ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное решение относится к области компьютерных технологий, в частности, к автоматизированной системе для сбора данных в сети Интернет.
УРОВЕНЬ ТЕХНИКИ
[0002] Автоматизированный сбор новостей в сети Интернет широко применяется на сегодняшний день. Часто применяются различные методы парсинга информации с новостных источников, позволяющие выгружать данные с веб-ресурсов для их последующей обработки.
[0003] В заявке US 20070198459 Al (Current Assignee Accenture Global Services Ltd, 23.08.2007) раскрывается система для онлайн анализа источников информации, содержащая модуль сбора информации из сети и модуль аналитики, выполняющий анализ ретроспективного изменения данных в рамках анализируемого новостного топика.
[0004] Недостатками данного решения является отсутствие механизма проверки семантической связности текста, представленного в том или ином новостном источнике, что не позволяет проверить качество размещенной в сети информации, а также ее соответствие, как таковое, новостному источнику, а не иному типу данных, например, рекламному объявлению. В итоге такого рода решения позволяют осуществлять сбор данных без их предварительного анализа в части отношения к новостному источнику, вследствие чего снижается релевантность и качество собираемой информации.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0005] Заявленная система позволяет решить техническую проблему в части повышения точности собираемой информации за счет выполнения проверки собираемой информации на предмет семантически связного текста, характеризующего новостной источник.
[0006] Техническим результатом является повышение точности сбора новостных данных, за счет анализа новостных лент веб-сайтов на предмет наличия семантически связного текста в новостных источниках.
[0007] Заявленный технический результат достигается за счет реализации системы сбора и обработки новостей в сети Интернет, содержащей:
модуль анализатора, выполненный с возможностью
поиска доменных имен в сети Интернет, содержащих новостные источники;
анализа HTML-кода веб страниц соответствующих доменных имен для выявления новостных лент;
определение типа новостных лент и алгоритма обработки соответствующей ленты для извлечения ссылки на текстовую информацию новостного источника;
передачу выявленных ссылок на новостные ленты, их тип и алгоритм обработки в базу данных;
модуль скраппинга, выполненный с возможностью обработки данных, сохраненных в базе данных, с помощью которого осуществляется
обработка сохраненных ссылок на новостные ленты с помощью применения алгоритма анализа разметки веб-ресурса, определенного модулем анализатора, при которой выполняется переход по ссылке на веб-ресурс, проверка ссылки на дубликацию с хранимой информацией в базе данных, и получение HTML-кода для последующей обработки текстовых данных;
модуль парсинга, выполненный с возможностью
получения HTML-кода от модуля скраппинга;
извлечение текстовой информации из HTML-кода с помощью по меньшей мере двух алгоритмов сбора текстовых данных, каждый из которых, осуществляет выбор HTML-ноды с наибольшим отношением символов, характеризующих связный текст новостного источника, к общему их количеству;
обработку результатов извлечения каждого алгоритма моделью машинного обучения, причем модель выполнена с возможностью
анализировать наличие характеристик, присущих источникам, не являющихся новостным источниками, при этом характеристики представляют собой по меньшей мере стоп-слова и спецсимволы;
детектировать семантически связный текст, характеризующий новостной источник;
сохранения извлеченного текста в базу данных.
[0008] В одном из частных примеров реализации анализ HTML-кода осуществляется для главной страницы веб-ресурса и для всех страниц 1-го уровня вложенности.
[0009] В другом частном примере реализации определяется наличие наличия ссылок, их количества и признаков совпадений по ключевым словам, соответствующих новостному источнику.
[0010] В другом частном примере реализации модуль скраппинга выполнен с возможностью анализа лент следующих типов:
- RSS - RSS, Atom, JSON стандарты;
- HTML страницы;
- HTML страницы, обрабатываемые с помощью ХРАТН выражений.
