СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
Настоящая заявка содержит список последовательностей, который представлен на электронном носителе в формате ASCII и полностью включен в настоящее описание посредством ссылки. Указанная ASCII копия, созданная 5 мая 2016, озаглавлена PAT057215-US-PSP_SL.txt и имеет размер 207763 байт.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амину, его фармацевтически приемлемым солям и сокристаллам и к фармацевтическим композициям, содержащим указанные соединения, для применения в лечении рака, в частности карциномы, точнее, для применения в лечении рака легких и, более конкретно, для применения в лечении немелкоклеточного рака легких.
Другие задачи настоящего изобретения заключаются в предоставлении способов лечения рака, в частности карциномы, точнее рака легких и, более конкретно, немелкоклеточного рака легких, путем введения соединения формулы (I) или путем введения фармацевтической композиции или комбинированного продукта, содержащего соединение формулы (I).
УРОВЕНЬ ТЕХНИКИ
Рак является одной из основных проблем в области здравоохранения во всем мире. В настоящее время это вторая по значимости причина смерти в Соединенных Штатах и в нескольких развитых странах, и предполагается, что он превзойдет по значимости болезни сердца в ближайшие несколько лет в качестве основной причины смерти в ближайшие несколько лет. (Siegel R L, et al, Cancer Statistics, 2015, CA Cancer J Clin 2015; 65:5-29. VC 2015 American Cancer Society и ссылки в настоящем описании).
Рак считается комплексным заболеванием, которое определяется процессами, происходящими как внутри, так и снаружи злокачественных клеток. Несколько исследований, проведенных на различных in vitro и животных моделях, включая, например, метастазы в легких, клетки аденокарциномы легких человека, клетки меланомы мыши, клетки рака яичника мыши, клетки рака молочной железы мыши, подтвердили, что таргетирование аденозинергической системы обеспечивает огромные возможности для развития различных методов лечения. Ряд доказательств подчеркивают важность аденозина как критического аутокринного и паракринного регуляторного фактора, который накапливается в микроокружении неопластических клеток. Внеклеточный аденозин, который обычно присутствует в высоких концентрациях в раковых тканях, является важным медиатором при изменении функций иммунных клеток при раке. Возможно, это связано с тем, что жестко регулируемые пути аденозиновых рецепторов иммунных клеток подвергаются существенным изменениям в опухолях, тем самым переключая функции этих клеток с иммунного контроля и защиты хозяина на стимуляцию трансформации и рост раковых клеток. (Antonioli L et al, Immunity, inflammation and cancer: a leading role for adenosine, Nature, 842, December 2013, Volume 13, and references therein).
Известно, что опухоли используют многочисленные механизмы иммуносупрессии для облегчения роста опухоли (Koebel CM. et al, Adaptive immunity maintains occult cancer in an equilibrium state, Nature. 2007, 450, 7171:903-907 and Schreiber RD. et al, Cancer immunoediting: Integrating immunity's roles in cancer suppression and promotion, Science. 2011, 331, 6024:1565-1570). Существуют исследования, в которых установлено, что один из таких механизмов опосредован катаболизмом внеклеточного АМФ в аденозин с иммуносупрессивными свойствами (Ohta A. et al, A2A adenosine receptor protects tumors from antitumor T cells. Proc Natl Acad Sci U S A. 2006; 103: 13132-13137 and Ohta A. et al, A2A adenosine receptor may allow expansion of T cells lacking effector functions in extracellular adenosine-rich microenvironments. J Immunol. 2009, 183, 9:5487-5493). Во-первых, происходит превращение внеклеточного АТФ в АМФ с участием эктофермента CD39. Дальнейшее дефосфорилирование АМФ с участием эктофермента CD73 приводит к образованию внеклеточного аденозина.
Во время этого процесса активность аденозинкиназы также подавляется, что приводит к ингибированию "спасательной" активности этого фермента и увеличению уровня аденозина. Например, при гипоксических состояниях во время воспаления или в микроокружении опухоли ингибирование аденозинкиназы вызывает 15-20-кратное увеличение как внеклеточного, так и внутриклеточного уровней аденозина (Decking UK. Et al, Hypoxia-induced inhibition of adenosine kinase potentiates cardiac adenosine release. Circ. Res. 1997; 81(2):154-164. doi: 10.1161/01.RES.81.2.154). Сгенерированный внеклеточный аденозин связывается с четырьмя известными рецепторами клеточной поверхности (A1, A2A, A2B и A3), которые экспрессируются во многих субпопуляциях иммунных клеток, включая Т-клетки, естественные киллерные (NK) клетки, естественные киллерные Т-клетки, макрофаги, дендритные клетки и супрессорные клетки миелоидного происхождения (MDSC). Иммуносупрессивное действие аденозина обусловлено в основном рецепторами подтипов A2A и A2B. Они имеют общий сигнальный путь, который приводит к активации аденилатциклазы и накоплению внутриклеточного цАМФ. Имеется несколько свидетельств, демонстрирующих, что внутриклеточный цАМФ является сигнальной молекулой, которая ингибирует передачу сигналов от Т-клеточных рецепторов на ранней и поздней стадиях в пути активации Т-клеток, инициируемой Т-клеточными рецепторами. (Ohta A, Sitkovsky M, Role of G-protein-coupled adenosine receptors in downregulation of inflammation and protection from tissue damage, Nature, 2001, 414: 916-920).
Было высказано предположение, что элиминация рецептора A2a, вызванная генетическими причинами или возникшая в результате подавления передачи сигналов от рецептора A2a с помощью антагонистов рецептора A2a, предотвращает ингибирование противоопухолевых Т-клеток и улучшает отторжение опухоли (Ohta A. et al, A2a adenosine receptor protects tumors from antitumor T cells. Proc Natl Acad Sci U S A. 2006; 103: 13132-13137).
Рецептор A2a функционирует как незаменимый отрицательный регулятор активированных Т-клеток для защиты нормальных тканей от чрезмерного сопутствующего повреждения, вызванного воспалительным процессом. Предполагается, что рецептор А2а может также "ошибочно" защищать раковые ткани. Из этого можно сделать вывод, что если это действительно так, то генетическая инактивация или фармакологический антагонизм рецептора A2a позволит предотвратить подавление противоопухолевых Т-клеток и тем самым улучшить отторжение опухоли благодаря таким "де-ингибированным" (восстановленным) Т-клеткам (Sitkovsky M. et al, Adenosine A2a receptor antagonists: blockade of adenosinergic effects and T regulatory cells, British Journal of Pharmacology, 2008, 153, S457-S464).
Рак легких является основной причиной смерти от рака во всем мире, и с 1985 года он становится самым распространенным раком во всем мире, как с точки зрения заболеваемости, так и смертности. В глобальном масштабе рак легких дает самый большой вклад в диагностику среди новых случаев рака (12,4% от общего числа новых случаев рака) и является основной причиной смерти от рака (17,6% от общего количества смертельных исходов от рака).
Рак легких возникает из клеток респираторного эпителия и может быть разделен на две основные категории. Мелкоклеточный рак легких (МРЛ, SCLC) является опухолью высокой степени злокачественности, происходящий из клеток с нейроэндокринными характеристиками, и составляет 15% случаев рака легких. Немелкоклеточный рак легких (НМРЛ, NSCLC), который приходится на оставшиеся 85% случаев, подразделяется дополнительно на 3 основные патологические подтипа: аденокарциному, плоскоклеточный рак и крупноклеточную карциному. Сама аденокарцинома составляет 38,5% от всех случаев рака легких, при том, что на долю плоскоклеточной карциномы приходится 20%, а крупноклеточная карцинома составляет 2,9%. За последние несколько десятилетий случаи аденокарциномы значительно участились, и аденокарцинома стала наиболее распространенным типом НМРЛ, которым ранее считалась плоскоклеточная карцинома. (De la Cruz, C et al, Lung Cancer: Epidemiology, Etiology, and Prevention, Clin Chest Med. 2011 December; 32(4)).
В частности, в случае НМРЛ, стадия заболевания определяет лечение, которое включает хирургическое вмешательство, радиацию, двухкомпонентную химиотерапию на основе препаратов платины и современные направленные методы лечения путем прерывания сигнальных путей, ответственных за пролиферацию и выживание клеток. Системная химиотерапия (платиновый дублет, таксаны, гемцитабин, пеметрексед) полезна на более ранних этапах заболевания (Azzoli CG. et al, 2011 Focused Update of 2009 American Society of Clinical Oncology Clinical Practice Guideline Update on Chemotherapy for Stage IV Non-Small-Cell Lung Cancer, J Oncol Pract. 2012; 8:63-6 doi:10.1200/JOP.2011.000374), что свидетельствует о ее ограниченной эффективности, и поэтому мультимодальная стратегия лечения стала важным способом лечения пациентов с НМРЛ. В нескольких исследованиях было показано, что две или более комбинации лекарственных средств обладают превосходной эффективностью, но при этом увеличивается токсичность (Yoshida T. et al, Comparison of adverse events and efficacy between gefitinib and erlotinib in patients with non-small-cell lung cancer: a retrospective analysis, Med Oncol. 2013; 30:349).
В последнее время разрабатывается несколько подходов для усиления противоракового ответа Т-клетками и восстановления их способности обнаруживать и атаковать раковые клетки; среди них были разработаны mAb, блокирующие цитотоксический лимфоцит-ассоциированный антиген 4 (CTLA4) и Т-клеточные события, опосредованные белком 1 запрограммированной клеточной смерти (PD-1).
Ипилимумаб, полностью человеческий анти-CTLA4 mAb, показал улучшенный клинический результат среди пациентов с SQCLC (Lynch TJ. et al, Ipilimumab in combination with paclitaxel and carboplatin as first-line treatment in stage IIIB/IV non-small-cell lung cancer: Results from a randomized, double-blind, multicenter phase II study, J Clin Oncol.2012; 30: 2046-54). Анти-PD-1 mAb (MEDI4735, BMS-936558, BMS-936559) продемонстрировали заметную устойчивую регрессию опухолей у тяжелых пациентов с НМРЛ, ранее проходивших лечение (Brahmer JR. et al, Safety and activity of anti-PD-L1 antibody in patients with advanced cancer, N Engl J Med. 2012; 366: 2455-65).
Имеются исследования, свидетельствующие об изменениях, вызывающих изменения в микроокружении внеклеточной опухоли. Одним из таких внеклеточных изменений является повышенная концентрация аденозина, которая нарушает опосредованное Т-клетками отторжение и поддерживает ангиогенез. В исследовании было показано, что существенное количество аденокарцином легких экспрессирует аденозиновый рецептор A2a, что подтверждается тестами антагонистов аденозинового рецептора A2a в качестве противоопухолевой терапии. (Mediavilla-Varela, M et al, Antagonism of adenosine A2a receptor expressed by lung adenocarcinoma tumor cells and cancer associated fibroblasts inhibits their growth, Cancer Biology & Therapy, September 2013, 14:9, 860-868).
Несмотря на развитие новых терапевтических средств, 5-летняя выживаемость при НМРЛ составляет всего лишь 14%, что указывает на необходимость продолжения изучения новых методов лечения (Spira A. et al, Multidisciplinary management of lung cancer, N Engl J Med. 2004; 350:379-92 doi: 10.1056/NEJMra035536).
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Остается необходимость в новых методах лечения и терапии рака.
В международной заявке на патент WO 2011/121418 A1 раскрыта группа 4-аминопиримидиновых соединений в качестве антагонистов рецепторов A2a и их применение при лечении состояний или заболеваний, улучшаемых в результате антагонизма указанных аденозиновых рецепторов. Хотя в описании WO 2011/121418 A1 не уделяется особое внимание лечению рака, авторы изобретения, изучавшие эффективность описанных в WO 2011/121418 A1 соединений в лечении рака, неожиданно обнаружили, что не все антагонисты A2A, охватываемые формулой изобретения WO 2011/121418 A1, эффективны в лечении рака, особенно карцином, в частности рака легких.
Авторы настоящего изобретения неожиданно обнаружили, что 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амин формулы (I)
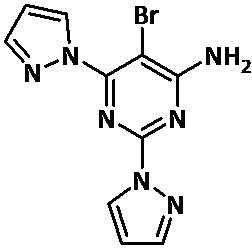 (I)
(I)
является существенно более эффективным в лечении рака, в частности карциномы, конкретнее рака легких, и более конкретно немелкоклеточного рака легких, по сравнению с другими антагонистами аденозинового рецептора А2а, раскрытыми в заявке на патент WO 2011/121418 A1. Кроме того, соединение формулы (I) показало синергетический эффект с другими иммунотерапевтическими агентами в стимуляции иммунной системы для лечения рака.
В одном из аспектов настоящее изобретение относится к 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амину формулы (I), его фармацевтически приемлемым солям и сокристаллам для применения в лечение рака, в частности карциномы, конкретнее рака легких, и более конкретно немелкоклеточного рака легких. 5-Бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амин обладает способностью стимулировать иммунную систему и блокировать один из механизмов уклонения, используемых опухолями. Другим преимуществом является профиль низкой токсичности указанного соединения, уже протестированного на разных моделях животных, в сравнении с классической химиотерапией и другими антагонистами аденозиновых рецепторов, известными в уровне техники. Другой отличительной особенностью является возможность его перорального введения.
Настоящее изобретение относится к 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амину, его фармацевтически приемлемым солям и сокристаллам, к фармацевтическим композициям, содержащим указанные соединения, и к комбинациям указанного соединения с одним или более иммунотерапевтическими агентами, полезными для лечения рака, для применения в лечении рака, в частности для применения в лечении карцином, конкретнее, для применения в лечении рака легких, и более конкретно для применения в лечении немелкоклеточного рака легких.
Изобретение также относится к способам лечения, профилактики или облегчения рака, включающим введение нуждающемуся в этом субъекту эффективного количества соединения формулы I; или его фармацевтически приемлемой соли. Кроме того, изобретение относится к способам лечения, профилактики или облегчения рака, включающим введение нуждающемуся в этом субъекту эффективного количества соединения формулы I; или его фармацевтически приемлемой соли, с одним или более иммунотерапевтическими агентами, как описано в настоящей заявке.
В другом варианте осуществления изобретение относится к комбинации, в частности фармацевтической комбинации, содержащей терапевтически эффективное количество соединения, представленного формулой (I), или его фармацевтически приемлемой соли или его сокристаллов и один или более иммунотерапевтически активных агентов, как описано в настоящей заявке.
В другом варианте осуществления изобретение относится к применению фармацевтической комбинации, содержащей терапевтически приемлемое количество соединения формулы (I) или его фармацевтически приемлемой соли или сокристаллов и один или более иммунотерапевтически активных агентов, для производства лекарственного средства для лечения рака.
Также раскрыты наборы, например терапевтические наборы, которые содержат иммунотерапевтический агент и соединение формулы (I), и инструкцию по применению.
В одном из вариантов осуществления описанная в настоящей заявке комбинация включает иммунотерапевтический агент, ингибитор PD-1. В некоторых вариантах осуществления комбинация используется для лечения рака, например, описанного в настоящей заявке рака, например солидной опухоли или гематологического злокачественного новообразования.
В одном из аспектов этого варианта осуществления ингибитор PD-1 представляет собой молекулу анти-PD-1 антитела, выбранную из ниволумаба, пембролизумаба и пидилизумаба.
В другом аспекте вышеуказанного варианта осуществления ингибитор PD-1 представляет собой молекулу анти-PD-1 антитела, которая раскрыта в документе US 2015/0210769, опубликованном 30 июля 2015 года и озаглавленном "Молекулы антитела к PD-1 и их применения" (ʺAntibody Molecules to PD-1 and Uses Thereof), который включен в настоящее описание во всей своей полноте посредством ссылки.
В другом варианте осуществления описанная в настоящей заявке комбинация включает иммунотерапевтический агент, ингибитор PD-L1. В некоторых вариантах осуществления комбинация используется для лечения рака, например, описанного в настоящей заявке рака, например солидной опухоли или гематологического злокачественного новообразования.
В одном из аспектов вышеуказанного варианта осуществления ингибитор PD-L1 представляет собой анти-PD-L1 антитело, выбранное из YW243.55.S70, MPDL3280A, MEDI-4736, MSB-0010718C и MDX-1105.
В другом аспекте вышеуказанного варианта осуществления ингибитор PD-L1 представляет собой молекулу анти-PD-L1 антитела, раскрытую в документе US 2016/0108123, поданном 13 октября 2015 года, озаглавленном "Молекулы антител к PD-L1 и их применения" (Antibody Molecules to PD-L1 and Uses Thereof), который включен в настоящее описание во всей своей полноте посредством ссылки.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
На Фиг.1а показана противоопухолевая активность перорально вводимого соединения формулы (I) в двух сингенных мышиных моделях рака. (показано среднее количество узлов в легких у 9-10 мышей/группы ± стандартные ошибки, *: Р <0,05 согласно t-критерию Стьюдента).
На Фиг.1b и 1c показана противоопухолевая активность перорально вводимого соединения А и соединения B в двух сингенных мышиных моделях рака. (показано среднее количество узлов в легких у 9-10 мышей/группы ± стандартные ошибки, *: Р <0,05 согласно t-критерию Стьюдента).
На Фиг. 2 показана способность комбинации соединения формулы (I) и анти-PD-L1-антитела существенно увеличивать секрецию гамма-интерферона в нестимулированных опухолевых клетках легких.
На Фиг. 3 показано, что секреция гамма-интерферона из опухолевых клеток легких, стимулированных IL-2, может быть существенно увеличена путем обработки соединением формулы (I). Эффект является более выраженным, когда клетки обрабатывают комбинацией соединения формулы (I) и анти-PD-1 антитела.
На Фиг.4-7 показано, что ни обработка опухолевых клеток, стимулированных IL-2, соединением А или соединением В, ни обработка соответствующей комбинацией соединений А или В с анти-PD-L1 или анти-PD-1 антителами не способна увеличить количество продуцируемого гамма-интерферона.
На Фиг.8a-8g показаны результаты, связанные с секрецией в среду различных интерлейкинов (IL-5, IL-17, IL-1b, IL-13, IL-10, TNFα и MIP 1b) благодаря стимуляции соединением формулы (I).
- На Фиг.9 показан структурный анализ гуманизированных клонов BAP049 (a, b, c, d и e представляют различные типы последовательностей каркасных участков). Также показаны концентрации mAb в образцах.
- На Фиг.10 показано ранжирование гуманизированных клонов BAP049 на основании данных FACS, конкурентного связывания и структурного анализа. Также показаны концентрации mAb в образцах.
На Фиг.2-8 используются следующие сокращения:
Tu=опухолевые клетки легких (без лечения); IFNg=интерферон-гамма; IL1b=интерлейкин-1b; IL13=интерлейкин-13; IL10=интерлейкин-10; IL5=интерлейкин-5; IL17=интерлейкин-17; TNFα=фактор некроза опухоли альфа; MIP1b=макрофагальный воспалительный белок 1бета
Анти-PD-L1=человеческое моноклональное антитело к рецептору PD-L1. Функциональная степень очистки, 100 мкг, приобретено у компании eBioscience, № 16-5983-82.
Анти-PD-1=человеческое моноклональное антитело к рецептору PD-1. Функциональная степень очистки, 100 мкг, приобретено у компании eBioscience, № 16-9989-82.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В одном из аспектов настоящее изобретение относится к 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амину формулы (I)
(I)
его фармацевтически приемлемым солям или сокристаллам для применения в лечении рака, в частности карциномы, точнее рака легких, и более конкретно немелкоклеточного рака легких.
В другом аспекте настоящее изобретение относится к применению 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амина формулы (I), его фармацевтически приемлемых солей или сокристаллов для изготовления лекарственного средства для лечения рака, в частности карциномы, точнее рака легких, и более конкретно немелкоклеточного рака легких.
В еще одном аспекте настоящее изобретение относится к применению фармацевтической композиции, содержащей 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амин формулы (I), его фармацевтически приемлемую соль или сокристаллы, для применения в лечении рака, в частности карциномы, конкретнее рака легких, и более конкретно немелкоклеточного рака легких.
В еще одном аспекте настоящее изобретение относится к применению фармацевтической композиции, содержащей 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амин формулы (I), его фармацевтически приемлемую соль или сокристаллы, для изготовления лекарственного средства для лечения рака, в частности карциномы, конкретнее рака легких, и более конкретно немелкоклеточного рака легких.
В другом аспекте настоящее изобретение относится к фармацевтической комбинации, содержащей 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амин формулы (I), его фармацевтически приемлемые соли или сокристаллы и один или более иммунотерапевтических агентов, полезных для лечения рака.
В другом аспекте настоящее изобретение относится к комбинации, описанной в настоящей заявке, для применения в лечении рака, в частности карциномы, конкретнее рака легких, и более конкретно немелкоклеточного рака легких.
В другом аспекте настоящее изобретение относится к применению фармацевтической комбинации, содержащей 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амин формулы (I), его фармацевтически приемлемые соли или сокристаллы и один или более иммунотерапевтических агентов, полезных для лечения рака, для изготовления лекарственного средства для лечения рака.
В еще одном аспекте настоящее изобретение относится к способам лечения рака, в частности карциномы, конкретнее рака легких, и более конкретно немелкоклеточного рака легких, путем введения:
- соединения формулы (I) или его фармацевтически приемлемых солей или сокристаллов или
- фармацевтической композиции, содержащей соединение формулы (I) или его фармацевтически приемлемые соли или сокристаллы, или
- комбинированный продукт, включающий соединение формулы (I) или его фармацевтически приемлемую соль или сокристаллы.
В предпочтительном варианте 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амин формулы (I), его фармацевтически приемлемая соль или сокристаллы, комбинации, содержащие указанные соединения и один или более иммунотерапевтических агентов, полезные для лечения рака, и фармацевтические композиции, содержащие указанные соединения, используются для лечения рака легких, в частности немелкоклеточного рака легких.
В предпочтительном варианте осуществления настоящего изобретения комбинированный продукт, включающий соединение формулы (I) или его фармацевтически приемлемую соль или сокристалл, предназначен для лечения рака легких, в частности немелкоклеточного рака легких. В более предпочтительном варианте осуществления настоящего изобретения комбинированный продукт, содержащий соединение формулы (I) или его фармацевтически приемлемую соль или сокристалл и анти-PD-L1 антитело, такое как MPDL3280A, MEDI4736, MDX-1105, или анти-PD-L1 антитело, описанное в US 2016/0108123-A1, предназначен для лечения рака легких, в частности немелкоклеточного рака легких.
Согласно другому варианту осуществления настоящего изобретения комбинированный продукт, содержащий соединение формулы (I) или его фармацевтически приемлемую соль или кокристалл и анти-PD-1 антитело, такое как MDX-1106, MK3475, CT-011, AMP-224, или молекулу анти-PD-1 антитела, описанную в WO 2000/112900, предназначен для лечения рака легких, в частности немелкоклеточного рака легких.
Настоящее изобретение может быть использовано в отношении человека или животного, более предпочтительно млекопитающего, более предпочтительно человека.
Определения
Как используется в настоящем описании, термин рак используется для обозначения группы заболеваний, связанных с аномальным ростом клеток, с возможностью инвазии или распространения на другие части тела. Рак классифицируется по типу клетки, на которую похожи опухолевые клетки и которая поэтому считается источником опухоли. Эти типы включают карциному, саркому, лимфому и лейкоз, опухоль из зародышевых клеток и бластому.
Как используется в настоящем описании, термин карцинома используется для обозначения раковых образований из эпителиальных клеток. Эта группа включает многие из наиболее распространенных видов рака, особенно у пожилых людей, и включает почти все виды рака, которые возникают в молочной железе, предстательной железе, легком, поджелудочной железе и толстой кишке.
Например, термин "рак" включает, без ограничения, солидную опухоль, гематологический рак (например, лейкемию, лимфому, миелому, например, множественную миелому) и метастатическое поражение. В одном из вариантов осуществления рак представляет собой солидную опухоль. Примеры солидных опухолей включают злокачественные опухоли, например, саркомы и карциномы, например, аденокарциномы различных систем органов, например, такие, которые поражают легкие, молочную железу, яичник, лимфоидные органы, желудочно-кишечный тракт (например, толстую кишку), анальный канал, половые органы и мочеполовой канал (например, клетки почек, уротелиальные клетки, клетки мочевого пузыря, простаты), глотку, ЦНС (например, головной мозг, нервные или глиальные клетки), голову и шею, кожу (например, меланома) и поджелудочную железу, а также аденокарциномы, которые включают злокачественные опухоли, такие как рак толстой кишки, рак прямой кишки, карциному почек, рак печени, немелкоклеточный рак легких, рак тонкого кишечника и рак пищевода. Рак может быть на ранней, промежуточной, поздней стадии или может быть метастатическим раком.
В одном из вариантов осуществления рак выбирают из рака легких (например, немелкоклеточного рака легких (НМРЛ) (например, НМРЛ с плоскоклеточной и/или неплоскоклеточной гистологией, или НМРЛ аденокарцинома)), меланомы (например, запущенной меланомы), рака почек (например, карциномы почек), рака печени, миеломы (например, множественной миеломы), рака предстательной железы, рака молочной железы (например, рака молочной железы, при котором отсутствует экспрессия одного, двух или всех эстрогенных рецепторов, прогестероновых рецепторов или Her2/neu, например, тройного негативного рака молочной железы), колоректального рака, рака поджелудочной железы, рака головы и шеи (например, плоскоклеточной карциномы головы и шеи (HNSCC)), рака ануса, рака желудка и пищевода, рака щитовидной железы, рака шейки матки, лимфопролиферативного заболевания (например, пост-трансплантационного лимфопролиферативного заболевания) или гематологического рака, Т-клеточной лимфомы, В-клеточной лимфомы, неходжкинской лимфомы и лейкемии (например, миелоидного лейкоза или лимфоидного лейкоза).
В другом варианте осуществления рак может представлять собой, например, рак, описанный в настоящей заявке, такой как рак легких (плоскоклеточный), рак легких (аденокарцинома), рак головы и шеи, рак шейки матки (плоскоклеточный), рак желудка, рак щитовидной железы, меланома, рак носоглотки (например, дифференцированная или недифференцированная метастатическая карцинома носоглотки или карцинома носоглотки с локальными рецидивами) или рак молочной железы.
В другом варианте осуществления рак выбирают из карциномы (например, запущенной или метастатической карциномы), меланомы или карциномы легких, например, немелкоклеточной карциномы легких.
В одном из вариантов осуществления рак представляет собой рак легких, например, немелкоклеточный рак легких или мелкоклеточный рак легких.
Как используется в настоящем описании, термин ʺрак легкихʺ (также известный как карцинома легких или легочная карцинома) используется для обозначения злокачественных опухолей легких, характеризующихся неконтролируемым ростом клеток в тканях легких.
Как используется в настоящем описании, термин ʺнемелкоклеточная карцинома легкихʺ (НМРЛ) используется для обозначения любого типа рака легких, отличающегося от мелкоклеточной карциномы (МРЛ).
Как используется в настоящем описании, термин "иммунотерапевтическое лечение" относится к широкому классу терапевтических средств, предназначенных для индукции иммуно-опосредованного разрушения опухолевых клеток. В упомянутых терапевтических средствах используются иммунотерапевтические агенты.
Как используется в настоящем описании, термин "иммунотерапевтические агенты" относятся к соединениям, полезным для осуществления иммунотерапевтического лечения рака, таким как агент, выбранный из группы, состоящей из анти-CTLA4 антител, таких как ипилимумаб и тремелимумаб; анти-PD-1 антител, таких как MDX-1106, MK3475, CT-011, AMP-224 или молекула анти-PD-1 антитела, описанная в WO-015/112900; и анти-PD-L1 антител, таких как MEDI4736, MDX-1105 или анти-PD-L1 антитело, описанное в US 2016/0108123.
Используемый в настоящей заявке термин "запрограммированная смерть 1" или "PD-1" включает изоформы млекопитающих, например PD-1 человека, видовые гомологи PD-1 человека и аналоги, содержащие по меньшей мере один общий эпитоп с PD-1. Аминокислотная последовательность PD-1, например PD-1 человека, известна в данной области, например из Shinohara T et al. (1994) Genomics 23(3):704-6; Finger LR, et al. Gene (1997) 197(1-2):177-87.
в настоящей заявке термин "лиганд запрограммированной смерти 1" или "PD-L1" включает изоформы млекопитающих, например PD-L1 человека, видовые гомологи PD-1 человека и аналоги, содержащие по меньшей мере один общий эпитоп с PD-L1. Аминокислотная последовательность PD-L1, например PD-1 человека, известна в данной области, например из Dong et al. (1999) Nat Med. 5(12):1365-9; Freeman et al. (2000) J Exp Med. 192(7):1027-34).
Используемый в настоящей заявке термин "сокристаллы" используется для обозначения кристаллических материалов, состоящих из двух или более молекул в одной и той же кристаллической решетке, более конкретно сокристаллов, образованных молекулой 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амина формулы (I), его фармацевтически приемлемой соли и фармацевтически приемлемой моно- или трикарбоновой кислоты, такой как миндальная, бензойная, уксусная, 1-гидрокси-2-нафтойная, пироглутамовая, бензойная, муравьиная, гиппуровая, молочная, пропионовая, глюкуроновая, пировиноградная, сорбиновая, масляная, валериановая, капроновая, каприловая, гликолевая, салициловая, фумаровая, малеиновая, яблочная, щавелевая, янтарная, винная, малоновая, глюконовая, глутаровая, адипиновая, пимелиновая, глутамовая, мезаконовая, цитраконовая, итаконовая, муциновая, фталевая, щавелевоуксусная, аспарагиновая, глутаминовая, ацетоуксусная, левулиновая, лимонная, изолимонная, аконитовая, пропан-1,2,3-трикарбоновая, более предпочтительно фармацевтически приемлемая дикарбоновая кислота, такая как фумаровая, малеиновая, яблочная, щавелевая, янтарная, винная, малоновая, глюконовая, глутаровая, адипиновая, пимелиновая, глутаминовая, мезаконовая, цитраконовая, итаконовая, муциновая, фталевая, щавелевоуксусная, аспарагиновая, глутаминовая, ацетоуксусная и левулиновая кислоты, и более конкретно янтарная, фумаровая и фталевая кислоты.
Используемые здесь термины "соль" или "соли" относятся к аддукту кислоты или основания с соединением по изобретению. "Соли" включают, в частности, "фармацевтически приемлемые соли". Термин "фармацевтически приемлемые соли" относится к солям, которые сохраняют биологическую эффективность и свойства соединений по настоящему изобретению и которые обычно не являются нежелательными с биологической или иной точки зрения. Во многих случаях соединения по настоящему изобретению способны образовывать кислые и/или основные соли в силу присутствия аминогруппы и/или карбоксильных групп или аналогичных им групп.
Фармацевтически приемлемые аддукты кислоты могут быть образованы с неорганическими кислотами и органическими кислотами. Примеры неорганической кислоты включают соляную, серную, фосфорную, дифосфорную, бромистоводородную, иодистоводородную и азотную кислоту, а примеры органических кислот включают лимонную, фумаровую, малеиновую, яблочную, миндальную, аскорбиновую, щавелевую, янтарную, винную, бензойную, уксусную, метансульфоновую, этансульфоновую, бензолсульфоновую или п-толуолсульфоновую кислоту. Фармацевтически приемлемые основания включают гидроксиды щелочных металлов (например, натрия или калия), щелочно-земельных металлов (например, кальция или магния) и органические основания, например алкиламины, арилалкиламины и гетероциклические амины.
Другими предпочтительными солями по изобретению являются соединения четвертичного аммония, в которых эквивалент аниона (Х-) связан с положительным зарядом атома N. Х- может быть анионом различных минеральных кислот, таким как, например, хлорид, бромид, йодид, сульфат, нитрат, фосфат, или анионом органической кислоты, таким как, например, ацетат, малеат, фумарат, цитрат, оксалат, сукцинат, тартрат, малат, манделат, трифторацетат, метансульфонат и п-толуолсульфонат. Х- предпочтительно представляет собой анион, выбранный из хлорида, бромида, йодида, сульфата, нитрата, ацетата, малеата, оксалата, сукцината или трифторацетата. Более предпочтительно Х- представляет собой хлорид, бромид, трифторацетат или метансульфонат.
Используемый в настоящей заявке термин "комбинация" относится либо к фиксированной комбинации в одной единичной дозированной форме, либо к комбинированному введению, где соединение формулы I и партнер комбинации (т.е. иммунотерапевтический агент) можно вводить независимо в одно и то же время или раздельно в пределах временных интервалов, особенно если эти временные интервалы обеспечивают появление кооперативного, например синергетического, эффекта от взаимодействия партнеров комбинации. Отдельные компоненты могут быть упакованы в набор или по отдельности. Один или оба компонента (например, порошки или жидкости) могут быть восстановлены или разбавлены до требуемой дозы перед введением.
Термины "совместное введение" или "комбинированное введение" или аналогичные, используемые в настоящей заявке, предназначены для охвата введения выбранного партнера комбинации одному нуждающемуся в этом субъекту (например, пациенту) и предназначены для включения режимов лечения, в которых агенты не обязательно вводятся одним и тем же способом введения или в одно и в то же время.
Термин "фармацевтическая комбинация" и "комбинированный продукт" используются взаимозаменяемо и относятся либо к фиксированной комбинации в одной дозированной форме, либо к нефиксированной комбинации, либо к набору частей для комбинированного введения, где два или более терапевтических агента могут быть введены независимо в одно и то же время или раздельно в пределах временных интервалов, особенно если эти временные интервалы обеспечивают появление кооперативного, например синергетического, эффекта от взаимодействия партнеров комбинации. Термин "фиксированная комбинация" означает, что оба, как соединение формулы I, так и партнер комбинации (т.е. иммунотерапевтический агент), вводятся пациенту одновременно в виде одного элемента или дозы. Термин "нефиксированная комбинация" означает, что оба, как соединение формулы I, так и партнер комбинации (т.е. иммунотерапевтический агент), вводятся пациенту в виде отдельных элементов одновременно или параллельно, или последовательно без каких-либо конкретных временных ограничений, при этом такое введение обеспечивает в организме пациента терапевтически эффективные уровни двух соединений. Последнее также относится к коктейльной терапии, например, к введению трех или более терапевтических агентов. В предпочтительном варианте осуществления фармацевтическая комбинация представляет собой нефиксированную комбинацию.
Термин "комбинированная терапия" относится к введению двух или более терапевтических агентов для лечения рака, как описано в настоящей заявке. Такое введение включает совместное введение этих терапевтических агентов по существу одновременно, например, в одной капсуле, имеющей фиксированное соотношение активных ингредиентов. Альтернативно, такое введение включает совместное введение в нескольких или в отдельных контейнерах (например, таблетки, капсулы, порошки и жидкости) для каждого активного ингредиента. Порошки и/или жидкости могут быть восстановлены или разбавлены до требуемой дозы перед введением. Кроме того, такое введение также охватывает использование каждого типа терапевтического агента последовательно либо примерно в одно и то же время, либо в разное время. В любом случае схема лечения оказывает благотворное влияние комбинации лекарственных веществ при лечении состояний или нарушений, описанных в настоящей заявке.
Используемый в настоящей заявке термин "фармацевтически приемлемый носитель" или "фармацевтически приемлемая несущая среда" используется взаимозаменяемо и включает любые и все растворители, дисперсионные среды, покрытия, поверхностно-активные вещества, антиоксиданты, консерванты (например, антибактериальные агенты, противогрибковые средства), изотонические агенты, агенты, замедляющие абсорбцию, соли, консерванты, стабилизаторы лекарственных средств, связующие вещества, наполнители, дезинтегрирующие агенты, лубриканты, подсластители, ароматизаторы, красители и т.п. и их комбинации, известные специалистам в данной области (см., например, Remington's Pharmaceutical Sciences, 18th Ed. Mack Printing Company, 1990, pp. 1289-1329). Предполагается, что в терапевтических или фармацевтических композициях возможно применение любого обычного носителя, за исключением случаев, когда такой носитель несовместим с активным ингредиентом.
Термин "терапевтически эффективное количество" соединения по настоящему изобретению (соединение формулы I) относится к количеству соединения формулы I, которое, как правило, вызывает биологический или медицинский ответ у субъекта, например, снижение уровня или ингибирование фермента или белковой активности или облегчение симптомов, облегчение состояний, замедление или задержку прогрессирования заболевания или предупреждение развития заболевания и т.д. В одном из неограничивающих вариантов осуществления термин "терапевтически эффективное количествоʺ относится к количеству соединения формулы I, которое при введении субъекту является эффективным для (1), по меньшей мере, частичного облегчения, ингибирования, профилактики или улучшения состояния или облегчения расстройства или заболевания (i), опосредованного рецептором A2a или (ii), связанного с активностью рецептора A2a, или (iii) характеризующегося активностью (нормальной или аномальной) рецептора A2a; или для (2) уменьшения или ингибирования активности рецептора А2а. В другом неограничивающем варианте осуществления термин ʺтерапевтически эффективное количествоʺ относится к количеству соединения формулы I, которое при введении в клетку или ткань или неклеточный биологический материал или среду является эффективным, по меньшей мере, с точки зрения частичного восстановления или ингибирования активности рецептора А2а; или, по меньшей мере, частичного снижения уровня или ингибирования экспрессии рецептора A2a.
