Настоящая заявка испрашивает приоритет на основании заявки на патент Китая №2019109262958, поданной в Национальное управление интеллектуальной собственности Китая 27 сентября 2019 года, и заявки на патент Китая №2019108046792, поданной 28 августа 2019 года, а также заявки на патент Китая №2019108046881, поданной 28 августа 2019 года, каждая из которых полностью включена в данный документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к технической области генной инженерии и микроорганизмов, и, в частности, к рекомбинантному штамму с модифицированным геном kdtA, способу его конструирования и его применению.
УРОВЕНЬ ТЕХНИКИ
L-треонин является одной из восьми незаменимых аминокислот, и представляет собой аминокислоту, которую люди и животные не могут синтезировать самостоятельно. L-треонин способен улучшать усвояемость зерна, регулировать баланс метаболизма in vivo и способствовать росту и развитию организмов, и поэтому он широко применяется в кормовой, медицинской и пищевой промышленности.
В настоящее время L-треонин может быть получен в основном с использованием метода химического синтеза, метода гидролиза белков и метода микробиологической ферментации, при этом метод микробиологической ферментации имеет преимущества, заключающиеся в низкой стоимости производства, высокой интенсивности производства и небольшом уровне загрязнения окружающей среды, поэтому данный метод является наиболее широко применяемым среди методов промышленного производства L-треонина. Для продуцирования L-треонина путем микробиологической ферментации могут быть использованы различные бактерии, такие как мутанты, полученные при индукции Escherichia coli (Е. coli), Corynebacterium и Serratia дикого типа, в качестве штаммов-продуцентов. Конкретные примеры включают мутанты, резистентные к аналогам аминокислот или различные аукстрофы, такие как метионин, треонин и изолейцин. Однако при традиционной мутационной селекции штамм растет медленно и производит больше побочных продуктов из-за случайных мутаций, так что получить высокопродуктивный штамм непросто. Следовательно, конструирование рекомбинантной Е. coli с помощью метаболической инженерии является эффективным способом получения L-треонина. В настоящее время сверхэкспрессия или аттенуация генов ключевых ферментов пути синтеза аминокислот и конкурентного пути, опосредованного экспрессионными плазмидами, является основным средством генетической модификации Е. coli. По-прежнему существует необходимость в разработке более экономичного способа получения L-треонина с высокой производительностью.
Е. coli в качестве хозяина для экзогенной экспрессии генов, обладает преимуществами, такими как чистый генетический фон, простые условия технической эксплуатации и культивирования, экономичная крупномасштабная ферментация, и поэтому эксперты в области генной инженерии уделяют ей все больше внимание. Геномная ДНК Е. coli представляет собой кольцевую молекулу в нуклеоиде, а также может быть представлено множество кольцевых плазмидных ДНК. Нуклеоид в клетках Е. coli имеет одну молекулу ДНК, длина которой составляет примерно 4700000 пар оснований, а также содержит 4400 генов, распределенных в молекуле ДНК, и каждый ген имеет среднюю длину примерно 1000 пар оснований. Среди штаммов Е. coli, используемых обычно в молекулярной биологии, наиболее часто используемыми штаммами в экспериментах по рекомбинации ДНК, за некоторым исключением, являются штамм Е. Coli К12 и его производные.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Согласно настоящему изобретению предложены рекомбинантный штамм на основе штамма Escherichia coli К12 или его производный штамм, способ его рекомбинантного конструирования и его применение для ферментационного получения аминокислоты. Настоящее изобретение главным образом относится к гену дикого типа kdtA (последовательность ОРС представлена в последовательности 73556-74833, идентификационный номер в GenBank СР032667.1), гену дикого типа spoT (последовательность ОРС представлена в последовательности 3815907-3818015, идентификационный номер в GenBank АР009048.1), гену дикого типа yebN (последовательность ОРС представлена в последовательности 1907402-1907968, идентификационный номер в GenBank АР009048.1) штамма К12 Е. coli и его производным (таким как MG1655 и W3110), а также в настоящем изобретении обнаружено, что мутантный ген, полученный при подвергании гена сайт-направленному мутагенезу, и рекомбинантный штамм, содержащий ген, могут быть использованы для продуцирования L-треонина, и по сравнению с немутантным штаммом дикого типа, полученный штамм значительно увеличивает производительность L-треонина и характеризуется хорошей стабильностью, а также имеет более низкую стоимость производства в качестве штамма для продуцирования L-треонина.
На основании указанных выше данных, настоящее изобретение обеспечивает следующие три технических решения:
Согласно первому техническому решению предложена нуклеотидная последовательность, содержащая последовательность, образованную вследствие мутации в 82-ом основании кодирующей последовательности гена kdtA дикого типа, представленная в SEQ ID NO: 1.
В соответствии с настоящим изобретением мутация представляет собой изменение в основании/нуклеотиде в сайте, и способ мутации может быть по меньшей мере одним, выбранным из следующих способов: мутагенез, сайт-направленный мутагенез в ходе ПЦР и/или гомологическая рекомбинация и т.д.
В соответствии с настоящим изобретением мутация заключается в том, что гуанин (Г) заменен на аденин (А) в 82-ом основании в SEQ ID NO: 1; в частности, мутантная нуклеотидная последовательность представлена в SEQ ID NO: 2.
Настоящее изобретение также обеспечивает рекомбинантный белок, кодируемый указанной выше нуклеотидной последовательностью.
Рекомбинантный белок, раскрытый в данном документе, содержит аминокислотную последовательность SEQ ID NO: 4.
Настоящее изобретение также обеспечивает рекомбинантный вектор, содержащий указанную выше нуклеотидную последовательность или рекомбинантный белок. Рекомбинантный вектор, раскрытый в данном документе, конструируют путем введения указанной выше нуклеотидной последовательности в плазмиду; в одном варианте осуществления плазмида представляет собой плазмиду pKOV. В частности, нуклеотидная последовательность и плазмида могут быть расщеплены эндонуклеазой с образованием комплементарных липких концов, которые лигируются для конструирования рекомбинантного вектора.
Настоящее изобретение также обеспечивает рекомбинантный штамм, который содержит кодирующую нуклеотидную последовательность гена akdtA, содержащую точечную мутацию, возникающую в кодирующей последовательности. Рекомбинантный штамм, раскрытый в данном документе, содержит указанную выше нуклеотидную последовательность.
В одном варианте реализации настоящего изобретения рекомбинантный штамм содержит нуклеотидную последовательность, представленную в SEQ ID NO: 2. В одном варианте реализации настоящего изобретения рекомбинантный штамм содержит аминокислотную последовательность, представленную в SEQ ID NO: 4. Рекомбинантный штамм, раскрытый в данном документе, конструируют путем введения указанного выше рекомбинантного вектора в штамм-хозяин; штамм-хозяин конкретно не определен, он может быть выбран из известных в данной области техники штаммов, продуцирующих L-треонин, которые содержат ген kdtA, например, Escherichia coli. В одном варианте настоящего изобретения штаммом-хозяином является штамм Е. coli К12 (W3110) или штамм Е. coli CGMCC 7.232. Рекомбинантный штамм, раскрытый в данном документе, использует плазмиду pKOV в качестве вектора.
Рекомбинантный штамм согласно настоящему изобретению может дополнительно содержать или не содержать другие модификации.
Настоящее изобретение также обеспечивает способ конструирования рекомбинантного штамма, который содержит следующий этап:
модификация нуклеотидной последовательности кодирующей области гена kdtA дикого типа, представленной в SEQ ID NO: 1, для обеспечения возможности возникновения мутации в 82-ом основании последовательности с получением рекомбинантного штамма, продуцирующего L-треонин, содержащего мутантный кодирующий ген kdtA. В соответствии со способом конструирования согласно настоящему изобретению модификация включает применение по меньшей мере одного из следующих способов: мутагенез, сайт-направленный мутагенез и/или гомологическая рекомбинация и т.п. В соответствии со способом конструирования согласно настоящему изобретению мутация заключается в том, что гуанин (Г) заменен на аденин (А) в 82-ом основании в SEQ ID NO: 1; в частности, мутантная нуклеотидная последовательность представлена в SEQ ID NO: 2.
Кроме того, способ конструирования включает следующие этапы:
(1) модификация нуклеотидной последовательности области открытой рамки считывания гена kdtA дикого типа, представленной в SEQ ID NO: 1, для обеспечения возможности возникновения мутации в 82-ом основании последовательности с получением мутантной нуклеотидной последовательности области открытой рамки считывания гена kdtA;
(2) лигирование мутантной нуклеотидной последовательности с плазмидой для конструирования рекомбинантного вектора; и
(3) введение рекомбинантного вектора в штамм-хозяин для получения рекомбинантного штамма, продуцирующего L-треонин, имеющего точечную мутацию. В соответствии со способом конструирования согласно настоящему изобретению этап (1) включает: конструирование кодирующей области гена kdtA, содержащей точечную мутацию, в частности включающее синтез двух пар праймеров для амплификации фрагментов кодирующей области гена kdtA в соответствии с кодирующей последовательностью гена kdtA, а также введение точечной мутации в кодирующую область гена kdtA дикого типа (SEQ ID NO: 1) с применением методик ПЦР сайт-направленного мутагенеза для получения нуклеотидной последовательности (SEQ ID NO: 2) кодирующей области гена kdtA, содержащей точечную мутацию, где нуклеотидная последовательность обозначена как kdtA(G82A).
В одном варианте реализации настоящего изобретения на этапе (1) праймерами являются:
Р1: 5' ЦГГГАТЦЦАЦЦАГТГААЦЦГЦЦААЦА 3' (SEQ ID NO: 5);
Р2: 5' ТГЦГЦГГАЦГТААГАЦТЦ 3' (SEQ ID NO: 6);
Р3: 5' ГАГТЦТТАЦГТЦЦГЦГЦА 3' (SEQ ID NO: 7); и
Р4: 5' ААГГААААААГЦГГЦЦГЦТТЦЦЦГЦАЦЦТТТАТТГ 3' (SEQ ID NO: 8).
В одном варианте реализации настоящего изобретения этап (1) включает: применение праймеров Р1/Р2 и Р3/Р4 для амплификации в ходе ПЦР с применением Е. coli К12 в качестве матрицы для получения двух выделенных фрагментов ДНК (kdtA Up и kdtA Down), имеющих длину 927 п. о. и 695 п. о. и содержащих кодирующие области гена kdtA; разделение и очистку двух фрагментов ДНК с использованием электрофореза в агарозном геле, а затем выполнение ПЦР с перекрывающимися праймерами с применением Р1 и Р4 в качестве праймеров и двух фрагментов ДНК в качестве матриц для получения kdtAG82A-Up-Down.
В одном варианте реализации настоящего изобретения нуклеотидная последовательность kdtAG82A-Up-Down имеет длину 1622 п.о.
В одном варианте реализации настоящего изобретения ПЦР-амплификацию осуществляют следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С в течение 30 с и элонгация при 72°С в течение 30 с (30 циклов). В одном варианте реализации настоящего изобретения ПЦР-амплификацию с перекрывающимися праймерами осуществляют следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С в течение 30 с и элонгация при 72°С в течение 60 с (30 циклов).
В соответствии со способом конструирования согласно настоящему изобретению этап
(2) включает: конструирование рекомбинантного вектора, в частности включающее разделение и очистку фрагмента kdtA(G82A)-Up-Down с использованием электрофореза в агарозном геле, затем расщепление очищенного фрагмента и плазмиды pKOV с использованием BamH I/Not I, и разделение и очистку расщепленного фрагмента kdtA(G82A)-Up-Down и расщепленной плазмиды pKOV с использованием электрофореза в агарозном геле с последующим лигированием для получения рекомбинантного вектора pKOY-kdtA(G82A).
В соответствии со способом конструирования согласно настоящему изобретению этап
(3) включает: конструирование рекомбинантного штамма, в частности включающее трансформацию рекомбинантного вектора pKOV-kdtA(G82A) в штамм-хозяин для получения рекомбинантного штамма.
В одном варианте реализации настоящего изобретения трансформация на этапе (3) представляет собой процесс электротрансформации; например, на этапе (3) рекомбинантный вектор вводят в штамм-хозяин.
В соответствии со способом конструирования согласно настоящему изобретению указанный способ дополнительно включает этап скрининга рекомбинантного штамма; например, скрининг осуществляют с использованием культуральной среды с хл ор амфе николо м.
Настоящее изобретение также обеспечивает рекомбинантный штамм, полученный с помощью указанного выше способа конструирования.
Настоящее изобретение также обеспечивает применение рекомбинантного штамма для получения L-треонина или увеличения ферментационного объема L-треонина. Применение рекомбинантного штамма для получения L-треонина включает ферментацию рекомбинантного штамма для получения L-треонина.
Согласно второму техническому решению предложена нуклеотидная последовательность, содержащая нуклеотидную последовательность, образованную вследствие мутации в 520-ом основании кодирующей последовательности гена spoT, представленная в SEQ ID NO: 13.
В соответствии с настоящим изобретением мутация представляет собой изменение в основании/нуклеотиде в сайте, и способ мутации может быть по меньшей мере одним, выбранным из следующих способов: мутагенез, сайт-направленный мутагенез в ходе ПЦР и/или гомологическая рекомбинация и т.д.
В соответствии с настоящим изобретением мутация заключается в том, что гуанин (Г) заменен на тимин (Т) в 520-ом основании в SEQ ID NO: 13; в частности, мутантная нуклеотидная последовательность представлена в SEQ ID NO: 14.
Настоящее изобретение обеспечивает рекомбинантный белок, кодируемый указанной выше нуклеотидной последовательностью.
Рекомбинантный белок, раскрытый в данном документе, содержит аминокислотную последовательность, представленную в SEQ ID NO: 16; в частности, рекомбинантный белок содержит замену глицина на цистеин в 174-ом положении аминокислотной последовательности, представленной в SEQ ID NO: 15.
Настоящее изобретение обеспечивает рекомбинантный вектор, содержащий указанную выше нуклеотидную последовательность или рекомбинантный белок. Рекомбинантный вектор, раскрытый в данном документе, конструируют путем введения указанной выше нуклеотидной последовательности в плазмиду; в одном варианте осуществления плазмида представляет собой плазмиду pKOV. В частности, нуклеотидная последовательность и плазмида могут быть расщеплены эндонуклеазой с образованием комплементарных липких концов, которые лигируются для конструирования рекомбинантного вектора.
