По настоящей заявке испрашивается приоритет в соответствии с предварительной заявкой на патент США серийный номер 62/256985, поданной 18 ноября 2015 года; которая включена в настоящее описание посредством ссылки в полном объеме.
Считываемый компьютером формат перечня нуклеотидных/аминокислотных последовательностей включен в качестве ссылки полностью. Файл, содержащий перечень последовательностей, представляет собой текстовый файл ASCII размером 353 килобайта, созданный 15 ноября 2016 года под названием ʺ24236WOPCTSEQʺ.
Область изобретения
Настоящее изобретение относится, в частности, к биспецифичным полипептидам, связывающимся с белком запрограммированной смерти клетки 1 (ʺPD1ʺ) и цитотоксическим Т-лимфоцит-ассоциированным белком 4 (ʺCTLA4ʺ). В частности, настоящее изобретение относится, частично, к биспецифичным полипептидам, которые содержат, по крайней мере, один (например, один или два) одинарный вариабельный домен тяжелой цепи иммуноглобулина (также обозначаемый в настоящем документе как ʺISVʺ или ʺISVDʺ), связывающийся с PD1 и, по крайней мере, один (например, один или два) одинарный вариабельный домен тяжелой цепи иммуноглобулина, связывающийся с CTLA4.
Уровень техники
Подавление иммунорегуляторных молекул, таких как антиген 4 цитотоксических Т лимфоцитов (CTLA4), представляет собой новую и перспективную стратегию, направленную на индуцирование регресса опухоли, стабилизацию заболевания и продление выживаемости путем воздействия иммунной системой. Антитело против CTLA4, ипилимумаб, в настоящее время продается по показаниям, включая меланому. У пациентов с меланомой, которые получали антитела против CTLA4, наблюдали характерные признаки регресса опухолей с длительным временем прогрессирования, а у пациентов с меланомой, злокачественной опухолью яичников, злокачественной опухолью предстательной железы и злокачественной опухолью почек, принимавших ипилимумаб, наблюдали продолжительный терапевтический эффект.
Рецептор программируемой смерти 1 (PD1) является иммуноингибирующим рецептором, который в основном экспрессируется на активированных Т и В-клетках. Было показано, что взаимодействие с его лигандами ослабляет ответы Т-клеток как in vitro, так и in vivo. Было показано, что блокирование взаимодействия между PD1 и одним из его лигандов, PD-L1, повышает опухолеспецифический CD8+ Т-клеточный иммунитет и поэтому может использоваться для устранения опухолевых клеток иммунной системой.
Блокирование взаимодействия PD1/PD-L1 может приводить к усилению опухолеспецифического Т-клеточного иммунитета и, соответственно, использоваться для устранения опухолевых клеток иммунной системой. Для решения этой задачи был проведен ряд исследований. На мышиной модели агрессивной злокачественной опухоли поджелудочной железы T. Nomi et al. (Clin. Cancer Res. 13: 2151-2157 (2007)) продемонстрировали терапевтическую эффективность блокирования PD1/PD-L1. Введение антител, направленных на PD1 или PD-L1, значительно подавляло рост опухоли. Блокирование антителами эффективно способствовало инфильтрации опухольреактивных CD8+ Т-клеток в опухоль, что приводило к повышающей регуляции противоопухолевых эффекторов, включая IFN-гамма, гранзим B и перфорин. Кроме того, авторы настоящего изобретения показали, что, для получения синергетического эффекта, блокирование PD1 может эффективно сочетаться с химиотерапией. В другом исследовании, используя модель плоскоклеточной карциномы у мышей, блокирование PD1 или PD-L1 с помощью антител значительно подавляло рост опухоли (Tsushima F. et al., Oral Oncol., 42: 268-274 (2006)).
Один из способов ингибирования понижающей регуляции иммунного ответа, опосредуемой CTLA4 и PD1, заключается в нарушении их взаимодействия со своими лигандами путем их связывания с мультиспецифичным нанотелом. Существует вероятность того, что нанотела, присутствующие у лам, могут вызвать нежелательный иммунный ответ, вызывающий нейтрализацию действия препарата, например, путем связывания нанотел естественными антителами в сыворотке пациента. Таким образом, новые методы, позволяющие гуманизировать нанотела с тем, чтобы уменьшить или устранить такой ответ, являются особенно ценными, как и нанотела, которые создаются с помощью таких методов.
Сущность изобретения
Настоящее изобретение относится к PD1/CTLA4-связывающему веществу или одинарному вариабельному домену мультиспецифичного иммуноглобулина (ISVD), например, нанотелу, которое связывается с PD1 человека и CTLA4 человека путем контактирования CTLA4 человека на одном или более из следующих остатков VRVTVL (аминокислоты 33-38 в SEQ ID NO: 195), ADSQVTEVC (аминокислоты 41-49 SEQ ID NO: 195) и CKVELMYPPPYYLG (аминокислоты 93-106 SEQ ID NO: 195), например, всех трех областях. Например, связывающее вещество защищает остатки от водородно-дейтериевого обмена в присутствии источника дейтерия, такого как D2O. В одном из вариантов осуществления изобретения, ISVD связывается с CTLA4 человека и генерирует тепловую карту связывания (например, полученную в анализе водородно-дейтериевого обмена), по существу, как показано на фигуре 17.
Настоящее изобретение также относится к PD1/CTLA4-связывающему веществу, содержащему: один или более ISVD, которые связываются с PD1, содержащих: CDR1, содержащий аминокислотную последовательность IHAMG (SEQ ID NO: 3) или GSIASIHAMG (SEQ ID NO: 6); CDR2, содержащий аминокислотную последовательность VITXSGGITYYADSVKG (SEQ ID NO: 4, где X представляет собой W или V) или VITWSGGITY (SEQ ID NO: 7); и CDR3, содержащий аминокислотную последовательность DKHQSSXYDY (SEQ ID NO: 5, где X представляет собой W или F); и один или более ISVD, которые связываются с CTLA4, содержащих: CDR1, содержащий аминокислотную последовательность FYGMG (SEQ ID NO: 10) или GGTFSFYGMG (SEQ ID NO: 13); CDR2, содержащий аминокислотную последовательность DIRTSAGRTYYADSVKG (SEQ ID NO: 11) или DIRTSAGRTY (SEQ ID NO: 14); и CDR3, содержащий аминокислотную последовательность EXSGISGWDY (SEQ ID NO: 12, где X представляет собой M или P); и, необязательно, экстендер периода полувыведения и/или С-концевой экстендер. В одном из вариантов осуществления изобретения, присутствует пептидный линкер между каждым ISVD в связывающем веществе, например, линкер 35GS.
Настоящее изобретение также относится к PD1/CTLA4-связывающему веществу, содержащему ISVD, который связывается с PD1, который содержит аминокислотную последовательность: DVQLVESGGG VVQPGGSLRL SCAASGSIAS IHAMGWFRQA PGKEREFVAV ITWSGGITYY ADSVKGRFTI SRDNSKNTVY LQMNSLRPED TALYYCAGDK HQSSWYDYWG QGTLVTVSS (SEQ ID NO: 135); и ISVD, который связывается с CTLA4, содержит аминокислотную последовательность: XVQLVESGGGVVQPGGSLRLSCAASGGTFSFYGMG
WFRQAPGKEREFVADIRTSAGRTYYADSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYYCAAEPSGISGWDYWGQGTLVTVSS (SEQ ID NO: 143), где X представляет собой D или E; или
X1VQLVESGGGVVQPGGSLRLSCAASGGTFSFYGMGWFRQAPGKEREFVADIRTSAGRTYYADSVKGRFTISRDX2SKNTVYLQMNSLRPEDTALYYCAAEPSGISGWDYWGQGTLVTVSS (SEQ ID NO: 196); где X1 представляет собой D или E и где X2 представляет собой S, V, G, R, Q, M, H, T, D, E, W, F, K, A, Y или P; и, необязательно, экстендер периода полувыведения и/или С-концевой экстендер. В одном из вариантов осуществления изобретения, между каждым ISVD в связывающем веществе, присутствует пептидный линкер, например, линкер 35GS.
Настоящее изобретение также относится к PD1/CTLA4-связывающему веществу, содержащему:
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143 (D1E);
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
HSA ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 144; и
C-концевой аланин,
или:
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
HSA ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 144; и
C-концевой аланин,
или
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143 (D1E);
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143 (D1E);
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
HSA ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 144; и
С-концевой аланин,
или
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135 (D1E);
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143 (D1E);
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143 (D1E);
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
HSA ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 144; и
C-концевой аланин.
Например, настоящее изобретение относится к PD1/CTLA4-связывающему веществу, содержащему аминокислотную последовательность, представленную в SEQ ID NO: 146, 149, 151 или 153.
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающее вещество включает экстендер периода полувыведения, например, HSA-связывающее вещество, например, ISVD сывороточного альбумина человека, который содержит:
CDR1, содержащий аминокислотную последовательность GFTFSSFGMS (SEQ ID NO: 177); CDR2, содержащий аминокислотную последовательность SISGSGSDTL (SEQ ID NO: 178); и CDR3, содержащий аминокислотную последовательность GGSLSR (SEQ ID NO: 179), например, содержащий аминокислотную последовательность: EVQLVESGGG VVQPGNSLRL SCAASGFTFS SFGMSWVRQA PGKGLEWVSS ISGSGSDTLYADSVKGRFTI SRDNAKTTLY LQMNSLRPED TALYYCTIGG SLSRSSQGTL VTVSSA (SEQ ID NO: 144).
Кроме того, настоящее изобретение относится к связывающему веществу (например, антитело, его антигенсвязывающий фрагмент, ISVD или нанотело), которое перекрестно блокирует PD1/CTLA4-связывающее вещество, описанное в настоящем документе, от связывания с PD1 и/или CTLA4.
Настоящее изобретение относится к PD1/CTLA4-связывающему веществу или мультиспецифичному связывающему веществу (например, мультиспецифичному ISVD, такому как нанотело), которое связывается с PD1 и CTLA4, содержащему: (i) связывающий фрагмент, который связывается с PD1, который содержит аминокислотную последовательность, представленную в SEQ ID NO: 1 или 2, но дополнительно включающую мутацию в одном или более положениях 11, 89, 110 и 112 относительно аминокислотной последовательности в SEQ ID NO: 1 или 2, где указанные положения нумеруются в соответствии с системой нумерации по Kabat, и необязательно также включающую любое количество дополнительных мутаций, которые указаны в настоящем документе или каким-либо иным образом, например, до 10 (например, 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10) дополнительных мутаций (например, точечные мутации, замены, делеции, вставки); и (ii) связывающий фрагмент, который связывается с CTLA4, который содержит аминокислотную последовательность, представленную в SEQ ID NO: 9, но включающую мутацию в одном или более положениях 11, 89, 110 и 112, соответствующих аминокислотной последовательности, представленной в SEQ ID NO: 9, где указанные положения нумеруются в соответствии с системой нумерации по Kabat, необязательно дополнительно содержащее любое количество дополнительных мутаций, которые указаны в настоящем документе или каким-либо иным образом, например, до 10 (например, 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10) дополнительные мутации (например, точечные мутации, замены, делеции, вставки). В представленном изобретении связывающий фрагмент, который связывается с PD1, содержит одну или более мутаций, соответствующих аминокислотной последовательности SEQ ID NO: 1 или 2, где аминокислотный остаток в положении 11 выбран из L или V; аминокислотный остаток в положении 89 выбран из T, V, I или L; аминокислотный остаток в положении 110 выбран из T, K или Q; и/или аминокислотный остаток в положении 112 выбран из S, K или Q; и где связывающий фрагмент, который связывается с CTLA4, содержит одну или более мутаций в соответствии с аминокислотной последовательностью SEQ ID NO: 9, где аминокислотный остаток в положении 11 выбран из L или V; аминокислотный остаток в положении 89 выбран из T, V или L; аминокислотный остаток в положении 110 выбран из T, K или Q; и/или аминокислотный остаток в положении 112 выбран из S, K или Q. В представленном изобретении связывающий фрагмент, который связывается с PD1, содержит одну или более мутаций в соответствии с аминокислотной последовательностью SEQ ID NO: 1 или 2, где: положение 89 соответствует L, и положение 11 соответствует V; или положение 89 соответствует L, и положение 110 соответствует K или Q; или положение 89 соответствует L, и положение 112 соответствует K или Q; или положение 89 соответствует L, и положение 11 соответствует V, и положение 110 соответствует K или Q; или положение 89 соответствует L, и положение 11 соответствует V, и положение 112 соответствует K или Q; или положение 11 соответствует V, и положение 110 соответствует K или Q; или положение 11 соответствует V, и положение 112 соответствует K или Q. В одном из вариантов осуществления изобретения, мультиспецифичное связывающее вещество содержит мутации в положениях 11, 89, 110 и 112, соответствующих SEQ ID NO: 1, 2 и/или 9 являются любыми из приведенных в таблице:
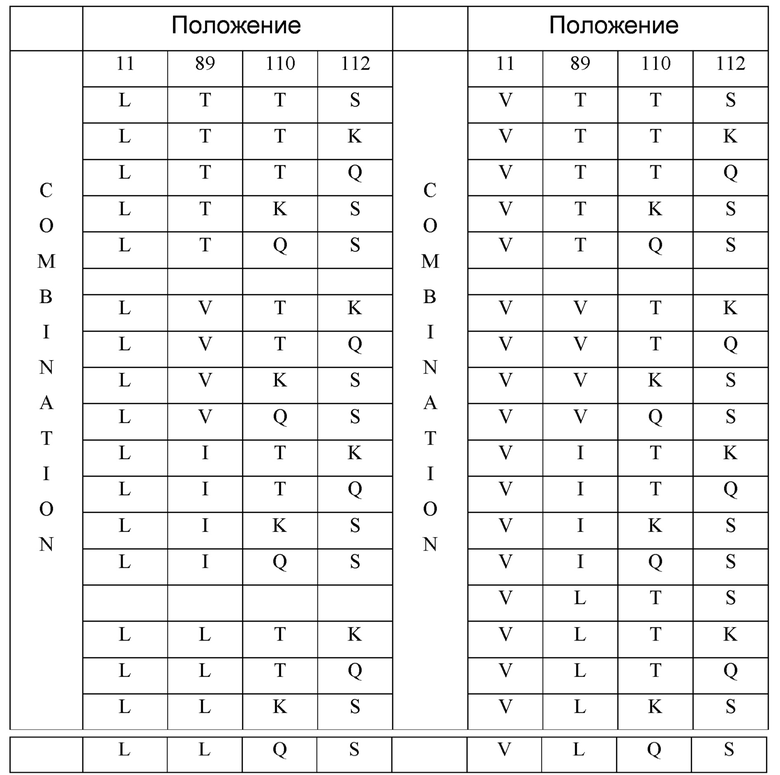
В варианте осуществления изобретения (i) связывающий фрагмент, который связывается с PD1, дополнительно содержит одну или более мутаций в положении, выбранном из группы, состоящей из 1, 14, 41, 74, 83 и 87, соответствующих аминокислотной последовательности SEQ ID NO: 1 или 2, где указанные положения нумеруются в соответствии с системой нумерации по Kabat; и/или (ii) связывающий фрагмент, который связывается с CTLA4, дополнительно содержит одну или более мутаций в положении, выбранном из группы, состоящей из 1, 14, 41, 74, 83 и 87, соответствующих аминокислотной последовательности SEQ ID NO: 9, где указанные положения нумеруются в соответствии с системой нумерации по Kabat. В одном из вариантов осуществления изобретения, мультиспецифичное связывающее вещество содержит C-концевое удлинение, например, 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10 аминокислот. Например, в одном из вариантов осуществления изобретения, C-концевое удлинение имеет формулу -X(n), где X и n являются следующими: (a) n=1 и X=Ala; (b) n=2 и каждый X=Ala; (c) n=3 и каждый X=Ala; (d) n=2 и, по крайней мере, один X=Ala и где оставшийся аминокислотный остаток(остатки) X независимо выбран(ы) из любой природной аминокислоты; (e) n=3 и, по крайней мере, один X=Ala и где оставшийся аминокислотный остаток(остатки) X независимо выбран(ы) из любой природной аминокислоты; (f) n=3 и, по крайней мере, два X=Ala и где оставшийся аминокислотный остаток(остатки) X независимо выбран(ы) из любой природной аминокислоты; (g) n=1 и X=Gly; (h) n=2 и каждый X=Gly; (i) n=3 и каждый X=Gly; (j) n=2 и, по крайней мере, один X=Gly, где оставшийся аминокислотный остаток(остатки) X независимо выбран(ы) из любой природной аминокислоты; (k) n=3 и, по крайней мере, один X=Gly, где оставшийся аминокислотный остаток(остатки) X независимо выбран(ы) из любой природной аминокислоты; (l) n=3 и, по крайней мере, два X=Gly, где оставшийся аминокислотный остаток(остатки) X независимо выбран(ы) из любой природной аминокислоты; (m) n=2 и каждый X=Ala или Gly; (n) n=3 и каждый X=Ala или Gly; (o) n=3 и, по крайней мере, один X=Ala или Gly, где оставшийся аминокислотный остаток(остатки) X независимо выбран(ы) из любой природной аминокислоты; или (p) n=3 и, по крайней мере, два X=Ala или Gly, где оставшийся аминокислотный остаток(остатки) X независимо выбран(ы) из любой природной аминокислоты, например, C-концевое удлинение, выбранное из группы, состоящей из A, AA, AAA, G, GG, GGG, AG, GA, AAG, AGG, AGA, GGA, GAA и GAG.
Настоящее изобретение также включает мультиспецифичное связывающее вещество (например, мультиспецифичный ISVD, такой как нанотело), которое содержит (i) связывающий фрагмент, который связывается с PD1, который содержит аминокислотную последовательность, имеющую, по крайней мере, 85% (например, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 99,5, 99,9 или 100%) идентичность последовательностей с аминокислотной последовательностью, представленной в элементе, выбранном из группы, состоящей из SEQ ID NO: 1, 2 и 16-47 который содержит CDR1, CDR2 и CDR3 иммуноглобулина, содержащего аминокислотную последовательность, представленную в SEQ ID NO: 1 или 2, где указанный связывающий фрагмент содержит, по крайней мере, одну мутацию, соответствующую аминокислотной последовательности, представленной в SEQ ID NO: 1 или 2, где указанная, по крайней мере одна, мутация находится в положении, выбранном из группы, состоящей из 11, 89, 110 и 112, где указанные положения нумеруются в соответствии с системой нумерации по Kabat; и/или (ii) связывающий фрагмент, который связывается с CTLA4, который содержит аминокислотную последовательность, имеющую, по крайней мере, 85% идентичность последовательностей с аминокислотной последовательностью, представленной в элементе, выбранном из группы, состоящей из SEQ ID NO: 9 и 48-83, который содержит CDR1, CDR2 и CDR3 иммуноглобулина, содержащего аминокислотную последовательность, представленную в SEQ ID NO: 9, где указанный связывающий фрагмент содержит, по крайней мере, одну мутацию, соответствующую аминокислотной последовательности, представленной в SEQ ID NO: 9, где указанная, по крайней мере, одна мутация находится в положении, выбранном из группы, состоящей из 11, 89, 110 и 112, где указанные положения нумеруются в соответствии с системой нумерации по Kabat.
Настоящее изобретение относится к мультиспецифичному связывающему веществу или полипептиду, содержащему аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 16-83 и 103-134.
Настоящее изобретение включает мультиспецифичное связывающее вещество, содержащее (i) связывающий фрагмент, который связывается с PD1, который содержит аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 16-47, и (ii) связывающий фрагмент, который связывается с CTLA4, который содержит аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 48-83.
В одном из вариантов осуществления изобретения, мультиспецифичное связывающее вещество (например, мультиспецифичный ISVD, такой как нанотело) дополнительно связывается с одним или более одинарными вариабельными доменами иммуноглобулина, нанотелами, антителами или их антигенсвязывающими группами. В одном из вариантов осуществления изобретения, мультиспецифичное связывающее вещество включает одну или более других связывающих фрагментов (например, одинарные вариабельные домены иммуноглобулина, нанотела, антитела или их антигенсвязывающие фрагменты), которые связываются с CD27, LAG3, PD1, BTLA, TIM3, ICOS, B7-H3, B7-H4, CD137, GITR, PD-L1, PD-L2, ILT1, ILT2 CEACAM1, CEACAM5, TIM3, TIGIT, VISTA, ILT3, ILT4, ILT5, ILT6, ILT7, ILT8, CD40, OX40, CD137, KIR2DL1, KIR2DL2, KIR2DL3, KIR2DL4, KIR2DL5A, KIR2DL5B, KIR3DL1, KIR3DL2, KIR3DL3, NKG2A, NKG2C, NKG2E, IL-10, IL-17 или TSLP.
Настоящее изобретение включает связывающее вещество или мультиспецифичное PD1/CTLA4-связывающее вещество в комбинации с дополнительным терапевтическим средством, таким как пембролизумаб. Настоящее изобретение также включает инъекционное устройство или сосуд, который содержит PD1/CTLA4-связывающее вещество или мультиспецифичное связывающее вещество и, необязательно, совместно с другим терапевтическим средством, таким как пембролизумаб. Настоящее изобретение также относится к полинуклеотиду, кодирующему PD1/CTLA4-связывающее вещество или мультиспецифичное связывающее вещество, как указано в настоящем документе, (например, содержащее нуклеотидную последовательность, представленную в SEQ ID NO: 145, 148, 150 или 152), а также векторы, содержащие такие полинуклеотиды и клетки-хозяева (например, клетка CHO или клетка Pichia), включающие такие полинуклеотиды и векторы.
Настоящее изобретение относится к способу получения PD1/CTLA4-связывающего вещества или мультиспецифичного связывающего вещества, как указано в настоящем документе, включающему введение полинуклеотида, кодирующего иммуноглобулины в клетку-хозяина, и культивирование клетки-хозяина (например, клетки СНО или клетки Pichia) в среде в условиях, благоприятных для экспрессии указанного иммуноглобулина из указанного полинуклеотида, и, необязательно, очищение иммуноглобулина от указанной клетки-хозяина и/или указанной среды. PD1/CTLA4-связывающее вещество или мультиспецифичные связывающие вещества, полученные таким способом, являются частью настоящего изобретения.
Настоящее изобретение также относится к способу предотвращения связывания PD1 с PD-L1 и/или PD-L2 и предотвращения связывания CTLA4 на Т-клетке с CD80 и/или CD86 на антигенпрезентирующей клетке, включающему контактирование PD1 с указанным PD1/CTLA4-связывающим веществом или мультиспецифичным связывающим веществом, как описано в настоящем документе, необязательно совместно с дополнительным терапевтическим средством.
Настоящее изобретение относится к способу усиления иммунного ответа у субъекта (например, млекопитающего, такого как человек), включающему введение эффективного количества PD1/CTLA4-связывающего вещества или мультиспецифичного связывающего вещества, как указано в настоящем документе, субъекту необязательно совместно с дополнительным терапевтическим средством.
Настоящее изобретение также относится к способу лечения или профилактики злокачественной опухоли или инфекционного заболевания у субъекта, включающему введение эффективного количества PD1/CTLA4-связывающего вещества или мультиспецифичного связывающего вещества, как указано в настоящем документе, необязательно совместно с дополнительным терапевтическим средством субъекту. Например, в одном из вариантов осуществления изобретения, злокачественная опухоль представляет собой метастатическую злокачественную опухоль, твердую опухоль, гематологическую злокачественную опухоль, лейкемию, лимфому, остеосаркому, рабдомиосаркому, нейробластому, злокачественную опухоль почек, лейкемию, переходно-клеточную злокачественную опухоль почек, злокачественную опухоль мочевого пузыря, опухоль Вильма, злокачественную опухоль яичников, злокачественную опухоль поджелудочной железы, злокачественную опухоль молочной железы, злокачественную опухоль простаты, злокачественную опухоль костей, злокачественную опухоль легких, немелкоклеточную злокачественную опухоль легкого, злокачественную опухоль желудка, злокачественную опухоль толстой и прямой кишки, злокачественную опухоль шейки матки, синовиальную саркому, злокачественную опухоль головы и шеи, плоскоклеточную карциному, множественную миелому, почечно-клеточную злокачественную опухоль, ретинобластому, гепатобластому, гепатоцеллюлярную карциному, меланому, рабдоидную опухоль почки, саркому Юинга, хондросаркому, злокачественную опухоль мозга, глиобластому, менингиому, аденому гипофиза, вестибулярную шванному, примитивную нейроэктодермальную опухоль, медуллобластому, астроцитому, анапластическую астроцитому, олигодендроглиому, эпендимому, папиллому хориоидного сплетения, полицитемию, тромбоцитемию, идиопатический миелофиброз, саркому мягких тканей, злокачественную опухоль щитовидной железы, злокачественную опухоль эндометрия, карциноидную злокачественную опухоль или злокачественную опухоль печени, злокачественную опухоль молочной железы или злокачественную опухоль желудка. В настоящем изобретении, инфекционное заболевание представляет собой бактериальную инфекцию, вирусную инфекцию или грибковую инфекцию. В одном из вариантов осуществления изобретения, где субъекту вводят дополнительное терапевтическое средство, и/или в отношении субъекта осуществляют терапевтическую процедуру, совместно с PD1/CTLA4-связывающим веществомили мультиспецифичным связывающим веществом.
Описание чертежей
Фигура 1. Таблица, в которой перечислены некоторые из аминокислотных положений, которые будут конкретно указаны в настоящем документе, и их нумерация в соответствии с некоторыми альтернативными системами нумерации (такими как Aho и IMGT).
Фигура 2. Нанотело 102C12 и последовательности эталона A (см. WO 2008/071447, SEQ ID NO:348).
Фигура 3 (A-B). (A) Последовательности PD1-связывающих фрагментов по настоящему изобретению. (B) выравнивание PD1-связывающих фрагментов с аминокислотными последовательностями SEQ ID NO: 1 и 2.
Фигура 4 (A-B). (A) Последовательности CTLA4-связывающих фрагментов по настоящему изобретению. (B) выравнивание CTLA4-связывающих фрагментов с аминокислотными последовательностями SEQ ID NO: 9.
Фигура 5. Последовательности, которые могут быть связаны со связывающими веществами по настоящему изобретению.
Фигура 6. Последовательности PD1/CTLA4-связывающих веществ по настоящему изобретению.
Фигура 7. Преобладающие N-связанные гликаны для моноклональных антител, продуцируемых клетками яичника китайского хомячка (CHO N-связанные гликаны) и в генетически сконструированных дрожжевых клетках (генетически сконструированные дрожжевые N-связанные гликаны): квадраты: N-ацетилглюкозамин (GlcNac); круги: манноза (Man); ромбы: галактоза (Gal); треугольники: фукоза (Fuc).
Фигура 8. Связывание нанотела F023700925, F023700918 и F023700912 и контрольного нанотела (IRR00051; анти-HER2/ERBB2 (двухвалентный анти-HER2 с 35GS, связанный с альбуминовым связывающим веществом)) с клетками CHO-K1, экспрессирующими CTLA4 человека.
Фигура 9. Связывание нанотела F023700925, F023700912 и контрольного нанотела (IRR00051) с клетками CHO-K1, экспрессирующими PD1 человека.
Фигура 10 (A-B). Блокирование связывания CTLA4 человека (на клетках CHO-K1) с (A) CD80 человека или (B) CD86 человека посредством F023700906, F023701051, F023701054 и F023701061.
Фигура 11 (A-H). Связывание нанотела F023700912 или F023700925 или контрольного нанотела (IRR00051) с (A) L клетками отрицательного контроля, (B) клетками отрицательного контроля CHO-K1, (C) huCD28+ L клетками, (D) huCD8альфа+ L клетками, (E) huLag-3+ CHO-K1 клетками (F) huBTLA+ CHO-K1 клетками, (G) huCTLA-4+ CHO-K клетками или (H) huPD-1+ CHO-K1 клетками.
Фигура 12 (A-B). Блокирование связывания CTLA4 человека (на клетках CHO-K1) с (A) CD80 человека или (B) CD86 человека посредством нанотела F02370906, F02371051, F023701054 или F023701061.
Фигура 13 (A-J). Средний объем опухолей panc08/.13 ± стандартная погрешность (A) и конкретные объемы опухолей на 37-й день (B) и объемы опухолей у отдельных гуманизированных мышей в процесса эксперимента у мышей, обработанных (C) изотипом контрольного антитела, (D) ипилимумабом (N297A), (E) ипилимумабом, (F) пембролизумабом, (G) ипилимумабом+пембролизумабом, (H) CTLA4 нанотелом F023700912 (5 мг/кг), (I) CTLA4 нанотелом F023700912 (15 мг/кг) или (J) пембролизумабом+CTLA4 нанотелом F023700912 (15 мг/кг).
Фигура 14 (A-B). Связывание естественных антител, отобранных у (а) здоровых и (b) имеющих злокачественную опухоль пациентов, с нанотелом F023700912, F023700925 или трехвалентным контрольным нанотелом T013700112 (не содержит мутации для ослабления связывания с естественными антителами).
Фигура 15 (A-D). Последовательности по настоящему изобретению.
Фигура 16 (A-B). Описание конструкций связывающего вещества по настоящему изобретению.
Фигура 17. Полученная посредством мечения дейтерием тепловая карта различий связывания CTLA4 человека с CTLA4-связывающим веществом F023700912.
Подробное описание изобретения
Настоящее изобретение относится к ISVD, которые содержат мутации, которые блокируют реактивность естественных антител (предсуществующих антител) к неоэпитопам в ISVD. Неоэпитопы являются эпитопами в белке, который обнаруживается при мутировании белка (например, процессинге) или при нарушении его фолдинга. Естественные антитела являются антителами, существующими в организме пациента до поступления ISVD. ISVD по настоящему изобретению основаны, отчасти, на антителах ламы, C-терминальные константные домены, которых были удалены; таким образом подвергая неоэпитопы на С-конце полученного VHH связыванию с естественным антителом. Было обнаружено, что сочетание мутаций остатков 11 и 89 (например, L11V и I89L или V89L) привело к неожиданному недостатку связывания с естественным антителом. Было также показано, что мутации в остатке 112 значительно ослабляют связывание с естественным антителом. Buyse & Boutton (WO2015/173325) включили данные, показывающие, что комбинация L11V и V89L мутации обеспечивает значительное усиление в ослаблении связывания естественных антител по сравнению только с одной мутацией L11V или только одной мутацией V89L. Например, в таблице H, приведенной Buyse & Boutton на стр. 97 представлены сравнительные данные для ISVD только с одной мутацией V89L (с или без C-концевого удлинения) и аналогичный ISVD с мутацией V89L в комбинации с мутацией L11V (также с или без С-концевого удлинения). Кроме того, хотя они были получены в двух отдельных экспериментах, данные, приведенные в таблице H для комбинации L11V/V89L, по сравнению с данными, приведенными в таблице B для только одной мутации L11V (в том же самом ISVD), показали, что уменьшение связывания естественных антител, которое получено посредством L11V/V89L комбинации, было больше, чем для только одной мутации L11V. Поскольку известно, что структура каркаса антител ламы является крайне высококонсервативной, эффект мутаций в положениях 11 и 89, вероятно, будет сохраняться для любого ISVD. Действительно, эффект был продемонстрирован на фигуре 14 с существующими связывающими веществами, F023700912, F023700925, которые, как было показано, демонстрируют очень низкие уровни связывания с естественными антителами.
В настоящей заявке аминокислотные остатки/положения в вариабельном домене тяжелой цепи иммуноглобулина будут нумероваться в соответствии с системой нумерации Kabat. Для удобства, на фигуре 1 представлена таблица, в которой перечислены некоторые из аминокислотных положений, которые будут конкретно указаны в настоящем документе, и их нумерация в соответствии с некоторыми альтернативными системами нумерации (такими как Aho и IMGT. Примечание: если в явной форме не указано иное, для настоящего описания и пунктов формулы изобретения, нумерация по Kabat является определяющей; другие системы нумерации приведены только в качестве справочной информации).
В отношении CDR, как хорошо известно в данной области техники, существует множество обозначений для определения и описания CDR фрагмента VH или VHH, например, определение по Kabat (которое основано на изменчивости последовательностей и является наиболее часто используемым) и определение по Chotia (которое основано на положении областей структурных петель). Делается ссылка, например, на веб-сайт www.bioinf.org.uk/abs/. Для целей настоящего описания и пунктов формулы изобретения, даже если могут быть также указаны CDR в соответствии с системой нумерации Kabat, CDR наиболее предпочтительно определяются исходя из определения Abm (которое основано на программном моделирования антител AbM Oxford Molecular), поскольку это считается оптимальным компромиссом между определениями по Kabat и Chotia. Повторно делается ссылка на веб-сайт www.bioinf.org.uk/abs/. См. Sequences of Proteins of Immunological Interest, Kabat, et al.; National Institutes of Health, Bethesda, Md.; 5th ed.; NIH Publ. No. 91-3242 (1991); Kabat (1978) Adv. Prot. Chem. 32:1-75; Kabat, et al., (1977) J. Biol. Chem. 252:6609-6616; Chothia, et al., (1987) J Mol. Biol. 196:901-917 или Chothia, et al., (1989) Nature 342:878-883; Chothia & Lesk (1987) J. Mol. Biol. 196: 901-917; Elvin A. Kabat, Tai Te Wu, Carl Foeller, Harold M. Perry, Kay S. Gottesman (1991) Sequences of Proteins of Immunological Interest; Protein Sequence and Structure Analysis of Antibody Variable Domains. In: Antibody Engineering Lab Manual (Ed.: Duebel, S. and Kontermann, R., Springer-Verlag, Heidelberg). В одном из вариантов осуществления изобретения, CDR определяется в соответствии с системой нумерации Kabat, например, где FR1 в VHH содержит аминокислотные остатки в положениях 1-30, CDR1 в VHH содержит аминокислотные остатки в положениях 31-35, FR2 в VHH содержит аминокислоты в положениях 36-49, CDR2 в VHH содержит аминокислотные остатки в положениях 50-65, FR3 в VHH содержит аминокислотные остатки в положениях 66-94, CDR3 в VHH содержит аминокислотные остатки в положениях 95-102 и FR4 в VHH содержит аминокислотные остатки в положениях 103-113.
В одном из вариантов осуществления изобретения, CDR определяются в соответствии с Kontermann и Dübel (Eds., Antibody Engineering, vol 2, Springer Verlag Heidelberg Berlin, Martin, Chapter 3, pp. 33-51, 2010).
Настоящее изобретение направлено на получение усовершенствованных PD1/CTLA4-связывающих веществ, в частности усовершенствованных PD1/CTLA4 биспецифичных ISVD и также, в частности, усовершенствованных анти-PD1/CTLA4 биспецифичных нанотел. PD1/CTLA4-связывающие вещества по настоящему изобретению включают связывающие вещества, которые включают CTLA4-связывающие фрагменты, которые включают полипептиды, которые являются вариантами полипептидов, содержащих последовательность SEQ ID NO: 9, которая мутирована в положении 1, 11, 14, 45, 73, 74, 83, 89, 96, 108, 110 и/или 112; и PD1-связывающие фрагменты, которые включают полипептиды, которые являются вариантами полипептидов, содержащих последовательность SEQ ID NO: 1 или 2, которая мутирована в положении 1, 11, 14, 52а, 73, 74, 83, 89, 100а, 110 и/или 112 (в любом порядке). Усовершенствованные PD1/CTLA4 биспецифичные связывающие вещества, предусмотренные в настоящем изобретении, также указаны в настоящем документе как ʺбиспецифичные PD1/CTLA4 связывающие вещества по изобретениюʺ или ʺбиспецифичные PD1/CTLA4-связывающие веществаʺ или ʺPD1/CTLA4-связывающие веществаʺ. Эти термины охватывают любую молекулу, которая включает CTLA4-связывающий фрагмент и PD1-связывающий фрагмент, как указано в настоящем документе. Например, термины включают молекулу, включающую CTLA4-связывающий фрагмент (например, ISVD, который содержит аминокислотную последовательность, представленную в элементе, выбранном из SEQ ID NO: 143 или 196) и PD1-связывающий фрагмент (например, ISVD, который включает аминокислотную последовательность, представленную в элементе, выбранном из группы, состоящей из SEQ ID NO: 103-134, 135, 136, 137, 140, 141 и 142), который может быть слитым белком и/или может быть присоединен к стандартному антителу или его антигенсвязывающему домену. PD1/CTLA4-связывающее вещество включает любое мультиспецифичное связывающее вещество, которое содержит CTLA4-связывающий фрагмент (например, включающий аминокислотную последовательность, указанную в элементе, выбранном из группы, состоящей из SEQ ID NO: 143 или 196) и PD1-связывающий фрагмент (например, включающий аминокислотную последовательность, указанную в элементе, выбранном из группы, состоящей из SEQ ID NO: 103-134, 135, 136, 137, 140, 141 и 142), который также связывается с другим эпитопом, таким как CD27, LAG3, другим эпитопом CTLA4, другим эпитопом PD1, BTLA, TIM3, ICOS, B7-H3, B7-H4, CD137, GITR, PD-L1, PD-L2, ILT1, ILT2 CEACAM1, CEACAM5, TIM3, TIGIT, VISTA, ILT3, ILT4, ILT5, ILT6, ILT7, ILT8, CD40, OX40, CD137, KIR2DL1, KIR2DL2, KIR2DL3, KIR2DL4, KIR2DL5A, KIR2DL5B, KIR3DL1, KIR3DL2, KIR3DL3, NKG2A, NKG2C, NKG2E, IL-10, IL-17 и/или TSLP.
Как было указано выше, ʺPD1-связывающие веществаʺ по настоящему изобретению являются любой из описанных в настоящем документе молекул, которые связываются с PD1 (например, ISVD, такой как нанотело), а также с любым антителом или антигенсвязывающим доменом, который связывается с PD1, и включает любые PD1-связывающие фрагменты, описанные в настоящем документе. PD1-связывающее вещество может быть селективным в отношении PD1 или может дополнительно включать связывающее вещество, которое связывается с LAG3, CD27, CTLA4, HSA, BTLA, TIM3, ICOS, B7-H3, B7-H4, CD137, GITR, PD-L1, PD-L2, ILT1, ILT2 CEACAM1, CEACAM5, TIM3, TIGIT, VISTA, ILT3, ILT4, ILT5, ILT6, ILT7, ILT8, CD40, OX40, CD137, KIR2DL1, KIR2DL2, KIR2DL3, KIR2DL4, KIR2DL5A, KIR2DL5B, KIR3DL1, KIR3DL2, KIR3DL3, NKG2A, NKG2C, NKG2E, IL-10, IL-17, TSLP, например, содержащий LAG3 связывающий фрагмент и CTLA4-связывающий фрагмент; LAG3 связывающий фрагмент и BTLA связывающий фрагмент; 1 или 2 PD1-связывающие фрагменты, 1 или 2 LAG3 связывающие фрагменты и HSA-связывающий фрагмент; или LAG3 связывающий фрагмент и BTLA связывающий фрагмент. Индивидуальное PD1-связывающее вещество может быть указано как PD1-связывающий фрагмент, если он является частью большей молекулы, например, поливалентной молекулы, такой как F023700910, F023700918, F023700920 или F023700925.
Как было указано выше, ʺCTLA4-связывающие веществаʺ по настоящему изобретению представляют собой любые молекулы, описанные в настоящем документе, которые связываются с CTLA4 (например, ISVD, такой как нанотело), а также любое антитело или антигенсвязывающий домен, который связывается с CTLA4 и включает любой из CTLA4-связывающих фрагментов, описанных в настоящем документе. CTLA4-связывающее вещество может включать связывающее вещество, которое связывается с PD1, LAG3, CD27, HSA, BTLA, TIM3, ICOS, B7-H3, B7-H4, CD137, GITR, PD-L1, PD-L2, ILT1, ILT2 CEACAM1, CEACAM5, TIM3, TIGIT, VISTA, ILT3, ILT4, ILT5, ILT6, ILT7, ILT8, CD40, OX40, CD137, KIR2DL1, KIR2DL2, KIR2DL3, KIR2DL4, KIR2DL5A, KIR2DL5B, KIR3DL1, KIR3DL2, KIR3DL3, NKG2A, NKG2C, NKG2E, IL-10, IL-17, TSLP, например, содержащий LAG3 связывающий фрагмент и PD1-связывающий фрагмент; LAG3 связывающий фрагмент и BTLA связывающий фрагмент; 1 или 2 PD1-связывающие фрагменты, 1 или 2 LAG3 связывающие фрагменты и HSA-связывающий фрагмент; или LAG3 связывающий фрагмент и BTLA связывающий фрагмент. Индивидуальное CTLA4-связывающее вещество может быть указано как CTLA4-связывающий фрагмент, если он является частью большей молекулы, например, поливалентной молекулы, такой как F023700910, F023700918, F023700920 или F023700925.
В общем случае структурная единица базового антитела содержит тетрамер. Каждый тетрамер включает две идентичные пары полипептидных цепей, причем каждая пара имеет одну ʺлегкуюʺ (около 25 кДа) и одну ʺтяжелуюʺ цепь (около 50-70 кДа). Аминоконцевая область каждой цепи включает вариабельный участок, содержащий от около 100 до 110 или больше аминокислот, ответственный в основном за распознавание антигена. Карбоксиконцевая область тяжелой цепи может определять константную область, в основном ответственную за эффекторную функцию. Как правило, легкие цепи человека классифицируются как легкие каппа- и лямбда-цепи. Кроме того, тяжелые цепи человека обычно классифицируют как мю, дельта, гамма, альфа или эпсилон и определяют изотип антитела как IgM, IgD, IgG, IgA и IgE соответственно. В легкой и тяжелой цепях, переменные и константные области соединяются областью ʺJʺ, содержащей около 12 или больше аминокислот, причем тяжелая цепь также включает ʺDʺ область, содержащую примерно 10 аминокислот. См. Fundamental Immunology Ch. 7 (Paul, W., ed., 2nd ed. Raven Press, N.Y. (1989). Примеры антигенсвязывающих доменов включают, но ими не ограничиваются, Fab, Fab', F(ab')2 и Fv фрагменты и одноцепочечные Fv-молекулы.
Термин ʺодинарный вариабельный домен иммуноглобулинаʺ (также называемый ʺISVʺ или ISVDʺ) обычно используется для обозначения вариабельных доменов иммуноглобулина (которые могут быть доменами тяжелой цепи или легкой цепи, включая домены VH, VHH или VL), которые могут образовывать функциональный антигенсвязывающий участок без взаимодействия с другим вариабельным доменом (например, без VH/VL взаимодействия, которое необходимо между доменами VH и VL стандартного четырех-цепочечного моноклонального антитела). Примеры ISVD будут очевидны для специалиста в данной области и, например, включают нанотела (включая VHH, гуманизированные VHH и/или верблюжьи VH, такие как VH человека верблюжьего типа), IgNAR, домены, (однодоменные) антитела (такие как dAbs™), которые являются доменами VH или которые получены из домена VH, и (однодоменные) антитела (такие как dAbs™), которые являются доменами VL или которые получены из домена VL. Обычно предпочтительны ISVD, которые основаны на и/или получены из вариабельных доменов тяжелой цепи (таких как домены VH или VHH). Наиболее предпочтительно, ISVD будет представлять собой нанотело.
Термин ʺнанотелоʺ, в целом, определен в WO 2008/020079 или WO 2009/138519 и, таким образом, в конкретном аспекте, обычно, обозначается как VHH, гуманизированное VHH или VH верблюжьего типа (например, VH человека верблюжьего типа) или обычно оптимизированное по последовательности VHH (такое как, например, оптимизированное для химической стабильности и/или растворимости, максимального перекрывания с известными каркасными областями человека и максимальной экспрессии). Следует отметить, что термины нанотело или нанотела являются зарегистрированными товарными знаками Ablynx N.V. и поэтому могут также указываться как Nanobody® и/или Nanobodies®).
Мультиспецифичное связывающее вещество представляет собой молекулу, которая содержит первый и второй CTLA4 и PD1 (или PD1 и CTLA4) связывающий фрагмент (например, ISVD или нанотело) и, необязательно, один или более (например, 1, 2, 3, 4, 5) дополнительных связывающих фрагментов (например, ISVD или нанотело), которые связываются с эпитопом, отличным от эпитопа CTLA4 и PD1-связывающих фрагментов (например, CD27, LAG3 и/или BTLA). Например, F023700910, F023700918, F023700920 и F023700925 представляют собой мультиспецифичные PD1/CTLA4-связывающие вещества, которые включают HSA-связывающее вещество.
Связывающий фрагмент или связывающий домен или связывающая единица представляет собой молекулу, такую как ISVD или нанотело, которая связывается с антигеном. Связывающий фрагмент или связывающий домен или связывающая единица может быть частью более крупной молекулы, такой как поливалентное или мультиспецифичное связывающее вещество, которое включает более одного фрагмента, домена или единицы, и/или которое содержит другой функциональный элемент, такой как, например, экстендер полувыведения (HLE), нацеливающий элемент и/или небольшую молекулу, такую как полиэтиленгликоль (PEG). Например, 102C12 (E1D,L11V,A14P,A74S,K83R,I89L) представляет собой PD1-связывающий фрагмент ISVD в F023700910.
Моновалентное CTLA4 или PD1-связывающее вещество (например, ISVD, такой как нанотело) представляет собой молекулу, которая содержит один антигенсвязывающий домен. Двухвалентное CTLA4/PD1-связывающее вещество (например, ISVD, такой как нанотело) содержит два антигенсвязывающих домена (например, стандартные антитела, включая биспецифичные антитела), которые связываются с CTLA4 и PD1. Поливалентное связывающее вещество содержит более одного антигенсвязывающего домена. Трехвалентное связывающее вещество содержит три антигенсвязывающих домена.
Моноспецифичныое CTLA4 или PD1-связывающее вещество (например, ISVD, такой как нанотело) связывается с одним антигеном (CTLA4 или PD1); биспецифичное CTLA4/PD1-связывающее вещество связывается с двумя различными антигенами (PD1 и CTLA4), и мультиспецифичное связывающее вещество связывается с более чем одним антигеном. Триспецифичное связывающее вещество связывается с тремя различными антигенами (например, PD1 и CTLA4 и, например, CD27, LAG3 или BTLA).
Бипаратопное связывающее вещество (например, ISVD, такое как нанотело) является моноспецифичным, но связывается с двумя различными эпитопами одного и того же антигена. Мультипаратопное связывающее вещество связывается с одним и тем же антигеном, но более чем с одним эпитопом в антигене.
Также, как уже указано в настоящем документе, аминокислотные остатки нанотела нумеруются в соответствии с общей нумерацией для VH, приведенной Kabat et al. (ʺSequence of proteins of immunological interestʺ, US Public Health Services, NIH Bethesda, MD, Publication No. 91), применительно к доменам VHH семейства верблюдовых, в статье Riechmann и Muyldermans, J. Immunol. Methods 2000 Jun 23; 240 (1-2): 185-195; или указаны в настоящем документе.
Альтернативные способы нумерации аминокислотных остатков доменов VH, которые также могут применяться аналогичным образом к доменам VHH семейства верблюдовых и к нанотелу, представляют собой метод, описанный Chothia et al. (Nature 342, 877-883 (1989)), так называемое ʺопределение AbMʺ и так называемое ʺопределение контактаʺ. Однако в настоящем описании, аспектах и цифрах, нумерация по Kabat применительно к доменам VHH по Riechmann и Muyldermans, будет соблюдаться, если не указано иное.
Используемый в настоящем документе термин ʺпериод полувыведенияʺ, относящийся к связывающему веществу, такому как PD1/CTLA4-связывающее вещество (например, содержащее ISVD (например, нанотела), которые связываются с PD1 и CTLA4), обычно можно определить согласно описанию в пункте o) на стр. 57 в WO 2008/020079 и, как указано выше, относится ко времени, затрачиваемому на снижение сывороточной концентрации аминокислотной последовательности, соединения или полипептида в крови на 50%, in vivo, например, в результате деградации последовательности или PD1/CTLA4-связывающего вещества и/или выведения или секвестрации последовательности или PD1/CTLA4-связывающего вещества с помощью природных механизмов. Период полувыведения PD1/CTLA4-связывающего вещества in vivo может быть определен любым способом, известным per se, например, с помощью фармакокинетического анализа. Подходящие способы будут ясны специалисту в данной области техники и могут, например, быть такими, как описано в пункте o) на стр. 57 WO 2008/020079. Как также указано в пункте o) на стр. 57 WO 2008/020079, период полувыведения может быть выражен с использованием таких параметров, как t1/2-альфа, t1/2-бета и площадь под кривой (AUC). При этом следует отметить, что термин ʺпериод полувыведенияʺ, в том виде, в котором он используется в настоящем документе, относится, в частности, к t1/2-бета или терминальному периоду полувыведения (в котором t1/2-альфа и/или AUC, или оба эти параметра, могут не подвергаться оценке). Ссылка, например, сделана на экспериментальную часть ниже, а также на стандартные справочники, такие как Kenneth, A et al: Chemical Stability of Pharmaceuticals: A Handbook for Pharmacists and Peters et al, Pharmacokinete analysis: A Practical Approach (1996). Также была сделана ссылка на работу "Pharmacokinetics", M Gibaldi & D Perron, опубликованную Marcel Dekker, 2nd Rev. edition (1982). Аналогично, термины ʺувеличение периода полувыведенияʺ или ʺувеличенный период полувыведенияʺ также определены в пункте o) на стр. 57 WO 2008/020079 и, в частности, относятся к увеличению t1/2-бета, либо с или без увеличения t1/2-альфа и/или AUC или обоих этих факторов.
Выражение ʺпоследовательности контроляʺ относится к полинуклеотидам, необходимым для экспрессии функционально связанной с ними кодирующей последовательности в конкретном организме-хозяине. Последовательности контроля, подходящие для прокариот, например, включают промотор, необязательно операторную последовательность и участок связывания рибосом. Эукариотические клетки, как известно, используют промоторы, сигналы полиаденилирования и энхансеры.
Нуклеиновая кислота или полинуклеотид ʺфункционально связанʺ, если он находится в функциональной взаимосвязи с другим полинуклеотидом. Например, ДНК для препоследовательности или секреторной лидерной последовательности функционально связана с ДНК полипептида, если она экспрессируется в виде белка-предшественника, который участвует в секреции полипептида; промотор или энхансер функционально связан с кодирующей последовательностью, если он влияет на транскрипцию последовательности; или участок связывания рибосомом функционально связан с кодирующей последовательностью, если он расположен так, чтобы способствовать трансляции. Как правило, но не всегда, ʺфункционально связанныйʺ означает, что ДНК последовательности, подлежащие связыванию, являются смежными, и, в случае секреторной лидерной последовательности, являются смежными и находятся в рамке считывания. Однако энхансеры не обязательно должны быть смежными. Связывание осуществляют лигированием на соответствующих участках рестрикции. Если такие участки не существуют, используют синтетические олигонуклеотидные адапторы или линкеры в соответствии с общепринятой практикой.
ʺВыделенныеʺ PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), полипептиды, полинуклеотиды и векторы по крайней мере частично не содержат другие биологические молекулы клеток или клеточной культуры, из которых их получают. Такие биологические молекулы включают нуклеиновые кислоты, белки, липиды, углеводы или другой материал, такой как клеточный дебрис и среда для роста. ʺВыделенноеʺ PD1/CTLA4-связывающее вещество может также по крайней мере частично не содержать компоненты системы экспрессии, такие как биологические молекулы из клетки-хозяина или его среды роста. Обычно, термин ʺвыделенныйʺ не предназначен для обозначения полного отсутствия таких биологических молекул или отсутствия воды, буферов или солей или компонентов фармацевтической композиции, которая включает антитела или фрагменты.
Следует также отметить, что фигуры, любой перечень последовательностей и экспериментальная часть/примеры приведены только для дополнительной иллюстрации изобретения и не должны интерпретироваться или толковаться как ограничивающие объем изобретения и/или прилагаемой формулы изобретения каким-либо способом, если явно не указано иное.
