Область техники
Изобретение относится к биотехнологии и касается создания нового способа анализа крови ВИЧ-инфицированных пациентов, который может быть использован для определения мутаций в генах неструктурных белков ВИЧ-1 суб-субтипа А6, ассоциированных с изменением функциональных свойств вируса, которые могут влиять на течение ВИЧ-инфекции, в том числе на риск развития коморбидных заболеваний у пациента.
Уровень техники
ВИЧ-инфекция - это хроническая и неизлечимая болезнь, этиологическим агентом которой является вирус иммунодефицита человека (ВИЧ). На сегодняшний день она является одной из основных проблем глобального здравоохранения. По данным Всемирной организации здравоохранения (ВОЗ) в 2022 г в мире насчитывалось 39 млн [33,1-45,7млн] ВИЧ-инфицированных лиц (https://www.who.int/teams/global-hiv-hepatitis-and-stis-programmes/hiv/strategic-information/hiv-data-and-statistics). В Российской федерации (РФ) общее количество лиц, живущих с ВИЧ-инфекцией, в 2022 году превысило 0,8 млн человек (по данным формы 61 Федерального регистра лиц, инфицированных ВИЧ), при этом случаи ВИЧ-инфекции зарегистрированы во всех субъектах РФ.
Попадая в организм человека ВИЧ проникает в клетки-мишени, связываясь с рецептором CD4, и одним из двух основных хемокиновых ко-рецепторов, CCR5 или CXCR4. разрушая клетку-хозяина, чаще всего Т-лимфоцит, во время ее репликации. Для ВИЧ-инфекции характерен длительный инкубационный период и пожизненное персистирование вируса в организме. Без терапии число CD4+ Т-лимфоцитов снижается и у пациентов развивается Синдром приобретённого иммунного дефицита (СПИД), что в свою очередь вызывает развитие оппортунистических инфекций, опухолей, и как следствие, летальный исход заболевания.
Открытие и глобальное внедрение методов быстрой диагностики и эффективной антиретровирусной терапии (АРТ) привело к значительному снижению смертности и заболеваемости, а также к увеличению группы людей, нуждающихся в пожизненной вирусной супрессивной терапии. Многие исследователи сходятся во мнении, что в настоящий момент эпидемия ВИЧ-инфекции перешла в новую стадию - стадию коморбидных и тяжелых форм, которая сопровождается высокой летальностью, несмотря на применение высокоэффективной АРТ. Коморбидность (син.: мультиморбидность, полиморбидность) - сосуществование двух и/или более синдромов или заболеваний, патогенетически взаимосвязанных между собой или совпадающих по времени у одного пациента независимо от активности каждого из них. Коморбидность видоизменяет классическую клиническую картину течения заболеваний, утяжеляет состояние больных, удлиняет диагностический процесс, усложняет лечение, приводя к вынужденной полипрагмазии и резкому увеличению экономических затрат на пациента. Кроме того, коморбидность является независимым фактором риска летального исхода.
Люди, живущие с ВИЧ, подвергаются большему риску мультиморбидности (туберкулез, вирусные гепатиты, вторичные и сопутствующие заболевания, соматические и психоневрологические болезни), чем население в целом. Эффективная профилактика или лечение сопутствующих заболеваний требует выявления ключевых патогенных факторов, способствующих развитию этих заболеваний у пациентов с ВИЧ.
В настоящее время в качестве одной из потенциальных причин развития коморбидных заболеваний исследователи рассматривают неструктурные белки ВИЧ, которые высвобождаются ВИЧ-инфицированными клетками во внеклеточное пространство, а затем поступают в кровоток и ткани. Поскольку современные препараты против ВИЧ ингибируют репликацию вируса, а, следовательно, и инфицирование новых клеток, но не блокируют транскрипцию и трансляцию вирусных РНК в уже инфицированных клетках, выработка белков ВИЧ происходит даже у пациентов, получающих АРТ.
Проведенные исследования показали, что мутации в генах некоторых белков ВИЧ, могут влиять на развитие коморбидных заболеваний. Например, мутация гена белка Tat (C31S) влияет на нейропатогенный потенциал этого белка и вероятность развития нейрокогнитивных заболеваний у ВИЧ-инфицированных пациентов. Также в литературе описана связь ряда полиморфизмов в гене белка nef с развитием у ВИЧ-инфицированных пациентов тяжелой легочной гипертензии, связанной с ремоделированием сосудов.
В настоящее время отсутствуют какие-либо тест-системы или способы анализа крови ВИЧ-инфицированных пациентов, позволяющие определить риск развития сопутствующих заболеваний. Вместе с тем, данная информация способна повлиять на выбор препаратов и общей стратегии лечения данных пациентов.
Таким образом, в уровне техники существует высокая потребность в разработке способа анализа крови ВИЧ-инфицированных пациентов, для выявления полиморфизмов ВИЧ, связанных с изменением характера течения ВИЧ-инфекции, в частности с развитием коморбидных заболеваний человека.
Раскрытие изобретения
Задачей заявленного изобретения является разработка универсального способа анализа крови ВИЧ-инфицированных пациентов для определения мутаций в генах ВИЧ, ассоциированных с изменением функциональных свойств вируса, которые могут влиять на течение ВИЧ-инфекции, в том числе на риски развития сопутствующих заболеваний.
Технический результат заключается в разработке способа анализа крови ВИЧ-инфицированных пациентов, позволяющего выявить мутации в генах неструктурных белков ВИЧ-1 суб-субтипа A6 (циркулирующего на территории Российской Федерации), ассоциированные с изменением функциональных свойств вируса, которые могут влиять на течение ВИЧ-инфекции, в том числе на риск развития коморбидных заболеваний у пациента.
Указанный технический результат достигается тем, что создан способ анализа крови ВИЧ-инфицированных пациентов, включающий этапы:
(1) Получение провирусной ДНК пациента.
(2) Первый раунд ПЦР, в котором ставят в отдельных пробирках 4 реакции ПЦР с парами праймеров SEQ ID:1 и SEQ ID NO:2, SEQ ID:3 и SEQ ID NO:4, SEQ ID:5 и SEQ ID NO:6, SEQ ID:7 и SEQ ID NO:8, соответственно, при этом в качестве экспериментального образца используется образец провирусной ДНК, полученный на этапе 1, в качестве отрицательного контроля используется буферный раствор, аналогичный буферному раствору в экспериментальном образце, а в качестве положительного контроля используется ДНК, содержащая соответствующий ген неструктурного белка ВИЧ-1 суб-субтипа А6. При этом все 4 реакции ПЦР имеют единые параметры амплификации.
(3) Второй раунд ПЦР, в котором ставят в отдельных пробирках 4 реакции ПЦР с парами праймеров SEQ ID:9 и SEQ ID NO:10, SEQ ID:11 и SEQ ID NO:12, SEQ ID:13 и SEQ ID NO:14, SEQ ID:15 и SEQ ID NO:16, соответственно, при этом в качестве экспериментальных образцов используются экспериментальные и контрольные ПЦР-смеси, полученные после первого раунда ПЦР. При этом все 4 реакции ПЦР имеют единые параметры амплификации.
(4) Секвенирование по Сэнгеру, которое проводят с парами праймеров SEQ ID:9 и SEQ ID NO:10, SEQ ID:11 и SEQ ID NO:12, SEQ ID:13 и SEQ ID NO:14, SEQ ID:15 и SEQ ID NO:16.
(5) Сбор нуклеотидных последовательностей генов неструктурных белков ВИЧ-1 суб-субтипа А6 на основе данных полученных на этапе 4.
