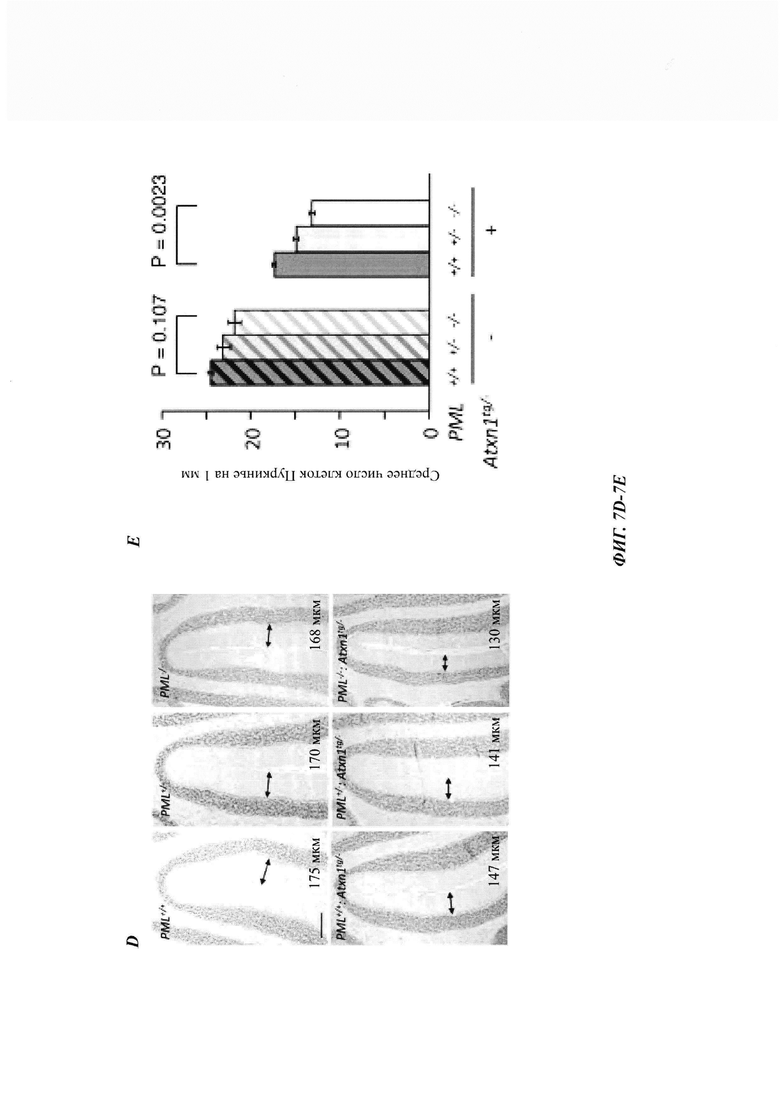
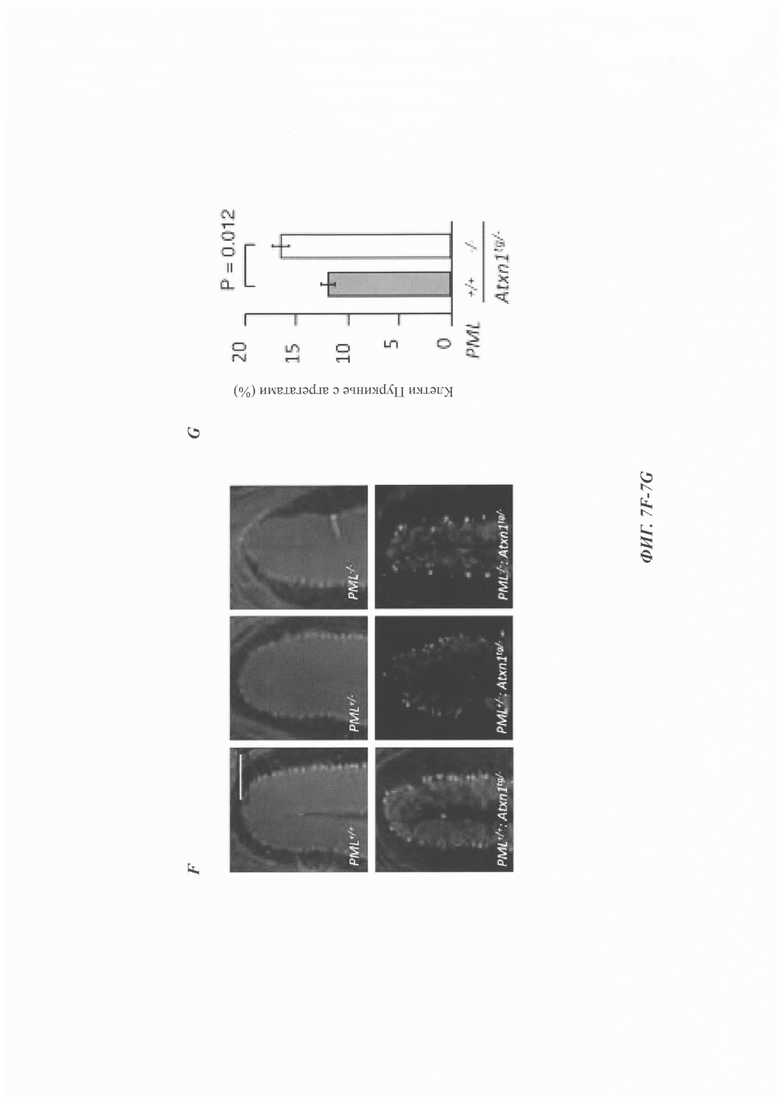
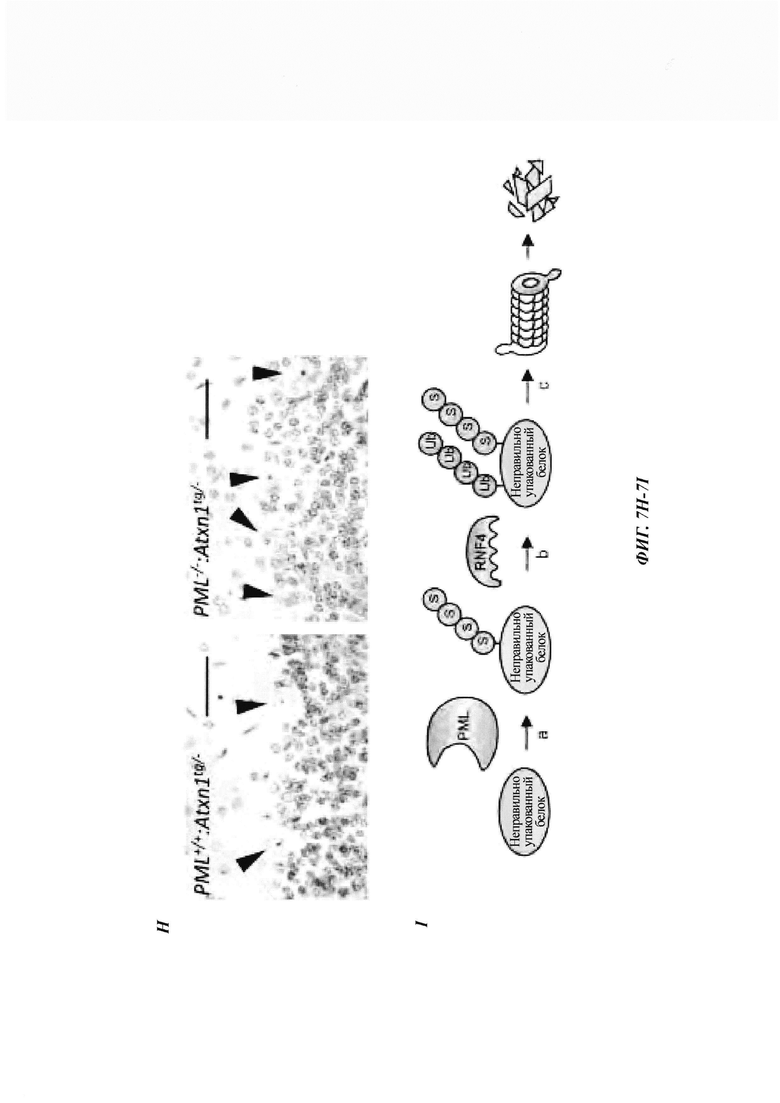
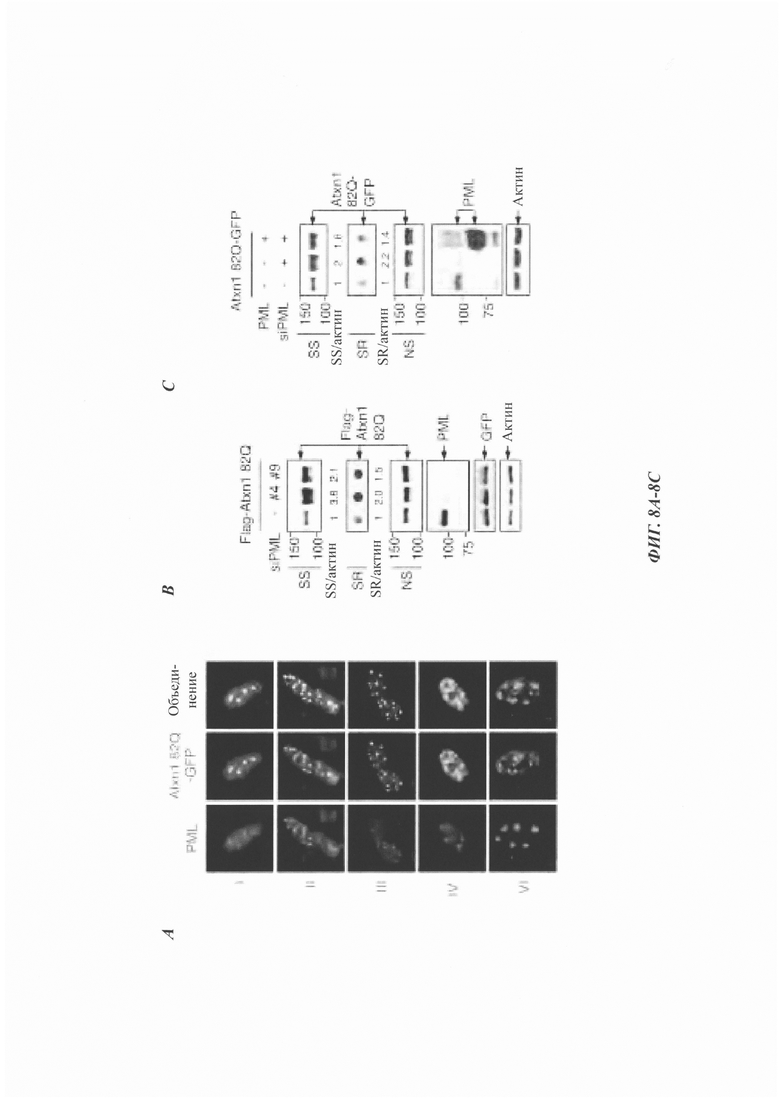
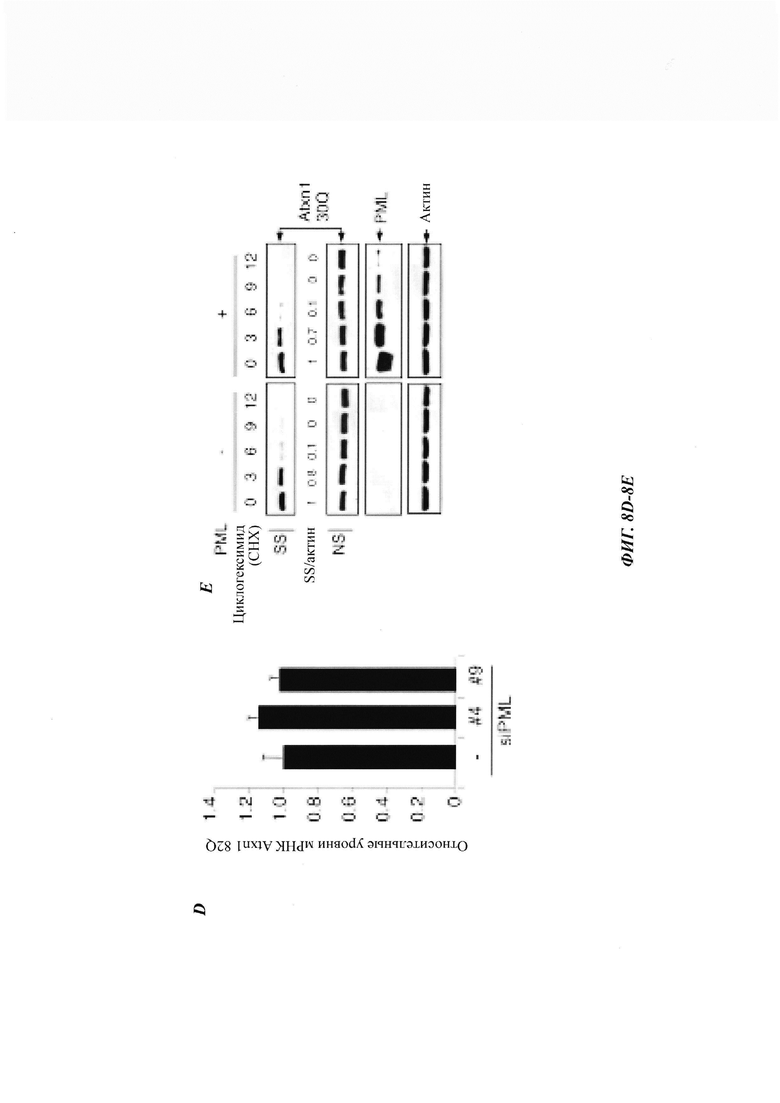
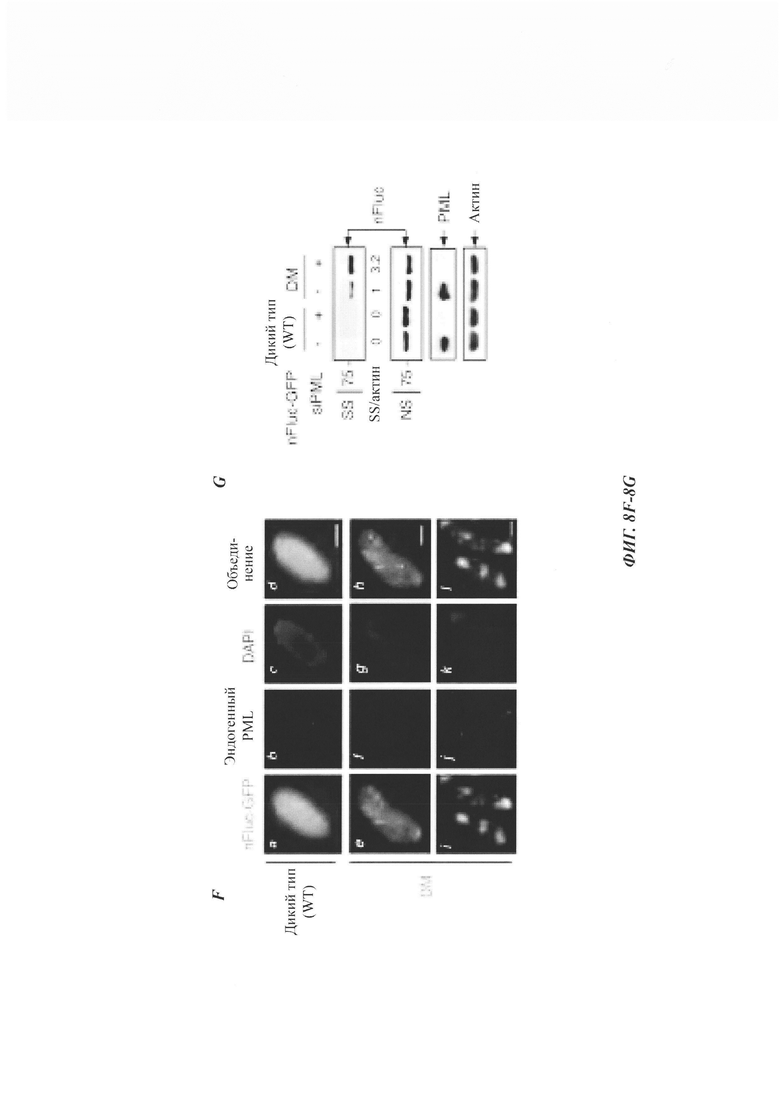
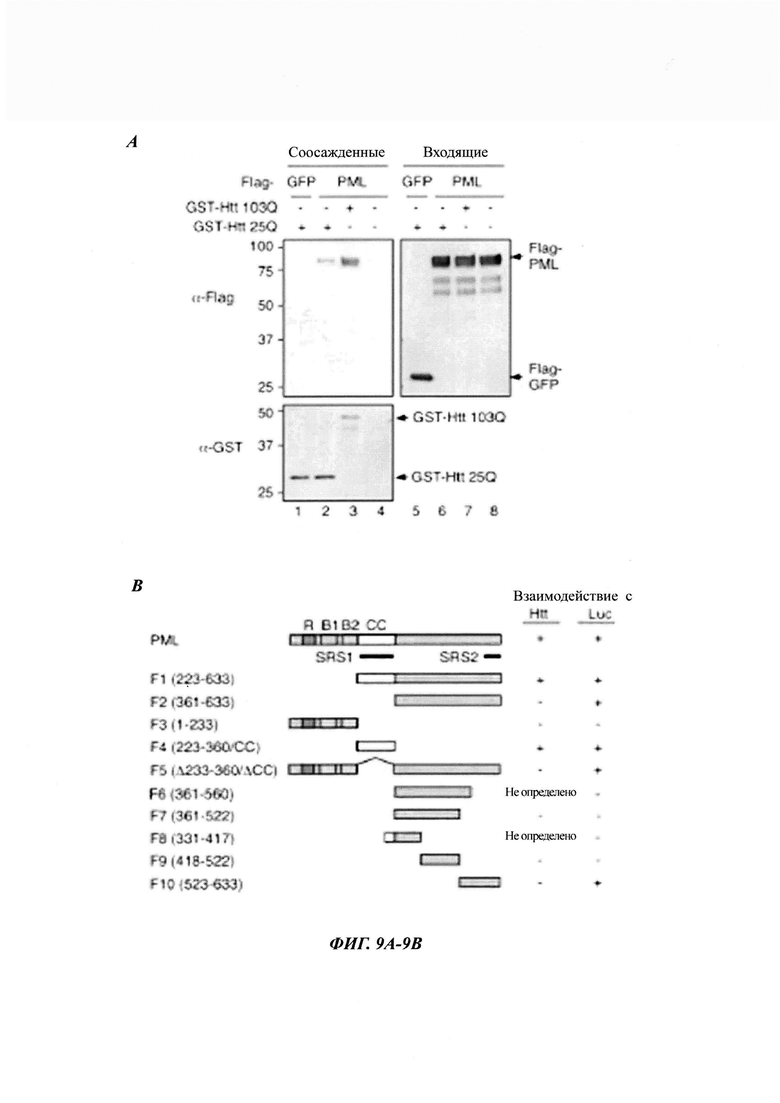

