Родственные заявки
По настоящей заявке испрашивается приоритет в соответствии с 35 USC §119(e) предварительной заявки на патент США №62/696362, поданной 11 июля 2018 г., содержание которой полностью включено в настоящий документ посредством ссылки.
Изложение перечня последовательностей
Файл ASCII под названием 77794 SequenceListing.txt, созданный 11 июля 2019 г. и содержащий 192512 байтов, представленный одновременно с подачей настоящей заявки, включен в настоящий документ посредством ссылки.
Область техники, к которой относится настоящее изобретение, и предшествующий уровень техники настоящего изобретения
Настоящее изобретение согласно его некоторым вариантам осуществления относится к слитому белку варианта SIRPα-4-1BBL и способам его применения.
Белки двойной передачи сигналов (DSP), также известные как белки, преобразующие сигнал (SCP), которые в настоящее время известны в настоящей области техники как бифункциональные слитые белки, которые связывают внеклеточную часть мембранного белка типа I (внеклеточный амино-конец), с внеклеточной частью мембранного белка типа II (внеклеточный карбоксильный конец), образуя слитый белок с двумя активными сторонами (смотрите, например, патенты США №7569663 и 8039437).
SIRPα (сигнально-регуляторный белок альфа) представляет собой рецептор клеточной поверхности суперсемейства иммуноглобулинов. SIRPα экспрессируется в основном на поверхности иммунных клеток из линии фагоцитов, таких как макрофаги и дендритные клетки (DC). CD47 представляет собой лиганд SIRPα. CD47 представляет собой молекулу клеточной поверхности в суперсемействе иммуноглобулинов. CD47 действует как ингибитор фагоцитоза посредством лигирования SIRPα, экспрессируемого на фагоцитах. CD47 широко экспрессируется в большинстве нормальных тканей. Таким образом, CD47 служит сигналом «не ешь меня» и маркером себя, поскольку потеря CD47 приводит к гомеостатическому фагоцитозу старых или поврежденных клеток. Было обнаружено, что CD47 экспрессируется на нескольких типах опухолей человека. Опухоли уклоняются от фагоцитоза макрофагов за счет экспрессии антифагоцитарных сигналов, включающих в себя CD47. В то время как CD47 повсеместно экспрессируется в низких количествах в нормальных клетках, множественные опухоли экспрессируют повышенные уровни CD47 по сравнению с их аналогами в нормальных клетках, а избыточная экспрессия CD47 позволяет опухолям избежать наблюдения врожденной иммунной системы за счет уклонения от фагоцитоза.
4-1BBL представляет собой активирующий лиганд рецептора 4-1ВВ (CD137), представителя суперсемейства рецепторов TNF, и мощную индуцированную активацией костимулирующую молекулу Т-клеток. 4-1BBL в природе образует гомотример, но передача сигнала через 4-1ВВ требует значительной олигомеризации 4-1BBL. 4-1BBL присутствует на множестве антигенпрезентирующих клеток (АРС), включая в себя дендритные клетки (DC), В-клетки и макрофаги. Рецептор 4-1ВВ не обнаруживается (<3%) на покоящихся Т-клетках или линиях Т-клеток, однако 4-1ВВ стабильно активируется при активации Т-клеток. Активация 4-1ВВ активирует гены выживания, усиливает деление клеток, индуцирует производство цитокинов и предотвращает вызванную активацией гибель Т-клеток.
Дополнительный предшествующий уровень техники включает в себя:
Weiskopf К et al. Science. (2013); 341(6141):88-91;
Публикация международной патентной заявки № WO 2017027422;
Публикация международной патентной заявки № WO 2001086003;
Публикация международной патентной заявки № WO 2001075067;
Публикация международной патентной заявки № WO 2017194641;
Публикация международной патентной заявки № WO 2014180288;
Публикация международной патентной заявки № WO 2017059168;
Публикация международной патентной заявки № WO 2001/049318;
Публикация международной патентной заявки № WO 2016/139668;
Публикация международной патентной заявки № WO 2014/106839;
Публикация международной патентной заявки № WO 2012/042480;
Публикация патентной заявки США №20150183881;
Публикация патентной заявки США № US 20070110746;
Публикация патентной заявки США № US 20070036783 и
Патент США № US 9562087.
Краткое раскрытие настоящего изобретения
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрен слитый белок SIRPα-4-1BBL, содержащий аминокислотную последовательность SIRPα и аминокислотную последовательность 4-1BBL, причем аминокислотная последовательность SIRPα составляет 100-119 аминокислот в длину, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 24 и 26, и/или причем аминокислотная последовательность 4-1BBL:
(a) составляет в длину 185-202 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28, составляет в длину 170-197 аминокислот, характеризуясь идентичностью, составляющей по меньшей мере 80%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, и не содержит аминокислотный сегмент G198-Е205, соответствующий SEQ ID NO: 3, составляет в длину 170-182 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 72 и не содержит аминокислотный сегмент А1-Е23, соответствующий SEQ ID NO: 3, или составляет в длину 184 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 70; и/или
(b) содержит три повтора аминокислотной последовательности 4-1BBL; и причем слитый белок способен по меньшей мере к одному из следующего:
(i) связывание CD47 и 4-1ВВ;
(ii) активация сигнального пути 4-1ВВ в клетке, экспрессирующей 4-1ВВ;
(iii) костимуляция иммунных клеток, экспрессирующих 4-1ВВ; и/или
(iv) усиление фагоцитоза патологических клеток, экспрессирующих CD47, фагоцитами по сравнению с таковым в отсутствие слитого белка SIRPα-4-1BBL.
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрен слитый белок SIRPα-4-1BBL, содержащий аминокислотную последовательность SIRPα и аминокислотную последовательность 4-1BBL, причем аминокислотная последовательность SIRPα составляет в длину 100-119 аминокислот, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 24 и 26, и/или причем аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28; и причем слитый белок способен по меньшей мере к одному из следующего:
(i) связывание CD47 и 4-1ВВ;
(ii) активация сигнального пути 4-1ВВ в клетке, экспрессирующей 4-1ВВ;
(iii) костимуляция иммунных клеток, экспрессирующих 4-1ВВ; и/или
(iv) усиление фагоцитоза патологических клеток, экспрессирующих CD47, фагоцитами по сравнению с таковым в отсутствие слитого белка SIRPα-4-1BBL.
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрен выделенный полипептид, содержащий аминокислотную последовательность SIRPα, причем аминокислотная последовательность SIRPα составляет 100-119 аминокислот в длину, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 24 и 26; и причем полипептид способен связываться с CD47.
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрен выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, причем аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28; и причем полипептид способен по меньшей мере к одному из следующего:
(i) связывание 4-1ВВ,
(ii) активация сигнального пути 4-1ВВ в клетке, экспрессирующей 4-1ВВ; и/или
(iii) костимуляция иммунных клеток, экспрессирующих 4-1ВВ.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность SIRPα составляет в длину по меньшей мере 115 аминокислот.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность SIRPα составляет в длину 116 аминокислот.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность SIRPα содержит мутацию по аминокислотному остатку, выбранному из группы, состоящей из L4, А27, Е47 и V92, соответствующих SEQ ID NO: 2.
Согласно некоторым вариантам осуществления настоящего изобретения мутация выбрана из группы, состоящей из L4I, A27I, E47V и V92I, соответствующих SEQ ID NO: 2.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность SIRPα не содержит ни одного из аминокислотных остатков K117-Y343, соответствующих SEQ ID NO: 2.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность SIRPα содержит SEQ ID NO: 24 или 26.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность SIRPα состоит из SEQ ID NO: 24 или 26.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22-23.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность 4-1BBL не содержит никаких аминокислотных остатков A1-V6 или A1-G14, соответствующих SEQ ID NO: 3.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 22, 23, 27 или 28.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 22, 23, 27 или 28.
Согласно некоторым вариантам осуществления настоящего изобретения:
(i) аминокислотная последовательность SIRPα приведена в SEQ ID NO: 2 или 25, а аминокислотная последовательность 4-1BBL приведена в SEQ ID NO: 22, 23, 27 или 28; или
(ii) аминокислотная последовательность SIRPα приведена в SEQ ID NO: 24 или 26, а аминокислотная последовательность 4-1BBL приведена в SEQ ID NO: 3, 22, 23, 27 или 28.
Согласно некоторым вариантам осуществления настоящего изобретения:
(i) аминокислотная последовательность SIRPα приведена в SEQ ID NO: 2, а аминокислотная последовательность 4-1BBL приведена в SEQ ID NO: 22 или 23; или
(ii) аминокислотная последовательность SIRPα приведена в SEQ ID NO: 24, а аминокислотная последовательность 4-1BBL приведена в SEQ ID NO: 22.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 72, 74 или 76.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 72, 74 или 76.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 70.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 70.
Согласно некоторым вариантам осуществления настоящего изобретения слитый белок SIRPα-4-1BBL содержит линкер между SIRPα и 4-1BBL.
Согласно некоторым вариантам осуществления настоящего изобретения слитый белок SIRPα-4-1BBL содержит линкер между каждым из трех повторов аминокислотной последовательности 4-1BBL.
Согласно некоторым вариантам осуществления настоящего изобретения линкер составляет в длину от одной до шести аминокислот.
Согласно некоторым вариантам осуществления настоящего изобретения линкер представляет собой линкер из одной аминокислоты.
Согласно некоторым вариантам осуществления настоящего изобретения линкер представляет собой глицин.
Согласно некоторым вариантам осуществления настоящего изобретения линкер не представляет собой домен Fc антитела или его фрагмент.
Согласно некоторым вариантам осуществления настоящего изобретения линкер представляет собой домен Fc антитела или его фрагмент.
Согласно некоторым вариантам осуществления настоящего изобретения слитый белок SIRPα-4-1BBL находится в форме по меньшей мере гомотримеров.
Согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере гомотример имеет молекулярную массу по меньшей мере 100 кДа, как определено с помощью SEC-MALS.
Согласно некоторым вариантам осуществления настоящего изобретения слитый белок SIRPα-4-1BBL или выделенный полипептид являются растворимыми.
Согласно некоторым вариантам осуществления настоящего изобретения выход продукции слитого белка по меньшей мере в 1,5 раза выше, чем выход продукции SEQ ID NO: 5 при тех же условиях продукции, условия продукции предусматривают экспрессию в клетке млекопитающего и культивирование при 32-37°С, 5-10% СО2 в течение 5-13 дней.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13, 15, 16, 18-21 и 45 49.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13 и 16.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 11, 13, 15, 16, 18-21 и 45-49.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 11, 13 и 16.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность слитого белка SIRPα-4-1BBL состоит из аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13, 15, 16, 18-21 и 45-49.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислотная последовательность слитого белка SIRPα-4-1BBL состоит из аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13 и 16.
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрен полинуклеотид, кодирующий слитый белок или полипептид SIRPα-4-1BBL.
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрена конструкция нуклеиновой кислоты, содержащая полинуклеотид и регуляторный элемент для управления экспрессией полинуклеотида в клетке-хозяине.
Согласно некоторым вариантам осуществления настоящего изобретения полинуклеотид содержит последовательность нуклеиновой кислоты, выбранную из группы, состоящей из SEQ ID NO: 55-66 и 68.
Согласно некоторым вариантам осуществления настоящего изобретения полинуклеотид содержит последовательность нуклеиновой кислоты, выбранную из группы, состоящей из SEQ ID NO: 55, 56 и 58.
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрена клетка-хозяин, содержащая слитый белок SIRPα-4-1BBL или полипептид, или полинуклеотид, или конструкцию нуклеиновой кислоты.
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрен способ получения слитого белка или полипептида SIRPα-4-1BBL, причем способ предусматривает экспрессию в клетке-хозяине полинуклеотида или конструкции нуклеиновой кислоты.
Согласно некоторым вариантам осуществления настоящего изобретения способ предусматривает выделение слитого белка или полипептида.
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрен способ лечения заболевания, при котором может быть полезна активация иммунных клеток, предусматривающий введение нуждающемуся в этом субъекту слитого белка SIRPα-4-1BBL или выделенного полипептида, полинуклеотида или конструкции нуклеиновой кислоты, или клетки-хозяина.
Согласно некоторым вариантам осуществления настоящего изобретения способ дополнительно предусматривает введение субъекту терапевтического средства для лечения заболевания.
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрен слитый белок SIRPα-4-1BBL или выделенный полипептид, полинуклеотид, или конструкция нуклеиновой кислоты, или клетка-хозяин, для применения при лечении заболевания, для которого может быть полезна активация иммунные клетки.
Согласно некоторым вариантам осуществления настоящего изобретения композиция дополнительно содержит терапевтическое средство для лечения заболевания.
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрено изделие, содержащее упаковочный материал, упаковывающий терапевтическое средство для лечения заболевания, которое может получить пользу от активации иммунных клеток; и слитый белок SIRPα-4-1BBL или выделенный полипептид, полинуклеотид или конструкцию нуклеиновой кислоты, или клетку-хозяина.
Согласно некоторым вариантам осуществления настоящего изобретения клетки заболевания экспрессируют CD47.
Согласно некоторым вариантам осуществления настоящего изобретения заболевание включает в себя гиперпролиферативное заболевание.
Согласно некоторым вариантам осуществления настоящего изобретения гиперпролиферативное заболевание включает в себя склероз или фиброз, идиопатический фиброз легких, псориаз, системный склероз/склеродермию, первичный билиарный холангит, первичный склерозирующий холангит, фиброз печени, профилактику радиационно-индуцированного фиброза легких, миелофиброза или забрюшинного фиброза.
Согласно некоторым вариантам осуществления настоящего изобретения гиперпролиферативное заболевание включает в себя рак.
Согласно некоторым вариантам осуществления настоящего изобретения рак выбран из группы, состоящей из лимфомы, лейкоза и карциномы.
Согласно некоторым вариантам осуществления настоящего изобретения заболевание включает в себя заболевание, связанное с иммуносупрессией или индуцированной лекарственными средствами иммуносупрессией.
Согласно некоторым вариантам осуществления настоящего изобретения, они включают в себя вирусы HIV, кори, гриппа, LCCM, RSV, риновирусы человека, EBV, CMV или Parvo.
Согласно некоторым вариантам осуществления настоящего изобретения заболевание включает в себя инфекцию.
Согласно аспекту некоторых вариантов осуществления настоящего изобретения предусмотрен способ активации иммунных клеток, причем способ предусматривает активацию иммунных клеток in vitro в присутствии слитого белка SIRPα-4-1BBL или выделенного полипептида, полинуклеотида или конструкции нуклеиновой кислоты или клетки-хозяина.
Согласно некоторым вариантам осуществления настоящего изобретения активация происходит в присутствии клеток, экспрессирующих CD47 или экзогенный CD47.
Согласно некоторым вариантам осуществления настоящего изобретения клетки, экспрессирующие CD47, включают в себя патологические клетки.
Согласно некоторым вариантам осуществления настоящего изобретения патологические клетки включают в себя раковые клетки.
Согласно некоторым вариантам осуществления настоящего изобретения активация происходит в присутствии противоракового средства.
Согласно некоторым вариантам осуществления настоящего изобретения терапевтическое средство для лечения заболевания или противораковое средство включает в себя антитело.
Согласно некоторым вариантам осуществления настоящего изобретения антитело выбрано из группы, состоящей из ритуксимаба, цетуксимаба, трастузумаба, эдреколомаба, альметузумаба, гемтузумаба, ибритумомаба, панитумумаба, белимумаба, бевацизумаба, биватузумаба, мертансина, блинатумуветомаба, блинатумуветомаба, блонтуветмаба, брентуксимаба ведотина, катумаксомаба, циксутумумаба, даклизумаба, адалимумаба, безлотоксумаба, цертолизумаба пегол, цитатузумаба богатокс, даратумумаба, динутуксимаба, элотузумаба, эртумаксомаба, этарацизумаба, гемтузумаба озогамицина, гирентуксимаба, неситумумаба, обинутузумаба, офатумумаба, пертузумаба, рамуцирумаба, силтуксимаба, тозитумомаба, трастузумаба, ниволумаба, пембролизумаба, дурвалумаба, атезолизумаба, авелумаба и ипилимумаба.
Согласно некоторым вариантам осуществления настоящего изобретения антитело выбрано из группы, состоящей из ритуксимаба, цетуксимаба и альметузумаба.
Согласно некоторым вариантам осуществления настоящего изобретения терапевтическое средство для лечения заболевания или противораковое средство включает в себя IMiD (например, талидомид, леналидомид, помалидомид).
Согласно некоторым вариантам осуществления настоящего изобретения способ предусматривает адоптивный перенос иммунных клеток после активации нуждающемуся в этом субъекту.
Согласно некоторым вариантам осуществления настоящего изобретения иммунные клетки включают в себя Т-клетки.
Согласно некоторым вариантам осуществления настоящего изобретения иммунные клетки включают в себя фагоциты.
Если не указано иное, все технические и/или научные термины, используемые в настоящем документе, характеризуются тем же значением, которое обычно понимается специалистом в настоящей области техники, к которой относится настоящее изобретение. Хотя способы и материалы, подобные или эквивалентные описанным в настоящем документе, можно применять на практике или при тестировании вариантов осуществления настоящего изобретения, ниже описаны иллюстративные способы и/или материалы. В случае конфликта описание патента, включая в себя определения, будет иметь преимущественную силу. Кроме того, материалы, способы и примеры являются только иллюстративными и не предназначены для ограничения.
Краткое описание графических материалов
Некоторые варианты осуществления настоящего изобретения описаны в настоящем документе только в качестве примера со ссылкой на сопровождающие графические материалы. Обращаясь теперь к конкретным подробным графическим материалам, следует подчеркнуть, что подробности представлены в качестве примера и в целях иллюстративного обсуждения вариантов осуществления настоящего изобретения. В этом отношении описание графических материалов делает очевидным для специалистов в настоящей области техники то, как варианты осуществления настоящего изобретения могут быть реализованы на практике.
На графических материалах:
Фиг. 1 представляет собой схематическое изображение слитого белка SIRPα-4-1BBL, называемого в настоящем документе «DSP107» (SEQ ID NO: 5), содержащего N-концевой сигнальный пептид и С-концевую his-метку (SEQ ID NO 43). Показаны сигнальный пептид (подчеркнутый, SEQ ID NO: 4), домен SIRPα (красный, SEQ ID NO: 2), глициновый линкер (черный), домен 4-1BBL (синий, SEQ ID NO: 3) и С-концевая His-метка (жирный черный).
На фиг. 2А-С показана предсказанная трехмерная структура DSP107 (SEQ ID NO: 5). Фиг. 2А представляет собой схематическую трехмерную модель. SIRPα показан серыми лентами, CD47 (рецептор SIRPα) показан зелеными лентами, 4-1BBL показан синими лентами и 2 дополнительные копии 4-1BBL (образующие тример) показаны голубым цветом. Фиг. 2В представляет собой схематическую полную атомарную 3D-модель. Фиг. 2С представляет собой схематическую 3D-модель. Домены, разрешенные в рентгеновских лучах, представлены его поверхностью и окрашены по шкале гидрофобности - от синего (наиболее гидрофильный) до коричневого (гидрофобный). 4-1BBL показывает более высокий уровень открытых гидрофобных участков.
Фиг. 3 представляет собой схематическое изображение домена и сегментов, идентифицированных в DSP107 (SEQ ID NO: 5). Ig-подобный домен V-типа выделен голубым цветом, Ig-подобный домен C1-type1 выделен желтым цветом, Ig-подобный домен C1-type2 выделен зеленым цветом, часть в рентгеновском разрешении выделена серым и фланговые/неструктурированные области отмечены красными прямоугольниками.
На фиг. 4 показана предсказанная трехмерная структура варианта слитого белка SIRPα-4-1BBL, называемого в настоящем документе «DSP107_var1» (SEQ ID NO: 11). Ha верхней панель показана трехмерная структура в представлении поверхности и окрашена по шкале гидрофобности: гидрофильная - синим, а гидрофобная - коричневым. На нижней панели показана трехмерная структура в ленточном представлении, окрашенном в соответствии с положением последовательности от N-конца (синий) к С-концу (красный).
На фиг. 5 показана предсказанная трехмерная структура варианта слитого белка SIRPα-4-1BBL, называемого в настоящем документе «DSP107_var2» (SEQ ID NO: 13). Ha верхней панель показана трехмерная структура в представлении поверхности и окрашена по шкале гидрофобности: гидрофильная - синим, а гидрофобная - коричневым. На нижней панели показана трехмерная структура в ленточном представлении, окрашенном в соответствии с положением последовательности от N-конца (синий) к С-концу (красный).
На фиг. 6 показана предсказанная трехмерная структура варианта слитого белка SIRPα-4-1BBL, называемого в настоящем документе «DSP107_var3.1» (SEQ ID NO: 15). На верхней панель показана трехмерная структура в представлении поверхности и окрашена по шкале гидрофобности: гидрофильная - синим, а гидрофобная - коричневым. На нижней панели показана трехмерная структура в ленточном представлении, окрашенном в соответствии с положением последовательности от N-конца (синий) к С-концу (красный).
На фиг. 7А-В показан анализ ДСН-ПААГ полученных слитых белков SIRPα-4-1BBL. DSP107 с N-концевой his-меткой [обозначен как (NH), SEQ ID NO: 44), DSP107 с С-концевой his-меткой [обозначен как (СН), SEQ ID NO: 1] и варианты DSP107 с С-концевой his-меткой [обозначенные как (CH)-V1, (CH)-V2 и (CH)-V3.1 (SEQ ID NO 12, 14 и 17, соответственно)] (2 мкг/лунку) разделяли на 4-20% ДСН-ПААГ в восстанавливающих (фиг. 7А) и невосстанавливающих (фиг. 7В) условиях. Миграцию белков на геле визуализировали окрашиванием e-Stain peds. Маркер белков молекулярного размера также был разделен в том же геле, и размеры указаны.
На фиг. 8А-С показан вестерн-блот-анализ полученных слитых белков SIRPα-4-1BBL. DSP107 с N-концевой his-меткой [обозначен как (NH), SEQ ID NO: 44], DSP107 с С-концевой his-меткой [обозначен как (СН), SEQ ID NO: 1], DSP107_V1 с С-концевой his-меткой [обозначен как (CH)-V1, SEQ ID NO: 12], DSP107_V2 с С-концевой his-меткой [обозначен как (CH)-V2), SEQ ID NO: 14] и DSP107_V3.1 с С-концевой his-меткой [обозначен как (CH)-V3.1, SEQ ID NO 17] (500 нг/лунку) разделяли на ДСН-ПААГ в невосстанавливающих (фиг. 8А) и восстанавливающих (фиг. 8В) условиях с последующим иммуноблоттингом с антителом к 4-1BBL. DSP107_V2 с С-концевой his-меткой [обозначенный как (CH)-V2), SEQ ID NO: 14] (50 нг/лунку) также разделяли на ДСН-ПААГ в восстанавливающих условиях с последующим иммуноблоттингом с антителом к SIRPα (фиг. 8С).
Фиг. 9 представляет собой график, демонстрирующий связывание DSP107 с N-концевой his-меткой [обозначенного как (NH), SEQ ID NO: 44], DSP107_V1 с С-концевой his-меткой [обозначенного как (CH)-V1, SEQ ID NO: 12] и DSP107_V2 с С-концевой his-меткой [обозначенного как (CH)-V2, SEQ ID NO: 14] с SIRPα и 4-1BBL аналогичным зависимым от дозы образом, как определено посредством анализа сэндвич-ELISA, с использованием антитела к 4-1BBL для связывания и SIRPα-биотинилированного антитела для обнаружения.
Фиг. 10 представляет собой гистограмму, демонстрирующую связывание фрагмента SIRPα DSP 107 с С-концевой his-меткой [обозначенного как (СН), SEQ ID NO: 1], DSP107_V1 с С-концевой his-меткой [обозначенного как (CH)-V1), SEQ ID NO: 12], DSP107_V2 с С-концевой his-меткой [обозначенного как (CH)-V2, SEQ ID NO: 14] и DSP107_V3.1 с С-концевой his-меткой [обозначенного как (CH)-V3.1, SEQ ID NO 17], как определено анализом проточной цитометрии. Показаны значения GMFI.
На фиг. 11 показаны графики, демонстрирующие, что полученные слитые белки SIRPα-4-1BBL способствуют пролиферации Т-клеток. РВМС инкубировали с 0,01 мкг/мл DSP107 с N-концевой his-меткой [обозначенного как (NH), SEQ ID NO: 44], DSP107_V1 с С-концевой his-меткой [обозначенного как (CH)-V1, SEQ ID NO: 12] или DSP107_V2 с C-концевой his-меткой [обозначенного как (CH)-V2, SEQ ID NO: 17] в присутствии анти-CD3, с IL-2 или без него, как указано; и пролиферацию определяли в указанные моменты времени путем измерения конфлюентности.
Фиг. 12 представляет собой гистограмму, демонстрирующую экспрессию 4-1ВВ на РВМС человека после стимуляции в присутствии субоптимальных концентраций анти-CD3 и/или IL-2 по сравнению с нестимулированными клетками (na) в указанные моменты времени. Показаны значения GMFI.
На фиг. 13А-С показано, что слитые белки SIRPα-4-1BBL вызывают блокирование взаимодействия SIRPα с 4-1BBL. На фиг. 13А показан план анализа: рекомбинантный CD47 человека был связан с планшетом для ELISA. В планшет добавляли слитый белок SIRPα-4-1BBL или антитело к CD47 положительного контроля. После промывки добавляли биотинилированный рекомбинантный SIRPα человека, а затем стрептавидин HRP и субстрат ТМВ. Взаимодействие SIRPα с CD47 измеряли по оптической плотности при 450 нм. Фиг. 13В представляет собой график, на котором показана блокада взаимодействия SIRPα с помощью DSP107 с N-концевой his-меткой [обозначенного как (NH), SEQ ID NO: 44], DSP 107 с С-концевой his-меткой [обозначенного как (СН), SEQ ID NO: 1], DSP107_V1 с С-концевой his-меткой [обозначенного как (CH-V1, SEQ ID NO: 12), DSP107_V2 с С-концевой his-меткой [обозначенного как (CH)-V2, SEQ ID NO: 14] и DSP107_V3.1 с С-концевой his-меткой [обозначенного как (CH)-V3.1, SEQ ID NO: 17] по сравнению с положительным контролем блокирующего антитела. Фиг. 13С представляет собой график, на котором показаны значения ЕС50, рассчитанные для ограниченного диапазона концентраций.
Фиг. 14А-В представляют собой гистограммы, демонстрирующие, что производимые слитые белки SIRPα-4-1BBL усиливают опосредованный полиморфноядерными лейкоцитами (PMN) фагоцитоз раковых клеток человека. Показан % фагоцитоза через 2 часа (фиг. 14А) или 18 часов (фиг. 14В) инкубации PMN и раковых клеток Ramos или DLD1 с DSP107 с С-концевой his-меткой [обозначенным как (СН), SEQ ID NO: 1], DSP107_V1 с С-концевой his-меткой [обозначенным как (CH)-V1, SEQ ID NO: 12], DSP107_V2 с С-концевой his-меткой [обозначенным как (CH)-V2, SEQ ID NO: 14] или DSP107_V3.1 с С-концевой his-меткой [обозначенным как (CH)-V3.1, SEQ ID NO: 17]; отдельно или в комбинации с ритуксимабом (RTX) или цетуксимабом (СТХ), как указано.
На фиг. 15 показаны гистограммы, демонстрирующие, что полученные слитые белки SIRPα-4-1BBL усиливают опосредованный макрофагами фагоцитоз клеток лимфомы человека. Показан % фагоцитоза после 2 часов инкубации макрофагов и раковых клеток SUDHL5, SUDHL4 и OCI-LY3 с DSP107 с С-концевой his-меткой [обозначенным как (СН), SEQ ID NO: 1], DSP107_V1 с С-концевой his-меткой [обозначенным как (CH)-V1, SEQ ID NO: 12], DSP107_V2 с С-концевой his-меткой [обозначенным как (CH)-V2, SEQ ID NO: 14] или DSP107_V3.1 с С-концевой his-меткой [обозначенным как (CH)-V3.1, SEQ ID NO: 17); отдельно или в комбинации с ритуксимабом (RTX), как указано.
Фиг. 16 представляет собой график, демонстрирующий, что DSP107_V2 с С-концевой his-меткой [обозначенный как (CH)-V2, SEQ ID NO: 14] усиливает опосредованный макрофагами фагоцитоз раковых клеток SUDHL4 после 2 часов инкубации в зависимости от дозы.
Фиг. 17 представляет собой столбчатую диаграмму, демонстрирующую концентрацию DSP107_V2 (SEQ ID NO: 13) в образцах мини-пулов, взятых на 11 день из подпитываемых периодических культур, как определено с помощью двустороннего анализа ELISA.
На фиг. 18 показан анализ ДСН-ПААГ DSP107_V2 (SEQ ID NO: 13). Очищенные образцы DSP107_V2 (5 мг) и мини-пулы, взятые на 11 день из подпитываемых периодических культур (5 мкл), разделяли на 4-20% ДСН-ПААГ в восстанавливающих условиях с последующим окрашиванием Кумасси.
На фиг. 19А-В показаны гистограммы, демонстрирующие мембранную экспрессию CD47 на сверхэкспрессирующих (OX) CD47 клетках человека СНО-K1 (фиг. 19А) и клетках SUDHL4 (фиг. 19В), а также отсутствие экспрессии на клетках СНО-K1 (фиг. 19А), как определено посредством анализа проточной цитометрии.
На фиг. 20 показаны гистограммы, демонстрирующие мембранную экспрессию 4-1ВВ и CD47 на клетках НТ1080 OX 4-1ВВ и отсутствие экспрессии 4-1ВВ на исходных (WT) клетках НТ1080, как определено посредством анализа проточной цитометрии.
На фиг. 21А-В показаны графики, демонстрирующие связывание фрагмента SIRPα DSP107_V2 (SEQ ID NO: 13) с клетками CHO-K1-CD47 (фиг. 21А) и клетками SUDHL4 (фиг. 21В) и отсутствие связывания с исходными клетками СНО-K1, как определяется посредством анализа проточной цитометрии. Показаны процентные доли положительно окрашенных клеток или значения GMFI.
На фиг. 22A-F показано связывание обоих групп DSP107_V2 (SEQ ID NO: 13) с клетками НТ1080, сверхэкспрессирующими 4-1ВВ (фиг. 22А-В, EF), или связывание группы SIRPα с CD47 на клетках НТ1080 WT (фиг. 22C-D), как определено посредством анализа проточной цитометрии. Добавление антитела к CD47 и/или антитела к 4-1ВВ, где указано, использовали для определения специфического связывания. Показаны процентные доли положительно окрашенных клеток и значения GMFI.
На фиг. 23А-В показано одновременное связывание DSP107_V2 (SEQ ID NO: 13) с клетками СНО K1-CD47 и НТ1080-4-1ВВ. DSP107_V2 (SEQ ID NO: 13) инкубировали с CFSE-меченными клетками НТ1080 OX 4-1ВВ и меченными CytoLight Red клетками СНО-K1 OX CD47 и образование дублетов определяли с помощью проточной цитометрии. На фиг. 23А показаны репрезентативные графики проточной цитометрии CFSE по сравнению с Cyto Light Red после инкубации меченых клеток с DSP107_V2 (SEQ ID NO: 13) по сравнению с контролем среды. Фиг. 23В представляет собой график, демонстрирующий средние результаты образования дублетов из трех независимых экспериментов.
На фиг. 24 показано одновременное связывание DSP107_V2 (SEQ ID NO: 13) с клетками СНО K1-CD47 и НТ1080-4-1ВВ. DSP107_V2 (SEQ ID NO: 13) инкубировали с CFSE-меченными клетками НТ1080 OX 4-1ВВ и меченными Cyto Light Red клетками СНО-K1 OX CD47 с антителом к CD47 или антителом к 4-1ВВ или без них, и образование дублетов определяли способом проточной цитометрии. Показаны средние результаты образования дублетов из двух независимых экспериментов после вычитания эффекта среды.
На фиг. 25А-В показана активация 4-1ВВ под действием DSP107_V2 (SEQ ID NO: 13), как определено по секреции IL8 клетками НТ1018-4-1ВВ в анализе с одной культурой.
На фиг. 26 показана активация 4-1ВВ под действием DSP107_V2 (SEQ ID NO: 13), как определено по секреции IL8 из клеток НТ1018-4-1ВВ в анализе совместного культивирования.
На фиг. 27 показаны гистограммы, демонстрирующие, что DSP107_V2 (SEQ ID NO: 13) индуцирует активацию Т-клеток дозозависимым образом, как определено по экспрессии маркеров активации CD25 и 4-1ВВ. РВМС от трех доноров инкубировали с указанными концентрациями DSP107_V2 (SEQ ID NO: 13) в присутствии связанного с планшетом анти-CD3; и экспрессию CD25 или 4-1ВВ определяли через 48 часов инкубации с помощью проточной цитометрии.
На фиг. 28 показаны репрезентативные изображения, демонстрирующие влияние DSP107-V2 (SEQ ID NO: 13) на пролиферацию РВМС, как определено Incucyte.
На фиг. 29 показаны гистограммы, демонстрирующие влияние DSP107_V2 (SEQ ID NO: 13) на пролиферацию Т-клеток, окрашенных CPD, полученных от трех доноров-людей, как определено с помощью проточной цитометрии.
На фиг. 30А-С показан эффект DSP107-V2 (SEQ ID NO: 13) на опосредованное Т-клетками уничтожение раковых клеток SNU387 (фиг. 30A), SNU423 (фиг. 30В) и Ovcar8 (фиг. 30С), как определено Incucyte.
На фиг. 31А-В показано влияние DSP107-V2 (SEQ ID NO: 13) на опосредованное Т-клетками уничтожение клеток мезотелиомы MSTO (фиг. 31А) и Н2052 (фиг. 31В), как определено с помощью проточной цитометрии.
На фиг. 32А-Е показано репрезентативное изображение (фиг. 32А) и графики (фиг. 32В-Е), демонстрирующие, что DSP107_V2 (SEQ ID NO: 13) усиливает опосредованный М1-макрофагами фагоцитоз различных клеточных линий лимфомы (фиг. 32B-D) и линии клеток рака толстой кишки DLD-1 (фиг. 32Е).
На фиг. 33А-Н показан эффект DSP107_V2 (SEQ ID NO: 13) на опосредованный гранулоцитами фагоцитоз различных клеточных линий лимфомы в качестве монотерапии и в комбинации с ритуксимабом (фиг. 33A-D) по сравнению с растворимым SIRPα, растворимым 4-1BBL или комбинацией обоих (фиг. 33D-F) Фагоцитоз клеточной линии карциномы толстой кишки DLD1 гранулоцитами под действием DSP107_V2 в монотерапии и в комбинации с трастузумабом (фиг. 33G-H).
Фиг. 34 представляет связывание DSP107_V2 (SEQ ID NO: 13) с линиями клеток карциномы толстой кишки МС38 (мыши) и DLD1 (человека).
На фиг. 35А-В показан эффект in vivo DSP107_V2 (SEQ ID NO: 13) и антитела к PD-L1 мыши на рост опухолей hCD47 МС38 (фиг. 35А) и выживаемость (фиг. 35В) у мышей с нокаутом h4-1BB.
На фиг. 36А-В показан эффект in vivo DSP107_V2 (SEQ ID NO: 13) на опухоли SUDHL6 DLBCL у гуманизированных мышей NSG. На фиг. 36А показана средняя масса опухоли, определенная после умерщвления мышей на 22 день. На фиг. 36 В показан средний объем опухоли, определенный до умерщвления мышей на 20 день.
На фиг. 37А-В показана предсказанная трехмерная структура варианта слияния SIRPα-4-1BBL, содержащего SIRPα (SEQ ID NO: 2) и три повтора аминокислотной последовательности 4-1BBL (SEQ ID NO: 78), в присутствии ее партнеров по связыванию (CD47 и 4-1ВВ). Фиг. 37А представляет собой схематическую трехмерную модель, а фиг. 37В представляет собой полную атомарную трехмерную модель. SIRPα представлен в виде темно-серых лент (вверху справа). 4-1BBL представлен темно-серыми лентами (слева). Сегменты спейсера/линкера представлены серыми и белыми лентами между структурными элементами SIRPα и 4-1BBL. CD47 представлен серыми лентами (вверху справа), а три рецептора 4-1ВВ представлены серыми лентами в комплексе с 4-1BBL (слева).
На фиг. 38 показан анализ SEC-MALS DSP107-V2 (SEQ ID NO: 13). Белок (150 мкг) загружали в колонку Superdex 200 Increase (GE Healthcare) и прогоняли при скорости потока 0,8 мл/мин с 10 мМ KPO4 рН 8,0 + 150 мМ NaCl в качестве подвижной фазы. Обнаружение проводили с помощью УФ, MALS и RI с использованием AKTA Explorer (GE) + MiniDawn TREOS + OPTILAB T-reX (WYATT).
Описание подробных вариантов осуществления настоящего изобретения
Настоящее изобретение, согласно некоторым его вариантам осуществления, относится к вариантам слитого белка SIRPα-4-1BBL и способам их применения.
Прежде чем подробно объяснять по меньшей мере один вариант осуществления настоящего изобретения, следует понимать, что настоящее изобретение не обязательно ограничивается в своем применении деталями, изложенными в нижеследующем описании или проиллюстрированных примерах. Настоящее изобретение может быть реализовано в других вариантах осуществления или применяться на практике или осуществляться различными способами.
Белки двойной передачи сигналов (DSP), также известные как белки, преобразующие сигнал (SCP), которые в настоящее время известны в настоящей области техники как бифункциональные слитые белки, которые связывают внеклеточную часть мембранного белка типа I (внеклеточный амино-конец), с внеклеточной частью мембранного белка типа II (внеклеточный карбоксильный конец), образуя гибридный белок с двумя активными сторонами.
Используя структурно-функциональные инструменты, авторы настоящего изобретения смогли создать слитые белки SIRPα-4-1BBL, содержащие вариант SIRPα и/или вариант 4-1BBL с улучшенными характеристиками продукции (например, более высоким выходом); и которые могут быть успешно применены для активации иммунных клеток (посредством костимуляции) в целом и лечения заболеваний, которые могут получить пользу от активации иммунных клеток (например, рака), в частности.
Без ограничения теорией в виде примера изобретателями в качестве механизма действия слитого белка SIRPα-4-1BBL согласно некоторых вариантах осуществления настоящего изобретения при лечении рака предложено следующее:
Из-за относительно высокой экспрессии CD47 на поверхности опухолевых клеток и в микроокружении опухоли фрагмент SIRPα слияния SIRPα-4-1BBL нацеливает молекулу на участки опухоли и метастазов, что приводит к связыванию слитого белка с CD47 в микроокружении опухоли.
Нацеливание слитого белка на опухолевые клетки и/или микроокружение опухоли способствует увеличению концентрации SIRPα-4-1BBL в микроокружении опухоли и последующей иммобилизации и олигомеризации фрагмента слитого белка 4-1BBL на участке опухоли, тем самым доставляя костимуляторный сигнал 4-1ВВ, который способствует активации Т-клеток, В-клеток, NK-клеток, особенно лимфоцитов, инфильтрирующих опухоль (TIL), и других иммунных клеток в месте опухоли, чтобы убить раковые клетки.
В дополнение к костимулирующему сигналу 4-1BBL 4-1ВВ, связывание фрагмента SIRPα гибридного белка с CD47 в опухолевом сайте конкурирует с эндогенным SIRPα, экспрессируемым на макрофагах и дендритных клетках, таким образом снимая ингибирование этих клеток и дополнительно способствуя фагоцитозу опухолевых клеток и активации дендритных клеток и Т-клеток в микроокружении опухоли.
Ожидается, что указанные выше активности слитого белка SIRPα-4-1BBL приведут к синергетическому эффекту на активацию TIL, дендритных клеток и макрофагов в микроокружении опухоли, что, как ожидается, будет более специфичным и устойчивым эффектом по сравнению с влиянием каждого фрагмента в отдельности, а также при использовании двух его различных фрагментов в комбинации.
Таким образом, согласно аспекту настоящего изобретения предусмотрен слитый белок SIRPα-4-1BBL, содержащий аминокислотную последовательность SIRPα и аминокислотную последовательность 4-1BBL, причем указанная аминокислотная последовательность SIRPα составляет 100-119 аминокислот в длину, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 24 и 26, и/или причем указанная аминокислотная последовательность 4-1BBL:
(а) составляет в длину 185-202 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28, составляет в длину 170-197 аминокислот, характеризуясь идентичностью, составляющей по меньшей мере 80%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, и не содержит аминокислотный сегмент G198-Е205, соответствующий SEQ ID NO: 3, составляет в длину 170-182 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 72, и не содержит аминокислотный сегмент А1-Е23, соответствующий SEQ ID NO: 3, или составляет в длину 184 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 70; и/или
(b) содержит три повтора аминокислотной последовательности 4-1BBL; и причем указанный слитый белок способен по меньшей мере к одному из следующего:
(i) связывание CD47 и 4-1ВВ;
(ii) активация указанного сигнального пути 4-1ВВ в клетке, экспрессирующей указанный 4-1ВВ;
(iii) костимуляция иммунных клеток, экспрессирующих указанный 4-1ВВ; и/или
(iv) усиление фагоцитоза патологических клеток, экспрессирующих указанный CD47, фагоцитами по сравнению с таковым в отсутствие указанного слитого белка SIRPα-4-1BBL.
Согласно альтернативному или дополнительному аспекту настоящего изобретения предусмотрен слитый белок SIRPα-4-1BBL, содержащий аминокислотную последовательность SIRPα и аминокислотную последовательность 4-1BBL, причем указанная аминокислотная последовательность SIRPα составляет в длину 100-119 аминокислот, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, состоящей из SEQ ID NO: 24 и 26, и/или причем указанная аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28; и причем указанный слитый белок способен по меньшей мере к одному из следующего:
(i) связывание CD47 и 4-1ВВ;
(ii) активация указанного сигнального пути 4-1ВВ в клетке, экспрессирующей указанный 4-1ВВ;
(iii) костимуляция иммунных клеток, экспрессирующих указанный 4-1ВВ; и/или
(iv) усиление фагоцитоза патологических клеток, экспрессирующих указанный CD47, фагоцитами по сравнению с таковым в отсутствие указанного слитого белка SIRPα-4-1BBL.
Согласно альтернативному или дополнительному аспекту настоящего изобретения предусмотрен выделенный полипептид, содержащий аминокислотную последовательность SIRPα, причем указанная аминокислотная последовательность SIRPα составляет в длину 100-119 аминокислот, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 24 и 26; и причем указанный полипептид способен связываться с CD47.
Согласно альтернативному или дополнительному аспекту настоящего изобретения предусмотрен выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, причем указанная аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28, составляет в длину 170-197 аминокислот, характеризуясь идентичностью, составляющей по меньшей мере 80%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, и не содержит аминокислотный сегмент G198-E205, соответствующий SEQ ID NO: 3, или составляет в длину 170-182 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 72, и не содержит аминокислотный сегмент А1-Е23, соответствующий SEQ ID NO: 3; и необязательно содержит три повтора указанной аминокислотной последовательности 4-1BBL; и причем указанный полипептид способен по меньшей мере к одному из следующего:
(i) связывание 4-1ВВ,
(ii) активация указанного сигнального пути 4-1ВВ в клетке, экспрессирующей указанный 4-1ВВ; и/или
(iii) костимуляция иммунных клеток, экспрессирующих указанный 4-1ВВ.
Согласно альтернативному или дополнительному аспекту настоящего изобретения предусмотрен выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, причем указанная аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28; и причем указанный полипептид способен по меньшей мере к одному из следующего:
(i) связывание 4-1ВВ,
(ii) активация указанного сигнального пути 4-1ВВ в клетке, экспрессирующей указанный 4-1ВВ; и/или
(iii) костимуляция иммунных клеток, экспрессирующих указанный 4-1ВВ.
Используемый в настоящем документе термин «SIRPα (сигнальный регуляторный белок альфа, также известный как CD172a)» относится к полипептиду гена SIRPA (ген ID 140885) или к функциональному гомологу, например его функциональному фрагменту. Согласно конкретным вариантам осуществления термин «SIRPα» относится к функциональному гомологу полипептида SIRPα. Согласно конкретным вариантам осуществления SIRPα представляет собой SIRPα человека. Согласно конкретному варианту осуществления белок SIRPα относится к белку человека, такому как указанный в следующем номере GenBank NP_001035111, NP_001035112, NP_001317657 или NP_542970.
Используемая в настоящем документе фраза «функциональный гомолог» или «функциональный фрагмент», относящаяся к SIRPα, относится к части полипептида, которая поддерживает активность полноразмерного SIRPα, например, связывание с CD47.
Согласно конкретному варианту осуществления белок CD47 относится к белку человека, например, представленному в следующих номерах GenBank NP_001768 или NP_942088.
Анализы для исследования связывания хорошо известны в настоящей области техники и включают в себя, без ограничения, проточную цитометрию, BiaCore, биослойную интерферометрию, анализ Blitz®, ВЭЖХ.
Согласно конкретным вариантам осуществления SIRPα связывается с CD47 с Kd 0,1-100 мкМ, 0,1-10 мкМ, 1-10 мкМ, 0,1-5 мкМ или 1-2 мкМ, как определено с помощью SPR, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления SIRPα содержит внеклеточный домен указанного SIRPα или его функциональный фрагмент.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит SEQ ID NO: 29.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα состоит из SEQ ID NO: 29.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα содержит SEQ ID NO: 30.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα состоит из SEQ ID NO: 30.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит SEQ ID NO: 2.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα состоит из SEQ ID NO: 2.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα содержит SEQ ID NO: 31 или 67.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα состоит из SEQ ID NO: 31 или 67.
Термин «SIRPα» также охватывает функциональные гомологи (встречающиеся в природе или полученные синтетическим/рекомбинантным путем), которые проявляют желаемую активность (т.е. связываются с CD47). Такие гомологи могут быть, например, по меньшей мере на 70%, по меньшей мере на 75%, по меньшей мере на 80%, по меньшей мере на 81%, по меньшей мере на 82%, по меньшей мере на 83%, по меньшей мере на 84%, по меньшей мере на 85%, по меньшей мере на 86%, по меньшей мере на 87%, по меньшей мере на 88%, по меньшей мере на 89%, по меньшей мере на 90%, по меньшей мере на 91%, по меньшей мере на 92%, по меньшей мере на 93%, по меньшей мере на 94%, по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентичны или гомологичны полипептиду SEQ ID NO: 2 или 29; или по меньшей мере на 70%, по меньшей мере на 75%, по меньшей мере на 80%, по меньшей мере на 81%, по меньшей мере на 82%, по меньшей мере на 83%, по меньшей мере на 84%, по меньшей мере на 85%, по меньшей мере на 86%, по меньшей мере на 87%, по меньшей мере на 88%, по меньшей мере на 89%, по меньшей мере на 90%, по меньшей мере на 91%, по меньшей мере на 92%, по меньшей мере на 93%, по меньшей мере на 94%, по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентичны кодирующей полинуклеотидной последовательности (как дополнительно описано ниже).
Согласно конкретным вариантам осуществления функциональные гомологи SIRPα по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99 или на 100% идентичны или гомологичны полипептиду SEQ ID NO: 2 или 29; или по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентичны кодирующей полинуклеотидной последовательности (как дополнительно описано ниже).
Используемые в настоящем документе термины «идентичность» или «идентичность последовательностей» относятся к глобальной идентичности, то есть идентичности по всем раскрытым в настоящем документе аминокислотным или нуклеиновым последовательностям, а не по их частям.
Идентичность или гомологию последовательностей можно определить с использованием любого алгоритма выравнивания последовательностей белка или нуклеиновой кислоты, такого как Blast, ClustalW и MUSCLE. Гомолог может также относиться к ортологу, варианту с делецией, вставкой или заменой, включая в себя аминокислотную замену, как дополнительно описано ниже.
Согласно конкретным вариантам осуществления полипептид SIRPα может содержать консервативные и неконсервативные аминокислотные замены (также называемые в настоящем документе мутациями). Такие замены известны в настоящей области техники и раскрыты, например, в Weiskopf K et а1. Наука. (2013); 341 (6141): 88-91, содержание которых полностью включено в настоящий документ посредством ссылки.
Когда процент идентичности последовательностей используется по отношению к белкам, признается, что положения остатков, которые не идентичны, часто отличаются консервативными аминокислотными заменами, когда аминокислотные остатки заменяются другими аминокислотными остатками со сходными химическими свойствами (например, зарядом или гидрофобностью) и, следовательно, не изменяют функциональные свойства молекулы. Если последовательности различаются консервативными заменами, процент идентичности последовательностей может быть увеличен для корректировки консервативного характера замены. Последовательности, которые отличаются такими консервативными заменами, считаются имеющими «сходство последовательностей» или «сходство». Средства для выполнения этой корректировки хорошо известны специалистам в настоящей области техники. Как правило, это включает в себя оценку консервативной замены как частичного, а не полного несоответствия, тем самым увеличивая процентную идентичность последовательностей. Таким образом, например, когда идентичной аминокислоте присваивается оценка 1, а неконсервативной замене присваивается оценка ноль, консервативной замене присваивается оценка от нуля до 1. Вычисляется оценка консервативных замен, например, согласно алгоритму HenikoffS и Henikoff JG. [Amino acid substitution matrices from protein blocks. Proc. Natl. Acad. Sci. U.S.A. 1992, 89(22): 10915-9].
Согласно конкретным вариантам осуществления одна или несколько аминокислотных мутаций расположены в аминокислотном остатке, выбранном из: L4, V6, А21, А27, 131, Е47, K53, Е54, Н56, V63, L66, K68, V92 и F96, соответствующих аминокислотной последовательности SIRPα, приведенной в SEQ ID NO: 2.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит мутацию по аминокислотному остатку, выбранному из группы, состоящей из L4, А27, Е47 и V92, соответствующей аминокислотной последовательности SIRPα, приведенной в SEQ ID NO: 2.
Согласно конкретным вариантам осуществления одна или несколько аминокислотных мутаций выбраны из группы, состоящей из: L4V или L4I, V6I или V6L, A21V, A27I или A27L, I31F или I31T, E47V или E47L, K53R, E54Q, Н56Р или H56R, V63I, L66T или L66G, K68R, V92I и F94L или F94V, соответствующей аминокислотной последовательности SIRPα, приведенной в SEQ ID NO: 2.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит мутацию, выбранную из группы, состоящей из L4I, A27I, E47V и V92I, соответствующей аминокислотной последовательности SIRPα, приведенной в SEQ ID NO: 2.
Используемая в настоящем документе фраза «соответствует аминокислотной последовательности SIRPα, приведенной в SEQ ID NO: 2» или «соответствующая SEQ ID NO: 2» предназначена для включения соответствующего аминокислотного остатка относительно любой другой аминокислотной последовательности SIRPα.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит SEQ ID NO: 25.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα состоит из SEQ ID NO: 25.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα содержит SEQ ID NO: 35.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα состоит из SEQ ID NO: 35.
Дополнительное описание консервативных аминокислотных и неконсервативных аминокислотных замен представлено ниже.
SIRPα согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентичен или гомологичен полипептиду SEQ ID NO: 24 или 26; или по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентичен кодирующей полинуклеотидной последовательности (как дополнительно описано ниже).
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα по меньшей мере на 95% идентична SEQ ID NO: 24 и/или 26.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентична SEQ ID NO: 24 и/или 26, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентична SEQ ID NO: 24.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентична SEQ Ш NO: 26.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα не содержит аминокислотный сегмент K117-Y343, соответствующий SEQ ID NO: 2.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα не содержит ни одного из аминокислотных остатков К117-Y343, соответствующих SEQ ID NO: 2.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα не содержит SEQ ID NO: 32 или какой-либо ее фрагмент.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα не содержит SEQ ID NO: 32.
Согласно конкретным вариантам осуществления С-конец аминокислотной последовательности SIRPα заканчивается SEQ ID NO: 8.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит SEQ ID NO: 24 или 26.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит SEQ ID NO: 24.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит SEQ ID NO: 26.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα состоит из SEQ ID NO: 24 или 26.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα состоит из SEQ ID NO: 24.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα состоит из SEQ ID NO: 26.
Согласно конкретным вариантам осуществления, последовательность нуклеиновой кислоты SIRPα по меньшей мере на 70%, по меньшей мере на 75%, по меньшей мере на 80%, по меньшей мере на 81%, по меньшей мере на 82%, по меньшей мере на 83%, по меньшей мере на 84%, по меньшей мере на 85%, по меньшей мере на 86%, по меньшей мере на 87%, по меньшей мере на 88%, по меньшей мере на 89%, по меньшей мере на 90%, по меньшей мере на 91%, по меньшей мере на 92%, по меньшей мере на 93%, по меньшей мере на 94%, по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентична SEQ ID NO: 33 и/или 34, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα по меньшей мере на 95% идентична SEQ ID NO: 33 и/или 34.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентична SEQ ID NO: 33 и/или 34.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентична SEQ ID NO: 33.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентична SEQ ID NO: 34.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα содержит SEQ ID NO: 33 или 34.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты содержит SEQ ID NO: 33.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα содержит SEQ ID NO: 34.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα состоит из SEQ ID NO: 33 или 34.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα состоит из SEQ ID NO: 33.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты SIRPα состоит из SEQ ID NO: 34.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит 100-500 аминокислот, 150-450 аминокислот, 200-400 аминокислот, 250-400 аминокислот, 300-400 аминокислот, 320-420 аминокислот, 340-350 аминокислот, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину 300-400 аминокислот.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину 340-450 аминокислот.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину 343 аминокислоты.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит 100-200 аминокислот, 100-150 аминокислот, 100-125 аминокислот, 100-120 аминокислот, 100-119 аминокислот, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину 100-119 аминокислот.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину 105-119 аминокислот, 110-119 аминокислот, 115-119 аминокислот, 105-118 аминокислот, 110-118 аминокислот, 115-118 аминокислот, 105-117 аминокислот, 110-117 аминокислот, 115-117 аминокислот, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину по меньшей мере 115 аминокислот.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину 115-119 аминокислот.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину 116 аминокислот.
Используемый в настоящем документе термин «4-1BBL (также известный как CD137L и TNFSF9)» относится к полипептиду гена TNFSF9 (ген ID 8744) или к функциональному гомологу, например, его функциональному фрагменту. Согласно конкретным вариантам осуществления термин «4-1BBL» относится к функциональному гомологу полипептида 4-1BBL. Согласно конкретным вариантам осуществления 4-1BBL представляет собой 4-1BBL человека. Согласно конкретному варианту осуществления белок 4-1BBL относится к белку человека, например, представленному в следующем номере GenBank NP_003802.
Используемая в настоящем документе фраза «функциональный гомолог» или «функциональный фрагмент», относящаяся к 4-1BBL, относится к части полипептида, которая поддерживает активность полноразмерного 4-1BBL, например (i) связывание 4-1ВВ, (ii) активация сигнального пути 4-1ВВ, (iii) активация иммунных клеток, экспрессирующих 4-1ВВ, (iv) образование гомотримеров.
Согласно конкретным вариантам осуществления функциональный гомолог, когда он связан с 4-1BBL, способен к (i), (ii), (iii), (i) + (ii), (i) + (iii), (ii) + (iii).
Согласно конкретным вариантам осуществления функциональный гомолог, когда он связан с 4-1BBL, способен к (i) + (ii) + (iii).
Согласно конкретным вариантам осуществления функциональный гомолог, когда он связан с 4-1BBL, способен к (iv), (i) + (iv), (ii) + (iv), (iii) + (iv), (i) + (ii) + (iv), (i) + (iii) + (iv), (ii) + (iii) + (iv).
Согласно конкретным вариантам осуществления функциональный гомолог, когда он связан с 4-1BBL, способен к (i) + (ii) + (iii) + (iv).
Согласно конкретному варианту осуществления белок 4-1ВВ относится к белку человека, такому как приведенный в следующем номере GenBank NP_001552.
Анализы для исследования связывания хорошо известны в настоящей области техники и дополнительно описаны в настоящем документе выше.
Согласно конкретным вариантам осуществления 4-1BBL связывается с 4-1ВВ с Kd приблизительно 0,1-1000 нМ, 0,1-100 нМ, 1-100 нМ или 55,2 нМ, как определено SPR, каждая возможность представляет собой отдельный вариант осуществления заявленного изобретение.
Анализы для исследования тримеризации хорошо известны в настоящей области техники и включают в себя, без ограничения, NATIVE-PAGE, SEC-HPLC 2Э-гели, гель-фильтрацию, SEC-MALS, аналитическое ультрацентрифугирование (AUC), масс-спектрометрию (MS), капиллярный гель-электрофорез (CGE).
Используемые в настоящем документе термины «активирование» или «активация» относятся к процессу стимуляции иммунной клетки (например, Т-клетки, В-клетки, NK-клетки, фагоцитарной клетки), который приводит к клеточной пролиферации, созреванию, продукции цитокинов, фагоцитозу и/или индукции регуляторных или эффекторных функций.
Согласно конкретным вариантам осуществления активация включает в себя ко стимуляцию.
Используемый в настоящем документе термин «костимулирование» или «костимуляция» относится к передаче вторичного антиген-независимого стимулирующего сигнала (например, сигнала 4-1ВВ), приводящего к активации иммунной клетки.
Согласно конкретным вариантам осуществления активация включает в себя подавление ингибирующего сигнала (например, сигнала CD47), приводящего к активации иммунной клетки.
Способы определения передачи стимулирующего или ингибирующего сигнала хорошо известны в настоящей области техники и также раскрыты в разделе «Примеры», который следует ниже, и включают в себя, без ограничения, анализ связывания с использованием, например, BiaCore, ВЭЖХ или проточной цитометрии, анализы ферментативной активности, такие как анализы активности киназ, и экспрессию молекул, участвующих в сигнальном каскаде, с использованием, например, ПЦР, вестерн-блоттинга, иммунопреципитации и иммуногистохимии. Дополнительно или альтернативно определение передачи сигнала (костимулирующего или ингибирующего) может осуществляться путем оценки активации или функции иммунных клеток. Способы оценки активации или функции иммунных клеток хорошо известны в настоящей области техники и включают в себя, без ограничения, анализы пролиферации, такие как окрашивание CFSE, MTS, Alamar blue, BRDU и включение тимидина, анализы цитотоксичности, такие как окрашивание CFSE, высвобождение хрома, Calcin AM, анализы секреции цитокинов, такие как окрашивание внутриклеточных цитокинов, ELISPOT и ELISA, экспрессию маркеров активации, таких как CD25, CD69, CD137, CD107a, PD1 и CD62L, с использованием проточной цитометрии.
Согласно конкретным вариантам осуществления определение сигнальной активности или активации осуществляется in vitro или ex vivo, например в реакции смешанных лимфоцитов (MLR), как описано ниже.
Для тех же условий культивирования сигнальная активность или активация или функция иммунных клеток, как правило, выражаются по сравнению с передачей сигналов, активацией или функцией в клетке того же вида, но не контактирующей со слитым белком SIRPα-4-1BBL, кодирующим его полинуклеотидом или кодирующей его клеткой-хозяином; или контактирующей с наполнителем-контролем, также называемым контролем.
Согласно конкретным вариантам осуществления 4-1BBL содержит внеклеточный домен указанного 4-1BBL или его функциональный фрагмент.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 36.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 36.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 37.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL состоит из SEQ ID NO: 37.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 3.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 3.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 38.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL состоит из SEQ ID NO: 38.
Термин «4-1BBL» также охватывает функциональные гомологи (встречающиеся в природе или полученные синтетическим/рекомбинантным путем), которые проявляют желаемую активность (как определено выше). Такие гомологи могут быть, например, по меньшей мере на 70%, по меньшей мере на 75%, по меньшей мере на 80%, по меньшей мере на 81%, по меньшей мере на 82%, по меньшей мере на 83%, по меньшей мере на 84%, по меньшей мере на 85%, по меньшей мере на 86%, по меньшей мере на 87%, по меньшей мере на 88%, по меньшей мере на 89%, по меньшей мере на 90%, по меньшей мере на 91%, по меньшей мере на 92%, по меньшей мере на 93%, по меньшей мере на 94%, по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентичны или гомологичны полипептиду SEQ ID NO: 3, 36; или по меньшей мере на 70%, по меньшей мере на 75%, по меньшей мере на 80%, по меньшей мере на 81%, по меньшей мере на 82%, по меньшей мере на 83%, по меньшей мере на 84%, по меньшей мере на 85%, по меньшей мере на 86%, по меньшей мере на 87%, по меньшей мере на 88%, по меньшей мере на 89%, по меньшей мере на 90%, по меньшей мере на 91%, по меньшей мере на 92%, по меньшей мере на 93%, по меньшей мере на 94%, по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентичны кодирующей полинуклеотидной последовательности (как дополнительно описано ниже).
Согласно конкретным вариантам осуществления функциональные гомологи 4-1BBL по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99 или на 100% идентичны или гомологичны полипептиду SEQ ID NO: 3, 36; или по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентичны кодирующей полинуклеотидной последовательности (как дополнительно описано ниже).
Согласно конкретным вариантам осуществления полипептид 4-1BBL может содержать консервативные аминокислотные замены, как дополнительно описано выше и ниже.
4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентичен или гомологичен полипептиду SEQ ID NO: 22, 23, 27 или 28; или по меньшей мере на 95%, по меньшей мере на 96%, по меньшей мере на 97%, по меньшей мере на 98%, по меньшей мере на 99% или на 100% идентичен кодирующей полинуклеотидной последовательности (как дополнительно описано ниже).
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 22, 23, 27 и/или 28, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 22 и/или 23.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 22.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 23.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 27.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит аминокислотный сегмент A1-V6, соответствующий SEQ ID NO: 3.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит аминокислотный сегмент A1-G14, соответствующий SEQ ID NO: 3.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит никаких аминокислотных остатков A1-V6 или А1-G14, соответствующих SEQ ID NO: 3.
Используемая в настоящем документе фраза «соответствующий SEQ ID NO: 3» предполагает включение соответствующего аминокислотного остатка относительно любой другой аминокислотной последовательности 4-1BBL.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит SEQ ID NO: 6 или 7 или какой-либо их фрагмент.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит SEQ ID NO: 6 или 7.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 22, 23, 27 или 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 22 или 23.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 22.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 23.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBLα содержит SEQ ID NO: 27.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 22, 23, 27 или 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 22 или 23.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 22.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 23.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBLα состоит из SEQ ID NO: 27.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 80%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 85%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 90%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит аминокислотный сегмент G198-E205, соответствующий SEQ ID NO: 3.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит ни одного из аминокислотных остатков G198-Е205, соответствующих SEQ ID NO: 3.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит SEQ ID NO: 97 или какой-либо ее фрагмент.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит SEQ ID NO: 97.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 74 или 76.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 74 или 76.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 72.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 85%, по отношению к SEQ ID NO: 72.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 90%, по отношению к SEQ ID NO: 72.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 72.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 72.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 72.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит аминокислотный сегмент А1-Е23, соответствующий SEQ ID NO: 3.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит ни одного из аминокислотных остатков А1-Е23, соответствующих SEQ ID NO: 3.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит SEQ ID NO: 98 или какой-либо ее фрагмент.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит SEQ ID NO: 98.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 72.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 72.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 70.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 85%, по отношению к SEQ ID NO: 70.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 90%, по отношению к SEQ ID NO: 70.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 70.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 70.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 70.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 70.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 70.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 70%, по меньшей мере 75%, по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 39, 40, 41 и/или 42, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретение.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 39, 40, 41 и/или 42.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 39, 40, 41 и/или 42.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 39 и/или 40.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 39, 40, 41 или 42.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 39 или 40.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 39.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 40.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 41.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 42.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL состоит из SEQ ID NO: 39, 40, 41 или 42.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL состоит из SEQ ID NO: 39 или 40.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL состоит из SEQ ID NO: 39.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL состоит из SEQ ID NO: 40.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBLα состоит из SEQ ID NO: 41.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL состоит из SEQ ID NO: 42.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 70%, по меньшей мере 75%, по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 75 и/или 77, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 75 и/или 77.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 75 и/или 77.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 75 или 77.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL состоит из SEQ ID NO: 75 или 77.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 70%, по меньшей мере 75%, по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 73.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 73.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 73.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 73.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL состоит из SEQ ID NO: 73.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 70%, по меньшей мере 75%, по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 71.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 71.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 71.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 71.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL состоит из SEQ ID NO: 71.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит 100-300 аминокислот, 150-250 аминокислот, 100-250 аминокислот, 150-220 аминокислот, 180-220 аминокислот, 180-210 аминокислот, 185-205 аминокислот, 190-210 аминокислот, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 190-210 аминокислот.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 204 аминокислоты.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 185-200 аминокислот.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 185-199 аминокислот.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 170-197 аминокислот.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 170-182 аминокислоты.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 184 аминокислоты.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 185, 191, 197 или 199 аминокислот, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 184 аминокислоты.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 183 аминокислоты.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 182 аминокислоты.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL составляет в длину 176 аминокислот.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL, содержащаяся в слитом белке SIRPα-1BBL или полипептиде 4-1BBL, описанном в настоящем документе, содержит три повтора аминокислотной последовательности 4-1BBL.
Согласно конкретным вариантам осуществления каждый из трех повторов способен по меньшей мере к одному из следующего: (i) связывание 4-1ВВ, (ii) активация сигнального пути 4-1ВВ, (iii) активация иммунных клеток, экспрессирующих 4-1ВВ, (iv) образование гомотримера.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL не содержит линкер между каждым из трех повторов указанной аминокислотной последовательности 4-1BBL.
Согласно другим конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит линкер между каждым из трех повторов аминокислотной последовательности 4-1BBL. Любой линкер, известный в настоящей области техники, может быть использован с конкретными вариантами осуществления настоящего изобретения. Неограничивающие примеры линкеров, которые можно использовать, подробно описаны ниже.
Согласно конкретному варианту осуществления линкер представляет собой линкер (GGGGS)×2+GGGG (SEQ ID NO: 82).
Согласно конкретным вариантам осуществления повторяющаяся последовательность может быть любой из 4-1BBL, как определено в настоящем документе.
Согласно конкретным вариантам осуществления три повтора характеризуются идентичной аминокислотной последовательностью 4-1BBL.
Согласно другим конкретным вариантам осуществления эти три повтора являются разными, т.е. характеризуются разными аминокислотными последовательностями 4-1BBL.
Согласно другим конкретным вариантам осуществления два из трех повторов характеризуются идентичной аминокислотной последовательностью 4-1BBL.
Согласно конкретным вариантам осуществления по меньшей мере один из повторов содержит аминокислотную последовательность 4-1BBL, раскрытую в настоящем документе.
Согласно конкретным вариантам осуществления по меньшей мере один из повторов состоит из аминокислотной последовательности 4-1ВВЦ раскрытой в настоящем документе.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит три повтора аминокислотной последовательности, содержащей SEQ ID NO: 23.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит три повтора аминокислотной последовательности, состоящей из SEQ ID NO: 23.
Таким образом, согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 78.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 78.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 85%, по отношению к SEQ ID NO: 78.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 90%, по отношению к SEQ ID NO: 78.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 78.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 78.
Согласно конкретным вариантам осуществления аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 78.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 70%, по меньшей мере 75%, по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 79.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 79.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 79.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL содержит SEQ ID NO: 79.
Согласно конкретным вариантам осуществления последовательность нуклеиновой кислоты 4-1BBL состоит из SEQ ID NO: 79.
Термины «DSP» и «слитый белок», «химерный белок» или «химера» используются в настоящем документе взаимозаменяемо и относятся к аминокислотной последовательности, состоящей из двух или более частей, которые не встречаются вместе в одной аминокислотной последовательности в природе.