Настоящее изобретение также обеспечивает рекомбинантный штамм, содержащий кодирующую нуклеотидную последовательность гена spoT, содержащую точечную мутацию в кодирующей последовательности, например, кодирующая нуклеотидная последовательность гена spoT, представленная в SEQ ID NO: 13, содержащая точечную мутацию в 520-ом основании.
В соответствии с настоящим изобретением мутация заключается в замене гуанина (Г) на тимин (Т) в 520-ом основании в SEQ ID NO: 13.
В одном варианте реализации настоящего изобретения рекомбинантный штамм содержит нуклеотидную последовательность, представленную в SEQ ID NO: 14.
В одном варианте реализации настоящего изобретения рекомбинантный штамм содержит аминокислотную последовательность, представленную в SEQ ID NO: 16. Рекомбинантный штамм, раскрытый в данном документе, конструируют путем введения указанного выше рекомбинантного вектора в штамм-хозяин; штамм-хозяин конкретно не определен, он может быть выбран из известных в данной области техники штаммов, продуцирующих L-треонин, которые содержат ген spoT, например, Escherichia coli. В одном варианте реализации настоящего изобретения штаммом-хозяином является штамм Е. coli К12 (W3110) или штамм Е. coli CGMCC 7.232.
Для рекомбинантного штамма, раскрытого в данном документе, использовали плазмиду pKOV в качестве вектора.
Рекомбинантный штамм согласно настоящему изобретению может дополнительно содержать или не содержать другие модификации.
Настоящее изобретение обеспечивает способ конструирования рекомбинантного штамма, который содержит следующий этап:
модификация нуклеотидной последовательности кодирующей области гена spoT, представленной в SEQ ID NO: 13, для обеспечения возможности возникновения мутации в 520-ом основании последовательности с получением рекомбинантного штамма, содержащего мутантный кодирующий ген spoT.
В соответствии со способом конструирования согласно настоящему изобретению модификация включает применение по меньшей мере одного из следующих способов: мутагенез, ПЦР сайт-направленный мутагенез и/или гомологическая рекомбинация и т.п.
В соответствии со способом конструирования согласно настоящему изобретению мутация заключается в том, что гуанин (Г) заменен на тимин (Т) в 520-ом основании в SEQ ID NO: 13; в частности, мутантная нуклеотидная последовательность представлена в SEQ ID NO: 14.
Кроме того, способ конструирования включает следующие этапы:
(1) модификация нуклеотидной последовательности области открытой рамки считывания гена spoT дикого типа, представленной в SEQ ID NO: 13, для обеспечения возможности возникновения мутации в 520-ом основании последовательности с получением мутантной нуклеотидной последовательности;
(2) лигирование мутантной нуклеотидной последовательности с плазмидой для конструирования рекомбинантного вектора; и
(3) введение рекомбинантного вектора в штамм-хозяин для получения рекомбинантного штамма, имеющего точечную мутацию.
В соответствии со способом конструирования согласно настоящему изобретению этап (1) включает: конструирование кодирующей области гена spoT, содержащей точечную мутацию, в частности включающее синтез двух пар праймеров для амплификации фрагментов кодирующей области гена spoT в соответствии с кодирующей последовательностью гена spoT, а также введение точечной мутации в кодирующую область гена spoT дикого типа (SEQ ID NO: 13) с применением методик ПЦР сайт-направленного мутагенеза для получения нуклеотидной последовательности (SEQ ID NO: 14) кодирующей области гена spoT, содержащей точечную мутацию, где нуклеотидная последовательность обозначена как spoT(G520T).
В одном варианте реализации настоящего изобретения на этапе (1) праймерами являются:
Р1: 5' ЦГГГАТЦЦГААЦАГЦААГАГЦАГГААГЦ 3' (SEQ ID NO: 17);
Р2: 5' ТГТГГТГГАТАЦАТАААЦГ 3' (SEQ ID NO: 18);
Р3: 5' ГЦАЦЦГТТТАТГТАТЦЦАЦЦ 3'(SEQ ID NO: 19); и
P4: 5' ААГГААААААГЦГГЦЦГЦАЦГАЦАААГТТЦАГЦЦААГЦ 3' (SEQ ID NO: 20).
В одном варианте реализации настоящего изобретения этап (1) включает: применение праймеров Р1/Р2 и Р3/Р4 для амплификации в ходе ПЦР с применением Е. coli К12 в качестве матрицы для получения двух выделенных фрагментов ДНК (spoT(G520T)-Up и spoT(G520T)-Down), имеющих длину 620 п.о. и 880 п.о. и содержащих кодирующие области гена spoT, содержащие точечную мутацию; разделение и очистку двух фрагментов ДНК с использованием электрофореза в агарозном геле, а затем выполнение ПЦР с перекрывающимися праймерами с применением Р1 и Р4 в качестве праймеров и двух фрагментов ДНК в качестве матриц для получения фрагмента spoT(G520T)-Up-Down.
В одном варианте реализации настоящего изобретения нуклеотидная последовательность фрагмента spoT(G520T)-Up-Down имеет длину 1500 п.о.
В одном варианте реализации настоящего изобретения ПЦР-амплификацию осуществляют следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С в течение 30 с и элонгация при 72°С в течение 30 с (30 циклов).
В одном варианте реализации настоящего изобретения ПЦР-амплификацию с перекрывающимися праймерами осуществляют следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С в течение 30 с и элонгация при 72°С в течение 60 с (30 циклов).
В соответствии со способом конструирования согласно настоящему изобретению этап (2) включает: конструирование рекомбинантного вектора, в частности включающее разделение и очистку фрагмента spoT(G520T)-Up-Down с использованием электрофореза в агарозном геле, затем расщепление очищенного фрагмента и плазмиды pKOV с использованием BamHI/Not I, и разделение и очистку расщепленного фрагмента и расщепленной плазмиды pKOV с использованием электрофореза в агарозном геле с последующим лигированием для получения рекомбинантного вектора pKOY-spoT(G520T).
В соответствии со способом конструирования согласно настоящему изобретению этап (3) включает: конструирование рекомбинантного штамма, в частности включающее введение рекомбинантного вектора pKOV-spoT(G520T) в штамм-хозяин для получения рекомбинантного штамма.
В одном варианте реализации настоящего изобретения введение на этапе (3) представляет собой процесс электротрансформации.
В соответствии со способом конструирования согласно настоящему изобретению способ дополнительно включает этап скрининга рекомбинантного штамма; например, скрининг осуществляют с использованием культуральной среды с хлорамфениколом. Настоящее изобретение также обеспечивает рекомбинантный штамм, полученный с помощью указанного выше способа конструирования.
Настоящее изобретение обеспечивает применение указанного выше рекомбинантного штамма для получения L-треонина.
Применение нуклеотидной последовательности, рекомбинантного белка, рекомбинантного вектора и рекомбинантного штамма для получения L-треонина включает ферментацию рекомбинантного штамма для получения L-треонина.
Согласно третьему техническому решению предложена нуклеотидная последовательность, содержащая нуклеотидную последовательность, образованную вследствие мутации в 74-ом основании кодирующей последовательности гена yebN дикого типа, представленная в SEQ ID NO: 23.
В соответствии с настоящим изобретением мутация заключается в том, что гуанин (Г) заменен на аденин (А) в 74-ом основании в SEQ ID NO: 23; в частности, нуклеотидная последовательность представлена в SEQ ID NO: 24. Мутация представляет собой изменение в основании/нуклеотиде в сайте, и способ мутации может быть по меньшей мере одним, выбранным из следующих способов: мутагенез, сайт-направленный мутагенез в ходе ПЦР и/или гомологическая рекомбинация и т.д.
Настоящее изобретение обеспечивает рекомбинантный белок, кодируемый указанной выше нуклеотидной последовательностью.
Рекомбинантный белок, раскрытый в данном документе, содержит аминокислотную последовательность, представленную в SEQ ID NO: 26; в частности, рекомбинантный белок содержит замену глицина на аспаргиновую кислоту в 25-ом положении аминокислотной последовательности, представленной в SEQ ID NO: 25. Настоящее изобретение обеспечивает рекомбинантный вектор, содержащий указанную выше нуклеотидную последовательность или рекомбинантный белок. Рекомбинантный вектор, раскрытый в данном документе, конструируют путем введения указанной выше нуклеотидной последовательности в плазмиду; в одном варианте осуществления плазмида представляет собой плазмиду pKOV. В частности, нуклеотидная последовательность и плазмида могут быть расщеплены эндонуклеазой с образованием комплементарных липких концов, которые лигируются для конструирования рекомбинантного вектора.
Настоящее изобретение также обеспечивает рекомбинантный штамм, содержащий кодирующую нуклеотидную последовательность гена yebN, содержащую точечную мутацию в кодирующей последовательности, например, кодирующая нуклеотидная последовательность Teu&yebN, представленная в SEQ ID NO: 23, содержащая точечную мутацию в 74-ом основании.
Согласно рекомбинантному штамму, кодирующая нуклеотидная последовательность гена yebN, содержит мутацию, при которой гуанин (Г) заменен на аденин (А) в 74-ом основании в SEQ ID NO: 23.
В одном варианте реализации настоящего изобретения рекомбинантный штамм содержит нуклеотидную последовательность, представленную в SEQ ID NO: 24. В одном варианте реализации настоящего изобретения рекомбинантный штамм содержит аминокислотную последовательность, представленную в SEQ ID NO: 26. Рекомбинантный штамм, раскрытый в данном документе, конструируют путем введения указанного выше рекомбинантного вектора в штамм-хозяин; штамм-хозяин конкретно не определен, он может быть выбран из известных в данной области техники штаммов, продуцирующих L-треонин, которые содержат ген yebN, например, Escherichia coli. В одном варианте реализации настоящего изобретения штаммом-хозяином является Е. coli К12, его производный штамм Е. coli К12 (W3110) или штамм E. coli CGMCC 7.232.
Для рекомбинантного штамма, раскрытого в данном документе, использовали плазмиду pKOV в качестве вектора.
Рекомбинантный штамм согласно настоящему изобретению может дополнительно содержать или не содержать другие модификации.
Настоящее изобретение обеспечивает способ конструирования рекомбинантного штамма, который содержит следующий этап:
модификация нуклеотидной последовательности кодирующей области гена yebN дикого типа, представленной в SEQ ID NO: 23, для обеспечения возможности возникновения мутации в 74-ом основании последовательности с получением рекомбинантного штамма, содержащего мутантный кодирующий ген yebN. В соответствии со способом конструирования согласно настоящему изобретению модификация включает применение по меньшей мере одного из следующих способов: мутагенез, ПЦР сайт-направленный мутагенез и/или гомологическая рекомбинация и т.п.
В соответствии со способом конструирования согласно настоящему изобретению мутация заключается в том, что гуанин (Г) заменен на аденин (А) в 74-ом основании в SEQ ID NO: 23; в частности, мутантная нуклеотидная последовательность представлена в SEQ ID NO: 24.
Кроме того, способ конструирования включает следующие этапы:
(1) модификация нуклеотидной последовательности области открытой рамки считывания гена yebN дикого типа, представленной в SEQ ID NO: 1, для обеспечения возможности возникновения мутации в 74-ом основании последовательности с получением мутантной нуклеотидной последовательности области открытой рамки считывания тепа, yebN;
(2) лигирование мутантной нуклеотидной последовательности с плазмидой для конструирования рекомбинантного вектора; и
(3) введение рекомбинантного вектора в штамм-хозяин для получения рекомбинантного штамма, содержащего точечную мутацию.
В соответствии со способом конструирования согласно настоящему изобретению этап (1) включает: конструирование кодирующей области reuayebN, содержащей точечную мутацию, в частности включающее синтез двух пар праймеров для амплификации фрагментов кодирующей области гена yebN в соответствии с кодирующей последовательностью гена yebN, а также введение точечной мутации в кодирующую область гена yebN дикого типа (SEQ ID NO: 23) с применением методик ПЦР сайт-направленного мутагенеза для получения нуклеотидной последовательности (SEQ ID NO: 24) кодирующей области гена yebN, содержащей точечную мутацию, где нуклеотидная последовательность обозначена как yebN(G74A).
В одном варианте реализации настоящего изобретения на этапе (1) праймерами являются:
Р1: 5' ЦГГГАТЦЦЦТТЦГЦЦААТГТЦТГГАТТГ 3' (SEQ ID NO: 27);
Р2: 5' АТГГАГГГТГГЦАТСТТТАЦ 3' (SEQ ID NO: 28);
Р3: 5' ТГЦАТЦААТЦГГТАААГАТГ 3' (SEQ ID NO: 29); и
Р4: 5' ААГГААААААГЦГГЦЦГЦЦААЦТЦГЦАЦТЦТГЦТГТА 3' (SEQ ID NO: 30). В одном варианте реализации настоящего изобретения этап (1) включает: применение праймеров Р1/Р2 и Р3/Р4 для амплификации в ходе ПЦР с применением Е. coli К12 в качестве матрицы для получения двух выделенных фрагментов ДНК (yebN(G74A)-Up и yebN(G74A)-Down), имеющих длину 690 п.о. и 700 п.о. и содержащих кодирующие области гена yebN, содержащие точечную мутацию; разделение и очистку двух фрагментов ДНК с использованием электрофореза в агарозном геле, а затем выполнение ПЦР с перекрывающимися праймерами с применением Р1 и Р4 в качестве праймеров и двух фрагментов ДНК в качестве матриц для получения фрагмента yebN(G74A)-Up-Down.
В одном варианте реализации настоящего изобретения нуклеотидная последовательность фрагмента yebN(G74A)-Up-Down имеет длину 1340 п.о.
В одном варианте реализации настоящего изобретения ПЦР-амплификацию осуществляют следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С в течение 30 с и элонгация при 72°С в течение 30 с (30 циклов).
В одном варианте реализации настоящего изобретения ПЦР-амплификацию с перекрывающимися праймерами осуществляют следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С в течение 30 с и элонгация при 72°С в течение 60 с (30 циклов).
