Изобретение относится к биотехнологии, медицине, молекулярной биологии и позволяет произвести пробоподготовку библиотек, содержащих целевые фрагменты генов главного комплекса гистосовместимости -HLA-A, HLA-B, HLA-C, HLA-DPB1, HLA-DQB1, HLA-DRB1 методом высокопроизводительного секвенирования, как при решении задач практической медицины, так и в научно-исследовательских целях.
Гены HLA (Human Leukocyte Antigen), располагающиеся на 6 хромосоме человека, кодируют белки, входящие в главный комплекс гистосовместимости (МНС) и ответственные за регуляцию иммунной системы. Гены HLA отличаются значительным полиморфизмом. Например, для гена HLA-A на сегодняшний день в базе данных IPD-IMGT/HLA Database содержится 4101 аллель.
Типирование генов HLA (определение конкретных аллелей), учитывая их роль в регуляции иммунной системы, может иметь самое широкое применение, как в практической медицине, так и для фундаментальной науки. Типирование генов HLA необходимо при трансплантации, так как несовместимость генов HLA донора и реципиента является основной причиной отторжения органов и клеток [Mahdi ВМ. A glow of HLA typing in organ transplantation. Clin Transl Med. 2013 Feb 23; 2(1): 6. doi: 10.1186/2001-1326-2-6. PMID: 23432791; PMCID: PMC3598844; Хамаганова Е.Г., Кузьмина Л.А. ОЦЕНКА HLA-СОВМЕСТИМОСТИ И ТРЕБОВАНИЯ К HLA-ТИПИРОВАНИЮ БОЛЬНОГО И ДОНОРА ПРИ ТРАНСПЛАНТАЦИИ АЛЛОГЕННЫХ ГЕМОПОЭТИЧЕСКИХ СТВОЛОВЫХ КЛЕТОК. Гематология и трансфузиология. 2019; 64(2): 175-187. https://doi.org/10.35754/0234-5730-2019-64-2-175-187.]. В настоящее время опубликованы работы, описывающих участие генов HLA в развитии многочисленных заболеваний, включая онкологические (меланома [Bonamigo RR, Carvalho AV, Sebastiani VR, Silva CM, Pinto AC. HLA and skin cancer. An Bras Dermatol. 2012 Jan-Feb; 87(1): 9-16; quiz 17-8. doi: 10.1590/s0365-05962012000100001. PMID: 22481646.], лимфома [Zhong C, Gragert L, Maiers M, Hill ВТ, Garcia-Gomez J, Gendzekhadze K, Senitzer D, Song J, Weisenburger D, Goldstein L, Wang SS. The association between HLA and non-Hodgkin lymphoma subtypes, among a transplant-indicated population. Leuk Lymphoma. 2019 Dec; 60(12): 2899-2908. doi: 10.1080/10428194.2019.1617858. Epub 2019 Jun 19. PMID: 31215275; PMCID: PMC6858537.]) и аутоиммунные (ревматоидный артрит [Oliveira LC, Porta G, Marin ML, Bittencourt PL, Kalil J, Goldberg AC. Autoimmune hepatitis, HLA and extended haplotypes. Autoimmun Rev. 2011 Feb;10(4): 189-93. doi: 10.1016/j.autrev.2010.09.024. Epub 2010 Oct 7. PMID: 20933106.], аутоиммунный гепатит [Kurkó J, Besenyei T, Laki J, Giant TT, Mikecz K, Szekanecz Z. Genetics of rheumatoid arthritis - a comprehensive review. Clin Rev Allergy Immunol. 2013 Oct; 45(2): 170-9. doi: 10.1007/s 12016-012-8346-7. PMID: 23288628; PMCID: PMC3655138.]) заболевания. Показано влияние генов HLA на развитии многочисленных инфекционных заболеваний, включая инфицирование ВИЧ [Hardie RA, Knight Е, Bruneau В, Semeniuk С, Gill K, Nagelkerke N, Kimani J, Wachihi C, Ngugi E, Luo M, Plummer FA. A common human leucocyte antigen-DP genotype is associated with resistance to HIV-1 infection in Kenyan sex workers. AIDS. 2008 Oct 1; 22(15): 2038-42. doi: 10.1097/QAD.0b013e328311dla0. PMID: 18784467; PMCID: PMC2683274.], вирусом гепатита В [Wang L, Zou ZQ, Wang K. Clinical Relevance of HLA Gene Variants in HBV Infection. J Immunol Res. 2016; 2016: 9069375. doi: 10.1155/2016/9069375. Epub 2016 May 8. PMID: 27243039; PMCID: PMC4875979], вирусом гепатита С [Vejbaesya S, Songsivilai S, Tanwandee T, Rachaibun S, Chantangpol R, Dharakul T. HLA association with hepatitis С virus infection. Hum Immunol. 2000 Mar; 61(3): 348-53. doi: 10.1016/s0198-8859(99)00131-7. PMID: 10689128], SARS-CoV-2 [Augusto DG, Yusufali T, Peyser ND, Butcher X, Marcus GM, Olgin JE, Pletcher MJ, Maiers M, Hollenbach JA. HLA-B*15:01 is associated with asymptomatic SARS-CoV-2 infection. medRxiv [Preprint]. 2021 Sep 10:2021.05.13.21257065. doi: 10.1101/2021.05.13.21257065. PMID: 34031661; PMCID: РМС8142661]. В некоторых работах авторы исследуют механизмы, лежащие в основе того, как определенные аллели HLA связаны с заболеваниями, например, механизмы, лежащие в основе защитного влияния аллеля HLA-B*53:01 при инфекции ВИЧ [Bisrat J Debebe, Lies Boelen, James С Lee, IAVI Protocol С Investigators, Chloe L Thio, Jacquie Astemborski, Gregory Kirk, Salim I Khakoo, Sharyne M Donfield, James J Goedert, Becca Asquith (2020) Identifying the immune interactions underlying HLA class I disease associations eLife 9: e54558 https://doi.org/10.7554/eLife.54558]. Подобные работы несомненно вносят вклад в развитие фундаментальной науки и позволяют понять молекулярные механизмы регуляции иммунной системы.
При решении задач молекулярной диагностики нуклеиновых кислот, помимо методов полимеразной цепной реакции (ПЦР) и секвенирования первого поколения по методу Сэнгера, широко используется секвенирование следующего поколения (NGS, Next Generation Sequencing).
В то время как в более ранних работах по типированию генов HLA использовалось преимущественно секвенирование по методу Сэнгера, в настоящее время все чаще используется метод NGS, благодаря одновременному прочтению протяженных участков генома и выявлению сразу большого количества мутаций/полиморфизмов. Так как полногеномное секвенирование имеет высокую стоимость и прочтение всего генома для исследований, связанных с типированием генов HLA, не требуется, в качестве альтернативы полногеномному секвенированию, при решении ряда задач типирования генов HLA может быть применено так называемое «таргетное» (целевое) секвенирование представляющих наибольший интерес участков данных генов. Целевая область фрагментов ДНК целевого гена или области генома направленно амплифицируются, а затем подвергаются высокопроизводительному секвенированию, так что стоимость значительно снижается, а необходимость последующего анализа данных также уменьшается. По сравнению с обычным методом NGS, таргетное секвенирование выполняется после целевой амплификации фрагментов генома. Таким образом стоимость секвенирования и анализа данных значительно снижаются. В настоящее время подобные подходы широко используются, например, для секвенирования экзома человека и отдельных генов.