Слитый белок согласно некоторым вариантам осуществления настоящего изобретения содержит аминокислотную последовательность SIRPα и аминокислотную последовательность 4-1BBL (называемую в настоящем документе слитым белком SIRPα-4-1BBL).
Согласно конкретным вариантам осуществления SIRPα является Ν-концевым по отношению к 4-1BBL.
Согласно другим конкретным вариантам осуществления SIRPα является С-концевым по отношению к 4-1BBL.
Слитый белок SIRPα-1BBL согласно некоторым вариантам осуществления настоящего изобретения может содержать любой SIRPα, как определено в настоящем документе; и любую аминокислотную последовательность 4-1BBL:
(a) составляющую в длину 185-202 аминокислоты и характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28, составляющую в длину 170-197 аминокислот и характеризующуюся идентичностью, составляющей по меньшей мере 80%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, и не содержащую аминокислотный сегмент G198-E205, соответствующий SEQ ID NO: 3, составляющую в длину 170-182 аминокислоты и характеризующуюся идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 72 и не содержащую аминокислотный сегмент А1-Е23, соответствующий SEQ ID NO: 3, или составляющую в длину 184 аминокислоты и характеризующуюся идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 70; и/или
(b) содержащую три повтора аминокислотной последовательности 4-1BBL; например, раскрытых в настоящем документе, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения. Слитый белок SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения может включать в себя любой SIRPα, как определено в настоящем документе; и любую аминокислотную последовательность 4-1BBL, составляющую в длину 185-202 аминокислоты и характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28, таких как, например, раскрытых в настоящем документе, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Слитый белок SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения может содержать любую аминокислотную последовательность SIRPα, составляющую в длину 100-119 аминокислот и характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 24 и/или 26, например, таким как раскрыты в настоящем документе; и любой 4-1BBL, как определено в настоящем документе, каждая возможность представляет отдельный вариант осуществления настоящего изобретения.
Слитый белок SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения может содержать любую аминокислотную последовательность SIRPα, составляющую в длину 100-119 аминокислот и характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 24 и/или 26, например, таким как раскрыты в настоящем документе; и любую аминокислотную последовательность 4-1BBL:
(a) составляющую в длину 185-202 аминокислоты и характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28, составляющую в длину 170-197 аминокислот, характеризующуюся идентичностью, составляющей по меньшей мере 80%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, и не содержащую аминокислотный сегмент G198-E205, соответствующий SEQ ID NO: 3, составляющую в длину 170-182 аминокислоты, характеризующуюся идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 72 и не содержащую аминокислотный сегмент А1-Е23, соответствующий SEQ ID NO: 3, или составляющую в длину 184 аминокислоты, характеризующуюся идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 70; и/или
(b) содержащую три повтора аминокислотной последовательности 4-1BBL; например, раскрытые в настоящем документе, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Слитый белок SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения может содержать любую аминокислотную последовательность SIRPα, составляющую в длину 100-119 аминокислот и характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 24 и/или 26, например, такими как раскрыто в настоящем документе; и любую аминокислотную последовательность 4-1BBL, составляющую в длину 185-202 аминокислоты и характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28, таких как, например, раскрытые в настоящем документе, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα характеризуется идентичностью, составляющей по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 2, 24-26 и/или 29; и аминокислотная последовательность 4-1BBL:
(а) составляет в длину 185-202 аминокислоты и характеризуется идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к аминокислотной последовательности, выбранной из группы состоящей из SEQ ID NO: 22, 23, 27 и 28, составляет в длину 170-197 аминокислот, характеризуется идентичностью, составляющей по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 74 и 76, и не содержит аминокислотный сегмент G198-E205, соответствующий SEQ ID NO: 3, составляет в длину 170-182 аминокислоты, характеризуется идентичностью, составляющей по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 72, и не содержит аминокислотный сегмент А1-Е23, соответствующий SEQ ID NO: 3, или составляет в длину 184 аминокислоты, характеризуется идентичностью, составляющей по меньшей мере 80%, по отношению к SEQ ID NO: 70; и/или
(b) содержит три повтора аминокислотной последовательности 4-1BBL; каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит SEQ ID NO: 2, 24-26 или 29; и аминокислотная последовательность 4-1BBL:
(a) составляет в длину 185-202 аминокислоты, включая в себя SEQ ID NO: 22, 23, 27 и 28, составляет в длину 170-197 аминокислот, включая в себя SEQ ID NO: 74 и 76, составляет в длину 170-182 аминокислоты, включая в себя SEQ ID NO: 72, или составляет в длину 184 аминокислоты, включая в себя SEQ ID NO: 70; и/или
(b) содержит три повтора аминокислотной последовательности 4-1BBL; каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα представляет собой такую, как приведена в SEQ ID NO: 2, 24-26 или 29; а аминокислотная последовательность 4-1BBL представляет собой такую, как приведена в SEQ ID NO: 22, 23, 27, 28, 74, 76, 72 или 70, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα характеризуется идентичностью, составляющей по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 2, 24-26 и/или 29; и аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты и характеризуется идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 22, 23, 27 и/или 28, каждая возможность представляет отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит SEQ ID NO: 2, 24-26 или 29; и аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты и содержит SEQ ID NO: 22, 23, 27 или 28, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα представляет собой такую, как приведена в SEQ ID NO: 2, 24-26 или 29; а аминокислотная последовательность 4-1BBL представляет собой такую, как приведена в SEQ ID NO: 22, 23, 27 или 28, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα характеризуется идентичностью, составляющей по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 2 или 25; и аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 22, 23, 27 и/или 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит SEQ ID NO: 2 или 25; и аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты и содержит SEQ ID NO: 22, 23, 27 или 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα представляет собой такую, как приведена в SEQ ID NO: 2 или 25, а аминокислотная последовательность 4-1BBL представляет собой такую, как приведена в SEQ ID NO: 22, 23, 27 или 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPa характеризуется идентичностью, составляющей по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере, 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 2; и аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 22 или 23.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα содержит SEQ ID NO: 2; а аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты и содержит SEQ ID NO: 22 или 23.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα представляет собой такую, как приведена в SEQ ID NO: 2, а аминокислотная последовательность 4-1BBL представляет собой такую, как приведена в SEQ ID NO: 22 или 23.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину 100-119 аминокислот, характеризуясь идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 24 и/или 26; и аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 3, 22, 23, 27, 28 и/или 36, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину от 100 до 119 аминокислот, включая в себя SEQ ID NO: 24 и/или 26; и аминокислотная последовательность 4-1BBL включает в себя SEQ ID NO: 3, 22, 23, 27, 28 и/или 36, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα представляет собой такую, как приведена в SEQ ID NO: 24 и/или 26; и аминокислотная последовательность 4-1BBL представляет собой такую, как приведена в SEQ ID NO: 3, 22, 23, 27, 28 и/или 36.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину 100-119 аминокислот, характеризуясь идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 24 или 26; и аминокислотная последовательность 4-1BBL характеризуется идентичностью, составляющей по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 3, 22, 23, 27 или 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину от 100 до 119 аминокислот, включая в себя SEQ ID NO: 24 и/или 26; и аминокислотная последовательность 4-1BBL включает в себя SEQ ID NO: 3, 22, 23, 27 или 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα представляет собой такую, как приведена в SEQ ID NO: 24 или 26, а аминокислотная последовательность 4-1BBL представляет собой такую, как приведена в SEQ ID NO: 3, 22, 23, 27 или 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет 100-119 аминокислот в длину, характеризуясь идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 24 и/или 26; и аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты и характеризуется идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 22, 23, 27 и/или 28, каждая возможность представляет отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину от 100 до 119 аминокислот, включая в себя SEQ ID NO: 24 и/или 26; и аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты, включая в себя SEQ ID NO: 22, 23, 27 и/или 28, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα представляет собой такую, как приведена в SEQ ID NO: 24 и/или 26; и аминокислотная последовательность 4-1BBL представляет собой такую, как приведена в SEQ ID NO: 22, 23, 27 и/или 28.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину 100-119 аминокислот, характеризуясь идентичностью, составляющей по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 24; и аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты, характеризуясь идентичностью, составляющей по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100%, по отношению к SEQ ID NO: 22.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα составляет в длину от 100 до 119 аминокислот, включая в себя SEQ ID NO: 24; и аминокислотная последовательность 4-1BBL составляет в длину 185-202 аминокислоты, включая в себя SEQ ID NO: 22.
Согласно конкретным вариантам осуществления аминокислотная последовательность SIRPα представляет собой такую, как приведена в SEQ ID NO: 24, а аминокислотная последовательность 4-1BBL представляет собой такую, как приведена в SEQ ID NO: 22.
Неограничивающие примеры конкретных комбинаций аминокислотной последовательности SIRPα и аминокислотной последовательности 4-1BBL, которые могут использоваться с конкретными вариантами осуществления настоящего изобретения, представлены в таблице 4 раздела Примеры, который следует ниже, который служит неотъемлемой частью описания.
Согласно конкретным вариантам осуществления выделенный полипептид, содержащий аминокислотную последовательность SIRPα, или выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, является растворимым (т.е. не иммобилизованным на синтетической или встречающейся в природе поверхности).
Согласно конкретным вариантам осуществления, выделенный полипептид, содержащий аминокислотную последовательность SIRPα, или выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, иммобилизован на синтетической или встречающейся в природе поверхности.
Согласно конкретным вариантам осуществления слитый белок SIRPα-4-1BBL является растворимым (т.е. не иммобилизован на синтетической или встречающейся в природе поверхности).
Согласно конкретным вариантам осуществления слитый белок SIRPα-4-1BBL иммобилизован на синтетической или встречающейся в природе поверхности.
Согласно конкретным вариантам осуществления слитый белок SIRPα-4-1BBL находится в форме по меньшей мере гомотримера.
Согласно конкретным вариантам осуществления по меньшей мере 10%, по меньшей мере 20%, по меньшей мере 30%, по меньшей мере 40%, по меньшей мере 50%, по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95% слитого белка SIRPα-4-1BBL находится в форме по меньшей мере гомотримера, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления по меньшей мере гомотример включает в себя гомотример.
Согласно конкретным вариантам осуществления по меньшей мере гомотример включает в себя гомотетрамер.
Согласно конкретным вариантам осуществления по меньшей мере гомотример включает в себя гомопентамер.
Согласно конкретным вариантам осуществления по меньшей мере гомотример включает в себя гомогексамер.
Способы определения тримеризации хорошо известны в настоящей области техники и включают в себя, без ограничения, NATIVE-PAGE, SEC-HPLC, 20-гели, гель-фильтрацию, SEC MALS, аналитическое ультрацентрифугирование (AUC), масс-спектрометрию (MS), капиллярный гель-электрофорез (CGE).
Согласно конкретным вариантам осуществления по меньшей мере гомотример составляет по меньшей мере 100 кДа, по меньшей мере 140 кДа, по меньшей мере 160 кДа, по меньшей мере 180 кДа, по меньшей мере 200 кДа, по меньшей мере 220 кДа, по меньшей мере 240 кДа, по меньшей мере 250 кДа по молекулярной массе, определенной с помощью SEC MALS.
Согласно конкретным вариантам осуществления по меньшей мере гомотример характеризуется молекулярной массой по меньшей мере 100 кДа, как определено с помощью SEC MALS.
Согласно конкретным вариантам осуществления по меньшей мере гомотример характеризуется молекулярной массой по меньшей мере 240 кДа, как определено с помощью SEC MALS.
Согласно конкретным вариантам осуществления по меньшей мере гомотример характеризуется молекулярной массой приблизительно 250-270 кДа, как определено с помощью SEC MALS.
Согласно конкретным вариантам осуществления SIRPα-4-1BBL не содержит линкер между SIRPα и 4-1BBL.
Согласно конкретным вариантам осуществления слитый белок SIRPα-4-1BBL содержит линкер между указанным SIRPα и указанным 4-1BBL.
Любой линкер, известный в настоящей области техники, может быть использован с конкретными вариантами осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления линкер может быть получен из природных многодоменных белков или представлять собой эмпирический линкер, как описано, например, в Chichili et al., (2013), Protein Sci. 22 (2): 153-167, Chen et al., (2013), Adv Drug Deliv Rev. 65 (10): 1357-1369, полное содержание которых включено в настоящий документ посредством ссылки. Согласно некоторым вариантам осуществления линкер может быть сконструирован с использованием баз данных для создания линкеров и компьютерных программ, таких как те, что описаны в Chen et al., (2013), Adv Drug Deliv Rev. 65 (10): 1357-1369 и Crasto et al (2000), Protein Eng. 13 (5): 309-312, полное содержание которых включено в настоящий документ посредством ссылки.
Согласно конкретным вариантам осуществления линкер представляет собой синтетический линкер, такой как ПЭГ.
Согласно конкретным вариантам осуществления линкер представляет собой домен Fc или шарнирную область антитела (например, IgG, IgA, IgD или IgE) или его фрагмент.
Согласно другим конкретным вариантам осуществления линкер не представляет собой домен Fc или шарнирную область антитела или его фрагмента.
Согласно конкретным вариантам осуществления линкер представляет собой домен Fc или шарнирную область IgG4 человека.
Согласно конкретным вариантам осуществления линкер домена Fc содержит SEQ ID NO: 95.
Согласно конкретным вариантам осуществления линкер представляет собой домен Fc или шарнирную область IgG1 человека.
Согласно конкретным вариантам осуществления линкер домена Fc содержит SEQ ID NO: 96.
Согласно конкретным вариантам осуществления домен Fc или линкер шарнирной области может содержать консервативные и неконсервативные аминокислотные замены (также называемые в настоящем документе мутации). Такие замены известны в настоящей области техники. Согласно конкретным вариантам осуществления линкер может быть функциональным. Например, без ограничения, линкер может функционировать для улучшения сворачивания и/или стабильности, улучшения экспрессии, улучшения фармакокинетики и/или повышения биоактивности слитого белка SIRPα-4-1BBL. В другом примере линкер может функционировать для нацеливания слитого белка SIRPα-4-1BBL на конкретный тип или местоположение клеток.
Согласно конкретным вариантам осуществления линкер представляет собой полипептид.
Неограничивающие примеры полипептидных линкеров включают в себя линкеры, имеющие последовательность LE, GGGGS (SEQ ID NO: 85), (GGGGS)n (n=1-4) (SEQ ID NO: 84), GGGGSGGGG (SEQ ID NO: 83), (GGGGS)x2 (SEQ ID NO: 86), (GGGGS)x2+GGGG (SEQ ID NO: 82), (Gly)8 (Gly)6, (EAAAK)n (n=1-3) (SEQ ID NO: 87), A(EAAAK)nA (n=2-5) (SEQ ID NO: 88), AEAAAKEAAAKA (SEQ ID NO: 89), A(EAAAK)4ALEA(EAAAK)4A (SEQ ID NO: 90), PAPAP (SEQ ID NO: 91), K ESGSVSS EQ LAQ FRS LD (SEQ ID NO: 92), EGKSSGSGSESKST (SEQ ID NO: 93), GS AGS A AGS GEF (SEQ ID NO: 94) и (XP)n, с X, обозначающим любую аминокислоту, например, Ala, Lys или Glu.
Согласно конкретным вариантам осуществления линкер выбран из группы, состоящей из GGGGS (SEQ ID NO: 85), (GGGGS)n (n=1-4) (SEQ ID NO: 84), GGGGSGGGG (SEQ ID NO: 83), (GGGGS)x2 (SEQ ID NO: 86), (GGGGS)x2+GGGG (SEQ ID NO: 82).
Согласно конкретным вариантам осуществления линкер представляет собой линкер (GGGGS)n(n=1-4) (SEQ ID NO: 84).
Согласно конкретным вариантам осуществления линкер представляет собой линкер GGGGSx2 (SEQ ID NO: 86).
Согласно конкретным вариантам осуществления линкер представляет собой линкер GGGGSGGGG (SEQ ID NO: 83).
Согласно конкретным вариантам осуществления линкер представляет собой линкер (GGGGS)x2+GGGG (SEQ ID NO: 82).
Согласно некоторым вариантам осуществления SIRPα-4-1BBL содержит линкер длиной от одной до шести аминокислот.
Согласно конкретным вариантам осуществления линкер по существу состоит из остатков глицина и/или серина (например, приблизительно 30% или приблизительно 40%, или приблизительно 50%, или приблизительно 60%, или приблизительно 70%, или приблизительно 80%, или приблизительно 90%, или приблизительно 95%, или приблизительно 97%, или 100% глицинов и серинов).
Согласно конкретным вариантам осуществления линкер представляет собой линкер из одной аминокислоты.
Согласно некоторым вариантам осуществления настоящего изобретения аминокислота, которая связывает SIRPα и 4-1BBL, представляет собой глицин, также называемый в настоящем документе слитым белком SIRPα-G-4-1BBL.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13, 15, 16, 18-21 и 45-49, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13, 15, 16 и 18-21 и 45-49, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13, 15, 16 и 18-21.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13, 15, 16 и 18-21.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13 и 16.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 11.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 13.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL характеризуется идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 16.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, характеризующуюся идентичностью, составляющей по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99%, по отношению к аминокислотной последовательности, выбранной из группа, состоящей из SEQ ID NO: 11, 13 и 16.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 11, 13, 15, 16, 18-21 и 45-49, каждая возможность представляет отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 11, 13, 15, 16 и 18-21.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 11, 13 и 16.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит SEQ ID NO: 11.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит SEQ ID NO: 13.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит SEQ ID NO: 16.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL состоит из аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13, 15, 16, 18-21 и 45-49, каждая возможность представляет отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL состоит из аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13, 15, 16 и 18-21.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL состоит из аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13 и 16.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL состоит из SEQ ID NO: 11.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL состоит из SEQ ID NO: 13.
Согласно конкретным вариантам осуществления аминокислотная последовательность слитого белка SIRPα-4-1BBL состоит из SEQ ID NO: 16.
Согласно конкретным вариантам осуществления слитый белок SIRPα-4-1BBL составляет 200-900 аминокислот, 200-800 аминокислот, 200-700 аминокислот, 250-650 аминокислот, 250-600 аминокислот, 250-550 аминокислот в длину, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретному варианту осуществления слитый белок SIRPα-4-1BBL составляет в длину 270-750 аминокислот.
Согласно конкретному варианту осуществления слитый белок SIRPα-4-1BBL составляет в длину 290-750 аминокислот.
Согласно конкретному варианту осуществления слитый белок SIRPα-4-1BBL составляет в длину 290-550 аминокислот.
Согласно конкретному варианту осуществления слитый белок SIRPα-4-1BBL составляет в длину 297-543 аминокислоты.
Согласно конкретному варианту осуществления слитый белок SIRPα-4-1BBL составляет в длину 296-542 аминокислоты.
Неограничивающие примеры конкретных слитых белков SIRPα-4-1BBL, которые могут использоваться с конкретными вариантами осуществления настоящего изобретения, представлены в таблице 4 раздела «Примеры», который следует ниже, который служит неотъемлемой частью описания.
Согласно конкретным вариантам осуществления выход продукции слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем выход продукции слитого белка SIRPα-4-1BBL, содержащего аминокислотную последовательность SIRPα, приведенную в SEQ ID NO: 2, и аминокислотную последовательность 4-1BBL, приведенную в SEQ ID NO: 3, при тех же условиях продукции, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления выход продукции слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза выше, чем выход продукции слитого белка SIRPα-4-1BBL, содержащего аминокислотную последовательность SIRPα, приведенную в SEQ ID NO: 2, и аминокислотную последовательность 4-1BBL, приведенную в SEQ ID NO: 3, при тех же условиях продукции.
Согласно конкретным вариантам осуществления выход продукции слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 2 раза выше, чем выход продукции слитого белка SIRPα-4-1BBL, содержащего аминокислотную последовательность SIRPα, приведенную в SEQ ID NO: 2, и аминокислотную последовательность 4-1BBL, приведенную в SEQ ID NO: 3, при тех же условиях продукции.
Согласно конкретным вариантам осуществления выход продукции слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем выход продукции SEQ ID NO: 5, при тех же условиях продукции, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления выход продукции слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза выше, чем выход продукции SEQ ID NO: 5 при тех же условиях продукции.
Согласно конкретным вариантам осуществления выход продукции слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 2 раза выше, чем выход продукции SEQ ID NO: 5 при тех же условиях продукции.
Согласно конкретным вариантам осуществления выход продукции выделенного полипептида, содержащего аминокислотную последовательность SIRPα, согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем выход продукции SEQ ID NO: 2, при тех же условиях продукции каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления выход продукции выделенного полипептида, содержащего аминокислотную последовательность 4-1BBL, согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем выход продукции SEQ ID NO: 3, при тех же условиях продукции каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления количество агрегатов слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере на 20%, по меньшей мере на 30%, по меньшей мере на 40%, по меньшей мере на 50%, по меньшей мере на 60%, по меньшей мере на 70%, по меньшей мере на 80%, по меньшей мере на 90% или по меньшей мере на 95% ниже, чем количество агрегатов слитого белка SIRPα-4-1BBL, содержащих аминокислотную последовательность SIRPα, приведенную в SEQ ID NO: 2, и аминокислотную последовательность 4-1BBL, приведенную в SEQ ID NO: 3, при тех же условиях продукции каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления количество агрегатов слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере на 20%, по меньшей мере на 30%, по меньшей мере на 40%, по меньшей мере на 50%, по меньшей мере на 60%, по меньшей мере на 70%, по меньшей мере на 80%, по меньшей мере на 90% или по меньшей мере на 95% ниже, чем количество агрегатов SEQ ID NO: 5, при тех же условиях продукции каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления количество агрегатов слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере на 20% ниже, чем количество агрегатов с SEQ ID NO: 5, при тех же условиях продукции каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления количество агрегатов слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере на 50% ниже, чем количество агрегатов с SEQ ID NO: 5, при тех же условиях продукции каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления активность слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем активность слитого белка SIRPα-4-1BBL, содержащего аминокислотную последовательность SIRPα, приведенную в SEQ ID NO: 2, и аминокислотную последовательность 4-1BBL, приведенную в SEQ ID NO: 3, например, при тех же условиях продукции каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления активность слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем активность SEQ ID NO: 5, например, при тех же условиях продукции каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления активность выделенного полипептида, содержащего аминокислотную последовательность SIRPα, согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем активность SEQ ID NO: 2, например, при тех же условиях продукции каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления активность выделенного полипептида, содержащего аминокислотную последовательность 4-1BBL, согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем активность SEQ ID NO: 3, например, при тех же условиях продукции каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления стабильность слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем стабильность слитого белка SIRPα-4-1BBL, содержащего аминокислотную последовательность SIRPα, приведенную в SEQ ID NO: 2, и аминокислотную последовательность 4-1BBL, приведенную в SEQ ID NO: 3, при тех же условиях продукции каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления стабильность слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем стабильность SEQ ID NO: 5 при тех же условиях продукции, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления стабильность выделенного полипептида, содержащего аминокислотную последовательность SIRPα, согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем стабильность SEQ ID NO: 2 при тех же условиях продукции, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления стабильность выделенного полипептида, содержащего аминокислотную последовательность 4-1BBL, согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем стабильность SEQ ID NO: 3 при тех же условиях продукции, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления безопасность слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем безопасность слитого белка SIRPα-4-1BBL, содержащего аминокислотную последовательность SIRPα, приведенную в SEQ ID NO: 2, и аминокислотную последовательность 4-1BBL, приведенную в SEQ ID NO: 3, при тех же условиях продукции, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления безопасность слитого белка SIRPα-4-1BBL согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем безопасность SEQ ID NO: 5 при тех же условиях продукции, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления безопасность выделенного полипептида, содержащего аминокислотную последовательность SIRPα, согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем безопасность SEQ ID NO: 2, при тех же условиях продукции, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления безопасность выделенного полипептида, содержащего аминокислотную последовательность 4-1BBL, согласно некоторым вариантам осуществления настоящего изобретения по меньшей мере в 1,5 раза, по меньшей мере в 2 раза, по меньшей мере в 2,5 раза, по меньшей мере в 3 раза, по меньшей мере в 5 раз выше, чем безопасность SEQ ID NO: 3 при тех же условиях продукции, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения. Согласно конкретным вариантам осуществления условия продукции предусматривают экспрессию в клетке млекопитающего и культивирование при температуре 32-37°С, 5-10% СО2 в течение 5-13 дней.
Неограничивающие примеры условий продукции, которые могут использоваться с конкретными вариантами осуществления настоящего изобретения, раскрыты в разделе «Примеры», который следует ниже.
Таким образом, например, вектор экспрессии, кодирующий слитый белок, выделенный полипептид, содержащий аминокислотную последовательность SIRPα, или выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, включая в себя искусственный сигнальный пептид (например, SEQ ID NO: 4) на Ν-конце и His-метку и стоп-кодон на С-конце экспрессируются в клетках млекопитающих, таких как клетки Expi293F или ExpiCHO. Затем трансдуцированные клетки культивируют при температуре 32-37°С 5-10% СО2 в клеточно-специфической культуральной среде в соответствии с инструкциями производителя клеток Expi293F или ExpiCHO (Thermo), и после по меньшей мере 5 дней культивирования белки собирают из супернатанта и очищают.
Согласно конкретным вариантам осуществления культуру используют в серийном, разделенном на части, подпитываемом режиме или в режиме перфузии.
Согласно конкретным вариантам осуществления культуру используют в условиях периодической подпитки.
Согласно конкретным вариантам осуществления культивирование проводят при температуре 37°С.
Согласно конкретным вариантам осуществления культивирование проводят при температуре 37°С со сдвигом срока до 32°С. Этот временной сдвиг может быть произведен для замедления клеточного метаболизма до достижения стационарной фазы.
Согласно конкретным вариантам осуществления выделенный полипептид, содержащий аминокислотную последовательность SIRPα, способен связываться с CD47.
Согласно конкретным вариантам осуществления выделенный полипептид, содержащий аминокислотную последовательность SIRPα, способен усиливать фагоцитоз патологических клеток, экспрессирующих CD47, фагоцитами по сравнению с таковым в отсутствие выделенного полипептида, содержащего аминокислотную последовательность SIRPα.
Согласно конкретным вариантам осуществления выделенный полипептид, содержащий аминокислотную последовательность SIRPα по некоторым вариантам осуществления настоящего изобретения, характеризуется повышенной активностью, как раскрыто в настоящем документе, по сравнению с SEQ ID NO: 2.
Согласно конкретным вариантам осуществления выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, способен по меньшей мере к одному из следующего:
(i) связывание 4-1ВВ,
(ii) активация указанного сигнального пути 4-1ВВ в клетке, экспрессирующей указанный 4-1ВВ; и/или
(iii) костимуляция иммунных клеток, экспрессирующих указанный 4-1ВВ.
Согласно конкретным вариантам осуществления выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL по некоторым вариантам осуществления настоящего изобретения, характеризуется повышенной активностью, как раскрыто в настоящем документе, по сравнению с SEQ ID NO: 3.
Согласно конкретным вариантам осуществления выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL способен к (i), (ii), (iii), (i)+(ii), (i)+(iii), (ii)+(iii), (i)+(ii)+(iii).
Согласно конкретным вариантам осуществления слитый белок SIRPα-4-1BBL способен по меньшей мере к одному из следующего:
(i) связывание CD47 и 4-1ВВ,
(ii) активация сигнального пути 4-1ВВ в иммунной клетке (например, Т-клетке), экспрессирующей 4-1ВВ;
(iii) активация иммунных клеток (например, Т-клеток), экспрессирующих указанный 4-1ВВ; и/или
(iv) усиление фагоцитоза патологических клеток, экспрессирующих CD47, фагоцитами по сравнению с таковым в отсутствие слитого белка SIRPα-4-1BBL.
Согласно конкретным вариантам осуществления слитый белок SIRPα-4-1BBL по некоторым вариантам осуществления настоящего изобретения характеризуется повышенной активностью, как раскрыто в настоящем документе, по сравнению со слитым белком, содержащим аминокислотную последовательность SIRPα, приведенную в SEQ ID NO: 2 и 4, и аминокислотную последовательность 4-1BBL, приведенную в SEQ ID NO: 3.
Согласно конкретным вариантам осуществления слитый белок SIRPα-4-1BBL по некоторым вариантам осуществления настоящего изобретения характеризуется повышенной активностью, как раскрыто в настоящем документе, по сравнению с SEQ ID NO: 5.
Согласно конкретным вариантам осуществления слитый белок SIRPα-4-1BBL способен к (i), (ii), (iii), (iv), (i)+(ii), (i)+(iii), (i)+(iv), (ii)+(iii), (ii)+(iv), (i)+(ii)+(iii), (i)+(ii)+(iv), (ii)+(iii)+(iv).
Согласно конкретным вариантам осуществления слитый белок SIRPα-4-1BBL способен к (i)+(ii)+(iii)+(iv).
Способы определения связывания, активации сигнального пути 4-1ВВ и активации иммунных клеток хорошо известны в настоящей области техники и дополнительно описаны в настоящем документе выше и ниже, а также в разделе «Примеры», который следует ниже.
Согласно конкретным вариантам осуществления слитый белок SIRPα-4-1BBL или выделенный полипептид, содержащий аминокислотную последовательность SIRPα, усиливает фагоцитоз патологических клеток, экспрессирующих CD47, фагоцитами.
Способы анализа фагоцитоза хорошо известны в настоящей области техники и также раскрыты в эксперименте 4 в разделе «Примеры», который следует ниже; и включают в себя, например, киллинг-анализы, проточную цитометрию и/или микроскопическую оценку (визуализация живых клеток, флуоресцентная микроскопия, конфокальная микроскопия, электронная микроскопия).
Согласно конкретным вариантам осуществления, усиление фагоцитоза составляет по меньшей мере 1,5-кратное, по меньшей мере 2-кратное, по меньшей мере 3-кратное, по меньшей мере 5-кратное, по меньшей мере 10-кратное или по меньшей мере 20-кратное по сравнению с фагоцитозом в отсутствие слитого белка SIRPα-4-1BBL или выделенного полипептида, содержащего аминокислотную последовательность SIRPα, кодирующего его полинуклеотида или конструкции нуклеиновой кислоты или экспрессирующей его клетки-хозяина по настоящему изобретению, как определено, например, посредством проточной цитометрии или микроскопической оценки.
Согласно другим конкретным вариантам осуществления увеличение выживаемости по меньшей мере на 5%, по меньшей мере на 10%, по меньшей мере на 20%, по меньшей мере на 30%, по меньшей мере на 40%, по меньшей мере на 50%, по меньшей мере на 60%, по меньшей мере на 70%, по меньшей мере на 80%, по меньшей мере на 90%, по меньшей мере на 95% или по меньшей мере на 100% выше, по сравнению с выживаемостью в отсутствие слитого белка SIRPα-4-1BBL или выделенного полипептида, содержащего аминокислотную последовательность SIRPα, кодирующего его полинуклеотида или конструкции нуклеиновой кислоты или экспрессирующей его клетки-хозяина по настоящему изобретению, как определено, например, посредством проточной цитометрии или микроскопической оценки.
Поскольку композиции по некоторым вариантам осуществления настоящего изобретения (например, слитый белок, выделенный полипептид, содержащий аминокислотную последовательность SIRPα, выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, кодирующий их полинуклеотид или нуклеиновая кислота или экспрессирующая их клетка-хозяин) способны активировать иммунные клетки, их можно использовать в способах активации иммунных клеток, in vitro, ex vivo и/или in vivo.
Таким образом, в соответствии с аспектом настоящего изобретения предусмотрен способ активации иммунных клеток, предусматривающий активацию иммунных клеток in vitro или ex vivo в присутствии слитого белка SIRPα-4-1BBL, выделенного полипептида, содержащего аминокислотную последовательность SIRPα, и/или выделенного полипептида, содержащего аминокислотную последовательность 4-1BBL, раскрытые в настоящем документе, кодирующего их полинуклеотида, кодирующей их конструкции нуклеиновой кислоты или экспрессирующей их клетки-хозяина.
В соответствии с другим аспектом настоящего изобретения предусмотрен способ активации Т-клеток, предусматривающий активацию Т-клеток in vitro или ex-vivo в присутствии слитого белка SIRPα-4-1BBL, описанного в настоящем документе, и клеток, экспрессирующих CD47.
В соответствии с другим аспектом настоящего изобретения предусмотрен способ активации фагоцитов, причем способ предусматривает активацию фагоцитов in vitro или ex vivo в присутствии слитого белка SIRPα-4-1BBL и/или выделенного полипептида, содержащего аминокислотную последовательность SIRPα, раскрытую в настоящем документе, и клеток, экспрессирующих CD47.
Согласно конкретным вариантам осуществления активация происходит в присутствии слитого белка SIRPα-4-1BBL, кодирующего его полинуклеотида, кодирующей его конструкции нуклеиновой кислоты или экспрессирующей его клетки-хозяина.
Согласно конкретным вариантам осуществления активация происходит в присутствии выделенного полипептида, содержащего аминокислотную последовательность SIRPα, кодирующего ее полинуклеотида, кодирующей ее конструкции нуклеиновой кислоты или экспрессирующей ее клетки-хозяина.
Согласно конкретным вариантам осуществления активация происходит в присутствии выделенного полипептида, содержащего аминокислотную последовательность 4-1BBL, кодирующего ее полинуклеотида, кодирующей ее конструкции нуклеиновой кислоты или экспрессирующей ее клетки-хозяина.
Согласно конкретным вариантам осуществления активация происходит в присутствии выделенного полипептида, содержащего аминокислотную последовательность SIRPα, кодирующего ее полинуклеотида, кодирующей ее конструкции нуклеиновой кислоты или экспрессирующей ее клетки-хозяина; и аминокислотную последовательность 4-1BBL, кодирующего ее полинуклеотида, кодирующей ее конструкции нуклеиновой кислоты или экспрессирующей ее клетки-хозяина.
Согласно конкретным вариантам осуществления иммунные клетки экспрессируют 4-1ВВ.
Согласно конкретным вариантам осуществления иммунные клетки включают в себя периферические мононуклеарные клетки крови (РВМС).
Используемый в настоящем документе термин «периферические мононуклеарные клетки крови (РВМС)» относится к клетке крови, содержащей одно ядро, и включает в себя лимфоциты, моноциты и дендритные клетки (DC).
Согласно конкретным вариантам осуществления РВМС выбраны из группы, состоящей из дендритных клеток (DC), Т-клеток, В-клеток, ΝΚ-клеток и ΝΚΤ-клеток.
Согласно конкретным вариантам осуществления РВМС включают в себя Т-клетки, В-клетки, ΝΚ-клетки и ΝΚΤ-клетки.
Способы получения РВМС хорошо известны в настоящей области техники, такие как забор цельной крови у субъекта и сбор в контейнер, содержащий антикоагулянт (например, гепарин или цитрат); и аферез. Далее, согласно конкретным вариантам осуществления по меньшей мере один тип РВМС очищается из периферической крови. Существует несколько способов и реагентов, известных специалистам в настоящей области техники для очистки РВМС из цельной крови, таких как лейкаферез, седиментация, центрифугирование в градиенте плотности (например, фиколл), элютриационное центрифугирование, фракционирование, химический лизис, например, эритроцитов (например, с помощью ACK), отбор конкретных типов клеток с использованием маркеров клеточной поверхности (с использованием, например, сортировщика FACS или способов магнитного разделения клеток, которые коммерчески доступны, например, от Invitrogen, Stemcell Technologies, Cellpro, Advanced Magnetics или Miltenyi Biotec) и истощение определенных типов клеток такими способами, как эрадикация (например, уничтожение) специфическими антителами или очистка на основе аффинности, основанная на отрицательной селекции (с использованием, например, способов магнитного разделения клеток, сортировщика FACS и/или мечения ELISA с захватом). Такие способы описаны, например, в THE HANDBOOK OF EXPERIMENTAL IMMUNOLOGY, Volumes 1 to 4, (D.N. Weir, editor) и FLOW CYTOMETRY AND CELL SORTING (A. Radbruch, editor, Springer Verlag, 2000).
Согласно конкретным вариантам осуществления иммунные клетки содержат инфильтрирующие опухоль лимфоциты.
Используемый в настоящем документе термин «инфильтрирующие опухоль лимфоциты (TIL)» относится к мононуклеарным лейкоцитам, которые не попали в кровоток и мигрировали в опухоль.
Согласно конкретным вариантам осуществления TIL выбраны из группы, состоящей из Т-клеток, В-клеток, ΝΚ-клеток и моноцитов.
Способы получения TIL хорошо известны в настоящей области техники, такие как получение образцов опухоли от субъекта, например, биопсия или аутопсия, и приготовление их суспензии отдельных клеток. Суспензию отдельных клеток можно получить любым подходящим способом, например, механически (дезагрегация опухоли с использованием, например, диссоциатора gentle MAC S(TM), Miltenyi Biotec, Auburn, CA) или ферментативно (например, коллагеназа или ДНКаза). После этого по меньшей мере один тип TIL может быть очищен из клеточной суспензии. Существует несколько способов и реагентов, известных специалистам в настоящей области техники, для очистки TIL желаемого типа, таких как отбор определенных типов клеток с использованием маркеров клеточной поверхности (с использованием, например, сортировщика FACS или способов магнитного разделения клеток, которые коммерчески доступны, например, от mvitrogen, Stemcell Technologies, Cellpro, Advanced Magnetics или Miltenyi Biotec), а также истощение определенных типов клеток такими способами, как эрадикация (например, уничтожение) специфическими антителами или очистка на основе аффинности на основе отрицательной селекции (с использованием, например, способов магнитного разделения клеток, FACS-сортировщик и/или захват ELISA-мечения). Такие способы описаны, например, в THE HANDBOOK OF EXPERIMENTAL IMMUNOLOGY, Volumes 1 to 4, (D.N. Weir, editor) и FLOW CYTOMETRY AND CELL SORTING (A. Radbruch, editor, Springer Verlag, 2000).
Согласно конкретным вариантам осуществления иммунные клетки содержат фагоциты.
Используемый в настоящем документе термин «фагоциты» относится к клетке, которая способна к фагоцитозу, и включает в себя как профессиональные, так и непрофессиональные фагоциты. Способы анализа фагоцитоза хорошо известны в настоящей области техники и дополнительно раскрыты в настоящем документе выше и ниже. Согласно конкретным вариантам осуществления фагоцитарные клетки выбирают из группы, состоящей из моноцитов, дендритных клеток (DC) и гранулоцитов.
Согласно конкретным вариантам осуществления фагоциты включают в себя гранулоциты.
Согласно конкретным вариантам осуществления фагоциты включают в себя моноциты.
Согласно конкретным вариантам осуществления иммунные клетки включают в себя моноциты.
Согласно конкретным вариантам осуществления термин «моноциты» относится как к циркулирующим моноцитам, так и к макрофагам (также называемым мононуклеарными фагоцитами), присутствующим в ткани.
Согласно конкретным вариантам осуществления моноциты включают в себя макрофаги. Как правило, фенотип макрофагов на клеточной поверхности включает в себя CD14, CD40, CD11b, CD64, F4/80 (Mbinm)/EMR1 (человек), лизоцим М, МАС-1/МАС-3 и CD68.
Согласно конкретным вариантам осуществления моноциты включают в себя циркулирующие моноциты. Как правило, фенотипы клеточной поверхности циркулирующих моноцитов включают в себя CD14 и CD16 (например, CD14++CD16-, CD14+CD16++, CD14++CD16+).
Согласно конкретным вариантам осуществления иммунные клетки включают в себя DC.
Используемый в настоящем документе термин «дендритные клетки (DC)» относится к любому представителю разнообразной популяции морфологически сходных типов клеток, обнаруживаемых в лимфоидных или нелимфоидных тканях. DC представляют собой класс профессиональных антигенпрезентирующих клеток и обладают высокой способностью сенсибилизировать HLA-рестриктированные Т-клетки. DC включают в себя, например, плазмацитоидные дендритные клетки, миелоидные дендритные клетки (включая в себя незрелые и зрелые дендритные клетки), клетки Лангерганса, интердигитальные клетки, фолликулярные дендритные клетки. Дендритные клетки можно распознать по функции или по фенотипу, особенно по фенотипу клеточной поверхности. Эти клетки характеризуются своей отличительной морфологией, имеющей вуалеподобные выступы на поверхности клетки, средним или высоким уровнем поверхностной экспрессии HLA-класса II и способностью презентировать антиген Т-клеткам, особенно наивным Т-клеткам (смотрите Steinman R, et al., Ann. Rev. Immunol. 1991; 9:271-196). Как правило, фенотип DC на клеточной поверхности включает в себя CDla+, CD4+, CD86+ или HLA-DR. Термин DC охватывает как незрелые, так и зрелые DC.
Согласно конкретным вариантам осуществления иммунные клетки включают в себя гранулоциты.
Используемый в настоящем документе термин «гранулоциты» относится к полиморфноядерным лейкоцитам, характеризующимся наличием гранул в их цитоплазме.
Согласно конкретным вариантам осуществления гранулоциты включают в себя нейтрофилы.
Согласно конкретным вариантам осуществления гранулоциты включают в себя тучные клетки.
Согласно конкретным вариантам осуществления иммунные клетки включают в себя Т-клетки.
Используемый в настоящем документе термин «Т-клетки» относится к дифференцированному лимфоциту с CD3+, рецептором Т-клеток (TCR)+, имеющим фенотип CD4+ или CD8+. Т-клетка может представлять собой эффекторную или регуляторную Т-клетку.
Используемый в настоящем документе термин «эффекторные Т-клетки» относится к Т-клетке, которая активирует или направляет другие иммунные клетки, например, производя цитокины, или обладает цитотоксической активностью, например, цитотоксический Т-лимфоцит CD4+, Th1/Th2, CD8+.
Используемый в настоящем документе термин «регуляторная Т-клетка» или «Treg» относится к Т-клетке, которая негативно регулирует активацию других Т-клеток, включая в себя эффекторные Т-клетки, а также клетки врожденной иммунной системы. Для Treg-клеток характерно устойчивое подавление ответов эффекторных Т-клеток. Согласно конкретному варианту осуществления Treg представляет собой CD4+CD25+Foxp3+ Т-клетку.
Согласно конкретным вариантам осуществления Т-клетки представляют собой CD4+Т-клетки.
Согласно другим конкретным вариантам осуществления Т-клетки представляют собой CD8+ Т-клетки.
Согласно конкретным вариантам осуществления Т-клетки представляют собой Т-клетки памяти. Неограничивающие примеры Т-клеток памяти включают в себя CD4+ Т-клетки эффекторной памяти с фенотипом CD3+/CD4+/CD45RA-/CCR7-, центральные CD4+ Т-клетки памяти с фенотипом CD3+/CD4+/CD45RA-/CCR7+, CD8+ Т-клетки эффекторной памяти с фенотипом CD3+/CD8+CD45RA-/CCR7- и центральные CD8+ Т-клетки памяти с фенотипом CD3+/CD8+CD45RA-/CCR7+.
Согласно конкретным вариантам осуществления Т-клетки включают в себя сконструированные Т-клетки, трансдуцированные последовательностью нуклеиновой кислоты, кодирующей представляющий интерес продукт экспрессии.
Согласно конкретным вариантам осуществления представляющий интерес продукт экспрессии представляет собой рецептор Т-клеток (TCR) или рецептор химерного антигена (CAR).
Используемая в настоящем документе фраза «трансдуцированная последовательностью нуклеиновой кислоты, кодирующей TCR» или «трансдукция последовательностью нуклеиновой кислоты, кодирующей TCR» относится к клонированию вариабельных α- и β-цепей из Т-клеток со специфичностью против желаемого антигена, представленного в контекст МНС. Способы трансдукции с помощью TCR известны в настоящей области техники и раскрыты, например, в Nicholson et al. Adv Hematol. 2012; 2012:404081; Wang and  Cancer Gene Ther. 2015 Mar; 22(2):85-94) и Lamers et al, Cancer Gene Therapy (2002) 9, 613-623.
Cancer Gene Ther. 2015 Mar; 22(2):85-94) и Lamers et al, Cancer Gene Therapy (2002) 9, 613-623.
Используемая в настоящем документе фраза «трансдуцированная последовательностью нуклеиновой кислоты, кодирующей CAR» или «трансдукция последовательностью нуклеиновой кислоты, кодирующей CAR» относится к клонированию последовательности нуклеиновой кислоты, кодирующей химерный антигенный рецептор (CAR), причем CAR включает в себя фрагмент распознавания антигена и фрагмент активации Т-клеток. Химерный антигенный рецептор (CAR) представляет собой искусственно созданный гибридный белок или полипептид, содержащий антигенсвязывающий домен антитела (например, вариабельный фрагмент одной цепи (scFv)), связанный с доменами передачи сигналов Т-клеток или активации Т-клеток. Способы трансдукции с помощью CAR известны в настоящей области техники и раскрыты, например, в Davila et al. Oncoimmunology. 2012 Dec 1; 1(9): 1577-1583; Wang and Cancer Gene Ther. 2015 Mar; 22(2):85-94); Maus etal. Blood. 2014 Apr 24; 123(17):2625-35; Porter DL The New England journal of medicine. 2011, 365(8):725-733; Jackson HJ, Nat Rev Clin Oncol. 2016; 13(6):370-383 и Globerson-Levin et al. Mol Ther. 2014; 22(5): 1029-1038.
Согласно конкретным вариантам осуществления иммунные клетки включают в себя В-клетки.
Используемый в настоящем документе термин «В-клетки» относится к лимфоциту с фенотипом В-клеточного рецептора (BCR)+, CD 19+ и/или В220+. В-клетки характеризуются своей способностью связывать определенный антиген и вызывать гуморальный ответ.
Согласно конкретным вариантам осуществления иммунные клетки включают в себя NK-клетки.
Используемый в настоящем документе термин «ΝΚ-клетки» относится к дифференцированным лимфоцитам с фенотипом CD16+ CD56+ и/или CD57+ TCR-. NK характеризуются своей способностью связываться с клетками, которые не могут экспрессировать «собственные» антигены MHC/HLA, и убивать их путем активации специфических цитолитических ферментов, способностью убивать опухолевые клетки или другие патологические клетки, которые экспрессируют лиганд для активирующих NK рецепторов, и способностью высвобождать белковые молекулы, называемые цитокинами, которые стимулируют или ингибируют иммунный ответ.
Согласно конкретным вариантам осуществления иммунные клетки включают в себя NKT-клетки.
Используемый в настоящем документе термин «ΝΚΤ-клетки» относится к специализированной популяции Т-клеток, которые экспрессируют полуинвариантный αβ-Т-клеточный рецептор, но также экспрессируют множество молекулярных маркеров, которые обычно связаны с ΝΚ-клетками, такие как ΝΚ1.1. ΝΚΤ-клетки включают в себя ΝΚ1.1+ и ΝΚ1.1-, а также клетки CD4+, CD4-, CD8+ и CD8-. TCR на ΝΚΤ-клетках уникален тем, что он распознает гликолипидные антигены, представленные МНС I-подобной молекулой CD1d. ΝΚΤ-клетки могут оказывать защитное или вредное действие из-за их способности производить цитокины, которые способствуют воспалению или иммунной толерантности.
Согласно конкретным вариантам осуществления иммунные клетки получают от здорового субъекта.
Согласно конкретным вариантам осуществления иммунные клетки получают от субъекта, страдающего патологией (например, раком).
Согласно конкретным вариантам осуществления активация происходит в присутствии клеток, экспрессирующих CD47 или экзогенный CD47.
Согласно конкретным вариантам осуществления активация происходит в присутствии экзогенного CD47.
Согласно конкретным вариантам осуществления экзогенный CD47 растворим.
Согласно другим конкретным вариантам осуществления экзогенный CD47 иммобилизован на твердой подложке.
Согласно конкретным вариантам осуществления активация происходит в присутствии клеток, экспрессирующих CD47.
Согласно конкретным вариантам осуществления клетки, экспрессирующие CD47, включают в себя патологические (больные) клетки.
Согласно конкретным вариантам осуществления клетки, экспрессирующие CD47, включают в себя раковые клетки.
Согласно конкретным вариантам осуществления активация происходит в присутствии стимулирующего средства, способного по меньшей мере передавать первичный активирующий сигнал [например, лигирование Т-клеточного рецептора (TCR) с основным комплексом гистосовместимости (МНС)/пептидным комплексом на антигенпрезентирующей клетке (АРС)], что приводит к пролиферации, созреванию, продукции цитокинов, фагоцитозу и/или индукции регуляторных или эффекторных функций иммунной клетки. Согласно конкретным вариантам осуществления стимулирующее средство также может передавать вторичный костимуляторный сигнал.
Способы определения количества стимулирующего средства и соотношения между стимулирующим средством и иммунными клетками находятся в пределах возможностей специалиста в настоящей области техники и поэтому в настоящем документе не указаны.
Стимулирующее средство может активировать иммунные клетки антиген-зависимым или -независимым (то есть поликлональным) способом.
Согласно конкретным вариантам осуществления стимулирующее средство включает в себя антиген-неспецифический стимулятор.
Неспецифические стимуляторы известны специалистам в настоящей области техники. Таким образом, в качестве неограничивающего примера, когда иммунные клетки содержат Т-клетки, антиген-неспецифический стимулятор может представлять собой средство, способное связываться с поверхностной структурой Т-клетки и индуцировать поликлональную стимуляцию Т-клетки, например, без ограничения: к антителу к CD3 в комбинации с костимулирующим белком, таким как антитело к CD28. Другие неограничивающие примеры включают в себя анти-CD2, анти-CD137, анти-CD134, Notch-лиганды, например Delta-подобный 1/4, Jaggedl/2 либо отдельно, либо в различных комбинациях с анти-CD3. Другие средства, которые могут индуцировать поликлональную стимуляцию Т-клеток, включают в себя, без ограничения, митогены, РНА, РМА-иономицин, СЕВ и CytoStim (Miltenyi Biotech). Согласно конкретным вариантам осуществления, антиген-неспецифический стимулятор включает в себя антитела к CD3 и CD28. Согласно конкретным вариантам осуществления стимулятор Т-клеток включает в себя шарики, покрытые анти-CD3 и анти-CD28, такие как шарики MACSiBeads CD3CD28, полученные от Miltenyi Biotec.
Согласно конкретным вариантам осуществления стимулирующее средство включает в себя антиген-специфический стимулятор.
Неограничивающие примеры антигенспецифических стимуляторов Т-клеток включают в себя загруженную антигеном антигенпрезентирующую клетку [АРС, например, дендритную клетку] и загруженный пептидом рекомбинантный МНС. Таким образом, например, стимулятор Т-клеток может представлять собой дендритную клетку, предварительно загруженную желаемым антигеном (например, опухолевым антигеном) или трансфицированную мРНК, кодирующей желаемый антиген.
Согласно конкретным вариантам осуществления антиген представляет собой злокачественный антиген.
Используемый в настоящем документе термин «злокачественный антиген» относится к антигену, сверхэкспрессируемому или экспрессируемому исключительно злокачественной клеткой по сравнению с незлокачественной клеткой. Злокачественный антиген может представлять собой известный злокачественный антиген или новый специфический антиген, который развивается в злокачественной клетке (т.е. неоантигены).
Неограничивающие примеры известных злокачественных антигенов включают в себя MAGE-AI, MAGE-A2, MAGE-A3, MAGE-A4, MAGE-AS, MAGE-A6, MAGE-A7, Μ AGE-AS, MAGE-A9, MAGE-A10, Μ AGE-A11, MAGE-A12, GAGE-I, GAGE-2, GAGE-3, GAGE-4, GAGE-5, GAGE-6, GAGE-7, GAGE-8, BAGE-1, RAGE-1, LB33/MUM-1, PRAME, NAG, MAGE-Xp2 (MAGE-B2), MAGE-Хр3 (MAGE-B3), MAGE-Xp4 (MAGE-B4), MAGE-С1/СТ7, MAGE-C2, NY-ESO-1, LAGE-1, SSX-1, SSX-2(HOM-MEL-40), SSX-3, SSX-4, SSX-5, SCP-1 и XAGE, меланоцитарные дифференцировочные антигены, p53, ras, СЕ A, MUCI, PMSA, PSA, тирозиназу, Melan-A, MART-I, gp100, gp75, альфаактинин-4, слитый белок Bcr-Abl, Casp-8, бета-катенин, cdc27, cdk.4, cdkn2a, coa-l, слитый белок dek-can, EF2, слитый белок ETV6-AML1, слитый белок LDLR-фукозилтрансферазА8, HLA-A2, HLA-A11, hsp70-2, KIAA0205, Mart2, Mum-2 и 3, neo-РАР, миозин класса I, OS-9, слитый белок pml-RAR альфа, PTPRK, K-ras, N-ras, триозофосфатизомеразу, GnTV, Herv-K-mel, NA-88, SP17 и TRP2-Int2, (MART-I), E2A-PRL, H4-RET, IGH-IGK, MYL-RAR, антигены вируса Эпштейна-Барра, EBNA, антигены E6 и Е7 вируса папилломы человека (HPV), TSP-180, MAGE-4, MAGE-5, MAGE-6, P185erbB2, plSOerbB-3, c-met, nm-23Hl, PSA, TAG-72-4, CA 19-9, CA 72-4, CAM 17.1, NuMa, K-ras, альфа-фетопротеин, 13HCG, BCA225, BTAA, CA 125, CA 15-3 (CA 27.29\BCAA), CA 195, CA 242, CA-50, CAM43, CD68YKP1, C0-029, FGF-5, 0250, Ga733 (EpCAM), HTgp-175, M344, MA-50, MG7-Ag, MOV 18, NB\170K, NYCO-I, RCASI, SDCCAG16, TA-90 (связывающий Mac-2 белок\связанный с циклофилином С белок), TAAL6, TAG72, TLP, TPS, белки, связанные с тирозиназой, TRP-1 или TRP-2.
Другие опухолевые антигены, которые могут экспрессироваться, хорошо известны в настоящей области техники (смотрите, например, W000/20581; Cancer Vaccines and Immunotherapy (2000) Eds Stern, Beverley and Carroll, Cambridge University Press, Cambridge). Последовательности этих опухолевых антигенов легко доступны в общедоступных базах данных, но их также можно найти в публикациях международных заявок WO 1992/020356 AI, WO 1994/005304 AI, WO 1994/023031 AI, WO 1995/020974 AI, WO 1995/023874 AI и WO 1996/026214 AI.
Альтернативно или дополнительно опухолевый антиген может быть идентифицирован с использованием злокачественных клеток, полученных от субъекта, например, посредством биопсии.
Таким образом, согласно конкретным вариантам осуществления стимулирующее средство включает в себя злокачественную клетку.
Согласно конкретным вариантам осуществления активация происходит в присутствии противоракового средства.
Согласно конкретным вариантам осуществления иммунные клетки очищаются после активации.
Таким образом, настоящее изобретение также рассматривает выделенные иммунные клетки, которые можно получить способами по настоящему изобретению.
Согласно конкретными вариантами осуществления иммунные клетки, используемые и/или полученные в соответствии с настоящим изобретением, могут быть свежевыделены, храниться, например, криоконсервированными (т.е. замороженными), например, при температуре жидкого азота на любой стадии в течение длительных периодов времени (например, месяцев, лет) для будущего применения; и клеточные линии.
Способы криоконсервации широко известны среднему специалисту в настоящей области техники и раскрыты, например, в публикациях международных патентных заявок № WO 2007054160 и WO 2001039594 и публикации патентной заявки США № US 20120149108.
Согласно конкретным вариантам осуществления клетки, полученные согласно настоящему изобретению, могут храниться в клеточном банке, депозитарии или хранилище.
Следовательно, настоящие идеи дополнительно предлагают применение выделенных иммунных клеток и способов по настоящему изобретению в качестве, без ограничения, источника для адоптивной терапии иммунными клетками заболеваний, которые могут получить пользу от активации иммунных клеток, например, гиперпролиферативное заболевание; заболевание, связанное с подавлением иммунитета и инфекциями.
Таким образом, согласно конкретным вариантам осуществления, способ настоящего изобретения предусматривает адоптивный перенос иммунных клеток после указанной активации нуждающемуся в этом субъекту.
Согласно конкретным вариантам осуществления предусмотрены иммунные клетки, полученные способами настоящего изобретения для применения в адоптивной клеточной терапии.
Клетки, используемые в соответствии с конкретными вариантами осуществления настоящего изобретения, могут быть аутологичными или неаутологичными; они могут быть сингенными или несингенными: аллогенными или ксеногенными по отношению к субъекту; каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Настоящие идеи также предполагают применение композиций по настоящему изобретению (например, слитый белок, выделенный полипептид, содержащий аминокислотную последовательность SIRPα, выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, кодирующий их полинуклеотид или конструкция нуклеиновой кислоты или экспрессирующая их клетка-хозяин) в способах лечения заболевания, при которых может быть полезна активация иммунных клеток.
Таким образом, в соответствии с другим аспектом настоящего изобретения предусмотрен способ лечения заболевания, которое может получить пользу от активации иммунных клеток, предусматривающий введение нуждающемуся в этом субъекту слитого белка SIRPα-4-1BBL, выделенного полипептида, содержащего аминокислотную последовательность SIRPα, и/или выделенного полипептида, содержащего аминокислотную последовательность 4-1BBL, описанные в настоящем документе, кодирующего их полинуклеотида или конструкции нуклеиновой кислоты или кодирующей их клетки-хозяина.
Согласно другому аспекту настоящего изобретения предусмотрен слитый белок SIRPα-4-1BBL, выделенный полипептид, содержащий аминокислотную последовательность SIRPα, и/или выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, описанные в настоящем документе, кодирующий их полинуклеотид или конструкция нуклеиновой кислоты или кодирующая их клетка-хозяин, для применения при лечении заболевания, которое может получить пользу от активации иммунных клеток.
Согласно конкретным вариантам осуществления лечение проводят слитым белком SIRPα-4-1BBL, кодирующим его полинуклеотидом, кодирующей его конструкцией нуклеиновой кислоты или экспрессирующей его клеткой-хозяином.
Согласно конкретным вариантам осуществления лечение проводят выделенным полипептидом, содержащим аминокислотную последовательность SIRPα, кодирующим его полинуклеотидом, кодирующей его конструкцией нуклеиновой кислоты или экспрессирующей его клеткой-хозяином.
Согласно конкретным вариантам осуществления лечение проводят выделенным полипептидом, содержащим аминокислотную последовательность 4-1BBL, кодирующим его полинуклеотидом, кодирующей его конструкцией нуклеиновой кислоты или экспрессирующей его клеткой-хозяином.
Согласно конкретным вариантам осуществления лечение проводят с помощью аминокислотной последовательности SIRPα, кодирующего ее полинуклеотида, кодирующей ее конструкции нуклеиновой кислоты или экспрессирующей ее клетки-хозяина, и аминокислотной последовательности 4-1BBL, кодирующего ее полинуклеотида, кодирующей ее конструкции нуклеиновой кислоты или экспрессирующей ее клетки-хозяина.
Термин «лечение» относится к ингибированию, предотвращению или остановке развития патологии (заболевания, нарушения или медицинского состояния) и/или к уменьшению, ремиссии или регрессу патологии или симптома патологии. Специалисты в настоящей области техники поймут, что для оценки развития патологии можно использовать различные методологии и анализы, и аналогичным образом можно использовать различные методологии и анализы для оценки уменьшения, ремиссии или регресса патологии.
Используемый в настоящем документе термин «субъект» включает в себя млекопитающих, например, людей любого возраста и пола. Согласно конкретным вариантам осуществления термин «субъект» относится к субъекту, который страдает патологией (заболеванием, нарушением или медицинским состоянием). Согласно конкретным вариантам осуществления этот термин охватывает людей, которые подвержены риску развития патологии.
Согласно конкретным вариантам осуществления субъект страдает заболеванием, связанным с клетками, экспрессирующими CD47.
Согласно конкретным вариантам осуществления патологические клетки субъекта экспрессируют CD47.
Используемая в настоящем документе фраза «заболевание, при котором может быть улучшена активация иммунных клеток» относится к заболеваниям, при которых активность иммунного ответа субъекта может быть достаточной, чтобы по меньшей мере облегчить симптомы заболевания или отсрочить появление симптомов, однако по любой причине активность иммунного ответа субъекта при этом менее чем оптимальна.
Неограничивающие примеры заболеваний, которые могут получить пользу от активации иммунных клеток, включают в себя гиперпролиферативные заболевания, заболевания, связанные с иммуносупрессией, вызванной лекарственными средствами иммуносупрессией (например, ингибиторами mTOR, ингибитором кальциневрина, стероидами) и инфекциями.
Согласно конкретным вариантам осуществления заболевание включает в себя гиперпролиферативное заболевание.
Согласно конкретным вариантам осуществления гиперпролиферативное заболевание включает в себя склероз или фиброз, идиопатический фиброз легких, псориаз, системный склероз/склеродермию, первичный билиарный холангит, первичный склерозирующий холангит, фиброз печени, профилактику индуцированного излучением фиброза легких, миелофиброз или ретроперитонеальный фиброз.
Согласно другим конкретным вариантам осуществления гиперпролиферативное заболевание включает в себя рак.
Таким образом, согласно другому аспекту настоящего изобретения предусмотрен способ лечения рака, предусматривающий введение слитого белка SIRPα-4-1BBL, выделенного полипептида, содержащего аминокислотную последовательность SIRPα, и/или выделенного полипептида, содержащего аминокислотную последовательность 4-1BBL, раскрытые в настоящем документе, нуждающемуся в этом субъекту.
Используемый в настоящем документе термин «рак» включает в себя как злокачественные, так и предраковые опухоли.
Что касается предзлокачественных или доброкачественных форм рака, необязательно их композиции и способы могут применяться для остановки прогрессирования предзлокачественного рака до злокачественной формы.
Рак, который можно лечить способами некоторых вариантов осуществления настоящего изобретения, может представлять собой любой солидный или несолидный рак и/или метастазы рака.
Согласно конкретным вариантам осуществления рак включает в себя злокачественный рак.
Примеры рака включают в себя, без ограничения, карциному, лимфому, бластому, саркому и лейкоз. Более конкретные примеры таких видов рака включают в себя плоскоклеточный рак, рак легкого (включая в себя мелкоклеточный рак легкого, немелкоклеточный рак легкого, аденокарциному легкого и плоскоклеточный рак легкого), рак брюшины, гепатоцеллюлярный рак, рак желудка (включая в себя рак желудочно-кишечного тракта), рак поджелудочной железы, глиобластому, рак шейки матки, рак яичников, рак печени, рак мочевого пузыря, гепатому, рак молочной железы, рак толстой кишки, колоректальный рак, карциному эндометрия или матки, карциному слюнной железы, почечный рак или рак почки, рак печени, рак простаты, рак вульвы, рак щитовидной железы, карциному печени и различные типы рака головы и шеи, а также В-клеточную лимфому (включая в себя низкой степени дифференцировки/фолликулярную неходжкинскую лимфому (NHL); лимфому Беркитта, диффузную В-крупноклеточную лимфому (DLBCL), мелкоклеточную лимфоцитарную (SL) NHL; фолликулярную NHL средней степени дифференцировки; диффузную NHL средней степени дифференцировки; иммунобластную NHL высокой степени дифференцировки; лимфобластную NHL высокой степени дифференцировки; мелко клеточную NHL с нерассеченными ядрами высокой степени дифференцировки; NHL с массивными поражениями лимфатических узлов; лимфому из клеток мантийной зоны; лимфому, связанную со СПИДом; и макроглобулине мию Вальденстрема); Т-клеточную лимфому, лимфому Ходжкина, хронический лимфоцитарный лейкоз (CLL); острый лимфобластный лейкоз (ALL); острый миелоидный лейкоз (AML), острый промиелоцитарный лейкоз (APL), лейкоз ворсистых клеток; хронический миелобластный лейкоз (CML) и посттрансплантационное лимфопролиферативное расстройство (PTLD), а также аномальную пролиферацию сосудов, связанную с факоматозами, отеком (например, связанным с опухолями головного мозга) и синдромом Мейгса. Предпочтительно рак выбран из группы, состоящей из рака молочной железы, колоректального рака, рака прямой кишки, немелкоклеточного рака легкого, неходжкинской лимфомы (NHL), почечно-клеточного рака, рака простаты, рака печени, рака поджелудочной железы, саркомы мягких тканей, саркомы Капоши, карциноидной карциномы, рака головы и шеи, меланомы, рака яичников, мезотелиомы и множественной миеломы. Раковые состояния, поддающиеся лечению по настоящему изобретению, включают в себя метастатический рак.
Согласно конкретным вариантам осуществления рак включает в себя предзлокачественный рак.
Предзлокачественный рак (или предраковые заболевания) хорошо охарактеризован и известен в настоящей области техники (смотрите, например, Berman JJ. and Henson DE., 2003. Classifying the precancers: a metadata approach. BMC Med Inform Decis Mak. 3:8). Классы предзлокачественных раков, поддающихся лечению с помощью способа по настоящему изобретению, включают в себя приобретенные мелкие или микроскопические предзлокачестве иные опухоли, приобретенные большие поражения с ядерной атипией, предшествующие поражения, возникающие с наследственными гиперпластическими синдромами, которые прогрессируют до рака, и приобретенные диффузные гиперплазии и диффузные метаплазии. Примеры малых или микроскопических предзлокачественных опухолей включают в себя HGSIL (высокая степень плоскоклеточного интраэпителиального поражения шейки матки), AIN (анальная интраэпителиальная неоплазия), дисплазия голосовых связок, аберрантные крипты (толстой кишки), ΡΓΝ (интраэпителиальная неоплазия предстательной железы). Примеры приобретенных крупных поражений с ядерной атипией включают в себя канальцевую аденому, AILD (ангиоиммунобластную лимфаденопатию с диспротеинемией), атипичную менингиому, полип желудка, парапсориаз с крупными бляшками, миелодисплазию, папиллярную переходно-клеточную карциному in-situ, рефрактерную анемию с избытком бластов и Шнейдериановую папиллому. Примеры предшественников поражений, происходящих с наследственными гиперпластическими синдромами, которые прогрессируют до рака, включают в себя синдром атипичных родинок, аденоматоз С-клеток и МЕА. Примеры приобретенной диффузной гиперплазии и диффузной метаплазии включают в себя СПИД, атипичную лимфоидную гиперплазию, костную болезнь Педжета, посттрансплантационное лимфопролиферативное заболевание и язвенный колит.
Согласно конкретным вариантам осуществления рак представляет собой лейкоз, хронический миеломоноцитарный лейкоз (CMML), хронический миелогенный лейкоз (CML), острый миелоидный лейкоз (AML), неходжкинскую лимфому (NHL), диффузную В-крупноклеточную лимфому (DLBCL), В-клеточный хронический лимфолейкоз (B-CLL), лимфому из клеток мантийной зоны (MCL), фолликулярную лимфому (FL), лимфому маргинальной зоны (MZL), острый лимфобластный лейкоз Pre-B (pre-B ALL), лейомиосаркому, рак яичников, рак молочной железы, рак толстой кишки, рак мочевого пузыря, глиобластому, гепатоцеллюлярную карциному, рак предстательной железы, острый лимфобластный лейкоз (ALL), множественную миелому, немелкоклеточную карциному легких (NSCLC), колоректальный рак, меланому, рак головы и шеи, В-клеточную лимфому маргинальной зоны, протоковую аденокарциному поджелудочной железы или рак головного мозга.