В случае, когда в настощем документе термин конкретно не определен, он имеет обычное принятое в данной области техники значение, которое будет понятно специалисту в данной области техники. Ссылка сделана, например, на стандартные справочники, такие как Sambrook et al, "Molecular Cloning: A Laboratory Manual" (2nd.Ed.), Vols. 1-3, Cold Spring Harbor Laboratory Press (1989); F. Ausubel et al, eds., "Current protocols in molecular biology", Green Publishing and Wiley Interscience, New York (1987); Lewin, ʺGenes IIʺ, John Wiley & Sons, New York, N.Y., (1985); Old et al., ʺPrinciples of Gene Manipulation: An Introduction to Genetic Engineeringʺ, 2nd edition, University of California Press, Berkeley, CA (1981); Roitt et al., ʺImmunologyʺ (6th. Ed.), Mosby/Elsevier, Edinburgh (2001); Roitt et al., Roitt's Essential Immunology, 10th Ed. Blackwell Publishing, UK (2001); и Janeway et al., ʺImmunobiologyʺ (6th Ed.), Garland Science Publishing/Churchill Livingstone, New York (2005), а также на общий уровень техники, описанный в настоящем документе.
Следующие свойства ассоциированы с указанными мутациями в PD1-связывающем веществе 102C12:
E1D: предотвращение образования пироглутаминовой кислоты в первой аминокислоте конструкции E1
L11V: Ослабление связывания естественного антитела
A14P: Гуманизация
W52aV: Предотвращение окисления W52a
N73P: Предотвращение деамидирования N73
N73Q: Предотвращение деамидирования N73
N73S: Предотвращение деамидирования N73
A74S: Гуманизация
K83R: Гуманизация
I89L: Ослабленое связывание с естественным антителом
W100aF: Предотвращение окисления W100a
или в CTLA4-связывающем веществе 11F1:
E1D: Предотвращение образования пироглутаминовой кислоты в первой аминокислоте конструкции E1
L11V: Снижение связывания естественного антитела
A14P: Гуманизация
Q45R: Мутированный для повышения стабильности
A74S: Гуманизация
K83R: Гуманизация
I89L: Ослабленое связывание с естественным антителом
M96P,Q или R: Предотвращение окисления M96
Q108L: Гуманизация
В объем настоящего изобретения включены поливалентные PD1/CTLA4-связывающие вещества, представленные на фиг.15, или включающие расположение фрагментов, представленных на фиг.16. В объем настоящего изобретения также включены PD1/CTLA4-связывающие вещества, включающие любое из PD1-связывающих веществ, представленных на фиг.15 (или любое PD1-связывающее вещество, содержащее CDR1, CDR2 и CDR3 такого PD1-связывающего вещества), или любое из поливалентных PD1-связывающих веществ (или один или более любых его PD1-связывающих фрагментов), включающих расположение PD1-связывающих фрагментов, приведенных на фигуре 16, и/или любое CTLA4-связывающее вещество, представленное на фигуре 15 (или любое CTLA4-связывающее вещество, содержащее CDR1, CDR2 и CDR3 такого LAG3-связывающего вещества) или любое из поливалентных CTLA4-связывающих веществ (или один или более любых его CTLA4-связывающих фрагментов), включающих расположение CTLA4-связывающих фрагментов, представленных на фигуре 16. Связывающие вещества, представленные на фигуре 15, в одном из вариантов осуществления изобретения, не включают C-концевой экстендер (например, A), FLAG и/или гистидиновые метки (например, HHHHHH (аминокислоты 148-153 SEQ ID NO: 176); AAHHHHHH (аминокислоты 146-153 SEQ ID NO: 176); или AAADYKDHDGDYKDHDIDYKDDDKGAAHHHHH (аминокислоты 120-153 SEQ ID NO: 176)). Любое такое связывающее вещество или CDR может, в одном из вариантов осуществления изобретения, быть вариантом того, что представлено на фигуре 15, например, включающее 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10 точечных мутаций, консервативные замены или делеции).
В одном из вариантов осуществления изобретения, CTLA4 является CTLA4 человека. В одном из вариантов осуществления изобретения, CTLA4 человека содержит аминокислотную последовательность:
MACLGFQRHK AQLNLATRTW PCTLLFFLLF IPVFCKAMHV AQPAVVLASS
RGIASFVCEY ASPGKATEVR VTVLRQADSQ VTEVCAATYM MGNELTFLDD
SICTGTSSGN QVNLTIQGLR AMDTGLYICK VELMYPPPYY LGIGNGTQIY
VIDPEPCPDS DFLLWILAAV SSGLFFYSFL LTAVSLSKML KKRSPLTTGV
YVKMPPTEPE CEKQFQPYFI PIN
(SEQ ID NO: 197)
В одном из вариантов осуществления изобретения, PD1 является PD1 человека. В одном из вариантов осуществления изобретения, PD1 человка содержит аминокислотную последовательность:
MQIPQAPWPV VWAVLQLGWR PGWFLDSPDR PWNPPTFSPA LLVVTEGDNA
TFTCSFSNTS ESFVLNWYRM SPSNQTDKLA AFPEDRSQPG QDCRFRVTQL
PNGRDFHMSV VRARRNDSGT YLCGAISLAP KAQIKESLRA ELRVTERRAE
VPTAHPSPSP RPAGQFQTLV VGVVGGLLGS LVLLVWVLAV ICSRAARGTI
GARRTGQPLK EDPSAVPVFS VDYGELDFQW REKTPEPPVP CVPEQTEYAT
IVFPSGMGTS SPARRGSADG PRSAQPLRPE DGHCSWPL
(SEQ ID NO: 198)
PD1-связывающие фрагменты
Один или более (например, один или два) PD1-связывающих фрагментов, присутствующих в PD1/CTLA4-связывающих веществах по изобретению (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4), предпочтительно являются следующими (также следует отметить, что, когда два или больше PD1-связывающих фрагмента присутствуют в PD1/CTLA4-связывающих веществах по изобретению, они могут быть одинаковыми или различными, и в случае, когда они являются различными, они предпочтительно все содержат соответсвующую комбинацию мутаций в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, как описано в настоящем документе, и предпочтительно также имеют аналогичные CDR, как описано в настоящем документе. Аминокислотные последовательности некоторых предпочтительных, но не ограничивающих примеров PD1-связывающих фрагментов, которые могут присутствовать в PD1/CTLA4-связывающих веществах по изобретению, представлены на фигуре 3А. На фигуре 3В представлено выравнивание этого PD1-связывающего фрагмента с аминокислотными последовательностями SEQ ID NO: 1 и 2.
Как уже было указано, PD1-связывающие фрагменты, присутствующие в PD1/CTLA4-связывающих веществах по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), описанных в настоящем документе, могут связываться (и в частности, могут специфично связываться) с PD1. В частности, они могут связываться с PD1 и препятствовать связыванию между PD1 и PD-L1 и/или PD-L2. Например, в одном из вариантов изобретения, PD1/CTLA4-связывающие вещества по настоящему изобретению связываются с PD1 и устраняют Т-клетки из PD1-опосредованного ингибирования иммунного ответа, опосредованного Т-клетками (например, путем устранения Т-клеток из PD1-опосредованного ингибирования пролиферации и продуцирования цитокинов).
Как подробно описано в настоящем документе, PD1-связывающие вещества по изобретению, которые, в одном из вариантов осуществления изобретения, в PD1/CTLA4-связывающих веществах по настоящему изобретению предпочтительно имеют одинаковую комбинацию CDR (т.е. CDR1, CDR2 и CDR3), которые присутствуют в 102C12 или эталоне A, или в связывающем веществе, содержащем последовательность 102C12 или эталона A (SEQ ID NO: 1 или 2). См. таблицу A-1.
Настоящее изобретение также включает PD1-связывающие вещества, которые являются вариантами 102C12, которые содержат аминокислотную последовательность, как указано в таблице А-2 ниже. В объем настоящего изобретения включены PD1-связывающие вещества, которые включают CDR1, CDR2 и CDR3 указанных вариантов, приведенных в таблице A-2 ниже.
Кроме того, настоящее изобретение включает PD1/CTLA4-связывающие вещества, содержащие PD1-связывающий фрагмент, который включает CDR1, CDR2 и CDR3 или аминокислотную последовательность 102C12 или один из его вариантов, приведенный в таблице A-2 ниже.
Таблица A-1. PD1-связывающее вещество 102C12.
ID
NO
Таблица A-2 Оптимизированные по последовательности PD1-связывающие вещества - варианты 102C12
102C12 (E1D, L11V, A14P, A74S, K83R, I89L)
Мишень: hPD-1
SEQ ID NO: 135
где X представляет собой W или V
(например, VITwSGGITYYADSVKG или VITvSGGITYYADSVKG)
где X представляет собой W или F
(например, DKHQSSwYDY или DKHQSSfYDY)
где X представляет собой W или V
(например, VITwSGGITY или VITvSGGITY)
где X представляет собой W или F
(например, DKHQSSwYDY или DKHQSSfYDY)
Описание: 1PD102C12 (A14P,A74S,K83R)
Мишень: hPD-1
SEQ ID NO: 136
Название: F023700706
Описание: 1PD102C12 (L11V, A14P, A74S, K83R, I89L)
Мишень: hPD-1
SEQ ID NO: 137
Название: F023701127
Описание: 1PD102C12 (E1D, L11V, A14P, A74S, K83R, I89L)-35GS-ALB11002-A
Мишень: hPD-1
SEQ ID NO: 138
Название: F023700933
Описание: 1PD102C12 (E1D, L11V, A14P, A74S, K83R, I89L)-35GS-1PD102C12(L11V, A14P, A74S, K83R, I89L)-35GS-ALB11002-A
Мишень: hPD-1
SEQ ID NO: 139
Название: F023701190
Описание: 1PD102C12 (E1D, L11V, A14P, W52aV, A74S, K83R, I89L, W100aF)
Мишень: hPD-1
SEQ ID NO: 140
Название: F023701192
Описание: 1PD102C12(E1D, L11V, A14P, W52aV, N73Q, A74S, K83R, I89L, W100aF)
Мишень: hPD-1
SEQ ID NO: 141
Название: F023701193
Описание: 1PD102C12(E1D, L11V, A14P, W52aV, N73P, A74S, K83R, I89L, W100aF)
Мишень: hPD-1
SEQ ID NO: 142
Настоящее изобретение включает варианты осуществления, содержащие один, два или три CDR в PD1-связывающем веществе, приведенные в таблице A-1 или A-2 выше (например, где связывающее вещество содержит аминокислотную последовательность SEQ ID NO: 1, 2, 135, 136, 137, 138, 139, 140, 141, 142 или 16-47)), или на фигуре 3, где каждый CDR содержит 0, 1, 2, 3, 4 или 5 аминокислотных замен, например, консервативных замен, и/или имеет 100, 99, 98, 97, 96 или 95% идентичность последовательностей относительно последовательностей CDR, приведенных в таблице A-1 или A-2, где PD1-связывающее вещество, имеющее такие CDR, сохраняет способность связываться с PD1. В одном из вариантов осуществления изобретения, первая аминокислота PD1-связывающего вещества по настоящему изобретению соответствует E. В одном из вариантов развития изобретения первая аминокислота PD1-связывающего вещества по настоящему изобретению соответствует D.
Номера остатков в соответствии с Kabat для некоторых остатков PDV PD1, приведенных в таблице A-1, представлены в последовательности ниже:
E1VQLVESGGGL11V12Q13A14GGSLRLSCAASG26S27I28A29S30IHAMGW36F37R38Q39 AP41GKERE46F47V48A49VITWSGGITYYADSVKGR66F67T68I69S70RDNA74KNTVYLQ M82N82aS82bL82cK83P84EDT87A88I89Y90Y91CAGDKHQSSWYDYW103G104Q105G106T107 L108V109T110V111S112S113 (SEQ ID NO: 2)
Номера остатков в соответствии с Kabat для некоторых остатков ISVD 102C12 (E1D, L11V, A14P, A74S, K83R, I89L) представлены в последовательности ниже:
D1VQLVESGGG V11VQP14GGSLRL SCAASGSIAS IHAMGWFRQA PGKEREFVAV ITWSGGITYY ADSVKGRFTI SRDNS74KNTVY LQMNSLR83PED TAL89YYCAGDK HQSSWYDYWG QGTLVTVSS
(SEQ ID NO: 135)
В WO 2008/071447 описаны нанотела, которое могут связываться с PD1 и использовать его. SEQ ID NO: 348 WO 2008/071447 описывает PD1 специфичное нанотело, обозначаемое как 102C12, последовательность которого приведена в настоящем документе как SEQ ID NO: 1. Эта последовательность и ее CDR также приведены в таблице A ниже (см. также фиг.2). SEQ ID NO: 2 представляет собой эталонную последовательность, которая основана на SEQ ID NO: 1, но с гуманизирующей мутацией Q108L.
Мутации могут быть указаны в настоящем документе и обозначаются своим номером по Kabat, как показано выше.
В WO 2008/071447 также описаны нанотела, которые могут связываться с CTLA4 и использовать его. SEQ ID NO: 1306 WO 2008/071447 описывает CTLA4 специфичное нанотело, обозначаемое 11F01, последовательность которого приведена в настоящем документе как SEQ ID NO: 9 (см. также фиг.2). Эта последовательность и ее CDR также приведены в таблице B ниже.
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающее вещество обладает одним или более следующими свойствами:
Связываться с CTLA4 (например, CTLA4 человека и/или яванского макака) (например, CTLA4-Fc слитный белок), например, с KD около 1 нМ (например, около 1,2 нМ);
Связываться с CTLA4 (например, CTLA4 человека) на поверхности клетки, например, CHO клетки;
Связываться с PD1 (например, PD1 человека) на поверхности клетки, например, CHO клетки;
Блокировать связывание CD80 и/или CD86 с CTLA4, например, клеточная поверхность, экспрессирующая CTAL4, например, на поверхности клетки CHO;
Не связывается с CD28 (например, человека), CD8 альфа (например, человека), LAG3 (например, человека) или BTLA (например, человека), например, на поверхности клетки такой как CHO клетки;
Связываться с сывороточным альбумином человека, макаки-резус и/или обезьяны (в случае, когда связывающее вещество включает связывающее вещество сывороточного альбумина, такое как ALB11002);
Ингибировать рост опухоли (например, опухолей поджелудочной железы, например, опухолей поджелудочной железы человека у мыши, экспрессирующие иммунные клетки человека)
Настоящее изобретение включает PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), содержащие один или более PD1-связывающих фрагментов, которые являются вариантами SEQ ID NO: 1 или 2 (102C12, WO 2008/071447: SEQ ID NO: 348, эталон A), которые содержат аминокислотную последовательность SEQ ID NO: 1 или 2, но содержат одну или более из следующих мутаций относительно последовательности SEQ ID NO: 1 или 2:
- 1D или 1E;
- 11V;
- 14P;
- 52aV;
- 73Q, 73P или 73S;
- 74S;
- 83R;
- 89T;
- 89L; или
- 100aF;
например, где PD1-связывающий фрагмент содержит одну или более из следующих множеств мутаций:
- 1D или 1E в комбинации с 11V, 14P, 74S, 83R и 89L;
- 1D в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 89L и 100aF;
- 1E в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 89L и 100aF;
- 89L в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R и 100aF, и необязательно, 1D;
- 89L в комбинации с 11V;
- 89L в комбинации с 110K или 110Q;
- 89L в комбинации с 112K или 112Q;
- 89L в комбинации с 11V, 14P,74S, 83R и, необязательно, 1D;
- 110K или 110Q в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 89L и 100aF и 1D или 1E;
- 112K или 112Q в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 89L и 100aF и 1D или 1E;
- 1D или 1E в комбинации с 11V, 14P, 74S, 83R и 89L; и 112K или 112Q;
- 1D или 1E в комбинации с 11V, 14P, 74S, 83R и 89L; и 110K или 110Q;
- 89L в комбинации с 11V и 110K или 110Q;
- 89L в комбинации с 11V и 112K или 112Q;
- 11V в комбинации с 110K или 110Q; или
- 11V в комбинации с 112K или 112Q.
В частности, PD1-связывающие фрагменты, присутствующие в PD1/CTLA4-связывающих веществах по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), содержат аминокислотную последовательность SEQ ID NO: 1 или 2, где:
- аминокислотный остаток в положении 1 выбран из E и D;
- аминокислотный остаток в положении 11 выбран из L и V;
- аминокислотный остаток в положении 14 выбран из A и P;
- аминокислотный остаток в положении 52a выбран из W и V;
- аминокислотный остаток в положении 73 выбран из P, S, N и Q;
- аминокислотный остаток в положении 74 выбран из A и S;
- аминокислотный остаток в положении 83 выбран из K и R;
- аминокислотный остаток в положении 89 выбран из T, V, I и L;
- аминокислотный остаток в положении 100a выбран из W и F;
- аминокислотный остаток в положении 110 выбран из T, K и Q; и
- аминокислотный остаток в положении 112 выбран из S, K и Q;
так, что, например, верно одно или более из следующих условий:
(i) положение 1 соответствует D;
(ii) положение 1 соответствует E;
(iii) положение 11 соответствует V;
(iv) положение 14 соответствует P;
(v) положение 52a соответствует V;
(vi) положение 73 соответствует Q, P или S;
(vii) положение 74 соответствует S;
(viii) положение 83 соответствует R;
(ix) положение 89 соответствует T;
(x) положение 89 соответствует L;
(xi) положение 100a соответствует F;
например, где, в PD1-связывающий фрагмент включает одну или более из следующих множеств мутаций:
a. положение 1 соответствует D или E, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R; и положение 89 соответствует L;
b. положение 1 представляет собой D или E, положение 11 соответствует V, положение 14 соответствует P, положение 52a соответствует V; положение 73 соответствует Q, P или S; положение 74 соответствует S, положение 83 соответствует R; положение 89 соответствует L; и положение 100a соответствует F;
c. положение 89 соответствует L, и положение 11 соответствует V;
d. положение 89 соответствует L, и положение 110 соответствует K или Q;
e. положение 89 соответствует L, и положение 112 соответствует K или Q;
f. положение 1 представляет собой D или E, положение 11 соответствует V, положение 14 соответствует P, положение 52a соответствует V; положение 73 соответствует Q, P или S; положение 74 соответствует S, положение 83 соответствует R; положение 89 соответствует L; положение 100a соответствует F и положение 110 соответствует K или Q;
g. положение 1 представляет собой D или E, положение 11 соответствует V, положение 14 соответствует P, положение 52a соответствует V; положение 73 соответствует Q, P или S; положение 74 соответствует S, положение 83 соответствует R; положение 89 соответствует L; положение 100a соответствует F и положение 112 соответствует K или Q;
h. положение 1 представляет собой D или E, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R; положение 89 соответствует L, и положение 110 соответствует K или Q;
i. положение 1 представляет собой D или E, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R; положение 89 соответствует L; и положение 112 соответствует K или Q;
j. положение 89 соответствует L, и положение 11 соответствует V, и положение 110 соответствует K или Q;
k. положение 89 соответствует L, и положение 11 соответствует V, и положение 112 соответствует K или Q;
l. положение 11 соответствует V, и положение 110 соответствует K или Q; или
m. положение 11 соответствует V, и положение 112 соответствует K или Q;
относительно аминокислотной последовательности SEQ ID NO: 1 или 2.
В конкретных вариантах осуществления, PD1-связывающие вещества (например, ISVD, такие как нанотело) по изобретению содержат аминокислотные последовательности, которые являются вариантами SEQ ID NO: 1 или SEQ ID NO: 2, в которых положение 89 соответствует T или L; или в которых 1 представляет собой D или E, 11 соответствует V, 14 соответствует P, 52a соответствует V; 73 соответствует S, Q или P; 74 соответствует S, 83 соответствует R, и 89 соответствует L и/или 100a соответствует F; или в которых 1 представляет собой D или E, 11 соответствует V, 14 соответствует P, 74 соответствует S, 83 соответствует R, и 89 соответствует L; или в которых положение 11 соответствует V, и положение 89 соответствует L (необязательно в соответствующей комбинации с мутацией 110K или 110Q и/или мутацией 112K или 112Q и в частности в комбинации с мутацией 110K или 110Q) являются особенно предпочтительными. Настоящее изобретение включает аминокислотные последовательности, в которых положение 11 соответствует V, и положение 89 соответствует L, необязательно с мутацией 110K или 110Q.
PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, предпочтительно содержат следующие CDR (в соответствии с системой нумерации Kabat):
- CDR1 (в соответствии с Kabat), который соответствует аминокислотной последовательности IHAMG (SEQ ID NO: 3); и
- CDR2 (в соответствии с Kabat), который соответствует аминокислотной последовательности VITXSGGITYYADSVKG (SEQ ID NO: 4; где X представляет собой W или V); и
- CDR3 (в соответствии с Kabat), который соответствует аминокислотной последовательности DKHQSSXYDY (SEQ ID NO: 5; где X представляет собой W или F).
Альтернативно, когда CDR представлены в соответствии с системой Abm, PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, предпочтительно содержат следующие CDR:
- CDR1 (в соответствии с Abm), который соответствует аминокислотной последовательности GSIASIHAMG (SEQ ID NO: 6); и
- CDR2 (в соответствии с Abm), который соответствует аминокислотной последовательности VITWSGGITY (SEQ ID NO: 7); и
- CDR3 (в соответствии с Abm), который соответствует аминокислотной последовательности DKHQSSXYDY (SEQ ID NO: 8, которая является такой же, как SEQ ID NO:5; где X представляет собой W или F).
Вышеуказанные предпочтительные CDR являются такими же, как и в 102C12 (SEQ ID NO: 1), в эталоне A (SEQ ID NO: 2) или связывающем веществе, содержащем аминокислотную последовательность SEQ ID NO: 16-47 или 135-142. Связывающие вещества, имеющие CDR1, CDR2 и CDR3 таких связывающих веществ, являются частью настоящего настоящего.
PD1-связывающий фрагмент (например, ISVD, такие как нанотело), который присутствует в PD1/CTLA4-связывающем веществе по изобретению в варианте осуществления изобретения, также имеет:
- степень идентичности последовательностей с эталонной аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренных конкретным аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется по алгоритму BLAST, где параметры алгоритма подобраны таким образом, чтобы получить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция); и/или
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1 "аминокислотных различий" (как определено в настоящем документе, и не учитывая ни одну из указанных выше мутаций в положении(положениях) 1, 11, 14, 52а, 73, 74, 83, 89, 100а, 110 и/или 112, которые могут присутствовать, и не учитывая любое С-концевое удлинение, которое может присутствовать) с эталонной аминокислотой последовательностью SEQ ID NO: 1 или 2 (в которой указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR).
В отношении различных аспектов и предпочтительных аспектов PD1-связывающих фрагментов (например, ISVD, такие как нанотела), присутствующих в PD1/CTLA4-связывающих веществах по изобретению, в части, касающейся степени идентичности последовательностей относительно SEQ ID NO: 1 или 2, и/или количества и вида ʺаминокислотных различийʺ, которые могут присутствовать в таком связывающем веществе по изобретению (то есть по сравнению с последовательностью SEQ ID NO: 1 или 2), следует отметить, что, когда говорят, что
(i) PD1-связывающий фрагмент имеет степень идентичности последовательностей с последовательностью SEQ ID NO: 1 или 2, составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95% (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей); и/или, когда сообщается, что
(ii) PD1-связывающий фрагмент имеет не больше, чем 7, предпочтительно не больше, чем 5, например, только 3, 2 или 1 ʺаминокислотных различийʺ с последовательностью SEQ ID NO: 1 или 2 (опять, не учитывая любое С-концевое удлинение, которое может присутствовать, и не учитывая мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренных конкретным рассматриваемым аспектом),
то это также включает последовательности, которые не имеют аминокислотных различий с последовательностью SEQ ID NO: 1 или 2, иных, чем мутации мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренных конкретным рассматриваемым аспектом) и любое С-концевое удлинение, которое может присутствовать.
Таким образом, в одном конкретном аспекте по изобретению, PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению, могут иметь 100% идентичность последовательностей с SEQ ID NO: 1 или 2 (включая CDR, но не учитывая мутацию(ии) или комбинацию мутаций в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, описанных в настоящем документе, и/или любое C-концевое удлинение, которое может присутствовать) и/или могут не иметь аминокислотных различий с SEQ ID NO: 1 или 2 (то есть исключая мутацию(мутации) или комбинацию мутаций 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, описанных в настоящем документе, и любое С-концевое удлинение, которое может присутствовать).
В случае, когда присутствуют любые аминокислотные различия (то есть кроме любого С-концевого удлинения и мутаций в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, которые предусмотрены конкретным рассматриваемым аспектом по изобретению), эти аминокислотные различия могут присутствовать в CDR и/или в каркасных областях, но они предпочтительно присутствуют только в каркасных областях (как определено системой Abm, то есть не в CDR, как определено в соответствии с системой Abm), т.е., таким образом, что PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению, имеют аналогичные CDR (определенные в соответствии с системой Abm), которые присутствуют в SEQ ID NO: 1 или 2.
Кроме того, когда PD1-связывающий фрагмент (например, ISVD, такой как нанотело), присутствующий в PD1/CTLA4-связывающем веществе по изобретению, имеет одно или более аминокислотных различий с последовательностью SEQ ID NO: 1 или 2 (помимо мутаций в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренных конкретным рассматриваемым аспектом), то некоторые конкретные, но не ограничивающие примеры таких мутаций/аминокислотных различий, которые могут присутствовать (т.е. по сравнению с последовательностями SEQ ID NO: 1 или 2), представляют собой, например, P41A, P41L, P41S или P41T (и, в частности, P41A) и/или T87A. Другими примерами мутаций являются (соответствующая комбинация) одна или более подходящих ʺгуманизирующихʺ замен; эталон, например, получен в WO 2009/138519 (или в известном уровне техники, указанном в WO 2009/138519) и WO 2008/020079 (или в известном уровне техники, указанном в WO 2008/020079), а также в таблицах A-3 - A-8 из WO 2008/020079 (которые представляют собой перечни, показывающие возможные гуманизирующие замены).
Кроме того, когда PD1-связывающий фрагмент (например, ISVD, такой как нанотело) присутствует в и/или образует N-концевую часть PD1/CTLA4-связывающего вещества по изобретению, то он предпочтительно содержит D в положении 1 (то есть E1D мутация по сравнению с этанолом А или 102C12). Предпочтительный, но неограничивающий пример такого N-концевого PD1-связывающего фрагмента приведен в виде SEQ ID NO: 31 (хотя могут быть также использованы другие PD1-связывающие фрагменты с мутацией E1D). Аналогично, в случае, когда PD1-связывающий фрагмент SEQ ID NO: 31 отсутствует в N-концевой области, а где-либо еще в PD1/CTLA4-связывающем веществе по изобретению, он предпочтительно содержит мутацию D1E). Соответственно, в еще одном аспекте, изобретение относится к PD1/CTLA4-связывающему веществу по изобретению (который подробно описан в настоящем документе), который имеет PD1-связывающий фрагмент (который подробно описан в настоящем документе) в своей N-концевой области, где указанный PD1-связывающий фрагмент имеет D в положении 1 и предпочтительно SEQ ID NO: 31, 135, 140, 141 или 142.
PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению в соответствии с аспектами, описанными в настоящем документе, предпочтительно являются такими, что они содержат подходящую комбинацию мутации L11V, мутации A14P, мутации A74S, мутации K83R, и/или мутации I89L и, необязательно, мутации E1D и предпочтительно подходящую комбинацию любых двух этих мутаций, например, всех этих мутаций. Когда PD1-связывающий фрагмент присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретнию, предпочтительна также мутация E1D относительно аминокислотной последовательности SEQ ID NO: 1 или 2. В виде предпочтительных, но не ограничивающих примеров, SEQ ID NO: 30, 31, 46, 47, 135, 136, 137, 138, 139, 140, 141 или 142 являются примерами PD1-связывающих фрагментов, имеющих дополнительные аминокислотные различия с SEQ ID NO: 1 или 2, A14P, A74S и K83R (кроме того, как указано в предыдущих параграфах, SEQ ID NO: 31 и 47 и 135 являются примерами фрагментов, которые также имеют мутацию E1D).
PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению в соответствии с аспектами, описанными в настоящем документе, предпочтительно являются такими, что они содержат подходящую комбинацию мутации L11V, мутации A14P, мутации A74S, мутации K83R и/или мутации I89L, и необязательно мутации E1D, и предпочтительно подходящую комбинацию любых двух этих мутаций, например, любых этих мутаций. Когда PD1-связывающий фрагмент присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, также предпочтительна мутация E1D относительно аминокислотной последовательности SEQ ID NO: 1 или 2. В виде предпочтительных, но не ограничивающих примеров, SEQ ID NO: 30, 31, 46, 47, 135, 136, 137, 138, 139, 140, 141 или 142 являются примерами PD1-связывающих фрагментов, имеющих дополнительные аминокислотные различия с SEQ ID NO: 1 или 2, A14P, A74S и K83R (помимо того, как указано в предыдущих параграфах, SEQ ID NO: 31 и 47 и 135 являются примерами фрагментов, которые также имеют мутацию E1D).
Таким образом, в первом аспекте, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающем веществе по изобретению, имеет:
- CDR1 (в соответствии с Kabat), который соответствует аминокислотной последовательности IHAMG (SEQ ID NO: 3); и
- CDR2 (в соответствии с Kabat), который соответствует аминокислотной последовательности VITXSGGITYYADSVKG (SEQ ID NO: 4; где X представляет собой W или V); и
- CDR3 (в соответствии с Kabat), который соответствует аминокислотной последовательности DKHQSSXYDY (SEQ ID NO: 5; где X представляет собой W или F);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1 ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и когда присутствует в С-концевой области PD1/CTLA4-связывающих веществ по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, в которой n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и когда присутствует в N-концевой области PD1/CTLA4-связывающих веществ по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 1 или 2),
в которой:
- аминокислотный остаток в положении 1 PD1-связывающего фрагмента выбран из E или D;
- аминокислотный остаток в положении 11 PD1-связывающего фрагмента выбран из L или V;
- аминокислотный остаток в положении 14 PD1-связывающего фрагмента выбран из A или P;
- аминокислотный остаток в положении 52a PD1-связывающего фрагмента выбран из W или V;
- аминокислотный остаток в положении 73 PD1-связывающего фрагмента выбран из N, P, S или Q;
- аминокислотный остаток в положении 74 PD1-связывающего фрагмента выбран из A или S;
- аминокислотный остаток в положении 83 PD1-связывающего фрагмента выбран из K или R;
- аминокислотный остаток в положении 89 PD1-связывающего фрагмента выбран из T, V, I или L;
- аминокислотный остаток в положении 100a PD1-связывающего фрагмента выбран из W или F;
- аминокислотный остаток в положении 110 PD1-связывающего фрагмента выбран из T, K или Q; и
- аминокислотный остаток в положении 112 PD1-связывающего фрагмента выбран из S, K или Q;
так что, например, PD1-связывающий фрагмент имеет одно или более из следующих:
(i) положение 1 соответствует E или D;
(ii) положение 11 соответствует V;
(iii) положение 14 соответствует P;
(iv) положение 52a соответствует V;
(v) положение 73 соответствует Q, P или S;
(vi) положение 74 соответствует S ;
(vii) положение 83 соответствует R;
(viii) положение 89 соответствует L или T; или
(ix) положение 100a соответствует F;
например, где PD1-связывающий фрагмент включает одну или более из следующего множества мутаций:
a. положение 89 соответствует L, и положение 11 соответствует V;
b. положение 89 соответствует L, и положение 110 соответствует K или Q;
c. положение 89 соответствует L, и положение 112 соответствует K или Q;
d. положение 1 представляет собой D или E, положение 11 соответствует V, положение 14 соответствует P, положение 52a соответствует V; положение 73 соответствует S, Q или P; положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, и положение 100a соответствует F;
e. положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R и положение 89 соответствует L;
f. положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R и положение 89 соответствует L;
g. положение 89 соответствует L, и положение 11 соответствует V, и положение 110 соответствует K или Q;
h. положение 89 соответствует L, и положение 11 соответствует V, и положение 112 соответствует K или Q;
i. положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, и положение 112 соответствует K или Q;
j. положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, и положение 112 соответствует K или Q;
k. положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, и положение 110 соответствует K или Q;
l. положение 1 представляет собой D или E, положение 11 соответствует V, положение 14 соответствует P, положение 52a соответствует V, positon 73 соответствует S, Q или P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 100a соответствует F и положение 110 соответствует K или Q;
m. положение 1 представляет собой D или E, положение 11 соответствует V, положение 14 соответствует P, положение 52a соответствует V, положение 73 соответствует S, Q или P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 100a соответствует F и положение 112 соответствует K или Q;
n. положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, и положение 112 соответствует K или Q;
o. положение 11 соответствует V, и положение 110 соответствует K или Q; или
p. положение 11 соответствует V, и положение 112 соответствует K или Q.
В дополнительном аспекте, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающем веществе по изобретению, имеет:
- CDR1 (в соответствии с Kabat), который соответствует аминокислотной последовательности IHAMG (SEQ ID NO: 3); и
- CDR2 (в соответствии с Kabat), который соответствует аминокислотной последовательности VITXSGGITYYADSVKG (SEQ ID NO: 4; где X представляет собой W или V); и
- CDR3 (в соответствии с Kabat), который соответствует аминокислотной последовательности DKHQSSXYDY (SEQ ID NO: 5; где X представляет собой W или F);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению (например, содержащие ISVD (например, нанотела), которое связывается с PD1 и CTLA4), предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 1 или 2),
так, что указанный PD1-связывающий фрагмент содержит один или более из следующих аминокислотных остатков (то есть мутации по сравнению с аминокислотной последовательностью SEQ ID NO: 1 или 2) в указанных положениях (нумерация в соответствии с Kabat):
- 89T или 89L;
- 1D или 1E;
- 14P;
- 52aV;
- 73Q, 73S или 73P;
- 74S;
- 83R;
- 89L; или
- 100aF;
например, где, PD1-связывающий фрагмент содержит одну или более из следующих множеств мутаций:
- 89L в комбинации с 1D, 11V, 14P, 74S и 83R;
- 89L в комбинации с 1E, 11V, 14P, 74S и 83R;
- 89L в комбинации с 1D, 11V, 14P, 52aV, 73S или 73Q или 73P; 74S, 83R и/или 100aF;
- 89L в комбинации с 1E, 11V, 14P, 52aV, 73S или 73Q или 73P; 74S, 83R и/или 100aF;
- 89L в комбинации с 11V;
- 89L в комбинации с 110K или 110Q;
- 89L в комбинации с 112K или 112Q;
- 89L в комбинации с 11V и 110K или 110Q;
- 89L в комбинации с 11V и 112K или 112Q;
- 112K или 112Q в комбинации с 1D, 11V, 14P, 74S, 83R и 89L;
- 110K или 110Q в комбинации с 1D, 11V, 14P, 74S, 83R и 89L;
- 112K или 112Q в комбинации с 1E, 11V, 14P, 74S, 83R и 89L;
- 110K или 110Q в комбинации с 1E, 11V, 14P, 74S, 83R и 89L;
- 112K или 112Q в комбинации с 1D, 11V, 14P, 52aV, 73S или 73P или 73Q, 74S, 83R, 89L, 100aF;
- 110K или 110Q в комбинации с 1D, 11V, 14P, 52aV, 73S или 73P или 73Q, 74S, 83R, 89L, 100aF;
- 112K или 112Q в комбинации с 1E, 11V, 14P, 52aV, 73S или 73P или 73Q, 74S, 83R, 89L, 100aF;
- 110K или 110Q в комбинации с 1E, 11V, 14P, 52aV, 73S или 73P или 73Q, 74S, 83R, 89L, 100aF;
- 11V в комбинации с 110K или 110Q; или
- 11V в комбинации с 112K или 112Q.
Как указано выше, в случае, когда PD1-связывающий фрагмент (например, ISVD, такой как нанотело) присутствует в PD1/CTLA4-связывающем веществе по изобретению (в C-концевой области, PD1-связывающий фрагмент (и, соответственно, полученное PD1/CTLA4-связывающее вещество по изобретению) предпочтительно имеет C-концевое удлинение X(n), как описано в настоящем документе и/или как описано в WO 2012/175741 или PCT/EP2015/060643 (WO2015/173325).
Как указано выше, в настоящем изобретении, PD1-связывающий фрагмент, в котором положение 1 соответствует E или D, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R, и положение 89 соответствует L; или в которой положение 89 соответствует T или в которой положение 1 соответствует E или D, положение 11 соответствует V, положение 14 соответствует P, положение 52a соответствует V, положение 73 соответствует S, Q или P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L и/или положение 100a соответствует F; или в котором положение 11 соответствует V, и положение 89 соответствует L (необязательно, в соответствующей комбинации с мутацией 110K или 110Q и/или 112K или 112Q мутацией и, в частности, в комбинации с 110K или 110Q мутацией) являются предпочтительными. Еще более предпочтительными являются PD1-связывающие фрагменты, в которых положение 11 соответствует V, и положение 89 соответствует L, необязательно с 110K или 110Q мутацией.
Таким образом, в одном предпочтительном аспекте, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающем веществе по изобретению, имеет:
- CDR1 (в соответствии с Kabat), который соответствует аминокислотной последовательности IHAMG (SEQ ID NO:3); и
- CDR2 (в соответствии с Kabat), который соответствует аминокислотной последовательности VITXSGGITYYADSVKG (SEQ ID NO:4; где X представляет собой W или V); и
- CDR3 (в соответствии с Kabat), который соответствует аминокислотной последовательности DKHQSSXYDY (SEQ ID NO:5; где X представляет собой W или F);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 1 или 2),
в которой:
- аминокислотный остаток в положении 1 PD1-связывающего фрагмента выбран из E и D;
- аминокислотный остаток в положении 11 PD1-связывающего фрагмента выбран из L и V;
- аминокислотный остаток в положении 14 PD1-связывающего фрагмента выбран из A и P;
- аминокислота в положении 52a PD1-связывающего фрагмента выбран из W и V;
- аминокислота в положении 73 PD1-связывающего фрагмента выбран из N, P, S и Q;
- аминокислотный остаток в положении 74 PD1-связывающего фрагмента выбран из A и S;
- аминокислотный остаток в положении 83 PD1-связывающего фрагмента выбран из K и R;
- аминокислотный остаток в положении 89 PD1-связывающего фрагмента выбран из T, L, I и V;
- аминокислота в положении 100a предпочтительно выбирана из W и F;
- аминокислотный остаток в положении 110 PD1-связывающего фрагмента выбран из T, K и Q (и предпочтительным является T); и
- аминокислотный остаток в положении 112 PD1-связывающего фрагмента выбран из S, K и Q (и в предпочтительно S).
В другом предпочтительном аспекте, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающем веществе по изобретению, которое связывается с PD1 и CTLA4) имеет:
- CDR1 (в соответствии с Kabat), который соответствует аминокислотной последовательности IHAMG (SEQ ID NO:3); и
- CDR2 (в соответствии с Kabat), который соответствует аминокислотной последовательности VITXSGGITYYADSVKG (SEQ ID NO:4; где X представляет собой W или V); и
- CDR3 (в соответствии с Kabat), который соответствует аминокислотной последовательности DKHQSSXYDY (SEQ ID NO:5; где X представляет собой W или F);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1 ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 1 или 2), в котором верно одно или более из следующих условий:
- аминокислотный остаток в положении 1 PD1 фрагмента соответствует E или D;
- аминокислотный остаток в положении 11 PD1 фрагмента соответствует V;
- аминокислотный остаток в положении 14 PD1 фрагмента соответствует P;
- аминокислотный остаток в положении 52a PD1 фрагмента соответствует V;
- аминокислотный остаток в положении 73 PD1 фрагмента соответствует S, Q или P;
- аминокислотный остаток в положении 74 PD1 фрагмента соответствует S;
- аминокислотный остаток в положении 83 PD1 фрагмента соответствует R
- аминокислотный остаток в положении 89 PD1 фрагмента соответствует L;
- аминокислотный остаток в положении 100a PD1 фрагмента соответствует F;
- аминокислотный остаток в положении 110 PD1 фрагмента предпочтительно выбиран из T, K или Q; или
- аминокислотный остаток в положении 112 PD1 фрагмента предпочтительно выбиран из S, K или Q.
В одном конкретном, но не ограничивающем аспекте, PD1 фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению, содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 1 или 2) в указанных положениях (нумерация в соответствии с Kabat):
- 11V в комбинации с 89L;
- 11V в комбинации с 89L, 1E, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R и 100aF;
- 11V в комбинации с 89L, 1D, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R и 100aF;
- 11V в комбинации с 89L, 1D, 14P, 74S и 83R;
- 11V в комбинации с 89L, 1E, 14P, 74S и 83R;
- 11V в комбинации с 110K или 110Q;
- 11V в комбинации с 112K или 112Q;
- 11V в комбинации с 89L, 1D, 14P, 74S, 83R и 110K или 110Q;
- 11V в комбинации с 89L, 1D, 14P, 74S, 83R и 112K или 112Q;
- 11V в комбинации с 89L, 1E, 14P, 74S, 83R и 110K или 110Q;
- 11V в комбинации с 89L, 1E, 14P, 74S, 83R и 112K или 112Q;
- 11V в комбинации с 89L, 1E, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 100aF и 110K или 110Q;
- 11V в комбинации с 89L, 1E, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 100aF и 112K или 112Q;
- 11V в комбинации с 89L, 1D, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 100aF и 110K или 110Q;
- 11V в комбинации с 89L, 1D, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 100aF и 112K или 112Q;
- 11V в комбинации с 89L и 110K или 110Q; или
- 11V в комбинации с 89L и 112K или 112Q;
и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 16-47 или 135-142 (например, в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1, 2, 16-47 или 135-142, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению, содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 1 или 2) в указанных положениях (нумерация в соответствии с Kabat):
- 89L в комбинации с 11V;
- 89L в комбинации с 89L, 1D, 11V, 14P, 74S и 83R;
- 89L в комбинации с 89L, 1E, 11V, 14P, 74S и 83R;
- 89L в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 100aF и/или 1D или 1E;
- 89L в комбинации с 110K или 110Q;
- 89L в комбинации с 112K или 112Q;
- 89L в комбинации с 89L, 1D, 11V, 14P, 74S, 83R; и 110K или 110Q;
- 89L в комбинации с 89L, 1E, 11V, 14P, 74S, 83R; и 112K или 112Q;
- 89L в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 89L, 100aF, 110K или 110Q и/или 1D или 1E;
- 89L в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 89L, 100aF, 112K или 112Q и/или 1D или 1E;
- 89L в комбинации с 11V и 110K или 110Q; или
- 89L в комбинации с 11V и 112K или 112Q;
и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 16-47 или 135-142 (например, в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению (содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 1 или 2) в указанных положениях (нумерация в соответствии с Kabat):
- 110K или 110Q в комбинации с 1E;
- 110K или 110Q в комбинации с 1D;
- 110K или 110Q в комбинации с 11V;
- 110K или 110Q в комбинации с 14P;
- 110K или 110Q в комбинации с 52aV;
- 110K или 110Q в комбинации с 73S или 73Q или 73P;
- 110K или 110Q в комбинации с 74S;
- 110K или 110Q в комбинации с 83R;
- 110K или 110Q в комбинации с 89L;
- 110K или 110Q в комбинации с 100aF; или
- 110K или 110Q в комбинации с 11V и 89L;
и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 116-47 или 135-142 (в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1, 2, 16-47 или 135-142, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению, содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 1 или 2) в указанных положениях (нумерация в соответствии с Kabat):
- 112K или 112Q в комбинации с 1D;
- 112K или 112Q в комбинации с 1E;
- 112K или 112Q в комбинации с 11V;
- 112K или 112Q в комбинации с 14P;
- 112K или 112Q в комбинации с 52aV;
- 112K или 112Q в комбинации с 73S или 73Q или 73P;
- 112K или 112Q в комбинации с 74S;
- 112K или 112Q в комбинации с 83R;
- 112K или 112Q в комбинации с 89L;
- 112K или 112Q в комбинации с 100aF; или
- 112K или 112Q в комбинации с 11V и 89L;
и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 16-47 или 135-142 (например, в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2, которые являются такими, как описано в настоящем документе.
В другом аспекте, PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению, содержат T в положении 89 и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 16-47 или 135-142 (например, в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2, которые являются такими, как описано в настоящем документе.
В другом аспекте, PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению, содержат V в положении 11 и L в положении 89, и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 16-47 или 135-142 (например, в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2, которые являются такими, как описано в настоящем документе.
Как указано выше, PD1-связывающие фрагменты (например, ISVD, такие как нанотела) присутствующие в PD1/CTLA4-связывающих веществах по изобретению в соответствии с аспектами, описанными в настоящем документе, предпочтительно являются такими, что они содержат подходящую комбинацию мутации L11V, мутации A14P, мутации, A74S мутации K83R и/или мутации I89L и необязательно мутации E1D, и предпочтительно соответствующую комбинацию любых двух этих мутаций, например, всех этих мутаций (в этом случае также, когда PD1-связывающий фрагмент присутствует в N-концевой области полипептида по изобретению, предпочтительны также мутации E1D) (относительно аминокислотной последовательности SEQ ID NO: 1 или 2).
В другом аспекте, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающих веществах по изобретению (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4), имеет:
- CDR1 (в соответствии с Abm), который соответствует аминокислотной последовательности GSIASIHAMG (SEQ ID NO: 6); и
- CDR2 (в соответствии с Abm), который соответствует аминокислотной последовательности VITXSGGITY (SEQ ID NO: 7; где X представляет собой W или V); и
- CDR3 (в соответствии с Abm), который соответствует аминокислотной последовательности DKHQSSXYDY (SEQ ID NO: 5; где X представляет собой W или F);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1 ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 1 или 2),
в которой:
- аминокислотный остаток в положении 1 PD1-связывающего фрагмента выбран из E или D;
- аминокислотный остаток в положении 11 PD1-связывающего фрагмента выбран из L или V;
- аминокислотный остаток в положении 14 PD1-связывающего фрагмента выбран из A или P;
- аминокислотный остаток в положении 52a PD1-связывающего фрагмента выбран из W and V;
- аминокислотный остаток в положении 73 PD1-связывающего фрагмента выбран из P, S, N and Q;
- аминокислотный остаток в положении 74 PD1-связывающего фрагмента выбран из A или S;
- аминокислотный остаток в положении 83 PD1-связывающего фрагмента выбран из K или R;
- аминокислотный остаток в положении 89 PD1-связывающего фрагмента выбран из T, V, I или L;
- аминокислотный остаток в положении 100a PD1-связывающего фрагмента выбран из W and F;
- аминокислотный остаток в положении 110 PD1-связывающего фрагмента выбран из T, K или Q; и
- аминокислотный остаток в положении 112 PD1-связывающего фрагмента выбран из S, K или Q;
так что, например, в PD1-связывающем фрагменте содержит одну или более следующих мутаций или множеств мутаций:
(i) положение 89 соответствует T или L;
(ii) положение 89 соответствует L, и положение 11 соответствует V;
(iii) положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R и положение 89 соответствует L;
(iv) положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R и положение 89 соответствует L;
(v) положение 1 представляет собой D или E, положение 11 соответствует V, положение 14 соответствует P, положение 52a соответствует V, положение 73 соответствует S, Q или P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, и положение 100a соответствует F;
(vi) положение 89 соответствует L, и положение 110 соответствует K или Q;
(vii) положение 89 соответствует L, и положение 112 соответствует K или Q;
(viii) положение 89 соответствует L, и положение 11 соответствует V, и положение 110 соответствует K или Q;
(ix) положение 89 соответствует L, и положение 11 соответствует V, и положение 112 соответствует K или Q;
(x) положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L; и положение 110 соответствует K или Q;
(xi) положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L; и положение 110 соответствует K или Q;
(xii) положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L; и положение 112 соответствует K или Q;
(xiii) положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L; и положение 112 соответствует K или Q;
(xiv) положение 1 представляет собой D или E, положение 11 соответствует V, положение 14 соответствует P, положение 52a соответствует V, положение 73 соответствует S, P или Q, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L; положение 100a соответствует F и положение 110 соответствует K или Q;
(xv) положение 1 представляет собой D или E, положение 11 соответствует V, положение 14 соответствует P, положение 52a соответствует V, положение 73 соответствует S, P или Q, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L; положение 100a соответствует F и положение 112 соответствует K или Q;
(xvi) положение 11 соответствует V, и положение 110 соответствует K или Q; или
(xvii) положение 11 соответствует V, и положение 112 соответствует K или Q.
В дополнительном аспекте, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в связывающем фрагменте по изобретению, имеет:
- CDR1 (в соответствии с Abm), который соответствует аминокислотной последовательности GSIASIHAMG (SEQ ID NO:6); и
- CDR2 (в соответствии с Abm), который соответствует аминокислотной последовательности VITXSGGITY (SEQ ID NO:7; где X представляет собой W или V); и
- CDR3 (в соответствии с Abm), который соответствует аминокислотной последовательности DKHQSSXYDY (SEQ ID NO:5; где X представляет собой W или F);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1 ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 1 или 2),
таким образом, что указанный PD1-связывающий фрагмент содержит следующие множества мутаций (то есть мутации по сравнению с аминокислотной последовательностью SEQ ID NO: 1 или 2) в указанных положениях (нумерация в соответствии с Kabat):
- 89T или 89L;
- 89L в комбинации с 11V;
- 89L в комбинации с 1D, 11V, 14P, 74S и 83R;
- 89L в комбинации с 1E, 11V, 14P, 74S и 83R;
- 89L в комбинации с 1D, 11V, 14P, 52aV, 73S или 73P или 73Q, 74S, 83R и 100aF;
- 89L в комбинации с 1E, 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R и 100aF;
- 89L в комбинации с 110K или 110Q;
- 89L в комбинации с 112K или 112Q;
- 89L в комбинации с 11V и 110K или 110Q;
- 89L в комбинации с 11V и 112K или 112Q;
- 89L в комбинации с 1D, 11V, 14P, 74S, 83R и 110K или 110Q;
- 89L в комбинации с 1E, 11V, 14P, 74S, 83R и 110K или 110Q;
- 89L в комбинации с 1D, 11V, 14P, 74S, 83R и 112K или 112Q;
- 89L в комбинации с 1E, 11V, 14P, 74S, 83R и 112K или 112Q;
- 89L в комбинации с 1E, 11V, 14P, 52aV, 73S или 73P или 73Q, 74S, 83R, 100aF и 110K или 110Q;
- 89L в комбинации с 1D, 11V, 14P, 52aV, 73S или 73P или 73Q, 74S, 83R, 100aF и 112K или 112Q;
- 11V в комбинации с 110K или 110Q; или
- 11V в комбинации с 112K или 112Q.
Как указано выше, в случае, когда PD1-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающем веществе по изобретению, используется в одновалентном формате и/или присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению (как определено в настоящем документе), PD1-связывающий фрагмент (и, соответственно, полученное PD1/CTLA4-связывающее вещество по изобретению) предпочтительно имеет C-концевое удлинение X(n), причем C-концевое удлинение может быть таким, как описано в настоящем документе для PD1/CTLA4-связывающего вещества по изобретению и/или как описано в WO 2012/175741 или PCT/EP2015/060643 (WO2015/173325).
Как указано выше, в настоящем изобретении, PD1-связывающие фрагменты (например, ISVD, такие как нанотела), в которых положение 1 соответствует E или D, положение 11 соответствует V, положение 14 соответствует P, положение 74 соответствует S, положение 83 соответствует R и положение 89 соответствует L, или в которых положение 89 соответствует T, или в которых положение 1 соответствует E или D, положение 11 соответствует V, положение 14 соответствует P, положение 52a соответствует V, положение 73 соответствует S, P или Q, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L и/или положение 100a соответствует F, или в которых положение 11 соответствует V, и положение 89 соответствует L (необязательно в соответствующей комбинации с мутацией 110K или 110Q и/или 112K или 112Q мутацией, и, в частности, в комбинации с 110K или 110Q мутацией), являются предпочтительными. Также предпочтительными являются PD1-связывающие фрагменты, в которых положение 11 соответствует V, и положение 89 соответствует L, необязательно с 110K или 110Q мутацией (относительно аминокислотной последовательности SEQ ID NO: 1 или 2).