(6) Анализ полученных последовательностей, в ходе которого выявляются мутации в генах неструктурных белков ВИЧ-1 суб-субтипа А6.
(7) Интерпретация результатов, в ходе которой выявляются мутации в генах неструктурных белков, ассоциированные с изменением функциональных свойств вируса, которые могут влиять на течение ВИЧ-инфекции, в том числе на риск развития коморбидных заболеваний у пациента.
Краткое описание фигур.
На фиг 1 представлен пример формирования консенсусной последовательности суб-субтипа А6 в онлайн программе Advanced Consensus Maker tool, где фигурной скобкой обозначены последовательности, загруженные из базы данных Лос-Аламос, а стрелкой отмечена полученная консенсусная последовательность.
На фиг. 2 приведен пример выбора праймера в программе BioEdit, где каждая последовательность, загруженная из базы данных Лос-Аламос представлена отдельной строкой. Темно-серым цветом в левом столбце выделены названия загруженных последовательностей. Рамкой выделена анализируемая область для выбора праймера. Праймер конструировался с учетом соответствия максимальному количеству нуклеотидных последовательностей.
На фиг. 3 приведен пример анализа праймера (картирования) в программе Sequence Locator, где верхняя стрелка указывает расположение олигонуклеотидов в геноме. Правая стрелка в среднем ряду указывает на столбец, в котором написаны номера позиций нуклеотидов праймеров в геноме ВИЧ. Левая стрелка в среднем ряду указывает на столбец, в котором описаны белки ВИЧ, которые кодирует анализируемая область. Нижняя стрелка указывает область, где приведены отличия от референсного штамма ВИЧ-1 субтипа В.
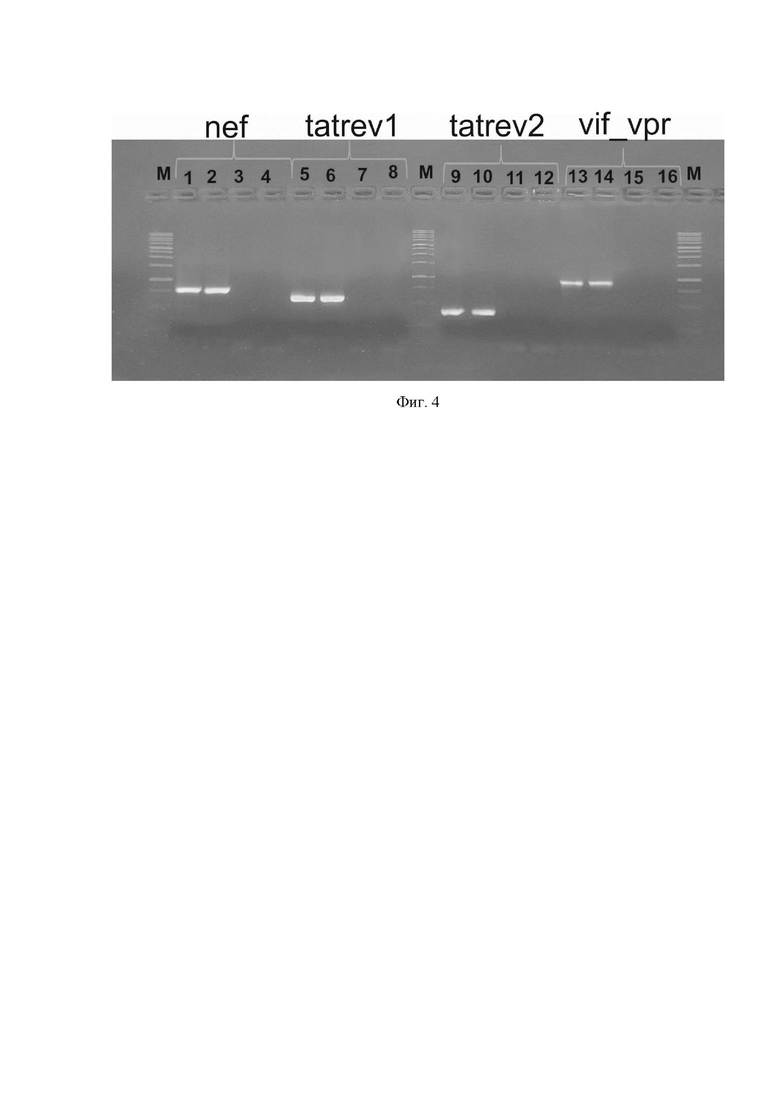
На фиг. 4 приведена электрофореграмма продуктов амплификации вирусной ДНК, после двух раундов ПЦР, где
M - маркер молекулярного веса ДНК;
nef - результаты амплификации с праймеров SEQ ID NO:9/SEQ ID NO:10, при этом 1 - пробирка 13 (анализируемый образец), 2 - пробирка 21 (положительный контроль), 3 - пробирка 17 (отрицательный контроль с первого раунда ПЦР), 4 - пробирка 25 (отрицательный контроль ПЦР второго раунда);
tatrev1 - результаты амплификации с праймеров SEQ ID NO:13/SEQ ID NO:14: 5 - пробирка 15 (анализируемый образец), 6 - пробирка 23 (положительный контроль), 7 - пробирка 19 (отрицательный контроль с первого раунда ПЦР), 8 - пробирка 27 (отрицательный контроль ПЦР второго раунда);
tatrev2 - результаты амплификации с праймеров SEQ ID NO:15/SEQ ID NO:16: 9 - пробирка 16 (анализируемый образец), 10 - пробирка 24 (положительный контроль), 11 - пробирка 20 (отрицательный контроль с первого раунда ПЦР), 12 - пробирка 28 (отрицательный контроль ПЦР второго раунда);
vif_vpr - результаты амплификации с праймеров SEQ ID NO:11/SEQ ID NO:12: 13 - пробирка 14 (анализируемый образец), 14 - пробирка 22 (положительный контроль); 15 - пробирка 18 (отрицательный контроль с первого раунда ПЦР), 16 - пробирка 26 (отрицательный контроль ПЦР второго раунда).
