Область изобретения
Настоящее изобретение относится к варианту геранилгеранилпирофосфатсинтазы; полинуклеотиду, кодирующему вариант; вектору, содержащему полинуклеотид; микроорганизму, содержащему любой один или более чем один из варианта, полинуклеотид а и вектора; способу получения тетратерпена, его предшественника или вещества, имеющего тетратерпен в качестве предшественника, с его применением; композиции для получения тетратерпена, его предшественника или вещества, имеющего тетратерпен в качестве предшественника; и применению микроорганизма, содержащего любой один или более чем один из варианта, полинуклеотид а и вектора, для получения тетратерпена, его предшественника и вещества, имеющего тетратерпен в качестве предшественника.
Предшествующий уровень техники
Терпеноиды, которые представляют собой группу, включающую каротиноиды, выполняют различные функции в растениях и животных и, таким образом, используются в различных промышленных областях, таких как продукты питания, корма и т.п. Терпеноиды известны как типичные вещества, демонстрирующие лечебные свойства растений, и как каротиноиды, они представляют собой тип терпенов. Среди них такие каротиноиды, как бета-каротин, представляют собой вещества, которые, как сообщается, выполняют такие функции, как устранение свободных радикалов, действие в качестве предшественников витамина А у животных, усиление иммунной системы позвоночных животных и уменьшение риска развития рака легкого.
Тем не менее, несмотря на эти преимущества, каротиноиды, например, бета-каротины не синтезируются в организме животного или синтезируются в недостаточных количествах. Кроме того, несмотря на попытки промышленного производства с использованием мутантных микроорганизмов (патент США №7745170), все еще трудно продуцировать бета-каротин с высокой чистотой из-за побочных продуктов.
В отношении побочных продуктов, геранилгеранилпирофосфат (GGPP, С20), который является ключевым предшественником для производства каротиноидов или терпеноидов, образуется путем связывания с фарнезилпирофосфатом (FPP, С15) и изопентенилпирофосфатом (IPP, С5) при помощи фермента геранилгеранилпирофосфатсинтазы в пути биосинтеза изопреноида. Однако, сквален (С30) может образоваться в виде побочного продукта из фарнезилпирофосфата (FPP, С15) при помощи скваленсинтазы (ERG9). Соответственно, существует потребность в разработке способа увеличения продукции GGPP, который является ключевым предшественником при биосинтезе каротиноидов или терпеноидов, и способа уменьшения продукции сквалена, который представляет собой конкурирующий путь.
Описание изобретения
Техническая задача
Проблема, решаемая в настоящем изобретении, заключается в том, чтобы предложить вариант геранилгеранилпирофосфатсинтазы и способ получения тетратерпена, его предшественника и вещества, имеющего тетратерпен в качестве предшественника, с его применением.
Техническое решение
Задача настоящего изобретения заключается в том, чтобы предложить вариант геранилгеранилпирофосфатсинтазы, где любая одна или более чем одна из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 от N-конца аминокислотной последовательности SEQ ID NO: 1, заменены на другую аминокислоту.
Еще одна задача настоящего изобретения заключается в том, чтобы предложить полинуклеотид, кодирующий указанный вариант.
Еще одна задача настоящего изобретения заключается в том, чтобы предложить вектор, включающий указанный полинуклеотид.
Еще одна задача настоящего изобретения заключается в том, чтобы предложить микроорганизм, включающий любой один или более чем один из варианта, полинуклеотида и вектора.
Еще одна задача настоящего изобретения заключается в том, чтобы предложить способ получения тетратерпена, его предшественника и вещества, имеющего тетратерпен в качестве предшественника, включающий культивирование микроорганизма в среде.
Еще одна задача настоящего изобретения заключается в том, чтобы предложить композицию для получения тетратерпена, его предшественника и вещества, имеющего тетратерпен в качестве предшественника, причем композиция включает вариант, вектор, микроорганизм или культуру микроорганизма.
Еще одна задача настоящего изобретения заключается в том, чтобы предложить применение любого одного или более чем одного из варианта, полинуклеотид а, вектора и микроорганизма для получения тетратерпена, его предшественника и вещества, имеющего тетратерпен в качестве предшественника.
Полезные эффекты
Микроорганизм, экспрессирующий вариант геранилгеранилпирофосфатсинтазы в соответствии с настоящим изобретением, может эффективно продуцировать тетратерпен, предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника, по сравнению с штаммом, не экспрессирующим этот вариант.
Подробное описание предпочтительных воплощений
Далее описание настоящего изобретения будет представлено подробно следующим образом. В то же самое время, каждое из описания и воплощения, раскрытого в данном описании изобретения, также может применяться к другим описаниям изобретения и воплощениям. Кроме того, все комбинации различных элементов, раскрытых в данном описании изобретения, находятся в объеме описания настоящего изобретения объема. Кроме того, объем настоящего изобретения не ограничен конкретным описанием, представленным ниже.
В одном аспекте настоящего изобретения предложен вариант геранилгеранилпирофосфатсинтазы, где любая одна или более чем одна из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 от N-конца аминокислотной последовательности SEQ ID NO: 1, заменена на другую аминокислоту.
Вариант геранилгеранилпирофосфатсинтазы относится к варианту, в котором любая одна или более чем одна из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 от N-конца SEQ ID NO: 1, заменена на другую аминокислоту в полипептиде, имеющем геранилгеранилпирофосфатсинтазную активность, или в геранилгеранилпирофосфатсинтазе.
Используемая здесь "геранилгеранилпирофосфатсинтаза (GGS1)" представляет собой фермент, способный катализировать синтез геранилгеранилпирофосфата (GGPP) из фарнезилпирофосфата (FPP).
Геранилгеранилпирофосфатсинтаза в соответствии с настоящим изобретением может представлять собой геранилгеранилпирофосфатсинтазу или полипептид, имеющий геранилгеранилпирофосфатсинтазную активность, в отношении которого модификация применена для получения варианта геранилгеранилпирофосфатсинтазы, предложенного в описании настоящего изобретения. В частности, геранилгеранилпирофосфатсинтаза может представлять собой природный полипептид или полипептид дикого типа, и может представлять собой его зрелый полипептид, и может включать его вариант или функциональный фрагмент, но любой из них может быть включен без ограничения при условии, что он может представлять собой родитель варианта геранилгеранилпирофосфатсинтазы в соответствии с настоящим изобретением.
В описании настоящего изобретения геранилгеранилпирофосфатсинтаза может представлять собой без ограничения полипептид в соответствии с SEQ ID NO: 1. Кроме того, геранилгеранилпирофосфатсинтаза может представлять собой полипептид, имеющий приблизительно 80%, 85%, 90%, 95%, 96%, 97%, 98% или 99% или более чем 99% идентичность последовательности с полипептидом в соответствии с SEQ ID NO: 1, и любой из них может оказаться в объеме геранилгеранилпирофосфатсинтазы без ограничения при условии того, что он может иметь активность, идентичную или соответствующую активности полипептида, состоящего из аминокислотной последовательности SEQ ID NO: 1.
Последовательность геранилгеранилпирофосфатсинтазы в соответствии с настоящим изобретением можно найти в NCBI (Национальный центр биотехнологической информации) GenBank и т.п, которая представляет собой известную базу данных. В частности, геранилгеранилпирофосфатсинтаза может представлять собой полипептид, кодируемый геном ggsl, но не ограничивается этим.
Используемый здесь термин "вариант" относится к полипептиду, имеющему аминокислотную последовательность, отличающуюся от последовательности варианта до модификации путем консервативной замены и/или модификации одной или более чем одной аминокислоты, но сохраняющему функции или свойства. Такие варианты как правило могут быть идентифицированы путем модификации одной или более чем одной из аминокислот аминокислотной последовательности полипептида и оценки свойств модифицированного полипептида. Иначе говоря, способность варианта может быть увеличена, остаться без изменений или уменьшена по сравнению со способностью полипептида до изменения. Кроме того, некоторые варианты могут включать варианты, в которых один или более чем один фрагмент, такой как N-концевая лидерная последовательность или трансмембранный домен, удалены. Другие варианты могут включать варианты, в которых фрагмент N- и/или С-конца удален из зрелого белка. Термин "вариант" может быть использован взаимозаменяемо с терминами, такими как модификация, модифицированный полипептид, модифицированный белок, мутант, мутеин и дивергент, и не ограничивается ими при условии того, что этот термин используется в значении вариации.
Кроме того, вариант может включать делеции или вставки аминокислот, которые обладают минимальным влиянием на свойства и вторичную структуру полипептида. Например, сигнальная (или лидерная) последовательность, вовлеченная котрансляционно или посттрансляционно в транслокацию белка, может быть конъюгирована по N-концу варианта. Вариант может быть конъюгирован с другими последовательностями или линкерами для идентификации, очистки или синтеза.
Вариант в соответствии с настоящим изобретением может представлять собой вариант геранилгеранилпирофосфатсинтазы, в котором любая одна или более чем одна аминокислота из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 от N-конца аминокислотной последовательности SEQ ID NO: 1, заменена на другую аминокислоту. В частности, аминокислоты по одной или более чем одной, двум или более, трем или более, четырем или более, пяти или более, или шести или более положениям из положений 29, 43, 90, 103, 122 и 141 могут быть заменены, но не ограничиваются этим.
В полипептиде, имеющем геранилгеранилпирофосфатсинтазную активность, или в геранилгеранилпирофосфатсинтазе, которая является родительской для варианта, аминокислота, соответствующий положению 29 от N-конца аминокислотной последовательности SEQ ID NO: 1, может представлять собой аспарагин; аминокислота, соответствующая положению 43, может представлять собой фенилаланин; аминокислота, соответствующая положению 90, может представлять собой лейцин; аминокислота, соответствующая положению 103, может представлять собой метионин; аминокислота, соответствующая положению 122, может представлять собой изолейцин; и/или аминокислота, соответствующая положению 141, может представлять собой аргинин, но не ограничивается этим.
В одном из воплощений вариант может включать одну или более чем одну замену из замены аминокислоты, соответствующей положению 29 от N-конца аминокислотной последовательности SEQ ID NO: 1, на аминокислоту, отличающуюся от аспарагина; замену аминокислоты, соответствующей положению 43, на аминокислоту, отличающуюся от фенилаланина; замену аминокислоты, соответствующей положению 90, на аминокислоту, отличающуюся от лейцина; замену аминокислоты, соответствующей положению 103, на аминокислоту, отличающуюся от метионина; замену аминокислоты, соответствующий положению 122, на аминокислоту, отличающуюся от изолейцина; и замену аминокислоты, соответствующей положению 141, на аминокислоту, отличающуюся от аргинина, но не ограничивается этим.
"Другая аминокислота" не ограничена при условии, что она представляет собой аминокислоту, отличающуюся от аминокислоты до замены. В то же самое время, в описании настоящего изобретения, при использовании выражения конкретная аминокислота заменена', очевидно, что аминокислота заменена на аминокислоту, отличную от аминокислоты до замены, если иное не описано как замена на отличающуюся аминокислоту.
Замена на другую аминокислоту может представлять собой замену на неполярную аминокислоту, полярную аминокислоту или положительно заряженную (основную) аминокислоту. В частности, неполярная аминокислота может быть выбрана из группы, состоящей из глицина, аланина, валина, лейцина, изолейцина, метионина и пролина, но не ограничивается этим. Полярная аминокислота может быть использована взаимозаменяемо с гидрофильной аминокислотой и может быть выбрана из группы, состоящей из серина, треонина, цистеина, тирозина, аспарагина и глутамина, и положительно заряженная (основная) аминокислота может быть выбрана из группы, состоящей из аргинина, лизина и гистидина, но не ограничивается этим.
В частности, вариант по настоящему изобретению может представлять собой вариант, в котором любая одна или более чем одна из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 в аминокислотной последовательности SEQ ID NO: 1, представляющей собой референсный белок, может быть заменена на аминокислоту, отличающуюся от аминокислоты до замены, среди неполярных аминокислот, полярных аминокислот или положительно заряженных (основных) аминокислот, но не ограничивается этим. Неполярная аминокислота может представлять собой изолейцин (Ile) или валин (Val), полярная аминокислота может представлять собой треонин (Thr) и положительно заряженная аминокислота может представлять собой аргинин (Arg) или лизин (Lys), но не ограничивается этим.
Кроме того, другая аминокислота может представлять собой любую аминокислоту, выбранную из группы, состоящей из треонина, изолейцина, аргинина, валина и лизина, но не ограничивается этим.
В одном из воплощений в варианте описания настоящего изобретения любая одна или более чем одна аминокислота из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 аминокислотной последовательности SEQ ID NO: 1, может быть заменена на любую аминокислоту, выбранную из группы, состоящей из треонина, изолейцина, аргинина, валина и лизина, но не ограничивается этим.
В одном из воплощений вариант в соответствии с настоящим изобретением может содержать замену, выбранную из группы, состоящей из замены аминокислоты, соответствующей положению 29 аминокислотной последовательности SEQ ID NO: 1, на треонин; замены аминокислоты, соответствующий положению 43, на изолейцин; замены, аминокислоты, соответствующий положению 90, на аргинин; замены аминокислоты, соответствующий положению 103, на изолейцин; замены аминокислоты, соответствующей положению 122, на валин; и замены аминокислоты, соответствующей положению 141, на лизин, и их комбинации, но не ограничивается этим.
Используемый здесь термин, "соответствующий" относится к аминокислотным остаткам в положениях, перечисленных в полипептиде, или аминокислотным остаткам, которые похожи, идентичны или гомологичны перечисленным в полипептиде. Идентификация аминокислоты в соответствующем положении может представлять собой определение конкретной аминокислоты в последовательности, которая относится к конкретной последовательности. Используемая здесь "соответствующая область" как правило относится к похожей или соответствующей положению в родственном белке или референсном белке.
Например, произвольная аминокислотная последовательность выравнивается с SEQ ID NO: 1, и на основании этого каждый аминокислотный остаток аминокислотной последовательности может быть пронумерован со ссылкой на номер положения аминокислотного остатка, соответствующего аминокислотному остатку в SEQ ID NO: 1. Например, алгоритм выравнивания последовательности, изложенный в описании настоящего изобретения, может определять положение аминокислоты или положение, в котором модификация, такая как замена, вставка или делеция, осуществляется путем сравнения с интересующей последовательностью (также названной как "референсная последовательность").
Для таких выравниваний, например, может быть использован алгоритм Нидлмана-Вунша (Needleman and Wunsch, 1970, J. Mol. Biol. 48: 443-453), программа Needleman в пакете EMBOSS (EMBOSS: The European Molecular Biology Open Software Suite, Rice et al., 2000), Trends Genet. 16: 276-277) и т.п., но не ограничивается ими, и подходящим образом может быть использована программа для выравнивания последовательностей, алгоритм попарного сравнения последовательностей и т.п., известные в области техники.
В одном из воплощений вариант в соответствии с настоящим изобретением может содержать замену любой одной или более чем одной аминокислоты из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 SEQ ID NO: 1, на другую аминокислоту, и иметь 80%, 85%, 90%, 95%, 96%, 97%, 98% или 99% или более чем 99% идентичность последовательности с полипептидом в соответствии с SEQ ID NO: 1.
В одном из воплощений вариант в соответствии с настоящим изобретением может включать аминокислотную последовательность, имеющую по меньшей мере 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 99,5%, 99,7% или 99,9% или более чем 99,9% гомологию или идентичность с аминокислотной последовательностью, представленной в SEQ ID NO: 3, SEQ ID NO: 5, SEQ ID NO: 7, SEQ ID NO: 9, SEQ ID NO: 11, SEQ ID NO: 13, SEQ ID NO: 15 или SEQ ID NO: 17.
В частности, вариант в соответствии с настоящим изобретением может иметь, может содержать или может состоять из аминокислотной последовательности, представленной в SEQ ID NO: 3, SEQ ID NO: 5, SEQ ID NO: 7, SEQ ID NO: 9, SEQ ID NO: 11, SEQ ID NO: 13, SEQ ID NO: 15 или SEQ ID NO: 17, или может по существу состоять из вышеприведенной аминокислотной последовательности.
В одном из воплощений вариант в соответствии с настоящим изобретением может включать аминокислотную последовательность, содержащую замену любой одной или более чем одной аминокислоты из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 на основе аминокислотной последовательности SEQ ID NO: 1, на другую аминокислоту и имеющую по меньшей мере 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, 99,5%, 99,7% или 99,9% или более чем 99,9% гомологию или идентичность с аминокислотной последовательностью, представленной в SEQ ID NO: 3, SEQ ID NO: 5, SEQ ID NO: 7, SEQ ID NO: 9, SEQ ID NO: 11, SEQ ID NO: 13, SEQ ID NO: 15 или SEQ ID NO: 17.
В одном из воплощений вариант в соответствии с настоящим изобретением может представлять собой любой один или более чем один, выбранный из полипептида, включающего аминокислотную последовательность, представленную в SEQ ID NO: 3, в которой метионин, представляющий собой аминокислоту, соответствующую положению 103 аминокислотной последовательности SEQ ID NO: 1, заменен на изолейцин; полипептида, включающего аминокислотную последовательность, представленную в SEQ ID NO: 5, в которой фенилаланин, представляющий собой аминокислоту, соответствующую положению 43 аминокислотной последовательности SEQ ID NO: 1, заменен на изолейцин; полипептида, включающего аминокислотную последовательность, представленную в SEQ ID NO: 7, в которой аспарагин, представляющий собой аминокислоту, соответствующую положению 29 аминокислотной последовательности SEQ ID NO: 1, заменен на треонин, и лейцин, представляющий собой аминокислоту, соответствующую положению 90, заменен на аргинин; полипептида, включающего аминокислотную последовательность, представленную в SEQ ID NO: 9, в котором аспарагин, представляющий собой аминокислоту, соответствующую положению 29 аминокислотной последовательности SEQ ID NO: 1, заменен на треонин; полипептида, включающего аминокислотную последовательность, представленную в SEQ ID NO: 11, в которой лейцин, представляющий собой аминокислоту, соответствующую положению 90 аминокислотной последовательности SEQ ID NO: 1, заменен на аргинин; полипептида, включающего аминокислотную последовательность, представленную в SEQ ID NO: 13, в которой изолейцин, представляющий собой аминокислоту, соответствующую положению 122 аминокислотной последовательности SEQ ID NO: 1, заменен на валин, и аргинин, представляющий собой аминокислоту, соответствующую положению 141, заменен на лизин; полипептида, включающего аминокислотную последовательность, представленную в SEQ ID NO: 15, в которой изолейцин, представляющий собой аминокислоту, соответствующую положению 122 аминокислотной последовательности SEQ ID NO: 1, заменен на валин; и полипептида, включающего аминокислотную последовательность, представленную в SEQ ID NO: 17, в которой аргинин, представляющий собой аминокислоту, соответствующую положению 141 аминокислотной последовательности SEQ ID NO: 1, заменен на лизин, но не ограничивается этим.
Также очевидно, что вариант, имеющий аминокислотную последовательность, имеющую делецию, модификацию, замену, консервативную замену или вставку некоторой последовательности, также входит в объем настоящего изобретения при условии, что аминокислотная последовательность имеет такую гомологию или идентичность и демонстрирует эффективность, соответствующую эффективности варианта в соответствии с настоящим изобретением.
Примеры варианта включают варианты, имеющие вставку или делецию последовательности, которая не изменяет функцию варианта в соответствии с настоящим изобретением, по N-концу, С-концу и/или внутри аминокислотной последовательности, или природную мутацию, молчащую мутацию или консервативную замену.
"Консервативная замена" обозначает замену одной аминокислоты на другую аминокислоту, имеющую похожие структурные и/или химические свойства. Такая аминокислотная замена как правило может осуществляться на основе сходства полярности, заряда, растворимости, гидрофобности, гидрофильности и/или амфипатической природы остатков. Как правило, консервативная замена вряд ли может влиять или не влиять на активность белков или полипептидов.
Использованный здесь термин "гомология" или "идентичность" относится к степени сходства между двумя данными аминокислотными последовательностями или нуклеотидными последовательностями, и она может быть выражена в процентах. Часто термины "гомология" и "идентичность" могут быть использованы взаимозаменяемо.
Гомология или идентичность последовательностей консервативных полинуклеотидов или полипептидов может быть определена при помощи стандартного алгоритма выравнивания, и может быть использована вместе со штрафами за пропуск по умолчанию, установленными в используемой программе. По существу, как правило гомологичные или идентичные последовательности могут гибридизоваться друг с другом в виде полноразмерных последовательностей или в виде части последовательностей в умеренно строгих или очень строгих условиях. Очевидно, что гибридизация также включают гибридизацию с полинуклеотидом, содержащим обычные кодоны или кодоны в соответствии с вырожденностью кодонов в полинуклеотиде.
Имеют ли любые две полинуклеотидные или полипептидные последовательности гомологию, сходство или идентичность, может быть определено, например, с использованием известного компьютерного алгоритма, такого как программа "FASTA", с использованием параметров по умолчанию, таких как в Pearson et al., (1988) [Proc. Natl. Acad. Sci. USA 85]:2444. В качестве альтернативы, они могут быть определены с использованием алгоритма Нидлмана-Вунша (Needleman and Wunsch, 1970, J. Mol. Biol. 48:443^153), осуществляемого в программе Needleman пакета EMBOSS (EMBOSS:The European Molecular Biology Open Software Suite, Rice et al., 2000, Trends Genet. 16:276-277) (версия 5.0.0 или более поздняя) (включающая программный пакет GCG (Devereux, J., etal., Nucleic Acids Research 12:387(1984)), BLASTP, BLASTN, FASTA (Atschul, [S.] [F.,] [ETAL, J MOLEC BIOL 215]: 403 (1990); Guide to Huge Computers, Martin J. Bishop, [ED.,] Academic Press, San Diego,1994, и [CARILLO ETA/.](1988) SIAM J Applied Math 48: 1073). Например, гомология, сходство или идентичность могут быть определены с использованием BLAST или ClustalW от Национального Центра Биотехнологической Информации.