Для того, чтобы идентифицировать ДНК исследуемого образца как содержащую определенные аллели генов HLA, достаточно секвенировать несколько регионов данных генов, включающих экзоны. При таргетном NGS секвенировании целевые регионы ДНК сначала амплифицируются с помощью специальных олигонуклеотидных праймеров, что позволяет изучать их затем избирательно. Далее, как правило, проводится этап лигирования служебных фрагментов олигонуклеотидов (адаптеров) с помощью особых дорогостоящих ферментов, и индексация с детекцией в режиме реального времени с помощью флуоресцентного интеркалирующего красителя.
Из уровня техники известны следующие протоколы и наборы реагентов для секвенирования генов HLA методом NGS:
Система «HLA-Эксперт» для типирования генов HLA методом высокопроизводительного секвенирования компании ДНК-технология (Россия). «HLA-Эксперт» включает набор реагентов для подготовки библиотек и программное обеспечение для биоинформатического анализа, позволяет типировать 9 генов на уровне высокого разрешения: HLA-A, HLA-B, HLA-C, HLA-DRB1, HLA-DQB1, HLA-DPB1, DRB3/4/5 [Янкевич Т.Э., Трофимов Ю.Д., Болдырева М.Н., Шубина Е.С., Гольцов А.Ю., Алтухова О.С, Суслова Т.А. Разработка системы «HLA-Эксперт» для типирования генов HLA с высоким разрешением методом NGS. Опыт использования. Вестник гематологии, №2, том 14, стр. 56, 2018]. Пробоподготовка осуществляется при помощи двух пулов праймеров.
Набор ScisG™ HLA v6 Kits компании Scisco Genetics technology (США) [https://sciscogenetics.com/pages/kits.html] позволяет типировать гены HLA-A, HLA-B, HLA-C, HLA-DRB1/3/4/5, HLA-DQA1, HLA-DQB1, HLA-DPA1, HLA-DPB1. В нем используется технология мультиплексной ПЦР, позволяющая конструировать библиотеку из фрагментов генов HLA с использованием множества пар праймеров и без лигирования адаптеров. Секвенирование подготовленной библиотеки производится на платформе MiSeq Illumina. Пробоподготовка осуществляется при помощи четырех пулов праймеров.
TruSight™ HLA Sequencing Panel компании Illumina (США) [https://www.illumina.com/clinical/hla-sequencing.html] позволяет типировать гены HLA-A, HLA-B, HLA-C, HLA-DRB1/3/4/5, HLA-DQA1, HLA-DQB1, HLA-DPA1, HLA-DPB1. Для данной панели используется технология, отличная от вышеперечисленных наборов. Фрагменты ДНК амплифицируются крупными фрагментами, длиной несколько т.п.н. (так называемая, long-range PCR). Далее полученные ампликоны фрагментируются набором Nextera® library preparation (Illumina), индексируются и полученная библиотека секвенируется на платформе Illumina.
Следует отметить сравнительно высокую цену всех вышеперечисленных наборов и отсутствие информации об используемых праймерах.
Также из уровня техники известен набор синтетических олигонуклеотидов для определения последовательности генов HLA-A, HLA-B, HLA-C, HLA-DQB1, HLA-DRB1 главного комплекса гистосовместимости [патент RTJ 2703545, дата приоритета 03.06.2019, опубл. 21.10.2019].
Известен способ ПЦР-секвенирования и его применение в генотипировании HLA по патенту RU 2587606 (дата приоритета 30.06.2011, опубл. 20.06.2016). Описан способ ПЦР-секвенирования, включающий следующие стадии: получение образца; амплификация; смешивание; фрагментация; секвенирование и сплайсинг. Данное изобретение также относится к праймерным меткам, используемым в указанном способе, а также к способу генотипирования, в частности, в анализе HLA, а также к ПЦР-праймерам для HLA-A/B, HLA-C и HLA-DQB1.
Упомянутые решения реализуется посредством метода полимеразной цепной реакции (ПЦР). Решения, основанные на ПЦР, имеют такой недостаток, как выявление лишь конкретной аллели, без возможности исследования соседних участков. Кроме того, выявление каждой аллели требует отдельной постановки ПЦР реакции, что увеличивает время исследования и количество требуемой ДНК.
В настоящее время существует необходимость в получении эффективных и простых способов приготовления библиотек для целевого секвенирования важных фрагментов генов HLA с возможностью кастомизации, т.е. изменения праймеров в панели для задач конкретного исследования.
Технической задачей, на решение которой направлено заявляемое решение, является разработка эффективного способа пробоподготовки для фрагментарного NGS-секвенирования ряда регионов генов HLA-A/B/C/DPB1/DQB1/DRB1, позволяющих определить аллели данных генов.
Заявляемое изобретение позволяет преодолеть недостатки предшествующего уровня техники и в значительной мере уменьшает трудо- и финансовые затраты при пробоподготовке к NGS.
Технический результат достигается за счет таргетного (целевого) секвенирования представляющих наибольший интерес участков генов HLA-A/B/C/DPB1/DQB1/DRB1, содержащих экзоны и позволяющих определить аллели данных генов в образце ДНК. Посредством применения оригинальных синтезированных олигонуклеотидных праймеров, имеющих адаптерные подпоследовательности в своем составе, возможна амплификация целевых участков генома, при этом не требуется проводить дорогостоящий этап лигирования адаптеров, используемый в ряде протоколов. При этом амплификацию проводят с использованием двух пулов олигонуклеотидных праймеров, где для первого пула применяют олигонуклеотидные праймеры, имеющие структуру SEQ ID NO: 1-38, а для второго пула применяют олигонуклеотидные праймеры, имеющие структуру SEQ ID NO: 39-77. Амплифицированные фрагменты ДНК, после проведения секвенирования, позволяют определить специфические аллели генов HLA-A/B/C/DPB1/DQB1/DRB1 в исследуемом образце.
Сложность выбора праймеров обусловлена необходимостью обеспечить амплификацию в формате мультиплекса всех аллелей указанных генов, при этом требуется не допустить амплификации нецелевых регионов ДНК человека. Например, в канонической сборке генома человека GRCh38 четвертый экзон гена HLA-A совпадает с соответствующим экзоном гена. HLA-H на 99,28%.