Согласно некоторым вариантам осуществления рак представляет собой острый миелоидный лейкоз, рак мочевого пузыря, рак молочной железы хронический лимфоцитарный лейкоз, хронический миелогенный лейкоз, колоректальный рак, диффузную крупноклеточную В-клеточную лимфому, эпителиальный рак яичников, эпителиальную опухоль, рак фаллопиевых труб, фолликулярную лимфому, мультиформную глиобластому, гепатоцеллюлярную карциному, рак головы и шеи, лейкоз, лимфому, лимфому из клеток мантийной зоны, меланому, мезотелиому, множественную миелому, рак носоглотки, неходжкинскую лимфому, немелкоклеточную карциному легких, рак яичников, рак предстательной железы или почечно-клеточную карциному.
Согласно конкретным вариантам осуществления рак выбран из группы, состоящей из лимфомы, лейкоза и карциномы.
Согласно конкретным вариантам осуществления рак выбран из группы, состоящей из лимфомы, лейкоза, рака толстой кишки, рака поджелудочной железы, рака яичников, рака легких и плоскоклеточной карциномы.
Согласно конкретным вариантам осуществления рак представляет собой карциному толстой кишки.
Согласно конкретным вариантам осуществления рак представляет собой карциному яичника.
Согласно конкретным вариантам осуществления рак представляет собой карциному легкого.
Согласно конкретным вариантам осуществления рак представляет собой карциному головы и шеи.
Согласно конкретным вариантам осуществления рак представляет собой лейкоз. Согласно конкретным вариантам осуществления лейкоз выбран из группы, состоящей из острого нелимфоцитарного лейкоза, хронического лимфоцитарного лейкоза, острого гранулоцитарного лейкоза, хронического гранулоцитарного лейкоза, острого промиелоцитарного лейкоза, Т-клеточного лейкоза взрослых, алейкемического лейкоза, лейкемического лейкоза, базофильного лейкоза, недифференцируемого лейкоза, лейкоза крупного рогатого скота, хронического миелоцитарного лейкоза, поражения кожи при лейкозе, эмбрионального лейкоза, эозинофильного лейкоза, лейкоза Росса, лейкоза ворсистых клеток, гемобластного лейкоза, гемоцитобластного лейкоза, гистиоцитарного лейкоза, лейкоза стволовых клеток, острого моноцитарного лейкоза, лейкопенического лейкоза, лимфатического лейкоза, лимфобластного лейкоза, лимфоцитарного лейкоза, лимфогенного лейкоза, лимфоидного лейкоза, лимфосаркома-клеточного лейкоза, тучноклеточного лейкоза, мегакариоцитарного лейкоза, микромиелобластного лейкоза, моноцитарного лейкоза, миелобластного лейкоза, миелоцитарного лейкоза, миелолейкоза, миеломоноцитарного лейкоза, лейкоза Нэгели, лейкоза плазматических клеток, плазмоцитарного лейкоза, промиелоцитарного лейкоза, лейкоза из клеток Ридера, лейкоза Шиллинга, лейкоза стволовых клеток, сублейкозного лейкоза и лейкоза недифференцированных клеток.
Согласно конкретным вариантам осуществления лейкоз представляет собой промиелоцитарный лейкоз, острый миелоидный лейкоз или хронический миелогенный лейкоз.
Согласно конкретным вариантам осуществления рак представляет собой лимфому.
Согласно конкретным вариантам осуществления лимфома представляет собой В-клеточную лимфому.
Согласно конкретным вариантам осуществления лимфома представляет собой Т-клеточную лимфому.
Согласно другим конкретным вариантам осуществления лимфома представляет собой лимфому Ходжкина.
Согласно конкретным вариантам осуществления лимфома не представляет собой лимфому Ходжкина.
Согласно конкретным вариантам осуществления неходжкинская лимфома выбрана из группы, состоящей из агрессивной NHL, трансформированной NHL, вялотекущей NHL, рецидивирующей NHL, рефрактерной NHL, неходжкинской лимфомы низкой степени дифференцировки, фолликулярной лимфомы, крупноклеточной лимфомы, В-клеточной лимфомы, Т-клеточной лимфомы, лимфомы из клеток мантийной зоны, лимфомы Беркитта, лимфомы из ΝΚ-клеток, диффузной В-крупноклеточной лимфомы, острой лимфобластной лимфомы и Т-клеточного рака кожи, включая в себя грибовидный микоз/синдром Сезри.
Согласно конкретным вариантам осуществления рак представляет собой множественную миелому.
Согласно по меньшей мере некоторым вариантам осуществления множественная миелома выбрана из группы, состоящей из множественных миелом, которые продуцируют легкие цепи каппа-типа и/или легкие цепи лямбда-типа; агрессивной множественной миеломы, включая в себя лейкоз первичных плазматических клеток (PCL); доброкачественных заболеваний плазматических клеток, таких как MGUS (моноклональная гаммопатия с неопределенным значением), макроглобулине ми и Вальденстрема (WM, также известной как лимфоплазмоцитарная лимфома), которая может переходить в множественную миелому; тлеющей множественной миеломы (SMM), медленнорастущей множественной миеломы, предраковых форм множественной миеломы, которые также могут переходить в множественную миелому; первичного амилоидоза.
Согласно конкретным вариантам осуществления рак определяется наличием опухолей, которые имеют инфильтрирующие опухоль лимфоциты (TIL) в микроокружении опухоли и/или опухоли с относительно высокой экспрессией CD47 в микроокружении опухоли.
Согласно конкретным вариантам осуществления клетки рака экспрессируют CD47.
Согласно конкретным вариантам осуществления заболевание включает в себя заболевание, связанное с иммуносупрессией или вызванной лекарственными средствами иммуносупрессией (например, ингибиторами mTOR, ингибитором кальцине врина, стероидами).
Согласно конкретным вариантам осуществления заболевание включает в себя вирусы HIV, кори, гриппа, LCCM, RSV, риновирусы человека, EBV, CMV, Parvo.
Согласно конкретным вариантам осуществления заболевание включает в себя инфекцию.
Используемый в настоящем документе термин «инфекция» или «инфекционное заболевание» относится к заболеванию, вызванному патогеном. Конкретные примеры патогенов включают в себя вирусные патогены, бактериальные патогены, например, внутриклеточные микобактериальные патогены (такие как, например, Mycobacterium tuberculosis), внутриклеточные бактериальные патогены (такие как, например, Listeria monocytogenes) или внутриклеточные простейшие патогены (такие как, например, Leishmania и Trypanosoma).
Конкретные типы вирусных патогенов, вызывающих инфекционные заболевания, поддающиеся лечению в соответствии с идеями настоящего изобретения, включают в себя, без ограничения, ретровирусы, цирковирусы, парвовирусы, паповавирусы, аденовирусы, герпесвирусы, иридовирусы, поксвирусы, гепаднавирусы, пикорнивирусы, флавикавирусы, тогорнавирусы, реовирусы, ортомиксо вирусы, парамиксовирусы, рабдовирусы, буньявирусы, коронавирусы, аренавирусы и филовирусы.
Конкретные примеры вирусных инфекций, которые можно лечить в соответствии с идеями настоящего изобретения, включают в себя, без ограничения, синдром приобретенного иммунодефицита (СПИД), индуцированный вирусом иммунодефицита человека (HIV), грипп, риновирусную инфекцию, вирусный менингит, инфекцию вируса Эпштейна-Барра (EBV), вирусную инфекцию гепатита А, В или С, корь, инфекцию вируса папилломы/бородавки, инфекцию цитомегаловируса (CMV), инфекцию вируса простого герпеса, желтую лихорадку, инфекцию вируса Эбола, бешенство и т.д.
Согласно конкретным вариантам осуществления раскрытые в настоящем документе композиции (например, слитый белок SIRPα-4-1BBL, полипептид, содержащий аминокислотную последовательность SIRPα, полипептид, содержащий аминокислотную последовательность 4-1BBL, кодирующий их полинуклеотид или конструкция нуклеиновой кислоты и/или экспрессирующая их клетка-хозяин) можно вводить субъекту в сочетании с другим установленной или экспериментальной терапевтической схемой введения для лечения заболевания, которое может получить пользу от активации иммунных клеток (например, рака), включая в себя, без ограничения, анальгетики, химиотерапевтические средства, радиотерапевтические средства, цитотоксические способы лечения (кондиционирование), гормональную терапию, антитела и другие схемы лечения (например, хирургическое вмешательство), которые хорошо известны в настоящей области техники.
Согласно конкретным вариантам осуществления, раскрытые в настоящем документе композиции (например, слитый белок SIRPα-4-1BBL, полипептид, содержащий аминокислотную последовательность SIRPα, полипептид, содержащий аминокислотную последовательность 4-1BBL, кодирующий их полинуклеотид или конструкция нуклеиновой кислоты и/или экспрессирующая их клетка-хозяин) можно вводить субъекту в сочетании с трансплантацией адоптивных клеток, например, без ограничения, трансплантация клеток костного мозга, гемопоэтических стволовых клеток, РВМС, стволовых клеток пуповинной крови и/или индуцированных плюрипотентных стволовых клеток.
Согласно конкретным вариантам осуществления терапевтическое средство, вводимое в комбинации с композицией некоторых вариантов осуществления настоящего изобретения, включает в себя противораковое средство.
Таким образом, согласно другому аспекту настоящего изобретения предусмотрен способ лечения рака, предусматривающий введение нуждающемуся в этом субъекту противоракового средства и слитого белка SIRPα-4-1BBL, выделенного полипептида, содержащего аминокислотную последовательность SIRPα, и/или полипептида, содержащего аминокислотную последовательность 4-1BBL, описанную в настоящем документе, кодирующего их полинуклеотида, кодирующей их конструкции нуклеиновой кислоты или экспрессирующей их клетки-хозяина.
Противораковые средства, которые можно применять в конкретных вариантах осуществления настоящего изобретения, включают в себя, без ограничения, следующие противораковые лекарственные средства: ацивицин; акларубицин; акодазол гидрохлорид; акронин; адриамицин; адозелезин; альдеслейкин; альтретамин; амбомицин; аметантрон ацетат; аминоглутетимид; амсакрин; анастрозол; антрамицин; аспарагиназа; асперлин; азацитидин; азетепа; азотомицин; батимастат; бензодепа; бикалутамид; бисантрена гидрохлорид; биснафида димезилат; бизелезин; блеомицина сульфат; брекинар натрий; бропиримин; бусульфан; кактиномицин; калустерон; карацемид; карбетимер; карбоплатин; кармустин; карубицина гидрохлорид; карзелезин; цедефингол; хлорамбуцил; циролемицин; цисплатин; кладрибин; криснатол мезилат; циклофосфамид; цитарабин; дакарбазин; дактиномицин; даунорубицина гидрохлорид; децитабин; дексормаплатин; дезагуанин; дезагуанина мезилат; диазиквон; доцетаксел; доксорубицин; доксорубицина гидрохлорид; дролоксифен; дролоксифена цитрат; дромостанолона пропионат; дуазомицин; эдатрексат; эфлорнитина гидрохлорид; эльзамитруцин; энлоплатин; энпромат; эпипропидин; эпирубицина гидрохлорид; эрбулозол; эзорубицина гидрохлорид; эстрамустин; эстрамустина фосфат натрия; этанидазол; этопозид; этопозида фосфат; этоприн; фадрозола гидрохлорид; фазарабин; фенретинид; флоксуридин; флударабина фосфат; фторурацил; фторцитабин; фосквидон; фострицин натрия; гемцитабин; гемцитабина гидрохлорид; гидроксимочевина; идарубицина гидрохлорид; ифосфамид; илмофозин; интерферон альфа-2а; интерферон альфа-2b; интерферон альфа-n1; интерферон альфа-n3; интерферон бета-Ia; интерферон гамма-Ib; ипроплатин; иринотекана гидрохлорид; ланреотида ацетат; летрозол; лейпролида ацетат; лиарозола гидрохлорид; лометрексол натрия; ломустин; лозоксантрона гидрохлорид; масопрокол; майтанзин; мехлорэтамина гидрохлорид; мегестрола ацетат; меленгестрола ацетат; мелфалан; меногарил; меркаптопурин; метотрексат; метотрексат натрия; метоприн; метуредепа; митиндомид; митокарцин; митокромин; митогиллин; митомальцин; митомицин; митоспер; митотане; митоксантрона гидрохлорид; микофеноловая кислота; нокодазол; ногаламицин; ормаплатин; оксисуран; паклитаксел; пегаспаргаз; пелиомицин; пентамустин; пепломицина сульфат; перфосфамид; пипоброман; пипосульфан; пироксантрона гидрохлорид; пликамицин; пломестан; порфимер натрия; порфиромицин; преднимустин; прокарбазина гидрохлорид; пуромицин; пуромицина гидрохлорид; пиразофурин; рибоприн; роглетимид; сафингол; сафингола гидрохлорид; семустин; симтразен; натрий спарфосат; спарсомицин; спирогермания гидрохлорид; спиромустин; спироплатин; стрептонигрин; стрептозоцин; сулофенур; талисомицин; таксол; текогалан натрия; тегафур; телоксантрона гидрохлорид; темопорфин; тенипозид; тероксирон; тестолактон; тиамиприн; тиогуанин; тиотепа; тиазофуирин; тирапазамин; топотекана гидрохлорид; цитрат торемифена; трестолона ацетат; трицирибина фосфат; триметрексат; триметрексат глюкуронат; трипторелин; тубулозола гидрохлорид; урациловый иприт; уредепа; вапреотид; вертепорфин; винбластина сульфат; винкристина сульфат; виндезин; виндезинсульфат; винепидина сульфат; винглицината сульфат; винлеурозина сульфат; винорелбина тартрат; винрозидина сульфат; винзолидина сульфат; ворозол; зениплатин; зиностатин; зорубицина гидрохлорид. Дополнительные противоопухолевые средства включают в себя те, которые описаны в главе 52 Antineoplastic Agents (Paul Calabresi and Bruce A. Chabner) и во введении к ним, 1202-1263, Goodman and Gilman's "The Pharmacological Basis of Therapeutics", Eighth Edition, 1990, McGraw-Hill, Inc. (Health Professions Division).
Согласно конкретным вариантам осуществления противораковое средство включает в себя антитело.
Согласно конкретным вариантам осуществления антитело выбрано из группы, состоящей из ритуксимаба, цетуксимаба, трастузумаба, эдреколомаба, алемтузумаба, гемтузумаба, ибритумомаба, панитумумаба, белимумаба, бевацизумаба, биватузумаба мертансина, блинатумумаба, блонтуветмаба, брентуксимаба ведотина, катумаксомаба, циксутумумаба, даклизумаба, адалимумаба, безлотоксумаба, цертолизумаба пэгол, цитатузумаба богатокс, даратумумаба, динутуксимаба, элотузумаба, эртумаксомаба, этарацизумаба, гемтузумаба озогамицина, гирентуксимаба, нецитумумаба, обинутузумаба, офатумумаба, пертузумаба, рамуцирумаба, силтуксимаба, тозитумомаба, трастузумаба, ниволумаба, пембролизумаба, дурвалумаба, атезолизумаба, авелумаба и ипилимумаба.
Согласно конкретным вариантам осуществления антитело выбрано из группы, состоящей из ритуксимаба и цетуксимаба.
Согласно конкретным вариантам осуществления терапевтическое средство или противораковое средство включает в себя IMiD (например, талидомид, леналидомид, помалидомид).
Согласно конкретным вариантам осуществления IMiD выбран из группы, состоящей из талидомида, леналидомида и помалидомида.
Согласно конкретным вариантам осуществления терапевтическое средство, вводимое в комбинации с композицией некоторых вариантов осуществления настоящего изобретения, включает в себя противоинфекционное средство (например, антибиотики и противовирусные средства).
Согласно конкретным вариантам осуществления терапевтическое средство, вводимое в комбинации с композицией некоторых вариантов осуществления настоящего изобретения, включает в себя иммуносупрессорное средство (например, GCSF и другие стимуляторы костного мозга, стероиды).
Согласно конкретным вариантам осуществления комбинированная терапия характеризуется аддитивным эффектом.
Согласно конкретным вариантам осуществления комбинированная терапия характеризуется синергетическим эффектом.
В соответствии с другим аспектом настоящего изобретения предусмотрено изделие, содержащее упаковочный материал, упаковывающий терапевтическое средство для лечения заболевания, которое может получить пользу от активации иммунных клеток; и слитый белок SIRPα-4-1BBL, выделенный полипептид, содержащий аминокислотную последовательность SIRPα, и/или выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, описанные в настоящем документе, кодирующий их полинуклеотид, кодирующую их конструкцию нуклеиновой кислоты или экспрессирующую их клетку-хозяина. Согласно конкретным вариантам осуществления изделие идентифицируется для лечения заболевания, при котором может быть улучшена активация иммунных клеток.
Согласно конкретным вариантам осуществления терапевтическое средство для лечения указанного заболевания и слитый белок SIRPα-4-1BBL, выделенный полипептид, содержащий аминокислотную последовательность SIRPα, и/или выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, кодирующий их полинуклеотид, кодирующая их конструкция нуклеиновой кислоты или экспрессирующая их клетка-хозяин упакованы в отдельные емкости.
Согласно конкретным вариантам осуществления терапевтическое средство для лечения указанного заболевания и слитый белок SIRPα-4-1BBL, выделенный полипептид, содержащий аминокислотную последовательность SIRPα, и/или выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, кодирующий их полинуклеотид, кодирующая их конструкция нуклеиновой кислоты или экспрессирующая их клетка-хозяин упакованы в совместный состав.
Согласно конкретным вариантам осуществления изделие включает в себя слитый белок SIRPα-4-1BBL, кодирующий его полинуклеотид, кодирующую его конструкцию нуклеиновой кислоты или экспрессирующую его клетку-хозяина.
Согласно конкретным вариантам осуществления изделие включает в себя выделенный полипептид, содержащий аминокислотную последовательность SIRPα, кодирующий его полинуклеотид, кодирующую его конструкцию нуклеиновой кислоты или экспрессирующую его клетку-хозяина.
Согласно конкретным вариантам осуществления изделие включает в себя выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, кодирующий его полинуклеотид, кодирующую его конструкцию нуклеиновой кислоты или экспрессирующую его клетку-хозяина.
Согласно конкретным вариантам осуществления изделие включает в себя аминокислотную последовательность SIRPα, кодирующий ее полинуклеотид, кодирующую ее конструкцию нуклеиновой кислоты или экспрессирующую ее клетку-хозяина; и аминокислотную последовательность 4-1BBL, кодирующий ее полинуклеотид, кодирующую ее конструкцию нуклеиновой кислоты или экспрессирующую ее клетку-хозяина.
Таким образом, согласно другому аспекту настоящего изобретения предусмотрено изделие, содержащее упаковочный материал, упаковывающий выделенный полипептид, содержащий аминокислотную последовательность SIRPα, раскрытую в настоящем документе, кодирующий ее полинуклеотид, кодирующую ее конструкцию нуклеиновой кислоты или экспрессирующую ее клетку-хозяина; и выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, описанную в настоящем документе, кодирующий ее полинуклеотид, кодирующую ее конструкцию нуклеиновой кислоты или экспрессирующую ее клетку-хозяина.
Согласно конкретным вариантам осуществления выделенный полипептид, содержащий аминокислотную последовательность SIRPα, раскрытую в настоящем документе, кодирующий ее полинуклеотид, кодирующую ее конструкцию нуклеиновой кислоты или экспрессирующую ее клетку-хозяина; и выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, кодирующий ее полинуклеотид, кодирующую ее конструкцию нуклеиновой кислоты или экспрессирующую ее клетку-хозяина упакованы в отдельные контейнеры.
Согласно конкретным вариантам осуществления выделенный полипептид, содержащий аминокислотную последовательность SIRPα, раскрытую в настоящем документе, кодирующий ее полинуклеотид, кодирующую ее конструкцию нуклеиновой кислоты или экспрессирующую ее клетку-хозяина; и выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, раскрытую в настоящем документе, кодирующий ее полинуклеотид, кодирующую ее конструкцию нуклеиновой кислоты или экспрессирующую ее клетку-хозяина упакованы в совместный состав.
Согласно конкретным вариантам осуществления выделенный полипептид, содержащий аминокислотную последовательность SIRPα; и/или выделенный полипептид, содержащий аминокислотную последовательность 4-1BBL, присоединен к гетерологичному терапевтическому фрагменту или содержит его. Терапевтический фрагмент может представлять собой любую молекулу, включая в себя небольшие химические соединения и полипептиды.
Неограничивающие примеры терапевтических групп, которые можно использовать с конкретными вариантами осуществления настоящего изобретения, включают в себя цитотоксический фрагмент, токсический фрагмент, фрагмент цитокина, иммуномодулирующий фрагмент, полипептид, антитело, лекарственное средство, химическое вещество и/или радиоизотоп.
Согласно некоторым вариантам осуществления настоящего изобретения терапевтический фрагмент конъюгирован путем трансляционного слияния полинуклеотида, кодирующего полипептид некоторых вариантов осуществления настоящего изобретения, с последовательностью нуклеиновой кислоты, кодирующей терапевтический фрагмент.
Дополнительно или альтернативно терапевтический фрагмент может быть химически конъюгирован (связан) с полипептидом некоторых вариантов осуществления настоящего изобретения с использованием любого способа конъюгирования, известного специалисту в настоящей области техники. Например, пептид можно конъюгировать с представляющим интерес средством с использованием сложного эфира N-гидроксисукцинимида 3-(2-пиридилдитио)пропионовой кислоты (также называемого N-сукцинимидил-3-(2-пиридилдитио)пропионатом) («SDPD») (Sigma, № в каталоге Р-3415; смотрите, например, Cumber et al. 1985, Methods of Enzymology 112: 207-224), процедуру конъюгации с глутаральдегидом (смотрите, например, G.T. Hermanson 1996, "Antibody Modification and Conjugation, in Bioconjugate Techniques, Academic Press, San Diego) или процедуру конъюгации карбодиимида [смотрите, например, J. March, Advanced Organic Chemistry: Reaction's, Mechanism, and Structure, pp. 349-50 & 372-74 (3d ed.), 1985; B. Neises et al. 1978, Angew Chem., Int. Ed. Engl. 17:522; A. Hassner et al. 1978, Tetrahedron Lett. 4475; E.P. Boden et al. 1986, J. Org. Chem. 50:2394 и L.J. Mathias 1979, Synthesis 561].
Терапевтический фрагмент может быть присоединен, например, к полипептиду некоторых вариантов осуществления настоящего изобретения с использованием стандартных способов химического синтеза, широко практикуемых в настоящей области техники [смотрите, например, hypertexttransferprotocol://worldwideweb (dot) chemistry (dot) org/portal/Chemistry)], например, используя любую подходящую химическую связь, прямую или непрямую, например, через пептидную связь (когда функциональная группа представляет собой полипептид) или через ковалентную связь с промежуточным линкерным элементом, таким как линкерный пептид или другой химический фрагмент, такой как органический полимер. Химерные пептиды могут быть связаны посредством связывания на карбокси- (С) или амино- (N) концах пептидов или посредством связывания с внутренними химическими группами, такими как прямые, разветвленные или циклические боковые цепи, внутренние атомы углерода или азота и т.п.
Используемые в настоящем документе термины «белок», «пептид» и «полипептид», которые используются в настоящем документе взаимозаменяемо, охватывают нативные пептиды (продукты разложения, синтетически синтезированные пептиды или рекомбинантные пептиды) и пептидомиметики (как правило, синтетически синтезированные пептиды), как а также пептоиды и семипептоиды, которые являются аналогами пептидов, которые могут иметь, например, модификации, делающие пептиды более стабильными в организме или более способными проникать в клетки. Такие модификации включают в себя, без ограничения, модификацию N-конца, модификацию С-конца, модификацию пептидной связи, модификации основной цепи и модификацию остатков. Способы получения пептид о миметических соединений хорошо известны в настоящей области техники и описаны, например, в Quantitative Drug Design, С.A. Ramsden Gd., Chapter 17.2, F. Choplin Pergamon Press (1992), которая включена в качестве ссылки, как если бы она была полностью изложена в настоящем документе. Более подробная информация по этому поводу приводится ниже.
Пептидные связи (-CO-NH-) внутри пептида могут быть замещены, например, N-метилированными амидными связями (-N(CH3)-CO-), сложноэфирными связями (-С(=O)-О-), кетометиленовыми связями (-СО-СН2-), сульфинилметиленовыми связями (-S(=O)-СН2-), α-аза связями (-NH-N(R)-CO-), где R представляет собой любой алкил (например, метил), аминными связями (-CH2-NH-), сульфидными связями (-CH2-S-), этиленовыми связями (-СН2-СН2-), гидроксиэтиленовыми связями (-СН(ОН)-СН2-), тиоамидными связями (-CS-NH-), олефиновыми двойными связями (-СН=СН-), фторированными олефиновыми двойными связями (-CF=CH-), ретроамидными связями (-NH-CO-), пептидными производными (-N(R)-CH2-CO-), где R представляет собой «нормальную» боковую цепь, естественно присутствующую на атоме углерода.
Эти модификации могут происходить в любой из связей пептидной цепи и даже в нескольких (2-3) связях одновременно.
Природные ароматические аминокислоты, Trp, Tyr и Phe, могут быть заменены неприродными ароматическими аминокислотами, такими как 1,2,3,4-тетрагидроизохинолин-3-карбоновая кислота (Tic), нафтилаланин, метилированные в кольцо производные Phe, галогенированные производные Phe или О-метил-Tyr.
Пептиды некоторых вариантов осуществления настоящего изобретения могут также включать в себя одну или несколько модифицированных аминокислот или один или несколько мономеров, не представляющих собой аминокислоты (например, жирные кислоты, сложные углеводы и т.д.).
Термин «аминокислота» или «аминокислоты» включает в себя 20 встречающихся в природе аминокислот; те аминокислоты, которые часто посттрансляционно модифицируются in vivo, включая в себя, например, гидроксипролин, фосфосерин и фосфотреонин; и другие необычные аминокислоты, включая в себя, без ограничения, 2-аминоадипиновую кислоту, гидроксилизин, изодесмозин, норвалин, норлейцин и орнитин. Кроме того, термин «аминокислота» включает в себя как D-, так и L-аминокислоты.
В таблицах 1 и 2 ниже перечислены встречающиеся в природе аминокислоты (таблица 1), а также нетрадиционные или модифицированные аминокислоты (например, синтетические, таблица 2), которые можно использовать с некоторыми вариантами осуществления настоящего изобретения.
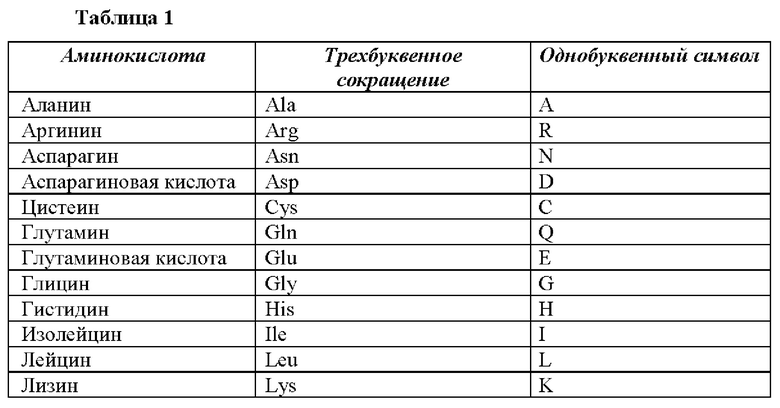
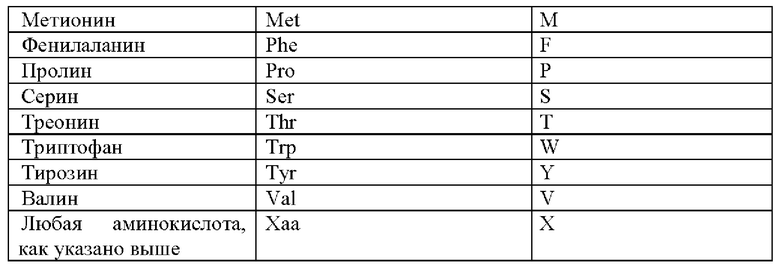
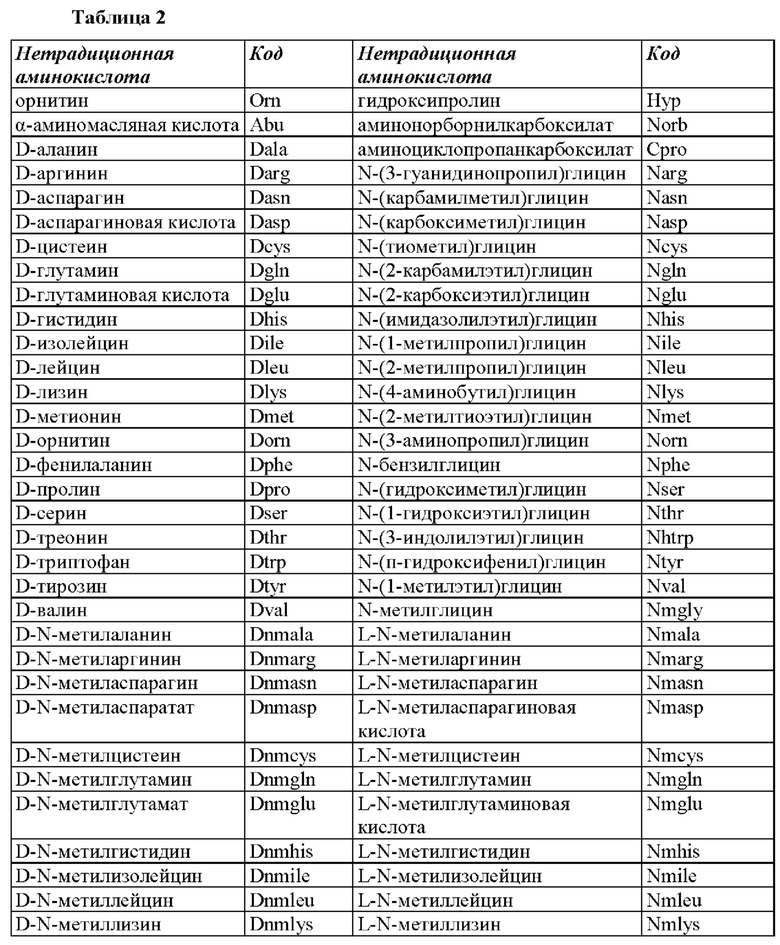
Пептиды некоторых вариантов осуществления настоящего изобретения предпочтительно используются в линейной форме, хотя следует понимать, что в случаях, когда циклизация не оказывает серьезного влияния на характеристики пептида, также можно использовать циклические формы пептида.
Поскольку настоящие пептиды предпочтительно используются в терапевтических целях, которые требуют, чтобы пептиды были в растворимой форме, пептиды некоторых вариантов осуществления настоящего изобретения предпочтительно содержат одну или несколько неприродных или природных полярных аминокислот, включая в себя, без ограничения, серии и треонин, которые способны увеличивать растворимость пептидов благодаря своей гидроксилсодержащей боковой цепи.
Аминокислоты пептидов по настоящему изобретению могут быть заменены консервативно или неконсервативно.
Используемый в настоящем документе термин «консервативная замена» относится к замене аминокислоты, присутствующей в нативной последовательности в пептиде, на встречающиеся в природе или не встречающиеся в природе амино- или пептидомиметики, характеризующиеся аналогичными стерическими свойствами. Если боковая цепь нативной аминокислоты, которую необходимо заменить, является полярной или гидрофобной, консервативная замена должна происходить на природную аминокислоту, неприродную аминокислоту или пептидомиметический фрагмент, который также является полярным или гидрофобным (в дополнение к тем же стерическим свойствам, что и боковая цепь замененной аминокислоты).
Поскольку встречающиеся в природе аминокислоты, как правило, группируются в соответствии с их свойствами, консервативные замены встречающимися в природе аминокислотами могут быть легко определены с учетом того факта, что в соответствии с настоящим изобретением рассматривается замена заряженных аминокислот на стерически схожие незаряженные аминокислоты в качестве консервативных замен.
Для получения консервативных замен не встречающимися в природе аминокислотами также можно использовать аналоги аминокислот (синтетические аминокислоты), хорошо известные в настоящей области техники. Пептид о миметик встречающейся в природе аминокислоты хорошо описан в литературе, известной квалифицированному практикующему специалисту.
При использовании консервативных замен заменяющая аминокислота должна содержать такую же или аналогичную функциональную группу в боковой цепи, что и исходная аминокислота.
Таблицы консервативных замен, содержащие функционально похожие аминокислоты, хорошо известны в настоящей области техники. Руководство относительно того, какие аминокислотные изменения, вероятно, будут фенотипически молчащими, можно также найти в Bowie et al., 1990, Science 247: 1306 1310. Такие консервативно модифицированные варианты дополняют и не исключают полиморфные варианты, межвидовые гомологи и аллели. Типичные консервативные замены включают в себя, без ограничения: 1) аланин (А), глицин (G); 2) аспарагиновую кислоту (D), глутаминовую кислоту (Е); 3) аспарагин (N), глутамин (Q); 4) аргинин (R), лизин (K); 5) изолейцин (I), лейцин (L), метионин (М), валин (V); 6) фенилаланин (F), тирозин (Y), триптофан (W); 7) серии (S), треонин (Т) и 8) цистеин (С), метионин (М) (смотрите, например, Creighton, Proteins (1984)). Аминокислоты могут быть заменены на основе свойств, связанных с боковыми цепями, например, аминокислоты с полярными боковыми цепями могут быть заменены, например, на серии (S) и треонин (Т); аминокислоты, основанные на электрическом заряде боковых цепей, например, аргинин (R) и гистидин (Н); и аминокислоты, которые имеют гидрофобные боковые цепи, например, валин (V) и лейцин (L). Как указано, изменения, как правило, имеют незначительный характер, такие как консервативные аминокислотные замены, которые существенно не влияют на укладку или активность белка.
Используемая в настоящем документе фраза «неконсервативные замены» относится к замене аминокислоты, присутствующей в исходной последовательности, другой природной или неприродной аминокислотой, характеризующейся другими электрохимическими и/или стерическими свойствами. Таким образом, боковая цепь заменяющей аминокислоты может быть значительно больше (или меньше), чем боковая цепь заменяемой нативной аминокислоты, и/или может содержать функциональные группы со значительно отличающимися электронными свойствами, чем замещаемая аминокислота. Примеры неконсервативных замен этого типа включают в себя замену фенилаланина или циклогексилметилглицина на аланин, изолейцина на глицин или -NH-CH[(-CH2)5-COOH]-CO- на аспарагиновую кислоту. Те неконсервативные замены, которые подпадают под объем настоящего изобретения, представляют собой замены, которые все еще составляют пептид, обладающий антибактериальными свойствами.
N- и С-концы пептидов по настоящему изобретению могут быть защищены функциональными группами. Подходящие функциональные группы описаны в Green and Wuts, «Protecting Groups in Organic Synthesis», John Wiley and Sons, Chapters 5 and 7, 1991, идеи которых включены в настоящий документ посредством ссылки. Предпочтительными защитными группами являются те, которые облегчают транспорт присоединенного к ним соединения в клетку, например, за счет снижения гидрофильности и увеличения липофильности соединений.
Согласно конкретным вариантам осуществления одна или несколько аминокислот могут быть модифицированы, например, добавлением функциональной группы (концептуально рассматривается как «химически модифицированная»). Например, боковые аминокислотные остатки, встречающиеся в нативной последовательности, необязательно могут быть модифицированы, хотя, как описано ниже, альтернативно могут быть модифицированы другие части белка в дополнение к боковым аминокислотным остаткам или вместо них. Модификация необязательно может быть выполнена во время синтеза молекулы, если соблюдается процесс химического синтеза, например, путем добавления химически модифицированной аминокислоты. Однако также возможна химическая модификация аминокислоты, когда она уже присутствует в молекуле (модификация «in situ»). Модификации пептида или белка могут быть введены путем синтеза гена, сайт-направленным (например, на основе ПЦР) или случайным мутагенезом (например, EMS) путем делеции экзонуклеаз, химической модификации или слияния полинуклеотидных последовательностей, кодирующих гетер о логичный домен или связывающий белок, например.
Используемый в настоящем документе термин «химическая модификация», когда относится к пептиду, относится к пептиду, в котором по меньшей мере один из его аминокислотных остатков модифицирован либо естественными процессами, такими как процессинг или другие посттрансляционные модификации, либо способами химической модификации, которые хорошо известны в настоящей области техники. Неограничивающие иллюстративные типы модификации включают в себя карбоксиметилирование, ацетилирование, ацилирование, фосфорилирование, гликозилирование, амидирование, ADP-рибозилирование, ацилирование жирных кислот, добавление фарнезильной группы, изофарнезильной группы, углеводной группы, группы жирной кислоты, линкера для конъюгирования, функционализация, образование якоря GPI, ковалентное присоединение липида или производного липида, метилирование, миристилирование, пегилирование, пренилирование, фосфорилирование, убиквитинирование или любой аналогичный процесс и известные защитные/блокирующие группы. Эфирные связи необязательно могут быть использованы для присоединения гидроксила серина или треонина к гидроксилу сахара. Амидные связи необязательно могут быть использованы для присоединения карбоксильных групп глутамата или аспартата к аминогруппе на сахаре (Garg and Jeanloz, Advances in Carbohydrate Chemistry and Biochemistry, Vol. 43, Academic Press (1985); Kunz, Ang. Chem. hit. Ed. English 26:294-308 (1987)). Ацетальные и кетальные связи необязательно могут быть образованы между аминокислотами и углеводами. Ацильные производные жирных кислот могут быть необязательно получены, например, ацилированием свободной аминогруппы (например, лизина) (Toth et al., Peptides: Chemistry, Structure and Biology, Rivier and Marshal, eds., ESCOM Publ., Leiden, 1078-1079 (1990)).
Согласно конкретным вариантам осуществления модификации включают в себя добавление циклоалкановой части к пептиду, как описано в заявке РСТ № WO 2006/050262, включенной в настоящий документ посредством ссылки, как если бы они были полностью изложены в настоящем документе. Эти фрагменты предназначены для использования с биомолекулами и могут необязательно использоваться для придания различных свойств белкам.
Кроме того, необязательно может быть модифицирована любая точка пептида. Например, пегилирование фрагмента гликозилирования в белке необязательно может быть выполнено, как описано в заявке РСТ № WO 2006/050247, включенной в настоящий документ посредством ссылки, как если бы она была полностью изложена в настоящем документе. Одна или несколько групп полиэтиленгликоля (ПЭГ) могут быть необязательно добавлены для О-связанного и/или N-связанного гликозилирования. Группа ПЭГ необязательно может быть разветвленной или линейной. Необязательно любой тип водорастворимого полимера может быть присоединен к сайту гликозилирования на белке через гликозильный линкер.
Под «пегилированным белком» подразумевается белок или его фрагмент, обладающий биологической активностью, содержащий фрагмент полиэтиленгликоля (ПЭГ), ковалентно связанный с аминокислотным остатком белка.
Под «полиэтиленгликолем» или «ПЭГ» подразумевается соединение полиалкиленгликоля или его производное, со связывающими средствами или без них или дериватизацию с сочетанием или активирующими фрагментами (например, с тиолом, трифлатом, трезилатом, азирдином, оксираном или предпочтительно с малеимидным фрагментом). Соединения, такие как малеимидомонометокси ПЭГ, являются типичными или активированными соединениями ПЭГ по настоящему изобретению. В настоящем изобретении могут использоваться другие соединения полиалкиленгликоля, такие как полипропиленгликоль. Другие подходящие соединения полиалкиленгликоля включают в себя, без ограничения, заряженные или нейтральные полимеры следующих типов: декстран, коломиновые кислоты или другие полимеры на основе углеводов, полимеры аминокислот и производные биотина.
Согласно конкретным вариантам осуществления пептид модифицируют, чтобы иметь измененный образец гликозилирования (т.е. измененный по сравнению с исходным или нативным типом гликозилирования). В данном контексте «измененный» означает удаление одного или нескольких углеводных фрагментов и/или добавление по меньшей мере одного сайта гликозилирования к исходному белку.
Гликозилирование белков, как правило, является N-связанным или О-связанным. N-связанный относится к присоединению углеводного фрагмента к боковой цепи остатка аспарагина. Трипептидные последовательности, аспарагин-Х-серин и аспарагин-Х-треонин, где X представляет собой любую аминокислоту, кроме пролина, представляют собой последовательности распознавания для ферментативного присоединения углеводного фрагмента к боковой цепи аспарагина. Таким образом, присутствие любой из этих трипептидных последовательностей в полипептиде создает потенциальный сайт гликозилирования. О-связанное гликозилирование относится к присоединению одного из сахаров N-ацетилгалактозамина, галактозы или ксилозы к гидроксиаминокислоте, чаще всего серину или треонину, хотя также можно использовать 5-гидроксипролин или 5-гидроксилизин.
Добавление сайтов гликозилирования к пептиду, как правило, осуществляется путем изменения аминокислотной последовательности пептида таким образом, чтобы он содержал одну или несколько из описанных выше трипептидных последовательностей (для сайтов N-связанного гликозилирования). Изменение также может быть выполнено добавлением или заменой одного или нескольких остатков серина или треонина в последовательности исходного пептида (для сайтов О-связанного гликозилирования). Аминокислотная последовательность пептида также может быть изменена путем внесения изменений на уровне ДНК.
Другим способом увеличения количества углеводных фрагментов в пептидах является химическое или ферментативное связывание гликозидов с аминокислотными остатками пептида. В зависимости от используемого способа связывания сахара могут быть присоединены к (а) аргинину и гистидину, (b) свободным карбоксильным группам, (с) свободным сульфгидрильным группам, таким как группы цистеина, (d) свободным гидроксильным группам, таким как группы серина, треонина или гидроксипролина, (е) ароматическим остаткам, таким как остатки фенилаланина, тирозина или триптофана, или (f) амидной группе глутамина. Эти способы описаны, например, в WO 87/05330 и в Aplin and Wriston, CRC Crit. Rev. Biochem., 22: 259-306 (1981).
Удаление любых углеводных фрагментов, присутствующих в пептиде, может осуществляться химическим, ферментативным путем или путем внесения изменений на уровне ДНК. Химическое дегликозилирование требует воздействия на пептид трифторметансульфоновой кислоты или эквивалентного соединения. Эта обработка приводит к расщеплению большинства или всех сахаров, за исключением связывающего сахара (N-ацетилглюкозамина или N-ацетилгалактозамина), оставляя аминокислотную последовательность нетронутой.
Химическое дегликозилирование описано в Hakimuddin et al., Arch. Biochem. Biophys., 259: 52 (1987) и Edge et al., Anal. Biochem., 118: 131 (1981). Ферментативное расщепление углеводных фрагментов пептидов может быть достигнуто путем использования различных эндо- и экзогликозидаз, как описано в Thotakura et al., Meth. Enzymol., 138: 350 (1987).
Согласно конкретным вариантам осуществления пептид содержит обнаруживаемую метку. Используемый в настоящем документе термин «обнаруживаемая метка» относится к любому фрагменту, который может быть обнаружен квалифицированным практикующим специалистом с использованием способов, известных в настоящей области техники. Обнаруживаемые метки могут представлять собой пептидные последовательности. Необязательно, обнаруживаемая метка может быть удалена с помощью химических средств или ферментативных средств, таких как протеолиз. Обнаруживаемые метки некоторых вариантов осуществления настоящего изобретения можно использовать для очистки пептида. Например, термин «обнаруживаемая метка» включает в себя метку хитинсвязывающего белка (СВР), метку мальтозосвязывающего белка (МВР), метку глутатион-S-трансферазы (GST), поли(His)-метку, метку FLAG, метки эпитопа, такие как V5-метка, c-myc-метка и НА-метка, и флуоресцентные метки, такие как зеленый флуоресцентный белок (GFP), красный флуоресцентный белок (RFP), желтый флуоресцентный белок (YFP), синий флуоресцентный белок (BFP) и голубой флуоресцентный белок (CFP); а также производные этих меток или любая другая метка, известная в настоящей области техники. Термин «обнаруживаемая метка» также включает в себя термин «обнаруживаемый маркер».
Согласно конкретному варианту осуществления пептид содержит обнаруживаемую метку, прикрепленную к его N-концу (например, поли(His)-метку).
Согласно конкретному варианту осуществления пептид содержит обнаруживаемую метку, прикрепленную к его С-концу (например, поли(His)-метку).
Согласно конкретным вариантам осуществления N-конец пептида не содержит обнаруживаемой метки (например, поли(His)-метки).
Согласно конкретным вариантам осуществления С-конец пептида не содержит обнаруживаемой метки (например, поли(His)-метки).
Согласно конкретным вариантам осуществления пептид слит с расщепляемым фрагментом. Таким образом, например, для облегчения восстановления экспрессированная кодирующая последовательность может быть сконструирована для кодирования пептида некоторых вариантов осуществления настоящего изобретения и слитого расщепляемого фрагмента. Согласно одному варианту осуществления пептид сконструирован таким образом, чтобы его можно было легко выделить с помощью аффинной хроматографии; например, путем иммобилизации на колонке, специфической для расщепляемого фрагмента. Согласно одному варианту осуществления сайт расщепления создается между пептидом и расщепляемым фрагментом, и пептид может быть высвобожден из хроматографической колонки обработкой подходящим ферментом или средством, которое специфически расщепляет гибридный белок в этом сайте [например, смотрите Booth et al., Immunol. Lett. 19:65-70 (1988) и Gardella et al., J. Biol. Chem. 265:15854-15859 (1990)]. Согласно конкретным вариантам осуществления пептид представляет собой выделенный пептид.
Пептиды некоторых вариантов осуществления настоящего изобретения могут быть синтезированы и очищены любыми способами, которые известны специалистам в области пептидного синтеза, такими как, без ограничения, твердофазные и рекомбинантные способы.
Для твердофазного пептидного синтеза краткое изложение многих способов можно найти в J. М. Stewart and J. D. Young, Solid Phase Peptide Synthesis, W. H. Freeman Co. (San Francisco), 1963 и J. Meienhofer, Hormonal Proteins and Peptides, vol. 2, p. 46, Academic Press (New York), 1973. Классический синтез раствора смотрите в G. Schroder and K. Lupke, The Peptides, vol. 1, Academic Press (New York), 1965.
Как правило, эти способы предусматривают последовательное добавление одной или нескольких аминокислот или соответственно защищенных аминокислот к растущей пептидной цепи. Как правило, либо амино-, либо карбоксильная группа первой аминокислоты защищена подходящей защитной группой. Защищенную или дериватизированную аминокислоту затем можно либо присоединить к инертной твердой подложке, либо использовать в растворе путем добавления следующей аминокислоты в последовательности, имеющей комплементарную (амино- или карбоксильную) группу, защищенную подходящим образом, в условиях, подходящих для образования амидной связи. Затем с этого вновь добавленного аминокислотного остатка удаляют защитную группу и затем добавляют следующую аминокислоту (соответственно защищенную) и так далее. После того, как все желаемые аминокислоты были связаны в надлежащей последовательности, любые оставшиеся защитные группы (и любую твердую основу) удаляют последовательно или одновременно с получением конечного пептидного соединения. Путем простой модификации этой общей процедуры можно добавлять более одной аминокислоты за раз к растущей цепи, например, путем связывания (в условиях, которые не рацемизируют хиральные центры) защищенного трипептида с должным образом защищенным дипептидом с образованием после снятия защиты пентапептида и так далее. Дополнительное описание пептидного синтеза раскрыто в патенте США №6472505.
Предпочтительный способ получения пептидных соединений некоторых вариантов осуществления настоящего изобретения предусматривает твердофазный пептидный синтез.
Крупномасштабный синтез пептидов описан в Andersson Biopolymers 2000; 55 (3): 227-50.
Согласно конкретным вариантам осуществления пептид синтезируется с использованием систем экспрессии in vitro. Такие способы синтеза in vitro хорошо известны в настоящей области техники, и компоненты системы коммерчески доступны.
Согласно конкретным вариантам осуществления пептид получают с помощью технологии рекомбинантной ДНК. «Рекомбинантный» пептид или белок относится к пептиду или белку, полученному способами рекомбинантной ДНК; т.е. полученные из клеток, трансформированных экзогенной конструкцией ДНК, кодирующей желаемый пептид или белок.
Таким образом, согласно другому аспекту настоящего изобретения предусмотрен выделенный полинуклеотид, содержащий последовательность нуклеиновой кислоты, кодирующую любой из описанных выше слитых белков.
Согласно конкретным вариантам осуществления полинуклеотид по меньшей мере на 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 88%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% гомологичен нуклеиновой последовательности, приведенной в SEQ ID No. 55-66 или 68, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления полинуклеотид по меньшей мере на 95%, 96%, 97%, 98% или 99% гомологичен нуклеиновой последовательности, приведенной в SEQ ID No. 55-66 или 68.
Согласно конкретным вариантам осуществления полинуклеотид содержит последовательность нуклеиновой кислоты, выбранную из группы, состоящей из SEQ ID NO: 55-66 и 68, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления полинуклеотид состоит из последовательности нуклеиновой кислоты, выбранной из группы, состоящей из SEQ ID NO: 55-66 и 68, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления полинуклеотид содержит последовательность нуклеиновой кислоты, выбранную из группы, состоящей из SEQ ID NO: 55-61 и 68.
Согласно конкретным вариантам осуществления полинуклеотид состоит из последовательности нуклеиновой кислоты, выбранной из группы, состоящей из SEQ ID NO: 55-61 и 68.
Согласно конкретным вариантам осуществления полинуклеотид содержит последовательность нуклеиновой кислоты, выбранную из группы, состоящей из SEQ ID NO: 55, 56 и 58.
Согласно конкретным вариантам осуществления полинуклеотид состоит из последовательности нуклеиновой кислоты, выбранной из группы, состоящей из SEQ ID NO: 55, 56 и 58.
В соответствии с другим аспектом настоящего изобретения предусмотрен выделенный полинуклеотид, содержащий последовательность нуклеиновой кислоты, кодирующую любую из описанных выше аминокислотных последовательностей SIRPα, составляющую в длину 100-119 аминокислот и характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к SEQ ID NO: 24 и/или 26, или любую из описанных выше аминокислотных последовательностей 4-1BBL, составляющую в длину 185-202 аминокислоты и характеризующуюся идентичностью, составляющей по меньшей мере 95%, по отношению к аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 22, 23, 27 и 28.
Согласно конкретным вариантам осуществления полинуклеотид по меньшей мере на 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 88%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% гомологичен нуклеиновой последовательности, приведенной в SEQ ID No. 33 или 34, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления полинуклеотид по меньшей мере на 95%, 96%, 97%, 98% или 99% гомологичен нуклеиновой последовательности, приведенной в SEQ ID No. 33 или 34.
Согласно конкретным вариантам осуществления полинуклеотид включает в себя SEQ ID NO: 33 или 34.
Согласно конкретным вариантам осуществления полинуклеотид состоит из SEQ ID NO: 33 или 34.
Согласно конкретным вариантам осуществления полинуклеотид по меньшей мере на 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 88%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% гомологичен нуклеиновой последовательности, приведенной в SEQ ID NO: 39, 40, 41, 42, 73, 75, 77 или 79, каждая возможность представляет отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления полинуклеотид по меньшей мере на 70%, 75%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 88%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% гомологичен нуклеиновой последовательности, приведенной в SEQ ID NO: 39, 40, 41 или 42, каждая возможность представляет собой отдельный вариант осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления полинуклеотид по меньшей мере на 95%, 96%, 97%, 98% или 99% гомологичен нуклеиновой последовательности, приведенной в SEQ ID NO: 39, 40, 41, 42, 73, 75, 77 или 79.
Согласно конкретным вариантам осуществления полинуклеотид по меньшей мере на 95%, 96%, 97%, 98% или 99% гомологичен нуклеиновой последовательности, приведенной в SEQ ID NO: 39, 40, 41 или 42.
Согласно конкретным вариантам осуществления полинуклеотид включает в себя SEQ ID NO: 39, 40, 41, 42, 73, 75, 77 или 79.
Согласно конкретным вариантам осуществления полинуклеотид включает в себя SEQ ID NO: 39, 40, 41 или 42.
Согласно конкретным вариантам осуществления полинуклеотид состоит из SEQ ID NO: 39, 40, 41, 42, 73, 75, 77 или 79.
Согласно конкретным вариантам осуществления полинуклеотид состоит из SEQ ID NO: 39, 40, 41 или 42.
Используемый в настоящем документе термин «полинуклеотид» относится к одноцепочечной или двухцепочечной последовательности нуклеиновой кислоты, которая выделена и представлена в форме последовательности РНК, комплементарной полинуклеотидной последовательности (кДНК), геномной полинуклеотидной последовательности и/или составной полинуклеотидной последовательности (например, комбинации вышеперечисленного).
Для экспрессии экзогенного полипептида в клетках млекопитающих полинуклеотидную последовательность, кодирующую полипептид, предпочтительно лигируют в конструкцию нуклеиновой кислоты, подходящую для экспрессии в клетках млекопитающих. Такая конструкция нуклеиновой кислоты включает в себя промоторную последовательность для управления транскрипцией полинуклеотидной последовательности в клетке конститутивным или индуцибельным образом.
Следовательно, согласно конкретным вариантам осуществления, предусмотрена конструкция нуклеиновой кислоты, содержащая полинуклеотид и регуляторный элемент для управления экспрессией указанного полинуклеотид а в клетке-хозяине.
Согласно конкретным вариантам осуществления регуляторный элемент представляет собой гетерологичный регуляторный элемент.
Конструкция нуклеиновой кислоты (также называемая в настоящем документе «вектором экспрессии») по некоторым вариантам осуществления настоящего изобретения включает в себя дополнительные последовательности, которые делают этот вектор пригодным для репликации и интеграции в прокариотах, эукариотах или, предпочтительно, и там и там (например, челночные векторы). Кроме того, типичный вектор клонирования может также содержать последовательность инициации транскрипции и трансляции, терминатор транскрипции и трансляции и сигнал полиаденилирования. В качестве примера такие конструкции, как правило, содержат 5'-LTR, сайт связывания тРНК, сигнал упаковки, источник синтеза второй цепи ДНК и 3'-LTR или его часть.
Конструкция нуклеиновой кислоты по некоторым вариантам осуществления настоящего изобретения, как правило, включает в себя сигнальную последовательность для секреции пептида из клетки-хозяина, в которую он помещен. Предпочтительно сигнальная последовательность для этой цели представляет собой сигнальную последовательность млекопитающего или сигнальную последовательность вариантов полипептида некоторых вариантов осуществления настоящего изобретения.
Эукариотические промоторы, как правило, содержат два типа узнаваемых последовательностей: ТАТА-бокс и расположенные выше против хода транскрипции промоторные элементы. Считается, что ТАТА-бокс, расположенный на 25-30 пар оснований выше против хода транскрипции от сайта инициации транскрипции, участвует в управлении РНК-полимеразой, чтобы начать синтез РНК. Другие расположенные выше против хода транскрипции промоторные элементы определяют скорость, с которой начинается транскрипция.
Предпочтительно промотор, используемый конструкцией нуклеиновой кислоты в некоторых вариантах осуществления настоящего изобретения, активен в конкретной трансформированной популяции клеток. Примеры промоторов, специфических для определенного типа клеток и/или тканеспецифических промоторов, включают в себя промоторы, такие как специфический для печени альбумин [Pinkert et al., (1987) Genes Dev. 1: 268-277], лимфоид-специфические промоторы [Calame et al., (1988) Adv. Immunol. 43:235-275]; в частности промоторы Т-клеточных рецепторов [Winoto et al., (1989) EMBO J. 8:729-733] и иммуноглобулинов; [Banerji et al. (1983) Cell 33729-740], нейрон-специфические промоторы, такие как промотор нейрофиламента [Byrne et al. (1989) Proc. Natl. Acad. Sci. USA 86:5473-5477], специфические для поджелудочной железы промоторы [Edlunch et al. (1985) Science 230:912-916] или специфические для молочной железы промоторы, такие как промотор молочной сыворотки (патент США №4873316 и публикация европейской заявки №264166).
Энхансерные элементы могут стимулировать транскрипцию до 1000 раз со связанных гомологичных или гетерологичных промоторов. Энхансеры активны при размещении ниже по ходу транскрипции или выше против хода транскрипции от сайта инициации транскрипции. Многие энхансерные элементы, полученные из вирусов, имеют широкий диапазон хозяев и активны во множестве тканей. Например, энхансер раннего гена SV40 подходит для многих типов клеток. Другие комбинации энхансера/промотора, которые подходят для некоторых вариантов осуществления настоящего изобретения, включают в себя те, которые получены из вируса полиомы, цитомегаловируса человека или мыши (CMV), длительный повтор из различных ретровирусов, таких как вирус лейкоза мышей, вирус саркомы мышей или Рауса и HIV. Смотрите публикацию Enhancers and Eukaryotic Expression, Cold Spring Harbor Press, Cold Spring Harbor, N.Y. 1983, которая включена в настоящий документ посредством ссылки.
При конструировании вектора экспрессии промотор предпочтительно располагается приблизительно на таком же расстоянии от сайта начала гетерологичной транскрипции, как и от сайта начала транскрипции в его естественных условиях. Однако, как известно в настоящей области техники, можно учесть некоторые вариации этого расстояния без потери функции промотора.
Последовательности полиаденилирования также могут быть добавлены к вектору экспрессии для повышения эффективности трансляции мРНК SIRPα-4-1BBL, SIRPα или 4-1BBL. Для точного и эффективного полиаденилирования требуются два различных элемента последовательности: последовательности, богатые GU или U, расположенные ниже по ходу транскрипции от сайта полиаденилирования, и высококонсервативная последовательность из шести нуклеотидов, AAUAAA, расположенная на 11-30 нуклеотидов выше против хода транскрипции. Сигналы терминации и полиаденилирования, которые подходят для некоторых вариантов осуществления настоящего изобретения, включают в себя сигналы, полученные из SV40.
В дополнение к уже описанным элементам вектор экспрессии некоторых вариантов осуществления настоящего изобретения, как правило, может содержать другие специализированные элементы, предназначенные для повышения уровня экспрессии клонированных нуклеиновых кислот или для облегчения идентификации клеток, несущих рекомбинантную ДНК. Например, ряд вирусов животных содержит последовательности ДНК, которые способствуют экстрахромосомной репликации вирусного генома в пермиссивных типах клеток. Плазмиды, несущие эти вирусные репликоны, реплицируются эписомно до тех пор, пока соответствующие факторы обеспечиваются генами, переносимыми либо в плазмиде, либо в геноме клетки-хозяина.
Вектор может содержать или не содержать эукариотический репликон. Если присутствует эукариотический репликон, то вектор может быть амплифицирован в эукариотических клетках с использованием соответствующего селектируемого маркера. Если вектор не содержит эукариотический репликон, эписомальная амплификация невозможна. Вместо этого рекомбинантная ДНК интегрируется в геном сконструированной клетки, где промотор управляет экспрессией желаемой нуклеиновой кислоты.
Вектор экспрессии по некоторым вариантам осуществления настоящего изобретения может дополнительно содержать дополнительные полинуклеотидные последовательности, которые позволяют, например, трансляцию нескольких белков из одной мРНК, такой как внутренний участок посадки рибосомы (IRES), и последовательности для геномной интеграции промоторно-химерного полипептида.
Следует понимать, что отдельные элементы, содержащиеся в векторе экспрессии, могут быть расположены во множестве конфигураций. Например, энхансерные элементы, промоторы и т.п. и даже полинуклеотидная последовательность(и), кодирующая SIRPα-4-1BBL, полипептид, содержащий аминокислотную последовательность SIRPα, или полипептид, содержащий аминокислотную последовательность 4-1BBL, могут быть расположены в конфигурации «голова к хвосту», могут присутствовать в виде перевернутого комплемента или в комплементарной конфигурации в виде антипараллельной нити. Хотя такое разнообразие конфигураций более вероятно для некодирующих элементов вектора экспрессии, также предусмотрены альтернативные конфигурации кодирующей последовательности в векторе экспрессии.
Примеры векторов экспрессии млекопитающих включают в себя, без ограничения, pcDNA3, pcDNA3.1(+/-), pGL3, pZeoSV2(+/-), pSecTag2, pDisplay, pEF/myc/cyto, pCMV/myc/cyto, pCR3.1, PSinRep5, DH26S, DHBB, pNMT1, pNMT41, pNMT81, которые доступны от Invitrogen, pCI, которые доступны от Promega, pMbac, pPbac, pBK-RSV и pBK-CMV, которые доступны от Strategene, pTRES, которые доступны от Clontech и их производные.
Также можно использовать векторы экспрессии, содержащие регуляторные элементы из эукариотических вирусов, таких как ретровирусы. Векторы SV40 включают в себя pSVT7 и рМТ2. Векторы, полученные из вируса папилломы крупного рогатого скота, включают в себя pBV-1MTHA, а векторы, полученные из вируса Эпштейна-Барра, включают в себя рНЕВО и p2O5. Другие иллюстративные векторы включают в себя pMSG, pAV009/A+, рМТО10/А+, pMAMneo-5, бакуловирус pDSVE и любой другой вектор, позволяющий экспрессию белков под управлением раннего промотора SV-40, более позднего промотора SV-40, промотора металлотионеина, мышиного промотора вируса опухоли молочной железы, промотора вируса саркомы Рауса, промотора полиэдрина или других промоторов, эффективных для экспрессии в эукариотических клетках.
Как описано выше, вирусы представляют собой очень специализированные инфекционные средства, которые эволюционировали во многих случаях, чтобы ускользнуть от защитных механизмов хозяина. Как правило, вирусы инфицируют и размножаются в определенных типах клеток. Нацеленная специфичность вирусных векторов использует его природную специфичность для специфического нацеливания на предопределенные типы клеток и, таким образом, введения рекомбинантного гена в инфицированную клетку. Таким образом, тип вектора, используемого в некоторых вариантах осуществления настоящего изобретения, будет зависеть от типа трансформируемых клеток. Возможность выбора подходящих векторов в соответствии с типом трансформируемых клеток находится в пределах возможностей рядового специалиста в настоящей области техники, и поэтому в настоящем документе не приводится общего описания соображений выбора. Например, клетки костного мозга могут быть нацелены с использованием вируса Т-клеточного лейкоза человека типа I (HTLV-I), а клетки почек могут быть нацелены с использованием гетерологичного промотора, присутствующего в нуклеополигедровирусе бакуловируса Autographa californica (AcMNPV), как описано в Liang CY et al., 2004 (Arch Virol. 149: 51-60).
Рекомбинантные вирусные векторы применимы для экспрессии in vivo SIRPα-4-1BBL, SIRPα или 4-1BBL, поскольку они предлагают такие преимущества, как латеральное инфицирование и специфичность нацеливания. Латеральная инфекция присуща жизненному циклу, например, ретровируса, и представляет собой процесс, посредством которого одна инфицированная клетка производит множество дочерних вирионов, которые отпочковываются и заражают соседние клетки. В результате быстро заражается большая площадь, большая часть которой изначально не была инфицирована исходными вирусными частицами. Это контрастирует с вертикальным типом инфекции, при которой инфекционный агент распространяется только через дочернее потомство. Также могут быть получены вирусные векторы, которые не могут распространяться латерально. Эта характеристика может быть полезна, если желаемой целью является введение определенного гена только в локализованное количество клеток-мишеней.
Для введения вектора экспрессии некоторых вариантов осуществления настоящего изобретения в клетки можно использовать различные способы. Такие способы, как правило, описаны в Sambrook et al., Molecular Cloning: A Laboratory Manual, Cold Springs Harbor Laboratory, New York (1989, 1992), в Ausubel et al., Current Protocols in Molecular Biology, John Wiley and Sons, Baltimore, Md. (1989), Chang et al., Somatic Gene Therapy, CRC Press, Ann Arbor, Mich. (1995), Vega et al., Gene Targeting, CRC Press, Ann Arbor Mich. (1995), Vectors: A Survey of Molecular Cloning Vectors and Their Uses, Butterworths, Boston Mass. (1988) и Gilboa et at. [Biotechniques 4 (6): 504-512, 1986] и включают в себя, например, стабильную или временную трансфекцию, липофекцию, электропорацию и инфицирование рекомбинантными вирусными векторами. Кроме того, смотрите патенты США №5464764 и 5487992 для способов положительно-отрицательной селекции.
Введение нуклеиновых кислот путем вирусной инфекции дает несколько преимуществ по сравнению с другими способами, такими как липофекция и электропорация, поскольку может быть получена более высокая эффективность трансфекции из-за инфекционной природы вирусов.
В настоящее время предпочтительные способы переноса нуклеиновых кислот in vivo предусматривают трансфекцию вирусными или невирусными конструкциями, такими как аденовирус, лентивирус, вирус простого герпеса I или аденоассоциированный вирус (AAV), а также системы на основе липидов. Подходящими липидами для липид-опосредованного переноса гена являются, например, DOTMA, DOPE и DC-Chol [Tonkinson et al., Cancer Investigation, 14 (1): 54-65 (1996)]. Наиболее предпочтительными конструкциями для использования в генной терапии являются вирусы, наиболее предпочтительно аденовирусы, AAV, лентивирусы или ретровирусы. Вирусная конструкция, такая как ретровирусная конструкция, включает в себя по меньшей мере один промотор/энхансер транскрипции или определяющий локус элемент(ы), или другие элементы, которые контролируют экспрессию гена другими способами, такими как альтернативный сплайсинг, экспорт ядерной РНК или посттрансляционная модификация информационной РНК. Такие векторные конструкции также включают в себя сигнал упаковки, длинные концевые повторы (LTR) или их части, а также сайты связывания праймеров с положительной и отрицательной цепью, подходящие для используемого вируса, если он уже не присутствует в вирусной конструкции. Кроме того, такая конструкция, как правило, включает в себя сигнальную последовательность для секреции пептида из клетки-хозяина, в которую он помещен. Предпочтительно сигнальная последовательность для этой цели представляет собой сигнальную последовательность млекопитающего или сигнальную последовательность вариантов полипептида некоторых вариантов осуществления настоящего изобретения. Необязательно, конструкция может также включать в себя сигнал, который направляет полиаденилирование, а также один или несколько сайтов рестрикции и последовательность терминации трансляции. В качестве примера такие конструкции, как правило, включают в себя 5'-LTR, сайт связывания тРНК, сигнал упаковки, источник синтеза второй цепи ДНК и 3'-LTR или его часть. Могут использоваться другие векторы, которые не являются вирусными, такие как катионные липиды, полилизин и дендримеры.
Как уже упоминалось, помимо необходимых элементов для транскрипции и трансляции вставленной кодирующей последовательности, экспрессионная конструкция некоторых вариантов осуществления настоящего изобретения может также содержать последовательности, сконструированные для повышения стабильности, продукции, очистки, выхода или токсичности экспрессированного пептида. Например, может быть сконструирована экспрессия слитого белка или расщепляемого слитого белка, содержащего белок SIRPα-4-1BBL или полипептид в соответствии с некоторыми вариантами осуществления настоящего изобретения и гетерологичный белок. Такой слитый белок можно сконструировать так, чтобы слитый белок можно было легко выделить с помощью аффинной хроматографии; например, путем иммобилизации на колонке, специфической для гетерологичного белка. Если сайт расщепления создан между белком SIRPα-4-1BBL или полипептидом по некоторым вариантам осуществления настоящего изобретения и гетерологичным белком, белок или полипептид SIRPα-4-1BBL могут быть высвобождены из хроматографической колонки путем обработки подходящим ферментом или средством, разрушающим сайт расщепления [например, смотрите Booth et al. (1988) Immunol. Lett. 19: 65-70 и Gardella et al. (1990) J. Biol. Chem. 265: 15854-15859].
Настоящее изобретение также относится к клеткам, содержащим описанную в настоящем документе композицию.