Используемый в настоящей заявке термин "субъект" относится к животному. Как правило, животное является млекопитающим. Субъект также относится, например, к приматам (например, людям, мужчинам или женщинам), коровам, овцам, козам, лошадям, собакам, кошкам, кроликам, крысам, мышам, рыбам, птицам и т.п. В некоторых вариантах осуществления субъектом является примат. В других вариантах осуществления субъектом является человек.
Используемый в настоящей заявке термин "лечить", "лечащий" или "лечение" любого заболевания или расстройства относится в одном из вариантов осуществления к облегчению болезни или расстройства (т.е. замедлению или остановке или задержке развития заболевания или, по меньшей мере, одного из его клинических симптомов). В другом варианте осуществления "лечить", "лечащий" или "лечение" относится к облегчению или улучшению по меньшей мере одного физического параметра, включая такой, который не является заметным для пациента. В другом варианте осуществления "лечить", "лечащий" или "лечение" относится к модулированию заболевания или расстройства либо на физическом уровне (например, стабилизация заметного симптома), физиологическом уровне (например, стабилизация физического параметра), либо на обоих уровнях. В еще одном варианте осуществления "лечить", "лечащий" или "лечение" относится к предотвращению или задержке начала или развития или прогрессирования заболевания или расстройства.
Как используется в настоящем описании, субъект "нуждается" в лечении, если такой субъект получает от такого лечения пользу с биологической, медицинской точки зрения или с точки зрения качества жизни.
Комбинированная терапия
В одном из вариантов осуществления фармацевтическая комбинация (или комбинированный продукт) включает соединение формулы (I) или его фармацевтически приемлемую соль или сокристалл и один или более иммунотерапевтических агентов, выбранных из группы, состоящей из анти-CTLA4 антител, таких как ипилимумаб и тремелимумаб; анти-PD-1 антител, таких как MDX-1106 (ниволумаб), MK3475 (пембролизумаб), CT-011 (пидилизумаб), AMP-224 или молекула анти-PD-1 антитела, описанная в WO 0201/112900 (US2015/0210769); и анти-PD-L1 антител, таких как MPDL3280A, MEDI4736 и MDX-1105 или молекула анти-PD-L1 антитела, раскрытая в документе US 2016/0108123, поданном 13 октября 2015 г. и озаглавленном "Молекулы антител к PD-L1 и их применения" (Antibody Molecules to PD-L1 and Uses Thereof).
Компоненты комбинированного продукта находятся в одной и той же лекарственной форме или в отдельных лекарственных формах.
В предпочтительном варианте осуществления комбинированный продукт включает соединение формулы (I) или его фармацевтически приемлемую соль или сокристалл и один или более иммунотерапевтических агентов, полезных для лечения рака; в частности, в иммунотерапевтическом лечении рака такой агент выбирают из группы, состоящей из анти-PD-1 антител, таких как MDX-1106, MK3475, CT-011, AMP-224 или молекула анти-PD-1 антитела, описанная в WO 02015/112900 (US 2205/0210769); и анти-PD-L1 антител, таких как MPDL3280A, MEDI4736, MDX-1105 или молекула анти-PD-L1, описанная в US 2016/0108123.
Пример молекулы анти-PD-L1-антитела
В одном из вариантов осуществления комбинированный продукт включает соединение формулы (I) или его фармацевтически приемлемую соль или его сокристалл и молекулу анти-PD-L1 антитела, которые описаны в настоящей заявке.
Лиганд 1 запрограммированной смерти (PD-L1) был описан как лиганд 1 иммуноингибирующего рецептора запрограммированной смерти (PD-1). Связывание PD-L1 с PD-1 приводит к ингибированию пролиферации лимфоцитов, опосредуемой Т-клеточными рецепторами, и секреции цитокинов (Freeman et al. (2000) J Exp Med 192:1027-34). Таким образом, блокирование PD-L1 может привести к усилению противоопухолевого иммунитета.
PD-L1 экспрессируется несколькими типами клеток. Например, PD-L1 экспрессируется на активированных Т-клетках, дендритных клетках (DC), естественных киллерных (NK) клетках, макрофагах, В-клетках, моноцитах и клетках эндотелия сосудов. PD-L1 экспрессируется во многих раковых опухолях, включая рак легких человека, карциномы яичников и толстой кишки и различные миеломы (Iwai et al. (2002) PNAS 99:12293-7; Ohigashi et al. (2005) Clin Cancer Res 11:2947-53; Okazaki et al. (2007). Intern. Immun. 19:813-24; Thompson et al. (2006) Cancer Res. 66:3381-5). Экспрессия PD-L1 сильно коррелирует с неблагоприятным прогнозом при различных типах рака, включая рак почек, яичников, мочевого пузыря, груди, желудка и поджелудочной железы.
Многие опухоль-инфильтрирующие Т-лимфоциты преимущественно экспрессируют PD-1 по сравнению с Т-лимфоцитами в нормальных тканях и Т-лимфоцитами периферической крови. Это указывает на то, что увеличенная экспрессия PD-1 опухолереактивными Т-клетками может способствовать нарушению иммунных реакций против опухолей (Ahmadzadeh et al. (2009) Blood 114:1537-44). Таким образом, сигнализация PD-L1, опосредованная опухолевыми клетками, экспрессирующими PD-L1 и взаимодействующими с Т-клетками, экспрессирующими PD-1, может приводить к ослаблению активации Т-клеток и уклонению от надзора иммунной системы (Sharpe et al. (2002) Nat Rev Immunol. 2:116-26; Keir et al. (2008) Annu Rev Immunol. 26:677-704). Блокада PD-1 может подавлять гематогенное распространение слабо иммуногенных опухолевых клеток за счет усиленного рекрутирования эффекторных Т-клеток (Iwai et al. (2005) Int. Immunol. 17:133-144).
Анти-PD-L1 может усилить Т-клеточный иммунитет, например, путем блокирования его ингибирующих взаимодействий как с PD-1, так и с B7-1. Анти-PD-1 также может обеспечивать иммунную регуляцию через PD-L2/PD-1. Оба, PD-1 и B7-1, экспрессируются на Т-клетках, В-клетках, DC и макрофагах, что обеспечивает возможность двунаправленного взаимодействия между B7-1 и PD-L1 на этих типах клеток. PD-L1 на негемопоэтических клетках может взаимодействовать с B7-1, а также с PD-1 на Т-клетках.
В некоторых вариантах осуществления молекулу анти-PD-L1 антитела выбирают из YW243.55.S70, MPDL3280A, MEDI-4736, MSB-0010718C или MDX-1105.
В некоторых вариантах осуществления анти-PD-L1 антитело представляет собой MSB0010718C. MSB0010718C (также называемое A09-246-2, Merck Serono) представляет собой моноклональное антитело, которое связывается с PD-L1. MSB0010718C и другие гуманизированные анти-PD-L1-антитела описаны в WO 023/790174 и имеют описанную в настоящей заявке последовательность (или последовательность, по существу идентичную или сходную с ней, например последовательность, идентичную указанной последовательности на, по меньшей мере, 85%, 90%, 95% или более). Аминокислотные последовательности тяжелой и легкой цепей MSB0010718C включают по меньшей мере следующие:
Тяжелая цепь (SEQ ID NO: 24, раскрытая в WO2013/079174)
EVQLLESGGGLVQPGGSLRLSCAASGFTFSSYIMMWVRQAPGKGLEWVSSIYPSGGITFYADKGRFTISRDNSKNTLYLQMNSLRAEDTAVYYCARIKLGTVTTVDYWGQGTLVTVSS (SEQ ID NO: 245)
Легкая цепь (SEQ ID NO: 25, раскрытая в WO2013/079174)
QSALTQPASVSGSPGQSITISCTGTSSDVGGYNYVSWYQQHPGKAPKLMIYDVSN RPSGVSNRFSGSKSGNTASLTISGLQAEDEADYYCSSYTSSSTRVFGTGTKVTVL (SEQ ID NO: 246)
В одном из вариантов осуществления ингибитор PD-L1 представляет собой YW243.55.S70. Антитело YW243.55.S70 представляет собой анти-PD-L1, описанное в WO 2010/077634 (последовательности вариабельных областей тяжелой и легкой цепей показаны в SEQ ID NO. 20 и 21, соответственно) и имеющее описанную в этом документе последовательность (или последовательность, по существу идентичную или аналогичную ей, например, последовательность, идентичную указанной последовательности на, по меньшей мере, 85%, 90%, 95% или более).
В одном из вариантов осуществления ингибитор PD-L1 представляет собой MDX-1105. MDX-1105, также известный как BMS-936559, представляет собой анти-PD-L1 антитело, описанное в WO2007/005874 и имеющее описанную в этом документе последовательность (или последовательность, по существу идентичную или аналогичную ей, например последовательность, идентичную указанной последовательности на, по меньшей мере, 85% 90%, 95% или более).
В одном из вариантов осуществления ингибитор PD-L1 представляет собой MDPL3280A (Genentech/Roche). MDPL3280A представляет собой человеческое Fc-оптимизированное IgG1-моноклональное антитело, которое связывается с PD-L1. MDPL3280A и другие человеческие моноклональные антитела к PD-L1 раскрыты в патенте США № 7,943,743 и публикации US 20120039906.
В другом варианте осуществления ингибитор PD-L1 представляет собой молекулу анти-PD-L1 антитела, раскрытую в документе US 2016/0108123, поданном 13 октября 2015 года, озаглавленном "Молекулы антител к PD-L1 и их применение" (Antibody Molecules to PD-L1 and Uses Thereof), включенном в настоящее описание во всей своей полноте посредством ссылки.
В одном из вариантов осуществления молекула анти-PD-L1 антитела включает по меньшей мере один или два вариабельных домена тяжелой цепи (необязательно включающих константную область), по меньшей мере один или два вариабельных домена легкой цепи (необязательно включающих константную область) или и то, и другое, содержащие аминокислотную последовательность любого из: BAP058-hum01, BAP058-hum02, BAP058-hum03, BAP058-hum04, BAP058-hum05, BAP058-hum06, BAP058-hum07, BAP058-hum08, BAP058-hum09, BAP058-hum10, BAP058-hum11, BAP058-hum12, BAP058-hum13, BAP058-hum14, BAP058-hum15, BAP058-hum16, BAP058-hum17, BAP058-Clone-K, BAP058-Clone-L, BAP058-Clone-M, BAP058-Clone-N или BAP058-Clone-O; или приведенную в таблице 1 US 2016/0108123, или кодируемую нуклеотидной последовательностью, приведенной в таблице 1; или последовательность, по существу идентичную (например, идентичную на, по меньшей мере, 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей.
В другом варианте осуществления молекула анти-PD-L1 антитела включает по меньшей мере одну, две или три определяющие комплементарность области (CDR) вариабельной области тяжелой цепи и/или вариабельной области легкой цепи антитела, описанного в настоящей заявке, например, антитела, выбранного из любого из: BAP058-hum01, BAP058-hum02, BAP058-hum03, BAP058-hum04, BAP058-hum05, BAP058-hum06, BAP058-hum07, BAP058-hum08, BAP058-hum09, BAP058-hum10, BAP058-hum11, BAP058-hum12, BAP058-hum13, BAP058-hum14, BAP058-hum15, BAP058-hum16, BAP058-hum17, BAP058-Clone-K, BAP058-Clone-L, BAP058-Clone-M, BAP058-Clone-N или BAP058-Clone-O; или описанные в таблице 1 US 2016/0108123, или кодируемые нуклеотидной последовательностью, приведенной в таблице 1 US 2016/0108123; или последовательность, по существу идентичную (например, идентичную на, по меньшей мере, 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей.
В еще одном варианте осуществления молекула анти-PD-L1 антитела включает по меньшей мере одну, две или три CDR (или все CDR) вариабельной области тяжелой цепи, содержащей аминокислотную последовательность, показанную в таблице 1 US 2016/0108123 или кодируемую нуклеотидной последовательностью, показанной в таблице 1 US 2016/0108123. В одном из вариантов осуществления одна или более CDR (или все CDR) имеют одно, два, три, четыре, пять, шесть или более изменений, например аминокислотных замен или делеций, относительно аминокислотной последовательности, показанной в таблице 1 US 2016/0108123 или кодируемой нуклеотидной последовательностью, показанной в таблице 1 US 2016/0108123.
В другом варианте осуществления молекула анти-PD-L1 антитела включает по меньшей мере одну, две или три CDR (или все CDR) вариабельной области легкой цепи, содержащей аминокислотную последовательность, показанную в таблице 1 US 2016/0108123 или кодируемую нуклеотидной последовательностью, показанной в таблице 1. В одном из вариантов осуществления одна или более CDR (или все CDR) имеют одно, два, три, четыре, пять, шесть или более изменений, например аминокислотных замен или делеций, относительно аминокислотной последовательности, показанной в таблице 1 US 2016/0108123 или кодируемой нуклеотидной последовательностью, показанной в таблице 1 US 2016/0108123. В некоторых вариантах осуществления молекула анти-PD-L1 антитела включает замену в CDR легкой цепи, например одну или более замен в CDR1, CDR2 и/или CDR3 легкой цепи.
В другом варианте осуществления молекула анти-PD-L1 антитела включает по меньшей мере одну, две, три, четыре, пять или шесть CDR (или все CDR) вариабельной области тяжелой и легкой цепей, содержащие аминокислотную последовательность, показанную в Таблица 1 или кодируемую нуклеотидной последовательностью, показанной в таблице 1 US 2016/0108123. В одном из вариантов осуществления одна или более CDR (или все CDR) имеют одно, два, три, четыре, пять, шесть или более изменений, например аминокислотных замен или делеций, относительно аминокислотной последовательности, показанной в таблице 1 US 2016/0108123 или кодируемой нуклеотидной последовательностью, показанной в таблице 1 US 2016/0108123.
В одном из вариантов осуществления молекула анти-PD-L1 антитела включает по меньшей мере одну, две или три CDR или гипервариабельные петли вариабельной области тяжелой цепи описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP058-hum01, BAP058-hum02, BAP058-hum03, BAP058-hum04, BAP058-hum05, BAP058-hum06, BAP058-hum07, BAP058-hum08, BAP058-hum09, BAP058-hum10, BAP058-hum11, BAP058-hum12, BAP058-hum13, BAP058-hum14, BAP058-hum15, BAP058-hum16, BAP058-hum17, BAP058-Clone-K, BAP058-Clone-L, BAP058-Clone-M, BAP058-Clone-N или BAP058-Clone-O, в соответствии с определением Kabat и Chothia (например, по меньшей мере одну, две или три CDR или гипервариабельные петли в соответствии с определением Kabat и Chothia, как указано в таблице 1 US 2016/0108123); или кодируемые нуклеотидной последовательностью, показанной в таблице 1 US 2016/0108123; или последовательность, по существу идентичную (например, идентичную на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей; или имеющую по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например консервативных замен) относительно одной, двух или трех CDR или гипервариабельных петель в соответствии с Kabat и/или Chothia, показанных в таблице 1 US 2016/0108123.
В одном из вариантов осуществления молекула анти-PD-L1 антитела может включать CDR1 VH в соответствии с Kabat et al. ((1991), ʺSequences of Proteins of Immunological Interest,ʺ 5th Ed. Public Health Service, National Institutes of Health, Bethesda, MD) или гипервариабельную петлю 1 VH согласно Chothia et al. (1992) J. Mol. Biol. 227:799-817, или их комбинацию, например, как показано в таблице 1 US 2016/0108123. В одном из вариантов осуществления такая комбинация CDR по Kabat и Chothia для CDR1 VH содержит аминокислотную последовательность GYTFTSYWMY (SEQ ID NO: 244) или аминокислотную последовательность, по существу идентичную ей (например, имеющую по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например, консервативных замен)). Молекула анти-PD-L1 антитела может дополнительно включать, например, CDR 2-3 VH в соответствии с Kabat et al. и CDR 1-3 VL в соответствии с Kabat et al., например, как показано в таблице 1 US 2016/0108123.
В предпочтительном варианте осуществления молекула анти-PD-L1 антитела, предназначенная для использования в изобретении, содержит:
(а) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 228, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 229, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 233, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 234, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 235;
(b) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 225; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 226; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 230, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 231, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 232;
(с) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 244; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 229; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 233, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 234, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 235; или
(d) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 244; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 226; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 230, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 231, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 232.
В одном из аспектов предыдущего варианта осуществления молекула анти-PD-L1 антитела, предназначенная для использования в изобретении, содержит вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 236, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 239.
В одном из аспектов предыдущего варианта осуществления молекула анти-PD-L1 антитела, предназначенная для использования в изобретении, содержит тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 243, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 241.
Таблица А. Аминокислотные и нуклеотидные последовательности гуманизированного анти-PD-L1 mAb BAP058-hum013. Показаны аминокислотные и нуклеотидные последовательности CDR тяжелых и легких цепей, вариабельные области тяжелой и легкой цепей, а также тяжелая и легкая цепи.
Примеры молекулы анти-PD-1 антитела
В одном из вариантов осуществления комбинированный продукт содержит соединение формулы (I) или его фармацевтически приемлемую соль или сокристалл и молекулу анти-PD-1 антитела, описанные в настоящей заявке.
PD-1 представляет собой член семейства CD28/CTLA-4, экспрессируемый, например, активированными CD4+ и CD8+ Т-клетками, Treg и B-клетками. Он отрицательно регулирует сигнализацию и функцию эффекторных Т-клеток. Индукция PD-1 происходит на опухоль-инфильтрующих Т-клетках и может приводить к функциональному истощению или дисфункции (Keir et al. (2008) Annu. Rev. Immunol. 26:677-704; Pardoll et al. (2012) Nat Rev Cancer 12(4):252-64). PD-1 передает коингибирующий сигнал при связывании с любым из двух своих лигандов, лиганда 1 запрограммированной смерти (PD-L1) или лиганда 2 запрограммированной смерти (PD-L2). PD-L1 экспрессируется на нескольких типах клеток, включая Т-клетки, естественные киллерные (NK) клетки, макрофаги, дендритные клетки (DC), В-клетки, эпителиальные клетки, клетки сосудистого эндотелия, а также многие типы опухолей. Высокий уровень экспрессии PD-L1 в опухолях мыши и человека связан с плохими клиническими результатами при различных раковых заболеваниях (Keir et al. (2008) Annu. Rev. Immunol. 26:677-704; Pardoll et al. (2012) Nat Rev Cancer 12(4):252-64). PD-L2 экспрессируется дендритными клетками, макрофагами и некоторыми опухолями. В доклинических и клинических исследованиях была достоверно подтверждена блокада пути PD-1 для иммунотерапии рака. Как доклинические, так и клинические исследования показали, что блокада анти-PD-1 может восстановить активность эффекторных Т-клеток и привести к устойчивому противоопухолевому ответу. Например, блокада пути PD-1 может восстановить истощенную/нарушенную эффекторную функцию Т-клеток (например, пролиферацию, секрецию IFN-g или цитолитическую функцию) и/или ингибировать функцию Treg клеток (Keir et al. (2008) Annu. Rev. Immunol. 26:677-704; Pardoll et al. (2012) Nat Rev Cancer 12(4):252-64). Блокада пути PD-1 может быть осуществлена с помощью антитела, его антигенсвязывающего фрагмента, иммуноадгезина, слитого белка или олигопептида PD-1, PD-L1 и/или PD-L2.
В одном из вариантов осуществления ингибитор PD-1 представляет собой анти-PD-1 антитело, выбранное из ниволумаба, пембролизумаба и пидилизумаба.
В некоторых вариантах осуществления анти-PD-1 антитело представляет собой ниволумаб. Альтернативные названия для ниволумаба включают MDX-1106, MDX-1106-04, ONO-4538 или BMS-936558. В некоторых вариантах осуществления анти-PD-1 антитело представляет собой ниволумаб (регистрационный номер CAS: 946414-94-4). Ниволумаб является полностью человеческим IgG4 моноклональным антителом, которое специфически блокирует PD-1. Ниволумаб (клон 5C4) и другие человеческие моноклональные антитела, которые специфически связываются с PD1, описаны в US 8,008,449 и WO2006/121168. В одном из вариантов осуществления ингибитор PD-1 представляет собой ниволумаб и имеет описанную в настоящей заявке последовательность (или последовательность, по существу, идентичную или аналогичную ей, например последовательность, идентичную указанной последовательности на, по меньшей мере, 85%, 90%, 95% или более).
Аминокислотные последовательности тяжелой и легкой цепей ниволумаба являются следующими:
Тяжелая цепь:
QVQLVESGGGVVQPGRSLRLDCKASGITFSNSGMHWVRQAPGKGLEWVAVIWYDGSKRYYADSVKGRFTISRDNSKNTLFLQMNSLRAEDTAVYYCATNDDYWGQGTLVTVSSASTKGPSVFPLAPCSRSTSESTAALGCLVKDYFPEPVTVSWNSGALTSGVHTFPAVLQSSGLYSLSSVVTVPSSSLGTKTYTCNVDHKPSNTKVDKRVESKYGPPCPPCPAPEFLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSQEDPEVQFNWYVDGVEVHNAKTKPREEQFNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKGLPSSIEKTISKAKGQPREPQVYTLPPSQEEMTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSRLTVDKSRWQEGNVFSCSVMHEALHNHYTQKSLSLSLGK (SEQ ID NO: 247)
Легкая цепь:
EIVLTQSPATLSLSPGERATLSCRASQSVSSYLAWYQQKPGQAPRLLIYDASNRATGIPARFSGSGSGTDFTLTISSLEPEDFAVYYCQQSSNWPRTFGQGTKVEIKRTVAAPSVFIFPPSDEQLKSGTASVVCLLNNFYPREAKVQWKVDNALQSGNSQESVTEQDSKDSTYSLSSTLTLSKADYEKHKVYACEVTHQGLSSPVTKSFNRGEC (SEQ IS NO: 248)
В некоторых вариантах осуществления анти-PD-1 антитело представляет собой пембролизумаб. Пембролизумаб (также называемый ламбролизумаб, MK-3475, MK03475, SCH-900475 или KEYTRUDA®; Merck) представляет собой гуманизированное IgG4 моноклональное антитело, которое связывается с PD-1. Пембролизумаб и другие гуманизированные анти-PD-1 антитела описаны в Hamid, O. et al. (2013) New England Journal of Medicine 369 (2):134-44, US 8,354,509 и WO2009/114335. Пембролизумаб имеет следующие аминокислотные последовательности тяжелой и легкой цепей:
Тяжелая цепь (SEQ ID NO: 249)
Легкая цепь (SEQ ID NO: 250)
В одном из вариантов осуществления ингибитор PD-1 представляет собой пембролизумаб, раскрытый, например, в US 8354509 и WO 2009/114335 и имеет последовательность, раскрытую в настоящей заявке (или последовательность, по существу, идентичную или аналогичную ей, например, последовательность, идентичную указанной последовательности на, по меньшей мере, 85%, 90%, 95% или более).
В некоторых вариантах осуществления анти-PD-1 антитело представляет собой пидилизумаб. Пидилизумаб (CT-011; Cure Tech) представляет собой гуманизированное IgG1k моноклональное антитело, которое связывается с PD1. Пидилизумаб и другие гуманизированные анти-PD-1 моноклональные антитела описаны в WO2009/101611.
Другие анти-PD-1 антитела включают, среди прочих, AMP 514 (амплиммун), например, анти-PD-1 антитела, описанные в US 8609089, US 2010028330 и/или US 20120114649.
В некоторых вариантах осуществления ингибитор PD-1 представляет собой иммуноадгезин (например, иммуноадгезин, содержащий внеклеточную или PD-1 связывающую часть PD-L1 или PD-L2, слитого с константной областью (например, Fc-областью последовательности иммуноглобулина). В некоторых вариантах осуществления ингибитор PD-1 представляет собой AMP-224 (B7-DCIg, амплиммун, например, раскрытый в WO2010/027827 и WO2011/066342), который является растворимым Fc-слитым рецептором PD-L2, блокирующим взаимодействие между PD-1 и B7-H1.
В одном из вариантов осуществления анти-PD-1 антитело представляет собой молекулу анти-PD-1 антитела, описанную в документе WO2015/112900 (US2015/0210769), опубликованном 30 июля 2015 года и озаглавленном "Молекулы антител к PD-1 и их применение" (Antibody Molecules to PD-1 and Uses Thereof), который полностью включен в настоящее описание посредством ссылки.
В некоторых вариантах осуществления молекула анти-PD-1 антитела (например, выделенная или рекомбинантная молекула антитела) имеет одно или более из следующих свойств:
(i) связывается с PD-1, например PD-1 человека, с высоким сродством, например, с константой сродства, равной по меньшей мере примерно 107 М-1, обычно примерно 108 М-1 и, преимущественно, примерно от 109 М-1 до 1010 М-1 или выше;
(ii) по существу не связывается с CD28, CTLA-4, ICOS или BTLA;
(iii) ингибирует или уменьшает связывание PD-1 с лигандом PD-1, например PD-L1 или PD-L2, или обоими;
(iv) специфически связывается с эпитопом на PD-1, например, тем же или аналогичным эпитопом, что и эпитоп, распознаваемый мышиным моноклональным антителом BAP049 или химерным антителом BAP049, например BAP049-chi или BAP049-chi-Y;
(v) показывает такое же или аналогичное сродство или специфичность связывания, или и то, и другое, как любое из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E;
(vi) показывает такое же или аналогичное сродство или специфичность связывания, или и то и другое, что и молекула антитела (например, вариабельная область тяжелой цепи и вариабельная область легкой цепи), приведенная в таблице B;
(vii) показывает такое же или аналогичное сродство или специфичность связывания, или и то и другое, что и молекула антитела (например, вариабельная область тяжелой цепи и вариабельная область легкой цепи), имеющая аминокислотную последовательность, приведенную в таблице B;
(viii) показывает такое же или аналогичное сродство или специфичность связывания, или и то и другое, что и молекула антитела (например, вариабельная область тяжелой цепи и вариабельная область легкой цепи), кодируемая нуклеотидной последовательностью, приведенной в таблице B;
(ix) ингибирует, например конкурентно ингибирует, связывание второй молекулы анти-PD-1 антитела, где вторая молекула антитела представляет собой молекулу антитела, описанную в настоящей заявке, например молекулу антитела, выбранную, например, из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E;
(x) связывает тот же эпитоп или эпитоп, перекрывающийся с таковым второй молекулой анти-PD-1 антитела, где вторая молекула антитела представляет собой молекулу антитела, описанную в настоящей заявке, например молекулу антитела, выбранную, например, из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E;
(xi) конкурирует за связывание и/или связывает тот же эпитоп, что и вторая молекула анти-PD-1 антитела, где вторая молекула антитела представляет собой молекулу антитела, описанную в настоящей заявке, например молекулу антитела, выбранную, например, из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E;
(xii) имеет одно или более биологических свойств молекулы антитела, описанной в настоящей заявке, например, молекулы антитела, выбранной, например, из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E;
(xiii) имеет одно или более фармакокинетических свойств молекулы антитела, описанной в настоящей заявке, например молекулы антитела, выбранной, например, из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E;
(xiv) ингибирует одну или более активностей PD-1, например, приводит к одному или более из: увеличению количества опухоль-инфильтрующих лимфоцитов, увеличению пролиферации, опосредованной T-клеточными рецепторами, или уменьшению уклонения злокачественных клеток от надзора иммунной системы;
(xv) связывает PD-1 человека и является кросс-реактивным в отношении PD-1 яванского макака;
(xvi) связывается с одним или более остатками в нити C, петле CC', нити C' или петле FG PD-1 или комбинацией двух, трех или всех из: нити C, петли CC', нити C' или петли FG PD-1, например, где связывание анализируют методом ELISA или Biacore; или
(xvii) имеет область VL, которая является более важной для связывания с PD-1, чем область VH.
В некоторых вариантах осуществления молекула антитела связывается с PD-1 с высоким сродством, например, с KD, который является примерно таким же, или по меньшей мере на примерно 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80% или 90% выше или ниже чем KD молекулы мышиного или химерного анти-PD-1 антитела, например молекулы мышиного или химерного анти-PD-1 антитела, описанной в настоящей заявке. В некоторых вариантах осуществления изобретения величина KD молекулы мышиного или химерного анти-PD-1 антитела составляет менее примерно 0,4, 0,3, 0,2, 0,1 или 0,05 нМ, например, измеренная методом Biacore. В некоторых вариантах осуществления изобретения величина KD молекулы мышиного или химерного анти-PD-1 антитела составляет менее примерно 0,2 нМ, например, примерно 0,135 нМ. В других вариантах осуществления величина KD молекулы мышиного или химерного анти-PD-1 антитела составляет менее примерно 10, 5, 3, 2 или 1 нМ, например, измеренная путем связывания на клетках, экспрессирующих PD-1 (например, 300.19 клетках). В некоторых вариантах осуществления изобретения величина KD молекулы мышиного или химерного анти-PD-1 антитела составляет менее примерно 5 нМ, например, примерно 4,60 нМ (или примерно 0,69 мкг/мл).
В некоторых вариантах осуществления молекула анти-PD-1 антитела связывается с PD-1 с Koff ниже, чем 1×10-4, 5×10-5 или 1×10-5 с-1, например, примерно 1,65×10-5 с-1. В некоторых вариантах осуществления молекула анти-PD-1 антитела связывается с PD-1 с Kon выше, чем 1×104, 5×104, 1×105 или 5×105 М-1с-1, или 5×105 М-1с-1, например, примерно 1,23×105 M-1с-1.
В некоторых вариантах осуществления уровень экспрессии молекулы антитела выше, например, по меньшей мере примерно в 0,5, 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10 раз выше, чем уровень экспрессии молекулы мышиного или химерного антитела, например молекулы мышиного или химерного анти-PD-1-антитела, описанного в настоящей заявке. В некоторых вариантах осуществления молекула антитела экспрессируется в клетках СНО.
В некоторых вариантах осуществления молекула анти-PD-1 антитела уменьшает одну или более ассоциированных с PD-1 активностей с величиной IC50 (концентрация при 50% ингибировании), которая является примерно такой же или ниже, например, по меньшей мере, примерно на 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80% или 90% ниже, чем IC50 молекулы мышиного или химерного анти-PD-1 антитела, например молекулы мышиного или химерного анти-PD-1 антитела, описанной в настоящей заявке. В некоторых вариантах осуществления величина IC50 молекулы мышиного или химерного анти-PD-1 антитела составляет менее примерно 6, 5, 4, 3, 2 или 1 нМ, например, измеренная путем связывания на клетках, экспрессирующих PD-1 (например, клетках 300.19). В некоторых вариантах осуществления величина IC50 молекулы мышиного или химерного анти-PD-1 антитела составляет менее примерно 4 нМ, например, примерно 3,40 нМ (или примерно 0,51 мкг/мл). В некоторых вариантах осуществления сниженная активность, ассоциированная с PD-1, представляет собой связывание PD-L1 и/или PD-L2 с PD-1. В некоторых вариантах осуществления молекула анти-PD-1 антитела связывается с мононуклеарными клетками периферической крови (PBMC), активированными стафилококковым энтеротоксином B (SEB). В других вариантах осуществления молекула анти-PD-1 антитела увеличивает экспрессию IL-2 в цельной крови, активируемой SEB. Например, анти-PD-1 антитело увеличивает экспрессию IL-2 по меньшей мере примерно в 2, 3, 4 или 5 раз по сравнению с экспрессией IL-2, в случае использования изотипного контроля (например, IgG4).
В некоторых вариантах осуществления молекула анти-PD-1 антитела обладает улучшенной стабильностью, например, является по меньшей мере, примерно в 0,5, 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10 раз более стабильной in vivo или in vitro, чем молекула мышиного или химерного анти-PD-1 антитела, например молекула мышиного или химерного анти-PD-1 антитела, описанная в настоящей заявке.
В одном из вариантов осуществления молекула анти-PD-1 антитела представляет собой молекулу гуманизированного антитела и имеет степень риска, основанную на анализе Т-клеточных эпитопов, в пределах от 300 до 700, от 400 до 650, от 450 до 600, или степень риска, как описано в настоящей заявке.
В другом варианте осуществления молекула анти-PD-1 антитела содержит, по меньшей мере, одну антигенсвязывающую область, например вариабельную область или ее антигенсвязывающий фрагмент, описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенную в таблице B, или кодируемую нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную, по меньшей мере, на 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей.
В другом варианте осуществления молекула анти-PD-1 антитела содержит, по меньшей мере, одну, две, три или четыре вариабельные области описанного в заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенные в таблице B, или кодируемые нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную, по меньшей мере, на 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей.
В еще одном варианте осуществления молекула анти-PD-1 антитела содержит по меньшей мере одну или две вариабельные области тяжелой цепи описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенные в таблице B, или кодируемые нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную, по меньшей мере, на 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей.
В еще одном варианте осуществления молекула анти-PD-1 антитела содержит по меньшей мере одну или две вариабельные области легкой цепи описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенные в таблице B, или кодируемые нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную, по меньшей мере, на 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей.
В другом варианте осуществления молекула анти-PD-1 антитела включает константную область тяжелой цепи IgG4, например IgG4 человека. В одном из вариантов осуществления IgG4 человека включает замену в положении 228 согласно нумерации по EU (например, замену Ser на Pro). В другом варианте осуществления молекула анти-PD-1 антитела включает константную область тяжелой цепи IgG1, например IgG1 человека. В одном из вариантов осуществления IgG1 человека включает замену в положении 297 согласно нумерации по EU (например, замену Asn на Ala). В одном из вариантов осуществления IgG1 человека включает замену в положении 265 согласно нумерации по EU, замену в положении 329 согласно нумерации по EU или обе эти замены (например, замену Asp на Ala в положении 265 и/или замену Pro на Ala в положении 329). В одном из вариантов осуществления IgG1 человека включает замену в положении 234 согласно нумерации по EU, замену в положении 235 согласно нумерации по EU или обе эти замены (например, замену Leu на Ala в положении 234 и/или замену Leu на Ala в положении 235). В одном из вариантов осуществления константная область тяжелой цепи содержит аминокислотную последовательность, представленную в таблице D, или последовательность, по существу идентичную ей (например, на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более).
В еще одном варианте осуществления молекула анти-PD-1 антитела включает константную область легкой цепи каппа, например константную область легкой цепи каппа человека. В одном из вариантов осуществления константная область легкой цепи содержит аминокислотную последовательность, представленную в таблице D, или последовательность, по существу идентичную ей (например, на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или выше).
В другом варианте осуществления молекула анти-PD-1 антитела включает константную область тяжелой цепи IgG4, например IgG4 человека, и константную область легкой цепи каппа, например константную область легкой цепи каппа человека, например константную область тяжелой и легкой цепей, содержащую аминокислотную последовательность, представленную в таблице D, или последовательность, по существу идентичную ей (например, идентичную на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более). В одном из вариантов осуществления IgG4 человека включает замену в положении 228 согласно нумерации по EU (например, замену Ser на Pro). В еще одном варианте осуществления молекула анти-PD-1 антитела включает константную область тяжелой цепи IgG1, например IgG1 человека, и константную область легкой цепи каппа, например константную область легкой цепи каппа человека, например, константную область тяжелой и легкой цепей, содержащую аминокислотную последовательность, представленную в таблице D, или последовательность, по существу идентичную ей (например, на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более). В одном из вариантов осуществления IgG1 человека включает замену в положении 297 согласно нумерации по EU (например, замену Asn на Ala). В одном из вариантов осуществления IgG1 человека включает замену в положении 265 согласно нумерации по EU, замену в положении 329 согласно нумерации по EU или обе эти замены (например, замену Asp на Ala в положении 265 и/или замену Pro на Ala в положении 329). В одном из вариантов осуществления IgG1 человека включает замену в положении 234 согласно нумерации по EU, замену в положении 235 согласно нумерации по EU или обе эти замены (например, замену Leu на Ala в положении 234 и/или замену Leu на Ala в положении 235).
В другом варианте осуществления молекула анти-PD-1 антитела включает вариабельный домен и константную область тяжелой цепи, вариабельный домен и константную область легкой цепи, или и то, и другое, содержащие аминокислотную последовательность BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенную в таблице B, или кодируемую нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей.