Предложенные в изобретении синтетические олигонуклеотидные праймеры для пробоподготовки образцов для типирования генов главного комплекса гистосовместимости HLA-A, HLA-B, HLA-C, HLA-DPB1, HLA-DQB1, HLA-DRB1 методом NGS секвенирования имеет следующую структуру: SEQ ID NO: 1-77. При этом олигонуклеотидные праймеры, имеющие структуры SEQ ID NO: 1, 3, 4, 6, 8, 11, 13, 15, 17, 19, 20, 22, 24, 26, 28, 30, 32, 34, 35, 37, 39, 41, 43, 44, 46, 48, 50, 52, 53, 56, 58, 60, 63, 64, 66, 67, 69, 70, 72, 73, 75 выполняют функции прямых праймеров, а олигонуклеотидные праймеры, имеющие структуры SEQ ID NO: 2, 5, 7, 9, 10, 12, 14, 16, 18, 21, 23, 25, 27, 29, 31, 33, 36, 38, 40, 42, 45, 47, 49, 51, 54, 55, 57, 59, 61, 62, 65, 68, 71, 74, 76, 77 выполняют функции обратных праймеров.
Кроме того, олигонуклеотидные праймеры содержат в своем составе универсальные адаптерные последовательности, представленные в перечне последовательностей как SEQ ID NO: 78 и 79, позволяющие в дальнейшем облегчить индексацию продуктов амплификации. Адаптерные последовательности SEQ ID NO: 78, расположены на концах олигонуклеотидов SEQ ID NO: 1, 3, 4, 6, 8, 11, 13, 15, 17, 19, 20, 22, 24, 26, 28, 30, 32, 34, 35, 37, 39, 41, 43, 44, 46, 48, 50, 52, 53, 56, 58, 60, 63, 64, 66, 67, 69, 70, 72, 73, 75. Адаптерные последовательности SEQ ID NO: 79, расположены на концах олигонуклеотидов SEQ ID NO: 2, 5, 7, 9, 10, 12, 14, 16, 18, 21, 23, 25, 27, 29, 31, 33, 36, 38, 40, 42, 45, 47, 49, 51, 54, 55, 57, 59, 61, 62, 65, 68, 71, 74, 76, 77.
По сравнению с известным протоколом пробоподготовки Illumina Nextera XT (https://www.illumina.com/products/by4ype/sequencing-kits/library-prep-kits/nextera-xt-dna.html), предлагаемый способ пробоподготовки позволяет избежать этапов тагментации и отбора фрагментов с необходимыми длинами, поскольку продукты амплификации изначально имеют длину до 600 пар нуклеотидов без учета адаптерных последовательностей (то есть совместимы с наборами реагентов компании Illumina для ее секвенирующих платформ), а также содержат адаптерные последовательности для дальнейшей индексации, что существенно упрощает и удешевляет анализ полученных при секвенировании данных.
При разработке применяемых в данном способе праймеров для таргетной амплификации фрагментов генов HLA-A/B/C/DPB1/DQB1/DRB1 олигонуклеотидные праймеры были подобраны вручную с учетом имеющейся информации об известных аллелях указанных генов. Этот процесс включал в себя загрузку множества референсных последовательностей аллелей генов HLA-A/B/C/DPB1/DQB1/DRB1 из базы данных IPD-IMGT/HLA Database (https://www.ebi.ac.uk/ipd/imgt/hla/) и выравнивание последовательностей с целью определения консервативных для данных аллелей фрагментов. Температуры плавления олигонуклеотидов и характер взаимодействий между ними определялись с помощью инструмента Multiple Primer Analyzer от Thermo Fisher Scientific (США). С помощью программы blastn оценивалась специфичность каждой полученной последовательности ко всем известным организмам, в частности, Homo sapiens, что позволяет исключить неспецифическое взаимодействие между праймерами и участками ДНК человека и других организмов. Кроме того, синтезированные олигонуклеотиды содержат дополнительные последовательности, облегчающие и удешевляющие процесс индексации продуктов амплификации. Расстояния между праймерами в парах были подобраны таким образом, чтобы длина исследуемого региона была в пределах 600 п.н., что позволяет избежать этапа отбора фрагментов с заданной длиной, и совместимо с длиной прочтений большинства наборов реагентов для секвенирования от компании Illumina.
Полученные олигонуклеотиды на одном конце содержат праймерную последовательность, комплементарную участкам генома, а на другом - адаптерные последовательности, следовательно, полученные после амплификации целевые фрагменты сразу фланкированы такими адаптерными последовательностями. Олигонуклеотиды, используемые для индексации, в свою очередь, комплементарны адаптерным последовательностям с одного конца и соответствуют индексам с другого.
В качестве индексных последовательностей используют олигонуклеотиды, несущие различные индексы, которые позволяют отличать данные секвенирования молекул из разных образцов. Примеры подобных индексных последовательностей доступны на сайтах производителей наборов реагентов для высокопроизводительного секвенирования.
Таким образом, в процессе индексации происходят этапы отжига олигонуклеотидов на концах целевых фрагментов и амплификации. После этого продукты амплификации подвергаются высокопроизводительному секвенированию на платформе Illumina. Данный подход является стандартом пробоподготовки библиотек для секвенирования и, например, использован в наборах HLA-Эксперт и ScisGo™ HLA v6 Kits.
Заявляемое изобретение является результатом работы в рамках исследования, выполненной в ФБУН ЦНИИ Эпидемиологии Роспотребнадзора (Москва, Россия). Представленный способ был отработан более чем на 300 образцах биологического материала, представляющих собой ДНК, выделенную из крови и буккальных клеток эпителия (соскобов носоглотки) при помощи набора «РИБО-преп» (AmpliSens, Россия) согласно рекомендациям производителя.
Выделение ДНК из клинического материала производилось с помощью комплекта реагентов в соответствии с инструкцией производителя. Для выделения ДНК может быть использован комплект реагентов «РИБО-преп» (AmpliSens, Россия) или любой аналогичный коммерческий набор для выделения ДНК.
Материалом для исследования является геномная ДНК человека. Для анализа одного образца требуется 20 нг ДНК (2 мкл ДНК с концентрацией 10 нг/мкл). Две реакции амплификации проводят с использованием ДНК в качестве матрицы и двух пулов специфических олигонуклеотидов. Первый пул олигонуклеотидов содержит олигонуклеотиды SEQ ID NO: 1-38, второй пул олигонуклеотидов содержит олигонуклеотиды SEQ ID NO: 39-77 с концентрацией в реакционной смеси, указанной в Таблице 1.