В соответствии со способом конструирования согласно настоящему изобретению этап (2) включает: конструирование рекомбинантного вектора, в частности включающее разделение и очистку фрагмента yebN(G74A)-Up-Down с использованием электрофореза в агарозном геле, затем расщепление очищенного фрагмента и плазмиды pKOV с использованием BamH I/Not I, и разделение и очистку расщепленного фрагмента yebN(G74A)-Up-Down и расщепленной плазмиды pKOV с использованием электрофореза в агарозном геле с последующим лигированием для получения рекомбинантного вектора pKON-yebN(G74A).
В соответствии со способом конструирования согласно настоящему изобретению этап (3) включает: конструирование рекомбинантного штамма, в частности включающий введение рекомбинантного вектора pKOV-yebN(G74A) в штамм-хозяин для получения рекомбинантного штамма.
В одном варианте реализации настоящего изобретения введение на этапе (3) представляет собой процесс электротрансформации.
В соответствии со способом конструирования согласно настоящему изобретению способ дополнительно включает этап скрининга рекомбинантного штамма; например, скрининг осуществляют с использованием культуральной среды с хлорамфениколом. Настоящее изобретение также обеспечивает рекомбинантный штамм, полученный с помощью указанного выше способа конструирования.
Настоящее изобретение обеспечивает применение указанной выше нуклеотидной последовательности, рекомбинантного белка, рекомбинантного вектора и рекомбинантного штамма для получения L-треонина.
Применение рекомбинантного штамма для получения L-треонина включает ферментацию рекомбинантного штамма для получения L-треонина.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Указанные выше и другие признаки и преимущества настоящего изобретения описаны и проиллюстрированы более подробно в последующем описании примеров настоящего изобретения. Следует понимать, что следующие примеры предназначены для иллюстрации технических решений настоящего изобретения и никоим образом не предназначены для ограничения объема правовой охраны настоящего изобретения, определенного в формуле изобретения и ее эквивалентах.
Если не указано иное, представленные в настоящем описании материалы и реагенты либо коммерчески доступны, либо могут быть получены специалистом в данной области техники в свете предшествующего уровня техники.
Пример 1
(1) Конструирование Плазмиды pKOV-kdtA(G82A) с Кодирующей Областью Гена kdtA, Содержащей Сайт-Направленную Мутацию (G28A) (эквивалентно замене аланина на треонин в 28-ом положении (А28Т) в аминокислотной последовательности SEQ ID NO: 3, кодирующей белок дикого типа, причем измененной аминокислотной последовательностью является SEQ ID NO: 4). 3-дезокси-О-маннозосульфамилтрансферазу кодировали геном kdtA, и в штамме Е. coli К12 и его производном штамме (например, MG1655) последовательность ОРС гена kdtA дикого типа представлена в последовательности 73556-74833, идентификационный номер в GenBank СР032667.1. Две пары праймеров для амплификации kdtA были сконструированы и синтезированы в соответствии с последовательностью, и вектор был сконструирован для основания Г, замененного на основание А в 82-ом положении, в последовательности кодирующей области гена kdtA исходного штамма. Праймеры (синтезированные Shanghai Invitrogen Corporation) имели следующее строение:
Р1: 5' ЦГГГАТЦЦАЦЦАГТГААЦЦГЦЦААЦА 3' (SEQ ID NO: 5);
Р2: 5' ТГЦГЦГГАЦГТААГАЦТЦ 3' (SEQ ID NO: 6);
Р3: 5' ГАГТЦТТАЦГТЦЦГЦГЦА 3' (SEQ ID NO: 7); и
Р4: 5' ААГГААААААГЦГГЦЦГЦТТЦЦЦГЦАЦЦТТТАТТГ 3' (SEQ ID NO: 8). Способ конструирования был следующим: применение праймеров Р1/Р2 и Р3/Р4 для амплификации в ходе ПЦР с использованием в качестве матрицы генома дикого штамма Е. coli К12, для получения двух фрагментов ДНК, имеющих длину 927 п. о. и 695 п. о. и точечную мутацию (фрагменты kdtA(G82A)-Up и kdtA(G82A)-Down). Амплификацию с помощью метода ПЦР выполняли следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С в течение 30 с и элонгация при 72°С в течение 30 с (30 циклов). Два фрагмента ДНК были разделены и очищены с помощью электрофореза в агарозном геле, и затем два очищенных фрагмента ДНК использовали в качестве матриц, а Р1 и Р4 использовали в качестве праймеров для выполнения ПЦР с перекрывающимися праймерами, чтобы получить фрагмент (kdtA(G82A)-Up-Down), имеющий длину примерно 1622 п.о.. Амплификацию с помощью метода ПЦР с перекрывающимися праймерами выполняли следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С в течение 30 с и элонгация при 72°С в течение 60 с (30 циклов). Фрагмент kdtA(G82A)-Up-Down был разделен и очищен с использованием метода электрофореза в агарозном геле, затем очищенный фрагмент и плазмида pKOV (приобретена у Addgene) были расщеплены BanK VNotl, и расщепленный фрагмент kdtA(G82A)-Up-Down и расщепленная плазмида pKOV были разделены и очищены с использованием метода электрофореза в агарозном геле с последующим лигированием для получения вектора pKO V- kdtA(G82A). Вектор рКО V-kdtA(GS2A) был отправлен в компанию, занимающуюся секвенированием, для секвенирования и идентификации, результат показан в SEQ ID NO: 11, и вектор рКО V -kdtA(GS2A) с правильной точечной мутацией (kdtA(GS2A)) был сохранен для последующего использования. (2) Конструирование Модифицированного Штамма с геном kdtA(GS2A). Содержащим Точечную Мутацию
Ген kdtA дикого типа был сохранен на хромосомах штамма Escherichia coli дикого типа Е. coli К12 (W3110) и штамма Е. coli CGMCC 7.232, обладающего высокой способностью к продуцированию L-треонина (сохранен в China General Microbiological Culture Collection Center). Сконструированная плазмида pKOV-kdtA(GS2A) была перенесена в Е. coli K12 (W3110) и Е. coliCGM.CC 7.232, соответственно, и путем аллельной замены основание Г было заменено на основание А в 82-ом положении последовательностей гена kdtA в хромосомах двух штаммов. Указанный способ осуществляли следующим образом: трансформация плазмиды рКО V -kdtA(G82A) в компетентные клетки бактерии-хозяина посредством процесса электротрансформации, и добавление клеток в 0,5 мл жидкой культуральной среды SOC; перемешивание смеси в шейкере при 30°С и 100 об/мин в течение 2 часов; нанесение на твердую культуральную среду LB, содержащую хлорамфеникол (34 мг/мл), 100 мкл культурального раствора, и культивирование при 30°С в течение 18 часов; отбор выращенных моноклональных колоний, инокуляция колоний в 10 мл жидкой культуральной среды LB, и культивирование при при 37°С и 200 об/мин в течение 8 часов; нанесение на твердую культуральную среду LB, содержащую хлорамфеникол (34 мг/мл), 100 мкл культурального раствора, и культивирование при 42°С в течение 12 часов; отбор 15 единичных колоний, инокуляция колоний в 1 мл жидкой среды LB и культивирование при 37°С и 200 об/мин в течение 4 часов; нанесение на твердую культуральную среду, содержащую 10% сахарозы, 100 мкл культурального раствора, и культивирование при 30°С в течение 24 часов; отбор моноклональных колоний и выделение колоний на твердой культуральной среде LB, содержащей хлорамфеникол (34 мг/мл) и в соотношении один к одному с твердой культуральной средой LB; и отбор штаммов, которые растут на твердой культуральной среде LB и не растут на твердой культуральной среде LB, содержащей хлорамфеникол (34 мг/мл) для индентификации методом ПЦР-амплификации. Праймеры (синтезированные Shanghai hivitrogen Corporation) для применения в ПЦР-амплификации были следующими:
Р5: 5' ЦТТЦЦЦГАААГЦЦГАТТГ3' (SEQ ID NO: 9); и
Р6: 5' АЦАААТАТАЦТТТААТЦ 3' (SEQ ID NO: 10).
SSCP (Анализ конформационного полиморфизма однонитевой ДНК) электрофорез выполняли на продукте, амплифицированном в ходе ПЦР; амплифицированный фрагмент плазмиды pKOV-kdtA(G82A) использовали для положительного контроля, амплифицированный фрагмент Escherichia coli дикого типа использовали для отрицательного контроля, и воду использовали для бланковой пробы. В SSCP-электрофорезе одноцепочечные нуклеотидные цепочки, имеющие одинаковую длину, но разное строение последовательностей, образовали различные пространственные структуры в ледяной ванне, а также обладали различной подвижностью во время электрофореза. Следовательно, положение фрагмента при электрофорезе не соответствует положению материала, используемого для отрицательного контроля, и штаммом, в случае которого положение фрагмента при электрофорезе соответствует положению материала, используемого для положительного контроля, является штамм с успешно замененной аллелью. ПЦР-амплификацию выполняли на целевом фрагменте путем применения штамма с успешно замененной аллелью в качестве матрицы и применения праймеров Р5 и Р6, а затем целевой фрагмент лигировали с вектором pMD19-T для секвенирования. Путем сравнения последовательностей, полученных в результате секвенирования было определено, что рекон, образованный путем замены основания Г на основание А в 82-ом положении в последовательности кодирующей области гена kdtA является успешно модифицированным штаммом, и результаты секвенирования показаны в SEQ ID NO: 12. Рекон, полученный от Е. coli K12 (W3110) был назван YPThr07, и рекон, полученный от E. coli CGMCC 7.232 был назван YPThr 08.
(3) Эксперимент по Ферментации Треонина
Штамм Е. coli K12 (W3110), штамм Е. coli CGMCC 7.232 и мутантные штаммы YPThr07 и YPThr08 инокулировали при 25 мл в жидкой культуральной среде, описанной в Таблице 1, соответственно, и культивировали при 37°С и 200 об/мин в течение 12 часов. Затем 1 мл полученной культуры каждого штамма инокулировали в 25 мл жидкой питательной среды, описанной в Таблице 1, и подвергали ферментации при 37°С и 200 об/мин в течение 36 часов. Содержание L-треонина определяли с помощью метода ВЭЖХ, отбирвали три копии каждого штамма, рассчитывали среднее значение, результаты представлены в Таблице 2.
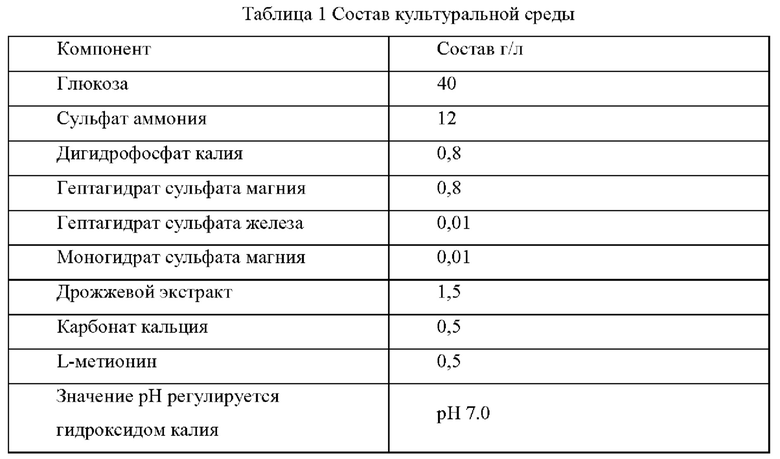
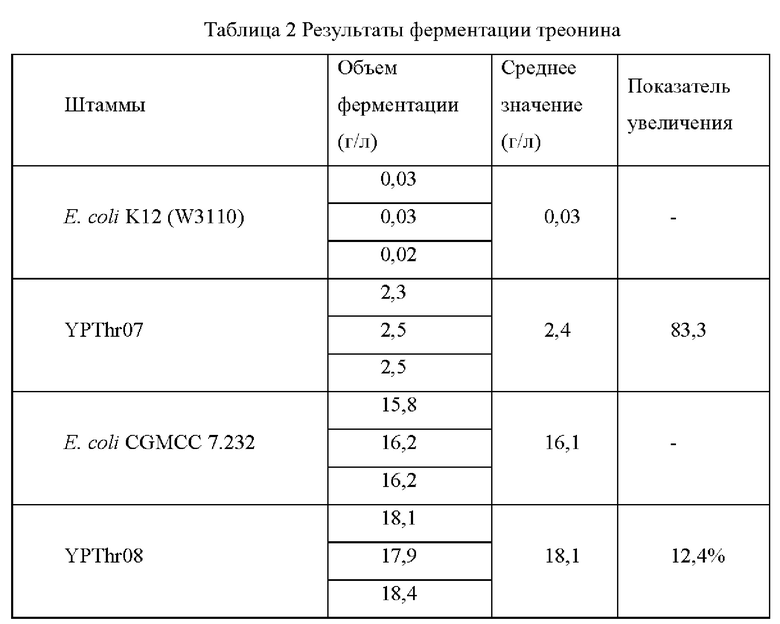
Как видно из результатов Таблицы 2, замена аланина в 28-ом положении аминокислотной последовательности гена kdtA на треонин способствует увеличению продуктивности L-треонина для исходного штамма, продуцирующего L-треонин, как с высокой, так и с низкой продуктивностью.