Гомология, сходство или идентичность между полинуклеотидами или полипептидами могут быть определены путем сравнения информации о последовательностях с использованием компьютерной программы GAP, такой как представленная, например, в Needleman et al. (1970), JMol Biol. 48:443, как раскрыто в Smith and Waterman, Adv. Appl. Math (1981) 2:482. Кратко, программа GAP определяет гомологию, сходство или идентичность в виде величины, получаемой путем деления количества одинаковым образом выровненных символов (т.е. нуклеотидов или аминокислот) на общее количество символов в более короткой из двух последовательностей. Параметры по умолчанию для программы GAP могут включать: (1) матрицу двоичного сравнения (содержащую величину 1 в случае идентичности и 0 в случае не идентичности) и взвешенную матрицу сравнения в соответствии с Gribskov et al. (1986), Nucl. Acids Res. 14:6745, как раскрыто в Schwartz and Dayhoff, eds., Atlas of Protein Sequence and Structure, National Biomedical Research Foundation, pp.353-358 (1979) (или версия EDNAFULL (EMBOSS в NCBI NUC4.4) матрица замен); (2) штраф 3,0 за каждый пропуск и дополнительно штраф 0,10 за каждый символ в каждом пропуске (или штраф за внесение пропуска 10 и штраф за удлинение пропуска 0,5) и (3) отсутствие штрафа за концевые пропуски.
В одном из воплощений вариант в соответствии с настоящим изобретением может иметь геранилгеранилпирофосфатсинтазную активность. В одном из воплощений вариант в соответствии с настоящим изобретением может иметь активность, которая увеличивает способность продуцировать тетратерпен, предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника, по сравнению с диким типом или немодифицированной геранилгеранилпирофосфатсинтазой. В одном из воплощений вариант в соответствии с настоящим изобретением может иметь активность, которая уменьшает уровень образования побочных продуктов в пути продукции тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника, по сравнению с диким типом или немодифицированной геранилгеранилпирофосфатсинтазой. В одном из воплощений вариант в соответствии с настоящим изобретением может иметь активность, которая уменьшает уровень образования сквалена по сравнению с диким типом или немодифицированной геранилгеранилпирофосфатсинтазой. В одном из воплощений вариант в соответствии с настоящим изобретением может иметь усиленную активность по сравнению с диким типом или немодифицированной геранилгеранилпирофосфатсинтазой, но не ограничивается этим.
В еще одном аспекте настоящего изобретения предложен полинуклеотид, кодирующий вариант в соответствии с настоящим изобретением.
Используемый здесь термин "полинуклеотид" представляет собой цепь ДНК или РНК, имеющую определенную длину или большую длину в виде полимера из нуклеотидов, в котором нуклеотидные мономеры связаны в длинную цепь при помощи ковалентных связей, и, конкретней, относится к полинуклеотидному фрагменту, кодирующему вариант, имеющий геранилгеранилпирофосфатную активность.
Полинуклеотид, кодирующий вариант в соответствии с настоящим изобретением, может включать нуклеотидную последовательность, кодирующую аминокислотную последовательность, представленную в SEQ ID NO: 3, SEQ ID NO: 5, SEQ ID NO: 7, SEQ ID NO: 9, SEQ ID NO: 11, SEQ ID NO: 13, SEQ ID NO: 15 или SEQ ID NO: 17. В одном из воплощений полинуклеотид в соответствии с настоящим изобретением может иметь или может включать последовательность в соответствии с SEQ ID NO: 4, SEQ ID NO: 6, SEQ ID NO: 8, SEQ ID NO: 10, SEQ ID NO: 12, SEQ ID NO: 14, SEQ ID NO: 16 или SEQ ID NO: 18. Кроме того, полинуклеотид в соответствии с настоящим изобретением может состоять из или может по существу состоять из последовательности в соответствии с SEQ ID NO: 4, SEQ ID NO: 6, SEQ ID NO: 8, SEQ ID NO: 10, SEQ ID NO: 12, SEQ ID NO: 14, SEQ ID NO: 16 или SEQ ID NO: 18.
В полинуклеотиде в соответствии с настоящим изобретением различные модификации могут быть осуществлены в кодирующей области при условии того, что аминокислотная последовательность варианта в соответствии с настоящим изобретением не изменена в соответствии с вырожденностью кодонов или кодонами, предпочтительными для организмов, которые, как предполагается, экспрессируют вариант в соответствии с настоящим изобретением. В частности, полинуклеотид в соответствии с настоящим изобретением может иметь или может включать нуклеотидную последовательность, имеющую 80% или более, 90% или более, 95% или более, 96% или более, 97% или более, 98% или более и менее чем 100% гомологию или идентичность с последовательностью в соответствии с SEQ ID NO: 4, SEQ ID NO: 6, SEQ ID NO: 8, SEQ ID NO: 10, SEQ ID NO: 12, SEQ ID NO: 14, SEQ ID NO: 16 или SEQ ID NO: 18, или может состоять из или по существу состоять из нуклеотидной последовательности, имеющей 80% или более, 90% или более, 95% или более, 96% или более, 97% или более, 98% или более и менее чем 100% гомологию или идентичность с последовательностью в соответствии с SEQ ID NO: 4, SEQ ID NO: 6, SEQ ID NO: 8, SEQ ID NO: 10, SEQ ID NO: 12, SEQ ID NO: 14, SEQ ID NO: 16 или SEQ ID NO: 18, но не ограничивается этим.
В этой связи, в SEQ ID NO: 4, SEQ ID NO: 6, SEQ ID NO: 8, SEQ ID NO: 10, SEQ ID NO: 12, SEQ ID NO: 14, SEQ ID NO: 16 или SEQ ID NO: 18 последовательности, имеющей гомологию или идентичность, кодоны, кодирующие аминокислоты, соответствующие положениям 29, 43, 90, 103, 122 и 141 настоящего изобретения, могут представлять собой любой из кодонов, кодирующих треонин, изолейцин, аргинин, валин или лизин.
Кроме того, полинуклеотид в соответствии с настоящим изобретением может включать зонд, который может быть получен из известной генной последовательности, например, может включать последовательность без ограничения при условии, что она представляет собой последовательность, которая способна гибридизоваться с последовательностью, комплементарной всей или части полинуклеотидной последовательности в соответствии с настоящим изобретением в строгих условиях. "Строгие условия" обозначает условия, при которых возможна специфическая гибридизация между полинуклеотидами. Эти условия, в частности, описаны в литературе (смотри J. Sambrook et at, Molecular Cloning, A Laboratory Manual, 2nd Edition, Cold Spring Harbor Laboratory press, Cold Spring Harbor, New York, 1989; F. M. Ausubel et al., Current Protocols in Molecular Biology, John Wiley & Sons, Inc., New York, 9.50-9.51, 11.7-11.8). Их примеры включают условия, при которых полинуклеотиды, имеющие более высокую гомологию или идентичность, т.е. полинуклеотиды, имеющие 70% или более, 75% или более, 80% или более, 85% или более, 90% или более, 95% или более, 96% или более, 97% или более, 98% или более или 99% или более гомологию или идентичность, гибридизуются друг с другом, тогда как полинуклеотиды, имеющие меньшую гомологию или идентичность, не гибридизуются друг с другом, или условия, при которых отмывку осуществляют однократно, в частности, от двух до трех раз, при концентрации соли и температуре, эквивалентных 60°С, 1×SSC (раствор цитрата и хлорида натрия), 0,1% SDS (додецилсульфат натрия), в частности, 60°С, 0,1×SSC, 0,1% SDS, конкретней, 68°С, 0,1×SSC, 0,1% SDS, которые представляют собой условия отмывки для обычной гибридизации по Саузерну.
Для гибридизации требуется, чтобы две нуклеиновые кислоты имели комплементарные последовательности, хотя ошибки спаривания между основаниями возможны в зависимости от строгости условий гибридизации. Термин "комплементарный" используют для описания взаимодействия между нуклеотидными основаниями, которые могут гибридизоваться друг с другом. Например, в случае ДНК аденозин комплементарен тимину, и цитозин комплементарен гуанину. Следовательно, полинуклеотид в соответствии с настоящим изобретением может включать по существу похожие последовательности нуклеиновых кислот, а также выделенные фрагменты нуклеиновых кислот, комплементарные всей последовательности.
В частности, полинуклеотид, имеющий гомологию или идентичность с полинуклеотидом в соответствии с настоящим изобретением, может быть обнаружен с использованием условий гибридизации, включающих стадию гибридизации при величине Tm 55°С и вышеописанных условий. Кроме того, величина Tm может составлять 60°С, 63°С или 65°С, но не ограничивается ими, и может быть подходящим образом скорректирована специалистом в данной области техники в зависимости от задачи.
Подходящая строгость условий для гибридизации полинуклеотид а зависит от длины и степени комплементарно сти полинуклеотид а, и эти переменные хорошо известны в области техники (например, Sambrook et at, выше).
В еще одном аспекте в соответствии с настоящим изобретением предложен вектор, включающий полинуклеотид в соответствии с настоящим изобретением. Вектор может представлять собой экспрессирующий вектор для экспрессии полинуклеотид а в клетках-хозяевах, но не ограничивается этим.
Вектор в соответствии с настоящим изобретением может включать конструкцию ДНК, включающую нуклеотидную последовательность полинуклеотид а, кодирующую интересующий полипептид, который функционально связан с подходящей областью, регулирующей экспрессию (или последовательностью, контролирующей экспрессию), таким образом, чтобы обеспечивать экспрессию интересующего полипептида в подходящем хозяине. Область, регулирующая экспрессию, может включать промотор, способный инициировать транскрипцию, любую операторную последовательность для контроля такой транскрипции, последовательность, кодирующую подходящий сайт для связывания с рибосомой на мРНК, и последовательность, контролирующую прекращение транскрипции и трансляции. Этот вектор может быть трансформирован в подходящую клетку-хозяина и затем реплицироваться или функционировать независимо от генома хозяина, или может быть интегрирован в сам геном.
Вектор, используемый в настоящем изобретении, не ограничен конкретным образом, и можно использовать любой вектор, известный в области техники. Примеры обычно используемых векторов включают природные или рекомбинантные плазмиды, космиды, вирусы и бактериофаги. Например, в качестве фагового вектора или космидного вектора могут быть использованы pWE15, М13, MBL3, MBL4, IXII, ASHII, APII, t10, t11, Charon4A и Charon21A и т.п., и в качестве плазмидного вектора могут быть использованы система pDC, система pBR, система pUC, система pBluescriptII, система pGEM, система pTZ, система pCL, система рЕТ и т.п. В частности, может быть использован вектор pDC, pDCM2 (публикация патента Кореи №10-2020-0136813), pACYC177, pACYC184, pCL, pECCG117, pUC19, pBR322, pMW118, pCC1BAC, pIMR53 и т.п.
Например, полинуклеотид, кодирующий интересующий полипептид, может быть встроен в хромосому с помощью вектора для внутриклеточного встраивания в хромосому. Встраивание полинуклеотид а в хромосому может быть осуществлено без ограничения при помощи любого способа, известного в области техники, например, при помощи гомологичной рекомбинации. Вектор может дополнительно включать селективный маркер для подтверждения встраивания в хромосому. Селективный маркер предназначен для отбора клеток, трансформированных векторами, то есть для подтверждения встраивания интересующей молекулы нуклеиновой кислоты, и могут быть использованы маркеры, которые подтверждают селективные фенотипы, такие как резистентность к лекарственным средствам, потребность в питательных веществах, резистентность к цитотоксическим агентам или экспрессия поверхностных полипептидов. В среде, обработанной селективным агентом, только клетки, экспрессирующие селективный маркер, выживают или демонстрируют другие фенотипические характеристики, и, таким образом, могут быть отобраны трансформированные клетки.
Используемый здесь термин "трансформация" означает, что вектор, включающий полинуклеотид, кодирующий полипептид-мишень, вводят в клетку-хозяина или микроорганизм таким образом, что полипептид, кодируемый полинуклеотидом, может экспрессироваться в клетке-хозяине. Трансформированный полинуклеотид может быть расположен независимо от положения путем встраивания в хромосому клетки-хозяина или расположен за пределами хромосомы при условии того, что он может экспрессироваться в клетке-хозяине. Кроме того, полинуклеотид включает ДНК и/или РНК, кодирующие интересующий полипептид. Полинуклеотид может быть введен в любой форме при условии того, что он может быть введен в клетку-хозяина и экспрессироваться. Например, полинуклеотид может быть введен в клетку-хозяина в форме экспрессионной кассеты, которая представляет собой генетическую конструкцию, содержащую все элементы, требующиеся для ее автономной экспрессии. Экспрессионная кассета обычно может включать промотор, функционально связанный с полинуклеотидом, сигнал прекращения транскрипции, сайт связывания с рибосомой и сигнал прекращения трансляции. Экспрессионная кассета может находиться в форме экспрессирующего вектора, способного к саморепликации. Кроме того, полинуклеотид без ограничения может быть введен в клетку-хозяина сам по себе и функционально связан с последовательностью, требующейся для его экспрессии в клетке-хозяине.
Кроме того, термин "функционально связанный" означает, что полинуклеотидная последовательность функционально связана с промоторной последовательностью, которая инициирует и опосредует транскрипцию полинуклеотида, кодирующего желаемый вариант в соответствии с настоящим изобретением.
В еще одном аспекте в соответствии с настоящим изобретением предложен микроорганизм, включающий любой один или более чем один из вариантов в соответствии с настоящим изобретением, полинуклеотид, кодирующий вариант; и вектор, включающий полинуклеотид.
Используемый здесь термин "микроорганизм" или "штамм" включает все микроорганизмы дикого типа или естественным образом или искусственно генетически модифицированные микроорганизмы, и он может представлять собой микроорганизм, в котором конкретный механизм ослаблен или усилен вследствие встраивания чужеродного гена или путем усиления или инактивации активности эндогенного гена, и может представлять собой микроорганизм, включающий генетическую модификацию, для продукции интересующего полипептида, белка или продукта.
Микроорганизм в соответствии с настоящим изобретением может представлять собой микроорганизм, включающий любой один или более чем один из вариантов в соответствии с настоящим изобретением, полинуклеотид в соответствии с настоящим изобретением и вектор, включающий полинуклеотид в соответствии с настоящим изобретением; микроорганизм, модифицированный для экспрессии варианта в соответствии с настоящим изобретением или полинуклеотид а в соответствии с настоящим изобретением; микроорганизм, экспрессирующий вариант в соответствии с настоящим изобретением или полинуклеотид в соответствии с настоящим изобретением; или микроорганизм (например, рекомбинантный микроорганизм), имеющей активность варианта в соответствии с настоящим изобретением, но не ограничивается этим. Микроорганизм может представлять собой микроорганизм, который модифицирован таким образом, чтобы дополнительно включать полинуклеотиды, кодирующие белки ликофенциклазу/фитоенсинтазу (crtYB) и фитоендесатуразу (crtI), таким образом демонстрируя активности белков, или микроорганизм, в котором активности белков усилены. Ликофенциклаза/фитоенсинтаза или фитоендесатураза может представлять собой белок, полученный из Xanthophyllomyces dendrorhous, но не ограничивается этим. В конкретном воплощении полинуклеотид, кодирующий ликофенциклазу/фитоенсинтазу или фитоендесатуразу, может иметь или может включать последовательность в соответствии с SEQ ID NO: 27 или SEQ ID NO: 28, соответственно. В полинуклеотиде различные модификации может быть осуществлены в кодирующей области при условии того, что аминокислотная последовательность не меняется в отношении вырожденности кодонов или кодонов, предпочтительных для микроорганизмов, которые, как предполагают, экспрессируют вариант в соответствии с настоящим изобретением. В частности, полинуклеотид может иметь или может включать нуклеотидную последовательность, имеющую 80% или более, 85% или более, 90% или более, 95% или более, 96% или более, 97% или более, 98% или более и менее чем 100% гомологию или идентичность с последовательностью в соответствии с SEQ ID NO: 27 или SEQ ID NO: 28, или может состоять из или может по существу состоять из нуклеотидной последовательности, имеющей 80% или более, 85% или более, 90% или более, 95% или более, 96% или более, 97% или более, 98% или более и менее чем 100% гомологию или идентичность с последовательностью в соответствии с SEQ ID NO: 27 или SEQ ID NO: 28, но не ограничивается этим.
Микроорганизм в соответствии с настоящим изобретением может продуцировать тетратерпен, предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника, и может иметь пониженное образование побочных продуктов, которые образуются в пути продукции тетратерпена, или может иметь уменьшенную продукцию сквалена, но не ограничивается этим.
Используемый здесь термин "тетратерпен" относится к полимеру (С40), в котором восемь изопренов полимеризованы среди терпенов, и может включать вещества, основанные на тетратерпене. Терпен представляет собой полимер из изопреновых мономеров, и терпен, полученный путем полимеризации двух изопреновых (С5) мономеров, представляет собой монотерпен (С10), и терпен, полученный путем полимеризации трех изопреновых мономеров, представляет собой сесквитерпен (С15), и такие терпены могут быть классифицированы в зависимости от количества полимеризованных изопреновых мономеров.
В частности, тетратерпен может представлять собой каротиноид, но не ограничивается этим.
В описании настоящего изобретения предшественник тетратерпена может представлять собой геранилгеранилпирофосфат (GGPP), но не ограничивается этим.
В описании настоящего изобретения, вещество, имеющее тетратерпен в качестве предшественника, может представлять собой любое вещество, выбранное из группы, состоящей из ретиналя и ретинола, но не ограничивается этим.
Используемый здесь "тетратерпеноид" представляет собой модифицированный тетратерпен. Тетратерпеноид может представлять собой тетратерпен, с которым связана(ы) функциональная(ые) группа(ы).
Используемый здесь "каротиноид" относится к тетратерпену или его производным, которые обеспечивают цвет, такой как желтый у фруктов и овощей, и может быть использован взаимозаменяемо с вышеприведенным тетратерпеном и тетратерпеноидом.
В частности, каротиноид может представлять собой любой один или более чем один, выбранный из группы, состоящей из ксантофилла, каротина, альфа-каротина, бета-каротина, гамма-каротина, лютеина, ликофена, зеаксантина, капсантина, кантаксантина и астаксантина, но не ограничивается этим.
В настоящем изобретении предшественник каротиноида может представлять собой геранилгеранилпирофосфат (GGPP), но не ограничивается этим.
В настоящем изобретении вещество, имеющее каротиноид в качестве предшественника, может представлять собой любое одно или более чем одно, выбранное из группы, состоящей из ретиналя и ретинола, но не ограничивается этим.
Используемый здесь "бета-каротин" представляет собой одно из основанных на каротиноиде веществ и имеет бета-кольца по обеим концам молекулы среди каротенов.
В настоящем изобретении предшественник бета-каротина может представлять собой любой один или более чем один, выбранный из группы, состоящей из фитоена, фитофлуена, ликофена и гамма-каротина, но не ограничивается этим.
В настоящем изобретении вещество, имеющее бета-каротин в качестве предшественника, может представлять собой любое одно или более чем одно, выбранное из группы, состоящей из ретиналя, ретинола и витамина А, но не ограничивается этим.
Тетратерпен, предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника, может представлять собой каротиноид, предшественник каротиноида или вещество, имеющее каротиноид в качестве предшественника, или может представлять собой бета-каротин, предшественник бета-каротина или вещество, имеющее бета-каротин в качестве предшественника, но не ограничивается этим.
В настоящем изобретении любой один или более чем один из вариантов, полинуклеотидов, векторов и микроорганизмов может быть использован для получения тетратерпена, и микроорганизм может продуцировать тетратерпен, и может продуцировать предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника.
В настоящем изобретении любой один или более чем один из варианта, полинуклеотид а, вектора и микроорганизма может быть использован для получения каротиноида, и микроорганизм может продуцировать каротиноид и может продуцировать предшественник каротиноида или вещество, имеющее каротиноид в качестве предшественника.
В настоящем изобретении любой один или более чем один из вариантов, полинуклеотидов, векторов и микроорганизмов может быть использован для получения бета-каротина, и микроорганизм может продуцировать бета-каротин и может продуцировать предшественник бета-каротина или вещество, имеющее бета-каротин в качестве предшественника.
В одном из воплощений геранилгеранилпирофосфат (GGPP) продуцируется геранилгеранилпирофосфатсинтазой в пути биосинтеза изопреноида, и, таким образом, микроорганизм может также продуцировать геранилгеранилпирофосфат.
В настоящем изобретении побочные продукты, образующиеся в пути продукции тетратерпена, относятся к веществам, отличающимся от тетратерпена, предшественника тетратерпена и вещества, имеющего тетратерпен в качестве предшественника, в частности, сквалену, но не ограничиваются этим. Бета-каротин может продуцироваться в пути продукции каротиноида или изопреноида. В этом процессе две молекулы фарнезилпирофосфата (FPP, С15) потребляются скваленсинтазой (ERG9), и сквален (С30) может образовываться в качестве побочного продукта.
Используемый здесь "сквален" представляет собой углеводород (C30H50) и представляет собой вещество, которое также используется в биосинтезе стероидных гомонов, витамина D и т.п. Микроорганизм в соответствии с настоящим изобретением может иметь уменьшенный уровень побочных продуктов, которые образуются в пути продукции тетратерпена, и, в частности, может иметь уменьшенное образование сквалена, но не ограничивается этим.
Микроорганизм или штамм в соответствии с настоящим изобретением может представлять собой микроорганизм, в природе имеющий способность продуцировать геранилгеранилпирофосфатсинтазу или тетратерпен, или микроорганизм, полученный путем введения в него варианта в соответствии с настоящим изобретением или кодирующего его полинуклеотида (или вектора, включающего полинуклеотид) и/или путем обеспечения способности продуцировать тетратерпен, предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника для родительского штамма, не имеющего способность продуцировать геранилгеранилпирофосфатсинтазу или тетратерпен, но не ограничивается этим.
