Настоящее изобретение относится к отделению (выделению) источников аудиосигналов, в частности, к адаптивному сигнальному управлению качеством звука отделенных выходных сигналов и, в частности, к устройству и способу отделения источников с использованием оценки и управления качеством звука.
При отделении источников качество выходных сигналов ухудшается, и это ухудшение монотонно увеличивается вместе с ослаблением сигналов помех.
Отделение источников аудиосигналов проводилось в прошлом.
Отделение (выделение) источников аудиосигналов направлено на получение целевого сигнала 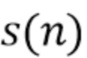 при заданном совокупном сигнале
при заданном совокупном сигнале 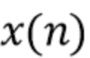 ,
,
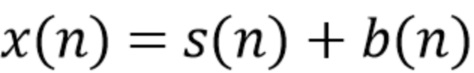 (1),
(1),
где 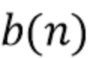 содержит все сигналы помех и в дальнейшем называется "сигналом помех". Результатом отделения
содержит все сигналы помех и в дальнейшем называется "сигналом помех". Результатом отделения 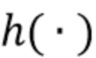 является оценка целевого сигнала
является оценка целевого сигнала 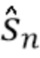 ,
,
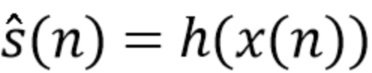 (2)
(2)
и, возможно, дополнительно оценку сигнала помех 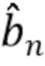 ,
,
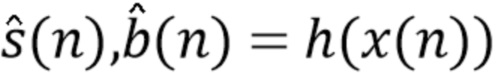 (3)
(3)
Такая обработка обычно вносит артефакты в выходной сигнал, которые ухудшают качество звука. Это ухудшение качества звука монотонно увеличивается с величиной отделения, ослабления сигналов помех. Во многих приложениях не требуется полное отделение, а частичное усиление, звуки помех ослаблены, но все еще присутствуют в выходном сигнале.
Это имеет дополнительное преимущество в том, что качество звука выше, чем в полностью отделенных сигналах, поскольку вносится меньше артефактов, а утечка сигналов помех частично маскирует воспринимаемые артефакты.
Частичная маскировка аудиосигнала означает, что его громкость (например, воспринимаемая интенсивность) частично снижается. Кроме того, может быть желательно и необходимо, чтобы вместо достижения большого ослабления качество звука на выходе не опускалось ниже заданного уровня качества звука.
Примером такого применения является улучшение диалога. Аудио сигналы в теле- и радиовещании и звук в фильмах часто представляют собой смешение речевых сигналов и фоновых сигналов, например, звуков окружающей среды и музыки. Когда эти сигналы смешиваются таким образом, что уровень речи слишком низок по сравнению с уровнем фона, у слушателя могут возникнуть трудности с пониманием того, что было сказано, или понимание требует очень больших усилий при прослушивании, и это приводит к утомлению слушателя. В таких сценариях могут быть применены способы автоматического снижения уровня фона, но результат должен иметь высокое качество звука.
На предшествующем уровне техники существуют различные способы отделения источников. Отделение целевого сигнала из смешения сигналов обсуждалось на предшествующем уровне техники. Эти способы можно разделить категориями на два подхода. Первая категория способов основана на сформулированных предположениях о модели сигнала и/или модели смешивания. Модель сигнала описывает характеристики входных сигналов, здесь и . Модель смешивания описывает характеристики того, как входные сигналы объединяются для получения смешенного сигнала , здесь посредством сложения.
На основе этих предположений способ разрабатывается аналитически или эвристически. Например, способ независимого компонентного анализа (Independent Component Analysis) может быть получен, если предположить, что смешение содержит два исходных сигнала, которые статистически независимы, смешение была захвачено двумя микрофонами, и смешивание было получено путем сложения обоих сигналов (производящего мгновенное смешение). Обратный процесс смешивания затем математически выводится как инверсия матрицы смешивания, и элементы этой матрицы отделения смешивания вычисляются в соответствии с указанным способом. Большинство аналитических способов получены путем формулировки задачи отделения как численной оптимизации критерия, например, среднеквадратичной ошибки между истинной целью и оцененной целью.
Вторая категория управляется данными. В этом случае оценивается представление целевых сигналов или оценивается набор параметров для извлечения целевых сигналов из входного смешения. Оценка основана на модели, которая была обучена на наборе обучающих данных, отсюда название "управляемая данными". Оценка получается путем оптимизации критерия, например, путем минимизации среднеквадратичной ошибки между истинной целью и оцененной целью, учитывая обучающие данные. Примером для этой категории являются искусственные нейронные сети (Artificial Neural Networks, ANN), которые были обучены выдавать оценку речевого сигнала при наличии смешения речевого сигнала и сигнала помех. Во время обучения регулируемые параметры искусственной нейронной сети определяются таким образом, чтобы критерий производительности, вычисленный для набора обучающих данных, был оптимизирован - в среднем по всему набору данных.
Что касается отделения источников, решение, оптимальное в смысле среднеквадратичной ошибки или оптимальное по любому другому числовому критерию, не обязательно является решением с наивысшим качеством звука, которое предпочитают люди-слушатели.
Вторая проблема связана с тем, что отделение источников всегда приводит к двум эффектам: во-первых, к желаемому ослаблению звуков помех и, во-вторых, к нежелательному ухудшению качества звука. Оба эффекта коррелированы, например, увеличение желаемого эффекта приводит к увеличению нежелательного эффекта. Конечная цель состоит в том, чтобы управлять компромиссом между ними.
Качество звука может быть оценено, например, количественно с помощью теста на прослушивание или с помощью вычислительных моделей качества звука. Качество звука имеет множество аспектов, в дальнейшем называемых компонентами качества звука (Sound Quality Components, SQC).
Например, качество звука определяется воспринимаемой интенсивностью артефактов (это компоненты сигнала, которые были внесены обработкой сигналов, например, отделением источников, и которые снижают качество звука).
Или, например, качество звука определяется воспринимаемой интенсивностью сигналов помех, или, например, разборчивостью речи (когда целевой сигнал является речью), или, например, общим качеством звука.
Существуют различные вычислительные модели качества звука, которые вычисляют (оценивают) компоненты качества звука, 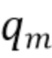 ,
, 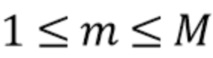 , где
, где 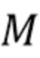 обозначает количество компонентов качества звука.
обозначает количество компонентов качества звука.
Такие способы обычно оценивают компонент качества звука с учетом целевого сигнала и оценки целевого сигнала,
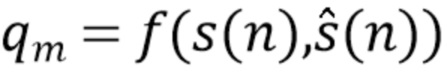 (4)
(4)
или учитывая также сигнал помех,
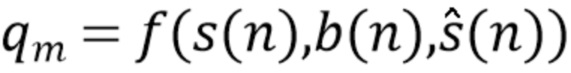 (5).
(5).
В практическом применении целевые сигналы (и сигналы помех ) не доступны, иначе не требовалось бы отделение. Когда доступны только входной сигнал и оценки целевого сигнала 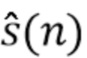 , компоненты качества звука не могут быть вычислены с помощью этих способов.
, компоненты качества звука не могут быть вычислены с помощью этих способов.
В предшествующем уровне техники были описаны различные вычислительные модели для оценки аспектов качества звука, включая разборчивость.
Оценка слепого отделения источников (Blind Source Separation Evaluation, BSSEval) (см. [1]) представляет собой набор инструментов для многокритериальной оценки производительности. Оцениваемый сигнал подвергается декомпозиции посредством ортогональной проекции на компонент целевого сигнала, помехи от других источников и артефакты. Метрики вычисляются как энергетические соотношения этих компонентов и выражаются в дБ. Этими метриками являются отношение источника (исходного сигнала) к искажениям (Source to Distortion Ratio, SDR), отношение источника к помехам (Source to Interference Ratio, SIR) и отношение источника к артефактам (Source to Artifact Ratio, SAR).
Способы перцептивной оценки отделения источников аудио (Perceptual Evaluation methods for Audio Source Separation, PEASS) (см. [2]) были разработаны как перцептивно мотивированный преемник способа BSSEval. Выполняется проекция сигнала на временных сегментах с помощью гамматонового фильтр-банка.
PEMO-Q (см. [3]) используется для обеспечения множественных признаков. Четыре оценки восприятия получаются из этих признаков с использованием нейронной сети, обученной с помощью субъективных оценок. Оценками восприятия являются: общая оценка восприятия (Overall Perceptual Score, OPS), оценка восприятия, связанная с помехами (Interference-related Perceptual Score, IPS), оценка восприятия, связанная с артефактами (Artifact-related Perceptual Score, APS) и оценка восприятия, связанная с целевым сигналом (Target-related Perceptual Score, TPS).
Оценка восприятия качества аудио (Perceptual Evaluation of Audio Quality, PEAQ) (см. [4]) представляет собой метрику, разработанную для аудиокодирования. Она использует периферийную модель уха для вычисления представлений базилярной мембраны опорного и испытательного сигнала. Аспекты различия между этими представлениями определяются количественно несколькими выходными переменными. Посредством нейронной сети, обученной с помощью субъективных данных, эти переменные объединяются, чтобы получить основной результат, например, общую оценку различий (Overall Difference Grade, ODG).
Оценка восприятия качества речи (Perceptual Evaluation of Speech Quality, PESQ) (см. [5]) представляет собой метрику, разработанную для речи, передаваемой по телекоммуникационным сетям. Следовательно, способ содержит предварительную обработку, которая имитирует телефонную трубку. Показатели для звуковых помех вычисляются по заданной громкости сигналов и объединяются в оценках PESQ. На их основе прогнозируется оценка MOS посредством полиномиальной функции отображения (см. [6]).
ViSQOLAudio (см. [7]) представляет собой метрику, разработанную для музыки, закодированной на низких битовых скоростях, разработанную на основе виртуального объективного слушателя качества речи (Virtual Speech Quality Objective Listener, ViSQOL). Обе метрики основаны на модели периферийной слуховой системы, чтобы создать внутренние представления сигналов, названных нейрограммами. Они сравниваются через адаптацию индекса структурного сходства, первоначально разработанного для оценки качества сжатых изображений.
