Область техники
Настоящее изобретение относится к новому варианту синтазы ацетогидроксикислот и его применению, и, в частности, варианту синтазы ацетогидроксикислот, микроорганизму, содержащему данный вариант, или способу получения L-аминокислоты с разветвленной цепью.
Предшествующий уровень техники
Известно, что аминокислоты с разветвленной цепью (например, L-валин, L-лейцин и L-изолейцин) повышают уровни белка у индивида и играют важную роль в качестве источника энергии при выполнении физических упражнений и ввиду этого широко используются в разных областях медицины, в продуктах питания и так далее. Что касается биосинтеза аминокислот с разветвленной цепью, то одни и те же ферменты используются в параллельных путях биосинтеза, и поэтому путем ферментации трудно получить единственный тип аминокислоты с разветвленной цепью в промышленном масштабе. При получении аминокислот с разветвленной цепью роль синтазы ацетогидроксикислот (т.е. первого фермента биосинтеза аминокислот с разветвленной цепью) является наиболее важной; однако предыдущие исследования синтазы ацетогидроксикислот были сфокусированы главным образом на устранении ингибирования по типу обратной связи, обусловленного модификациями малой субъединицы синтазы ацетогидроксикислот (белка IlvN) (Protein Expr. Purif., 2015 May, 109: 106-12, US2014-0335574, US2009-496475, US2006-303888, US2008-245610), что свидетельствует о серьезном отсутствии релевантных исследований.
Синтаза ацетогидроксикислот представляет собой фермент, играющий важную роль при получении ацетомолочной кислоты из двух молекул пирувата и получении 2-ацето-2-гидроксибутирата из кетомасляной кислоты и пирувата. Синтаза ацетогидроксикислот катализирует декарбоксилирование пирувата и реакцию конденсации с другой молекулой пирувата с получением ацетолактата, который является предшественником валина и лейцина; или катализирует декарбоксилирование пирувата и реакцию конденсации с 2-кетобутиратом с получением ацетогидроксибутирата, который является предшественником изолейцина. Соответственно, синтаза ацетогидроксикислот является очень важным ферментом, вовлеченным в начальный процесс биосинтеза L-аминокислот с разветвленной цепью.
Описание
Техническая проблема
Авторы настоящего изобретения приложили усилия для эффективного получения L-аминокислот с разветвленной цепью, и в конечном итоге они разработали вариант большой субъединицы. Далее авторы настоящего изобретения подтвердили, что L-аминокислоты с разветвленной цепью могут быть с высоким выходом получены из микроорганизма, содержащего данный вариант, тем самым завершая настоящее изобретение.
Техническое решение
Настоящим изобретением решается задача получения варианта синтазы ацетогидроксикислот.
Другая задача настоящего изобретения заключается в получении полинуклеотида, кодирующего данный вариант синтазы ацетогидроксикислот, вектора, содержащего данный полинуклеотид, и трансформанта, в который введен этот вектор.
Еще одна задача настоящего изобретения заключается в получении микроорганизма, продуцирующего L-аминокислоту с разветвленной цепью, при этом данный микроорганизм содержит вариант синтазы ацетогидроксикислот или в него введен вектор.
Еще одна задача настоящего изобретения заключается в разработке способа получения L-аминокислоты с разветвленной цепью, который включает: культивирование микроорганизма, продуцирующего L-аминокислоту с разветвленной цепью, в среде; и извлечение L-аминокислоты с разветвленной цепью из микроорганизма или среды, в которой его культивировали.
Полезные эффекты
Когда в микроорганизм введен активный вариант синтазы ацетогидроксикислот по настоящему изобретению, способность микроорганизма продуцировать L-аминокислоту с разветвленной цепью может существенно повыситься. Поэтому такой микроорганизм может быть широко использован для крупномасштабного получения L-аминокислот с разветвленной цепью.
Наилучший вариант
Для решения указанных выше задач, согласно одному из аспектов настоящего изобретения, предложен вариант синтазы ацетогидроксикислот, где в большой субъединице синтазы ацетогидроксикислот (т.е. большой субъединице синтазы ацетолактата; белке IlvB) 96-я аминокислота (т.е. треонин) заменена на аминокислоту, отличающуюся от треонина, 503-я аминокислота (т.е. триптофан) заменена на аминокислоту, отличающуюся от триптофана, или обе аминокислоты, 96-я аминокислота (т.е. треонин) и 503-я аминокислота (т.е. триптофан), заменены на другую аминокислоту.
В частности, большая субъединица синтазы ацетогидроксикислот может иметь аминокислотную последовательность SEQ ID NO: 1. Более конкретно, вариант синтазы ацетогидроксикислот может представлять собой вариант синтазы ацетогидроксикислот, у которого на его N-конце в аминокислотной последовательности SEQ ID NO: 1 96-я аминокислота (т.е. треонин) или 503-я аминокислота (т.е. триптофан) заменена на другую аминокислоту; или и 96-я аминокислота (т.е. треонин), и 503-я аминокислота (т.е. триптофан) каждая заменена на другую аминокислоту.
Используемый в данном описании термин «синтаза ацетогидроксикислот» относится к ферменту, вовлеченному в биосинтез L-аминокислот с разветвленной цепью, и он может быть вовлечен в первую стадию биосинтеза L-аминокислот с разветвленной цепью. В частности, синтаза ацетогидроксикислот может катализировать декарбоксилирование пирувата и реакцию конденсации с другой молекулой пирувата с образованием ацетолактата (т.е. предшественника валина) или может катализировать декарбоксилирование пирувата и реакцию конденсации с 2-кетобутиратом с образованием ацетогидроксибутирата (т.е. предшественника изолейцина). В частности, исходя из ацетомолочной кислоты осуществляется биосинтез L-валина путем последовательных реакций, катализируемых изомероредуктазой ацетогидроксикислот, дегидратазой дигидроксикислот и трансаминазой В. Кроме того, исходя из ацетомолочной кислоты осуществляется биосинтез L-лейцина как конечного продукта последовательных реакций, катализируемых изомероредуктазой ацетогидроксикислот, дегидратазой дигидроксикислот, 2-изопропилмалатсинтазой, изопропилмалатизомеразой, 3-изопропилмалатдегидрогеназой и трансаминазой В. В то же время, исходя из ацетогидроксибутирата осуществляется биосинтез L-изолейцина как конечного продукта последовательных реакций, катализируемых изомероредуктазой ацетогидроксикислот, дегидратазой дигидроксикислот и трансаминазой В. Соответственно, синтаза ацетогидроксикислот является важным ферментом в пути биосинтеза L-аминокислот с разветвленной цепью.
Синтаза ацетогидроксикислот кодируется двумя генами, т.е. ilvB и ilvN. Ген ilvB кодирует большую субъединицу синтазы ацетогидроксикислот (IlvB), а ген ilvN кодирует малую субъединицу синтазы ацетогидроксикислот (IlvN).
В настоящем изобретении синтаза ацетогидроксикислот может представлять собой фермент, происходящий из микроорганизма рода Corynebacterium и, в частности, из Corynebacterium glutamicum. Более конкретно, в качестве большой субъединицы синтазы ацетогидроксикислот могут быть включены без ограничения любой белок, имеющий активность белка IlvB и гомологию или идентичность с аминокислотной последовательностью SEQ ID NO: 1, составляющую 70% или более, в частности, 80% или более, более конкретно 85% или более, еще конкретнее 90% или более и даже еще конкретнее 95%, а также белок, имеющий аминокислотную последовательность SEQ ID NO: 1. Кроме того, вследствие вырожденности кодонов полинуклеотид, кодирующий белок, имеющий активность белка IlvB, может быть по-разному модифицирован в кодирующей области в пределах диапазона, модификации в котором не приводят к изменению аминокислотной последовательности белка, экспрессируемого с этой кодирующей области, с учетом кодонов, являющихся предпочтительными в организме, в котором будет экспрессирован данный белок. Нуклеотидная последовательность может быть включена, без ограничения, при условии, что она кодирует аминокислотную последовательность SEQ ID NO: 1 и, в частности, она может представлять собой кодирующую нуклеотидную последовательность SEQ ID NO: 2.
Используемый в данном описании термин «вариант синтазы ацетогидроксикислот» относится к белку, в котором одна или более аминокислот модифицированы (например, добавлены, удалены или заменены) в аминокислотной последовательности белка - синтазы ацетогидроксикислот. В частности, вариант синтазы ацетогидроксикислот представляет собой белок, активность которого эффективно повышена по сравнению с его диким типом или состоянием до модификации вследствие осуществления модификации по настоящему изобретению.
Используемый в данном описании термин «модификация» относится к общему способу улучшения ферментов, и можно использовать любой способ, известный в данной области техники, без ограничения, включая такие стратегии, как рациональный дизайн и направленная эволюция. Например, стратегии рационального дизайна включают способ точного введения аминокислоты в конкретное положение (сайт-направленный мутагенез или сайт-специфический мутагенез) и так далее, а стратегии направленной эволюции включают способ индуцирования неспецифического мутагенеза и так далее. Кроме того, модификацией может быть модификация, индуцированная природной мутацией без манипулирования извне. В частности, вариантом синтазы ацетогидроксикислот может быть вариант, который выделен, рекомбинантный белок или вариант, который произошел неприродным путем, однако этим варианты синтазы ацетогидроксикислот не ограничиваются.
Вариантом синтазы ацетогидроксикислот по настоящему изобретению может быть, в частности, белок IlvB, имеющий аминокислотную последовательность SEQ ID NO: 1, у которого на его N-конце 96-я аминокислота (т.е. треонин) или 503-я аминокислота (т.е. триптофан) подвергнута мутации; или и 96-я аминокислота (треонин), и 503-я аминокислота (триптофан) одновременно заменены на другую аминокислоту, однако этим вариант синтазы ацетогидроксикислот не ограничивается. Например, вариант синтазы ацетогидроксикислот по настоящему изобретению может представлять собой белок IlvB, в котором 96-я аминокислота (треонин) заменена на серии, цистеин или аланин, либо 503-я аминокислота (триптофан) заменена на глутамин, аспарагин или лейцин. Кроме того, очевидно, что любой вариант синтазы ацетогидроксикислот, имеющий аминокислотную последовательность, в которой 96-я аминокислота или 503-я аминокислота заменена на другую аминокислоту и одновременно часть аминокислотной последовательности удалена, модифицирована, заменена или добавлена, может проявлять активность, идентичную или соответствующую активности варианта синтазы ацетогидроксикислот по настоящему изобретению.
Кроме того, сами по себе большие субъединицы вариантов синтазы ацетогидроксикислот с описанными выше модификациями, синтаза ацетогидроксикислот, включая большие субъединицы вариантов синтазы ацетогидроксикислот, и синтаза ацетогидроксикислот, включая как большие, так и малые субъединицы вариантов синтазы ацетогидроксикислот, все могут быть включены в объем термина вариант синтазы ацетогидроксикислот по настоящему изобретению, однако этим вариант синтазы ацетогидроксикислот не ограничивается.
В настоящем изобретении было подтверждено, что количество полученной L-аминокислоты с разветвленной цепью может быть увеличено в результате замены 96-н аминокислоты и 503-й аминокислоты белка синтазы ацетогидроксикислот на различные другие аминокислоты и, таким образом, это подтверждает, что аминокислотные положения 96 и 503 являются важными в случае модификации белка синтазы ацетогидроксикислот в отношении продуцирования L-аминокислот с разветвленной цепью. Однако, поскольку замененные аминокислоты в воплощениях настоящего изобретения являются лишь репрезентативными воплощениями, демонстрирующими эффекты настоящего изобретения, то объем настоящего изобретения не следует ограничивать этими воплощениями, и очевидно, что когда 96-я аминокислота (треонин) заменена на аминокислоту, отличающуюся от треонина, 503-я аминокислота (триптофан) заменена на аминокислоту, отличающуюся от триптофана, или обе аминокислоты, 96-я и 503-я аминокислоты, заменены на другую аминокислоту, тогда варианты синтазы ацетогидроксикислот могут проявлять эффекты, соответствующие эффектам, описанным в воплощениях.
Кроме того, вариант синтазы ацетогидроксикислот по настоящему изобретению может иметь аминокислотную последовательность, представленную любой из последовательностей SEQ ID NO: 28-33, однако этим аминокислотная последовательность варианта синтазы ацетогидроксикислот не ограничивается. Кроме того, любой полипептид, имеющий гомологию или идентичность с вышеупомянутыми аминокислотными последовательностями, составляющую по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95% или по меньшей мере 99%, также может быть включен без ограничения, при условии, что эти полипептиды обладают активностью, по существу идентичной или соответствующей активности варианта синтазы ацетогидроксикислот в результате внесения модификаций по настоящему изобретению.
Понятия гомологии и идентичности относятся к степени сходства между двумя указанными аминокислотными последовательностями или нуклеотидными последовательностями и могут быть выражены в процентном отношении.
Термины «гомология» и «идентичность» часто могут быть использованы взаимозаменяемо друг с другом.
Гомологию или идентичность последовательностей для консервативного полинуклеотида или полипептида можно определить с использованием стандартного алгоритма выравнивания и штрафов за разрыв по умолчанию, установленных используемой программой, и они могут быть использованы в комбинации. По существу, гомологичные или идентичные последовательности могут гибридизоваться в условиях умеренной или высокой жесткости по всей их последовательности или по меньшей мере примерно на 50%, примерно на 60%, примерно на 70%, примерно на 80% или примерно на 90% всей длины. Что касается полинуклеотидов, подлежащих гибридизации, то также можно рассматривать полинуклеотиды, включающие вырожденный кодон вместо какого-либо кодона.
Тот факт, имеют ли любые две полинуклеотидные или полипептидные последовательности гомологию, сходство или идентичность, можно определить, например, с использованием известного компьютерного алгоритма, такого как программа «FASTA», использующая параметры по умолчанию как в Pearson et al. (1988) Proc. Natl. Acad. Sci. USA, 85: 2444. Альтернативно, они могут быть определены с использованием алгоритма Нидлмана-Вунша (Needleman and Wunsch, 1970, J. Mol. Biol., 48: 443-453), который реализован в программе Нидлмана из пакета EMBOSS (EMBOSS: The European Molecular Biology Open Software Suite, Rice et al., 2000, Trends Genet. 16: 276-277) (версия 5.0.0 или более поздняя) (в том числе пакета программ GCG (Devereux J., et al., Nucleic Acids Research, 12: 387 (1984)), BLASTP, BLASTN, FASTA (Atschul S.F. et al., J. Molec. Biol., 215: 403 (1990); Guide to Huge Computers, Martin J. Bischop (ed)., Academic Press, San Diego, 1994 и Carillo et al., (1988) SIAM J. Applied Math. 48: 1073). Например, гомологию, сходство или идентичность можно определить, используя BLAST или ClustalW (кластерный анализ W множественных выравниваний) от Национального центра биотехнологической информации.
Гомологию, сходство или идентичность полинуклеотидов или полипептидов можно определить путем сравнения информации о последовательностях, используя компьютерную программу GAP (например, Needleman et al. (1970), J. Mol. Biol., 48: 443), которая описана в Smith and Waterman, Adv. Appl. Math. (1981) 2: 482. Кратко, программа GAP определяет сходство в виде числа выравненных символов (т.е. нуклеотидов или аминокислот), которые оказываются аналогичными, деленного на общее число символов в более короткой из этих двух последовательностей. Параметры по умолчанию для программы GAP могут включать: (1) матрицу унарного сравнения (содержащую значение 1 для идентичности и 0 для отсутствия идентичности) и взвешенную матрицу сравнения (или матрицу замен EDN AFULL (EMBOSS версия NCBI NUC4.4)) из Gribskov et al. (1986) Nucl. Acids Res., 14: 6745, как описано в Schwartz and Dayhoff, eds., Atlas Of Protein Sequence And Structure, National Biomedical Research Foundation, pp. 353-358 (1979); (2) штраф 3,0 для каждого разрыва и дополнительный штраф 0,10 за каждый символ в каждом разрыве (или штраф за внесение разрыва 10, штраф за удлинение разрыва 0,5); и (3) отсутствие штрафа за внесение концевых разрывов. Поэтому термин «гомология» или «идентичность», использованный в данном описании, указывает на соответствие между последовательностями.
Согласно другому аспекту настоящего изобретения предложен полинуклеотид, кодирующий вариант синтазы ацетогидроксикислот по настоящему изобретению.
Использованный в данном описании термин «полинуклеотид» имеет значение с точки зрения включения молекулы ДНК или РНК, и нуклеотид, который представляет собой их основную структурную единицу, включает в себя не только природный нуклеотид, но также аналог, в котором участок сахарида или основания модифицирован. В настоящем изобретении полинуклеотид может представлять собой полинуклеотид, выделенный из клетки, или искусственно синтезированный полинуклеотид, однако этим полинуклеотид не ограничивается.
Полинуклеотид, кодирующий вариант синтазы ацетогидроксикислот по настоящему изобретению, может включать без ограничения любую нуклеотидную последовательность, которая кодирует белок, имеющий активность варианта синтазы ацетогидроксикислот по настоящему изобретению. В частности, вследствие вырожденности кодонов или с учетом предпочтительных кодонов в микроорганизме, в котором будет экспрессирован белок, могут быть выполнены различные модификации в кодирующей белок области в объеме, не приводящему к изменению аминокислотной последовательности данного белка. Полинуклеотид может включать без ограничения любую нуклеотидную последовательность, кодирующую аминокислотную последовательность SEQ ID NO: 28-33, и, в частности, последовательность, имеющую нуклеотидную последовательность SEQ ID NO: 34-39. Кроме того, любой полипептид, имеющий гомологию или идентичность с вышеупомянутыми аминокислотными последовательностями, составляющую по меньшей мере 70%, по меньшей мере 75%, по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 97% или по меньшей мере 99%, также может быть включен без ограничения, при условии, что эти полипептиды обладают активностью, по существу идентичной или соответствующей активности данного варианта синтазы ацетогидроксикислот в результате внесения модификаций по настоящему изобретению, обусловленной вырожденностью кодонов.
Альтернативно, в результате гибридизации в жестких условиях с зондом, который может быть получен на основании последовательности известного гена (например, последовательности, комплементарной всей или части нуклеотидной последовательности), любая последовательность, кодирующая белок, имеющий активность белков, состоящих из аминокислотной последовательности SEQ ID NO: 28-33, может быть включена без ограничения.