Например, микроорганизм или штамм в соответствии с настоящим изобретением может представлять собой клетку или микроорганизм, который трансформирован полинуклеотидом в соответствии с настоящим изобретением или вектором, включающим полинуклеотид, кодирующий вариант в соответствии с настоящим изобретением, для экспрессии варианта в соответствии с настоящим изобретением. В отношении задач в соответствии с настоящим изобретением микроорганизм или штамм в соответствии с настоящим изобретением может включать любой микроорганизм, который содержит вариант в соответствии с настоящим изобретением, для продукции тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника. Например, микроорганизм или штамм в соответствии с настоящим изобретением может представлять собой рекомбинантный штамм, в котором полинуклеотид, кодирующий вариант в соответствии с настоящим изобретением, введен в природный дикий тип микроорганизма или продуцирующий тетратерпен микроорганизм для экспрессии варианта геранилгеранилпирофосфатсинтазы и для того, чтобы иметь увеличенную способность продуцировать тетратерпен, предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника. Рекомбинантный штамм может представлять собой микроорганизм, имеющий увеличенную способность продуцировать тетратерпен, предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника, по сравнению с природным диким типом микроорганизма или микроорганизма, в котором геранилгеранилпирофосфатсинтаза немодифицирована (т.е. дикий тип микроорганизма, экспрессирующего геранилгеранилпирофосфатсинтазу), но не ограничивается этим.
Например, рекомбинантный штамм может иметь приблизительно на 1% или более, в частности, приблизительно на 3%, приблизительно на 5% или более увеличенную способность по сравнению со способностью продуцировать тетратерпен, предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника, родительским штаммом до модификации или немодифицированным микроорганизмом. Тем не менее, при условии того, что рекомбинантный штамм имеет увеличенную способность + величину по сравнению со способностью продуцировать родительским штаммом до модификации или немодифицированным микроорганизмом, он не ограничивается этим.
В качестве еще одного примера, рекомбинантный штамм может продуцировать побочные продукты, образующиеся в пути продукции тетратерпена, уровень которых уменьшается приблизительно на 85% или меньше, приблизительно на 80% или меньше, приблизительно на 75% или меньше, приблизительно на 70% или меньше, приблизительно на 65% или меньше, приблизительно на 60% или меньше, приблизительно на 55% или меньше, приблизительно на 50% или меньше, приблизительно на 30% или меньше или приблизительно на 10% или меньше по сравнению с родительским штаммом до модификации или немодифицированным микроорганизмом, или может не продуцировать побочные продукты, но не ограничивается этим.
Используемый здесь термин "приблизительно" включает относится к диапазону, который включает все из ±0,5, ±0,4, ±0,3, ±0,2, ±0,1 и т.п., и он включает все величины, которые эквивалентны или близкие величине непосредственно после термина "приблизительно", но не ограничивается этим.
Используемый здесь термин "немодифицированный микроорганизм" не исключает штаммы, включающие мутацию, которая в природе может возникать у микроорганизмов, и может представлять собой штамм дикого типа или сам природный штамм, или может представлять собой штамм до того, как характеристика изменена путем генетической вариации вследствие природных или искусственных факторов. Например, немодифицированный микроорганизм может представлять собой штамм, в котором вариант геранилгеранилпирофосфатсинтазы в соответствии с настоящим изобретением не введен или пока не введен. Термин "немодифицированный микроорганизм" может быть использован взаимозаменяемо с "штаммом перед модификацией", "штаммом до модификации", "микроорганизмом перед модификацией", "микроорганизмом до модификации", "неизмененным штаммом", "немодифицированным штаммом", "неизмененным микроорганизмом" или "референсным микроорганизмом".
В одном из воплощений микроорганизм в соответствии с настоящим изобретением может представлять собой микроорганизм, относящийся к Yarrowia sp., и, в частности, Yarrowia lipolytica, но не ограничивается этим.
Использованный здесь термин "усиление" полипептидной активности означает то, что активность полипептида увеличивается по сравнению с эндогенной активностью. Усиление может быть использовано взаимозаменяемо с терминами, такими как активация, повышающая регуляция, сверхэкспрессия и увеличение и т.п. Здесь активация, усиление, повышающая регуляция, сверхэкспрессия и увеличение могут включать как демонстрацию активности, которая исходно не проявляется, так и демонстрацию улучшенной активности по сравнению с эндогенной активностью или активностью до модификации. "Эндогенная активность" означает активность конкретного полипептида, исходно проявляемой родительским штаммом до изменения характеристики или немодифицированным микроорганизмом, когда свойство изменяется путем генетической вариации вследствие природных или искусственных факторов. Последнее может быть использовано взаимозаменяемо с "активностью до модификации". Тот факт, что активность полипептида "усилена", "подвергнута повышающей регуляции", "сверхэкспрессируется" или "увеличена" по сравнению с эндогенной активностью, означает то, что активность полипептида улучшена по сравнению с активностью и/или концентрацией (уровнем экспрессии) конкретного полипептида, исходно демонстрируемой родительским штаммом до изменения характеристики или немодифицированным микроорганизмом.
Усиление может быть достигнуто путем введения чужеродного полипептида или путем усиления эндогенной активности и/или концентрации (уровня экспрессии) полипептида. Усиление активности полипептида можно подтвердить путем увеличения степени активности и уровня экспрессии соответствующего полипептида, или количества продукта, продуцируемого из соответствующего полипептида.
Для усиления активности полипептида могут применяться различные способы, хорошо известные в области техники, и этот способ не ограничен при условии того, что он может усиливать активность интересующего полипептида по сравнению с активностью микроорганизма перед модификацией. В частности, может быть использована генетическая инженерия и/или белковая инженерия, хорошо известные специалистам в данной области техники, которые представляют собой обычные способы молекулярной биологии, но способ не ограничен ими (например, Sitnicka et al. Functional Analysis of Genes. Advances in Cell Biology. 2010, Vol. 2. 1-16, Sambrook et al. Molecular Cloning 2012, и т.п.).
В частности, усиление активности полипептида в соответствии с настоящим изобретением может быть достигнуто путем:
1) увеличения числа копий полинуклеотида, кодирующего полипептид, в клетках;
2) замены области, регулирующей экспрессию гена, кодирующего полипептид, на хромосоме на последовательность, демонстрирующую сильную активность;
3) модификации нуклеотидной последовательности, кодирующей стартовый кодон области 5'-UTR генного транскрипта, кодирующего полипептид;
4) модификации аминокислотной последовательности полипептида для усиления активности полипептида;
5) модификации полинуклеотидной последовательности, кодирующей полипептид, для усиления активности полипептида (например, модификация полинуклеотидной последовательности гена полипептида для кодирования полипептида, модифицированного для усиления активности полипептида);
6) введения чужеродного полипептида, демонстрирующего активность полипептида или чужеродного полинуклеотида, кодирующего полипептид;
7) оптимизации кодона полинуклеотида, кодирующего полипептид;
8) анализа третичной структуры полипептида для выбора и для модификации или химической модификации экспонируемого сайта; или
9) комбинации двух или более чем двух, выбранных из 1)-8), но не ограничиваясь конкретно ими.
Конкретней:
1) увеличение числа копий в клетке полинуклеотида, кодирующего полипептид, может быть осуществлено путем введения в клетку-хозяина вектора, который реплицируется и функционирует независимо от хозяина, и с которым функционально связан полинуклеотид, кодирующий соответствующий полипептид. В качестве альтернативы, увеличение может быть достигнуто путем введения одной копии или двух, или более чем двух копий полинуклеотида, кодирующего соответствующий полипептид, в хромосому клетки-хозяина. Введение в хромосому может быть осуществлено путем введения вектора, способного встраивать полинуклеотид в хромосому клетки-хозяина, в клетку-хозяина, но не ограничивается этим. Вектор является таким, как описано выше.
2) Замена области, регулирующей экспрессию гена (или последовательности, контролирующей экспрессию), кодирующего полипептид, на хромосоме на последовательность, демонстрирующую сильную активность, может быть достигнуто, например, путем осуществления вариации в последовательности путем делеции, вставки, не консервативной или консервативной замены, или путем их комбинации, или путем замены на последовательность, демонстрирующую более сильную активность, таким образом, что дополнительно усиливается активность области, контролирующей экспрессию. Область, регулирующая экспрессию, может включать без ограничения промотор, операторную последовательность, последовательность, кодирующую сайт связывания с рибосомой, последовательность, контролирующую прекращение транскрипции или трансляции и т.п.Например, замена может представлять собой замену исходного промотора на сильный промотор, но не ограничивается этим.
Примеры известного сильного промотора включают промоторы cj1-cj7 (патент США № US 7662943 В2), промотор lac, промотор trp, промотор trc, промотор tac, промотор PR фага лямбда, промотор PL, промотор tet, промотор gapA, промотор SPL7, промотор SPL13(sm3) (патент США № US 10584338 В2), промотор O2 (патент США № US 10273491 В2), промотор tkt, промотор уссА, но не ограничивается этим.
3) Модификация нуклеотидной последовательности, кодирующей стартовый кодон области 5'-UTR транскрипта гена, кодирующего полипептид, может представлять собой, например, замену на нуклеотидную последовательность, кодирующую еще один стартовый кодон, имеющий более высокий уровень экспрессии полипептида по сравнению с эндогенным стартовым кодоном, но не ограничивается этим.
4) и 5) Модификация аминокислотной последовательности или полинуклеотидной последовательности может быть осуществлена путем вариации последовательности путем делеции, вставки, неконсервативной или консервативной замены аминокислотной последовательности полипептидной последовательности или полинуклеотидной последовательности, кодирующей полипептид, или путем их комбинации или путем замены на аминокислотную последовательность или полинуклеотидную последовательность, модифицированную таким образом, чтобы демонстрировать более сильную активность, или аминокислотную последовательность или полинуклеотидную последовательность, модифицированную таким образом, что активность полипептида усиливалась, но не ограничивается этим. Замена, в частности, может быть осуществлена путем встраивания полинуклеотида в хромосому путем гомологичной рекомбинации, но не ограничивается этим. Используемый здесь вектор может дополнительно включать селективный маркер для подтверждения встраивания в хромосому. Селективный маркер является тем же самым, как описано выше.
6) Введение чужеродного полинуклеотида, демонстрирующего активность полипептида, может представлять собой введение в клетку-хозяина чужеродного полинуклеотида, кодирующего полипептид, который демонстрирует активность, идентичную или похожую на активность полипептида. Чужеродный полинуклеотид не ограничен своим происхождением или последовательностью при условии того, что он демонстрирует активность, идентичную или похожую на активность полипептида. Способ, используемый для введения, может быть осуществлен специалистом в данной области техники путем подходящего выбора известного способа трансформации. Когда введенный полинуклеотид экспрессируется в клетке-хозяине, тогда может продуцироваться полипептид, и его активность может быть увеличена.
7) Оптимизация кодонов полинуклеотида, кодирующего полипептид, может представлять собой оптимизацию кодонов эндогенного полинуклеотида для увеличения транскрипции или трансляции в клетке-хозяине, или оптимизацию кодонов чужеродного полинуклеотида таким образом, чтобы осуществлять оптимизированную транскрипцию и трансляции в клетке-хозяине.
8) Анализ третичной структуры полипептида для выбора и модификации или химической модификации экспонируемого сайта может осуществляться, например, для определения кандидата белка-матрицы в соответствии со степенью сходства последовательности путем сравнения информации о последовательности анализируемого полипептида с базой данных, в которой хранится информация о последовательностях известных белков, для подтверждения структуры, основанной на этом, и для отбора и модификации или химической модификации экспонируемого сайта, который предполагается модифицировать или химически модифицировать.
Такое усиление полипептидной активности может представлять собой увеличение активности или концентрации (уровня экспрессии) соответствующего полипептида на основе активности или концентрации полипептида, экспрессируемого в штамме дикого типа или микробном штамме до модификации, или увеличение количества продукта, продуцируемого из соответствующего полипептида, но не ограничивается этим.
В микроорганизме в соответствии с настоящим изобретением частичная или полная модификация полинуклеотида может быть вызвана путем (а) гомологичной рекомбинации с использованием вектора для встраивания хромосому в микроорганизме или редактирования генома с использованием сконструированной нуклеазы (например, CRISPR-Cas9) и/или (б) обработки светом, таким как ультрафиолетовые лучи и излучение, и/или химические вещества, но не ограничивается этим. Способ модификации части или всего гена может включать способ с использованием технологии рекомбинантной ДНК. Например, путем введения нуклеотидной последовательности или вектора, включающего нуклеотидную последовательность, гомологичную интересующему гену, в микроорганизм для того, чтобы вызвать гомологичную рекомбинацию, часть или весь ген может быть удален. Вводимая нуклеотидная последовательность или вектор может включать доминирующий селективный маркер, но не ограничивается этим.
В еще одном аспекте описания настоящего изобретения предложен способ получения тетратерпена, предшественника тетратерпена и вещества, имеющего тетратерпен в качестве предшественника, причем способ включает культивирование в среде микроорганизма, включающего любой один или более чем один из вариантов в соответствии с настоящим изобретением; полинуклеотид, кодирующий вариант; и вектор, включающий полинуклеотид. Способ получения тетратерпена, предшественника тетратерпена и вещества, имеющего тетратерпен в качестве предшественника, может представлять собой способ уменьшения продукции сквалена, но не ограничивается этим.
Использованный здесь термин "культивирование" относится к выращиванию микроорганизма в соответствии с настоящим изобретением в подходящим образом скорректированных условиях окружающей среды. Процедура культивирования в соответствии с настоящим изобретением может быть осуществлена в соответствии с подходящими средами или условиями культивирования, известными в области техники. Такое культивирование может быть легко скорректировано в зависимости от выбранного микроорганизма специалистом в данной области техники. В частности, культивирование может иметь периодический тип, непрерывный тип и/или тип подпитываемой культуры, но не ограничивается этим.
Используемая здесь "среда" относится к смеси, содержащей в качестве основных ингредиентов питательные вещества, требующиеся для культивирования микроорганизма в соответствии с настоящим изобретением, причем среда обеспечивает питательные вещества, включая воду, необходимые для жизнедеятельности и роста, факторы роста и т.п. В частности, в отношении сред и других условий в культуре, используемых для культивирования микроорганизма в соответствии с настоящим изобретением, без какого-либо конкретного ограничения может быть использована любая среда, используемая для обычной культуры микроорганизмов. Тем не менее, микроорганизм в соответствии с настоящим изобретением может культивироваться в аэробных условиях в обычной среде, содержащей подходящие источники углерода, источники азота, источники фосфора, неорганические соединения, аминокислоты и/или витамины, при контролировании температуры, рН и т.п.
В описании настоящего изобретения источник углерода может включать углеводы, такие как глюкоза, сахароза, лактоза, фруктоза, мальтоза и т.п; сахарные спирты, такие как маннит, сорбит и т.п; органические кислоты, такие как пировиноградная кислота, молочная кислота, лимонная кислота и т.п; и аминокислоты, такие как глутаминовая кислота, метионин, лизин и т.п. Кроме того, могут быть использованы природные органические питательных вещества, такие как гидролизаты крахмала, мелассы, сырые мелассы, рисовые отруби, маниок, выжимки сахарного тростника и жидкий кукурузный экстракт, и, в частности, могут быть использованы углеводы, такие как глюкоза и стерилизованные предварительно обработанные мелассы (т.е. мелассы, преобразованные в редуцированные сахара), и без ограничения могут быть использованы подходящие количества различных других источников углерода. Эти источники углерода могут быть использованы сами по себе или в комбинации двух или более чем двух из них, но не ограничиваются этим.
В качестве источников азота могут быть использованы источники неорганического азота, такие как аммиак, сульфат аммония, хлорид аммония, ацетат аммония, фосфат аммония, карбонат аммония, нитрат аммония и т.п; аминокислоты, такие как глутаминовая кислота, метионин, глютамин и т.п; и источники органического азота, такие как пептон, NZ-амин, мясной экстракт, дрожжевой экстракт, солодовый экстракт, жидкий кукурузный экстракт, гидролизат казеина, рыба или продукты ее деградации, обезжиренный соевый жмых или продукт его деградации и т.п. Эти источники азота могут быть использованы сами по себе или в комбинации двух или более из них, но не ограничиваются этим.
Источники фосфора могут включать первичный кислый фосфат калия, гидрофосфат калия и соответствующие им содержащие натрий соли. В качестве неорганических соединений могут быть использованы хлорид натрия, хлорид кальция, хлорид железа, сульфат магния, сульфат железа, сульфат марганца, карбонат кальция и т.д, и дополнительно могут быть включены аминокислоты, витамины и/или подходящие предшественники. Эти составляющие ингредиенты или предшественники могут быть добавлены к среде партиями или непрерывным образом. Тем не менее, описание настоящего изобретения не ограничивается этим.
Кроме того, рН среды может быть скорректирован путем добавления подходящим образом в среду во время культивирования микроорганизма в соответствии с настоящим изобретением соединений, таких как гидроксид аммония, гидроксид калия, аммиак, фосфорная кислота и серная кислота. Кроме того, во время культивирования для подавления образования пены может быть добавлен пеногаситель, такого как сложный эфир полигликоля и жирной кислоты. Кроме того, кислород или содержащий кислород газ могут быть инжектированы в среду для поддержания в среде аэробных условий, или не инжектируют никакой газ, или азот, водород или углекислый газ могут быть инжектированы для поддержания анаэробных и неаэробных условий в среде, но газ не ограничивается этим.
При культивировании в соответствии с настоящим изобретением температура в культуре может поддерживаться при 20°С-45°С, в частности, при 25°С-40°С, 20°С-35°С или 25-35°С, и культивирование может быть осуществлено в течение приблизительно от 10 до 160 часов, но не ограничивается этим.
Тетратерпен, предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника, которые продуцируются при культивировании в соответствии с настоящим изобретением, могут высвобождаться в среду или могут оставаться в клетках.
Способ получения тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника, в соответствии с настоящим изобретением, может дополнительно включать получение микроорганизма в соответствии с настоящим изобретением, приготовление среды для культивирования микроорганизма или их комбинацию (независимо от последовательности, в любой последовательности), например, до или после культивирования.
Способ получения тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника, в соответствии с настоящим изобретением может дополнительно включать выделение тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника, из среды, образующейся в результате культивирования (среда, в которой осуществляют культивирование), или из микроорганизма в соответствии с настоящим изобретением. Выделение может быть дополнительно осуществлено после культивирования.
Выделение может представлять собой сбор желаемого тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника, путем использования подходящего способа, известного в области техники, в соответствии со способом культивирования микроорганизма в соответствии с настоящим изобретением, например, периодического способа культивирования, непрерывного способа культивирования или культивирования с подпиткой. Например, могут быть использованы центрифугирование, фильтрование, обработка агентом, осаждающим кристаллизованный белок (высаливание), экстракция, разрушение клеток, ультразвуковая обработка, ультрафильтрация, диализ, различные типы хроматографии, такие как хроматография на молекулярных ситах (гель-фильтрация), адсорбционная хроматография, ионообменная хроматография и аффинная хроматография, HPLC (высокоэффективная жидкостная хроматография (ВЭЖХ)) и комбинация этих способов, и желаемый тетратерпен, предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника, может быть выделен из среды или микроорганизма с использованием подходящего способа, известного в области техники.
Кроме того, способ получения тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника, в соответствии с настоящим изобретением может дополнительно включать очистку. Очистка может быть осуществлена путем использования подходящего способа, известного в области техники. В примере воплощения, когда способ получения тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника, в соответствии с настоящим изобретением включает как выделение, так и очистку, тогда выделение и очистка могут быть осуществлены прерывисто (или непрерывно) независимо от последовательности, или могут быть осуществлены одновременно или интегрированы в одну стадию, но не ограничиваются этим.
Способ получения вещества, имеющего тетратерпен в качестве предшественника, в соответствии с настоящим изобретением может дополнительно включать превращение тетратерпена в вещество, имеющее тетратерпен в качестве предшественника. В способе получения вещества, имеющего тетратерпен в качестве предшественника, в соответствии с настоящим изобретением, превращение может быть дополнительно включено после культивирования или выделения. Превращение может быть осуществлено с использованием подходящего способа, известного в области техники. Например, превращение может быть осуществлено с использованием бета-каротин 15,15'-оксигеназы или ретинолдегидрогеназы, но не ограничивается этим.
Вариант, полинуклеотид, вектор, микроорганизм, тетратерпен, предшественник тетратерпена и вещество, имеющее тетратерпен в качестве предшественника, являются такими, как описано выше.
В еще одном аспекте описания настоящего изобретения предложена композиция для получения тетратерпена, его предшественника и вещества, имеющего тетратерпен в качестве предшественника, причем композиция включает вариант в соответствии с настоящим изобретением; вектор в соответствии с настоящим изобретением; микроорганизм, включающий вариант в соответствии с настоящим изобретением, полинуклеотид, кодирующий вариант, вектор, включающий полинуклеотид, или полинуклеотид в соответствии с настоящим изобретением; культуру микроорганизма; или комбинацию двух или более чем двух из них.
Композиция в соответствии с настоящим изобретением дополнительно может включать любой подходящий эксципиент, который обычно используют в композиции для получения тетратерпена, его предшественника и вещества, имеющего тетратерпен в качестве предшественника, и примеры эксципиента могут включать консервант, увлажнитель, диспергатор, суспендирующий агент, буфер, стабилизирующий агент, изотонический агент и т.п., но не ограничиваются этим.
Вариант, полинуклеотид, вектор, микроорганизм, среда, тетратерпен, предшественник тетратерпена и вещество, имеющее тетратерпен в качестве предшественника, являются такими, как описано выше.
В еще одном аспекте описания настоящего изобретения предложено применение любого одного или более чем одного из вариантов, полинуклеотида, вектора и микроорганизма в соответствии с настоящим изобретением для получения тетратерпена, предшественника тетратерпена и вещества, имеющего тетратерпен в качестве предшественника.
Вариант, полинуклеотид, вектор, микроорганизм, тетратерпен, предшественник тетратерпена и вещество, имеющее тетратерпен в качестве предшественника, являются такими, как описано выше.
Способ осуществления изобретения
Далее описание настоящего изобретения будет описано более подробно со ссылкой на примеры. Тем не менее, эти примеры и экспериментальные примеры приведены только для иллюстрации настоящего изобретения, и не предполагается, что объем настоящего изобретения ограничен этими примерами и экспериментальными примерами.