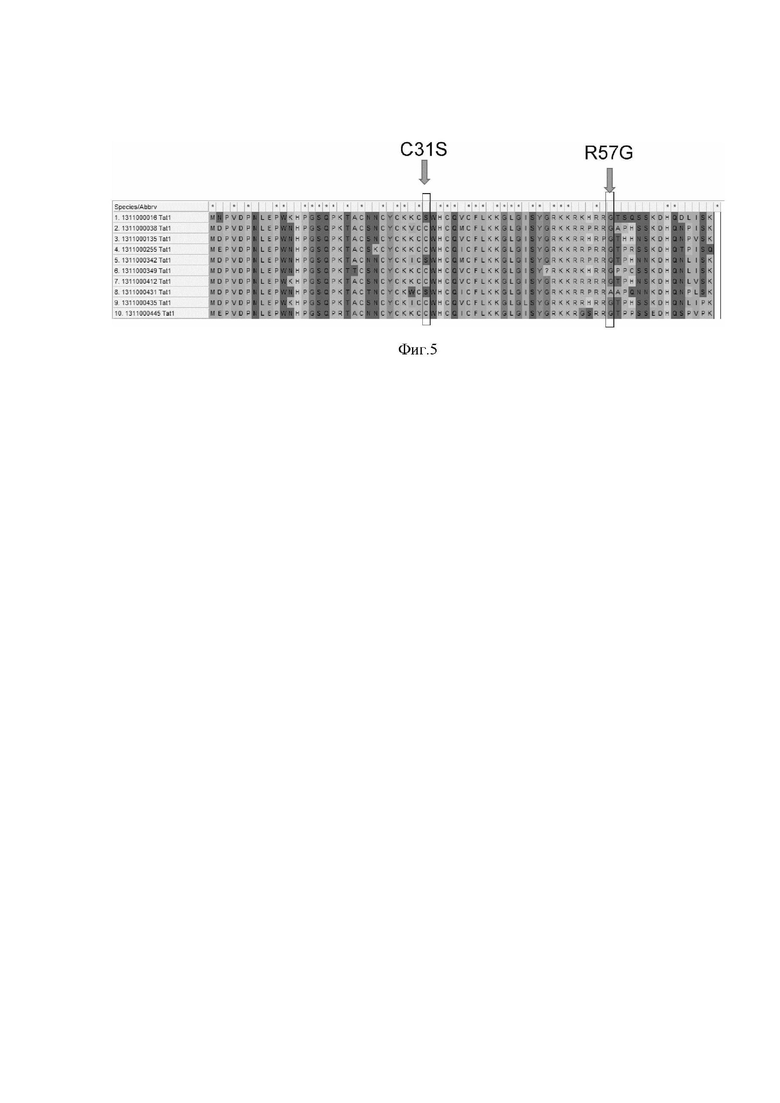
На фиг. 5 приведены результаты анализа полученных от пациента последовательностей на выявление функционально значимых замен в фрагменте белка Tat, кодируемом первым экзоном гена tat, где
C31S - функционально значимая замена в 31 положении белка Tat с цистеина на серин;
R57G - функционально значимая замена в 57 положении белка Tat c аргинина на глицин.
Реализация изобретения
Для создания универсального способа анализа крови ВИЧ-инфицированных пациентов, на первом этапе была определена консенсусная последовательность вируса на основе 186 полногеномных нуклеотидных последовательностей ВИЧ-1 суб-субтипа А6 из международной базы данных Лос-Аламос. Далее были подобраны 4 пары праймеров для первого раунда ПЦР, обеспечивающие возможность проведения анализа генов всех неструктурных белков (таблица 1): с праймеров Vif1p и Vif1o амплифицировали гены vif и vpr, с TatRevF1 и Vpu1o - первый экзон генов tat, rev и ген vpu, c T2R1p и T2R1o - второй экзон генов tat и rev. Кроме того была разработана универсальная программа амплификации для всех праймеров, использующихся в первом раунде ПЦР. Аналогичным образом было подобрано 4 пары праймеров для второго раунда ПЦР, обеспечивающие возможность проведения анализа генов 6 неструктурных белков ВИЧ-1 (таблица 2). Также была разработана универсальная программа амплификации для второго раунда ПЦР. Таким образом, ключевой особенностью разработанного способа анализа крови является то, что в каждом раунде ПЦР анализ всех 6 генов неструктурных белков ВИЧ-1 (два из которых кодируются двумя экзонами) проводится одновременно и всего в 4-х пробирках.
В дальнейшем проводили секвенирование по Сэнгеру ампликонов, полученных во время второго раунда ПЦР. Затем для каждого гена осуществляли сбор контига на основе электрофореграмм, полученных с прямого и обратного праймера.
Сбор нуклеотидных последовательностей осуществлялся относительно консенсусных последовательностей генов неструктурных ВИЧ-1 суб-субтипа А6.
В ходе анализа полученных последовательностей выявляли мутации в генах неструктурных белков ВИЧ-1 суб-субтипа А6. Интерпретация результата заключалась в сравнении полученных результатов для конкретного пациента с базой данных мутаций, ассоциированных с изменением функциональных свойств вируса и с возможным влиянием на течение ВИЧ-инфекции, в том числе на риск развития коморбидных заболеваний у пациента, которая была сформирована на основе анализа данных мировой литературы (ФГБУ «НИЦЭМ им. Н.Ф. Гамалеи» Минздрава России).
Разработанный способ был успешно апробирован на 354 клинических образцах цельной крови ВИЧ-инфицированных пациентов.
Осуществление изобретения подтверждается следующими примерами.
Пример 1. Получение консенсусной полногеномной последовательности для ВИЧ-1 суб-субтипа А6 для дальнейшего конструирования праймеров
На первом этапе работы был проведен сравнительный анализ полногеномных нуклеотидных последовательностей ВИЧ-1 суб-субтипа А6 с целью формирования консенсусной последовательности ВИЧ-1 суб-субтипа А6 для дальнейшего использования ее при выборе олигонуклеотидов для ПЦР и последующего секвенирования. Для этого из международной базы данных Лос-Аламос были загружены 186 полногеномных нуклеотидных последовательностей ВИЧ-1 суб-субтипа А6 со следующими номерами: AF413987, AF193275, AY500393, AY829203, AY829205, AY829206, AY829208, AY829209, AY829210, AY829212, DQ207944, DQ823356, DQ823357, DQ823358, DQ823359, DQ823360, DQ823361, DQ823365, DQ823366, DQ823367, EF545108, EF589039, EF589040, EF589041, EF589042,EF589043, EF589044,EU861977, FJ388892,FJ388906,FJ388950,FJ388951, FJ864679, JF683763, JF683780,JF683798, JQ292891, JQ292892, JQ292893, JQ292894,JQ292895, JQ292896, JQ292897, JQ292898, JQ292899, JQ292900, JX500694, JX500695, JX500696,KF716491, KF716492, KT983615, KU749399, KU749400, KU749401, KU749403, AKU749404, KU749405, KU749407, KY238326, KY238327, KY658681, KY658682, MF109697, MG902950, MG902951, MH330337, MH330338, MH330339, MH330340, MH330341, MH330342, MH330343, MH330344, MH330345, MH330346, MH330347, MH330348, MH330349, MH330350, MH330351,MH330352,MH330353,MH330354, MH330355, MH330356, MH330357, MH330358, MH330359, MH330361, MH330363, MH330364, MH330365, MH330367, MH330370, MH330371, MH330372, MH330373, MH330374, MH330375, MH330376, MH330377, MH330378, MH330379, MH330380, MH330381, MN485977, MN703135, MN703136, MN703137, MN703138, MN703139, MN736699, MT222944, MT222945, MT222946, MT222947, MT222948, MT222949, MT318157, MT334907, MT334908, MT334909, MT334910, MT334911, MT334912, MT334913, MT334915, MT334916, MT334918, MT334919, MT334920, MT334921, MT334924, MT334925, MT334926, MT334927, MT334928, MT334929, MT334930, MT334931, MT334932, MT369950, MT369951, MT369952, MT369953, MT369955, MT369956, MT369957, MT369958, MT369960, MT369961, MT369963, MT369964, MT369965, MT369966, MT369967, MT369968, MT369970, MT369972, MT369973, MT369974, MT369975, MT369977, MT369978, MT369980, MT369982, MT369983, MT369984, MT369987, MT369989, MT369990, MT369993, MT369994, MT369995, MT369997, MT369998, MT369999, MT370000, MT370001, MT370002, MT370003, MT370005, MT370006, MT370007, MT370008.
Консенсусная последовательность была сформирована при помощи программного обеспечения Advanced Consensus Maker tool на сайте базы данных Los Alamos (https://www.hiv.lanl.gov/content/sequence/ CONSENSUS/AdvCon.html). На Фиг.1 приведен пример формирования консенсусной последовательности суб-субтипа А6 в онлайн программе Advanced Consensus Maker tool.