Индекс качества аудио слуховых аппаратов (Hearing-Aid Audio Quality Index, HAAQI) (см. [8]) представляет собой индекс, предназначенный для прогнозирования качества музыки для людей, использующих слуховые аппараты. Индекс основан на модели слуховой периферии, расширенной для учета последствий потери слуха. Это соответствует базе данных оценок качества, сделанных слушателями с нормальным или ослабленным слухом. Моделирование потери слуха можно обойти, и индекс становится действительным также для людей с нормальным слухом. Основываясь на той же слуховой модели, авторы HAAQI также предложили индекс качества речи - индекс качества речи слуховых аппаратов (Hearing-Aid Speech Quality Index, HASQI) (см. [9]), и индекс разборчивости речи - индекс восприятия речи слуховых аппаратов (Hearing-Aid Speech Perception Index, HASPI) (см. [10]).
Кратковременная объективная разборчивость (Short-Time Objective Intelligibility, STOI) (см. [11]) представляет собой показатель, который, как ожидается, будет иметь монотонное соотношение со средней разборчивостью речи. Она особенно относится к речи, обработанной с помощью некоторого частотно-временного взвешивания.
В [12] искусственная нейронная сеть обучается таким образом, чтобы оценивать отношение источника к искажению, учитывая только входной сигнал и выходной оцененный целевой сигнал, где вычисление отношения источника к искажению обычно принимало бы в качестве входных данных также истинную цель и сигнал помех. Множество алгоритмов отделения выполняется параллельно на одном и том же входном сигнале. Оценки отношения источника к искажению используются, чтобы выбрать для каждого временного интервала выходные данные алгоритма с наилучшим отношением источника к искажению. Следовательно, не сформулирован контроль над компромиссом между качеством звука и отделением, и не предложен контроль параметров алгоритма отделения. Кроме того, используется отношение источника к искажению, которое не мотивировано восприятием и, как было показано, плохо коррелировано с воспринимаемым качеством, например, в [13].
Кроме того, в последнее время появились работы по улучшению речи с помощью контролируемого обучения, в которых оценки компонентов качества звука интегрируются в функции затрат, в то время как традиционно модели улучшения речи оптимизируются на основе среднеквадратичной ошибки (MSE) между оцененной и чистой речью. Например, в [14], [15], [16] используются функции затрат на основе STOI, а не на MSE. В [17] используется обучение с подкреплением на основе PESQ или PEASS. Тем не менее, отсутствует контроль над компромиссом между качеством звука и отделением.
В [18] предложено устройство обработки аудио, в котором показатель слышимости используется вместе с показателем идентификации артефактов для управления частотно-временным усилением, применяемым обработкой. Это делается, например, для того чтобы обеспечить максимальное снижение уровня шума при условии отсутствия артефактов, компромисс между качеством звука и отделением фиксирован. Кроме того, система не предполагает контролируемого обучения. Для выявления артефактов используется коэффициент эксцесса, показатель, который напрямую сравнивает выходные и входные сигналы (возможно, в сегментах, где отсутствует речь), без необходимости определения истинной цели и сигнала помех. Этот простой показатель дополняется показателем слышимости.
Задача настоящего изобретения состоит в том, чтобы обеспечить улучшенные концепции для отделения источников. Задача настоящего изобретения решена посредством устройства по п. 1, способа по п. 16 и компьютерной программы по п. 17 формулы изобретения.
