Область изобретения
Настоящее изобретение относится к модифицированному полипептиду с пониженной активностью цитратсинтазы и к способу получения L-аминокислоты с использованием этого модифицированного полипептида.
Предшествующий уровень техники
Микроорганизм рода Corynebacterium, в частности Corynebacterium glutamicum, представляет собой грамположительный микроорганизм, который широко используют в получении L-аминокислоты и других полезных веществ. Для получения L-аминокислоты и других полезных веществ проводятся различные исследования по разработке микроорганизмов с высокой продуктивностью и технологий для процессов ферментации. Например, главным образом используют подходы, специфичные в отношении целевого материала (например, повышение экспрессии генов, кодирующих ферменты, вовлеченные в биосинтез L-лизина, или удаление генов, не являющихся необходимыми для биосинтеза) (патент Кореи No. 10-0838038).
Между тем, среди L-аминокислот L-лизин, L-треонин, L-метионин, L-изолейцин и L-глицин представляют собой аминокислоты, происходящие из аспартата, и уровень биосинтеза оксалоацетата (то есть, предшественника аспартата) может влиять на уровни биосинтеза этих L-аминокислот.
Цитратсинтаза (CS) представляет собой фермент, который продуцирует цитрат путем катализа конденсации ацетил-СоА и оксалоацетата, продуцируемого микроорганизмом во время гликолиза, и также он является важным ферментом для направления потока углерода в метаболический путь ТСА (трикарбоновых кислот).
Ранее в литературе сообщалось о фенотипических изменениях в L-лизин-продуцирующих штаммах, обусловленных делецией в гене gitA, кодирующем цитратсинтазу (Ooyen et al., Biotechnol. Bioeng., 109(8): 2070-2081, 2012). Однако такие штаммы с делецией гена gltA имеют недостаток в том, что не только их рост ингибируется, но также их скорости потребления сахара значительно снижаются, что таким образом приводит к низкому уровню продуцирования лизина в единицу времени.
Соответственно, все еще существует потребность в исследованиях, в которых может быть учтено как эффективное увеличение продуктивности L-аминокислот, так и рост штаммов.
Описание
Техническая задача
Авторы настоящего изобретения подтвердили, что при использовании нового модифицированного полипептида, цитратсинтазная активность которого понижена до определенного уровня, уровень продуцирования L-аминокислоты может быть повышен без замедления скорости роста штамма, тем самым выполняя настоящее изобретение.
Техническое решение
Одна задача настоящего изобретения заключается в том, чтобы предложить модифицированный полипептид с цитратсинтазной активностью, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1, представляющая собой аспарагин, заменена на другую аминокислоту.
Другая задача настоящего изобретения заключается в том, чтобы предложить полинуклеотид, кодирующий указанный модифицированный полипептид.
Еще одна задача настоящего изобретения заключается в том, чтобы предложить микроорганизм рода Corynebacterium, продуцирующий происходящую из аспартата L-аминокислоту, содержащую указанный модифицированный полипептид.
Еще одна задача настоящего изобретения заключается в том, чтобы предложить способ получения L-аминокислоты, включающий культивирование микроорганизма рода Corynebacterium в среде и выделение L-аминокислоты из культивируемого микроорганизма или среды.
Полезный эффект изобретения
При использовании нового модифицированного полипептида по настоящему изобретению с пониженной цитратсинтазной активностью уровень продуцирования происходящей из аспартата L-аминокислоты может быть дополнительно повышен без замедления скорости роста.
Краткое описание графических материалов
На Фиг. 1 показана кривая роста штамма, в котором в гене gltA произведена делеция и модификация.
Наилучшее воплощение изобретения
Далее представлено подробное описание настоящего изобретения. Между тем, соответствующие описания и воплощения, раскрытые в настоящем изобретении, также могут быть применены к другим описаниям и воплощениям. То есть, все комбинации различных элементов, раскрытых в настоящем описании, попадают в объем настоящего изобретения. Кроме того, объем настоящего изобретения не ограничен конкретным описанием, приведенным ниже.
Для решения вышеизложенных задач в одном аспекте настоящего изобретения предложен модифицированный полипептид, обладающий активностью цитратсинтазы, где указанный модифицированный полипептид включает по меньшей мере одну модификацию в аминокислотной последовательности SEQ ID NO: 1, и эта по меньшей мере одна модификация включает замену 241ой аминокислоты в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагина) на другую аминокислоту.
В частности, модифицированный полипептид может быть описан как модифицированный полипептид, обладающий цитратсинтазной активностью, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагин) заменена на другую аминокислоту.
В настоящем описании SEQ ID NO: 1 относится к аминокислотной последовательности, обладающей активностью цитратсинтазы, и в частности, белковой последовательности, обладающей активностью цитратсинтазы, кодируемой геном gltA. Аминокислотная последовательность SEQ ID NO: 1 может быть получена из NCBI GenBank, которая является общедоступной базой данных. Например, аминокислотная последовательность SEQ ID NO: 1 может иметь происхождение из Corynebacterium glutamicum, но аминокислотная последовательность не ограничена этим и может включать без ограничения любую последовательность, обладающую такой же активностью как вышеуказанная аминокислотная последовательность. Кроме того, аминокислотная последовательность может включать аминокислотную последовательность SEQ ID NO: 1 или любую аминокислотную последовательность, имеющую 80% или более гомологии или идентичности с аминокислотной последовательностью SEQ ID NO: 1, но аминокислотная последовательность не ограничена этим. В частности, аминокислотная последовательность может включать аминокислотную последовательность SEQ ID NO: 1 и любую аминокислотную последовательность, имеющую по меньшей мере 80%, 90%, 95%, 96%, 97%, 98% или 99% или больше гомологии с аминокислотной последовательностью SEQ ID NO: 1. Кроме того, очевидно, что любой белок, имеющий аминокислотную последовательность, в которой часть аминокислотной последовательности делетирована, модифицирована, заменена или добавлена, также можно использовать в настоящем изобретении, при условии что белок обладает такой гомологией или идентичностью по аминокислотной последовательности с аминокислотной последовательностью вышеописанного белка и оказывает действие, соответствующее таковому вышеописанного белка.
То есть, в настоящем изобретении, хотя он описан как "белок или полипептид, имеющий аминокислотную последовательность определенной SEQ ID NO" или "белок или полипептид, состоящий из аминокислотной последовательности определенной SEQ ID NO", очевидно, что любой белок, обладающий биологической активностью по существу такой же или эквивалентной таковой полипептида, состоящего из аминокислотной последовательности соответствующей SEQ ID NO, можно использовать в настоящем изобретении, даже если аминокислотная последовательность может иметь делецию, модификацию, замену или вставку в части последовательности. Например, очевидно, что понятие "полипептид, состоящий из аминокислотной последовательности SEQ ID NO: 1" может относиться к "полипептиду, состоящему из аминокислотной последовательности SEQ ID NO: 1". Дополнительно, в случае, когда полипептид обладает активностью такой же или эквивалентной таковой модифицированного полипептида по настоящему изобретению, мутация, которая может произойти вследствие вставки незначащей последовательности выше по ходу транскрипции или ниже по ходу транскрипции от аминокислотной последовательности соответствующей SEQ ID NO, природная мутация или молчащая мутация в ней не исключены в дополнение к модификации 241ой аминокислоты или соответствующей ей модификации, и очевидно, что в случаях, когда полипептид имеет в последовательности такую вставку или мутацию, полученные в результате полипептиды также могут входить в объем настоящего изобретения.
Как его используют здесь, термин "гомология" или "идентичность" отражает соответствие между двумя данными аминокислотными последовательностями или нуклеотидными последовательностями и может быть выражена в процентах. Эти два термина "гомология" и "идентичность" часто используют взаимозаменяемо друг с другом.
Гомологию или идентичность последовательностей консервативных полинуклеотидных или полипептидных последовательностей можно определить с помощью стандартных алгоритмов выравнивания с использованием штрафа за пропуск в последовательности по умолчанию, установливаемого используемой программой. Обычно ожидают, что по существу гомологичные или идентичные последовательности гибридизуются в умеренно строгих или очень строгих условиях, вдоль всей длины или по меньшей мере примерно 50%, примерно 60%, примерно 70%, примерно 80% или примерно 90% всей длины целевых полинуклеотидов или полипептидов. В отношении гибридизации также рассматривают полинуклеотиды, которые содержат вырожденные кодоны вместо кодонов в гибридизуемых полипептидах.
Обладают ли две любые полинуклеотидные или полипептидные последовательности гомологией или идентичностью, можно определить с помощью известного компьютерного алгоритма, такого как программа "FASTA", с использованием параметров по умолчанию как описано Pearson et al. (Proc. Natl. Acad. Sci. USA 85: 2444, (1988)). Альтернативно, гомологию или идентичность можно определить с использованием алгоритма Нидлмана-Вунша (Needleman and Wunsch, 1970, J. Mol. Biol. 48: 443-453), который выполняется в программе "Needleman" пакета "EMBOSS" (EMBOSS: The European Molecular Biology Open Software Suite, Rice et at, 2000, Trends Genet. 16: 276-277) (предпочтительно, версия 5.0.0 или более поздние версии) (пакета программ GCG (Devereux, J., et at, Nucleic Acids Research 12: 387 (1984)), BLASTP, BLASTN, FASTA (Atschul, [S.] [F.,] et at, J Molec Bio 215]: 403 (1990); Guide to Huge Computers, Martin J. Bishop, [ED.], Academic Press, San Diego, 1994 и [CARILLO ETA/.](1988) SIAM J Applied Math 48: 1073). Например, гомологию, сходство или идентичность можно определить, используя "BLAST" или "ClustalW" от Национального Центра Биотехнологической Информации.
Гомологию, сходство или идентичность между полинуклеотидами или полипептидами можно определить путем сравнения информации о последовательностях, используя, например, компьютерную программу "GAP" (например, Needleman et al. (1970), J Mol Biol. 48: 443) как описано в литературе (Smith and Waterman, Adv. Appl. Math (1981) 2:482). Таким образом, программа "GAP" определяет гомологию, сходство или идентичность как величину, полученную путем деления числа одинаково выровненных символов (то есть, нуклеотидов или аминокислот) на общее число символов в более короткой из двух последовательностей. Параметры по умолчанию для программы "GAP" могут включать: (1) одинарную матрицу сравнения (содержащую значение 1 для совпадений и 0 для несовпадений) и взвешенную матрицу сравнения от Gribskov et al. (1986), Nucl. Acids Res. 14: 6745, как раскрыто в литературе (Schwartz and Dayhoff, eds., Atlas of Protein Sequence and Structure, National Biomedical Research Foundation, pp. 353-358, 1979); (2) штраф 3,0 за каждый пропуск и дополнительно штраф 0,10 за каждый символ в каждом пропуске (или штраф за внесение пропуска 10 и штраф за продление пропуска 0,5); и (3) отсутствие штрафа за окончание пропуска.
Дополнительно, обладают ли две полинуклеотидные или полипептидные последовательности гомологией, сходством или идентичностью, можно определить путем сравнения этих последовательностей путем экспериментов с гибридизацией по Саузерну, и подходящие условия гибридизации, которые следует определить, могут быть определены способом, известным специалисту в данной области техники (например, J. Sambrook et al., Molecular Cloning, A Laboratory Manual, 2nd Edition, Cold Spring Harbor Laboratory press, Cold Spring Harbor, New York, 1989; F.M. Ausubel et al, Current Protocols in Molecular Biology, John Wiley & Sons, Inc., New York).
Как его используют здесь, термин "модифицированный полипептид" относится к полипептиду, в котором одна или более чем одна аминокислота отличается от таковых в изложенной последовательности консервативной заменой и/или модификацией, но функции или свойства полипептида сохраняются. Модифицированный полипептид отличается от таких последовательностей, которые определены путем замены, делеции или вставки нескольких аминокислот. Обычно такой модифицированный полипептид может быть идентифицирован путем модификации одной из полипептидных последовательностей и оценки свойств модифицированного полипептида. То есть, активность модифицированного полипептида может быть увеличена, остаться неизмененной или быть уменьшена относительно таковой нативного белка. Обычно такой модифицированный полипептид может быть идентифицирован путем модификации одной из полипептидных последовательностей и оценки активности модифицированного полипептида. Дополнительно, частично модифицированный полипептид может включать модифицированный полипептид, из которого удалена одна или более чем одна его часть (например N-концевая лидерная последовательность, трансмембранный домен и так далее). Другие модифицированные полипептиды могут включать такие полипептиды, из которых удалена их часть с N- и/или С-конца каждого зрелого белка. В настоящем описании термин "модифицированный" можно использовать взаимозаменяемо с такими терминами как "модификация", "модифицированный белок", "модифицированный полипептид", "мутант", "мутеин", "дивергент", "вариант" и так далее, и термин не ограничен этим, при условии что его используют в значении модификации.
Как его используют здесь, термин "консервативная замена" относится к замене одной аминокислоты на другую аминокислоту, обладающую сходными структурными и/или химическими свойствами. Вариант (модифицированный полипептид) может иметь, например, одну или более чем одну консервативную замену, в то же время сохраняя одну или более чем одну биологическую активность. Обычно эта аминокислотная замена может быть выполнена на основе сходства полярности, электрического заряда, растворимости, гидрофобности, гидрофильности и/или амфипатической природы аминокислотных остатков. Например, среди аминокислот, несущих электрический заряд, положительно заряженные (основные) аминокислоты включают аргинин, лизин и гистидин; и отрицательно заряженные (кислые) аминокислоты включают глутаминовую кислоту и аспарагиновую кислоту; и среди незаряженных аминокислот неполярные аминокислоты включают глицин, аланин, валин, лейцин, изолейцин, метионин, фенилаланин, триптофан и пролин; полярные или гидрофильные аминокислоты включают серии, треонин, цистеин, тирозин, аспарагин и глутамин; и среди полярных аминокислот ароматические аминокислоты включают фенилаланин, триптофан и тирозин.