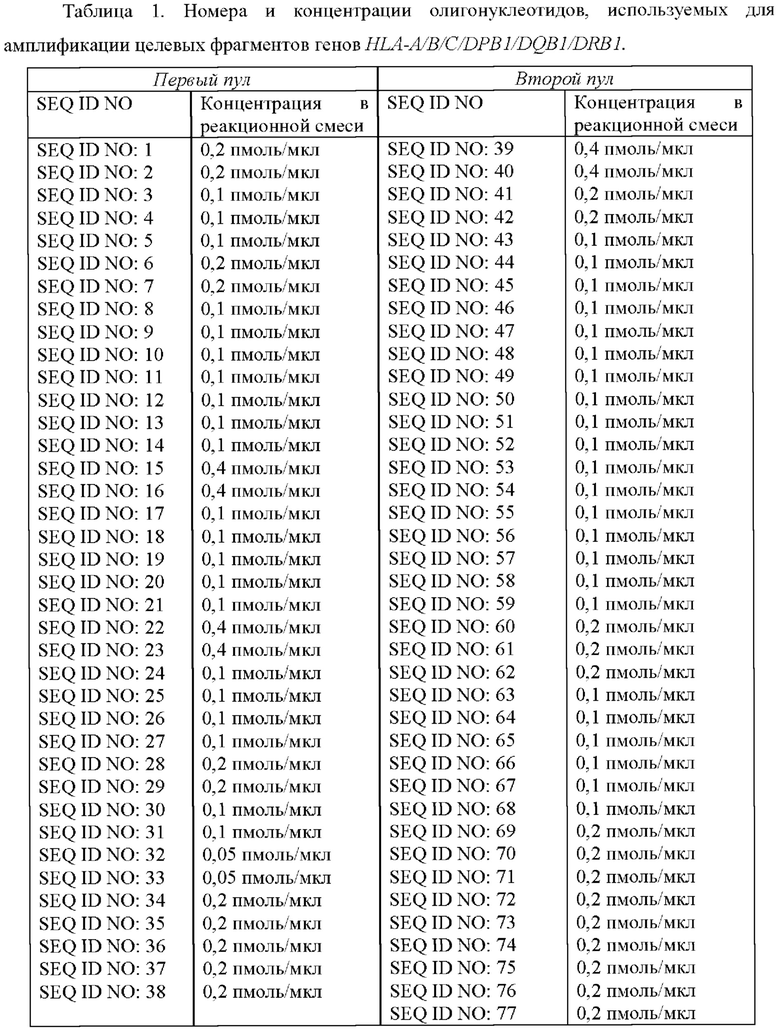
ПЦР-микс объемом 20 мкл на одну реакцию содержит 10 мкл ПЦР-смеси-2 blue (AmpliSens, Россия), 1,4 мкл эквимолярной смеси четырех дезоксирибонуклеозидтрифосфатов со стоковой концентрацией 4,4 мМ, олигонуклеотиды в указанных в Таблице 1 концентрациях и воду milli-Q. ДНК-матрицу добавляют в количестве 5 мкл (концентрация ДНК от 2 до 50 нг/мкл), итоговый объем реакции составляет 25 мкл. Продуктами амплификации являются целевые участки генов HLA-A/B/C/DPB1/DQB1/DRB1. Длины получаемых фрагментов составляют 270-596 п.н. без учета длин адаптерных и индексных последовательностей, что обеспечивает их полное покрытие при использовании набора реагентов для секвенирования MiSeq Reagent Kit v3 (600-cycle) Illumina (США).
Температурный профиль амплификации для получения ПЦР-продукта:

Затем проводят очистку ПЦР-продуктов от реакционной смеси с использованием магнитных частиц, например, AMPure ХР beads (Beckman Coulter, США) в объемном отношении 1:0,8.
После этого осуществляют индексацию полученных фрагментов. Синтезированные олигонуклеотиды на одном конце содержат праймерную последовательность, комплементарную целевым участкам генов, а на другом - адаптерные последовательности двух типов: для прямых праймеров - SEQ ID NO: 78; для обратных праймеров - SEQ ID NO: 79, соответственно. Таким образом, полученные после амплификации целевые фрагменты сразу фланкируются адаптерными последовательностями, что существенно ускоряет и удешевляет пробоподготовку. Олигонуклеотидные праймеры, используемые для индексации, в свою очередь, на одном конце содержат последовательности, соответствующие индексам, а на другом - последовательности, соответствующие упомянутым ранее адаптерным последовательностям. Таким образом, в процессе индексации происходят этапы отжига олигонуклеотидов на концах целевых фрагментов и амплификации продукта.
ПЦР-микс объемом 15 мкл на одну реакцию содержит 10 мкл ПЦР-смеси-2 blue (AmpliSens, Россия), 1,4 мкл эквимолярной смеси четырех дезоксирибонуклеозидтрифосфатов со стоковой концентрацией 4,4 мМ, соответствующие олигонуклеотиды в концентрации 0,25 пмоль/мкл и воду milli-Q. ДНК-матрица добавляется в количестве 5 мкл, итоговый объем реакции составляет 20 мкл.
Температурный профиль индексации:
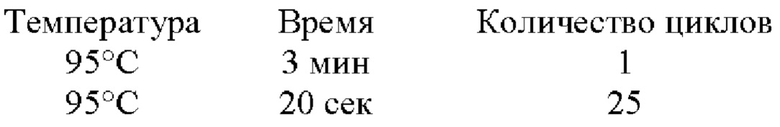

Длины полученных продуктов амплификации могут быть проанализированы с помощью электрофореза в 1% агарозном геле. Далее повторно проводят очистку от реакционной смеси с использованием магнитных частиц, например, AMPure ХР beads (Beckman Coulter, США) в объемном отношении 1:0,8.
В результате получаются готовые для секвенирования библиотеки, содержащие целевые фрагменты генов HLA-A/B/C/DPB1/DQB1/DRB1, которые позволяют определить аллели данных генов в исходном образце ДНК.
Реализация заявляемого изобретения поясняется следующими примерами:
Пример 1. Получение набора олигонуклеотидных праймеров, используемого в способе пробоподготовки образцов для типирования генов главного комплекса гистосовместимости HLA-A, HLA-B, HLA-C, HLA-DPB1, HLA-DQB1, HLA-DRB1.
При разработке применяемых в заявляемом способе оригинальных синтезированных олигонуклеотидных праймеров для таргетной амплификации фрагментов генов HLA-A/B/C/DPB1/DQB1/DRB1 олигонуклеотидные последовательности были подобраны вручную с учетом имеющейся информации об известных аллелях данных генов.
Данный процесс включал в себя загрузку множества референсных последовательностей аллелей генов HLA-A/B/C/DPB1/DQB1/DRB1 из базы данных IPD-IMGT/HLA Database (https://www.ebi.ac.uk/ipd/imgt/hla/) и выравнивание последовательностей с целью определения консервативных для указанных аллелей фрагментов.
Температуры плавления олигонуклеотидов и характер взаимодействий между ними определялись с помощью инструмента Multiple Primer Analyzer от Thermo Fisher Scientific (США). С помощью программы blastn оценивалась специфичность каждой полученной последовательности ко всем известным организмам, в частности, Homo sapiens, что позволило исключить неспецифическое взаимодействие между праймерами и участками ДНК человека и других организмов.
