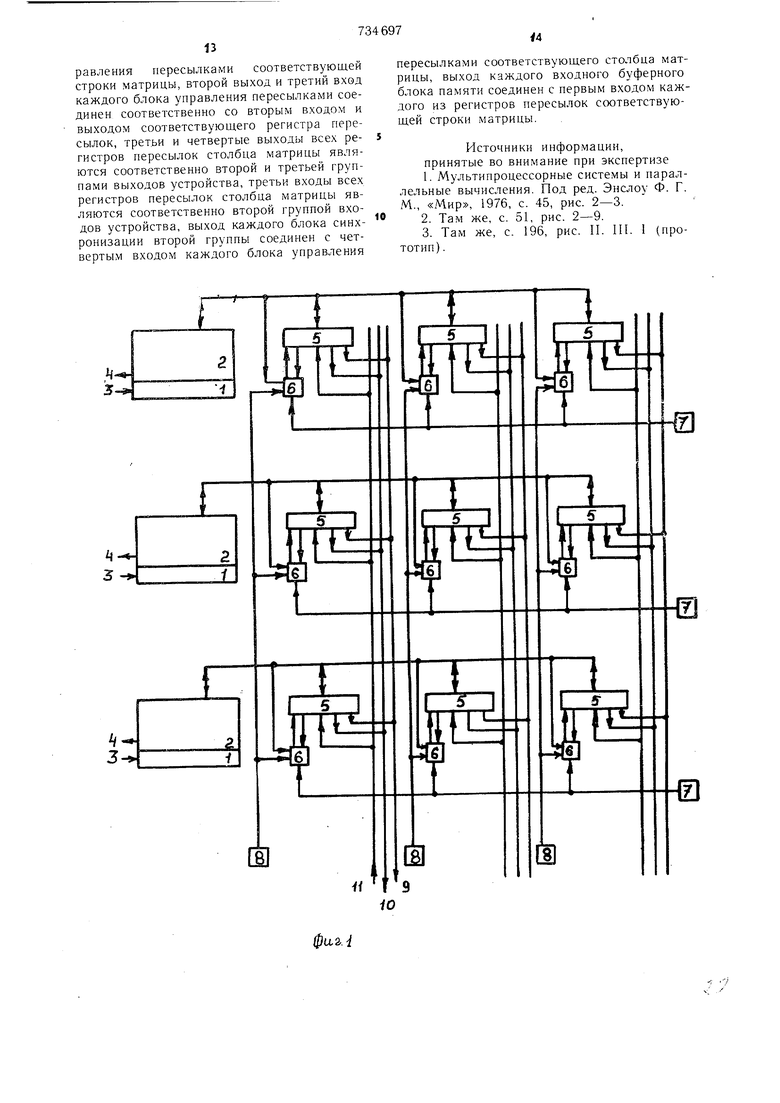
(54) КОММУТАЦИОННОЕ УСТРОЙСТВО ДЛЯ МУЛЬТИПРОЦЕССОРНОЙ СИСТЕМЫ Изобретение относится к вычислительной технике и может быть использовано в многопроцессорных вычислительных системах с 1одульной структурой памяти. Известно коммутационное устрой(:тво для мультипроцессорной системы, содержащее несколько магистралей, каждая из которых связана со всеми модулями оперативной памяти и всеми процессорами 1. Однако данное устройство характеризуется низким быстродействием, недостаточной гибкостью, большой СЛОЖНОСТЬЮ) управления и недостаточной живучестью, что особенно сильно сказывается при размещении модулей оперативной памяти (ОП) и процессоров в разных физических блоках (стойках) системы. В этом случае из-за большой длины магистралей, соединяющих между собой процессоры и модули ОП, резко возрастает время обмена информацией, которое состоит из времени посылки запроса к центральному блоку управления связями, времени ожидания в очереди (если таковая есть), времени ожидания, когда освободится связь, соединяющая требуемый модуль памяти, которое складывается из времени обработки очереди запросов на обмен, времени установления соединения, времени сообщения процессору и модулю ОП, что связь установлена и обмен разрешен, времени посылки адреса из процессора к ОП, времени считывания или записи в ОП, времени посылки операнда из ОП процессору (или посылки сообщения о том, что запись прозведена и можно засылать следующий адрес). Ситуация осложняется тем, что два процессора могут одновременно потребовать установления соединения к одному и тому же модулю оперативной памяти. Возникшую конфликтную ситуацию необходимо разрещить в пользу одного из процессоров. Сделать это тем сложнее, чем больше число процессоров и чем больше число магистралей и модулей ОП. Помимо высокой сложности управления при разрешении подобных конфликтных ситуаций резко снижается быстродействие устройства, так как к времени пересылки слова, рассматриваемому выше, добавятся время, необходимое для обнаружения конфликтной ситуации, время, необходимое для ее разрешения (если она возникла), и время для проверки установилось ли требуемое соединение. Все это требует обмена управляющей информацией между обменивающимися блоками: блоком управления связями, процессорами и модулями ОП, а если блоки расположены в разных стойках, время это может быть недопустимо большим. Кроме того, если два блока обмениваются между собой, они являются недоступными для любого другого блока, что приводит к снижению гибкости устройства. Известно также коммутационное устройство для мультипроцессорной системы, содержащее многовходовые модули оперативной памяти 2. Этому устройству присущи все указанные недостатки с той лищь разницей, что разрещение конфликтных ситуаций перенесено в блок управления модулем ОП, что удобно сделать при относительно небольшом числе входов последнего. С ростом числа входов в модуль ОП сложность управления им и время обмена возрастают. Наиболее близким техническим решением к изобретению является ком.мутационное устройство для мультипроцессорной системы, содержащее в.