Дополнительно, варианты (модифицированный полипептид) могут включать делецию или вставку аминокислот, оказывающих минимальный эффект в отношении характеристик и вторичной структуры полипептида. Например, полипептид может быть конъюгирован с сигнальной (или лидерной) последовательностью на N-конце белка, которая вовлечена в котрансляционный или посттрансляционный перенос белков. Дополнительно, полипептид также может быть конъюгирован с другой последовательностью или линкером для его идентификации, очистки или синтез.
Модифицированный полипептид по настоящему изобретению может представлять собой модифицированный полипептид с пониженной цитратсинтазной активностью по сравнению с таковой аминокислотной последовательности SEQ ID NO: 1, где указанный модифицированный полипептид включает по меньшей мере одну модификацию аминокислоты в SEQ ID NO: 1, и эта по меньшей мере одна модификация включает замену 241ой аминокислоты в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагин) на другую аминокислоту. Модифицированный полипептид может быть описан как модифицированный полипептид с пониженной цитратсинтазной активностью по сравнению с таковой аминокислотной последовательности SEQ ID NO: 1, в котором 241 м аминокислота в аминокислотной последовательности SEQ ID NO: 1 заменена на другую аминокислоту.
Фраза "замена на другую аминокислоту" не ограничена, при условии что заменяющая аминокислота отличается от аминокислоты до замены. То есть, когда 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 заменена на другую аминокислоту, другая аминокислота не ограничена, при условии что другая аминокислота представляет собой аминокислоту, отличную от аспарагина.
Модифицированный полипептид по настоящему изобретению может представлять собой полипептид, обладающий уменьшенной или пониженной активностью цитратсинтазы по сравнению с полипептидом до модификации, нативным полипептидом дикого типа или немодифицированным полипептидом, но модифицированный полипептид не ограничен этим.
В частности, модифицированный полипептид по настоящему изобретению может представлять собой таковой, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагин) заменена на глицин, аланин, аргинин, аспартат, цистеин, глутамат, глутамин, гистидин, пролин, серии, тирозин, изолейцин, лейцин, лизин, триптофан, валин, метионин, фенилаланин или треонин. Более конкретно, модифицированный полипептид может представлять собой полипептид, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагин) заменена на аминокислоту, отличную от лизина, но замена не ограничена этим. Альтернативно, модифицированный полипептид может представлять собой полипептид, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагин) заменена на аминокислоту, отличную от кислой или основной аминокислоты, или заменена на аминокислоту, имеющую незаряженную аминокислоту, но замена не ограничена этим. Альтернативно, модифицированный полипептид может представлять собой полипептид, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагин) заменена на неполярную аминокислоту или гидрофильную аминокислоту и, в частности, на ароматическую аминокислоту (например фенилаланин, триптофан и тирозин) или гидрофильную аминокислоту (например серии, треонин, тирозин, цистеин, аспарагин и глутамин), но модифицированный полипептид не ограничен этим. Более конкретно, модифицированный полипептид может представлять собой полипептид с пониженной цитратсинтазной активностью, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагин) заменена на треонин, серии или тирозин, но модифицированный полипептид не ограничен этим. Еще более конкретно, модифицированный полипептид может представлять собой полипептид с пониженной цитратсинтазной активностью, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагин) заменена на треонин, но модифицированный полипептид не ограничен этим.
Такой модифицированный полипептид обладает цитратсинтазной активностью, пониженной по сравнению с таковой полипептида, имеющего аминокислотную последовательность SEQ ID NO: 1. Очевидно, что модифицированный полипептид, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 заменена на другую аминокислоту, включает модифицированные полипептиды, в которых любая аминокислота, соответствующая 241ой аминокислоте, заменена на другую аминокислоту.
В частности, среди модифицированных полипептидов модифицированный полипептид, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагин) заменена на другую аминокислоту, может представлять собой полипептид, состоящий из SEQ ID NO: 3, 59 и 61, и более конкретно, модифицированный полипептид, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагин) заменена на треонин, серии или тирозин, может представлять собой полипептид, состоящий из каждой из SEQ ID NO: 3, 59 и 61, но модифицированный полипептид не ограничен этим. Дополнительно, модифицированный полипептид может включать аминокислотные последовательности SEQ ID NO: 3, 59 и 61 или аминокислотные последовательности, имеющие по меньшей мере 80% гомологии с каждой из аминокислотных последовательностей SEQ ID NO: 3, 59 и 61, но модифицированный полипептид не ограничен этим. В частности, модифицированный полипептид по настоящему изобретению может включать аминокислотные последовательности SEQ ID NO: 3, 59 и 61 или аминокислотные последовательности, которые имеют по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% гомологии с каждой из аминокислотных последовательностей SEQ ID NO: 3, 59 и 61. Кроме того, очевидно, что любой белок, имеющий аминокислотную последовательность с делецией, модификацией, заменой или вставкой в части аминокислотной последовательности, в дополнение к 241ой аминокислоте аминокислотной последовательности, также может быть включен в объем настоящего изобретения, при условии что аминокислотная последовательность имеет гомологию, описанную выше, и обладает эффектом, соответствующим эффекту этого белка.
Как его используют здесь, термин "цитратсинтаза (CS)" относится к ферменту, который продуцирует цитрат, катализируя конденсацию ацетил-СоА и оксалоацетата, продуцируемых во время гликолиза в микроорганизме, и она является важным ферментом, который направляет поток углерода в метаболический путь ТСА (цикл трикарбоновых кислот). В частности, цитратсинтаза действует как фактор регуляции скорости на первой стадии цикла ТСА в качестве фермента для синтеза цитрата. Дополнительно, цитратсинтаза катализирует реакцию конденсации двухуглеродного остатка ацетата из ацетил-СоА и молекулы 4-углеродного оксалоацетата с образованием 6-углеродного ацетата. В настоящем описании термин "цитратсинтаза" можно использовать взаимозаменяемо с термином "фермент для синтеза цитрата" или "CS".
В другом аспекте настоящего изобретения предложен полинуклеотид, кодирующий указанный модифицированный полипептид.
Как его используют здесь, термин "полинуклеотид", который представляет собой полимер нуклеотидов, состоящий из нуклеотидных мономеров, соединенных в длинную цепь ковалентными связями, представляет собой цепь ДНК или РНК, имеющую по меньшей мере определенную длину, и более конкретно, полинуклеотидный фрагмент, кодирующий указанный модифицированный полипептид.
Полинуклеотид, кодирующий модифицированный полипептид по настоящему изобретению, может включать без ограничения любую полинуклеотидную последовательность, кодирующую модифицированный полипептид с пониженной цитратсинтазной активностью по настоящему изобретению. В настоящем изобретении ген, кодирующий аминокислотную последовательность полипептида-цитратсинтазы, может представлять собой ген gltA, в частности ген, имеющий происхождение из Corynebacterium glutamicum, но ген не ограничен этим.
Полинуклеотид по настоящему изобретению может подвергаться различным модификациям в кодирующей области без изменения аминокислотной последовательности полинуклеотида вследствие вырожденности генетического кода или с учетом кодонов, предпочтительных для организма, в котором должен экспрессироваться данный полинуклеотид. В частности, любая полинуклеотидная последовательность, кодирующая модифицированный полипептид, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 заменена на другую аминокислоту, может быть включена без ограничения. Например, полинуклеотид по настоящему изобретению может представлять собой таковой, состоящий из аминокислотных последовательностей SEQ ID NO: 3, 59 и 61, соответственно, или полинуклеотидных последовательностей, кодирующих полипептиды, имеющие гомологию последовательности с этими полипептидами, но полинуклеотид не ограничен этим. Более конкретно, полинуклеотид по настоящему изобретению может представлять собой полинуклеотид, состоящий из каждой из полинуклеотидных последовательностей SEQ ID NO: 4, 60 и 62, но полинуклеотид по настоящему изобретению не ограничен этим.
Дополнительно, зонд, который может быть получен из известной генной последовательности, например, любой последовательности, которая может гибридизоваться с последовательностью, комплементарной всей или части полинуклеотидной последовательности в строгих условиях, для кодирования белка, обладающего активностью модифицированного полипептида, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 заменена на другую аминокислоту, может быть включен без ограничения.
Фраза "строгие условия" относится к условиям, в которых допускается специфичная гибридизация между полинуклеотидами. Такие условия более точно описаны в литературе (например J. Sambrook et at, supra). Строгие условия могут включать условия, в которых гены, имеющие высокий процент гомологии, например, гомологию 40% или больше, в частности гомологию 90% или больше, более конкретно гомологию 95% или больше, намного более конкретно гомологию 97% или больше, еще более конкретно гомологию 99% или больше, гибридизуются друг с другом, и гены, имеющие меньший процент гомологии, чем описано выше, не гибридизуются друг с другом, или обычные условия промывки для гибридизации по Саузерну (то есть, промывка однократная, более определенно двукратная или трехкратная в условиях концентрации соли и температуры, соответствующих 60°С, 1×SSC (стандатрный раствор хлорида и цитрата натрия), 0,1% SDS (додецилсульфат натрия), в частности, 60°С, 0,1×SSC, 0,1% SDS, и более конкретно 68°С, 0,1×SSC, 0,1% SDS), но строгие условия не ограничены этим и могут быть соответствующим образом скорректированы специалистом в данной области техники.
Для гибридизации необходимо, чтобы два полинуклеотида содержали комплементарные последовательности, хотя несовпадения между основаниями возможны в зависимости от строгости гибридизации. Термин "комплементарный" используется для описания взаимного соотношения между нуклеотидными основаниями, которые могут гибридизоваться друг с другом. Например, в отношении ДНК, аденозин является комплементарным тимину, а цитозин является комплементарным гуанину. Следовательно, настоящее изобретение может включать выделенные нуклеотидные фрагменты, комплементарные полной последовательности, а также полинуклеотидные последовательности по существу подобные им.
В частности, полинуклеотиды, имеющие гомологию, могут быть определены с использованием условий гибридизации, включающих стадию гибридизации при значении Tm 55°С в вышеописанных условиях. Кроме того, значение Tm может составлять 60°С, 63°С или 65°С, но значение Tm не ограничено этим и может быть соответствующим образом скорректировано специалистом в данной области техники в зависимости от поставленной им задачи.
Подходящая степень строгости гибридизации полинуклеотидов зависит от длины полинуклеотидов и степени комплементарности, и эти переменные хорошо известны в данной области техники (см. Sambrook et al, supra, 9.50-9.51, 11.7-11.8).
В еще одном аспекте настоящего изобретения предложен микроорганизм, содержащий модифицированный полипептид. В частности, в настоящем изобретении предложен микроорганизм рода Corynebacterium, продуцирующий L-аминокислоту, содержащий модифицированный полипептид. Более конкретно, в настоящем изобретении предложен микроорганизм рода Corynebacterium, продуцирующий происходящую из аспартата L-аминокислоту, содержащий модифицированный полипептид. Например, предложенный микроорганизм может представлять собой микроорганизм, трансформированный вектором, содержащим полинуклеотид, кодирующий модифицированный полипептид, но микроорганизм не ограничен этим.
Микроорганизмы, содержащие модифицированный полипептид по настоящему изобретению, обладают улучшенной способностью продуцировать L-аминокислоту по сравнению с микроорганизмом, содержащим полипептид дикого типа, без ингибирования роста или скорости потребления сахара микроорганизмом. Следовательно, L-аминокислота может быть получена из этих микроорганизмов с высоким выходом. В частности, это можно интерпретировать так, что в микроорганизме, содержащем модифицированный полипептид, может установиться подходящий баланс между потоком углерода, направляемым в путь ТСА, и количеством поступающего оксалоацетата, используемого в качестве предшественника в биосинтезе L-аминокислоты путем регулирования активности цитратсинтазы, и в результате, микроорганизм, содержащий модифицированный полипептид, может повышать уровень продуцирования L-аминокислоты, но интерпретация не ограничена этим.
Как его используют здесь, термин "L-аминокислота" относится к органическому соединению, содержащему аминную и карбоксильную функциональную группу, и в частности, аминокислоту в форме α-аминокислоты или в форме L-стереоизомера (L-форма). L-аминокислота может представлять собой аспарагин, глицин, аланин, аргинин, аспартат, цистеин, глутаминовую кислоту, глутамин, гистидин, пролин, серии, тирозин, изолейцин, лейцин, лизин, триптофан, валин, метионин, фенилаланин или треонин. Дополнительно, L-аминокислота может представлять собой L-гомосерин (α-аминокислоту) или ее производное в качестве предшественника L-аминокислоты, но L-аминокислота не ограничена этим. Производное L-гомосерина может представлять собой, например, производное, выбранное из группы, состоящей из О-ацетилгомосерина, O-сукцинилгомосерина и O-фосфогомосерина, но производное L-гомосерина не ограничено этим.
Как его используют здесь, термин "аспартат" относится к а-аминокислоте, которая используется в биосинтезе белков, и может быть использована взаимозаменяемо с аспарагиновой кислотой. Обычно, аспартат продуцируется из оксалоацетата, который является предшественником аспартата, и может превращаться in vivo в L-лизин, L-метионин, L-гомосерин или их производные, L-треонин, L-изолейцин и так далее.