В еще одном варианте осуществления молекула анти-PD-1 антитела включает, по меньшей мере, одну, две или три определяющие комплементарность области (CDR) вариабельной области тяжелой цепи антитела, описанного в настоящей заявке, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C,BAP049-Clone-D или BAP049-Clone-E; или приведенные в таблице B, или кодируемые нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную на по меньшей мере, 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей.
В другом варианте осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две или три CDR (или все CDR) вариабельной области тяжелой цепи, содержащей аминокислотную последовательность, приведенную в таблице В или кодируемую нуклеотидной последовательностью, приведенной в таблице В. В одном из вариантов осуществления одна или более CDR (или все CDR) имеют одно, два, три, четыре, пять, шесть или более изменений, например аминокислотных замен или делеций, относительно аминокислотной последовательности, приведенной в таблице В или кодируемой нуклеотидной последовательностью, приведенной в таблице В.
В еще одном варианте осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две или три CDR вариабельной области легкой цепи описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенные в таблице B, или кодируемые нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей.
В другом варианте осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две или три CDR (или все CDR) вариабельной области легкой цепи, содержащей аминокислотную последовательность, приведенную в таблице В или кодируемую нуклеотидной последовательностью, приведенной в таблице В. В одном из вариантов осуществления одна или более CDR (или все CDR) имеют одно, два, три, четыре, пять, шесть или более изменений, например аминокислотных замен или делеций, относительно аминокислотной последовательности, показанной в таблице В или кодируемой нуклеотидной последовательностью, приведенной в таблице В. В некоторых вариантах осуществления молекула анти-PD-1 антитела включает замену в CDR легкой цепи, например одну или более замен в CDR1, CDR2 и/или CDR3 легкой цепи. В одном из вариантов осуществления молекула анти-PD-1 антитела включает замену в CDR3 легкой цепи в положении 102 вариабельной области легкой цепи, например замену цистеина на тирозин или цистеина на сериновый остаток, в положении 102 вариабельной области легкой цепи в соответствии с таблицей B (например, SEQ ID NO:16 или 24 для мышиной или химерной, немодифицированной; или любой из SEQ ID NO: 34, 42, 46, 54, 58, 62, 66, 70, 74, или 78 для модифицированной последовательности).
В другом варианте осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две, три, четыре, пять или шесть CDR (или все CDR) вариабельной области тяжелой и легкой цепей, содержащих аминокислотную последовательность, приведенную в таблице В или кодируемую нуклеотидной последовательностью, приведенной в таблице В. В одном из вариантов осуществления одна или более CDR (или все CDR) имеют одно, два, три, четыре, пять, шесть или более изменений, например аминокислотных замен или делеций, относительно аминокислотной последовательности, приведенной в таблице В или кодируемой нуклеотидной последовательностью, приведенной в таблице В.
В одном из вариантов осуществления молекула анти-PD-1 антитела включает все шесть CDR описанного в настоящей заявке антитела, например антитела, выбранного из любого из BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенных в таблице B, или кодируемых нуклеотидной последовательностью, приведенной в таблице B или близкородственные CDR, например CDR, которые идентичны или которые имеют по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например, консервативных замен). В одном из вариантов осуществления молекула анти-PD-1 антитела может включать любой описанный в настоящей заявке CDR. В некоторых вариантах осуществления молекула анти-PD-1 антитела включает замену в CDR легкой цепи, например одну или более замен в CDR1, CDR2 и/или CDR3 легкой цепи. В одном из вариантов осуществления молекула анти-PD-1 антитела включает замену в CDR3 легкой цепи в положении 102 вариабельной области легкой цепи, например замену цистеина на тирозин или цистеина на сериновый остаток, в положении 102 вариабельной области легкой цепи в соответствии с таблицей B (например, SEQ ID NO:16 или 24 для мышиной или химерной, немодифицированной; или любой из SEQ ID NO: 34, 42, 46, 54, 58, 62, 66, 70, 74, или 78 для модифицированной последовательности).
В другом варианте осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две или три CDR согласно Kabat et al. (например, по меньшей мере одну, две или три CDR согласно определению Kabat, как указано в таблице B) вариабельной области тяжелой цепи антитела, описанного в настоящей заявке, например антитела, выбранного из любого из BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенные в таблице B, или кодируемые нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей; или которые имеют по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например консервативных замен) относительно одной, двух или трех CDR согласно Kabat et al., показанных в таблице B.
В другом варианте осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две или три CDR согласно Kabat et al. (например, по меньшей мере одну, две или три CDR согласно определению Kabat, как указано в таблице B) вариабельной области легкой цепи антитела, описанного в настоящей заявке, например антитела, выбранного из любого из BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенные в таблице B, или кодируемые нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей; или которые имеют по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например консервативных замен) относительно одной, двух или трех CDR согласно Kabat et al., показанных в таблице B.
В еще одном варианте осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две, три, четыре, пять или шесть CDR согласно Kabat et al. (например, по меньшей мере одну, две, три, четыре, пять или шесть CDR согласно определению Kabat, как указано в таблице B) вариабельных областей тяжелой и легкой цепей антитела, описанного в настоящей заявке, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенных в таблице B, или кодируемых нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей; или которые имеют по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например консервативных замен) относительно одной, двух или трех CDR согласно Kabat et al., показанных в таблице B.
В еще одном варианте осуществления молекула анти-PD-1 антитела включает все шесть CDR согласно Kabat et al. (например, все шесть CDR согласно определению Kabat, как указано в таблице B) вариабельных областей тяжелой и легкой цепей описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенных в таблице B, или кодируемых нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей; или которые имеют по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например консервативных замен) относительно одной, двух или трех CDR согласно Kabat et al., показанных в таблице B. В одном из вариантов осуществления молекула анти-PD-1 антитела может включать любую описанную в настоящей заявке CDR.
В другом варианте осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две или три гипервариабельные петли по Chothia (например, по меньшей мере одну, две или три гипервариабельные петли согласно определению Chothia, как указано в таблице B) вариабельной области тяжелой цепи описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенные в таблице B, или кодируемые нуклеотидной последовательностью, приведенной в таблице B; или, по меньшей мере, аминокислоты этих гипервариабельных петель, которые контактируют с PD-1; или которые имеют по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например консервативных замен) относительно одной, двух или трех гипервариабельных петель согласно Chothia et al., показанных в таблице B.
В другом варианте осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две или три гипервариабельные петли по Chothia (например, по меньшей мере одну, две или три гипервариабельные петли согласно определению Chothia, как указано в таблице B) вариабельной области легкой цепи описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенные в таблице B, или кодируемые нуклеотидной последовательностью, приведенной в таблице B; или, по меньшей мере, аминокислоты этих гипервариабельных петель, которые контактируют с PD-1; или которые имеют по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например консервативных замен) относительно одной, двух или трех гипервариабельных петель согласно Chothia et al., показанных в таблице B.
В еще одном варианте осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две, три, четыре, пять или шесть гипервариабельных петель (например, по меньшей мере одну, две, три, четыре, пять или шесть гипервариабельных петель согласно определению Chothia, как указано в таблице B) вариабельных областей тяжелой и легкой цепей описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или описанных в таблице B, или кодируемых нуклеотидной последовательностью, приведенной в таблице B; или, по меньшей мере, аминокислоты этих гипервариабельных петель, которые контактируют с PD-1; или которые имеют по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например консервативных замен) относительно одной, двух, трех, четырех, пяти или шести гипервариабельных петель согласно Chothia et al., показанных в таблице B.
В одном из вариантов осуществления молекула анти-PD-1 антитела включает все шесть гипервариабельных петель (например, все шесть гипервариабельных петель согласно определению Chothia, как указано в таблице B) описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E, или близкородственных гипервариабельных петель например, гипервариабельных петель, которые идентичны или имеют по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например, консервативных замен); или которые имеют по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например консервативных замен) относительно всех шести гипервариабельных петель согласно Chothia et al., показанных в таблице B. В одном из вариантов осуществления молекула анти-PD-1 антитела может включать любую описанную в настоящей заявке гипервариабельную петлю.
В еще одном варианте осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две или три гипервариабельные петли, которые имеют такие же канонические структуры, что и соответствующая гипервариабельная петля антитела, описанного в настоящей заявке, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E, например, такой же канонической структуры, как по меньшей мере у петли 1 и/или петли 2 вариабельных доменов тяжелой и/или легкой цепи антитела, описанного в настоящей заявке. См., например, Chothia et al., (1992) J. Mol. Biol. 227:799-817; Tomlinson et al., (1992) J. Mol. Biol. 227:776-798 для описаний гипервариабельных канонических структур. Эти структуры могут быть определены путем изучения таблиц, описанных в этих ссылочных документах.
В некоторых вариантах осуществления молекула анти-PD-1 антитела включает комбинацию CDR или гипервариабельных петель, определенных согласно Kabat et al. и Chothia et al.
В одном из вариантов осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две или три CDR или гипервариабельные петли вариабельной области тяжелой цепи антитела, описанного в настоящей заявке, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E, согласно определению Kabat и Chothia (например, по меньшей мере, одну, две или три CDR или гипервариабельные петли согласно определению Kabat и Chothia, как указано в таблице B); или кодируемые нуклеотидной последовательностью, приведенной в таблице B; или последовательность, по существу идентичную (например, идентичную на по меньшей мере 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более) любой из вышеуказанных последовательностей; или которые имеют по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например консервативных замен) относительно одной, двух или трех CDR или гипервариабельных петель согласно Kabat и/или Chothia, показанных в таблице B.
Например, молекула анти-PD-1 антитела может включать CDR1 VH согласно Kabat et al. или гипервариабельную петлю 1 VH согласно Chothia et al., или их комбинацию, например, как показано в таблице B. В одном из вариантов осуществления комбинация CDR по Kabat и Chothia для CDR1 VH содержит аминокислотную последовательность GYTFTTYWMH (SEQ ID NO: 224) или аминокислотную последовательность, по существу идентичную ей (например, имеющую по меньшей мере одно изменение аминокислоты, но не более двух, трех или четырех изменений (например, замен, делеций или вставок, например, консервативных замен)). Молекула анти-PD-1 антитела может дополнительно включать, например, CDR 2-3 VH согласно Kabat et al. и CDR 1-3 VL согласно Kabat et al., например, как показано в таблице B. Соответственно, в некоторых вариантах осуществления каркасные участки определяются на основе комбинации CDR, определенных согласно Kabat et al., и гипервариабельных петель, определенных согласно Chothia et al. Например, молекула анти-PD-1 антитела может включать FR1 VH, определенную на основе гипервариабельной петли 1 VH согласно Chothia et al., и FR2 VH, определенную на основе CDR 1-2 VH согласно Kabat et al., например, как показано в таблице B. Молекула анти-PD-1 антитела может дополнительно включать, например, FR 3-4 VH, определенные на основе CDR 2 VH согласно Kabat et al., и FR 1-4 VL, определенные на основе CDR 1-3 VL согласно Kabat et al.
Молекула анти-PD-1 антитела может содержать любую комбинацию CDR или гипервариабельных петель согласно определениям Kabat и Chothia. В одном из вариантов осуществления молекула анти-PD-1 антитела включает по меньшей мере одну, две или три CDR вариабельной области легкой цепи антитела, описанного в настоящей заявке, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E, согласно определению Kabat и Chothia (например, по меньшей мере одну, две или три CDR согласно определениям Kabat и Chothia, как указано в таблице B).
В варианте осуществления, например варианте осуществления, включающем вариабельную область, CDR (например, CDR по Chothia или CDR по Kabat) или другую последовательность, указанную в настоящей заявке, например в таблице B, молекула антитела представляет собой молекулу моноспецифического антитела, молекулу биспецифического антитела или представляет собой молекулу антитела, которое содержит антигенсвязывающий фрагмент антитела, например полу-антитело, или антигенсвязывающий фрагмент полу-антитела. В некоторых вариантах осуществления молекула антитела представляет собой молекулу биспецифического антитела, имеющего первую специфичность связывания для PD-1 и вторую специфичность связывания для TIM-3, LAG-3, CEACAM (например, CEACAM-1 и/или CEACAM-5), PD-L1 или PD-L2.
В одном из вариантов осуществления молекула анти-PD-1 антитела включает:
(а) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 4, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33;
(b) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 1; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32;
(с) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33; или
(d) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32.
В одном из вариантов осуществления молекула анти-PD-1 антитела содержит VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 4, аминокислотную последовательность VHCDR2, представленную в SEQ ID NO: 5, и аминокислотную последовательность VHCDR3, представленную в SEQ ID NO:3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, представленную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, представленную в SEQ ID NO: 33.
В одном из вариантов осуществления молекула анти-PD-1 антитела содержит VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 1; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32.
В одном из вариантов осуществления молекула анти-PD-1 антитела содержит VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO:5, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO:3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO:13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO:14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO:33.
В одном из вариантов осуществления молекула анти-PD-1 антитела содержит VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32.
В одном из вариантов осуществления молекула антитела представляет собой гуманизированную молекулу антитела. В другом варианте осуществления молекула антитела представляет собой молекулу моноспецифического антитела. В еще одном варианте осуществления молекула антитела представляет собой молекулу биспецифического антитела.
В одном варианте осуществления молекула анти-PD-1 антитела включает:
(i) вариабельную область тяжелой цепи (VH), включающую аминокислотную последовательность VHCDR1, выбранную из SEQ ID NO: 1, SEQ ID NO: 4 и SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; а также
(ii) вариабельную область легкой цепи (VL), включающую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32.
В одном из вариантов осуществления молекула анти-PD-1 антитела включает:
(i) вариабельную область тяжелой цепи (VH), включающую аминокислотную последовательность VHCDR1, выбранную из SEQ ID NO: 1, SEQ ID NO: 4 или SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; а также
(ii) вариабельную область легкой цепи (VL), включающую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33.
В одном из вариантов осуществления молекула анти-PD-1 антитела содержит аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 1. В другом варианте осуществления молекула анти-PD-1 антитела содержит аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 4. В еще одном варианте осуществления молекула анти-PD-1 антитела содержит аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224.
В одном из вариантов осуществления каркасный участок вариабельной области легкой или тяжелой цепи (например, участок, охватывающий по меньшей мере FR1, FR2, FR3 и необязательно FR4) молекулы анти-PD-1 антитела может быть выбран из: (a) каркасного участка вариабельной области легкой или тяжелой цепи, включающего по меньшей мере 80%, 85%, 87% 90%, 92%, 93%, 95%, 97%, 98% или предпочтительно 100% аминокислотных остатков каркасного участка вариабельной области легкой или тяжелой цепи человека, например, остатка каркасного участка вариабельной области легкой или тяжелой цепи человеческого зрелого антитела, последовательности зародышевой линии человека или консенсусной последовательности человека; (b) каркасного участка вариабельной области легкой или тяжелой цепи, включающего от 20 до 80%, от 40 до 60%, от 60% до 90% или от 70% до 95% аминокислотных остатков каркасного участка вариабельной области легкой или тяжелой цепи человека, например, остатка каркасного участка вариабельной области легкой или тяжелой цепи зрелого антитела человека, последовательности зародышевой линии человека или консенсусной последовательности человека; (c) каркасного участка, не относящегося к человеку (например, каркасного участка грызунов); или (d) каркасного участка, не относящегося к человеку, который модифицирован, например, путем удаления антигенных или цитотоксических детерминант, например, деиммунизирован или частично гуманизирован. В одном из вариантов осуществления каркасный участок вариабельной области легкой или тяжелой цепи (в частности, FR1, FR2 и/или FR3) включает последовательность каркасного участка вариабельной области легкой или тяжелой цепи, идентичную на по меньшей мере 70, 75, 80, 85, 87, 88, 90, 92, 94, 95, 96, 97, 98, 99% каркасному участку сегмента VL или VH гена человеческой зародышевой линии.
В некоторых вариантах осуществления молекула анти-PD-1 антитела включает вариабельный домен тяжелой цепи, имеющий по меньшей мере одно, два, три, четыре, пять, шесть, семь, десять, пятнадцать, двадцать или более изменений, например аминокислотных замен или делеций, относительно аминокислотной последовательности BAP049-chi-HC, например аминокислотной последовательности FR-участка в пределах всей всей вариабельной области, например SEQ ID NO: 18, 20, 22 или 30. В одном из вариантов осуществления молекула анти-PD-1 антитела содержит вариабельный домен тяжелой цепи, имеющий одно или более из: E в положении 1, V в положении 5, A в положении 9, V в положении 11, K в положении 12, K в положении 13, E в положении 16, L в положении 18, R в положении 19, I или V в положении 20, G в положении 24, I в положении 37, A или S в положении 40, T в положении 41, S в положении 42, R в положении 43, M или L в положении 48, V или F в положении 68, T в положении 69, I в положении 70, S в положении 71, A или R в положении 72, K или N в положении 74, Т или К в положении 76, S или N в положении 77, L в положении 79, L в положении 81, E или Q в положении 82, M в положении 83, S или N в положении 84, R в положении 87, A в положении 88 или Т в положении 91 аминокислотной последовательности BAP049-chi-HC, например аминокислотной последовательности FR в пределах всей вариабельной области, например SEQ ID NO: 18, 20, 22 или 30.
Альтернативно или в комбинации с заменами в тяжелой цепи BAP049-chi-HC, описанными в настоящей заявке, молекула анти-PD-1 антитела содержит вариабельный домен легкой цепи, имеющий по меньшей мере одно, два, три, четыре, пять, шесть, семь, десять, пятнадцать, двадцать или более аминокислотных изменений, например аминокислотных замен или делеций, относительно аминокислотной последовательности BAP049-chi-LC, например аминокислотной последовательности, приведенной в SEQ ID NO: 24 или 26. В одном из вариантов осуществления молекула анти-PD-1 антитела содержит вариабельный домен тяжелой цепи, имеющий одно или более из: E в положении 1, V в положении 2, Q в положении 3, L в положении 4, T в положении 7, D или L или A в положении 9, F или T в положении 10, Q в положении 11, S или P в положении 12, L или A в положении 13, S в положении 14, P или L, или V в положении 15, K в положение 16, Q или D в положении 17, R в положении 18, A в положении 19, S в положении 20, I или L в положении 21, T в положении 22, L в положении 43, K в положении 48, A или S в положении 49, R или Q в положении 51, Y в положении 55, I в положении 64, S или P в положении 66, S в положении 69, Y в положении 73, G в положении 74, E в положении 76, F на положение 79, N в положении 82, N в положении 83, L или I в положении 84, E в положении 85, S или P в положении 86, D в положении 87, A или F, или I в положении 89, T или Y в положении 91, F в положении 93 или Y в положении 102 аминокислотной последовательности BAP049-chi-LC, например аминокислотной последовательности, приведенной в SEQ ID NO: 24 или 26.
В других вариантах осуществления молекула анти-PD-1 антитела включает один, два, три или четыре каркасных участка тяжелой цепи (например, аминокислотную последовательность VHFW, показанную в таблице C, или кодируемую нуклеотидной последовательностью, показанной в таблице C), или последовательность, по существу идентичную ей.
В других вариантах осуществления молекула анти-PD-1 антитела включает один, два, три или четыре каркасных участка легкой цепи (например, аминокислотную последовательность VLFW, показанную в таблице C, или кодируемую нуклеотидной последовательностью, показанной в таблице C), или последовательность, по существу идентичную ей.
В других вариантах осуществления молекула анти-PD-1 антитела включает один, два, три или четыре каркасных участка тяжелой цепи (например, аминокислотную последовательность VHFW, показанную в таблице C, или кодируемую нуклеотидной последовательностью, показанной в таблице C), или последовательность, по существу идентичную ей; и один, два, три или четыре каркасных участка легкой цепи (например, аминокислотную последовательность VLFW, показанную в таблице C, или кодируемую нуклеотидной последовательностью, показанной в таблице C), или последовательность, по существу идентичную ей.
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасный участок 1 тяжелой цепи (VHFW1) BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E (например, SEQ ID NO: 147). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 1 тяжелой цепи (VHFW1) BAP049-hum14 или BAP049-hum15 (например, SEQ ID NO: 151).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасный участок 2 тяжелой цепи (VHFW2) BAP049-hum01, BAP049-hum02, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum09, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C или BAP049-Clone-E (например, SEQ ID NO: 153). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 2 тяжелой цепи (VHFW2) BAP049-hum03, BAP049-hum04, BAP049-hum08, BAP049-hum10, BAP049-hum14, BAP049-hum15 или BAP049-Clone-D(например, SEQ ID NO: 157). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 2 тяжелой цепи (VHFW2) BAP049-hum16 (например, SEQ ID NO: 160).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасный участок 3 тяжелой цепи (VHFW3) BAP049-hum01, BAP049-hum02, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum09, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C или BAP049-Clone-E (например, SEQ ID NO: 162). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 3 тяжелой цепи (VHFW3) BAP049-hum03, BAP049-hum04, BAP049-hum08, BAP049-hum10, BAP049-hum14, BAP049-hum15, BAP049-hum16 или BAP049-Clone-D (например, SEQ ID NO: 166).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасный участок 4 тяжелой цепи (VHFW4) BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E (например, SEQ ID NO: 169).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасный участок 1 легкой цепи (VLFW1) BAP049-hum08, BAP049-hum09, BAP049-hum15, BAP049-hum16 или BAP049-Clone-C (например, SEQ ID NO: 174). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 1 легкой цепи (VLFW1) BAP049-hum01, BAP049-hum04, BAP049-hum05, BAP049-hum07, BAP049-hum10, BAP049-hum11, BAP049-hum14, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-D или BAP049-Clone-E (например, SEQ ID NO: 177). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 1 легкой цепи (VLFW1) BAP049-hum06 (например, SEQ ID NO: 181). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 1 легкой цепи (VLFW1) BAP049-hum13 (например, SEQ ID NO: 183). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 1 легкой цепи (VLFW1) BAP049-hum02, BAP049-hum03 или BAP049-hum12 (например, SEQ ID NO: 185).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасный участок 2 легкой цепи (VLFW2) BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum06, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-D или BAP049-Clone-E (например, SEQ ID NO: 187). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 2 легкой цепи (VLFW2) BAP049-hum04, BAP049-hum05, BAP049-hum07, BAP049-hum13 или BAP049-Clone-C (например, SEQ ID NO: 191). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 2 легкой цепи (VLFW2) BAP049-hum12 (например, SEQ ID NO: 194).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасный участок 3 легкой цепи (VLFW3) BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E (например, SEQ ID NO: 196). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 3 легкой цепи (VLFW3) BAP049-hum02 или BAP049-hum03 (например, SEQ ID NO: 200). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 3 легкой цепи (VLFW3) BAP049-hum01 или BAP049-Clone-A (например, SEQ ID NO: 202). В некоторых вариантах осуществления молекула антитела содержит каркасный участок 3 легкой цепи (VLFW3) BAP049-hum04, BAP049-hum05 или BAP049-Clone-B (например, SEQ ID NO: 205).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасный участок 4 легкой цепи (VLFW4) BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E (например, SEQ ID NO: 208).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum01, BAP049-hum02, BAP049-hum05, BAP049-hum06, BAP-hum07, BAP049-hum09, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C или BAP049-Clone-E (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 153 (VHFW2) и SEQ ID NO: 162 (VHFW3)). В некоторых вариантах осуществления молекула антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum03, BAP049-hum04, BAP049-hum08, BAP049-hum10 или BAP049-Clone-D (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 157 (VHFW2) и SEQ ID NO: 166 (VHFW3)). В некоторых вариантах осуществления молекула антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum14 или BAP049-hum15 (например, SEQ ID NO: 151 (VHFW1), SEQ ID NO: 157 (VHFW2) и SEQ ID NO: 166 (VHFW3)). В некоторых вариантах осуществления молекула антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum16 (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 160 (VHFW2) и SEQ ID NO: 166 (VHFW3)). В некоторых вариантах осуществления молекула антитела дополнительно содержит каркасный участок 4 тяжелой цепи (VHFW4) BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E (например, SEQ ID NO: 169).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 легкой цепи BAP049-hum01 или BAP049-Clone-A (например, SEQ ID NO: 177 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 202 (VLFW3)). В некоторых вариантах осуществления молекула антитела содержит каркасные участки 1-3 легкой цепи BAP049-hum02 или BAP049-hum03 (например, SEQ ID NO: 185 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 200 (VLFW3)). В некоторых вариантах осуществления молекула антитела содержит каркасные участки 1-3 легкой цепи BAP049-hum04, BAP049-hum05 или BAP049-Clone-B (например, SEQ ID NO: 177 (VLFW1), SEQ ID NO: 191 (VLFW2) и SEQ ID NO: 205 (VLFW3)). В некоторых вариантах осуществления молекула антитела содержит каркасные участки 1-3 легкой цепи BAP049-hum06 (например, SEQ ID NO: 181 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 196 (VLFW3)). В некоторых вариантах осуществления молекула антитела содержит каркасные участки 1-3 легкой цепи BAP049-hum07 (например, SEQ ID NO: 177 (VLFW1), SEQ ID NO: 191 (VLFW2) и SEQ ID NO: 196 (VLFW3)). В некоторых вариантах осуществления молекула антитела содержит каркасные участки 1-3 легкой цепи BAP049-hum08, BAP049-hum09, BAP049-hum15, BAP049-hum16 или BAP049-Clone-C (например, SEQ ID NO: 174 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 196 (VLFW3)). В некоторых вариантах осуществления молекула антитела содержит каркасные участки 1-3 легкой цепи BAP049-hum10, BAP049-hum11, BAP049-hum14, BAP049-Clone-D или BAP049-Clone-E (например, SEQ ID NO: 177 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 196 (VLFW3)). В некоторых вариантах осуществления молекула антитела содержит каркасные участки 1-3 легкой цепи BAP049-hum12 (например, SEQ ID NO: 185 (VLFW1), SEQ ID NO: 194 (VLFW2) и SEQ ID NO: 196 (VLFW3)). В некоторых вариантах осуществления молекула антитела содержит каркасные участки 1-3 легкой цепи BAP049-hum13 (например, SEQ ID NO: 183 (VLFW1), SEQ ID NO: 191 (VLFW2) и SEQ ID NO: 196 (VLFW3)). В некоторых вариантах осуществления молекула антитела дополнительно содержит каркасный участок 4 легкой цепи (VLFW4) BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E (например, SEQ ID NO: 208).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum01 или BAP049-Clone-A (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 153 (VHFW2) и SEQ ID NO: 162 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum01 или BAP049-Clone-A (например, SEQ ID NO: 177 (VLFW1), SEQ ID NO: 187 (VLFW2)) и SEQ ID NO: 202 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum02 (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 153 (VHFW2) и SEQ ID NO: 162 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum02 (например, SEQ ID NO: 185 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 200 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum03 (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 157 (VHFW2) и SEQ ID NO: 166 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum03 (например, SEQ ID NO: 185 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 200 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum04 (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 157 (VHFW2) и SEQ ID NO: 166 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum04 (например, SEQ ID NO: 177 (VLFW1), SEQ ID NO: 191 (VLFW2) и SEQ ID NO: 205 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum05 или BAP049-Clone-B (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 153 (VHFW2) и SEQ ID NO: 162 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum05 или BAP049-Clone-B (например, SEQ ID NO: 177 (VLFW1), SEQ ID NO: 191 (VLFW2) и SEQ ID NO: 205 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum06 (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 153 (VHFW2) и SEQ ID NO: 162 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum06 (например, SEQ ID NO: 181 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 196 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum07 (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 153 (VHFW2) и SEQ ID NO: 162 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum07 (например, SEQ ID NO: 177 (VLFW1), SEQ ID NO: 191 (VLFW2) и SEQ ID NO: 196 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum08 (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 157 (VHFW2) и SEQ ID NO: 166 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum08 (например, SEQ ID NO: 174 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 196 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum09 или BAP049-Clone-C (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 153 (VHFW2) и SEQ ID NO: 162 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum09 или BAP049-Clone-C (например, SEQ ID NO: 174 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 196 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum10 или BAP049-Clone-D (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 157 (VHFW2) и SEQ ID NO: 166 (VHFW3)) и каркасные участки легкой цепи 1-3 BAP049-hum10 или BAP049-Clone-D (например, SEQ ID NO: 177 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 196 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum11 или BAP049-Clone-E (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 153 (VHFW2) и SEQ ID NO: 162 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum11 или BAP049-Clone-E (например, SEQ ID NO: 177 (VLFW1), SEQ ID NO: 187 (VLFW2)) и SEQ ID NO: 196 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum12 (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 153 (VHFW2) и SEQ ID NO: 162 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum12 (например, SEQ ID NO: 185 (VLFW1), SEQ ID NO: 194 (VLFW2) и SEQ ID NO: 196 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum13 (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 153 (VHFW2) и SEQ ID NO: 162 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum13 (например, SEQ ID NO: 183 (VLFW1), SEQ ID NO: 191 (VLFW2) и SEQ ID NO: 196 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum14 (например, SEQ ID NO: 151 (VHFW1), SEQ ID NO: 157 (VHFW2) и SEQ ID NO: 166 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum14 (например, SEQ ID NO: 177 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 196 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum15 (например, SEQ ID NO: 151 (VHFW1), SEQ ID NO: 157 (VHFW2) и SEQ ID NO: 166 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum15 (например, SEQ ID NO: 174 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 196 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасные участки 1-3 тяжелой цепи BAP049-hum16 (например, SEQ ID NO: 147 (VHFW1), SEQ ID NO: 160 (VHFW2) и SEQ ID NO: 166 (VHFW3)) и каркасные участки 1-3 легкой цепи BAP049-hum16 (например, SEQ ID NO: 174 (VLFW1), SEQ ID NO: 187 (VLFW2) и SEQ ID NO: 196 (VLFW3)).
В некоторых вариантах осуществления молекула анти-PD-1 антитела дополнительно содержит каркасный участок 4 тяжелой цепи (VHFW4) BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E (например, SEQ ID NO: 169) и каркасный участок легкой цепи 4 (VLFW4) BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E (например, SEQ ID NO: 208).
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит каркасный участок тяжелой цепи, имеющий комбинацию каркасных участков FW1, FW2 и FW3, как показано на фиг. 9 или 10. В другом варианте осуществления молекула антитела содержит каркасный участок легкой цепи, имеющий комбинацию каркасных участков FW1, FW2 и FW3, как показано на фиг. 9 или 10. В других вариантах осуществления молекула антитела содержит каркасный участок тяжелой цепи, имеющий комбинацию каркасных участков FW1, FW2 и FW3, как показано на фиг. 9 или 10, и каркасный участок легкой цепи, имеющий комбинацию каркасных участков FW1, FW2 и FW3, как показано на фиг. 9 или 10.
В одном из вариантов осуществления вариабельный домен тяжелой или легкой цепи или обеих цепей молекулы анти-PD-1 антитела включает аминокислотную последовательность, которая по существу идентична описанной в настоящей заявке аминокислоте, например, идентична на по меньшей мере, 80%, 85%, 90%, 92%, 95%, 97%, 98%, 99% или более вариабельной области описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E; или приведенную таблице B, или кодируемую нуклеотидной последовательностью, приведенной в таблице B; или которая отличается по меньшей мере 1 или 5 остатками, но менее 40, 30, 20 или 10 остатками, от вариабельной области описанного в настоящей заявке антитела.
В одном из вариантов осуществления вариабельная область тяжелой или легкой цепи или обеих цепей молекулы анти-PD-1 антитела включает аминокислотную последовательность, кодируемую описанной в настоящей заявке последовательностью нуклеиновой кислоты, или нуклеиновой кислоты, которая гибридизуется с последовательностью нуклеиновой кислоты, описанной в настоящей заявке (например, последовательностью нуклеиновой кислоты, показанной в таблицах 1 и 2), или ее комплементом, например, в условиях низкой жесткости, средней жесткости или высокой жесткости или в других условиях гибридизации, описанных в настоящей заявке.
В другом варианте осуществления молекула анти-PD-1 антитела содержит, по меньшей мере, одну, две, три или четыре антигенсвязывающие области, например вариабельные области, имеющие аминокислотную последовательность, приведенную в таблице B, или последовательность, по существу идентичную ей (например, последовательность, идентичную на по меньшей мере, примерно 85%, 90%, 95%, 99% или более) или которая отличается не более чем 1, 2, 5, 10 или 15 аминокислотными остатками от последовательностей, показанных в таблице B. В другом варианте осуществления молекула анти-PD-1 антитела включает домен VH и/или VL, кодируемый нуклеиновой кислотой, имеющей нуклеотидную последовательность, приведенную в таблице B, или последовательность, по существу идентичную ей (например, последовательность, идентичную ей на по меньшей мере, примерно 85%, 90%, 95%, 99% или более) или которая отличается не более чем на 3, 6, 15, 30 или 45 нуклеотидов от последовательностей, показанных в таблице B.
В еще одном варианте осуществления молекула анти-PD-1 антитела содержит по меньшей мере одну, две или три CDR вариабельной области тяжелой цепи, имеющей аминокислотную последовательность, приведенную в таблице B, или последовательность, по существу, гомологичную ей (например, последовательность, идентичную ей на по меньшей мере примерно 85%, 90%, 95%, 99% или более и/или имеющую одну, две, три или более замен, вставок или делеций, например консервативных замен). В еще одном варианте осуществления молекула анти-PD-1 антитела содержит по меньшей мере одну, две или три CDR вариабельной области легкой цепи, имеющей аминокислотную последовательность, приведенную в таблице B, или последовательность, по существу гомологичную ей (например, последовательность идентичную ей на по меньшей мере примерно 85%, 90%, 95%, 99% или более и/или имеющую одну, две, три или более замен, вставок или делеций, например консервативных замен). В еще одном варианте осуществления молекула анти-PD-1 антитела содержит по меньшей мере одну, две, три, четыре, пять или шесть CDR вариабельных областей тяжелой и легкой цепей, имеющих аминокислотную последовательность, приведенную в таблице B), или последовательность, по существу, гомологичную ей (например, последовательность, идентичную ей на по меньшей мере 85%, 90%, 95%, 99% или более и/или имеющую одну, две, три или более замен, вставок или делеций, например консервативных замен).
В одном из вариантов осуществления молекула анти-PD-1 антитела содержит по меньшей мере одну, две или три CDR и/или гипервариабельные петли вариабельной области тяжелой цепи, имеющей аминокислотную последовательность описанного в настоящей заявке антитела, например антитела, выбранного из любого из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E, как суммировано в Таблице B, или последовательность, по существу идентичную ей (например, последовательность, идентичную ей на по меньшей мере, примерно 85%, 90%, 95%, 99% или более и/или имеющую одну, две, три или более замен, вставок или делеций, например, консервативных замен). В другом варианте осуществления молекула анти-PD-1 антитела содержит по меньшей мере одну, две или три CDR и/или гипервариабельные петли вариабельной области легкой цепи, имеющей аминокислотную последовательность описанного в настоящей заявке антитела, например антитела, выбранного из любой из: BAP049-hum01, BAP049-hum02, BAP049-hum03, BAP049-hum04, BAP049-hum05, BAP049-hum06, BAP049-hum07, BAP049-hum08, BAP049-hum09, BAP049-hum10, BAP049-hum11, BAP049-hum12, BAP049-hum13, BAP049-hum14, BAP049-hum15, BAP049-hum16, BAP049-Clone-A, BAP049-Clone-B, BAP049-Clone-C, BAP049-Clone-D или BAP049-Clone-E, как суммировано в Таблице B, или последовательность, по существу идентичную ей (например, последовательность, идентичную ей на по меньшей мере, примерно 85%, 90%, 95%, 99% или более и/или имеющую одну, две, три или более замен, вставок или делеций, например, консервативных замен). В одном из вариантов осуществления молекула анти-PD-1 антитела включает все шесть CDR и/или гипервариабельных петель, описанных в настоящей заявке, например, описанных в таблице B.
В одном из вариантов осуществления молекула анти-PD-1 антитела имеет вариабельную область, которая идентична последовательности или которая отличается от описанной в настоящей заявке вариабельной области (например, описанной в настоящей заявке FR-области) 1, 2, 3 или 4 аминокислотами.
В одном из вариантов осуществления молекула анти-PD-1 антитела представляет собой полное антитело или его фрагмент (например, Fab, F(ab')2, Fv или одноцепочечный Fv-фрагмент (scFv)). В некоторых вариантах осуществления молекула анти-PD-1 антитела представляет собой моноклональное антитело или антитело с одной специфичностью. Молекула анти-PD-1 антитела также может быть гуманизированной, химерной, верблюжьей, акульей или молекулой антитела, продуцированной in vitro. В одном из вариантов осуществления молекула анти-PD-1 антитела представляет собой молекулу гуманизированного антитела. Тяжелая и легкая цепи молекулы анти-PD-1 антитела могут быть полноразмерными (например, антитело может включать по меньшей мере одну, а предпочтительно две полные тяжелые цепи и по меньшей мере одну, а предпочтительно две полные легкие цепи) или может включать антигенсвязывающий фрагмент (например, Fab, F(ab')2, Fv, одноцепочечный Fv-фрагмент, однодоменное антитело, диатело (dAb), бивалентное антитело или биспецифическое антитело или его фрагмент, однодоменный вариант или антитело верблюда).