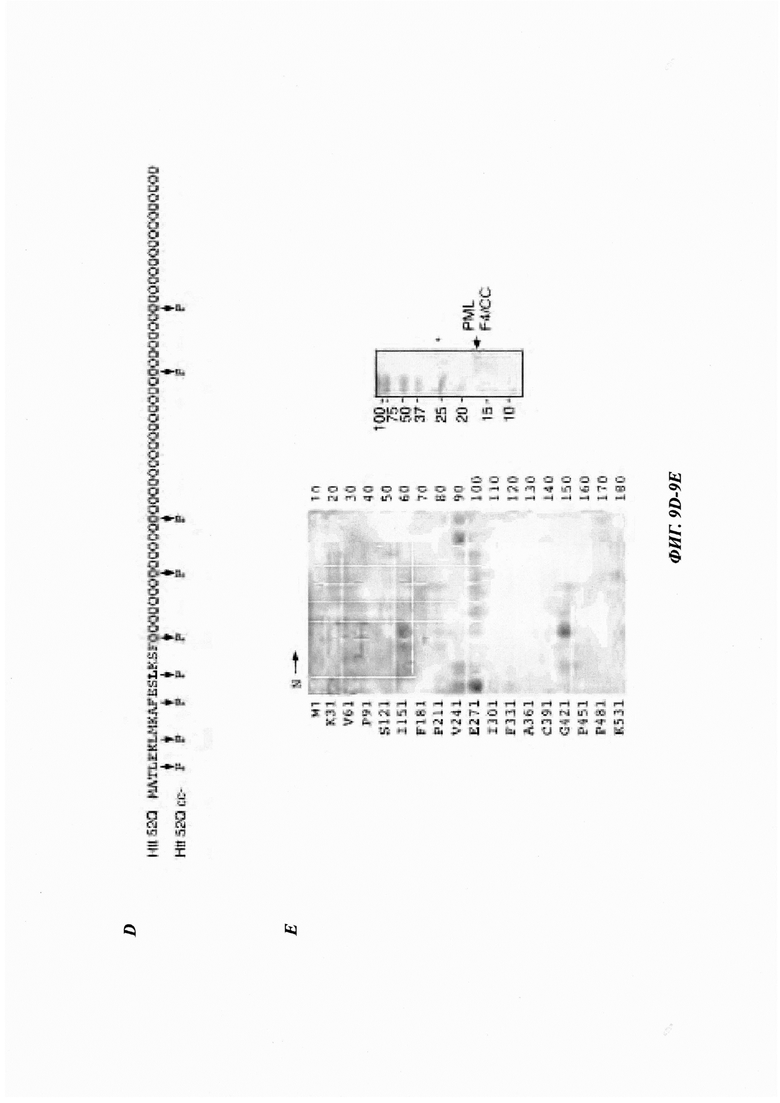



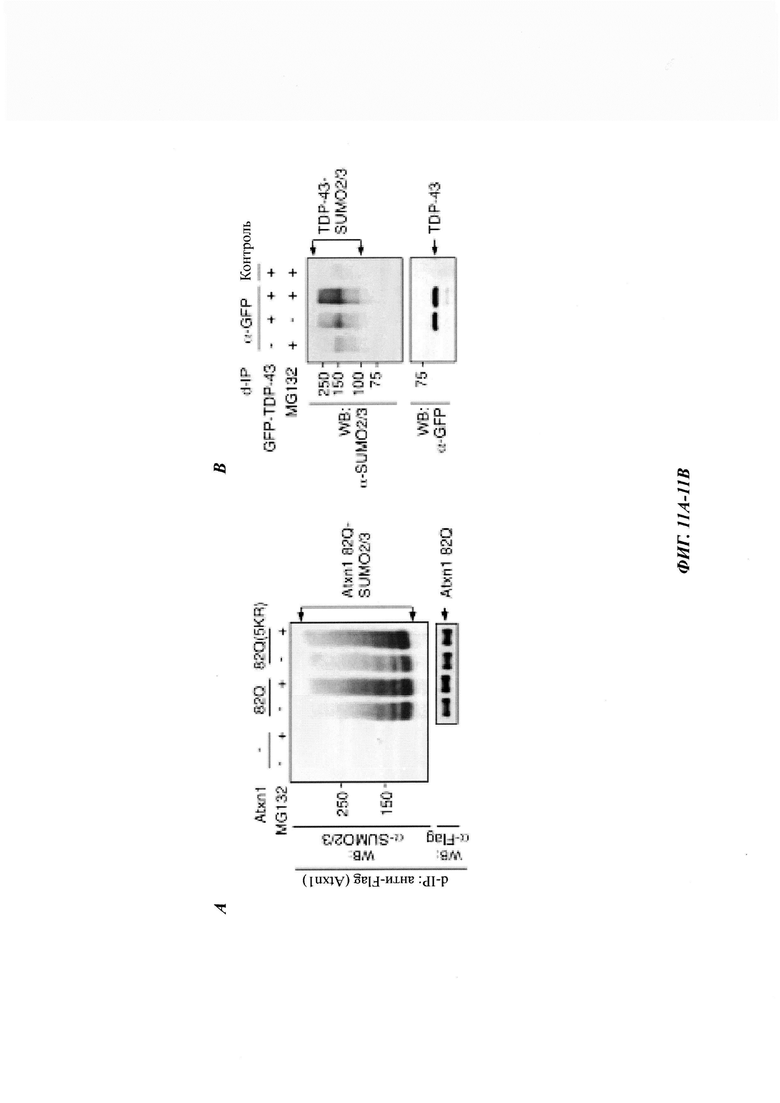
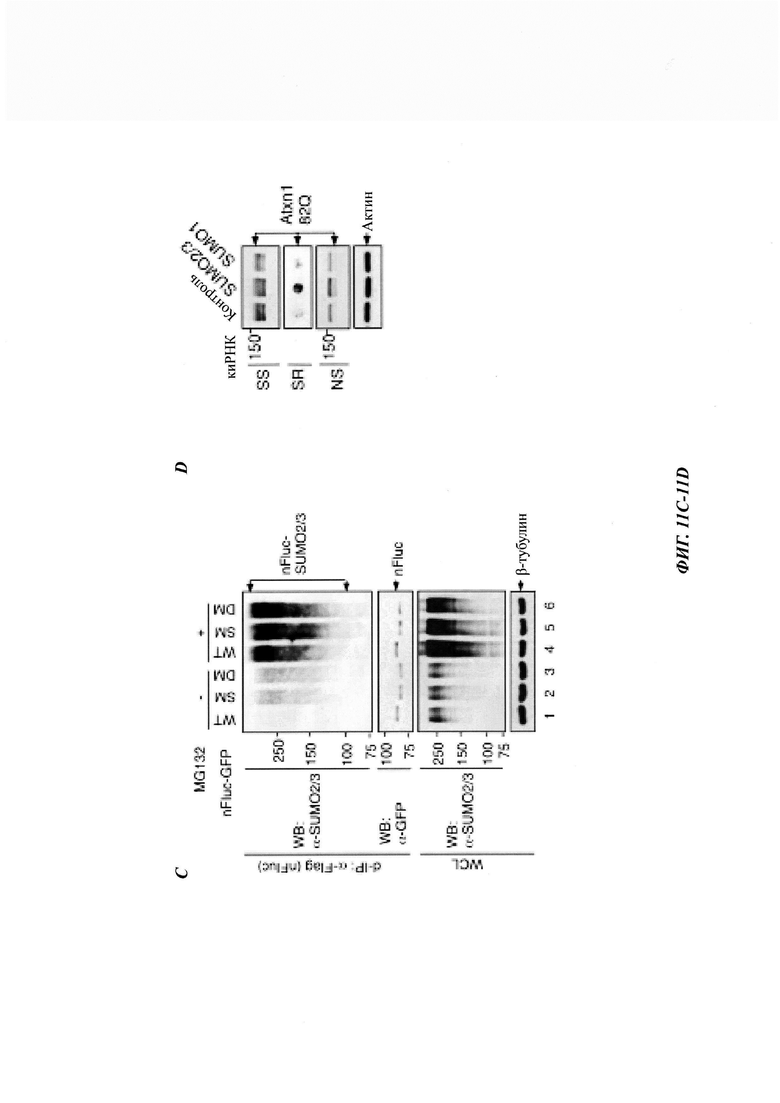