ходные и выходные буферные блоки памяти, причем первый выход всех выходных буферных блоков памяти является первой группой выходов устройства, вход всех входных буферных блоков памяти является первой группой входов устройства, и блок управления коммутатором 3. Недостатками данного устройства являются высокая сложность управления, трудность в разрешении конфликтных ситуаций, сильная зависимость времени установления связи от числа входов и выходов. Кроме того, если необходимо увеличить число модулей ОП или число процессоров, или и то и другое, то необходимо полностью заменять коммутационное устройство вместе с управлением, что является препятствием для расширения системы. Кроме того, устройство обладает недостаточной гибкостью, которая выражается в невозможности одновременной работы нескольких процессоров с одним и тем же модулем ОП и в слишком большом времени переключения с одной установленной связи на другую. Цель изобретения - повышение быстродействия и гибкости. Поставленная цель достигается тем, что в коммутационное устройство для мультипроцессорной системы введены две группы блоков синхронизации, регистры пересылок и блоки управления пересылками, образующие матрицу, причем второй выход и первый вход каждого выходного буферного блока памяти соединены соответственно с первым входом и первым выходом каждого блока управления пересылками соответствующей стро ки матрицы и соответственно с первым входом и первым выходом каждого регистра пересылок той же строки матрицы, выход каждого блока синхронизации первой группы соединен со вторым входом каждого блока управления пересылками соответствующей строки матрицы, второй выход и третий вход каждого блока управления пересылками соединен соответственно со вторым входом и выходом соответствующего регистра пересылок, третьи и четвертые выходы всех регистров пересылок столбца матрицы являются соответственно второй и третьи группами выходов устройства, третьи входы всех регистров пересылок столбца матрицы являются соответственно второй группой входов устройства, выход каждого блока синхронизации второй груп.пы соединен с четвертым входом каждого блока управления пересылками соответствуюп его столбца матрицы, выход каждого входного буферного блока памяти соединен с первым входом каждого из регистров пересылок соответствующей строки матрицы. На фиг. 1 изображена схема коммутационного устройства для мультипроцессорной системы; на фиг. 2 - то же, схема функционирования; а на фиг. 3 - информационные потоки между основными блоками устройства. Устройство содержит (фиг. 1) входные 1 и выходные 2 буферные блоки памяти (ББП), приче.м первый вход каждого входного ББП 1 подключен к соответствующей горизонтальной входной щине 3, выход каждого выходного ББП 2 подключен к соответствующей горизонтальной выходной шине 4, регистры 5 пересылок и блоки 6 управления пересылка.ми, образующие матрицу, а также две группы блоков 7 и 8 синхронизации, причем второй выход и первый вход каждого выходного ББП 2 соединены соответственно с первым входом и первы.м выходом каждого блока б управления пересылками соответствующей строки матрицы и соответственно с первым входом и первым выходом каждого, регистра 5 пересылок той же строки матрицы, выход каждого блока 7 синхронизации первой группы соединен со вторым входом каждого блока 6 управления пересылками соответствующей строки .матрицы, второй выход и третий вход каждого блока 6.управления пересылками соединен соответственно со вторыми входом и выходом одноименного регистра 5 пересылок, третьи и четвертые выходы всех регистров 5 пересылок, третьи и четвертые входы всех регистров пересылок столбца подключены соответственно к первой 9 и второй 10 соответствующим вертикальным выходным шинам, третьи входы всех регистров 5 пересылок столбца матрицы подключены к соответствующей вертикальной входной шине 11, выход каждого блока 8 синхронизации второй группы соединен с четвертым входом каждого блока 6 управления пересылками соответствующего столбца .матрицы, выход каждого входного ББП 1 соединен с третьим входом каждого из регистров 5 пересылок соответствующей строки матрицы.