Обеспечено устройство для формирования отделенного аудиосигнала из входного аудиосигнала. Входной аудиосигнал содержит участок целевого аудиосигнала и участок разностного аудиосигнала. Участок разностного аудиосигнала указывает разность между входным аудиосигналом и участком целевого аудиосигнала. Устройство содержит разделитель источника, модуль определения и процессор сигналов. Разделитель источника сконфигурирован для определения оцененного целевого сигнала, который зависит от входного аудиосигнала, оцененный целевой сигнал является оценкой сигнала, который содержит только участок целевого аудиосигнала. Модуль определения сконфигурирован для определения одного или нескольких результирующих значений в зависимости от оцененного качества звука оцененного целевого сигнала, чтобы получить одно или несколько значений параметров, причем одно или несколько значений параметров представляют собой одно или несколько результирующих значений или зависят от одного или нескольких результирующих значений. Процессор сигналов сконфигурирован для формирования отделенного аудиосигнала в зависимости от одного или нескольких значений параметров и в зависимости по меньшей мере от одного из оцененного целевого сигнала и входного аудиосигнала и оцененного разностного сигнала, причем оцененный разностный сигнал является оценкой сигнала, который содержит только участок разностного аудиосигнала.
Кроме того, обеспечен способ формирования отделенного аудиосигнала из входного аудиосигнала. Входной аудиосигнал содержит участок целевого аудиосигнала и участок разностного аудиосигнала. Участок разностного аудиосигнала указывает разность между входным аудиосигналом и участком целевого аудиосигнала. Способ содержит:
- определение оцененного целевого сигнала, который зависит от входного аудиосигнала, оцененный целевой сигнал является оценкой сигнала, который содержит только участок целевого аудиосигнала;
- определение одного или нескольких результирующих значений в зависимости от оцененного качества звука оцененного целевого сигнала, чтобы получить одно или несколько значений параметров, причем одно или несколько значений параметров представляют собой одно или несколько результирующих значений или зависят от одного или нескольких результирующих значений; и
- формирование отделенного аудиосигнала в зависимости от одного или нескольких значений параметров и в зависимости по меньшей мере от одного из оцененного целевого сигнала и входного аудиосигнала и от оцененного разностного сигнала, оцененный разностный сигнал является оценкой сигнала, который содержит только участок разностного аудиосигнала.
Кроме того, обеспечена компьютерная программа для реализации описанного выше способа при ее исполнении на процессоре компьютера или процессоре сигналов.
Далее варианты осуществления настоящего изобретения описаны более подробно со ссылкой на следующие фигуры.
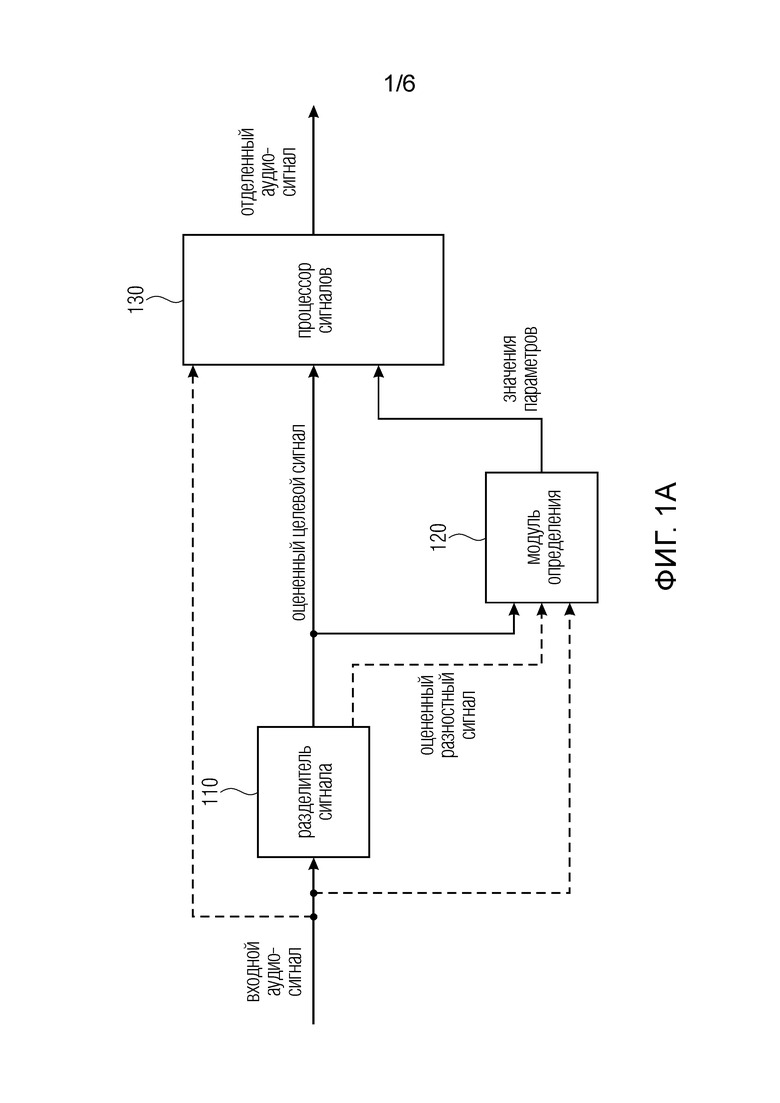
Фиг. 1a иллюстрирует устройство для формирования отделенного аудиосигнала из входного аудиосигнала в соответствии с вариантом осуществления,
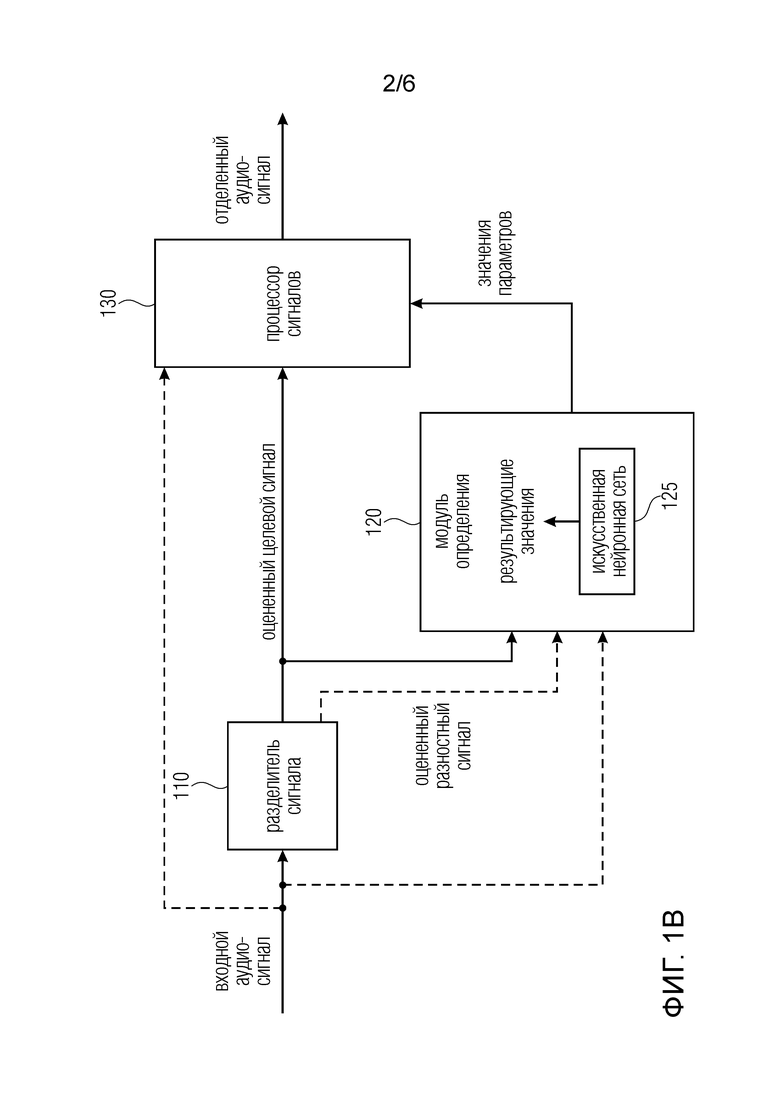
Фиг. 1b иллюстрирует устройство для формирования отделенного аудиосигнала в соответствии с другим вариантом осуществления, дополнительно содержащее искусственную нейронную сеть,
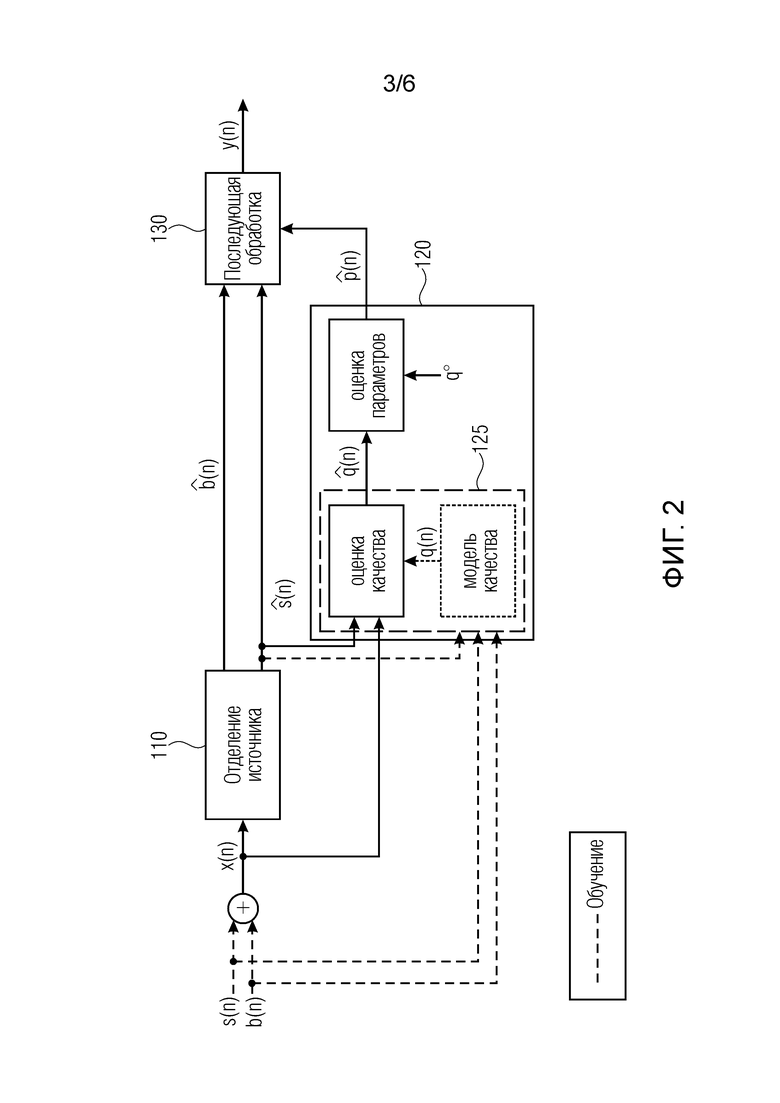
Фиг. 2 иллюстрирует устройство в соответствии с вариантом осуществления, которое сконфигурировано для использования оценки качества звука, и которое сконфигурировано для проведения последующей обработки,
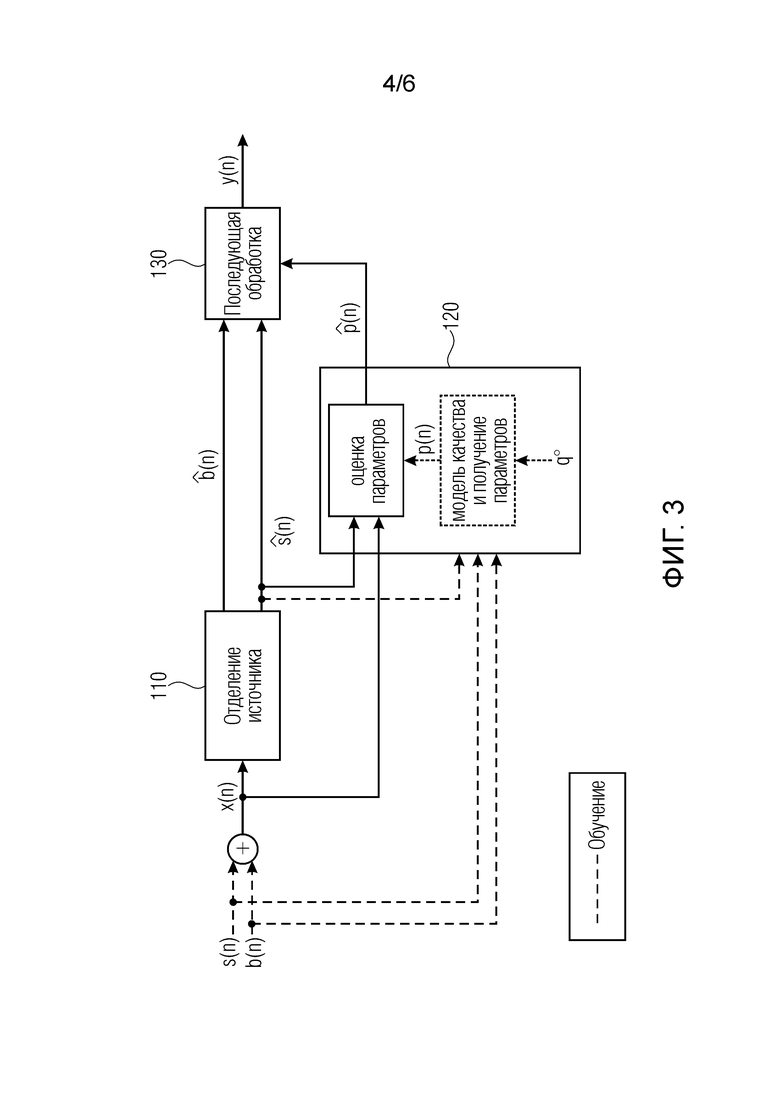
Фиг. 3 иллюстрирует устройство в соответствии с другим вариантом осуществления, в котором проводится прямая оценка параметров последующей обработки,
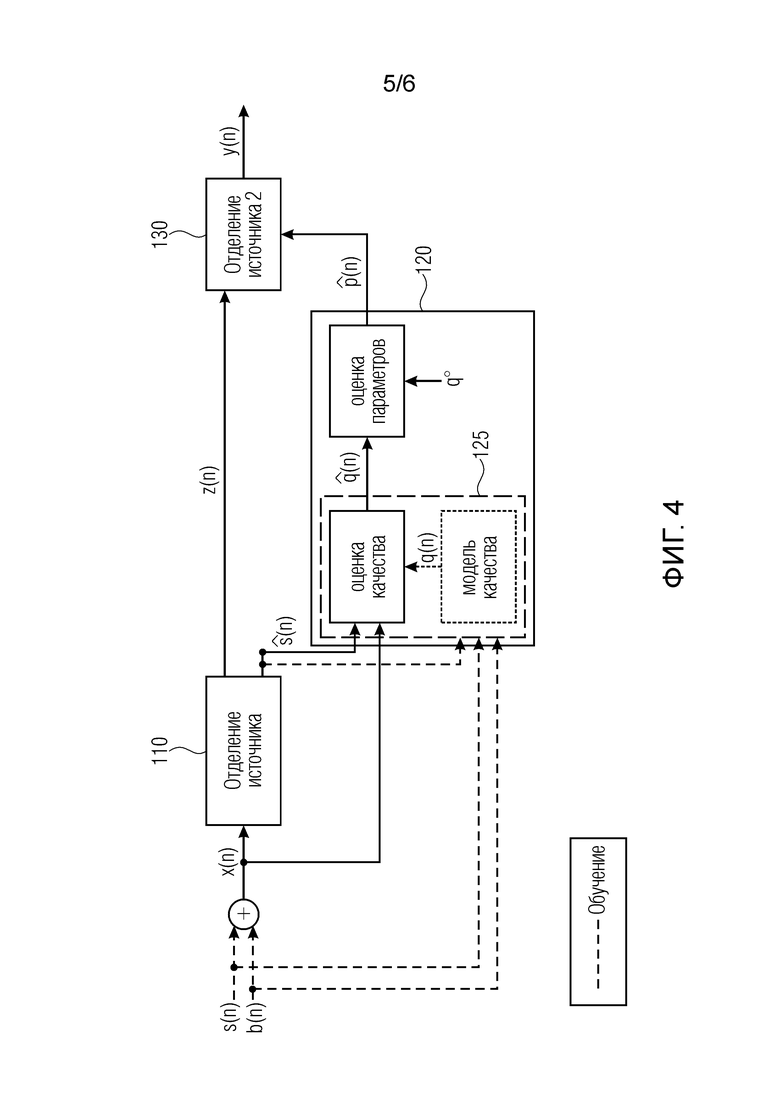
Фиг. 4 иллюстрирует устройство в соответствии с дополнительным вариантом осуществления, в котором проводится оценка качества звука и вторичное отделение, и
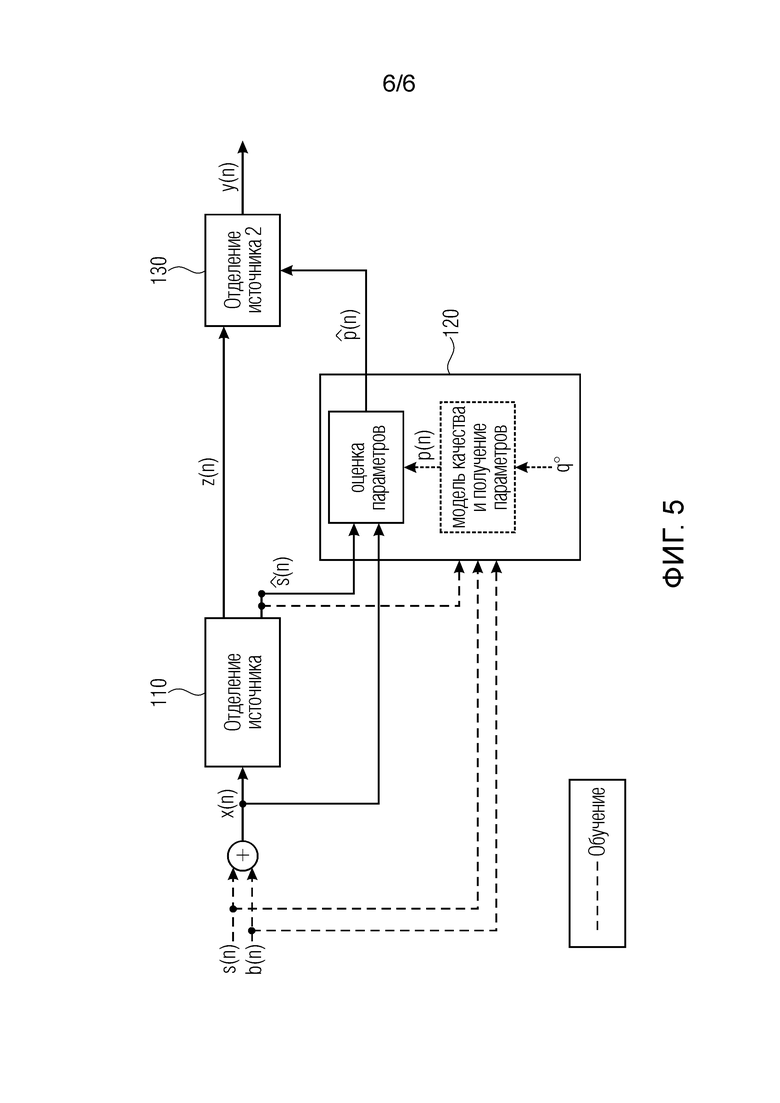
Фиг. 5 иллюстрирует устройство в соответствии с другим вариантом осуществления, в котором проводится прямая оценка параметров отделения.