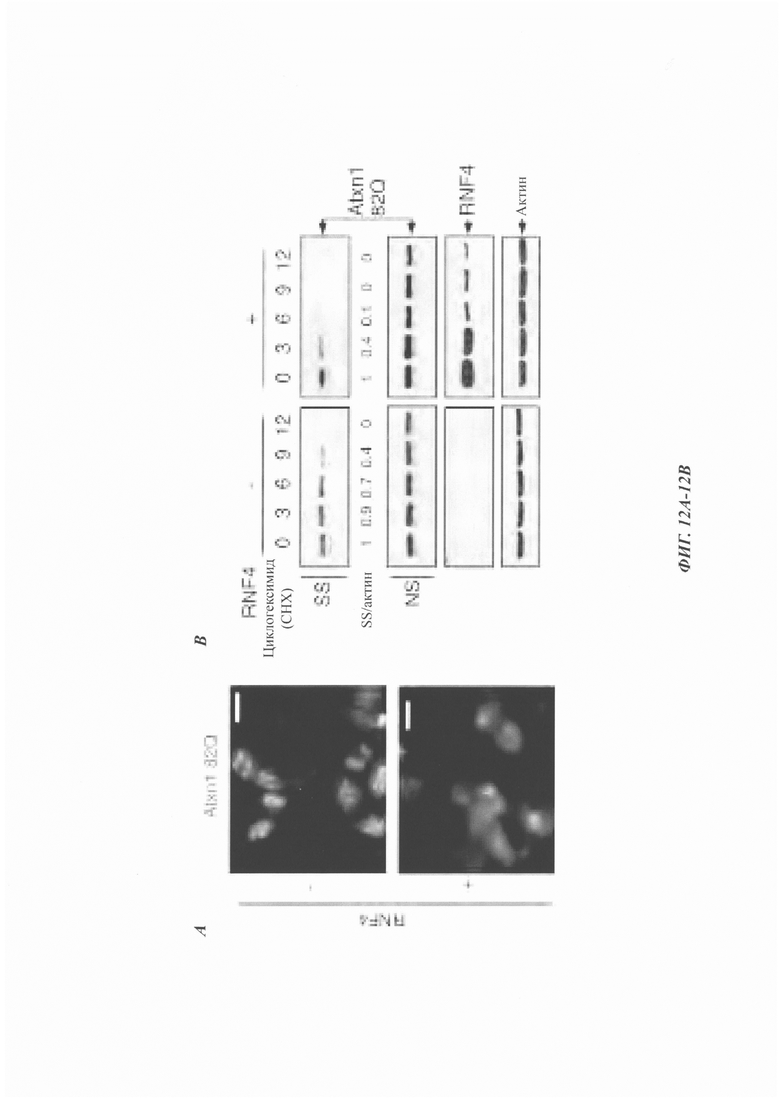

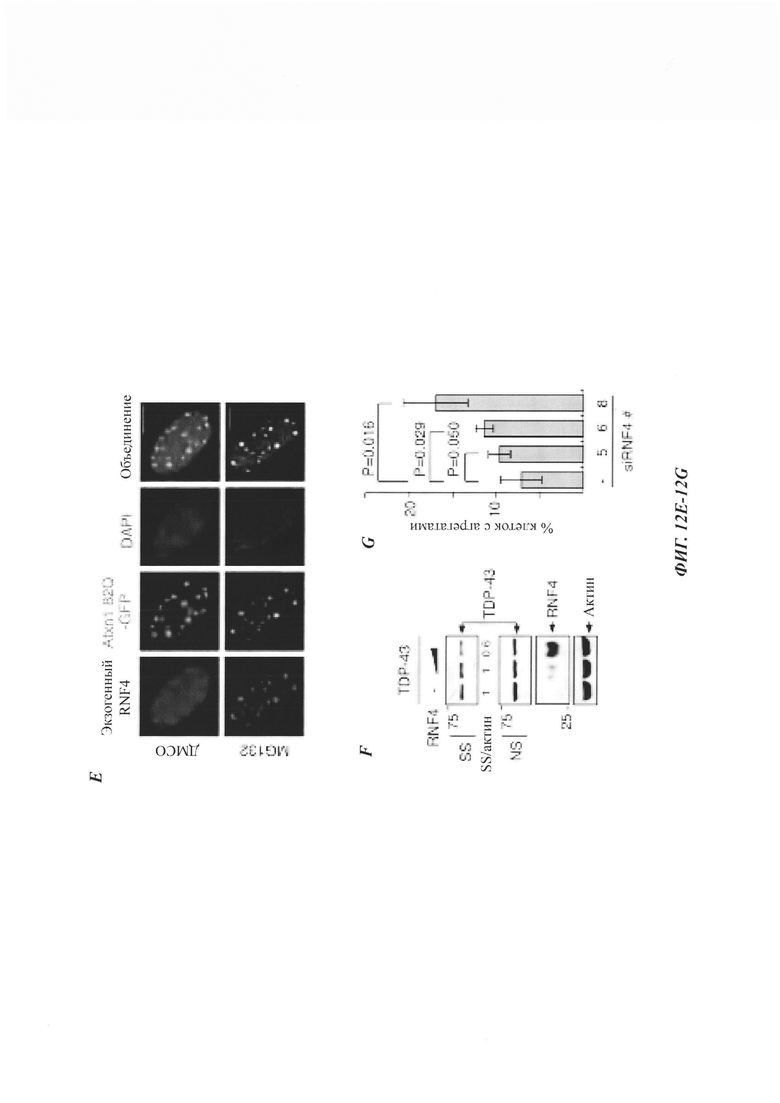


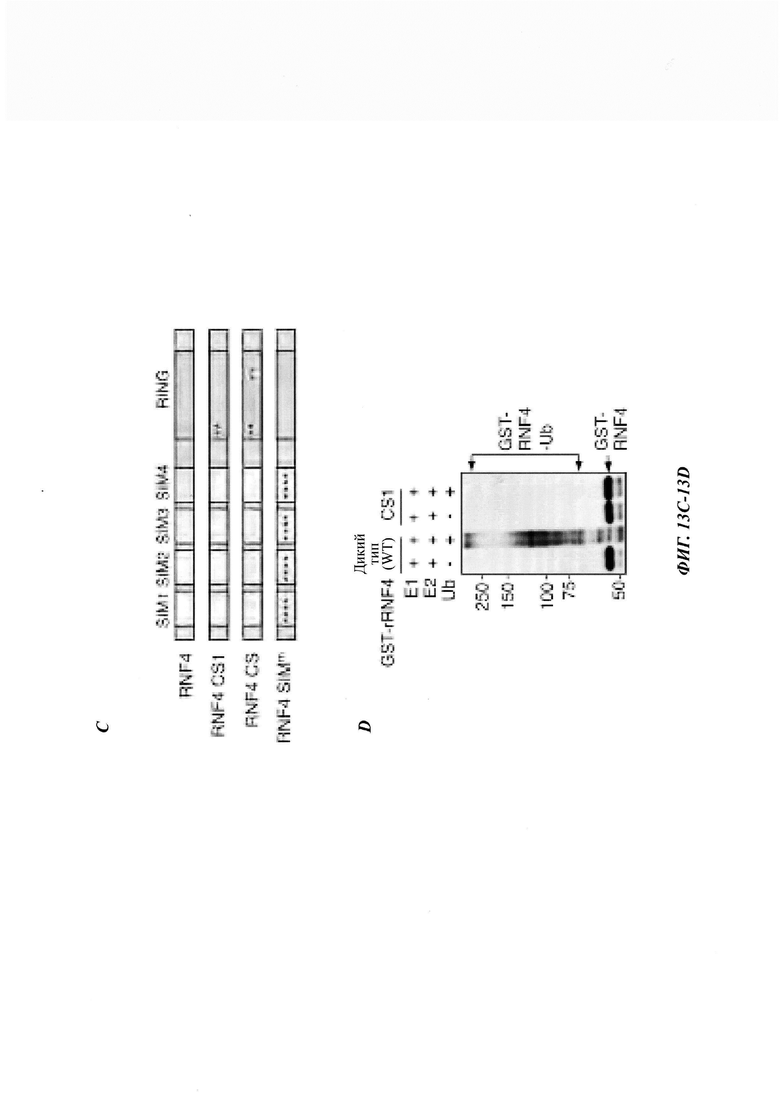

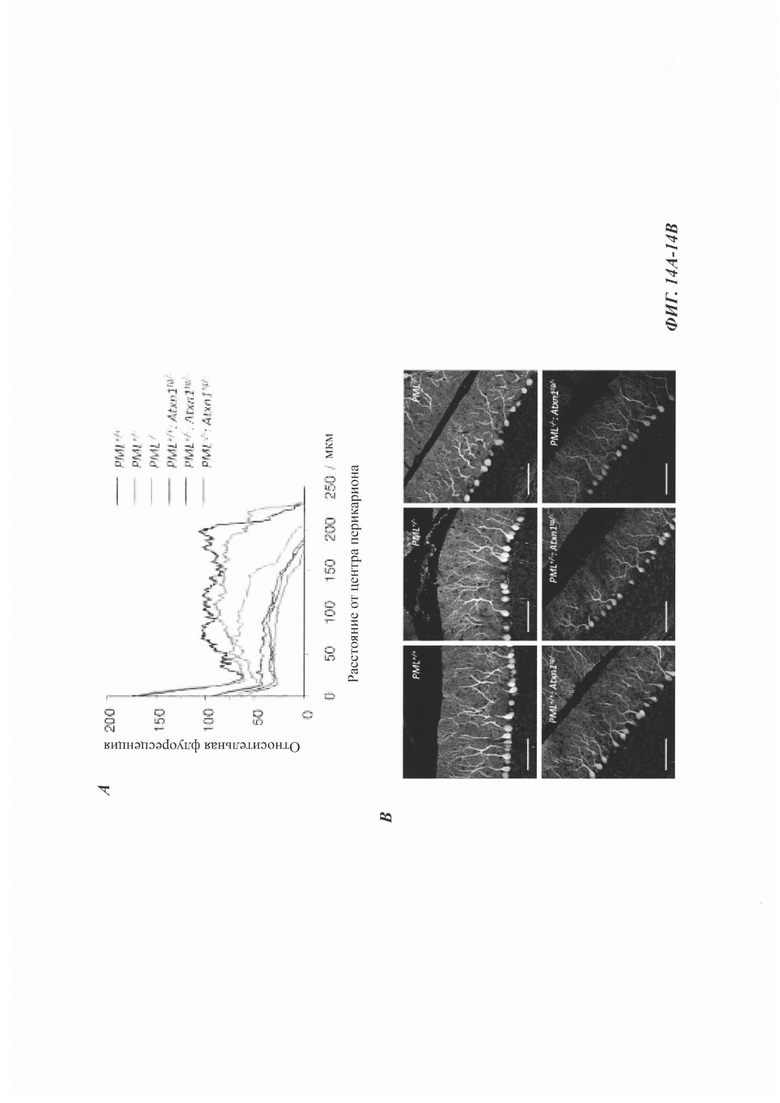
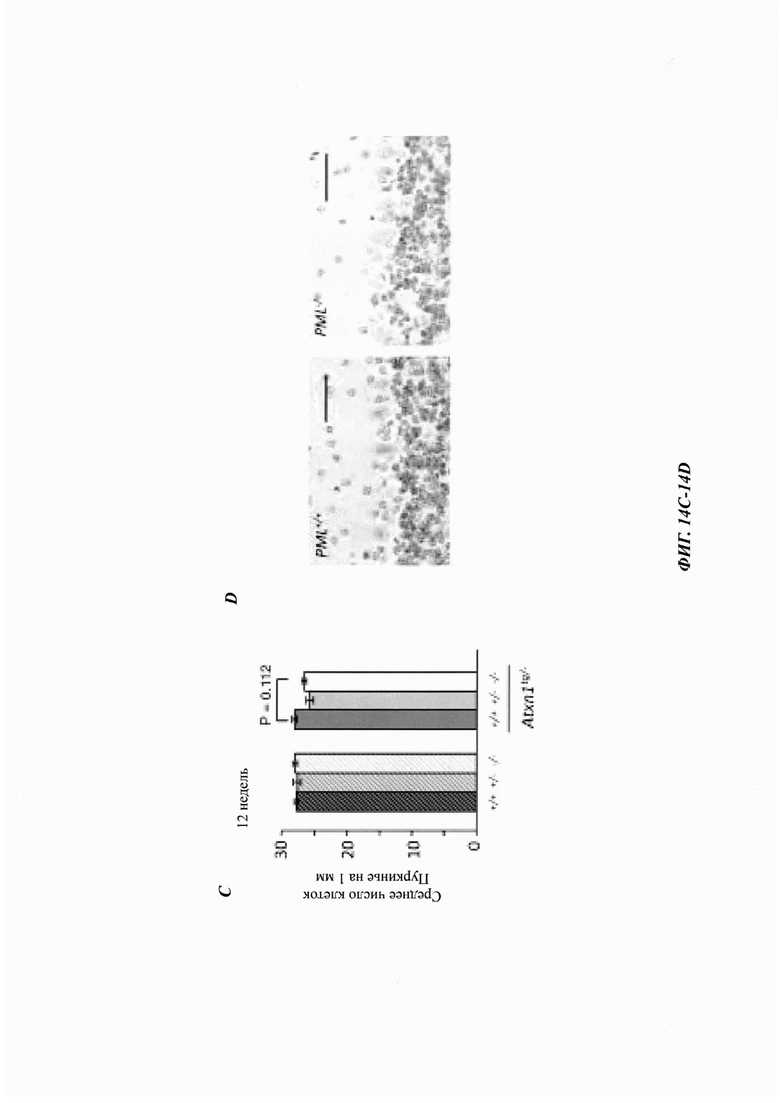
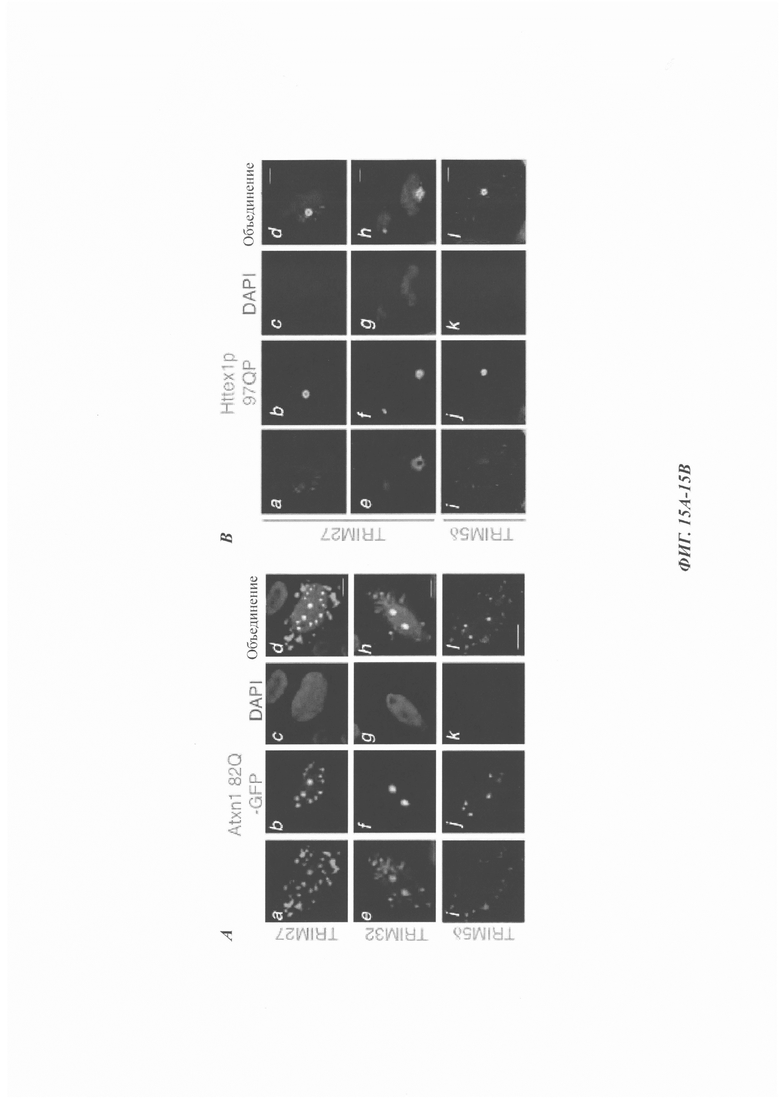
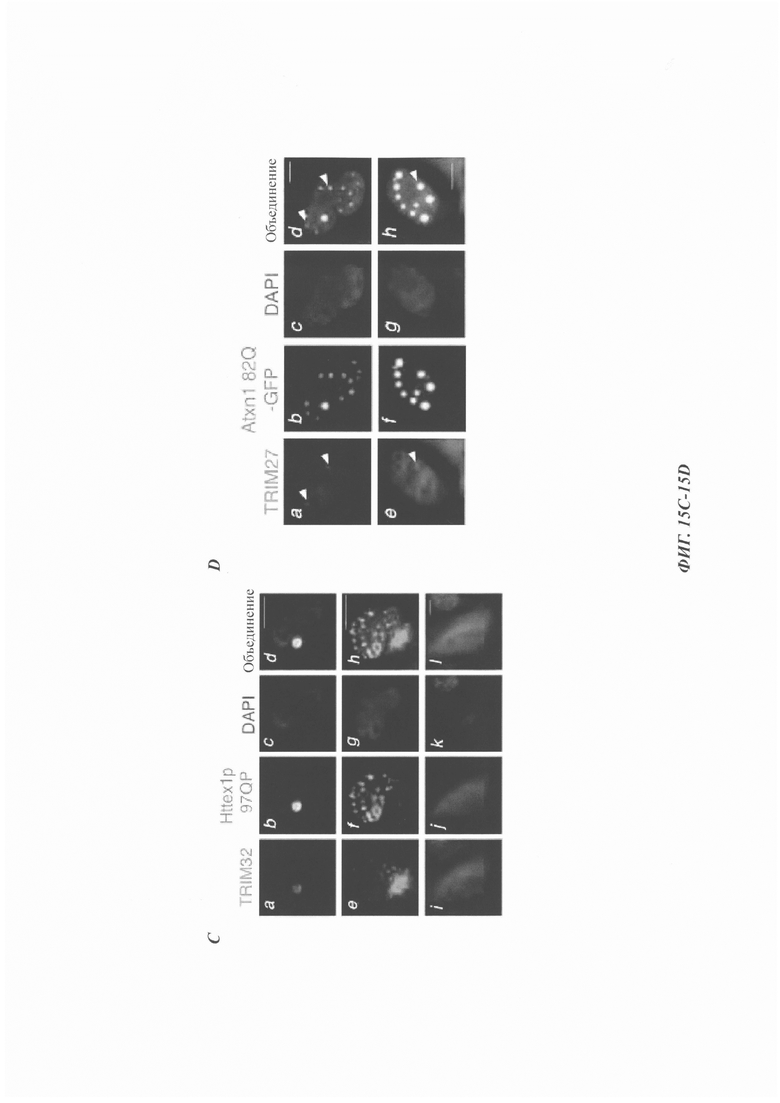
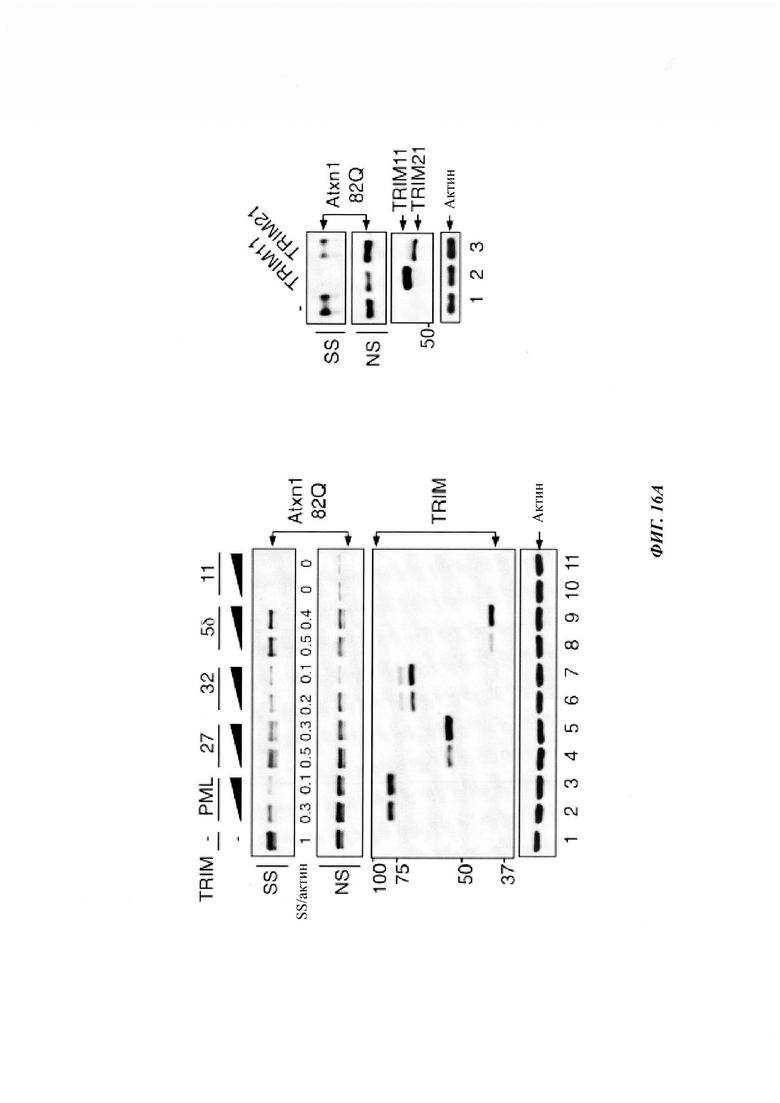