[0011] Заявленный технический результат достигается также за счет выполнения способа сбора и обработки новостей в сети Интернет, выполняемого с помощью процессора и содержащего этапы, на которых:
выполняют поиск доменных имен в сети Интернет, содержащих новостные источники;
осуществляют анализ HTML-кода веб страниц соответствующих доменных имен для выявления новостных лент;
определяют тип новостных лент и алгоритм обработки соответствующей ленты для извлечения ссылки на текстовую информацию новостного источника;
передают выявленные ссылки на новостные ленты, их тип и алгоритм обработки в базу данных;
выполняют обработку данных, сохраненных в базе данных, в ходе которой обрабатывают сохраненные ссылки на новостные ленты с помощью алгоритма анализа разметки веб-ресурса, при этом выполняется переход по ссылке на веб-ресурс, проверка ссылки на дубликацию с хранимой информацией в базе данных, и получение HTML-кода для последующей обработки текстовых данных;
на основании полученного HTML-кода от модуля выполняют извлечение текстовой информации из HTML-кода с помощью по меньшей мере двух алгоритмов сбора текстовых данных, каждый из которых осуществляет выбор HTML-ноды с наибольшим отношением символов, характеризующих связный текст новостного источника, к общему их количеству;
обрабатывают результаты извлечения каждого алгоритма моделью машинного обучения, причем модель выполнена с возможностью
анализировать наличие характеристик, присущих источникам, не являющихся новостным источниками, при этом характеристики представляют собой по меньшей мере стоп-слова и спецсимволы;
детектировать семантически связный текст, характеризующий новостной источник;
сохранения извлеченного текста в базу данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0012] На Фиг. 1 представлена концептуальная схема заявленного решения.
[0013] На Фиг. 2 представлен пример HTML-кода, извлекаемого с ресурса модулем анализатора.
[0014] На Фиг. 3 представлен пример извлечения ссылок из HTML-кода.
[0015] На Фиг. 4 представлен пример записи ссылки на новостной источник в базе данных.
[0016] На Фиг. 5 представлен пример ХРАТН выражения.
[0017] На Фиг. 6 представлен пример обработки HTML ленты.
[0018] На Фиг. 7 представлен пример извлеченного текста из новостного источника.
[0019] На Фиг. 8 представлена общая схема вычислительного устройства.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
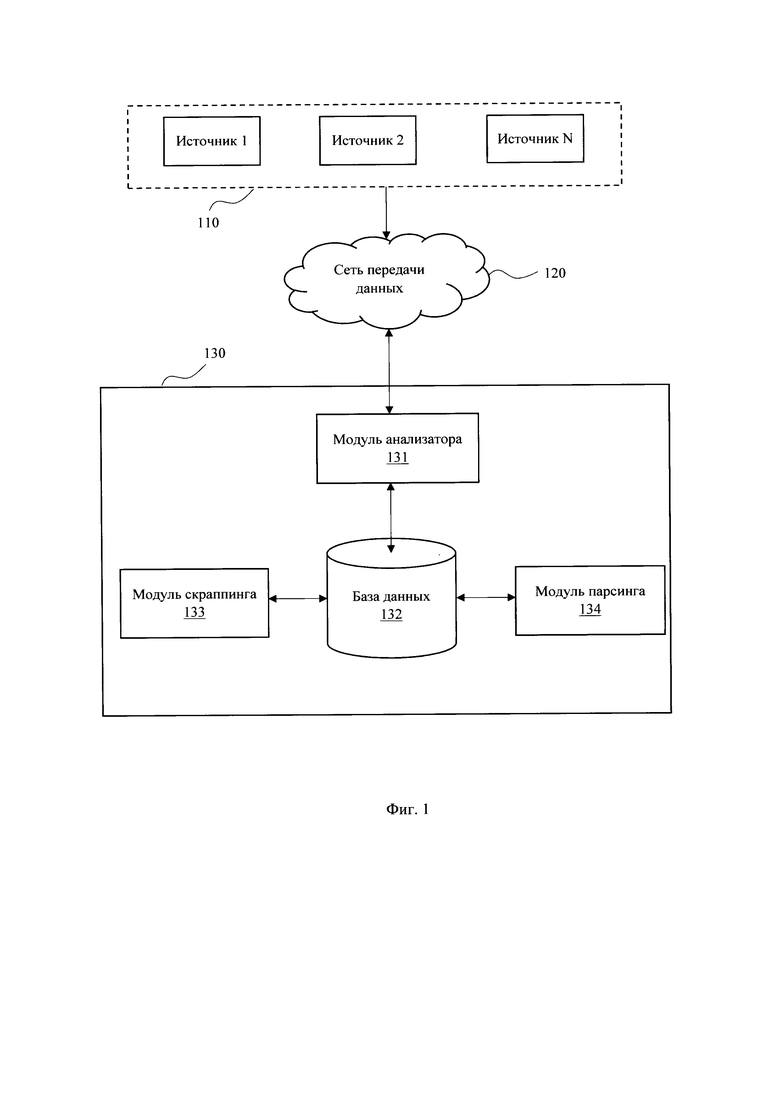
[0020] На Фиг. 1 представлена общая схема заявленной системы (130), выполняющей сбор информации с веб-сайтов, содержащих новостные источники (110). Система (130) может выполняться на базе единого вычислительного устройства, например, сервера, или представлять собой программно-аппаратный комплекс, в котором каждый из ее элементов расположен на отдельной вычислительной машине, связанный в рамках единого функционального обеспечения с другими элементами посредство информационной сети.