В результате были получены праймеры, имеющие структуры SEQ ID NO: 1, 3, 4, 6, 8, 11, 13, 15, 17, 19, 20, 22, 24, 26, 28, 30, 32, 34, 35, 37, 39, 41, 43, 44, 46, 48, 50, 52, 53, 56, 58, 60, 63, 64, 66, 67, 69, 70, 72, 73, 75, которые выполняют функции прямых праймеров, и олигонуклеотидные праймеры, имеющие структуры SEQ ID NO: 2, 5, 7, 9, 10, 12, 14, 16, 18, 21, 23, 25, 27, 29, 31, 33, 36, 38, 40, 42, 45, 47, 49, 51, 54, 55, 57, 59, 61, 62, 65, 68, 71, 74, 76, 77, выполняющие функции обратных праймеров.
Расстояния между праймерами в парах были подобраны таким образом, чтобы длина исследуемого региона была в пределах 600 п.н., что позволяет избежать этапа отбора фрагментов с заданной длиной, и совместимо с длиной прочтений большинства наборов реагентов для секвенирования от компании Illumina.
Кроме того, синтезированные олигонуклеотидные праймеры содержали дополнительные адаптерные последовательности SEQ ID NO: 78, 79, облегчающие и удешевляющие процесс индексации продуктов амплификации. При этом адаптерные последовательности SEQ ID NO: 78 расположили на концах прямых праймеров, а адаптерные последовательности SEQ ID NO: 79 расположили на концах обратных праймеров.
Поскольку полученные олигонуклеотидные праймеры на одном конце содержат праймерную последовательность, комплементарную участкам генома, а на другом -адаптерные последовательности, полученные после амплификации целевые фрагменты сразу были фланкированы такими адаптерными последовательностями.
Олигонуклеотидные праймеры, используемые для индексации, на одном конце содержат последовательности, соответствующие индексам, а на другом последовательности, соответствующие адаптерным последовательностям SEQ ID NO: 78, 79.
В качестве индексных последовательностей используют олигонуклеотиды, несущие различные индексы, которые позволяют отличать данные секвенирования молекул из разных образцов.
Использовалась информация об индексных последовательностях, опубликованная на сайтах производителей наборов реагентов для высокопроизводительного секвенирования.
Таким образом, в процессе индексации происходят этапы отжига олигонуклеотидов на концах целевых фрагментов и амплификации. После этого продукты амплификации подвергаются высокопроизводительному секвенированию на платформе Illumina.
Пример 2. Секвенирование генов HLA-A, В, С, DPB1, DQB1, DRB1 в образце ДНК, выделенной из буккальных клеток эпителия.
У сотрудника лаборатории взят соскоб из носоглотки, выделение ДНК осуществлялось при помощи набора реагентов «РИБО-преп» (AmpliSens, Россия) согласно рекомендациям производителя. Концентрация выделенной ДНК была измерена набором «Quantum-211» (Евроген, Россия) и составила 13,8 нг/мкл.
Амплификация осуществлялась с применением оригинального синтезированного набора олигонуклеотидных праймеров в двух реакциях, в каждой использовался отдельный пул олигонуклеотидов и выделенная ДНК в качестве матрицы.
Первый пул олигонуклеотидов содержал олигонуклеотиды SEQ ID NO: 1-38, второй пул олигонуклеотидов содержит олигонуклеотиды SEQ ID NO: 39-77 с концентрацией в реакционной смеси, указанной в Таблице 1.
ПЦР-микс объемом 20 мкл на одну реакцию содержал 10 мкл ПЦР-смеси-2 blue (AmpliSens, Россия), 1,4 мкл эквимолярной смеси четырех дезоксирибонуклеозидтрифосфатов со стоковой концентрацией 4,4 мМ, олигонуклеотиды в указанных в Таблице 1 концентрациях и воду milli-Q. ДНК-матрица добавлялась в количестве 5 мкл (концентрация ДНК 13,8 нг/мкл), итоговый объем реакции составлял 25 мкл.
Температурный профиль амплификации для получения ПЦР-продукта:

Далее проводилась очистка ПЦР-продуктов от реакционной смеси с использованием магнитных частиц AMPure ХР beads (Beckman Coulter, США) в объемном отношении 1:0,8. После этого осуществлялась индексация полученных фрагментов с применением адаптерных последовательностей SEQ ID NO: 78, 79.
ПЦР-микс объемом 15 мкл на одну реакцию содержал 10 мкл ПЦР-смеси-2 blue (AmpliSens, Россия), 1,4 мкл эквимолярной смеси четырех дезоксирибонуклеозидтрифосфатов со стоковой концентрацией 4,4 мМ, соответствующие олигонуклеотиды в концентрации 0,25 пмоль/мкл и воду milli-Q. ДНК-матрица добавлялась в количестве 5 мкл, итоговый объем реакции составлял 20 мкл.
Температурный профиль индексации:
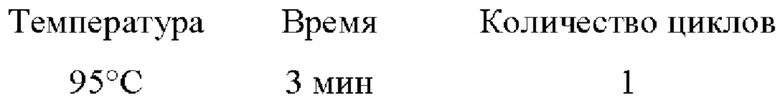

Длины полученных продуктов амплификации были проанализированы с помощью электрофореза в 1% агарозном геле. Далее повторно производилась очистка от реакционной смеси с использованием магнитных частиц AMPure ХР beads (Beckman Coulter, США) в объемном отношении 1:0,8. Концентрация полученной библиотеки измерялась при помощи набора QuDye dsDNA HS Assay Kit (Lumiprobe, Россия) и составила 40,8 нг/мкл для каждого пула. Индексированные последовательности были секвенированы на приборе Illumina MiSeq с использованием реагентов MiSeq Reagent Kit v3 (600-cycle). Результаты исследования были проанализированы биоинформатически с помощью утилит FastQC, bwa и samtools. По результатам биоинформатического анализа в исходном образце были определены следующие аллели гена HLA: А*02:01, А*03:01, В*40:02, В*52:01, С*02:02, С*12:16, DPB1*02:01, DPB1*04:01, DQB1*05:02, DQB1*06:01, DRB1*15:02, DRB1*16:01. Найденные аллели совпали с результатами полногеномного секвенирования, которое ранее было выполнено для данного сотрудника.
Пример 3. Секвенирование генов HLA-A, В, С, DPB1, DQB1, DRB1 в образце ДНК, выделенной из образца гомогената печени.
Для выделения ДНК был взят клинический образец гомогената печени человека, выделение ДНК осуществлялось при помощи набора реагентов «РИБО-преп» (AmpliSens, Россия) согласно рекомендациям производителя. Концентрация выделенной ДНК была измерена набором «Quantum-211» (Евроген, Россия) и составила 11,9 нг/мкл.
Амплификация осуществлялась с применением оригинального синтезированного набора олигонуклеотидных праймеров в двух реакциях, в каждой использовался отдельный пул олигонуклеотидов и выделенная ДНК в качестве матрицы.