Термин «жесткие условия» относится к условиям, в которых возможно осуществление специфической гибридизации между полинуклеотидами. Такие условия описаны подробно в литературе (например, J. Sambrook и др., выше). Жесткие условия могут включать условия, при которых гены, имеющие высокую гомологию или идентичность (например, гены, имеющие по меньшей мере 80%, в частности, по меньшей мере 85%, более конкретно по меньшей мере 90%, еще конкретнее по меньшей мере 95%, даже еще конкретнее по меньшей мере 97% или наиболее конкретно по меньшей мере 99% гомологии), могут гибридизоваться друг с другом; условия, при которых гены, имеющие более низкую гомологию или идентичность, не могут гибридизоваться друг с другом; или условия, представляющие собой обычные условия промывки для гибридизации по Саузерну (например, при концентрации соли и температуре, соответствующих 60°С, 1 SSC (раствор хлорида и цитрата натрия), 0,1% додецилсульфата натрия (SDS); в частности, 60°С, 0,1 SSC, 0,1% SDS; более конкретно 68°С, 0,1 SSC, 0,1%) SDS, один раз, в частности, два раза или три раза).
Для гибридизации необходимо, чтобы две нуклеиновые кислоты имели комплементарные последовательности, хотя в зависимости от жесткости условий гибридизации могут быть возможны ошибочные спаривания между основаниями. Термин «комплементарный» используется для описания взаимосвязи между нуклеотидными основаниями, которые могут гибридизоваться друг с другом. Например, что касается ДНК, то аденозин комплементарен тимину, а цитозин комплементарен гуанину. Соответственно, настоящее изобретение также может включать выделенные фрагменты нуклеиновой кислоты, ком плементарные полной последовательности, а также по существу сходным последовательностям нуклеиновых кислот.
В частности, полинуклеотид, имеющий гомологию или идентичность, можно обнаружить с использованием условий гибридизации, включающих стадию гибридизации при Тпл 55°С, и посредством реализации описанных выше условий. Кроме того, значение Тпл может составлять 60°С, 63°С или 65°С, но этим не ограничивается, и может соответствующим образом регулироваться специалистами в данной области техники сообразно задаче. Подходящая для гибридизации полинуклеотидов жесткость зависит от длины полинуклеотидов и степени комплементарности, и такие переменные хорошо известны в данной области техники (см. Sambrook и др., выше, 9.50-9.51, 11.7-11.8).
Согласно еще одному аспекту настоящего изобретения предложен вектор, включающий в себя полинуклеотид, кодирующий модифицированный вариант синтазы ацетогидроксикислот по настоящему изобретению.
Использованный в данном описании термин «вектор» относится к любому носителю для клонирования и/или переноса нуклеотидов в клетку-хозяина. Вектором может быть репликон, обеспечивающий возможность репликации фрагмента(ов), объединенного(ых) с другим(ими) фрагментом(ами) ДНК. Термин «репликон» относится к любой генетической единице, функционирующей в виде самореплицирующейся единицы для осуществления репликации ДНК in vivo, то есть способной к репликации путем саморегуляции. В частности, вектором могут быть плазмиды, фаги, космиды, хромосомы или вирусы в природном или рекомбинированном состоянии. Например, в качестве фагового вектора или космидного вектора могут быть использованы pWE15, М13, λMBL3, λMBL4, λIXII, λASHII, λAPI, λt10, λt11, Charon4A, Charon21A и т.д., а в качестве плазмидного вектора могут быть использованы векторы на основе pBR, pUC, pBluescriptll, pGEM, pTZ, pCL, pET и так далее. Особых ограничений в выборе векторов, которые могут быть использованы в настоящем изобретении, нет, а может быть использован любой известный экспрессирующий вектор. Кроме того, вектор может включать транспозон или искусственную хромосому.
В настоящем изобретении, особых ограничений в выборе вектора нет, при условии, что он включает в себя полинуклеотид, кодирующий вариант синтазы ацетогидроксикислот по настоящему изобретению. Вектором может быть вектор, который может реплицироваться и/или экспрессировать молекулу нуклеиновой кислоты в эукариотических или прокариотических клетках, включая клетки млекопитающих (например, клетки людей, обезьян, кроликов, крыс, хомяков, мышей и т.д.), клетки растений, клетки дрожжей, клетки насекомых и клетки бактерий (например, Е. coli и т.д.), и, в частности, может быть вектор, который функционально связан с подходящим промотором, в результате чего полинуклеотид может экспрессироваться в клетке-хозяине, и может включать в себя по меньшей мере один селектируемый маркер.
Кроме того, использованный в данном описании термин «функционально связанный» означает функциональную связь между последовательностью промотора, с использованием которой инициируется и опосредуется транскрипция данного полинуклеотида, кодирующего целевой белок по настоящему изобретению, и последовательностью вышеупомянутого гена.
Согласно еще одному аспекту настоящего изобретения предложен трансформант, в который введен вектор по настоящему изобретению.
В настоящем изобретении трансформантом может быть любая поддающаяся трансформации клетка, в которую может быть введен вышеупомянутый вектор и в которой может экспрессироваться вариант синтазы ацетогидроксикислот по настоящему изобретению. В частности, трансформантом могут быть любые трансформированные клетки бактерий, принадлежащих роду Escherichia, роду Corynebacterium, роду Streptomyces, роду Brevibacterium, роду Serratia, роду Providencia, Salmonella typhimurium и т.д.; клетки дрожжей; клетки грибов из Pichiapastoris и т.д.; трансфицированные клетки насекомых (например, Drosophila, Spodoptera Sf9 и т.д.); и трансфицированные клетки животных (например, клетки яичников китайского хомячка (СНО), клетки линии SP2/0 (миеломы мыши), лимфобластоидные клетки человека, COS (клетки африканской зеленой мартышки), клетки линии NSO (миеломы мыши), 293Т, клетки меланомы крупного рогатого скота, НТ-1080, почки новорожденного хомяка (ВНК), почки эмбриона человека (НЕК), PERC.6 (сетчатки человека)); или трансфицированные клетки растений, однако трансформант этим, в частности, не ограничивается.
Согласно еще одному аспекту настоящего изобретения предложен микроорганизм, продуцирующий L-аминокислоты с разветвленной цепью, при этом данный микроорганизм содержит вариант синтазы ацетогидроксикислот, или в который введен вектор, содержащий полинуклеотид, кодирующий этот вариант.
Использованный в данном описании термин «L-аминокислота с разветвленной цепью» относится к аминокислоте с разветвленной алкильной группой в боковой цепи, и он включает в себя валин, лейцин и изолейцин. В частности, в настоящем изобретении L-аминокислота с разветвленной цепью может представлять собой L-валин или L-лейцин, но этим не ограничивается.
Использованный в данном описании термин «микроорганизм» включает в себя любой микроорганизм дикого типа и естественным образом или искусственно генетически модифицированный микроорганизм, и это понятие включает в себя любой из микроорганизмов, в котором конкретный механизм ослаблен или усилен благодаря введению экзогенного гена, либо благодаря усилению или ослаблению активности эндогенного гена. Термин «микроорганизм» относится ко всем микроорганизмам, которые могут экспрессировать вариант синтазы ацетогидроксикислот по настоящему изобретению. В частности, микроорганизм может представлять собой Corynebacterium glutamicum, Corynebacterium ammoniagenes, Brevibacterium lactofermentum, Brevibacterium flavum, Corynebacterium thermoaminogenes, Corynebacterium efficiens и т.д., и более конкретно Corynebacterium glutamicum, однако этим микроорганизм не ограничивается.
Использованный в данном описании термин «микроорганизм, продуцирующий L-аминокислоты с разветвленной цепью», может относиться к природному микроорганизму или модифицированному микроорганизму, который обладает способностью продуцировать L-аминокислоты с разветвленной цепью в результате модификации, и, в частности, может относиться к неприродному рекомбинантному микроорганизму, однако этим микроорганизм не ограничивается. Микроорганизмом, продуцирующим L-аминокислоты с разветвленной цепью, является микроорганизм, который содержит вариант синтазы ацетогидроксикислот по настоящему изобретению или в который введен вектор, содержащий полинуклеотид, кодирующий данный вариант, и этот микроорганизм может иметь существенно более высокую способность продуцировать L-аминокислоты с разветвленной цепью по сравнению с микроорганизмом дикого типа, микроорганизмом, содержащим белок - синтазу ацетогидроксикислот природого типа, немодифицированным микроорганизмом, содержащим белок - синтазу ацетогидроксикислот, и микроорганизмом, не содержащим белка - синтазы ацетогидроксикислот.
Согласно еще одному аспекту настоящего изобретения предложен способ получения L-аминокислот с разветвленной цепью, который включает: культивирование микроорганизма, продуцирующего L-аминокислоты с разветвленной цепью; и извлечение L-аминокислот с разветвленной цепью из микроорганизма или культуральной среды с вышеупомянутой стадии.
Использованный в данном описании термин «культивирование» относится к культивированию микроорганизма в искусственно регулируемых условиях окружающей среды. В настоящем изобретении способ получения L-аминокислоты с разветвленной цепью, в котором используется микроорганизм, способный к продуцированию L-аминокислоты с разветвленной цепью, может быть осуществлен широко известным в данной области техники образом. В частности, культивирование может быть выполнено посредством периодического процесса, периодического процесса с подпиткой или повторяющегося периодического процесса с подпиткой, однако этим процесс периодического культивирования не ограничивается.
Среда, используемая для культивирования, должна удовлетворять требованиям для конкретного применяемого штамма. Например, культуральная среда, подходящая для применения при культивировании штамма Corynebacterium, известна в данной области техники (например, см. Руководство по методам общей бактериологии от Американского общества бактериологов, Вашингтон, округ Колумбия, США, 1981).
Источниками сахаридов, которые можно использовать в культуральной среде, могут быть сахариды и углеводы (например, глюкоза, сахароза, лактоза, фруктоза, мальтоза, крахмал и целлюлоза); масла и жиры (например, соевое масло, подсолнечное масло, арахисовое масло и кокосовое масло); жирные кислоты (например, пальмитиновая кислота, стеариновая кислота и линолевая кислота); спирты (например, глицерин и этанол); и органические кислоты (например, уксусная кислота). Эти вещества могут быть использованы по отдельности или в комбинации, однако способы применения этим не ограничиваются.
Примеры источников азота, которые можно использовать в культуральной среде, могут включать пептон, дрожжевой экстракт, мясной сок, экстракт солода, жидкий кукурузный экстракт, порошок соевой муки и мочевину или неорганические соединения (например, сульфат аммония, хлорид аммония, фосфат аммония, карбонат аммония и нитрат аммония). Эти источники азота также могут быть использованы по отдельности или в комбинации, однако способы применения этим не ограничиваются.
Источники фосфора, которые можно использовать в культуральной среде, могут включать дигидрофосфат калия, гидрофосфат калия или соответствующие им натрий-содержащие соли. Помимо этого, культуральная среда может содержать соли металлов, необходимые для роста клеток. Кроме того, в дополнение к упомянутым выше веществам можно использовать вещества, необходимые для роста (например, аминокислоты и витамины). Кроме того, могут быть использованы предшественники, подходящие для культуральной среды. Вышеупомянутые исходные вещества можно добавлять в достаточной степени в культуральную жидкость в ходе процесса культивирования периодическим или непрерывным образом, однако способ добавления этим не ограничивается.
Значение рН культуральной жидкости можно корректировать применением основного соединения (например, гидроксида натрия, гидроксида калия или аммиака) или кислотного соединения (например, фосфорной кислоты или серной кислоты) соответствующим образом. Кроме того, путем использования противовспенивающего агента (например, сложного полигликолевого эфира жирной кислоты) можно предотвращать образование пены. В культуральную жидкость можно вводить кислород или газовую смесь, содержащую кислород (например, воздух), чтобы поддерживать аэробные условия в культуральной жидкости. Обычно температура культуральной жидкости может находиться в диапазоне от 20°С до 45°С и, в частности, 25°С-40°С. Культивирование можно продолжать до тех пор, пока не будет получено максимальное количество L-аминокислоты с разветвленной цепью, и, в частности, в течение 10-160 часов. L-аминокислота с разветвленной цепью может высвобождаться в культуральную среду или содержаться в клетках, но этим не ограничиваться.
Способ извлечения L-аминокислоты с разветвленной цепью из микроорганизма или культуральной жидкости может включать способы, хорошо известные в данной области техники; например, можно использовать центрифугирование, фильтрацию, обработку вызывающим кристаллизацию белков осаждающим веществом (метод высаливания), экстракцию, ультразвуковое разрушение, ультрафильтрацию, диализ, различные виды хроматографии (например, хроматографию на молекулярных ситах (гель-фильтрацию), адсорбционную хроматографию, ионообменную хроматографию, аффинную хроматографию и т.д.), высокоэффективную жидкостную хроматографию (ВЭЖХ) и их комбинацию, однако данные способы этим не ограничиваются. Кроме того, стадия извлечения L-аминокислоты с разветвленной цепью может дополнительно включать процесс очистки, и этот процесс очистки может быть осуществлен с использованием соответствующего способа, известного в данной области техники.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Далее настоящее изобретение будет описано более подробно со ссылкой на приведенные ниже примеры. Однако эти примеры приведены только в целях иллюстрации, и не подразумевается, что настоящее изобретение ограничено этими примерами.
Пример 1. Получение библиотеки ДНК, кодирующей модифицированную синтазу ацетогидроксикислот, с использованием искусственного мутагенеза
В этом примере библиотеку векторов для вставки в хромосому посредством одиночного кроссинговера с целью получения вариантов синтазы ацетогидроксикислот создавали приведенным далее способом. Проводили допускающую ошибки полимеразную цепную реакцию (ПЦР) для гена ilvB (SEQ ID NO: 2), кодирующего синтазу ацетогидроксикислот (SEQ ID NO: 1), происходящую из Corynebacterium glutamicum АТСС14067 (АТСС означает Американскую коллекцию типовых культур), и тем самым получали варианты гена ilvB (2395 пар оснований (п.о.)) из вариантов гена ilvB со случайным образом внесенной мутацией (модификацией) в виде нуклеотидной замены. Допускающую ошибки ПЦР проводили с применением набора для случайного мутагенеза Genemorphll (Stratagene), используя геномную ДНК Corynebacterium glutamicum АТСС 14067 в качестве матрицы вместе с праймером 1 (SEQ ID NO: 3) и праймером 2 (SEQ ID NO: 4):
праймер 1 (SEQ ID NO: 3): 5'-AACCG GTATC GACAA ТССАА Т-3',
праймер 2 (SEQ ID NO: 4): 5'-GGGTC ТСТСС TTATG ССТС-3'.
Допускающую ошибки ПЦР проводили таким образом, чтобы в амплифицированный фрагмент гена могли быть внесены модификации в соотношении 0-3,5 мутации на 1 тысячу пар основании (т.п.о.) амплифицированного фрагмента гена. ПЦР проводили в общей сложности за 30 циклов, как приведено ниже: денатурация при 96°С в течение 30 с, отжиг при 53°С в течение 30 с и элонгация при 72°С в течение 2 мин.
Амплифицированные фрагменты гена включали в вектор pCR2.1-ТОРО (далее «pCR2.1») с использованием набора для клонирования pCR2.1-ТОРО ТА (Invitrogen), осуществляли трансформацию клеток Е. coli DH5α и клетки высевали на твердую среду LB (Лурия-Бертани), содержащую канамицин (25 мг/л). Отбирали 20 колоний трансформированных клеток и после получения из них плазм ид анализировали их нуклеотидные последовательности. В результате было подтверждено, что внесение модификаций осуществлялось в разные положения с частотой 2,1 мутации/т.п.о. Плазмиды выделяли примерно из 20000 колоний трансформированных клеток E. coli и обозначали как «библиотека pCR2.1-ilvB(mt)».
Кроме того, получали плазмиду, содержащую ген ilvB дикого типа, для применения в качестве контроля. ПЦР проводили с использованием геномной ДНК Corynebacterium glutamicum АТСС14067 в качестве матрицы вместе с праймером 1 (SEQ ID NO: 3) и праймером 2 (SEQ ID NO: 4) в тех же описанных выше условиях. В качестве полимеразы использовали ДНК-полимеразу высокой точности PfuUltra™ (Stratagene) и полученную плазмиду обозначали как «pCR2.1-ilvB(WT)».
Пример 2. Получение ilvB-дефицитного штамма
ilvB-Дефицитный штамм для введения библиотеки pCR2.1-ilvB(mt) получали, используя штамм КССМ11201Р (патент Кореи (KR) №10-1117022) в качестве родительского штамма.
Для получения ilvB-дефицитного вектора проводили ПЦР, используя хромосомную ДНК из Corynebacterium glutamicum АТСС 14067 дикого типа в качестве матрицы и набор праймеров, состоящий из праймера 3 (SEQ ID NO: 5) и праймера 4 (SEQ ID NO: 6), и набор праймеров, состоящий из праймера 5 (SEQ ID NO: 7) и праймера 6 (SEQ ID NO: 8):
праймер 3 (SEQ ID NO: 5): 5'-GCGTC TAGAG ACTTG CACGA GGAAA CG-3';
праймер 4 (SEQ ID NO: 6): 5'-CAGCC AAGTC CCTCA GAATT GATGT AGCAATTATC C-3';
праймер 5 (SEQ ID NO: 7): 5'-GGATA ATTGC TACAT CAATT CTGAG GGACT TGGCT G-3';
праймер 6 (SEQ ID NO: 8): 5'-GCGTC TAGAA CCACA GAGTC TGGAG CC-3'.
ПЦР проводили так, как приведено ниже: денатурация при 95°С в течение 5 мин; 30 циклов с денатурацией при 95°С в течение 30 с, отжигом при 55°С в течение 30 с и элонгацией при 72°С в течение 30 с; и элонгация при 72°С в течение 7 мин.
В итоге получали фрагмент ДНК размером 731 п.о. (SEQ ID NO: 9), который включает расположенный в направлении 5' участок промотора гена ilvB, и фрагмент ДНК размером 712 п.о. (SEQ ID NO: 10), содержащий 3'-конец гена ilvB.
ПЦР проводили, используя амплифицированные фрагменты ДНК (SEQ ID NO: 9 и 10) и набор праймеров, состоящий из праймера 3 (SEQ ID NO: 5) и праймера 6 (SEQ ID NO: 8). ПЦР проводили так, как приведено ниже: денатурация при 95°С в течение 5 мин; 30 циклов с денатурацией при 95°С в течение 30 с, отжигом при 55°С в течение 30 с и элонгацией при 72°С в течение 60 с; и элонгация при 72°С в течение 7 мин.