Пример 2
(1) Конструирование Плазмиды pKOV-spoT(G520T) с Кодирующей Областью Гена spoT, Содержащей Сайт-Направленную Мутацию (G520T) (эквивалентно замене глицина на цистеин в 174-ом положении (G174C) в кодирующей белок аминокислотной последовательности SEQ ID NO: 15, измененной аминокислотной последовательностью является SEQ ID NO: 16)
Фермент SPOT кодировали геном spoT, и в штамме Е. coli K12 и его производном штамме (например, W3110), последовательность ОРС гена spoT дикого типа представлена в последовательности 3815907-3818015, идентификационный номер в GenBank АР009048.1. Две пары праймеров для амплификации spoT были сконструированы и синтезированы в соответствии с последовательностью, и вектор был сконструирован для основания Г, замененного на основание А в 520-ом положении, в последовательности кодирующей области гена spoT исходного штамма. Праймеры (синтезированные Шанхайской корпорацией mvitrogen) имеют следующее строение:
Р1: 5' ЦГГГАТЦЦГААЦАГЦААГАГЦАГГААГЦ 3' (подчеркнутая часть обозначает участок вырезки эндонуклеазой рестрикции BamYL I) (SEQ ID NO: 17);
P2: 5' ТГТГГТГГАТАЦАТАААЦГ 3' (SEQ ID NO: 18);
P3: 5' ГЦАЦЦГТТТАТГТАТЦЦАЦЦ 3' (SEQ ID NO: 19); и
P1: 5' ААГГААААААГЦГГЦЦГЦАЦГАЦАААГТТЦАГЦЦААГЦ 3' (подчеркнутая часть обозначает участок вырезки эндонуклеазой рестрикции Not I)(SEQ ID NO: 20); Способ конструирования был следующим: применение праймеров Р1/Р2 и Р3/Р4 для амплификации в ходе ПЦР с использованием в качестве матрицы генома дикого штамма Е. coli K12, для получения двух фрагментов ДНК, имеющих длину 620 п.о. и 880 п.о. и точечную мутацию (фрагменты spoT(G520T)-Up и spoT(G520T)-Down). ПЦР-система: 10 × Ex Taq буфер 5 мкл, смесь dNTP (2,5 ммоль каждая) 4 мкл, Mg2+(25 ммоль) 4 мкл, праймеры (10 пмоль) 2 мкл каждый, Ex Taq (5 Ед/мкл) 0,25 мкл, общий объем 50 мкл, где ПЦР проводили следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С при 30 с, элонгация при 72°С в течение 30 с (30 циклов). Два фрагмента ДНК были разделены и очищены с помощью электрофореза в агарозном геле, и затем два очищенных фрагмента ДНК использовали в качестве матриц, а Р1 и Р4 использовали в качестве праймеров для выполнения ПЦР с перекрывающимися праймерами, чтобы получить фрагмент (spoT(G520T)-Up-Down), имеющий длину примерно 1500 п. о.. ПЦР-система: 10 х Ex Taq буфер 5 мкл, смесь dNTP (2,5 ммоль каждая) 4 мкл, Mg2+(25 ммоль) 4 мкл, праймеры (10 пмоль) 2 мкл каждый, Ex Taq (5 Ед/мкл) 0,25 мкл, общий объем 50 мкл, где ПЦР с перекрывающимися праймерами проводили следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С при 30 с, элонгация при 72°С в течение 60 с (30 циклов). Фрагмент spoT(G520T)-Up-Down был разделен и очищен с использованием метода электрофореза в агарозном геле, затем очищенный фрагмент и плазмида pKOV (приобретена у Addgene) были расщеплены BamH I/NotI, и расщепленный фрагмент spoT(G520T)-Up-Down и расщепленная плазмида pKOV были разделены и очищены с использованием метода электрофореза в агарозном геле с последующим лигированием для получения вектора рКО V-spoT(G520T). Вектор pKOV-spoT(G520T) был отправлен в компанию, занимающуюся секвенированием, для секвенирования и идентификации, а вектор pKOY-spoT(G520T) с корректной точечной мутацией (spoT(G520T)) был сохранен для последующего использования.
(2) Конструирование Модифицированного Штамма с геном spoT(G520T), Содержащим Точечную Мутацию
Ген spoT дикого типа был сохранен на хромосомах штамма Escherichia coli дикого типа Е. coli K12 (W3110) и штамма Е. coli CGMCC 7.232, обладающего высокой способностью к продуцированию L-треонина (сохранен в China General Microbiological Culture Collection Center). Сконструированная плазмида pKOV-spoT(G520T) была перенесена в Е. coli K12 (W3110) и Е. coliCGM.CC 7.232, соответственно, и путем аллельной замены основание Г было заменено на основание Т в 520-м положении последовательностей гена spoT в хромосомах двух штаммов. Указанный способ осуществляли следующим образом: трансформация плазмиды pKO V-spoT(G520T) в компетентные клетки бактерии-хозяина посредством процесса электротрансформации, и добавление клеток в 0.5 мл жидкой культуральной среды SOC; перемешивание смеси в шейкере при 30°С и 100 об/мин в течение 2 часов; нанесение на твердую культуральную среду LB, содержащую хлорамфеникол (34 мкг/мл), 100 мкл культурального раствора, и культивирование при 30°С в течение 18 часов; отбор выращенных моноклональных колоний, инокуляция колоний в 10 мл жидкой культуральной среды LB, и культивирование при при 37°С и 200 об/мин в течение 8 часов; нанесение на твердую культуральную среду LB, содержащую хлорамфеникол (34 мкг/мл), 100 мкл культурального раствора, и культивирование при 42°С в течение 12 часов; отбор 15 единичных колоний, инокуляция колоний в 1 мл жидкой среды LB и культивирование при 37°С и 200 об/мин в течение 4 часов; нанесение на твердую культуральную среду, содержащую 10% сахарозы, 100 мкл культурального раствора, и культивирование при 30°С в течение 24 часов; отбор моноклональных колоний и выделение колоний на твердой культуральной среде LB, содержащей хлорамфеникол (34 мкг/мл) и в соотношении один к одному с твердой культуральной средой LB; и отбор штаммов, которые растут на твердой культуральной среде LB и не растут на твердой культуральной среде LB, содержащей хлорамфеникол (34 мкг/мл) для индентификации методом ПЦР-амплификации. Праймеры (синтезированные Shanghai Invitrogen Corporation) для амплификации в ходе ПЦР были следующими:
Р5: 5' ЦТТТЦГЦААГАТГАТТАТГГ 3' (SEQ ID NO: 21); и
Р6: 5' ЦАЦГГТАТТЦЦЦГЦТТЦЦТГ 3' (SEQ ID NO: 22).
ПЦР-система: 10 × Ex Taq буфер 5 мкл, смесь dNTP (2,5 ммоль каждая) 4 мкл, Mg2+(25 ммоль) 4 мкл, праймеры (10 пмоль) 2 мкл каждый, Ex Taq (5 Ед/мкл) 0,25 мкл, общий объем 50 мкл, где ПЦР-амплификацию проводили следующим образом: преденатурация при 94°С в течение 5 минут, (денатурация при 94°С в течение 30 с, отжиг при 52°С при 30 с, элонгация при 72°С в течение 30 с, 30 циклов), и переэлонгация при 72°С в течение 10 минут. SSCP (Анализ конформационного полиморфизма однонитевой ДНК) электрофорез выполняли на продукте, амплифицированном в ходе ПЦР; амплифицированный фрагмент плазмиды pKOV-spoT(G520T) использовали для положительного контроля, амплифицированный фрагмент Escherichia coli дикого типа использовали для отрицательного контроля, и воду использовали для бланковой пробы. В SSCP-электрофорезе одноцепочечные нуклеотидные цепочки, имеющие одинаковую длину, но разное строение последовательностей, образовали различные пространственные структуры в ледяной ванне, а также обладали различной подвижностью во время электрофореза. Следовательно, положение фрагмента при электрофорезе не соответствует положению материала, используемого для отрицательного контроля, и штаммом, в случае которого положение фрагмента при электрофорезе соответствует положению материала, используемого для положительного контроля, является штамм с успешно замененной аллелью. ПЦР-амплификация была выполнена на целевом фрагменте путем применения штамма с успешно замененной аллелью в качестве матрицы и применения праймеров Р5 и Р6, а затем целевой фрагмент лигировали с вектором pMD19-T для секвенирования. Путем сравнения последовательностей, полученных в результате секвенирования было определено, что рекон, образованный путем замены основания Г на основание Т в 520-м положении в последовательности кодирующей области гена spoT является успешно модифицированным штаммом. Рекон, полученный от Е. coli K12 (W3110) был назван YPThr03, и рекон, полученный от Е. coli CGMCC 7.232 был назван YPThr 04.
(3) Эксперимент по Ферментации Треонина
Штамм Е. coli К12 (W3110), штамм Е. coli CGMCC 7.232 и мутантные штаммы YPThr03 и YPThr04 инокулировали при 25 мл в жидкой культуральной среде, описанной в Таблице 1, соответственно, и культивировали при 37°С и 200 об/мин в течение 12 часов. Затем 1 мл полученной культуры каждого штамма инокулировали в 25 мл жидкой питательной среды, описанной в Таблице 1, и подвергали ферментации при 37°С и 200 об/мин в течение 36 часов. Содержание L-треонина определяли с помощью метода ВЭЖХ, отбирали три копии каждого штамма, рассчитывали среднее значение, результаты представлены в Таблице 2.
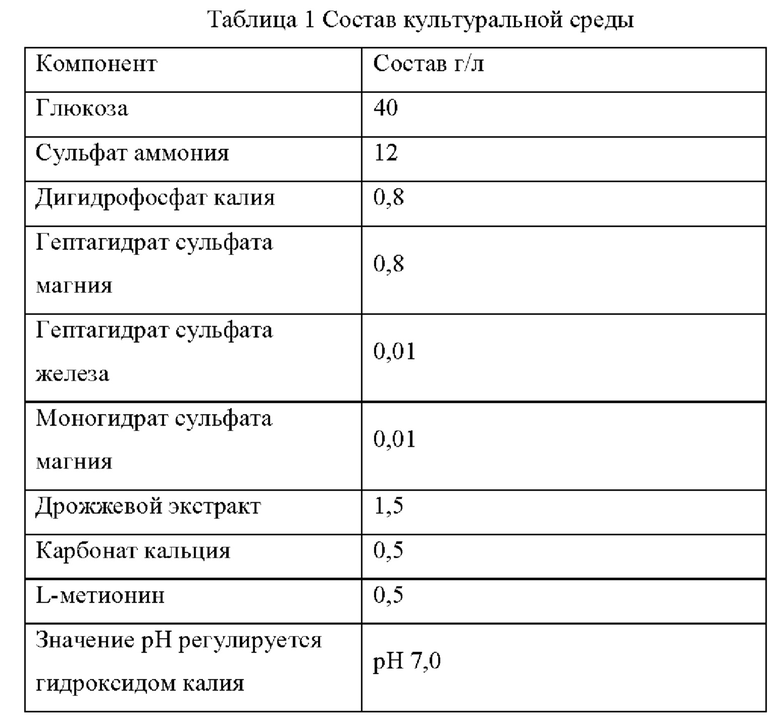
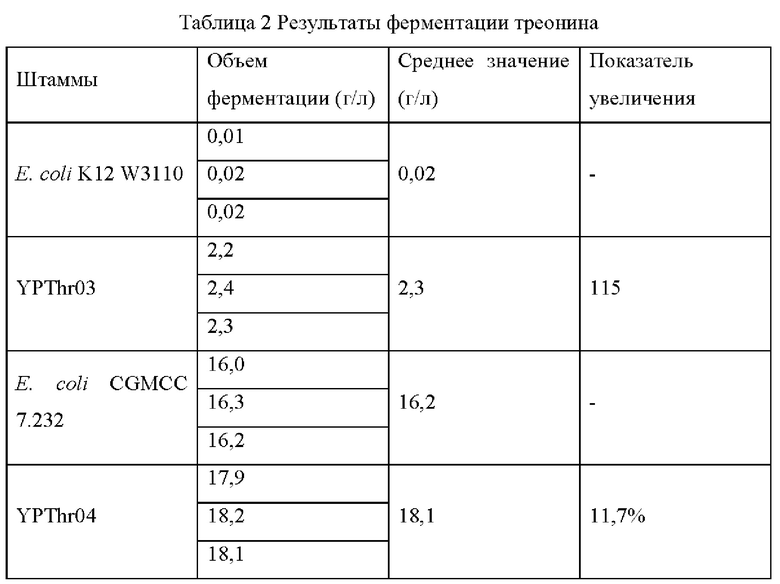
Как видно из результатов Таблицы 2, замена глицина в 174-ом положении аминокислотной последовательности гена spoT на цистеин способствует увеличению продуктивности L-треонина для исходного штамма, продуцирующего L-треонин, как с высокой, так и с низкой продуктивностью.
Пример 3:
(1) Конструирование Плазмиды pKOV-yebN(G74A) с Кодирующей Областью Гена yebN, Содержащей Сайт-Направленную Мутацию (G74A) (эквивалентно замене глицина на аспаргиновую кислоту в 25-м основании (G25D) в кодирующей белок аминокислотной последовательности SEQ ID NO: 25, измененной аминокислотной последовательностью является SEQ ID NO: 26)
Фермент YEBN кодировали геном yebN, и в штамме Е. coli К12 и его производном штамме (например, W3110) последовательность ОРС гена yebN дикого типа представлена в последовательности 1907402-1907968, идентификационный номер в GenBank АР009048.1. Две пары праймеров для амплификации yebN были сконструированы и синтезированы в соответствии с последовательностью, и вектор был сконструирован для основания Г, замененного на основание А в 74-ом положении, в последовательности кодирующей области гена yebN исходного штамма. Праймеры (синтезированные Шанхайской корпорацией mvitrogen) имеют следующее строение:
Р1: 5' ЦГГГАТЦЦЦТТЦГЦЦААТГТЦТГГАТТГ 3' (подчеркнутая часть обозначает участок вырезки эндонуклеазой рестрикции Bam Н I) (SEQ ID NO: 27);
Р2: 5' АТГГАГГГТГГЦАТЦТТТАЦ 3' (SEQ ID NO: 28);
Р3: 5' ТГЦАТЦААТЦГГТАААГАТГ 3' (SEQ ID NO:29); и
Р4: 5' ААГГААААААГЦГГЦЦГЦЦААЦТЦЦГЦАЦТЦТГЦТГТА 3' (подчеркнутая часть обозначает участок вырезки эндонуклеазой рестрикции Not I) (SEQ ID NO: 30). Способ конструирования был следующим: применение праймеров Р1/Р2 и Р3/Р4 для амплификации в ходе ПЦР с использованием в качестве матрицы генома дикого штамма Е. coli K12, для получения двух фрагментов ДНК, имеющих длину 690 п. о. и 700 п. о. и точечную мутацию (фрагменты yebN(G74A)-Up и yebN(G74A)-Down). ПЦР-система: 10 × Ex Taq буфер 5 мкл, смесь dNTP (2,5 ммоль каждая) 4 мкл, Mg2+(25 ммоль) 4 мкл, праймеры (10 пмоль) 2 мкл каждый, Ex Taq (5 Ед/мкл) 0,25 мкл, общий объем 50 мкл, где ПЦР проводили следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С при 30 с, элонгация при 72°С в течение 30 с (30 циклов). Два фрагмента ДНК были разделены и очищены с помощью электрофореза в агарозном геле, и затем два очищенных фрагмента ДНК использовали в качестве матриц, а Р1 и Р4 использовали в качестве праймеров для выполнения ПЦР с перекрывающимися праймерами, чтобы получить фрагмент (yebN(G74A)-Up-Down), имеющий длину примерно 1340 п.о.