Таким образом, согласно конкретным вариантам осуществления предусмотрена клетка-хозяин, содержащая слитый белок SIRPα-4-1BBL, полипептид, содержащий аминокислотную последовательность SIRPα, и/или полипептид, содержащий аминокислотную последовательность 4-1BBL, описанные в настоящем документе, кодирующий их полинуклеотид или кодирующую их конструкцию нуклеиновой кислоты.
Как упоминалось выше, различные прокариотические или эукариотические клетки могут использоваться в качестве систем экспрессии хозяина для экспрессии полипептидов некоторых вариантов осуществления настоящего изобретения. Они включают в себя, без ограничения, такие микроорганизмы, как бактерии, трансформированные рекомбинантной ДНК бактериофага, плазмидной ДНК или вектором экспрессии космидной ДНК, содержащей кодирующую последовательность; дрожжи, трансформированные рекомбинантными векторами экспрессии дрожжей, содержащими кодирующую последовательность; системы клеток растений, инфицированные векторами экспрессии рекомбинантного вируса (например, вирусом мозаики цветной капусты, CaMV; вирусом табачной мозаики, TMV) или трансформированные векторами экспрессии рекомбинантных плазмид, такими как плазмида Ti, содержащая кодирующую последовательность. Системы экспрессии млекопитающих также могут использоваться для экспрессии полипептидов по некоторым вариантам осуществления настоящего изобретения.
Примеры бактериальных конструкций включают в себя серию рЕТ векторов экспрессии Е. coli (Studier et al. (1990) Methods in Enzymol. 185: 60-89).
Примеры эукариотических клеток, которые можно использовать вместе с идеями настоящего изобретения, включают в себя, без ограничения, клетки млекопитающих, клетки грибов, клетки дрожжей, клетки насекомых, клетки водорослей или клетки растений.
В дрожжах можно использовать ряд векторов, содержащих конститутивные или индуцируемые промоторы, как описано в заявке на патент США №: 5932447. В качестве альтернативы можно использовать векторы, которые способствуют интеграции последовательностей чужеродной ДНК в хромосому дрожжей.
В случаях, когда используются векторы экспрессии растений, экспрессия кодирующей последовательности может управляться рядом промоторов. Например, вирусные промоторы, такие как промоторы 35S РНК и 19S РНК CaMV [Brisson et al. (1984) Nature 310: 511-514] или промотор белка оболочки TMV [Takamatsu et al. (1987) EMBO J. 6: 307-311]. Альтернативно, могут использоваться промоторы растений, такие как малая субъединица RUBISCO [Coruzzi et al. (1984) EMBO J. 3: 1671-1680 и Brogli et al., (1984) Science 224: 838-843] или промоторы теплового шока, например, соевый hspl7.5-E или hsp17.3-B [Gurley et al. (1986) Mol. Cell. Biol. 6:559-565]. Эти конструкции могут быть введены в клетки растений с использованием плазмиды Ti, плазмиды Ri, вирусных векторов растений, прямой трансформации ДНК, микроинъекции, электропорации и других способов, хорошо известных специалисту в настоящей области техники. Смотрите, например, Weissbach & Weissbach, 1988, Methods for Plant Molecular Biology, Academic Press, NY, Section VIII, pp 421-463.
Другие системы экспрессии, такие как системы клеток-хозяев насекомых и млекопитающих, которые хорошо известны в настоящей области техники, также могут быть использованы в некоторых вариантах осуществления настоящего изобретения.
Согласно конкретным вариантам осуществления клетка представляет собой клетку млекопитающего.
Согласно конкретному варианту осуществления клетка представляет собой клетку человека.
Согласно конкретному варианту осуществления клетка представляет собой линию клеток.
Согласно другому конкретному варианту осуществления клетка представляет собой первичную клетку.
Клетка может быть получена из подходящей ткани, включая в себя, без ограничения, кровь, мышцы, нерв, головной мозг, сердце, легкое, печень, поджелудочную железу, селезенку, тимус, пищевод, желудок, кишечник, почки, семенники, яичники, волосы, кожу, кость, молочную железу, матку, мочевой пузырь, спинной мозг или различные биологические жидкости. Клетки могут происходить из любой стадии развития, включая в себя стадии эмбриона, плода и взрослого, а также из онтодермального происхождения, т.е. эктодермального, мезодермального и энтодермального происхождения.
Неограничивающие примеры клеток млекопитающих включают в себя линию CV1 почки обезьяны, трансформированную SV40 (COS, например, COS-7, АТСС CRL 1651); линию эмбриональных почек человека (клетки HEK293 или HEK293, субклонированные для роста в суспензионной культуре, Graham et al., J. Gen Virol., 36:59 1977); клетки почек детеныша хомячка (BHK, АТСС CCL 10); клетки сертоли мыши (ТМ4, Mather, Biol. Reprod., 23: 243-251, 1980); клетки почек обезьяны (CV1 АТСС CCL 70); клетки почек африканской зеленой мартышки (VERO-76, АТСС CRL-1587); клетки карциномы шейки матки человека (HeLa, ATCC CCL 2); NIH3T3, Jurkat, клетки почек собаки (MDCK, АТСС CCL 34); клетки печени буйволовой крысы (BRL 3А, АТСС CRL 1442); клетки легких человека (W138, АТСС CCL 75); клетки печени человека (Hep G2, НВ 8065); опухоль молочной железы мыши (ММТ 060562, АТСС CCL51); клетки TRI (Mather et al., Annals N.Y. Acad. Sci., 383: 44-68 1982); клетки MRC 5; клетки FS4 и линию гепатомы человека (Hep G2), PER.C6, K562 и клетки яичника китайского хомячка (СНО).
Согласно некоторым вариантам осуществления настоящего изобретения клетка млекопитающего выбрана из группы, состоящей из клеток яичника китайского хомячка (СНО), HEK293, PER.C6, НТ1080, NS0, Sp2/0, BHK, Namalwa, COS, HeLa и Vero.
Согласно некоторым вариантам осуществления настоящего изобретения клетка-хозяин включает в себя клетку яичника китайского хомячка (СНО), PER.C6 и 293 (например, Expi293F).
Согласно другому аспекту настоящего изобретения предусмотрен способ получения слитого белка SIRPα-4-1BBL, полипептида, содержащего аминокислотную последовательность SIRPα, или полипептида, содержащего аминокислотную последовательность 4-1BBL, способ, предусматривающий экспрессию в клетке-хозяине, описанных в настоящем документе полинуклеотид а или конструкции нуклеиновой кислоты.
Согласно конкретным вариантам осуществления способы предусматривают выделение слитого белка или полипептида.
Согласно конкретным вариантам осуществления выделение рекомбинантного полипептида осуществляется по истечении соответствующего периода времени в культуре. Фраза «выделение рекомбинантного полипептида» относится к сбору всей ферментационной среды, содержащей полипептид, и не требует дополнительных стадий разделения или очистки. Несмотря на вышесказанное, полипептиды по некоторым вариантам осуществления настоящего изобретения могут быть очищены с использованием различных стандартных способов очистки белка, таких как, без ограничения, аффинная хроматография, ионообменная хроматография, фильтрация, электрофорез, хроматография гидрофобного взаимодействия, гель-фильтрационная хроматография, обращенно-фазовая хроматография, хроматография конканавалина А, хроматография в смешанном режиме, аффинная хроматография с металлами, аффинная хроматография с лектинами, хроматофокусирование и дифференциальная солюбилизация.
Согласно конкретным вариантам осуществления после синтеза и очистки терапевтическая эффективность пептида может быть проанализирована либо in vivo, либо in vitro. Такие способы известны в настоящей области техники и включают в себя, например, жизнеспособность клеток, выживаемость трансгенных мышей и экспрессию маркеров активации.
Композиции (например, слитый белок SRIPα-4-1BBL, полипептид, содержащий аминокислотную последовательность SIRPα, полипептид, содержащий аминокислотную последовательность 4-1BBL, описанные в настоящем документе, кодирующий их полинуклеотид, кодирующую их конструкцию нуклеиновой кислоты и/или клетки) согласно некоторым вариантам осуществления настоящего изобретения можно вводить в организм как таковой или в фармацевтическую композицию, где она смешана с подходящими носителями или вспомогательными веществами.
Таким образом, согласно некоторым вариантам осуществления настоящее изобретение относится к фармацевтической композиции, содержащей терапевтически эффективное количество раскрытых в настоящем документе композиций.
Используемый в настоящем документе термин «фармацевтическая композиция» относится к препарату одного или нескольких активных ингредиентов, описанных в настоящем документе, с другими химическими компонентами, такими как физиологически подходящие носители и вспомогательные вещества. Назначение фармацевтической композиции заключается в том, чтобы облегчить введение соединения в организм.
В настоящем документе термин «активный ингредиент» относится к композиции (например, слитый белок SIRPα-4-1BBL, полипептид, содержащий аминокислотную последовательность SIRPα, полипептид, содержащий аминокислотную последовательность 4-1BBL, полинуклеотид, конструкция нуклеиновой кислоты и/или клетки, описанные в настоящем документе), отвечающей за биологический эффект.
В настоящем документе термин «вспомогательное вещество» относится к инертному веществу, добавляемому в фармацевтическую композицию для дальнейшего облегчения введения активного ингредиента. Примеры вспомогательных веществ, без ограничения, включают в себя карбонат кальция, фосфат кальция, различные сахара и типы крахмала, производные целлюлозы, желатин, растительные масла и полиэтиленгликоли.
В настоящем документе и далее фразы «физиологически приемлемый носитель» и «фармацевтически приемлемый носитель», которые могут использоваться взаимозаменяемо, относятся к носителю или разбавителю, который не вызывает значительного раздражения организма и не отменяет биологическую активность и свойства вводимого соединения. Под этими фразами включено вспомогательное средство.
Используемый в настоящем документе термин «фармацевтически приемлемый носитель» включает в себя любой и все растворители, дисперсионные среды, покрытия, антибактериальные и противогрибковые средства, изотонические средства и средства, замедляющие абсорбцию, и т.п., которые являются физиологически совместимыми. Предпочтительно носитель подходит для внутривенного, внутримышечного, подкожного, парентерального, спинального или эпидермального введения (например, путем инъекции или инфузии). В зависимости от пути введения активное соединение, т.е. полипептид, полинуклеотид, конструкция нуклеиновой кислоты и/или клетка, как описано в настоящем документе, может включать в себя одну или несколько фармацевтически приемлемых солей. «Фармацевтически приемлемая соль» относится к соли, которая сохраняет желаемую биологическую активность исходного соединения и не оказывает каких-либо нежелательных токсикологических эффектов (смотрите, например, Berge, SM, et al. (1977) J. Pharm. Sci. 66: 1-19). Примеры таких солей включают в себя соли присоединения кислот и соли присоединения оснований. Соли присоединения кислот включают в себя соли, полученные из нетоксичных неорганических кислот, таких как хлористоводородная, азотная, фосфорная, серная, бромистоводородная, йодистоводородная, фосфорная и т.п., а также из нетоксичных органических кислот, таких как алифатические моно- и дикарбоновые кислоты, фенилзамещенные алкановые кислоты, гидроксиалкановые кислоты, ароматические кислоты, алифатические и ароматические сульфоновые кислоты и т.п. Соли присоединения оснований включают в себя соли, полученные из щелочноземельных металлов, таких как натрий, калий, магний, кальций и т.п., а также из нетоксичных органических аминов, таких как N,N'-дибензилэтилендиамин, N-метилглюкамин, хлорпрокаин, холин, диэтаноламин, этилендиамин, новокаин и т.п.
Фармацевтическая композиция согласно по меньшей мере некоторым вариантам осуществления настоящего изобретения также может включать в себя фармацевтически приемлемые антиоксиданты. Примеры фармацевтически приемлемых антиоксидантов включают в себя: (1) такие водорастворимые антиоксиданты, как аскорбиновая кислота, гидрохлорид цистеина, бисульфат натрия, метабисульфит натрия, сульфит натрия и т.п.; (2) такие маслорастворимые антиоксиданты, как аскорбилпальмитат, бутилированный гидроксианизол (ВНА), бутилированный гидрокситолуол (ВНТ), лецитин, пропилгаллат, альфа-токоферол и т.п.; и (3) такие хелатирующие средства с металлами, как лимонная кислота, этилендиаминтетрауксусная кислота (ЭДТА), сорбит, винная кислота, фосфорная кислота и т.п. Фармацевтическая композиция согласно по меньшей мере некоторым вариантам осуществления настоящего изобретения также может включать в себя такие добавки, как детергенты и солюбилизирующие средства (например, TWEEN 20 (полисорбат-20), TWEEN 80 (полисорбат-80)) и консерванты (например, тимерсол, бензил алкоголь) и наполнители (например, лактоза, маннитол).
Примеры подходящих водных и неводных носителей, которые могут использоваться в фармацевтических композициях согласно по меньшей мере некоторым вариантам осуществления настоящего изобретения, включают в себя воду, забуференный физиологический раствор с различным содержанием буфера (например, трис-HCl, ацетат, фосфат), рН и ионную силу, этанол, полиолы (такие как глицерин, пропиленгликоль, полиэтиленгликоль и т.п.) и их подходящие смеси, такие растительные масла, как оливковое масло, и такие органические сложные эфиры для инъекций, как этилолеат.
Надлежащую текучесть можно поддерживать, например, путем использования материалов покрытия, таких как лецитин, путем поддержания необходимого размера частиц в случае дисперсий и использования поверхностно-активных веществ.
Эти композиции могут также содержать вспомогательные средства, такие как консерванты, смачивающие средства, эмульгирующие средства и диспергирующие средства. Предотвращение присутствия микроорганизмов может быть обеспечено как процедурами стерилизации, смотрите выше, так и включением различных антибактериальных и противогрибковых средств, например, парабена, хлорбутанола, фенолсорбиновой кислоты и т.п. Также может быть желательно включить в композиции изотонические средства, такие как сахара, хлорид натрия и т.п. Кроме того, пролонгированная абсорбция фармацевтической формы для инъекций может быть обеспечена включением средств, замедляющих абсорбцию, таких как моностеарат алюминия и желатин.
Фармацевтически приемлемые носители включают в себя стерильные водные растворы или дисперсии и стерильные порошки для немедленного приготовления стерильных растворов или дисперсий для инъекций. Использование таких сред и средств для фармацевтически активных веществ известно в настоящей области техники. За исключением случаев, когда любая обычная среда или средство несовместимы с активным соединением, предполагается их использование в фармацевтических композициях согласно по меньшей мере некоторым вариантам осуществления настоящего изобретения. В композиции также могут быть включены дополнительные активные соединения.
Терапевтические композиции, как правило, должны быть стерильными и стабильными в условиях производства и хранения. Композиция может быть приготовлена в виде раствора, микроэмульсии, липосомы или другой упорядоченной структуры, подходящей для высокой концентрации лекарственного средства. Носитель может представлять собой растворитель или дисперсионную среду, содержащую, например, воду, этанол, полиол (например, глицерин, пропиленгликоль, жидкий полиэтиленгликоль и т.п.) и их подходящие смеси. Подходящую текучесть можно поддерживать, например, за счет использования покрытия, такого как лецитин, путем поддержания необходимого размера частиц в случае дисперсии и за счет использования поверхностно-активных веществ. Во многих случаях будет предпочтительно включать в композицию изотонические средства, например, сахара, многоатомные спирты, такие как маннит, сорбит или хлорид натрия. Пролонгированное всасывание композиций для инъекций может быть достигнуто путем включения в композицию средства, замедляющего абсорбцию, например, солей моностеарата и желатина. Стерильные растворы для инъекций могут быть приготовлены путем включения активного соединения в необходимом количестве в соответствующий растворитель с одним или комбинацией ингредиентов, перечисленных выше, при необходимости, с последующей стерилизационной микрофильтрацией. Как правило, дисперсии готовят путем включения активного соединения в стерильный носитель, который содержит основную дисперсионную среду и другие требуемые ингредиенты из перечисленных выше. В случае стерильных порошков для приготовления стерильных растворов для инъекций предпочтительными способами приготовления являются вакуумная сушка и сублимационная сушка (лиофилизация), которые дают порошок активного ингредиента плюс любой дополнительный желаемый ингредиент из его раствора, предварительно стерилизованный фильтрованием.
Стерильные растворы для инъекций могут быть приготовлены путем включения активного соединения в необходимом количестве в соответствующий растворитель с одним или комбинацией ингредиентов, перечисленных выше, при необходимости, с последующей стерилизационной микрофильтрацией. Как правило, дисперсии готовят путем включения активного соединения в стерильный носитель, который содержит основную дисперсионную среду и другие требуемые ингредиенты из перечисленных выше. В случае стерильных порошков для приготовления стерильных растворов для инъекций предпочтительными способами приготовления являются вакуумная сушка и сублимационная сушка (лиофилизация), которые дают порошок активного ингредиента плюс любой дополнительный желаемый ингредиент из его раствора, предварительно стерилизованный фильтрованием.
Количество активного ингредиента, которое может быть объединено с материалом носителя для получения единичной лекарственной формы, будет варьироваться в зависимости от пациента, которого подвергают лечению, и конкретного способа введения. Количество активного ингредиента, которое может быть объединено с материалом носителя для получения единичной лекарственной формы, как правило, будет представлять собой такое количество композиции, которое оказывает терапевтический эффект. Как правило, из ста процентов это количество будет составлять от приблизительно 0,01 процента до приблизительно девяноста девяти процентов активного ингредиента, предпочтительно от приблизительно 0,1 процента до приблизительно 70 процентов, наиболее предпочтительно от приблизительно 1 процента до приблизительно 30 процентов активного ингредиента в сочетании с фармацевтически приемлемым носителем.
Схема приема лекарственного средства корректируются для обеспечения оптимального желаемого ответа (например, терапевтического ответа). Например, можно вводить один болюс, можно вводить несколько разделенных доз с течением времени или дозу можно пропорционально уменьшать или увеличивать в зависимости от необходимости терапевтической ситуации. Особенно выгодно составлять парентеральные композиции в виде стандартной дозированной формы для простоты введения и единообразия дозировки. Используемая в настоящем документе лекарственная форма относится к физически дискретным единицам, подходящим в качестве единичных доз для подлежащих лечению субъектов; каждая единица содержит заранее определенное количество активного соединения, рассчитанное для получения желаемого терапевтического эффекта, в сочетании с необходимым фармацевтическим носителем. Спецификация стандартных дозированных форм согласно по меньшей мере некоторым вариантам осуществления настоящего изобретения продиктована и напрямую зависит от (а) уникальных характеристик активного соединения и конкретного терапевтического эффекта, который должен быть достигнут, и (b) присущих ограничений в области приготовления такого активного соединения для лечения чувствительности у людей.
Технологии составления и введения лекарственных средств можно найти в последней редакции "Remington's Pharmaceutical Sciences," Mack Publishing Co., Easton, PA, которая включена в настоящий документ посредством ссылки.
Фармацевтические композиции согласно некоторым вариантам осуществления настоящего изобретения могут быть получены способами, хорошо известными в настоящей области техники, например, посредством обычных процессов смешивания, растворения, гранулирования, изготовления драже, растирания в порошок, эмульгирования, инкапсулирования, захвата или лиофилизации.
Композицию по настоящему изобретению можно вводить одним или несколькими путями введения с использованием одного или нескольких способов, известных в настоящей области техники. Как будет понятно специалисту в настоящей области техники, путь и/или способ введения будет варьироваться в зависимости от желаемых результатов. Предпочтительные пути введения терапевтических средств согласно, по меньшей мере, некоторым вариантам осуществления настоящего изобретения включают в себя внутрисосудистую доставку (например, инъекцию или инфузию), внутривенную, внутримышечную, внутрикожную, внутрибрюшинную, подкожную, спинальную, пероральную, энтеральную, ректальную, легочную (например, ингаляцию), назальную, местную (включая в себя трансдермальную, трансбуккальную и сублингвальную), внутрипузырную, интравитреальную, внутрибрюшинную, вагинальную, доставку в головной мозг (например, интрацеребровентрикулярную, интрацеребральную и усиленную конвекцией диффузию), доставку в ЦНС (например, интратекальную, периспинальную и интраспинальную) или парентеральную (включая в себя подкожную, внутримышечную, внутрибрюшинную, внутривенную (IV) и внутрикожную), трансдермальную (пассивную или с использованием ионофореза или электропорации), трансмукозальную (например, сублингвальное, назальное, вагинальное, ректальное или сублингвальное введение), введение через имплант или другие парентеральные пути введения, например, путем инъекции или инфузии, или другие пути доставки и/или формы введения, известные в настоящей области техники. Используемая в настоящем документе фраза «парентеральное введение» означает способы введения, отличные от энтерального и местного, как правило, путем инъекции, и включает в себя, без ограничения, внутривенную, внутримышечную, внутриартериальную, интратекальную, внутрикапсульную, внутриглазничную, внутрисердечную, внутрикожную, внутрибрюшинную, транстрахеальную, подкожную, субкутикулярную, внутрисуставную, субкапсулярную, субарахноидальную, интраспинальную, эпидуральную и внутригрудинную инъекцию и инфузию или с использованием биоразлагаемых вставок, и может быть приготовлена в виде лекарственных форм, подходящих для каждого пути введения. Согласно конкретному варианту осуществления белок, терапевтическое средство или фармацевтическую композицию согласно по меньшей мере некоторым вариантам осуществления настоящего изобретения можно вводить внутрибрюшинно или внутривенно.
Согласно конкретным вариантами осуществления раскрытые в настоящем документе композиции вводятся в водном растворе путем парентеральной инъекции. Композиция также может быть в форме суспензии или эмульсии. Как правило, предусмотрены фармацевтические композиции для парентеральной инъекции, включающие в себя эффективные количества описанных в настоящем документе композиций, и необязательно включают в себя фармацевтически приемлемые разбавители, консерванты, солюбилизаторы, эмульгаторы, вспомогательные средства и/или носители. Такие композиции необязательно включают в себя один или несколько следующих компонентов: разбавители, стерильная вода, забуференный физиологический раствор с различным содержанием буфера (например, трис-HCl, ацетат, фосфат), рН и ионная сила; и добавки, такие как детергенты и солюбилизирующие вещества (например, TWEEN 20 (полисорбат-20), TWEEN 80 (полисорбат-80)), антиоксиданты (например, такие водорастворимые антиоксиданты, как аскорбиновая кислота, метабисульфит натрия, гидрохлорид цистеина, бисульфат натрия, метабисульфит натрия, сульфит натрия; такие маслорастворимые антиоксиданты, как аскорбилпальмитат, бутилированный гидроксианизол (ВНА), бутилированный гидрокситолуол (ВНТ), лецитин, пропилгаллат, альфа-токоферол; и такие хелатирующие средства с металлами, как лимонная кислота, этилендиаминтетрауксусная кислота (ЭДТА), сорбит, винная кислота, фосфорная кислота) и консерванты (например, тимерсол, бензиловый спирт) и наполнители (например, лактоза, маннит). Примерами неводных растворителей или носителей являются этанол, пропиленгликоль, полиэтиленгликоль, такие растительные масла, как оливковое масло и кукурузное масло, желатин и такие органические сложные эфиры для инъекций, как этилолеат. Композиции можно сушить вымораживанием (лиофилизировать) или сушить в вакууме и повторно растворять/ресуспендировать непосредственно перед использованием. Композицию можно стерилизовать, например, фильтрацией через фильтр, задерживающий бактерии, путем включения стерилизующих средств в композиции, облучения композиций или нагревания композиций.
Различные раскрытые в настоящем документе композиции (например, полипептиды) можно применять местно. Местное введение неэффективно для большинства пептидных составов, хотя оно может быть эффективным, особенно при нанесении на легкие, носовые, оральные (сублингвальные, буккальные), влагалищные или ректальные слизистые оболочки.
Композиции по настоящему изобретению могут доставляться в легкие при вдыхании и проходить через эпителиальную выстилку легких в кровоток при доставке либо в виде аэрозоля, либо в виде высушенных распылением частиц, имеющих аэродинамический диаметр менее чем приблизительно 5 микрон. Можно использовать широкий спектр механических устройств, разработанных для доставки терапевтических продуктов в легкие, включая в себя, без ограничения, небулайзеры, ингаляторы с отмеренными дозами и порошковые ингаляторы, все из которых знакомы специалистам в настоящей области техники. Некоторыми конкретными примерами имеющихся в продаже устройств являются небулайзер Ultravent (Mallinckrodt Inc., Сент-Луис, Миссури); небулайзер Acorn II (Marquest Medical Products, Энглвуд, Колорадо); ингалятор с отмеренной дозой вентолина (Glaxo Inc., Research Triangle Park, N.C.) и порошковый ингалятор Spinhaler (Fisons Corp., Бедфорд, Массачусетс). Nektar, Alkermes и Mannkind содержат препараты в виде порошка инсулина для ингаляции, одобренные или проходящие клинические испытания, в которых технология может быть применена к составам, описанным в настоящем документе.
Составы для введения на слизистую оболочку, как правило, представляют собой высушенные распылением частицы лекарственного средства, которые могут быть включены в таблетку, гель, капсулу, суспензию или эмульсию. Стандартные фармацевтические вспомогательные вещества доступны от любого разработчика. Пероральные составы могут быть в форме жевательной резинки, гелевых полосок, таблеток или леденцов.
Также могут быть приготовлены трансдермальные составы. Как правило, это мази, лосьоны, спреи или пластыри, которые можно приготовить по стандартной технологии. Трансдермальные составы потребуют включения усилителей проникновения. Фактические уровни дозировки активных ингредиентов в фармацевтических композициях по настоящему изобретению могут варьироваться для получения количества активного ингредиента, которое эффективно для достижения желаемого терапевтического ответа для конкретного пациента, композиции и способа введения без токсичности для пациента. Выбранный уровень дозировки будет зависеть от множества фармакокинетических факторов, включая в себя активность конкретных применяемых композиций по настоящему изобретению, способа введения, времени введения, скорости выведения конкретного применяемого соединения, продолжительности действия лечение, других лекарственных средств, соединений и/или материалов, используемых в комбинации с конкретными применяемыми композициями, возраста, пола, массы, состояния, общего состояния здоровья и предшествующего медицинского анамнеза пациента, подвергаемого лечению, и подобных факторов, хорошо известных в области медицины.
Согласно конкретным вариантам осуществления раскрытые в настоящем документе композиции вводят субъекту в терапевтически эффективном количестве. Используемый в настоящем документе термин «эффективное количество» или «терапевтически эффективное количество» означает дозу, достаточную для лечения, ингибирования или облегчения одного или нескольких симптомов подвергаемого лечению заболевания или для иного обеспечения желаемого фармакологического и/или физиологического эффекта. Точная дозировка будет варьироваться в зависимости от множества факторов, таких как переменные, зависящие от субъекта (например, возраст, состояние иммунной системы и т.д.), заболевание и проводимое лечение. Для описанных в настоящем документе полипептидных композиций, кодирующих их конструкций полинуклеотидов и нуклеиновых кислот и описанных в настоящем документе клеток, по мере проведения дальнейших исследований будет появляться информация, касающаяся соответствующих уровней дозировки для лечения различных состояний у различных пациентов, и рядовой квалифицированный специалист, учитывая терапевтический контекст, возраст и общее состояние здоровья реципиента, поможет определить правильную дозировку. Выбранная дозировка зависит от желаемого терапевтического эффекта, от пути введения и от продолжительности желаемого лечения. Для полипептидных композиций млекопитающим, как правило, вводят уровни доз от 0,0001 до 100 мг/кг массы тела в день, а чаще - от 0,001 до 20 мг/кг. Например, дозировки могут составлять 0,3 мг/кг массы тела, 1 мг/кг массы тела, 3 мг/кг массы тела, 5 мг/кг массы тела или 10 мг/кг массы тела или в диапазоне 1-10 мг/кг. Иллюстративная схема лечения предусматривает введение 5 раз в неделю, 4 раза в неделю, 3 раза в неделю, 2 раза в неделю, один раз в неделю, один раз в две недели, один раз в три недели, один раз в четыре недели, один раз в месяц, один раз каждые 3 месяца или раз в 3-6 месяцев. Как правило, для внутривенной инъекции или инфузии дозировка может быть ниже. Схемы приема лекарственных средств корректируются для обеспечения оптимального желаемого ответа (например, терапевтического ответа). Например, можно вводить один болюс, можно вводить несколько разделенных доз с течением времени или доза может быть пропорционально уменьшена или увеличена в зависимости от необходимости терапевтической ситуации. Особенно выгодно составлять парентеральные композиции в виде стандартной дозированной формы для простоты введения и единообразия дозировки. Используемая в настоящем документе лекарственная форма относится к физически дискретным единицам, подходящим в качестве единичных доз для подлежащих лечению субъектов; каждая единица содержит заранее определенное количество активного соединения, рассчитанное для получения желаемого терапевтического эффекта, в сочетании с необходимым фармацевтическим носителем. Спецификация стандартных дозированных форм согласно по меньшей мере некоторым вариантам осуществления настоящего изобретения продиктована и напрямую зависит от (а) уникальных характеристик активного соединения и конкретного терапевтического эффекта, который должен быть достигнут, и (b) присущих ограничений в области приготовления такого активного соединения для лечения чувствительности у людей.
Необязательно, полипептидный состав можно вводить в количестве от 0,0001 до 100 мг/кг массы пациента/день, предпочтительно от 0,001 до 20,0 мг/кг/день, в соответствии с любой подходящей схемой времени. Терапевтическая композиция согласно по меньшей мере некоторым вариантам осуществления по меньшей мере с некоторыми вариантами осуществления настоящего изобретения может вводиться, например, три раза в день, два раза в день, один раз в день, три раза в неделю, два раза в неделю или один раз в неделю, один раз каждые две недели или 3, 4, 5, 6, 7 или 8 недель. Более того, композицию можно вводить в течение короткого или длительного периода времени (например, 1 неделю, 1 месяц, 1 год, 5 лет).
Альтернативно, раскрытые в настоящем документе композиции можно вводить в виде препаратов с замедленным высвобождением, и в этом случае требуется менее частое введение. Дозировка и частота варьируются в зависимости от периода полувыведения терапевтического средства в организме пациента. В общем, человеческие антитела показывают самый длительный период полужизни, за ними следуют гуманизированные антитела, химерные антитела и отличные от человеческих антитела. Период полужизни слитых белков может широко варьироваться. Дозировка и частота приема могут варьироваться в зависимости от того, является ли лечение профилактическим или терапевтическим. В профилактических целях относительно небольшая доза вводится через относительно нечастые интервалы в течение длительного периода времени. Некоторые пациенты продолжают получать лечение всю оставшуюся жизнь. При терапевтическом применении иногда требуется относительно высокая доза с относительно короткими интервалами до тех пор, пока прогрессирование заболевания не уменьшится или не прекратится, и предпочтительно до тех пор, пока у пациента не появится частичное или полное улучшение симптомов заболевания. После этого пациенту может быть назначена профилактическая схема приема.
Согласно определенным вариантам осуществления полипептид, полинуклеотид, конструкция нуклеиновой кислоты или клеточные композиции вводят локально, например, путем инъекции непосредственно в участок, который необходимо лечить. Как правило, инъекция вызывает повышенную локализованную концентрацию композиции, которая больше, чем та, которая может быть достигнута системным введением. Полипептидные композиции можно комбинировать с матрицей, как описано выше, чтобы способствовать созданию увеличенной локальной концентрации полипептидных композиций за счет уменьшения пассивной диффузии полипептидов из подлежащего лечению участка.
Фармацевтические композиции по настоящему изобретению можно вводить с помощью медицинских устройств, известных в настоящей области техники. Например, согласно необязательному варианту осуществления фармацевтическая композиция согласно по меньшей мере некоторым вариантам осуществления настоящего изобретения может вводиться с помощью устройства для подкожных инъекций с иглами, такого как устройства, описанные в патентах США №5399163; 5383851; 5312335; 5064413; 4941880; 4790824 или 4596556. Примеры хорошо известных имплантатов и модулей, используемых в настоящем изобретении, включают в себя: патент США №4487603, в котором описан имплантируемый микроинфузионный насос для дозированного введения лекарственных средств с контролируемой скоростью; патент США №4486194, в котором раскрыто терапевтическое устройство для введения лекарственных средств через кожу; патент США №4447233, в котором раскрыт насос для инфузии лекарственных средств для доставки лекарственных средств с точной скоростью инфузии; патент США №4447224, в котором раскрыт имплантируемый инфузионный аппарат с регулируемым потоком для непрерывной доставки лекарственных средств; патент США №4439196, в котором раскрыта осмотическая система доставки лекарственных средств, имеющая многокамерные отсеки; и патент США №4475196, в котором раскрыта система осмотической доставки лекарственных средств. Эти патенты включены в настоящий документ посредством ссылки. Многие другие такие имплантаты, системы доставки и модули известны специалистам в настоящей области техники.
Активные соединения могут быть получены с носителями, которые будут защищать соединение от быстрого высвобождения, такими как состав с контролируемым высвобождением, включая в себя имплантаты, трансдермальные пластыри и микрокапсулированные системы доставки. Могут использоваться биоразлагаемые, биосовместимые полимеры, такие как этиленвинилацетат, полиангидриды, полигликолевая кислота, коллаген, полиортоэфиры и полимолочная кислота. Многие способы приготовления таких составов запатентованы или обычно известны специалистам в настоящей области техники. Смотрите, например, Sustained and Controlled Release Drug Delivery Systems, J. R. Robinson, ed., Marcel Dekker, Inc., New York, 1978. Полимерные устройства с контролируемым высвобождением могут быть изготовлены для длительного системного высвобождения после имплантации полимерного устройства (стержня, цилиндра, пленки, диска) или впрыскивания (микрочастицы). Матрица может быть в форме микрочастиц, таких как микросферы, где пептиды диспергированы в твердой полимерной матрице или микрокапсулах, где ядро состоит из материала, отличного от материала полимерной оболочки, а пептид диспергирован или суспендирован в ядре, которое может быть жидким или твердым по природе. Если в настоящем документе не указано иное, микрочастицы, микросферы и микрокапсулы используются взаимозаменяемо. В качестве альтернативы полимер может быть отлит в виде тонкой пластины или пленки размером от нанометров до четырех сантиметров, порошка, полученного измельчением или другими стандартными способами, или даже геля, такого как гидрогель.
Для доставки активных средств, раскрытых в настоящем документе, можно использовать либо небиоразлагаемые, либо биоразлагаемые матрицы, хотя биоразлагаемые матрицы предпочтительны. Это могут быть природные или синтетические полимеры, хотя предпочтительны синтетические полимеры из-за лучшей характеристики профилей разложения и высвобождения. Полимер выбирают в зависимости от периода, в течение которого желательно высвобождение. В некоторых случаях линейное высвобождение может быть наиболее полезным, хотя в других импульсное высвобождение или «массовое высвобождение» может обеспечить более эффективные результаты. Полимер может быть в форме гидрогеля (как правило, абсорбирующего до приблизительно 90% по массе воды) и, необязательно, может быть сшитым многовалентными ионами или полимерами.
Матрицы могут быть сформированы испарением растворителя, распылительной сушкой, экстракцией растворителем и другими способами, известными специалистам в настоящей области техники. Биоразлагаемые микросферы могут быть получены с использованием любого из способов, разработанных для изготовления микросфер для доставки лекарственных средств, например, как описано Mathiowitz and Langer, J. Controlled Release, 5:13-22 (1987); Mathiowitz, et al., Reactive Polymers, 6:275-283 (1987) и Mathiowitz, et al., J. Appl Polymer ScL, 35:755-774 (1988).
Устройства могут быть составлены для местного высвобождения для лечения области имплантации или инъекции, которые будут обычно доставлять дозу, намного меньшую, чем дозировка для лечения всего тела, или для системной доставки. Их можно имплантировать или вводить подкожно, в мышцу, жир или проглатывать. Согласно определенным вариантам осуществления, чтобы гарантировать, что терапевтические соединения согласно по меньшей мере некоторым вариантам осуществления настоящего изобретения проникают через ВВВ (при желании), они могут быть составлены, например, в липосомах. Относительно способов производства липосом смотрите, например, патент США №4522811; 5374548 и 5399331. Липосомы могут содержать один или несколько фрагментов, которые селективно транспортируются в определенные клетки или органы, таким образом улучшая адресную доставку лекарственного средства (смотрите, например, V. V. Ranade (1989) J. Clin. Pharmacol. 29:685). Иллюстративные нацеливающие фрагменты включают в себя фолат или биотин (смотрите, например, патент США №5416016, выданный Low et al.); маннозиды (Umezawa et al., (1988) Biochem. Biophys. Res. Commun. 153:1038); антитела (P. G. Bloeman et al. (1995) FEBS Lett. 357:140; M. Owais et al. (1995) Antimicrob. Agents Chemother. 39:180); рецептор поверхностно-активного белка A (Briscoe et al. (1995) Am. J Physiol. 1233:134); p120 (Schreier et al. (1994) J. Biol. Chem. 269:9090); смотрите также K. Keinanen; M. L. Laukkanen (1994) FEBS Lett. 346:123; J. J. Killion; I. J. Fidler (1994) Immunomethods 4:273.
Композиции согласно некоторым вариантам осуществления настоящего изобретения могут, если желательно, быть представлены в упаковке или дозирующем устройстве, таком как одобренный FDA набор, который может содержать одну или несколько единичных дозированных форм, содержащих активный ингредиент. Упаковка может, например, содержать металлическую или пластиковую фольгу, такую как блистерная упаковка. К упаковке или дозатору могут прилагаться инструкции по применению. На упаковке или дозаторе также может быть размещено уведомление, связанное с контейнером, в форме, предписанной правительственным агентством, регулирующим производство, применение или продажу фармацевтических препаратов, причем это уведомление отражает одобрение агентством формы композиций или введение человеку или животному. Такое уведомление, например, может относиться к маркировке, одобренной Управлением по контролю за продуктами и лекарственными средствами США для рецептурных лекарств, или к утвержденному вкладышу продукта. Композиции, содержащие препарат по настоящему изобретению, составленный в совместимом фармацевтическом носителе, также могут быть приготовлены, помещены в соответствующий контейнер и помечены для лечения указанного состояния, как дополнительно подробно описано выше.
Используемый в настоящем документе термин «приблизительно» относится к ±10%.
Термины «содержит», «содержащий», «включает в себя», «включая в себя», «имеющий» и родственные им слова по корню и значению означают «включая в себя, без ограничения».
Термин «состоящий из» означает «включающий в себя и ограниченный».
Термин «состоящий по существу из» означает, что композиция, способ или структура могут включать в себя дополнительные ингредиенты, стадии и/или части, но только в том случае, если дополнительные ингредиенты, стадии и/или части не изменяют существенно основные и новые характеристики заявленного состава, способа или структуры.
Используемые в настоящем документе формы единственного числа включают в себя множественные ссылки, если контекст явно не диктует иное. Например, термин «соединение» или «по меньшей мере одно соединение» может включать в себя множество соединений, включая в себя их смеси.
В настоящей заявке различные варианты осуществления настоящего изобретения могут быть представлены в формате диапазона. Следует понимать, что описание в формате диапазона дано просто для удобства и краткости и не должно рассматриваться как жесткое ограничение объема настоящего изобретения. Соответственно, следует считать, что описание диапазона конкретно раскрывает все возможные поддиапазоны, а также отдельные числовые значения в этом диапазоне. Например, описание диапазона, такого как от 1 до 6, должно рассматриваться как конкретно раскрытые поддиапазоны, такие как от 1 до 3, от 1 до 4, от 1 до 5, от 2 до 4, от 2 до 6, от 3 до 6 и т.д., а также отдельные числа в этом диапазоне, например, 1, 2, 3, 4, 5 и 6. Это применимо независимо от ширины диапазона.
Всякий раз, когда в настоящем документе указывается числовой диапазон, подразумевается, что он включает в себя любое процитированное число (дробное или целое) в пределах указанного диапазона. Фразы «диапазон/диапазоны между» первым указанным числом и вторым указанным числом и «диапазон/диапазоны от» первого указанного числа «до» второго указанного числа используются в настоящем документе взаимозаменяемо и предназначены для включения первого и второго указанных чисел и всех дробных и целых чисел между ними.
Используемый в настоящем документе термин «способ» относится к методам, средствам, технологиям и процедурам для выполнения данной задачи, включая в себя, без ограничения, те методы, средства, технологии и процедуры, которые либо известны, либо легко разработаны из известных методов, средств, технологий и процедур практикующими специалистами в химии, фармакологии, биологии, биохимии и медицине.
Когда делается ссылка на конкретные списки последовательностей, следует понимать, что такая ссылка также включает в себя последовательности, которые по существу соответствуют ее комплементарной последовательности, включая в себя минорные вариации последовательности, возникающие, например, в результате ошибок секвенирования, ошибок клонирования или других изменений, приводящих к замене оснований, делеции оснований или добавлению оснований при условии, что частота таких изменений составляет менее чем 1 из 50 нуклеотидов, альтернативно, менее чем 1 из 100 нуклеотидов, альтернативно, менее чем 1 из 200 нуклеотидов, альтернативно, менее чем 1 из 500 нуклеотидов, альтернативно, менее чем 1 из 1000 нуклеотидов, альтернативно, менее чем 1 из 5000 нуклеотидов, альтернативно, менее чем 1 из 10000 нуклеотидов.
ПРИМЕРЫ
Сделана ссылка на следующие примеры, которые вместе с вышеприведенными описаниями иллюстрируют некоторые варианты осуществления настоящего изобретения без ограничения.
Как правило, используемая в настоящем документе номенклатура и лабораторные процедуры, используемые в настоящем изобретении, включают в себя молекулярные, биохимические, микробиологические и рекомбинантные способы ДНК. Такие способы подробно описаны в литературе. Смотрите, например, "Molecular Cloning: A laboratory Manual" Sambrook et al., (1989); "Current Protocols in Molecular Biology" Volumes I-III Ausubel, R. M., ed. (1994); Ausubel et al., "Current Protocols in Molecular Biology", John Wiley and Sons, Baltimore, Maryland (1989); Perbal, "A Practical Guide to Molecular Cloning", John Wiley & Sons, New York (1988); Watson et al., "Recombinant DNA", Scientific American Books, New York; Birren et al. (eds) "Genome Analysis: A Laboratory Manual Series", Vols. 1-4, Cold Spring Harbor Laboratory Press, New York (1998); методологии, изложенные в патентах США №4666828; 4683202; 4801531; 5192659 и 5272057; "Cell Biology: A Laboratory Handbook", Volumes I-III Cellis, J. E., ed. (1994); "Culture of Animal Cells - A Manual of Basic Technique" by Freshney, Wiley-Liss, N. Y. (1994), Third Edition; "Current Protocols in Immunology" Volumes I-III Coligan J. E., ed. (1994); Stites et al. (eds), "Basic and Clinical Immunology" (8th Edition), Appleton & Lange, Norwalk, CT (1994); Mishell and Shiigi (eds), "Selected Methods in Cellular Immunology", W. H. Freeman and Co., New York (1980); доступные иммуноанализы подробно описаны в патентной и научной литературе, смотрите, например, патенты США №3791932; 3839153; 3850752; 3850578; 3853987; 3867517; 3879262; 3901654; 3935074; 3984533; 3996345; 4034074; 4098876; 4879219; 5011771 и 5281521; "Oligonucleotide Synthesis" Gait, М. J., ed. (1984); "Nucleic Acid Hybridization" Hames, B. D., and Higgins S. J., eds. (1985); "Transcription and Translation" Hames, B. D., and Higgins S. J., eds. (1984); "Animal Cell Culture" Freshney, R. I., ed. (1986); "Immobilized Cells and Enzymes" IRL Press, (1986); "A Practical Guide to Molecular Cloning" Perbal, В., (1984) and "Methods in Enzymology" Vol. 1-317, Academic Press; "PCR Protocols: A Guide To Methods And Applications", Academic Press, San Diego, CA (1990); Marshak et al., "Strategies for Protein Purification and Characterization - A Laboratory Course Manual" CSHL Press (1996); все они включены в ссылки, как если бы они были полностью изложены в настоящем документе. В этом документе приводятся другие общие ссылки. Предполагается, что приведенные в нем процедуры хорошо известны в настоящей области техники и предоставлены для удобства читателя. Вся информация, содержащаяся в нем, включена в настоящий документ посредством ссылки.
ПРИМЕР 1
ВЫБОР ВАРИАНТОВ SIRPα-4-1BBL
Структурный анализ слитого белка SIRPα-4-1BBL, называемого в настоящем документе «DSP107», содержащего N-концевой сигнальный пептид и С-концевую his-метку (SEQ ID NO: 43, фиг. 1), проведен для оптимизации следующих параметров:
• Складывание - правильное складывание для обеспечения связывания с мишенями, минимизации потенциального дисульфидного изменения;
• Целостность - отсутствие открытых протеолитических сайтов;
• Мультимеризация - исследование потенциальной мультимеризации двух доменов. В частности, оптимизация тримеризации образования С-концевого домена;
• Высокая экспрессия в системе экспрессии млекопитающих и
• Низкая иммуногенность.
В частности, для домена SIRPα (соответствующего аминокислотам 31-373 ЕМ домена UniProt ID Р78324, SEQ ID NO: 2):
1. Комплексную модель SIRPα создавали на основе структур PDB: 2JJS, 2JJT, 2UV3, 2WNG, 4СММ, 4KJY, 6BIT. Поскольку С-концевая часть SIRPα отсутствует в этих структурах PDB (начиная с VAL338, т.е. VSAHPKEQGSNTAAENTGSNERNIY, SEQ ID NO: 9), применяли способы моделирования и моделирования гомологии для создания вероятной предсказанной модели.
2. Структурный анализ. Структурный анализ проводили, чтобы выделить потенциальные элементы в слитом белке, которые могут повлиять на желаемый профиль. Эти анализы включают в себя следующее:
- Идентификация гидрофобных сегментов, которые могут вызывать агрегацию белков и ненативную олигомеризацию, с использованием расчета поверхности электростатического потенциала с помощью алгоритмов на основе Delphi и CHARMM.
- Моделирование гомологии слитых белков на основе опубликованных рентгеновских структур.
- Прогнозирование структуры для областей без определенной структуры с высоким разрешением (с использованием серверов прогнозирования структуры: robetta, TASSER и PEP-FOLD3).
- Прогнозирование потенциальных сайтов расщепления в последовательности слитого белка (или предлагаемого варианта) в соответствии с сервером PROSPER для предсказания протеолитических сайтов.
3. Для оценки стыковки DSP107 экспрессируемого домена SIRPα с 4-1BBL создавали грубую модель для потенциальных неправильно свернутых форм.
Для 4-1BBL (соответствует аминокислотам 50-254 ЕМ домена UniProt ID Р41273, SEQ ID NO: 3):
1. Модель внеклеточного (EC) домена 4-1BB-L создавали на основе структуры PDB: 2X29. Поскольку N-концевая часть 4-1BBL отсутствует и не была разрешена на рентгеновских снимках, кажется, что этот сегмент (ACPWAVSGARASPGSAASPRLREGPELSPD, SEQ ID NO: 10) подвергает гидрофобные остатки действию растворителя, и попытки предсказать его структуру указали на неструктурированную область. Это может снизить стабильность слияния DSP107, а также может помешать правильной ориентации для тримеризации через 4-1BBL.
2. Слитый белок анализировали на протеолитические сайты с использованием сервера PROSPER.
3. Обнаружена петля в разрешенном домене 4-1BBL, обращенная наружу к растворителю, что означает, что это может быть область, которая подвергается процессингу.
На фиг. 2А-3 и в таблице 3 ниже показаны сгенерированные трехмерные модели, идентифицированные домены и сегменты, а также предсказанные протеолитические сайты, обнаруженные при анализе слитого белка DSP107.
В совокупности структурный анализ показал следующее:
1. Ожидается, что удаление N-концевого сегмента домена 4-1BBL (ACPWAVSGARASPG, SEQ ID NO: 6 / ACPWAV, SEQ ID NO: 7) снизит гибкость и гидрофобность DSP107.
2. Удаление Ig-подобного С1 типа 1 и Ig-подобного С1 типа 2 уменьшит размер белка, сохраняя при этом его взаимодействующий с CD47 домен активным. Следовательно, С-конец SIRPα должен заканчиваться: TELSVRAKPS (SEQ ID NO: 8), связанным с 4-1BBL.
3. В N-концевом сегменте домена 4-1BBL (ACPWAVSGARASPG, SEQ ID NO: 6 / ACPWAV, SEQ ID NO: 7) имеется свободный остаток Cys, который может препятствовать правильному сворачиванию/перегруппировке из-за неправильных дисульфидных связей.
4. 6-His-метка на N-конце SIRPα, как ожидается, будет взаимодействовать с исходными 3 глутаминовыми кислотами SIRPα и приводить к маскированию этой области.
5. Кажется, что на фланкирующих/неструктурированных областях мало сайтов расщепления.
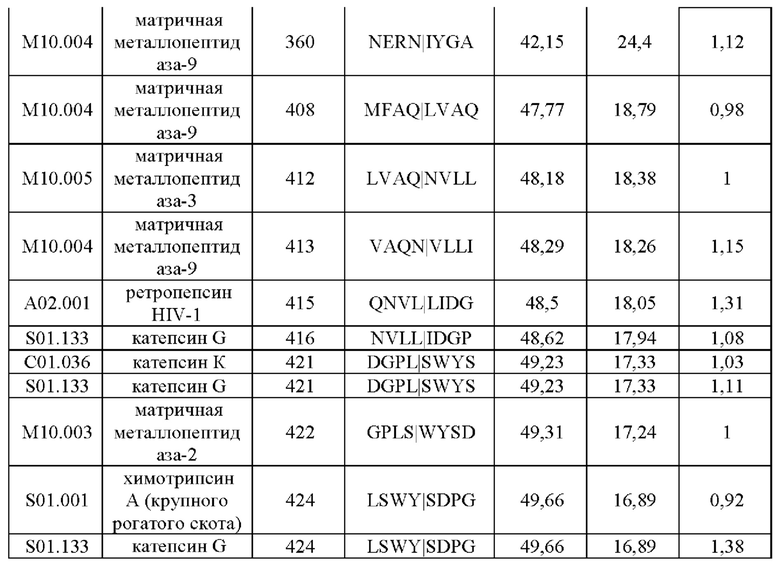
На основании структурного анализа сконструировали несколько вариантов SIRPα, имеющих аминокислотную последовательность SEQ ID NO: 24 или 26, которая может быть слита с 4-1BBL или любым его вариантом.
Кроме того, на основе структурного анализа сконструировали несколько вариантов 4-1BBL, имеющих аминокислотную последовательность SEQ ID NO: 22, 23, 27, 28, 70, 72, 74 или 76, которые могут быть слиты с SIRPα или любым его вариантом.
Более того, чтобы избежать необходимости тримеризации слитого белка для индукции активности фрагмента 4-1BBL, разработали варианты 4-1BBL, содержащие 3 повтора аминокислотной последовательности 4-1BBL, которые могут быть слиты с SIRPα или любым его вариантом. Иллюстративная последовательность такого варианта 4-1BBL включает в себя три повтора SEQ ID NO: 23, содержащих линкер (GGGGS)x2+GGGG (SEQ ID NO: 82) между повторами имеет аминокислотную последовательность SEQ ID NO: 78.
В качестве примера слияния SIRPα-4-1BBL, содержащего такие 3 повтора аминокислотной последовательности 4-1BBL, предсказанные трехмерные модели были сгенерированы с использованием моделирования гомологии с последующим уточнением боковых цепей и петли. Этот анализ моделей предсказал возможное связывание с лигандами и отсутствие интерференции между различными доменами (фиг. 37А-В).
После этого было разработано несколько вариантов SIRPα-4-1BBL. Их последовательность, включая обоснование для их выбора и их 3D-модель, показаны в таблице 4 ниже и на фиг. 4-6 и 37.

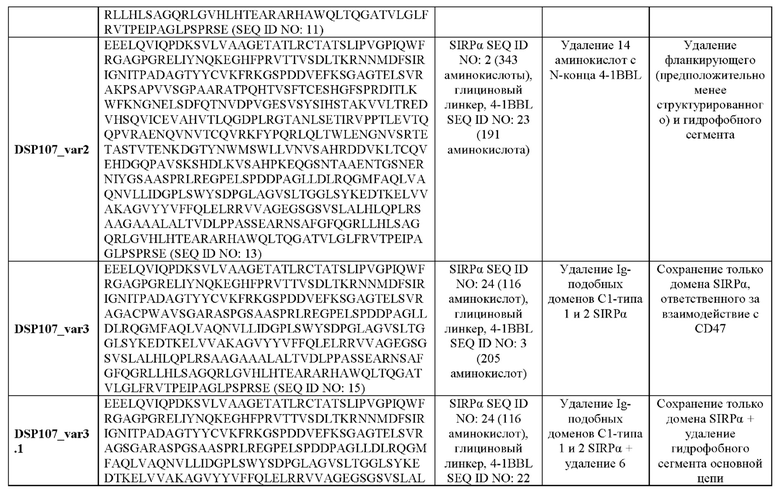

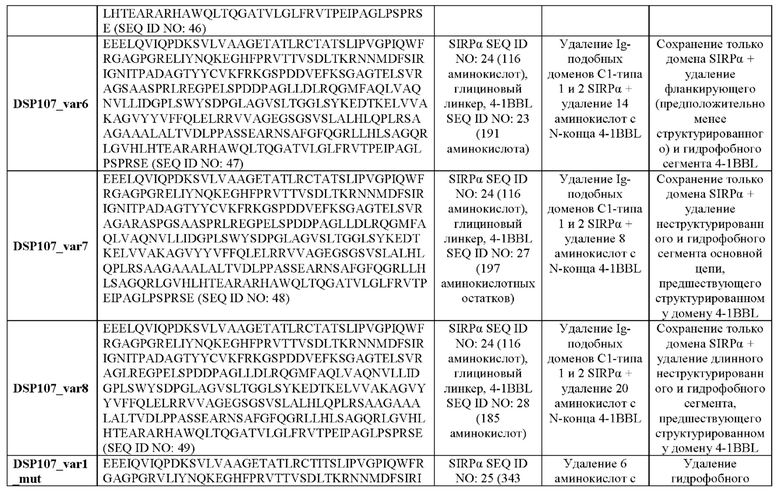
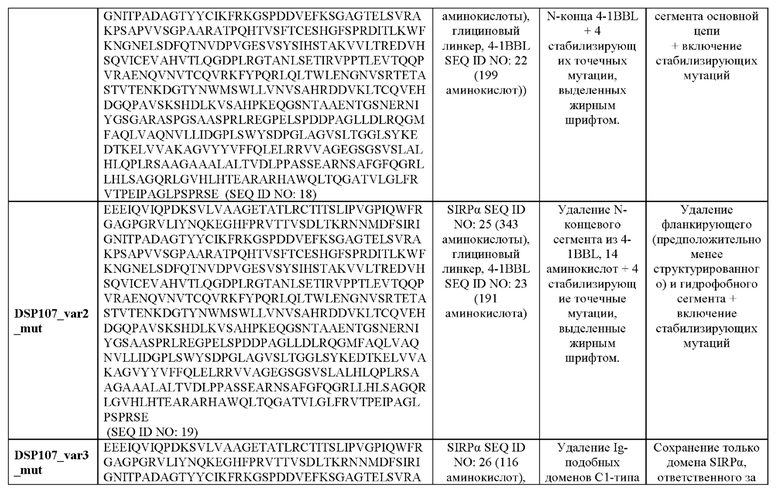
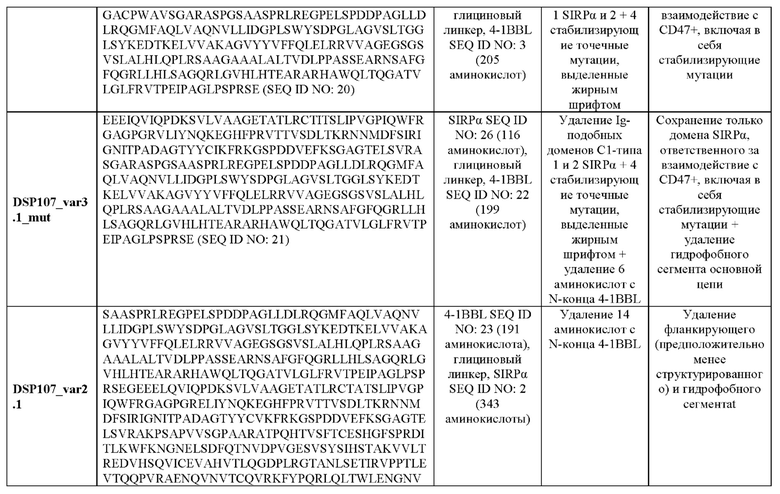

ПРИМЕР 2
ПРОИЗВОДСТВО ВАРИАНТОВ SIRPα-4-1BBL
Для сравнительного функционального анализа и оценки продукции получали несколько слитых белков SIRPα-4-1BBL, меченных гистидином.
Производство слитого белка SIRPα-4-1BBL, обозначаемого в настоящем документе как «DSP107», содержащего С-концевую метку His (SEQ ID NO: 1) и три варианта SIRPα-4-1BBL, называемых в настоящем документе «DSP107_V1», «DSP107_V2» и «DSP107_V3.1», содержащий С-концевую метку His (SEQ ID NO: 12, 14 и 17, соответственно), осуществляли в клетках ExpiCHO.
Производство «DSP107», содержащего N-концевую метку His (SEQ ID NO: 44), осуществляли в клетках Expi293F.
Клетки трансфицировали вектором экспрессии pcDNA3.4, клонированным с кодирующей последовательностью для полного слитого белка и трех вариантов. Последовательности клонировали в вектор с использованием рестрикционных ферментов EcoRI и HindIII с добавлением последовательности Kozak, искусственного сигнального пептида (MGWSCIILFLVATATGVH, SEQ ID NO: 4) на N-конце, 6 His-метки на N-конце или на С-конце и стоп-кодона на С-конце (SEQ ID NO: 51-54 и 69). Белки собирали из супернатанта клеточной культуры и очищали одностадийной очисткой на колонке HisTrap™ FF Crude.
В этих условиях получения выход DSP107 с С-концевой his-меткой (SEQ ID NO: 1) составлял приблизительно 67 мг на 1 литр культуры. Для сравнения, выход DSP107_V1 (SEQ ID NO: 12) и DSP107_V2 (SEQ ID NO: 14) с С-концевой his-меткой составлял приблизительно 150 мг на 1 литр культуры; и выход DSP107_V3.1 с С-концевой his-меткой (SEQ ID NO: 17) составлял приблизительно 212 мг на 1 литр культуры. Выход определяли путем измерения белка ВСА в конечном продукте.
После этого белки с His-меткой очищали эксклюзионной хроматографией для сбора фракции очищенного тримера. 10 мг меченных His DSP107_V1 и DSP107_V2 (SEQ ID NO: 12 и 14) загружали в колонку Superdex 200 (60 + 100 × 1,6 см) с PBS в качестве подвижной фазы и со скоростью потока 1 мл/мин. Собирали основной пик, соответствующий тримерам белка.
Производство двух вариантов слитого белка SIRPα-4-1BBL, обозначенных в настоящем документе как «DSP107_V1» и «DSP107_V2» (SEQ ID NO: 11 и 13 соответственно), осуществляли в клетках СНО-K1 и CHO-S (только DSP107-V2).
Клетки СНО-K1 трансфицировали вектором экспрессии pGenHT1.0, клонированным с кодирующими последовательностями для вариантов DSP107_V1 и DSP107_V2. Последовательности клонировали в вектор с добавлением последовательности Kozak и искусственного сигнального пептида (MGWSCIILFLVATATGVH, SEQ ID NO: 4) на N-конце. Клетки CHO-S трансфицировали вектором экспрессии pMAXX1, клонированным с кодирующей последовательностью для варианта DSP107_V2. Последовательность клонировали в вектор с добавлением 5' нетранслированной последовательности ДНК, последовательности Kozak и сигнального пептида тяжелой цепи ритуксимаба (MGWSLILLFLVAVATRVLS, SEQ ID NO: 99). Трансфицированные клетки отбирали как мини-пулы, и экспрессию вариантов DSP107 оценивали либо в периодической культуре, либо в культуре с подпиткой. Белки собирали из супернатанта клеточной культуры и оценивали с помощью ELISA (фиг. 17) и ДСН-ПААГ (фиг. 18).
Выход 5-дневной периодической культуры выбранных мини-пулов, полученных из СНО-K1, составлял до 75 мг/л для DSP107_V1 и до 327 мг/л для DSP107_V2. Выход выбранных мини-пулов, полученных из CHO-S, в течение 11 дней с подпиткой составлял до 1200 мг/л.
ПРИМЕР 3
ОПРЕДЕЛЕНИЕ ОЛИГОМЕРНОГО СОСТОЯНИЯ ВАРИАНТОВ SIRPα-4-1BBL
Материалы - DSP107, содержащий N-концевую his-метку (SEQ ID NO: 44); и DSP107 (SEQ ID NO: 1), DSP107_V1 (SEQ ID NO: 12), DSP107_V2 (SEQ ID NO: 14) и DSP107_V3.1 (SEQ ID NO: 17) с С-концевой his-меткой, полученные, как описано в примере 2 выше. Маркер молекулярной массы белка Spectra BR (Thermo Fisher Scientific, № в каталоге 26634), 4-20% полиакриламидный гель (BioRad, № в каталоге 556-8094), электроды e-Stain (GenScript, № в каталоге L02011), буфер для загрузки Laemmeli (BioRad, № в каталоге 161-0747).
Способы -
Анализ ДСН-ПААГ - Два мкг белка из каждого образца смешивали с загрузочным буфером с β-меркаптоэтанолом или без него (восстанавливающие и невосстанавливающие условия, соответственно), нагревали в течение 5 минут при температуре 95°С и разделяли на 4-20% градиентном полиакриламидном гель-электрофорезе ДСН-ПААГ. Миграцию белков на геле визуализировали путем окрашивания пэдами e-Stain и промывки с использованием оборудования e-Stain (GenScript) в соответствии с инструкциями производителя.
Масс-спектрометрический (MC) анализ - 5 мкг каждого образца белка трипсинизировали либо после модификации cys IAA без восстановления, либо после восстановления восстановительным диметилированием и модификации cys IAA. Образцы анализировали с помощью масс-спектрометра HFX (Thermo) и идентифицировали с помощью программного обеспечения Discoverer версии 1.4 по сравнению с базой данных uniprot человека и с базами данных-ловушек (для определения уровня ложного обнаружения FDR) и с конкретными последовательностями с использованием поисковой машины Sequest. Кроме того, для обнаружения s-s-связи использовали программы massmatrix и starvoX.
Анализ SEC-MALS. Белки загружали в колонку Superdex 200 Increase (GE Healthcare) и прогоняли со скоростью 0,8 мл/мин с 10 мМ KPO4 рН 8,0 + 150 мМ NaCl в качестве подвижной фазы. Обнаружение проводили с помощью УФ, MALS и RI с использованием AKTA Explorer (GE) + MiniDawn TREOS + OPTILAB T-reX (WYATT).
Результаты. Анализ ДСН-ПААГ продуцированных вариантов SIRPα-4-1BBL продемонстрировал, что DSP107 с N-концевой his-меткой и DSP107 с С-концевой his-меткой (SEQ ID NO: 44 и 1), а также DSP107_V1 и DSP107_V2 с С-концевой his-меткой, мигрировали в восстановительных условиях немного медленнее, чем маркер молекулярной массы 70 кДа (фиг. 7А). Как и ожидалось, в аналогичных условиях DSP107-V3.1 с С-концевой his-меткой (SEQ ID NO: 17) мигрировал иначе, чем другие варианты, появляющиеся в том же месте, что и маркер 40 кДа. В невосстанавливающих условиях DSP107 с N-концевой his-меткой и DSP107 с С-концевой his-меткой (SEQ ID NO: 44 и 1) проявлялись в основном как высокомолекулярные белки (~210 кДа) (фиг. 7В). Небольшие фракции этих белков, а также DSP107_V1 и DSP107_V2, с С-концевой his-меткой, мигрировали аналогично их миграции в восстанавливающих условиях (т.е. ~ 75 кДа). Это может указывать на то, что слитый белок DSP107 содержит мультимеры, связанные с S-S. DSP107-V3.1 с С-концевой his-меткой мигрировал аналогичным образом в восстанавливающих и невосстанавливающих условиях, как DSP107-V1 и DSP107-V2 с С-концевой his-меткой, предполагая, что предполагаемая S-S связь в белке DSP107 опосредована свободным остатком цистеина (Cys346), который был удален из последовательности всех трех вариантов.
Масс-спектрометрический анализ (МС) восстановленного по сравнению с невосстановленным DSP107 с N-концевой his-меткой и DSP107 с С-концевой his-меткой показал, что Cys346 частично связан S-S. Этот результат коррелировал с присутствием димеров в анализе невосстанавливающего ДСН-ПААГ DSP107 с N-концевой his-меткой и DSP107 с С-концевой his-меткой (SEQ ID NO: 44 и 1). С другой стороны, Cys346 был удален из DSP_V1, DSP107_V2 и DSP107-V3.1 с С-концевой his-меткой, и, соответственно, олигомеры высокого порядка не были обнаружены в анализе невосстанавливающего ДСН-ПААГ трех вариантов.
Анализ SEC-MALS продуцированных белков SIRPα-4-1BBL показал, что все три варианта SIRPα-4-1BBL с His-меткой (SEQ ID NO: 12, 14 и 17) и немеченый DSP107_V2 (SEQ ID NO: 13) образуют тримеры. Расчетная масса общего белка составляла приблизительно 258 кДа для DSP107_V1 с С-концевой his-меткой (SEQ ID NO: 12), 269 кДа для меченого his DSP107_V2 (SEQ ID NO: 14), 107 кДа для меченого his DSP107_V3.1 (SEQ ID NO: 17) и 210±20 кДа для DSP107_V2 (SEQ ID NO: 13) (фиг. 38).
ПРИМЕР 4
ВАРИАНТЫ SIRPα-4-1BBL СОДЕРЖАТ ОБА ДОМЕНА
Материалы - DSP107 с N-концевой his-меткой (SEQ ID NO: 44); и DSP107 с С-концевой his-меткой (SEQ ID NO: 1), DSP107_VI (SEQ ID NO: 12. DSP107_V2 (SEQ ID NO: 14) и DSP107_V3.1 (SEQ ID NO: 17), полученные, как описано в примере 2). Для вестерн-блоттинга: белковый маркер Spectra BR (Thermo Fisher Scientific, № в каталоге 26634), буфер для загрузки Laemmeli (BioRad, № в каталоге 161-0747), 4-20% полиакриламидный гель (BioRad, № в каталоге 556-8094), анти-4-1BBL (BioVision, 5369-100), анти-SIRPα-биотинилированный, (# LS-C370337, LsBio), вторичный конъюгат козьих антител против кроличьих IgG (Н+L)-HRP (R&D, № в каталоге 170-6515), белок стрептавидин, HRP: (# 21126, Thermoscientific), субстрат для вестерн-блоттинга ECL Plus (Pierce, № в каталоге 32132). Для сэндвич-ELISA: антитело к 4-1BBL (захватывающее антитело из совпадающей пары; Abnova # H00008744-AP41), биотинилированное антитело к SIRPα (LsBio # LS-C370337), белок стрептавидина, HRP (# 21126, Thermo Scientific), субстрат ТМВ (раствор субстрата 1-Step™ Ultra TMB-ELISA, Thermo Scientific # 34028).