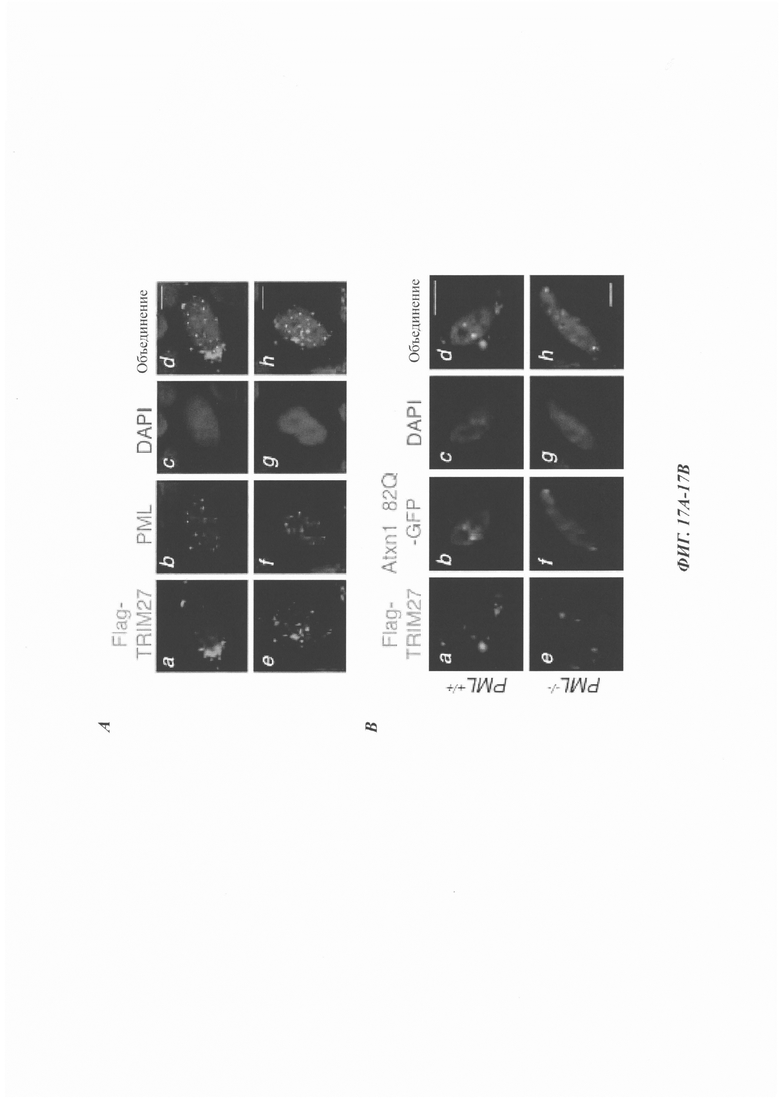
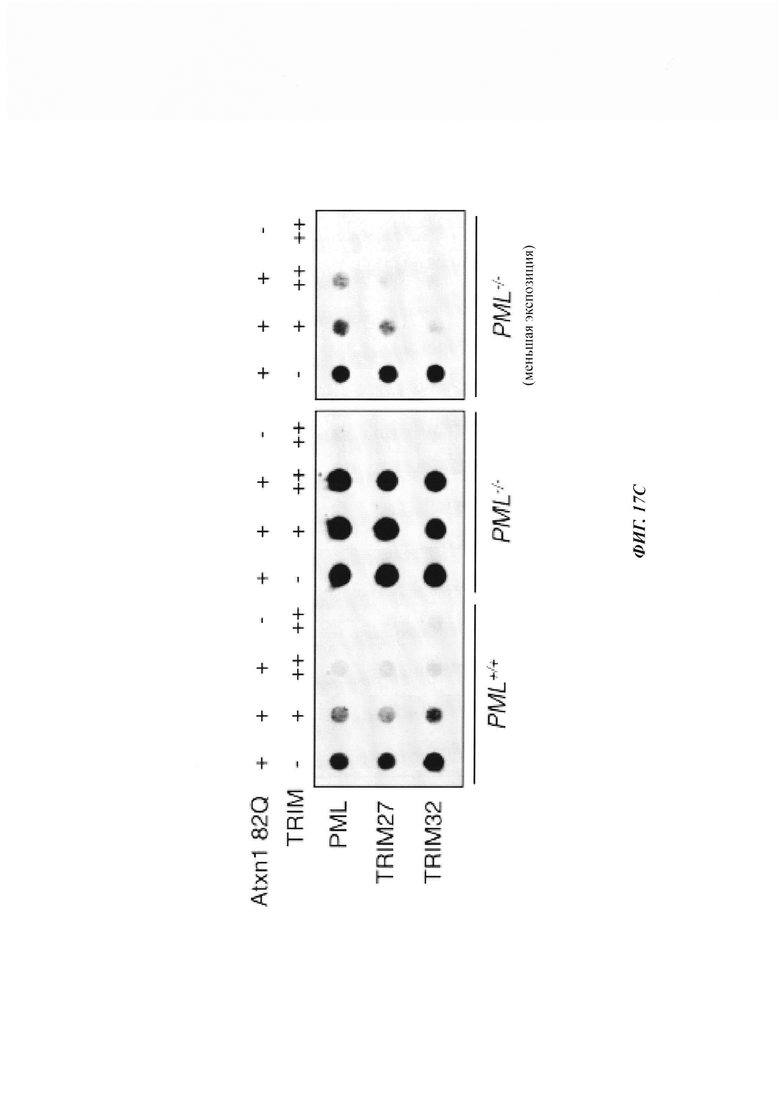
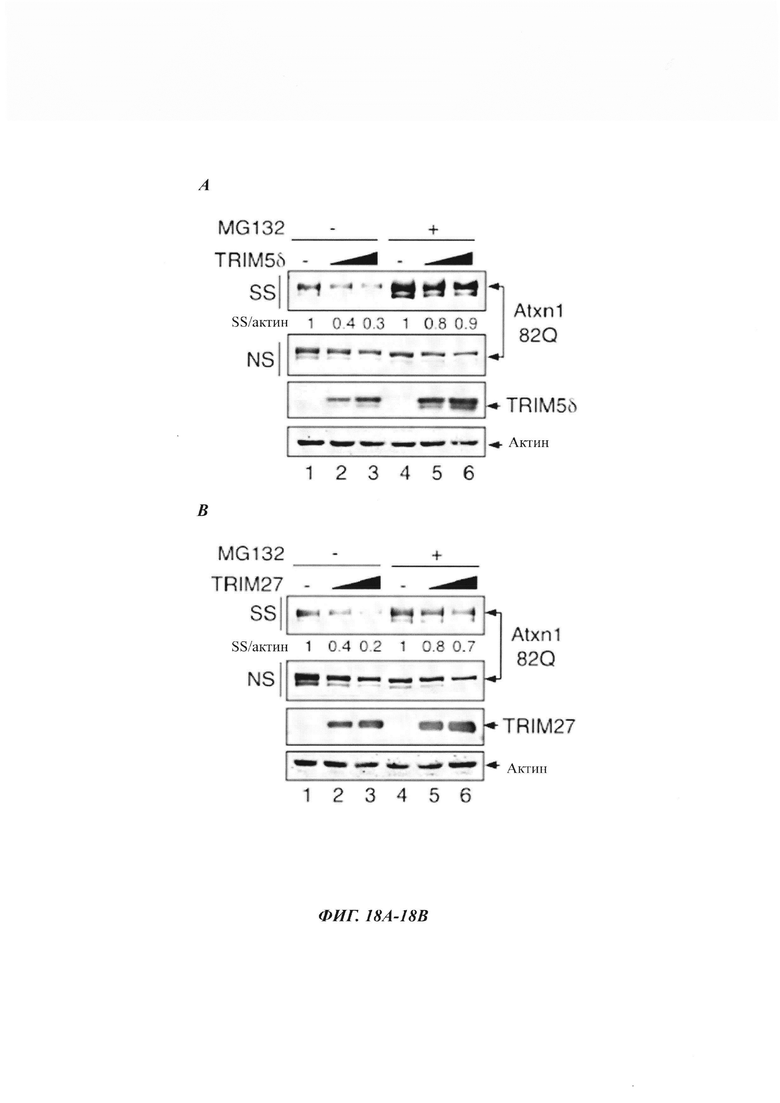
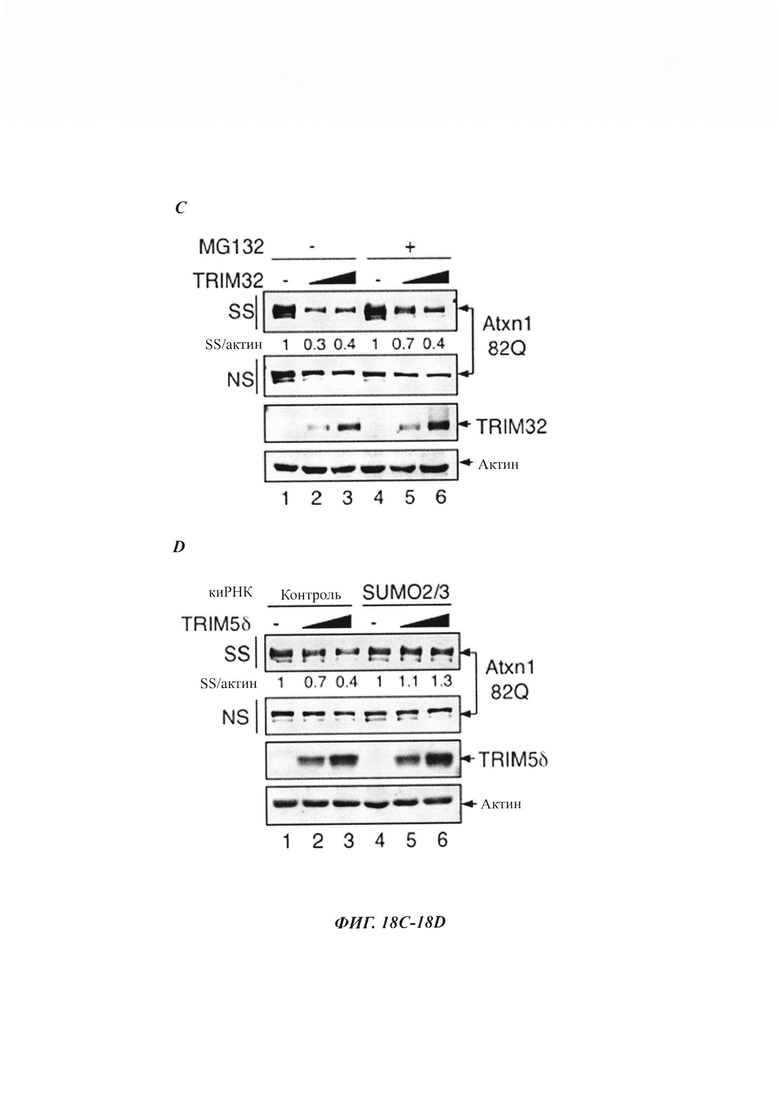
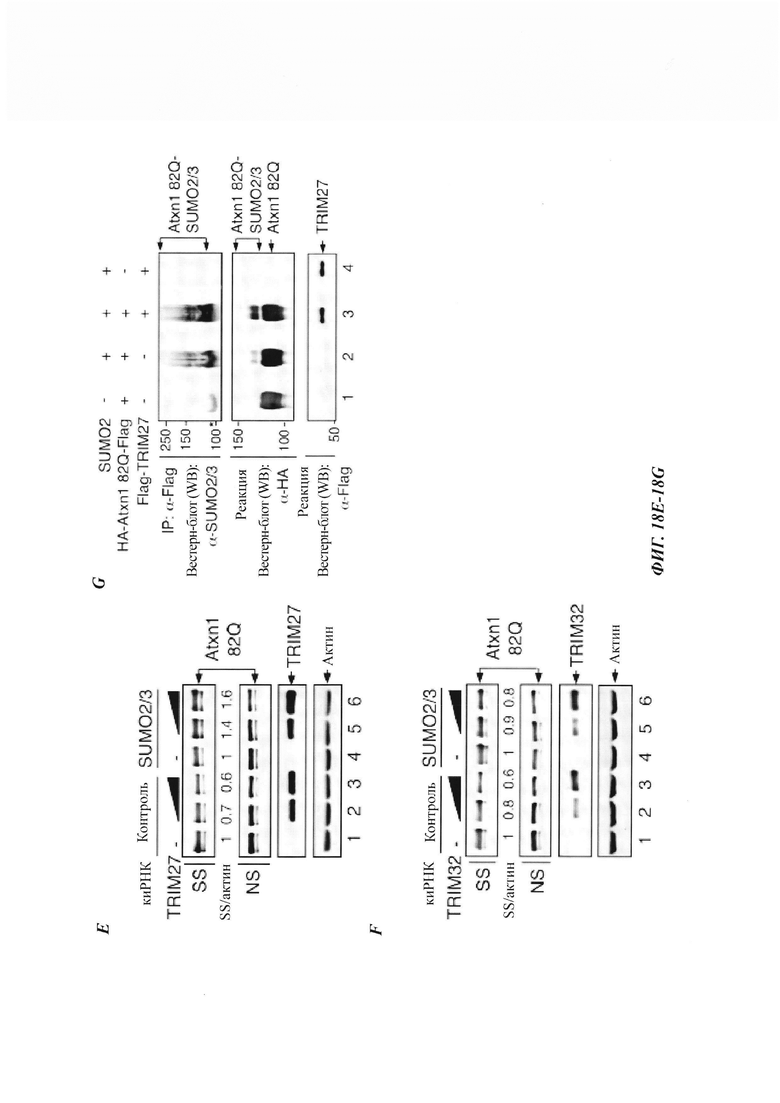

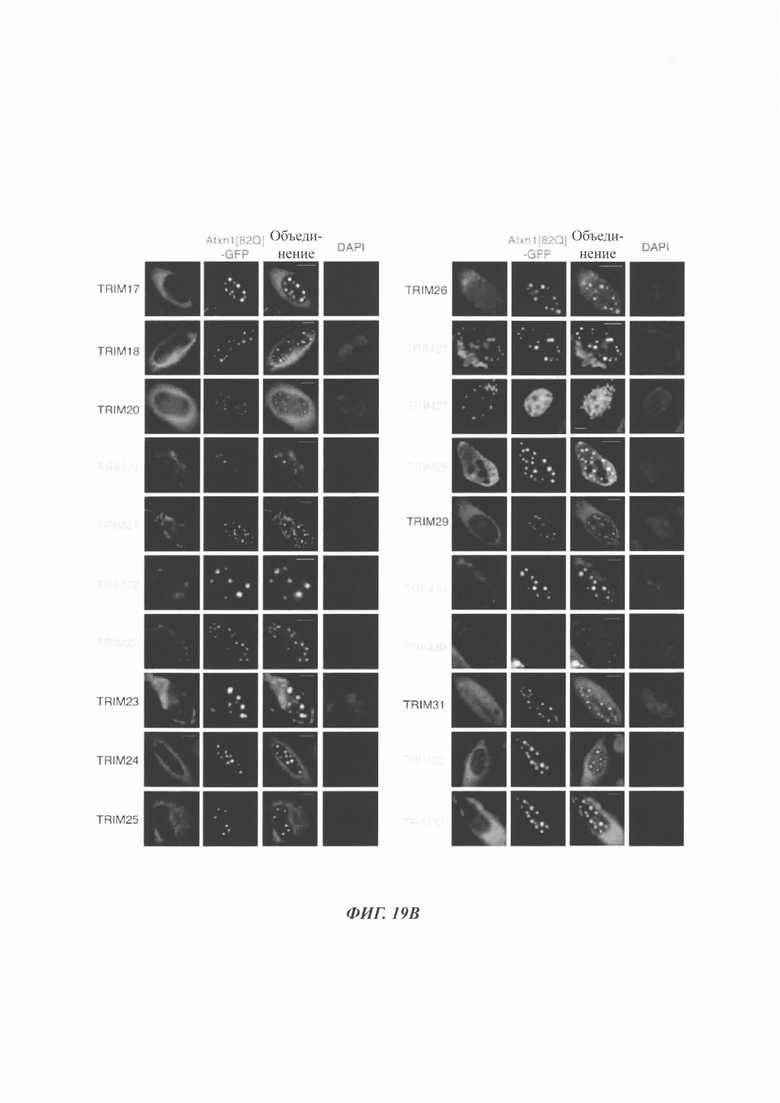

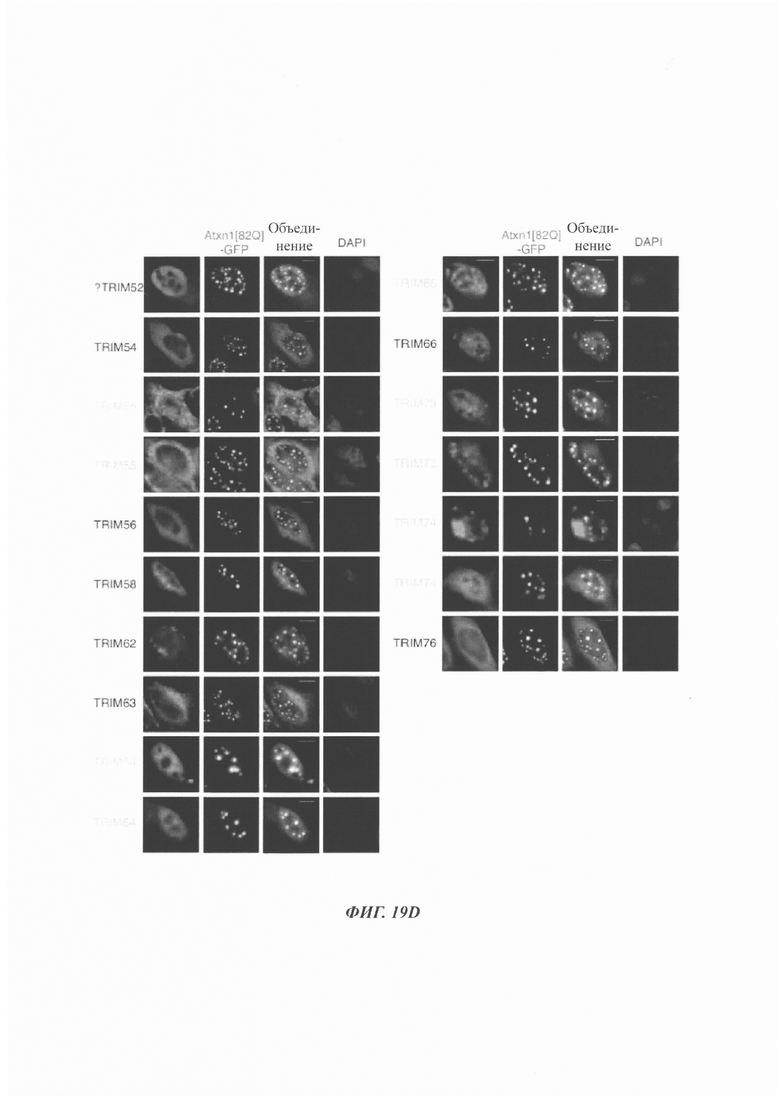

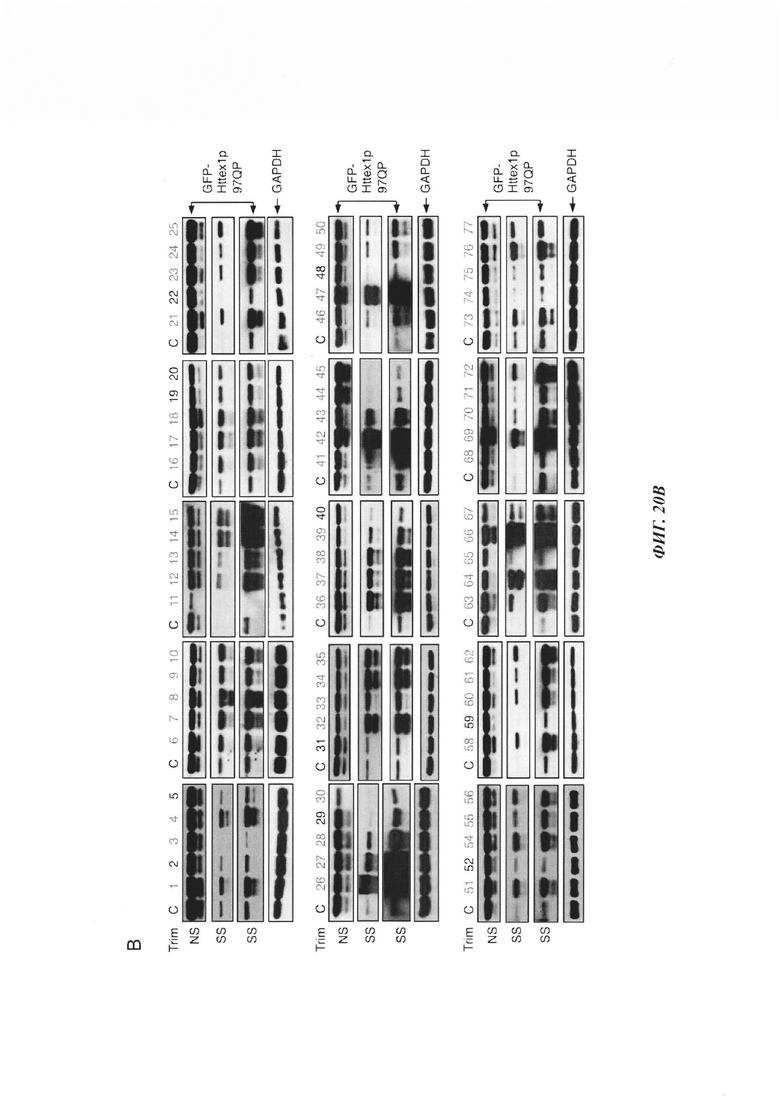
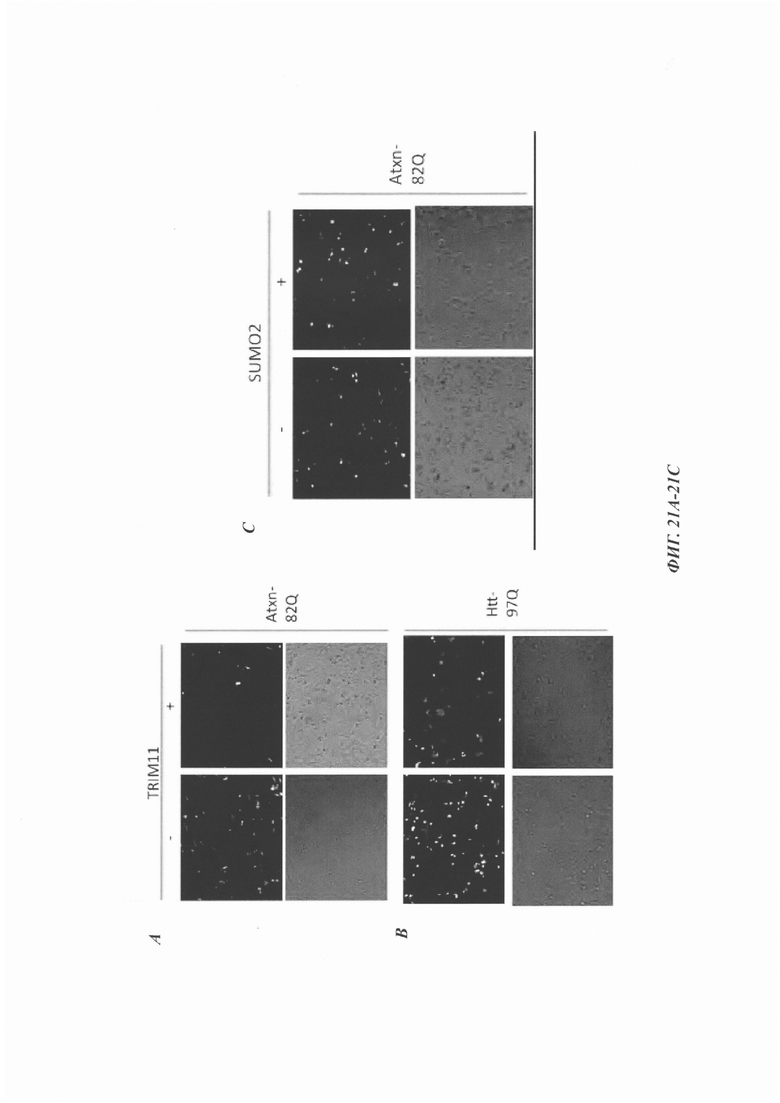