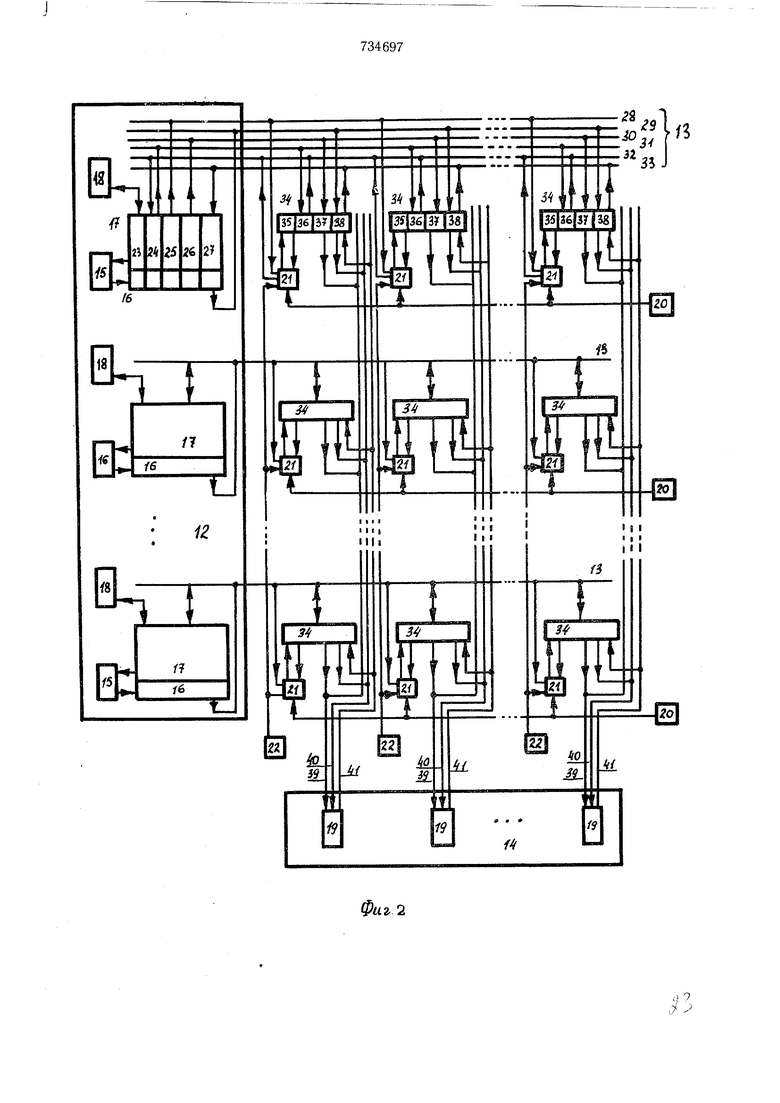
Схема функционирования коммутационного устройства содержит вычислительный блок 12, магистрали 13, оперативную память (ОП) 14, процессоры 15, входные ББП 16 выходные ББП 17, блоки 18 управления БУ, модуль ОП 19, блоки 20 синхронизации (БС) первой группы, блоки 21 управления пересылками (БУП), блоки 22 синхронизации второй группы, зону 23 ББП признаков, зону 24 ББП адреса, зону 25 ББП номера модуля ОП,зону 26 ББП адреса в модуле ОП, зону 27 ББП операнда, группу шин магистрали (ГШМ) номера модуля ОП 28, ГШМ операнда 29, ГШМ адреса в модуле ОП 30,ТШМ адреса ББП 31, 32, ГШМоперанда 33, регистры 34 пересылок (РП), зону 35 РП признаков, зону 36 РП адреса ББП, зону 37 РП адреса в модуле ОП, зону 38 РП операнда, информационные шины 39 модуля, адресные шины 40 модуля ОП, информационные шины 41 модуля ОП.