Как его используют здесь, термин "происходящая из аспартата L-аминокислота" относится к веществу, которое может быть образовано путем биосинтеза при использовании аспартата в качестве предшественника, и происходящая из аспартата L-аминокислота не ограничена, при условии что L-аминокислота может продуцироваться путем биосинтеза с использованием аспартата в качестве предшественника. Происходящая из аспартата L-аминокислота может включать не только происходящую из аспартата L-аминокислоту, но также ее производное. Например, L-аминокислота и ее производное могут представлять собой L-лизин, L-треонин, L-метионин, L-глицин, гомосерин или его производное (О-ацетилгомосерин, O-сукцинилгомосерин и О-фосфогомосерин), L-изолейцин и/или кадаверин, но L-аминокислота и ее производное не ограничены этим. В частности, L-аминокислота и ее производное могут представлять собой L-лизин, L-треонин, L-метионин, гомосерин или его производное и/или L-изолейцин, и более конкретно, L-аминокислота и ее производное могут представлять собой L-лизин, L-треонин и/или L-изолейцин, но L-аминокислота и ее производное не ограничены этим.
Как его используют здесь, термин "вектор" относится к ДНК-продукту, включающему нуклеотидную последовательность полинуклеотида, кодирующего целевой белок, которая функционально связана с подходящей регуляторной последовательностью для экспрессии целевого белка в подходящем хозяине. Регуляторная последовательность включает промотор, способный инициировать транскрипцию, произвольную операторную последовательность для контроля транскрипции, последовательность, кодирующую подходящий сайт связывания мРНК с рибосомой, и последовательности для контроля терминации транскрипции и трансляции. Будучи трансформированным в подходящую клетку-хозяин, вектор может реплицироваться или функционировать независимо от генома хозяина или может сам интегрировать в геном.
Вектор, используемый в настоящем изобретении, конкретно не ограничен, при условии что он может реплицироваться в клетке-хозяине, и может быть использован любой вектор, известный в данной области техники. Примеры традиционно используемого вектора могут включать природные или рекомбинантные плазмиды, космиды, вирусы и бактериофаги. Например, в качестве фагового вектора или космидного вектора можно использовать pWE15, М13, MBL3, MBL4, LXII, ASHII, APII, t10, t11, Charon4A, Charon21A и так далее; и в качестве плазмидного вектора можно использовать векторы на основе pBR, pUC, pBluescriptII, pGEM, pTZ, pCL, pET и так далее. В частности, можно использовать векторы pDZ, pACYC177, pACYC184, pCL, pECCG117, pUC19, pBR322, pMW118, pCC1BAC и так далее.
Вектор, который можно использовать в настоящем изобретении, конкретно не ограничен, и можно использовать любой известный вектор экспрессии. Дополнительно, полинуклеотид, кодирующий целевой белок, может быть встроен в хромосому с использованием вектора для внутриклеточной вставки в хромосому. Вставка полинуклеотид а в хромосому может быть выполнена любым способом, известным в данной области техники (например, гомологичной рекомбинацией), но способ не ограничен этим. Вектор может дополнительно включать селективный маркер для подтверждения успешной вставки гена в хромосому. Селективный маркер предназначен для скрининга клеток, трансформированных вектором, то есть, для определения того, произошла ли вставка целевой полинуклеотидной молекулы. Можно использовать маркеры, которые обеспечивают селектируемые фенотипы (например, устойчивость к лекарственным средствам, ауксотрофию, устойчивость к цитотоксическим агентам или экспрессию поверхностных белков). В условиях обработки агентом селекции только клетки, экспрессирующие селективный маркер, могут выживать или экспрессировать другие фенотипические черты, и таким образом, трансформированные клетки могут быть отобраны.
Как его используют здесь, термин "трансформация" относится к введению вектора, включающего полинуклеотид, кодирующий целевой белок, в клетку-хозяина таким образом, что белок, кодируемый этим полинуклеотидом, может экспрессироваться в клетке-хозяине. До тех пор пока трансформированный полинуклеотид может экспрессироваться в клетке-хозяине, не имеет значения, является ли он интегрированным в хромосому клетки-хозяина и локализованным внутри нее или локализован вне хромосомы. Кроме того, полинуклеотид включает ДНК и РНК, кодирующие целевой белок. Полинуклеотид может быть введен в любой форме, при условии что он может быть введен в клетку-хозяина и экспрессироваться в ней. Например, полинуклеотид может быть введен в клетку-хозяина в форме экспрессионной кассеты, которая представляет собой генную конструкцию, включающую все элементы, необходимые для ее автономной экспрессии. Экспрессионная кассета может включать промотор, функционально связанный с полинуклеотидом, терминатор транскрипции, сайт связывания с рибосомой или терминатор трансляции. Экспрессионная кассета может находиться в форме самореплицирующегося вектора экспрессии. Кроме того, полинуклеотид может быть введен в клетку-хозяина как есть и функционально связан с последовательностями, необходимыми для экспрессии в клетке-хозяине, но введение полинуклеотида в клетку не ограничено этим. Способ трансформации включает любой способ введения полинуклеотида в клетку и может быть выполнен путем выбора подходящего стандартного метода, известного в данной области техники, в зависимости от клетки-хозяина. Например, способ может включать электропорацию, преципитацию фосфатом кальция (Са(H2PO4)2, CaHPO4 или Са3(PO4)2), преципитацию хлоридом кальция (CaCl2), микроинъекцию, полиэтиленгликолевый (PEG) метод, DEAE-декстрановый метод, катионно-липосомный метод, метод с ацетатом лития и DMSO (диметилсульфоксид) и так далее, но способ не ограничен этим.
Дополнительно, как его используют здесь, термин "функциональная связь" означает, что полинуклеотидная последовательность функционально связана с промоторной последовательностью, которая инициирует и опосредует транскрипцию полинуклеотида, кодирующего целевой белок по настоящему изобретению. Функциональная связь может быть выполнена с использованием технологии генетической рекомбинации, известной в данной области техники, и сайт-специфическое разрезание и сшивание ДНК могут быть выполнены с использованием ферментов для разрезания и лигирования, известных в данной области техники, и так далее, но получение функциональной связи не ограничено этим.
Как его используют здесь, понятие "микроорганизм, содержащий модифицированный полипептид" относится к клетке-хозяину или микроорганизму, которая(ый) включает полинуклеотид, кодирующий модифицированный полипептид, или клетке-хозяину или микроорганизму, которая(ый) трансформирован вектором, включающим полинуклеотид, кодирующий модифицированный полипептид, и следовательно способен экспрессировать в себе модифицированный полипептид. Клетка-хозяин или микроорганизм могут быть природного дикого типа или такими, в которых произошла природная или искусственная генетическая модификация. В частности, микроорганизм по настоящему изобретению может представлять собой таковой, обладающий активностью цитратсинтазы, где 241ая аминокислота, представляющая собой аспарагин, заменена на другую аминокислоту, таким образом экспрессируя модифицированный полипептид, но микроорганизм не ограничен этим. Дополнительно, микроорганизм, включающий модифицированный полипептид, может представлять собой микроорганизм, который продуцирует L-аминокислоту. В частности, микроорганизм, содержащий модифицированный полипептид, может представлять собой микроорганизм с улучшенной способностью к продуцированию L-аминокислоты по сравнению с его природным типом или немодифицированным родительским штаммом, но микроорганизм не ограничен этим. Дополнительно, микроорганизм, содержащий модифицированный полипептид, может представлять собой микроорганизм, который продуцирует происходящую из аспартата L-аминокислоту. В частности, микроорганизм, включающий модифицированный полипептид, может представлять собой микроорганизм с улучшенной способностью к продуцированию происходящей из аспартата L-аминокислоты по сравнению с его природным типом или немодифицированным родительским штаммом, но микроорганизм не ограничен этим.
Примеры микроорганизма могут включать штамм микроорганизма рода Escherichia, Serratia, Erwinia, Enterobacteria, Salmonella, Streptomyces, Pseudomonas, Brevibacterium, Corynebacterium и так далее, и в частности микроорганизм рода Corynebacterium.
Например, микроорганизм рода Corynebacterium может представлять собой Corynebacterium glutamicum, Corynebacterium ammoniagenes, Brevibacterium lactofermentum, Brevibacterium flavum, Corynebacterium thermoaminogenes, Corynebacterium efficiens и так далее, но микроорганизм рода Corynebacterium не обязательно ограничен этим. Более конкретно, микроорганизм рода Corynebacterium может представлять собой Corynebacterium glutamicum, но микроорганизм не ограничен этим.
В определенном воплощении микроорганизм может представлять собой микроорганизм, который продуцирует L-лизин, в котором модификация gltA введена в микроорганизм рода Corynebacterium, где активности белков, кодируемых тремя типами модифицированных генов: рус, hom и lysC, увеличены и таким образом увеличена способность продуцировать L-лизин.
Дополнительно, микроорганизм может представлять собой микроорганизм, который продуцирует L-треонин и L-изолейцин, в котором введена модификация в ген, кодирующий гомосериндегидрогеназу, которая продуцирует гомосерин (то есть, общее промежуточное соединение в путях биосинтеза L-треонина и L-изолейцина), тем самым усиливая активность этого гена, но микроорганизм не ограничен этим. В частности, микроорганизм может представлять собой микроорганизм, который продуцирует L-изолейцин, в котором введена дополнительная модификация в ген, кодирующий L-треониндегидратазу, тем самым усиливая активность гена, но микроорганизм не ограничен этим. Соответственно, для задач настоящего изобретения микроорганизм, который продуцирует L-аминокислоту, может представлять собой микроорганизм, в котором дополнительно добавлен модифицированный полипептид, и тем самым увеличена способность продуцировать целевую L-аминокислоту.
В другом аспекте настоящего изобретения предложен способ получения L-аминокислоты, включающий культивирование микроорганизма в среде и выделение L-аминокислоты из культивируемого микроорганизма или среды. В частности, L-аминокислота может представлять собой происходящую из аспартата L-аминокислоту.
Способ легко может определить специалист в данной области техники с учетом оптимизированных условий культивирования и параметров ферментативной активности. В частности, микроорганизм можно культивировать известными способами периодического культивирования, непрерывного культивирования, периодического культивирования с подпиткой и так далее, но способ культивирования конкретно не ограничен этим. В частности, условия культивирования конкретно не ограничены, но рН (например от рН 5 до рН 9, в частности от рН 6 до рН 8 и более конкретно рН 6,8) может быть соответствующим образом подведен с использованием щелочного соединения (например гидроксида натрия, гидроксида калия или аммиака) или кислотного соединения (например фосфорной кислоты или серной кислоты). Аэробные условия можно поддерживать путем добавления в культуру кислорода или смеси газов, содержащей кислород. Температуру в культуре можно поддерживать от 20°С до 45°С и, в частности, от 25°С до 40°С, и культивирование можно проводить в течение примерно от 10 до 160 часов, но условия культивирования не ограничены этим. L-аминокислота, полученная путем культивирования, может секретироваться в среду или может оставаться внутри клеток.
Дополнительно, в культуральной среде можно использовать источники углерода, такие как сахара и углеводы (например глюкозу, сахарозу, лактозу, фруктозу, мальтозу, мелассу, крахмал и целлюлозу), масла и жиры (например соевое масло, подсолнечное масло, арахисовое масло и кокосовое масло), жирные кислоты (например пальмитиновую кислоту, стеариновую кислоту и линолевую кислоту), спирты (например глицерин и этанол) и органические кислоты (например уксусную кислоту), по отдельности или в комбинации, но источники углерода не ограничены этим; можно использовать источники азота, такие как азот-содержащие органические соединения (например пептон, дрожжевой экстракт, мясной сок, солодовый экстракт, жидкий кукурузный экстракт, соевую муку и мочевину) или неорганические соединения (например сульфат аммония, хлорид аммония, фосфат аммония, карбонат аммония и нитрат аммония) по отдельности или в комбинации, но источники азота не ограничены этим; и можно использовать источники калия, такие как дигидрофосфат калия, гидроортофосфат калия или соответствующие им натрийсодержащие соли по отдельности или в комбинации, но источники калия не ограничены этим. Дополнительно в среде могут содержаться другие необходимые стимулирующие рост вещества, включая соли металлов (например сульфат магния или сульфат железа), аминокислоты и витамины.
В способе выделения L-аминокислоты, полученной на стадии культивирования, по настоящему изобретению можно выделять целевую аминокислоту из культуры с использованием подходящего способа, известного в данной области техники, в соответствии со способом культивирования. Например, можно использовать центрифугирование, фильтрацию, анионообменную хроматографию, кристаллизацию, ВЭЖХ (высокоэффективная жидкостная хроматография) и так далее, и желаемую L-аминокислоту можно выделять из среды или из микроорганизма с использованием подходящего способа, известного в данной области техники.
Кроме того, стадия выделения может включать процесс очистки. Процесс очистки может быть выполнен с использованием подходящего способа, известного в данной области техники. Следовательно, выделенная L-аминокислота может находиться в очищенной форме или в ферментационной жидкости микроорганизма, содержащей эту L-аминокислоту.
ПОДРОБНОЕ ОПИСАНИЕ ВОПЛОЩЕНИЙ ИЗОБРЕТЕНИЯ
Ниже настоящее изобретение будет описано подробно путем приведения примеров воплощений. Однако эти примеры воплощений предназначены исключительно для иллюстративных целей и не предназначены ограничивать объем настоящего изобретения.
Пример 1: Получение векторной библиотеки для введения модификации в ORF (открытая рамка считывания) гена gltA С целью поиска модифицированных штаммов, в которых уровень экспрессии или активность гена gltA Corynebacterium glutamicum понижены, была получена библиотека с использованием следующего способа.