ПЦР-система: 10 × Ex Taq буфер 5 мкл, смесь dNTP (2,5 ммоль каждая) 4 мкл, Mg2+(25 ммоль) 4 мкл, праймеры (10 пмоль) 2 мкл каждый, Ex Taq (5 Ед/мкл) 0,25 мкл, общий объем 50 мкл, где ПЦР с перекрывающимися праймерами проводили следующим образом: денатурация при 94°С в течение 30 с, отжиг при 52°С при 30 с, элонгация при 72°С в течение 60 с (30 циклов).
Фрагмент yebN(G74A)-Up-Down был разделен и очищен с использованием метода электрофореза в агарозном геле, затем очищенный фрагмент и плазмида pKOV (приобретена у Addgene) были расщеплены BamH I/NotI, и расщепленный фрагмент yebN(G74A)-Up-Down и расщепленная плазмида pKOV были разделены и очищены с использованием метода электрофореза в агарозном геле с последующим лигированием для получения вектора pKO V - yebN(G74A) Вектор pKOY-yebN(G74A) был отправлен в компанию, занимающуюся секвенированием, для секвенирования и идентификации, а вектор pKOV-yebN(G74A) с корректной точечной мутацией (yebN(G74A)) был сохранен для последующего использования.
(2) Конструирование Модифицированного Штамма с геном yebN(G74A), Содержащим Точечную Мутацию
Ген yebN дикого типа был сохранен на хромосомах штамма Escherichia coli дикого типа Е. coli K12 (W3110) и штамма Е. coli CGMCC 7.232, обладающего высокой способностью к продуцированию L-треонина (сохранен в China General Microbiological Culture Collection Center). Сконструированная плазмида pKOV-yebN(G74A) была перенесена в Е. coli K12 (W3110) и Е. coZ/CGMCC 7.232, соответственно, и путем аллельной замены основание Г было заменено на основание А в 74-омположении последовательностей генауе&Ув хромосомах двух штаммов.
Указанный способ осуществляли следующим образом: трансформация плазмиды рКО V -yebN(G74A) в компетентные клетки бактерии-хозяина посредством процесса электротрансформации, и добавление клеток в 0.5 мл жидкой культуральной среды SOC; перемешивание смеси в шейкере при 30°С и 100 об/мин в течение 2 часов; нанесение на твердую культуральную среду LB, содержащую хлорамфеникол (34 мкг/мл), 100 мкл культурального раствора, и культивирование при 30°С в течение 18 часов; отбор выращенных моноклональных колоний, инокуляция колоний в 10 мл жидкой культуральной среды LB, и культивирование при при 37°С и 200 об/мин в течение 8 часов; нанесение на твердую культуральную среду LB, содержащую хлорамфеникол (34 мкг/мл), 100 мкл культурального раствора, и культивирование при 42°С в течение 12 часов; отбор 1-5 единичных колоний, инокуляция колоний в 1 мл жидкой среды LB и культивирование при 37°С и 200 об/мин в течение 4 часов; нанесение на твердую культуральную среду, содержащую 10% сахарозы, 100 мкл культурального раствора, и культивирование при 30°С в течение 24 часов; отбор моноклональных колоний и выделение колоний на твердой культуральной среде LB, содержащей хлорамфеникол (34 мкг/мл) и в соотношении один к одному с твердой культуральной средой LB; и отбор штаммов, которые растут на твердой культуральной среде LB и не растут на твердой культуральной среде LB, содержащей хлорамфеникол (34 мкг/мл) для индентификации методом ПЦР-амплификации. Праймеры (синтезированные Shanghai Invitrogen Corporation) для амплификации в ходе ПЦР были следующими:
Р5: 5' ЦЦАТЦАЦГГЦТТГТТГТТЦ 3' (SEQ ID NO: 31); и
Р6: 5' АЦГААААЦЦЦТЦААТААТЦ 3' (SEQ ID NO: 32).
ПЦР-система: 10 × Ex Taq буфер 5 мкл, смесь dNTP (2,5 ммоль каждая) 4 мкл, Mg2+(25 ммоль) 4 мкл, праймеры (10 пмоль) 2 мкл каждый, Ex Taq (5 Ед/мкл) 0,25 мкл, общий объем 50 мкл, где ПЦР-амплификацию проводили следующим образом: преденатурация при 94°С в течение 5 минут, (денатурация при 94°С в течение 30 с, отжиг при 52°С при 30 с, элонгация при 72°С в течение 30 с, 30 циклов), и переэлонгация при 72°С в течение 10 минут.SSCP (Анализ конформационного полиморфизма однонитевой ДНК) электрофорез выполняли на продукте, амплифицированном в ходе ПЦР; амплифицированный фрагмент плазмиды pKOV-yebN(G74A) использовали для положительного контроля, амплифицированный фрагмент Escherichia coli дикого типа использовали для отрицательного контроля, и воду использовали для бланковой пробы. В SSCP-электрофорезе одноцепочечные нуклеотидные цепочки, имеющие одинаковую длину, но разное строение последовательностей, образовали различные пространственные структуры в ледяной ванне, а также обладали различной подвижностью во время электрофореза. Следовательно, положение фрагмента при электрофорезе не соответствует положению материала, используемого для отрицательного контроля, и штаммом, в случае которого положение фрагмента при электрофорезе соответствует положению материала, используемого для положительного контроля, является штамм с успешно замененной аллелью. ПЦР-амплификация была выполнена на целевом фрагменте путем применения штамма с успешно замененной аллелью в качестве матрицы и применения праймеров Р5 и Р6, а затем целевой фрагмент лигировали с вектором pMD19-T для секвенирования. Путем сравнения последовательностей, полученных в результате секвенирования было определено, что рекон, образованный путем замены основания Г на основание А в 74-м положении в последовательности кодирующей области гена yebN является успешно модифицированным штаммом. Рекон, полученный от Е. coli K12 (W3110) был назван YPThr05, и рекон, полученный от Е. coli CGMCC 7.232 был назван YPThr 06.
(3) Эксперимент по Ферментации Треонина
Штамм Е. coli К12 (W3110), штамм Е. coli CGMCC 7.232 и мутантные штаммы YPThr05 и YPThr06 инокулировали при 25 мл в жидкой культуральной среде, описанной в Таблице 1, соответственно, и культивировали при 37°С и 200 об/мин в течение 12 часов. Затем 1 мл полученной культуры каждого штамма инокулировали в 25 мл жидкой питательной среды, описанной в Таблице 1, и подвергали ферментации при 37°С и 200 об/мин в течение 36 часов. Содержание L-треонина определяли с помощью метода ВЭЖХ, отбирали три копии каждого штамма, рассчитывали среднее значение, результаты представлены в Таблице 2.
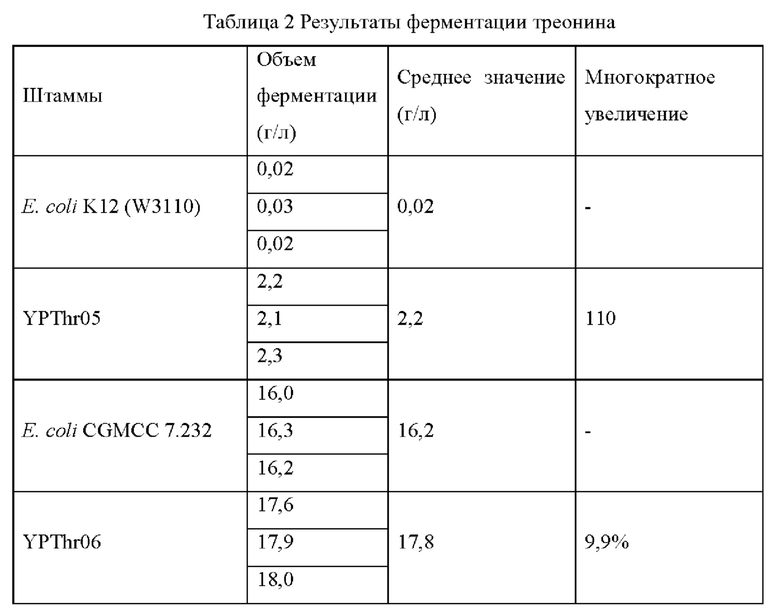
Как видно из результатов Таблицы 2, замена глицина в 25-ом положении аминокислотной последовательности гена yebN на аспаргиновую кислоту способствует увеличению продуцирования L-треонина исходным штаммом, продуцирующим L-треонин, как с высокой, так и с низкой продуктивностью.
Примеры согласно настоящему изобретению описаны выше. Однако настоящее изобретение не ограничивается приведенными выше примерами. Любые изменения, эквиваленты, улучшения и т.п., внесенные без отступления от существа и принципа настоящего изобретения, подпадают под объем правовой охраны настоящего изобретения.
--->
Лист последовательностей
<110> Heilongjiang Eppen Biotech Co., Ltd
<120> РЕКОМБИНАНТНЫЙ ШТАММ НА ОСНОВЕ ESCHERICHIACOLI, СПОСОБ ЕГО
КОНСТРУИРОВАНИЯ И ЕГО ПРИМЕНЕНИЕ
<130> CPWO20110939
<160> 32
<170> SIPOSequenceListing 1.0
<210> 1
<211> 1278
<212> ДНК
<213> Escherichia coli
<400> 1
atgctcgaat tgctttacac cgcccttctc taccttattc agccgctgat ctggatacgg
60
ctctgggtgc gcggacgtaa ggctccggcc tatcgaaaac gctggggtga acgttacggt
120
ttttaccgcc atccgctaaa accaggcggc attatgctgc actccgtctc cgtcggtgaa
180
actctggcgg caatcccgtt ggtgcgcgcg ctgcgtcatc gttatcctga tttaccgatt
240
accgtaacaa ccatgacgcc aaccggttcg gagcgcgtac aatcggcttt cgggaaggat
300
gttcagcacg tttatctgcc gtatgatctg cccgatgcac tcaaccgttt cctgaataaa
360
gtcgacccta aactggtgtt gattatggaa accgaactat ggcctaacct gattgcggcg
420
ctacataaac gtaaaattcc gctggtgatc gctaacgcgc gactctctgc ccgctcggcc
480
gcaggttatg ccaaactggg taaattcgtc cgtcgcttgc tgcgtcgtat tacgctgatt
540
gctgcgcaaa atgaagaaga tggtgcacgt tttgtggcgc tgggcgcaaa aaataatcag
600
gtgaccgtta ccggtagcct gaaattcgat atttctgtaa cgccgcagtt ggctgctaaa
660
gccgtgacgc tgcgccgcca gtgggcacca caccgcccgg tatggattgc caccagcact
720
cacgaaggcg aagagagtgt ggtgatcgcc gcacatcagg cattgttaca gcaattcccg
780
aatttattgc tcatcctggt accccgtcat ccggaacgct tcccggatgc gattaacctt
840
gtccgccagg ctggactaag ctatatcaca cgctcttcag gggaagtccc ctccaccagc
900
acgcaggttg tggttggcga tacgatgggc gagttgatgt tactgtatgg cattgccgat
960
ctcgcctttg ttggcggttc actggttgaa cgtggtgggc ataatccgct ggaagctgcc
1020
gcacacgcta ttccggtatt gatggggccg catactttta actttaaaga catttgcgcg
1080
cggctggagc aggcaagcgg gctgattacc gttaccgatg ccactacgct tgcaaaagag
1140
gtttcctctt tactcaccga cgccgattac cgtagtttct atggccgtca tgccgttgaa
1200
gtactgtatc aaaaccaggg cgcgctacag cgtctgcttc aactgctgga accttacctg
1260
ccaccgaaaacgcattga
1278
<210> 2
<211> 1278
<212> ДНК
<213> Искусственная последовательность
<400> 2
atgctcgaattgctttacaccgcccttctctaccttattcagccgctgatctggatacgg
60
ctctgggtgcgcggacgtaagactccggcctatcgaaaacgctggggtgaacgttacggt
120
ttttaccgccatccgctaaaaccaggcggcattatgctgcactccgtctccgtcggtgaa
180
actctggcggcaatcccgttggtgcgcgcgctgcgtcatcgttatcctgatttaccgatt
240
accgtaacaaccatgacgccaaccggttcggagcgcgtacaatcggctttcgggaaggat
300
gttcagcacgtttatctgccgtatgatctgcccgatgcactcaaccgtttcctgaataaa
360
gtcgaccctaaactggtgttgattatggaaaccgaactatggcctaacctgattgcggcg
420
ctacataaacgtaaaattccgctggtgatcgctaacgcgcgactctctgcccgctcggcc
480
gcaggttatgccaaactgggtaaattcgtccgtcgcttgctgcgtcgtattacgctgatt
540
gctgcgcaaaatgaagaagatggtgcacgttttgtggcgctgggcgcaaaaaataatcag
600
gtgaccgttaccggtagcctgaaattcgatatttctgtaacgccgcagttggctgctaaa
660
gccgtgacgctgcgccgccagtgggcaccacaccgcccggtatggattgccaccagcact