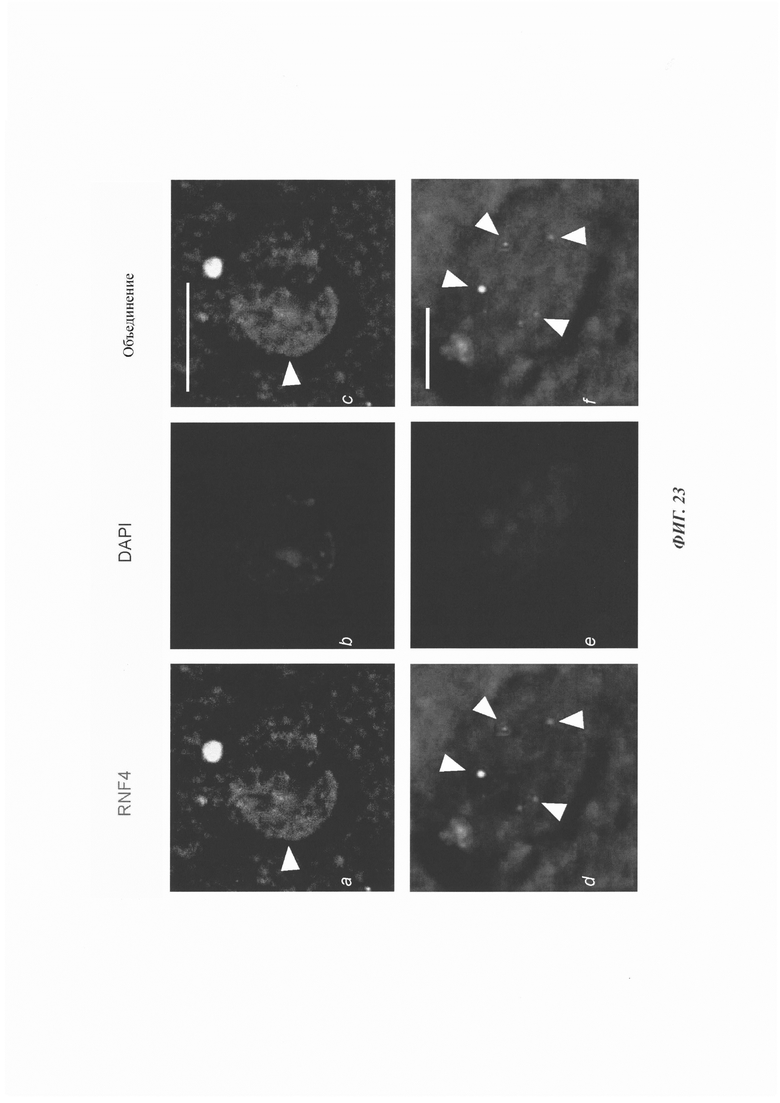
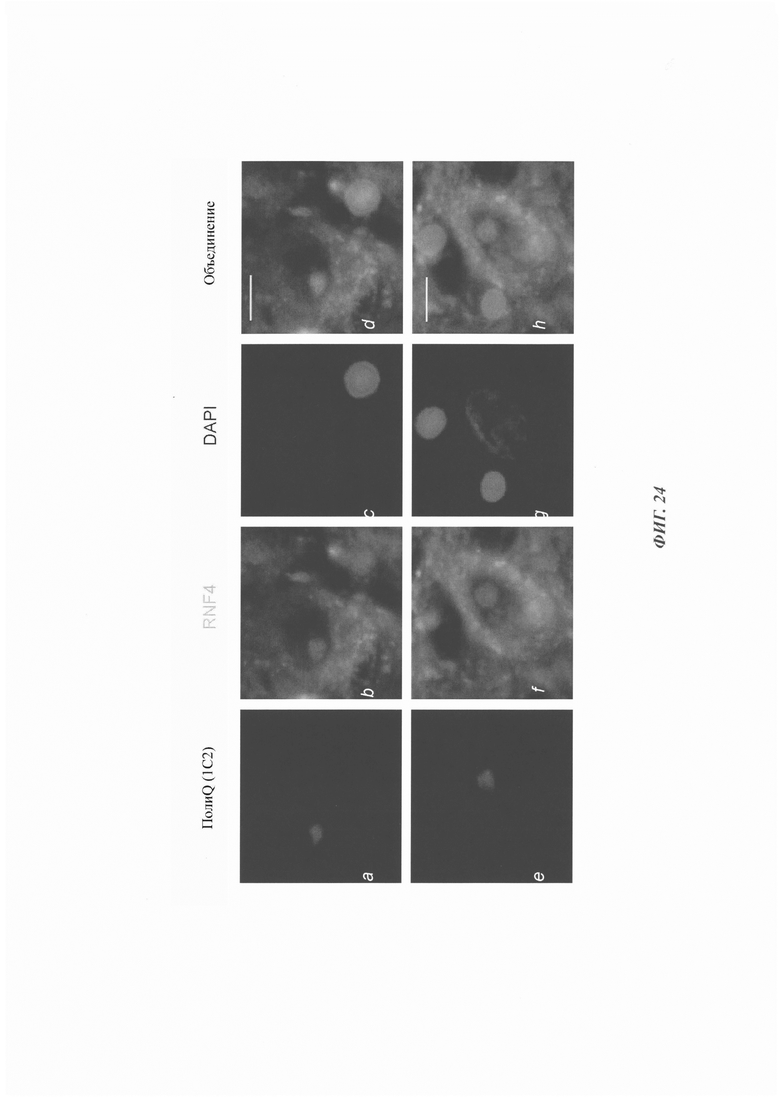



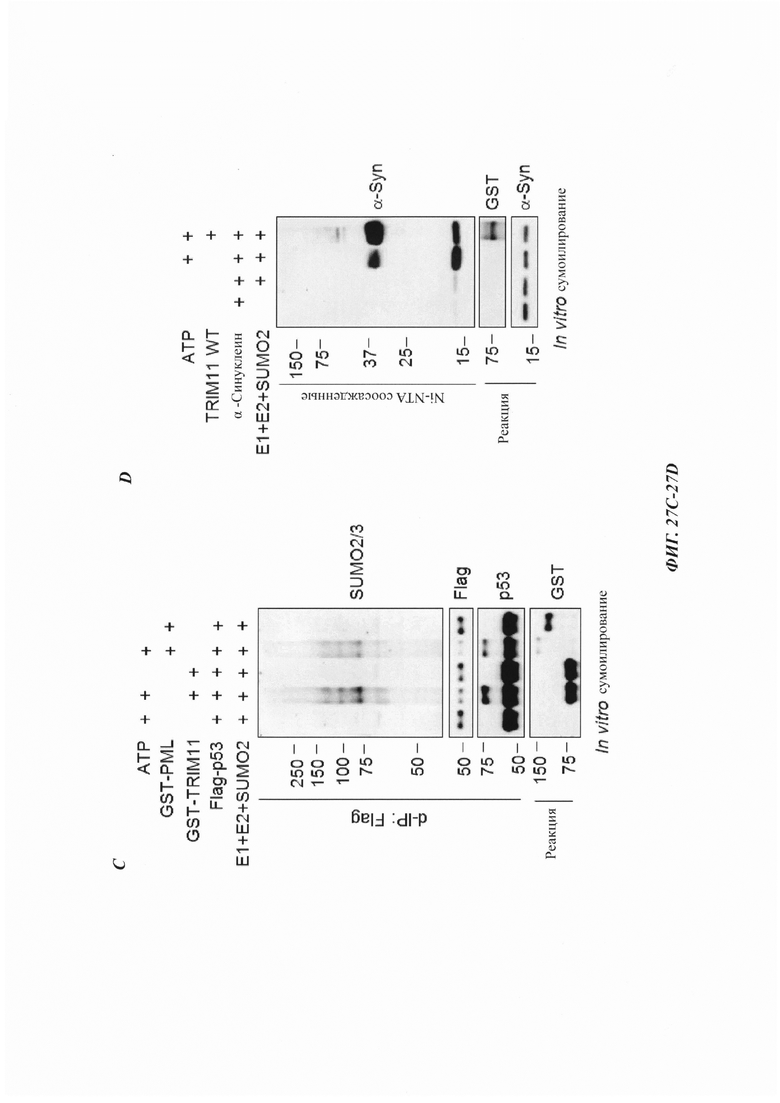

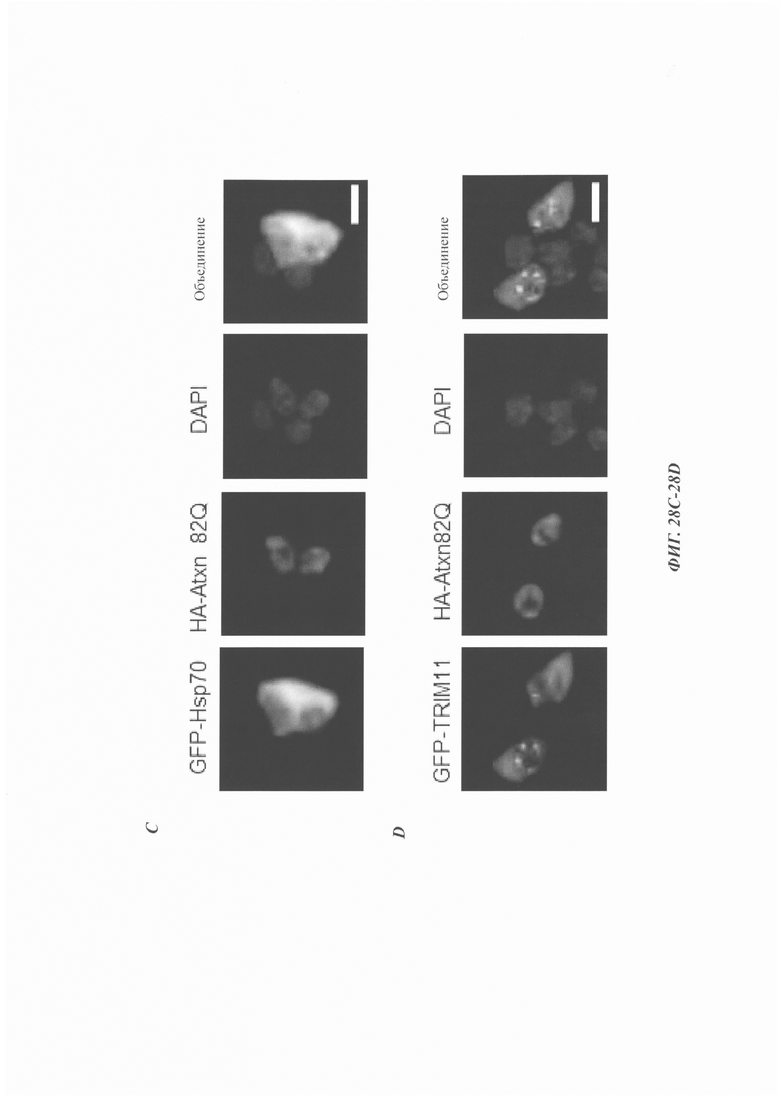
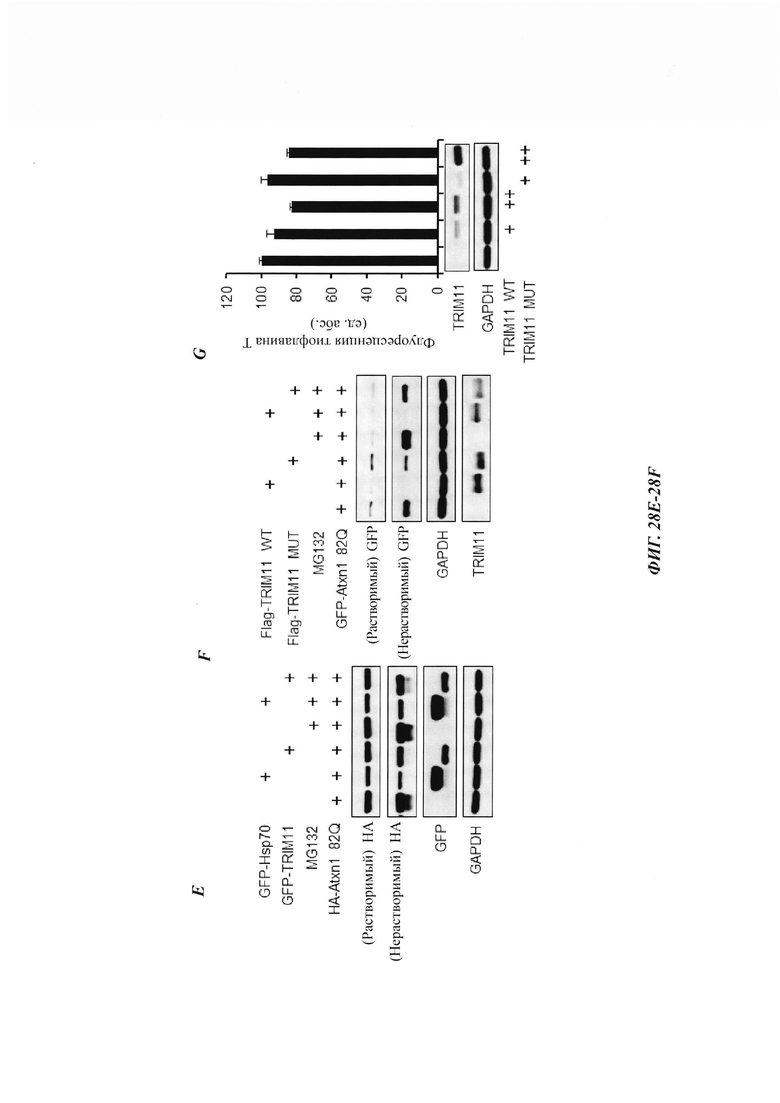
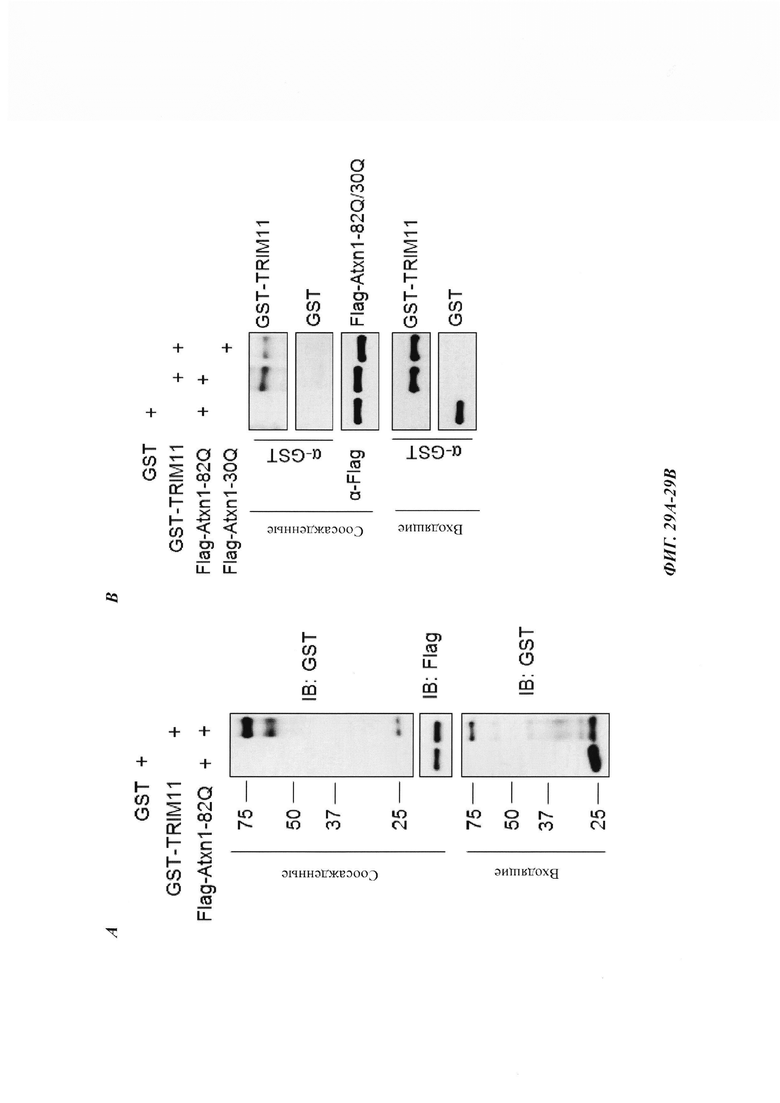