В итоге была проведена амплификация фрагмента ДНК размером 1407 п.о. (SEQ ID NO: 11, далее «фрагмент гена ilvB»), в котором соединены фрагмент ДНК, включающий расположенный в направлении 5' участок промотора гена ilvB, и фрагмент ДНК, включающий 3'-конец гена ilvB.
Вектор pDZ (патент KR №10-0924065), который не может реплицироваться в Corynebacterium glutamicum, и амплифицированный выше фрагмент гена ilvB, каждый обрабатывали ферментом рестрикции XbaI, лигировали с использованием ДНК-лигазы и клонировали. Полученную плазмиду обозначали как «pDZ-ilvB».
Corynebacterium glutamicum KCCM11201P трансформировали плазмидой pDZ-ilvB, применяя метод электропорации (Appl. Microbiol. Biotechnol. (1999) 52: 541-545), и трансформированные штаммы получали на селективных средах, содержащих канамицин (25 мг/л) и L-валин, L-лейцин и L-изолейцин, каждый в концентрации 2 мМ. Получали штамм, в котором данный ген оказывается инактивированным в результате встраивания в геном фрагмента гена ilvB с использованием процесса двойного кроссинговера, и этот штамм обозначали как KCCM11201PilvB.
Пример 3. Получение библиотеки модифицированных штаммов синтазы ацетогидроксикислот и отбор штаммов с повышенной способностью продуцировании L-аминокислот
Полученный выше штамм KCCM11201PilvB трансформировали с применением гомологичной рекомбинации, используя полученную выше библиотеку pCR2.1-ilvB(mt), трансформанты высевали на комплексную среду для чашек, содержащую канамицин (25 мг/л), и в результате этого получали примерно 10000 колоний. Колонии обозначали KCCM11201PilvB/pCR2.1-ilvB(mt)-1-KCCM11201PilvB/pCR2.1-ilvB(mt)-10000.
Кроме того, полученным выше вектором pCR2.1-ilvB(WT) трансформировали штамм KCCM11201PilvB для получения контрольного штамма, и этот штамм обозначали как KCCM11201PilvB/pCR2.1-ilvB(WT).
Комплексная среда для чашек (рН 7,0)
Глюкоза (10 г), пептон (10 г), мясной экстракт (5 г), дрожжевой экстракт (5 г), сердечно-мозговая вытяжка (18,5 г), NaCl (2,5 г), мочевина (2 г), сорбит (91 г), агар (20 г) (из расчета на 1 л дистиллированной воды).
Каждую из примерно 25000 колоний, полученных выше, инокулировали в 300 мкл селективной среды, состав которой указан ниже, и культивировали в 96-луночном планшете с глубокими лунками при 32°С и 1000 об/мин в течение 24 часов. Для анализа количества L-аминокислот, продуцированных в культуральной среде, использовали нингидриновый способ (J. Biol. Chem., 1948, 176: 367-388). После завершения культивирования проводили взаимодействие 10 мкл культурального супернатанта и 190 мкл раствора для нингидриновой реакции при 65°С в течение 30 минут. Измеряли поглощение на длине волны 570 нм, используя спектрофотометр, и сравнивали с таковым для контроля, т.е. KCCM11201PilvB/pCR2.1-ilvB(WT), и отбирали примерно 213 модифицированных штаммов, демонстрирующих поглощение с увеличением по меньшей мере на 10%. Другие колонии показали подобное или пониженное поглощение по сравнению с таковым у контроля.
Селективная среда (рН 8,0)
Глюкоза (10 г), (NH4)2SO4 (5,5 г), MgSO4⋅7H2O (1,2 г), KH2PO4 (0,8 г), K2HPO4 (16,4 г), биотип (100 мкг), тиамин-HCl (1000 мкг), кальциевая соль пантотеновой кислоты (2000 мкг) и никотинамид (2000 мкг) (из расчета на 1 л дистиллированной воды).
Описанный выше способ повторно выполняли для выбранных 213 штаммов, и отбирали первые 60 видов штаммов из списка с улучшенной способностью к продуцированию L-аминокислот по сравнению с KCCM11201PilvB/pCR2.1-ilvB(WT).
Пример 4. Подтверждение способности штаммов, выбранных из библиотеки модифицированных штаммов синтазы ацетогидроксикислот, продуцировать L-валин
Проводили анализ 60 видов штаммов, отобранных в примере 3, на предмет их L-валин-продуцирующей способности, после их культивирования приведенным ниже способом.
Каждый из штаммов, соответственно, инокулировалн в 250 мл коническую колбу с угловыми перегородками, содержащую 25 мл посевной среды, и культивировали при встряхивании при 30°С и 200 об/мин в течение 20 часов. Затем 1 мл бульона с затравочной культурой инокулировалн в 250 мл коническую колбу с угловыми перегородками, содержащую 24 мл культуральной среды, содержащей описанные ниже компоненты, и культивировали со встряхиванием (200 об/мин) при 30°С в течение 72 часов. Анализ концентрации L-валина в каждой культуральной среде проводили посредством ВЭЖХ.
Среда для продуцирования (рН 7,0)
Глюкоза (100 г), (NH4)2SO4 (40 г), соевый белок (2,5 г), твердая фракция кукурузного экстракта (5 г), мочевина (3 г), KH2PO4 (1 г), MgSO4⋅7H2O (0,5 г), биотип (100 мкг), тиамин-HCl (1000 мкг), кальциевая соль пантотеновой кислоты (2000 мкг), никотинамид (3000 мкг) и СаСО3 (30 г) (из расчета на 1 л дистиллированной воды).
Среди выбранных 60 видов штаммов отбирали 2 вида штаммов, демонстрирующих повышение концентрации L-валина, и повторно проводили культивирование и анализ. Результаты анализа концентрации L-валина показаны ниже в Таблице 1. Остальные 58 видов штаммов фактически показали снижение концентрации L-валина.
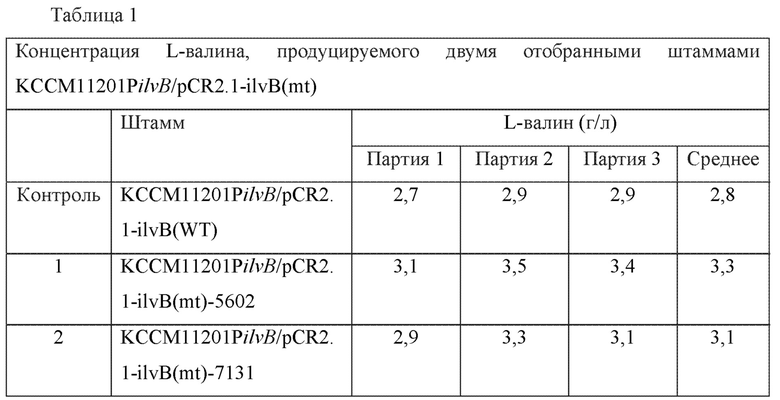
По результатам анализа концентрации L-валина для 2-х отобранных штаммов подтверждали, что максимальное увеличение выхода L-валина в случае этих двух штаммов составляло 20,7% по сравнению с контрольным штаммом KCCM11201PilvB/pCR2.1-ilvB(WT).
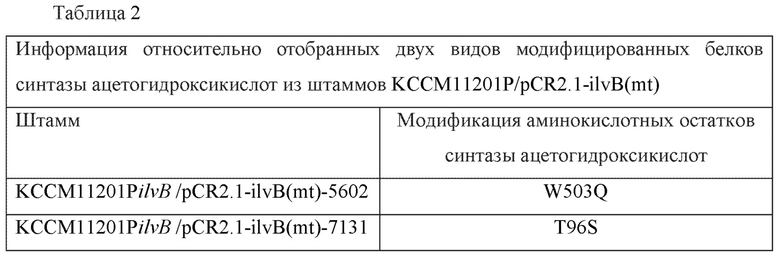
Пример 5. Подтверждение наличия модификации гена ilvB в штаммах, выбранных из библиотеки модифицированных штаммов синтазы ацетогидроксикислот
Для подтверждения наличия случайных модификаций, внесенных в синтазу ацетогидроксикислот в случае 2-х отобранных в примере 4 штаммов, проводили анализ нуклеотидных последовательностей гена ilvB. Чтобы определить нуклеотидные последовательности, проводили ПЦР, используя набор праймеров, состоящий из праймера 7 (SEQ ID NO: 12) и праймера 8 (SEQ ID NO: 13):
праймер 7 (SEQ ID NO: 12): 5'-CGCTT GATAA TACGC ATG-3',
праймер 8 (SEQ ID NO: 13): 5'-GAACA TACCT GATAC GCG-3'.
Каждый из полученных модифицированных фрагментов гена ilvB подвергали анализу в отношении нуклеотидной последовательности и результаты сравнивали с нуклеотидной последовательностью гена ilvB дикого типа (т.е. SEQ ID NO: 2). В результате были подтверждены нуклеотидные последовательности модифицированного гена ilvB и аминокислотные последовательности модифицированных белков синтазы ацетогидроксикислот. Информация относительно отобранных двух видов модифицированных белков синтазы ацетогидроксикислот представлена ниже в Таблице 2.
Пример 6. Получение вектора для внесения модификации в синтазу ацетогидроксикислот
Для подтверждения эффектов белков синтазы ацетогидроксикислот с модификациями, подтвержденными в примере 5, получали вектор со способностью внесения в хромосому модифицированных генов белков синтазы ацетогидроксикислот.
На основании подтвержденных нуклеотидных последовательностей синтезировали набор праймеров, состоящий из праймера 9 (SEQ ID NO: 14) и праймера 10 (SEQ ID NO: 15), и набор праймеров, состоящий из праймера 11 (SEQ ID NO: 16) и праймера 12 (SEQ ID NO: 17), у которых на 5'-конце был встроен сайт рестрикции для XbaI. Затем проводили ПЦР, используя каждую из хромосомных ДНК двух отобранных видов штаммов в качестве матрицы вместе с этими наборами праймеров, и таким образом амплифицировали модифицированные фрагменты гена ilvB. ПЦР проводили так, как приведено ниже: денатурация при 94°С в течение 5 мин; 30 циклов с денатурацией при 94°С в течение 30 с, отжигом при 56°С в течение 30 с и элонгацией при 72°С в течение 2 мин; и элонгация при 72°С в течение 7 мин.
Праймер 9 (SEQ ID NO: 14): 5'-CGCTC TAGAC AAGCA GGTTG AGGTT CC-3',
праймер 10 (SEQ ID NO: 15): 5'-CGCTC TAGAC ACGAG GTTGA ATGCG CG-3',
праймер 11 (SEQ ID NO: 16): 5'-CGCTC TAGAC CCTCG ACAAC ACTCA CC-3',
праймер 12 (SEQ ID NO: 17): 5' -CGCTC TAGAT GCCAT CAAGG TGGTG AC-3'.
Эти два вида генных фрагментов, амплифицированных посредством ПЦР, обрабатывали XbaI, получая соответствующие фрагменты ДНК, и вставляли эти фрагменты в вектор pDZ для введения в хромосому, содержащий сайт рестрикции для XbaI, осуществляли трансформацию E. coli DH5α и трансформанты высевали на твердой среде LB, содержащей канамицин (25 мг/л).
Колонии клеток, трансформированных вектором со встроенным целевым геном, отбирали посредством ПЦР и получали плазмиды, используя общеизвестный способ выделения плазмид. Эти плазмиды обозначали как pDZ-ilvB(W503Q) и pDZ-ilvB(T96S), при этом каждое обозначение соответствует модификациям, внесенным в ген ilvB.
Пример 7. Получение происжодящих из КССМ11201Р штаммов с модификацией синтазы ацетогидроксикислот и сравнение их L-валин-продуцирующей способности
Каждым из векторов двух видов с внесенными новыми модификациями, полученных в примере 6, трансформировали штамм Corynebacterium glutamicum КССМ11201Р, который представляет собой штамм, продуцирующий L-валин, применяя двухстадийную гомологичную хромосомную рекомбинацию. Затем отбирали штаммы с введенным в хромосому модифицированным геном ilvB, используя анализ нуклеотидных последовательностей. Штаммы с введенным модифицированным геном ilvB обозначали как КССМ11201Р::ilvB(W503Q) и KCCM11201P::ilvB(T96S). Кроме того, для трансформации полученного выше штамма КССМ11201Р::ilvB(W503Q) использовали вектор pDZ-ilvB(T96S), выбранный из векторов с внесенной выше модификацией. Далее штаммы, в которые были внесены два вида модификаций хромосомы, обозначали как KCCM11201P::ilvB(W503Q/T96S).
Штаммы культивировали аналогично тому, как описано в примере 4, и в культивируемых штаммах анализировали концентрации L-валина (Таблица 3).
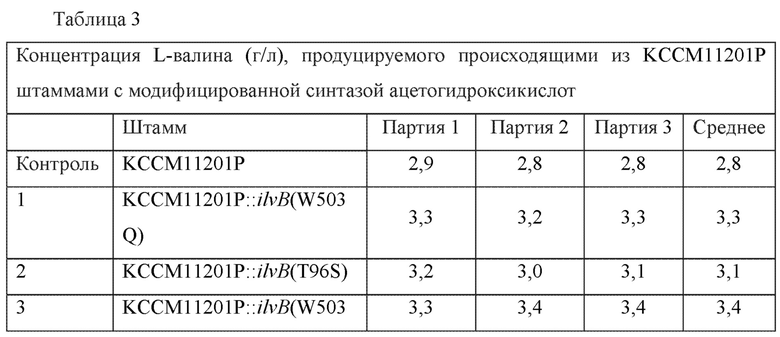

В результате, для двух новых штаммов с внесенными модификациями (КССМ11201Р::ilvB(W503Q) и KCCM11201P::ilvB(T96S)) продемонстрировано повышение максимально на 17,8% L-валин-продуцирующей способности по сравнению с родительским штаммом, а для штамма с обеими внесенными модификациями (KCCM11201P::ilvB(W503Q/T96S) продемонстрировано повышение L-валин-продуцирующей способности на 21,4% по сравнению с родительским штаммом.
Соответственно, с учетом того, что синтаза ацетогидроксикислот представляет собой первый фермент в путях биосинтеза L-аминокислот с разветвленной цепью, ожидается, что варианты большой субъединицы синтазы ацетогидроксикислот по настоящему изобретению будут оказывать влияние на усиление продуцирования L-изолейцина и L-лейцина, а также L-валина.
Авторы настоящего изобретения обозначили штаммы с улучшенной способностью к продуцированию L-валина (т.е. КССМ11201Р::ilvB(W503Q) и KCCM11201P::ilvB(T96S)) как Corynebacterium glutamicum KCJ-0793 и Corynebacterium glutamicum KCJ-0796 и депонировали их в Корейский центр культур микроорганизмов (КССМ) 25 января 2016 г. с номерами доступа КССМ11809Р и КССМ11810Р.
Пример 8. Получение сверхэкспрессирующего вектора для биосинтеза L-валина, содержащего ДНК, кодирующую модифицированную синтазу ацетогидроксикислот
В качестве контрольной группы из штамма Corynebacterium glutamicum КССМ11201Р, который является штаммом, продуцирующим L-валин, получали сверхэкспрессирующий вектор для биосинтеза L-валина. Кроме того, получали сверхэкспрессирующие векторы для биосинтеза L-валина, в которые включены модифицированные ДНК, кодирующие синтазу ацетогидроксикислот, из каждого из штаммов КССМ11201Р::ilvB(W503Q) и KCCM11201P::ilvB(T96S), полученных в примере 7.
Для получения указанных выше векторов синтезировали праймер 13 (SEQ ID NO: 18), на 5'-конце которого был встроен сайт рестрикции для BamHI, и праймер 14 (SEQ ID NO: 19), на 3'-конце которого был встроен сайт рестрикции для XbaI. С применением этого набора праймеров проводили ПЦР, используя в качестве матрицы каждую из хромосомных ДНК штамма Corynebacterium glutamicum КССМ11201Р (т.е. штамма, продуцирующего L-валин) и штаммов, полученных в примере 7 (т.е. КССМ11201Р::ilvB(W503Q) и KCCM11201P::ilvB(T96S)), и тем самым получали два вида амплифицированных модифицированных фрагментов гена ilvBN. ПЦР проводили так, как приведено ниже: денатурация при 94°С в течение 5 мин; 30 циклов с денатурацией при 94°С в течение 30 с, отжигом при 56°С в течение 30 с и элонгацией при 72°С в течение 4 мин; и элонгация при 72°С в течение 7 мин.
Праймер 13 (SEQ ID NO: 18): 5'-CGAGG ATCCA ACCGG TATCG ACAAT ССААТ-3',
праймер 14 (SEQ ID NO: 19): 5'-CTGTC TAGAA ATCGT GGGAG TTAAA CTCGC-3'.
Эти два вида генных фрагментов, амплифицированных посредством ПЦР, обрабатывали BamHI и XbaI, получая их соответствующие фрагменты ДНК. Эти фрагменты ДНК вставляли в сверхэкспрессирующий вектор pECCG 117, содержащий сайты рестрикции для BamHI. и XbaI, осуществляли трансформацию Е. coli DH5α и трансформанты высевали на твердой среде LB, содержащей канамицин (25 мг/л).
Колонии клеток, трансформированных вектором со встроенным целевым геном, отбирали посредством ПЦР и получали плазмиды, используя общеизвестный способ выделения плазмид. Эти плазмиды обозначали как pECCG117-ilvBN, pECCG117-ilvB(W503Q)N и pECCG117-ilvB(T96S)N, при этом каждое обозначение соответствует модификациям, внесенным в ген ilvB.
Пример 9. Получение сверхэкспрессируюшего вектора для биосинтеза L-валина, содержащего ДНК, кодирующую модифицированную синтазу ацетогидроксикислот, в которой аминокислота в одном и том же положении заменена на другую аминокислоту
Для подтверждения влияния места расположения модификации в модифицированных белках синтазы ацетогидроксикислот, подтвержденной в примере 5, получали векторы, у которых 96-я аминокислота заменена на аминокислоту, отличающуюся от треонина или серина, а 503-я аминокислота заменена на аминокислоту, отличающуюся от триптофана или глутамина.
В частности, на основе штамма Corynebacterium glutamicum КССМ11201Р, являющегося штаммом, продуцирующим L-валин, получали сверхэкспрессирующие векторы для биосинтеза L-валина, у которых имеется модификация в виде замены 503-й аминокислоты синтазы ацетогидроксикислот на аспарагин или лейцин либо модификация в виде замены 96-й аминокислоты на аланин или цистеин. Замененные аминокислоты представляют собой только примеры репрезентативных аминокислот, которые могут быть заменены, и такие аминокислоты не ограничиваются ими.