720
cacgaaggcgaagagagtgtggtgatcgccgcacatcaggcattgttacagcaattcccg
780
aatttattgctcatcctggtaccccgtcatccggaacgcttcccggatgcgattaacctt
840
gtccgccaggctggactaagctatatcacacgctcttcaggggaagtcccctccaccagc
900
acgcaggttgtggttggcgatacgatgggcgagttgatgttactgtatggcattgccgat
960
ctcgcctttgttggcggttcactggttgaacgtggtgggcataatccgctggaagctgcc
1020
gcacacgctattccggtattgatggggccgcatacttttaactttaaagacatttgcgcg
1080
cggctggagcaggcaagcgggctgattaccgttaccgatgccactacgcttgcaaaagag
1140
gtttcctctttactcaccgacgccgattaccgtagtttctatggccgtcatgccgttgaa
1200
gtactgtatcaaaaccagggcgcgctacagcgtctgcttcaactgctggaaccttacctg
1260
ccaccgaaaa cgcattga
1278
<210> 3
<211> 425
<212> БЕЛОК
<213> Escherichia coli
<400> 3
Met Leu Glu Leu Leu Tyr Thr Ala Leu Leu Tyr Leu Ile Gln Pro Leu
1 5 10 15
Ile Trp Ile Arg Leu Trp Val Arg Gly Arg Lys Ala Pro Ala Tyr Arg
20 25 30
Lys Arg Trp Gly Glu Arg Tyr Gly Phe Tyr Arg His Pro Leu Lys Pro
35 40 45
Gly Gly Ile Met Leu His Ser Val Ser Val Gly Glu Thr Leu Ala Ala
50 55 60
Ile Pro Leu Val Arg Ala Leu Arg His Arg Tyr Pro Asp Leu Pro Ile
65 70 75 80
Thr Val Thr Thr Met Thr Pro Thr Gly Ser Glu Arg Val Gln Ser Ala
85 90 95
Phe Gly Lys Asp Val Gln His Val Tyr Leu Pro Tyr Asp Leu Pro Asp
100 105 110
Ala Leu Asn Arg Phe Leu Asn Lys Val Asp Pro Lys Leu Val Leu Ile
115 120 125
Met Glu Thr Glu Leu Trp Pro Asn Leu Ile Ala Ala Leu His Lys Arg
130 135 140
Lys Ile Pro Leu Val Ile Ala Asn Ala Arg Leu Ser Ala Arg Ser Ala
145 150 155 160
Ala Gly Tyr Ala Lys Leu Gly Lys Phe Val Arg Arg Leu Leu Arg Arg
165 170 175
Ile Thr Leu Ile Ala Ala Gln Asn Glu Glu Asp Gly Ala Arg Phe Val
180 185 190
Ala Leu Gly Ala Lys Asn Asn Gln Val Thr Val Thr Gly Ser Leu Lys
195 200 205
Phe Asp Ile Ser Val Thr Pro Gln Leu Ala Ala Lys Ala Val Thr Leu
210 215 220
Arg Arg Gln Trp Ala Pro His Arg Pro Val Trp Ile Ala Thr Ser Thr
225 230 235 240
His Glu Gly Glu Glu Ser Val Val Ile Ala Ala His Gln Ala Leu Leu
245 250 255
Gln Gln Phe Pro Asn Leu Leu Leu Ile Leu Val Pro Arg His Pro Glu
260 265 270
Arg Phe Pro Asp Ala Ile Asn Leu Val Arg Gln Ala Gly Leu Ser Tyr
275 280 285
Ile Thr Arg Ser Ser Gly Glu Val Pro Ser Thr Ser Thr Gln Val Val
290 295 300
Val Gly Asp Thr Met Gly Glu Leu Met Leu Leu Tyr Gly Ile Ala Asp
305 310 315 320
Leu Ala Phe Val Gly Gly Ser Leu Val Glu Arg Gly Gly His Asn Pro
325 330 335
Leu Glu Ala Ala Ala His Ala Ile Pro Val Leu Met Gly Pro His Thr
340 345 350
Phe Asn Phe Lys Asp Ile Cys Ala Arg Leu Glu Gln Ala Ser Gly Leu
355 360 365
Ile Thr Val Thr Asp Ala Thr Thr Leu Ala Lys Glu Val Ser Ser Leu
370 375 380
Leu Thr Asp Ala Asp Tyr Arg Ser Phe Tyr Gly Arg His Ala Val Glu
385 390 395 400
Val Leu Tyr Gln Asn Gln Gly Ala Leu Gln Arg Leu Leu Gln Leu Leu
405 410 415
Glu Pro Tyr Leu Pro Pro Lys Thr His
420 425
<210> 4
<211> 425
<212> БЕЛОК
<213> Искусственная последовательность
<400> 4
Met Leu Glu Leu Leu Tyr Thr Ala Leu Leu Tyr Leu Ile Gln Pro Leu
1 5 10 15
Ile Trp Ile Arg Leu Trp Val Arg Gly Arg Lys Thr Pro Ala Tyr Arg
20 25 30
Lys Arg Trp Gly Glu Arg Tyr Gly Phe Tyr Arg His Pro Leu Lys Pro
35 40 45
Gly Gly Ile Met Leu His Ser Val Ser Val Gly Glu Thr Leu Ala Ala
50 55 60
Ile Pro Leu Val Arg Ala Leu Arg His Arg Tyr Pro Asp Leu Pro Ile
65 70 75 80
Thr Val Thr Thr Met Thr Pro Thr Gly Ser Glu Arg Val Gln Ser Ala
85 90 95
Phe Gly Lys Asp Val Gln His Val Tyr Leu Pro Tyr Asp Leu Pro Asp
100 105 110
Ala Leu Asn Arg Phe Leu Asn Lys Val Asp Pro Lys Leu Val Leu Ile
115 120 125
Met Glu Thr Glu Leu Trp Pro Asn Leu Ile Ala Ala Leu His Lys Arg
130 135 140
Lys Ile Pro Leu Val Ile Ala Asn Ala Arg Leu Ser Ala Arg Ser Ala
145 150 155 160
Ala Gly Tyr Ala Lys Leu Gly Lys Phe Val Arg Arg Leu Leu Arg Arg
165 170 175
Ile Thr Leu Ile Ala Ala Gln Asn Glu Glu Asp Gly Ala Arg Phe Val
180 185 190
Ala Leu Gly Ala Lys Asn Asn Gln Val Thr Val Thr Gly Ser Leu Lys
195 200 205
Phe Asp Ile Ser Val Thr Pro Gln Leu Ala Ala Lys Ala Val Thr Leu
210 215 220
Arg Arg Gln Trp Ala Pro His Arg Pro Val Trp Ile Ala Thr Ser Thr
225 230 235 240
His Glu Gly Glu Glu Ser Val Val Ile Ala Ala His Gln Ala Leu Leu
245 250 255
Gln Gln Phe Pro Asn Leu Leu Leu Ile Leu Val Pro Arg His Pro Glu
260 265 270
Arg Phe Pro Asp Ala Ile Asn Leu Val Arg Gln Ala Gly Leu Ser Tyr
275 280 285
Ile Thr Arg Ser Ser Gly Glu Val Pro Ser Thr Ser Thr Gln Val Val
290 295 300
Val Gly Asp Thr Met Gly Glu Leu Met Leu Leu Tyr Gly Ile Ala Asp
305 310 315 320
Leu Ala Phe Val Gly Gly Ser Leu Val Glu Arg Gly Gly His Asn Pro
325 330 335
Leu Glu Ala Ala Ala His Ala Ile Pro Val Leu Met Gly Pro His Thr
340 345 350
Phe Asn Phe Lys Asp Ile Cys Ala Arg Leu Glu Gln Ala Ser Gly Leu
355 360 365
Ile Thr Val Thr Asp Ala Thr Thr Leu Ala Lys Glu Val Ser Ser Leu
370 375 380
Leu Thr Asp Ala Asp Tyr Arg Ser Phe Tyr Gly Arg His Ala Val Glu
385 390 395 400
Val Leu Tyr Gln Asn Gln Gly Ala Leu Gln Arg Leu Leu Gln Leu Leu
405 410 415
Glu Pro Tyr Leu Pro Pro Lys Thr His
420 425
<210> 5
<211> 26
<212> ДНК
<213> Искусственная последовательность
<400> 5
cgggatccaccagtgaaccgccaaca
26
<210> 6
<211> 18
<212> ДНК
<213> Искусственная последовательность
<400> 6
tgcgcggacgtaagactc
18
<210> 7
<211> 18
<212> ДНК
<213> Искусственная последовательность
<400> 7
gagtcttacgtccgcgca
18
<210> 8
<211> 35
<212> ДНК
<213> Искусственная последовательность
<400> 8
aaggaaaaaagcggccgcttcccgcacctttattg
35
<210> 9
<211> 18
<212> ДНК
<213> Искусственная последовательность
<400> 9
cttcccgaaagccgattg
18
<210> 10
<211> 18
<212> ДНК
<213> Искусственная последовательность
<400> 10
acaaaatatactttaatc
18
<210> 11
<211> 1596
<212> ДНК
<213> Искусственная последовательность
<400> 11
accagtgaaccgccaacaaaggcgagatcggcaatgccatacagtaacatcaactcgccc
60
atcgtatcgccaaccacaacctgcgtgctggtggaggggacttcccctgaagagcgtgtg
120
atatagcttagtccagcctggcggacaaggttaatcgcatccgggaagcgttccggatga
180
cggggtaccaggatgagcaataaattcgggaattgctgtaacaatgcctgatgtgcggcg
240
atcaccacactctcttcgccttcgtgagtgctggtggcaatccataccgggcggtgtggt
300
gcccactggcggcgcagcgtcacggctttagcagccaactgcggcgttacagaaatatcg
360
aatttcaggctaccggtaacggtcacctgattattttttgcgcccagcgccacaaaacgt
420
gcaccatcttcttcattttgcgcagcaatcagcgtaatacgacgcagcaagcgacggacg
480
aatttacccagtttggcataacctgcggccgagcgggcagagagtcgcgcgttagcgatc
540
accagcggaattttacgtttatgtagcgccgcaatcaggttaggccatagttcggtttcc
600
ataatcaacaccagtttagggtcgactttattcaggaaacggttgagtgcatcgggcaga
660
tcatacggcagataaacgtgctgaacatccttcccgaaagccgattgtacgcgctccgaa
720
ccggttggcgtcatggttgttacggtaatcggtaaatcaggataacgatgacgcagcgcg
780
cgcaccaacgggattgccgccagagtttcaccgacggagacggagtgcagcataatgccg
840
cctggttttagcggatggcggtaaaaaccgtaacgttcaccccagcgttttcgataggcc
900
ggagacttacgtccgcgcacccagagccgtatccagatcagcggctgaataaggtagaga
960
agggcggtgtaaagcaattcgagcatagtaaatagctgacttatggatgtgctggggatt
1020
ctatgtatttagctgtggctttaccattacttttcccgtttttgacttaaatagcttcag
1080
tttggtctgatctgccgctacatcttcattttttttgtatttttatgcgattcattgaaa
1140
ctcggccccattttcaaatctacataggccgtactgacattatcgaaatgctatttttta
1200
tctatttgatttttatgattaaagtatattttgtgtataaaaatcattcgggtcggattg
1260
ctgcgaaagaaatgatacactagcacgtcaaagtaagtgcgttatcagtattcaggtagc
1320
tgttgagcctggggcggtagcgtgcttttttctgcttaacttaaccagacaatcacacaa
1380
aagagtcgctagtggaaaagccatttcgaaaaatcctggtcataaagatgcgatatcatg
1440
gggatatgttattaactactcctgtcatcagtacgctcaagcagaattatcctgatgcaa
1500
aaatcgatatgctgctttatcaggacaccatccctattttgtctgaaaacccggaaatta
1560
atgcgctctatgggataagcaataaaggtgcgggaa
1596
<210> 12
<211> 544
<212> ДНК
<213> Искусственная последовательность
<400> 12
cttcccgaaagccgattgtacgcgctccgaaccggttggcgtcatggttgttacggtaat
60
cggtaaatcaggataacgatgacgcagcgcgcgcaccaacgggattgccgccagagtttc
120
accgacggagacggagtgcagcataatgccgcctggttttagcggatggcggtaaaaacc
180
gtaacgttcaccccagcgttttcgataggccggagacttacgtccgcgcacccagagccg
240
tatccagatcagcggctgaataaggtagagaagggcggtgtaaagcaattcgagcatagt
300
aaatagctgacttatggatgtgctggggattctatgtatttagctgtggctttaccatta
360
cttttcccgtttttgacttaaatagcttcagtttggtctgatctgccgctacatcttcat
420
tttttttgtatttttatgcgattcattgaaactcggccccattttcaaatctacataggc
480
cgtactgacattatcgaaatgctattttttatctatttgatttttatgattaaagtatat
540
tttg
544
<210> 13
<211> 2109
<212> ДНК
<213>Escherichiacoli
<400> 13
atgtatctgtttgaaagcctgaatcaactgattcaaacctacctgccggaagaccaaatc
60
aagcgtctgcggcaggcgtatctcgttgcacgtgatgctcacgaggggcaaacacgttca
120
agcggtgaaccctatatcacgcacccggtagcggttgcctgcattctggccgagatgaaa
180
ctcgactatgaaacgctgatggcggcgctgctgcatgacgtgattgaagatactcccgcc
240
acctaccaggatatggaacagctttttggtaaaagcgtcgccgagctggtagagggggtg
300
tcgaaacttgataaactcaagttccgcgataagaaagaggcgcaggccgaaaactttcgc
360
aagatgattatggcgatggtgcaggatatccgcgtcatcctcatcaaacttgccgaccgt
420
acccacaacatgcgcacgctgggctcacttcgcccggacaaacgtcgccgcatcgcccgt
480
gaaactctcgaaatttatagcccgctggcgcaccgtttaggtatccaccacattaaaacc
540
gaactcgaagagctgggttttgaggcgctgtatcccaaccgttatcgcgtaatcaaagaa
600
gtggtgaaagccgcgcgcggcaaccgtaaagagatgatccagaagattctttctgaaatc
660
gaagggcgtttgcaggaagcgggaataccgtgccgcgtcagtggtcgcgagaagcatctt
720
tattcgatttactgcaaaatggtgctcaaagagcagcgttttcactcgatcatggacatc
780
tacgctttccgcgtgatcgtcaatgattctgacacctgttatcgcgtgctgggccagatg
840
cacagcctgtacaagccgcgtccgggccgcgtgaaagactatatcgccattccaaaagcg
900
aacggctatcagtctttgcacacctcgatgatcggcccgcacggtgtgccggttgaggtc
960
cagatccgtaccgaagatatggaccagatggcggagatgggtgttgccgcgcactgggct
1020