Пример 2. Конструирование олигонуклеотидов (праймеров) для первого и второго раундов ПЦР
Основной задачей данного этапа работы являлось конструирование праймеров, специфичных суб-субтипу А6 ВИЧ-1, позволяющих провести ПЦР всех генов неструктурных белков за минимальное время и с минимальным количеством олигонуклеотидов.
Праймеры - короткие одноцепочечные синтетические фрагменты ДНК, комплементарные специфичным участкам матричной ДНК. Это один из важнейших компонентов ПЦР, от которого напрямую зависит качество ПЦР продукта. Праймеры выполняют функцию «затравки» для ДНК-полимеразы, которая присоединяет нуклеотиды к дочерней цепи по принципу комплементарности в направлении от 5’ к 3’ концу матричной ДНК. Для получения целевого фрагмента в ПЦР используют два праймера, которые комплементарны противоположным цепям ДНК в участках, ограничивающих выбранную область ДНК. Таким образом, длина амплифицируемого фрагмента определяется расстоянием между праймерами.
Конструирование праймеров - это возможно, наиболее критический параметр для успешного проведения ПЦР. Последовательность праймера определяет целый ряд показателей, таких как позиция и длина продукта, его температура плавления и, безусловно, выход продукта. Плохо сконструированный праймер может привести к малому количеству продукта или его полному отсутствию.
При подборе праймеров необходимо соблюдать ряд правил:
1. Праймеры должны иметь высокую специфичность к матрице ДНК, чтобы обеспечить амплификацию чистого монопродукта в результате ПЦР без амплификации неспецифичных фрагментов ДНК.
2. Последовательность, комплементарная последовательности праймеров, должна встречаться в исследуемой ДНК не чаще одного раза.
3. Последние три нуклеотида 3’-конца праймера должны быть обязательно полностью комплементарны матрице ДНК, так как ДНК-полимераза присоединяет новые нуклеотиды к гидроксильным группам 3'-конца растущей цепи, и для успешного присоединения полимеразе требуется полное конформационное совпадение концевых нуклеотидов на 3'-конце.
4. Нуклеотидная последовательность праймеров не должна содержать повторяющиеся элементы и палиндромы, поскольку это может привести к неизбирательному отжигу и, как следствие, к получению неспецифичного продукта.
5. Область отжига праймеров должна происходить на консервативном участке матрицы ДНК, т.е. располагаться вне зон точечных мутаций, делеций или вставок. При попадании праймера на зону с мутациями возможно отсутствие ПЦР-продукта из-за несоответствия нуклеотидной последовательности праймера к области отжига на матрице, синтез неспецифического продукта из-за некорректного отжига праймера в другой области.
6. Оптимальная длина праймера находится в диапазоне 16-25 нуклеотидов, так как более короткие праймеры могут слабо связываться с матрицей из-за малого количества образующихся водородных связей, быть менее специфичными, поскольку чем короче последовательность праймера, тем менее она уникальна и тем чаще она может встречаться в геноме.
7. Соотношение AT/GC нуклеотидов в последовательности праймера должно быть близко к 1:1. Следует учитывать, что большое количество AT-оснований приводит к снижению температуры плавления праймеров, а большое количество GC-оснований - соответственно, к ее увеличению.
8. Разница в температурах отжига прямого и обратного праймеров должна быть в пределах 1-2 градусов, при увеличении разницы в температуре отжига между праймерами на 3 и более градусов оптимальную температуру отжига подбирают экспериментальным путем, при этом повышается вероятность амплификации неспецифических продуктов. Повышение температуры отжига праймеров улучшает качество ПЦР-продукта за счет уменьшения неспецифичного связывания праймера с матрицей, но при этом количество ПЦР-продукта может быть невелико. Понижение температуры отжига праймеров исключает преждевременную диссоциацию праймеров с матрицей на этапе элонгации ДНК, что дает увеличение количество ПЦР-продукта, но при этом есть риск появления неспецифичных ПЦР-продуктов.
9. Для улучшения качества отжига праймеров рекомендуется подбирать нуклеотидные последовательности праймеров так, чтобы последние 2-4 нуклеотида на 3’-конце праймера содержали GC-основания. Для праймера с высоким содержанием GC-оснований данное условие становится менее строгим и позволяет допустить наличие 1-2 AT-оснований на 3’-конце праймера.
10. На 3’-конце праймера не должно быть моно- (например, CCСC), ди- (например, GСGСGС) или тринуклеотидных повторов, поскольку такие повторы могут существенно уменьшать специфичность отжига праймеров, так как достаточно часто встречаются в геноме.
11. Нуклеотидные последовательности праймеров не должны образовывать стабильные вторичные структуры, быть само- или взаимно комплементарными. Наличие вторичных структур на праймере, в том числе шпильки на 3’-конце праймера, приводит к уменьшению эффективности связывания праймера с матрицей, затруднению присоединения ДНК-полимеразы и, соответственно, отсутствию элонгации. Взаимная комплементарность праймеров между собой (как прямых, так и обратных) и друг с другом особенно на 3'-концах приводит к образованию и амплификации димеров праймеров в ущерб целевому продукту, при этом чем длиннее участки взаимной комплементарности, тем эффективнее проходит амплификация димеров праймеров [Козырева А.А., Злотина А.М., Головкин А.С., Калинина О.В., Костарева А.А. Конструирование праймеров для ПЦР в программе Primer-BLAST. Трансляционная Медицина, 2021, том 8, №3, стр. 37].
Конструирование праймеров проводили с использованием BioEdit version 7.2.5 и MEGA v.10.2.2. (www.megasoftware.net) и программы Sequence Locator на сайте базы данных Лос-Аламос (Sequence Locator Tool (lanl.gov)).
На фиг. 2 приведен пример выбора праймера в программе BioEdit.
На фиг. 3 приведен пример анализа праймера (картирования) в программе Sequence Locator. При этом картирование генома ВИЧ в мире и в базе данных Лос-Аламос, в частности, происходит относительно референсной нуклеотидной последовательности, которая представляет собой почти полногенномную последовательность штамма HXB2 (K03455), который был получен из клинического образца крови пациента, забранного в 1983г. В настоящее время доменная организация белков ВИЧ также оценивается относительно этого штамма. При этом, штамм HXB2 принадлежит субтипу В ВИЧ-1, который наиболее широко распространен в Европе, Америке и Австралии. Однако, в России наиболее широко распространен вариант ВИЧ-1 суб-субтипа А6. В связи с этим существуют отличия в нуклеотидных последовательностях циркулирующих в России вариантов вируса от нуклеотидной последовательности HXB2, которые учитывались при выборе праймеров.
В данной работе праймеры были подобраны таким образом, чтобы минимальным количеством обеспечить возможность проведения анализа всех неструктурных белков ВИЧ-1 суб-субтип А6. Информация о праймерах, разработанных для первого раунда ПЦР, представлена в таблице 1. Жирным шрифтом с подчеркиванием отмечены нуклеотиды, которые у вариантов ВИЧ-1 суб-субтипа А6 отличались от нуклеотидов в референсной последовательности HXB2 (K03455). Так, праймеры Nef1p и Nef1o обеспечивают возможность амплификации участка генома, кодирующего ген nef, праймеры Vif1p и Vif1o - участка генома, кодирующего гены vif и vpr, праймеры TatRevF1 и Vpu1o - участка генома, кодирующего первый экзон генов tat, rev и ген vpu, праймеры T2R1p и T2R1o - участка генома, кодирующего второй экзон генов tat и rev.