Таким образом, в одном предпочтительном аспекте, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающем веществе по изобретению, имеет:
- CDR1 (в соответствии с Abm), который соответствует аминокислотной последовательности GSIASIHAMG (SEQ ID NO:6); и
- CDR2 (в соответствии с Abm), который соответствует аминокислотной последовательности VITXSGGITY (SEQ ID NO:7; где X представляет собой W или V); и
- CDR3 (в соответствии с Abm), который соответствует аминокислотной последовательности DKHQSSXYDY (SEQ ID NO:5; где X представляет собой W или F);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 1 или 2),
в которой
- аминокислотный остаток в положении 1 PD1-связывающего фрагмента выбран из E или D;
- аминокислотный остаток в положении 11 PD1-связывающего фрагмента выбран из L или V;
- аминокислотный остаток в положении 14 PD1-связывающего фрагмента выбран из A или P;
- аминокислотный остаток в положении 52a PD1-связывающего фрагмента выбран из W и V;
- аминокислотный остаток в положении 73 PD1-связывающего фрагмента выбран из P, N, S и Q;
- аминокислотный остаток в положении 74 PD1-связывающего фрагмента выбран из A или S;
- аминокислотный остаток в положении 83 PD1-связывающего фрагмента выбран из K или R;
- аминокислотный остаток в положении 89 PD1-связывающего фрагмента выбран из T, V I или L;
- аминокислотный остаток в положении 100a PD1-связывающего фрагмента выбран из W и F;
- аминокислотный остаток в положении 110 PD1-связывающего фрагмента выбран из T, K или Q (и предпочтительным является T); и
- аминокислотный остаток в положении 112 PD1-связывающего фрагмента выбран из S, K или Q (и предпочтительным является S).
В другом предпочтительном аспекте, PD1-связывающий фрагмент, который присутствует в PD1/CTLA4-связывающем веществе по изобретению, имеет:
- CDR1 (в соответствии с Abm), который соответствует аминокислотной последовательности GSIASIHAMG (SEQ ID NO: 6); и
- CDR2 (в соответствии с Abm), который соответствует аминокислотной последовательности VITXSGGITY (SEQ ID NO: 7; где X представляет собой W или V); и
- CDR3 (в соответствии с Abm), который соответствует аминокислотной последовательности DKHQSSXYDY (SEQ ID NO: 5; где X представляет собой W или F);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 1 или 2 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 1 или 2),
в котором верно одно или более из следующих условий:
- аминокислотный остаток в положении 1 PD1-связывающего фрагмента представляет собой D или E;
- аминокислотный остаток в положении 11 PD1-связывающего фрагмента соответствует V;
- аминокислотный остаток в положении 14 PD1-связывающего фрагмента соответствует P;
- аминокислотный остаток в положении 52a PD1-связывающего фрагмента соответствует V;
- аминокислотный остаток в положении 73 PD1-связывающего фрагмента соответствует S, P или Q;
- аминокислотный остаток в положении 74 PD1-связывающего фрагмента соответствует S;
- аминокислотный остаток в положении 83 PD1-связывающего фрагмента соответствует R;
- аминокислотный остаток в положении 89 PD1-связывающего фрагмента соответствует L;
- аминокислотный остаток в положении 100a PD1-связывающего фрагмента соответствует F;
- аминокислотный остаток в положении 110 PD1-связывающего фрагмента выбран из T, K и Q; или
- аминокислотный остаток в положении 112 PD1-связывающего фрагмента выбран из S, K и Q.
В одном конкретном, но не ограничивающем аспекте, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), присутствующий в PD1/CTLA4-связывающем веществе по изобретению (например, содержащий ISVD (например, нанотела), который связываются с PD1 и CTLA4), содержит следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 1 или 2) в указанных положениях (нумерация в соответствии с Kabat):
- 11V в комбинации с 89L;
- 11V в комбинации с 1D, 14P, 74S, 83R и 89L;
- 11V в комбинации с 1E, 14P, 74S, 83R и 89L;
- 11V в комбинации с 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 89L, 100aF и 1E или 1D;
- 11V в комбинации с 110K или 110Q;
- 11V в комбинации с 112K или 112Q;
- 11V в комбинации с 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 89L, 100aF, 110K или 110Q и 1E или 1D;
- 11V в комбинации с 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 89L, 100aF, 112K или 112Q и 1E или 1D;
- 11V в комбинации с 89L и 110K или 110Q;
- 11V в комбинации с 89L и 112K или 112Q;
- 110K или 110Q в комбинации с 1D, 11V,14P, 74S, 83R и 89L;
- 110K или 110Q в комбинации с 1E, 11V, 14P, 74S, 83R и 89L;
- 112K или 112Q в комбинации с 1D, 11V,14P, 74S, 83R и 89L; или
- 112K или 112Q в комбинации с 1E, 11V, 14P, 74S, 83R и 89L
и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 16-47 или 135-142 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), присутствующий в PD1/CTLA4-связывающем веществе по изобретению, содержит следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 1 или 2) в указанных положениях (нумерация в соответствии с Kabat):
- 89L в комбинации с 11V;
- 89L в комбинации с 1E, 11V, 14P, 74S и 83R;
- 89L в комбинации с 1D, 11V, 14P, 74S и 83R;
- 89L в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 100aF и 1E или 1D;
- 89L в комбинации с 110K или 110Q;
- 89L в комбинации с 112K или 112Q;
- 89L в комбинации с 1E, 11V, 14P, 74S, 83R и 110K или 110Q;
- 89L в комбинации с 1D, 11V, 14P, 74S, 83R и 110K или 110Q;
- 89L в комбинации с 1E, 11V, 14P, 74S, 83R и 112K или 112Q;
- 89L в комбинации с 1D, 11V, 14P, 74S, 83R и 112K или 112Q;
- 89L в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 100aF, 110K или 110Q и 1E или 1D;
- 89L в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 100aF, 112K или 112Q и 1E или 1D;
- 89L в комбинации с 11V и 110K или 110Q; или
- 89L в комбинации с 11V и 112K или 112Q;
и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 16-47 или 135-142 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), присутствующий в PD1/CTLA4-связывающем веществе по изобретению, содержит следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO:2) в указанных положениях (нумерация в соответствии с Kabat):
- 110K или 110Q в комбинации с 11V;
- 110K или 110Q в комбинации с 1E, 11V, 14P, 74S, 83R и 89L;
- 110K или 110Q в комбинации с 1D, 11V, 14P, 74S, 83R и 89L;
- 110K или 110Q в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 89L и 100aF и 1E или 1D.
- 110K или 110Q в комбинации с 89L; или
- 110K или 110Q в комбинации с 11V и 89L;
и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 16-47 или 135-142 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 1 или 2) в указанных положениях (нумерация в соответствии с Kabat):
- 112K или 112Q в комбинации с 11V;
- 112K или 112Q в комбинации с 1E, 11V, 14P, 74S, 83R и 89L;
- 112K или 112Q в комбинации с 1D, 11V, 14P, 74S, 83R и 89L;
- 112K или 112Q в комбинации с 11V, 14P, 52aV, 73S или 73Q или 73P, 74S, 83R, 89L и 100aF и 1E или 1D;
- 112K или 112Q в комбинации с 89L; или
- 112K или 112Q в комбинации с 11V и 89L;
и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 16-47 или 135-142 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2, которые являются такими, как описано в настоящем документе.
В другом аспекте, PD1-связывающее(ие) вещество(а), присутствующее(ие) в PD1/CTLA4-связывающем веществе по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), содержат T или L в положении 89 и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 16-47 или 135-142 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2, которые являются такими, как описано в настоящем документе.
В другом аспекте, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), присутствующий в PD1/CTLA4-связывающем веществе по изобретению, содержит V в положении 11 и L в положении 89, и имеют CDR, например, которые описаны в SEQ ID NO: 1, 2, 16-47 или 135-142 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 1 или 2, которые являются такими, как описано в настоящем документе.
Как указано выше, PD1-связывающий фрагмент (например, ISVD, такой как нанотело), присутствующий в PD1/CTLA4-связывающем веществе по изобретению в соответствии с аспектами, описанными в настоящем документе, предпочтительно являются такими, что они содержат подходящую комбинацию необязательной мутации E1D, мутации L11V, мутации A14P, мутации A74S, мутации K83R и/или мутации I89L; и предпочтительно подходящую комбинацию любых двух из этих мутаций, например, любые пять или шесть из этих мутаций (когда PD1-связывающий фрагмент присутствует в N-концевой области полипептида по изобретению, предпочтительна также мутация E1D) (относительно аминокислотной последовательности SEQ ID NO: 1 или 2).
Некоторые предпочтительные, но не ограничивающие примеры PD1-связывающих фрагментов, которые могут присутствовать в PD1/CTLA4-связывающих веществах по изобретению, приведены в SEQ ID NO: 16-47 или 135-142, и PD1/CTLA4-связывающее вещество по изобретению, которое соответственно содержат одну или более из этих последовательностей, образуют дополнительные аспекты по изобретению.
Некоторые предпочтительные PD1-связывающие фрагменты, которые могут присутствовать в PD1/CTLA4-связывающем веществе по изобретению, представляют собой последовательности SEQ ID NO: 30, 31, 16-47 или 135-142. Из них SEQ ID NO: 31 особенно соответствует тому, чтобы присутствовать в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, SEQ ID NO: 46 особенно соответствует тому, чтобы присутствовать в C-концевой области PD1/CTLA4-связывающего вещества по изобретению.
В случае, когда PD1-связывающий фрагмент (например, ISVD, такой как нанотело) присутствует в и/или образует C-концевую область PD1/CTLA4-связывающего вещества по изобретению, он предпочтительно имеет C-концевое удлинение формулы (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток из природных аминокислотных остатков (хотя в соответствии с одним предпочтительным аспектом, он не содержит какие-либо цистеиновые остатки) и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I).
В соответствии с некоторыми предпочтительными, но неограничивающими примерами таких С-концевых удлинений X(n), X и n могут быть такими, как подробно описано в настоящем документе для PD1/CTLA4-связывающих веществ по изобретению (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4).
В одном из вариантов осуществления изобретения, в случае, когда PD1-связывающие фрагменты (например, ISVD, (например, нанотела), присутствующие в PD1/CTLA4-связывающем веществе по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), содержат мутации в положениях 110 или 112 (относительно аминокислотной последовательности SEQ ID NO: 1 или 2) (необязательно в комбинации с мутациями в положениях 1, 11, 14, 74, 83 и/или 89, как описано в настоящем документе), 5 С-концевые аминокислотные остатки каркаса 4 (начиная с положения 109) можно заменить следующим образом:
(i) если C-концевое удлинение отсутствует: VTVKS (SEQ ID NO: 88), VTVQS (SEQ ID NO: 89), VKVSS (SEQ ID NO: 90) или VQVSS (SEQ ID NO: 91); или
(ii) если C-концевое удлинение присутствует: VTVKSX(n) (SEQ ID NO: 92), VTVQSX(n) (SEQ ID NO: 93), VKVSSX(n) (SEQ ID NO: 94) или VQVSSX(n) (SEQ ID NO: 95), например, VTVKSA (SEQ ID NO: 96), VTVQSA (SEQ ID NO: 97), VKVSSA (SEQ ID NO: 98) или VQVSSA (SEQ ID NO: 99).
В одном из вариантов осуществления изобретения, в случае, когда PD1-связывающие фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), не содержат мутаций в положениях 110 или 112 (но только мутации в положении 1 (необязательно), 11, 14, 74, 83 и/или 89, как описано в настоящем документе) (относительно аминокислотной последовательности SEQ ID NO: 1 или 2), 5 С-концевых аминокислотных остатков в каркасе 4 (начиная с положения 109) обычно заменяются следующим образом:
(i) в случае, когда C-концевое удлинение отсутствует: VTVSS (SEQ ID NO: 100) (как в последовательности SEQ ID NO:2);
или
(ii) в случае, когда C-концевое удлинение присутствует: VTVSSX(n) (SEQ ID NO: 101), например, VTVSSA (SEQ ID NO:102). В этих С-концевых последовательностях, X и n являются такими, как определено в настоящем документе для C-концевых удлинений.
CTLA4-связывающие фрагменты
Предпочтительно, один или более (например, один или два) CTLA4-связывающих фрагмента присутствуют в PD1/CTLA4-связывающих веществах по изобретению (например, содержащих ISVD (например, нанотела), которые связаны с PD1 и CTLA4) (также следует отметить, что в случае, когда два или больше CTLA4-связывающих фрагментов присутствуют в PD1/CTLA4-связывающем веществе по изобретению, они могут быть одинаковыми или различными, и в случае, когда они различны, они предпочтительно все содержат (подходящую комбинацию) мутации в положениях 1, 11, 14, 45, 74, 83, 89, 96, 108, 110 и/или 112, как описано в настоящем документе, и предпочтительно также имеют аналогичные CDR, как описано в настоящем документе) (относительно аминокислотной последовательности SEQ ID NO: 9). На фигуре 4А перечислены аминокислотные последовательности некоторых предпочтительных, но неограничивающих примеров CTLA4-связывающих веществ, которые могут присутствовать в полипептидах (например, PD1/CTLA4-связывающие вещества) по изобретению. На фигуре 4B представлено выравнивание этих CTLA4-связывающих фрагментов с последовательностью SEQ ID NO: 9.
Как подробно описано в настоящем документе, CTLA4-связывающие вещества по изобретению, которые присутствуют, в варианте осуществления изобретения, в PD1/CTLA4-связывающих веществах по настоящему изобретению, предпочтительно имеют аналогичную комбинацию CDR (то есть CDR1, CDR2 и CDR3), которые присутствуют в 11F1 или в связывающем веществе, содержащем последовательность 11F1 (SEQ ID NO: 9). См. таблицу B-1.
Настоящее изобретение также включает CTLA4-связывающие вещества, которые являются вариантами 11F1, которые содержат аминокислотную последовательность, как указано в таблице B-2 ниже. В объем настоящего изобретения включены CTLA4-связывающие вещества, которые включают CDR1, CDR2 и CDR3 указанных вариантов, приведенных в таблице B-2 ниже.
Кроме того, настоящее изобретение включает PD1/CTLA4-связывающие вещества, содержащие CTLA4-связывающий фрагмент, который включает CDR1, CDR2 и CDR3 или аминокислотную последовательность 11F1 или один из его вариантов, приведенных в таблице B-2 ниже.
Таблица B-1. CTLA4-связывающее вещество 11F1 (11F01).
ID
NO
WO 2008/071447
SEQ ID NO: 1306
(11F01 или 4CTLA011F01)
Таблица B-2. Варианты CTLA4-связывающего вещества 11F1.
WFRQAPGKEREFVADIRTSAGRTYYADSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYYCAAEPSGISGWDYWGQGTLVTVSS
(например, EMSGISGWDY или EPSGISGWDY)
(например, EMSGISGWDY или EPSGISGWDY)
где X представляет собой S, V, G, R, Q, M, H, T, D, E, W, F, K, A, Y или P
*CDR подчеркнуты и/или выделены жирным шрифтом.
Настоящее изобретение включает варианты осуществления, содержащие один, два или три CDR в CTLA4-связывающем веществе, указанные в таблице B-1 или B-2 выше (например, 11F01 или 11F01 (E1D, L11V, A14P, Q45R, A74S, K83R, V89L, M96P, Q108L)), где каждый CDR содержит 0, 1, 2, 3, 4 или 5 аминокислотных замен, например, консервативных замен, и/или имеет` 100, 99, 98, 97, 96 или 95% идентичность относительно последовательностей CDR, приведенных в таблице B-1 или B-2, где CTLA4-связывающее вещество, имеющее такие CDR, сохраняет способность связываться с CTLA4. В одном из вариантов осуществления, первая аминокислота CTLA4-связывающего вещества по настоящему изобретению соответствует E. В одном из вариантов развития изобретения, первая аминокислота PD1-связывающего вещества по настоящему изобретению соответствует D.
Остаток 1 или SEQ ID NO: 104 может соответствовать D или E. Если остаток 1 представляет собой D, CTLA4-связывающее вещество может быть обозначено как 1D, и если остаток 1 представляет собой E, CTLA4-связывающее вещество может быть обозначено как 1E.
Номера остатков в соответствии с Kabat для некоторых остатков CTLA4-связывающих веществ (например, ISVD, такой как нанотело) на основе нанотела 11F01, которые описаны в настоящем документе, представлены в последовательности ниже:
E1VQLVESGGGL11V12Q13A14GGSLRLSCAASG26G27T28F29S30FYGMGW36F37R38 Q39APGKEQ45E46F47V48A49DIRTSAGRTYYADSVKGR66F67T68I69S70RDN73A74KNTVYL QMN82aS82bL82cK83P84EDT87A88V89Y90Y91CAAEM96SGISGWDYW103G104Q105G106T Q108V109T110V111S112S113
(SEQ ID NO: 9)
Номера остатков в соответствии с Kabat для некоторых остатков CTLA4-связывающего вещества 11F01 (E1D, L11V, A14P, Q45R, A74S, K83R, V89L, M96P, Q108L), которые описаны в настоящем документе, представлены в последовательности ниже:
D1VQLVESGGGV11VQP14GGSLRLSCAASGGTFSFYGMGWFRQAPGKER45EFVA DIRTSAGRTYYADSVKGRFTISRDN73S74KNTVYLQMNSLR83PEDTAL89YYCAAEP96SGI SGWDYWGQGTL108VTVSS
(SEQ ID NO: 143)
Мутации могут быть указаны в настоящем документе и обозначаются своим номером в соответствии с системой Kabat, как показано выше.
В одном из вариантов осуществления изобретения, CTLA4-связывающее вещество 11F01 содержит мутацию в положении 73, например, N73X, где X представляет собой S, V, G, R, Q, M, H, T, D, E, W, F, K, A, Y или P (или любая аминокислота, отличная от N).
Как указано выше, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, описанных в настоящем документе, могут связываться (и в частности, могут специфично связываться) с CTLA4. В частности, они могут связываться с CTLA4 и тем самым препятствовать связыванию CD80 и/или CD86, например, на антигенпрезентирующей клетке, с CTLA4, например, на Т-клетках. В одном из вариантов осуществления изобретения, полученное таким образом блокирование передачи сигналов CTLA4 пролонгирует активацию Т-клеток, восстанавливает пролиферацию Т-клеток и, тем самым, усиливает опосредованный Т-клетками иммунитет, что теоретически повышает способность пациента усиливать противоопухолевый иммунный ответ.
Обычно CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствующие в PD1/CTLA4-связывающих веществах по изобретению, представляют собой варианты SEQ ID NO: 9 (11F01, WO 2008/071447: SEQ ID NO: 1306), которые включают следующие мутации или множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 9):
- 89T или 89L;
- 89L в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 96P и 108L;
- 89L в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 96P и 108L;
- 89L в комбинации с 11V;
- 89L в комбинации с 110K или 110Q;
- 89L в комбинации с 112K или 112Q;
- 89L в комбинации с 11V и 110K или 110Q;
- 89L в комбинации с 11V и 112K или 112Q;
- 89L в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 110K или 110Q;
- 89L в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 110K или 110Q;
- 89L в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 112K или 112Q; или
- 89L в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 112K или 112Q;
- 11V в комбинации с 110K или 110Q; или
- 11V в комбинации с 112K или 112Q.
В одном из вариантов осуществления изобретения, в CTLA4-связывающих фрагментах (например, ISVD, такие как нанотела), присутствущих в PD1/CTLA4-связывающих веществах по изобретению:
- аминокислотный остаток в положении 1 выбран из E или D;
- аминокислотный остаток в положении 11 выбран из L или V;
- аминокислотный остаток в положении 14 выбран из A или P;
- аминокислотный остаток в положении 45 выбран из Q или R;
- аминокислотный остаток в положении 74 выбран из A или S;
- аминокислотный остаток в положении 83 выбран из K или R;
- аминокислотный остаток в положении 89 выбран из T, V или L;
- аминокислотный остаток в положении 96 выбран из M или P;
- аминокислотный остаток в положении 108 выбран из Q или L;
- аминокислотный остаток в положении 110 выбран из T, K или Q; и
- аминокислотный остаток в положении 112 выбран из S, K или Q;
так, что, например, CTLA4-связывающий фрагмент содержит одну или более из следующих мутаций или множеств мутаций:
(i) положение 89 соответствует T или L;
(ii) положение 89 соответствует L, и положение 11 соответствует V;
(iii) положение 89 соответствует L, положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 96 соответствует P, и положение 108 соответствует L;
(iv) положение 89 соответствует L, положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 96 соответствует P, и положение 108 соответствует L;
(v) положение 89 соответствует L, и положение 110 соответствует K или Q;
(vi) положение 89 соответствует L, и положение 112 соответствует K или Q;
(vii) положение 89 соответствует L, и положение 11 соответствует V, и положение 110 соответствует K или Q;
(viii) положение 89 соответствует L, и положение 11 соответствует V, и положение 112 соответствует K или Q;
(ix) положение 89 соответствует L, положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 96 соответствует P, положение 108 соответствует L, и положение 110 соответствует K или Q
(x) положение 89 соответствует L, положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 96 соответствует P, положение 108 соответствует L, и положение 110 соответствует K или Q
(xi) положение 89 соответствует L, положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 96 соответствует P, положение 108 соответствует L, и положение 112 соответствует K или Q;
(xii) положение 89 соответствует L, положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 96 соответствует P, положение 108 соответствует L, и положение 112 соответствует K или Q;
(xiii) положение 11 соответствует V, и положение 110 соответствует K или Q; или
(xiv) положение 11 соответствует V, и положение 112 соответствует K или Q.
Присутствие CTLA4-связывающих фрагментов, в которых положение 89 соответствует T или в которой положение 1 соответствует E или D, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, положение 108 соответствует L или в которой положение 11 соответствует V, и положение 89 соответствует L (необязательно в соответствующей комбинации с мутацией 110K или 110Q и/или 112K или 112Q мутацией и, в частности, в комбинации с 110K или 110Q мутацией), являются предпочтительными. Также предпочтительными являются CTLA4-связывающие фрагменты, в которых положение 11 соответствует V, и положение 89 соответствует L, необязательно с 110K или 110Q мутацией.
CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, предпочтительно содержат следующие CDR (в соответствии с системой нумерации Kabat):
- CDR1 (в соответствии с Kabat), который соответствует аминокислотной последовательности FYGMG (SEQ ID NO: 10); и
- CDR2 (в соответствии с Kabat), который соответствует аминокислотной последовательности DIRTSAGRTYYADSVKG (SEQ ID NO: 11); и
- CDR3 (в соответствии с Kabat), который соответствует аминокислотной последовательности EXSGISGWDY (SEQ ID NO: 12; где X представляет собой M или P).
Альтернативно, в случае, когда CDR представлены в соответствии с системой Abm, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, предпочтительно содержащие следующие CDR:
- CDR1 (в соответствии с Abm), который соответствует аминокислотной последовательности GGTFSFYGMG (SEQ ID NO: 13); и
- CDR2 (в соответствии с Abm), который соответствует аминокислотной последовательности DIRTSAGRTY (SEQ ID NO: 14); и
- CDR3 (в соответствии с Abm), который соответствует аминокислотной последовательности EXSGISGWDY (SEQ ID NO: 15, которая является такой же, как SEQ ID NO: 4; где X представляет собой M или P).
Вышеуказанные предпочтительные CDR являются такими же, как и в 11F01 (SEQ ID NO: 9).
CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, предпочтительно также имеют:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция); и/или
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 45, 74, 83, 89, 96, 108, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 9 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR).
В отношении различных аспектов и предпочтительных аспектов по изобретению, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция) по изобретению, предусмотренных в настоящем изобретении, в части, касающейся степени идентичности последовательностей в отношении SEQ ID NO: 9 и/или количества и вида ʺаминокислотных различийʺ, которые могут присутствовать в таком связывающем веществе по изобретению (то есть по сравнению с последовательностью SEQ ID NO: 9), следует отметить, что, когда говорят, что
(i) CTLA4-связывающий фрагмент имеет степень идентичности последовательностей с последовательностью SEQ ID NO: 9, составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95% (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей); и/или когда сообщается, что
(ii) CTLA4-связывающий фрагмент имеет не больше, чем 7, предпочтительно не больше, чем 5, например, только 3, 2 или 1, ʺаминокислотных различийʺ с последовательностью SEQ ID NO: 9 (опять, не учитывая любое C-концевое удлинение, которое может присутствовать, и не учитывая мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренных конкретным рассматриваемым аспектом),
то также включены последовательности, которые не имеют аминокислотных различий с последовательностью SEQ ID NO: 9, исключая мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренных конкретным рассматриваемым аспектом) и любое С-концевое удлинение, которое может присутствовать.
Таким образом, в одном конкретном аспекте по изобретению, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, могут иметь 100% идентичность последовательностей с SEQ ID NO: 9 (включая CDR, но не учитывая мутацию(ии) или комбинацию мутаций в положениях 1, 11, 14, 45, 74, 83, 89, 96, 108, 110 и/или 112, описанных в настоящем документе, и/или любое C-концевое удлинение, которое может присутствовать) и/или могут не иметь аминокислотных различий с SEQID NO: 9 (то есть исключая мутацию(ии) или комбинацию мутаций в положениях 1, 11, 14, 45, 74, 83, 89, 96, 108, 110 и/или 112, описанных в настоящем документе, и любое С-концевое удлинение, которое может присутствовать).
В случае, когда присутствуют любые аминокислотные различия (то есть помимо любого C-концевого удлинения и мутаций в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, которые предусмотрены конкретным рассматриваемым аспектом по изобретению), эти аминокислотные различия могут присутствовать в CDR и/или в каркасных областях, но они предпочтительно присутствуют только в каркасных областях (как определено системой Abm, то есть не в CDR, определенных в соответствии с системой Abm), то есть так, чтобы CTLA4-связывающие фрагменты, присутствующие в PD1/CTLA4-связывающих веществах по изобретению, имели аналогичные CDR (определенные в соответствии с системой Abm), которые присутствуют в SEQ ID NO: 48-83 или 143.
Кроме того, когда CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению в соответствии с любым аспектом по изобретению, имеют идин или более аминокислотных различий с последовательностью SEQ ID NO: 9 (помимо мутаций в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренных конкретным рассматриваемым аспектом), тогда некоторые конкретные, но не ограничивающие примеры таких мутаций/аминокислотных различий, которые могут присутствовать (например, по сравнению с последовательностями SEQ ID NO: 9), представляют собой, например, P41A, P41L, P41S или P41T (и, в частности, P41A) и/или T87A (относительно аминокислотной последовательности SEQ ID NO: 9). Другими примерами мутаций являются (подходящая комбинация) одна или более соответствующих ʺгуманизирующихʺ замен, таких как Q108L; ссылка, например, сделана на WO 2009/138519 (или в известном уровне техники, указанном в WO 2009/138519) и WO 2008/020079 (или в известном уровне техники, указанном в WO 2008/020079), а также таблицы A-3 - A-8 из WO 2008/020079 (которые представляют собой перечни, показывающие возможные гуманизирующие замены). Предпочтительно CTLA4-связывающее(ии) вещество(а), присутствующее(ие) в полипептидах по изобретению, содержит, по крайней мере, гуманизирующую замену Q108L. Кроме того, метиониновый остаток в положении 96 (нумерация по Kabat) может быть заменен другим природным аминокислотным остатком, таким как Pro (кроме Cys, Asp или Asn).
Кроме того, в случае, когда CTLA4-связывающий фрагмент (например, ISVD, такой как нанотело) присутствует в и/или образует N-концевую часть PD1/CTLA4-связывающих веществ по изобретению, тогда он предпочтительно содержит D в положении 1 (то есть E1D мутация по сравнению с SEQ ID NO: 9). Предпочтительный, но неограничивающий пример таких N-концевых CTLA4-связывающих фрагментов приведен в виде SEQ ID NO: 64 и 65 и 143 (хотя могут также быть использованы другие связывающие фрагменты CTLA4 с мутацией E1D. Аналогично, в случае, когда CTLA связывающие фрагмент SEQ ID NO: 64 или 65 или 143 не присутствует в N-концевой области, а где-либо еще в PD1/CTLA4-связывающем веществе по изобретению, он предпочтительно содержит мутацию D1E (1E). Соответственно, в дополнительном аспекте, изобретение относится к PD1/CTLA4-связывающему веществу по изобретению (которое подробно описано в настоящем документе), которое имеет CTLA4-связывающий фрагмент (который подробно описан в настоящем документе) в своей N-концевой области, где указанный CTLA4-связывающий фрагмент имеет D в положении 1 (1D) и представляет собой предпочтительно SEQ ID NO: 64 или 65 или 143.
CTLA4-связывающие фрагменты присутствуют в PD1/CTLA4-связывающих веществах по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), в соответствии с аспектами, описанными в настоящем документе, предпочтительно являются такими, что они содержат подходящую комбинацию необязательной мутации E1D, мутации L11V, мутации A14P, мутации Q45R, мутации A74S, мутации K83R, мутации V89L, мутации M96P и мутации Q108L. В одном из вариантов осуществления изобретения, такие CTLA4-связывающие фрагменты содержат подходящую комбинацию Q108L с любыми другими E1D (необязательно), L11V, A14P, Q45R, A74S, K83R, V89L, M96P, Q108L. Предпочтительно CTLA4-связывающие фрагменты содержат комбинацию любых таких мутаций, например, любых двух этих других мутаций, более предпочтительно с любыми тремя этими мутациями (например, с комбинацией A14P, A74S и K83R), например, со всеми четырьмя или девятью или десятью этими мутациями (и этом случае также, когда CTLA4-связывающий фрагмент является моновалентным или присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно также E1D мутация) (относительно аминокислотной последовательности SEQ ID NO: 9). Кроме того, в одном из вариантов осуществления изобретения, метиониновый остаток связывающего фрагмента CTLA4, в положении 96 (нумерация по Kabat), может быть заменен другим природным аминокислотным остатком, таким как Pro (за исключением, например, Cys, Asp или Asn). С помощью предпочтительных, но не ограничивающих примеров, SEQ ID NO: 62-65 и 80-83 и 143 являются примерами CTLA4-связывающих фрагментов, имеющих дополнительные аминокислотные различия с SEQ ID NO: 9, например, E1D (необязательно), L11V, A14P, Q45R, A74S, K83R, V89L, M96P и Q108L (кроме того, как указано в предыдущих параграфах, SEQ ID NO: 64, 65 и 82 и 83 также имеют E1D мутацию).
Таким образом, в первом аспекте, CTLA4-связывающий фрагмент (например, ISVD, такой как нанотело), присутствующий в PD1/CTLA4-связывающем веществе по изобретению, имеет:
- CDR1 (в соответствии с Kabat), который соответствует аминокислотной последовательности FYGMG (SEQ ID NO: 10); и
- CDR2 (в соответствии с Kabat), который соответствует аминокислотной последовательности DIRTSAGRTYYADSVKG (SEQ ID NO: 11); и
- CDR3 (в соответствии с Kabat), который соответствует аминокислотной последовательности EXSGISGWDY (SEQ ID NO: 12; где X представляет собой M или P);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 11, 89, 110 или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 9 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 9),
в котором:
- аминокислотный остаток в положении 1 CTLA4-связывающего фрагмента выбран из E или D;
- аминокислотный остаток в положении 11 CTLA4-связывающего фрагмента выбран из L или V;
- аминокислотный остаток в положении 14 CTLA4-связывающего фрагмента выбран из A или P;
- аминокислотный остаток в положении 45 CTLA4-связывающего фрагмента выбран из Q или R;
- аминокислотный остаток в положении 74 CTLA4-связывающего фрагмента выбран из A или S;
- аминокислотный остаток в положении 83 CTLA4-связывающего фрагмента выбран из K или R;
- аминокислотный остаток в положении 89 CTLA4-связывающего фрагмента выбран из T, V или L;
- аминокислотный остаток в положении 96 CTLA4-связывающего фрагмента выбран из M или P;
- аминокислотный остаток в положении 108 CTLA4-связывающего фрагмента выбран из Q или L;
- аминокислотный остаток в положении 110 CTLA4-связывающего фрагмента выбран из T, K или Q; и
- аминокислотный остаток в положении 112 CTLA4-связывающего фрагмента выбран из S, K или Q;
так что, например, CTLA4-связывающий фрагмент содержит одну или более из следующих мутаций:
(i) положение 1 соответствует E или D;
(ii) положение 11 соответствует V;
(iii) положение 14 соответствует P;
(iv) положение 45 соответствует R;
(v) положение 74 соответствует S;
(vi) положение 83 соответствует R;
(vii) положение 89 соответствует L или T;
(viii) положение 96 соответствует P;
(ix) положение 108 соответствует L;
например, где, CTLA4-связывающий фрагмент содержит одну или более из множеств мутаций:
a. положение 89 соответствует L, и положение 11 соответствует V;
b. положение 89 соответствует L, и положение 110 соответствует K или Q;
c. положение 89 соответствует L, и положение 112 соответствует K или Q;
d. положение 89 соответствует L, и положение 11 соответствует V, и положение 110 соответствует K или Q;
e. положение 89 соответствует L, и положение 11 соответствует V, и положение 112 соответствует K или Q;
f. положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, и положение 108 соответствует L положение;
g. положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, и положение 108 соответствует L;
h. положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, положение 108 соответствует L положение и 110 соответствует K или Q;
i. положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, положение 108 соответствует L положение и 110 соответствует K или Q;
j. положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, положение 108 соответствует L, и положение 112 соответствует K или Q;
k. положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, положение 108 соответствует L, и положение 112 соответствует K или Q;
l. положение 11 соответствует V, и положение 110 соответствует K или Q; или
m. положение 11 соответствует V, и положение 112 соответствует K или Q.
В дополнительном аспекте, CTLA4-связывающий фрагмент, присутствующий в PD1/CTLA4-связывающем веществе по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) имеет:
- CDR1 (в соответствии с Kabat), который соответствует аминокислотной последовательности FYGMG (SEQ ID NO: 10); и
- CDR2 (в соответствии с Kabat), который соответствует аминокислотной последовательности DIRTSAGRTYYADSVKG (SEQ ID NO: 11); и
- CDR3 (в соответствии с Kabat), который соответствует аминокислотной последовательности EXSGISGWDY (SEQ ID NO: 12; где X представляет собой M или P);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 11, 89, 110 или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 9 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 9),
так, что указанный CTLA4-связывающий фрагмент содержит один или более из следующих аминокислотных остатков (то есть мутации по сравнению с аминокислотной последовательностью SEQ ID NO: 9) в указанных положениях (нумерация в соответствии с Kabat):
- 1D или 1E;
- 11V;
- 14P;
- 45R;
- 74S;
- 83R;
- 89L или 8T;
- 96P;
- 108L;
например, где CTLA4-связывающий фрагмент содержит одну или более из множеств мутаций:
- 1E в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; и 108L;
- 1D в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; и 108L;
- 89L в комбинации с 11V;
- 89L в комбинации с 110K или 110Q;
- 89L в комбинации с 112K или 112Q;
- 89L в комбинации с 11V и 110K или 110Q;
- 89L в комбинации с 11V и 112K или 112Q;
- 1E в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; 108L и 110K или 110Q;
- 1D в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; 108L и 110K или 110Q;
- 1E в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; 108 L и 112K или 112Q;
- 1D в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; 108L и 112K или 112Q;
- 11V в комбинации с 110K или 110Q; или
- 11V в комбинации с 112K или 112Q.
Как указано выше, в случае, когда CTLA4-связывающий фрагмент (например, ISVD, такой как нанотело), присутствующий в PD1/CTLA4-связывающих веществах по изобретению, используется в одновалентном формате и/или присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению (как определено в настоящем документе), CTLA4-связывающий фрагмент (и, соответственно, полученное PD1/CTLA4-связывающее вещество по изобретению) предпочтительно имеет C-концевое удлинение X(n) как описано в настоящем документе и/или как описано в WO 2012/175741 или PCT/EP2015/060643 (WO2015/173325).
Как указано выше, в настоящем изобретении, CTLA4-связывающие фрагменты, в которых положение 89 соответствует T или в которых положение 1 соответствует E или D, положение 11 соответствует V; положение 14 соответствует P; положение 45 соответствует R; положение 74 соответствует S; положение 83 соответствует R; положение 89 соответствует L; положение 96 соответствует P; и положение 108 соответствует L или в которых положение 11 соответствует V, и положение 89 соответствует L (необязательно в соответствующей комбинации с мутацией 110K или 110Q и/или 112K или 112Q мутацией, и, в частности, в комбинации с 110K или 110Q мутацией), являются предпочтительными. Также предпочтительными являются CTLA4 фрагменты, в которых положение 11 соответствует V, и положение 89 соответствует L, необязательно с 110K или 110Q мутацией.
Таким образом, в одном предпочтительном аспекте, CTLA4-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающем веществе по изобретению, имеет:
- CDR1 (в соответствии с Kabat), который соответствует аминокислотной последовательности FYGMG (SEQ ID NO: 10); и
- CDR2 (в соответствии с Kabat), который соответствует аминокислотной последовательности DIRTSAGRTYYADSVKG (SEQ ID NO: 11); и
- CDR3 (в соответствии с Kabat), который соответствует аминокислотной последовательности EXSGISGWDY (SEQ ID NO: 12; где X представляет собой M или P);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 9 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и, в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и, в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 9),
в котором:
- аминокислотный остаток в положении 1 CTLA4-связывающего фрагмента выбран из E или D
- аминокислотный остаток в положении 11 CTLA4-связывающего фрагмента выбран из L или V;
- аминокислотный остаток в положении 14 CTLA4-связывающего фрагмента выбран из A или P;
- аминокислотный остаток в положении 45 CTLA4-связывающего фрагмента выбран из Q или R;
- аминокислотный остаток в положении 74 CTLA4-связывающего фрагмента выбран из A или S;
- аминокислотный остаток в положении 83 CTLA4-связывающего фрагмента выбран из K или R;
- аминокислотный остаток в положении 89 CTLA4-связывающего фрагмента выбран из T, V или L;
- аминокислотный остаток в положении 96 CTLA4-связывающего фрагмента выбран из M или P;
- аминокислотный остаток в положении 108 CTLA4-связывающего фрагмента выбран из Q или L;
- аминокислотный остаток в положении 110 CTLA4-связывающего фрагмента предпочтительно выбиран из T, K или Q (и предпочтительным является T); и
- аминокислотный остаток в положении 112 CTLA4-связывающего фрагмента предпочтительно выбиран из S, K или Q (и предпочтительным является S).
В другом предпочтительном аспекте, CTLA4-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающем веществе, имеет:
- CDR1 (в соответствии с Kabat), который соответствует аминокислотной последовательности FYGMG (SEQ ID NO: 10); и
- CDR2 (в соответствии с Kabat), который соответствует аминокислотной последовательности DIRTSAGRTYYADSVKG (SEQ ID NO: 11); и
- CDR3 (в соответствии с Kabat), который соответствует аминокислотной последовательности EXSGISGWDY (SEQ ID NO: 12; где X представляет собой M или P);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 11, 89, 110 или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 9 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 9), в котором верно одно или более из следующих условий:
- аминокислотный остаток в положении 1 CTLA4-связывающего фрагмента соответствует E или D;
- аминокислотный остаток в положении 11 CTLA4-связывающего фрагмента соответствует V;
- аминокислотный остаток в положении 14 CTLA4-связывающего фрагмента соответствует P;
- аминокислотный остаток в положении 45 CTLA4-связывающего фрагмента соответствует R;
- аминокислотный остаток в положении 74 CTLA4-связывающего фрагмента соответствует S;
- аминокислотный остаток в положении 83 CTLA4-связывающего фрагмента соответствует R;
- аминокислотный остаток в положении 89 CTLA4-связывающего фрагмента соответствует L;
- аминокислотный остаток в положении 96 CTLA4-связывающего фрагмента соответствует P;
- аминокислотный остаток в положении 108 CTLA4-связывающего фрагмента соответствует L;
- аминокислотный остаток в положении 110 CTLA4-связывающего фрагмента выбран из T, K или Q; или
- аминокислотный остаток в положении 112 CTLA4-связывающего фрагмента выбран из S, K или Q.
В одном конкретном, но не ограничивающем аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 9) в указанных положениях (нумерация в соответствии с Kabat):
- 11V в комбинации с 89L;
- 11V в комбинации с 1D, 14P, 45R, 74S, 83R, 89L, 96P и 108L;
- 11V в комбинации с 1E, 14P, 45R, 74S, 83R, 89L, 96P и 108L;
- 11V в комбинации с 110K или 110Q;
- 11V в комбинации с 112K или 112Q;
- 11V в комбинации с 1D, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 110K или 110Q;
- 11V в комбинации с 1E, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 110K или 110Q;
- 11V в комбинации с 1D, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 112K или 112Q;
- 11V в комбинации с 1E, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 112K или 112Q;
- 11V в комбинации с 89L и 110K или 110Q; или
- 11V в комбинации с 89L и 112K или 112Q;
и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (например, в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 9) в указанных положениях (нумерация в соответствии с Kabat):
- 89L в комбинации с 11V;
- 89L в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 96P и 108L;
- 89L в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 96P и 108L;
- 89L в комбинации с 110K или 110Q;
- 89L в комбинации с 112K или 112Q;
- 89L в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 96P, 108L и 110K или 110Q;
- 89L в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 96P, 108L и 110K или 110Q;
- 89L в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 96P, 108L и 112K или 112Q;
- 89L в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 96P, 108L и 112K или 112Q;
- 89L в комбинации с 11V и 110K или 110Q; или
- 89L в комбинации с 11V и 112K или 112Q;
и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (например, в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 9) в указанных положениях (нумерация в соответствии с Kabat):
- 110K или 110Q в комбинации с 11V;
- 110K или 110Q в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L;
- 110K или 110Q в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L;
- 110K или 110Q в комбинации с 89L; или
- 110K или 110Q в комбинации с 11V и 89L;
и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (например, в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 9) в указанных положениях (нумерация в соответствии с Kabat):
- 112K или 112Q в комбинации с 11V;
- 112K или 112Q в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L;
- 112K или 112Q в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L;
- 112K или 112Q в комбинации с 89L; или
- 112K или 112Q в комбинации с 11V и 89L;
и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (например, в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
В другом аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат T или L в положении 89 (например, 1D или 1E, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L) и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
В другом аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат V в положении 11 и L в положении 89 (например, 1D или 1E, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L) и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (например, в соответствии с Kabat), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
Как указано выше, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению в соответствии с аспектами, описанными в настоящем документе, предпочтительно являются такими, что они содержат подходящую комбинацию необязательной мутации E1D, мутации L11V, мутации A14P, мутации Q45R, мутации A74S, мутации K83R, мутации V89L, мутации M96P и/или мутации Q108L, и предпочтительно подходящую комбинацию Q108L с любой одной из других мутаций A14P, Q45R, A74S и K83R и предпочтительно в комбинации с любыми двумя из этих других мутаций, более предпочтительно с любыми тремя из этих мутаций (например, с комбинацией A14P, A74S и K83R), например, со всеми четырьмя этими мутациями (и кроме того, в случае, когда CTLA4-связывающее вещество является одновалентным или присутствует в N-концевой области соединения или полипептида по изобретению, предпочтительна также мутация E1D) (относительно аминокислотной последовательности SEQ ID NO: 9). Кроме того, метиониновый остаток в положении 96 (нумерация по Kabat) может быть заменен другим природным аминокислотным остатком, таким как Pro (кроме Cys, Asp или Asn).
В другом аспекте, CTLA4-связывающий фрагмент (например, ISVD, такой как нанотело), присутствующий в PD1/CTLA4-связывающем веществе по изобретению, имеет:
- CDR1 (в соответствии с Abm), который соответствует аминокислотной последовательности GGTFSFYGMG (SEQ ID NO: 13); и
- CDR2 (в соответствии с Abm), который соответствует аминокислотной последовательности DIRTSAGRTY (SEQ ID NO: 14); и
- CDR3 (в соответствии с Abm), который соответствует аминокислотной последовательности EXSGISGWDY (SEQ ID NO: 12; где X представляет собой M или P);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 9 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 9),
в которой:
- аминокислотный остаток в положении 1 CTLA4-связывающего фрагмента выбран из E или D;
- аминокислотный остаток в положении 11 CTLA4-связывающего фрагмента выбран из L или V;
- аминокислотный остаток в положении 14 CTLA4-связывающего фрагмента выбран из A или P;
- аминокислотный остаток в положении 45 CTLA4-связывающего фрагмента выбран из Q или R;
- аминокислотный остаток в положении 74 CTLA4-связывающего фрагмента выбран из A или S;
- аминокислотный остаток в положении 83 CTLA4-связывающего фрагмента выбран из K или R;
- аминокислотный остаток в положении 89 CTLA4-связывающего фрагмента выбран из T, V или L;
- аминокислотный остаток в положении 96 CTLA4-связывающего фрагмента выбран из M или P;
- аминокислотный остаток в положении 108 CTLA4-связывающего фрагмента выбран из Q или L;
- аминокислотный остаток в положении 110 CTLA4-связывающего фрагмента выбран из T, K или Q; и
- аминокислотный остаток в положении 112 CTLA4-связывающего фрагмента выбран из S, K или Q;
так, что например, верно одно или более из следующих условий:
(i) положение 1 соответствует E или D;
(ii) положение 11 соответствует V;
(iii) положение 14 соответствует P;
(iv) положение 45 соответствует R;
(v) положение 74 соответствует S;
(vi) положение 83 соответствует R;
(vii) положение 89 соответствует L или T;
(viii) положение 96 соответствует P;
(ix) положение 108 соответствует L;
например, где CTLA4-связывающее вещество содержит одну или более следующих множеств мутаций:
a. положение 89 соответствует L, и положение 11 соответствует V;
b. положение 89 соответствует L, и положение 110 соответствует K или Q;
c. положение 89 соответствует L, и положение 112 соответствует K или Q;
d. положение 89 соответствует L, и положение 11 соответствует V, и положение 110 соответствует K или Q;
e. положение 89 соответствует L, и положение 11 соответствует V, и положение 112 соответствует K или Q;
f. положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, и положение 108 соответствует L положение;
g. положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, и положение 108 соответствует L;
h. положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, положение 108 соответствует L положение и 110 соответствует K или Q;
i. положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, положение 108 соответствует L положение и 110 соответствует K или Q;
j. положение 1 соответствует D, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, положение 108 соответствует L, и положение 112 соответствует K или Q;
k. положение 1 соответствует E, положение 11 соответствует V, положение 14 соответствует P, положение 45 соответствует R, положение 74 соответствует S, положение 83 соответствует R, положение 89 соответствует L, положение 96 соответствует P, положение 108 соответствует L, и положение 112 соответствует K или Q;
l. положение 11 соответствует V, и положение 110 соответствует K или Q; или
m. положение 11 соответствует V, и положение 112 соответствует K или Q.
В дополнительном аспекте, CTLA4-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающем веществе по изобретению, имеет:
- CDR1 (в соответствии с Abm), который соответствует аминокислотной последовательности GGTFSFYGMG (SEQ ID NO: 13); и
- CDR2 (в соответствии с Abm), который соответствует аминокислотной последовательности DIRTSAGRTY (SEQ ID NO: 14); и
- CDR3 (в соответствии с Abm), который соответствует аминокислотной последовательности EXSGISGWDY (SEQ ID NO: 12; где X представляет собой M или P);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 9 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и, в случае, когда присутствует в C-концевой области полипептида по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей из аланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 9),
так, что указанный CTLA4-связывающий фрагмент содержит один или более из следующих аминокислотных остатков (то есть мутации по сравнению с аминокислотной последовательностью SEQ ID NO: 9) в указанных положениях (нумерация в соответствии с Kabat):
- 1E или 1D;
- 11V;
- 14P;
- 45R;
- 74S;
- 83R;
- 89L или 89T;
- 96P; или
- 108L;
например, где CTLA4-связывающий фрагмент содержит одну или более из множеств мутаций:
- 89L в комбинации с 11V;
- 89L в комбинации с 110K или 110Q;
- 89L в комбинации с 112K или 112Q;
- 89L в комбинации с 11V и 110K или 110Q;
- 89L в комбинации с 11V и 112K или 112Q;
- 1E в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; и 108L;
- 1D в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; и 108L;
- 1E в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; 108L и 110K или 110Q;
- 1D в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; 108L и 110K или 110Q;
- 1E в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; 108 L и 112K или 112Q;
- 1D в комбинации с 11V; 14P; 45R; 74S; 83R; 89L; 96P; 108L и 112K или 112Q;
- 11V в комбинации с 110K или 110Q; или
- 11V в комбинации с 112K или 112Q.
Как указано выше, в случае, когда CTLA4 фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающих веществах по изобретению, используется в одновалентном формате и/или присутствует в C-концевой области полипептида по изобретению (как определено в настоящем документе), CTLA4-связывающее вещество (и, следовательно, полученный в результате полипептид по изобретению) предпочтительно имеет C-концевое удлинение X(n), причем C-концевое удлинение может быть таким, как описано в настоящем документе для CTLA4-связывающего(их) вещества(веществ), присутствующего(их) в полипептидах по изобретению, и/или как описано в WO 2012/175741 или PCT/EP2015/060643 (WO2015/173325).
Как указано выше, в настоящем изобретении, CTLA4 фрагмент, в котором положение 89 соответствует T, или в котором положение 11 соответствует V, и положение 89 соответствует L (необязательно в соответствующей комбинации с мутацией 110K или 110Q и/или 112K или 112Q мутацией, и, в частности, в комбинации с 110K или 110Q мутацией), являются предпочтительными. Также предпочтительными являются CTLA4-связывающие вещества, в которых положение 11 соответствует V, и положение 89 соответствует L, необязательно с 110K или 110Q мутацией; или в котором положение 1 представляет собой D или E, положение 11 соответствует V; положение 14 соответствует P; положение 45 соответствует R; положение 74 соответствует S; положение 83 соответствует R; положение 89 соответствует L; положение 96 соответствует P, и положение 108 соответствует L.
Таким образом, в одном предпочтительном аспекте, CTLA4 фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающих веществах по изобретению, имеет:
- CDR1 (в соответствии с Abm), который соответствует аминокислотной последовательности GGTFSFYGMG (SEQ ID NO: 13); и
- CDR2 (в соответствии с Abm), который соответствует аминокислотной последовательности DIRTSAGRTY (SEQ ID NO: 14); и
- CDR3 (в соответствии с Abm), который соответствует аминокислотной последовательности EXSGISGWDY (SEQ ID NO: 12; где X представляет собой M или P);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 9 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 9),
в котором
- аминокислотный остаток в положении 1 CTLA4-связывающего фрагмента выбран из E и D;
- аминокислотный остаток в положении 11 CTLA4-связывающего фрагмента выбран из L и V;
- аминокислотный остаток в положении 14 CTLA4-связывающего фрагмента выбран из A и P;
- аминокислотный остаток в положении 45 CTLA4-связывающего фрагмента выбран из Q и R;
- аминокислотный остаток в положении 74 CTLA4-связывающего фрагмента выбран из A и S;
- аминокислотный остаток в положении 83 CTLA4-связывающего фрагмента выбран из K и R;
- аминокислотный остаток в положении 89 CTLA4-связывающего фрагмента выбран из T, V и L;
- аминокислотный остаток в положении 96 CTLA4-связывающего фрагмента выбран из M и P;
- аминокислотный остаток в положении 108 CTLA4-связывающего фрагмента выбран из Q и L;
- аминокислотный остаток в положении 110 CTLA4-связывающего фрагмента выбран из T, K и Q (и предпочтительным является T); и
- аминокислотный остаток в положении 112 CTLA4-связывающего фрагмента выбран из S, K и Q (и предпочтительным является S).