Для получения этих векторов сначала проводили ПЦР, используя хромосомную ДНК штамма Corynebacterium glutamicum КССМ11201Р в качестве матрицы и набор праймеров, состоящий из праймера 13 (SEQ ID NO: 18) и праймера 15 (SEQ ID NO: 20), и набор праймеров, состоящий из праймера 16 (SEQ ID NO: 21) и праймера 14 (SEQ ID NO: 19), и тем самым получали фрагмент ДНК размером примерно 2041 п.о., содержащий на 5'-конце сайт рестрикции для BamHI, и фрагмент ДНК размером 1055 п.о., содержащий на 3'-конце сайт рестрикции для XbaI. ГИДР проводили так, как приведено ниже: денатурация при 94°С в течение 5 мин; 30 циклов с денатурацией при 94°С в течение 30 с, отжигом при 56°С в течение 30 с и элонгацией при 72°С в течение 2 мин; и элонгация при 72°С в течение 7 мин.
Праймер 15 (SEQ ID NO: 20): 5'-СТТСА TAGAA TAGGG TCTGG TTTTG GCGAA CCATG CCCAG-3',
праймер 16 (SEQ ID NO: 21): 5'-CTGGG CATGG TTCGC CAAAA CCAGA CCCTA TTCTA TGAAG-3'.
Затем проводили ПЦР, используя эти два амплифицированных фрагмента ДНК в качестве матрицы и набор праймеров, состоящий из праймера 13 (SEQ ID NO: 18) и праймера 14 (SEQ ID NO: 19). ПЦР проводили так, как приведено ниже: денатурация при 94°С в течение 5 мин; 30 циклов с денатурацией при 94°С в течение 30 с, отжигом при 56°С в течение 30 с и элонгацией при 72°С в течение 4 мин; и элонгация при 72°С в течение 7 мин.
В результате получали фрагмент гена ilvBN с модификацией, при которой 503-я аминокислота синтазы ацетогидроксикислот заменена на аспарагин.
Аналогичным образом проводили ПЦР используя хромосомную ДНК штамма Corynebacterium glutamicum KCCM11201P в качестве матрицы и набор праймеров, состоящий из праймера 13 (SEQ ID NO: 18) и праймера 17 (SEQ ID NO: 22), и набор праймеров, состоящий из праймера 18 (SEQ ID NO: 23) и праймера 14 (SEQ ID NO: 19), и тем самым получали фрагмент ДНК размером примерно 2041 п.о., содержащий на 5'-конце сайт рестрикции для BamHI., и фрагмент ДНК размером 1055 п.о., содержащий на 3'-конце сайт рестрикции для XbaI.
Праймер 17 (SEQ ID NO: 22): 5'-СТТСА TAGAA TAGGG TCTGC AGTTG GCGAA CCATG CCCAG-3',
праймер 18 (SEQ ID NO: 23): 5'-CTGGG CATGG TTCGC CAACT GCAGA CCCTA TTCTA TGAAG-3'.
Затем проводили ПЦР, используя эти два амплифицированных фрагмента ДНК в качестве матрицы и набор праймеров, состоящий из праймера 13 (SEQ ID NO: 18) и праймера 14 (SEQ ID NO: 19).
В результате получали фрагмент гена ilvBN с модификацией, при которой 503-я аминокислота синтазы ацетогидроксикислот заменена на лейцин.
Аналогичным образом проводили ПЦР, используя хромосомную ДНК штамма Corynebacterium glutamicum KCCM1120IP в качестве матрицы и набор праймеров, состоящий из праймера 13 (SEQ ID NO: 18) и праймера 19 (SEQ ID NO: 24), и набор праймеров, состоящий из праймера 20 (SEQ ID NO: 23) и праймера 14 (SEQ ID NO: 19), и тем самым получали фрагмент ДНК размером примерно 819 п.о., содержащий на 5'-конце сайт рестрикции для BamHL, и фрагмент ДНК размером 2276 п.о., содержащий на 3'-конце сайт рестрикции для XbaI.
Праймер 19 (SEQ ID NO: 24): 5'-GGTTG CGCCT GGGCC AGATG CTGCA ATGCA GACGC CAAC-3',
праймер 20 (SEQ ID NO: 25): 5'-GTTGG CGTCT GCATT GCAGC ATCTG GCCCA GGCGC AACC-3'.
Затем проводили ПЦР, используя эти два амплифицированных фрагмента ДНК в качестве матрицы и набор праймеров, состоящий из праймера 13 (SEQ ID NO: 18) и праймера 14 (SEQ ID NO: 19).
В результате получали фрагмент гена ilvBN с модификацией, при которой 96-я аминокислота синтазы ацетогидроксикислот заменена на аланин.
Аналогичным образом проводили ПЦР, используя хромосомную ДНК штамма Corynebacterium glutamicum KCCM11201P в качестве матрицы и набор праймеров, состоящий из праймера 13 (SEQ ID NO: 18) и праймера 21 (SEQ ID NO: 26), и набор праймеров, состоящий из праймера 22 (SEQ ID NO: 27) и праймера 14 (SEQ ID NO: 19), и тем самым получали фрагмент ДНК размером примерно 819 п.о., содержащий на 5'-конце сайт рестрикции для BamHI, и фрагмент ДНК размером 2276 п.о., содержащий на 3'-конце сайт рестрикции для XbaI.
Праймер 21 (SEQ ID NO: 26): 5'-GGTTG CGCCT GGGCC AGAGC ATGCA ATGCA GACGC CAAC-3',
праймер 22 (SEQ ID NO: 27): 5'-GTTGG CGTCT GCATT GCATG CTCTG GCCCA GGCGC AACC-3'.
Затем проводили ПЦР, используя эти два амплифицированных фрагмента ДНК в качестве матрицы и набор праймеров, состоящий из праймера 13 (SEQ ID NO: 18) и праймера 14 (SEQ ID NO: 19).
В результате получали фрагмент гена ilvBN с модификацией, при которой 96-я аминокислота синтазы ацетогидроксикислот заменена на цистеин.
С использованием того же способа, что и в примере 8, эти четыре вида ПЦР-амплифицированных модифицированных генных фрагментов обрабатывали ферментами рестрикции BamHX и XbaI и тем самым получали их соответствующие фрагменты ДНК. Каждый из этих фрагментов ДНК вставляли в сверхэкспрессирующий вектор pECCG117, содержащий сайты рестрикции для BamHX и XbaI, осуществляли трансформацию E. coli DH5α и трансформанты высевали на твердой среде LB, содержащей канамицин (25 мг/л).
Колонии клеток, трансформированных вектором со встроенным целевым геном, отбирали посредством ПЦР и получали плазмиды, используя общеизвестный способ выделения плазмид. Каждую из этих плазмид обозначали как pECCG117-ilvB(W503N)N, pECCG117-ilvB(W503L)N, pECCG117-ilvB(T96A)N и pECCG 117-ilvB(T96C)N, при этом каждое обозначение соответствует модификациям последовательности, внесенным в ген ilvB.
Пример 10. Получение штаммов, в которые введена модифицированная синтаза ацетогидроксикислот, происходящая из штамма дикого типа, и сравнение L-валин-продуцирующей способности
Каждый из сверхэкспрессирующих векторов для биосинтеза L-валина, полученных в примерах 8 и 9 (т.е. pECCG117-ilvBN, pECCG117-ilvB(W503Q)N, pECCG117-ilvB(T96S)N и pECCG117-ilvB(W503N)N, pECCG117-ilvB(W503L)N, pECCG117-ilvB(T96A)N и pECCG117-ilvB(T96C)N), вводили в штамм Corynebacterium glutamicum дикого типа (ATCC13032), используя электропорацию. Каждый из полученных штаммов обозначали как Corynebacterium glutamicum АТСС13032::pECCG117-ilvBN, Corynebacterium glutamicum ATCC13032::pECCG117-ilvB(W503Q)N, Corynebacterium glutamicum ATCC13032::pECCG117-ilvB(T96S)N, Corynebacterium glutamicum ATCC13032::pECCG117-ilvB(W503N)N, Corynebacterium glutamicum ATCC13032::pECCG117-ilvB(W503L)N, Corynebacterium glutamicum ATCC13032::pECCG117-ilvB(T96A)N и Corynebacterium glutamicum ATCC13032::pECCG117-ilvB(T96C)N.
Поскольку штаммы, трансформированные этими векторами, будут обладать устойчивостью к канамицину, наличие трансформации подтверждали путем проверки роста этих штаммов в среде, содержащей канамицин в концентрации 25 мг/л.
Каждый из штаммов инокулировалн в коническую колбу с угловыми перегородками емкостью 250 мл, содержащую 25 мл среды для продуцирования, и культивировали в инкубаторе со встряхиванием при 200 об/мин и при 30°С в течение 72 часов. Анализ концентрации L-валина в каждой культуральной жидкости проводили посредством ВЭЖХ (Таблица 4).

В результате, было подтверждено, в случае новых модификаций, при которых 96-я или 503-я аминокислота синтазы ацетогидроксикислот заменена на другую аминокислоту, продемонстрировано повышение максимально на 700% L-валин-продуцирующей способности по сравнению с контрольной группой. Этот результат подтвердил важность аминокислотных положений 96 и 503 синтазы ацетогидроксикислот, и ожидается, что аминокислоты в этих положениях будут влиять на способность продуцировать другие аминокислоты с разветвленной цепью, наряду с L-валином.
Пример 11. Получение штаммов, в которые введена модифицированная синтаза ацетогидроксикислот, и сравнение L-валин-продуцирующей способности
Чтобы подтвердить, оказывают ли варианты большой субъединицы по настоящему изобретению влияние на повышение способности к продуцированию других L-аминокислот с разветвленной цепью, исследовали способность к продуцированию L-лейцина в качестве другого воплощения L-аминокислот с разветвленной цепью.
В частности, каждый из двух векторов с внесенными новыми модификациями, полученных в примере 6, использовали для трансформации штамма Corynebacterium glutamicum KCCM11201P (заявка на патент Корен №10-2015-0119785 и публикация заявки на патент Корен №10-2017-0024653), представляющего собой L-лейцин-продуцирующий штамм, применяя двухстадийную гомологичную рекомбинацию. Затем посредством анализа нуклеотидной последовательности отбирали штаммы с введенным в хромосому модифицированным геном ilvB, и штаммы с введенным модифицированным геном ilvB обозначали как КССМ11661Р::IlvB(W503Q) и KCCM11661P::ilvB(T96S).
Штамм Corynebacterium glutamicum KCCM11661P, обладающий устойчивостью к норлейцину (NL), представляет собой мутантный штамм, происходящий из Corynebacterium glutamicum АТСС 14067, и его получали так, как приведено ниже.
В частности, штамм Corynebacterium glutamicum АТСС 14067 культивировали в среде для активации в течение 16 часов, и активированный штамм инокулировали в среду для затравки, которую стерилизовали при 121°С в течение 5 минут, и культивировали в течение 14 часов и отбирали 5 мл этой культуральной жидкости. Отобранную культуральную жидкость промывали 100 мМ буфером на основе лимонной кислоты, и в нее добавляли N-метил-N'-нитро-N-нитрозогуанидин (NTG) до конечной концентрации 200 мг/л и проводили взаимодействие в течение 20 минут, и промывали 100 мМ фосфатным буфером. Штаммы, обработанные NTG, высевали на чашки с минимальной средой, рассчитывали показатель гибели, и в результате было показано, что показатель гибели составляет 85%.
Чтобы получить мутантный штамм, обладающий устойчивостью к норлейцину (NL), NTG-обработанные штаммы высевали на чашки с минимальной средой, содержащей NL в конечной концентрации 20 мМ, 30 мМ, 40 мМ и 50 мМ, соответственно. Затем штаммы культивировали при 30°С в течение 5 суток и таким образом получали NL-устойчивый мутантный штамм.
Среда для активации
Мясной сок (1%), полипептон (1%), NaCl (0,5%), дрожжевой экстракт (1%), агар (2%), рН 7,2.
Среда для затравки
Глюкоза (5%), бактопептон (1%), NaCl (0,25%), дрожжевой экстракт (1%), мочевина (0,4%), рН 7,2.
Минимальная среда
Глюкоза (1%), сульфат аммония (0,4%), сульфат магния (0,04%), дигидрофосфат калия (0,1%), мочевина (0,1%), тиамин (0,001%), биотин (200 мкг/л), агар (2%), рН 7,0.
Полученный таким образом мутантный штамм обозначали как Corynebacterium glutamicum KCJ-24 и депонировали в Корейский центр культур микроорганизмов (КССМ), который признан Международным органом по депонированию в соответствии с Будапештским договором, 22 января 2015 г. с номером доступа КССМ11661Р.
Штаммы КССМ11661Р::ilvB(W503Q) и KCCM11661P::ilvB(T96S) культивировали аналогично тому, как описано в примере 4, и анализировали концентрацию L-лейцина в каждой культуральной жидкости (Таблица 5).

Для этих двух штаммов с внесенными новыми модификациями (т.е. КССМ11661Р::ilvB(W503Q) и KCCM11661P::ilvB(T96S)) было продемонстрировано повышение максимально на 26,9% L-лейцин-продуцирующей способности по сравнению с родительским штаммом.
Пример 12. Получение штаммов, в которые введена синтаза ацетогидроксикислот, происходящая из КССМ11662Р, и сравнение L-лейцин-продуцирующей способности
Каждый из двух векторов с внесенными новыми модификациями, полученных в примере 6, использовали для трансформации штамма Corynebacterium glutamicum КССМ11662Р (заявка на патент Кореи №10-2015-0119785 и публикация заявки на патент Кореи №10-2017-0024653), представляющего собой L-лейцин-продуцирующий штамм, применяя двухстадийную гомологичную рекомбинацию. Затем посредством анализа нуклеотидной последовательности отбирали штаммы с введенным в хромосому модифицированным геном ilvB, и штаммы с введенным модифицированным геном ilvB обозначали как KCCM11662P::ilvB(W503Q) и KCCM11662P::ilvB(T96S).
Штамм Corynebacterium glutamicum КССМ11662Р, обладающий устойчивостью к норлейцину (NL), представляет собой мутантный штамм, происходящий из Corynebacterium glutamicum АТСС 13869, и его получали так, как приведено ниже.
В частности, применяя штамм Corynebacterium glutamicum АТСС 13869 в качестве родительского штамма, проводили культивирование этого штамма аналогично способу, применяемому для получения КССМ11661Р в примере 11, и в итоге получали NL-устойчивый мутантный штамм.
Полученный таким образом мутантный штамм обозначали как Corynebacterium glutamicum KCJ-28 и депонировали в Корейский центр культур микроорганизмов (КССМ), который признан Международным органом по депонированию в соответствии с Будапештским договором, 22 января 2015 г. с номером доступа КССМ11662Р.
Штаммы KCCM11662P::ilvB(W503Q) и KCCM11662P::ilvB(T96S) культивировали аналогично тому, как описано в примере 4, и анализировали концентрацию L-лейцина в каждой культуральной жидкости (Таблица 6).
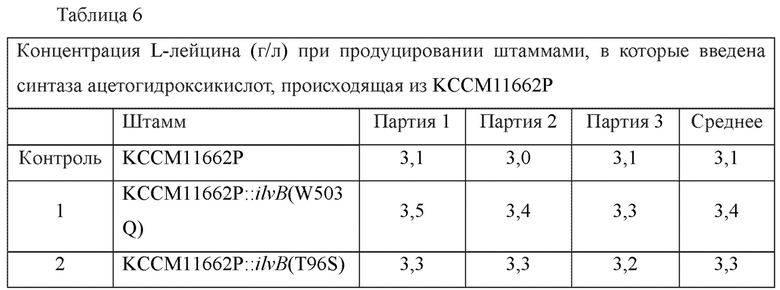
Для этих двух штаммов с внесенными новыми модификациями (т.е. KCCM11662P::ilvB(W503Q) и KCCM11662P::ilvB(T96S)) было продемонстрировано
повышение максимально на 13,3% L-лейцин-продуцирующей способности по сравнению с родительским штаммом.
На основании вышеизложенного специалист в данной области техники, к которой относится настоящее изобретение, сможет понять, что настоящее изобретение может быть воплощено в других конкретных формах без изменения технических понятий или существенных признаков настоящего изобретения. В связи с этим, типичные воплощения, описанные в данной заявке, приведены только в целях иллюстрации, и их не следует истолковывать как ограничивающие объем настоящего изобретения. Напротив, подразумевается, что настоящее изобретение охватывает не только типичные воплощения, но также и различные альтернативные, модифицированные, эквивалентные и другие воплощения, которые могут быть включены в пределы сущности и объема настоящего изобретения, как определено прилагаемой формулой изобретения.