Важной особенностью разработанных праймеров также является небольшая разница в температуре отжига, что позволило подобрать одинаковые параметры для всех реакций ПЦР. Таким образом, реакцию амплификации первого раунда ПЦР для анализа 6 генов неструктурных белков, два из которых кодируются двумя экзонами, возможно проводить в 4-х пробирках в одном приборе одновременно.
Таблица 1. Последовательность праймеров для проведения первого раунда ПЦР
Для проведения второй стадии ПЦР и последующего секвенирования были сконструированы праймеры, указанные в таблице 2. Данные праймеры также были подобраны таким образом, чтобы минимальным количеством обеспечить возможность проведения анализа всех неструктурных белков ВИЧ-1 суб-субтип А6. Так, праймеры Nef2p и NefR2_v1 позволяют амплифицировать участок генома, кодирующего ген nef, праймеры Vif2p и Vif2o - участок генома, кодирующего гены vif и vpr, праймеры TatRevf2_v1 и Vpu2o - участок генома, кодирующего первый экзон генов tat, rev и ген vpu, а праймеры T2R2p и T2R2o - участок генома, кодирующего второй экзон генов tat и rev. Праймеры подбирали таким образом, чтобы они имели примерно одинаковую температуру отжига, что позволило подобрать одинаковые параметры для всех реакций ПЦР.
Таким образом, реакцию амплификации второго раунда ПЦР для анализа 6 генов неструктурных белков, два из которых кодируются двумя экзонами, возможно проводить в 4-х пробирках в одном приборе одновременно.
Таблица 2. Последовательность праймеров для проведения второго раунда ПЦР и секвенирования
Таким образом, в результате проведенной работы было создано 4 пары праймеров для первого раунда ПЦР (SEQ ID NO:1/ SEQ ID NO:2; SEQ ID NO:3/ SEQ ID NO:4; SEQ ID NO:5/ SEQ ID NO:6; SEQ ID NO:7/ SEQ ID NO:8), которые позволяют проводить анализ 6 генов неструктурных белков ВИЧ-1 (два из которых кодируются двумя экзонами) в 4-х пробирках в одном приборе одновременно. Также было создано 4 пары праймеров для второго раунда ПЦР (SEQ ID NO:9/ SEQ ID NO:10; SEQ ID NO:11/ SEQ ID NO:12; SEQ ID NO:13/ SEQ ID NO:14; SEQ ID NO:15/ SEQ ID NO:16), которые позволяют проводить анализ 6 генов неструктурных белков ВИЧ-1 (два из которых кодируются двумя экзонами) в 4-х пробирках в одном приборе одновременно.
Пример 3. Анализ крови ВИЧ-инфицированного пациента разработанным способом
Первым этапом разработанного способа анализа крови является выделение провирусной ДНК пациента. В данном примере выделение провирусной ДНК проводили методом высаливания из лейкоцитов цельной крови ВИЧ-инфицированного пациента [Miller S.A., Dykes D.D., Polesky H.F. A simple salting out procedure for extracting DNA from human nucleated cells. Nucleic. Acids. Res. 1988; 16(3): 1215. https://doi.org/10.1093/nar/16.3.1215]. В дальнейшем 5 мкл выделенной провирусной ДНК использовали для проведения первого раунда ПЦР.
Реакцию амплификации первого раунда ПЦР проводили в пробирке, содержащей следующий состав реакционной смеси: 5 мкл ДНК (или деионизированной воды), 2,5 мкл 10-кратного ПЦР-буфера, 2 мкл рабочего раствора dNTPs; праймер прямой в конечной концентрации 1,0 мкМ, праймер обратный в конечной концентрации 1,0 мкМ, 1-2,5 единицы Taq ДНК-полимеразы; деионизированная вода (до объема смеси 20 мкл). В каждой пробирке реакционная смесь отличалась ДНК и праймерами. Всего было получено:
- 4 экспериментальных пробирки, содержащих 5 мкл выделенной провирусной ДНК и пары праймеров:
Пробирка 1 - SEQ ID NO:1/SEQ ID NO:2;
Пробирка 2 - SEQ ID NO:3/SEQ ID NO:4;
Пробирка 3 - SEQ ID NO:5/SEQ ID NO:6;
Пробирка 4 - SEQ ID NO:7/SEQ ID NO:8,
- 4 пробирки отрицательного контроля 1 раунда ПЦР, содержащих 5 мкл деионизированной воды и пары праймеров:
Пробирка 5: SEQ ID NO:1/SEQ ID NO:2;
Пробирка 6: SEQ ID NO:3/SEQ ID NO:4;
Пробирка 7: SEQ ID NO:5/SEQ ID NO:6;
Пробирка 8: SEQ ID NO:7/SEQ ID NO:8,
- 4 пробирки положительного контроля, включающих образец ДНК, содержащий соответствующий ген неструктурного белка ВИЧ-1, и пары праймеров:
Пробирка 9: SEQ ID NO:1/SEQ ID NO:2;
Пробирка 10: SEQ ID NO:3/SEQ ID NO:4;
Пробирка 11: SEQ ID NO:5/SEQ ID NO:6;
Пробирка 12: SEQ ID NO:7/SEQ ID NO:8,
Все пробирки поместили в амплификатор для первого раунда ПЦР.
Программа амплификации первого раунда ПЦР: 95° - 5 мин; затем (95° - 30 сек; 57°- 1 мин, 72° - 1 мин. 20 сек) 35 циклов. Далее 72° - 7 мин, 4° - ∞. Запуская одну программу амплификации для первого раунда ПЦР на приборе, можно проводить амплификацию всех генов неструктурных белков. После окончания первого раунда ПЦР 5 мкл из каждой пробирки использовали для проведения второго раунда ПЦР.
Реакцию амплификации второго раунда ПЦР проводили в пробирке, содержащей следующий состав реакционной смеси: 5 мкл реакционной смеси из первого раунда ПЦР (или деионизированной воды), 5 мкл 10-кратного ПЦР-буфера; 4 мкл рабочего раствора dNTPs; праймер прямой в конечной концентрации 1,0 мкМ; праймер обратный в конечной концентрации 1,0 мкМ; 1-2,5 единицы Taq ДНК-полимеразы; dH2O (до объема смеси 45 мкл).
В каждой пробирке реакционная смесь отличалась ДНК и праймерами. Всего было получено:
- 4 экспериментальных пробирки, содержащих
Пробирка 13: 5 мкл реакционной смеси из пробирки 1 и праймеры - SEQ ID NO:9/SEQ ID NO:10;
Пробирка 14: 5 мкл реакционной смеси из пробирки 2 и праймеры - SEQ ID NO:11/SEQ ID NO:12;
Пробирка 15: 5 мкл реакционной смеси из пробирки 3 и праймеры - SEQ ID NO:13/SEQ ID NO:14;
Пробирка 16: 5 мкл реакционной смеси из пробирки 4 и праймеры - SEQ ID NO:15/SEQ ID NO:16;
- 4 пробирки отрицательного контроля 1 раунда, содержащих
Пробирка 17: 5 мкл реакционной смеси из пробирки 5 и праймеры - SEQ ID NO:9/SEQ ID NO:10;
Пробирка 18: 5 мкл реакционной смеси из пробирки 6 и праймеры - SEQ ID NO:11/SEQ ID NO:12;
Пробирка 19: 5 мкл реакционной смеси из пробирки 7 и праймеры - SEQ ID NO:13/SEQ ID NO:14;
Пробирка 20: 5 мкл реакционной смеси из пробирки 8 и праймеры - SEQ ID NO:15/SEQ ID NO:16;
- 4 пробирки положительного контроля, содержащих
Пробирка 21: 5 мкл реакционной смеси из пробирки 8 и праймеры - SEQ ID NO:9/SEQ ID NO:10;
Пробирка 22: 5 мкл реакционной смеси из пробирки 10 и праймеры - SEQ ID NO:11/SEQ ID NO:12;
Пробирка 23: 5 мкл реакционной смеси из пробирки 11 и праймеры - SEQ ID NO:13/SEQ ID NO:14;
Пробирка 24: 5 мкл реакционной смеси из пробирки 12 и праймеры - SEQ ID NO:15/SEQ ID NO:16;
- 4 пробирки отрицательного контроля 2 раунда ПЦР, содержащих
Пробирка 25: 5 мкл деионизированной воды и праймеры - SEQ ID NO:9/SEQ ID NO:10;
Пробирка 26: 5 мкл деионизированной воды и праймеры - SEQ ID NO:11/SEQ ID NO:12;
Пробирка 27: 5 мкл деионизированной воды и праймеры - SEQ ID NO:13/SEQ ID NO:14;
Пробирка 28: 5 мкл деионизированной воды и праймеры - SEQ ID NO:15/SEQ ID NO:16;
Все пробирки поместили в амплификатор для второго раунда ПЦР.