Первый пул олигонуклеотидов содержал олигонуклеотиды SEQ ID NO: 1-38, второй пул олигонуклеотидов содержит олигонуклеотиды SEQ ID NO: 39-77 с концентрацией в реакционной смеси, указанной в Таблице 1.
ПЦР-микс объемом 20 мкл на одну реакцию содержал 10 мкл ПЦР-смеси-2 blue (AmpliSens, Россия), 1,4 мкл эквимолярной смеси четырех дезоксирибонуклеозидтрифосфатов со стоковой концентрацией 4,4 мМ, олигонуклеотиды в указанных в таблице концентрациях и воду milli-Q. ДНК-матрица добавлялась в количестве 5 мкл (концентрация ДНК 11,9 нг/мкл), итоговый объем реакции составлял 25 мкл.
Температурный профиль амплификации для получения ПЦР-продукта:

Далее проводилась очистка ПЦР-продуктов от реакционной смеси с использованием магнитных частиц AMPure ХР beads (Beckman Coulter, США) в объемном отношении 1:0,8.
После этого осуществлялась индексация полученных фрагментов с применением адаптерных последовательностей SEQ ID NO: 78, 79.
ПЦР-микс объемом 15 мкл на одну реакцию содержал 10 мкл ПЦР-смеси-2 blue (AmpliSens, Россия), 1,4 мкл эквимолярной смеси четырех дезоксирибонуклеозидтрифосфатов со стоковой концентрацией 4,4 мМ, соответствующие олигонуклеотиды в концентрации 0,25 пмоль/мкл и воду milli-Q. ДНК-матрица добавлялась в количестве 5 мкл, итоговый объем реакции составлял 20 мкл.
Температурный профиль индексации:

Длины полученных продуктов амплификации были проанализированы с помощью электрофореза в 1% агарозном геле. Далее повторно производилась очистка от реакционной смеси с использованием магнитных частиц AMPure ХР beads (Beckman Coulter, США) в объемном отношении 1:0,8. Концентрация полученной библиотеки измерялась при помощи набора QuDye dsDNA HS Assay Kit (Lumiprobe, Россия) и составила 29,9 нг/мкл для 1 пула и 23,7 нг/мкл для 2 пула. Индексированные последовательности были секвенированы на приборе Illumina MiSeq с использованием реагентов MiSeq Reagent Kit v3 (600-cycle). Результаты исследования были проанализированы биоинформатически с помощью утилит FastQC, bwa и samtools. По результатам биоинформатического анализа в исходном образце были определены следующие аллели гена HLA: А*11:01, А*23:01, В*44:03, В*52:01, С*04:01, С*12:02, DPB1*03:01, DPB1*30:01, DQB1*02:02, DQB1*05:01, DRB1*01:01, DRB1*13:01.
Пример 4. Секвенирование генов HLA-A, В, С, DPB1, DQB1, DRB1 в образце ДНК, выделенной из цельной крови.
Для выделения ДНК был взят клинический образец цельной крови в пробирке с ЭДТА, выделение ДНК осуществлялось при помощи набора реагентов «РИБО-преп» (AmpliSens, Россия) согласно рекомендациям производителя. Концентрация выделенной ДНК была измерена набором «Quantum-211» (Евроген, Россия) и составила 14,9 нг/мкл.
Амплификация осуществлялась с применением оригинального синтезированного набора олигонуклеотидных праймеров в двух реакциях, в каждой использовался отдельный пул олигонуклеотидов и выделенная ДНК в качестве матрицы.
Первый пул олигонуклеотидов содержал олигонуклеотиды SEQ ID NO: 1-38, второй пул олигонуклеотидов содержит олигонуклеотиды SEQ ID NO: 39-77 с концентрацией в реакционной смеси, указанной в Таблице 1.
ПЦР-микс объемом 20 мкл на одну реакцию содержал 10 мкл ПЦР-смеси-2 blue (AmpliSens, Россия), 1,4 мкл эквимолярной смеси четырех дезоксирибонуклеозидтрифосфатов со стоковой концентрацией 4,4 мМ, олигонуклеотиды в указанных в таблице концентрациях и воду milli-Q. ДНК-матрица добавлялась в количестве 5 мкл (концентрация ДНК 14,9 нг/мкл), итоговый объем реакции составлял 25 мкл.
Температурный профиль амплификации для получения ПЦР-продукта:

Далее проводилась очистка ПЦР-продуктов от реакционной смеси с использованием магнитных частиц AMPure ХР beads (Beckman Coulter, США) в объемном отношении 1:0,8.
После этого осуществлялась индексация полученных фрагментов с применением адаптерных последовательностей SEQ ID NO: 78, 79.
ПЦР-микс объемом 15 мкл на одну реакцию содержал 10 мкл ПЦР-смеси-2 blue (AmpliSens, Россия), 1,4 мкл эквимолярной смеси четырех дезоксирибонуклеозидтрифосфатов со стоковой концентрацией 4,4 мМ, соответствующие олигонуклеотиды в концентрации 0,25 пмоль/мкл и воду milli-Q. ДНК-матрица добавлялась в количестве 5 мкл, итоговый объем реакции составлял 20 мкл.
Температурный профиль индексации:

Длины полученных продуктов амплификации были проанализированы с помощью электрофореза в 1% агарозном геле. Далее повторно производилась очистка от реакционной смеси с использованием магнитных частиц AMPure ХР beads (Beckman Coulter, США) в объемном отношении 1:0,8. Концентрация полученной библиотеки измерялась при помощи набора QuDye dsDNA HS Assay Kit (Lumiprobe, Россия) и составила 37,2 нг/мкл для 1 пула и 41,0 нг/мкл для 2 пула. Индексированные последовательности были секвенированы на приборе Illumina MiSeq с использованием реагентов MiSeq Reagent Kit v3 (600-cycle). Результаты исследования были проанализированы биоинформатически с помощью утилит FastQC, bwa и samtools. По результатам биоинформатического анализа в исходном образце были определены следующие аллели гена HLA: А*03:02 (гомозигота), В*07:05, В*51:01, С*15:05 (гомозигота), DPB1*02:01, DPB1*04:01, DQB1*03:01, DQB1*04:02, DRB1*08:01, DRB1* 11:04.
Заявленное решение позволяет произвести пробоподготовку библиотек, содержащие целевые фрагменты генов HLA-A/B/C/DPB1/DQB1/DRB1 и по результатам секвенирования определить аллели данных генов, содержащиеся в исходном образце.