Сначала были введены 0-4,5 модификаций на 1 т.п.н. фрагмента ДНК (1814 п.н.), включающего ген gltA (1314 п.н.), с использованием набора для случайного мутагенеза GenemorphII (Stratagene). Склонную к ошибкам ПЦР выполняли с использованием хромосомы Corynebacterium glutamicum АТСС13032 (WT) в качестве матрицы вместе с праймерами (SEQ ID NO: 5 и 6) (Таблица 1). В частности, реакционную смесь, содержащую хромосому штамма WT (дикого типа) (500 нг), праймеры 5 и 6 (по 125 нг каждого), реакционный буфер Mutazyme II (1-кратный), смесь dNTP (дезоксирибонуклеозидтрифосфаты) (40 мМ) и ДНК-полимеразу Mutazyme II (2,5U), подвергали денатрурации при 94°С в течение 2 минут с последующим проведением 25 циклов денатурации при 94°С в течение 1 минуты, отжига при 56°С в течение 1 минуты и полимеризации при 72°С в течение 3 минут и затем полимеризации при 72°С в течение 10 минут.
Амплифицированные фрагменты гена лигировали в вектор pCRII с использованием набора для клонирования ТОРО ТА (Invitrogen), трансформировали в Е.coli DH5α, и трансформированную Е.coli DH5α высевали на твердую среду LB (Лурия-Бертани), содержащую канамицин (25 мг/л). 20 типов трансформированных колоний отбирали и полученные из них плазмиды подвергали анализу последовательности. В результате было подтверждено, что модификации были введены в сайты, отличные друг от друга, с частотой 0,5 мутаций/т.п.н. Наконец, примерно 10000 колоний трансформированной Е.coli собирали, и плазмиды были выделены из них и обозначены как библиотека pTOPO-gltA(mt).

Пример 2: Получение штаммов с делецией gltA и скрининг штаммов, модифицированных по gltA, на основе скорости роста
Для получения штамма дикого типа Corynebacterium glutamicum АТСС13032 с делецией гена gltA был получен вектор pDZ-ΔgltA с делецией гена gltA следующим образом. Более конкретно, вектор pDZ-ΔgltA (патент Кореи No. 10-0924065) был получен таким образом, что фрагменты ДНК (каждый по 600 п.н.), расположенные 5' и 3' от гена gltA, были лигированы в вектор pDZ-ΔgltA. Были синтезированы праймеры (SEQ ID NO: 7 и 8), в которых сайт распознавания фермента рестрикции (XbaI) был вставлен во фрагмент 5' и фрагмент 3', соответственно, на основе нуклеотидной последовательности описанного гена gltA (SEQ ID NO: 2), и праймеры (SEQ ID NO: 9 и 10), каждый из которых расположен на расстоянии 600 п.н. от праймеров (SEQ ID NO: 7 и 8) (Таблица 2). 5'-концевой фрагмент был получен путем ПЦР с использованием хромосомы Corynebacterium glutamicum АТСС13032 в качестве матрицы вместе с праймерами (SEQ ID NO: 7 и 9). Аналогично, фрагмент гена, расположенный на 3'-конце гена gltA, был получен путем ПЦР с использованием праймеров (SEQ ID NO: 8 и 10). ПЦР проводили следующим образом: денатурация при 94°С в течение 2 минут; 30 циклов денатурации при 94°С в течение 1 минуты, отжига при 56°С в течение 1 минуты и полимеризации при 72°С в течение 40 секунд; и полимеризация при 72°С в течение 10 минут.
Между тем, фрагменты ДНК, амплифицированные путем ПЦР как описано выше, лигировали в вектор pDZ, который разрезали ферментом рестрикции (XbaI) и затем нагревали при 65°С в течение 20 минут, трансформировали ими Е.coli DH5α и трансформированные DH5α Е.coli высевали на твердую среду LB, содержащую канамицин (25 мг/л). Колонии, трансформированные вектором, в который был вставлен целевой ген путем ПЦР с использованием праймеров (SEQ ID NO: 7 и 8), отбирали, и из колоний была получена плазмида с использованием традиционного способа выделения плазмид, которая получила название pDZ-ΔgltA.

Полученным вектором pDZ-ΔgltA трансформировали Corynebacterium glutamicum АТСС13032 методом электрического импульса (Van der Rest et al, Appl. Microbiol. Biotecnol. 52:541-545, 1999), и штамм с делецией гена gltA был получен путем гомологичной рекомбинации. Штамм с делецией гена gltA получил название Corynebacterium glutamicum WT::ΔgltA.
Дополнительно провели трансформацию библиотекой pTOPO-gltA(mt) методом электрического импульса с использованием штамма WT::ΔgltA. Трансформированный штамм высевали на комбинированную среду для планшета, содержащую канамицин (25 мг/л), и из него было получено примерно 500 колоний. Полученные колонии инокулировали в 96-луночный планшет, в котором содержалась посевная культуральная среда (200 мкл/лунка), и штамм культивировали при 32°С при скорости 1000 об/мин в течение примерно 9 часов.
Комбинированная среда для планшета (рН 7,0)
Глюкоза (10 г), пептон (10 г), мясной экстракт (5 г), дрожжевой экстракт (5 г), сердечно-мозговая вытяжка (18,5 г), NaCl (2,5 г), мочевина (2 г), сорбит (91 г), агар (20 г) (на 1 л дистиллированной воды)
Посевная культуральная среда (рН 7,0)
Глюкоза (20 г), пептон (10 г), дрожжевой экстракт (5 г), мочевина (1,5 г), KH2PO4 (4 г), K2HPO4 (8 г), MgSO4⋅7H2O (0,5 г), биотин (100 мкг), тиамин ⋅ HCl (1000 мкг), кальций-пантотеновая кислота (2000 мкг), никотинамид (2000 мкг) (на 1 л дистиллированной воды).
Рост клеток во время культивирования контролировали с помощью микроридера-УФ-спектрофотометра (Shimazu) (Фиг. 1). Штаммы WT и WT::ΔgltA использовали в качестве контрольных групп. Три типа штаммов, в которых клеточная масса была меньше, но скорость роста клеток поддерживалась на более высоком уровне по сравнению с таковыми штамма дикого типа (WT), были отобраны и получили названия от WT::gltA(mt)-1 до WT::gltA(mt)-3. Оставшиеся 497 штаммов демонстрировали похожую или увеличенную клеточную массу или уменьшенную скорость роста по сравнению с таковыми штаммов WT и WT::ΔgltA (контрольные группы).
Пример 3: Подтверждение нуклеотидных последовательностей трех штаммов, модифицированных по gltA
Для подтверждения нуклеотидных последовательностей гена gltA трех выбранных штаммов (то есть, WT::gltA(mt)-1 - WT::gltA(mt)-3), фрагменты ДНК, включающие ген gltA в хромосоме, амплифицировали с использованием праймеров (SEQ ID NO: 5 и 6), определенных в Примере 1. ПЦР проводили следующим образом: денатурация при 94°С в течение 2 минут; 30 циклов денатурации при 94°С в течение 1 минуты, отжига при 56°С в течение 1 минуты и полимеризации при 72°С в течение 40 секунд; и полимеризация при 72°С в течение 10 минут.
Нуклеотидные последовательности амплифицированных генов анализировали, и в результате было подтверждено, что эти нуклеотидные последовательности обычно демонстрировали введение от 1 до 2 модификаций в нуклеотидную последовательность, локализованную от 721 п.н. до 723 п.н. вниз по ходу транскрипции от инициирующего кодона ORF (открытая рамка считывания) гена gltA. То есть, было подтверждено, что штаммы WT::gltA(mt)-1 - WT::gltA(mt)-3 представляли собой штаммы, модифицированные по цитратсинтазе (CS), в которых нуклеотидные последовательности в положении с 721го по 723е изменены с исходных 'ААС на 'АСС или 'ACT' (то есть, замена 241ой аминокислоты на N-конце гена gltA с аспарагина на треонин).
Пример 4: Получение различных штаммов, в которых 241ая аминокислота гена gltA (то есть, аспарагин) заменена на другую аминокислоту
Была предпринята попытка заменить 241ую аминокислоту в аминокислотной последовательности SEQ ID NO: 1 (то есть, аспарагин) (который присутствует у штамма дикого типа) на аминокислоту, отличную от аспарагина.
Для введения 19 типов модификаций гетерогенной нуклеотидной замены, включая N241T, которая представляет собой модификацию, подтвержденную в Примере 3, каждый рекомбинантный вектор был получен следующим образом.
Сначала праймеры (SEQ ID NO: 11 и 12), в которых сайт, распознаваемый ферментом рестрикции (XbaI), был вставлен в 5'-фрагмент и в 3'-фрагмент, соответственно, на расстоянии примерно 600 п.н. или вниз по ходу транскрипции, или вверх по ходу транскрипции от положений от 721го до 723го нуклеотидной последовательности гена gltA, синтезировали с использованием геномной ДНК, экстрагированной из штамма WT, в качестве матрицы. Для введения 19 типов гетерогенных модификаций с заменой нуклеотидов были синтезированы праймеры (SEQ ID NO: с 13 по 48) для замены в положении от 721го до 723го нуклеотидной последовательности гена gltA (Таблица 3).
В частности, была получена плазмида pDZ-gltA(N241A) в такой форме, что фрагменты ДНК (по 600 п.н. каждый), расположенные на 5'- и 3'-концах гена gltA, лигировали в вектор pDZ (Патент Кореи No. 2009-0094433). 5'-концевой фрагмент гена gltA был получен путем ПЦР с использованием хромосомы штамма WT в качестве матрицы вместе с праймерами (SEQ ID NO: 11 и 13). ПЦР проводили следующим образом: денатурация при 94°С в течение 2 минут; 30 циклов денатурации при 94°С в течение 1 минуты, отжига при 56°С в течение 1 минуты и полимеризации при 72°С в течение 40 секунд; и полимеризация при 72°С в течение 10 минут. Аналогично, 3'-концевой фрагмент гена гена gltA был получен путем ПЦР с использованием праймеров (SEQ ID NO: 12 и 14). Амплифицированные фрагменты ДНК очищали с использованием набора для очистки ПЦР (Quiagen) и использовали в качестве фрагментов ДНК для вставки для получения векторов.
Между тем, фрагменты ДНК для вставки, амплифицированные путем ПЦР, и вектор pDZ, который разрезали ферментом рестрикции (XbaI) и затем нагревали при 65°С в течение 20 минут, лигировали с использованием набора для клонирования Infusion и затем трансформировали ими Е.coli DH5α. Штамм высевали на твердую среду LB, содержащую канамицин (25 мг/л). Трансформированные колонии, в которых целевой ген был вставлен в вектор путем ПЦР с использованием праймеров (SEQ ID NO: 11 и 12), отбирали и плазмиду получали с использованием известных традиционных методов выделения плазмид и обозначали как pDZ-gltA(N241A).
Аналогично были получены плазмиды следующим образом: pDZ-gltA(N241V) с использованием праймеров (SEQ ID NO: 11 и 15 и SEQ ID NO: 12 и 16); pDZ-gltA(N241Q) с использованием праймеров (SEQ ID NO: 11 и 17 и SEQ ID NO: 12 и 18); pDZ-gltA(N241H) с использованием праймеров (SEQ ID NO: 11 и 19 и SEQ ID NO: 12 и 20); pDZ-gltA(N241R) с использованием праймеров (SEQ ID NO: 11 и 21 и SEQ ID NO: 12 и 22); pDZ-gltA(N241P) с использованием праймеров (SEQ ID NO: 11 и 23 и SEQ ID NO: 12 и 24); pDZ-gltA(N241L) с использованием праймеров (SEQ ID NO: 11 и 25 и SEQ ID NO: 12 и 26); pDZ-gltA(N241Y) с использованием праймеров (SEQ ID NO: 11 и 27 и SEQ ID NO: 12 и 28); pDZ-gltA(N241S) с использованием праймеров (SEQ ID NO: 11 и 29 и SEQ ID NO: 12 и 30); pDZ-gltA(N241K) с использованием праймеров (SEQ ID NO: 11 и 31 и SEQ ID NO: 12 и 32); pDZ-gltA(N241M) с использованием праймеров (SEQ ID NO: 11 и 33 и SEQ ID NO: 12 и 34); pDZ-gltA(N241I) с использованием праймеров (SEQ ID NO: 11 и 35 и SEQ ID NO: 12 и 36); pDZ-gltA(N241E) с использованием праймеров (SEQ ID NO: 11 и 37 и SEQ ID NO: 12 и 38); pDZ-gltA(N241D) с использованием праймеров (SEQ ID NO: 11 и 39 и SEQ ID NO: 12 и 40); pDZ-gltA(N241G) с использованием праймеров (SEQ ID NO: 11 и 41 и SEQ ID NO: 12 и 42); pDZ-gltA(N241W) с использованием праймеров (SEQ ID NO: 11 и 43 и SEQ ID NO: 12 и 44); pDZ-gltA(N241C) с использованием праймеров (SEQ ID NO: 11 и 45 и SEQ ID NO: 12 и 46); pDZ-gltA(N241F) с использованием праймеров (SEQ ID NO: 11 и 47 и SEQ ID NO: 12 и 48); и pDZ-gltA(N241T) с использованием праймеров (SEQ ID NO: 11 и 49 и SEQ ID NO: 12 и 50).