[0021] Система (130) содержит совокупность модулей, которые реализуют заданный функционал. Модули могут выполняться конструктивно в виде программно-аппаратных решений (например, система на чипе, микроконтроллеров и т.п.) или в виде программных модулей, функционирующих в рамках единого программного обеспечения, реализующего алгоритм работы системы (130) с помощью вычислительного устройства.
[0022] Сбор информации системой (130) из сети Интернет осуществляется посредством модуля анализатора (131), выполняющему подключение к веб-сайтам с новостными источниками (110) через информационную сеть (120).
[0023] Модуль анализатора (131) выполняет поиск доменных имен в сети Интернет, содержащих новостные источники (110). После подключения к источникам модуль (131) выполняет анализ HTML-кода веб-страниц соответствующих доменных имен на предмет выявления новостных лент. Анализ новостных источников выполняется с помощью анализа главной страницы веб-ресурса, а также всех страниц 1-го уровня вложенности. На Фиг. 2 представлен пример извлечения HTML-кода из источника (110) домена https://press.sber.ru.
[0024] Алгоритм обработки модуля (131) использует два типа алгоритмов rssfmder и htmlfinder, которые обеспечивают анализ веб-страниц и выявление ссылок на RSS-ленты или HTML-ленты. Пример определения ссылок на новостные ленты представлен на Фиг. 3. После выявления одной или нескольких новостных лент модуль (131) выполняет определение типа новостных лент и алгоритма обработки соответствующей ленты для извлечения ссылки на текстовую информацию новостного источника. Первым работает алгоритм rssfinder, т.к. rss ленты проще в обработке, если по итогу работы rssfinder ничего не выявил, то активируется алгоритм htmlfinder. При этом возможны случаи, когда ссылка некорректная или источник не доступен (нет отклика от сервера), в таком случае тип ленты определяется в процессе выявления и зависит от того, какой алгоритм вернул значения, и самого факта получения ответов от сервера источника.
[0025] При работе модуля (131) также определяется наличие ссылок, их количества и признаков совпадений по ключевым словам, соответствующих новостному источнику, например, таким как: "rss", "feed", "news", "articles", "новости", "статьи", или исключающих (".png", ".pdf", паттерны: \* login.*', 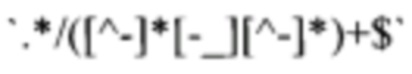 и др.). Выявленные ссылки на новостные ленты, а также их тип (HTML или RSS) и применимый алгоритм обработки для последующего извлечения ссылок на новости передаются в базу данных (132). Пример записи в базе данных представлен на Фиг. 4.
и др.). Выявленные ссылки на новостные ленты, а также их тип (HTML или RSS) и применимый алгоритм обработки для последующего извлечения ссылок на новости передаются в базу данных (132). Пример записи в базе данных представлен на Фиг. 4.