В другом предпочтительном аспекте, CTLA4-связывающий фрагмент (например, ISVD, такой как нанотело), который присутствует в PD1/CTLA4-связывающем веществе по изобретению, имеет:
- CDR1 (в соответствии с Abm), который соответствует аминокислотной последовательности GGTFSFYGMG (SEQ ID NO: 13); и
- CDR2 (в соответствии с Abm), который соответствует аминокислотной последовательности DIRTSAGRTY (SEQ ID NO: 14); и
- CDR3 (в соответствии с Abm), который соответствует аминокислотной последовательности EXSGISGWDY (SEQ ID NO: 12; где X представляет собой M или P);
и имеет:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9 (в которой CDR, любое C-концевое удлинение, которое может присутствовать, а также мутации в положениях 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, предусмотренные конкретным рассматриваемым аспектом, не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%, когда сравнение выполняется посредством алгоритма BLAST, где параметры алгоритма выбираются таким образом, чтобы обеспечить наибольшее совпадение между соответствующими последовательностями по всей длине соответствующих эталонных последовательностей (например, прогнозируемый предел: 10; длина сегмента: 3; максимальное количество совпадений в запрашиваемом диапазоне: 0; матрица BLOSUM 62; цена делеции: открытие 11, продолжение 1; условная композиционная оценочная матричная коррекция);
и/или имеет:
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ (как определено в настоящем документе, и не учитывая любую из выщеуказанных мутаций в положении(положениях) 1, 11, 14, 45, 74, 83 89, 96, 108, 110 и/или 112, которые могут присутствовать, и не учитывая любое C-концевое удлинение, которое может присутствовать) с аминокислотной последовательностью SEQ ID NO: 9 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и в случае, когда присутствует в C-концевой области PD1/CTLA4-связывающего вещества по изобретению, предпочтительно имеет:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I);
и в случае, когда присутствует в N-концевой области полипептида по изобретению, предпочтительно имеет D в положении 1 (то есть мутация E1D по сравнению с SEQ ID NO: 9),
в котором верно одно или более из следующих условий:
- аминокислотный остаток в положении 1 CTLA4-связывающего фрагмента соответствует E или D;
- аминокислотный остаток в положении 11 CTLA4-связывающего фрагмента соответствует V;
- аминокислотный остаток в положении 14 CTLA4-связывающего фрагмента соответствует P;
- аминокислотный остаток в положении 45 CTLA4-связывающего фрагмента соответствует R;
- аминокислотный остаток в положении 74 CTLA4-связывающего фрагмента соответствует S;
- аминокислотный остаток в положении 83 CTLA4-связывающего фрагмента соответствует R;
- аминокислотный остаток в положении 89 CTLA4-связывающего фрагмента соответствует L;
- аминокислотный остаток в положении 96 CTLA4-связывающего фрагмента соответствует P;
- аминокислотный остаток в положении 108 CTLA4-связывающего фрагмента соответствует L;
- аминокислотный остаток в положении 110 CTLA4-связывающего фрагмента предпочтительно выбиран из T, K и Q; или
- аминокислотный остаток в положении 112 CTLA4-связывающего фрагмента предпочтительно выбиран из S, K и Q.
В одном конкретном, но не ограничивающем аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 9) в указанных положениях (нумерация в соответствии с Kabat):
- 11V в комбинации с 89L;
- 11V в комбинации с 1D, 14P, 45R, 74S, 83R, 89L, 96P и 108L;
- 11V в комбинации с 1E, 14P, 45R, 74S, 83R, 89L, 96P и 108L;
- 11V в комбинации с 110K или 110Q;
- 11V в комбинации с 112K или 112Q;
- 11V в комбинации с 1D, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 110K или 110Q;
- 11V в комбинации с 1E, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 110K или 110Q;
- 11V в комбинации с 1D, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 112K или 112Q;
- 11V в комбинации с 1E, 14P, 45R, 74S, 83R, 89L, 96P, 108L и 112K или 112Q;
- 11V в комбинации с 89L и 110K или 110Q; или
- 11V в комбинации с 89L и 112K или 112Q;
и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 9) в указанных положениях (нумерация в соответствии с Kabat):
- 89L в комбинации с 11V;
- 89L в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 96P и 108L;
- 89L в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 96P и 108L;
- 89L в комбинации с 110K или 110Q;
- 89L в комбинации с 112K или 112Q;
- 89L в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 96P, 108L и 110K или 110Q;
- 89L в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 96P, 108L и 110K или 110Q;
- 89L в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 96P, 108L и 112K или 112Q;
- 89L в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 96P, 108L и 112K или 112Q;
- 89L в комбинации с 11V и 110K или 110Q; или
- 89L в комбинации с 11V и 112K или 112Q;
и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 9) в указанных положениях (нумерация в соответствии с Kabat):
- 110K или 110Q в комбинации с 11V;
- 110K или 110Q в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L;
- 110K или 110Q в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L;
- 110K или 110Q в комбинации с 89L; или
- 110K или 110Q в комбинации с 11V и 89L;
и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
В другом конкретном, но не ограничивающем аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат следующие множества мутаций (то есть мутации по сравнению с последовательностью SEQ ID NO: 9) в указанных положениях (нумерация в соответствии с Kabat):
- 112K или 112Q в комбинации с 11V;
- 112K или 112Q в комбинации с 1D, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L;
- 112K или 112Q в комбинации с 1E, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L;
- 112K или 112Q в комбинации с 89L; или
- 112K или 112Q в комбинации с 11V и 89L;
и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
В другом аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат T или L в положении 89 (например, 1D или 1E, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L) и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
В другом аспекте, CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат V в положении 11 и L в положении 89 (например, 1D или 1E, 11V, 14P, 45R, 74S, 83R, 89L 96P и 108L) и имеют CDR, например, которые описаны в SEQ ID NO: 9 или 48-83 или 143 (например, в соответствии с Abm), и имеют общую степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 9, которые являются такими, как описано в настоящем документе.
Как указано выше, CTLA4-связывающие фрагменты, присутствующие в PD1/CTLA4-связывающих веществах по изобретению в соответствии с аспектами, описанными в настоящем документе, предпочтительно являются такими, что они содержат подходящую комбинацию необязательной мутации E1D, мутации L11V, мутации A14P, мутации Q45R, мутации A74S, мутации K83R, мутации V89L, мутации M96P и мутации Q108L, и предпочтительно подходящую комбинацию Q108L с любой одной из других мутаций A14P, Q45R, A74S и K83R и предпочтительно в сочетании с любыми двумя из этих других мутаций, более предпочтительно с любыми тремя из этих мутаций (например, с комбинацией A14P, A74S и K83R), например, со всеми четырьмя этими мутациями (и в этом случае также, когда CTLA4-связывающие фрагменты являются одновалентными или присутствуют в N-концевой области соединения или полипептида по изобретению, предпочтительно также E1D мутация) (относительно аминокислотной последовательности SEQ ID NO: 9). Также метиониновый остаток в положении 96 (нумерация по Kabat) может быть заменен другим природным аминокислотным остатком, таким как Pro (кроме Cys, Asp или Asn).
Некоторые предпочтительные, но не ограничивающие примеры CTLA4-связывающих фрагментов (например, ISVD, такие как нанотела), которые могут присутствовать в PD1/CTLA4-связывающих веществах по изобретению, приведены в SEQ ID NO: 50-83 и 143, и PD1/CTLA4-связывающие вещества по изобретению, которые соответственно содержат одну или более из этих последовательностей, образуют дополнительные аспекты по изобретению.
Примерами CTLA4-связывающих фрагментов (например, ISVD, таких как нанотела), которые могут присутствовать в PD1/CTLA4-связывающих веществ веществах по изобретению, представляют собой последовательности SEQ ID NO: 62-65 и 80-83 и 143. Из них SEQ ID NO: 64 и 65 особенно подходят для присутствия в N-концевой области PD1/CTLA4-связывающих веществ по изобретению, а SEQ ID NO: 80 и 81 особенно подходит для присутствия в C-концевой области PD1/CTLA4-связывающих веществ по изображению.
В случае, когда CTLA4-связывающий фрагмент (например, ISVD, такой как нанотело) присутствует в и/или образует C-концевую область PD1/CTLA4-связывающего вещества, в котором они присутствуют (или когда они, в иных случаях, имеют ʺоткрытуюʺ C-концевую область в таком PD1/CTLA4-связывающем веществе, обычно подразумевая, что C-концевая область ISVD не ассоциируется или не связана с константным доменом (таким как домен CH1), в этом случае ссылка также сделана на WO 2012/175741 и PCT/EP2015/60643 (WO 2015173325)), предпочтительно также имеет С-концевое удлинение формулы (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток из природных аминокислотных остатков (хотя в соответствии с одним предпочтительным аспектом, он не содержит какие-либо цистеиновые остатки), и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I).
В соответствии с некоторыми предпочтительными, но неограничивающими примерами таких C-концевых удлинений X(n), X и n могут быть такими, как подробно описано в настоящем документе для PD1/CTLA4-связывающих веществ по изобретению (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4).
В случае, когда CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, содержат мутации в положениях 110 или 112 (необязательно в комбинации с мутациями в положении 11 и/или 89, как описано в настоящем документе) (относительно аминокислотной последовательности SEQ ID NO: 9), 5 С-концевых аминокислотных остатков в каркасе 4 (начиная с положения 109) можно заменить следующим образом:
(i) если C-концевое удлинение отсутствует: VTVKS (SEQ ID NO:88), VTVQS (SEQ ID NO:89), VKVSS (SEQ ID NO: 90) или VQVSS (SEQ ID NO: 91); или
(ii) если C-концевое удлинение присутствует: VTVKSX(n) (SEQ ID NO: 92), VTVQSX(n) (SEQ ID NO: 93), VKVSSX(n) (SEQ ID NO: 94) или VQVSSX(n) (SEQ ID NO: 95), например, VTVKSA (SEQ ID NO: 96), VTVQSA (SEQ ID NO: 97), VKVSSA (SEQ ID NO: 98) или VQVSSA (SEQ ID NO: 99).
В случае, когда CTLA4-связывающие фрагменты (например, ISVD, такие как нанотела), присутствущие в PD1/CTLA4-связывающих веществах по изобретению, не содержат мутаций в положениях 110 или 112 (но только мутации в положении 1, 11, 14, 45, 74, 83, 89, 96 и/или 108, как описано в настоящем документе), С-концевые аминокислотные остатки в каркасе 4 (начиная с положения 109) обычно будут либо:
(i) в случае, когда C-концевое удлинение отсутствует: VTVSS (SEQ ID NO:100) (как в последовательности SEQ ID NO:2); либо
(ii) в случае, когда C-концевое удлинение присутствует: VTVSSX(n) (SEQ ID NO:101) such as VTVSSA (SEQ ID NO:102). В этих С-концевых последовательностях, X и n являются такими, как определено в настоящем документе для C-концевых удлинений.
PD1/CTLA4-связывающие вещества
Как подробно описано в настоящем документе, PD1/CTLA4-связывающие вещества, предусмотренные в настоящем изобретении (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), содержат, по крайней мере, один (например, один или два) PD1-связывающий фрагмент, описанный в настоящем документе, и, по крайней мере, один (например, один или два) CTLA4-связывающий фрагмент, описанный в настоящем документе, и необязательно экстендер периода полувыведения, такой как ISVD, который связывается с сывороточным белком, таким как сывороточный альбумин, например, человеческий сывороточный альбумин (HSA), например, ALB11002. Настоящее изобретение относится к PD1/CTLA4-связывающим веществам F023700910, F023700918, F023700920 и F023700925, указанным в настоящем документе.
Настоящее изобретение относится к получению усовершенствованных PD1/CTLA4-связывающих веществ, в частности усовершенствованных PDV/CTLA4 биспецифичных ISVD и, более конкретно, усовершенствованных PD1/CTLA4 биспецифичных нанотел. PD1/CTLA4-связывающие вещества по настоящему изобретению включают PD1/CTLA4-связывающие вещества, которые включают CTLA4-связывающие фрагменты, которые включают полипептиды, которые являются вариантами полипептидов, содержащих аминокислотную последовательность SEQ ID NO: 9, которая мутирована в положении 11, 14, 45, 74, 83, 89, 96, 108, 110 и/или 112 (например, SEQ ID NO: 143); и PD1-связывающие фрагменты, которые включают полипептиды, которые являются вариантами полипептидов, содержащих аминокислотную последовательность SEQ ID NO: 1 или 2, которая мутирована в положении 1, 11, 14, 52a, 73, 74, 83, 89, 100a, 110 и/или 112 (например, SEQ ID NO: 135, 136, 137, 138, 139, 140, 141 или 142). В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающие вещества содержат аминокислотные последовательности, представленные в SEQ ID NO: 103-134, 146, 149, 151 или 153.
В частности, как PD1-связывающее(ие) вещество(а), присутствующее(ие) в полипептидах по изобретению, так и CTLA4-связывающее(ие) вещество(а), присутствующее(ие) в полипептидах по изобретению, будут содержать (комбинацию мутаций в положениях 11, 89, 110 и/или 112, которые подробно описаны в настоящем документе (используя нумерацию по Kabat).
PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) по изобретению, в одном из вариантов осуществления изобретения, также содержат C-концевое удлинение X(n), как подробно описано в настоящем документе. Как описано в WO 2012/175741 (а также, например, в WO 2013/024059 и PCT/EP2015/060643 (WO2015/173325)), C-концевое аланиновое удлинение может препятствовать связыванию так называемых ʺестественных антителʺ (предположительно IgG) с предполагаемым эпитопом, который находится в C-концевой области PD1/CTLA4-связывающих веществ (например, ISVD, такой как нанотело). Подразумевается, что этот эпитоп включает, в числе других остатков, экспонированные на поверхности аминокислотные остатки C-концевой последовательности VTVSS (SEQ ID NO: 100), а также аминокислотный остаток в положении 14 (и аминокислотные остатки, находящиеся рядом/близко к налогичным в аминокислотной последовательности, например, положения 11, 13 и 15), и могут также содержать аминокислотный остаток в положении 83 (и аминокислотные остатки, находящиеся рядом/близко к налогичным в аминокислотной последовательности, например, положения 82, 82a, 82b и 84) и/или аминокислотный остаток в положении 108 (и аминокислотные остатки, близкие к тому же в аминокислотной последовательности, например, положение 107).
Однако, хотя присутствие такого C-концевого аланина (или C-концевого удлинения в целом) может значительно уменьшить (и, в некоторых случаях, по существу полностью предотвратить) связывание ʺестественных антителʺ, которые могут быть обнаружены в сыворотке ряда субъектов (как здоровых субъектов, так и больных), было обнаружено, что сыворотки некоторых субъектов (например, сыворотки пациентов с некоторыми иммунными заболеваниями, такими как системная красная волчанка (SLE), могут содержать естественные антитела, которые могут связываться с С-концевой областью ISVD (в случае, когда такая область открыта), даже в случае, когда ISVD содержит такой C-концевой аланин (или в более широком смысле, такое C-концевое удлинение). Ссылка вновь сделана на находящуюся на рассмотрении неопубликованную повторно PCT заявку PCT/EP2015/060643 (WO2015/173325), поданную правоприемником 13 мая 2015 года, под названием ʺImproved immunoglobulin variable domainsʺ.
Соответственно, одной из конкретных целей изобретения является получение PD1/CTLA4-связывающих веществ (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4), которые имеют слабое (или пониженное) связывание так называемыми "естественными антителами" и, в частности, такими, которые описаны в PCT/EP2015/060643 (WO-015/173325) (например, такими естественными антителами, которые могут связываться с открытой C-концевой областью ISV даже в присутствии C-коневого удлинения).
Согласно изобретению эта цель достигается посредством:
(i) присутствия, в PD1/CTLA4-связывающих веществах по изобретению (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4), C-концевого удлинения X(n); в комбинации с
(ii) присутствием, в одном или более и предпочтительно всех PD1/CTLA4-связывающих веществ по изобретению (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4), некоторых аминокислотных остатков/мутаций в положениях 11, 89, 110 и/или 112 (соответствующих SEQ ID NO: 1, 2 и 9, указанный выше) PD1/CTLA4-связывающих веществ, причем остатки/мутации подробно описаны в настоящем документе. Предпочтительно, указанные мутации присутствуют в, по меньшей мере, С-концевом PD1 или CTLA4-связывающем фрагменте PD1/CTLA4-связывающих веществ по изобретению, и, более предпочтительно, во всех связывающих фрагментах, присутствующих в PD1/CTLA4-связывающих веществах по изобретению, то есть в PD1-связывающих фрагментах и в CTLA4-связывающих фрагментах, а также в фрагменте, связывающимся с сывороточным альбумином (если присутствует).
В таблице С представлены некоторые предпочтительные неограничивающие возможные комбинации аминокислотных остатков, которые могут присутствовать в положениях 11, 89, 110 и 112 PD1/CTLA4-связывающих веществ (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA-4), которые присутствуют в полипептидах по изобретению.
Таблица C: Возможные комбинации мутаций в аминокислотных положениях 11, 89, 110 и 112 в PD1 и CTLA4-связывающих фрагментах SEQ ID NO: 1, 2 и/или 9.
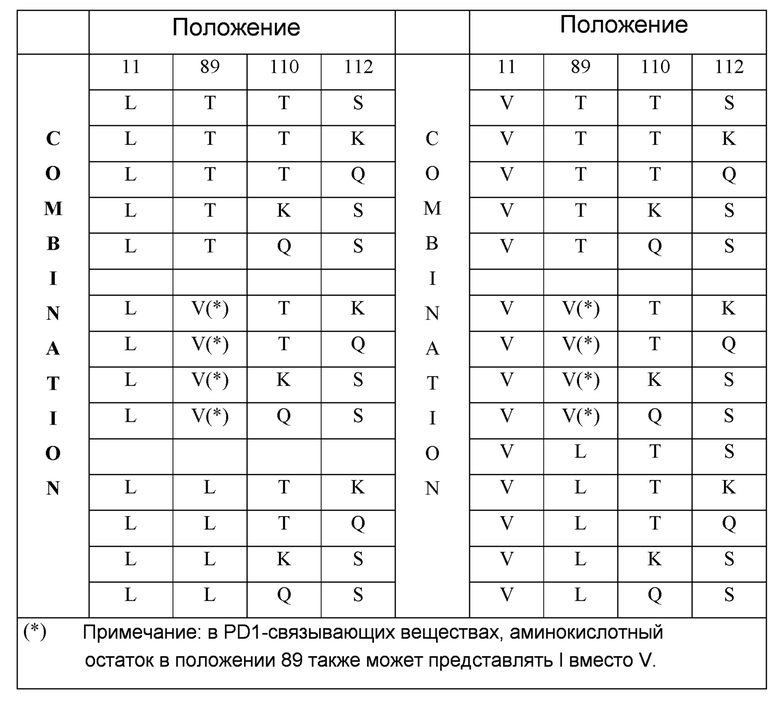
В варианте осуществления изобретения, связывающий фрагмент, который связывается с PD1 и/или CTLA4, содержит 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10 или более дополнительных мутаций, например, где каждая независимо выбрана из замен, вставок и делеций.
С-концевое удлинение, присутствующее в связывающих веществах PD1/CTLA4 по изобретению (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4), может быть таким, как описано в WO 2012/175741 и PCT/EP2015/60643 (WO-015/173325), и предпочтительно имеет формулу (X)n, в которой n равно от 1 до 10, предпочтительно от 1 до 5, таких как 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток из природных аминокислотных остатков (хотя в соответствии с одним предпочтительным аспектом, он не содержит какие-либо цистеиновые остатки), и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I).
В соответствии с некоторыми предпочтительными, но неограничивающими примерами таких C-концевых удлинений X(n), X и n могут быть следующими:
(a) n=1 и X=Ala;
(b) n=2 и каждый X=Ala;
(c) n=3 и каждый X=Ala;
(d) n=2 и, по крайней мере, один X=Ala (с остальным аминокислотным остатком(остатками) X, который независимо выбран из любой природной аминокислоты, но предпочтительно независимо выбран из Val, Leu и/или Ile);
(e) n=3 и, по крайней мере, один X=Ala (с остальным аминокислотным остатком(остатками) X, который независимо выбран из любой природной аминокислоты, но предпочтительно независимо выбран из Val, Leu и/или Ile);
(f) n=3 и, по крайней мере, два X=Ala (с остальным аминокислотным остатком(остатками) X, который независимо выбран из любой природной аминокислоты, но предпочтительно независимо выбран из Val, Leu и/или Ile);
(g) n=1 и X=Gly;
(h) n=2 и каждый X=Gly;
(i) n=3 и каждый X=Gly;
(j) n=2 и, по крайней мере, один X=Gly (с остальным аминокислотным остатком(остатками) X, который независимо выбран из любой природной аминокислоты, но предпочтительно независимо выбран из Val, Leu и/или Ile);
(k) n=3 и, по крайней мере, один X=Gly (с остальным аминокислотным остатком(остатками) X, который независимо выбран из любой природной аминокислоты, но предпочтительно независимо выбран из Val, Leu и/или Ile);
(l) n=3 и, по крайней мере, два X=Gly (с остальным аминокислотным остатком(остатками) X, который независимо выбран из любой природной аминокислоты, но предпочтительно независимо выбран из Val, Leu и/или Ile);
(m) n=2 и каждый X=Ala или Gly;
(n) n=3 и каждый X=Ala или Gly;
(o) n=3 и, по крайней мере, один X=Ala или Gly (с остальным аминокислотным остатком(остатками) X, который независимо выбран из любой природной аминокислоты, но предпочтительно независимо выбран из Val, Leu и/или Ile); или
(p) n=3 и, по крайней мере, два X=Ala или Gly (с остальным аминокислотным остатком(остатками) X, который независимо выбран из любой природной аминокислоты, но предпочтительно независимо выбран из Val, Leu и/или Ile);
причем аспекты (a), (b), (c), (g), (h), (i), (m) и (n), являются особенно предпочтительными, и аспекты, в которых n=1 или 2, являются предпочтительными, а аспекты, в которых n=1, являются особенно предпочтительными.
Следует также отметить, что, предпочтительно, любое С-концевое удлинение, присутствующее в PD1/CTLA4-связывающих веществах по изобретению (например, включающее ISVD (например, нанотела), которые связываются с PD1 и CTLA4), не содержит (свободный) цистеиновый остаток (если указанный цистеиновый остаток не используется или не предназначен для дальнейшей функционализации, например, для пегилирования).
Некоторые конкретные, но не ограничивающие примеры используемых С-концевых удлинений представляют собой следующие аминокислотные последовательности: A, AA, AAA, G, GG, GGG, AG, GA, AAG, AGG, AGA, GGA, GAA или GAG.
PD1/CTLA4-связывающие вещества по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), также, в одном из вариантов осуществления изобретения, содержат остаток аспарагиновой кислоты (D) в положении 1 (то есть первый аминокислотный остаток в N-концевой области полипептида предпочтительно представляет собой D).
В одном из вариантов осуществления изобретения, экстендер периода полувыведения представляет собой ISVD (например, нанотело), который связывается с сывороточным белком, таким как сывороточный альбумин, например, человеческий сывороточный альбумин (HSA). В частности, такой ISVD, связывающийся с сывороточным альбумином, или нанотело, может быть (одно-) доменным антителом или dAb против человеческого сывороточного альбумина, как описано, например, в ЕР 2139918, WO 2011/006915, WO 2012/175400, WO 2014/111550, и может, в частности, быть нанотелом, связывающимся с сывороточным альбумином, как описано в WO 2004/041865, WO 2006/122787, WO 2012/175400 или PCT/EP2015/060643 (WO-015/173325). Предпочтительные ISVD, связывающиеся с сывороточным альбумином, представляют собой нанотело Alb-1 (см. WO 2006/122787) или его гуманизированные варианты, такие как Alb-8 (WO 2006/122787, SEQ ID NO: 62), Alb-23 (WO 2012/175400, SEQ ID NO: 1) и другие гуманизированные (и предпочтительно также оптимизированные по последовательности) варианты Alb-1 и/или варианты Alb-8 или Alb-23 (или, в более широком смысле, ISVD, которые имеют по существу аналогичные CDR, что и Alb-1, Alb-8 и Alb-23). Аминокислотные последовательности некоторых предпочтительных, но не ограничивающих связывающих веществ сывороточных альбуминов, которые могут присутствовать в PD1/CTLA4-связывающих веществах по изобретению, приведены на фигуре 5 в виде SEQ ID NO: 84 и 85. В одном из вариантов осуществления изобретения, HSA-связывающим ISVD является ALB11002.
Такой ISVD, связывающийся с сывороточным альбумином, в случае, когда он присутствует, может содержать в своей последовательности одну или более мутаций в каркасе, которые ослабляют связывание естественными антителами. В частности, в случае, когда такой ISVD, связывающийся с сывороточным альбумином, представляет собой нанотело или (одно-) доменное антитело, которое, по существу, состоит из и/или является производным домена VH, связывающийся с сывороточным альбумином ISVD, может содержать (подходящую комбинацию) аминокислотных остатков/мутаций в положениях 11, 89, 110 и/или 112, которые являются такими, как описано в PCT/EP2015/060643 (WO2015/173325) и/или которые по существу являются такими, как описано в настоящем документе для CTLA4 и PD1-связывающих фрагментов, присутствующих в PD1/CTLA4-связывающих веществах по изобретению (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4). Например, в PCT/EP2015/060643 (WO-015/173325) описан ряд вариантов Alb-1, Alb-8 и Alb-23, которые содержат аминокислотные остатки/мутации в положениях 11, 89, 110 и/или 112, которые ослабляют связывание естественными антителами, которые могут быть использованы в соединениях по изобретению.
Когда такой связывающий сывороточный альбумин ISVD присутствует в C-концевой области PD1/CTLA4-связывающего вещества по настоящему изобретению (например, включающего ISVD (например, нанотела), который связываются с PD1 и CTLA4), связывающийся с сывороточным альбумином ISVD (и как результат, соединение по изобретению), в одном из вариантов осуществления изобретения имеет C-концевое удлинение X(n), причем C-концевое удлинение может быть таким, как описано в настоящем документе для PD1 или CTLA4-связывающих фрагментов, присутствующих в PD1/CTLA4-связывающих веществах в соответствии с изобретением, и/или как описано в WO 2012/175741 или PCT/EP2015/060643 (WO2015/173325). Кроме того, в одном из вариантов осуществления изобретения, присутствуют мутации, которые ослабляют связывание естественных антител, например, (подходящая комбинация) аминокислотных остатков/мутаций в положениях 11, 89, 110 и/или 112, описанных в PCT/EP2015/060643 (WO2015/173325).
Хотя присутствие/использование ISVD, связывающегося с сывороточным альбумином, является предпочтительным способом обеспечения PD1/CTLA4-связывающих веществ по изобретению (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4) с увеличенным периода полувыведения, другие средства увеличения периода полувыведения связывающего вещества PD1/CTLA4 по изобретению, например, использование других связывающих доменов, связывающихся с сывороточным альбумином, использование связывания ISVD с другими сывороточными белками, такими как трансферрин или IgG, пегилирование, слияние с человеким альбумином (например, HSA) или его соответствующим фрагментом, или использование подходящего пептида, связывающего сывороточный альбумин, также включены в объем настоящего изобретения.
Соответственно, в дополнительном аспекте изобретение относится к PD1/CTLA4-связывающим веществам (например, содержащим ISVD (например, нанотела), которые связываются с PD1 и CTLA4), которые содержат, по крайней мере, один (например, один или два) PD1-связывающих фрагмента, описанных в настоящем документе, и, по крайней мере, один (например, один или два) CTLA4-связывающих фрагмента, описанных в настоящем документе, и, необязательно, один или более (например, один или два) экстендеров периода полувыведения, например один или два ISVD, которые связываются с сывороточным белком, таким как сывороточный альбумин, например, HSA (например, ALB11002), где указанный PD1/CTLA4-связывающее вещество имеет период полувыведения (как определено в настоящем документе) у субъекта-человека, по крайней мере, 1 день, предпочтительно, по крайней мере, 3 дня, более предпочтительно, по крайней мере, 7 дней, например, по крайней мере, 10 дней.
Как указано выше, PD1/CTLA4-связывающие вещества по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), предпочтительно также имеют увеличенный период полувыведения (как определено в настоящем документе), под которым обычно подразумевается, что полипептид имеет период полувыведения (как определено в настоящем документе), который, по меньшей мере, в 2 раза, предпочтительно, по крайней мере, 5 раз, например, по крайней мере, в 10 раз или более чем в 20 раз, больше, чем период полувыведения моновалентного PD1-связывающего вещества, который присутствует в полипептиде по изобретению, а также период полувыведения (как определено в настоящем документе), который, по крайней мере, в 2 раза, предпочтительно, по крайней мере, 5 раз, например, по крайней мере, в 10 раз или больше, чем 20 раз, больше, чем период полувыведения моновалентного CTLA4-связывающего фрагмента, который присутствует в PD1/CTLA4-связывающих веществах по изобретению (что определено либо на человеке и/или на подходящей модели животных, таких как мышь или яванский макак).
В одном из вариантов осуществления изобретения, экстендер периода полувыведения представляет собой ISVD (например, нанотело), который связывается с человеческим сывороточным альбумином, например, ALB11002 представлен в таблице D ниже или на фигуре 5.
Таблица D. Человеческий сывороточный альбумин (HSA) связывающее вещество ALB11002
ID
NO
SDTLYADSVKGRFTISRDNAKTTLYLQMNSLRPEDTAV
YYCTIGGSLSRSSQGTLVTVSS
GSGSDTLYADSVKGRFTISRDNSKNTLYLQMNSLRPEDTALYYCTIGGSLS
RSSQGTLVTVSS
* CDR подчеркнуты и/или выделены жирным шрифтом. Необязательно, ALB11002 не содержит C-концевой аланин. Необязательно, HSA-связывающее вещество содержит аминокислотную последовательность, представленную в SEQ ID NO: 144, но которая содержит 11L и/или 93V, например, EVQLVESGGGVVQPGNSLRLSCAASGFTFSSFGMSWVRQAPGKGLEWVSSISGSGSDTLYADSVKGRFTISRDNAKTTLYLQMNSLRPEDTALYYCTIGGSLSRSSQGTLVTVSS (SEQ ID NO: 144)
В одном из вариантов осуществления изобретения, экстендер периода полувыведения представляет собой HSA ISVD (например, нанотело), содержащий:
- CDR1, который содержит аминокислотную последовательность GFTFSSFGMS (SEQ ID NO: 199) или SFGMS (аминокислоты 6-10 в SEQ ID NO: 199); и
- CDR2, который содержит аминокислотную последовательность SISGSGSDTL (SEQ ID NO: 200) или SISGSGSDTL (аминокислоты 1-10 в SEQ ID NO: 200); и
- CDR3, который содержит аминокислотную последовательность GGSLSR (SEQ ID NO: 201);
и, необязательно, имеющий:
- степень идентичности последовательностей с аминокислотной последовательностью SEQ ID NO: 84, 85 или 144 (в которой любое C-концевое удлинение, которое может присутствовать, а также CDR не учитываются при определении степени идентичности последовательностей), составляющую, по крайней мере, 85%, предпочтительно, по крайней мере, 90%, более предпочтительно, по крайней мере, 95%;
и/или
- не больше, чем 7, например, не больше, чем 5, предпочтительно не больше, чем 3, например, только 3, 2 или 1, ʺаминокислотных различийʺ с аминокислотной последовательностью SEQ ID NO: 84, 85 или 144 (в которых указанные аминокислотные различия, если они присутствуют, могут присутствовать в каркасах и/или CDR, но предпочтительно присутствуют только в каркасах, а не в CDR);
и необязательно имеющий:
- C-концевое удлинение (X)n, где n равно от 1 до 10, предпочтительно от 1 до 5, например 1, 2, 3, 4 или 5(и предпочтительно 1 или 2, например 1); и каждый Х представляет собой независимо выбранный (предпочтительно природный) аминокислотный остаток, и предпочтительно независимо выбранное из группы, состоящей изаланина (А), глицина (G), валина (V), лейцина (L) или изолейцина (I).
В PD1/CTLA4-связывающих веществах по изобретению (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4), PD1-связывающие фрагменты, CTLA4-связывающие фрагменты (и связывающийся с сывороточным альбумином ISV, если присутствует) могут быть непосредственно связаны друг с другом или через один или более соответствующих линкеров. Некоторые предпочтительные, но неограничивающие линкеры представляют собой линкер 9GS, 15GS или 35GS (любая комбинация 9, 15 или 35 G и S аминокислот, таких как, например, GGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGS) (SEQ ID NO: 86). В одном из вариантов осуществления изобретения, линкер представляет собой (GGGGS)n (SEQ ID NO: 180), где n равно 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10.
Настоящее изобретение включает PD1/CTLA4-связывающие вещества по изобретению (например, содержащие ISVD (например, нанотела), которые связаны с PD1 и CTLA4), которые могут, помимо одного или более PD1-связывающих фрагментов, одного или более CTLA4-связывающих фрагментов и необязательного, связывающегося с сывороточным альбумином ISVD, (если присутствует), содержать один или более других аминокислотных последовательностей, химических структурных единиц или фрагментов. Эти другие аминокислотные последовательности, химические структурные единицы или фрагменты могут придать одно или более желаемых свойств (получаемым в результате) PD1/CTLA4-связывающим веществам по изобретению и/или могут изменять свойства (получаемых в результате) PD1/CTLA4-связывающих веществ по изображению желаемым образом, например, для получения (готовых) PD1/CTLA4-связывающих веществ по изобретению с желаемой биологической и/или терапевтической активностью (например, для получения готового соединения по изобретению с аффинностью и активностью в отношении терапевтически релевантной мишени, другой чем PD1 и CTLA4, с тем, чтобы полученное в результате соединение стало ʺтриспецифичнымʺ в отношении PD1, CTLA4 и такой другой терапевтически релевантной мишени, для модификации или улучшения фармакокинетических и/или фармакодинамических свойств, для нацеливания PD1/CTLA4-связывающего вещества по изобретению на специфические клетки, ткани или органы (включая клетки злокачественной опухоли и ткани злокачественной опухоли), чтобы обеспечить цитотоксический эффект и/или служить в качестве обнаруживаемой метки или маркера. Некоторые неограничивающие примеры таких других аминокислотных последовательностей, химических структурных единиц или фрагментов представляют собой:
- один или более связывающих доменов или связывающих единиц, которые направлены против терапевтически релевантной мишени, другой чем PD1 и CTLA4 (то есть, чтобы получить PD1/CTLA4-связывающее вещество по изобретению, которое является триспецифичным в отношении PD1, CTLA4 и другой терапевтически релевантной мишени, например, CD27, LAG3, BTLA, TIM3, ICOS, B7-H3, B7-H4, CD137, GITR, PD-L1, PD-L2, ILT1, ILT2 CEACAM1, CEACAM5, TIM3, TIGIT, VISTA, ILT3, ILT4, ILT5, ILT6, ILT7, ILT8, CD40, OX40, CD137, KIR2DL1, KIR2DL2, KIR2DL3, KIR2DL4, KIR2DL5A, KIR2DL5B, KIR3DL1, KIR3DL2, KIR3DL3, NKG2A, NKG2C, NKG2E, IL-10, IL-17 или TSLP); и/или
- один или более связывающих доменов или связывающих единиц, которые нацеливают PD1/CTLA4-связывающие вещества по изобретению на желаемую клетку, ткань или орган (такие как клетка); и/или
- один или более связывающих доменов или связывающих единиц, которые обеспечивают повышенную специфичность в отношении PD1 (обычно они могут связываться с PD1, но, как правило, сами по себе по существу не могут быть функциональными против PD1); и/или
- один или более связывающих доменов или связывающих веществ единиц, которые обеспечивают повышенную специфичность против CTLA4 (обычно они могут связываться с CTLA4, но, как правило, сами по себе по существу не могут быть функциональными против CTLA4); и/или
- связывающий домен, связывающая единица или другая химическая структурная единица, которая позволяет PDI/CTLA4-связывающим веществам по изобретению интернализироваться в (желаемую) клетку (например, интернализирующее анти-EGFR нанотело, описанное в WO 2005/044858); и/или
- нагрузку, такая как цитотоксическая нагрузка; и/или
- детектируемый маркер или метка, например, радиоактивный или флуоресцентный маркер; и/или
- метку, которая может содействовать иммобилизации, детекции и/или очистке PD1/CTLA4-связывающего вещества по изобретению, например, гистидиновая метка или FLAG3-маркер; и/или
- метку, которая может быть функционализирована, такая как С-концевая GGC или GGGC метка.
Объем изобретения включает связывающие вещества PD1/CTLA4 по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), которые также могут содержать одну или более частей или фрагментов стандартного антитела (предпочтительно человека) (например, его Fc-часть или функциональный фрагмент или один или более константных доменов) и/или антитела семейства верблюдовых только с тяжелыми цепями (например, один или более константных доменов).
В случае, когда PD1/CTLA4-связывающие вещества по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), содержат один или более дополнительных связывающих доменов или связывающих единиц (например, описанных в предыдущих абзацах), эти другие связывающие домены или связывающие единицы предпочтительно содержат один или более ISVD, и более предпочтительно все ISVD. Например и без ограничений, указанные один или более дополнительных связывающих доменов или связывающих веществ единиц могут представлять собой одно или более нанотел (включая VHH, гуманизированные VHH и/или VH верблюжьего типа, такие как VH человека верблюжьего типа), (однодоменное) антитело представляет собой домен VH или которое является производным домена VH, dAb, который является или по существу состоит из домена VH или который является производным домена VH или даже (одно-) доменного антитела, или dAb, который является или по существу состоит из домена VL. В частности, указанные один или более связывающих доменов или связывающих единиц, в случае, когда присутствуют, могут содержать одно или более нанотел, и более конкретно все нанотела.
В случае, когда PD1/CTLA4-связывающее вещество по изобретению имеет ISVD в своей C-концевой области (C-концевой связывающий фрагмент (например, ISVD, такой как нанотело) может представлять собой PD1-связывающий фрагмент, CTLA4-связывающий фрагмент, фрагмент человека, связывающийся с сывороточным альбумином (например, ISVD, такой как нанотело, например, ABL1002) или другой ISVD, как указано в предыдущих параграфах), тогда PD1/CTLA4-связывающее вещество по изобретению (то есть указанный C-концевой ISVD) предпочтительно имеет C-концевое удлинение X(n), как описано в настоящем документе.
В случае, когда PD1/CTLA4-связывающие вещества по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), содержат, в дополнение к одному или более PD1-связывающим фрагментам, один или более CTLA4-связывающих фрагментов и связывающий фрагмент, связывающийся с сывороточным альбумином, (например, ISVD, такой как нанотело) (если присутствует) любой дополнительный связывающий фрагмент (например, ISVD) (как указано в предыдущих параграфах), и где такие дополнительные ISVD являются нанотелами или являются ISVD, которые, по существу, состоят из и/или являются производными VH последовательностей, тогда согласно предпочтительному аспекту изобретения указанный один или более (предпочтительно все) такие ISVD, присутствующие в PD1/CTLA4-связывающем веществе по изобретению, будут содержать в своей последовательности одну или более мутаций в каркасе, которые ослаблюят связывание естественными антителами. В частности, в соответствии с этим аспектом изобретения, такие дополнительные ISVD могут содержать (подходящую комбинацию) аминокислотные остатки/мутации в положениях 11, 89, 110 и/или 112, которые являются такими, как описано в PCT/EP2015/060643 (WO 02015/173325) и/или которые по существу являются такими, как описано в настоящем документе для PD1-связывающих фрагментов и CTLA4-связывающих фрагментов. В одном конкретном аспекте, в случае, когда полипептид по изобретению имеет ISVD в своей C-концой области (причем C-концевой ISVD может представлять собой PD1-связывающее вещество, CTLA4-связывающие фрагменты, фрагмент, связывающийся с сывороточным альбумином (например, ISVD) или другим ISVD, как указано в предыдущих параграфах), тогда, по крайней мере, указанный ISVD, который присутствует в и/или образует C-конец, имеет такие мутации в каркасе, которые ослабляют связывание естественными антителами (и указанный C-концевой ISVD будет предпочтительно также иметь C-концевое удлинение X(n), как описано в настоящем документе).
В другом аспекте, изобретение относится к PD1/CTLA4-связывающему веществу (например, содержащему ISVD (например, нанотела), которые связываются с PD1 и CTLA4), которое содержит, по крайней мере, один PD1-связывающий фрагмент (например, ISVD), по крайней мере, один CTLA4-связывающий фрагмент (например, ISVD) (где PD1/CTLA4-связывающее вещество подробно описано в настоящем документе), в котором PD1-связывающий фрагмент (например, ISVD) выбран из SEQ ID NO: 16-47 и 135-142 и в котором CTLA4-связывающий фрагмент (например, ISVD) выбран из SEQ ID NO: 50-83, 143 и 196.
В другом аспекте, настоящее изобретение относится к PD1/CTLA4-связывающему веществу (например, содержащему ISVD (например, нанотела), которые связываются с PD1 и CTLA4), которое содержит, по крайней мере, один PD1-связывающий фрагмент (например, ISVD) и, по крайней мере, один CTLA4-связывающий фрагмент (например, ISVD) (причем PD1/CTLA4-связывающее вещество подробно описано в настоящем документе), в котором PD1-связывающий фрагмент (например, ISVD) выбран из SEQ ID NO: 30, 31, 46, 47 и 135 и в котором CTLA4-связывающий фрагмент (например, ISVD) выбран из SEQ ID NO: 62-65 и/или 80-83 и/или 143.
Кроме того, все эти PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) предпочтительно содержат C-концевое удлинение X(n) (как описано в настоящем документе) и D в положении 1 и, как подробно описано в настоящем документе, могут содержать фрагмент, связывающийся с сывороточным альбумином (например, ISVD).
Из настоящего описания будет ясно, что PD1/CTLA4-связывающие вещества по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) содержат, по меньшей мере, два связывающих фрагмента (например, ISVD, такие как нанотела) (то есть, по меньшей мере, двухвалентные) и, по меньшей мере, нацелены на PD1 и CTLA4 (то есть являются, по меньшей мере, биспецифичными). PD1/CTLA4-связывающие вещества могут дополнительно иметь различные ʺформатыʺ, то есть быть, по существу, двухвалентными, трехвалентными или поливалентными, могут быть биспецифичными, триспецифичными или мультиспецифичными и могут быть бипаратопными (как определено в настоящем документе и, например, в WO 2009/068625) в отношении PD1 и/или CTLA4. Например и без ограничений, PD1/CTLA4-связывающие вещества по изобретению могут:
- по существу состоять из одного PD1-связывающего фрагмента (как описано в настоящем документе) и одного CTLA связывающего фрагмента (как описано в настоящем документе);
- по существу состоять из двух PD1-связывающих фрагментов (как описано в настоящем документе) и одного CTLA связывающего фрагмента (как описано в настоящем документе);
- по существу состоять из одного PD1-связывающего фрагмента (как описано в настоящем документе) и двух CTLA связывающих фрагментов (как описано в настоящем документе);
- по существу состоять из двух PD1-связывающих фрагментов (как описано в настоящем документе) и двух CTLA связывающих фрагментов (как описано в настоящем документе);
- по существу состоять из одного PD1-связывающего фрагмента (как описано в настоящем документе), одного CTLA связывающего фрагмента (как описано в настоящем документе) одного связывающего фрагмента (например, ISVD) против человеческого сывороточного альбумина (как описано в настоящем документе);
- по существу состоять из двух PD1-связывающих фрагментов (как описано в настоящем документе), одного CTLA связывающего фрагмента (как описано в настоящем документе) и одного ISVD связывающего фрагмента (например, ISVD) против человеческого сывороточного альбумина (как описано в настоящем документе);
- по существу состоять из одного PD1-связывающего фрагмента (как описано в настоящем документе), двух CTLA связывающих фрагментов (как описано в настоящем документе) одного связывающего фрагмента (например, ISVD) против человеческого сывороточного альбумина (как описано в настоящем документе);
- по существу состоять из двух PD1-связывающих фрагментов (как описано в настоящем документе), двух CTLA связывающих фрагментов (как описано в настоящем документе) одного связывающего фрагмента (например, ISVD) против человеческого сывороточного альбумина (как описано в настоящем документе);
- по существу состоять из одного PD1-связывающего фрагмента (как описано в настоящем документе), одного CTLA связывающего фрагмента (как описано в настоящем документе) и одного дополнительного связывающего фрагмента (например, ISVD) против PD1 (который может быть или может не быть функциональным в отношении PD1);
- по существу состоять из одного PD1-связывающего фрагмента (как описано в настоящем документе), одного CTLA связывающего фрагмента (как описано в настоящем документе) и одногодополнительного связывающего фрагмента (например, ISVD) против CTLA4 (который может быть или может не быть функциональным в отношении CTLA4);
- по существу состоять из одного PD1-связывающего фрагмента (как описано в настоящем документе), одного CTLA связывающего фрагмента (как описано в настоящем документе), одного дополнительного связывающего фрагмента (например, ISVD) против PD1 (который может быть или может не быть функциональным в отношении PD1) одного связывающего фрагмента (например, ISVD) против человеческого сывороточного альбумина (как описано в настоящем документе); или
- по существу состоять из одного PD1-связывающего фрагмента (как описано в настоящем документе), одного CTLA связывающего фрагмента (как описано в настоящем документе), одного дополнительного связывающего фрагмента (например, ISVD) против CTLA4 (который может быть или может не быть функциональным в отношении CTLA4), одного связывающего фрагмента (например, ISVD) против человеческого сывороточного альбумина (как описано в настоящем документе)
Другие подходящие форматы для PD1/CTLA4-связывающего вещества по изобретению (например, содержащие ISVD (например, нанотела), которые связаны с PD1 и CTLA4) будут ясны специалисту в данной области с помощью настоящего описания.
Как будет ясно квалифицированному специалисту, в случае, когда PD1/CTLA4-связывающее вещество по изобретению (например, содержащее ISVD (например, нанотела), которые связаны с PD1 и CTLA4) предназначено для местного применения (то есть к коже или глазам) или, например, имеет (локализованное) терапевтическое действие где-либо в желудочно-кишечном тракте (то есть после перорального введения или введения посредством суппозиториев) или в легких (то есть после введения путем ингаляции), или иным образом предназначено для непосредственного применения к предполагаемому месту его действия (например, путем прямой инъекции), PD1/CTLA4-связывающее вещество по изобретению обычно не требует увеличения периода полувыведения. В этих случаях предпочтительным может быть использование бивалентного биспецифичного PD1/CTLA4-связывающего вещества по изобретению или другого PD1/CTLA4-связывающего вещества по изобретению без увеличения периода полувыведения.
Некоторые предпочтительные, но неограничивающие примеры полипептидов по изобретению без увеличения периода полувыведения схематически представлены в таблице C-1 ниже, и каждая из этих форм является еще одним аспектом по изобретению. Другие примеры подходящих полипептидов по изобретению без увеличения периода полувыведения будут ясны для квалифицированного специалиста с помощью настоящего описания. Кроме того, эти полипептиды предпочтительно имеют D в положении 1.
Таблица C-1. Схематическое изображение CTLA4/PD1-связывающих веществ по изобретению без ISVD, увеличивающего период полувыведения.
- ʺ[PD1-связывающий фрагмент]ʺ=PD1-связывающий домен или единица (например, ISVD, такой как нанотело), например, как указано в настоящем документе, например, любой в SEQ ID NO: 16-47 или 135-142.
- ʺ[CTLA4-связывающий фрагмент]ʺ=CTLA4-связывающий домен или единица (например, ISVD, такой как нанотело), например, как указано в настоящем документе, например, любой в SEQ ID NO: 48-83 или 143 или 196
- ʺ[другой PD1-связывающий фрагмент]ʺ=(функциональная или нефункциональная) связывающая единица или домен (например, ISVD, такой как нанотело) против PD1, например, другой, чем PD1-связывающий фрагмент, как описано в настоящем документе
- ʺ[другой CTLA4-связывающий фрагмент]ʺ=(функциональная или нефункциональная) связывающая единица или домен (например, ISVD, такой как нанотело) против CTLA4, например, другой, чем CTLA4-связывающий фрагмент, как описано в настоящем документе
- ʺ[нацеливающий домен]ʺ=связывающий домен или единица (например, ISVD, такой как нанотело), который нацеливает PD1/CTLA4-связывающее вещество по изобретению на конкретную клетку, ткань или орган
- ʺ-ʺ=соответствующий линкер (такой как 9GS, 15GS или 35GS)
Как будет ясно квалифицированному специалисту в данной области, в случае, когда PD1/CTLA4-связывающее вещество по изобретению (например, содержащее ISVD (например, нанотела), которые связаны с PD1 и CTLA4) предназначено для системного введения и/или для профилактики и/или лечения хронического заболевания или расстройства, обычно будет предпочтительно, чтобы указанное PD1/CTLA4-связывающее вещество по изобретению имело увеличенный период полувыведения (как определено в настоящем документе), то есть по сравнению с CTLA4 и PD1-связывающими фрагментами, присутствующими в таком PD1/CTLA4-связывающем веществе по изобретению. Более предпочтительно, такое PD1/CTLA4-связывающее вещество по изобретению будет содержать связывающий фрагмент, увеличивающий период полувыведения, такой как, предпочтительно, ISVD и, в частности, нанотело, связывающееся с человеческим сывороточным альбумином (как описано в настоящем документе).
Некоторые предпочтительные, но неограничивающие примеры таких PD1/CTLA4-связывающих веществ по изобретению (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4) схематически представлены в таблице C-2 ниже, и каждая из них образует дополнительный аспект по изобретению. Другие примеры подходящих PD1/CTLA4-связывающих веществ по изобретению с увеличением периода полувыведения будут понятны специалисту с помощью настоящего описания. В общем случае, для PD1/CTLA4-связывающего вещества по изобретению с увеличенным периодом полувыведения, присутствие C-концевого удлинения является весьма предпочтительным. Кроме того, эти полипептиды предпочтительно имеют D в положении 1.
Таблица C-2. Схематическое изображение некоторых CTLA4/PD1-связывающих веществ по изобретению с фрагментом, увеличивающим период полувыведения.
- ʺ[PD1-связывающий фрагмент]ʺ=PD1-связывающий домен или единица (например, ISVD, такой как нанотело), например, как указано в настоящем документе, например, любой в SEQ ID NO: 16-47 или 135-142.
- ʺ[CTLA4-связывающий фрагмент]ʺ=CTLA4-связывающий домен или единица (например, ISVD, такой как нанотело), например, как указано в настоящем документе, например, любой в SEQ ID NO: 48-83 или 143 или 196
- ʺ[HLE]ʺ=фрагмент, связывающийся с сывороточным альбумином например, ISVD, такой как нанотело
- ʺ[другой ISVD против PD1]ʺ=(функциональная или нефункциональная) связывающая единица или домен (например, ISVD, такой как нанотело) против PD1, например, другой, чем PD1-связывающий фрагмент
- ʺ[другой ISVD против CTLA4]ʺ=(функциональная или нефункциональная) связывающая единица или домен (например, ISVD, такой как нанотело) против CTLA4, например, другой, чем CTLA4-связывающий фрагмент
- ʺ[нацеливающий домен]ʺ=домен (например, ISVD, такой как нанотело), который нацеливает PD1/CTLA4-связывающее вещество по изобретению на специфическую клетку, ткань или орган
- ʺ-ʺ=соответствующий линкер (например, 9GS, 15GS или 35GS)
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающее вещество содержит структуру:
[PD1-связывающий фрагмент]-[PD1-связывающий фрагмент]-[CTLA4-связывающий фрагмент]-[CTLA4-связывающий фрагмент]-[связывающийся с альбумином фрагмент];
[CTLA4-связывающий фрагмент]-[CTLA4-связывающий фрагмент]-[PD1-связывающий фрагмент]-[PD1-связывающий фрагмент]-[связывающийся с альбумином фрагмент];
[PD1-связывающий фрагмент]-[CTLA4-связывающий фрагмент]-[связывающийся с альбумином фрагмент];
[CTLA4-связывающий фрагмент]-[PD1-связывающий фрагмент]-[связывающийся с альбумином фрагмент];
[PD1-связывающий фрагмент]-[CTLA4-связывающий фрагмент]-[CTLA4-связывающий фрагмент]-[связывающийся с альбумином фрагмент];
[CTLA4-связывающий фрагмент]-[CTLA4-связывающий фрагмент]-[PD1-связывающий фрагмент]-[связывающийся с альбумином фрагмент];
[PD1-связывающий фрагмент]-[PD1-связывающий фрагмент]-[CTLA4-связывающий фрагмент]-[связывающийся с альбумином фрагмент]; или
[CTLA4-связывающий фрагмент]-[PD1-связывающий фрагмент]-[PD1-связывающий фрагмент]-[связывающийся с альбумином фрагмент];
каждая необязательно включающая C-концевой аланин.
Некоторые предпочтительные, но не ограничивающие примеры PD1/CTLA4-связывающих веществ по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) приведены на фигуре 6 или SEQ ID NO: 103-134, 146, 149, 151 или 153.