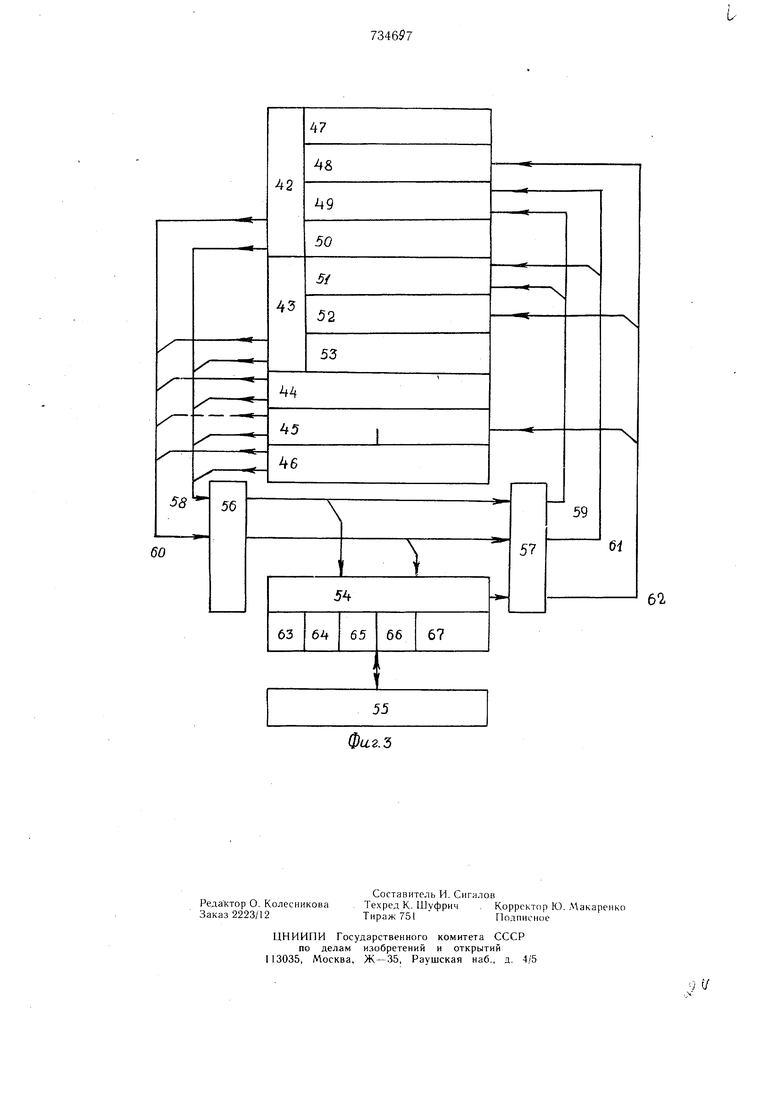
Кроме того, зону 42 ББП группы признаков (см. фиг. 3), зону 43 ББП адреса ББП, зону 44 ББП номера модуля ОП, зону 45 ББП операнда, зону 46 ББП адреса в модуле ОП, разряд 47 признака «готов к обмену, разряд 48 признака «обмен завершен, разряд 49 признака «занят обменом, разряд 50 признака «вид обмена, дешифратор 51 адреса ББП, 52, адрес 53 ББП (номер строки ББП), регистр 54 пересылок (РП), оперативную память 55, магистраль 56 ББП Ofl, магистраль 57 ОП ББП, поток 58 операндов и сопутствуюшей информации на запись в ОП, поток 59 информации об операндах, для которых запись произведена, поток 60 адресов на считывание из ОП, поток 61 информации об операндах, стоящих в очереди на считывание из ОП, поток 62 считанных из ОП операндов, содержимое зон РП 54-63-67, разряд 63 признака занятости РП, разряд 64 признака вида обмена с ОП, адрес 65 в ББП, адрес 66 в модуле ОП, операнд 67.
Совокупность зон 42-46 (фиг. 3) образует строку входного или выходного ББП, обозначенных соответственно 1 и 2 на фиг. 1 и 16-17 на фиг. 2, вертикальные выходные шины 9 и 10 на фиг. 1 соответствуют информационным входным 39 и адресным шинам 40 модуля ОП на фиг. 2, а вертикальные входные шицы 11 на фиг. 1 соответствуют информационным входным шинам 41 модуля ОП на фиг. 2.
Предложенное коммутационное устройство для мультипроцессорной системы обеспечивает связь между ОП и любыми другими функциональными блоками вычислительной системь, такими как процессоры ввода-вывода, управляющие блоки и устройства, арифметико-логические устройства, процессоры операционной системы и др. Совокупность последних устройств (за исключением ОП) назовем вычислительным блоком системы, а сами устройства - процессорами, независимо от выполняе.мых ими функций.
Конфликтные ситуации, возникаюшие при обрашении нескольких процессоров к одному и тому же модулю ОП, во всех вычислительных системах разрешаются путем последовательного предоставления процессорам доступа к этому модулю ОП, вследствие чего; во избежание простоев и обеспечения загрузки работой во время разрешения конфликтных ситуаций, процессорам придаются ББП.
Все запросы к ОП и всю информацию из ОП процессоры получают через свои ББП. Несколько процессоров могут иметь один ББП (так называемый распределенный ББП) и наоборот.