[0026] Сохраненная информация в базе данных (132) далее обрабатывается с помощью модулей скраппинга (133) и парсинга (134). Модуль скраппинга (133) обеспечивает обработку сохраненных ссылок на новостные ленты с помощью применения алгоритма анализа разметки веб-ресурса, определенного модулем анализатора (131), при которой выполняется переход по ссылке на веб-ресурс источника (110) для проверки ссылки на дубликацию с хранимой информацией в базе данных (132), а также получения HTML-кода для последующей обработки текстовых данных модулем парсинга (134). Пример извлечения ссылок из HTML-кода представлен на Фиг. 3.
[0027] Модуль скраппинга (133) выполняет непрерывную работу и итеративно обрабатывает таблицу ссылок на ленты из базы данных (132). В асинхронном режиме в модуле (133) работает три цикла, поддерживающие обработку 3-х типов лент: RSS - RSS, Atom, JSON стандарты (1й тип); HTML - обычные HTML-страницы (2й тип); HTML-страницы, обрабатываемые с помощью ХРАТН выражений (3й тип), для которых путь к ссылкам на новости конфигурируется вручную. Пример записи ХРАТН выражения представлен на Фиг. 5.
[0028] Каждый из циклов обрабатывает часть соответствующих его алгоритму ссылок, при работе которых происходит обращение по ссылке к источнику (110) для анализа полученного HTML-кода для извлечения ссылок на новостные данные. Пример промежуточной обработки для HTML ленты представлен на Фиг. 6. Все полученные ссылки на новости проверяются на дублирование путем обращения к базе данных (132), если ссылка содержится в базе данных (132) - то она исключается из обработки, иначе - записывается в базу данных (132) и передается на дальнейшую обработку.
[0029] Модуль парсинга (134) обрабатывает полученный HTML-код от модуля скраппинга (133). В ходе работы модуля (134) осуществляется извлечение текстовой информации из HTML-кода с помощью по меньшей мере двух алгоритмов сбора текстовых данных, каждый из которых, осуществляет выбор HTML-ноды с наибольшим отношением символов, характеризующих связный текст новостного источника, к общему их количеству. Под HTML-нодой понимается иерархический узел HTML разметки, например, <head>, <body> и т.п.
[0030] Один из применяемых алгоритмов основан на измерении количества непробельных символов в HTML-ноде источника. Другой алгоритм анализирует HTML-ноды по количеству полезного текста, и выполняет извлечение текста из набравших больший вес нод. Путем тестирования этих алгоритмов на одном наборе данных была выявлена разность множеств качественных текстов. Алгоритмы работают параллельно и сравнивается оценка результатов моделью машинного обучения, например, нейросетевым алгоритмом, обученным на примерах новостных источников, представляющих собой эталонные новостные тексты. Модель машинного обучения, применяемая в рамках работы модуля парсинга (134) выполняет анализ наличия характеристик, присущих источникам, не являющихся новостными источниками. Такого рода характеристики, как правило, представляют собой стоп-слова и спецсимволы (например, номера телефонов, последовательность цифр, и т.п.). На основании обработки моделью получаемых результатов работы указанных выше алгоритмов выполняется выявление наиболее семантически связного текста, что явно характеризует новостной источник. Полученный текст впоследствии сохраняется в базу данных (132) для последующего предоставления пользователю или передачи в автоматизированную систему подбора новостей по ключевым словам. Пример извлеченного текста представлен на Фиг. 7
[0031] Заявленная система (130) может быть реализована на базе единого вычислительного устройства (200), например, сервере. На Фиг. 8 представлен общий вид такого вычислительного устройства (200).
[0032] В общем случае вычислительное устройство (200) содержит объединенные общей шиной информационного обмена один или несколько процессоров (201), средства памяти, такие как ОЗУ (202) и ПЗУ (203), интерфейсы ввода/вывода (204), устройства ввода/вывода (205), и устройство для сетевого взаимодействия (206). [0033] Процессор (201) (или несколько процессоров, многоядерный процессор) могут выбираться из ассортимента устройств, широко применяемых в текущее время, например, компаний Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. В качестве процессора (501) может также применяться графический процессор, например, Nvidia, AMD, Graphcore и пр.