В других вариантах осуществления молекула анти-PD-1 антитела имеет константную область (Fc) тяжелой цепи, выбранную, например, из константных областей тяжелой цепи IgG1, IgG2, IgG3, IgG4, IgM, IgA1, IgA2, IgD и IgE; в частности, выбранных из, например, константных областей тяжелой цепи IgG1, IgG2, IgG3 и IgG4, более конкретно, константной области тяжелой цепи IgG1 или IgG2 (например, человеческого IgG1, IgG2 или IgG4). В одном из вариантов осуществления константная область тяжелой цепи представляет собой человеческий IgG1. В другом варианте осуществления молекула анти-PD-1 антитела имеет константную область легкой цепи, выбранную, например, из константных областей легкой цепи каппа или лямбда, предпочтительно каппа (например, каппа человека). В одном из вариантов осуществления константная область изменена, например, мутирована для того, чтобы модифицировать свойства молекулы анти-PD-1 антитела (например, для увеличения или уменьшения одного или более из: связывания Fc-рецептора, гликозилирования антитела, количества цистеиновых остатков, функции эффекторных клеток или функции комплемента). Например, константная область мутирована в положениях 296 (M на Y), 298 (S на T), 300 (T на E), 477 (H на K) и 478 (N на F) для изменения связывания Fc-рецептора (например, мутированные положения соответствуют положениям 132 (M на Y), 134 (S на T), 136 (T на E), 313 (H на K) и 314 (N на F) в SEQ ID NO: 212 или 214, или положениях 135 (M на Y), 137 (S на T), 139 (Т на Е), 316 (H на K) и 317 (N на F) в SEQ ID NO: 215, 216, 217 или 218), В другом варианте осуществления константная область тяжелой цепи IgG4, например человеческого IgG4, мутирована в положении 228 в соответствии с нумерацией по EU (например, S на P), например, как показано в таблице D. В некоторых вариантах осуществления молекулы анти-PD-1 антитела содержат человеческий IgG4, мутированный в положении 228 в соответствии с нумерацией по EU (например, S на P), например, как показано в таблице D; и константную область легкой цепи каппа, например, как показано в таблице D. В еще одном варианте осуществления константная область тяжелой цепи IgG1, например IgG1 человека, мутирована в одном или более из: положении 297 в соответствии с нумерацией по EU (например, N на A), положении 265 в соответствии с нумерацией по EU (например, D на A), положении 329 в соответствии с нумерацией по EU (например, P на A), положении 234 в соответствии с нумерацией по EU (например, L на A) или положении 235 в соответствии с нумерацией по EU (например, L на A), например, как показано в таблице D. В некоторых вариантах осуществления молекулы анти-PD-1 антитела содержат человеческий IgG1, мутированный в одном или более из вышеуказанных положений, например, как показано в таблице D; и константную область легкой цепи каппа, например, как показано в таблице D.
В одном из вариантов осуществления молекула анти-PD-1 антитела является изолированной или рекомбинантной.
В одном из вариантов осуществления молекула анти-PD-1 антитела представляет собой гуманизированную молекулу антитела.
В одном из вариантов осуществления молекула анти-PD-1 антитела имеет степень риска, основанную на анализе Т-клеточных эпитопов, менее 700, 600, 500, 400 или менее.
В одном из вариантов осуществления молекула анти-PD-1 антитела представляет собой молекулу гуманизированного антитела и имеет степень риска, основанную на анализе Т-клеточных эпитопов, в пределах от 300 до 700, от 400 до 650, от 450 до 600, или степень риска, как описано в настоящей заявке.
В одном из вариантов осуществления молекула анти-PD-1 антитела включает:
(а) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 4, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33;
(b) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 1; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32;
(с) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33; или
(d) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32.
В некоторых вариантах осуществления молекула анти-PD-1 антитела содержит:
(i) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, выбранную из SEQ ID NO: 1, SEQ ID NO: 4 или SEQ ID NO: 224; аминокислотную последовательность VHCDR2 SEQ ID NO: 2; и аминокислотную последовательность VHCDR3 SEQ ID NO: 3; а также
(ii) вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32.
В других вариантах осуществления молекула анти-PD-1 антитела содержит:
(i) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, выбранную из SEQ ID NO: 1, SEQ ID NO: 4 или SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; а также
(ii) вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33.
В вариантах осуществления вышеупомянутых молекул антитела VHCDR1 содержит аминокислотную последовательность, приведенную в SEQ ID NO: 1. В других вариантах осуществления VHCDR1 содержит аминокислотную последовательность, приведенную в SEQ ID NO: 4. В других вариантах осуществления аминокислотная последовательность VHCDR1 представлена в SEQ ID NO: 224.
В вариантах осуществления вышеупомянутые молекулы антитела имеют вариабельную область тяжелой цепи, содержащую по меньшей мере один каркасный участок (FW), содержащий аминокислотную последовательность, приведенную в любой из: SEQ ID NO: 147, 151, 153, 157, 160, 162, 166 или 169, или аминокислотную последовательность, идентичную им по меньшей мере на 90% или имеющую не более двух аминокислотных замен, вставок или делеций относительно аминокислотной последовательности, приведенной в любой из: SEQ ID NO: 147, 151, 153, 157, 160, 162, 166 или 169.
В других вариантах осуществления вышеупомянутые молекулы антитела имеют вариабельную область тяжелой цепи, содержащую по меньшей мере один каркасный участок, содержащий аминокислотную последовательность, приведенную в любой из: SEQ ID NO: 147, 151, 153, 157, 160, 162, 166 или 169.
В других вариантах осуществления вышеупомянутые молекулы антитела имеют вариабельную область тяжелой цепи, содержащую по меньшей мере два, три или четыре каркасных участка, содержащих аминокислотные последовательности, приведенные в любой из: SEQ ID NO: 147, 151, 153, 157, 160, 162, 166 или 169.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат аминокислотную последовательность VHFW1, приведенную в SEQ ID NO: 147 или 151, аминокислотную последовательность VHFW2, приведенную в SEQ ID NO: 153, 157 или 160, и аминокислотную последовательность VHFW3, приведенную в SEQ ID NO: 162 или 166, и, необязательно, дополнительно содержат аминокислотную последовательность VHFW4, приведенную в SEQ ID NO: 169.
В других вариантах осуществления вышеупомянутые молекулы антитела имеют вариабельную область легкой цепи, содержащую по меньшей мере один каркасный участок, содержащий аминокислотную последовательность, приведенную в любой из: SEQ ID NO: 174, 177, 181, 183, 185, 187, 191, 194, 196, 200, 202, 205 или 208, или аминокислотную последовательность, идентичную им по меньшей мере на 90% или имеющую не более двух аминокислотных замен, вставок или делеций относительно аминокислотной последовательности, приведенной в любой из: 174, 177, 181, 183, 185, 187, 191, 194, 196, 200, 202, 205 или 208.
В других вариантах осуществления вышеупомянутые молекулы антитела имеют вариабельную область легкой цепи, содержащую по меньшей мере один каркасный участок, содержащий аминокислотную последовательность, приведенную в любой из: SEQ ID NO: 174, 177, 181, 183, 185, 187, 191, 194, 196, 200, 202, 205 или 208.
В других вариантах осуществления вышеупомянутые молекулы антитела имеют вариабельную область легкой цепи, содержащую по меньшей мере два, три или четыре каркасных участка, содержащих аминокислотные последовательности, приведенные в любой из: SEQ ID NO: 174, 177, 181, 183, 185, 187, 191, 194, 196, 200, 202, 205 или 208.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат аминокислотную последовательность VLFW1, приведенную в SEQ ID NO: 174, 177, 181, 183 или 185, аминокислотную последовательность VLFW2, приведенную в SEQ ID NO: 187, 191 или 194, и аминокислотную последовательность VLFW3, приведенную в SEQ ID NO: 196, 200, 202 или 205, и, необязательно, дополнительно содержащую аминокислотную последовательность VLFW4, приведенную в SEQ ID NO: 208.
В других вариантах осуществления вышеупомянутые антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, идентичную по меньшей мере, на 85% любой из: SEQ ID NO: 38, 50, 82 или 86.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 38, 50, 82 или 86.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен легкой цепи, содержащий аминокислотную последовательность, идентичную по меньшей мере, на 85%, любой из: SEQ ID NO: 42, 46, 54, 58, 62, 66, 70, 74 или 78.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 42, 46, 54, 58, 62, 66, 70, 74 или 78.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 38.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 40.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 91.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 50.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 52 или SEQ ID NO: 102.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 82.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 84.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 86.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 88.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 42.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 44.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 46.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 48.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 54.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 56.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 58.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 60.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 62.
В других вариантах осуществления вышеупомянутые антитела содержат легкую цепь, содержащую аминокислотную последовательность SEQ ID NO: 64.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 66.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 68.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 70.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 72.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 74.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 76.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 78.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 80.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 38, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 42.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 38, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 66.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 38, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 70.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 50, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 70.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 38, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 46.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 50, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 46.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 50, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 54.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 38, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 54.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 38, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 58.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 38, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 62.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 50, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 66.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 38, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 74.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 38, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 78.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 82, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 70.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 82, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 66.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 86, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность, приведенную в SEQ ID NO: 66.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 91, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 44.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 91, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 56.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 91, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 68.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 91, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 72.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 102, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 72.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 40, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 44.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 40, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 48.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 52, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 48.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 52, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 56.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 40, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 56.
В других вариантах осуществления вышеупомянутые антитела содержат тяжелую цепь, содержащую аминокислотную последовательность SEQ ID NO: 40, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 60.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 40, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 64.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 52, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 68.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 40, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 68.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 52, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 72.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 40, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 72.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 40, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 76.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 40, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 80.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 84, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 72.
В других вариантах осуществления вышеупомянутые антитела содержат тяжелую цепь, содержащую аминокислотную последовательность SEQ ID NO: 84, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 68.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат тяжелую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 88, и легкую цепь, содержащую аминокислотную последовательность, приведенную в SEQ ID NO: 68.
В других вариантах осуществления вышеупомянутые молекулы антитела выбирают из Fab, F(ab')2, Fv или одноцепочечного Fv-фрагмента (scFv).
В других вариантах осуществления вышеупомянутые молекулы антитела содержат константную область тяжелой цепи, выбранную из IgG1, IgG2, IgG3 и IgG4.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат константную область легкой цепи, выбранную из константных областей легкой цепи каппа или лямбда.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат константную область тяжелой цепи IgG4 человека с мутацией в положении 228 в соответствии с нумерацией по EU или в положении 108 в SEQ ID NO: 212 или 214 и константную область легкой цепи каппа.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат константную область тяжелой цепи IgG4 человека с мутацией серина на пролин в положении 228 в соответствии с нумерацией по EU или в положении 108 в SEQ ID NO: 212 или 214 и константную область легкой цепи каппа.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат константную область тяжелой цепи IgG1 человека с мутацией аспарагина на аланин в положении 297 в соответствии с нумерацией по EU или в положении 180 в SEQ ID NO: 216 и константную область легкой цепи каппа.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат константную область тяжелой цепи IgG1 человека с мутацией аспартата на аланин в положении 265 в соответствии с нумерацией по EU или в положении 148 в SEQ ID NO: 217 и мутацией пролина на аланин в положении 329 в соответствии с нумерацией по EU или в положении 212 в SEQ ID NO: 217 и константную область легкой цепи каппа.
В других вариантах осуществления вышеупомянутые молекулы антитела содержат константную область тяжелой цепи человека IgG1 с мутацией лейцина на аланин в положении 234 в соответствии с нумерацией по EU или в положении 117 в SEQ ID NO: 218 и мутацией лейцина на аланин в положении 235 в соответствии с нумерацией по EU или в положении 118 в SEQ ID NO: 218 и константную область легкой цепи каппа.
В других вариантах осуществления вышеупомянутые молекулы антитела способны связываться с PD-1 человека с константой диссоциации (KD) менее примерно 0,2 нМ.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела связываются с PD-1 человека с KD менее чем примерно 0,2 нМ, 0,15 нМ, 0,1 нМ, 0,05 нМ или 0,02 нМ, например, в пределах от примерно 0,13 нМ до 0,03 нМ, например, от примерно 0,077 nM до 0,08 нМ, например, равной примерно 0,083 нМ, например, измеренной методом Biacore.
В других вариантах осуществления вышеупомянутые молекулы антитела связываются с PD-1 яванского макака с KD менее примерно 0,2 нМ, 0,15 нМ, 0,1 нМ, 0,05 нМ или 0,02 нМ, например, в пределах от примерно 0,11 нМ до 0,08 нМ, например, равной примерно 0,093 nM, например, измеренной методом Biacore.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела связываются как с PD-1 человека, так и с PD-1 яванского макака с аналогичным значениями KD, например, в наномолярном диапазоне, например, измеренными методом Biacore. В некоторых вариантах осуществления вышеупомянутые молекулы антитела связываются со слитым белком PD-1-Ig человека с KD менее примерно 0,1 нМ, 0,075 нМ, 0,05 нМ, 0,025 нМ или 0,01 нМ, например, равной примерно 0,04 нМ, например, измеренной методом ELISA.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела связываются с клетками Jurkat, которые экспрессируют PD-1 человека (например, клетками Jurkat, трансфицированными PD-1 человека) с KD менее чем примерно 0,1 нМ, 0,075 нМ, 0,05 нМ, 0,025 нМ или 0,01 нМ, например, равной примерно 0,06 нМ, например, измеренной FACS-анализом.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела связываются с T-клетками яванского макака с KD менее примерно 1 нМ, 0,75 нМ, 0,5 нМ, 0,25 нМ или 0,1 нМ, например, равной примерно 0,4 нМ, например, измеренной FACS-анализом.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела связываются с клетками, которые экспрессируют PD-1 яванского макака (например, клетками, трансфицированными PD-1 яванского макака), с KD менее примерно 1 нМ, 0,75 нМ, 0,5 нМ, 0,25 нМ или 0,01 нМ, например, равной примерно 0,6 нМ, например, измеренной FACS-анализом.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела не являются перекрестно-реактивными с мышиным или крысиным PD-1. В других вариантах осуществления вышеуказанные антитела являются перекрестно-реактивными с PD-1 резус макака. Например, перекрестная реактивность может быть измерена методом Biacore или анализом связывания с использованием клеток, которые экспрессируют PD-1 (например, клеток 300.19, экспрессирующих PD-1 человека). В других вариантах осуществления вышеупомянутые молекулы антитела связывают внеклеточный Ig-подобный домен PD-1.
В других вариантах осуществления вышеупомянутые молекулы антитела способны снижать уровень связывания PD-1 с PD-L1, PD-L2 или с обоими, или клеткой, которая экспрессирует PD-L1, PD-L2 или оба. В некоторых вариантах осуществления вышеупомянутые молекулы антитела снижают (например, блокируют) связывание PD-L1 с клеткой, которая экспрессирует PD-1 (например, клетками 300.19, экспрессирующими PD-1 человека) с IC50 менее примерно 1,5 нМ, 1 нМ, 0,8 нМ, 0,6 нМ, 0,4 нМ, 0,2 нМ или 0,1 нМ, например, в пределах от примерно 0,79 нМ до примерно 1,09 нМ, например, равной примерно 0,94 нМ или примерно 0,78 нМ или менее, например, примерно 0,3 нМ. В некоторых вариантах осуществления вышеупомянутые антитела снижают (например, блокируют) связывание PD-L2 с клеткой, которая экспрессирует PD-1 (например, клетками 300.19, экспрессирующими PD-1 человека) с IC50 менее чем примерно 2 нМ, 1,5 нМ, 1 нМ, 0,5 нМ или 0,2 нМ, например, в пределах от примерно 1,05 нМ до примерно 1,55 нМ или равной примерно 1,3 нМ или менее, например, примерно 0,9 нМ.
В других вариантах осуществления вышеупомянутые молекулы антитела способны усиливать антигенспецифический ответ Т-клеток.
В вариантах осуществления молекула антитела представляет собой молекулу моноспецифического антитела или молекулу биспецифического антитела. В вариантах осуществления молекула антитела имеет первую специфичность связывания для PD-1 и вторую специфичность связывания для TIM-3, LAG-3, CEACAM (например, CEACAM-1, CEACAM-3 и/или CEACAM-5), PD-L1 или PD-L2. В вариантах осуществления молекула антитела содержит антигенсвязывающий фрагмент антитела, например, полуантитело или антигенсвязывающий фрагмент полуантитела.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела увеличивают экспрессию IL-2 в клетках, активированных стафилококковым энтеротоксином B (SEB) (например, при 25 мкг/мл) по меньшей мере в 2, 3, 4, 5 раз, например, примерно в 2-3 раза, например, примерно в 2-2,6 раз, например, примерно в 2,3 раза, по сравнению с экспрессией IL-2, когда используется изотипный контроль (например, IgG4), например, измеренную с помощью анализа активации Т-клеток SEB или ex vivo анализа цельной крови человека.
В некоторых вариантах осуществления вышеупомянутые молекулы антител увеличивают экспрессию IFN-γ в Т-клетках, стимулированных анти-CD3 (например, при 0,1 мкг/мл), по меньшей мере, примерно в 2, 3, 4, 5 раз, например, примерно в пределах от 1,2 до 3,4 раз, например, примерно в 2,3 раза по сравнению с экспрессией IFN-γ, когда используется изотипный контроль (например, IgG4), например, измеренную с помощью анализа активности IFN-γ.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела увеличивают экспрессию IFN-γ в Т-клетках, активированных SEB (например, при 3 пг/мл), по меньшей мере, в 2, 3, 4, 5 раз, например, в пределах от 0,5 до 4,5, например, примерно в 2,5 раза по сравнению с экспрессией IFN-γ, когда используется изотипный контроль (например, IgG4), например, измеренную с помощью анализа активности IFN-γ.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела увеличивают экспрессию IFN-γ Т-клетках, активированных CMV-пептидом, по меньшей мере, в 2, 3, 4, 5 раз, например, примерно в пределах от 2 до 3,6 раз, например, примерно в 2,8 раза по сравнению с экспрессией IFN-γ, когда используется изотипный контроль (например, IgG4), например, измеренную с помощью анализа активности IFN-γ.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела увеличивают пролиферацию CD8+ T-клеток, активированных CMV-пептидом, по меньшей мере, примерно в 1, 2, 3, 4, 5 раз, например, примерно в 1,5 раза по сравнению с пролиферацией CD8+ T клеток, когда используется изотипный контроль (например, IgG4), например, измеренную по процентному содержанию CD8+ Т-клеток, которые прошли через, по меньшей мере, n (например, n=2 или 4) делений клеток.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела имеют Cmax в пределах от примерно 100 мкг/мл до примерно 500 мкг/мл, от примерно 150 мкг/мл до примерно 450 мкг/мл, от примерно 250 мкг/мл до примерно 350 мкг/мл, или от примерно 200 мкг/мл до примерно 400 мкг/мл, например, равную примерно 292,5 мкг/мл, например, измеренную у обезьяны.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела имеют T1/2 в интервале от примерно 250 часов до примерно 650 часов, от примерно 300 часов до примерно 600 часов, от примерно 350 часов до примерно 550 часов или от примерно 400 часов до примерно 500 часов, например, равное примерно 465,5 часов, например, как измеренное у обезьяны.
В некоторых вариантах осуществления вышеупомянутые молекулы антитела связываются с PD-1 с Kd менее чем 5×10-4, 1×10-4, 5×10-5 или 1×10-5 с-1, например, примерно 2,13×10-4 с-1, например, измеренной методом Biacore. В некоторых вариантах осуществления вышеупомянутые молекулы антитела связываются с PD-1 с Ka более чем 1×104, 5×104, 1×105 или 5×105 M-1с-1, например, примерно 2,78×105 М-1с-1, например, измеренной методом Biacore.
В некоторых вариантах осуществления вышеупомянутые молекулы анти-PD-1 антитела связываются с одним или более остатками в нити C, петле CC', нити C' и петле FG PD-1. Доменная структура PD-1 описана, например, в Cheng et al., ʺStructure and Interactions of the Human Programmed Cell Death 1 Receptorʺ J. Biol. Chem. 2013, 288:11771-11785. Как описано у Cheng et. al., нить C содержит остатки F43-M50, петля CC' содержит остатки S51-N54, нить C' содержит остатки Q55-F62, а петля FG содержит остатки L108-I114 (нумерация аминокислот дана по Chang et al.). Соответственно, в некоторых вариантах осуществления анти-PD-1 антитело, описанное в настоящей заявке, связывается по меньшей мере с одним остатком в одном или более отрезках: F43-M50, S51-N54, Q55-F62 и L108-I114 PD-1. В некоторых вариантах анти-PD-1 антитело, описанное в настоящей заявке, связывается по меньшей мере с одним остатком в двух, трех или всех четырех отрезках F43-M50, S51-N54, Q55-F62 и L108-I114 PD-1. В некоторых вариантах осуществления анти-PD-1 антитело связывается с остатком в PD-1, который также является частью сайта связывания для одного или обоих PD-L1 и PD-L2.
В другом аспекте изобретение относится к изолированной молекуле нуклеиновой кислоты, кодирующей любую из вышеупомянутых молекул антитела, векторам и клеткам-хозяевам.
Также предоставляется изолированная нуклеиновая кислота, кодирующая вариабельную область тяжелой цепи антитела или вариабельную область легкой цепи или обе области любой из вышеуказанных молекул антитела.
В одном из вариантов осуществления изолированная нуклеиновая кислота кодирует 1-3 CDR тяжелой цепи, где указанная нуклеиновая кислота содержит нуклеотидную последовательность, приведенную в SEQ ID NO: 108-112, 223, 122-126, 133-137 или 144-146.
В другом варианте осуществления изолированная нуклеиновая кислота кодирует 1-3 CDR легкой цепи, где указанная нуклеиновая кислота содержит нуклеотидную последовательность, приведенную в SEQ ID NO: 113-120, 127-132 или 138-143.
В других вариантах осуществления вышеуказанная нуклеиновая кислота дополнительно содержит нуклеотидную последовательность, кодирующую вариабельный домен тяжелой цепи, где указанная нуклеотидная последовательность идентична по меньшей мере на 85% любой из SEQ ID NO: 39, 51, 83, 87, 90, 95 или 101.
В других вариантах осуществления вышеуказанная нуклеиновая кислота дополнительно содержит нуклеотидную последовательность, кодирующую вариабельный домен тяжелой цепи, где указанная нуклеотидная последовательность содержит любую из SEQ ID NO: 39, 51, 83, 87, 90, 95 или 101.
В других вариантах осуществления вышеуказанная нуклеиновая кислота дополнительно содержит нуклеотидную последовательность, кодирующую тяжелую цепь, где указанная нуклеотидная последовательность идентична по меньшей мере на 85% любой из SEQ ID NO: 41, 53, 85, 89, 92, 96 или 103.
В других вариантах осуществления вышеуказанная нуклеиновая кислота дополнительно содержит нуклеотидную последовательность, кодирующую тяжелую цепь, где указанная нуклеотидная последовательность содержит любую из SEQ ID NO: 41, 53, 85, 89, 92, 96 или 103.
В других вариантах осуществления вышеуказанная нуклеиновая кислота дополнительно содержит нуклеотидную последовательность, кодирующую вариабельный домен легкой цепи, где указанная нуклеотидная последовательность идентична по меньшей мере на 85% любой из SEQ ID NO: 45, 49, 57, 61, 65, 69, 73, 77, 81, 94, 98, 100, 105 или 107.
В других вариантах осуществления вышеуказанная нуклеиновая кислота дополнительно содержит нуклеотидную последовательность, кодирующую вариабельный домен легкой цепи, где указанная нуклеотидная последовательность содержит любую из SEQ ID NO: 45, 49, 57, 61, 65, 69, 73, 77, 81, 94, 98, 100, 105 или 107.
В других вариантах осуществления вышеуказанная нуклеиновая кислота дополнительно содержит нуклеотидную последовательность, кодирующую легкую цепь, где указанная нуклеотидная последовательность идентична по меньшей мере на 85% любой из SEQ ID NO: 45, 49, 57, 61, 65, 69, 73, 77, 81, 94, 98, 100, 105 или 107.
В других вариантах осуществления вышеуказанная нуклеиновая кислота дополнительно содержит нуклеотидную последовательность, кодирующую легкую цепь, где указанная нуклеотидная последовательность содержит любую из SEQ ID NO: 45, 49, 57, 61, 65, 69, 73, 77, 81, 94, 98, 100, 105 или 107.
В некоторых вариантах осуществления предлагается один или более векторов экспрессии и клетки-хозяева, содержащие вышеуказанные нуклеиновые кислоты.
Также предлагается способ получения молекулы антитела или ее фрагмента, включающий культивирование клетки-хозяина, как описано в настоящей заявке, в условиях, подходящих для экспрессии генов.
В одном из аспектов изобретение относится к способу получения молекулы антитела, описанной в настоящей заявке. Способ включает: предоставление антигена PD-1 (например, антигена, содержащего, по меньшей мере, часть эпитопа PD-1); получение молекулы антитела, которая специфически связывается с полипептидом PD-1; и оценку, связывается ли молекула антитела специфически с полипептидом PD-1, или оценку эффективности молекулы антитела в модулировании, например ингибировании, активности PD-1. Способ может дополнительно включать введение молекулы антитела субъекту, например человеку или животному, не являющемуся человеком.
В другом аспекте изобретение относится к композициям, например фармацевтическим композициям, которые включают фармацевтически приемлемый носитель, наполнитель или стабилизатор и по меньшей мере один из терапевтических агентов, например молекулы анти-PD-1 антитела, описанные в настоящей заявке. В одном из вариантов осуществления композиция, например фармацевтическая композиция, включает комбинацию молекулы антитела и одного или более агентов, например терапевтического агента или молекулы другого антитела, описанного в настоящей заявке. В одном из вариантов осуществления молекула антитела конъюгирована с меткой или терапевтическим агентом.
Таблица B. Аминокислотные и нуклеотидные последовательности молекул мышиных, химерных и гуманизированных антител к PD-1. Молекулы антител включают мышиное mAb BAP049, химерные mAb BAP049-chi и BAP049-chi-Y и гуманизированные mAb BAP049-hum01 - BAP049-hum16 и BAP049-Clone-A - BAP049-Clone-E. Показаны аминокислотные и нуклеотидные последовательности CDR тяжелых и легких цепей, вариабельных областей тяжелых и легких цепей, а также тяжелых и легких цепей.
Таблица С. Аминокислотные и нуклеотидные последовательности каркасных участков тяжелой и легкой цепей гуманизированных анти-PD-1 mAb BAP049-hum01 - BAP049-hum16 и BAP049-Clone-A - BAP049-Clone-E
(тип a)
GAAGTGCAGCTGGTGCAGTCTGGCGCCGAAGTGAAGAAGCCTGGCGAGTCCCTGCGGATCTCCTGCAAGGGCTCT (SEQ ID NO: 149)
GAGGTGCAGCTGGTGCAGTCAGGCGCCGAAGTGAAGAAGCCCGGCGAGTCACTGAGAATTAGCTGTAAAGGTTCA (SEQ ID NO: 150)
(тип b)
(тип a)
(SEQ ID NO: 153)
TGGGTGCGACAGGCTACCGGCCAGGGCCTGGAATGGATGGGC (SEQ ID NO: 155)
tgggtccgccaggctaccggtcaaggcctcgagtggatgggt (SEQ ID NO: 156)
(тип b)
(SEQ ID NO: 157)
TGGATCCGGCAGTCCCCCTCTAGGGGCCTGGAATGGCTGGGC (SEQ ID NO: 159)
(тип c)
(SEQ ID NO: 160)
(тип a)
AGAGTGACCATCACCGCCGACAAGTCCACCTCCACCGCCTACATGGAACTGTCCTCCCTGAGATCCGAGGACACCGCCGTGTACTACTGCACCCGG (SEQ ID NO: 164)
AGAGTGACTATCACCGCCGATAAGTCTACTAGCACCGCCTATATGGAACTGTCTAGCCTGAGATCAGAGGACACCGCCGTCTACTACTGCACTAGG (SEQ ID NO: 165)
(тип b)
AGGTTCACCATCTCCCGGGACAACTCCAAGAACACCCTGTACCTGCAGATGAACTCCCTGCGGGCCGAGGACACCGCCGTGTACTACTGTACCAGA (SEQ ID NO: 168)
(SEQ ID NO: 169)
TGGGGCCAGGGCACCACAGTGACCGTGTCCTCT (SEQ ID NO: 171)
TGGGGTCAAGGCACTACCGTGACCGTGTCTAGC (SEQ ID NO: 172)
TGGGGCCAGGGCACAACAGTGACCGTGTCCTCC (SEQ ID NO: 173)
(тип a)
GAGATCGTGCTGACCCAGTCCCCCGACTTCCAGTCCGTGACCCCCAAAGAAAAAGTGACCATCACATGC (SEQ ID NO: 176)
(тип b)
(SEQ ID NO: 177)
GAGATCGTGCTGACCCAGTCCCCTGCCACCCTGTCACTGTCTCCAGGCGAGAGAGCTACCCTGTCCTGC (SEQ ID NO: 179)
Gagatcgtcctgactcagtcacccgctaccctgagcctgagccctggcgagcgggctacactgagctgt (SEQ ID NO: 180)
(тип c)
(тип d)
(тип e)
(тип a)
(SEQ ID NO: 187)
TGGTATCAGCAGAAGCCCGGCCAGGCCCCCAGACTGCTGATCTAC (SEQ ID NO: 189)
tggtatcagcagaagcccggtcaagcccctagactgctgatctac (SEQ ID NO: 190)
(тип b)
(SEQ ID NO: 191)
tggtatcagcagaagcccggtaaagcccctaagctgctgatctac (SEQ ID NO: 193)
(тип c)
(SEQ ID NO: 194)
(тип a)
GGCGTGCCCTCTAGATTCTCCGGCTCCGGCTCTGGCACCGACTTTACCTTCACCATCTCCAGCCTGGAAGCCGAGGACGCCGCCACCTACTACTGC (SEQ ID NO: 198)
GGCGTGCCCTCTAGGTTTAGCGGTAGCGGTAGTGGCACCGACTTCACCTTCACTATCTCTAGCCTGGAAGCCGAGGACGCCGCTACCTACTACTGT (SEQ ID NO: 199)
(тип b)
(тип c)
GGCGTGCCCTCTAGATTCTCCGGCTCCGGCTCTGGCACCGAGTTTACCCTGACCATCTCCAGCCTGCAGCCCGACGACTTCGCCACCTACTACTGC (SEQ ID NO: 204)
(тип d)
ggcgtgccctctaggtttagcggtagcggtagtggcaccgacttcaccttcactatctctagcctgcagcccgaggatatcgctacctactactgt (seq id no: 207)
TTCGGCCAGGGCACCAAGGTGGAAATCAAG (SEQ ID NO: 210)
ttcggtcaaggcactaaggtcgagattaag (SEQ ID NO: 211)
Таблица D. Аминокислотные последовательности константной области тяжелой цепи IgG человека и легкой цепи каппа человека.
ASTKGPSVFP LAPCSRSTSE STAALGCLVK DYFPEPVTVS WNSGALTSGV HTFPAVLQSS GLYSLSSVVT VPSSSLGTKT YTCNVDHKPS NTKVDKRVES KYGPPCPPCP APEFLGGPSV FLFPPKPKDT LMISRTPEVT CVVVDVSQED PEVQFNWYVD GVEVHNAKTK PREEQFNSTY RVVSVLTVLH QDWLNGKEYK CKVSNKGLPS SIEKTISKAK GQPREPQVYT LPPSQEEMTK NQVSLTCLVK GFYPSDIAVE WESNGQPENN YKTTPPVLDS DGSFFLYSRL TVDKSRWQEG NVFSCSVMHE ALHNHYTQKS LSLSLGK (SEQ ID NO: 212)
RTVAAPSVFI FPPSDEQLKS GTASVVCLLN NFYPREAKVQ WKVDNALQSG NSQESVTEQD SKDSTYSLSS TLTLSKADYE KHKVYACEVT HQGLSSPVTK
SFNRGEC (SEQ ID NO: 213)
ASTKGPSVFP LAPCSRSTSE STAALGCLVK DYFPEPVTVS WNSGALTSGV HTFPAVLQSS GLYSLSSVVT VPSSSLGTKT YTCNVDHKPS NTKVDKRVES KYGPPCPPCP APEFLGGPSV FLFPPKPKDT LMISRTPEVT CVVVDVSQED PEVQFNWYVD GVEVHNAKTK PREEQFNSTY RVVSVLTVLH QDWLNGKEYK CKVSNKGLPS SIEKTISKAK GQPREPQVYT LPPSQEEMTK NQVSLTCLVK GFYPSDIAVE WESNGQPENN YKTTPPVLDS DGSFFLYSRL TVDKSRWQEG NVFSCSVMHE ALHNHYTQKS LSLSLG (SEQ ID NO: 214)
ASTKGPSVFP LAPSSKSTSG GTAALGCLVK DYFPEPVTVS WNSGALTSGV HTFPAVLQSS GLYSLSSVVT VPSSSLGTQT YICNVNHKPS NTKVDKRVEP KSCDKTHTCP PCPAPELLGG PSVFLFPPKP KDTLMISRTP EVTCVVVDVS HEDPEVKFNW YVDGVEVHNA KTKPREEQYN STYRVVSVLT VLHQDWLNGK EYKCKVSNKA LPAPIEKTIS KAKGQPREPQ VYTLPPSREE MTKNQVSLTC LVKGFYPSDI AVEWESNGQP ENNYKTTPPV LDSDGSFFLY SKLTVDKSRW QQGNVFSCSV MHEALHNHYT QKSLSLSPGK (SEQ ID NO: 215)
ASTKGPSVFP LAPSSKSTSG GTAALGCLVK DYFPEPVTVS WNSGALTSGV HTFPAVLQSS GLYSLSSVVT VPSSSLGTQT YICNVNHKPS NTKVDKRVEP KSCDKTHTCP PCPAPELLGG PSVFLFPPKP KDTLMISRTP EVTCVVVDVS HEDPEVKFNW YVDGVEVHNA KTKPREEQYA STYRVVSVLT VLHQDWLNGK EYKCKVSNKA LPAPIEKTIS KAKGQPREPQ VYTLPPSREE MTKNQVSLTC LVKGFYPSDI AVEWESNGQP ENNYKTTPPV LDSDGSFFLY SKLTVDKSRW
QQGNVFSCSV MHEALHNHYT QKSLSLSPGK (SEQ ID NO: 216)
ASTKGPSVFP LAPSSKSTSG GTAALGCLVK DYFPEPVTVS WNSGALTSGV HTFPAVLQSS GLYSLSSVVT VPSSSLGTQT YICNVNHKPS NTKVDKRVEP KSCDKTHTCP PCPAPELLGG PSVFLFPPKP KDTLMISRTP EVTCVVVAVS HEDPEVKFNW YVDGVEVHNA KTKPREEQYN STYRVVSVLT VLHQDWLNGK EYKCKVSNKA LAAPIEKTIS KAKGQPREPQ VYTLPPSREE MTKNQVSLTC LVKGFYPSDI AVEWESNGQP ENNYKTTPPV LDSDGSFFLY SKLTVDKSRW QQGNVFSCSV MHEALHNHYT QKSLSLSPGK (SEQ ID NO: 217)
ASTKGPSVFP LAPSSKSTSG GTAALGCLVK DYFPEPVTVS WNSGALTSGV HTFPAVLQSS GLYSLSSVVT VPSSSLGTQT YICNVNHKPS NTKVDKRVEP KSCDKTHTCP PCPAPEAAGG PSVFLFPPKP KDTLMISRTP EVTCVVVDVS HEDPEVKFNW YVDGVEVHNA KTKPREEQYN STYRVVSVLT VLHQDWLNGK EYKCKVSNKA LPAPIEKTIS KAKGQPREPQ VYTLPPSREE MTKNQVSLTC LVKGFYPSDI AVEWESNGQP ENNYKTTPPV LDSDGSFFLY SKLTVDKSRW QQGNVFSCSV MHEALHNHYT QKSLSLSPGK (SEQ ID NO: 218)
Терапевтические наборы
В одном из варианте осуществления изобретение относится к набору, содержащему две или более отдельные фармацевтические композиции, по меньшей мере одна из которых содержит соединение формулы (I). В одном из варианте осуществления набор содержит средства для раздельного содержания указанных композиций, такие как контейнер, разделенный флакон или разделенный пакет из фольги. Примером такого набора является блистерная упаковка, которая обычно используется для упаковки таблеток, капсул и т.п.