Пример 1. Конструирование библиотек варианта вектора GGS1
Для амплификации гена GGS1, кодирующего геранилгеранилпирофосфатсинтазу, на хромосоме Yarrowia lipolytica, получали аминокислотную последовательность в соответствии с SEQ ID NO: 1 и полинуклеотидную последовательность в соответствии с SEQ ID NO: 2 GGS1 (YALI0D17050) на основе нуклеотидной последовательности, зарегистрированной в Kyoto Encyclopedia of Genes and Genomes (Энциклопедия генов и геномов Института химических исследований в Киото) (KEGG). Вносящий разнообразие набор для произвольного мутагенеза путем ПЦР (полимеразная цепная реакция) (Takara) использовали для того, чтобы осуществить произвольные мутации при помощи ПЦР с внесением ошибок (ep-PCR). Условия ПЦР и способы были соответственно оптимизированы в соответствии с условиями буфера 1 и условиями буфера 2 в руководстве пользователя. Конкретные условия ПЦР с внесением ошибок представлены в таблице 1 ниже.
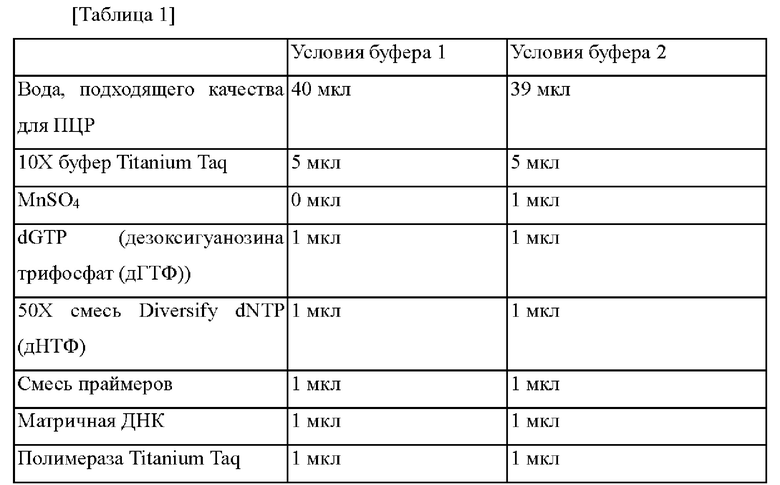
ПЦР осуществляли с использованием геномной ДНК Yarrowia lipolytica PO1f в качестве матрицы и праймеров в соответствии с SEQ ID NO: 19 и SEQ ID NO: 20. Условия ПЦР были следующими: 32 цикла, состоящие из денатурации при 95°С в течение 1 минуты; отжига при 55°С в течение 1 минуты; и полимеризации при 68°С в течение 1 минуты. Библиотеку вектора, экспрессирующего вариант GGS1, основанную на векторе pIMR53-EXP1p-CYC1t, создавали путем смешивания продуктов ПЦР GGS1 для двух условий, которые амплифицировали при помощи ПЦР.
Вектор pIMR53-EXP1p-CYC1t конструировали следующим образом. Для амплификации EXP1p осуществляли ПЦР с использованием геномной ДНК Yarrowia lipolytica PO1f в качестве матрицы и праймеров в соответствии с SEQ ID NO: 21 и SEQ ID NO: 22, и для амплификации терминатора CYC1t осуществляли ПЦР с использованием геномной ДНК Saccharomyce cerevisiae в качестве матрицы и праймеров в соответствии с SEQ ID NO: 23 и SEQ ID NO: 24. Условия ПЦР были следующими: 32 цикла, состоящие из денатурации при 95°С в течение 1 минуты; отжига при 55°С в течение 1 минуты; и полимеризации при 68°С в течение 1 минуты. Кроме того, осуществляли ПЦР с использованием вектора pIMR53 в качестве матрицы и праймеров в соответствии с SEQ ID NO: 25 и SEQ ID NO: 26. Условия ПЦР были следующими: 32 цикла, состоящие из денатурации при 95°С в течение 1 минуты; отжига при 55°С в течение 1 минуты; и полимеризации при 68°С в течение 5 минут.
В результате получали 6774 п.о. линеаризованного pIMR53, 1050 п.о. EXP1p и 289 п.о. CYC1t. Фрагменты ДНК EXP1p и CYC1t, амплифицированные при помощи ПЦР, конъюгировали с вектором pIMR53 с использованием Infusion cloning kit (mvitrogen), трансформировали в Е. coli DH5α, и высевали на твердую среду LB (Луриа-Бертани), содержащую 30 мг/л ампициллина. После выбора колоний, трансформированных плазмидой, в которые целевой промотор EXP1p и терминатор CYC1t встроены путем ПЦР, получали плазмиду с использованием общеизвестного способа экстракции плазмиды, и эта плазмида была названа pIMR53-EXP1p-CYC1t.
Пример 2. Получение штамма платформы Yarrowia lipolytica для продукции бета-каротина
Пример 2-1. Получение полученного из X. Dendrorhous штамма с вставкой crtYB-crtI
Для получения штамма платформы для продукции бета-каротина, гены ликопенциклазы/фитоенсинтазы (crtYB) и фитоендесатуразы (crtI), полученные из Xanthophyllomyces dendrorhous, встраивали в геном штамма дрожжей Yarrowia lipolytica СС08-0125 (инвентарный №. KCCM12972P) с высоким содержанием жиров. В отношении crtYB получали полинуклеотид в соответствии с SEQ ID NO: 27, основанный на нуклеотидной последовательности (GenBank: AY177204.1), зарегистрированной в поисковой базе National Center for Biotechnology Information (NCBI), и в отношении crtI, получали полинуклеотид в соответствии с SEQ ID NO: 28, основанный на нуклеотидной последовательности (GenBank: AY177424.1), зарегистрированной в NCBI. Полинуклеотидные последовательности crtYB и crtI синтезировали в Macrogen Inc. в форме TEFINtp-crtYB-CYC1t (SEQ ID NO: 29) и TEFINtp-crtI-CYC1t (SEQ ID NO: 30), соответственно, и кассету, встроенную в сайт гена MHY1 (YALI0B21582g), конструировали с использованием гена URA3 (SEQ ID NO: 31) Y. lipolytica в качестве селективного маркера. ПЦР осуществляли с использованием синтезированного crtYB, гена crtI и геномной ДНК KCCM12972P в качестве матриц и праймеров в соответствии с SEQ ID NO: 32 и SEQ ID NO: 33, SEQ ID NO: 34 и SEQ ID NO: 35, SEQ ID NO: 36 и SEQ ID NO: 37, SEQ ID NO: 38 и SEQ ID NO: 39, SEQ ID NO: 40 и SEQ ID NO: 41, SEQ ID NO: 42 и SEQ ID NO: 43, соответственно. Условия ПЦР были следующими: 35 циклов, состоящих из денатурации при 95°С в течение 1 минуты; отжига при 55°С в течение 1 минуты; и полимеризации при 72°С в течение 3 минут и 30 секунд. Образующиеся в результате пять фрагментов ДНК получали в виде одной кассеты путем ПЦР с перекрывающимися праймерами.
Полученную таким образом кассету встраивали в штамм KCCM12972P при помощи способа теплового шока (D.-C. Chen et al., Appl Microbiol Biotechnol, 1997), и затем получали колонии, образующиеся на твердой среде (YLMM1) без урацила. Колонии, в которых встраивание кассеты в геном подтверждали с использованием праймеров в соответствии с SEQ ID NO: 44 и SEQ ID NO: 45, наносили на твердую среду 5-FOA и культивировали при 30°С в течение 3 суток. Маркер URA3 выделяли путем получения колоний, выросших на твердой среде 5-FOA.
Пример 2-2. Получение штамма с усиленным HMGR
Кассету конструировали для замены на промотор TEFINt, представляющий собой область нативного промотора (SEQ ID NO: 46) гена 3-гидрокси-3-метилглутарил-СоА редуктазы (HMGR) штамма, полученного в примере 2-1, в который были встроены гены crtYB и crtI. ПЦР осуществляли с использованием геномной ДНК KCCM12972P в качестве матрицы и праймеров в соответствии с SEQ ID NO: 47 и SEQ ID NO: 48, SEQ ID NO: 49 и SEQ ID NO: 50, SEQ ID NO: 51 и SEQ ID NO: 52, SEQ ID NO: 53 и SEQ ID NO: 54, SEQ ID NO: 55 и SEQ ID NO: 56, соответственно. Условия ПЦР были следующими: 35 циклов, состоящих из денатурации при 95°С в течение 1 минуты; отжига при 55°С в течение 1 минуты; и полимеризации при 72°С в течение 1 минуты и 30 секунд. Образующиеся в результате пять фрагментов ДНК получали в виде одной кассеты путем ПЦР с перекрывающимися праймерами.
Полученную таким образом кассету встраивали в штамм, полученный в примере 2-1, при помощи способа теплового шока, и затем получали колонии, образующиеся на твердой среде (YLMM1) без урацила. Колонии, в которых встраивание кассеты было подтверждено с использованием праймеров в соответствии с SEQ ID NO: 57 и SEQ ID NO: 58, наносили на твердую среду 5-FOA и культивировали при 30°С в течение 3 суток. Маркер URA3 выделяли путем получения колоний, выросших на твердой среде 5-FOA. Наконец полученный штамм платформы, продуцирующей бета-каротин, был назван СС08-1023.
<Yarrowia lipolytica минимальные среды 1 (YLMM1)>
20 г/л глюкозы, 6,7 г/л основы азотного агара для дрожжей без аминокислот, 2 г/л синтетических добавок отсеивающей среды для дрожжей без урацила и 15 г/л агара.
<5-Фтороротовая кислота (5-FOA)>
20 г/л глюкозы, 6,7 г/л основы азотного агара для дрожжей без аминокислот, 2 г/л синтетических добавок отсеивающей среды для дрожжей без урацила, 50 мкг/мл урацила, 1 г/л 5-фтороротовой кислоты (5-FOA) и 15 г/л агара.
Пример 3. Первичный выбор штамма с усиленной активностью GGS1
Для первичного отбора штаммов с усиленной активностью GGS1 осуществляли первичный отбор по окрашиванию.
Для начала, pIMR53 (отрицательный контроль; NC), pIMR53-EXP1p-GGS1 (дикий тип, SEQ ID NO: 2)-CYC1t вектор (положительный контроль; PC), и сконструированную в примере 1 библиотеку векторов, экспрессирующую произвольный вариант GGS1, соответственно, путем теплового шока трансформировали в штамм Yarrowia lipolytica СС08-1023, продуцирующий небольшое количество бета-каротина. Затем отбирали колонии, образующиеся на твердой среде без урацила.
350 мкл жидкой минимальной среды 2 Yarrowia lipolytica (YLMM2) без урацила дозировали в каждую лунку 96-луночных планшетов с глубокими лунками (25 планшетов), и полученные колонии инокулировали и культивировали при 30°С в течение 48 часов. Затем их инокулировали на твердую среду YLMM1 без урацила и культивировали при 30°С в течение 3 суток. После окончания культивирования 36 видов оранжевых штаммов, которые по цвету были темнее по сравнению с штаммом, трансформированным вектором (CC08-1023/pIMR53-EXP1p-GGS1-CYC1t) в качестве положительного контроля, сначала отбирали из 2400 видов штаммов. Способ получения вышеописанного YLMM2 и его композиции является следующим.
<YLMM2 (рН 7,2)>
40 г/л глюкозы, 1,7 г/л основы азотного агара для дрожжей без аминокислот и сульфата аммония, 0,5 г/л урацила и 2,5 г/л сульфата аммония, растворенного в 0,1 М буфере фосфата натрия (рН 7,2)
Пример 4. Вторичный отбор штамма с усиленной активностью GGS1
Для вторичного отбора штаммов с усиленной активностью GGS1 тестирование в колбе осуществляли на 36 видах штаммов, исходно отобранных в примере 3.
В колбу с угловыми перегородками объемом 250 мл, содержащую 50 мл минимальной среды 2 Yarrowia lipolytica (YLMM2) без урацила, инокулировали 36 видов штаммов и штамм, трансформированный вектором в качестве положительного контроля (ПК (PC)), при исходной ОП (оптической плотности) 1, соответственно, и культивировали при 30°С в течение 48 часов при встряхивании при 250 об./мин.
После завершения культивирования 1 мл культуральной среды центрифугировали, и супернатант удаляли. Затем добавляли 0,5 мл диметилсульфоксида (DMSO (ДМСО), Sigma), и клетки разрушали путем встряхивания при 2000 об./мин в течение 10 минут при 55°С. Кроме того, добавляли 0,5 мл ацетона (Sigma) и встряхивали при 2000 об./мин в течение 15 минут при 45°С для экстрагирования бета-каротина и сквалена. Экстрагированные вещества анализировали в отношении концентрации с использованием оборудования для ВЭЖХ (HPLC). Результаты тестирования в колбе отобранных штаммов и результаты измерения ОП, концентрации и содержание бета-каротина и сквалена представлены в таблице 2 ниже.
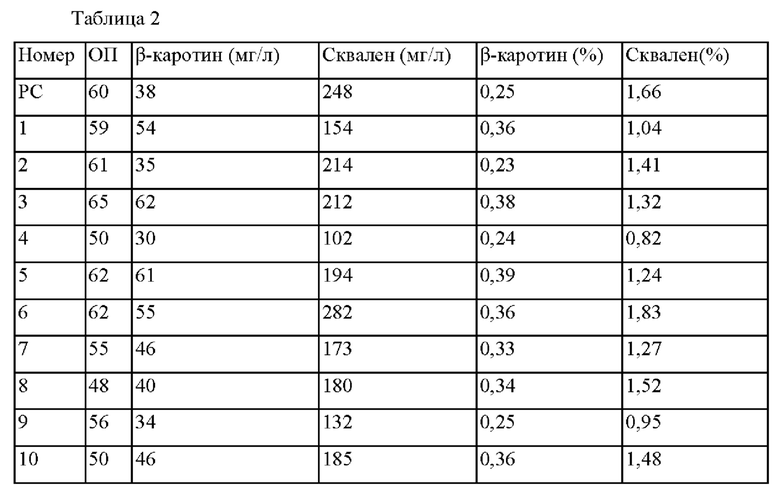
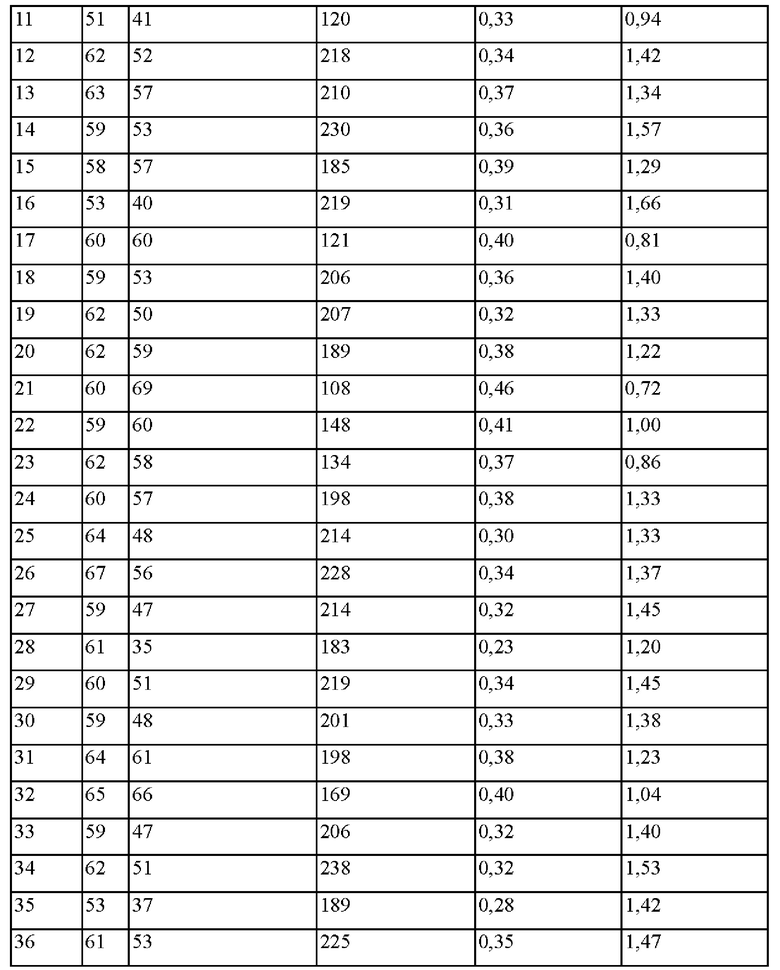
Затем концентрации бета-каротина и сквалена, экстрагированных из тестируемых образцов, делили на DCW (сухую массу клеток (СМК)) (г/л), которую использовали в качестве стандарта для вторичного отбора. Подтвердили, что величина (β-каротин (%)) концентрации бета-каротина, деленная на СМК (DCW) (г/л), увеличивалась в 33 видах тестируемых штаммов за исключением штамма №2, №4, №9 и №28, по сравнению с положительным контролем (ПК (PC)). Подтвердили, что величина концентрации сквалена, деленная на СМК (DCW) (г/л), уменьшалась во всех тестируемых штаммах по сравнению с положительным контролем ПК (PC).
Таким образом, референсные величины определяли на основе величин, рассчитанных в соответствии с положительным контролем (ПК (PC)), и отбирали штаммы, соответствующие обоим условиям, и в общей сложности отобрали четыре группы кандидатов, соответствующих как условию 1, так и условию 2. Референсные величины для вторичного отбора и отобранные после вторичного отбора четыре кандидата представлены в таблице 3 ниже.
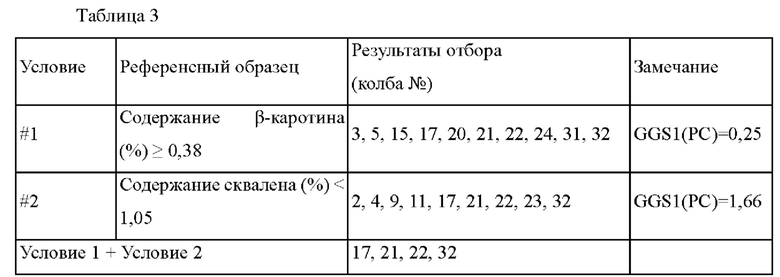
Трансформированные плазмиды экстрагировали из четырех видов отобранных штаммов, и анализ последовательности осуществляли для подтверждения произвольных мутаций, расположенных в ORF (открытой рамке считывания (ОРС)) GGS1. Трансформированную плазмиду GGS1 экстрагировали из выбранного штамма с использованием набора Zymoprep yeast plasmid miniprep kit 2 (Zymo research), и для того, чтобы увеличить надежность анализа последовательности, осуществляли двунаправленное секвенирование с использованием праймеров в соответствии с SEQ ID NO: 59 и SEQ ID NO: 60. Аминокислотные мутации, которые были идентифицированы в результате анализа последовательности ОРС (ORF) GGS1, представлены в таблице 4 ниже, и подтвердили, что четыре вида групп кандидатов имеют одну мутацию или две мутации среди представленных в таблице 4 ниже.
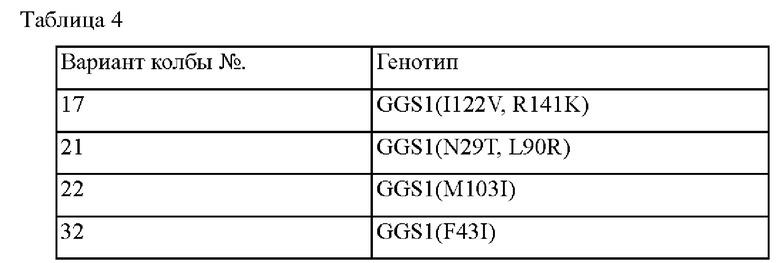
Пример 5. Верификация активности выбранного варианта GGS1
Эксперимент осуществляли для верификации активностей вариантов GGS1, выбранных в примере 3 и примере 4.
Для этого осуществляли тестирование в колбе в общей сложности для 10 видов штаммов, которые готовили путем трансформации каждого из векторов, экспрессирующих отрицательный контроль (NC) и положительный контроль (PC), и экспрессирующих векторов для четырех видов вариантов (вариант М1031, вариант F43I, вариант N29T и L90R, и вариант I122V и R141K), выбранных в примере 4, и четырех видов родственных единичных вариантов (вариант N29T, вариант L90R, вариант I122V и вариант R141K).
Способ получения экспрессирующих векторов для каждого из четырех видов единичных вариантов (вариант N29T, вариант L90R вариант, вариант I122V вариант и вариант R141K) является следующим. Для получения фрагментов ДНК четырех видов единичных вариантов (вариант N29T, вариант L90R, вариант I122V и вариант R141K) осуществляли ПЦР с использованием вектора pIMR53-EXP1p-GGS1-CYC1t, содержащего последовательность дикого типа GGS1 в качестве матрицы, и праймеров в соответствии с SEQ ID NO: 61 и SEQ ID NO: 62, SEQ ID NO: 63 и SEQ ID NO: 64, SEQ ID NO: 65 и SEQ ID NO: 66, SEQ ID NO: 67 и SEQ ID NO: 68, соответственно. Условия ПЦР были следующими: 32 цикла, состоящих из денатурации при 95°С в течение 1 минуты; отжига при 55°С в течение 1 минуты; и полимеризации при 68°С в течение 5 минут. Экспрессирующие векторы для варианта N29T и L90R или варианта I122V и R141K, которые представляют собой двойной вариант, получали путем осуществления ПЦР с использованием экспрессирующего вектора N29T или экспрессирующего вектора I122V, полученного выше, в качестве матрицы и праймера в соответствии с SEQ ID NO: 63 и SEQ ID NO: 64 и праймера в соответствии с SEQ ID NO: 67 и SEQ ID NO: 68 тем же самым образом.
В результате ДНК с внедренным вариантом, амплифицированные при помощи ПЦР, трансформировали в Е. coli DH5α с использованием Infusion cloning kit (Invitrogen), и высевали на твердую среду LB, содержащую 30 мг/л ампициллина. После выбора колоний, которые были трансформированы плазмидами, в которые были внедрены четыре вида векторов с трансформированным вариантом GGS1, плазмиды получали с использованием общеизвестного способа экстракции плазмид, и последовательности для вариантов подтверждали с использованием SEQ ID NO: 59 и SEQ ID NO: 60.