Каждым из полученных векторов трансформировали лизин-продуцирующий штамм Corynebacterium glutamicum KCCM11016P (патент Кореи No. 10-0159812) методом электрического импульса. 19 штаммов, в которых модификация гетерогенной нуклеотидной заменой была введена в ген gltA каждого штамма, были названы следующим образом: KCCM11016P::gltA(N241A), KCCM11016P::gltA(N241V), KCCM11016P::gltA(N241Q), KCCM11016P::gltA(N241H), KCCM11016P::gltA(N241R), KCCM11016P::gltA(N241P), KCCM11016P::gltA(N241L), KCCM11016P::gltA(N241Y), KCCM11016P::gltA(N241S), KCCM11016P::gltA(N241K), KCCM11016P::gltA(N241M), KCCM11016P::gltA(N241I), KCCM11016P::gltA(N241E), KCCM11016P::gltA(N241D), KCCM11016P::glt4(N241G), KCCM11016P::gltA(N241W), KCCM11016P::gltA(N241C), KCCM11016P::glt4(N241F) и KCCM11016P::gltA(N241T).
Пример 5: Анализ продуктивности по лизину и измерение цитратсинтазной (CS) активности штаммов, модифицированных по gltA
Цитратсинтазную (CS) активность штаммов, полученных в Примере 4, измеряли опубликованным ранее способом (Ooyen et al., Biotechnol. Bioeng, 109(8): 2070-2081, 2012). Ген gltA штамма KCCM11016P был делетирован способом, используемым в Примере 1, и полученный в результате штамм получил название KCCM11016P::ΔgltA. При использовании штаммов KCCM11016P и KCCM11016P::ΔgltA в качестве контрольных групп выбранные 19 типов штаммов культивировали как описано ниже и измеряли скорость потребления сахара, выход продуцирования лизина, концентрацию глутаминовой кислоты (GA) (то есть, репрезентативного побочного продукта в культуральной среде) и ферментативную активность CS.
Сначала каждый из штаммов инокулировали в колбы на 250 мл с угловыми перегородками, содержащие 25 мл посевной культуральной среды, и культивировали в инкубаторе-встряхивателе (200 об/мин) при 30°С в течение 20 часов. Затем в каждую из колб на 250 мл с угловыми перегородками, содержащих 24 мл продукционной среды для L-лизина, инокулировали 1 мл посевного культурального бульона и культивировали в инкубаторе-встряхивателе (200 об/мин) при 32°С в течение 72 часов. Состав посевной культуральной среды и продукционной среды показаны ниже. После завершения культивирования концентрации L-лизина и глутаминовой кислоты в каждой культуре измеряли путем ВЭЖХ (Waters 2478).
Посевная культуральная среда (рН 7,0)
Глюкоза (20 г), пептон (10 г), дрожжевой экстракт (5 г), мочевина (1,5 г), KH2PO4 (4 г), K2HPO4 (8 г), MgSO4⋅7H2O (0,5 г), биотин (100 мкг), Тиамин-HCl (1000 мкг), кальций-пантотеновая кислота (2000 мкг), никотинамид (2000 мкг) (на 1 л дистиллированной воды)
Продукционная среда (рН 7,0)
Глюкоза (100 г), (NH4)2SO4 40 г, (40 г), соевый белок (2,5 г), твердая фракция кукурузного экстракта (5 г), мочевина (3 г), KH2PO4 (1 г), MgSO4⋅7H2O (0,5 г), биотин (100 мкг), тиамин-HCl (1000 мкг), кальций-пантотеновая кислота (2000 мкг), никотинамид (3000 мкг) и СаСО3 (30 г) (на 1 л дистиллированной воды).
Для измерения ферментативной активности CS клетки отделяли центрифугированием, дважды промывали 100 мМ буфером Трис-HCl (рН 7,2, 3 мМ L-цистеин, 10 мМ MgCl2) и полученные в результате клетки, наконец, ресуспендировали в 2 мл такого же буфера. Суспензию клеток механически разрушали в течение 10 минут традиционным методом перемешивания со стеклянными шариками и супернатант отделяли посредством двух раундов центрифугирования (13000 об/мин, 4°С, 30 минут) и использовали в качестве неочищенного экстракта для измерения ферментативной активности CS. Для измерения ферментативной активности CS неочищенный экстракт добавляли в реакционную смесь для измерения ферментативной активности (50 мМ Трис; 200 мМ глутамат калия, рН 7,5; 0,1 мМ 5,50-дитиобис(2-нитробензойная кислота, DTNB), 0,2 мМ оксалоацетат, 0,15 мМ ацетил-СоА) и проводили реакцию при 30°С.Активность CS определяли в форме соотношения путем измерения поглощения DTNB, расщепленной в минуту, относительно такового у родительского штамма при 412 нм. Результаты по лизин-продуцирующей способности, скоростям потребления сахара, составам культурального бульона и ферментативной активности CS показаны в Таблице 4 ниже.


В случае штамма с делецией гена gltA выход лизина у этого штамма демонстрировал увеличение примерно на 5,5%р по сравнению с таковым родительского штамма, но этот штамм не обладал способностью потреблять сахар вплоть до более поздней стадии культивирования. То есть, в случае когда ген gltA делетирован и следовательно штамм почти не имеет активности CS, рост штамма ингибирован, тем самым затрудняя промышленное применение этого штамма. Было подтверждено, что во всех случаях, когда штамм включал модифицированный полипептид, в котором 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1 была заменена на другую аминокислоту, активность CS была понижена, в то время как рост штамма поддерживался на промышленно применимом уровне. Дополнительно, поскольку активность CS штамма была понижена, выход лизина у этого штамма демонстрировал тенденцию к увеличению на величину примерно от 3%р до 5%р по сравнению с таковым родительского штамма. В частности, в случае трех модифицированных штаммов (то есть N241S, N241Y и N241T) из модифицированных штаммов, в которых активность CS была понижена до уровня от 30% до 60%, эти штаммы демонстрировали увеличение выхода лизина на величину примерно от 3%р до 5%р по сравнению с таковым их родительского штамма, в то же время показывая сходные уровни скорости потребления сахара. Дополнительно, было подтверждено, что штаммы, у которых выход лизина был увеличен по сравнению с таковым их родительского штамма, демонстрировали уменьшение количества глутаминовой кислоты (GA) в культуральном бульоне. То есть, это объясняется тем, что введение модификации по настоящему изобретению в эти штаммы оказывает эффект по улучшению выхода лизина у этих штаммов, в то же время уменьшая количество побочных продуктов у этих штаммов.
Эти результаты показывают, что уровень продуцирования лизина может быть увеличен путем создания подходящего баланса между потоком углерода, направленным в путь ТСА, и количеством поступаемого оксалоацетата (то есть, предшественника биосинтеза лизина). В частности, принимая во внимание то, что количество глутаминовой кислоты, которая обычно образуется как побочный продукт в большом количестве во время культивирования для получения лизина, было уменьшено, было подтверждено, что снижение активности гена gltA ингибирует поток углерода в путь ТСА и тем самым индуцирует поток углерода в направлении биосинтеза лизина, обладая тем самым значительной эффективностью в увеличении продуктивности по лизину.
Из штаммов, полученных выше, штамм KCCM11016P::gltA(N241T) был депонирован 20 ноября 2017 года в Корейской Коллекции Корейского Центра Культур Микроорганизмов (KCCM), являющейся международным органом депонирования в соответствии с Будапештским Договором, и ему был присвоен номер доступа KCCM12154P.
Пример 6: Анализ лизин-продуцирующей способности выбранных штаммов, модифицированных по gltA
Модификации трех штаммов, модифицированных по gltA, выбранных в Примере 5, были введены в L-лизин-продуцирующие штаммы Corynebacterium glutamicum (то есть, KCCM10770P (патент Кореи No. 10-0924065) и KCCM11347P (патент Кореи No. 10-0073610)). Эти три штамма были выбраны на основании критериев того, что они имеют пониженную активность CS, имеют скорость потребления сахара, близкую к таковой их родительского штамма, и увеличенный выход лизина по сравнению с таковым их родительского штамма. Три типа векторов из Примера 4 (то есть, pDZ-gltA(N241S), pDZ-gltA(N241Y) и pDZ-gltA(N241T)) вводили в два штамма Corynebacterium glutamicum (то есть, KCCM10770P и KCCM11347P) методом электрического импульса для получения шести штаммов (то есть, KCCM10770P::gltA(N241S), KCCM10770P::gltA(N241Y), KCCM10770P::gltA(N241T), KCCM11347P::gltA(N241S), KCCM11347P::gltA(N241Y) и KCCM11347P::gltA(N241T)). Две контрольные группы штаммов (то есть, KCCM10770P и KCCM11347P) и шесть штаммов с модификациями по типу нуклеотидной замены в гене gltA культивировали таким же образом как в Примере 5 и анализировали лизин-продуцирующую способность, скорость потребления сахара и состав культуральной жидкости этих штаммов.
После культивирования этих штаммов в течение определенного периода времени анализировали лизин-продуцирующую способность, скорость потребления сахара и состав культурального бульона. Результаты представлены в Таблице 5 ниже.

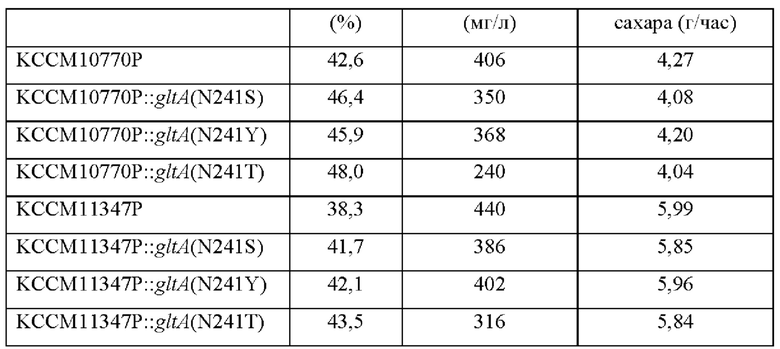
Как видно из результатов, представленных в Таблице 5 выше, в случае двух лизин-продуцирующих штаммов (то есть, KCCM10770P и KCCM11347P), модифицированных таким образом, что 241ая аминокислота последовательности gltA была заменена на другую аминокислоту, все штаммы демонстрировали увеличенный выход продуцирования лизина, уменьшенный выход побочных продуктов и близкую скорость потребления сахара в сравнении с таковыми родительского штамма. Было подтверждено, что среди трех типов модификаций, штамм, имеющий модификацию (N241T) (то есть, модификацию, где 241ая аминокислота (аспарагин) была заменена на треонин) показал наибольшее увеличение выхода лизина, в то же время демонстрируя близкий уровень или немного повышенный уровень скорости потребления сахара в сравнении с таковыми их родительского штамма. Дополнительно было подтверждено, что штамм с модификацией N241T демонстрировал наибольшую степень уменьшения выхода глутаминовой кислоты. Эти результаты подтверждают, что ослабление активности гена gltA приводило к уменьшению потока углерода в путь ТСА, тем самым вызывая уменьшение количества глутаминовой кислоты в культуральном бульоне, что подтверждают результаты из Примера 6.
Пример 7: Получение и анализ лизин-продуцирующей способности штамма CJ3P, в который введена модификация gltA(N241T)
Для подтверждения того, проявляют ли другие L-лизин-продуцирующие штаммы Corynebacterium glutamicum такой же эффект как описано выше, штамм, в который была введена модификация gltA(N241T), был получен с использованием Corynebacterium glutamicum CJ3P (Binder et al. Genome Biology, 2012, 13:R40), который обеспечен L-лизин-продуцирующей способностью, путем введения трех типов модификаций [то есть, pyc(P458S), hom(V59A) и lysC(T311I)] в штамм дикого типа, таким же образом как в Примере 6. Штамм, полученный таким образом, получил название CJ3::glt4(N241T). Контрольные группы (то есть, штаммы CJ3P и CJ3::glt4(N241T)) культивировали таким же образом как в Примере 5, и лизин-продуцирующую способность, скорость потребления сахара и состав культурального бульона анализировали, и результаты показаны в Таблице 6 ниже.

В результате анализа лизин-продуцирующей способности, скорости потребления сахара и состава культурального бульона, было подтверждено, что штамм, в который была введена модификация glt4(N241T)), демонстрировал увеличение выхода лизина и уменьшение концентрации глутаминовой кислоты, в то же время поддерживая скорость потребления сахара на близком уровне.
Пример 8: Получение треонинового штамма, в который введена модификация gltA (N241T), и анализ треонин-продуцирующей способности
Для однозначного подтверждения изменений в L-треонин-продуцирующей способности при введении модификации gltA(N241T) обеспечивали сверхэкспрессию гена, кодирующего гомосериндегидрогеназу, которая продуцирует гомосерин (то есть, общее промежуточное соединение в путях биосинтеза L-треонина и L-изолейцина), путем модификации. В частности, был получен штамм, в котором известная модификация hom(G378E) (R. Winkels, S. et al., Appl. Microbiol. Biotechnol. 45, 612-620, 1996) была введена в штамм CJ3P::gltA(N241T), используемый в Примере 7. Дополнительно, штамм, в котором только модификация hom(G378E) была введена в CJ3P, был получен в качестве контрольной группы. Рекомбинантные векторы для введения модификаций были получены способом, описанным ниже.