Набор по изобретению может быть использован для введения различных дозированных форм, например для перорального и парентерального введения, для введения отдельных композиций с различными интервалами дозирования или для титрования отдельных композиций относительно другой. Для соблюдения режима приема лекарственного средства набор по изобретению обычно содержит инструкции по введению.
В случае комбинированной терапии по изобретению соединение формулы I и другой иммунотерапевтический агент могут быть изготовлены и/или составлены одним тем же или разными производителями. Кроме того, соединение по изобретению и другое терапевтическое средство могут быть объединены в комбинированной терапии: (i) до применения комбинированного продукта врачом (например, в случае набора, содержащего соединение по изобретению и другой терапевтический агент); (ii) самим врачом (или под руководством врача) незадолго перед введением; (iii) в организме самого пациента, например, при последовательном введении соединения по изобретению и другого терапевтического агента.
Соответственно, настоящее изобретение относится к применению соединения формулы (I) для лечения рака, при котором лекарственное средство готово для введения с другим иммунотерапевтическим агентом. Изобретение также относится к применению иммунотерапевтического агента для лечения рака, где лекарственное средство вводят с соединением формулы (I).
Изобретение также относится к соединению формулы (I) для применения в способе лечения рака, где соединение формулы (I) получают для введения с другим иммунотерапевтическим агентом. Изобретение также относится к другому иммунотерапевтическому агенту для применения в способе лечения рака, где другой иммунотерапевтический агент готовят для введения с соединением формулы (I). Изобретение также относится к соединению формулы (I) для применения в способе лечения рака, где соединение формулы (I) вводят с другим иммунотерапевтическим агентом. Изобретение также относится к другому иммунотерапевтическому агенту для применения в способе лечения рака, где другой терапевтический агент вводят с соединением формулы (I).
Изобретение также относится к применению соединения формулы (I) для лечения рака, в котором пациент ранее (например, в течение 24 часов) получал лечение другим иммунотерапевтическим агентом. Изобретение также относится к применению другого иммунотерапевтического агента для лечения рака, в котором пациент ранее (например, в течение 24 часов) получал лечение соединением формулы (I).
Фармацевтическая композиция, комбинация, дозирование и введение
В одном из вариантов осуществления фармацевтическая композиция содержит эффективное количество соединения формулы (I) или его фармацевтически приемлемую соль или сокристалл и фармацевтически приемлемую несущую среду или носитель.
В другом варианте осуществления изобретение относится к фармацевтической комбинации, содержащей терапевтически приемлемое количество соединения формулы (I) или его фармацевтически приемлемой соли и один или более иммунотерапевтически активных агентов, для изготовления лекарственного средства для лечения рака.
В одном из вариантов осуществления композиция содержит, по меньшей мере, два фармацевтически приемлемых носителя, таких как описаны в настоящей заявке. Предпочтительно, фармацевтически приемлемые носители являются стерильными. Фармацевтическая композиция может быть составлена для конкретных способов введения, таких как пероральное введение, парентеральное введение и ректальное введение, внутривенное введение и т.д. Кроме того, фармацевтические композиции по настоящему изобретению могут быть приготовлены в твердой форме (включая, без ограничений, капсулы, таблетки, пилюли, гранулы, порошки или свечи) или в жидкой форме (включая, без ограничений, растворы, суспензии или эмульсии). Фармацевтические композиции могут быть подвергнуты обычным фармацевтическим операциям, таким как стерилизация, и/или могут содержать обычные инертные разбавители, смазывающие агенты или буферные агенты, а также вспомогательные вещества, такие как консерванты, стабилизаторы, смачивающие агенты, эмульгаторы и буферы и т.д.
Как правило, фармацевтические композиции представляют собой таблетки или желатиновые капсулы, содержащие активный ингредиент вместе с одним или более из:
а) разбавителей, например лактозы, декстрозы, сахарозы, маннита, сорбита, целлюлозы и/или глицина;
b) смазывающих агентов, например диоксида кремния, талька, стеариновой кислоты, ее магниевой или кальциевой соли и/или полиэтиленгликоля; для таблеток также
с) связующих веществ, например магний-алюминий силиката, крахмальной пасты, желатина, трагаканта, метилцеллюлозы, карбоксиметилцеллюлозы натрия и/или поливинилпирролидона; при необходимости
d) разрыхлителей, например крахмала, агара, альгиновой кислоты или ее натриевой соли или шипучих смесей; а также
e) абсорбентов, красителей, ароматизаторов и подсластителей.
Таблетки могут быть покрыты пленкой или энтеросолюбильным покрытием в соответствии с любым способом, известным в данной области техники.
Подходящие композиции для перорального введения включают эффективное количество соединения по изобретению в форме таблеток, лепешек, водных или масляных суспензий, диспергируемых порошков или гранул, эмульсии, твердых или мягких капсул или сиропов, или эликсиров. Композиции, предназначенные для перорального применения, получают в соответствии с любым способом, известным в данной области техники для изготовления фармацевтических композиций, и такие композиции могут содержать один или более агентов, выбранных из группы, состоящей из подсластителей, ароматизаторов, красителей и консервантов, для обеспечения фармацевтических препаратов с особыми приятными вкусовыми качествами. Таблетки могут содержать активный ингредиент в смеси с нетоксичными фармацевтически приемлемыми наполнителями, которые пригодны для изготовления таблеток. Такие наполнители представляют собой, например, инертные разбавители, такие как карбонат кальция, карбонат натрия, лактоза, фосфат кальция или фосфат натрия; гранулирующие агенты и разрыхлители, например кукурузный крахмал или альгиновая кислота; связывающие вещества, например крахмал, желатин или аравийская камедь; и смазывающие агенты, например стеарат магния, стеариновая кислота или тальк. Таблетки не покрыты оболочкой или покрыты оболочкой известными способами для задержки распада и абсорбции в желудочно-кишечном тракте, таким образом, обеспечивая пролонгированное действие в течение более длительного периода времени. Например, можно использовать материал, обеспечивающий временную задержку, такой как глицерилмоностеарат или глицерилдистеарат. Препараты для перорального применения могут быть представлены в виде твердых желатиновых капсул, в которых активный ингредиент смешивают с инертным твердым разбавителем, например карбонатом кальция, фосфатом кальция или каолином, или в виде мягких желатиновых капсул, в которых активный ингредиент смешивают с водой или маслом например, арахисовым маслом, жидким парафином или оливковым маслом.
Некоторые инъецируемые композиции представляют собой водные изотонические растворы или суспензии, а свечи преимущественно получают из жирных эмульсий или суспензий. Указанные композиции могут быть стерилизованы и/или содержать вспомогательные вещества, такие как консерванты, стабилизаторы, смачивающие или эмульгирующие агенты, промоторы растворов, соли для регулирования осмотического давления и/или буферы. Кроме того, они могут также содержать другие терапевтически ценные вещества. Указанные композиции получают в соответствии с обычными способами смешивания, гранулирования или нанесения покрытия, соответственно, и содержат примерно 0,1-75% или примерно 1-50% активного ингредиента.
В предпочтительном варианте осуществления соединение формулы (I) или его фармацевтически приемлемая соль или сокристаллы для применения в лечении рака предназначены для введения парентеральным или пероральным способом, предпочтительно пероральным способом.
Фармацевтическая композиция или комбинация по настоящему изобретению может находиться в стандартной дозированной форме, содержащей примерно 1-1000 мг активного ингредиента(ов) из расчета введения субъекту массой примерно 50-70 кг, или примерно 1-650 мг или примерно 1-350 мг или примерно 1-200 мг активных ингредиентов. Терапевтически эффективная доза соединения, фармацевтической композиции или их комбинаций зависит от вида субъекта, массы тела, возраста и состояния субъекта, расстройства или заболевания или его тяжести. Врач, клиницист или ветеринар, обладающий обычными навыками в данной области, может легко определить эффективное количество каждого из активных ингредиентов, необходимых для профилактики, лечения или подавления прогрессирования расстройства или заболевания.
Вышеуказанные свойства дозированных форм продемонстрированы с помощью in vitro и in vivo тестов с использованием преимущественно млекопитающих, например мышей, крыс, собак, обезьян, или изолированных органов, тканей и их препаратов. Соединения по настоящему изобретению (соединение формулы I) могут быть применены in vitro в виде растворов, например водных растворов, и in vivo либо энтерально, парентерально, преимущественно внутривенно, например в виде суспензии, либо в виде водного раствора. Доза для in vitro применения может иметь концентрацию в пределах от 10-3 до 10-9 мол. Терапевтически эффективное количество для in vivo применения может варьировать в зависимости от способа введения в пределах от примерно 0,1 до 500 мг/кг или от примерно 1 до 100 мг/кг или от 1 до 10 мг/кг. В определенном варианте осуществления соединение формулы I вводят перорально в дозе примерно от 1 до 30 мг/кг, например, примерно от 1 до 25 мг/кг, примерно от 1 до 20 мг/кг, примерно от 1 до 6 мг/кг. Режим дозирования может варьировать, например, от одного до двух раз в день. В одном из вариантов осуществления соединение формулы I вводят в дозе примерно 80 мг, 160 мг, 320 мг или 640 мг два раза в день из расчета введения субъекту массой примерно 50-70 кг.
Дозирование и введение иммунотерапевтического агента
Иммунотерапевтический агент (такой как молекулу анти-PD-1 антитела или анти-PD-L1 антитела) можно вводить субъекту системно (например, перорально, парентерально, подкожно, внутривенно, ректально, внутримышечно, внутрибрюшинно, интраназально, трансдермально или путем ингаляции или с помощью внутриполостного импланта), локально или путем нанесения на слизистые оболочки, например, носа, горла и бронхов.
Специалисты могут определить дозы и терапевтические режимы введения для иммунотерапевтического агента (молекулы анти-PD-1 антитела или молекулы анти-PD-L1 антитела). В некоторых вариантах осуществления иммунотерапевтический агент (например, молекулу анти-PD-1 антитела) вводят путем инъекции (например, подкожной или внутривенной) в дозе от примерно 1 до 30 мг/кг, например, от примерно 5 до 25 мг/кг, от примерно 10 до 20 мг/кг, от примерно 1 до 5 мг/кг или примерно 3 мг/кг. Режим дозирования может варьировать, например, от одного раза в неделю до одного раза в 2, 3 или 4 недели. В одном из вариантов осуществления молекулу анти-PD-1 антитела вводят еженедельно в дозе от примерно 10 до 20 мг/кг. В другом варианте осуществления молекулу анти-PD-1 антитела вводят в дозе от 1 до 10 мг/кг или от примерно 1 до 5 мг/кг или примерно 3 мг/кг каждые 4 недели.
Например, молекулу анти-PD-1 антитела вводят или используют в базовой или фиксированной дозе. В некоторых вариантах осуществления молекулу анти-PD-1 антитела вводят путем инъекции (например, подкожной или внутривенной) в дозе (например, базовой дозе) от примерно 200 до 500 мг, например, от примерно 250 до 450 мг, от примерно 300 до 400 мг, от примерно 250 до 350 мг, от примерно 350 до 450 мг или примерно 300 мг, или примерно 400 мг. Режим дозирования (например, режим введения базовой дозы) может варьировать от, например, одного раза в неделю до одного раза каждые 2, 3, 4, 5 или 6 недель. В одном из вариантов осуществления молекулу анти-PD-1 антитела вводят в дозе от примерно 300 до 400 мг один раз каждые три недели или один раз в четыре недели. В одном из вариантов осуществления молекулу анти-PD-1 антитела вводят в дозе примерно 300 мг один раз в три недели. В одном из вариантов осуществления молекулу анти-PD-1 антитела вводят в дозе примерно 400 мг один раз в четыре недели. В одном из вариантов осуществления молекулу анти-PD-1 антитела вводят в дозе примерно 300 мг один раз в четыре недели. В одном из вариантов осуществления молекулу анти-PD-1 антитела вводят в дозе примерно 400 мг один раз в три недели.
В другом варианте осуществления молекулу анти-PD-1 антитела вводят в базовой дозе от примерно 300 до 400 мг один раз каждые три недели или один раз в четыре недели. В подмножестве этого варианта осуществления молекулу анти-PD-1 антитела вводят в базовой дозе примерно 400 мг каждые четыре недели. В еще одном подмножестве этого варианта осуществления молекулу анти-PD-1 антитела вводят в базовой дозе примерно 300 мг каждые три недели.
В одном из вариантов осуществления настоящего изобретения соединение формулы (I), его фармацевтически приемлемые соли или сокристаллы и иммунотерапевтические агенты, полезные для лечения рака, являются частями одной и той же композиции.
В другом варианте осуществления настоящего изобретения соединение формулы (I), его фармацевтически приемлемые соли или сокристаллы и иммунотерапевтические агенты, полезные для лечения рака, являются частями отдельных композиций, предназначенных для введения одновременно или последовательно.
В одном из вариантов осуществления соединение формулы I можно вводить либо одновременно, либо до, либо после одного или более иммунотерапевтических агентов (например, анти-CTLA4 антитела, анти-PD-1 антитела и анти-PD-L1 антитела). Соединение формулы I можно вводить отдельно таким же или другим способом введения или вместе в одной фармацевтической композиции с иммунотерапевтическими агентами. Предпочтительным иммунотерапевтическим агентом является, например, антитело, которое является терапевтически активным, или терапевтическая активность которого усиливается при его введении пациенту в комбинации с соединением формулы I.
В еще одном варианте осуществления соединение формулы (I) и иммунотерапевтический агент можно вводить одновременно или последовательно в любом порядке. Можно использовать любую комбинацию и последовательность введения соединения формулы (I) и иммунотерапевтического агента (например, как описано в настоящей заявке). Соединение формулы (I) и/или иммунотерапевтический агент можно вводить в периоды активного проявления расстройства или в период ремиссии или в периоды, когда заболевание проявляется менее активно. Иммунотерапевтический агент можно вводить перед лечением соединением формулы (I), одновременно с этим лечением, после него или во время ремиссии расстройства.
В предпочтительном варианте осуществления соединение формулы I вводят (натощак) два раза в день перед введением иммунотерапевтического агента (например, молекулы анти-PD-1 антитела, описанного в настоящей заявке).
В одном из вариантов осуществления изобретение относится к продукту, содержащему соединение формулы (I) и по меньшей мере еще один иммунотерапевтический агент, в виде комбинированного препарата для одновременного, раздельного или последовательного применения в терапии. В одном из вариантов осуществления терапия представляет собой лечение заболевания или состояния, опосредованного рецептором А2а. Продукты, представленные в виде комбинированного препарата, включают композицию, содержащую соединение формулы (I), и иммунотерапевтический агент(ы), находящиеся в одной и той же фармацевтической композиции, или соединение формулы (I) и другой терапевтический агент(ы) (например, анти-CTLA4 антитела, анти-PD-1 антитела и анти-PD-L1 антитела в отдельной форме), например, в виде набора.
В одном из вариантов осуществления изобретение относится к фармацевтической композиции, содержащей соединение формулы (I) и иммунотерапевтический агент(ы) (например, анти-CTLA4 антитело, анти-PD-1 антитело и анти-PD-L1 антитело). Необязательно, фармацевтическая композиция может содержать фармацевтически приемлемый носитель, описанный выше.
Ниже описаны варианты осуществления изобретения:
1 - Соединение формулы (I):
(I)
или его фармацевтически приемлемая соль или сокристалл для применения в лечении рака.
2 - Соединение для применения в соответствии с вариантом осуществления 1, где рак представляет собой рак легких.
3 - Соединение для применения в соответствии с вариантом осуществления 2, где рак легких представляет собой немелкоклеточный рак легких.
4 - Соединение для применения в соответствии с любым из вариантов осуществления 1-3, где указанное соединение вводят парентеральным или пероральным способом.
5 - Соединение для применения в соответствии с вариантом осуществления 4, где указанное соединение вводят пероральным способом.
6 - Комбинированный продукт, содержащий терапевтически эффективное количество соединения формулы (I) или его фармацевтически приемлемую соль или сокристалл и один или более иммунотерапевтических агентов, выбранных из группы, состоящей из анти-CTLA4 антитела, анти-PD-1 антитела и анти-PD-L1 антитела.
7 - Комбинация, как определено в варианте осуществления 6, для применения в лечении рака.
8 - Комбинация для применения в соответствии с вариантом осуществления 7, где рак представляет собой рак легких.
9 - Комбинация для применения в соответствии с вариантом осуществления 8, где рак легких представляет собой рак немелкоклеточный рак легких.
10 - Комбинация для применения в соответствии с любым из вариантов осуществления 6-9, где иммунотерапевтический агент выбирают из группы, состоящей из ипилимумаба, тремелимумаба, ниволумаба, пембролизумаба, CT-011, AMP-224, MPDL3280A, MEDI4736 и MDX-1105.
11 - Комбинация для применения в соответствии с вариантом осуществления 10, где иммунотерапевтический агент выбирают из группы, состоящей из MPDL3280A, MEDI4736 и MDX-1105.
12 - Комбинация для применения в соответствии с вариантом осуществления 10, где иммунотерапевтический агент выбирают из группы, состоящей из ниволумаба, пембролизумаба, пидилизумаба и AMP-224.
13 - Комбинация для применения в соответствии с вариантом осуществления 6, где иммунотерапевтическим агентом является анти-PD-1 антитело.
14 - Комбинация для применения в соответствии с вариантом осуществления 13, где анти-PD-1 антитело содержит:
(а) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 4, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33;
(b) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 1; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32;
(с) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33; или
(d) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32,
15 - Комбинацию для применения в соответствии с вариантом осуществления 13, где анти-PD-1 антитело содержит:
(а) вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность SEQ ID NO: 91, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность SEQ ID NO: 72.
16 - Комбинация для применения в соответствии с любым из вариантов осуществления 13-15, где молекулу анти-PD-1 антитела вводят в дозе примерно 300 мг один раз в три недели
17 - Комбинация для применения в соответствии с любым из вариантов осуществления 13-15, где молекулу анти-PD-1 антитела вводят в дозе примерно 400 мг один раз в четыре недели.
18 - Комбинация для применения в соответствии с вариантом осуществления 6, где иммунотерапевтический агент представляет собой анти-PD-L1 антитело.
19 - Комбинация для применения в соответствии с вариантом осуществления 18, где молекула анти-PD-L1 антитела содержит:
(а) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 228, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 229, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 233, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 234, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 235;
(b) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 225; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 226; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 230, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 231, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 232;
(с) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 244; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 229; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 233, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 234, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 235; или
(d) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 244; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 226; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 230, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 231, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 232.
20 - Комбинация для применения в соответствии с вариантом осуществления 18, где молекула анти-PD-L1 антитела содержит вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность SEQ ID NO: 236 и вариабельный домен легкой цепи, содержащий аминокислотную последовательность SEQ ID NO: 239.
21 - Фармацевтическая композиция, содержащая соединение формулы (I) или его фармацевтически приемлемую соль или сокристалл и фармацевтически приемлемую несущую среду или носитель для применения в лечении рака.
22 - Композиция для применения в соответствии с вариантом осуществления 21, где рак представляет собой рак легких.
23 - Композиция для применения в соответствии с вариантом осуществления 22, где рак легких представляет собой немелкоклеточный рак легких.
24 - Применение соединения формулы (I)
(I)
или его фармацевтически приемлемой соли или сокристалла для изготовления лекарственного средства для лечения рака.
25 - Применение в соответствии с вариантом осуществления 24, где рак представляет собой рак легких.
26 - Применение в соответствии с вариантом осуществления 25, где рак легких представляет собой немелкоклеточный рак легких.
27 - Применение в соответствии с любым из вариантов осуществления 24-26, где указанное соединение вводят парентеральным или пероральным способом.
28 - Применение в соответствии с вариантом осуществления 27, где указанное соединение вводят пероральным способом.
29 - Применение комбинированного продукта, включающего терапевтически эффективное количество соединения формулы (I) или его фармацевтически приемлемой соли или сокристалла и одного или более иммунотерапевтических агентов, выбранных из группы, состоящей из анти-CTLA4 антитела, анти-PD-1 антитела и анти-PD-L1 антитела, для изготовления лекарственного средства для лечения рака.
30 - Применение в соответствии с вариантом осуществления 29, где рак представляет собой рак легких.
31 - Применение в соответствии с вариантом осуществления 30, где рак легких представляет собой немелкоклеточный рак легких.
32 - Применение в соответствии с любым из вариантов осуществления 29-31, где иммунотерапевтический агент выбирают из группы, состоящей из ипилимумаба, тремелимумаба, ниволумаба, пембролизумаба, CT-011, AMP-224, MPDL3280A, MEDI4736 и MDX-1105.
33 - Применение в соответствии с вариантом осуществления 32, где иммунотерапевтический агент выбирают из группы, состоящей из MPDL3280A, MEDI4736 и MDX-1105.
34 - Применение в соответствии с вариантом осуществления 32, где иммунотерапевтический агент выбирают из группы, состоящей из ниволумаба, пембролизумаба, пидилизумаба и AMP-224.
35 - Применение в соответствии с вариантом осуществления 29, где иммунотерапевтический агент представляет собой анти-PD-1 антитело.
36 - Применение в соответствии с вариантом осуществления 35, где анти-PD-1 антитело содержит:
(а) вариабельную оюласть тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 4, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33;
(b) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 1; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32;
(с) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33; или
(d) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32.
37 - Применение в соответствии с вариантом осуществления 35, где анти-PD-1 антитело содержит:
(а) вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность SEQ ID NO: 91, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность SEQ ID NO: 72.
38 - Применение по любому из вариантов осуществления 35-37, где молекулу анти-PD-1 антитела вводят в дозе примерно 300 мг один раз в три недели.
39 - Применение по любому из вариантов осуществления 35-37, где молекулу анти-PD-1 антитела вводят в дозе примерно 400 мг один раз каждые четыре недели.
40 - Применение в соответствии с вариантом осуществления 29, где иммунотерапевтический агент представляет собой анти-PD-L1 антитело.
41 - Применение в соответствии с вариантом осуществления 40, где молекула анти-PD-L1 антитела содержит:
(а) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 228, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 229, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 233, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 234, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 235;
(b) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 225; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 226; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 230, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 231, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 232;
(с) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 244; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 229; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 233, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 234, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 235; или
(d) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 244; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 226; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 230, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 231, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 232.
42 - Применение в соответствии с вариантом 40, в котором молекула анти-PD-L1 антитела содержит вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность SEQ ID NO: 236 и вариабельный домен легкой цепи, содержащий аминокислотную последовательность SEQ ID NO: 239.
43 - Комбинация для применения в соответствии с любым из вариантов осуществления 6-20 или применение комбинации в соответствии с любым из вариантов осуществления 29-42, где комбинацию иммунотерапевтического агента вводят вместе в виде одной композиции или вводят отдельно в двух или более разных формах композиций.
44 - Комбинация для применения в соответствии с любым из вариантов осуществления 6-20 или применение комбинации в соответствии с любым из вариантов осуществления 29-42, где иммунотерапевтический агент вводят одновременно, до или после соединения формулы (I).
Примеры
Соединение формулы (I) по настоящему изобретению может быть получено с помощью процедуры, раскрытой в заявке на патент WO 2011/121418 A1, которая включена в настоящую заявку посредством ссылки. Конкретные соединения, используемые в описанных ниже анализах, представляют собой:
- Соединение формулы (I) по настоящему изобретению, пример 1 в WO 2011/121418 A1: 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амин.
- Соединение А по настоящему изобретению, пример 46 в WO 2011/121418 A1: 5-хлор-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амин.
- Соединение B по настоящему изобретению, пример 48 в WO 2011/121418 A1: 4-амино-2,6-ди-(1Н-пиразол-1-ил)пиримидин-5-карбонитрил.
Как описано в заявке на патент WO 2011/121418 A1, указанные соединения имеют следующую аффинность связывания с аденозиновым рецептором hA2A.
1 - Противоопухолевая активность соединения формулы (I) у мышей
Самок мышей дикого типа C57Bl/6 приобретали в компании Charles River и содержали в центре реабилитации центрального госпиталя в Монреале (Centre de Recherche du Centre Hospitalier de l'Université de Montréal). Все эксперименты проводили в соответствии с руководящими принципами, изложенными Комитетом по экспериментальной этике животных. Сингенным мышам C57B1/6 инъецировали (i) 3×105 опухолевых клеток B16-CD73+ внутривенно и ежедневно обрабатывали в течение 15 дней 15 мг/кг/день несущей средой в качестве контроля или соединением формулы (I) через желудочный зонд или (ii) 2×105 опухолевых клеток MCA205 внутривенно и обрабатывали ежедневно в течение 7 дней 30 мг/кг/день несущей средой в качестве контроля или соединением формулы (I) через желудочный зонд. Несущая среда состояла из 0,1% Твин 80 и 0,5% натрий карбоксиметилцеллюлозы (NaCMC) в воде. Мышей подвергали эвтаназии на 15-й день, брали легкие, и с помощью препаровальной лупы подсчитывали узлы опухоли.
Как показано на фиг.1а, пероральное введение соединения формулы (I) в значительной степени уменьшает опухолевую массу (узлы и метастазы в легких) у мышей, которым были внутривенно введены опухолевые клетки B16-CD73+ или MCA205.
Пероральное введение соединений А и В (оба соединения в количестве 30 мг/кг/день) в аналогичных условиях на фармацевтическом факультете в университете Барселоны не привело к значительному сокращению количества узлов в легких, как показано на фиг.1b и 1c.
2 - Ex-vivo изучение эффективности соединения формулы (I) отдельно и в комбинации с анти-PD-1 и анти-PDL-1 антителами в эксплантатах опухоли легких человека, полученных от пациентов
Ex-vivo исследование проводили, используя непосредственно резистентные опухоли легких человека. Свежерезецированные опухоли NSCLC получали через Tissue Core в цетре Moffitt Cancer. Опухоль дезагрегировали в течение 2 часов в растворе коллагеназы/ДНКазы в присутствии полного коктейля ингибиторов протеаз (Roche). Подсчитывали общее количество клеток (Tu). 200 000 клеток/лунка инкубировали в течение 3 дней и стимулировали IL-2 (6000 единиц/мл), соединением формулы (I) (1 мкМ), соединением A (1 мкМ), соединением B (1 мкМ), анти-PD-L1 антителом (10 мг/мл), анти-PD-1 антителом (10 мг/мл) или комбинацией соединения формулы (I) с анти-PD-L1 антителом (человеческое моноклональное антитело к рецептору PD-L1, функционально активное, очищенное, 100 мкг, приобретенное у компании eBioscience, № 16-5983-82) (10 мг/мл) и анти-PD-1 антителом (человеческое моноклональное антитело к рецептору PD-1, функционально активное, очищенное, 100 мкг, приобретенное у компании eBioscience, № 16-9989-82) (10 мг/мл), соответственно. IL-2 использовался в некоторых экспериментах для стимуляции продуцирования IFN-γ в этих опухолевых клетках с высокой степенью резистентности. Как и ожидалось, без обработки или при добавлении небольшого количества IL-2 Т-клетки проявляли небольшую активность. Добавление либо анти-PD-L1, либо соединения формулы (I) частично восстанавливало реактивность TIL (определенную по измерению концентрации IFNg) в некоторых образцах, а комбинация к тому же улучшала функцию TIL (измеренную по концентрации IFNg). IFNg (IFN-γ ELISA R&D Systems) определяли как показатель реактивности Т-клеток к аутологичным опухолевым клеткам. Результаты показаны на фиг. 2-7.
В других опухолях добавление либо анти-PD-L1, либо соединения формулы (I) не влияло на функцию TIL (измеренную по концентрации IFNg), но комбинация показала синергетическую активность в отношении восстановления функции TIL.
Соединения А и В тестировали в аналогичных экспериментальных условиях, за исключением того, что свежерезерцированные опухоли NSCLC получали из клиники (Hospital Clínico) в Барселоне. Оба соединения не увеличили секрецию IFNg в опухолевых клетках, ни в случае их применения отдельно, ни в комбинации с анти-PD-L1 или анти-PD-1 антителом.
3 - Анализ секреции интерлейкинов в эксплантатах резистентных опухолей легкого человека после обработки соединением формулы (I)
Супернатанты, полученные в ex vivo экспериментах, отбирали для Bioplex-анализа для измерения концентрации различных интерлейкинов. На фиг. 8а-g приведены результаты, полученные в каждом случае.
Соединение формулы (I) позволило в значительной степени увеличить секрецию различных интерлейкинов в среде, в частности, IL5 (интерлейкина 5), IL17 (интерлейкина 17), IL1b (интерлейкина 1b), IL13 (интерлейкина 13), IL10 (интерлейкина 10), фактора некроза опухоли α (TNFα) и MIP1b. Это можно рассматривать как явный сигнал иммунной стимуляции инфильтрирующих лимфоцитов, присутствующих в опухолях.
Комбинация соединения формулы (I) с анти-PDL-1 или анти-PD-1 антителом синергически усиливала секрецию различных интерлейкинов этих опухолей.
4. План исследования, комбинация соединения формулы (I) с анти-PD-1 антителом
Пациентами в этом исследовании могут быть мужчины или женщины в возрасте 18 лет и старше, которые имеют гистологически или цитологически подтвержденный запущенный или метастатический НМРЛ с по меньшей мере одним измеряемым очагом поражения.
Соединение формулы I вводят пациенту перорально два раза в день, натощак в дозе 80 мг, 160 мг, 320 мг или 640 мг в течение всего 28-ми дневного цикла. Анти-PD-1 антитело вводят в дозе примерно 300 мг или примерно 400 мг один раз каждые 3 недели или один раз каждые 4 недели. Анти-PD-1 антитело вводят путем IV инфузии в течение от 30 минут до 2 часов. Соединение формулы I вводят натощак непосредственно перед инфузией анти-PD-1 антитела.
Для определения эффективности проводят оценку исходного состояния как можно ближе к началу лечения и не более чем за 4 недели до начала лечения. Дополнительно к сканированию в исходном состоянии выполняют сканирование через 4-6 недель после первоначального документально подтвержденного объективного ответа с целью получения подтверждающих результатов. Ответ и прогрессирование оценивают в этом исследовании с использованием новых международных критериев, предложенных в соответствии с пересмотренными критериях оценки ответной реакции для солидных опухолей (RECIST) (версия 1.1, Eisenhauer EA, Therasse P, Bogaerts J, et al. New response evaluation criteria in solid tumours: revised RECIST guideline (version 1.1). Eur J Cancer 2009;45:228-47). Используют изменения в наибольшем диаметре (одномерное измерение) опухолевых поражений и в самом коротком диаметре в случае лимфатических узлов, пораженных метастазами (Schwartz LH, Bogaerts J, Ford R, et al. Evaluation of lymph nodes with RECIST 1.1. Eur J Cancer 2009;45:261-7).
Для характеристики каждого идентифицированного и зарегистрированного поражения в исходном состоянии и во время наблюдения используют одни и те же способы оценки и один и тот же метод. Используют оценку на основе полученных изображений, например, методом рентгенографии грудной клетки, обычной КТ и МРТ.