Способы -
Анализ вестерн-блоттинг - Белки (500 нг или 50 нг на дорожку) обрабатывали в восстанавливающих или невосстанавливающих условиях (в загрузочном буфере, содержащем β-меркаптоэтанол, и кипятили в течение 5 минут при температуре 95°С, или в буфере для образцов без β-меркаптоэтанола без нагревания, соответственно) и разделяли на геле ДСН-ПААГ с градиентом 4-20%. Белки переносили на PVDF-мембрану и инкубировали в течение ночи с первичными антителами к 4-1BBL (1:10000) или биотинилированными анти-SIRPα (1:1000) с последующей инкубацией в течение 1 часа с вторичным антителом, конъюгированным с HRP (1:10000) или субстратом стрептавидин-HRP (1:20000), соответственно. Сигналы обнаруживали после развития ECL.
Сэндвич-ELISA - планшеты покрывают антителом к 4-1BBL (2,5 мкг/мл в PBS) и блокируют в блокирующем растворе (PBS, 1% BSA, 0,005% Tween). Полученные слитые белки SIRPα-4-1BBL, серийно разведенные в блокирующем растворе, добавляли в покрытые планшеты и инкубировали в течение 2 часов с последующей инкубацией с обнаружением анти-SIRPα-биотинилированных антител (1:100) и последующим обнаружением с помощью стрептавидин-HRP и субстрата ТМВ в соответствии с рекомендациями производителя. Планшеты анализировали с использованием планшет-ридера (Thermo Scientific, Multiscan FC) при 450 нм, со ссылкой на 620 нм.
Результаты - Разделение DSP107 с N-концевой his-меткой (SEQ ID NO: 44), DSP107 с С-концевой his-меткой (SEQ ID NO: 1) и трех вариантов DSP107 с С-концевой his-меткой (DSP107_V1, DSP107_V2 и DSP107_V3.1 (SEQ ID NO: 12, 14 и 17) на геле ДСН-ПААГ в невосстанавливающих и восстанавливающих условиях с последующим иммуноблоттингом с антителом к 4-1BBL (фиг. 8А-В) или антителом к SIRPα (фиг. 8С), продемонстрировало, что присутствуют как N-концевая сторона молекулы, так и С-концевая сторона молекулы. В соответствии с анализом ДСН-ПААГ (пример 3 выше), анализ вестерн-блоттинг продемонстрировал, что DSP107 с N-концевой his-меткой и белки DSP107, DSP107_V1 и DSP107_V2 с С-концевой his-меткой мигрировали в восстанавливающих условиях с приблизительным размером 75 кДа, что соответствует ожидаемому размеру мономера DSP107. Дополнительные полосы с более высокой молекулярной массой также были обнаружены с помощью антитела к 4-1BBL в DSP107 с N-концевой his-меткой и слитых белках DSP107 с С-концевой his-меткой в невосстанавливающих условиях, предполагая образование S-S-связанного мультимера.
Далее разрабатывали способ сэндвич-ELISA для обнаружения продуцируемых слитых белков SIRPα-4-1BBL с использованием захватывающего антитела, которое связывается с доменом 4-1BBL, и обнаруживающего антитела, которое связывается с доменом SIRPα. Как показано на фиг. 9, DSP107 с N-концевой his-меткой, а также DSP107_V1 и DSP107_V2 с С-концевой his-меткой обнаруживали и количественно оценивали аналогичным зависимым от дозы образом с использованием двухстороннего ELISA, что указывает на то, что все исследованные слитые белки содержат как N-концевой домен, так и С-концевой домен.
ПРИМЕР 5
ВАРИАНТЫ SIRPα-4-1BBL СВЯЗЫВАЮТСЯ С CD47 И 4-1ВВ
Анализ связывания фрагмента SIRPα белка SIRPα-4-1BBL с CD47
Связывание домена SIRPα SIRPα-4-1BBL с CD47 человека оценивали с использованием клеточной линии СНО-K1, которая сверхэкспрессирует CD47, или клеточной линии В-клеточной лимфомы человека SUDHL4, эндогенно экспрессирующей CD47. Клетки СНО-K1 WT служили отрицательным контролем. Связывание домена 4-1BBL SIRPα-4-1BBL с 4-1ВВ человека оценивали с использованием линии клеток фибросаркомы человека НТ1080, которая сверхэкспрессирует 4-1ВВ (Wyzgol A. et al., J Immunol. 2009 183:1851-61). Клеточная линия дикого типа НТ1080 служила отрицательным контролем. Клетки инкубировали с различными концентрациями продуцируемых слитых белков SIRPα-4-1BBL с последующим иммуноокрашиванием вторичным антителом к 4-1BBL для обнаружения связывания с CD47. Альтернативно, DSP107_V2 был биотинилирован для измерения общей связывающей способности молекулы. Специфическое связывание оценивали с использованием блокирующего антитела к CD47 или блокирующего антитела к 4-1ВВ или комбинации обоих антител. Связывание анализировали с помощью проточной цитометрии (FACS).
Материалы -DSP107 (SEQ ID NO: 1), DSP107_V1 (SEQ ID NO: 12, DSP107_V2(SEQ ID NO: 14) и DSP107_V3.1 (SEQ ID NO: 17) с С-концевой his-меткой HDSP107_V2 (SEQ ID NO: 13), полученный, как описано в примере 2 выше.
Клеточные линии CHO-K1-WT и CHO-K1-CD47 (Bommel et а1, 2017, Oncoimmunology 7(2): е1386361), клетки SUDHL4 (АТСС CRL-2957), клетки НТ1080 (АТСС CCL-121), клетки НТ1080 со сверхэкспрессией 4-1ВВ (Wyzgol А. et al., J Immunol. 2009 183:1851-61), краситель Fixable Viability (BD Biosciences, № в каталоге 562247), блокатор Fc человека. True stain FCX (Biolegend, № в каталоге 422302), набор EZ-Link NHS-РЕС4-биотин (Thermo Scientific, № в каталоге A3 9259) и следующие антитела: к 4-1BBL (Biolegend, № в каталоге 311506), к CD47 («Inhibrix-like», произведенные GenScript в соответствии с медицинскими инструкциями KAHR; Biolegend, № в каталоге 323124), к 4-1ВВ (BD, № в каталоге 552532 Biolegend, № в каталоге 309810), изотип IgG1, k (Biolegend, № в каталоге 400112), стрептавидин АРС (SA) (Biolegend, № в каталоге 405207), CFSE (Thermo Fisher, № в каталоге С34554), CytoLight Red (hicucyte, № в каталоге 4706).
Способы. Мембранную экспрессию CD47 или 4-1ВВ оценивали с помощью проточной цитометрии с использованием конъюгированных с аллофикоцианином (АРС) антител к CD47 и к 4-1ВВ, соответственно, и соответствующих изотипических контролей. Для определения связывания SIRPα-4-1BBL с CD47 клетки предварительно инкубировали с блокатором Fc человека перед инкубацией с различными концентрациями (0,01-50 мкг/мл или 0,156-80 мкг/мл, или 0,05-25 мкг/мл, как указано) продуцированных белков SIRPα-4-1BBL в течение 30 минут или 1 часа на льду с последующим иммуноокрашиванием антителами к 4-1BBL, фиксацией и анализом проточной цитометрией. Чтобы определить связывание SIRPα-4-1BBL с 4-1ВВ, SIRPα-4-1BBL биотинилировали с использованием набора EZ-Link NHS-PEG4-биотин в соответствии с протоколом производителя. После этого клетки промывали и инкубировали в течение 1 часа при температуре 37°C с антителом, блокирующим CD47, чтобы предотвратить связывание плеча SIRPα с CD47, или связывание проводили без блокирования, чтобы продемонстрировать полное связывание молекулы (ее двумя лигандами) с клеткой. После инкубации к клеткам добавляли биотинилированный SIRPα-4-1BBL (серийные разведения: 0,05-50 мкг/мл; 0,238-238 нМ) и инкубировали в течение 20 минут при температуре 4°С.После инкубации клетки промывали, окрашивали антителами для обнаружения, АРС-стрептавидин (SA) и инкубировали в течение 30 минут при температуре 4°С, промывали и анализировали проточной цитометрией. Клетки CHO-K1-CD47 окрашивали CFSE в соответствии с инструкциями производителя, а сверхэкспрессирующие клетки НТ1080 окрашивали CytoLight Red. Две окрашенные клеточные линии смешивали в соотношении 1:1 (30000 клеток на клеточную линию). В некоторых экспериментах добавляли блокирующие антитела (αCD47, α41BB - 10 мкг/мл) и инкубировали в течение 30 минут при температуре 4°С.Добавляли DSP107_V2 (seq ID: 13) в концентрации 5 мкг/мл и инкубировали в течение 30 минут при комнатной температуре. Клетки анализировали с помощью проточной цитометрии для двух красителей.
Результаты. Высокая мембранная экспрессия CD47 наблюдалась на клетках со сверхэкспрессией CHO-K1-CD47, клетках SUDHL4 и клетках НТ1018, но не на клетках СНО-K1 (фиг. 19А-В и 20). Все исследованные слитые белки, связанные с CD47 на CHO-K1-CD47 и DSP107_V2 (SEQ ID NO: 13), связывались с клетками SUDHL4 и с 4-1ВВ и CD47 на клетках НТ1080, сверхэкспрессирующих 4-1ВВ, дозозависимым образом (фиг. 10, 21А-В и 22A-F). Результаты показывают, что общее связывание биотинилированного DSP107_V2 с клетками НТ1080 4-1ВВ ОХ было выше по сравнению со связыванием с исходными клетками НТ1080 (фиг. 22A-F). Кроме того, связывание с клетками НТ1080 WT было полностью прекращено после блокады CD47 с помощью специфического блокирующего антитела; а связывание с клетками НТ1080 4-1ВВ ОХ было снижено лишь частично. Точно так же только частичное блокирование клеток НТ1080 4-1ВВ ОХ было индуцировано антителами к 4-1ВВ. Полное прекращение связывания DSP107_V2 было достигнуто с помощью двойного блокирования как CD47, так и аналогов 4-1ВВ с использованием обоих антител (фиг. 22A-F). Белки не связывались с клетками СНО-K1-WT (фиг. 21А_В). Изотипический контроль, инкубированный с наивысшей концентрацией белка, не показал фонового окрашивания.
Затем оценивали одновременное связывание DSP107_V2 (SEQ ID NO: 13) с CFSE-меченными клетками НТ1080 4-1ВВ ОХ и меченными CytoLight Red клетками СНО-K1 CD47 ОХ. После инкубации наблюдали образование дублетов совместно окрашенных комплексов DSP107_V2 как с CD47, так и с 4-1ВВ ОХ-клетками (фиг. 23А), что свидетельствует о сближении соседних клеток через иммуногенный синапс. Средние результаты трех независимых экспериментов, сравнивающих DSP107_V2 со средним контролем, продемонстрировали значительное увеличение дублетов, от ~10% до > 30% (фиг. 23В и 24). Важно отметить, что образование дублетов с помощью DSP107_V2 сильно ингибировалось при совместной инкубации с блокирующими антителами к CD47 или к 4-1ВВ. Это открытие согласуется с механизмом действия SIRPα-4-1BBL, связываясь одновременно с CD47 и 4-1ВВ.
Связывание SIRPα-4-1BBL с партнерами по связыванию CD47 и 4-1ВВ человека, мыши и яванского макака
Связывание произведенных слитых белков SIRPα-4-1BBL с CD47 и 4-1ВВ определяли с помощью анализов поверхностного плазменного резонанса (SPR).
Материалы - DSP107 с N-концевой his-меткой (SEQ ID NO: 44); и DSP107_V1 (SEQ ID NO: 12), DSP107_V2 (SEQ ID NO: 14) и DSP107_V2 (SEQ ID NO: 13) с С-концевой his-меткой, полученные, как описано в примере 2 выше.
Сенсорный чип СМ5 серии S (GE, № в каталоге BR100530), набор для улавливания антител человека (GE, № в каталоге BR 100839), PDL1-hFc человека (R&D, № в каталоге 156-В7-100), CD47-hFc человека (R&D, № в каталоге 4670-CD-050), CD47-hFc мыши (R&D, № в каталоге 1866-CD-050), CD47-hFc яванского макака (ACROBiosystems, № в каталоге CD7-C5252), 4-1BB-hFc человека (LsBio, № в каталоге LS-G4041-100), 4-1BB-hFc мыши (R&D, № в каталоге 937-4 В-050), 4-1BB-hFc яванского макака (R&D, № в каталоге 9324-4 В-100).
Способы. Анализы SPR проводили с использованием биосенсора Biacore T100 (GE Healthcare). Антитело к IgG человека (анти-Fc) с концентрацией 25 мкг/мл из набора для захвата антител человека связывали со всеми четырьмя проточными каналами чипа (Fcl-4), используя стандартный протокол аминового связывания, как рекомендовано производителем. Связывание CD47 и 4-1ВВ с чипом выполняли в рабочем буфере HBS-EP + (10 мМ HEPES рН 7,3, 150 мМ NaCl, 3 мМ EDTA, 0,0 5% Tween20): PDL1 человека (отрицательный контроль) загружали в эталонный канал Fcl (10 мкг/мл в 1-м эксперименте и 5 мкг/мл во 2-м эксперименте, в течение 10 секунд при 20 мкл/мин), в то время как Fc2-4 загружали белками CD47-hFc человека, мыши и яванского макака (10 мкг/мл в 1-м эксперименте и 5 мкг/мл во 2-м эксперименте в течение 5 секунд при 20 мкл/мин). После автоматической регенерации чипа его повторно загружали PDL1-hFc человека по каналу Fcl, а также белками 4-1BB-hFc человека, мыши и яванского макака (10, 5 и 7,5 мкг/мл в 1-м эксперименте; 5, 2,5 и 3,75 мкг/мл во 2-м эксперименте, соответственно, в течение 5 секунд при 20 мкл/мин) на каналах Fc2-4. Чип был полностью заряжен всеми аналогами (среднее иммобилизованное количество лиганда составляло 150RU). Далее, по всем четырем каналам пропускали DSP107 (SEQ ID NO: 44) с N-концевой his-меткой, DSP107_V1 (SEQ ID NO: 12) и DSP107_V2 (SEQ ID NO: 14) с С-концевой his-меткой. Этот процесс итеративно повторяли с различными концентрациями слитых белков SIRPα-4-1BBL (500-0,1 2 нМ, в серийных разведениях 1:2) при скорости потока 50 мкл/мин (время ассоциации: 120 секунд; время диссоциации: 300 секунд для белков CD47 и 600 секунд для белков 4-1ВВ). 3М раствор MgCl2 вводили (45 секунд при 20 мкл/мин) в конце каждого цикла для восстановления активной поверхности путем удаления захваченных молекул. Параметры связывания оценивали с использованием модели кинетического связывания 1:1 в программном обеспечении BiaEvaluation v. 3.0.2 (GE Healthcare).
Результаты. Кинетический анализ продемонстрировал, что DSP107 с N-концевой his-меткой и два SIRPα-4-1BBL, DSP107_V1 и DSP107_V2 с С-концевой his-меткой, характеризуются сходной и высокой аффинностью к CD47 человека и яванского макака, а также более низкой аффинностью к CD47 мыши (таблица 5А ниже). Кинетический анализ DSP107_V2 (SEQ ID NO: 13) показал сходную и высокую аффинность к CD47 человека и яванского макака, а также отсутствие аффинности к CD47 мыши (таблицы 5В-С). Все четыре исследованных слитых белка SIRPα-4-1BBL демонстрируют сходную и высокую аффинность к 4-1ВВ человека и яванского макака и не связываются с 4-1ВВ мыши. Ни один из исследованных слитых белков SIRPα-4-1BBL не связывался с отрицательным контролем PDL1 человека.
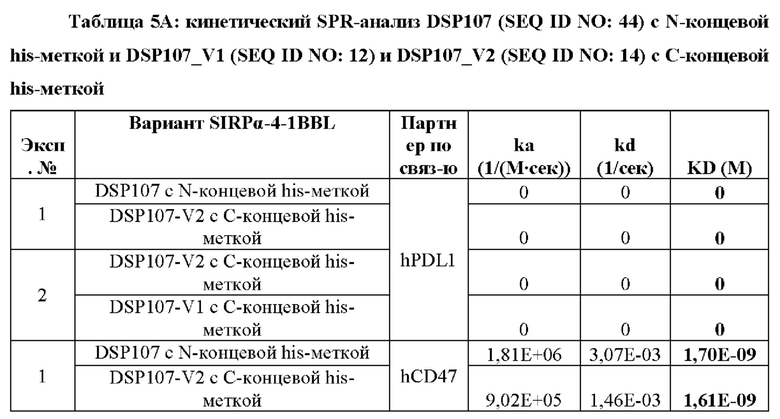
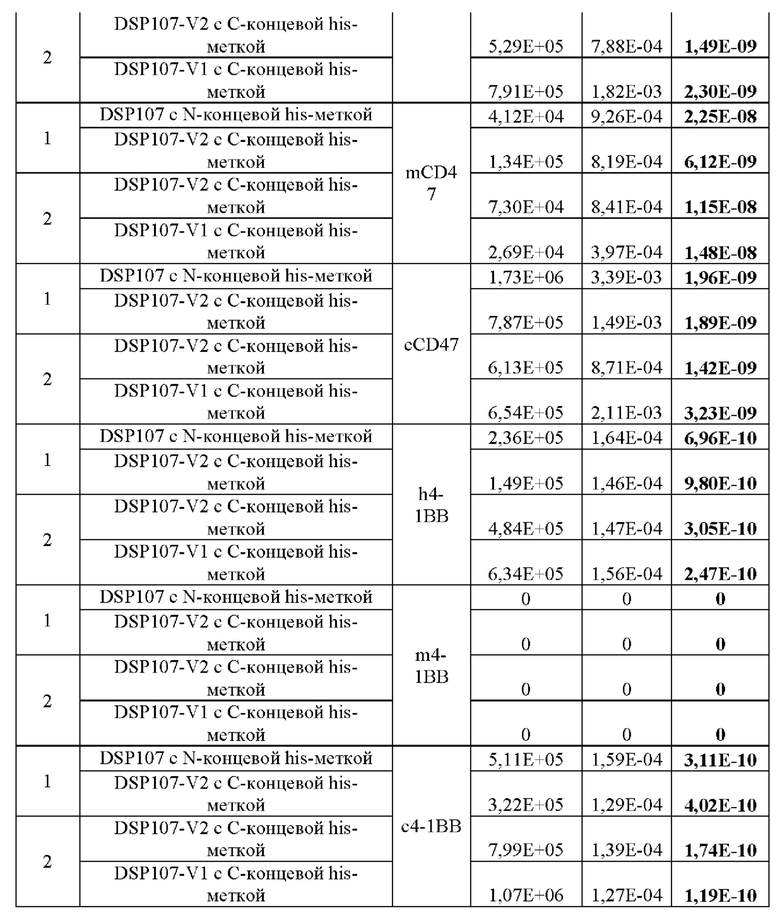
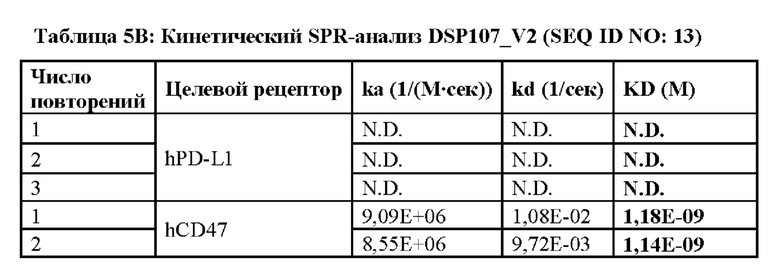
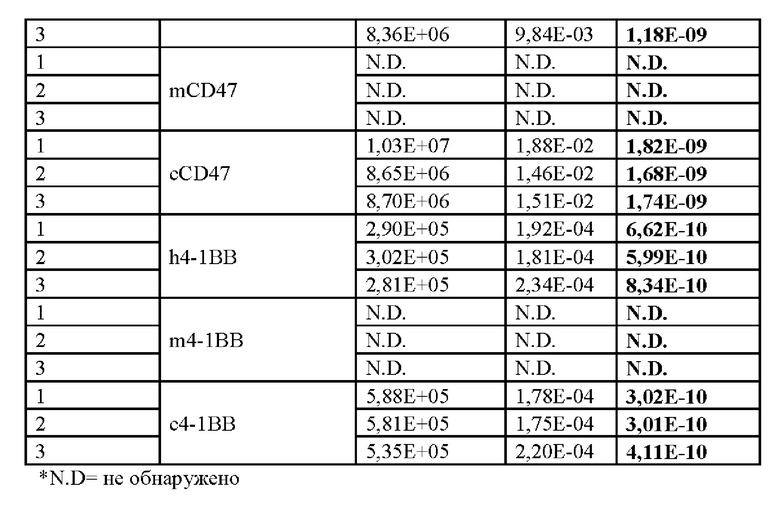
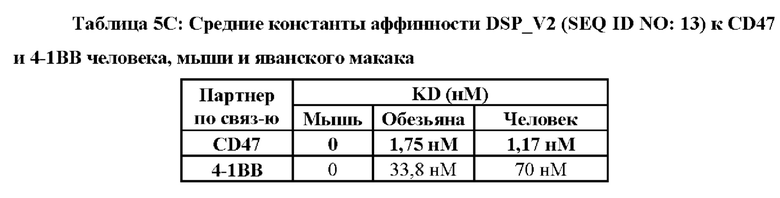
ПРИМЕР 6
АКТИВАЦИЯ 4-1ВВ ВАРИАНТАМИ SIRPα-4-1BBL
Эффект активации рецептора 4-1ВВ продуцированными слитыми белками SIRPα-4-1BBL исследуют с использованием клеток НТ1080, которые сверхэкспрессируют рецептор 4-1ВВ. В частности, клеточная линия НТ1080-4-1ВВ сверхэкспрессирует 4-1ВВ и, как известно, секретирует IL8 при связывании 4-1BBL (Wyzgol et al., 2009, J Immunol. 183 (3): 1851-61). Следовательно, ожидается, что связывание 4-1BBL с рецептором 4-1ВВ на поверхности этих клеток приведет к активации сигнального пути с последующей секрецией IL8. С этой целью клетки инкубируют в присутствии различных концентраций His-меченного SIRPα-4-1BBL, и секрецию IL8 в культуральную среду определяют с помощью ELISA.
Материалы - DSP107 (SEQ ID NO: 44) с N-концевой his-меткой и DSP107 (SEQ ID NO: 1),DSP107_V1 (SEQ ID NO: 12, DSP107_V2 (SEQ ID NO: 14) и DSP107_V3.1 (SEQ ID NO: 17) с С-концевой his-меткой и DSP107_V2 (SEQ ID NO: 13), полученные, как описано в примере 2 выше.
Клетки НТ1080-4-1ВВ (Wyzgol, et al, 2009, The Journal of Immunology), рекомбинантный белок CD47 человека с меткой His (ACRO Biosystem, № в каталоге CD7-Н5227), рекомбинантный белок 4-1BBL человека с меткой His (Cell Signaling, № в каталоге 8460LF), набор для ELISA IL8 (№ в каталоге D8000C, R&D), DMEM (№ в каталоге 01-055-1А, Biological Industries), FBS (№ в каталоге 10270106, Rhenium), AIM V (среда, не содержащая сыворотки) (Thermo Scientific), антитело к CD47 (Invitrogen, № в каталоге 16-0479-85, клон В6Н12).
Способы. Анализ одной культуры: плоскодонные 96-луночные планшеты покрывали 5 мкг/мл рекомбинантным белком CD47 человека, меченного His. После стадии промывки добавляли слитый белок SIRPα-4-1BBL (0-5 мкг/мл) и инкубировали в течение 1 часа при температуре 37°С. Клетки WT HT1080 или НТ1018-4-1ВВ добавляли в лунки (10000 клеток/лунку) и инкубировали в течение 24 часов при температуре 37°С в бессывороточной среде. После инкубации концентрацию IL-8 в супернатанте определяли с помощью набора для ELISA IL-8 в соответствии с протоколом производителя. Планшеты анализировали с использованием планшет-ридера (Thermo Scientific, Multiscan FC) при 450 нм, со ссылкой на 540 нм. Эффект SIRPα-4-1BBL также сравнивали с действием его отдельных растворимых компонентов, SIRPα человека, 4-1BBL человека или их комбинации. Для определения специфичности связывания конкурент антитела, блокирующего CD47, добавляли к культурам за 1 час до добавления слитого белка SIRPα-4-1BBL, чтобы заблокировать его связывание через плечо SIRPα.
Анализ совместного культивирования: клетки СНО-K1 WT или CHO-K1-CD47 высевали в плоскодонные 96-луночные планшеты (10000 клеток/лунку) и инкубировали в течение ночи при температуре 37°С. На следующий день супернатант отбрасывали, добавляли слитый белок SIRPα-4-1BBL (0-10 мкг/мл) и инкубировали в течение 1 часа при температуре 37°С с последующей стадией промывки. Затем добавляли клетки HT1080 WT или НТ1080-4-1ВВ (10000 клеток/лунку) и инкубировали в течение 24 часов при температуре 37°С.После инкубации концентрацию IL-8 в супернатанте определяли с помощью набора для ELISA IL-8 в соответствии с протоколом производителя. Планшеты анализировали с использованием планшет-ридера (Thermo Scientific, Multiscan FC) при 450 нм, со ссылкой на 540 нм.
Результаты. В тесте на одной культуре DSP107-V2 (SEQ ID NO: 13) индуцировал секрецию IL-8 клетками НТ1080-4-1ВВ в присутствии CD47, связанного с планшетом, тогда как в отсутствие CD47 был очевиден значительно более низкий эффект активации (фиг. 25А, р<0,003; ~3-кратное снижение). Активность как связанного с планшетом, так и растворимого DSP107_V2 полностью подавлялась антителом к CD47. Блокирование растворимого DSP107_V2 может быть связано с отменой его низкого связывания с эндогенным CD47, экспрессируемым на клетках НТ1080.
Кроме того, DSP107_V2 активировал передачу сигналов 4-1ВВ более эффективно (~3-кратное увеличение), чем растворимый 4-1BBL или комбинация растворимого SIRPα и 4-1BBL (фиг. 25В). Как и ожидалось, растворимый SIRPα не оказывал эффекта из-за отсутствия взаимодействия с рецептором 4-1ВВ.
Кроме того, секреция IL-8 клетками НТ1080-4-1ВВ после обработки DSP107_V2 была значительно увеличена (р<0,0032) (~3,5 раза) в присутствии клеток CHO-K1-CD47 по сравнению с клетками СНО-K1 WT. Секреция IL-8 полностью блокировалась антителом к CD47, что дополнительно предполагает, что перекрестная презентация необходима для передачи костимулирующего сигнала плечом 4-1BBL через рецептор 4-1ВВ (фиг. 26).
ПРИМЕР 7
АКТИВАЦИЯ Т-КЛЕТОК ВАРИАНТАМИ SIRPα-4-1BBL
Для активации Т-клетки требуются два сигнала: лигирование рецептора Т-клетки (TCR) с комплексом главного комплекса гистосовместимости (МНС) с пептидом на антигенпрезентирующей клетке (АРС) и перекрестное сшивание ко стимулирующих рецепторов на Т-клетке с соответствующими лигандами на АРС. 4-1ВВ представляет собой костимулирующий рецептор Т-клеток, который после лигирования с 4-1BBL способствует размножению, выживанию, дифференцировке и экспрессии цитокинов как CD8+, так и CD4+ Т-клеток.
В настоящей области техники известны многочисленные способы для определения активации Т-клеток, включая в себя, без ограничения, следующие:
- Экспрессия маркеров активации на поверхности Т-клеток (например: CD25, CD69, CD62L, CD137, CD107a, PD1 и т.д.). Экспрессию маркеров активации исследуют окрашиванием клеток специфическими антителами и анализом посредством проточной цитометрии (FACS).
- Секреция воспалительных цитокинов (например: IL2, IL6, IL8, INF гамма и т.д.). Секрецию воспалительных цитокинов исследуют с помощью ELISA.
- Пролиферация, измеряемая путем предварительного окрашивания Т-клеток CFSE (сукцинимидиловый эфир карбоксифлуоресцеина) и определения отклонения клеток с помощью разведения CFSE, которое определяется с помощью FACS.
- Уничтожение целевой клетки, например, раковых клеток, которое измеряется путем предварительной маркировки раковых клеток, например, с использованием реагента Calcine-AM и измерения высвобождения кальция в культуральную среду с помощью люминесцентного ридера.
С этой целью влияние продуцированных слитых белков SIRPα-4-1BBL на пролиферацию мононуклеарных клеток периферической крови (РВМС) человека оценивали следующим образом:
Материалы - DSP107 с N-концевой his-меткой (SEQ ID NO: 44); DSP107_V1 (SEQ ID NO: 12) и DSP107_V2 (SEQ ID NO: 14) с С-концевой his-меткой, полученные, как описано в примере 2 выше.
Фиколл-пак (№ в каталоге 17-1440-03, GE Healthcare), RPMI 1640 (№ в каталоге 01-100-1А, Biological industries), FBS (№ в каталоге 12657-029, Gibco), L-глутамин (№ в каталоге 25030-024, Gibco), Pen Strep (№ в каталоге 15140-122, Gibco), очищенное на листьях антитело к CD3 человека (№ в каталоге BLG-317315, BioLegend), рекомбинантный IL-2 человека (№ в каталоге 589106, Biolegend), антитело к 4-1ВВ (№ в каталоге BLG-106109), антитело к IgG (№ в каталоге BLG-402012).
Способы. РВМС человека выделяли из периферической крови здорового донора с использованием способа с фиколл-паком (Grienvic et al., 2016, Biopreserv Biobank. 14 (5):410-415). После этого клетки культивировали в течение 7 дней с добавлением различных концентраций различных His-меченных белков SIRPα-4-1BBL в присутствии субоптимальных концентраций анти-CD3 (30 нг/мл) или IL-2 (1000 Ед/мл) или анти-CD3 плюс IL-2. Пролиферацию РВМС определяли с помощью системы анализа живых клеток IncuCyte® S3 (hicuCyte) в соответствии с протоколом производителя. Клетки исследовали на поверхностную экспрессию 4-1ВВ в день 0 и день эксперимента с помощью проточной цитометрии.
Результаты - Инкубация РВМС с DSP107 с N-концевой his-меткой, DSP107_V1 с С-концевой his-меткой и DSP107_V2 с С-концевой his-меткой увеличивала конфлюэнтность клеток, что указывает на более высокую скорость пролиферации клеток, стимулированных антителом к CD3, с добавлением IL-2 или без него (фиг. 11). Оптимальную индукцию получали при концентрации 0,01 мкг/мл всех исследованных слитых белков SIRPα-4-1BBL. Таким образом, связывание DSP107 с N-концевой и С-концевой his-меткой, DSP107_V1 с С-концевой his-меткой и DSP107_V2 с С-концевой his-меткой позволило 4-1BBL/4-1BB-опосредованную костимуляцию и индукцию пролиферации Т-клеток. Эти результаты коррелируют с индуцированной экспрессией 4-1ВВ после стимуляции анти-CD3 с IL-2 или без него (фиг. 12).
В следующей постановке влияние DSP107_V2 (SEQ ID NO: 13) на пролиферацию РВМС и Т-клеток человека оценивали следующим образом:
Материалы - DSP107_V2 (SEQ ID NO: 13), полученный, как описано в примере 2 выше.
Фиколл-пак (№ в каталоге 17-1440-03, GE Healthcare), RPMI 1640 (№ в каталоге 01-100-1А, Biological industries), FBS (№ в каталоге 12657-029, Gibco), L-глутамин (№ в каталоге 25030-024, Gibco), Pen Strep (№ в каталоге 15140-122, Gibco), рекомбинантный IL-2 человека (№ в каталоге 589106, Biolegend), Dynabeads, активирующий анти-CD3/CD28, набор EasySep Direct Human T-cell Isolation (STEMCELL Technologies), краситель для пролиферации клеток (CPD, e-Biosciences, № в каталоге 65-0842-85), рекомбинантный белок CD47, меченный His (ACRO Biosystem, № в каталоге CD7-H5227).
Способы. РВМС человека выделяли из периферической крови здоровых доноров с использованием способа с фиколл-паком (Grienvic et al., 2016, Biopreserv Biobank. 14 (5): 410-415). Затем для анализа Incucyte плоскодонные 96-луночные планшеты покрывали поли-L-орнитином (0,01%, 50 мкл, инкубировали в течение 1 часа при температуре 37°С), чтобы обеспечить адгезию клеток РВМС. РВМС засевали (50000 на лунку) в присутствии rhIL-2 (1000 Ед/мл) и DSP107_V2 (0,33 мкг/мл). Планшеты инкубировали в течение 5 дней при температуре 37°С в машине hicuCyte. Изображения для фазового скрининга получали каждые 3 часа, и плотность клеток анализировали с использованием системы анализа живых клеток IncuCyte (Sartorius). Для анализа проточной цитометрии Т-клетки выделяли из РВМС с помощью магнитных шариков для отрицательной селекции (набор EasySep Direct Human T-cell Isolation, STEMCELL Technologies) и окрашивали красителем для пролиферации клеток (CPD) в соответствии с инструкциями производителя. Окрашенные Т-клетки культивировали в течение 3 или 5 дней в 96-луночных планшетах или после предварительного покрытия планшетов рекомбинантным белком CD47, меченным His (2 мкг/мл, в течение 3 часов при температуре 37°С), в присутствии субоптимальных концентраций человеческого активатора Т-клеток Dynabeads против CD3/CD28 (1:10 гранул на Т-клетку) и DSP107_V2 (0,3-3 мкг/мл). Затем CD3+ Т-клетки анализировали с помощью проточной цитометрии на уровни CPD.
Результаты. DSP107_V2 (SEQ ID NO: 13) увеличивал пролиферацию свежевыделенных РВМС человека, индуцированных IL-2, как было определено с помощью анализа фазовых изображений, полученных с помощью программного обеспечения Incucyte. В частности, плотность клеток резко увеличилась после 5 дней инкубации РВМС с IL-2 (1000 Ед/мл) и 1,6 нМ (0,33 мкг/мл) DSP107_V2 по сравнению с РВМС, обработанными только IL-2. Репрезентативные изображения показаны на фиг. 28. Точно так же DSP107_V2 (SEQ ID NO: 13) значительно усиливал пролиферацию на 16-35%, р<0,0025) Т-клеток, окрашенных CPD, индуцированных субоптимальным уровнем анти-CD3/CD28 Dynabeads в присутствии CD47, связанного с планшетом, по данным проточной цитометрии (фиг. 29).
Эффект продуцированных слитых белков SIRPα-4-1BBL на экспрессию маркеров активации Т-клеток оценивали следующим образом:
Материалы - DSP107_V2 (SEQ ID NO: 13), полученный, как описано в примере 2 выше.
Фиколл-пак (№ в каталоге 17-1440-03, GE Healthcare), RPMI 1640 (№ в каталоге 01-100-1А, Biological Industries), FBS (№ в каталоге 12657-029, Gibco), L-глутамин (№ в каталоге 25030-024, Gibco), Pen Strep (№ в каталоге 15140-122, Gibco), очищенное на листьях антитело к CD3 человека (№ в каталоге BLG-317315, BioLegend), антитело к 4-1ВВ (№ в каталоге BLG-106109). РЕ-антитело к CD25 (Biolegend. № в каталоге 302606). FITC-антитело к CD3 человека (Biolegend, № в каталоге 317310).
Способы. РВМС человека выделяли из периферической крови здоровых доноров с помощью стандартного способа в градиенте фиколл в соответствии с инструкциями производителя. 96-луночные планшеты предварительно покрывали антителом к CD3 человека (0,5 мкг/мл) путем инкубации в течение трех часов при температуре 37°С. РВМС от трех доноров культивировали в планшетах с предварительно нанесенным анти-CD3 покрытием (100000 клеток/лунку) с различными концентрациями DSP107_V2 (SEQ ID NO: 13, 0-5 мкг/мл) в течение 48 часов при температуре 37°С, 5% CO2. После инкубации гейтированные CD3+ Т-клетки анализировали проточной цитометрией на экспрессию маркеров активации CD25 и 4-1ВВ.
Результаты - экспрессия маркеров активации CD25 и 4-1ВВ индуцировалась на Т-клетках анти-CD3 и значительно усиливалась DSP107_V2 (SEQ ID NO: 13) дозозависимым образом у всех трех исследованных доноров (фиг. 27, 0,0012 < р < 0,041 для экспрессии 4-1ВВ; 0,0039 < р < 0,047 для экспрессии CD25).
Влияние произведенных слитых белков SIRPα-4-1BBL на опосредованное Т-клетками уничтожение раковых клеток-мишеней оценивали следующим образом:
Материалы и способы. Для анализа hicucyte четыре линии раковых клеток АТСС, гепатоцеллюлярной карциномы (НСС) SNU423, SNU387 и SNU423 и линию клеток рака яичников Ovcar8 трансдуцировали с помощью реагента IncuCyte NucLight Red Lentivirus Reagent (EFIa, Puro; 3TU/Cell), подходящего для трансдукции клеток с помощью не нарушающей ограниченной ядром красной флуоресцентной метки. Отбор пуромицина (2 мкг/мл) применяли для получения стабильных клеточных линий. Ядерно-красную флуоресценцию и экспрессию CD47 на поверхности линий раковых клеток подтверждали с помощью проточной цитометрии перед анализом (данные не показаны). Т-клетки выделяли из образцов периферической крови двух здоровых доноров с помощью магнитных шариков отрицательной селекции. Выделенные Т-клетки культивировали совместно с различными линиями раковых клеток при соотношении эффектора к опухоли (Е:Т) 5:1 и активировали субоптимальной концентрацией парамагнитными микрочастицами dynabeads к CD3/CD28 (1:10 шариков на клеток) и DSP107_V2 (SEQ ID NO: 13), полученные, как описано в примере 2 выше (0,11, 0,33 и 1 мкг/мл). Реагент субстрата каспазы 3/7 зеленой флуоресценции IncuCyte добавляли к совместной культуре для маркировки апоптических клеток. Клетки инкубировали в течение 5 дней в машине Incucyte. Фазовые, зеленые и красные флуоресцентные изображения регистрировали каждые 1,5 часа, а перекрывающиеся зеленый и красный флуоресцентные («желтые») сигналы количественно определяли как сигналы апоптических раковых клеток.
Для анализа проточной цитометрии апоптических опухолевых клеток, меченных CFSE, РВМС выделяли из периферической крови здорового донора и размножали с использованием анти-CD3 и IL-2 в течение 11 дней. Линии раковых клеток мезотелиомы MSTO и Н2052 (АТСС) окрашивали CFSE согласно протоколу. Экспансированные РВМС и окрашенные раковые клетки совместно культивировали при нескольких соотношениях Е:Т в присутствии 0,1 мкг/мл или 1 мкг/мл DSP107_V2 (SEQ ID NO: 13), полученного, как описано в примере 2 выше. Живые раковые клетки, меченные CFSE, анализировали с помощью проточной цитометрии после отделения трипсином.
Результаты. DSP107_V2 усиливал гибель линий гепатоцеллюлярных, яичниковых и мезотелиомных злокачественных клеток, опосредованное Т-клетками (фиг. 30А-С и 31А-В).
В частности, анализ Incucyte показал, что совместное культивирование клеточных линий гепатоцеллюлярного рака и рака яичников в присутствии Т-клеток, активированных субоптимальной концентрацией парамагнитных микрочастиц Dynabeads к CD3/CD28, приводило к уничтожению раковых клеток; и добавление DSP107_V2 усиливало опосредованное Т-клетками уничтожение клеток SNU387, SNU423 и Ovcar8 на 49%, 27% и 23%, соответственно (фиг. 30А-С). После инкубации этих линий раковых клеток только с DSP107_V2 (фиг. 30А-С) гибель не наблюдалась, что свидетельствует об отсутствии прямого цитотоксического действия на линии раковых клеток в отсутствие Т-клеток.
Анализ проточной цитометрии показал, что совместное культивирование линий раковых клеток мезотелиомы, меченных CFSE, с Т-клетками при различных соотношениях Е:Т приводило к гибели раковых клеток, которая усиливалась в присутствии DSP107_V2 (индуцировалась гибель клеток до 52% посредством DSP107_V2, по сравнению с отсутствием гибели в отсутствие DSP107_V2, при соотношении Е:Т = 1:1 - 1:5, фиг. 31А-В).
Как и в случае клеточных линий гепатоцеллюлярного рака и рака яичников, не наблюдалось уничтожения меченных CFSE линий раковых клеток мезотелиомы после инкубации с DSP107_V2 в отсутствие Т-клеток.
ПРИМЕР 8
ВЛИЯНИЕ ВАРИАНТОВ SIRPα-4-1BBL НА БЛОКИРОВАНИЕ СВЯЗИ CD47
Часть SIRPα в SIRPα-4-1BBL предназначена для блокирования сигнала «не ешь меня» путем блокирования взаимодействия эндогенного SIRPα, экспрессируемого на антигенпрезентирующих клетках (АРС), с CD47, экспрессируемым на опухолевых клетках.
С этой целью оценивали эффект производимых слитых белков SIRPα-4-1BBL в качестве блокаторов этого взаимодействия.
Материалы - DSP107 с N-концевой his-меткой (SEQ ID NO: 44); DSP107 (SEQ ID NO: 1), DSP107_V1(SEQ ID NO: 12, DSP107_V2 (SEQ ID NO: 14) и DSP107_V3.1 (SEQ ID NO: 17) с С-концевой his-меткой и DSP107_V2 (SEQ ID NO: 13), полученные, как описано в примере 2 выше.
Рекомбинантный CD47 человека (Acrobiosystems, CD7-H5227), нейтрализующие антитела к hCD47 (Novus, AF4670), биотинилированный SIRPα (Acrobiosystems, CDA-H82F2).
Способы - Планшеты ELISA покрывали в течение ночи рекомбинантным CD47 человека. Планшеты промывали и инкубировали в течение 1 часа с различными концентрациями продуцированных слитых белков SIRPα-4-1BBL или положительного контроля антитела к CD47. После этого добавляли биотинилированный SIRPα; и после 1 часа инкубации планшеты промывали и блоттировали стрептавидин-HRP и субстратом ТМВ в соответствии со стандартным протоколом ELISA (фиг. 13А). Планшеты анализировали с использованием планшет-ридера (Thermo Scientific, Multiscan EC) при 450 нм, со ссылкой на 620 нм.
Результаты. Все исследованные слитые белки SIRPα-4-1BBL эффективно блокировали взаимодействие SIRPα с CD47, аналогично блокирующему антителу положительного контроля (фиг. 13В). Значения ЕС50 находились в диапазоне 0,075-0,238 мкг/мл (фиг. 13С).
ПРИМЕР 9
ВЛИЯНИЕ ВАРИАНТОВ SIRPα-4-1BBL НА МАКРОФАГИ И ПОЛИМОРФОЯДЕРНЫЕ КЛЕТКИ
Как уже упоминалось, часть SIRPα слитого белка SIRPα-4-1BBL предназначена для блокирования сигнала «не ешь меня», индуцированного опухолевыми клетками, экспрессирующими CD47, по отношению к эндогенному SIRPα, экспрессируемому на АРС, таких как макрофаги и гранулоциты, посредством конкуренции и блокирования взаимодействия CD47 на опухолевых клетках с эндогенным SIRPα. Эта блокировка сигнала «не ешь меня» вызывает фагоцитоз опухолевых клеток.
С этой целью влияние произведенных слитых белков SIRPα-4-1BBL на фагоцитоз опухолевых клеток макрофагами или полиморфноядерными клетками человека (PMN) оценивали с использованием анализа на основе проточной цитометрии или флуоресцентной микроскопии.
Материалы - DSP107 с N-концевой his-меткой (SEQ ID NO: 1); DSP107_V1 (SEQ ID NO: 12, DSP107_V2 (SEQ ID NO: 14) и DSP107_V3.1 (SEQ ID NO: 17) с С-концевой his-меткой и DSP107_V2 (SEQ ID NO: 13), полученные, как описано в примере 2 выше.
Линии раковых клеток человека Ramos (лимфома), DLD-1 (карцинома толстой кишки), Daudi, SUDHL5, SUDHL4, U2932, SUDHL2, SUDHL6, SUDHL10, DUDHL4 и OCI-LY3 (лимфомы).
Способы. Полиморфноядерные клетки (PMN) и РВМС выделяли из образцов крови здоровых добровольцев центрифугированием в градиенте плотности с последующим лизисом эритроцитов хлоридом аммония.
Для анализа PMN раковые клетки Ramos и DLD-1 метили Vybrant DiD и смешивали с выделенными PMN в соотношении эффектор-мишень 1:1. Смешанные культуры обрабатывали в течение 2 часов произведенным слитым белком SIRPα-4-1BBL, отдельно или в комбинации с терапевтическими антителами ритуксимабом (RTX; к CD20) или цетуксимабом (СТХ; к EGFR); или в течение 18 часов только с продуцированными слитыми белками SIRPα-4-1BBL. После этого фагоцитоз раковых клеток PMN анализировали с помощью проточной цитометрии.
Для анализа макрофагов моноциты дополнительно обогащали из выделенных РВМС путем сортировки MACS с использованием магнитных шариков CD14 MicroBeads (Miltenyi Biotec). Моноциты дифференцировали в макрофаги (МО) в культуральной среде RPMI 1640 + 10% FCS с добавлением GM-CSF (50 нг/мл) и M-CSF (50 нг/мл) в течение 7 дней. Для создания макрофагов типа 1 (M1) клетки МО примировали LPS и IFN-γ в течение дополнительных 24 часов. В качестве альтернативы, для создания макрофагов типа 2 (М2) клетки МО инкубировали с 100 нг/мл IL-4 в течение 24 часов. Раковые клетки SUDHL5, SUDHL4, OCI-LY3, SUDHL2, SUDHL6, SUDHL10, SC-1, Ramos и Daudi метили цитоплазматическим красителем V450 и смешивали с выделенными и дифференцированными in vitro макрофагами I типа (M1) в соотношении эффектор : мишень 1:1 или 1:5. Смешанные культуры обрабатывали произведенными слитыми белками SIRPα-4-1BBL в течение 2-2,5 часов, отдельно или в комбинации с RTX, трастузумабом или СТХ. После инкубации опухолевые клетки, которые не были поглощены, вымывали, а макрофаги окрашивали антителом к CD11b AF 594. Фагоцитоз раковых клеток макрофагами анализировали с помощью флуоресцентной микроскопии. В других экспериментах hicucyte оценивал фагоцитоз следующим образом: опухолевые клетки из различных клеточных линий лимфомы предварительно окрашивали CFSE, а макрофаги предварительно окрашивали красным цитоплазматическим красителем IncuCyte Cytolight в соответствии с протоколом производителя. Окрашенные опухолевые клетки и макрофаги совместно культивировали при соотношении макрофагов к опухолевым клеткам 1:5, и фазовые красные и зеленые изображения получали посредством hicucyte. Фагоцитоз количественно определяли как долю макрофагов, положительных по поглощению опухолевыми клетками («желтый» сигнал), от общего количества макрофагов (красный сигнал).
Результаты. Все исследованные слитые белки SIRPα-4-1BBL, меченные His, усиливали PMN-опосредованный фагоцитоз раковых клеток Ramos и DLD1 после 2 часов инкубации в сочетании с терапевтическими антителами ритуксимабом (RTX) или цетуксимабом (СТХ) (фиг. 14А). Дальнейшее усиление опосредованного PMN фагоцитоза раковых клеток Ramos и DLD1 было продемонстрировано через 18 часов инкубации (фиг. 14 В).
Кроме того, все исследованные слитые белки SIRPα-4-1BBL, меченные His, усиливали опосредованный макрофагами фагоцитоз клеточных линий лимфомы SUDHL4, SUDHL5 и Oci-Ly3 после 2 часов инкубации, который дополнительно усиливался при сочетании с ритуксимабом (RTX) (фиг. 15). Кроме того, DSP107_V2 с С-концевой his-меткой (SEQ ID NO: 14) увеличивал опосредованный макрофагами фагоцитоз SUDHL4 после 2 часов инкубации в зависимости от дозы (фиг. 16).
Кроме того, индуцированный ритуксимабом фагоцитоз опухолевых клеток макрофагами Ml усиливался после инкубации с 2,5 мкг/мл DSP107_V2 (SEQ ID NO: 13) (фиг. 32А). DSP107_V2 также увеличивал количество клеток Ramos, поглощаемых каждым макрофагом (фиг. 32 В).
Затем исследовали широкую панель клеточных линий лимфомы с использованием системы визуализации Incucyte. Опосредованный макрофагами M1 фагоцитоз линий раковых клеток наблюдали после инкубации макрофагов M1 с раковыми клетками и 2,1 мкг/мл DSP107_V2 в качестве единственного средства (фиг. 32С). Дополнительный фагоцитарный эффект также наблюдали при использовании DSP107_V2 в комбинации с ритуксимабом по сравнению с эффектом, вызванным ритуксимабом в качестве единственного средства (фиг. 32D).
Интересно, что DSP107_V2 (SEQ ID NO: 13) также усиливал фагоцитоз, индуцированный макрофагами М0 и М2, как в качестве отдельного средства, так и в комбинации с ритуксимабом, однако в меньшей степени, чем наблюдаемый для макрофагов M1 (данные не показаны).
В аналогичных экспериментах с клетками карциномы толстой кишки DLD-1 значительно больше клеток DLD-1 было фагоцитировано макрофагами с обработкой одним средством DSP107_V2 (2,1 мкг/мл) по сравнению с контрольной средой (фиг. 32Е). Кроме того, комбинированная терапия DSP107_V2 и трастузумабом (антитело к Her2) четко продемонстрировала усиление фагоцитоза опухолевых клеток по сравнению с лечением трастузумабом в качестве одного средства (фиг. 32Е).
ПРИМЕР 10
ВЛИЯНИЕ ВАРИАНТОВ SIRPα-4-1BBL НА ГРАНУЛОЦИТАРНЫЕ КЛЕТКИ
Материалы и способы. Лейкоциты выделяли из периферической крови здоровых доноров по стандартной методике. Опухолевые клетки предварительно окрашивали CFSE (Thermo Fisher) или раствором для маркировки клеток Vybrant DiD (Thermo Fisher) в соответствии с протоколом производителя. Выделенные лейкоциты и окрашенные опухолевые клетки смешивали при соотношении лейкоцитов к опухолевым клеткам 1:1 и инкубировали в присутствии DSP107_V2 (SEQ ID NO: 13) с терапевтическим антителом ритуксимабом (1 мкг/мл) или без него. Поглощение опухолевых клеток гранулоцитами впоследствии оценивали с помощью проточной цитометрии, количественно определяя популяцию Vybrant DiD-положительных гранулоцитов. Для оценки фагоцитоза клеточных линий карциномы клетки карциномы толстой кишки DLD-1 окрашивали CFSE и совместно культивировали с макрофагами при соотношении макрофаги: опухолевые клетки 1:5 в течение 2 часов в присутствии любого DSP107_V2 (SEQ ID NO: 13), или трастузумаба (антитело к рецептору 2 эпидермального фактора роста человека (HER2); 0,1 мкг/мл), или комбинации DSP107_V2 и трастузумаба. После инкубации клетки отделяли от планшета с использованием раствора трипсин/EDTA, макрофаги окрашивали с использованием CD11b-APC Ab, а образцы анализировали с помощью FACS. Эффект DSP107_V2 (SEQ ID NO: 13) на поглощение опухолевых клеток гранулоцитами также сравнивали с His-меченным SIRPα или растворимым 4-1BBL или их комбинацией.
Результаты. Эффект DSP107_V2 и комбинации растворимого His-меченного SIRPα плюс растворимого 4-1BBL на опосредованный гранулоцитами фагоцитоз опухолевых клеток дополнительно оценивали на множественных линиях клеток лимфомы. Фагоцитоз после инкубации с DSP107_V2 или комбинацией его растворимых компонентов исследовали как отдельное средство и сравнивали с культуральной средой. Фагоцитоз опухолевых клеток также исследовали с ритуксимабом в качестве единственного средства и в комбинации с DSP107_V2 или комбинацией его растворимых компонентов. Через 2,5 часа инкубации с 2,1 мкг/мл DSP107_V2 опосредованный гранулоцитами фагоцитоз клеток лимфомы стимулировался DSP107_V2, но не комбинацией растворимого SIRPα и растворимого 4-1BBL (фиг. 33В). Ритуксимаб также продемонстрировал сильную стимуляцию одиночным средством фагоцитоза опухолевых клеток, опосредованного гранулоцитами. Этот эффект усиливался в комбинации с DSP107_V2, но не в комбинации со смесью растворимого SIRPα и растворимого 4-1BBL (фиг. 33B-F).
ПРИМЕР 11
ПРОТИВООПУХОЛЕВЫЙ ЭФФЕКТ ВАРИАНТОВ SIRPα-4-1BBL IN-VIVO
Для исследования эффективности полученных слитых белков SIRPα-4-1BBL при лечении рака используют четыре различные модели мышей in vivo:
1. Мыши Nude-SCID, инокулированные опухолевыми клетками человека. В этой модели слитый белок SIRPα-4-1BBL взаимодействует с CD47 мыши и человека (экспрессируется на опухолевых клетках), и исследуют влияние слитого белка на активность макрофагов мыши.
2. Мыши NSG, инокулированные стволовыми клетками человека и опухолевыми клетками человека. В этой модели слитый белок SIRPα-4-1BBL взаимодействует с CD47 мыши и человека (экспрессируется на опухолевых и иммунных клетках) и с 4-1ВВ на Т-клетках человека. Исследуют влияние гибридного белка на макрофаги мыши и человека, а также на Т-клетки человека.
3. Мыши с нокаутом C57BL/6 - 4-1ВВ- человека, инокулированные карциномой толстой кишки мыши МС38 или другой линией раковых клеток, или линией раковых клеток, сверхэкспрессирующей CD47 человека. В этой модели внеклеточный домен 4-1ВВ мыши заменен доменом 4-1ВВ человека. Следовательно, слитый белок SIRPα-4-1BBL может взаимодействовать с 4-1ВВ человека, экспрессируемым на Т-клетках мыши. Слитый белок взаимодействует с CD47 мыши и человека на опухолевых клетках. Исследуют влияние слитого белка на макрофаги мыши, а также на Т-клетки мыши.
4. Сингенные модели опухолей мыши, экспрессирующие CD47 мыши. В этих моделях слитый белок SIRPα-4-1BBL взаимодействует с CD47 мыши на опухолевых клетках. Исследуют влияние слитого белка на макрофаги мыши.
Способы -
Во всех четырех моделях мышам прививают опухолевые клетки внутривенно (IV), внутрибрюшинно (IP), подкожно (SC) или ортотопически. Как только опухоль пальпируется (~ 80 мм3), мышей обрабатывают внутривенно, внутрибрюшинно, подкожно или ортотопически разными дозами и разными схемами слитых белков SIRPα-4-1BBL; например, с N-концевой his-меткой (SEQ ID NO: 44), DSP107 с С-концевой his-меткой (SEQ ID NO: 1), DSP107_VI с С-концевой his-меткой (SEQ ID NO: 12), DSP107_V2 с С-концевой his-меткой (SEQ ID NO: 14) и DSP107_V3.1 с С-концевой his-меткой (SEQ ID NO: 17), полученными, как описано в примере 1 выше.
У мышей наблюдают за массой и клиническими признаками. Опухоли измеряют штангенциркулем несколько раз в неделю, объем опухоли рассчитывают по следующему уравнению: V = длина × ширина2/2. Массу мышей измеряют рутинно. Рост опухоли и выживаемость отслеживают на протяжении всего эксперимента.
Инфильтрацию иммунных клеток в опухоль проверяют путем резекции опухоли или дренирования лимфатических узлов, расщепления и иммунного фенотипирования с использованием окрашивания специфическими антителами и анализа с помощью проточной цитометрии. Дополнительно или альтернативно, инфильтрацию иммунных клеток или степень некроза опухолей определяют путем резекции опухолей, заливки парафином и получения срезов для иммуногистохимического окрашивания специфическими антителами.
При умерщвлении мышей органы собирают и помещают в парафиновые блоки для окрашивания Н&Е и IHC.
Образцы крови берут у мышей в разные моменты времени, в соответствии с общими процедурами, для следующих тестов: анализ PK, измерение цитокинов в плазме, профилирование FACS субпопуляций клеток крови в циркуляции, гематологические исследования, химические тесты сыворотки, анализ антител к лекарственным средствам (ADA) и анализ нейтрализующих антител (NAB).
ПРИМЕР 12
ПРОТИВООПУХОЛЕВЫЙ ЭФФЕКТ ВАРИАНТОВ SIRPα-4-1BBL IN-VIVO ПРИ ИСПОЛЬЗОВАНИИ МОДЕЛИ НОКАУТА 4-1ВВ ЧЕЛОВЕКА У МЫШЕЙ
Для того чтобы исследовать эффект слитых белков вариантов SIRPα-4-1BBL на мышах, использовали мышей с нокаутом 4-1ВВ (h4-1BB) человека (фон C57BL/6). В качестве модели опухоли были выбраны человеческие CD47-экспрессирующие клетки МС38 (hCD47 MC38). Следует отметить, что было показано, что SIRPα у мышей C57BL/6 не взаимодействует с CD47 человека [Yamauchi, Т., et al., (2013) Blood, 121 (8): р. 1316-25]:, и поэтому в этой модели не может происходить фагоцитоз клеток hCD47 MC38 нативными фагоцитами. Кроме того, связывание DSP107 с клетками карциномы толстой кишки мыши WT MC38 сравнивали со связыванием клеток карциномы толстой кишки человека DLD1 с использованием анализа посредством проточной цитометрии (фиг. 34). На основании низкого связывания DSP107 с мышиным MC38 клетки hCD47 MC38 отбирали для исследования эффективности in vivo. Следовательно, ожидалось, что плечо SIRPα гибридных белков вариантов SIRPα-4-1BBL будет нацелено на опухолевые клетки, экспрессирующие CD47 человека, но не окажет какого-либо влияния на стимулирование фагоцитоза опухолевых клеток в этой модели.
Материалы и способы. Самкам мышей C57BL/6 с нокаутом h4-1BB в возрасте 8-9 недель (Crown Bioscience) подкожно инокулировали 1×106 клеток hCD47 MC38 (Crown Bioscience). Лечение начинали после того, как опухоли достигли размера 60-100 мм3. После случайного распределения шесть животных в группе получали внутрибрюшинные (IP) инъекции DSP107_V2 (SEQ ID NO: 13; 250 мкг/инъекцию; 12,5 мг/кг), вводимые один раз в день в дни 0, 1, 2, 3 и 4 или антитела к PD-L1 мыши (клон 10F.9G2, Bioxcell; 60 мкг/инъекция), вводимые внутрибрюшинно каждые две недели в течение 3 недель, или комбинацию DSP107_V2 (SEQ ID NO: 13) и антитела к PD-L1 мыши. Контрольным мышам вводили 200 мкл забуференного фосфатом физиологического раствора (PBS). DSP107_V2 вводили только в течение первой недели эксперимента, чтобы избежать потенциального развития мышиных антител против человеческих. Объем опухоли определяли три раза в неделю с помощью штангенциркуля, и индивидуальные объемы рассчитывали по формуле: V = ([ширина]2 × длина)/2. Мышей умерщвляли индивидуально, как только опухоли достигли объема 3000 мм3.
Результаты. Лечение анти PD-L1 или DSP107_V2 (SEQ ID NO: 13) в качестве единственного средства ингибировало рост опухоли (50,4% и 29,5%, соответственно, фиг. 35А). Процент ингибирования роста опухоли (TGI) дополнительно увеличивался при объединении PD-L1 или DSP107_V2 (83%, р=0,02 по сравнению с контролем, обработанным носителем). Кроме того, на основании анализа Mental сох, комбинированное лечение DSP107_V2 и анти PD-L1 привело к статистически значимому улучшению выживаемости по сравнению с контрольными мышами, получавшими носитель (р=0,01; 35В).
ПРИМЕР 13
ЭФФЕКТ АНТИ-DLBCL IN-VIVO ВАРИАНТОВ SIRPα-4-1BBL С ИСПОЛЬЗОВАНИЕМ МЫШИНОЙ МОДЕЛИ NSG
Эффект вариантов слитых белков SIRPα-4-1BBL при лечении опухолей DLBCL человека in-vivo в контексте иммунной системы человека оценивали с использованием мышей NSG, ино купированных клетками DLBCL человека SUDHL6 и РВМС человека. Этим мышам дополнительно вводили варианты слитого белка SIRPα-4-1BBL в качестве единственного средства. За мышами наблюдали в отношении роста опухоли.
Материалы и способы - самкам мышей NSG в возрасте 14 недель инокулировали S.C. 1×106 клеток SUDHL6 в день 0. На 7 день мышей случайным образом разделяли на следующие две группы:
1. Пять мышей - РВМС
2. Шесть мышей - РВМС + DSP107_V2 (SEQ ID NO: 13).
РВМС выделяли из периферической крови здорового донора с использованием стандартного способа в градиенте фиколла в соответствии с инструкциями производителя. На 7-й день мышам сделали прививку I.V. с выделенными РВМС 1×106 клеток на мышь. Замороженные РВМС от одних и тех же доноров использовали для повторной инъекции мышам на 13 день (1×106 клеток на мышь). Мышей из группы DSP107_V2 лечили 250 мкг/мышь DSP107_V2 (SEQ ID NO: 13) I.P. день введения, день без введения, в течение 2 недель, начиная с 7 дня. Мышей наблюдали на предмет любых клинических признаков. Опухоли измеряли с помощью микрометра. Объем опухоли рассчитывали по следующему уравнению: длина × длина × ширина/2. Мышей умерщвляли на 22 день, опухоли удаляли и взвешивали.
Результаты. Лечение РВМС и DSP107_V2 ингибировало рост опухоли приблизительно в 3,7 раза по сравнению с контрольной группой, в которой вводили только РВМС, к 20 дню (фиг. 36А). Лечение РВМС + DSP107_V2 значительно снижало массу опухоли, как было определено после умерщвления мышей на 22 день (фиг. 36 В). Важно отметить, что ни один из способов лечения не повлиял на массу мышей, что свидетельствует об отсутствии серьезных побочных эффектов на здоровье мышей (данные не показаны).
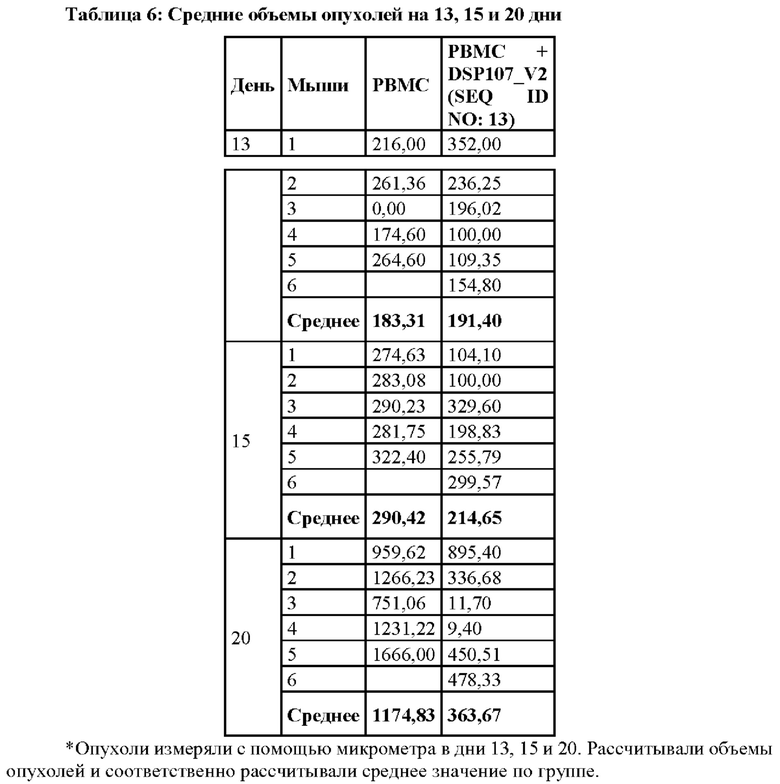
Хотя настоящее изобретение было описано в связи с его конкретными вариантами осуществления, очевидно, что многие альтернативы, модификации и вариации будут очевидны для специалистов в настоящей области техники. Соответственно, предполагается, что оно охватывает все такие альтернативы, модификации и вариации, которые находятся в пределах сущности и широкого объема прилагаемой формулы изобретения.
Все публикации, патенты и заявки на патенты, упомянутые в настоящей заявке, полностью включены в настоящее описание посредством ссылки в той же степени, как если бы каждая отдельная публикация, патент или заявка на патент были специально и индивидуально указаны для включения в настоящее описание посредством ссылки. Кроме того, цитирование или идентификация любой ссылки в настоящей заявке не должно толковаться как признание того, что такая ссылка доступна в качестве известного уровня техники для настоящего изобретения. В той степени, в которой используются заголовки разделов, их не следует рассматривать как обязательные ограничения.
Кроме того, любой приоритетный(ые) документ(ы) настоящей заявки полностью включен в настоящее описание посредством ссылки.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> КАХР Медикал Лтд.