--->
Перечень последовательностей
<110> CJ CheilJedang Corporation
<120> ACETOHYDROXY ACID SYNTHASE VARIANT, MICROORGANISM COMPRISING THE
SAME, AND METHOD OF PRODUCING L-BRANCHED-CHAIN AMINO ACID USING
THE SAME
<130> OPA18190
<150> KR 10-2017-0087978
<151> 2017-07-11
<160> 39
<170> KopatentIn 2.0
<210> 1
<211> 626
<212> PRT
<213> Artificial Sequence
<220>
<223> синтаза ацетогидроксикислот
<400> 1
Met Asn Val Ala Ala Ser Gln Gln Pro Thr Pro Ala Thr Val Ala Ser
1 5 10 15
Arg Gly Arg Ser Ala Ala Pro Glu Arg Met Thr Gly Ala Gln Ala Ile
20 25 30
Val Arg Ser Leu Glu Glu Leu Asn Ala Asp Ile Val Phe Gly Ile Pro
35 40 45
Gly Gly Ala Val Leu Pro Val Tyr Asp Pro Leu Tyr Ser Ser Thr Lys
50 55 60
Val Arg His Val Leu Val Arg His Glu Gln Gly Ala Gly His Ala Ala
65 70 75 80
Thr Gly Tyr Ala Gln Val Thr Gly Arg Val Gly Val Cys Ile Ala Thr
85 90 95
Ser Gly Pro Gly Ala Thr Asn Leu Val Thr Pro Ile Ala Asp Ala Asn
100 105 110
Leu Asp Ser Val Pro Met Val Ala Ile Thr Gly Gln Val Gly Ser Gly
115 120 125
Leu Leu Gly Thr Asp Ala Phe Gln Glu Ala Asp Ile Arg Gly Ile Thr
130 135 140
Met Pro Val Thr Lys His Asn Phe Met Val Thr Asp Pro Asn Asp Ile
145 150 155 160
Pro Gln Ala Leu Ala Glu Ala Phe His Leu Ala Ile Thr Gly Arg Pro
165 170 175
Gly Pro Val Leu Val Asp Ile Pro Lys Asp Val Gln Asn Ala Glu Leu
180 185 190
Asp Phe Val Trp Pro Pro Lys Ile Asp Leu Pro Gly Tyr Arg Pro Val
195 200 205
Ser Thr Pro His Ala Arg Gln Ile Glu Gln Ala Val Lys Leu Ile Gly
210 215 220
Glu Ala Lys Lys Pro Val Leu Tyr Ile Gly Gly Gly Val Ile Lys Ala
225 230 235 240
Asp Ala His Glu Glu Leu Arg Ala Phe Ala Glu Tyr Thr Gly Ile Pro
245 250 255
Val Val Thr Thr Leu Met Ala Leu Gly Thr Phe Pro Glu Ser His Glu
260 265 270
Leu His Met Gly Met Pro Gly Met His Gly Thr Val Ser Ala Val Gly
275 280 285
Ala Leu Gln Arg Ser Asp Leu Leu Ile Ala Ile Gly Ser Arg Phe Asp
290 295 300
Asp Arg Val Thr Gly Asp Val Asp Thr Phe Ala Pro Asp Ala Lys Ile
305 310 315 320
Ile His Ala Asp Ile Asp Pro Ala Glu Ile Gly Lys Ile Lys Gln Val
325 330 335
Glu Val Pro Ile Val Gly Asp Ala Arg Glu Val Leu Ala Arg Leu Leu
340 345 350
Glu Thr Thr Lys Ala Ser Lys Ala Glu Thr Glu Asp Ile Ser Glu Trp
355 360 365
Val Asp Tyr Leu Lys Gly Leu Lys Ala Arg Phe Pro Arg Gly Tyr Asp
370 375 380
Glu Gln Pro Gly Asp Leu Leu Ala Pro Gln Phe Val Ile Glu Thr Leu
385 390 395 400
Ser Lys Glu Val Gly Pro Asp Ala Ile Tyr Cys Ala Gly Val Gly Gln
405 410 415
His Gln Met Trp Ala Ala Gln Phe Val Asp Phe Glu Lys Pro Arg Thr
420 425 430
Trp Leu Asn Ser Gly Gly Leu Gly Thr Met Gly Tyr Ala Val Pro Ala
435 440 445
Ala Leu Gly Ala Lys Ala Gly Ala Pro Asp Lys Glu Val Trp Ala Ile
450 455 460
Asp Gly Asp Gly Cys Phe Gln Met Thr Asn Gln Glu Leu Thr Thr Ala
465 470 475 480
Ala Val Glu Gly Phe Pro Ile Lys Ile Ala Leu Ile Asn Asn Gly Asn
485 490 495
Leu Gly Met Val Arg Gln Trp Gln Thr Leu Phe Tyr Glu Gly Arg Tyr
500 505 510
Ser Asn Thr Lys Leu Arg Asn Gln Gly Glu Tyr Met Pro Asp Phe Val
515 520 525
Thr Leu Ser Glu Gly Leu Gly Cys Val Ala Ile Arg Val Thr Lys Ala
530 535 540
Glu Glu Val Leu Pro Ala Ile Gln Lys Ala Arg Glu Ile Asn Asp Arg
545 550 555 560
Pro Val Val Ile Asp Phe Ile Val Gly Glu Asp Ala Gln Val Trp Pro
565 570 575
Met Val Ser Ala Gly Ser Ser Asn Ser Asp Ile Gln Tyr Ala Leu Gly
580 585 590
Leu Arg Pro Phe Phe Asp Gly Asp Glu Ser Ala Ala Glu Asp Pro Ala
595 600 605
Asp Ile His Glu Ala Val Ser Asp Ile Asp Ala Ala Val Glu Ser Thr
610 615 620
625
<210> 2
<211> 1881
<212> DNA
<213> Artificial Sequence
<220>
<223> синтаза ацетогидроксикислот
<400> 2
gtgaatgtgg cagcttctca acagcccact cccgccacgg ttgcaagccg tggtcgatcc 60
gccgcccctg agcggatgac aggtgcacag gcaattgttc gatcgctcga ggagcttaac 120
gccgacatcg tgttcggtat tcctggtggt gcggtgctac cggtgtatga cccgctctat 180
tcctccacaa aggtgcgcca cgtcctggtg cgccacgagc agggcgcagg ccacgcagca 240
accggctacg cgcaggttac tggacgcgtt ggcgtctgca ttgcaacctc tggcccaggc 300
gcaaccaact tggttacccc aatcgctgat gcaaacttgg actccgttcc catggttgcc 360
atcaccggcc aggtcggaag tggcctgctg ggtaccgatg ctttccagga agccgatatc 420
cgcggcatca ccatgccagt gaccaagcac aacttcatgg tcaccgaccc caacgacatt 480
ccacaggcat tggctgaggc attccacctc gcgattactg gtcgccctgg ccctgttctg 540
gtggatattc ctaaggatgt ccaaaacgct gaattggatt tcgtctggcc accaaagatc 600
gacctgccag gctaccgccc agtttctact ccgcatgctc gacagattga gcaggctgtc 660
aaactgatcg gtgaagccaa aaagccagtc ctttacattg gcggcggcgt tatcaaggct 720
gatgcacacg aagaactgcg tgcatttgct gagtacaccg gcatcccagt tgtcaccacc 780
ttgatggcat tgggtacctt cccagagtcc cacgagctgc acatgggtat gccaggcatg 840
cacggcaccg tgtccgctgt tggcgcactg cagcgcagtg acctgctgat tgctatcggt 900
tcccgcttcg acgaccgcgt caccggtgac gttgacacct tcgcacctga tgccaagatc 960
attcacgctg acattgatcc tgccgaaatc ggcaagatca agcaggttga ggttccaatc 1020
gtgggcgatg cccgcgaggt tcttgctcgt ctgctggaaa ccaccaaggc aagcaaggca 1080
gagaccgagg acatctccga gtgggttgat tacctcaagg gcctcaaggc acgtttccca 1140
cgtggctacg acgagcagcc aggcgatctg ctggcaccac agtttgtcat tgaaaccctg 1200
tccaaggaag ttggccccga cgcaatttac tgcgccggcg ttggccagca ccagatgtgg 1260
gcagctcagt tcgttgactt tgaaaagcca cgcacctggc tcaactctgg cggcctgggc 1320
accatgggct acgcagttcc tgcggctctt ggagcaaagg ctggcgcacc tgacaaggaa 1380
gtctgggcta tcgacggcga cggctgtttc cagatgacca accaggaact caccaccgcc 1440
gcagttgaag gtttccccat taagatcgca ctaatcaaca acggaaacct gggcatggtt 1500
cgccaatggc agaccctatt ctatgaagga cggtactcaa atactaaact tcgtaaccag 1560
ggcgagtaca tgcccgactt tgttaccctt tctgagggac ttggctgtgt tgccatccgc 1620
gtcaccaaag cggaggaagt actgccagcc atccaaaagg ctcgagagat caacgaccgc 1680
ccagtagtca tcgacttcat cgtcggtgaa gacgcacagg tatggccaat ggtgtctgct 1740
ggatcatcca actccgatat ccagtacgca ctcggattgc gcccattctt tgatggtgat 1800
gaatctgcag cagaagatcc tgccgacatt cacgaagccg tcagcgacat tgatgccgcc 1860
gttgaatcga ccgaggcata a 1881
<210> 3
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 1
<400> 3
aaccggtatc gacaatccaa t 21
<210> 4
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 2
<400> 4
gggtctctcc ttatgcctc 19
<210> 5
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 3
<400> 5
gcgtctagag acttgcacga ggaaacg 27
<210> 6
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 4
<400> 6
cagccaagtc cctcagaatt gatgtagcaa ttatcc 36
<210> 7
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 5
<400> 7
ggataattgc tacatcaatt ctgagggact tggctg 36
<210> 8
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 6
<400> 8
gcgtctagaa ccacagagtc tggagcc 27
<210> 9
<211> 731
<212> DNA
<213> Artificial Sequence
<220>
<223> 5'-фрагмент ilvB
<400> 9
gcgtctagag acttgcacga ggaaacgcat ggtgaccatc cacggcatgc cgaccaccgt 60
tggcggtgtg acttccgtgg ctgggtgcac atcgagttca ccgaggattt ccggtgcgat 120
tttctcctgg ccaagtgcgc gacgagtcgc agcttcagag cgcgcgatga catctgtgat 180
gttttcagaa cccaacatgg ggatcggaat aacgacaacc gcacgcgacc agttattaga 240
attgttgatg cacactttcg ccgtggagtt ggggatgatc acggtctctt gtgcaatcgt 300
gcgaattttg gtcgcgcgca tggtgatctc aatgacggtg ccttcgacaa cgatgccgtt 360
gccctcaaaa cgcacccagt cacccacgcc gaattgcttt tccgtcagga tgaaaaatcc 420
ggccaagaag tccgcaacaa tcgactgcgc accaaggcca atggcagctg acgcaatggt 480
tgccggaatc gcagcgcccg cgagagagaa accaaaagcc tgcatcgcgg agacggcaag 540
catgaaaaac gccacaattt gcgcgatata aacgccaacg ccagcgaacg cgagctggtt 600
cttagtggtg tccgcatcgg ctgcagactc cactcgccgc ttgataatac gcatggccag 660
tcggccgata cgtggaatca aaaacgccaa gaccaggata attgctacat caattctgag 720
ggacttggct g 731
<210> 10
<211> 712
<212> DNA
<213> Artificial Sequence
<220>
<223> 3'-фрагмент ilvB
<400> 10
ggataattgc tacatcaatt ctgagggact tggctgtgtt gccatccgcg tcaccaaagc 60
ggaggaagta ctgccagcca tccaaaaggc tcgagagatc aacgaccgcc cagtagtcat 120
cgacttcatc gtcggtgaag acgcacaggt atggccaatg gtgtctgctg gatcatccaa 180
ctccgatatc cagtacgcac tcggattgcg cccattcttt gatggtgatg aatctgcagc 240
agaagatcct gccgacattc acgaagccgt cagcgacatt gatgccgccg ttgaatcgac 300
cgaggcataa ggagagaccc aagatggcta attctgacgt cacccgccac atcctgtccg 360
tactcgttca ggacgtagac ggaatcattt cccgcgtatc aggtatgttc acccgacgcg 420
cattcaacct cgtgtccctc gtgtctgtaa agaccgaaac actcggcatc aaccgcatca 480
cggttgttgt cgacgccgac gagctcaaca ttgagcagat caccaagcag ctcaacaagc 540
tgatccccgt gctcaaagtc gtgcgacttg atgaagagac caccatcgcc cgcgcaatca 600
tgctggttaa ggtctctgcg gatagcacca accgtccgca gatcgtcgac gccgcgaaca 660
tcttccgcgc ccgagtcgtc gacgtggctc cagactctgt ggttctagac gc 712
<210> 11
<211> 1407
<212> DNA
<213> Artificial Sequence
<220>
<223> 5'- + 3'-фрагмент ilvB
<400> 11
gcgtctagag acttgcacga ggaaacgcat ggtgaccatc cacggcatgc cgaccaccgt 60
tggcggtgtg acttccgtgg ctgggtgcac atcgagttca ccgaggattt ccggtgcgat 120
tttctcctgg ccaagtgcgc gacgagtcgc agcttcagag cgcgcgatga catctgtgat 180
gttttcagaa cccaacatgg ggatcggaat aacgacaacc gcacgcgacc agttattaga 240
attgttgatg cacactttcg ccgtggagtt ggggatgatc acggtctctt gtgcaatcgt 300
gcgaattttg gtcgcgcgca tggtgatctc aatgacggtg ccttcgacaa cgatgccgtt 360
gccctcaaaa cgcacccagt cacccacgcc gaattgcttt tccgtcagga tgaaaaatcc 420
ggccaagaag tccgcaacaa tcgactgcgc accaaggcca atggcagctg acgcaatggt 480
tgccggaatc gcagcgcccg cgagagagaa accaaaagcc tgcatcgcgg agacggcaag 540
catgaaaaac gccacaattt gcgcgatata aacgccaacg ccagcgaacg cgagctggtt 600
cttagtggtg tccgcatcgg ctgcagactc cactcgccgc ttgataatac gcatggccag 660
tcggccgata cgtggaatca aaaacgccaa gaccaggata attgctacat caattctgag 720
ggacttggct gtgttgccat ccgcgtcacc aaagcggagg aagtactgcc agccatccaa 780
aaggctcgag agatcaacga ccgcccagta gtcatcgact tcatcgtcgg tgaagacgca 840
caggtatggc caatggtgtc tgctggatca tccaactccg atatccagta cgcactcgga 900
ttgcgcccat tctttgatgg tgatgaatct gcagcagaag atcctgccga cattcacgaa 960
gccgtcagcg acattgatgc cgccgttgaa tcgaccgagg cataaggaga gacccaagat 1020
ggctaattct gacgtcaccc gccacatcct gtccgtactc gttcaggacg tagacggaat 1080
catttcccgc gtatcaggta tgttcacccg acgcgcattc aacctcgtgt ccctcgtgtc 1140
tgtaaagacc gaaacactcg gcatcaaccg catcacggtt gttgtcgacg ccgacgagct 1200
caacattgag cagatcacca agcagctcaa caagctgatc cccgtgctca aagtcgtgcg 1260
acttgatgaa gagaccacca tcgcccgcgc aatcatgctg gttaaggtct ctgcggatag 1320
caccaaccgt ccgcagatcg tcgacgccgc gaacatcttc cgcgcccgag tcgtcgacgt 1380
ggctccagac tctgtggttc tagacgc 1407
<210> 12
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 7
<400> 12
cgcttgataa tacgcatg 18
<210> 13
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 8
<400> 13
gaacatacct gatacgcg 18
<210> 14
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 9
<400> 14
cgctctagac aagcaggttg aggttcc 27
<210> 15
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 10
<400> 15
cgctctagac acgaggttga atgcgcg 27
<210> 16
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 11
<400> 16
cgctctagac cctcgacaac actcacc 27
<210> 17
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 12
<400> 17
cgctctagat gccatcaagg tggtgac 27
<210> 18
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 13
<400> 18
cgaggatcca accggtatcg acaatccaat 30
<210> 19
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 14
<400> 19
ctgtctagaa atcgtgggag ttaaactcgc 30
<210> 20
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 15
<400> 20
cttcatagaa tagggtctgg ttttggcgaa ccatgcccag 40
<210> 21
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 16
<400> 21
ctgggcatgg ttcgccaaaa ccagacccta ttctatgaag 40
<210> 22
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 17
<400> 22
cttcatagaa tagggtctgc agttggcgaa ccatgcccag 40
<210> 23
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 18
<400> 23
ctgggcatgg ttcgccaact gcagacccta ttctatgaag 40
<210> 24
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 19
<400> 24
ggttgcgcct gggccagatg ctgcaatgca gacgccaac 39
<210> 25
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 20
<400> 25
gttggcgtct gcattgcagc atctggccca ggcgcaacc 39
<210> 26
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 21
<400> 26
ggttgcgcct gggccagagc atgcaatgca gacgccaac 39
<210> 27
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> праймер 22
<400> 27
gttggcgtct gcattgcatg ctctggccca ggcgcaacc 39
<210> 28
<211> 626
<212> PRT
<213> Artificial Sequence
<220>
<223> T96S
<400> 28
Met Asn Val Ala Ala Ser Gln Gln Pro Thr Pro Ala Thr Val Ala Ser
1 5 10 15
Arg Gly Arg Ser Ala Ala Pro Glu Arg Met Thr Gly Ala Gln Ala Ile
20 25 30