--->
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE ST26SequenceListing SYSTEM "ST26SequenceListing_V1_2.dtd" PUBLIC "-
//WIPO//DTD Sequence Listing 1.2//EN">
<ST26SequenceListing productionDate="2023-06-28" softwareVersion="1.0.0"
softwareName="WIPO Sequence" fileName="HLA-A, HLA-B, HLA-C, HLA-DPB1, HLA-
DQB1, HLA-DRB1" dtdVersion="V1_2">
<ApplicationIdentification>
<IPOfficeCode>RU</IPOfficeCode>
<ApplicationNumberText>No</ApplicationNumberText>
<FilingDate>2023-06-28</FilingDate>
</ApplicationIdentification>
<ApplicantFileReference>1</ApplicantFileReference>
<EarliestPriorityApplicationIdentification>
<IPOfficeCode>RU</IPOfficeCode>
<ApplicationNumberText>No</ApplicationNumberText>
<FilingDate>2023-06-27</FilingDate>
</EarliestPriorityApplicationIdentification>
<ApplicantName languageCode="ru">ФБУН ЦНИИ Эпидемиологии
Роспотребнадзора</ApplicantName>
<ApplicantNameLatin>FBUN CRIE</ApplicantNameLatin>
<InventionTitle languageCode="ru">Способ пробоподготовки образцов
для типирования
генов главного комплекса гистосовместимости HLA-A, HLA-B, HLA-C, HLA-DPB1,
HLA-DQB1, HLA-DRB1 и олигонуклеотидные праймеры для его
реализации</InventionTitle>
<SequenceTotalQuantity>79</SequenceTotalQuantity>
<SequenceData sequenceIDNumber="1">
<INSDSeq>
<INSDSeq_length>17</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..17</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>agcagaggggtcagggc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="2">
<INSDSeq>
<INSDSeq_length>17</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..17</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>agggccccttgcttctc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="3">
<INSDSeq>
<INSDSeq_length>18</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..18</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tcgggcaggtctcagcca</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="4">
<INSDSeq>
<INSDSeq_length>18</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..18</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tcgggcgggtctcagcca</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="5">
<INSDSeq>
<INSDSeq_length>17</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..17</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cgtccgtgggggatgag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="6">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cagtttaggccaaaaatccccc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="7">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtcactctctggtacaggatct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="8">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>agtgtcccatgacagatgcaaaa</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="9">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ggtctccagagaggctcct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="10">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctaaaggtcagagaggctcct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="11">
<INSDSeq>
<INSDSeq_length>18</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..18</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cccctcaccttcccctct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="12">
<INSDSeq>
<INSDSeq_length>24</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..24</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtttccagaaatgtgtgactgcag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="13">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>agttctaaagtccccacgcac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="14">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tttcgctgtcgaacctcacgaac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="15">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctactacaaccagagcgag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="16">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cggcgacctataggagatgg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="17">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ttctactacaaccagagcgagg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="18">
<INSDSeq>
<INSDSeq_length>18</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..18</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tccccactgcccctggta</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="19">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>aacccacaactgctttcccc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="20">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>aacccacagctgctttcccc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="21">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtcacaaaggagaggtgtgaag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="22">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cccgcttaggaccacagaac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="23">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cccatgaatccccaacccaa</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="24">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cattccagacttggcaacagag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="25">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>acatggccccagggtatagat</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="26">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctgggtctgtccttcccag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="27">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gagattcccttcctggaggag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="28">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cctttccagatgctagggaaatt</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="29">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cagcccatcttccccttttcc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="30">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cttcctccattaagagggtcag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="31">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>aggcttggttctggggaaca</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="32">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tctctgtctgaagctgcagg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="33">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtggggatgaaaggagatgac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="34">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ttctgccccattttcaaagctct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="35">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ttctgtctcattttcaaagctct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="36">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ccatgcactgatgatttctgga</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="37">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ggtgataaggcatgagacagaa</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="38">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>aaccagtagcaaccaggtcc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="39">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctcctttctggtatctcacag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="40">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>acgaacacagacacatgcagg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="41">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cggagggaaatggcctctg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="42">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>atggggagtcgtgacctgc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="43">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>catgaaagatgcaaagcgcctg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="44">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>atgagagatgcaaagcgcctg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="45">
<INSDSeq>
<INSDSeq_length>18</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..18</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>acccctcaccccttccct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="46">
<INSDSeq>
<INSDSeq_length>26</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..26</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtcatacttctggaaattccttttgg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="47">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cccactctagaccccaagaatc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="48">
<INSDSeq>
<INSDSeq_length>17</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..17</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctccaagggccgtgtct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="49">
<INSDSeq>
<INSDSeq_length>18</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..18</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tcctctccgcagaggccg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="50">
<INSDSeq>
<INSDSeq_length>17</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..17</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tagggcgcaggacccgg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="51">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gcggggattttggcctaaac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="52">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctggagtgtcccaagagagat</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="53">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ttggagtgtcgcaagagagat</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="54">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gctcttcaccccttcccta</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="55">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>actcctcaccccttcccta</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="56">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cagactctgtccaatcccag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="57">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tataggggatgaacctctttctc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="58">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ggtacatcagatccatcaggtc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="59">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ccccatgctcactttgtcct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="60">
<INSDSeq>
<INSDSeq_length>17</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..17</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ggcggttccacagctcc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="61">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctgctctgccctaggtccc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="62">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tgctctgcccctaggtccc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="63">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cttttcctgtctgttactgccct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="64">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ctttccctgtctgttactgccct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="65">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>catcagggataagagatgggaag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="66">
<INSDSeq>
<INSDSeq_length>24</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..24</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>caggagcaaggaaatcagtaactt</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="67">
<INSDSeq>
<INSDSeq_length>24</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..24</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cacaagcaaggaaatcagtaactt</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="68">
<INSDSeq>
<INSDSeq_length>25</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..25</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>catgtgatgcaaaggttttattggt</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="69">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cagtgtcttctcaggaggc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="70">
<INSDSeq>
<INSDSeq_length>17</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..17</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtgtcttccccggaggc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="71">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>attctaaatgctcacagatggcg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="72">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cagagcctgggtttgcaga</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="73">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ccagagcctaggtttacaga</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="74">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gaagtcagaaagctgctcac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="75">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>saaagcataatagcttgtggcct</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="76">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cttcacctctcactagggaaac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="77">
<INSDSeq>
<INSDSeq_length>24</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..24</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ggcctccaaatctgtttcttaaag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="78">
<INSDSeq>
<INSDSeq_length>33</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..33</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tcgtcggcagcgtcagatgtgtataagagacag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="79">
<INSDSeq>
<INSDSeq_length>34</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..34</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier>
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>HLA</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtctcgtgggctcggagatgtgtataagagacag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
</ST26SequenceListing>
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ секвенирования экзонов гена HLA-DQA1 и набор синтетических олигонуклеотидов для его реализации | 2024 |
|
RU2833819C1 |
| Способ секвенирования экзонов гена HLA-DPA1 и набор синтетических олигонуклеотидов для его реализации | 2024 |
|
RU2837865C1 |
| Способ пробоподготовки образцов ДНК вируса гепатита В для полногеномного секвенирования и олигонуклеотидные праймеры для его реализации | 2023 |
|
RU2818585C1 |
| Нуклеотидная последовательность, кодирующая фермент литиказу, и панель олигонуклеотидов для получения синтетической нуклеотидной последовательности гена литиказы | 2023 |
|
RU2826150C1 |
| Способ анализа соматических мутаций в генах IDH1 и IDH2 с использованием LNA-блокирующей ПЦР и гибридизации с биологическим микрочипом | 2024 |
|
RU2839291C1 |
| Способ генотипирования гена TLR2 по полиморфизму rs3804100 и набор олигонуклеотидных праймеров и зондов для его реализации | 2023 |
|
RU2805860C1 |
| Способ генотипирования гена TLR2 по полиморфизму rs5743708 и набор олигонуклеотидных праймеров и зондов для его реализации | 2023 |
|
RU2805861C1 |
| Способ генотипирования полиморфного локуса rs1043618 (G>С) гена HSPA1A у человека методом ПЦР в режиме «реального времени» с применением аллель-специфических флуоресцентных зондов | 2024 |
|
RU2828869C1 |
| Способ генотипирования гена TLR1 по полиморфизму rs5743551 и набор олигонуклеотидных праймеров и зондов для его реализации | 2023 |
|
RU2805859C1 |
| Способ генотипирования гена TLR6 по полиморфизму rs5743810 и набор олигонуклеотидных праймеров и зондов для его реализации | 2023 |
|
RU2805863C1 |
Изобретение относится к области биотехнологии. Описан способ пробоподготовки образцов для типирования генов главного комплекса гистосовместимости HLA-A, HLA-B, HLA-C, HLA-DPB1, HLA-DQB1, HLA-DRB1. Также описаны пулы олигонуклеотидных праймеров для реализации данного способа. Техническим результатом данного изобретения является разработка эффективного способа пробоподготовки для фрагментарного NGS-секвенирования ряда регионов генов HLA-A/B/C/DPB1/DQB1/DRB1, позволяющих определить аллели данных генов. 3 н. и 7 з.п. ф-лы, 9 табл., 4 пр.