В частности, в колбу с угловыми перегородками объемом 250 мл, содержащую 50 мл минимальной среды 2 Yarrowia lipolytica (YLMM2) без урацила, инокулировали 10 видов штаммов при исходной ОП 1, соответственно, и культивировали при 30°С в течение 48 часов при встряхивании при 250 об./мин.
После завершения культивирования 1 мл культуральной среды центрифугировали, и супернатант удаляли. Затем добавляли 0,5 мл диметилсульфоксида (DMSO (ДМСО), Sigma), и клетки разрушали путем встряхивания при 2000 об./мин в течение 10 минут при 55°С. Кроме того, добавляли 0,5 мл ацетона (Sigma) и встряхивали при 2000 об./мин в течение 15 минут при 45°С для экстрагирования бета-каротина и сквалена. Их концентрации анализировали с использованием оборудования для ВЭЖХ (HPLC). Результаты измерения ОП, концентраций и содержания бета-каротина и сквалена представлены в таблице 5 ниже.
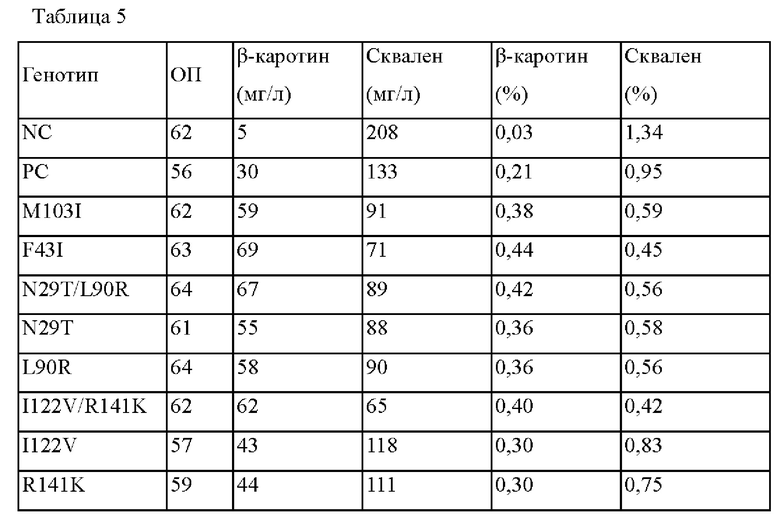
В соответствии с представленным в таблице 5 подтвердили, что концентрация бета-каротина увеличивалась на 143%-230% и концентрация сквалена уменьшалась на 11%-51% во всех выбранных вариантах GGS1 с применением мутации M103L F43I, N29T, L90R, I122V и/или R141K по сравнению с положительным контролем ПК (PC). Следовательно, среди 6 видов штаммов, в которые был внедрен единичный вариант, штамм, в который был внедрен вариант F43I, демонстрировал самый лучший эффект. В случае вариантов I122V и R141K эффекты увеличения концентрации бета-каротина и уменьшения продукции сквалена дополнительно усиливались при одновременном применении обоих вариантов по сравнению с применением вариантов по одному. В случае вариантов N29T и L90R эффект уменьшения продукции сквалена дополнительно усиливался при одновременном применении обоих вариантов по сравнению с применением вариантов по одному.
Пример 6. Получение и оценка штамма с внедренным вариантом GGS1
Предполагалось верифицировать эффект, когда вариант GGS1 F43I, который определяли как превосходный в предшествующем примере, действительно внедряли в штамм.
Для этого на основе СС08-1023 последовательно получали штамм (СС08-1214), в котором промотор гена GGS1 был заменен, и штамм (СС08-1215), экспрессирующий вариант, в котором фенилаланин в положении 43 в GGS1 был заменен на изолейцин.
Пример 6-1. Получение штамма с заменой промотора GGS1 ("СС08-1214")
Для конструирования кассеты, которая способна заменить промотор GGS1 на промотор TEFINt на хромосоме Yarrowia lipolytica, получали полинуклеотидную последовательность в соответствии с SEQ ID NO: 69, содержащую промотор TEF1 (YALI0C09141p) и точки сплайсинга, на основе нуклеотидной последовательности, зарегистрированной в Kyoto Encyclopedia of Genes and Genomes (Энциклопедия генов и геномов Института химических исследований в Киото) (KEGG). Кроме того, для замены промотора GGS1 получали полинуклеотидную последовательность GGS1 (YALI0D17050g) в соответствии с SEQ ID NO: 2. Осуществляли ПЦР с использованием геномной ДНК Yarrowia lipolytica PO1f в качестве матрицы и праймеров в соответствии с SEQ ID NO: 70 и SEQ ID NO: 71, SEQ ID NO: 72 и SEQ ID NO: 73, SEQ ID NO: 74 и SEQ ID NO: 75, и SEQ ID NO: 76 и SEQ ID NO: 77, соответственно. Затем осуществляли ПЦР с использованием ауксотрофного маркера URA3 в качестве матрицы и праймеров в соответствии с SEQ ID NO: 78 и SEQ ID NO: 79. Условия ПЦР были следующими: 35 циклов, состоящих из денатурации при 95°С в течение 1 минуты; отжига при 55°С в течение 1 минуты; и полимеризации при 72°С в течение 1 минуты и 30 минут.
В результате получали 1500 п.о. плеча 5'UTR arm, 531 п.о. 5'UTR_RP, 1500 п.о. плеча GGS1 и 1533 п.о. URA3. Фрагменты ДНК, амплифицированные при помощи ПЦР, получали в единичной кассете замены промотора GGS1 путем ПЦР с перекрывающимися праймерами, и дизайн кассеты строили в следующей последовательности плечо 5'UTR-TEFINt-URA3-TEFINt-плечо GGS1.
Кассету для замены промотора GGS1 трансформировали в СС08-1023 путем теплового шока и отбирали на твердой среде YLMM1 без урацила. Выбранные первичные штаммы подвергали вторичному кроссоверу для окончательного получения штамма, в котором промотор гена GGS1 был заменен на промотор TEFINt. Полученный таким образом штамм был назван "СС08-1214".
Пример 6-2. Получение варианта штамма GGS1(F43I) ("СС08-1215")
Для введения последовательности, экспрессирующей вариант F43I белка GGS1, в хромосому Yarrowia lipolytica конструировали кассету, в которой тимин в положению 127 полинуклеотидной последовательности в соответствии с SEQ ID NO: 2 заменяли на аденин.
В частности, осуществляли ПЦР с использованием геномной ДНК Yarrowia lipolytica PO1f в качестве матрицы и праймеров в соответствии с SEQ ID NO: 80 и SEQ ID NO: 81, SEQ ID NO: 82 и SEQ ID NO: 83, SEQ ID NO: 84 и SEQ ID NO: 85, SEQ ID NO: 86 и SEQ ID NO: 83, SEQ ID NO: 84 и SEQ ID NO: 87, и SEQ ID NO: 90 и SEQ ID NO: 91, соответственно. Кроме того, осуществляли ПЦР с использованием ауксотрофного маркера URA3 в качестве матрицы и праймеров в соответствии с SEQ ID NO: 88 и SEQ ID NO: 89. Условия ПЦР были следующими: 35 циклов, состоящих из денатурации при 95°С в течение 1 минуты; отжига при 55°С в течение 1 минуты; и полимеризации при 72°С в течение 1 минуты и 30 минут.
В результате получали 1500 п.о. плеча 5'UTR, 661 п.о. TEFINt-GGS1 l, 1390 п.о. GGS1_2, 661 п.о. RP_1, 1390 п.о. RP_2, 1500 п.о. плеча 3'UTR и 1533 п.о. URA3. Фрагменты ДНК, амплифицированные при помощи ПЦР, получали в единичной кассете для замены промотора GGS1 путем ПЦР с перекрывающимися праймерами, и дизайн кассеты строили в последовательности плечо 5'UTR-TEFINt-GGS1_1- GGS1_2-RP1- плечо RP_2-3'UTR.
Кассету для замены варианта GGS1 (F43I) трансформировали в СС08-1214 путем теплового шока и отбирали на твердой среде YLMM1 без урацила. Отобранные первичные штаммы подвергали вторичному кроссоверу для окончательного получения штамма, экспрессирующего вариант F43I, в котором аминокислотный остаток в положении 43 в GGS1 заменяли на изолейцин. Полученный таким образом штамм был назван "СС08-1215".
Пример 6-3. Оценка штамма с внедренным вариантом GGS1
Тестирование в колбе осуществляли на СС08-1215 вместе с СС08-1023 в качестве отрицательного контроля и СС08-1214 в качестве положительного контроля.
В частности, СС08-1215, СС08-1023 (отрицательный контроль) и СС08-1214 (положительный контроль) инокулировали в колбу с угловыми перегородками объемом 250 мл, содержащую 50 мл минимальной среды 2 Yarrowia lipolytica (YLMM2) с урацилом при исходной ОП 1, и культивировали при 30°С в течение 48 часов при встряхивании при 250 об./мин, соответственно.
После завершения культивирования 1 мл культуральной среды центрифугировали и супернатант удаляли. Затем добавляли 0,5 мл диметилсульфоксида (ДМСО (DMSO), Sigma), и клетки разрушали путем встряхивания при 2000 об./мин в течение 10 минут при 55°С. Кроме того, добавляли 0,5 мл ацетона (Sigma) и встряхивали при 2000 об./мин в течение 15 минут при 45°С для экстрагирования бета-каротина и сквалена. Их концентрации анализировали с использованием оборудования для ВЭЖХ (HPLC). Проанализированные ОП и результаты измерения концентраций и содержания бета-каротина и сквалена представлены в таблице 6 ниже.
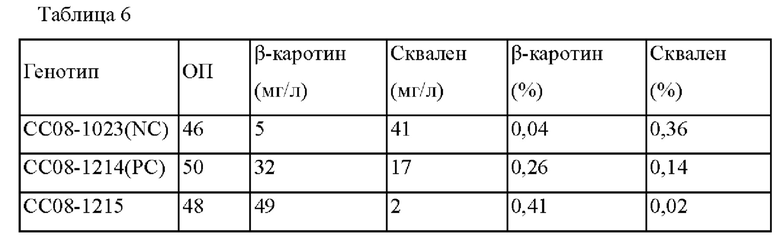
В соответствии с представленным в таблице 6 подтвердили, что концентрация бета-каротина увеличивалась на 51,3%, а концентрация сквалена уменьшалась на 88,5% в выбранном штамме СС08-1215 с применением варианта F43I, по сравнению с СС08-1214(РС). Следовательно, подтвердили, что введение единичного варианта F43I оказывало действия, увеличивающие концентрацию бета-каротина и уменьшающие продукцию сквалена, даже при реальном применении в отношении штамма.
Эти результаты подтвердили, что продукция бета-каротина может быть увеличена путем введения варианта GGS1 в соответствии с настоящим изобретением. Также подтвердили, что эффективность продукции бета-каротина может быть дополнительно усилена путем уменьшения синтеза сквалена, который представляет собой конкурентный путь для продукции бета-каротина, вследствие введения варианта GGS1.
Вышеприведенные результаты также подтвердили, что подобно продукции бета-каротина, эффективность продукции тетратерпенов, вовлекающая GGS1, может быть дополнительно усилена.
На основе вышеприведенного описания, специалисту в данной области техники будет понято, что настоящее изобретение может быть реализовано в отличающейся специфической форме без изменения его технической сущности или существенных характеристик. В этой связи следует понимать, что вышеприведенное воплощение не является ограничивающим, а иллюстративным во всех аспектах. Объем изобретения определяется формулой изобретения, нежели чем предшествующим ей описанием, и, следовательно, предполагается, что все изменения и модификации, которые оказываются в границах и пределах формулы изобретения, или эквивалентах таких границ и пределов, охвачены формулой изобретения.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> CJ CheilJedang Corporation
<120> ВАРИАНТ ГЕРАНИЛГЕРАНИЛПИРОФОСФАТСИНТАЗЫ И СПОСОБ ПОЛУЧЕНИЯ ТЕТРАТЕРПЕНА, ЕГО ПРЕДШЕСТВЕННИКА И ВЕЩЕСТВА, ИМЕЮЩЕГО ТЕТРАТЕРПЕН В КАЧЕСТВЕ ПРЕДШЕСТВЕННИКА, С ЕГО ПРИМЕНЕНИЕМ
<130> OPA22028
<150> KR 10-2021-0074819
<151> 2021-06-09
<160> 91
<170> KoPatentIn 3.0
<210> 1
<211> 327
<212> PRT
<213> Artificial Sequence
<220>
<223> GGS1_WT
<400> 1
Met Asp Tyr Asn Ser Ala Asp Phe Lys Glu Ile Trp Gly Lys Ala Ala
1 5 10 15
Asp Thr Ala Leu Leu Gly Pro Tyr Asn Tyr Leu Ala Asn Asn Arg Gly
20 25 30
His Asn Ile Arg Glu His Leu Ile Ala Ala Phe Gly Ala Val Ile Lys
35 40 45
Val Asp Lys Ser Asp Leu Glu Thr Ile Ser His Ile Thr Lys Ile Leu
50 55 60
His Asn Ser Ser Leu Leu Val Asp Asp Val Glu Asp Asn Ser Met Leu
65 70 75 80
Arg Arg Gly Leu Pro Ala Ala His Cys Leu Phe Gly Val Pro Gln Thr
85 90 95
Ile Asn Ser Ala Asn Tyr Met Tyr Phe Val Ala Leu Gln Glu Val Leu
100 105 110
Lys Leu Lys Ser Tyr Asp Ala Val Ser Ile Phe Thr Glu Glu Met Ile
115 120 125
Asn Leu His Arg Gly Gln Gly Met Asp Leu Tyr Trp Arg Glu Thr Leu
130 135 140
Thr Cys Pro Ser Glu Asp Glu Tyr Leu Glu Met Val Val His Lys Thr
145 150 155 160
Gly Gly Leu Phe Arg Leu Ala Leu Arg Leu Met Leu Ser Val Ala Ser
165 170 175
Lys Gln Glu Asp His Glu Lys Ile Asn Phe Asp Leu Thr His Leu Thr
180 185 190
Asp Thr Leu Gly Val Ile Tyr Gln Ile Leu Asp Asp Tyr Leu Asn Leu
195 200 205
Gln Ser Thr Glu Leu Thr Glu Asn Lys Gly Phe Cys Glu Asp Ile Ser
210 215 220
Glu Gly Lys Phe Ser Phe Pro Leu Ile His Ser Ile Arg Thr Asn Pro
225 230 235 240
Asp Asn His Glu Ile Leu Asn Ile Leu Lys Gln Arg Thr Ser Asp Ala
245 250 255
Ser Leu Lys Lys Tyr Ala Val Asp Tyr Met Arg Thr Glu Thr Lys Ser
260 265 270
Phe Asp Tyr Cys Leu Lys Arg Ile Gln Ala Met Ser Leu Lys Ala Ser
275 280 285
Ser Tyr Ile Asp Asp Leu Ala Ala Ala Gly His Asp Val Ser Lys Leu
290 295 300
Arg Ala Ile Leu His Tyr Phe Val Ser Thr Ser Asp Cys Glu Glu Arg
305 310 315 320
Lys Tyr Phe Glu Asp Ala Gln
325
<210> 2
<211> 984
<212> DNA
<213> Artificial Sequence
<220>
<223> ggs1_WT
<400> 2
atggattata acagcgcgga tttcaaggag atatggggca aggccgccga caccgcgctg 60
ctgggaccgt acaactacct cgccaacaac cggggccaca acatcagaga acacttgatc 120
gcagcgttcg gagcggttat caaggtggac aagagcgatc tcgagaccat ttcgcacatc 180
accaagattt tgcataactc gtcgctgctt gttgatgacg tggaagacaa ctcgatgctc 240
cgacgaggcc tgccggcagc ccattgtctg tttggagtcc cccaaaccat caactccgcc 300
aactacatgt actttgtggc tctgcaggag gtgctcaagc tcaagtctta tgatgccgtc 360
tccattttca ccgaggaaat gatcaacttg catagaggtc agggtatgga tctctactgg 420
agagaaacac tcacttgccc ctcggaagac gagtatctgg agatggtggt gcacaagacc 480
ggtggactgt ttcggctggc tctgagactt atgctgtcgg tggcatcgaa acaggaggac 540
catgaaaaga tcaactttga tctcacacac cttaccgaca cactgggagt catttaccag 600
attctggatg attacctcaa cctgcagtcc acggaattga ccgagaacaa gggattctgc 660
gaagatatca gcgaaggaaa gttttcgttt ccgctgattc acagcatacg caccaacccg 720
gataaccacg agattctcaa cattctcaaa cagcgaacaa gcgacgcttc actcaaaaag 780
tacgccgtgg actacatgag aacagaaacc aagagtttcg actactgcct caagaggata 840
caggccatgt cactcaaggc aagttcgtac attgatgatc tagcagcagc tggccacgat 900
gtctccaagc tacgagccat tttgcattat tttgtgtcca cctctgactg tgaggagaga 960
aagtactttg aggatgcgca gtga 984
<210> 3
<211> 327
<212> PRT
<213> Artificial Sequence
<220>
<223> GGS1_M103I
<400> 3
Met Asp Tyr Asn Ser Ala Asp Phe Lys Glu Ile Trp Gly Lys Ala Ala
1 5 10 15
Asp Thr Ala Leu Leu Gly Pro Tyr Asn Tyr Leu Ala Asn Asn Arg Gly
20 25 30
His Asn Ile Arg Glu His Leu Ile Ala Ala Phe Gly Ala Val Ile Lys
35 40 45
Val Asp Lys Ser Asp Leu Glu Thr Ile Ser His Ile Thr Lys Ile Leu
50 55 60
His Asn Ser Ser Leu Leu Val Asp Asp Val Glu Asp Asn Ser Met Leu
65 70 75 80
Arg Arg Gly Leu Pro Ala Ala His Cys Leu Phe Gly Val Pro Gln Thr
85 90 95
Ile Asn Ser Ala Asn Tyr Ile Tyr Phe Val Ala Leu Gln Glu Val Leu
100 105 110
Lys Leu Lys Ser Tyr Asp Ala Val Ser Ile Phe Thr Glu Glu Met Ile
115 120 125
Asn Leu His Arg Gly Gln Gly Met Asp Leu Tyr Trp Arg Glu Thr Leu
130 135 140
Thr Cys Pro Ser Glu Asp Glu Tyr Leu Glu Met Val Val His Lys Thr
145 150 155 160
Gly Gly Leu Phe Arg Leu Ala Leu Arg Leu Met Leu Ser Val Ala Ser
165 170 175
Lys Gln Glu Asp His Glu Lys Ile Asn Phe Asp Leu Thr His Leu Thr
180 185 190
Asp Thr Leu Gly Val Ile Tyr Gln Ile Leu Asp Asp Tyr Leu Asn Leu
195 200 205
Gln Ser Thr Glu Leu Thr Glu Asn Lys Gly Phe Cys Glu Asp Ile Ser
210 215 220
Glu Gly Lys Phe Ser Phe Pro Leu Ile His Ser Ile Arg Thr Asn Pro
225 230 235 240
Asp Asn His Glu Ile Leu Asn Ile Leu Lys Gln Arg Thr Ser Asp Ala
245 250 255
Ser Leu Lys Lys Tyr Ala Val Asp Tyr Met Arg Thr Glu Thr Lys Ser
260 265 270
Phe Asp Tyr Cys Leu Lys Arg Ile Gln Ala Met Ser Leu Lys Ala Ser
275 280 285
Ser Tyr Ile Asp Asp Leu Ala Ala Ala Gly His Asp Val Ser Lys Leu
290 295 300
Arg Ala Ile Leu His Tyr Phe Val Ser Thr Ser Asp Cys Glu Glu Arg
305 310 315 320
Lys Tyr Phe Glu Asp Ala Gln
325
<210> 4
<211> 984
<212> DNA
<213> Artificial Sequence
<220>
<223> ggs1_G309A
<400> 4
atggattata acagcgcgga tttcaaggag atatggggca aggccgccga caccgcgctg 60
ctgggaccgt acaactacct cgccaacaac cggggccaca acatcagaga acacttgatc 120
gcagcgttcg gagcggttat caaggtggac aagagcgatc tcgagaccat ttcgcacatc 180
accaagattt tgcataactc gtcgctgctt gttgatgacg tggaagacaa ctcgatgctc 240
cgacgaggcc tgccggcagc ccattgtctg tttggagtcc cccaaaccat caactccgcc 300
aactacatat actttgtggc tctgcaggag gtgctcaagc tcaagtctta tgatgccgtc 360
tccattttca ccgaggaaat gatcaacttg catagaggtc agggtatgga tctctactgg 420
agagaaacac tcacttgccc ctcggaagac gagtatctgg agatggtggt gcacaagacc 480
ggtggactgt ttcggctggc tctgagactt atgctgtcgg tggcatcgaa acaggaggac 540
catgaaaaga tcaactttga tctcacacac cttaccgaca cactgggagt catttaccag 600
attctggatg attacctcaa cctgcagtcc acggaattga ccgagaacaa gggattctgc 660
gaagatatca gcgaaggaaa gttttcgttt ccgctgattc acagcatacg caccaacccg 720
gataaccacg agattctcaa cattctcaaa cagcgaacaa gcgacgcttc actcaaaaag 780
tacgccgtgg actacatgag aacagaaacc aagagtttcg actactgcct caagaggata 840
caggccatgt cactcaaggc aagttcgtac attgatgatc tagcagcagc tggccacgat 900
gtctccaagc tacgagccat tttgcattat tttgtgtcca cctctgactg tgaggagaga 960
aagtactttg aggatgcgca gtga 984
<210> 5
<211> 327
<212> PRT
<213> Artificial Sequence
<220>
<223> GGS1_F43I
<400> 5
Met Asp Tyr Asn Ser Ala Asp Phe Lys Glu Ile Trp Gly Lys Ala Ala
1 5 10 15
Asp Thr Ala Leu Leu Gly Pro Tyr Asn Tyr Leu Ala Asn Asn Arg Gly
20 25 30
His Asn Ile Arg Glu His Leu Ile Ala Ala Ile Gly Ala Val Ile Lys
35 40 45
Val Asp Lys Ser Asp Leu Glu Thr Ile Ser His Ile Thr Lys Ile Leu
50 55 60
His Asn Ser Ser Leu Leu Val Asp Asp Val Glu Asp Asn Ser Met Leu
65 70 75 80
Arg Arg Gly Leu Pro Ala Ala His Cys Leu Phe Gly Val Pro Gln Thr
85 90 95
Ile Asn Ser Ala Asn Tyr Met Tyr Phe Val Ala Leu Gln Glu Val Leu
100 105 110
Lys Leu Lys Ser Tyr Asp Ala Val Ser Ile Phe Thr Glu Glu Met Ile
115 120 125