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающее вещество по настоящему изобретению представляет собой F023700910, F023700918, F023700920 или F023700925, представленные ниже.
F023700910 может кодироваться полинуклеотидом, содержащим нуклеотидную последовательность:


(SEQ ID NO:145)
F023700910 содержит аминокислотную последовательность:
DVQLVESGGGVVQPGGSLRLSCAASGSIASIHAMG
WFRQAPGKEREFVAVITWSGGITYYADSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYY
CAGDKHQSSWYDYWGQGTLVTVSSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSE
VQLVESGGGVVQPGGSLRLSCAASGGTFSFYGMGWFRQAPGKEREFVADIRTSAGRTYYA
DSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYYCAAEPSGISGWDYWGQGTLVTVSSGG
GGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSEVQLVESGGGVVQPGNSLRLSCAASGF
TFSSFGMSWVRQAPGKGLEWVSSISGSGSDTLYADSVKGRFTISRDNAKTTLYLQMNSLR
PEDTALYYCTIGGSLSRSSQGTLVTVSSA
(SEQ ID NO: 146); необязательно содержащий сигнальный пептид, такой как MRFPSIFTAVLFAASSALAAPVNTTTEDETAQIPAEAVIGYSDLEGDFDVAVLPFSNSTNNGLLFINTTIASIAAKEEGVSLEKR (SEQ ID NO: 147)
F023700910 содержит следующие фрагменты:
PD1-связывающее вещество 102C12 (E1D,L11V,A14P,A74S,K83R,I89L);
Пептидный линкер;
CTLA4-связывающее вещество 11F01 (L11V,A14P,Q45R,A74S,K83R,V89L,M96P,Q108L);
Пептидный линкер;
Связывающее вещество сывороточного альбумина человека ALB11002;
Аланин C-концевого экстендера.
Например:
PD1-связывающее вещество SEQ ID NO: 135;
35GS линкер SEQ ID NO: 86;
CTLA4-связывающее вещество SEQ ID NO: 143 (необязательно, D1E);
35GS линкер SEQ ID NO: 86;
HSA-связывающее вещество SEQ ID NO: 144;
Аланин
F023700918 может кодироваться полинуклеотидом, содержащим нуклеотидную последовательность:





(SEQ ID NO: 148)
F023700918 содержит аминокислотную последовательность:
DVQLVESGGGVVQPGGSLRLSCAASGSIASIHAMG
WFRQAPGKEREFVAVITWSGGITYYADSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYY
CAGDKHQSSWYDYWGQGTLVTVSSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSE
VQLVESGGGVVQPGGSLRLSCAASGSIASIHAMGWFRQAPGKEREFVAVITWSGGITYYA
DSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYYCAGDKHQSSWYDYWGQGTLVTVSSGG
GGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSEVQLVESGGGVVQPGGSLRLSCAASGG
TFSFYGMGWFRQAPGKEREFVADIRTSAGRTYYADSVKGRFTISRDNSKNTVYLQMNSLR
PEDTALYYCAAEPSGISGWDYWGQGTLVTVSSGGGGSGGGGSGGGGSGGGGSGGGGSGGG
GSGGGGSEVQLVESGGGVVQPGNSLRLSCAASGFTFSSFGMSWVRQAPGKGLEWVSSISG
SGSDTLYADSVKGRFTISRDNAKTTLYLQMNSLRPEDTALYYCTIGGSLSRSSQGTLVTV
SSA
(SEQ ID NO: 149); необязательно содержащий сигнальный пептид, такой как MRFPSIFTAVLFAASSALAAPVNTTTEDETAQIPAEAVIGYSDLEGDFDVAVLPFSNSTNNGLLFINTTIASIAAKEEGVSLEKR (SEQ ID NO: 147)
F023700918 содержит следующие фрагменты:
PD1-связывающее вещество 102C12 (E1D,L11V,A14P,A74S,K83R,I89L);
пептидный линкер;
PD1-связывающее вещество 102C12 (L11V,A14P,A74S,K83R,I89L);
пептидный линкер;
CTLA4-связывающее вещество 11F01 (L11V,A14P,Q45R,A74S,K83R,V89L,M96P,Q108L);
пептидный линкер;
Вещество, связывающееся с сывороточным альбумином человека ALB11002;
C-концевой экстендер аланин.
Например:
PD1-связывающее вещество SEQ ID NO: 135 (необязательно, D1E);
35GS линкер SEQ ID NO: 86;
PD1-связывающее вещество SEQ ID NO: 135 (необязательно, D1E);
35GS линкер SEQ ID NO: 86;
CTLA4-связывающее вещество SEQ ID NO: 143 (необязательно, D1E);
35GS линкер SEQ ID NO: 86;
HSA-связывающее вещество SEQ ID NO: 144;
Аланин
F023700920 может кодироваться полинуклеотидом, содержащим нуклеотидную последовательность:






(SEQ ID NO: 150)
F023700920 содержит аминокислотную последовательность:
DVQLVESGGGVVQPGGSLRLSCAASGSIASIHAMG
WFRQAPGKEREFVAVITWSGGITYYADSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYY
CAGDKHQSSWYDYWGQGTLVTVSSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSE
VQLVESGGGVVQPGGSLRLSCAASGGTFSFYGMGWFRQAPGKEREFVADIRTSAGRTYYA
DSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYYCAAEPSGISGWDYWGQGTLVTVSSGG
GGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSEVQLVESGGGVVQPGGSLRLSCAASGG
TFSFYGMGWFRQAPGKEREFVADIRTSAGRTYYADSVKGRFTISRDNSKNTVYLQMNSLR
PEDTALYYCAAEPSGISGWDYWGQGTLVTVSSGGGGSGGGGSGGGGSGGGGSGGGGSGGG
GSGGGGSEVQLVESGGGVVQPGNSLRLSCAASGFTFSSFGMSWVRQAPGKGLEWVSSISG
SGSDTLYADSVKGRFTISRDNAKTTLYLQMNSLRPEDTALYYCTIGGSLSRSSQGTLVTV
SSA
(SEQ ID NO: 151); необязательно содержащий сигнальный пептид, такой как MRFPSIFTAVLFAASSALAAPVNTTTEDETAQIPAEAVIGYSDLEGDFDVAVLPFSNSTNNGLLFINTTIASIAAKEEGVSLEKR (SEQ ID NO: 147)
F023700920 содержит следующие фрагменты:
PD1-связывающее вещество 102C12 (E1D,L11V,A14P,A74S,K83R,I89L);
пептидный линкер;
CTLA4-связывающее вещество 11F01 (L11V,A14P,Q45R,A74S,K83R,V89L,M96P,Q108L);
пептидный линкер;
CTLA4-связывающее вещество 11F01 (L11V,A14P,Q45R,A74S,K83R,V89L,M96P,Q108L);
пептидный линкер;
Вещество, связывающееся с сывороточным альбумином человека ALB11002;
C-концевой экстендер Аланин
Например:
PD1-связывающее вещество SEQ ID NO: 135;
35GS линкер SEQ ID NO: 86;
CTLA4-связывающее вещество SEQ ID NO: 143 (необязательно, D1E);
35GS линкер SEQ ID NO: 86;
CTLA4-связывающее вещество SEQ ID NO: 143 (необязательно, D1E);
35GS линкер SEQ ID NO: 86;
HSA-связывающее вещество SEQ ID NO: 144;
Аланин
F023700925 может кодироваться полинуклеотидом, содержащим нуклеотидную последовательность:






(SEQ ID NO: 152)
F023700925 содержит аминокислотную последовательность:
DVQLVESGGGVVQPGGSLRLSCAASGSIASIHAMG
WFRQAPGKEREFVAVITWSGGITYYADSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYY
CAGDKHQSSWYDYWGQGTLVTVSSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSE
VQLVESGGGVVQPGGSLRLSCAASGSIASIHAMGWFRQAPGKEREFVAVITWSGGITYYA
DSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYYCAGDKHQSSWYDYWGQGTLVTVSSGG
GGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSEVQLVESGGGVVQPGGSLRLSCAASGG
TFSFYGMGWFRQAPGKEREFVADIRTSAGRTYYADSVKGRFTISRDNSKNTVYLQMNSLR
PEDTALYYCAAEPSGISGWDYWGQGTLVTVSSGGGGSGGGGSGGGGSGGGGSGGGGSGGG
GSGGGGSEVQLVESGGGVVQPGGSLRLSCAASGGTFSFYGMGWFRQAPGKEREFVADIRT
SAGRTYYADSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYYCAAEPSGISGWDYWGQGT
LVTVSSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGSEVQLVESGGGVVQPGNSLR
LSCAASGFTFSSFGMSWVRQAPGKGLEWVSSISGSGSDTLYADSVKGRFTISRDNAKTTL
YLQMNSLRPEDTALYYCTIGGSLSRSSQGTLVTVSSA
(SEQ ID NO: 153); необязательно содержащий сигнальный пептид, такой как MRFPSIFTAVLFAASSALAAPVNTTTEDETAQIPAEAVIGYSDLEGDFDVAVLPFSNSTNNGLLFINTTIASIAAKEEGVSLEKR (SEQ ID NO: 147)
F023700925 содержит следующие фрагменты:
PD1-связывающее вещество 102C12 (E1D, L11V, A14P, A74S, K83R, I89L);
пептидный линкер;
PD1-связывающее вещество 102C12 (L11V, A14P, A74S, K83R, I89L);
пептидный линкер;
CTLA4-связывающее вещество 11F01 (L11V, A14P, Q45R, A74S, K83R, V89L, M96P, Q108L);
пептидный линкер;
CTLA4-связывающее вещество 11F01 (L11V, A14P, Q45R, A74S, K83R, V89L, M96P, Q108L);
пептидный линкер;
Вещество, связывающееся с сывороточным альбумином человека ALB11002;
C-концевой экстендер аланин.
Например:
PD1-связывающее вещество SEQ ID NO: 135;
35GS линкер SEQ ID NO: 86;
PD1-связывающее вещество SEQ ID NO: 135 (необязательно, D1E);
35GS линкер SEQ ID NO: 86;
CTLA4-связывающее вещество SEQ ID NO: 143 (необязательно, D1E);
35GS линкер SEQ ID NO: 86;
CTLA4-связывающее вещество SEQ ID NO: 143 (необязательно, D1E);
35GS линкер SEQ ID NO: 86;
HSA-связывающее вещество SEQ ID NO: 144;
Аланин.
Настоящее изобретение включает любое связывающее вещество, содержащее PD1, CTLA4 и HSA-связывающие фрагменты F023700910, F023700918, F023700920 или F023700925.
Настоящее изобретение включает варианты осуществления, где PD1/CTLA4-связывающие вещества по настоящему изобретению содержат 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10 аминокислотные замены, например, консервативные аминокислотные замены, и/или имеют 80, 85, 90, 91, 92, 93, 94, 95, 96, 97, 98 или 99% идентичность последовательности относительно последовательностей, представленных в SEQ ID NO: 146, 149, 151 или 153, например, где PD1/CTLA4-связывающее вещество, имеющее такие замены и/или идентичность последовательности, сохраняет способность связываться с PD1 и CTLA4. В одном из вариантов осуществления изобретения, первая аминокислота PD1/CTLA4-связывающего вещества по настоящему изобретению соответствует E. В одном из вариантов осуществления изобретения, первая аминокислота PD1/CTLA4-связывающего вещества по настоящему изобретению соответствует D.
Настоящее изобретение также относится к устройству для инъекций, содержащему любые PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), полипептиды или полинуклеотиды, описанные в настоящем документе, или их фармацевтические композиции. Устройство для инъекций представляет собой устройство, которое вводит вещество в организм пациента парентеральным способом, таким как внутримышечный, подкожный или внутривенный способ введения. Например, устройство для инъекций может представлять собой шприц (например, предварительно заполненный фармацевтической композицией, например, автоматический шприц), который, например, включает цилиндр или втулку для удержания текучей инъецируемой среды (например, содержащее PD1/CTLA4-связывающее вещество или его фармацевтическую композицию), иглу для прокалывания кожи и/или кровеносных сосудов для инъекции жидкости; и плунжер для выталкивания жидкости из цилиндра через отверстие иглы. В одном из вариантов осуществления изобретения, устройство для инъекций, которое содержит PD1/CTLA4-связывающее вещество или его фармацевтическую композицию, представляет собой внутривенное (IV) устройство для инъекций. Такое устройство включает PD1/CTLA4-связывающее вещество или его фармацевтическую композицию в канюле или троакаре/игле, которые могут быть присоединены к трубке, которая может быть присоединена к мешку или резервуару для хранения жидкости (например, физиологического раствора или раствора Рингера лактата, содержащего NaCl, лактат натрия, KCl, CaCl2 и необязательно, глюкозу), вводимые в организм субъекта через канюлю или троакар/иглу. В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающее вещество или его фармацевтическая композиция может быть введено в устройство после того, как трокар и канюля введены в вену субъекта, а троакар удален из введенной канюли. Устройство IV может, например, вводиться в периферическую вену (например, в руку или ладонь); верхнюю полую вену или нижнюю полую вену или в правое предсердие сердца (например, центральное IV); или в подключичную, внутреннюю яремную или бедренную вену и, например, продвигается к сердцу, пока не достигнет верхней полой вены или правого предсердия (например, центральный венозный катетер). В одном из вариантов осуществления изобретения, устройство для инъекций представляет собой автоинжектор; безыгольный шприц или внешний инфузионный насос. В безыгольном шприце используется узкая струя жидкости высокого давления, которая проникает в эпидермис, чтобы ввести PD1/CTLA4-связывающее вещество или его фармацевтическую композицию в организм пациента. Внешний инфузионный насос представляет собой медицинские устройства, которые доставляют PD1/CTLA4-связывающее вещество или его фармацевтическую композицию в организм пациента в контролируемых количествах. Внешние инфузионные насосы могут иметь электрический источник питания или могут быть механическими. Различные насосы функционируют различными способами, например, шприцевой насос удерживает жидкость в резервуаре шприца, а подвижный поршень контролирует подачу жидкости, эластомерный насос удерживает жидкость в растяжимом резервуаре баллонного типа, а давление эластичных стенок баллона приводит в движение доставляемую жидкость. В перистальтическом насосе система роликов зажимает гибкую трубку по ее длине, толкая жидкость вперед. В многоканальном насосе, жидкости могут поступать из нескольких резервуаров с разными скоростями.
Связывание с эпитопом и перекресное блокирование
Настоящее изобретение относится к PD1/CTLA4-связывающим веществам по настоящему изобретению (например, F023700910, F023700918, F023700920 или F023700925), а также связывающим веществам, например, ISVD (например, нанотела), и антителам и их антигенсвязывающим доменам, которые связываются с тем же PD1 и/или CTLA4 эпитопом таких связывающих веществ. Например, настоящее изобретение включает связывающие вещества, которые связываются с CTLA4 человека путем контактирования с теми же остатками, что и F023700912 (SEQ ID NO: 193), или которые контактируют с теми же остатками, что и его CTLA4-связывающий фрагмент (11F01 (E1D, L11V, A14P, Q45R, A74S, K83R, V89L, M96P, Q108L)) Например, настоящее изобретение относится к связывающим веществам, которые связываются с CTLA4 человека на остатках VRVTVL (остатки 33-38 в SEQ ID NO: 195), ADSQVTEVC (остатки 41-49 в SEQ ID NO: 195) и/или CKVELMYPPPYYLG (остатки 93-106 в SEQ ID NO: 195), например, все три участка, CTLA4 человека. В одном из вариантов осуществления изобретения, связывающее вещество демонстрирует связывание с CTLA4 человека на этих остатках в исследовании водород-дейтериевого обмена, например, защищает остатки от обмена водорода на дейтерий в присутствии дейтерия, такого как D2O, например, как показано на тепловой карте связывания, по существу, как представлено на фиг.17.
Настоящее изобретение также относится к перекрестно-конкурирующим связывающим веществам, которые способны перекресно-конкурировать за связывание с любым из описанных в настоящем документе связывающих веществ (например, F023700910, F023700918, F023700920 или F023700925). Такие перекресно-конкурирующие связывающие вещества могут представлять собой любую молекулу, которая демонстрирует такое перекресное конкурирование, например, ISVD, антитело, антитело или его антигенсвязывающий фрагмент.
В общем случае, связывающее вещество вещество (например, ISVD, такой как нанотело) или антитело или его антигенсвязывающий фрагмент, который ʺперекрестно блокируетʺ эталонное связывающее вещество или ʺперекресно конкурируетʺ с ʺэталонным связывающим веществомʺ (например, F023700910, F023700918, F023700920 или F023700925)), относится к связывающему веществу (например, ISVD, такой как нанотело) или антителу или его антигенсвязывающему фрагменту, который блокирует связывание эталонного связывающего вещества со своим антигеном в перекрестном конкурентном анализе на 50% или больше, и наоборот, эталонное связывающее вещество блокирует связывание связывающего вещества (например, ISVD, такого как нанотело) или антитела или его антигенсвязывающего фрагмента с его антигеном в перекрестном конкурентном анализе на 50% или больше. Перекрестное блокирование может быть определено с использованием любого анализа, известного в данной области, включая поверхностно-плазмонный резонанс (SPR), ферментный иммуносорбентный анализ (ELISA) и проточную цитометрию.
В одном из вариантов осуществления изобретения, перекресное блокирование определяется применением анализа Biacore. Для удобства ссылка делается на два связывающих вещества, в объем настоящего изобретения включены антитела и их антигенсвязывающие фрагменты, например, фрагменты Fab, которые перекрестно блокируют связывающее вещество по настоящему изобретению. Оборудование Biacore (например Biacore 3000) работает в соответствии с рекомендации изготовителя.
Таким образом, в одном перекрестном конкурентном анализе, PD1 или CTLA4 соединяют с чипом CM5 Biacore, используя стандартные реакции конъюгации аминов для получения поверхности с PD1 или LAG3 покрытием. Например, 200-800 резонансных единиц PD1 или CTLA4 могут связываться с чипом (или любое количество, которое обеспечивает легко измеряемые уровни связывания, но которое является легко насыщаемым концентрациями используемого аналитического реагента).
Два связывающих вещества (называемых A* и B*), оцениваемые по их способности перекрестно блокировать друг друга, смешивают при молярном отношении участков связывания один к одному в подходящем буфере для образования аналитической смеси.
Концентрация каждого связывающего вещества в аналитической смеси должна быть достаточно высокой для быстрого насыщения участков связывания для этого связывающего вещества на молекулах PD1 или CTLA4, захваченных на чипе Biacore. Связывающие вещества в смеси находятся при одной и той же молярной концентрации.
Также подготавливаются отдельные растворы, содержащие только связывающее вещество A* и только связывающее вещество B*. Связывающее вещество A* и связывающее вещество B* в этих растворах должны быть в аналогичном буфере и при аналогичной концентрации, как и в аналитической смеси.
Аналитическую смесь пропускают через чип Biacore с покрытием PD1 или CTLA4 и регистрируют общее количество связываний. Затем чип обрабатывают таким образом, чтобы удалить связанные связывающие вещества, не повреждая связанные с чипом PD1 или CTLA4. В одном из вариантов осуществления изобретения, это выполняется путем обработки чипа 30 мМ HCl в течение 60 секунд.
Затем только раствор связывающего вещества A* пропускают по поверхности с покрытием PD1 или CTLA4 и регистрируют количество связываний. Чип повторно обрабатывают, чтобы полностью удалить связанное связывающее вещество не повреждая PD1 или CTLA4, связанные с чипом.
Потом по поверхности с покрытием PD1 или CTLA4 пропускают только раствор связывающего вещества B* и регистрируют количество связываний.
Затем вычисляют максимальное теоретическое связывание смеси связывающего вещества A* и связывающего вещества B*, и сумму связывания каждого связывающего вещества в случае, когда пропускают только по поверхности PD1 или CTLA4. Если фактическое зарегистрированное связывание смеси меньше этого теоретического максимума, то два связывающих вещества перекресно блокируют друг друга.
Таким образом, обычно, перекресно блокирующее связывающее вещество согласно изобретению представляет собой соединение, которое будет связываться с PD1 или CTLA4 в вышеуказанном перекресном конкурентном анализе Biacore, таким образом, что во время анализа и в присутствии второго связывающего вещества, регистрируемое связывание происходит в диапазоне, например, от 80% до 0,1% (например, от 80% до 4%) от максимального теоретического связывания, например, от 75% до 0,1% (например, от 75% до 4%) от максимального теоретического связывания, например, от 70% до 0,1% (например, от 70% до 4%) максимального теоретического связывания (как определено выше) двух связывающих веществ в комбинации.
В одном из вариантов осуществления изобретения, анализ ELISA используется для определения того, PD1 и/или CTLA4-связывающее вещество перекрестно блокирует или может перекрестно блокировать в соответствии с изобретением.
Общий принцип анализа заключается в том, что PD1 или CTLA4-связывающее вещество наносят на лунки ELISA планшета. В раствор добавляют избыточное количество второго потенциально перекрестно-блокирующего анти-PD1 или CTLA4-связывающего вещества (то есть несвязанного с планшетом ELISA). Затем в лунки добавляют ограниченное количество PD1 или CTLA4. Связывающее вещество с покрытием и связывающее вещество в растворе конкурируют за связывание с ограниченным количеством молекул PD1 или CTLA4. Для удаления PD1 или CTLA4, которые не связаны со связывающим веществом с покрытием, планшет промывают, а также удаляют второе связывающее вещество в фазе раствора, а также любые комплексы, образованные между вторым связывающим веществом в фазе раствора и PD1 или CTLA4. Затем количество связанных PD1 или CTLA4 определяют с использованием соответствующего реагента для обнаружения PD1 или CTLA4. Связывающее вещество в растворе, которое способно перекрестно блокировать связывающее вещество с покрытием, может привести к уменьшению количества молекул PD1 или CTLA4, с которыми связывающее вещество с покрытием может связываться относительно количества молекул PD1 или CTLA4, с которыми связывающее вещество с покрытием может связываться в отсутствии второго связывающего вещества в фазе раствора.
Способы экспрессии
Настоящее изобретение включает рекомбинантные способы получения PD1/CTLA4-связывающих веществ (например, ISVD, такой как нанотело) по настоящему изобретению (например, F023700910, F023700918, F023700920 или F023700925), включающие (i) введение полинуклеотида, кодирующего аминокислотную последовательность указанного PD1/CTLA4-связывающего вещества, например, где полинуклеотид находится в векторе и/или функционально связан с промотором; (ii) культивирование клетки-хозяина (например, CHO или Pichia или Pichia pastoris) в условиях, благоприятных для экспрессии полинуклеотида, и (iii) необязательно выделение PD1/CTLA4-связывающего вещества из клетки-хозяина и/или среды, в которой клетка-хозяин выращивается. См., например, WO 04/041862, WO 2006/122786, WO 2008/020079, WO 2008/142164 или WO 2009/068627.
Изобретение также относится к полинуклеотидам, которые кодируют PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4), описанные в настоящем документе (например, F023700910, F023700918, F023700920 или F023700925). В одном из вариантов осуществления изобретения, полинуклеотиды могут быть функционально связаны с одной или более контрольными последовательностями. Полинуклеотид может быть в форме плазмиды или вектора. Кроме того, такие полинуклеотиды могут быть, обычно, такими, как описано в опубликованных патентных заявках Ablynx N.V, таких как, например, WO 04/041862, WO 2006/122786, WO 2008/020079, WO 2008/142164 или WO 2009/068627.
Изобретение также относится к нуклеотидным последовательностям или нуклеиновым кислотам, которые кодируют PD1/CTLA4-связывающие вещества по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925). Также изобретение включает генетические конструкции, которые включают вышеуказанные нуклеотидные последовательности или нуклеиновые кислоты и один или более элементов для генетических конструкций, известных per se. Генетическая конструкция может быть в виде плазмиды или вектора. Кроме того, такие конструкции могут быть, обычно, такими, как описано в опубликованных патентных заявках Ablynx N.V., таких как, например, WO 2004/041862, WO 2006/122786, WO 2008/020079, WO 2008/142164 или WO 2009/068627.
Изобретение также относится к носителям или клеткам-хозяевам, которые содержат такие нуклеотидные последовательности или нуклеиновые кислоты и/или которые экспрессируют (или способны экспрессировать) PD1/CTLA4-связывающие вещества по изобретению (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925). Кроме того, такие клетки-хозяева могут быть, обычно, такими, как описано в опубликованных патентных заявках, поданных Ablynx N.V, таких как, например, WO 2004/041862, WO 2006/122786, WO 2008/020079, WO 2008/142164 или WO 2009/068627.
PD1/CTLA4-связывающее вещество (например, содержащее ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925), полипептиды, соединения и полинуклеотиды (например, векторы), описанные в настоящем документе, предпочтительно вводят в кровоток. Таким образом, их можно вводить любым подходящим способом, который позволяет PD1/CTLA4-связывающим веществам, полипептидам, соединениям и полинуклеотидам вводиться в кровоток, например внутривенно, путем инъекции или инфузии, или любым другим подходящим способом (включая пероральное введение, подкожное введение, внутримышечное введение, введение через кожу, интраназальное введение, введение через легкие и так далее), что позволяет PD1/CTLA4-связывающим веществам, полипептидам, соединениям и полинуклеотидам проникать в кровоток. Подходящие пути и способы введения будут ясны специалисту в данной области, также, например, после изучения опубликованных патентных заявок Ablynx NV, таких как, например, WO 04/041862, WO 2006/122786, WO 2008/020079, WO 2008/142164 или WO 2009/068627.
Эукариотические и прокариотические клетки-хозяева, включая клетки млекопитающих в качестве хозяев для экспрессии PD1/CTLA4-связывающих веществ (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4 (например, F023700910, F023700918, F023700920 или F023700925)), хорошо известны в данной области и включают многие иммортализованные линии клеток, доступные от Американской коллекции типовых культур (ATCC). К ним относятся, в числе прочих, овариальные клетки китайского хомячка (CHO), NSO, клетки SP2, клетки HeLa, клетки почки новорожденного хомяка (BHK), клетки почек обезьяны (COS), клетки гепатоцеллюлярной карциномы человека (например, Hep G2), клетки A549, клетки 3T3, клетки HEK-293 и ряд других клеточных линий. Клетки-хозяева млекопитающих включают клетки человека, мыши, крысы, собаки, обезьяна, свиньи, козы, быка, лошади и хомяка. Особенно предпочтительные клеточные линии выбирают в зависимости от того, какие клеточные линии имеют высокие уровни экспрессии. Другими клеточными линиями, которые могут быть использованы, являются клеточные линии насекомых (например, Spodoptera frugiperda или Trichoplusia ni), клетки земноводных, бактериальные клетки, клетки растений и клетки грибов. Клетки грибов включают клетки дрожжевых и нитевидных грибов, включая, например, Pichia pastoris, Pichia finlandica, Pichia trehalophila, Pichia koclamae, Pichia membranaefaciens, Pichia minuta (Ogataea minuta, Pichia lindneri), Pichia opuntiae, Pichia thermotolerans, Pichia salictaria, Pichia guercuum, Pichia pijperi, Pichia stiptis, Pichia methanolica, Pichia sp., Saccharomyces cerevisiae, Saccharomyces sp., Hansenula polymorpha, Kluyveromyces sp., Kluyveromyces lactis, Candida albicans, Aspergillus nidulans, Aspergillus niger, Aspergillus oryzae, Trichoderma reesei, Chrysosporium lucknowense, Fusarium sp., Fusarium gramineum, Fusarium venenatum, Physcomitrella patens и Neurospora crassa. Pichia sp., любые Saccharomyces sp., Hansenula polymorpha, любые Kluyveromyces sp., Candida albicans, любые Aspergillus sp., Trichoderma reesei, Chrysosporium lucknowense, любые Fusarium sp., Yarrowia lipolytica и Neurospora crassa.
Кроме того, экспрессия PD1/CTLA4-связывающего вещества (например, содержащего ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) из линий клеток-продуцентов может быть усовершенствован с использованием ряда известных методов. Например, система экспрессии гена глутаминсинтетазы (система GS) является общим способом усиления экспрессии в определенных условиях. Система GS рассматривается, в целом или частично, применительно к европейским патентам № 0216846, 0256055 и 0323997 и европейской патентной заявке № 89303964.4. Таким образом, в одном из вариантов осуществления изобретения, клетки-хозяева млекопитающих (например, CHO) не содержат ген глутаминсинтетазы и выращиваются в отсутствие глутамина в среде, где, однако, полинуклеотид, кодирующий цепь иммуноглобулина, содержит ген глутаминсинтетазы, который восполняет дефицит гена в клетке-хозяине.
Настоящее изобретение относится к способам очистки PD1/CTLA4-связывающего вещества (например, содержащего ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925), включающие введение образца (например, культуральной среды, клеточного лизата или фракции клеточного лизата, например, растворимой фракции лизата), включающего PD1/CTLA4-связывающее вещество, в среду для очистки (например, катионообменная среда, анионообменная среда, гидрофобная обменная среда, среда для аффинной очистки (например, белок-A, белок-G, белок-A/G, белок-L)), и либо сбор очищенного PD1/CTLA4-связывающего вещества из проточной фракции указанного образца, которое не связывается со средой; или, удаление проточной фракции и элюирование связанного PD1/CTLA4-связывающего вещества из среды и сбор элюата. В одном из вариантов осуществления изобретения, среда находится в колонке, в которую вводят образец. В одном из вариантов осуществления изобретения, способ очистки осуществляют после рекомбинантной экспрессии антитела или фрагмента в клетке-хозяине, например, где клетка-хозяин сначала лизируется и, необязательно, лизат очищается от нерастворимых веществ до очистки на среде; или где PD1/CTLA4-связывающее вещество секретируется в культуральную среду клеткой-хозяином, а среду или ее фракцию наносят на среду для очистки.
В общем случае, гликопротеины, продуцируемые в конкретной клеточной линии или трансгенном животном, будут иметь профиль гликозилирования, который характерен для гликопротеинов, продуцируемых в клеточной линии или трансгенном животном. Поэтому конкретный профиль гликозилирования PD1/CTLA4-связывающего вещества (например, включающего ISVD (например, нанотела) (например, F023700910, F023700918, F023700920 или F023700925), которые связываются с PD1 и CTLA4) будет зависеть от конкретной клеточной линии или трансгенного животного, применяемого для продуцирования PD1/CTLA4-связывающего вещества. PD1/CTLA4-связывающие вещества, содержащие только нефукозилированные N-гликаны, являются частью настоящего изобретения и могут использоваться, поскольку, как было показано, нефукозилированные антитела проявляют большую эффективность, чем их фукозилированные аналоги как in vitro, так и in vivo (См., например, Shinkawa et al., J. Biol. Chem. 278: 3466-3473 (2003), патенты США №№ 6946292 и 7214775). Эти PD1/CTLA4-связывающие вещества с нефукозилированными N-гликанами, наиболее вероятно, не будут иммуногенными, поскольку их углеводные структуры являются нормальным компонентом популяции, которая существует в сывороточном IgG человека.
Настоящее изобретение включает PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925), содержащие N-связанные гликаны, которые обычно добавляют к иммуноглобулинам, продуцируемым клетками яичника китайского хомячка (CHO N-связанные гликаны) или к генетически сконструированным дрожжевым клеткам (генетически сконструированные дрожжевые N-связанные гликаны), таким как, например, Pichia pastoris. Например, в одном из вариантов осуществления изобретения, PD1/CTLA4-связывающее вещество содержит один или более ʺгенетически сконструированных дрожжевых N-связанных гликановʺ или ʺCHO N-связанных гликановʺ, которые представленные на фиг.7 (например, G0 и/или G0-F и/или G1 и/или G1-F и/или и/или G2-F и/или Man5). В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающее вещество включает генетически сконструированные дрожжевые N-связанные гликаны, то есть G0 и/или G1 и/или G2, необязательно, дополнительно включающие Man5. В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающие вещества содержат CHO N-связанные гликаны, то есть G0-F, G1-F и G2-F, необязательно, дополнительно включающие G0 и/или G1 и/или G2 и/или Man5. В одном из вариантов осуществления изобретения, от около 80% до около 95% (например, около 80-90%, около 85%, около 90% или около 95%) всех N-связанных гликанов на PD1/CTLA4-связывающих веществ представляют собой генетически сконструированные дрожжевые N-связанные гликаны или CHO N-связанные гликаны. См. Nett et al. Yeast. 28(3): 237-252 (2011); Hamilton et al. Science. 313(5792): 1441-1443 (2006); Hamilton et al. Curr Opin Biotechnol. 18(5): 387-392 (2007). Например, в одном из вариантов осуществления изобретения, генетически сконструированная дрожжевая клетка представляет собой GFI5.0 или YGLY8316 или штаммы, указанные в патенте США № 7795002 или Zha et al. Methods Mol Biol. 988:31-43 (2013). См. также публикацию международной патентной заявки № WO2013/066765.
Комбинации
В конкретных вариантах осуществления, PD1/CTLA4-связывающие вещества (например, включающие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925), могут использоваться отдельно или совместно с другими дополнительными терапевтическими средствами и/или терапевтическими процедурами для лечения или профилактики любых заболеваний, таких как злокачественная опухоль, например, как описано в настоящем документе, у субъекта, нуждающегося в таком лечении или профилактике. Композиции или наборы, например, фармацевтические композиции, содержащие фармацевтически приемлемый носитель, содержащие такие связывающие вещества вещества в сочетании с дополнительными терапевтическими средствами, также являются частью настоящего изобретения.
Термин ʺсовместно сʺ означает, что компоненты, PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, Нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) вместе с другим агентом, таким как как пембролизумаб или ниволумаб, могут объединяться в составе одной композиции, например, для одновременной доставки, или объединяться в составе отдельных, двух или больше, композиций (например, набор). Каждый компонент может вводиться субъекту в другой момент времени, чем когда вводится другой компонент; например, каждое введение может осуществляться неодновременно (например, раздельно или последовательно) с интервалами за определенный период времени. Кроме того, отдельные компоненты могут вводиться субъекту аналогичным или другим способом (например, PD1/CTLA4-связывающее вещество по настоящему изобретению вводят парентерально, а паклитаксел вводят перорально).
В конкретных вариантах осуществления, PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) могут использоваться в ассоциации с противоопухолевым терапевтическим средством или иммуномодулирующим лекарственным средством, таким как иммуномодулирующий ингибитор рецепторов, например, антитело или его антигенсвязывающий фрагмент, который специфично связывается с рецептором.
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925), находятся в ассоциации с одним или более ингибиторами (например, небольшая органическая молекула или антитело или его антигенсвязывающий фрагмент), такой как: ингибитор MTOR (мишень рапамицина в клетках млекопитающих), цитотоксический агент, препарат на основе платины ингибитор BRAF, ингибитор CDK4/6, ингибитор EGFR, ингибитор VEGF, стабилизатор микротрубочек, таксан, ингибитор CD20, ингибитор CD52, ингибитор CD30, ингибитор RANK (активатор рецептора ядерного фактора каппа-B), ингибитор RANKL (лиганд рецептора активатора ядерного фактора каппа-В), ингибитор ERK, ингибитор МАР-киназы, ингибитор АКТ, ингибитор MEK, ингибитор PI3K, ингибитор HER1, ингибитор HER2, ингибитор HER3, ингибитор HER4, ингибитор Bcl2, ингибитор CD22, ингибитор CD79b, ингибитор ErbB2 или ингибитор фарнезил-протеинтрансферазы.
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающее вещество (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) сочетается с одним или более из следующих веществ: анти-CTLA4 антитела или их антигенсвязывающие домены (например, ипилимумаб), анти-PD1 антитело или его антигенсвязывающий домен (например, пембролизумаб, ниволумаб, CT-011), анти-PDL1, анти-CTLA4, анти-TIM3, анти-CS1, (например, элотузумаб), анти-KIR2DL1/2/3 (например, лирилумаб), анти-CD27, анти-CD137 (например, урелумаб), анти-GITR (например, TRX518), анти-PD-L1 (например, BMS-936559, MSB0010718C или MPDL3280A), анти-PD-L2, анти-ILT1, анти-ILT2, анти-ILT3, анти-ILT4, анти-ILT5, анти-ILT6, анти-ILT7, анти-ILT8, анти-CD40, анти-OX40, анти-CD137, анти-KIR2DL1, анти-KIR2DL2/3, анти-KIR2DL4, анти-KIR2DL5A, анти-KIR2DL5B, анти-KIR3DL1, анти-KIR3DL2, анти-KIR3DL3, анти-NKG2A, анти-NKG2C, анти-NKG2E, или любой органический низкомолекулярный ингибитор таких мишеней; IL-10, анти-IL10, анти-TSLP (тимусный стромальный лимфопоэтин) или пегилированный IL-10.
В одном из вариантов осуществления изобретения, молекулярная масса фрагмента полиэтиленгликоля (PEG) в пегилированной молекуле IL-10 составляет около 12000 дальтон или около 20000 дальтон. В одном из вариантов осуществления изобретения, пегилированный IL-10 (например, пегилированный IL-10 человека) содержит одну или более молекул полиэтиленгликоля, ковалентно присоединенных через линкер (например, C2-12 алкил, такой как --CH2CH2CH2--) к одному аминокислотному остатку одной субъединицы IL-10, где указанный аминокислотный остаток представляет собой альфа-аминогруппу N-концевого аминокислотного остатка или эпсилон-аминогруппу лизинового остатка. В одном из вариантов осуществления изобретения, пегилированный IL-10 представляет собой: (PEG)b-L-NH-IL-10; где b равно 1-9, и L представляет собой C2-12 алкильный линкерный фрагмент, ковалентно присоединенный к азоту (N) одного аминокислотного остатка в IL-10. В одном из вариантов осуществления изобретения, IL-10 пегилированного IL-10 имеет формулу: [X--O(CH2CH2O)n]b-L-NH-IL-10, где X представляет собой H или C1-4 алкил; n равно от 20 до 2300; b равно от 1 до 9; и L представляет собой C1-11 алкильный линкерный фрагмент, который ковалентно присоединен к азоту (N) альфа-аминогруппы на аминоконце одной субъединицы IL-10; при условии, что, когда b больше 1, общее количество n не превышает 2300. См. США 70552686.
В одном из вариантов осуществления изобретения, анти-IL-10 антитело или его антигенсвязывающий домен (например, гуманизированное антитело) содержит CDR, приведенные ниже:
CDR-L1: KTSQNIFENLA (SEQ ID NO: 154);
CDR-L2: NASPLQA (SEQ ID NO: 155);
CDR-L3: HQYYSGYT (SEQ ID NO: 156);
CDR-H1: GFTFSDYHMA (SEQ ID NO: 157);
CDR-H2: SITLDATYTYYRDSVRG (SEQ ID NO: 158);
CDR-H3: HRGFSVWLDY (SEQ ID NO: 159)
(См. US7662379)
В одном из вариантов осуществления изобретения, анти-TSLP антитело или его антигенсвязывающий домен (например, гуманизированное антитело) содержит CDR, приведенные ниже:
CDR-H1: GYIFTDYAMH (SEQ ID NO: 160);
CDR-H2: TFIPLLDTSDYNQNFK (SEQ ID NO: 161);
CDR-H3: MGVTHSYVMDA (SEQ ID NO: 162);
CDR-L1: RASQPISISVH (SEQ ID NO: 163);
CDR-L2: FASQSIS (SEQ ID NO: 164);
CDR-L3: QQTFSLPYT (SEQ ID NO: 165)
(см. WO2008/76321)
В одном из вариантов осуществления изобретения, анти-CD27 антитело или его антигенсвязывающий домен (например, гуманизированное антитело) содержит CDR, приведенные ниже:
CDR-H1: GFIIKATYMH (SEQ ID NO: 166);
CDR-H2: RIDPANGETKYDPKFQV (SEQ ID NO: 167);
CDR-H3: YAWYFDV (SEQ ID NO: 168);
CDR-L1: RASENIYSFLA (SEQ ID NO: 169);
CDR-L2: HAKTLAE (SEQ ID NO: 170);
CDR-L3: QHYYGSPLT (SEQ ID NO: 171);
(см. WO2012/04367).
Таким образом, настоящее изобретение включает композиции, содержащие PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела) (например, F023700910, F023700918, F023700920 или F023700925), которые связываются с PD1 и CTLA4) совместно с пембролизумабом; а также способы лечения или профилактики злокачественной опухоли у субъекта, включающие введение субъекту эффективного количества PD1/CTLA4-связывающего вещества в сочетании с пембролизумабом (например, пембролизумабом, вводимым в дозе 200 мг один раз в три недели). Необязательно, объект также вводят совместно с другим дополнительным терапевтическим средством.
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) сочетаются с антителом - пембролизумабом, который содержит тяжелую цепь иммуноглобулина (или ее CDR-H1, CDR-H2 и CDR-H3), содержащую аминокислотную последовательность:
QVQLVQSGVEVKKPGASVKVSCKASGYTFTNYYMYWVRQAPGQGLEWMGGINPSNGGTNFNEKFKNRVTLTTDSSTTTAYMELKSLQFDDTAVYYCARRDYRFDMGFDYWGQGTTVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK; (SEQ ID NO: 172) и легкую цепь иммуноглобулина (или ее CDR-L1, CDR-L2 и CDR-L3), содержащую аминокислотную последовательность:
EIVLTQSPATLSLSPGERATLSCRASKGVSTSGYSYLHWYQQKPGQAPRLLIYLASYLESGVPARFSGSGSGTDFTLTISSLEPEDFAVYYCQHSRDLPLTFGGGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC (SEQ ID NO: 173).
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925), сочетаются с антителом, содержащим тяжелую цепь иммуноглобулина (или ее CDR-H1, CDR-H2 и CDR-H3), содержащую аминокислотную последовательность:
QVQLVESGGGVVQPGRSLRLDCKASGITFSNSGMHWVRQAPGKGLEWVAVIWYDGSKRYYADSVKGRFTISRDNSKNTLFLQMNSLRAEDTAVYYCATNDDYWGQGTLVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK (SEQ ID NO: 174); и легкую цепь иммуноглобулина (или ее CDR-L1, CDR-L2 и CDR-L3), содержащую аминокислотную последовательность:
EIVLTQSPATLSLSPGERATLSCRASQSVSSYLAWYQQKPGQAPRLLIYDASNRATGIPARFSGSGSGTDFTLTISSLEPEDFAVYYCQQSSNWPRTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC (SEQ ID NO: 175).
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связаны с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) сочетается с любым одним или более из следующих веществ: 13-цис-ретиноевая кислота, 3-[5-(метилсульфонилпиперадиметил)индолил]хинолон, 4-гидрокситамоксифен, 5-деооксиуридин, 5'-деокси-5-фторуридин, 5-фторурацил, 6-мекаптопурин, 7-гидроксистауроспорин, А-443654, абиратерона ацетат, абраксан, ABT-578, аколбифен, ADS-100380, афлиберцепт, ALT-110, альтретамин, амифостин, аминоглютетимид, амрубицин, амсакрин, анагрелид, анастрозол, ангиостатин, AP-23573, ARQ-197, арзоксифен, AS-252424, AS-605240, аспарагиназа, ATI3387, AT-9263, атрацентан, акситиниб, AZD1152, вакцина бацилла Кальмета-Герена (BCG), батабулин, BC-210, безодутокс, бевацизумаб, BGJ398, бикалютамид, Bio111, BIO140, BKM120, блеомицин, BMS-214662, BMS-247550, BMS-275291, BMS-310705, бортезимиб, бусерелин, бусульфан, кальцитриол, камптотецин, канертиниб, капецитабин, карбоплатин, кармустин, CC8490, CEA (вакцина на основе рекомбинантного вируса осповакцины-карциноэмбрионального антигена), цедираниб, CG-1521, CG-781, хламидоцин, хлорамбуцил, хлоротоксин, циленгитид, цимитидин, цисплатин, кладрибин, клодронат, кобиметниб, COL-3, CP-724714, циклофосфамид, ципротерон, ципротеронацетат, цитарабин, цитозинарабинозид, дабрафениб, дакарбазин, дациностат, дактиномицин, далотузумаб, данузертиб, дазатаниб, даунорубицин, декатаниб, дегуэлин, денилейкин, деоксикоформицин, депсипептид, диарилпропионитрил, диэтилстилбестрол, дифтитокс, DNE03, доцетаксел, довитиниб, доксорубицин, дролоксифен, эдодекарин, эдотреотид, меченный иттрием-90, эдотреотид, EKB-569, EMD121974, энкорафениб, эндостатин, энзалутамид, энзастаурин, эпирубицин, эпитилон B, ERA-923, эрбитукс, эрлотиниб, эстрадиол, эстрамустин, этопозид, эверолимус, экземестан, фиклатузумаб, финастерид, флавопиридол, флуксуридин, флударабин, флудрокортизон, флуоксиместерон, флутамид, режим FOLFOX, фулвестрант, галетерон, ганетеспиб, гефитиниб, гемцитабин, гиматекан, глюкопиранозил липид А, гозерелин, гозерелина ацетат, госсипол, GSK461364, GSK690693, HMR-3339, гидроксипрогестеронкапроат, гидроксимочевина, IC87114, идарубицин, идоксифен, ифосфамид, IM862, иматиниб, IMC-1C11, имиквимод, INC280, INCB24360, INO1001, интерферон, интерлейкин-2, интерлейкин-12, ипилимумаб, иринотекан, JNJ-16241199, кетоконазол, KRX-0402, лапатиниб, лазофоксифен, LEE011, летрозол, лейковорин, лейпролид, лейпролида ацетат, левамизол, включенный в липосомы паклитаксел, ломустин, лонафарниб, люкантон, LY292223, LY292696, LY293646, LY293684, LY294002, LY317615, LY3009120, маримастат, мехлорэтамин, медроксипрогестеронацетат, мегестролацетат, MEK162, мелфалан, меркаптопурин, месна, метотрексат, митрамицин, митомицин, митотан, митоксантрон, суспензия убитой нагреванием Mycobacterium obuense, тозасертиб, MLN8054, натитоклакс, неовастат, нератипиб, неурадиаб, нилотиниб, нилутимид, нолатрексед, NVP-BEZ235, облимерсен, октреотид, офатумумаб, ореговомаб, орнатузумаб, ортерол, оксалиплатин, паклитаксел, палбоциклиб, памидронат, панитумумаб, пазопаниб, PD0325901, PD184352, ПЭГ-интерферон, пеметрексед, пентостатин, перифозин, фенилаланиниприт, PI-103, пиктилисиб, PIK-75, пипендоксифен, PKI-166, пликамицин, поли-ICLC, порфимер, преднизон, прокарбазин, прогестины, полисахарид, связанный с белком PSK (полученный из Basidiomycete coriolus versicolor), PLX8394, PX-866, R-763, ралоксифен, ралтитрексед, разоксин, ридафоролимус, ритуксимаб, ромидепсин, RTA744, рубитекан, скриптаид, Sdx102, селициклиб, селуметиниб, семаксаниб, SF1126, сиролимус, SN36093, сорафениб, спиронолактон, скваламин, SR13668, стрептозоцин, SU6668, субероиланалид-гидроксамовая кислота, сунитиниб, синтетический эстроген, талампанел, талимоген лагерпарепвек, тамоксифен, темозоломид, темсиролимус, тенипозид, тесмилифен, тестостерон, тетрандрин, TGX-221, талидомид, 6-тиогуанин, тиотепа, тицилимумаб, типифарниб, тивозаниб, TKI-258, TLK286, TNF α (фактор некроза опухолей альфа), топотекан, торемифена цитрат, трабектедин, траметиниб, трастузумаб, третиноин, трихостатин A, моногидрат трицирибинфосфата, трифорелина памоат, TSE-424, урациловый иприт, вальпроевая кислота, валрубицин, вандетаниб, ваталаниб, ловушка для VEGF, вемурафениб, винбластин, винкристин, виндезин, винорелбин, витаксин, витеспан, вориностат, VX-745, вортманнин, Xr311, Z-100 экстракт горячей водой Bacillus tuberculosis, занолимумаб, ZK186619, ZK-304709, ZM336372 или ZSTK474.
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) сочетаются с одним или более антиэметиками, включая, но ими не ограничиваясь: касопитант (GlaxoSmithKline), нетупитант (MGI-Helsinn) и другие антагонисты рецептора NK-1, палоносетрон (продается под названием Aloxi от компании MGI Pharma), апрепитант (продается под названием Emend от компании Merck and Co.; Rahway, NJ), дифенгидрамин (продается под названием Benadryl® от компании by Pfizer; New York, NY), гидроксизин (продается под названием Atarax® от компании Pfizer; New York, NY), метоклопрамид (продается под названием Reglan® от компании AH Robins Co,; Richmond, VA), лоразепам (продается под названием Ativan® от компании Wyeth; Madison, NJ), алпразолам (продается под названием Xanax® от компании Pfizer; New York, NY), галоперидол (продается под названием Haldol® от компании Ortho-McNeil; Raritan, NJ), дроперидол (Inapsine®), дронабинол (продается под названием Marinol® от компании Solvay Pharmaceuticals, Inc.; Marietta, GA), дексаметазон (продается под названием Decadron® от компании Merck and Co.; Rahway, NJ), метилпреднизолон (продается под названием Medrol® от компании Pfizer; New York, NY), прохлорперазин (продается под названием Compazine® от компании Glaxosmithkline; Research Triangle Park, NC), гранизетрон (продается под названием Kytril® от компании Hoffmann-La Roche Inc.; Nutley, NJ), онданзетрон (продается под названием Zofran® от компании Glaxosmithkline; Research Triangle Park, NC), долазетрон (продается под названием Anzemet® от компании Sanofi-Aventis; New York, NY), тропизетрон (продается под названием Navoban® от компании Novartis; East Hanover, NJ).
Другие побочные эффекты лечения злокачественной опухоли включают дефицит красных и белых кровяных телец. Соответственно, в одном из вариантов осуществления изобретения, PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связаны с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) сочетаются с агентом, который лечит или предотвращает такой дефицит, как, например, филграстим, ПЭГ-филграстим, эритропоэтин, эпоэтин альфа или дарбепоэтин альфа.
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) сочетаются с вакциной. В одном из вариантов осуществления изобретения, вакцина представляет собой противоопухолевую вакцину, пептидную вакцину, РНК-вакцину или ДНК-вакцину. Например, вакцина представляет собой опухолевую клетку (например, облученную опухолевую клетку) или дендритную клетку (например, дендритную клетку, в которую введен опухолевый пептид).
В одном из вариантов осуществления изобретения, PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) вводятся совместно с терапевтической процедурой. Терапевтическая процедура представляет собой одну или более стадий, выполняемых врачом или клиницистом при лечении субъекта, предназначенной для облегчения одного или более симптомов (например, злокачественной опухоли и/или инфекционного заболевания) у подвергаемого лечению субъекта, или путем вызывания регрессии или устранения таких симптомов, или путем ингибирования развития такого(их) симптома(ов), например, симптомов злокачественной опухоли, таких как рост опухоли или метастазирование, любой клинически определяемой степени.
В одном из вариантов осуществления изобретения, терапевтическая процедура представляет собой противоопухолевую лучевую терапию. Например, в одном из вариантов осуществления изобретения, лучевая терапия представляет собой наружную дистанционную лучевую терапию (EBT): способ доставки пучка высокоэнергетических рентгеновских лучей в место локализации опухоли. Луч генерируется вне пациента (например, линейным ускорителем) и нацеливается на участок опухоли. Эти рентгеновские лучи могут разрушать клетки злокачественной опухоли, и тщательное планирование лечения позволяет сохранить окружающие здоровые ткани. Источники радиоактивного излучения не размещаются внутри организма пациента. В одном из вариантов осуществления изобретения, лучевая терапия представляет собой протонную терапию: тип конформной терапии при которой вместо рентгеновских лучей пораженную ткань бомбардируют протонами. В одном из вариантов осуществления изобретения, лучевая терапия представляет собой конформную наружную дистанционную лучевую терапию: процедуру, которая использует передовые технологии для адаптации лучевой терапии к структурам организма человека.
В одном из вариантов осуществления изобретения, лучевая терапия представляет собой брахитерапию: временное размещение радиоактивных веществ в организме, обычно используемое для получения дополнительной дозы или увеличения, лучевого воздействия на пораженную область.