Программа амплификации второго раунда ПЦР: 95° - 5 мин; (95° - 30 сек; 53°- 1 мин, 72° - 1мин 20 сек) 35 циклов. Далее 72° - 10 мин, 4° - ∞. Запуская одну программу амплификации для второго раунда ПЦР на приборе, можно проводить амплификацию всех генов неструктурных белков.
Далее полученные ПЦР продукты анализировали методом электрофореза в 2% агарозном геле в стандартном трис-ацетатном буфере (рН 8,0). Для этого по 5 мкл каждого образца смешивали с 1 мкл буфера для нанесения проб в отдельные лунки агарозного геля (агароза Е низкий ЕЕО, Диаэм, - 2 гр. на 100 мл ТАЕ - буфера), смешанного с бромистым этидием (5 мкл). Электрофорез проводили при напряжении 130 В. Результаты элекрофореза учитывали, просматривая гель в ультрафиолетовом свете с длиной волны 254 нм (фиг. 4).
Для определения нуклеотидных последовательностей генов неструктурных белков проводили секвенирование по Сэнгеру [Sanger, F. DNA sequencing with chain-terminating inhibitors / F. Sanger, S. Nicklen, A.R. Coulson // Proceeding of the National Academy of Sciences. - 1977. - Vol. 74, No 12. - P. 5463-5467]. Секвенирование проводили с праймеров второй стадии (табл. 2).
Затем для каждого гена осуществляли сбор контига на основе электрофореграмм, полученных с прямого и обратного праймера. Таким образом, каждый анализируемый фрагмент был прочитан два раза. При этом гены tat и rev содержали два фрагмента, так как кодируются двумя экзонами.
Сбор нуклеотидных последовательностей осуществлялся относительно консенсусных последовательность генов неструктурных ВИЧ-1 суб-субтипа А6. Предварительно для каждого гена была сформирована консенсусная последовательность, а для генов tat и rev по две консенсусные последовательности, отдельно для каждого экзона. Для этого из Базы данных базы данных Лос-Аламос были загружены следующие нуклеотидные последовательности суб-субтипа А6.
Таблица 3
DQ823366, DQ823367, EF545108, EF589039, EF589040, EF589041, EF589042, EF589043, EF589044, EU861977, FJ864679, JQ292891, JQ292892, JQ292893, JQ292894, JQ292895, JQ292896, JQ292897, JQ292898, JQ292899, JQ292900, JX500694, JX500695, JX500696, KF716491, KF716492, KT983615, KU749399, KU749400, KU749401, KU749403, KU749404, KU749405, KU749407, KY238326, KY658681, KY658682, MG902950, MG902951, MH330337, MH330338, MH330339, MH330340, MH330341, MH330342, MH330343, MH330344, MH330345, MH330346, MH330347, MH330348, MH330349, MH330350, MH330351, MH330352, MH330353, MH330354, MH330355, MH330356, MH330357, MH330358, MH330359, MH330361, MH330363, MH330364, MH330365, MH330367, MH330370, MH330371, MH330372, MH330373, MH330374, MH330375, MH330376, MH330377, MH330378, MH330379, MH330380, MH330381, MH396295, MN485977, MN703135, MN703136, MN703137, MN703138, MN703139, MN736699, MT222944, MT222945, MT222946, MT222947, MT222948, MT222949, MT318157, MT334907, MT334908, MT334909, MT334910, MT334911, MT334912, MT334913, MT334915, MT334916, MT334918, MT334919, MT334920, MT334921, MT334924, MT334925, MT334926, MT334927, MT334928, MT334929, MT334930, MT334931, MT334932, MT369950, MT369951, MT369952, MT369953, MT369955, MT369956, MT369957, MT369958, MT369960, MT369964, MT369965, MT369966, MT369967, MT369968, MT369970, MT369972, MT369973, MT369974, MT369975, MT369977, MT369978, MT369980, MT369982, MT369983, MT369984, MT369987, MT369989, MT369990, MT369993, MT369994, MT369995, MT369997, MT369998, MT369999, MT370000, MT370001, MT370002, MT370003, MT370005, MT370006, MT370007, MT370008, MZ327293, MZ327294, MZ427710, MZ427717, MZ427720, MZ427722, MZ427723, MZ427726, MZ427727, MZ427731, MZ427733, MZ427734, MZ427738, MZ427743, MZ427744, MZ427746, MZ427747, MZ427749, MZ427756, MZ427757, MZ427758, MZ427759, MZ427762, MZ427764, MZ427765, MZ427766, MZ427767, MZ427769, MZ427770, MZ427771, OM826727, OM826758, ON959204, OP056071, OQ979187
(1 экзон)
(2 экзон)
(1 экзон)
MH330358, MH330361, MH330367, KT983615, MH330338, MH330343, MH330342, MG902950, MH330339, MH330346, MG902951, MH330345, MH330341, MH330344, MH330337, MH330340, KU749399, KU749400, KU749407, KU749404, KU749405, KU749403, KU749401, KY658681, MH330381, MH330379, MH330378, MH330377, MH330376, MH330375, MH330374, MH330373, MH330372, MH330371, MH330370, MH330356, MH330380, MN703138, MT222945, MT222947, MT222946, MT222948, MN703139, MN703136, MT222944, MT222949, MN703137, MN703135, MT334921, MT334930, MT334918, MT369978, MT369966, MT334927, MT370006, MT369998, MT334911, MT370008, MT370005, MT369952, MT334910, MT334907, MT334928, MT369994, MT369955, MT369973, MT369951, MT369964, MT369965, MT369960, MT369995, MT370007, MT369999, MT369975, MT369972, MT370003, MT318157, MT369968, MT334906, MT369997, MT334912, MT334908, MT370002, MT369958, MT369993, MT334929, MT369983, MT334931, MT370000, MT334916, MT334926, MT369950, MT369953, MT334913, MT334924, MT369963, MT369990, MT369974, MT369967, MT334920, MT369980, MT334932, MT334919, MT370001, MT369961, MT369982, MT369984, MT369956, MT334915, MT369977, MT334925, MT369989, MT334909, MT369987, MT369970, MT369957, MZ427744, MZ427768, MZ327294, MZ427747, MZ427733, MZ427759, MZ427773, MZ427731, MZ427722, MZ427757, MZ427764, MZ427758, MZ427734, MZ427723, MZ427765, MZ427720, MZ427727, MZ427771, MZ427766, MZ427710, MZ427769, MZ427738, MZ427717, MZ427770, MZ427749, MZ427726, MZ427767, MZ427743, MZ427756, MZ327293, MZ427746, JX500694, MF109697, MN485977, MN736699
Далее осуществлялся анализ полученных последовательностей в программе MEGA v.10.2.2, целью которого было выявление мутаций в генах неструктурных белков ВИЧ-1, выделенного от конкретного пациента. На последнем этапе работы проводили интерпретацию полученного результата, которая заключалась в сравнении полученных результатов с базой данных мутаций, ассоциированных с изменением функциональных свойств вируса и с возможным влиянием на течение ВИЧ-инфекции, в том числе на риск развития коморбидных заболеваний у пациента, которая была сформирована на основе анализа данных мировой литературы (ФГБУ «НИЦЭМ им. Н.Ф. Гамалеи» Минздрава России).