Фиг. 1a иллюстрирует устройство для формирования отделенного аудиосигнала из входного аудиосигнала в соответствии с вариантом осуществления. Входной аудиосигнал содержит участок целевого аудиосигнала и участок разностного аудиосигнала. Участок разностного аудиосигнала указывает разность между входным аудиосигналом и участком целевого аудиосигнала.
Устройство содержит разделитель 110 источника, модуль 120 определения и процессор 130 сигналов.
Разделитель 110 источника сконфигурирован для определения оцененного целевого сигнала, который зависит от входного аудиосигнала, оцененный целевой сигнал является оценкой сигнала, который содержит только участок целевого аудиосигнала.
Модуль 120 определения сконфигурирован для определения одного или нескольких результирующих значений в зависимости от оцененного качества звука оцененного целевого сигнала, чтобы получить одно или несколько значений параметров, причем одно или несколько значений параметров представляют собой одно или несколько результирующих значений или зависят от одного или нескольких результирующих значений.
Процессор 130 сигналов сконфигурирован для формирования отделенного аудиосигнала в зависимости от одного или нескольких значений параметров и в зависимости по меньшей мере от одного из оцененного целевого сигнала и входного аудиосигнала и от оцененного разностного сигнала. Оцененный разностный сигнал является оценкой сигнала, который содержит только участок разностного аудиосигнала.
Факультативно в варианте осуществления модуль 120 определения, например, может быть сконфигурирован для определения одного или нескольких результирующих значений в зависимости от оцененного целевого сигнала и в зависимости по меньшей мере от одного из входного аудиосигнала и оцененного разностного сигнала.
Варианты осуществления обеспечивают мотивированное восприятием и адаптируемое к сигналу управление компромиссом между качеством звука и отделением c использованием контролируемого обучения. Это может быть достигнуто двумя способами. Первый способ оценивает качество звука выходного сигнала и использует эту оценку, чтобы адаптировать параметры отделения или последующую обработку отделенных сигналов. Во втором варианте осуществления регрессионный метод непосредственно выдает управляющие параметры, в результате чего качество звука выходного сигнала отвечает предварительно заданным требованиям.
В соответствии с вариантами осуществления анализ входного сигнала и выходного сигнала отделения проводится для получения оценки качества звука и определения параметров обработки на основе , чтобы качество звука на выходе (при использовании определенных параметров обработки) было не нижнее заданного значения качества.
В некоторых вариантах осуществления анализ выдает показатель качества в (9). Из показателя качества вычисляется управляющий параметр 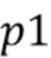 в формуле (13) ниже (например, масштабный коэффициент), и окончательные выходные данные получаются посредством микширования начальных выходных данных и входных данных, как в формуле (13) ниже. Вычисление
в формуле (13) ниже (например, масштабный коэффициент), и окончательные выходные данные получаются посредством микширования начальных выходных данных и входных данных, как в формуле (13) ниже. Вычисление  может выполняться итерационно или посредством регрессии, причем параметры регрессии получаются в результате обучения из набора обучающих сигналов, см. фиг. 2. В вариантах осуществления управляющий параметр может представлять собой не масштабный коэффициент, а, например, параметр сглаживания и т.п.
может выполняться итерационно или посредством регрессии, причем параметры регрессии получаются в результате обучения из набора обучающих сигналов, см. фиг. 2. В вариантах осуществления управляющий параметр может представлять собой не масштабный коэффициент, а, например, параметр сглаживания и т.п.
В некоторых вариантах осуществления анализ приводит к управляющему параметру в (13) непосредственно, см. фиг. 3.
Фиг. 4 и фиг. 5 определяют дополнительные варианты осуществления.
Некоторые варианты осуществления достигают управления качеством звука на этапе последующей обработки, как описано ниже.
Подмножество описанных в настоящем документе вариантов осуществления может применяться независимо от способа отделения. Некоторые описанные в настоящем документе варианты осуществления управляют процессом отделения.
Отделение источника c использованием спектрального взвешивания обрабатывает сигналы в частотно-временной области или кратковременной спектральной области. Входной сигнал преобразуется посредством оконного преобразования Фурье (STFT) или обрабатывается с помощью набора фильтров, что дает в результате комплекснозначные коэффициенты преобразования STFT или сигналы 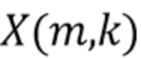 частотных подполос, где
частотных подполос, где 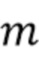 обозначает индекс временного кадра,
обозначает индекс временного кадра, 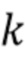 обозначает индекс частотного интервала или индекс частотной подполосы. Комплекснозначные коэффициенты преобразования STFT или сигналы частотных подполос требуемого сигнала представляют собой
обозначает индекс частотного интервала или индекс частотной подполосы. Комплекснозначные коэффициенты преобразования STFT или сигналы частотных подполос требуемого сигнала представляют собой 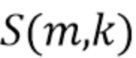 , и сигнал помех представляет собой
, и сигнал помех представляет собой 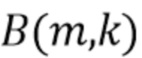 .
.
Отделенные (выделенные) выходные сигналы вычисляются посредством спектрального взвешивания как
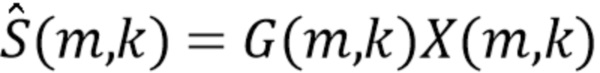 (6),
(6),
где спектральные весовые коэффициенты 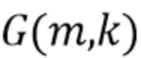 поэлементно умножаются на входной сигнал. Цель состоит в том, чтобы ослабить элементы в , где источник помех является большим. С этой целью спектральные весовые коэффициенты могут быть вычислены на основе оценки цели
поэлементно умножаются на входной сигнал. Цель состоит в том, чтобы ослабить элементы в , где источник помех является большим. С этой целью спектральные весовые коэффициенты могут быть вычислены на основе оценки цели 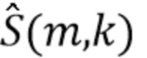 , оценки источника помех
, оценки источника помех 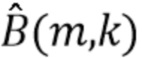 или оценки отношения сигнала к источнику помех, например,
или оценки отношения сигнала к источнику помех, например,
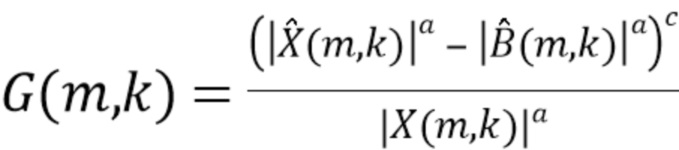 (7)
(7)
или
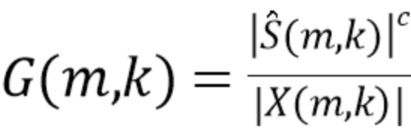 (8),
(8),
где 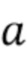 и
и 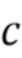 - параметры, управляющие отделением. Например, увеличение может привести к большему ослаблению источника помех, но также и к более сильному ухудшению качества звука. Спектральные весовые коэффициенты могут быть дополнительно модифицированы, например, посредством задания порога, чтобы
- параметры, управляющие отделением. Например, увеличение может привести к большему ослаблению источника помех, но также и к более сильному ухудшению качества звука. Спектральные весовые коэффициенты могут быть дополнительно модифицированы, например, посредством задания порога, чтобы 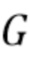 было больше порога. Модифицированные коэффициенты усиления
было больше порога. Модифицированные коэффициенты усиления 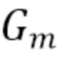 вычисляются как
вычисляются как
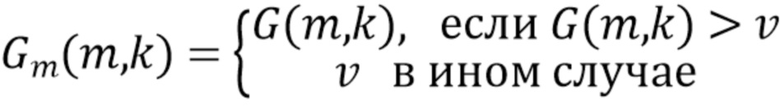 .
.
Увеличение порога v сокращает ослабление источника помех и сокращает потенциальное ухудшение качества звука.
Оценка требуемых величин (цели 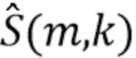 , источника помех или отношения сигнала к источнику помех) является основой этих способов, и в прошлом были разработаны различные способы оценки. Они следуют одному из двух описанных выше подходов.
, источника помех или отношения сигнала к источнику помех) является основой этих способов, и в прошлом были разработаны различные способы оценки. Они следуют одному из двух описанных выше подходов.
Затем выходной сигнал вычисляется с использованием обратной обработки преобразования STFT или набора фильтров.