Ввиду значительного разнообразия типов процессоров, работающих с ОП, столь же разнообразной будет и информация, которой процессоры обмениваются с ОП, это команды (или их части), модификаторы, операнды, форматные коды и др. Не теряя общности, все виды информации разделим на три типа: управляющую информацию, адреса и операнды (под операндами понимается все, что может содержаться в ячейках оперативной памяти). Ввиду того, что многопроцессорная система может иметь значительные физические размеры, процессоры и оперативная память могут оказаться в разных физических стойках, что делает малопригодными известные коммутационные устройства, так как увеличивающееся время «отклика (при размещении ОП и процессоров в разных стойках) резко снижает их быстродействие.
В предложенном устройстве нет необходимости ожидать отклика после посылки очередного адреса или операнда, или отклика о том, что требуемая связь между процессором и модулем ОП установлена и разрешены все конфликтные ситуации.
Все запросы на обмен, поступаюшие в коммутационное устройство из БПП, не могут быть удовлетворены немедленно, но заранее неизвестно, какие именно будут выполнены. Кроме того, при достаточно большой длине магистрали, соединяющей ББП с ОП, посла запрос на обмен, ББП не сможет немедленно получить инфор.мацию о том, удовлетворен ли запрос. В связи с этим принцип работы интерфейса основан на том, что запросы на обмен отсылаются из ББП все сразу последовательно, не ожидая отклика коммутационного устройства (т. е. информацию о том, могут ли они быть удовлетворены немедленно). Неудовлетворенные заявки не воспринимаются ком.мутационным устройством и теряются в нем, не сохраняются в ББП и в случае отсутствия отклика о том, что они приняты к обмену, они посылаются в ко.ммутационное устройство вновь также последовательно. Только после того, как ББП получит отклик коммутационного устройства о том, что заявка удовлетворена, она может быть удалена из ББП. Указанный принцип реализуется в устройстве благодаря использованию распределенной регистровой памяти (регистров пересылок - РП), выполняющей функции коммутатора и накопителя заявок на обмен с моделями ОП. Таким образом, с помощью РП образуется очередь к каждому модулю ОП. Рассмотрим потоки в коммутационном устройстве (фиг. 3). ББП состоит из двух частей с точки зрения обмена: входного ББП и выходного ББП, при этом щины записи и считывания дли обоих ББП объединены, за исключением зоны ББП операнда. Операнд можно записать из ОП только во входной ББП и считать в ОП только из выходного ББП; все перемещения операндов между входным и выходным ББП осуществляет процессор 15 (фиг. 2). Если процессору 15 (фиг. 2) требуется произвести обмен некоторой группой операндов с ОП, то в общем случае неважно, в каком порядке этот обмен будет осуществляться (если существуют приоритеты между заявками данного процессора к ОП, то соответствующая последовательность засылки заявок в коммутационное устройство формируется блоком 18 соответствующего ББП), важно лищь получить информацию из ОП за возможно малое время. Поэтому в устройстве все запросы процессоров посылаются последовательно через коммутационное устройство, не дожидаясь отклика о том, принят ли данный запрос к обмену или нет. «Отклики поступают из коммутационного устройства ББП (с некоторой задержкой) только на те заявки, которые приняты регистрами пересылок к обмену. Если же заявка не может быть принята немедленно (соответствующий РП занят), то эта заявка теряется в коммутационном устройстве, но сохраняется в ББП. После окончания засылки всех заявок в коммутационное устройство, начинается повторная засылка в РП тех заявок, на которые не получено отклика. Это продолжается до получения отклика на все заявки. Рассмотрим потоки информации, возникающие при записи в ОП из ББП. Предполагается, что в магистралях 56 и 57 происходит задержка информации на фиксированное время (в каждой магистрали 56 и 57), возможно различное для каждой магистрали 13 на фиг. 2. Например, это случается тогда, когда ОП и ББП размещены в разных физических стойках системы. При записи в ОП на магистраль 56 поступает поток 58 информации, а возвращается через магистраль 57 поток 59 информации. О том, что данный операнд необходимо записать в ББП, сообщает процессор, помещая «1 в разряде признака «готов к обмену 47. Перед началом процесса обмена содержимое разрядов признака «занят обменом 49 устанавливается в «О для всех ячеек БЗУ. Разряд признака «вид обмена 50 указывает на вид обмена, соверщаемого с ОП (в данном случае запись). По содержимому разрядов признаков «готов к обмену 47 и «занят обменом 49 по цепочке очередности выбирается произвольно (или по приоритету) ячейка (например, первая сверху), содержащая «О в разряде признаков «занят обменом и «1 в разряде «готов к обмену. Тем самым содержимое разрядов «вид обмена 50,. «адрес ББП 53, «адрес ОП 44 и «операнд 45 выдается на магистраль 56. Сразу после завершения считывания указанной ячейки из ББП происходит аналогичное считывание следующей ячейки ББП, содержащее «1 в разряде «готов к обмену 47 и «О в разряде «занято обмено.м 49. Таким образом, в .магистраль 56 поступает поток заявок на запись в ОП со скоростью работы ББП. Через время Т первая заявка достигает регистра пересылок 54 и помещается в регистр с номером, соответсвующим номеру модуля ОП, в который необходимо записать указанную заявку, если этот регистр не занят. В этом случае в магистраль 57 поступает «остаток (после записи в РП 54) от заявки «адрес в ББП и «1 от блока управления пересылками 21 (см. фиг. 2), образующий поток 59. Этот «остаток поступает в ББП через время Т. «Адрес в БЗУ дешифрируется дешифратором 51 и в найденную таким образом ячейку в разряд признаков «занят обменом 49 помещается «1, переданная блоком управления пересылками 21 (см. фиг. 2). «1 в разряде признаков «занят обмено.м 49 указывает, что заявка, расположенная в соответствующей ячейке ББП, находится в очереди к модулю ОП (т. е. поступила в РП). Иначе говоря, на эту заявку получен «отклик из коммутационного устройства. Потоки на считывание из ББП и на запись в ББП не пересекаются (с.м. фиг. 3), поэто.му формирование потока в магистраль 56 и обработка потока из магистрали 57 происходит в ББП без конфликтов. Помещенные в РП 54 заявки от различных ББП образуют очереди к модулям ОП, которые обслуживаются с помощью блоков синхронизации памяти 22 (см. фиг. 2). Рассмотренный циклический процесс посылки заявок по магистрали 56 .может породить несколько одинаковых заявок вместо одной: когда в ББП не поступил «отклик из коммутационного устройства, ББП повторно посылает ту же заявку. Цик,1ическая посылка неудовлетворенных заявок в коммутационном устройстве осуществляется до тех пор, пока не будет получен «отклик на все запросы. Точно такие же потоки, как и при записи в ОП 58 и 59 возникают при считывании из on 60 и 61. Отличие состоит лишь в том, что при считывании из ОП возникает еще один поток информации 62 по магистрали 57. Когда поступившая в РП заявка удовлетворена (т. е. операнд) считан из ОП на регистр), операнд необходимо переслать в ББП по магистрали 57. Поскольку момент завершения считывания операнда в РП из ОП не предсказуем, для потока 62 необходимо предусмотреть отдельные группы шин магистрали 57, чтобы исключить конфликты потока 62 с потоками 59 или 61. Рассмотрим подробно функционирование РП. Из магистрали 56 в регистр пересылок 54 поступает следуюшая информация: «вид обмена 64, «адрес ББП 65, «адрес в модуле ОП 66 и «операнд 67. Сразу после поступления в соответствуюший регистр стро ки матрицы указанной информации «признак занятости регистр 63 меняет свое состояние на противоположное и подрегистр становится недоступным для магистрали 56 или 57. Теперь к РП 54 имеет доступ только соответствующий модуль ОП 55. После обмена с ОП 55 РП 54 снова становится доступным для магистрали 56, если в разряд «вид обмена находится признак «записи в ОП или для магистрали 57, при признаке «считывание из ОП. В первом случае из магистрали 56 и РП 54 может поступить очередная заявка на обмен с ОП, а во втором случае в магистраль 57 в момент, определенный блоком синхронизации 20, поступает операнд 67, считанный из ОП, совместно с адресом ББП 65 и признаком «обмен завершен из блока управления пересылками 21, после чего в разряд «вид обмена 64 устанавливается признак записи. В результате образуется поток 62. Рассмотрим функционирование коммутационного устройства в целом (фиг. 2). Считывание операндов из ОП происходит в следующем порядке. В зоне группы признаков 23 (в выходном ББП 17) содержится информация о том, что в соответствующей строке ББП находится заявка на считывание из ОП, т. е. присутствует адрес в ОП, состоящий из двух частей: номера модуля 25и адреса в модуле 