В данном случае в белке Tat идентифицированы замены C31S и R57G (фиг. 5), ассоциированные со снижением нейропатогенетического потенциала вируса, а также присутствие вместо функционально значимого домена 78RGD80 мотива - 78QRD80, функциональное значение которого на настоящий момент неизвестно.
В белке Rev обнаружена вставка 95QSQGTET96, ассоциированная со снижением активности белка Rev.
В белке Vpu замены S61A, ассоциированной с повышенной внутриклеточной экспрессией и внутриклеточной стабильностью, не обнаружено.
В белке Vpr аминокислоты N41 и A55, ассоциированные с более выраженным нейрокогнитивным дефицитом, не обнаружены, детектированы аминокислоты - аминокислоты I37 и S41, ассоциированные с заметно более низкими проявлениями нейрокогнитивного дефицита.
В белке Vif мутация K22H, связанная с низким количеством клеток CD4+ и более высокой вирусной нагрузкой, не обнаружена.
В белке Nef были обнаружены два (L58V, Y81F) из 10 полиморфизма потенциально ассоциированные с легочной гипертензией; мутаций, ассоциированных с развитием лекарственной устойчивости к долутегравиру, не выявлено.
Данному пациенту могут быть даны рекомендации: избегать назначение абакавира, так как его применение в некоторых исследованиях связывают с развитием сердечно-сосудистых заболеваний.
Таким образом, результаты проведенной работы показали, что разработанный способ может быть успешно использован для выявления мутаций в генах неструктурных белков вируса ВИЧ-1 суб-субтипа А6, что позволяет предположить возможные риски развития коморбидных заболеваний у конкретного пациента.
Разработанный способ был успешно апробирован на 354 клинических образцах цельной крови ВИЧ-инфицированных пациентов.
Промышленная применимость
Разработанный способ в дальнейшем может быть использован для создания коммерческой тест-системы, позволяющей обнаруживать у ВИЧ-инфицированных пациентов мутации неструктурных белков ВИЧ, ассоциированные с изменением функциональных свойств вируса, которые могут влиять на течение ВИЧ-инфекции, в том числе на риск развития коморбидных заболеваний у пациента.
Как известно, современные антиретровирусные препараты обладают побочными эффектами: нейротоксичностью, повышенным риском развития сердечно-сосудистых заболеваний и т.д. Выделение групп риска среди ВИЧ-инфицированных пациентов позволит откорректировать применяемые для их лечения схемы терапии и снизить риск возникновения коморбидных заболеваний или отсрочить их манифестацию.
--->
<ST26SequenceListing dtdVersion="V1_3" fileName="HIV.xml"
softwareName="WIPO Sequence" softwareVersion="2.3.0"
productionDate="2024-02-21">
<ApplicationIdentification>
<IPOfficeCode>RU</IPOfficeCode>
<ApplicationNumberText/>
<FilingDate>2024-03-04</FilingDate>
</ApplicationIdentification>
<ApplicantFileReference>2024-03-04</ApplicantFileReference>
<ApplicantName languageCode="ru">федеральное государственное
бюджетное учреждение "Национальный исследовательский центр
эпидемиологии и микробиологии имени почетного академика Н.Ф.Гамалеи"
Министерства здравоохранения Российской Федерации</ApplicantName>
<ApplicantNameLatin>The National Research Center for Epidemiology and
Microbiology named after Honorary Academician N.F. Gamaleya of the
Ministry of Health of the Russian Federation</ApplicantNameLatin>
<InventionTitle languageCode="ru">Способ анализа крови
ВИЧ-инфицированных пациентов.</InventionTitle>
<SequenceTotalQuantity>16</SequenceTotalQuantity>
<SequenceData sequenceIDNumber="1">
<INSDSeq>
<INSDSeq_length>26</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..26</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q2">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtagctgggtggacagatagggttat</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="2">
<INSDSeq>
<INSDSeq_length>26</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..26</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q4">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gcactcaaggcaagctttattgaggc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="3">
<INSDSeq>
<INSDSeq_length>24</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..24</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q6">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gcaggtaagagagcaagctgaaca</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="4">
<INSDSeq>
<INSDSeq_length>25</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..25</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q8">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtctccgcttcttcctgccatagga</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="5">
<INSDSeq>
<INSDSeq_length>24</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..24</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q10">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>cagaattgggtgccaacatagcag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="6">
<INSDSeq>
<INSDSeq_length>26</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..26</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q12">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gcccagacattgtgtacttctttatc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="7">
<INSDSeq>
<INSDSeq_length>23</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..23</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q14">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ccagcaggaaaagaatgaacaag</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="8">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q16">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tgtctgattctcctaggtat</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="9">
<INSDSeq>
<INSDSeq_length>26</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..26</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q18">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>acatacctaggagaatcagacagggc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="10">
<INSDSeq>
<INSDSeq_length>19</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..19</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q20">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gcagcatctgagggttagc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="11">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q22">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gctactctggaaaggtgaagg</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="12">
<INSDSeq>
<INSDSeq_length>21</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..21</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q24">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>tacaaggagtcttgggctgac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="13">
<INSDSeq>
<INSDSeq_length>22</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..22</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q26">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gtgccaacatagcagaataggc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="14">
<INSDSeq>
<INSDSeq_length>20</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..20</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q28">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>gcatctctccacacaggtac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="15">
<INSDSeq>