--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> CAMACHO GOMEZ, JUAN ALBERTO
CASTRO-PALOMINO LARIA, JULIO CESAR
BILIC, SANELA
HOWARD, DANNY ROLAND
CAMERON, JOHN SCOTT
<120> 5-БРОМ-2,6-ДИ-(1H-ПИРАЗОЛ-1-ИЛ)ПИРИМИДИН-4-АМИН ДЛЯ ПРИМЕНЕНИЯ В
ЛЕЧЕНИИ РАКА
<130> PAT057215-US-PSP
<140>
<141>
<150> EP 15382425.5
<151> 2015-08-11
<160> 250
<170> PatentIn version 3.5
<210> 1
<211> 5
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 1
Thr Tyr Trp Met His
1 5
<210> 2
<211> 17
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 2
Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe Lys
1 5 10 15
Asn
<210> 3
<211> 8
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 3
Trp Thr Thr Gly Thr Gly Ala Tyr
1 5
<210> 4
<211> 7
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 4
Gly Tyr Thr Phe Thr Thr Tyr
1 5
<210> 5
<211> 6
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 5
Tyr Pro Gly Thr Gly Gly
1 5
<210> 6
<211> 117
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 6
Gln Val Gln Leu Gln Gln Pro Gly Ser Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Thr Ser Leu Thr Val Asp Thr Ser Ser Thr Thr Ala Tyr
65 70 75 80
Met His Leu Ala Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala
115
<210> 7
<211> 351
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 7
caggtccagc tgcagcaacc tgggtctgag ctggtgaggc ctggagcttc agtgaagctg 60
tcctgcaagg cgtctggcta cacattcacc acttactgga tgcactgggt gaggcagagg 120
cctggacaag gccttgagtg gattggaaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaaaaacag gacctcactg actgtagaca catcctccac cacagcctac 240
atgcacctcg ccagcctgac atctgaggac tctgcggtct attactgtac aagatggact 300
actgggacgg gagcttattg gggccaaggg actctggtca ctgtctctgc a 351
<210> 8
<211> 117
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 8
Gln Val Gln Leu Gln Gln Ser Gly Ser Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Thr Ser Leu Thr Val Asp Thr Ser Ser Thr Thr Ala Tyr
65 70 75 80
Met His Leu Ala Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Leu
100 105 110
Val Thr Val Ser Ala
115
<210> 9
<211> 351
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 9
caggtccagc tgcagcagtc tgggtctgag ctggtgaggc ctggagcttc agtgaagctg 60
tcctgcaagg cgtctggcta cacattcacc acttactgga tgcactgggt gaggcagagg 120
cctggacaag gccttgagtg gattggaaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaaaaacag gacctcactg actgtagaca catcctccac cacagcctac 240
atgcacctcg ccagcctgac atctgaggac tctgcggtct attactgtac aagatggact 300
actgggacgg gagcttattg gggccaaggg actctggtca ctgtctctgc a 351
<210> 10
<211> 17
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 10
Lys Ser Ser Gln Ser Leu Leu Asp Ser Gly Asn Gln Lys Asn Phe Leu
1 5 10 15
Thr
<210> 11
<211> 7
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 11
Trp Ala Ser Thr Arg Glu Ser
1 5
<210> 12
<211> 9
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 12
Gln Asn Asp Tyr Ser Tyr Pro Cys Thr
1 5
<210> 13
<211> 13
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 13
Ser Gln Ser Leu Leu Asp Ser Gly Asn Gln Lys Asn Phe
1 5 10
<210> 14
<211> 3
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 14
Trp Ala Ser
1
<210> 15
<211> 6
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 15
Asp Tyr Ser Tyr Pro Cys
1 5
<210> 16
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 16
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Phe Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Val Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Cys Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile
100 105 110
Lys
<210> 17
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 17
gacattgtga tgacccagtc tccatcctcc ctgactgtga cagcaggaga gaaggtcact 60
atgagctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaaccagg gcagcctcct aaactgttga tcttctgggc atccactagg 180
gaatctgggg tccctgatcg cttcacaggc agtggatctg taacagattt cactctcacc 240
atcagcagtg tgcaggctga agacctggca gtttattact gtcagaatga ttatagttat 300
ccgtgcacgt tcggaggggg gaccaagctg gaaataaaa 339
<210> 18
<211> 117
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 18
Gln Val Gln Leu Gln Gln Pro Gly Ser Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Thr Ser Leu Thr Val Asp Thr Ser Ser Thr Thr Ala Tyr
65 70 75 80
Met His Leu Ala Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 19
<211> 351
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 19
caggtccagc tgcagcagcc tgggtctgag ctggtgaggc ctggagcttc agtgaagctg 60
tcctgcaagg cgtctggcta cacattcacc acttactgga tgcactgggt gaggcagagg 120
cctggacaag gccttgagtg gattggaaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaaaaacag gacctcactg actgtagaca catcctccac cacagcctac 240
atgcacctcg ccagcctgac atctgaggac tctgcggtct attactgtac aagatggact 300
actgggacgg gagcttattg gggccagggc accaccgtga ccgtgtcctc c 351
<210> 20
<211> 444
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 20
Gln Val Gln Leu Gln Gln Pro Gly Ser Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Thr Ser Leu Thr Val Asp Thr Ser Ser Thr Thr Ala Tyr
65 70 75 80
Met His Leu Ala Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro
210 215 220
Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe
225 230 235 240
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
245 250 255
Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe
260 265 270
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
275 280 285
Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
290 295 300
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
305 310 315 320
Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala
325 330 335
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln
340 345 350
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
355 360 365
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
370 375 380
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
385 390 395 400
Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu
405 410 415
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
420 425 430
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440
<210> 21
<211> 1332
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 21
caggtccagc tgcagcagcc tgggtctgag ctggtgaggc ctggagcttc agtgaagctg 60
tcctgcaagg cgtctggcta cacattcacc acttactgga tgcactgggt gaggcagagg 120
cctggacaag gccttgagtg gattggaaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaaaaacag gacctcactg actgtagaca catcctccac cacagcctac 240
atgcacctcg ccagcctgac atctgaggac tctgcggtct attactgtac aagatggact 300
actgggacgg gagcttattg gggccagggc accaccgtga ccgtgtcctc cgcttccacc 360
aagggcccat ccgtcttccc cctggcgccc tgctccagga gcacctccga gagcacagcc 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacgaagac ctacacctgc 600
aacgtagatc acaagcccag caacaccaag gtggacaaga gagttgagtc caaatatggt 660
cccccatgcc caccgtgccc agcacctgag ttcctggggg gaccatcagt cttcctgttc 720
cccccaaaac ccaaggacac tctcatgatc tcccggaccc ctgaggtcac gtgcgtggtg 780
gtggacgtga gccaggaaga ccccgaggtc cagttcaact ggtacgtgga tggcgtggag 840
gtgcataatg ccaagacaaa gccgcgggag gagcagttca acagcacgta ccgtgtggtc 900
agcgtcctca ccgtcctgca ccaggactgg ctgaacggca aggagtacaa gtgcaaggtg 960
tccaacaaag gcctcccgtc ctccatcgag aaaaccatct ccaaagccaa agggcagccc 1020
cgagagccac aggtgtacac cctgccccca tcccaggagg agatgaccaa gaaccaggtc 1080
agcctgacct gcctggtcaa aggcttctac cccagcgaca tcgccgtgga gtgggagagc 1140
aatgggcagc cggagaacaa ctacaagacc acgcctcccg tgctggactc cgacggctcc 1200
ttcttcctct acagcaggct aaccgtggac aagagcaggt ggcaggaggg gaatgtcttc 1260
tcatgctccg tgatgcatga ggctctgcac aaccactaca cacagaagag cctctccctg 1320
tctctgggta aa 1332
<210> 22
<211> 117
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 22
Gln Val Gln Leu Gln Gln Ser Gly Ser Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Thr Ser Leu Thr Val Asp Thr Ser Ser Thr Thr Ala Tyr
65 70 75 80
Met His Leu Ala Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 23
<211> 351
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 23
caggtccagc tgcagcagtc tgggtctgag ctggtgaggc ctggagcttc agtgaagctg 60
tcctgcaagg cgtctggcta cacattcacc acttactgga tgcactgggt gaggcagagg 120
cctggacaag gccttgagtg gattggaaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaaaaacag gacctcactg actgtagaca catcctccac cacagcctac 240
atgcacctcg ccagcctgac atctgaggac tctgcggtct attactgtac aagatggact 300
actgggacgg gagcttattg gggccagggc accaccgtga ccgtgtcctc c 351
<210> 24
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 24
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Phe Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Val Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Cys Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 25
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 25
gacattgtga tgacccagtc tccatcctcc ctgactgtga cagcaggaga gaaggtcact 60
atgagctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaaccagg gcagcctcct aaactgttga tcttctgggc atccactagg 180
gaatctgggg tccctgatcg cttcacaggc agtggatctg taacagattt cactctcacc 240
atcagcagtg tgcaggctga agacctggca gtttattact gtcagaatga ttatagttat 300
ccgtgcacgt tcggccaagg gaccaaggtg gaaatcaaa 339
<210> 26
<211> 220
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 26
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Phe Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Val Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Cys Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 27
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 27
gacattgtga tgacccagtc tccatcctcc ctgactgtga cagcaggaga gaaggtcact 60
atgagctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaaccagg gcagcctcct aaactgttga tcttctgggc atccactagg 180
gaatctgggg tccctgatcg cttcacaggc agtggatctg taacagattt cactctcacc 240
atcagcagtg tgcaggctga agacctggca gtttattact gtcagaatga ttatagttat 300
ccgtgcacgt tcggccaagg gaccaaggtg gaaatcaaac gtacggtggc tgcaccatct 360
gtcttcatct tcccgccatc tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420
ctgctgaata acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc 480
caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag cacctacagc 540
ctcagcagca ccctgacgct gagcaaagca gactacgaga aacacaaagt ctacgcctgc 600
gaagtcaccc atcagggcct gagctcgccc gtcacaaaga gcttcaacag gggagagtgt 660
<210> 28
<400> 28
000
<210> 29
<400> 29
000
<210> 30
<211> 444
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 30
Gln Val Gln Leu Gln Gln Ser Gly Ser Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Thr Ser Leu Thr Val Asp Thr Ser Ser Thr Thr Ala Tyr
65 70 75 80
Met His Leu Ala Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro
210 215 220
Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe
225 230 235 240
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
245 250 255
Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe
260 265 270
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
275 280 285
Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
290 295 300
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
305 310 315 320
Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala
325 330 335
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln
340 345 350
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
355 360 365
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
370 375 380
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
385 390 395 400
Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu
405 410 415
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
420 425 430
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440
<210> 31
<211> 1332
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 31
caggtccagc tgcagcagtc tgggtctgag ctggtgaggc ctggagcttc agtgaagctg 60
tcctgcaagg cgtctggcta cacattcacc acttactgga tgcactgggt gaggcagagg 120
cctggacaag gccttgagtg gattggaaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaaaaacag gacctcactg actgtagaca catcctccac cacagcctac 240
atgcacctcg ccagcctgac atctgaggac tctgcggtct attactgtac aagatggact 300
actgggacgg gagcttattg gggccagggc accaccgtga ccgtgtcctc cgcttccacc 360
aagggcccat ccgtcttccc cctggcgccc tgctccagga gcacctccga gagcacagcc 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacgaagac ctacacctgc 600
aacgtagatc acaagcccag caacaccaag gtggacaaga gagttgagtc caaatatggt 660
cccccatgcc caccgtgccc agcacctgag ttcctggggg gaccatcagt cttcctgttc 720
cccccaaaac ccaaggacac tctcatgatc tcccggaccc ctgaggtcac gtgcgtggtg 780
gtggacgtga gccaggaaga ccccgaggtc cagttcaact ggtacgtgga tggcgtggag 840
gtgcataatg ccaagacaaa gccgcgggag gagcagttca acagcacgta ccgtgtggtc 900
agcgtcctca ccgtcctgca ccaggactgg ctgaacggca aggagtacaa gtgcaaggtg 960
tccaacaaag gcctcccgtc ctccatcgag aaaaccatct ccaaagccaa agggcagccc 1020
cgagagccac aggtgtacac cctgccccca tcccaggagg agatgaccaa gaaccaggtc 1080
agcctgacct gcctggtcaa aggcttctac cccagcgaca tcgccgtgga gtgggagagc 1140
aatgggcagc cggagaacaa ctacaagacc acgcctcccg tgctggactc cgacggctcc 1200
ttcttcctct acagcaggct aaccgtggac aagagcaggt ggcaggaggg gaatgtcttc 1260
tcatgctccg tgatgcatga ggctctgcac aaccactaca cacagaagag cctctccctg 1320
tctctgggta aa 1332
<210> 32
<211> 9
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 32
Gln Asn Asp Tyr Ser Tyr Pro Tyr Thr
1 5
<210> 33
<211> 6
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 33
Asp Tyr Ser Tyr Pro Tyr
1 5
<210> 34
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 34
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Phe Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Val Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 35
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 35
gacattgtga tgacccagtc tccatcctcc ctgactgtga cagcaggaga gaaggtcact 60
atgagctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaaccagg gcagcctcct aaactgttga tcttctgggc atccactagg 180
gaatctgggg tccctgatcg cttcacaggc agtggatctg taacagattt cactctcacc 240
atcagcagtg tgcaggctga agacctggca gtttattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaa 339
<210> 36
<211> 220
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 36
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Phe Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Val Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 37
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 37
gacattgtga tgacccagtc tccatcctcc ctgactgtga cagcaggaga gaaggtcact 60
atgagctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaaccagg gcagcctcct aaactgttga tcttctgggc atccactagg 180
gaatctgggg tccctgatcg cttcacaggc agtggatctg taacagattt cactctcacc 240
atcagcagtg tgcaggctga agacctggca gtttattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaac gtacggtggc tgcaccatct 360
gtcttcatct tcccgccatc tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420
ctgctgaata acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc 480
caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag cacctacagc 540
ctcagcagca ccctgacgct gagcaaagca gactacgaga aacacaaagt ctacgcctgc 600
gaagtcaccc atcagggcct gagctcgccc gtcacaaaga gcttcaacag gggagagtgt 660
<210> 38
<211> 117
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 38
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Thr Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 39
<211> 351
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 39
gaagtgcagc tggtgcagtc tggagcagag gtgaaaaagc ccggggagtc tctgaggatc 60
tcctgtaagg gttctggcta cacattcacc acttactgga tgcactgggt gcgacaggcc 120
actggacaag ggcttgagtg gatgggtaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaagaacag agtcacgatt accgcggaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtac aagatggact 300
actgggacgg gagcttattg gggccagggc accaccgtga ccgtgtcctc c 351
<210> 40
<211> 444
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 40
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Thr Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro
210 215 220
Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe
225 230 235 240
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
245 250 255
Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe
260 265 270
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
275 280 285
Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
290 295 300
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
305 310 315 320
Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala
325 330 335
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln
340 345 350
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
355 360 365
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
370 375 380
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
385 390 395 400
Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu
405 410 415
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
420 425 430
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440
<210> 41
<211> 1332
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 41
gaagtgcagc tggtgcagtc tggagcagag gtgaaaaagc ccggggagtc tctgaggatc 60
tcctgtaagg gttctggcta cacattcacc acttactgga tgcactgggt gcgacaggcc 120
actggacaag ggcttgagtg gatgggtaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaagaacag agtcacgatt accgcggaca aatccacgag cacagcctac 240
atggagctga gcagcctgag atctgaggac acggccgtgt attactgtac aagatggact 300
actgggacgg gagcttattg gggccagggc accaccgtga ccgtgtcctc cgcttccacc 360
aagggcccat ccgtcttccc cctggcgccc tgctccagga gcacctccga gagcacagcc 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacgaagac ctacacctgc 600
aacgtagatc acaagcccag caacaccaag gtggacaaga gagttgagtc caaatatggt 660
cccccatgcc caccgtgccc agcacctgag ttcctggggg gaccatcagt cttcctgttc 720
cccccaaaac ccaaggacac tctcatgatc tcccggaccc ctgaggtcac gtgcgtggtg 780
gtggacgtga gccaggaaga ccccgaggtc cagttcaact ggtacgtgga tggcgtggag 840
gtgcataatg ccaagacaaa gccgcgggag gagcagttca acagcacgta ccgtgtggtc 900
agcgtcctca ccgtcctgca ccaggactgg ctgaacggca aggagtacaa gtgcaaggtg 960
tccaacaaag gcctcccgtc ctccatcgag aaaaccatct ccaaagccaa agggcagccc 1020
cgagagccac aggtgtacac cctgccccca tcccaggagg agatgaccaa gaaccaggtc 1080
agcctgacct gcctggtcaa aggcttctac cccagcgaca tcgccgtgga gtgggagagc 1140
aatgggcagc cggagaacaa ctacaagacc acgcctcccg tgctggactc cgacggctcc 1200
ttcttcctct acagcaggct aaccgtggac aagagcaggt ggcaggaggg gaatgtcttc 1260
tcatgctccg tgatgcatga ggctctgcac aaccactaca cacagaagag cctctccctg 1320
tctctgggta aa 1332
<210> 42
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 42
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ala Pro Arg Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 43
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 43
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaacctgg ccaggctccc aggctcctca tctattgggc atccactagg 180
gaatctgggg tcccatcaag gttcagcggc agtggatctg ggacagaatt cactctcacc 240
atcagcagcc tgcagcctga tgattttgca acttattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaa 339
<210> 44
<211> 220
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 44
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ala Pro Arg Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Leu Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 45
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 45
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaacctgg ccaggctccc aggctcctca tctattgggc atccactagg 180
gaatctgggg tcccatcaag gttcagcggc agtggatctg ggacagaatt cactctcacc 240
atcagcagcc tgcagcctga tgattttgca acttattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaac gtacggtggc tgcaccatct 360
gtcttcatct tcccgccatc tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420
ctgctgaata acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc 480
caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag cacctacagc 540
ctcagcagca ccctgacgct gagcaaagca gactacgaga aacacaaagt ctacgcctgc 600
gaagtcaccc atcagggcct gagctcgccc gtcacaaaga gcttcaacag gggagagtgt 660
<210> 46
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 46
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ala Pro Arg Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Ile
50 55 60
Pro Pro Arg Phe Ser Gly Ser Gly Tyr Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Asn Asn Ile Glu Ser Glu Asp Ala Ala Tyr Tyr Phe Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 47
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 47
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaacctgg ccaggctccc aggctcctca tctattgggc atccactagg 180
gaatctggga tcccacctcg attcagtggc agcgggtatg gaacagattt taccctcaca 240
attaataaca tagaatctga ggatgctgca tattacttct gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaa 339
<210> 48
<211> 220
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 48
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ala Pro Arg Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Ile
50 55 60
Pro Pro Arg Phe Ser Gly Ser Gly Tyr Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Asn Asn Ile Glu Ser Glu Asp Ala Ala Tyr Tyr Phe Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 49
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 49
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaacctgg ccaggctccc aggctcctca tctattgggc atccactagg 180
gaatctggga tcccacctcg attcagtggc agcgggtatg gaacagattt taccctcaca 240
attaataaca tagaatctga ggatgctgca tattacttct gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaac gtacggtggc tgcaccatct 360
gtcttcatct tcccgccatc tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420
ctgctgaata acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc 480
caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag cacctacagc 540
ctcagcagca ccctgacgct gagcaaagca gactacgaga aacacaaagt ctacgcctgc 600
gaagtcaccc atcagggcct gagctcgccc gtcacaaaga gcttcaacag gggagagtgt 660
<210> 50
<211> 117
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 50
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu Trp Leu
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 51
<211> 351
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 51
gaagtgcagc tggtgcagtc tggagcagag gtgaaaaagc ccggggagtc tctgaggatc 60
tcctgtaagg gttctggcta cacattcacc acttactgga tgcactggat caggcagtcc 120
ccatcgagag gccttgagtg gctgggtaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaagaacag attcaccatc tccagagaca attccaagaa cacgctgtat 240
cttcaaatga acagcctgag agccgaggac acggccgtgt attactgtac aagatggact 300
actgggacgg gagcttattg gggccagggc accaccgtga ccgtgtcctc c 351
<210> 52
<211> 444
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 52
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu Trp Leu
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro
210 215 220
Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe
225 230 235 240
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
245 250 255
Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe
260 265 270
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
275 280 285
Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
290 295 300
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
305 310 315 320
Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala
325 330 335
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln
340 345 350
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
355 360 365
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
370 375 380
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
385 390 395 400
Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu
405 410 415
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
420 425 430
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440
<210> 53
<211> 1332
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 53
gaagtgcagc tggtgcagtc tggagcagag gtgaaaaagc ccggggagtc tctgaggatc 60
tcctgtaagg gttctggcta cacattcacc acttactgga tgcactggat caggcagtcc 120
ccatcgagag gccttgagtg gctgggtaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaagaacag attcaccatc tccagagaca attccaagaa cacgctgtat 240
cttcaaatga acagcctgag agccgaggac acggccgtgt attactgtac aagatggact 300
actgggacgg gagcttattg gggccagggc accaccgtga ccgtgtcctc cgcttccacc 360
aagggcccat ccgtcttccc cctggcgccc tgctccagga gcacctccga gagcacagcc 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacgaagac ctacacctgc 600
aacgtagatc acaagcccag caacaccaag gtggacaaga gagttgagtc caaatatggt 660
cccccatgcc caccgtgccc agcacctgag ttcctggggg gaccatcagt cttcctgttc 720
cccccaaaac ccaaggacac tctcatgatc tcccggaccc ctgaggtcac gtgcgtggtg 780
gtggacgtga gccaggaaga ccccgaggtc cagttcaact ggtacgtgga tggcgtggag 840
gtgcataatg ccaagacaaa gccgcgggag gagcagttca acagcacgta ccgtgtggtc 900
agcgtcctca ccgtcctgca ccaggactgg ctgaacggca aggagtacaa gtgcaaggtg 960
tccaacaaag gcctcccgtc ctccatcgag aaaaccatct ccaaagccaa agggcagccc 1020
cgagagccac aggtgtacac cctgccccca tcccaggagg agatgaccaa gaaccaggtc 1080
agcctgacct gcctggtcaa aggcttctac cccagcgaca tcgccgtgga gtgggagagc 1140
aatgggcagc cggagaacaa ctacaagacc acgcctcccg tgctggactc cgacggctcc 1200
ttcttcctct acagcaggct aaccgtggac aagagcaggt ggcaggaggg gaatgtcttc 1260
tcatgctccg tgatgcatga ggctctgcac aaccactaca cacagaagag cctctccctg 1320
tctctgggta aa 1332
<210> 54
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 54
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys
35 40 45
Ala Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Gln Pro Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 55
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 55
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtatcagc agaaaccagg gaaagctcct aagctcctga tctattgggc atccactagg 180
gaatctgggg tcccatcaag gttcagtgga agtggatctg ggacagattt tactttcacc 240
atcagcagcc tgcagcctga agatattgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaa 339
<210> 56
<211> 220
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 56
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys
35 40 45
Ala Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Gln Pro Glu Asp Ile Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 57
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 57
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtatcagc agaaaccagg gaaagctcct aagctcctga tctattgggc atccactagg 180
gaatctgggg tcccatcaag gttcagtgga agtggatctg ggacagattt tactttcacc 240
atcagcagcc tgcagcctga agatattgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaac gtacggtggc tgcaccatct 360
gtcttcatct tcccgccatc tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420
ctgctgaata acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc 480
caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag cacctacagc 540
ctcagcagca ccctgacgct gagcaaagca gactacgaga aacacaaagt ctacgcctgc 600
gaagtcaccc atcagggcct gagctcgccc gtcacaaaga gcttcaacag gggagagtgt 660
<210> 58
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 58
Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ala Pro Arg Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 59
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 59
gatattgtga tgacccagac tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaacctgg ccaggctccc aggctcctca tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaa 339
<210> 60
<211> 220
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 60
Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ala Pro Arg Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 61
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 61
gatattgtga tgacccagac tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaacctgg ccaggctccc aggctcctca tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaac gtacggtggc tgcaccatct 360
gtcttcatct tcccgccatc tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420
ctgctgaata acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc 480
caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag cacctacagc 540
ctcagcagca ccctgacgct gagcaaagca gactacgaga aacacaaagt ctacgcctgc 600
gaagtcaccc atcagggcct gagctcgccc gtcacaaaga gcttcaacag gggagagtgt 660
<210> 62
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 62
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys
35 40 45
Ala Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 63
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 63
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtatcagc agaaaccagg gaaagctcct aagctcctga tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaa 339
<210> 64
<211> 220
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 64
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys
35 40 45
Ala Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 65
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 65
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtatcagc agaaaccagg gaaagctcct aagctcctga tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaac gtacggtggc tgcaccatct 360
gtcttcatct tcccgccatc tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420
ctgctgaata acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc 480
caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag cacctacagc 540
ctcagcagca ccctgacgct gagcaaagca gactacgaga aacacaaagt ctacgcctgc 600
gaagtcaccc atcagggcct gagctcgccc gtcacaaaga gcttcaacag gggagagtgt 660
<210> 66
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 66
Glu Ile Val Leu Thr Gln Ser Pro Asp Phe Gln Ser Val Thr Pro Lys
1 5 10 15
Glu Lys Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ala Pro Arg Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 67
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 67
gaaattgtgc tgactcagtc tccagacttt cagtctgtga ctccaaagga gaaagtcacc 60
atcacctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaacctgg ccaggctccc aggctcctca tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaa 339
<210> 68
<211> 220
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 68
Glu Ile Val Leu Thr Gln Ser Pro Asp Phe Gln Ser Val Thr Pro Lys
1 5 10 15
Glu Lys Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ala Pro Arg Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 69
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 69
gaaattgtgc tgactcagtc tccagacttt cagtctgtga ctccaaagga gaaagtcacc 60
atcacctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaacctgg ccaggctccc aggctcctca tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaac gtacggtggc tgcaccatct 360
gtcttcatct tcccgccatc tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420
ctgctgaata acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc 480
caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag cacctacagc 540
ctcagcagca ccctgacgct gagcaaagca gactacgaga aacacaaagt ctacgcctgc 600
gaagtcaccc atcagggcct gagctcgccc gtcacaaaga gcttcaacag gggagagtgt 660
<210> 70
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 70
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ala Pro Arg Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 71
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 71
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaacctgg ccaggctccc aggctcctca tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaa 339
<210> 72
<211> 220
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 72
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Ala Pro Arg Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 73
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 73
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtaccagc agaaacctgg ccaggctccc aggctcctca tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaac gtacggtggc tgcaccatct 360
gtcttcatct tcccgccatc tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420
ctgctgaata acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc 480
caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag cacctacagc 540
ctcagcagca ccctgacgct gagcaaagca gactacgaga aacacaaagt ctacgcctgc 600
gaagtcaccc atcagggcct gagctcgccc gtcacaaaga gcttcaacag gggagagtgt 660
<210> 74
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 74
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Leu Gln Lys Pro Gly Gln
35 40 45
Ser Pro Gln Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 75
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 75
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtacctgc agaagccagg gcagtctcca cagctcctga tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaa 339
<210> 76
<211> 220
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 76
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Leu Gln Lys Pro Gly Gln
35 40 45
Ser Pro Gln Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 77
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 77
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttgacc 120
tggtacctgc agaagccagg gcagtctcca cagctcctga tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaac gtacggtggc tgcaccatct 360
gtcttcatct tcccgccatc tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420
ctgctgaata acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc 480
caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag cacctacagc 540
ctcagcagca ccctgacgct gagcaaagca gactacgaga aacacaaagt ctacgcctgc 600
gaagtcaccc atcagggcct gagctcgccc gtcacaaaga gcttcaacag gggagagtgt 660
<210> 78
<211> 113
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 78
Asp Val Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys
35 40 45
Ala Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 79
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 79
gatgttgtga tgactcagtc tccactctcc ctgcccgtca cccttggaca gccggcctcc 60
atctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttaacc 120
tggtatcagc agaaaccagg gaaagctcct aagctcctga tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaa 339
<210> 80
<211> 220
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 80
Asp Val Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Lys Ser Ser Gln Ser Leu Leu Asp Ser
20 25 30
Gly Asn Gln Lys Asn Phe Leu Thr Trp Tyr Gln Gln Lys Pro Gly Lys
35 40 45
Ala Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr
65 70 75 80
Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Tyr Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp
115 120 125
Glu Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn
130 135 140
Phe Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu
145 150 155 160
Gln Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp
165 170 175
Ser Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr
180 185 190
Glu Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser
195 200 205
Ser Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215 220
<210> 81
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 81
gatgttgtga tgactcagtc tccactctcc ctgcccgtca cccttggaca gccggcctcc 60
atctcctgca agtccagtca gagtctgtta gacagtggaa atcaaaagaa cttcttaacc 120
tggtatcagc agaaaccagg gaaagctcct aagctcctga tctattgggc atccactagg 180
gaatctgggg tcccctcgag gttcagtggc agtggatctg ggacagattt cacctttacc 240
atcagtagcc tggaagctga agatgctgca acatattact gtcagaatga ttatagttat 300
ccgtacacgt tcggccaagg gaccaaggtg gaaatcaaac gtacggtggc tgcaccatct 360
gtcttcatct tcccgccatc tgatgagcag ttgaaatctg gaactgcctc tgttgtgtgc 420
ctgctgaata acttctatcc cagagaggcc aaagtacagt ggaaggtgga taacgccctc 480
caatcgggta actcccagga gagtgtcaca gagcaggaca gcaaggacag cacctacagc 540
ctcagcagca ccctgacgct gagcaaagca gactacgaga aacacaaagt ctacgcctgc 600
gaagtcaccc atcagggcct gagctcgccc gtcacaaaga gcttcaacag gggagagtgt 660
<210> 82
<211> 117
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 82
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu Trp Leu
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 83
<211> 351
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 83
caggttcagc tggtgcagtc tggagctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggcta cacattcacc acttactgga tgcactggat caggcagtcc 120
ccatcgagag gccttgagtg gctgggtaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaagaacag attcaccatc tccagagaca attccaagaa cacgctgtat 240
cttcaaatga acagcctgag agccgaggac acggccgtgt attactgtac aagatggact 300
actgggacgg gagcttactg gggccagggc accaccgtga ccgtgtcctc c 351
<210> 84
<211> 444
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 84
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu Trp Leu
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro
210 215 220
Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe
225 230 235 240
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
245 250 255
Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe
260 265 270
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
275 280 285
Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
290 295 300
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
305 310 315 320
Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala
325 330 335
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln
340 345 350
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
355 360 365
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
370 375 380
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
385 390 395 400
Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu
405 410 415
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
420 425 430
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440
<210> 85
<211> 1332
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 85
caggttcagc tggtgcagtc tggagctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggcta cacattcacc acttactgga tgcactggat caggcagtcc 120
ccatcgagag gccttgagtg gctgggtaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaagaacag attcaccatc tccagagaca attccaagaa cacgctgtat 240
cttcaaatga acagcctgag agccgaggac acggccgtgt attactgtac aagatggact 300
actgggacgg gagcttactg gggccagggc accaccgtga ccgtgtcctc cgcttccacc 360
aagggcccat ccgtcttccc cctggcgccc tgctccagga gcacctccga gagcacagcc 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacgaagac ctacacctgc 600
aacgtagatc acaagcccag caacaccaag gtggacaaga gagttgagtc caaatatggt 660
cccccatgcc caccgtgccc agcacctgag ttcctggggg gaccatcagt cttcctgttc 720
cccccaaaac ccaaggacac tctcatgatc tcccggaccc ctgaggtcac gtgcgtggtg 780
gtggacgtga gccaggaaga ccccgaggtc cagttcaact ggtacgtgga tggcgtggag 840
gtgcataatg ccaagacaaa gccgcgggag gagcagttca acagcacgta ccgtgtggtc 900
agcgtcctca ccgtcctgca ccaggactgg ctgaacggca aggagtacaa gtgcaaggtg 960
tccaacaaag gcctcccgtc ctccatcgag aaaaccatct ccaaagccaa agggcagccc 1020
cgagagccac aggtgtacac cctgccccca tcccaggagg agatgaccaa gaaccaggtc 1080
agcctgacct gcctggtcaa aggcttctac cccagcgaca tcgccgtgga gtgggagagc 1140
aatgggcagc cggagaacaa ctacaagacc acgcctcccg tgctggactc cgacggctcc 1200
ttcttcctct acagcaggct aaccgtggac aagagcaggt ggcaggaggg gaatgtcttc 1260
tcatgctccg tgatgcatga ggctctgcac aaccactaca cacagaagag cctctccctg 1320
tctctgggta aa 1332
<210> 86
<211> 117
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 86
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 87
<211> 351
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 87
gaagtgcagc tggtgcagtc tggagcagag gtgaaaaagc ccggggagtc tctgaggatc 60
tcctgtaagg gttctggcta cacattcacc acttactgga tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggtaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaagaacag attcaccatc tccagagaca attccaagaa cacgctgtat 240
cttcaaatga acagcctgag agccgaggac acggccgtgt attactgtac aagatggact 300
actgggacgg gagcttattg gggccagggc accaccgtga ccgtgtcctc c 351
<210> 88
<211> 444
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 88
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro
210 215 220
Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe
225 230 235 240
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
245 250 255
Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe
260 265 270
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
275 280 285
Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
290 295 300
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
305 310 315 320
Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala
325 330 335
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln
340 345 350
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
355 360 365
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
370 375 380
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
385 390 395 400
Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu
405 410 415
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
420 425 430
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440
<210> 89
<211> 1332
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 89
gaagtgcagc tggtgcagtc tggagcagag gtgaaaaagc ccggggagtc tctgaggatc 60
tcctgtaagg gttctggcta cacattcacc acttactgga tgcactgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggtaat atttatcctg gtactggtgg ttctaacttc 180
gatgagaagt tcaagaacag attcaccatc tccagagaca attccaagaa cacgctgtat 240
cttcaaatga acagcctgag agccgaggac acggccgtgt attactgtac aagatggact 300
actgggacgg gagcttattg gggccagggc accaccgtga ccgtgtcctc cgcttccacc 360
aagggcccat ccgtcttccc cctggcgccc tgctccagga gcacctccga gagcacagcc 420
gccctgggct gcctggtcaa ggactacttc cccgaaccgg tgacggtgtc gtggaactca 480
ggcgccctga ccagcggcgt gcacaccttc ccggctgtcc tacagtcctc aggactctac 540
tccctcagca gcgtggtgac cgtgccctcc agcagcttgg gcacgaagac ctacacctgc 600
aacgtagatc acaagcccag caacaccaag gtggacaaga gagttgagtc caaatatggt 660
cccccatgcc caccgtgccc agcacctgag ttcctggggg gaccatcagt cttcctgttc 720
cccccaaaac ccaaggacac tctcatgatc tcccggaccc ctgaggtcac gtgcgtggtg 780
gtggacgtga gccaggaaga ccccgaggtc cagttcaact ggtacgtgga tggcgtggag 840
gtgcataatg ccaagacaaa gccgcgggag gagcagttca acagcacgta ccgtgtggtc 900
agcgtcctca ccgtcctgca ccaggactgg ctgaacggca aggagtacaa gtgcaaggtg 960
tccaacaaag gcctcccgtc ctccatcgag aaaaccatct ccaaagccaa agggcagccc 1020
cgagagccac aggtgtacac cctgccccca tcccaggagg agatgaccaa gaaccaggtc 1080
agcctgacct gcctggtcaa aggcttctac cccagcgaca tcgccgtgga gtgggagagc 1140
aatgggcagc cggagaacaa ctacaagacc acgcctcccg tgctggactc cgacggctcc 1200
ttcttcctct acagcaggct aaccgtggac aagagcaggt ggcaggaggg gaatgtcttc 1260
tcatgctccg tgatgcatga ggctctgcac aaccactaca cacagaagag cctctccctg 1320
tctctgggta aa 1332
<210> 90
<211> 351
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 90
gaagtgcagc tggtgcagtc tggcgccgaa gtgaagaagc ctggcgagtc cctgcggatc 60
tcctgcaagg gctctggcta caccttcacc acctactgga tgcactgggt gcgacaggct 120
accggccagg gcctggaatg gatgggcaac atctatcctg gcaccggcgg ctccaacttc 180
gacgagaagt tcaagaacag agtgaccatc accgccgaca agtccacctc caccgcctac 240
atggaactgt cctccctgag atccgaggac accgccgtgt actactgcac ccggtggaca 300
accggcacag gcgcttattg gggccagggc accacagtga ccgtgtcctc t 351
<210> 91
<211> 443
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 91
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Val Arg Gln Ala Thr Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro
210 215 220
Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe
225 230 235 240
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
245 250 255
Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe
260 265 270
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
275 280 285
Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
290 295 300
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
305 310 315 320
Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala
325 330 335
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln
340 345 350
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
355 360 365
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
370 375 380
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
385 390 395 400
Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu
405 410 415
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
420 425 430
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440
<210> 92
<211> 1329
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 92
gaagtgcagc tggtgcagtc tggcgccgaa gtgaagaagc ctggcgagtc cctgcggatc 60
tcctgcaagg gctctggcta caccttcacc acctactgga tgcactgggt gcgacaggct 120
accggccagg gcctggaatg gatgggcaac atctatcctg gcaccggcgg ctccaacttc 180
gacgagaagt tcaagaacag agtgaccatc accgccgaca agtccacctc caccgcctac 240
atggaactgt cctccctgag atccgaggac accgccgtgt actactgcac ccggtggaca 300
accggcacag gcgcttattg gggccagggc accacagtga ccgtgtcctc tgcttctacc 360
aaggggccca gcgtgttccc cctggccccc tgctccagaa gcaccagcga gagcacagcc 420
gccctgggct gcctggtgaa ggactacttc cccgagcccg tgaccgtgtc ctggaacagc 480
ggagccctga ccagcggcgt gcacaccttc cccgccgtgc tgcagagcag cggcctgtac 540
agcctgagca gcgtggtgac cgtgcccagc agcagcctgg gcaccaagac ctacacctgt 600
aacgtggacc acaagcccag caacaccaag gtggacaaga gggtggagag caagtacggc 660
ccaccctgcc ccccctgccc agcccccgag ttcctgggcg gacccagcgt gttcctgttc 720
ccccccaagc ccaaggacac cctgatgatc agcagaaccc ccgaggtgac ctgtgtggtg 780
gtggacgtgt cccaggagga ccccgaggtc cagttcaact ggtacgtgga cggcgtggag 840
gtgcacaacg ccaagaccaa gcccagagag gagcagttta acagcaccta ccgggtggtg 900
tccgtgctga ccgtgctgca ccaggactgg ctgaacggca aagagtacaa gtgtaaggtc 960
tccaacaagg gcctgccaag cagcatcgaa aagaccatca gcaaggccaa gggccagcct 1020
agagagcccc aggtctacac cctgccaccc agccaagagg agatgaccaa gaaccaggtg 1080
tccctgacct gtctggtgaa gggcttctac ccaagcgaca tcgccgtgga gtgggagagc 1140
aacggccagc ccgagaacaa ctacaagacc acccccccag tgctggacag cgacggcagc 1200
ttcttcctgt acagcaggct gaccgtggac aagtccagat ggcaggaggg caacgtcttt 1260
agctgctccg tgatgcacga ggccctgcac aaccactaca cccagaagag cctgagcctg 1320
tccctgggc 1329
<210> 93
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 93
gagatcgtgc tgacccagtc ccctgccacc ctgtcactgt ctccaggcga gagagctacc 60
ctgtcctgca agtcctccca gtccctgctg gactccggca accagaagaa cttcctgacc 120
tggtatcagc agaagcccgg ccaggccccc agactgctga tctactgggc ctccacccgg 180
gaatctggcg tgccctctag attctccggc tccggctctg gcaccgagtt taccctgacc 240
atctccagcc tgcagcccga cgacttcgcc acctactact gccagaacga ctactcctac 300
ccctacacct tcggccaggg caccaaggtg gaaatcaag 339
<210> 94
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 94
gagatcgtgc tgacccagtc ccctgccacc ctgtcactgt ctccaggcga gagagctacc 60
ctgtcctgca agtcctccca gtccctgctg gactccggca accagaagaa cttcctgacc 120
tggtatcagc agaagcccgg ccaggccccc agactgctga tctactgggc ctccacccgg 180
gaatctggcg tgccctctag attctccggc tccggctctg gcaccgagtt taccctgacc 240
atctccagcc tgcagcccga cgacttcgcc acctactact gccagaacga ctactcctac 300
ccctacacct tcggccaggg caccaaggtg gaaatcaagc gtacggtggc cgctcccagc 360
gtgttcatct tccccccaag cgacgagcag ctgaagagcg gcaccgccag cgtggtgtgt 420
ctgctgaaca acttctaccc cagggaggcc aaggtgcagt ggaaggtgga caacgccctg 480
cagagcggca acagccagga gagcgtcacc gagcaggaca gcaaggactc cacctacagc 540
ctgagcagca ccctgaccct gagcaaggcc gactacgaga agcacaaggt gtacgcctgt 600
gaggtgaccc accagggcct gtccagcccc gtgaccaaga gcttcaacag gggcgagtgc 660
<210> 95
<211> 351
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 95
gaggtgcagc tggtgcagtc aggcgccgaa gtgaagaagc ccggcgagtc actgagaatt 60
agctgtaaag gttcaggcta caccttcact acctactgga tgcactgggt ccgccaggct 120
accggtcaag gcctcgagtg gatgggtaat atctaccccg gcaccggcgg ctctaacttc 180
gacgagaagt ttaagaatag agtgactatc accgccgata agtctactag caccgcctat 240
atggaactgt ctagcctgag atcagaggac accgccgtct actactgcac taggtggact 300
accggcacag gcgcctactg gggtcaaggc actaccgtga ccgtgtctag c 351
<210> 96
<211> 1329
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 96
gaggtgcagc tggtgcagtc aggcgccgaa gtgaagaagc ccggcgagtc actgagaatt 60
agctgtaaag gttcaggcta caccttcact acctactgga tgcactgggt ccgccaggct 120
accggtcaag gcctcgagtg gatgggtaat atctaccccg gcaccggcgg ctctaacttc 180
gacgagaagt ttaagaatag agtgactatc accgccgata agtctactag caccgcctat 240
atggaactgt ctagcctgag atcagaggac accgccgtct actactgcac taggtggact 300
accggcacag gcgcctactg gggtcaaggc actaccgtga ccgtgtctag cgctagcact 360
aagggcccgt ccgtgttccc cctggcacct tgtagccgga gcactagcga atccaccgct 420
gccctcggct gcctggtcaa ggattacttc ccggagcccg tgaccgtgtc ctggaacagc 480
ggagccctga cctccggagt gcacaccttc cccgctgtgc tgcagagctc cgggctgtac 540
tcgctgtcgt cggtggtcac ggtgccttca tctagcctgg gtaccaagac ctacacttgc 600
aacgtggacc acaagccttc caacactaag gtggacaagc gcgtcgaatc gaagtacggc 660
ccaccgtgcc cgccttgtcc cgcgccggag ttcctcggcg gtccctcggt ctttctgttc 720
ccaccgaagc ccaaggacac tttgatgatt tcccgcaccc ctgaagtgac atgcgtggtc 780
gtggacgtgt cacaggaaga tccggaggtg cagttcaatt ggtacgtgga tggcgtcgag 840
gtgcacaacg ccaaaaccaa gccgagggag gagcagttca actccactta ccgcgtcgtg 900
tccgtgctga cggtgctgca tcaggactgg ctgaacggga aggagtacaa gtgcaaagtg 960
tccaacaagg gacttcctag ctcaatcgaa aagaccatct cgaaagccaa gggacagccc 1020
cgggaacccc aagtgtatac cctgccaccg agccaggaag aaatgactaa gaaccaagtc 1080
tcattgactt gccttgtgaa gggcttctac ccatcggata tcgccgtgga atgggagtcc 1140
aacggccagc cggaaaacaa ctacaagacc acccctccgg tgctggactc agacggatcc 1200
ttcttcctct actcgcggct gaccgtggat aagagcagat ggcaggaggg aaatgtgttc 1260
agctgttctg tgatgcatga agccctgcac aaccactaca ctcagaagtc cctgtccctc 1320
tccctggga 1329
<210> 97
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 97
gagatcgtcc tgactcagtc acccgctacc ctgagcctga gccctggcga gcgggctaca 60
ctgagctgta aatctagtca gtcactgctg gatagcggta atcagaagaa cttcctgacc 120
tggtatcagc agaagcccgg taaagcccct aagctgctga tctactgggc ctctactaga 180
gaatcaggcg tgccctctag gtttagcggt agcggtagtg gcaccgactt caccttcact 240
atctctagcc tgcagcccga ggatatcgct acctactact gtcagaacga ctatagctac 300
ccctacacct tcggtcaagg cactaaggtc gagattaag 339
<210> 98
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 98
gagatcgtcc tgactcagtc acccgctacc ctgagcctga gccctggcga gcgggctaca 60
ctgagctgta aatctagtca gtcactgctg gatagcggta atcagaagaa cttcctgacc 120
tggtatcagc agaagcccgg taaagcccct aagctgctga tctactgggc ctctactaga 180
gaatcaggcg tgccctctag gtttagcggt agcggtagtg gcaccgactt caccttcact 240
atctctagcc tgcagcccga ggatatcgct acctactact gtcagaacga ctatagctac 300
ccctacacct tcggtcaagg cactaaggtc gagattaagc gtacggtggc cgctcccagc 360
gtgttcatct tcccccccag cgacgagcag ctgaagagcg gcaccgccag cgtggtgtgc 420
ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt ggaaggtgga caacgccctg 480
cagagcggca acagccagga gagcgtcacc gagcaggaca gcaaggactc cacctacagc 540
ctgagcagca ccctgaccct gagcaaggcc gactacgaga agcataaggt gtacgcctgc 600
gaggtgaccc accagggcct gtccagcccc gtgaccaaga gcttcaacag gggcgagtgc 660
<210> 99
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 99
gagatcgtgc tgacccagtc ccccgacttc cagtccgtga cccccaaaga aaaagtgacc 60
atcacatgca agtcctccca gtccctgctg gactccggca accagaagaa cttcctgacc 120
tggtatcagc agaagcccgg ccaggccccc agactgctga tctactgggc ctccacccgg 180
gaatctggcg tgccctctag attctccggc tccggctctg gcaccgactt taccttcacc 240
atctccagcc tggaagccga ggacgccgcc acctactact gccagaacga ctactcctac 300
ccctacacct tcggccaggg caccaaggtg gaaatcaag 339
<210> 100
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 100
gagatcgtgc tgacccagtc ccccgacttc cagtccgtga cccccaaaga aaaagtgacc 60
atcacatgca agtcctccca gtccctgctg gactccggca accagaagaa cttcctgacc 120
tggtatcagc agaagcccgg ccaggccccc agactgctga tctactgggc ctccacccgg 180
gaatctggcg tgccctctag attctccggc tccggctctg gcaccgactt taccttcacc 240
atctccagcc tggaagccga ggacgccgcc acctactact gccagaacga ctactcctac 300
ccctacacct tcggccaggg caccaaggtg gaaatcaagc gtacggtggc cgctcccagc 360
gtgttcatct tccccccaag cgacgagcag ctgaagagcg gcaccgccag cgtggtgtgt 420
ctgctgaaca acttctaccc cagggaggcc aaggtgcagt ggaaggtgga caacgccctg 480
cagagcggca acagccagga gagcgtcacc gagcaggaca gcaaggactc cacctacagc 540
ctgagcagca ccctgaccct gagcaaggcc gactacgaga agcacaaggt gtacgcctgt 600
gaggtgaccc accagggcct gtccagcccc gtgaccaaga gcttcaacag gggcgagtgc 660
<210> 101
<211> 351
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 101
gaagtgcagc tggtgcagtc tggcgccgaa gtgaagaagc ctggcgagtc cctgcggatc 60
tcctgcaagg gctctggcta caccttcacc acctactgga tgcactggat ccggcagtcc 120
ccctctaggg gcctggaatg gctgggcaac atctaccctg gcaccggcgg ctccaacttc 180
gacgagaagt tcaagaacag gttcaccatc tcccgggaca actccaagaa caccctgtac 240
ctgcagatga actccctgcg ggccgaggac accgccgtgt actactgtac cagatggacc 300
accggaaccg gcgcctattg gggccagggc acaacagtga ccgtgtcctc c 351
<210> 102
<211> 443
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 102
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser Gly Tyr Thr Phe Thr Thr Tyr
20 25 30
Trp Met His Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu Trp Leu
35 40 45
Gly Asn Ile Tyr Pro Gly Thr Gly Gly Ser Asn Phe Asp Glu Lys Phe
50 55 60
Lys Asn Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Trp Thr Thr Gly Thr Gly Ala Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu
115 120 125
Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys
130 135 140
Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser
145 150 155 160
Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser
165 170 175
Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser
180 185 190
Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn
195 200 205
Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro
210 215 220
Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe
225 230 235 240
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
245 250 255
Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe
260 265 270
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
275 280 285
Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
290 295 300
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
305 310 315 320
Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala
325 330 335
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln
340 345 350
Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
355 360 365
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
370 375 380
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
385 390 395 400
Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu
405 410 415
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
420 425 430
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly
435 440
<210> 103
<211> 1329
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 103
gaagtgcagc tggtgcagtc tggcgccgaa gtgaagaagc ctggcgagtc cctgcggatc 60
tcctgcaagg gctctggcta caccttcacc acctactgga tgcactggat ccggcagtcc 120
ccctctaggg gcctggaatg gctgggcaac atctaccctg gcaccggcgg ctccaacttc 180
gacgagaagt tcaagaacag gttcaccatc tcccgggaca actccaagaa caccctgtac 240
ctgcagatga actccctgcg ggccgaggac accgccgtgt actactgtac cagatggacc 300
accggaaccg gcgcctattg gggccagggc acaacagtga ccgtgtcctc cgcttctacc 360
aaggggccca gcgtgttccc cctggccccc tgctccagaa gcaccagcga gagcacagcc 420
gccctgggct gcctggtgaa ggactacttc cccgagcccg tgaccgtgtc ctggaacagc 480
ggagccctga ccagcggcgt gcacaccttc cccgccgtgc tgcagagcag cggcctgtac 540
agcctgagca gcgtggtgac cgtgcccagc agcagcctgg gcaccaagac ctacacctgt 600
aacgtggacc acaagcccag caacaccaag gtggacaaga gggtggagag caagtacggc 660
ccaccctgcc ccccctgccc agcccccgag ttcctgggcg gacccagcgt gttcctgttc 720
ccccccaagc ccaaggacac cctgatgatc agcagaaccc ccgaggtgac ctgtgtggtg 780
gtggacgtgt cccaggagga ccccgaggtc cagttcaact ggtacgtgga cggcgtggag 840
gtgcacaacg ccaagaccaa gcccagagag gagcagttta acagcaccta ccgggtggtg 900
tccgtgctga ccgtgctgca ccaggactgg ctgaacggca aagagtacaa gtgtaaggtc 960
tccaacaagg gcctgccaag cagcatcgaa aagaccatca gcaaggccaa gggccagcct 1020
agagagcccc aggtctacac cctgccaccc agccaagagg agatgaccaa gaaccaggtg 1080
tccctgacct gtctggtgaa gggcttctac ccaagcgaca tcgccgtgga gtgggagagc 1140
aacggccagc ccgagaacaa ctacaagacc acccccccag tgctggacag cgacggcagc 1200
ttcttcctgt acagcaggct gaccgtggac aagtccagat ggcaggaggg caacgtcttt 1260
agctgctccg tgatgcacga ggccctgcac aaccactaca cccagaagag cctgagcctg 1320
tccctgggc 1329
<210> 104
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 104
gagatcgtgc tgacccagtc ccctgccacc ctgtcactgt ctccaggcga gagagctacc 60
ctgtcctgca agtcctccca gtccctgctg gactccggca accagaagaa cttcctgacc 120
tggtatcagc agaagcccgg ccaggccccc agactgctga tctactgggc ctccacccgg 180
gaatctggcg tgccctctag attctccggc tccggctctg gcaccgactt taccttcacc 240
atctccagcc tggaagccga ggacgccgcc acctactact gccagaacga ctactcctac 300
ccctacacct tcggccaggg caccaaggtg gaaatcaag 339
<210> 105
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 105
gagatcgtgc tgacccagtc ccctgccacc ctgtcactgt ctccaggcga gagagctacc 60
ctgtcctgca agtcctccca gtccctgctg gactccggca accagaagaa cttcctgacc 120
tggtatcagc agaagcccgg ccaggccccc agactgctga tctactgggc ctccacccgg 180
gaatctggcg tgccctctag attctccggc tccggctctg gcaccgactt taccttcacc 240
atctccagcc tggaagccga ggacgccgcc acctactact gccagaacga ctactcctac 300
ccctacacct tcggccaggg caccaaggtg gaaatcaagc gtacggtggc cgctcccagc 360
gtgttcatct tccccccaag cgacgagcag ctgaagagcg gcaccgccag cgtggtgtgt 420
ctgctgaaca acttctaccc cagggaggcc aaggtgcagt ggaaggtgga caacgccctg 480
cagagcggca acagccagga gagcgtcacc gagcaggaca gcaaggactc cacctacagc 540
ctgagcagca ccctgaccct gagcaaggcc gactacgaga agcacaaggt gtacgcctgt 600
gaggtgaccc accagggcct gtccagcccc gtgaccaaga gcttcaacag gggcgagtgc 660
<210> 106
<211> 339
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 106
gagatcgtcc tgactcagtc acccgctacc ctgagcctga gccctggcga gcgggctaca 60
ctgagctgta aatctagtca gtcactgctg gatagcggta atcagaagaa cttcctgacc 120
tggtatcagc agaagcccgg tcaagcccct agactgctga tctactgggc ctctactaga 180
gaatcaggcg tgccctctag gtttagcggt agcggtagtg gcaccgactt caccttcact 240
atctctagcc tggaagccga ggacgccgct acctactact gtcagaacga ctatagctac 300
ccctacacct tcggtcaagg cactaaggtc gagattaag 339
<210> 107
<211> 660
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 107
gagatcgtcc tgactcagtc acccgctacc ctgagcctga gccctggcga gcgggctaca 60
ctgagctgta aatctagtca gtcactgctg gatagcggta atcagaagaa cttcctgacc 120
tggtatcagc agaagcccgg tcaagcccct agactgctga tctactgggc ctctactaga 180
gaatcaggcg tgccctctag gtttagcggt agcggtagtg gcaccgactt caccttcact 240
atctctagcc tggaagccga ggacgccgct acctactact gtcagaacga ctatagctac 300
ccctacacct tcggtcaagg cactaaggtc gagattaagc gtacggtggc cgctcccagc 360
gtgttcatct tcccccccag cgacgagcag ctgaagagcg gcaccgccag cgtggtgtgc 420
ctgctgaaca acttctaccc ccgggaggcc aaggtgcagt ggaaggtgga caacgccctg 480
cagagcggca acagccagga gagcgtcacc gagcaggaca gcaaggactc cacctacagc 540
ctgagcagca ccctgaccct gagcaaggcc gactacgaga agcataaggt gtacgcctgc 600
gaggtgaccc accagggcct gtccagcccc gtgaccaaga gcttcaacag gggcgagtgc 660
<210> 108
<211> 15
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 108
acttactgga tgcac 15
<210> 109
<211> 51
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 109
aatatttatc ctggtactgg tggttctaac ttcgatgaga agttcaagaa c 51
<210> 110
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 110
tggactactg ggacgggagc ttat 24
<210> 111
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 111
ggctacacat tcaccactta c 21
<210> 112
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 112
tatcctggta ctggtggt 18
<210> 113
<211> 51
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 113
aagtccagtc agagtctgtt agacagtgga aatcaaaaga acttcttgac c 51
<210> 114
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 114
tgggcatcca ctagggaatc t 21
<210> 115
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 115
cagaatgatt atagttatcc gtgcacg 27
<210> 116
<211> 39
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 116
agtcagagtc tgttagacag tggaaatcaa aagaacttc 39
<210> 117
<211> 9
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 117
tgggcatcc 9
<210> 118
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 118
gattatagtt atccgtgc 18
<210> 119
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 119
cagaatgatt atagttatcc gtacacg 27
<210> 120
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 120
gattatagtt atccgtac 18
<210> 121
<211> 51
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 121
aagtccagtc agagtctgtt agacagtgga aatcaaaaga acttcttaac c 51
<210> 122
<211> 15
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 122
acctactgga tgcac 15
<210> 123
<211> 51
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 123
aacatctatc ctggcaccgg cggctccaac ttcgacgaga agttcaagaa c 51
<210> 124
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 124
tggacaaccg gcacaggcgc ttat 24
<210> 125
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 125
ggctacacct tcaccaccta c 21
<210> 126
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 126
tatcctggca ccggcggc 18
<210> 127
<211> 51
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 127
aagtcctccc agtccctgct ggactccggc aaccagaaga acttcctgac c 51
<210> 128
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 128
tgggcctcca cccgggaatc t 21
<210> 129
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 129
cagaacgact actcctaccc ctacacc 27
<210> 130
<211> 39
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 130
tcccagtccc tgctggactc cggcaaccag aagaacttc 39
<210> 131
<211> 9
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 131
tgggcctcc 9
<210> 132
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 132
gactactcct acccctac 18
<210> 133
<211> 15
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 133
acctactgga tgcac 15
<210> 134
<211> 51
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 134
aatatctacc ccggcaccgg cggctctaac ttcgacgaga agtttaagaa t 51
<210> 135
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 135
tggactaccg gcacaggcgc ctac 24
<210> 136
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 136
ggctacacct tcactaccta c 21
<210> 137
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 137
taccccggca ccggcggc 18
<210> 138
<211> 51
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 138
aaatctagtc agtcactgct ggatagcggt aatcagaaga acttcctgac c 51
<210> 139
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 139
tgggcctcta ctagagaatc a 21
<210> 140
<211> 27
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 140
cagaacgact atagctaccc ctacacc 27
<210> 141
<211> 39
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 141
agtcagtcac tgctggatag cggtaatcag aagaacttc 39
<210> 142
<211> 9
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 142
tgggcctct 9
<210> 143
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 143
gactatagct acccctac 18
<210> 144
<211> 51
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 144
aacatctacc ctggcaccgg cggctccaac ttcgacgaga agttcaagaa c 51
<210> 145
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 145
tggaccaccg gaaccggcgc ctat 24
<210> 146
<211> 18
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 146
taccctggca ccggcggc 18
<210> 147
<211> 25
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 147
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Glu
1 5 10 15
Ser Leu Arg Ile Ser Cys Lys Gly Ser
20 25
<210> 148
<211> 75
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 148
gaagtgcagc tggtgcagtc tggagcagag gtgaaaaagc ccggggagtc tctgaggatc 60
tcctgtaagg gttct 75
<210> 149
<211> 75
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 149
gaagtgcagc tggtgcagtc tggcgccgaa gtgaagaagc ctggcgagtc cctgcggatc 60
tcctgcaagg gctct 75
<210> 150
<211> 75
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 150
gaggtgcagc tggtgcagtc aggcgccgaa gtgaagaagc ccggcgagtc actgagaatt 60
agctgtaaag gttca 75
<210> 151
<211> 25
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 151
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser
20 25
<210> 152
<211> 75
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 152
caggttcagc tggtgcagtc tggagctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttct 75
<210> 153
<211> 14
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 153
Trp Val Arg Gln Ala Thr Gly Gln Gly Leu Glu Trp Met Gly
1 5 10
<210> 154
<211> 42
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 154
tgggtgcgac aggccactgg acaagggctt gagtggatgg gt 42
<210> 155
<211> 42
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 155
tgggtgcgac aggctaccgg ccagggcctg gaatggatgg gc 42
<210> 156
<211> 42
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 156
tgggtccgcc aggctaccgg tcaaggcctc gagtggatgg gt 42
<210> 157
<211> 14
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 157
Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu Trp Leu Gly
1 5 10
<210> 158
<211> 42
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 158
tggatcaggc agtccccatc gagaggcctt gagtggctgg gt 42
<210> 159
<211> 42
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 159
tggatccggc agtccccctc taggggcctg gaatggctgg gc 42
<210> 160
<211> 14
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 160
Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met Gly
1 5 10
<210> 161
<211> 42
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 161
tgggtgcgac aggcccctgg acaagggctt gagtggatgg gt 42
<210> 162
<211> 32
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 162
Arg Val Thr Ile Thr Ala Asp Lys Ser Thr Ser Thr Ala Tyr Met Glu
1 5 10 15
Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys Thr Arg
20 25 30
<210> 163
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 163
agagtcacga ttaccgcgga caaatccacg agcacagcct acatggagct gagcagcctg 60
agatctgagg acacggccgt gtattactgt acaaga 96
<210> 164
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 164
agagtgacca tcaccgccga caagtccacc tccaccgcct acatggaact gtcctccctg 60
agatccgagg acaccgccgt gtactactgc acccgg 96
<210> 165
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 165
agagtgacta tcaccgccga taagtctact agcaccgcct atatggaact gtctagcctg 60
agatcagagg acaccgccgt ctactactgc actagg 96
<210> 166
<211> 32
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 166
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
1 5 10 15
Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Thr Arg
20 25 30
<210> 167
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 167
agattcacca tctccagaga caattccaag aacacgctgt atcttcaaat gaacagcctg 60
agagccgagg acacggccgt gtattactgt acaaga 96
<210> 168
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 168
aggttcacca tctcccggga caactccaag aacaccctgt acctgcagat gaactccctg 60
cgggccgagg acaccgccgt gtactactgt accaga 96
<210> 169
<211> 11
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 169
Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
1 5 10
<210> 170
<211> 33
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 170
tggggccagg gcaccaccgt gaccgtgtcc tcc 33
<210> 171
<211> 33
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 171
tggggccagg gcaccacagt gaccgtgtcc tct 33
<210> 172
<211> 33
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 172
tggggtcaag gcactaccgt gaccgtgtct agc 33
<210> 173
<211> 33
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 173
tggggccagg gcacaacagt gaccgtgtcc tcc 33
<210> 174
<211> 23
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 174
Glu Ile Val Leu Thr Gln Ser Pro Asp Phe Gln Ser Val Thr Pro Lys
1 5 10 15
Glu Lys Val Thr Ile Thr Cys
20
<210> 175
<211> 69
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 175
gaaattgtgc tgactcagtc tccagacttt cagtctgtga ctccaaagga gaaagtcacc 60
atcacctgc 69
<210> 176
<211> 69
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 176
gagatcgtgc tgacccagtc ccccgacttc cagtccgtga cccccaaaga aaaagtgacc 60
atcacatgc 69
<210> 177
<211> 23
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 177
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys
20
<210> 178
<211> 69
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 178
gaaattgtgt tgacacagtc tccagccacc ctgtctttgt ctccagggga aagagccacc 60
ctctcctgc 69
<210> 179
<211> 69
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 179
gagatcgtgc tgacccagtc ccctgccacc ctgtcactgt ctccaggcga gagagctacc 60
ctgtcctgc 69
<210> 180
<211> 69
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 180
gagatcgtcc tgactcagtc acccgctacc ctgagcctga gccctggcga gcgggctaca 60
ctgagctgt 69
<210> 181
<211> 23
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 181
Asp Ile Val Met Thr Gln Thr Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys
20
<210> 182
<211> 69
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 182
gatattgtga tgacccagac tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgc 69
<210> 183
<211> 23
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 183