Далее описывается отделение источника с использованием оценки целевого сигнала в соответствии с вариантами осуществления.
Представление целевого сигнала также может быть оценено непосредственно по входному сигналу, например, с помощью искусственной нейронной сети. Недавно были предложены различные способы, в которых искусственная нейронная сеть обучалась для оценки целевого временного сигнала, или его коэффициентов STFT, или величин коэффициентов STFT.
Что касается качества звука, компонент качества звука (SQC) получается посредством применения модели контролируемого обучения 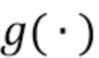 для оценки результатов этой вычислительной модели,
для оценки результатов этой вычислительной модели,
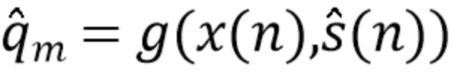 (9).
(9).
Способ контролируемого обучения реализован следующим образом.
1. Конфигурация модели контролируемого обучения с помощью обучаемых параметров, 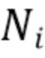 входных переменных и
входных переменных и 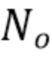 выходных переменных.
выходных переменных.
2. Формирование набора данных с помощью сигналов-примеров для цели и смешения .
3. Вычисление оценки для целевых сигналов посредством отделения источников, 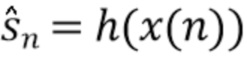 .
.
4. Вычисление компонентов качества звука из полученных сигналов посредством вычислительных моделей качества звука в соответствии с (9) или (10).
5. Обучение модели контролируемого обучения таким образом, чтобы она выдавала оценки 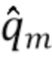 с учетом соответствующих сигналов-примеров для предполагаемой цели (результата отделения источников) и смешения . В качестве альтернативы, обучение модели контролируемого обучения таким образом, чтобы она выдавала оценки с учетом и
с учетом соответствующих сигналов-примеров для предполагаемой цели (результата отделения источников) и смешения . В качестве альтернативы, обучение модели контролируемого обучения таким образом, чтобы она выдавала оценки с учетом и 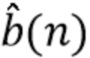 (если)
(если) 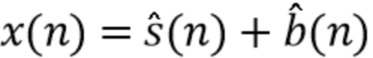 .
.
6. В применении обученная модель получает оцененную цель (результат отделения источников), полученную из смешения с использованием способа отделения источников вместе со смешением .
Обеспечено применение способов контролируемого обучения для контроля качества отделенного выходного сигнала.
Далее описывается оценка качества звука с использованием контролируемого обучения соответствии с вариантами осуществления.
Фиг. 1b иллюстрирует вариант осуществления, в котором модуль 120 определения содержит искусственную нейронную сеть 125. Искусственная нейронная сеть 125, например, может быть сконфигурирована для определения одного или нескольких результирующих значений в зависимости от оцененного целевого сигнала. Искусственная нейронная сеть 125, например, может быть сконфигурирована для приема множества входных значений, каждое из множества входных значений зависит по меньшей мере от одного из оцененного целевого сигнала и оцененного разностного сигнала и от входного аудиосигнала. Искусственная нейронная сеть 125, например, может быть сконфигурирована для определения одного или нескольких результирующих значений в качестве одного или нескольких выходных значений искусственной нейронной сети 125.
Факультативно в варианте осуществления искусственная нейронная сеть 125, например, может быть сконфигурирована для определения одного или нескольких результирующих значений в зависимости от оцененного целевого сигнала и по меньшей мере одного сигнала из входного аудиосигнала и оцененного разностного сигнала.
В варианте осуществления каждое из множества входных значений, например, может зависеть по меньшей мере от одного из оцененного целевого сигнала и оцененного разностного сигнала и от входного аудиосигнала. Одно или несколько результирующих значений, например, могут указывать оцененное качество звука оцененного целевого сигнала.
В соответствии с вариантом осуществления каждое из множества входных значений может, например, зависеть по меньшей мере от одного из оцененного целевого сигнала и оцененного разностного сигнала и от входного аудиосигнала. Одно или несколько результирующих значений, например, могут представлять собой одно или несколько значений параметров.
В варианте осуществления искусственная нейронная сеть 125, например, может быть сконфигурирована для обучения посредством приема множества наборов обучающих данных, причем каждый из множества наборов обучающих данных содержит множество входных обучающих значений искусственной нейронной сети 125 и одно или несколько выходных обучающих значений искусственной нейронной сети 125, причем каждое из множества выходных обучающих значений, например, может зависеть по меньшей мере от одного из обучающего целевого сигнала и обучающего разностного сигнала и от обучающего входного сигнала, причем каждое из одного или нескольких выходных обучающих значений, например, может зависеть от оценки качества звука обучающего целевого сигнала.
В вариантах осуществления оценка для компонента качества звука получается посредством контролируемого обучения с использованием модели контролируемого обучения (SLM), например, искусственной нейронной сети (Artificial Neural Network, ANN) 125. Искусственная нейронная сеть 125, например, может представлять собой полностью соединенную искусственную нейронную сеть 125, которая содержит входной слой с A блоками, по меньшей мере один скрытый слой с входными уровнями, каждый по меньшей мере с двумя блоками, и выходной слой с одним или несколькими блоками.
Модель контролируемого обучения может быть реализована как регрессионная модель или модель классификации. Регрессионная модель оценивает одно целевое значение на выходе одного блока в выходном слое. В качестве альтернативы задача регрессии может быть сформулирована как задача классификации посредством квантования выходного значения по меньшей на 3 этапа с использованием выходного слоя с 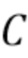 блоками, где равно количеству этапов квантования.
блоками, где равно количеству этапов квантования.
Для каждого этапа квантования используется один выходной блок.
Модель контролируемого обучения сначала обучается с помощью набора данных, который содержит несколько примеров смешенного сигнала 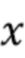 , оцененной цели
, оцененной цели 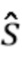 и компонента качества звука , где компонент качества звука был вычислен из оцененной цели и истинной цели
и компонента качества звука , где компонент качества звука был вычислен из оцененной цели и истинной цели 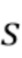 , например. Один элемент набора данных обозначен как
, например. Один элемент набора данных обозначен как 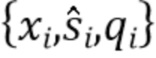 . Выходной результат модели контролируемого обучения здесь обозначен как
. Выходной результат модели контролируемого обучения здесь обозначен как 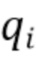 .
.
Количество блоков во входном слое 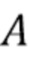 соответствует количеству входных значений. Вводы в модели вычисляются из входных сигналов. Каждый сигнал может быть факультативно обработан посредством набора фильтров частотно-временного преобразования, например, краткосрочного преобразования Фурье (STFT). Например, ввод может быть построен посредством конкатенации коэффициентов STFT, вычисленных из
соответствует количеству входных значений. Вводы в модели вычисляются из входных сигналов. Каждый сигнал может быть факультативно обработан посредством набора фильтров частотно-временного преобразования, например, краткосрочного преобразования Фурье (STFT). Например, ввод может быть построен посредством конкатенации коэффициентов STFT, вычисленных из 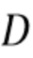 смежных кадров из
смежных кадров из 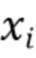 и
и 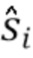 , где
, где 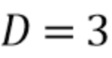 или
или 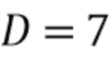 . Если
. Если 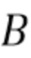 - общее количество спектральных коэффициентов на кадр, то общее количество входных коэффициентов равно
- общее количество спектральных коэффициентов на кадр, то общее количество входных коэффициентов равно 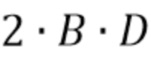 .
.
Каждый блок искусственной нейронной сети 125 вычисляет свое выходное значение как линейную комбинацию входных значений, которые затем факультативно обрабатываются с помощью нелинейной функции сжатия,
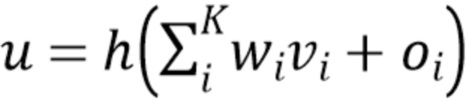 (10),
(10),
где 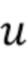 обозначает выход одного нейрона,
обозначает выход одного нейрона, 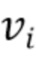 обозначают
обозначают 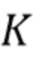 входных значений,
входных значений, 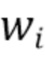 обозначают весовых коэффициентов для линейной комбинации, и
обозначают весовых коэффициентов для линейной комбинации, и 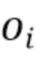 обозначают дополнительных составляющих смещения. Для блоков в первом скрытом слое количество входных значений равно количеству входных коэффициентов D. Все и являются параметрами искусственной нейронной сети 125, которые определяются в способе обучения.
обозначают дополнительных составляющих смещения. Для блоков в первом скрытом слое количество входных значений равно количеству входных коэффициентов D. Все и являются параметрами искусственной нейронной сети 125, которые определяются в способе обучения.
Блоки одного слоя соединены с блоками следующего слоя, выходы блоков предыдущего слоя являются входами в блоки следующего слоя.
Обучение выполняется посредством минимизации ошибки предсказания с использованием численного метода оптимизации, например, метода градиентного спуска. Ошибка предсказания для одного элемента является функцией разности 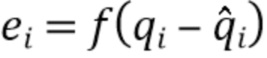 . Ошибка предсказания для всего набора данных или подмножества набора данных, используемого в качестве критерия оптимизации, является, например, среднеквадратичной ошибкой MSE или средней абсолютной ошибкой MAE, где
. Ошибка предсказания для всего набора данных или подмножества набора данных, используемого в качестве критерия оптимизации, является, например, среднеквадратичной ошибкой MSE или средней абсолютной ошибкой MAE, где 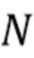 обозначает количество элементов в наборе данных.
обозначает количество элементов в наборе данных.
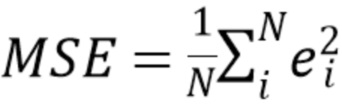 (11)
(11)
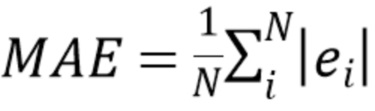 (12)
(12)
Другие показатели ошибок возможны для целей обучения, если они являются монотонными функциями 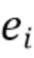 и дифференцируемыми. Кроме того, существуют другие структуры и элементы для построения искусственных нейронных сетей, например, слои сверточной нейронной сети или слои рекуррентной нейронной сети.
и дифференцируемыми. Кроме того, существуют другие структуры и элементы для построения искусственных нейронных сетей, например, слои сверточной нейронной сети или слои рекуррентной нейронной сети.
Все они имеют общее в том, что они реализуют отображение из многомерного входа на одно- или многомерный выход, причем функция отображения управляется набором параметров (например, и ), которые определяются в процедуре обучения посредством оптимизации скалярного критерия.