В одном из вариантов осуществления изобретения, хирургическая процедура, применяемая совместно с PD1/CTLA4-связывающими веществами(например, содержащими ISVD (например, нанотела), которые связаны с PD1 и CTLA4), является хирургической туморэктомией.
Терапевтические применения
Изобретение включает способ профилактики и/или лечения, по крайней мере, одного заболевания или расстройства, которое можно предотвратить или лечить с помощью PD1/CTLA4-связывающих веществ (например, содержащих ISVD (например, нанотела), которые связаны с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) по настоящему, необязательно совместно с дополнительным терапевтическим средством или терапевтической процедурой, который включает введение субъекту, нуждающемуся в такой профилактике и/или лечении, фармацевтически активного количества PD1/CTLA4-связывающего вещества, и/или содержащей его фармацевтической композиции.
ʺЛечитьʺ или ʺобрабатыватьʺ означает введение PD1/CTLA4-связывающих веществ (например, содержащих ISVD (например, нанотела), которые связаны с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) по настоящему изобретению, субъекту (например, млекопитающему, такому как человек), имеющему один или более симптомов заболевания, в отношении которого PD1/CTLA4-связывающие вещества являются эффективными, например, при лечении субъекта, имеющего злокачественную опухоль или инфекционное заболевание, или потенциально имеющего злокачественную опухоль или инфекционное заболевание, в отношении которого агент обладает терапевтической активностью. Обычно, PD1/CTLA4-связывающее вещество вводят в ʺэффективном количествеʺ или ʺэффективной дозеʺ, которая облегчает один или более симптомов (например, злокачественной опухоли или инфекционного заболевания) у подвергаемого лечению субъекта или популяции, или путем вызывания регрессии или устранения таких симптомов, или путем ингибирования развития такого(их) симптома(ов), например, симптомов злокачественной опухоли, таких как рост опухоли или метастазирование, любой клинически определяемой степени. Эффективное количество PD1/CTLA4-связывающего вещества может изменяться в зависимости от таких факторов, как стадия заболевания, возраст и масса пациента, а также способность лекарственного средства вызывать желаемый ответ у субъекта.
Субъектом, подлежащим лечению, может быть любое теплокровное животное, но, в частности, им является млекопитающее, и более конкретно человек. Как будет понятно квалифицированному специалисту в данной области, субъектом, подлежащим лечению, будет в частности человек, страдающий или предрасположенный к возникновению заболеваний и расстройств, указанных в настоящем документе.
Для получения фармацевтических или стерильных композиций PD1/CTLA4-связывающих веществ (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4) по настоящему изобретению (например, F023700910, F023700918, F023700920 или F023700925), PD1/CTLA4-связывающие вещества смешивают с фармацевтически приемлемым носителем или вспомогательным веществом. См., например, Remington's Pharmaceutical Sciences и US Pharmacopeia: National Formulary, Mack Publishing Company, Easton, PA (1984). Такие композиции являются частью настоящего изобретения.
В объем настоящего изобретения включены высушенные, например, лиофилизированные композиции, содержащие PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925), или их фармацевтическая композиция, которая включает фармацевтически приемлемый носитель, но по существу не содержит воду.
Композиции терапевтических и диагностических веществ могут быть получены путем смешивания с приемлемыми носителями, вспомогательными веществами или стабилизаторами в форме, например, лиофилизированных порошков, суспензий, водных растворов или суспензий (см., например, Hardman, et al. (2001) Goodman and Gilman's The Pharmacological Basis of Therapeutics, McGraw-Hill, New York, NY; Gennaro (2000) Remington: The Science and Practice of Pharmacy, Lippincott, Williams, and Wilkins, New York, NY; Avis, et al. (eds.) (1993) Pharmaceutical Dosage Forms: Parenteral Medications, Marcel Dekker, NY; Lieberman, et al. (eds.) (1990) Pharmaceutical Dosage Forms: Tablets, Marcel Dekker, NY; Lieberman, et al. (eds.) (1990) Pharmaceutical Dosage Forms: Disperse Systems, Marcel Dekker, NY; Weiner and Kotkoskie (2000) Excipient Toxicity and Safety, Marcel Dekker, Inc., New York, NY).
Обычно, для профилактики и/или лечения заболеваний и расстройств, указанных в настоящем документе, и в зависимости от конкретного заболевания или расстройства, подлежащего лечению, эффективности и/или периода полувыведения применяемых PD1/CTLA4-связывающих веществ (например, содержих ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925), конкретного способа введения и конкретного фармацевтического состава или композиции, связывающие вещества по изобретению PD1/CTLA4 обычно будут вводиться в количестве от 1 грамма до 0,01 мкг/кг массы тела в сутки, предпочтительно от 0,1 грамма до 0,1 мкг/кг массы тела в сутки, например, около 1, 10, 100 или 1000 мкг/кг массы тела в сутки, либо непрерывно (например, путем инфузии) в виде однократной суточной дозы или в виде нескольких разделенных доз в течение суток. Обычно клиницист может определить подходящую суточную дозу, в зависимости от факторов, указанных в настоящем документе. Также будет ясно, что в конкретных случаях клиницист может выбрать отклонение от этих количеств, например, с учетом приведенных выше факторов и своего экспертного мнения. В общем случае, некоторые рекомендации в отношении вводимых количеств могут быть получены исходя из обычно вводимых количеств для сопоставимых стандартных антител или фрагментов антител против аналогичной мишени, вводимых по существу тем же способом, с учетом различий аффинности/авидности, эффективности, биораспределения, периода полувыведения и аналогичных факторов, хорошо известных специалисту в данной области.
Способ введения субъекту PD1/CTLA4-связывающих веществ (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4) (например, F023700910, F023700918, F023700920 или F023700925) может изменяться. Способы введения включают: пероральный, ректальный, трансмукозальный, интестинальный, парентеральный; внутримышечный, подкожный, интрадермальный, интрамедуллярный, интратекальный, прямое внутрижелудочковое введение, внутривенный, внутрибрюшинный, интраназальный, внутриглазный, ингаляционный, инсуффляционный, местный, наружний, трансдермальный или внутриартериальный.
Определение подходящей дозы осуществляет клиницист, например, используя параметры или факторы, известные или предполагаемые в данной области для воздействия на лечение. В общем случае, при определении дозы, доза начинается с количества, несколько меньшего, чем оптимальная доза, и затем повышается с небольшим увеличением до тех пор, пока не будет достигнут желаемый или оптимальный эффект по сравнению с любыми отрицательными побочными эффектами. Важные диагностические меры включают оценку симптомов, например, воспаление или уровень продуцируемых воспалительных цитокинов. В общем случае, желательно, чтобы применяемый биологический препарат, который будет использоваться, был получен из тех же видов, что и животное, на которое направлено лечение, тем самым сводя к минимуму любой иммунный ответ на реагент. В случае субъекта-человека, могут быть желательными, например, химерные, гуманизированные и полностью человеческие антитела. Доступно руководство по выбору соответствующих доз (см. например, Wawrzynczak (1996) Антитело Therapy, Bios Scientific Pub. Ltd, Oxfordshire, UK; Kresina (ed.) (1991) Monoclonal Antibodies, Cytokines and Arthritis, Marcel Dekker, New York, NY; Bach (ed.) (1993) Monoclonal Antibodies and Peptide Therapy in Autoimmune Diseases, Marcel Dekker, New York, NY; Baert et al. (2003) New Engl. J. Med. 348:601-608; Milgrom et al. (1999) New Engl. J. Med. 341:1966-1973; Slamon et al. (2001) New Engl. J. Med. 344:783-792; Beniaminovitz et al. (2000) New Engl. J. Med. 342:613-619; Ghosh et al. (2003) New Engl. J. Med. 348:24-32; Lipsky et al. (2000) New Engl. J. Med. 343:1594-1602).
Независимо от того, был ли ослаблен симптом заболевания, можно оценить любое клиническое измерение, обычно используемое врачами или другими квалифицированными медицинскими работниками для оценки степени тяжести или развития этого симптома. Хотя вариант осуществления настоящего изобретения (например, способ лечения или продукт производства) может не быть эффективным в ослаблении симптома(ов) конкретного заболевания у каждого субъекта, он должен облегчить симптом(ы) конкретного заболевания у статистически значимого числа субъектов, что определяется любым статистическим исследованием, известным в данной области, таким как параметрический t-критерий Стьюдента, тест хи-квадрат, U-тест Манна-Уитни, критерий Крускала-Уоллиса (H-критерий), критерий Джонкхиера-Терпстра и критерий Уилкоксона.
Подлежащим лечению может быть любое млекопитающее, такое как собака, кошка, лошадь, кролик, корова, мышь, обезьяна или горилла, предпочтительно человек. Как будет понятно специалисту в данной области техники, субъектом, подлежащим лечению, будет, в частности, человек, страдающий или предрасположенный к возникновению заболеваний и расстройств, указанных в настоящем документе.
Обычно, схема лечения будет выполняться до тех пор, пока не будет достигнут желаемый терапевтический эффект, и/или до тех пор, пока необходимо сохранять желаемый терапевтический эффект. В этом случае также, это может определить клиницист.
Поскольку PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) по настоящему изобретению (например, F023700910, F023700918, F023700920 или F023700925) способны связываться с PD1 и CTLA4, они могут в частности применяться для лечения или профилактики злокачественной опухоли, метастатической злокачественной опухоли, твердой опухоли, гематологической злокачественной опухоли, лейкемии, лимфомы, остеосаркомы, рабдомиосаркомы, нейробластомы, злокачественной опухоли почек, лейкемии, переходно-клеточной злокачественной опухоли почек, злокачественной опухоли мочевого пузыря, опухоли Вильма, злокачественной опухоли яичников, злокачественной опухоли поджелудочной железы, злокачественной опухоли молочной железы, злокачественной опухоли простаты, злокачественной опухоли костей, злокачественной опухоли легких, немелкоклеточной злокачественной опухоли легкого, злокачественной опухоли желудка, злокачественной опухоли толстой и прямой кишки, злокачественной опухоли шейки матки, синовиальной саркомы, злокачественной опухоли головы и шеи, плоскоклеточной карциномы, множественной миеломы, почечно-клеточной злокачественной опухоли, ретинобластомы, гепатобластомы, гепатоцеллюлярной карциномы, меланомы, рабдоидной опухоли почки, саркомы Юинга, хондросаркомы, злокачественной опухоли мозга, глиобластомы, менингиомы, аденомы гипофиза, вестибулярной шванномы, примитивной нейроэктодермальной опухоли, медуллобластомы, астроцитомы, анапластической астроцитомы, олигодендроглиомы, эпендимомы, папилломы хориоидного сплетения, полицитемии, тромбоцитемии, идиопатического миелофиброза, саркомы мягких тканей, злокачественной опухоли щитовидной железы, злокачественной опухоли эндометрия, карциноидной злокачественной опухоли или злокачественной опухоли печени, злокачественной опухоли молочной железы и злокачественной опухоли желудка.
PD1/CTLA4-связывающие вещества (например, содержащие ISVD (например, нанотела), которые связываются с PD1 и CTLA4) по настоящему изобретению (например, F023700910, F023700918, F023700920 или F023700925) могут использоваться для лечения или профилактики инфекционных заболеваний, таких как например, вирусная инфекция, бактериальная инфекция, грибковая инфекция или паразитарная инфекция. В одном из вариантов осуществления изобретения, вирусная инфекция представляет собой заражение вирусом, выбранным из группы, состоящей из вируса иммунодефицита человека (ВИЧ), вируса эболы, вируса гепатита (A, B или C), вируса герпеса (например, VZV, HSV-I, HAV-6, HSV-II и CMV, вирус Эпштейна Барра), аденовируса, вируса гриппа, флавивирусов, эховируса, риновируса, вируса Коксаки, коронавируса, респираторно-синцитиального вируса, вируса эпидемического паротита, ротавируса, вируса кори, вируса краснухи, парвовируса, вируса осповакцины, Т-лимфотропного вируса человека, вируса лихорадки денге, папилломавируса, вируса моллюска, полиовируса, вируса бешенства, вируса Джона Каннингхэма или вируса аргивирального энцефалита. В одном из вариантов осуществления изобретения, бактериальная инфекция представляет собой заражение бактериями, выбранными из группы, состоящей из Chlamydia, бактерии рода риккетсии, микобактерий, стафилококков, стрептококков, пневмонококков, менингококков и гонококков, клебсиелла, протеус, серратия, псевдомонада, Legionella, Corynebacterium diphtheriae, Salmonella, палочковидная бактерия, Vibrio cholerae, Clostridium tetan, Clostridium botulinum, Bacillus anthricis, Yersinia pestis, Mycobacterium leprae, Mycobacterium lepromatosis и Borriella. В одном из вариантов осуществления изобретения, грибковая инфекция представляет собой заражение грибами, выбранными из группы, состоящей из Candida (albicans, krusei, glabrata, tropicalis, etc.), Cryptococcus neoformans, Aspergillus (fumigatus, niger, etc.), Genus Mucorales (mucor, absidia, rhizopus), Sporothrix schenkii, Blastomyces dermatitidis, Paracoccidioides brasiliensis, Coccidioides immitis и Histoplasma capsulatum. В одном из вариантов осуществления изобретения, паразитарная инфекция представляет собой заражение паразитом, выбранным из группы, состоящей из Entamoeba histolytica, Balantidium coli, Naegleria fowleri, Acanthamoeba, Giardia lambia, Cryptosporidium, Pneumocystis carinii, Plasmodium vivax, Babesia microti, Trypanosoma brucei, Trypanosoma cruzi, Leishmania donovani, Toxoplasma gondii, Nippostrongylus brasiliensis.
Изобретение также относится к способам лечения вышеуказанных заболеваний и расстройств, которые обычно включают введение субъекту, нуждающемуся таком лечении (то есть страдающему одним из вышеуказанных заболеваний), терапевтически эффективного количества PD1/CTLA4-связывающих веществ (например, содержащих ISVD (например, нанотела), которые связываются с PD1 и CTLA4) по настоящему изобретению (например, F023700910, F023700918, F023700920 или F023700925). Изобретение также относится к PD1/CTLA4-связывающим веществам (например, содержащим ISVD (например, нанотела), которые связываются с PD1 и CTLA4) для использования в профилактике или лечении одного из вышеуказанных заболеваний или расстройств.
Другие аспекты, варианты осуществления, преимущества и применения по изобретению станут понятны из дальнейшего описания настоящего изобретения.
Примеры
Эти примеры предназначены для иллюстрации настоящего изобретения и не являются их ограничением. Композиции и методы, представленные в примерах, образуют часть настоящего изобретения.
Пример 1: Связывание нанотела F023700906 с CTLA-4-Fc.
Моновалентное нанотело F023700906 (CTLA4-связывающее вещество 11F01 (L11V, A14P, Q45R, A74S, K83R, V89L, M96P, Q108L)-FLAG3-HIS6), структурный блок F023700925, демонстрирует связывание с молекулой слияния, содержащей CTLA-4-Fc как от человека, так и от яванского макака. Скорость передачи, скорость и аффинность определяли с использованием CTLA4-hFc человека и яванского макака (таблица ниже).
Таблица E. Связывание F023700906 с CTLA4 человека и яванского макака
Пример 2: Связывание F023700918 и F023700925 с CTLA-4 человека.
F023700918 и F023700925 демонстрировали связывание с CTLA-4 человека, экспрессированным на поверхности клетки. С помощью проточной цитометрии исследовали связывание партии, включающей F023700918 (закрашенные квадраты), F023700925 (закрашенные треугольники), F023700912 (закрашенные круги) и нерелевантные Nb (ромбы), с hCTLA4-сверхэкспрессирующими клетками CHO-K1. Нанотела обнаруживали посредством ALB11-связывающего mAB ABH0074. Данные проточной цитометрии, полученные в этом эксперименте, показаны на фигуре 8.
Пример 3: Поверхностное связывание PD-1 человека посредством F023700925.
F023700925 продемонстрировал связывание с PD-1 человека, экспрессируемого на поверхности клетки. Методом проточной цитометрии исследовали связывание партии, включающей F023700925 (закрашенные квадраты) и F023700912 (закрашенные круги) и нерелевантные Nb IRR00051 (закрашенные треугольники), с hPD1-сверхэкспрессирующими клетками CHO-K1. Nb обнаруживали посредством ALB11-связывающего mAB ABH0074. Данные проточной цитометрии, полученные в этом эксперименте, приведены на фигуре 9.
Пример 4: CTLA-4/CD80 человека и исследование блокирования CD86.
F023700906, структурный блок F023700925, а также F023701051, F023701054 и F023701061 блокируют связывание CTLA-4 человека с его лигандами CD80 и CD86. Анализ методом проточной цитометрии образцов обнаружения вариантов N73X (закрашенные квадраты, закрашенные треугольники, закрашенные треугольники в перевернутом положении) Nb F023700906 (закрашенные круги) с фиксированными концентрациями (EC30) в (A) hCD80-hFc или (B) hCD86-hFc на hCTLA4-сверхэкспрессирующих клетках CHO-K1. Лиганды обнаруживали с помощью слитого белка, содержащего Fc человеческого IgG. Данные проточной цитометрии, полученные в этом эксперименте, представлены на фигуре 10 (А-В).
Пример 5: Исследование специфичности связывания.
Оценка специфичности F023700925 спрогнозировала избирательное связывание с CTLA-4 и PD-1. Оценку специфичности против BTLA, CD8, CTLA4, LAG3 и CD28 проводили на сверхэкспрессирующих клетках с использованием проточной цитометрии, при этом связывание ICOS оценивали в анализе ELISA в виде рекомбинантного белка (hICOS-hFc). Экспрессию BTLA, CD8, PD1, CTLA4, LAG3, CD28 оценивали с помощью непосредственно меченных мишень-специфичных Abs. Анти-hICOS и анти-hCTLA4/анти-hPD1 положительные контроли были все положительными. В анализах ELISA не наблюдали связывания с hICOS. На фигуре 11 (AH) показано связывание с L-клетками отрицательного контроля, клетками CHO-K1 отрицательного контроля, клетками huCD28+ L, клетками huCD8альфа+L-, клетками huLag-3+ CHO-K1, клетками huBTLA+ CHO-K1, клетками huCTLA-4+ CHO-К1 и клетками huPD-1+ CHO-K1, соответственно. Для F023700925 связывание с BTLA, CD8, LAG3, CD28 не наблюдали, при этом наблюдали сильное связывание F023700925 на клетках PD-1+ или CTLA-4+ CHO-K1. Данные проточной цитометрии, полученные в этом эксперименте, представлены на фигуре 11 (A-H).
Пример 6: Исследование связывания с сывороточным альбумином.
F023700925 связывается с альбумином человека, макака-резус и мыши, прогнозируя длительный период полувыведения по сравнению с нанотелом, не связывающимся с альбумином. При анализе с использованием поверхностного плазмонного резонанса (SPR) наблюдали связывание с сывороточным альбумином человека, макака-резус и мыши.
Таблица F. Исследование связывания F023700925 с сывороточным альбумином человека, макака-резус и мыши
Человеческий сывороточный альбумин: каталожный номер A3782, Sigma, партия SLBD7204V
Сывороточный альбумин макака-резус: BioWorld, каталожный номер 22070099-1, партия L15091001DA,
Мышечный плазменный альбумин: Innovative Research, партия 1012,
Аппарат и сенсорный чип: Biacore T100 (GE Healthcare); CM5 (ID T160713-2, GE Healthcare, партия 10242599
F023700912 представляет собой 11F01 (E1D, L11V, A14P, Q45R, A74S, K83R, V89L, M96P, Q108L)-35GS-11F01 (L11V, A14P, Q45R, A74S, K83R, V89L, M96P, Q108L)-35GS- ALB11002-A
Пример 7: Кинетический анализ связывания вариантов.
Некоторое количество вариантов F023700906, структурный блок F023700925, в положении N73 синтезировали с исключением деамидирования на этом участке. Все возможные замены оценивали при скорости диссоциации вместе с существующим SO F023700906 (таблица G). Варианты F023701051 [11F01 (L11V, A14P, Q45R, N73Q, A74S, K83R, V89L, M96P, Q108L)-FLAG3-HIS6], F023701054 [11F01 (L11V, A14P, Q45R, N73T, A74S, K83R, V89L, M96P, Q108L)-FLAG3-HIS6] и F023701061 [11F01 (L11V, A14P, Q45R, N73Y, A74S, K83R, V89L, M96P, Q108L)-FLAG3-HIS6] сравнивали с F023700906 по их способности блокировать связывание (A) CD80 или (B) CD86 с CTLA-4-экспрессирующими клетками CHO-K1. Все эти варианты были способны блокировать связывание CD80 и CD84 с CTLA-4. Данные проточной цитометрии, полученные в этом эксперименте, приведены на фигуре 12 (A-B).
Пример 8: F023700912 устраняет сформированные твердые опухоли у гуманизированных мышей.
Гуманизированным мышам (Jackson Laboratories) имплантировали опухолевые клетки Panc 08.13. Мышей с развившимися опухолями (~100 мм3, n=9-10/группа) обрабатывали следующим образом: 1-изотипические контроли (hIgG1-2 мг/кг и hIgG4-3 мг/кг); 2-ипилимумаб-N297A (3 мг/кг); 3-ипилимумаб (3 мг/кг); 4-пембролизумаб (2 мг/кг); 5-ипилимумаб (3 мг/кг)+пембролизумаб (2 мг/кг); 6-F023700912 (5 мг/кг, обозначенный как CTLA4-Nab 5), 7- F023700912 (15 мг/кг, обозначенный как CTLA4-Nab-15) и 8- F023700912 (15 мг/кг)+пембролизумаб (2 мг/кг). Все антитела вводили подкожно каждые 7 дней по 6 доз. F023700912 вводили подкожно каждые 3,5 дня по 11 доз. Объем опухоли и массу тела измеряли каждые 4-5 дней. Представляли средние объемы опухолей ± стандартная погрешность (A), отдельные объемы опухолей на день 37 (B) и объемы опухолей у отдельных мышей в течение эксперимента (C). Также были показаны средние (средние ± стандартная погрешность) (D) и индивидуальные (E) изменения массы организма в каждой обрабатываемой группе. Количество мышей, которые были обнаружены мертвыми или подвергнуты гуманной эфтаназии вследствие потери массы тела, обозначали как ʺ#ʺ. ʺ↑ʺ обозначает антитело, и ʺ↑ʺ обозначает график дозирования нанотела. Данные объема опухоли, полученные в этом эксперименте, приведены на фигуре 13 (A-J). Эти данные показали, что F023700912 обладает высокой эффективностью в ингибировании роста опухоли.
Пример 9: Связывание F023700912 и F023700925 с естественными антителами, отобранными у здоровых людей и людей, пораженных злокачественной опухолью.
Эталонное трехвалентное нанотело, 013700112 (не модифицированное для ослабления связывания с естественными антителами), демонстрировало связывание с несколькими образцами сыворотки, полученными от (фигура 14А) здоровых субъектов или (фигура 14В) больных злокачественной опухолью. Оптимизированное по последовательности трехвалентное нанотело аналогичного размера, F023700912, демонстрировало более низкую частоту связывания с аналогичными образцами сыворотки. F023700925 состояло из тех же структурных блоков, что и F023700912. Несмотря на больший размер, пятивалентное F023700925 нанотело больше не связывается с естественным Abs, по сравнению с эталонным нанотелом 013700112. Связывание естественных антител с нанотелами, захваченными на сывороточном альбумине человека (HSA), оценивали с использованием ProteOn XPR36 (Bio-Rad Laboratories, Inc.). В качестве подвижного буфера использовали PBS/Tween (забуференный фосфатом физиологический раствор, pH 7,4, 0,005% Tween20), и эксперименты проводили при 25°C. Лигандные полосы сенсорного чипа ProteOn GLC активировали с помощью EDC/NHS (скорость потока 30 мкл/мин) и HSA вводили при 10 мкг/мл в ацетатном буфере ProteOn pH 4,5 (скорость потока 100 мкл/мин), чтобы обеспечить уровни иммобилизации около 3600 единиц ответа. После иммобилизации, поверхности деактивировали этаноламин гидрохлоридом (скорость потока 30 мкл/мин). Нанотела вводили в течение 2 минут при 45 мкл/мин на поверхность HSA, чтобы обеспечить уровень захвата нанотела около 600 единиц ответа для трехвалентного F023700912 и около 1000 единиц ответа для пятивалентного F023700925. Образцы, содержащие естественные антитела, разбавляли 1:10 в PBS-Tween20 (0,005%) перед инъецированием в течение 2 минут при 45 мкл/мин с последующей стадией диссоциации в течение 400 сек. После каждого цикла (то есть перед новой стадией захвата нанотела и инъекции образца крови) поверхности HSA регенерировали инъекцией HCl (100 мМ) в течение 2 мин при 45 мкл/мин. Обработку сенсограммы и анализ данных выполняли с помощью ProteOn Manager 3.1.0 (Bio-Rad Laboratories, Inc.). Сенсограммы, показывающие связывание естественных антител, были получены после двойного контрольного вычитания 1) диссоциации нанотело-HSA и 2) неспецифного связывания с эталонной лигандной полосой, содержащей только HSA. Уровни связывания естественных антител определяли путем задания приведенных значений через 125 секунд (через 5 секунд после окончания ассоциации). В качестве эталона, образцы, содержащие естественные антитела, также исследовали на связывание с трехвалентным нанотелом, не модифицированным для ослабления связывания этих естественных антител (T013700112).
Пример 10: Эпитопное картирование анти-hCTLA4 нанотела с использованием масс-спектрометрии водородно-дейтериевого обмена
Контактные области между анти-hCTLA4 нанотелом, F023700912 определяли с помощью анализа масс-спектрометрии водородно-дейтериевого обмена (HDX-MS). С помощью HDX-MS определяли инкорпорацию дейтерия в амидный скелет белка, и изменения в этой инкорпорации зависили от экспозиции водорода растворителя. Осуществляли сравнение уровней обмена дейтерия в образцах, не содержащих антиген, и образцов, связанных с нанотелом, для идентификации областей антигена, которые могут контактировать с нанотелом.
Остатками CTLA4 человека, наиболее сильно защищенными от дейтерирования посредством нанотела, F023700912, были VRVTVL (остатки 33-38 SEQ ID NO: 195), ADSQVTEVC (остатки 41-49 в SEQ ID NO: 195) и CKVELMYPPPYYLG (остатки 93-106 в SEQ ID NO: 195).
Таблица G. Аминокислотные последовательности (SEQ ID NO: 195)
--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Merck, Sharp & Dohme Corp.
<120> PD1/CTLA4-связывающие вещества
<130> 24236
<150> 62/256,985
<151> 2015-11-18
<160> 201
<170> Патентная версия 3.5
<210> 1
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 1
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Ser Ser
115
<210> 2
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 2
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 3
<211> 5
<212> Белок
<213> Лама
<400> 3
Ile His Ala Met Gly
1 5
<210> 4
<211> 17
<212> Белок
<213> Лама
<220>
<221> Прочий признак
<222> (4)..(4)
<223> X представляет собой W или V
<400> 4
Val Ile Thr Xaa Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 5
<211> 10
<212> Белок
<213> Лама
<220>
<221> Прочий признак
<222> (7)..(7)
<223> X представляет собой W или F
<400> 5
Asp Lys His Gln Ser Ser Xaa Tyr Asp Tyr
1 5 10
<210> 6
<211> 10
<212> Белок
<213> Лама
<400> 6
Gly Ser Ile Ala Ser Ile His Ala Met Gly
1 5 10
<210> 7
<211> 10
<212> Белок
<213> Лама
<220>
<221> Прочий признак
<222> (4)..(4)
<223> X представляет собой W или V
<400> 7
Val Ile Thr Xaa Ser Gly Gly Ile Thr Tyr
1 5 10
<210> 8
<211> 10
<212> Белок
<213> Лама
<220>
<221> Прочий признак
<222> (7)..(7)
<223> X представляет собой W или F
<400> 8
Asp Lys His Gln Ser Ser Xaa Tyr Asp Tyr
1 5 10
<210> 9
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 9
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Ser Ser
115
<210> 10
<211> 5
<212> Белок
<213> Лама
<400> 10
Phe Tyr Gly Met Gly
1 5
<210> 11
<211> 17
<212> Белок
<213> Лама
<400> 11
Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 12
<211> 10
<212> Белок
<213> Лама
<220>
<221> Прочий признак
<222> (2)..(2)
<223> X is M or P
<400> 12
Glu Xaa Ser Gly Ile Ser Gly Trp Asp Tyr
1 5 10
<210> 13
<211> 10
<212> Белок
<213> Лама
<400> 13
Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly
1 5 10
<210> 14
<211> 10
<212> Белок
<213> Лама
<400> 14
Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr
1 5 10
<210> 15
<211> 10
<212> Белок
<213> Лама
<220>
<221> Прочий признак
<222> (2)..(2)
<223> X is M or P
<400> 15
Glu Xaa Ser Gly Ile Ser Gly Trp Asp Tyr
1 5 10
<210> 16
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 16
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 17
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 17
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Lys Val Ser Ser
115
<210> 18
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 18
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Gln Val Ser Ser
115
<210> 19
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 19
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Lys Ser
115
<210> 20
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 20
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Gln Ser
115
<210> 21
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 21
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Lys Val Ser Ser
115
<210> 22
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 22
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Gln Val Ser Ser
115
<210> 23
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 23
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Lys Ser
115
<210> 24
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 24
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Gln Ser
115
<210> 25
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 25
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 26
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 26
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Lys Val Ser Ser
115
<210> 27
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 27
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Gln Val Ser Ser
115
<210> 28
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 28
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Lys Ser
115
<210> 29
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 29
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Gln Ser
115
<210> 30
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 30
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 31
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 31
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 32
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 32
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala
115 120
<210> 33
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 33
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Lys Val Ser Ser Ala
115 120
<210> 34
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 34
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Gln Val Ser Ser Ala
115 120
<210> 35
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 35
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Lys Ser Ala
115 120
<210> 36
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 36
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Gln Ser Ala
115 120
<210> 37
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 37
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Lys Val Ser Ser Ala
115 120
<210> 38
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 38
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Gln Val Ser Ser Ala
115 120
<210> 39
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 39
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Lys Ser Ala
115 120
<210> 40
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 40
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Gln Ser Ala
115 120
<210> 41
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 41
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala
115 120
<210> 42
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 42
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Lys Val Ser Ser Ala
115 120
<210> 43
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 43
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Gln Val Ser Ser Ala
115 120
<210> 44
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 44
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Lys Ser Ala
115 120
<210> 45
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 45
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Gln Ser Ala
115 120
<210> 46
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 46
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala
115 120
<210> 47
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 47
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala
115 120
<210> 48
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 48
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Ser Ser
115
<210> 49
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 49
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Lys Val Ser Ser
115
<210> 50
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 50
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Gln Val Ser Ser
115
<210> 51
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 51
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Lys Ser
115
<210> 52
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 52
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Gln Ser
115
<210> 53
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 53
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Lys Val Ser Ser
115
<210> 54
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 54
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Gln Val Ser Ser
115
<210> 55
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 55
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Lys Ser
115
<210> 56
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 56
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Gln Ser
115
<210> 57
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 57
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Ser Ser
115
<210> 58
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 58
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Lys Val Ser Ser
115
<210> 59
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 59
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Gln Val Ser Ser
115
<210> 60
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 60
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Lys Ser
115
<210> 61
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 61