Asp Val Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys
20
<210> 184
<211> 69
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 184
gatgttgtga tgactcagtc tccactctcc ctgcccgtca cccttggaca gccggcctcc 60
atctcctgc 69
<210> 185
<211> 23
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 185
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys
20
<210> 186
<211> 69
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 186
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgc 69
<210> 187
<211> 15
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 187
Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile Tyr
1 5 10 15
<210> 188
<211> 45
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 188
tggtaccagc agaaacctgg ccaggctccc aggctcctca tctat 45
<210> 189
<211> 45
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 189
tggtatcagc agaagcccgg ccaggccccc agactgctga tctac 45
<210> 190
<211> 45
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 190
tggtatcagc agaagcccgg tcaagcccct agactgctga tctac 45
<210> 191
<211> 15
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 191
Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Tyr
1 5 10 15
<210> 192
<211> 45
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 192
tggtatcagc agaaaccagg gaaagctcct aagctcctga tctat 45
<210> 193
<211> 45
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 193
tggtatcagc agaagcccgg taaagcccct aagctgctga tctac 45
<210> 194
<211> 15
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 194
Trp Tyr Leu Gln Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile Tyr
1 5 10 15
<210> 195
<211> 45
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 195
tggtacctgc agaagccagg gcagtctcca cagctcctga tctat 45
<210> 196
<211> 32
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 196
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Phe Thr Ile Ser Ser Leu Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys
20 25 30
<210> 197
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 197
ggggtcccct cgaggttcag tggcagtgga tctgggacag atttcacctt taccatcagt 60
agcctggaag ctgaagatgc tgcaacatat tactgt 96
<210> 198
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 198
ggcgtgccct ctagattctc cggctccggc tctggcaccg actttacctt caccatctcc 60
agcctggaag ccgaggacgc cgccacctac tactgc 96
<210> 199
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 199
ggcgtgccct ctaggtttag cggtagcggt agtggcaccg acttcacctt cactatctct 60
agcctggaag ccgaggacgc cgctacctac tactgt 96
<210> 200
<211> 32
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 200
Gly Ile Pro Pro Arg Phe Ser Gly Ser Gly Tyr Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Asn Asn Ile Glu Ser Glu Asp Ala Ala Tyr Tyr Phe Cys
20 25 30
<210> 201
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 201
gggatcccac ctcgattcag tggcagcggg tatggaacag attttaccct cacaattaat 60
aacatagaat ctgaggatgc tgcatattac ttctgt 96
<210> 202
<211> 32
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 202
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 203
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 203
ggggtcccat caaggttcag cggcagtgga tctgggacag aattcactct caccatcagc 60
agcctgcagc ctgatgattt tgcaacttat tactgt 96
<210> 204
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 204
ggcgtgccct ctagattctc cggctccggc tctggcaccg agtttaccct gaccatctcc 60
agcctgcagc ccgacgactt cgccacctac tactgc 96
<210> 205
<211> 32
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 205
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Phe Thr Ile Ser Ser Leu Gln Pro Glu Asp Ile Ala Thr Tyr Tyr Cys
20 25 30
<210> 206
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 206
ggggtcccat caaggttcag tggaagtgga tctgggacag attttacttt caccatcagc 60
agcctgcagc ctgaagatat tgcaacatat tactgt 96
<210> 207
<211> 96
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 207
ggcgtgccct ctaggtttag cggtagcggt agtggcaccg acttcacctt cactatctct 60
agcctgcagc ccgaggatat cgctacctac tactgt 96
<210> 208
<211> 10
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 208
Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
1 5 10
<210> 209
<211> 30
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 209
ttcggccaag ggaccaaggt ggaaatcaaa 30
<210> 210
<211> 30
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 210
ttcggccagg gcaccaaggt ggaaatcaag 30
<210> 211
<211> 30
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 211
ttcggtcaag gcactaaggt cgagattaag 30
<210> 212
<211> 327
<212> Протеин
<213> Homo sapiens
<400> 212
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
100 105 110
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
130 135 140
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly Lys
325
<210> 213
<211> 107
<212> Протеин
<213> Homo sapiens
<400> 213
Arg Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu
1 5 10 15
Gln Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe
20 25 30
Tyr Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln
35 40 45
Ser Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser
50 55 60
Thr Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu
65 70 75 80
Lys His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser
85 90 95
Pro Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
100 105
<210> 214
<211> 326
<212> Протеин
<213> Homo sapiens
<400> 214
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser Arg
1 5 10 15
Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys Thr
65 70 75 80
Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala Pro
100 105 110
Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys
115 120 125
Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val
130 135 140
Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val Asp
145 150 155 160
Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Phe
165 170 175
Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp
180 185 190
Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly Leu
195 200 205
Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg
210 215 220
Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr Lys
225 230 235 240
Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp
245 250 255
Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys
260 265 270
Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser
275 280 285
Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe Ser
290 295 300
Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser
305 310 315 320
Leu Ser Leu Ser Leu Gly
325
<210> 215
<211> 330
<212> Протеин
<213> Homo sapiens
<400> 215
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 216
<211> 330
<212> Протеин
<213> Homo sapiens
<400> 216
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Ala Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 217
<211> 330
<212> Протеин
<213> Homo sapiens
<400> 217
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Ala Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Ala Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 218
<211> 330
<212> Протеин
<213> Homo sapiens
<400> 218
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 10 15
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
20 25 30
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
35 40 45
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
50 55 60
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65 70 75 80
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
85 90 95
Arg Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Ala Ala Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Glu Glu
225 230 235 240
Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
325 330
<210> 219
<400> 219
000
<210> 220
<400> 220
000
<210> 221
<400> 221
000
<210> 222
<400> 222
000
<210> 223
<211> 24
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
олигонуклеотид
<400> 223
tggactactg ggacgggagc ttac 24
<210> 224
<211> 10
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 224
Gly Tyr Thr Phe Thr Thr Tyr Trp Met His
1 5 10
<210> 225
<211> 5
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 225
Ser Tyr Trp Met Tyr
1 5
<210> 226
<211> 17
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 226
Arg Ile Asp Pro Asn Ser Gly Ser Thr Lys Tyr Asn Glu Lys Phe Lys
1 5 10 15
Asn
<210> 227
<211> 11
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 227
Asp Tyr Arg Lys Gly Leu Tyr Ala Met Asp Tyr
1 5 10
<210> 228
<211> 7
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 228
Gly Tyr Thr Phe Thr Ser Tyr
1 5
<210> 229
<211> 6
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 229
Asp Pro Asn Ser Gly Ser
1 5
<210> 230
<211> 11
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 230
Lys Ala Ser Gln Asp Val Gly Thr Ala Val Ala
1 5 10
<210> 231
<211> 7
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 231
Trp Ala Ser Thr Arg His Thr
1 5
<210> 232
<211> 9
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 232
Gln Gln Tyr Asn Ser Tyr Pro Leu Thr
1 5
<210> 233
<211> 7
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 233
Ser Gln Asp Val Gly Thr Ala
1 5
<210> 234
<211> 3
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 234
Trp Ala Ser
1
<210> 235
<211> 6
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 235
Tyr Asn Ser Tyr Pro Leu
1 5
<210> 236
<211> 120
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 236
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Val Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met Tyr Trp Val Arg Gln Ala Arg Gly Gln Arg Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Asn Ser Gly Ser Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Asn Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Arg Lys Gly Leu Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 237
<211> 360
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 237
gaggtccagc tggtacagtc tggggctgag gtgaagaagc ctggggctac agtgaaaatc 60
tcctgcaagg tttctggcta caccttcacc agttactgga tgtactgggt gcgacaggct 120
cgtggacaac gccttgagtg gataggtagg attgatccta atagtgggag tactaagtac 180
aatgagaagt tcaagaacag attcaccatc tccagagaca attccaagaa cacgctgtat 240
cttcaaatga acagcctgag agccgaggac acggccgtgt attactgtgc aagggactat 300
agaaaggggc tctatgctat ggactactgg ggccagggca ccaccgtgac cgtgtcctcc 360
<210> 238
<211> 1341
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 238
gaggtccagc tggtacagtc tggggctgag gtgaagaagc ctggggctac agtgaaaatc 60
tcctgcaagg tttctggcta caccttcacc agttactgga tgtactgggt gcgacaggct 120
cgtggacaac gccttgagtg gataggtagg attgatccta atagtgggag tactaagtac 180
aatgagaagt tcaagaacag attcaccatc tccagagaca attccaagaa cacgctgtat 240
cttcaaatga acagcctgag agccgaggac acggccgtgt attactgtgc aagggactat 300
agaaaggggc tctatgctat ggactactgg ggccagggca ccaccgtgac cgtgtcctcc 360
gcttccacca agggcccatc cgtcttcccc ctggcgccct gctccaggag cacctccgag 420
agcacagccg ccctgggctg cctggtcaag gactacttcc ccgaaccggt gacggtgtcg 480
tggaactcag gcgccctgac cagcggcgtg cacaccttcc cggctgtcct acagtcctca 540
ggactctact ccctcagcag cgtggtgacc gtgccctcca gcagcttggg cacgaagacc 600
tacacctgca acgtagatca caagcccagc aacaccaagg tggacaagag agttgagtcc 660
aaatatggtc ccccatgccc accgtgccca gcacctgagt tcctgggggg accatcagtc 720
ttcctgttcc ccccaaaacc caaggacact ctcatgatct cccggacccc tgaggtcacg 780
tgcgtggtgg tggacgtgag ccaggaagac cccgaggtcc agttcaactg gtacgtggat 840
ggcgtggagg tgcataatgc caagacaaag ccgcgggagg agcagttcaa cagcacgtac 900
cgtgtggtca gcgtcctcac cgtcctgcac caggactggc tgaacggcaa ggagtacaag 960
tgcaaggtgt ccaacaaagg cctcccgtcc tccatcgaga aaaccatctc caaagccaaa 1020
gggcagcccc gagagccaca ggtgtacacc ctgcccccat cccaggagga gatgaccaag 1080
aaccaggtca gcctgacctg cctggtcaaa ggcttctacc ccagcgacat cgccgtggag 1140
tgggagagca atgggcagcc ggagaacaac tacaagacca cgcctcccgt gctggactcc 1200
gacggctcct tcttcctcta cagcaggcta accgtggaca agagcaggtg gcaggagggg 1260
aatgtcttct catgctccgt gatgcatgag gctctgcaca accactacac acagaagagc 1320
ctctccctgt ctctgggtaa a 1341
<210> 239
<211> 107
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 239
Ala Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Val Gly Thr Ala
20 25 30
Val Ala Trp Tyr Leu Gln Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile
35 40 45
Tyr Trp Ala Ser Thr Arg His Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Glu Ala
65 70 75 80
Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys
100 105
<210> 240
<211> 321
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 240
gccatccagt tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgca aggccagtca ggatgtgggt actgctgtag cctggtacct gcagaagcca 120
gggcagtctc cacagctcct gatctattgg gcatccaccc ggcacactgg ggtcccctcg 180
aggttcagtg gcagtggatc tgggacagat ttcaccttta ccatcagtag cctggaagct 240
gaagatgctg caacatatta ctgtcagcag tataacagct atcctctcac gttcggccaa 300
gggaccaagg tggaaatcaa a 321
<210> 241
<211> 214
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 241
Ala Ile Gln Leu Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Lys Ala Ser Gln Asp Val Gly Thr Ala
20 25 30
Val Ala Trp Tyr Leu Gln Lys Pro Gly Gln Ser Pro Gln Leu Leu Ile
35 40 45
Tyr Trp Ala Ser Thr Arg His Thr Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Phe Thr Ile Ser Ser Leu Glu Ala
65 70 75 80
Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Tyr Asn Ser Tyr Pro Leu
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 242
<211> 642
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полинуклеотид
<400> 242
gccatccagt tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga cagagtcacc 60
atcacttgca aggccagtca ggatgtgggt actgctgtag cctggtacct gcagaagcca 120
gggcagtctc cacagctcct gatctattgg gcatccaccc ggcacactgg ggtcccctcg 180
aggttcagtg gcagtggatc tgggacagat ttcaccttta ccatcagtag cctggaagct 240
gaagatgctg caacatatta ctgtcagcag tataacagct atcctctcac gttcggccaa 300
gggaccaagg tggaaatcaa acgtacggtg gctgcaccat ctgtcttcat cttcccgcca 360
tctgatgagc agttgaaatc tggaactgcc tctgttgtgt gcctgctgaa taacttctat 420
cccagagagg ccaaagtaca gtggaaggtg gataacgccc tccaatcggg taactcccag 480
gagagtgtca cagagcagga cagcaaggac agcacctaca gcctcagcag caccctgacg 540
ctgagcaaag cagactacga gaaacacaaa gtctacgcct gcgaagtcac ccatcagggc 600
ctgagctcgc ccgtcacaaa gagcttcaac aggggagagt gt 642
<210> 243
<211> 447
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 243
Glu Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Val Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Met Tyr Trp Val Arg Gln Ala Arg Gly Gln Arg Leu Glu Trp Ile
35 40 45
Gly Arg Ile Asp Pro Asn Ser Gly Ser Thr Lys Tyr Asn Glu Lys Phe
50 55 60
Lys Asn Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Arg Lys Gly Leu Tyr Ala Met Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 244
<211> 10
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
пептид
<400> 244
Gly Tyr Thr Phe Thr Ser Tyr Trp Met Tyr
1 5 10
<210> 245
<211> 118
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 245
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ile Met Met Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Tyr Pro Ser Gly Gly Ile Thr Phe Tyr Ala Asp Lys Gly
50 55 60
Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr Leu Gln
65 70 75 80
Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys Ala Arg
85 90 95
Ile Lys Leu Gly Thr Val Thr Thr Val Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Leu Val Thr Val Ser Ser
115
<210> 246
<211> 110
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 246
Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro Gly Gln
1 5 10 15
Ser Ile Thr Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly Gly Tyr
20 25 30
Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys Leu
35 40 45
Met Ile Tyr Asp Val Ser Asn Arg Pro Ser Gly Val Ser Asn Arg Phe
50 55 60
Ser Gly Ser Lys Ser Gly Asn Thr Ala Ser Leu Thr Ile Ser Gly Leu
65 70 75 80
Gln Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Ser Ser Tyr Thr Ser Ser
85 90 95
Ser Thr Arg Val Phe Gly Thr Gly Thr Lys Val Thr Val Leu
100 105 110
<210> 247
<211> 440
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 247
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Asp Cys Lys Ala Ser Gly Ile Thr Phe Ser Asn Ser
20 25 30
Gly Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Trp Tyr Asp Gly Ser Lys Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Phe
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Asn Asp Asp Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser
100 105 110
Ser Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Cys Ser
115 120 125
Arg Ser Thr Ser Glu Ser Thr Ala Ala Leu Gly Cys Leu Val Lys Asp
130 135 140
Tyr Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr
145 150 155 160
Ser Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr
165 170 175
Ser Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Lys
180 185 190
Thr Tyr Thr Cys Asn Val Asp His Lys Pro Ser Asn Thr Lys Val Asp
195 200 205
Lys Arg Val Glu Ser Lys Tyr Gly Pro Pro Cys Pro Pro Cys Pro Ala
210 215 220
Pro Glu Phe Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro
225 230 235 240
Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val
245 250 255
Val Asp Val Ser Gln Glu Asp Pro Glu Val Gln Phe Asn Trp Tyr Val
260 265 270
Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln
275 280 285
Phe Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln
290 295 300
Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Gly
305 310 315 320
Leu Pro Ser Ser Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro
325 330 335
Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Gln Glu Glu Met Thr
340 345 350
Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser
355 360 365
Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr
370 375 380
Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr
385 390 395 400
Ser Arg Leu Thr Val Asp Lys Ser Arg Trp Gln Glu Gly Asn Val Phe
405 410 415
Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys
420 425 430
Ser Leu Ser Leu Ser Leu Gly Lys
435 440
<210> 248
<211> 214
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 248
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Tyr
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Asp Ala Ser Asn Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Glu Pro
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Ser Ser Asn Trp Pro Arg
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly
115 120 125
Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala
130 135 140
Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln
145 150 155 160
Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser
165 170 175
Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr
180 185 190
Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser
195 200 205
Phe Asn Arg Gly Glu Cys
210
<210> 249
<211> 447
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 249
Gln Val Gln Leu Val Gln Ser Gly Val Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Tyr Met Tyr Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Asn Pro Ser Asn Gly Gly Thr Asn Phe Asn Glu Lys Phe
50 55 60
Lys Asn Arg Val Thr Leu Thr Thr Asp Ser Ser Thr Thr Thr Ala Tyr
65 70 75 80
Met Glu Leu Lys Ser Leu Gln Phe Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Arg Asp Tyr Arg Phe Asp Met Gly Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val
115 120 125
Phe Pro Leu Ala Pro Cys Ser Arg Ser Thr Ser Glu Ser Thr Ala Ala
130 135 140
Leu Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser
145 150 155 160
Trp Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val
165 170 175
Leu Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro
180 185 190
Ser Ser Ser Leu Gly Thr Lys Thr Tyr Thr Cys Asn Val Asp His Lys
195 200 205
Pro Ser Asn Thr Lys Val Asp Lys Arg Val Glu Ser Lys Tyr Gly Pro
210 215 220
Pro Cys Pro Pro Cys Pro Ala Pro Glu Phe Leu Gly Gly Pro Ser Val
225 230 235 240
Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr
245 250 255
Pro Glu Val Thr Cys Val Val Val Asp Val Ser Gln Glu Asp Pro Glu
260 265 270
Val Gln Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys
275 280 285
Thr Lys Pro Arg Glu Glu Gln Phe Asn Ser Thr Tyr Arg Val Val Ser
290 295 300
Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys
305 310 315 320
Cys Lys Val Ser Asn Lys Gly Leu Pro Ser Ser Ile Glu Lys Thr Ile
325 330 335
Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro
340 345 350
Pro Ser Gln Glu Glu Met Thr Lys Asn Gln Val Ser Leu Thr Cys Leu
355 360 365
Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn
370 375 380
Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser
385 390 395 400
Asp Gly Ser Phe Phe Leu Tyr Ser Arg Leu Thr Val Asp Lys Ser Arg
405 410 415
Trp Gln Glu Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu
420 425 430
His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Leu Gly Lys
435 440 445
<210> 250
<211> 218
<212> Протеин
<213> Искусственная последовательность
<220>
<223> Описание искусственной последовательности : Синтетический
полипептид
<400> 250
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Leu Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Lys Gly Val Ser Thr Ser
20 25 30
Gly Tyr Ser Tyr Leu His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro
35 40 45
Arg Leu Leu Ile Tyr Leu Ala Ser Tyr Leu Glu Ser Gly Val Pro Ala
50 55 60
Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser
65 70 75 80
Ser Leu Glu Pro Glu Asp Phe Ala Val Tyr Tyr Cys Gln His Ser Arg
85 90 95
Asp Leu Pro Leu Thr Phe Gly Gly Gly Thr Lys Val Glu Ile Lys Arg
100 105 110
Thr Val Ala Ala Pro Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln
115 120 125
Leu Lys Ser Gly Thr Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr
130 135 140
Pro Arg Glu Ala Lys Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser
145 150 155 160
Gly Asn Ser Gln Glu Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr
165 170 175
Tyr Ser Leu Ser Ser Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys
180 185 190
His Lys Val Tyr Ala Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro
195 200 205
Val Thr Lys Ser Phe Asn Arg Gly Glu Cys
210 215
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| ВИДЫ КОМБИНИРОВАННОЙ ТЕРАПИИ С ИСПОЛЬЗОВАНИЕМ ХИМЕРНЫХ АНТИГЕННЫХ РЕЦЕПТОРОВ И ИНГИБИТОРОВ PD-1 | 2017 |
|
RU2809160C2 |
| РЕЖИМ ДОЗИРОВАНИЯ ИНГИБИТОРА WNT И МОЛЕКУЛЫ АНТИТЕЛА К PD-1 В КОМБИНАЦИИ | 2018 |
|
RU2767533C2 |
| РЕЖИМ ВВЕДЕНИЯ ДОЗ ДЛЯ ЛЕЧЕНИЯ ЗАБОЛЕВАНИЯ, МОДУЛИРУЕМОГО CSF-1R | 2021 |
|
RU2835316C1 |
| 1-(4-АМИНО-5-БРОМ-6-(1H-ПИРАЗОЛ-1-ИЛ)ПИРИМИДИН-2-ИЛ)-1H-ПИРАЗОЛ-4-ОЛ И ЕГО ПРИМЕНЕНИЕ В ЛЕЧЕНИИ РАКА | 2018 |
|
RU2791531C2 |
| МОЛЕКУЛЫ АНТИТЕЛ К CD73 И ПУТИ ИХ ПРИМЕНЕНИЯ | 2018 |
|
RU2791192C2 |
| АНТИТЕЛА К ENTPD2, ВИДЫ КОМБИНИРОВАННОЙ ТЕРАПИИ И СПОСОБЫ ПРИМЕНЕНИЯ АНТИТЕЛ И ВИДОВ КОМБИНИРОВАННОЙ ТЕРАПИИ | 2019 |
|
RU2790991C2 |
| МОНОКЛОНАЛЬНОЕ АНТИТЕЛО ИЛИ ЕГО АНТИГЕНСВЯЗЫВАЮЩИЙ ФРАГМЕНТ, КОТОРОЕ СПЕЦИФИЧЕСКИ СВЯЗЫВАЕТСЯ С IL-4Rα, И ЕГО ПРИМЕНЕНИЕ | 2021 |
|
RU2808563C2 |
| МОЛЕКУЛЫ АНТИТЕЛ К PD-1 И ИХ ПРИМЕНЕНИЯ | 2016 |
|
RU2788092C2 |
| НОВАЯ КОМБИНАЦИЯ ДЛЯ ПРИМЕНЕНИЯ ПРИ ЛЕЧЕНИИ ЗЛОКАЧЕСТВЕННОГО НОВООБРАЗОВАНИЯ | 2016 |
|
RU2742494C2 |
| АНТИТЕЛА К РЕЦЕПТОРУ-1 НАТРИЙУРЕТИЧЕСКОГО ПЕПТИДА И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2020 |
|
RU2827871C2 |
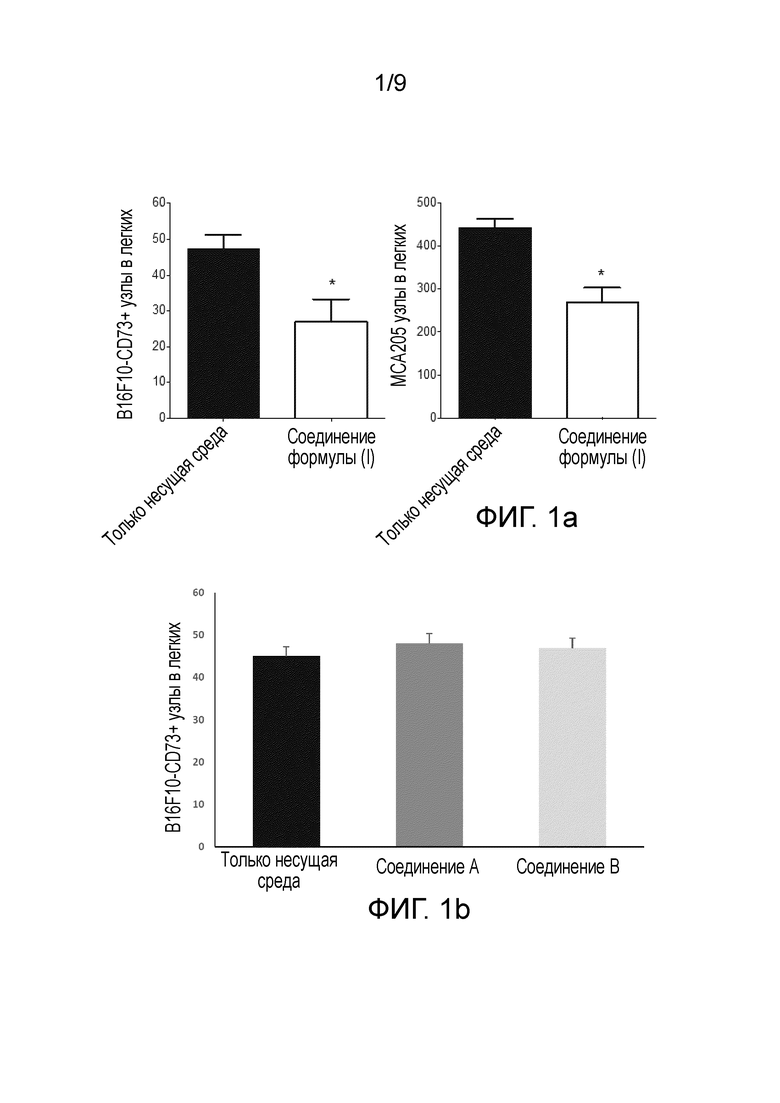

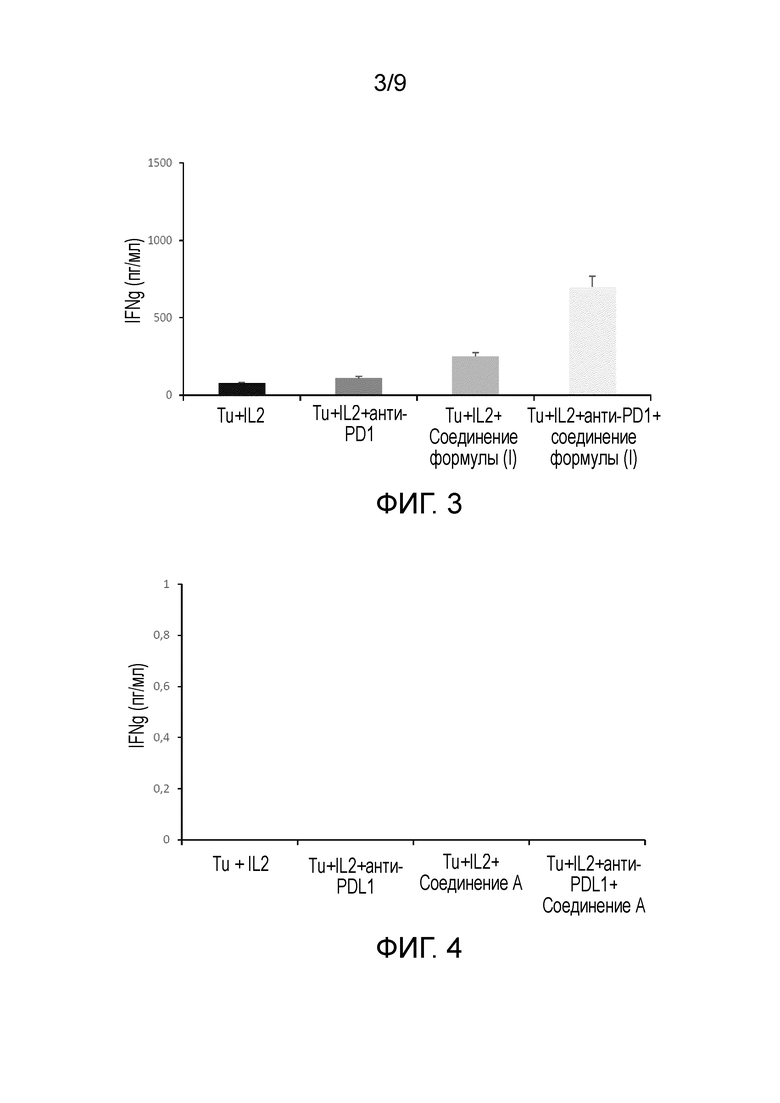
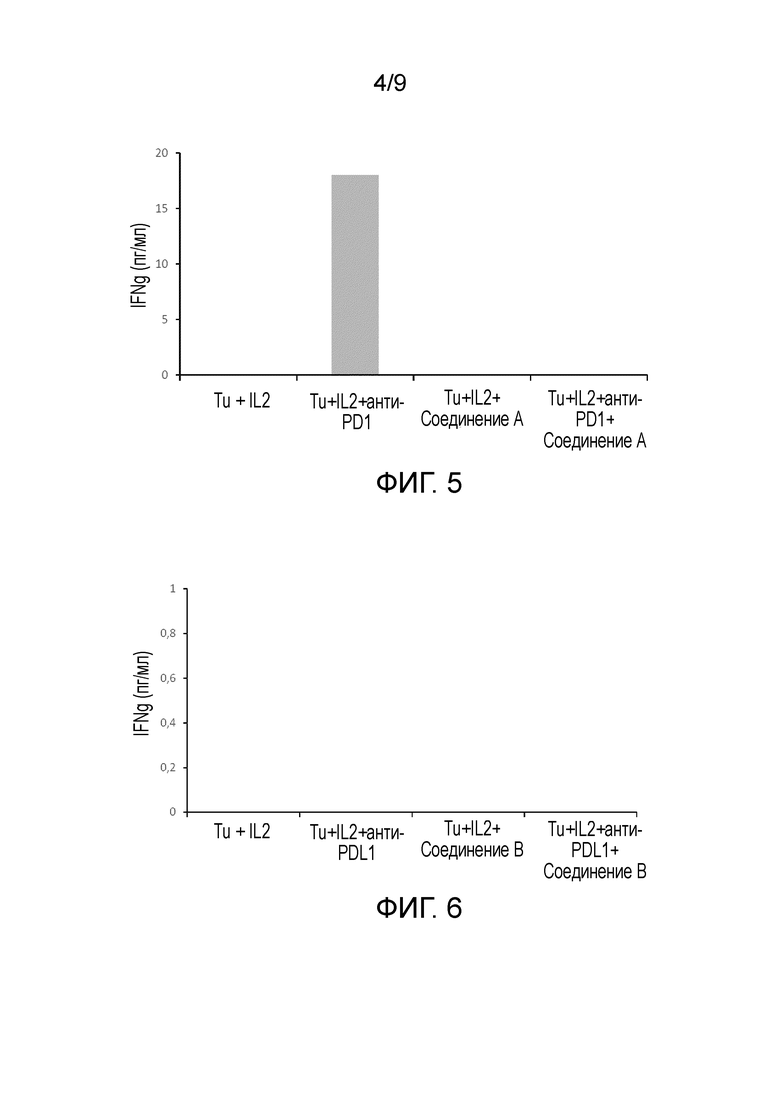
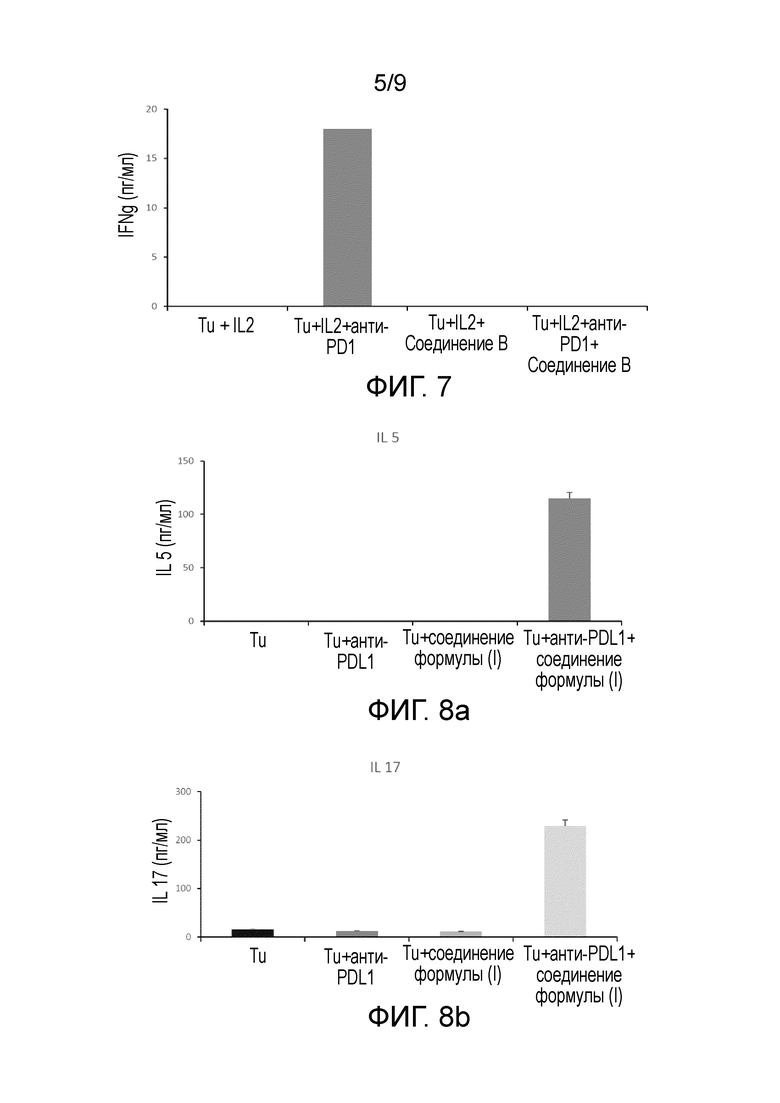
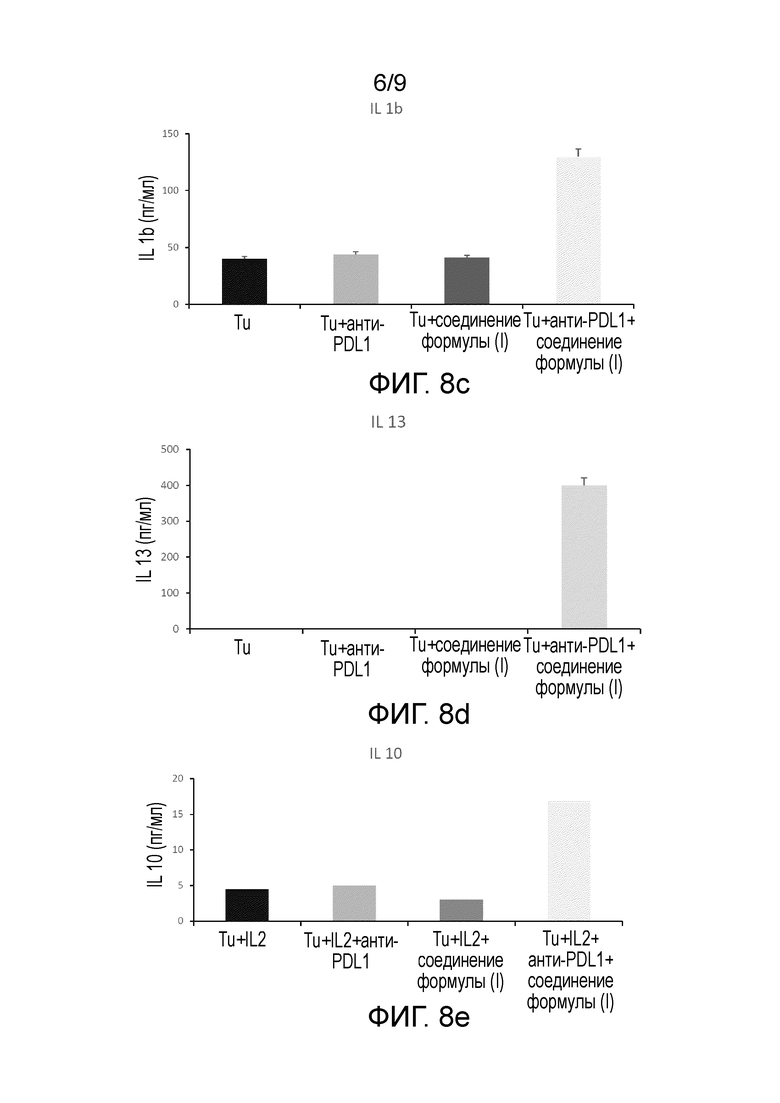
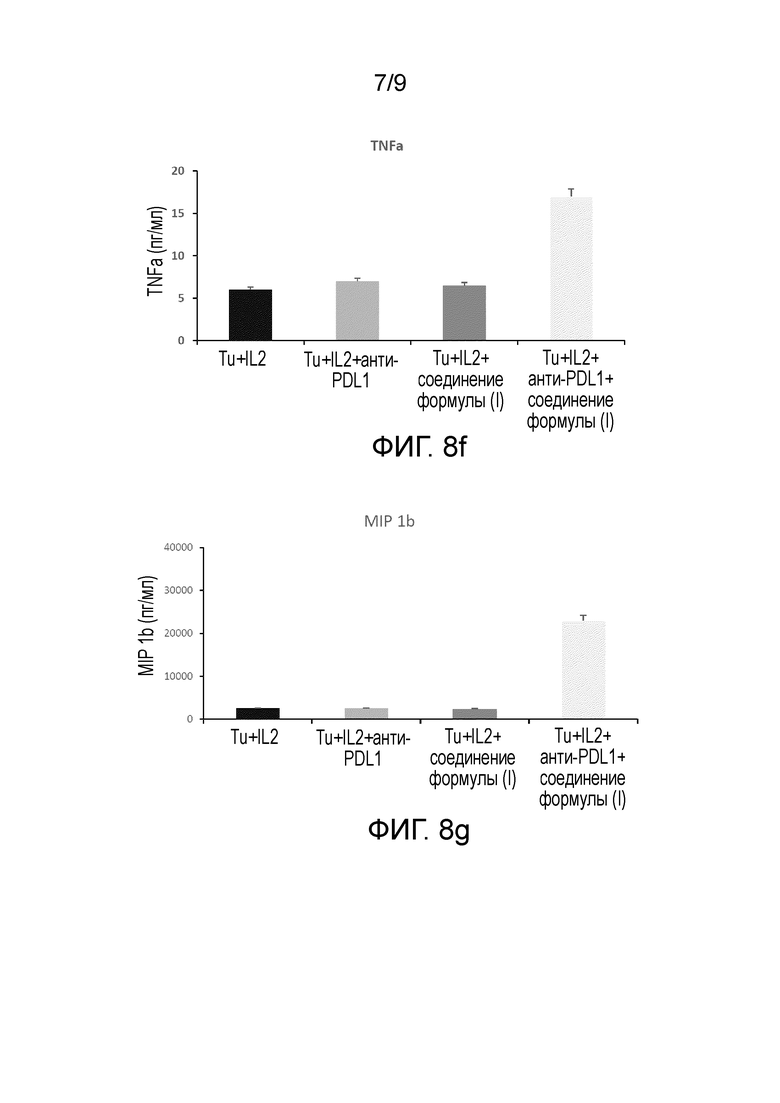
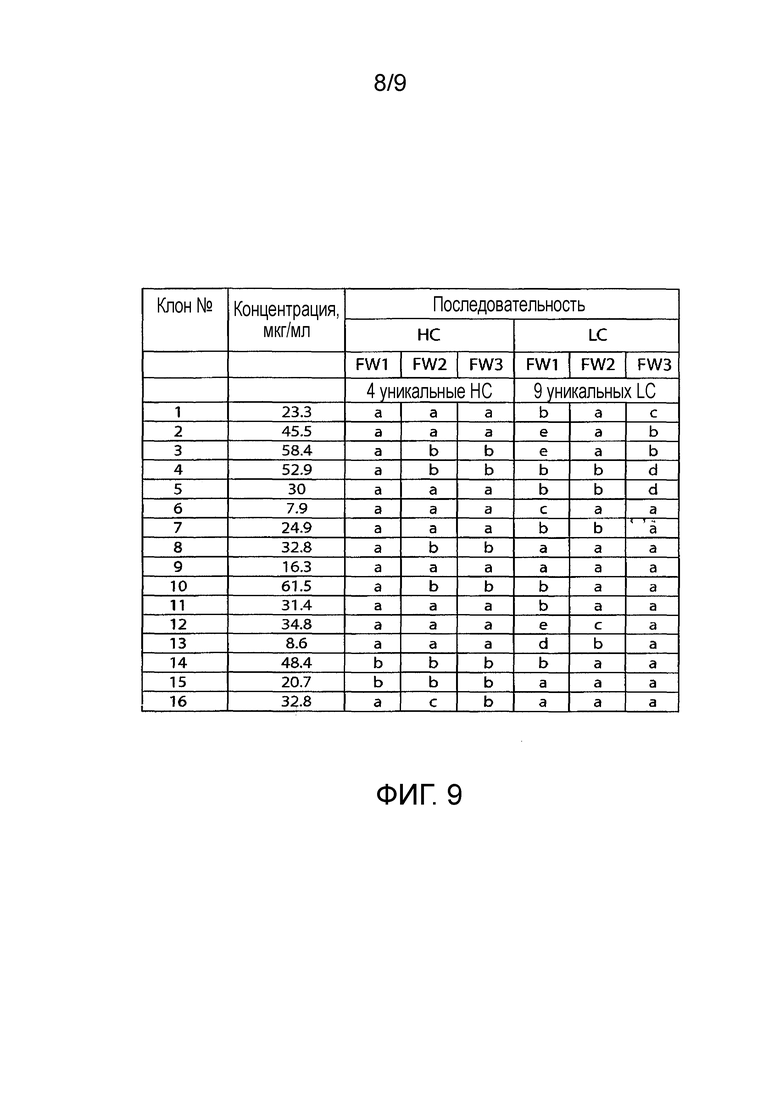
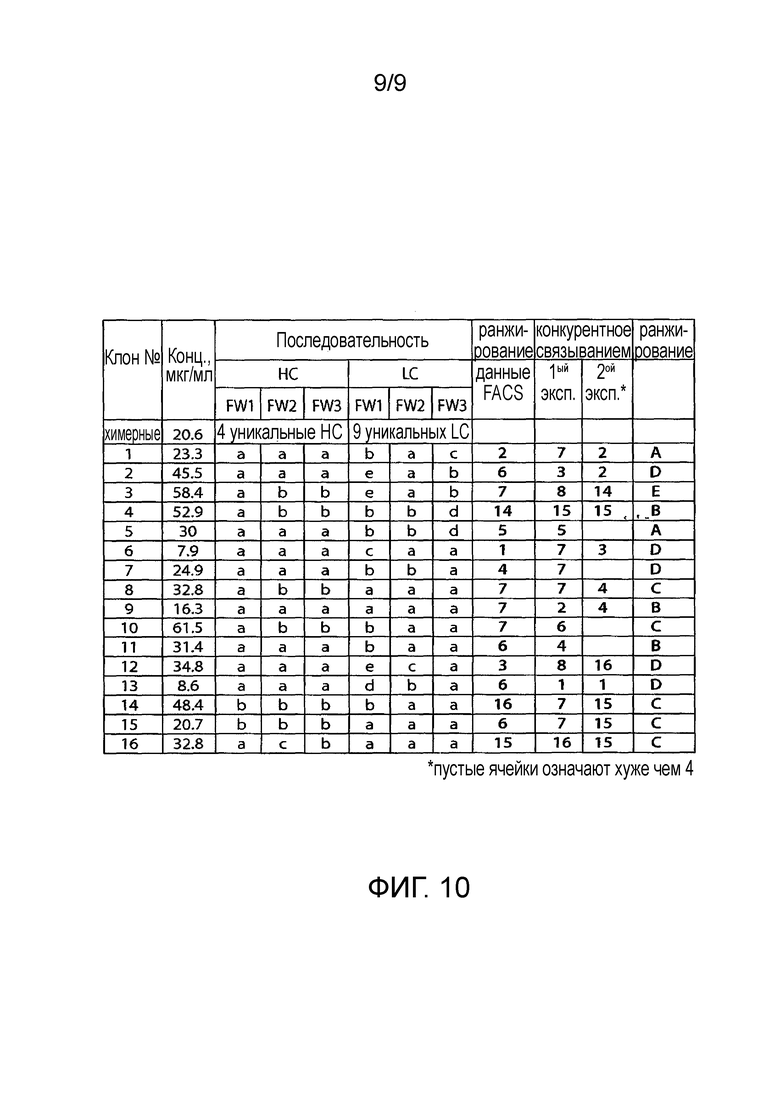
Группа изобретений относится к биотехнологии и медицине. Предложены фармацевтическая комбинация и способ для лечения немелкоклеточного рака легких на основе 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амина, а также применение 5-бром-2,6-ди-(1Н-пиразол-1-ил)пиримидин-4-амина для лечения рака. Фармацевтическая комбинация содержит терапевтически эффективное количество 5-бром-2,6-ди(1Н-пиразол-1-ил)пиримидин-4-амина формулы (I): 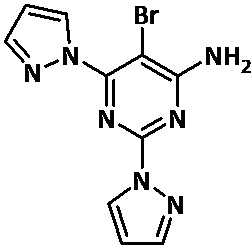 , или его фармацевтически приемлемую соль и один или более иммунотерапевтических агентов, выбранных из группы, состоящей из анти-CTLA4 антитела, анти-PD-1 антитела и анти-PD-L1 антитела. Пероральное введение соединения формулы (I) в значительной степени уменьшает опухолевую массу, кроме того соединение формулы (I) показало синергетический эффект с иммунотерапевтическими агентами в стимуляции иммунной системы для лечения рака. 3 н. и 28 з.п. ф-лы, 10 ил., 4 табл., 4 пр.
, или его фармацевтически приемлемую соль и один или более иммунотерапевтических агентов, выбранных из группы, состоящей из анти-CTLA4 антитела, анти-PD-1 антитела и анти-PD-L1 антитела. Пероральное введение соединения формулы (I) в значительной степени уменьшает опухолевую массу, кроме того соединение формулы (I) показало синергетический эффект с иммунотерапевтическими агентами в стимуляции иммунной системы для лечения рака. 3 н. и 28 з.п. ф-лы, 10 ил., 4 табл., 4 пр.
1. Фармацевтическая комбинация, содержащая терапевтически эффективное количество соединения формулы (I):
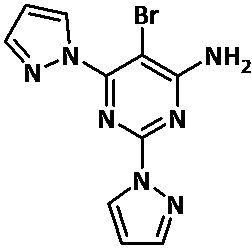 (I)
(I)
или его фармацевтически приемлемую соль и один или более иммунотерапевтических агентов, выбранных из группы, состоящей из анти-CTLA4 антитела, анти-PD-1 антитела и анти-PD-L1 антитела, для лечения немелкоклеточного рака легких.
2. Фармацевтическая комбинация по п. 1, где иммунотерапевтический агент выбран из группы, состоящей из ипилимумаба, тремелимумаба, ниволумаба, пембролизумаба, CT-011, AMP-224, MPDL3280A, MEDI4736 и MDX-1105.
3. Фармацевтическая комбинация по п. 2, где иммунотерапевтический агент выбран из группы, состоящей из MPDL3280A, MEDI4736 и MDX-1105.
4. Фармацевтическая комбинация по п. 1, где иммунотерапевтический агент выбран из группы, состоящей из ниволумаба, пембролизумаба, пидилизумаба и AMP-224.
5. Фармацевтическая комбинация по п. 1, где иммунотерапевтический агент представляет собой анти-PD-1 антитело.
6. Фармацевтическая комбинация по п. 5, где анти-PD-1 антитело содержит:
(а) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 4, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33;
(b) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 1; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32;
(с) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33; или
(d) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32.
7. Фармацевтическая комбинация по п.1, где анти-PD-1 антитело содержит вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность SEQ ID NO: 38, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность SEQ ID NO: 70.
8. Фармацевтическая комбинация по п. 1, в которой анти-PD-1 антитело содержит тяжелую цепь, содержащую аминокислотную последовательность SEQ ID NO: 91, и легкую цепь, содержащую аминокислотную последовательность SEQ ID NO: 72.
9. Фармацевтическая комбинация по п. 1, где иммунотерапевтический агент представляет собой анти-PD-L1 антитело.
10. Фармацевтическая комбинация по п. 9, где молекула анти-PD-L1 антитела содержит:
(а) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 228, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 229, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 233, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 234, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 235;
(b) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 225; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 226; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 230, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 231, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 232;
(с) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 244; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 229; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 233, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 234, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 235; или
(d) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 244; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 226; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 230, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 231, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 232.
11. Фармацевтическая комбинация по п. 1, где молекула анти-PD-L1 антитела содержит вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность SEQ ID NO: 236, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность SEQ ID NO: 239.
12. Фармацевтическая комбинация по п. 1, где комбинацию иммунотерапевтического агента вводят вместе в одной композиции или вводят раздельно в двух или более различных формах композиций.
13. Фармацевтическая комбинация по п. 1, где иммунотерапевтический агент вводят одновременно или до, или после введения соединения формулы (I).
14. Способ лечения немелкоклеточного рака легких, включающий введение нуждающемуся в этом субъекту терапевтически эффективного количества соединения формулы (I):
(I)
или его фармцевтически приемлемой соли отдельно или в комбинации с одним или более иммунотерапевтическими агентами, выбранными из группы, состоящей из анти-CTLA4 антител, анти-PD-1 антител и анти-PD-L1 антител.
15. Способ по п. 14, где иммунотерапевтический агент выбран из группы, состоящей из ипилимумаба, тремелимумаба, ниволумаба, пембролизумаба, CT-011, AMP-224, MPDL3280A, MEDI4736 и MDX-1105.
16. Способ по п. 15, где иммунотерапевтический агент выбран из группы, состоящей из MPDL3280A, MEDI4736 и MDX-1105.
17. Способ по п. 14, где иммунотерапевтический агент выбран из группы, состоящей из ниволумаба, пембролизумаба, пидилизумаба и AMP-224.
18. Способ по п. 14, где иммунотерапевтический агент представляет собой анти-PD-1 антитело.
19. Способ по п. 14, где анти-PD-1 антитело содержит:
(а) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 4, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33;
(b) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 1; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32;
(с) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 5; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 13, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 14, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 33; или
(d) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 224; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 2; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 3; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 10, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 11, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 32.
20. Способ по п. 14, где анти-PD-1 антитело содержит вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность SEQ ID NO: 38, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность SEQ ID NO: 70.
21. Способ по п. 14, в котором анти-PD-1 антитело содержит тяжелую цепь, содержащую аминокислотную последовательность SEQ ID NO: 91, и легкую цепь, содержащую аминокислотную последовательность SEQ ID NO: 72.
22. Способ по п. 14, где молекулу анти-PD-1 антитела вводят в дозе примерно 300 мг один раз в три недели.
23. Способ по п. 14, где молекулу анти-PD-1 антитела вводят в дозе примерно 400 мг один раз в четыре недели.
24. Способ по п. 14, где иммунотерапевтический агент представляет собой анти-PD-L1 антитело.
25. Способ по п. 14, где молекула анти-PD-L1 антитела содержит:
(а) вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 228, аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 229, и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 233, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 234, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 235;
(b) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 225; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 226; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 230, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 231, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 232;
(с) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 244; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 229; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 233, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 234, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 235; или
(d) VH, содержащую аминокислотную последовательность VHCDR1, приведенную в SEQ ID NO: 244; аминокислотную последовательность VHCDR2, приведенную в SEQ ID NO: 226; и аминокислотную последовательность VHCDR3, приведенную в SEQ ID NO: 227; и VL, содержащую аминокислотную последовательность VLCDR1, приведенную в SEQ ID NO: 230, аминокислотную последовательность VLCDR2, приведенную в SEQ ID NO: 231, и аминокислотную последовательность VLCDR3, приведенную в SEQ ID NO: 232.
26. Способ по п. 14, где молекула анти-PD-L1 антитела содержит вариабельный домен тяжелой цепи, содержащий аминокислотную последовательность SEQ ID NO: 236, и вариабельный домен легкой цепи, содержащий аминокислотную последовательность SEQ ID NO: 239.
27. Способ по п. 14, где комбинацию иммунотерапевтического агента вводят вместе в одной композиции или вводят раздельно в двух или более различных формах композиций.
28. Способ по п. 14, где иммунотерапевтический агент вводят одновременно или до, или после введения соединения формулы (I).
29. Применение соединения формулы (I):
(I);
для лечения рака.
30. Применение по п. 29, где рак представляет собой рак легких.
31. Применение по п. 30, где рак представляет собой немелкоклеточный рак легких.
| ПОСАДОЧНАЯ МАШИНА | 1930 |
|
SU21565A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Клапанный регулятор для паровозов | 1919 |
|
SU103A1 |
| Скоропечатный станок для печатания со стеклянных пластинок | 1922 |
|
SU35A1 |
| Мягчильный аппарат для сыромятных кож | 1927 |
|
SU13132A1 |
| BRAHMER J.R., PARDOLL D.M | |||
| Immune checkpoint inhibitors: making immunotherapy a reality for the treatment of lung cancer | |||