После обучения модель контролируемого обучения может использоваться для оценки качества звука неизвестной оцененной цели с учетом смешения без необходимости в истинной цели .
Что касается вычислительных моделей качества звука, в экспериментах в соответствии с вариантами осуществления успешно использовались различные вычислительные модели для оценки аспектов качества звука (включая разборчивость), такие как вычислительные модели, описанные в [1]-[11], в частности оценка слепого отделения источников (BSSEval) (см. [1]), способы оценки восприятия для отделения источников аудио (PEASS) (см. [2]), PEMO-Q (см. [3]), оценка восприятия качества аудио (PEAQ) (см. [4]), оценка восприятия качества речи (PESQ) (см. [5] и [6]), ViSQOLAudio (см. [7), индекс качества аудио слухового аппарата (HAAQI) (см. [8]), индекс качества речи слухового аппарата (HASQI) (см. [9), индекс восприятия речи слухового аппарата (HASPI) (см. [10]), и кратковременная объективная разборчивость (STOI) (см. [11]).
Таким образом, в соответствии с вариантом осуществления оценка качества звука обучающего целевого сигнала, например, может зависеть от одной или нескольких вычислительных моделей качества звука.
Например, в варианте осуществления оценка качества звука обучающего целевого сигнала может зависеть от одной или нескольких следующих вычислительных моделей качества звука:
Оценка слепого отделения источников,
Методы оценки восприятия для отделения источников аудио,
Оценка восприятия качества аудио,
Оценка восприятия качества речи,
Аудио с виртуальным объективным слушателем качества речи,
Индекс качества аудио слухового аппарата,
Индекс качества речи слухового аппарата,
Индекс восприятия речи слухового аппарата, и
Кратковременная объективная разборчивость.
Другие вычислительные модели качества звука, например, также могут использоваться в других вариантах осуществления.
Далее описывается управление качеством звука.
Управление качеством звука может быть реализовано посредством оценки компонента качества звука и вычисления параметров обработки на основе оценки компонента качества звука или посредством прямой оценки оптимальных параметров обработки таким образом, чтобы компонент качества звука соответствовал целевому значению 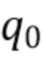 (или не опускался ниже этого целевого значения).
(или не опускался ниже этого целевого значения).
Оценка компонента качества звука была описана выше. Аналогичным образом оптимальные параметры обработки могут быть оценены посредством обучения регрессионного метода с помощью требуемых значений оптимальных параметров обработки. Оптимальные параметры обработки вычисляются, как описано ниже. Эта обработка в дальнейшем называется модулем оценки параметров (Parameter Estimation Module, PEM).
Целевое значение для качества звука будет определять компромисс между отделением и качеством звука. Этот параметр может управляться пользователем или указываться в зависимости от сценария воспроизведения звука. Воспроизведение звука в домашних условиях в спокойной обстановке на высококачественном оборудовании может извлечь преимущество из более высокого качества звука и меньшего отделения. Воспроизведение звука в транспортных средствах в шумной среде через динамики, встроенные в смартфон, может извлечь преимущество из более низкого качества звука, но более высокого отделения и разборчивости речи.
Кроме того, оценочные величины (либо компонент качества звука, либо параметры обработки) могут быть дополнительно применены либо для управления последующей обработкой, либо для управления вторичным отделением.
Таким образом, для реализации предложенного способа могут использоваться четыре разных концепции. Эти концепции проиллюстрированы на фиг. 2, фиг. 3, фиг. 4 и фиг. 5 и описаны далее.
Фиг. 2 иллюстрирует устройство в соответствии с вариантом осуществления, которое сконфигурировано для использования оценки качества звука, и которое сконфигурировано для проведения последующей обработки.
В соответствии с таким вариантом осуществления модуль 120 определения, например, может быть сконфигурирован для оценки, в зависимости по меньшей мере от одного из оцененного целевого сигнала и входного аудиосигнала и от оцененного разностного сигнала, значения качества звука как одного или нескольких результирующих значений, причем значение качества звука указывает оцененное качество звука оцененного целевого сигнала. Модуль 120 определения, например, может быть сконфигурирован для определения одного или нескольких значений параметров в зависимости от значения качества звука.
Таким образом в соответствии с вариантом осуществления модуль 120 определения, например, может быть сконфигурирован для определения, в зависимости от оцененного качества звука оцененного целевого сигнала, управляющего параметра как одного или нескольких значений параметра. Процессор 130 сигналов, например, может быть сконфигурирован для определения отделенного аудиосигнала в зависимости от управляющего параметра и в зависимости по меньшей мере от одного из оцененного целевого сигнала и входного аудиосигнала и от оцененного разностного сигнала.
Далее описаны конкретные варианты осуществления.
На первом этапе применяется отделение. Отделенный сигнал и необработанный сигнал вводятся в модуль оценки качества (Quality Estimation Module, QEM). QEM вычисляет оценку для компонентов качества звука, 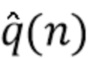 .
.
Оценочные компоненты качества звука используются для вычисления набора параметров 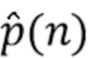 для управления последующей обработкой.
для управления последующей обработкой.
Переменные 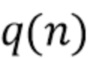 , ,
, , 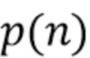 и могут изменяться во времени, но зависимость от времени в дальнейшем опущена для ясности обозначения.
и могут изменяться во времени, но зависимость от времени в дальнейшем опущена для ясности обозначения.
Такая последующая обработка, например, добавляет масштабированную или отфильтрованную копию входного сигнала к масштабированной или отфильтрованной копии выходного сигнала и тем самым сокращает ослабление сигналов помех (например, эффект отделения), например,
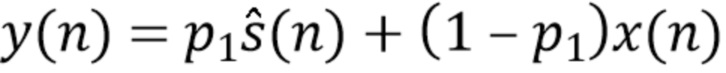 (13),
(13),
где параметр 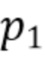 управляет величиной отделения.
управляет величиной отделения.
В других вариантах осуществления, например, может использоваться формула:
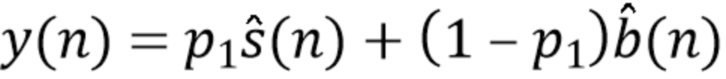 ,
,
где 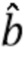 - оцененный разностный сигнал.
- оцененный разностный сигнал.
Сокращение отделения приводит к
1) сокращению количества артефактов и
2) увеличению утечки звуков помех, которая маскирует артефакты отделения.
Таким образом, в варианте осуществления процессор 120 сигналов, например, может быть сконфигурирован для определения отделенного аудиосигнала в зависимости от формулы (13), где 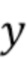 - отделенный аудиосигнал, - оцененный целевой сигнал, - входной аудиосигнал, - управляющий параметр, и
- отделенный аудиосигнал, - оцененный целевой сигнал, - входной аудиосигнал, - управляющий параметр, и 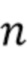 - индекс.
- индекс.
Параметр вычисляется с учетом оценки качества звука  и целевого показателя качества ,
и целевого показателя качества ,
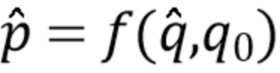 (14).
(14).
Эта функция 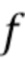 , например, может представлять собой итерационный экстенсивный поиск, как проиллюстрировано с помощью следующего псевдокода.
, например, может представлять собой итерационный экстенсивный поиск, как проиллюстрировано с помощью следующего псевдокода.

В качестве альтернативы соотношение 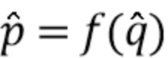 может быть вычислено следующим образом.
может быть вычислено следующим образом.
1. Вычисление 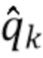 для набора значений
для набора значений 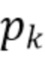 ,
, 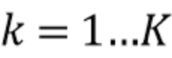 .
.
2. Вычисление остающихся значений посредством интерполяции и экстраполяции.
Например, когда параметр обработки 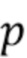 управляет последующей обработкой, как в уравнении (13), вычисляется для фиксированного количества значений , например, соответствующих 18, 12 и 6 дБ относительного усиления .
управляет последующей обработкой, как в уравнении (13), вычисляется для фиксированного количества значений , например, соответствующих 18, 12 и 6 дБ относительного усиления .
Таким образом, отображение аппроксимируется, и 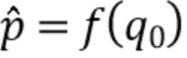 может быть выбрано.
может быть выбрано.
Подводя итог, в варианте осуществления процессор 130 сигналов, например, может быть сконфигурирован для формирования отделенного аудиосигнала посредством определения первой версии отделенного аудиосигнала и посредством изменения отделенного аудиосигнала один или несколько раз для получения одной или нескольких промежуточных версий отделенного аудиосигнала. Модуль 120 определения, например, может быть сконфигурирован для изменения значения качества звука в зависимости от одного из одного или нескольких промежуточных значений отделенного аудиосигнала. Процессор 130 сигналов, например, может быть сконфигурирован для прекращения изменения отделенного аудиосигнала, если значение качества звука больше или равно заданному значению качества.
Фиг. 3 иллюстрирует устройство в соответствии с другим вариантом осуществления, в котором проводится прямая оценка параметров последующей обработки.
Сначала применяется отделение. Отделенные сигналы вводятся в модуль оценки параметра (Parameter Estimation Module, PEM). Оценочные параметры применяются для управления последующей обработкой. PEM был обучен непосредственно оценивать p(n) на основе отделенного сигнала и входного сигнала . Это означает, что операция в уравнении 14 перемещена в фазу обучения, и регрессионный метод обучается оценивать 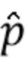 вместо . Следовательно, производится обучение следующей функции.
вместо . Следовательно, производится обучение следующей функции.
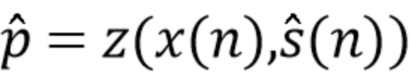 (15).
(15).
Очевидно, что эта процедура имеет преимущество в том, что требует меньше вычислений, в отличие от описанной выше процедуры. Это достигается за счет меньшей гибкости, поскольку модель обучается для фиксированной настройки . Однако несколько моделей могут быть обучены на разных значениях . Таким образом, окончательная гибкость в выборе может быть сохранена.
В варианте осуществления процессор сигналов 130, например, может быть сконфигурирован для формирования отделенного аудиосигнала в зависимости от одного или нескольких значений параметров и в зависимости от последующей обработки оцененного целевого сигнала.
Фиг. 4 иллюстрирует устройство в соответствии с дополнительным вариантом осуществления, в котором проводятся оценка качества звука и вторичное отделение.