Для получения вектора для введения hom(G378E) сначала праймеры (SEQ ID NO: 51 и 52), в которых сайт распознавания фермента рестрикции (XbaI) был вставлен в 5'-концевой фрагмент и 3'-концевой фрагмент, соответственно, на расстоянии примерно 600 п.н. или вниз по ходу транскрипции, или вверх по ходу транскрипции от положений с 1131го до 1134го нуклеотидной последовательности гена horn, синтезировали с использованием геномной ДНК, экстрагированной из штамма WT в качестве матрицы. Праймеры (SEQ ID NO: 53 и 54) для замены нуклеотидной последовательности гена hom (Таблица 7). Плазмида pDZ-hom(G378E) была получена в форме, где фрагменты ДНК (по 600 п.н. каждый), расположенные на каждом из 5' и 3'-концов, были присоединены к вектору pDZ (патент Кореи No. 2009-0094433). 5'-концевой фрагмент гена hom был получен путем ПЦР с использованием хромосомы штамма WT в качестве матрицы вместе с праймерами (SEQ ID NO: 51 и 53). ПЦР проводили следующим образом: денатурация при 94°С в течение 2 минут; 30 циклов денатурации при 94°С в течение 1 минуты, отжига при 56°С в течение 1 минуты и полимеризации при 72°С в течение 40 секунд; и полимеризация при 72°С в течение 10 минут.Аналогично, 3'-концевой фрагмент гена hom был получен путем ПЦР с использованием праймеров (SEQ ID NO: 52 и 54). Амплифицированный фрагмент ДНК очищали с использованием набора для очистки ПЦР (Quiagen) и использовали в качестве фрагмента ДНК для вставки для получения вектора. Между тем, вектор pDZ, который был обработан ферментом рестрикции XbaI и нагрет при 65°С в течение 20 минут, лигировали с фрагментом ДНК для вставки, амплифицированным путем ПЦР с использованием набора для клонирования Infusion, и лигированным продуктом трансформировали Е.coli DH5α и высевали ее на твердую среду LB, содержащую канамицин (25 мг/л). Колонии, трансформированные вектором, в который был вставлен целевой ген, полученный путем ПЦР с использованием праймеров (SEQ ID NO: 51 и 52), отбирали и плазмиду получали путем общеизвестного метода выделения плазмид, и таким образом был получен вектор для введения модификации по типу нуклеотидной замены hom (G378E) в хромосому (то есть, pDZ-hom(G378E)).

Были получены штаммы, в которых нуклеотидная модификация введена в ген hom в штаммах CJ3P и CJ3P::gltA(N241T) с помощью вектора pDZ-hom(G378E) с использованием такого же способа как в Примере 6 (то есть, CJ3P::hom(G378E) и CJ3P::gltA(N241T)-hom(G378E)). Полученные штаммы двух типов культивировали с использованием такого же способа как в Примере 5, и анализировали концентрацию треонина, скорость потребления сахара и состав культурального бульона. Результаты представлены в Таблице 8 ниже.

В результате анализа концентрации треонина, скорости потребления сахара и состава культурального бульона было подтверждено, что концентрация треонина увеличивалась при близкой скорости потребления сахара, при этом концентрация глутаминовой кислоты снижалась у штамма, в который была введена модификация glt4(N241T).
Пример 9: Получение изолейцинового штамма, в который введена gltA-модификация (N241T), и анализ изолейцин-продуиирующей способности
Для подтверждения эффекта введения модификации glt4(N241T) в отношении L-изолейцин-продуцирующей способности, ген, кодирующий L-треониндегидратазу, также сверхэкспрессировали путем модификации, о которой сообщалось ранее. В частности, был получен штамм, в котором известная модификация ilvA(V323A) (S. Morbach et al., Appl. Enviro. Microbiol., 62(12): 4345-4351, 1996) была введена в штамм CJ3P::gltA(N241T)-hom(G378E), используемый в Примере 7. Дополнительно штамм, в котором только модификация ilvA(V323A) была введена в CJ3P::hom(G378E), был получен в качестве контрольной группы. Рекомбинантные векторы для введения модификаций были получены способом, описанным ниже.
Для получения вектора для введения ilvA(V323A) сначала праймеры (SEQ ID NO: 55 и 56), в которых сайт распознавания фермента рестрикции (XbaI) был вставлен в 5'-концевой фрагмент и в 3'-концевой фрагмент, соответственно, на расстоянии примерно 600 п.н. или ниже по ходу транскрипции, или выше по ходу транскрипции от положений от 966го до 969го нуклеотидной последовательности гена ilvA, синтезировали с использованием геномной ДНК, экстрагированной из штамма WT, в качестве матрицы. Дополнительно, были получены праймеры (SEQ ID NO: 57 и 58) для замены нуклеотидной последовательности гена ilvA (Таблица 9). Плазмида pDZ-ilvA(V323A) была получена в форме, где фрагменты ДНК (по 600 п.н. каждый), расположенные на каждом из 5'- и 3'-концов, были присоединены к вектору pDZ (Патент Кореи No. 2009-0094433). 5'-концевой фрагмент гена ilvA был получен путем ПЦР с использованием хромосомы штамма WT в качестве матрицы вместе с праймерами (SEQ ID NO: 55 и 57). ПЦР проводили следующим образом: денатурация при 94°С в течение 2 минут; 30 циклов денатурации при 94°С в течение 1 минуты, отжига при 56°С в течение 1 минуты и полимеризации при 72°С в течение 40 секунд; и полимеризация при 72°С в течение 10 минут.
Аналогично, З'-концевой фрагмент гена ilvA был получен путем ПЦР с использованием праймеров (SEQ ID NO: 56 и 58). Амплифицированный фрагмент ДНК очищали с использованием набора для очистки ПЦР (Quiagen) и использовали в качестве фрагмента ДНК для вставки для получения вектора. Между тем, вектор pDZ, который был обработан ферментом рестрикции XbaI и нагрет при 65°С в течение 20 минут, лигировали с фрагментом ДНК для вставки, амплифицированным путем ПЦР, с использованием набора для клонирования Infusion, и лигированным продуктом трансформировали Е.coli DH5α и высевали ее на твердую среду LB, содержащую канамицин (25 мг/л). Колонии, трансформированные вектором, в который был вставлен целевой ген, полученный путем ПЦР с использованием праймеров (SEQ ID NO: 55 и 56), отбирали, плазмиды получали путем общеизвестных методов выделения плазмид, и таким образом был получен вектор для введения модификации по типу нуклеотидной замены ilvA(V323A) в хромосому (то есть, pDZ-ilvA(V323A)).

Были получены штаммы, в которых нуклеотидная модификация введена в ген ilvA в штаммах CJ3P::hom(G378E) и CJ3P::gltA(N241T)-hom(G378E) с помощью вектора pDZ-ilvA(G378E) с использованием такого же способа как в Примере 6 (то есть, CJ3P::hom(G378E)-ilvA(V323A) и CJ3P::glt4(N241T)-hom(G378E)-ilvA(V323A)).
Полученные штаммы двух типов культивировали с использованием такого же способа как в Примере 5 и анализировали концентрацию изолейцина и GA в культуральной среде и скорость потребления сахара. Результаты представлены в Таблице 10 ниже.

В результате анализа концентрации треонина, скорости потребления сахара и состава культурального бульона было подтверждено, что концентрация изолейцина увеличивалась при близком уровне скорости потребления сахара, в то время как концентрация глутаминовой кислоты снижалась у штамма, в который была введена модификация gltA(N241T).
На основании вышеизложенного специалист в области техники, к которой принадлежит настоящее изобретение, понимает, что настоящее изобретение может быть выполнено в других конкретных формах без изменения технических идей или существенных характеристик настоящего изобретения. В этом отношении примеры воплощений, раскрытые здесь, предназначены исключительно для иллюстративных целей, и их не следует рассматривать как ограничивающие объем настоящего изобретения каким-либо образом. Напротив, настоящее изобретение предназначено охватывать не только примеры воплощений, но также различные альтернативы, модификации, эквиваленты и другие воплощения, которые могут быть включены в идею и объем настоящего изобретения, как определено в прилагаемой формуле изобретения.
--->
<110> CJ CheilJedang Corporation
<120> Modified polypeptide with attenuated activity of citrate synthase and a method for producing L-amino acid using the same
<130> OPA18433
<150> KR 10-2018-0017400
<151> 2018-02-13
<160> 62
<170> KoPatentIn 3.0
<210> 1
<211> 437
<212> PRT
<213> Corynebacterium glutamicum
<220>
<221> PEPTIDE
<222> (1)..(437)
<223> gltA
<400> 1
Met Phe Glu Arg Asp Ile Val Ala Thr Asp Asn Asn Lys Ala Val Leu
1 5 10 15
His Tyr Pro Gly Gly Glu Phe Glu Met Asp Ile Ile Glu Ala Ser Glu
20 25 30
Gly Asn Asn Gly Val Val Leu Gly Lys Met Leu Ser Glu Thr Gly Leu
35 40 45
Ile Thr Phe Asp Pro Gly Tyr Val Ser Thr Gly Ser Thr Glu Ser Lys
50 55 60
Ile Thr Tyr Ile Asp Gly Asp Ala Gly Ile Leu Arg Tyr Arg Gly Tyr
65 70 75 80
Asp Ile Ala Asp Leu Ala Glu Asn Ala Thr Phe Asn Glu Val Ser Tyr
85 90 95
Leu Leu Ile Asn Gly Glu Leu Pro Thr Pro Asp Glu Leu His Lys Phe
100 105 110
Asn Asp Glu Ile Arg His His Thr Leu Leu Asp Glu Asp Phe Lys Ser
115 120 125
Gln Phe Asn Val Phe Pro Arg Asp Ala His Pro Met Ala Thr Leu Ala
130 135 140
Ser Ser Val Asn Ile Leu Ser Thr Tyr Tyr Gln Asp Gln Leu Asn Pro
145 150 155 160
Leu Asp Glu Ala Gln Leu Asp Lys Ala Thr Val Arg Leu Met Ala Lys
165 170 175
Val Pro Met Leu Ala Ala Tyr Ala His Arg Ala Arg Lys Gly Ala Pro
180 185 190
Tyr Met Tyr Pro Asp Asn Ser Leu Asn Ala Arg Glu Asn Phe Leu Arg
195 200 205
Met Met Phe Gly Tyr Pro Thr Glu Pro Tyr Glu Ile Asp Pro Ile Met
210 215 220
Val Lys Ala Leu Asp Lys Leu Leu Ile Leu His Ala Asp His Glu Gln
225 230 235 240
Asn Cys Ser Thr Ser Thr Val Arg Met Ile Gly Ser Ala Gln Ala Asn
245 250 255
Met Phe Val Ser Ile Ala Gly Gly Ile Asn Ala Leu Ser Gly Pro Leu
260 265 270
His Gly Gly Ala Asn Gln Ala Val Leu Glu Met Leu Glu Asp Ile Lys
275 280 285
Ser Asn His Gly Gly Asp Ala Thr Glu Phe Met Asn Lys Val Lys Asn
290 295 300
Lys Glu Asp Gly Val Arg Leu Met Gly Phe Gly His Arg Val Tyr Lys
305 310 315 320
Asn Tyr Asp Pro Arg Ala Ala Ile Val Lys Glu Thr Ala His Glu Ile
325 330 335
Leu Glu His Leu Gly Gly Asp Asp Leu Leu Asp Leu Ala Ile Lys Leu
340 345 350
Glu Glu Ile Ala Leu Ala Asp Asp Tyr Phe Ile Ser Arg Lys Leu Tyr
355 360 365
Pro Asn Val Asp Phe Tyr Thr Gly Leu Ile Tyr Arg Ala Met Gly Phe
370 375 380
Pro Thr Asp Phe Phe Thr Val Leu Phe Ala Ile Gly Arg Leu Pro Gly
385 390 395 400
Trp Ile Ala His Tyr Arg Glu Gln Leu Gly Ala Ala Gly Asn Lys Ile
405 410 415
Asn Arg Pro Arg Gln Val Tyr Thr Gly Asn Glu Ser Arg Lys Leu Val
420 425 430
Pro Arg Glu Glu Arg
435
<210> 2
<211> 1314
<212> DNA
<213> Corynebacterium glutamicum
<220>
<221> gene
<222> (1)..(1314)
<223> gltA
<400> 2
atgtttgaaa gggatatcgt ggctactgat aacaacaagg ctgtcctgca ctaccccggt 60
ggcgagttcg aaatggacat catcgaggct tctgagggta acaacggtgt tgtcctgggc 120
aagatgctgt ctgagactgg actgatcact tttgacccag gttatgtgag cactggctcc 180
accgagtcga agatcaccta catcgatggc gatgcgggaa tcctgcgtta ccgcggctat 240
gacatcgctg atctggctga gaatgccacc ttcaacgagg tttcttacct acttatcaac 300
ggtgagctac caaccccaga tgagcttcac aagtttaacg acgagattcg ccaccacacc 360
cttctggacg aggacttcaa gtcccagttc aacgtgttcc cacgcgacgc tcacccaatg 420