tataaagagcacggcgaaaccagtactaccgcacaaatccgcgcccagcgctggatgcaa
1080
agcctgctggagctgcaacagagcgccggtagttcgtttgaatttatcgagagcgttaaa
1140
tccgatctcttcccggatgagatttacgttttcacaccggaagggcgcattgtcgagctg
1200
cctgccggtgcaacgcccgtcgacttcgcttatgcagtgcataccgatatcggtcatgcc
1260
tgcgtgggcgcacgcgttgaccgccagccttacccgctgtcgcagccgcttaccagcggt
1320
caaaccgttgaaatcattaccgctccgggcgctcgcccgaatgccgcttggctgaacttt
1380
gtcgttagctcgaaagcgcgcgccaaaattcgtcagttgctgaaaaacctcaagcgtgat
1440
gattctgtaagcctgggccgtcgtctgctcaaccatgctttgggtggtagccgtaagctg
1500
aatgaaatcccgcaggaaaatattcagcgcgagctggatcgcatgaagctggcaacgctt
1560
gacgatctgctggcagaaatcggacttggtaacgcaatgagcgtggtggtcgcgaaaaat
1620
ctgcaacatggggacgcctccattccaccggcaacccaaagccacggacatctgcccatt
1680
aaaggtgccgatggcgtgctgatcacctttgcgaaatgctgccgccctattcctggcgac
1740
ccgattatcgcccacgtcagccccggtaaaggtctggtgatccaccatgaatcctgccgt
1800
aatatccgtggctaccagaaagagccagagaagtttatggctgtggaatgggataaagag
1860
acggcgcaggagttcatcaccgaaatcaaggtggagatgttcaatcatcagggtgcgctg
1920
gcaaacctgacggcggcaattaacaccacgacttcgaatattcaaagtttgaatacggaa
1980
gagaaagatggtcgcgtctacagcgcctttattcgtctgaccgctcgtgaccgtgtgcat
2040
ctggcgaatatcatgcgcaaaatccgcgtgatgccagacgtgattaaagtcacccgaaac
2100
cgaaattaa
2109
<210> 14
<211> 2109
<212> ДНК
<213> Искусственная последовательность
<400> 14
atgtatctgtttgaaagcctgaatcaactgattcaaacctacctgccggaagaccaaatc
60
aagcgtctgcggcaggcgtatctcgttgcacgtgatgctcacgaggggcaaacacgttca
120
agcggtgaaccctatatcacgcacccggtagcggttgcctgcattctggccgagatgaaa
180
ctcgactatgaaacgctgatggcggcgctgctgcatgacgtgattgaagatactcccgcc
240
acctaccaggatatggaacagctttttggtaaaagcgtcgccgagctggtagagggggtg
300
tcgaaacttgataaactcaagttccgcgataagaaagaggcgcaggccgaaaactttcgc
360
aagatgattatggcgatggtgcaggatatccgcgtcatcctcatcaaacttgccgaccgt
420
acccacaacatgcgcacgctgggctcacttcgcccggacaaacgtcgccgcatcgcccgt
480
gaaactctcgaaatttatagcccgctggcgcaccgtttatgtatccaccacattaaaacc
540
gaactcgaagagctgggttttgaggcgctgtatcccaaccgttatcgcgtaatcaaagaa
600
gtggtgaaagccgcgcgcggcaaccgtaaagagatgatccagaagattctttctgaaatc
660
gaagggcgtttgcaggaagcgggaataccgtgccgcgtcagtggtcgcgagaagcatctt
720
tattcgatttactgcaaaatggtgctcaaagagcagcgttttcactcgatcatggacatc
780
tacgctttccgcgtgatcgtcaatgattctgacacctgttatcgcgtgctgggccagatg
840
cacagcctgtacaagccgcgtccgggccgcgtgaaagactatatcgccattccaaaagcg
900
aacggctatcagtctttgcacacctcgatgatcggcccgcacggtgtgccggttgaggtc
960
cagatccgtaccgaagatatggaccagatggcggagatgggtgttgccgcgcactgggct
1020
tataaagagcacggcgaaaccagtactaccgcacaaatccgcgcccagcgctggatgcaa
1080
agcctgctggagctgcaacagagcgccggtagttcgtttgaatttatcgagagcgttaaa
1140
tccgatctcttcccggatgagatttacgttttcacaccggaagggcgcattgtcgagctg
1200
cctgccggtgcaacgcccgtcgacttcgcttatgcagtgcataccgatatcggtcatgcc
1260
tgcgtgggcgcacgcgttgaccgccagccttacccgctgtcgcagccgcttaccagcggt
1320
caaaccgttgaaatcattaccgctccgggcgctcgcccgaatgccgcttggctgaacttt
1380
gtcgttagctcgaaagcgcgcgccaaaattcgtcagttgctgaaaaacctcaagcgtgat
1440
gattctgtaagcctgggccgtcgtctgctcaaccatgctttgggtggtagccgtaagctg
1500
aatgaaatcccgcaggaaaatattcagcgcgagctggatcgcatgaagctggcaacgctt
1560
gacgatctgctggcagaaatcggacttggtaacgcaatgagcgtggtggtcgcgaaaaat
1620
ctgcaacatggggacgcctccattccaccggcaacccaaagccacggacatctgcccatt
1680
aaaggtgccgatggcgtgctgatcacctttgcgaaatgctgccgccctattcctggcgac
1740
ccgattatcgcccacgtcagccccggtaaaggtctggtgatccaccatgaatcctgccgt
1800
aatatccgtggctaccagaaagagccagagaagtttatggctgtggaatgggataaagag
1860
acggcgcaggagttcatcaccgaaatcaaggtggagatgttcaatcatcagggtgcgctg
1920
gcaaacctgacggcggcaattaacaccacgacttcgaatattcaaagtttgaatacggaa
1980
gagaaagatggtcgcgtctacagcgcctttattcgtctgaccgctcgtgaccgtgtgcat
2040
ctggcgaatatcatgcgcaaaatccgcgtgatgccagacgtgattaaagtcacccgaaac
2100
cgaaattaa
2109
<210> 15
<211> 702
<212> БЕЛОК
<213> Escherichia coli
<400> 15
Met Tyr Leu Phe Glu Ser Leu Asn Gln Leu Ile Gln Thr Tyr Leu Pro
1 5 10 15
Glu Asp Gln Ile Lys Arg Leu Arg Gln Ala Tyr Leu Val Ala Arg Asp
20 25 30
Ala His Glu Gly Gln Thr Arg Ser Ser Gly Glu Pro Tyr Ile Thr His
35 40 45
Pro Val Ala Val Ala Cys Ile Leu Ala Glu Met Lys Leu Asp Tyr Glu
50 55 60
Thr Leu Met Ala Ala Leu Leu His Asp Val Ile Glu Asp Thr Pro Ala
65 70 75 80
Thr Tyr Gln Asp Met Glu Gln Leu Phe Gly Lys Ser Val Ala Glu Leu
85 90 95
Val Glu Gly Val Ser Lys Leu Asp Lys Leu Lys Phe Arg Asp Lys Lys
100 105 110
Glu Ala Gln Ala Glu Asn Phe Arg Lys Met Ile Met Ala Met Val Gln
115 120 125
Asp Ile Arg Val Ile Leu Ile Lys Leu Ala Asp Arg Thr His Asn Met
130 135 140
Arg Thr Leu Gly Ser Leu Arg Pro Asp Lys Arg Arg Arg Ile Ala Arg
145 150 155 160
Glu Thr Leu Glu Ile Tyr Ser Pro Leu Ala His Arg Leu Gly Ile His
165 170 175
His Ile Lys Thr Glu Leu Glu Glu Leu Gly Phe Glu Ala Leu Tyr Pro
180 185 190
Asn Arg Tyr Arg Val Ile Lys Glu Val Val Lys Ala Ala Arg Gly Asn
195 200 205
Arg Lys Glu Met Ile Gln Lys Ile Leu Ser Glu Ile Glu Gly Arg Leu
210 215 220
Gln Glu Ala Gly Ile Pro Cys Arg Val Ser Gly Arg Glu Lys His Leu
225 230 235 240
Tyr Ser Ile Tyr Cys Lys Met Val Leu Lys Glu Gln Arg Phe His Ser
245 250 255
Ile Met Asp Ile Tyr Ala Phe Arg Val Ile Val Asn Asp Ser Asp Thr
260 265 270
Cys Tyr Arg Val Leu Gly Gln Met His Ser Leu Tyr Lys Pro Arg Pro
275 280 285
Gly Arg Val Lys Asp Tyr Ile Ala Ile Pro Lys Ala Asn Gly Tyr Gln
290 295 300
Ser Leu His Thr Ser Met Ile Gly Pro His Gly Val Pro Val Glu Val
305 310 315 320
Gln Ile Arg Thr Glu Asp Met Asp Gln Met Ala Glu Met Gly Val Ala
325 330 335
Ala His Trp Ala Tyr Lys Glu His Gly Glu Thr Ser Thr Thr Ala Gln
340 345 350
Ile Arg Ala Gln Arg Trp Met Gln Ser Leu Leu Glu Leu Gln Gln Ser
355 360 365
Ala Gly Ser Ser Phe Glu Phe Ile Glu Ser Val Lys Ser Asp Leu Phe
370 375 380
Pro Asp Glu Ile Tyr Val Phe Thr Pro Glu Gly Arg Ile Val Glu Leu
385 390 395 400
Pro Ala Gly Ala Thr Pro Val Asp Phe Ala Tyr Ala Val His Thr Asp
405 410 415
Ile Gly His Ala Cys Val Gly Ala Arg Val Asp Arg Gln Pro Tyr Pro
420 425 430
Leu Ser Gln Pro Leu Thr Ser Gly Gln Thr Val Glu Ile Ile Thr Ala
435 440 445
Pro Gly Ala Arg Pro Asn Ala Ala Trp Leu Asn Phe Val Val Ser Ser
450 455 460
Lys Ala Arg Ala Lys Ile Arg Gln Leu Leu Lys Asn Leu Lys Arg Asp
465 470 475 480
Asp Ser Val Ser Leu Gly Arg Arg Leu Leu Asn His Ala Leu Gly Gly
485 490 495
Ser Arg Lys Leu Asn Glu Ile Pro Gln Glu Asn Ile Gln Arg Glu Leu
500 505 510
Asp Arg Met Lys Leu Ala Thr Leu Asp Asp Leu Leu Ala Glu Ile Gly
515 520 525
Leu Gly Asn Ala Met Ser Val Val Val Ala Lys Asn Leu Gln His Gly
530 535 540
Asp Ala Ser Ile Pro Pro Ala Thr Gln Ser His Gly His Leu Pro Ile
545 550 555 560
Lys Gly Ala Asp Gly Val Leu Ile Thr Phe Ala Lys Cys Cys Arg Pro
565 570 575
Ile Pro Gly Asp Pro Ile Ile Ala His Val Ser Pro Gly Lys Gly Leu
580 585 590
Val Ile His His Glu Ser Cys Arg Asn Ile Arg Gly Tyr Gln Lys Glu
595 600 605
Pro Glu Lys Phe Met Ala Val Glu Trp Asp Lys Glu Thr Ala Gln Glu
610 615 620
Phe Ile Thr Glu Ile Lys Val Glu Met Phe Asn His Gln Gly Ala Leu
625 630 635 640
Ala Asn Leu Thr Ala Ala Ile Asn Thr Thr Thr Ser Asn Ile Gln Ser
645 650 655
Leu Asn Thr Glu Glu Lys Asp Gly Arg Val Tyr Ser Ala Phe Ile Arg
660 665 670
Leu Thr Ala Arg Asp Arg Val His Leu Ala Asn Ile Met Arg Lys Ile
675 680 685
Arg Val Met Pro Asp Val Ile Lys Val Thr Arg Asn Arg Asn
690 695 700
<210> 16
<211> 702
<212> БЕЛОК
<213> Escherichia coli
<400> 16
Met Tyr Leu Phe Glu Ser Leu Asn Gln Leu Ile Gln Thr Tyr Leu Pro
1 5 10 15
Glu Asp Gln Ile Lys Arg Leu Arg Gln Ala Tyr Leu Val Ala Arg Asp
20 25 30
Ala His Glu Gly Gln Thr Arg Ser Ser Gly Glu Pro Tyr Ile Thr His
35 40 45
Pro Val Ala Val Ala Cys Ile Leu Ala Glu Met Lys Leu Asp Tyr Glu
50 55 60
Thr Leu Met Ala Ala Leu Leu His Asp Val Ile Glu Asp Thr Pro Ala
65 70 75 80
Thr Tyr Gln Asp Met Glu Gln Leu Phe Gly Lys Ser Val Ala Glu Leu
85 90 95
Val Glu Gly Val Ser Lys Leu Asp Lys Leu Lys Phe Arg Asp Lys Lys
100 105 110
Glu Ala Gln Ala Glu Asn Phe Arg Lys Met Ile Met Ala Met Val Gln
115 120 125
Asp Ile Arg Val Ile Leu Ile Lys Leu Ala Asp Arg Thr His Asn Met
130 135 140
Arg Thr Leu Gly Ser Leu Arg Pro Asp Lys Arg Arg Arg Ile Ala Arg
145 150 155 160
Glu Thr Leu Glu Ile Tyr Ser Pro Leu Ala His Arg Leu Cys Ile His
165 170 175
His Ile Lys Thr Glu Leu Glu Glu Leu Gly Phe Glu Ala Leu Tyr Pro
180 185 190
Asn Arg Tyr Arg Val Ile Lys Glu Val Val Lys Ala Ala Arg Gly Asn
195 200 205
Arg Lys Glu Met Ile Gln Lys Ile Leu Ser Glu Ile Glu Gly Arg Leu
210 215 220
Gln Glu Ala Gly Ile Pro Cys Arg Val Ser Gly Arg Glu Lys His Leu
225 230 235 240
Tyr Ser Ile Tyr Cys Lys Met Val Leu Lys Glu Gln Arg Phe His Ser
245 250 255
Ile Met Asp Ile Tyr Ala Phe Arg Val Ile Val Asn Asp Ser Asp Thr
260 265 270
Cys Tyr Arg Val Leu Gly Gln Met His Ser Leu Tyr Lys Pro Arg Pro
275 280 285
Gly Arg Val Lys Asp Tyr Ile Ala Ile Pro Lys Ala Asn Gly Tyr Gln
290 295 300
Ser Leu His Thr Ser Met Ile Gly Pro His Gly Val Pro Val Glu Val
305 310 315 320
Gln Ile Arg Thr Glu Asp Met Asp Gln Met Ala Glu Met Gly Val Ala
325 330 335
Ala His Trp Ala Tyr Lys Glu His Gly Glu Thr Ser Thr Thr Ala Gln
340 345 350
Ile Arg Ala Gln Arg Trp Met Gln Ser Leu Leu Glu Leu Gln Gln Ser
355 360 365
Ala Gly Ser Ser Phe Glu Phe Ile Glu Ser Val Lys Ser Asp Leu Phe
370 375 380
Pro Asp Glu Ile Tyr Val Phe Thr Pro Glu Gly Arg Ile Val Glu Leu
385 390 395 400
Pro Ala Gly Ala Thr Pro Val Asp Phe Ala Tyr Ala Val His Thr Asp
405 410 415
Ile Gly His Ala Cys Val Gly Ala Arg Val Asp Arg Gln Pro Tyr Pro
420 425 430