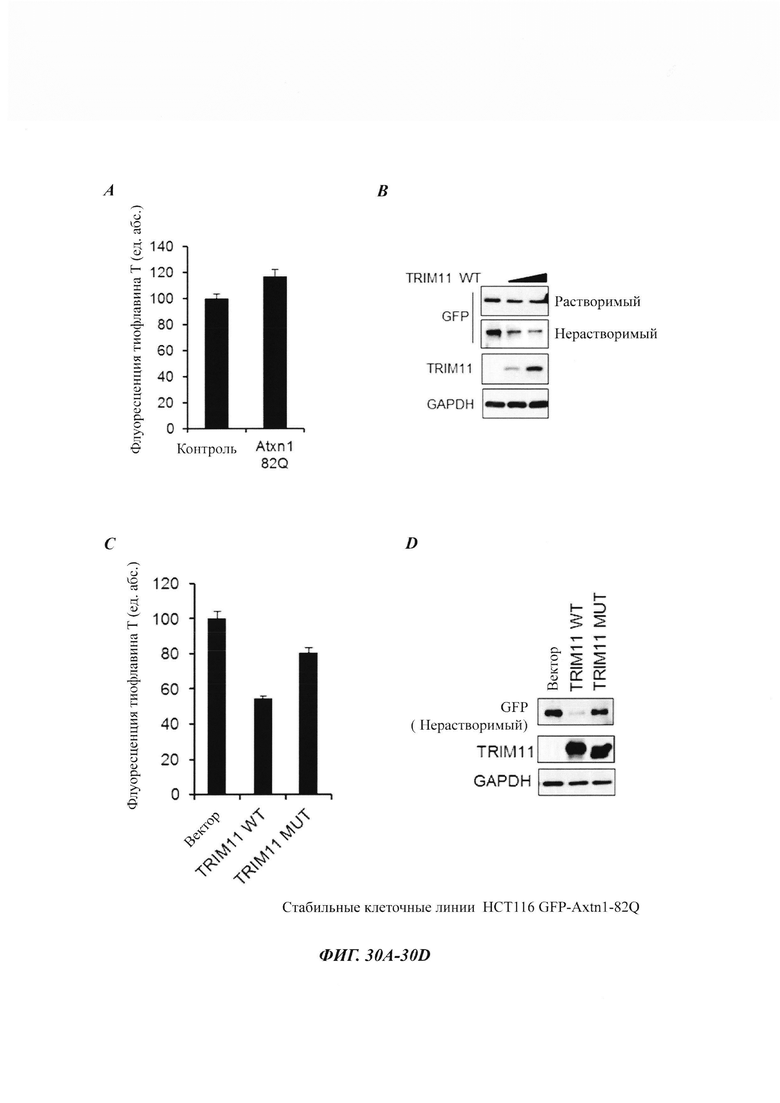
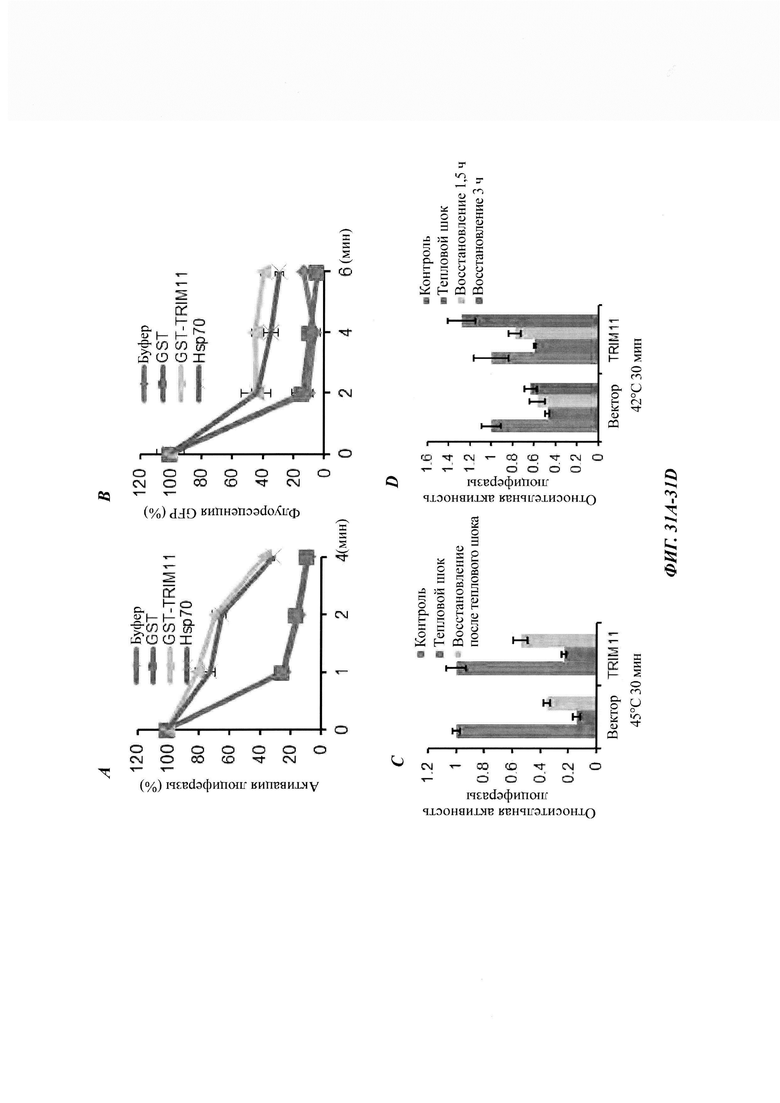
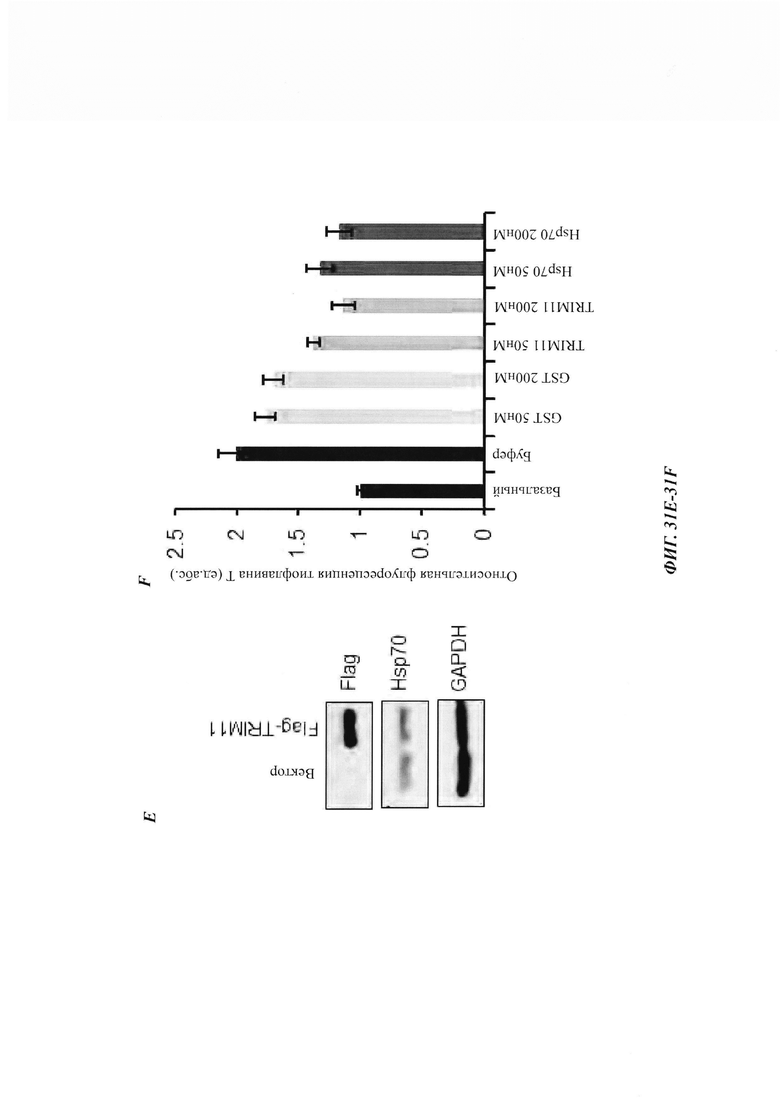
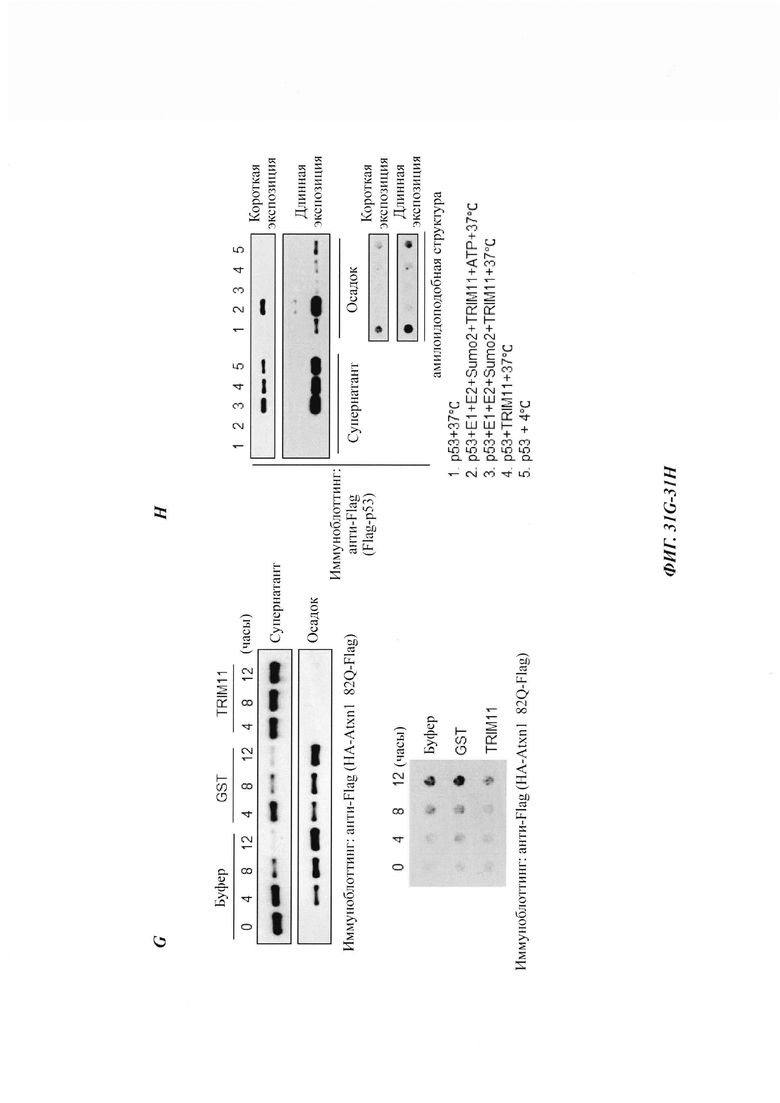


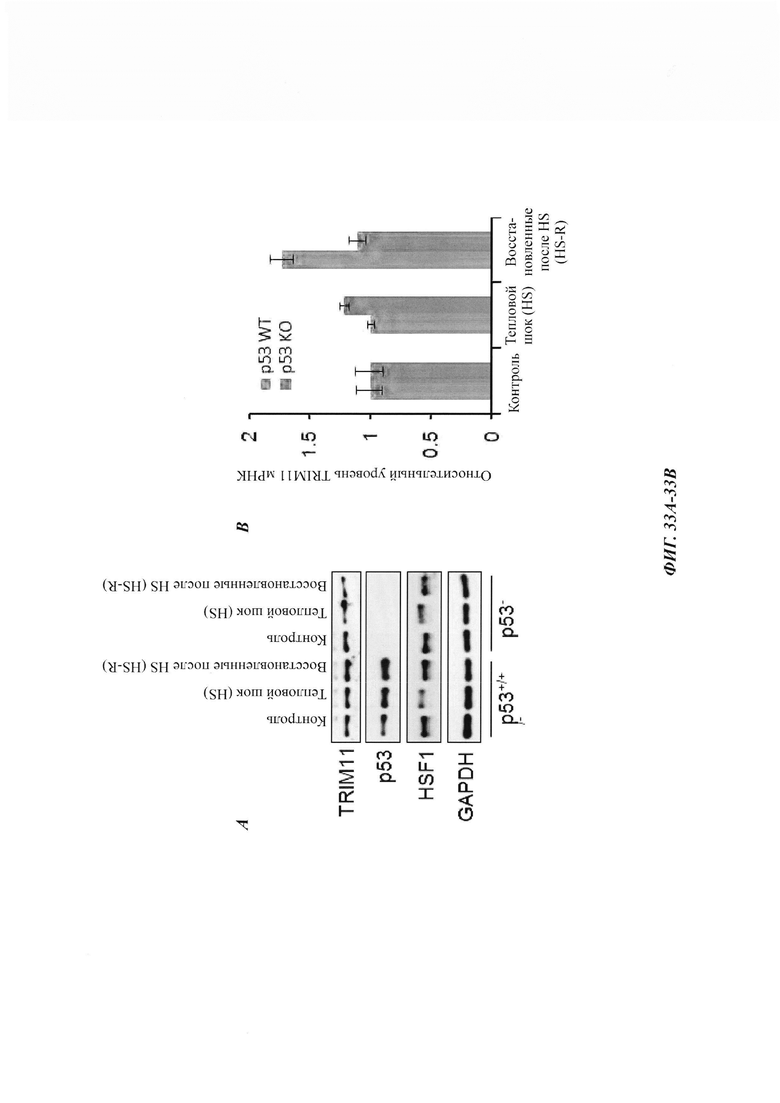
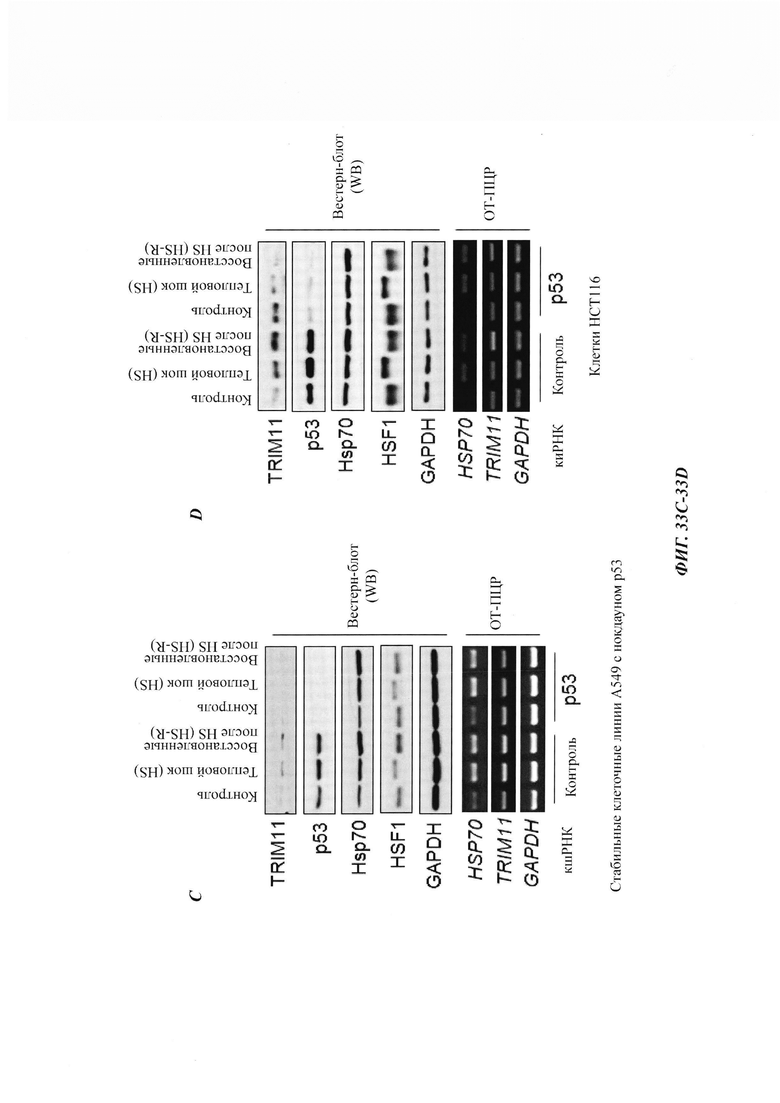
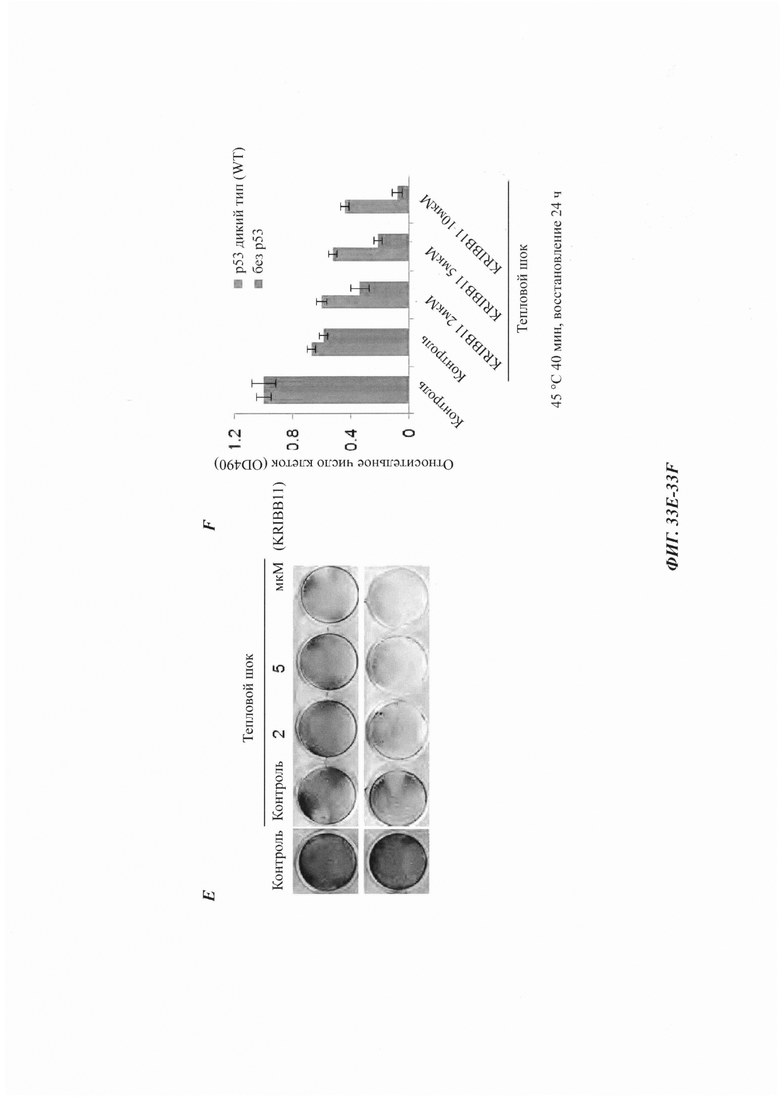
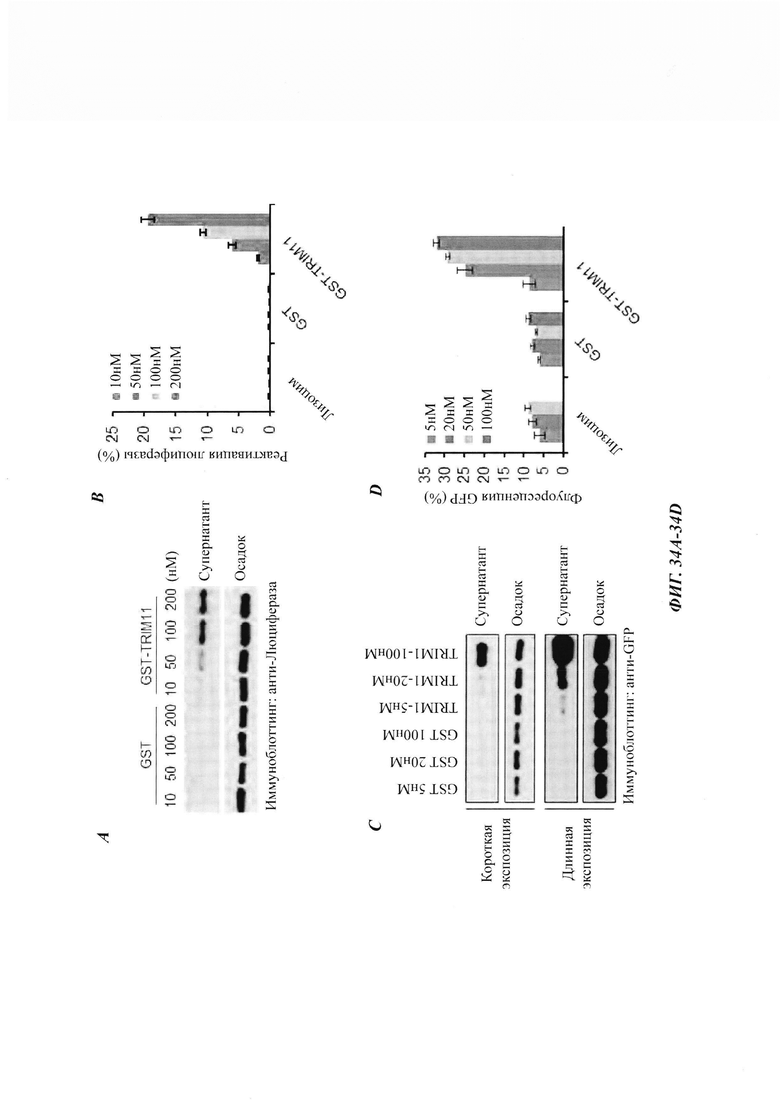
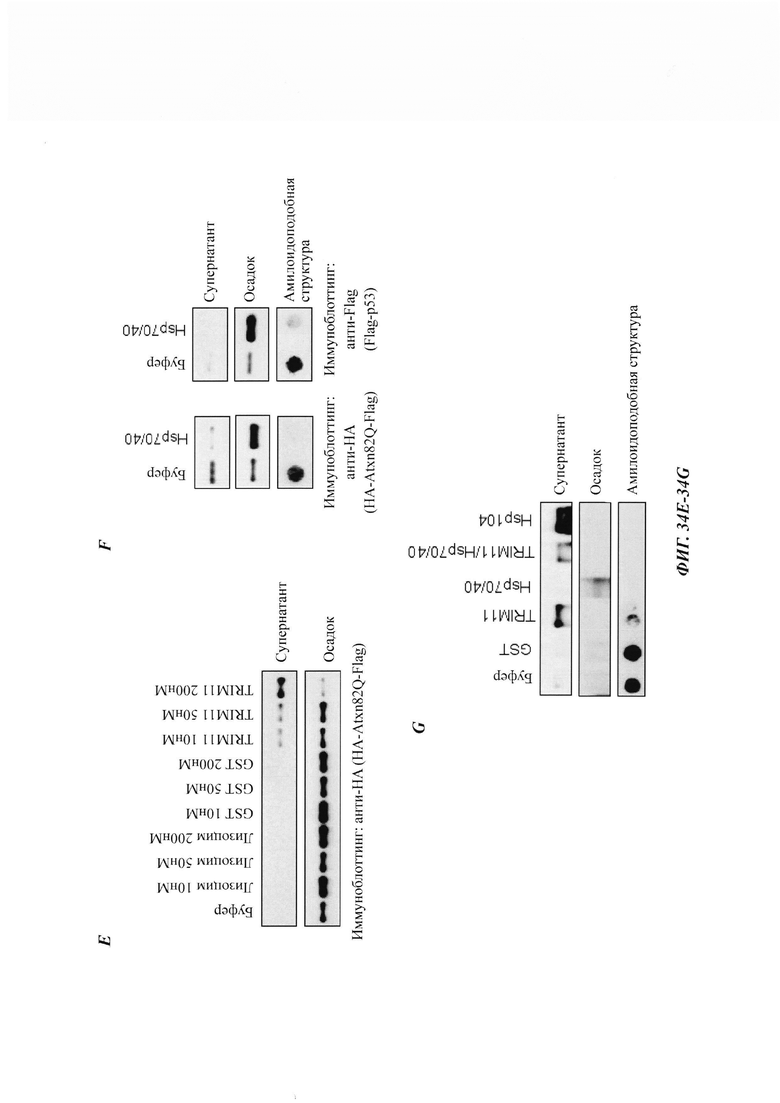