26. Блок 18 управления рассматривает содержимое зоны группы признаков 23 всех строк выходного ББП 17 и выбирает по цепочке очередности первую сверху строку, содержащую заявку на обмен с ОП. После этого содержимое выбранной строки ББП 17 поступает на магистраль 13; без задержки выбирается следующая строка,и соответствующая заявка тоже поступает на магистраль 13. Поступление заявки в магистраль 13 означает, что из зоны 25 ББП 17 номер модуля ОП поступает по группе шин магистрали 13 на входы всех блоков управления пересылками 21 соответствующих регистров пересылок, из зоны 26адрес в модуле ОП по группе шин 30 поступает на входы зон 37 всех регистров 34 соответствующей строки матрицы, из зоны 24 адрес (номер строки) ББП 17 по группе щин 31 поступает на входы зон 36 регистров 24 соответствующей строки матрицы. Номер модуля ОП, поступивший на входы соответствующих блоков управления пересылками 21, сравнивается в каждом из этих блоков с его собственным номером (совпадающим с номером модуля ОП). При совпадении указанных номеров содержимое заявки записывается в соответствующие зоны 36-38 регистра 34, если соответствующий регистр 34 свободен, на что указывает соответствующее состояние признака занятости в зоне 35 (см. также разряд 63 на фиг. 3), а также признак в разряде «вид обмена (см. разряд 64 на фиг. 3). В момент записи заявки в регистр 34 блок 21 управления изменяет состояние признака занятости на противоположное и выдает в группу шин 32 сигнал «отклика, состоящий из адреса в ББП 17. (Группа шин 32 магистрали 13 состоит из двух подгрупп: первая - для передачи адреса ББП при «отклике, а вторая - для передачи адреса ББП при записи в ББП считанных из ОП операндов, находящихся в регистрах пересылок 34). При отклике адрес ББП по первой подгруппе группы шин 32 поступает на вход дешифратора 51 (фиг. 3), срабатывание которого приводит к записи «Ь в разряд 49 «занят обменом. Если подрегистр 34 занят, то заявка теряется. Вместе с номером модуля ОП по группе шин 28 в подрегистр 24 (в зону признаков 35) поступает признак вида обмена с ОП (запись или считывание). После записи заявки в соответствующий регистр 34 последний становится доступным для обмена с ОП. Работа регистров 34, соответствующих одноименному модулю 19 ОП, синхронизируется блоком 22 синхронизации. Блок 22 синхронизации реализирует принцип цепочки очередности для всех одноименных регистров 34, содержащих заявки на обмен с ОП; очередность выборки заявок устанавливается произвольно (например, по принципу «первая сверху) или по приоритетам. Адрес в модуле ОП из зоны 37 выбранного блоком 22 регистра 34 по адресным щинам 40 поступает на регистр адреса соответствующего модуля ОП. Если осуществляется запись в ОП, то одновременно с адресом в модуле ОП по информационным шинам 39 операнд из зоны 38 выбранного регистра 34 поступает на регистр числа модуля ОП, а блок 22 синхронизации изменяет состояние признака занятости в зоне 35 на противоположное (соответствующее состоянию «регистр свободен); регистр 34 становится доступным для записи в него новой
заявки из ББП. Если же осуществляется считывание из модуля ОП, то считанный операнд из регистра числа модуля ОП по информационным шинам 39 поступает в зону 38 выбранного регистра 34, блок синхронизации 22 изменяет состояние признака занятости в зоне 35 на противоположное, которое вместе с признаком «считывание в разряде «вид обмена указывает на то, что данный регистр 34 становится доступным для считывания операнда в ББП по магистрали 13 (но недоступен для записи новой заявки).
Работа регистров 34 одной строки матрицы синхронизируется блоком 20.
Блок 20 синхронизации реализует принцип цепочки очередности для всехрегистров 34 одной строки матрицы, содержащих операнды, считанные из ОП для пересылки в ББП; очередность выборки операндов устанавливается произвольно (например, по принципу «первый слева) или по приоритетам. Адрес ББП из зоны 36 выбранного блоком 20 (по совокупности признаков «свободен в разряде признаков занятости и «считывание в разряде «вид обмена) регистра 34 по второй подгруппе группы щин 32 и операнда из зоны 38 по группе щин 33 магистрали 13 поступает в ББП, соответствующий данной строке матрицы. Адрес ББП поступает на вход дешифратора 52 (фиг. 3), в зону 45 выбранной дещифраторо.м 52 строки ББП записывается операнд, а в разряд 48 «обмен заверщен той же строки записывается «1.