Asn Leu His Arg Gly Gln Gly Met Asp Leu Tyr Trp Arg Glu Thr Leu
130 135 140
Thr Cys Pro Ser Glu Asp Glu Tyr Leu Glu Met Val Val His Lys Thr
145 150 155 160
Gly Gly Leu Phe Arg Leu Ala Leu Arg Leu Met Leu Ser Val Ala Ser
165 170 175
Lys Gln Glu Asp His Glu Lys Ile Asn Phe Asp Leu Thr His Leu Thr
180 185 190
Asp Thr Leu Gly Val Ile Tyr Gln Ile Leu Asp Asp Tyr Leu Asn Leu
195 200 205
Gln Ser Thr Glu Leu Thr Glu Asn Lys Gly Phe Cys Glu Asp Ile Ser
210 215 220
Glu Gly Lys Phe Ser Phe Pro Leu Ile His Ser Ile Arg Thr Asn Pro
225 230 235 240
Asp Asn His Glu Ile Leu Asn Ile Leu Lys Gln Arg Thr Ser Asp Ala
245 250 255
Ser Leu Lys Lys Tyr Ala Val Asp Tyr Met Arg Thr Glu Thr Lys Ser
260 265 270
Phe Asp Tyr Cys Leu Lys Arg Ile Gln Ala Met Ser Leu Lys Ala Ser
275 280 285
Ser Tyr Ile Asp Asp Leu Ala Ala Ala Gly His Asp Val Ser Lys Leu
290 295 300
Arg Ala Ile Leu His Tyr Phe Val Ser Thr Ser Asp Cys Glu Glu Arg
305 310 315 320
Lys Tyr Phe Glu Asp Ala Gln
325
<210> 6
<211> 984
<212> DNA
<213> Artificial Sequence
<220>
<223> ggs1_T127A
<400> 6
atggattata acagcgcgga tttcaaggag atatggggca aggccgccga caccgcgctg 60
ctgggaccgt acaactacct cgccaacaac cggggccaca acatcagaga acacttgatc 120
gcagcgatcg gagcggttat caaggtggac aagagcgatc tcgagaccat ttcgcacatc 180
accaagattt tgcataactc gtcgctgctt gttgatgacg tggaagacaa ctcgatgctc 240
cgacgaggcc tgccggcagc ccattgtctg tttggagtcc cccaaaccat caactccgcc 300
aactacatgt actttgtggc tctgcaggag gtgctcaagc tcaagtctta tgatgccgtc 360
tccattttca ccgaggaaat gatcaacttg catagaggtc agggtatgga tctctactgg 420
agagaaacac tcacttgccc ctcggaagac gagtatctgg agatggtggt gcacaagacc 480
ggtggactgt ttcggctggc tctgagactt atgctgtcgg tggcatcgaa acaggaggac 540
catgaaaaga tcaactttga tctcacacac cttaccgaca cactgggagt catttaccag 600
attctggatg attacctcaa cctgcagtcc acggaattga ccgagaacaa gggattctgc 660
gaagatatca gcgaaggaaa gttttcgttt ccgctgattc acagcatacg caccaacccg 720
gataaccacg agattctcaa cattctcaaa cagcgaacaa gcgacgcttc actcaaaaag 780
tacgccgtgg actacatgag aacagaaacc aagagtttcg actactgcct caagaggata 840
caggccatgt cactcaaggc aagttcgtac attgatgatc tagcagcagc tggccacgat 900
gtctccaagc tacgagccat tttgcattat tttgtgtcca cctctgactg tgaggagaga 960
aagtactttg aggatgcgca gtga 984
<210> 7
<211> 327
<212> PRT
<213> Artificial Sequence
<220>
<223> GGS1_N29T/L90R
<400> 7
Met Asp Tyr Asn Ser Ala Asp Phe Lys Glu Ile Trp Gly Lys Ala Ala
1 5 10 15
Asp Thr Ala Leu Leu Gly Pro Tyr Asn Tyr Leu Ala Thr Asn Arg Gly
20 25 30
His Asn Ile Arg Glu His Leu Ile Ala Ala Phe Gly Ala Val Ile Lys
35 40 45
Val Asp Lys Ser Asp Leu Glu Thr Ile Ser His Ile Thr Lys Ile Leu
50 55 60
His Asn Ser Ser Leu Leu Val Asp Asp Val Glu Asp Asn Ser Met Leu
65 70 75 80
Arg Arg Gly Leu Pro Ala Ala His Cys Arg Phe Gly Val Pro Gln Thr
85 90 95
Ile Asn Ser Ala Asn Tyr Met Tyr Phe Val Ala Leu Gln Glu Val Leu
100 105 110
Lys Leu Lys Ser Tyr Asp Ala Val Ser Ile Phe Thr Glu Glu Met Ile
115 120 125
Asn Leu His Arg Gly Gln Gly Met Asp Leu Tyr Trp Arg Glu Thr Leu
130 135 140
Thr Cys Pro Ser Glu Asp Glu Tyr Leu Glu Met Val Val His Lys Thr
145 150 155 160
Gly Gly Leu Phe Arg Leu Ala Leu Arg Leu Met Leu Ser Val Ala Ser
165 170 175
Lys Gln Glu Asp His Glu Lys Ile Asn Phe Asp Leu Thr His Leu Thr
180 185 190
Asp Thr Leu Gly Val Ile Tyr Gln Ile Leu Asp Asp Tyr Leu Asn Leu
195 200 205
Gln Ser Thr Glu Leu Thr Glu Asn Lys Gly Phe Cys Glu Asp Ile Ser
210 215 220
Glu Gly Lys Phe Ser Phe Pro Leu Ile His Ser Ile Arg Thr Asn Pro
225 230 235 240
Asp Asn His Glu Ile Leu Asn Ile Leu Lys Gln Arg Thr Ser Asp Ala
245 250 255
Ser Leu Lys Lys Tyr Ala Val Asp Tyr Met Arg Thr Glu Thr Lys Ser
260 265 270
Phe Asp Tyr Cys Leu Lys Arg Ile Gln Ala Met Ser Leu Lys Ala Ser
275 280 285
Ser Tyr Ile Asp Asp Leu Ala Ala Ala Gly His Asp Val Ser Lys Leu
290 295 300
Arg Ala Ile Leu His Tyr Phe Val Ser Thr Ser Asp Cys Glu Glu Arg
305 310 315 320
Lys Tyr Phe Glu Asp Ala Gln
325
<210> 8
<211> 984
<212> DNA
<213> Artificial Sequence
<220>
<223> ggs1_A86C_T269G
<400> 8
atggattata acagcgcgga tttcaaggag atatggggca aggccgccga caccgcgctg 60
ctgggaccgt acaactacct cgccaccaac cggggccaca acatcagaga acacttgatc 120
gcagcgttcg gagcggttat caaggtggac aagagcgatc tcgagaccat ttcgcacatc 180
accaagattt tgcataactc gtcgctgctt gttgatgacg tggaagacaa ctcgatgctc 240
cgacgaggcc tgccggcagc ccattgtcgg tttggagtcc cccaaaccat caactccgcc 300
aactacatgt actttgtggc tctgcaggag gtgctcaagc tcaagtctta tgatgccgtc 360
tccattttca ccgaggaaat gatcaacttg catagaggtc agggtatgga tctctactgg 420
agagaaacac tcacttgccc ctcggaagac gagtatctgg agatggtggt gcacaagacc 480
ggtggactgt ttcggctggc tctgagactt atgctgtcgg tggcatcgaa acaggaggac 540
catgaaaaga tcaactttga tctcacacac cttaccgaca cactgggagt catttaccag 600
attctggatg attacctcaa cctgcagtcc acggaattga ccgagaacaa gggattctgc 660
gaagatatca gcgaaggaaa gttttcgttt ccgctgattc acagcatacg caccaacccg 720
gataaccacg agattctcaa cattctcaaa cagcgaacaa gcgacgcttc actcaaaaag 780
tacgccgtgg actacatgag aacagaaacc aagagtttcg actactgcct caagaggata 840
caggccatgt cactcaaggc aagttcgtac attgatgatc tagcagcagc tggccacgat 900
gtctccaagc tacgagccat tttgcattat tttgtgtcca cctctgactg tgaggagaga 960
aagtactttg aggatgcgca gtga 984
<210> 9
<211> 327
<212> PRT
<213> Artificial Sequence
<220>
<223> GGS1_N29T
<400> 9
Met Asp Tyr Asn Ser Ala Asp Phe Lys Glu Ile Trp Gly Lys Ala Ala
1 5 10 15
Asp Thr Ala Leu Leu Gly Pro Tyr Asn Tyr Leu Ala Thr Asn Arg Gly
20 25 30
His Asn Ile Arg Glu His Leu Ile Ala Ala Phe Gly Ala Val Ile Lys
35 40 45
Val Asp Lys Ser Asp Leu Glu Thr Ile Ser His Ile Thr Lys Ile Leu
50 55 60
His Asn Ser Ser Leu Leu Val Asp Asp Val Glu Asp Asn Ser Met Leu
65 70 75 80
Arg Arg Gly Leu Pro Ala Ala His Cys Leu Phe Gly Val Pro Gln Thr
85 90 95
Ile Asn Ser Ala Asn Tyr Met Tyr Phe Val Ala Leu Gln Glu Val Leu
100 105 110
Lys Leu Lys Ser Tyr Asp Ala Val Ser Ile Phe Thr Glu Glu Met Ile
115 120 125
Asn Leu His Arg Gly Gln Gly Met Asp Leu Tyr Trp Arg Glu Thr Leu
130 135 140
Thr Cys Pro Ser Glu Asp Glu Tyr Leu Glu Met Val Val His Lys Thr
145 150 155 160
Gly Gly Leu Phe Arg Leu Ala Leu Arg Leu Met Leu Ser Val Ala Ser
165 170 175
Lys Gln Glu Asp His Glu Lys Ile Asn Phe Asp Leu Thr His Leu Thr
180 185 190
Asp Thr Leu Gly Val Ile Tyr Gln Ile Leu Asp Asp Tyr Leu Asn Leu
195 200 205
Gln Ser Thr Glu Leu Thr Glu Asn Lys Gly Phe Cys Glu Asp Ile Ser
210 215 220
Glu Gly Lys Phe Ser Phe Pro Leu Ile His Ser Ile Arg Thr Asn Pro
225 230 235 240
Asp Asn His Glu Ile Leu Asn Ile Leu Lys Gln Arg Thr Ser Asp Ala
245 250 255
Ser Leu Lys Lys Tyr Ala Val Asp Tyr Met Arg Thr Glu Thr Lys Ser
260 265 270
Phe Asp Tyr Cys Leu Lys Arg Ile Gln Ala Met Ser Leu Lys Ala Ser
275 280 285
Ser Tyr Ile Asp Asp Leu Ala Ala Ala Gly His Asp Val Ser Lys Leu
290 295 300
Arg Ala Ile Leu His Tyr Phe Val Ser Thr Ser Asp Cys Glu Glu Arg
305 310 315 320
Lys Tyr Phe Glu Asp Ala Gln
325
<210> 10
<211> 984
<212> DNA
<213> Artificial Sequence
<220>
<223> ggs1_A86C
<400> 10
atggattata acagcgcgga tttcaaggag atatggggca aggccgccga caccgcgctg 60
ctgggaccgt acaactacct cgccaccaac cggggccaca acatcagaga acacttgatc 120
gcagcgttcg gagcggttat caaggtggac aagagcgatc tcgagaccat ttcgcacatc 180
accaagattt tgcataactc gtcgctgctt gttgatgacg tggaagacaa ctcgatgctc 240
cgacgaggcc tgccggcagc ccattgtctg tttggagtcc cccaaaccat caactccgcc 300
aactacatgt actttgtggc tctgcaggag gtgctcaagc tcaagtctta tgatgccgtc 360
tccattttca ccgaggaaat gatcaacttg catagaggtc agggtatgga tctctactgg 420
agagaaacac tcacttgccc ctcggaagac gagtatctgg agatggtggt gcacaagacc 480
ggtggactgt ttcggctggc tctgagactt atgctgtcgg tggcatcgaa acaggaggac 540
catgaaaaga tcaactttga tctcacacac cttaccgaca cactgggagt catttaccag 600
attctggatg attacctcaa cctgcagtcc acggaattga ccgagaacaa gggattctgc 660
gaagatatca gcgaaggaaa gttttcgttt ccgctgattc acagcatacg caccaacccg 720
gataaccacg agattctcaa cattctcaaa cagcgaacaa gcgacgcttc actcaaaaag 780
tacgccgtgg actacatgag aacagaaacc aagagtttcg actactgcct caagaggata 840
caggccatgt cactcaaggc aagttcgtac attgatgatc tagcagcagc tggccacgat 900
gtctccaagc tacgagccat tttgcattat tttgtgtcca cctctgactg tgaggagaga 960
aagtactttg aggatgcgca gtga 984
<210> 11
<211> 327
<212> PRT
<213> Artificial Sequence
<220>
<223> GGS1_L90R
<400> 11
Met Asp Tyr Asn Ser Ala Asp Phe Lys Glu Ile Trp Gly Lys Ala Ala
1 5 10 15
Asp Thr Ala Leu Leu Gly Pro Tyr Asn Tyr Leu Ala Asn Asn Arg Gly
20 25 30
His Asn Ile Arg Glu His Leu Ile Ala Ala Phe Gly Ala Val Ile Lys
35 40 45
Val Asp Lys Ser Asp Leu Glu Thr Ile Ser His Ile Thr Lys Ile Leu
50 55 60
His Asn Ser Ser Leu Leu Val Asp Asp Val Glu Asp Asn Ser Met Leu
65 70 75 80
Arg Arg Gly Leu Pro Ala Ala His Cys Arg Phe Gly Val Pro Gln Thr
85 90 95
Ile Asn Ser Ala Asn Tyr Met Tyr Phe Val Ala Leu Gln Glu Val Leu
100 105 110
Lys Leu Lys Ser Tyr Asp Ala Val Ser Ile Phe Thr Glu Glu Met Ile
115 120 125
Asn Leu His Arg Gly Gln Gly Met Asp Leu Tyr Trp Arg Glu Thr Leu
130 135 140
Thr Cys Pro Ser Glu Asp Glu Tyr Leu Glu Met Val Val His Lys Thr
145 150 155 160
Gly Gly Leu Phe Arg Leu Ala Leu Arg Leu Met Leu Ser Val Ala Ser
165 170 175
Lys Gln Glu Asp His Glu Lys Ile Asn Phe Asp Leu Thr His Leu Thr
180 185 190
Asp Thr Leu Gly Val Ile Tyr Gln Ile Leu Asp Asp Tyr Leu Asn Leu
195 200 205
Gln Ser Thr Glu Leu Thr Glu Asn Lys Gly Phe Cys Glu Asp Ile Ser
210 215 220
Glu Gly Lys Phe Ser Phe Pro Leu Ile His Ser Ile Arg Thr Asn Pro
225 230 235 240
Asp Asn His Glu Ile Leu Asn Ile Leu Lys Gln Arg Thr Ser Asp Ala
245 250 255
Ser Leu Lys Lys Tyr Ala Val Asp Tyr Met Arg Thr Glu Thr Lys Ser
260 265 270
Phe Asp Tyr Cys Leu Lys Arg Ile Gln Ala Met Ser Leu Lys Ala Ser
275 280 285
Ser Tyr Ile Asp Asp Leu Ala Ala Ala Gly His Asp Val Ser Lys Leu
290 295 300
Arg Ala Ile Leu His Tyr Phe Val Ser Thr Ser Asp Cys Glu Glu Arg
305 310 315 320
Lys Tyr Phe Glu Asp Ala Gln
325
<210> 12
<211> 984
<212> DNA
<213> Artificial Sequence
<220>
<223> ggs1_T269G
<400> 12
atggattata acagcgcgga tttcaaggag atatggggca aggccgccga caccgcgctg 60
ctgggaccgt acaactacct cgccaacaac cggggccaca acatcagaga acacttgatc 120
gcagcgttcg gagcggttat caaggtggac aagagcgatc tcgagaccat ttcgcacatc 180
accaagattt tgcataactc gtcgctgctt gttgatgacg tggaagacaa ctcgatgctc 240
cgacgaggcc tgccggcagc ccattgtcgg tttggagtcc cccaaaccat caactccgcc 300
aactacatgt actttgtggc tctgcaggag gtgctcaagc tcaagtctta tgatgccgtc 360
tccattttca ccgaggaaat gatcaacttg catagaggtc agggtatgga tctctactgg 420
agagaaacac tcacttgccc ctcggaagac gagtatctgg agatggtggt gcacaagacc 480
ggtggactgt ttcggctggc tctgagactt atgctgtcgg tggcatcgaa acaggaggac 540
catgaaaaga tcaactttga tctcacacac cttaccgaca cactgggagt catttaccag 600
attctggatg attacctcaa cctgcagtcc acggaattga ccgagaacaa gggattctgc 660
gaagatatca gcgaaggaaa gttttcgttt ccgctgattc acagcatacg caccaacccg 720
gataaccacg agattctcaa cattctcaaa cagcgaacaa gcgacgcttc actcaaaaag 780
tacgccgtgg actacatgag aacagaaacc aagagtttcg actactgcct caagaggata 840
caggccatgt cactcaaggc aagttcgtac attgatgatc tagcagcagc tggccacgat 900
gtctccaagc tacgagccat tttgcattat tttgtgtcca cctctgactg tgaggagaga 960
aagtactttg aggatgcgca gtga 984
<210> 13
<211> 327
<212> PRT
<213> Artificial Sequence
<220>
<223> GGS1_I122V/R141K
<400> 13
Met Asp Tyr Asn Ser Ala Asp Phe Lys Glu Ile Trp Gly Lys Ala Ala
1 5 10 15
Asp Thr Ala Leu Leu Gly Pro Tyr Asn Tyr Leu Ala Asn Asn Arg Gly
20 25 30
His Asn Ile Arg Glu His Leu Ile Ala Ala Phe Gly Ala Val Ile Lys
35 40 45
Val Asp Lys Ser Asp Leu Glu Thr Ile Ser His Ile Thr Lys Ile Leu
50 55 60
His Asn Ser Ser Leu Leu Val Asp Asp Val Glu Asp Asn Ser Met Leu
65 70 75 80
Arg Arg Gly Leu Pro Ala Ala His Cys Leu Phe Gly Val Pro Gln Thr
85 90 95
Ile Asn Ser Ala Asn Tyr Met Tyr Phe Val Ala Leu Gln Glu Val Leu
100 105 110
Lys Leu Lys Ser Tyr Asp Ala Val Ser Val Phe Thr Glu Glu Met Ile
115 120 125
Asn Leu His Arg Gly Gln Gly Met Asp Leu Tyr Trp Lys Glu Thr Leu
130 135 140
Thr Cys Pro Ser Glu Asp Glu Tyr Leu Glu Met Val Val His Lys Thr
145 150 155 160
Gly Gly Leu Phe Arg Leu Ala Leu Arg Leu Met Leu Ser Val Ala Ser
165 170 175
Lys Gln Glu Asp His Glu Lys Ile Asn Phe Asp Leu Thr His Leu Thr
180 185 190
Asp Thr Leu Gly Val Ile Tyr Gln Ile Leu Asp Asp Tyr Leu Asn Leu
195 200 205
Gln Ser Thr Glu Leu Thr Glu Asn Lys Gly Phe Cys Glu Asp Ile Ser
210 215 220
Glu Gly Lys Phe Ser Phe Pro Leu Ile His Ser Ile Arg Thr Asn Pro
225 230 235 240
Asp Asn His Glu Ile Leu Asn Ile Leu Lys Gln Arg Thr Ser Asp Ala
245 250 255
Ser Leu Lys Lys Tyr Ala Val Asp Tyr Met Arg Thr Glu Thr Lys Ser
260 265 270
Phe Asp Tyr Cys Leu Lys Arg Ile Gln Ala Met Ser Leu Lys Ala Ser
275 280 285
Ser Tyr Ile Asp Asp Leu Ala Ala Ala Gly His Asp Val Ser Lys Leu
290 295 300
Arg Ala Ile Leu His Tyr Phe Val Ser Thr Ser Asp Cys Glu Glu Arg
305 310 315 320
Lys Tyr Phe Glu Asp Ala Gln
325
<210> 14
<211> 984
<212> DNA
<213> Artificial Sequence
<220>
<223> ggs1_A364G_G422A
<400> 14
atggattata acagcgcgga tttcaaggag atatggggca aggccgccga caccgcgctg 60
ctgggaccgt acaactacct cgccaacaac cggggccaca acatcagaga acacttgatc 120
gcagcgttcg gagcggttat caaggtggac aagagcgatc tcgagaccat ttcgcacatc 180
accaagattt tgcataactc gtcgctgctt gttgatgacg tggaagacaa ctcgatgctc 240
cgacgaggcc tgccggcagc ccattgtctg tttggagtcc cccaaaccat caactccgcc 300
aactacatgt actttgtggc tctgcaggag gtgctcaagc tcaagtctta tgatgccgtc 360
tccgttttca ccgaggaaat gatcaacttg catagaggtc agggtatgga tctctactgg 420
aaagaaacac tcacttgccc ctcggaagac gagtatctgg agatggtggt gcacaagacc 480
ggtggactgt ttcggctggc tctgagactt atgctgtcgg tggcatcgaa acaggaggac 540
catgaaaaga tcaactttga tctcacacac cttaccgaca cactgggagt catttaccag 600
attctggatg attacctcaa cctgcagtcc acggaattga ccgagaacaa gggattctgc 660
gaagatatca gcgaaggaaa gttttcgttt ccgctgattc acagcatacg caccaacccg 720
gataaccacg agattctcaa cattctcaaa cagcgaacaa gcgacgcttc actcaaaaag 780
tacgccgtgg actacatgag aacagaaacc aagagtttcg actactgcct caagaggata 840
caggccatgt cactcaaggc aagttcgtac attgatgatc tagcagcagc tggccacgat 900
gtctccaagc tacgagccat tttgcattat tttgtgtcca cctctgactg tgaggagaga 960
aagtactttg aggatgcgca gtga 984
<210> 15
<211> 327
<212> PRT
<213> Artificial Sequence
<220>
<223> GGS1_I122V
<400> 15
Met Asp Tyr Asn Ser Ala Asp Phe Lys Glu Ile Trp Gly Lys Ala Ala
1 5 10 15
Asp Thr Ala Leu Leu Gly Pro Tyr Asn Tyr Leu Ala Asn Asn Arg Gly
20 25 30
His Asn Ile Arg Glu His Leu Ile Ala Ala Phe Gly Ala Val Ile Lys
35 40 45
Val Asp Lys Ser Asp Leu Glu Thr Ile Ser His Ile Thr Lys Ile Leu
50 55 60
His Asn Ser Ser Leu Leu Val Asp Asp Val Glu Asp Asn Ser Met Leu
65 70 75 80
Arg Arg Gly Leu Pro Ala Ala His Cys Leu Phe Gly Val Pro Gln Thr
85 90 95
Ile Asn Ser Ala Asn Tyr Met Tyr Phe Val Ala Leu Gln Glu Val Leu
100 105 110
Lys Leu Lys Ser Tyr Asp Ala Val Ser Val Phe Thr Glu Glu Met Ile
115 120 125
Asn Leu His Arg Gly Gln Gly Met Asp Leu Tyr Trp Arg Glu Thr Leu
130 135 140
Thr Cys Pro Ser Glu Asp Glu Tyr Leu Glu Met Val Val His Lys Thr
145 150 155 160
Gly Gly Leu Phe Arg Leu Ala Leu Arg Leu Met Leu Ser Val Ala Ser
165 170 175
Lys Gln Glu Asp His Glu Lys Ile Asn Phe Asp Leu Thr His Leu Thr
180 185 190
Asp Thr Leu Gly Val Ile Tyr Gln Ile Leu Asp Asp Tyr Leu Asn Leu
195 200 205
Gln Ser Thr Glu Leu Thr Glu Asn Lys Gly Phe Cys Glu Asp Ile Ser
210 215 220
Glu Gly Lys Phe Ser Phe Pro Leu Ile His Ser Ile Arg Thr Asn Pro
225 230 235 240
Asp Asn His Glu Ile Leu Asn Ile Leu Lys Gln Arg Thr Ser Asp Ala
245 250 255
Ser Leu Lys Lys Tyr Ala Val Asp Tyr Met Arg Thr Glu Thr Lys Ser
260 265 270
Phe Asp Tyr Cys Leu Lys Arg Ile Gln Ala Met Ser Leu Lys Ala Ser
275 280 285
Ser Tyr Ile Asp Asp Leu Ala Ala Ala Gly His Asp Val Ser Lys Leu
290 295 300
Arg Ala Ile Leu His Tyr Phe Val Ser Thr Ser Asp Cys Glu Glu Arg
305 310 315 320
Lys Tyr Phe Glu Asp Ala Gln
325
<210> 16
<211> 984
<212> DNA
<213> Artificial Sequence
<220>
<223> ggs1_A364G
<400> 16
atggattata acagcgcgga tttcaaggag atatggggca aggccgccga caccgcgctg 60
ctgggaccgt acaactacct cgccaacaac cggggccaca acatcagaga acacttgatc 120
gcagcgttcg gagcggttat caaggtggac aagagcgatc tcgagaccat ttcgcacatc 180