Val Arg Ser Leu Glu Glu Leu Asn Ala Asp Ile Val Phe Gly Ile Pro
35 40 45
Gly Gly Ala Val Leu Pro Val Tyr Asp Pro Leu Tyr Ser Ser Thr Lys
50 55 60
Val Arg His Val Leu Val Arg His Glu Gln Gly Ala Gly His Ala Ala
65 70 75 80
Thr Gly Tyr Ala Gln Val Thr Gly Arg Val Gly Val Cys Ile Ala Ser
85 90 95
Ser Gly Pro Gly Ala Thr Asn Leu Val Thr Pro Ile Ala Asp Ala Asn
100 105 110
Leu Asp Ser Val Pro Met Val Ala Ile Thr Gly Gln Val Gly Ser Gly
115 120 125
Leu Leu Gly Thr Asp Ala Phe Gln Glu Ala Asp Ile Arg Gly Ile Thr
130 135 140
Met Pro Val Thr Lys His Asn Phe Met Val Thr Asp Pro Asn Asp Ile
145 150 155 160
Pro Gln Ala Leu Ala Glu Ala Phe His Leu Ala Ile Thr Gly Arg Pro
165 170 175
Gly Pro Val Leu Val Asp Ile Pro Lys Asp Val Gln Asn Ala Glu Leu
180 185 190
Asp Phe Val Trp Pro Pro Lys Ile Asp Leu Pro Gly Tyr Arg Pro Val
195 200 205
Ser Thr Pro His Ala Arg Gln Ile Glu Gln Ala Val Lys Leu Ile Gly
210 215 220
Glu Ala Lys Lys Pro Val Leu Tyr Ile Gly Gly Gly Val Ile Lys Ala
225 230 235 240
Asp Ala His Glu Glu Leu Arg Ala Phe Ala Glu Tyr Thr Gly Ile Pro
245 250 255
Val Val Thr Thr Leu Met Ala Leu Gly Thr Phe Pro Glu Ser His Glu
260 265 270
Leu His Met Gly Met Pro Gly Met His Gly Thr Val Ser Ala Val Gly
275 280 285
Ala Leu Gln Arg Ser Asp Leu Leu Ile Ala Ile Gly Ser Arg Phe Asp
290 295 300
Asp Arg Val Thr Gly Asp Val Asp Thr Phe Ala Pro Asp Ala Lys Ile
305 310 315 320
Ile His Ala Asp Ile Asp Pro Ala Glu Ile Gly Lys Ile Lys Gln Val
325 330 335
Glu Val Pro Ile Val Gly Asp Ala Arg Glu Val Leu Ala Arg Leu Leu
340 345 350
Glu Thr Thr Lys Ala Ser Lys Ala Glu Thr Glu Asp Ile Ser Glu Trp
355 360 365
Val Asp Tyr Leu Lys Gly Leu Lys Ala Arg Phe Pro Arg Gly Tyr Asp
370 375 380
Glu Gln Pro Gly Asp Leu Leu Ala Pro Gln Phe Val Ile Glu Thr Leu
385 390 395 400
Ser Lys Glu Val Gly Pro Asp Ala Ile Tyr Cys Ala Gly Val Gly Gln
405 410 415
His Gln Met Trp Ala Ala Gln Phe Val Asp Phe Glu Lys Pro Arg Thr
420 425 430
Trp Leu Asn Ser Gly Gly Leu Gly Thr Met Gly Tyr Ala Val Pro Ala
435 440 445
Ala Leu Gly Ala Lys Ala Gly Ala Pro Asp Lys Glu Val Trp Ala Ile
450 455 460
Asp Gly Asp Gly Cys Phe Gln Met Thr Asn Gln Glu Leu Thr Thr Ala
465 470 475 480
Ala Val Glu Gly Phe Pro Ile Lys Ile Ala Leu Ile Asn Asn Gly Asn
485 490 495
Leu Gly Met Val Arg Gln Trp Gln Thr Leu Phe Tyr Glu Gly Arg Tyr
500 505 510
Ser Asn Thr Lys Leu Arg Asn Gln Gly Glu Tyr Met Pro Asp Phe Val
515 520 525
Thr Leu Ser Glu Gly Leu Gly Cys Val Ala Ile Arg Val Thr Lys Ala
530 535 540
Glu Glu Val Leu Pro Ala Ile Gln Lys Ala Arg Glu Ile Asn Asp Arg
545 550 555 560
Pro Val Val Ile Asp Phe Ile Val Gly Glu Asp Ala Gln Val Trp Pro
565 570 575
Met Val Ser Ala Gly Ser Ser Asn Ser Asp Ile Gln Tyr Ala Leu Gly
580 585 590
Leu Arg Pro Phe Phe Asp Gly Asp Glu Ser Ala Ala Glu Asp Pro Ala
595 600 605
Asp Ile His Glu Ala Val Ser Asp Ile Asp Ala Ala Val Glu Ser Thr
610 615 620
625
<210> 29
<211> 626
<212> PRT
<213> Artificial Sequence
<220>
<223> T96A
<400> 29
Met Asn Val Ala Ala Ser Gln Gln Pro Thr Pro Ala Thr Val Ala Ser
1 5 10 15
Arg Gly Arg Ser Ala Ala Pro Glu Arg Met Thr Gly Ala Gln Ala Ile
20 25 30
Val Arg Ser Leu Glu Glu Leu Asn Ala Asp Ile Val Phe Gly Ile Pro
35 40 45
Gly Gly Ala Val Leu Pro Val Tyr Asp Pro Leu Tyr Ser Ser Thr Lys
50 55 60
Val Arg His Val Leu Val Arg His Glu Gln Gly Ala Gly His Ala Ala
65 70 75 80
Thr Gly Tyr Ala Gln Val Thr Gly Arg Val Gly Val Cys Ile Ala Ala
85 90 95
Ser Gly Pro Gly Ala Thr Asn Leu Val Thr Pro Ile Ala Asp Ala Asn
100 105 110
Leu Asp Ser Val Pro Met Val Ala Ile Thr Gly Gln Val Gly Ser Gly
115 120 125
Leu Leu Gly Thr Asp Ala Phe Gln Glu Ala Asp Ile Arg Gly Ile Thr
130 135 140
Met Pro Val Thr Lys His Asn Phe Met Val Thr Asp Pro Asn Asp Ile
145 150 155 160
Pro Gln Ala Leu Ala Glu Ala Phe His Leu Ala Ile Thr Gly Arg Pro
165 170 175
Gly Pro Val Leu Val Asp Ile Pro Lys Asp Val Gln Asn Ala Glu Leu
180 185 190
Asp Phe Val Trp Pro Pro Lys Ile Asp Leu Pro Gly Tyr Arg Pro Val
195 200 205
Ser Thr Pro His Ala Arg Gln Ile Glu Gln Ala Val Lys Leu Ile Gly
210 215 220
Glu Ala Lys Lys Pro Val Leu Tyr Ile Gly Gly Gly Val Ile Lys Ala
225 230 235 240
Asp Ala His Glu Glu Leu Arg Ala Phe Ala Glu Tyr Thr Gly Ile Pro
245 250 255
Val Val Thr Thr Leu Met Ala Leu Gly Thr Phe Pro Glu Ser His Glu
260 265 270
Leu His Met Gly Met Pro Gly Met His Gly Thr Val Ser Ala Val Gly
275 280 285
Ala Leu Gln Arg Ser Asp Leu Leu Ile Ala Ile Gly Ser Arg Phe Asp
290 295 300
Asp Arg Val Thr Gly Asp Val Asp Thr Phe Ala Pro Asp Ala Lys Ile
305 310 315 320
Ile His Ala Asp Ile Asp Pro Ala Glu Ile Gly Lys Ile Lys Gln Val
325 330 335
Glu Val Pro Ile Val Gly Asp Ala Arg Glu Val Leu Ala Arg Leu Leu
340 345 350
Glu Thr Thr Lys Ala Ser Lys Ala Glu Thr Glu Asp Ile Ser Glu Trp
355 360 365
Val Asp Tyr Leu Lys Gly Leu Lys Ala Arg Phe Pro Arg Gly Tyr Asp
370 375 380
Glu Gln Pro Gly Asp Leu Leu Ala Pro Gln Phe Val Ile Glu Thr Leu
385 390 395 400
Ser Lys Glu Val Gly Pro Asp Ala Ile Tyr Cys Ala Gly Val Gly Gln
405 410 415
His Gln Met Trp Ala Ala Gln Phe Val Asp Phe Glu Lys Pro Arg Thr
420 425 430
Trp Leu Asn Ser Gly Gly Leu Gly Thr Met Gly Tyr Ala Val Pro Ala
435 440 445
Ala Leu Gly Ala Lys Ala Gly Ala Pro Asp Lys Glu Val Trp Ala Ile
450 455 460
Asp Gly Asp Gly Cys Phe Gln Met Thr Asn Gln Glu Leu Thr Thr Ala
465 470 475 480
Ala Val Glu Gly Phe Pro Ile Lys Ile Ala Leu Ile Asn Asn Gly Asn
485 490 495
Leu Gly Met Val Arg Gln Trp Gln Thr Leu Phe Tyr Glu Gly Arg Tyr
500 505 510
Ser Asn Thr Lys Leu Arg Asn Gln Gly Glu Tyr Met Pro Asp Phe Val
515 520 525
Thr Leu Ser Glu Gly Leu Gly Cys Val Ala Ile Arg Val Thr Lys Ala
530 535 540
Glu Glu Val Leu Pro Ala Ile Gln Lys Ala Arg Glu Ile Asn Asp Arg
545 550 555 560
Pro Val Val Ile Asp Phe Ile Val Gly Glu Asp Ala Gln Val Trp Pro
565 570 575
Met Val Ser Ala Gly Ser Ser Asn Ser Asp Ile Gln Tyr Ala Leu Gly
580 585 590
Leu Arg Pro Phe Phe Asp Gly Asp Glu Ser Ala Ala Glu Asp Pro Ala
595 600 605
Asp Ile His Glu Ala Val Ser Asp Ile Asp Ala Ala Val Glu Ser Thr
610 615 620
625
<210> 30
<211> 626
<212> PRT
<213> Artificial Sequence
<220>
<223> T96C
<400> 30
Met Asn Val Ala Ala Ser Gln Gln Pro Thr Pro Ala Thr Val Ala Ser
1 5 10 15
Arg Gly Arg Ser Ala Ala Pro Glu Arg Met Thr Gly Ala Gln Ala Ile
20 25 30
Val Arg Ser Leu Glu Glu Leu Asn Ala Asp Ile Val Phe Gly Ile Pro
35 40 45
Gly Gly Ala Val Leu Pro Val Tyr Asp Pro Leu Tyr Ser Ser Thr Lys
50 55 60
Val Arg His Val Leu Val Arg His Glu Gln Gly Ala Gly His Ala Ala
65 70 75 80
Thr Gly Tyr Ala Gln Val Thr Gly Arg Val Gly Val Cys Ile Ala Cys
85 90 95
Ser Gly Pro Gly Ala Thr Asn Leu Val Thr Pro Ile Ala Asp Ala Asn
100 105 110
Leu Asp Ser Val Pro Met Val Ala Ile Thr Gly Gln Val Gly Ser Gly
115 120 125
Leu Leu Gly Thr Asp Ala Phe Gln Glu Ala Asp Ile Arg Gly Ile Thr
130 135 140
Met Pro Val Thr Lys His Asn Phe Met Val Thr Asp Pro Asn Asp Ile
145 150 155 160
Pro Gln Ala Leu Ala Glu Ala Phe His Leu Ala Ile Thr Gly Arg Pro
165 170 175
Gly Pro Val Leu Val Asp Ile Pro Lys Asp Val Gln Asn Ala Glu Leu
180 185 190
Asp Phe Val Trp Pro Pro Lys Ile Asp Leu Pro Gly Tyr Arg Pro Val
195 200 205
Ser Thr Pro His Ala Arg Gln Ile Glu Gln Ala Val Lys Leu Ile Gly
210 215 220
Glu Ala Lys Lys Pro Val Leu Tyr Ile Gly Gly Gly Val Ile Lys Ala
225 230 235 240
Asp Ala His Glu Glu Leu Arg Ala Phe Ala Glu Tyr Thr Gly Ile Pro
245 250 255
Val Val Thr Thr Leu Met Ala Leu Gly Thr Phe Pro Glu Ser His Glu
260 265 270
Leu His Met Gly Met Pro Gly Met His Gly Thr Val Ser Ala Val Gly
275 280 285
Ala Leu Gln Arg Ser Asp Leu Leu Ile Ala Ile Gly Ser Arg Phe Asp
290 295 300
Asp Arg Val Thr Gly Asp Val Asp Thr Phe Ala Pro Asp Ala Lys Ile
305 310 315 320
Ile His Ala Asp Ile Asp Pro Ala Glu Ile Gly Lys Ile Lys Gln Val
325 330 335
Glu Val Pro Ile Val Gly Asp Ala Arg Glu Val Leu Ala Arg Leu Leu
340 345 350
Glu Thr Thr Lys Ala Ser Lys Ala Glu Thr Glu Asp Ile Ser Glu Trp
355 360 365
Val Asp Tyr Leu Lys Gly Leu Lys Ala Arg Phe Pro Arg Gly Tyr Asp
370 375 380
Glu Gln Pro Gly Asp Leu Leu Ala Pro Gln Phe Val Ile Glu Thr Leu
385 390 395 400
Ser Lys Glu Val Gly Pro Asp Ala Ile Tyr Cys Ala Gly Val Gly Gln
405 410 415
His Gln Met Trp Ala Ala Gln Phe Val Asp Phe Glu Lys Pro Arg Thr
420 425 430
Trp Leu Asn Ser Gly Gly Leu Gly Thr Met Gly Tyr Ala Val Pro Ala
435 440 445
Ala Leu Gly Ala Lys Ala Gly Ala Pro Asp Lys Glu Val Trp Ala Ile
450 455 460
Asp Gly Asp Gly Cys Phe Gln Met Thr Asn Gln Glu Leu Thr Thr Ala
465 470 475 480
Ala Val Glu Gly Phe Pro Ile Lys Ile Ala Leu Ile Asn Asn Gly Asn
485 490 495
Leu Gly Met Val Arg Gln Trp Gln Thr Leu Phe Tyr Glu Gly Arg Tyr
500 505 510
Ser Asn Thr Lys Leu Arg Asn Gln Gly Glu Tyr Met Pro Asp Phe Val
515 520 525
Thr Leu Ser Glu Gly Leu Gly Cys Val Ala Ile Arg Val Thr Lys Ala
530 535 540
Glu Glu Val Leu Pro Ala Ile Gln Lys Ala Arg Glu Ile Asn Asp Arg
545 550 555 560
Pro Val Val Ile Asp Phe Ile Val Gly Glu Asp Ala Gln Val Trp Pro
565 570 575
Met Val Ser Ala Gly Ser Ser Asn Ser Asp Ile Gln Tyr Ala Leu Gly
580 585 590
Leu Arg Pro Phe Phe Asp Gly Asp Glu Ser Ala Ala Glu Asp Pro Ala
595 600 605
Asp Ile His Glu Ala Val Ser Asp Ile Asp Ala Ala Val Glu Ser Thr
610 615 620
625
<210> 31
<211> 626
<212> PRT
<213> Artificial Sequence
<220>
<223> W503Q
<400> 31
Met Asn Val Ala Ala Ser Gln Gln Pro Thr Pro Ala Thr Val Ala Ser
1 5 10 15
Arg Gly Arg Ser Ala Ala Pro Glu Arg Met Thr Gly Ala Gln Ala Ile
20 25 30
Val Arg Ser Leu Glu Glu Leu Asn Ala Asp Ile Val Phe Gly Ile Pro
35 40 45
Gly Gly Ala Val Leu Pro Val Tyr Asp Pro Leu Tyr Ser Ser Thr Lys
50 55 60
Val Arg His Val Leu Val Arg His Glu Gln Gly Ala Gly His Ala Ala
65 70 75 80
Thr Gly Tyr Ala Gln Val Thr Gly Arg Val Gly Val Cys Ile Ala Thr
85 90 95
Ser Gly Pro Gly Ala Thr Asn Leu Val Thr Pro Ile Ala Asp Ala Asn
100 105 110
Leu Asp Ser Val Pro Met Val Ala Ile Thr Gly Gln Val Gly Ser Gly
115 120 125
Leu Leu Gly Thr Asp Ala Phe Gln Glu Ala Asp Ile Arg Gly Ile Thr
130 135 140
Met Pro Val Thr Lys His Asn Phe Met Val Thr Asp Pro Asn Asp Ile
145 150 155 160
Pro Gln Ala Leu Ala Glu Ala Phe His Leu Ala Ile Thr Gly Arg Pro
165 170 175
Gly Pro Val Leu Val Asp Ile Pro Lys Asp Val Gln Asn Ala Glu Leu
180 185 190
Asp Phe Val Trp Pro Pro Lys Ile Asp Leu Pro Gly Tyr Arg Pro Val
195 200 205
Ser Thr Pro His Ala Arg Gln Ile Glu Gln Ala Val Lys Leu Ile Gly
210 215 220
Glu Ala Lys Lys Pro Val Leu Tyr Ile Gly Gly Gly Val Ile Lys Ala
225 230 235 240
Asp Ala His Glu Glu Leu Arg Ala Phe Ala Glu Tyr Thr Gly Ile Pro
245 250 255
Val Val Thr Thr Leu Met Ala Leu Gly Thr Phe Pro Glu Ser His Glu
260 265 270
Leu His Met Gly Met Pro Gly Met His Gly Thr Val Ser Ala Val Gly
275 280 285
Ala Leu Gln Arg Ser Asp Leu Leu Ile Ala Ile Gly Ser Arg Phe Asp
290 295 300
Asp Arg Val Thr Gly Asp Val Asp Thr Phe Ala Pro Asp Ala Lys Ile
305 310 315 320
Ile His Ala Asp Ile Asp Pro Ala Glu Ile Gly Lys Ile Lys Gln Val
325 330 335
Glu Val Pro Ile Val Gly Asp Ala Arg Glu Val Leu Ala Arg Leu Leu
340 345 350
Glu Thr Thr Lys Ala Ser Lys Ala Glu Thr Glu Asp Ile Ser Glu Trp
355 360 365
Val Asp Tyr Leu Lys Gly Leu Lys Ala Arg Phe Pro Arg Gly Tyr Asp
370 375 380
Glu Gln Pro Gly Asp Leu Leu Ala Pro Gln Phe Val Ile Glu Thr Leu
385 390 395 400
Ser Lys Glu Val Gly Pro Asp Ala Ile Tyr Cys Ala Gly Val Gly Gln
405 410 415
His Gln Met Trp Ala Ala Gln Phe Val Asp Phe Glu Lys Pro Arg Thr
420 425 430
Trp Leu Asn Ser Gly Gly Leu Gly Thr Met Gly Tyr Ala Val Pro Ala
435 440 445
Ala Leu Gly Ala Lys Ala Gly Ala Pro Asp Lys Glu Val Trp Ala Ile
450 455 460
Asp Gly Asp Gly Cys Phe Gln Met Thr Asn Gln Glu Leu Thr Thr Ala
465 470 475 480
Ala Val Glu Gly Phe Pro Ile Lys Ile Ala Leu Ile Asn Asn Gly Asn
485 490 495
Leu Gly Met Val Arg Gln Gln Gln Thr Leu Phe Tyr Glu Gly Arg Tyr
500 505 510
Ser Asn Thr Lys Leu Arg Asn Gln Gly Glu Tyr Met Pro Asp Phe Val
515 520 525
Thr Leu Ser Glu Gly Leu Gly Cys Val Ala Ile Arg Val Thr Lys Ala
530 535 540
Glu Glu Val Leu Pro Ala Ile Gln Lys Ala Arg Glu Ile Asn Asp Arg
545 550 555 560
Pro Val Val Ile Asp Phe Ile Val Gly Glu Asp Ala Gln Val Trp Pro
565 570 575
Met Val Ser Ala Gly Ser Ser Asn Ser Asp Ile Gln Tyr Ala Leu Gly
580 585 590
Leu Arg Pro Phe Phe Asp Gly Asp Glu Ser Ala Ala Glu Asp Pro Ala
595 600 605
Asp Ile His Glu Ala Val Ser Asp Ile Asp Ala Ala Val Glu Ser Thr
610 615 620
625
<210> 32
<211> 626
<212> PRT
<213> Artificial Sequence