Сначала применяется отделение. Отделенные сигналы вводятся в QEM. Оценочные компоненты качества звука используются для вычисления набора параметров для управления вторичным отделением. Во вторичное отделение 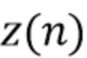 вводятся либо входной сигнал , либо результат первого отделения , линейная комбинация обоих
вводятся либо входной сигнал , либо результат первого отделения , линейная комбинация обоих 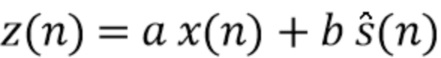 , где и
, где и 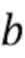 являются весовыми коэффициентами, или промежуточный результат из первого отделения.
являются весовыми коэффициентами, или промежуточный результат из первого отделения.
Таким образом, в таком варианте осуществления процессор 130 сигналов, например, может быть сконфигурирован для формирования отделенного аудиосигнала в зависимости от одного или нескольких значений параметров и в зависимости от линейной комбинации оцененного целевого сигнала и входного аудиосигнала, или процессор 130 сигналов, например, может быть сконфигурирован для формирования отделенного аудиосигнала в зависимости от одного или нескольких значений параметров и в зависимости от линейной комбинации оцененного целевого сигнала и оцененного разностного сигнала.
Подходящими параметрами для управления вторичным отделением являются, например, параметры, которые модифицируют спектральные весовые коэффициенты.
На фиг. 5 показано устройство в соответствии с другим вариантом осуществления, в котором проводится прямая оценка параметров отделения.
Сначала применяется отделение. Отделенные сигналы вводятся в PEM. Оценочные параметры управляют вторичным отделением.
Во вторичное отделение z(n) вводятся либо входной сигнал x(n), либо результат первого отделения , линейная комбинация обоих , где и являются весовыми коэффициентами, или промежуточный результат из первого отделения.
Например, выполняется управление следующими параметрами: , и из уравнений (5), (6) и  , как описано выше.
, как описано выше.
Что касается итерационной обработки в соответствии с вариантами осуществления, фиг. 4 и 5 изображают итерационную обработку с одной итерацией. В общем случае она может быть повторена несколько раз и реализована в цикле.
Итерационная обработка (без промежуточной оценки качества) очень похожа на другие предыдущие способы, которые выполняют конкатенацию нескольких отделений.
Такой подход, например, может подойти для объединения нескольких разных способов (что лучше, чем повторение одного способа).
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют собой описание соответствующего способа, в котором модуль или устройство соответствуют этапу способа или признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего модуля, элемента или признака соответствующего устройства. Некоторые или все этапы способа могут быть исполнены посредством (или с использованием) аппаратного устройства, такого как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах осуществления один или несколько из наиболее важных этапов способа могут быть исполнены таким устройством.
В зависимости от некоторых требований реализации варианты осуществления изобретения могут быть реализованы в аппаратном или программном обеспечении, по меньшей мере частично в аппаратном обеспечении или по меньшей мере частично в программном обеспечении. Реализация может быть выполнена с использованием цифрового запоминающего носителя, например, дискеты, цифрового универсального диска (DVD), диска Blu-Ray, компакт-диска (CD), постоянного запоминающего устройства (ПЗУ; ROM), программируемого постоянного запоминающего устройства (ППЗУ; PROM), стираемого программируемого постоянного запоминающего устройства (СППЗУ; EPROM), электрически стираемого программируемого постоянного запоминающего устройства (ЭСППЗУ; EEPROM) и флэш-памяти, имеющего сохраненные на нем считываемые в электронном виде сигналы, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, в результате чего выполняется соответствующий способ. Таким образом, цифровой запоминающий носитель может являться машиночитаемым.
Некоторые варианты осуществления в соответствии с изобретением содержат носитель данных, имеющий читаемые в электронном виде управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой, в результате чего выполняется один из способов, описанных в настоящем документе.
Обычно варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, причем программный код выполняет один из способов, когда компьютерный программный продукт исполняется на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных в настоящем документе способов, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления способа изобретения, таким образом, представляет собой компьютерную программу, имеющую программный код для выполнения одного из описанных здесь способов, когда компьютерная программа выполняется на компьютере.
Дополнительным вариантом осуществления способов изобретения, таким образом, является носитель данных (или цифровой запоминающий носитель, или машиночитаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Носитель данных, цифровой запоминающий носитель или носитель с записанными данными обычно являются материальными и/или непереходными носителями.
Дополнительным вариантом осуществления способа настоящего изобретения, таким образом, являются поток данных или последовательность сигналов, представляющие компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов, например, могут быть сконфигурированы для переноса через соединение передачи данных, например, через интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, сконфигурированное или адаптированное для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления в соответствии с изобретением содержит устройство или систему, сконфигурированную для переноса на приемник (например, в электронном или оптическом виде) компьютерной программы для выполнения одного из способов, описанных в настоящем документе. Приемник, например, может являться компьютером, мобильным устройством, запоминающим устройством и т.п. Устройство или система, например, могут содержать файловый сервер для переноса компьютерной программы на приемник.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторой или всей функциональности способов, описанных в настоящем документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в настоящем документе. Обычно способы предпочтительно выполняются любым аппаратным устройством.
Устройство, описанное в настоящем документе, может быть реализовано с использованием аппаратного устройства, с использованием компьютера или с использованием комбинации аппаратного устройства и компьютера.
Способы, описанные в настоящем документе, могут быть выполнены с использованием аппаратного устройства, с использованием компьютера или с использованием комбинации аппаратного устройства и компьютера.
Описанные выше варианты осуществления являются лишь иллюстрацией принципов настоящего изобретения. Подразумевается, что модификации и вариации размещений и подробностей, описанных в настоящем документе, будут очевидны для других специалистов в данной области техники. Таким образом, подразумевается, что изобретение ограничено только объемом последующей патентной формулы изобретения, а не конкретными подробностями, представленными посредством описания и разъяснения изложенных в настоящем документе вариантов осуществления.
Литература
[1] E. Vincent, R. Gribonval, and C. Fйvotte, “Performance measurement in blind audio source separation,” IEEE Transactions on Audio, Speech and Language Processing, vol. 14, no. 4, pp. 1462-1469, 2006.
[2] V. Emiya, E. Vincent, N. Harlander, and V. Hohmann, “Subjective and objective quality assessment of audio source separation,” IEEE Trans. Audio, Speech and Language Process., vol. 19, no. 7, 2011.
[3] R. Huber and B. Kollmeier, “PEMO-Q - a new method for objective audio quality assessment using a model of audatory perception,” IEEE Trans. Audio, Speech and Language Process., vol. 14, 2006.
[4] ITU-R Rec. BS.1387-1, “Method for objective measurements of perceived audio quality,” 2001.
[5] ITU-T Rec. P.862, “Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs,” 2001.
[6] ITU-T Rec. P.862.1, “Mapping function for transforming P.862 raw results scores to MOS-LQO,” 2003.
[7] A. Hines, E. Gillen et al., “ViSQOLAudio: An Objective Audio Quality Metric for Low Bitrate Codecs,” J. Acoust. Soc. Am., vol. 137, no. 6, 2015.
[8] J. M. Kates and K. H. Arehart, “The Hearing-Aid Audio Quality Index (HAAQI),” IEEE Trans. Audio, Speech and Language Process., vol. 24, no. 2, 2016, evaluation code kindly provided by Prof. J.M. Kates.
[9] J. M. Kates and K. H. Arehart, “The Hearing-Aid Speech Quality Index (HASQI) version 2,” Journal of the Audio Engineering Society, vol. 62, no. 3, pp. 99-117, 2014.
[10] J. M. Kates and K. H. Arehart, “The Hearing-Aid Speech Perception Index (HASPI),” Speech Communication, vol. 65, pp. 75-93, 2014.
[11] C. Taal, R. Hendriks, R. Heusdens, and J. Jensen, “An algorithm for intelligibility prediction of time-frequency weighted noisy speech,” IEEE Trans. Audio, Speech and Language Process., vol. 19, no. 7, 2011.
[12] E. Manilow, P. Seetharaman, F. Pishdadian, and B. Pardo, “Predicting algorithm efficacy for adaptive multi-cue source separation,” in Applications of Signal Processing to Audio and Acoustics (WASPAA), 2017 IEEE Workshop on, 2017, pp. 274-278.
[13] M. Cartwright, B. Pardo, G. J. Mysore, and M. Hoffman, “Fast and easy crowdsourced perceptual audio evaluation,” in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on, 2016.
[14] S.-W. Fu, T.-W. Wang, Y. Tsao, X. Lu, and H. Kawai, “End-to-end waveform utterance enhancement for direct evaluation metrics optimization by fully convolutional neural networks,” IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), vol. 26, no. 9, 2018.
[15] Y. Koizumi, K. Niwa, Y. Hioka, K. Koabayashi, and Y. Haneda, “Dnn-based source enhancement to increase objective sound quality assessment score,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018.
[16] Y. Zhao, B. Xu, R. Giri, and T. Zhang, “Perceptually guided speech enhancement using deep neural networks,” in Acoustics, Speech and Signal Processing (ICASSP), 2018 IEEE International Conference on, 2018.
[17] Y. Koizumi, K. Niwa, Y. Hioka, K. Kobayashi, and Y. Haneda, “Dnn-based source enhancement self-optimized by reinforcement learning using sound quality measurements,” in Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on, 2017.
[18] J. Jensen and M. S. Pedersen, “Audio processing device comprising artifact reduction,” US Patent US 9,432,766 B2, Aug. 30, 2016.