accaagattt tgcataactc gtcgctgctt gttgatgacg tggaagacaa ctcgatgctc 240
cgacgaggcc tgccggcagc ccattgtctg tttggagtcc cccaaaccat caactccgcc 300
aactacatgt actttgtggc tctgcaggag gtgctcaagc tcaagtctta tgatgccgtc 360
tccgttttca ccgaggaaat gatcaacttg catagaggtc agggtatgga tctctactgg 420
agagaaacac tcacttgccc ctcggaagac gagtatctgg agatggtggt gcacaagacc 480
ggtggactgt ttcggctggc tctgagactt atgctgtcgg tggcatcgaa acaggaggac 540
catgaaaaga tcaactttga tctcacacac cttaccgaca cactgggagt catttaccag 600
attctggatg attacctcaa cctgcagtcc acggaattga ccgagaacaa gggattctgc 660
gaagatatca gcgaaggaaa gttttcgttt ccgctgattc acagcatacg caccaacccg 720
gataaccacg agattctcaa cattctcaaa cagcgaacaa gcgacgcttc actcaaaaag 780
tacgccgtgg actacatgag aacagaaacc aagagtttcg actactgcct caagaggata 840
caggccatgt cactcaaggc aagttcgtac attgatgatc tagcagcagc tggccacgat 900
gtctccaagc tacgagccat tttgcattat tttgtgtcca cctctgactg tgaggagaga 960
aagtactttg aggatgcgca gtga 984
<210> 17
<211> 327
<212> PRT
<213> Artificial Sequence
<220>
<223> GGS1_R141K
<400> 17
Met Asp Tyr Asn Ser Ala Asp Phe Lys Glu Ile Trp Gly Lys Ala Ala
1 5 10 15
Asp Thr Ala Leu Leu Gly Pro Tyr Asn Tyr Leu Ala Asn Asn Arg Gly
20 25 30
His Asn Ile Arg Glu His Leu Ile Ala Ala Phe Gly Ala Val Ile Lys
35 40 45
Val Asp Lys Ser Asp Leu Glu Thr Ile Ser His Ile Thr Lys Ile Leu
50 55 60
His Asn Ser Ser Leu Leu Val Asp Asp Val Glu Asp Asn Ser Met Leu
65 70 75 80
Arg Arg Gly Leu Pro Ala Ala His Cys Leu Phe Gly Val Pro Gln Thr
85 90 95
Ile Asn Ser Ala Asn Tyr Met Tyr Phe Val Ala Leu Gln Glu Val Leu
100 105 110
Lys Leu Lys Ser Tyr Asp Ala Val Ser Ile Phe Thr Glu Glu Met Ile
115 120 125
Asn Leu His Arg Gly Gln Gly Met Asp Leu Tyr Trp Lys Glu Thr Leu
130 135 140
Thr Cys Pro Ser Glu Asp Glu Tyr Leu Glu Met Val Val His Lys Thr
145 150 155 160
Gly Gly Leu Phe Arg Leu Ala Leu Arg Leu Met Leu Ser Val Ala Ser
165 170 175
Lys Gln Glu Asp His Glu Lys Ile Asn Phe Asp Leu Thr His Leu Thr
180 185 190
Asp Thr Leu Gly Val Ile Tyr Gln Ile Leu Asp Asp Tyr Leu Asn Leu
195 200 205
Gln Ser Thr Glu Leu Thr Glu Asn Lys Gly Phe Cys Glu Asp Ile Ser
210 215 220
Glu Gly Lys Phe Ser Phe Pro Leu Ile His Ser Ile Arg Thr Asn Pro
225 230 235 240
Asp Asn His Glu Ile Leu Asn Ile Leu Lys Gln Arg Thr Ser Asp Ala
245 250 255
Ser Leu Lys Lys Tyr Ala Val Asp Tyr Met Arg Thr Glu Thr Lys Ser
260 265 270
Phe Asp Tyr Cys Leu Lys Arg Ile Gln Ala Met Ser Leu Lys Ala Ser
275 280 285
Ser Tyr Ile Asp Asp Leu Ala Ala Ala Gly His Asp Val Ser Lys Leu
290 295 300
Arg Ala Ile Leu His Tyr Phe Val Ser Thr Ser Asp Cys Glu Glu Arg
305 310 315 320
Lys Tyr Phe Glu Asp Ala Gln
325
<210> 18
<211> 984
<212> DNA
<213> Artificial Sequence
<220>
<223> ggs1_G422A
<400> 18
atggattata acagcgcgga tttcaaggag atatggggca aggccgccga caccgcgctg 60
ctgggaccgt acaactacct cgccaacaac cggggccaca acatcagaga acacttgatc 120
gcagcgttcg gagcggttat caaggtggac aagagcgatc tcgagaccat ttcgcacatc 180
accaagattt tgcataactc gtcgctgctt gttgatgacg tggaagacaa ctcgatgctc 240
cgacgaggcc tgccggcagc ccattgtctg tttggagtcc cccaaaccat caactccgcc 300
aactacatgt actttgtggc tctgcaggag gtgctcaagc tcaagtctta tgatgccgtc 360
tccattttca ccgaggaaat gatcaacttg catagaggtc agggtatgga tctctactgg 420
aaagaaacac tcacttgccc ctcggaagac gagtatctgg agatggtggt gcacaagacc 480
ggtggactgt ttcggctggc tctgagactt atgctgtcgg tggcatcgaa acaggaggac 540
catgaaaaga tcaactttga tctcacacac cttaccgaca cactgggagt catttaccag 600
attctggatg attacctcaa cctgcagtcc acggaattga ccgagaacaa gggattctgc 660
gaagatatca gcgaaggaaa gttttcgttt ccgctgattc acagcatacg caccaacccg 720
gataaccacg agattctcaa cattctcaaa cagcgaacaa gcgacgcttc actcaaaaag 780
tacgccgtgg actacatgag aacagaaacc aagagtttcg actactgcct caagaggata 840
caggccatgt cactcaaggc aagttcgtac attgatgatc tagcagcagc tggccacgat 900
gtctccaagc tacgagccat tttgcattat tttgtgtcca cctctgactg tgaggagaga 960
aagtactttg aggatgcgca gtga 984
<210> 19
<211> 58
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 19
catatctaca gcattaatta agcagatcca aaaggatcca tggattataa cagcgcgg 58
<210> 20
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 20
gaatgtaagc gtgacataac taattacatg aggtacctca ctgcgcatcc tcaaagtac 59
<210> 21
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 21
gaggcccttt cgtcttcaag aattcgagtt tggcgcccgt 40
<210> 22
<211> 60
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 22
tgacataact aattacatga ggtaccggat ccttttggat ctgcttaatt aatgctgtag 60
60
<210> 23
<211> 60
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 23
ctacagcatt aattaagcag atccaaaagg atccggtacc tcatgtaatt agttatgtca 60
60
<210> 24
<211> 55
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 24
agtcagacag atactcgtcg cggccgcggc gcgccgcaaa ttaaagcctt cgagc 55
<210> 25
<211> 55
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 25
gctcgaaggc tttaatttgc ggcgcgccgc ggccgcgacg agtatctgtc tgact 55
<210> 26
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 26
acgggcgcca aactcgaatt cttgaagacg aaagggcctc 40
<210> 27
<211> 2019
<212> DNA
<213> Artificial Sequence
<220>
<223> X. dendrorhous crtYB
<400> 27
atgacggctc tcgcatatta ccagatccat ctgatctata ctctcccaat tcttggtctt 60
ctcggcctgc tcacttcccc gattttgaca aaatttgaca tctacaaaat atcgatcctc 120
gtatttattg cgtttagtgc aaccacacca tgggactcat ggatcatcag aaatggcgca 180
tggacatatc catcagcgga gagtggccaa ggcgtgtttg gaacgtttct agatgttcca 240
tatgaagagt acgctttctt tgtcattcaa accgtaatca ccggcttggt ctacgtcttg 300
gcaactaggc accttctccc atctctcgcg cttcccaaga ctagatcgtc cgccctttct 360
ctcgcgctca aggcgctcat ccctctgccc attatctacc tatttaccgc tcaccccagc 420
ccatcgcccg acccgctcgt gacagatcac tacttctaca tgcgggcact ctccttactc 480
atcaccccac ctaccatgct cttggcagca ttatcaggcg aatatgcttt cgattggaaa 540
agtggccgag caaagtcaac tattgcagca atcatgatcc cgacggtgta tctgatttgg 600
gtagattatg ttgctgtcgg tcaagactct tggtcgatca acgatgagaa gattgtaggg 660
tggaggcttg gaggtgtact acccattgag gaagctatgt tcttcttact gacgaatcta 720
atgattgttc tgggtctgtc tgcctgcgat catactcagg ccctatacct gctacacggt 780
cgaactattt atggcaacaa aaagatgcca tcttcatttc ccctcattac accgcctgtg 840
ctctccctgt tttttagcag ccgaccatac tcttctcagc caaaacgtga cttggaactg 900
gcagtcaagt tgttggagga aaagagccgg agcttttttg ttgcctcggc tggatttcct 960
agcgaagtta gggagaggct ggttggacta tacgcattct gccgggtgac tgatgatctt 1020
atcgactctc ctgaagtatc ttccaacccg catgccacaa ttgacatggt ctccgatttt 1080
cttaccctac tatttgggcc cccgctacac ccttcgcaac ctgacaagat cctttcttcg 1140
cctttacttc ctccttcgca cccttcccga cccacgggaa tgtatcccct cccgcctcct 1200
ccttcgctct cgcctgccga gctcgttcaa ttccttaccg aaagggttcc cgttcaatac 1260
catttcgcct tcaggttgct cgctaagttg caagggctga tccctcgata cccactcgac 1320
gaactcctta gaggatacac cactgatctt atctttccct tatcgacaga ggcagtccag 1380
gctcggaaga cgcctatcga gaccacagct gacttgctgg actatggtct atgtgtagca 1440
ggctcagtcg ccgagctatt ggtctatgtc tcttgggcaa gtgcaccaag tcaggtccct 1500
gccaccatag aagaaagaga agctgtgtta gtggcaagcc gagagatggg aactgccctt 1560
cagttggtga acattgctag ggacattaaa ggggacgcaa cagaagggag attttaccta 1620
ccactctcat tctttggtct tcgggatgaa tcaaagcttg cgatcccgac tgattggacg 1680
gaacctcggc ctcaagattt cgacaaactc ctcagtctat ctccttcgtc cacattacca 1740
tcttcaaacg cctcagaaag cttccggttc gaatggaaga cgtactcgct tccattagtc 1800
gcctacgcag aggatcttgc caaacattct tataagggaa ttgaccgact tcctaccgag 1860
gttcaagcgg gaatgcgagc ggcttgcgcg agctacctac tgatcggccg agagatcaaa 1920
gtcgtttgga aaggagacgt cggagagaga aggacagttg ccggatggag gagagtacgg 1980
aaagtcttga gtgtggtcat gagcggatgg gaagggcag 2019
<210> 28
<211> 1966
<212> DNA
<213> Artificial Sequence
<220>
<223> X. dendrorhous crtI
<400> 28
atgggaaaag aacaagatca ggataaaccc acagctatca tcgtgggatg tggtatcggt 60
ggaatcgcca ctgccgctcg tcttgctaaa gaaggtttcc aggtcacggt gttcgagaag 120
aacgactact ccggaggtcg atgctcttta atcgagcgag atggttatcg attcgatcag 180
gggcccagtt tgctgctctt gccagatctc ttcaagcaga cattcgaaga tttgggagag 240
aagatggaag attgggtcga tctcatcaag tgtgaaccca actatgtttg ccacttccac 300
gatgaagaga ctttcactct ttcaaccgac atggcgttgc tcaagcggga agtcgagcgt 360
tttgaaggca aagatggatt tgatcggttc ttgtcgttta tccaagaagc ccacagacat 420
tacgagcttg ctgtcgttca cgtcctgcag aagaacttcc ctggcttcgc agcattctta 480
cggctacagt tcattggcca aatcctggct cttcacccct tcgagtctat ctggacaaga 540
gtttgtcgat atttcaagac cgacagatta cgaagagtct tctcgtttgc agtgatgtac 600
atgggtcaaa gcccatacag tgcgcccgga acatattcct tgctccaata caccgaattg 660
accgagggca tctggtatcc gagaggaggc ttttggcagg ttcctaatac tcttcttcag 720
atcgtcaagc gcaacaatcc ctcagccaag ttcaatttca acgctccagt ttcccaggtt 780
cttctctctc ctgccaagga ccgagcgact ggtgttcgac ttgaatccgg cgaggaacat 840
cacgccgatg ttgtgattgt caatgctgac ctcgtttacg cctccgagca cttgattcct 900
gacgatgcca gaaacaagat tggccaactg ggtgaagtca agagaagttg gtgggctgac 960
ttagttggtg gaaagaagct caagggaagt tgcagtagtt tgagcttcta ctggagcatg 1020
gaccgaatcg tggacggtct gggcggacac aatatcttct tggccgagga cttcaaggga 1080
tcattcgaca caatcttcga ggagttgggt ctcccagccg atccttcctt ttacgtgaac 1140
gttccctcgc gaatcgatcc ttctgccgct cccgaaggca aagatgctat cgtcattctt 1200
gtgccgtgtg gccatatcga cgcttcgaac cctcaagatt acaacaagct tgttgctcgg 1260
gcaaggaagt ttgtgatcca cacgctttcc gccaagcttg gacttcccga ctttgaaaaa 1320
atgattgtgg cagagaaggt tcacgatgct ccctcttggg agaaagaatt caacctcaag 1380
gacggaagca tcttgggact ggctcacaac tttatgcaag ttcttggttt caggccgagc 1440
accagacatc ccaagtatga caagttgttc tttgtcgggg cttcgactca tcccggaact 1500
ggggttccca tcgtcttggc tggagccaag ttaactgcca accaagttct cgaatccttt 1560
gaccgatccc cagctccaga tcccaatatg tcactctccg taccatatgg aaaacctctc 1620
aaatcaaatg gaacgggtat cgattctcag gtccagctga agttcatgga tttggagaga 1680
tgggtatacc ttttggtgtt gttgattggg gccgtgatcg ctcgatccgt tggtgttctt 1740
gctttctgaa gcaagacaac gatcctttct tagagtttta ttttagtctc ttcctgtgtt 1800
ctctctatat acatactctg ctcgtctgtt ctcttctcga gggttcctct ttactttgtg 1860
tcagagtcat acccggtctc tcaacgtccg tttgagggct agacaattgt tagtctcgaa 1920
atctccatca cctcaagtct gatgttcatc atctttttta ttcgtt 1966
<210> 29
<211> 2830
<212> DNA
<213> Artificial Sequence
<220>
<223> TEFINtp-crtYB-CYC1t
<400> 29
agagaccggg ttggcggcgc atttgtgtcc caaaaaacag ccccaattgc cccaattgac 60
cccaaattga cccagtagcg ggcccaaccc cggcgagagc ccccttctcc ccacatatca 120
aacctccccc ggttcccaca cttgccgtta agggcgtagg gtactgcagt ctggaatcta 180
cgcttgttca gactttgtac tagtttcttt gtctggccat ccgggtaacc catgccggac 240
gcaaaataga ctactgaaaa tttttttgct ttgtggttgg gactttagcc aagggtataa 300
aagaccaccg tccccgaatt acctttcctc ttcttttctc tctctccttg tcaactcaca 360
cccgaaatcg ttaagcattt ccttctgagt ataagaatca ttcaaaatgg tgagtttcag 420
aggcagcagc aattgccacg ggctttgagc acacggccgg gtgtggtccc attcccatcg 480
acacaagacg ccacgtcatc cgaccagcac tttttgcagt actaaccgca gacggctctc 540
gcatattacc agatccatct gatctatact ctcccaattc ttggtcttct cggtctgctc 600
acttccccga ttttgacaaa atttgacatc tacaaaatat cgatcctcgt atttattgcg 660
tttagtgcaa ccacaccatg ggactcatgg atcatcagaa atggcgcatg gacatatcca 720
tcagcggaga gtggccaagg cgtgtttgga acgtttctag atgttccata tgaagagtac 780
gctttctttg tcattcaaac cgtaatcacc ggcttggtct acgtcttggc aactaggcac 840
cttctcccat ctctcgcgct tcccaagact agatcgtccg ccctttctct cgcgctcaag 900
gcgctcatcc ctctgcccat tatctaccta tttaccgctc accccagccc atcgcccgac 960
ccgctcgtga cagatcacta cttctacatg cgggcactct ccttactcat caccccacct 1020
accatgctct tggcagcatt atcaggcgaa tatgctttcg attggaaaag tggccgagca 1080
aagtcaacta ttgcagcaat catgatcccg acggtgtatc tgatttgggt agattatgtt 1140
gctgtcggtc aagactcttg gtcgatcaac gatgagaaga ttgtagggtg gaggcttgga 1200
ggtgtactac ccattgagga agctatgttc ttcttactga cgaatctaat gattgttctg 1260
ggtctgtctg cctgcgatca tactcaggcc ctatacctgc tacacggtcg aactatttat 1320
ggcaacaaaa agatgccatc ttcatttccc ctcattacac cgcctgtgct ctccctgttt 1380
tttagcagcc gaccatactc ttctcagcca aaacgtgact tggaactggc agtcaagttg 1440
ttggaggaaa agagccggag cttttttgtt gcctcggctg gatttcctag cgaagttagg 1500
gagaggctgg ttggactata cgcattctgc cgggtgactg atgatcttat cgactctcct 1560
gaagtatctt ccaacccgca tgccacaatt gacatggtct ccgattttct taccctacta 1620
tttgggcccc cgctacaccc ttcgcaacct gacaagatcc tttcttcgcc tttacttcct 1680
ccttcgcacc cttcccgacc cacgggaatg tatcccctcc cgcctcctcc ttcgctctcg 1740
cctgccgagc tcgttcaatt ccttaccgaa agggttcccg ttcaatacca tttcgccttc 1800
aggttgctcg ctaagttgca agggctgatc cctcgatacc cactcgacga actccttaga 1860
ggatacacca ctgatcttat ctttccttta tcgacagagg cagtccaggc tcggaagacg 1920
cctatcgaga ccacagctga cttgctggac tatggtctat gtgtagcagg ctcagtcgcc 1980
gagctattgg tctatgtctc ttgggcaagt gcaccaagtc aggtccctgc caccatagaa 2040
gaaagagaag ctgtgttagt ggcaagccga gagatgggaa ctgcccttca gttggtgaac 2100
attgctaggg acattaaagg ggacgcaaca gaagggagat tttacctacc actctcattc 2160
tttggtcttc gggatgaatc aaagcttgcg atcccgactg attggacgga acctcggcct 2220
caagatttcg acaaactcct cagtctatct ccttcgtcca cattaccatc ttcaaacgcc 2280
tcagaaagct tccggttcga atggaagacg tactcgcttc cattagtcgc ctacgcagag 2340
gatcttgcca aacattctta taagggaatt gaccgacttc ctaccgaggt tcaagcggga 2400
atgcgagcgg cttgcgcgag ctacctactg atcggccgag agatcaaagt cgtttggaaa 2460
ggagacgtcg gagagagaag gacagttgcc ggatggagga gagtacggaa agtcttgagt 2520
gtggtcatga gcggatggga agggcagtaa ctcgagtcat gtaattagtt atgtcacgct 2580
tacattcacg ccctcccccc acatccgctc taaccgaaaa ggaaggagtt agacaacctg 2640
aagtctaggt ccctatttat ttttttatag ttatgttagt attaagaacg ttatttatat 2700
ttcaaatttt tctttttttt ctgtacagac gcgtgtacgc atgtaacatt atactgaaaa 2760
ccttgcttga gaaggttttg ggacgctcga aggctttaat ttgcggcgcg cggaggccct 2820
ttcgtcttca 2830
<210> 30
<211> 2555
<212> DNA
<213> Artificial Sequence
<220>
<223> TEFINtp-crtI-CYC1t
<400> 30
agagaccggg ttggcggcgc atttgtgtcc caaaaaacag ccccaattgc cccaattgac 60
cccaaattga cccagtagcg ggcccaaccc cggcgagagc ccccttctcc ccacatatca 120
aacctccccc ggttcccaca cttgccgtta agggcgtagg gtactgcagt ctggaatcta 180
cgcttgttca gactttgtac tagtttcttt gtctggccat ccgggtaacc catgccggac 240
gcaaaataga ctactgaaaa tttttttgct ttgtggttgg gactttagcc aagggtataa 300
aagaccaccg tccccgaatt acctttcctc ttcttttctc tctctccttg tcaactcaca 360
cccgaaatcg ttaagcattt ccttctgagt ataagaatca ttcaaaatgg tgagtttcag 420
aggcagcagc aattgccacg ggctttgagc acacggccgg gtgtggtccc attcccatcg 480
acacaagacg ccacgtcatc cgaccagcac tttttgcagt actaaccgca gggaaaagaa 540
caagatcagg ataaacccac agctatcatc gtgggatgtg gtatcggtgg aatcgccact 600
gccgctcgtc ttgctaaaga aggtttccag gtcacggtgt tcgagaagaa cgactactcc 660
ggaggtcgat gctctttaat cgagcgagat ggttatcgat tcgatcaggg gcccagtttg 720
ctgctcttgc cagatctctt caagcagaca ttcgaagatt tgggagagaa gatggaagat 780
tgggtcgatc tcatcaagtg tgaacccaac tatgtttgcc acttccacga tgaagagact 840
ttcactcttt caaccgacat ggcgttgctc aagcgggaag tcgagcgttt tgaaggcaaa 900
gatggatttg atcggttctt gtcgtttatc caagaagccc acagacatta cgagcttgct 960
gtcgttcacg tcctgcagaa gaacttccct ggcttcgcag cattcttacg gctacagttc 1020
attggccaaa tcctggctct tcaccccttc gagtctatct ggacaagagt ttgtcgatat 1080
ttcaagaccg acagattacg aagagtcttc tcgtttgcag tgatgtacat gggtcaaagc 1140
ccatacagtg cgcccggaac atattccttg ctccaataca ccgaattgac cgagggcatc 1200
tggtatccga gaggaggctt ttggcaggtt cctaatactc ttcttcagat cgtcaagcgc 1260
aacaatccct cagccaagtt caatttcaac gctccagttt cccaggttct tctctctcct 1320
gccaaggacc gagcgactgg tgttcgactt gaatccggcg aggaacatca cgccgatgtt 1380
gtgattgtca atgctgacct cgtttacgcc tccgagcact tgattcctga cgatgccaga 1440
aacaagattg gccaactggg tgaagtcaag agaagttggt gggctgactt agttggtgga 1500
aagaagctca agggaagttg cagtagtttg agcttctact ggagcatgga ccgaatcgtg 1560
gacggtctgg gcggacacaa tatcttcttg gccgaggact tcaagggatc attcgacaca 1620
atcttcgagg agttgggtct cccagccgat ccttcctttt acgtgaacgt tccctcgcga 1680
atcgatcctt ctgccgctcc cgaaggcaaa gatgctatcg tcattcttgt gccgtgtggc 1740
catatcgacg cttcgaaccc tcaagattac aacaagcttg ttgctcgggc aaggaagttt 1800
gtgatccaca cgctttccgc caagcttgga cttcccgact ttgaaaaaat gattgtggca 1860
gagaaggttc acgatgctcc ctcttgggag aaagaattca acctcaagga cggaagcatc 1920
ttgggactgg ctcacaactt tatgcaagtt cttggtttca ggccgagcac cagacatccc 1980