<220>
<223> W503N
<400> 32
Met Asn Val Ala Ala Ser Gln Gln Pro Thr Pro Ala Thr Val Ala Ser
1 5 10 15
Arg Gly Arg Ser Ala Ala Pro Glu Arg Met Thr Gly Ala Gln Ala Ile
20 25 30
Val Arg Ser Leu Glu Glu Leu Asn Ala Asp Ile Val Phe Gly Ile Pro
35 40 45
Gly Gly Ala Val Leu Pro Val Tyr Asp Pro Leu Tyr Ser Ser Thr Lys
50 55 60
Val Arg His Val Leu Val Arg His Glu Gln Gly Ala Gly His Ala Ala
65 70 75 80
Thr Gly Tyr Ala Gln Val Thr Gly Arg Val Gly Val Cys Ile Ala Thr
85 90 95
Ser Gly Pro Gly Ala Thr Asn Leu Val Thr Pro Ile Ala Asp Ala Asn
100 105 110
Leu Asp Ser Val Pro Met Val Ala Ile Thr Gly Gln Val Gly Ser Gly
115 120 125
Leu Leu Gly Thr Asp Ala Phe Gln Glu Ala Asp Ile Arg Gly Ile Thr
130 135 140
Met Pro Val Thr Lys His Asn Phe Met Val Thr Asp Pro Asn Asp Ile
145 150 155 160
Pro Gln Ala Leu Ala Glu Ala Phe His Leu Ala Ile Thr Gly Arg Pro
165 170 175
Gly Pro Val Leu Val Asp Ile Pro Lys Asp Val Gln Asn Ala Glu Leu
180 185 190
Asp Phe Val Trp Pro Pro Lys Ile Asp Leu Pro Gly Tyr Arg Pro Val
195 200 205
Ser Thr Pro His Ala Arg Gln Ile Glu Gln Ala Val Lys Leu Ile Gly
210 215 220
Glu Ala Lys Lys Pro Val Leu Tyr Ile Gly Gly Gly Val Ile Lys Ala
225 230 235 240
Asp Ala His Glu Glu Leu Arg Ala Phe Ala Glu Tyr Thr Gly Ile Pro
245 250 255
Val Val Thr Thr Leu Met Ala Leu Gly Thr Phe Pro Glu Ser His Glu
260 265 270
Leu His Met Gly Met Pro Gly Met His Gly Thr Val Ser Ala Val Gly
275 280 285
Ala Leu Gln Arg Ser Asp Leu Leu Ile Ala Ile Gly Ser Arg Phe Asp
290 295 300
Asp Arg Val Thr Gly Asp Val Asp Thr Phe Ala Pro Asp Ala Lys Ile
305 310 315 320
Ile His Ala Asp Ile Asp Pro Ala Glu Ile Gly Lys Ile Lys Gln Val
325 330 335
Glu Val Pro Ile Val Gly Asp Ala Arg Glu Val Leu Ala Arg Leu Leu
340 345 350
Glu Thr Thr Lys Ala Ser Lys Ala Glu Thr Glu Asp Ile Ser Glu Trp
355 360 365
Val Asp Tyr Leu Lys Gly Leu Lys Ala Arg Phe Pro Arg Gly Tyr Asp
370 375 380
Glu Gln Pro Gly Asp Leu Leu Ala Pro Gln Phe Val Ile Glu Thr Leu
385 390 395 400
Ser Lys Glu Val Gly Pro Asp Ala Ile Tyr Cys Ala Gly Val Gly Gln
405 410 415
His Gln Met Trp Ala Ala Gln Phe Val Asp Phe Glu Lys Pro Arg Thr
420 425 430
Trp Leu Asn Ser Gly Gly Leu Gly Thr Met Gly Tyr Ala Val Pro Ala
435 440 445
Ala Leu Gly Ala Lys Ala Gly Ala Pro Asp Lys Glu Val Trp Ala Ile
450 455 460
Asp Gly Asp Gly Cys Phe Gln Met Thr Asn Gln Glu Leu Thr Thr Ala
465 470 475 480
Ala Val Glu Gly Phe Pro Ile Lys Ile Ala Leu Ile Asn Asn Gly Asn
485 490 495
Leu Gly Met Val Arg Gln Asn Gln Thr Leu Phe Tyr Glu Gly Arg Tyr
500 505 510
Ser Asn Thr Lys Leu Arg Asn Gln Gly Glu Tyr Met Pro Asp Phe Val
515 520 525
Thr Leu Ser Glu Gly Leu Gly Cys Val Ala Ile Arg Val Thr Lys Ala
530 535 540
Glu Glu Val Leu Pro Ala Ile Gln Lys Ala Arg Glu Ile Asn Asp Arg
545 550 555 560
Pro Val Val Ile Asp Phe Ile Val Gly Glu Asp Ala Gln Val Trp Pro
565 570 575
Met Val Ser Ala Gly Ser Ser Asn Ser Asp Ile Gln Tyr Ala Leu Gly
580 585 590
Leu Arg Pro Phe Phe Asp Gly Asp Glu Ser Ala Ala Glu Asp Pro Ala
595 600 605
Asp Ile His Glu Ala Val Ser Asp Ile Asp Ala Ala Val Glu Ser Thr
610 615 620
625
<210> 33
<211> 626
<212> PRT
<213> Artificial Sequence
<220>
<223> W503L
<400> 33
Met Asn Val Ala Ala Ser Gln Gln Pro Thr Pro Ala Thr Val Ala Ser
1 5 10 15
Arg Gly Arg Ser Ala Ala Pro Glu Arg Met Thr Gly Ala Gln Ala Ile
20 25 30
Val Arg Ser Leu Glu Glu Leu Asn Ala Asp Ile Val Phe Gly Ile Pro
35 40 45
Gly Gly Ala Val Leu Pro Val Tyr Asp Pro Leu Tyr Ser Ser Thr Lys
50 55 60
Val Arg His Val Leu Val Arg His Glu Gln Gly Ala Gly His Ala Ala
65 70 75 80
Thr Gly Tyr Ala Gln Val Thr Gly Arg Val Gly Val Cys Ile Ala Thr
85 90 95
Ser Gly Pro Gly Ala Thr Asn Leu Val Thr Pro Ile Ala Asp Ala Asn
100 105 110
Leu Asp Ser Val Pro Met Val Ala Ile Thr Gly Gln Val Gly Ser Gly
115 120 125
Leu Leu Gly Thr Asp Ala Phe Gln Glu Ala Asp Ile Arg Gly Ile Thr
130 135 140
Met Pro Val Thr Lys His Asn Phe Met Val Thr Asp Pro Asn Asp Ile
145 150 155 160
Pro Gln Ala Leu Ala Glu Ala Phe His Leu Ala Ile Thr Gly Arg Pro
165 170 175
Gly Pro Val Leu Val Asp Ile Pro Lys Asp Val Gln Asn Ala Glu Leu
180 185 190
Asp Phe Val Trp Pro Pro Lys Ile Asp Leu Pro Gly Tyr Arg Pro Val
195 200 205
Ser Thr Pro His Ala Arg Gln Ile Glu Gln Ala Val Lys Leu Ile Gly
210 215 220
Glu Ala Lys Lys Pro Val Leu Tyr Ile Gly Gly Gly Val Ile Lys Ala
225 230 235 240
Asp Ala His Glu Glu Leu Arg Ala Phe Ala Glu Tyr Thr Gly Ile Pro
245 250 255
Val Val Thr Thr Leu Met Ala Leu Gly Thr Phe Pro Glu Ser His Glu
260 265 270
Leu His Met Gly Met Pro Gly Met His Gly Thr Val Ser Ala Val Gly
275 280 285
Ala Leu Gln Arg Ser Asp Leu Leu Ile Ala Ile Gly Ser Arg Phe Asp
290 295 300
Asp Arg Val Thr Gly Asp Val Asp Thr Phe Ala Pro Asp Ala Lys Ile
305 310 315 320
Ile His Ala Asp Ile Asp Pro Ala Glu Ile Gly Lys Ile Lys Gln Val
325 330 335
Glu Val Pro Ile Val Gly Asp Ala Arg Glu Val Leu Ala Arg Leu Leu
340 345 350
Glu Thr Thr Lys Ala Ser Lys Ala Glu Thr Glu Asp Ile Ser Glu Trp
355 360 365
Val Asp Tyr Leu Lys Gly Leu Lys Ala Arg Phe Pro Arg Gly Tyr Asp
370 375 380
Glu Gln Pro Gly Asp Leu Leu Ala Pro Gln Phe Val Ile Glu Thr Leu
385 390 395 400
Ser Lys Glu Val Gly Pro Asp Ala Ile Tyr Cys Ala Gly Val Gly Gln
405 410 415
His Gln Met Trp Ala Ala Gln Phe Val Asp Phe Glu Lys Pro Arg Thr
420 425 430
Trp Leu Asn Ser Gly Gly Leu Gly Thr Met Gly Tyr Ala Val Pro Ala
435 440 445
Ala Leu Gly Ala Lys Ala Gly Ala Pro Asp Lys Glu Val Trp Ala Ile
450 455 460
Asp Gly Asp Gly Cys Phe Gln Met Thr Asn Gln Glu Leu Thr Thr Ala
465 470 475 480
Ala Val Glu Gly Phe Pro Ile Lys Ile Ala Leu Ile Asn Asn Gly Asn
485 490 495
Leu Gly Met Val Arg Gln Leu Gln Thr Leu Phe Tyr Glu Gly Arg Tyr
500 505 510
Ser Asn Thr Lys Leu Arg Asn Gln Gly Glu Tyr Met Pro Asp Phe Val
515 520 525
Thr Leu Ser Glu Gly Leu Gly Cys Val Ala Ile Arg Val Thr Lys Ala
530 535 540
Glu Glu Val Leu Pro Ala Ile Gln Lys Ala Arg Glu Ile Asn Asp Arg
545 550 555 560
Pro Val Val Ile Asp Phe Ile Val Gly Glu Asp Ala Gln Val Trp Pro
565 570 575
Met Val Ser Ala Gly Ser Ser Asn Ser Asp Ile Gln Tyr Ala Leu Gly
580 585 590
Leu Arg Pro Phe Phe Asp Gly Asp Glu Ser Ala Ala Glu Asp Pro Ala
595 600 605
Asp Ile His Glu Ala Val Ser Asp Ile Asp Ala Ala Val Glu Ser Thr
610 615 620
625
<210> 34
<211> 1881
<212> DNA
<213> Artificial Sequence
<220>
<223> T96S
<400> 34
gtgaatgtgg cagcttctca acagcccact cccgccacgg ttgcaagccg tggtcgatcc 60
gccgcccctg agcggatgac aggtgcacag gcaattgttc gatcgctcga ggagcttaac 120
gccgacatcg tgttcggtat tcctggtggt gcggtgctac cggtgtatga cccgctctat 180
tcctccacaa aggtgcgcca cgtcctggtg cgccacgagc agggcgcagg ccacgcagca 240
accggctacg cgcaggttac tggacgcgtt ggcgtctgca ttgcatcctc tggcccaggc 300
gcaaccaact tggttacccc aatcgctgat gcaaacttgg actccgttcc catggttgcc 360
atcaccggcc aggtcggaag tggcctgctg ggtaccgatg ctttccagga agccgatatc 420
cgcggcatca ccatgccagt gaccaagcac aacttcatgg tcaccgaccc caacgacatt 480
ccacaggcat tggctgaggc attccacctc gcgattactg gtcgccctgg ccctgttctg 540
gtggatattc ctaaggatgt ccaaaacgct gaattggatt tcgtctggcc accaaagatc 600
gacctgccag gctaccgccc agtttctact ccgcatgctc gacagattga gcaggctgtc 660
aaactgatcg gtgaagccaa aaagccagtc ctttacattg gcggcggcgt tatcaaggct 720
gatgcacacg aagaactgcg tgcatttgct gagtacaccg gcatcccagt tgtcaccacc 780
ttgatggcat tgggtacctt cccagagtcc cacgagctgc acatgggtat gccaggcatg 840
cacggcaccg tgtccgctgt tggcgcactg cagcgcagtg acctgctgat tgctatcggt 900
tcccgcttcg acgaccgcgt caccggtgac gttgacacct tcgcacctga tgccaagatc 960
attcacgctg acattgatcc tgccgaaatc ggcaagatca agcaggttga ggttccaatc 1020
gtgggcgatg cccgcgaggt tcttgctcgt ctgctggaaa ccaccaaggc aagcaaggca 1080
gagaccgagg acatctccga gtgggttgat tacctcaagg gcctcaaggc acgtttccca 1140
cgtggctacg acgagcagcc aggcgatctg ctggcaccac agtttgtcat tgaaaccctg 1200
tccaaggaag ttggccccga cgcaatttac tgcgccggcg ttggccagca ccagatgtgg 1260
gcagctcagt tcgttgactt tgaaaagcca cgcacctggc tcaactctgg cggcctgggc 1320
accatgggct acgcagttcc tgcggctctt ggagcaaagg ctggcgcacc tgacaaggaa 1380
gtctgggcta tcgacggcga cggctgtttc cagatgacca accaggaact caccaccgcc 1440
gcagttgaag gtttccccat taagatcgca ctaatcaaca acggaaacct gggcatggtt 1500
cgccaatggc agaccctatt ctatgaagga cggtactcaa atactaaact tcgtaaccag 1560
ggcgagtaca tgcccgactt tgttaccctt tctgagggac ttggctgtgt tgccatccgc 1620
gtcaccaaag cggaggaagt actgccagcc atccaaaagg ctcgagagat caacgaccgc 1680
ccagtagtca tcgacttcat cgtcggtgaa gacgcacagg tatggccaat ggtgtctgct 1740
ggatcatcca actccgatat ccagtacgca ctcggattgc gcccattctt tgatggtgat 1800
gaatctgcag cagaagatcc tgccgacatt cacgaagccg tcagcgacat tgatgccgcc 1860
gttgaatcga ccgaggcata a 1881
<210> 35
<211> 1881
<212> DNA
<213> Artificial Sequence
<220>
<223> T96A
<400> 35
gtgaatgtgg cagcttctca acagcccact cccgccacgg ttgcaagccg tggtcgatcc 60
gccgcccctg agcggatgac aggtgcacag gcaattgttc gatcgctcga ggagcttaac 120
gccgacatcg tgttcggtat tcctggtggt gcggtgctac cggtgtatga cccgctctat 180
tcctccacaa aggtgcgcca cgtcctggtg cgccacgagc agggcgcagg ccacgcagca 240
accggctacg cgcaggttac tggacgcgtt ggcgtctgca ttgcagcatc tggcccaggc 300
gcaaccaact tggttacccc aatcgctgat gcaaacttgg actccgttcc catggttgcc 360
atcaccggcc aggtcggaag tggcctgctg ggtaccgatg ctttccagga agccgatatc 420
cgcggcatca ccatgccagt gaccaagcac aacttcatgg tcaccgaccc caacgacatt 480
ccacaggcat tggctgaggc attccacctc gcgattactg gtcgccctgg ccctgttctg 540
gtggatattc ctaaggatgt ccaaaacgct gaattggatt tcgtctggcc accaaagatc 600
gacctgccag gctaccgccc agtttctact ccgcatgctc gacagattga gcaggctgtc 660
aaactgatcg gtgaagccaa aaagccagtc ctttacattg gcggcggcgt tatcaaggct 720
gatgcacacg aagaactgcg tgcatttgct gagtacaccg gcatcccagt tgtcaccacc 780
ttgatggcat tgggtacctt cccagagtcc cacgagctgc acatgggtat gccaggcatg 840
cacggcaccg tgtccgctgt tggcgcactg cagcgcagtg acctgctgat tgctatcggt 900
tcccgcttcg acgaccgcgt caccggtgac gttgacacct tcgcacctga tgccaagatc 960
attcacgctg acattgatcc tgccgaaatc ggcaagatca agcaggttga ggttccaatc 1020
gtgggcgatg cccgcgaggt tcttgctcgt ctgctggaaa ccaccaaggc aagcaaggca 1080
gagaccgagg acatctccga gtgggttgat tacctcaagg gcctcaaggc acgtttccca 1140
cgtggctacg acgagcagcc aggcgatctg ctggcaccac agtttgtcat tgaaaccctg 1200
tccaaggaag ttggccccga cgcaatttac tgcgccggcg ttggccagca ccagatgtgg 1260
gcagctcagt tcgttgactt tgaaaagcca cgcacctggc tcaactctgg cggcctgggc 1320
accatgggct acgcagttcc tgcggctctt ggagcaaagg ctggcgcacc tgacaaggaa 1380
gtctgggcta tcgacggcga cggctgtttc cagatgacca accaggaact caccaccgcc 1440
gcagttgaag gtttccccat taagatcgca ctaatcaaca acggaaacct gggcatggtt 1500
cgccaatggc agaccctatt ctatgaagga cggtactcaa atactaaact tcgtaaccag 1560
ggcgagtaca tgcccgactt tgttaccctt tctgagggac ttggctgtgt tgccatccgc 1620
gtcaccaaag cggaggaagt actgccagcc atccaaaagg ctcgagagat caacgaccgc 1680
ccagtagtca tcgacttcat cgtcggtgaa gacgcacagg tatggccaat ggtgtctgct 1740
ggatcatcca actccgatat ccagtacgca ctcggattgc gcccattctt tgatggtgat 1800
gaatctgcag cagaagatcc tgccgacatt cacgaagccg tcagcgacat tgatgccgcc 1860
gttgaatcga ccgaggcata a 1881
<210> 36
<211> 1881
<212> DNA
<213> Artificial Sequence
<220>
<223> T96C
<400> 36
gtgaatgtgg cagcttctca acagcccact cccgccacgg ttgcaagccg tggtcgatcc 60
gccgcccctg agcggatgac aggtgcacag gcaattgttc gatcgctcga ggagcttaac 120
gccgacatcg tgttcggtat tcctggtggt gcggtgctac cggtgtatga cccgctctat 180
tcctccacaa aggtgcgcca cgtcctggtg cgccacgagc agggcgcagg ccacgcagca 240
accggctacg cgcaggttac tggacgcgtt ggcgtctgca ttgcatgctc tggcccaggc 300
gcaaccaact tggttacccc aatcgctgat gcaaacttgg actccgttcc catggttgcc 360
atcaccggcc aggtcggaag tggcctgctg ggtaccgatg ctttccagga agccgatatc 420
cgcggcatca ccatgccagt gaccaagcac aacttcatgg tcaccgaccc caacgacatt 480
ccacaggcat tggctgaggc attccacctc gcgattactg gtcgccctgg ccctgttctg 540
gtggatattc ctaaggatgt ccaaaacgct gaattggatt tcgtctggcc accaaagatc 600
gacctgccag gctaccgccc agtttctact ccgcatgctc gacagattga gcaggctgtc 660
aaactgatcg gtgaagccaa aaagccagtc ctttacattg gcggcggcgt tatcaaggct 720
gatgcacacg aagaactgcg tgcatttgct gagtacaccg gcatcccagt tgtcaccacc 780
ttgatggcat tgggtacctt cccagagtcc cacgagctgc acatgggtat gccaggcatg 840
cacggcaccg tgtccgctgt tggcgcactg cagcgcagtg acctgctgat tgctatcggt 900
tcccgcttcg acgaccgcgt caccggtgac gttgacacct tcgcacctga tgccaagatc 960
attcacgctg acattgatcc tgccgaaatc ggcaagatca agcaggttga ggttccaatc 1020
gtgggcgatg cccgcgaggt tcttgctcgt ctgctggaaa ccaccaaggc aagcaaggca 1080