[0034] ОЗУ (202) представляет собой оперативную память и предназначено для хранения исполняемых процессором (201) машиночитаемых инструкций для выполнение необходимых операций по логической обработке данных. ОЗУ (202), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.).
[0035] ПЗУ (203) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
[0036] Для организации работы компонентов устройства (200) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (204). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, Fire Wire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0037] Для обеспечения взаимодействия пользователя с вычислительным устройством (500) применяются различные средства (205) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0038] Средство сетевого взаимодействия (206) обеспечивает передачу данных устройством (200) посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (206) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
[0039] Дополнительно могут применяться также средства спутниковой навигации в составе устройства (200), например, GPS, ГЛОНАСС, BeiDou, Galileo.
[0040] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.



Настоящее техническое решение относится к области вычислительной техники. Технический результат заключается в повышении точности сбора и обработки текстовой информации с веб-страницы. Технический результат достигается за счёт модуля анализатора для поиска доменных имен в сети Интернет, содержащих новостные источники, анализа HTML-кода для выявления новостных лент, извлечения ссылки на текст новостного источника, передачи выявленных ссылок, их тип и алгоритм обработки в базу данных (БД); модуля скраппинга для обработки данных с помощью применения алгоритма анализа разметки веб-ресурса; модуля парсинга для получения HTML-кода от модуля скраппинга, извлечения текста из HTML-кода с помощью двух алгоритмов сбора текстовых данных, каждый из которых осуществляет выбор HTML-ноды с наибольшим отношением символов, характеризующих связный текст новостного источника, к общему их количеству, обработки результатов извлечения алгоритмов моделью машинного обучения для анализа наличия характеристик источников, не являющихся новостным и детектирования семантически связного текста, характеризующего новостной источник. 2 н. и 3 з.п. ф-лы, 8 ил.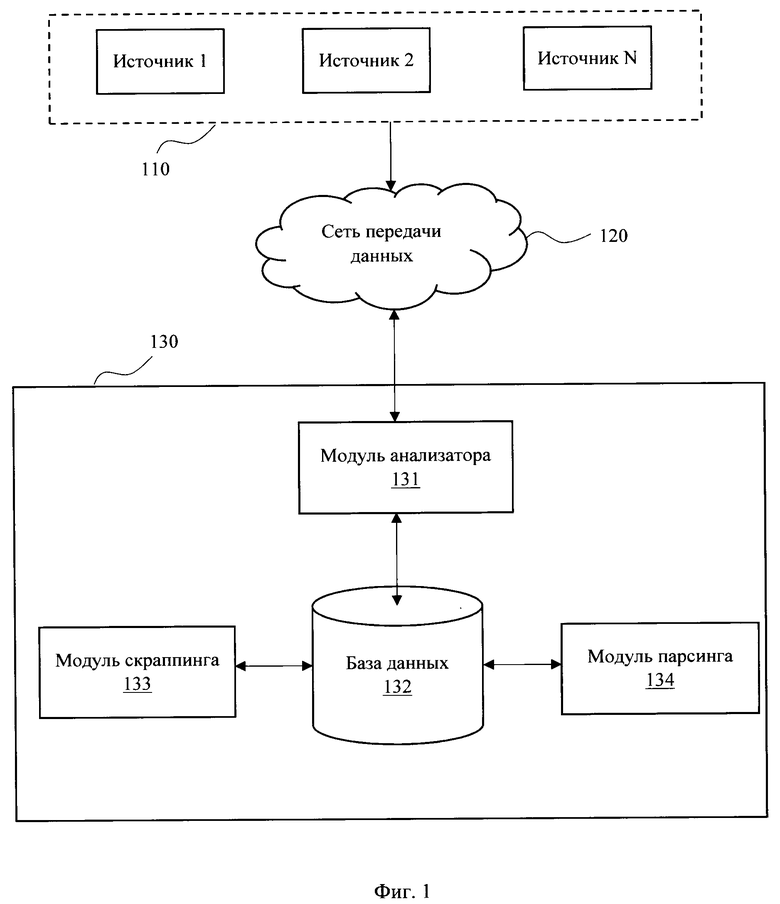
1. Система сбора и обработки новостей в сети Интернет, содержащая:
модуль анализатора, выполненный с возможностью
поиска доменных имен в сети Интернет, содержащих новостные источники;
анализа HTML-кода веб страниц соответствующих доменных имен для выявления новостных лент;
определение типа новостных лент и алгоритма обработки соответствующей ленты для извлечения ссылки на текстовую информацию новостного источника;
передачу выявленных ссылок на новостные ленты, их тип и алгоритм обработки в базу данных;
модуль скраппинга, выполненный с возможностью обработки данных, сохраненных в базе данных, с помощью которого осуществляется
обработка сохраненных ссылок на новостные ленты с помощью применения алгоритма анализа разметки веб-ресурса, определенного модулем анализатора, при которой выполняется переход по ссылке на веб-ресурс, проверка ссылки на дубликацию с хранимой информацией в базе данных, и получение HTML-кода для последующей обработки текстовых данных;