aagtatgaca agttgttctt tgtcggggct tcgactcatc ccggaactgg ggttcccatc 2040
gtcttggctg gagccaagtt aactgccaac caagttctcg aatcctttga ccgatcccca 2100
gctccagatc ccaatatgtc actctccgta ccatatggaa aacctctcaa atcaaatgga 2160
acgggtatcg attctcaggt ccagctgaag ttcatggatt tggagagatg ggtatacctt 2220
ttggtattgt tgattggggc cgtgatcgct cgatccgttg gtgttcttgc tttctgactc 2280
gagtcatgta attagttatg tcacgcttac attcacgccc tccccccaca tccgctctaa 2340
ccgaaaagga aggagttaga caacctgaag tctaggtccc tatttatttt tttatagtta 2400
tgttagtatt aagaacgtta tttatatttc aaatttttct tttttttctg tacagacgcg 2460
tgtacgcatg taacattata ctgaaaacct tgcttgagaa ggttttggga cgctcgaagg 2520
ctttaatttg ccggccgcga cgagtatctg tctga 2555
<210> 31
<211> 1533
<212> DNA
<213> Artificial Sequence
<220>
<223> селективный маркер URA3
<400> 31
tgcctcctgt ctgactcgtc attgccgcct ttggagtacg actccaacta tgagtgtgct 60
tggatcactt tgacgataca ttcttcgttg gaggctgtgg gtctgacagc tgcgttttcg 120
gcgcggttgg ccgacaacaa tatcagctgc aacgtcattg ctggctttca tcatgatcac 180
atttttgtcg gcaaaggcga cgcccagaga gccattgacg ttctttctaa tttggaccga 240
tagccgtata gtccagtcta tctataagtt caactaactc gtaactatta ccataacata 300
tacttcactg ccccagataa ggttccgata aaaagttctg cagactaaat ttatttcagt 360
ctcctcttca ccaccaaaat gccctcctac gaagctcgag ctaacgtcca caagtccgcc 420
tttgccgctc gagtgctcaa gctcgtggca gccaagaaaa ccaacctgtg tgcttctctg 480
gatgttacca ccaccaagga gctcattgag cttgccgata aggtcggacc ttatgtgtgc 540
atgatcaaga cccatatcga catcattgac gacttcacct acgccggcac tgtgctcccc 600
ctcaaggaac ttgctcttaa gcacggtttc ttcctgttcg aggacagaaa gttcgcagat 660
attggcaaca ctgtcaagca ccagtacaag aacggtgtct accgaatcgc cgagtggtcc 720
gatatcacca acgcccacgg tgtacccgga accggaatca ttgctggcct gcgagctggt 780
gccgaggaaa ctgtctctga acagaagaag gaggacgtct ctgactacga gaactcccag 840
tacaaggagt tcctggtccc ctctcccaac gagaagctgg ccagaggtct gctcatgctg 900
gccgagctgt cttgcaaggg ctctctggcc actggcgagt actccaagca gaccattgag 960
cttgcccgat ccgaccccga gtttgtggtt ggcttcattg cccagaaccg acctaagggc 1020
gactctgagg actggcttat tctgaccccc ggggtgggtc ttgacgacaa gggagacgct 1080
ctcggacagc agtaccgaac tgttgaggat gtcatgtcta ccggaacgga tatcataatt 1140
gtcggccgag gtctgtacgg ccagaaccga gatcctattg aggaggccaa gcgataccag 1200
aaggctggct gggaggctta ccagaagatt aactgttaga ggttagacta tggatatgtc 1260
atttaactgt gtatatagag agcgtgcaag tatggagcgc ttgttcagct tgtatgatgg 1320
tcagacgacc tgtctgatcg agtatgtatg atactgcaca acctgtgtat ccgcatgatc 1380
tgtccaatgg ggcatgttgt tgtgtttctc gatacggaga tgctgggtac aagtagctaa 1440
tacgattgaa ctacttatac ttatatgagg cttgaagaaa gctgacttgt gtatgactta 1500
ttctcaacta catccccagt cacaatacca cca 1533
<210> 32
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 32
gtgcgcttct ctcgtctcgg taaccctgtc 30
<210> 33
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 33
atgcgccgcc aacccggtct ctggggtgtg gtggatgggg tgtg 44
<210> 34
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 34
cacaccccat ccaccacacc ccagagaccg ggttggcggc gcat 44
<210> 35
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 35
cgccgccaac ccggtctctt gaagacgaaa gggcctccg 39
<210> 36
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 36
cggaggccct ttcgtcttca agagaccggg ttggcggcg 39
<210> 37
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 37
gacgagtcag acaggaggca tcagacagat actcgtcgcg 40
<210> 38
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 38
cgcgacgagt atctgtctga tgcctcctgt ctgactcgtc 40
<210> 39
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 39
atgacgagtc agacaggagg catggtggta ttgtgactgg ggat 44
<210> 40
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 40
atccccagtc acaataccac catgcctcct gtctgactcg tcat 44
<210> 41
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 41
cggcgtcctt ctcgtagtcc gcttttggtg gtgaagagga gact 44
<210> 42
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 42
agtctcctct tcaccaccaa aagcggacta cgagaaggac gccg 44
<210> 43
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 43
ccactcgtca ccaacagtgc cgtgtgttgc 30
<210> 44
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 44
tcgtacgtct ataccaacag atgg 24
<210> 45
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 45
cgcatacaca cacactgccg gggg 24
<210> 46
<211> 550
<212> DNA
<213> Artificial Sequence
<220>
<223> нативная промоторная область HMGR
<400> 46
tccacacgtc gttctttttt ccttagcctt ttttgcagtg cgcgtgtccc aaaccccagc 60
tctacacacc agcacaaaca aagttaagct cagggttgtc gttgaggtcg cttactgtag 120
tcagtgctcg tatggttcgt tcaattttcg ccaaaaatcg ttttgccttt gtatcttggg 180
aataacatca actgtggttc ttcaacaggc ctaaggaacg aaacaagccg gaccaagatc 240
aggttcaagg tgagtactga gaaggaatag aaggcctaaa ggcgcaaacc gacaggtggc 300
aacagctcca caccgaccac gaaggccacg aaatcaaggg gtcctaaagt tagtctttgt 360
ggcctcgacg gtcagcgaaa acgcgagacc acaacgcgat cagaaccagg acctaaacaa 420
cacaggacgg ggtcacaata ggcttgaaca gcaagtacaa gctgtgatct ctctatattt 480
gattctcaaa ccacccctga ctacttcagc gcctctgtga cacagccccc ctatcatccg 540
actaacacag 550
<210> 47
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 47
acaatgcctc gaggaggttt aaaagtaact 30
<210> 48
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 48
gcgccgccaa cccggtctct ctgtgttagt cggatgatag g 41
<210> 49
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 49
cctatcatcc gactaacaca gagagaccgg gttggcggcg c 41
<210> 50
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 50
gacgagtcag acaggaggca ctgcggttag tactgcaaaa ag 42
<210> 51
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 51
ctttttgcag tactaaccgc agtgcctcct gtctgactcg tc 42
<210> 52
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 52
atgcgccgcc aacccggtct cttggtggta ttgtgactgg ggat 44
<210> 53
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 53
atccccagtc acaataccac caagagaccg ggttggcggc gcat 44
<210> 54
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 54
ctttccaata gctgcttgta gctgcggtta gtactgcaaa a 41
<210> 55
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 55
ttttgcagta ctaaccgcag ctacaagcag ctattggaaa g 41
<210> 56
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 56
gcttaatgtg attgatctca aacttgatag 30
<210> 57
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 57
gctgtctctg cgagagcacg tcga 24
<210> 58
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 58
ggttcgcaca acttctcggg tggc 24
<210> 59
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 59
ccttgtttag tttggctcc 19
<210> 60
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 60
aaagccagca atgacgttgc 20
<210> 61
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 61
accgtacaac tacctcgcca ccaaccgggg ccacaacatc 40
<210> 62
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 62
gatgttgtgg ccccggttgg tggcgaggta gttgtacggt 40
<210> 63
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 63
cctgccggca gcccattgtc ggtttggagt cccccaaacc 40
<210> 64
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 64
ggtttggggg actccaaacc gacaatgggc tgccggcagg 40
<210> 65
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 65
gtcttatgat gccgtctccg ttttcaccga ggaaatgat 39
<210> 66
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 66
atcatttcct cggtgaaaac ggagacggca tcataagac 39
<210> 67
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 67
gggtatggat ctctactgga aagaaacact cacttgcccc 40
<210> 68
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 68
ggggcaagtg agtgtttctt tccagtagag atccataccc 40
<210> 69
<211> 531
<212> DNA
<213> Artificial Sequence
<220>
<223> Промотор TEFINt
<400> 69
agagaccggg ttggcggcgc atttgtgtcc caaaaaacag ccccaattgc cccaattgac 60
cccaaattga cccagtagcg ggcccaaccc cggcgagagc ccccttctcc ccacatatca 120
aacctccccc ggttcccaca cttgccgtta agggcgtagg gtactgcagt ctggaatcta 180
cgcttgttca gactttgtac tagtttcttt gtctggccat ccgggtaacc catgccggac 240
gcaaaataga ctactgaaaa tttttttgct ttgtggttgg gactttagcc aagggtataa 300
aagaccaccg tccccgaatt acctttcctc ttcttttctc tctctccttg tcaactcaca 360
cccgaaatcg ttaagcattt ccttctgagt ataagaatca ttcaaaatgg tgagtttcag 420
aggcagcagc aattgccacg ggctttgagc acacggccgg gtgtggtccc attcccatcg 480
acacaagacg ccacgtcatc cgaccagcac tttttgcagt actaaccgca g 531
<210> 70
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 70
atctcttcta gatagatgcc t 21
<210> 71
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 71
gcgccgccaa cccggtctct gagatttgcc acccaacgtc g 41
<210> 72
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 72
cgacgttggg tggcaaatct cagagaccgg gttggcggcg c 41
<210> 73
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 73
gacgagtcag acaggaggca ctgcggttag tactgcaaaa ag 42
<210> 74
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 74
ctttttgcag tactaaccgc agtgcctcct gtctgactcg tc 42
<210> 75
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 75
gcgccgccaa cccggtctct tggtggtatt gtgactgggg atg 43
<210> 76
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 76
ttttgcagta ctaaccgcag gattataaca gcgcggattt c 41
<210> 77
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 77
taacctggtc aaataccaat g 21
<210> 78
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 78
catccccagt cacaatacca ccaagagacc gggttggcgg cgc 43
<210> 79
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 79
gaaatccgcg ctgttataat cctgcggtta gtactgcaaa a 41
<210> 80
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 80
atctcttcta gatagatgcc t 21
<210> 81
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 81
gcgccgccaa cccggtctct gagatttgcc acccaacgtc g 41
<210> 82
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 82
cgacgttggg tggcaaatct cagagaccgg gttggcggcg c 41
<210> 83
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 83
ctccgatcgc tgcgatcaag 20
<210> 84
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 84
cttgatcgca gcgatcggag 20
<210> 85
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 85
gacgagtcag acaggaggca taacctggtc aaataccaat g 41
<210> 86
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 86
cccagtcaca ataccaccag attataacag cgcggatttc 40
<210> 87
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 87
tcaacaattg taacaacttg taacctggtc aaataccaat 40
<210> 88
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 88
cattggtatt tgaccaggtt atgcctcctg tctgactcgt c 41
<210> 89
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 89
gaaatccgcg ctgttataat ctggtggtat tgtgactggg 40
<210> 90
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 90
attggtattt gaccaggtta caagttgtta caattgttga 40
<210> 91
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<223> Праймер
<400> 91
tgaaagtcct ggaagcagta c 21
<---
Изобретение относится к биотехнологии, а именно к полипептиду, вовлеченному в получение тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника; полинуклеотиду, кодирующему такой полипептид; вектору, несущему полинуклеотид; микроорганизму, содержащему любой один из варианта, полинуклеотида и вектора; способу получения тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника. Изобретение позволяет получать тетратерпен, предшественник тетратерпена или вещество, имеющее тетратерпен в качестве предшественника, с высокой степенью эффективности. 10 н. и 15 з.п. ф-лы, 6 табл., 6 пр.
1. Полипептид, вовлеченный в получение тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника, где любая одна или более чем одна из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 от N-конца аминокислотной последовательности SEQ ID NO: 1, заменена на другую аминокислоту.
2. Полипептид по п. 1, включающий одну или более чем одну замену из замены аминокислоты, соответствующей положению 29 от N-конца аминокислотной последовательности SEQ ID NO: 1, на аминокислоту, отличную от аспарагина; замены аминокислоты, соответствующей положению 43, на аминокислоту, отличную от фенилаланина; замены аминокислоты, соответствующей положению 90, на аминокислоту, отличную от лейцина; замены аминокислоты, соответствующей положению 103, на аминокислоту, отличную от метионина; замены аминокислоты, соответствующей положению 122, на аминокислоту, отличную от изолейцина; и замены аминокислоты, соответствующей положению 141, на аминокислоту, отличную от аргинина.
3. Полипептид по п. 1, где замена на другую аминокислоту представляет собой замену на неполярную аминокислоту, полярную аминокислоту или положительно заряженную (основную) аминокислоту.
4. Полипептид по п. 1, где другая аминокислота представляет собой любую аминокислоту, выбранную из группы, состоящей из треонина (Thr), изолейцина (Ile), аргинина (Arg), валина (Val) и лизина (Lys).
5. Полинуклеотид, кодирующий полипептид по любому из пп. 1-4.
6. Микроорганизм для получения тетратерпена, предшественника тетратерпена или вещества, имеющего тетратерпен в качестве предшественника, содержащий любой один или более чем один из полипептида по любому из пп. 1-4 и полинуклеотида, кодирующего указанный полипептид.
7. Микроорганизм по п. 6, принадлежащий к Yarrowia sp.
8. Микроорганизм по п. 6, представляющий собой Yarrowia lipolytica.
9. Микроорганизм по п. 6, продуцирующий бета-каротин, предшественник бета-каротина или вещество, имеющее бета-каротин в качестве предшественника.
10. Способ получения тетратерпена, включающий культивирование микроорганизма по п. 6 в среде.
11. Способ по п. 10, дополнительно включающий выделение тетратерпена из среды или из микроорганизма.
12. Способ по п. 10, где микроорганизм принадлежит к Yarrowia sp.
13. Способ по п. 10, снижающий продуцирование сквалена.
14. Способ получения предшественника тетратерпена, включающий культивирование микроорганизма по п. 6 в среде.
15. Способ по п. 14, дополнительно включающий выделение предшественника тетратерпена из среды или из микроорганизма.
16. Способ по п. 14, где микроорганизм принадлежит к Yarrowia sp.
17. Способ по п. 14, снижающий продуцирование сквалена.
18. Способ получения вещества, имеющего тетратерпен в качестве предшественника, включающий культивирование микроорганизма по п. 6 в среде.
19. Способ по п. 18, дополнительно включающий выделение вещества, имеющего тетратерпен в качестве предшественника, из среды или из микроорганизма.
20. Способ по п. 18, где микроорганизм принадлежит к Yarrowia sp.
21. Способ по п. 18, снижающий продуцирование сквалена.
22. Композиция для получения тетратерпена, его предшественника или вещества, имеющего тетратерпен в качестве предшественника, содержащая полипептид по п. 1, микроорганизм по п. 6 или культуру указанного микроорганизма и эксципиент.
23. Применение микроорганизма, содержащего любой один или более чем один из полипептида, где любая одна или более чем одна из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 от N-конца аминокислотной последовательности SEQ ID NO: 1, заменена на другую аминокислоту; и полинуклеотида, кодирующего указанный полипептид, для получения тетратерпена.
24. Применение микроорганизма, содержащего любой один или более чем один из полипептида, где любая одна или более чем одна из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 от N-конца аминокислотной последовательности SEQ ID NO: 1, заменена на другую аминокислоту; и полинуклеотида, кодирующего указанный полипептид, для получения предшественника тетратерпена.
25. Применение микроорганизма, содержащего любой один или более чем один из полипептида, где любая одна или более чем одна из аминокислот, соответствующих положениям 29, 43, 90, 103, 122 и 141 от N-конца аминокислотной последовательности SEQ ID NO: 1, заменена на другую аминокислоту; и полинуклеотида, кодирующего полипептид, для получения вещества, имеющего тетратерпен в качестве предшественника.
| JP 2019532655 A, 14.11.2019 | |||
| US 20070130634 A9, 07.06.2007 | |||
| US 6410827 B1, 25.06.2002 | |||
| EP 3532611 B1, 01.12.2021 | |||
| Устройство для очистки ткани от загрязнений во время отделки | 1932 |
|
SU28892A1 |