gagaccgagg acatctccga gtgggttgat tacctcaagg gcctcaaggc acgtttccca 1140
cgtggctacg acgagcagcc aggcgatctg ctggcaccac agtttgtcat tgaaaccctg 1200
tccaaggaag ttggccccga cgcaatttac tgcgccggcg ttggccagca ccagatgtgg 1260
gcagctcagt tcgttgactt tgaaaagcca cgcacctggc tcaactctgg cggcctgggc 1320
accatgggct acgcagttcc tgcggctctt ggagcaaagg ctggcgcacc tgacaaggaa 1380
gtctgggcta tcgacggcga cggctgtttc cagatgacca accaggaact caccaccgcc 1440
gcagttgaag gtttccccat taagatcgca ctaatcaaca acggaaacct gggcatggtt 1500
cgccaatggc agaccctatt ctatgaagga cggtactcaa atactaaact tcgtaaccag 1560
ggcgagtaca tgcccgactt tgttaccctt tctgagggac ttggctgtgt tgccatccgc 1620
gtcaccaaag cggaggaagt actgccagcc atccaaaagg ctcgagagat caacgaccgc 1680
ccagtagtca tcgacttcat cgtcggtgaa gacgcacagg tatggccaat ggtgtctgct 1740
ggatcatcca actccgatat ccagtacgca ctcggattgc gcccattctt tgatggtgat 1800
gaatctgcag cagaagatcc tgccgacatt cacgaagccg tcagcgacat tgatgccgcc 1860
gttgaatcga ccgaggcata a 1881
<210> 37
<211> 1881
<212> DNA
<213> Artificial Sequence
<220>
<223> W503Q
<400> 37
gtgaatgtgg cagcttctca acagcccact cccgccacgg ttgcaagccg tggtcgatcc 60
gccgcccctg agcggatgac aggtgcacag gcaattgttc gatcgctcga ggagcttaac 120
gccgacatcg tgttcggtat tcctggtggt gcggtgctac cggtgtatga cccgctctat 180
tcctccacaa aggtgcgcca cgtcctggtg cgccacgagc agggcgcagg ccacgcagca 240
accggctacg cgcaggttac tggacgcgtt ggcgtctgca ttgcaacctc tggcccaggc 300
gcaaccaact tggttacccc aatcgctgat gcaaacttgg actccgttcc catggttgcc 360
atcaccggcc aggtcggaag tggcctgctg ggtaccgatg ctttccagga agccgatatc 420
cgcggcatca ccatgccagt gaccaagcac aacttcatgg tcaccgaccc caacgacatt 480
ccacaggcat tggctgaggc attccacctc gcgattactg gtcgccctgg ccctgttctg 540
gtggatattc ctaaggatgt ccaaaacgct gaattggatt tcgtctggcc accaaagatc 600
gacctgccag gctaccgccc agtttctact ccgcatgctc gacagattga gcaggctgtc 660
aaactgatcg gtgaagccaa aaagccagtc ctttacattg gcggcggcgt tatcaaggct 720
gatgcacacg aagaactgcg tgcatttgct gagtacaccg gcatcccagt tgtcaccacc 780
ttgatggcat tgggtacctt cccagagtcc cacgagctgc acatgggtat gccaggcatg 840
cacggcaccg tgtccgctgt tggcgcactg cagcgcagtg acctgctgat tgctatcggt 900
tcccgcttcg acgaccgcgt caccggtgac gttgacacct tcgcacctga tgccaagatc 960
attcacgctg acattgatcc tgccgaaatc ggcaagatca agcaggttga ggttccaatc 1020
gtgggcgatg cccgcgaggt tcttgctcgt ctgctggaaa ccaccaaggc aagcaaggca 1080
gagaccgagg acatctccga gtgggttgat tacctcaagg gcctcaaggc acgtttccca 1140
cgtggctacg acgagcagcc aggcgatctg ctggcaccac agtttgtcat tgaaaccctg 1200
tccaaggaag ttggccccga cgcaatttac tgcgccggcg ttggccagca ccagatgtgg 1260
gcagctcagt tcgttgactt tgaaaagcca cgcacctggc tcaactctgg cggcctgggc 1320
accatgggct acgcagttcc tgcggctctt ggagcaaagg ctggcgcacc tgacaaggaa 1380
gtctgggcta tcgacggcga cggctgtttc cagatgacca accaggaact caccaccgcc 1440
gcagttgaag gtttccccat taagatcgca ctaatcaaca acggaaacct gggcatggtt 1500
cgccaacagc agaccctatt ctatgaagga cggtactcaa atactaaact tcgtaaccag 1560
ggcgagtaca tgcccgactt tgttaccctt tctgagggac ttggctgtgt tgccatccgc 1620
gtcaccaaag cggaggaagt actgccagcc atccaaaagg ctcgagagat caacgaccgc 1680
ccagtagtca tcgacttcat cgtcggtgaa gacgcacagg tatggccaat ggtgtctgct 1740
ggatcatcca actccgatat ccagtacgca ctcggattgc gcccattctt tgatggtgat 1800
gaatctgcag cagaagatcc tgccgacatt cacgaagccg tcagcgacat tgatgccgcc 1860
gttgaatcga ccgaggcata a 1881
<210> 38
<211> 1881
<212> DNA
<213> Artificial Sequence
<220>
<223> W503N
<400> 38
gtgaatgtgg cagcttctca acagcccact cccgccacgg ttgcaagccg tggtcgatcc 60
gccgcccctg agcggatgac aggtgcacag gcaattgttc gatcgctcga ggagcttaac 120
gccgacatcg tgttcggtat tcctggtggt gcggtgctac cggtgtatga cccgctctat 180
tcctccacaa aggtgcgcca cgtcctggtg cgccacgagc agggcgcagg ccacgcagca 240
accggctacg cgcaggttac tggacgcgtt ggcgtctgca ttgcaacctc tggcccaggc 300
gcaaccaact tggttacccc aatcgctgat gcaaacttgg actccgttcc catggttgcc 360
atcaccggcc aggtcggaag tggcctgctg ggtaccgatg ctttccagga agccgatatc 420
cgcggcatca ccatgccagt gaccaagcac aacttcatgg tcaccgaccc caacgacatt 480
ccacaggcat tggctgaggc attccacctc gcgattactg gtcgccctgg ccctgttctg 540
gtggatattc ctaaggatgt ccaaaacgct gaattggatt tcgtctggcc accaaagatc 600
gacctgccag gctaccgccc agtttctact ccgcatgctc gacagattga gcaggctgtc 660
aaactgatcg gtgaagccaa aaagccagtc ctttacattg gcggcggcgt tatcaaggct 720
gatgcacacg aagaactgcg tgcatttgct gagtacaccg gcatcccagt tgtcaccacc 780
ttgatggcat tgggtacctt cccagagtcc cacgagctgc acatgggtat gccaggcatg 840
cacggcaccg tgtccgctgt tggcgcactg cagcgcagtg acctgctgat tgctatcggt 900
tcccgcttcg acgaccgcgt caccggtgac gttgacacct tcgcacctga tgccaagatc 960
attcacgctg acattgatcc tgccgaaatc ggcaagatca agcaggttga ggttccaatc 1020
gtgggcgatg cccgcgaggt tcttgctcgt ctgctggaaa ccaccaaggc aagcaaggca 1080
gagaccgagg acatctccga gtgggttgat tacctcaagg gcctcaaggc acgtttccca 1140
cgtggctacg acgagcagcc aggcgatctg ctggcaccac agtttgtcat tgaaaccctg 1200
tccaaggaag ttggccccga cgcaatttac tgcgccggcg ttggccagca ccagatgtgg 1260
gcagctcagt tcgttgactt tgaaaagcca cgcacctggc tcaactctgg cggcctgggc 1320
accatgggct acgcagttcc tgcggctctt ggagcaaagg ctggcgcacc tgacaaggaa 1380
gtctgggcta tcgacggcga cggctgtttc cagatgacca accaggaact caccaccgcc 1440
gcagttgaag gtttccccat taagatcgca ctaatcaaca acggaaacct gggcatggtt 1500
cgccaaaacc agaccctatt ctatgaagga cggtactcaa atactaaact tcgtaaccag 1560
ggcgagtaca tgcccgactt tgttaccctt tctgagggac ttggctgtgt tgccatccgc 1620
gtcaccaaag cggaggaagt actgccagcc atccaaaagg ctcgagagat caacgaccgc 1680
ccagtagtca tcgacttcat cgtcggtgaa gacgcacagg tatggccaat ggtgtctgct 1740
ggatcatcca actccgatat ccagtacgca ctcggattgc gcccattctt tgatggtgat 1800
gaatctgcag cagaagatcc tgccgacatt cacgaagccg tcagcgacat tgatgccgcc 1860
gttgaatcga ccgaggcata a 1881
<210> 39
<211> 1881
<212> DNA
<213> Artificial Sequence
<220>
<223> W503L
<400> 39
gtgaatgtgg cagcttctca acagcccact cccgccacgg ttgcaagccg tggtcgatcc 60
gccgcccctg agcggatgac aggtgcacag gcaattgttc gatcgctcga ggagcttaac 120
gccgacatcg tgttcggtat tcctggtggt gcggtgctac cggtgtatga cccgctctat 180
tcctccacaa aggtgcgcca cgtcctggtg cgccacgagc agggcgcagg ccacgcagca 240
accggctacg cgcaggttac tggacgcgtt ggcgtctgca ttgcaacctc tggcccaggc 300
gcaaccaact tggttacccc aatcgctgat gcaaacttgg actccgttcc catggttgcc 360
atcaccggcc aggtcggaag tggcctgctg ggtaccgatg ctttccagga agccgatatc 420
cgcggcatca ccatgccagt gaccaagcac aacttcatgg tcaccgaccc caacgacatt 480
ccacaggcat tggctgaggc attccacctc gcgattactg gtcgccctgg ccctgttctg 540
gtggatattc ctaaggatgt ccaaaacgct gaattggatt tcgtctggcc accaaagatc 600
gacctgccag gctaccgccc agtttctact ccgcatgctc gacagattga gcaggctgtc 660
aaactgatcg gtgaagccaa aaagccagtc ctttacattg gcggcggcgt tatcaaggct 720
gatgcacacg aagaactgcg tgcatttgct gagtacaccg gcatcccagt tgtcaccacc 780
ttgatggcat tgggtacctt cccagagtcc cacgagctgc acatgggtat gccaggcatg 840
cacggcaccg tgtccgctgt tggcgcactg cagcgcagtg acctgctgat tgctatcggt 900
tcccgcttcg acgaccgcgt caccggtgac gttgacacct tcgcacctga tgccaagatc 960
attcacgctg acattgatcc tgccgaaatc ggcaagatca agcaggttga ggttccaatc 1020
gtgggcgatg cccgcgaggt tcttgctcgt ctgctggaaa ccaccaaggc aagcaaggca 1080
gagaccgagg acatctccga gtgggttgat tacctcaagg gcctcaaggc acgtttccca 1140
cgtggctacg acgagcagcc aggcgatctg ctggcaccac agtttgtcat tgaaaccctg 1200
tccaaggaag ttggccccga cgcaatttac tgcgccggcg ttggccagca ccagatgtgg 1260
gcagctcagt tcgttgactt tgaaaagcca cgcacctggc tcaactctgg cggcctgggc 1320
accatgggct acgcagttcc tgcggctctt ggagcaaagg ctggcgcacc tgacaaggaa 1380
gtctgggcta tcgacggcga cggctgtttc cagatgacca accaggaact caccaccgcc 1440
gcagttgaag gtttccccat taagatcgca ctaatcaaca acggaaacct gggcatggtt 1500
cgccaactgc agaccctatt ctatgaagga cggtactcaa atactaaact tcgtaaccag 1560
ggcgagtaca tgcccgactt tgttaccctt tctgagggac ttggctgtgt tgccatccgc 1620
gtcaccaaag cggaggaagt actgccagcc atccaaaagg ctcgagagat caacgaccgc 1680
ccagtagtca tcgacttcat cgtcggtgaa gacgcacagg tatggccaat ggtgtctgct 1740
ggatcatcca actccgatat ccagtacgca ctcggattgc gcccattctt tgatggtgat 1800
gaatctgcag cagaagatcc tgccgacatt cacgaagccg tcagcgacat tgatgccgcc 1860
gttgaatcga ccgaggcata a 1881
1
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| ВАРИАНТ АЛЬДОЛАЗЫ AROG И СПОСОБ ПОЛУЧЕНИЯ АМИНОКИСЛОТЫ С РАЗВЕТВЛЕННОЙ ЦЕПЬЮ С ЕГО ИСПОЛЬЗОВАНИЕМ | 2021 |
|
RU2826456C1 |
| Микроорганизмы, продуцирующие L-валин, и способ получения L-валина с их использованием | 2021 |
|
RU2822660C1 |
| ВАРИАНТ ПРЕФЕНАТДЕГИДРАТАЗЫ И СПОСОБ ПОЛУЧЕНИЯ АМИНОКИСЛОТ С РАЗВЕТВЛЕННОЙ ЦЕПЬЮ С ЕГО ИСПОЛЬЗОВАНИЕМ | 2022 |
|
RU2827315C1 |
| МУТИРОВАННЫЙ БЕЛОК SPOT И СПОСОБ ПОЛУЧЕНИЯ L-АМИНОКИСЛОТ С ЕГО ПРИМЕНЕНИЕМ | 2022 |
|
RU2837657C2 |
| Новый вариант цитратсинтазы и способ получения L-аминокислот c его применением | 2022 |
|
RU2836733C1 |
| НОВЫЙ ПОЛИПЕПТИД И СПОСОБ ПОЛУЧЕНИЯ L-ЛЕЙЦИНА С ЕГО ИСПОЛЬЗОВАНИЕМ | 2021 |
|
RU2811433C1 |
| НОВЫЙ ВАРИАНТ ЦИТРАТСИНТАЗЫ И СПОСОБ ПОЛУЧЕНИЯ L-ВАЛИНА C ЕГО ПРИМЕНЕНИЕМ | 2022 |
|
RU2835063C1 |
| ВАРИАНТ ИЗ РОДА YARROWIA И СПОСОБ ПОЛУЧЕНИЯ ЖИРА С ЕГО ИСПОЛЬЗОВАНИЕМ | 2021 |
|
RU2817101C1 |
| Новый вариант белка и способ получения L-лизина с его применением | 2021 |
|
RU2793405C1 |
| Новый вариант пролиндегидрогеназы и способ получения L-валина с его применением | 2021 |
|
RU2795067C1 |
Изобретение относится к биотехнологии и представляет собой вариант синтазы ацетогидроксикислот, где в большой субъединице синтазы ацетогидроксикислот (большой субъединице синтазы ацетолактата; белке IlvB) 96-я аминокислота (треонин) заменена на аминокислоту, отличающуюся от треонина, 503-я аминокислота (триптофан) заменена на аминокислоту, отличающуюся от триптофана, или обе аминокислоты, 96-я аминокислота (треонин) и 503-я аминокислота (триптофан), заменены на другую аминокислоту. Изобретение касается также способа получения L-аминокислоты с разветвленной цепью с использованием такого варианта синтазы ацетогидрокислот. Изобретение позволяет получать L-аминокислоты с разветвленной цепью с высокой степенью эффективности. 5 н. и 7 з.п. ф-лы, 6 табл., 12 пр.
1. Вариант синтазы ацетогидроксикислот, где в большой субъединице синтазы ацетогидроксикислот (большой субъединице синтазы ацетолактата; белке IlvB) 96-я аминокислота (треонин) заменена на аминокислоту, отличающуюся от треонина, 503-я аминокислота (триптофан) заменена на аминокислоту, отличающуюся от триптофана, или обе аминокислоты, 96-я аминокислота (треонин) и 503-я аминокислота (триптофан), заменены на другую аминокислоту.
2. Вариант синтазы ацетогидроксикислот по п. 1, где белок IlvB содержит аминокислотную последовательность SEQ ID NO: 1.
3. Вариант синтазы ацетогидроксикислот по п. 1, где 96-я аминокислота (треонин) заменена на серин, цистеин или аланин.
4. Вариант синтазы ацетогидроксикислот по п. 1, где 503-я аминокислота (триптофан) заменена на глутамин, аспарагин или лейцин.
5. Вариант синтазы ацетогидроксикислот по п. 1, содержащий аминокислотную последовательность с любой SEQ ID NO: 28-33.
6. Полинуклеотид, кодирующий вариант синтазы ацетогидроксикислот по любому из пп. 1-5.
7. Вектор экспрессии, содержащий полинуклеотид, кодирующий вариант синтазы ацетогидроксикислот по любому из пп. 1-5.
8. Микроорганизм рода Corynebacterium, продуцирующий L-аминокислоту с разветвленной цепью, содержащий вариант синтазы ацетогидроксикислот по любому из пп. 1-5, полинуклеотид по п. 6 или вектор по п. 7.
9. Микроорганизм, продуцирующий L-аминокислоту с разветвленной цепью по п. 8, где микроорганизм рода Corynebacterium представляет собой Corynebacterium glutamicum.
10. Микроорганизм, продуцирующий L-аминокислоту с разветвленной цепью по п. 8, где L-аминокислота с разветвленной цепью представляет собой L-валин или L-лейцин.
11. Способ получения L-аминокислоты с разветвленной цепью, включающий:
(а) культивирование микроорганизма, продуцирующего L-аминокислоту с разветвленной цепью, по любому из пп. 8-10 в среде; и
(б) извлечение L-аминокислоты с разветвленной цепью, полученной на стадии (а), из микроорганизма или среды, в которой его культивировали, со стадии (а).
12. Способ получения L-аминокислоты с разветвленной цепью по п. 11, где L-аминокислота с разветвленной цепью представляет собой L-валин или L-лейцин.
| US 20140335574 A1, 13.11.2014 | |||
| WO 2014142463 A1, 18.09.2014 | |||
| СПОСОБ ПРОДУЦИРОВАНИЯ АМИНОКИСЛОТ СЕМЕЙСТВА АСПАРТАТА С ИСПОЛЬЗОВАНИЕМ МИКРООРГАНИЗМОВ | 2010 |
|
RU2535973C2 |