Leu Ser Gln Pro Leu Thr Ser Gly Gln Thr Val Glu Ile Ile Thr Ala
435 440 445
Pro Gly Ala Arg Pro Asn Ala Ala Trp Leu Asn Phe Val Val Ser Ser
450 455 460
Lys Ala Arg Ala Lys Ile Arg Gln Leu Leu Lys Asn Leu Lys Arg Asp
465 470 475 480
Asp Ser Val Ser Leu Gly Arg Arg Leu Leu Asn His Ala Leu Gly Gly
485 490 495
Ser Arg Lys Leu Asn Glu Ile Pro Gln Glu Asn Ile Gln Arg Glu Leu
500 505 510
Asp Arg Met Lys Leu Ala Thr Leu Asp Asp Leu Leu Ala Glu Ile Gly
515 520 525
Leu Gly Asn Ala Met Ser Val Val Val Ala Lys Asn Leu Gln His Gly
530 535 540
Asp Ala Ser Ile Pro Pro Ala Thr Gln Ser His Gly His Leu Pro Ile
545 550 555 560
Lys Gly Ala Asp Gly Val Leu Ile Thr Phe Ala Lys Cys Cys Arg Pro
565 570 575
Ile Pro Gly Asp Pro Ile Ile Ala His Val Ser Pro Gly Lys Gly Leu
580 585 590
Val Ile His His Glu Ser Cys Arg Asn Ile Arg Gly Tyr Gln Lys Glu
595 600 605
Pro Glu Lys Phe Met Ala Val Glu Trp Asp Lys Glu Thr Ala Gln Glu
610 615 620
Phe Ile Thr Glu Ile Lys Val Glu Met Phe Asn His Gln Gly Ala Leu
625 630 635 640
Ala Asn Leu Thr Ala Ala Ile Asn Thr Thr Thr Ser Asn Ile Gln Ser
645 650 655
Leu Asn Thr Glu Glu Lys Asp Gly Arg Val Tyr Ser Ala Phe Ile Arg
660 665 670
Leu Thr Ala Arg Asp Arg Val His Leu Ala Asn Ile Met Arg Lys Ile
675 680 685
Arg Val Met Pro Asp Val Ile Lys Val Thr Arg Asn Arg Asn
690 695 700
<210> 17
<211> 28
<212> ДНК
<213> Искусственная последовательность
<400> 17
cgggatccgaacagcaagagcaggaagc
28
<210> 18
<211> 19
<212> ДНК
<213> Искусственная последовательность
<400> 18
tgtggtggatacataaacg
19
<210> 19
<211> 20
<212> ДНК
<213> Искусственная последовательность
<400> 19
gcaccgtttatgtatccacc
20
<210> 20
<211> 38
<212> ДНК
<213> Искусственная последовательность
<400> 20
aaggaaaaaagcggccgcacgacaaagttcagccaagc
38
<210> 21
<211> 20
<212> ДНК
<213> Искусственная последовательность
<400> 21
ctttcgcaagatgattatgg
20
<210> 22
<211> 20
<212> ДНК
<213> Искусственная последовательность
<400> 22
cacggtattcccgcttcctg
20
<210> 23
<211> 567
<212> ДНК
<213>Escherichiacoli
<400> 23
atgaatatcactgctactgttcttcttgcgtttggtatgtcgatggatgcatttgctgca
60
tcaatcggtaaaggtgccaccctccataaaccgaaattttctgaagcattgcgaaccggc
120
cttatttttggtgccgtcgaaaccctgacgccgctgatcggctggggaatgggcatgtta
180
gccagccggtttgtccttgaatggaaccactggattgcgtttgtgctgctgatattcctc
240
ggcgggcgaatgattattgagggttttcgtggcgcagatgatgaagatgaagagccgcgc
300
cgtcgacacggtttctggctactggtaaccaccgcgattgccaccagcctggatgccatg
360
gctgtgggtgttggtcttgctttcctgcaggtcaacattatcgcgaccgcattggccatt
420
ggttgtgcaaccttgattatgtcaacattagggatgatggttggtcgctttatcggctca
480
attattgggaaaaaagcggaaattctcggcgggctggtgctgatcggcatcggcgtccag
540
atcctctggacgcacttccacggttaa
567
<210> 24
<211> 567
<212> ДНК
<213> Искусственная последовательность
<400> 24
atgaatatcactgctactgttcttcttgcgtttggtatgtcgatggatgcatttgctgca
60
tcaatcggtaaagatgccaccctccataaaccgaaattttctgaagcattgcgaaccggc
120
cttatttttggtgccgtcgaaaccctgacgccgctgatcggctggggaatgggcatgtta
180
gccagccggtttgtccttgaatggaaccactggattgcgtttgtgctgctgatattcctc
240
ggcgggcgaatgattattgagggttttcgtggcgcagatgatgaagatgaagagccgcgc
300
cgtcgacacggtttctggctactggtaaccaccgcgattgccaccagcctggatgccatg
360
gctgtgggtgttggtcttgctttcctgcaggtcaacattatcgcgaccgcattggccatt
420
ggttgtgcaaccttgattatgtcaacattagggatgatggttggtcgctttatcggctca
480
attattgggaaaaaagcggaaattctcggcgggctggtgctgatcggcatcggcgtccag
540
atcctctgga cgcacttcca cggttaa
567
<210> 25
<211> 188
<212> БЕЛОК
<213> Escherichia coli
<400> 25
Met Asn Ile Thr Ala Thr Val Leu Leu Ala Phe Gly Met Ser Met Asp
1 5 10 15
Ala Phe Ala Ala Ser Ile Gly Lys Gly Ala Thr Leu His Lys Pro Lys
20 25 30
Phe Ser Glu Ala Leu Arg Thr Gly Leu Ile Phe Gly Ala Val Glu Thr
35 40 45
Leu Thr Pro Leu Ile Gly Trp Gly Met Gly Met Leu Ala Ser Arg Phe
50 55 60
Val Leu Glu Trp Asn His Trp Ile Ala Phe Val Leu Leu Ile Phe Leu
65 70 75 80
Gly Gly Arg Met Ile Ile Glu Gly Phe Arg Gly Ala Asp Asp Glu Asp
85 90 95
Glu Glu Pro Arg Arg Arg His Gly Phe Trp Leu Leu Val Thr Thr Ala
100 105 110
Ile Ala Thr Ser Leu Asp Ala Met Ala Val Gly Val Gly Leu Ala Phe
115 120 125
Leu Gln Val Asn Ile Ile Ala Thr Ala Leu Ala Ile Gly Cys Ala Thr
130 135 140
Leu Ile Met Ser Thr Leu Gly Met Met Val Gly Arg Phe Ile Gly Ser
145 150 155 160
Ile Ile Gly Lys Lys Ala Glu Ile Leu Gly Gly Leu Val Leu Ile Gly
165 170 175
Ile Gly Val Gln Ile Leu Trp Thr His Phe His Gly
180 185
<210> 26
<211> 188
<212> БЕЛОК
<213> Искусственная последовательность
<400> 26
Met Asn Ile Thr Ala Thr Val Leu Leu Ala Phe Gly Met Ser Met Asp
1 5 10 15
Ala Phe Ala Ala Ser Ile Gly Lys Asp Ala Thr Leu His Lys Pro Lys
20 25 30
Phe Ser Glu Ala Leu Arg Thr Gly Leu Ile Phe Gly Ala Val Glu Thr
35 40 45
Leu Thr Pro Leu Ile Gly Trp Gly Met Gly Met Leu Ala Ser Arg Phe
50 55 60
Val Leu Glu Trp Asn His Trp Ile Ala Phe Val Leu Leu Ile Phe Leu
65 70 75 80
Gly Gly Arg Met Ile Ile Glu Gly Phe Arg Gly Ala Asp Asp Glu Asp
85 90 95
Glu Glu Pro Arg Arg Arg His Gly Phe Trp Leu Leu Val Thr Thr Ala
100 105 110
Ile Ala Thr Ser Leu Asp Ala Met Ala Val Gly Val Gly Leu Ala Phe
115 120 125
Leu Gln Val Asn Ile Ile Ala Thr Ala Leu Ala Ile Gly Cys Ala Thr
130 135 140
Leu Ile Met Ser Thr Leu Gly Met Met Val Gly Arg Phe Ile Gly Ser
145 150 155 160
Ile Ile Gly Lys Lys Ala Glu Ile Leu Gly Gly Leu Val Leu Ile Gly
165 170 175
Ile Gly Val Gln Ile Leu Trp Thr His Phe His Gly
180 185
<210> 27
<211> 28
<212> ДНК
<213> Искусственная последовательность
<400> 27
cgggatccct tcgccaatgt ctggattg
28
<210> 28
<211> 20
<212> ДНК
<213> Искусственная последовательность
<400> 28
atggagggtg gcatctttac
20
<210> 29
<211> 20
<212> ДНК
<213> Искусственная последовательность
<400> 29
tgcatcaatc ggtaaagatg
20
<210> 30
<211> 38
<212> ДНК
<213> Искусственная последовательность
<400> 30
aaggaaaaaa gcggccgcca actccgcact ctgctgta
38
<210> 31
<211> 19
<212> ДНК
<213> Искусственная последовательность
<400> 31
ccatcacggcttgttgttc
19
<210> 32
<211> 19
<212> ДНК
<213> Искусственная последовательность
<400> 32
acgaaaaccctcaataatc
19
<---
Изобретение относится к биотехнологии. Предложен нуклеотид для ферментативного получения L-треонина, содержащий нуклеотидную последовательность, образованную вследствие мутации, заключающуюся в замене гуанина (Г) на аденин (А) в 82-м основании кодирующей последовательности гена kdtA дикого типа, представленной в SEQ ID NO: 1. Также предложены рекомбинантный белок для ферментативного получения L-треонина, кодируемый указанным нуклеотидом, вектор, содержащий указанный нуклеотид, рекомбинантная бактерия, содержащая указанный нуклеотид, их применение для ферментативного получения L-треонина, а также способ конструирования указанной рекомбинантной бактерии. Изобретение обеспечивает продукцию L-треонина в высокой концентрации. 6 н. и 4 з.п. ф-лы, 6 табл., 3 пр.
1. Нуклеотид для ферментативного получения L-треонина, содержащий нуклеотидную последовательность, образованную вследствие мутации, заключающейся в замене гуанина (Г) на аденин (А) в 82-ом основании кодирующей последовательности гена kdtA дикого типа, представленной в SEQ ID NO: 1.
2. Нуклеотид по п. 1, где мутантная нуклеотидная последовательность представлена в SEQ ID NO: 2.
3. Рекомбинантный белок для ферментативного получения L-треонина, кодируемый нуклеотидом по п. 1, где указанная аминокислотная последовательность рекомбинантного белка представлена в SEQ ID NO: 4.
4. Рекомбинантный вектор для ферментативного получения L-треонина, содержащий нуклеотид по п. 1.
5. Рекомбинантный вектор по п. 4, где рекомбинантный вектор образован путем введения нуклеотидной последовательности в плазмиду.
6. Рекомбинантная бактерия для ферментативного получения L-треонина, содержащая нуклеотид по п. 1.
7. Рекомбинантная бактерия по п. 6, где рекомбинантную бактерию конструируют путем введения рекомбинантного вектора по п. 4 в штамм-хозяин; указанный штамм-хозяин выбран из E. Coli K12, его производного штамма E. coli K12 (W3110) или штамма E. coli CGMCC 7.232.
8. Способ конструирования рекомбинантной бактерии по п. 6, включающий следующие этапы:
(1) модификация нуклеотидной последовательности гена дикого типа, представленной в SEQ ID NO: 1, для получения мутантной нуклеотидной последовательности, представленной в SEQ ID NO: 2;
(2) лигирование мутантной нуклеотидной последовательности с плазмидой для конструирования рекомбинантного вектора; и
(3) введение рекомбинантного вектора в штамм-хозяин для получения рекомбинантной бактерии.
9. Способ конструирования рекомбинантной бактерии по п. 8, отличающийся тем, что указанная плазмида представляет собой плазмиду pKOV.
10. Применение нуклеотида по п. 1, рекомбинантного белка по п. 3, рекомбинантного вектора по п. 4 или рекомбинантной бактерии по п. 6 для ферментативного получения L-треонина.
| СПОСОБ УМЕНЬШЕНИЯ КОЛИЧЕСТВА ВРЕДНЫХ ГАЗОВ, ВЫДЕЛЯЮЩИХСЯ ПРИ ПРЯДЕНИИ ВИСКОЗНОГО ШЕЛКА | 1931 |
|
SU32667A1 |
| Escherichia coli str | |||
| Способ гальванического снятия позолоты с серебряных изделий без заметного изменения их формы | 1923 |
|
SU12A1 |
| Счетный прибор | 1924 |
|
SU1655A1 |
| СПОСОБ УМЕНЬШЕНИЯ КОЛИЧЕСТВА ВРЕДНЫХ ГАЗОВ, ВЫДЕЛЯЮЩИХСЯ ПРИ ПРЯДЕНИИ ВИСКОЗНОГО ШЕЛКА | 1931 |
|
SU32667A1 |
| CN 107267568 A, 20.10.2017 | |||
| US 2010221776 A1, 02.09.2010 | |||
| СПОСОБ ПОЛУЧЕНИЯ L-ТРЕОНИНА, ШТАММ ESCHERICHIA COLI - ПРОДУЦЕНТ ТРЕОНИНА (ВАРИАНТЫ) | 2002 |
|
RU2244007C2 |