Пекер, Ирис
Блоч, Итай
<120> ВАРИАНТЫ СЛИТОГО БЕЛКА SIRPальфа-4-1BBL И СПОСОБЫ ИХ ПРИМЕНЕНИЯ
<130> 77794
<150> US 62/696,362
<151> 2018-07-11
<160> 99
<170> PatentIn версия 3.5
<210> 1
<211> 555
<212> PRT
<213> Искусственная последовательность
<220>
<223> ИСХОДНЫЙ SIRPa-4-1BBL с C-концевой His-меткой
<400> 1
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr Gly Ala Cys Pro Trp Ala Val Ser Gly
340 345 350
Ala Arg Ala Ser Pro Gly Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly
355 360 365
Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln
370 375 380
Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp Gly
385 390 395 400
Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu Thr
405 410 415
Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala Lys
420 425 430
Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val Val
435 440 445
Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln Pro
450 455 460
Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp Leu
465 470 475 480
Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly
485 490 495
Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu His
500 505 510
Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala Thr
515 520 525
Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly Leu Pro
530 535 540
Ser Pro Arg Ser Glu His His His His His His
545 550 555
<210> 2
<211> 343
<212> PRT
<213> Искусственная последовательность
<220>
<223> ИСХОДНЫЙ ДОМЕН SIRPa
<400> 2
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr
340
<210> 3
<211> 205
<212> PRT
<213> Искусственная последовательность
<220>
<223> ИСХОДНЫЙ ДОМЕН 4-1BBL
<400> 3
Ala Cys Pro Trp Ala Val Ser Gly Ala Arg Ala Ser Pro Gly Ser Ala
1 5 10 15
Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro
20 25 30
Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala
35 40 45
Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro
50 55 60
Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp
65 70 75 80
Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe
85 90 95
Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val
100 105 110
Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala
115 120 125
Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg
130 135 140
Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly
145 150 155 160
Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His Ala
165 170 175
Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr
180 185 190
Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
195 200 205
<210> 4
<211> 19
<212> PRT
<213> Искусственная последовательность
<220>
<223> СИГНАЛЬНЫЙ ПЕПТИД
<400> 4
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser
<210> 5
<211> 549
<212> PRT
<213> Искусственная последовательность
<220>
<223> ИСХОДНЫЙ SIRPa-4-1BBL без His-метки
<400> 5
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr Gly Ala Cys Pro Trp Ala Val Ser Gly
340 345 350
Ala Arg Ala Ser Pro Gly Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly
355 360 365
Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln
370 375 380
Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp Gly
385 390 395 400
Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu Thr
405 410 415
Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala Lys
420 425 430
Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val Val
435 440 445
Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln Pro
450 455 460
Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp Leu
465 470 475 480
Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly
485 490 495
Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu His
500 505 510
Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala Thr
515 520 525
Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly Leu Pro
530 535 540
Ser Pro Arg Ser Glu
545
<210> 6
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> частичная последовательность n-конца домена 4-1BBL
<400> 6
Ala Cys Pro Trp Ala Val Ser Gly Ala Arg Ala Ser Pro Gly
1 5 10
<210> 7
<211> 6
<212> PRT
<213> Искусственная последовательность
<220>
<223> частичная последовательность n-конца домена 4-1BBL
<400> 7
Ala Cys Pro Trp Ala Val
1 5
<210> 8
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> частичная последовательность C-конца SIRP-альфа
<400> 8
Thr Glu Leu Ser Val Arg Ala Lys Pro Ser
1 5 10
<210> 9
<211> 25
<212> PRT
<213> Искусственная последовательность
<220>
<223> частичная последовательность SIRP-альфа
<400> 9
Val Ser Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn
1 5 10 15
Thr Gly Ser Asn Glu Arg Asn Ile Tyr
20 25
<210> 10
<211> 30
<212> PRT
<213> Искусственная последовательность
<220>
<223> частичная последовательность 4-1BB-L
<400> 10
Ala Cys Pro Trp Ala Val Ser Gly Ala Arg Ala Ser Pro Gly Ser Ala
1 5 10 15
Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp
20 25 30
<210> 11
<211> 543
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107_var1 без His-метки
<400> 11
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr Gly Ser Gly Ala Arg Ala Ser Pro Gly
340 345 350
Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp
355 360 365
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
370 375 380
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
385 390 395 400
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
405 410 415
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
420 425 430
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
435 440 445
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
450 455 460
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
465 470 475 480
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
485 490 495
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
500 505 510
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
515 520 525
Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
530 535 540
<210> 12
<211> 549
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107_var1 с His-меткой
<400> 12
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr Gly Ser Gly Ala Arg Ala Ser Pro Gly
340 345 350
Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp
355 360 365
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
370 375 380
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
385 390 395 400
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
405 410 415
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
420 425 430
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
435 440 445
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
450 455 460
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
465 470 475 480
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
485 490 495
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
500 505 510
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
515 520 525
Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu His
530 535 540
His His His His His
545
<210> 13
<211> 535
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107_var2 без His-метки
<400> 13
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr Gly Ser Ala Ala Ser Pro Arg Leu Arg
340 345 350
Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu
355 360 365
Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile
370 375 380
Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser
385 390 395 400
Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val
405 410 415
Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg
420 425 430
Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu
435 440 445
Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val
450 455 460
Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe
465 470 475 480
Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His
485 490 495
Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly
500 505 510
Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly
515 520 525
Leu Pro Ser Pro Arg Ser Glu
530 535
<210> 14
<211> 541
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107_var2 с His-меткой
<400> 14
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr Gly Ser Ala Ala Ser Pro Arg Leu Arg
340 345 350
Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu
355 360 365
Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile
370 375 380
Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser
385 390 395 400
Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val
405 410 415
Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg
420 425 430
Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu
435 440 445
Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val
450 455 460
Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe
465 470 475 480
Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His
485 490 495
Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly
500 505 510
Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly
515 520 525
Leu Pro Ser Pro Arg Ser Glu His His His His His His
530 535 540
<210> 15
<211> 322
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107_var3 без His-метки
<400> 15
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Gly Ala Cys Pro Trp Ala Val Ser Gly Ala Arg Ala
115 120 125
Ser Pro Gly Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu
130 135 140
Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe
145 150 155 160
Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser
165 170 175
Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu
180 185 190
Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val
195 200 205
Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu
210 215 220
Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser
225 230 235 240
Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala
245 250 255
Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu
260 265 270
His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala
275 280 285
Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly
290 295 300
Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg
305 310 315 320
Ser Glu
<210> 16
<211> 316
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107_var3.1 без His-метки
<400> 16
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Gly Ser Gly Ala Arg Ala Ser Pro Gly Ser Ala Ala
115 120 125
Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala
130 135 140
Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln
145 150 155 160
Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly
165 170 175
Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr
180 185 190
Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln
195 200 205
Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser
210 215 220
Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala
225 230 235 240
Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn
245 250 255
Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln
260 265 270
Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp
275 280 285
Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro
290 295 300
Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
305 310 315
<210> 17
<211> 322
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107_var3.1 с His-меткой
<400> 17
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Gly Ser Gly Ala Arg Ala Ser Pro Gly Ser Ala Ala
115 120 125
Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala
130 135 140
Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln
145 150 155 160
Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly
165 170 175
Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr
180 185 190
Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln
195 200 205
Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser
210 215 220
Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala
225 230 235 240
Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn
245 250 255
Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln
260 265 270
Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp
275 280 285
Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro
290 295 300
Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu His His His His
305 310 315 320
His His
<210> 18
<211> 543
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107_Var1Mut без His-метки
<400> 18
Glu Glu Glu Ile Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ile Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Val Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Ile Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr Gly Ser Gly Ala Arg Ala Ser Pro Gly
340 345 350
Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp
355 360 365
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
370 375 380
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
385 390 395 400
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
405 410 415
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
420 425 430
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
435 440 445
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
450 455 460
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
465 470 475 480
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
485 490 495
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
500 505 510
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
515 520 525
Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
530 535 540
<210> 19
<211> 535
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107_Var2Mut без His-метки
<400> 19
Glu Glu Glu Ile Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ile Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Val Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Ile Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr Gly Ser Ala Ala Ser Pro Arg Leu Arg
340 345 350
Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu
355 360 365
Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile
370 375 380
Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser
385 390 395 400
Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val
405 410 415
Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg
420 425 430
Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu
435 440 445
Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val
450 455 460
Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe
465 470 475 480
Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His
485 490 495
Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly
500 505 510
Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly
515 520 525
Leu Pro Ser Pro Arg Ser Glu
530 535
<210> 20
<211> 322
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107_Var3Mut без His-метки
<400> 20
Glu Glu Glu Ile Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ile Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Val Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Ile Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Gly Ala Cys Pro Trp Ala Val Ser Gly Ala Arg Ala
115 120 125
Ser Pro Gly Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu
130 135 140
Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe
145 150 155 160
Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser
165 170 175
Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu
180 185 190
Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val
195 200 205
Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu
210 215 220
Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser
225 230 235 240
Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala
245 250 255
Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu
260 265 270
His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala
275 280 285
Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly
290 295 300
Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg
305 310 315 320
Ser Glu
<210> 21
<211> 315
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP170_Var3.1Mut без His-метки
<400> 21
Glu Glu Glu Ile Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ile Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Val Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Ile Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Ser Gly Ala Arg Ala Ser Pro Gly Ser Ala Ala Ser
115 120 125
Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly
130 135 140
Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn
145 150 155 160
Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu
165 170 175
Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys
180 185 190
Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu
195 200 205
Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu
210 215 220
Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu
225 230 235 240
Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser
245 250 255
Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg
260 265 270
Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln
275 280 285
Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu
290 295 300
Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
305 310 315
<210> 22
<211> 199
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность из 199 аминокислот сегмента 4-1BBL
<400> 22
Ser Gly Ala Arg Ala Ser Pro Gly Ser Ala Ala Ser Pro Arg Leu Arg
1 5 10 15
Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu
20 25 30
Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile
35 40 45
Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser
50 55 60
Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val
65 70 75 80
Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg
85 90 95
Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu
100 105 110
Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val
115 120 125
Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe
130 135 140
Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His
145 150 155 160
Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly
165 170 175
Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly
180 185 190
Leu Pro Ser Pro Arg Ser Glu
195
<210> 23
<211> 191
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность из 191 аминокислоты сегмента 4-1BBL
<400> 23
Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp
1 5 10 15
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
20 25 30
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
35 40 45
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
50 55 60
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
65 70 75 80
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
85 90 95
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
100 105 110
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
115 120 125
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
130 135 140
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
145 150 155 160
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
165 170 175
Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
180 185 190
<210> 24
<211> 116
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность из 116 аминокислот сегмента SIRPa
<400> 24
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala
115
<210> 25
<211> 343
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность из 343 аминокислот SIRPa с 4 точечными мутациями
<400> 25
Glu Glu Glu Ile Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ile Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Val Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Ile Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr
340
<210> 26
<211> 116
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность из 116 аминокислот SIRPa с 4 точечными мутациями
<400> 26
Glu Glu Glu Ile Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ile Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Val Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Ile Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala
115
<210> 27
<211> 197
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность из 197 аминокислот сегмента 4-1BBL
<400> 27
Ala Arg Ala Ser Pro Gly Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly
1 5 10 15
Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln
20 25 30
Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp Gly
35 40 45
Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu Thr
50 55 60
Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala Lys
65 70 75 80
Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val Val
85 90 95
Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln Pro
100 105 110
Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp Leu
115 120 125
Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly
130 135 140
Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu His
145 150 155 160
Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala Thr
165 170 175
Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly Leu Pro
180 185 190
Ser Pro Arg Ser Glu
195
<210> 28
<211> 185
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность из 185 аминокислот сегмента 4-1BBL
<400> 28
Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu
1 5 10 15
Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu
20 25 30
Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly
35 40 45
Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu
50 55 60
Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu
65 70 75 80
Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu
85 90 95
His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu
100 105 110
Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe
115 120 125
Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly
130 135 140
Val His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr
145 150 155 160
Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro
165 170 175
Ala Gly Leu Pro Ser Pro Arg Ser Glu
180 185
<210> 29
<211> 504
<212> PRT
<213> Искусственная последовательность
<220>
<223> аминокислотная последовательность полноразмерного SIRP
<400> 29
Met Glu Pro Ala Gly Pro Ala Pro Gly Arg Leu Gly Pro Leu Leu Cys
1 5 10 15
Leu Leu Leu Ala Ala Ser Cys Ala Trp Ser Gly Val Ala Gly Glu Glu
20 25 30
Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala Ala Gly
35 40 45
Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro Val Gly
50 55 60
Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu Ile Tyr
65 70 75 80
Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser Asp Leu
85 90 95
Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn Ile Thr
100 105 110
Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys Gly Ser
115 120 125
Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu Ser Val
130 135 140
Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala Arg Ala
145 150 155 160
Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly Phe Ser
165 170 175
Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu Leu Ser
180 185 190
Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser Tyr Ser
195 200 205
Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val His Ser
210 215 220
Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp Pro Leu
225 230 235 240
Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro Thr Leu
245 250 255
Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn Val Thr
260 265 270
Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr Trp Leu
275 280 285
Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val Thr Glu
290 295 300
Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val Asn Val
305 310 315 320
Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu His Asp
325 330 335
Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser Ala His
340 345 350
Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly Ser Asn
355 360 365
Glu Arg Asn Ile Tyr Ile Val Val Gly Val Val Cys Thr Leu Leu Val
370 375 380
Ala Leu Leu Met Ala Ala Leu Tyr Leu Val Arg Ile Arg Gln Lys Lys
385 390 395 400
Ala Gln Gly Ser Thr Ser Ser Thr Arg Leu His Glu Pro Glu Lys Asn
405 410 415
Ala Arg Glu Ile Thr Gln Asp Thr Asn Asp Ile Thr Tyr Ala Asp Leu
420 425 430
Asn Leu Pro Lys Gly Lys Lys Pro Ala Pro Gln Ala Ala Glu Pro Asn
435 440 445
Asn His Thr Glu Tyr Ala Ser Ile Gln Thr Ser Pro Gln Pro Ala Ser
450 455 460
Glu Asp Thr Leu Thr Tyr Ala Asp Leu Asp Met Val His Leu Asn Arg
465 470 475 480
Thr Pro Lys Gln Pro Ala Pro Lys Pro Glu Pro Ser Phe Ser Glu Tyr
485 490 495
Ala Ser Val Gln Val Pro Arg Lys
500
<210> 30
<211> 1512
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты полноразмерного SIRP
<400> 30
atggagcccg ccggcccggc ccccggccgc ctcgggccgc tgctctgcct gctgctcgcc 60
gcgtcctgcg cctggtcagg agtggcgggt gaggaggagc tgcaggtgat tcagcctgac 120
aagtccgtat cagttgcagc tggagagtcg gccattctgc actgcactgt gacctccctg 180
atccctgtgg ggcccatcca gtggttcaga ggagctggac cagcccggga attaatctac 240
aatcaaaaag aaggccactt cccccgggta acaactgttt cagagtccac aaagagagaa 300
aacatggact tttccatcag catcagtaac atcaccccag cagatgccgg cacctactac 360
tgtgtgaagt tccggaaagg gagccctgac acggagttta agtctggagc aggcactgag 420
ctgtctgtgc gtgccaaacc ctctgccccc gtggtatcgg gccctgcggc gagggccaca 480
cctcagcaca cagtgagctt cacctgcgag tcccacggct tctcacccag agacatcacc 540
ctgaaatggt tcaaaaatgg gaatgagctc tcagacttcc agaccaacgt ggaccccgta 600
ggagagagcg tgtcctacag catccacagc acagccaagg tggtgctgac ccgcgaggac 660
gttcactctc aagtcatctg cgaggtggcc cacgtcacct tgcaggggga ccctcttcgt 720
gggactgcca acttgtctga gaccatccga gttccaccca ccttggaggt tactcaacag 780
cccgtgaggg cagagaacca ggtgaatgtc acctgccagg tgaggaagtt ctacccccag 840
agactacagc tgacctggtt ggagaatgga aacgtgtccc ggacagaaac ggcctcaacc 900
gttacagaga acaaggatgg tacctacaac tggatgagct ggctcctggt gaatgtatct 960
gcccacaggg atgatgtgaa gctcacctgc caggtggagc atgacgggca gccagcggtc 1020
agcaaaagcc atgacctgaa ggtctcagcc cacccgaagg agcagggctc aaataccgcc 1080
gctgagaaca ctggatctaa tgaacggaac atctatattg tggtgggtgt ggtgtgcacc 1140
ttgctggtgg ccctactgat ggcggccctc tacctcgtcc gaatcagaca gaagaaagcc 1200
cagggctcca cttcttctac aaggttgcat gagcccgaga agaatgccag agaaataaca 1260
caggacacaa atgatatcac atatgcagac ctgaacctgc ccaaggggaa gaagcctgct 1320
ccccaggctg cggagcccaa caaccacacg gagtatgcca gcattcagac cagcccgcag 1380
cccgcgtcgg aggacaccct cacctatgct gacctggaca tggtccacct caaccggacc 1440
cccaagcagc cggcccccaa gcctgagccg tccttctcag agtacgccag cgtccaggtc 1500
ccgaggaagt ga 1512
<210> 31
<211> 1029
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 2
<400> 31
gaggaggagc tgcaggtgat tcagcctgac aagtccgtat cagttgcagc tggagagtcg 60
gccattctgc actgcactgt gacctccctg atccctgtgg ggcccatcca gtggttcaga 120
ggagctggac cagcccggga attaatctac aatcaaaaag aaggccactt cccccgggta 180
acaactgttt cagagtccac aaagagagaa aacatggact tttccatcag catcagtaac 240
atcaccccag cagatgccgg cacctactac tgtgtgaagt tccggaaagg gagccctgac 300
acggagttta agtctggagc aggcactgag ctgtctgtgc gtgccaaacc ctctgccccc 360
gtggtatcgg gccctgcggc gagggccaca cctcagcaca cagtgagctt cacctgcgag 420
tcccacggct tctcacccag agacatcacc ctgaaatggt tcaaaaatgg gaatgagctc 480
tcagacttcc agaccaacgt ggaccccgta ggagagagcg tgtcctacag catccacagc 540
acagccaagg tggtgctgac ccgcgaggac gttcactctc aagtcatctg cgaggtggcc 600
cacgtcacct tgcaggggga ccctcttcgt gggactgcca acttgtctga gaccatccga 660
gttccaccca ccttggaggt tactcaacag cccgtgaggg cagagaacca ggtgaatgtc 720
acctgccagg tgaggaagtt ctacccccag agactacagc tgacctggtt ggagaatgga 780
aacgtgtccc ggacagaaac ggcctcaacc gttacagaga acaaggatgg tacctacaac 840
tggatgagct ggctcctggt gaatgtatct gcccacaggg atgatgtgaa gctcacctgc 900
caggtggagc atgacgggca gccagcggtc agcaaaagcc atgacctgaa ggtctcagcc 960
cacccgaagg agcagggctc aaataccgcc gctgagaaca ctggatctaa tgaacggaac 1020
atctatatt 1029
<210> 32
<211> 227
<212> PRT
<213> Искусственная последовательность
<220>
<223> УДАЛЕННАЯ ЧАСТЬ SEQ ID NO: 2 ДЛЯ ПОЛУЧЕНИЯ ВАРИАНТА 116 AA
<400> 32
Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala Arg Ala Thr Pro
1 5 10 15
Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly Phe Ser Pro Arg
20 25 30
Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu Leu Ser Asp Phe
35 40 45
Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser Tyr Ser Ile His
50 55 60
Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val His Ser Gln Val
65 70 75 80
Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp Pro Leu Arg Gly
85 90 95
Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro Thr Leu Glu Val
100 105 110
Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn Val Thr Cys Gln
115 120 125
Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr Trp Leu Glu Asn
130 135 140
Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val Thr Glu Asn Lys
145 150 155 160
Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val Asn Val Ser Ala
165 170 175
His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu His Asp Gly Gln
180 185 190
Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser Ala His Pro Lys
195 200 205
Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly Ser Asn Glu Arg
210 215 220
Asn Ile Tyr
225
<210> 33
<211> 348
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 24
<400> 33
gaagaggaac tgcaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccgc cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaga gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagct 348
<210> 34
<211> 348
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 26
<400> 34
gaagaggaaa tccaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccat cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagagt gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcatcaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagct 348
<210> 35
<211> 1029
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 25
<400> 35
gaagaggaaa tccaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccat cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagagt gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcatcaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctaa accttctgct 360
cccgtggtgt ctggccctgc cgctagagct acacctcagc acaccgtgtc ttttacctgc 420
gagtcccacg gcttcagccc tagagacatc accctgaagt ggttcaagaa cggcaacgag 480
ctgtccgact tccagaccaa cgtggaccct gtgggagagt ccgtgtccta ctccatccac 540
tctaccgcca aggtggtgct gacccgagag gacgtgcaca gccaagtgat ctgtgaagtg 600
gcccacgtga ccctccaggg cgatcctttg agaggcaccg ccaacctgtc cgagacaatc 660
agagtgcctc ctacactgga agtgacccag cagcctgtgc gggccgagaa tcaagtgaac 720
gtgacctgcc aagtgcggaa gttctaccct cagagactgc agctgacctg gctggaaaac 780
ggcaatgtgt ccagaaccga gacagcctcc accgtgaccg agaacaagga tggcacctac 840
aattggatgt cctggctgct cgtgaacgtg tccgctcaca gagatgacgt gaagctgaca 900
tgccaggtgg aacacgatgg ccagcctgcc gtgtctaagt cccacgacct gaaagtgtct 960
gctcacccca aagagcaggg ctccaatacc gccgctgaga acaccggctc caacgagaga 1020
aacatctac 1029
<210> 36
<211> 254
<212> PRT
<213> Искусственная последовательность
<220>
<223> аминокислотная последовательность полноразмерного 4-1BBL
<400> 36
Met Glu Tyr Ala Ser Asp Ala Ser Leu Asp Pro Glu Ala Pro Trp Pro
1 5 10 15
Pro Ala Pro Arg Ala Arg Ala Cys Arg Val Leu Pro Trp Ala Leu Val
20 25 30
Ala Gly Leu Leu Leu Leu Leu Leu Leu Ala Ala Ala Cys Ala Val Phe
35 40 45
Leu Ala Cys Pro Trp Ala Val Ser Gly Ala Arg Ala Ser Pro Gly Ser
50 55 60
Ala Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp
65 70 75 80
Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val
85 90 95
Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp
100 105 110
Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu
115 120 125
Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe
130 135 140
Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser
145 150 155 160
Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala
165 170 175
Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala
180 185 190
Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala
195 200 205
Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His
210 215 220
Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val
225 230 235 240
Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
245 250
<210> 37
<211> 765
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты полноразмерного 4-1BBL
<400> 37
atggaatacg cctctgacgc ttcactggac cccgaagccc cgtggcctcc cgcgccccgc 60
gctcgcgcct gccgcgtact gccttgggcc ctggtcgcgg ggctgctgct gctgctgctg 120
ctcgctgccg cctgcgccgt cttcctcgcc tgcccctggg ccgtgtccgg ggctcgcgcc 180
tcgcccggct ccgcggccag cccgagactc cgcgagggtc ccgagctttc gcccgacgat 240
cccgccggcc tcttggacct gcggcagggc atgtttgcgc agctggtggc ccaaaatgtt 300
ctgctgatcg atgggcccct gagctggtac agtgacccag gcctggcagg cgtgtccctg 360
acggggggcc tgagctacaa agaggacacg aaggagctgg tggtggccaa ggctggagtc 420
tactatgtct tctttcaact agagctgcgg cgcgtggtgg ccggcgaggg ctcaggctcc 480
gtttcacttg cgctgcacct gcagccactg cgctctgctg ctggggccgc cgccctggct 540
ttgaccgtgg acctgccacc cgcctcctcc gaggctcgga actcggcctt cggtttccag 600
ggccgcttgc tgcacctgag tgccggccag cgcctgggcg tccatcttca cactgaggcc 660
agggcacgcc atgcctggca gcttacccag ggcgccacag tcttgggact cttccgggtg 720
acccccgaaa tcccagccgg actcccttca ccgaggtcgg aataa 765
<210> 38
<211> 615
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 3
<400> 38
gcctgcccct gggccgtgtc cggggctcgc gcctcgcccg gctccgcggc cagcccgaga 60
ctccgcgagg gtcccgagct ttcgcccgac gatcccgccg gcctcttgga cctgcggcag 120
ggcatgtttg cgcagctggt ggcccaaaat gttctgctga tcgatgggcc cctgagctgg 180
tacagtgacc caggcctggc aggcgtgtcc ctgacggggg gcctgagcta caaagaggac 240
acgaaggagc tggtggtggc caaggctgga gtctactatg tcttctttca actagagctg 300
cggcgcgtgg tggccggcga gggctcaggc tccgtttcac ttgcgctgca cctgcagcca 360
ctgcgctctg ctgctggggc cgccgccctg gctttgaccg tggacctgcc acccgcctcc 420
tccgaggctc ggaactcggc cttcggtttc cagggccgct tgctgcacct gagtgccggc 480
cagcgcctgg gcgtccatct tcacactgag gccagggcac gccatgcctg gcagcttacc 540
cagggcgcca cagtcttggg actcttccgg gtgacccccg aaatcccagc cggactccct 600
tcaccgaggt cggaa 615
<210> 39
<211> 624
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 22
<400> 39
atctacggcg cctgtccttg ggctgtgtct ggcgctagag catctcctgg ctctgctgcc 60
tctcctagac tgagagaggg acctgagctg tctcctgatg atcctgctgg cctgctggat 120
ctgagacagg gcatgtttgc tcagctggtg gcccagaacg tgctgctgat tgatggccct 180
ctgtcctggt actctgatcc tggattggct ggcgtgtccc tgactggcgg cctgtcttac 240
aaagaggaca ccaaagaact ggtggtggcc aaggccggcg tgtactacgt gttctttcag 300
ctggaactgc ggagagtggt ggccggcgaa ggatctggat ctgtgtctct ggcactgcat 360
ctgcagcccc tgagatctgc tgcaggcgct gctgctctgg ctctgacagt tgatctgcct 420
cctgcctcct ccgaggccag aaactccgcc tttggcttcc aaggcagact gctgcatctg 480
tctgccggcc agagactggg agtccatctg catacagagg ctagagccag gcacgcctgg 540
cagttgacac aaggtgctac agtgctgggc ctgttcagag tgaccccaga gattccagcc 600
ggcctgcctt ctccaagatc cgag 624
<210> 40
<211> 573
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 23
<400> 40
tctgctgcct ctcctagact gagagaggga cctgagctgt ctcctgatga tcctgctggc 60
ctgctggatc tgagacaggg catgtttgct cagctggtgg cccagaacgt gctgctgatt 120
gatggccctc tgtcctggta ctctgatcct ggattggctg gcgtgtccct gactggcggc 180
ctgtcttaca aagaggacac caaagaactg gtggtggcca aggccggcgt gtactacgtg 240
ttctttcagc tggaactgcg gagagtggtg gccggcgaag gatctggatc tgtgtctctg 300
gcactgcatc tgcagcccct gagatctgct gcaggcgctg ctgctctggc tctgacagtt 360
gatctgcctc ctgcctcctc cgaggccaga aactccgcct ttggcttcca aggcagactg 420
ctgcatctgt ctgccggcca gagactggga gtccatctgc atacagaggc tagagccagg 480
cacgcctggc agttgacaca aggtgctaca gtgctgggcc tgttcagagt gaccccagag 540
attccagccg gcctgccttc tccaagatcc gag 573
<210> 41
<211> 591
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 27
<400> 41
gctagagcat ctcctggctc tgctgcctct cctagactga gagagggacc tgagctgtct 60
cctgatgatc ctgctggcct gctggatctg agacagggca tgtttgctca gctggtggcc 120
cagaacgtgc tgctgattga tggccctctg tcctggtact ctgatcctgg attggctggc 180
gtgtccctga ctggcggcct gtcttacaaa gaggacacca aagaactggt ggtggccaag 240
gccggcgtgt actacgtgtt ctttcagctg gaactgcgga gagtggtggc cggcgaagga 300
tctggatctg tgtctctggc actgcatctg cagcccctga gatctgctgc aggcgctgct 360
gctctggctc tgacagttga tctgcctcct gcctcctccg aggccagaaa ctccgccttt 420
ggcttccaag gcagactgct gcatctgtct gccggccaga gactgggagt ccatctgcat 480
acagaggcta gagccaggca cgcctggcag ttgacacaag gtgctacagt gctgggcctg 540
ttcagagtga ccccagagat tccagccggc ctgccttctc caagatccga g 591
<210> 42
<211> 555
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 28
<400> 42
ctgagagagg gacctgagct gtctcctgat gatcctgctg gcctgctgga tctgagacag 60
ggcatgtttg ctcagctggt ggcccagaac gtgctgctga ttgatggccc tctgtcctgg 120
tactctgatc ctggattggc tggcgtgtcc ctgactggcg gcctgtctta caaagaggac 180
accaaagaac tggtggtggc caaggccggc gtgtactacg tgttctttca gctggaactg 240
cggagagtgg tggccggcga aggatctgga tctgtgtctc tggcactgca tctgcagccc 300
ctgagatctg ctgcaggcgc tgctgctctg gctctgacag ttgatctgcc tcctgcctcc 360
tccgaggcca gaaactccgc ctttggcttc caaggcagac tgctgcatct gtctgccggc 420
cagagactgg gagtccatct gcatacagag gctagagcca ggcacgcctg gcagttgaca 480
caaggtgcta cagtgctggg cctgttcaga gtgaccccag agattccagc cggcctgcct 540
tctccaagat ccgag 555
<210> 43
<211> 574
<212> PRT
<213> Искусственная последовательность
<220>
<223> ИСХОДНЫЙ SIRPa-4-1BBL с сигнальным пептидом и His-меткой на С-конце
<400> 43
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val
20 25 30
Leu Val Ala Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser
35 40 45
Leu Ile Pro Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly
50 55 60
Arg Glu Leu Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr
65 70 75 80
Thr Val Ser Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg
85 90 95
Ile Gly Asn Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys
100 105 110
Phe Arg Lys Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly
115 120 125
Thr Glu Leu Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly
130 135 140
Pro Ala Ala Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu
145 150 155 160
Ser His Gly Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn
165 170 175
Gly Asn Glu Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu
180 185 190
Ser Val Ser Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg
195 200 205
Glu Asp Val His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu
210 215 220
Gln Gly Asp Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg
225 230 235 240
Val Pro Pro Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn
245 250 255
Gln Val Asn Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu
260 265 270
Gln Leu Thr Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala
275 280 285
Ser Thr Val Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp
290 295 300
Leu Leu Val Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys
305 310 315 320
Gln Val Glu His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu
325 330 335
Lys Val Ser Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu
340 345 350
Asn Thr Gly Ser Asn Glu Arg Asn Ile Tyr Gly Ala Cys Pro Trp Ala
355 360 365
Val Ser Gly Ala Arg Ala Ser Pro Gly Ser Ala Ala Ser Pro Arg Leu
370 375 380
Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp
385 390 395 400
Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu
405 410 415
Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val
420 425 430
Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val
435 440 445
Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg
450 455 460
Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His
465 470 475 480
Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr
485 490 495
Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly
500 505 510
Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val
515 520 525
His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln
530 535 540
Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala
545 550 555 560
Gly Leu Pro Ser Pro Arg Ser Glu His His His His His His
565 570
<210> 44
<211> 555
<212> PRT
<213> Искусственная последовательность
<220>
<223> ИСХОДНЫЙ SIRPa-4-1BBL с сигнальным пептидом и His-меткой на N-конце
<400> 44
His His His His His His Glu Glu Glu Leu Gln Val Ile Gln Pro Asp
1 5 10 15
Lys Ser Val Leu Val Ala Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr
20 25 30
Ala Thr Ser Leu Ile Pro Val Gly Pro Ile Gln Trp Phe Arg Gly Ala
35 40 45
Gly Pro Gly Arg Glu Leu Ile Tyr Asn Gln Lys Glu Gly His Phe Pro
50 55 60
Arg Val Thr Thr Val Ser Asp Leu Thr Lys Arg Asn Asn Met Asp Phe
65 70 75 80
Ser Ile Arg Ile Gly Asn Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr
85 90 95
Cys Val Lys Phe Arg Lys Gly Ser Pro Asp Asp Val Glu Phe Lys Ser
100 105 110
Gly Ala Gly Thr Glu Leu Ser Val Arg Ala Lys Pro Ser Ala Pro Val
115 120 125
Val Ser Gly Pro Ala Ala Arg Ala Thr Pro Gln His Thr Val Ser Phe
130 135 140
Thr Cys Glu Ser His Gly Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp
145 150 155 160
Phe Lys Asn Gly Asn Glu Leu Ser Asp Phe Gln Thr Asn Val Asp Pro
165 170 175
Val Gly Glu Ser Val Ser Tyr Ser Ile His Ser Thr Ala Lys Val Val
180 185 190
Leu Thr Arg Glu Asp Val His Ser Gln Val Ile Cys Glu Val Ala His
195 200 205
Val Thr Leu Gln Gly Asp Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu
210 215 220
Thr Ile Arg Val Pro Pro Thr Leu Glu Val Thr Gln Gln Pro Val Arg
225 230 235 240
Ala Glu Asn Gln Val Asn Val Thr Cys Gln Val Arg Lys Phe Tyr Pro
245 250 255
Gln Arg Leu Gln Leu Thr Trp Leu Glu Asn Gly Asn Val Ser Arg Thr
260 265 270
Glu Thr Ala Ser Thr Val Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp
275 280 285
Met Ser Trp Leu Leu Val Asn Val Ser Ala His Arg Asp Asp Val Lys
290 295 300
Leu Thr Cys Gln Val Glu His Asp Gly Gln Pro Ala Val Ser Lys Ser
305 310 315 320
His Asp Leu Lys Val Ser Ala His Pro Lys Glu Gln Gly Ser Asn Thr
325 330 335
Ala Ala Glu Asn Thr Gly Ser Asn Glu Arg Asn Ile Tyr Gly Ala Cys
340 345 350
Pro Trp Ala Val Ser Gly Ala Arg Ala Ser Pro Gly Ser Ala Ala Ser
355 360 365
Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly
370 375 380
Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn
385 390 395 400
Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu
405 410 415
Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys
420 425 430
Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu
435 440 445
Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu
450 455 460
Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu
465 470 475 480
Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser
485 490 495
Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg
500 505 510
Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln
515 520 525
Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu
530 535 540
Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
545 550 555
<210> 45
<211> 541
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107 вар. 4 [SIRP SEQ ID NO: 2 (343 аминокислоты), глициновый
линкер, 4-1BBL SEQ ID NO: 27 (197 аминокислот)]
<400> 45
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr Gly Ala Arg Ala Ser Pro Gly Ser Ala
340 345 350
Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro
355 360 365
Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala
370 375 380
Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro
385 390 395 400
Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp
405 410 415
Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe
420 425 430
Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val
435 440 445
Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala
450 455 460
Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg
465 470 475 480
Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly
485 490 495
Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His Ala
500 505 510
Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr
515 520 525
Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
530 535 540
<210> 46
<211> 529
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107 вар. 5: SIRP SEQ ID NO: 2 (343 аминокислоты), глициновый
линкер, 4-1BBL SEQ ID NO: 28 (185 аминокислот)
<400> 46
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
115 120 125
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
130 135 140
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
145 150 155 160
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
165 170 175
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
180 185 190
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
195 200 205
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
210 215 220
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
225 230 235 240
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
245 250 255
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
260 265 270
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
275 280 285
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
290 295 300
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
305 310 315 320
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
325 330 335
Ser Asn Glu Arg Asn Ile Tyr Gly Leu Arg Glu Gly Pro Glu Leu Ser
340 345 350
Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala
355 360 365
Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp
370 375 380
Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser
385 390 395 400
Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr
405 410 415
Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly
420 425 430
Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala
435 440 445
Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser
450 455 460
Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His
465 470 475 480
Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg
485 490 495
Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu
500 505 510
Phe Arg Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser
515 520 525
Glu
<210> 47
<211> 308
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107 вар. 6: SIRP SEQ ID NO: 24 (116 аминокислот), глициновый
линкер, 4-1BBL SEQ ID NO: 23 (191 аминокислота):]
<400> 47
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Gly Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly Pro
115 120 125
Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly
130 135 140
Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro
145 150 155 160
Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly
165 170 175
Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala
180 185 190
Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala
195 200 205
Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu
210 215 220
Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro
225 230 235 240
Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg
245 250 255
Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu His Thr
260 265 270
Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val
275 280 285
Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser
290 295 300
Pro Arg Ser Glu
305
<210> 48
<211> 314
<212> PRT
<213> Искусственная последовательность
<220>
<223> Вар. 7: SIRP SEQ ID NO: 24 (116 аминокислот), глициновый линкер, 4-1BBL SEQ ID NO: 27 (197 аминокислот)
<400> 48
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Gly Ala Arg Ala Ser Pro Gly Ser Ala Ala Ser Pro
115 120 125
Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu
130 135 140
Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val
145 150 155 160
Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala
165 170 175
Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu
180 185 190
Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu
195 200 205
Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala
210 215 220
Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala
225 230 235 240
Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala
245 250 255
Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu
260 265 270
Gly Val His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu
275 280 285
Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile
290 295 300
Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
305 310
<210> 49
<211> 302
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107 вар. 8: SIRP SEQ ID NO: 24 (116 аминокислот), глициновый
линкер, 4-1BBL SEQ ID NO: 28 (185 аминокислот)
<400> 49
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
1 5 10 15
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
20 25 30
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
35 40 45
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
50 55 60
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
65 70 75 80
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
85 90 95
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
100 105 110
Ser Val Arg Ala Gly Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp
115 120 125
Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val
130 135 140
Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp
145 150 155 160
Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu
165 170 175
Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe
180 185 190
Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser
195 200 205
Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala
210 215 220
Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala
225 230 235 240
Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala
245 250 255
Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His
260 265 270
Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val
275 280 285
Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu
290 295 300
<210> 50
<211> 1722
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 44
<400> 50
atgggctggt cctgcatcat cctgtttctg gtggctaccg ctaccggcgt gcactcccac 60
caccaccatc accacgaaga ggaactgcaa gtgatccagc ctgacaagtc cgtgctggtg 120
gctgctggcg aaaccgccac actgagatgt accgccacct ctctgatccc tgtgggccct 180
atccagtggt ttagaggcgc tggacctggc agagagctga tctacaacca gaaagagggc 240
cactttccta gagtgaccac cgtgtccgac ctgaccaagc ggaacaacat ggacttctcc 300
atccggatcg gcaacatcac ccctgctgat gccggcacct actactgcgt gaagttccgg 360
aagggctccc ctgacgacgt cgagtttaaa tccggcgctg gcaccgaact gtccgtgcga 420
gctaaacctt ctgctcccgt ggtgtctggc cctgccgcta gagctacacc tcagcacacc 480
gtgtctttta cctgcgagtc ccacggcttc agccctagag acatcaccct gaagtggttc 540
aagaacggca acgagctgtc cgacttccag accaacgtgg accctgtggg agagtccgtg 600
tcctactcca tccactctac cgccaaggtg gtgctgaccc gagaggacgt gcacagccaa 660
gtgatctgtg aagtggccca cgtgaccctc cagggcgatc ctttgagagg caccgccaac 720
ctgtccgaga caatcagagt gcctcctaca ctggaagtga cccagcagcc tgtgcgggcc 780
gagaatcaag tgaacgtgac ctgccaagtg cggaagttct accctcagag actgcagctg 840
acctggctgg aaaacggcaa tgtgtccaga accgagacag cctccaccgt gaccgagaac 900
aaggatggca cctacaattg gatgtcctgg ctgctcgtga acgtgtccgc tcacagagat 960
gacgtgaagc tgacatgcca ggtggaacac gatggccagc ctgccgtgtc taagtcccac 1020
gacctgaaag tgtctgctca ccccaaagag cagggctcca ataccgccgc tgagaacacc 1080
ggctccaacg agagaaacat ctacggcgcc tgtccttggg ctgtgtctgg cgctagagca 1140
tctcctggct ctgctgcctc tcctagactg agagagggac ctgagctgtc tcctgatgat 1200
cctgctggcc tgctggatct gagacagggc atgtttgctc agctggtggc ccagaacgtg 1260
ctgctgattg atggccctct gtcctggtac tctgatcctg gattggctgg cgtgtccctg 1320
actggcggcc tgtcttacaa agaggacacc aaagaactgg tggtggccaa ggccggcgtg 1380
tactacgtgt tctttcagct ggaactgcgg agagtggtgg ccggcgaagg atctggatct 1440
gtgtctctgg cactgcatct gcagcccctg agatctgctg caggcgctgc tgctctggct 1500
ctgacagttg atctgcctcc tgcctcctcc gaggccagaa actccgcctt tggcttccaa 1560
ggcagactgc tgcatctgtc tgccggccag agactgggag tccatctgca tacagaggct 1620
agagccaggc acgcctggca gttgacacaa ggtgctacag tgctgggcct gttcagagtg 1680
accccagaga ttccagccgg cctgccttct ccaagatccg ag 1722
<210> 51
<211> 1749
<212> DNA
<213> Искусственная последовательность
<220>
<223> Клонированная последовательность (CH)-DSP-107 с C-концевой His-меткой
<400> 51
gaattcccgc cgccaccatg ggctggtcct gcatcatcct gtttctggtg gctaccgcta 60
ccggcgtgca ctccgaagag gaactgcaag tgatccagcc tgacaagtcc gtgctggtgg 120
ctgctggcga aaccgccaca ctgagatgta ccgccacctc tctgatccct gtgggcccta 180
tccagtggtt tagaggcgct ggacctggca gagagctgat ctacaaccag aaagagggcc 240
actttcctag agtgaccacc gtgtccgacc tgaccaagcg gaacaacatg gacttctcca 300
tccggatcgg caacatcacc cctgctgatg ccggcaccta ctactgcgtg aagttccgga 360
agggctcccc tgacgacgtc gagtttaaat ccggcgctgg caccgaactg tccgtgcgag 420
ctaaaccttc tgctcccgtg gtgtctggcc ctgccgctag agctacacct cagcacaccg 480
tgtcttttac ctgcgagtcc cacggcttca gccctagaga catcaccctg aagtggttca 540
agaacggcaa cgagctgtcc gacttccaga ccaacgtgga ccctgtggga gagtccgtgt 600
cctactccat ccactctacc gccaaggtgg tgctgacccg agaggacgtg cacagccaag 660
tgatctgtga agtggcccac gtgaccctcc agggcgatcc tttgagaggc accgccaacc 720
tgtccgagac aatcagagtg cctcctacac tggaagtgac ccagcagcct gtgcgggccg 780
agaatcaagt gaacgtgacc tgccaagtgc ggaagttcta ccctcagaga ctgcagctga 840
cctggctgga aaacggcaat gtgtccagaa ccgagacagc ctccaccgtg accgagaaca 900
aggatggcac ctacaattgg atgtcctggc tgctcgtgaa cgtgtccgct cacagagatg 960
acgtgaagct gacatgccag gtggaacacg atggccagcc tgccgtgtct aagtcccacg 1020
acctgaaagt gtctgctcac cccaaagagc agggctccaa taccgccgct gagaacaccg 1080
gctccaacga gagaaacatc tacggcgcct gtccttgggc tgtgtctggc gctagagcat 1140
ctcctggctc tgctgcctct cctagactga gagagggacc tgagctgtct cctgatgatc 1200
ctgctggcct gctggatctg agacagggca tgtttgctca gctggtggcc cagaacgtgc 1260
tgctgattga tggccctctg tcctggtact ctgatcctgg attggctggc gtgtccctga 1320
ctggcggcct gtcttacaaa gaggacacca aagaactggt ggtggccaag gccggcgtgt 1380
actacgtgtt ctttcagctg gaactgcgga gagtggtggc cggcgaagga tctggatctg 1440
tgtctctggc actgcatctg cagcccctga gatctgctgc aggcgctgct gctctggctc 1500
tgacagttga tctgcctcct gcctcctccg aggccagaaa ctccgccttt ggcttccaag 1560
gcagactgct gcatctgtct gccggccaga gactgggagt ccatctgcat acagaggcta 1620
gagccaggca cgcctggcag ttgacacaag gtgctacagt gctgggcctg ttcagagtga 1680
ccccagagat tccagccggc ctgccttctc caagatccga gcaccaccac catcaccact 1740
gataagctt 1749
<210> 52
<211> 1731
<212> DNA
<213> Искусственная последовательность
<220>
<223> Клонированная последовательность (CH)-V1 DSP-107 с C-концевой His-меткой
<400> 52
gaattcccgc cgccaccatg ggctggtcct gcatcatcct gtttctggtg gctaccgcta 60
ccggcgtgca ctccgaagag gaactgcaag tgatccagcc tgacaagtcc gtgctggtgg 120
ctgctggcga aaccgccaca ctgagatgta ccgccacctc tctgatccct gtgggcccta 180
tccagtggtt tagaggcgct ggacctggca gagagctgat ctacaaccag aaagagggcc 240
actttcctag agtgaccacc gtgtccgacc tgaccaagcg gaacaacatg gacttctcca 300
tccggatcgg caacatcacc cctgctgatg ccggcaccta ctactgcgtg aagttccgga 360
agggctcccc tgacgacgtc gagtttaaat ccggcgctgg caccgaactg tccgtgcgag 420
ctaaaccttc tgctcccgtg gtgtctggcc ctgccgctag agctacacct cagcacaccg 480
tgtcttttac ctgcgagtcc cacggcttca gccctagaga catcaccctg aagtggttca 540
agaacggcaa cgagctgtcc gacttccaga ccaacgtgga ccctgtggga gagtccgtgt 600
cctactccat ccactctacc gccaaggtgg tgctgacccg agaggacgtg cacagccaag 660
tgatctgtga agtggcccac gtgaccctcc agggcgatcc tttgagaggc accgccaacc 720
tgtccgagac aatcagagtg cctcctacac tggaagtgac ccagcagcct gtgcgggccg 780
agaatcaagt gaacgtgacc tgccaagtgc ggaagttcta ccctcagaga ctgcagctga 840
cctggctgga aaacggcaat gtgtccagaa ccgagacagc ctccaccgtg accgagaaca 900
aggatggcac ctacaattgg atgtcctggc tgctcgtgaa cgtgtccgct cacagagatg 960
acgtgaagct gacatgccag gtggaacacg atggccagcc tgccgtgtct aagtcccacg 1020
acctgaaagt gtctgctcac cccaaagagc agggctccaa taccgccgct gagaacaccg 1080
gctccaacga gagaaacatc tacggctctg gcgctagggc ctctcctgga tctgctgctt 1140
ctcccagact gagagagggc cctgagctgt ctcctgatga tcctgctgga ctgctggatc 1200
tgagacaggg catgtttgct cagctggtgg cccagaacgt gctgctgatt gatggccctc 1260
tgtcctggta ctctgatcct ggattggctg gcgtgtccct gactggcggc ctgtcttaca 1320
aagaggacac caaagaactg gtggtggcca aggccggcgt gtactacgtg ttctttcagc 1380
tggaactgcg gagagtggtg gccggcgaag gatctggatc tgtgtctctg gctctgcatc 1440
tgcagcccct gagatctgca gcaggcgctg cagctctggc actgacagtt gatctgcctc 1500
ctgcctcctc cgaggccaga aactccgcct ttggcttcca aggcagactg ctgcacctgt 1560
ctgctggaca gagactggga gtgcacctcc acacagaggc cagagctaga catgcctggc 1620
agttgacaca gggcgctaca gtgctgggcc tgttcagagt gacacctgag attccagccg 1680
gcctgccttc tccaagatcc gagcaccacc accatcacca ctgataagct t 1731
<210> 53
<211> 1707
<212> DNA
<213> Искусственная последовательность
<220>
<223> Клонированная последовательность (CH)-V2 DSP-107 с C-концевой His-меткой
<400> 53
gaattcccgc cgccaccatg ggctggtcct gcatcatcct gtttctggtg gctaccgcta 60
ccggcgtgca ctccgaagag gaactgcaag tgatccagcc tgacaagtcc gtgctggtgg 120
ctgctggcga aaccgccaca ctgagatgta ccgccacctc tctgatccct gtgggcccta 180
tccagtggtt tagaggcgct ggacctggca gagagctgat ctacaaccag aaagagggcc 240
actttcctag agtgaccacc gtgtccgacc tgaccaagcg gaacaacatg gacttctcca 300
tccggatcgg caacatcacc cctgctgatg ccggcaccta ctactgcgtg aagttccgga 360
agggctcccc tgacgacgtc gagtttaaat ccggcgctgg caccgaactg tccgtgcgag 420
ctaaaccttc tgctcccgtg gtgtctggcc ctgccgctag agctacacct cagcacaccg 480
tgtcttttac ctgcgagtcc cacggcttca gccctagaga catcaccctg aagtggttca 540
agaacggcaa cgagctgtcc gacttccaga ccaacgtgga ccctgtggga gagtccgtgt 600
cctactccat ccactctacc gccaaggtgg tgctgacccg agaggacgtg cacagccaag 660
tgatctgtga agtggcccac gtgaccctcc agggcgatcc tttgagaggc accgccaacc 720
tgtccgagac aatcagagtg cctcctacac tggaagtgac ccagcagcct gtgcgggccg 780
agaatcaagt gaacgtgacc tgccaagtgc ggaagttcta ccctcagaga ctgcagctga 840
cctggctgga aaacggcaat gtgtccagaa ccgagacagc ctccaccgtg accgagaaca 900
aggatggcac ctacaattgg atgtcctggc tgctcgtgaa cgtgtccgct cacagagatg 960
acgtgaagct gacatgccag gtggaacacg atggccagcc tgccgtgtct aagtcccacg 1020
acctgaaagt gtctgctcac cccaaagagc agggctccaa taccgccgct gagaacaccg 1080
gctccaacga gagaaacatc tacggctctg ccgcctctcc tagactgaga gagggacctg 1140
agctgtctcc tgatgatcct gctggcctgc tggatctgag acagggcatg tttgctcagc 1200
tggtggccca gaacgtgctg ctgattgatg gccctctgtc ctggtactct gatcctggat 1260
tggctggcgt gtccctgact ggcggcctgt cttacaaaga ggacaccaaa gaactggtgg 1320
tggccaaggc cggcgtgtac tacgtgttct ttcagctgga actgcggaga gtggtggccg 1380
gcgaaggatc tggatctgtg tctctggctc tgcatctgca gcccctgaga tctgctgcag 1440
gcgctgctgc tctggcactg acagttgatc tgcctcctgc ctcctccgag gccagaaact 1500
ccgcctttgg cttccaaggc agactgctgc atctgtctgc cggccagaga ctgggagtcc 1560
atctgcatac agaggccaga gctagacacg cttggcagtt gacacagggc gctacagtgc 1620
tgggcctgtt cagagtgaca cctgagatcc cagccggcct gccttctcca agatctgagc 1680
accaccacca tcaccactga taagctt 1707
<210> 54
<211> 1047
<212> DNA
<213> Искусственная последовательность
<220>
<223> Клонированная последовательность (CH)-V3.1 DSP-107 с C-концевой His-меткой
<400> 54
gaattcccgc cgccaccatg ggctggtcct gcatcatcct gtttctggtg gctaccgcta 60
ccggcgtgca ctccgaagag gaactgcaag tgatccagcc tgacaagtcc gtgctggtgg 120
ctgctggcga aaccgccaca ctgagatgta ccgccacctc tctgatccct gtgggcccta 180
tccagtggtt tagaggcgct ggacctggca gagagctgat ctacaaccag aaagagggcc 240
actttcctag agtgaccacc gtgtccgacc tgaccaagcg gaacaacatg gacttctcca 300
tccggatcgg caacatcacc cctgctgatg ccggcaccta ctactgcgtg aagttccgga 360
agggctcccc tgacgacgtc gagtttaaat ccggcgctgg caccgagctg tccgtcagag 420
cttctggtgc tagagcctct cctggctctg ccgcttctcc tagactgaga gagggacctg 480
agctgtctcc tgatgatcct gctggcctgc tggatctgag acagggcatg tttgctcagc 540
tggtggccca gaacgtgctg ctgattgatg gccctctgtc ctggtactct gatcctggat 600
tggctggcgt gtccctgact ggcggcctgt cttacaaaga ggacaccaaa gaactggtgg 660
tggccaaggc cggcgtgtac tacgtgttct ttcagctgga actgcggaga gtggtggccg 720
gcgaaggatc tggatctgtg tctctggcac tgcatctgca gcctctgaga tctgctgcag 780
gcgctgctgc tctggctctg acagttgatc tgcctcctgc ctcctccgag gccagaaact 840
ccgcctttgg cttccaaggc agactgctgc atctgtctgc cggccagaga ctgggagtcc 900
atctgcatac agaggccaga gctagacacg cttggcagtt gacacagggc gctacagtgc 960
tgggcctgtt cagagtgaca cctgagatcc cagccggcct gccttctcca agatctgagc 1020
accaccacca tcaccactga taagctt 1047
<210> 55
<211> 1629
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 11 (DSP107_var1 без His-метки
<400> 55
gaagaggaac tgcaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccgc cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaga gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctaa accttctgct 360
cccgtggtgt ctggccctgc cgctagagct acacctcagc acaccgtgtc ttttacctgc 420
gagtcccacg gcttcagccc tagagacatc accctgaagt ggttcaagaa cggcaacgag 480
ctgtccgact tccagaccaa cgtggaccct gtgggagagt ccgtgtccta ctccatccac 540
tctaccgcca aggtggtgct gacccgagag gacgtgcaca gccaagtgat ctgtgaagtg 600
gcccacgtga ccctccaggg cgatcctttg agaggcaccg ccaacctgtc cgagacaatc 660
agagtgcctc ctacactgga agtgacccag cagcctgtgc gggccgagaa tcaagtgaac 720
gtgacctgcc aagtgcggaa gttctaccct cagagactgc agctgacctg gctggaaaac 780
ggcaatgtgt ccagaaccga gacagcctcc accgtgaccg agaacaagga tggcacctac 840
aattggatgt cctggctgct cgtgaacgtg tccgctcaca gagatgacgt gaagctgaca 900
tgccaggtgg aacacgatgg ccagcctgcc gtgtctaagt cccacgacct gaaagtgtct 960
gctcacccca aagagcaggg ctccaatacc gccgctgaga acaccggctc caacgagaga 1020
aacatctacg gctctggcgc tagggcctct cctggatctg ctgcttctcc cagactgaga 1080
gagggccctg agctgtctcc tgatgatcct gctggactgc tggatctgag acagggcatg 1140
tttgctcagc tggtggccca gaacgtgctg ctgattgatg gccctctgtc ctggtactct 1200
gatcctggat tggctggcgt gtccctgact ggcggcctgt cttacaaaga ggacaccaaa 1260
gaactggtgg tggccaaggc cggcgtgtac tacgtgttct ttcagctgga actgcggaga 1320
gtggtggccg gcgaaggatc tggatctgtg tctctggctc tgcatctgca gcccctgaga 1380
tctgcagcag gcgctgcagc tctggcactg acagttgatc tgcctcctgc ctcctccgag 1440
gccagaaact ccgcctttgg cttccaaggc agactgctgc acctgtctgc tggacagaga 1500
ctgggagtgc acctccacac agaggccaga gctagacatg cctggcagtt gacacagggc 1560
gctacagtgc tgggcctgtt cagagtgaca cctgagattc cagccggcct gccttctcca 1620
agatccgag 1629
<210> 56
<211> 1605
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 13 (DSP107_var2 без His-метки)
<400> 56
gaagaggaac tgcaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccgc cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaga gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctaa accttctgct 360
cccgtggtgt ctggccctgc cgctagagct acacctcagc acaccgtgtc ttttacctgc 420
gagtcccacg gcttcagccc tagagacatc accctgaagt ggttcaagaa cggcaacgag 480
ctgtccgact tccagaccaa cgtggaccct gtgggagagt ccgtgtccta ctccatccac 540
tctaccgcca aggtggtgct gacccgagag gacgtgcaca gccaagtgat ctgtgaagtg 600
gcccacgtga ccctccaggg cgatcctttg agaggcaccg ccaacctgtc cgagacaatc 660
agagtgcctc ctacactgga agtgacccag cagcctgtgc gggccgagaa tcaagtgaac 720
gtgacctgcc aagtgcggaa gttctaccct cagagactgc agctgacctg gctggaaaac 780
ggcaatgtgt ccagaaccga gacagcctcc accgtgaccg agaacaagga tggcacctac 840
aattggatgt cctggctgct cgtgaacgtg tccgctcaca gagatgacgt gaagctgaca 900
tgccaggtgg aacacgatgg ccagcctgcc gtgtctaagt cccacgacct gaaagtgtct 960
gctcacccca aagagcaggg ctccaatacc gccgctgaga acaccggctc caacgagaga 1020
aacatctacg gctctgccgc ctctcctaga ctgagagagg gacctgagct gtctcctgat 1080
gatcctgctg gcctgctgga tctgagacag ggcatgtttg ctcagctggt ggcccagaac 1140
gtgctgctga ttgatggccc tctgtcctgg tactctgatc ctggattggc tggcgtgtcc 1200
ctgactggcg gcctgtctta caaagaggac accaaagaac tggtggtggc caaggccggc 1260
gtgtactacg tgttctttca gctggaactg cggagagtgg tggccggcga aggatctgga 1320
tctgtgtctc tggctctgca tctgcagccc ctgagatctg ctgcaggcgc tgctgctctg 1380
gcactgacag ttgatctgcc tcctgcctcc tccgaggcca gaaactccgc ctttggcttc 1440
caaggcagac tgctgcatct gtctgccggc cagagactgg gagtccatct gcatacagag 1500
gccagagcta gacacgcttg gcagttgaca cagggcgcta cagtgctggg cctgttcaga 1560
gtgacacctg agatcccagc cggcctgcct tctccaagat ctgag 1605
<210> 57
<211> 966
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 15 (DSP107_var3 без His-метки)
<400> 57
gaagaggaac tgcaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccgc cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaga gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctgg cgcctgtcct 360
tgggctgtgt ctggcgctag agcatctcct ggctctgctg cctctcctag actgagagag 420
ggacctgagc tgtctcctga tgatcctgct ggcctgctgg atctgagaca gggcatgttt 480
gctcagctgg tggcccagaa cgtgctgctg attgatggcc ctctgtcctg gtactctgat 540
cctggattgg ctggcgtgtc cctgactggc ggcctgtctt acaaagagga caccaaagaa 600
ctggtggtgg ccaaggccgg cgtgtactac gtgttctttc agctggaact gcggagagtg 660
gtggccggcg aaggatctgg atctgtgtct ctggcactgc atctgcagcc cctgagatct 720
gctgcaggcg ctgctgctct ggctctgaca gttgatctgc ctcctgcctc ctccgaggcc 780
agaaactccg cctttggctt ccaaggcaga ctgctgcatc tgtctgccgg ccagagactg 840
ggagtccatc tgcatacaga ggctagagcc aggcacgcct ggcagttgac acaaggtgct 900
acagtgctgg gcctgttcag agtgacccca gagattccag ccggcctgcc ttctccaaga 960
tccgag 966
<210> 58
<211> 945
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 16: (DSP107_var3.1 без His-метки)
<400> 58
gaagaggaac tgcaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccgc cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaga gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gagctgtccg tcagagcttc tggtgctaga 360
gcctctcctg gctctgccgc ttctcctaga ctgagagagg gacctgagct gtctcctgat 420
gatcctgctg gcctgctgga tctgagacag ggcatgtttg ctcagctggt ggcccagaac 480
gtgctgctga ttgatggccc tctgtcctgg tactctgatc ctggattggc tggcgtgtcc 540
ctgactggcg gcctgtctta caaagaggac accaaagaac tggtggtggc caaggccggc 600
gtgtactacg tgttctttca gctggaactg cggagagtgg tggccggcga aggatctgga 660
tctgtgtctc tggcactgca tctgcagcct ctgagatctg ctgcaggcgc tgctgctctg 720
gctctgacag ttgatctgcc tcctgcctcc tccgaggcca gaaactccgc ctttggcttc 780
caaggcagac tgctgcatct gtctgccggc cagagactgg gagtccatct gcatacagag 840
gccagagcta gacacgcttg gcagttgaca cagggcgcta cagtgctggg cctgttcaga 900
gtgacacctg agatcccagc cggcctgcct tctccaagat ctgag 945
<210> 59
<211> 1629
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 18 (DSP107_Var1Mut без His-метки)
<400> 59
gaagaggaaa tccaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccat cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaat gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatcgact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctaa accttctgct 360
cccgtggtgt ctggccctgc cgctagagct acacctcagc acaccgtgtc ttttacctgc 420
gagtcccacg gcttcagccc tagagacatc accctgaagt ggttcaagaa cggcaacgag 480
ctgtccgact tccagaccaa cgtggaccct gtgggagagt ccgtgtccta ctccatccac 540
tctaccgcca aggtggtgct gacccgagag gacgtgcaca gccaagtgat ctgtgaagtg 600
gcccacgtga ccctccaggg cgatcctttg agaggcaccg ccaacctgtc cgagacaatc 660
agagtgcctc ctacactgga agtgacccag cagcctgtgc gggccgagaa tcaagtgaac 720
gtgacctgcc aagtgcggaa gttctaccct cagagactgc agctgacctg gctggaaaac 780
ggcaatgtgt ccagaaccga gacagcctcc accgtgaccg agaacaagga tggcacctac 840
aattggatgt cctggctgct cgtgaacgtg tccgctcaca gagatgacgt gaagctgaca 900
tgccaggtgg aacacgatgg ccagcctgcc gtgtctaagt cccacgacct gaaagtgtct 960
gctcacccca aagagcaggg ctccaatacc gccgctgaga acaccggctc caacgagaga 1020
aacatctacg gctctggcgc tagggcctct cctggatctg ctgcttctcc cagactgaga 1080
gagggccctg agctgtctcc tgatgatcct gctggactgc tggatctgag acagggcatg 1140
tttgctcagc tggtggccca gaacgtgctg ctgattgatg gccctctgtc ctggtactct 1200
gatcctggat tggctggcgt gtccctgact ggcggcctgt cttacaaaga ggacaccaaa 1260
gaactggtgg tggccaaggc cggcgtgtac tacgtgttct ttcagctgga actgcggaga 1320
gtggtggccg gcgaaggatc tggatctgtg tctctggctc tgcatctgca gcccctgaga 1380
tctgcagcag gcgctgcagc tctggcactg acagttgatc tgcctcctgc ctcctccgag 1440
gccagaaact ccgcctttgg cttccaaggc agactgctgc acctgtctgc tggacagaga 1500
ctgggagtgc acctccacac agaggccaga gctagacatg cctggcagtt gacacagggc 1560
gctacagtgc tgggcctgtt cagagtgaca cctgagattc cagccggcct gccttctcca 1620
agatccgag 1629
<210> 60
<211> 1605
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 19: (DSP107_Var2Mut без His-метки)
<400> 60
gaagaggaaa tccaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccat cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaat gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatcgact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctaa accttctgct 360
cccgtggtgt ctggccctgc cgctagagct acacctcagc acaccgtgtc ttttacctgc 420
gagtcccacg gcttcagccc tagagacatc accctgaagt ggttcaagaa cggcaacgag 480
ctgtccgact tccagaccaa cgtggaccct gtgggagagt ccgtgtccta ctccatccac 540
tctaccgcca aggtggtgct gacccgagag gacgtgcaca gccaagtgat ctgtgaagtg 600
gcccacgtga ccctccaggg cgatcctttg agaggcaccg ccaacctgtc cgagacaatc 660
agagtgcctc ctacactgga agtgacccag cagcctgtgc gggccgagaa tcaagtgaac 720
gtgacctgcc aagtgcggaa gttctaccct cagagactgc agctgacctg gctggaaaac 780
ggcaatgtgt ccagaaccga gacagcctcc accgtgaccg agaacaagga tggcacctac 840
aattggatgt cctggctgct cgtgaacgtg tccgctcaca gagatgacgt gaagctgaca 900
tgccaggtgg aacacgatgg ccagcctgcc gtgtctaagt cccacgacct gaaagtgtct 960
gctcacccca aagagcaggg ctccaatacc gccgctgaga acaccggctc caacgagaga 1020
aacatctacg gctctgccgc ctctcctaga ctgagagagg gacctgagct gtctcctgat 1080
gatcctgctg gcctgctgga tctgagacag ggcatgtttg ctcagctggt ggcccagaac 1140
gtgctgctga ttgatggccc tctgtcctgg tactctgatc ctggattggc tggcgtgtcc 1200
ctgactggcg gcctgtctta caaagaggac accaaagaac tggtggtggc caaggccggc 1260
gtgtactacg tgttctttca gctggaactg cggagagtgg tggccggcga aggatctgga 1320
tctgtgtctc tggctctgca tctgcagccc ctgagatctg ctgcaggcgc tgctgctctg 1380
gcactgacag ttgatctgcc tcctgcctcc tccgaggcca gaaactccgc ctttggcttc 1440
caaggcagac tgctgcatct gtctgccggc cagagactgg gagtccatct gcatacagag 1500
gccagagcta gacacgcttg gcagttgaca cagggcgcta cagtgctggg cctgttcaga 1560
gtgacacctg agatcccagc cggcctgcct tctccaagat ctgag 1605
<210> 61
<211> 966
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 20 (DSP107_Var3Mut без His-метки)
<400> 61
gaagaggaaa tccaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccat cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagagt gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcatcaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctgg cgcctgtcct 360
tgggctgtgt ctggcgctag agcatctcct ggctctgctg cctctcctag actgagagag 420
ggacctgagc tgtctcctga tgatcctgct ggcctgctgg atctgagaca gggcatgttt 480
gctcagctgg tggcccagaa cgtgctgctg attgatggcc ctctgtcctg gtactctgat 540
cctggattgg ctggcgtgtc cctgactggc ggcctgtctt acaaagagga caccaaagaa 600
ctggtggtgg ccaaggccgg cgtgtactac gtgttctttc agctggaact gcggagagtg 660
gtggccggcg aaggatctgg atctgtgtct ctggcactgc atctgcagcc cctgagatct 720
gctgcaggcg ctgctgctct ggctctgaca gttgatctgc ctcctgcctc ctccgaggcc 780
agaaactccg cctttggctt ccaaggcaga ctgctgcatc tgtctgccgg ccagagactg 840
ggagtccatc tgcatacaga ggctagagcc aggcacgcct ggcagttgac acaaggtgct 900
acagtgctgg gcctgttcag agtgacccca gagattccag ccggcctgcc ttctccaaga 960
tccgag 966
<210> 62
<211> 1623
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 45 (вар. 4)
<400> 62
gaagaggaac tgcaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccgc cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaga gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctaa accttctgct 360
cccgtggtgt ctggccctgc cgctagagct acacctcagc acaccgtgtc ttttacctgc 420
gagtcccacg gcttcagccc tagagacatc accctgaagt ggttcaagaa cggcaacgag 480
ctgtccgact tccagaccaa cgtggaccct gtgggagagt ccgtgtccta ctccatccac 540
tctaccgcca aggtggtgct gacccgagag gacgtgcaca gccaagtgat ctgtgaagtg 600
gcccacgtga ccctccaggg cgatcctttg agaggcaccg ccaacctgtc cgagacaatc 660
agagtgcctc ctacactgga agtgacccag cagcctgtgc gggccgagaa tcaagtgaac 720
gtgacctgcc aagtgcggaa gttctaccct cagagactgc agctgacctg gctggaaaac 780
ggcaatgtgt ccagaaccga gacagcctcc accgtgaccg agaacaagga tggcacctac 840
aattggatgt cctggctgct cgtgaacgtg tccgctcaca gagatgacgt gaagctgaca 900
tgccaggtgg aacacgatgg ccagcctgcc gtgtctaagt cccacgacct gaaagtgtct 960
gctcacccca aagagcaggg ctccaatacc gccgctgaga acaccggctc caacgagaga 1020
aacatctacg gagctagagc atctcctggc tctgctgcct ctcctagact gagagaggga 1080
cctgagctgt ctcctgatga tcctgctggc ctgctggatc tgagacaggg catgtttgct 1140
cagctggtgg cccagaacgt gctgctgatt gatggccctc tgtcctggta ctctgatcct 1200
ggattggctg gcgtgtccct gactggcggc ctgtcttaca aagaggacac caaagaactg 1260
gtggtggcca aggccggcgt gtactacgtg ttctttcagc tggaactgcg gagagtggtg 1320
gccggcgaag gatctggatc tgtgtctctg gcactgcatc tgcagcccct gagatctgct 1380
gcaggcgctg ctgctctggc tctgacagtt gatctgcctc ctgcctcctc cgaggccaga 1440
aactccgcct ttggcttcca aggcagactg ctgcatctgt ctgccggcca gagactggga 1500
gtccatctgc atacagaggc tagagccagg cacgcctggc agttgacaca aggtgctaca 1560
gtgctgggcc tgttcagagt gaccccagag attccagccg gcctgccttc tccaagatcc 1620
gag 1623
<210> 63
<211> 1587
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 46 (вар. 5)
<400> 63
gaagaggaac tgcaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccgc cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaga gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctaa accttctgct 360
cccgtggtgt ctggccctgc cgctagagct acacctcagc acaccgtgtc ttttacctgc 420
gagtcccacg gcttcagccc tagagacatc accctgaagt ggttcaagaa cggcaacgag 480
ctgtccgact tccagaccaa cgtggaccct gtgggagagt ccgtgtccta ctccatccac 540
tctaccgcca aggtggtgct gacccgagag gacgtgcaca gccaagtgat ctgtgaagtg 600
gcccacgtga ccctccaggg cgatcctttg agaggcaccg ccaacctgtc cgagacaatc 660
agagtgcctc ctacactgga agtgacccag cagcctgtgc gggccgagaa tcaagtgaac 720
gtgacctgcc aagtgcggaa gttctaccct cagagactgc agctgacctg gctggaaaac 780
ggcaatgtgt ccagaaccga gacagcctcc accgtgaccg agaacaagga tggcacctac 840
aattggatgt cctggctgct cgtgaacgtg tccgctcaca gagatgacgt gaagctgaca 900
tgccaggtgg aacacgatgg ccagcctgcc gtgtctaagt cccacgacct gaaagtgtct 960
gctcacccca aagagcaggg ctccaatacc gccgctgaga acaccggctc caacgagaga 1020
aacatctacg gactgagaga gggacctgag ctgtctcctg atgatcctgc tggcctgctg 1080
gatctgagac agggcatgtt tgctcagctg gtggcccaga acgtgctgct gattgatggc 1140
cctctgtcct ggtactctga tcctggattg gctggcgtgt ccctgactgg cggcctgtct 1200
tacaaagagg acaccaaaga actggtggtg gccaaggccg gcgtgtacta cgtgttcttt 1260
cagctggaac tgcggagagt ggtggccggc gaaggatctg gatctgtgtc tctggcactg 1320
catctgcagc ccctgagatc tgctgcaggc gctgctgctc tggctctgac agttgatctg 1380
cctcctgcct cctccgaggc cagaaactcc gcctttggct tccaaggcag actgctgcat 1440
ctgtctgccg gccagagact gggagtccat ctgcatacag aggctagagc caggcacgcc 1500
tggcagttga cacaaggtgc tacagtgctg ggcctgttca gagtgacccc agagattcca 1560
gccggcctgc cttctccaag atccgag 1587
<210> 64
<211> 924
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 47 (вар. 6)
<400> 64
gaagaggaac tgcaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccgc cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaga gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctgg atctgctgcc 360
tctcctagac tgagagaggg acctgagctg tctcctgatg atcctgctgg cctgctggat 420
ctgagacagg gcatgtttgc tcagctggtg gcccagaacg tgctgctgat tgatggccct 480
ctgtcctggt actctgatcc tggattggct ggcgtgtccc tgactggcgg cctgtcttac 540
aaagaggaca ccaaagaact ggtggtggcc aaggccggcg tgtactacgt gttctttcag 600
ctggaactgc ggagagtggt ggccggcgaa ggatctggat ctgtgtctct ggcactgcat 660
ctgcagcccc tgagatctgc tgcaggcgct gctgctctgg ctctgacagt tgatctgcct 720
cctgcctcct ccgaggccag aaactccgcc tttggcttcc aaggcagact gctgcatctg 780
tctgccggcc agagactggg agtccatctg catacagagg ctagagccag gcacgcctgg 840
cagttgacac aaggtgctac agtgctgggc ctgttcagag tgaccccaga gattccagcc 900
ggcctgcctt ctccaagatc cgag 924
<210> 65
<211> 942
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 48 (вар. 7)
<400> 65
gaagaggaac tgcaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccgc cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaga gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctgg agctagagca 360
tctcctggct ctgctgcctc tcctagactg agagagggac ctgagctgtc tcctgatgat 420
cctgctggcc tgctggatct gagacagggc atgtttgctc agctggtggc ccagaacgtg 480
ctgctgattg atggccctct gtcctggtac tctgatcctg gattggctgg cgtgtccctg 540
actggcggcc tgtcttacaa agaggacacc aaagaactgg tggtggccaa ggccggcgtg 600
tactacgtgt tctttcagct ggaactgcgg agagtggtgg ccggcgaagg atctggatct 660
gtgtctctgg cactgcatct gcagcccctg agatctgctg caggcgctgc tgctctggct 720
ctgacagttg atctgcctcc tgcctcctcc gaggccagaa actccgcctt tggcttccaa 780
ggcagactgc tgcatctgtc tgccggccag agactgggag tccatctgca tacagaggct 840
agagccaggc acgcctggca gttgacacaa ggtgctacag tgctgggcct gttcagagtg 900
accccagaga ttccagccgg cctgccttct ccaagatccg ag 942
<210> 66
<211> 906
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 49 (вар. 8)
<400> 66
gaagaggaac tgcaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccgc cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaga gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctgg actgagagag 360
ggacctgagc tgtctcctga tgatcctgct ggcctgctgg atctgagaca gggcatgttt 420
gctcagctgg tggcccagaa cgtgctgctg attgatggcc ctctgtcctg gtactctgat 480
cctggattgg ctggcgtgtc cctgactggc ggcctgtctt acaaagagga caccaaagaa 540
ctggtggtgg ccaaggccgg cgtgtactac gtgttctttc agctggaact gcggagagtg 600
gtggccggcg aaggatctgg atctgtgtct ctggcactgc atctgcagcc cctgagatct 660
gctgcaggcg ctgctgctct ggctctgaca gttgatctgc ctcctgcctc ctccgaggcc 720
agaaactccg cctttggctt ccaaggcaga ctgctgcatc tgtctgccgg ccagagactg 780
ggagtccatc tgcatacaga ggctagagcc aggcacgcct ggcagttgac acaaggtgct 840
acagtgctgg gcctgttcag agtgacccca gagattccag ccggcctgcc ttctccaaga 900
tccgag 906
<210> 67
<211> 1029
<212> DNA
<213> Искусственная последовательность
<220>
<223> альтернативная последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 2 (исходный фрагмент SIRP)
<400> 67
gaagaggaac tgcaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccgc cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagaga gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcgtgaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gaactgtccg tgcgagctaa accttctgct 360
cccgtggtgt ctggccctgc cgctagagct acacctcagc acaccgtgtc ttttacctgc 420
gagtcccacg gcttcagccc tagagacatc accctgaagt ggttcaagaa cggcaacgag 480
ctgtccgact tccagaccaa cgtggaccct gtgggagagt ccgtgtccta ctccatccac 540
tctaccgcca aggtggtgct gacccgagag gacgtgcaca gccaagtgat ctgtgaagtg 600
gcccacgtga ccctccaggg cgatcctttg agaggcaccg ccaacctgtc cgagacaatc 660
agagtgcctc ctacactgga agtgacccag cagcctgtgc gggccgagaa tcaagtgaac 720
gtgacctgcc aagtgcggaa gttctaccct cagagactgc agctgacctg gctggaaaac 780
ggcaatgtgt ccagaaccga gacagcctcc accgtgaccg agaacaagga tggcacctac 840
aattggatgt cctggctgct cgtgaacgtg tccgctcaca gagatgacgt gaagctgaca 900
tgccaggtgg aacacgatgg ccagcctgcc gtgtctaagt cccacgacct gaaagtgtct 960
gctcacccca aagagcaggg ctccaatacc gccgctgaga acaccggctc caacgagaga 1020
aacatctac 1029
<210> 68
<211> 945
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты для SEQ ID NO: 21
<400> 68
gaagaggaaa tccaagtgat ccagcctgac aagtccgtgc tggtggctgc tggcgaaacc 60
gccacactga gatgtaccat cacctctctg atccctgtgg gccctatcca gtggtttaga 120
ggcgctggac ctggcagagt gctgatctac aaccagaaag agggccactt tcctagagtg 180
accaccgtgt ccgacctgac caagcggaac aacatggact tctccatccg gatcggcaac 240
atcacccctg ctgatgccgg cacctactac tgcatcaagt tccggaaggg ctcccctgac 300
gacgtcgagt ttaaatccgg cgctggcacc gagctgtccg tcagagcttc tggtgctaga 360
gcctctcctg gctctgccgc ttctcctaga ctgagagagg gacctgagct gtctcctgat 420
gatcctgctg gcctgctgga tctgagacag ggcatgtttg ctcagctggt ggcccagaac 480
gtgctgctga ttgatggccc tctgtcctgg tactctgatc ctggattggc tggcgtgtcc 540
ctgactggcg gcctgtctta caaagaggac accaaagaac tggtggtggc caaggccggc 600
gtgtactacg tgttctttca gctggaactg cggagagtgg tggccggcga aggatctgga 660
tctgtgtctc tggcactgca tctgcagcct ctgagatctg ctgcaggcgc tgctgctctg 720
gctctgacag ttgatctgcc tcctgcctcc tccgaggcca gaaactccgc ctttggcttc 780
caaggcagac tgctgcatct gtctgccggc cagagactgg gagtccatct gcatacagag 840
gccagagcta gacacgcttg gcagttgaca cagggcgcta cagtgctggg cctgttcaga 900
gtgacacctg agatcccagc cggcctgcct tctccaagat ctgag 945
<210> 69
<211> 1749
<212> DNA
<213> Искусственная последовательность
<220>
<223> Клонированная последовательность (NH)-DSP-107 с his-меткой на N-конце
<400> 69
gaattcccgc cgccaccatg ggctggtcct gcatcattct gtttctggtg gccacagcca 60
ccggcgtgca ctctcaccat catcaccacc atgaagagga actgcaagtg atccagcctg 120
acaagagcgt gctggtggct gctggcgaaa cagccacact gagatgtacc gccacctctc 180
tgatccctgt gggccctatc cagtggttta gaggcgctgg acctggcaga gagctgatct 240
acaaccagaa agagggacac ttccccagag tgaccaccgt gtccgacctg accaagcgga 300
acaacatgga cttcagcatc cggatcggca acatcacccc tgccgatgcc ggcacctact 360
actgcgtgaa gttcagaaag ggcagccccg acgacgtcga gtttaaaagc ggagccggca 420
cagagctgag cgtgcgggct aaaccttctg ctcctgtggt gtctggacct gccgctagag 480
ctacacctca gcacaccgtg tcttttacct gcgagagcca cggcttcagc cccagagata 540
tcaccctgaa gtggttcaag aacggcaacg agctgtccga cttccagacc aacgtggacc 600
ctgtgggaga gagcgtgtcc tacagcatcc acagcacagc caaggtggtg ctgacccggg 660
aagatgtgca ctcccaagtg atttgcgagg tggcccacgt taccctgcaa ggcgatcctc 720
tgagaggcac cgccaatctg agcgagacaa tccgggtgcc acctacactg gaagtgaccc 780
agcagcctgt gcgggccgag aatcaagtga acgtgacctg ccaagtgcgg aagttctacc 840
ctcagagact gcagctgacc tggctggaaa acggcaatgt gtccagaacc gagacagcca 900
gcaccgtgac cgagaacaag gatggcacct acaattggat gagctggctg ctcgtgaatg 960
tgtctgccca ccgggacgat gtgaagctga catgccaggt ggaacacgat ggccagcctg 1020
ccgtgtctaa gagccacgac ctgaaggtgt ccgctcatcc caaagagcag ggctctaata 1080
ctgccgccga gaacaccggc agcaacgaga gaaatatcta cggcgcttgt ccttgggccg 1140
tttctggcgc tagagcctct cctggatctg ccgcttctcc cagactgaga gagggacctg 1200
agctgagccc tgatgatcct gctggactgc tggatctgag acagggcatg tttgcccagc 1260
tggtggccca gaatgtgctg ctgattgatg gccctctgtc ctggtacagc gatcctggac 1320
ttgctggcgt tagcctgact ggcggcctga gctacaaaga ggacaccaaa gaactggtgg 1380
tggccaaggc cggcgtgtac tacgtgttct ttcagctgga actgcggaga gtggtggccg 1440
gcgaaggatc tggatctgtg tctctggctc tgcatctgca gcctctgaga tctgctgctg 1500
gtgctgctgc tctggccctg acagttgatc tgcctcctgc ctctagcgag gccagaaact 1560
ccgcctttgg cttccaaggc agactgctgc acctgagcgc tggacagaga ctgggagtcc 1620
atctgcacac agaagccaga gctagacacg cctggcagct gacacaaggc gctacagtgc 1680
tgggcctgtt cagagtgacc cctgagattc cagccggcct gccatctcct agatctgagt 1740
gataagctt 1749
<210> 70
<211> 184
<212> PRT
<213> Искусственная последовательность
<220>
<223> 4-1BBL -21-0 184 аминокислоты
<400> 70
Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp
1 5 10 15
Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu
20 25 30
Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val
35 40 45
Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val
50 55 60
Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg
65 70 75 80
Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His
85 90 95
Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr
100 105 110
Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly
115 120 125
Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val
130 135 140
His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln
145 150 155 160
Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala
165 170 175
Gly Leu Pro Ser Pro Arg Ser Glu
180
<210> 71
<211> 552
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 70
<400> 71
agagagggcc ctgagctgtc tcctgatgat cctgctggac tgctggacct gagacagggc 60
atgtttgctc agctggtggc ccagaacgtg ctgctgattg atggccctct gtcctggtac 120
tctgatcctg gattggctgg cgtgtccctg actggcggcc tgtcttacaa agaggacacc 180
aaagaactgg tggtcgccaa ggccggcgtg tactacgtgt tctttcagct ggaactgcgg 240
agagtggtgg ctggcgaagg atctggatct gtgtctctgg ccctgcatct gcagcctctg 300
agaagtgctg caggcgctgc tgcactggct ctgacagttg atctgcctcc tgcctcctcc 360
gaggccagaa actccgcctt tggcttccaa ggcagactgc tgcatctgtc tgccggacag 420
agactgggag tgcacctcca tacagaggcc agagctagac acgcttggca gttgacacag 480
ggcgctacag tgctgggcct gtttagagtg acacctgaga tcccagccgg cctgccatct 540
ccaagatctg aa 552
<210> 72
<211> 182
<212> PRT
<213> Искусственная последовательность
<220>
<223> 4-1BBL -23-0 182 аминокислоты
<400> 72
Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp Leu Arg
1 5 10 15
Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu Ile Asp
20 25 30
Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val Ser Leu
35 40 45
Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val Val Ala
50 55 60
Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg Arg Val
65 70 75 80
Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His Leu Gln
85 90 95
Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr Val Asp
100 105 110
Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly Phe Gln
115 120 125
Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val His Leu
130 135 140
His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln Gly Ala
145 150 155 160
Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala Gly Leu
165 170 175
Pro Ser Pro Arg Ser Glu
180
<210> 73
<211> 546
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 72
<400> 73
ggccctgagc tgtctcctga tgatcctgct ggactgctgg acctgagaca gggcatgttt 60
gctcagctgg tggcccagaa cgtgctgctg attgatggcc ctctgtcctg gtactctgat 120
cctggattgg ctggcgtgtc cctgactggc ggcctgtctt acaaagagga caccaaagaa 180
ctggtggtcg ccaaggccgg cgtgtactac gtgttctttc agctggaact gcggagagtg 240
gtggctggcg aaggatctgg atctgtgtct ctggccctgc atctgcagcc tctgagaagt 300
gctgcaggcg ctgctgcact ggctctgaca gttgatctgc ctcctgcctc ctccgaggcc 360
agaaactccg cctttggctt ccaaggcaga ctgctgcatc tgtctgccgg acagagactg 420
ggagtgcacc tccatacaga ggccagagct agacacgctt ggcagttgac acagggcgct 480
acagtgctgg gcctgtttag agtgacacct gagatcccag ccggcctgcc atctccaaga 540
tctgaa 546
<210> 74
<211> 183
<212> PRT
<213> Искусственная последовательность
<220>
<223> 4-1BBL -14-8 183 аминокислоты
<400> 74
Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp
1 5 10 15
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
20 25 30
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
35 40 45
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
50 55 60
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
65 70 75 80
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
85 90 95
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
100 105 110
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
115 120 125
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
130 135 140
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
145 150 155 160
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
165 170 175
Val Thr Pro Glu Ile Pro Ala
180
<210> 75
<211> 551
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 74 551 п.н.