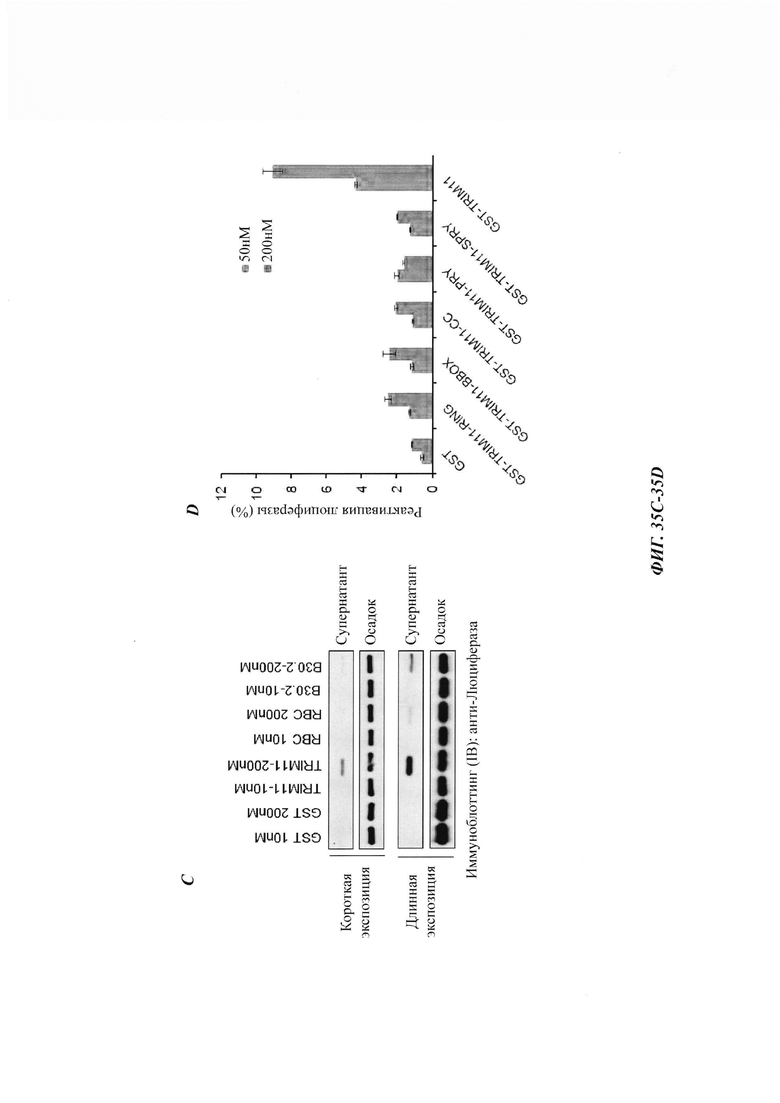
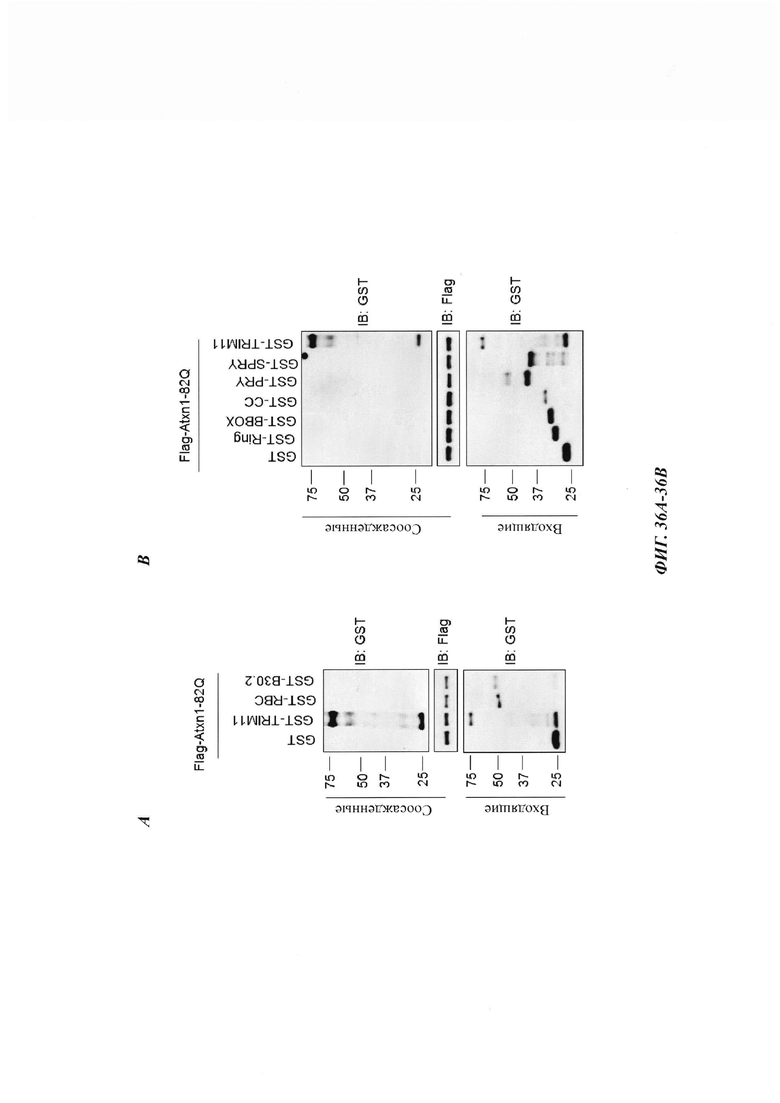

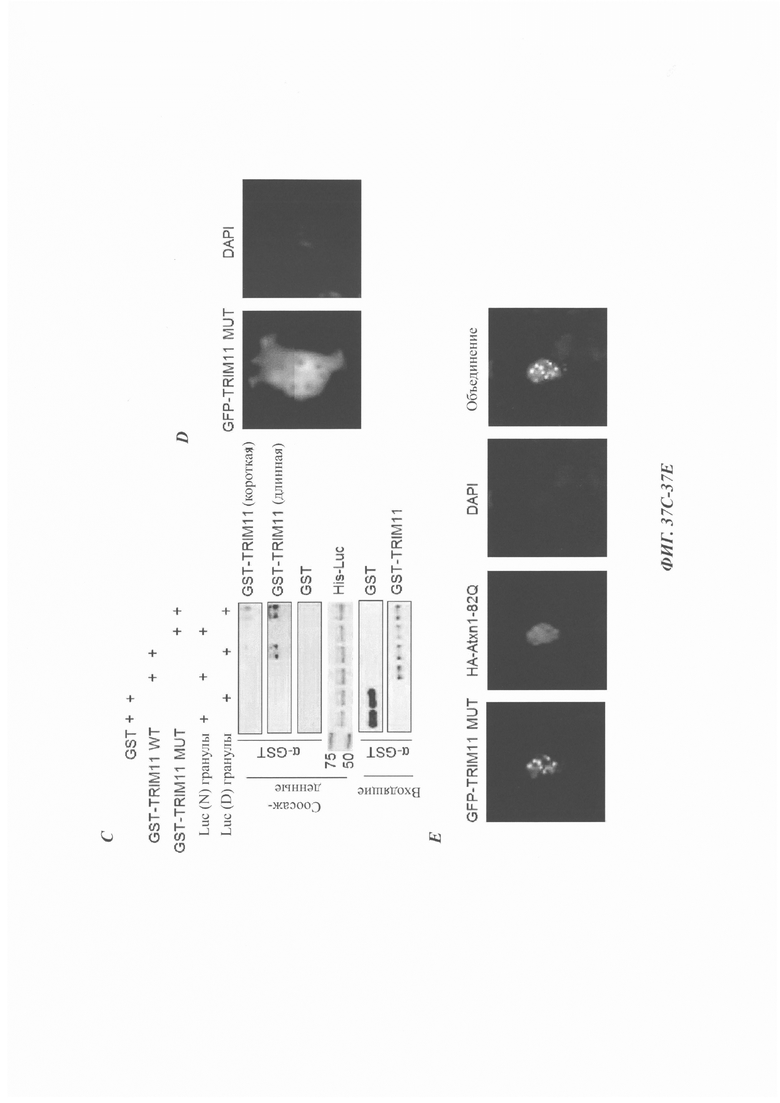
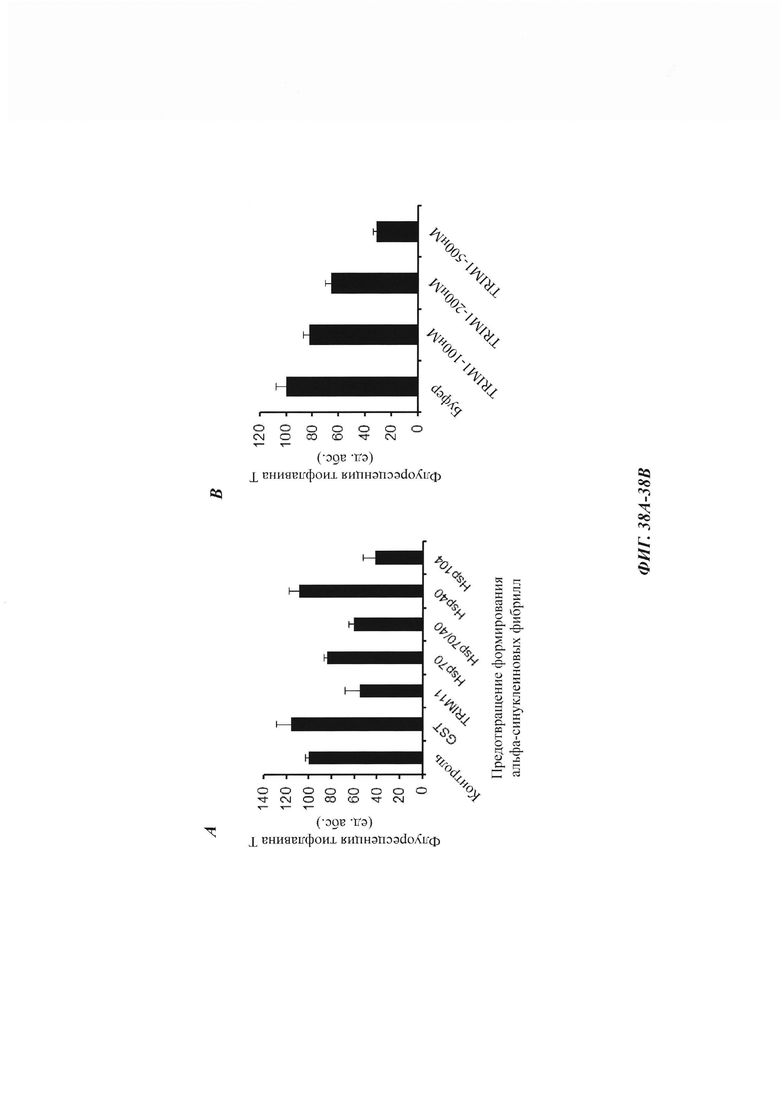
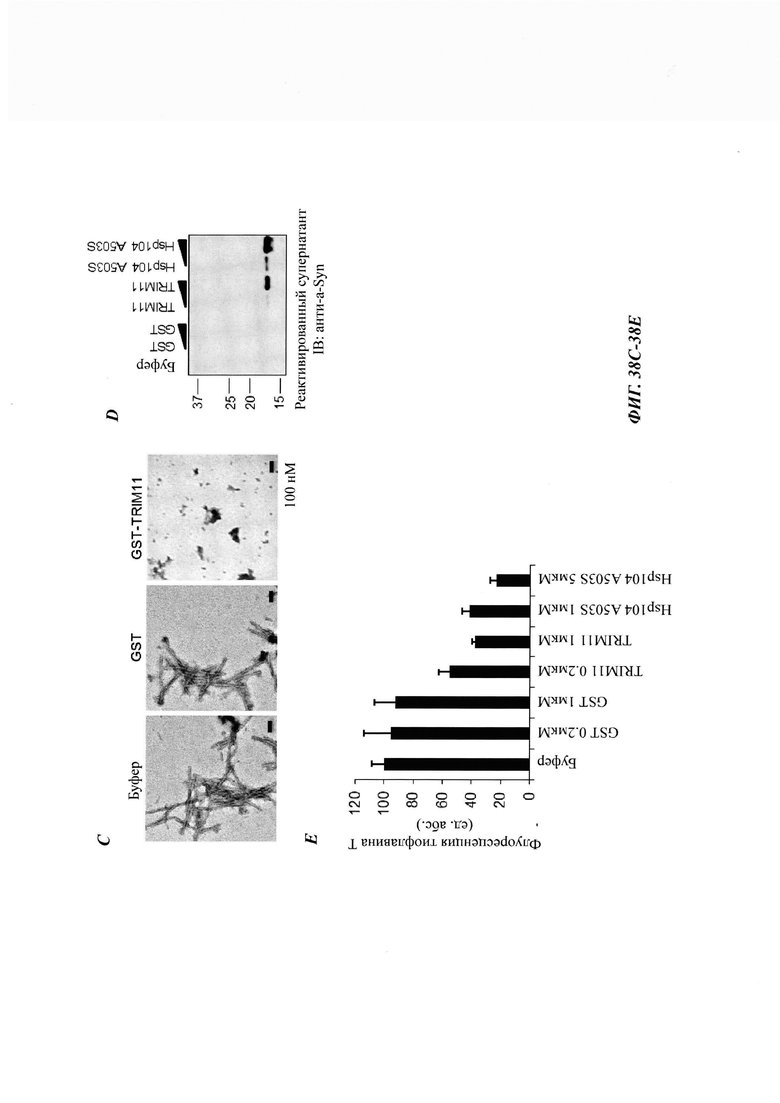
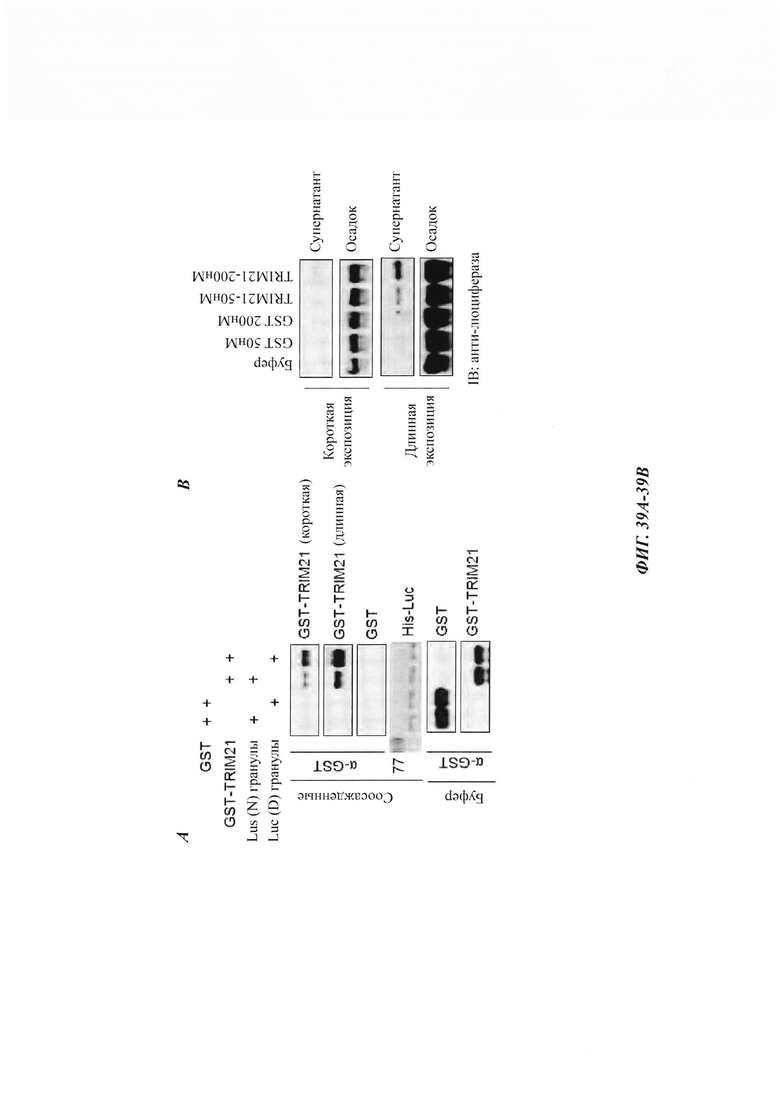