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Gln Ser
115
<210> 62
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 62
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 63
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 63
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 64
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 64
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 65
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 65
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 66
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 66
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Ser Ser Ala
115 120
<210> 67
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 67
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Lys Val Ser Ser Ala
115 120
<210> 68
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 68
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Gln Val Ser Ser Ala
115 120
<210> 69
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 69
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Lys Ser Ala
115 120
<210> 70
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 70
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Gln Ser Ala
115 120
<210> 71
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 71
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Lys Val Ser Ser Ala
115 120
<210> 72
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 72
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Gln Val Ser Ser Ala
115 120
<210> 73
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 73
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Lys Ser Ala
115 120
<210> 74
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 74
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Gln Ser Ala
115 120
<210> 75
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 75
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Ser Ser Ala
115 120
<210> 76
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 76
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Lys Val Ser Ser Ala
115 120
<210> 77
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 77
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Gln Val Ser Ser Ala
115 120
<210> 78
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 78
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Lys Ser Ala
115 120
<210> 79
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 79
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Gln Val Thr Val Gln Ser Ala
115 120
<210> 80
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 80
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala
115 120
<210> 81
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 81
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala
115 120
<210> 82
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 82
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala
115 120
<210> 83
<211> 120
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 83
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala
115 120
<210> 84
<211> 115
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 84
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 85
<211> 115
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 85
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 86
<211> 35
<212> Белок
<213> Искусственная последовательность
<220>
<223> 35GS linker
<400> 86
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser
35
<210> 87
<211> 34
<212> Белок
<213> Искусственная последовательность
<220>
<223> His6-FLAG3 tag
<400> 87
His His His His His His Gly Ala Ala Asp Tyr Lys Asp His Asp Gly
1 5 10 15
Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys Gly
20 25 30
Ala Ala
<210> 88
<211> 5
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<400> 88
Val Thr Val Lys Ser
1 5
<210> 89
<211> 5
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<400> 89
Val Thr Val Gln Ser
1 5
<210> 90
<211> 5
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<400> 90
Val Lys Val Ser Ser
1 5
<210> 91
<211> 5
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<400> 91
Val Gln Val Ser Ser
1 5
<210> 92
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<220>
<221> Прочий признак
<222> (6)..(6)
<223> X представляет собой 1-10 аминокислот, независимо выбранных из
природных аминокислот
<400> 92
Val Thr Val Lys Ser Xaa
1 5
<210> 93
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<220>
<221> Прочий признак
<222> (6)..(6)
<223> X представляет собой 1-10 аминокислот, независимо выбранных из
природных аминокислот
<400> 93
Val Thr Val Gln Ser Xaa
1 5
<210> 94
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<220>
<221> Прочий признак
<222> (6)..(6)
<223> X представляет собой 1-10 аминокислот, независимо выбранных из
природных аминокислот
<400> 94
Val Lys Val Ser Ser Xaa
1 5
<210> 95
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<220>
<221> Прочий признак
<222> (6)..(6)
<223> X представляет собой 1-10 аминокислот, независимо выбранных из
природных аминокислот
<400> 95
Val Gln Val Ser Ser Xaa
1 5
<210> 96
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<400> 96
Val Thr Val Lys Ser Ala
1 5
<210> 97
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<400> 97
Val Thr Val Gln Ser Ala
1 5
<210> 98
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<400> 98
Val Lys Val Ser Ser Ala
1 5
<210> 99
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<400> 99
Val Gln Val Ser Ser Ala
1 5
<210> 100
<211> 5
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<400> 100
Val Thr Val Ser Ser
1 5
<210> 101
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<220>
<221> Прочий признак
<222> (6)..(6)
<223> X представляет собой 1-10 аминокислот, независимо выбранных из
природных аминокислот
<400> 101
Val Thr Val Ser Ser Xaa
1 5
<210> 102
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> C-концевой экстендер
<400> 102
Val Thr Val Ser Ser Ala
1 5
<210> 103
<211> 732
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 103
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Gln Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met
485 490 495
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val Ala Asp
500 505 510
Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala
545 550 555 560
Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu
565 570 575
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
580 585 590
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
595 600 605
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
610 615 620
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
625 630 635 640
Ser Gly Phe Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala
645 650 655
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
660 665 670
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
675 680 685
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
690 695 700
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
705 710 715 720
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Ala
725 730
<210> 104
<211> 732
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 104
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met
485 490 495
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp
500 505 510
Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala
545 550 555 560
Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu
565 570 575
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
580 585 590
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
595 600 605
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
610 615 620
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
625 630 635 640
Ser Gly Phe Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala
645 650 655
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
660 665 670
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
675 680 685
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
690 695 700
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
705 710 715 720
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Ala
725 730
<210> 105
<211> 732
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 105
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Gln Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met
485 490 495
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val Ala Asp
500 505 510
Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala
545 550 555 560
Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu
565 570 575
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
580 585 590
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
595 600 605
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Leu Glu Ser Gly
610 615 620
Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
625 630 635 640
Ser Gly Phe Thr Phe Arg Ser Phe Gly Met Ser Trp Val Arg Gln Ala
645 650 655
Pro Gly Lys Gly Pro Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
660 665 670
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
675 680 685
Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
690 695 700
Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
705 710 715 720
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Ala
725 730
<210> 106
<211> 732
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 106
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met
485 490 495
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp
500 505 510
Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala
545 550 555 560
Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu
565 570 575
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
580 585 590
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
595 600 605
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Leu Glu Ser Gly
610 615 620
Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
625 630 635 640
Ser Gly Phe Thr Phe Arg Ser Phe Gly Met Ser Trp Val Arg Gln Ala
645 650 655
Pro Gly Lys Gly Pro Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
660 665 670
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
675 680 685
Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
690 695 700
Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
705 710 715 720
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Ala
725 730
<210> 107
<211> 732
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 107
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Gln Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met
485 490 495
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val
500 505 510
Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly
545 550 555 560
Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
565 570 575
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
580 585 590
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
595 600 605
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
610 615 620
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
625 630 635 640
Ser Gly Phe Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala
645 650 655
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
660 665 670
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
675 680 685
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
690 695 700
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
705 710 715 720
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Ala
725 730
<210> 108
<211> 732
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 108
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met
485 490 495
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val
500 505 510
Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly
545 550 555 560
Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
565 570 575
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
580 585 590
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
595 600 605
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
610 615 620
Gly Gly Leu Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
625 630 635 640
Ser Gly Phe Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala
645 650 655
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
660 665 670
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
675 680 685
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
690 695 700
Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
705 710 715 720
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Ala
725 730
<210> 109
<211> 732
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 109
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Gln Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met
485 490 495
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val
500 505 510
Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly
545 550 555 560
Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
565 570 575
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
580 585 590
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
595 600 605
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Leu Glu Ser Gly
610 615 620
Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
625 630 635 640
Ser Gly Phe Thr Phe Arg Ser Phe Gly Met Ser Trp Val Arg Gln Ala
645 650 655
Pro Gly Lys Gly Pro Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
660 665 670
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
675 680 685
Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
690 695 700
Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
705 710 715 720
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Ala
725 730
<210> 110
<211> 732
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 110
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met
485 490 495
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val
500 505 510
Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly
545 550 555 560
Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu
565 570 575
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
580 585 590
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
595 600 605
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Leu Glu Ser Gly
610 615 620
Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala
625 630 635 640
Ser Gly Phe Thr Phe Arg Ser Phe Gly Met Ser Trp Val Arg Gln Ala
645 650 655
Pro Gly Lys Gly Pro Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
660 665 670
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
675 680 685
Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
690 695 700
Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
705 710 715 720
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Ala
725 730
<210> 111
<211> 424
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 111
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Gln Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
305 310 315 320
Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
325 330 335
Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
340 345 350
Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys
370 375 380
Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly
405 410 415
Thr Leu Val Thr Val Ser Ser Ala
420
<210> 112
<211> 424
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 112
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
305 310 315 320
Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
325 330 335
Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
340 345 350
Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys
370 375 380
Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly
405 410 415
Thr Leu Val Thr Val Ser Ser Ala
420
<210> 113
<211> 424
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 113
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Gln Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
325 330 335
Phe Arg Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
340 345 350
Pro Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly
405 410 415
Thr Leu Val Thr Val Ser Ser Ala
420
<210> 114
<211> 424
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 114
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
325 330 335
Phe Arg Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
340 345 350
Pro Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly
405 410 415
Thr Leu Val Thr Val Ser Ser Ala
420
<210> 115
<211> 424
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 115
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
305 310 315 320
Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
325 330 335
Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
340 345 350
Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys
370 375 380
Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly
405 410 415
Thr Leu Val Thr Val Ser Ser Ala
420
<210> 116
<211> 424
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 116
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val
305 310 315 320
Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
325 330 335
Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
340 345 350
Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys
370 375 380
Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Val Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly
405 410 415
Thr Leu Val Thr Val Ser Ser Ala
420
<210> 117
<211> 424
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 117
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
325 330 335
Phe Arg Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
340 345 350
Pro Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly
405 410 415
Thr Leu Val Thr Val Ser Ser Ala
420
<210> 118
<211> 424
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 118
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
325 330 335
Phe Arg Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
340 345 350
Pro Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly
405 410 415
Thr Leu Val Thr Val Ser Ser Ala
420
<210> 119
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 119
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Gln Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Gln Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 120
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 120
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 121
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 121
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Gln Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Gln Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 122
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 122
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 123
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 123
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Gln Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 124
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 124
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 125
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 125
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Gln Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 126
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 126
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 127
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 127
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 128
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 128
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Gln Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 129
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 129
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 130
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 130
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Gln Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 131
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 131
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 132
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 132
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 133
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 133
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Gln Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 134
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 134
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Met Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile
325 330 335
Ala Ser Ile His Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Leu Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 135
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 135
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 136
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 136
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 137
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 137
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 138
<211> 270
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 138
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg
180 185 190
Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser
195 200 205
Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu
245 250 255
Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Ala
260 265 270
<210> 139
<211> 424
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 139
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
325 330 335
Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
340 345 350
Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys
370 375 380
Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly
405 410 415
Thr Leu Val Thr Val Ser Ser Ala
420
<210> 140
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 140
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Val Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Phe Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 141
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 141
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Val Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Gln Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Phe Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 142
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 142
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Val Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Pro Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Phe Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 143
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 143
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 144
<211> 110
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<220>
<221> Прочий признак
<222> (11)..(11)
<223> X представляет собой L или V
<220>
<221> Прочий признак
<222> (93)..(93)
<223> X представляет собой L или V
<400> 144
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Xaa Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Xaa Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu
100 105 110
<210> 145
<211> 1272
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 145
gacgtgcaat tggtggagtc tggtggcgga gttgtccagc ctggcggcag tctgcggtta 60
tcttgcgccg cttctggcag cattgccagt attcacgcta tgggttggtt caggcaggct 120
cctggtaaag aacgtgagtt tgtggctgtg attacttggt ccggtggtat tacttactac 180
gctgatagcg ttaagggccg gtttacaatt tcccgtgata atagcaaaaa taccgtctat 240
ctgcaaatga acagtctgcg cccggaagat accgccctgt attactgtgc gggcgataaa 300
catcagtcct catggtatga ctactggggg caagggaccc tggtcacggt ctcctccgga 360
ggcggtgggt caggtggcgg aggcagcggt ggaggaggta gtggcggtgg cggtagtggg 420
ggtggaggca gcggaggcgg aggcagtggg ggcggtggat ccgaggtgca gttggtggag 480
tctgggggag gagtggtgca gccggggggc tctctgagac tctcctgtgc agcctctggt 540
ggcaccttca gtttctatgg catgggctgg ttccgccagg ctccagggaa ggagcgcgag 600
tttgtagcag atattagaac cagtgctggt aggacatact atgcagactc cgtgaagggc 660
cgattcacca tctccagaga caacagcaag aacacggtgt atctgcaaat gaacagcctg 720
cgccctgagg acacggccct gtattactgt gcagcagagc caagtggaat aagtggttgg 780
gactactggg gccaggggac cctggtcacg gtctcgagcg gaggcggtgg gtcaggtggc 840
ggaggcagcg gtggaggagg tagtggcggt ggcggtagtg ggggtggagg cagcggaggc 900
ggaggcagtg ggggcggtgg ctcagaggta caactagtgg agtctggagg tggcgttgtg 960
caaccgggta acagtctgcg ccttagctgc gcagcgtctg gctttacctt cagctccttt 1020
ggcatgagct gggttcgcca ggctccggga aaaggactgg aatgggtttc gtctattagc 1080
ggcagtggta gcgatacgct ctacgcggac tccgtgaagg gccgtttcac catctcccgc 1140
gataacgcca aaactacact gtatctgcaa atgaatagcc tgcgtcctga agatacggcc 1200
ctgtattact gtactattgg tggctcgtta agccgttctt cacagggtac cctggtcacc 1260
gtctcctcag cg 1272
<210> 146
<211> 424
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 146
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Pro Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
325 330 335
Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
340 345 350
Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys
370 375 380
Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly
405 410 415
Thr Leu Val Thr Val Ser Ser Ala
420
<210> 147
<211> 85
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 147
Met Arg Phe Pro Ser Ile Phe Thr Ala Val Leu Phe Ala Ala Ser Ser
1 5 10 15
Ala Leu Ala Ala Pro Val Asn Thr Thr Thr Glu Asp Glu Thr Ala Gln
20 25 30
Ile Pro Ala Glu Ala Val Ile Gly Tyr Ser Asp Leu Glu Gly Asp Phe
35 40 45
Asp Val Ala Val Leu Pro Phe Ser Asn Ser Thr Asn Asn Gly Leu Leu
50 55 60
Phe Ile Asn Thr Thr Ile Ala Ser Ile Ala Ala Lys Glu Glu Gly Val
65 70 75 80
Ser Leu Glu Lys Arg
85
<210> 148
<211> 1734
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 148
gacgtgcaat tggtggagtc tggtggcgga gttgtccagc ctggcggcag tctgcggtta 60
tcttgcgccg cttctggcag cattgccagt attcacgcta tgggttggtt caggcaggct 120
cctggtaaag aacgtgagtt tgtggctgtg attacttggt ccggtggtat tacttactac 180
gctgatagcg ttaagggccg gtttacaatt tcccgtgata atagcaaaaa taccgtctat 240
ctgcaaatga acagtctgcg cccggaagat accgccctgt attactgtgc gggcgataaa 300
catcagtcct catggtatga ctactggggg caagggaccc tggtcacggt ctcctccgga 360
ggcggtgggt caggtggcgg aggcagcggt ggaggaggta gtggcggtgg cggtagtggg 420
ggtggaggca gcggaggcgg aggcagtggg ggcggtggat cagaggtgca gttggtggag 480
tctggtggcg gagttgtcca gcctggcggc agtctgcggt tatcttgcgc cgcttctggc 540
agcattgcca gtattcacgc tatgggttgg ttcaggcagg ctcctggtaa agaacgtgag 600
tttgtggctg tgattacttg gtccggtggt attacttact acgctgatag cgttaagggc 660
cggtttacaa tttcccgtga taatagcaaa aataccgtct atctgcaaat gaacagtctg 720
cgcccggaag ataccgccct gtattactgt gcgggcgata aacatcagtc ctcatggtat 780
gactactggg ggcaagggac cctggtcacg gtctcctcag gaggcggtgg gtcaggtggc 840
ggaggcagcg gtggaggagg tagtggcggt ggcggtagtg ggggtggagg cagcggaggc 900
ggaggcagtg ggggcggtgg atccgaggtg cagttggtgg agtctggggg aggagtggtg 960
cagccggggg gctctctgag actctcctgt gcagcctctg gtggcacctt cagtttctat 1020
ggcatgggct ggttccgcca ggctccaggg aaggagcgcg agtttgtagc agatattaga 1080
accagtgctg gtaggacata ctatgcagac tccgtgaagg gccgattcac catctccaga 1140
gacaacagca agaacacggt gtatctgcaa atgaacagcc tgcgccctga ggacacggcc 1200
ctgtattact gtgcagcaga gccaagtgga ataagtggtt gggactactg gggccagggg 1260
accctggtca cggtctcgag cggaggcggt gggtcaggtg gcggaggcag cggtggagga 1320
ggtagtggcg gtggcggtag tgggggtgga ggcagcggag gcggaggcag tgggggcggt 1380
ggctcagagg tacaactagt ggagtctgga ggtggcgttg tgcaaccggg taacagtctg 1440
cgccttagct gcgcagcgtc tggctttacc ttcagctcct ttggcatgag ctgggttcgc 1500
caggctccgg gaaaaggact ggaatgggtt tcgtctatta gcggcagtgg tagcgatacg 1560
ctctacgcgg actccgtgaa gggccgtttc accatctccc gcgataacgc caaaactaca 1620
ctgtatctgc aaatgaatag cctgcgtcct gaagatacgg ccctgtatta ctgtactatt 1680
ggtggctcgt taagccgttc ttcacagggt accctggtca ccgtctcctc agcg 1734
<210> 149
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 149
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 150
<211> 1734
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 150
Gly Ala Cys Gly Thr Gly Cys Ala Ala Thr Thr Gly Gly Thr Gly Gly
1 5 10 15
Ala Gly Thr Cys Thr Gly Gly Thr Gly Gly Cys Gly Gly Ala Gly Thr
20 25 30
Thr Gly Thr Cys Cys Ala Gly Cys Cys Thr Gly Gly Cys Gly Gly Cys
35 40 45
Ala Gly Thr Cys Thr Gly Cys Gly Gly Thr Thr Ala Thr Cys Thr Thr
50 55 60
Gly Cys Gly Cys Cys Gly Cys Thr Thr Cys Thr Gly Gly Cys Ala Gly
65 70 75 80
Cys Ala Thr Thr Gly Cys Cys Ala Gly Thr Ala Thr Thr Cys Ala Cys
85 90 95
Gly Cys Thr Ala Thr Gly Gly Gly Thr Thr Gly Gly Thr Thr Cys Ala
100 105 110
Gly Gly Cys Ala Gly Gly Cys Thr Cys Cys Thr Gly Gly Thr Ala Ala
115 120 125
Ala Gly Ala Ala Cys Gly Thr Gly Ala Gly Thr Thr Thr Gly Thr Gly
130 135 140
Gly Cys Thr Gly Thr Gly Ala Thr Thr Ala Cys Thr Thr Gly Gly Thr
145 150 155 160
Cys Cys Gly Gly Thr Gly Gly Thr Ala Thr Thr Ala Cys Thr Thr Ala
165 170 175
Cys Thr Ala Cys Gly Cys Thr Gly Ala Thr Ala Gly Cys Gly Thr Thr
180 185 190
Ala Ala Gly Gly Gly Cys Cys Gly Gly Thr Thr Thr Ala Cys Ala Ala
195 200 205
Thr Thr Thr Cys Cys Cys Gly Thr Gly Ala Thr Ala Ala Thr Ala Gly
210 215 220
Cys Ala Ala Ala Ala Ala Thr Ala Cys Cys Gly Thr Cys Thr Ala Thr
225 230 235 240
Cys Thr Gly Cys Ala Ala Ala Thr Gly Ala Ala Cys Ala Gly Thr Cys
245 250 255
Thr Gly Cys Gly Cys Cys Cys Gly Gly Ala Ala Gly Ala Thr Ala Cys
260 265 270
Cys Gly Cys Cys Cys Thr Gly Thr Ala Thr Thr Ala Cys Thr Gly Thr
275 280 285
Gly Cys Gly Gly Gly Cys Gly Ala Thr Ala Ala Ala Cys Ala Thr Cys
290 295 300
Ala Gly Thr Cys Cys Thr Cys Ala Thr Gly Gly Thr Ala Thr Gly Ala
305 310 315 320
Cys Thr Ala Cys Thr Gly Gly Gly Gly Gly Cys Ala Ala Gly Gly Gly
325 330 335
Ala Cys Cys Cys Thr Gly Gly Thr Cys Ala Cys Gly Gly Thr Cys Thr
340 345 350
Cys Cys Thr Cys Cys Gly Gly Ala Gly Gly Cys Gly Gly Thr Gly Gly
355 360 365
Gly Thr Cys Ala Gly Gly Thr Gly Gly Cys Gly Gly Ala Gly Gly Cys
370 375 380
Ala Gly Cys Gly Gly Thr Gly Gly Ala Gly Gly Ala Gly Gly Thr Ala
385 390 395 400
Gly Thr Gly Gly Cys Gly Gly Thr Gly Gly Cys Gly Gly Thr Ala Gly
405 410 415
Thr Gly Gly Gly Gly Gly Thr Gly Gly Ala Gly Gly Cys Ala Gly Cys
420 425 430
Gly Gly Ala Gly Gly Cys Gly Gly Ala Gly Gly Cys Ala Gly Thr Gly
435 440 445
Gly Gly Gly Gly Cys Gly Gly Thr Gly Gly Ala Thr Cys Cys Gly Ala
450 455 460
Gly Gly Thr Gly Cys Ala Gly Thr Thr Gly Gly Thr Gly Gly Ala Gly
465 470 475 480
Thr Cys Thr Gly Gly Gly Gly Gly Ala Gly Gly Ala Gly Thr Gly Gly
485 490 495
Thr Gly Cys Ala Gly Cys Cys Gly Gly Gly Gly Gly Gly Cys Thr Cys
500 505 510
Thr Cys Thr Gly Ala Gly Ala Cys Thr Cys Thr Cys Cys Thr Gly Thr
515 520 525
Gly Cys Ala Gly Cys Cys Thr Cys Thr Gly Gly Thr Gly Gly Cys Ala
530 535 540
Cys Cys Thr Thr Cys Ala Gly Thr Thr Thr Cys Thr Ala Thr Gly Gly
545 550 555 560
Cys Ala Thr Gly Gly Gly Cys Thr Gly Gly Thr Thr Cys Cys Gly Cys
565 570 575
Cys Ala Gly Gly Cys Thr Cys Cys Ala Gly Gly Gly Ala Ala Gly Gly
580 585 590
Ala Gly Cys Gly Cys Gly Ala Gly Thr Thr Thr Gly Thr Ala Gly Cys
595 600 605
Ala Gly Ala Thr Ala Thr Thr Ala Gly Ala Ala Cys Cys Ala Gly Thr
610 615 620
Gly Cys Thr Gly Gly Thr Ala Gly Gly Ala Cys Ala Thr Ala Cys Thr
625 630 635 640
Ala Thr Gly Cys Ala Gly Ala Cys Thr Cys Cys Gly Thr Gly Ala Ala
645 650 655
Gly Gly Gly Cys Cys Gly Ala Thr Thr Cys Ala Cys Cys Ala Thr Cys
660 665 670
Thr Cys Cys Ala Gly Ala Gly Ala Cys Ala Ala Cys Ala Gly Cys Ala
675 680 685
Ala Gly Ala Ala Cys Ala Cys Gly Gly Thr Gly Thr Ala Thr Cys Thr
690 695 700
Gly Cys Ala Ala Ala Thr Gly Ala Ala Cys Ala Gly Cys Cys Thr Gly
705 710 715 720
Cys Gly Cys Cys Cys Thr Gly Ala Gly Gly Ala Cys Ala Cys Gly Gly
725 730 735
Cys Cys Cys Thr Gly Thr Ala Thr Thr Ala Cys Thr Gly Thr Gly Cys
740 745 750
Ala Gly Cys Ala Gly Ala Gly Cys Cys Ala Ala Gly Thr Gly Gly Ala
755 760 765
Ala Thr Ala Ala Gly Thr Gly Gly Thr Thr Gly Gly Gly Ala Cys Thr
770 775 780
Ala Cys Thr Gly Gly Gly Gly Cys Cys Ala Gly Gly Gly Gly Ala Cys
785 790 795 800
Cys Cys Thr Gly Gly Thr Cys Ala Cys Gly Gly Thr Cys Thr Cys Gly
805 810 815
Ala Gly Cys Gly Gly Ala Gly Gly Cys Gly Gly Thr Gly Gly Gly Thr
820 825 830
Cys Ala Gly Gly Thr Gly Gly Cys Gly Gly Ala Gly Gly Cys Ala Gly
835 840 845
Cys Gly Gly Thr Gly Gly Ala Gly Gly Ala Gly Gly Thr Ala Gly Thr
850 855 860
Gly Gly Cys Gly Gly Thr Gly Gly Cys Gly Gly Thr Ala Gly Thr Gly
865 870 875 880
Gly Gly Gly Gly Thr Gly Gly Ala Gly Gly Cys Ala Gly Cys Gly Gly
885 890 895
Ala Gly Gly Cys Gly Gly Ala Gly Gly Cys Ala Gly Thr Gly Gly Gly
900 905 910
Gly Gly Cys Gly Gly Thr Gly Gly Ala Thr Cys Ala Gly Ala Gly Gly
915 920 925
Thr Gly Cys Ala Gly Thr Thr Gly Gly Thr Gly Gly Ala Gly Thr Cys
930 935 940
Thr Gly Gly Gly Gly Gly Ala Gly Gly Ala Gly Thr Gly Gly Thr Gly
945 950 955 960
Cys Ala Gly Cys Cys Gly Gly Gly Gly Gly Gly Cys Thr Cys Thr Cys
965 970 975
Thr Gly Ala Gly Ala Cys Thr Cys Thr Cys Cys Thr Gly Thr Gly Cys
980 985 990
Ala Gly Cys Cys Thr Cys Thr Gly Gly Thr Gly Gly Cys Ala Cys Cys
995 1000 1005
Thr Thr Cys Ala Gly Thr Thr Thr Cys Thr Ala Thr Gly Gly Cys
1010 1015 1020
Ala Thr Gly Gly Gly Cys Thr Gly Gly Thr Thr Cys Cys Gly Cys
1025 1030 1035
Cys Ala Gly Gly Cys Thr Cys Cys Ala Gly Gly Gly Ala Ala Gly
1040 1045 1050
Gly Ala Gly Cys Gly Cys Gly Ala Gly Thr Thr Thr Gly Thr Ala
1055 1060 1065
Gly Cys Ala Gly Ala Thr Ala Thr Thr Ala Gly Ala Ala Cys Cys
1070 1075 1080
Ala Gly Thr Gly Cys Thr Gly Gly Thr Ala Gly Gly Ala Cys Ala
1085 1090 1095
Thr Ala Cys Thr Ala Thr Gly Cys Ala Gly Ala Cys Thr Cys Cys
1100 1105 1110
Gly Thr Gly Ala Ala Gly Gly Gly Cys Cys Gly Ala Thr Thr Cys
1115 1120 1125
Ala Cys Cys Ala Thr Cys Thr Cys Cys Ala Gly Ala Gly Ala Cys
1130 1135 1140
Ala Ala Cys Ala Gly Cys Ala Ala Gly Ala Ala Cys Ala Cys Gly
1145 1150 1155
Gly Thr Gly Thr Ala Thr Cys Thr Gly Cys Ala Ala Ala Thr Gly
1160 1165 1170
Ala Ala Cys Ala Gly Cys Cys Thr Gly Cys Gly Cys Cys Cys Thr
1175 1180 1185
Gly Ala Gly Gly Ala Cys Ala Cys Gly Gly Cys Cys Cys Thr Gly
1190 1195 1200
Thr Ala Thr Thr Ala Cys Thr Gly Thr Gly Cys Ala Gly Cys Ala
1205 1210 1215
Gly Ala Gly Cys Cys Ala Ala Gly Thr Gly Gly Ala Ala Thr Ala
1220 1225 1230
Ala Gly Thr Gly Gly Thr Thr Gly Gly Gly Ala Cys Thr Ala Cys
1235 1240 1245
Thr Gly Gly Gly Gly Cys Cys Ala Gly Gly Gly Gly Ala Cys Cys
1250 1255 1260
Cys Thr Gly Gly Thr Cys Ala Cys Gly Gly Thr Cys Thr Cys Cys