<INSDSeq_length>18</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..18</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q30">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>aggcagggatactcaccc</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
<SequenceData sequenceIDNumber="16">
<INSDSeq>
<INSDSeq_length>26</INSDSeq_length>
<INSDSeq_moltype>DNA</INSDSeq_moltype>
<INSDSeq_division>PAT</INSDSeq_division>
<INSDSeq_feature-table>
<INSDFeature>
<INSDFeature_key>source</INSDFeature_key>
<INSDFeature_location>1..26</INSDFeature_location>
<INSDFeature_quals>
<INSDQualifier>
<INSDQualifier_name>mol_type</INSDQualifier_name>
<INSDQualifier_value>other DNA</INSDQualifier_value>
</INSDQualifier>
<INSDQualifier id="q32">
<INSDQualifier_name>organism</INSDQualifier_name>
<INSDQualifier_value>synthetic construct</INSDQualifier_value>
</INSDQualifier>
</INSDFeature_quals>
</INSDFeature>
</INSDSeq_feature-table>
<INSDSeq_sequence>ataaccctatctgtcccttcagctac</INSDSeq_sequence>
</INSDSeq>
</SequenceData>
</ST26SequenceListing>
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| Наборы олигонуклеотидов для выявления ДНК бактерии Helicobacter pylori в клиническом материале методом полимеразной цепной реакции в режиме реального времени | 2024 |
|
RU2839157C1 |
| Способ анализа соматических мутаций в генах IDH1 и IDH2 с использованием LNA-блокирующей ПЦР и гибридизации с биологическим микрочипом | 2024 |
|
RU2839291C1 |
| Способ выявления рекомбинантных форм вируса гепатита C и мутаций лекарственной устойчивости вируса гепатита С к препаратам прямого противовирусного действия методом полимеразной цепной реакции с последующим секвенированием | 2023 |
|
RU2824565C1 |
| Нуклеотидная последовательность, кодирующая фермент литиказу, и панель олигонуклеотидов для получения синтетической нуклеотидной последовательности гена литиказы | 2023 |
|
RU2826150C1 |
| Способ преимплантационного генетического тестирования болезни Гентингтона | 2024 |
|
RU2840728C1 |
| Способ определения генотипа ротавирусов первой и второй геногрупп и реассортантов между ними методом мультиплексной ПЦР | 2024 |
|
RU2833073C1 |
| Нуклеиновая кислота для аллотопической экспрессии гена MT-ND4 | 2023 |
|
RU2809065C1 |
| СПОСОБ ВЫЯВЛЕНИЯ STREPTOCOCCUS MUTANS МЕТОДОМ ИЗОТЕРМИЧЕСКОЙ ПЕТЛЕВОЙ АМПЛИФИКАЦИИ | 2022 |
|
RU2799413C1 |
| Способ определения мутаций лекарственной устойчивости ВИЧ в генах протеазы и обратной транскриптазы | 2023 |
|
RU2824667C1 |
| НАБОР ПРАЙМЕРОВ ДЛЯ ВЫЯВЛЕНИЯ STREPTOCOCCUS MUTANS МЕТОДОМ ИЗОТЕРМИЧЕСКОЙ ПЕТЛЕВОЙ АМПЛИФИКАЦИИ | 2022 |
|
RU2799414C1 |



Изобретение относится к биотехнологии и вирусологии. Предложен способ анализа крови ВИЧ-инфицированных пациентов для определения мутаций в генах ВИЧ, ассоциированных с изменением функциональных свойств вируса. Способ включает получение провирусной ДНК пациента, проведение первого раунда ПЦР, в котором ставят в отдельных пробирках 4 реакции ПЦР с парами праймеров SEQ ID:1 и SEQ ID NO:2, SEQ ID:3 и SEQ ID NO:4, SEQ ID:5 и SEQ ID NO:6, SEQ ID:7 и SEQ ID NO:8, соответственно, при этом все 4 реакции ПЦР имеют единые параметры амплификации. В качестве экспериментального образца используют образец провирусной ДНК, полученный от пациента, в качестве отрицательного контроля используют буферный раствор, аналогичный буферному раствору в экспериментальном образце, а в качестве положительного контроля используют ДНК, содержащую соответствующий ген неструктурного белка ВИЧ-1 суб-субтипа А6. Затем проводят второй раунд ПЦР, в котором ставят в отдельных пробирках 4 реакции ПЦР с парами праймеров SEQ ID:9 и SEQ ID NO:10, SEQ ID:11 и SEQ ID NO:12, SEQ ID:13 и SEQ ID NO:14, SEQ ID:15 и SEQ ID NO:16, соответственно, при этом в качестве экспериментальных образцов используются экспериментальные и контрольные ПЦР-смеси, полученные после первого раунда ПЦР, при этом все 4 реакции ПЦР имеют единые параметры амплификации. Далее проводят секвенирование по Сэнгеру с парами праймеров SEQ ID:9 и SEQ ID NO:10, SEQ ID:11 и SEQ ID NO:12, SEQ ID:13 и SEQ ID NO:14, SEQ ID:15 и SEQ ID NO:16. Осуществляют сбор нуклеотидных последовательностей генов неструктурных белков ВИЧ-1 суб-субтипа А6 на основе данных, полученных на этапе секвенирования по Сэнгеру. Проводят анализ полученных последовательностей, в ходе которого выявляют мутации в генах неструктурных белков ВИЧ-1 суб-субтипа А6 и осуществляют интерпретацию результатов, в ходе которой выявляют мутации в генах неструктурных белков, ассоциированные с изменением функциональных свойств вируса. Способ анализа крови ВИЧ-инфицированных пациентов позволяет выявить мутации в генах неструктурных белков ВИЧ-1 суб-субтипа A6, циркулирующего на территории Российской Федерации, ассоциированные с изменением функциональных свойств вируса, которые могут влиять на течение ВИЧ-инфекции, в том числе на риск развития коморбидных заболеваний у пациента. 5 ил., 3 табл., 3 пр.
Способ анализа крови ВИЧ-инфицированных пациентов для определения мутаций в генах ВИЧ, ассоциированных с изменением функциональных свойств вируса, включающий:
(1) этап получения провирусной ДНК пациента;
(2) первый раунд ПЦР, в котором ставят в отдельных пробирках 4 реакции ПЦР с парами праймеров SEQ ID:1 и SEQ ID NO:2, SEQ ID:3 и SEQ ID NO:4, SEQ ID:5 и SEQ ID NO:6, SEQ ID:7 и SEQ ID NO:8, соответственно, при этом в качестве экспериментального образца используется образец провирусной ДНК, полученный на этапе получения провирусной ДНК пациента, в качестве отрицательного контроля используется буферный раствор, аналогичный буферному раствору в экспериментальном образце, а в качестве положительного контроля используется ДНК, содержащая соответствующий ген неструктурного белка ВИЧ-1 суб-субтипа А6, при этом все 4 реакции ПЦР имеют единые параметры амплификации;
(3) второй раунд ПЦР, в котором ставят в отдельных пробирках 4 реакции ПЦР с парами праймеров SEQ ID:9 и SEQ ID NO:10, SEQ ID:11 и SEQ ID NO:12, SEQ ID:13 и SEQ ID NO:14, SEQ ID:15 и SEQ ID NO:16, соответственно, при этом в качестве экспериментальных образцов используются экспериментальные и контрольные ПЦР-смеси, полученные после первого раунда ПЦР, при этом все 4 реакции ПЦР имеют единые параметры амплификации;
(4) секвенирование по Сэнгеру, которое проводят с парами праймеров SEQ ID:9 и SEQ ID NO:10, SEQ ID:11 и SEQ ID NO:12, SEQ ID:13 и SEQ ID NO:14, SEQ ID:15 и SEQ ID NO:16;
(5) сбор нуклеотидных последовательностей генов неструктурных белков ВИЧ-1 суб-субтипа А6 на основе данных, полученных на этапе секвенирования по Сэнгеру;
(6) анализ полученных последовательностей, в ходе которого выявляют мутации в генах неструктурных белков ВИЧ-1 суб-субтипа А6;
(7) интерпретация результатов, в ходе которой выявляют мутации в генах неструктурных белков, ассоциированные с изменением функциональных свойств вируса.
| Способ прогностической оценки гепатотоксичности у ВИЧ-инфицированных лиц при антиретровирусной терапии на основе определения делеционного полиморфизма генов биотрансформации ксенобиотиков GSTM1, GSTT1, CYP2D6 человека и набор олигодезоксирибонуклеотидных праймеров и флуоресцентно меченых зондов | 2022 |
|
RU2807530C1 |
| Augustine O | |||
| Udeze et al | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| Глинщикова О.А | |||
| и др | |||
| Определение генетических | |||