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в обеспечении максимального снижения уровня шума при условии отсутствия артефактов. Технический результат достигается за счет определения оцененного целевого сигнала, который зависит от входного аудиосигнала, определения результирующих значений в зависимости от оцененного качества звука оцененного целевого сигнала, чтобы получить одно или несколько значений параметров, и формирования отделенного аудиосигнала в зависимости от одного или нескольких значений параметров и в зависимости от одного из оцененного целевого сигнала, и входного аудиосигнала, и оцененного разностного сигнала, причем оцененный разностный сигнал является оценкой сигнала, который содержит только участок разностного аудиосигнала, причем формирование отделенного аудиосигнала проводят в зависимости от значений параметров и в зависимости от линейной комбинации оцененного целевого сигнала и входного аудиосигнала; или при этом формирование отделенного аудиосигнала проводят в зависимости от значений параметров и в зависимости от линейной комбинации оцененного целевого сигнала и оцененного разностного сигнала. 3 н. и 13 з.п. ф-лы, 6 ил.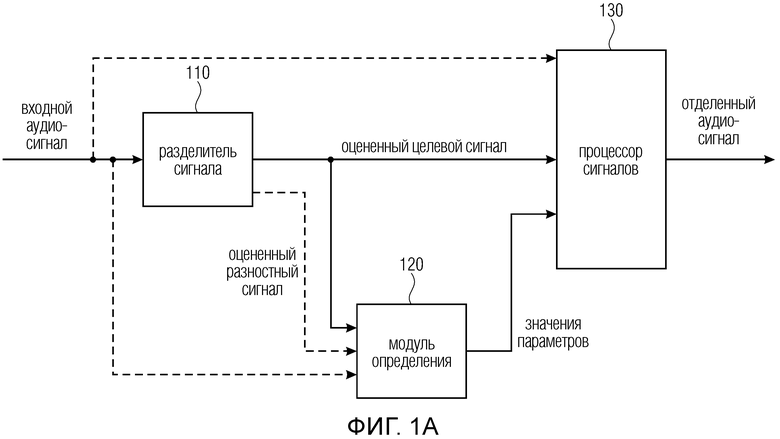
1. Устройство для формирования отделенного аудиосигнала из входного аудиосигнала, причем входной аудиосигнал содержит участок целевого аудиосигнала и участок разностного аудиосигнала, причем участок разностного аудиосигнала указывает разность между входным аудиосигналом и участком целевого аудиосигнала, причем устройство содержит:
разделитель (110) источника для определения оцененного целевого сигнала, который зависит от входного аудиосигнала, причем оцененный целевой сигнал является оценкой сигнала, который содержит только участок целевого аудиосигнала,
модуль (120) определения, причем модуль (120) определения выполнен с возможностью определять одно или несколько результирующих значений в зависимости от оцененного качества звука оцененного целевого сигнала, чтобы получить одно или несколько значений параметров, причем одно или несколько значений параметров представляют собой одно или несколько результирующих значений или зависят от одного или нескольких результирующих значений, и
процессор (130) сигналов для формирования отделенного аудиосигнала в зависимости от одного или нескольких значений параметров и в зависимости по меньшей мере от одного из оцененного целевого сигнала, и входного аудиосигнала, и оцененного разностного сигнала, причем оцененный разностный сигнал является оценкой сигнала, который содержит только участок разностного аудиосигнала,
причем процессор (130) сигналов выполнен с возможностью формировать отделенный аудиосигнал в зависимости от одного или нескольких значений параметров и в зависимости от линейной комбинации оцененного целевого сигнала и входного аудиосигнала, или
при этом процессор (130) сигналов выполнен с возможностью формировать отделенный аудиосигнал в зависимости от одного или нескольких значений параметров и в зависимости от линейной комбинации оцененного целевого сигнала и оцененного разностного сигнала.
2. Устройство по п. 1,
в котором модуль (120) определения выполнен с возможностью определять, в зависимости от оцененного качества звука оцененного целевого сигнала, управляющий параметр как одно или несколько значений параметров, и
в котором процессор сигналов выполнен с возможностью определять отделенный аудиосигнал в зависимости от управляющего параметра и в зависимости по меньшей мере от одного из оцененного целевого сигнала, и входного аудиосигнала, и оцененного разностного сигнала.
3. Устройство по п. 2,
в котором процессор (130) сигналов выполнен с возможностью определять отделенный аудиосигнал в зависимости от:
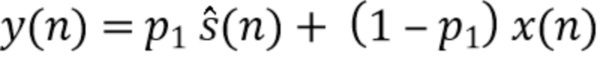 ,
,
или в зависимости от:
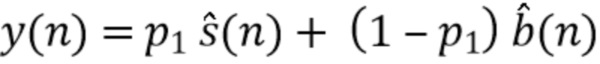 ,
,
где 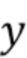 - отделенный аудиосигнал,
- отделенный аудиосигнал,
где 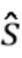 - оцененный целевой сигнал,
- оцененный целевой сигнал,
где 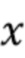 - входной аудиосигнал,
- входной аудиосигнал,
где 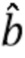 - оцененный разностный сигнал,
- оцененный разностный сигнал,
где 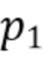 - управляющий параметр, и
- управляющий параметр, и
где 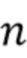 - индекс.
- индекс.
4. Устройство по п. 2,
в котором модуль (120) определения выполнен с возможностью оценивать, в зависимости по меньшей мере от одного из оцененного целевого сигнала, и входного аудиосигнала, и оцененного разностного сигнала, значение качества звука как одно или несколько результирующих значений, причем значение качества звука указывает оцененное качество звука оцененного целевого сигнала, и
в котором модуль (120) определения выполнен с возможностью определять одно или несколько значений параметров в зависимости от значения качества звука.
5. Устройство по п. 4,
в котором процессор (130) сигналов выполнен с возможностью формировать отделенный аудиосигнал посредством определения первой версии отделенного аудиосигнала и посредством изменения отделенного аудиосигнала один или несколько раз для получения одной или нескольких промежуточных версий отделенного аудиосигнала,
в котором модуль (120) определения выполнен с возможностью изменять значение качества звука в зависимости от одного из одного или нескольких промежуточных значений отделенного аудиосигнала, и
в котором процессор (130) сигналов выполнен с возможностью прекращать изменение отделенного аудиосигнала, если значение качества звука больше или равно заданному значению качества.
6. Устройство по п. 1,
в котором модуль (120) определения выполнен с возможностью определять одно или несколько результирующих значений в зависимости от оцененного целевого сигнала и в зависимости по меньшей мере от одного из входного аудиосигнала и оцененного разностного сигнала.
7. Устройство по п. 1,
в котором модуль (120) определения содержит искусственную нейронную сеть (125) для определения одного или нескольких результирующих значений в зависимости от оцененного целевого сигнала, причем искусственная нейронная сеть (125) выполнена с возможностью принимать множество входных значений, каждое из множества входных значений зависит по меньшей мере от одного из оцененного целевого сигнала, и оцененного разностного сигнала, и входного аудиосигнала, и причем искусственная нейронная сеть (125) выполнена с возможностью определять одно или несколько результирующих значений как одно или несколько выходных значений искусственной нейронной сети (125).
8. Устройство по п. 7,
в котором каждое из множества входных значений зависит по меньшей мере от одного из оцененного целевого сигнала, и оцененного разностного сигнала, и входного аудиосигнала, и
в котором одно или несколько результирующих значений указывают оцененное качество звука оцененного целевого сигнала.
9. Устройство по п. 7,
в котором каждое множество входных значений зависит по меньшей мере от одного из оцененного целевого сигнала, и оцененного разностного сигнала, и от входного аудиосигнала, и
в котором одно или несколько результирующих значений представляют собой одно или несколько значений параметров.
10. Устройство по п. 7,
в котором искусственная нейронная сеть (125) выполнена с возможностью обучаться посредством приема множества наборов обучающих данных, причем каждый из множества наборов обучающих данных содержит множество входных обучающих значений искусственной нейронной сети (125) и одно или несколько выходных обучающих значений искусственной нейронной сети (125), причем каждое из множества выходных обучающих значений зависит по меньшей мере от одного из обучающего целевого сигнала, и обучающего разностного сигнала, и обучающего входного сигнала, причем каждое из одного или нескольких выходных обучающих значений зависит от оценки качества звука обучающего целевого сигнала.
11. Устройство по п. 10,
в котором оценка качества звука обучающего целевого сигнала зависит от одной или нескольких вычислительных моделей качества звука.
12. Устройство по п. 11,
в котором одна или несколько вычислительных моделей качества звука являются по меньшей мере одной из следующих моделей:
оценка слепого отделения источников,
способы оценки восприятия для отделения источников аудио,
оценка восприятия качества аудио,
оценка восприятия качества речи,
аудио с виртуальным объективным слушателем качества речи,
индекс качества аудио слухового аппарата,
индекс качества речи слухового аппарата,
индекс восприятия речи слухового аппарата, и
кратковременная объективная разборчивость.
13. Устройство по п. 7,
в котором искусственная нейронная сеть (125) выполнена с возможностью определять одно или несколько результирующих значений в зависимости от оцененного целевого сигнала и в зависимости по меньшей мере от одного из входного аудиосигнала и оцененного разностного сигнала.
14. Устройство по п. 1,
в котором процессор (130) сигналов выполнен с возможностью формировать отделенный аудиосигнал в зависимости от одного или нескольких значений параметров и в зависимости от последующей обработки оцененного целевого сигнала.
15. Способ формирования отделенного аудиосигнала из входного аудиосигнала, причем входной аудиосигнал содержит участок целевого аудиосигнала и участок разностного аудиосигнала, причем участок разностного аудиосигнала указывает разность между входным аудиосигналом и участком целевого аудиосигнала, причем способ содержит этапы, на которых:
определяют оцененный целевой сигнал, который зависит от входного аудиосигнала, причем оцененный целевой сигнал является оценкой сигнала, который содержит только участок целевого аудиосигнала,
определяют одно или несколько результирующих значений в зависимости от оцененного качества звука оцененного целевого сигнала, чтобы получить одно или несколько значений параметров, причем одно или несколько значений параметров представляют собой одно или несколько результирующих значений или зависят от одного или нескольких результирующих значений, и
формируют отделенный аудиосигнал в зависимости от одного или нескольких значений параметров и в зависимости по меньшей мере от одного из оцененного целевого сигнала, и входного аудиосигнала, и оцененного разностного сигнала, причем оцененный разностный сигнал является оценкой сигнала, который содержит только участок разностного аудиосигнала,
причем формирование отделенного аудиосигнала проводят в зависимости от одного или нескольких значений параметров и в зависимости от линейной комбинации оцененного целевого сигнала и входного аудиосигнала; или
при этом формирование отделенного аудиосигнала проводят в зависимости от одного или нескольких значений параметров и в зависимости от линейной комбинации оцененного целевого сигнала и оцененного разностного сигнала.
16. Машиночитаемый носитель, содержащий программный код для выполнения способа по п. 15 при его исполнении на процессоре компьютера или процессоре сигналов.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| УСТРОЙСТВА И СПОСОБЫ ДЛЯ ОБРАБОТКИ АУДИО СИГНАЛА С ЦЕЛЬЮ ПОВЫШЕНИЯ РАЗБОРЧИВОСТИ РЕЧИ, ИСПОЛЬЗУЯ ФУНКЦИЮ ВЫДЕЛЕНИЯ НУЖНЫХ ХАРАКТЕРИСТИК | 2009 |
|
RU2507608C2 |