1265 1270 1275
Thr Cys Ala Gly Gly Ala Gly Gly Cys Gly Gly Thr Gly Gly Gly
1280 1285 1290
Thr Cys Ala Gly Gly Thr Gly Gly Cys Gly Gly Ala Gly Gly Cys
1295 1300 1305
Ala Gly Cys Gly Gly Thr Gly Gly Ala Gly Gly Ala Gly Gly Thr
1310 1315 1320
Ala Gly Thr Gly Gly Cys Gly Gly Thr Gly Gly Cys Gly Gly Thr
1325 1330 1335
Ala Gly Thr Gly Gly Gly Gly Gly Thr Gly Gly Ala Gly Gly Cys
1340 1345 1350
Ala Gly Cys Gly Gly Ala Gly Gly Cys Gly Gly Ala Gly Gly Cys
1355 1360 1365
Ala Gly Thr Gly Gly Gly Gly Gly Cys Gly Gly Thr Gly Gly Ala
1370 1375 1380
Thr Cys Ala Gly Ala Gly Gly Thr Gly Cys Ala Ala Cys Thr Ala
1385 1390 1395
Gly Thr Gly Gly Ala Gly Thr Cys Thr Gly Gly Ala Gly Gly Thr
1400 1405 1410
Gly Gly Cys Gly Thr Thr Gly Thr Gly Cys Ala Ala Cys Cys Gly
1415 1420 1425
Gly Gly Thr Ala Ala Cys Ala Gly Thr Cys Thr Gly Cys Gly Cys
1430 1435 1440
Cys Thr Thr Ala Gly Cys Thr Gly Cys Gly Cys Ala Gly Cys Gly
1445 1450 1455
Thr Cys Thr Gly Gly Cys Thr Thr Thr Ala Cys Cys Thr Thr Cys
1460 1465 1470
Ala Gly Cys Thr Cys Cys Thr Thr Thr Gly Gly Cys Ala Thr Gly
1475 1480 1485
Ala Gly Cys Thr Gly Gly Gly Thr Thr Cys Gly Cys Cys Ala Gly
1490 1495 1500
Gly Cys Thr Cys Cys Gly Gly Gly Ala Ala Ala Ala Gly Gly Ala
1505 1510 1515
Cys Thr Gly Gly Ala Ala Thr Gly Gly Gly Thr Thr Thr Cys Gly
1520 1525 1530
Thr Cys Thr Ala Thr Thr Ala Gly Cys Gly Gly Cys Ala Gly Thr
1535 1540 1545
Gly Gly Thr Ala Gly Cys Gly Ala Thr Ala Cys Gly Cys Thr Cys
1550 1555 1560
Thr Ala Cys Gly Cys Gly Gly Ala Cys Thr Cys Cys Gly Thr Gly
1565 1570 1575
Ala Ala Gly Gly Gly Cys Cys Gly Thr Thr Thr Cys Ala Cys Cys
1580 1585 1590
Ala Thr Cys Thr Cys Cys Cys Gly Cys Gly Ala Thr Ala Ala Cys
1595 1600 1605
Gly Cys Cys Ala Ala Ala Ala Cys Thr Ala Cys Ala Cys Thr Gly
1610 1615 1620
Thr Ala Thr Cys Thr Gly Cys Ala Ala Ala Thr Gly Ala Ala Thr
1625 1630 1635
Ala Gly Cys Cys Thr Gly Cys Gly Thr Cys Cys Thr Gly Ala Ala
1640 1645 1650
Gly Ala Thr Ala Cys Gly Gly Cys Cys Cys Thr Gly Thr Ala Thr
1655 1660 1665
Thr Ala Cys Thr Gly Thr Ala Cys Thr Ala Thr Thr Gly Gly Thr
1670 1675 1680
Gly Gly Cys Thr Cys Gly Thr Thr Ala Ala Gly Cys Cys Gly Thr
1685 1690 1695
Thr Cys Thr Thr Cys Ala Cys Ala Gly Gly Gly Thr Ala Cys Cys
1700 1705 1710
Cys Thr Gly Gly Thr Cys Ala Cys Cys Gly Thr Cys Thr Cys Cys
1715 1720 1725
Thr Cys Ala Gly Cys Gly
1730
<210> 151
<211> 578
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 151
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Pro Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met
485 490 495
Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser
500 505 510
Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile
545 550 555 560
Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser
565 570 575
Ser Ala
<210> 152
<211> 2196
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 152
gacgtgcaat tggtggagtc tggtggcgga gttgtccagc ctggcggcag tctgcggtta 60
tcttgcgccg cttctggcag cattgccagt attcacgcta tgggttggtt caggcaggct 120
cctggtaaag aacgtgagtt tgtggctgtg attacttggt ccggtggtat tacttactac 180
gctgatagcg ttaagggccg gtttacaatt tcccgtgata atagcaaaaa taccgtctat 240
ctgcaaatga acagtctgcg cccggaagat accgccctgt attactgtgc gggcgataaa 300
catcagtcct catggtatga ctactggggg caagggaccc tggtcacggt ctcctccgga 360
ggcggtgggt caggtggcgg aggcagcggt ggaggaggta gtggcggtgg cggtagtggg 420
ggtggaggca gcggaggcgg aggcagtggg ggcggtggat cagaggtgca gttggtggag 480
tctggtggcg gagttgtcca gcctggcggc agtctgcggt tatcttgcgc cgcttctggc 540
agcattgcca gtattcacgc tatgggttgg ttcaggcagg ctcctggtaa agaacgtgag 600
tttgtggctg tgattacttg gtccggtggt attacttact acgctgatag cgttaagggc 660
cggtttacaa tttcccgtga taatagcaaa aataccgtct atctgcaaat gaacagtctg 720
cgcccggaag ataccgccct gtattactgt gcgggcgata aacatcagtc ctcatggtat 780
gactactggg ggcaagggac cctggtcacg gtctcctcag gaggcggtgg gtcaggtggc 840
ggaggcagcg gtggaggagg tagtggcggt ggcggtagtg ggggtggagg cagcggaggc 900
ggaggcagtg ggggcggtgg atccgaggtg cagttggtgg agtctggggg aggagtggtg 960
cagccggggg gctctctgag actctcctgt gcagcctctg gtggcacctt cagtttctat 1020
ggcatgggct ggttccgcca ggctccaggg aaggagcgcg agtttgtagc agatattaga 1080
accagtgctg gtaggacata ctatgcagac tccgtgaagg gccgattcac catctccaga 1140
gacaacagca agaacacggt gtatctgcaa atgaacagcc tgcgccctga ggacacggcc 1200
ctgtattact gtgcagcaga gccaagtgga ataagtggtt gggactactg gggccagggg 1260
accctggtca cggtctcgag cggaggcggt gggtcaggtg gcggaggcag cggtggagga 1320
ggtagtggcg gtggcggtag tgggggtgga ggcagcggag gcggaggcag tgggggcggt 1380
ggatcagagg tgcagttggt ggagtctggg ggaggagtgg tgcagccggg gggctctctg 1440
agactctcct gtgcagcctc tggtggcacc ttcagtttct atggcatggg ctggttccgc 1500
caggctccag ggaaggagcg cgagtttgta gcagatatta gaaccagtgc tggtaggaca 1560
tactatgcag actccgtgaa gggccgattc accatctcca gagacaacag caagaacacg 1620
gtgtatctgc aaatgaacag cctgcgccct gaggacacgg ccctgtatta ctgtgcagca 1680
gagccaagtg gaataagtgg ttgggactac tggggccagg ggaccctggt cacggtctcc 1740
tcaggaggcg gtgggtcagg tggcggaggc agcggtggag gaggtagtgg cggtggcggt 1800
agtgggggtg gaggcagcgg aggcggaggc agtgggggcg gtggatcaga ggtgcaacta 1860
gtggagtctg gaggtggcgt tgtgcaaccg ggtaacagtc tgcgccttag ctgcgcagcg 1920
tctggcttta ccttcagctc ctttggcatg agctgggttc gccaggctcc gggaaaagga 1980
ctggaatggg tttcgtctat tagcggcagt ggtagcgata cgctctacgc ggactccgtg 2040
aagggccgtt tcaccatctc ccgcgataac gccaaaacta cactgtatct gcaaatgaat 2100
agcctgcgtc ctgaagatac ggccctgtat tactgtacta ttggtggctc gttaagccgt 2160
tcttcacagg gtaccctggt caccgtctcc tcagcg 2196
<210> 153
<211> 732
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 153
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Ala Ser Ile His
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Val Ile Thr Trp Ser Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Gly Asp Lys His Gln Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Ser Ile Ala Ser Ile His Ala Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Val Ile Thr Trp Ser
195 200 205
Gly Gly Ile Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Gly Asp Lys His Gln
245 250 255
Ser Ser Trp Tyr Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr
325 330 335
Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu
340 345 350
Arg Glu Phe Val Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys
370 375 380
Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr
405 410 415
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser
420 425 430
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
435 440 445
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val
450 455 460
Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu
465 470 475 480
Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met
485 490 495
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp
500 505 510
Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly
515 520 525
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln
530 535 540
Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala
545 550 555 560
Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu
565 570 575
Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
580 585 590
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
595 600 605
Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly
610 615 620
Gly Gly Val Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala
625 630 635 640
Ser Gly Phe Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala
645 650 655
Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser
660 665 670
Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg
675 680 685
Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro
690 695 700
Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg
705 710 715 720
Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Ala
725 730
<210> 154
<211> 11
<212> Белок
<213> Крыса
<400> 154
Lys Thr Ser Gln Asn Ile Phe Glu Asn Leu Ala
1 5 10
<210> 155
<211> 7
<212> Белок
<213> Крыса
<400> 155
Asn Ala Ser Pro Leu Gln Ala
1 5
<210> 156
<211> 8
<212> Белок
<213> Крыса
<400> 156
His Gln Tyr Tyr Ser Gly Tyr Thr
1 5
<210> 157
<211> 10
<212> Белок
<213> Крыса
<400> 157
Gly Phe Thr Phe Ser Asp Tyr His Met Ala
1 5 10
<210> 158
<211> 17
<212> Белок
<213> Крыса
<400> 158
Ser Ile Thr Leu Asp Ala Thr Tyr Thr Tyr Tyr Arg Asp Ser Val Arg
1 5 10 15
Gly
<210> 159
<211> 10
<212> Белок
<213> Крыса
<400> 159
His Arg Gly Phe Ser Val Trp Leu Asp Tyr
1 5 10
<210> 160
<211> 10
<212> Белок
<213> Крыса
<400> 160
Gly Tyr Ile Phe Thr Asp Tyr Ala Met His
1 5 10
<210> 161
<211> 16
<212> Белок
<213> Крыса
<400> 161
Thr Phe Ile Pro Leu Leu Asp Thr Ser Asp Tyr Asn Gln Asn Phe Lys
1 5 10 15
<210> 162
<211> 11
<212> Белок
<213> Крыса
<400> 162
Met Gly Val Thr His Ser Tyr Val Met Asp Ala
1 5 10
<210> 163
<211> 11
<212> Белок
<213> Крыса
<400> 163
Arg Ala Ser Gln Pro Ile Ser Ile Ser Val His
1 5 10
<210> 164
<211> 7
<212> Белок
<213> Крыса
<400> 164
Phe Ala Ser Gln Ser Ile Ser
1 5
<210> 165
<211> 9
<212> Белок
<213> Крыса
<400> 165
Gln Gln Thr Phe Ser Leu Pro Tyr Thr
1 5
<210> 166
<211> 10
<212> Белок
<213> Мышь
<400> 166
Gly Phe Ile Ile Lys Ala Thr Tyr Met His
1 5 10
<210> 167
<211> 17
<212> Белок
<213> Мышь
<400> 167
Arg Ile Asp Pro Ala Asn Gly Glu Thr Lys Tyr Asp Pro Lys Phe Gln
1 5 10 15
Val
<210> 168
<211> 7
<212> Белок
<213> Мышь
<400> 168
Tyr Ala Trp Tyr Phe Asp Val
1 5
<210> 169
<211> 11
<212> Белок
<213> Мышь
<400> 169
Arg Ala Ser Glu Asn Ile Tyr Ser Phe Leu Ala
1 5 10
<210> 170
<211> 7
<212> Белок
<213> Мышь
<400> 170
His Ala Lys Thr Leu Ala Glu
1 5
<210> 171
<211> 9
<212> Белок
<213> Мышь
<400> 171
Gln His Tyr Tyr Gly Ser Pro Leu Thr
1 5
<210> 172
<211> 447
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная мышь
<400> 172
Gln Val Gln Leu Val Gln Ser Gly Val Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Asn Pro Ser Asn Gly Gly Thr Asn Phe Asn Glu Lys Phe
50 55 60
Lys Asn Arg Val Thr Leu Thr Thr Asp Ser Ser Thr Thr Thr Ala Tyr
65 70 75 80
Met Glu Leu Lys Ser Leu Gln Phe Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Asp Tyr Arg Phe Asp Met Gly Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 173
<211> 218
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная мышь
<400> 173
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Lys Gly Val Ser Thr Ser
20 25 30
Gly Tyr Ser Tyr Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Arg Leu Leu Ile Tyr Leu Ala Ser Tyr Leu Glu Ser Gly Val Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln His Ser Arg
85 90 95
Asp Leu Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<210> 174
<211> 440
<212> Белок
<213> Homo sapiens
<400> 174
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Asp Cys Lys Ala Ser Gly Ile Thr Phe Ser Asn Ser
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Tyr Asp Gly Ser Lys Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Phe
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Asn Asp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
100 105 110
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser
115 120 125
Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
130 135 140
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
145 150 155 160
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
165 170 175
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys
180 185 190
Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp
195 200 205
Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala
210 215 220
Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
225 230 235 240
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
245 250 255
Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val
260 265 270
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
275 280 285
Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
290 295 300
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly
305 310 315 320
Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
325 330 335
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr
340 345 350
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
355 360 365
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
370 375 380
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
385 390 395 400
Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe
405 410 415
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
420 425 430
Ser Leu Ser Leu Ser Leu Gly Lys
435 440
<210> 175
<211> 214
<212> Белок
<213> Homo sapiens
<400> 175
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Ser Asn Trp Pro Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 176
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 176
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 177
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 177
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Ser Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 178
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 178
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Val Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 179
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 179
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Gly Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 180
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 180
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Arg Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 181
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 181
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Gln Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 182
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 182
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Met Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 183
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 183
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp His Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 184
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 184
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Thr Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 185
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 185
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asp Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 186
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 186
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Glu Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 187
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 187
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Trp Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 188
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 188
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Phe Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 189
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 189
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Lys Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 190
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 190
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Ala Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 191
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 191
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Tyr Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 192
<211> 153
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 192
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Pro Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Ala Ala Ala Asp Tyr Lys Asp His Asp
115 120 125
Gly Asp Tyr Lys Asp His Asp Ile Asp Tyr Lys Asp Asp Asp Asp Lys
130 135 140
Gly Ala Ala His His His His His His
145 150
<210> 193
<211> 424
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 193
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr Gly Met Gly Trp Phe Arg
180 185 190
Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Asp Ile Arg Thr Ser
195 200 205
Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Ala Ala Glu Pro Ser Gly
245 250 255
Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
260 265 270
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
275 280 285
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
290 295 300
Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val
305 310 315 320
Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr
325 330 335
Phe Ser Ser Phe Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly
340 345 350
Leu Glu Trp Val Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr
355 360 365
Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys
370 375 380
Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala
385 390 395 400
Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly
405 410 415
Thr Leu Val Thr Val Ser Ser Ala
420
<210> 194
<211> 270
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<400> 194
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
115 120 125
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
130 135 140
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu
145 150 155 160
Ser Gly Gly Gly Val Val Gln Pro Gly Asn Ser Leu Arg Leu Ser Cys
165 170 175
Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe Gly Met Ser Trp Val Arg
180 185 190
Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser Ser Ile Ser Gly Ser
195 200 205
Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile
210 215 220
Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr Leu Gln Met Asn Ser Leu
225 230 235 240
Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Thr Ile Gly Gly Ser Leu
245 250 255
Ser Arg Ser Ser Gln Gly Thr Leu Val Thr Val Ser Ser Ala
260 265 270
<210> 195
<211> 138
<212> Белок
<213> Homo sapiens
<400> 195
Ala Met His Val Ala Gln Pro Ala Val Val Leu Ala Ser Ser Arg Gly
1 5 10 15
Ile Ala Ser Phe Val Cys Glu Tyr Ala Ser Pro Gly Lys Ala Thr Glu
20 25 30
Val Arg Val Thr Val Leu Arg Gln Ala Asp Ser Gln Val Thr Glu Val
35 40 45
Cys Ala Ala Thr Tyr Met Met Gly Asn Glu Leu Thr Phe Leu Asp Asp
50 55 60
Ser Ile Cys Thr Gly Thr Ser Ser Gly Asn Gln Val Asn Leu Thr Ile
65 70 75 80
Gln Gly Leu Arg Ala Met Asp Thr Gly Leu Tyr Ile Cys Lys Val Glu
85 90 95
Leu Met Tyr Pro Pro Pro Tyr Tyr Leu Gly Ile Gly Asn Gly Thr Gln
100 105 110
Ile Tyr Val Ile Asp Pro Glu Pro Cys Pro Asp Ser Asp Phe His His
115 120 125
His His His His His His His Gly Gly Gln
130 135
<210> 196
<211> 119
<212> Белок
<213> Искусственная последовательность
<220>
<223> Гуманизированная лама
<220>
<221> Прочий признак
<222> (1)..(1)
<223> X представляет собой E или D
<220>
<221> Прочий признак
<222> (74)..(74)
<223> X представляет собой S, V, G, R, Q, M, H, T, D, E, W, F, K, A, Y или P
<400> 196
Xaa Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Gly Thr Phe Ser Phe Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Asp Ile Arg Thr Ser Ala Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Xaa Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Glu Pro Ser Gly Ile Ser Gly Trp Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 197
<211> 223
<212> Белок
<213> Homo sapiens
<220>
<221> зрелый пептид
<222> (36)..(223)
<400> 197
Met Ala Cys Leu Gly Phe Gln Arg His Lys Ala Gln Leu Asn Leu Ala
-35 -30 -25 -20
Thr Arg Thr Trp Pro Cys Thr Leu Leu Phe Phe Leu Leu Phe Ile Pro
-15 -10 -5
Val Phe Cys Lys Ala Met His Val Ala Gln Pro Ala Val Val Leu Ala
-1 1 5 10
Ser Ser Arg Gly Ile Ala Ser Phe Val Cys Glu Tyr Ala Ser Pro Gly
15 20 25
Lys Ala Thr Glu Val Arg Val Thr Val Leu Arg Gln Ala Asp Ser Gln
30 35 40 45
Val Thr Glu Val Cys Ala Ala Thr Tyr Met Met Gly Asn Glu Leu Thr
50 55 60
Phe Leu Asp Asp Ser Ile Cys Thr Gly Thr Ser Ser Gly Asn Gln Val
65 70 75
Asn Leu Thr Ile Gln Gly Leu Arg Ala Met Asp Thr Gly Leu Tyr Ile
80 85 90
Cys Lys Val Glu Leu Met Tyr Pro Pro Pro Tyr Tyr Leu Gly Ile Gly
95 100 105
Asn Gly Thr Gln Ile Tyr Val Ile Asp Pro Glu Pro Cys Pro Asp Ser
110 115 120 125
Asp Phe Leu Leu Trp Ile Leu Ala Ala Val Ser Ser Gly Leu Phe Phe
130 135 140
Tyr Ser Phe Leu Leu Thr Ala Val Ser Leu Ser Lys Met Leu Lys Lys
145 150 155
Arg Ser Pro Leu Thr Thr Gly Val Tyr Val Lys Met Pro Pro Thr Glu
160 165 170
Pro Glu Cys Glu Lys Gln Phe Gln Pro Tyr Phe Ile Pro Ile Asn
175 180 185
<210> 198
<211> 288
<212> Белок
<213> Homo sapiens
<220>
<221> зрелый пептид
<222> (21)..(288)
<400> 198
Met Gln Ile Pro Gln Ala Pro Trp Pro Val Val Trp Ala Val Leu Gln
-20 -15 -10 -5
Leu Gly Trp Arg Pro Gly Trp Phe Leu Asp Ser Pro Asp Arg Pro Trp
-1 1 5 10
Asn Pro Pro Thr Phe Ser Pro Ala Leu Leu Val Val Thr Glu Gly Asp
15 20 25
Asn Ala Thr Phe Thr Cys Ser Phe Ser Asn Thr Ser Glu Ser Phe Val
30 35 40
Leu Asn Trp Tyr Arg Met Ser Pro Ser Asn Gln Thr Asp Lys Leu Ala
45 50 55 60
Ala Phe Pro Glu Asp Arg Ser Gln Pro Gly Gln Asp Cys Arg Phe Arg
65 70 75
Val Thr Gln Leu Pro Asn Gly Arg Asp Phe His Met Ser Val Val Arg
80 85 90
Ala Arg Arg Asn Asp Ser Gly Thr Tyr Leu Cys Gly Ala Ile Ser Leu
95 100 105
Ala Pro Lys Ala Gln Ile Lys Glu Ser Leu Arg Ala Glu Leu Arg Val
110 115 120
Thr Glu Arg Arg Ala Glu Val Pro Thr Ala His Pro Ser Pro Ser Pro
125 130 135 140
Arg Pro Ala Gly Gln Phe Gln Thr Leu Val Val Gly Val Val Gly Gly
145 150 155
Leu Leu Gly Ser Leu Val Leu Leu Val Trp Val Leu Ala Val Ile Cys
160 165 170
Ser Arg Ala Ala Arg Gly Thr Ile Gly Ala Arg Arg Thr Gly Gln Pro
175 180 185
Leu Lys Glu Asp Pro Ser Ala Val Pro Val Phe Ser Val Asp Tyr Gly
190 195 200
Glu Leu Asp Phe Gln Trp Arg Glu Lys Thr Pro Glu Pro Pro Val Pro
205 210 215 220
Cys Val Pro Glu Gln Thr Glu Tyr Ala Thr Ile Val Phe Pro Ser Gly
225 230 235
Met Gly Thr Ser Ser Pro Ala Arg Arg Gly Ser Ala Asp Gly Pro Arg
240 245 250
Ser Ala Gln Pro Leu Arg Pro Glu Asp Gly His Cys Ser Trp Pro Leu
255 260 265
<210> 199
<211> 10
<212> Белок
<213> Искусственная последовательность
<220>
<223> Лама Sp.
<400> 199
Gly Phe Thr Phe Ser Ser Phe Gly Met Ser
1 5 10
<210> 200
<211> 17
<212> Белок
<213> Искусственная последовательность
<220>
<223> Лама Sp.
<400> 200
Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 201
<211> 6
<212> Белок
<213> Искусственная последовательность
<220>
<223> Лама Sp.
<400> 201
Gly Gly Ser Leu Ser Arg
1 5
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ КОМБИНИРОВАННОГО ЛЕЧЕНИЯ ЗЛОКАЧЕСТВЕННЫХ НОВООБРАЗОВАНИЙ, ВКЛЮЧАЮЩИЕ СРЕДСТВА, БЛОКИРУЮЩИЕ CTLA-4 И PD-1 | 2020 |
|
RU2833523C2 |
| УСОВЕРШЕНСТВОВАННЫЕ АГЕНТЫ, СВЯЗЫВАЮЩИЕ СЫВОРОТОЧНЫЙ АЛЬБУМИН | 2018 |
|
RU2797270C2 |
| УЛУЧШЕННЫЕ ОДИНОЧНЫЕ ВАРИАБЕЛЬНЫЕ ДОМЕНЫ ИММУНОГЛОБУЛИНА, СВЯЗЫВАЮЩИЕСЯ С СЫВОРОТОЧНЫМ АЛЬБУМИНОМ | 2017 |
|
RU2765384C2 |
| УСОВЕРШЕНСТВОВАННЫЕ СВЯЗЫВАЮЩИЕСЯ С СЫВОРОТОЧНЫМ АЛЬБУМИНОМ ВЕЩЕСТВА | 2018 |
|
RU2789495C2 |
| ПОЛИПЕПТИДЫ, СВЯЗЫВАЮЩИЕСЯ С ADAMTS5, MMP13 И АГГРЕКАНОМ | 2018 |
|
RU2786659C2 |
| ММР13-СВЯЗЫВАЮЩИЕ ИММУНОГЛОБУЛИНЫ | 2018 |
|
RU2784069C2 |
| СВЯЗЫВАЮЩИЕ ADAMTS ИММУНОГЛОБУЛИНЫ | 2018 |
|
RU2781182C2 |
| УСОВЕРШЕНСТВОВАННЫЕ АГЕНТЫ, СВЯЗЫВАЮЩИЕ TNF | 2016 |
|
RU2774823C2 |
| УЛУЧШЕННЫЕ ВАРИАБЕЛЬНЫЕ ДОМЕНЫ ИММУНОГЛОБУЛИНА | 2015 |
|
RU2746738C2 |
| УЛУЧШЕННЫЕ ВАРИАБЕЛЬНЫЕ ДОМЕНЫ ИММУНОГЛОБУЛИНА | 2015 |
|
RU2809788C2 |
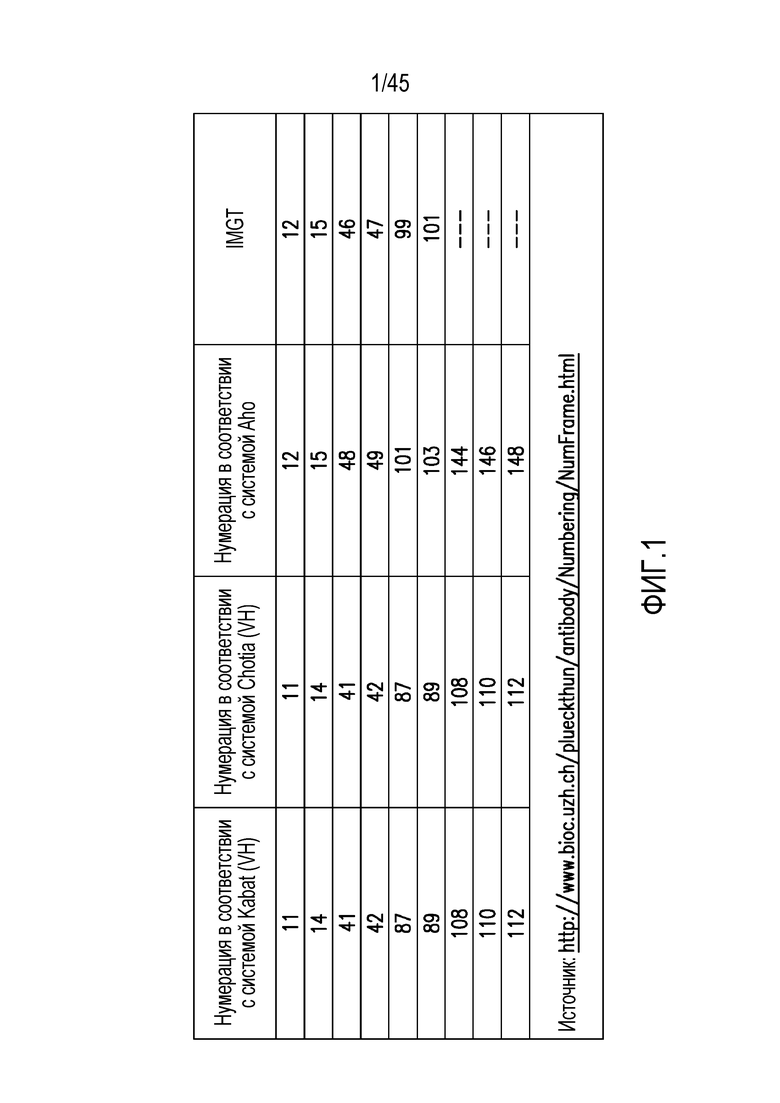
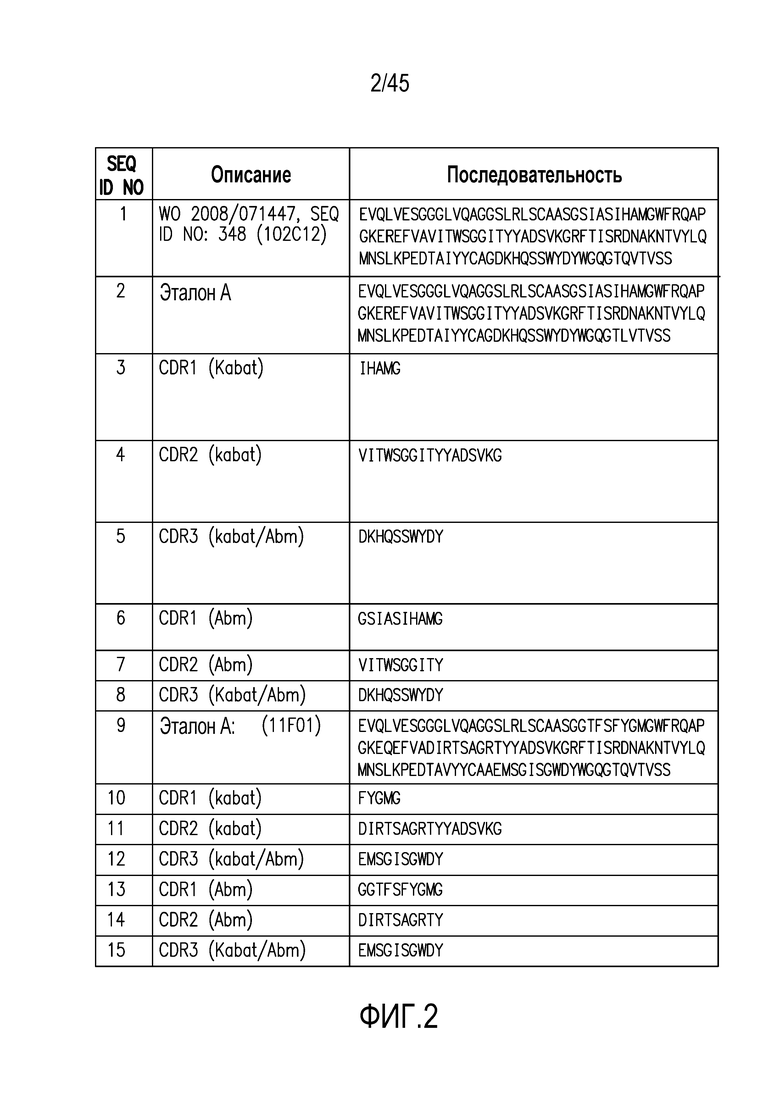
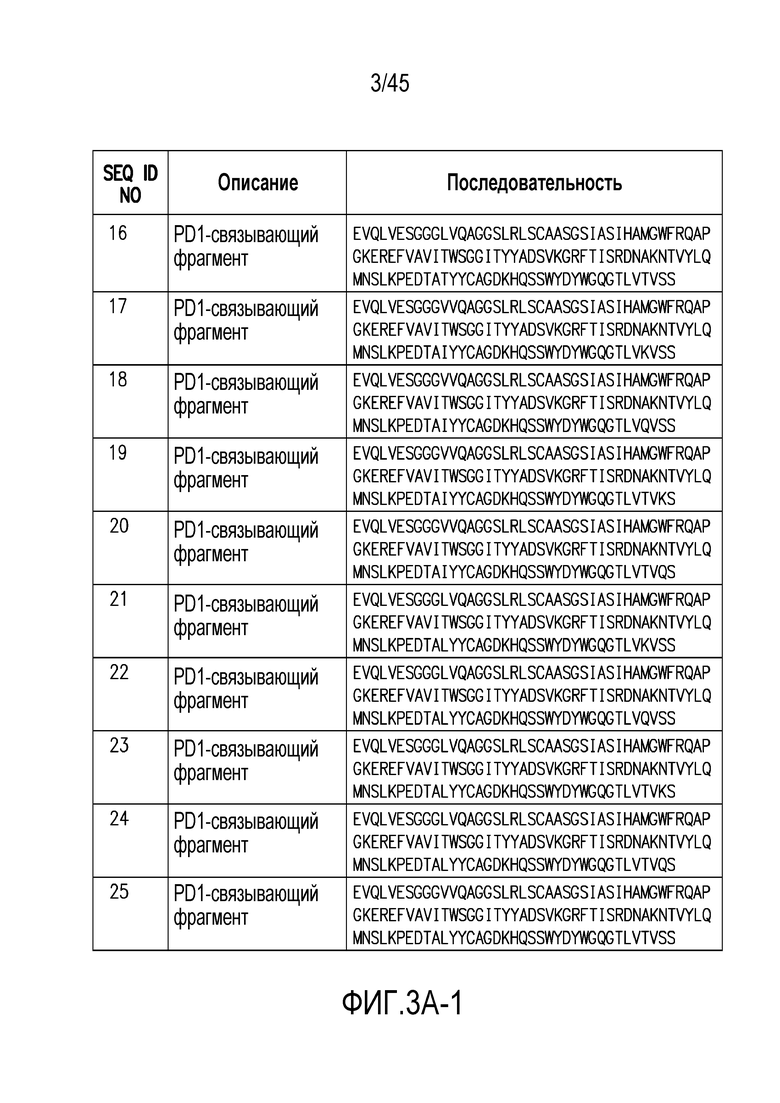
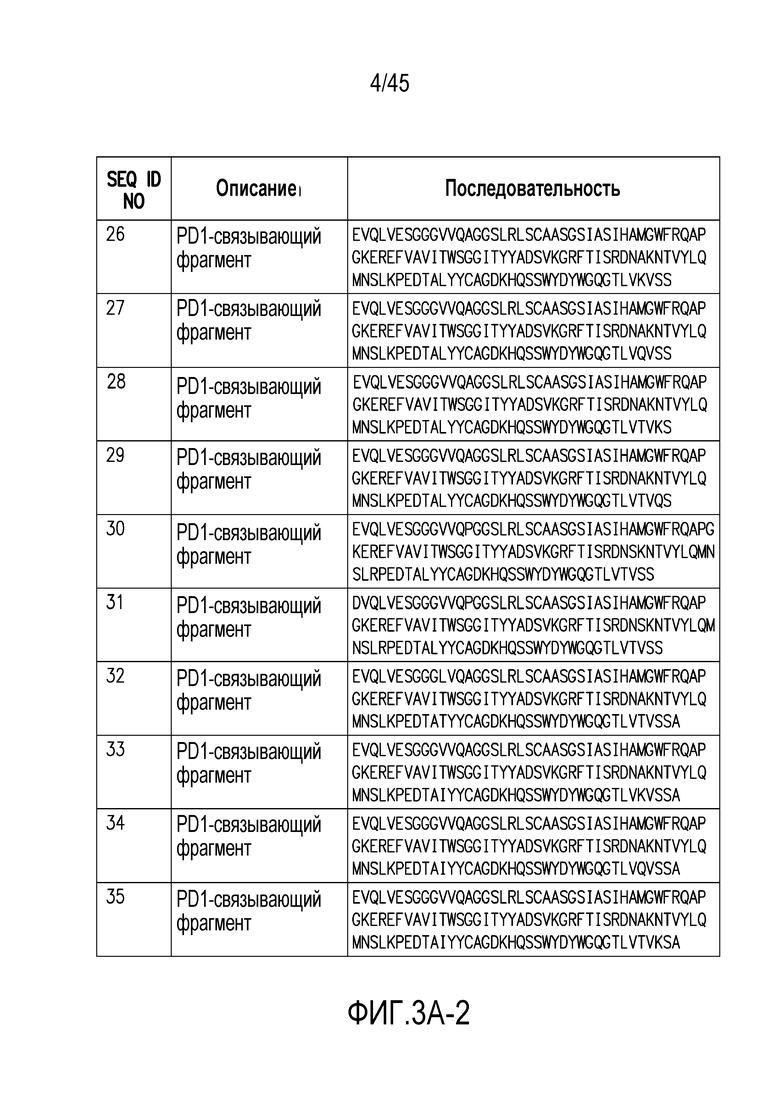
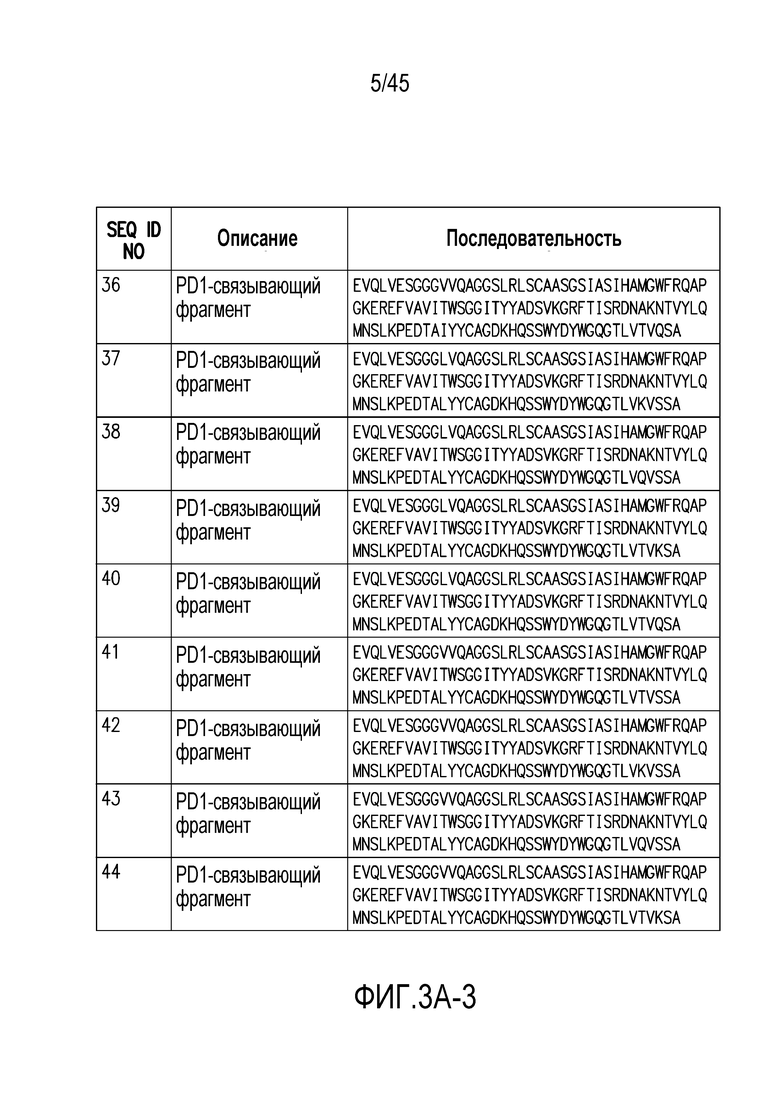
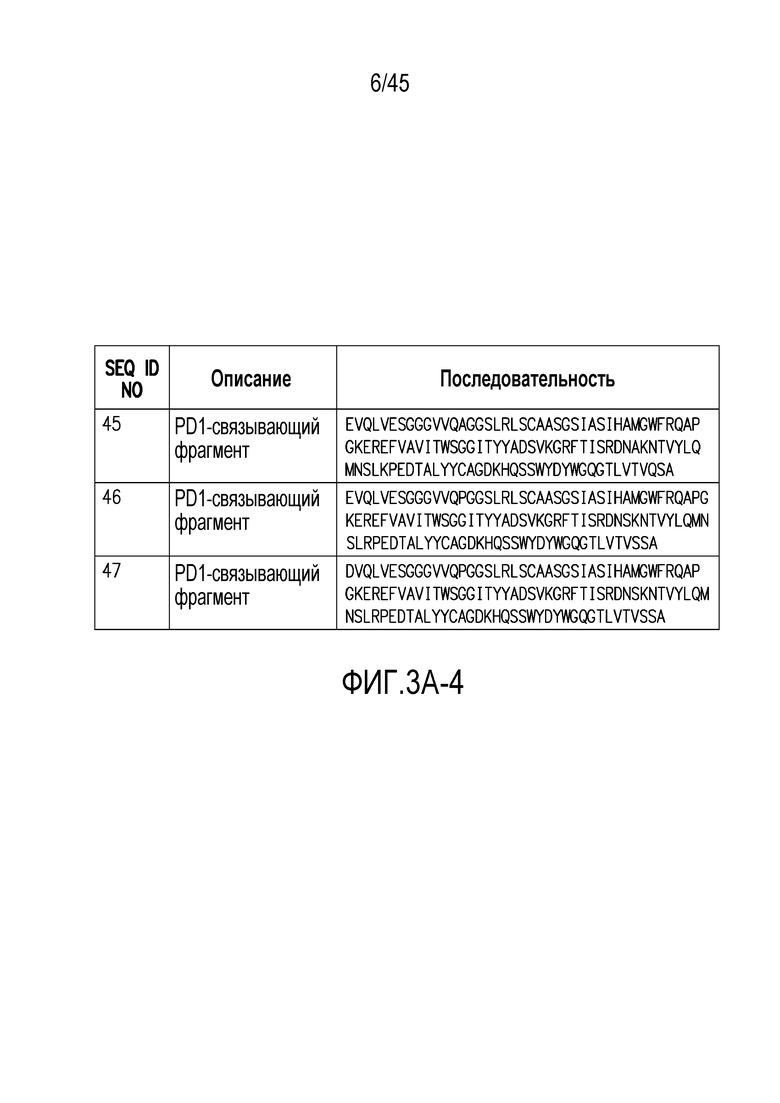








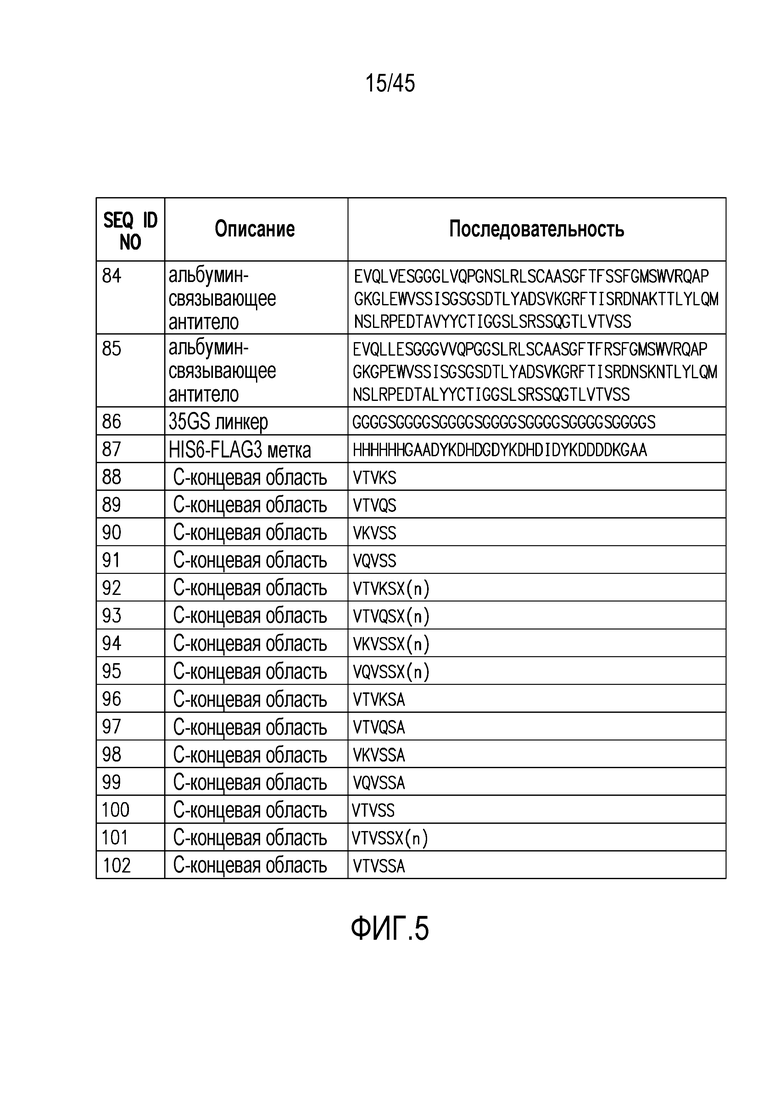









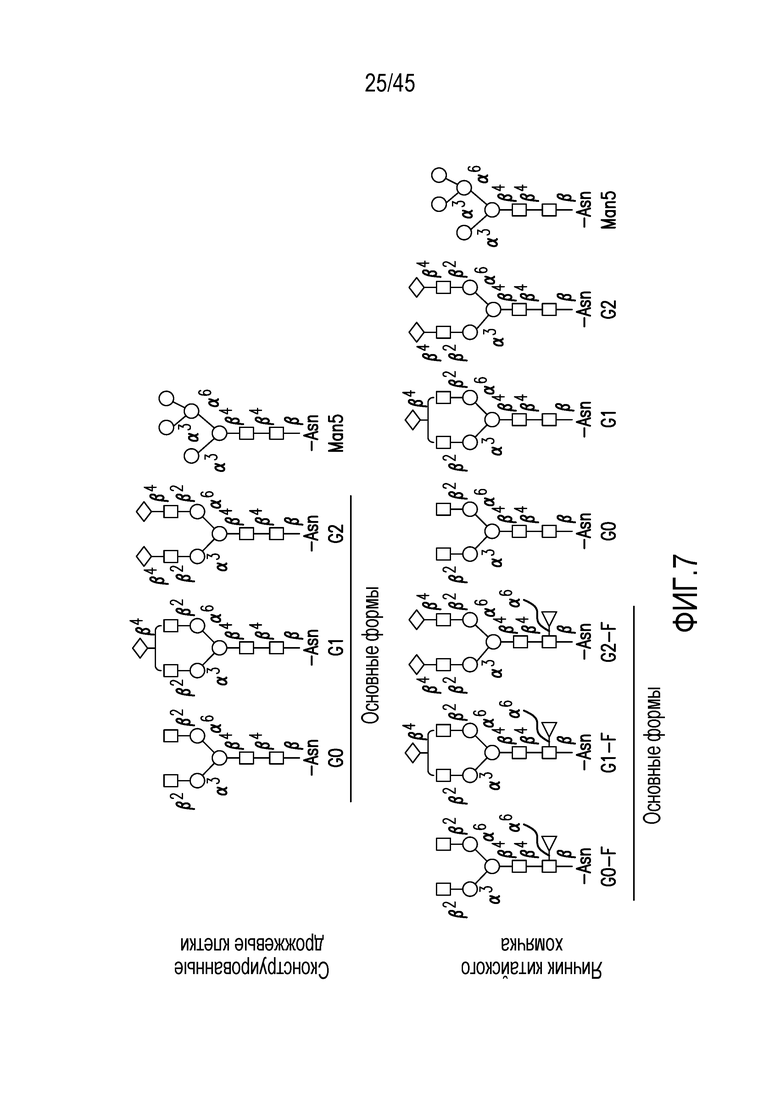
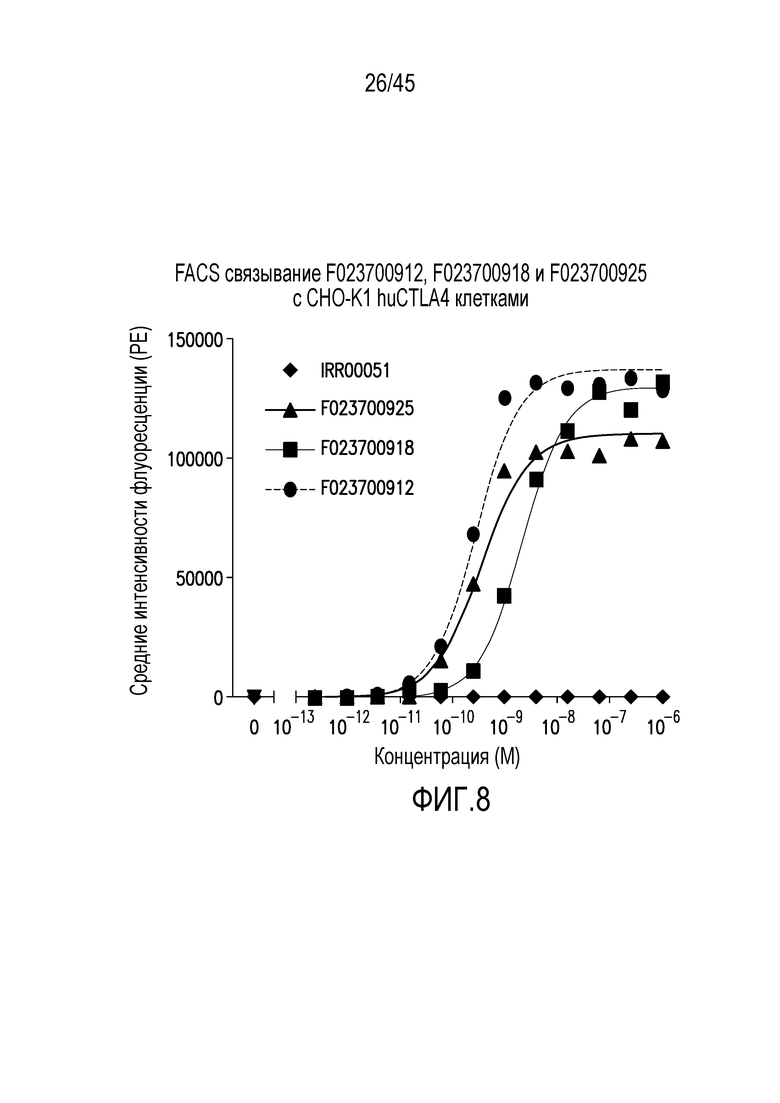
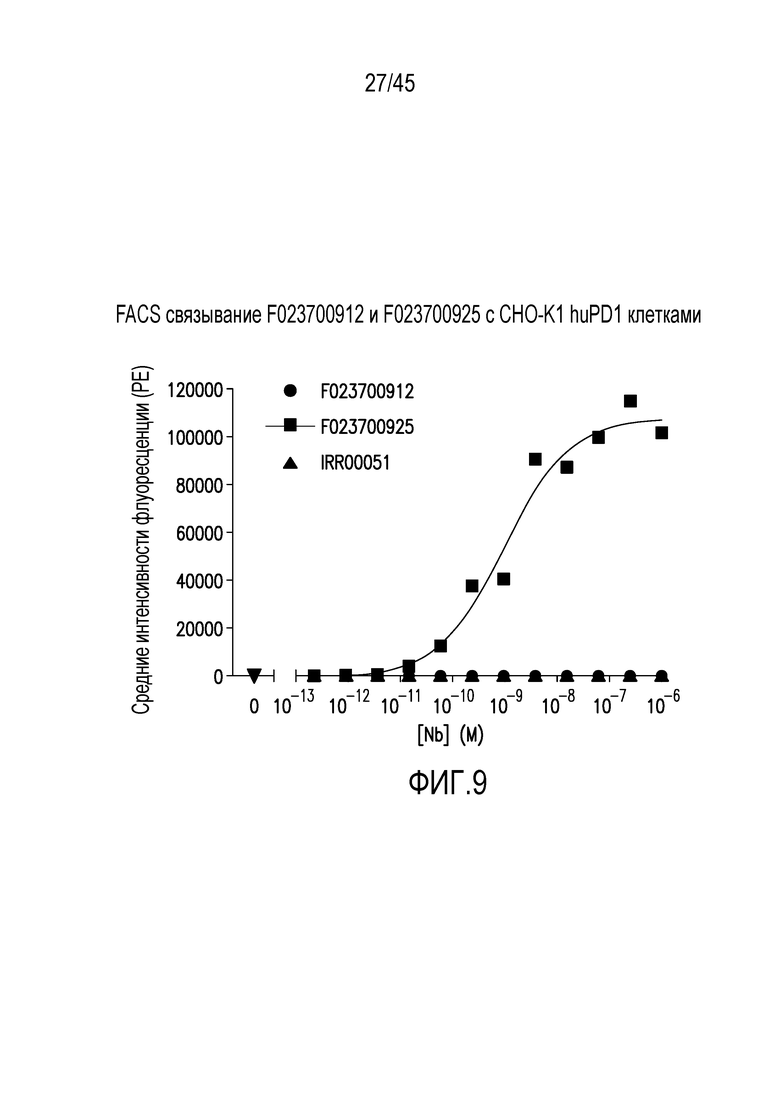
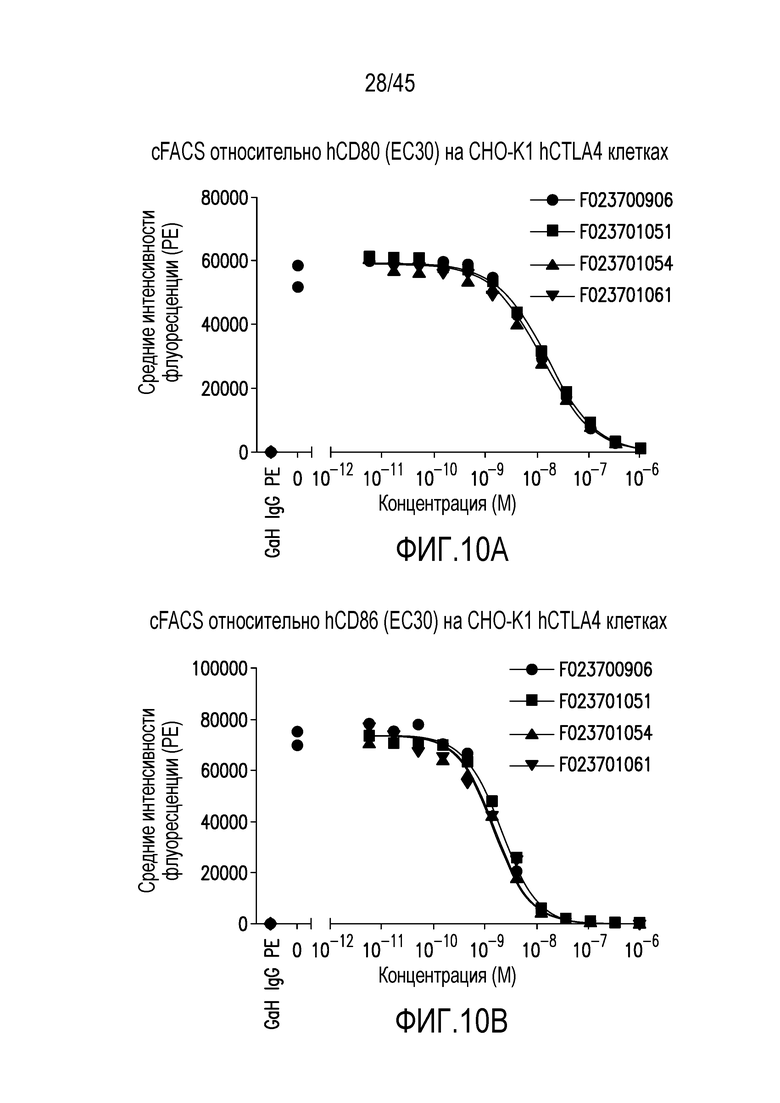

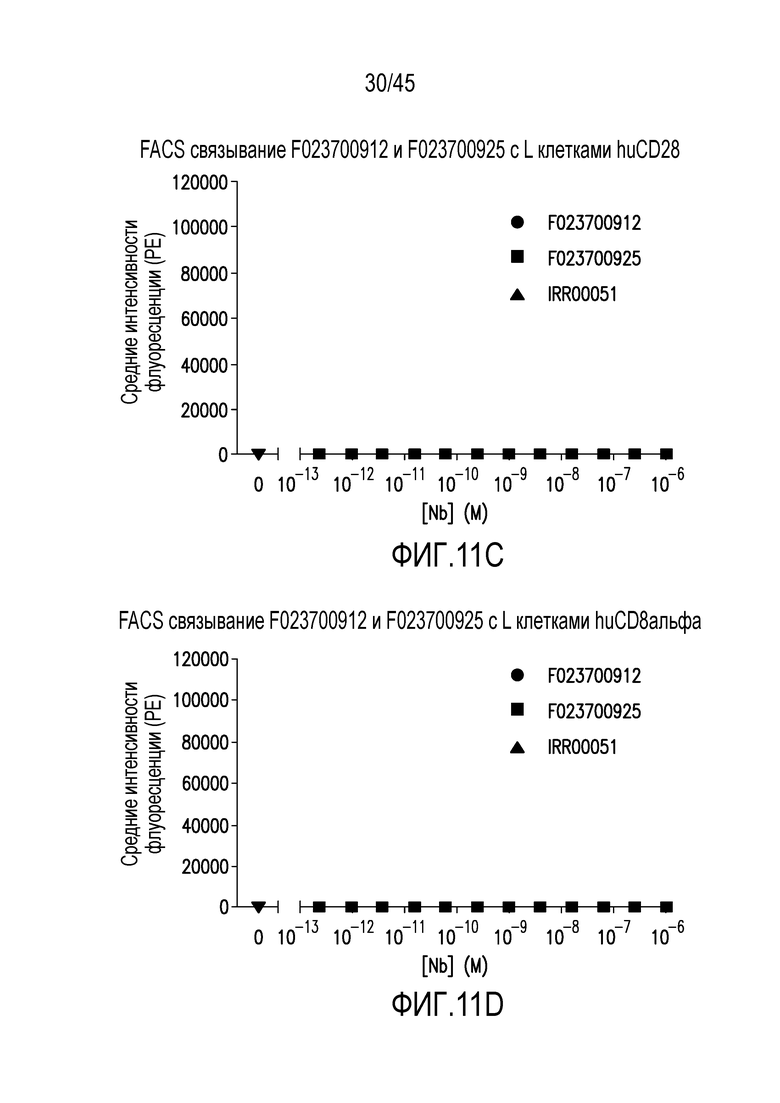
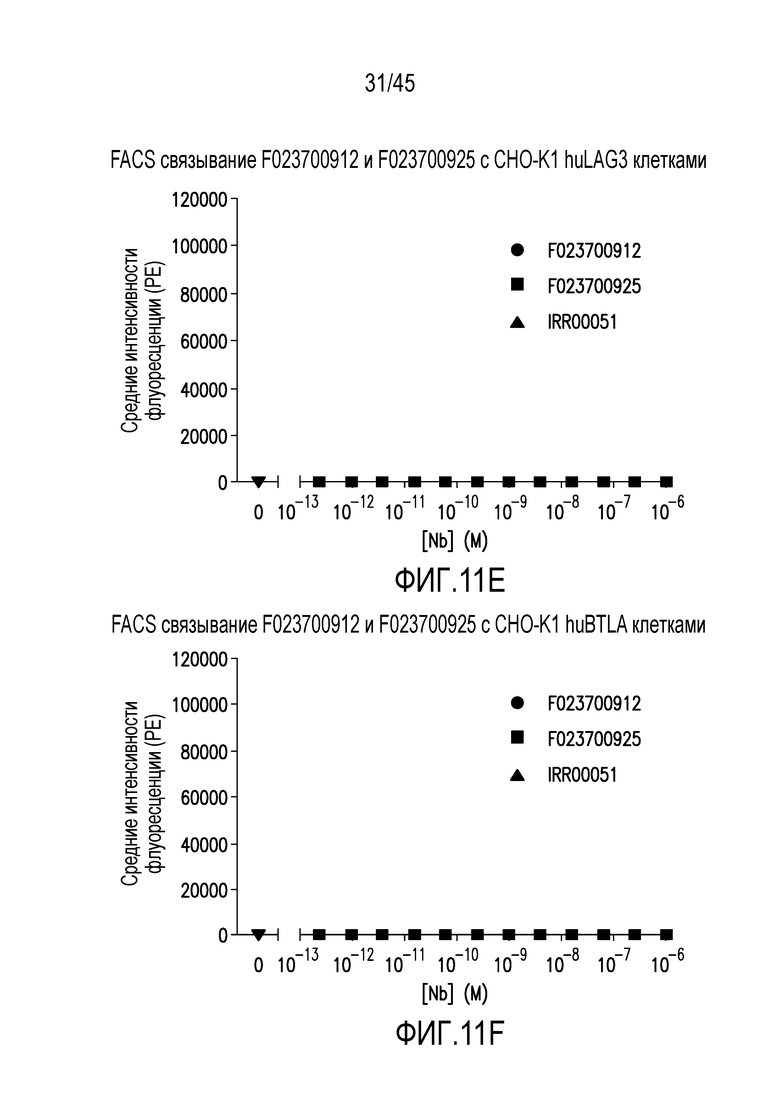
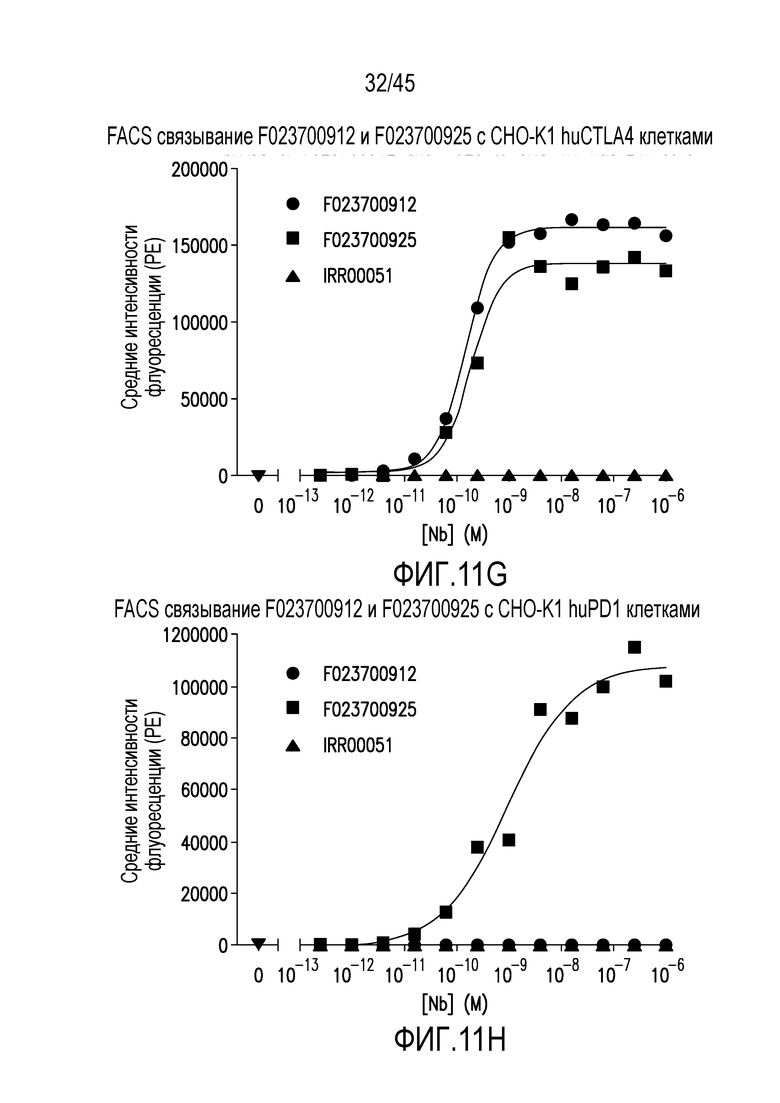
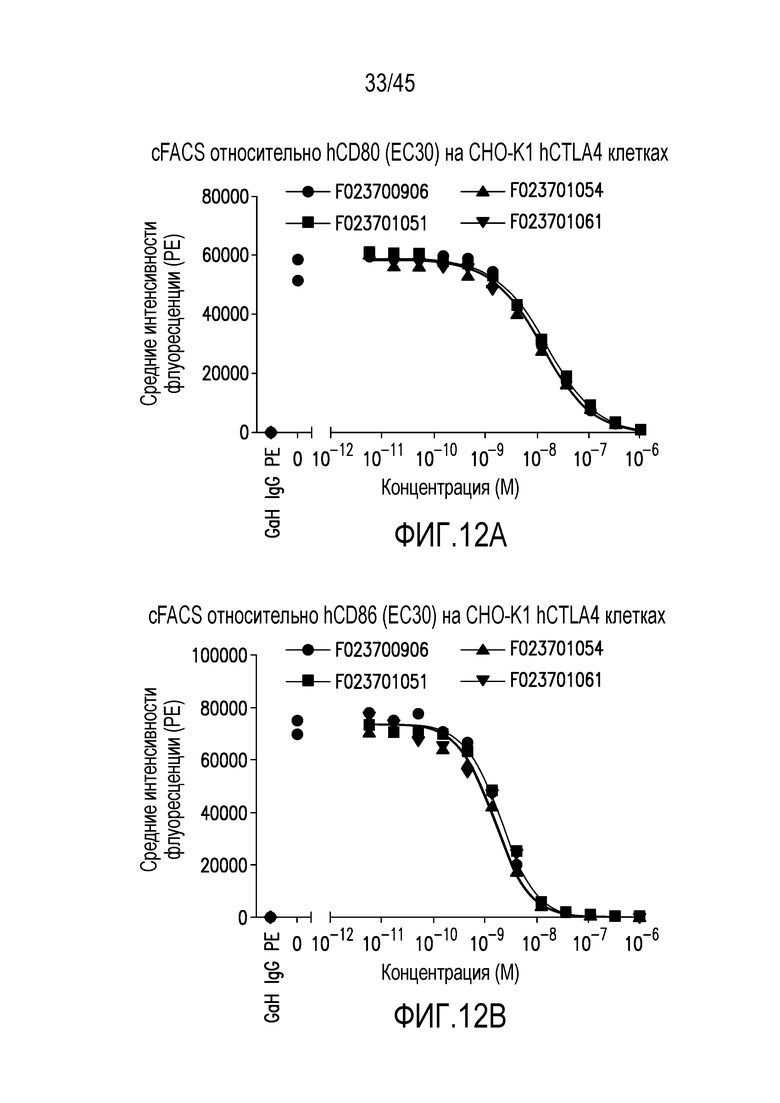
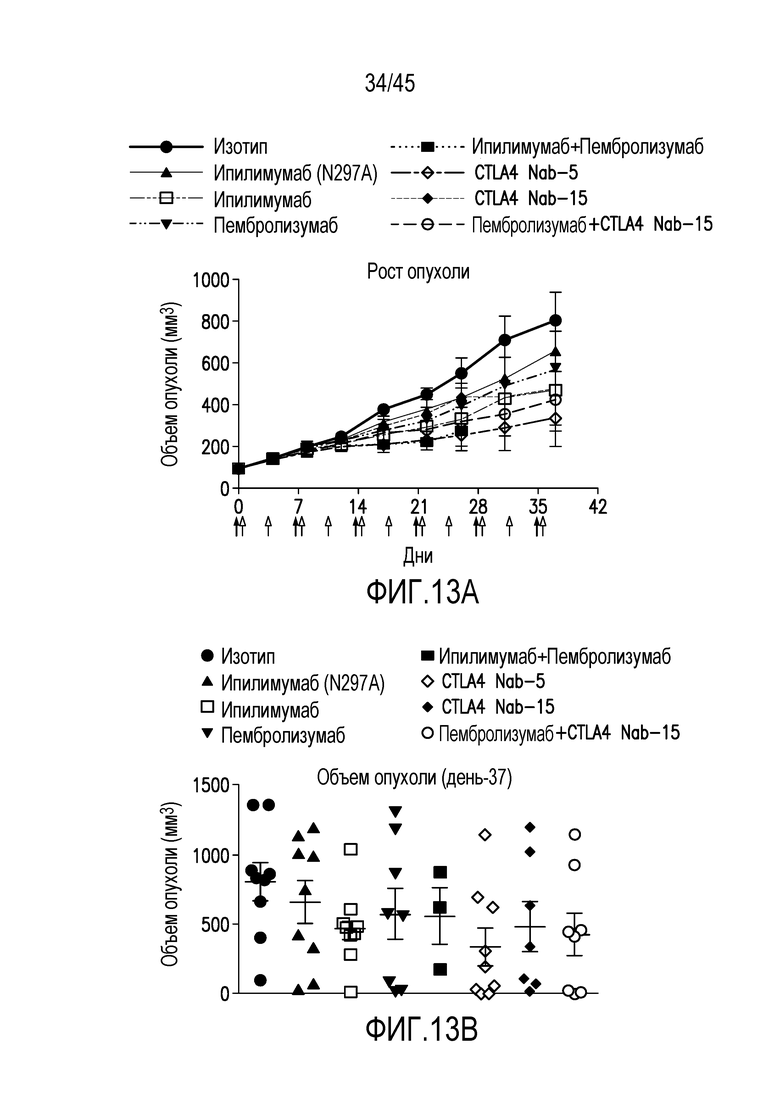
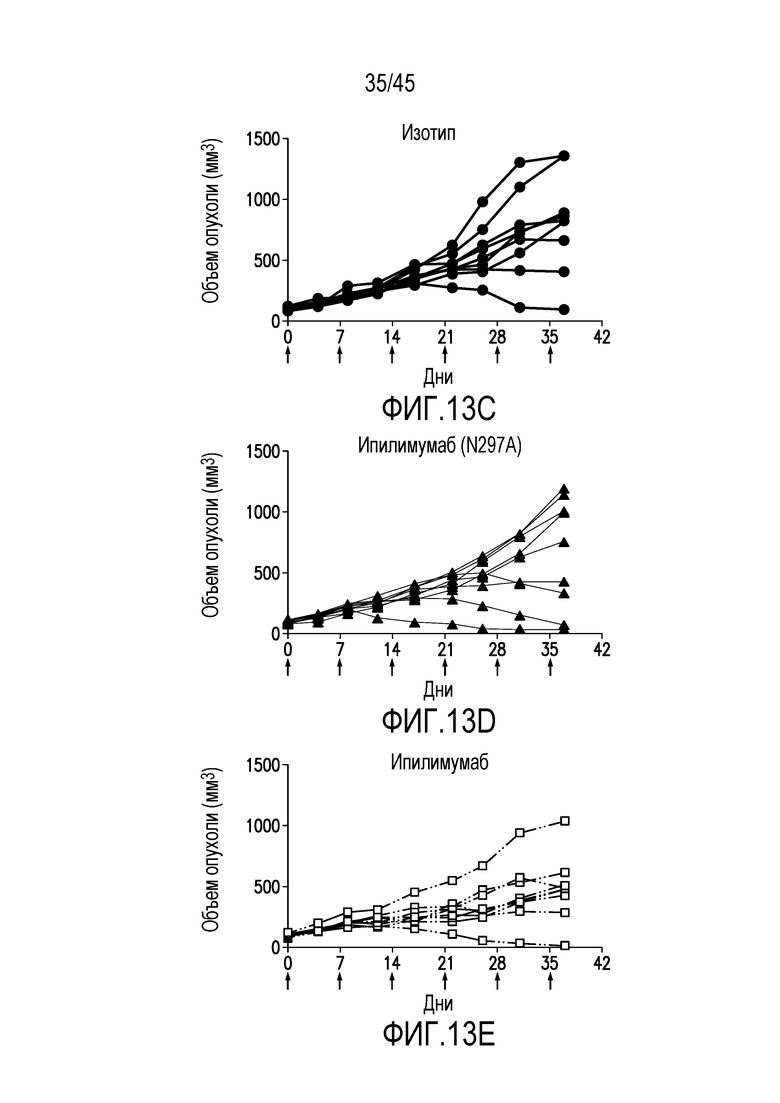
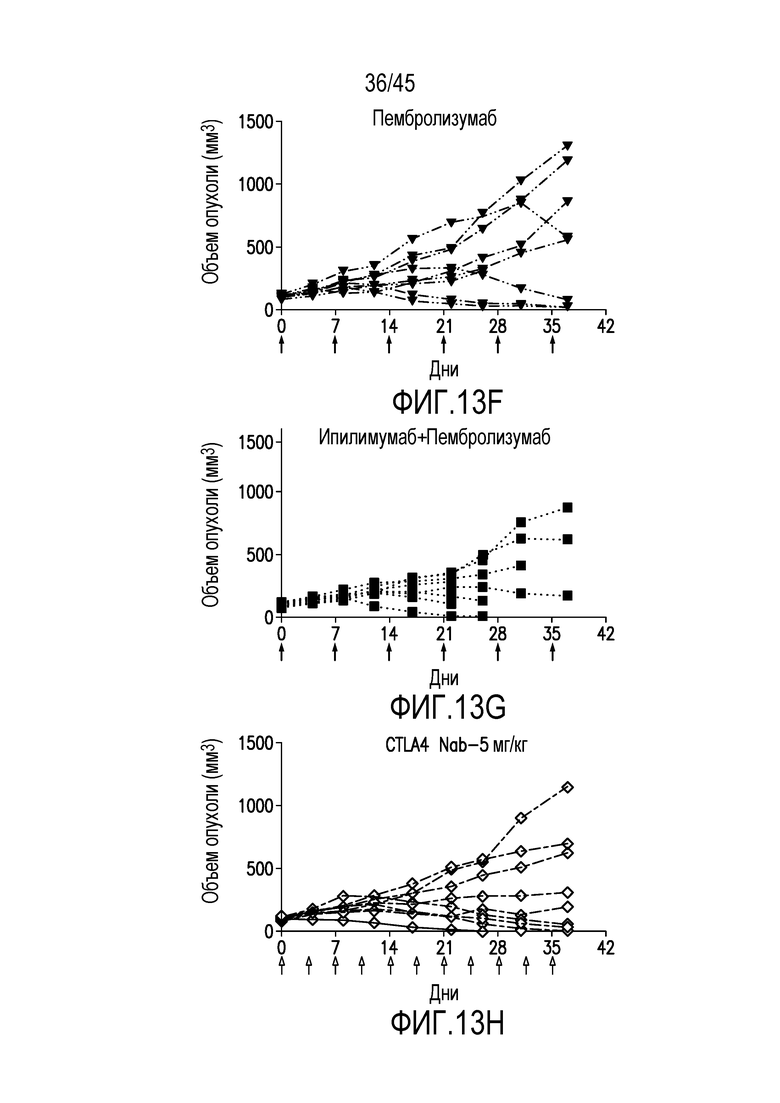
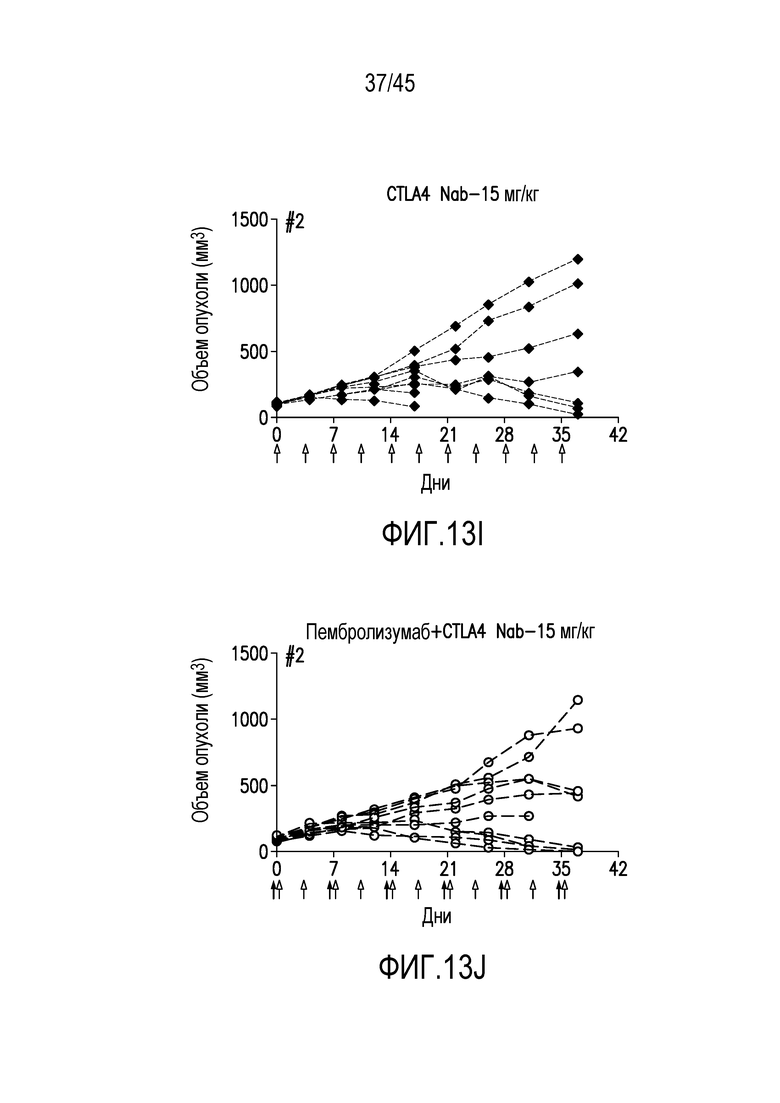
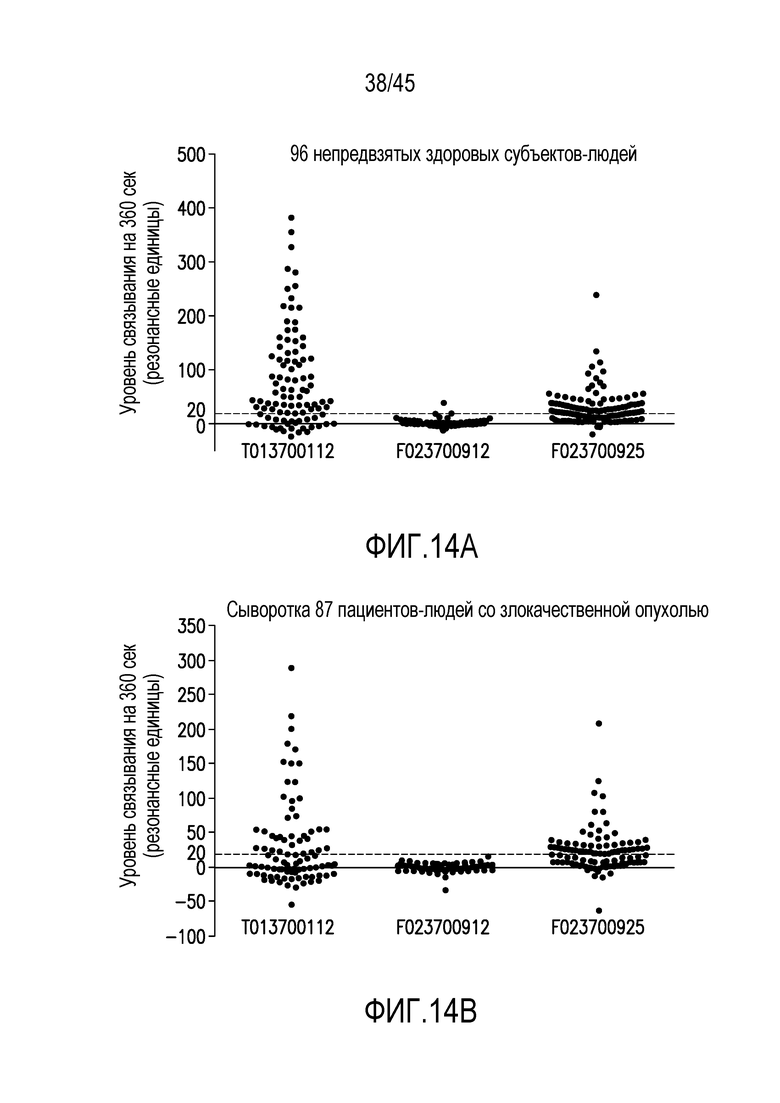




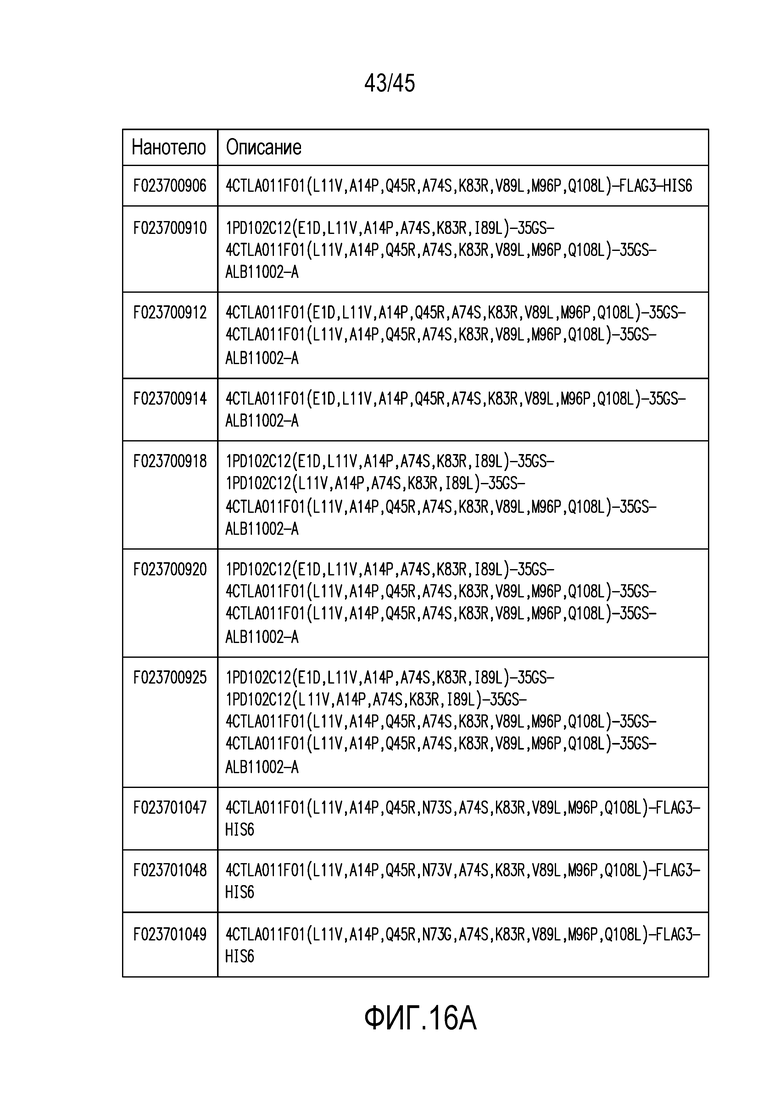
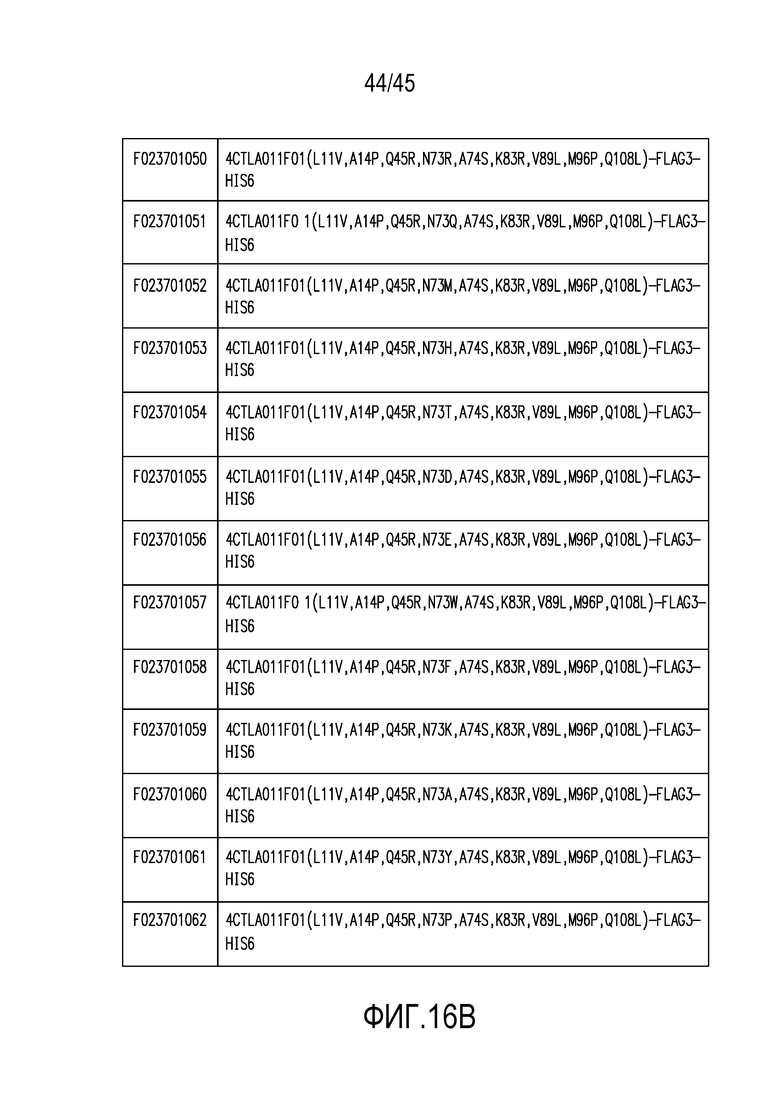
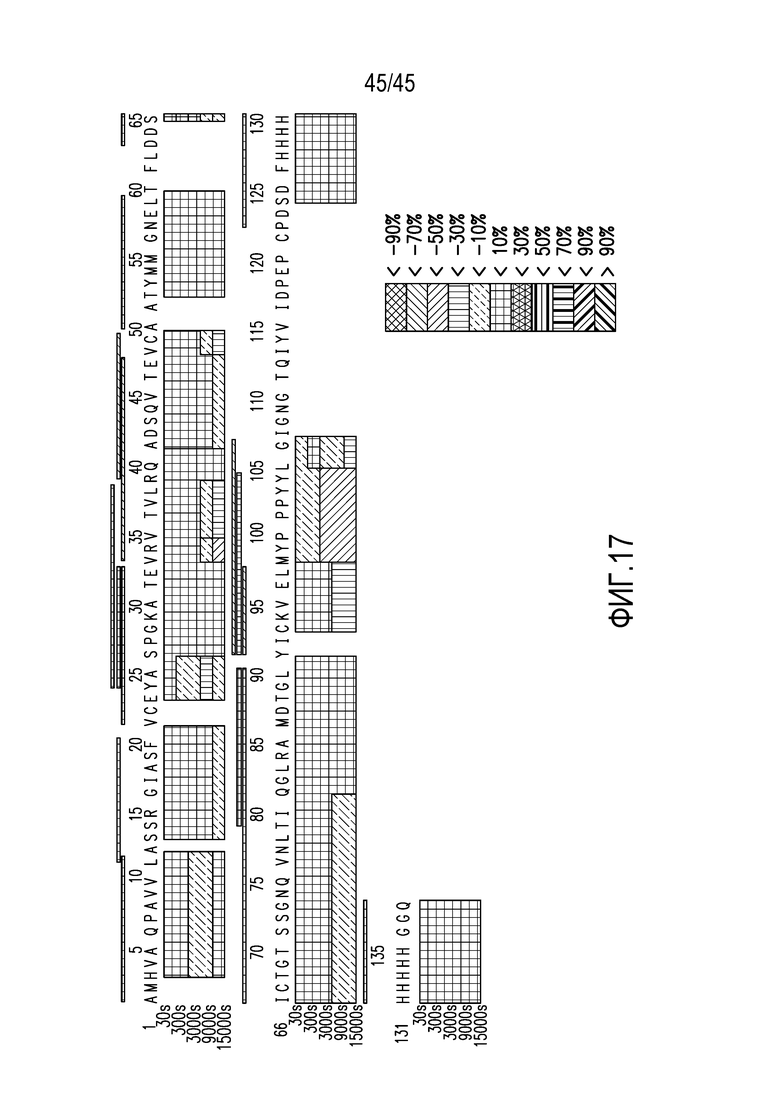
Настоящее изобретение относится к области биотехнологии, конкретно к мультиспецифичным белкам, и может быть использовано в медицине. Изобретение позволяет получить молекулу вещества, содержащего более одного вариабельного домена иммуноглобулина (ISVD) или нанотела и способного к специфичному связыванию как с PD1, так и с CTLA4. Конструкция таких белков позволяет снизить частоту связывания естественными антителами в организме субъекта. Изобретение может быть использовано в получении лекарственного препарата для повышения иммунного ответа у субъекта, а также при лечении различных злокачественных опухолей и/или лечении инфекционных заболеваний. 11 н. и 14 з.п. ф-лы, 17 ил., 12 табл., 10 пр.
1. PD1/CTLA4-связывающее вещество, содержащее один или более одинарных вариабельных доменов иммуноглобулина (ISVD), которые связываются с PD1, содержащие аминокислотную последовательность:
DVQLVESGGG VVQPGGSLRL SCAASGSIAS IHAMGWFRQA PGKEREFVAV ITWSGGITYY ADSVKGRFTI SRDNSKNTVY LQMNSLRPED TALYYCAGDK HQSSWYDYWG QGTLVTVSS (SEQ ID NO: 135)
или вариант SEQ ID NO: 135, где D1 заменен на E; и
один или более ISVD, которые связываются с CTLA4, содержащие аминокислотную последовательность:
XVQLVESGGGVVQPGGSLRLSCAASGGTFSFYGMG
WFRQAPGKEREFVADIRTSAGRTYYADSVKGRFTISRDNSKNTVYLQMNSLRPEDTALYYCAAEPSGISGWDYWGQGTLVTVSS (SEQ ID NO: 143),
где X представляет собой D или E;
или
X1VQLVESGGGVVQPGGSLRLSCAASGGTFSFYGMGWFRQAPGKEREFVADIRTSAGRTYYADSVKGRFTISRDX2SKNTVYLQMNSLRPEDTALYYCAAEPSGISGWDYWGQGTLVTVSS(SEQ ID NO: 196),
где X1 представляет собой D или E и где X2 представляет собой S, V, G, R, Q, M, H, T, D, E, W, F, K, A, Y или P;
и, необязательно, экстендер периода полувыведения и/или С-концевой экстендер.
2. PD1/CTLA4-связывающее вещество по п. 1, содержащее пептидный линкер между каждым ISVD.
3. PD1/CTLA4-связывающее вещество по п. 1 или 2, содержащее:
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135, или вариант SEQ ID NO: 135, где D1 заменен на E;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143 (D1E);
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
ISVD сывороточного альбумина человека, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 144; и
C-концевой аланин.
4. PD1/CTLA4-связывающее вещество по п. 1 или 2, содержащее:
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135, или вариант SEQ ID NO: 135, где D1 заменен на E;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135, или вариант SEQ ID NO: 135, где D1 заменен на E;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143, или вариант SEQ ID NO: 196, где X1 заменен на E;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
ISVD сывороточного альбумина человека, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 144; и
C-концевой аланин.
5. PD1/CTLA4-связывающее вещество по п. 1 или 2, содержащее:
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135, или вариант SEQ ID NO: 135, где D1 заменен на E;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143, или вариант SEQ ID NO: 196, где X1 заменен на E;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143, или вариант SEQ ID NO: 196, где X1 заменен на E;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
ISVD сывороточного альбумина человека, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 144; и
С-концевой аланин.
6. PD1/CTLA4-связывающее вещество по п. 1 или 2, содержащее:
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
PD1 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 135, или вариант SEQ ID NO: 135, где D1 заменен на E;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143, или вариант SEQ ID NO: 196, где X1 заменен на E;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
CTLA4 ISVD, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 143, или вариант SEQ ID NO: 196, где X1 заменен на E;
линкер 35GS, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 86;
ISVD сывороточного альбумина человека, содержащий аминокислотную последовательность, представленную в SEQ ID NO: 144; и
C-концевой аланин.
7. PD1/CTLA4-связывающее вещество по п. 1 или 2, которое содержит пептидный линкер, где пептидный линкер содержит аминокислотную последовательность GGGGSGGGGSGGGGSGGGGSGGGGSGGGGSGGGGS (SEQ ID NO: 86).
8. PD1/CTLA4-связывающее вещество по любому из пп. 1-7, содержащее аминокислотную последовательность, представленную в SEQ ID NO: 146, 149, 151 или 153.
9. PD1/CTLA4-связывающее вещество по любому из пп. 1, 2 или 7, которое содержит экстендер периода полувыведения, который представляет собой ISVD сывороточного альбумина человека, который содержит:
CDR1, содержащий аминокислотную последовательность GFTFSSFGMS (SEQ ID NO: 199) или SFGMS (аминокислоты 6-10 в SEQ ID NO: 199);
CDR2, содержащий аминокислотную последовательность SISGSGSDTL (SEQ ID NO: 200) или SISGSGSDTL (аминокислоты 1-10 в SEQ ID NO: 200); и
CDR3, содержащий аминокислотную последовательность GGSLSR (SEQ ID NO: 201).
10. PD1/CTLA4-связывающее вещество по любому из пп. 1-9, которое содержит экстендер периода полувыведения, который представляет собой ISVD, который связывается с сывороточным альбумином человека и содержит аминокислотную последовательность:
EVQLVESGGG VVQPGNSLRL SCAASGFTFS SFGMSWVRQA PGKGLEWVSS ISGSGSDTLYADSVKGRFTI SRDNAKTTLY LQMNSLRPED TALYYCTIGG SLSRSSQGTL VTVSSA (SEQ ID NO: 144).
11. PD1/CTLA4-связывающее вещество по п. 1 или 2, которое содержит С-концевой экстендер, который представляет собой аланин.
12. Полинуклеотид, кодирующий PD1/CTLA4-связывающее вещество по любому из пп. 1-11.
13. Полинуклеотид по п. 12, содержащий нуклеотидную последовательность, представленную в SEQ ID NO: 145, 148, 150 или 152.
14. Экспрессионный вектор, содержащий полинуклеотид по п. 12 или 13.
15. Клетка-хозяин для экспрессии PD1/CTLA4-связывающего вещества по любому из пп. 1-11, содержащая вектор по п. 14.
16. Способ получения PD1/CTLA4-связывающего вещества по любому из пп. 1-11, включающий введение полинуклеотида по п. 12, кодирующего PD1/CTLA4-связывающее вещество, в клетку-хозяина и культивирование клетки-хозяина в среде в условиях, благоприятных для экспрессии указанного PD1/CTLA4-связывающего вещества из указанного полинуклеотида, и, необязательно, очистку PD1/CTLA4-связывающего вещества от указанной клетки-хозяина и/или указанной среды.
17. Фармацевтическая композиция для предотвращения связывания PD1 с PD-L1 и/или PD-L2, содержащая PD1/CTLA4-связывающее вещество по любому из пп. 1-11.
18. Фармацевтическая композиция для предотвращения связывания CTLA4 с CD80 и/или CD86, содержащая PD1/CTLA4-связывающее вещество по любому из пп. 1-11.
19. Фармацевтическая композиция для лечения или профилактики злокачественной опухоли у субъекта, включающая эффективное количество PD1/CTLA4-связывающего вещества по любому из пп. 1-11.
20. Фармацевтическая композиция по п. 19, где злокачественная опухоль представляет собой метастатическую злокачественную опухоль, твердую опухоль, гематологическую злокачественную опухоль, лейкемию, лимфому, остеосаркому, рабдомиосаркому, нейробластому, злокачественную опухоль почек, лейкемию, переходно-клеточную злокачественную опухоль почек, злокачественную опухоль мочевого пузыря, опухоль Вильма, злокачественную опухоль яичников, злокачественную опухоль поджелудочной железы, злокачественную опухоль молочной железы, злокачественную опухоль простаты, злокачественную опухоль костей, злокачественную опухоль легких, немелкоклеточную злокачественную опухоль легкого, злокачественную опухоль желудка, злокачественную опухоль толстой и прямой кишки, злокачественную опухоль шейки матки, синовиальную саркому, злокачественную опухоль головы и шеи, плоскоклеточную карциному, множественную миелому, почечно-клеточную злокачественную опухоль, ретинобластому, гепатобластому, гепатоцеллюлярную карциному, меланому, рабдоидную опухоль почки, саркому Юинга, хондросаркому, злокачественную опухоль мозга, глиобластому, менингиому, аденому гипофиза, вестибулярную шванному, примитивную нейроэктодермальную опухоль, медуллобластому, астроцитому, анапластическую астроцитому, олигодендроглиому, эпендимому, папиллому хориоидного сплетения, полицитемию, тромбоцитемию, идиопатический миелофиброз, саркому мягких тканей, злокачественную опухоль щитовидной железы, злокачественную опухоль эндометрия, карциноидную злокачественную опухоль или злокачественную опухоль печени, злокачественную опухоль молочной железы или злокачественную опухоль желудка.
21. Фармацевтическая композиция для лечения или профилактики инфекционного заболевания у субъекта, включающая эффективное количество PD1/CTLA4-связывающего вещества по любому из пп. 1-11.
22. Фармацевтическая композиция по п. 21, где инфекционное заболевание представляет собой бактериальную инфекцию, вирусную инфекцию или грибковую инфекцию.
23. Фармацевтическая композиция по любому из пп. 19-22, где субъекту вводят дополнительное терапевтическое средство или в отношении субъекта осуществляют терапевтическую процедуру совместно с PD1/CTLA4-связывающим веществом.
24. PD1/CTLA4-связывающее вещество, содержащее аминокислотную последовательность, представленную SEQ ID NO: 146, SEQ ID NO: 149, SEQ ID NO: 151 или SEQ ID NO: 153.
25. Фармацевтическая композиция для лечения или профилактики инфекционного заболевания у субъекта, содержащая эффективное количество PD1/CTLA4-связывающего вещества по п. 24 и фармацевтически приемлемый носитель.
| WO 2008071447 A2, 19.06.2008 | |||
| LARKIN J | |||
| et al.: Combined Nivolumab and Ipilimumab or Monotherapy in Untreated Melanoma | |||
| New England J | |||
| Med | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Устройство для одновременного приема и передачи по радиотелефону | 1921 |
|
SU373A1 |
| Прибор для равномерного смешения зерна и одновременного отбирания нескольких одинаковых по объему проб | 1921 |
|
SU23A1 |
| SHIN D.S | |||
| et al.: The evolution of checkpoint blockade as a cancer therapy: what's here, what's next? Current Opinion in Immunology, 2015, v | |||
| Способ сопряжения брусьев в срубах | 1921 |
|
SU33A1 |
| Прибор для равномерного смешения зерна и одновременного отбирания нескольких одинаковых по объему проб | 1921 |
|
SU23A1 |
| WO 2013024059 A2, | |||