модуль парсинга, выполненный с возможностью
получения HTML-кода от модуля скраппинга;
извлечения текстовой информации из HTML-кода с помощью по меньшей мере двух алгоритмов сбора текстовых данных, каждый из которых осуществляет выбор HTML-ноды с наибольшим отношением символов, характеризующих связный текст новостного источника, к общему их количеству;
обработку результатов извлечения каждого алгоритма моделью машинного обучения, причем модель выполнена с возможностью
анализировать наличие характеристик, присущих источникам, не являющихся новостным источниками, при этом характеристики представляют собой по меньшей мере стоп-слова и спецсимволы;
детектировать семантически связный текст, характеризующий новостной источник;
сохранения извлеченного текста в базу данных.
2. Система по п. 1, характеризующая тем, что анализ HTML-кода осуществляется для главной страницы веб-ресурса и для всех страниц 1-го уровня вложенности.
3. Система по п. 2, характеризующая тем, что определяется наличие наличия ссылок, их количества и признаков совпадений по ключевым словам, соответствующих новостному источнику.
4. Система по п. 1, характеризующая тем, что модуль скраппинга выполнен с возможностью анализа лент следующих типов:
- RSS - RSS, Atom, JSON стандарты;
- HTML страницы;
- HTML страницы, обрабатываемые с помощью ХРАТН выражений.
5. Способ сбора и обработки новостей в сети Интернет, выполняемый с помощью процессора и содержащий этапы, на которых:
выполняют поиск доменных имен в сети Интернет, содержащих новостные источники;
осуществляют анализ HTML-кода веб-страниц соответствующих доменных имен для выявления новостных лент;
определяют тип новостных лент и алгоритм обработки соответствующей ленты для извлечения ссылки на текстовую информацию новостного источника;
передают выявленные ссылки на новостные ленты, их тип и алгоритм обработки в базу данных;
выполняют обработку данных, сохраненных в базе данных, в ходе которой обрабатывают сохраненные ссылки на новостные ленты с помощью алгоритма анализа разметки веб-ресурса, при этом выполняется переход по ссылке на веб-ресурс, проверка ссылки на дубликацию с хранимой информацией в базе данных, и получение HTML-кода для последующей обработки текстовых данных;
на основании полученного HTML-кода от модуля выполняют извлечение текстовой информации из HTML-кода с помощью по меньшей мере двух алгоритмов сбора текстовых данных, каждый из которых осуществляет выбор HTML-ноды с наибольшим отношением символов, характеризующих связный текст новостного источника, к общему их количеству;
обрабатывают результаты извлечения каждого алгоритма моделью машинного обучения, причем модель выполнена с возможностью
анализировать наличие характеристик, присущих источникам, не являющихся новостными источниками, при этом характеристики представляют собой по меньшей мере стоп-слова и спецсимволы;
детектировать семантически связный текст, характеризующий новостной источник;
сохранения извлеченного текста в базу данных.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| ВЕБ-КРОЛИНГ НА ОСНОВЕ ТЕОРИИ СТАТИСТИЧЕСКИХ РЕШЕНИЙ И ПРОГНОЗИРОВАНИЕ ИЗМЕНЕНИЯ ВЕБ-СТРАНИЦЫ | 2005 |
|
RU2405197C2 |