1. Способ пробоподготовки образцов для типирования генов главного комплекса гистосовместимости HLA-A, HLA-B, HLA-C, HLA-DPB1, HLA-DQB1, HLA-DRB1, включающий стадии:
(a) выделение ДНК из биологического материала;
(b) проведение ПЦР с применением двух пулов олигонуклеотидных праймеров, где для первого пула применяют олигонуклеотидные праймеры, имеющие структуру SEQ ID NO: 1-38, а для второго пула применяют олигонуклеотидные праймеры, имеющие структуру SEQ ID NO: 39-77;
(c) очистку продуктов ПЦР при помощи магнитных частиц;
(d) индексацию полученных ампликонов при помощи праймеров, содержащих адаптерные последовательности SEQ ID NO: 78, 79;
(e) повторную очистку продуктов ПЦР при помощи магнитных частиц.
2. Способ по п. 1, где реакционная смесь для первого пула содержит олигонуклеотидные праймеры в следующей концентрации: SEQ ID NO: 1, 2, 6, 7, 28, 29, 34-38 - по 0,2 пмоль/мкл каждый; SEQ ID NO: 3-5, 8-14, 17-21, 24-27, 30, 31 - по 0,1 пмоль/мкл каждый; SEQ ID NO: 15, 16, 22, 23 - по 0,4 пмоль/мкл каждый; SEQ ID NO: 32, 33 - по 0,05 пмоль/мкл каждый.
3. Способ по п. 1, где реакционная смесь для второго пула содержит олигонуклеотидные праймеры в следующей концентрации: SEQ ID NO: 39, 40 - по 0,4 пмоль/мкл каждый; SEQ ID NO: 41, 42, 60-62, 69-77 - по 0,2 пмоль/мкл каждый; SEQ ID NO: 43-59, 63-68 - по 0,1 пмоль/мкл каждый.
4. Способ по п. 1, в котором адаптерные последовательности SEQ ID NO: 78 расположены на концах олигонуклеотидных праймеров, имеющих структуру SEQ ID NO: 1, 3, 4, 6, 8, 11, 13, 15, 17, 19, 20, 22, 24, 26, 28, 30, 32, 34, 35, 37, 39, 41, 43, 44, 46, 48, 50, 52, 53, 56, 58, 60, 63, 64, 66, 67, 69, 70, 72, 73, 75, а адаптерные последовательности SEQ ID NO: 79 расположены на концах олигонуклеотидных праймеров, имеющих структуру SEQ ID NO: 2, 5, 7, 9, 10, 12, 14, 16, 18, 21, 23, 25, 27, 29, 31, 33, 36, 38, 40, 42, 45, 47, 49, 51, 54, 55, 57, 59, 61, 62, 65, 68, 71, 74, 76, 77.
5. Пул олигонуклеотидных праймеров для реализации способа по п. 1, имеющих структуру SEQ ID NO: 1-38, для выполнения функции праймеров, комплементарных участкам генов HLA-A/B/C/DPB1/DQB1/DRB1.
6. Пул олигонуклеотидных праймеров по п. 5, где функции прямых праймеров выполняют олигонуклеотидные праймеры, имеющие структуру SEQ ID NO: 1, 3, 4, 6, 8, 11, 13, 15, 17, 19, 20, 22, 24, 26, 28, 30, 32, 34, 35, 37.
7. Пул олигонуклеотидных праймеров по п. 5, где функции обратных праймеров выполняют олигонуклеотидные праймеры, имеющие структуру SEQ ID NO: 2, 5, 7, 9, 10, 12, 14, 16, 18, 21, 23, 25, 27, 29, 31, 33, 36, 38.
8. Пул олигонуклеотидных праймеров для реализации способа по п. 1, имеющих структуру SEQ ID NO: 39-77, для выполнения функции праймеров, комплементарных участкам генов HLA-A/B/C/DPB1/DQB1/DRB1.
9. Пул олигонуклеотидных праймеров по п. 8, где функции прямых праймеров выполняют олигонуклеотидные праймеры, имеющие структуру SEQ ID NO: 39, 41, 43, 44, 46, 48, 50, 52, 53, 56, 58, 60, 63, 64, 66, 67, 69, 70, 72, 73, 75.
10. Пул олигонуклеотидных праймеров по п. 8, где функции обратных праймеров выполняют олигонуклеотидные праймеры, имеющие структуру SEQ ID NO: 40, 42, 45, 47, 49, 51, 54, 55, 57, 59, 61, 62, 65, 68, 71, 74, 76, 77.
| US 10704095 B2, 07.07.2020 | |||
| НОВЫЙ СПОСОБ ПЦР-СЕКВЕНИРОВАНИЯ И ЕГО ПРИМЕНЕНИЕ В ГЕНОТИПИРОВАНИИ HLA | 2011 |
|
RU2587606C2 |
| Янкевич Т.Э., Трофимов Ю.Д | |||
| и др | |||
| Разработка системы "HLA-Эксперт" для типирования генов HLA с высоким разрешением методом NGS | |||
| Опыт использования | |||
| Вестник гематологии, 2018, 14(2), с.56-56. | |||