gcaaccttgg cttcctcggt taacattttg tctacctact accaggacca gctgaaccca 480
ctcgatgagg cacagcttga taaggcaacc gttcgcctca tggcaaaggt tccaatgctg 540
gctgcgtacg cacaccgcgc acgcaagggt gctccttaca tgtacccaga caactccctc 600
aatgcgcgtg agaacttcct gcgcatgatg ttcggttacc caaccgagcc atacgagatc 660
gacccaatca tggtcaaggc tctggacaag ctgctcatcc tgcacgctga ccacgagcag 720
aactgctcca cctccaccgt tcgtatgatc ggttccgcac aggccaacat gtttgtctcc 780
atcgctggtg gcatcaacgc tctgtccggc ccactgcacg gtggcgcaaa ccaggctgtt 840
ctggagatgc tcgaagacat caagagcaac cacggtggcg acgcaaccga gttcatgaac 900
aaggtcaaga acaaggaaga cggcgtccgc ctcatgggct tcggacaccg cgtttacaag 960
aactacgatc cacgtgcagc aatcgtcaag gagaccgcac acgagatcct cgagcacctc 1020
ggtggcgacg atcttctgga tctggcaatc aagctggaag aaattgcact ggctgatgat 1080
tacttcatct cccgcaagct ctacccgaac gtagacttct acaccggcct gatctaccgc 1140
gcaatgggct tcccaactga cttcttcacc gtattgttcg caatcggtcg tctgccagga 1200
tggatcgctc actaccgcga gcagctcggt gcagcaggca acaagatcaa ccgcccacgc 1260
caggtctaca ccggcaacga atcccgcaag ttggttcctc gcgaggagcg ctaa 1314
<210> 3
<211> 437
<212> PRT
<213> Unknown
<220>
<223> N241T
<400> 3
Met Phe Glu Arg Asp Ile Val Ala Thr Asp Asn Asn Lys Ala Val Leu
1 5 10 15
His Tyr Pro Gly Gly Glu Phe Glu Met Asp Ile Ile Glu Ala Ser Glu
20 25 30
Gly Asn Asn Gly Val Val Leu Gly Lys Met Leu Ser Glu Thr Gly Leu
35 40 45
Ile Thr Phe Asp Pro Gly Tyr Val Ser Thr Gly Ser Thr Glu Ser Lys
50 55 60
Ile Thr Tyr Ile Asp Gly Asp Ala Gly Ile Leu Arg Tyr Arg Gly Tyr
65 70 75 80
Asp Ile Ala Asp Leu Ala Glu Asn Ala Thr Phe Asn Glu Val Ser Tyr
85 90 95
Leu Leu Ile Asn Gly Glu Leu Pro Thr Pro Asp Glu Leu His Lys Phe
100 105 110
Asn Asp Glu Ile Arg His His Thr Leu Leu Asp Glu Asp Phe Lys Ser
115 120 125
Gln Phe Asn Val Phe Pro Arg Asp Ala His Pro Met Ala Thr Leu Ala
130 135 140
Ser Ser Val Asn Ile Leu Ser Thr Tyr Tyr Gln Asp Gln Leu Asn Pro
145 150 155 160
Leu Asp Glu Ala Gln Leu Asp Lys Ala Thr Val Arg Leu Met Ala Lys
165 170 175
Val Pro Met Leu Ala Ala Tyr Ala His Arg Ala Arg Lys Gly Ala Pro
180 185 190
Tyr Met Tyr Pro Asp Asn Ser Leu Asn Ala Arg Glu Asn Phe Leu Arg
195 200 205
Met Met Phe Gly Tyr Pro Thr Glu Pro Tyr Glu Ile Asp Pro Ile Met
210 215 220
Val Lys Ala Leu Asp Lys Leu Leu Ile Leu His Ala Asp His Glu Gln
225 230 235 240
Thr Cys Ser Thr Ser Thr Val Arg Met Ile Gly Ser Ala Gln Ala Asn
245 250 255
Met Phe Val Ser Ile Ala Gly Gly Ile Asn Ala Leu Ser Gly Pro Leu
260 265 270
His Gly Gly Ala Asn Gln Ala Val Leu Glu Met Leu Glu Asp Ile Lys
275 280 285
Ser Asn His Gly Gly Asp Ala Thr Glu Phe Met Asn Lys Val Lys Asn
290 295 300
Lys Glu Asp Gly Val Arg Leu Met Gly Phe Gly His Arg Val Tyr Lys
305 310 315 320
Asn Tyr Asp Pro Arg Ala Ala Ile Val Lys Glu Thr Ala His Glu Ile
325 330 335
Leu Glu His Leu Gly Gly Asp Asp Leu Leu Asp Leu Ala Ile Lys Leu
340 345 350
Glu Glu Ile Ala Leu Ala Asp Asp Tyr Phe Ile Ser Arg Lys Leu Tyr
355 360 365
Pro Asn Val Asp Phe Tyr Thr Gly Leu Ile Tyr Arg Ala Met Gly Phe
370 375 380
Pro Thr Asp Phe Phe Thr Val Leu Phe Ala Ile Gly Arg Leu Pro Gly
385 390 395 400
Trp Ile Ala His Tyr Arg Glu Gln Leu Gly Ala Ala Gly Asn Lys Ile
405 410 415
Asn Arg Pro Arg Gln Val Tyr Thr Gly Asn Glu Ser Arg Lys Leu Val
420 425 430
Pro Arg Glu Glu Arg
435
<210> 4
<211> 1314
<212> DNA
<213> Unknown
<220>
<223> N241T
<400> 4
atgtttgaaa gggatatcgt ggctactgat aacaacaagg ctgtcctgca ctaccccggt 60
ggcgagttcg aaatggacat catcgaggct tctgagggta acaacggtgt tgtcctgggc 120
aagatgctgt ctgagactgg actgatcact tttgacccag gttatgtgag cactggctcc 180
accgagtcga agatcaccta catcgatggc gatgcgggaa tcctgcgtta ccgcggctat 240
gacatcgctg atctggctga gaatgccacc ttcaacgagg tttcttacct acttatcaac 300
ggtgagctac caaccccaga tgagcttcac aagtttaacg acgagattcg ccaccacacc 360
cttctggacg aggacttcaa gtcccagttc aacgtgttcc cacgcgacgc tcacccaatg 420
gcaaccttgg cttcctcggt taacattttg tctacctact accaggacca gctgaaccca 480
ctcgatgagg cacagcttga taaggcaacc gttcgcctca tggcaaaggt tccaatgctg 540
gctgcgtacg cacaccgcgc acgcaagggt gctccttaca tgtacccaga caactccctc 600
aatgcgcgtg agaacttcct gcgcatgatg ttcggttacc caaccgagcc atacgagatc 660
gacccaatca tggtcaaggc tctggacaag ctgctcatcc tgcacgctga ccacgagcag 720
acctgctcca cctccaccgt tcgtatgatc ggttccgcac aggccaacat gtttgtctcc 780
atcgctggtg gcatcaacgc tctgtccggc ccactgcacg gtggcgcaaa ccaggctgtt 840
ctggagatgc tcgaagacat caagagcaac cacggtggcg acgcaaccga gttcatgaac 900
aaggtcaaga acaaggaaga cggcgtccgc ctcatgggct tcggacaccg cgtttacaag 960
aactacgatc cacgtgcagc aatcgtcaag gagaccgcac acgagatcct cgagcacctc 1020
ggtggcgacg atcttctgga tctggcaatc aagctggaag aaattgcact ggctgatgat 1080
tacttcatct cccgcaagct ctacccgaac gtagacttct acaccggcct gatctaccgc 1140
gcaatgggct tcccaactga cttcttcacc gtattgttcg caatcggtcg tctgccagga 1200
tggatcgctc actaccgcga gcagctcggt gcagcaggca acaagatcaa ccgcccacgc 1260
caggtctaca ccggcaacga atcccgcaag ttggttcctc gcgaggagcg ctaa 1314
<210> 5
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 5
atgtttgaaa gggatatcgt g 21
<210> 6
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 6
ttagcgctcc tcgcgaggaa c 21
<210> 7
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 7
cggggatcct ctagacgatg aaaaacgccc 30
<210> 8
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 8
caggtcgact ctagactgca cgtggatcgt 30
<210> 9
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 9
actgggacta tttgttcgga aaaa 24
<210> 10
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 10
cgaacaaata gtcccagttc aacg 24
<210> 11
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 11
cggggatcct ctagaagatg ctgtctgaga ctgga 35
<210> 12
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 12
caggtcgact ctagacgcta aatttagcgc tcctc 35
<210> 13
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 13
ggaggtggag catgcctgct cgtggtcagc 30
<210> 14
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 14
gaccacgagc aggcatgctc cacctccacc 30
<210> 15
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 15
ggaggtggag cagacctgct cgtggtcagc 30
<210> 16
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 16
gaccacgagc aggtctgctc cacctccacc 30
<210> 17
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 17
ggaggtggag cactgctgct cgtggtcagc 30
<210> 18
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 18
gaccacgagc agcagtgctc cacctccacc 30
<210> 19
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 19
ggaggtggag cagtgctgct cgtggtcagc 30
<210> 20
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 20
gaccacgagc agcactgctc cacctccacc 30
<210> 21
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 21
ggaggtggag cagcgctgct cgtggtcagc 30
<210> 22
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 22
gaccacgagc agcgctgctc cacctccacc 30
<210> 23
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 23
ggaggtggag catggctgct cgtggtcagc 30
<210> 24
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 24
gaccacgagc agccatgctc cacctccacc 30
<210> 25
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 25
ggaggtggag cacagctgct cgtggtcagc 30
<210> 26
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 26
gaccacgagc agctgtgctc cacctccacc 30
<210> 27
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 27
ggaggtggag cagtactgct cgtggtcagc 30
<210> 28
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 28
gaccacgagc agtactgctc cacctccacc 30
<210> 29
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 29
ggaggtggag caggactgct cgtggtcagc 30
<210> 30
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 30
gaccacgagc agtcctgctc cacctccacc 30
<210> 31
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 31
ggaggtggag cacttctgct cgtggtcagc 30
<210> 32
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 32
gaccacgagc agaagtgctc cacctccacc 30
<210> 33
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 33
ggaggtggag cacatctgct cgtggtcagc 30
<210> 34
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 34
gaccacgagc agatgtgctc cacctccacc 30
<210> 35
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 35
ggaggtggag cagatctgct cgtggtcagc 30
<210> 36
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 36
gaccacgagc agatctgctc cacctccacc 30
<210> 37
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 37
ggaggtggag cattcctgct cgtggtcagc 30
<210> 38
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 38
gaccacgagc aggaatgctc cacctccacc 30
<210> 39
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 39
ggaggtggag cagtcctgct cgtggtcagc 30
<210> 40
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 40
gaccacgagc aggactgctc cacctccacc 30
<210> 41
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 41
ggaggtggag cagccctgct cgtggtcagc 30
<210> 42
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 42
gaccacgagc agggctgctc cacctccacc 30
<210> 43
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 43
ggaggtggag cagcactgct cgtggtcagc 30
<210> 44
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 44
gaccacgagc agtggtgctc cacctccacc 30
<210> 45
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 45
ggaggtggag cagcactgct cgtggtcagc 30
<210> 46
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 46
gaccacgagc agtgctgctc cacctccacc 30
<210> 47
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 47
ggaggtggag cagaactgct cgtggtcagc 30
<210> 48
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 48
gaccacgagc agttctgctc cacctccacc 30
<210> 49
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 49
ggaggtggag caggtctgct cgtggtcagc 30
<210> 50
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 50
gaccacgagc agacctgctc cacctccacc 30
<210> 51
<211> 29
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 51
tcctctagac tggtcgcctg atgttctac 29
<210> 52
<211> 29
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 52
gactctagat tagtcccttt cgaggcgga 29
<210> 53
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 53
gccaaaacct ccacgcgatc 20
<210> 54
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 54
atcgcgtgga ggttttggct 20
<210> 55
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 55
acggatccca gactccaaag caaaagcg 28
<210> 56
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 56
acggatccaa ccaaacttgc tcacactc 28
<210> 57
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 57
acaccacggc agaaccaggt gcaaaggaca 30
<210> 58
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер
<400> 58
ctggttctgc cgtggtgtgc atcatctctg 30
<210> 59
<211> 437
<212> PRT
<213> Unknown
<220>
<223> N241S
<400> 59
Met Phe Glu Arg Asp Ile Val Ala Thr Asp Asn Asn Lys Ala Val Leu
1 5 10 15
His Tyr Pro Gly Gly Glu Phe Glu Met Asp Ile Ile Glu Ala Ser Glu
20 25 30
Gly Asn Asn Gly Val Val Leu Gly Lys Met Leu Ser Glu Thr Gly Leu
35 40 45