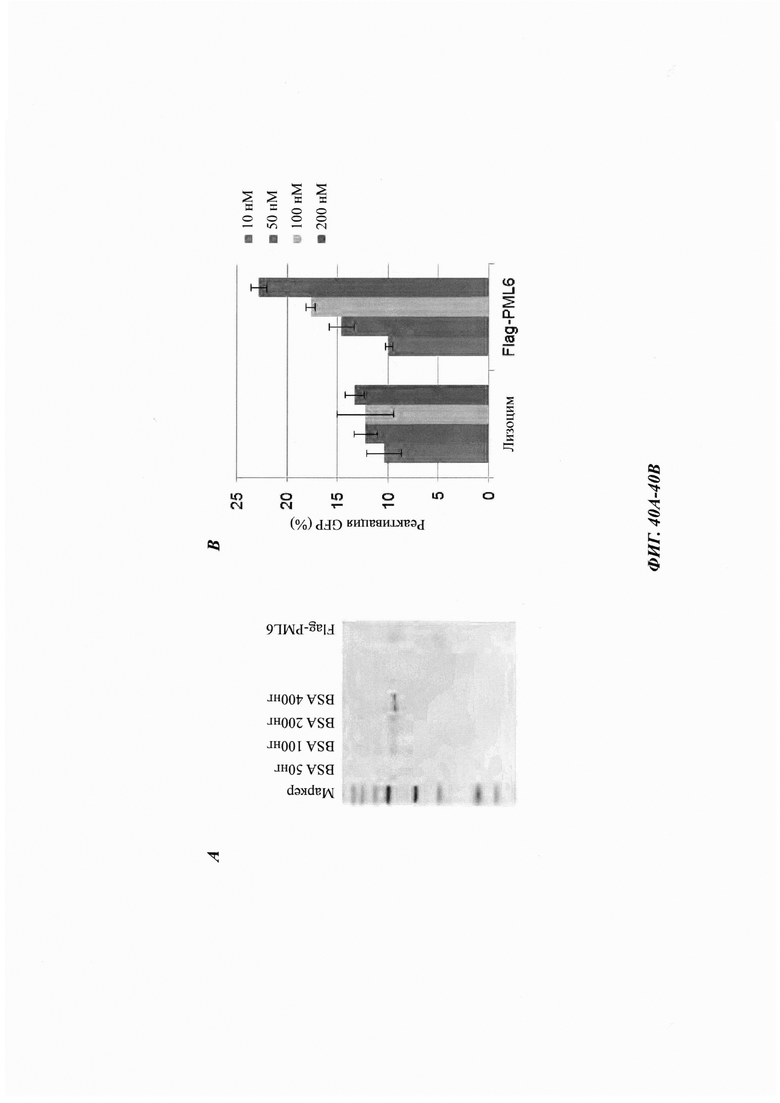

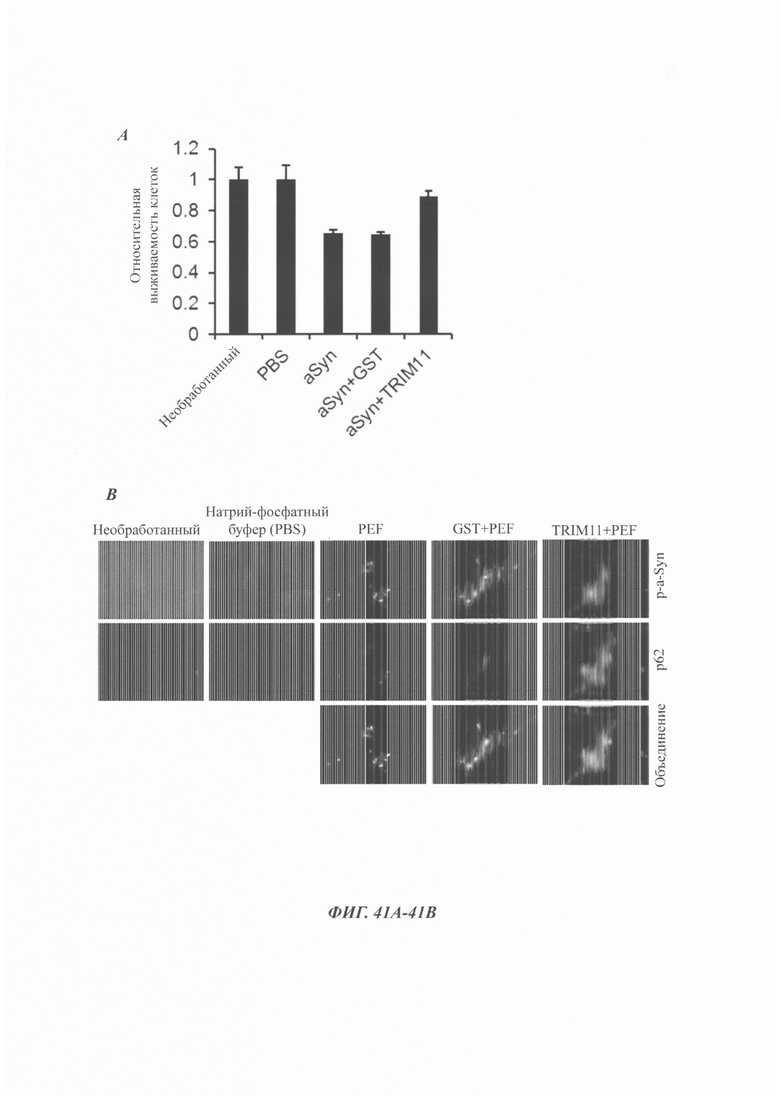

Группа изобретений относится к способам усиления деградации неправильно упакованных белков и белковых агрегатов. Композиция для лечения или профилактики заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковыми агрегатами, содержит вектор на основе аденоассоциированного вируса (AAV), содержащий последовательность нуклеиновой кислоты, кодирующей человеческий TRIM11, где указанное заболевание или нарушение представляет собой нейродегенеративное заболевание или нарушение. Также раскрыты способ лечения или профилактики заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковыми агрегатами, у нуждающегося в этом субъекта, композиция и способ лечения или профилактики заболевания или нарушения, ассоциированного с деградацией функционального мутантного белка, где указанное заболевание или нарушение представляет собой муковисцидоз, способ получения рекомбинантного белка. 5 н. и 4 з.п. ф-лы, 42 ил., 4 табл., 5 пр.
1. Композиция для лечения или профилактики заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковыми агрегатами, где указанная композиция содержит модулятор, выбранный из группы, состоящей из:
a. модулятора одного или более чем одного из TRIM-белков (семейство белков с трехсторонним мотивом); и
b. модулятора одной или более чем одной убиквитин-лигазы, нацеленной на малый убиквитин-подобный модификатор (SUMO, от англ. Small Ubiquitin-like Modifier) (STUbl, от англ. SUMO-targeted ubiquitin ligase).
2. Композиция по п. 1, где указанный модулятор повышает экспрессию или активность одного или более чем одного из TRIM-белков.
3. Композиция по п. 1, где указанный модулятор представляет собой по меньшей мере один из группы, состоящей из химического соединения, белка, пептида, пептидомиметика, антитела, рибозима, низкомолекулярного химического соединения, нуклеиновой кислоты, вектора, киРНК и антисмысловой нуклеиновой кислоты.
4. Композиция по п. 1, где указанный модулятор повышает экспрессию или активность по меньшей мере одного, выбранного из группы, состоящей из: человеческого TRIM3, TRIM4, TRIM5, TRIM6, TRIM7, TRIM9, TRIM10, TRIM11, TRIM13, TRIM14, TRIM15, TRIM16, TRIM17, TRIM19 (также называемого в данном документе "PML" - белок промиелоцитарного лейкоза), TRIM20, TRIM21, TRIM24, TRIM25, TRIM27, TRIM28, TRIM29, TRIM31, TRIM32, TRIM34, TRIM36, TRIM39, TRIM40, TRIM41, TRIM43, TRIM44, TRIM45, TRIM46, TRIM49, TRIM50, TRIM52, TRIM56, TRIM58, TRIM59, TRIM62, TRIM65, TRIM67, TRIM69, TRIM70, TRIM71, TRIM72, TRIM74 и TRIM75; и мышиного TRIM30.
5. Композиция по п. 1, которая содержит по меньшей мере один, выбранный из группы, состоящей из следующих:
a. изолированный пептид, содержащий один или более чем один из TRIM-белков;
b. изолированная молекула нуклеиновой кислоты, кодирующая один или более чем один пептид, включающий один или более чем один из TRIM-белков.
6. Композиция по п. 5, где изолированный пептид дополнительно содержит пептид, проникающий в клетку (СРР), чтобы обеспечить проникновение изолированного пептида в клетку.
7. Композиция по п. 6, где СРР содержит домен трансдукции белка из tat-белка вируса иммунодефицита человека (ВИЧ).
8. Композиция по п. 1, где указанное заболевание или нарушение выбрано из группы, состоящей из следующих:
a. полиQ-нарушение;
b. нейродегенеративное заболевание или нарушение, выбранное из группы, состоящей из спиноцеребеллярной атаксии (SCA) типа 1 (SCA1), SCA2, SCA3, SCA6, SCA7, SCA17, болезни Хантингтона, дентаторубро-паллидолюисовой атрофии (DRPLA), болезни Альцгеймера, болезни Паркинсона, бокового амиотрофического склероза (ALS), трансмиссивной губчатой энцефалопатии (прионное заболевание), тауопатии и лобно-височной дегенерации (FTLD);
c. заболевание или нарушение выбраное из группы, состоящей из AL-амилоидоза, АА-амилоидоза, семейной средиземноморской лихорадки, старческого системного амилоидоза, семейной амилоидотической полинейропатии, амилоидоза, связанного с гемодиализом, ApoAI-амилоидоза, ApoAII-амилоидоза, ApoAIV-амилоидоза, финского наследственного амилоидоза, лизоцимного амилоидоза, фибриногенового амилоидоза, исландской наследственной церебральной амилоидной ангиопатии, диабета II типа, медуллярной карциномы щитовидной железы, предсердного амилоидоза, наследственных кровоизлияний в мозг с амилоидозом, пролактиномы гипофиза, локализованного амилоидоза в месте инъекции, аортального медиального амилоидоза, наследственной решетчатой дистрофии роговицы, амилоидоза роговицы, связанного с трихиазом, катаракты, кальцификации эпителиальной одонтогенной опухоли, легочного альвеолярного протеиноза, миозита с тельцами включения и узелкового амилоидоза кожи; и
d. рак, ассоциированный с р53-мутантными агрегатами.
9. Способ лечения или профилактики заболевания или нарушения, ассоциированного с неправильно упакованным белком или белковыми агрегатами, у нуждающегося в этом субъекта, где указанный способ включает введение субъекту композиции по п. 1.
10. Способ по п. 9, который содержит введение композиции по меньшей мере в одну нервную клетку субъекта.
11. Композиция для лечения или профилактики заболевания или нарушения, ассоциированного с деградацией функционального мутантного белка, где указанная композиция содержит модулятор одного или более чем одного из TRIM-белков.
12. Композиция по п. 11, где указанный модулятор повышает экспрессию или активность одного или более чем одного из TRIM-белков.
13. Композиция по п. 11, где указанный модулятор представляет по меньшей мере один, выбранный из группы, состоящей из химического соединения, белка, пептида, пептидомиметика, антитела, рибозима, низкомолекулярного химического соединения, нуклеиновой кислоты, вектора, киРНК и антисмысловой нуклеиновой кислоты.
14. Композиция по п. 11, где указанное заболевание или нарушение представляет собой муковисцидоз.
15. Способ лечения или профилактики заболевания или нарушения, ассоциированного с деградацией функционального мутантного белка у субъекта, нуждающегося в этом, где указанный способ включает введение субъекту композиции по п. 11.
16. Композиция по п. 1, где указанный модулятор повышает экспрессию или активность одной или более чем одной из STUbL.
17. Композиция по п. 1, где указанный модулятор повышает экспрессию или активность RNF4.
18. Способ получения рекомбинантного белка, содержащий введение модулятора одного или более чем одного из TRIM-белков в клетку, модифицированную для экспрессии рекомбинантного белка.
19. Способ по п. 18, где указанный модулятор содержит по меньшей мере один, выбранный из группы, состоящей из следующих:
a. изолированный пептид, содержащий один или более чем один из TRIM-белков; и
b. изолированная молекула нуклеиновой кислоты, кодирующая один или более чем один пептид, включающий один или более из TRIM-белков.
20. Композиция по п. 5, включающая вектор на основе аденоассоциированного вируса (AAV), содержащий последовательность нуклеиновой кислоты, кодирующей один или более чем один пептид, включающий один или более из TRIM-белков.
21. Композиция по п. 20, включающая вектор AAV9, содержащий последовательность нуклеиновой кислоты, кодирующей пептид, включающий TRIM11.
| GUO L | |||
| et al | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Устройство двукратного усилителя с катодными лампами | 1920 |
|
SU55A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Прибор для нагревания перетягиваемых бандажей подвижного состава | 1917 |
|
SU15A1 |
| US 2009208455 A1, 20.08.2009 | |||
| WO 2014086835 A1, 12.06.2014 | |||
| URANO T | |||
| et al | |||
| Приспособление для плетения проволочного каркаса для железобетонных пустотелых камней | 1920 |
|
SU44A1 |