Таким образом, предложенное коммутационное устройство по сравнению с известными обладает повышенным быстродействием за счет того, что отсутствуют потери времени на установление связей непосредственно между процессорами и модулями ОП (при одинаковом с известными коммутационными устройствами времени пересылок операндов) между отдельно взятыми модулем ОП и процессором), а также за счет отсутствия потерь времени на разрещение конфликтных ситуаций, возникающих при одновременном обращении нескольких процессоров к одному модулю ОП; меньшей сложностью управления за счет исключения необходимости централизованного обнаружения и устранения конфликтных ситуаций при одновре.менном обращении нескольких процессоров к одному модулю ОП, за счет отсутствия централизованного механизма приоритетного обслуживания процессоров и их заявок, а также за счет отсутствия памяти для хранения управляющей информации об установленных связях между процессорами и модулями ОП и информации об очередях требований процессоров на установление связей с модулями ОП; управление предложенным коммутационным устройством является децентрализованным (блоки 18, 20, 21, 22, управляющие коммутационным устройством работают соверщенно независимо друг от друга) и сводится к реализации блоками 18, 20, 22 функций цепочек очередности (т. е. функций распределения) и функций сравнения по совпадению (блоки 21); повышенной гибкостью за счет воз.можности наращивания коммутационного устройства путем простого добавления к нему отдельных звеньев без изменения уже существующих связей и элементов: при увеличении числа .модулей ОП соответственно увеличивается число регистров 34, блоков 21, в каждом из регистров пересылок, а также число блоков 22, а при увеличении числа процессоров соответственно увеличивается число ма.гистралей 13, число регистров пересылок 24 и число блоков 20 и 21; гибкость увеличивается также за счет того, что предложенное коммутационное устройство может использоваться в системах с различной длиной магистралей (в том числе и в системах, в которых магистрали одного и того же функционального назначения имеют различную длину); расширенными функциональны.ми возможностями за счет возможности обмена нескольких процессоров одновременно с одним и тем же модулем памяти, а также за счет указанной выше возможности использования предложенного ком.мутационного устройства в системах с различной длиной магистралей; .повышенной живучестью за счет децентрализации управления ком.мутационным устройством: отказ любого блока, относящегося к какой-либо его магистрали (например, блоков 18, 16, 17, 24, 20, 21, 13) соответствует лишь отказу одноименного процессора, но не приводит к потере работоспособности коммутационного устройства в целом.
Формула изобретения
Коммутационное устройство для .мультипроцессорной системы, содержащее входные и выходные буферные блоки памяти, причем первый выход всех выходных буферных блоков памяти является первой группой выходов устройства, вход всех входных буферных блоков памяти является первой группой входов устройства, отличающееся тем, что, с целью повышения быстродействия и гибкости, в устройство введены две группы блоков синхронизации, регистры пересылок, блоки управления пересылками, образующие матрицу, причем второй выход и первый в.ход каждого выходного буферного блока памяти соединены соответственно с первым входом и первым выходом каждого блока управления пересылками соответствующей строки матрицы и соответственно с первым входом и первым выходом каждого регистра пересылок той же строки матрицы, выход каждого блока синхронизации первой группы соединен со вторым входом каждого блока управления пересылками соответствующей строки матрицы, второй выход и третий вход каждого блока управления пересылками соединен соответственно со вторым входом и выходом соответствующего регистра пересылок, третьи и четвертые выходы всех регистров пересылок столбца матрицы являются соответственно второй и третьей группами выходов устройства, третьи входы всех регистров пересылок столбца матрицы являются соответственно второй группой входов устройства, выход каждого блока синхронизации второй группы соединен с четвертым входом каждого блока управления
пересылками соответствующего столбца матрицы, выход каждого входного буферного блока памяти соединен с первым входом каждого из регистров пересылок соответствующей строки матрицы.
Источники информации, принятые во внимание при экспертизе
1.Мультипроцессорные системы и параллельные вычисления. Под ред. Энслоу Ф. Г. М., «Мир, 1976, с. 45, рис. 2-3.
2.Там же, с. 51, рис. 2-9.
3.Там же, с. 196, рис. II. III. 1 (прототип) .
1
ff
|3SI36|3 J3S
2
25
24
26
21
/б
Izol
/7
/б
t...
I
12
I
) 11 111
и I
/
f6
fS
11
(I
LS
L.
{I
M
5
19
Ж.
i
jfi
/
«Jf4





| название | год | авторы | номер документа |
|---|---|---|---|
| Процессор | 1974 |
|
SU526902A1 |
| Устройство для сопряжения процессора с общей магистралью | 1985 |
|
SU1291998A1 |
| Вычислительная система | 1977 |
|
SU692400A1 |
| Программируемый процессор спектральной обработки сигналов | 1982 |
|
SU1092517A1 |
| СПОСОБ ОБЕСПЕЧЕНИЯ СВЯЗИ В КОММУНИКАЦИОННОЙ СРЕДЕ, КОМПЬЮТЕРНАЯ СИСТЕМА И ЭНЕРГОНЕЗАВИСИМЫЙ МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДАННЫХ | 2012 |
|
RU2574815C2 |
| МНОГОПРОЦЕССОРНАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2012 |
|
RU2502126C1 |
| Устройство для обучения | 1988 |
|
SU1663618A1 |
| Управляющая векторная вычислительная система | 1982 |
|
SU1120340A1 |
| Адаптивная система обработки данных | 1984 |
|
SU1241250A1 |
| Устройство для обработки информации | 1977 |
|
SU742942A1 |
фиг 2
43
52
45
5с
56
60
54
63
64
Х
X
59
Т
6i
57
62
67
55 Фа 2.3