Ile Thr Phe Asp Pro Gly Tyr Val Ser Thr Gly Ser Thr Glu Ser Lys
50 55 60
Ile Thr Tyr Ile Asp Gly Asp Ala Gly Ile Leu Arg Tyr Arg Gly Tyr
65 70 75 80
Asp Ile Ala Asp Leu Ala Glu Asn Ala Thr Phe Asn Glu Val Ser Tyr
85 90 95
Leu Leu Ile Asn Gly Glu Leu Pro Thr Pro Asp Glu Leu His Lys Phe
100 105 110
Asn Asp Glu Ile Arg His His Thr Leu Leu Asp Glu Asp Phe Lys Ser
115 120 125
Gln Phe Asn Val Phe Pro Arg Asp Ala His Pro Met Ala Thr Leu Ala
130 135 140
Ser Ser Val Asn Ile Leu Ser Thr Tyr Tyr Gln Asp Gln Leu Asn Pro
145 150 155 160
Leu Asp Glu Ala Gln Leu Asp Lys Ala Thr Val Arg Leu Met Ala Lys
165 170 175
Val Pro Met Leu Ala Ala Tyr Ala His Arg Ala Arg Lys Gly Ala Pro
180 185 190
Tyr Met Tyr Pro Asp Asn Ser Leu Asn Ala Arg Glu Asn Phe Leu Arg
195 200 205
Met Met Phe Gly Tyr Pro Thr Glu Pro Tyr Glu Ile Asp Pro Ile Met
210 215 220
Val Lys Ala Leu Asp Lys Leu Leu Ile Leu His Ala Asp His Glu Gln
225 230 235 240
Ser Cys Ser Thr Ser Thr Val Arg Met Ile Gly Ser Ala Gln Ala Asn
245 250 255
Met Phe Val Ser Ile Ala Gly Gly Ile Asn Ala Leu Ser Gly Pro Leu
260 265 270
His Gly Gly Ala Asn Gln Ala Val Leu Glu Met Leu Glu Asp Ile Lys
275 280 285
Ser Asn His Gly Gly Asp Ala Thr Glu Phe Met Asn Lys Val Lys Asn
290 295 300
Lys Glu Asp Gly Val Arg Leu Met Gly Phe Gly His Arg Val Tyr Lys
305 310 315 320
Asn Tyr Asp Pro Arg Ala Ala Ile Val Lys Glu Thr Ala His Glu Ile
325 330 335
Leu Glu His Leu Gly Gly Asp Asp Leu Leu Asp Leu Ala Ile Lys Leu
340 345 350
Glu Glu Ile Ala Leu Ala Asp Asp Tyr Phe Ile Ser Arg Lys Leu Tyr
355 360 365
Pro Asn Val Asp Phe Tyr Thr Gly Leu Ile Tyr Arg Ala Met Gly Phe
370 375 380
Pro Thr Asp Phe Phe Thr Val Leu Phe Ala Ile Gly Arg Leu Pro Gly
385 390 395 400
Trp Ile Ala His Tyr Arg Glu Gln Leu Gly Ala Ala Gly Asn Lys Ile
405 410 415
Asn Arg Pro Arg Gln Val Tyr Thr Gly Asn Glu Ser Arg Lys Leu Val
420 425 430
Pro Arg Glu Glu Arg
435
<210> 60
<211> 1314
<212> DNA
<213> Unknown
<220>
<223> N241S
<400> 60
atgtttgaaa gggatatcgt ggctactgat aacaacaagg ctgtcctgca ctaccccggt 60
ggcgagttcg aaatggacat catcgaggct tctgagggta acaacggtgt tgtcctgggc 120
aagatgctgt ctgagactgg actgatcact tttgacccag gttatgtgag cactggctcc 180
accgagtcga agatcaccta catcgatggc gatgcgggaa tcctgcgtta ccgcggctat 240
gacatcgctg atctggctga gaatgccacc ttcaacgagg tttcttacct acttatcaac 300
ggtgagctac caaccccaga tgagcttcac aagtttaacg acgagattcg ccaccacacc 360
cttctggacg aggacttcaa gtcccagttc aacgtgttcc cacgcgacgc tcacccaatg 420
gcaaccttgg cttcctcggt taacattttg tctacctact accaggacca gctgaaccca 480
ctcgatgagg cacagcttga taaggcaacc gttcgcctca tggcaaaggt tccaatgctg 540
gctgcgtacg cacaccgcgc acgcaagggt gctccttaca tgtacccaga caactccctc 600
aatgcgcgtg agaacttcct gcgcatgatg ttcggttacc caaccgagcc atacgagatc 660
gacccaatca tggtcaaggc tctggacaag ctgctcatcc tgcacgctga ccacgagcag 720
tcctgctcca cctccaccgt tcgtatgatc ggttccgcac aggccaacat gtttgtctcc 780
atcgctggtg gcatcaacgc tctgtccggc ccactgcacg gtggcgcaaa ccaggctgtt 840
ctggagatgc tcgaagacat caagagcaac cacggtggcg acgcaaccga gttcatgaac 900
aaggtcaaga acaaggaaga cggcgtccgc ctcatgggct tcggacaccg cgtttacaag 960
aactacgatc cacgtgcagc aatcgtcaag gagaccgcac acgagatcct cgagcacctc 1020
ggtggcgacg atcttctgga tctggcaatc aagctggaag aaattgcact ggctgatgat 1080
tacttcatct cccgcaagct ctacccgaac gtagacttct acaccggcct gatctaccgc 1140
gcaatgggct tcccaactga cttcttcacc gtattgttcg caatcggtcg tctgccagga 1200
tggatcgctc actaccgcga gcagctcggt gcagcaggca acaagatcaa ccgcccacgc 1260
caggtctaca ccggcaacga atcccgcaag ttggttcctc gcgaggagcg ctaa 1314
<210> 61
<211> 437
<212> PRT
<213> Unknown
<220>
<223> N241Y
<400> 61
Met Phe Glu Arg Asp Ile Val Ala Thr Asp Asn Asn Lys Ala Val Leu
1 5 10 15
His Tyr Pro Gly Gly Glu Phe Glu Met Asp Ile Ile Glu Ala Ser Glu
20 25 30
Gly Asn Asn Gly Val Val Leu Gly Lys Met Leu Ser Glu Thr Gly Leu
35 40 45
Ile Thr Phe Asp Pro Gly Tyr Val Ser Thr Gly Ser Thr Glu Ser Lys
50 55 60
Ile Thr Tyr Ile Asp Gly Asp Ala Gly Ile Leu Arg Tyr Arg Gly Tyr
65 70 75 80
Asp Ile Ala Asp Leu Ala Glu Asn Ala Thr Phe Asn Glu Val Ser Tyr
85 90 95
Leu Leu Ile Asn Gly Glu Leu Pro Thr Pro Asp Glu Leu His Lys Phe
100 105 110
Asn Asp Glu Ile Arg His His Thr Leu Leu Asp Glu Asp Phe Lys Ser
115 120 125
Gln Phe Asn Val Phe Pro Arg Asp Ala His Pro Met Ala Thr Leu Ala
130 135 140
Ser Ser Val Asn Ile Leu Ser Thr Tyr Tyr Gln Asp Gln Leu Asn Pro
145 150 155 160
Leu Asp Glu Ala Gln Leu Asp Lys Ala Thr Val Arg Leu Met Ala Lys
165 170 175
Val Pro Met Leu Ala Ala Tyr Ala His Arg Ala Arg Lys Gly Ala Pro
180 185 190
Tyr Met Tyr Pro Asp Asn Ser Leu Asn Ala Arg Glu Asn Phe Leu Arg
195 200 205
Met Met Phe Gly Tyr Pro Thr Glu Pro Tyr Glu Ile Asp Pro Ile Met
210 215 220
Val Lys Ala Leu Asp Lys Leu Leu Ile Leu His Ala Asp His Glu Gln
225 230 235 240
Tyr Cys Ser Thr Ser Thr Val Arg Met Ile Gly Ser Ala Gln Ala Asn
245 250 255
Met Phe Val Ser Ile Ala Gly Gly Ile Asn Ala Leu Ser Gly Pro Leu
260 265 270
His Gly Gly Ala Asn Gln Ala Val Leu Glu Met Leu Glu Asp Ile Lys
275 280 285
Ser Asn His Gly Gly Asp Ala Thr Glu Phe Met Asn Lys Val Lys Asn
290 295 300
Lys Glu Asp Gly Val Arg Leu Met Gly Phe Gly His Arg Val Tyr Lys
305 310 315 320
Asn Tyr Asp Pro Arg Ala Ala Ile Val Lys Glu Thr Ala His Glu Ile
325 330 335
Leu Glu His Leu Gly Gly Asp Asp Leu Leu Asp Leu Ala Ile Lys Leu
340 345 350
Glu Glu Ile Ala Leu Ala Asp Asp Tyr Phe Ile Ser Arg Lys Leu Tyr
355 360 365
Pro Asn Val Asp Phe Tyr Thr Gly Leu Ile Tyr Arg Ala Met Gly Phe
370 375 380
Pro Thr Asp Phe Phe Thr Val Leu Phe Ala Ile Gly Arg Leu Pro Gly
385 390 395 400
Trp Ile Ala His Tyr Arg Glu Gln Leu Gly Ala Ala Gly Asn Lys Ile
405 410 415
Asn Arg Pro Arg Gln Val Tyr Thr Gly Asn Glu Ser Arg Lys Leu Val
420 425 430
Pro Arg Glu Glu Arg
435
<210> 62
<211> 1314
<212> DNA
<213> Unknown
<220>
<223> N241Y
<400> 62
atgtttgaaa gggatatcgt ggctactgat aacaacaagg ctgtcctgca ctaccccggt 60
ggcgagttcg aaatggacat catcgaggct tctgagggta acaacggtgt tgtcctgggc 120
aagatgctgt ctgagactgg actgatcact tttgacccag gttatgtgag cactggctcc 180
accgagtcga agatcaccta catcgatggc gatgcgggaa tcctgcgtta ccgcggctat 240
gacatcgctg atctggctga gaatgccacc ttcaacgagg tttcttacct acttatcaac 300
ggtgagctac caaccccaga tgagcttcac aagtttaacg acgagattcg ccaccacacc 360
cttctggacg aggacttcaa gtcccagttc aacgtgttcc cacgcgacgc tcacccaatg 420
gcaaccttgg cttcctcggt taacattttg tctacctact accaggacca gctgaaccca 480
ctcgatgagg cacagcttga taaggcaacc gttcgcctca tggcaaaggt tccaatgctg 540
gctgcgtacg cacaccgcgc acgcaagggt gctccttaca tgtacccaga caactccctc 600
aatgcgcgtg agaacttcct gcgcatgatg ttcggttacc caaccgagcc atacgagatc 660
gacccaatca tggtcaaggc tctggacaag ctgctcatcc tgcacgctga ccacgagcag 720
tactgctcca cctccaccgt tcgtatgatc ggttccgcac aggccaacat gtttgtctcc 780
atcgctggtg gcatcaacgc tctgtccggc ccactgcacg gtggcgcaaa ccaggctgtt 840
ctggagatgc tcgaagacat caagagcaac cacggtggcg acgcaaccga gttcatgaac 900
aaggtcaaga acaaggaaga cggcgtccgc ctcatgggct tcggacaccg cgtttacaag 960
aactacgatc cacgtgcagc aatcgtcaag gagaccgcac acgagatcct cgagcacctc 1020
ggtggcgacg atcttctgga tctggcaatc aagctggaag aaattgcact ggctgatgat 1080
tacttcatct cccgcaagct ctacccgaac gtagacttct acaccggcct gatctaccgc 1140
gcaatgggct tcccaactga cttcttcacc gtattgttcg caatcggtcg tctgccagga 1200
tggatcgctc actaccgcga gcagctcggt gcagcaggca acaagatcaa ccgcccacgc 1260
caggtctaca ccggcaacga atcccgcaag ttggttcctc gcgaggagcg ctaa 1314
<---

Настоящее изобретение относится к области биотехнологии, а именно к модифицированному полипептиду с пониженной активностью цитратсинтазы и к способу получения происходящей из аспартата L-аминокислоты с использованием этого модифицированного полипептида. Модифицированный полипептид, обладающий цитратсинтазной активностью, где 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1, представляющая собой аспарагин, заменена на другую аминокислоту. Изобретение также относится к микроорганизму рода Corynebacterium, содержащему модифицированный полипептид по п. 1, для продукции L-аминокислоты, к способу получения L-аминокислоты, включающему культивирование микроорганизма по п. 6 в среде и выделение L-аминокислоты из культивируемого микроорганизма или среды. Изобретение позволяет при использовании нового модифицированного полипептида, цитратсинтазная активность которого понижена до определенного уровня, повысить уровень продуцирования L-аминокислоты без замедления скорости роста штамма. 4 н. и 9 з.п. ф-лы, 1 ил., 10 табл., 8 пр.
1. Модифицированный полипептид, обладающий цитратсинтазной активностью, где 241ая аминокислота в аминокислотной последовательности SEQ ID NO: 1, представляющая собой аспарагин, заменена на другую аминокислоту.
2. Модифицированный полипептид по п. 1, где 241ая аминокислота, представляющая собой аспарагин, заменена на аминокислоту, отличную от лизина.
3. Модифицированный полипептид по п. 1, где другая аминокислота представляет собой ароматическую аминокислоту или гидрофильную аминокислоту.
4. Модифицированный полипептид по п. 1, где 241ая аминокислота, представляющая собой аспарагин, заменена на треонин, серин или тирозин.
5. Полинуклеотид, кодирующий модифицированный полипептид по п. 1.
6. Микроорганизм рода Corynebacterium, содержащий модифицированный полипептид по п. 1, для продукции L-аминокислоты.
7. Микроорганизм по п. 6, где микроорганизм рода Corynebacterium продуцирует L-аминокислоту.
8. Микроорганизм по п. 6, где микроорганизм рода Corynebacterium продуцирует происходящую из аспартата L-аминокислоту.
9. Микроорганизм по п. 6, где микроорганизм рода Corynebacterium продуцирует по меньшей мере одну L-аминокислоту, выбранную из группы, состоящей из лизина, треонина, метионина, гомосерина или его производного и изолейцина.
10. Микроорганизм по п. 6, где микроорганизм рода Corynebacterium представляет собой Corynebacterium glutamicum.
11. Способ получения L-аминокислоты, включающий культивирование микроорганизма по п. 6 в среде и выделение L-аминокислоты из культивируемого микроорганизма или среды.
12. Способ по п. 11, где L-аминокислота представляет собой происходящую из аспартата L-аминокислоту.
13. Способ по п. 11, где L-аминокислота представляет собой по меньшей мере одну L-аминокислоту, выбранную из группы, состоящей из лизина, треонина, метионина, гомосерина или его производного и изолейцина.
| МИКРООРГАНИЗМЫ Corynebacterium, СПОСОБНЫЕ УТИЛИЗИРОВАТЬ КСИЛОЗУ, И СПОСОБ ПОЛУЧЕНИЯ L-ЛИЗИНА С ПРИМЕНЕНИЕМ ТАКИХ МИКРООРГАНИЗМОВ | 2013 |
|
RU2584593C2 |
| L-ЛИЗИН-ПРОДУЦИРУЮЩАЯ БАКТЕРИЯ Corynebacterium glutamicum ИЛИ Brevibacterium flavum, УСТОЙЧИВАЯ К ФУЗИДИНОВОЙ КИСЛОТЕ, И СПОСОБ МИКРОБИОЛОГИЧЕСКОГО СИНТЕЗА L-ЛИЗИНА С ЕЕ ИСПОЛЬЗОВАНИЕМ | 2013 |
|
RU2549690C1 |
| Способ получения L-лизина с использованием микроорганизмов, обладающих способностью продуцировать L-лизин | 2012 |
|
RU2616870C1 |
| KR 1020160000098 A, 04.01.2016. | |||