<400> 75
gatctgccgc ttctcctaga ctgagagagg gccctgagct gtctcctgat gatcctgctg 60
gactgctgga cctgagacag ggcatgtttg ctcagctggt ggcccagaac gtgctgctga 120
ttgatggccc tctgtcctgg tactctgatc ctggattggc tggcgtgtcc ctgactggcg 180
gcctgtctta caaagaggac accaaagaac tggtggtcgc caaggccggc gtgtactacg 240
tgttctttca gctggaactg cggagagtgg tggctggcga aggatctgga tctgtgtctc 300
tggccctgca tctgcagcct ctgagaagtg ctgcaggcgc tgctgcactg gctctgacag 360
ttgatctgcc tcctgcctcc tccgaggcca gaaactccgc ctttggcttc caaggcagac 420
tgctgcatct gtctgccgga cagagactgg gagtgcacct ccatacagag gccagagcta 480
gacacgcttg gcagttgaca cagggcgcta cagtgctggg cctgtttaga gtgacacctg 540
agatcccagc c 551
<210> 76
<211> 176
<212> PRT
<213> Искусственная последовательность
<220>
<223> 4-1BBL -21-8 176 аминокислот
<400> 76
Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu Asp
1 5 10 15
Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu Leu
20 25 30
Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly Val
35 40 45
Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu Val
50 55 60
Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu Arg
65 70 75 80
Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu His
85 90 95
Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu Thr
100 105 110
Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe Gly
115 120 125
Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly Val
130 135 140
His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr Gln
145 150 155 160
Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro Ala
165 170 175
<210> 77
<211> 528
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 76 528 п.н.
<400> 77
agagagggcc ctgagctgtc tcctgatgat cctgctggac tgctggacct gagacagggc 60
atgtttgctc agctggtggc ccagaacgtg ctgctgattg atggccctct gtcctggtac 120
tctgatcctg gattggctgg cgtgtccctg actggcggcc tgtcttacaa agaggacacc 180
aaagaactgg tggtcgccaa ggccggcgtg tactacgtgt tctttcagct ggaactgcgg 240
agagtggtgg ctggcgaagg atctggatct gtgtctctgg ccctgcatct gcagcctctg 300
agaagtgctg caggcgctgc tgcactggct ctgacagttg atctgcctcc tgcctcctcc 360
gaggccagaa actccgcctt tggcttccaa ggcagactgc tgcatctgtc tgccggacag 420
agactgggag tgcacctcca tacagaggcc agagctagac acgcttggca gttgacacag 480
ggcgctacag tgctgggcct gtttagagtg acacctgaga tcccagcc 528
<210> 78
<211> 601
<212> PRT
<213> Искусственная последовательность
<220>
<223> sc3x4-1BBL -14-0 601 аминокислота
<400> 78
Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp
1 5 10 15
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
20 25 30
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
35 40 45
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
50 55 60
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
65 70 75 80
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
85 90 95
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
100 105 110
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
115 120 125
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
130 135 140
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
145 150 155 160
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
165 170 175
Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu Gly
180 185 190
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ala Ala
195 200 205
Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala
210 215 220
Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln
225 230 235 240
Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly
245 250 255
Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr
260 265 270
Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln
275 280 285
Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser
290 295 300
Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala
305 310 315 320
Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn
325 330 335
Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln
340 345 350
Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp
355 360 365
Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro
370 375 380
Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu Gly Gly Gly Gly
385 390 395 400
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Ala Ala Ser Pro Arg
405 410 415
Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp Asp Pro Ala Gly Leu Leu
420 425 430
Asp Leu Arg Gln Gly Met Phe Ala Gln Leu Val Ala Gln Asn Val Leu
435 440 445
Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser Asp Pro Gly Leu Ala Gly
450 455 460
Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys Glu Asp Thr Lys Glu Leu
465 470 475 480
Val Val Ala Lys Ala Gly Val Tyr Tyr Val Phe Phe Gln Leu Glu Leu
485 490 495
Arg Arg Val Val Ala Gly Glu Gly Ser Gly Ser Val Ser Leu Ala Leu
500 505 510
His Leu Gln Pro Leu Arg Ser Ala Ala Gly Ala Ala Ala Leu Ala Leu
515 520 525
Thr Val Asp Leu Pro Pro Ala Ser Ser Glu Ala Arg Asn Ser Ala Phe
530 535 540
Gly Phe Gln Gly Arg Leu Leu His Leu Ser Ala Gly Gln Arg Leu Gly
545 550 555 560
Val His Leu His Thr Glu Ala Arg Ala Arg His Ala Trp Gln Leu Thr
565 570 575
Gln Gly Ala Thr Val Leu Gly Leu Phe Arg Val Thr Pro Glu Ile Pro
580 585 590
Ala Gly Leu Pro Ser Pro Arg Ser Glu
595 600
<210> 79
<211> 1803
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты, кодирующая SEQ ID NO: 78
<400> 79
tctgccgcca gccctaggct gcgcgaggga cccgagctga gcccagacga tcccgccggc 60
ctgctggacc tgaggcaggg aatgttcgca cagctggtgg cccagaacgt gctgctgatc 120
gacggccctc tgtcctggta ctctgatcca ggcctggccg gcgtgtccct gacaggaggc 180
ctgtcttata aggaggatac caaggagctg gtggtggcaa aggcaggcgt gtactacgtg 240
ttcttccagc tggagctgag gagagtggtg gcaggagagg gcagcggctc cgtgtctctg 300
gccctgcacc tccagcctct gcggagcgcc gccggcgccg ccgccctggc cctgaccgtg 360
gatctgcctc cagccagctc cgaggccagg aatagcgcct tcggctttca gggccgcctg 420
ctgcacctgt ccgccggcca gcggctggga gtgcacctgc acacagaggc cagagcccgg 480
cacgcatggc agctgacaca gggagcaacc gtgctgggcc tgttccgcgt gacccctgag 540
atcccagccg gcctgccaag cccccggtcc gagggcggcg gcggctctgg cggaggaggc 600
agcggaggcg gcggctctgc cgccagcccc aggctgcgcg agggacccga gctgtcccca 660
gacgatcctg ccggcctgct ggacctgcgc cagggaatgt ttgcccagct ggtggctcaa 720
aacgtgctgt taatcgacgg ccctctgagc tggtactctg atcctggcct ggccggcgtg 780
agcctgaccg gcggcctgtc ctacaaagag gatactaaag agctggtggt cgccaaagcc 840
ggcgtgtact acgtgttctt ccaactggag ctgaggaggg tcgtcgccgg cgaaggcagc 900
ggctccgtgt ctctggccct gcacctccag ccgctgagga gcgccgccgg cgccgccgcc 960
ctggccctga cggtggacct gccacctgcc tctagcgagg caagaaattc tgccttcggc 1020
ttccagggca ggctgctgca cctgagcgcc ggccagcgcc tgggcgtcca cctgcatacc 1080
gaagccagag cccggcatgc ctggcagctg acccagggcg ccaccgtgct gggcctgttc 1140
agagtgaccc cagagatccc cgccggcctg cctagcccaa ggtccgaagg cggcggcggc 1200
tccggcggcg gaggctctgg aggagggggc tctgccgcca gcccaaggct gcgcgaggga 1260
cccgagctgt cgcctgacga tccagccggc ctgctggacc tgcgtcaggg catgttcgcc 1320
cagctggtgg ctcagaacgt gctgttaatc gacggcccac tgtcttggta ttctgatccc 1380
ggcctggccg gcgtgtctct gacaggaggc ctgagctaca aagaggatac aaaagagctg 1440
gtggtcgcta aagctggcgt gtactacgtg ttcttccaac tggagctgcg cagggtcgtc 1500
gccggcgagg gcagcggctc cgtgtctctg gccctgcacc tccagccatt acggagcgcc 1560
gccggcgccg ccgccctggc cctgactgtg gacctgccac cagcctcctc tgaggcacgg 1620
aacagcgcct tcggcttcca aggcagactg ctgcacctgt ctgccggcca gaggctgggc 1680
gtccacctgc acaccgaagc cagagcccgg cacgcctggc agctgactca gggcgctacc 1740
gtgctgggcc tgttccgcgt aaccccagag atccctgccg gcctgcccag ccctcggtcc 1800
gag 1803
<210> 80
<211> 535
<212> PRT
<213> Искусственная последовательность
<220>
<223> DSP107_Var2
<400> 80
Ser Ala Ala Ser Pro Arg Leu Arg Glu Gly Pro Glu Leu Ser Pro Asp
1 5 10 15
Asp Pro Ala Gly Leu Leu Asp Leu Arg Gln Gly Met Phe Ala Gln Leu
20 25 30
Val Ala Gln Asn Val Leu Leu Ile Asp Gly Pro Leu Ser Trp Tyr Ser
35 40 45
Asp Pro Gly Leu Ala Gly Val Ser Leu Thr Gly Gly Leu Ser Tyr Lys
50 55 60
Glu Asp Thr Lys Glu Leu Val Val Ala Lys Ala Gly Val Tyr Tyr Val
65 70 75 80
Phe Phe Gln Leu Glu Leu Arg Arg Val Val Ala Gly Glu Gly Ser Gly
85 90 95
Ser Val Ser Leu Ala Leu His Leu Gln Pro Leu Arg Ser Ala Ala Gly
100 105 110
Ala Ala Ala Leu Ala Leu Thr Val Asp Leu Pro Pro Ala Ser Ser Glu
115 120 125
Ala Arg Asn Ser Ala Phe Gly Phe Gln Gly Arg Leu Leu His Leu Ser
130 135 140
Ala Gly Gln Arg Leu Gly Val His Leu His Thr Glu Ala Arg Ala Arg
145 150 155 160
His Ala Trp Gln Leu Thr Gln Gly Ala Thr Val Leu Gly Leu Phe Arg
165 170 175
Val Thr Pro Glu Ile Pro Ala Gly Leu Pro Ser Pro Arg Ser Glu Gly
180 185 190
Glu Glu Glu Leu Gln Val Ile Gln Pro Asp Lys Ser Val Leu Val Ala
195 200 205
Ala Gly Glu Thr Ala Thr Leu Arg Cys Thr Ala Thr Ser Leu Ile Pro
210 215 220
Val Gly Pro Ile Gln Trp Phe Arg Gly Ala Gly Pro Gly Arg Glu Leu
225 230 235 240
Ile Tyr Asn Gln Lys Glu Gly His Phe Pro Arg Val Thr Thr Val Ser
245 250 255
Asp Leu Thr Lys Arg Asn Asn Met Asp Phe Ser Ile Arg Ile Gly Asn
260 265 270
Ile Thr Pro Ala Asp Ala Gly Thr Tyr Tyr Cys Val Lys Phe Arg Lys
275 280 285
Gly Ser Pro Asp Asp Val Glu Phe Lys Ser Gly Ala Gly Thr Glu Leu
290 295 300
Ser Val Arg Ala Lys Pro Ser Ala Pro Val Val Ser Gly Pro Ala Ala
305 310 315 320
Arg Ala Thr Pro Gln His Thr Val Ser Phe Thr Cys Glu Ser His Gly
325 330 335
Phe Ser Pro Arg Asp Ile Thr Leu Lys Trp Phe Lys Asn Gly Asn Glu
340 345 350
Leu Ser Asp Phe Gln Thr Asn Val Asp Pro Val Gly Glu Ser Val Ser
355 360 365
Tyr Ser Ile His Ser Thr Ala Lys Val Val Leu Thr Arg Glu Asp Val
370 375 380
His Ser Gln Val Ile Cys Glu Val Ala His Val Thr Leu Gln Gly Asp
385 390 395 400
Pro Leu Arg Gly Thr Ala Asn Leu Ser Glu Thr Ile Arg Val Pro Pro
405 410 415
Thr Leu Glu Val Thr Gln Gln Pro Val Arg Ala Glu Asn Gln Val Asn
420 425 430
Val Thr Cys Gln Val Arg Lys Phe Tyr Pro Gln Arg Leu Gln Leu Thr
435 440 445
Trp Leu Glu Asn Gly Asn Val Ser Arg Thr Glu Thr Ala Ser Thr Val
450 455 460
Thr Glu Asn Lys Asp Gly Thr Tyr Asn Trp Met Ser Trp Leu Leu Val
465 470 475 480
Asn Val Ser Ala His Arg Asp Asp Val Lys Leu Thr Cys Gln Val Glu
485 490 495
His Asp Gly Gln Pro Ala Val Ser Lys Ser His Asp Leu Lys Val Ser
500 505 510
Ala His Pro Lys Glu Gln Gly Ser Asn Thr Ala Ala Glu Asn Thr Gly
515 520 525
Ser Asn Glu Arg Asn Ile Tyr
530 535
<210> 81
<211> 699
<212> DNA
<213> Искусственная последовательность
<220>
<223> последовательность нуклеиновой кислоты SEQ ID NO: 80
<400> 81
tctgctgcct ctcctagact gagagaggga cctgagctgt ctcctgatga tcctgctggc 60
ctgctggatc tgagacaggg catgtttgct cagctggtgg cccagaacgt gctgctgatt 120
gatggccctc tgtcctggta ctctgatcct ggattggctg gcgtgtccct gactggcggc 180
ctgtcttaca aagaggacac caaagaactg gtggtggcca aggccggcgt gtactacgtg 240
ttctttcagc tggaactgcg gagagtggtg gccggcgaag gatctggatc tgtgtctctg 300
gcactgcatc tgcagcccct gagatctgct gcaggcgctg ctgctctggc tctgacagtt 360
gatctgcctc ctgcctcctc cgaggccaga aactccgcct ttggcttcca aggcagactg 420
ctgcatctgt ctgccggcca gagactggga gtccatctgc atacagaggc tagagccagg 480
cacgcctggc agttgacaca aggtgctaca gtgctgggcc tgttcagagt gaccccagag 540
attccagccg gcctgccttc tccaagatcc gagggcgaag aggaactgca agtgatccag 600
cctgacaagt ccgtgctggt ggctgctggc gaaaccgcca cactgagatg taccgccacc 660
tctctgatcc ctgtgggccc tatccagtgg tttagaggc 699
<210> 82
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 82
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
1 5 10
<210> 83
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 83
Gly Gly Gly Gly Ser Gly Gly Gly Gly
1 5
<210> 84
<211> 5
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<220>
<221> ПОВТОР
<222> (1)..(5)
<223> может повторяться 1-4 раза
<400> 84
Gly Gly Gly Gly Ser
1 5
<210> 85
<211> 5
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 85
Gly Gly Gly Gly Ser
1 5
<210> 86
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 86
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10
<210> 87
<211> 5
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<220>
<221> ПОВТОР
<222> (1)..(5)
<223> может повторяться 1-3 раза
<400> 87
Glu Ala Ala Ala Lys
1 5
<210> 88
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<220>
<221> ПОВТОР
<222> (2)..(6)
<223> повтор 2-5 раз
<400> 88
Ala Glu Ala Ala Ala Lys Ala
1 5
<210> 89
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 89
Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Ala
1 5 10
<210> 90
<211> 46
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 90
Ala Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys
1 5 10 15
Glu Ala Ala Ala Lys Ala Leu Glu Ala Glu Ala Ala Ala Lys Glu Ala
20 25 30
Ala Ala Lys Glu Ala Ala Ala Lys Glu Ala Ala Ala Lys Ala
35 40 45
<210> 91
<211> 5
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 91
Pro Ala Pro Ala Pro
1 5
<210> 92
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 92
Lys Glu Ser Gly Ser Val Ser Ser Glu Gln Leu Ala Gln Phe Arg Ser
1 5 10 15
Leu Asp
<210> 93
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 93
Glu Gly Lys Ser Ser Gly Ser Gly Ser Glu Ser Lys Ser Thr
1 5 10
<210> 94
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 94
Gly Ser Ala Gly Ser Ala Ala Gly Ser Gly Glu Phe
1 5 10
<210> 95
<211> 229
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 95
Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe
1 5 10 15
Glu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
20 25 30
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
35 40 45
Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp Gly Val
50 55 60
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser
65 70 75 80
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
85 90 95
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu Pro Ser
100 105 110
Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
115 120 125
Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys Asn Gln
130 135 140
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
145 150 155 160
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
165 170 175
Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu
180 185 190
Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser Cys Ser
195 200 205
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
210 215 220
Leu Ser Leu Gly Lys
225
<210> 96
<211> 232
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 96
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala
1 5 10 15
Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
20 25 30
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
35 40 45
Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val
50 55 60
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
65 70 75 80
Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
85 90 95
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala
100 105 110
Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
115 120 125
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr
130 135 140
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
145 150 155 160
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
165 170 175
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
180 185 190
Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe
195 200 205
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
210 215 220
Ser Leu Ser Leu Ser Pro Gly Lys
225 230
<210> 97
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 97
Gly Leu Pro Ser Pro Arg Ser Glu
1 5
<210> 98
<211> 23
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 98
Ala Cys Pro Trp Ala Val Ser Gly Ala Arg Ala Ser Pro Gly Ser Ala
1 5 10 15
Ala Ser Pro Arg Leu Arg Glu
20
<210> 99
<211> 19
<212> PRT
<213> Искусственная последовательность
<220>
<223> полипептидный линкер
<400> 99
Met Gly Trp Ser Leu Ile Leu Leu Phe Leu Val Ala Val Ala Thr Arg
1 5 10 15
Val Leu Ser
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| СЛИТЫЙ БЕЛОК SIRPα-4-1BBL И СПОСОБЫ ЕГО ПРИМЕНЕНИЯ | 2018 |
|
RU2769769C2 |
| ХИМЕРНЫЕ БЕЛКИ НА ОСНОВЕ TIGIT И LIGHT | 2018 |
|
RU2775490C2 |
| АНТИТЕЛО ПРОТИВ SIRPα | 2019 |
|
RU2791002C2 |
| СЛИТЫЙ БЕЛОК И ЕГО ПРИМЕНЕНИЕ | 2019 |
|
RU2800923C2 |
| АНТИ-SIRPα АНТИТЕЛА | 2018 |
|
RU2771174C2 |
| СЛИТЫЙ БЕЛОК И ЕГО ПРИМЕНЕНИЕ | 2020 |
|
RU2811120C2 |
| HER-2-НАПРАВЛЕННЫЕ АНТИГЕНСВЯЗЫВАЮЩИЕ МОЛЕКУЛЫ, СОДЕРЖАЩИЕ 4-1BBL | 2019 |
|
RU2815451C2 |
| СВЯЗЫВАНИЕ СЛИТОГО БЕЛКА С БЕЛКОМ CD47 И ЕГО ПРИМЕНЕНИЕ | 2019 |
|
RU2787521C2 |
| Терапевтические антитела к CD47 | 2016 |
|
RU2748401C2 |
| БИСПЕЦИФИЧНЫЙ СЛИТЫЙ БЕЛОК И ЕГО ПРИМЕНЕНИЕ | 2021 |
|
RU2801528C2 |
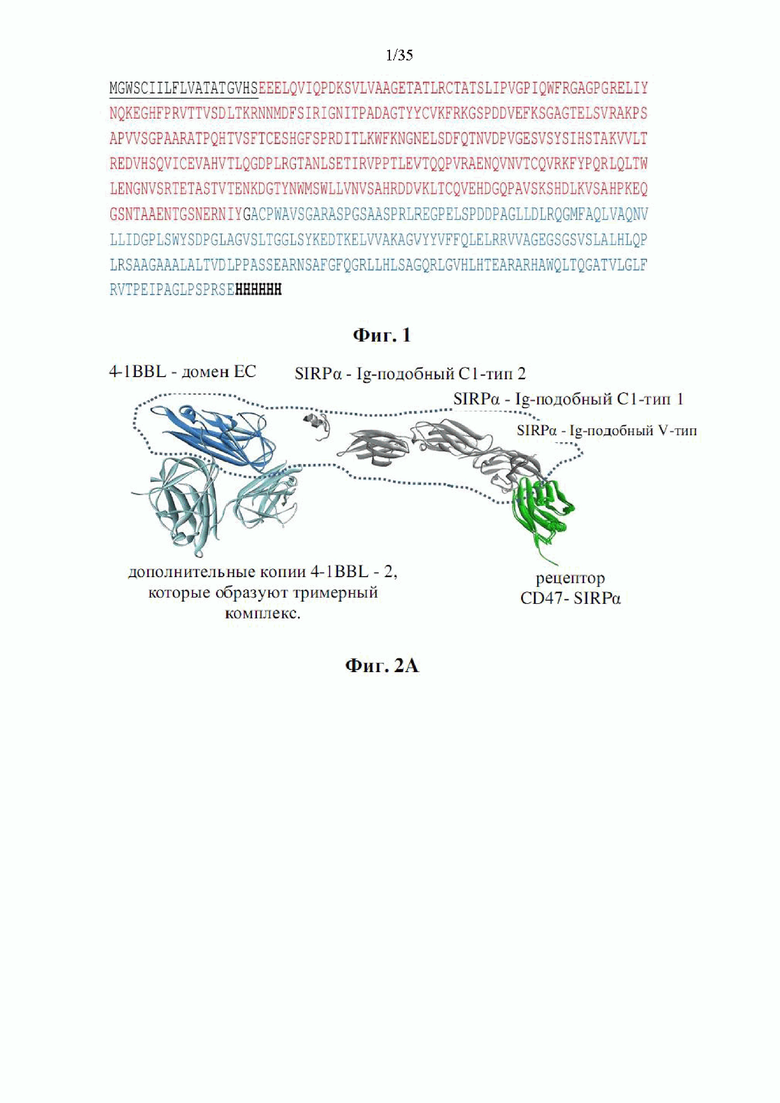
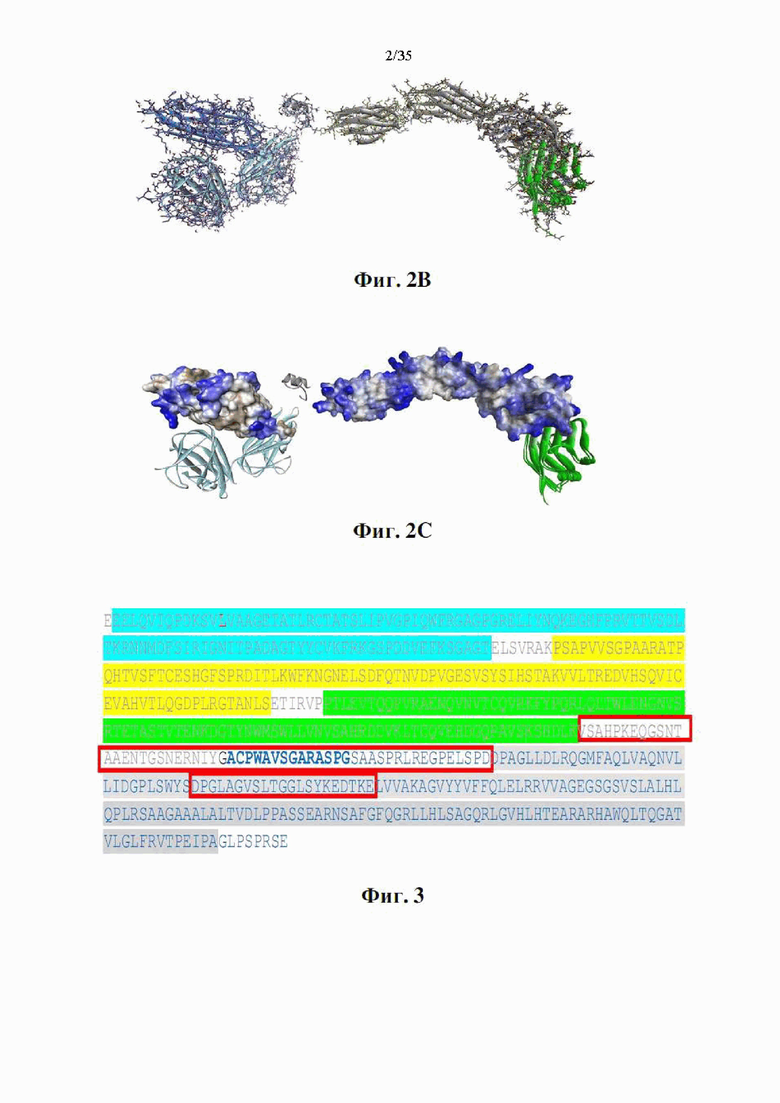
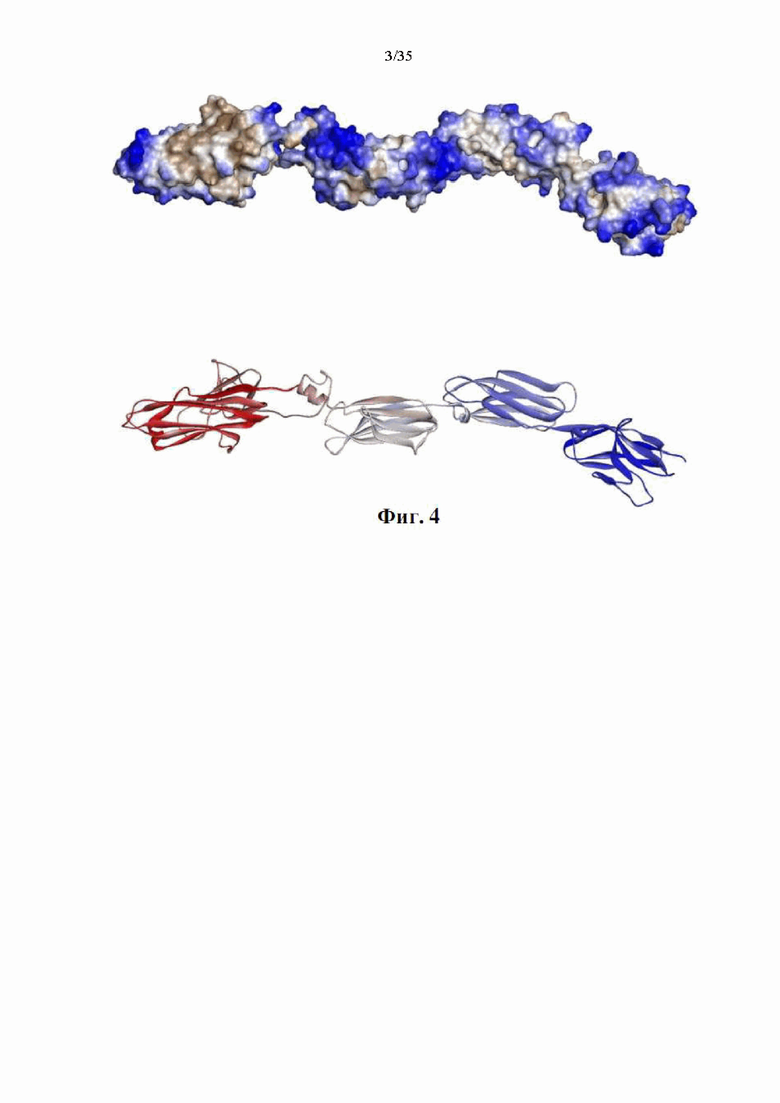
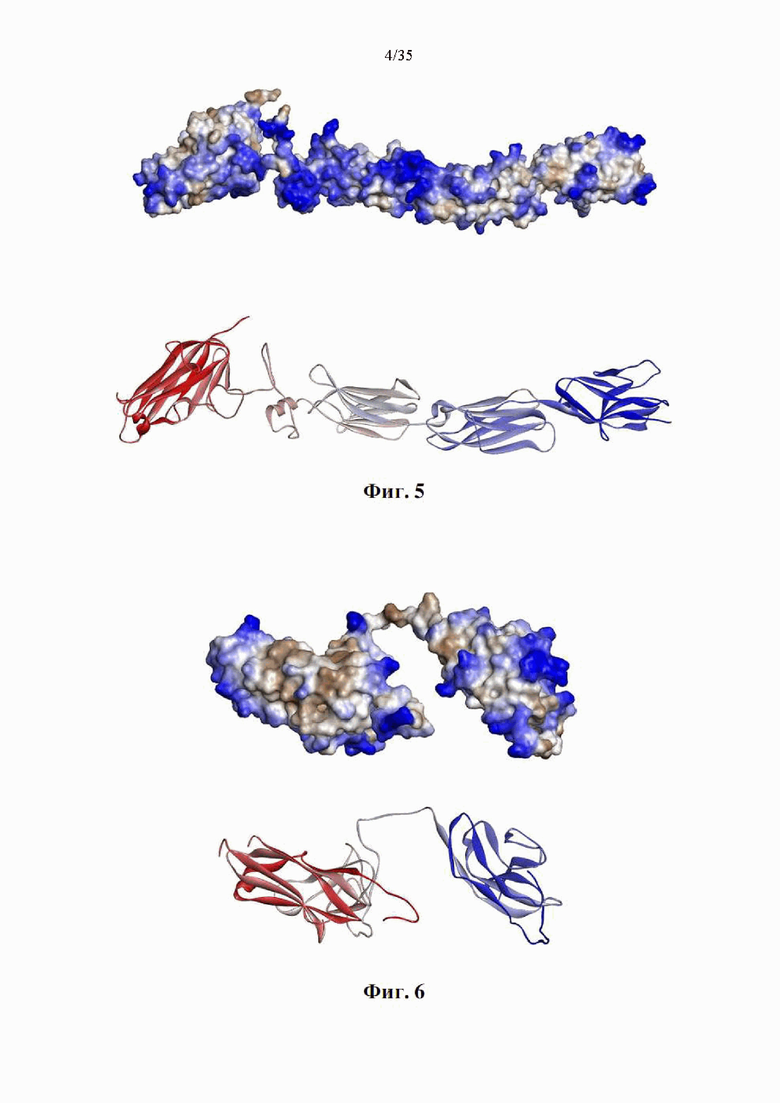
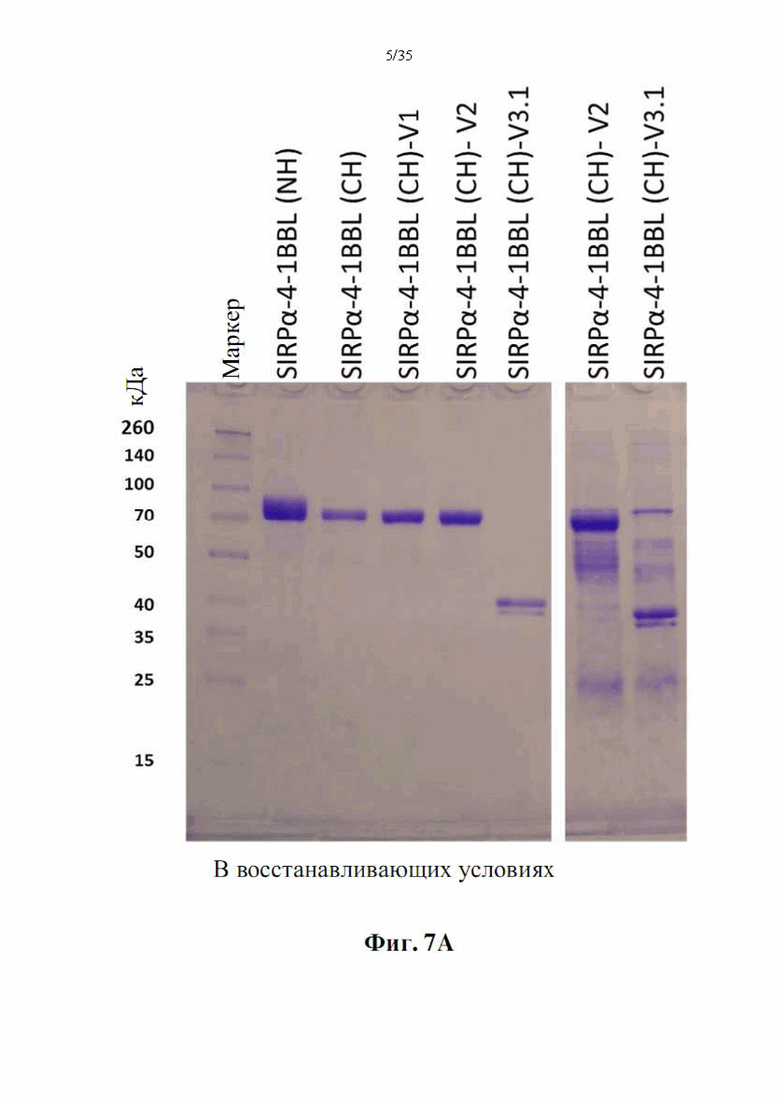
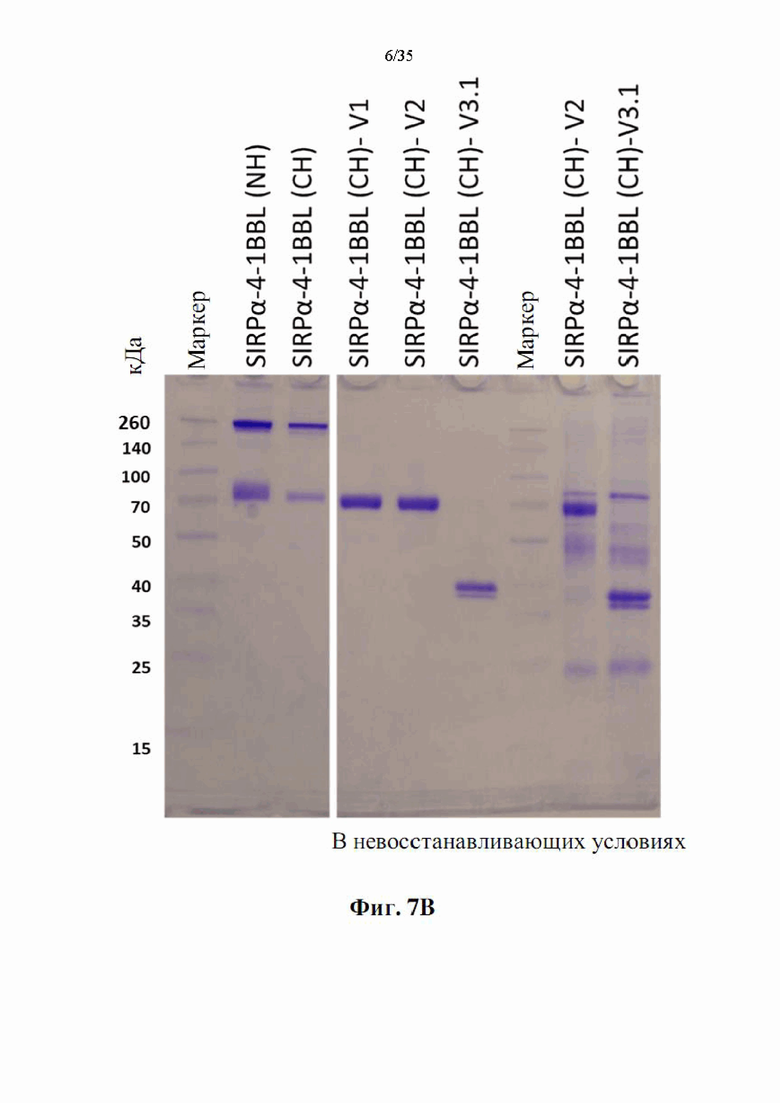
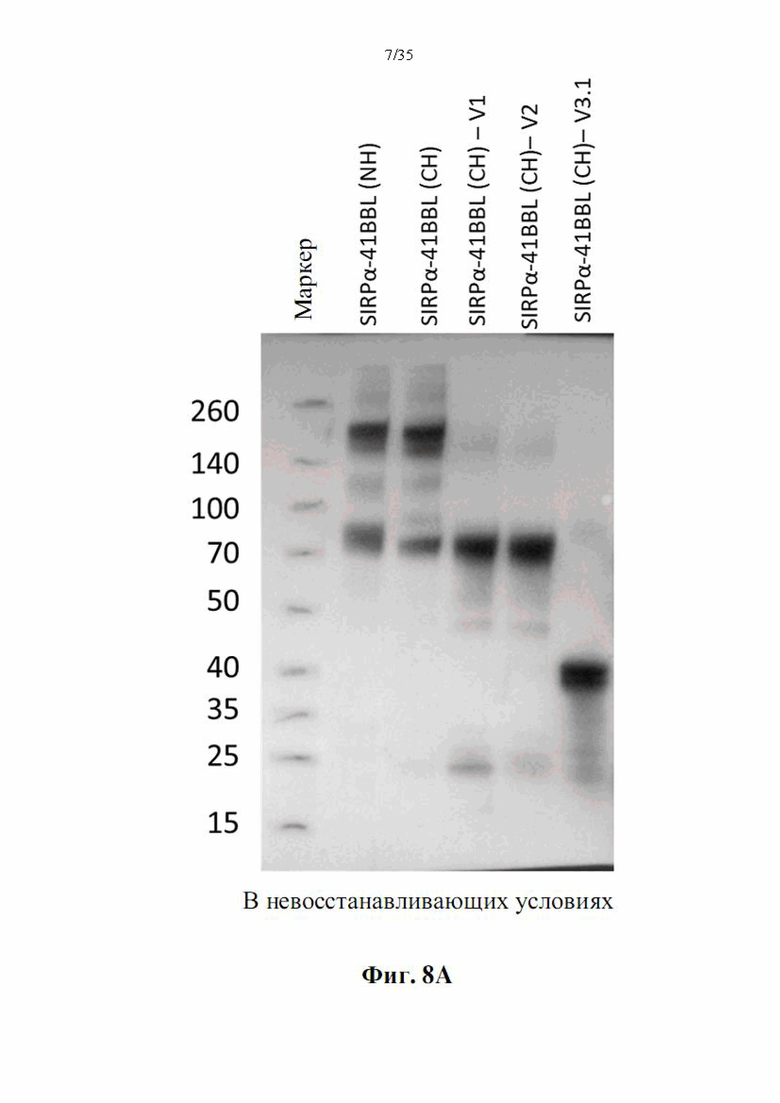
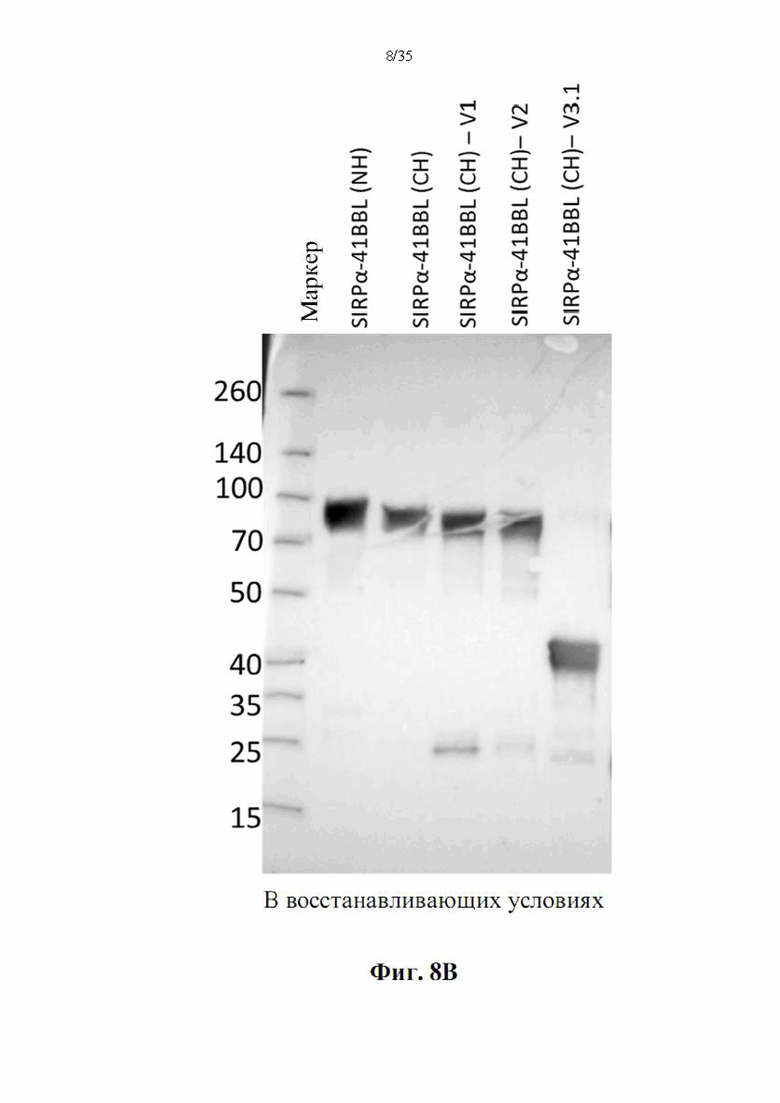
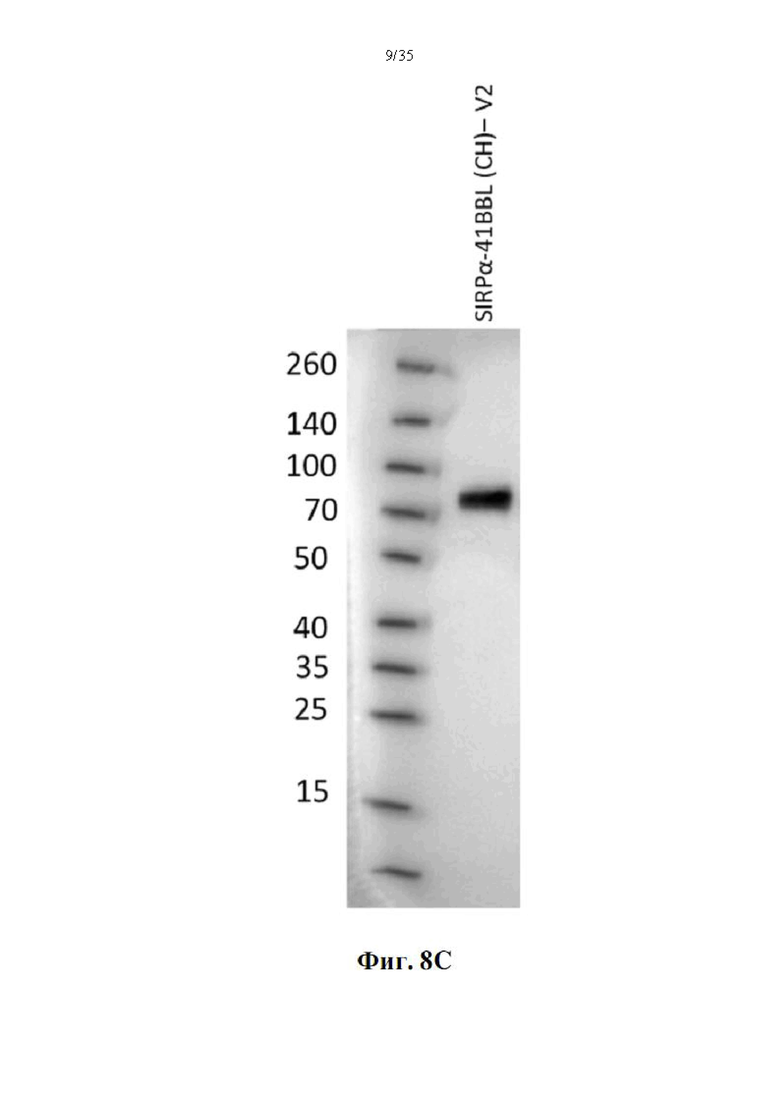
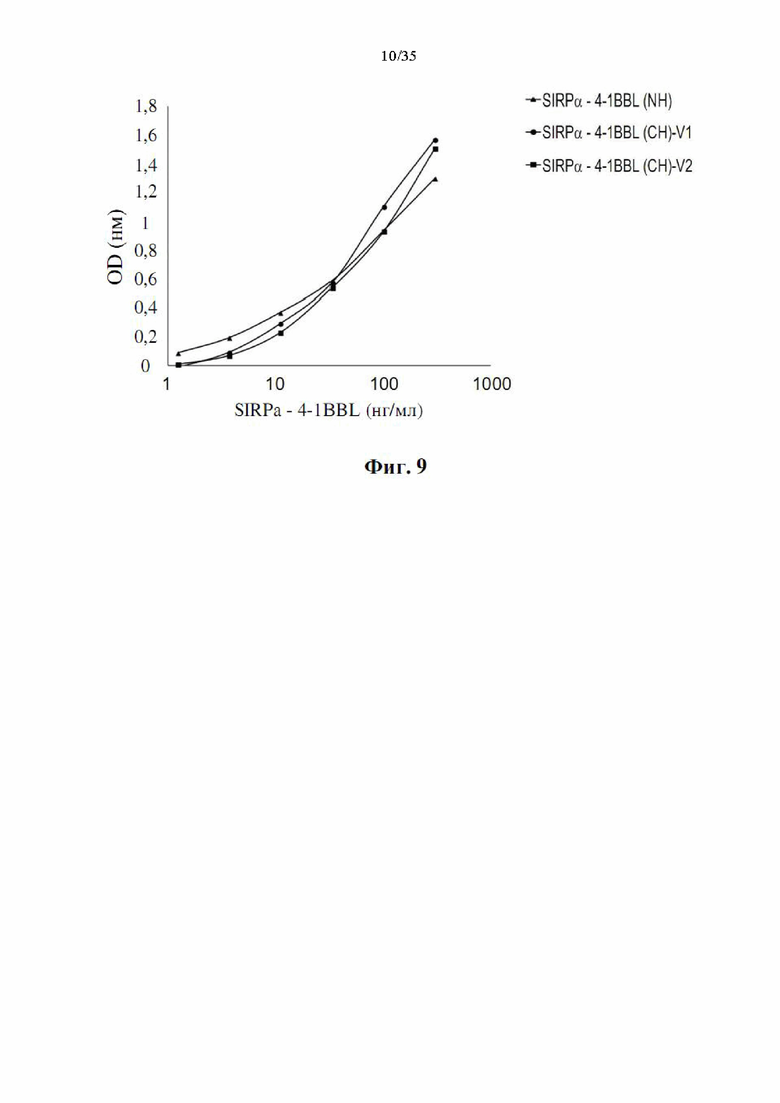
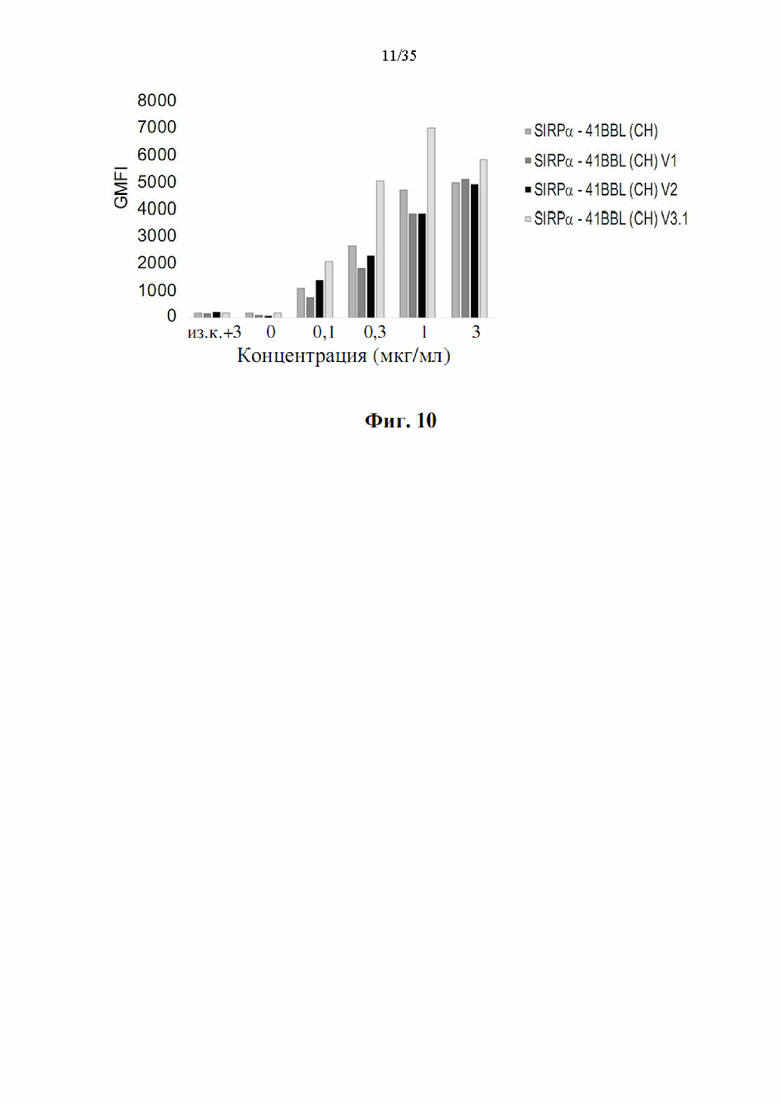
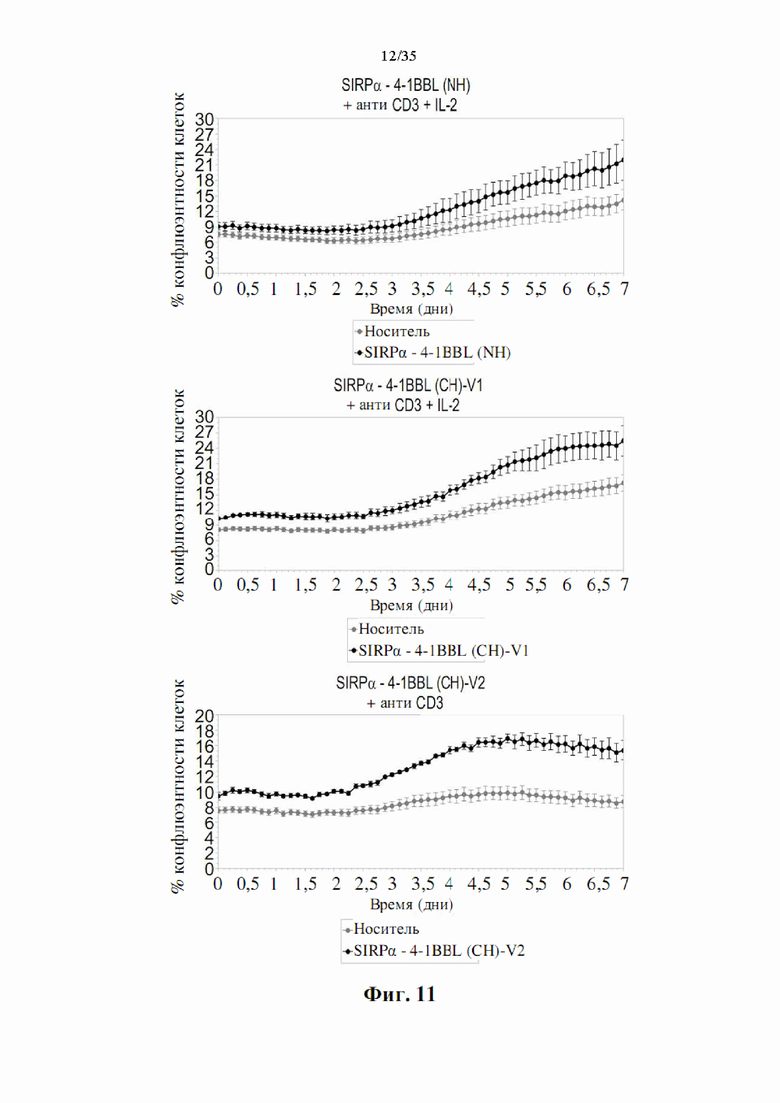
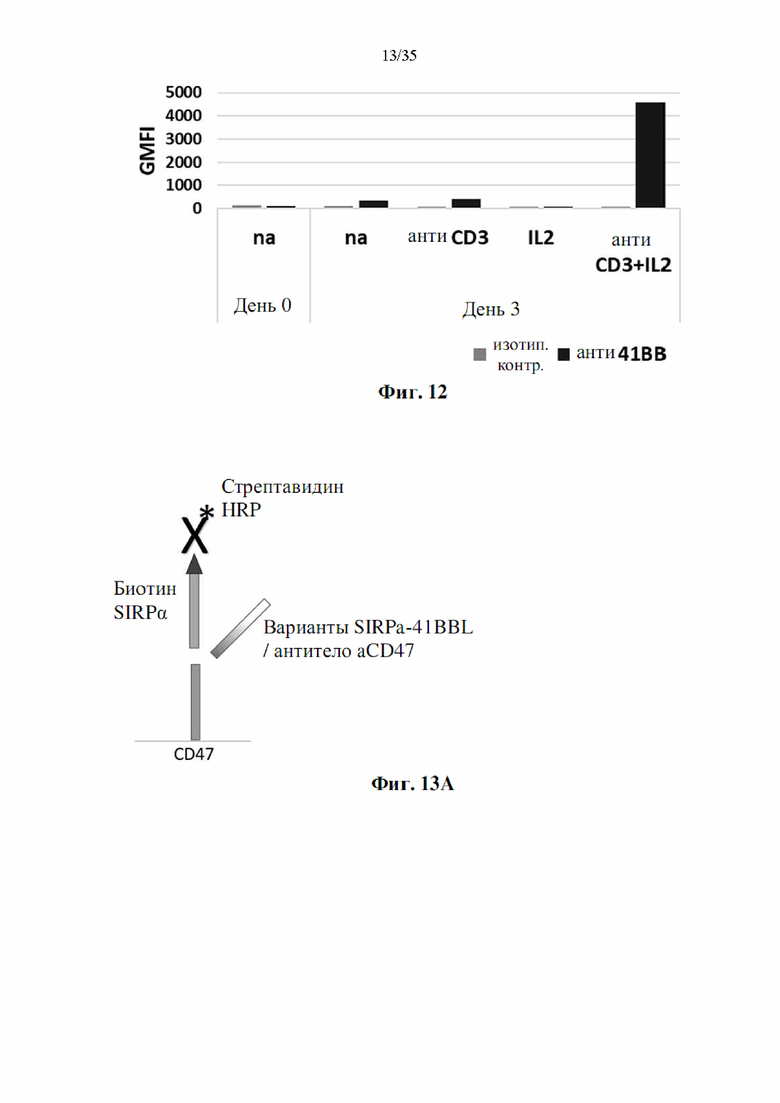
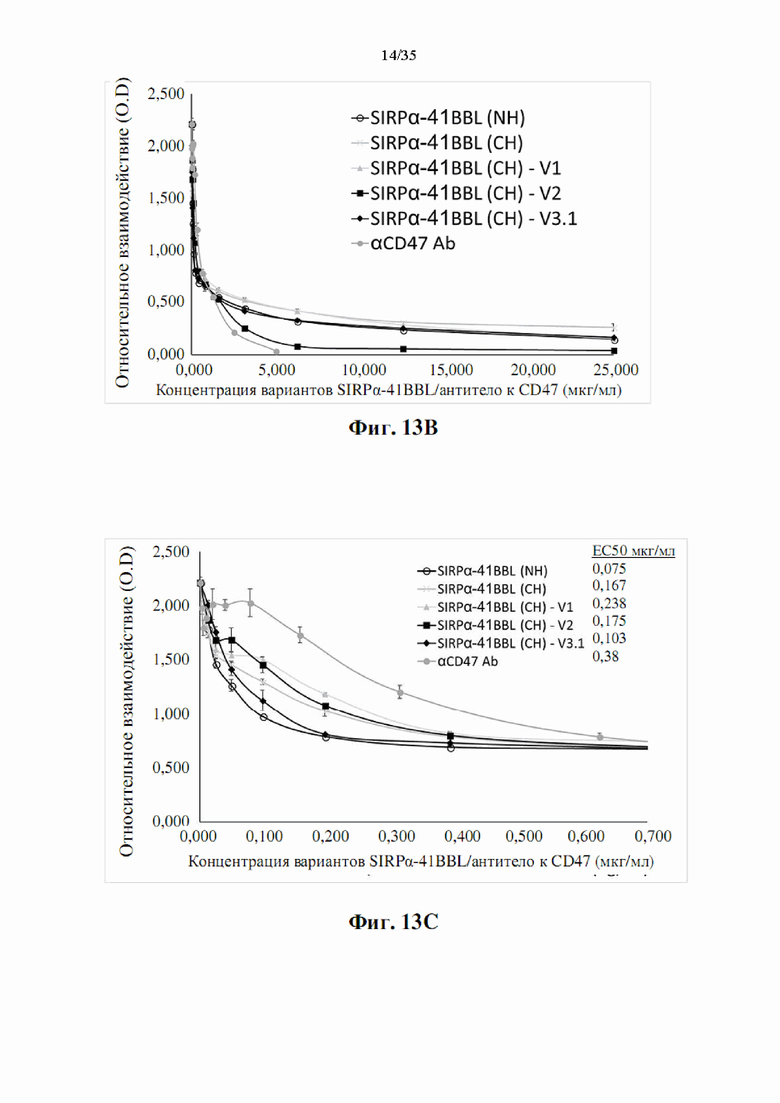
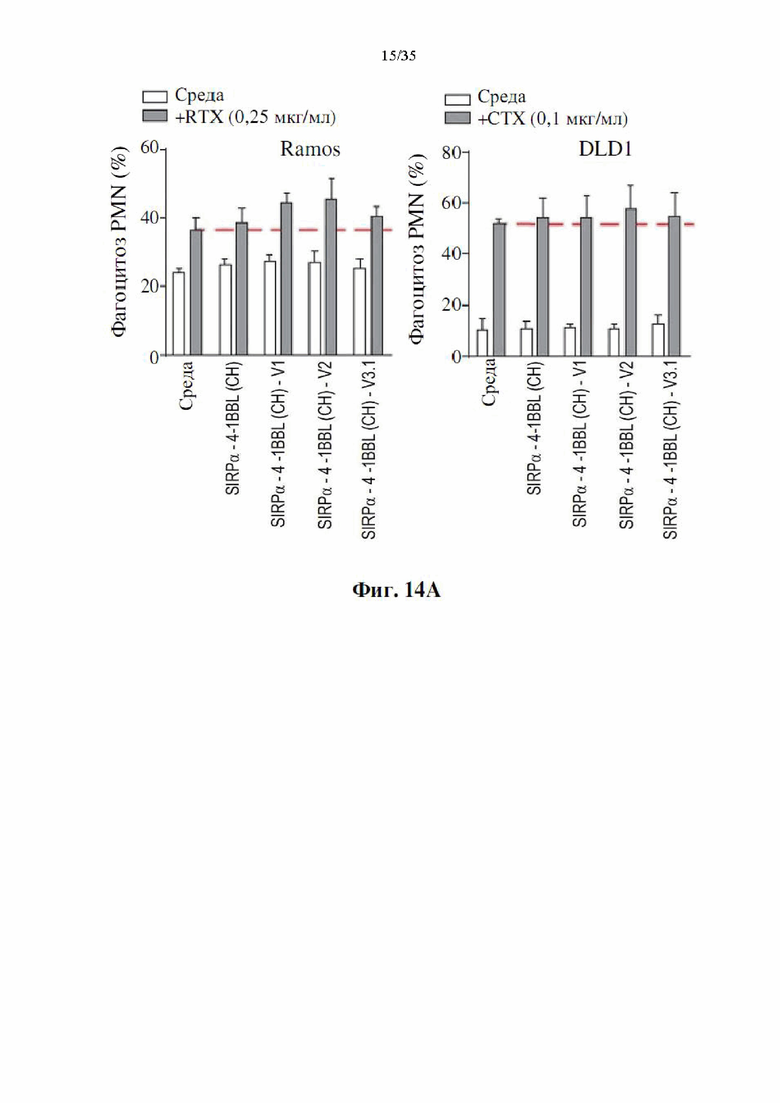
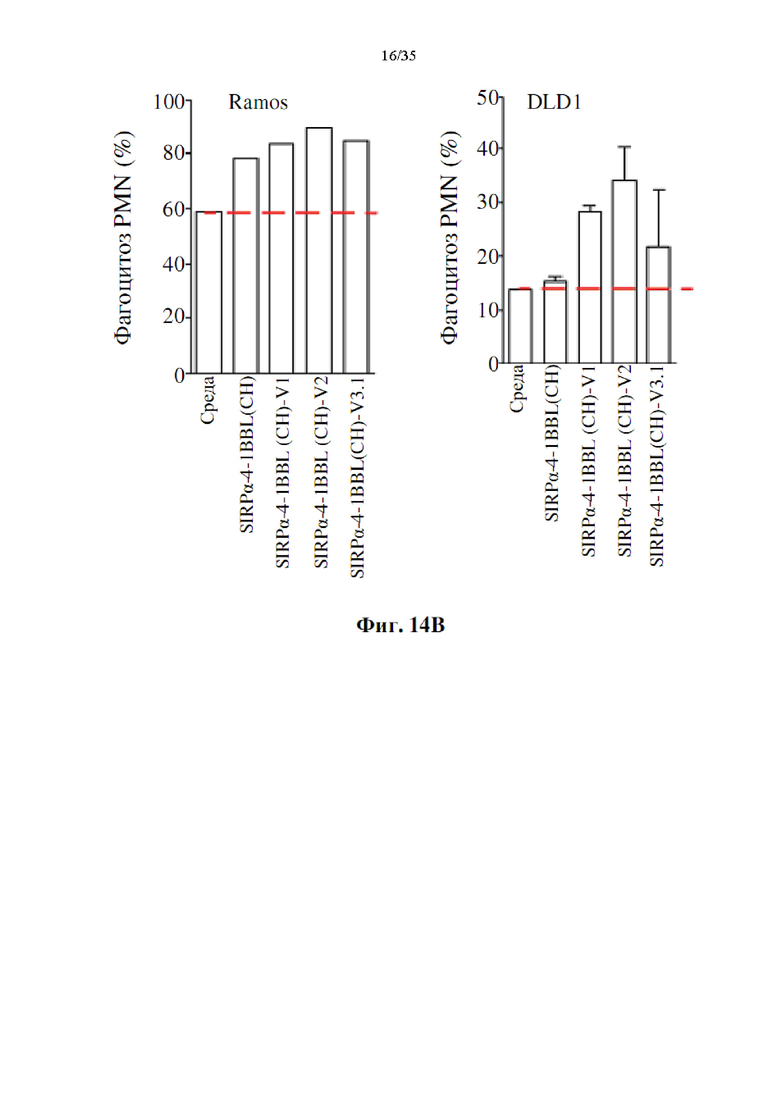
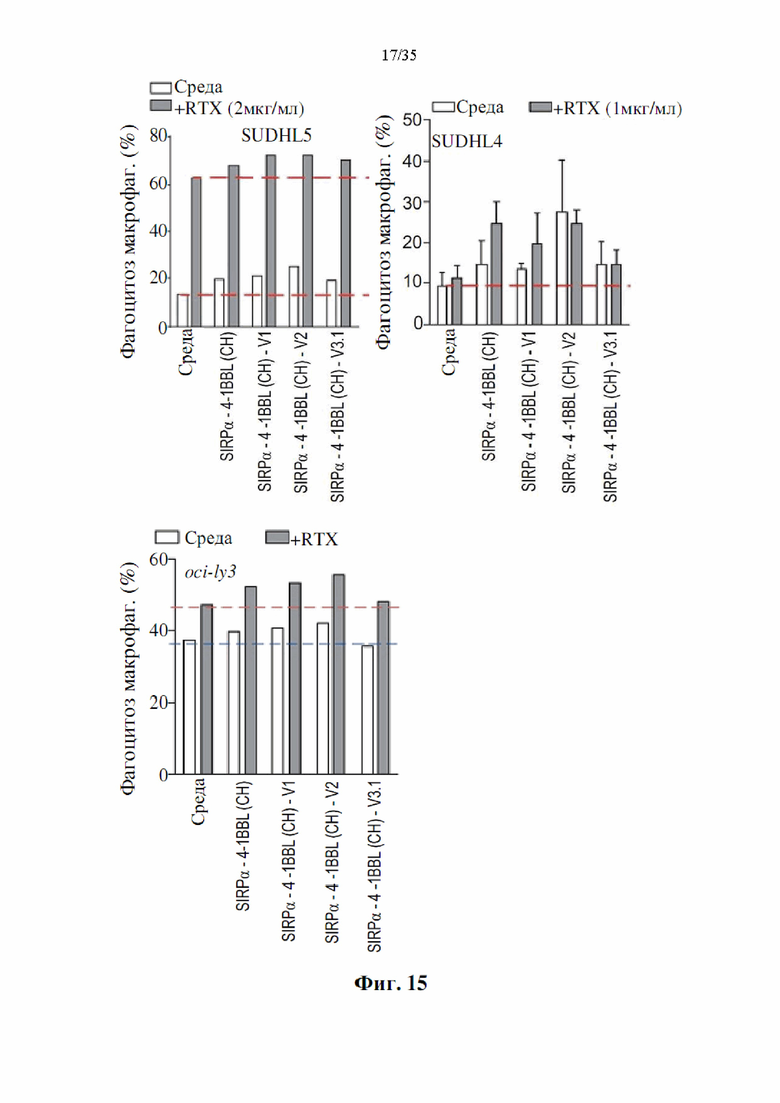
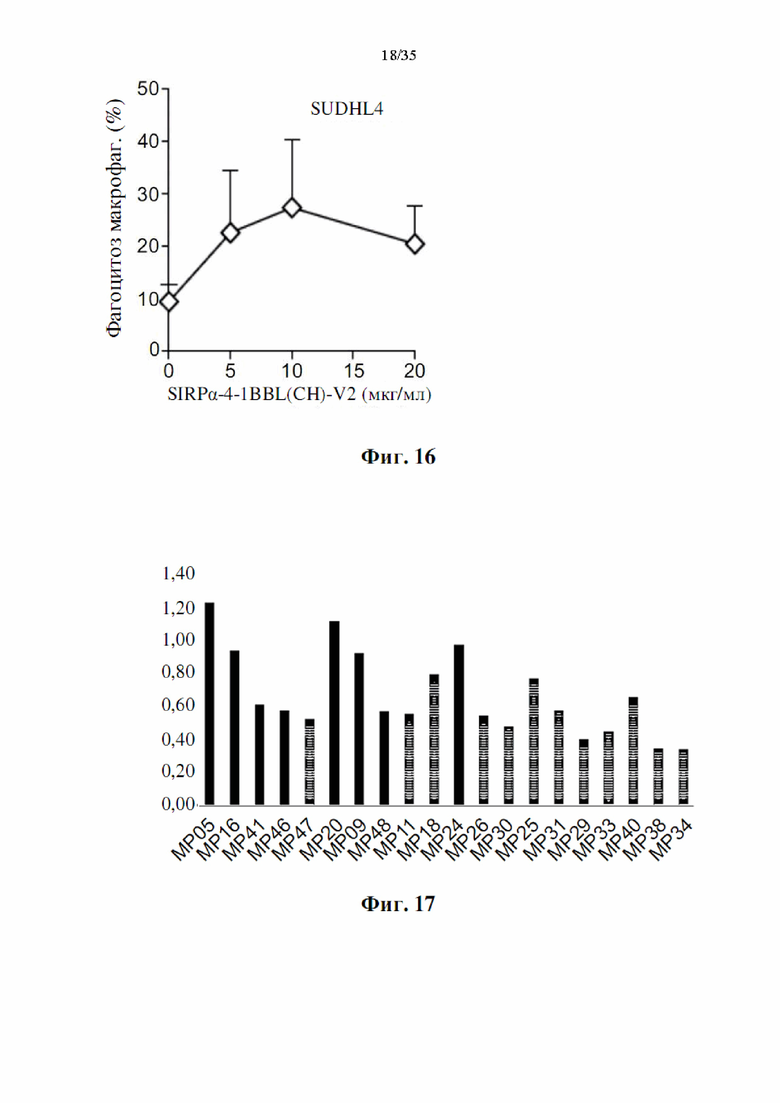
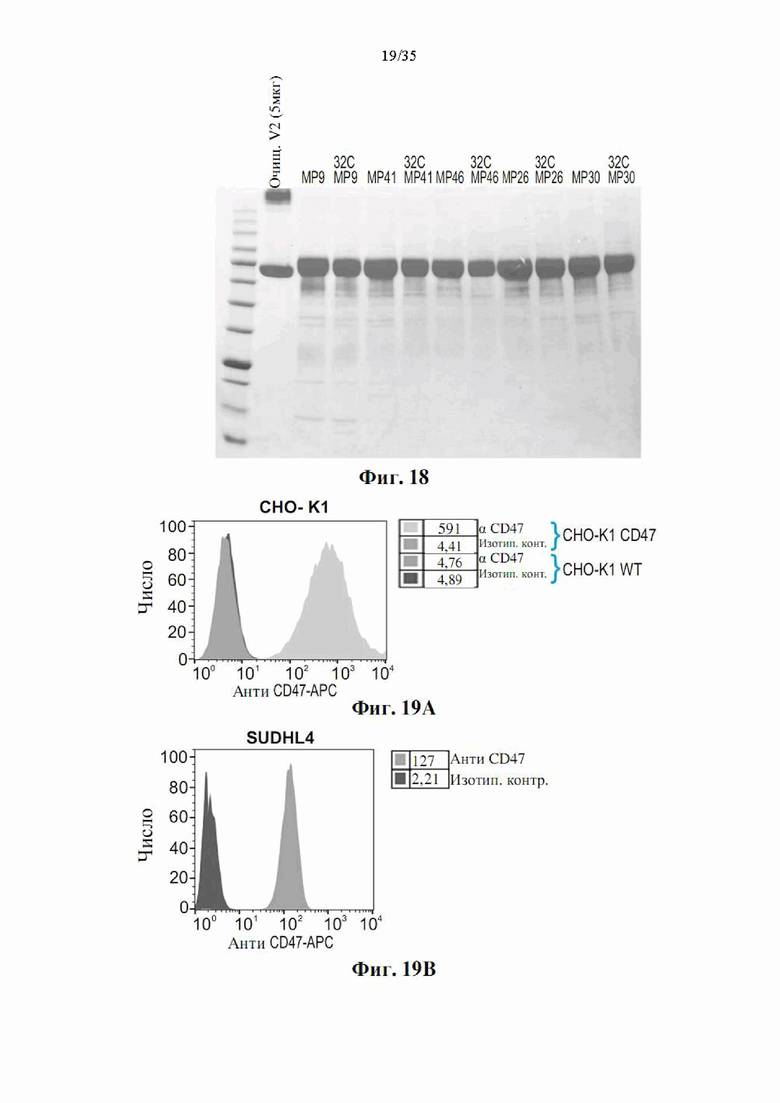
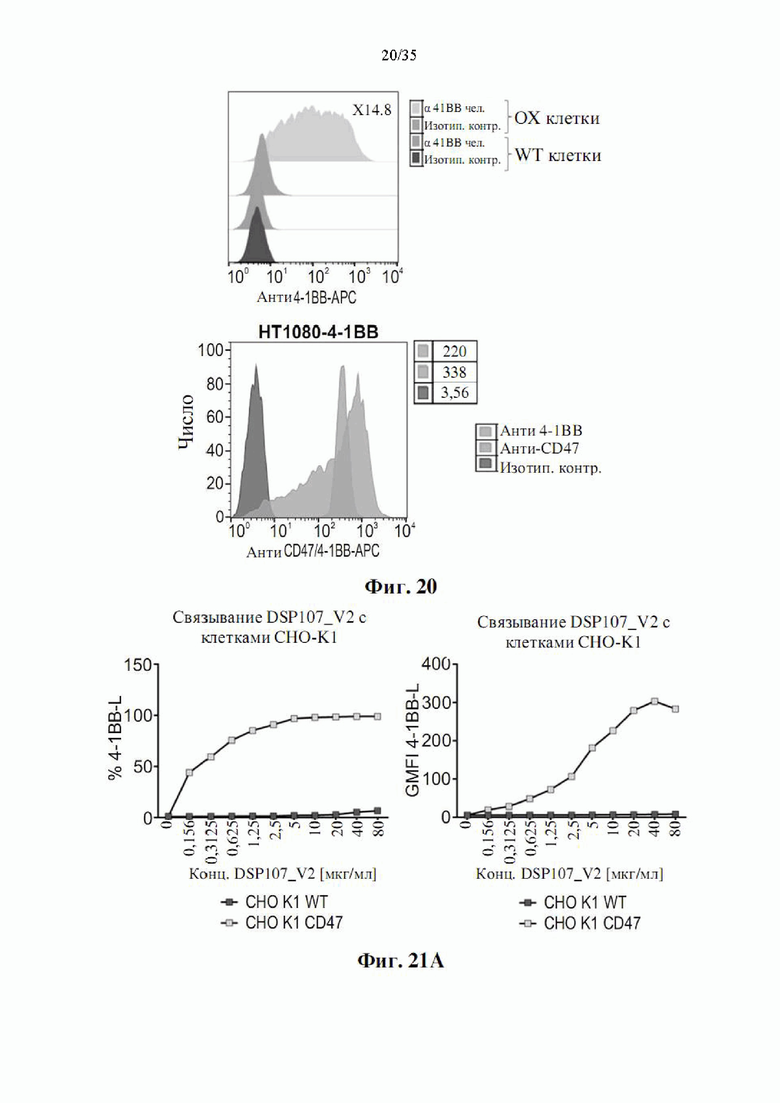
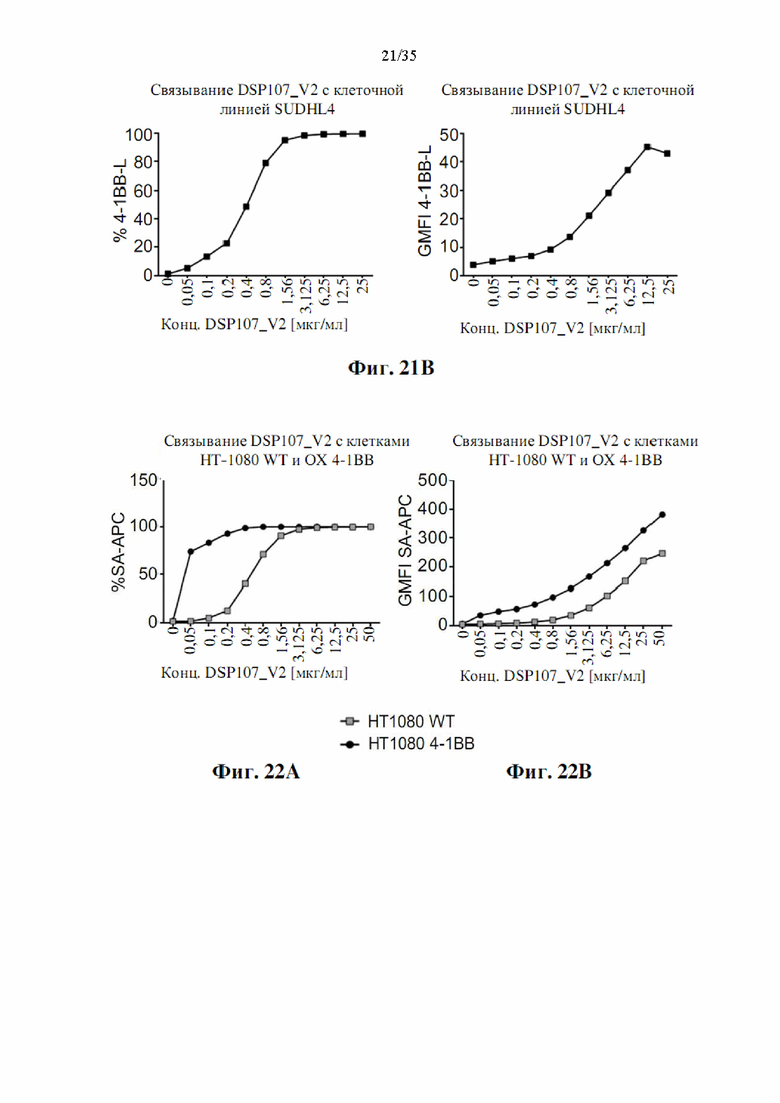
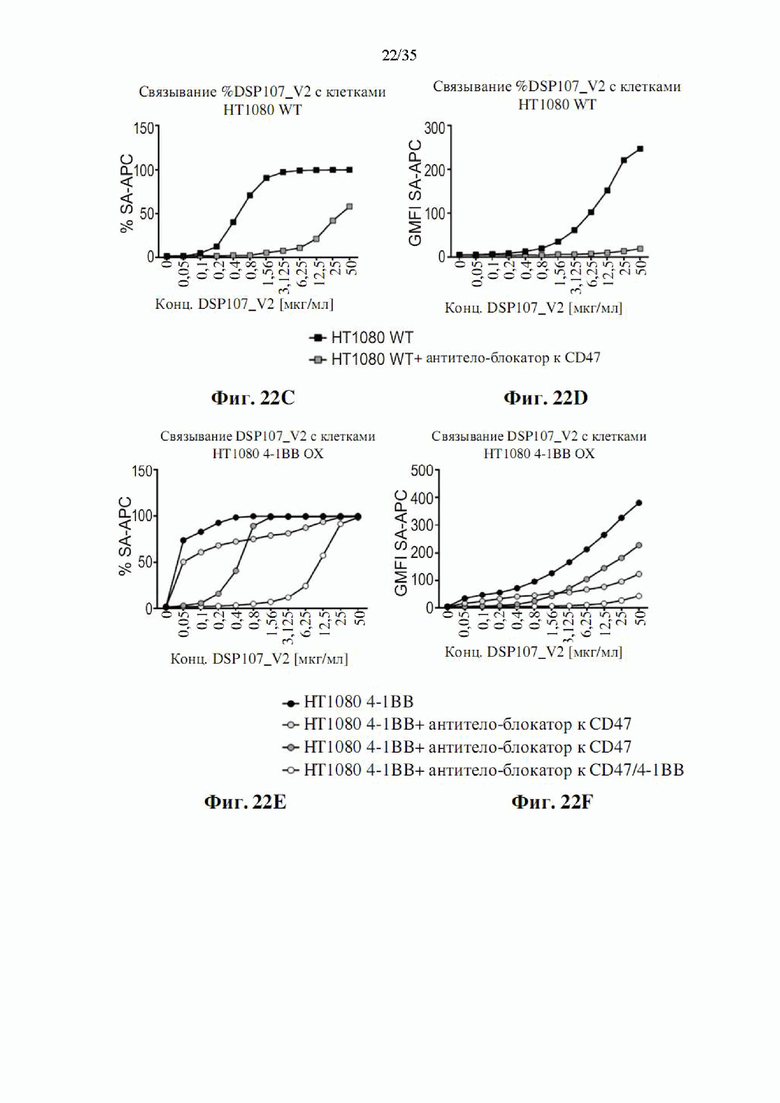
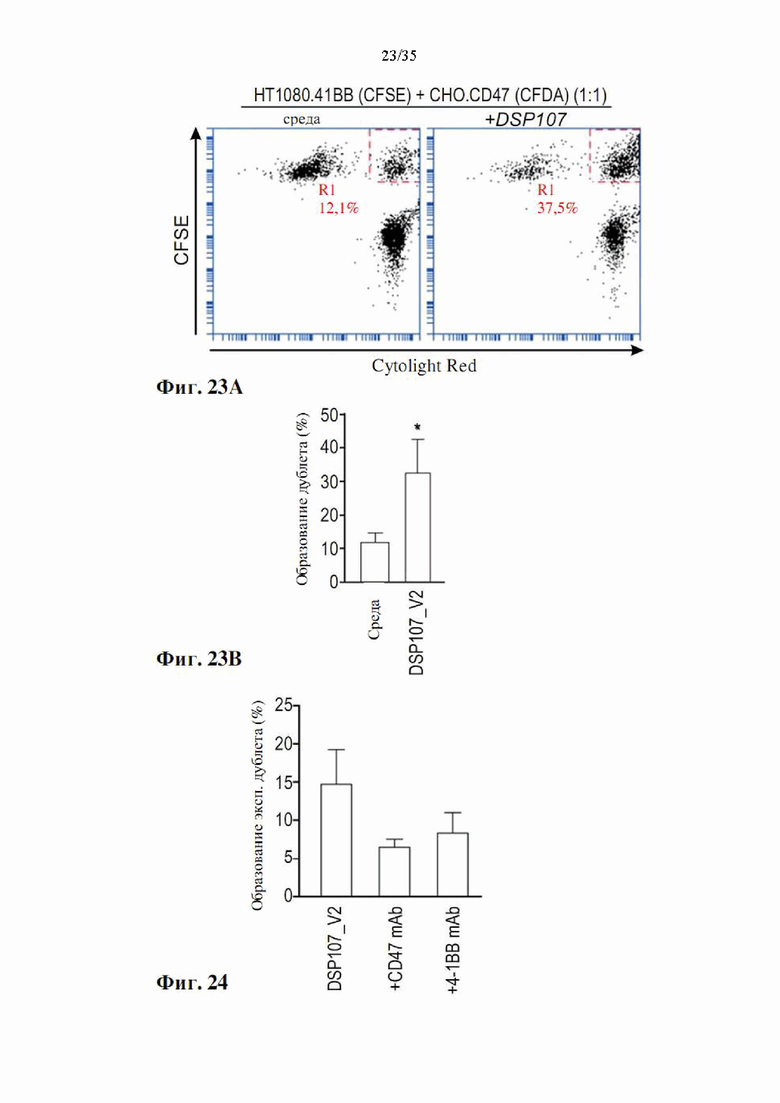
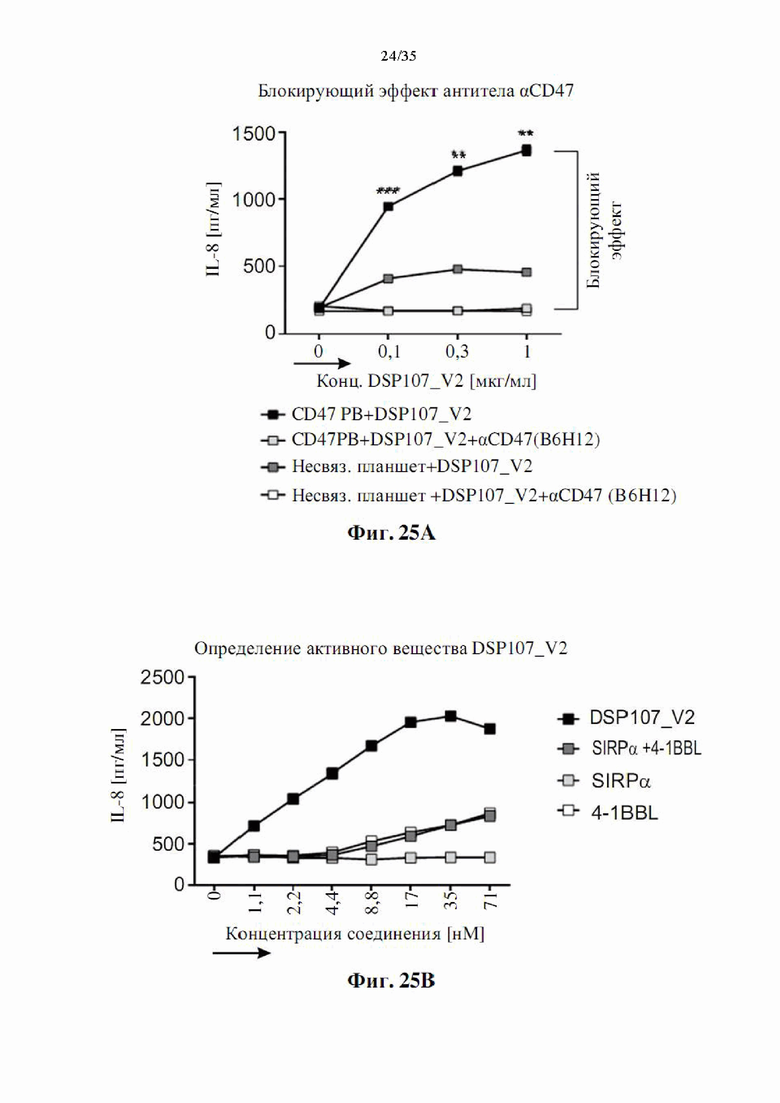
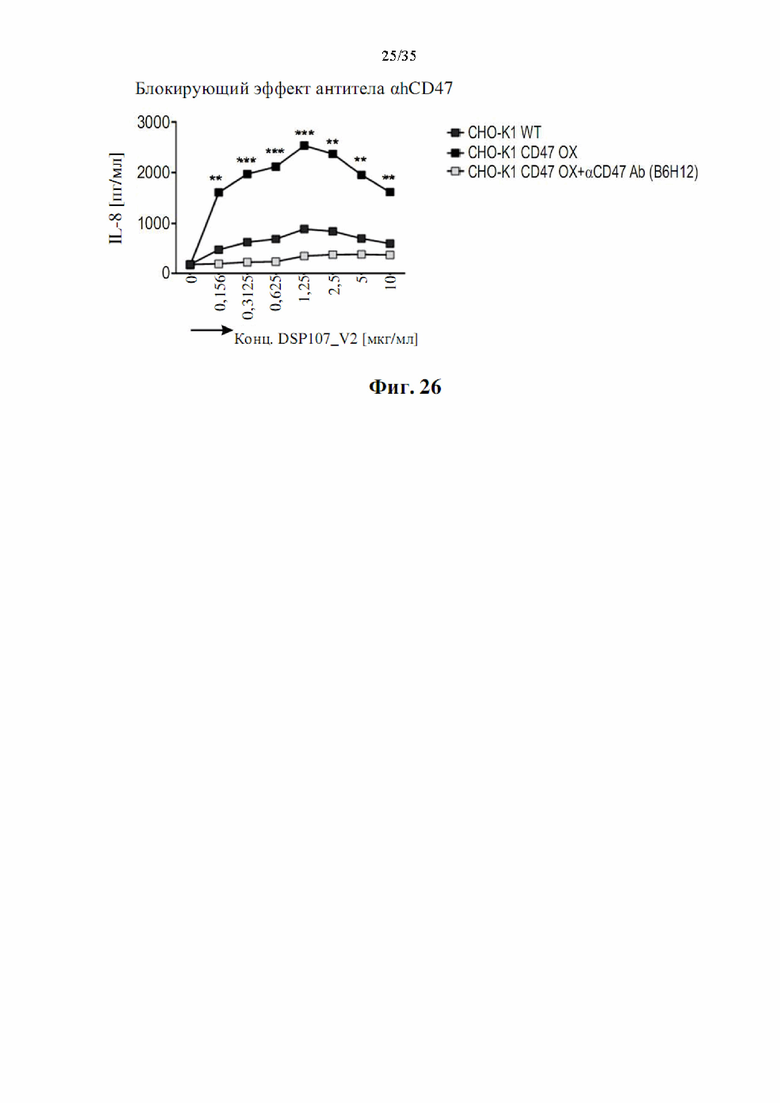
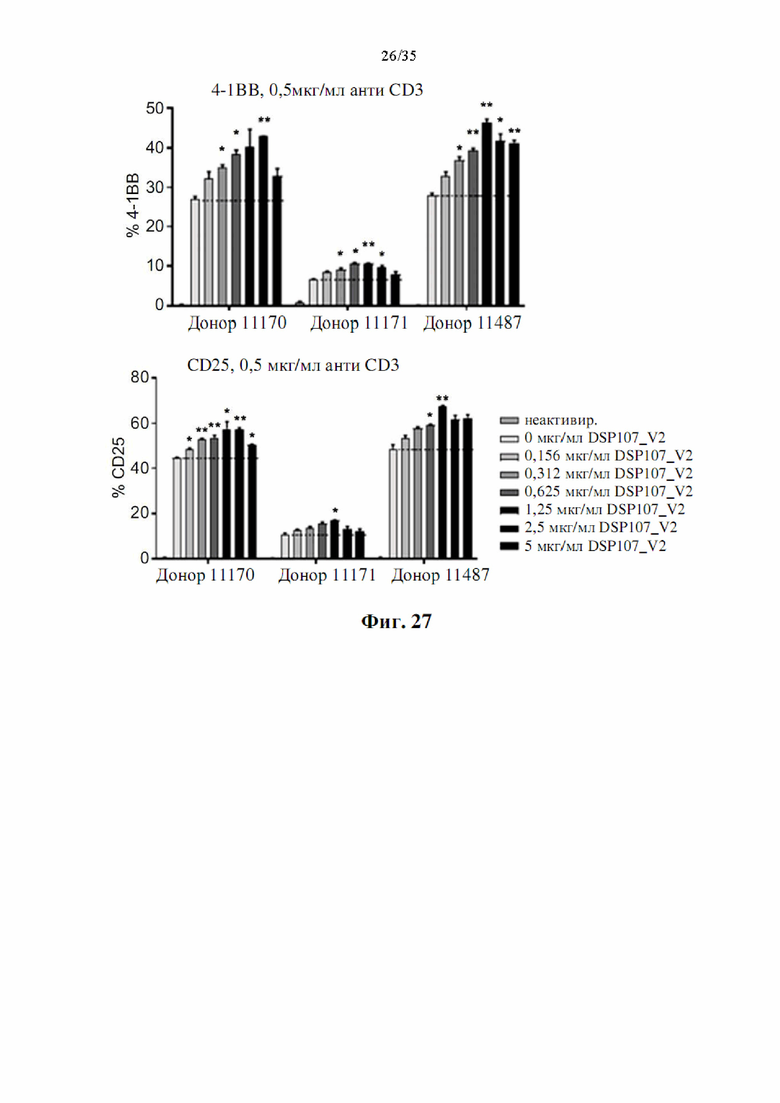
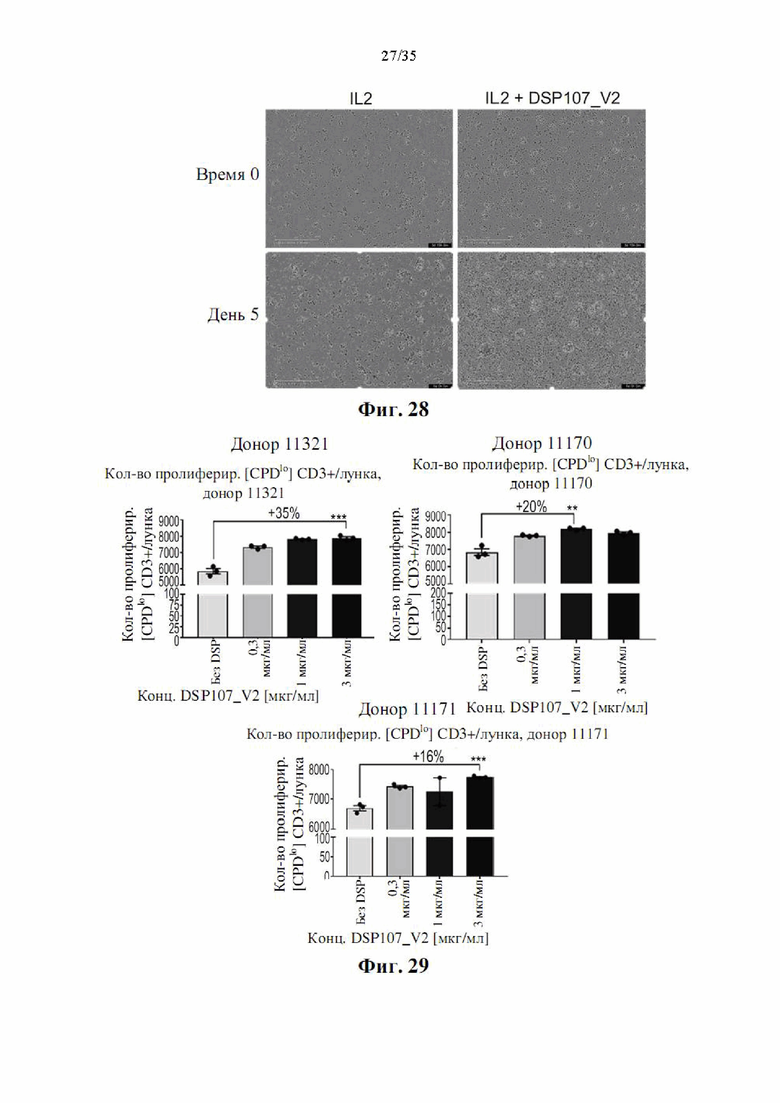
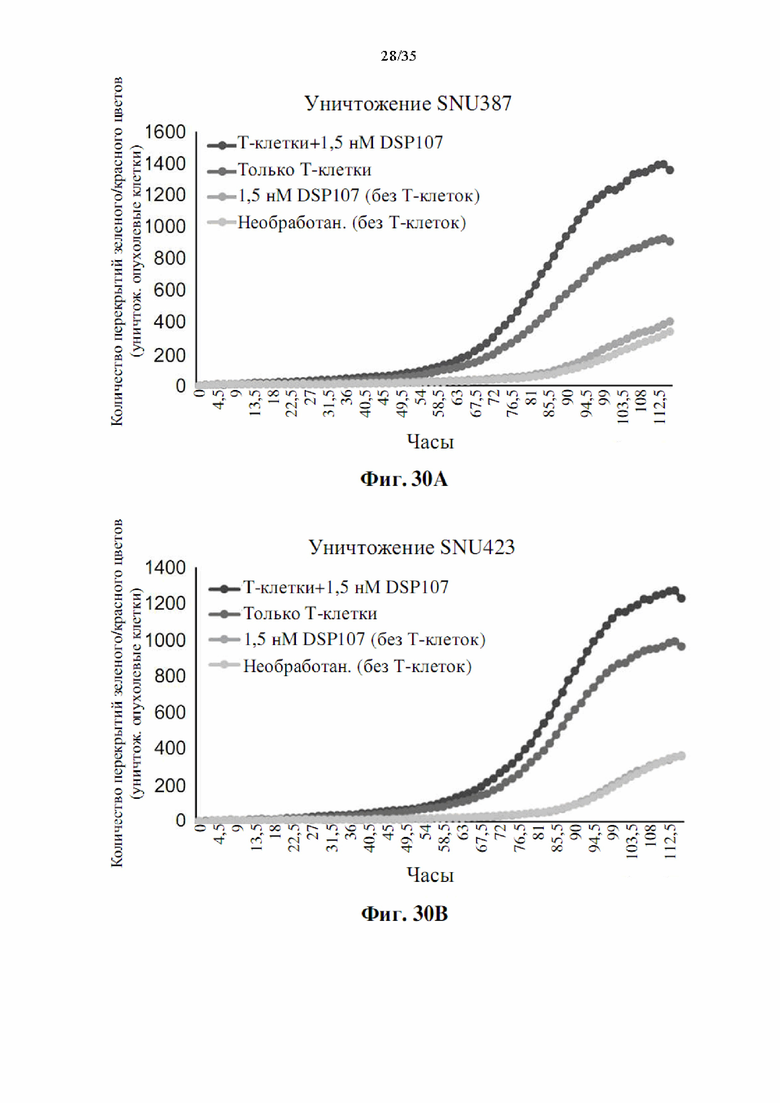
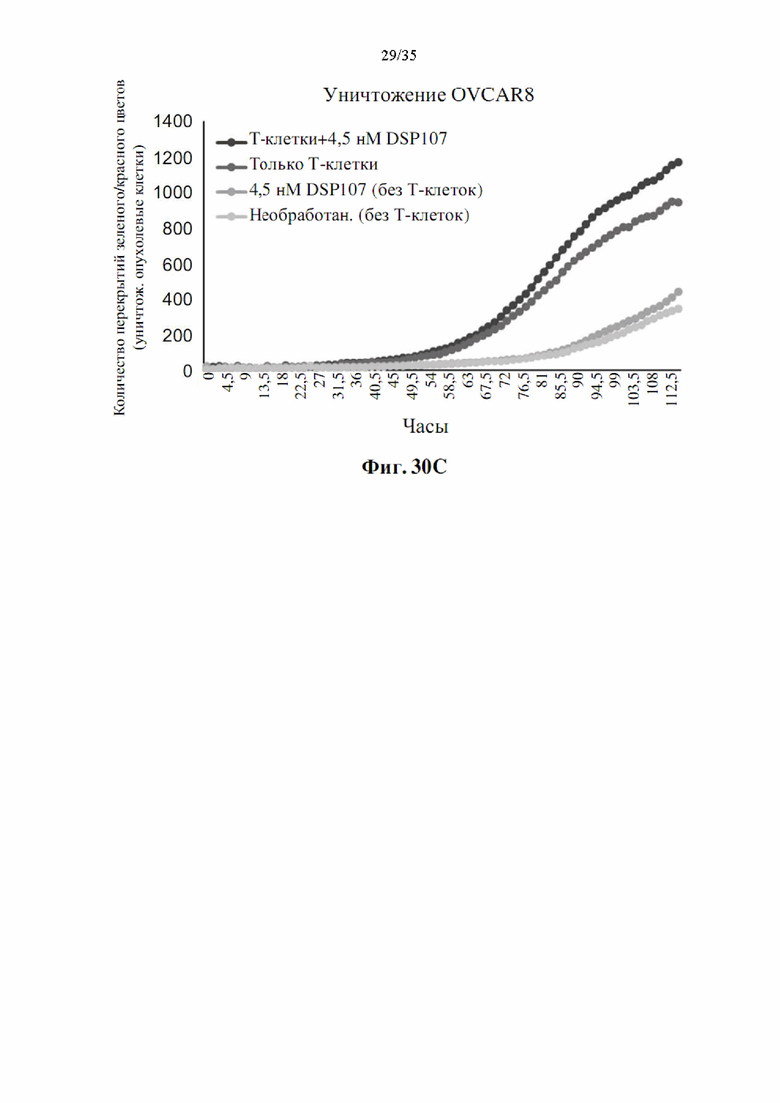
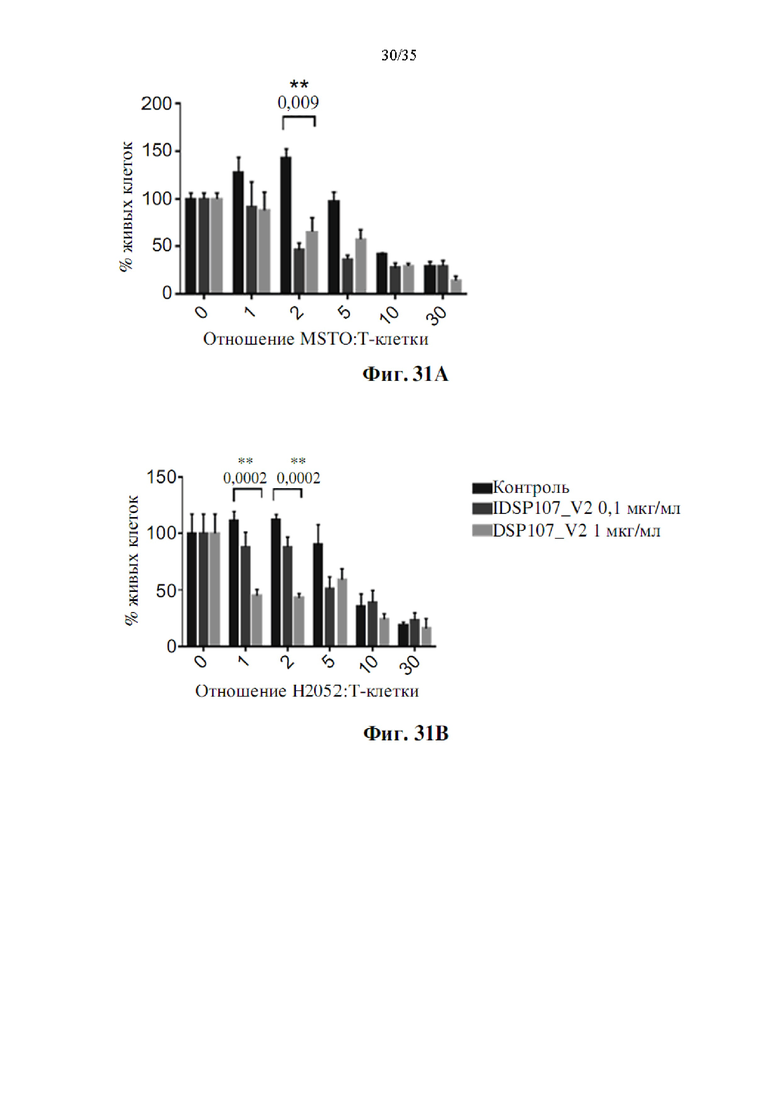
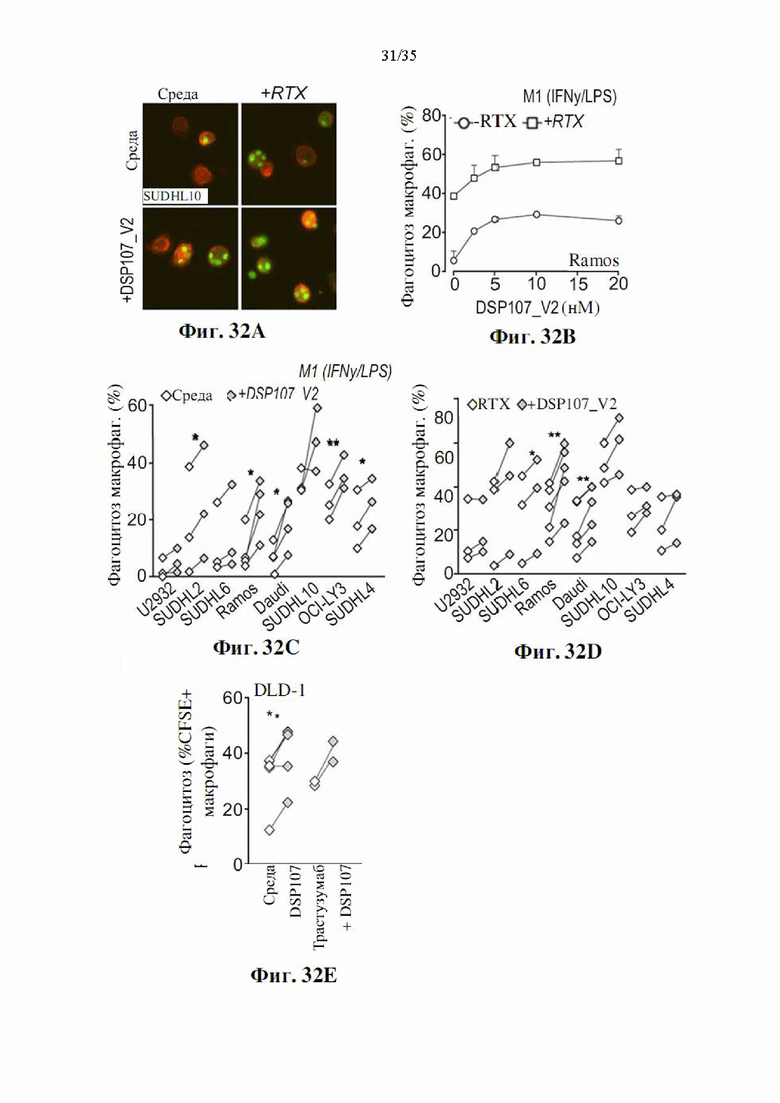
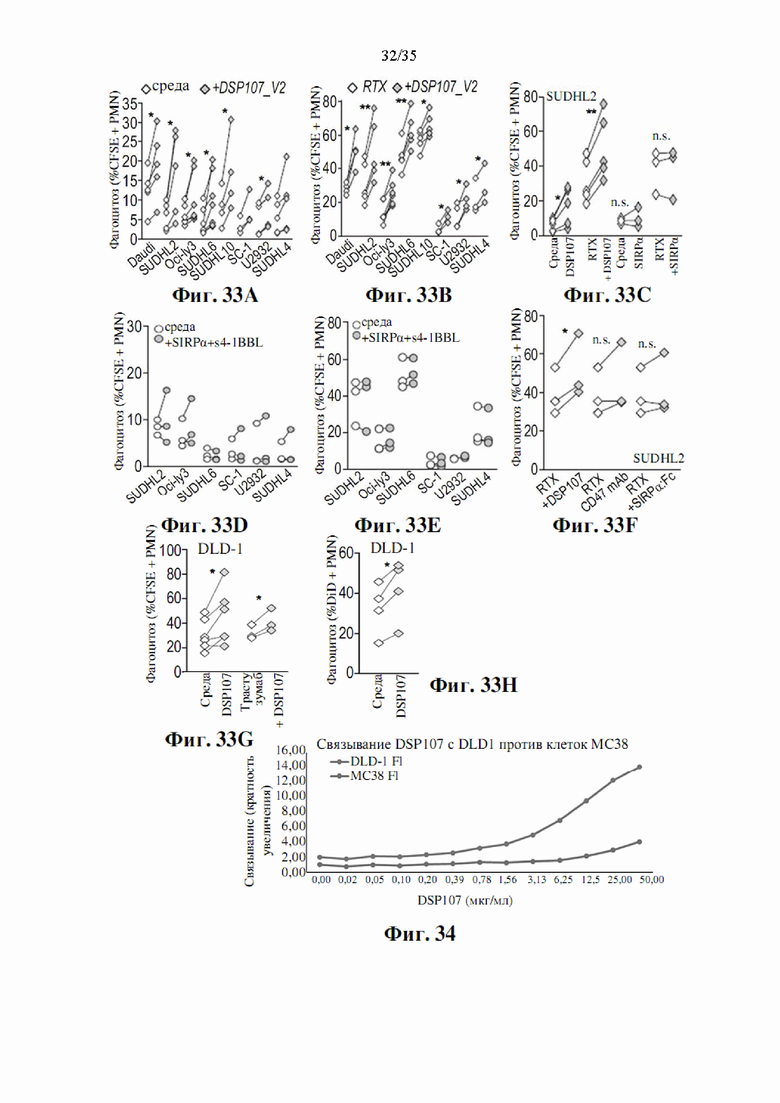
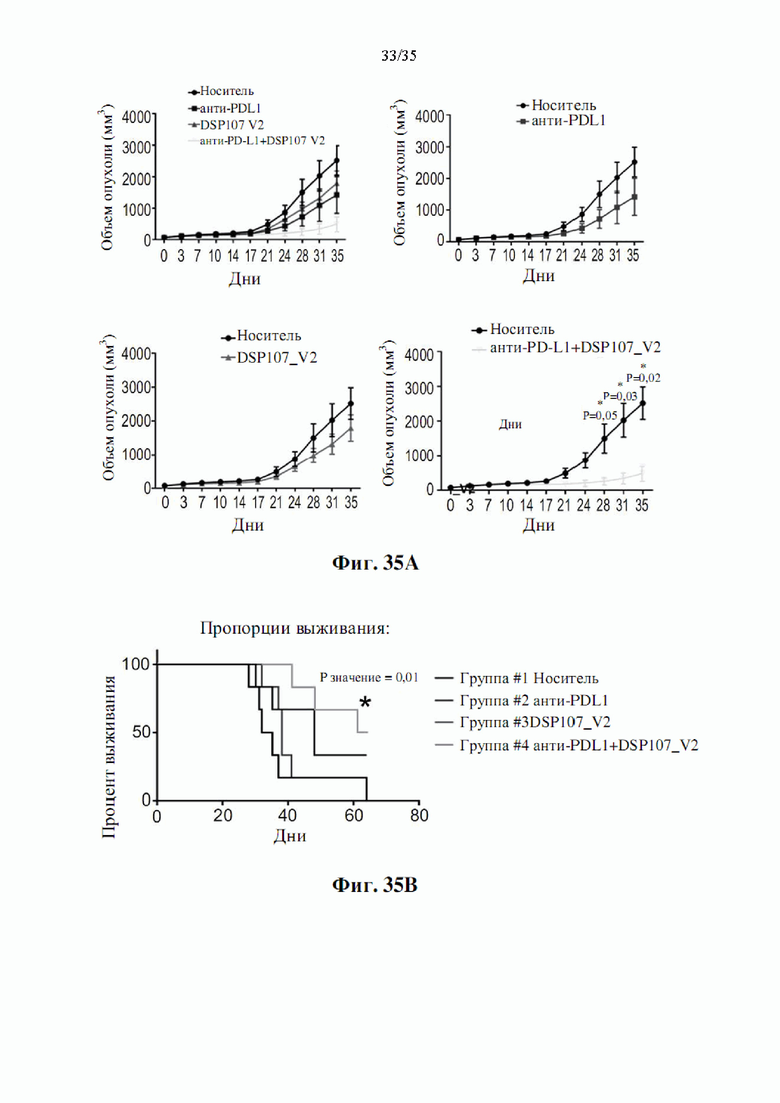
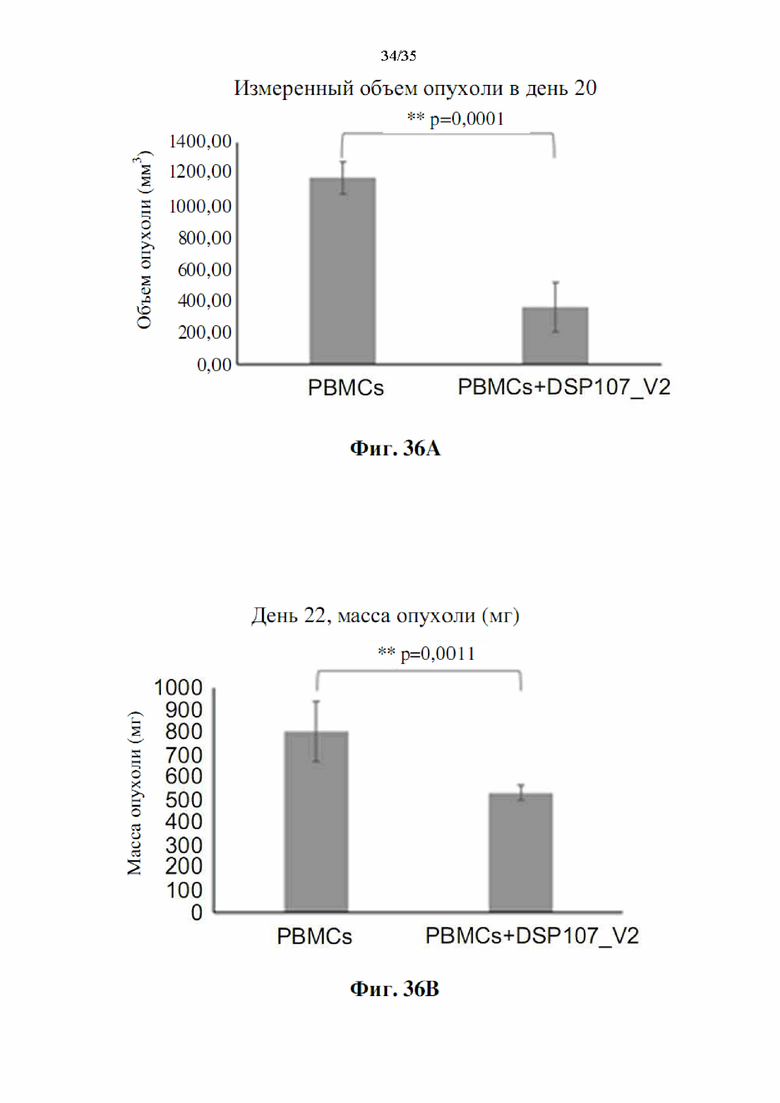
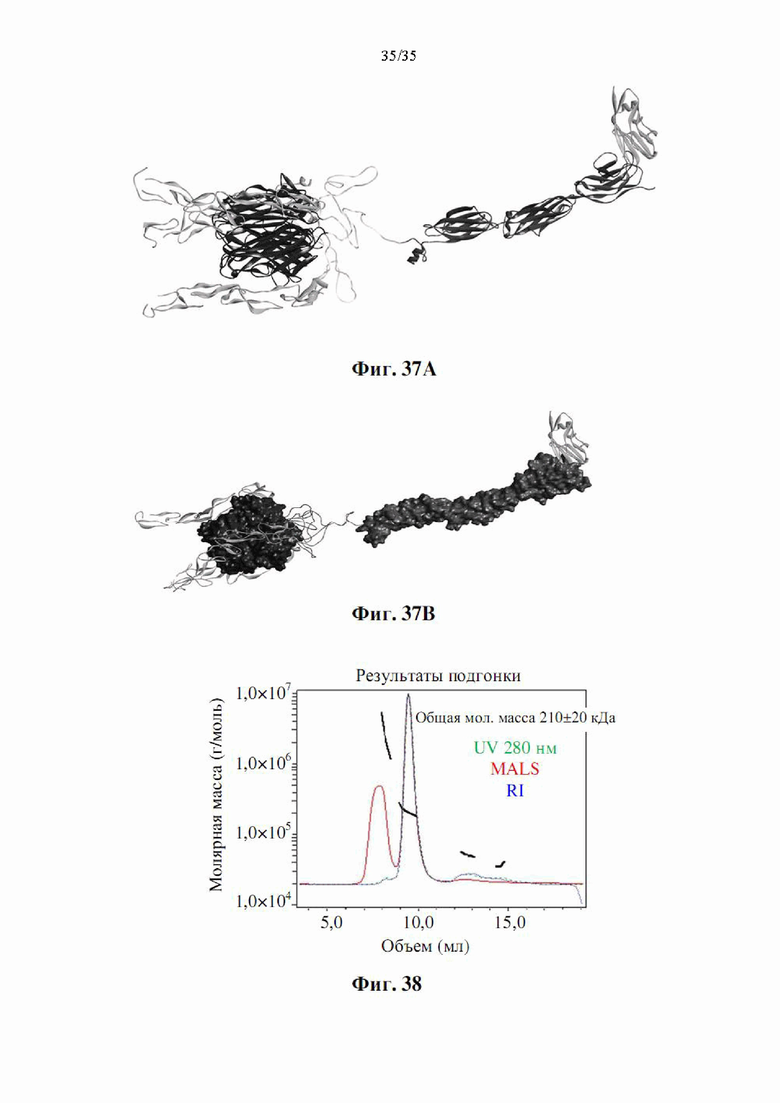
Изобретение относится к области биотехнологии, в частности к слитому белку SIRPα-4-1BBL, содержащему на его N-конце аминокислотную последовательность сигнального регуляторного белка α (SIRPα), а на его С-конце аминокислотную последовательность 4-1ВВ лиганда (4-1BBL), способу его получения, а также к набору, его содержащему. Также раскрыты полинуклеотид, кодирующий вышеуказанный белок, а также клетка и вектор, его содержащие. Изобретение эффективно для лечения рака, экспрессирующего CD47. 8 н. и 14 з.п. ф-лы, 38 ил., 6 табл., 13 пр.
1. Слитый белок SIRPα-4-1BBL для использования в качестве лекарственного средства для лечения рака, экспрессирующего CD47, содержащий на его N-конце аминокислотную последовательность сигнального регуляторного белка α (SIRPα), причем указанная аминокислотная последовательность SIRPα приведена в SEQ ID NO: 2 или представляет собой составляющий по меньшей мере 115 аминокислот в длину фрагмент указанной SEQ ID NO: 2, способный связывать CD47, и на его С-конце аминокислотную последовательность 4-1ВВ лиганда (4-1BBL), причем указанная аминокислотная последовательность 4-1BBL содержит фрагмент SEQ ID NO: 3, способный связывать 4-1ВВ, причем указанный фрагмент не содержит аминокислотный сегмент A1-V6 SEQ ID NO: 3, приведенный в SEQ ID NO: 7, и любой аминокислотный остаток указанного сегмента, и составляет по меньшей мере 185 аминокислот в длину; причем указанный слитый белок характеризуется линкером, состоящим из одного глицина, между указанным SIRPα и указанным 4-1BBL и причем указанный слитый белок способен на следующее:
(i) связывание CD47 и 4-1ВВ;
(ii) активация указанного сигнального пути 4-1ВВ в клетке, экспрессирующей указанный 4-1ВВ;
(iii) костимуляция иммунных клеток, экспрессирующих указанный 4-1ВВ; и
(iv) усиление фагоцитоза патологических клеток, экспрессирующих указанный CD47, фагоцитами по сравнению с таковым в отсутствие указанного слитого белка SIRPα-4-1BBL.
2. Слитый белок SIRPα-4-1BBL по п. 1, в котором указанная аминокислотная последовательность SIRPα содержит фрагмент SEQ ID NO: 2, способный связывать CD47, причем указанный фрагмент не содержит аминокислотный сегмент K117 - Y343 SEQ ID NO: 2 и любой аминокислотный остаток указанного сегмента.
3. Слитый белок SIRPα-4-1BBL по п. 1, в котором указанная аминокислотная последовательность SIRPα составляет в длину 116 аминокислот.
4. Слитый белок SIRPα-4-1BBL по п. 1, в котором указанная аминокислотная последовательность SIRPα содержит SEQ ID NO: 24.
5. Слитый белок SIRPα-4-1BBL по п. 1, в котором указанная аминокислотная последовательность SIRPα состоит из SEQ ID NO: 24.
6. Слитый белок SIRPα-4-1BBL по п. 1, в котором указанная аминокислотная последовательность 4-1BBL содержит SEQ ID NO: 22, 23, 27 или 28.
7. Слитый белок SIRPα-4-1BBL по п. 1, в котором указанная аминокислотная последовательность 4-1BBL состоит из SEQ ID NO: 22, 23, 27 или 28.
8. Слитый белок SIRPα-4-1BBL по п. 1, в котором:
(i) указанная аминокислотная последовательность SIRPα приведена в SEQ ID NO: 2, а указанная аминокислотная последовательность 4-1BBL приведена в SEQ ID NO: 22, 23, 27 или 28; или
(ii) указанная аминокислотная последовательность SIRPα приведена в SEQ ID NO: 24, а указанная аминокислотная последовательность 4-1BBL приведена в SEQ ID NO: 3, 22, 23, 27 или 28.
9. Слитый белок SIRPα-4-1BBL по п. 1, в котором:
(i) указанная аминокислотная последовательность SIRPα приведена в SEQ ID NO: 2, а указанная аминокислотная последовательность 4-1BBL приведена в SEQ ID NO: 23;
(ii) указанная аминокислотная последовательность SIRPα приведена в SEQ ID NO: 24, а указанная аминокислотная последовательность 4-1BBL приведена в SEQ ID NO: 22;
(iii) указанная аминокислотная последовательность SIRPα приведена в SEQ ID NO: 2, а указанная аминокислотная последовательность 4-1BBL приведена в SEQ ID NO: 22.
10. Слитый белок SIRPα-4-1BBL по п. 1, причем выход продукции указанного слитого белка по меньшей мере в 1,5 раза выше, чем выход продукции SEQ ID NO: 5 при тех же условиях производства, указанные условия производства включают в себя экспрессию в клетке млекопитающего и культивирование при 32-37°С, 5-10% СО2 в течение 5-13 дней.
11. Слитый белок SIRPα-4-1BBL по п. 1, причем указанная аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 11, 13, 16 и 45-49.
12. Слитый белок SIRPα-4-1BBL по п. 1, причем указанная аминокислотная последовательность слитого белка SIRPα-4-1BBL состоит из аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13, 16 и 45-49.
13. Слитый белок SIRPα-4-1BBL по п. 1, причем указанная аминокислотная последовательность слитого белка SIRPα-4-1BBL содержит аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 11, 13, 16.
14. Слитый белок SIRPα-4-1BBL по п. 1, причем указанная аминокислотная последовательность слитого белка SIRPα-4-1BBL состоит из аминокислотной последовательности, выбранной из группы, состоящей из SEQ ID NO: 11, 13, 16.
15. Полинуклеотид, кодирующий слитый белок SIRPα-4-1BBL по любому из пп. 1-14.
16. Вектор экспрессии, содержащий полинуклеотид по п. 15 и регуляторный элемент для управления экспрессией указанного полинуклеотида в клетке-хозяине.
17. Клетка-хозяин для применения в производстве лекарственного средства для лечения рака, экспрессирующего CD47, содержащая слитый белок SIRPα-4-1BBL по любому из пп. 1-14, полинуклеотид по п. 15 или вектор экспрессии по п. 16.
18. Способ получения слитого белка SIRPα-4-1BBL, предусматривающий экспрессию в клетке-хозяине полинуклеотида по п. 15 или вектора экспрессии по п. 16.
19. Способ по п. 18, предусматривающий выделение слитого белка.
20. Способ лечения рака, экспрессирующего CD47, у нуждающегося в этом субъекта, предусматривающий введение субъекту слитого белка SIRPα-4-1BBL по любому из пп. 1-14, полинуклеотида по п. 15, вектора экспрессии по п. 16 или клетки-хозяина по п. 17.
21. Набор для лечения рака, экспрессирующего CD47, у нуждающегося в этом субъекта, содержащий упаковочный материал, упаковывающий противораковое средство;
и слитый белок SIRPα-4-1BBL по любому из пп. 1-14, полинуклеотид по п. 15, вектор экспрессии по п. 16 или клетку-хозяина по п. 17.
22. Способ активации иммунных клеток, предусматривающий активацию иммунных клеток in vitro в присутствии клеток рака, экспрессирующих CD47, и слитого белка SIRPα-4-1BBL по любому из пп. 1-14, полинуклеотида по п. 15, вектора экспрессии по п. 16 или клетки-хозяина по п. 17.
| WO 2010070047 A1, 24.06.2010 | |||
| WO 2016024021 A1, 18.02.2016 | |||
| YARON PEREG, CEO, Kahr MedicaKAHR Medical Dual Signaling Proteins (DSP) Platform - the Next Generation of Cancer Immunotherapy, May 2018, найдено в Интернет [https://kenes-exhibitions.com/old/biomed2018/?cr3ativconference=next-generation-oncology-treatments] | |||
| КОСОБОКОВА Е | |||
| Н | |||
| и др |

